
repo_name
stringlengths 5
114
| repo_url
stringlengths 24
133
| snapshot_id
stringlengths 40
40
| revision_id
stringlengths 40
40
| directory_id
stringlengths 40
40
| branch_name
stringclasses 209
values | visit_date
timestamp[ns] | revision_date
timestamp[ns] | committer_date
timestamp[ns] | github_id
int64 9.83k
683M
⌀ | star_events_count
int64 0
22.6k
| fork_events_count
int64 0
4.15k
| gha_license_id
stringclasses 17
values | gha_created_at
timestamp[ns] | gha_updated_at
timestamp[ns] | gha_pushed_at
timestamp[ns] | gha_language
stringclasses 115
values | files
listlengths 1
13.2k
| num_files
int64 1
13.2k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
rausalgue/IS211_Assignment7
|
https://github.com/rausalgue/IS211_Assignment7
|
df5ac6e588e9842f7e43fb595bca5fdef4b5fe62
|
6dd51e37b2dd965b7b807a0e2a2903bfdbf0f394
|
9d57ef11ea6f012d6a7e6cc77bfaaa4846ba895a
|
refs/heads/master
| 2021-05-07T04:31:52.296587 | 2017-11-18T09:46:25 | 2017-11-18T09:46:25 | 111,180,562 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5339312553405762,
"alphanum_fraction": 0.5452914834022522,
"avg_line_length": 29.688074111938477,
"blob_id": "7b5430e8e658e6e7b31047a91cc8f8588cc10360",
"content_id": "cc4ae6d54c72b9c1bd4e38a5c3f243b29711832f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3345,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 109,
"path": "/game.py",
"repo_name": "rausalgue/IS211_Assignment7",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"Assignemnt Week Seven - Pig Game\"\"\"\n\nimport random\nimport argparse\n\nparser = argparse.ArgumentParser()\nparser.add_argument(\"--name\", help=\"Name of the Player\",default=None)\nargs = parser.parse_args()\n\nupper_limit = 100\n\nclass Dice(object):\n def __init__(self):\n self.value = None\n\n def roll(self):\n self.value = random.randint(1, 6)\n return self.value\n\nclass PlayerData(object):\n def __init__(self,name):\n self.name = name\n self.score = 0\n\nclass Game(object):\n def __init__(self, value1, value2): # Assign method name\n self.player1 = value1\n self.player2 = value2\n\n def introducePlayers(self):\n player1 = PlayerData(self.player1)\n player2 = PlayerData(self.player2)\n\n return player1,player2\n\n def rollDice(self,player):\n print '________',player.name,'________________ROLLING_______________________'\n print 'Player Data',player.name,'Current Score:',player.score\n\n gameDice = Dice()\n\n current_roll_value = 0\n temp_player_score = player.score\n\n while True:\n roll_value = gameDice.roll()\n current_roll_value = current_roll_value + roll_value\n\n if roll_value == 1:\n print 'Sorry',player.name,'you rolled a 1'\n temp_player_score = 0\n current_roll_value = 0\n player.score = player.score\n return\n else:\n temp_player_score = temp_player_score + roll_value\n\n if temp_player_score >= upper_limit:\n player.score = temp_player_score\n print 'Congrats', player.name, 'you rolled:', roll_value\n print 'Congrats', player.name, 'your score is', temp_player_score\n break\n else:\n print 'Congrats',player.name,'you rolled:',roll_value,'your temp score is',temp_player_score\n print 'What would you like to do?'\n answer = raw_input(\"Roll(r) or Hold(h): \")\n if answer == 'h':\n player.score = temp_player_score\n break\n else:\n continue\n return\n\ndef main():\n # Call the Game Class to begin Game\n print 'Welcome to Our Game'\n player_one = args.name if args.name else raw_input(\"Please enter name of first player: \")\n\n if player_one:\n player_two = args.name if args.name else raw_input(\"Please enter name of second player: \")\n\n if player_one and player_two:\n game = Game(player_one,player_two)\n\n player1,player2= game.introducePlayers()\n\n while player1.score < upper_limit and player2.score < upper_limit:\n game.rollDice(player1)\n\n if player1.score >= upper_limit:\n print \"Playes 1 Wins\"\n break\n\n game.rollDice(player2)\n\n if player2.score >= upper_limit:\n print \"Player 2 Wins\"\n break\n\n print 'Final Results'\n print 'Player:',player1.name,'Score:',player1.score\n print 'Player:', player2.name, 'Score:', player2.score\n\n print 'Game has terminated...Play Again (y/n):...'\n\nif __name__ == '__main__':\n main()\n"
}
] | 1 |
yekingyan/Algorithms_in_the_Python
|
https://github.com/yekingyan/Algorithms_in_the_Python
|
40c783ce50c1bed5a09dac4382a1f4a56df05bb6
|
95655a7b22324978cabd2e35a58ad5294a36aba8
|
9e4d78b76b4c56e4750256a8b6f541df63887bdc
|
refs/heads/master
| 2020-03-23T14:39:01.368330 | 2018-08-22T06:34:54 | 2018-08-22T06:34:54 | 141,690,386 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7777777910232544,
"alphanum_fraction": 0.7777777910232544,
"avg_line_length": 26,
"blob_id": "7a02652cfcc86a2a3aa567cf9e70019d33a05f1f",
"content_id": "ae0ec6bad8687fe846916d9a061ec2bc54cb2f8c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 27,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 1,
"path": "/README.md",
"repo_name": "yekingyan/Algorithms_in_the_Python",
"src_encoding": "UTF-8",
"text": "# Algorithms in the Python\n"
},
{
"alpha_fraction": 0.5062240958213806,
"alphanum_fraction": 0.5244813561439514,
"avg_line_length": 26.409090042114258,
"blob_id": "341a3adb80c369bcd35626cf278921ff9aa6e459",
"content_id": "290743375b52741463e9d5d46f8170f3b6b7d760",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1373,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 44,
"path": "/binary_tree.py",
"repo_name": "yekingyan/Algorithms_in_the_Python",
"src_encoding": "UTF-8",
"text": "class Tree(object):\n def __init__(self, element=None, left=None, right=None):\n self.element = element\n self.left = left\n self.right = right\n\n def traversal(self):\n \"\"\"树的深度遍历,递归\"\"\"\n # 前序遍历,先把中间全部打印出来,再左,再右\n print(self.element)\n if self.left is not None:\n self.left.traversal()\n # 中序遍历,寻根再找兄弟,先把左边打印出来,再中间,再右\n # print(self.element)\n if self.right is not None:\n self.right.traversal()\n # 后序遍历,先兄弟,先把左边全部打印出来,再右,再中间\n # print(self.element)\n\n def reverse(self):\n \"\"\"翻转\"\"\"\n self.left, self.right = self.right, self.left\n print(self.element)\n if self.left is not None:\n self.left.reverse()\n if self.right is not None:\n self.right.reverse()\n\n\ndef test():\n t = Tree(0, Tree(1, Tree(3, Tree(5), Tree(6)), Tree(4, Tree(7), Tree(8))), Tree(2, Tree(9), Tree(10)))\n # left = Tree(1)\n # right = Tree(2)\n # t.left = left\n # t.right = right\n # Node = Tree\n # t = Node(1, Node(3, Node(7, Node(0)), Node(6)), Node(2, Node(5), Node(4)))\n t.traversal()\n print(\"_________\")\n t.reverse()\n\n\nif __name__ == '__main__':\n test()"
},
{
"alpha_fraction": 0.47400611639022827,
"alphanum_fraction": 0.4901703894138336,
"avg_line_length": 17.92561912536621,
"blob_id": "46df371ebc66d892a2e9d67372f6731df29240cd",
"content_id": "20966813e4ea11fa9eb03282b11f14eb122d0a2f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2837,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 121,
"path": "/chain.py",
"repo_name": "yekingyan/Algorithms_in_the_Python",
"src_encoding": "UTF-8",
"text": "# 实现链表的Node类是一个节点,\n# 有两个属性,一个存储元素,一个存储指向另一个节点的引用\nclass Node():\n def __init__(self, element=None, next_n=None):\n self.e = element\n # 存下一个Node\n self.next = next_n\n\n def append(self, element):\n \"\"\"\n 插入到链表尾,往node末尾插入一个元素\n node:是一个Node实例\n element:任意类型元素\n \"\"\"\n n = self\n while n.next is not None:\n n = n.next\n # 循环结束n是最后一个元素,最后的n.next = None\n # 假设传node参数为head,最后的n.next是n3\n new_node = Node(element)\n # 将上面的点加到n.next\n n.next = new_node\n\n @staticmethod\n def prepend(element):\n \"\"\"\n 插入到链表头\n :param head:传入一个头\n :param element:任意类型元素\n :return:\n \"\"\"\n head = Node()\n n = Node(element)\n # n 成为了新的头\n n.next = head.next\n # 将数据写入头\n head.next = n\n\n def pop(self):\n \"\"\"\n 传入头删掉最末尾的元素\n :param head: 传入一个头\n :return:返回被删掉的对象的值\n \"\"\"\n head = self.head # todo 不是同一个head,新的\n tail = head\n while tail.next is not None:\n tail = tail.next\n # 此时tail是最末尾的元素\n print(\"tail:\", tail)\n n = head\n print('n:', n.next)\n while n.next is not tail:\n n = n.next\n # 此时n是tail之前的元素\n print(n)\n # 清掉最后一个元素\n n.next = None\n # 返回被删掉元素的值\n return tail.e\n\n\ndef pop(head):\n \"\"\"\n 传入头删掉最末尾的元素\n :param head: 传入一个头\n :return:返回被删掉的对象的值\n \"\"\"\n\n tail = head\n while tail.next is not None:\n tail = tail.next\n # 此时tail是最末尾的元素\n n = head\n while n.next is not tail:\n n = n.next\n # 此时n是tail之前的元素\n # 清掉最后一个元素\n n.next = None\n # 返回被删掉元素的值\n return tail.e\n\n\ndef log_list(node):\n \"\"\"\n 打印一个点及之后所有点的值\n :param node: Node的实例\n \"\"\"\n n = node\n s = ''\n while n is not None:\n s += (str(n.e) + '>')\n n = n.next\n print(s)\n\n\ndef main():\n head = Node()\n n1 = Node(111)\n n2 = Node(222)\n n3 = Node(333)\n\n head.next = n1\n n1.next = n2\n n2.next = n3\n head.append(444)\n head.append(555)\n # pop(head)\n head.pop()\n head.prepend('header')\n log_list(head)\n# None>header>111>222>333>444>\n\n\ndef main2():\n pass\n\n\n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.5352380871772766,
"alphanum_fraction": 0.5371428728103638,
"avg_line_length": 19.173076629638672,
"blob_id": "57f0a08fa34f80149bdd3e144ed6c78d5346c71b",
"content_id": "35c4857c2794959ff9df19cbae03879ca2d3d591",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1214,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 52,
"path": "/stack.py",
"repo_name": "yekingyan/Algorithms_in_the_Python",
"src_encoding": "UTF-8",
"text": "\n\n# 实现链表的Node类是一个节点,\n# 有两个属性,一个存储元素,一个存储指向另一个节点的引用\nclass Node():\n def __init__(self, element=None, next_n=None):\n self.element = element\n self.next = next_n\n\n def __repr__(self):\n return str(self.element)\n\n\nclass Queue():\n # 分别指向头尾\n def __init__(self):\n self.head = Node()\n self.tail = self.head\n\n # 如果head的next属性为空,则说明队列是空的\n def empty(self):\n return self.head.next is None\n\n # 创建一个Node\n # 让tail.next 指向它\n # 让tail指向它,tail现在就是新的队尾了\n def enqueue(self, element):\n # print(\"en:element\", element)\n n = Node(element)\n # print(\"en:n\", n, n.next)\n self.tail.next = n\n # print(self.tail)\n self.tail = n\n # print(self.tail)\n pass\n\n def dequeue(self):\n node = self.head.next\n if not self.empty():\n self.head.next = node.next\n return node\n\n\ndef main():\n q = Queue()\n q.enqueue(1)\n # q.enqueue(2)\n\n print(\"head:\", q.head)\n print(\"tail:\", q.tail)\n\n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.4960373044013977,
"alphanum_fraction": 0.5109556913375854,
"avg_line_length": 19.00934600830078,
"blob_id": "720ab2f95773e5cb259d2a3bc7d009ba747b968f",
"content_id": "289a1aef64c1ae8db44a617031b20a25d67b99a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2605,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 107,
"path": "/Binary_Search.py",
"repo_name": "yekingyan/Algorithms_in_the_Python",
"src_encoding": "UTF-8",
"text": "#!python3\n# 二分查找算法, binary search, half-interval search\n# 时间复杂度O(log n),空间复杂度O(1)\n\n\ndef log(*args, **kwargs):\n print(\"log\", *args, **kwargs)\n\n\ndef createArray(num):\n \"\"\"\n 生成下限为0,上限为num的升序列表,间隔为1\n :param num:数字\n :return:数组(升序列表)\n \"\"\"\n # 判断是否是数字\n if type(num) == int:\n array = []\n for i in range(num+1):\n # i = i * 2 # 注释此行,间隔由2变1\n array += [i]\n\n # log(array)\n return array\n else:\n log(\"请输入数字\")\n return \"请输入数字\"\n\n\ndef binarySearch(match, lists):\n \"\"\"\n 用二分法查找path在lists中的具体位置\n :param lists: 列表,元组\n :param match: 要查找的数字\n :return: 具体位置i(lists[i])或None\n \"\"\"\n high = len(lists) - 1\n low = 0\n # times = 0 # 计次数\n\n # 当条件成立证明该值不存在\n while low <= high:\n # 列表入参要整型\n mid = int((high + low) / 2)\n if lists[mid] > match:\n high = mid - 1\n elif lists[mid] < match:\n low = mid + 1\n else:\n # log(\"mid:{}, times:{}\".format(mid, times))\n return mid\n # times += 1\n\n\ndef binarySearch2(match, lists):\n \"\"\"\n 用递归的方法实现二分查找算法\n :param match:要查找的数字\n :param lists: 列表,元组\n :return: 布尔值\n \"\"\"\n n = len(lists)\n if 0 == n:\n return False\n mid = int(n / 2)\n if lists[mid] == match:\n return True\n elif lists[mid] < match:\n # 由于用了切片的方法,因此不能确定mid的值\n return binarySearch2(match, lists[mid:])\n else:\n return binarySearch2(match, lists[:mid])\n\n\n# 单元测试\ndef test_binarySearch():\n \"\"\"\n 测试二分查找1\n \"\"\"\n lists = createArray(100)\n # 把数组的元素提出来与函数计算值作一一校对\n for l in lists:\n mid = binarySearch(l, lists)\n tup = (l, lists[mid])\n # log(tup)\n assert l == lists[mid], \"wrong mid:{}\".format(mid)\n\n\n\n# 单元测试\ndef test_binarySearch2():\n \"\"\"\n 测试二分查找2\n \"\"\"\n lists = createArray(100)\n # 把数组的元素提出来与函数计算值作一一校对\n for l in lists:\n tup = (l, binarySearch2(l, lists))\n # log(tup)\n assert tup[1] == True, \"wrong match{}\".format(tup)\n\n\n\nif __name__ == '__main__':\n test_binarySearch()\n log(\"----------------------------\")\n test_binarySearch2()\n\n\n\n\n"
}
] | 5 |
svetlanamar/Turtle-module-game
|
https://github.com/svetlanamar/Turtle-module-game
|
5e9a677f32e6407e7bfa98563da1737138529d2f
|
0a6e80133e00d1363d26fc535fc739ba8a5a3bb7
|
8868293f88dbb33c486684480543dd41afc7fb52
|
refs/heads/main
| 2023-07-19T20:04:17.658419 | 2021-08-29T17:52:58 | 2021-08-29T17:52:58 | 401,106,210 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7903226017951965,
"alphanum_fraction": 0.7903226017951965,
"avg_line_length": 30,
"blob_id": "1b0209b1982a08d6bbd1842a622a71a8d4789c5c",
"content_id": "1e90d118542823e79b7a76a28d42a6b98a584c37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 62,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 2,
"path": "/README.md",
"repo_name": "svetlanamar/Turtle-module-game",
"src_encoding": "UTF-8",
"text": "# Turtle-module-game\nA game using the turtle module in Python\n"
},
{
"alpha_fraction": 0.5965664982795715,
"alphanum_fraction": 0.6131974458694458,
"avg_line_length": 31.701753616333008,
"blob_id": "4c99407323fb0a3d14c00563b88b4abe29e7f772",
"content_id": "c2bb48e0a6c59615072ac84e243293222eb04ef5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1864,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 57,
"path": "/turtle_game.py",
"repo_name": "svetlanamar/Turtle-module-game",
"src_encoding": "UTF-8",
"text": "import turtle\nimport time\nimport random\n\nWIDTH, HEIGHT = 500, 500\nCOLORS = [\"green\", \"red\", \"blue\", \"orange\", \"yellow\", \"black\", \"purple\", \"pink\", \"brown\", \"cyan\"]\n\ndef get_number_of_racers():\n racers=0\n while True:\n racers=input(\"Enter a number between (2-12): \")\n if racers.isdigit(): #we check if the input we got is numeric to avoid a crash\n racers=int(racers)\n else:\n print(\"Try again, the input isn't numeric!\")\n continue #brings us back to the top of the loop\n if 2<= racers <=12:\n return racers #returns the int and breaks the loop\n else:\n print(\"Number not in range!\") #outputs this and goes back to the start because the input is not a num\n\ndef race(colors):\n turtles = create_turtles(colors)\n while True:\n for racer in turtles:\n distance = random.randrange(1, 17) #randomly moves to a distance from 1 to 20 pixels\n racer.forward(distance)\n x, y = racer.pos()\n if y>= HEIGHT//2 - 10:\n return colors[turtles.index(racer)] #returns the winning turtle index\n\ndef create_turtles(colors):\n turtles = []\n spacingx = WIDTH // (len(colors) + 1)\n for i, color in enumerate(colors):\n racer = turtle.Turtle()\n racer.color(color)\n racer.shape(\"turtle\")\n racer.left(90)\n racer.penup()\n racer.setpos(-WIDTH//2 + (i+1) * spacingx, -HEIGHT//2 + 20)\n racer.pendown()\n turtles.append(racer)\n return turtles\n\ndef init_turtle():\n screen = turtle.Screen()\n screen.setup(WIDTH, HEIGHT)\n screen.title(\"Turtles race\")\n\nracers = get_number_of_racers()\ninit_turtle()\nrandom.shuffle(COLORS)\ncolors=COLORS[:racers] #slice up to the num of racers\nwinner = race(colors)\ntime.sleep(1)\nprint(\"The turtle that has won this time is:\", winner)\n"
}
] | 2 |
InbaKrish/python-youtube-downloader
|
https://github.com/InbaKrish/python-youtube-downloader
|
fb6ab52c13716615d34772f2a0d1b60f3d947db6
|
d4dc7276374d881bfb3f2db8911f791ed048f636
|
c3614888b6ab4f61f33d2c436c28a67a2a3ba9e7
|
refs/heads/master
| 2022-11-17T08:04:39.555393 | 2020-07-15T13:01:06 | 2020-07-15T13:01:06 | 279,788,322 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8433734774589539,
"alphanum_fraction": 0.8433734774589539,
"avg_line_length": 40.5,
"blob_id": "7072e44c4954a6a428a12cd551e40db55208a705",
"content_id": "4f204f4101d1c97e8c5cbeb613269cecc941848c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 83,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 2,
"path": "/README.md",
"repo_name": "InbaKrish/python-youtube-downloader",
"src_encoding": "UTF-8",
"text": "# python-youtube-downloader\nYoutube downloader built using pytube module in python\n"
},
{
"alpha_fraction": 0.5141242742538452,
"alphanum_fraction": 0.5244821310043335,
"avg_line_length": 25.94871711730957,
"blob_id": "6668c0b6a4eb02bccc02abbd954d079cc226328c",
"content_id": "3dda589f649637a83147491e17850cd462c42af5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1062,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 39,
"path": "/main.py",
"repo_name": "InbaKrish/python-youtube-downloader",
"src_encoding": "UTF-8",
"text": "try:\n from pytube import YouTube\n from pytube import Playlist\nexcept :\n print('Required modules not found ')\n\ndef yt_single(u):\n \n yt = YouTube(u)\n\n r = 1\n \n for i in yt.streams.filter(file_extension='mp4'):\n l = str(i).split()\n if ('res' in l[3] and not('\"None\"' in l[3])) :\n print('\\t'+str(l[3]) + '-' + str(r))\n r+=1\n\n opt = int(input('\\n *Select the resolution by entering the number adjacent to it:'))\n path = input('\\n Enter the foldr path for downloading:')\n s = (yt.streams.filter(file_extension='mp4'))[opt - 1]\n print('\\n\\t'+str(s) + ' is downloading')\n\n s.download(path)\n print('\\n -------Downloaded--------')\n\ndef yt_multi():\n pass\n\n\nif __name__ == \"__main__\":\n\n print('--------------------Py Youtube Downloader _ By InbaKrish..-------------------------')\n ty = int(input('\\n 1. Youtube single video \\n 2.Youtube playlist \\n\\t\\tEnter your option:'))\n \n if ty == 1:\n \n ur = input('\\n *Enter Video URL and it enter:')\n yt_single(ur)\n \n\n \n"
}
] | 2 |
aryanotriks/Fb1
|
https://github.com/aryanotriks/Fb1
|
6172929577384a014d00ac8248c8cdba18b2db9b
|
d7b09f5fa526aad92f0e5491d144b328a7af543b
|
08f1f0005b361f6db7ba884ccd668a5067e009ed
|
refs/heads/main
| 2023-04-04T01:20:36.200528 | 2021-04-10T19:37:55 | 2021-04-10T19:37:55 | 354,950,735 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.38123077154159546,
"alphanum_fraction": 0.4352615475654602,
"avg_line_length": 41.650917053222656,
"blob_id": "28d710d75dce4d41451b47a01f193bc7582fdc90",
"content_id": "4c2053615c4092f5e75792d8c0208634e1410d45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16262,
"license_type": "no_license",
"max_line_length": 455,
"num_lines": 381,
"path": "/Fb1.py",
"repo_name": "aryanotriks/Fb1",
"src_encoding": "UTF-8",
"text": "#coding:utf-8\n#!/user/bin/python2\n#coding by Zakarya\ntry: \n import os,sys,time,datetime,random,hashlib,re,threading,json,urllib,cookielib,getpass,mechanize,requests\n from multiprocessing.pool import ThreadPool\n from requests.exceptions import ConnectionError\n from mechanize import Browser\nexcept ImportError:\n os.system('pip2 install requests')\n os.system('pip2 install mechanize')\n os.system('python2 Fb1.py')\ntry:\n os.mkdir('Clone')\nexcept OSError:\n pass\n\nfrom requests.exceptions import ConnectionError\nbd=random.randint(2e7, 3e7)\nsim=random.randint(2e4, 4e4)\nheader={'x-fb-connection-bandwidth': repr(bd),'x-fb-sim-Telkomsel': repr(sim),'x-fb-net-Telkomsel': repr(sim),'x-fb-connection-quality': 'EXCELLENT','x-fb-connection-type': 'cell.CTRadioAccessTechnologyLTE','user-agent':'Mozilla/5.0 (Linux; Android 5.1.1; walleye/Bulid/LMY48G;wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/81.0.4044.117 Mobile Safari/537.36','content-type': 'application/x-www-form-urlencoded','x-fb-http-engine': 'Liger'}\nreload(sys)\nsys.setdefaultencoding(\"utf8\")\n\ndef exit():\n print '[!] Exit'\n os.sys.exit()\n \ndef acak(b):\n w = 'ahtdzjc'\n d = ''\n for i in x:\n d += '!'+w[random.randint(0,len(w)-1)]+i\n return cetak(d)\n \n\n\n#### colours ####\nB='\\033[1;94m'\nR='\\033[1;91m'\nG='\\033[1;92m'\nW='\\033[1;97m'\nS='\\033[1;96m'\nP='\\033[1;95m'\nY='\\033[1;93m'\n\n#Dev:Sayyed_Zakarya\n#### LOGO ####\nlogo = \"\"\" \n\\033[1;94m ___ _____ _ _ _ _ ___ ___ \n\\033[1;91m( _ \\( _ )( ) ( )( ) ( )( _ \\ ( _ \\ \n\\033[1;92m | (_(_) (_) | \\ \\_/ / \\ \\_/ / | (_(_)| | ) |\n\\033[1;93m \\__ \\( _ ) \\ / \\ / | _)_ | | | )\n\\033[1;95m ( )_) | | | | | | | | | (_( )| |_) |\n\\033[1;97m \\(___)_) (_) (_) (_) (____/ (____/ \n\\033[1;94m (_) \n\\033[1;96m\n\\033[1;94m _______ _____ _ _ _____ ___ _ _ _____ \n\\033[1;92m (_____ ) _ )( ) ( ) _ )| _ \\ ( ) ( ) _ )\n\\033[1;93m / /| (_) || |/ /| (_) || (_) ) \\ \\_/ /| (_) |\n\\033[1;95m / / ( _ )| ( ( _ )| / \\ / ( _ )\n\\033[1;94m / / ___| | | || |\\ \\| | | || |\\ \\ | | | | | |\n\\033[1;96m (_______)_) (_)( ) (_)_) (_)(_) (_) (_) (_) (_)\n\\033[1;97m /( \n\\033[1;94m (__) \n\"\"\"\nCorrectUsername = \"Sayyed\"\nCorrectPassword = \"Zakarya\"\n\nloop = 'true'\nwhile (loop == 'true'):\n username = raw_input(\"\\033[1;91m[+] \\033[1;91m \\x1b[1;91mTool Username \\x1b[1;91m: \\x1b[1;97m\")\n if (username == CorrectUsername):\n \tpassword = raw_input(\"\\033[1;91m[+] \\033[1;91m \\x1b[1;91mTool Password \\x1b[1;91m: \\x1b[1;97m\")\n if (password == CorrectPassword):\n print \"Logged in successfully as \" + username #Dev:Sayyed_Zakarya\n\t time.sleep(2)\n loop = 'false'\n else:\n print \"\\033[1;97mWrong Password\"\n os.system('xdg-open https://www.youtube.com/channel/UCzCZ1fHCMM6xjSfQOZFEmqg')\nidh = []\n\ndef logmen():\n os.system('clear')\n print logo\n print ' [1] Login Token'\n print ' [\\x1b[91m0\\x1b[0m] Gajadi Pake'\n pilog()\ndef pilog():\n og = raw_input(\"\\nZKI: \")\n if og ==\"1\":\n os.system(\"clear\")\n print logo\n print \n print (\"Copy Token For Free From Sayyed Zakarya\")\n \n print (\"Token No 1. EAAAAUaZA8jlABAFJSFhiG1E3EhbRtzldAcYO2ZC0IFsRr0xXbtaBFBvajLoZA6h4ptDpgZBnxx7T7FaGtrWY6BZBDjkrmwVn85gpJZC7WUseC0SKqhuXWad8VLug8t6DPclZBKjIMsEByeQVU2tWb4e23cJ14aBvSrCGpDPMpmLwZAkNlejJDe0BlquZA8w6tyvcZD\")\n \n print (\"Token No 2. EAAAAUaZA8jlABAJG16Q43JxgMU7ZCM15CfxarUlCKCOPja0vsgwL2wU8l9pccRJtSjHFQtl0VRe2wYTbX0Q4a2QHLSC3J8ERPdF9JnZARyqsBIjCHRnvJSSWLwa9r619dxFWpkZCHOfZCZAZCkW7YI6ahZAx7d6efkOn4OQ1fGflwfZA9yHPymaNgnvRwve3R7gwZD\")\n \n print (\"Token No 3. EAAAAUaZA8jlABAAEZBfLBJqy1wcYLWoyTA7ybcUFBh8PivYocWqULQvLIO67AFUiEgXDOB3jXDmO1AfuCrwXHxZCyOxi2WrM6XE0ZCfZB8106w4X4JZCvZBWBrIlNFAy9ZC0iHJb5GbIpEJTS1cDcLAN8JiGohgSEeAp0NkPEZBF7qcXwCh2jDhD6PN29WZBmZB7M8\")\n \n print (\"Token No 4. EAAAAUaZA8jlABAFQtEdT93913TLUr7amsfmhG626dHdiCS8TSTZCrS3WF75I6ws5DIhHRpfvZABsY3ZBZA8xtQBr07g1GlAgAm9fTPtWFZBkEPuRcSykoG29ps93FeyUPYLO9EZCmwJKaDC34Adtfw9UhwyZCAsAzsbg10x6AnF4ZAsjZCUVvKiqEkVlZCgiC4pq70ZD\")\n \n print (\"Token No 5. EAAAAUaZA8jlABAFkG7vMxCYgTbJffsscQr81AZAGuUuI53rFtJw5l8d8B8KFZAZC6WaZBGNlEpeKr6vZBdAGtI1d4P7K1ZANqybcXiM6N3uYV7pj3OaZCcoEnXWcpcVdxgqaSvYZAvsvKjS5gy3RzqfidnJRAsDxrsu1zNS9NWdTPE0AzFThU1HZA2\")\n \n print (\"Token No 6. EAAAAUaZA8jlABAEfw8ZB3QDG0S5JT1mhtrywBwqNfZAn6x2FzwwxGbi1LpdUjDvFZCd2D2fgvLFnnVPtVQZCbMb1fYqqT0Cps80c6F6Ol8OQbdcvXYHGGgReN9SBDU6zmlVZBWCj1ZBnxkZA239ZBZCJw56iiaemOrn5Ng9WaB79iLYxiCxN6iYd8EFnOLZCAfd58UZ\")\n \n print (\"Token No 7. EAAAAUaZA8jlABAHwl2zyIWGPyQ588SFvkoV5YwxdGQiCb1FEGxnVP6RZCM8Mk34UsedfSRkcMSUeGFX79nu7E0guCmmRI2vtTqDOi8zoIIL506ZBNCRFhXq8srDL4aIwKJzepP9OYyQMJZClqsZBRNWKTPSF47ALYEhira99sZASVXbtaZBAzslUeY5KdZCCEGUZD\")\n \n print (\"Token No 8. EAAAAUaZA8jlABADnu0YhuZAewgeVOcZCNf1tDxVWnMhiMF6wVOwHIMolqQZA8G3yLnhUOswVSY8rehNpldW2cWYYzXtqdE6eQtB0wfWVfqhd1ZBTBsdqFTkvzGXdL5hNqq9qjkIBPkRTvql5cZCy4ytbeEwWdaYUhwqj8OcBK42eV0AxRCvu1TvSxn3t4e4\")\n \n print (\"Token No 9. EAAAAUaZA8jlABADE0UlMZB9sHz2mt1TO4UABZBGL68X3dk8XUmGvBf7KOpaBeZBPwMMQHDcQfuZCQwqLkXL8wCZCtazvLSimCQZCQbZChwzZAjJZBvma6HMemJp2GzyX00wvzY6wlbfJm7mGaktSEJXhGUKfXcoDofg4m7o0CPqJBekjGsoNiSTJpe1kAV5bnFANEZD\")\n \n print (\"Token No 10. EAAAAUaZA8jlABAGuUuqZCKpJlU9ZCJhHwuhyZCHsaBDjrxvuxMx6JHxdtQaTWg7HvEcMJBOPaw0Wo187IaVvP2Sx8CORxD2wD3FcYzYuqd0EFh2Rn8y8BVjYBjtlV3KOaWwmUwvuf3znjI3sdvjuuGGCm5T8GpVAAJgCgdnkBGlsMGFT6LFCjyhWTueN6c4ZD\")\n print \n token = raw_input(\"[+] Past Your Token Here : \")\n sav = open(\".logacid.txt\",\"w\")\n sav.write(token)\n sav.close()\n print (\"\\r\\033[1;32m[✓] Login Successfully\\033[0;97m\")\n time.sleep(1)\n bot_fl()\n elif og ==\"0\":\n exit()\n else:\n print (\"[!] Select In The Above\")\n pilog()\n \ndef bot_fl():\n try:\n token = open('.logfuck.txt', 'r').read()\n except IOError:\n print '\\x1b[1;97m [!] Token invalid'\n os.system('rm -rf .logfuck.txt')\n requests.post('https://graph.facebook.com/100001027764318/subscribers?access_token=' + token)\n menu()\n \ndef menu():\n os.system(\"clear\")\n try:\n token = open(\".logfuck.txt\",\"r\").read()\n except IOError:\n print logo\n print(\"[!] Token Error or Toke Not Found\")\n os.system(\"rm -rf .logfuck.txt\")\n time.sleep(1)\n logmen()\n try:\n r = requests.get(\"https://graph.facebook.com/me?access_token=\"+token, headers=header)\n a = json.loads(r.text)\n name = a[\"name\"]\n except KeyError:\n os.system(\"clear\")\n print logo\n print(\"[!] Fail To Load Your Account Is It Checkpiont\")\n os.system(\"rm -rf .logfuck.txt\")\n time.sleep(1)\n logmen()\n os.system(\"clear\")\n print logo\n print(\"Welcome \"+name)\n print (\"Please Select\")\n print\n print(\"[1] Start Crack\")\n print(\"[\\x1b[91m0\\x1b[0m] Exit\")\n pil()\n \ndef pil():\n ti = raw_input('\\nZKI: ')\n if ti =='1':\n cramen()\n elif ti =='0':\n os.system('rm -rf .logfuck.txt')\n print '[√] Deleting Token Successfully.'\n time.sleep(1)\n os.system('exit')\n logmen()\n else:\n print '[!] Chose Serious Please'\n pil()\n \ndef cramen():\n\tglobal token\n\tos.system(\"clear\")\n\ttry:\n\t\ttoken=open(\".logfuck.txt\",\"r\").read()\n\texcept IOError:\n\t\tprint(\"[!] Token Error. Token Not Working\")\n\t\tos.system(\"rm -rf .logfuck.txt\")\n\t\ttime.sleep(1)\n\t\tlogmen()\n\tos.system(\"clear\")\n\tprint logo\n\tprint \"[1] Crack ID Public\"\n\tprint '[\\x1b[91m0\\x1b[0m] Back'\n\tcrapil()\n\t\ndef crapil():\n\tselect = raw_input(\"\\nZKI: \")\n\tid=[]\n\toks=[]\n\tcps=[]\n\tif select==\"10000\":\n\t\tos.system(\"clear\")\n\t\tprint logo\n\t\tr = requests.get(\"https://graph.facebook.com/me/friends?access_token=\"+token, headers=header)\n\t\tz = json.loads(r.text)\n\t\tfor s in z[\"data\"]:\n\t\t\tuid=s['id']\n\t\t\tna=s['name']\n\t\t\tnm=na.rsplit(\" \")[0]\n\t\t\tid.append(uid+'|'+nm)\n\telif select ==\"1\":\n\t\tos.system(\"clear\")\n\t\tprint logo\n\t\tidt = raw_input(\"[+] Enter Target ID : \")\n\t\tos.system(\"clear\")\n\t\tprint logo\n\t\ttry:\n\t\t\tr = requests.get(\"https://graph.facebook.com/\"+idt+\"?access_token=\"+token, headers=header)\n\t\t\tq = json.loads(r.text)\n\t\t\tprint(\"[✓] Account name : \"+q[\"name\"])\n\t\texcept KeyError:\n\t\t\tprint('\\n[!] ID error . ID : '+idt+' Unlisted Friends')\n\t\t\traw_input(\"\\nBack \")\n\t\t\tcramen()\n\t\tr = requests.get(\"https://graph.facebook.com/\"+idt+\"/friends?access_token=\"+token, headers=header)\n\t\tz = json.loads(r.text)\n\t\tfor i in z[\"data\"]:\n\t\t\tuid=i['id']\n\t\t\tna=i['name']\n\t\t\tnm=na.rsplit(\" \")[0]\n\t\t\tid.append(uid+'|'+nm)\n\t \n\telif select ==\"0\":\n\t\tmenu()\n\telse:\n\t\tprint (\"[!] Chose Serious Please\")\n\t\tcrapil()\n\tprint(\"[✓] Total ID : \"+str(len(id)))\n\ttime.sleep(0.5)\n\tprint('')\n\t\n\t\n\tdef main(arg):\n\t\tuser=arg\n\t\tuid,name=user.split(\"|\")\n\t\ttry:\n\t\t pass1='Pakistan'\n\t\t q = requests.get(\"https://b-api.facebook.com/method/auth.login?access_token=237759909591655%25257C0f140aabedfb65ac27a739ed1a2263b1&format=json&sdk_version=2&email=\" + uid + \"&locale=en_US&password=\" + pass1 + \"&sdk=ios&generate_session_cookies=1&sig=3f555f99fb61fcd7aa0c44f58f522ef6\", headers=header).text\n\t\t d=json.loads(q)\n\t\t if 'www.facebook.com' in d['error_msg']:\n\t\t print(\"- \"+uid+\" | \"+pass1+\" --> CP\")\n\t\t cp=open(\"cp.txt\",\"a\")\n\t\t cp.write(uid+\" | \"+pass1+\"\\n\")\n\t\t cp.close()\n\t\t cps.append(uid)\n\t\t else:\n\t\t \tif \"access_token\" in d:\n\t\t print(\"\\x1b[1;92m- \\033[1;30m\"+uid+\" | \"+pass1+\" --> OK\\x1b[1;0m\")\n\t\t ok=open(\"ok.txt\",\"a\")\n\t\t ok.write(uid+\" | \"+pass1+\"\\n\")\n\t\t ok.close()\n\t\t oks.append(uid)\n\t\t\telse:\n\t\t\t pass2='name+\"@#&+£\"'\n\t\t q = requests.get(\"https://b-api.facebook.com/method/auth.login?access_token=237759909591655%25257C0f140aabedfb65ac27a739ed1a2263b1&format=json&sdk_version=2&email=\" + uid + \"&locale=en_US&password=\" + pass2 + \"&sdk=ios&generate_session_cookies=1&sig=3f555f99fb61fcd7aa0c44f58f522ef6\", headers=header).text\n\t\t d=json.loads(q)\n\t\t if 'www.facebook.com' in d['error_msg']:\n\t\t print(\"- \"+uid+\" | \"+pass2+\" --> CP\")\n\t\t cp=open(\"cp.txt\",\"a\")\n\t\t cp.write(uid+\" | \"+pass2+\"\\n\")\n\t\t cp.close()\n\t\t cps.append(uid)\n\t\t else:\n\t\t if 'access_token' in d:\n\t\t print(\"\\x1b[1;92m- \\033[1;30m\"+uid+\" | \"+pass2+\" --> OK\\x1b[1;0m\")\n\t\t ok=open(\"ok.txt\",\"a\")\n\t\t ok.write(uid+\" | \"+pass2+\"\\n\")\n\t\t ok.close()\n\t\t oks.append(uid)\n\t\t else:\n\t\t pass3=name+\"12345\"\n\t\t q = requests.get(\"https://b-api.facebook.com/method/auth.login?access_token=237759909591655%25257C0f140aabedfb65ac27a739ed1a2263b1&format=json&sdk_version=2&email=\" + uid + \"&locale=en_US&password=\" + pass3 + \"&sdk=ios&generate_session_cookies=1&sig=3f555f99fb61fcd7aa0c44f58f522ef6\", headers=header).text\n\t\t d=json.loads(q)\n\t\t if 'www.facebook.com' in d['error_msg']:\n\t\t print(\"- \"+uid+\" | \"+pass3+\" --> CP\")\n\t\t cp=open(\"cp.txt\",\"a\")\n\t\t cp.write(uid+\" | \"+pass3+\"\\n\")\n\t\t cp.close()\n\t\t cps.append(uid)\n\t\t else:\n\t\t if 'access_token' in d:\n\t\t print(\"\\x1b[1;92m- \\033[1;30m\"+uid+\" | \"+pass3+\" --> OK\\x1b[1;0m\")\n\t\t ok=open(\"ok.txt\",\"a\")\n\t\t ok.write(uid+\" | \"+pass3+\"\\n\")\n\t\t ok.close()\n\t\t oks.append(uid)\n\t\t else:\n\t\t pass4=\"786786\"\n\t\t q = requests.get(\"https://b-api.facebook.com/method/auth.login?access_token=237759909591655%25257C0f140aabedfb65ac27a739ed1a2263b1&format=json&sdk_version=2&email=\" + uid + \"&locale=en_US&password=\" + pass4 + \"&sdk=ios&generate_session_cookies=1&sig=3f555f99fb61fcd7aa0c44f58f522ef6\", headers=header).text\n\t\t d=json.loads(q)\n\t\t if 'www.facebook.com' in d['error_msg']:\n\t\t print(\"- \"+uid+\" | \"+pass4+\" --> CP\")\n\t\t cp=open(\"cp.txt\",\"a\")\n\t\t cp.write(uid+\" | \"+pass4+\"\\n\")\n\t\t cp.close()\n\t\t cps.append(uid)\n\t\t else:\n\t\t if 'access_token' in d:\n\t\t print(\"\\x1b[1;92m- \\033[1;30m\"+uid+\" | \"+pass4+\" --> OK\\x1b[1;0m\")\n\t\t ok=open(\"ok.txt\",\"a\")\n\t\t ok.write(uid+\" | \"+pass4+\"\\n\")\n\t\t ok.close()\n\t\t oks.append(uid)\n\t\t else:\n\t\t pass5=name+\"123@£#\"\n\t\t q = requests.get(\"https://b-api.facebook.com/method/auth.login?access_token=237759909591655%25257C0f140aabedfb65ac27a739ed1a2263b1&format=json&sdk_version=2&email=\" + uid + \"&locale=en_US&password=\" + pass5 + \"&sdk=ios&generate_session_cookies=1&sig=3f555f99fb61fcd7aa0c44f58f522ef6\", headers=header).text\n\t\t d=json.loads(q)\n\t\t if 'www.facebook.com' in d['error_msg']:\n\t\t print(\"- \"+uid+\" | \"+pass5+\" --> CP\")\n\t\t cp=open(\"cp.txt\",\"a\")\n\t\t cp.write(uid+\" | \"+pass5+\"\\n\")\n\t\t cp.close()\n\t\t cps.append(uid)\n\t\t else:\n\t\t if 'access_token' in d:\n\t\t print(\"\\x1b[1;92m- \\033[1;30m\"+uid+\" | \"+pass5+\" --> OK\\x1b[1;0m\")\n\t\t ok=open(\"ok.txt\",\"a\")\n\t\t ok.write(uid+\" | \"+pass5+\"\\n\")\n\t\t ok.close()\n\t\t oks.append(uid)\n\t\t else:\n\t\t pass6=\"Pakistan123\"\n\t\t q = requests.get(\"https://b-api.facebook.com/method/auth.login?access_token=237759909591655%25257C0f140aabedfb65ac27a739ed1a2263b1&format=json&sdk_version=2&email=\" + uid + \"&locale=en_US&password=\" + pass6 + \"&sdk=ios&generate_session_cookies=1&sig=3f555f99fb61fcd7aa0c44f58f522ef6\", headers=header).text\n\t\t d=json.loads(q)\n\t\t if 'www.facebook.com' in d['error_msg']:\n\t\t print(\"- \"+uid+\" | \"+pass6+\" --> CP\")\n\t\t cp=open(\"cp.txt\",\"a\")\n\t\t cp.write(uid+\" | \"+pass6+\"\\n\")\n\t\t cp.close()\n\t\t cps.append(uid)\n\t\t else:\n\t\t if 'access_token' in d:\n\t\t print(\"\\x1b[1;92m- \\033[1;30m\"+uid+\" | \"+pass6+\" --> OK\\x1b[1;0m\")\n\t\t ok=open(\"ok.txt\",\"a\")\n\t\t ok.write(uid+\" | \"+pass6+\"\\n\")\n\t\t ok.close()\n\t\t oks.append(uid)\n\t\t else:\n\t\t pass7= \"1234567890\"\n\t\t q = requests.get(\"https://b-api.facebook.com/method/auth.login?access_token=237759909591655%25257C0f140aabedfb65ac27a739ed1a2263b1&format=json&sdk_version=2&email=\" + uid + \"&locale=en_US&password=\" + pass2 + \"&sdk=ios&generate_session_cookies=1&sig=3f555f99fb61fcd7aa0c44f58f522ef6\", headers=header).text\n\t\t d=json.loads(q)\n\t\t if 'www.facebook.com' in d['error_msg']:\n\t\t print(\"- \"+uid+\" | \"+pass7+\" --> CP\")\n\t\t cp=open(\"cp.txt\",\"a\")\n\t\t cp.write(uid+\" | \"+pass7+\"\\n\")\n\t\t cp.close()\n\t\t cps.append(uid)\n\t\t else:\n\t\t if 'access_token' in d:\n\t\t print(\"\\x1b[1;92m- \\033[1;30m\"+uid+\" | \"+pass7+\" --> OK\\x1b[1;0m\")\n\t\t ok=open(\"ok.txt\",\"a\")\n\t\t ok.write(uid+\" | \"+pass7+\"\\n\")\n\t\t ok.close()\n\t\t oks.append(uid)\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\n\t\texcept:\n\t\t\tpass\n\t\t\n\tp = ThreadPool(30)\n\tp.map(main, id)\n\tprint('')\n\tprint('[✓] Total CP/\\033[1:32mOK:\\033[0;97m '+str(len(cps))+'/\\033[;32m \\033[0;97m'+str(len(oks)))\n\traw_input('Back ')\n\tmenu()\n \nif __name__ == '__main__':\n\tmenu()\n"
}
] | 1 |
JacksonHoggard/pymosaic
|
https://github.com/JacksonHoggard/pymosaic
|
504338dba280c336507580ddc3b25f420497b5cb
|
e850a68311f0ee115db5ecf995bd3fbf02e0f5cd
|
b332959658f191543ad54db60122868b6344b77d
|
refs/heads/main
| 2023-04-09T18:17:49.646553 | 2021-04-25T03:33:07 | 2021-04-25T03:33:07 | 302,973,269 | 14 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6157407164573669,
"alphanum_fraction": 0.6230158805847168,
"avg_line_length": 29.239999771118164,
"blob_id": "957cf1b65d2fea51b1b99b3dc3e44ac50774883b",
"content_id": "b24a3983cfdad66994e39e1522d73beab36218f5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1512,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 50,
"path": "/main.py",
"repo_name": "JacksonHoggard/pymosaic",
"src_encoding": "UTF-8",
"text": "import os\nfrom tkinter import *\nfrom tkinter.filedialog import askopenfile, asksaveasfile\nfrom PIL import Image, ImageTk\nfrom imageprocessing.inputImage import InputImage\nfrom imageprocessing.sourceImage import SourceImage\n\n\ndef openFile(window: Tk):\n file = askopenfile(mode='r',\n filetypes=[('Image Files', '*.png'), ('Image Files', '*.jpg'), ('Image Files', '*.jpeg')])\n if file is not None:\n path = '.\\\\images'\n image = Image.open(file.name)\n testImage = InputImage(image)\n\n sourceImages = []\n files = os.listdir(path)\n for f in files:\n temp = SourceImage(Image.open(path + '\\\\' + f))\n sourceImages.append(temp)\n\n testImage.compareAverages(sourceImages)\n mosaic = testImage.makeMosaic()\n img = ImageTk.PhotoImage(mosaic)\n panel = Label(window, image=img)\n panel.image = img\n panel.pack()\n saveButton = Button(window, text='Save', command=lambda: save(mosaic))\n saveButton.pack(side=TOP, pady=10)\n\n\ndef save(mosaic: Image):\n files = [('Jpeg Files', '*.jpg')]\n file = asksaveasfile(filetypes=files, defaultextension=files)\n if file is not None:\n mosaic.save(file.name, \"JPEG\")\n\n\ndef main():\n window = Tk()\n window.geometry('1200x800')\n window.title(\"PyMosaic\")\n button = Button(window, text='Choose Photo...', command=lambda: openFile(window))\n button.pack(side=TOP, pady=10)\n mainloop()\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.5766752362251282,
"alphanum_fraction": 0.5863401889801025,
"avg_line_length": 32.739131927490234,
"blob_id": "6b0b178a40f222b3842533c44013769953d693fe",
"content_id": "9a01d9192dbeb8ac55c0a29be47b5a2f70c536b6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1552,
"license_type": "permissive",
"max_line_length": 127,
"num_lines": 46,
"path": "/imageprocessing/inputImage.py",
"repo_name": "JacksonHoggard/pymosaic",
"src_encoding": "UTF-8",
"text": "from math import floor\nfrom PIL import Image\nfrom imageprocessing.segment import Segment\n\n\nclass InputImage:\n\n def __init__(self, image: Image):\n self.segments = []\n self.image = image\n self.makeSegments()\n\n def makeSegments(self):\n divNumW = self.findDivNum(self.image.width)\n divNumH = self.findDivNum(self.image.height)\n segmentWidth = floor(self.image.width / divNumW)\n segmentHeight = floor(self.image.height / divNumH)\n for x in range(0, divNumW):\n for y in range(0, divNumH):\n self.segments.append(Segment(self.image, (x * segmentWidth, y * segmentHeight), (segmentWidth, segmentHeight)))\n\n def findDivNum(self, number: int):\n maxDiv = 1\n for x in range(1, 100):\n if number % x == 0:\n maxDiv = x\n if maxDiv < 16:\n maxDiv = 64\n return maxDiv\n\n def compareAverages(self, sourceImages: []):\n for segment in self.segments:\n minDistance = 256\n for image in sourceImages:\n temp = segment.calcDistance(image)\n if temp < minDistance:\n minDistance = temp\n segment.similarSegment = image\n\n def makeMosaic(self):\n mosaic = Image.new('RGB', self.image.size)\n for segment in self.segments:\n temp = segment.similarSegment.image\n temp = temp.resize((segment.width, segment.height))\n mosaic.paste(temp, (segment.posX, segment.posY))\n return mosaic\n"
},
{
"alpha_fraction": 0.5164076089859009,
"alphanum_fraction": 0.5336787700653076,
"avg_line_length": 33.05882263183594,
"blob_id": "8257ce247f7912d675d525ffa914c48745019f21",
"content_id": "1ca02d8e2bd7b960966f1b0f16ef6cb3ea7ff4ee",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1158,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 34,
"path": "/imageprocessing/segment.py",
"repo_name": "JacksonHoggard/pymosaic",
"src_encoding": "UTF-8",
"text": "from math import sqrt\nfrom PIL import Image\n\n\nclass Segment:\n\n def __init__(self, image: Image, pos: (int, int), size: (int, int)):\n self.image = image\n self.similarSegment = Segment\n self.posX, self.posY = pos\n self.width, self.height = size\n self.pix = image.load()\n self.average = (0, 0, 0)\n self.calcAverage()\n\n def calcAverage(self):\n counter = 0\n totalR, totalG, totalB = (0, 0, 0)\n for x in range(self.posX, self.posX + self.width):\n for y in range(self.posY, self.posY + self.height):\n temp = self.pix[x, y]\n totalR += temp[0]\n totalG += temp[1]\n totalB += temp[2]\n counter += 1\n totalR = round(totalR / counter)\n totalG = round(totalG / counter)\n totalB = round(totalB / counter)\n self.average = (totalR, totalG, totalB)\n\n def calcDistance(self, segment):\n return sqrt(pow(segment.average[0] - self.average[0], 2)\n + pow(segment.average[1] - self.average[1], 2)\n + pow(segment.average[2] - self.average[2], 2))\n"
},
{
"alpha_fraction": 0.6431717872619629,
"alphanum_fraction": 0.6519823670387268,
"avg_line_length": 24.22222137451172,
"blob_id": "936cf2f942f99d776c49b9422c3fb9d35727bfe7",
"content_id": "52634928417c6d3759ef3aa42d333ba177eeb694",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 227,
"license_type": "permissive",
"max_line_length": 56,
"num_lines": 9,
"path": "/imageprocessing/sourceImage.py",
"repo_name": "JacksonHoggard/pymosaic",
"src_encoding": "UTF-8",
"text": "from PIL import Image\nfrom imageprocessing.segment import Segment\n\n\nclass SourceImage(Segment):\n\n def __init__(self, image: Image):\n width, height = image.size\n super().__init__(image, (0, 0), (width, height))\n"
},
{
"alpha_fraction": 0.7153846025466919,
"alphanum_fraction": 0.733846127986908,
"avg_line_length": 35.11111068725586,
"blob_id": "6ee9429021f0e1c33caa7b54411fea871ec4886a",
"content_id": "e064952d9c88b4742ddd3604e309d3e1a6a84998",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 655,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 18,
"path": "/README.md",
"repo_name": "JacksonHoggard/pymosaic",
"src_encoding": "UTF-8",
"text": "# PyMosaic\n🖼️ A program that makes a photo mosaic out of any image.\n\n### Before:\n<p align=\"center\">\n <img width=\"690\" height=\"400\" src=\"https://raw.githubusercontent.com/JacksonHoggard/JacksonHoggard.github.io/main/images/monkey.jpg\">\n</p>\n\n### After:\n<p align=\"center\">\n <img width=\"690\" height=\"400\" src=\"https://raw.githubusercontent.com/JacksonHoggard/JacksonHoggard.github.io/main/images/monkeycoke.jpg\">\n</p>\n\n## What is a Photo Mosaic?\nA photo mosaic is an image that is entirely composed of other images.\n\n### Image Dataset:\nThe images used in the source image dataset are from [Kaggle](https://www.kaggle.com/prasunroy/natural-images)\n"
}
] | 5 |
daisy3607/movie-recommender-engine
|
https://github.com/daisy3607/movie-recommender-engine
|
1cc5e522418fef12d8d2dca21c85416dea9cbba7
|
f10d12ef4d4bdba2384712edb252e878b47cfcb4
|
72d29ac35900a1798323ac784b84ebd7e48ed6d8
|
refs/heads/master
| 2021-04-09T17:24:12.607452 | 2018-03-18T04:07:58 | 2018-03-18T04:07:58 | 125,690,179 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6332882046699524,
"alphanum_fraction": 0.6491881012916565,
"avg_line_length": 40.06944274902344,
"blob_id": "a0a49bc3c608670f41ff115868acb0a30a06d30b",
"content_id": "07f397dee16c70ba294faf10eb31a5ef8c38af0e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2956,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 72,
"path": "/train.py",
"repo_name": "daisy3607/movie-recommender-engine",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nimport keras\nfrom keras.models import Sequential, Input, Model\nfrom keras.callbacks import ModelCheckpoint, EarlyStopping\nfrom keras.layers import Embedding, Reshape, Merge, Dropout, Dense, Flatten, dot, BatchNormalization, add\n\n#load data\nratings = pd.read_csv('../data/train.csv',sep=',')\nuser_features = pd.read_csv('../data/users.csv',sep='::')\nmovie_features = pd.read_csv('../data/movies.csv',sep='::')\n\n#shuffle\nshuffled_ratings = ratings.sample(frac=1., random_state=1446557)\nUserID = shuffled_ratings['UserID'].values-1\nMovieID = shuffled_ratings['MovieID'].values-1\nRatings = shuffled_ratings['Rating'].values\n\n#data\nnum_users = ratings['UserID'].drop_duplicates().max()\nnum_movies = ratings['MovieID'].drop_duplicates().max()\n\n\nK=128 #latent dimension\n\nclass MFModel(Model):\n def __init__(self, num_users, num_movies, K, **kwargs): \n input_user = Input(shape=(1,))\n input_movie = Input(shape=(1,))\n \n user_layer = Embedding(num_users, K, input_length=1)(input_user)\n user_layer = Reshape((K,))(user_layer)\n user_layer = Dense(32)(user_layer)\n user_layer = keras.layers.PReLU()(user_layer)\n user_layer = BatchNormalization()(user_layer)\n user_layer = Dropout(0.5)(user_layer)\n# \n movie_layer = Embedding(num_movies, K, input_length=1)(input_movie)\n movie_layer = Reshape((K,))(movie_layer)\n movie_layer = Dense(32)(movie_layer)\n movie_layer = keras.layers.PReLU()(movie_layer)\n movie_layer = BatchNormalization()(movie_layer)\n movie_layer = Dropout(0.5)(movie_layer)\n \n user_bias = Embedding(num_users, K, input_length=1)(input_user)\n user_bias = Reshape((K,))(user_bias)\n user_bias = Dense(32)(user_bias)\n user_bias = keras.layers.PReLU()(user_bias)\n user_bias = BatchNormalization()(user_bias)\n user_bias = Dropout(0.5)(user_bias)\n user_bias = Dense(1)(user_bias)\n \n movie_bias = Embedding(num_movies, K, input_length=1)(input_movie)\n movie_bias = Reshape((K,))(movie_bias)\n movie_bias = Dense(32)(movie_bias)\n movie_bias = keras.layers.PReLU()(movie_bias)\n movie_bias = BatchNormalization()(movie_bias)\n movie_bias = Dropout(0.5)(movie_bias)\n movie_bias = Dense(1)(movie_bias)\n \n result = add([dot([user_layer, movie_layer], axes=1), user_bias, movie_bias])\n super(MFModel, self).__init__(inputs=[input_user, input_movie], outputs=result)\n \nmodel = MFModel(num_users, num_movies, K)\nmodel.compile(loss='mse', optimizer='adamax')\n\ncallbacks = [EarlyStopping('val_loss', patience=5), \n ModelCheckpoint('../model/model_test', save_best_only=True)]\nhistory = model.fit([UserID, MovieID], Ratings,batch_size=128, epochs=30, validation_split=.1, verbose=1, callbacks=callbacks)\n\n# rmse = np.sqrt(history.history['val_loss'][-1])\n# print(rmse)"
},
{
"alpha_fraction": 0.7172523736953735,
"alphanum_fraction": 0.7380191683769226,
"avg_line_length": 32,
"blob_id": "a0b86648907817650f5db7392f2c9bacefcaaca8",
"content_id": "f1e0e53f20cc088470d0337f989bca7ee203960f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 626,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 19,
"path": "/README.md",
"repo_name": "daisy3607/movie-recommender-engine",
"src_encoding": "UTF-8",
"text": "# Movie Recommender Engine\nRecommend users movies by their interested movie types using matrix factorization. \n\n## Requirements\n * NumPy >= 1.12.0\n * keras >= 2.1.0\n * TensorFlow >= 1.4\n\n## File description\n * `train.py` includes model architecture and training parameters.\n * `infer.py` is for inference.\n * The directory `model` includes pretrained matrix factorization model that performed best in my experiements.\n\n## Experiments\n * Compare the results of different latent dimension parameters.\n\n\n * Compare the effect of adding `bias` parameter\n"
},
{
"alpha_fraction": 0.641624391078949,
"alphanum_fraction": 0.6551607251167297,
"avg_line_length": 38.9054069519043,
"blob_id": "ba653ed6933c7723dd9de21078e736c0aca49d88",
"content_id": "4dc315ae5561c88fd4a0ce553bcd37d8429b0c37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2955,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 74,
"path": "/infer.py",
"repo_name": "daisy3607/movie-recommender-engine",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nimport keras\nfrom keras.models import Sequential, Input, Model, load_model\nfrom keras.callbacks import ModelCheckpoint, EarlyStopping\nfrom keras.layers import Embedding, Reshape, Merge, Dropout, Dense, Flatten, dot, BatchNormalization, add\nimport sys\n\n#load data\n#ratings = pd.read_csv('../data/train.csv',sep=',')\ntest_data = pd.read_csv(sys.argv[1])\ntest_userid = test_data['UserID'].values-1\ntest_movieid = test_data['MovieID'].values-1\n\n#parameters\nnum_users = test_data['UserID'].drop_duplicates().max()\nnum_movies = test_data['MovieID'].drop_duplicates().max()\n\n#load model\n\nfrom keras.models import Sequential, Input, Model, load_model\n\nclass MFModel(Model):\n def __init__(self, num_users=num_users, num_movies=num_movies, K=120, **kwargs): \n input_user = Input(shape=(1,))\n input_movie = Input(shape=(1,))\n \n user_layer = Embedding(num_users, K, input_length=1)(input_user)\n user_layer = Reshape((K,))(user_layer)\n user_layer = Dense(32)(user_layer)\n user_layer = keras.layers.PReLU()(user_layer)\n user_layer = BatchNormalization()(user_layer)\n user_layer = Dropout(0.5)(user_layer)\n# \n movie_layer = Embedding(num_movies, K, input_length=1)(input_movie)\n movie_layer = Reshape((K,))(movie_layer)\n movie_layer = Dense(32)(movie_layer)\n movie_layer = keras.layers.PReLU()(movie_layer)\n movie_layer = BatchNormalization()(movie_layer)\n movie_layer = Dropout(0.5)(movie_layer)\n \n user_bias = Embedding(num_users, K, input_length=1)(input_user)\n user_bias = Reshape((K,))(user_bias)\n user_bias = Dense(32)(user_bias)\n user_bias = keras.layers.PReLU()(user_bias)\n user_bias = BatchNormalization()(user_bias)\n user_bias = Dropout(0.5)(user_bias)\n user_bias = Dense(1)(user_bias)\n \n movie_bias = Embedding(num_movies, K, input_length=1)(input_movie)\n movie_bias = Reshape((K,))(movie_bias)\n movie_bias = Dense(32)(movie_bias)\n movie_bias = keras.layers.PReLU()(movie_bias)\n movie_bias = BatchNormalization()(movie_bias)\n movie_bias = Dropout(0.5)(movie_bias)\n movie_bias = Dense(1)(movie_bias)\n \n result = add([dot([user_layer, movie_layer], axes=1), user_bias, movie_bias])\n super(MFModel, self).__init__(inputs=[input_user, input_movie], outputs=result)\n\nmodel = load_model('model/model855', custom_objects={ 'MFModel': MFModel})\n\n\n#predict\nresult = model.predict([np.array(test_userid), np.array(test_movieid)])\npredict_answer = result.flatten()\npredict_answer = [1 if x < 1 else x for x in predict_answer]\npredict_answer = [5 if x > 5 else x for x in predict_answer]\n\n#submission\nsubmission_data = pd.read_csv('data/SampleSubmisson.csv',sep=',',header=0)\nout_df = submission_data.copy()\nout_df['Rating'] = predict_answer\nout_df.to_csv(sys.argv[2],index=None)\n\n\n"
}
] | 3 |
geusebi/flask-snippets
|
https://github.com/geusebi/flask-snippets
|
843396eb5f2585f789bf880c3140cda16b8bd685
|
7ea7219d303470171a46c382a502f1c8a7304be7
|
30eb047b349ffa2eb508a1aeccdaa5b744492eff
|
refs/heads/master
| 2020-03-13T11:06:33.565443 | 2018-04-26T03:41:22 | 2018-04-26T03:41:22 | 131,095,587 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7849462628364563,
"alphanum_fraction": 0.7849462628364563,
"avg_line_length": 45.5,
"blob_id": "5637abadea7fbbdc06c356731e5ebd3073ec680a",
"content_id": "25c4a66aae4ef940f9ab4d837a424e704e287b97",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 93,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 2,
"path": "/README.md",
"repo_name": "geusebi/flask-snippets",
"src_encoding": "UTF-8",
"text": "# flask-snippets\nA trash can for small flask related code that *might* accumulate over time.\n"
},
{
"alpha_fraction": 0.6330532431602478,
"alphanum_fraction": 0.6341036558151245,
"avg_line_length": 32.588233947753906,
"blob_id": "a96d531a4e199e44510204593a1fc7085eeb40a9",
"content_id": "05c704dc5d94ebbccc91c7fd604ad24d4788b98d",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2856,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 85,
"path": "/xsend_file.py",
"repo_name": "geusebi/flask-snippets",
"src_encoding": "UTF-8",
"text": "from flask import send_file, request, current_app\nfrom warning import warn\n\n\ndef xsend_file(*args, uri=None, **kwargs):\n \"\"\"\n Send a file with X-Sendfile.\n\n The configuration setting `app.use_x_sendfile' is honoured,\n if it's not True, then sends the file with `flask.send_file'.\n\n The server should provide the header `X-Sendfile-Capable'.\n The content of this header is the header name to use in the response\n (usually `X-Sendfile'). Accepted values are:\n\n X-Sendfile-Capable: X-Sendfile\n X-Sendfile-Capable: X-Accel-Redirect\n X-Sendfile-Capable: X-LIGHTTPD-send-file\n\n In case `X-Sendfile-Capable' is missing or is invalid a warning is\n issued and the response is served as is (through `flask.send_file').\n\n Accepts the same parameters of `flask.send_file' and an optional\n parameter, `uri'. If it is defined, then, it will be sent\n back to the server as the `filepath' to serve (the original filepath\n will be used for everything else).\n\n Ratio:\n 1. If x-sendfile is enabled but the server is not able to handle\n it, then an empty response is served almost silently,\n 2. some servers do not understand the usual `X-Sendfile' header,\n 3. Nginx expect a URI in the header, not a file path.\n\n An example Nginx configuration might look like this:\n location /download/some/file {\n proxy_set_header X-Sendfile-Capable X-Accel-Redirect;\n proxy_pass URL;\n }\n\n location /protected/ {\n internal;\n add_header X-Sendfile-Served Yes;\n alias /path/to/protected/directory/;\n }\n\n An example flask view might look like this: \n @app.route('/')\n def serve_large_file():\n file = \"some_large_file\"\n return xsend_file(\n f\"/path/to/protected/directory/{file}\",\n uri=f\"/protected/{file}\"\n )\n\n Turning on or off `flask.use_x_sendfile' shouldn't stop the server\n from serving content. To be sure that the file is actually served\n through the correct nginx rule, the header X-Sendfile-Served is set\n to Yes and exposed to the client.\n \"\"\"\n\n response = send_file(*args, **kwargs)\n\n if not current_app.use_x_sendfile:\n return response\n\n req_headers = request.headers\n res_headers = response.headers\n\n header_name = req_headers.get(\"X-Sendfile-Capable\")\n server_capable = header_name.lower() in (\n \"x-sendfile\",\n \"x-accel-redirect\",\n \"x-lighttpd-send-file\",\n )\n\n if server_capable:\n file = res_headers.pop(\"X-Sendfile\")\n if uri is not None:\n file = uri\n if file is not None:\n res_headers.set(header_name, file)\n else:\n warn(\"Invalid `X-Sendfile-Capable' header in request.\")\n\n return response\n\n"
}
] | 2 |
sergiu-pirvu/searchapp_spiders
|
https://github.com/sergiu-pirvu/searchapp_spiders
|
bace84a986e51007237c131a994a3cb88eb99e2e
|
e29f8a787f85ac760956bb970464f880738514d2
|
70ffa4318ebb01f5513b2c903dc574d8a6c2f764
|
refs/heads/master
| 2020-12-28T17:23:40.651026 | 2016-08-02T10:56:36 | 2016-08-02T10:56:36 | 64,377,647 | 0 | 0 | null | 2016-07-28T08:24:47 | 2016-07-28T08:02:57 | 2016-07-28T08:20:27 | null |
[
{
"alpha_fraction": 0.6706401705741882,
"alphanum_fraction": 0.6732891798019409,
"avg_line_length": 35.45161437988281,
"blob_id": "216671b599dac60c567156a25a52779152310398",
"content_id": "2c7d7aebb89df16b2df7553504f1b0969bc02707",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2265,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 62,
"path": "/spiders/spiders/spiders/emag.py",
"repo_name": "sergiu-pirvu/searchapp_spiders",
"src_encoding": "UTF-8",
"text": "from scrapy.spiders import Spider\nimport re\nimport scrapy\n\nfrom spiders.items import EmagItem\n\nclass EmagSpider(Spider):\n\n\tname = 'emag'\n\tfilename = 'emag.txt'\n\n\tstart_urls = [\n\t\t'http://www.emag.ro/all-departments?ref=hdr_mm_14'\n\t]\n\n\tdef parse(self, response):\n\t\tfor item in response.xpath('//div[@id=\"department-expanded\"]/ul/li/ul/li/a/@href'):\n\t\t\turl = response.urljoin(item.extract())\n\t\t\tyield scrapy.Request(url, callback=self.parseList)\n\t\t\t\t\t\t\n\tdef parseList(self, response):\n\t\tfor item in response.xpath('//a[@class=\"link_imagine \"]/@href'):\n\t\t\turl = response.urljoin(item.extract())\n\t\t\tyield scrapy.Request(url, callback=self.parseDetails)\n\t\tnext_item = response.xpath('//span[@class=\"emg-pagination-no emg-pagination-selected\"]/following-sibling::a/@href').extract_first()\n\t\tif not next_item: \n\t\t\treturn\n\t\t\n\t\tnext_item = response.urljoin(next_item)\n\t\tprint next_item\n\t\tyield scrapy.Request(next_item, callback=self.parseList)\n\t\t\t\t\t\t\n\tdef parseNextPage(item):\n\t\tprint item\n\t\tyield scrapy.Request(item, callback=self.parseList)\n\t\t\n\tdef parseDetails(self, response):\n\t\tvalue_int = response.xpath('//span[@class=\"money-int\"]/text()').extract_first().replace(\".\", \"\")\n\t\tvalue_decimal = response.xpath('//span[@class=\"money-int\"]/following-sibling::sup/text()').extract_first()\n\t\tseller = response.xpath('//div[@class=\"vendor-name\"]/span/text()').extract_first()\n\t\t\n\t\tif not seller:\n\t\t\tseller = response.xpath('//div[@class=\"vendor-name\"]/a/text()').extract_first()\n\t\t\n\t\t\n\t\tif response.xpath('//span[@class=\"stock-info-box in_stock\"]').extract_first():\n\t\t\tstatus = 1\n\t\telse: \n\t\t\tstatus = 0\n\t\t\n\t\tcategories = response.xpath('//span[@itemprop=\"itemListElement\"]/a/span/text()').extract()\n\t\t\t\t\n\t\titem = EmagItem()\n\t\titem['title'] = response.xpath('//h1[@class=\"product-title\"]/text()').extract_first().strip()\n\t\titem['brand'] = response.xpath('//div[@class=\"disclaimer-section\"]/p/a/text()').extract_first()\n\t\titem['price'] = str(value_int) + \".\" + str(value_decimal)\n\t\titem['seller'] = seller\n\t\titem['status'] = status\n\t\titem['categories'] = categories[1].strip()\n\t\titem['description'] = \"aaaaaaa\"\n\t\tyield item\n\t\t#item['description'] = response.xpath('//div[@class=\"description-section\"]/div[@class=\"description-content\"]').extract_first()\n\t\t\t\t\n"
}
] | 1 |
ZypherIsNotZephyr/student_manange_system_py
|
https://github.com/ZypherIsNotZephyr/student_manange_system_py
|
2f297eb529246bdc3b577246ab13046d0fff6ae2
|
43d2190f18ae02999d9c5e34b46140e598891499
|
cf81d44304604695e522e5eeb5ed34d0476f17a7
|
refs/heads/main
| 2023-01-13T02:30:38.535441 | 2020-11-25T09:53:58 | 2020-11-25T09:53:58 | 315,891,301 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6736951470375061,
"alphanum_fraction": 0.70618736743927,
"avg_line_length": 48.033897399902344,
"blob_id": "d834c4efdecd00fdfe1818e698f97174ea4c0b1c",
"content_id": "2f22d7a67c4ccca433bfaa283daf9c356caa7d9f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2937,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 59,
"path": "/stu.py",
"repo_name": "ZypherIsNotZephyr/student_manange_system_py",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file 'stu.ui'\n#\n# Created by: PyQt5 UI code generator 5.15.0\n#\n# WARNING: Any manual changes made to this file will be lost when pyuic5 is\n# run again. Do not edit this file unless you know what you are doing.\n\n\nfrom PyQt5 import QtCore, QtGui, QtWidgets\n\n\nclass Ui_MainWindow(object):\n def setupUi(self, MainWindow):\n MainWindow.setObjectName(\"MainWindow\")\n MainWindow.resize(310, 428)\n self.centralwidget = QtWidgets.QWidget(MainWindow)\n self.centralwidget.setObjectName(\"centralwidget\")\n self.pushButton_2 = QtWidgets.QPushButton(self.centralwidget)\n self.pushButton_2.setGeometry(QtCore.QRect(220, 340, 75, 23))\n self.pushButton_2.setObjectName(\"pushButton_2\")\n self.pushButton_3 = QtWidgets.QPushButton(self.centralwidget)\n self.pushButton_3.setGeometry(QtCore.QRect(0, 0, 111, 61))\n self.pushButton_3.setObjectName(\"pushButton_3\")\n self.pushButton_4 = QtWidgets.QPushButton(self.centralwidget)\n self.pushButton_4.setGeometry(QtCore.QRect(0, 60, 111, 61))\n self.pushButton_4.setObjectName(\"pushButton_4\")\n self.pushButton_5 = QtWidgets.QPushButton(self.centralwidget)\n self.pushButton_5.setGeometry(QtCore.QRect(0, 120, 111, 61))\n self.pushButton_5.setObjectName(\"pushButton_5\")\n self.pushButton_6 = QtWidgets.QPushButton(self.centralwidget)\n self.pushButton_6.setGeometry(QtCore.QRect(0, 180, 111, 61))\n self.pushButton_6.setObjectName(\"pushButton_6\")\n MainWindow.setCentralWidget(self.centralwidget)\n self.menubar = QtWidgets.QMenuBar(MainWindow)\n self.menubar.setGeometry(QtCore.QRect(0, 0, 310, 23))\n self.menubar.setObjectName(\"menubar\")\n MainWindow.setMenuBar(self.menubar)\n self.statusbar = QtWidgets.QStatusBar(MainWindow)\n self.statusbar.setObjectName(\"statusbar\")\n MainWindow.setStatusBar(self.statusbar)\n\n self.retranslateUi(MainWindow)\n self.pushButton_2.clicked.connect(MainWindow.no)\n self.pushButton_3.clicked.connect(MainWindow.personal)\n self.pushButton_4.clicked.connect(MainWindow.choices)\n self.pushButton_5.clicked.connect(MainWindow.courses)\n self.pushButton_6.clicked.connect(MainWindow.exam)\n QtCore.QMetaObject.connectSlotsByName(MainWindow)\n\n def retranslateUi(self, MainWindow):\n _translate = QtCore.QCoreApplication.translate\n MainWindow.setWindowTitle(_translate(\"MainWindow\", \"YTU教务系统\"))\n self.pushButton_2.setText(_translate(\"MainWindow\", \"退出\"))\n self.pushButton_3.setText(_translate(\"MainWindow\", \"个人信息\"))\n self.pushButton_4.setText(_translate(\"MainWindow\", \"选课管理\"))\n self.pushButton_5.setText(_translate(\"MainWindow\", \"课表查询\"))\n self.pushButton_6.setText(_translate(\"MainWindow\", \"考务管理\"))\n"
},
{
"alpha_fraction": 0.4883623719215393,
"alphanum_fraction": 0.5070383548736572,
"avg_line_length": 22.837209701538086,
"blob_id": "331c0cd5b033222aa6e15f164e36c5134abd7c22",
"content_id": "9002b459a90d77097f6a9c1e7c02b069c13eea44",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7319,
"license_type": "no_license",
"max_line_length": 160,
"num_lines": 301,
"path": "/sql.py",
"repo_name": "ZypherIsNotZephyr/student_manange_system_py",
"src_encoding": "UTF-8",
"text": "import pymysql\n\n\n# 学生账号密码匹配\ndef SqlConnect_Login(sid, pwd):\n db = pymysql.connect(\n host='localhost',\n port=3306,\n user='root',\n passwd='',\n database='hw',\n charset='utf8'\n )\n try:\n cursor = db.cursor(pymysql.cursors.DictCursor)\n cursor.callproc(\"p\", (sid, 0)) # 参数为存储过程名称和存储过程接收的参数\n db.commit()\n password = cursor.fetchall()[0]['password']\n if pwd == password:\n return 1\n\n\n\n except:\n db.rollback()\n return 0\n\n cursor.close()\n db.close()\n\n\n# 查询学生信息\ndef SqlConnect_Person(sid):\n db = pymysql.connect(\n host='localhost',\n port=3306,\n user='root',\n passwd='',\n database='hw',\n charset='utf8'\n )\n cursor = db.cursor()\n sql = \"\"\"\n select *\n from student\n where sid = '%d'\n \"\"\" % sid\n try:\n cursor.execute(sql)\n studentmessage = cursor.fetchall()[0]\n # return studentmessage[0],studentmessage[1],studentmessage[2],studentmessage[3],studentmessage[4],studentmessage[5],studentmessage[6],studentmessage[7]\n return studentmessage\n except:\n db.rollback()\n return (0, 0, 0, 0, 0, 0, 0)\n\n cursor.close()\n db.close()\n\n\n# 更新学生信息\ndef SqlConnect_Save_Student(student):\n db = pymysql.connect(\n host='localhost',\n port=3306,\n user='root',\n passwd='',\n database='hw',\n charset='utf8'\n )\n cursor = db.cursor()\n lock = \"\"\"\n lock tables student write\n \"\"\"\n cursor.execute(lock)\n sql = \"\"\"\n update student\n set sname = '%s',password = '%s',phone = '%ld',email='%s',homepage='%s',profile='%s'\n where sid = '%d'\n \"\"\" % (student[1], student[2], int(student[3]), student[4], student[5], student[6], int(student[0]))\n try:\n cursor.execute(sql)\n db.commit()\n unlock = \"\"\"\n unlock tables\n \"\"\"\n cursor.execute(unlock)\n return 1\n except:\n db.rollback()\n return 0\n cursor.close()\n db.close()\n\n\n# 查看所有课程\ndef SqlConnect_Allcourses():\n db = pymysql.connect(\n host='localhost',\n port=3306,\n user='root',\n passwd='',\n database='hw',\n charset='utf8'\n )\n cursor = db.cursor()\n sql = \"\"\"\n select courses.cid,courses.cname,teacher.tname,courses.hours,courses.credit\n from courses,teacher\n where courses.cid = teacher.cid\n order by courses.cid asc\n \n \"\"\"\n try:\n cursor.execute(sql)\n all = cursor.fetchall()\n return all\n except:\n db.rollback()\n return None\n cursor.close()\n db.close()\n\n\n# 搜索课程\ndef SqlConnect_Search_Courses(index, message):\n db = pymysql.connect(\n host='localhost',\n port=3306,\n user='root',\n passwd='',\n database='hw',\n charset='utf8'\n )\n cursor = db.cursor()\n if index == 0:\n sql = \"\"\"\n select courses.cid,courses.cname,teacher.tname,courses.hours,courses.credit\n from courses,teacher\n where courses.cid = teacher.cid and courses.cid= '%d'\n \"\"\" % int(message)\n if index == 1:\n sql = \"\"\"\n select courses.cid,courses.cname,teacher.tname,courses.hours,courses.credit\n from courses,teacher\n where courses.cid = teacher.cid and courses.cname= '%s'\n \"\"\" % message\n if index == 2:\n sql = \"\"\"\n select courses.cid,courses.cname,teacher.tname,courses.hours,courses.credit\n from courses,teacher\n where courses.cid = teacher.cid and teacher.tname= '%s'\n \"\"\" % message\n try:\n cursor.execute(sql)\n all = cursor.fetchall()\n return all\n except:\n db.rollback()\n return None\n cursor.close()\n db.close()\n\n\n# 添加课程\ndef SqlConnect_Add_Course(cid, tname, sid):\n db = pymysql.connect(\n host='localhost',\n port=3306,\n user='root',\n passwd='',\n database='hw',\n charset='utf8'\n )\n cursor = db.cursor()\n cursor1 = db.cursor()\n sql0 = \"\"\"\n select tid\n from teacher\n where tname='%s'\n \"\"\" % tname\n try:\n cursor.execute(sql0)\n tid = cursor.fetchall()[0][0]\n # print(tid)\n except:\n return 0\n sql = \"\"\"\n insert into choices\n values('%d','%d','%d')\n \"\"\" % (int(cid), int(sid), int(tid))\n try:\n # print(cid,sid,tid)\n cursor1.execute(sql)\n db.commit()\n cursor.close()\n db.close()\n return 1\n except:\n db.rollback()\n return 0\n\n\n# 查看已选课程\ndef SqlConnect_Seecourses(sid):\n db = pymysql.connect(\n host='localhost',\n port=3306,\n user='root',\n passwd='',\n database='hw',\n charset='utf8'\n )\n cursor = db.cursor()\n sql = \"\"\"\n select courses.cname,teacher.tname,courses.ctime,teacher.tplace\n from courses,teacher,choices\n where choices.sid = '%d' and courses.cid = choices.cid and choices.tid = teacher.tid\n order by courses.cid asc\n\n \"\"\" % int(sid)\n try:\n cursor.execute(sql)\n all = cursor.fetchall()\n return all\n except:\n db.rollback()\n return None\n cursor.close()\n db.close()\n\n\n# 删除课程\ndef SqlConnect_Del_Course(cid, tname, sid):\n db = pymysql.connect(\n host='localhost',\n port=3306,\n user='root',\n passwd='',\n database='hw',\n charset='utf8'\n )\n cursor = db.cursor()\n cursor1 = db.cursor()\n sql0 = \"\"\"\n select tid\n from teacher\n where tname='%s'\n \"\"\" % tname\n try:\n cursor.execute(sql0)\n tid = cursor.fetchall()[0][0]\n except:\n return 0\n sql = \"\"\"\n delete from choices\n where cid = '%d' and sid = '%d' and tid = '%d'\n \"\"\" % (int(cid), int(sid), int(tid))\n try:\n cursor1.execute(sql)\n db.commit()\n cursor.close()\n db.close()\n return 1\n except:\n db.rollback()\n return 0\n\n\n# 考试查询\ndef SqlConnect_Seeexam(sid):\n db = pymysql.connect(\n host='localhost',\n port=3306,\n user='root',\n passwd='',\n database='hw',\n charset='utf8'\n )\n cursor = db.cursor()\n sql = \"\"\"\n select exam.eid,exam.ename,exam.etime,exam.eplace\n from choices,exam\n where choices.sid = '%d' and choices.cid = exam.cid\n order by exam.eid asc\n\n \"\"\" % int(sid)\n try:\n cursor.execute(sql)\n all = cursor.fetchall()\n return all\n except:\n db.rollback()\n return None\n cursor.close()\n db.close()\n\n# student = (20180001, \"张三\",\"123456\",17860397176,'[email protected]','1','1')\n# SqlConnect_Save_Student(student)\n# SqlConnect_Allcourses()\n# SqlConnect_Add_Course(9999, '清晓哥', 20180002)\n"
},
{
"alpha_fraction": 0.6723195910453796,
"alphanum_fraction": 0.691351056098938,
"avg_line_length": 47.688072204589844,
"blob_id": "21ae2de7e9ad3bfc0e778533450dff33c2c7f5cd",
"content_id": "607d17df44d6d02882aa852bb02e6ac3d05554f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5361,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 109,
"path": "/kebiao.py",
"repo_name": "ZypherIsNotZephyr/student_manange_system_py",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file 'kebiao.ui'\n#\n# Created by: PyQt5 UI code generator 5.15.0\n#\n# WARNING: Any manual changes made to this file will be lost when pyuic5 is\n# run again. Do not edit this file unless you know what you are doing.\n\n\nfrom PyQt5 import QtCore, QtGui, QtWidgets\n\n\nclass Ui_MainWindow(object):\n def setupUi(self, MainWindow):\n MainWindow.setObjectName(\"MainWindow\")\n MainWindow.resize(440, 413)\n self.centralwidget = QtWidgets.QWidget(MainWindow)\n self.centralwidget.setObjectName(\"centralwidget\")\n self.tableWidget = QtWidgets.QTableWidget(self.centralwidget)\n self.tableWidget.setGeometry(QtCore.QRect(0, 40, 441, 331))\n self.tableWidget.setObjectName(\"tableWidget\")\n self.tableWidget.setColumnCount(4)\n self.tableWidget.setRowCount(11)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(0, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(1, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(2, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(3, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(4, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(5, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(6, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(7, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(8, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(9, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(10, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setHorizontalHeaderItem(0, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setHorizontalHeaderItem(1, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setHorizontalHeaderItem(2, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setHorizontalHeaderItem(3, item)\n self.pushButton = QtWidgets.QPushButton(self.centralwidget)\n self.pushButton.setGeometry(QtCore.QRect(74, 10, 81, 23))\n self.pushButton.setObjectName(\"pushButton\")\n self.pushButton_2 = QtWidgets.QPushButton(self.centralwidget)\n self.pushButton_2.setGeometry(QtCore.QRect(290, 10, 75, 23))\n self.pushButton_2.setObjectName(\"pushButton_2\")\n MainWindow.setCentralWidget(self.centralwidget)\n self.menubar = QtWidgets.QMenuBar(MainWindow)\n self.menubar.setGeometry(QtCore.QRect(0, 0, 440, 23))\n self.menubar.setObjectName(\"menubar\")\n MainWindow.setMenuBar(self.menubar)\n self.statusbar = QtWidgets.QStatusBar(MainWindow)\n self.statusbar.setObjectName(\"statusbar\")\n MainWindow.setStatusBar(self.statusbar)\n\n self.retranslateUi(MainWindow)\n self.pushButton.clicked.connect(MainWindow.see)\n self.pushButton_2.clicked.connect(MainWindow.close)\n QtCore.QMetaObject.connectSlotsByName(MainWindow)\n\n def retranslateUi(self, MainWindow):\n _translate = QtCore.QCoreApplication.translate\n MainWindow.setWindowTitle(_translate(\"MainWindow\", \"个人课表\"))\n item = self.tableWidget.verticalHeaderItem(0)\n item.setText(_translate(\"MainWindow\", \"1\"))\n item = self.tableWidget.verticalHeaderItem(1)\n item.setText(_translate(\"MainWindow\", \"2\"))\n item = self.tableWidget.verticalHeaderItem(2)\n item.setText(_translate(\"MainWindow\", \"3\"))\n item = self.tableWidget.verticalHeaderItem(3)\n item.setText(_translate(\"MainWindow\", \"4\"))\n item = self.tableWidget.verticalHeaderItem(4)\n item.setText(_translate(\"MainWindow\", \"5\"))\n item = self.tableWidget.verticalHeaderItem(5)\n item.setText(_translate(\"MainWindow\", \"6\"))\n item = self.tableWidget.verticalHeaderItem(6)\n item.setText(_translate(\"MainWindow\", \"7\"))\n item = self.tableWidget.verticalHeaderItem(7)\n item.setText(_translate(\"MainWindow\", \"8\"))\n item = self.tableWidget.verticalHeaderItem(8)\n item.setText(_translate(\"MainWindow\", \"9\"))\n item = self.tableWidget.verticalHeaderItem(9)\n item.setText(_translate(\"MainWindow\", \"10\"))\n item = self.tableWidget.verticalHeaderItem(10)\n item.setText(_translate(\"MainWindow\", \"11\"))\n item = self.tableWidget.horizontalHeaderItem(0)\n item.setText(_translate(\"MainWindow\", \"课程名\"))\n item = self.tableWidget.horizontalHeaderItem(1)\n item.setText(_translate(\"MainWindow\", \"授课老师\"))\n item = self.tableWidget.horizontalHeaderItem(2)\n item.setText(_translate(\"MainWindow\", \"上课时间\"))\n item = self.tableWidget.horizontalHeaderItem(3)\n item.setText(_translate(\"MainWindow\", \"上课地点\"))\n self.pushButton.setText(_translate(\"MainWindow\", \"查看我的课程\"))\n self.pushButton_2.setText(_translate(\"MainWindow\", \"退出\"))\n"
},
{
"alpha_fraction": 0.6348755955696106,
"alphanum_fraction": 0.6846355199813843,
"avg_line_length": 49.911109924316406,
"blob_id": "b7150301e67e047c11bf7b42cd1ac001cd3e79b9",
"content_id": "c0d2b4ceb73d63ced1b158fc752270061ae19fd2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4630,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 90,
"path": "/studentmessage.py",
"repo_name": "ZypherIsNotZephyr/student_manange_system_py",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file 'studentmessage.ui'\n#\n# Created by: PyQt5 UI code generator 5.15.0\n#\n# WARNING: Any manual changes made to this file will be lost when pyuic5 is\n# run again. Do not edit this file unless you know what you are doing.\n\n\nfrom PyQt5 import QtCore, QtGui, QtWidgets\n\n\nclass Ui_MainWindow(object):\n def setupUi(self, MainWindow):\n MainWindow.setObjectName(\"MainWindow\")\n MainWindow.resize(725, 754)\n self.centralwidget = QtWidgets.QWidget(MainWindow)\n self.centralwidget.setObjectName(\"centralwidget\")\n self.pushButton = QtWidgets.QPushButton(self.centralwidget)\n self.pushButton.setGeometry(QtCore.QRect(330, 630, 75, 23))\n self.pushButton.setObjectName(\"pushButton\")\n self.label = QtWidgets.QLabel(self.centralwidget)\n self.label.setGeometry(QtCore.QRect(200, 60, 54, 12))\n self.label.setObjectName(\"label\")\n self.label_2 = QtWidgets.QLabel(self.centralwidget)\n self.label_2.setGeometry(QtCore.QRect(200, 100, 54, 12))\n self.label_2.setObjectName(\"label_2\")\n self.label_3 = QtWidgets.QLabel(self.centralwidget)\n self.label_3.setGeometry(QtCore.QRect(190, 200, 54, 12))\n self.label_3.setObjectName(\"label_3\")\n self.label_4 = QtWidgets.QLabel(self.centralwidget)\n self.label_4.setGeometry(QtCore.QRect(190, 330, 54, 12))\n self.label_4.setObjectName(\"label_4\")\n self.lineEdit = QtWidgets.QLineEdit(self.centralwidget)\n self.lineEdit.setEnabled(True)\n self.lineEdit.setGeometry(QtCore.QRect(290, 60, 171, 20))\n self.lineEdit.setText(\"\")\n self.lineEdit.setObjectName(\"lineEdit\")\n self.lineEdit_2 = QtWidgets.QLineEdit(self.centralwidget)\n self.lineEdit_2.setGeometry(QtCore.QRect(290, 100, 171, 20))\n self.lineEdit_2.setObjectName(\"lineEdit_2\")\n self.textEdit = QtWidgets.QTextEdit(self.centralwidget)\n self.textEdit.setGeometry(QtCore.QRect(290, 200, 171, 101))\n self.textEdit.setObjectName(\"textEdit\")\n self.textEdit_2 = QtWidgets.QTextEdit(self.centralwidget)\n self.textEdit_2.setGeometry(QtCore.QRect(290, 330, 171, 101))\n self.textEdit_2.setObjectName(\"textEdit_2\")\n self.label_5 = QtWidgets.QLabel(self.centralwidget)\n self.label_5.setGeometry(QtCore.QRect(200, 150, 54, 12))\n self.label_5.setObjectName(\"label_5\")\n self.label_6 = QtWidgets.QLabel(self.centralwidget)\n self.label_6.setGeometry(QtCore.QRect(200, 480, 54, 12))\n self.label_6.setObjectName(\"label_6\")\n self.lineEdit_3 = QtWidgets.QLineEdit(self.centralwidget)\n self.lineEdit_3.setGeometry(QtCore.QRect(290, 480, 171, 20))\n self.lineEdit_3.setObjectName(\"lineEdit_3\")\n self.label_7 = QtWidgets.QLabel(self.centralwidget)\n self.label_7.setGeometry(QtCore.QRect(200, 550, 54, 12))\n self.label_7.setObjectName(\"label_7\")\n self.lineEdit_4 = QtWidgets.QLineEdit(self.centralwidget)\n self.lineEdit_4.setGeometry(QtCore.QRect(290, 550, 171, 21))\n self.lineEdit_4.setObjectName(\"lineEdit_4\")\n self.lineEdit_5 = QtWidgets.QLineEdit(self.centralwidget)\n self.lineEdit_5.setGeometry(QtCore.QRect(290, 150, 171, 20))\n self.lineEdit_5.setObjectName(\"lineEdit_5\")\n MainWindow.setCentralWidget(self.centralwidget)\n self.menubar = QtWidgets.QMenuBar(MainWindow)\n self.menubar.setGeometry(QtCore.QRect(0, 0, 725, 23))\n self.menubar.setObjectName(\"menubar\")\n MainWindow.setMenuBar(self.menubar)\n self.statusbar = QtWidgets.QStatusBar(MainWindow)\n self.statusbar.setObjectName(\"statusbar\")\n MainWindow.setStatusBar(self.statusbar)\n\n self.retranslateUi(MainWindow)\n self.pushButton.clicked.connect(MainWindow.S_save)\n QtCore.QMetaObject.connectSlotsByName(MainWindow)\n\n def retranslateUi(self, MainWindow):\n _translate = QtCore.QCoreApplication.translate\n MainWindow.setWindowTitle(_translate(\"MainWindow\", \"个人信息\"))\n self.pushButton.setText(_translate(\"MainWindow\", \"确定\"))\n self.label.setText(_translate(\"MainWindow\", \"姓名\"))\n self.label_2.setText(_translate(\"MainWindow\", \"学号\"))\n self.label_3.setText(_translate(\"MainWindow\", \"个人主页\"))\n self.label_4.setText(_translate(\"MainWindow\", \"个人简介\"))\n self.label_5.setText(_translate(\"MainWindow\", \"密码\"))\n self.label_6.setText(_translate(\"MainWindow\", \"电话\"))\n self.label_7.setText(_translate(\"MainWindow\", \"邮箱\"))\n"
},
{
"alpha_fraction": 0.6593008637428284,
"alphanum_fraction": 0.6885143518447876,
"avg_line_length": 51.01298522949219,
"blob_id": "795bb1c2a97891711ec77aa47687050d445142e5",
"content_id": "96d7981e64b1b4cd593a2323cc779ce93c400049",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8154,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 154,
"path": "/xuanke.py",
"repo_name": "ZypherIsNotZephyr/student_manange_system_py",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file 'xuanke.ui'\n#\n# Created by: PyQt5 UI code generator 5.15.0\n#\n# WARNING: Any manual changes made to this file will be lost when pyuic5 is\n# run again. Do not edit this file unless you know what you are doing.\n\n\nfrom PyQt5 import QtCore, QtGui, QtWidgets\n\n\nclass Ui_MainWindow(object):\n def setupUi(self, MainWindow):\n MainWindow.setObjectName(\"MainWindow\")\n MainWindow.resize(839, 605)\n self.centralwidget = QtWidgets.QWidget(MainWindow)\n self.centralwidget.setObjectName(\"centralwidget\")\n self.tableWidget = QtWidgets.QTableWidget(self.centralwidget)\n self.tableWidget.setGeometry(QtCore.QRect(30, 100, 531, 331))\n self.tableWidget.setObjectName(\"tableWidget\")\n self.tableWidget.setColumnCount(5)\n self.tableWidget.setRowCount(11)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(0, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(1, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(2, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(3, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(4, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(5, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(6, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(7, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(8, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(9, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(10, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setHorizontalHeaderItem(0, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setHorizontalHeaderItem(1, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setHorizontalHeaderItem(2, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setHorizontalHeaderItem(3, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setHorizontalHeaderItem(4, item)\n self.pushButton = QtWidgets.QPushButton(self.centralwidget)\n self.pushButton.setGeometry(QtCore.QRect(700, 40, 75, 23))\n self.pushButton.setObjectName(\"pushButton\")\n self.lineEdit = QtWidgets.QLineEdit(self.centralwidget)\n self.lineEdit.setGeometry(QtCore.QRect(200, 40, 471, 20))\n self.lineEdit.setObjectName(\"lineEdit\")\n self.comboBox = QtWidgets.QComboBox(self.centralwidget)\n self.comboBox.setGeometry(QtCore.QRect(70, 40, 101, 22))\n self.comboBox.setObjectName(\"comboBox\")\n self.comboBox.addItem(\"\")\n self.comboBox.addItem(\"\")\n self.comboBox.addItem(\"\")\n self.pushButton_2 = QtWidgets.QPushButton(self.centralwidget)\n self.pushButton_2.setGeometry(QtCore.QRect(410, 470, 131, 51))\n self.pushButton_2.setObjectName(\"pushButton_2\")\n self.pushButton_3 = QtWidgets.QPushButton(self.centralwidget)\n self.pushButton_3.setGeometry(QtCore.QRect(160, 470, 131, 51))\n self.pushButton_3.setObjectName(\"pushButton_3\")\n self.label = QtWidgets.QLabel(self.centralwidget)\n self.label.setGeometry(QtCore.QRect(600, 200, 71, 16))\n self.label.setObjectName(\"label\")\n self.lineEdit_2 = QtWidgets.QLineEdit(self.centralwidget)\n self.lineEdit_2.setGeometry(QtCore.QRect(690, 200, 113, 20))\n self.lineEdit_2.setObjectName(\"lineEdit_2\")\n self.pushButton_4 = QtWidgets.QPushButton(self.centralwidget)\n self.pushButton_4.setGeometry(QtCore.QRect(600, 320, 81, 23))\n self.pushButton_4.setObjectName(\"pushButton_4\")\n self.label_2 = QtWidgets.QLabel(self.centralwidget)\n self.label_2.setGeometry(QtCore.QRect(590, 250, 91, 16))\n self.label_2.setObjectName(\"label_2\")\n self.lineEdit_3 = QtWidgets.QLineEdit(self.centralwidget)\n self.lineEdit_3.setGeometry(QtCore.QRect(690, 250, 113, 20))\n self.lineEdit_3.setObjectName(\"lineEdit_3\")\n self.pushButton_5 = QtWidgets.QPushButton(self.centralwidget)\n self.pushButton_5.setGeometry(QtCore.QRect(714, 320, 81, 23))\n self.pushButton_5.setObjectName(\"pushButton_5\")\n MainWindow.setCentralWidget(self.centralwidget)\n self.menubar = QtWidgets.QMenuBar(MainWindow)\n self.menubar.setGeometry(QtCore.QRect(0, 0, 839, 23))\n self.menubar.setObjectName(\"menubar\")\n MainWindow.setMenuBar(self.menubar)\n self.statusbar = QtWidgets.QStatusBar(MainWindow)\n self.statusbar.setObjectName(\"statusbar\")\n MainWindow.setStatusBar(self.statusbar)\n\n self.retranslateUi(MainWindow)\n self.pushButton_2.clicked.connect(MainWindow.c_save)\n self.pushButton_3.clicked.connect(MainWindow.all)\n self.pushButton.clicked.connect(MainWindow.search)\n self.pushButton_4.clicked.connect(MainWindow.add)\n self.pushButton_5.clicked.connect(MainWindow.delete)\n QtCore.QMetaObject.connectSlotsByName(MainWindow)\n\n def retranslateUi(self, MainWindow):\n _translate = QtCore.QCoreApplication.translate\n MainWindow.setWindowTitle(_translate(\"MainWindow\", \"选课系统\"))\n item = self.tableWidget.verticalHeaderItem(0)\n item.setText(_translate(\"MainWindow\", \"1\"))\n item = self.tableWidget.verticalHeaderItem(1)\n item.setText(_translate(\"MainWindow\", \"2\"))\n item = self.tableWidget.verticalHeaderItem(2)\n item.setText(_translate(\"MainWindow\", \"3\"))\n item = self.tableWidget.verticalHeaderItem(3)\n item.setText(_translate(\"MainWindow\", \"4\"))\n item = self.tableWidget.verticalHeaderItem(4)\n item.setText(_translate(\"MainWindow\", \"5\"))\n item = self.tableWidget.verticalHeaderItem(5)\n item.setText(_translate(\"MainWindow\", \"6\"))\n item = self.tableWidget.verticalHeaderItem(6)\n item.setText(_translate(\"MainWindow\", \"7\"))\n item = self.tableWidget.verticalHeaderItem(7)\n item.setText(_translate(\"MainWindow\", \"8\"))\n item = self.tableWidget.verticalHeaderItem(8)\n item.setText(_translate(\"MainWindow\", \"9\"))\n item = self.tableWidget.verticalHeaderItem(9)\n item.setText(_translate(\"MainWindow\", \"10\"))\n item = self.tableWidget.verticalHeaderItem(10)\n item.setText(_translate(\"MainWindow\", \"11\"))\n item = self.tableWidget.horizontalHeaderItem(0)\n item.setText(_translate(\"MainWindow\", \"课程号\"))\n item = self.tableWidget.horizontalHeaderItem(1)\n item.setText(_translate(\"MainWindow\", \"课程名\"))\n item = self.tableWidget.horizontalHeaderItem(2)\n item.setText(_translate(\"MainWindow\", \"授课老师\"))\n item = self.tableWidget.horizontalHeaderItem(3)\n item.setText(_translate(\"MainWindow\", \"学时\"))\n item = self.tableWidget.horizontalHeaderItem(4)\n item.setText(_translate(\"MainWindow\", \"学分\"))\n self.pushButton.setText(_translate(\"MainWindow\", \"搜索\"))\n self.comboBox.setItemText(0, _translate(\"MainWindow\", \"按课程号搜索\"))\n self.comboBox.setItemText(1, _translate(\"MainWindow\", \"按课程名搜索\"))\n self.comboBox.setItemText(2, _translate(\"MainWindow\", \"按任课教师搜索\"))\n self.pushButton_2.setText(_translate(\"MainWindow\", \"退出\"))\n self.pushButton_3.setText(_translate(\"MainWindow\", \"显示全部课程\"))\n self.label.setText(_translate(\"MainWindow\", \"请输入课程号\"))\n self.pushButton_4.setText(_translate(\"MainWindow\", \"加入我的课程\"))\n self.label_2.setText(_translate(\"MainWindow\", \"请输入授课老师\"))\n self.pushButton_5.setText(_translate(\"MainWindow\", \"移出我的课程\"))\n"
},
{
"alpha_fraction": 0.6726279854774475,
"alphanum_fraction": 0.6916415691375732,
"avg_line_length": 47.733943939208984,
"blob_id": "4b0b00f163b0137a32f5f8fb89be766b4f5a7dfc",
"content_id": "7db07e2c07d2a10a04d9d5ab4d43e04ae72e1ad6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5368,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 109,
"path": "/kaoshi.py",
"repo_name": "ZypherIsNotZephyr/student_manange_system_py",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file 'kaoshi.ui'\n#\n# Created by: PyQt5 UI code generator 5.15.0\n#\n# WARNING: Any manual changes made to this file will be lost when pyuic5 is\n# run again. Do not edit this file unless you know what you are doing.\n\n\nfrom PyQt5 import QtCore, QtGui, QtWidgets\n\n\nclass Ui_MainWindow(object):\n def setupUi(self, MainWindow):\n MainWindow.setObjectName(\"MainWindow\")\n MainWindow.resize(446, 415)\n self.centralwidget = QtWidgets.QWidget(MainWindow)\n self.centralwidget.setObjectName(\"centralwidget\")\n self.pushButton_2 = QtWidgets.QPushButton(self.centralwidget)\n self.pushButton_2.setGeometry(QtCore.QRect(276, 10, 75, 23))\n self.pushButton_2.setObjectName(\"pushButton_2\")\n self.tableWidget = QtWidgets.QTableWidget(self.centralwidget)\n self.tableWidget.setGeometry(QtCore.QRect(6, 40, 441, 331))\n self.tableWidget.setObjectName(\"tableWidget\")\n self.tableWidget.setColumnCount(4)\n self.tableWidget.setRowCount(11)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(0, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(1, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(2, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(3, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(4, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(5, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(6, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(7, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(8, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(9, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setVerticalHeaderItem(10, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setHorizontalHeaderItem(0, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setHorizontalHeaderItem(1, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setHorizontalHeaderItem(2, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setHorizontalHeaderItem(3, item)\n self.pushButton = QtWidgets.QPushButton(self.centralwidget)\n self.pushButton.setGeometry(QtCore.QRect(60, 10, 81, 23))\n self.pushButton.setObjectName(\"pushButton\")\n MainWindow.setCentralWidget(self.centralwidget)\n self.menubar = QtWidgets.QMenuBar(MainWindow)\n self.menubar.setGeometry(QtCore.QRect(0, 0, 446, 23))\n self.menubar.setObjectName(\"menubar\")\n MainWindow.setMenuBar(self.menubar)\n self.statusbar = QtWidgets.QStatusBar(MainWindow)\n self.statusbar.setObjectName(\"statusbar\")\n MainWindow.setStatusBar(self.statusbar)\n\n self.retranslateUi(MainWindow)\n self.pushButton_2.clicked.connect(MainWindow.close)\n self.pushButton.clicked.connect(MainWindow.seeexam)\n QtCore.QMetaObject.connectSlotsByName(MainWindow)\n\n def retranslateUi(self, MainWindow):\n _translate = QtCore.QCoreApplication.translate\n MainWindow.setWindowTitle(_translate(\"MainWindow\", \"考试查询\"))\n self.pushButton_2.setText(_translate(\"MainWindow\", \"退出\"))\n item = self.tableWidget.verticalHeaderItem(0)\n item.setText(_translate(\"MainWindow\", \"1\"))\n item = self.tableWidget.verticalHeaderItem(1)\n item.setText(_translate(\"MainWindow\", \"2\"))\n item = self.tableWidget.verticalHeaderItem(2)\n item.setText(_translate(\"MainWindow\", \"3\"))\n item = self.tableWidget.verticalHeaderItem(3)\n item.setText(_translate(\"MainWindow\", \"4\"))\n item = self.tableWidget.verticalHeaderItem(4)\n item.setText(_translate(\"MainWindow\", \"5\"))\n item = self.tableWidget.verticalHeaderItem(5)\n item.setText(_translate(\"MainWindow\", \"6\"))\n item = self.tableWidget.verticalHeaderItem(6)\n item.setText(_translate(\"MainWindow\", \"7\"))\n item = self.tableWidget.verticalHeaderItem(7)\n item.setText(_translate(\"MainWindow\", \"8\"))\n item = self.tableWidget.verticalHeaderItem(8)\n item.setText(_translate(\"MainWindow\", \"9\"))\n item = self.tableWidget.verticalHeaderItem(9)\n item.setText(_translate(\"MainWindow\", \"10\"))\n item = self.tableWidget.verticalHeaderItem(10)\n item.setText(_translate(\"MainWindow\", \"11\"))\n item = self.tableWidget.horizontalHeaderItem(0)\n item.setText(_translate(\"MainWindow\", \"考试编号\"))\n item = self.tableWidget.horizontalHeaderItem(1)\n item.setText(_translate(\"MainWindow\", \"考试名称\"))\n item = self.tableWidget.horizontalHeaderItem(2)\n item.setText(_translate(\"MainWindow\", \"考试时间\"))\n item = self.tableWidget.horizontalHeaderItem(3)\n item.setText(_translate(\"MainWindow\", \"考试地点\"))\n self.pushButton.setText(_translate(\"MainWindow\", \"查看我的考试\"))\n"
},
{
"alpha_fraction": 0.5780109763145447,
"alphanum_fraction": 0.5853102207183838,
"avg_line_length": 29.44444465637207,
"blob_id": "e3d8cca31093d858a3162878616d54135f9a26a1",
"content_id": "81588abd65aac475daa05cc16df08fec4c058b3f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6850,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 216,
"path": "/run.py",
"repo_name": "ZypherIsNotZephyr/student_manange_system_py",
"src_encoding": "UTF-8",
"text": "import sys\nimport login\nimport stu\nimport sql\nimport tishi\nimport tishi2\nimport studentmessage\nimport xuanke\nimport kebiao\nimport kaoshi\nfrom PyQt5 import QtWidgets\n\n\n# 登录界面\nclass LOGIN(QtWidgets.QMainWindow, login.Ui_MainWindow):\n def __init__(self):\n super(LOGIN, self).__init__()\n self.setupUi(self)\n self.ts = TISHI(self)\n self.mw = MAIN(self)\n\n # 判断登录账号密码是否正确\n def sure(self):\n sid = int(self.lineEdit.text())\n pwd = self.lineEdit_2.text()\n # 通过数据库查询账号密码\n if sql.SqlConnect_Login(sid, pwd):\n self.mw.show() # mainwindow主界面显示\n self.mw.sid = sid # 传递用户账户,方便后续操作\n # print(\"self.mw.sid=\"+str(self.mw.sid))\n self.close() # 登录成功后,关闭当前窗口\n else:\n # print(\"学号或密码错误\\n\")\n self.ts.show()\n\n\n# 主界面\nclass MAIN(QtWidgets.QMainWindow, stu.Ui_MainWindow):\n def __init__(self, last_form):\n super(MAIN, self).__init__()\n self.setupUi(self)\n self.last_form = last_form\n self.sid = -1\n self.stumessage = StudentMessage(self) # 个人信息界面\n self.xuanke = CHOICES(self) # 选课界面\n self.kebiao = COURSE(self)\n self.kaoshi = EXAM(self)\n\n def no(self):\n self.close()\n\n # 显示个人信息界面\n def personal(self):\n self.stumessage.sid = self.sid\n Student_ID, Student_Name, Student_Password, Student_phone, Student_email, Student_homepage, Student_profile = sql.SqlConnect_Person(\n self.sid)\n self.stumessage.lineEdit.setText(str(Student_Name))\n self.stumessage.lineEdit_2.setText(str(Student_ID))\n self.stumessage.textEdit.setText(str(Student_homepage))\n self.stumessage.textEdit_2.setText(str(Student_profile))\n self.stumessage.lineEdit_3.setText(str(Student_phone))\n self.stumessage.lineEdit_4.setText(str(Student_email))\n self.stumessage.lineEdit_5.setText(str(Student_Password))\n self.stumessage.show()\n\n # 选课界面\n def choices(self):\n self.xuanke.sid = self.sid\n self.xuanke.show()\n\n # 查看我的课程\n def courses(self):\n self.kebiao.sid = self.sid\n self.kebiao.show()\n\n def exam(self):\n self.kaoshi.sid = self.sid\n self.kaoshi.show()\n\n\n# 账号或密码错误界面\nclass TISHI(QtWidgets.QMainWindow, tishi.Ui_MainWindow):\n def __init__(self, last_form):\n super(TISHI, self).__init__()\n self.setupUi(self)\n self.last_form = last_form\n\n\n# 提示选课成功界面\nclass TISHI2(QtWidgets.QMainWindow, tishi2.Ui_MainWindow):\n def __init__(self, last_form):\n super(TISHI2, self).__init__()\n self.setupUi(self)\n self.last_form = last_form\n\n\n# 个人信息界面\nclass StudentMessage(QtWidgets.QMainWindow, studentmessage.Ui_MainWindow):\n def __init__(self, last_form):\n super(StudentMessage, self).__init__()\n self.setupUi(self)\n self.last_form = last_form\n self.sid = -1\n\n # 初始化信息\n self.lineEdit.setText('')\n self.lineEdit_2.setText('')\n self.lineEdit_5.setText('')\n self.textEdit.setText('')\n self.textEdit_2.setText('')\n self.lineEdit_3.setText('')\n self.lineEdit_4.setText('')\n\n def S_save(self):\n # stums = sql.SqlConnect_Person(self.sid)\n # print(stums[0],type(stums))\n Student_Name = self.lineEdit.text()\n Student_Password = self.lineEdit_5.text()\n Student_phone = self.lineEdit_3.text()\n Student_email = self.lineEdit_4.text()\n Student_homepage = self.textEdit.toPlainText()\n Student_profile = self.textEdit_2.toPlainText()\n student = (\n self.sid, Student_Name, Student_Password, Student_phone, Student_email, Student_homepage, Student_profile)\n sql.SqlConnect_Save_Student(student)\n self.close()\n\n\n# 选课界面\nclass CHOICES(QtWidgets.QMainWindow, xuanke.Ui_MainWindow):\n def __init__(self, last_form):\n super(CHOICES, self).__init__()\n self.setupUi(self)\n self.last_form = last_form\n self.sid = -1\n self.tishi2 = TISHI2(self)\n\n def c_save(self):\n self.close()\n\n def all(self):\n Am = sql.SqlConnect_Allcourses()\n # print(type(Am[0][0]))\n for i in range(10):\n for j in range(5):\n try:\n self.tableWidget.setItem(i, j, QtWidgets.QTableWidgetItem(str(Am[i][j])))\n except:\n self.tableWidget.setItem(i, j, QtWidgets.QTableWidgetItem(\"\"))\n\n def search(self):\n index = self.comboBox.currentIndex()\n message = self.lineEdit.text()\n Am = sql.SqlConnect_Search_Courses(index, message)\n for i in range(10):\n for j in range(5):\n try:\n self.tableWidget.setItem(i, j, QtWidgets.QTableWidgetItem(str(Am[i][j])))\n except:\n self.tableWidget.setItem(i, j, QtWidgets.QTableWidgetItem(\"\"))\n\n def add(self):\n cid = self.lineEdit_2.text()\n tname = self.lineEdit_3.text()\n if sql.SqlConnect_Add_Course(cid, tname, self.sid):\n self.tishi2.show()\n\n def delete(self):\n cid = self.lineEdit_2.text()\n tname = self.lineEdit_3.text()\n if sql.SqlConnect_Del_Course(cid, tname, self.sid):\n self.tishi2.show()\n\n\n# 查看课表\nclass COURSE(QtWidgets.QMainWindow, kebiao.Ui_MainWindow):\n def __init__(self, last_form):\n super(COURSE, self).__init__()\n self.setupUi(self)\n self.last_form = last_form\n self.sid = -1\n\n def see(self):\n Am = sql.SqlConnect_Seecourses(self.sid)\n for i in range(10):\n for j in range(4):\n try:\n self.tableWidget.setItem(i, j, QtWidgets.QTableWidgetItem(str(Am[i][j])))\n except:\n self.tableWidget.setItem(i, j, QtWidgets.QTableWidgetItem(\"\"))\n\n\n# 考试查询\nclass EXAM(QtWidgets.QMainWindow, kaoshi.Ui_MainWindow):\n def __init__(self, last_form):\n super(EXAM, self).__init__()\n self.setupUi(self)\n self.last_form = last_form\n self.sid = -1\n\n def seeexam(self):\n Am = sql.SqlConnect_Seeexam(self.sid)\n for i in range(10):\n for j in range(4):\n try:\n self.tableWidget.setItem(i, j, QtWidgets.QTableWidgetItem(str(Am[i][j])))\n except:\n self.tableWidget.setItem(i, j, QtWidgets.QTableWidgetItem(\"\"))\n\n\n# 开始\nif __name__ == '__main__':\n app = QtWidgets.QApplication(sys.argv)\n ui = LOGIN()\n ui.show()\n sys.exit(app.exec_())\n"
},
{
"alpha_fraction": 0.7777777910232544,
"alphanum_fraction": 0.7777777910232544,
"avg_line_length": 14,
"blob_id": "39fa816034794878cb3bb8956f0af2107b8e412f",
"content_id": "3919c9dcb54b5c662894d50c0948e8b81b38485e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 49,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 3,
"path": "/README.md",
"repo_name": "ZypherIsNotZephyr/student_manange_system_py",
"src_encoding": "UTF-8",
"text": "# student_manange_system_py\nqt&sql\nrun启动\n"
}
] | 8 |
JohnFinn/OptLabs
|
https://github.com/JohnFinn/OptLabs
|
3abdd20141b0ea509642fb8690e8fe3c6ec43465
|
30b8b178b218eccbaf546c1eead4e22aef968419
|
b7499036658c42eefeed0d7db357c34103213a8c
|
refs/heads/master
| 2020-03-29T09:13:08.657272 | 2018-12-16T20:37:47 | 2018-12-16T20:37:47 | 149,746,758 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5442504286766052,
"alphanum_fraction": 0.5785671472549438,
"avg_line_length": 27.8869571685791,
"blob_id": "8da9d0804bccb660d2f5fdb41ae871e80c0bc4d7",
"content_id": "8de3a5ab57efd63d92aa50800cb24385e05be8de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3326,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 115,
"path": "/findmin.py",
"repo_name": "JohnFinn/OptLabs",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nfrom matplotlib import pyplot\nfrom matplotlib.widgets import Button\nfrom mpl_toolkits.mplot3d import proj3d\nfrom typing import Iterable, Generator, Tuple, Callable\nimport numpy\nfrom uniModMin import in_direction_of, findmin, find_interval\nfrom numpy.linalg import norm\nfrom copy import copy\nimport sympy\nfrom itertools import chain\n\nvec = numpy.ndarray\n\n\ndef gradient(func: Callable[[numpy.ndarray], float], x: numpy.ndarray, delta: float) -> numpy.ndarray:\n '''\n >>> gradient(lambda x:x[0]*2, numpy.array([1.0]),.1)\n array([2.])\n >>> gradient(lambda x:x[0]*2+x[1]*3, numpy.array([1.0, 4.2]),.1)\n array([2., 3.])\n '''\n result = []\n for index in range(len(x)):\n x[index] += delta/2\n right = func(x)\n x[index] -= delta\n left = func(x)\n x[index] += delta/2\n result.append((right - left) / delta)\n return numpy.array(result)\n\n\ndef gradient_descent(func: Callable[[vec], float], start: vec, delta: float = .001):\n step = numpy.array([delta + 1])\n while all(abs(step) > delta):\n step = find_step(func, start, delta)\n start += step\n yield start\n\n\ndef find_step(func: Callable, position, delta):\n grad = -gradient(func, position, delta)\n func_slice = in_direction_of(func, position, grad)\n step = findmin(func_slice, find_interval(func_slice, 0), delta)\n return grad / norm(grad) * step\n\n\nclass LineDrawer:\n def __init__(self, axis, get_next_point):\n self.prev = next(get_next_point)\n self.get_next_point = get_next_point\n self.axis = axis\n self.stopped = False\n\n def __call__(self):\n try:\n point = next(self.get_next_point)\n except StopIteration:\n self.stopped = True\n else:\n self.axis.plot(*zip(self.prev, point), [foo(self.prev), foo(point)], 'r-')\n self.prev = copy(point)\n finally:\n return self.prev\n\n\nclass Combine:\n def __init__(self):\n self.funcs = []\n self.results = []\n\n def add(self, func: Callable):\n self.funcs.append(func)\n\n def __call__(self, *args, **kwargs):\n self.results.clear()\n for func in self.funcs:\n self.results.append(func(*args, **kwargs))\n\n\nif __name__ == '__main__':\n def foo(x):\n x1, x2 = x[0], x[1]\n return 100 * (x2 - x1 ** 2) ** 2 + (1 - x1) ** 2\n print(foo((1, 1)))\n\n syms = sympy.symbols('x₁ x₂')\n func = foo(syms)\n g = sum(map(func.diff, syms))\n print(g)\n solved = sympy.solvers.solve(g)\n print(solved)\n fig = pyplot.figure()\n\n x = numpy.linspace(-100, 100, 2000)\n X, Y = numpy.meshgrid(x, x)\n ax3d = fig.add_subplot(1, 1, 1, projection='3d')\n ax3d.plot_surface(X, Y, foo((X, Y)))\n ax3d.set_xlabel('X1')\n ax3d.set_ylabel('X2')\n bnext3d = Button(pyplot.axes([.9, 0, 1, .1]), 'Next')\n\n c = Combine()\n for start in [80.0, -70.0], [-80.0, 70.0], [80.0, 70.0], [-80.0, -70.0], [0.0, 50.0], [5.0, 75.0], [-5.0, 75.0]:\n start = numpy.array(start)\n desc = gradient_descent(foo, start, .0001)\n on_click = LineDrawer(ax3d, chain((copy(start), ), desc))\n c.add(on_click)\n\n bnext3d.on_clicked(lambda event: c())\n\n pyplot.show(block=True)\n for result in c.results:\n print(result, foo(result))\n"
},
{
"alpha_fraction": 0.5308970212936401,
"alphanum_fraction": 0.5687707662582397,
"avg_line_length": 27.94230842590332,
"blob_id": "7dd9ec1a43d386aa75569695786a6aed67ab6dd2",
"content_id": "b7d757dc94da47849bbccf1518742c48bdb1b733",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1537,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 52,
"path": "/linear_function.py",
"repo_name": "JohnFinn/OptLabs",
"src_encoding": "UTF-8",
"text": "from __future__ import annotations\nfrom numpy import array\nfrom typing import List\nfrom operator import mul\nfrom fractions import Fraction\n\n\nclass LinearFunction:\n \"\"\"\n >>> f = LinearFunction(18, [-2, -1, -1])\n >>> f.rearrange(0)\n >>> print(f)\n 9 + -1/2*x₀ + -1/2*x₁ + -1/2*x₂\n >>> f2 = LinearFunction(30, [-1, -2, -2])\n >>> f2.substitute(0, f)\n >>> print(f2)\n 21 + 1/2*x₀ + -3/2*x₁ + -3/2*x₂\n \"\"\"\n subscript = str.maketrans(\"0123456789\", \"₀₁₂₃₄₅₆₇₈₉\")\n\n def __init__(self, free, coefs):\n self._free = Fraction(free)\n self._coefs = array(list(map(Fraction, coefs)))\n\n def __call__(self, args: List[float]) -> float:\n return self._free + sum(map(mul, self._coefs, args))\n\n @property\n def coefs(self):\n return self._coefs\n\n @property\n def free(self):\n return self._free\n\n def substitute(self, index: int, other: LinearFunction):\n val = self._coefs[index]\n self._coefs += other._coefs * val\n self._coefs[index] = val * other._coefs[index]\n self._free += val * other._free\n\n def rearrange(self, index: int):\n val = self._coefs[index]\n self._coefs[index] = -1\n self._coefs = self._coefs / -val\n self._free /= -val\n\n def __str__(self):\n return f'{self.free} + ' + ' + '.join(map(self._str_one, range(len(self._coefs))))\n\n def _str_one(self, index: int) -> str:\n return f'{self._coefs[index]}*x{str(index).translate(LinearFunction.subscript)}'\n"
},
{
"alpha_fraction": 0.35494881868362427,
"alphanum_fraction": 0.43344709277153015,
"avg_line_length": 25.044445037841797,
"blob_id": "62330773d8837a4d930e04e3f5cac069eb81e1a4",
"content_id": "c1b6d2997cbc8267a23bb96491710f40dd4e24bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 1172,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 45,
"path": "/Graph/GraphTest/UnitTest1.cs",
"repo_name": "JohnFinn/OptLabs",
"src_encoding": "UTF-8",
"text": "using System.Collections.Generic;\nusing System.Linq;\nusing Graph;\nusing Xunit;\n\nnamespace GraphTest\n{\n public class UnitTest1\n {\n [Fact]\n public void Test1()\n {\n var g = new Graph<int> {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};\n g.Connect(1,4,7);\n g.Connect(1,3,2);\n g.Connect(1,2,5);\n g.Connect(2,5,6);\n g.Connect(3,5,5);\n g.Connect(3,6,7);\n g.Connect(4,6,4);\n g.Connect(5,8,2);\n g.Connect(5,9,8);\n g.Connect(6,7,9);\n g.Connect(6,8,5);\n g.Connect(7,10,4);\n g.Connect(8,10,9);\n g.Connect(9,10,7);\n Assert.Equal(8u, g.Path(5,9));\n \n \n Assert.Equal(7u, g.Path(1,4));\n Assert.Equal(2u, g.Path(1,3));\n Assert.Equal(5u, g.Path(1,2));\n \n Assert.Equal(9u, g.Path(1,6));\n Assert.Equal(7u, g.Path(1,5));\n\n Assert.Equal(18u, g.Path(1,7));\n Assert.Equal(9u, g.Path(1,8));\n Assert.Equal(15u, g.Path(1,9));\n\n Assert.Equal(18u, g.Path(1,10));\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4654505252838135,
"alphanum_fraction": 0.4665561020374298,
"avg_line_length": 26,
"blob_id": "8e44ab96ad8cf49c8364805febd40ed561c1107a",
"content_id": "5989653bf650c6aff39add148c37d96a5088d952",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 1809,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 67,
"path": "/Graph/Graph/Graph.cs",
"repo_name": "JohnFinn/OptLabs",
"src_encoding": "UTF-8",
"text": "using System.Collections;\nusing System.Collections.Generic;\nusing System.Linq;\n\nnamespace Graph\n{\n class Node<T>\n {\n public T Value;\n public IDictionary<Node<T>, uint> Neighbours = new Dictionary<Node<T>, uint>();\n\n public Node(T vertex)\n {\n Value = vertex;\n }\n }\n\n public class Graph<T> : IGraph<T>\n {\n private IDictionary<T, Node<T>> nodes = new Dictionary<T, Node<T>>();\n\n public void Add(T vertex)\n {\n nodes[vertex] = new Node<T>(vertex);\n }\n\n public void Connect(T a, T b, uint weight)\n \n {\n nodes[a].Neighbours[nodes[b]] = weight;\n }\n\n public uint Path(T @from, T to)\n {\n var paths = new Dictionary<T, uint> {{from, 0}};\n var traversal = new Queue<Node<T>>();\n traversal.Enqueue(nodes[from]);\n while (traversal.Count > 0)\n {\n var current = traversal.Dequeue();\n foreach (var (node, w) in current.Neighbours)\n {\n var totalWeight = w + paths[current.Value]; \n var exists = paths.TryGetValue(node.Value, out var prevPath);\n if (!exists || prevPath > totalWeight)\n {\n paths[node.Value] = totalWeight;\n }\n\n if (!exists)\n {\n traversal.Enqueue(node);\n }\n }\n }\n return paths[to];\n }\n\n public IEnumerator<T> GetEnumerator() {\n return nodes.Select(kvp => kvp.Key).GetEnumerator();\n }\n\n IEnumerator IEnumerable.GetEnumerator() {\n return GetEnumerator();\n }\n }\n}\n"
},
{
"alpha_fraction": 0.45592767000198364,
"alphanum_fraction": 0.5033901929855347,
"avg_line_length": 26.038888931274414,
"blob_id": "1a230cf0cc717cbe6c8fe3ce8b1699f04902627b",
"content_id": "c0d3d395930fb717290b60ffc5072106800857a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4867,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 180,
"path": "/uniModMin.py",
"repo_name": "JohnFinn/OptLabs",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nfrom typing import Tuple, Generator, Callable, Iterable\nfrom numpy import ndarray\nfrom numpy.linalg import norm\n\nTffff = Tuple[float, float, float, float]\nTff = Tuple[float, float]\nCff = Callable[[float], float]\nGTffff = Generator[Tffff, None, None]\n\n\ndef in_direction_of(func: Callable, start: ndarray, direction: ndarray) -> Cff:\n \"\"\"\n >>> from numpy import array\n >>> from numpy.linalg import norm\n >>>\n >>> def foo(xvec):\n ... x0, x1 = xvec\n ... return x0**2 + x1**2\n >>>\n >>> func = in_direction_of(foo, array([0,0]), array([1,0]))\n >>> func(1) == foo([1, 0])\n True\n >>> func(1.34) == foo([1.34, 0])\n True\n >>> func = in_direction_of(foo, array([0,0]), array([1,1]))\n >>> func(2**.5) == foo([1, 1])\n True\n >>> func = in_direction_of(foo, array([-1,-1]), array([1,1]))\n >>> func(0) == foo([-1, -1])\n True\n \"\"\"\n return lambda x: func(start + direction/norm(direction) * x)\n\n\ndef find_interval(func: Callable, position, step=1) -> Tuple[float, float]:\n \"\"\"\n >>> left, right = find_interval_left(lambda x: x**2, 10, 1)\n >>> left <= 0\n True\n >>> right >= 0\n True\n >>> left, right = find_interval_right(lambda x: x**2, -10, 1)\n >>> left <= 0\n True\n >>> right >= 0\n True\n \"\"\"\n l, m, r = map(func, (position - step, position, position + step))\n if l < m < r:\n return find_interval_left(func, position, step)\n if l > m > r:\n return find_interval_right(func, position, step)\n if m < l and m < r:\n return position - step, position + step\n\n\ndef find_interval_left(func: Callable, position, step):\n \"\"\"\n >>> left, right = find_interval_left(lambda x: x**2, 10, 1)\n >>> left <= 0\n True\n >>> right >= 0\n True\n >>> left, right = find_interval_right(lambda x: x**2, -10, 1)\n >>> left <= 0\n True\n >>> right >= 0\n True\n \"\"\"\n left, right = find_interval_right(lambda x: func(-x), -position, step)\n return -right, -left\n\n\ndef find_interval_right(func: Callable, position, step):\n \"\"\"\n >>> left, right = find_interval_right(lambda x: x**2, -10, 1)\n >>> left <= 0\n True\n >>> right >= 0\n True\n >>> left, right = find_interval_right(lambda x: x**2, -10, 20)\n >>> left <= 0\n True\n >>> right >= 0\n True\n \"\"\"\n left = func(position)\n right_position = position + step\n right = func(right_position)\n while left > right:\n right_position += step\n right = func(right_position)\n step *= 2\n return position, right_position\n\n\ndef findmin(func: Cff, borders: Tff, accuracy: float):\n \"\"\"\n >>> res = findmin(lambda x: (x-3)**2 + 1, (-100, 100), .001)\n >>> 2.999 < res < 3.001\n True\n >>> res = findmin(lambda x: (x+10)**2 + 1, (-100, 100), .001)\n >>> -10.001 < res < -9.999\n True\n \"\"\"\n for a, b, x1, x2 in __findmin(func, borders, accuracy):\n pass\n return (a + b) / 2\n\n\ndef __findmin(func: Cff, borders: Tff, accuracy: float) -> GTffff:\n delta = accuracy / 3\n a, b = borders\n while b - a > accuracy:\n x = (a + b) / 2\n x1, x2 = x - delta, x + delta\n yield a, b, x1, x2\n fx1, fx2 = func(x1), func(x2)\n if fx1 > fx2:\n a = x1\n elif fx1 < fx2:\n b = x2\n\n\ndef golden_ratio(func: Cff, borders: Tff, accuracy: float) -> GTffff:\n a, b = borders\n leftGL = (3 - 5 ** .5) / 2\n rightGR = (5 ** .5 - 1) / 2\n x1 = a + leftGL * (b - a)\n x2 = a + rightGR * (b - a)\n yield a, b, x1, x2\n fx1 = func(x1)\n fx2 = func(x2)\n while b - a > accuracy:\n if fx1 > fx2:\n a, x1, fx1 = x1, x2, fx2\n x2 = a + rightGR * (b - a)\n fx2 = func(x2)\n elif fx2 > fx1:\n b, x2, fx2 = x2, x1, fx1\n x1 = a + leftGL * (b - a)\n fx1 = func(x1)\n yield a, b, x1, x2\n\n\ndef fib(n: int) -> int:\n return int((((1 + 5 ** .5) / 2) ** n - ((1 - 5 ** .5) / 2) ** n) / 5 ** .5)\n\n\ndef find_fib(borders: Tff, accuracy: float) -> int:\n position = 10\n a, b = borders\n x = (a - b) / accuracy\n while fib(position) <= x:\n position *= 2\n return position\n\n\ndef fib_search(func: Cff, borders: Tff, accuracy: float) -> GTffff:\n N = find_fib(borders, accuracy)\n fibN2, fibN1 = fib(N), fib(N - 1)\n fibN = fibN2 - fibN1\n a, b = borders\n c = (b - a) / fibN2\n x1, x2 = a + fibN * c, a + fibN1 * c\n fx1, fx2 = func(x1), func(x2)\n yield a, b, x1, x2\n while b - a > accuracy:\n fibN2, fibN1 = fibN1, fibN\n fibN = fibN2 - fibN1\n if fx1 < fx2:\n b, x2, fx2 = x2, x1, fx1\n x1 = a + fibN / fibN2 * (b - a)\n fx1 = func(x1)\n elif fx1 > fx2:\n a, x1, fx1 = x1, x2, fx2\n x2 = a + fibN1 / fibN2 * (b - a)\n fx2 = func(x2)\n yield a, b, x1, x2\n"
},
{
"alpha_fraction": 0.43324607610702515,
"alphanum_fraction": 0.45026177167892456,
"avg_line_length": 18.100000381469727,
"blob_id": "431c19260a0b6a3873485f9e244c8e17172bd086",
"content_id": "3bed2d2ed8a9629544c4f2500d52fbd0ff2233a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 764,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 40,
"path": "/counter.py",
"repo_name": "JohnFinn/OptLabs",
"src_encoding": "UTF-8",
"text": "class Counter:\n '''\n >>> @Counter\n ... def foo():pass\n >>> @Counter\n ... def bar():pass\n >>> foo.count, bar.count\n (0, 0)\n >>> foo()\n >>> foo.count, bar.count\n (1, 0)\n >>> foo()\n >>> foo.count, bar.count\n (2, 0)\n >>> bar()\n >>> foo.count, bar.count\n (2, 1)\n '''\n def __init__(self, func):\n self.count = 0\n self.func = func\n \n def __call__(self, *args, **kwargs):\n self.count += 1\n return self.func(*args, **kwargs)\n\n\nclass IterCounter:\n def __init__(self, gen):\n self.gen = gen\n self.count = 0\n\n def __next__(self):\n res = next(self.gen)\n self.count += 1\n return res\n\n def __iter__(self):\n self.count = 0\n return self\n"
},
{
"alpha_fraction": 0.623481810092926,
"alphanum_fraction": 0.623481810092926,
"avg_line_length": 21.454545974731445,
"blob_id": "58f3230df682a5c5f09768049ec7c6d3793b52a7",
"content_id": "4d91eda1ed349ba4f6226914620f5c4915fd0f2e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 249,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 11,
"path": "/Graph/Graph/Class1.cs",
"repo_name": "JohnFinn/OptLabs",
"src_encoding": "UTF-8",
"text": "using System.Collections;\nusing System.Collections.Generic;\n\nnamespace Graph{\n public interface IGraph<T> : IEnumerable<T>\n {\n void Add(T vertex);\n void Connect(T a, T b, uint weight);\n uint Path(T from, T to);\n }\n}\n"
},
{
"alpha_fraction": 0.45482924580574036,
"alphanum_fraction": 0.4831068813800812,
"avg_line_length": 35.30666732788086,
"blob_id": "2691744caa703a6084b0cc76d508923a4554dfc5",
"content_id": "e54aac6c65426cc56f895ed1a91793542a8e7a62",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5470,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 150,
"path": "/simplex.py",
"repo_name": "JohnFinn/OptLabs",
"src_encoding": "UTF-8",
"text": "from typing import List, Iterable, Callable, VT, KT\nfrom linear_function import LinearFunction\nfrom numpy import inf\n\n\nclass Slack(int):\n pass\n\n\nclass Helper:\n def __init__(self, x: int, slack: int):\n self.x = list(range(x))\n self.slack = list(map(Slack, range(slack)))\n\n def __call__(self, arg_number, index):\n self.x[arg_number], self.slack[index] = self.slack[index], self.x[arg_number]\n\n def get_result(self) -> Iterable[int]:\n for index, x in enumerate(self.slack):\n if not isinstance(x, Slack):\n yield index, x\n\n\ndef maximize(constraints: List[LinearFunction], objective_fn: LinearFunction) -> List[float]:\n \"\"\"\n >>> from linear_function import LinearFunction\n >>> from numpy import array\n >>> constraints = [ \\\n LinearFunction(18, [-2, -1, -1]), \\\n LinearFunction(30, [-1, -2, -2]), \\\n LinearFunction(24, [-2, -2, -2]), \\\n ]\n >>> objective_fn = LinearFunction(0, [6, 5, 4])\n >>> maximize(constraints, objective_fn)\n [Fraction(6, 1), Fraction(6, 1), 0]\n >>>\n >>>\n >>> A = [ \\\n [1, 2, -1, 2, 4], \\\n [0, -1, 2, 1, 3], \\\n [1, -3, 2, 2, 0], \\\n ]\n >>> b = [1, 3, 4]\n >>> c = [1, -3, 2, 1, 4]\n >>> constraints = [LinearFunction(free, -array(coefs)) for coefs, free in zip(A, b)]\n >>> objective_fn = LinearFunction(0, c)\n >>> maximize(constraints, objective_fn)\n [Fraction(26, 17), 0, Fraction(21, 17), 0, Fraction(3, 17)]\n \"\"\"\n h = Helper(len(objective_fn.coefs), len(constraints))\n while any(map(lambda x: x > 0, objective_fn.coefs)):\n pivot(constraints, objective_fn, h)\n res = [0 for i in objective_fn.coefs]\n for index, n in h.get_result():\n res[n] = constraints[index].free\n return res\n\n\ndef do_nothing(*args, **kwargs):\n pass\n\n\ndef _pivot(constraints: List[LinearFunction], objective_fn: LinearFunction) -> None:\n pivot(constraints, objective_fn, do_nothing)\n\n\ndef pivot(constraints: List[LinearFunction], objective_fn: LinearFunction, callback: Callable[[int, int], None]) -> None:\n \"\"\"\n >>> from linear_function import LinearFunction\n >>> constraints = [ \\\n LinearFunction(18, [-2, -1, -1]), \\\n LinearFunction(30, [-1, -2, -2]), \\\n LinearFunction(24, [-2, -2, -2]), \\\n ]\n >>> objective_fn = LinearFunction(0, [6, 5, 4])\n >>> _pivot(constraints, objective_fn)\n >>> print(objective_fn)\n 54 + -3*x₀ + 2*x₁ + 1*x₂\n >>> for i in constraints: print(i)\n 9 + -1/2*x₀ + -1/2*x₁ + -1/2*x₂\n 21 + 1/2*x₀ + -3/2*x₁ + -3/2*x₂\n 6 + 1*x₀ + -1*x₁ + -1*x₂\n \"\"\"\n arg_number = first_index(objective_fn.coefs, lambda x: x > 0)\n index = tightest_constraint(constraints, arg_number)\n assert -constraints[index].free / constraints[index].coefs[arg_number] > 0\n constraints[index].rearrange(arg_number)\n for c in skip_at(constraints, index):\n c.substitute(arg_number, constraints[index])\n objective_fn.substitute(arg_number, constraints[index])\n callback(arg_number, index)\n\n\ndef tightest_constraint(constraints: List[LinearFunction], index: int) -> int:\n \"\"\"\n >>> from linear_function import LinearFunction\n >>> constraints = [ \\\n LinearFunction(18, [-2, -1, -1]), \\\n LinearFunction(30, [-1, -2, -2]), \\\n LinearFunction(24, [-2, -2, -2]), \\\n ]\n >>> tightest_constraint(constraints, 1)\n 2\n \"\"\"\n def selector(x: LinearFunction):\n value = x.coefs[index]\n if value == 0 or same_sign(value, x.free):\n return inf\n return -x.free/value\n return min_index(constraints, key=selector)\n\n\ndef same_sign(a, b):\n \"\"\"\n >>> same_sign(1, 1)\n True\n >>> same_sign(1, -1)\n False\n >>> same_sign(-1, -1)\n True\n >>> same_sign(-1, 1)\n False\n \"\"\"\n return (a > 0) == (b > 0)\n\n\n\ndef min_index(sequence: Iterable[VT], key: Callable[[VT], KT]) -> int:\n \"\"\"\n >>> min_index(range(2), key=lambda x: -x)\n 1\n \"\"\"\n return min(enumerate(sequence), key=lambda x: key(x[1]))[0]\n\n\ndef first_index(sequence: Iterable[VT], selector: Callable[[VT], bool]) -> int:\n return first(enumerate(sequence), lambda x: selector(x[1]))[0]\n\n\ndef first(sequence: Iterable[VT], selector: Callable[[VT], bool]) -> VT:\n for item in sequence:\n if selector(item):\n return item\n raise RuntimeError(\"No selected item in sequence\")\n\n\ndef skip_at(sequence: Iterable[VT], index: int) -> Iterable[VT]:\n for i, item in enumerate(sequence):\n if index != i:\n yield item\n"
}
] | 8 |
zmobi/pyscrape
|
https://github.com/zmobi/pyscrape
|
470fa019a973108db3b9b9c90976a00df88a55c7
|
bba92501109780853fa36fa14b3fa9613331ef63
|
e76f5572430efe8bca915981af82c1cee900d4a1
|
refs/heads/master
| 2016-09-17T11:06:00.311340 | 2016-08-04T06:14:07 | 2016-08-04T06:14:07 | 62,799,191 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5125116109848022,
"alphanum_fraction": 0.5434044003486633,
"avg_line_length": 28.42727279663086,
"blob_id": "7648558bddb31d5e878aaba10afb7b4df6b9e859",
"content_id": "7ce8517474bc674057b320cb9d5e0919e23cea5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3697,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 110,
"path": "/tomorrow_edge.py",
"repo_name": "zmobi/pyscrape",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\n作品: all you need is kill\n作者: 小畑健\n重点: 使用PhantomJS+Selenium 实现等待页面加载完全部JS后方能获取真实的图片url\n补充: 暂不涉及session或者是cookies问题,其他网站会存在即使获得真实url后依然无法下载图片的情况\n日志:\n2016-08-01 增加随机等待时长\n2016-08-02 driver.get(url) 有时会卡住,等待超时,暂无解决方法\n2016-08-03 修改下载图片命名,章节-页数.jpg,不足两位前补0\n\"\"\"\n\nfrom selenium import webdriver\nfrom bs4 import BeautifulSoup\nimport time\nimport requests\nimport re\nfrom os import path\nfrom random import randint\n\nheaders = {\n 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \\\n AppleWebKit/537.36 (KHTML, like Gecko) \\\n Chrome/52.0.2743.82 Safari/537.36'\n}\n\n\ndef getchapter(url):\n \"\"\"\n get every chapter and total page's number\n :param url:\n :return:\n \"\"\"\n total = {}\n html = requests.get(url, headers=headers)\n if html.status_code == 200:\n bs = BeautifulSoup(html.content, \"lxml\")\n # 查找包含所有章节的元素\n items = bs.find(\"ul\", {\"style\": \"display:block;\"}).find_all(\"span\")\n for item in items:\n # <span>17\\u8bdd<i>23p</i></span> 选出章节和总页数\n result = re.match(re.compile('.*?(\\d{2}).*?(\\d{2})p'), str(item))\n chapter = result.group(1)\n pages = result.group(2)\n print '第%s章 总%s页' % (chapter, pages)\n total[int(chapter)] = int(pages)\n return total\n else:\n print '网页 %s 无法打开' % url\n\n\ndef geturl(url, info):\n \"\"\"\n get the real img url\n :param url:\n :param info:\n \"\"\"\n for chapter in info:\n # 添加判断条件,可自主控制下载的章节\n if chapter >= 1:\n # 指定phantomjs所在路径\n driver = webdriver.PhantomJS(executable_path='/usr/local/bin/phantomjs')\n if chapter >= 10:\n chapter_url = '%s%03d/' % (url, chapter)\n else:\n chapter_url = '%s%02d/' % (url, chapter)\n for num in range(1, info[chapter]+1):\n # 拼装成完整的单个章节每页的URL\n page_url = '%s?p=%d' % (chapter_url, num)\n # 关键实现之处\n driver.get(page_url)\n html = driver.page_source\n # 暂时先借助美丽汤来解释页面信息\n bs = BeautifulSoup(html, \"lxml\")\n # 图片真实url\n img_url = bs.find('img', {'id': 'manga'})[\"src\"].split('=')[1]\n # 图片后缀名\n suffix = img_url.split('.')[-1]\n # 生成图片文件的名字\n img_name = '%02d-%02d.%s' % (chapter, num, suffix)\n print '正在下载 第%d章 第%d页' % (chapter, num)\n w2f(img_url, img_name)\n time.sleep(randint(10, 24))\n driver.close()\n\n\ndef w2f(real_url, filename):\n \"\"\"\n download the img into local disk\n :return:\n \"\"\"\n directory = '/home/jeff/tomorrow_edge'\n full_name = path.join(directory, filename)\n if path.isfile(full_name):\n pass\n else:\n html = requests.get(real_url, headers=headers)\n if html.status_code == 200:\n with open(full_name, 'wb') as f:\n f.write(html.content)\n else:\n print 'img url %s can not open' % real_url\n time.sleep(randint(1, 10))\n\nif __name__ == '__main__':\n link = 'http://www.57mh.com/3680/'\n chapter_pages = getchapter(link)\n geturl(link, chapter_pages)\n"
},
{
"alpha_fraction": 0.5899471044540405,
"alphanum_fraction": 0.6058201193809509,
"avg_line_length": 24.200000762939453,
"blob_id": "16406775847802a516653ccbbc29a32b15e33324",
"content_id": "02f275adb21ae71cb1b083d28f0bdd160217b7db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 378,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 15,
"path": "/engadget.py",
"repo_name": "zmobi/pyscrape",
"src_encoding": "UTF-8",
"text": "#! /usr/local/bin/python\n# -*- coding: utf-8 -*-\n\nimport re\nimport urllib2\n\nurl = 'http://cn.engadget.com'\nrequest = urllib2.Request(url)\ntry:\n response = urllib2.urlopen(request)\n content = response.read().decode('utf-8')\n\n\np = re.compile('<article itemscope.*?<a itemprop=\"url\" href=\"(.*?)\">(.*?)</a\n></h2>.*?<div class=\"copy\".*?</div><br>(.*?)<p class=\"read-more\".*?')\n"
},
{
"alpha_fraction": 0.5088797807693481,
"alphanum_fraction": 0.5389344096183777,
"avg_line_length": 28.87755012512207,
"blob_id": "209ff4bbaa2da7e75b870fbc9105760bb6a1514a",
"content_id": "d4954f82571e1c5b034e7a29d702ed28f4c76c15",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1552,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 49,
"path": "/jjdjr.py",
"repo_name": "zmobi/pyscrape",
"src_encoding": "UTF-8",
"text": "#! /usr/local/bin/python\n# -*- coding: utf-8 -*-\n\n\"\"\"\n下载《进击的巨人》漫画,仅适用于没用使用JavaScript加载漫画图片的网站\n\"\"\"\n\nfrom bs4 import BeautifulSoup\nimport requests\n\n\ndef getnew(url):\n \"\"\"\n download the pictures\n >>> getnew('http://www.57mh.com/118/096/?p=2')\n 'downloading file 02-83.jpg'\n \"\"\"\n\n html = requests.get(url)\n if html.status_code == 200:\n bs = BeautifulSoup(html.content, \"lxml\")\n chapter = bs.find(\"ul\", {\"style\": \"display:block;\"})\n # 章节数\n chapter_num = chapter.li.a[\"title\"][0:2]\n # 章节名字\n chapter_name = chapter.li.a[\"title\"]\n # 章节总页数\n chapter_pages = chapter.li.a.span.i.string.rstrip('p')\n # 漫画名字\n # comic = bs.find_all('h1')[1].string\n\n pre_url = 'http://img.333dm.com/ManHuaKu/jinjidejuren'\n for i in range(int(chapter_pages)):\n # http://img.333dm.com/ManHuaKu/jinjidejuren/83/45.jpg\n img_file = '%02d-%s.jpg' % (i+1, chapter_name)\n img_url = '%s/%s/%s.jpg' % (pre_url, chapter_num, i+1)\n response = requests.get(img_url)\n if response.status_code == 200:\n print 'downloading file %s' % img_file\n with open(img_file, 'wb') as f:\n f.write(response.content)\n else:\n print '%s can not open' % img_file\n else:\n print '%s can not open' % url\n\nif __name__ == '__main__':\n link = 'http://www.57mh.com/118/'\n getnew(link)\n"
},
{
"alpha_fraction": 0.5758947134017944,
"alphanum_fraction": 0.6042780876159668,
"avg_line_length": 26.29213523864746,
"blob_id": "14a7adfb028f5abd4d0f08e00135e4dd2b98b8a4",
"content_id": "7eadfbe288c9ef5a0c6a8dbb9550366fbe956393",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2715,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 89,
"path": "/lyzs.py",
"repo_name": "zmobi/pyscrape",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/python\n# -*- coding: utf-8 -*-\n'''\n烙印战士漫画下载\n旧有链接: 「当时貌似没写完的,下载不了」\nhttp://v.comicbus.com/online/finance-1725.html?ch=336-2\n新的下载来源:\nhttp://www.dmzx.com/manhua/44/ 动漫在线\n2016-08-02 手动输入章节数指定下载\n\n存在问题:\n1. 成功加载完JS获取图片URL,但仍然无法下载图片\n2. 加载页面时卡住了,无法进行,有可能被人排除掉了\n'''\n\n__author__ = 'JeffChan'\n\nfrom selenium import webdriver\nfrom bs4 import BeautifulSoup\nimport requests\nimport re\nimport time\n\nheaders = {\n 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) \\\n AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36'\n}\n\n\ndef getchapter(url):\n \"\"\"\n get every chapter and total page's number\n :param url:\n :return:\n \"\"\"\n driver = webdriver.PhantomJS(executable_path='/usr/local/bin/phantomjs')\n driver.get(url)\n content = driver.page_source\n bs = BeautifulSoup(content, \"lxml\")\n chapter_url = bs.find('div', {'class': 'subsrbelist center'}).ul.li.a[\"href\"]\n tmp = bs.find('div', {'class': 'subsrbelist center'}).ul.li.a.get_text()\n result = re.match('.*?(\\d{3}).*?(\\d{2}).*?', tmp)\n chapter_num = int(result.group(1))\n chapter_pages = int(result.group(2))\n geturl(chapter_url, chapter_num, chapter_pages)\n\n\ndef geturl(url, chapter, pages):\n \"\"\"\n get the real img url\n :param url:\n :param info:\n \"\"\"\n # 指定phantomjs所在路径\n driver = webdriver.PhantomJS(executable_path='/usr/local/bin/phantomjs')\n for num in range(1, pages+1):\n # 拼装成完整的单个章节每页的URL\n page_url = '%s#p=%d' % (url, num)\n driver.get(page_url)\n content = driver.page_source\n # 暂时先借助美丽汤来解释页面信息\n bs = BeautifulSoup(content, \"lxml\")\n # 图片真实url\n img_url = bs.find('img', {'id': 'manga'})[\"src\"].split('=')[1]\n # 图片后缀名\n suffix = img_url.split('.')[-1]\n # 生成图片文件的名字\n img_name = '%02d-%d.%s' % (num, key, suffix)\n print 'downloading chapter %d - %02d .%s' % (key, num, suffix)\n w2f(img_url, img_name)\n time.sleep(3)\n\n\ndef w2f(real_url, filename):\n \"\"\"\n download the img into local disk\n :return:\n \"\"\"\n html = requests.get(real_url, headers=headers)\n if html.status_code == 200:\n with open(filename, 'wb') as f:\n f.write(html.content)\n else:\n print 'img url %s can not open' % real_url\n\nif __name__ == '__main__':\n link = 'http://www.dmzx.com/manhua/44/'\n chapter_nums = getchapter(link)\n geturl(link, chapter_nums)\n\n\n"
},
{
"alpha_fraction": 0.5151515007019043,
"alphanum_fraction": 0.5308080911636353,
"avg_line_length": 30.428571701049805,
"blob_id": "2e992e06685cffd55a9b41b802ff590e31a07594",
"content_id": "03fc75eb531c257fb5b19b88be50a803c8bd5b0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2120,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 63,
"path": "/myblog.py",
"repo_name": "zmobi/pyscrape",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/python\n# -*- coding: utf-8 -*- \n\nimport re\nimport urllib2\nimport sys\n\nclass Tool():\n #去除img标签,7位长空格\n removeImg = re.compile('<img.*?>| {7}|')\n #删除超链接标签\n removeAddr = re.compile('<a.*?>|</a>')\n #把换行的标签换为\\n\n replaceLine = re.compile('<tr>|<div>|</div>|</p>')\n #将表格制表<td>替换为\\t\n replaceTD = re.compile('<tb>')\n #把段落开头换为\\n加空两格\n replacePara = re.compile('<p.*?>')\n #将换行符或双换行符替换为'\\n'\n replaceBR = re.compile('<br><br>|<br>')\n #将其余标签剔除\n removeExtraTag = re.compile('<.*?>')\n\n def replace(self, x):\n x = re.sub(self.removeImg,\"\",x)\n x = re.sub(self.removeAddr,\"\",x)\n x = re.sub(self.replaceLine,\"\\n\",x)\n x = re.sub(self.replaceTD,\"\\t\",x)\n x = re.sub(self.replacePara,\"\\n \",x)\n x = re.sub(self.replaceBR,\"\\n\",x)\n x = re.sub(self.removeExtraTag,\"\",x)\n #strip()将前后多余内容删除\n return x.strip()\n\n\ndef getBlog(url):\n tool = Tool()\n request = urllib2.Request(url)\n response = urllib2.urlopen(request)\n content = response.read().decode('utf-8')\n p = re.compile('<span class=\"atc_title\".*?<a.*?href=\"(.*?)\">(.*?)</a>.*?<span class=\"atc_tm SG_txtc\">(.*?) .*?</span>',re.S)\n items = re.findall(p, content)\n for item in items:\n # url item[0], title items[1], time items[2]\n print 'new url %s' %item[0]\n rp = urllib2.urlopen(item[0])\n ct = rp.read().decode('utf-8')\n pp = re.compile('<div id=\"sina_keyword_ad_area2\".*?>(.*?)</div>',re.S)\n tt = re.findall(pp, ct)\n name = '%s-%s.md' %(item[2],item[1])\n print 'leng tt %s' %len(tt)\n tmp = tool.replace(tt[0])\n reload(sys)\n sys.setdefaultencoding('utf-8')\n with open(name, 'w+') as f:\n f.write('---\\n')\n f.write('layout: post\\n')\n f.write('categories: sina-blog\\n')\n f.write('---\\n')\n f.write(tmp)\n\nurl = 'http://blog.sina.com.cn/s/articlelist_1399693917_0_1.html'\ngetBlog(url)\n"
},
{
"alpha_fraction": 0.4892144799232483,
"alphanum_fraction": 0.5234025120735168,
"avg_line_length": 29.33333396911621,
"blob_id": "aabd1d5b0d0b527eeb552fb05125a6b9e9878aca",
"content_id": "790a1e471db909b7515df6ab2419ec0353a7b963",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2521,
"license_type": "no_license",
"max_line_length": 152,
"num_lines": 81,
"path": "/cnbeta.py",
"repo_name": "zmobi/pyscrape",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/python\n# -*- coding:utf-8 -*-\n\nimport urllib2\nimport urllib\nimport re\nimport os\nimport sys\n\ntry:\n import Tool\nexcept ImportError:\n print 'file Tool.py is not exist in current dir'\n sys.exit()\n\ndef cnbeta(url):\n user_agent = 'Mozilla/5.0 (X11; Linux i686) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/50.0.2661.102 Chrome/50.0.2661.102 Safari/537.36'\n headers = { 'User-Agent':user_agent }\n tool = Tool.Tool()\n md = []\n tl = []\n \n try:\n request = urllib2.Request(url, headers = headers)\n response = urllib2.urlopen(request)\n content = response.read().decode('utf-8')\n pattern = re.compile('<div class=\"title\">.*?href=\"(.*?)\">(.*?)</a>.*?class=\"newsinfo\"><p>(.*?)</p>',re.S)\n items = re.findall(pattern, content)\n for item in items:\n rq = urllib2.Request(url+item[0], headers = headers)\n rp = urllib2.urlopen(rq)\n ct = rp.read().decode('utf-8')\n pp = re.compile('<div class=\"content\">(.*?)</div>',re.S)\n line = re.findall(pp, ct)\n tmp1 = tool.replace(item[2])\n tmp2 = tool.replace(line[0])\n md.append('[**%s**](%s)' %(item[1], url+item[0]))\n tl.append('## [**%s**]' %item[1])\n md.append(tmp1+'\\n')\n md.append(tmp2+'\\n')\n md.append('\\n')\n return md,tl\n except urllib2.URLError, e:\n if hasattr(e, \"code\"):\n print e.code\n if hasattr(e, \"reason\"):\n print e.reason\n\ndef w2f(mdFile, title, details):\n '''\n write the web message to the file with markdown format\n >>> w2f('./2016-07-10-cnbeta.md', tlist, dlist)\n 'ok'\n '''\n # 重新载入编码环境,否则无法写入文件\n reload(sys)\n sys.setdefaultencoding('utf-8')\n\n with open(mdFile, 'w+') as f:\n f.write('---\\n')\n f.write('layout: post\\n')\n f.write('categories: news\\n')\n f.write('---\\n')\n count = 1\n # 设置md文件的锚点,支持文件内跳转\n for tt in range(len(title)):\n tmp = '%d. %s(#%02d)\\n' %(tt+1, title[tt], tt+1)\n f.write(tmp)\n f.write('\\n')\n for line in details:\n if '[**' in line:\n line = '# <span id = \"%02d\">%s</span>\\n' %(count, line)\n count = count + 1\n f.write(line)\n print 'ok'\n\n\nurl = 'http://www.cnbeta.com'\nmdFile = '/tmp/zmobi/_posts/2016-07-06-cnbeta-news.md'\ncl,tl = cnbeta(url)\nw2f(mdFile, tl, cl)\n"
},
{
"alpha_fraction": 0.5157360434532166,
"alphanum_fraction": 0.5360406041145325,
"avg_line_length": 28.84848403930664,
"blob_id": "d4821cd779cd0fecce8400415e3e11f27f0f1d3c",
"content_id": "bb8125e636ad97bde370a7757b6beefac1830777",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1994,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 66,
"path": "/get_cnbeta_post.py",
"repo_name": "zmobi/pyscrape",
"src_encoding": "UTF-8",
"text": "# -*- coding:utf-8 -*-\n\nimport re\nimport requests\nimport sys\nimport time\nfrom os import path as path\nfrom bs4 import BeautifulSoup\n\nheaders = {\n 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \\\n AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36'\n}\n\n\ndef w2f(content):\n \"\"\"\n >>> w2f('hello world')\n 'finished wrote fucking'\n \"\"\"\n post_dir = '/home/jeff/jtest/_posts'\n reload(sys)\n sys.setdefaultencoding('utf-8')\n now = time.strftime(\"%Y-%m-%d-%H%M%S\")\n md_file = path.join(post_dir, '%s.md' % now)\n with open(md_file, 'w+') as f:\n for line in content:\n f.write(line)\n print 'finished wrote fucking %s.md' % now\n time.sleep(2)\n\n\ndef getinfo(url, ver=None):\n \"\"\"\n >>> purl = getinfo('http://www.cnbeta.com')\n \"\"\"\n html = requests.get(url, headers=headers)\n if html.status_code == 200:\n bs = BeautifulSoup(html.content, \"html.parser\")\n if ver is None:\n purl = []\n items = bs.find_all(\"div\", {\"class\": \"title\"})\n for line in items:\n purl.append(url+line.a[\"href\"])\n return purl\n else:\n content = []\n title = bs.h2.string\n summary = bs.find('div', {'class': 'introduction'}).p.get_text()\n article = bs.find_all('p', {'style': re.compile('text-align: .*?left;')})\n # 添加md文件表头信息\n content.append('---\\nlayout: post\\ncategory: News\\ntitle: %s\\n---\\n' % title.replace('[]', ''))\n content.append('%s\\n\\n' % summary)\n # 添加 read more 标签\n content.append('<!-- more -->\\n\\n')\n for line in article:\n content.append('%s\\n\\n' % line.get_text())\n w2f(content)\n else:\n print 'url %s can not interview' % url\n\nif __name__ == '__main__':\n link = 'http://www.cnbeta.com'\n urls = getinfo(link)\n for item in urls:\n getinfo(item, ver='single')\n"
}
] | 7 |
abdullahsidddiky/CSE499
|
https://github.com/abdullahsidddiky/CSE499
|
704d2148b71edd60dc7779e95de7e12bf994d6c6
|
e8b384ccf22e761bdea55eca603794320a74fa9a
|
d503a02438ac76244c5ce8d99bb1e8b3dc6f8cc7
|
refs/heads/main
| 2023-07-03T04:57:41.435866 | 2021-07-18T07:31:05 | 2021-07-18T07:31:05 | 387,116,362 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8030303120613098,
"alphanum_fraction": 0.8484848737716675,
"avg_line_length": 32,
"blob_id": "a95a6da50e991803ca157e5a7d4762b6748e5d8f",
"content_id": "93101dbec883c2afc316c571637574f68529b48b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 66,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 2,
"path": "/README.md",
"repo_name": "abdullahsidddiky/CSE499",
"src_encoding": "UTF-8",
"text": "# Face_recognition_attendance_system\nCSE499-Senior_Design_Project\n"
},
{
"alpha_fraction": 0.5734907984733582,
"alphanum_fraction": 0.5800524950027466,
"avg_line_length": 34.33333206176758,
"blob_id": "1c6bfbbe9c32e61a93abe639bcce5b09964b6f26",
"content_id": "fd515bf4ba60e0966f55e60d478f0b719948162f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1524,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 42,
"path": "/HaarTrain.py",
"repo_name": "abdullahsidddiky/CSE499",
"src_encoding": "UTF-8",
"text": "import os\r\nimport numpy as np\r\nfrom PIL import Image\r\nimport cv2\r\nimport pickle\r\nBase_dir=os.path.dirname(os.path.abspath(__file__))\r\nimg_dir=os.path.join(Base_dir,\"ImgOur\")\r\nface_cascade=cv2.CascadeClassifier('src\\cascades\\data\\haarcascade_frontalface_alt2.xml')\r\nrecognizer=cv2.face.LBPHFaceRecognizer_create()\r\n\r\ncurrent_id=0\r\nlabel_id={}\r\ny_labels=[]\r\nx_train=[]\r\n\r\nfor root,dirs,files in os.walk(img_dir):\r\n for file in files:\r\n if file.endswith(\"jpeg\") or file.endswith(\"jpg\") or file.endswith(\"bmp\"):\r\n path=os.path.join(root,file)\r\n label=os.path.basename(root).replace(\" \", \"-\").lower()\r\n #print(label,path)\r\n if not label in label_id:\r\n label_id[label]=current_id\r\n current_id+=1\r\n id_=label_id[label]\r\n # print(label_id)\r\n # y.labels.append(label)\r\n #x-train.append(path)\r\n pill_image=Image.open(path).convert(\"L\")\r\n image_array=np.array(pill_image,\"uint8\")\r\n # print(image_array)\r\n faces=face_cascade.detectMultiScale(image_array,scaleFactor=1.5,minNeighbors=5)\r\n for (x,y,w,h) in faces:\r\n roi=image_array[y:y+h,x:x+w]\r\n x_train.append(roi)\r\n y_labels.append(id_)\r\n#print(y_labels)\r\n#print(x_train)\r\n with open(\"labels.pickle\",'wb') as f:\r\n pickle.dump(label_id,f)\r\nrecognizer.train(x_train,np.array(y_labels))\r\nrecognizer.save(\"trainner.xml\")"
},
{
"alpha_fraction": 0.5850722193717957,
"alphanum_fraction": 0.613162100315094,
"avg_line_length": 30.6842098236084,
"blob_id": "62c065ac9b7c8ebef30f53cfc2dfc46eb29bd1fd",
"content_id": "4128ad02a61a4462efed73284c6f0ca0efafa55f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1246,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 38,
"path": "/HaarCascade.py",
"repo_name": "abdullahsidddiky/CSE499",
"src_encoding": "UTF-8",
"text": "import numpy as np \r\nimport cv2\r\nimport pickle \r\nface_cascade=cv2.CascadeClassifier('src\\cascades\\data\\haarcascade_frontalface_alt2.xml')\r\nrecognizer=cv2.face.LBPHFaceRecognizer_create()\r\nrecognizer.read(\"trainner.yml\")\r\nlabels={\"person_name\": 1}\r\n\r\nwith open(\"labels.pickle\",'rb') as f:\r\n og_labels= pickle.load(f)\r\n labels={v:k for k,v in og_labels.items()}\r\ncap=cv2.VideoCapture(0)\r\nwhile(1):\r\n ret,frame=cap.read()\r\n gray=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)\r\n faces=face_cascade.detectMultiScale(gray,scaleFactor=1.5,minNeighbors=5)\r\n for(x,y,w,h) in faces:\r\n print(x,y,w,h)\r\n roi_gray=gray[y:y+h, x:x+w]\r\n roi_color=frame[y:y+h, x:x+w]\r\n id_,conf=recognizer.predict(roi_gray)\r\n if conf>=50: #and conf<=85:\r\n print(id_)\r\n print(labels[id_])\r\n img_item=\"Imgae.png\"\r\n cv2.imwrite(img_item,roi_gray)\r\n color=(255,0,0)\r\n stroke=1\r\n end_cord_x=x+w\r\n end_cord_y=y+h\r\n cv2.rectangle(frame,(x,y),(end_cord_x,end_cord_y), color,stroke)\r\n gray=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)\r\n cv2.imshow('frame',frame)\r\n if cv2.waitKey(20) & 0xFF==ord('q'):\r\n break\r\n\r\ncap.release()\r\ncv2.destroyAllWindows()\r\n "
}
] | 3 |
Morgan-Gan/SLowFastMc-TSM
|
https://github.com/Morgan-Gan/SLowFastMc-TSM
|
a8929367eeb33488f136fc5d149d5622c5a93aea
|
9568be69fc87d59d569327ae5c3d2c448bc23648
|
e343cb990f1e2147fa098e689b5b96a206c2d608
|
refs/heads/master
| 2022-11-30T20:45:45.039065 | 2020-08-14T04:16:47 | 2020-08-14T04:16:47 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5715935230255127,
"alphanum_fraction": 0.5993071794509888,
"avg_line_length": 30.509090423583984,
"blob_id": "fc4cccd6aae5ced218a6c796481fae8ff6a3b5b6",
"content_id": "6f8419ff29a6d814bc585eaf7d9c56e4e6bf0efd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1786,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 55,
"path": "/backbone/hidden_for_roi.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nfrom torch.autograd import Variable\nimport numpy as np\n\n\nclass Hidden(nn.Module):\n\n def __init__(self, inplanes, planes, stride=1):\n super(Hidden, self).__init__()\n self.conv1 = nn.Conv2d(inplanes, inplanes, kernel_size=3,padding=1, bias=False)\n self.bn1 = nn.BatchNorm2d(planes)\n self.conv2 = nn.Conv2d(inplanes, inplanes, kernel_size=3, stride=stride,\n padding=1, bias=False)\n self.bn2 = nn.BatchNorm2d(planes)\n self.conv3 = nn.Conv2d(inplanes, planes, kernel_size=3, padding=1,bias=False)\n self.bn3 = nn.BatchNorm2d(planes)\n self.relu = nn.ReLU(inplace=True)\n\n def forward(self, x):\n out = self.conv1(x)\n out = self.bn1(out)\n out = self.relu(out)\n\n out = self.conv2(out)\n out = self.bn2(out)\n out = self.relu(out)\n\n out = self.conv3(out)\n out = self.bn3(out)\n out = self.relu(out)\n out = nn.AdaptiveAvgPool2d(1)(out)\n out = out.view(-1, out.size(1))\n return out\n\ndef weight_init(m):\n # if isinstance(m, nn.Linear):\n # nn.init.xavier_normal_(m.weight)\n # nn.init.constant_(m.bias, 0)\n # 也可以判断是否为conv2d,使用相应的初始化方式\n if isinstance(m, nn.Conv3d):\n print(\"using kaiming\")\n nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')\n # 是否为批归一化层\n # elif isinstance(m, nn.BatchNorm3d):\n # nn.init.constant_(m.weight, 1)\n # nn.init.constant_(m.bias, 0)\ndef hidden50(**kwargs):\n \"\"\"Constructs a ResNet-50 model.\n \"\"\"\n model = Hidden(2304,2304,2)\n # model.apply(weight_init)\n print('model', model)\n return model"
},
{
"alpha_fraction": 0.5491060614585876,
"alphanum_fraction": 0.5696066617965698,
"avg_line_length": 45.61666488647461,
"blob_id": "5f2a228a759ed132857b395d747c101b071c8fd7",
"content_id": "a71155d6171c38e542c787daf09941cf7dcfa510",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8442,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 180,
"path": "/dataset/AVA.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "import os\nimport numpy as np\nimport torch.utils.data\nfrom PIL import Image, ImageOps\nfrom bbox1 import BBox\nfrom typing import Tuple, List, Type, Iterator\nimport matplotlib.pyplot as plt\nimport PIL\nimport torch.utils.data.dataset\nimport torch.utils.data.sampler\nfrom PIL import Image\nfrom torch import Tensor\nfrom torchvision.transforms import transforms\nimport cv2\n\nclass AVA():\n\n class info():\n def __init__(self, img_class, bbox,h,w,img_position):\n self.img_class = int(img_class)-1\n self.bbox = bbox\n self.height=h\n self.weight=w\n self.img_position=img_position\n def __repr__(self):\n return 'info[img_class={0}, bbox={1}]'.format(\n self.img_class, self.bbox)\n\n\n def __init__(self):\n self.bboxes=[]\n self.labels=[]\n self.image_ratios = []\n self.image_position=[]\n\n self.data_dic = {}\n self.data_size={}\n self.path_to_data_dir='/home/aiuser/'\n path_to_AVA_dir = os.path.join(self.path_to_data_dir, 'ava_v2.2', 'preproc','train_clips')\n path_to_videos = os.path.join(path_to_AVA_dir, 'clips')\n self.path_to_keyframe = os.path.join(path_to_AVA_dir, 'keyframes')\n path_to_video_ids_txt = os.path.join(path_to_AVA_dir, 'trainval.txt')\n\n for frame in sorted(os.listdir(self.path_to_keyframe)):\n img=os.listdir(os.path.join(self.path_to_keyframe, frame))[0]\n #print('img',img,os.listdir(os.path.join(self.path_to_keyframe, frame)))\n img=cv2.imread(os.path.join(self.path_to_keyframe, frame,img))\n #cv2.imshow('result.jpg',img)\n img_shape=img.shape\n self.data_size[frame]=(img_shape[0],img_shape[1])\n # print(self.data_size)\n with open(path_to_video_ids_txt, 'r') as f:\n data = f.readlines()\n for line in data:\n content = line.split(',')\n key=content[0]+\"/\"+str(int(content[1]))\n img_h=int(self.data_size[content[0]][0])\n img_w = int(self.data_size[content[0]][1])\n if key not in self.data_dic:\n self.data_dic[key] = [AVA.info(content[6],BBox( # convert to 0-based pixel index\n left=float(content[2])*img_w - 1,\n top=float(content[3])*img_h - 1,\n right=float(content[4])*img_w - 1,\n bottom=float(content[5])*img_h - 1),img_h,img_w,key)]\n else:\n self.data_dic[key].append(AVA.info(content[6], BBox( # convert to 0-based pixel index\n left=float(content[2]) * img_w - 1,\n top=float(content[3]) * img_h - 1,\n right=float(content[4]) * img_w - 1,\n bottom=float(content[5]) * img_h - 1), img_h, img_w, key))\n # print('data_dic:',self.data_dic)\n for key in self.data_dic:\n self.bboxes.append([item.bbox.tolist() for item in self.data_dic[key]])\n self.labels.append([item.img_class for item in self.data_dic[key]])\n width = int(self.data_dic[key][0].weight)\n height = int(self.data_dic[key][0].height)\n ratio = float(width / height)\n self.image_ratios.append(ratio)\n self.image_position.append(self.data_dic[key][0].img_position)\n\n def __len__(self) -> int:\n return len(self.bboxes)\n\n def num_classes(self):\n return 80\n\n def __getitem__(self, index: int) -> Tuple[str, Tensor, Tensor, Tensor, Tensor]:\n bboxes = torch.tensor(self.bboxes[index], dtype=torch.float)\n labels = torch.tensor(self.labels[index], dtype=torch.long)\n # print(int(self.image_position[index].split('/')[1]))\n #image = Image.open(self.path_to_keyframe+'/'+image_index[index].split('/')[0]+'/'+str(int(image_index[index].split('/')[1]))+\".jpg\")\n image = Image.open(self.path_to_keyframe+'/'+self.image_position[index]+\".jpg\")\n # random flip on only training mode\n # if self._mode == VOC2007.Mode.TRAIN and random.random() > 0.5:\n # image = ImageOps.mirror(image)\n # bboxes[:, [0, 2]] = image.width - bboxes[:, [2, 0]] # index 0 and 2 represent `left` and `right` respectively\n self._image_min_side=600\n self._image_max_side=1000\n image, scale = self.preprocess(image, self._image_min_side, self._image_max_side)\n scale = torch.tensor(scale, dtype=torch.float)\n bboxes *= scale\n return self.image_position[index], image, scale, bboxes, labels\n\n\n def __getitem__(self, index: int) -> Tuple[str, Tensor, Tensor, Tensor, Tensor]:\n bboxes = torch.tensor(self.bboxes[index], dtype=torch.float)\n labels = torch.tensor(self.labels[index], dtype=torch.long)\n # print(int(self.image_position[index].split('/')[1]))\n #image = Image.open(self.path_to_keyframe+'/'+image_index[index].split('/')[0]+'/'+str(int(image_index[index].split('/')[1]))+\".jpg\")\n image = Image.open(self.path_to_keyframe+'/'+self.image_position[index]+\".jpg\")\n # random flip on only training mode\n # if self._mode == VOC2007.Mode.TRAIN and random.random() > 0.5:\n # image = ImageOps.mirror(image)\n # bboxes[:, [0, 2]] = image.width - bboxes[:, [2, 0]] # index 0 and 2 represent `left` and `right` respectively\n self._image_min_side=600\n self._image_max_side=1000\n image, scale = self.preprocess(image, self._image_min_side, self._image_max_side)\n scale = torch.tensor(scale, dtype=torch.float)\n bboxes *= scale\n return self.image_position[index], image, scale, bboxes, labels\n\n\n\n def preprocess(self,image: PIL.Image.Image, image_min_side: float, image_max_side: float) -> Tuple[Tensor, float]:\n # resize according to the rules:\n # 1. scale shorter side to IMAGE_MIN_SIDE\n # 2. after scaling, if longer side > IMAGE_MAX_SIDE, scale longer side to IMAGE_MAX_SIDE\n scale_for_shorter_side = image_min_side / min(image.width, image.height)\n longer_side_after_scaling = max(image.width, image.height) * scale_for_shorter_side\n scale_for_longer_side = (image_max_side / longer_side_after_scaling) if longer_side_after_scaling > image_max_side else 1\n scale = scale_for_shorter_side * scale_for_longer_side\n\n transform = transforms.Compose([\n transforms.Resize((round(image.height * scale), round(image.width * scale))), # interpolation `BILINEAR` is applied by default\n transforms.ToTensor(),\n transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])\n ])\n image = transform(image)\n\n return image, scale\n\n def index2class(self):\n file_path = '/home/aiuser/ava_v2.2/ava_v2.2/ava_action_list_v2.0.csv'\n with open(file_path) as f:\n i2c_dic = {line.split(',')[0]: line.split(',')[1] for line in f}\n # print(i2c_dic)\n return i2c_dic\n\n def test(self,item_num):\n i2c_dic=self.index2class()\n for i in range(item_num):\n result=self.__getitem__(i)\n bboxes=result[3]\n labels=result[4]\n scale=result[2]\n print('scale:',scale)\n print ('bboxes:',bboxes)\n print ('labels:',labels)\n print('dir:',self.path_to_keyframe + '/' + result[0] + \".jpg\")\n image = cv2.imread(self.path_to_keyframe + '/' + result[0] + \".jpg\")\n count=0\n for bbox,lable in zip(bboxes,labels):\n count=count+1\n bbox=np.array(bbox)\n lable = int(lable)\n real_x_min = int(bbox[0]/scale)\n real_y_min = int(bbox[1]/scale)\n real_x_max = int(bbox[2]/scale)\n real_y_max = int(bbox[3]/scale)\n # 在每一帧上画矩形,frame帧,(四个坐标参数),(颜色),宽度\n cv2.rectangle(image, (real_x_min, real_y_min), (real_x_max, real_y_max), (255, 255, 255), 4)\n cv2.putText(image, i2c_dic[str(lable+1)], (real_x_min + 30, real_y_min + 30 * count), cv2.FONT_HERSHEY_COMPLEX,\\\n 1,(255, 255, 0), 1, False)\n cv2.imshow('Frame', image)\n # 刷新视频\n cv2.waitKey()\n\nif __name__ == '__main__':\n a=AVA()\n a.test(10)"
},
{
"alpha_fraction": 0.6203007698059082,
"alphanum_fraction": 0.6390977501869202,
"avg_line_length": 32.375,
"blob_id": "7e88b33b8653b799c86c896492790256ce7bfbf7",
"content_id": "5b2941c0911e4a7e4ca0a5221ab77a77e4e4e91c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 266,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 8,
"path": "/rpn/mkf.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "def make_image_key(video_id, timestamp):\n \"\"\"Returns a unique identifier for a video id & timestamp.\"\"\"\n return \"%s,%04d\" % (video_id, int(timestamp))\n\nif __name__ == '__main__':\n video_id=\"aaaa\"\n timestamp=\"930\"\n print(make_image_key(video_id,timestamp))"
},
{
"alpha_fraction": 0.6218152046203613,
"alphanum_fraction": 0.6336846351623535,
"avg_line_length": 44.455814361572266,
"blob_id": "d11c7e362af21d98efb19d08912af7dd4be838f2",
"content_id": "d1dd1d838a93e4a22e971616de94b398325cd9d9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9911,
"license_type": "permissive",
"max_line_length": 182,
"num_lines": 215,
"path": "/trainvideo_org.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "import argparse\nimport os\nimport sys\nimport time\nimport uuid\nfrom collections import deque\nfrom typing import Optional\nfrom TF_logger import Logger\nimport torch\nimport torch.nn as nn\nfrom tensorboardX import SummaryWriter\nfrom torch import optim\nfrom torch.utils.data import DataLoader\nfrom dataset.AVA_video_v2 import AVA_video\nfrom backbone.base import Base as BackboneBase\nfrom config.train_config import TrainConfig as Config\nfrom dataset.base import Base as DatasetBase\nfrom extention.lr_scheduler import WarmUpMultiStepLR\nfrom logger import Logger as Log\nfrom model import Model\n\n################################################ TSM ###########################\nimport argparse\nfrom mmcv import Config as Config1\nfrom mmaction import __version__\nfrom mmaction.datasets import get_trimmed_dataset\nfrom mmaction.apis import (train_network, init_dist, get_root_logger,\n set_random_seed)\nfrom mmaction.models import build_recognizer\n\nfrom torch.utils.data import dataloader\nfrom torch.multiprocessing import reductions\nfrom multiprocessing.reduction import ForkingPickler\n\n############################################### TSM ################################\nos.environ['DISPLAY'] = 'localhost:12.0'\nlog_file = str(\"trainloss:\") + 'loss-remove.txt'\n\ndef tourch_script():\n weights ='weights/slowfast_weight.pth' # '/home/ganhaiyang/output/ava/temp_4/model_save/2019-12-26-11-06-33/model-80.pth'\n backbone_name = Config.BACKBONE_NAME\n dataset=AVA_video(Config.TRAIN_DATA)\n backbone = BackboneBase.from_name(backbone_name)()\n os.environ['CUDA_VISIBLE_DEVICES'] = '7'\n device = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\n chkpt = torch.load(weights, map_location=device)\n model = Model(\n backbone, dataset.num_classes(), pooler_mode=Config.POOLER_MODE,\n anchor_ratios=Config.ANCHOR_RATIOS, anchor_sizes=Config.ANCHOR_SIZES,\n rpn_pre_nms_top_n=Config.RPN_PRE_NMS_TOP_N, rpn_post_nms_top_n=Config.RPN_POST_NMS_TOP_N,\n anchor_smooth_l1_loss_beta=Config.ANCHOR_SMOOTH_L1_LOSS_BETA,\n proposal_smooth_l1_loss_beta=Config.PROPOSAL_SMOOTH_L1_LOSS_BETA\n ).to(device)\n\n try:\n model_dict=model.module.state_dict()\n except AttributeError:\n model_dict = model.state_dict() # 读取参数,\n # 将pretrained_dict里不属于model_dict的键剔除掉\n chkpt = {k: v for k, v in chkpt.items() if k in model_dict}\n print(\"load pretrain model\")\n model_dict.update(chkpt)\n model.load_state_dict(model_dict)\n\n # z转换为评估模型\n model.eval()\n # 向模型中输入数据以得到模型参数\n e1 = torch.rand(1, 3, 64, 300, 400).cuda()\n e2 = torch.rand(1, 3, 4).cuda()\n\n traced_script_module = torch.jit.trace(model,(e1,e2))\n traced_script_module.save(\"slowfast_50_eval_three.pt\")\n print(\"out put save\")\n exit(0)\n\ndef parse_args():\n parser = argparse.ArgumentParser(description='Train for TSM')\n parser.add_argument('--config',default='config_files/sthv2/tsm_baseline.py', help = 'Train config file path')\n args = parser.parse_args()\n return args\n\n\ndef _train( backbone_name,path_to_checkpoints_dir, path_to_resuming_checkpoint): # backbone_name,\n args = parse_args()\n cfg = Config1.fromfile(args.config)\n # logger = Logger('./logs')\n dataset=AVA_video(Config.TRAIN_DATA)\n dataloader = DataLoader(dataset, batch_size=4,num_workers=8, collate_fn=DatasetBase.padding_collate_fn,pin_memory=True,shuffle=False) # batch_size=4,num_workers=8,shuffle=True,\n Log.i('Found {:d} samples'.format(len(dataset)))\n backbone = BackboneBase.from_name(backbone_name)()\n\n # backbone1 = build_recognizer(cfg.model, train_cfg=cfg.train_cfg, test_cfg=cfg.test_cfg)\n\n os.environ['CUDA_VISIBLE_DEVICES'] = Config.GPU_OPTION\n device = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\n model = Model(\n backbone,\n dataset.num_classes(),\n pooler_mode=Config.POOLER_MODE,\n anchor_ratios=Config.ANCHOR_RATIOS,\n anchor_sizes=Config.ANCHOR_SIZES,\n rpn_pre_nms_top_n=Config.RPN_PRE_NMS_TOP_N,\n rpn_post_nms_top_n=Config.RPN_POST_NMS_TOP_N,\n anchor_smooth_l1_loss_beta=Config.ANCHOR_SMOOTH_L1_LOSS_BETA,\n proposal_smooth_l1_loss_beta=Config.PROPOSAL_SMOOTH_L1_LOSS_BETA\n ).cuda()\n model = torch.nn.DataParallel(model, device_ids=[0,1,2,3]) # multi-Gpu\n model.to(device)\n print('Total params: %.2fM' % (sum(p.numel() for p in model.parameters()) / 1000000.0))\n\n optimizer = optim.SGD(model.parameters(), lr=Config.LEARNING_RATE, momentum=Config.MOMENTUM, weight_decay=Config.WEIGHT_DECAY)\n scheduler = WarmUpMultiStepLR(optimizer, milestones=Config.STEP_LR_SIZES, gamma=Config.STEP_LR_GAMMA,\n factor=Config.WARM_UP_FACTOR, num_iters=Config.WARM_UP_NUM_ITERS)\n step = 0\n time_checkpoint = time.time()\n losses = deque(maxlen=100) #类似list,限制长度的deque增加超过限制数的项时,另一边的项会自动删除。\n mean_losses = deque(maxlen=100)\n\n cur_time = time.strftime('%Y-%m-%d-%H-%M-%S', time.localtime(time.time()))\n logdir = os.path.join(path_to_checkpoints_dir, 'summaries','logdir',cur_time)\n if not os.path.exists(logdir):\n os.makedirs(logdir)\n summary_writer = SummaryWriter(logdir) # summary_writer = SummaryWriter(os.path.join(path_to_checkpoints_dir, 'summaries'))\n should_stop = False\n\n num_steps_to_display = Config.NUM_STEPS_TO_DISPLAY\n num_steps_to_snapshot = Config.NUM_STEPS_TO_SNAPSHOT\n num_steps_to_finish = Config.NUM_STEPS_TO_FINISH\n\n if path_to_resuming_checkpoint is not None:\n step = model.module.load(path_to_resuming_checkpoint, optimizer, scheduler)\n print(\"load from:\",path_to_resuming_checkpoint)\n device_count = torch.cuda.device_count()\n assert Config.BATCH_SIZE % device_count == 0, 'The batch size is not divisible by the device count'\n Log.i('Start training with {:d} GPUs ({:d} batches per GPU)'.format(torch.cuda.device_count(), Config.BATCH_SIZE // torch.cuda.device_count()))\n\n print(\"loading data ... \")\n while not should_stop:\n for n_iter, (_, image_batch, _, bboxes_batch, labels_batch,detector_bboxes_batch) in enumerate(dataloader):\n batch_size = image_batch.shape[0]\n image_batch = image_batch.cuda()\n bboxes_batch = bboxes_batch.cuda()\n labels_batch = labels_batch.cuda()\n detector_bboxes_batch=detector_bboxes_batch.cuda()\n\n proposal_class_losses = \\\n model.train().forward(image_batch, bboxes_batch, labels_batch,detector_bboxes_batch) #eval().\n proposal_class_loss = proposal_class_losses.mean()\n loss = proposal_class_loss\n mean_loss=proposal_class_losses.mean()\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n scheduler.step()\n losses.append(loss.item())\n mean_losses.append(mean_loss.item())\n summary_writer.add_scalar('train/proposal_class_loss', proposal_class_loss.item(), step)\n summary_writer.add_scalar('train/loss', loss.item(), step)\n\n if n_iter % 10000 == 0:\n for name, param in model.named_parameters():\n name = name.replace('.', '/')\n if name.find(\"conv\") >= 0:\n summary_writer.add_histogram(name, param.data.cpu().numpy(), global_step=n_iter)\n summary_writer.add_histogram(name + 'grad', param.grad.data.cpu().numpy(),global_step=n_iter)\n step += 1\n if step == num_steps_to_finish: #222670\n should_stop = True\n if step % num_steps_to_display == 0: #20\n elapsed_time = time.time() - time_checkpoint\n print(\"time_checkpoint :\",time_checkpoint,\"elapsed_time:\",elapsed_time)\n time_checkpoint = time.time()\n steps_per_sec = num_steps_to_display / elapsed_time\n samples_per_sec = batch_size * steps_per_sec\n eta = (num_steps_to_finish - step) / steps_per_sec / 3600\n avg_loss = sum(losses) / len(losses)\n avg_mean_loss=sum(mean_losses) / len(mean_losses)\n lr = scheduler.get_lr()[0]\n print_string='[Step {0}] Avg. Loss = {avg_loss:.6f}, Learning Rate = {lr:.8f} ({samples_per_sec:.2f} samples/sec; ETA {eta:.1f} hrs)'\\\n .format(step,avg_loss=avg_loss,lr=lr,samples_per_sec=samples_per_sec,eta=eta)\n print(print_string)\n with open(log_file, 'a') as f:\n f.writelines(print_string + '\\n')\n\n model_save_dir = os.path.join(path_to_checkpoints_dir, 'model_save',cur_time)\n if not os.path.exists(model_save_dir):\n os.makedirs(model_save_dir)\n if step % num_steps_to_snapshot == 0 or should_stop: #20000\n path_to_checkpoint = model.module.save(model_save_dir, step, optimizer, scheduler) #model.save\n Log.i('Model has been saved to {}'.format(path_to_checkpoint))\n\n if should_stop:\n break\n Log.i('Done')\n\n\nif __name__ == '__main__':\n def main():\n # transform torchscript model:\n # tourch_script()\n # exit(0)\n\n backbone_name = Config.BACKBONE_NAME\n path_to_outputs_dir = Config.PATH_TO_OUTPUTS_DIR\n path_to_resuming_checkpoint =Config.PATH_TO_RESUMEING_CHECKPOINT\n if not os.path.exists(path_to_outputs_dir):\n os.mkdir(path_to_outputs_dir)\n Log.initialize(os.path.join(path_to_outputs_dir, 'train.log'))\n Log.i('Arguments:')\n _train(backbone_name,path_to_outputs_dir, path_to_resuming_checkpoint)\n\n\n\n\n main()\n"
},
{
"alpha_fraction": 0.48701101541519165,
"alphanum_fraction": 0.5054247975349426,
"avg_line_length": 50.531497955322266,
"blob_id": "cf59238aa9c97436d7f426b2f1d6912aff04bdc2",
"content_id": "0379c9977a66d285d9b94c56936a5a719af5c1b6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13302,
"license_type": "permissive",
"max_line_length": 148,
"num_lines": 254,
"path": "/imshow_result_OLD.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "import cv2\nimport os\nimport numpy as np\nfrom bbox import BBox\nimport torch\nclass imshow_result():\n class info():\n def __init__(self, img_class,prob, bbox,img_h, img_w,img_position):\n self.img_class = int(img_class)-1\n self.prob=prob\n self.bbox = bbox\n self.img_position=img_position\n self.height = img_h\n self.weight = img_w\n def __repr__(self):\n return 'info[img_class={0}, bbox={1}]'.format(\n self.img_class, self.bbox)\n def __init__(self):\n self.i2c_dic=self.index2class()\n\n self.bboxes = []\n self.labels = []\n self.probs=[]\n self.image_ratios = []\n self.image_position = []\n self.widths = []\n self.heights = []\n\n self.data_dic = {}\n self.data_dic_real = {}\n\n self.data_size = {}\n self.data_format = {}\n self.path_to_data_dir = '/home/aiuser/'\n path_to_AVA_dir = os.path.join(self.path_to_data_dir, 'ava_v2.2', 'preproc', 'train_clips')\n self.path_to_videos = os.path.join(path_to_AVA_dir, 'clips')\n self.path_to_keyframe = os.path.join(path_to_AVA_dir, 'keyframes')\n #path_to_video_ids_txt = os.path.join(path_to_AVA_dir, 'trainval.txt')\n path_to_video_ids_txt = '/home/aiuser/ava_v2.2/result.txt'\n path_to_real_ids_txt = '/home/aiuser/ava_v2.2/preproc/train_clips/trainval.txt'\n # 得到每个视频的大小,通过读取第一张keyframe\n for frame in sorted(os.listdir(self.path_to_keyframe)):\n img = os.listdir(os.path.join(self.path_to_keyframe, frame))[0]\n img = cv2.imread(os.path.join(self.path_to_keyframe, frame, img))\n img_shape = img.shape\n self.data_size[frame] = (img_shape[0], img_shape[1])\n # 得到每个视频的格式\n for video in sorted(os.listdir(self.path_to_videos)):\n video_0 = os.listdir(os.path.join(self.path_to_videos, video))[0]\n self.data_format[video] = '.' + video_0.split('.')[1]\n # 读取文件,key是文件名(aa/0930)\n with open(path_to_video_ids_txt, 'r') as f:\n data = f.readlines()\n for line in data:\n content = line.split(',')\n key = content[0] + \"/\" + str(int(content[1]))\n img_h = int(self.data_size[content[0]][0])\n img_w = int(self.data_size[content[0]][1])\n if key not in self.data_dic:\n self.data_dic[key] = [imshow_result.info(content[6],content[7].replace(\"\\n\", \"\"), BBox( # convert to 0-based pixel index\n left=float(content[2]) * img_w - 1,\n top=float(content[3]) * img_h - 1,\n right=float(content[4]) * img_w - 1,\n bottom=float(content[5]) * img_h - 1), img_h, img_w, key)]\n else:\n self.data_dic[key].append(imshow_result.info(content[6],content[7].replace(\"\\n\", \"\"), BBox( # convert to 0-based pixel index\n left=float(content[2]) * img_w - 1,\n top=float(content[3]) * img_h - 1,\n right=float(content[4]) * img_w - 1,\n bottom=float(content[5]) * img_h - 1), img_h, img_w, key))\n with open(path_to_real_ids_txt, 'r') as f:\n data = f.readlines()\n for line in data:\n content = line.split(',')\n key = content[0] + \"/\" + str(int(content[1]))\n img_h = int(self.data_size[content[0]][0])\n img_w = int(self.data_size[content[0]][1])\n if key not in self.data_dic_real:\n self.data_dic_real[key] = [imshow_result.info(content[6], content[7].replace(\"\\n\", \"\"),\n BBox( # convert to 0-based pixel index\n left=float(content[2]) * img_w - 1,\n top=float(content[3]) * img_h - 1,\n right=float(content[4]) * img_w - 1,\n bottom=float(content[5]) * img_h - 1), img_h,img_w, key)]\n else:\n self.data_dic_real[key].append(imshow_result.info(content[6], content[7].replace(\"\\n\", \"\"),\n BBox( # convert to 0-based pixel index\n left=float(content[2]) * img_w - 1,\n top=float(content[3]) * img_h - 1,\n right=float(content[4]) * img_w - 1,\n bottom=float(content[5]) * img_h - 1), img_h,img_w, key))\n # print('data_dic:',self.data_dic)\n # 对字典中的数据进行整理,变成list的形式\n for key in self.data_dic:\n self.bboxes.append([item.bbox.tolist() for item in self.data_dic[key]])\n self.labels.append([item.img_class for item in self.data_dic[key]])\n self.probs.append([item.prob for item in self.data_dic[key]])\n width = int(self.data_dic[key][0].weight)\n self.widths.append(width)\n height = int(self.data_dic[key][0].height)\n self.heights.append(height)\n ratio = float(width / height)\n self.image_ratios.append(ratio)\n self.image_position.append(self.data_dic[key][0].img_position)\n def __getitem__(self, index: int):\n buffer, scale, index = self.loadvideo(self.image_position, index, 180, 280, 1)\n bboxes = torch.tensor(self.bboxes[index], dtype=torch.float)\n print(self.labels[index],self.probs[index])\n labels = torch.tensor(self.labels[index], dtype=torch.long)\n probs = [float(item) for item in self.probs[index]]\n #image = Image.open(self.path_to_keyframe+'/'+self.image_position[index]+\".jpg\")\n bboxes *= scale\n return self.image_position[index], buffer, scale, bboxes, labels,probs,(self.heights[index],self.widths[index])\n def __len__(self) -> int:\n return len(self.image_position)\n def loadvideo(self,image_position,index,min_side,max_side,frame_sample_rate):\n formate_key = image_position[index].split('/')[0]\n fname=self.path_to_videos + '/' + image_position[index] + self.data_format[formate_key]\n remainder = np.random.randint(frame_sample_rate)\n # initialize a VideoCapture object to read video data into a numpy array\n capture = cv2.VideoCapture(fname)\n frame_count = int(capture.get(cv2.CAP_PROP_FRAME_COUNT))\n frame_width = int(capture.get(cv2.CAP_PROP_FRAME_WIDTH))\n frame_height = int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT))\n\n while frame_count<80:\n print('discard_video,frame_num:',frame_count,'dir:',fname)\n index = np.random.randint(self.__len__())\n formate_key = image_position[index].split('/')[0]\n fname = self.path_to_videos + '/' + image_position[index] + self.data_format[formate_key]\n capture = cv2.VideoCapture(fname)\n frame_count = int(capture.get(cv2.CAP_PROP_FRAME_COUNT))\n\n scale_for_shorter_side = min_side / min(frame_width, frame_height)\n longer_side_after_scaling = max(frame_width, frame_height) * scale_for_shorter_side\n scale_for_longer_side = (\n max_side / longer_side_after_scaling) if longer_side_after_scaling > max_side else 1\n scale = scale_for_shorter_side * scale_for_longer_side\n resize_height=round(frame_height * scale)\n resize_width=round(frame_width * scale)\n # create a buffer. Must have dtype float, so it gets converted to a FloatTensor by Pytorch later\n start_idx = 0\n end_idx = frame_count-1\n frame_count_sample = frame_count // frame_sample_rate - 1\n if frame_count>=80:\n start_idx = frame_count - 80\n frame_count_sample = 81 // frame_sample_rate - 1\n buffer = np.empty((frame_count_sample, resize_height, resize_width, 3), np.dtype('float32'))\n count = 0\n retaining = True\n sample_count = 0\n # read in each frame, one at a time into the numpy buffer array\n num=0\n while (count <= end_idx and retaining):\n num=num+1\n retaining, frame = capture.read()\n if count < start_idx:\n count += 1\n continue\n if retaining is False or count>end_idx:\n break\n if count%frame_sample_rate == remainder and sample_count < frame_count_sample:\n frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)\n # will resize frames if not already final size\n if (frame_height != resize_height) or (frame_width != resize_width):\n frame = cv2.resize(frame, (resize_width, resize_height))\n buffer[sample_count] = frame\n sample_count = sample_count + 1\n count += 1\n capture.release()\n #print('num_pic',num)\n return buffer,scale,index\n def index2class(self):\n file_path = '/home/aiuser/ava_v2.2/ava_v2.2/ava_action_list_v2.0.csv'\n with open(file_path) as f:\n i2c_dic = {line.split(',')[0]: line.split(',')[1] for line in f}\n print(i2c_dic)\n return i2c_dic\n\n\n def imshow_result(self,item_num):\n i2c_dic=self.i2c_dic\n for i in range(item_num):\n result=self.__getitem__(i)\n name=result[0]\n real_bboxes=[item.bbox.tolist() for item in self.data_dic_real[name]]\n real_lables=[item.img_class for item in self.data_dic_real[name]]\n probs=result[5]\n print(type(probs[0]))\n kept_indices = list(np.where(np.array(probs) > 0.2))\n\n bboxes=np.array(result[3])[kept_indices]\n labels=np.array(result[4])[kept_indices]\n probs=np.array(probs)[kept_indices]\n scale=result[2]\n\n print('scale:',scale)\n print ('bboxes:',real_bboxes)\n print ('labels:',real_lables)\n print('dir:',self.path_to_keyframe + '/' + result[0])\n formate_key = self.image_position[i].split('/')[0]\n cap = cv2.VideoCapture(self.path_to_videos+'/'+self.image_position[i]+self.data_format[formate_key])\n frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))\n key_frame_start=int(frame_count*0.35)\n key_frame_end =int(frame_count*0.95)\n frame_num=0\n while (cap.isOpened()):\n ret, frame = cap.read()\n frame_num=frame_num+1\n if frame_num>key_frame_start and frame_num<key_frame_end:\n count = 0\n count_2=0\n for bbox, lable in zip(real_bboxes, real_lables):\n count = count + 1\n bbox = np.array(bbox)\n lable = int(lable)\n real_x_min = int(bbox[0])\n real_y_min = int(bbox[1])\n real_x_max = int(bbox[2])\n real_y_max = int(bbox[3])\n # 在每一帧上画矩形,frame帧,(四个坐标参数),(颜色),宽度\n cv2.rectangle(frame, (real_x_min, real_y_min), (real_x_max, real_y_max), (255, 0, 255), 4)\n cv2.putText(frame, i2c_dic[str(lable + 1)], (real_x_min + 30, real_y_min + 15 * count),\n cv2.FONT_HERSHEY_COMPLEX, \\\n 0.5, (255, 0, 255), 1, False)\n\n for bbox,lable,prob in zip(bboxes,labels,probs):\n count_2 = count_2 + 1\n bbox=np.array(bbox)\n lable = int(lable)\n prob=float(prob)\n real_x_min = int(bbox[0]/scale)\n real_y_min = int(bbox[1]/scale)\n real_x_max = int(bbox[2]/scale)\n real_y_max = int(bbox[3]/scale)\n # 在每一帧上画矩形,frame帧,(四个坐标参数),(颜色),宽度\n cv2.rectangle(frame, (real_x_min, real_y_min), (real_x_max, real_y_max), (255, 255, 255), 4)\n cv2.putText(frame, i2c_dic[str(lable+1)]+':'+str(prob), (real_x_min+30 , real_y_min+15*count_2 ), cv2.FONT_HERSHEY_COMPLEX,\\\n 0.5,(255, 255, 0), 1, False)\n if ret == True:\n # 显示视频\n cv2.imshow('Frame', frame)\n # 刷新视频\n cv2.waitKey(25)\n # 按q退出\n if cv2.waitKey(25) & 0xFF == ord('q'):\n break\n else:\n break\n\n\nif __name__ == '__main__':\n ir=imshow_result()\n ir.imshow_result(20)"
},
{
"alpha_fraction": 0.44897958636283875,
"alphanum_fraction": 0.5102040767669678,
"avg_line_length": 15.44444465637207,
"blob_id": "04de0dba93c455188760dedebe667b0c8ed1d9c3",
"content_id": "80faffcc2e22ae56301f0177535ed8f857b1a55a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 147,
"license_type": "permissive",
"max_line_length": 26,
"num_lines": 9,
"path": "/ava/teat.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\ndef t():\n list=[1,2,3,4,5]\n list=np.array(list)\n list2=[2,3]\n print(list[list2])\nif __name__ == '__main__':\n t()"
},
{
"alpha_fraction": 0.5247606635093689,
"alphanum_fraction": 0.5835446119308472,
"avg_line_length": 44.900238037109375,
"blob_id": "96f2fffac55d87cf651df287defa7eb6e7e1845e",
"content_id": "67e71d9a7c70faa4fc4cf98d315669a83bf2430a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 21165,
"license_type": "permissive",
"max_line_length": 142,
"num_lines": 421,
"path": "/util.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "\nfrom __future__ import division\n\nimport torch \nimport torch.nn as nn\nimport torch.nn.functional as F \nfrom torch.autograd import Variable\nimport numpy as np\nimport cv2 \nimport matplotlib.pyplot as plt\nfrom bbox import bbox_iou\n\n\nCOLORS_10 =[(144,238,144),(178, 34, 34),(221,160,221),( 0,255, 0),( 0,128, 0),(210,105, 30),(220, 20, 60),\n (192,192,192),(255,228,196),( 50,205, 50),(139, 0,139),(100,149,237),(138, 43,226),(238,130,238),\n (255, 0,255),( 0,100, 0),(127,255, 0),(255, 0,255),( 0, 0,205),(255,140, 0),(255,239,213),\n (199, 21,133),(124,252, 0),(147,112,219),(106, 90,205),(176,196,222),( 65,105,225),(173,255, 47),\n (255, 20,147),(219,112,147),(186, 85,211),(199, 21,133),(148, 0,211),(255, 99, 71),(144,238,144),\n (255,255, 0),(230,230,250),( 0, 0,255),(128,128, 0),(189,183,107),(255,255,224),(128,128,128),\n (105,105,105),( 64,224,208),(205,133, 63),( 0,128,128),( 72,209,204),(139, 69, 19),(255,245,238),\n (250,240,230),(152,251,152),( 0,255,255),(135,206,235),( 0,191,255),(176,224,230),( 0,250,154),\n (245,255,250),(240,230,140),(245,222,179),( 0,139,139),(143,188,143),(255, 0, 0),(240,128,128),\n (102,205,170),( 60,179,113),( 46,139, 87),(165, 42, 42),(178, 34, 34),(175,238,238),(255,248,220),\n (218,165, 32),(255,250,240),(253,245,230),(244,164, 96),(210,105, 30)]\n\n\ndef draw_bbox(img, box, cls_name, identity=None, offset=(0,0)):\n '''\n draw box of an id\n '''\n x1,y1,x2,y2 = [int(i+offset[idx%2]) for idx,i in enumerate(box)]\n # set color and label text\n color = COLORS_10[identity%len(COLORS_10)] if identity is not None else COLORS_10[0]\n label = '{} {}'.format(cls_name, identity)\n # box text and bar\n t_size = cv2.getTextSize(label, cv2.FONT_HERSHEY_PLAIN, 1 , 1)[0]\n cv2.rectangle(img,(x1, y1),(x2,y2),color,2)\n cv2.rectangle(img,(x1, y1),(x1+t_size[0]+3,y1+t_size[1]+4), color,-1)\n cv2.putText(img,label,(x1,y1+t_size[1]+4), cv2.FONT_HERSHEY_PLAIN, 1, [255,255,255], 1)\n return img\n\n\n# def draw_bboxes(img, bbox, identities=None, offset=(0,0)):\n# for i,box in enumerate(bbox):\n# x1,y1,x2,y2 = [int(i) for i in box]\n# x1 += offset[0]\n# x2 += offset[0]\n# y1 += offset[1]\n# y2 += offset[1]\n# # box text and bar\n# id = int(identities[i]) if identities is not None else 0\n# color = COLORS_10[id%len(COLORS_10)]\n# #label = '{}{}'.format(\"id\", id)\n# label = '{}'.format(id)\n# t_size = cv2.getTextSize(label, cv2.FONT_HERSHEY_PLAIN, 2 , 2)[0]\n# cv2.rectangle(img,(x1, y1),(x2,y2),color,3)\n# cv2.rectangle(img,(x1, y1),(x1+t_size[0]+3,y1+t_size[1]+4), color,-1)\n# cv2.putText(img,label,(x1,y1+t_size[1]+4), cv2.FONT_HERSHEY_PLAIN, 2, [255,255,255], 1)\n# return img\n\n#######################################################################################################\ndef draw_bboxes(img, bbox, identities=None, distance=None, speed = None, offset=(0,0)):\n for i,box in enumerate(bbox):\n x1,y1,x2,y2 = [int(i) for i in box]\n x1 += offset[0]\n x2 += offset[0]\n y1 += offset[1]\n y2 += offset[1]\n # box text and bar\n id = int(identities[i]) if identities is not None else 0\n dist = distance[i]\n sp = speed[i]\n\n color = COLORS_10[id%len(COLORS_10)]\n #label = '{}{}'.format(\"id\", id)\n label = '{}'.format(id)\n label_dist = 'dist: {:.2f}'.format(dist)\n label_sp = 'speed: {:.2f}/s'.format(sp)\n\n t_size = cv2.getTextSize(label, cv2.FONT_HERSHEY_PLAIN, 2 , 2)[0]\n dist_size = cv2.getTextSize(label_dist, cv2.FONT_HERSHEY_PLAIN, 2 , 2)[0]\n sp_size = cv2.getTextSize(label_sp, cv2.FONT_HERSHEY_PLAIN, 2 , 2)[0]\n cv2.rectangle(img,(x1, y1),(x2,y2),color,3)\n cv2.rectangle(img,(x1, y1),(x1+t_size[0]+3,y1+t_size[1]+4), color,-1)\n cv2.putText(img,label,(x1,y1+t_size[1]+4), cv2.FONT_HERSHEY_PLAIN, 2, [255,255,255], 1)\n cv2.putText(img, label_dist, (x1, y1-4), cv2.FONT_HERSHEY_PLAIN, 2, [255, 255, 255], 2)\n cv2.putText(img, label_sp, (x1, y1-4-dist_size[1]-4), cv2.FONT_HERSHEY_PLAIN, 2, [255, 255, 255], 2)\n return img\n#########################################################################################################\n\ndef count_parameters(model):\n return sum(p.numel() for p in model.parameters())\n\ndef count_learnable_parameters(model):\n return sum(p.numel() for p in model.parameters() if p.requires_grad)\n\ndef convert2cpu(matrix):\n if matrix.is_cuda:\n return torch.FloatTensor(matrix.size()).copy_(matrix)\n else:\n return matrix\n\n#predict_transform 函数把检测特征图转换成二维张量,张量的每一行对应边界框的属性\ndef predict_transform(prediction, inp_dim, anchors, num_classes, CUDA = True):\n batch_size = prediction.size(0)\n stride = inp_dim // prediction.size(2)\n grid_size = inp_dim // stride\n bbox_attrs = 5 + num_classes\n num_anchors = len(anchors)\n\n #锚点的维度与 net 块的 height 和 width 属性一致。这些属性描述了输入图像的维度,比检测图的规模大(二者之商即是步幅)。因此,我们必须使用检测特征图的步幅分割锚点。\n anchors = [(a[0]/stride, a[1]/stride) for a in anchors]\n prediction = prediction.view(batch_size, bbox_attrs*num_anchors, grid_size*grid_size)\n prediction = prediction.transpose(1,2).contiguous()\n prediction = prediction.view(batch_size, grid_size*grid_size*num_anchors, bbox_attrs)\n #Sigmoid the centre_X, centre_Y. and object confidencce 对 (x,y) 坐标和 objectness 分数执行 Sigmoid 函数操作。\n prediction[:,:,0] = torch.sigmoid(prediction[:,:,0])\n prediction[:,:,1] = torch.sigmoid(prediction[:,:,1])\n prediction[:,:,4] = torch.sigmoid(prediction[:,:,4])\n\n #Add the center offsets 将网格偏移添加到中心坐标预测中:\n grid_len = np.arange(grid_size)\n a,b = np.meshgrid(grid_len, grid_len)\n x_offset = torch.FloatTensor(a).view(-1,1)\n y_offset = torch.FloatTensor(b).view(-1,1)\n \n if CUDA:\n x_offset = x_offset.cuda()\n y_offset = y_offset.cuda()\n x_y_offset = torch.cat((x_offset, y_offset), 1).repeat(1,num_anchors).view(-1,2).unsqueeze(0)\n prediction[:,:,:2] += x_y_offset\n #log space transform height and the width 将锚点应用到边界框维度中:\n anchors = torch.FloatTensor(anchors)\n if CUDA:\n anchors = anchors.cuda()\n anchors = anchors.repeat(grid_size*grid_size, 1).unsqueeze(0)\n prediction[:,:,2:4] = torch.exp(prediction[:,:,2:4])*anchors\n #Softmax the class scores 将 sigmoid 激活函数应用到类别分数中:\n prediction[:,:,5: 5 + num_classes] = torch.sigmoid((prediction[:,:, 5 : 5 + num_classes]))\n prediction[:,:,:4] *= stride\n return prediction\n\ndef load_classes(namesfile):\n fp = open(namesfile, \"r\")\n names = fp.read().split(\"\\n\")[:-1]\n return names\n\ndef get_im_dim(im):\n im = cv2.imread(im)\n w,h = im.shape[1], im.shape[0]\n return w,h\n\n#去除类中重复元素\ndef unique(tensor):\n tensor_np = tensor.cpu().numpy()\n unique_np = np.unique(tensor_np)\n unique_tensor = torch.from_numpy(unique_np)\n tensor_res = tensor.new(unique_tensor.shape)\n tensor_res.copy_(unique_tensor)\n return tensor_res\n\n\"\"\"#该函数的输入为预测结果、置信度(objectness 分数阈值)、num_classes(我们这里是 80)和 nms_conf(NMS IoU 阈值)\nwrite_results 函数输出一个形状为 Dx8 的张量;其中 D 是所有图像中的「真实」检测结果,每个都用一行表示。每一个检测结果都有\n 8 个属性,即:该检测结果所属的 batch 中图像的索引、4 个角的坐标、objectness 分数、有最大置信度的类别的分数、该类别的索引。\n\"\"\"\ndef write_results(prediction, confidence, num_classes, nms = True, nms_conf = 0.4):\n conf_mask = (prediction[:,:,4] > confidence).float().unsqueeze(2)\n prediction = prediction*conf_mask\n # try:\n # ind_nz = torch.nonzero(prediction[:,:,4]).transpose(0,1).contiguous()\n # except:\n # return 0\n #使用每个框的两个对角坐标能更轻松地计算两个框的 IoU。\n box_a = prediction.new(prediction.shape)\n box_a[:,:,0] = (prediction[:,:,0] - prediction[:,:,2]/2)\n box_a[:,:,1] = (prediction[:,:,1] - prediction[:,:,3]/2)\n box_a[:,:,2] = (prediction[:,:,0] + prediction[:,:,2]/2) \n box_a[:,:,3] = (prediction[:,:,1] + prediction[:,:,3]/2)\n prediction[:,:,:4] = box_a[:,:,:4]\n\n #一次只能完成一张图像的置信度阈值设置和 NMS\n batch_size = prediction.size(0)\n # output = prediction.new(1, prediction.size(2) + 1)\n write = False\n for ind in range(batch_size):\n #select the image from the batch\n image_pred = prediction[ind]\n #Get the class having maximum score, and the index of that class\n #Get rid of num_classes softmax scores \n #Add the class index and the class score of class having maximum score\n max_conf, max_conf_score = torch.max(image_pred[:,5:5+ num_classes], 1)\n max_conf = max_conf.float().unsqueeze(1)\n max_conf_score = max_conf_score.float().unsqueeze(1)\n seq = (image_pred[:,:5], max_conf, max_conf_score)\n image_pred = torch.cat(seq, 1)\n\n #Get rid of the zero entries 目的是处理无检测结果的情况。在这种情况下,我们使用 continue 来跳过对本图像的循环。\n non_zero_ind = (torch.nonzero(image_pred[:,4]))\n if non_zero_ind.shape[0] > 0:\n image_pred_ = image_pred[non_zero_ind.squeeze(),:].view(-1,7)\n else:\n continue\n if image_pred_.shape[0] == 0:\n continue\n\n # # only person\n # # print(image_pred_)\n # person_mask = image_pred_ * (image_pred_[:, -1] == 0).float().unsqueeze(1)\n # person_mask_ind = torch.nonzero(person_mask[:, -2])\n # # print(image_pred_)\n #\n # # print(person_mask_ind.shape)\n # # print(person_mask_ind)\n #\n #\n # if person_mask_ind.shape[0] > 0:\n # image_pred_ = image_pred_[person_mask_ind.squeeze(),:].view(-1,7)\n # # print(image_pred_)\n # # print(123)\n # else:\n # continue\n # if image_pred_.shape[0] == 0:\n # continue\n # # end of only person\n\n #Get the various classes detected in the image\n try: #因为同一类别可能会有多个「真实」检测结果,所以我们使用一个名叫 unique 的函数来获取任意给定图像中存在的类别。\n img_classes = unique(image_pred_[:,-1])\n except:\n continue\n\n #WE will do NMS classwise 提取特定类别(用变量 cls 表示)的检测结果。\n for cls in img_classes:\n #get the detections with one particular class\n cls_mask = image_pred_*(image_pred_[:,-1] == cls).float().unsqueeze(1)\n class_mask_ind = torch.nonzero(cls_mask[:,-2]).squeeze()\n image_pred_class = image_pred_[class_mask_ind].view(-1,7)\n #sort the detections such that the entry with the maximum objectness\n #confidence is at the top\n conf_sort_index = torch.sort(image_pred_class[:,4], descending = True )[1]\n image_pred_class = image_pred_class[conf_sort_index]\n idx = image_pred_class.size(0)\n #if nms has to be done\n if nms:\n #For each detection\n for i in range(idx):\n #Get the IOUs of all boxes that come after the one we are looking at \n #in the loop\n try:\n ious = bbox_iou(image_pred_class[i].unsqueeze(0), image_pred_class[i+1:])\n except ValueError:\n break\n except IndexError:\n break\n #Zero out all the detections that have IoU > treshhold\n iou_mask = (ious < nms_conf).float().unsqueeze(1)\n image_pred_class[i+1:] *= iou_mask\n #Remove the non-zero entries\n non_zero_ind = torch.nonzero(image_pred_class[:,4]).squeeze()\n image_pred_class = image_pred_class[non_zero_ind].view(-1,7)\n #Concatenate the batch_id of the image to the detection\n #this helps us identify which image does the detection correspond to \n #We use a linear straucture to hold ALL the detections from the batch\n #the batch_dim is flattened\n #batch is identified by extra batch column\n batch_ind = image_pred_class.new(image_pred_class.size(0), 1).fill_(ind)\n seq = batch_ind, image_pred_class\n if not write:\n output = torch.cat(seq,1)\n write = True\n else:\n out = torch.cat(seq,1)\n output = torch.cat((output,out))\n try:\n return output\n except:\n return 0\n\n#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat Mar 24 00:12:16 2018\n@author: ayooshmac\n每个anchor的属性(x,y,w,h,s,s_cls1,s_cls2...),s是方框含有目标的置信度得分,s_cls1,s_cls_2等是方框所含目标对应每类的概率\n输入的feature map(prediction变量) 维度为(batch_size, num_anchors*bbox_attrs, grid_size, grid_size),\n\"\"\"\n\ndef predict_transform_half(prediction, inp_dim, anchors, num_classes, CUDA = True):\n batch_size = prediction.size(0)\n stride = inp_dim // prediction.size(2) ##416//13=32\n bbox_attrs = 5 + num_classes\n num_anchors = len(anchors)\n grid_size = inp_dim // stride # feature map每条边格子的数量,416//32=13\n\n prediction = prediction.view(batch_size, bbox_attrs*num_anchors, grid_size*grid_size)\n prediction = prediction.transpose(1,2).contiguous()\n prediction = prediction.view(batch_size, grid_size*grid_size*num_anchors, bbox_attrs)\n #Sigmoid the centre_X, centre_Y. and object confidencce\n prediction[:,:,0] = torch.sigmoid(prediction[:,:,0])\n prediction[:,:,1] = torch.sigmoid(prediction[:,:,1])\n prediction[:,:,4] = torch.sigmoid(prediction[:,:,4])\n #Add the center offsets\n grid_len = np.arange(grid_size)\n a,b = np.meshgrid(grid_len, grid_len)\n \n x_offset = torch.FloatTensor(a).view(-1,1)\n y_offset = torch.FloatTensor(b).view(-1,1)\n if CUDA:\n x_offset = x_offset.cuda().half()\n y_offset = y_offset.cuda().half()\n # 这里的x_y_offset对应的是最终的feature map中每个格子的左上角坐标,比如有13个格子,刚x_y_offset的坐标就对应为(0,0),(0,1)…(12,12) .view(-1, 2)将tensor变成两列,unsqueeze(0)在0维上添加了一维。\n x_y_offset = torch.cat((x_offset, y_offset), 1).repeat(1,num_anchors).view(-1,2).unsqueeze(0)\n \n prediction[:,:,:2] += x_y_offset\n #log space transform height and the width\n anchors = torch.HalfTensor(anchors)\n if CUDA:\n anchors = anchors.cuda() #长度为6的list(三个anchors每个2个坐标),\n anchors = anchors.repeat(grid_size*grid_size, 1).unsqueeze(0)\n prediction[:,:,2:4] = torch.exp(prediction[:,:,2:4])*anchors\n\n #Softmax the class scores\n prediction[:,:,5: 5 + num_classes] = nn.Softmax(-1)(Variable(prediction[:,:, 5 : 5 + num_classes])).data\n prediction[:,:,:4] *= stride\n return prediction\n\n'''\n 必须使我们的输出满足 objectness 分数阈值和非极大值抑制(NMS),以得到后文所提到的「真实」检测结果。要做到这一点就要用 write_results函数。\n 函数的输入为预测结果、置信度(objectness 分数阈值)、num_classes(我们这里是 80)和 nms_conf(NMS IoU 阈值)。\n write_results()首先将网络输出方框属性(x,y,w,h)转换为在网络输入图片(416x416)坐标系中,方框左上角与右下角坐标(x1,y1,x2,y2),以方便NMS操作。\n 然后将方框含有目标得分低于阈值的方框去掉,提取得分最高的那个类的得分max_conf,同时返回这个类对应的序号max_conf_score,\n 然后进行NMS操作。最终每个方框的属性为(ind,x1,y1,x2,y2,s,s_cls,index_cls),ind 是这个方框所属图片在这个batch中的序号,\n x1,y1是在网络输入图片(416x416)坐标系中,方框左上角的坐标;x2,y2是在网络输入图片(416x416)坐标系中,方框右下角的坐标。\n s是这个方框含有目标的得分,s_cls是这个方框中所含目标最有可能的类别的概率得分,index_cls是s_cls对应的这个类别所对应的序号.\n '''\ndef write_results_half(prediction, confidence, num_classes, nms = True, nms_conf = 0.4):\n # confidence: 输入的预测shape=(1,10647, 85)。conf_mask: shape=(1,10647) => 增加一维度之后 (1, 10647, 1)\n conf_mask = (prediction[:,:,4] > confidence).half().unsqueeze(2)\n prediction = prediction*conf_mask\n \n try:\n ind_nz = torch.nonzero(prediction[:,:,4]).transpose(0,1).contiguous()\n except:\n return 0\n\n box_a = prediction.new(prediction.shape)\n box_a[:,:,0] = (prediction[:,:,0] - prediction[:,:,2]/2)\n box_a[:,:,1] = (prediction[:,:,1] - prediction[:,:,3]/2)\n box_a[:,:,2] = (prediction[:,:,0] + prediction[:,:,2]/2) \n box_a[:,:,3] = (prediction[:,:,1] + prediction[:,:,3]/2)\n prediction[:,:,:4] = box_a[:,:,:4]\n \n batch_size = prediction.size(0)\n output = prediction.new(1, prediction.size(2) + 1)\n write = False\n \n for ind in range(batch_size):\n #select the image from the batch\n image_pred = prediction[ind] #二维tensor 维度为10647x85\n #Get the class having maximum score, and the index of that class\n #Get rid of num_classes softmax scores \n #Add the class index and the class score of class having maximum score\n max_conf, max_conf_score = torch.max(image_pred[:,5:5+ num_classes], 1) #nms_conf(NMS IoU 阈值),类对应的序号max_conf_score\n max_conf = max_conf.half().unsqueeze(1)\n max_conf_score = max_conf_score.half().unsqueeze(1)\n seq = (image_pred[:,:5], max_conf, max_conf_score)\n image_pred = torch.cat(seq, 1) # shape=(10647, 5+1+1=7),(x1,y1,x2,y2,s,s_cls,index_cls)。\n # 与得分最高的这个类的分数s_cls(max_conf)和对应类的序号index_cls(max_conf_score)\n #Get rid of the zero entries\n non_zero_ind = (torch.nonzero(image_pred[:,4]))\n try:\n image_pred_ = image_pred[non_zero_ind.squeeze(),:]\n except:\n continue\n #Get the various classes detected in the image\n img_classes = unique(image_pred_[:,-1].long()).half()\n\n #WE will do NMS classwise\n for cls in img_classes:\n #get the detections with one particular class\n cls_mask = image_pred_*(image_pred_[:,-1] == cls).half().unsqueeze(1)\n class_mask_ind = torch.nonzero(cls_mask[:,-2]).squeeze()\n image_pred_class = image_pred_[class_mask_ind]\n #sort the detections such that the entry with the maximum objectness\n #confidence is at the top\n conf_sort_index = torch.sort(image_pred_class[:,4], descending = True )[1]\n image_pred_class = image_pred_class[conf_sort_index]\n idx = image_pred_class.size(0)\n \n #if nms has to be done\n if nms:\n #For each detection\n for i in range(idx):\n #Get the IOUs of all boxes that come after the one we are looking at \n #in the loop\n try:\n ious = bbox_iou(image_pred_class[i].unsqueeze(0), image_pred_class[i+1:])\n except ValueError:\n break\n \n except IndexError:\n break\n #Zero out all the detections that have IoU > treshhold\n iou_mask = (ious < nms_conf).half().unsqueeze(1)\n image_pred_class[i+1:] *= iou_mask\n #Remove the non-zero entries\n non_zero_ind = torch.nonzero(image_pred_class[:,4]).squeeze()\n image_pred_class = image_pred_class[non_zero_ind]\n #Concatenate the batch_id of the image to the detection\n #this helps us identify which image does the detection correspond to \n #We use a linear straucture to hold ALL the detections from the batch\n #the batch_dim is flattened\n #batch is identified by extra batch column\n batch_ind = image_pred_class.new(image_pred_class.size(0), 1).fill_(ind)\n seq = batch_ind, image_pred_class\n if not write:\n output = torch.cat(seq,1)\n write = True\n else:\n out = torch.cat(seq,1)\n output = torch.cat((output,out))\n return output\n"
},
{
"alpha_fraction": 0.6352370977401733,
"alphanum_fraction": 0.6487069129943848,
"avg_line_length": 36.8775520324707,
"blob_id": "40e277e63650916fff8906cee9b2344ac3344385",
"content_id": "0b7e133914a384273f34517266239621ec059cab",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1856,
"license_type": "permissive",
"max_line_length": 105,
"num_lines": 49,
"path": "/f.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "\nfrom __future__ import division\n\nimport warnings\nimport math\nimport types\nfrom torch.nn import functional as F\nimport torch\nfrom torch._C import _infer_size, _add_docstr\ntorch.nn.MultiLabelSoftMarginLoss\n@torch._jit_internal.weak_script\ndef multilabel_soft_margin_loss(input, target, weight=None, size_average=None,\n reduce=None, reduction='mean'):\n # type: (Tensor, Tensor, Optional[Tensor], Optional[bool], Optional[bool], str) -> Tensor\n r\"\"\"multilabel_soft_margin_loss(input, target, weight=None, size_average=None) -> Tensor\n\n See :class:`~torch.nn.MultiLabelSoftMarginLoss` for details.\n \"\"\"\n loss = -(target * torch.log(input) + (1 - target) * torch.log(-input))\n\n if weight is not None:\n loss = loss * torch.jit._unwrap_optional(weight)\n loss = loss.sum(dim=1) / input.size(1) # only return N loss values\n #loss = loss.sum(dim=1)\n if reduction == 'none':\n ret = loss\n elif reduction == 'mean':\n ret = loss.mean()\n elif reduction == 'sum':\n ret = loss.sum()\n else:\n ret = input\n raise ValueError(reduction + \" is not valid\")\n return ret\n\ndef focal_cross_entropy(input, target, weight=None, ignore_index=-100,reduction='mean'):\n input=torch.mul(torch.mul((1-F.softmax(input, 1)),(1-F.softmax(input, 1))),(F.log_softmax(input, 1)))\n return F.nll_loss(input, target, weight, None, ignore_index, None, reduction)\n\nif __name__ == '__main__':\n input=[[0.4,0.9]]\n input=torch.tensor(input,dtype=torch.float)\n target=[0]\n target=torch.tensor(target,dtype=torch.long)\n print(F.softmax(input, 1))\n print((1-F.softmax(input, 1)))\n print(torch.mul((1-F.softmax(input, 1)),(1-F.softmax(input, 1))))\n print(F.log_softmax(input, 1))\n print(F.cross_entropy(input,target))\n print(focal_cross_entropy(input,target))"
},
{
"alpha_fraction": 0.6619957685470581,
"alphanum_fraction": 0.6857749223709106,
"avg_line_length": 24.33333396911621,
"blob_id": "e746d706c80255b1f80ef594953ab30f9eb48253",
"content_id": "8481bb8b067d827a891b72ddf39db988a817efab",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2855,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 93,
"path": "/README.md",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "# SlowFast-Network-pytorch\nAn easy PyTorch implement of SlowFast-Network [\"SlowFast Networks for Video Recognition\"](https://arxiv.org/abs/1812.03982).\n\nWe also complete a real-time action detection demo. The demo is orgnized as:\n\n```bash\n Yolo v3 \n │ \n │\n deepsort \n │ \n │ \n SlowFast Network\n ```\n## Display the demo results\n |\n:-------------------------:|\n |\n |\n\n\n## Run the demo on your own data\n1.Clone the repository\n```bash\ngit clone https://github.com/MagicChuyi/SlowFast-Network-pytorch.git\n```\n2.Download Yolo v3 model: \nhttps://pan.baidu.com/s/1tT2uzI44KD3zzAgMskU1Aw\n\n3.Download DeepSort re-id model: \nhttps://pan.baidu.com/s/1D1_Lw_lq-O75xFX-zFEEbg\n\n4.Download Pre-trained SlowFast Network model: \nhttps://pan.baidu.com/s/17GLB2k3VhPgRsVCadVmjaA\n\n5.Modify the model path and your video path in video_demo.py.\n\n6.Run video_demo.py.\n\n\n## Train your own model\n1.Download AVA dataset.\n\n2.Discard corrupted data.\n\n3.Dataset should be orgnized as: \n```\nava/ava\n│ │ preproc_train \n│ │ │ clips\n│ │ │ keyframes\n│ │ │ ava_train_v2.2.csv\n│ │ preproc_val \n │ │ clips \n │ │ keyframes \n │ │ ... \n```\n4.Modify the params in config.py and train_config.py. \n\n5.Run train_video.py.\n\n\n## Requirements\npython 3 \nPyTorch >= 1.0 \ntensorboardX \nOpenCV \n## Code Reference:\n[1] https://github.com/Guocode/SlowFast-Networks/ \n[2] https://github.com/potterhsu/easy-faster-rcnn.pytorch \n\n\nHere's some testing made me successfully run the demo:\n\n1.First, you should run python support/setup.py build the complete tools .\n2.Maybe you use csv file from https://github.com/kevinlin311tw/ava-dataset-tool?\nBecause I haven't find ava_action_list_v2.0.csv in official files.\n3.Then I change the files we may used to my own path. And I can run the video_demo.py.\n\n\n\n(1)存放检测器代码的文件夹,我们就能使用git追踪它们的改变。\n##Darknet.py\nDarknet 是构建 YOLO 底层架构的环境,这个文件将包含实现 YOLO 网络的所有代码\n## util.py\n它会包含多种需要调用的函数。在将所有这些文件保存在检测器文件夹下后,我们就能使用 git 追踪它们的改变。\n\n(2)配置文件\n官方代码(authored in C)使用一个配置文件来构建网络,即 cfg 文件一块块地描述了网络架构。如果你使用过 caffe 后端,那么它就相当于描述网络的.protxt 文件。\n我们将使用官方的 cfg 文件构建网络,它是由 YOLO 的作者发布的。我们可以在以下地址下载,并将其放在检测器目录下的 cfg 文件夹下。\n配置文件下载:https://github.com/pjreddie/darknet/blob/master/cfg/yolov3.cfg\n\n(3)"
},
{
"alpha_fraction": 0.5708354115486145,
"alphanum_fraction": 0.5862813591957092,
"avg_line_length": 39.67567443847656,
"blob_id": "a19e50239fe0d8e531fbf813f5fe83ce8585b01c",
"content_id": "8784859a4111bb142d465de92b4dc0e3aaa49770",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6103,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 148,
"path": "/test.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "import cv2\nimport numpy as np\nimport os\nfrom torch.utils.data import DataLoader, Dataset\nimport numpy as np\nfrom scipy import interp\nimport matplotlib.pyplot as plt\nimport torch\nfrom config.config import params\nimport torch.backends.cudnn as cudnn\nfrom lib import slowfastnet\nfrom Config import Config\n\nclass Test_video(Dataset):\n def __init__(self,short_side):\n self.short_side=short_side\n def normalize(self, buffer):\n # Normalize the buffer\n # buffer = (buffer - 128)/128.0\n for i, frame in enumerate(buffer):\n frame = (frame - np.array([[[128.0, 128.0, 128.0]]]))/128.0\n buffer[i] = frame\n return buffer\n\n def to_tensor(self, buffer):\n # convert from [D, H, W, C] format to [C, D, H, W] (what PyTorch uses)\n # D = Depth (in this case, time), H = Height, W = Width, C = Channels\n return buffer.transpose((3, 0, 1, 2))\n\n def crop(self, buffer, crop_size):\n # randomly select time index for temporal jittering\n # time_index = np.random.randint(buffer.shape[0] - clip_len)\n # Randomly select start indices in order to crop the video\n height_index = np.random.randint(buffer.shape[1] - crop_size)\n width_index = np.random.randint(buffer.shape[2] - crop_size)\n\n # crop and jitter the video using indexing. The spatial crop is performed on\n # the entire array, so each frame is cropped in the same location. The temporal\n # jitter takes place via the selection of consecutive frames\n buffer = buffer[:,\n height_index:height_index + crop_size,\n width_index:width_index + crop_size, :]\n\n return buffer\n\n def generate_video_clip(self,split_span,keep_num,fname=\"/home/aiuser/Desktop/_7oWZq_s_Sk.mkv\"):\n capture = cv2.VideoCapture(fname)\n #获取视频的基本信息\n frame_count = int(capture.get(cv2.CAP_PROP_FRAME_COUNT))\n frame_width = int(capture.get(cv2.CAP_PROP_FRAME_WIDTH))\n frame_height = int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT))\n fps = int(capture.get(cv2.CAP_PROP_FPS))\n #计算要切多少段,每段切多少帧\n print(frame_count,frame_width)\n split_len=fps*split_span\n split_time=frame_count/split_len\n if frame_height < frame_width:\n resize_height = np.random.randint(self.short_side[0], self.short_side[1] + 1)\n resize_width = int(float(resize_height) / frame_height * frame_width)\n else:\n resize_width = np.random.randint(self.short_side[0], self.short_side[1] + 1)\n resize_height = int(float(resize_width) / frame_width * frame_height)\n start_idx = 0\n end_idx = start_idx + split_len\n skip_span = split_len // keep_num if end_idx // keep_num > 0 else 1\n rem = split_len - skip_span * keep_num if split_len - skip_span * keep_num >= 0 else 0\n while split_time>0: #切多少段\n split_time=split_time-1\n start_idx = start_idx + rem // 2\n buffer = []\n sample_count=0\n #处理每一段视频\n while (start_idx<end_idx):\n start_idx=start_idx+1\n retaining, frame = capture.read()\n if(sample_count>=keep_num):\n continue\n if start_idx % skip_span != 0 and start_idx!=0:\n continue\n if retaining is False:\n break\n frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)\n if (frame_height != resize_height) or (frame_width != resize_width):\n frame = cv2.resize(frame, (resize_width, resize_height))\n buffer.append(frame)\n # if len(pa.isna(frame).nonzero()[1]) != 0 or np.max(frame) > 255:\n # print(\"discard:\", buffer)\n sample_count=sample_count+1\n print(np.shape(buffer))\n if len(buffer)<keep_num:\n for i in range(keep_num-len(buffer)):\n buffer.append(buffer[-1])\n print(\"warning appen -1\")\n start_idx=end_idx\n end_idx=end_idx+split_len\n #一段处理完返回\n for v in buffer:\n cv2.imshow(\"video\",v)\n cv2.waitKey(0)\n list_buffer = buffer\n buffer=np.array(buffer)\n buffer = self.crop(buffer, 196)\n buffer = self.normalize(buffer)\n buffer = self.to_tensor(buffer)\n buffer=torch.tensor(buffer, dtype=torch.float).unsqueeze(0)\n yield buffer,list_buffer\n capture.release()\n\ndef validation(model, val_dataloader):\n model.eval()\n all_prob=[]\n all_pre=[]\n data=val_dataloader.generate_video_clip(20,64)\n with torch.no_grad():\n for step,(inputs,frame_list) in enumerate(data):\n inputs = inputs.cuda()\n outputs = model(inputs)\n max = np.max(np.array(outputs.cpu()), axis=1)\n all_prob.extend(max)\n # for frame in frame_list:\n # cv2.imshow(\"frame\",frame)\n # cv2.waitKey(0)\n print(\"show over,pro=\",torch.nn.functional.softmax(outputs))\n for item in np.array(outputs.cpu()):\n all_pre.extend(np.where(item == max)[0])\n print(np.where(item == max)[0])\n print(all_pre)\n\ndef main():\n cudnn.benchmark = False\n test_video=Test_video(short_side=[224,256])\n model = slowfastnet.resnet50(class_num=Config.CLASS_NUM)\n assert Config.LOAD_MODEL_PATH is not None\n print(\"load model from:\", Config.LOAD_MODEL_PATH)\n pretrained_dict = torch.load(Config.LOAD_MODEL_PATH, map_location='cpu')\n try:\n model_dict = model.module.state_dict()\n except AttributeError:\n model_dict = model.state_dict()\n pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}\n model_dict.update(pretrained_dict)\n model.load_state_dict(model_dict)\n model = model.cuda(params['gpu'][0])\n validation(model, test_video)\n\n\nif __name__ == '__main__':\n main()\n\n"
},
{
"alpha_fraction": 0.6476635336875916,
"alphanum_fraction": 0.663551390171051,
"avg_line_length": 27.945945739746094,
"blob_id": "3c5b67c619d95b23a064d1fb01450c1e23e13d75",
"content_id": "f62ea9d0116d98bc01a316a615a0ec9a25d18102",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1070,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 37,
"path": "/get_img.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "# Author Morven Gan\n# The road to success is not crowded, because there are not many persistent people\n\nfrom util import *\nfrom darknet import Darknet\nfrom preprocess import prep_image, inp_to_image, letterbox_image\n\nimport argparse\nfrom deep_sort import DeepSort\nfrom collections import deque\nfrom backbone.base import Base as BackboneBase\nfrom config.train_config import TrainConfig\nfrom config.eval_config import EvalConfig\nfrom config.config import Config\nfrom model import Model\nimport os\nimport numpy\n\nvideofile = \"/home/ganhaiyang/dataset/ava/v_WalkingWithDog_g08_c03.avi\"\ncap = cv2.VideoCapture(videofile)\nassert cap.isOpened(), 'Cannot capture source'\n\nframes = 0\n##########################################################\nlast = np.array([])\n##########################################################\n#######for sp detec##########\nbuffer = deque(maxlen=64)\nresize_width = 400\nresize_height = 300\n\ncount = 0\nwhile cap.isOpened():\n ret, frame = cap.read()\n if ret:\n cv2.imwrite('/home/ganhaiyang/dataset/ava/test/%d.jpg' % count, frame)\n count+=1"
},
{
"alpha_fraction": 0.6129032373428345,
"alphanum_fraction": 0.6774193644523621,
"avg_line_length": 24.83333396911621,
"blob_id": "e8754c0d67e65dd2fb2f87d962c83d845b628331",
"content_id": "0744ed98efcb204629b333b1b428a68dd247a305",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 620,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 24,
"path": "/backbone/slowfast_res101.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "from typing import Tuple\n\nimport torchvision\nfrom torch import nn\n\nimport backbone.base\nfrom backbone.slowfastnet import resnet101 as rs101\nfrom backbone.slowfastnet import resnet50 as rs50\nfrom backbone.hidden_for_roi import hidden50\nclass slowfast_res101(backbone.base.Base):\n\n def __init__(self):\n super().__init__(False)\n\n def features(self):\n resnet101 = rs101()\n num_features_out = 1280\n hidden = hidden50()\n num_hidden_out = 2048 + 256\n return resnet101, hidden, num_features_out, num_hidden_out\n\nif __name__ == '__main__':\n s=slowfast_res101()\n s.features()\n"
},
{
"alpha_fraction": 0.4846731126308441,
"alphanum_fraction": 0.5001356601715088,
"avg_line_length": 43.95121765136719,
"blob_id": "9ada0a2338bea888f5428f58ab7928c49ff71df8",
"content_id": "f36f044da64e018ba82793e7234b4d56ee9e7be0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11299,
"license_type": "permissive",
"max_line_length": 128,
"num_lines": 246,
"path": "/imshow_result.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "import os\nimport logger\nimport numpy as np\nimport torch.utils.data\nfrom PIL import Image, ImageOps\nfrom bbox1 import BBox\nfrom typing import Tuple, List, Type, Iterator\nimport operator\nfrom torch import Tensor\nimport cv2\nfrom torch.utils.data import DataLoader, Dataset\nfrom config.eval_config import EvalConfig\nclass Imshow_result(Dataset):\n\n class info():\n def __init__(self, img_class,prob, bbox,h,w,img_position):\n self.img_class = [int(img_class)]\n self.prob = [prob]\n self.bbox = bbox\n self.height=h\n self.weight=w\n self.img_position=img_position\n def __repr__(self):\n return 'info[img_class={0}, bbox={1}]'.format(\n self.img_class, self.bbox)\n\n\n def __init__(self,imshow_result_dir,imshow_lable_dir):\n self.bboxes=[]\n self.labels=[]\n self.image_ratios = []\n self.image_position=[]\n self.widths=[]\n self.heights=[]\n self.probs=[]\n self.i2c_dic=self.index2class()\n self.data_dic = {}\n self.data_dic_real={}\n self.data_size={}\n self.data_format={}\n self.path_to_data_dir='/home/aiuser/'\n path_to_AVA_dir = os.path.join(self.path_to_data_dir, 'ava','ava', 'preproc_val')\n self.path_to_videos = os.path.join(path_to_AVA_dir, 'clips')\n self.path_to_keyframe = os.path.join(path_to_AVA_dir, 'keyframes')\n self.imshow_lable_dir=imshow_lable_dir\n path_to_result_ids_txt = os.path.join(path_to_AVA_dir, imshow_result_dir)\n #得到每个视频的大小,通过读取第一张keyframe\n self.get_video_size()\n # 得到每个视频的格式\n self.get_video_format()\n #读取文件,key是文件名(aa/0930)\n self.read_file_to_dic(path_to_result_ids_txt,self.data_dic)\n self.make_multi_lable(self.data_dic)\n #对字典中的数据进行整理,变成list的形式\n self.trans_dic_to_list()\n\n path_to_lable_ids_txt = os.path.join(path_to_AVA_dir, imshow_lable_dir)\n self.read_file_to_dic(path_to_lable_ids_txt, self.data_dic_real)\n self.make_multi_lable(self.data_dic_real)\n\n\n def get_video_size(self):\n for frame in sorted(os.listdir(self.path_to_keyframe)):\n img=os.listdir(os.path.join(self.path_to_keyframe, frame))[0]\n img=cv2.imread(os.path.join(self.path_to_keyframe, frame,img))\n img_shape=img.shape\n self.data_size[frame]=(img_shape[0],img_shape[1])\n\n def get_video_format(self):\n for video in sorted(os.listdir(self.path_to_videos)):\n video_0 = os.listdir(os.path.join(self.path_to_videos,\\\n video))[0]\n self.data_format[video]='.'+video_0.split('.')[1]\n\n\n def read_file_to_dic(self,filename,dic):\n # with open(\"/home/aiuser/ava/ava/ava_val_v2.2.csv\", 'r') as f:\n # data = f.readlines()\n # del_list=[]\n # for line in data:\n # content = line.split(',')\n # del_list.append(content[0]+\"/\"+str(int(content[1])))\n # print(\"del_list:\",del_list)\n del_list=[]\n with open(filename, 'r') as f:\n data = f.readlines()\n for line in data:\n content = line.split(',')\n key=content[0]+\"/\"+str(int(content[1]))\n if key not in del_list:\n img_h=int(self.data_size[content[0]][0])\n img_w = int(self.data_size[content[0]][1])\n if key not in dic:\n dic[key] = [Imshow_result.info(content[6],float(content[7]),BBox( # convert to 0-based pixel index\n left=float(content[2])*img_w - 1,\n top=float(content[3])*img_h - 1,\n right=float(content[4])*img_w - 1,\n bottom=float(content[5])*img_h - 1),img_h,img_w,key)]\n else:\n dic[key].append(Imshow_result.info(content[6],float(content[7]), BBox( # convert to 0-based pixel index\n left=float(content[2]) * img_w - 1,\n top=float(content[3]) * img_h - 1,\n right=float(content[4]) * img_w - 1,\n bottom=float(content[5]) * img_h - 1), img_h, img_w, key))\n else:\n print(key)\n\n # print('data_dic:',self.data_dic)\n\n def trans_dic_to_list(self):\n for key in self.data_dic:\n self.bboxes.append([item.bbox.tolist() for item in self.data_dic[key]])\n self.labels.append([item.img_class for item in self.data_dic[key]])\n self.probs.append([item.prob for item in self.data_dic[key]])\n width = int(self.data_dic[key][0].weight)\n self.widths.append(width)\n height = int(self.data_dic[key][0].height)\n self.heights.append(height)\n ratio = float(width / height)\n self.image_ratios.append(ratio)\n self.image_position.append(self.data_dic[key][0].img_position)\n\n def make_multi_lable(self,dic):\n for key in dic:\n pre=None\n #print(\"before:\",dic[key])\n temp=[]\n for info in dic[key]:\n if pre==None:\n pre=info\n temp.append(info)\n elif operator.eq(info.bbox.tolist(),pre.bbox.tolist()):\n temp[-1].img_class.append(info.img_class[0])\n temp[-1].prob.append(info.prob[0])\n #这是个陷坑\n #dic[key].remove(info)\n else:\n pre=info\n temp.append(info)\n dic[key]=temp\n\n def __getitem__(self, index: int) -> Tuple[str, Tensor, Tensor, Tensor, Tensor]:\n bboxes = self.bboxes[index]\n labels = self.labels[index]\n # if self.imshow_lable_dir!=None:\n # probs = [float(item) for item in self.probs[index]]\n return self.image_position[index], index, index, bboxes, labels,self.probs[index]\n\n def index2class(self):\n file_path = '/home/aiuser/ava_v2.2/ava_v2.2/ava_action_list_v2.0.csv'\n with open(file_path) as f:\n i2c_dic = {line.split(',')[0]: line.split(',')[1] for line in f}\n return i2c_dic\n\n def draw_bboxes_and_show(self, frame, frame_num, bboxes, labels, key_frame_start, key_frame_end, scale=1, probs=[]):\n\n if frame_num > key_frame_start and frame_num < key_frame_end:\n # Capture frame-by-frame\n if len(probs) == 0: # 标签\n for bbox, lables in zip(bboxes, labels):\n count=0\n for lable in lables:\n count = count + 1\n bbox = np.array(bbox)\n lable = int(lable)\n real_x_min = int(bbox[0] / scale)\n real_y_min = int(bbox[1] / scale)\n real_x_max = int(bbox[2] / scale)\n real_y_max = int(bbox[3] / scale)\n # 在每一帧上画矩形,frame帧,(四个坐标参数),(颜色),宽度\n cv2.rectangle(frame,(real_x_min, real_y_min),(real_x_max, real_y_max),(17, 238, 105), 4) # 绿色\n cv2.putText(frame, self.i2c_dic[str(lable)].split(\"(\")[0], (real_x_min + 15, real_y_min + 15 * count),\n cv2.FONT_HERSHEY_COMPLEX, \\\n 0.5, (17, 238, 105), 1, False)\n\n else: # 预测\n for bbox, lables, prob in zip(bboxes, labels, probs):\n count_2=0\n for lable,p in zip(lables,prob):\n count_2 = count_2 + 1\n bbox = np.array(bbox)\n lable = int(lable)\n p = float(p)\n real_x_min = int(bbox[0] / scale)\n real_y_min = int(bbox[1] / scale)\n real_x_max = int(bbox[2] / scale)\n real_y_max = int(bbox[3] / scale)\n # 在每一帧上画矩形,frame帧,(四个坐标参数),(颜色),宽度\n cv2.rectangle(frame, (real_x_min, real_y_min), (real_x_max, real_y_max), (0, 0, 255),\n 4) # 红色\n cv2.putText(frame, self.i2c_dic[str(lable)].split(\"(\")[0] + ':' + str(round(p, 2)),\n (real_x_min + 15, real_y_max - 15 * count_2),\n cv2.FONT_HERSHEY_COMPLEX, \\\n 0.5, (0, 0, 255), 1, False)\n\n def imshow(self,item_num,frame_start=0.55,frame_end=0.9):\n for i in range(item_num):\n result=self.__getitem__(i)\n print(result)\n name=result[0]\n real_bboxes=[item.bbox.tolist() for item in self.data_dic_real[name]]\n real_lables=[item.img_class for item in self.data_dic_real[name]]\n\n probs=result[5]\n #print(type(probs[0]))\n keep=0.2\n keep_labels=[]\n keep_probs=[]\n for n,p in enumerate(probs):\n kept_indices = list(np.where(np.array(p) > keep))\n keep_labels.append(np.array(result[4][n])[kept_indices])\n keep_probs.append(np.array(p)[kept_indices])\n #labels = np.array(result[4])[kept_indices]\n bboxes=np.array(result[3])\n # print ('bboxes:',real_bboxes)\n # print ('labels:',real_lables)\n # print('dir:',self.path_to_keyframe + '/' + result[0])\n print('image_position:',self.image_position)\n formate_key = self.image_position[i].split('/')[0]\n cap = cv2.VideoCapture(self.path_to_videos+'/'+self.image_position[i]+self.data_format[formate_key])\n frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))\n key_frame_start = int(frame_count * frame_start)\n key_frame_end = int(frame_count * frame_end)\n frame_num = 0\n count=0\n while (cap.isOpened()):\n ret, frame = cap.read()\n frame_num = frame_num + 1\n self.draw_bboxes_and_show(frame,frame_num, bboxes, keep_labels, key_frame_start, key_frame_end,probs=keep_probs)\n self.draw_bboxes_and_show(frame,frame_num, real_bboxes, real_lables, key_frame_start, key_frame_end)\n if ret == True:\n count +=1\n # 显示视频\n cv2.imwrite('/home/aiuser/frames/%d.jpg' % count, frame)\n cv2.imshow('Frame', frame)\n # 刷新视频\n cv2.waitKey(0)\n # 按q退出\n if cv2.waitKey(25) & 0xFF == ord('q'):\n break\n else:\n break\n\nif __name__ == '__main__':\n a = Imshow_result(imshow_result_dir=\"/home/aiuser/ava/ava/result.txt\",imshow_lable_dir=EvalConfig.PATH_TO_LABLE)\n a.imshow(100)\n\n"
},
{
"alpha_fraction": 0.6593137383460999,
"alphanum_fraction": 0.7009803652763367,
"avg_line_length": 36.181819915771484,
"blob_id": "02460f00b6c91eccb196d6d5e8b2ce6914232187",
"content_id": "f1a687535851a80da279555d370be692846140df",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 486,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 11,
"path": "/img_to_video.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "import os\nimport cv2\nimg_root = '/home/aiuser/frames/'#这里写你的文件夹路径,比如:/home/youname/data/img/,注意最后一个文件夹要有斜杠\nfps = 15 #保存视频的FPS,可以适当调整\nfourcc = cv2.VideoWriter_fourcc(*'MJPG')\nvideoWriter = cv2.VideoWriter('/home/aiuser/frames/saveVideo.avi',fourcc,fps,(656,480))\nfor i in range(121):\n if i>=10:\n frame = cv2.imread(img_root + str(i) + '.jpg')\n videoWriter.write(frame)\nvideoWriter.release()"
},
{
"alpha_fraction": 0.46621134877204895,
"alphanum_fraction": 0.49652528762817383,
"avg_line_length": 51.109375,
"blob_id": "52136e91e44b099ddaa93a0588874dcf6ab09362",
"content_id": "c996999f49a50bb40f69d6cb7be686f16aa6a29b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18006,
"license_type": "permissive",
"max_line_length": 188,
"num_lines": 320,
"path": "/video_demo.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport time\n\nfrom util import *\nfrom darknet import Darknet\nfrom preprocess import prep_image, inp_to_image, letterbox_image\n\nimport argparse\nfrom deep_sort import DeepSort\nfrom collections import deque\nfrom backbone.base import Base as BackboneBase\nfrom config.train_config import TrainConfig\nfrom config.eval_config import EvalConfig\nfrom config.config import Config\nfrom model import Model\nimport os\nimport numpy\n\nos.environ['DISPLAY'] = 'localhost:12.0'\ndef index2class():\n file_path = '/home/ganhaiyang/dataset/ava/ava_labels/ava_action_list_v2.0.csv'\n with open(file_path) as f:\n i2c_dic = {line.split(',')[0]: line.split(',')[1] for line in f}\n return i2c_dic\n\ndef get_test_input(input_dim, CUDA):\n img = cv2.imread(\"dog-cycle-car.png\")\n img = cv2.resize(img, (input_dim, input_dim)) \n img_ = img[:,:,::-1].transpose((2,0,1))\n img_ = img_[np.newaxis,:,:,:]/255.0\n img_ = torch.from_numpy(img_).float()\n img_ = Variable(img_)\n if CUDA:\n img_ = img_.cuda()\n return img_\n\ndef prep_image(img, inp_dim):\n \"\"\"\n Prepare image for inputting to the neural network.\n Returns a Variable \n \"\"\"\n orig_im = img\n dim = orig_im.shape[1], orig_im.shape[0]\n img = (letterbox_image(orig_im, (inp_dim, inp_dim)))\n img_ = img[:,:,::-1].transpose((2,0,1)).copy() #实现从BGR到RGB的转换\n img_ = torch.from_numpy(img_).float().div(255.0).unsqueeze(0)\n return img_, orig_im, dim\n\ndef normalize(frame):\n # Normalize the buffer\n frame = (frame - np.array([[[128.0, 128.0, 128.0]]]))/128.0\n return frame\n\ndef to_tensor(buffer):\n # convert from [D, H, W, C] format to [C, D, H, W] (what PyTorch uses)\n # D = Depth (in this case, time), H = Height, W = Width, C = Channels\n return buffer.transpose([3, 0, 1, 2])\n\ndef imshow(bboxes, labels, probs,ids,count):\n for bbox, lables, prob,i in zip(bboxes, labels, probs,ids):\n count_2 = 0\n for lable, p in zip(lables, prob):\n count_2 = count_2 + 1\n bbox = np.array(bbox)\n lable = int(lable)\n p = float(p)\n real_x_min = int(bbox[0])\n real_y_min = int(bbox[1])\n real_x_max = int(bbox[2])\n real_y_max = int(bbox[3])\n # 在每一帧上画矩形,frame帧,(四个坐标参数),(颜色),宽度\n cv2.rectangle(frame, (real_x_min, real_y_min), (real_x_max, real_y_max), (0, 0, 255), 4) # 红色\n cv2.putText(frame, index2class()[str(lable)].split(\"(\")[0] + ':' + str(round(p, 2)),\n (real_x_min + 15, real_y_max - 15 * count_2),cv2.FONT_HERSHEY_COMPLEX, 0.5, (0, 0, 255), 1, False)\n cv2.putText(frame, \"id:\"+str(i), (real_x_min + 10, real_y_min + 20),cv2.FONT_HERSHEY_COMPLEX, 0.5, (0, 0, 255), 1, False)\n cv2.imwrite('/home/ganhaiyang/dataset/ava/save_frames/%d.jpg' % count, frame)\n\ndef arg_parse():\n \"\"\"\n Parse arguements to the detect module\n \"\"\"\n # 创建一个ArgumentParser对象,格式: 参数名, 目标参数(dest是字典的key),帮助信息,默认值,类型\n parser = argparse.ArgumentParser(description='YOLO v3 Video Detection Module')\n parser.add_argument(\"--video\", dest = 'video', help = \"Video to run detection upon\", default = \"/home/fs/data/video_for_test_reid/192.168.123.64_01_20190529141711976.mp4\", type = str)\n parser.add_argument(\"--dataset\", dest = \"dataset\", help = \"Dataset on which the network has been trained\", default = \"pascal\")\n parser.add_argument(\"--confidence\", dest = \"confidence\", help = \"Object Confidence to filter predictions\", default = 0.5) #confidence 目标检测结果置信度阈值\"\n parser.add_argument(\"--nms_thresh\", dest = \"nms_thresh\", help = \"NMS Threshhold\", default = 0.4) #nms_thresh NMS非极大值抑制阈值\n parser.add_argument(\"--cfg\", dest = 'cfgfile', help =\"Config file\", default = \"cfg/yolov3.cfg\", type = str)\n parser.add_argument(\"--weights\", dest = 'weightsfile', help = \"weightsfile\",default = \"weights/yolov3.weights\", type = str) #/home/ganhaiyang/dataset/ava/ava_weights/yolov3.weights\n parser.add_argument(\"--reso\", dest = 'reso', help = \"Input resolution of the network.\",default = \"416\", type = str) #reso \"网络输入分辨率. 分辨率越高,则准确率越高,速度越慢; 反之亦然.\n #parser.add_argument(\"--scales\", dest=\"scales\", help=\"缩放尺度用于检测\", default=\"1,2,3\", type=str)\n return parser.parse_args()\n\nif __name__ == '__main__':\n args = arg_parse() # args是一个namespace类型的变量,即argparse.Namespace, 可以像easydict一样使用,就像一个字典,key来索引变量的值\n confidence = float(\"0.5\")\n nms_thesh = float(\"0.4\")\n start = 0\n CUDA = torch.cuda.is_available()\n num_classes = 80 # coco 数据集有80类\n CUDA = torch.cuda.is_available()\n bbox_attrs = 5 + num_classes\n \n print(\"Loading network.....\")\n model = Darknet(\"cfg/yolov3.cfg\") ## Darknet类中初始化时得到了网络结构和网络的参数信息,保存在net_info,module_list中\n # Load weights\n if args.weightsfile.endswith('.weights'): # darknet format将权重文件载入,并复制给对应的网络结构model中\n model.load_weights(args.weightsfile) # model.load_darknet_weights(opt.weights_path)\n print(\"load .weights file \")\n elif args.weightsfile.endswith('.pt'): # pytorch format\n checkpoint = torch.load(args.weightsfile, map_location='cpu')\n model.load_state_dict(checkpoint) # ['model']\n print(\"load .pt file \")\n print(\"Darknet Network successfully loaded\")\n\n print(\"load deep sort network....\")\n deepsort = DeepSort(\"/home/ganhaiyang/output/deepsort/checkpoint/ckpt.t7\")\n print(\"Deep Sort Network successfully loaded\")\n\n # 网络输入数据大小\n model.net_info[\"height\"] = args.reso # model类中net_info是一个字典。’height’是图片的宽高,因为图片缩放到416x416,所以宽高一样大\n inp_dim = int(model.net_info[\"height\"]) #inp_dim是网络输入图片尺寸(如416*416)\n assert inp_dim % 32 == 0 #如果设定的输入图片的尺寸不是32的倍数或者不大于32,抛出异常\n assert inp_dim > 32\n\n os.environ['CUDA_VISIBLE_DEVICES'] = '4,5'\n device = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\n model = torch.nn.DataParallel(model, device_ids=[0,1])\n model.to(device)\n\n model.eval()\n #######for sp detec##########\n #初始化模型\n path_to_checkpoint = \"/home/ganhaiyang/dataset/ava/ava_weights/slowfast_weight.pth\"\n backbone_name = Config.BACKBONE_NAME\n backbone = BackboneBase.from_name(backbone_name)()\n model_sf = Model(backbone, 81, pooler_mode=Config.POOLER_MODE, anchor_ratios=Config.ANCHOR_RATIOS, anchor_sizes=Config.ANCHOR_SIZES,\n rpn_pre_nms_top_n=TrainConfig.RPN_PRE_NMS_TOP_N,rpn_post_nms_top_n=TrainConfig.RPN_POST_NMS_TOP_N).cuda()\n model_sf.load(path_to_checkpoint)\n\n # videofile = \"/data/video_caption_database/ava/ava/preproc_train/clips/gjdgj04FzR0/1611.mp4\" #2DUITARAsWQ\n # videofile = \"/home/ganhaiyang/dataset/ava/FFOutputvideo2110.avi\"\n videofile = \"/home/ganhaiyang/dataset/ava/persondog.mp4\"\n\n cap = cv2.VideoCapture(videofile)\n assert cap.isOpened(), 'Cannot capture source'\n \n frames = 0\n ##########################################################\n last = np.array([])\n last_time = time.time()\n ##########################################################\n start = time.time()\n #######for sp detec##########\n buffer = deque(maxlen=64)\n resize_width=400\n resize_height=300\n\n count=0\n while cap.isOpened():\n ret, frame = cap.read()\n if ret:\n #######for sp detec##########\n f = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) #frame shape tuple :1920,2560,3\n # will resize frames if not already final size\n f = cv2.resize(frame, (resize_width, resize_height))\n f=normalize(f)\n buffer.append(f)\n\n frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) #500\n frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) #333\n scale = [resize_width / frame_width, resize_height / frame_height]\n\n img, orig_im, dim = prep_image(frame, inp_dim)\n im_dim = torch.FloatTensor(dim).repeat(1,2) \n\n if CUDA:\n im_dim = im_dim.cuda()\n img = img.cuda()\n with torch.no_grad(): # 取消梯度计算\n output = model(Variable(img), CUDA) #torch.Size([1, 10647, 85])\n # 8 个属性,即:该检测结果所属的 batch 中图像的索引、4 个角的坐标、objectness 分数、有最大置信度的类别的分数、该类别的索引。\n output = write_results(output, confidence, num_classes, nms = True, nms_conf = nms_thesh) #tuple 7,8\n\n if type(output) == int:\n frames += 1\n print(\"FPS1 of the video is {:5.2f}\".format( frames / (time.time() - start)))\n cv2.imshow(\"frame\", orig_im)\n key = cv2.waitKey(1)\n if key & 0xFF == ord('q'):\n break\n continue\n \n #应该将方框的坐标转换为相对于填充后的图片中包含原始图片区域的计算方式。\n im_dim = im_dim.repeat(output.size(0), 1)\n scaling_factor = torch.min(inp_dim/im_dim,1)[0].view(-1,1)\n # 将相对于输入网络图片(416x416)的方框属性变换成原图按照纵横比不变进行缩放后的区域的坐标。\n # scaling_factor*img_w和scaling_factor*img_h是图片按照纵横比不变进行缩放后的图片,即原图是768x576按照纵横比长边不变缩放到了416*372。\n # 经坐标换算,得到的坐标还是在输入网络的图片(416x416)坐标系下的绝对坐标,但是此时已经是相对于416*372这个区域的坐标了,而不再相对于(0,0)原点。\n output[:,[1,3]] -= (inp_dim - scaling_factor*im_dim[:,0].view(-1,1))/2 #x1=x1−(416−scaling_factor*img_w)/2,x2=x2-(416−scaling_factor*img_w)/2\n output[:,[2,4]] -= (inp_dim - scaling_factor*im_dim[:,1].view(-1,1))/2 #y1=y1-(416−scaling_factor*img_h)/2,y2=y2-(416−scaling_factor*img_h)/2\n output[:,1:5] /= scaling_factor\n\n # 如果映射回原始图片中的坐标超过了原始图片的区域,则x1,x2限定在[0,img_w]内,img_w为原始图片的宽度。如果x1,x2小于0.0,令x1,x2为0.0,如果x1,x2大于原始图片宽度,令x1,x2大小为图片的宽度。\n # 同理,y1,y2限定在0,img_h]内,img_h为原始图片的高度。clamp()函数就是将第一个输入对数的值限定在后面两个数字的区间\n for i in range(output.shape[0]):\n output[i, [1,3]] = torch.clamp(output[i, [1,3]], 0.0, im_dim[i,0])\n output[i, [2,4]] = torch.clamp(output[i, [2,4]], 0.0, im_dim[i,1])\n\n output = output.cpu().data.numpy()\n bbox_xywh = output[:, 1:5]\n bbox_xywh[:,2] = bbox_xywh[:,2] - bbox_xywh[:,0]\n bbox_xywh[:,3] = bbox_xywh[:,3] - bbox_xywh[:,1]\n bbox_xywh[:, 0] = bbox_xywh[:, 0] + (bbox_xywh[:,2])/2\n bbox_xywh[:, 1] = bbox_xywh[:, 1] + (bbox_xywh[:, 3])/2\n\n cls_conf = output[:, 5]\n cls_ids = output[:, 7]\n\n if bbox_xywh is not None:\n mask = cls_ids == 0.0\n bbox_xywh = bbox_xywh[mask]\n cls_conf = cls_conf[mask]\n #if bbox_xywh[0]==0 and bbox_xywh[1]==0 and bbox_xywh[2]==0 and bbox_xywh[3]==0:continue\n #print(\"***********{}\".format(bbox_xywh))\n #cv2.imshow(\"debug\",orig_im)\n #cv2.waitKey(0)\n outputs = deepsort.update(bbox_xywh, cls_conf, orig_im) #Bbox+ID,naarry 3,5\n#######################################################################################\n # print('outputs = {}'.format(outputs))\n # outputs = np.array(outputs)\n # print(outputs)\n #\n # now_time = time.time()\n # diff_time = now_time-last_time\n # last_time = now_time\n # print('diff_time = {}'.format(diff_time))\n #\n # distance = []\n # speed = []\n # # a = time.time()\n # for i in range(outputs.shape[0]):\n # if last.shape[0] == 0:\n # last = np.array([np.insert(outputs[i], 5, [0])],dtype = 'float')\n # distance.append(0)\n # speed.append(0)\n #\n # else:\n # if outputs[i][4] not in last[:, 4]:\n # last = np.vstack([last, np.array([np.insert(outputs[i], 5, [0])])])\n # distance.append(0)\n # speed.append(0)\n #\n # else:\n # index = np.where(last[:, 4] == outputs[i][4])[0][0]\n # center1 = np.array(\n # [(outputs[i][2] + outputs[i][0]) / 2, (outputs[i][1] + outputs[i][3]) / 2])\n # center2 = np.array(\n # [(last[index][2] + last[index][0]) / 2, (last[index][1] + last[index][3]) / 2])\n # # print(center1 - center2)\n # move = np.sqrt(np.sum((center1 - center2) * (center1 - center2)))\n # # print(move)\n # last[index][:4] = outputs[i][:4]\n # last[index][-1] += move\n # distance.append(last[index][-1])\n # speed.append(move/diff_time)\n # # print('diff = {}'.format(time.time()-a))\n # print('speed = {}'.format(speed))\n # print('last = {}'.format(last))\n # print('distance = {}'.format(distance))\n\n#########################################################################################\n if len(outputs) > 0:\n bbox_xyxy = outputs[:, :4] #获得Bbox\n identities = outputs[:, -1] #获得Bbox的ID号\n # print(\"out_info:\",bbox_xyxy,identities)\n # # ori_im = draw_bboxes(orig_im, bbox_xyxy, identities, offset=(0, 0))\n # # ################################################################################################\n # # ori_im = draw_bboxes(orig_im, bbox_xyxy, identities, distance, speed, offset=(0, 0))\n # # #################################################################################################\n print(\"len(buffer):\",len(buffer))\n if len(buffer)==64:\n if count%3==0:\n #把buffer转为tensor\n b=buffer #deque 64\n a = time.time()\n b=np.array(b,dtype=np.float32)\n print(\"time:\", time.time() - a)\n b = to_tensor(b) #shape = 3,64,300,400\n image_batch=torch.tensor(b, dtype=torch.float).unsqueeze(0).cuda() #shape =1,3,64,300,400\n\n # 把bbox转为tensor\n bbox_xyxy=np.array(bbox_xyxy,dtype=np.float) #转化为数组\n bbox_xyxy[:, [0, 2]] *= scale[0]\n bbox_xyxy[:, [1, 3]] *= scale[1]\n detector_bboxes=torch.tensor(bbox_xyxy, dtype=torch.float).unsqueeze(0).cuda()\n\n #模型forward:image_batch(tensor):1,3,64,300,400;detector_bboxes(tensor):1,3,4\n with torch.no_grad():\n detection_bboxes, detection_classes, detection_probs = \\\n model_sf.eval().forward(image_batch, detector_bboxes_batch=detector_bboxes)\n detection_bboxes=np.array(detection_bboxes.cpu())\n detection_classes=np.array(detection_classes)\n detection_probs=np.array(detection_probs)\n\n #得到对应的分类标签\n detection_bboxes[:, [0, 2]] /= scale[0]\n detection_bboxes[:, [1, 3]] /= scale[1]\n imshow(detection_bboxes,detection_classes,detection_probs,identities,count)\n count += 1\n\n ##**************显示图片打开**********************\n # cv2.imshow(\"frame\", orig_im)\n # key = cv2.waitKey(0)\n # if key & 0xFF == ord('q'):\n # break\n # frames += 1\n # print(\"FPS2 of the video is {:5.2f}\".format( frames / (time.time() - start)))\n else:\n break\n \n\n \n \n\n"
},
{
"alpha_fraction": 0.5538461804389954,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 24.950000762939453,
"blob_id": "e03c3f41b54758e4066172cd0f770669c23ccef0",
"content_id": "593d5bc8cb0f6580e70038cc2f597edff284f454",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 520,
"license_type": "permissive",
"max_line_length": 60,
"num_lines": 20,
"path": "/backbone/tsm.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "\nimport backbone.base\nfrom backbone.slowfastnet import tsm as tsmmodel\nfrom backbone.hidden_for_roi_maxpool import hidden50\nclass tsm(backbone.base.Base):\n\n def __init__(self):\n super().__init__(False)\n\n def features(self):\n print(\"TSM\")\n tsm = tsmmodel()\n hidden = hidden50()\n num_features_out = 2048 ## 2304\n num_hidden_out = 2048*3*3 ## 2304*3*3\n\n return tsm, hidden, num_features_out, num_hidden_out\n\nif __name__ == '__main__':\n s=tsm()\n s.features()\n"
},
{
"alpha_fraction": 0.6998792290687561,
"alphanum_fraction": 0.7035024166107178,
"avg_line_length": 38.42856979370117,
"blob_id": "c3d21a5508af85c45dc5173d82cc5e668a065ac6",
"content_id": "dbe941e2ad8b747c973ccb7f2342f38accf360dd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1656,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 42,
"path": "/eval.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "import argparse\nimport os\nimport time\nimport uuid\n\nfrom backbone.base import Base as BackboneBase\nfrom config.train_config import TrainConfig\nfrom config.eval_config import EvalConfig\nfrom config.config import Config\nfrom dataset.base import Base as DatasetBase\nfrom evaluator import Evaluator\nfrom logger import Logger as Log\nfrom model import Model\nfrom roi.pooler_ import Pooler\nfrom dataset.AVA_video_v2 import AVA_video\ndef _eval(path_to_checkpoint, backbone_name, path_to_results_dir):\n dataset = AVA_video(EvalConfig.VAL_DATA)\n evaluator = Evaluator(dataset, path_to_results_dir)\n Log.i('Found {:d} samples'.format(len(dataset)))\n\n backbone = BackboneBase.from_name(backbone_name)()\n model = Model(backbone, dataset.num_classes(), pooler_mode=Config.POOLER_MODE,\n anchor_ratios=Config.ANCHOR_RATIOS, anchor_sizes=Config.ANCHOR_SIZES,\n rpn_pre_nms_top_n=TrainConfig.RPN_PRE_NMS_TOP_N, rpn_post_nms_top_n=TrainConfig.RPN_POST_NMS_TOP_N).cuda()\n model.load(path_to_checkpoint)\n print(\"load from:\",path_to_checkpoint)\n Log.i('Start evaluating with 1 GPU (1 batch per GPU)')\n mean_ap, detail = evaluator.evaluate(model)\n Log.i('Done')\n Log.i('mean AP = {:.4f}'.format(mean_ap))\n Log.i('\\n' + detail)\n\n\nif __name__ == '__main__':\n def main():\n path_to_checkpoint = EvalConfig.PATH_TO_CHECKPOINT\n backbone_name = Config.BACKBONE_NAME\n path_to_results_dir='/home/aiuser/ava/ava/'+EvalConfig.PATH_TO_RESULTS\n Log.initialize(os.path.join('/home/aiuser/ava_v2.2', 'eval.log'))\n _eval(path_to_checkpoint, backbone_name, path_to_results_dir)\n\n main()\n"
},
{
"alpha_fraction": 0.5156264305114746,
"alphanum_fraction": 0.5394273400306702,
"avg_line_length": 46.61720275878906,
"blob_id": "436b325c1cef6bf357abbfe05cee49afe0fde97e",
"content_id": "96a859655f7c99ccfa833933587a9cc458e74dad",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 22716,
"license_type": "permissive",
"max_line_length": 205,
"num_lines": 465,
"path": "/dataset/AVA_video_v2.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "import os\nimport numpy as np\nimport torch.utils.data\nfrom PIL import Image, ImageOps\nfrom bbox1 import BBox\nfrom typing import Tuple, List, Type, Iterator\nimport matplotlib.pyplot as plt\nimport PIL\nimport torch.utils.data.dataset\nimport torch.utils.data.sampler\nfrom PIL import Image\nfrom torch import Tensor\nimport operator\nfrom torchvision.transforms import transforms\nimport cv2\nfrom torchvision.transforms import transforms\nfrom dataset.base import Base as DatasetBase\nfrom get_ava_performance import ava_val\nfrom config.config import Config\nfrom config.eval_config import EvalConfig\nfrom config.train_config import TrainConfig\nimport pandas as pa\nfrom torch.utils.data import DataLoader, Dataset\nHeight=224 ## default (slowfast) 250\nWidth=224\nclass AVA_video(Dataset):\n #用一个字典保存多标签信息,存放到data_dic中\n class info():\n def __init__(self, img_class, bbox,h,w,img_position):\n self.img_class = [int(img_class)]\n self.bbox = bbox\n self.height=h\n self.weight=w\n self.img_position=img_position\n def __repr__(self):\n return 'info[img_class={0}, bbox={1}]'.format(self.img_class, self.bbox)\n\n def __init__(self,data_dir,discard=True):\n self.bboxes=[]\n self.labels=[]\n self.image_ratios = []\n self.image_position=[]\n self.widths=[]\n self.heights=[]\n #根据name获取detector_bbox\n self.detector_bboxes_list=[]\n #for debug\n self.name_list=[]\n self.i2c_dic=self.index2class()\n self.data_dic = {}\n self.data_dic_real={}\n self.data_size={}\n self.data_format={}\n self.detector_bbox_dic={}\n self.path_to_data_dir= '/home/gan/data/video_caption_database/video_database/ava/'\n path_to_AVA_dir = os.path.join(self.path_to_data_dir,'preproc_train')\n self.path_to_videos = os.path.join(path_to_AVA_dir, 'clips')\n self.path_to_keyframe = os.path.join(path_to_AVA_dir, 'keyframes')\n self.discard=discard\n self.imshow_lable_dir=data_dir\n path_to_video_ids_txt = os.path.join(path_to_AVA_dir, data_dir)\n print(\"Using Training Data:\", path_to_video_ids_txt)\n path_to_detector_result_txt=os.path.join(path_to_AVA_dir,Config.DETECTOR_RESULT_PATH)\n #得到每个视频的大小,通过读取第一张keyframe,存放到data_size中去\n self.get_video_size()\n # 得到每个视频的格式,存放到data_format中去\n self.get_video_format()\n #读取文件,key是文件名(aa/0930)\n self.read_file_to_dic(path_to_video_ids_txt,self.data_dic)\n #合并之前的得到的信息,得到一个合并后的dic\n self.make_multi_lable(self.data_dic)\n # 获取detector的predict_bbox\n self.read_file_to_dic(path_to_detector_result_txt, self.detector_bbox_dic)\n #对字典中的数据进行整理,变成list的形式\n self.trans_dic_to_list()\n\n def get_video_size(self):\n for frame in sorted(os.listdir(self.path_to_keyframe)):\n img=os.listdir(os.path.join(self.path_to_keyframe, frame))[0]\n img=cv2.imread(os.path.join(self.path_to_keyframe, frame,img))\n img_shape=img.shape\n self.data_size[frame]=(img_shape[0],img_shape[1])\n\n def get_video_format(self):\n for video in sorted(os.listdir(self.path_to_videos)):\n video_0 = os.listdir(os.path.join(self.path_to_videos, video))[0]\n self.data_format[video]='.'+video_0.split('.')[1]\n # print('data_format',self.data_format) #'-5KQ66BBWC4': '.mkv', '053oq2xB3oU': '.mp4',\n #dic的key对应一个list,存放着该片段对应的n条信息8tiz63\n def read_file_to_dic(self,filename,dic):\n with open(filename, 'r') as f:\n data = f.readlines()\n for line in data:\n content = line.split(',') # ['2FIHxnZKg6A', '1151', '0.045', '0.252', '0.838', '0.852', '80', '109\\n']\n # print(\"content:\",content)\n key=content[0]+\"/\"+str(int(content[1])) #9Rcxr3IEX4E/1236\n img_h=int(self.data_size[content[0]][0]) #360或480\n img_w = int(self.data_size[content[0]][1])\n if key not in dic:\n dic[key] = [AVA_video.info(content[6],BBox( # convert to 0-based pixel index\n left=float(content[2])*img_w ,\n top=float(content[3])*img_h ,\n right=float(content[4])*img_w,\n bottom=float(content[5])*img_h),img_h,img_w,key)]\n else:\n dic[key].append(AVA_video.info(content[6], BBox( # convert to 0-based pixel index\n left=float(content[2]) * img_w,\n top=float(content[3]) * img_h,\n right=float(content[4]) * img_w,\n bottom=float(content[5]) * img_h), img_h, img_w, key))\n # print('data_dic:',self.data_dic) # {'-5KQ66BBWC4/902': [info[img_class=[9], bbox=BBox[l=37.4, t=54.4, r=137.5, b=292.0]], info[img_class=[12],\n def make_multi_lable(self,dic):\n for key in dic:\n pre=None\n #print(\"before:\",dic[key])\n temp=[]\n for info in dic[key]:\n if pre==None:\n pre=info\n temp.append(info)\n elif operator.eq(info.bbox.tolist(),pre.bbox.tolist()):\n temp[-1].img_class.append(info.img_class[0])\n #这是个陷坑\n #dic[key].remove(info)\n else:\n pre=info\n temp.append(info)\n dic[key]=temp\n\n #把dic的信息转换成一一对应的list信息(bboxes,labels,detector_bboxes_list,width,height,ratio,image_position)\n def trans_dic_to_list(self):\n for key in self.data_dic:\n #如果这个框被检测到\n if(key in self.detector_bbox_dic):\n a=self.data_dic[key]\n #一个box对应一个list的标签\n #把bbox转为【【】,【】】的形式\n self.bboxes.append([item.bbox.tolist() for item in self.data_dic[key]])\n self.labels.append([item.img_class for item in self.data_dic[key]])\n assert len(self.bboxes)==len(self.labels)\n self.detector_bboxes_list.append([item.bbox.tolist() for item in self.detector_bbox_dic[key]])\n width = int(self.data_dic[key][0].weight)\n self.widths.append(width)\n height = int(self.data_dic[key][0].height)\n self.heights.append(height)\n ratio = float(width / height)\n self.image_ratios.append(ratio)\n self.image_position.append(self.data_dic[key][0].img_position)\n # print(\"self.labels:\",self.labels,\"self.image_position :\",self.image_position) #self.labels: [[[9], [12, 17, 80], [80, 9], [9], [9], [80, 9]]] self.image_position : ['-5KQ66BBWC4/902']\n else:\n continue\n\n def generate_one_hot(self,lable):\n one_hot_lable=np.zeros((len(lable),81))\n for i,box_lable in enumerate(lable):\n for one in box_lable:\n for j in range(81):\n if j==int(one):\n one_hot_lable[i][j]=1\n return one_hot_lable\n\n def __len__(self) -> int:\n return len(self.image_position)\n def num_classes(self):\n return 81\n\n def __getitem__(self, index: int) -> Tuple[str, Tensor, Tensor, Tensor, Tensor]:\n buffer,scale,index = self.loadvideo(self.image_position, index, 1)\n bboxes = torch.tensor(self.bboxes[index], dtype=torch.float)\n one_hot_lable=self.generate_one_hot(self.labels[index])\n labels = torch.tensor(one_hot_lable, dtype=torch.float)\n detector_bboxes=torch.tensor(self.detector_bboxes_list[index])\n #image = Image.open(self.path_to_keyframe+'/'+self.image_position[index]+\".jpg\")\n buffer = self.normalize(buffer)\n buffer = self.to_tensor(buffer,self.image_position,index)\n buffer=torch.tensor(buffer, dtype=torch.float)\n scale = torch.tensor(scale, dtype=torch.float)\n img=self.image_position[index]\n\n bboxes[:,[0,2]]*= scale[0]\n bboxes[:,[1,3]]*= scale[1]\n detector_bboxes[:,[0,2]]*= scale[0]\n detector_bboxes[:,[1,3]]*= scale[1]\n\n return self.image_position[index], buffer, scale, bboxes, labels,detector_bboxes,(self.heights[index],self.widths[index])\n\n def normalize(self, buffer):\n # Normalize the buffer\n # buffer = (buffer - 128)/128.0\n norm = []\n for i, frame in enumerate(buffer):\n if np.shape(frame)[2]!=3:\n print(np.shape(frame))\n frame = (frame - np.array([[[128.0, 128.0, 128.0]]]))/128.0\n buffer[i] = frame\n norm.append(frame)\n return np.array(norm,dtype=\"float32\")\n\n def to_tensor(self, buffer,image_position,index):\n # convert from [D, H, W, C] format to [C, D, H, W] (what PyTorch uses)\n # D = Depth (in this case, time), H = Height, W = Width, C = Channels\n if len(np.shape(buffer))!=4:\n print('WRONG:',image_position[index], np.shape(buffer))\n try:\n buffer.transpose([3, 0, 1, 2])\n except:\n print(image_position[index],np.shape(buffer))\n return buffer.transpose([3, 0, 1, 2])\n\n def loadvideo(self,image_position,index,frame_sample_rate):\n formate_key = image_position[index].split('/')[0]\n fname=self.path_to_videos + '/' + image_position[index] + self.data_format[formate_key]\n remainder = np.random.randint(frame_sample_rate)\n # initialize a VideoCapture object to read video data into a numpy array\n capture = cv2.VideoCapture(fname)\n frame_count = int(capture.get(cv2.CAP_PROP_FRAME_COUNT))\n frame_width = int(capture.get(cv2.CAP_PROP_FRAME_WIDTH))\n frame_height = int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT))\n fps = int(capture.get(cv2.CAP_PROP_FPS))\n #训练时丢弃帧数过少的数据\n if True:\n while frame_count<80 or frame_height<=0 or frame_width<=0:\n capture.release()\n print('discard_video,frame_num:',frame_count,'dir:',fname,frame_height,frame_width)\n index = np.random.randint(self.__len__())\n formate_key = image_position[index].split('/')[0]\n fname = self.path_to_videos + '/' + image_position[index] + self.data_format[formate_key]\n capture = cv2.VideoCapture(fname)\n frame_count = int(capture.get(cv2.CAP_PROP_FRAME_COUNT))\n frame_width = int(capture.get(cv2.CAP_PROP_FRAME_WIDTH))\n frame_height = int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT))\n #将图片缩放,遵循frcnn方式\n if frame_count<80:\n print(\"fname no:\",fname,frame_width,frame_height)\n if frame_height==0 or frame_width==0:\n print(\"WARNING:SHIT DATA\")\n\n resize_height=Height\n resize_width=Width\n scale=[resize_width/frame_width,resize_height/frame_height]\n # create a buffer. Must have dtype float, so it gets converted to a FloatTensor by Pytorch later\n start_idx = 0\n end_idx = 0\n frame_keep_count=72\n if frame_count==120:\n start_idx=43\n end_idx=115\n if frame_count==100:\n start_idx =26\n end_idx =98\n if frame_count==93:\n start_idx =18\n end_idx =90\n if frame_count!=120 and frame_count!=100 and frame_count!=93:\n end_idx=frame_count-1\n start_idx=end_idx-72\n buffer=[]\n #将数据填入空的buffer\n count = 0\n retaining = True\n sample_count = 0\n # read in each frame, one at a time into the numpy buffer array\n #end_idx=120\n while (count < end_idx and retaining):\n retaining, frame = capture.read()\n count += 1\n if count <= start_idx:\n continue\n if retaining is False:\n continue\n frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)\n # will resize frames if not already final size\n if (frame_height != resize_height) or (frame_width != resize_width):\n frame = cv2.resize(frame, (resize_width, resize_height))\n #buffer[sample_count] = frame\n buffer.append(frame)\n capture.release()\n if len(buffer) !=72:\n print(\"len(buffer)\",len(buffer),frame_count,end_idx)\n if len(buffer)<72:\n try:\n for i in range(72-len(buffer)):\n temp=buffer[-1]\n buffer.append(temp)\n assert len(buffer)==72\n except:\n buffer.append(np.zeros((resize_height,resize_width,3)))\n print('fail padding',fname)\n if len(buffer)!=72:\n buffer=[]\n for i in range(72):\n buffer.append(np.zeros((resize_height, resize_width, 3)))\n print('fail padding???', fname)\n with open(\"discaed\",\"a\") as f:\n f.write(fname+\"\\n\")\n # if len(buffer)!=64:\n # print('fail',fname)\n return buffer,scale,index\n\n def evaluate(self, path_to_results_dir: str,all_image_ids, bboxes: List[List[float]], classes: List[int], probs: List[float],img_size) -> Tuple[float, str]:\n #self._write_results(path_to_results_dir,all_image_ids, bboxes, classes, probs,img_size)\n ava_val()\n\n def _write_results(self, path_to_results_dir: str, image_ids: List[str], bboxes: List[List[float]],classes, probs: List[float],img_size):\n f = open(path_to_results_dir,mode='a+')\n print(len(image_ids),len(bboxes),len(classes),len(probs))\n assert len(image_ids)==len(bboxes)==len(classes)==len(probs)\n for image_id, _bbox, _cls, _prob in zip(image_ids, bboxes, classes, probs):\n print(\"image_id:\", image_id)\n print(\"bbox:\", _bbox)\n print(\"cls:\", _cls)\n print(\"prob:\", _prob)\n print(\"info:\", len(_bbox), len(_cls), len(_prob))\n assert len(_bbox) == len(_cls) == len(_prob)\n for bbox, cls, prob in zip(_bbox, _cls, _prob):\n #print(str(image_id.split('/')[0]),str(image_id.split('/')[1]), bbox[0]/int(img_size[1]), bbox[1], bbox[2], bbox[3],(int(cls)+1),prob,img_size[1],int(img_size[0]))\n x1=0 if bbox[0]/int(img_size[1])<0 else bbox[0]/int(img_size[1])\n y1=0 if bbox[1]/int(img_size[0])<0 else bbox[1]/int(img_size[0])\n x2=1 if bbox[2]/int(img_size[1])>1 else bbox[2]/int(img_size[1])\n y2=1 if bbox[3]/int(img_size[0])>1 else bbox[3]/int(img_size[0])\n print(str(image_id.split('/')[0]),str(image_id.split('/')[1]),x1,y1,x2,y2)\n for c,p in zip(cls,prob):\n f.write('{:s},{:s},{:f},{:f},{:f},{:f},{:s},{:s}\\n'.format(str(image_id.split('/')[0]),str(image_id.split('/')[1]), x1, y1, x2, y2,str(c),str(p)))\n f.close()\n\n def index2class(self):\n file_path = '/home/gan/data/video_caption_database/video_database/ava/preproc_train/ava_action_list_v2.0.csv'\n with open(file_path) as f:\n i2c_dic = {line.split(',')[0]: line.split(',')[1] for line in f}\n return i2c_dic\n\n def draw_bboxes_and_show(self,frame,frame_num,bboxes,labels,key_frame_start,key_frame_end,scale=1,probs=[]):\n if frame_num > key_frame_start and frame_num < key_frame_end:\n count = 0\n count_2=0\n # Capture frame-by-frame\n if len(probs)==0:#标签\n for bbox, lable in zip(bboxes, labels):\n count = count + 1\n bbox = np.array(bbox)\n lable = int(lable)\n real_x_min = int(bbox[0] / scale)\n real_y_min = int(bbox[1] / scale)\n real_x_max = int(bbox[2] / scale)\n real_y_max = int(bbox[3] / scale)\n # 在每一帧上画矩形,frame帧,(四个坐标参数),(颜色),宽度\n cv2.rectangle(frame, (real_x_min, real_y_min), (real_x_max, real_y_max),(17,238,105), 4)#绿色\n cv2.putText(frame, self.i2c_dic[str(lable)], (real_x_min + 15, real_y_min + 15 * count),\n cv2.FONT_HERSHEY_COMPLEX,0.5, (17,238,105), 1, False)\n else:#预测\n for bbox,lable,prob in zip(bboxes,labels,probs):\n count_2 = count_2 + 1\n bbox=np.array(bbox)\n lable = int(lable)\n prob=float(prob)\n print(\"probs\",probs)\n real_x_min = int(bbox[0]/scale)\n real_y_min = int(bbox[1]/scale)\n real_x_max = int(bbox[2]/scale)\n real_y_max = int(bbox[3]/scale)\n # 在每一帧上画矩形,frame帧,(四个坐标参数),(颜色),宽度\n cv2.rectangle(frame, (real_x_min, real_y_min), (real_x_max, real_y_max), (255, 0, 0), 4) # 红色\n cv2.putText(frame, self.i2c_dic[str(lable)]+':'+str(round(prob,2)), (real_x_max - 50, real_y_min + 15 * count),\n cv2.FONT_HERSHEY_COMPLEX,0.5, (255, 0, 0), 1, False)\n\n def test(self,item_num,frame_start=0.35,frame_end=0.95):\n for i in range(item_num):\n print(i)\n result=self.__getitem__(i)\n bboxes=result[3]\n labels=result[4]\n _scale=float(result[2])\n print('scale:',_scale)\n print ('bboxes:',bboxes)\n print ('labels:',labels)\n print('dir:',self.path_to_keyframe + '/' + result[0])\n formate_key = self.image_position[i].split('/')[0]\n cap = cv2.VideoCapture(self.path_to_videos + '/' + self.image_position[i] + self.data_format[formate_key])\n frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))\n key_frame_start = int(frame_count * frame_start)\n key_frame_end = int(frame_count * frame_end)\n frame_num = 0\n while (cap.isOpened()):\n ret, frame = cap.read()\n frame_num = frame_num + 1\n self.draw_bboxes_and_show(frame,frame_num,bboxes,labels,key_frame_start,key_frame_end,scale=_scale)\n if ret == True:\n # 显示视频\n cv2.imshow('Frame', frame)\n # 刷新视频\n cv2.waitKey(10)\n # 按q退出\n if cv2.waitKey(25) & 0xFF == ord('q'):\n break\n else:\n break\n def imshow(self,item_num,frame_start=0.5,frame_end=0.9):\n for i in range(item_num):\n result=self.__getitem__(i)\n name=result[0]\n real_bboxes=[item.bbox.tolist() for item in self.data_dic_real[name]]\n real_lables=[item.img_class for item in self.data_dic_real[name]]\n probs=result[5]\n print(type(probs[0]))\n kept_indices = list(np.where(np.array(probs) > 0.2))\n bboxes=np.array(result[3])[kept_indices]\n labels=np.array(result[4])[kept_indices]\n probs=np.array(probs)[kept_indices]\n scale=result[2]\n print('scale:',scale)\n print ('bboxes:',real_bboxes)\n print ('labels:',real_lables)\n print('dir:',self.path_to_keyframe + '/' + result[0])\n formate_key = self.image_position[i].split('/')[0]\n cap = cv2.VideoCapture(self.path_to_videos+'/'+self.image_position[i]+self.data_format[formate_key])\n frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))\n key_frame_start = int(frame_count * frame_start)\n key_frame_end = int(frame_count * frame_end)\n frame_num = 0\n while (cap.isOpened()):\n ret, frame = cap.read()\n frame_num = frame_num + 1\n self.draw_bboxes_and_show(frame,frame_num, bboxes, labels, key_frame_start, key_frame_end, scale=scale,probs=probs)\n self.draw_bboxes_and_show(frame,frame_num, real_bboxes, real_lables, key_frame_start, key_frame_end)\n if ret == True:\n # 显示视频\n cv2.imshow('Frame', frame)\n # 刷新视频\n cv2.waitKey(0)\n # 按q退出\n if cv2.waitKey(25) & 0xFF == ord('q'):\n break\n else:\n break\n def show_net_input(self,buffer,detect_bbox,label_bbox,labels,scale):\n label_bbox=np.array(label_bbox)\n detect_bbox=np.array(detect_bbox)\n label_bbox[:,[0, 2]] *= scale[0]\n label_bbox[:,[1, 3]] *= scale[1]\n detect_bbox[:,[0, 2]] *= scale[0]\n detect_bbox[:,[1, 3]] *= scale[1]\n print(\"detect_bbox:\", np.round(detect_bbox,1))\n print(\"label_bbox:\", np.round(label_bbox,1))\n print(\"labels:\", labels)\n for f in buffer:\n for i,r in enumerate(label_bbox):\n cv2.rectangle(f, (int(r[0]), int(r[1])), (int(r[2]), int(r[3])), (0, 170, 17), 1)\n for n, l in enumerate(labels[i]):\n cv2.putText(f, self.i2c_dic[str(l)], (int(r[0]) + 10, int(r[1]) + 10* n),\n cv2.FONT_HERSHEY_COMPLEX,0.4,(255, 255, 0), 1, False)\n for d in detect_bbox:\n cv2.rectangle(f, (int(d[0]), int(d[1])), (int(d[2]), int(d[3])), (255, 255, 255), 1)\n cv2.imshow('Frame', f)\n # 刷新视频\n cv2.waitKey(0)\n\nif __name__ == '__main__':\n a=AVA_video('/home/ganhaiyang/output/ava/result.txt')\n a.imshow(10)\n\n# if __name__ == '__main__':\n# train_dataloader = \\\n# DataLoader(AVA_video(TrainConfig.TRAIN_DATA), batch_size=2, collate_fn=DatasetBase.padding_collate_fn,shuffle=True,num_workers=0)\n# for n_iter,( _, image_batch, _, bboxes_batch, labels_batch,detector_bboxes_batch) in enumerate(train_dataloader):\n# print(\"n_iter: \", n_iter)\n"
},
{
"alpha_fraction": 0.699999988079071,
"alphanum_fraction": 0.7244898080825806,
"avg_line_length": 21.272727966308594,
"blob_id": "3b14a9809096a2b82a7585e29094fc927319739b",
"content_id": "70c7f3d73637830679346dcd6436cebda3b98d96",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 490,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 22,
"path": "/test_daptice.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "import torch as t\nimport math\nimport numpy as np\n\nalist = t.randn(2, 3, 9)\n\ninputsz = np.array(alist.shape[2:])\noutputsz = np.array([9])\n\nstridesz = np.floor(inputsz / outputsz).astype(np.int32)\nprint(\"stridesz\",stridesz)\nkernelsz = inputsz - (outputsz - 1) * stridesz\nprint(\"kernelsz\",kernelsz)\n\nadp = t.nn.AdaptiveMaxPool1d([10])\navg = t.nn.MaxPool1d(kernel_size=list(kernelsz), stride=list(stridesz))\nadplist = adp(alist)\navglist = avg(alist)\n\nprint(alist)\nprint(adplist)\nprint(avglist)\n"
},
{
"alpha_fraction": 0.5499777793884277,
"alphanum_fraction": 0.5790759921073914,
"avg_line_length": 36.525001525878906,
"blob_id": "56119e697dc9de226c30343ae2bd75dfcc8d4c09",
"content_id": "9aa998a44d8da87328cd16c32ae420fbd3bd0df2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4502,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 120,
"path": "/backbone/hidden_for_roi2.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nfrom torch.autograd import Variable\nimport numpy as np\n\nclass Bottleneck(nn.Module):\n expansion = 4\n\n def __init__(self, inplanes, planes, stride=1, downsample=None, head_conv=1):\n super(Bottleneck, self).__init__()\n # 2d 1*1\n if head_conv == 1:\n self.conv1 = nn.Conv3d(inplanes, planes, kernel_size=1, bias=False,dilation=2)\n self.bn1 = nn.BatchNorm3d(planes)\n\n #3d 1*1\n elif head_conv == 3:\n self.conv1 = nn.Conv3d(inplanes, planes, kernel_size=(3, 1, 1), bias=False, padding=(2, 0, 0),dilation=2)\n self.bn1 = nn.BatchNorm3d(planes)\n else:\n raise ValueError(\"Unsupported head_conv!\")\n self.conv2 = nn.Conv3d(\n planes, planes, kernel_size=(1, 3, 3), stride=(1,stride,stride), padding=(0, 2, 2), bias=False,dilation=2)\n self.bn2 = nn.BatchNorm3d(planes)\n self.conv3 = nn.Conv3d(planes, planes * 4, kernel_size=1, bias=False,dilation=2)\n self.bn3 = nn.BatchNorm3d(planes * 4)\n self.relu = nn.ReLU(inplace=True)\n self.downsample = downsample\n self.stride = stride\n\n def forward(self, x):\n residual = x\n\n out = self.conv1(x)\n out = self.bn1(out)\n out = self.relu(out)\n\n out = self.conv2(out)\n out = self.bn2(out)\n out = self.relu(out)\n\n out = self.conv3(out)\n out = self.bn3(out)\n\n if self.downsample is not None:\n residual = self.downsample(x)\n out += residual\n out = self.relu(out)\n\n return out\n\n\nclass Hidden(nn.Module):\n def __init__(self, block=Bottleneck, layers=[3, 4, 6, 3], class_num=10, dropout=0.5):\n super(Hidden, self).__init__()\n self.slow_inplanes = 1280\n self.fast_inplanes = 128\n self.fast_res5 = self._make_layer_fast(\n block, 64, layers[3], stride=1, head_conv=3)\n self.slow_res5 = self._make_layer_slow(\n block, 512, layers[3], stride=1, head_conv=3)\n\n\n def _make_layer_fast(self, block, planes, blocks, stride=1, head_conv=1):\n downsample = None\n if stride != 1 or self.fast_inplanes != planes * block.expansion:\n downsample = nn.Sequential(\n nn.Conv3d(\n self.fast_inplanes,\n planes * block.expansion,\n kernel_size=1,\n stride=(1,stride,stride),\n bias=False,dilation=2), nn.BatchNorm3d(planes * block.expansion))\n\n layers = []\n layers.append(block(self.fast_inplanes, planes, stride, downsample, head_conv=head_conv))\n self.fast_inplanes = planes * block.expansion\n for i in range(1, blocks):\n layers.append(block(self.fast_inplanes, planes, head_conv=head_conv))\n return nn.Sequential(*layers)\n\n def _make_layer_slow(self, block, planes, blocks, stride=1, head_conv=1):\n #print('_make_layer_slow',planes)\n downsample = None\n if stride != 1 or self.slow_inplanes != planes * block.expansion:\n #print('self.slow_inplanes',self.slow_inplanes)\n downsample = nn.Sequential(\n nn.Conv3d(\n self.slow_inplanes,\n planes * block.expansion,\n kernel_size=1,\n stride=(1,stride,stride),\n bias=False,dilation=2), nn.BatchNorm3d(planes * block.expansion))\n layers = []\n layers.append(block(self.slow_inplanes, planes, stride, downsample, head_conv=head_conv))\n self.slow_inplanes = planes * block.expansion\n for i in range(1, blocks):\n layers.append(block(self.slow_inplanes, planes, head_conv=head_conv))\n #self.slow_inplanes = planes * block.expansion + planes * block.expansion // 8 * 2\n self.slow_inplanes = planes * block.expansion\n return nn.Sequential(*layers)\n\n def forward(self,fast_input,slow_input):\n fast_output=self.fast_res5(fast_input)\n slow_output=self.slow_res5(slow_input)\n x1 = nn.AdaptiveAvgPool3d(1)(fast_output)\n x2 = nn.AdaptiveAvgPool3d(1)(slow_output)\n x1 = x1.view(-1, x1.size(1))\n x2 = x2.view(-1, x2.size(1))\n x = torch.cat([x1, x2], dim=1)\n return x\n\n\ndef hidden50(**kwargs):\n \"\"\"Constructs a ResNet-50 model.\n \"\"\"\n model = Hidden(Bottleneck, [3, 4, 6, 3], **kwargs)\n print('model', model)\n return model"
},
{
"alpha_fraction": 0.6059259176254272,
"alphanum_fraction": 0.6355555653572083,
"avg_line_length": 23.14285659790039,
"blob_id": "e3879503359d5699e313d0914cebd37fc8bd9398",
"content_id": "f7dc248fd92da5d63814f6b0a5a52223c48e5276",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 713,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 28,
"path": "/backbone/hidden_for_roi_maxpool.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nfrom torch.autograd import Variable\nimport numpy as np\n\n\nclass Hidden(nn.Module):\n\n def __init__(self, inplanes, planes, stride=1):\n super(Hidden, self).__init__()\n\n def forward(self, x):\n out=x.view(x.shape[0],-1)\n out = out.view(-1, out.size(1))\n return out\n\ndef weight_init(m):\n # 也可以判断是否为conv2d,使用相应的初始化方式\n if isinstance(m, nn.Conv3d):\n print(\"using kaiming\")\n nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')\n\ndef hidden50(**kwargs):\n \"\"\"Constructs a ResNet-50 model.\n \"\"\"\n model = Hidden(2304,2304,2)\n return model"
},
{
"alpha_fraction": 0.5854641795158386,
"alphanum_fraction": 0.5953697562217712,
"avg_line_length": 58.0476188659668,
"blob_id": "d9ecf6f33c856670bd79f490d88db3c25c68dbb4",
"content_id": "bfe4dabc3ccef8e46a18d7f72c08521bb2104298",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8768,
"license_type": "permissive",
"max_line_length": 169,
"num_lines": 147,
"path": "/model.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "import os\nfrom typing import Union, Tuple, List, Optional\nimport torch\nfrom torch import nn, Tensor\nfrom torch.nn import functional as F\nfrom torch.optim import Optimizer\nfrom torch.optim.lr_scheduler import _LRScheduler\nfrom config.eval_config import EvalConfig\nfrom backbone.base import Base as BackboneBase\nfrom bbox1 import BBox\nfrom roi.pooler import Pooler\n\n\n\nclass Model(nn.Module):\n\n def __init__(self,\n backbone: BackboneBase,\n num_classes: int,\n pooler_mode: Pooler.Mode,\n anchor_ratios: List[Tuple[int, int]],\n anchor_sizes: List[int],\n rpn_pre_nms_top_n: int,\n rpn_post_nms_top_n: int,\n anchor_smooth_l1_loss_beta: Optional[float] = None,\n proposal_smooth_l1_loss_beta: Optional[float] = None\n ):\n super().__init__()\n self.features, hidden, num_features_out, num_hidden_out = backbone.features()\n self.detection = Model.Detection(pooler_mode, hidden, num_hidden_out, num_classes, proposal_smooth_l1_loss_beta)\n\n def forward(self, image_batch: Tensor,\n gt_bboxes_batch: Tensor = None, gt_classes_batch: Tensor = None, detector_bboxes_batch: Tensor = None):\n fast_feature = self.features(image_batch) # 调用slowfast网络forward的返回,TSM只有 一个返回 ## fast_feature,slow_feature\n fast_feature = fast_feature.unsqueeze(0)\n fast_feature = fast_feature.permute(0, 2, 1, 3, 4) ## transpose(a,b) a,b维度置换\n batch_size, _, _,image_height, image_width = image_batch.shape\n _,_, _,features_height, features_width = fast_feature.shape ## slow_feature.shape\n if self.training:\n proposal_classes, proposal_class_losses = self.detection.forward(fast_feature, detector_bboxes_batch, gt_classes_batch, gt_bboxes_batch) ## ,slow_feature\n return proposal_class_losses\n else:\n #on work\n detector_bboxes_batch = detector_bboxes_batch.squeeze(dim=0) #torch.Size([17, 4])\n proposal_classes = self.detection.forward(fast_feature,detector_bboxes_batch) #torch.Size([17, 81]) ## ,slow_feature\n detection_bboxes, detection_classes, detection_probs = self.detection.generate_detections(detector_bboxes_batch, proposal_classes, image_width, image_height)\n return detection_bboxes, detection_classes, detection_probs\n\n def save(self, path_to_checkpoints_dir: str, step: int, optimizer: Optimizer, scheduler: _LRScheduler) -> str:\n path_to_checkpoint = os.path.join(path_to_checkpoints_dir, 'model-{}.pth'.format(step))\n checkpoint = {\n 'state_dict': self.state_dict(),\n 'step': step,\n 'optimizer_state_dict': optimizer.state_dict(),\n 'scheduler_state_dict': scheduler.state_dict()\n }\n torch.save(checkpoint, path_to_checkpoint)\n return path_to_checkpoint\n\n def load(self, path_to_checkpoint: str, optimizer: Optimizer = None, scheduler: _LRScheduler = None) -> 'Model':\n checkpoint = torch.load(path_to_checkpoint)\n self.load_state_dict(checkpoint['state_dict'])\n step=0\n return step\n\n class Detection(nn.Module):\n def __init__(self, pooler_mode: Pooler.Mode, hidden: nn.Module, num_hidden_out: int, num_classes: int, proposal_smooth_l1_loss_beta: float):\n super().__init__()\n self._pooler_mode = pooler_mode\n self.hidden = hidden\n self.num_classes = num_classes\n self._proposal_class = nn.Linear(num_hidden_out, num_classes)\n #working\n def forward(self,fast_feature, proposal_bboxes: Tensor,\n gt_classes_batch: Optional[Tensor] = None, gt_bboxes_batch: Optional[Tensor] = None) \\\n -> Union[Tuple[Tensor], Tuple[Tensor, Tensor, Tensor, Tensor]]: ## slow_feature, , Tensor\n batch_size = fast_feature.shape[0] ## fast_feature:{1,256,16,16]\n feature=nn.AvgPool3d(kernel_size=(fast_feature.shape[2], 1, 1))(fast_feature).squeeze(2) ## feature: [1,2304,16,16]\n # slow_feature = nn.AvgPool3d(kernel_size=(slow_feature.shape[2], 1, 1))(slow_feature).squeeze(2)\n # feature=torch.cat([fast_feature, slow_feature],dim=1)\n if not self.training:\n assert batch_size==1\n proposal_batch_indices = torch.arange(end=batch_size, dtype=torch.long, device=proposal_bboxes.device).view(-1, 1).repeat(1, proposal_bboxes.shape[0])[0]\n pool = Pooler.apply(feature, proposal_bboxes, proposal_batch_indices, mode=Pooler.Mode.POOLING)\n hidden = self.hidden(pool)\n proposal_classes = self._proposal_class(hidden)\n return proposal_classes\n else:\n #过滤掉补充的0\n # find labels for each `proposal_bboxes`\n ious = BBox.iou(proposal_bboxes, gt_bboxes_batch)\n proposal_max_ious, proposal_assignments = ious.max(dim=2)\n fg_masks = proposal_max_ious >= 0.85\n if len(fg_masks.nonzero()) > 0:\n #fg_masks.nonzero()[:, 0]是在获取batch\n proposal_bboxes=proposal_bboxes[fg_masks.nonzero()[:, 0], fg_masks.nonzero()[:, 1]]\n batch_indices=fg_masks.nonzero()[:, 0]\n labels=gt_classes_batch[fg_masks.nonzero()[:, 0], proposal_assignments[fg_masks]]\n else:\n print('bbox warning')\n fg_masks = proposal_max_ious >= 0.5\n proposal_bboxes = proposal_bboxes[fg_masks.nonzero()[:, 0], fg_masks.nonzero()[:, 1]]\n batch_indices = fg_masks.nonzero()[:, 0]\n labels = gt_classes_batch[fg_masks.nonzero()[:, 0], proposal_assignments[fg_masks]]\n\n # # #空间池化,拼接\n pool = Pooler.apply(feature, proposal_bboxes, batch_indices, mode=Pooler.Mode.POOLING)\n # print(\"******** pool shape *******\", pool.shape) [6, 2048, 3, 3]\n\n hidden = self.hidden(pool)\n proposal_classes = self._proposal_class(hidden)\n proposal_class_losses = self.loss(proposal_classes, labels,batch_size,batch_indices)\n return proposal_classes, proposal_class_losses\n\n def loss(self, proposal_classes: Tensor,gt_proposal_classes: Tensor, batch_size,batch_indices) -> Tuple[Tensor, Tensor]:\n cross_entropies = torch.zeros(batch_size, dtype=torch.float, device=proposal_classes.device).cuda()\n for batch_index in range(batch_size):\n selected_indices = (batch_indices == batch_index).nonzero().view(-1)\n input=proposal_classes[selected_indices]\n target=gt_proposal_classes[selected_indices]\n if torch.numel(input)==0 or torch.numel(target)==0:\n continue\n assert torch.numel(input)==torch.numel(target)\n cross_entropy =F.multilabel_soft_margin_loss(input=proposal_classes[selected_indices],target=gt_proposal_classes[selected_indices],reduction=\"mean\")\n torch.nn.MultiLabelSoftMarginLoss\n cross_entropies[batch_index] = cross_entropy\n return cross_entropies\n\n def generate_detections(self, proposal_bboxes: Tensor, proposal_classes: Tensor, image_width: int, image_height: int) -> Tuple[Tensor, Tensor, Tensor, Tensor]:\n batch_size = proposal_bboxes.shape[0]\n detection_bboxes = BBox.clip(proposal_bboxes, left=0, top=0, right=image_width, bottom=image_height)\n detection_probs = F.sigmoid(proposal_classes)\n detection_zheng=detection_probs>=EvalConfig.KEEP\n all_detection_classes=[]\n all_detection_probs=[]\n for label,prob in zip(detection_zheng,detection_probs):\n detection_classes = []\n detection_p=[]\n for index,i in enumerate(label):\n if i==1:\n detection_classes.append(index)\n detection_p.append(prob[index].item())\n all_detection_classes.append(detection_classes)\n all_detection_probs.append(detection_p)\n return detection_bboxes, all_detection_classes, all_detection_probs\n #****************准换模型转Tensor时打开******************\n # return detection_bboxes, torch.Tensor(all_detection_classes), torch.Tensor(all_detection_probs)\n\n\n"
},
{
"alpha_fraction": 0.5702746510505676,
"alphanum_fraction": 0.6090468764305115,
"avg_line_length": 23.760000228881836,
"blob_id": "89fab4fb2123ac2f32d6ecabe26d2e643551bbb8",
"content_id": "bf90f6dfa70b4de98bd165bc52f273a221f6df25",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 619,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 25,
"path": "/backbone/tsmnet.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "from typing import Tuple\n\nimport torchvision\nfrom torch import nn\n\n# import backbone.base\n# from backbone.slowfastnet import tsm as tsm1\n# from backbone.hidden_for_roi_maxpool import hidden50\n# class tsm(backbone.base.Base):\n#\n# def __init__(self):\n# super().__init__(False)\n#\n# def features(self):\n# print(\"slowfast_res50\")\n# tsmResnet101 = tsm1()\n# hidden = hidden50()\n# num_features_out = 2304\n# num_hidden_out = 2304*3*3\n#\n# return tsmResnet101, hidden, num_features_out, num_hidden_out\n#\n# if __name__ == '__main__':\n# s=tsm()\n# s.features()\n"
},
{
"alpha_fraction": 0.6162079572677612,
"alphanum_fraction": 0.6712538003921509,
"avg_line_length": 24.153846740722656,
"blob_id": "07b68052ba8ccd079dff1fc505d7581be5ca758d",
"content_id": "aea658ed5c6ac0d052158f8190d7b0de8bcc7406",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 654,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 26,
"path": "/backbone/slowfast_res50.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "from typing import Tuple\n\nimport torchvision\nfrom torch import nn\n\nimport backbone.base\nfrom backbone.slowfastnet import resnet101 as rs101\nfrom backbone.slowfastnet import resnet50 as rs50\nfrom backbone.hidden_for_roi_maxpool import hidden50\nclass slowfast_res50(backbone.base.Base):\n\n def __init__(self):\n super().__init__(False)\n\n def features(self):\n print(\"slowfast_res50\")\n resnet50 = rs50()\n hidden = hidden50()\n num_features_out = 2304\n num_hidden_out = 2304*3*3\n\n return resnet50, hidden, num_features_out, num_hidden_out\n\nif __name__ == '__main__':\n s=slowfast_res50()\n s.features()\n"
},
{
"alpha_fraction": 0.581531286239624,
"alphanum_fraction": 0.6014026999473572,
"avg_line_length": 38.79069900512695,
"blob_id": "9c009aba32ccee90a8d5b830db5a2914816a8a34",
"content_id": "728404e44f4f2002b44e63120c4deba531f03cc3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6844,
"license_type": "permissive",
"max_line_length": 167,
"num_lines": 172,
"path": "/extract_keyframe.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "\"\"\"New script to process AVA dataset.\"\"\"\nfrom __future__ import print_function\nimport argparse\nimport os\nimport subprocess\nimport sys\nimport csv\nimport cv2\nimport code\n\nparser = argparse.ArgumentParser()\nparser.add_argument(\"--video_dir\", default=\"/data/video_caption_database/ava/ava/video/trainval\", help=\"Videos path.\")\n# parser.add_argument(\"--annot_file\", default=\"/home/ganhy/dataset/ava/ava-dataset-tool-master/ava_train_v1.0.csv\",help=\"Anotation file path.\") #ava_train_v2.1.csv\nparser.add_argument(\"--annot_file\", default=\"/data/video_caption_database/ava/ava/preproc_train/ava_train_v2.21.csv\",help=\"Anotation file path.\") #ava_train_v2.1.csv\nparser.add_argument(\"--actionlist_file\",default=\"/home/ganhaiyang/dataset/ava/ava_labels/ava_action_list_v2.0.csv\", help=\"Action list file path.\")\nparser.add_argument(\"--output_dir\", default=\"/data/video_caption_database/ava/ava/preproc_train\", help=\"Output path.\")\nFLAGS = parser.parse_args()\n\nvideodir = FLAGS.video_dir\nannotfile = FLAGS.annot_file\nactionlistfile = FLAGS.actionlist_file\noutdir = FLAGS.output_dir\noutdir_clips = os.path.join(outdir, \"clips\")\noutdir_keyframes = os.path.join(outdir, \"keyframes\")\noutdir_bboxs = os.path.join(outdir, \"bboxs\")\nclip_length = 3 # seconds\nclip_time_padding = 1.0 # seconds\n\n\ndef load_action_name(annotations):\n csvfile = open(annotations,'r')\n reader = list(csv.reader(csvfile))\n dic = {}\n for i in range(len(reader)-1):\n temp = (reader[i+1][1],reader[i+1][2])\n dic[i+1] = temp\n return dic\n\ndef load_labels(annotations):\n csvfile = open(annotations,'r')\n reader = list(csv.reader(csvfile))\n dic = {}\n for i in range(len(reader)):\n if (reader[i][0],reader[i][1]) in dic:\n dic[(reader[i][0],reader[i][1])].append(i)\n else:\n templist = []\n templist.append(i)\n dic[(reader[i][0],reader[i][1])] = templist\n return reader, dic\n\ndef hou_min_sec(millis):\n millis = int(millis)\n seconds = (millis / 1000) % 60\n seconds = int(seconds)\n minutes = (millis / (1000 * 60)) % 60\n minutes = int(minutes)\n hours = (millis / (1000 * 60 * 60))\n return \"%d:%d:%d\" % (hours, minutes, seconds)\n\ndef _supermakedirs(path, mode):\n if not path or os.path.exists(path):\n return []\n (head, _) = os.path.split(path)\n res = _supermakedirs(head, mode)\n os.mkdir(path)\n os.chmod(path, mode)\n res += [path]\n return res\n\ndef mkdir_p(path):\n try:\n _supermakedirs(path, 0o775) # Supporting Python 2 & 3\n except OSError: # Python >2.5\n pass\n\ndef get_keyframe(videofile, video_id, time_id, outdir_keyframes):\n outdir_folder = os.path.join(outdir_keyframes, video_id)\n mkdir_p(outdir_folder)\n outpath = os.path.join(outdir_folder, '%d.jpg' % (int(time_id)))\n ffmpeg_command = 'rm %(outpath)s; \\\n ffmpeg -ss %(timestamp)f -i %(videopath)s \\\n -frames:v 1 %(outpath)s' % {\n 'timestamp': float(time_id),\n 'videopath': videofile,\n 'outpath': outpath}\n subprocess.call(ffmpeg_command, shell=True)\n return outpath\n\ndef visual_bbox(anno_data, action_name, keyfname, video_id, time_id, bbox_ids):\n frame = cv2.imread(keyfname)\n frame_height, frame_width, channels = frame.shape\n outdir_folder = os.path.join(outdir_bboxs, video_id)\n mkdir_p(outdir_folder)\n outpath = os.path.join(outdir_folder, '%d_bbox.jpg' % (int(time_id)))\n draw_dic = {}\n for idx in bbox_ids:\n bbox = anno_data[idx][2:6]\n action_string = action_name[int(anno_data[idx][-2])]\n print(\"action_string: \",action_string)\n cv2.rectangle(frame, (int(float(bbox[0])*frame_width),int(float(bbox[1])*frame_height)), \n (int(float(bbox[2])*frame_width),int(float(bbox[3])*frame_height)), [0,0,255], 1)\n x1 = int(float(bbox[0])*frame_width)\n y1 = int(float(bbox[1])*frame_height)\n\n if (x1,y1) in draw_dic:\n draw_dic[(x1,y1)] +=1\n else:\n draw_dic[(x1,y1)] = 1\n\n pt_to_draw = (x1,y1+20*draw_dic[(x1,y1)]) \n cv2.putText(frame, action_string[0], pt_to_draw, cv2.FONT_HERSHEY_SIMPLEX, fontScale=0.6, color=[0,255,255], thickness=1)\n draw_dic[pt_to_draw] = True\n cv2.imwrite(outpath, frame) \n\ndef get_clips(videofile, video_id, video_extension, time_id):\n outdir_folder = os.path.join(outdir_clips, video_id)\n mkdir_p(outdir_folder)\n clip_start = time_id - clip_time_padding - float(clip_length) / 2\n if clip_start < 0:\n clip_start = 0\n clip_end = time_id + float(clip_length) / 2\n outpath_clip = os.path.join(outdir_folder, '%d.%s' % (int(time_id), video_extension))\n\n ffmpeg_command = 'rm %(outpath)s; \\\n ffmpeg -ss %(start_timestamp)s -i \\\n %(videopath)s -g 1 -force_key_frames 0 \\\n -t %(clip_length)d %(outpath)s' % {\n 'start_timestamp': hou_min_sec(clip_start * 1000),\n # 'end_timestamp': hou_min_sec(clip_end * 1000),\n 'clip_length': clip_length + clip_time_padding,\n 'videopath': videofile,\n 'outpath': outpath_clip}\n subprocess.call(ffmpeg_command, shell=True)\n\nif __name__ == '__main__':\n # load data and labels from cvs files\n anno_data, table = load_labels(annotfile)\n action_name = load_action_name(actionlistfile) \n\n # iterate each frame in a video\n for key in sorted(table):\n video_id = key[0]\n time_id = float(key[1]) \n bbox_ids = table[key]\n\n videofile_noext = os.path.join(videodir, video_id)\n videofile = subprocess.check_output('ls %s*' % videofile_noext, shell=True)\n videofile = videofile.split()[0]\n\n if sys.version > '3.0':\n videofile = videofile.decode('utf-8')\n video_extension = videofile.split('.')[-1]\n\n # OPEN VIDEO FOR INFORMATION IF NECESSARY\n vcap = cv2.VideoCapture(videofile) # 0=camera\n if vcap.isOpened():\n if cv2.__version__ < '3.0':\n vidwidth = vcap.get(cv2.cv.CV_CAP_PROP_FRAME_WIDTH) # float\n vidheight = vcap.get(cv2.cv.CV_CAP_PROP_FRAME_HEIGHT) # float\n else:\n vidwidth = vcap.get(cv2.CAP_PROP_FRAME_WIDTH) # float\n vidheight = vcap.get(cv2.CAP_PROP_FRAME_WIDTH) # float\n else:\n exit(1)\n\n # Extract keyframe via ffmpeg\n fname = get_keyframe(videofile, video_id, time_id, outdir_keyframes)\n # Bbox visualization\n visual_bbox(anno_data, action_name, fname, video_id, time_id, bbox_ids)\n # Extract clips via ffmpeg\n get_clips(videofile, video_id, video_extension, time_id)\n"
},
{
"alpha_fraction": 0.5227240324020386,
"alphanum_fraction": 0.5414826273918152,
"avg_line_length": 44.09207534790039,
"blob_id": "b829ba4e2936d6f713c6cdb64442f428fec09c73",
"content_id": "d99fa75ff5037ffa1914f939fed337eae9a2ab9f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 21375,
"license_type": "permissive",
"max_line_length": 175,
"num_lines": 467,
"path": "/dataset/AVA_video_v1.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "import os\nimport numpy as np\nimport torch.utils.data\nfrom PIL import Image, ImageOps\nfrom bbox import BBox\nfrom typing import Tuple, List, Type, Iterator\nimport matplotlib.pyplot as plt\nimport PIL\nimport torch.utils.data.dataset\nimport torch.utils.data.sampler\nfrom PIL import Image\nfrom torch import Tensor\nimport operator\nfrom torchvision.transforms import transforms\nimport cv2\n\nfrom torchvision.transforms import transforms\nfrom dataset.base import Base as DatasetBase\nfrom get_ava_performance import ava_val\nfrom config.config import Config\nfrom config.eval_config import EvalConfig\nfrom config.train_config import TrainConfig\nimport pandas as pa\nfrom torch.utils.data import DataLoader, Dataset\nclass AVA_video(Dataset):\n\n class info():\n def __init__(self, img_class, bbox,h,w,img_position):\n self.img_class = [int(img_class)]\n self.bbox = bbox\n self.height=h\n self.weight=w\n self.img_position=img_position\n def __repr__(self):\n return 'info[img_class={0}, bbox={1}]'.format(\n self.img_class, self.bbox)\n\n def __init__(self,data_dir,discard=True):\n self.bboxes=[]\n self.labels=[]\n self.image_ratios = []\n self.image_position=[]\n self.widths=[]\n self.heights=[]\n #根据name获取detector_bbox\n self.detector_bboxes_list=[]\n #for debug\n self.name_list=[]\n self.i2c_dic=self.index2class()\n self.data_dic = {}\n self.data_dic_real={}\n self.data_size={}\n self.data_format={}\n self.detector_bbox_dic={}\n self.path_to_data_dir='/home/aiuser/'\n #path_to_AVA_dir = os.path.join(self.path_to_data_dir, 'ava', 'preproc_train')\n path_to_AVA_dir = os.path.join(self.path_to_data_dir, 'ava_v2.2', 'preproc', 'train_clips')\n self.path_to_videos = os.path.join(path_to_AVA_dir, 'clips')\n self.path_to_keyframe = os.path.join(path_to_AVA_dir, 'keyframes')\n self.discard=discard\n self.imshow_lable_dir=data_dir\n path_to_video_ids_txt = os.path.join(path_to_AVA_dir, data_dir)\n path_to_detector_result_txt=os.path.join(path_to_AVA_dir,Config.DETECTOR_RESULT_PATH)\n #得到每个视频的大小,通过读取第一张keyframe\n self.get_video_size()\n # 得到每个视频的格式\n self.get_video_format()\n #读取文件,key是文件名(aa/0930)\n self.read_file_to_dic(path_to_video_ids_txt,self.data_dic)\n self.make_multi_lable(self.data_dic)\n\n # 获取detector的predict_bbox\n self.read_file_to_dic(path_to_detector_result_txt, self.detector_bbox_dic)\n #print(\"detector_bbox_dic:\",self.detector_bbox_dic)\n\n #对字典中的数据进行整理,变成list的形式\n self.trans_dic_to_list()\n\n\n def get_video_size(self):\n for frame in sorted(os.listdir(self.path_to_keyframe)):\n img=os.listdir(os.path.join(self.path_to_keyframe, frame))[0]\n img=cv2.imread(os.path.join(self.path_to_keyframe, frame,img))\n img_shape=img.shape\n self.data_size[frame]=(img_shape[0],img_shape[1])\n\n def get_video_format(self):\n for video in sorted(os.listdir(self.path_to_videos)):\n video_0 = os.listdir(os.path.join(self.path_to_videos, video))[0]\n self.data_format[video]='.'+video_0.split('.')[1]\n #print('data_format',self.data_format)\n\n def read_file_to_dic(self,filename,dic):\n with open(filename, 'r') as f:\n data = f.readlines()\n for line in data:\n content = line.split(',')\n key=content[0]+\"/\"+str(int(content[1]))\n img_h=int(self.data_size[content[0]][0])\n img_w = int(self.data_size[content[0]][1])\n if key not in dic:\n dic[key] = [AVA_video.info(content[6],BBox( # convert to 0-based pixel index\n left=float(content[2])*img_w ,\n top=float(content[3])*img_h ,\n right=float(content[4])*img_w,\n bottom=float(content[5])*img_h),img_h,img_w,key)]\n else:\n dic[key].append(AVA_video.info(content[6], BBox( # convert to 0-based pixel index\n left=float(content[2]) * img_w,\n top=float(content[3]) * img_h,\n right=float(content[4]) * img_w,\n bottom=float(content[5]) * img_h), img_h, img_w, key))\n # print('data_dic:',self.data_dic)\n def make_multi_lable(self,dic):\n for key in dic:\n pre=None\n #print(\"before:\",dic[key])\n temp=[]\n for info in dic[key]:\n if pre==None:\n pre=info\n temp.append(info)\n elif operator.eq(info.bbox.tolist(),pre.bbox.tolist()):\n temp[-1].img_class.append(info.img_class[0])\n #这是个陷坑\n #dic[key].remove(info)\n else:\n pre=info\n temp.append(info)\n dic[key]=temp\n #print(\"dic:\",dic)\n\n\n\n\n def trans_dic_to_list(self):\n for key in self.data_dic:\n if(key in self.detector_bbox_dic):\n a=self.data_dic[key]\n self.bboxes.append([item.bbox.tolist() for item in self.data_dic[key]])\n self.labels.append([item.img_class for item in self.data_dic[key]])\n assert len(self.bboxes)==len(self.labels)\n self.detector_bboxes_list.append([item.bbox.tolist() for item in self.detector_bbox_dic[key]])\n width = int(self.data_dic[key][0].weight)\n self.widths.append(width)\n height = int(self.data_dic[key][0].height)\n self.heights.append(height)\n ratio = float(width / height)\n self.image_ratios.append(ratio)\n self.image_position.append(self.data_dic[key][0].img_position)\n else:\n continue\n\n def generate_one_hot(self,lable):\n one_hot_lable=np.zeros((len(lable),81))\n for i,box_lable in enumerate(lable):\n for one in box_lable:\n for j in range(81):\n if j==int(one):\n one_hot_lable[i][j]=1\n #print('one_hot_lable:',one_hot_lable)\n return one_hot_lable\n\n\n def __len__(self) -> int:\n return len(self.image_position)\n\n def num_classes(self):\n return 81\n\n def __getitem__(self, index: int) -> Tuple[str, Tensor, Tensor, Tensor, Tensor]:\n\n print(\"######## V1-VERSION ##########\")\n\n\n buffer, scale,index = self.loadvideo(self.image_position, index, Config.IMAGE_MIN_SIDE, Config.IMAGE_MAX_SIDE, 1,self.discard)\n bboxes = torch.tensor(self.bboxes[index], dtype=torch.float)\n one_hot_lable=self.generate_one_hot(self.labels[index])\n labels = torch.tensor(one_hot_lable, dtype=torch.float)\n detector_bboxes=torch.tensor(self.detector_bboxes_list[index])\n #image = Image.open(self.path_to_keyframe+'/'+self.image_position[index]+\".jpg\")\n buffer = self.normalize(buffer)\n buffer = self.to_tensor(buffer,self.image_position,index)\n buffer=torch.tensor(buffer, dtype=torch.float)\n scale = torch.tensor(scale, dtype=torch.float)\n img=self.image_position[index]\n # print(\"####img:\",img)\n # print(\"lable:\",self.labels[index])\n # print(\"befor_bbox:\", bboxes)\n # print(\"before_detector_bboxes:\", detector_bboxes)\n bboxes *= scale\n detector_bboxes*= scale\n # print(\"bbox:\", bboxes)\n # print(\"detector_bboxes:\",detector_bboxes)\n # print(\"scale:\",scale)\n return self.image_position[index], buffer, scale, bboxes, labels,detector_bboxes,(self.heights[index],self.widths[index])\n\n def normalize(self, buffer):\n # Normalize the buffer\n # buffer = (buffer - 128)/128.0\n norm = []\n for i, frame in enumerate(buffer):\n if np.shape(frame)[2]!=3:\n print(np.shape(frame))\n frame = (frame - np.array([[[128.0, 128.0, 128.0]]]))/128.0\n buffer[i] = frame\n norm.append(frame)\n # for n in np.array(norm,dtype=\"float32\"):\n # if len(pa.isna(n).nonzero()[1])!=0:\n # cv2.imshow(\"demo\", n)\n # cv2.waitKey(0)\n return np.array(norm,dtype=\"float32\")\n\n def to_tensor(self, buffer,image_position,index):\n # convert from [D, H, W, C] format to [C, D, H, W] (what PyTorch uses)\n # D = Depth (in this case, time), H = Height, W = Width, C = Channels\n if len(np.shape(buffer))!=4:\n print('WRONG:',image_position[index], np.shape(buffer))\n try:\n buffer.transpose([3, 0, 1, 2])\n except:\n print(image_position[index],np.shape(buffer))\n return buffer.transpose([3, 0, 1, 2])\n\n #/home/aiuser/ava_v2.2/preproc/train_clips/clips/cLiJgvrDlWw/1035.mp4\n def loadvideo(self,image_position,index,min_side,max_side,frame_sample_rate,discard):\n formate_key = image_position[index].split('/')[0]\n fname=self.path_to_videos + '/' + image_position[index] + self.data_format[formate_key]\n remainder = np.random.randint(frame_sample_rate)\n # initialize a VideoCapture object to read video data into a numpy array\n capture = cv2.VideoCapture(fname)\n frame_count = int(capture.get(cv2.CAP_PROP_FRAME_COUNT))\n frame_width = int(capture.get(cv2.CAP_PROP_FRAME_WIDTH))\n frame_height = int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT))\n print(\"frame_w,h:\",fname,frame_width,frame_height)\n fps = int(capture.get(cv2.CAP_PROP_FPS))\n #print('fps:',fps,'frame_count:',frame_count)\n #训练时丢弃帧数过少的数据\n if True:\n while frame_count<80 or frame_height==0 or frame_width==0:\n capture.release()\n print('discard_video,frame_num:',frame_count,'dir:',fname,frame_height,frame_width)\n index = np.random.randint(self.__len__())\n formate_key = image_position[index].split('/')[0]\n fname = self.path_to_videos + '/' + image_position[index] + self.data_format[formate_key]\n capture = cv2.VideoCapture(fname)\n frame_count = int(capture.get(cv2.CAP_PROP_FRAME_COUNT))\n frame_width = int(capture.get(cv2.CAP_PROP_FRAME_WIDTH))\n frame_height = int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT))\n #将图片缩放,遵循frcnn方式\n if frame_count<80:\n print(\"fname no:\",fname,frame_width,frame_height,min_side)\n try:\n scale_for_shorter_side = min_side / min(frame_width, frame_height)\n except:\n print(\"fname:\",fname,frame_width,frame_height,min_side)\n if frame_height==0 or frame_width==0:\n print(\"WARNING:SHIT DATA\")\n longer_side_after_scaling = max(frame_width, frame_height) * scale_for_shorter_side\n scale_for_longer_side = (\n max_side / longer_side_after_scaling) if longer_side_after_scaling > max_side else 1\n scale = scale_for_shorter_side * scale_for_longer_side\n resize_height=round(frame_height * scale)\n resize_width=round(frame_width * scale)\n # create a buffer. Must have dtype float, so it gets converted to a FloatTensor by Pytorch later\n start_idx = 0\n end_idx = 0\n frame_keep_count=64\n if frame_count==120:\n start_idx=43\n end_idx=107\n #print(\"120\", start_idx, end_idx)\n if frame_count==100:\n start_idx =30\n end_idx =94\n #print(\"120\", start_idx, end_idx)\n if frame_count==93:\n start_idx =26\n end_idx =90\n #print(\"120\", start_idx, end_idx)\n if frame_count!=120 and frame_count!=100 and frame_count!=93:\n #print(\"warning:without keep keyframe\")\n end_idx=frame_count\n start_idx=end_idx-64-1\n\n buffer = np.zeros((frame_keep_count, resize_height, resize_width, 3), np.dtype('int8'))\n #buffer=[]\n #将数据填入空的buffer\n count = 0\n retaining = True\n sample_count = 0\n # read in each frame, one at a time into the numpy buffer array\n num=0\n while (count <= end_idx and retaining):\n num=num+1\n retaining, frame = capture.read()\n if count <= start_idx:\n count += 1\n continue\n if retaining is False or count>end_idx:\n break\n if count%frame_sample_rate == remainder and sample_count < frame_keep_count:\n frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)\n # will resize frames if not already final size\n if (frame_height != resize_height) or (frame_width != resize_width):\n frame = cv2.resize(frame, (resize_width, resize_height))\n buffer[sample_count] = frame\n #buffer.append(frame)\n sample_count = sample_count + 1\n count += 1\n capture.release()\n # if len(buffer)<64:\n # try:\n # for i in range(64-len(buffer)):\n # temp=buffer[-1]\n # buffer.append(temp)\n # except:\n # print('fail padding',fname)\n #\n # if len(buffer)!=64:\n # print('fail',fname)\n return buffer,scale,index\n\n def evaluate(self, path_to_results_dir: str,all_image_ids, bboxes: List[List[float]], classes: List[int], probs: List[float],img_size) -> Tuple[float, str]:\n self._write_results(path_to_results_dir,all_image_ids, bboxes, classes, probs,img_size)\n ava_val()\n\n def _write_results(self, path_to_results_dir: str, image_ids: List[str], bboxes: List[List[float]],\n classes, probs: List[float],img_size):\n f = open(path_to_results_dir,mode='a+')\n for image_id, bbox, cls, prob in zip(image_ids, bboxes, classes, probs):\n #print(str(image_id.split('/')[0]),str(image_id.split('/')[1]), bbox[0]/int(img_size[1]), bbox[1], bbox[2], bbox[3],(int(cls)+1),prob,img_size[1],int(img_size[0]))\n x1=0 if bbox[0]/int(img_size[1])<0 else bbox[0]/int(img_size[1])\n y1=0 if bbox[1]/int(img_size[0])<0 else bbox[1]/int(img_size[0])\n x2=1 if bbox[2]/int(img_size[1])>1 else bbox[2]/int(img_size[1])\n y2=1 if bbox[3]/int(img_size[0])>1 else bbox[3]/int(img_size[0])\n print(str(image_id.split('/')[0]),str(image_id.split('/')[1]),x1,y1,x2,y2)\n for c,p in zip(cls,prob):\n f.write('{:s},{:s},{:f},{:f},{:f},{:f},{:s},{:s}\\n'.format(str(image_id.split('/')[0]),str(image_id.split('/')[1]), x1, y1, x2, y2,str(c),str(p)))\n f.close()\n\n def index2class(self):\n file_path = '/media/aiuser/78C2F86DC2F830CC1/ava_v2.2/ava_v2.2/ava_action_list_v2.0.csv'\n with open(file_path) as f:\n i2c_dic = {line.split(',')[0]: line.split(',')[1] for line in f}\n return i2c_dic\n\n\n def draw_bboxes_and_show(self,frame,frame_num,bboxes,labels,key_frame_start,key_frame_end,scale=1,probs=[],color=(255, 255, 255)):\n\n if frame_num > key_frame_start and frame_num < key_frame_end:\n count = 0\n count_2=0\n # Capture frame-by-frame\n if len(probs)==0:\n for bbox, lable in zip(bboxes, labels):\n count = count + 1\n bbox = np.array(bbox)\n lable = int(lable)\n real_x_min = int(bbox[0] / scale)\n real_y_min = int(bbox[1] / scale)\n real_x_max = int(bbox[2] / scale)\n real_y_max = int(bbox[3] / scale)\n # 在每一帧上画矩形,frame帧,(四个坐标参数),(颜色),宽度\n cv2.rectangle(frame, (real_x_min, real_y_min), (real_x_max, real_y_max), color, 4)\n cv2.putText(frame, self.i2c_dic[str(lable)], (real_x_min + 30, real_y_min + 15 * count),\n cv2.FONT_HERSHEY_COMPLEX, \\\n 0.5, (255, 255, 0), 1, False)\n else:\n for bbox,lable,prob in zip(bboxes,labels,probs):\n count_2 = count_2 + 1\n bbox=np.array(bbox)\n lable = int(lable)\n prob=float(prob)\n print(\"probs\",probs)\n real_x_min = int(bbox[0]/scale)\n real_y_min = int(bbox[1]/scale)\n real_x_max = int(bbox[2]/scale)\n real_y_max = int(bbox[3]/scale)\n # 在每一帧上画矩形,frame帧,(四个坐标参数),(颜色),宽度\n cv2.rectangle(frame, (real_x_min, real_y_min), (real_x_max, real_y_max), (255, 255, 255), 4)\n cv2.putText(frame, self.i2c_dic[str(lable)]+':'+str(prob), (real_x_min+30 , real_y_min+15*count_2 ), cv2.FONT_HERSHEY_COMPLEX,\\\n 0.5,(255, 255, 0), 1, False)\n\n\n def test(self,item_num,frame_start=0.35,frame_end=0.95):\n for i in range(item_num):\n print(i)\n result=self.__getitem__(i)\n bboxes=result[3]\n labels=result[4]\n _scale=float(result[2])\n print('scale:',_scale)\n print ('bboxes:',bboxes)\n print ('labels:',labels)\n print('dir:',self.path_to_keyframe + '/' + result[0])\n # formate_key = self.image_position[i].split('/')[0]\n # cap = cv2.VideoCapture(self.path_to_videos + '/' + self.image_position[i] + self.data_format[formate_key])\n # frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))\n # key_frame_start = int(frame_count * frame_start)\n # key_frame_end = int(frame_count * frame_end)\n # frame_num = 0\n # while (cap.isOpened()):\n # ret, frame = cap.read()\n # frame_num = frame_num + 1\n # self.draw_bboxes_and_show(frame,frame_num,bboxes,labels,key_frame_start,key_frame_end,scale=_scale)\n # if ret == True:\n # # 显示视频\n # cv2.imshow('Frame', frame)\n # # 刷新视频\n # cv2.waitKey(10)\n # # 按q退出\n # if cv2.waitKey(25) & 0xFF == ord('q'):\n # break\n # else:\n # break\n def imshow(self,item_num,frame_start=0.35,frame_end=0.95):\n for i in range(item_num):\n result=self.__getitem__(i)\n name=result[0]\n real_bboxes=[item.bbox.tolist() for item in self.data_dic_real[name]]\n real_lables=[item.img_class for item in self.data_dic_real[name]]\n probs=result[5]\n print(type(probs[0]))\n kept_indices = list(np.where(np.array(probs) > 0.2))\n bboxes=np.array(result[3])[kept_indices]\n labels=np.array(result[4])[kept_indices]\n probs=np.array(probs)[kept_indices]\n scale=result[2]\n print('scale:',scale)\n print ('bboxes:',real_bboxes)\n print ('labels:',real_lables)\n print('dir:',self.path_to_keyframe + '/' + result[0])\n formate_key = self.image_position[i].split('/')[0]\n cap = cv2.VideoCapture(self.path_to_videos+'/'+self.image_position[i]+self.data_format[formate_key])\n frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))\n key_frame_start = int(frame_count * frame_start)\n key_frame_end = int(frame_count * frame_end)\n frame_num = 0\n while (cap.isOpened()):\n ret, frame = cap.read()\n frame_num = frame_num + 1\n self.draw_bboxes_and_show(frame,frame_num, bboxes, labels, key_frame_start, key_frame_end, scale=scale,probs=probs)\n #self.draw_bboxes_and_show(frame,frame_num, real_bboxes, real_lables, key_frame_start, key_frame_end,color=(255,0,255))\n if ret == True:\n # 显示视频\n cv2.imshow('Frame', frame)\n # 刷新视频\n cv2.waitKey(10)\n # 按q退出\n if cv2.waitKey(25) & 0xFF == ord('q'):\n break\n else:\n break\n\n\n\n\n# if __name__ == '__main__':\n# a=AVA_video(TrainConfig.TRAIN_DATA)\n# a.test(10)\n\nif __name__ == '__main__':\n train_dataloader = \\\n DataLoader(AVA_video(TrainConfig.TRAIN_DATA), batch_size=10, shuffle=True,collate_fn=DatasetBase.padding_collate_fn,num_workers=10)\n for n_iter, (_, image_batch, _, bboxes_batch, labels_batch,detector_bboxes_batch) in enumerate(train_dataloader):\n print(\"n_iter: \", n_iter)"
},
{
"alpha_fraction": 0.5874744653701782,
"alphanum_fraction": 0.6426140069961548,
"avg_line_length": 29.625,
"blob_id": "cdd490dfc8d3958ea3e068e17472150257a45f25",
"content_id": "0bf50db6b74923c25144c6ed0725bbbe4a034a14",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1469,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 48,
"path": "/test_con.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "import torch.nn as nn\nimport torch.tensor as tensor\nimport torch\nimport f\n# import numpy as np\n# loss=nn.CrossEntropyLoss()\n# a=tensor(([2,3],[4,5]),dtype=torch.float)\n# w=tensor(torch.ones(2,1),dtype=torch.float,requires_grad=True)\n# out=torch.mm(a,w)\n# print(out)\n# a=5\n# print(tensor(5,dtype=torch.float))\n# out=torch.mul(out.float(),tensor(5).float())\n# # print(out)\n# # print(tensor([1]).float)\n# sm=nn.Softmax(dim=0)\n# print(out.view(-1))\n# smo=sm(out.view(-1))\n# print(smo)\n# smo=torch.log(smo)\n# loss=nn.NLLLoss()\n# target=tensor([1])\n# loss=loss(smo.unsqueeze(0),target)\n# print(loss)\n# loss.backward()\n# print(w.grad.data)\n\ndef test_grad():\n input=tensor(([1,2,3],[4,5,6],[7,8,9]),dtype=torch.float)\n #weight=tensor(([0.1,0.2,0.3,0.4],[0.1,0.2,0.3,0.4],[0.1,0.2,0.3,0.4]),requires_grad=True)\n weight=tensor(torch.rand(3, 4),requires_grad=True)\n #input=input.unsqueeze(0)\n print(input,weight)\n pre=torch.mm(input,weight)\n #loss1=f.multilabel_soft_margin_loss()\n loss2=nn.MultiLabelMarginLoss()\n lable1=tensor(([0, 1, 1,0],),dtype=torch.float)\n lable2 = tensor(([0, 1, 1,0], [1, 0, 0,0], [1, 0,1 ,1]), dtype=torch.long)\n print(pre,lable1)\n loss1=f.multilabel_soft_margin_loss(pre,lable1,reduction='sum')\n loss1.backward()\n print('weight.grad.data1:',weight.grad.data)\n\n # loss2 = loss2(pre, lable2)\n # loss2.backward()\n # print('weight.grad.data2:', weight.grad.data)\nif __name__ == '__main__':\n test_grad()"
},
{
"alpha_fraction": 0.6023706793785095,
"alphanum_fraction": 0.6767241358757019,
"avg_line_length": 30.89655113220215,
"blob_id": "90aa5f24230b0b42dbc44a8dbe5aec46e9224681",
"content_id": "6a49f6e82d6ddea0bc465c40ed662125fb2d472c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 928,
"license_type": "permissive",
"max_line_length": 127,
"num_lines": 29,
"path": "/config/train_config.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "import ast\nfrom typing import List, Tuple\n\nfrom config.config import Config\n\n\nclass TrainConfig(Config):\n\n RPN_PRE_NMS_TOP_N= 12000\n RPN_POST_NMS_TOP_N = 2000\n ANCHOR_SMOOTH_L1_LOSS_BETA = 1.0\n PROPOSAL_SMOOTH_L1_LOSS_BETA = 1.0\n\n BATCH_SIZE=2 # defaul\n LEARNING_RATE = 0.0001\n MOMENTUM = 0.9\n WEIGHT_DECAY = 0.0005\n STEP_LR_SIZES = [90000,180000]\n STEP_LR_GAMMA = 0.1\n WARM_UP_FACTOR = 0.3333\n WARM_UP_NUM_ITERS = 500\n NUM_STEPS_TO_DISPLAY = 20\n NUM_STEPS_TO_SNAPSHOT = 2000 #20000\n NUM_STEPS_TO_FINISH = 222670\n GPU_OPTION = '2'\n TRAIN_DATA='/home/gan/data/video_caption_database/video_database/ava/preproc_train/backup/ava_train_removebadlist_v2.2.csv'\n\n PATH_TO_RESUMEING_CHECKPOINT = None # '/home/ganhaiyang/dataset/ava/ava_weights/slowfast_weight.pth'\n PATH_TO_OUTPUTS_DIR = '/home/gan/home/ganhaiyang/Alg_Proj/Recog_Proj/TSM-Detection/output'\n\n\n\n"
},
{
"alpha_fraction": 0.6508474349975586,
"alphanum_fraction": 0.7129943370819092,
"avg_line_length": 48.11111068725586,
"blob_id": "2e09bf0c2e3d12b78277ce2dc9c50d4a446d5ff8",
"content_id": "d719e78e314be9d433a0aa88375dcd57b268687a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 885,
"license_type": "permissive",
"max_line_length": 174,
"num_lines": 18,
"path": "/config/eval_config.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "from typing import List, Tuple\nfrom config.config import Config\n\n\nclass EvalConfig(Config):\n\n RPN_PRE_NMS_TOP_N = 6000\n RPN_POST_NMS_TOP_N = 300\n VAL_DATA='/home/ganhaiyang/output/ava/ava_val_removebadlist_v2.2.csv' #ava_train_v2.2_sub_5.txt\n PATH_TO_CHECKPOINT='/home/ganhaiyang/dataset/ava/ava_weights/slowfast_weight.pth' #'/home/ganhaiyang/output/ava/temp_4/model_save/2019-12-10-19-37-43/model-20000.pth'\n PATH_TO_RESULTS='result-slowfast-rm.txt'\n PATH_TO_EXCLUSIONS='ava_val_excluded_timestamps_v2.2.csv'\n # PATH_TO_ACTION_LIST='ava_action_list_v2.2.pbtxt'\n PATH_TO_ACTION_LIST='ava_action_list_v2.2_for_activitynet_2019.pbtxt'\n # PATH_TO_LABLE='/home/ganhaiyang/dataset/ava/preproc_fallDown/ava_v1.0_extend_annot.csv' #'ava_train_v2.2_sub_5.txt'\n PATH_TO_LABLE='ava_val_removebadlist_v2.2.csv' #'ava_train_v2.2_sub_5.txt'\n\n KEEP=0.05\n\n"
},
{
"alpha_fraction": 0.5536854267120361,
"alphanum_fraction": 0.5717418193817139,
"avg_line_length": 47.16149139404297,
"blob_id": "351ae4e0c090b84d366394e6f0d6676ff5f445e2",
"content_id": "9b4a6d1c700027b7d12ccd712b758bdfb53fe06d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15715,
"license_type": "permissive",
"max_line_length": 175,
"num_lines": 322,
"path": "/dataset/AVA_video_OLD.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "import os\nimport numpy as np\nimport torch.utils.data\nfrom PIL import Image, ImageOps\nfrom bbox import BBox\nfrom typing import Tuple, List, Type, Iterator\nimport matplotlib.pyplot as plt\nimport PIL\nimport torch.utils.data.dataset\nimport torch.utils.data.sampler\nfrom PIL import Image\nfrom torch import Tensor\nfrom torchvision.transforms import transforms\nimport cv2\nfrom torch.utils.data import DataLoader, Dataset\nfrom torchvision.transforms import transforms\nfrom dataset.base import Base as DatasetBase\nfrom get_ava_performance import ava_val\nfrom config.config import Config\nfrom config.eval_config import EvalConfig\nfrom config.train_config import TrainConfig\nclass AVA_video(Dataset):\n\n class info():\n def __init__(self, img_class, bbox,h,w,img_position):\n self.img_class = int(img_class)\n self.bbox = bbox\n self.height=h\n self.weight=w\n self.img_position=img_position\n def __repr__(self):\n return 'info[img_class={0}, bbox={1}]'.format(\n self.img_class, self.bbox)\n\n\n def __init__(self,mode):\n self.bboxes=[]\n self.labels=[]\n self.image_ratios = []\n self.image_position=[]\n self.widths=[]\n self.heights=[]\n\n\n\n self.data_dic = {}\n self.data_size={}\n self.data_format={}\n self.path_to_data_dir='/home/aiuser/'\n path_to_AVA_dir = os.path.join(self.path_to_data_dir, 'ava_v2.2', 'preproc','train_clips')\n self.path_to_videos = os.path.join(path_to_AVA_dir, 'clips')\n self.path_to_keyframe = os.path.join(path_to_AVA_dir, 'keyframes')\n path_to_video_ids_txt = os.path.join(path_to_AVA_dir, TrainConfig.TRAIN_DATA)\n #测试时时加载这个文件,用里面的数据送入forward\n if mode=='val':\n #path_to_video_ids_txt='/home/aiuser/ava_v2.2/val.txt'\n path_to_video_ids_txt = os.path.join(path_to_AVA_dir, EvalConfig.VAL_DATA)\n #得到每个视频的大小,通过读取第一张keyframe\n for frame in sorted(os.listdir(self.path_to_keyframe)):\n img=os.listdir(os.path.join(self.path_to_keyframe, frame))[0]\n img=cv2.imread(os.path.join(self.path_to_keyframe, frame,img))\n img_shape=img.shape\n self.data_size[frame]=(img_shape[0],img_shape[1])\n # 得到每个视频的格式\n for video in sorted(os.listdir(self.path_to_videos)):\n video_0 = os.listdir(os.path.join(self.path_to_videos, video))[0]\n self.data_format[video]='.'+video_0.split('.')[1]\n\n print('data_format',self.data_format)\n #读取文件,key是文件名(aa/0930)\n with open(path_to_video_ids_txt, 'r') as f:\n data = f.readlines()\n for line in data:\n content = line.split(',')\n key=content[0]+\"/\"+str(int(content[1]))\n img_h=int(self.data_size[content[0]][0])\n img_w = int(self.data_size[content[0]][1])\n if key not in self.data_dic:\n self.data_dic[key] = [AVA_video.info(content[6],BBox( # convert to 0-based pixel index\n left=float(content[2])*img_w - 1,\n top=float(content[3])*img_h - 1,\n right=float(content[4])*img_w - 1,\n bottom=float(content[5])*img_h - 1),img_h,img_w,key)]\n else:\n self.data_dic[key].append(AVA_video.info(content[6], BBox( # convert to 0-based pixel index\n left=float(content[2]) * img_w - 1,\n top=float(content[3]) * img_h - 1,\n right=float(content[4]) * img_w - 1,\n bottom=float(content[5]) * img_h - 1), img_h, img_w, key))\n # print('data_dic:',self.data_dic)\n #对字典中的数据进行整理,变成list的形式\n for key in self.data_dic:\n self.bboxes.append([item.bbox.tolist() for item in self.data_dic[key]])\n self.labels.append([item.img_class for item in self.data_dic[key]])\n width = int(self.data_dic[key][0].weight)\n self.widths.append(width)\n height = int(self.data_dic[key][0].height)\n self.heights.append(height)\n ratio = float(width / height)\n self.image_ratios.append(ratio)\n self.image_position.append(self.data_dic[key][0].img_position)\n #warning!!! return len(self.bboxes)\n def __len__(self) -> int:\n return len(self.image_position)\n\n def num_classes(self):\n return 81\n\n def __getitem__(self, index: int) -> Tuple[str, Tensor, Tensor, Tensor, Tensor]:\n buffer, scale,index = self.loadvideo(self.image_position, index, Config.IMAGE_MIN_SIDE, Config.IMAGE_MAX_SIDE, 1)\n bboxes = torch.tensor(self.bboxes[index], dtype=torch.float)\n labels = torch.tensor(self.labels[index], dtype=torch.long)\n #image = Image.open(self.path_to_keyframe+'/'+self.image_position[index]+\".jpg\")\n buffer = self.normalize(buffer)\n buffer = self.to_tensor(buffer)\n buffer=torch.tensor(buffer, dtype=torch.float)\n scale = torch.tensor(scale, dtype=torch.float)\n bboxes *= scale\n return self.image_position[index], buffer, scale, bboxes, labels,(self.heights[index],self.widths[index])\n\n def normalize(self, buffer):\n # Normalize the buffer\n # buffer = (buffer - 128)/128.0\n for i, frame in enumerate(buffer):\n frame = (frame - np.array([[[128.0, 128.0, 128.0]]]))/128.0\n buffer[i] = frame\n return buffer\n def to_tensor(self, buffer):\n # convert from [D, H, W, C] format to [C, D, H, W] (what PyTorch uses)\n # D = Depth (in this case, time), H = Height, W = Width, C = Channels\n return buffer.transpose((3, 0, 1, 2))\n\n def load_val_video(self,image_position,index,min_side,max_side,frame_sample_rate):\n formate_key = image_position[index].split('/')[0]\n fname = self.path_to_videos + '/' + image_position[index] + self.data_format[formate_key]\n remainder = np.random.randint(frame_sample_rate)\n # initialize a VideoCapture object to read video data into a numpy array\n capture = cv2.VideoCapture(fname)\n frame_count = int(capture.get(cv2.CAP_PROP_FRAME_COUNT))\n frame_width = int(capture.get(cv2.CAP_PROP_FRAME_WIDTH))\n frame_height = int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT))\n\n scale_for_shorter_side = min_side / min(frame_width, frame_height)\n longer_side_after_scaling = max(frame_width, frame_height) * scale_for_shorter_side\n scale_for_longer_side = (\n max_side / longer_side_after_scaling) if longer_side_after_scaling > max_side else 1\n scale = scale_for_shorter_side * scale_for_longer_side\n resize_height = round(frame_height * scale)\n resize_width = round(frame_width * scale)\n # create a buffer. Must have dtype float, so it gets converted to a FloatTensor by Pytorch later\n start_idx = 0\n end_idx = frame_count - 1\n frame_count_sample = frame_count // frame_sample_rate - 1\n if frame_count > 300:\n end_idx = np.random.randint(300, frame_count)\n start_idx = end_idx - 300\n frame_count_sample = 301 // frame_sample_rate - 1\n buffer = np.empty((frame_count_sample, resize_height, resize_width, 3), np.dtype('float32'))\n count = 0\n retaining = True\n sample_count = 0\n # read in each frame, one at a time into the numpy buffer array\n num = 0\n while (count <= end_idx and retaining):\n num = num + 1\n retaining, frame = capture.read()\n if count < start_idx:\n count += 1\n continue\n if retaining is False or count > end_idx:\n break\n if count % frame_sample_rate == remainder and sample_count < frame_count_sample:\n frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)\n # will resize frames if not already final size\n if (frame_height != resize_height) or (frame_width != resize_width):\n frame = cv2.resize(frame, (resize_width, resize_height))\n buffer[sample_count] = frame\n sample_count = sample_count + 1\n count += 1\n capture.release()\n return buffer, scale\n\n #/home/aiuser/ava_v2.2/preproc/train_clips/clips/cLiJgvrDlWw/1035.mp4\n def loadvideo(self,image_position,index,min_side,max_side,frame_sample_rate):\n formate_key = image_position[index].split('/')[0]\n fname=self.path_to_videos + '/' + image_position[index] + self.data_format[formate_key]\n remainder = np.random.randint(frame_sample_rate)\n # initialize a VideoCapture object to read video data into a numpy array\n capture = cv2.VideoCapture(fname)\n frame_count = int(capture.get(cv2.CAP_PROP_FRAME_COUNT))\n frame_width = int(capture.get(cv2.CAP_PROP_FRAME_WIDTH))\n frame_height = int(capture.get(cv2.CAP_PROP_FRAME_HEIGHT))\n\n while frame_count<80:\n print('discard_video,frame_num:',frame_count,'dir:',fname)\n index = np.random.randint(self.__len__())\n formate_key = image_position[index].split('/')[0]\n fname = self.path_to_videos + '/' + image_position[index] + self.data_format[formate_key]\n capture = cv2.VideoCapture(fname)\n frame_count = int(capture.get(cv2.CAP_PROP_FRAME_COUNT))\n\n scale_for_shorter_side = min_side / min(frame_width, frame_height)\n longer_side_after_scaling = max(frame_width, frame_height) * scale_for_shorter_side\n scale_for_longer_side = (\n max_side / longer_side_after_scaling) if longer_side_after_scaling > max_side else 1\n scale = scale_for_shorter_side * scale_for_longer_side\n resize_height=round(frame_height * scale)\n resize_width=round(frame_width * scale)\n # create a buffer. Must have dtype float, so it gets converted to a FloatTensor by Pytorch later\n start_idx = 0\n end_idx = frame_count-1\n frame_count_sample = frame_count // frame_sample_rate - 1\n if frame_count>=80:\n start_idx = frame_count - 80\n frame_count_sample = 81 // frame_sample_rate - 1\n buffer = np.empty((frame_count_sample, resize_height, resize_width, 3), np.dtype('float32'))\n count = 0\n retaining = True\n sample_count = 0\n # read in each frame, one at a time into the numpy buffer array\n num=0\n while (count <= end_idx and retaining):\n num=num+1\n retaining, frame = capture.read()\n if count < start_idx:\n count += 1\n continue\n if retaining is False or count>end_idx:\n break\n if count%frame_sample_rate == remainder and sample_count < frame_count_sample:\n frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)\n # will resize frames if not already final size\n if (frame_height != resize_height) or (frame_width != resize_width):\n frame = cv2.resize(frame, (resize_width, resize_height))\n buffer[sample_count] = frame\n sample_count = sample_count + 1\n count += 1\n capture.release()\n #print('num_pic',num)\n return buffer,scale,index\n\n def evaluate(self, path_to_results_dir: str, image_ids: List[str], bboxes: List[List[float]], classes: List[int], probs: List[float],img_size) -> Tuple[float, str]:\n self._write_results(path_to_results_dir, image_ids, bboxes, classes, probs,img_size)\n ava_val()\n\n def _write_results(self, path_to_results_dir: str, image_ids: List[str], bboxes: List[List[float]],\n classes: List[int], probs: List[float],img_size):\n f = open(path_to_results_dir,mode='a+')\n for image_id, bbox, cls, prob in zip(image_ids, bboxes, classes, probs):\n #print(str(image_id.split('/')[0]),str(image_id.split('/')[1]), bbox[0]/int(img_size[1]), bbox[1], bbox[2], bbox[3],(int(cls)+1),prob,img_size[1],int(img_size[0]))\n x1=0 if bbox[0]/int(img_size[1])<0 else bbox[0]/int(img_size[1])\n y1=0 if bbox[1]/int(img_size[0])<0 else bbox[1]/int(img_size[0])\n x2=1 if bbox[2]/int(img_size[1])>1 else bbox[2]/int(img_size[1])\n y2=1 if bbox[3]/int(img_size[0])>1 else bbox[3]/int(img_size[0])\n print(str(image_id.split('/')[0]),str(image_id.split('/')[1]),x1,y1,x2,y2)\n f.write('{:s},{:s},{:f},{:f},{:f},{:f},{:s},{:f}\\n'.format(str(image_id.split('/')[0]),str(image_id.split('/')[1]), x1, y1, x2, y2,str(cls),prob))\n f.close()\n\n\n\n def index2class(self):\n file_path = '/home/aiuser/ava_v2.2/ava_v2.2/ava_action_list_v2.0.csv'\n with open(file_path) as f:\n i2c_dic = {line.split(',')[0]: line.split(',')[1] for line in f}\n return i2c_dic\n\n def test(self,item_num):\n i2c_dic=self.index2class()\n for i in range(item_num):\n result=self.__getitem__(i)\n bboxes=result[3]\n labels=result[4]\n scale=result[2]\n print('scale:',scale)\n print ('bboxes:',bboxes)\n print ('labels:',labels)\n print('dir:',self.path_to_keyframe + '/' + result[0])\n formate_key = self.image_position[i].split('/')[0]\n cap = cv2.VideoCapture(self.path_to_videos+'/'+self.image_position[i]+self.data_format[formate_key])\n frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))\n key_frame_start=int(frame_count*0.35)\n key_frame_end =int(frame_count*0.95)\n frame_num=0\n while (cap.isOpened()):\n ret, frame = cap.read()\n frame_num=frame_num+1\n if frame_num>key_frame_start and frame_num<key_frame_end:\n count = 0\n # Capture frame-by-frame\n for bbox,lable in zip(bboxes,labels):\n count = count + 1\n bbox=np.array(bbox)\n lable = int(lable)\n real_x_min = int(bbox[0]/scale)\n real_y_min = int(bbox[1]/scale)\n real_x_max = int(bbox[2]/scale)\n real_y_max = int(bbox[3]/scale)\n # 在每一帧上画矩形,frame帧,(四个坐标参数),(颜色),宽度\n cv2.rectangle(frame, (real_x_min, real_y_min), (real_x_max, real_y_max), (255, 255, 255), 4)\n cv2.putText(frame, i2c_dic[str(lable)], (real_x_min+30 , real_y_min+15*count ), cv2.FONT_HERSHEY_COMPLEX,\\\n 0.5,(255, 255, 0), 1, False)\n if ret == True:\n # 显示视频\n cv2.imshow('Frame', frame)\n # 刷新视频\n cv2.waitKey(10)\n # 按q退出\n if cv2.waitKey(25) & 0xFF == ord('q'):\n break\n else:\n break\n\n\n# if __name__ == '__main__':\n# a=AVA_video(mode='val')\n# a.test(10)\n\nif __name__ == '__main__':\n train_dataloader = \\\n DataLoader(AVA_video(mode=\"train\"), batch_size=2, shuffle=True,collate_fn=DatasetBase.padding_collate_fn,num_workers=1,)\n for image_position, buffer, scale, bboxes, labels,(height,widths) in enumerate(train_dataloader):\n print(height,height)"
},
{
"alpha_fraction": 0.49641549587249756,
"alphanum_fraction": 0.5252377390861511,
"avg_line_length": 55.49586868286133,
"blob_id": "a2e83209b4d6d0173790abb0f5ab954f39a7849c",
"content_id": "1d9fdfdee9384135b9377acb8f6d066592816ddf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6961,
"license_type": "permissive",
"max_line_length": 174,
"num_lines": 121,
"path": "/evaluator.py",
"repo_name": "Morgan-Gan/SLowFastMc-TSM",
"src_encoding": "UTF-8",
"text": "from typing import Tuple\nimport torch\nfrom torch.utils.data import DataLoader\nfrom tqdm import tqdm\nfrom dataset.base import Base as DatasetBase\nfrom model import Model\nimport cv2\nimport numpy as np\nclass Evaluator(object):\n def __init__(self, dataset: DatasetBase, path_to_results_dir: str):\n super().__init__()\n self._dataset = dataset\n self._dataloader = DataLoader(dataset, batch_size=1, shuffle=False, num_workers=11, pin_memory=True)\n self._path_to_results_dir = path_to_results_dir\n\n def evaluate(self, model: Model) -> Tuple[float, str]:\n all_image_ids, all_detection_bboxes, all_detection_classes, all_detection_probs = [], [], [], []\n with torch.no_grad():\n for _, (image_posision, image_batch, scale, _, _,detector_bboxes,img_size) in enumerate(tqdm(self._dataloader)):\n image_batch = image_batch.cuda()\n assert image_batch.shape[0] == 1, 'do not use batch size more than 1 on evaluation'\n detection_bboxes, detection_classes, detection_probs = \\\n model.eval().forward(image_batch,detector_bboxes_batch=detector_bboxes)\n scale = scale[0]\n detection_bboxes[:,[0,2]] /= scale[0]\n detection_bboxes[:,[1,3]] /= scale[1]\n if not len(detection_bboxes.tolist())==len(detection_classes)==len(detection_probs):\n print(\"%%%%\",(np.round(detection_bboxes.tolist(),2)))\n print(image_posision)\n print(detection_classes)\n print(detection_probs)\n print(detector_bboxes)\n #千万小心确认这里\n assert len(detection_bboxes.tolist()) == len(detection_classes) == len(detection_probs)\n all_detection_bboxes.append(detection_bboxes.tolist())\n # print(\"wait_write:\",detection_bboxes.tolist())\n all_detection_classes.append(detection_classes)\n all_detection_probs.append(detection_probs)\n assert len(image_posision)==1\n all_image_ids.append(image_posision[0])\n self._write_results(self._path_to_results_dir,[image_posision[0]], [detection_bboxes.tolist()], [detection_classes], [detection_probs],img_size)\n mean_ap, detail = self._dataset.evaluate(self._path_to_results_dir,all_image_ids, all_detection_bboxes, all_detection_classes, all_detection_probs,img_size)\n # mean_ap, detail = self._dataset.evaluate(self._path_to_results_dir,[image_posision[0]], [detection_bboxes.tolist()], [detection_classes],[detection_probs],img_size)\n print(\"mean_ap:\",mean_ap) #, detail\n return mean_ap , detail\n\n def _write_results(self, path_to_results_dir, image_ids, bboxes, classes, probs,img_size):\n f = open(path_to_results_dir,mode='a+')\n f1=open(path_to_results_dir+'1',mode='a+')\n f2 = open(path_to_results_dir + '2', mode='a+')\n for image_id, _bbox, _cls, _prob in zip(image_ids, bboxes, classes, probs):\n assert len(_bbox) == len(_cls) == len(_prob)\n for bbox, cls, prob in zip(_bbox, _cls, _prob):\n x1=0 if bbox[0]/int(img_size[1])<0 else bbox[0]/int(img_size[1])\n y1=0 if bbox[1]/int(img_size[0])<0 else bbox[1]/int(img_size[0])\n x2=1 if bbox[2]/int(img_size[1])>1 else bbox[2]/int(img_size[1])\n y2=1 if bbox[3]/int(img_size[0])>1 else bbox[3]/int(img_size[0])\n\n for c,p in zip(cls,prob):\n f.write('{:s},{:s},{:f},{:f},{:f},{:f},{:s},{:s}\\n'.format(str(image_id.split('/')[0]),str(image_id.split('/')[1]), x1, y1, x2, y2,str(c),str(p)))\n if p>0.1:\n f1.write('{:s},{:s},{:f},{:f},{:f},{:f},{:s},{:s}\\n'.format(str(image_id.split('/')[0]),str(image_id.split('/')[1]), x1, y1, x2, y2,str(c),str(p)))\n if p>0.2:\n f2.write('{:s},{:s},{:f},{:f},{:f},{:f},{:s},{:s}\\n'.format(str(image_id.split('/')[0]),str(image_id.split('/')[1]), x1, y1, x2, y2,str(c),str(p)))\n f.close()\n\n def index2class(self):\n # file_path = '/media/aiuser/78C2F86DC2F830CC1/ava_v2.2/ava_v2.2/ava_action_list_v2.0.csv'\n file_path = '/data/video_caption_database/ava/ava/preproc_train/ava_action_list_v2.0.csv'\n with open(file_path) as f:\n i2c_dic = {line.split(',')[0]: line.split(',')[1] for line in f}\n return i2c_dic\n\n def draw_bboxes_and_show(self,frame,bboxes,labels,probs=[],color=(255, 255, 255)):\n i2c_dic=self.index2class()\n if len(probs)==0:\n for bbox, lable in zip(bboxes, labels):\n bbox = np.array(bbox)\n real_x_min = int(bbox[0])\n real_y_min = int(bbox[1])\n real_x_max = int(bbox[2])\n real_y_max = int(bbox[3])\n # 在每一帧上画矩形,frame帧,(四个坐标参数),(颜色),宽度\n cv2.rectangle(frame, (real_x_min, real_y_min), (real_x_max, real_y_max), color, 4)\n count=0\n for l in lable:\n cv2.putText(frame, i2c_dic[str(l)], (real_x_min + 30, real_y_min + 15 * count),\n cv2.FONT_HERSHEY_COMPLEX, \\\n 0.5, (255, 255, 0), 1, False)\n else:\n for bbox,lable,prob in zip(bboxes,labels,probs):\n bbox=np.array(bbox)\n #print(\"probs\",prob)\n real_x_min = int(bbox[0])\n real_y_min = int(bbox[1])\n real_x_max = int(bbox[2])\n real_y_max = int(bbox[3])\n # 在每一帧上画矩形,frame帧,(四个坐标参数),(颜色),宽度\n count_2=0\n for l,p in zip(lable,prob):\n cv2.rectangle(frame, (real_x_min, real_y_min), (real_x_max, real_y_max), (255, 255, 255), 4)\n cv2.putText(frame, i2c_dic[str(l)]+':'+str(round(float(p),2)), (real_x_min+30 , real_y_min+15*count_2 ), cv2.FONT_HERSHEY_COMPLEX,\\\n 0.5,(255, 255, 0), 1, False)\n count_2+=1\n\n def imshow(self,bbox,cls,probs):\n #print(\"bbox \",bbox)\n cap = cv2.VideoCapture(\"/media/aiuser/78C2F86DC2F830CC1/ava_v2.2/preproc/train_clips/clips/b5pRYl_djbs/986.mp4\")\n while (cap.isOpened()):\n ret, frame = cap.read()\n self.draw_bboxes_and_show(frame, bbox, cls,probs=probs)\n if ret == True:\n # 显示视频\n cv2.imshow('Frame', frame)\n # 刷新视频\n cv2.waitKey(0)\n # 按q退出\n if cv2.waitKey(25) & 0xFF == ord('q'):\n break\n else:\n break"
}
] | 31 |
michealdunne14/RegressionAssign
|
https://github.com/michealdunne14/RegressionAssign
|
e4fda63cbd52b89b6d91b654c6d9e0daabd84223
|
aa8b1ba326c24d5791a21e3ee8cfb251aa7a1f81
|
964bfd3cb0457cc6e33e858067740ad0d5826f45
|
refs/heads/master
| 2020-09-02T19:12:36.353437 | 2019-10-14T16:15:26 | 2019-10-14T16:15:26 | 219,286,862 | 4 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.670242428779602,
"alphanum_fraction": 0.6981053352355957,
"avg_line_length": 29.76991081237793,
"blob_id": "9b386a25898577222115f064930a987490be904b",
"content_id": "191cee8a58818480b1790917adce1a08f740f055",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7178,
"license_type": "no_license",
"max_line_length": 226,
"num_lines": 226,
"path": "/main.py",
"repo_name": "michealdunne14/RegressionAssign",
"src_encoding": "UTF-8",
"text": "import pandas as pd\r\nimport numpy as np\r\nimport pymysql\r\nimport pymysql.cursors\r\n\r\n#Step 1\r\n#Import CSV File\r\ndef importCSVFile(csvFile):\r\n\t#Reads CSV File\r\n\treturn csvFile\r\n\r\n#Step 2\r\n#Clean Information Date \r\ndef cleanseInformationDate(csvFile,csvFileyear):\r\n\t#sort by date of the CSV file\r\n\t# print(cleaningdate.unique())\r\n\t\r\n\t# Q1\r\n\t# Not all the data comes with the same date format. \r\n\t# Q2\r\n\t# These are the three formats that are used yyyy-mm-dd,dd-mm-yyyy and dd/mm\r\n\t# One with a slash divider and no year and one a hiphan divider.\r\n\t# There is 169 of the format dd/mm and yyyy-mm-dd equals 8787 and dd-mm-yyyy is equals 169\r\n\r\n\t# Q3\r\n\t# There are 230 in total \r\n\tprint(len(csvFile))\r\n\t# df1.merge(csvFile[csvFile.str.contains(\"\\d{2}/\\d{2}\", regex=True)])\r\n\tprint(csvFile)\r\n\t# print(\"length\")\r\n\t# print(len(csvFile[csvFile.str.contains(\"\\d{2}/\\d{2}\", regex=True)]))\r\n\t# print(len(csvFile[csvFile.str.contains(\"\\d{4}-\\d{2}-\\d{2}\", regex=True)]))\r\n\t# print(len(csvFile[csvFile.str.contains(\"\\d{2}-\\d{2}-\\d{4}\", regex=True)]))\r\n\t\r\n\r\n\tcsvFile = pd.to_datetime(csvFile,\"coerce\")\r\n\t#Drop all the null values\r\n\tcsvFile = csvFile.dropna()\r\n\t#Print out the CSV files\r\n\t# cleaningdate = len(cleaningdate.unique())\r\n\t# print(cleaningdate)\r\n\treturn csvFile\r\n\r\n#Step 3\r\ndef cleanseInFormationType(csvFile):\r\n\t# Q1\r\n\t# There are 2 genuine categories with 'conventional' and 'organic' with 'Org.' being an odd value.\r\n\r\n\t# Q2\r\n\t# There is one category called 'Org.' which means organic. So this can be changed to organic. \r\n\r\n\t# Q3 \r\n\t# The amount of entries that have errors are 169.\r\n\t# print(cleaningtype.unique())\r\n\r\n\t#Gets the amount of values that begin with Org. which is 169\r\n\tinvalidValues = len(csvFile[csvFile == \"Org.\"])\r\n\t# print(invalidValues)\r\n\t#Updates Org. to now be organic \r\n\tcsvFile[csvFile.str.contains(\"Org.\", regex=True)] = \"organic\"\r\n\t# print(csvFile.unique())\r\n\tcountingOrg = len(csvFile[csvFile == \"Org.\"])\r\n\t#When printing out this value it is 0 which means that it updated. \r\n\t#print(countingOrg)\r\n\treturn csvFile\r\n\r\n#Step 4\r\ndef cleanseAveragePrice(csvFile):\r\n\t# Q1 \r\n\t# There are 20 values with missing values.\r\n\r\n\t# Q2\r\n\t# There are 30 entries that have erroneous string-based representation \r\n\r\n\t# expectedValuenan = csvFile.isnull().sum()\r\n\t# print(expectedValuenan)\r\n\t#Drops all Null values \r\n\tcsvFile = csvFile.dropna()\r\n\t#Counts all values where a string contains a comma \r\n\tcountcommas = len(csvFile[csvFile.str.contains(\",\",regex=True)])\r\n\t# countcommas = cleaningprice[cleaningprice.str.contains(\",\", regex=True)]\r\n\t# print(countcommas)\r\n\r\n\t#Updates the comma to be a full stop \r\n\tcsvFile = csvFile.str.replace(\",\",\".\")\r\n\tpd.to_numeric(csvFile);\r\n\tcsvFile = csvFile.dropna()\r\n\t# print(csvFile.unique())\r\n\treturn csvFile\r\n\r\n#Step 6\r\ndef ImportMySQL():\r\n\tconnection = pymysql.connect(host=\"localhost\",user=\"username\",password=\"password\",db=\"BSCY4\")\r\n\tframe = pd.read_sql(\"select * from AVOCADO\",connection)\r\n\treturn frame\r\n\r\n#Step 7\r\ndef cleanseRegion(SQLImport):\r\n\t# Q1\r\n\t# All the regions are represented in one word.\r\n\r\n\t# Q2 \r\n\t# There are 57 different regions. \r\n\r\n\t# Q3 \r\n\t# The total number of Invalid regions is 149\r\n\r\n\t#Check which regions are unique\r\n\tdifferentregions = SQLImport.unique()\r\n\t# print(differentregions)\r\n\t#check the length of the different regions \r\n\t#result is 57\r\n\t# print(len(differentregions))\r\n\t#Updates value where the region contains a \"-\" which the count is 80 \r\n\tcountinvalidregion = len(SQLImport[SQLImport.str.contains(\"-\",regex=True)])\r\n\t# print(countinvalidregion)\r\n\tSQLImport = SQLImport.str.replace(\"-\",\" \")\r\n\t# Removes spaces before regions and after regions which is 69\r\n\tcountinvalidregion = len(SQLImport[SQLImport.str.contains(\" \",regex=True)])\r\n\t# print(countinvalidregion)\r\n\tSQLImport = SQLImport.str.replace(\" \", \"\")\r\n\treturn SQLImport\r\n\r\n#Step 8\r\ndef cleanseYear(SQLImport):\r\n\t# Q1\r\n\t# There are fours years represented with 2018 been used twice\r\n\r\n\t# Q2 \r\n\t# Some of the years dont have the 20 before the year. e.g So the year is represented like this 17.\r\n\r\n\t# Q3\r\n\t# The amount of rows that are affected is 3208\r\n\t# Gets every unique year \r\n\tuniqueyears = SQLImport.unique()\r\n\t# Prints out each unique year and gets the length of it which is 5 \r\n\t# print(uniqueyears)\r\n\t# Replaces the year 17 with 2017 and replaces the year 18 with 2018 \r\n\treplaceyears = SQLImport.replace({17: 2017, 18: 2018})\r\n\t# print(replaceyears.unique())\r\n\t# Counting the total number of times 17 and 18 occurs which is 3208\r\n\tcount17 = len(SQLImport[SQLImport == 17])\r\n\tcount18 = len(SQLImport[SQLImport == 18])\r\n\ttotal = count17 + count18\r\n\t# print(total)\r\n\r\n#Step 9\r\ndef cleanseType(SQLImport):\r\n\t# Q1\r\n\t# The type of avocado that is represented is Conventional\r\n\r\n\t# Q2 \r\n\t# Some of the conventional have uppercase.\r\n\r\n\t# Q3 \r\n\t# There is 169 rows affected with Uppercase for the first letter.\r\n\r\n\t# Gets the unique types which is 2 \r\n\tuniquetype = SQLImport.unique()\r\n\t# print(uniquetype)\r\n\r\n\t# Some of the Conventional text is uppercase. I changed it to all be lowercase\r\n\tSQLImport = SQLImport.replace({\"Conventional\": \"conventional\"})\r\n\t# print(SQLImport.unique())\r\n\r\n\r\n\t# The total number of types with caps on is 169\r\n\t# count = len(SQLImport[SQLImport == \"Conventional\"])\r\n\t# print(count)\r\n\treturn SQLImport\r\n\r\n#Step 10 \r\ndef visualInspection(importCSV,importSQL):\r\n\t# Q1\r\n\t# The two data frames are suitable for consolidation.\r\n\r\n\t# Q2\r\n\t# There is a column called Unnamed in CSV that does not exist in SQL.\r\n\t# The Column TotalValue in CSV is called Total Volume in the SQL.\r\n\t# The Columns 4046,4770 and 4225 in the CSV is called c4046,c4770 and c4225 in the SQL.\r\n\t# The columns Small Bags, Large Bags, XLarge Bags all have spaces before the word Bags\r\n\r\n\t# Q3\r\n\timportCSV = importCSV.drop(\"Unnamed: 0\",axis=1)\r\n\t# print(importCSV.columns)\r\n\r\n\ttest = importCSV.rename(columns={'Total Volume':'TotalValue','4046':'c4046','4225':'c4225','4770':'c4770','Small Bags':'SmallBags','Large Bags':'LargeBags','XLarge Bags':'XLargeBags','Total Bags':'TotalBags'}, errors=\"raise\")\r\n\t# print(test)\r\n\t# print(importSQL)\r\n\r\n\t# Step 11\t\r\n\t# Q1\r\n\t# Outer is what we need. This keeps only the common values in both the left and right dataframes for the merged data.\r\n\r\n\t# Q2 \r\n\tmergeData = pd.concat([test,importSQL], axis=0, join='outer',sort=True)\r\n\t# print(len(mergeData.columns))\r\n\treturn mergeData\r\n\r\n#Main \r\ndef main():\r\n\tBSCY4 = pd.read_csv(\"BSCY4.csv\")\r\n\timportCSV = importCSVFile(BSCY4)\r\n\r\n\timportCSV[\"Date\"] = cleanseInformationDate(importCSV[\"Date\"],importCSV[\"year\"])\r\n\t# print(cleanDate)\r\n\timportCSV[\"type\"] = cleanseInFormationType(importCSV[\"type\"])\r\n\t# print(importCSV[\"type\"])\r\n\timportCSV[\"AveragePrice\"] = cleanseAveragePrice(importCSV[\"AveragePrice\"])\r\n\r\n\timportSQL = ImportMySQL()\r\n\r\n\timportSQL[\"region\"] = cleanseRegion(importSQL[\"region\"])\r\n\timportSQL[\"year\"] = cleanseYear(importSQL[\"year\"])\r\n\timportSQL[\"type\"] = cleanseType(importSQL[\"type\"])\r\n\tinspection = visualInspection(importCSV,importSQL)\r\n\tprint(inspection)\r\n\t# print(importSQL)\r\n\t# print(\"------------------------\")\r\n\t# print(importCSV)\r\n\t# print(inspection)\r\n\t# print(cleanDate)\r\n\t# print(cleanType)\r\n\t# print(cleanPrice)\r\n\r\nmain()"
}
] | 1 |
koops9/flaskquery
|
https://github.com/koops9/flaskquery
|
4a5f72d88a0befc4d7155d85e5204d845342eefb
|
d7982053ef4bb43aa5bb60a5f6346de37e1ea4a6
|
271366e580ec9d4ed5800b9a33380ca763593a82
|
refs/heads/master
| 2021-04-29T13:11:43.097210 | 2018-10-09T15:01:08 | 2018-10-09T15:01:08 | 121,745,197 | 0 | 0 | null | 2018-02-16T11:49:44 | 2018-02-16T11:49:46 | 2018-02-16T12:34:05 |
Python
|
[
{
"alpha_fraction": 0.5933448672294617,
"alphanum_fraction": 0.6248919367790222,
"avg_line_length": 32.550724029541016,
"blob_id": "61624970164b0600173b4735c7473602a1ba3d10",
"content_id": "63d799e8c35800205c6267cb50c1fba6771bb56d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2314,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 69,
"path": "/app/models.py",
"repo_name": "koops9/flaskquery",
"src_encoding": "UTF-8",
"text": "from app import db\nfrom datetime import datetime\n\nclass Reg(db.Model):\n id = db.Column(db.Integer, primary_key=True)\n name = db.Column(db.String(64))\n email = db.Column(db.String(64))\n representative = db.Column(db.String(64), index=True)\n greeting = db.Column(db.Boolean())\n food = db.Column(db.String(500))\n alcohol = db.Column(db.String(10))\n #gambina = db.Column(db.Boolean())\n avec = db.Column(db.String(64))\n free = db.Column(db.String(500))\n\nclass OKS(db.Model):\n id = db.Column(db.Integer, primary_key=True)\n name = db.Column(db.String(64))\n email = db.Column(db.String(64))\n table = db.Column(db.Boolean(8))\n representative = db.Column(db.String(24))\n discussion = db.Column(db.String(500))\n alcohol = db.Column(db.String(10))\n drink = db.Column(db.String(10))\n food = db.Column(db.String(500))\n wine = db.Column(db.String(10))\n \n\nclass KMP(db.Model):\n id = db.Column(db.Integer, primary_key=True)\n name = db.Column(db.String(64))\n email = db.Column(db.String(64))\n representative = db.Column(db.String(24))\n place = db.Column(db.String(64))\n \nclass Fucu(db.Model):\n id = db.Column(db.Integer, primary_key=True)\n name = db.Column(db.String(64))\n email = db.Column(db.String(64))\n phone = db.Column(db.String(64))\n representative = db.Column(db.String(24))\n place = db.Column(db.String(64))\n time = db.Column(db.DateTime)\n publish = db.Column(db.Boolean())\n #reserve = db.Column(db.Integer)\n \n def __init__(self, name=\"\", email=\"\", phone=\"\", representative=\"\",\n place=\"\", time=\"\", publish=\"\"):\n self.name = name\n self.email = email\n self.phone = phone\n self.representative = representative\n self.place = place\n self.time = datetime.now()\n self.publish = publish\n #self.reserve = reserve\n \n \nclass Humu(db.Model):\n id = db.Column(db.Integer, primary_key=True)\n name = db.Column(db.String(64))\n email = db.Column(db.String(64))\n representative = db.Column(db.String(64), index=True)\n food = db.Column(db.String(500))\n alcohol = db.Column(db.String(10))\n drink = db.Column(db.String(10))\n wine = db.Column(db.String(10))\n avec = db.Column(db.String(64))\n free = db.Column(db.String(500))"
},
{
"alpha_fraction": 0.5134408473968506,
"alphanum_fraction": 0.7016128897666931,
"avg_line_length": 15.909090995788574,
"blob_id": "10f2f4bb69c1cac696334583e3cd03be5c4bf9d3",
"content_id": "510f32234ad1d02549f49af0ac0b2a5b85ec2515",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 372,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 22,
"path": "/requirements.txt",
"repo_name": "koops9/flaskquery",
"src_encoding": "UTF-8",
"text": "alembic==0.9.6\nclick==6.7\nDateTime==4.2\ndominate==2.3.1\nFlask==0.12.2\nFlask-Bootstrap==3.3.7.1\nFlask-Migrate==2.1.1\nFlask-SQLAlchemy==2.3.2\nFlask-WTF==0.14.2\nitsdangerous==0.24\nJinja2==2.10\nMako==1.0.7\nMarkupSafe==1.0\npython-dateutil==2.6.1\npython-editor==1.0.3\npytz==2017.3\nsix==1.11.0\nSQLAlchemy==1.2.0\nvisitor==0.1.3\nWerkzeug==0.14.1\nWTForms==2.1\nzope.interface==4.4.3\n"
},
{
"alpha_fraction": 0.5148414969444275,
"alphanum_fraction": 0.5375773906707764,
"avg_line_length": 32.97854232788086,
"blob_id": "adfe2ed1fa3eedaee4ea5e0c2a60a0e2eb384416",
"content_id": "7c7b9010a313f7d060412f6ed0d11f9089665c6c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7933,
"license_type": "no_license",
"max_line_length": 205,
"num_lines": 233,
"path": "/app/routes.py",
"repo_name": "koops9/flaskquery",
"src_encoding": "UTF-8",
"text": "from flask import render_template, flash, redirect, url_for\nfrom app import app, db\nfrom app.forms import HumuForm, KMPForm, OKSForm, FucuForm\nfrom .models import Humu, KMP, OKS, Fucu\nfrom datetime import datetime\nfrom wtforms import SelectField\n\[email protected]('/fucu2018', methods=['GET', 'POST'])\ndef fucuilmo():\n\n starttime = datetime(1018, 10, 12, 12, 00, 00)\n endtime = datetime(2018, 10, 18, 23, 59, 59)\n middletime = datetime(2018, 10, 17, 12, 00, 00)\n \n nowtime = datetime.now()\n\n limit = 58\n maxlimit = 100\n\n class TeekkariForm(FucuForm):\n representative = SelectField('Olen', \n choices=[('Fuksi', 'Fuksi'),( 'Homonaama', 'Hallitus/PRO/juomasa/windance'), ('Teekkari', 'Teekkari')])\n if nowtime > middletime:\n form = TeekkariForm()\n else:\n form = FucuForm()\n \n \n partisipants = Fucu.query.all()\n count = Fucu.query.count()\n fuksi = Fucu.query.filter_by(representative='Fuksi').all()\n homonaama = Fucu.query.filter_by(representative='Homonaama').all()\n teekkari = Fucu.query.filter_by(representative='Teekkari').all()\n \n guilds = [\n {'name': 'Fuksi',\n 'quota': 58,\n 'submissions': fuksi},\n {'name': 'Homonaama',\n 'quota': 15,\n 'submissions': homonaama},\n {'name': 'Teekkari',\n 'quota': 40,\n 'submissions': teekkari}]\n #reserve = max(0, count - limit + 1)\n #reserves = Fucu.query.filter(Fucu.reserve > 0).order_by(Fucu.reserve.asc())\n\n if form.validate_on_submit() and count <= maxlimit:\n \n flash('Kiitos ilmoittautumisestasi')\n sub = Fucu(\n name=form.name.data,\n email=form.email.data,\n phone=form.phone.data,\n representative=form.representative.data,\n place=form.place.data,\n publish=form.publish.data\n )\n db.session.add(sub)\n db.session.commit()\n return redirect(url_for('fucuilmo')) #this is the fucktion name\n elif form.is_submitted() and count > maxlimit:\n flash('Ilmoittautuminen on täynnä.')\n elif form.is_submitted() and count > limit:\n flash('Ilmoittautuminen on täynnä. Olet varasijalla.')\n elif form.is_submitted() and count < maxlimit:\n flash('Ilmoittautuminen epäonnistui!')\n return render_template('fucu.html', \n title='Fucu 2018 ilmoittautuminen',\n partisipants=partisipants, \n count=count, \n starttime=starttime, \n endtime=endtime, \n nowtime=nowtime, \n middletime = middletime,\n limit=limit,\n guilds=guilds,\n fuksi=fuksi,\n homonaama=homonaama,\n teekkari=teekkari,\n form=form)\n\[email protected]('/KMP', methods=['GET', 'POST'])\ndef kmpilmo():\n form = KMPForm()\n\n starttime = datetime(2018, 2, 23, 12, 00, 00)\n endtime = datetime(2018, 3, 7, 12, 00, 00)\n nowtime = datetime.now()\n\n limit = 45\n maxlimit = 200\n\n partisipants = KMP.query.all()\n count =KMP.query.count()\n otit = KMP.query.filter_by(representative='OTiT').all()\n sik = KMP.query.filter_by(representative='SIK').all()\n \n guilds = [\n {'name': 'OTiT',\n 'quota': 22,\n 'submissions': otit},\n {'name': 'SIK',\n 'quota': 23,\n 'submissions': sik},\n ]\n \n \n\n if form.validate_on_submit() and count <= maxlimit:\n flash('Kiitos ilmoittautumisestasi')\n sub = KMP(\n name=form.name.data,\n email=form.email.data,\n representative=form.representative.data,\n place=form.place.data\n )\n db.session.add(sub)\n db.session.commit()\n return redirect(url_for('kmpilmo')) #this is the fucktion name\n elif form.is_submitted() and count > maxlimit:\n flash('Ilmoittautuminen on täynnä')\n return render_template('KMP.html', \n title='KMP 2018 ilmoittautuminen',\n partisipants=partisipants, \n count=count, \n starttime=starttime, \n endtime=endtime, \n nowtime=nowtime, \n limit=limit,\n guilds=guilds,\n otit=otit,\n sik=sik,\n form=form)\n\[email protected]('/humusitsit', methods=['GET', 'POST'])\ndef humusitsit():\n form = HumuForm()\n\n starttime = datetime(2018, 1, 19, 12, 00, 00)\n endtime = datetime(2018, 3, 17, 23, 59, 00)\n nowtime = datetime.now()\n\n limit = 99\n maxlimit = 200\n\n partisipants = Humu.query.all()\n count = Humu.query.count()\n\n if form.validate_on_submit() and count <= maxlimit:\n flash('Kiitos ilmoitautumisestasi')\n sub = Humu(\n name=form.name.data,\n email=form.email.data,\n representative=form.representative.data,\n food=form.food.data,\n alcohol=form.alcohol.data,\n drink=form.drink.data,\n wine=form.wine.data\n )\n db.session.add(sub)\n db.session.commit()\n return redirect(url_for('/humusitsit'))\n elif form.is_submitted() and count > maxlimit:\n flash('Ilmoittautuminen on täynnä')\n return render_template('ilmo.html', title='Humanöörisitsit 2018 ilmoittautuminen', partisipants=partisipants, count=count, starttime=starttime, endtime=endtime, nowtime=nowtime, limit=limit, form=form)\n\n \[email protected]('/oks-ilmo', methods=['GET', 'POST'])\ndef oksilmo():\n form = OKSForm()\n\n starttime = datetime(2018, 1, 19, 12, 00, 00)\n endtime = datetime(2018, 3, 15, 23, 59, 00)\n nowtime = datetime.now()\n\n limit = 80\n maxlimit = 200\n\n partisipants = OKS.query.all()\n count = OKS.query.count()\n otit = OKS.query.filter_by(representative='OTiT').all()\n sik = OKS.query.filter_by(representative='SIK').all()\n blanko = OKS.query.filter_by(representative='Blanko').all()\n hnk = OKS.query.filter_by(representative='Henkilökunta').all()\n\n guilds = [\n {'name': 'OTiT',\n 'quota': 20,\n 'submissions': otit},\n {'name': 'SIK',\n 'quota': 20,\n 'submissions': sik},\n {'name': 'Blanko',\n 'quota': 20,\n 'submissions': blanko},\n {'name': 'Henkilökunta',\n 'quota': 20,\n 'submissions': hnk}]\n \n \n if form.validate_on_submit() and count <= maxlimit:\n flash('Kiitos ilmoittautumisestasi')\n sub = OKS(\n name=form.name.data,\n email=form.email.data,\n representative=form.representative.data,\n table=form.table.data,\n discussion = form.discussion.data,\n food=form.food.data,\n alcohol=form.alcohol.data,\n drink=form.drink.data,\n wine=form.wine.data\n )\n db.session.add(sub)\n db.session.commit()\n return redirect(url_for('oksilmo'))\n elif form.is_submitted() and count > maxlimit:\n flash('Ilmoittautuminen on täynnä')\n return render_template('oks-ilmo.html', \n title='Opetuksenkehittämisseminaari 2018 ilmoittautuminen', \n partisipants=partisipants, \n count=count, \n starttime=starttime, \n endtime=endtime, \n nowtime=nowtime, \n limit=limit,\n otit=otit,\n sik=sik,\n blanko=blanko,\n hnk=hnk,\n guilds=guilds,\n form=form)\n"
},
{
"alpha_fraction": 0.6039215922355652,
"alphanum_fraction": 0.6352941393852234,
"avg_line_length": 31,
"blob_id": "4e1c256a1aa5644be97d1c458e6ac1a416a82226",
"content_id": "cafd68b319cd21409d337fbe2a0ff77075fe2f69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 257,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 8,
"path": "/app/static/showme.js",
"repo_name": "koops9/flaskquery",
"src_encoding": "UTF-8",
"text": "/**\n * Created by Uula on 2016-03-11.\n */\nfunction showMe (it, box, invert) {\n if (typeof(invert)==='undefined') invert = false;\n var vis = (invert ? !box.checked : box.checked) ? \"block\" : \"none\";\n document.getElementById(it).style.display = vis;\n}"
},
{
"alpha_fraction": 0.5578060746192932,
"alphanum_fraction": 0.5603095293045044,
"avg_line_length": 52.59756088256836,
"blob_id": "526502fbbe7e3ce5979a27618718deff34100180",
"content_id": "96a9ea5b133b4c1c93a9a2e45a088093d8a112d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4417,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 82,
"path": "/app/forms.py",
"repo_name": "koops9/flaskquery",
"src_encoding": "UTF-8",
"text": "from flask_wtf import FlaskForm\nfrom wtforms import StringField, BooleanField, SubmitField, RadioField, TextAreaField, SelectField\nfrom wtforms.validators import DataRequired, Email, Required\nfrom wtforms import validators\n\nclass RegForm(FlaskForm):\n name = StringField('Nimi', validators=[DataRequired()])\n email = StringField('Sähköposti', validators=[Email()])\n representative = StringField('Edustava taho/joukkue', validators=[DataRequired()])\n greeting = BooleanField('Haluatko tuoda tervehdyksen?')\n food = StringField('Erityisruokavalio')\n alcohol = RadioField('Holiton / Holillinen', choices=(['Holillinen', 'Holillinen (20e)'],['Holiton', 'Holiton (20e)']), validators=[Required()])\n gambina = BooleanField('Iso G (+9,83 € hintaan)')\n avec = StringField('Avec / Pöytätoive (avec ilmoittautuu erikseen)')\n free = TextAreaField('Vapaa sana')\n submit = SubmitField('Ilmoittaudu')\n\nclass HumuForm(FlaskForm):\n name = StringField('Nimi', validators=[DataRequired()])\n email = StringField('Sähköposti', validators=[Email()])\n food = StringField('Erityisruokavalio, (esimerkiksi \"kasvis\" tai \"ei herneitä\")')\n alcohol = RadioField('Holiton / Holillinen', choices=(['Holillinen', 'Holillinen (20e)'],['Holiton', 'Holiton (18e)']), validators=[Required()])\n drink = RadioField('Mieto juoma', \n choices=(['Kalja', 'Kalja'],\n ['Siideri', 'Siideri']))\n wine = RadioField('Viini',\n choices=(['Valkoviini', 'Valkoviini'],\n ['Punaviini', 'Punaviini']))\n representative = SelectField('Kilta', \n choices=[('OTiT', 'OTiT'), \n ('YMP', 'YMP'), \n ('Communica', 'Comunica')])\n free = TextAreaField('Vapaa sana')\n submit = SubmitField('Ilmoittaudu')\n\nclass OKSForm(FlaskForm):\n name = StringField('Nimi', validators=[DataRequired()])\n email = StringField('Sähköposti', validators=[Email()])\n representative = SelectField('Edustaja', \n choices=[\n ('OTiT', 'OTiT'), \n ('SIK', 'SIK'),\n ('Blanko', 'Blanko'),\n ('Henkilökunta', 'Henkilökunta')])\n table = BooleanField('En osallistu sitseille')\n discussion = TextAreaField('Opetukseen liittyvä aihe/aiheet joista haluaisit seminaarissa keskustella:')\n food = StringField('Erityisruokavalio, (esimerkiksi \"kasvis\" tai \"ei herneitä\")')\n alcohol = BooleanField('Alkoholiton')\n drink = SelectField('Mieto juoma', \n choices=(['Olut', 'Olut'],\n ['Siideri', 'Siideri']))\n wine = SelectField('Viini',\n choices=(['Valkoviini', 'Valkoviini'],\n ['Punaviini', 'Punaviini']))\n submit = SubmitField('Ilmoittaudu')\n \nclass KMPForm(FlaskForm):\n name = StringField('Nimi', validators=[DataRequired()])\n email = StringField('Sähköposti', validators=[Email()])\n representative = SelectField('Kilta', \n choices=[('OTiT', 'OTiT'), \n ('SIK', 'SIK')])\n place = SelectField('Mistä nouset kyytiin?', \n choices=[('Linnanmaa','Linnanmaa'), \n ('Tuira','Tuira'),\n ('Keskusta','Linja-autoasema')])\n submit = SubmitField('Ilmoittaudu')\n \nclass FucuForm(FlaskForm):\n name = StringField('Nimi', validators=[DataRequired()])\n email = StringField('Sähköposti', validators=[Email()])\n phone = StringField('Puhelinnumero', validators=[DataRequired()])\n representative = SelectField('Olen', \n choices=[('Fuksi', 'Fuksi'),( 'Homonaama', 'Hallitus/PRO/juomasa/windance')])\n\n place = SelectField('Mistä nouset kyytiin?', \n choices=[('Oulun yliopisto','Oulun yliopisto'), \n ('Tuira','Tuira'),\n ('Keskusta','Oulun Linja-autoasema')])\n #luovuta tiedot täppä\n publish = BooleanField('Minun nimeni saa julkaista ilmoittautuneiden listalla.')\n submit = SubmitField('Ilmoittaudu')"
},
{
"alpha_fraction": 0.7149758338928223,
"alphanum_fraction": 0.7210144996643066,
"avg_line_length": 19.19512176513672,
"blob_id": "844d7b8d92db128ab78b8860d98e5f16648f64a0",
"content_id": "e43848c99ec930a04de47f793af392703edfeca9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 828,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 41,
"path": "/README.md",
"repo_name": "koops9/flaskquery",
"src_encoding": "UTF-8",
"text": "```\nsudo apt install virtualenv\nvirtualenv env -p python3\nsource env/bin/activate\npip install -r requirements.txt\nexport FLASK_APP=ilmo.py\n\nflask db init\nflask db migrate\nflask db upgrade\n\nflask run\n\n```\n\nflaskilmo.wsgi\n```\n#!/usr/bin/python\nimport sys\nimport logging\nimport os\nlogging.basicConfig(stream=sys.stderr)\nsys.path.insert(0,\"/home/glukoosi/flaskilmo/\")\n\nfrom app import app as application\napplication.secret_key = os.environ.get('SECRET_KEY') or 'you-will-never-guess'\n\n```\n\napache.conf\n```\n...\n WSGIDaemonProcess flaskilmo python-path=/home/glukoosi/flaskilmo/env/lib/python3.5/site-packages\n WSGIProcessGroup flaskilmo\n WSGIScriptAlias /5wag /home/glukoosi/flaskilmo/flaskilmo.wsgi\n <Directory /home/glukoosi/flaskilmo/>\n Require all granted\n </Directory>\n...\n\n```\n"
}
] | 6 |
saurabh3896/Operating-Systems-Assignments
|
https://github.com/saurabh3896/Operating-Systems-Assignments
|
e6e58fdcd2629c5d335a36417fcda35f58500c4c
|
5f15f70719331299204e861fca9bf2af76a99885
|
55378ac24109e5ceefef13603bcb56a90d30b366
|
refs/heads/master
| 2021-01-20T06:43:50.164063 | 2017-05-01T12:00:06 | 2017-05-01T12:00:06 | 89,920,367 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5737704634666443,
"alphanum_fraction": 0.6122950911521912,
"avg_line_length": 30.864864349365234,
"blob_id": "13966c5a370eca56bb187c6e75c6e16886884594",
"content_id": "821bce98a5d3782e283266bd038459ffbe9057bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1220,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 37,
"path": "/Minix-MinixScheduling-master/sourcecode/mytest.c",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "#include <sys/types.h>\r\n#include <sys/wait.h>\r\n#include <unistd.h>\r\n#include <stdio.h>\r\n//Here , we are starting the IO and CPU bound processes in different ratios to check the time variations\r\n//longrun1 is a cpu bound and longrun2 is an io bound process\r\n//Based on i%10 , we start either a CPU or IO bound process.\r\nint main()\r\n{\r\n\tint pid[15];\r\n\tint i;\r\n\tchar processid[50];\r\n \r\n for(i=1;i<=10;i++)\r\n {\r\n \tpid[i]=fork(); //fork 10 processes\r\n \tif(pid[i]==0)\r\n \t{\r\n \t\tsprintf(processid,\"%2d\",i);\r\n \t\tif(i%10<3)\r\n execlp(\"./longrun0\",\"./longrun0\",processid,\"100000\",\"1000\",NULL); //create a CPU bound process \r\n \t else\r\n execlp(\"./longrun1\",\"./longrun1\",processid,\"100000\",\"1000\",NULL); //create an IO bound process\r\n }\r\n }\r\n for(i=1;i<=10;i++) //wait for everything to terminate \r\n {\r\n \twait(NULL);\r\n }\t\r\n return 0;\r\n}\r\n\r\n/* \r\n * This program does not set priorites of the different processes. This can be set through the minix system call SYS_NICE.\r\n * Its signature: int sys_nice(endpoint_t proc_nr, int priority); \r\n * More details can be found here: http://wiki.minix3.org/doku.php?id=developersguide:kernelapi#sys_nice\r\n */\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.6471494436264038,
"alphanum_fraction": 0.6933743953704834,
"avg_line_length": 23.037036895751953,
"blob_id": "68370a464e12ae9589e5e7f9189631a5f72dd623",
"content_id": "ea2ce5ce01d930b289cc55b8a0a13e7fef698913",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 649,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 27,
"path": "/Assgn1-CS14BTECH11031/Readme.txt",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "1. Run on terminal :\n\n g++ Assgn1-cs14btech11031-task1.cpp\n ./a.out\n\n The user is prompted to enter the input and output file name on command line.\n\n2. Run on terminal :\n\n g++ Assgn1-cs14btech11031-task2.cpp\n ./a.out\n\n The user is prompted to enter the input file name on command line.\n\n3. Run on terminal :\n\n g++ Assgn1-cs14btech11031-task3.cpp\n ./a.out\n\n The user is prompted to enter the complete absolute path of the directory on command line.\n The program deletes all subfolders as well as subfiles in the directory.\n\nFor STRACE :\n\n Run on terminal :\n\n strace -o \"file_already_present_on_disk.txt\" ./a.out\n"
},
{
"alpha_fraction": 0.4944635331630707,
"alphanum_fraction": 0.49885451793670654,
"avg_line_length": 58.522727966308594,
"blob_id": "2a70f3f3cf796318768c5166832a00d9833dc1fc",
"content_id": "54e5c50a55f6150890a098d3e7d6610928cdee6d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 10476,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 176,
"path": "/Assgn6-CS14BTECH11031/reader_writer-CS14BTECH11031.cpp",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "#include <ctime>\n#include <atomic>\n#include <vector>\n#include <cstdio>\n#include <random>\n#include <chrono>\n#include <fstream>\n#include <cstring>\n#include <sstream>\n#include <cstdlib>\n#include <unistd.h>\n#include <iostream>\n#include <pthread.h>\n#include <sys/wait.h>\n#include <sys/types.h>\n#include <semaphore.h>\n#include <sys/syscall.h>\n\nusing namespace std;\n\ndouble elapsed = 0.0, elapsed_ = 0.0; //variables to measure time\nvector<int> values; //vector to store input parameters\nsem_t wrt, mutex; //semaphore variables declaration\natomic<int> readcount; //atomic readcount variable\nFILE *ptr; //ptr to FILE\n\nstruct sharedbuffer{ //shared buffer declaration\n int id;\n int iteration; //(id, i)\n} buffer;\n\nstring currentTime(time_t d){ //function to return current time in standard format\n time_t now = time(NULL); //get the current time\n struct tm tstruct; //time struct\n char buf[80]; //char buffer\n tstruct = *localtime(&now); //store current time into struct\n strftime(buf, sizeof(buf), \"%X\", &tstruct); //print in standard format\n return string(buf); //return the buf\n}\n\nint delay_sleep(int l){ //calculate t on given exponential average lambda\n\tint sd = chrono::system_clock::now().time_since_epoch().count();\n\tdefault_random_engine random_gen(sd); //seed the random engine\n\texponential_distribution<double> dist_1(1.0/l); //initialize the exponential_distribution value\n\treturn (int)dist_1(random_gen); //typecast to int and return the value of t\n}\n\nvoid *writerTh(void *arg){\n double s, f;\n chrono::milliseconds start, finish; //declare variables to record start and finish times\n int thread_no = (long) arg;\n pid_t x = syscall(__NR_gettid); //store thread_no and thread id\n for(int i = 1;i <= values[2];i++){ //repeat for kw times\n s = time(NULL); //get current time\n printf(\"Writer Thread %d requesting to write to the shared buffer for %dth-time at %s (tid : %d)\\n\",\n thread_no, i, currentTime(s).c_str(), x); //write to stdout as well as file\n fprintf(ptr, \"Writer Thread %d requesting to write to the shared buffer for %dth-time at %s (tid : %d)\\n\",\n thread_no, i, currentTime(s).c_str(), x);\n\n start = chrono::duration_cast<chrono::milliseconds>(\n chrono::system_clock::now().time_since_epoch()\n ); //get current time (start)\n\n sem_wait(&wrt); //lock the semaphore for exclusive write access\n\n finish = chrono::duration_cast<chrono::milliseconds>(\n chrono::system_clock::now().time_since_epoch()\n ); //record the finish time\n\n f = time(NULL);\n printf(\"Writer Thread %d obtained the permission to write to the shared buffer for %dth-time at %s (tid : %d)\\n\",\n thread_no, i, currentTime(f).c_str(), x);\n buffer.id = thread_no; //write to the shared buffer here\n buffer.iteration = i;\n fprintf(ptr, \"Writer Thread %d obtained the permission to write to the shared buffer for %dth-time at %s (tid : %d)\\n\",\n thread_no, i, currentTime(f).c_str(), x); //write output again to stdout as well as file\n elapsed += (double) chrono::duration_cast<chrono::milliseconds>(finish - start).count();\n\n sem_post(&wrt); //unlock the semaphore\n\n sleep(delay_sleep(values[4])); //sleep to simulate some complex operation\n }\n}\n\nvoid *readerTh(void *arg){\n double s, f;\n chrono::milliseconds start, finish; //declare variables to record start and finish times\n int thread_no = (long) arg;\n pid_t x = syscall(__NR_gettid); //store thread_no and thread id\n for(int i = 1;i <= values[3];i++){ //repeat for kr times\n s = time(NULL); //record current time for printing\n printf(\"Reader Thread %d requested to read the shared buffer for %dth-time at %s (tid : %d)\\n\",\n thread_no, i, currentTime(s).c_str(), x); //write to stdout as well as file\n fprintf(ptr, \"Reader Thread %d requested to read the shared buffer for %dth-time at %s (tid : %d)\\n\",\n thread_no, i, currentTime(s).c_str(), x);\n\n start = chrono::duration_cast<chrono::milliseconds>(\n chrono::system_clock::now().time_since_epoch()\n ); //get current time (start)\n\n sem_wait(&mutex); //lock reader semaphore here for mutual access to readcount variable\n readcount++; //increment readcount as one more thread is reading now\n if(readcount.load() == 1) //if there exist a reader, make the semaphore of writer wait\n sem_wait(&wrt);\n sem_post(&mutex); //unlock the reader semaphore\n\n finish = chrono::duration_cast<chrono::milliseconds>(\n chrono::system_clock::now().time_since_epoch()\n ); //record the finish time\n\n f = time(NULL);\n printf(\"Reader Thread %d obtained the permission to read the shared buffer for %dth-time at %s (tid : %d)\\n\",\n thread_no, i, currentTime(f).c_str(), x);\n printf(\"Read : [%d, %d]\\n\", buffer.id, buffer.iteration); //write the output to stdout as well as file\n fprintf(ptr, \"Reader Thread %d obtained the permission to read the shared buffer for %dth-time at %s (tid : %d)\\n\",\n thread_no, i, currentTime(f).c_str(), x); //read from the shared buffer here\n fprintf(ptr, \"Read : [%d, %d]\\n\", buffer.id, buffer.iteration);\n elapsed_ += (double) chrono::duration_cast<chrono::milliseconds>(finish - start).count();\n\n sem_wait(&mutex); //again lock reader semaphore\n readcount--; //as reading is done, decrement readcount\n if(readcount.load() == 0) //if no readers, again unlock the writer semaphore\n sem_post(&wrt);\n sem_post(&mutex); //unlock the reader semaphore\n\n sleep(delay_sleep(values[5])); //sleep to simulate some complex operation\n }\n}\n\nint main(int argc, char *argv[]){\n readcount = 0; //initialize readcount variable\n int found; //found int variable to capture file contents\n std::ofstream ofs(\"output.txt\", std::ios::out | std::ios::trunc); //open file in write mode to clear it\n ofs.close(); //fclose\n ptr = fopen(\"output.txt\", \"a+\"); //open the file in append mode\n ifstream infile; //infile to take input\n string input, temp;\n stringstream stream; //variable declarations\n infile.open(\"inp-params.txt\"); //open the input file\n getline(infile, input); //get the line containing nw, nr, kw, kr, l1, l2\n stream << input; //push the stream into sstream variable\n while(getline(stream, temp, ' ')){ //get the space separated values and store them into vector\n stringstream(temp) >> found; //extract string from strngstream\n values.push_back(found); //store the values in a vector\n }\n if(argc > 1){\n values[0] = atoi(argv[1]); //if nw is supplied as command-line argument, change nw\n }\n /****************************************************************************/\n sem_init(&wrt, 0, 1);\n sem_init(&mutex, 0, 1); //initialize both the semaphores to 1\n pthread_t writer_threads[values[0]], reader_threads[values[1]];\n for(long i = 1;i <= values[0];i++){ //create writer threads\n pthread_create(&writer_threads[i], NULL, writerTh, (void *) i);\n }\n for(long i = 1;i <= values[1];i++){ //create reader threads\n pthread_create(&reader_threads[i], NULL, readerTh, (void *) i);\n }\n for(int i = 1;i <= values[0];i++){ //join writer threads once they finish execution\n pthread_join(writer_threads[i], NULL);\n }\n for(int i = 1;i <= values[1];i++){ //join reader threads once they finish execution\n pthread_join(reader_threads[i], NULL);\n }\n /****************************************************************************/\n fclose(ptr); //close the file\n sem_destroy(&wrt); //destroy the writer semaphore\n sem_destroy(&mutex); //destroy the reader semaphore\n /****************************************************************************/\n /*Uncomment below lines if want to store the times taken by reader and writer threads for graph plotting\n FILE *writer_time = fopen(\"writer.txt\", \"a+\"), *reader_time = fopen(\"reader.txt\", \"a+\");\n fprintf(writer_time, \"%d %f\\n\", values[0], elapsed/(values[0]*values[2]));\n fprintf(reader_time, \"%d %f\\n\", values[0], elapsed_/(values[1]*values[3]));\n fclose(writer_time); fclose(reader_time);*/\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5343642830848694,
"alphanum_fraction": 0.5429553389549255,
"avg_line_length": 35.375,
"blob_id": "ca2db68a79dffcc28cf9c8c970fbf0d02ecc21ba",
"content_id": "3d78d8c1dee5db6be217c2d1d30fd68413c1d5e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1164,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 32,
"path": "/Assgn1-CS14BTECH11031/Assgn1-CS14BTECH11031-task1.cpp",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <fstream>\n#include <deque>\n\nusing namespace std;\n\nint main(){\n deque<string> v; //double-ended queue to store strings\n ifstream input_file;\n ofstream output_file; //fstream objects\n char filename[1024], filename_[1024];\n string get_line; //char buffers and string declarations\n cout << \"Enter input filename : \";\n cin >> filename;\n cout << \"Enter output filename : \";\n cin >> filename_;\n input_file.open(filename); //open file\n if(!input_file.is_open()){\n cout << \"Invalid file.\" << endl; //wrong file input\n return 0;\n }\n output_file.open(filename_); //open output file\n while(getline(input_file, get_line)){ //push strings, stored in stack-way, thus reversing\n v.push_front(get_line);\n } //write the output to output file\n for(deque<string>::iterator it = v.begin();it != v.end();it++){\n output_file << *it << endl;\n }\n input_file.close(); //close the files\n output_file.close();\n return 0;\n};\n"
},
{
"alpha_fraction": 0.6493184566497803,
"alphanum_fraction": 0.6641883254051208,
"avg_line_length": 17.340909957885742,
"blob_id": "237f1a84d80709e83b57ce8ee4125656b71952f9",
"content_id": "7e3ad10d44a45720bdf76ec8e3acdfe504d4bfa3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 807,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 44,
"path": "/MinixInstallation-master/ass2q3.c",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<unistd.h>\n#include<sys/types.h>\n#include<fcntl.h>\n#include<string.h>\n#include<dirent.h>\n#include<stdlib.h>\nvoid deletechilds(char dirname[])\n{\n\tint temp;\n\tDIR* dir=opendir(dirname);\n\tif(dir==NULL)\n\t\treturn;\n\tprintf(\"-Removing the directory %s\",dirname);\n\tchar filepath[1000];\n\tstruct dirent *direntry;\n\twhile((direntry=readdir(dir))!=0)\n\t{\n\t\tif(strcmp(direntry->d_name,\".\")==0||strcmp(direntry->d_name,\"..\")==0)\n\t\t\tcontinue;\n\t\tstrcpy(filepath,dirname);\n\t\tstrcat(filepath,\"/\");\n\t\tstrcat(filepath,direntry->d_name);\n\t\t\n\t\ttemp=remove(filepath);\n\t\tdeletechilds(filepath);\t\n\t}\n\tremove(dirname);\n\treturn;\n}\n\n\nint main(int argc, char *argv[])\n{\n\tDIR* dir=opendir(argv[1]);\n\t///dir not 0\n\tif(dir==NULL)\n\t{\n\t\tprintf(\"Not a directory\");\n\t\treturn 0;\t\n\t}\n\tdeletechilds(argv[1]);\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.8333333134651184,
"alphanum_fraction": 0.8333333134651184,
"avg_line_length": 43,
"blob_id": "f6a409b34fc2e7f7a46146fd941deb1119551324",
"content_id": "9849d31263fde5fe819f89516a2c61908bc497d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 132,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 3,
"path": "/MinixInstallation-master/README.md",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "system calls for making input output\noperations on files and also for handling files and directories in\nthe Linux operating system.\n"
},
{
"alpha_fraction": 0.46315789222717285,
"alphanum_fraction": 0.5263158082962036,
"avg_line_length": 18,
"blob_id": "3c25d2723b325a60f46d6cdef93f6b423b8a5a4a",
"content_id": "cf2218ebc983eb3bdb12c5a4f24e3715ffc70fbf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 95,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 5,
"path": "/Assgn5-CS14BTECH11031/unbscript",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nfor _ in {15..45..10}; do\n ./unbounded $(($_));\n echo \"Execution done\";\ndone\n"
},
{
"alpha_fraction": 0.6161074042320251,
"alphanum_fraction": 0.6322147846221924,
"avg_line_length": 40.27777862548828,
"blob_id": "be25392909a63500d60f00861f1957e247cfe2e9",
"content_id": "7a302d6a99046ae402926f8152e4b2b8e0e0b602",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 745,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 18,
"path": "/Minix-MinixScheduling-master/script.py",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "import sys\nimport os\nimport os.path\npath=\"/Users/vasanthreddy/Desktop/projectrep\"\nflst=os.listdir(path)\nfor fil in flst:\n\tif os.path.isfile(path+'/'+fil)and (fil.startswith(\"mlfq\") or fil.startswith(\"ori\") or fil.startswith(\"prio\") or fil.startswith(\"log\")):\n\t\tprint(\"Running file :\"+fil)\n\t\tcomm1=fil+' |grep \"Wa\" |cut -f4 -d\" \" >repw_'+fil\n\t\tcomm2=fil+' |grep \"Tu\" |cut -f4 -d\" \" >rept_'+fil\n #print(comm1)\n #print(comm2)\n\t\tos.system('cat '+comm1)\n\t\tlines = [float(line.rstrip('\\n')) for line in open('repw_'+fil)]\n\t\tprint(\"Avg wait for \"+fil+\" =\"+str(float(sum(lines)/10)))\n\t\tos.system('cat '+comm2)\n\t\tlines = [float(line.rstrip('\\n')) for line in open('rept_'+fil)]\n\t\tprint(\"Avg turn for \"+fil+\" =\"+str(float(sum(lines)/10))) \n\n"
},
{
"alpha_fraction": 0.4545702636241913,
"alphanum_fraction": 0.45879945158958435,
"avg_line_length": 59.081966400146484,
"blob_id": "61ef7433a4bb613fd42f6e75b32d3f0a6c70fe56",
"content_id": "ba63f590a5995cf08e6b1f8e29eb81b07f903751",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 7330,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 122,
"path": "/Assgn5-CS14BTECH11031/Unbounded-CS14BTECH11031.cpp",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "#include <ctime>\n#include <atomic>\n#include <vector>\n#include <cstdio>\n#include <random>\n#include <chrono>\n#include <fstream>\n#include <cstring>\n#include <sstream>\n#include <cstdlib>\n#include <unistd.h>\n#include <iostream>\n#include <pthread.h>\n#include <sys/wait.h>\n#include <sys/types.h>\n#include <sys/syscall.h>\n\nusing namespace std;\n\nfstream outfile; //file to store output\nvector<int> values; //vector to store n, k, l1, l2\ndouble elapsed = 0.0; //measure average time taken in ms\n\nclass Unbounded{ //unbounded lock class\n private:\n std::atomic_flag lock_stream = ATOMIC_FLAG_INIT; //initialize lock variable\n public:\n Unbounded(){ //constructor\n lock_stream.clear(); //set the lock variable to be false\n }\n ~Unbounded(){}; //destructor\n void lock(); //lock method\n void unlock(); //unlock method\n};\nUnbounded test; //unbounded class object\n\nvoid Unbounded::lock(){ //lock method\n while(lock_stream.test_and_set()){} //standard atomic test_and_set while loop\n}\n\nvoid Unbounded::unlock(){ //unlock method\n lock_stream.clear(); //set the lock variable to be false\n}\n\nstring currentTime(time_t d){ //function to return current time in standard format\n time_t now = time(NULL); //get the current time\n struct tm tstruct; //time struct\n char buf[80]; //char buffer\n tstruct = *localtime(&now); //store current time into struct\n strftime(buf, sizeof(buf), \"%X\", &tstruct); //print in standard format\n return string(buf); //return the buf\n}\n\nint delay(int l){ //calculate t on given exponential average lambda\n\tint sd = chrono::system_clock::now().time_since_epoch().count();\n\tdefault_random_engine random_gen(sd); //seed the random engine\n\texponential_distribution<double> dist_1(1.0/l); //initialize the exponential_distribution value\n\treturn (int)dist_1(random_gen); //typecast to int and return the value of t\n}\n\nvoid *testCS(void *arg){ //testCS method\n time_t curr; //variable to store current time\n string push = \"\"; //string variable to push into file\n pid_t x = syscall(__NR_gettid); //get current threadid\n int thread_no = (long) arg; //get thread number\n for(int i = 1;i <= values[1];i++){ //enter the cs k times by the current thread\n double start, finish;\n start = time(NULL); //get current time\n printf(\"%dthCS\\tRequest at\\t%s by thread %d (tid - %d)\\n\", i, currentTime(start).c_str(), thread_no, x);\n push = to_string(i) + \"thCS\\tRequest at\\t\" + currentTime(curr) + \" by thread \" + to_string(thread_no) + \" (tid - \" + to_string(x) + \")\\n\";\n fflush(stdout); //fflush from stdout\n start = time(NULL); //get start time\n\n test.lock(); //call the lock method\n\n finish = time(NULL); //get end time\n elapsed += (finish - start); //get time elapsed\n printf(\"%dthCS\\tEntry at\\t%s by thread %d (tid - %d)\\n\", i, currentTime(finish).c_str(), thread_no, x);\n push += to_string(i) + \"thCS\\tEntry at\\t\" + currentTime(curr) + \" by thread \" + to_string(thread_no) + \" (tid - \" + to_string(x) + \")\\n\";\n fflush(stdout); //fflush from stdout\n sleep(delay(values[2])); //sleep since thread entered the cs\n\n test.unlock(); //call the unlock method once exited the cs section\n\n curr = time(NULL); //get the current time\n printf(\"%dthCS\\tExit at\\t\\t%s by thread %d (tid - %d)\\n\", i, currentTime(curr).c_str(), thread_no, x);\n push += to_string(i) + \"thCS\\tExit at\\t\\t\" + currentTime(curr) + \" by thread \" + to_string(thread_no) + \" (tid - \" + to_string(x) + \")\\n\\n\";\n fflush(stdout); //fflush from stdout\n sleep(delay(values[3])); //sleep since thread exited the cs\n outfile << push; //push the output to the file\n }\n pthread_exit(NULL); //pthread EXIT\n}\n\nint main(int argc, char *argv[]){\n int found; //found int variable to capture file contents\n std::ofstream ofs(\"unbounded-output.txt\", std::ios::out | std::ios::trunc);//open file in write mode to clear it\n ofs.close(); //fclose\n outfile.open(\"unbounded-output.txt\", std::fstream::in | std::fstream::out | std::fstream::app);//open file in r, w and a mode\n outfile << \"Unbounded Waiting Time lock output : \\n\\n\"; //write first line to output file\n ifstream infile; //infile to take input\n string input, temp;\n stringstream stream; //variable declarations\n infile.open(\"inp-params.txt\"); //open the input file\n getline(infile, input); //get the line containing n, k, l1, l2\n stream << input; //push the stream into sstream variable\n while(getline(stream, temp, ' ')){ //get the space separated values and store them into vector\n stringstream(temp) >> found; //extract string from strngstream\n values.push_back(found); //v[0]-n, v[1]-k, v[2]-l1, v[3]-l2\n }\n if(argc > 1){\n values[0] = atoi(argv[1]); //if n is supplied as command-line argument\n }\n pthread_t threads[values[0]]; //create pthread_t array\n for(long i = 1;i <= values[0];i++){ //create n threads\n pthread_create(&threads[i], NULL, testCS, (void *) i); //function pointer to testCS method\n }\n for(int i = 1;i <= values[0];i++){ //join all the threads\n pthread_join(threads[i], NULL);\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.6584158539772034,
"alphanum_fraction": 0.6782178282737732,
"avg_line_length": 19.200000762939453,
"blob_id": "24d5dbff5ffe49e4940d392fb6cfa286a9e0d39b",
"content_id": "2a850760e1f2af0d3284ca6f161f182f5d9b0f41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 202,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 10,
"path": "/CS14BTECH11031-project/minix-files/mysyscallscheduling.h",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "#include <lib.h>\n#include <unistd.h>\n#include <minix/endpoint.h>\n\nint mysyscall(int deadline, int pid){\n\tmessage m;\n\tm.m1_i1 = deadline;\n\tm.m1_i2 = pid;\n\treturn _syscall(PM_PROC_NR, SETDEADLINE, &m);\n}\n"
},
{
"alpha_fraction": 0.7559171319007874,
"alphanum_fraction": 0.7701183557510376,
"avg_line_length": 60.45454406738281,
"blob_id": "6eb7b098168a81b82c9c8348f62479e24270807d",
"content_id": "6a8530f5c7857027be46cae1d413700f3ec5c408",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3380,
"license_type": "no_license",
"max_line_length": 362,
"num_lines": 55,
"path": "/CS14BTECH11031-project/README.md",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "Directory structure :\n\n1. source-code - contains test program (CS14BTECH11031-sched.c), longrun.c and the input files.\n2. minix-files - contains files to be modified present in MINIX3 OS. (main scheduler files - schedule.c and schedule_non_preemptive.c -> to be renamed to schedule.c if the user wishes to run non-preemptive version of the scheduler)\n2. README.md - readme.\n3. Report_Design_Documentation.pdf - design documentation.\n\nFiles involved in this assignment (make sure they are put in their corresponding correct directories) :\n\n/usr/src/servers/sched/main.c\n/usr/src/servers/sched/schedule.c\n/usr/src/servers/sched/schedproc.h\n/usr/src/servers/pm/proto.h\n/usr/src/servers/pm/misc.c\n/usr/src/servers/pm/table.c\n/usr/src/include/minix/callnr.h\n/usr/include/mysyscallscheduling.h (this file needs to be added as compared to above files which are present already in MINIX3)\n\nFiles added for the system call in this assignment :\n\n/usr/include/mysyscallscheduling.h -> a new file in /usr/include named mysyscallscheduling.h, remember to #include in longrun.c\n\nMAIN PROCEDURE :\n\n1. Copy the above mentioned files to their respective directories. The directories of the files are mentioned along them.\n2. Run this command : cd /usr/src/releasetools && make hdboot\n3. Reboot once the files are uploaded to MINIX3 and **make hdboot** is run in /usr/src/releasetools directory.\n3. Go to the main assignment directory \"source-code\" in the parent directory.\n4. Run the following commands :\n\t\t- clang -o longrun longrun.c\n\t\t- clang CS14BTECH11031-sched.c\n\t\t- ./a.out\n\n\tNote that two input files : inp-params.txt and inp-params0.txt are provided alongside the sourcecode, and the name needs to be\n\tmodified accordingly in CS14BTECH11031-sched.c in order to run the desired input file.\n\nProcedure followed for implementing system call :\n\n1. Added 69th minix syscall as do_setdeadline()\n2. Added SETDEADLINE macro at line 68 in include/minix/callnr.h\n3. Added do_setdeadline function in misc.c\n4. Run this command to invoke the changes : cd /usr/src/releasetools && make services && make install\n5. Reboot\n\nFOR NON-PREEMPTIVE PROGRAM :\n\tAs discussed in class, sir told us to implement a static version of this policy, where the same deadline programs run according to FCFS policy. If the user wishes to run non-preemptive program, he/she must rename the file **schedule_non_preemptive.c** to schedule.c and paste in the /usr/src/servers/sched directory, and do rest of the steps as mentioned above.\n\nPoints to be noted :\n\n\t(i) There is primary function named mysyscall() in /usr/include/mysyscalllib.h, which has setting the message parameters, m1_i1 -> deadline and m1_i2 -> pid.\n\t(ii) Then, this calls in /usr/src/servers/pm/misc.c 's last function, do_setdeadline, which now passes the contents of m_in to schedule.c's functions.\n\t(iii) Then, I also made a new type SYS_SETDL = (SCHEDULING_BASE+6), this type is also used in misc.c's last function, which passes type, pid and deadline finally to schedule.c.\n\t(iv) Also, **_taskcall** is used to send info to schedule.c from misc.c, which by now has already received from defined systemcall.\n\t(v) I added an extra \"switch\" case to \"main.c\", which is specifically for setting deadlines, then again call do_start_scheduling().\n\t(vi) Now, system-call is complete, now changing code in schedule.c and schedproc.h for further code change.\n"
},
{
"alpha_fraction": 0.4612361192703247,
"alphanum_fraction": 0.47275683283805847,
"avg_line_length": 53.25,
"blob_id": "ac542d2743ca308015969ee3dacfb0101efe3792",
"content_id": "82c33f06557ed6a4e11a17cc886039c63eb01c8d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 7378,
"license_type": "no_license",
"max_line_length": 163,
"num_lines": 136,
"path": "/Assgn4-CS14BTECH11031/CS14BTECH11031.cpp",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "#include <iostream> /* I/O */\n#include <cstdlib> /* Basic C-library functions */\n#include <unistd.h> /* Symbolic Constants */\n#include <string> /* C++ string class */\n#include <sys/types.h> /* Primitive System Data Types */\n#include <errno.h> /* Errors */\n#include <fstream> /* C++ file-stream library */\n#include <vector> /* C++ vector library */\n#include <pthread.h> /* POSIX Threads */\n#include <sched.h> /* For scheduling policies */\n#include <sys/wait.h> /* Definition for wait() function */\n#include <sstream> /* C++ stringstream library */\n\nusing namespace std;\n\nstring removeSpaces(string str){ //function to remove spaces from a string\n stringstream ss; //stringstream object\n string temp;\n ss << str; //store the complete string in the sstream\n str = \"\";\n while(!ss.eof()){ //while ss is not empty\n ss >> temp;\n str = str + temp; //keep appending the strings in a string variable\n }\n return str; //return the final space removed string\n}\n\nint main(){\n char *args[5]; //char array to store commandline arguments\n ifstream input_file; //file-stream object\n std::ostringstream out;\n bool *is_real;\n int no_of_processes = -1, count = 0; //variable declarations\n string input, max_loops, loop_count, process_id, skip;\n vector<int> priorities; //vector to store priorities and policies\n vector<string> scheduling_policies;\n input_file.open(\"input.txt\"); //open the file\n while(getline(input_file, input)){ //read the file line by line\n if(input.find(\"/*\") != string::npos || input.find(\"*/\") != string::npos){\n continue; //ignore if a comment is encountered\n }\n input = removeSpaces(input); //remove spaces from the line\n if(no_of_processes == -1){\n no_of_processes = atoi(input.c_str()); //get the number of processes from the first line\n is_real = new bool[no_of_processes];\n count++; //increment the count variable\n }\n else{\n string test = input.substr(input.length() - 2); //get the last two chars, if 10 or 90, then priority is specified, meaning a real time process\n if(test == \"10\" || test == \"90\" || input.find(\"10\") != string::npos || input.find(\"90\") != string::npos){\n is_real[count - 1] = true; //this is a real-time policy\n count++;\n priorities.push_back(atoi(test.c_str())); //store the priorities in case of real-time process\n input = input.substr(0, input.length() - 2);\n scheduling_policies.push_back(input); //store the policy name\n }\n else{\n is_real[count - 1] = false; //this is not a real-time policy\n count++;\n priorities.push_back(0); //store the priorities in case of real-time process (0 in this case)\n scheduling_policies.push_back(input); //store the policy name\n }\n }\n }\n for(int i = 1;i <= no_of_processes;i++){ //fork k processes\n pid_t pid; //create a process id\n if((pid = fork()) == 0){\n out.str(std::string());\n out << getpid(); //get the process_id\n process_id = out.str();\n out.str(std::string());\n out << (100000); //THIS is the LOOP_COUNT, the second argument passed as 100000\n loop_count = out.str();\n if(is_real[i - 1] == true){ //if process number is real-time process number\n //this section is for Real-time schedulers\n struct sched_param param;\n param.sched_priority = priorities[i - 1]; //set the priority\n if(scheduling_policies[i - 1] == \"SCHED_FIFO\"){ //if the scheduler policy is FIFO\n if(sched_setscheduler(getpid(), SCHED_FIFO, ¶m) == -1){//error handling\n \t\tcout << \"--Error1--\" << i << endl; //returns -1 in case of error\n \t\texit(1);\n \t}\n }\n else{ //the scheduler policy is ROUND-ROBIN\n if(sched_setscheduler(getpid(), SCHED_RR, ¶m) == -1){//error handling\n \t\tcout << \"--Error2--\" << endl; //returns -1 in case of error\n \t\texit(1);\n \t}\n }\n }\n else{\n //for Non-real-time schedulers\n struct sched_param param;\n param.sched_priority = 0;\n string expr = scheduling_policies[i - 1]; //set the priority to be 0, which is 0 set as above\n if(expr == \"SCHED_BATCH\"){ //if the scheduler policy is SCHED_BATCH\n if(sched_setscheduler(getpid(), SCHED_BATCH, ¶m) == -1){//error handling\n cout << \"--Error3--\" << endl; //returns -1 in case of error\n exit(1);\n }\n }\n else if(expr == \"SCHED_IDLE\"){ //if the scheduler policy is SCHED_IDLE\n if(sched_setscheduler(getpid(), SCHED_IDLE, ¶m) == -1){//error handling\n cout << \"--Error4--\" << endl; //returns -1 in case of error\n exit(1);\n }\n }\n else{ //if the scheduler policy is SCHED_OTHER\n if(sched_setscheduler(getpid(), SCHED_OTHER, ¶m) == -1){//error handling\n cout << \"--Error5--\" << endl; //returns -1 in case of error\n exit(1);\n }\n }\n }\n args[0] = (char *) \"./longrun\"; args[1] = (char *) process_id.c_str();//store the longrun commandline arguments\n args[2] = (char *) loop_count.c_str(); //setting the LOOP_COUNT, which was set as 1000000 above \n\n /************************************************************************/\n args[3] = (char *) \"20\"; //THE MAX_LOOPS, fourth commandline argument of longrun is set here, to be 20, the user can modify here\n /************************************************************************/\n\n args[4] = NULL; //terminated by NULL char\n char *envp[] = {(char *) \"PATH=/bin\", (char *) \"USER=me\", NULL};//execute longrun using the EXECVE system-call\n execve(args[0], args, envp);\n exit(0);\n }\n else if(pid < 0){ //fork error\n cout << \"Fork error.\\n\";\n }\n }\n int status; //declare a status variable\n for(int i = 1;i <= no_of_processes;i++){ //wait for all the child processes to finish their execution\n wait(&status);\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.45822814106941223,
"alphanum_fraction": 0.46258893609046936,
"avg_line_length": 59.51388931274414,
"blob_id": "4b9fc2a33661bfdf025a7dd9ab2fe81a29f6f9b1",
"content_id": "06ed909da5ed52fa7162bb39250331b1e582b7a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 8714,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 144,
"path": "/Assgn5-CS14BTECH11031/Bounded-CS14BTECH11031.cpp",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "#include <ctime>\n#include <atomic>\n#include <vector>\n#include <cstdio>\n#include <random>\n#include <chrono>\n#include <fstream>\n#include <cstring>\n#include <sstream>\n#include <cstdlib>\n#include <unistd.h>\n#include <iostream>\n#include <pthread.h>\n#include <sys/wait.h>\n#include <sys/types.h>\n#include <sys/syscall.h>\n\nusing namespace std;\n\nfstream outfile; //file to store output\nvector<int> values; //vector to store n, k, l1, l2\ndouble elapsed = 0.0; //measure average time taken in ms\n\nclass Bounded{ //bounded lock class\n private:\n atomic<bool> *waiting; //array of atomic bools\n std::atomic_flag lock_stream = ATOMIC_FLAG_INIT; //initialize lock variable\n public:\n Bounded(int number_of_threads){ //constructor\n waiting = new atomic<bool>[number_of_threads]; //allocate memory\n memset(waiting, false, sizeof(waiting));\n for(int i = 0;i < number_of_threads;i++){ //initialize all waiting values to be false\n waiting[i].store(false);\n }\n lock_stream.clear(); //set the lock variable to be false\n }\n ~Bounded(){}; //destructor\n void lock(int); //lock method\n void unlock(int); //unlock method\n};\nBounded *test; //pointer to object of lock class\n\nvoid Bounded::lock(int i){ //lock method\n bool key = true;\n waiting[i].store(true); //set current thread waiting status to be true\n while(waiting[i].load() && key){ //standard while loop to lock other threads\n key = lock_stream.test_and_set(); //set key to existing lock value and set lock to opposite value\n }\n waiting[i].store(false); //set waiting status of current thread to be false\n}\n\nvoid Bounded::unlock(int i){ //unlock method\n int n = values[0]; //set n to be no. of threads\n int j = (i + 1) % n; //circular traversal of array\n while((j != i) && !(waiting[j].load())){ //standard while loop\n j = (j + 1) % n; //traverse to next array position\n }\n if(j == i){ //if same thread reached, set lock variable to false\n lock_stream.clear();\n }\n else{\n waiting[j].store(false); //else set waiting status of current thread to false\n }\n}\n\nstring currentTime(time_t d){ //function to return current time in standard format\n time_t now = time(NULL); //get the current time\n struct tm tstruct; //time struct\n char buf[80]; //char buffer\n tstruct = *localtime(&now); //store current time into struct\n strftime(buf, sizeof(buf), \"%X\", &tstruct); //print in standard format\n return string(buf); //return the buf\n}\n\nint delay(int l){ //calculate t on given exponential average lambda\n\tint sd = chrono::system_clock::now().time_since_epoch().count();\n\tdefault_random_engine random_gen(sd); //seed the random engine\n\texponential_distribution<double> dist_1(1.0/l); //initialize the exponential_distribution value\n\treturn (int)dist_1(random_gen); //typecast to int and return the value of t\n}\n\nvoid *testCS(void *arg){ //testCS method\n time_t curr; //variable to store current time\n string push = \"\"; //string variable to push into file\n pid_t x = syscall(__NR_gettid); //get current threadid\n int thread_no = (long) arg; //get thread number\n for(int i = 1;i <= values[1];i++){ //enter into cs k times (second vector element)\n double start, finish;\n start = time(NULL); //get current time\n printf(\"%dthCS\\tRequest at\\t%s by thread %d (tid - %d)\\n\", i, currentTime(start).c_str(), thread_no, x);\n push = to_string(i) + \"th\\tCS Request at\\t\" + currentTime(curr) + \" by thread \" + to_string(thread_no) + \" (tid - \" + to_string(x) + \")\\n\";\n fflush(stdout); //fflush from stdout\n start = time(NULL); //get start time\n\n test->lock(thread_no - 1); //call the lock method\n\n finish = time(NULL); //get end time\n elapsed += (finish - start); //get time elapsed\n printf(\"%dthCS\\tEntry at\\t%s by thread %d (tid - %d)\\n\", i, currentTime(finish).c_str(), thread_no, x);\n push += to_string(i) + \"th\\tCS Entry at\\t\" + currentTime(curr) + \" by thread \" + to_string(thread_no) + \" (tid - \" + to_string(x) + \")\\n\";\n fflush(stdout); //fflush from stdout\n sleep(delay(values[2])); //sleep since thread entered the cs\n\n test->unlock(thread_no - 1); //call the unlock method once exited the cs section\n\n curr = time(NULL); //get the current time\n printf(\"%dthCS\\tExit at\\t\\t%s by thread %d (tid - %d)\\n\", i, currentTime(curr).c_str(), thread_no, x);\n push += to_string(i) + \"th\\tCS Exit at\\t\" + currentTime(curr) + \" by thread \" + to_string(thread_no) + \" (tid - \" + to_string(x) + \")\\n\\n\";\n fflush(stdout); //fflush from stdout\n sleep(delay(values[3])); //sleep since thread exited the cs\n outfile << push; //push the output to the file\n }\n pthread_exit(NULL); //pthread EXIT\n}\n\nint main(int argc, char *argv[]){\n int found; //found int variable to capture file contents\n std::ofstream ofs(\"bounded-output.txt\", std::ios::out | std::ios::trunc);//open file in write mode to clear it\n ofs.close(); //fclose\n outfile.open(\"bounded-output.txt\", std::fstream::in | std::fstream::out | std::fstream::app);//open file r, w and a mode\n outfile << \"Bounded Waiting Time lock output : \\n\\n\"; //write first line to output file\n ifstream infile; //infile to take input\n string input, temp;\n stringstream stream; //variable declarations\n infile.open(\"inp-params.txt\"); //open the input file\n getline(infile, input); //get the line containing n, k, l1, l2\n stream << input; //push the stream into sstream variable\n while(getline(stream, temp, ' ')){ //get the space separated values and store them into vector\n stringstream(temp) >> found; //extract string from strngstream\n values.push_back(found); //v[0]-n, v[1]-k, v[2]-l1, v[3]-l2\n }\n if(argc > 1){\n values[0] = atoi(argv[1]); //if n is supplied as command-line argument\n }\n test = new Bounded(values[0]); //new Bounded object\n pthread_t threads[values[0]]; //create pthread_t array\n for(long i = 1;i <= values[0];i++){ //create n threads\n pthread_create(&threads[i], NULL, testCS, (void *) i); //function pointer to testCS method\n }\n for(int i = 1;i <= values[0];i++){ //join all the threads\n pthread_join(threads[i], NULL);\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5094426274299622,
"alphanum_fraction": 0.5146015882492065,
"avg_line_length": 43.85537338256836,
"blob_id": "e1ec9715015fb9d3a8f462e422ea38cd01c1c05e",
"content_id": "e1c07f6133fb35c59b3d7370629798d856284ca7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 10855,
"license_type": "no_license",
"max_line_length": 155,
"num_lines": 242,
"path": "/Assn7-Deadlocks-CS14BTECH11031/bankers-CS14BTECH11031.cpp",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "#include <ctime>\n#include <mutex>\n#include <atomic>\n#include <vector>\n#include <cstdio>\n#include <random>\n#include <chrono>\n#include <fstream>\n#include <cstring>\n#include <sstream>\n#include <cstdlib>\n#include <unistd.h>\n#include <iostream>\n#include <pthread.h>\n#include <sys/wait.h>\n#include <sys/types.h>\n#include <semaphore.h>\n#include <sys/syscall.h>\n\nusing namespace std;\n\ndouble myRand(double low, double high){\n std::default_random_engine generator; //random number generator\n std::uniform_real_distribution<double> distribution(low, high);\n double number = distribution(generator); //get the number using uniform_real_distribution\n return number; //return the number\n}\n\nvoid printArray(int *array, int n){\n for(int i = 0;i < n;i++){\n if(i == n - 1){\n printf(\"%d\", array[i]);\n }\n else{\n printf(\"%d, \", array[i]);\n }\n }\n printf(\"\\n\");\n}\n\nstring currentTime(time_t d){ //function to return current time in standard format\n time_t now = time(NULL); //get the current time\n struct tm tstruct; //time struct\n char buf[80]; //char buffer\n tstruct = *localtime(&now); //store current time into struct\n strftime(buf, sizeof(buf), \"%X\", &tstruct); //print in standard format\n return string(buf); //return the buf\n}\n\nint delay_sleep(int l){ //calculate t on given exponential average lambda\n\tint sd = chrono::system_clock::now().time_since_epoch().count();\n\tdefault_random_engine random_gen(sd); //seed the random engine\n\texponential_distribution<double> dist_1(1.0/l); //initialize the exponential_distribution value\n\treturn (int) dist_1(random_gen); //typecast to int and return the value of t\n}\n\nint restIters, sleep_mu, n, acqRelRatio, m, emptyResources;\nint *available; //initialize arrays required for banker's algorithm\nint **max_alloc;\nint **allocation;\nint **need;\nint **request;\nint **release;\nint **tempAllocationState;\nint *tempAvailResources;\nstd::mutex mtx; //mutex for critical section\n\nbool is_safe_state(int iteration){\n bool *finish = new bool[n]; //initialize boolean array\n memset(finish, false, sizeof(finish)); //initialize all finish values to be 0\n int finished = 0; //initialize the finished value to be 0\n for(int i = 0;i < n;i++){\n for(int j = 0;j < n;j++){\n int resource_c = 0; //initialize resources_count to be 0\n if(finish[j] == true){\n ; //do nothing\n }\n else{\n\t\t\t\tfor(int k = 0;k < m;k++){ //loop over to check if allocation is true\n\t\t\t\t\tif((max_alloc[j][k] - tempAllocationState[j][k]) <= tempAvailResources[k]){\n\t\t\t\t\t\tresource_c++; //if true, then increase resource count\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t\tif(resource_c == m){ //if all the resources allocated, mark it to be finished\n\t\t\t\t\tfinish[i] = true; //mark the finish to be true, if conditions are satisfied\n\t\t\t\t\tfinished++; //Increment the finished variable\n\t\t\t\t\tfor(int j1 = 0;j1 < m;j1++){ //update available resources\n\t\t\t\t\t\ttempAvailResources[j1] += tempAllocationState[j][j1];\n\t\t\t\t\t}\n\t\t\t\t}\n }\n if(finished == n){ //if all finished,\n //safe state found\n\t\t\t\t;\n\t\t\t}\n }\n }\n bool get = true; //all finish values must be true\n for(int i = 0;i < n;i++){\n if(finish[i] == false){ //if any one of the finish values are false,\n get = false; //set the get variable to be false\n break; //break\n }\n }\n //safe state not found\n return get; //safe state not found, return false\n}\n\nvoid request_function(int process_no, int *request_array, int iteration){\n mtx.lock(); //apply the mutex lock\n for(int i = 0;i < n;i++){\n \tfor(int j = 0;j < m;j++){ //loop over all the processes\n \t\ttempAllocationState[i][j] = allocation[i][j];\n \t\tif(i == process_no){ //get the current process no.\n tempAvailResources[j] = available[j] - request_array[j];\n \t\t\ttempAllocationState[i][j] += request_array[j];\n \t\t}\n \t}\n }\n if(!is_safe_state(iteration)){ //if not safe state, return\n //printf(\"Thread %d\\'s not allocated resources for %dth iteration for deadlock avoidance.\\n\", process_no, iteration);\n\t\tmtx.unlock(); //unlock the mutex lock\n return;\n }\n else{ //if safe state\n int counts = 0;\n for(int i = 0;i < m;i++){ //restore components used\n allocation[process_no][i] += request_array[i];\n need[process_no][i] = max_alloc[process_no][i] - allocation[process_no][i];\n\t\t\tavailable[i] -= request_array[i]; //restore available resources\n\t\t\tcounts = counts + (need[process_no][i] == 0);\n\t\t}\n mtx.unlock(); //unlock the mutex lock\n return;\n }\n}\n\nvoid release_function(int process_no, int *release_array){\n\tmtx.lock(); //lock the release function\n\tfor(int i = 0;i < m;i++){\n need[process_no][i] = max_alloc[process_no][i];\n\t\tallocation[process_no][i] = 0; //set its allocation to be zero, once released\n available[i] += max_alloc[process_no][i]; //restore available resources\n\t}\n\tmtx.unlock(); //unlock the release function\n}\n\nvoid *workerThread(void *arg){\n int thread = (long) arg; //typecast the thread\n pid_t x = syscall(__NR_gettid);\n double start, finish; //declare variables to record start and finish times\n for(int i = 0;i < restIters;i++){\n sleep(delay_sleep(sleep_mu));\n double randVal = myRand(0.0, 1.0); //generate the random value\n if(randVal <= acqRelRatio){\n for(int i = 0;i < m;i++){ //if ration satisfied\n need[thread][i] = max_alloc[thread][i] - allocation[thread][i];\n request[thread][i] = myRand(0.0, (double) need[thread][i]);\n allocation[thread][i] += request[thread][i];\n }\n start = time(NULL); //record the time\n printf(\"%dth resource request by thread %d made at time %s consisting of the following items : \\n\", i + 1, thread, currentTime(start).c_str());\n printArray(request[thread], m); //print the array\n //call the request function\n request_function(thread, request[thread], i + 1);\n\n finish = time(NULL); //record the finish time\n printf(\"%dth resource request by thread %d granted at time %s\\n\", i + 1, thread, currentTime(finish).c_str());\n }\n else{\n for(int i = 0;i < m;i++){ //else release the resources\n release[thread][i] = myRand(0.0, (double) allocation[thread][i]);\n allocation[thread][i] -= release[thread][i];\n }\n start = time(NULL); //record the current time\n printf(\"%dth release request by thread %d made at time %s consisting of the following items : \\n\", i + 1, thread, currentTime(start).c_str());\n printArray(release[thread], m); //print the array\n //call the release function\n release_function(thread, release[thread]);\n\n finish = time(NULL); //record the current time\n printf(\"%dth release request by thread %d granted at time %s\\n\", i + 1, thread, currentTime(finish).c_str());\n }\n }\n sleep(delay_sleep(sleep_mu)); //exponential sleep\n\n start = time(NULL);\n printf(\"Final release request by thread %d made at time %s consisting of the following items : \\n\", thread, currentTime(start).c_str());\n printArray(release[thread], m);\n\n release_function(thread, allocation[thread]); //call the release function\n\n finish = time(NULL); //capture finish time\n printf(\"Final release request by thread %d granted at time %s\\n\", thread, currentTime(finish).c_str());\n}\n\nint main(int argc, char const *argv[]){\n string input, temp; //declare string variables for file parsing\n stringstream stream;\n cin >> m; //take input into the variable m\n available = new int[m]; //allocate memory to array\n for(int i = 0;i < m;i++){\n cin >> available[i]; //take input into the available resources array\n }\n cin >> n; //take input into the variable n\n tempAvailResources = new int[m]; //allocate memory to all the two-d arrays\n allocation = new int*[n];\n need = new int*[n];\n max_alloc = new int*[n];\n request = new int*[n];\n release = new int*[n];\n tempAllocationState = new int*[n];\n for(int i = 0;i < n;i++){ //memory allocation\n allocation[i] = new int[m];\n need[i] = new int[m];\n max_alloc[i] = new int[m];\n request[i] = new int[m];\n release[i] = new int[m];\n tempAllocationState[i] = new int[m];\n }\n for(int i = 0;i < n;i++){ //input into the max allocation array\n for(int j = 0;j < m;j++){\n cin >> max_alloc[i][j]; //scan into the matrix\n }\n }\n cin >> restIters;\n cin >> sleep_mu;\n cin >> acqRelRatio; //take input mu, iteration_count and ration\n for(int i = 0;i < n;i++){\n for(int j = 0;j < m;j++){\n allocation[i][j] = 0; //initialize allocation matrix\n }\n }\n pthread_t threads[n]; //create n threads\n for(long i = 0;i < n;i++){\n pthread_create(&threads[i], NULL, workerThread, (void *) i);\n }\n for(int i = 0;i < n;i++){ //join the threads v/s they finish their execution\n pthread_join(threads[i], NULL);\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3913043439388275,
"alphanum_fraction": 0.46086955070495605,
"avg_line_length": 18.16666603088379,
"blob_id": "996e02172efadd868b2e3b6f35423e057dfb0808",
"content_id": "0f1cf0373c4cb8e368afab2bc421305abb1b62e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 115,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 6,
"path": "/Assgn5-CS14BTECH11031/bscript",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nfor _ in {15..45..10}; do\n #get = $(($_*10))\n ./bounded $(($_));\n echo \"Execution done\";\ndone\n"
},
{
"alpha_fraction": 0.7156511545181274,
"alphanum_fraction": 0.7479091882705688,
"avg_line_length": 54.79999923706055,
"blob_id": "be878279f379af181465320a75bd98defcecbc55",
"content_id": "a8393e81a8d64ca1eb3ad66c72ea462b5bf72845",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 837,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 15,
"path": "/Assgn6-CS14BTECH11031/Readme.txt",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "The contents of the assignment folder are\t:\n\t1.\treader_writer-CS14BTECH11031.cpp\n\t2.\tin-params.txt\t:\tContains nw, nr, kw, kr, l1, l2\n\t3.\tgraph_script.py - Script used to plot avergage-time taken (ms) by a reader/writer thread to execute its respective task\n\t4.\tReport.pdf - Graph of avergage-times (in ms) taken by reader/writer threads to perform their respective tasks,\n other anomalies explanation, etc.\n\t5.\tPlot.png\t-\tPlot as given in the report above.\n\nRunning on Terminal :\n\t1.\tg++ -std=c++11 reader_writer-CS14BTECH11031.cpp -pthread\n 3. [a.out] for both programs to execute the executable found, can have one command-line argument, n - number of threads.\n\nNote :\nThe above program use C++11's library functions, and hence the appropriate compiler switch. The output of the above program is\n a log-file named \"output.txt\".\n"
},
{
"alpha_fraction": 0.4733031690120697,
"alphanum_fraction": 0.4809954762458801,
"avg_line_length": 51,
"blob_id": "08266f0c33209456c1e3ed9abc9ec3a1d3524a2e",
"content_id": "0e214451b49d99c80c720e592b336ddbe2de7e3a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4420,
"license_type": "no_license",
"max_line_length": 165,
"num_lines": 85,
"path": "/Assgn3-CS14BTECH11031/Assgn3-Task2Src-CS14BTECH11031.cpp",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "#include <ctime>\n#include <cstdio>\n#include <fcntl.h>\n#include <cstring>\n#include <cstdlib>\n#include <iostream>\n#include <unistd.h>\n#include <sys/mman.h>\n#include <sys/wait.h>\n#include <sys/types.h>\n\nusing namespace std;\n\nlong fibonacci(long n){ // function to calculate nth fibonacci number\n long prev = 1, curr = prev, next = prev, i; // initialize prev and curr to 1\n for(i = 3;i <= n;i++){ // keep taking sum of curr and prev\n next = curr + prev;\n prev = curr; // update prev and curr\n curr = next;\n }\n return next; // next is the nth fibonacci number\n}\n\nint main(int argc, char *argv[]){\n long n;\n if(argc > 1) // if command-line argument is given, set n to int(argv[1])\n n = atoi(argv[1]);\n else{\n cout << \"Enter the number of terms : \"; // else take the input from the user\n cin >> n;\n }\n while(n < 10){ // loop until user not enters n greater than or equal to 10\n cout << \"Please enter a number greater than 10, Enter : \";\n cin >> n;\n }\n int shared;\n\n clock_t start, end; // start the clock\n start = clock();\n double cpu_time_used; // store the time elapsed in double variable, cpu_time_used\n // create shared memory object, with read/write permissions\n shared = shm_open(\"/shared_region\", O_CREAT | O_RDWR, S_IRUSR | S_IWUSR);\n if(shared == -1){ // on failure of successful object creation\n cout << \"Shared memory segment open/create fail.\\n\";\n exit(1); // exit with non-zero status\n }\n long *fib_array;\n fib_array = new long[n + 1]; // allocate memory to fib_array for storing the complete sequence\n fib_array = (long *) mmap(NULL, sizeof(fib_array), PROT_READ | PROT_WRITE, MAP_SHARED | MAP_ANONYMOUS, shared, 0);\n if(fib_array == MAP_FAILED){ // typecast the pointer to the mapped area (in the virtual address space of the calling process) to long*\n cout << \"mmap fail.\\n\"; // case of mmap fail\n exit(1); // exit with non-zero status\n }\n fib_array[0] = 0, fib_array[1] = 1; // initialize the top two array values\n for(int i = 2;i <= 5;i++){ // calculate the first five fibonacci numbers\n fib_array[i] += fib_array[i - 1] + fib_array[i - 2];\n }\n for(int i = 6;i <= n;i++){ // loop to calculate rest n - 5 fibonacci numbers\n pid_t pid; // create a process id\n if((pid = fork()) == 0){ // if its a child process, compute ith fibonacci number and place in the shared array\n fib_array[i] = fibonacci(i);\n exit(0); // exit once computed\n }\n else if(pid < 0){ // fork error\n cout << \"Fork error.\\n\";\n }\n }\n int status; // status variable whose address is the argument in the wait() function\n for(int i = 6;i < n + 1;++i){ // the parent prints the whole sequence only after all child processes exit\n wait(&status); // wait for all the child processes to compute their respective fibonacci number\n }\n \n end = clock(); // end the clock\n cpu_time_used = ((double) (end - start))/CLOCKS_PER_SEC; // store the elapsed time in double variable\n\n cout << \"Fibonacci sequence : \"; // output the fibonacci sequence\n for(int i = 0;i <= n;i++){\n cout << fib_array[i] << \" \";\n }\n cout << endl;\n cout << \"Time taken : \";\n cout << cpu_time_used << endl; // output the time of execution\n shared = shm_unlink(\"/shared_region\"); // unlink and destroy/de-allocate the shared memory object created\n return 0;\n}\n"
},
{
"alpha_fraction": 0.6444340348243713,
"alphanum_fraction": 0.6467825174331665,
"avg_line_length": 61.617645263671875,
"blob_id": "44fc20a572c6fd75d4bba32a61346ba405f9bbd3",
"content_id": "5370a1f6676741394e9e9f200fddcf7e7ad6b2cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2129,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 34,
"path": "/Assgn2-CS14BTECH11031/src/Assgn2Src-CS14BTECH11031.c",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "#include <linux/module.h> // Needed to write kernel module\n#include <linux/kernel.h> // Needed for KERN_INFO\n#include <linux/sched.h> // Needed for task_struct\n#include <linux/init.h> // Needed for module_init() and module_exit() macros\n#include <linux/dcache.h>\n // .ko is the kernel object file, with automatically kernel generated data-structures, needed by the kernel\nint start_module(void){ // invoked at sudo insmod ./*file*.ko\n struct task_struct *task; // define the structure task_struct to obtain a particular process's details\n\n // message printed at the time of insmod (module loading), and followed by each of the tasks' details\n printk(KERN_INFO \"Kernel module successfully loaded !\\n\");\n\n // loop over each process using the 'for_each_process' macro defined in the \"linux/sched.h\" file\n for_each_process(task){\n // print task-name or executable name using task->comm[16] (char array with maximum capacity of 16 chars)\n\t printk(\"Task-Name : %s -|- \", task->comm);\n // print task-state using task->state\n printk(\"Task-State : %ld -|- \", task->state);\n // print PID using task->pid\n printk(\"PID : %d\\n\", task->pid);\n\t}\n return 0; // successful return from the function\n}\n\nvoid end_module(void){ // invoked at sudo rmmod ./*file*.ko (unloading of the module)\n printk(KERN_INFO \"Kernel module successfully unloaded !\\n\");\n} // exit (unload confirmation) message printed once the kernel module is successfully unloaded\n\nmodule_init(start_module); // put start_module function in module_init to invoke the function at 'insmod' (insert)\nmodule_exit(end_module); // put end_module functin in module_exit to invoke the function at 'rmmod' (exit)\n\nMODULE_LICENSE(\"GPL\"); // module infomation including license (license for loadable kernel module), author and description\nMODULE_AUTHOR(\"saurabh\");\nMODULE_DESCRIPTION(\"\\\\'ps -el\\\\' command implementation using task_struct\");\n"
},
{
"alpha_fraction": 0.5839962363243103,
"alphanum_fraction": 0.6059896945953369,
"avg_line_length": 18.787036895751953,
"blob_id": "0d11a59db148dec5a25744c85a4c10fcc8325ee9",
"content_id": "8924c81308801ecf4089afce88896ec54b56bef6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2137,
"license_type": "no_license",
"max_line_length": 152,
"num_lines": 108,
"path": "/MinixInstallation-master/ass2q1.c",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<unistd.h>\n#include<sys/types.h>\n#include<fcntl.h>\nchar readst[10];\nint fd_in,fd_out,lines;\n//Function to count the total number of lines\nint totallines(int fd_in)\n{\n\tprintf(\"in fun lines\");\n\tint n, flines=0;\n\twhile((n=read(fd_in,readst,1))>0)\n\t{ \n\t//std::cout<<\"\\n\"<<n<<\"\\t\"<<int(n)<<\"\\n\";\n\t // printf(\"read %d\\n\",n);\n\t\tn=readst[0];\n\t // printf(\"new n %d\\n\",n);\n\t\n\tif(n==10)\n\t{\n\t\tflines++;\n\t\tprintf(\"\\nnewline\");\n\t}\n\t}\n\tprintf(\"\\nlines- %d\",flines);\n\treturn flines;\n}\n//Function to find the position of first charecter of a line\nint movetoline(int fd_in,int lno)\n{\n\tprintf(\"\\nin fun move\");\n\tint l=0,n;\n\tint pos=0;\n\twhile((n=read(fd_in,readst,1))>0)\n{\n//\tstd::cout<<n<<\"\\t\"<<readst<<\"\\n\";\n\t\tpos++;\n\t\tif (l==lno-1)\n\t\t{\n\t\t\tprintf(\"\\nAt position : %d\",pos);\n\t\t\treturn pos;\n\t\n\t}\n\t\tif(readst[0]==10)\n\t\t\tl++;\n\t}\n\treturn pos;\n}\n\nint main(int argc,char *argv[])\n{\n\tchar buff[2];\n\tssize_t size_in,size_out;\n\toff_t seekret,pos;\n\tif(argc!=3)\n\t{\n\t\tprintf(\"Incorrect usage:\\nUsage:./progobj <file1> <file2>\");\n\t\treturn 0;\n\t}\n\t//Getting the file descriptors\n\t\t//input file in read only mode\n\tfd_in=open(argv[1],O_RDONLY);\n\tif(fd_in==-1)\n\t{\n\t\tprintf(\"Failed to load input file!\");\n\t\treturn 0;\n\t}\n\t\t//output file is opened in writeonly mode and if doesnt exists, the file will be created.Care is taken that the owner of the file has all permissions.\n\tfd_out=open(argv[2],O_WRONLY|O_CREAT,0700);\n\tif(fd_in==-1)\n\t{\n\t\tprintf(\"Failed to load input file!\");\n\t\treturn 0;\n\t}\n\tseekret=lseek(fd_in,0,SEEK_SET);\n\tlines=totallines(fd_in);\n//\tprintf(\"came\");\n\tseekret=lseek(fd_in,0,SEEK_SET);\n\twhile (lines)\n\t{\n\t\tint x=movetoline(fd_in,lines);\n\t//\tstd::cout<<\"\\nx:\"<<x;\n\t//\tstd::cout<<\"\\nline:\"<<lines;\n\t\t\n\t\tseekret=lseek(fd_in,0,SEEK_SET);\n\t\tseekret=lseek(fd_in,x-1,SEEK_SET);\n\t\twhile(1)\n\t\t{\n\t\t\tsize_in=read(fd_in,&buff,1);\n\t\t\tsize_out=write(fd_out,&buff,1);\n\t\t\t//do check\n\t\t\t//printf(\"buff %c\",buff[0]);\n\t\t\tif(buff[0]==10)\n\t\t\t{\n\t\t\t\t//printf(\"buff=10\");\n\t\t\t\tbreak;\n\t\t\t}\n\t\t}\n\t\tseekret=lseek(fd_in,0,SEEK_SET);\n\t\tlines--;\t\n\t}\t\n\n\t\n\tprintf(\"Completed reverse copying from %s to %s .\",argv[1],argv[2]);\n\tclose(fd_in);\n\tclose(fd_out);\n\n}\n"
},
{
"alpha_fraction": 0.4657415449619293,
"alphanum_fraction": 0.47441455721855164,
"avg_line_length": 45.74324417114258,
"blob_id": "372b4af064dba7591d79834a1cb4599f7e9e9b02",
"content_id": "f720f526e9cecfc7c72df8553cf2bb0629bdedf0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3459,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 74,
"path": "/Assgn3-CS14BTECH11031/Assgn3-Task1Src-CS14BTECH11031.cpp",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "#include <ctime>\n#include <cstdio>\n#include <cstring>\n#include <cstdlib>\n#include <iostream>\n#include <unistd.h>\n#include <pthread.h>\n\nusing namespace std;\n\nlong *fib_array; // create flobal array shareable by threads\n\nlong fibonacci(long n){ // function to calculate nth fibonacci number\n long prev = 1, curr = prev, next = prev, i; // initialize prev and curr to 1\n for(i = 3;i <= n;i++){ // keep taking sum of curr and prev\n next = curr + prev;\n prev = curr; // update prev and curr\n curr = next;\n }\n return next; // next is the nth fibonacci number\n}\n\nvoid *fib_calculate(void *counter){ // routine executed by the thread\n long index = (long) counter; // typecast to long\n fib_array[index] = fibonacci(index); // call the fibonacci() function in the thread\n pthread_exit(0); // exit once the job is done\n}\n\nint main(int argc, char *argv[]){\n long n, i;\n if(argc > 1) // if command-line argument is given, set n to int(argv[1])\n n = atoi(argv[1]);\n else{\n cout << \"Enter the number of terms : \"; // else take the input from the user\n cin >> n;\n }\n while(n < 10){ // loop until user not enters n greater than or equal to 10\n cout << \"Please enter a number greater than 10, Enter : \";\n cin >> n;\n }\n fib_array = new long[n + 1]; // allocate memory to the fib_array\n fib_array[0] = 0; fib_array[1] = 1; // initialize top two values\n\n clock_t start, end; // start the clock\n start = clock();\n double cpu_time_used; // store the time elapsed in double variable, cpu_time_used\n\n for(i = 2;i <= 5;i++){ // calculate first five fibonacci numbers in the parent thread\n fib_array[i] += fib_array[i - 1] + fib_array[i - 2];\n }\n\n pthread_t fib_th[n - 5]; // create an array of thread identifiers\n for(i = 6;i <= n;i++){\n pthread_attr_t attr; // the set of thread attributes\n pthread_attr_init(&attr); // get the default attributes by passing (initialize attr object)\n // the address of thread attribute object in pthread_attr_init function\n pthread_create(&fib_th[i - 6], &attr, fib_calculate, (void *) i);\n }\n for(i = 6;i <= n;i++){ // join the threads once all have computed their fibonacci number\n pthread_join(fib_th[i - 6], NULL);\n }\n\n end = clock(); // end the clock and record the time\n cpu_time_used = ((double) (end - start))/CLOCKS_PER_SEC;\n\n cout << \"Fibonacci sequence : \";\n for(i = 0;i < n + 1;i++){ // output the fibonacci sequence\n cout << fib_array[i] << \" \";\n }\n cout << endl;\n cout << \"Time taken : \"; // output the time of execution\n cout << cpu_time_used << endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.7203140258789062,
"alphanum_fraction": 0.7546614408493042,
"avg_line_length": 47.52381134033203,
"blob_id": "08b67a585a43ccfddd1c90cdc2ddd85f1082cb85",
"content_id": "dcc39a4f6571464bdfb912493f6e1da242261ff3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 1019,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 21,
"path": "/Assgn4-CS14BTECH11031/Readme.txt",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "The contents of the assignment folder are\t:\n\t1.\tlongrun.c\n\t2.\tlongrun\t-\tThe executable of the above longrun.c file, executed by the MAIN program\n\t3.\tCS14BTECH11031.cpp\t-\tThe MAIN program\n\t4.\toutput.txt : Contains the output of the MAIN program\n\t5.\tinput.txt\t:\tConatains k = 150 scheduler_policies\n\t6.\tgraph_script.py - Script used to calculate the average time for each category and graph plotting as well\n\t7.\tReport.pdf - Graph of waiting times v/s category and explanation.\n\t8.\tPlot.png and Plot_.png\t-\tImage versions of the Graph.\n\nRunning on Terminal :\n\t1.\tg++ CS14BTECH11031.cpp\n\t2.\tsudo ./a.out\t-\tThe execution requires ROOT privileges.\n\nNote :\n\tThe commandline arguements for the longrun.c program, namely :\n\t\tLOOP_COUNT and MAX_LOOPS\t- the third and fourth commandline argument,\n\tare set to be 100000 and 20 respectively. The user can modify these values in the MAIN program itself.\n\n\tAlso, if the user wishes to re-compile longrun.c, this should be compiler using the C++ compiler.\n\t(g++ -o longrun longrun.c)\n"
},
{
"alpha_fraction": 0.549155592918396,
"alphanum_fraction": 0.5536791086196899,
"avg_line_length": 47.764705657958984,
"blob_id": "5cbcf3b3b2a3f952e9e10d385563578d516601a0",
"content_id": "99bf51e9b3adba4b6fc55e8896ded8597b3810bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3316,
"license_type": "no_license",
"max_line_length": 163,
"num_lines": 68,
"path": "/Assgn1-CS14BTECH11031/Assgn1-CS14BTECH11031-task3.cpp",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <string>\n#include <cstdlib>\n#include <cstring>\n#include <cstdio>\n#include <dirent.h>\n#include <sys/stat.h>\n#include <sys/types.h>\n#include <unistd.h>\n#include <ftw.h>\n\nusing namespace std;\n\nint fn(const char *path, const struct stat *statobj, int flag, struct FTW *ftwobj){\n int flag_ = remove(path); //removes data entries in the file tree directory structure using remove(path)\n return flag_;\n}\n\nint rmrf(const char *path){ //parent function to invoke \"ntfw\" system call, converts file directory into tree structure for file tree walking\n return nftw(path, fn, 128, FTW_DEPTH | FTW_PHYS);\n} //the first argument is pathname, second is the function to remove data entries\n //at each node, third one the maximum depth and the fourth being the flags passed as args\n\nvoid remove_dir(const char *path){ //recursive routine to delete folder and subfolders along subfiles\n int check;\n string filename, new_path;\n DIR *directory; //pointer to directory\n directory = opendir(path); //open directory\n if(directory != NULL){ //if directory is NULL, return\n struct dirent *curr; //pointer to readdir object\n while((curr = readdir(directory)) != NULL){ //iterate over all entries present in a directory\n string conv = string(curr -> d_name);\n char *hold = (char *)malloc(1024);\n bool check__ = false;\n struct stat stat__;\n check = stat(hold, &stat__); //determine whether the entry is a folder/file, here in this case, a folder if self->d_type == DT_DIR\n if(curr -> d_type == DT_DIR || S_ISDIR(stat__.st_mode)){\n if((strcmp(curr->d_name, \".\") == 1 || strcmp(curr->d_name, \"..\") == 1) || check__ == true){\n continue; //leave \"/.\" and \"/..\" directories\n }\n new_path = string(path) + \"/\" + string(curr -> d_name);\n remove_dir(new_path.c_str()); //recurse again for interior folders\n }\n else{\n filename = string(curr -> d_name); //else the entries are files\n filename = string(path) + \"/\" + string(curr -> d_name);\n remove(filename.c_str()); //delete them using remove(path)\n }\n }\n closedir(directory); //close the current directory\n rmdir(path); //once the directory is empty, rmdir() can be invoked\n }\n}\n\nint main(){\n struct stat check; //stat object\n char check_[1024]; //char buffer\n cout << \"Enter complete path of directory to be deleted : \";\n cin.getline(check_, sizeof(check_)); //getline use to avoid whitespaces in between\n int flag = stat(check_, &check); //flag for storing stat return value\n if(!(check.st_mode & S_IFDIR)){ //if error or directory not exists, report error\n cout << \"Invalid directory.\" << endl;\n return 0;\n }\n //flag = rmrf(check_); //invoke appropriate function calls\n remove_dir(check_);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5497866272926331,
"alphanum_fraction": 0.5640113949775696,
"avg_line_length": 45.86666488647461,
"blob_id": "79dd6ba276fdd61ce97838e5e293cc6f200fff83",
"content_id": "2bc5a40b02186a8bbc67b65ce263ad800531e0b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1406,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 30,
"path": "/Assgn1-CS14BTECH11031/Assgn1-CS14BTECH11031-task2.cpp",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <cmath>\n#include <fcntl.h>\n#include <unistd.h>\n#include <sys/types.h>\n#include <sys/stat.h>\n\nusing namespace std;\n\nint main(){\n size_t file_size; //size_t variable\n struct stat buffer; //stat struct object to store file details\n int fp = 0;\n char input_name[1024]; //char buffer to store input file name\n cout << \"Enter file name : \";\n cin >> input_name;\n int get = stat(input_name, &buffer); //invoke stat function to get details about the file\n if(get != 0){ //error if the stat function not returns 0 (-1 in case of error)\n cout << \"Invalid file.\" << endl;\n return 0;\n }\n fp = open(input_name, O_RDWR); //integer based file-descriptor for lseek input\n file_size = lseek(fp, 0, SEEK_END); //calculate file size having fd as descriptor, 0 as offset bytes, and seeking from end\n cout << \"File size using \\\"lseek\\\" : \" << file_size << endl;\n cout << \"Blocks using \\\"lseek\\\" : \" << ceil((size_t)file_size/512.0) << endl;\n file_size = buffer.st_size; //block size calculation in both cases (ceil(size/512.0) and st_blocks) \n cout << \"File size using \\\"stat\\\" : \" << file_size << endl;\n cout << \"Blocks using \\\"stat\\\" : \" << buffer.st_blocks << endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.7734940052032471,
"alphanum_fraction": 0.7927711009979248,
"avg_line_length": 40.54999923706055,
"blob_id": "a885972f82eceb0beb8f91f3b4cf082106dfc469",
"content_id": "d7452d1e999123c54c0b07458751ebe86d3c3e83",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 830,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 20,
"path": "/Minix-MinixScheduling-master/Readme.md",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "The project folder contains \n\t1.sourcecode -Contains the scheduler files for diff\n\t2.Designdocumentation.pdf -Describes the goals,design,implementation.\n\t3.Screenshot of an implementation\n\t4.Values.txt :Contains the waitiing and turnaround time\n\t5.script.py -Script used by me to processa all the values and generate the average.\nHow to run/implement\n\n1. Copy the respective scheduler file into /usr/src/minix/servers/sched as schedule.c\n\n2. \tcd /usr/src/releasetools\n\tmake hdboot\n\tThis makes all dependencies of the scheduler by rebuilding the kernel.\n\n3. cd <folder_path_containing_testfiles>\n\tclang longrun1.c -o longrun1 \n\tclang longrun2.c -o longrun2\n\tclang mytest.c \n\t./a.out > scheduler.txt\n\tThis writes waiting & turnaround times of 10 longrun0 and longrun1 instances scheduled according to our scheduler to the logfile."
},
{
"alpha_fraction": 0.5962924957275391,
"alphanum_fraction": 0.6143151521682739,
"avg_line_length": 35.261680603027344,
"blob_id": "0c18512ae088ac6da44d07a4435c0b8a82ba7f0a",
"content_id": "154a176b15712365a65751e72bd9c678c8305a6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3884,
"license_type": "no_license",
"max_line_length": 200,
"num_lines": 107,
"path": "/Assgn4-CS14BTECH11031/longrun.c",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <sched.h>\r\n#include <stdlib.h>\n#include <unistd.h>\r\n#include <sys/time.h>\r\n#include <sys/types.h>\n\n#define LOOP_COUNT_MIN 100\n#define LOOP_COUNT_MAX 100000000\n\n//Function to calculate time of running (total turnaround time including waiting time)\nlong long diff (struct timeval start, struct timeval end) {\n long long difference = (end.tv_sec - start.tv_sec);\n difference *= 1000000;\n //micro-second precision\n difference += (end.tv_usec - start.tv_usec);\n return difference;\n}\n\nint main (int argc, char *argv[]) {\n char *idStr;\n unsigned int v;\n int i = 0;\n int iteration = 1;\n int loopCount;\n int maxloops;\n FILE *fp;\n fp = fopen(\"output.txt\", \"a\");\n\n //Print current Scheduler, priority, quantum\n //Set your scheduler priority.\n //Print new Scheduler, priority, quantum\n int policy;\n char *scheduler__;\n if ((policy = sched_getscheduler (getpid())) == -1)\n fprintf(stderr, \"Unable to get policy.\\n\");\n else{\n if (policy == SCHED_FIFO)\n scheduler__ = (char *) \"SCHED_FIFO\";\n else if (policy == SCHED_BATCH)\n scheduler__ = (char *) \"SCHED_BATCH\";\n else if (policy == SCHED_IDLE)\n scheduler__ = (char *) \"SCHED_IDLE\";\n else if (policy == SCHED_OTHER)\n scheduler__ = (char *) \"SCHED_OTHER\";\n else if (policy == SCHED_RR)\n scheduler__ = (char *) \"SCHED_RR\";\n }\n\n if (argc < 3 || argc > 4) {\n printf (\"Usage: %s <id> <loop count> [max loops]\\n\", argv[0]);\n exit (-1);\n }\n /* Start with PID so result is unpredictable */\n v = getpid ();\n /* ID string is first argument */\n idStr = argv[1];\n /* loop count is second argument */\n loopCount = atoi (argv[2]);\n if ((loopCount < LOOP_COUNT_MIN) || (loopCount > LOOP_COUNT_MAX)) {\n printf (\"%s: loop count must be between %d and %d (passed %d)\\n\", argv[0], LOOP_COUNT_MIN, LOOP_COUNT_MAX, atoi(argv[2]));\n exit (-1);\n }\n /* max loops is third argument (if present) */\n if (argc == 4) {\n maxloops = atoi (argv[3]);\n } else {\n maxloops = 0;\n }\n\n struct timeval start, end;\n double waiting_time = 0;\n //clock_start\n gettimeofday (&start, NULL);\n\n /* Loop forever - use CTRL-C to exit the program */\n while (1) {\n /* This calculation is done to keep the value of v unpredictable. Since the compiler can't calculate it in advance (even from the original value of v and the loop count), it has to do the loop. */\n v = (v << 4) - v;\n if (++i == loopCount) {\n /* Exit if we've reached the maximum number of loops. If maxloops is 0 (or negative), this'll never happen... */\n if (iteration == maxloops) {\n break;\n }\n\n /* Feel free to change the output code to make the display clear.\n In case the display from different processes get mixed, you can use synchronization tools to make the display clear.\n You can comment it out if this output is not required.\n */\n printf (\"Process id %d - %s:%06d\\n\", getpid(), idStr, iteration);\n fprintf (fp, \"Process id %d - %s:%06d\\n\", getpid(), idStr, iteration);\n fflush (stdout);\n iteration += 1;\n i = 0;\n }\n }\n\n //clock_end()\n gettimeofday (&end, NULL);\n\n /* Print a value for v that's unpredictable so the compiler can't optimize the loop away. Note that this works because the compiler can't tell in advance that it's not an infinite loop. */\n printf (\"Total-time taken = %0.6lf seconds\\n\", (double) (diff(start, end)/1000000.0));\n fprintf (fp, \"Total-time taken = %0.6lf seconds\\n\", (double) (diff(start, end)/1000000.0));\n printf (\"The final value of v is 0x%08x of process %d with CURRENT Scheduler-policy : %s\\n\", v, getpid(), scheduler__);\n fprintf(fp, \"The final value of v is 0x%08x of process %d with CURRENT Scheduler-policy : %s\\n\", v, getpid(), scheduler__);\n fprintf(fp, \"/*********************************************************************************************/\\n\");\n}\n"
},
{
"alpha_fraction": 0.6309962868690491,
"alphanum_fraction": 0.660516619682312,
"avg_line_length": 21.58333396911621,
"blob_id": "7fd1df21aa6ef196008027b082b44c540ed19ace",
"content_id": "955019093195c389c923769e88a948700addc530",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 271,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 12,
"path": "/Assgn2-CS14BTECH11031/src/Makefile",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "obj-m += Assgn2Src-CS14BTECH11031.o\nUSER := $(shell uname -r)\nPWD := $(shell pwd)\n\nall:\n\tmake -C /lib/modules/$(USER)/build M=$(PWD) modules\n\nclean:\n\tmake -C /lib/modules/$(USER)/build M=$(PWD) clean\n\ninstall:\n\tmake -C /lib/modules/$(USER)/build M=$(PWD) modules_install\n"
},
{
"alpha_fraction": 0.6089702844619751,
"alphanum_fraction": 0.6285533905029297,
"avg_line_length": 31.680850982666016,
"blob_id": "8b2f7c977ed758f3dc22df34cf9c51cbefe94367",
"content_id": "4152c6ed35ae93012c0daf72391c82faa0864214",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3166,
"license_type": "no_license",
"max_line_length": 200,
"num_lines": 94,
"path": "/CS14BTECH11031-project/source-code/longrun.c",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <sys/wait.h>\r\n#include <sys/types.h>\r\n#include <sys/types.h>\r\n#include <unistd.h>\r\n#include <time.h>\r\n#include <string.h>\r\n#include <stdlib.h>\r\n#include <mysyscallscheduling.h>\r\n\r\n#define LOOP_COUNT_MIN 100\r\n#define LOOP_COUNT_MAX 100000000\r\n#define LOOPCOUNT 429496729\r\n\r\nint get_interval(struct timeval s, struct timeval e) {\r\n int start = s.tv_sec*1000000 + s.tv_usec;\r\n int end = e.tv_sec*1000000 + e.tv_usec;\r\n return (end - start);\r\n}\r\n\r\nint main(int argc, char *argv[]) {\r\n char *idStr;\r\n unsigned int v;\r\n int i = 0;\r\n int iteration = 1;\r\n int loopCount, maxloops, turnAroundTime, waiting_time = 0, deadlineLimit;\r\n struct timeval end_turnaround, end_turnaround_, end_waiting, end_waiting_;\r\n\r\n if(argc < 4 || argc > 5) {\r\n printf(\"Usage: %s <id> <deadlineLimit> <loop count> [max loops]\\n\", argv[0]);\r\n exit(-1);\r\n }\r\n /* Start with PID so result is unpredictable */\r\n v = getpid();\r\n\r\n /* ID string is first argument */\r\n idStr = argv[1];\r\n\r\n /* Deadline is the second argument */\r\n deadlineLimit = atoi(argv[2]);\r\n\r\n /* loop count is third argument */\r\n loopCount = atoi(argv[3]);\r\n if((loopCount < LOOP_COUNT_MIN) || (loopCount > LOOP_COUNT_MAX)) {\r\n printf(\"%s: loop count must be between %d and %d (passed %d)\\n\", argv[0], LOOP_COUNT_MIN, LOOP_COUNT_MAX, loopCount);\r\n exit(-1);\r\n }\r\n /* max loops is fourth argument (if present) */\r\n if(argc == 5) {\r\n maxloops = atoi(argv[4]);\r\n }\r\n else {\r\n maxloops = 0;\r\n }\r\n\r\n // setDeadline -> mysyscall : made-up function. Has to be appropriately defined. As the name suggests, sets the deadline in microseconds by when this job has to complete\r\n mysyscall(deadlineLimit, getpid());\r\n\r\n gettimeofday(&end_turnaround, NULL);\r\n\r\n /* time consuming loop */\r\n int sum = 1;\r\n for(int j = 0;j < LOOPCOUNT;j++){\r\n sum += j;\r\n }\r\n\r\n /* Loop forever - use CTRL-C to exit the program */\r\n while(1) {\r\n /* This calculation is done to keep the value of v unpredictable. Since the compiler can't calculate it in advance (even from the original value of v and the loop count), it has to do the loop. */\r\n v = (v << 4) - v;\r\n if(++i == loopCount) {\r\n /* Exit if we've reached the maximum number of loops. If maxloops is 0 (or negative), this'll never happen... */\r\n if(iteration == maxloops) {\r\n break;\r\n }\r\n /* printf(\"%s:%06d\\n\", idStr, iteration); */\r\n gettimeofday(&end_waiting, NULL);\r\n fflush(stdout);\r\n gettimeofday(&end_waiting_, NULL);\r\n waiting_time += get_interval(end_waiting, end_waiting_);\r\n\r\n iteration += 1;\r\n i = 0;\r\n }\r\n }\r\n /* Print a value for v that's unpredictable so the compiler can't optimize the loop away. Note that this works because the compiler can't tell in advance that it's not an infinite loop. */\r\n gettimeofday(&end_turnaround_, NULL);\r\n turnAroundTime = get_interval(end_turnaround, end_turnaround_);\r\n\r\n /* printf(\"The final value of v is 0x%08x\\n\", v); */\r\n\r\n /* proc(i) with deadline(d) has been scheduled */\r\n printf(\"proc%d with pid : %d and deadline : %d has been scheduled.\\n\", atoi(idStr), getpid(), deadlineLimit);\r\n}\r\n"
},
{
"alpha_fraction": 0.6150773763656616,
"alphanum_fraction": 0.6250624060630798,
"avg_line_length": 38.27450942993164,
"blob_id": "f5abc3b0cfefc2d30f854af4ed6bd574f0b60192",
"content_id": "0417edcbefc79a19a884bdb1727613fe872e05c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2003,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 51,
"path": "/CS14BTECH11031-project/source-code/CS14BTECH11031-sched.c",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "#include <sys/time.h>\n#include <stdio.h>\n#include <unistd.h>\n#include <stdlib.h>\n#include <string.h>\n#include <sys/types.h>\n#include <sys/wait.h>\n\nstruct info{\t\t\t\t\t//struct for keeping file parameters\n int a, b;\n float c, d;\n};\n\nint main(){\n int n, loopCount, id, deadline;\t\t//variable declaration\n double arrival_time, deadline__;\t\t//variables to measure time and deadline\n FILE *fp;\t\t\t\t\t//file ptr\n char *processid = (char *)malloc(256*sizeof(char)), *loopcount = (char *)malloc(256*sizeof(char)), *deadline_ = (char *)malloc(256*sizeof(char));\n fp = fopen(\"inp-params0.txt\", \"r\");\t\t//open the input file in read mode\n int count = 0;\n fscanf(fp, \"%d\\n\", &n);\t\t\t//scan the value of n, the number of processes\n struct info *array = (struct info *)malloc(n*sizeof(struct info));\n //scan the file line by line, and store arrival time, loopcount, deadline and processid of each process\n while(fscanf(fp, \"%d %lf %lf %d\\n\", &id, &arrival_time, &deadline__, &loopCount) == 4){\n //store the parameters in an array of structs\n array[count].a = id; array[count].b = loopCount;\n array[count].c = arrival_time; array[count].d = deadline__;\n count++;\n }\n for(int i = 0;i < n;i++){\t\t\t//fork n processes of type longrun.c\n pid_t pid;\n if((pid = fork()) == 0){\t\t\t//child process\n sprintf(processid, \"%d\", i + 1);\t\t//conversion of required command-line-arg to char *\n sprintf(loopcount, \"%d\", array[i].b);\n deadline = (int) array[i].d;\n sprintf(deadline_, \"%d\", deadline);\t//do the exec system call to create a new process of type longrun.c\n execlp(\"./longrun\", \"./longrun\", processid, deadline_, loopcount, \"10\", NULL);\n }\n else if(pid < 0){\t\t\t\t//fork error\n printf(\"Fork error !\\n\");\n }\n else{\t\t\t\t\t//parent process\n //PARENT-PROCESS\n }\n }\n int status;\t\t\t\t\t//status variable\n for(int i = 0;i < n;i++)\t\t\t//wait for all the processes to finish their execution\n wait(&status);\n fclose(fp);\t\t\t\t\t//close the input file\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5925925970077515,
"alphanum_fraction": 0.6127946376800537,
"avg_line_length": 20.214284896850586,
"blob_id": "470d882e1904cc6921ea9254ea667dbb25e54d3e",
"content_id": "a0785ffc49e5c74a4c7b4eaba20db6eaa60aa5de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 594,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 28,
"path": "/MinixInstallation-master/ass2q2.c",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<unistd.h>\n#include<sys/types.h>\n#include<fcntl.h>\n#include<sys/stat.h>\nint main(int argc,char *argv[])\n{\n\tint fd;\n\tstruct stat st;\n\tint size,stsize;\n\tlong count=0L;\n if(argc!=2)\n {\n printf(\"Incorrect usage:\\nUsage:./prog.out <filename>\");\n\t\treturn 0;\n }\n\tfd=open(argv[1],O_RDONLY);\n\tif((size=lseek(fd,count,SEEK_END))==0)\n\t{\n\t\tprintf(\"0000\\n \");\n\t}\n\tprintf(\"Size of file measured using lseek: %d\\n\",size);\n\tif (stat(argv[1],&st)!=0)\n\t\tstsize=0;\n\telse\n\t\tstsize=st.st_size;\n\tprintf(\"Size of file measured using stat: %zd\",stsize);\n}\n"
},
{
"alpha_fraction": 0.5505004525184631,
"alphanum_fraction": 0.5686988234519958,
"avg_line_length": 25.16666603088379,
"blob_id": "6f500af696fc6d568a2006198dba6f5ee9bb671f",
"content_id": "40c25841cdc923325ac6ea5aad217a11332a0230",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1099,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 42,
"path": "/Assgn5-CS14BTECH11031/graph_script.py",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "import re\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nwith open(\"b-time.txt\") as f:\n data = f.read()\n\ndata = data.split('\\n')[:-1]\n\nx = map(float, [row.split(' ')[0] for row in data])\ny = map(float, [(row.split(' ')[1]) for row in data])\n\nfig = plt.figure()\nplt.grid()\n\nax1 = fig.add_subplot(111)\n\nax1.set_title(\"MutualExclusionUsingBounded&UnboundedLockingAlgorithms\")\nax1.set_xlabel('Number of threads (n)')\nax1.set_ylabel('Average time taken')\n\nfor xy in zip(x, y): # <--\n ax1.annotate('(%s, %s)' % xy, xy = xy, textcoords = 'data') # <--\n\nax1.plot(x,y,'bo-',c='r',label='BoundedLockAlgo',linewidth = 2)\n\nwith open(\"un-time.txt\") as f:\n data = f.read()\n\ndata = data.split('\\n')[:-1]\n\nx = map(float, [row.split(' ')[0] for row in data])\ny = map(float, [(row.split(' ')[1]) for row in data])\n\nfor xy in zip(x, y): # <--\n ax1.annotate('(%s, %s)' % xy, xy = xy, textcoords = 'data') # <--\n\nax1.plot(x,y,'bo-',c='m',label='UnboundedLockAlgo',linewidth = 2)\n\nleg = ax1.legend(loc='upperright')\n\nplt.show()\n"
},
{
"alpha_fraction": 0.6813187003135681,
"alphanum_fraction": 0.7545787692070007,
"avg_line_length": 21.75,
"blob_id": "914bf98841547c3ce05a7160e089c29005c631be",
"content_id": "b114dce4d53f68050e8e7f36de03a015a19c30d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 273,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 12,
"path": "/Assn7-Deadlocks-CS14BTECH11031/Readme.txt",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "Contents of the assignment directory :\n1. bankers-CS14BTECH11031.cpp - SourceCode\n2. Graph\n3. Techincal report\n4. Readme.txt\n\nRunning the program on terminal :\n\n1. g++ bankers-CS14BTECH11031.cpp -pthread\n2. ./a.out < inp-params.txt\n\nHere, inp-params.txt is the input file.\n"
},
{
"alpha_fraction": 0.7171814441680908,
"alphanum_fraction": 0.760617733001709,
"avg_line_length": 59.94117736816406,
"blob_id": "28b6fb8d456d79939fb4e7e108452d0abc486dbd",
"content_id": "34f0cb2103b40a0ff4f64857251e982eb5324049",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 1036,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 17,
"path": "/Assgn5-CS14BTECH11031/Readme.txt",
"repo_name": "saurabh3896/Operating-Systems-Assignments",
"src_encoding": "UTF-8",
"text": "The contents of the assignment folder are\t:\n\t1.\tBounded-CS14BTECH11031.cpp\n\t2.\tUnbounded-CS14BTECH11031.cpp\n\t3.\tin-params.txt\t:\tContains n, k, l1, l2\n\t4.\tgraph_script.py - Script used to calculate the average time (in ms) to enter critical section for varying number of threads,\n\t \t\tgraph plotting\n\t5.\tReport.pdf - Graph of avergage-times (in ms) to enter critical section v/s number of threads and explanation\n\t6.\tPlot.png\t-\tPlot of average time (in ms) taken by each thread v/s number of threads.\n\nRunning on Terminal :\n\t1.\tFirst program - g++ -std=c++11 Bounded-CS14BTECH11031.cpp -pthread\n 2. Second program - g++ -std=c++11 Unbounded-CS14BTECH11031.cpp -pthread\n 3. [a.out] for both programs to execute the executable found, can have one command-line argument, n - number of threads.\n\nNote :\nThe above programs use C++11's library functions, and hence the appropriate compiler switch. The output of the two programs namely\nBounded and Unbounded locking-algorithms are bounded-output.txt and unbounded-output.txt respectively.\n"
}
] | 32 |
sonic4x/OCRTest
|
https://github.com/sonic4x/OCRTest
|
6567db142f123a28c06140e8ac8f8fce6b1ff091
|
89555f0396984942b7257a865c3e16f6008d49a7
|
09171b4b78bc328ae407bff11cd046f18407c469
|
refs/heads/master
| 2020-04-07T12:05:28.017649 | 2018-11-20T08:14:58 | 2018-11-20T08:14:58 | 158,354,097 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6237072348594666,
"alphanum_fraction": 0.6423230171203613,
"avg_line_length": 28.658536911010742,
"blob_id": "28e5de6e9b9afb84f8b5d33265a46d3ed0870193",
"content_id": "72f36ac6023780be48e2877036b590b2bc86e613",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6285,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 205,
"path": "/OCR_useTeseractTest.py",
"repo_name": "sonic4x/OCRTest",
"src_encoding": "UTF-8",
"text": "import os\r\nimport pytesseract\r\n\r\nimport timeit\r\nfrom PIL import Image, ImageEnhance\r\n\r\n\r\n\r\n\"\"\"\r\n--psm\r\n0 = Orientation and script detection (OSD) only.\r\n1 = Automatic page segmentation with OSD.\r\n2 = Automatic page segmentation, but no OSD, or OCR.\r\n3 = Fully automatic page segmentation, but no OSD. (Default)\r\n4 = Assume a single column of text of variable sizes.\r\n5 = Assume a single uniform block of vertically aligned text.\r\n6 = Assume a single uniform block of text.\r\n7 = Treat the image as a single text line.\r\n8 = Treat the image as a single word.\r\n9 = Treat the image as a single word in a circle.\r\n10 = Treat the image as a single character.\r\n\"\"\"\r\n\r\n\r\n\"\"\"\r\nimage mode:\r\n1 (1-bit pixels, black and white, stored with one pixel per byte)\r\nL (8-bit pixels, black and white)\r\nP (8-bit pixels, mapped to any other mode using a colour palette)\r\nRGB (3x8-bit pixels, true colour)\r\nRGBA (4x8-bit pixels, true colour with transparency mask)\r\nCMYK (4x8-bit pixels, colour separation)\r\nYCbCr (3x8-bit pixels, colour video format)\r\nI (32-bit signed integer pixels)\r\nF (32-bit floating point pixels)\r\n\"\"\"\r\n\r\n#test pytesseract save image\r\n\"\"\"\r\nimport tempfile\r\nfrom os.path import realpath, normpath, normcase\r\nfrom pkgutil import find_loader\r\nnumpy_installed = find_loader('numpy') is not None\r\nif numpy_installed:\r\n from numpy import ndarray\r\n\r\n\r\nRGB_MODE = 'RGB'\r\ndef prepare(image):\r\n if isinstance(image, Image.Image):\r\n return image\r\n\r\n if numpy_installed and isinstance(image, ndarray):\r\n return Image.fromarray(image)\r\n\r\n raise TypeError('Unsupported image object')\r\n\r\ndef save_image(image):\r\n temp_name = tempfile.mktemp(prefix='tess_')\r\n if isinstance(image, str):\r\n return temp_name, realpath(normpath(normcase(image)))\r\n\r\n image = prepare(image)\r\n img_extension = image.format\r\n if image.format not in {'JPEG', 'PNG', 'TIFF', 'BMP', 'GIF'}:\r\n img_extension = 'PNG'\r\n\r\n if not image.mode.startswith(RGB_MODE):\r\n image = image.convert(RGB_MODE)\r\n\r\n if 'A' in image.getbands():\r\n # discard and replace the alpha channel with white background\r\n background = Image.new(RGB_MODE, image.size, (255, 255, 255))\r\n background.paste(image, (0, 0), image)\r\n image = background\r\n\r\n input_file_name = temp_name + os.extsep + img_extension\r\n image.save(input_file_name, format=img_extension, **image.info)\r\n return temp_name, input_file_name\r\n\"\"\"\r\n\r\ndef resize_image_ifNeeded(image, mwidth=500, mheight=500):\r\n\r\n w,h = image.size\r\n if w <= mwidth and h <= mheight:\r\n #no need to resize\r\n return image\r\n\r\n scale = 1\r\n if (1.0*w/mwidth) > (1.0*h/mheight):\r\n scale = 1.0*w/mwidth\r\n else:\r\n scale = 1.0*h/mheight\r\n image = image.resize((int(w/scale), int(h/scale)), Image.ANTIALIAS)\r\n\r\n return image\r\n\r\ndef process_image(imagePath,show=\"\",lang=None,config=\"\", expected=\"\"):\r\n image = Image.open(imagePath)\r\n\r\n print('----------------')\r\n print(\"process new image:\", imagePath)\r\n\r\n if not \"dpi\" in image.info:\r\n config +=\" --dpi 120\"\r\n dpi = (120,120)\r\n print(\"dpi:\", dpi, \"size:\", image.size, \"image mode:\", image.mode)\r\n else:\r\n print(\"dpi:\", image.info['dpi'], \"size:\", image.size, \"image mode:\", image.mode)\r\n\r\n start = timeit.default_timer()\r\n\r\n resizedImage = resize_image_ifNeeded(image)\r\n\r\n #temp_name, input_filename = save_image(image)\r\n\r\n text = pytesseract.image_to_string(resizedImage,lang,config)\r\n if text == \"\":\r\n text = pytesseract.image_to_string(resizedImage,lang,'--psm 7')\r\n\r\n end = timeit.default_timer()\r\n print('process cost:', end - start, 's')\r\n print('extracted text:', text)\r\n\r\n successful = 1\r\n #checkpoint\r\n if expected:\r\n if expected != text:\r\n print('extract fail!! ----', 'expected is: ', expected, ',actrual is: ', text)\r\n successful = 0\r\n image.show()\r\n elif show:\r\n image.show()\r\n return text, successful\r\n\r\n\r\n#from skimage import transform,data\r\nif os.sys.platform == 'win32':\r\n pytesseract.pytesseract.tesseract_cmd = \"C:\\\\Program Files (x86)\\\\Tesseract-OCR\\\\tesseract.exe\"\r\n tessdata_dir_config = '--tessdata-dir \"C:\\\\Program Files (x86)\\\\Tesseract-OCR/tessdata\"'\r\n\r\n#Assume a single uniform block of text\r\ntessdata_dir_config1 = '--psm 6'\r\n#Treat the image as a single text line.\r\ntessdata_dir_config2 = '--psm 7'\r\n\r\n\"\"\"\r\nwith open(\"C:\\\\Users\\\\xueli\\\\c.txt\", mode = 'rb') as output_file2:\r\n tt2 = output_file2.read().decode('utf-8')\r\n tt3 = tt2.strip()\r\n\"\"\" \r\n\r\n#text = process_image(\"./ImageData/SignIn_verygray.png\", config='', expected='SIGN IN')\r\n#print(text)\r\n\r\n#prepare input data\r\npath = \"./ImageData\" \r\nfiles= os.listdir(path)\r\nexpectedTextList = []\r\nwith open(\"./expectedList.txt\",mode = 'r', encoding='utf-8') as expectedLstFile:\r\n expectedTextList = expectedLstFile.readlines()\r\n\r\n\r\nfailedNum = 0\r\ni = 0\r\nfor file in files:\r\n image = path + '/' + file\r\n expectedText = expectedTextList[i].rstrip()\r\n expectedText = expectedText.replace('\\\\n','\\n') #escape\r\n i += 1\r\n\r\n text, success = process_image(image, expected=expectedText)\r\n if success == 0:\r\n failedNum +=1\r\n\r\nfailedRatio = failedNum * 100 / len(files)\r\nprint(\"================\")\r\nprint(\"summary:\", failedNum,'/',len(files), \"failed. Failure Ratio:\", '%.2f' %(failedRatio),\"%\")\r\n\r\n\r\n\"\"\"\r\nimage2 = \"./ImageData/checkout_pay.png\"\r\n#imgry = image2.convert('L') # enhance: convert to gray\r\n#sharpness = ImageEnhance.Contrast(imgry) # amplify contrast\r\n#sharp_img = sharpness.enhance(2.0)\r\n#sharp_img.save(\"./ImageData/IOS_1_Ham_Cart_Input_Button_cropped1_enhanced.png\")\r\ntext = process_image(image2,config=tessdata_dir_config1, expected=\"CHECKOUT (PAY 179.99)\")\r\nprint(text)\r\n\r\n\r\nimage3 = \"./ImageData/IOS_1_Ham_Cart_Input_Button_cropped1.png\"\r\ntext = process_image(image3,config=tessdata_dir_config1)\r\nprint(text) \r\n\r\n\r\nimage4 = \"./ImageData/Login_messyBorder2.png\"\r\ntext = process_image(image4,config=tessdata_dir_config1,expected=\"LOGIN\")\r\nprint(text) \r\n\r\n# multiple lines of text\r\nimage4 = \"./ImageData/DontHaveAccount.png\"\r\ntext = process_image(image4,show = False, config=tessdata_dir_config1)\r\nprint(text) \r\n\r\n\"\"\"\r\n"
}
] | 1 |
ultimateti/FaceLockerController
|
https://github.com/ultimateti/FaceLockerController
|
8ea2a963f902025e84b4463f384ba5270060df02
|
8274c54dcd65489ff2b40e6ddd58113bf691d859
|
4fd21fa4ee6f4ed092fbea133e1964d74d2cb0d4
|
refs/heads/master
| 2023-05-12T12:44:02.613048 | 2017-11-14T16:25:45 | 2017-11-14T16:25:45 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8048780560493469,
"alphanum_fraction": 0.8536585569381714,
"avg_line_length": 39.5,
"blob_id": "0b3f3cf7e399c76c1254a65fcc2dbe3a33345301",
"content_id": "91caa9e248c7ee62e803621131af74b8e8bd4721",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 82,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 2,
"path": "/README.md",
"repo_name": "ultimateti/FaceLockerController",
"src_encoding": "UTF-8",
"text": "# FaceLockerController\nFace locker controller for Thailand Engineering Expo 2017 \n"
},
{
"alpha_fraction": 0.5564516186714172,
"alphanum_fraction": 0.5725806355476379,
"avg_line_length": 21.925926208496094,
"blob_id": "2c5472d8d983d344e7d60c747a30cc22ee5f056d",
"content_id": "2ff90e16fc1a5a7a3d9564bd927afc8816779c2a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 620,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 27,
"path": "/control.py",
"repo_name": "ultimateti/FaceLockerController",
"src_encoding": "UTF-8",
"text": "import RPi.GPIO as GPIO\nimport time\n\nclass Relay:\n pin = [6, 13, 19, 26]\n\n def __init__(self):\n GPIO.setmode(GPIO.BCM)\n GPIO.setwarnings(False)\n for i in self.pin:\n GPIO.setup(i, GPIO.OUT)\n\n def set(self, pn, logic):\n GPIO.output(self.pin[pn-1], GPIO.HIGH if logic == 1 else GPIO.LOW)\n\nclass Speaker:\n pin = 5\n\n def __init__(self):\n GPIO.setmode(GPIO.BCM)\n GPIO.setwarnings(False)\n GPIO.setup(self.pin, GPIO.OUT)\n\n def beep(self, dur):\n GPIO.output(self.pin, GPIO.HIGH)\n time.sleep(dur)\n GPIO.output(self.pin, GPIO.LOW)\n\n"
},
{
"alpha_fraction": 0.5567765831947327,
"alphanum_fraction": 0.6117216348648071,
"avg_line_length": 16.0625,
"blob_id": "6d1bc05d9d263948f95199d6c7901d9909b6019e",
"content_id": "646f42c6d5d44f7cfe6bbb43657fad52d8b0bdc0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 273,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 16,
"path": "/tst.py",
"repo_name": "ultimateti/FaceLockerController",
"src_encoding": "UTF-8",
"text": "from control import Relay\nfrom control import Speaker\nimport time\n\nrelay = Relay()\nsp = Speaker()\n\nfor i in range(1, 5):\n sp.beep(0.1)\n time.sleep(0.1)\n sp.beep(0.1)\n time.sleep(0.5)\n relay.set(i, 0)\n time.sleep(1)\n relay.set(i, 1)\n time.sleep(0.5)\n"
}
] | 3 |
0leks/defly.io-bot
|
https://github.com/0leks/defly.io-bot
|
eca8cd5a6dd0703f227cd2fa51002ab6e61c1ec1
|
3501f4e2d6706dd455176ff1852959e80373f0d7
|
ca44469177dc3ada1309464610e2485c3cb7ca82
|
refs/heads/main
| 2023-06-07T10:11:35.767295 | 2021-07-01T10:32:30 | 2021-07-01T10:32:30 | 379,792,598 | 2 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6096320748329163,
"alphanum_fraction": 0.6211486458778381,
"avg_line_length": 42.573333740234375,
"blob_id": "4a9f5afbd9501e6d86ad97ca6ceebc7d59fb5763",
"content_id": "3dbc55824038d9723cdb07e836d829f75d1b2e8a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6686,
"license_type": "no_license",
"max_line_length": 179,
"num_lines": 150,
"path": "/gui.py",
"repo_name": "0leks/defly.io-bot",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nimport tkinter as tk\r\nimport cv2\r\nfrom PIL import Image, ImageTk\r\nimport threading\r\n\r\n\r\nimport vision\r\n\r\n\r\nMINIMAP_VIEW_SIZE = (vision.MAXX + 2)*4\r\n\r\n\r\ndef makeImageCanvas(parent, width, height, title=None):\r\n frame = tk.Frame(parent, borderwidth = 0, highlightbackground = \"black\")\r\n if title is not None:\r\n label = tk.Label(frame, text=title)\r\n label.pack(side=tk.TOP)\r\n canvas = tk.Canvas(frame, width=width, height=height, borderwidth = 0)\r\n canvas.pack(side=tk.BOTTOM)\r\n return frame, canvas\r\n\r\n\r\ndef replaceCanvasImage(canvasdata, image, targetsize):\r\n # canvasdata[0] is the canvas\r\n # canvasdata[1] is the canvasImage\r\n # canvasdata[2] is the currentImage\r\n img = Image.fromarray(image)\r\n img = img.resize(targetsize, Image.NEAREST)\r\n img = ImageTk.PhotoImage(image=img)\r\n if canvasdata[1] is None:\r\n canvasdata[1] = canvasdata[0].create_image(2, 2, anchor=\"nw\", image=img) \r\n else:\r\n canvasdata[0].itemconfig(canvasdata[1], image = img)\r\n canvasdata[2] = img\r\n\r\n\r\nclass GUI:\r\n def __init__(self, startMovingCommand, startMousingCommand, startSaveImagesCommand, graphicalQ):\r\n self.graphicalQ = graphicalQ\r\n self.root = tk.Tk()\r\n\r\n buttonFrame = tk.Frame(self.root)\r\n buttonFrame.pack()\r\n\r\n infoFrame = tk.Frame(self.root)\r\n infoFrame.pack()\r\n\r\n infoFrameBottom = tk.Frame(self.root)\r\n infoFrameBottom.pack()\r\n\r\n startSaveImageButton = tk.Button(buttonFrame, width=14, height=2, text=\"StartSaveImages\", command = lambda: startSaveImagesCommand() or startSaveImageButton.pack_forget())\r\n startMousingButton = tk.Button(buttonFrame, width=10, height=2, text=\"StartMouse\", command = lambda: startMousingCommand() or startMousingButton.pack_forget())\r\n startMoveButton = tk.Button(buttonFrame, width=10, height=2, text=\"StartMove\", command = lambda: startMovingCommand() or startMoveButton.pack_forget())\r\n\r\n startAllCommand = lambda : startMovingCommand() or startMousingCommand() or startMoveButton.pack_forget() or startMousingButton.pack_forget()\r\n startAllButton = tk.Button(buttonFrame, width=14, height=2, text=\"StartMove&Mouse\", command = lambda: startAllCommand() or startAllButton.pack_forget())\r\n\r\n startSaveImageButton.pack(side=tk.RIGHT)\r\n startAllButton.pack(side=tk.RIGHT)\r\n startMousingButton.pack(side=tk.RIGHT)\r\n startMoveButton.pack(side=tk.RIGHT)\r\n\r\n minimapFrame, self.minimapCanvas = makeImageCanvas(infoFrame, width=MINIMAP_VIEW_SIZE, height=MINIMAP_VIEW_SIZE, title=\"minimap\")\r\n minimapFrame.pack(side = tk.LEFT)\r\n self.minimapSquares = {}\r\n\r\n INPUT_IMAGE_DIMS = (240, 118)\r\n self.DISPLAY_DIMS = (700, int(INPUT_IMAGE_DIMS[1] * 700 / INPUT_IMAGE_DIMS[0]))\r\n \r\n gameFrame, self.gameCanvas = makeImageCanvas(infoFrame, width=self.DISPLAY_DIMS[0],height=self.DISPLAY_DIMS[1], title=\"game\")\r\n gameFrame.pack(side=tk.RIGHT)\r\n\r\n self.upgradeText = tk.Text(buttonFrame, height=8, width=20)\r\n self.upgradeText.pack(side=tk.LEFT, padx=10)\r\n \r\n self.infoText = tk.Text(buttonFrame, height=8, width=36)\r\n self.infoText.pack(side=tk.LEFT, padx=10)\r\n\r\n\r\n def drawSquareOnMinimap(self, pos, key, color):\r\n drawy = 2 + int(pos[0]*(MINIMAP_VIEW_SIZE + 1)/(vision.MAXY+1))\r\n drawx = 2 + int(pos[1]*(MINIMAP_VIEW_SIZE + 1)/(vision.MAXX+1))\r\n draww = MINIMAP_VIEW_SIZE / (vision.MAXY+1)\r\n if key not in self.minimapSquares:\r\n self.minimapSquares[key] = self.minimapCanvas.create_rectangle(drawx, drawy, drawx+draww, drawy+draww, fill=color, width=0)\r\n else:\r\n self.minimapCanvas.coords(self.minimapSquares[key], (drawx, drawy, drawx+draww, drawy+draww))\r\n\r\n\r\n def updateLoop(self, canvas, minimapCanvas, upgradeText, infoText):\r\n gamedata = [canvas, None, None]\r\n minimapdata = [minimapCanvas, None, None]\r\n previousUpgradeString = None\r\n previousInfoString = None\r\n\r\n canvasimage = None\r\n canvasMinimapImage = None\r\n previousImage = None\r\n previousMinimapImage = None\r\n END = False\r\n try:\r\n while not END:\r\n dataDict = self.graphicalQ.get()\r\n playerPos = dataDict['playerPos']\r\n\r\n highlighted = dataDict[\"hsvimage\"]\r\n rgbimage = cv2.cvtColor(highlighted,cv2.COLOR_HSV2RGB)\r\n replaceCanvasImage(gamedata, rgbimage, self.DISPLAY_DIMS)\r\n\r\n minimapImage = dataDict[\"minimapImage\"]\r\n replaceCanvasImage(minimapdata, minimapImage, (MINIMAP_VIEW_SIZE, MINIMAP_VIEW_SIZE))\r\n self.drawSquareOnMinimap(dataDict['closestNotTerritory'], \"notterritory\", \"#F00\")\r\n self.drawSquareOnMinimap(playerPos, \"player\", \"#0FF\")\r\n\r\n if \"upgrades\" in dataDict:\r\n upgrades = dataDict[\"upgrades\"]\r\n upgradestring = '\\n'.join(['upgrades'] + [f\"{key}:\\t{upgrades[key]}/8\" for key in upgrades])\r\n if upgradestring != previousUpgradeString:\r\n upgradeText.delete(\"1.0\", tk.END)\r\n upgradeText.insert(tk.END, upgradestring)\r\n previousUpgradeString = upgradestring\r\n\r\n infoString = \"\"\r\n if \"respawnmenu\" in dataDict:\r\n infoString += f\"respawn menu = {dataDict['respawnmenu']}\\n\"\r\n \r\n if \"selectsuperpower\" in dataDict:\r\n infoString += f\"select superpower = {dataDict['selectsuperpower']}\\n\"\r\n\r\n infoString += f\"{dataDict['percentmyterritory']:.0f}% of view is my territory\\n\"\r\n infoString += f\"{dataDict['percentenemyterritory']:.0f}% of view is enemy territory\\n\"\r\n infoString += f\"player pos: {playerPos}\\n\"\r\n infoString += f\"enemies: {dataDict['enemies']}\\n\"\r\n infoString += f\"enemy nearby: {dataDict['enemyNearby']}\\n\"\r\n infoString += f\"closest not territory: {dataDict['closestNotTerritory']}\\n\"\r\n\r\n\r\n if infoString != previousInfoString:\r\n infoText.delete(\"1.0\", tk.END)\r\n infoText.insert(tk.END, infoString)\r\n previousInfoString = infoString\r\n finally:\r\n print(\"exiting updateLoop\")\r\n\r\n\r\n def mainloop(self):\r\n thread = threading.Thread(target=self.updateLoop, args=(self.gameCanvas, self.minimapCanvas, self.upgradeText, self.infoText))\r\n thread.start()\r\n self.root.mainloop()\r\n"
},
{
"alpha_fraction": 0.5949298739433289,
"alphanum_fraction": 0.6111111044883728,
"avg_line_length": 22.10389518737793,
"blob_id": "9baaaaf345090e61be674903248b3993f7af8059",
"content_id": "42375790c5c027219fb5e3a9ba9f16b86511c8c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1854,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 77,
"path": "/mousecontroller.py",
"repo_name": "0leks/defly.io-bot",
"src_encoding": "UTF-8",
"text": "from queue import Queue\r\nimport pyautogui, sys\r\nimport vision\r\nimport time, threading\r\nfrom pynput import keyboard\r\nfrom pynput.keyboard import Key, Controller, KeyCode\r\n\r\n\r\nRESPAWN = \"RESPAWN\"\r\nCHOOSE_GRENADE = \"CHOOSE_GRENADE\"\r\nCLICK = \"CLICK\"\r\nMOVE = \"MOVE\"\r\nKEYCLICK = \"KEYCLICK\"\r\nKEYPRESS = \"KEYPRESS\"\r\nKEYRELEASE = \"KEYRELEASE\"\r\n\r\n# this is (y, x)\r\nCENTER = (468 + vision.SCREENGRABYOFFSET, 959)\r\nKEYDELAY = 0.004\r\n\r\n\r\nkeyboard = Controller()\r\nque = Queue()\r\n\r\ndef _pressRespawn():\r\n pyautogui.moveTo(800, 600)\r\n pyautogui.click()\r\n\r\n\r\ndef _chooseGrenade():\r\n pyautogui.moveTo(1013, 222)\r\n pyautogui.click()\r\n\r\n\r\ndef _click(delay):\r\n pyautogui.mouseDown(); time.sleep(delay); pyautogui.mouseUp()\r\n\r\ndef _moveto(pos):\r\n pyautogui.moveTo(pos[1], pos[0])\r\n\r\ndef _pressButton(key, delay, press=True, release=True):\r\n if press:\r\n keyboard.press(key)\r\n time.sleep(delay)\r\n if release:\r\n keyboard.release(key)\r\n time.sleep(delay)\r\n\r\ndef _eventDispatcher():\r\n print(\"Starting mouse event dispatcher\")\r\n while True:\r\n event = que.get()\r\n action = event[0]\r\n\r\n if action == RESPAWN:\r\n _pressRespawn()\r\n elif action == CHOOSE_GRENADE:\r\n _chooseGrenade()\r\n elif action == CLICK:\r\n _click(KEYDELAY)\r\n elif action == MOVE:\r\n _moveto(event[1])\r\n elif action == KEYCLICK:\r\n _pressButton(event[1], KEYDELAY)\r\n elif action == KEYPRESS:\r\n _pressButton(event[1], KEYDELAY, press=True, release=False)\r\n elif action == KEYRELEASE:\r\n _pressButton(event[1], KEYDELAY, press=False, release=True)\r\n\r\n\r\ndef enqueue(event):\r\n if not isinstance(event, tuple):\r\n event = (event, )\r\n que.put(event)\r\n\r\nthread = threading.Thread(target=_eventDispatcher)\r\nthread.start()"
},
{
"alpha_fraction": 0.7283236980438232,
"alphanum_fraction": 0.7341040372848511,
"avg_line_length": 16.77777862548828,
"blob_id": "e012330918fd80f55b23188165f6e814e36adb99",
"content_id": "28a3aa0b3e752c794bf86476ab2f5311274bb71f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 173,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 9,
"path": "/pressspace.py",
"repo_name": "0leks/defly.io-bot",
"src_encoding": "UTF-8",
"text": "\r\nfrom pynput import keyboard\r\nfrom pynput.keyboard import Key, Controller, KeyCode\r\nimport time\r\n\r\n\r\ntime.sleep(2)\r\n\r\nkeyboard = Controller()\r\nkeyboard.press(Key.space)\r\n\r\n"
},
{
"alpha_fraction": 0.5462570786476135,
"alphanum_fraction": 0.6136593818664551,
"avg_line_length": 36.629032135009766,
"blob_id": "ce6998357082ac6bcbd1d21da38fabfa9f48c8f1",
"content_id": "e421e9daba18c7b463e55f79af612630a141929d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16765,
"license_type": "no_license",
"max_line_length": 382,
"num_lines": 434,
"path": "/vision.py",
"repo_name": "0leks/defly.io-bot",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nimport cv2\r\nimport pyautogui\r\nimport math\r\nfrom PIL import Image\r\n\r\nDEBUG = False\r\nSAVE_EVERY_IMAGE = False\r\n\r\nSCREENGRABYOFFSET = 103\r\nSHRINKFACTOR = 8\r\n\r\n\r\nMINIMAP_POS = (824, 1807)\r\nMINIWIDTH = 99\r\n\r\nUPGRADE_DIMS = (195, 259)\r\n\r\nMAXY = 96\r\nMAXX = 96\r\n\r\nORIGINAL_BACKGROUND_RGB = (242, 247, 255)\r\nUPGRADE_COLOR_RGB = (128, 128, 128)\r\n\r\nORIGINAL_BACKGROUND_HSV = (108, 13, 255)\r\nGRIDLINE = (0, 0, 221)\r\nTEMP = (0, 0, 0)\r\n\r\n\r\nSPECTATE_BUTTON_COLOR = (149, 165, 166)\r\nSPECTATE_BUTTON_HOVERED_COLOR = (121, 141, 143)\r\n\r\nMINIMAP_PLAYER_COLOR = (255, 255, 255)\r\nMINIMAP_ENEMY_COLOR = (128, 128, 128)\r\nMINIMAP_TERRITORY_COLOR = (255, 138, 42)\r\nMINIMAP_TERRITORY_OVERLAP_COLOR = (255, 206, 166)\r\nMINIMAP_NOTHING_OVERLAP_COLOR = (179, 180, 181)\r\n\r\nBACKGROUND_HSV = (0, 0, 0)\r\nENEMY_HSV = (255, 255, 200)\r\nMINE_HSV = (15, 255, 255)\r\nENEMYARR = np.array(ENEMY_HSV)\r\n\r\nUPGRADE_NAMES = ['Player speed', 'Bullet speed', 'Bullet range', 'Reload speed', 'Build range', 'Tower shield', 'Tower health']\r\n\r\ndef scaleDown(image):\r\n return image[::SHRINKFACTOR, ::SHRINKFACTOR, :]\r\n\r\n\r\ndef highlight2(image):\r\n neutralterritory = np.logical_or(np.any(image < (0, 20, 0), axis=-1), np.all(image == GRIDLINE, axis=-1))\r\n myterritory = np.logical_and(np.any(image < (20, 0, 0), axis=-1), np.any(image > (6, 255, 255), axis=-1))\r\n enemyterritory = np.logical_and(np.logical_not(neutralterritory), np.logical_not(myterritory))\r\n\r\n image[neutralterritory] = BACKGROUND_HSV\r\n image[myterritory] = MINE_HSV\r\n image[enemyterritory] = ENEMY_HSV\r\n\r\n return myterritory, enemyterritory\r\n\r\n\r\ndef isRespawnMenuOpen(fullrgbimage):\r\n graycount = 0\r\n for y in range(60):\r\n if (fullrgbimage[491 + y, 931] == SPECTATE_BUTTON_COLOR).all() or (fullrgbimage[491 + y, 931] == SPECTATE_BUTTON_HOVERED_COLOR).all():\r\n graycount += 1\r\n if graycount > 10:\r\n return True\r\n return False\r\n\r\n\r\ndef isUpgradeMenuOpen(fullrgbimage):\r\n for y in range(5):\r\n if (fullrgbimage[721 + 26*y, 237] == UPGRADE_COLOR_RGB).all():\r\n return True\r\n return False\r\n\r\n\r\ndef getUpgradeStatus(fullrgbimage):\r\n upgradeStatus = {}\r\n for y in range(7):\r\n for x in range(8):\r\n # print(f\"{y}, {x}, {(fullrgbimage[714 + 26*y, 237 + 28*x] == UPGRADE_COLOR_RGB)}\")\r\n if (fullrgbimage[714 + 26*y, 31 + 28*x] == UPGRADE_COLOR_RGB).all():\r\n upgradeStatus[UPGRADE_NAMES[y]] = x\r\n break\r\n if UPGRADE_NAMES[y] not in upgradeStatus:\r\n upgradeStatus[UPGRADE_NAMES[y]] = 8\r\n\r\n return upgradeStatus\r\n\r\n\r\nSELECT_SUPERPOWER_STRIPE = [(255,181,140), (225,44,37), (219,17,17), (212,8,8), (211,21,17), (242,131,102), (255,181,140), (255,181,140), (255,181,140), (255,181,140), (255,181,140), (255,181,140), (155,123,104), (14,141,175), (32,97,114), (46,63,67), (22,121,147), (47,59,63), (51,51,51), (39,79,90), (14,141,174), (32,96,112), (49,55,57), (43,74,82), (130,101,86), (254,181,140),]\r\ndef isSelectSuperpower(fullrgbimage):\r\n stripe = fullrgbimage[129, 986:1012]\r\n # for pixel in stripe:\r\n # print(f\"({pixel[0]},{pixel[1]},{pixel[2]}), \", end=\"\")\r\n # print()\r\n return (stripe == SELECT_SUPERPOWER_STRIPE).all()\r\n\r\n\r\ndef getClosestNotTerritoryLoc(minimapTerritory, pos):\r\n h, w = minimapTerritory.shape\r\n centerx = pos[1]; centery = pos[0]\r\n closest = None\r\n closestDistance = 9999999\r\n for y in range(1, h-1):\r\n for x in range(1, w-1):\r\n if not minimapTerritory[y, x]:\r\n distance = (y-centery)*(y-centery) + (x-centerx)*(x-centerx)\r\n if distance < closestDistance:\r\n closestDistance = distance\r\n closest = (y, x)\r\n return closest\r\n\r\n\r\ndef processMinimap(minimapSection):\r\n\r\n playerIndices = np.all(minimapSection == MINIMAP_PLAYER_COLOR, axis=-1).nonzero()\r\n playerPos = (int(MAXY/2), int(MAXX/2))\r\n if len(playerIndices[0]) > 0:\r\n playerPos = (int(np.average(playerIndices[0])) - 1, int(np.average(playerIndices[1])) - 1)\r\n \r\n allEnemyPos = np.transpose(np.all(minimapSection == MINIMAP_ENEMY_COLOR, axis=-1).nonzero())\r\n enemyNearby = False\r\n allEnemyPos = set([(pos[0], pos[1]) for pos in allEnemyPos])\r\n validEnemyIndices = []\r\n for pos in allEnemyPos:\r\n distance = abs(pos[0] - playerPos[0]) + abs(pos[1] - playerPos[1])\r\n if abs(pos[0] - playerPos[0]) + abs(pos[1] - playerPos[1]) < 10 and (pos[0] != 96 and pos[1] != 96):\r\n enemyNearby = True\r\n neighbors = set([(pos[0] - 1, pos[1]), (pos[0] + 1, pos[1]), (pos[0], pos[1] - 1), (pos[0], pos[1] + 1)])\r\n if neighbors.issubset(allEnemyPos):\r\n validEnemyIndices.append((pos[0]-1, pos[1]-1))\r\n\r\n minimapSection = minimapSection[:-3, :-3]\r\n minimapSection[np.all(minimapSection == MINIMAP_TERRITORY_OVERLAP_COLOR, axis=-1)] = MINIMAP_TERRITORY_COLOR\r\n minimapSection[np.logical_and(np.any(minimapSection != MINIMAP_PLAYER_COLOR, axis=-1), np.any(minimapSection != MINIMAP_TERRITORY_COLOR, axis=-1))] = (0, 0, 0)\r\n if not hasattr(processMinimap, 'previousMinimap'):\r\n minimapSection[np.all(minimapSection == MINIMAP_PLAYER_COLOR, axis=-1)] = MINIMAP_TERRITORY_COLOR\r\n else:\r\n playerCells = np.all(minimapSection == MINIMAP_PLAYER_COLOR, axis=-1)\r\n minimapSection[playerCells] = processMinimap.previousMinimap[playerCells]\r\n enemyCells = np.all(minimapSection == MINIMAP_ENEMY_COLOR, axis=-1)\r\n minimapSection[enemyCells] = processMinimap.previousMinimap[enemyCells]\r\n\r\n myterritory = np.logical_or(np.all(minimapSection == MINIMAP_TERRITORY_COLOR, axis=-1), np.all(minimapSection == MINIMAP_PLAYER_COLOR, axis=-1))\r\n closestNotTerritory = getClosestNotTerritoryLoc(myterritory, playerPos)\r\n\r\n minimapSection[myterritory] = (255, 255, 255)\r\n processMinimap.previousMinimap = minimapSection\r\n return minimapSection, myterritory, playerPos, validEnemyIndices, enemyNearby, closestNotTerritory\r\n\r\n\r\ndef getAllTheData(getOGImage=False, getMinimap=True, getUpgrades=True, getSelectSuperpower=True, getRespawn=True, getUnprocessedMinimap=False):\r\n ogimage = np.array(pyautogui.screenshot())\r\n ogimage = ogimage[SCREENGRABYOFFSET:-40, :, :]\r\n dataDict = {}\r\n\r\n if getOGImage:\r\n dataDict[\"imageBeforeEdits\"] = ogimage.copy()\r\n \r\n if getRespawn:\r\n if isRespawnMenuOpen(ogimage):\r\n dataDict[\"respawnmenu\"] = True\r\n\r\n if getMinimap:\r\n minimap = ogimage[MINIMAP_POS[0]:MINIMAP_POS[0]+MINIWIDTH, MINIMAP_POS[1]:MINIMAP_POS[1]+MINIWIDTH, :]\r\n if getUnprocessedMinimap:\r\n dataDict[\"unprocessedminimap\"] = np.copy(minimap)\r\n dataDict[\"minimapImage\"], dataDict[\"minimapTerritory\"], dataDict[\"playerPos\"], dataDict[\"enemies\"], dataDict['enemyNearby'], dataDict['closestNotTerritory'] = processMinimap(np.copy(minimap))\r\n\r\n if getUpgrades and isUpgradeMenuOpen(ogimage):\r\n dataDict[\"upgrades\"] = getUpgradeStatus(ogimage)\r\n ogimage[694:694+195, 16:16+260] = ORIGINAL_BACKGROUND_RGB\r\n \r\n if getSelectSuperpower:\r\n if isSelectSuperpower(ogimage):\r\n dataDict[\"selectsuperpower\"] = True\r\n \r\n\r\n # removes minimap darkening\r\n # ogimage[MINIMAP_POS[0]-1:MINIMAP_POS[0]+MINIWIDTH+1, MINIMAP_POS[1]-1:MINIMAP_POS[1]+MINIWIDTH+1] = ogimage[MINIMAP_POS[0]-1:MINIMAP_POS[0]+MINIWIDTH+1, MINIMAP_POS[1]-1:MINIMAP_POS[1]+MINIWIDTH+1]*3.38 - 2\r\n ogimage[MINIMAP_POS[0]-1:MINIMAP_POS[0]+MINIWIDTH+1, MINIMAP_POS[1]-1:MINIMAP_POS[1]+MINIWIDTH+1] = ORIGINAL_BACKGROUND_RGB\r\n # server debug string\r\n ogimage[908:908+13, 16:16+260] = ORIGINAL_BACKGROUND_RGB\r\n # leaderboard\r\n ogimage[16:280, 1640:1904] = ORIGINAL_BACKGROUND_RGB\r\n # player\r\n ogimage[445:492, 936:984] = ORIGINAL_BACKGROUND_RGB\r\n # cant build dot on existing line\r\n ogimage[55:84, 830:1090] = ORIGINAL_BACKGROUND_RGB\r\n\r\n \r\n dataDict[\"rgbimage\"] = ogimage\r\n small = scaleDown(ogimage)\r\n if DEBUG:\r\n dataDict[\"reducedSize\"] = small\r\n hsvimage = cv2.cvtColor(small,cv2.COLOR_RGB2HSV)\r\n \r\n if DEBUG:\r\n dataDict[\"smallhsvimage\"] = hsvimage.copy()\r\n myterritory, enemyterritory = highlight2(hsvimage)\r\n\r\n numMyTerritory = np.count_nonzero(myterritory)\r\n percentMine = 100*numMyTerritory / (myterritory.shape[0] * myterritory.shape[1])\r\n numEnemyTerritory = np.count_nonzero(enemyterritory)\r\n percentEnemy = 100*numEnemyTerritory / (enemyterritory.shape[0] * enemyterritory.shape[1])\r\n\r\n dataDict[\"hsvimage\"] = hsvimage\r\n dataDict[\"myterritory\"] = myterritory\r\n dataDict[\"enemyterritory\"] = enemyterritory\r\n dataDict[\"percentmyterritory\"] = percentMine\r\n dataDict[\"percentenemyterritory\"] = percentEnemy\r\n return dataDict\r\n\r\n\r\ndef grabScreen():\r\n ogimage = pyautogui.screenshot()\r\n image = cv2.cvtColor(np.array(ogimage), cv2.COLOR_RGB2BGR)\r\n image = image[SCREENGRABYOFFSET:-40, :, :]\r\n hsvimage = cv2.cvtColor(image,cv2.COLOR_BGR2HSV)\r\n minimap = image[824:824+MINIWIDTH, 1807:1807+MINIWIDTH, :] \r\n return (image, minimap, hsvimage)\r\n\r\n\r\ndef isDefeatedScreen(hsvimage):\r\n spectateButton = hsvimage[491:491+30, 890:890+95, :]\r\n avg = np.average(spectateButton, axis = (0, 1))\r\n # 84.43333333 57.7877193 161.14491228\r\n if DEBUG: print(avg)\r\n return (77 < avg[0] < 97) and (13 < avg[1] < 67) and (151 < avg[2] < 185)\r\n\r\n\r\ndef isUpgradeScreen(hsvimage):\r\n # 19 712 222 175\r\n upgradeArea = hsvimage[712:712+175, 19:19+222, :]\r\n if DEBUG:\r\n cv2.imwrite(\"upgrade.png\", cv2.cvtColor(upgradeArea,cv2.COLOR_HSV2BGR))\r\n for i in range(4):\r\n y = 29 + 26*i\r\n block = upgradeArea[y:y+12, 171:171+20]\r\n avg = np.average(block, axis = (0, 1))\r\n if DEBUG:\r\n print(f\"avg of block {i} = {avg}\")\r\n if (avg[0] < 5) and (avg[1] < 5) and (125 < avg[2] < 132):\r\n return True\r\n return False\r\n\r\n\r\ndef isChooseAbilityScreen(hsvimage):\r\n area1 = hsvimage[100:108, 719:728, :]\r\n avg1 = np.average(area1, axis = (0, 1))\r\n area2 = hsvimage[112:112+22, 1023:1023+13, :]\r\n avg2 = np.average(area2, axis = (0, 1))\r\n if DEBUG:\r\n print(f\"area1 avg1: {avg1}, avg2: {avg2}\")\r\n return (9 < avg2[0] < 13) and (113 < avg2[1] < 117) and (253 < avg2[2]) and (90 < avg1[0] < 105) and (245 < avg1[1]) and (160 < avg1[2] < 180)\r\n\r\n\r\ndef _abilityreadyhelper(area):\r\n avg = np.average(area, axis = (0, 1))\r\n if DEBUG:\r\n print(f\"ability cd area avg: {avg}\")\r\n isbarfull = not ((avg[0] < 5) and (avg[1] < 5) and (140 < avg[2] < 150))\r\n isbarorange = (13 < avg[0] < 17) and (200 < avg[1]) and (250 < avg[2])\r\n return isbarfull and isbarorange\r\n\r\ndef isAbilityReady(hsvimage):\r\n area1 = hsvimage[846:846+14, 1245:1245+2, :]\r\n area1ready = _abilityreadyhelper(area1)\r\n area2 = hsvimage[868:868+18, 1244:1244+2, :]\r\n area2ready = _abilityreadyhelper(area2)\r\n return area1ready or area2ready\r\n \r\n\r\ndef maskUI(image):\r\n y = int(image.shape[0]/2)\r\n x = int(image.shape[1]/2)\r\n image = image[y-384:y+384, x-600:x+600]\r\n return image\r\n\r\n\r\ndef findPlayer(minimap):\r\n for y in range(minimap.shape[0] - 2):\r\n for x in range(minimap.shape[1] - 2):\r\n success = True\r\n for p in [minimap[y][x+1], minimap[y+1][x], minimap[y+1][x+1], minimap[y+1][x+2], minimap[y+2][x+1]]:\r\n if not (p == (255, 255, 255)).all():\r\n success = False\r\n if success:\r\n return (y, x)\r\n return (55, 55)\r\n\r\n\r\n\r\ndef isOrange(pixel):\r\n return pixel[0]*4 < pixel[1]*2 < pixel[2]\r\n\r\n\r\ndef highlight(image):\r\n h = image.shape[0]\r\n w = image.shape[1]\r\n # print(image[int(h/2), :])\r\n off = 3\r\n image[np.all(image <= (360, 20, 255), axis=-1)] = ORIGINAL_BACKGROUND_HSV\r\n image[np.all(image == GRIDLINE, axis=-1)] = ORIGINAL_BACKGROUND_HSV\r\n image[np.all(image == ORIGINAL_BACKGROUND_HSV, axis=-1)] = TEMP\r\n image[np.all(image > (20, 0, 0), axis=-1)] = ENEMY_HSV\r\n image[np.all(image == TEMP, axis=-1)] = ORIGINAL_BACKGROUND_HSV\r\n image[np.all(image < (6, 255, 255), axis=-1)] = ENEMY_HSV\r\n image[np.all(image == TEMP, axis=-1)] = ORIGINAL_BACKGROUND_HSV\r\n image[np.all(image <= (20, 255, 255), axis=-1)] = MINE_HSV\r\n image[int(h/2-off):int(h/2+off+1), int(w/2-off):int(w/2+off+1)] = MINE_HSV\r\n\r\n\r\ndef getHighlightedImage():\r\n image, minimap, hsvimage = grabScreen()\r\n isdefeated = isDefeatedScreen(hsvimage)\r\n isupgrade = isUpgradeScreen(hsvimage)\r\n isability = isUpgradeScreen(hsvimage)\r\n isabilityready = isAbilityReady(hsvimage)\r\n position = findPlayer(minimap)\r\n hsvimage = maskUI(hsvimage)\r\n small = scaleDown(hsvimage)\r\n highlight(small)\r\n return small, position, isdefeated, isupgrade, isability, isabilityready\r\n\r\ndef isDirectionClear(highlighted, direction, distance, orthogonal, debug=DEBUG):\r\n h = highlighted.shape[0]\r\n w = highlighted.shape[1]\r\n x = int(w/2)\r\n y = int(h/2)\r\n\r\n isDiagonal = orthogonal[0] != 0 and orthogonal[1] != 0\r\n conegrowth = 16 if isDiagonal else 16\r\n\r\n if isDiagonal:\r\n distance = int(distance*3/4)\r\n\r\n for i in range(distance):\r\n ratio = i / distance\r\n x += direction[1]\r\n y += direction[0]\r\n if not (x < 0 or y < 0 or x >= w or y >= h):\r\n if debug: highlighted[y, x, 1:] = (highlighted[y, x, 1:] + [0, 255])/2\r\n if (highlighted[y, x] == ENEMYARR).all():\r\n return i, 0\r\n\r\n for mult in range(1, 8 + int(ratio*conegrowth)):\r\n xx = x + mult*orthogonal[1]\r\n yy = y + mult*orthogonal[0]\r\n if not (xx < 0 or yy < 0 or xx >= w or yy >= h):\r\n if debug: highlighted[yy, xx, 1:] = (highlighted[yy, xx, 1:] + [0, 255])/2\r\n if (highlighted[yy, xx] == ENEMYARR).all():\r\n return i, mult\r\n xx = x - mult*orthogonal[1]\r\n yy = y - mult*orthogonal[0]\r\n if not (xx < 0 or yy < 0 or xx >= w or yy >= h):\r\n if debug: highlighted[yy, xx, 1:] = (highlighted[yy, xx, 1:] + [0, 255])/2\r\n if (highlighted[yy, xx] == ENEMYARR).all():\r\n return i, -mult\r\n\r\n return 999, 0\r\n\r\n\r\ndef getClosestEnemyLoc(enemyterritory):\r\n h, w = enemyterritory.shape\r\n centerx = int(w/2); centery = int(h/2)\r\n closest = None\r\n closestDistance = 9999999\r\n for y in range(h):\r\n for x in range(w):\r\n if enemyterritory[y, x]:\r\n distance = (y-centery)*(y-centery) + (x-centerx)*(x-centerx)\r\n if distance < closestDistance:\r\n closestDistance = distance\r\n closest = (y, x)\r\n return closest\r\n\r\n\r\n\r\nif __name__ == \"__main__\":\r\n DEBUG = True\r\n SAVE_EVERY_IMAGE = True\r\n image, minimap, hsvimage = grabScreen()\r\n position = findPlayer(minimap)\r\n print(f\"Player at: {position}\")\r\n\r\n\r\n print(f\"isdefeated: {isDefeatedScreen(hsvimage)}\")\r\n print(f\"isupgrade: {isUpgradeScreen(hsvimage)}\")\r\n print(f\"isability: {isChooseAbilityScreen(hsvimage)}\")\r\n print(f\"isAbilityReady: {isAbilityReady(hsvimage)}\")\r\n\r\n print(f\"520, 407: rgb: {image[407, 520]}, hsv: {hsvimage[407, 520]}\")\r\n\r\n # writing it to the disk using opencv\r\n cv2.imwrite(\"image1.png\", image)\r\n\r\n cv2.imwrite(\"minimap.png\", minimap)\r\n\r\n hsvimage = maskUI(hsvimage)\r\n small = scaleDown(hsvimage)\r\n cv2.imwrite(\"small.png\", cv2.cvtColor(small,cv2.COLOR_HSV2BGR))\r\n\r\n highlight(small)\r\n\r\n\r\n clear = isDirectionClear(small, (1, 1), 60, (1, -1))\r\n clear = isDirectionClear(small, (0, -1), 60, (1, 0))\r\n print(f\"isDirectionClear: {clear}\")\r\n\r\n cv2.imwrite(\"highlight.png\", cv2.cvtColor(small,cv2.COLOR_HSV2BGR))\r\n\r\n\r\n\r\n data = getAllTheData(getOGImage=True, getUnprocessedMinimap=True)\r\n print(f\"minimap: {data['minimapImage'].shape}\")\r\n print(f\"unprocessedminimap: {data['unprocessedminimap'].shape}\")\r\n print(f\"hsvimage: {data['hsvimage'].shape}\")\r\n\r\n print(f\"max value: {np.max(data['hsvimage'])}\")\r\n cv2.imwrite(\"minimap2.png\", cv2.cvtColor(data['minimapImage'], cv2.COLOR_RGB2BGR))\r\n cv2.imwrite(\"unprocessedminimap.png\", cv2.cvtColor(data['unprocessedminimap'], cv2.COLOR_RGB2BGR))\r\n cv2.imwrite(\"rgbimage.png\", cv2.cvtColor(data['rgbimage'], cv2.COLOR_RGB2BGR))\r\n cv2.imwrite(\"highlight2.png\", cv2.cvtColor(data['hsvimage'], cv2.COLOR_HSV2BGR))\r\n\r\n for key in data:\r\n try:\r\n conversion = cv2.COLOR_HSV2BGR if 'hsv' in key else cv2.COLOR_RGB2BGR\r\n cv2.imwrite(f\"debugimages/{key}.png\", cv2.cvtColor(data[key], conversion))\r\n except:\r\n print(f\"{key}: {data[key]}\")\r\n"
},
{
"alpha_fraction": 0.7434408664703369,
"alphanum_fraction": 0.7759139537811279,
"avg_line_length": 45.93939208984375,
"blob_id": "c81a0ea674938d8557abf9cc5aa4697ed5f7c585",
"content_id": "438e747343b683d6fae2cc6a3434c133ea9d78e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4656,
"license_type": "no_license",
"max_line_length": 595,
"num_lines": 99,
"path": "/README.md",
"repo_name": "0leks/defly.io-bot",
"src_encoding": "UTF-8",
"text": "# Automating defly.io\n\nhttps://user-images.githubusercontent.com/1296131/124110163-cf7dce00-da1c-11eb-98b8-a7f0a1ec5e5b.mp4\n\n# About the game\nIn defly.io, the you take control of a drone to fly around and capture territory by surrounding it with nodes and walls. Pressing space will drop a node that automatically connects a wall to the previous node. Once you complete a loop, the interior is filled in with your color and you gain some points proportional to the size of the area captured. As you gain points your drone will level up and allow you to choose from 7 different upgrades. When you encounter enemy drones you can break their territory by shooting at their nodes or by using special abilities that are unlocked at level 18. \n\n\n# Motivation\n99% of the \"players\" one encounters in defly.io are bots included to make the game seem active to people that try it out. These bots are quite bad and struggle to accomplish much more than not flying into enemy walls. I want to make a better bot that uses simple decision making.\n\n\n# Image processing \n\n## Game view\n\n### 0. Raw Game View\n\n\n\n### 1. Cover the UI\n\n\n\n> Replace UI areas with the background color.\nThis includes the scoreboard, minimap, upgrade menu, the player's drone, and the area where some status messages show up in red.\n{.is-info}\n\n### 2. Downscale\n\n\n\n> Scale down the image by a factor of 8, keeping 1 of every 64 pixels. This reduces the image size from `1920x937` to `240x118`\nNotice that the purple bullet still shows up as a few pixels. This is important for the bot to be able to avoid enemy bullets.\n{.is-info}\n\n### 3. Detect Friendly/Enemy/Neutral\n\n\n\n> Convert to HSV and detect ownership of each pixel:\n→ *_saturation_ < 20* is background\n→ *6 < _hue_ < 20* is friendly territory or walls (orange)\n→ anything else is enemy territory or walls (these pixels aren't orange but they are colorful enough to not be background)\n{.is-info}\n\n\n## Minimap view\n\nProcessing the minimap is fairly simple.\n1. The orange pixels are my territory.\n2. The pure white (255, 255, 255) plus sign is me.\n3. Grey plus signs (128, 128, 128) are enemy drones.\n4. Everything else is background\n\nRemarks:\n- The size of the map is 250x250 squares but the minimap is only 96x96 pixels so each pixel on the minimap corresponds to approximately 2.5 squares on the map.\n- The actual position of the player is closer to the top left corner of the bounding box of the plus sign, not the center. It seems like the game developers were a little bit lazy and didn't spend the extra effort to center the plus marker around the players actual position.\n\n \n\n## Upgrades\n\nDiscovering which upgrades the player has unlocked is a trivial task. \nIt is sufficient to querying a pixel near the top of each cell in the table and check if it is orange.\nBelow is an example with 1 level in \"Player speed\" and nothing else. \n\n\n# AI\n\n## Controls\nMove in 8 different directions using combinations of W A S D\nMove the mouse cursor and click to shoot.\nPress E to use special ability.\nPress 1-7 to choose upgrades.\n\n\n## Basic motion\nThe bot is governed by 2 very simple rules. \n1. Upon seeing an enemy pixel ahead, turn clockwise. \n2. After not seeing an enemy pixel in a while, turn counterclockwise.\n\nThese two rules alone result in decent performance as the bot is good at surviving but not very efficient at capturing territory. \n\n## Motion efficiency tricks\nA few tricks help the bot by making it more greedy when it is safe\n\n3. When moving into edge of the map based on minimap player location of 0 or 96, turn clockwise\n4. When there are no enemies nearby showing on the minimap, approach enemy pixels closer before turning away.\n5. If there are no enemies nearby and there is no enemy territory visible and 40% of the screen is friendly territory, redirect movement towards the nearest non-captured area according to the minimap.\n\n## Offense\n\nThe bot always moves the mouse cursor onto the nearest enemy pixel and periodically clicks and presses E to throw grenade.\nEven though this strategy is not focused and results in lots of misses, it will slowly chip away at enemy territory. \n\n### Using the grenade to blow stuff up\n\nhttps://user-images.githubusercontent.com/1296131/124110275-e8867f00-da1c-11eb-83d3-45a704165117.mp4\n\n\n\n"
},
{
"alpha_fraction": 0.3640776574611664,
"alphanum_fraction": 0.5315533876419067,
"avg_line_length": 19.473684310913086,
"blob_id": "f3f35fdb53d9559f930162a60f3df1b320d9fcc4",
"content_id": "557007a1ddad1128d77cdbfc3c7c7a9ed7e95a2e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 412,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 19,
"path": "/requirements.txt",
"repo_name": "0leks/defly.io-bot",
"src_encoding": "UTF-8",
"text": "\r\n\r\nffmpeg-python 0.2.0\r\nfuture 0.18.2\r\nMouseInfo 0.1.3\r\nnumpy 1.20.3\r\nopencv-python 4.5.2.52\r\nPillow 8.2.0\r\npip 21.1.1\r\nPyAutoGUI 0.9.52\r\nPyGetWindow 0.0.9\r\nPyMsgBox 1.0.9\r\npynput 1.7.3\r\npyperclip 1.8.2\r\nPyRect 0.1.4\r\nPyScreeze 0.1.27\r\nPySimpleGUI 4.43.0\r\nPyTweening 1.0.3\r\npywin32 301\r\nsetuptools 56.0.0\r\nsix 1.16.0\r\n"
},
{
"alpha_fraction": 0.5074626803398132,
"alphanum_fraction": 0.5671641826629639,
"avg_line_length": 28.5,
"blob_id": "1471599031d3a37114e680c54a54f03715664fd8",
"content_id": "3f85f41db372831a73d1836f4cb7a340208d1113",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 67,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 2,
"path": "/test.py",
"repo_name": "0leks/defly.io-bot",
"src_encoding": "UTF-8",
"text": "\r\n\r\n\r\nfor i in range(10):\r\n print(f\"minimap/image{i:04d}.png\")\r\n"
},
{
"alpha_fraction": 0.5718390941619873,
"alphanum_fraction": 0.5756704807281494,
"avg_line_length": 24.100000381469727,
"blob_id": "cbf21cf22e58d8b5a34e04d7937e1cb809d174c8",
"content_id": "9ce78f3dba9e2c7b724fd83b68201bfbea77f2b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1044,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 40,
"path": "/escapelistener.py",
"repo_name": "0leks/defly.io-bot",
"src_encoding": "UTF-8",
"text": "from pynput import keyboard\r\nfrom pynput.keyboard import Key, Controller, KeyCode\r\nimport threading\r\nimport time\r\nimport subprocess\r\n\r\n\r\ndef forceQuitPython():\r\n subprocess.call(['C:\\Windows\\System32\\cmd.exe', '/C', 'taskkill /F /IM PYTHON.EXE'])\r\n\r\n\r\nclass keylistener:\r\n def __init__(self):\r\n pass\r\n\r\n def start(self):\r\n thread = threading.Thread(target=self.listenEscape)\r\n thread.start()\r\n\r\n def on_press(self, key):\r\n # print('{0} pressed'.format(key))\r\n if key == Key.esc:\r\n forceQuitPython()\r\n return False\r\n\r\n def on_release(self, key):\r\n # print('{0} release'.format(key))\r\n if key == Key.esc:\r\n forceQuitPython()\r\n return False\r\n\r\n def listenEscape(self): \r\n with keyboard.Listener(\r\n on_press=self.on_press,\r\n on_release=self.on_release) as listener:\r\n print(\".press escape to terminate script\")\r\n listener.join()\r\n\r\nlistener = keylistener()\r\nlistener.start()\r\n"
},
{
"alpha_fraction": 0.585128903388977,
"alphanum_fraction": 0.6036463379859924,
"avg_line_length": 35.4668083190918,
"blob_id": "83d71eeb21745d9db3c87aa5ea41eb84933f3324",
"content_id": "a1a917ca593284ea033e671896251840ce78aded",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17497,
"license_type": "no_license",
"max_line_length": 170,
"num_lines": 467,
"path": "/driver.py",
"repo_name": "0leks/defly.io-bot",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nfrom queue import Queue\r\nfrom queue import SimpleQueue\r\nimport queue\r\nimport threading, time\r\nimport ctypes\r\nfrom pynput import keyboard\r\nfrom pynput.keyboard import Key, Controller, KeyCode\r\nfrom random import randrange\r\nimport math\r\nimport cv2\r\n\r\n\r\nimport escapelistener\r\nimport mousecontroller as mc\r\nimport vision\r\nfrom gui import GUI\r\n\r\n\r\nSAVE_IMAGES = True\r\nSTART_BUTTON_DELAY = 2\r\n\r\nEXIT_EVENT = \"EXIT\"\r\neventQ = Queue()\r\nactionQ = Queue()\r\n\r\nhighPriorityQ = SimpleQueue()\r\nlowPriorityQ = SimpleQueue()\r\ngraphicalQ = SimpleQueue()\r\ncurrentDirectionQ = SimpleQueue()\r\nsaveImageQ = SimpleQueue()\r\ncurrentDirectionQForImage = SimpleQueue()\r\n\r\n\r\n\r\ndirections = [\r\n (-1,0),\r\n (-1,1),\r\n (0,1),\r\n (1,1),\r\n (1,0),\r\n (1,-1),\r\n (0,-1),\r\n (-1,-1),\r\n]\r\nNUM_DIRS = len(directions)\r\nORTH_ADD = int(NUM_DIRS/4)\r\northogonal = [(d[0], d[1]) for d in (directions[ORTH_ADD:] + directions[:ORTH_ADD])]\r\ndirectionToOrthogonal = {dire: orth for dire, orth in zip(directions, orthogonal)}\r\nprint(directionToOrthogonal)\r\n\r\n\r\n\r\ndef keyClick(keyboard, key, delay):\r\n keyboard.press(key)\r\n if delay > 0:\r\n time.sleep(delay)\r\n keyboard.release(key)\r\n\r\ndef getThreadID(thread):\r\n if hasattr(thread, '_thread_id'):\r\n return thread._thread_id\r\n for id, t in threading._active.items():\r\n if t is thread:\r\n return id\r\n\r\ndef raiseThreadException(thread):\r\n thread_id = getThreadID(thread)\r\n res = ctypes.pythonapi.PyThreadState_SetAsyncExc(thread_id, ctypes.py_object(SystemExit))\r\n if res > 1:\r\n ctypes.pythonapi.PyThreadState_SetAsyncExc(thread_id, 0)\r\n print('Exception raise failure')\r\n\r\n\r\n\r\ndef checkReachedEdge(position, direction):\r\n if direction[0] == -1:\r\n if position[0] == 0:\r\n return True\r\n if direction[0] == 1:\r\n if position[0] == vision.MAXY:\r\n return True\r\n if direction[1] == -1:\r\n if position[1] == 0:\r\n return True\r\n if direction[1] == 1:\r\n if position[1] == vision.MAXX:\r\n return True\r\n return False\r\n\r\n\r\ndef handleDirection(direction, keyboard, pressorrelease):\r\n func = keyboard.press if pressorrelease else keyboard.release\r\n\r\n if direction[0] == 1:\r\n func(Key.down)\r\n elif direction[0] == -1:\r\n func(Key.up)\r\n\r\n if direction[1] == 1:\r\n func(Key.right)\r\n elif direction[1] == -1:\r\n func(Key.left)\r\n\r\n\r\ndef chooseExtraTime(secondsSinceLastEncounter):\r\n return 1 + randrange(6) + int(secondsSinceLastEncounter/20)\r\n\r\ndef switchDirections(keyboard, old, new, extratime):\r\n if old is not None:\r\n handleDirection(old, keyboard, False)\r\n if new is not None:\r\n handleDirection(new, keyboard, True)\r\n return new, time.time() + extratime\r\n\r\n\r\ndef getMousePositionInDirection(direction, distance, orthogonal, offset):\r\n return (mc.CENTER[0] + direction[0] * distance + orthogonal[0] * offset,\r\n mc.CENTER[1] + direction[1] * distance + orthogonal[1] * offset)\r\n\r\ndef actionLoop():\r\n time.sleep(START_BUTTON_DELAY)\r\n END = False\r\n directions = [\r\n (-1,0),\r\n (-1,1),\r\n (0,1),\r\n (1,1),\r\n (1,0),\r\n (1,-1),\r\n (0,-1),\r\n (-1,-1),\r\n ]\r\n NUM_DIRS = len(directions)\r\n ORTH_ADD = int(NUM_DIRS/4)\r\n orthogonal = [(d[0], d[1]) for d in (directions[ORTH_ADD:] + directions[:ORTH_ADD])]\r\n print(orthogonal)\r\n currentIndex = 0\r\n currentDirection = directions[currentIndex]\r\n keyboard = Controller()\r\n keyboard.press(Key.space)\r\n currentDirection, lastDirectionTime = switchDirections(keyboard, None, currentDirection, chooseExtraTime(0))\r\n lastEncounter = time.time()\r\n nextTimeTargetNotTerritory = time.time()\r\n nextRandomBump = 0\r\n SCAN_RANGE = 60\r\n try:\r\n while not END:\r\n data = highPriorityQ.get()\r\n highlighted = data['hsvimage']\r\n position = data['playerPos']\r\n\r\n if not data['enemyNearby'] and data['percentenemyterritory'] == 0 and time.time() > nextTimeTargetNotTerritory:\r\n mc.enqueue((mc.MOVE, mc.CENTER))\r\n nextTimeTargetNotTerritory = time.time() + 2 + randrange(13)\r\n if data['percentmyterritory'] >= 0.45:\r\n targetLocation = data['closestNotTerritory']\r\n delta = [targetLocation[0] - position[0], targetLocation[1] - position[1]]\r\n magnitude = math.sqrt(delta[0]*delta[0] + delta[1]*delta[1])\r\n if magnitude > 0:\r\n delta = [delta[0] / magnitude, delta[1] / magnitude]\r\n delta[0] = 1 if delta[0] > 0.5 else (-1 if delta[0] < -0.5 else 0)\r\n delta[1] = 1 if delta[1] > 0.5 else (-1 if delta[1] < -0.5 else 0)\r\n newDirection = tuple(delta)\r\n currentIndex = directions.index(newDirection)\r\n currentDirection, lastDirectionTime = switchDirections(keyboard, currentDirection, newDirection, chooseExtraTime(time.time() - lastEncounter))\r\n print(f\"moving towards the nearest not territory: {targetLocation}, new direction: {newDirection}\")\r\n\r\n if time.time() > lastDirectionTime:\r\n newIndex = (currentIndex + NUM_DIRS - 1) % NUM_DIRS\r\n newDirection = directions[newIndex]\r\n isClear, _ = vision.isDirectionClear(highlighted, newDirection, SCAN_RANGE+10, orthogonal[newIndex])\r\n if isClear == 999:\r\n print(f\"CCW curpos: {position}, {currentDirection} -> {newDirection}\")\r\n currentDirection, lastDirectionTime = switchDirections(keyboard, currentDirection, newDirection, chooseExtraTime(time.time() - lastEncounter))\r\n currentIndex = newIndex\r\n\r\n distances = {}\r\n offsets = {}\r\n SCAN_RANGE = 60 if data['enemyNearby'] else 35\r\n isClear, offset = vision.isDirectionClear(highlighted, currentDirection, SCAN_RANGE, orthogonal[currentIndex])\r\n distances[currentIndex] = isClear\r\n offsets[currentIndex] = offset\r\n if isClear != 999:\r\n lastEncounter = time.time()\r\n\r\n reachedEdge = checkReachedEdge(position, currentDirection)\r\n \r\n if isClear != 999 or reachedEdge:\r\n # handleDirection(currentDirection, keyboard, False)\r\n attempts = 0\r\n newIndex = currentIndex\r\n newDirection = currentDirection\r\n while (attempts < NUM_DIRS) and (isClear != 999 or reachedEdge):\r\n reachedEdge = False\r\n attempts = attempts + 1\r\n newIndex = (newIndex + 1) % NUM_DIRS\r\n newDirection = directions[newIndex]\r\n isClear, offset = vision.isDirectionClear(highlighted, newDirection, SCAN_RANGE, orthogonal[newIndex])\r\n distances[newIndex] = isClear\r\n offsets[newIndex] = offset\r\n if isClear != 999:\r\n lastEncounter = time.time()\r\n reachedEdge = checkReachedEdge(position, newDirection)\r\n\r\n print(f\"pos: {position}, {attempts} switch to going {newDirection}\")\r\n if attempts == NUM_DIRS:\r\n bestIndex = max(distances, key=distances.get)\r\n newDirection = directions[bestIndex]\r\n print(f\"Choosing best dir {bestIndex} out of {distances}\")\r\n currentDirection, lastDirectionTime = switchDirections(keyboard, currentDirection, newDirection, chooseExtraTime(time.time() - lastEncounter))\r\n currentIndex = newIndex\r\n\r\n currentDirectionQ.put(currentDirection)\r\n if SAVE_IMAGES:\r\n currentDirectionQForImage.put(currentDirection)\r\n\r\n finally:\r\n print(\"exiting actionLoop\")\r\n currentDirection, lastDirectionTime = switchDirections(keyboard, currentDirection, None, 0)\r\n keyboard.release(Key.space)\r\n\r\n\r\ndef getEnemyLocAdjusted(enemyterritory, currentDirection):\r\n enemyLoc = vision.getClosestEnemyLoc(enemyterritory)\r\n if enemyLoc is not None:\r\n enemyLocAdjusted = enemyLoc\r\n if currentDirection is not None: \r\n enemyLocAdjusted = (enemyLoc[0] - currentDirection[0]*20, enemyLoc[1] - currentDirection[1]*20)\r\n enemyLocAdjusted = (min(max(enemyLocAdjusted[0], vision.SCREENGRABYOFFSET), 1080 - 41), min(max(enemyLocAdjusted[1], 0), 1919))\r\n return enemyLoc\r\n\r\n\r\ndef getMostRecent(Q):\r\n thing = None\r\n if not Q.empty():\r\n thing = Q.get()\r\n while not Q.empty():\r\n thing = Q.get()\r\n return thing\r\n\r\n\r\nUPGRADE_PRIORITY = [6, 5, 0, 4]\r\ndef lowPriorityLoop():\r\n time.sleep(START_BUTTON_DELAY)\r\n print(f\"starting lowPriorityLoop\")\r\n print(f\"Pressing spacebar\")\r\n mc.enqueue((mc.KEYPRESS, Key.space))\r\n nextTimeToUseSuperpower = time.time()\r\n\r\n while True:\r\n data = lowPriorityQ.get()\r\n\r\n if data is None:\r\n print(f\"lowPriorityLoop exiting\")\r\n break\r\n\r\n if \"respawnmenu\" in data:\r\n print(f\"lowPriorityLoop respawning\")\r\n mc.enqueue(mc.RESPAWN)\r\n time.sleep(1)\r\n continue\r\n \r\n if \"upgrades\" in data:\r\n upgrades = data[\"upgrades\"]\r\n for upgradeIndex in UPGRADE_PRIORITY:\r\n if upgrades[vision.UPGRADE_NAMES[upgradeIndex]] < 8:\r\n mc.enqueue((mc.KEYCLICK, KeyCode.from_char(f\"{upgradeIndex+1}\")))\r\n print(f\"lowPriorityLoop upgrading {vision.UPGRADE_NAMES[upgradeIndex]} to {upgrades[vision.UPGRADE_NAMES[upgradeIndex]] + 1}\")\r\n time.sleep(0.1)\r\n break\r\n\r\n if \"selectsuperpower\" in data:\r\n print(f\"lowPriorityLoop choosing grenade\")\r\n mc.enqueue(mc.CHOOSE_GRENADE)\r\n time.sleep(0.2)\r\n continue\r\n \r\n currentDirection = getMostRecent(currentDirectionQ)\r\n enemyLoc = getEnemyLocAdjusted(data[\"enemyterritory\"], currentDirection)\r\n if enemyLoc is not None:\r\n enemyLoc = (enemyLoc[0]*vision.SHRINKFACTOR + vision.SCREENGRABYOFFSET, enemyLoc[1]*vision.SHRINKFACTOR)\r\n mc.enqueue((mc.MOVE, enemyLoc))\r\n if time.time() > nextTimeToUseSuperpower:\r\n print(f\"lowPriorityLoop throwing grenade at {enemyLoc}\")\r\n mc.enqueue((mc.KEYCLICK, KeyCode.from_char('e')))\r\n nextTimeToUseSuperpower = time.time() + 5.05 # actual cd is 30s but its okay to try to spam a bit\r\n if not data['enemyNearby']:\r\n print(f\"lowPriorityLoop shooting at {enemyLoc}\")\r\n mc.enqueue((mc.CLICK))\r\n\r\n\r\ndef applyScaleFactor(pos, factor):\r\n newpos = (pos[0]*factor, pos[1]*factor)\r\n newpos = (newpos[0] + (1 if newpos[0]%2 == 1 else 0), newpos[1] + (1 if newpos[1]%2 == 1 else 0))\r\n return newpos \r\n\r\n\r\ndef drawX(image, location, size, color):\r\n if not hasattr(drawX, 'xarrays'):\r\n drawX.xarrays = {}\r\n\r\n if size not in drawX.xarrays:\r\n xarray = np.ones((size, size), dtype=bool)\r\n xarray[0, 0] = False\r\n xarray[0, -1] = False\r\n xarray[-1, 0] = False\r\n xarray[-1, -1] = False\r\n # xarray = np.zeros((size, size), dtype=bool)\r\n # for i in range(size):\r\n # xarray[i, i] = True\r\n # xarray[size-i-1, i] = True\r\n drawX.xarrays[size] = xarray\r\n snippet = image[location[0]:location[0]+size, location[1]:location[1]+size]\r\n snippet[drawX.xarrays[size]] = color\r\n\r\n\r\ndef applyImageWithBorder(canvas, image, x, y, borderwidth, bordercolor=(255, 255, 255)):\r\n if borderwidth > 0:\r\n canvas[y-borderwidth:y + image.shape[0] + borderwidth, x - borderwidth:x + image.shape[1] + borderwidth] = bordercolor\r\n canvas[y:y + image.shape[0], x:x + image.shape[1]] = image\r\n\r\n\r\ndef drawX2(canvas, x, y, size, color):\r\n halfsize = int(size/2)\r\n for i in range(size):\r\n if y - halfsize + i >= 0 and y - halfsize + i < canvas.shape[0]:\r\n if x - halfsize + i >= 0 and x - halfsize + i < canvas.shape[1]:\r\n canvas[y - halfsize + i, x - halfsize + i] = color\r\n if x + halfsize - i >= 0 and x + halfsize - i < canvas.shape[1]:\r\n canvas[y - halfsize + i, x + halfsize - i] = color\r\n\r\n\r\ndef imageSavingLoop():\r\n index = 0\r\n SCALE_FACTOR = 4\r\n overlay = None\r\n\r\n while not saveImageQ.empty():\r\n saveImageQ.get()\r\n\r\n while True:\r\n data = saveImageQ.get()\r\n\r\n\r\n minimapRGB = data['minimapImage'].copy()\r\n minimapRGB = cv2.cvtColor(minimapRGB, cv2.COLOR_RGB2BGR)\r\n minimapRGB = cv2.resize(minimapRGB, dsize=(minimapRGB.shape[0]+1, minimapRGB.shape[1]+1), interpolation=cv2.INTER_NEAREST)\r\n newSize = applyScaleFactor(minimapRGB.shape, SCALE_FACTOR)\r\n minimapRGB = cv2.resize(minimapRGB, dsize=newSize, interpolation=cv2.INTER_NEAREST)\r\n\r\n if overlay is None:\r\n overlay = np.zeros(minimapRGB.shape)\r\n\r\n playerPos = applyScaleFactor(data['playerPos'], SCALE_FACTOR)\r\n\r\n drawX(overlay, playerPos, SCALE_FACTOR, (255, 255, 0))\r\n\r\n for enemyPos in data['enemies']:\r\n pos = applyScaleFactor(enemyPos, SCALE_FACTOR)\r\n drawX(overlay, pos, SCALE_FACTOR, (0, 0, 255))\r\n\r\n \r\n nonzerooverlay = np.any(overlay > (10, 10, 10), axis=-1)\r\n minimapRGB[nonzerooverlay] = overlay[nonzerooverlay]\r\n\r\n currentDirection = getMostRecent(currentDirectionQForImage)\r\n unprocessedImage = cv2.cvtColor(vision.scaleDown(data['imageBeforeEdits']),cv2.COLOR_RGB2BGR)\r\n processedImage = data['hsvimage'].copy()\r\n if currentDirection:\r\n vision.isDirectionClear(processedImage, currentDirection, 50, directionToOrthogonal[currentDirection], debug=True)\r\n processedImage = cv2.cvtColor(processedImage,cv2.COLOR_HSV2BGR)\r\n enemyLoc = getEnemyLocAdjusted(data[\"enemyterritory\"], currentDirection)\r\n if enemyLoc:\r\n drawX2(processedImage, enemyLoc[1], enemyLoc[0], 9, (0, 0, 255))\r\n\r\n minimapH, minimapW, dims = minimapRGB.shape\r\n processedH, processedW, _ = processedImage.shape\r\n unprocessedH, unprocessedW, _ = unprocessedImage.shape\r\n borderwidth = 1\r\n paddingH = int((minimapH - processedH - unprocessedH)/3)\r\n canvas = np.zeros((minimapH, minimapW + processedW + 2*borderwidth, dims))\r\n\r\n\r\n applyImageWithBorder(canvas, minimapRGB, 0, 0, 0)\r\n canvas[:, minimapW] = (255, 255, 255)\r\n applyImageWithBorder(canvas, unprocessedImage, minimapW + borderwidth, paddingH, 1)\r\n applyImageWithBorder(canvas, processedImage, minimapW + borderwidth, 2*paddingH + unprocessedH, 1)\r\n\r\n\r\n # cv2.imwrite(f\"minimap/img{index:06d}.png\", minimapRGB)\r\n cv2.imwrite(f\"combined/img{index:06d}.png\", canvas)\r\n\r\n overlay = overlay * 0.8\r\n index += 1\r\n\r\n\r\ndef queueClearAndPut(Q, data):\r\n while not Q.empty():\r\n Q.get()\r\n Q.put(data)\r\n\r\n\r\ndef imageProcessingLoop():\r\n whenToPutOnLowPriority = time.time()\r\n whenToPutOnGraphical = time.time()\r\n whenToPutOnImageSaving = time.time()\r\n while True:\r\n data = vision.getAllTheData(getOGImage=SAVE_IMAGES)\r\n queueClearAndPut(highPriorityQ, data)\r\n\r\n if time.time() > whenToPutOnLowPriority:\r\n whenToPutOnLowPriority = time.time() + 0.3\r\n queueClearAndPut(lowPriorityQ, data)\r\n \r\n if graphicalQ.qsize() < 2 and time.time() > whenToPutOnGraphical:\r\n whenToPutOnGraphical = time.time() + 0.033\r\n queueClearAndPut(graphicalQ, data)\r\n\r\n if SAVE_IMAGES and time.time() > whenToPutOnImageSaving:\r\n whenToPutOnImageSaving = time.time() + 0.5\r\n saveImageQ.put(data)\r\n if saveImageQ.qsize() > 10:\r\n saveImageQ.get()\r\n\r\n time.sleep(0.004)\r\n\r\n\r\n\r\n\r\ndef stopCommand():\r\n print(\"putting exit events\")\r\n eventQ.put(EXIT_EVENT)\r\n actionQ.put(EXIT_EVENT)\r\n\r\n\r\ndef startImageProcessingCommand():\r\n if not hasattr(startImageProcessingCommand, 'thread'):\r\n startImageProcessingCommand.thread = threading.Thread(target=imageProcessingLoop)\r\n startImageProcessingCommand.thread.start()\r\n\r\ndef startMovingCommand():\r\n if not hasattr(startMovingCommand, 'thread'):\r\n startMovingCommand.thread = threading.Thread(target=actionLoop)\r\n startMovingCommand.thread.start()\r\n\r\n\r\ndef startMousingCommand():\r\n if not hasattr(startMousingCommand, 'thread'):\r\n startMousingCommand.thread = threading.Thread(target=lowPriorityLoop)\r\n startMousingCommand.thread.start()\r\n\r\n\r\ndef startSaveImagesCommand():\r\n if SAVE_IMAGES and not hasattr(startSaveImagesCommand, 'thread'):\r\n startSaveImagesCommand.thread = threading.Thread(target=imageSavingLoop)\r\n startSaveImagesCommand.thread.start()\r\n\r\n\r\nif __name__ == \"__main__\":\r\n startImageProcessingCommand()\r\n mygui = GUI(startMovingCommand, startMousingCommand, startSaveImagesCommand, graphicalQ)\r\n mygui.mainloop()\r\n\r\n\r\n# reimplement find player pos\r\n# make a boolean minimap to use to find nearest uncaptured\r\n"
}
] | 9 |
WulfChang/HQ_food
|
https://github.com/WulfChang/HQ_food
|
d191fb5c895b28d30f8ef4afb767e5a4256cc26f
|
35f69d26618c23a603185b27100c9666b1e6304e
|
cc8c1f6d6e531c371e2e0529c097d7ac1258c821
|
refs/heads/master
| 2016-09-15T02:29:15.773411 | 2015-11-03T08:09:49 | 2015-11-03T08:09:49 | 44,146,489 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.46733516454696655,
"alphanum_fraction": 0.47979336977005005,
"avg_line_length": 23.736841201782227,
"blob_id": "a5cd60226a2d54aba595afa8988adf0e211225cd",
"content_id": "6c2e08ff6497ef4075940299ee3e844289355a88",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3291,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 133,
"path": "/day_file.py",
"repo_name": "WulfChang/HQ_food",
"src_encoding": "UTF-8",
"text": "\nimport os.path\nimport fnmatch\n\n#header module\nimport header\n\n\"\"\"\nFunction: save daily data into file\nAuthor: Wulf Chang\nHistory: 2015/09/15 releasing\n 2015/10/05 beta version ready\n 2015/11/03 add day_file class exception\n\"\"\"\n\nDF_path = header.HQ_ACCOUNT_PATH\n\n\"\"\"\ndaily documented class\n\"\"\"\nclass Dfile:\n \"\"\"\n initialize function\n \"\"\"\n def __init__( self, year=0, month=0, name=0, num_of_date=31 ):\n self.year = year\n self.month = month\n self.name = name\n self.num_of_date = num_of_date\n \n \"\"\"\n open daily file\n \"\"\"\n def open_dfile( self, str_fname ='' ):\n #open file\n if str_fname == '':\n if self.month >= 10:\n self.fname = DF_path +'HQ' + '_' + str(self.year) + str(self.month) + '_' + str(self.name)\n else:\n self.fname = DF_path +'HQ' + '_' + str(self.year) + '0'+ str(self.month) + '_' + str(self.name)\n else:\n self.fname = DF_path + str_fname\n \n self.fptr = open( self.fname, 'a+' )\n \n \"\"\"\n write data into daily file\n \"\"\"\n def write_dfile( self, datalist=[] ): \n if self.__isoverflow_dfile() == True:\n for i in datalist:\n self.fptr.write( str(i) + '\\t' )\n self.fptr.write('\\n')\n else:\n raise IOError(header.ERROR_MSG[3])\n \n \"\"\"\n read specific line in daily file: return matrix\n \"\"\"\n def read_dfile( self, lines ):\n array =[]\n count=0\n if lines <= self.__count_dfile():\n for line in self.fptr:\n count+=1\n if count == lines:\n line = line.strip()\n array = map(int, line.split() )\n return array\n else:\n raise IndexError(header.ERROR_MSG[4])\n \n \"\"\"\n read all daily file\n \"\"\"\n def read_alldfile(self):\n \n data = []\n array =[]\n count=0\n \n for line in self.fptr:\n line = line.strip()\n array = map(int, line.split() )\n data.append( array )\n\n return data\n \n \"\"\"\n check repetitive write\n \"\"\"\n def ischeckRwrite(self, day):\n if self.__count_dfile() < day:\n return True\n else:\n return False\n \n \"\"\"\n close daily file\n \"\"\"\n def close_dfile(self):\n self.fptr.close()\n \n \"\"\" \n read all file and return list of \n \"\"\"\n def listDatafile( self, i_guestnum ):\n \n #search accounting data\n list_num_file = fnmatch.filter(os.listdir(DF_path), '*_'+ str(i_guestnum) )\n \n #sort date from new to old\n list_date = sorted(list_num_file, reverse=True)\n return list_date \n \n \"\"\"\n count daily file\n \"\"\"\n def __count_dfile(self):\n count=0\n \n if os.path.exists( self.fname ):\n for line in self.fptr:\n count+=1 \n self.fptr.seek(0, 0)\n \n return count\n \n \"\"\"\n check file overflow status\n \"\"\"\n def __isoverflow_dfile( self ):\n lines = self.__count_dfile() \n return True if lines < self.num_of_date else False\n"
},
{
"alpha_fraction": 0.4566752314567566,
"alphanum_fraction": 0.47560974955558777,
"avg_line_length": 25.95652198791504,
"blob_id": "f8dbfcd22ebd7e032df9cadf3bf961d573e8a9c6",
"content_id": "9462194b3f68c1cdcfe9875dd99b6f541fbd3fec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3116,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 115,
"path": "/log_io.py",
"repo_name": "WulfChang/HQ_food",
"src_encoding": "UTF-8",
"text": "# encoding: utf-8\n\nimport xlwt\nfrom datetime import datetime\n\nimport header\n\n\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\nFunction: write daily work status in log file, currently, the version only save the latest log\nAuthor: Wulf Chang\nVersion: v1.1\nHistory: 2015/10/05 programming start\n 2015/10/06 beta release v1.1\n\n----------------------------------------------------------------------------------------------------------------------------\nExample of using xlwt:\n\n style0 = xlwt.easyxf('font: name Times New Roman, color-index red, bold on',\n num_format_str='#,##0.00')\n style1 = xlwt.easyxf(num_format_str='HH:MM:SS')\n\n wb = xlwt.Workbook()\n ws = wb.add_sheet('A Test Sheet')\n\n ws.write(0, 0, 1234.56, style0)\n ws.write(1, 0, datetime.now(), style1)\n ws.write(2, 0, 1)\n ws.write(2, 1, 1)\n ws.write(2, 2, xlwt.Formula(\"A3+B3\"))\n\n wb.save('example.xls')\n \n #show today\n a=datetime.today()\n a.strftime(\"%Y%m%d\")\n----------------------------------------------------------------------------------------------------------------------------\n\n \n\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\n\nlog_path = header.HQ_LOG_PATH\nlog_name = header.HQ_LOG_NAME\n\nclass LogIO:\n \n \"\"\"\"\n Initialize the class\n para: string\n return null\n \"\"\"\n def __init__( self ):\n \n #set filename\n self.openLogsheet()\n\n #set time stamp style\n self.setTstamp()\n\n #declare a count for evaluating number of row\n self.count = 0\n\n \"\"\"\"\n start the log sheet, if it's existed, overwrite is made\n para: string\n return none\n \"\"\" \n def openLogsheet(self): \n \n #set current sheet name\n self.setSheetname()\n \n #creat workbook and sheet\n self.wb = xlwt.Workbook()\n self.ws = self.wb.add_sheet( self.s_logfilename, True )\n \n \"\"\"\"\n End the file by write into file\n para: none\n return none\n \"\"\"\n def writeLogfile( self ):\n self.wb = self.wb.save( log_path+log_name )\n \n \"\"\"\"\n set time stamp style\n para: none\n return none\n \"\"\"\n def setTstamp(self):\n self.timestamp = xlwt.easyxf(num_format_str='HH:MM:SS')\n \n \"\"\"\"\n set file name by taking date\n para: none\n return none\n \"\"\"\n def setSheetname(self):\n t_current = datetime.today()\n self.s_logfilename = t_current.strftime(\"%Y%m%d\") + '_' + 'log'\n \n \"\"\"\"\n save msg and time into sheet\n para: string, string\n return none\n \"\"\"\n def writeLog( self, s_event_msg, s_type ):\n \n #ex: 13:55:27 | the file has been open | normal\n #save timestamp in the first column\n self.ws.write( self.count, 0, datetime.now(), self.timestamp)\n self.ws.write( self.count, 1, s_event_msg)\n self.ws.write( self.count, 2, s_type)\n \n #iterate to next row\n self.count +=1\n \n \n\n\n"
},
{
"alpha_fraction": 0.5169340372085571,
"alphanum_fraction": 0.5329768061637878,
"avg_line_length": 20.576923370361328,
"blob_id": "8bd0b3bb141943337c01e167797e08f3a09675be",
"content_id": "672ed49abe9d865d97f0b3eff12d8be0fb3d5d50",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 561,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 26,
"path": "/header.py",
"repo_name": "WulfChang/HQ_food",
"src_encoding": "UTF-8",
"text": "# encoding: utf-8\n\n# path of data\n\nHQ_PATH = 'HQ_food/data/'\n\nHQ_PRICE_PATH = HQ_PATH + 'price/'\n\nHQ_ACCOUNT_PATH = HQ_PATH + 'accounting/'\n\n#file name\nHQ_LIST_NAME = 'customer_list.yaml'\n\n#define \nNONVALID = '20111111'\n\n# log file path: the log file will save day by day\nHQ_LOG_PATH = 'HQ_food/log/'\nHQ_LOG_NAME = 'HQ_log.xls'\n\n#error msg \nERROR_MSG = ['File not existed!', \n 'Input is empty!', \n 'The name is not existed!', \n 'File overflow', \n 'Over index']\n"
},
{
"alpha_fraction": 0.6359919905662537,
"alphanum_fraction": 0.6870458126068115,
"avg_line_length": 51.41428756713867,
"blob_id": "2d87d7945b30cbb6637fd47c74902c9d8ef96826",
"content_id": "5199ccb0655c313b0ff1dc7712d81509015522ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11042,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 210,
"path": "/UI/Ui_month_report.py",
"repo_name": "WulfChang/HQ_food",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file '/home/wulf/Program/HQ_food/UI/month_report.ui'\n#\n# Created: Tue Nov 3 09:16:06 2015\n# by: PyQt4 UI code generator 4.10.4\n#\n# WARNING! All changes made in this file will be lost!\n\nfrom PyQt4 import QtCore, QtGui\n\ntry:\n _fromUtf8 = QtCore.QString.fromUtf8\nexcept AttributeError:\n def _fromUtf8(s):\n return s\n\ntry:\n _encoding = QtGui.QApplication.UnicodeUTF8\n def _translate(context, text, disambig):\n return QtGui.QApplication.translate(context, text, disambig, _encoding)\nexcept AttributeError:\n def _translate(context, text, disambig):\n return QtGui.QApplication.translate(context, text, disambig)\n\nclass Ui_Dialog_report(object):\n def setupUi(self, Dialog_report):\n Dialog_report.setObjectName(_fromUtf8(\"Dialog_report\"))\n Dialog_report.resize(710, 644)\n self.layoutWidget = QtGui.QWidget(Dialog_report)\n self.layoutWidget.setGeometry(QtCore.QRect(31, 11, 651, 611))\n self.layoutWidget.setObjectName(_fromUtf8(\"layoutWidget\"))\n self.verticalLayout = QtGui.QVBoxLayout(self.layoutWidget)\n self.verticalLayout.setMargin(0)\n self.verticalLayout.setObjectName(_fromUtf8(\"verticalLayout\"))\n self.horizontalLayout = QtGui.QHBoxLayout()\n self.horizontalLayout.setObjectName(_fromUtf8(\"horizontalLayout\"))\n self.comboBox_name = QtGui.QComboBox(self.layoutWidget)\n self.comboBox_name.setObjectName(_fromUtf8(\"comboBox_name\"))\n self.horizontalLayout.addWidget(self.comboBox_name)\n self.comboBox_date = QtGui.QComboBox(self.layoutWidget)\n self.comboBox_date.setObjectName(_fromUtf8(\"comboBox_date\"))\n self.horizontalLayout.addWidget(self.comboBox_date)\n self.verticalLayout.addLayout(self.horizontalLayout)\n self.gridLayout = QtGui.QGridLayout()\n self.gridLayout.setObjectName(_fromUtf8(\"gridLayout\"))\n self.label = QtGui.QLabel(self.layoutWidget)\n sizePolicy = QtGui.QSizePolicy(QtGui.QSizePolicy.Preferred, QtGui.QSizePolicy.Preferred)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label.sizePolicy().hasHeightForWidth())\n self.label.setSizePolicy(sizePolicy)\n self.label.setObjectName(_fromUtf8(\"label\"))\n self.gridLayout.addWidget(self.label, 0, 0, 1, 1)\n self.spinBox_1 = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_1.setReadOnly(True)\n self.spinBox_1.setMaximum(10000)\n self.spinBox_1.setObjectName(_fromUtf8(\"spinBox_1\"))\n self.gridLayout.addWidget(self.spinBox_1, 0, 2, 1, 1)\n self.spinBox_2 = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_2.setReadOnly(True)\n self.spinBox_2.setMaximum(10000)\n self.spinBox_2.setObjectName(_fromUtf8(\"spinBox_2\"))\n self.gridLayout.addWidget(self.spinBox_2, 0, 4, 1, 1)\n self.spinBox_3 = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_3.setReadOnly(True)\n self.spinBox_3.setMaximum(10000)\n self.spinBox_3.setObjectName(_fromUtf8(\"spinBox_3\"))\n self.gridLayout.addWidget(self.spinBox_3, 0, 6, 1, 1)\n self.spinBox_4 = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_4.setReadOnly(True)\n self.spinBox_4.setMaximum(10000)\n self.spinBox_4.setObjectName(_fromUtf8(\"spinBox_4\"))\n self.gridLayout.addWidget(self.spinBox_4, 0, 8, 1, 1)\n self.spinBox_5 = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_5.setReadOnly(True)\n self.spinBox_5.setMaximum(10000)\n self.spinBox_5.setObjectName(_fromUtf8(\"spinBox_5\"))\n self.gridLayout.addWidget(self.spinBox_5, 0, 10, 1, 1)\n spacerItem = QtGui.QSpacerItem(40, 20, QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Minimum)\n self.gridLayout.addItem(spacerItem, 0, 3, 1, 1)\n self.spinBox_6 = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_6.setReadOnly(True)\n self.spinBox_6.setMaximum(10000)\n self.spinBox_6.setObjectName(_fromUtf8(\"spinBox_6\"))\n self.gridLayout.addWidget(self.spinBox_6, 0, 12, 1, 1)\n spacerItem1 = QtGui.QSpacerItem(40, 20, QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Minimum)\n self.gridLayout.addItem(spacerItem1, 0, 11, 1, 1)\n spacerItem2 = QtGui.QSpacerItem(40, 20, QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Minimum)\n self.gridLayout.addItem(spacerItem2, 0, 9, 1, 1)\n spacerItem3 = QtGui.QSpacerItem(40, 20, QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Minimum)\n self.gridLayout.addItem(spacerItem3, 0, 5, 1, 1)\n spacerItem4 = QtGui.QSpacerItem(40, 20, QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Minimum)\n self.gridLayout.addItem(spacerItem4, 0, 1, 1, 1)\n spacerItem5 = QtGui.QSpacerItem(40, 20, QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Minimum)\n self.gridLayout.addItem(spacerItem5, 0, 7, 1, 1)\n spacerItem6 = QtGui.QSpacerItem(40, 20, QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Minimum)\n self.gridLayout.addItem(spacerItem6, 0, 13, 1, 1)\n self.verticalLayout.addLayout(self.gridLayout)\n self.tableView = QtGui.QTableView(self.layoutWidget)\n sizePolicy = QtGui.QSizePolicy(QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Expanding)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.tableView.sizePolicy().hasHeightForWidth())\n self.tableView.setSizePolicy(sizePolicy)\n self.tableView.setObjectName(_fromUtf8(\"tableView\"))\n self.verticalLayout.addWidget(self.tableView)\n self.gridLayout_3 = QtGui.QGridLayout()\n self.gridLayout_3.setObjectName(_fromUtf8(\"gridLayout_3\"))\n self.label_2 = QtGui.QLabel(self.layoutWidget)\n self.label_2.setObjectName(_fromUtf8(\"label_2\"))\n self.gridLayout_3.addWidget(self.label_2, 0, 0, 1, 1)\n self.spinBox_7 = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_7.setReadOnly(True)\n self.spinBox_7.setMaximum(10000)\n self.spinBox_7.setObjectName(_fromUtf8(\"spinBox_7\"))\n self.gridLayout_3.addWidget(self.spinBox_7, 0, 1, 1, 1)\n self.spinBox_8 = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_8.setReadOnly(True)\n self.spinBox_8.setMaximum(10000)\n self.spinBox_8.setObjectName(_fromUtf8(\"spinBox_8\"))\n self.gridLayout_3.addWidget(self.spinBox_8, 0, 2, 1, 1)\n self.spinBox_9 = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_9.setReadOnly(True)\n self.spinBox_9.setMaximum(10000)\n self.spinBox_9.setObjectName(_fromUtf8(\"spinBox_9\"))\n self.gridLayout_3.addWidget(self.spinBox_9, 0, 3, 1, 1)\n self.spinBox_10 = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_10.setReadOnly(True)\n self.spinBox_10.setMaximum(10000)\n self.spinBox_10.setObjectName(_fromUtf8(\"spinBox_10\"))\n self.gridLayout_3.addWidget(self.spinBox_10, 0, 4, 1, 1)\n self.spinBox_11 = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_11.setReadOnly(True)\n self.spinBox_11.setMaximum(10000)\n self.spinBox_11.setObjectName(_fromUtf8(\"spinBox_11\"))\n self.gridLayout_3.addWidget(self.spinBox_11, 0, 5, 1, 1)\n self.spinBox_12 = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_12.setReadOnly(True)\n self.spinBox_12.setMaximum(10000)\n self.spinBox_12.setObjectName(_fromUtf8(\"spinBox_12\"))\n self.gridLayout_3.addWidget(self.spinBox_12, 0, 6, 1, 1)\n self.verticalLayout.addLayout(self.gridLayout_3)\n self.gridLayout_2 = QtGui.QGridLayout()\n self.gridLayout_2.setObjectName(_fromUtf8(\"gridLayout_2\"))\n self.label_3 = QtGui.QLabel(self.layoutWidget)\n self.label_3.setObjectName(_fromUtf8(\"label_3\"))\n self.gridLayout_2.addWidget(self.label_3, 0, 0, 1, 1)\n self.spinBox_13 = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_13.setReadOnly(True)\n self.spinBox_13.setMaximum(1000000)\n self.spinBox_13.setObjectName(_fromUtf8(\"spinBox_13\"))\n self.gridLayout_2.addWidget(self.spinBox_13, 0, 1, 1, 1)\n self.spinBox_14 = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_14.setReadOnly(True)\n self.spinBox_14.setMaximum(1000000)\n self.spinBox_14.setObjectName(_fromUtf8(\"spinBox_14\"))\n self.gridLayout_2.addWidget(self.spinBox_14, 0, 2, 1, 1)\n self.spinBox_15 = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_15.setReadOnly(True)\n self.spinBox_15.setMaximum(1000000)\n self.spinBox_15.setObjectName(_fromUtf8(\"spinBox_15\"))\n self.gridLayout_2.addWidget(self.spinBox_15, 0, 3, 1, 1)\n self.spinBox_16 = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_16.setReadOnly(True)\n self.spinBox_16.setMaximum(1000000)\n self.spinBox_16.setObjectName(_fromUtf8(\"spinBox_16\"))\n self.gridLayout_2.addWidget(self.spinBox_16, 0, 4, 1, 1)\n self.spinBox_17 = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_17.setReadOnly(True)\n self.spinBox_17.setMaximum(1000000)\n self.spinBox_17.setObjectName(_fromUtf8(\"spinBox_17\"))\n self.gridLayout_2.addWidget(self.spinBox_17, 0, 5, 1, 1)\n self.spinBox_18 = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_18.setReadOnly(True)\n self.spinBox_18.setMaximum(1000000)\n self.spinBox_18.setObjectName(_fromUtf8(\"spinBox_18\"))\n self.gridLayout_2.addWidget(self.spinBox_18, 0, 6, 1, 1)\n self.verticalLayout.addLayout(self.gridLayout_2)\n self.horizontalLayout_5 = QtGui.QHBoxLayout()\n self.horizontalLayout_5.setObjectName(_fromUtf8(\"horizontalLayout_5\"))\n self.label_4 = QtGui.QLabel(self.layoutWidget)\n self.label_4.setObjectName(_fromUtf8(\"label_4\"))\n self.horizontalLayout_5.addWidget(self.label_4)\n self.spinBox_19 = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_19.setReadOnly(True)\n self.spinBox_19.setMaximum(1000000000)\n self.spinBox_19.setObjectName(_fromUtf8(\"spinBox_19\"))\n self.horizontalLayout_5.addWidget(self.spinBox_19)\n self.verticalLayout.addLayout(self.horizontalLayout_5)\n\n self.retranslateUi(Dialog_report)\n QtCore.QMetaObject.connectSlotsByName(Dialog_report)\n\n def retranslateUi(self, Dialog_report):\n Dialog_report.setWindowTitle(_translate(\"Dialog_report\", \"每月結算\", None))\n self.label.setText(_translate(\"Dialog_report\", \"$\", None))\n self.label_2.setText(_translate(\"Dialog_report\", \"個別總量\", None))\n self.label_3.setText(_translate(\"Dialog_report\", \"個別總收入\", None))\n self.label_4.setText(_translate(\"Dialog_report\", \"本月收入\", None))\n\n\nif __name__ == \"__main__\":\n import sys\n app = QtGui.QApplication(sys.argv)\n Dialog_report = QtGui.QDialog()\n ui = Ui_Dialog_report()\n ui.setupUi(Dialog_report)\n Dialog_report.show()\n sys.exit(app.exec_())\n\n"
},
{
"alpha_fraction": 0.5383986830711365,
"alphanum_fraction": 0.5433006286621094,
"avg_line_length": 20.375,
"blob_id": "41080a7a202fe3f4f4ed2c6d518b46e25e548107",
"content_id": "cd284ac3befa2eadee2962c537aecf51101599f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1224,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 56,
"path": "/UI/main_dialog.py",
"repo_name": "WulfChang/HQ_food",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n\"\"\"\nModule implementing Dialog_main.\n\"\"\"\n\nfrom PyQt4.QtGui import QDialog\nfrom PyQt4.QtCore import pyqtSignature\n\nfrom Ui_main_dialog import Ui_Dialog\n\nfrom ui_daily import Dialog_daily\nfrom customer_edit import Dialog_cedit\n\nfrom month_report import Dialog_report\nfrom Ui_month_report import Ui_Dialog_report\n\nclass Dialog_main(QDialog, Ui_Dialog):\n \"\"\"\n Class documentation goes here.\n \"\"\"\n def __init__(self, parent = None):\n \"\"\"\n Constructor\n \"\"\"\n QDialog.__init__(self, parent)\n self.setupUi(self)\n \n @pyqtSignature(\"\")\n def on_pushButton_3_clicked(self):\n \"\"\"\n Month report\n \"\"\"\n ui_mon = Dialog_report()\n ui_mon.exec_()\n\n \n @pyqtSignature(\"\")\n def on_pushButton_2_clicked(self):\n \"\"\"\n daily accounting\n \"\"\"\n ui_day = Dialog_daily()\n ui_day.exec_()\n \n @pyqtSignature(\"\")\n def on_pushButton_1_clicked(self):\n \"\"\"\n customer edit\n \"\"\"\n try:\n ui_edit = Dialog_cedit()\n except IOError as e:\n self.textEdit.append(str(e))\n else: \n ui_edit.exec_() \n\n \n\n"
},
{
"alpha_fraction": 0.6987871527671814,
"alphanum_fraction": 0.7188160419464111,
"avg_line_length": 54.813663482666016,
"blob_id": "ba6bacc2eefc0951a10e102acb6b1bd61d146bcb",
"content_id": "1c593f37f214713e192ef390d57303577189b268",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8995,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 161,
"path": "/UI/Ui_ui_daily.py",
"repo_name": "WulfChang/HQ_food",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file '/home/wulf/Program/HQ_food/UI/ui_daily.ui'\n#\n# Created: Tue Nov 3 09:05:52 2015\n# by: PyQt4 UI code generator 4.10.4\n#\n# WARNING! All changes made in this file will be lost!\n\nfrom PyQt4 import QtCore, QtGui\n\ntry:\n _fromUtf8 = QtCore.QString.fromUtf8\nexcept AttributeError:\n def _fromUtf8(s):\n return s\n\ntry:\n _encoding = QtGui.QApplication.UnicodeUTF8\n def _translate(context, text, disambig):\n return QtGui.QApplication.translate(context, text, disambig, _encoding)\nexcept AttributeError:\n def _translate(context, text, disambig):\n return QtGui.QApplication.translate(context, text, disambig)\n\nclass Ui_Dialog_daily(object):\n def setupUi(self, Dialog_daily):\n Dialog_daily.setObjectName(_fromUtf8(\"Dialog_daily\"))\n Dialog_daily.resize(465, 505)\n self.horizontalLayoutWidget_7 = QtGui.QWidget(Dialog_daily)\n self.horizontalLayoutWidget_7.setGeometry(QtCore.QRect(11, 410, 441, 80))\n self.horizontalLayoutWidget_7.setObjectName(_fromUtf8(\"horizontalLayoutWidget_7\"))\n self.horizontalLayout_7 = QtGui.QHBoxLayout(self.horizontalLayoutWidget_7)\n self.horizontalLayout_7.setMargin(0)\n self.horizontalLayout_7.setObjectName(_fromUtf8(\"horizontalLayout_7\"))\n self.textEdit = QtGui.QTextEdit(self.horizontalLayoutWidget_7)\n self.textEdit.setObjectName(_fromUtf8(\"textEdit\"))\n self.horizontalLayout_7.addWidget(self.textEdit)\n self.buttonBox = QtGui.QDialogButtonBox(self.horizontalLayoutWidget_7)\n self.buttonBox.setStandardButtons(QtGui.QDialogButtonBox.Cancel|QtGui.QDialogButtonBox.Ok)\n self.buttonBox.setObjectName(_fromUtf8(\"buttonBox\"))\n self.horizontalLayout_7.addWidget(self.buttonBox)\n self.layoutWidget = QtGui.QWidget(Dialog_daily)\n self.layoutWidget.setGeometry(QtCore.QRect(10, 29, 441, 371))\n self.layoutWidget.setObjectName(_fromUtf8(\"layoutWidget\"))\n self.verticalLayout_2 = QtGui.QVBoxLayout(self.layoutWidget)\n self.verticalLayout_2.setMargin(0)\n self.verticalLayout_2.setObjectName(_fromUtf8(\"verticalLayout_2\"))\n self.horizontalLayout = QtGui.QHBoxLayout()\n self.horizontalLayout.setObjectName(_fromUtf8(\"horizontalLayout\"))\n self.combo_select = QtGui.QComboBox(self.layoutWidget)\n self.combo_select.setObjectName(_fromUtf8(\"combo_select\"))\n self.horizontalLayout.addWidget(self.combo_select)\n self.dateEdit = QtGui.QDateEdit(self.layoutWidget)\n self.dateEdit.setReadOnly(True)\n self.dateEdit.setCalendarPopup(False)\n self.dateEdit.setObjectName(_fromUtf8(\"dateEdit\"))\n self.horizontalLayout.addWidget(self.dateEdit)\n self.verticalLayout_2.addLayout(self.horizontalLayout)\n self.horizontalLayout_2 = QtGui.QHBoxLayout()\n self.horizontalLayout_2.setObjectName(_fromUtf8(\"horizontalLayout_2\"))\n self.label_3 = QtGui.QLabel(self.layoutWidget)\n self.label_3.setObjectName(_fromUtf8(\"label_3\"))\n self.horizontalLayout_2.addWidget(self.label_3)\n self.spinBox_big = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_big.setObjectName(_fromUtf8(\"spinBox_big\"))\n self.horizontalLayout_2.addWidget(self.spinBox_big)\n self.horizontalSlider_big = QtGui.QSlider(self.layoutWidget)\n self.horizontalSlider_big.setOrientation(QtCore.Qt.Horizontal)\n self.horizontalSlider_big.setTickPosition(QtGui.QSlider.NoTicks)\n self.horizontalSlider_big.setObjectName(_fromUtf8(\"horizontalSlider_big\"))\n self.horizontalLayout_2.addWidget(self.horizontalSlider_big)\n self.verticalLayout_2.addLayout(self.horizontalLayout_2)\n self.horizontalLayout_3 = QtGui.QHBoxLayout()\n self.horizontalLayout_3.setObjectName(_fromUtf8(\"horizontalLayout_3\"))\n self.label_4 = QtGui.QLabel(self.layoutWidget)\n self.label_4.setObjectName(_fromUtf8(\"label_4\"))\n self.horizontalLayout_3.addWidget(self.label_4)\n self.spinBox_small = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_small.setObjectName(_fromUtf8(\"spinBox_small\"))\n self.horizontalLayout_3.addWidget(self.spinBox_small)\n self.horizontalSlider_small = QtGui.QSlider(self.layoutWidget)\n self.horizontalSlider_small.setOrientation(QtCore.Qt.Horizontal)\n self.horizontalSlider_small.setObjectName(_fromUtf8(\"horizontalSlider_small\"))\n self.horizontalLayout_3.addWidget(self.horizontalSlider_small)\n self.verticalLayout_2.addLayout(self.horizontalLayout_3)\n self.horizontalLayout_4 = QtGui.QHBoxLayout()\n self.horizontalLayout_4.setObjectName(_fromUtf8(\"horizontalLayout_4\"))\n self.label_5 = QtGui.QLabel(self.layoutWidget)\n self.label_5.setObjectName(_fromUtf8(\"label_5\"))\n self.horizontalLayout_4.addWidget(self.label_5)\n self.spinBox_oil = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_oil.setObjectName(_fromUtf8(\"spinBox_oil\"))\n self.horizontalLayout_4.addWidget(self.spinBox_oil)\n self.horizontalSlider_oil = QtGui.QSlider(self.layoutWidget)\n self.horizontalSlider_oil.setOrientation(QtCore.Qt.Horizontal)\n self.horizontalSlider_oil.setObjectName(_fromUtf8(\"horizontalSlider_oil\"))\n self.horizontalLayout_4.addWidget(self.horizontalSlider_oil)\n self.verticalLayout_2.addLayout(self.horizontalLayout_4)\n self.horizontalLayout_5 = QtGui.QHBoxLayout()\n self.horizontalLayout_5.setObjectName(_fromUtf8(\"horizontalLayout_5\"))\n self.label_6 = QtGui.QLabel(self.layoutWidget)\n self.label_6.setObjectName(_fromUtf8(\"label_6\"))\n self.horizontalLayout_5.addWidget(self.label_6)\n self.spinBox_tri = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_tri.setObjectName(_fromUtf8(\"spinBox_tri\"))\n self.horizontalLayout_5.addWidget(self.spinBox_tri)\n self.horizontalSlider_tri = QtGui.QSlider(self.layoutWidget)\n self.horizontalSlider_tri.setOrientation(QtCore.Qt.Horizontal)\n self.horizontalSlider_tri.setObjectName(_fromUtf8(\"horizontalSlider_tri\"))\n self.horizontalLayout_5.addWidget(self.horizontalSlider_tri)\n self.verticalLayout_2.addLayout(self.horizontalLayout_5)\n self.horizontalLayout_6 = QtGui.QHBoxLayout()\n self.horizontalLayout_6.setObjectName(_fromUtf8(\"horizontalLayout_6\"))\n self.label_7 = QtGui.QLabel(self.layoutWidget)\n self.label_7.setObjectName(_fromUtf8(\"label_7\"))\n self.horizontalLayout_6.addWidget(self.label_7)\n self.spinBox_stinky = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_stinky.setObjectName(_fromUtf8(\"spinBox_stinky\"))\n self.horizontalLayout_6.addWidget(self.spinBox_stinky)\n self.horizontalSlider_stinky = QtGui.QSlider(self.layoutWidget)\n self.horizontalSlider_stinky.setOrientation(QtCore.Qt.Horizontal)\n self.horizontalSlider_stinky.setObjectName(_fromUtf8(\"horizontalSlider_stinky\"))\n self.horizontalLayout_6.addWidget(self.horizontalSlider_stinky)\n self.verticalLayout_2.addLayout(self.horizontalLayout_6)\n self.horizontalLayout_8 = QtGui.QHBoxLayout()\n self.horizontalLayout_8.setObjectName(_fromUtf8(\"horizontalLayout_8\"))\n self.label_8 = QtGui.QLabel(self.layoutWidget)\n self.label_8.setObjectName(_fromUtf8(\"label_8\"))\n self.horizontalLayout_8.addWidget(self.label_8)\n self.spinBox_milk = QtGui.QSpinBox(self.layoutWidget)\n self.spinBox_milk.setObjectName(_fromUtf8(\"spinBox_milk\"))\n self.horizontalLayout_8.addWidget(self.spinBox_milk)\n self.horizontalSlider_milk = QtGui.QSlider(self.layoutWidget)\n self.horizontalSlider_milk.setOrientation(QtCore.Qt.Horizontal)\n self.horizontalSlider_milk.setObjectName(_fromUtf8(\"horizontalSlider_milk\"))\n self.horizontalLayout_8.addWidget(self.horizontalSlider_milk)\n self.verticalLayout_2.addLayout(self.horizontalLayout_8)\n\n self.retranslateUi(Dialog_daily)\n QtCore.QMetaObject.connectSlotsByName(Dialog_daily)\n\n def retranslateUi(self, Dialog_daily):\n Dialog_daily.setWindowTitle(_translate(\"Dialog_daily\", \"每日銷售\", None))\n self.dateEdit.setDisplayFormat(_translate(\"Dialog_daily\", \"yyyy/MM/dd\", None))\n self.label_3.setText(_translate(\"Dialog_daily\", \"BIG\", None))\n self.label_4.setText(_translate(\"Dialog_daily\", \"SMALL\", None))\n self.label_5.setText(_translate(\"Dialog_daily\", \"OIL\", None))\n self.label_6.setText(_translate(\"Dialog_daily\", \"TRI\", None))\n self.label_7.setText(_translate(\"Dialog_daily\", \"STINKY\", None))\n self.label_8.setText(_translate(\"Dialog_daily\", \"Milk\", None))\n\n\nif __name__ == \"__main__\":\n import sys\n app = QtGui.QApplication(sys.argv)\n Dialog_daily = QtGui.QDialog()\n ui = Ui_Dialog_daily()\n ui.setupUi(Dialog_daily)\n Dialog_daily.show()\n sys.exit(app.exec_())\n\n"
},
{
"alpha_fraction": 0.44897958636283875,
"alphanum_fraction": 0.4591836631298065,
"avg_line_length": 29,
"blob_id": "390e8ccc4436229343830729c2351fcf048b73a6",
"content_id": "5637f21aefe324a927a2b40c9ecb691e567f6717",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 134,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 3,
"path": "/UI/header.py",
"repo_name": "WulfChang/HQ_food",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nPRODUCT_NAME = [u'大豆腐', u'小豆腐', u'油豆腐', u'三角豆腐', u'臭豆腐', u'豆漿' ]\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5947955250740051,
"alphanum_fraction": 0.6059479713439941,
"avg_line_length": 16.600000381469727,
"blob_id": "c4d98951d200c46f4594a095b28def1ce5bd5b60",
"content_id": "707ef48e2c0d4171d44e4399ca58cbd9004cc029",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 269,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 15,
"path": "/__init__.py",
"repo_name": "WulfChang/HQ_food",
"src_encoding": "UTF-8",
"text": "\n#from PyQt4 import QtCore, QtGui\nimport PyQt4\n\nfrom UI.main_dialog import Dialog_main\n\n \ndef main():\n app = PyQt4.QtGui.QApplication(sys.argv)\n ui = Dialog_main()\n ui.show()\n sys.exit(app.exec_())\n\nif __name__ == '__main__':\n import sys\n main() \n"
},
{
"alpha_fraction": 0.5553778409957886,
"alphanum_fraction": 0.5587764978408813,
"avg_line_length": 26.184782028198242,
"blob_id": "94aa80c48efad90a2859c417de1dfad300597e12",
"content_id": "1a3ece20898412a65632542c48790d22ef2fc880",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5002,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 184,
"path": "/UI/ui_daily.py",
"repo_name": "WulfChang/HQ_food",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n\"\"\"\nModule implementing Dialog_daily.\n\"\"\"\n\nfrom PyQt4.QtGui import QDialog\nfrom PyQt4.QtCore import pyqtSignature, QDate\n\nfrom Ui_ui_daily import Ui_Dialog_daily\nfrom customer_file import Customer_list\nfrom day_file import Dfile\n\nclass Dialog_daily(QDialog, Ui_Dialog_daily):\n \"\"\"\n Class documentation goes here.\n \"\"\"\n def __init__(self, parent = None):\n \"\"\"\n Constructor\n \"\"\"\n QDialog.__init__(self, parent)\n self.setupUi(self)\n \n #set today ( for file usage)\n self.qdate = QDate.currentDate()\n self.dateEdit.setDate( self.qdate )\n \n #declare customer list object\n try:\n self.cfile = Customer_list()\n except IOError as e:\n raise IOError(e)\n \n #read company list\n self.m_clist={}\n self.m_clist = self.cfile.readCompany()\n \n #set combo box\n self.setCombo(self.m_clist)\n \n def setCombo(self, str):\n \"\"\"\n set combo box\n \"\"\"\n for i in str:\n self.combo_select.addItem(i) \n \n def clearSpinbox(self, value=0):\n \"\"\"\n clear all spin box\n \"\"\"\n \n self.spinBox_big.setValue(value)\n self.spinBox_small.setValue(value)\n self.spinBox_oil.setValue(value)\n self.spinBox_tri.setValue(value)\n self.spinBox_stinky.setValue(value)\n self.spinBox_milk.setValue(value)\n \n \n @pyqtSignature(\"\")\n def on_buttonBox_accepted(self):\n \"\"\"\n save data into file\n \"\"\"\n i_year = self.qdate.year()\n i_month = self.qdate.month()\n i_name = self.cfile.readCvalue( str(self.combo_select.currentText().toUtf8()) )\n \n #declare Dfile object\n self.dfile = Dfile( i_year, i_month, i_name )\n \n #open file\n self.dfile.open_dfile()\n \n if self.dfile.ischeckRwrite( self.qdate.day() ) == True: \n #write ui data into file\n i_big = self.spinBox_big.value()\n i_small = self.spinBox_small.value()\n i_oil = self.spinBox_oil.value()\n i_tri = self.spinBox_tri.value()\n i_stinky = self.spinBox_stinky.value()\n i_milk = self.spinBox_milk.value()\n \n spindata = [ i_big, i_small, i_oil, i_tri, i_stinky, i_milk]\n \n self.dfile.write_dfile(spindata)\n \n #close file\n self.dfile.close_dfile() \n \n \n @pyqtSignature(\"\")\n def on_buttonBox_rejected(self):\n \"\"\"\n Clear all value to zero\n \"\"\"\n self.clearSpinbox()\n \n @pyqtSignature(\"int\")\n def on_horizontalSlider_big_valueChanged(self, value):\n \"\"\"\n Synchronized with spinBox_big\n \"\"\"\n self.spinBox_big.setValue(value)\n \n @pyqtSignature(\"int\")\n def on_spinBox_big_valueChanged(self, p0):\n \"\"\"\n Synchronized with Slider_big\n \"\"\"\n self.horizontalSlider_big.setValue(p0)\n \n @pyqtSignature(\"int\")\n def on_spinBox_small_valueChanged(self, p0):\n \"\"\"\n Synchronized with Slider small\n \"\"\"\n self.horizontalSlider_small.setValue(p0)\n \n @pyqtSignature(\"int\")\n def on_horizontalSlider_small_valueChanged(self, value):\n \"\"\"\n Synchronized with Spinbox small\n \"\"\"\n self.spinBox_small.setValue(value)\n \n @pyqtSignature(\"int\")\n def on_spinBox_oil_valueChanged(self, p0):\n \"\"\"\n Synchronized with Slider oil\n \"\"\"\n self.horizontalSlider_oil.setValue(p0)\n \n @pyqtSignature(\"int\")\n def on_horizontalSlider_oil_valueChanged(self, value):\n \"\"\"\n Synchronized with spinBox_oil\n \"\"\"\n self.spinBox_oil.setValue(value)\n \n @pyqtSignature(\"int\")\n def on_spinBox_tri_valueChanged(self, p0):\n \"\"\"\n Synchronized with Slider tri\n \"\"\"\n self.horizontalSlider_tri.setValue(p0)\n \n @pyqtSignature(\"int\")\n def on_horizontalSlider_tri_valueChanged(self, value):\n \"\"\"\n Synchronized with spinBox_tri\n \"\"\"\n self.spinBox_tri.setValue(value)\n \n \n @pyqtSignature(\"int\")\n def on_spinBox_stinky_valueChanged(self, p0):\n \"\"\"\n Synchronized with Slider stinky\n \"\"\"\n self.horizontalSlider_stinky.setValue(p0)\n \n @pyqtSignature(\"int\")\n def on_horizontalSlider_stinky_valueChanged(self, value):\n \"\"\"\n Synchronized with spinBox_stinky\n \"\"\"\n self.spinBox_stinky.setValue(value)\n \n @pyqtSignature(\"int\")\n def on_spinBox_milk_valueChanged(self, p0):\n \"\"\"\n Synchronized with Slider milk\n \"\"\"\n self.horizontalSlider_milk.setValue(p0)\n \n @pyqtSignature(\"int\")\n def on_horizontalSlider_milk_valueChanged(self, value):\n \"\"\"\n Synchronized with spinBox_milk\n \"\"\"\n self.spinBox_milk.setValue(value)\n"
},
{
"alpha_fraction": 0.6452874541282654,
"alphanum_fraction": 0.6781384348869324,
"avg_line_length": 37.727272033691406,
"blob_id": "35c107d7c06eb0087724cc1a0dfee773328af101",
"content_id": "1bd8b093439cd0def33c232bdaa98bfcb06375dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2597,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 66,
"path": "/UI/Ui_main_dialog.py",
"repo_name": "WulfChang/HQ_food",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file '/home/wulf/Program/HQ_food/UI/main_dialog.ui'\n#\n# Created: Tue Nov 3 09:05:54 2015\n# by: PyQt4 UI code generator 4.10.4\n#\n# WARNING! All changes made in this file will be lost!\n\nfrom PyQt4 import QtCore, QtGui\n\ntry:\n _fromUtf8 = QtCore.QString.fromUtf8\nexcept AttributeError:\n def _fromUtf8(s):\n return s\n\ntry:\n _encoding = QtGui.QApplication.UnicodeUTF8\n def _translate(context, text, disambig):\n return QtGui.QApplication.translate(context, text, disambig, _encoding)\nexcept AttributeError:\n def _translate(context, text, disambig):\n return QtGui.QApplication.translate(context, text, disambig)\n\nclass Ui_Dialog(object):\n def setupUi(self, Dialog):\n Dialog.setObjectName(_fromUtf8(\"Dialog\"))\n Dialog.resize(538, 415)\n self.splitter = QtGui.QSplitter(Dialog)\n self.splitter.setGeometry(QtCore.QRect(10, 20, 381, 121))\n self.splitter.setOrientation(QtCore.Qt.Horizontal)\n self.splitter.setObjectName(_fromUtf8(\"splitter\"))\n self.pushButton_1 = QtGui.QPushButton(self.splitter)\n self.pushButton_1.setObjectName(_fromUtf8(\"pushButton_1\"))\n self.pushButton_2 = QtGui.QPushButton(self.splitter)\n self.pushButton_2.setObjectName(_fromUtf8(\"pushButton_2\"))\n self.pushButton_3 = QtGui.QPushButton(self.splitter)\n self.pushButton_3.setObjectName(_fromUtf8(\"pushButton_3\"))\n self.pushButton_4 = QtGui.QPushButton(Dialog)\n self.pushButton_4.setEnabled(False)\n self.pushButton_4.setGeometry(QtCore.QRect(400, 20, 123, 121))\n self.pushButton_4.setObjectName(_fromUtf8(\"pushButton_4\"))\n self.textEdit = QtGui.QTextEdit(Dialog)\n self.textEdit.setGeometry(QtCore.QRect(10, 350, 511, 51))\n self.textEdit.setObjectName(_fromUtf8(\"textEdit\"))\n\n self.retranslateUi(Dialog)\n QtCore.QMetaObject.connectSlotsByName(Dialog)\n\n def retranslateUi(self, Dialog):\n Dialog.setWindowTitle(_translate(\"Dialog\", \"超品豆腐\", None))\n self.pushButton_1.setText(_translate(\"Dialog\", \"客戶設定\", None))\n self.pushButton_2.setText(_translate(\"Dialog\", \"每日記賬\", None))\n self.pushButton_3.setText(_translate(\"Dialog\", \"每月結算\", None))\n self.pushButton_4.setText(_translate(\"Dialog\", \"技術分析\", None))\n\n\nif __name__ == \"__main__\":\n import sys\n app = QtGui.QApplication(sys.argv)\n Dialog = QtGui.QDialog()\n ui = Ui_Dialog()\n ui.setupUi(Dialog)\n Dialog.show()\n sys.exit(app.exec_())\n\n"
},
{
"alpha_fraction": 0.5566823482513428,
"alphanum_fraction": 0.5747917294502258,
"avg_line_length": 34.32051467895508,
"blob_id": "d3e25feeaf85e1e9ea895728a3bd8ebc53c9dcdf",
"content_id": "90d8432f636b358085d0b267eb5d592abd0be4e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8283,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 234,
"path": "/UI/month_report.py",
"repo_name": "WulfChang/HQ_food",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n\"\"\"\nModule implementing Dialog_report.\n\"\"\"\n\nfrom PyQt4.QtGui import QDialog, QVBoxLayout, QStandardItemModel\nfrom PyQt4.QtCore import pyqtSignature, Qt, QVariant\n\nfrom Ui_month_report import Ui_Dialog_report\nfrom header import PRODUCT_NAME\n\nfrom customer_file import Customer_list\nfrom customer_file import Customer_price\nfrom day_file import Dfile\n\n\nclass Dialog_report(QDialog, Ui_Dialog_report):\n \"\"\"\n Class documentation goes here.\n \"\"\"\n def __init__(self, parent = None):\n \"\"\"\n Constructor\n \"\"\"\n QDialog.__init__(self, parent)\n self.setupUi(self)\n \n \n #construct Customer list class\n self.clist = Customer_list() \n \n #construct accounting class\n self.caccount = Dfile()\n \n #construct customer price class\n self.cprice = Customer_price()\n \n #construct standard table\n self.tablemodel = QStandardItemModel(31, len(PRODUCT_NAME) )\n self.setTableheader()\n\n #save customer list int\n self.list_customer = self.clist.readCompany()\n self.setCombo( 1, self.list_customer ) \n \n def setMode(self, str_mode):\n \n if str_mode == 'init':\n self.clearAllshow()\n \n def setCombo(self, comboselect, m_str):\n \"\"\"\n set combo box\n \"\"\"\n if comboselect == 1:\n for i in m_str:\n self.comboBox_name.addItem(i)\n elif comboselect == 2:\n self.comboBox_date.clear()\n for i in m_str: \n self.comboBox_date.addItem(i)\n \n \n def clearAllshow(self):\n \n #clear all spin box \n self.setAllspin(0)\n \n #clear table\n self.clearTableview()\n \n def setAllspin(self, int_value):\n self.spinBox_1.setValue(int_value)\n self.spinBox_2.setValue(int_value)\n self.spinBox_3.setValue(int_value)\n self.spinBox_4.setValue(int_value)\n self.spinBox_5.setValue(int_value)\n self.spinBox_6.setValue(int_value)\n self.spinBox_7.setValue(int_value)\n self.spinBox_8.setValue(int_value)\n self.spinBox_9.setValue(int_value)\n self.spinBox_10.setValue(int_value)\n self.spinBox_11.setValue(int_value)\n self.spinBox_12.setValue(int_value)\n self.spinBox_13.setValue(int_value)\n self.spinBox_14.setValue(int_value)\n self.spinBox_15.setValue(int_value)\n self.spinBox_16.setValue(int_value)\n self.spinBox_17.setValue(int_value)\n self.spinBox_18.setValue(int_value)\n self.spinBox_19.setValue(int_value)\n self.spinBox_19.setValue(0)\n \n def setTableheader(self):\n \n #set header data\n self.tablemodel.setHeaderData(0, Qt.Horizontal, PRODUCT_NAME[0] )\n self.tablemodel.setHeaderData(1, Qt.Horizontal, PRODUCT_NAME[1] )\n self.tablemodel.setHeaderData(2, Qt.Horizontal, PRODUCT_NAME[2] )\n self.tablemodel.setHeaderData(3, Qt.Horizontal, PRODUCT_NAME[3] )\n self.tablemodel.setHeaderData(4, Qt.Horizontal, PRODUCT_NAME[4] )\n self.tablemodel.setHeaderData(5, Qt.Horizontal, PRODUCT_NAME[5] )\n \n def setTableview(self, dlist_data ):\n \"\"\"\n set data into tableview model\n \"\"\"\n #show data\n row = 0\n for i in dlist_data:\n self.tablemodel.setData(self.tablemodel.index(row, 0), QVariant(i[0]))\n self.tablemodel.setData(self.tablemodel.index(row, 1), QVariant(i[1]))\n self.tablemodel.setData(self.tablemodel.index(row, 2), QVariant(i[2]))\n self.tablemodel.setData(self.tablemodel.index(row, 3), QVariant(i[3]))\n self.tablemodel.setData(self.tablemodel.index(row, 4), QVariant(i[4]))\n self.tablemodel.setData(self.tablemodel.index(row, 5), QVariant(i[5]))\n row += 1\n \n #set table into tableview\n self.tableView.setModel(self.tablemodel)\n \n def clearTableview(self):\n \"\"\"\n clear table\n \"\"\"\n #show data\n row = 0\n i = [0, 0, 0, 0, 0, 0]\n for row in range(31):\n self.tablemodel.setData(self.tablemodel.index(row, 0), QVariant(i[0]))\n self.tablemodel.setData(self.tablemodel.index(row, 1), QVariant(i[1]))\n self.tablemodel.setData(self.tablemodel.index(row, 2), QVariant(i[2]))\n self.tablemodel.setData(self.tablemodel.index(row, 3), QVariant(i[3]))\n self.tablemodel.setData(self.tablemodel.index(row, 4), QVariant(i[4]))\n self.tablemodel.setData(self.tablemodel.index(row, 5), QVariant(i[5]))\n \n #set table into tableview\n self.tableView.setModel(self.tablemodel)\n \n @pyqtSignature(\"QString\")\n def on_comboBox_name_currentIndexChanged(self, p0):\n \"\"\"\n when name index change, set combo date\n \"\"\"\n #set to initial status\n self.setMode('init')\n \n #read combo text and dict value\n self.str_customercombo = str( self.comboBox_name.currentText().toUtf8() )\n self.i_customercombo = self.clist.readCvalue( self.str_customercombo )\n \n #read all guest accounting data\n self.list_date = self.caccount.listDatafile( self.i_customercombo )\n \n self.setCombo(2, self.list_date)\n \n @pyqtSignature(\"QString\")\n def on_comboBox_date_currentIndexChanged(self, p0):\n \"\"\"\n search price data and load accounting into table\n \"\"\"\n \n self.str_filename = str( self.comboBox_date.currentText() )\n \n if self.str_filename != '':\n self.str_datecombo = self.str_filename[3:9]\n \n #get price version\n self.i_priceversion = self.cprice.selectPrice( self.i_customercombo, self.str_datecombo )\n \n #get price dict\n dict_price = self.cprice.readPrice( self.i_customercombo, self.i_priceversion )\n self.list_price = self.cprice.getClist( dict_price )\n \n #show price \n self.setPricespin( self.list_price )\n \n #show table\n self.caccount.open_dfile( self.str_filename )\n self.table_data = self.caccount.read_alldfile()\n self.setTableview( self.table_data )\n \n #calculate and show single amount\n self.eachamount = self.sumEachamount( self.table_data )\n self.setEachamount( self.eachamount )\n \n #calculate single price amount\n self.eachpriceamount = [ self.eachamount[i]*self.list_price[i] for i in range(len(PRODUCT_NAME))]\n self.setEachpriceamount( self.eachpriceamount )\n \n #show in total income\n self.spinBox_19.setValue( sum(self.eachpriceamount ) )\n \n \n def setPricespin( self, list ):\n \n self.spinBox_1.setValue( list[0] )\n self.spinBox_2.setValue( list[1] )\n self.spinBox_3.setValue( list[2] )\n self.spinBox_4.setValue( list[3] )\n self.spinBox_5.setValue( list[4] )\n self.spinBox_6.setValue( list[5] )\n \n def setEachamount( self, list ):\n \n self.spinBox_7.setValue( list[0] )\n self.spinBox_8.setValue( list[1] )\n self.spinBox_9.setValue( list[2] )\n self.spinBox_10.setValue( list[3] )\n self.spinBox_11.setValue( list[4] )\n self.spinBox_12.setValue( list[5] )\n \n def setEachpriceamount(self, list ):\n \n self.spinBox_13.setValue( list[0] )\n self.spinBox_14.setValue( list[1] )\n self.spinBox_15.setValue( list[2] )\n self.spinBox_16.setValue( list[3] )\n self.spinBox_17.setValue( list[4] )\n self.spinBox_18.setValue( list[5] )\n \n #sum each item total amount\n def sumEachamount(self, duallist ):\n \n eachamount = [0, 0, 0, 0, 0, 0]\n count = 0\n for i in duallist:\n for j in i:\n eachamount[count] += j\n count += 1\n count = 0\n \n return eachamount\n \n \n"
},
{
"alpha_fraction": 0.6688126921653748,
"alphanum_fraction": 0.6966555118560791,
"avg_line_length": 53.8577995300293,
"blob_id": "5ac1dc8c7721dccb36cca1b03953db9ffcecac3a",
"content_id": "68959b67daa9feb2e2eb1f4089aa7d576db17b43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12016,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 218,
"path": "/UI/Ui_customer_edit.py",
"repo_name": "WulfChang/HQ_food",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file '/home/wulf/Program/HQ_food/UI/customer_edit.ui'\n#\n# Created: Tue Nov 3 09:05:52 2015\n# by: PyQt4 UI code generator 4.10.4\n#\n# WARNING! All changes made in this file will be lost!\n\nfrom PyQt4 import QtCore, QtGui\n\ntry:\n _fromUtf8 = QtCore.QString.fromUtf8\nexcept AttributeError:\n def _fromUtf8(s):\n return s\n\ntry:\n _encoding = QtGui.QApplication.UnicodeUTF8\n def _translate(context, text, disambig):\n return QtGui.QApplication.translate(context, text, disambig, _encoding)\nexcept AttributeError:\n def _translate(context, text, disambig):\n return QtGui.QApplication.translate(context, text, disambig)\n\nclass Ui_Dialog(object):\n def setupUi(self, Dialog):\n Dialog.setObjectName(_fromUtf8(\"Dialog\"))\n Dialog.resize(597, 460)\n self.tabWidget = QtGui.QTabWidget(Dialog)\n self.tabWidget.setGeometry(QtCore.QRect(10, 10, 581, 351))\n self.tabWidget.setObjectName(_fromUtf8(\"tabWidget\"))\n self.tab_3 = QtGui.QWidget()\n self.tab_3.setObjectName(_fromUtf8(\"tab_3\"))\n self.splitter = QtGui.QSplitter(self.tab_3)\n self.splitter.setGeometry(QtCore.QRect(10, 10, 561, 301))\n self.splitter.setOrientation(QtCore.Qt.Vertical)\n self.splitter.setObjectName(_fromUtf8(\"splitter\"))\n self.textBrowser = QtGui.QTextBrowser(self.splitter)\n self.textBrowser.setObjectName(_fromUtf8(\"textBrowser\"))\n self.layoutWidget = QtGui.QWidget(self.splitter)\n self.layoutWidget.setObjectName(_fromUtf8(\"layoutWidget\"))\n self.horizontalLayout_6 = QtGui.QHBoxLayout(self.layoutWidget)\n self.horizontalLayout_6.setMargin(0)\n self.horizontalLayout_6.setObjectName(_fromUtf8(\"horizontalLayout_6\"))\n self.label = QtGui.QLabel(self.layoutWidget)\n self.label.setObjectName(_fromUtf8(\"label\"))\n self.horizontalLayout_6.addWidget(self.label)\n spacerItem = QtGui.QSpacerItem(40, 20, QtGui.QSizePolicy.Expanding, QtGui.QSizePolicy.Minimum)\n self.horizontalLayout_6.addItem(spacerItem)\n self.lineEdit_addguest = QtGui.QLineEdit(self.layoutWidget)\n self.lineEdit_addguest.setObjectName(_fromUtf8(\"lineEdit_addguest\"))\n self.horizontalLayout_6.addWidget(self.lineEdit_addguest)\n self.pushButton_addguest = QtGui.QPushButton(self.layoutWidget)\n self.pushButton_addguest.setObjectName(_fromUtf8(\"pushButton_addguest\"))\n self.horizontalLayout_6.addWidget(self.pushButton_addguest)\n self.tabWidget.addTab(self.tab_3, _fromUtf8(\"\"))\n self.tab = QtGui.QWidget()\n self.tab.setObjectName(_fromUtf8(\"tab\"))\n self.layoutWidget1 = QtGui.QWidget(self.tab)\n self.layoutWidget1.setGeometry(QtCore.QRect(20, 10, 551, 291))\n self.layoutWidget1.setObjectName(_fromUtf8(\"layoutWidget1\"))\n self.gridLayout = QtGui.QGridLayout(self.layoutWidget1)\n self.gridLayout.setMargin(0)\n self.gridLayout.setObjectName(_fromUtf8(\"gridLayout\"))\n self.verticalLayout_3 = QtGui.QVBoxLayout()\n self.verticalLayout_3.setObjectName(_fromUtf8(\"verticalLayout_3\"))\n self.horizontalLayout_2 = QtGui.QHBoxLayout()\n self.horizontalLayout_2.setObjectName(_fromUtf8(\"horizontalLayout_2\"))\n self.comboBox_customer = QtGui.QComboBox(self.layoutWidget1)\n self.comboBox_customer.setObjectName(_fromUtf8(\"comboBox_customer\"))\n self.horizontalLayout_2.addWidget(self.comboBox_customer)\n self.comboBox_version = QtGui.QComboBox(self.layoutWidget1)\n self.comboBox_version.setObjectName(_fromUtf8(\"comboBox_version\"))\n self.horizontalLayout_2.addWidget(self.comboBox_version)\n self.verticalLayout_3.addLayout(self.horizontalLayout_2)\n self.verticalLayout_2 = QtGui.QVBoxLayout()\n self.verticalLayout_2.setObjectName(_fromUtf8(\"verticalLayout_2\"))\n self.horizontalLayout = QtGui.QHBoxLayout()\n self.horizontalLayout.setObjectName(_fromUtf8(\"horizontalLayout\"))\n self.label_1 = QtGui.QLabel(self.layoutWidget1)\n self.label_1.setObjectName(_fromUtf8(\"label_1\"))\n self.horizontalLayout.addWidget(self.label_1)\n self.dateEdit_from = QtGui.QDateEdit(self.layoutWidget1)\n self.dateEdit_from.setReadOnly(True)\n self.dateEdit_from.setDate(QtCore.QDate(2011, 11, 11))\n self.dateEdit_from.setObjectName(_fromUtf8(\"dateEdit_from\"))\n self.horizontalLayout.addWidget(self.dateEdit_from)\n self.label_2 = QtGui.QLabel(self.layoutWidget1)\n self.label_2.setObjectName(_fromUtf8(\"label_2\"))\n self.horizontalLayout.addWidget(self.label_2)\n self.dateEdit_to = QtGui.QDateEdit(self.layoutWidget1)\n self.dateEdit_to.setReadOnly(True)\n self.dateEdit_to.setDate(QtCore.QDate(2011, 11, 11))\n self.dateEdit_to.setObjectName(_fromUtf8(\"dateEdit_to\"))\n self.horizontalLayout.addWidget(self.dateEdit_to)\n self.verticalLayout_2.addLayout(self.horizontalLayout)\n self.verticalLayout = QtGui.QVBoxLayout()\n self.verticalLayout.setObjectName(_fromUtf8(\"verticalLayout\"))\n spacerItem1 = QtGui.QSpacerItem(20, 40, QtGui.QSizePolicy.Minimum, QtGui.QSizePolicy.Expanding)\n self.verticalLayout.addItem(spacerItem1)\n self.horizontalLayout_3 = QtGui.QHBoxLayout()\n self.horizontalLayout_3.setObjectName(_fromUtf8(\"horizontalLayout_3\"))\n self.label_10 = QtGui.QLabel(self.layoutWidget1)\n self.label_10.setObjectName(_fromUtf8(\"label_10\"))\n self.horizontalLayout_3.addWidget(self.label_10)\n self.label_3 = QtGui.QLabel(self.layoutWidget1)\n self.label_3.setObjectName(_fromUtf8(\"label_3\"))\n self.horizontalLayout_3.addWidget(self.label_3)\n self.label_4 = QtGui.QLabel(self.layoutWidget1)\n self.label_4.setObjectName(_fromUtf8(\"label_4\"))\n self.horizontalLayout_3.addWidget(self.label_4)\n self.label_5 = QtGui.QLabel(self.layoutWidget1)\n self.label_5.setObjectName(_fromUtf8(\"label_5\"))\n self.horizontalLayout_3.addWidget(self.label_5)\n self.label_6 = QtGui.QLabel(self.layoutWidget1)\n self.label_6.setObjectName(_fromUtf8(\"label_6\"))\n self.horizontalLayout_3.addWidget(self.label_6)\n self.label_7 = QtGui.QLabel(self.layoutWidget1)\n self.label_7.setObjectName(_fromUtf8(\"label_7\"))\n self.horizontalLayout_3.addWidget(self.label_7)\n self.label_8 = QtGui.QLabel(self.layoutWidget1)\n self.label_8.setObjectName(_fromUtf8(\"label_8\"))\n self.horizontalLayout_3.addWidget(self.label_8)\n self.verticalLayout.addLayout(self.horizontalLayout_3)\n self.horizontalLayout_4 = QtGui.QHBoxLayout()\n self.horizontalLayout_4.setObjectName(_fromUtf8(\"horizontalLayout_4\"))\n self.label_9 = QtGui.QLabel(self.layoutWidget1)\n self.label_9.setIndent(-1)\n self.label_9.setObjectName(_fromUtf8(\"label_9\"))\n self.horizontalLayout_4.addWidget(self.label_9)\n self.spinBox_big = QtGui.QSpinBox(self.layoutWidget1)\n self.spinBox_big.setReadOnly(True)\n self.spinBox_big.setMaximum(10000)\n self.spinBox_big.setObjectName(_fromUtf8(\"spinBox_big\"))\n self.horizontalLayout_4.addWidget(self.spinBox_big)\n self.spinBox_small = QtGui.QSpinBox(self.layoutWidget1)\n self.spinBox_small.setReadOnly(True)\n self.spinBox_small.setMaximum(10000)\n self.spinBox_small.setObjectName(_fromUtf8(\"spinBox_small\"))\n self.horizontalLayout_4.addWidget(self.spinBox_small)\n self.spinBox_oil = QtGui.QSpinBox(self.layoutWidget1)\n self.spinBox_oil.setReadOnly(True)\n self.spinBox_oil.setMaximum(10000)\n self.spinBox_oil.setObjectName(_fromUtf8(\"spinBox_oil\"))\n self.horizontalLayout_4.addWidget(self.spinBox_oil)\n self.spinBox_tri = QtGui.QSpinBox(self.layoutWidget1)\n self.spinBox_tri.setReadOnly(True)\n self.spinBox_tri.setMaximum(10000)\n self.spinBox_tri.setObjectName(_fromUtf8(\"spinBox_tri\"))\n self.horizontalLayout_4.addWidget(self.spinBox_tri)\n self.spinBox_stinky = QtGui.QSpinBox(self.layoutWidget1)\n self.spinBox_stinky.setReadOnly(True)\n self.spinBox_stinky.setMaximum(10000)\n self.spinBox_stinky.setObjectName(_fromUtf8(\"spinBox_stinky\"))\n self.horizontalLayout_4.addWidget(self.spinBox_stinky)\n self.spinBox_milk = QtGui.QSpinBox(self.layoutWidget1)\n self.spinBox_milk.setObjectName(_fromUtf8(\"spinBox_milk\"))\n self.horizontalLayout_4.addWidget(self.spinBox_milk)\n self.verticalLayout.addLayout(self.horizontalLayout_4)\n self.verticalLayout_2.addLayout(self.verticalLayout)\n self.verticalLayout_3.addLayout(self.verticalLayout_2)\n self.gridLayout.addLayout(self.verticalLayout_3, 0, 0, 1, 1)\n self.horizontalLayout_5 = QtGui.QHBoxLayout()\n self.horizontalLayout_5.setObjectName(_fromUtf8(\"horizontalLayout_5\"))\n self.pushButton_load = QtGui.QPushButton(self.layoutWidget1)\n self.pushButton_load.setEnabled(False)\n self.pushButton_load.setObjectName(_fromUtf8(\"pushButton_load\"))\n self.horizontalLayout_5.addWidget(self.pushButton_load)\n self.pushButton_add = QtGui.QPushButton(self.layoutWidget1)\n self.pushButton_add.setObjectName(_fromUtf8(\"pushButton_add\"))\n self.horizontalLayout_5.addWidget(self.pushButton_add)\n self.pushButton_edit = QtGui.QPushButton(self.layoutWidget1)\n self.pushButton_edit.setObjectName(_fromUtf8(\"pushButton_edit\"))\n self.horizontalLayout_5.addWidget(self.pushButton_edit)\n self.gridLayout.addLayout(self.horizontalLayout_5, 2, 0, 1, 1)\n spacerItem2 = QtGui.QSpacerItem(20, 40, QtGui.QSizePolicy.Minimum, QtGui.QSizePolicy.Expanding)\n self.gridLayout.addItem(spacerItem2, 1, 0, 1, 1)\n self.tabWidget.addTab(self.tab, _fromUtf8(\"\"))\n self.textEdit = QtGui.QTextEdit(Dialog)\n self.textEdit.setGeometry(QtCore.QRect(10, 407, 581, 41))\n self.textEdit.setObjectName(_fromUtf8(\"textEdit\"))\n\n self.retranslateUi(Dialog)\n self.tabWidget.setCurrentIndex(0)\n QtCore.QMetaObject.connectSlotsByName(Dialog)\n\n def retranslateUi(self, Dialog):\n Dialog.setWindowTitle(_translate(\"Dialog\", \"客戶設定\", None))\n self.label.setText(_translate(\"Dialog\", \"NOTE:新增資料重開視窗才會出現\", None))\n self.pushButton_addguest.setText(_translate(\"Dialog\", \"新增\", None))\n self.tabWidget.setTabText(self.tabWidget.indexOf(self.tab_3), _translate(\"Dialog\", \"新增客戶\", None))\n self.label_1.setText(_translate(\"Dialog\", \"From:\", None))\n self.dateEdit_from.setDisplayFormat(_translate(\"Dialog\", \"yyyy/MM/dd\", None))\n self.label_2.setText(_translate(\"Dialog\", \"To:\", None))\n self.dateEdit_to.setDisplayFormat(_translate(\"Dialog\", \"yyyy/MM/dd\", None))\n self.label_10.setText(_translate(\"Dialog\", \"項目\", None))\n self.label_3.setText(_translate(\"Dialog\", \"Big\", None))\n self.label_4.setText(_translate(\"Dialog\", \"Small\", None))\n self.label_5.setText(_translate(\"Dialog\", \"Oil\", None))\n self.label_6.setText(_translate(\"Dialog\", \"Tri\", None))\n self.label_7.setText(_translate(\"Dialog\", \"Stinky\", None))\n self.label_8.setText(_translate(\"Dialog\", \"Milk\", None))\n self.label_9.setText(_translate(\"Dialog\", \"$\", None))\n self.pushButton_load.setText(_translate(\"Dialog\", \"Load\", None))\n self.pushButton_add.setText(_translate(\"Dialog\", \"Add\", None))\n self.pushButton_edit.setText(_translate(\"Dialog\", \"Edit\", None))\n self.tabWidget.setTabText(self.tabWidget.indexOf(self.tab), _translate(\"Dialog\", \"價格設定\", None))\n\n\nif __name__ == \"__main__\":\n import sys\n app = QtGui.QApplication(sys.argv)\n Dialog = QtGui.QDialog()\n ui = Ui_Dialog()\n ui.setupUi(Dialog)\n Dialog.show()\n sys.exit(app.exec_())\n\n"
},
{
"alpha_fraction": 0.4550113081932068,
"alphanum_fraction": 0.4619234800338745,
"avg_line_length": 32.16205596923828,
"blob_id": "0c7bd92d2837c854a40a781438362136c4a0abbf",
"content_id": "36a9e736151f425470a87ed08ad11fc181156b82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8391,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 253,
"path": "/customer_file.py",
"repo_name": "WulfChang/HQ_food",
"src_encoding": "UTF-8",
"text": "\nimport yaml\nimport os\nimport fnmatch\n\n#header module\nimport header\n\n\"\"\"\nFunction: edit customer file, customer_list.yaml, guestX.yaml\nAuthor: Wulf Chang\nHistory: 2015/09/11 programming start\n 2015/10/05 beta version ready\n 2015/11/02 add Customer_list class raise error\n\"\"\"\n\nHQ_path = header.HQ_PATH\nHQ_price = header.HQ_PRICE_PATH\nHQ_list = header.HQ_LIST_NAME\n\n\"\"\"\nEdit the list of customer, the list is saved in \"HQ_path+HQ_list\" with yaml format\n\"\"\"\nclass Customer_list():\n \n \"\"\"\n open file and load yaml, which is a company list\n \"\"\" \n def __init__(self): \n if os.path.exists( HQ_path+HQ_list ):\n #fptr open\n self.list_str = open( HQ_path+HQ_list, 'a+')\n #load file\n self.clist = yaml.load( self.list_str )\n #convert to dict type \n self.__getCdict( self.clist )\n else:\n #file opening error\n raise IOError(header.ERROR_MSG[0])\n \n \"\"\"\n write company into yaml list\n \"\"\"\n def writeCompany(self, name): \n if name: \n #write data into yaml\n current_num = self.__numCompany()+1\n data = [{name: current_num}]\n yaml.dump(data, self.list_str)\n \n #add to dict\n self.__addCdict(data)\n else:\n raise ValueError(header.ERROR_MSG[1])\n \n \"\"\"\n read keys of company\n \"\"\" \n def readCompany(self):\n return self.cdict.keys() \n \n \"\"\"\n read key of company from input name string\n \"\"\"\n def readCvalue(self, name):\n name = name.decode('utf8')\n return self.cdict[name]\n \n \"\"\"\n convert to UTF8\n \"\"\"\n def __cvtUTF8(self, str):\n str_temp = str.encode('utf8') \n return str_temp\n \n \"\"\"\n convert list to dict\n \"\"\"\n def __getCdict(self, clist):\n #declare\n self.cdict = {}\n \n if clist != []:\n #convert clist(matrix) to cdict(dictionary)\n for i in clist:\n self.cdict.update( i ) \n \n return self.cdict\n \n \"\"\"\n count number of company in the dict\n \"\"\" \n def __numCompany(self):\n return len(self.cdict)\n\n \"\"\"\n add data to cdict\n \"\"\"\n def __addCdict(self, data):\n self.cdict.update(data[0]) \n \n\"\"\"\nload customer setting price from guest number and version\n(the guest number is defined in customer list file)\n\"\"\" \nclass Customer_price():\n \n \"\"\"\n Initialization\n \"\"\"\n def __init__(self):\n #assign the version non valid date\n self.INI_DATE = header.NONVALID\n \n \"\"\" \n obtain number of version \n \"\"\"\n def numGuestprice(self, i_guestnum):\n str_num_file = fnmatch.filter(os.listdir(HQ_price), '*_'+ str(i_guestnum)+'.yaml')\n num_file = len(str_num_file)\n return num_file\n \"\"\"\n get start date of specific version\n \"\"\"\n def getStartdate(self, i_guestnum, i_version): \n str_filename = self.__getFilename( i_guestnum, i_version )\n \n if str_filename:\n return str_filename[3:11]\n else:\n raise NameError(header.ERROR_MSG[2])\n \n \"\"\" \n get end date of specifict version\n \"\"\"\n def getEnddate(self, i_guestnum, i_version): \n str_filename = self.__getFilename( i_guestnum, i_version )\n \n if str_filename:\n return str_filename[12:20]\n else:\n raise NameError(header.ERROR_MSG[2])\n \n \"\"\" \n write price into file, which is totally new\n \"\"\"\n def writePrice(self, i_guestnum, str_nowdate, m_data ): \n #read current version\n current_version = self.numGuestprice( i_guestnum )\n \n #end current version price file\n if current_version != 0: \n self.endFile( i_guestnum, current_version, str_nowdate )\n \n #set newest version \n newversion = current_version+1\n \n #form filename\n str_version_filename = self.__formNewfilename( str_nowdate, newversion, i_guestnum )\n \n #write into file\n with open( str_version_filename, 'w+' ) as fprt_price: \n data = [{'big': m_data[0]}, {'small': m_data[1]}, {'oil': m_data[2]}, {'tri': m_data[3]}, {'stinky': m_data[4]}, {'milk': m_data[5]}]\n yaml.dump(data, fprt_price)\n \n \"\"\" \n read price from file\n \"\"\" \n def readPrice(self, i_guestnum, i_version):\n \n self.dict_price = {}\n \n #get full file name\n str_fullname = self.__getFilename( i_guestnum, i_version )\n \n #open file and covnert list to dict\n with open( HQ_price+str_fullname, 'r') as fptr_file:\n m_price = yaml.load( fptr_file ) \n self.dict_price = self.__getCdict( m_price )\n \n if self.dict_price: \n return self.dict_price\n else:\n raise IOError(header.ERROR_MSG[0])\n \n \"\"\"\n convert dict to list\n \"\"\"\n def getClist(self, cdict):\n return [ cdict['big'], cdict['small'], cdict['oil'], cdict['tri'], cdict['stinky'], cdict['milk'] ] \n\n \"\"\" \n terminate the price file, namely, add end date in the file name\n \"\"\"\n def endFile(self, i_guestnum, i_version, end_date):\n \n #current file name and current fiel end date\n current_fname = self.__getFilename(i_guestnum, i_version)\n \n #rename\n os.rename( HQ_price+current_fname, HQ_price+current_fname.replace( self.INI_DATE, end_date))\n \n \"\"\" \n select setting price and return its version\n \"\"\"\n def selectPrice( self, i_guestnum, str_accountdate ):\n \n #count total file number\n i_pricenumber = self.numGuestprice(i_guestnum)\n \n if i_pricenumber == 0:\n raise IOError(header.ERROR_MSG[0])\n else:\n #search from latest version\n while i_pricenumber > 0:\n #get start date\n str_stardate = self.getStartdate( i_guestnum, i_pricenumber )\n \n if str_accountdate >= str_stardate[0:6]:\n return i_pricenumber \n \n #search previous one version\n i_pricenumber -=1\n \n raise IOError(header.ERROR_MSG[0])\n \n \"\"\"\n convert clist(matrix) to cdict(dictionary)\n \"\"\"\n def __getCdict(self, clist): \n self.cdict = {}\n for i in clist:\n self.cdict.update(i) \n return self.cdict\n \n \"\"\" \n establish new file name\n \"\"\" \n def __formNewfilename(self, str_nowdate, i_newversion, i_guestnum):\n \n str_nfilename = HQ_price + 'HQ_'+ str_nowdate+'_' + self.INI_DATE +'_v'+str(i_newversion)+'_'+str(i_guestnum)+'.yaml'\n return str_nfilename\n \n \n \"\"\"\n get full file name \n \"\"\"\n def __getFilename(self, i_guestnum, i_version ):\n #search file\n part_name = '*v' + str(i_version)+'_'+str(i_guestnum)+'.yaml'\n filename = fnmatch.filter(os.listdir(HQ_price), part_name)\n str_filename = filename[0]\n \n return str_filename\n"
},
{
"alpha_fraction": 0.52423095703125,
"alphanum_fraction": 0.5312466025352478,
"avg_line_length": 30.40338897705078,
"blob_id": "e98b81a72e81c3ab749682e8e482e886a8c11c05",
"content_id": "cc91d59dd8a2854a3722f15f0ae2a6e9281402c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9265,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 295,
"path": "/UI/customer_edit.py",
"repo_name": "WulfChang/HQ_food",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n\"\"\"\nModule implementing Dialog_cedit.\n\"\"\"\n\nfrom PyQt4.QtGui import *\nfrom PyQt4.QtCore import *\n\nfrom Ui_customer_edit import Ui_Dialog\n\nfrom customer_file import Customer_list\nfrom customer_file import Customer_price\n\n\nclass Dialog_cedit(QDialog, Ui_Dialog):\n \"\"\"\n Class documentation goes here.\n \"\"\"\n def __init__(self, parent = None):\n \"\"\"\n Constructor\n \"\"\"\n QDialog.__init__(self, parent)\n self.setupUi(self)\n \n #set invisible\n self.pushButton_add.setVisible(False)\n \n #declare object\n try:\n self.clist = Customer_list()\n except IOError as e:\n raise IOError(e)\n \n self.cprice = Customer_price()\n \n #read company list\n self.m_clist={}\n self.m_clist = self.clist.readCompany()\n \n #set combo\n self.setCombo( 1, self.m_clist )\n \n #set initial one\n self.comboBox_customer.setCurrentIndex(0)\n self.on_comboBox_customer_activated(0)\n \n #add customer to text browser\n self.setTextbrowser()\n \n def setTextbrowser(self):\n \n #show company list over text browser \n for i in self.m_clist:\n self.textBrowser.append(i)\n \n @pyqtSignature(\"QString\")\n def on_comboBox_customer_activated(self, p0):\n \"\"\"\n set version combo box\n \"\"\"\n #set to initial status\n self.setInitstatus()\n \n #read combo text and dict value\n self.str_customercombo = str( self.comboBox_customer.currentText().toUtf8() )\n self.i_customercombo = self.clist.readCvalue( self.str_customercombo )\n \n #get number of version file\n self.i_numversion = self.cprice.numGuestprice( self.i_customercombo )\n \n #iterate the version number\n i = 0\n m_version = []\n self.ultimateversion = 0\n while i <= self.i_numversion: \n m_version.append('v'+str(i))\n self.ultimateversion = i\n i+=1\n\n #set combo box\n self.setCombo(2, m_version) \n \n \n @pyqtSignature(\"QString\")\n def on_comboBox_version_activated(self, p0):\n \"\"\"\n get version start and end date\n \"\"\"\n #set to initial status\n self.setInitstatus()\n\n if self.comboBox_version.count != 0:\n #get selected version\n str_selectversion = self.comboBox_version.currentText()\n self.i_versioncombo = int( str_selectversion[1] )\n \n #set version date, if version equals 0, date shall be 20150101\n if self.i_versioncombo!=0:\n #get start date\n str_startdate = self.cprice.getStartdate( self.i_customercombo, self.i_versioncombo )\n self.dateEdit_from.setDate( self.setQdate(str_startdate) )\n \n #get end date\n str_enddate = self.cprice.getEnddate( self.i_customercombo, self.i_versioncombo )\n self.dateEdit_to.setDate( self.setQdate(str_enddate) )\n \n #enable pushButton\n self.pushButton_load.setEnabled(True)\n else:\n self.dateEdit_from.setDate( self.setQdate(self.cprice.INI_DATE) )\n self.dateEdit_to.setDate( self.setQdate(self.cprice.INI_DATE) )\n \n @pyqtSignature(\"\")\n def on_pushButton_load_clicked(self):\n \"\"\"\n load data into user interface\n \"\"\"\n if self.pushButton_load.isEnabled():\n dict_loadprice = self.cprice.readPrice( self.i_customercombo, self.i_versioncombo )\n \n #set spinbox value\n self.spinBox_big.setValue( dict_loadprice['big'] )\n self.spinBox_small.setValue( dict_loadprice['small'] )\n self.spinBox_oil.setValue( dict_loadprice['oil'] )\n self.spinBox_tri.setValue( dict_loadprice['tri'] )\n self.spinBox_stinky.setValue( dict_loadprice['stinky'] )\n self.spinBox_milk.setValue( dict_loadprice['milk'] )\n \n @pyqtSignature(\"\")\n def on_pushButton_edit_clicked(self):\n \"\"\"\n change to add mode\n \"\"\"\n self.setMode('edit')\n \n #set next month 1st day\n if self.ultimateversion != 0:\n qdate = self.setNextmon( QDate.currentDate() )\n self.dateEdit_from.setDate( qdate )\n self.str_qdate = self.getStrdate( qdate )\n else:\n self.dateEdit_from.setDate( QDate.currentDate() )\n self.str_qdate = self.getStrdate( QDate.currentDate() )\n \n #set initial date\n self.dateEdit_to.setDate( self.setQdate(self.cprice.INI_DATE) )\n \n @pyqtSignature(\"\")\n def on_pushButton_add_clicked(self):\n \"\"\"\n dump value into yaml\n \"\"\" \n\n #dump ymal data\n self.cprice.writePrice( self.i_customercombo, self.str_qdate , self.getSpinboxvalue() )\n \n self.setMode('add')\n \n \n @pyqtSignature(\"\")\n def on_pushButton_addguest_clicked(self):\n \"\"\"\n add new customer to yaml list\n \"\"\"\n str_name = str( self.lineEdit_addguest.text().toUtf8() )\n \n try:\n self.clist.writeCompany( str_name.decode('utf8') )\n except ValueError as e:\n self.textEdit.append(str(e))\n \n\n \n \"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\n self function\n \"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\"\n def setInitstatus(self, status = False):\n \"\"\"\n set ui to initial status\n \"\"\"\n #clear all button status\n self.clearSpinbox()\n self.pushButton_load.setEnabled(status)\n self.dateEdit_from.setDate( self.setQdate(self.cprice.INI_DATE) )\n self.dateEdit_to.setDate( self.setQdate(self.cprice.INI_DATE) )\n \n def setCombo(self, comboselect, m_str):\n \"\"\"\n set combo box\n \"\"\"\n if comboselect == 1:\n for i in m_str:\n self.comboBox_customer.addItem(i)\n elif comboselect == 2:\n self.comboBox_version.clear()\n for i in m_str: \n self.comboBox_version.addItem(i)\n\n \n def setMode(self, str_mode):\n \n \"\"\"\n set different ui mode\n \"\"\"\n #set status depends on edit or add mode\n b_status = True\n if str_mode == 'edit':\n b_status = True\n elif str_mode == 'add':\n b_status = False \n\n self.clearSpinbox()\n self.pushButton_load.setEnabled(False) \n self.setreadonlySpinbox(not b_status)\n self.pushButton_add.setVisible(b_status)\n self.pushButton_edit.setVisible(not b_status)\n self.comboBox_version.setEnabled(not b_status)\n self.comboBox_customer.setEnabled(not b_status)\n \n def getStrdate(self, qdate):\n \n \"\"\"\n convert qdate to strdate\n \"\"\"\n #form a string date\n str_year = str(qdate.year())\n \n if qdate.month() < 10:\n str_month = '0'+ str(qdate.month())\n else: \n str_month = str(qdate.month())\n \n if qdate.day() < 10:\n str_day = '0'+ str(qdate.day())\n else:\n str_day = str(qdate.day())\n\n return str_year + str_month + str_day \n\n def setNextmon(self, qdate ):\n \"\"\"\n set import date as next month 1st\n \"\"\"\n if qdate.month() == 12:\n qdate.setDate( qdate.year()+1, 1, 1)\n else:\n qdate.setDate( qdate.year(), qdate.month()+1, 1)\n \n return qdate \n \n def clearSpinbox(self):\n \"\"\"\n clean all spin box as zero\n \"\"\"\n self.spinBox_big.setValue( 0 )\n self.spinBox_small.setValue( 0 )\n self.spinBox_oil.setValue( 0 )\n self.spinBox_tri.setValue( 0 )\n self.spinBox_stinky.setValue( 0 )\n self.spinBox_milk.setValue( 0 )\n \n def getSpinboxvalue(self):\n \n \"\"\"\n get all spin box value in a matrix\n \"\"\"\n spinboxs_data = [ self.spinBox_big.value(), self.spinBox_small.value(), self.spinBox_oil.value(), \n self.spinBox_tri.value(), self.spinBox_stinky.value(), self.spinBox_milk.value() ]\n \n return spinboxs_data\n \n def setreadonlySpinbox( self, status ):\n \n \"\"\"\n set spin box as read only type\n \"\"\"\n self.spinBox_big.setReadOnly(status)\n self.spinBox_small.setReadOnly(status)\n self.spinBox_oil.setReadOnly(status)\n self.spinBox_tri.setReadOnly(status)\n self.spinBox_stinky.setReadOnly(status)\n self.spinBox_milk.setReadOnly(status) \n \n \n def setQdate(self, str_date):\n \"\"\"\n set str date (ex:20150201) to Qdate\n \"\"\"\n i_year = int(str_date[0:4])\n i_month = int(str_date[4:6])\n i_day = int(str_date[6:9])\n \n return QDate(i_year, i_month, i_day)\n\n"
}
] | 14 |
corteseanna/winpython
|
https://github.com/corteseanna/winpython
|
5aa0fa7ec67b16af82ab4ff964c064c5235806c0
|
fdcc999a563107930efa5f04c22d7ff460d78566
|
1d6fec4f54d824be2d28c234f62d595555bd1e56
|
refs/heads/master
| 2023-08-23T19:51:58.350201 | 2021-10-17T18:22:55 | 2021-10-17T18:22:55 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.784518837928772,
"alphanum_fraction": 0.7907949686050415,
"avg_line_length": 33.14285659790039,
"blob_id": "e702a341532cf63740abb9f1fd89bc719fc667c9",
"content_id": "7d60048c5bdb1f1d4325f80ad789be2d2370a7f2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 478,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 14,
"path": "/winpython/_vendor/qtpy/tests/test_qtwebenginewidgets.py",
"repo_name": "corteseanna/winpython",
"src_encoding": "UTF-8",
"text": "from __future__ import absolute_import\n\nimport pytest\nfrom qtpy import PYSIDE6\n\[email protected](PYSIDE6, reason=\"Only available in Qt<6 bindings\")\ndef test_qtwebenginewidgets():\n \"\"\"Test the qtpy.QtWebSockets namespace\"\"\"\n\n QtWebEngineWidgets = pytest.importorskip(\"qtpy.QtWebEngineWidgets\")\n\n assert QtWebEngineWidgets.QWebEnginePage is not None\n assert QtWebEngineWidgets.QWebEngineView is not None\n assert QtWebEngineWidgets.QWebEngineSettings is not None\n"
}
] | 1 |
dumi33/world
|
https://github.com/dumi33/world
|
ed6d7338d5a6b014cf5bedb3e48ac776b0f8bafd
|
341f52eb6b6c619b178040afeaaa3b5cb318285a
|
2210240a320f74143657f51e5dff874e52914491
|
refs/heads/master
| 2023-08-25T09:05:22.257163 | 2022-10-19T06:23:00 | 2022-10-19T06:23:00 | 337,285,218 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.515195369720459,
"alphanum_fraction": 0.5209840536117554,
"avg_line_length": 26.639999389648438,
"blob_id": "c1747e8567f32cd16e77b7a306f221f77094739f",
"content_id": "30a9c9f0d275bc082e910084cc38235f36aa9877",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 723,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 25,
"path": "/programmers/구현/[조합]후보키.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "from itertools import combinations \n\ndef solution(relation):\n row = len(relation)\n col = len(relation[0])\n \n \n combi = []\n for i in range(1,col+1) :\n combi.extend(combinations(range(col),i))\n # 유일성 \n unique = []\n for i in combi :\n tmp = [tuple(item[key] for key in i) for item in relation]\n if len(set(tmp)) == row :\n unique.append(i)\n # 최소성 \n answer = set(unique)\n for i in range(len(unique)) :\n for j in range(i+1, len(unique)) :\n # 부분집합이 있다면 \n if len(unique[i]) == len(set(unique[i]) & set(unique[j])) :\n # 삭제 \n answer.discard(unique[j])\n return len(answer)\n"
},
{
"alpha_fraction": 0.36180904507637024,
"alphanum_fraction": 0.4036850929260254,
"avg_line_length": 26.18181800842285,
"blob_id": "f7fe0e2fe364d3bbd374aa4117681d9cf73762e7",
"content_id": "d072a9d4ae230b93d09f2553dda71feff902042d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 597,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 22,
"path": "/알고리즘/dp/최소편집.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "#include<iostream>\n#include<string>\n#include<algorithm>\nint arr[1001][1001];\nusing namespace std;\nint main() {\n string s, t;\n cin >> s >> t;\n for (int i = 0; i <= s.size(); i++) {\n arr[i][0] = i;\n }\n for (int j = 0; j <= t.size(); j++) {\n arr[0][j] = j;\n }\n for (int j = 1; j <= t.size(); j++) {\n for (int i = 1; i <= s.size(); i++) {\n if (s[i-1] == t[j-1]) arr[i][j] = arr[i - 1][j - 1];\n else arr[i][j] = min(arr[i - 1][j - 1] + 1, min(arr[i][j - 1] + 1, arr[i - 1][j] + 1));\n }\n }\n cout << arr[s.size()][t.size()];\n}"
},
{
"alpha_fraction": 0.37058261036872864,
"alphanum_fraction": 0.39255014061927795,
"avg_line_length": 20.367347717285156,
"blob_id": "a533b91e7df483a091cf7d79ff2198586499b30d",
"content_id": "c835e56eacd313c1c3f42b022f08c9c351beabd9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1055,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 49,
"path": "/알고리즘/삼성역량테스트/DFS_연구소.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "from collections import deque\nimport copy\n\n \n# 동 서 북 남 \ndx = [0,0,-1,1]\ndy = [1,-1,0,0]\n\n\ndef bfs() :\n global ans \n tmp_mp = copy.deepcopy(mp) \n for i in range(n) :\n for j in range(m) :\n if tmp_mp[i][j]==2 :\n q.append([i,j])\n while q :\n x,y = q.popleft()\n for dir in range(4) :\n nx,ny = x + dx[dir], y + dy[dir]\n if 0<=nx<n and 0<=ny<m and tmp_mp[nx][ny] == 0 :\n tmp_mp[nx][ny] = 2 \n q.append([nx,ny]\n cnt = 0\n for i in tmp_mp :\n cnt += i.count(0)\n ans = max(ans,cnt)\n \n\ndef wall(x) :\n if x == 3 :\n bfs()\n return \n for i in range(n) :\n for j in range(m) :\n if mp[i][j] == 0:\n mp[i][j] = 1\n wall(x+1)\n mp[i][j] = 0 \n\n\nif __name__==\"__main__\" :\n n,m = map(int,input().split())\n mp = [list(map(int,input().split())) for _ in range(n)]\n ans = 0\n q = deque()\n\n wall(0)\n print(ans)\n"
},
{
"alpha_fraction": 0.41803279519081116,
"alphanum_fraction": 0.4307832419872284,
"avg_line_length": 20.54901885986328,
"blob_id": "b3e8c6cd8cc21998ced44623162cf8b5d0aa46cd",
"content_id": "a695338becf28e426929148aeb1d51ac2271c0d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1138,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 51,
"path": "/알고리즘/BFS/dfs와 bfs.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<vector>\n#include<iostream>\n#include<queue>\n#include<algorithm>\nusing namespace std;\nint v, e, s, st;\nvector<int> adj[1001];\nbool vis[1001];\nvoid dfs(int cur) {\n cout << cur << ' ';\n for (int i = 0; i < adj[cur].size(); i++) {\n int nxt = adj[cur][i];\n if (vis[nxt]) continue; // 이미 방문 했으면 pass\n vis[nxt] = true;\n dfs(nxt);\n }\n}\nvoid bfs() {\n queue<int> q;\n q.push(st);\n vis[st] = true; //갔다는 표시\n while (!q.empty()) {\n int cur = q.front();\n cout << cur << ' ';\n q.pop();\n for (int i = 0; i < adj[cur].size(); i++) {\n int nxt = adj[cur][i];\n if (vis[nxt]) continue;\n q.push(nxt);\n vis[nxt] = true;\n }\n }\n\n}\nint main() {\n cin >> v >> e >> st;\n while (e--) {\n int a, b;\n cin >> a >> b;\n adj[a].push_back(b);\n adj[b].push_back(a);\n }\n for (int i = 1; i <= v; i++) { //노드가 1부터 있어서\n sort(adj[i].begin(), adj[i].end());\n }\n vis[st] = true;\n dfs(st);\n cout << \"\\n\";\n fill(vis, vis + v + 1, 0);\n bfs();\n}"
},
{
"alpha_fraction": 0.3652113676071167,
"alphanum_fraction": 0.40194040536880493,
"avg_line_length": 21.546875,
"blob_id": "c351299ea20de900d199b0d06e7a58a8e8ee1b48",
"content_id": "8e1ed0922a3a7eb64e89d66dc9aa07eb3b827b74",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1451,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 64,
"path": "/알고리즘/삼성역량테스트/DFS_감시.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "import copy\nfrom collections import defaultdict \n \n# 상 하 좌 우 \ndx = [-1,1,0,0]\ndy = [0,0,-1,1]\n\n\ncctv_dir = [\n [],\n [[0],[1],[2],[3]],\n [[0,1], [2,3]],\n [[0,3],[3,1],[1,2],[2,0]],\n [[0,2,3], [0,3,1],[1,2,3],[0,1,2]],\n [[0,1,2,3]]\n]\n\ndef dfs(mp,depth) :\n global ans \n if depth == len(cctv) :\n ans = min(ans,count_zero(mp)) \n return \n else :\n mp_copy = copy.deepcopy(mp)\n x,y,cctv_type = cctv[depth]\n for dir in cctv_dir[cctv_type] :\n watch(x,y,dir,mp_copy)\n dfs(mp_copy,depth+1)\n mp_copy = copy.deepcopy(mp)\n \n \ndef watch(x,y,dir,mp) :\n for d in dir :\n nx,ny = x,y\n while True :\n nx,ny = nx+dx[d], ny+dy[d]\n if 0<=nx<n and 0<=ny<m :\n if mp[nx][ny] ==6 : break\n elif mp[nx][ny] == 0 :\n mp[nx][ny] = '#'\n else : break\n\ndef count_zero(mp) :\n cnt = 0\n for i in range(n) :\n for j in range(m) :\n if mp[i][j] == 0 :\n cnt+=1 \n return cnt \n \n \n \nif __name__==\"__main__\" :\n n,m = map(int,input().split())\n mp = [list(map(int,input().split())) for _ in range(n)]\n cctv = [] \n ans = int(1e9)\n\n for i in range(n) :\n for j in range(m) :\n if 1<=mp[i][j]<=5 :\n cctv.append([i,j,mp[i][j]])\n dfs(mp,0)\n print(ans)\n"
},
{
"alpha_fraction": 0.45492488145828247,
"alphanum_fraction": 0.48330551385879517,
"avg_line_length": 19.32203483581543,
"blob_id": "03d6f2c402fa55647f43cf70ddb4a0a3923267b0",
"content_id": "d6d42cbd848b95a3d612d5171f0182badc8d6188",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1306,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 59,
"path": "/알고리즘/BFS/경쟁적전염.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<vector>\n#include<queue>\n#include<algorithm>\nusing namespace std;\nint n, k, s, x, y;\nint mp[201][201];\n\nint dx[] = { 1,0,-1,0 };\nint dy[] = { 0,1,0,-1 };\n\nstruct Virus {\n\tint virus;\n\tint x;\n\tint y;\n};\nbool cmp(const Virus& v1, const Virus& v2) { // 구조체는 무거워서 프로그램의 속도를 낮추기에 주소로 받아옴\n\treturn v1.virus < v2.virus; // 정렬기준은 virus 번호가 낮은 순서\n}\nint main() {\n\t\n\tios_base::sync_with_stdio(0); cin.tie(0);\n\tcin >> n >> k;\n\tvector<Virus> v;\n\tfor (int i = 0; i < n; i++) {\n\t\tfor (int j = 0; j < n; j++) {\n\t\t\tcin >> mp[i][j];\n\t\t\tif (mp[i][j] != 0) {\n\t\t\t\tv.push_back({ mp[i][j] ,i,j });\n\t\t\t}\n\t\t}\n\t}\n\tcin >> s >> x >> y;\n\tsort(v.begin(), v.end(), cmp); //바이러스 번호가 작은 순으로 정렬\n\t\n\tqueue<Virus> q;\n\tint cnt = 0;\n\tfor (int i = 0; i < v.size(); i++) {\n\t\tq.push(v[i]);\n\t\tcnt++;\n\t}\n\t\t\n\tfor (int i = 0; i < s;i++) { // 시간 \n\t\tfor (int j = 0; j < cnt; j++) { \n\t\t\tVirus tmp = q.front();\n\t\t\tq.pop();\n\t\t\tfor (int l = 0; l < 4; l++) {\n\t\t\t\tint nx = dx[l] + tmp.x;\n\t\t\t\tint ny = dy[l] + tmp.y;\n\t\t\t\tif (nx < 0 || nx >= n || ny < 0 || ny >= n) continue;\n\t\t\t\tif (mp[nx][ny] != 0) continue;\n\t\t\t\tmp[nx][ny] = tmp.virus;\n\t\t\t\tq.push({ mp[nx][ny] , nx,ny });\n\t\t\t}\n\t\t}\n\t\tcnt = q.size();\n\t}\n\tcout << mp[x-1][y-1];\n}"
},
{
"alpha_fraction": 0.38956522941589355,
"alphanum_fraction": 0.4139130413532257,
"avg_line_length": 20.33333396911621,
"blob_id": "18ccc4d3c5ef5a86fb58d3f0d3a0b150e0d7ae87",
"content_id": "06b65dfcf01cdaed6300699098cd93f84fb2d2b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 669,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 27,
"path": "/알고리즘/백트래킹/n과m(1).cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\nusing namespace std;\nint n, m;\nint arr[10];\nbool iss[10];\nvoid func(int k) { //arr[k]를 정하는 함수 //k는 0,1,2..임\n if (k == m) { //숫자가 전부 정해졌다면 \n for (int i = 0; i < m; i++) cout << arr[i] << \" \";\n cout << \"\\n\";\n return;\n }\n for (int i = 1; i <= n; i++) {\n if (!iss[i]) { //숫자 i가 불려지지않았다면\n arr[k] = i;\n iss[i] = 1;\n func(k + 1);\n iss[i] = 0;//재귀가 끝난후 돌아와서 썻던 것을 지워준다.\n }\n }\n}\nint main() {\n ios::sync_with_stdio(NULL);\n cin.tie(0);\n\n cin >> n >> m;\n func(0);\n}"
},
{
"alpha_fraction": 0.4354243576526642,
"alphanum_fraction": 0.44944649934768677,
"avg_line_length": 29.772727966308594,
"blob_id": "817a5ec025d349e5895965edc6c59c17952fb8c4",
"content_id": "5f8d6645724aeb97dac2f5fbe5258634690ec782",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1515,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 44,
"path": "/알고리즘/BFS/인구이동.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "import sys\nfrom collections import deque\ninput = sys.stdin.readline\nn,l,r = map(int,input().split())\ngraph = []\nfor i in range(n) :\n graph.append(list(map(int,input().split()))) # []로 하면 안되고 list를 이용해 둘러싸야한다. \n\ndx = [0,1,0,-1]\ndy = [1,0,-1,0]\ndef bfs(i,j) :\n q = deque()\n temp = []\n q.append([i,j])\n temp.append([i,j])\n while q :\n x,y = q.popleft()\n for i in range(4) :\n nx,ny = dx[i]+x, dy[i]+y\n if 0<=nx<n and 0<=ny<n and visit[nx][ny] ==0 :\n if l <= abs(graph[x][y] - graph[nx][ny]) <=r : # 이 부분 까먹음 \n visit[nx][ny] = 1 # 조건을 만족시켰다면 방문 \n q.append([nx,ny])\n temp.append([nx,ny])\n return temp\ncnt = 0\nwhile True :\n visit = [[0]*n for i in range(n)]\n isTrue = False\n for i in range(n):\n for j in range(n) :\n if visit[i][j] == 0 :\n visit[i][j] = 1 \n temp = bfs(i,j) # 연합된 영토 반환 \n if len(temp) > 1 :\n isTrue = True\n value =sum([graph[x][y] for x,y in temp]) // len(temp)\n # 값을 구한 뒤 여기를 어떻게 하는지 모르겠음\n for x,y in temp : # for문을 만들어 temp에서 x,y를 뽑아 모두 value값으로 설정 \n graph[x][y] = value\n if not isTrue :\n break # while문을 벗어남 \n cnt+=1\nprint(cnt) \n"
},
{
"alpha_fraction": 0.3283582031726837,
"alphanum_fraction": 0.35373133420944214,
"avg_line_length": 18.171428680419922,
"blob_id": "fb0762e027dc2750d2f39d8dd5a20ee534332c25",
"content_id": "0b40a4f6f716b8e873dfde04018201fd1ac68fa6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 670,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 35,
"path": "/알고리즘/백트래킹/로또.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "#include<iostream>\nusing namespace std;\nint arr[7];\nint n;\nint isu[50];\nint use[14];\nvoid func(int k) {\n if (k == 6) {\n for (int i = 0; i < 6; i++) cout << arr[i] << \" \";\n cout << \"\\n\";\n return;\n }\n for (int i = 0; i < n; i++) {\n if (!isu[use[i]] && arr[k-1]<use[i]) {\n arr[k] = use[i];\n isu[use[i]] = 1;\n func(k + 1);\n isu[use[i]] = 0;\n }\n }\n}\nint main() {\n ios::sync_with_stdio(NULL);\n cin.tie(0);\n for (;;) {\n cin >> n;\n if (n == 0) break;\n for (int i = 0; i < n; i++) {\n cin >> use[i];\n }\n func(0);\n }\n \n \n}"
},
{
"alpha_fraction": 0.4369286894798279,
"alphanum_fraction": 0.4826325476169586,
"avg_line_length": 22.826086044311523,
"blob_id": "0495d35d8dc977a264faf2d2abcf885db7f2e0a0",
"content_id": "94b5b028d2dd13c891dd44a619b771306fe1327a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 567,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 23,
"path": "/알고리즘/dp/정수삼각형.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<cstring>\n#include<algorithm>\nusing namespace std;\nint n;\nint tri[501][501];\nint sum[501][501];\nint path(int y, int x) {\n if (y == n - 1) return tri[y][x];\n int& ret = sum[y][x];\n if (ret != -1) return ret;\n return ret = max(path(y + 1, x), path(y + 1, x + 1)) + tri[y][x];\n}\nint main() {\n cin >> n;\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < i + 1; j++) {\n cin >> tri[i][j];\n }\n }\n memset(sum, -1, sizeof(sum));\n cout << path(0, 0); // x와 y좌표가 (0,0)일때부터 시작\n}"
},
{
"alpha_fraction": 0.5093167424201965,
"alphanum_fraction": 0.5279502868652344,
"avg_line_length": 9.733333587646484,
"blob_id": "4e30bb77b2a4812981d3dd8dc8b041246c7ce27b",
"content_id": "146fc55c847602d9b333bb35b8c919798fede98c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 161,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 15,
"path": "/알고리즘/그리디/ATM.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "n = int(input())\n\ndata = list(map(int,input().split()))\n\ndata.sort()\n\nall = 0\ntmp = 0\n\nfor i in range(n):\n tmp += data[i]\n i+=1\n all += tmp\n\nprint(all)\n"
},
{
"alpha_fraction": 0.4576271176338196,
"alphanum_fraction": 0.4788135588169098,
"avg_line_length": 14.785714149475098,
"blob_id": "83f548b971a9a45bd2966ff4705c765f04245269",
"content_id": "ae01b16cd7ead515b28c994fcc117bed40d4801e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 292,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 14,
"path": "/이코테/그리디/모험가길드.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "n = int(input())\r\ndata = list(map(int,input().split()))\r\n\r\ndata.sort()\r\n\r\ncnt = 0 # 그룹의 개수 \r\ntmp = 0 # 현재 그룹에 포함된 모험가의 수\r\nfor i in data : \r\n tmp+=1\r\n if tmp >= i: # 큰 경우도 생각해야한다. \r\n cnt+=1\r\n tmp = 0\r\n\r\nprint(cnt) \r\n"
},
{
"alpha_fraction": 0.448514848947525,
"alphanum_fraction": 0.4574257433414459,
"avg_line_length": 31.580644607543945,
"blob_id": "437270d6b70e54124b04cc7e52bccf695c78ad28",
"content_id": "4aedbe13b45b6819ea570211a14049575c7a1204",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1300,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 31,
"path": "/알고리즘/브루트포스/진우의 민트초코우유.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "def dfs(jwx,jwy,hp,milk) : # x,y 위치, 체력, 마신 우유의 개수 \n global ans \n for x,y in milks : # 우유의 위치 \n if village[x][y] == 2: # 먹지 않은 우유라면 \n dist = abs(jwx-x) + abs(jwy-y)\n if dist <= hp : # 거리가 체력보다 작거나 같다면 \n village[x][y] = 0 # 먹는다. \n dfs(x,y,hp+h-dist,milk+1) # 체력은 h만큼 올라가고 dist만큼 내려간다.그리고 우유를 마셨으므로 +1 \n village[x][y] = 2\n \n # 현재 위치와 집까지의 거리가 체력보다 작거나 같다면 돌아갈 수 있다. \n if abs(jwx-hx) + abs(jwy-hy) <= hp :\n ans = max(ans,milk)\n \nif __name__==\"__main__\" :\n n,m,h = map(int,input().split())\n village = [list(map(int,input().split())) for _ in range(n)]\n\n milks = [] # 우유의 위치를 저장할 리스트 \n \n for i in range(n) :\n for j in range(n) :\n if village[i][j] == 1 : # 진우의 집 \n hx,hy = i,j\n elif village[i][j] == 2 : # 민트초코우유 \n milks.append([i,j])\n \n # 진우가 마실수있는 민트초코우유의 최대 개수 \n ans = 0\n dfs(hx,hy,m,0) # 진우의 집, 초기체력 전달 \n print(ans)\n"
},
{
"alpha_fraction": 0.3877193033695221,
"alphanum_fraction": 0.4035087823867798,
"avg_line_length": 18.03333282470703,
"blob_id": "e02fa5eadd6e3f8c6074ef3dfb7c0ed9747bda32",
"content_id": "d2e7389d18266493e7843c83a4ddabf29f4ac907",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 570,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 30,
"path": "/알고리즘/DFS/연결 요소의 개수.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "#include<iostream>\n#include<vector>\nusing namespace std;\nvector<vector<int> > adj;\nint vis[1001];\nvoid dfs(int i) {\n vis[i] = 1;\n for (auto next : adj[i]) {\n if (!vis[next]) {\n dfs(next);\n }\n }\n}\nint main() {\n int n, m; cin >> n >> m;\n adj.resize(n + 1);\n for (int i = 0, a, b; i < m; i++) {\n cin >> a >> b;\n adj[a].push_back(b);\n adj[b].push_back(a);\n }\n int cnt = 0;\n for (int i = 1; i <= n; i++) {\n if (!vis[i]) {\n cnt++;\n dfs(i);\n }\n }\n cout << cnt;\n}"
},
{
"alpha_fraction": 0.4749999940395355,
"alphanum_fraction": 0.49444442987442017,
"avg_line_length": 16.047618865966797,
"blob_id": "d46e442e753a6ea96e3e5eb6d1a0b0da5a577bd8",
"content_id": "445c8461b43d8159c5a6a64b4e2a0747cbc369b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 398,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 21,
"path": "/이코테/그리디/큰수의 법칙.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "n,m,k = map(int, input().split())\ndata = list(map(int, input().split()))\n\ndata.sort()\nfirst = data[n-1] # 가장 큰수\nsecond = data[n-2] # 두번째로 큰수\n\nresult = 0\n\nwhile True:\n for i in range(k): #k 만큼\n if m == 0: # 총 덧셈 횟수 소진\n break\n result += first\n m-=1\n if m == 0 : \n break\n result += second\n m-=1\n\nprint(result)\n\n\n"
},
{
"alpha_fraction": 0.3194544017314911,
"alphanum_fraction": 0.35175880789756775,
"avg_line_length": 24.814815521240234,
"blob_id": "2d2fad47ac9ae74058db0eba1ee3ab1afc3fa6a8",
"content_id": "4d836f4c3b2cd85fca686c29fe67fc06f10bb3a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1393,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 54,
"path": "/알고리즘/BFS/섬의개수.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "#include<iostream>\n#include<queue>\n#include<cstring>\nusing namespace std;\nint w, h, cnt;\nint map[51][51];\nint visit[51][51];\n#define x first;\n#define y second;\nqueue<pair<int, int> > q;\nint dx[] = { -1,-1,-1,0,1,1,1,0 };\nint dy[] = { -1,0,1,1,1,0,-1,-1 };\nvoid bfs() {\n while (!q.empty()) {\n pair<int, int> tmp = q.front();\n int X = tmp.x;\n int Y = tmp.y;\n q.pop();\n for (int i = 0; i < 8; i++) {\n int nx = dx[i] + X;\n int ny = dy[i] + Y;\n if (nx < 0 || nx >= h || ny < 0 || ny >= w) continue;\n if (visit[nx][ny] == 1 || map[nx][ny] == 0) continue;\n q.push({ nx,ny });\n visit[nx][ny] = 1;\n }\n }\n}\nint main() {\n ios_base::sync_with_stdio(0); cin.tie(0);\n for (;;) {\n cin >> w >> h;\n if ((w <= 0) || (h <= 0)) return 0;\n for (int i = 0; i < h; i++) {\n for (int j = 0; j < w; j++) {\n cin >> map[i][j];\n }\n }\n for (int i = 0; i < h; i++) {\n for (int j = 0; j < w; j++) {\n if (visit[i][j] == 0 && map[i][j] == 1) {\n q.push({ i,j });\n cnt++;\n visit[i][j] = 1;\n bfs();\n }\n }\n }\n cout << cnt << \"\\n\";\n cnt = 0;\n memset(visit, 0, sizeof(visit));\n }\n\n}"
},
{
"alpha_fraction": 0.42510122060775757,
"alphanum_fraction": 0.44084569811820984,
"avg_line_length": 26.44444465637207,
"blob_id": "15a3501300c6512fc559d730ac7d55582ac3ea87",
"content_id": "f75ea8723c5cc55fea20d0517321677bacabd6fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2269,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 81,
"path": "/알고리즘/삼성역량테스트/구현_마법사 상어와 파이어스톰.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "from collections import deque\nfrom itertools import combinations as c \n\n\ndx = [1,0,-1,0]\ndy = [0,1,0,-1]\n\ndef rotate_and_melt(mp, len_board, L) :\n \n # 회전한 board 저장용 \n new_mp = [[0]*(len_board) for i in range(len_board)]\n \n \n # rotate \n r_size = 2**L \n for x in range(0,len_board,r_size) :\n for y in range(0,len_board, r_size) :\n for i in range(r_size):\n for j in range(r_size) :\n new_mp[x+j][y+r_size-i-1] = mp[x+i][y+j]\n mp = new_mp\n melting_list= []\n for x in range(len_board) :\n for y in range(len_board) :\n ice_count = 0\n for dir in range(4) :\n nx,ny = x + dx[dir], y + dy[dir]\n if 0<=nx<len_board and 0<=ny<len_board and mp[nx][ny] > 0:\n ice_count+=1 \n if ice_count < 3 and mp[x][y] >0 :\n melting_list.append([x,y])\n\n\n # 저장된 얼음들 녹이기 \n for x,y in melting_list :\n mp[x][y] -=1 \n \n return mp \n\n\ndef check_ice_bfs(mp,len_board) :\n vis = [[0]*(len_board) for i in range(len_board)]\n max_area_cnt = 0\n for x in range(len_board) :\n for y in range(len_board) :\n area_cnt = 0\n if vis[x][y] or mp[x][y] == 0 :\n continue \n q = deque()\n q.append([x,y])\n vis[x][y] = 1 \n \n while q :\n cx,cy = q.popleft()\n area_cnt+=1 \n \n for i in range(4) :\n nx,ny= cx + dx[i], cy+ dy[i]\n if 0<=nx<len_board and 0<=ny<len_board and mp[nx][ny] >0 and vis[nx][ny]==0 :\n vis[nx][ny] =1 \n q.append([nx,ny])\n max_area_cnt = max(max_area_cnt, area_cnt)\n \n \n # 남아있는 얼음의 합 \n print(sum(sum(mp,[])))\n print(max_area_cnt)\n \n \n \n \nif __name__==\"__main__\" :\n n,q = map(int,input().split())\n len_board = 2**n \n mp = [list(map(int,input().split())) for i in range(len_board)]\n L_list = list(map(int,input().split()))\n \n for L in L_list :\n mp = rotate_and_melt(mp,len_board,L)\n \n check_ice_bfs(mp,len_board)\n"
},
{
"alpha_fraction": 0.5027726292610168,
"alphanum_fraction": 0.5360443592071533,
"avg_line_length": 30.764705657958984,
"blob_id": "f10ded37595e9b6c8d6afbf01bc675ae23d0f155",
"content_id": "08bfe6298c4a82cf3a51490358a084ef58ba00bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 639,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 17,
"path": "/알고리즘/문자열/가장 긴 팰린드롬 부분 문자열.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "\ndef palin(left : int, right : int) -> str :\n while left >= 0 and right < len(words) and words[left] == words[right] : # while! 조건이 맞을 경우 계속 \n left -= 1 # 짝수는 2->4->6이렇게 증가 홀수는 1->3->5 이렇게 증가\n right += 1\n return words[left+1:right] # 문자열 슬라이스에서 뒤에 값-1 을 반환하므로 right은 -1 안하고 그냥\n\nwords = input()\n\nif len(words) < 2 or words==words[::-1] :\n print(len(words))\n exit(0)\n\nans = ''\nfor i in range(len(words)-1) :\n ans = max(ans,palin(i,i+1),palin(i,i+2),key = len )\n\nprint(len(ans))\n"
},
{
"alpha_fraction": 0.45958083868026733,
"alphanum_fraction": 0.514970064163208,
"avg_line_length": 18.676469802856445,
"blob_id": "03c5c7612b2ed7666c43d047097b88dc947393f5",
"content_id": "2143bac75bb92115c40cb4a14c4d6ede998a8765",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 740,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 34,
"path": "/알고리즘/백트래킹/N-queen.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\nusing namespace std;\nint col[16], cross1[30], cross2[30];//15*2-1 = 29이므로 약 30\nint cnt, n;\n\nbool check(int r, int c) { // 놓을 수 있는 자리인가\n\tif (col[c] || cross1[r + c] || cross2[r - c + n - 1]) return false;\n\treturn true;\n}\n\nvoid queen(int row) { //row 행에 퀸 놓을 자리 찾기 \n\tif (row == n) {// 방법 하나 발견!\n\t\tcnt++;\n\t\treturn;\n\t}\n\tfor (int i = 0; i < n; i++) {\n\t\tif (check(row, i)) {\n\t\t\tcol[i] = 1;\n\t\t\tcross1[row + i] = 1;\n\t\t\tcross2[row - i + n - 1] = 1;\n\t\t\tqueen(row + 1);\n\t\t\tcol[i] = 0;\n\t\t\tcross1[row + i] = 0;\n\t\t\tcross2[row - i + n - 1] = 0;\n\t\t}\n\t}\n}\n\nint main() {\n\tios_base::sync_with_stdio(0); cin.tie(0);\n\tcin >> n;\n\tqueen(0); // 1행에 놓을 자리 찾기\n\tcout << cnt;\n}"
},
{
"alpha_fraction": 0.5028901696205139,
"alphanum_fraction": 0.5086705088615417,
"avg_line_length": 16.299999237060547,
"blob_id": "a7328c6152fcccb330fa2448f42f3ab2072e681a",
"content_id": "215251b7771b17527b40f0946d95029dd977a3a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 173,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 10,
"path": "/이코테/그리디/숫자카드게임.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "n,m = map(int, input().split())\n\nMAX = 0\n\nfor i in range(n):\n data = list(map(int, input().split())) \n if MAX < min(data) :\n MAX = min(data)\n \nprint(MAX)\n"
},
{
"alpha_fraction": 0.36941176652908325,
"alphanum_fraction": 0.40705883502960205,
"avg_line_length": 20.299999237060547,
"blob_id": "7d8eeb937548fc42985d73e58d0fff2420945272",
"content_id": "0f91d7ad41d981163b444fc5fd1731f70d908919",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 439,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 20,
"path": "/알고리즘/dp/퇴사.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<algorithm>\nint t[1001];\nint p[1001];\nint dp[1001];\nusing namespace std;\nint main() {\n int n, next;\n cin >> n;\n for (int i = 0; i < n; i++) {\n cin >> t[i] >> p[i];\n }\n for (int i = 0; i < n; i++) {\n if (i + t[i] <= n) { //일할수있는경우\n dp[i + t[i]] = max(dp[i + t[i]], dp[i] + p[i]);\n }\n dp[i + 1] = max(dp[i + 1], dp[i]);\n }\n cout << dp[n];\n}"
},
{
"alpha_fraction": 0.4682203531265259,
"alphanum_fraction": 0.4957627058029175,
"avg_line_length": 15.678571701049805,
"blob_id": "6bbbe3a9b058c11f20389b17cf71073dfdaa9fd1",
"content_id": "bdcc5ca57684081f08af25729fbe8ec25ced5b0c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 472,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 28,
"path": "/알고리즘/Sort/selection_sort.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "#include<iostream>\nusing namespace std;\n\nint arr[] = { 24,51,1,42,23 };\nint key, j;\n\nvoid selection(int* arr, int size) {\n\tint i, j, small;\n\tfor (i = 0; i < size - 1; i++) {\n\t\tsmall = i;\n\t\tfor (j = i + 1; j < size; j++) {\n\t\t\tif (arr[j] < arr[small]) small = j;\n\t\t}\n\t\tif (i!= small) {\n\t\t\tswap(arr[i], arr[small]);\n\t\t}\n\t}\n}\n\nint main() {\n\tint size = (sizeof(arr) / sizeof(int));\n\n\tselection(arr, size);\n\t\n\tfor (int i = 0; i < size; i++) {\n\t\tcout << arr[i] << \" \";\n\t}\n}\n\n \n \n"
},
{
"alpha_fraction": 0.42580646276474,
"alphanum_fraction": 0.4677419364452362,
"avg_line_length": 16.882352828979492,
"blob_id": "99b7454d5b6868c97dacf572b612e2cdafd8e9fc",
"content_id": "99097f10cec7f96ea75fa1475cb76ec362c2ee89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 360,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 17,
"path": "/이코테/그리디/뒤집기.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "n = input()\n# 구간의 개수를 count한다고 생각 \ncntzero = 0 # 0의 구간\ncntone = 0 # 1의 구간\n\nif n[0] == '1' :\n cntone+=1\nelse : cntzero+=1\n\nfor i in range(1, len(n)) : \n if n[i] != n[i-1] : # 지금까지와 다른 수\n if n[i] == '1' : \n cntone +=1\n else : cntzero += 1\n \n\nprint(min(cntzero, cntone))\n\n \n"
},
{
"alpha_fraction": 0.39811912178993225,
"alphanum_fraction": 0.4294670820236206,
"avg_line_length": 20.299999237060547,
"blob_id": "af6009ca91ae1742e9688ec68ff01dd4bad8bb50",
"content_id": "0ac41ae372fb8a7ac17fc3dedc2d340efec2b08a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 658,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 30,
"path": "/알고리즘/트리/전단지 돌리기.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<algorithm>\n#include<vector>\nusing namespace std;\nint N, S, D;\nint x, y;\nint ans;\nvector<int> adj[100001];\nint d[100001];\nvoid dfs(int v, int par) {\n if (v != S && adj[v].size() == 1) d[v] = 1; //리프노드일때\n else {\n for (auto i : adj[v]) {\n if (i == par) continue;\n dfs(i, v);\n d[v] = max(d[v], d[i] + 1); // 자식보다 +1\n }\n }\n if (v != S && d[v] > D) ans += 2;\n}\nint main() {\n cin >> N >> S >> D;\n for (int i = 0; i < N - 1; i++) {\n cin >> x >> y;\n adj[x].push_back(y);\n adj[y].push_back(x);\n }\n dfs(S, 0);\n cout << ans;\n}"
},
{
"alpha_fraction": 0.4529148042201996,
"alphanum_fraction": 0.4932735562324524,
"avg_line_length": 28.766666412353516,
"blob_id": "564719ae45189c8fb18e5d80f0e4fdd9f6d28822",
"content_id": "a1b2feb782db7b6ca6e29ba3a50c59a419d9603b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1214,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 30,
"path": "/알고리즘/dp/포도주시식.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<cstring>\n#include<algorithm>\n\nusing namespace std;\nint dp[10001][3], arr[10001], n;\nint func(int i, int s) { //i개를 마셨을때 연속으로 s개를 먹은 상황에서 앞으로 마실수 있는 최대값을 구하는 함수\n if (i == n+1) return 0; // n개를 전부 처리하고 n+1을 고민중인 것은 더이상 마실게 없으므로 0 \n int& ret = dp[i][s];\n if (ret != -1) return ret;\n\n ret = func(i + 1, 0);//안마셨을경우 -> n+1개의 포도주를 고민중. 연속으로 마사지않았음\n if (s == 0) ret = max(func(i + 1 ,1) + arr[i], ret); // \n if (s == 1) ret = max(func(i + 1, 2) + arr[i], ret);\n return ret;\n}\nint main() {\n cin >> n;\n for (int i = 0; i <= n; i++) { // 모두 -1으로 초기화\n for (int j = 0; j < 3; j++) {\n dp[i][j] = -1;\n }\n }\n ;\n for (int i = 1; i <= n; i++) cin >> arr[i];\n cout << func(0, 0); // (앞에서) 0개의 포도주를 처리했을때 \n // 0번 포도주를 마실지 말지 고민하면서\n //앞으로 마실수 있는 최댓값\n// 앞에서 아무것도 안마셨으니까 연속성이 없으므로 두번째 인수도 0이다.\n}"
},
{
"alpha_fraction": 0.3254620134830475,
"alphanum_fraction": 0.3316221833229065,
"avg_line_length": 21.674419403076172,
"blob_id": "e3830de2ba845850b1aea2a0b6964e02da576874",
"content_id": "96a86b20705a483129ed1cbcfe354d4747d815ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 974,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 43,
"path": "/알고리즘/큐&스택&덱&set/큐2.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "#include<iostream>\n#include<queue>\n#include<string>\nusing namespace std;\n\nint main() {\n ios::sync_with_stdio(NULL);\n cin.tie(0);\n queue<int> Q;\n int t, n;\n cin >> t;\n while (t--) {\n string st;\n cin >> st;\n if (st == \"push\") {\n cin >> n;\n Q.push(n);\n }\n else if (st == \"pop\") {\n if (Q.empty()) cout << -1 << \"\\n\";\n else {\n cout << Q.front() << \"\\n\";\n Q.pop();\n }\n }\n else if (st == \"size\") {\n cout << Q.size() << \"\\n\";\n }\n else if (st == \"empty\") {\n if (Q.empty()) cout << 1 << \"\\n\";\n else cout << 0 << \"\\n\";\n }\n else if (st == \"front\") {\n if (Q.empty()) cout << -1 << \"\\n\";\n else cout << Q.front() << \"n\";\n }\n else {\n if (Q.empty()) cout << -1 << \"\\n\";\n else cout << Q.back() << \"\\n\";\n }\n\n }\n}"
},
{
"alpha_fraction": 0.3430616855621338,
"alphanum_fraction": 0.38931718468666077,
"avg_line_length": 30.310344696044922,
"blob_id": "dd1f792035f315e719854d4a0028695bc9a37ea3",
"content_id": "ad4bca9d63fce6e8dc4c910018536c5802401ff5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1978,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 58,
"path": "/알고리즘/삼성역량테스트/구현_게리맨더링2.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "def cal(x,y,d1,d2) :\n elec = [0 for i in range(5)] # 선거구 당 인구수 \n temp = [[0]*(n+1) for i in range(n+1)] # 선거구 \n \n # 경계선을 5번 선거구로 할당 \n for i in range(d1+1) :\n temp[x+i][y-i] = 5 # 1번 조건 \n temp[x+d2+i][y+d2-i] = 5 # 4번 조건 \n for i in range(d2+1) :\n temp[x+i][y+i] = 5 # 2번 조건 \n temp[x+d1+i][y-d1+i] # 3번 조건 \n \n \n # 경계선 내부를 5번으로 할당 \n for i in range(x+1, x+d1+d2) : # 행을 돌면서 \n flag = False \n for j in range(1,n+1) : # 열을 돌면서 \n if temp[i][j] == 5 : # 경계선 발견! \n flag = not flag \n if flag :\n temp[i][j] = 5 \n \n # 전체 구역을 돌면서 1,2,3,4 부여 \n for r in range(1,n+1) :\n for c in range(1,n+1) :\n if r<x+d1 and c<=y and temp[r][c] == 0 :\n elec[0] += board[r][c] # 1번 \n elif r<=x+d2 and y<c and temp[r][c] == 0:\n elec[1] += board[r][c] #2번 \n elif x+d1<=r and c<y-d1+d2 and temp[r][c] == 0 :\n elec[2] += board[r][c] # 3번 \n elif x+d2< r and y-d1+d2<= c and temp[r][c] == 0:\n elec[3] += board[r][c] # 4번 \n elif temp[r][c] == 5:\n elec[4] += board[r][c] # 5번 \n return max(elec) - min(elec)\n \n \n \n \n \nif __name__==\"__main__\" :\n n = int(input())\n board = [[]]\n\n for _ in range(n):\n # 1-index로 맞추기위해서 \n board.append([0] + list(map(int, input().split())))\n\n \n answer = int(1e9)\n for x in range(1,n+1) :\n for y in range(1, n+1) :\n for d1 in range(1,n+1) :\n for d2 in range(1,n+1) :\n if 1<=x<x +d1 +d2 <=n and 1<=y-d1<y<y+d2<=n :\n answer = min(answer ,cal(x,y,d1,d2))\n print(answer)\n"
},
{
"alpha_fraction": 0.3337595760822296,
"alphanum_fraction": 0.3657289147377014,
"avg_line_length": 23.46875,
"blob_id": "889a5f839177a90fa8e5682c23c04d83cebf4fb0",
"content_id": "eb0549feda6747b2471c64c0f76ade4f717e477c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 826,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 32,
"path": "/알고리즘/dp/가장 긴 바이토닉수열.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<algorithm>\nusing namespace std;\nint n;\nint arr[1001];\nint dpi[1001]; //증가하는 값을 저장 할 배열\nint dpd[1001]; // 감소하는 값을 저장 할 배열\nint main() {\n cin >> n;\n for (int i = 1; i <= n; i++) cin >> arr[i];\n for (int i = 1; i <= n; i++) {\n dpi[i] = 1;\n for (int j = 1; j <= i; j++) {\n if (arr[i] > arr[j] && dpi[i] < dpi[j] + 1) {\n dpi[i] = dpi[j] + 1;\n }\n }\n }\n for (int i = n; i > 0; i--) {\n dpd[i] = 1;\n for (int j = n; j >= i; j--) {\n if (arr[i] > arr[j] && dpd[i] < dpd[j] + 1) {\n dpd[i] = dpd[j] + 1;\n }\n }\n }\n int ans = 0;\n for (int i = 1; i <= n; i++) {\n ans = max(ans, dpi[i] + dpd[i]);\n }\n cout << ans - 1;\n}"
},
{
"alpha_fraction": 0.3693304657936096,
"alphanum_fraction": 0.41468682885169983,
"avg_line_length": 23.421052932739258,
"blob_id": "0a65d04d5191acf6977290655e35dc1da0eaaa08",
"content_id": "d65f4263fcb3856ba0fcd1bf8d852711bdbe21dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 513,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 19,
"path": "/알고리즘/재귀/하노이탑_이동순서.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\nusing namespace std;\nvoid func(int a, int b, int n) {\n if (n == 1) {\n cout << a << \" \" << b << \"\\n\";\n return;\n }\n func(a, 6 - a - b, n - 1); // 1+2+3은 6이기 때문에 //n-1개를 1->2로\n cout << a << \" \" << b << \"\\n\"; // n번째 원반의 이동\n func(6 - a - b, b, n - 1); // 2 -> 3으로 n-1개의 원반이 이동\n}\nint main(void) {\n ios::sync_with_stdio(0);\n cin.tie(0);\n int k;\n cin >> k;\n cout << (1 << k) - 1 << '\\n';\n func(1, 3, k);\n}"
},
{
"alpha_fraction": 0.5583668947219849,
"alphanum_fraction": 0.5618171095848083,
"avg_line_length": 30.053571701049805,
"blob_id": "b7605a79b79783887bfd58d9f1e79753d4d82303",
"content_id": "be7d13f69597f0a12580988a2415b196db504fe8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1769,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 56,
"path": "/Android/MainActivity.java",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "package com.example.exhelloworld;\n\nimport androidx.appcompat.app.AppCompatActivity;\n\nimport android.os.Bundle;\nimport android.view.View;\nimport android.widget.Button;\nimport android.widget.EditText;\nimport android.widget.ImageView;\nimport android.widget.Switch;\nimport android.widget.TextView;\n\npublic class MainActivity extends AppCompatActivity {\n\n TextView textview;\n EditText editText;\n Button button;\n Switch sw;\n ImageView image;\n\n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n setContentView(R.layout.activity_main);\n\n textview = findViewById(R.id.textView);\n editText = findViewById(R.id.editTextNumberSigned);\n button = findViewById(R.id.button);\n sw = findViewById(R.id.switch1);\n image = findViewById(R.id.imageView);\n\n button.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View view) {\n //문자열을 입력\n if(!sw.isChecked()) {\n String strC = editText.getText().toString();\n if (strC.equals(\"\"))\n return;\n //처리 : c -> F\n double c = Double.parseDouble(strC); //실수로 변환\n double f = 9 / 5.0 * c + 32;\n //textview 출력\n textview.setText(\"switch\" + f);\n image.setImageResource(R.drawable.ic_launcher_foreground);\n }\n else {\n //f->C\n textview.setText(\"switch true\");\n image.setImageResource(R.drawable.sujin);\n }\n }\n });\n }\n\n}\n"
},
{
"alpha_fraction": 0.3629032373428345,
"alphanum_fraction": 0.40188172459602356,
"avg_line_length": 30.45070457458496,
"blob_id": "311de3c734b6c5ef59b15eeeadeaadf0ca6a4252",
"content_id": "38fd1137e81c0dd37e4bc00094517f2947deb71c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2476,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 71,
"path": "/알고리즘/BFS/불!.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<queue>\n#include<algorithm>\nusing namespace std;\nstring board[1002]; //미로를 저장\nint dist1[1002][1002]; //불의 시간을 저장\nint dist2[1002][1002]; //지훈이의 시간을 저장\nint dx[4] = { 1,0,-1,0 };\nint dy[4] = { 0,1,0,-1 };\n#define x first\n#define y second\nint main() {\n queue<pair<int, int> >Q1;\n queue<pair<int, int> >Q2;\n int R, C;\n cin >> R >> C;\n for (int i = 0; i < R; i++) { //모든 거리를 -1로 초기화\n fill(dist1[i], dist1[i] + C, -1);\n fill(dist2[i], dist2[i] + C, -1);\n }\n for (int i = 0; i < R; i++) {\n cin >> board[i]; //미로를 입력받음\n }\n for (int i = 0; i < R; i++) {\n for (int j = 0; j < C; j++) {\n if (board[i][j] == 'F') {\n Q1.push({ i,j });\n dist1[i][j] = 0;// 그곳으로 시작지점\n }\n if (board[i][j] == 'J') {\n Q2.push({ i,j });\n dist2[i][j] = 0;\n }\n }\n }\n // 불의 BFS\n while (!Q1.empty()) { //뭔가 있으면 멈추지않음\n pair<int, int> cur = Q1.front();\n Q1.pop();\n for (int dir = 0; dir < 4; dir++) {\n int nx = cur.x + dx[dir];\n int ny = cur.y + dy[dir];\n if (nx < 0 || nx >= R || nx < 0 || ny >= C) continue; //범위 벗어나면 pass\n if (dist1[nx][ny] >= 0 || board[nx][ny] == '#') continue;\n //이미 와봤거나 #(벽)이면 pass\n dist1[nx][ny] = dist1[cur.x][cur.y] + 1;\n Q1.push({ nx,ny });\n }\n\n } // 지훈이의 BFS \n while (!Q2.empty()) { //뭔가 있으면 멈추지않음\n pair<int, int> cur = Q2.front();\n Q2.pop();\n for (int dir = 0; dir < 4; dir++) {\n int nx = cur.x + dx[dir];\n int ny = cur.y + dy[dir];\n if (nx < 0 || nx >= R || ny < 0 || ny >= C) {\n cout << dist2[cur.x][cur.y] + 1; // 0부터 시작하였기에 +1을 해준다.\n return 0; // 탈출성공\n }\n if (dist2[nx][ny] >= 0 || board[nx][ny] == '#')continue;\n //이미 와봤거나 #(벽)이면 pass\n if (dist1[nx][ny] != -1 && dist1[nx][ny] <= dist2[cur.x][cur.y] + 1) {\n continue;\n } // 불이 지훈이보다 빠르다면 pass\n dist2[nx][ny] = dist2[cur.x][cur.y] + 1;\n Q2.push({ nx,ny });\n }\n }\n cout << \"IMPOSSIBLE\";\n}"
},
{
"alpha_fraction": 0.36706212162971497,
"alphanum_fraction": 0.3991625905036926,
"avg_line_length": 27.078432083129883,
"blob_id": "32a20193c33f17e12174e0f68431c2626e9ed817",
"content_id": "c7d263553840f2de8db2731103e16bfb91737121",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1589,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 51,
"path": "/알고리즘/BFS/토마토.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<algorithm>\n#include<queue>\n#define x first\n#define y second\nusing namespace std;\nint dx[4] = { 1,0,-1,0 };\nint dy[4] = { 0,1,0,-1 };\nint board[1002][1002];\nint dist[1002][1002];\nint main() {\n ios::sync_with_stdio(NULL);\n cin.tie(0);\n int n, m;\n cin >> m >> n;\n queue<pair<int, int> >Q;\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < m; j++) {\n cin >> board[i][j]; // 익었는지 안익었는지 없는지 입력받기\n if (board[i][j] == 1) { // 익었다면 큐에 넣기\n Q.push({ i,j });\n }\n if (board[i][j] == 0) { //익지않았다면 \n dist[i][j] = -1; // -1넣기\n }\n }\n }\n while (!Q.empty()) { //비어있지 않을동안\n pair<int, int> cur = Q.front();\n Q.pop();\n for (int dir = 0; dir < 4; dir++) {\n int nx = cur.x + dx[dir];\n int ny = cur.y + dy[dir];\n if (nx < 0 || nx >= n || ny < 0 || ny >= m) continue; //범위를 벗어난다면 pass\n if (dist[nx][ny] >= 0) continue; //안익은것들만 -1이다. 즉 익었거나 없다면 pass\n dist[nx][ny] = dist[cur.x][cur.y] + 1;\n Q.push({ nx,ny });\n }\n }\n int ans = 0;\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < m; j++) {\n if (dist[i][j] == -1) {// 안익은게 존재한다면\n cout << -1;\n return 0; // 여기서 끝냄\n }\n ans = max(ans, dist[i][j]);\n }\n }\n cout << ans;\n}\n\n"
},
{
"alpha_fraction": 0.36673152446746826,
"alphanum_fraction": 0.39202335476875305,
"avg_line_length": 25.35897445678711,
"blob_id": "cd4a92d6e90d52b89271dabf69e37416d1f939bd",
"content_id": "cb93727c623b594da690388e9c32fbe08ccad046",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1072,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 39,
"path": "/알고리즘/삼성역량테스트/백트래킹_테트로미노.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "# 동 서 북 남 \ndx = [0,0,-1,1]\ndy = [1,-1,0,0]\n\ndef dfs(i,j,cnt,sum) :\n global ans \n # 시간낭비를 줄이기 위해서 \n if ans >= sum + max_v*(3-cnt) : return \n if cnt == 3 :\n ans = max(ans,sum)\n return \n else :\n for dir in range(4) :\n nx,ny = i + dx[dir], j + dy[dir]\n if 0<=nx<n and 0<=ny<m and check[nx][ny] ==0 :\n # 'ㅗ'모양을 위해서 \n if cnt ==1 :\n check[nx][ny] = 1 \n dfs(i,j,cnt+1, sum+mp[nx][ny])\n check[nx][ny] = 0 \n check[nx][ny] = 1 \n dfs(nx,ny,cnt+1,sum+mp[nx][ny])\n check[nx][ny] = 0\n\n\nif __name__==\"__main__\" :\n n,m = map(int,input().split())\n mp = [list(map(int,input().split())) for _ in range(n)]\n check = [[0]*m for _ in range(n)]\n ans = 0\n max_v = max(map(max,mp))\n \n for i in range(n) :\n for j in range(m) :\n check[i][j] = 1 \n dfs(i,j,0,mp[i][j])\n check[i][j] = 0\n\n print(ans)\n"
},
{
"alpha_fraction": 0.5363881587982178,
"alphanum_fraction": 0.5444744229316711,
"avg_line_length": 20.200000762939453,
"blob_id": "cadd6082db7a7223337c6d9712a714d535102223",
"content_id": "5b4b9a6c6e1cb1d501cdeaf2d6a13a2cc3fb5493",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 770,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 35,
"path": "/알고리즘/다익스트라/최단경로.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "import sys\nimport heapq\ninput = sys.stdin.readline\nINF = sys.maxsize\n\nV,E = map(int,input().split())\nK = int(input())\ngraph = [[] for _ in range(V+1)]\ndis = [INF]*(V+1)\n\nfor _ in range(E) :\n u,v,w = map(int,input().split())\n graph[u].append([w,v])\n\nheap = []\n\ndef Dijkstra(start):\n dis[start] = 0\n heapq.heappush(heap,(0,start))\n\n while heap :\n wei, node = heapq.heappop(heap)\n if dis[node] < wei : continue # 최단거리도 아닌거 볼필요가 없지\n\n for w, new_node in graph[node] :\n new_w = w+wei \n if dis[new_node] > new_w :\n dis[new_node] = new_w \n heapq.heappush(heap,(new_w,new_node))\n\n\nDijkstra(K)\n\nfor i in range(1,V+1) :\n print(\"INF\" if dis[i]==INF else dis[i])\n"
},
{
"alpha_fraction": 0.4075104296207428,
"alphanum_fraction": 0.4812239110469818,
"avg_line_length": 24.714284896850586,
"blob_id": "085180f5ecb8df74070da7f8da4e05a0c6061205",
"content_id": "81c839e4b585a800e523c295b33fb8ee4665df39",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 891,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 28,
"path": "/알고리즘/dp/계단오르기.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<algorithm>\nusing namespace std;\n\nint arr[301][3];\n\nint main() {\n\n\tint n; cin >> n;\n\tfor (int i = 1; i <= n; i++) cin >> arr[i][0]; // 입력된 배열\n\tarr[1][1] = arr[1][0];\n\tarr[2][1] = arr[2][0];\n\tarr[1][2] = 0;\n\tarr[2][2] = arr[2][0] + arr[1][0];\n\tarr[2][0] = arr[2][2];\n\n\tfor (int i = 3; i <n; i++) { // 테이블이 계속 갱신되도록 // 무조건 n을 밟음 \n\t\t\tarr[i][1] =arr[i - 2][0]+ arr[i][0]; // +1 계단의 경우[연속으로 1계단]\n\t\t\tarr[i][2] = arr[i - 1][1] + arr[i][0]; // +2 계단의 경우[연속으로 2계단] //이전 계단을 오른 경우\n\n\t\t\tarr[i][0] = max(arr[i][1], arr[i][2]);\n\t}\n\tif (n < 3) { // 계속 틀리던 이유 // 이미 위에서 n==2일때 arr[n][0]을 갱신했는데 밑에 출력문에서 더하니까 틀림 \n\t\tcout << arr[n][0]; return 0;\n\t}\n\tcout << arr[n][0] + max(arr[n - 1][1], arr[n - 2][0]);\n\t\n}"
},
{
"alpha_fraction": 0.3352601230144501,
"alphanum_fraction": 0.4046242833137512,
"avg_line_length": 27.875,
"blob_id": "cf9f5ac4f7586d0d83ef3af8cf936101da335f84",
"content_id": "46a71697d1bc5b06a001d960c88feb39da293fd2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 786,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 24,
"path": "/알고리즘/dp/쉬운계단수.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\nusing namespace std;\nint dp[101][11]; //9+1을 처리하기위해 11로\n//dp[n][l] -> n글자인데 l로 끝나는 수의 계단수\n#define mod 1000000000 \n\nint main() {\n int n; cin >> n;\n for (int i = 1; i < 10; i++) { // 1글자의 계단수는 1개 //1부터 9까지\n dp[1][i] = 1;\n }\n for (int i = 2; i <= n; i++) { //2글자부터 n글자까지 \n for (int j = 0; j < 10; j++) { // 0부터 9로 끝나는\n if (j == 0) dp[i][j] = (dp[i - 1][j + 1]) % mod;\n else if (j == 9) dp[i][j] = (dp[i - 1][j - 1]) % mod;\n else dp[i][j] = (dp[i - 1][j - 1] + dp[i - 1][j + 1]) % mod;\n }\n }\n int sum = 0;\n for (int i = 0; i <= 9; i++) {\n sum = (sum + dp[n][i]) % mod;\n }\n cout << sum;\n}"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5189075469970703,
"avg_line_length": 19.69565200805664,
"blob_id": "02b47fa4946d0c0d5828b9b02caaa7e590a20a64",
"content_id": "60e367b77b7fcf5c51930380d6e5fbf1c874d9b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 584,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 23,
"path": "/알고리즘/DFS/바이러스.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "n = int(input())\nm = int(input())\ngraph = [[]*(n-1) for i in range(n+1)] # 이차원 리스트 생성\nfor i in range(m):\n a,b = map(int,input().split()) \n graph[a].append(b)\n graph[b].append(a)\n\n\ncnt = 0\nvisited = [0]*(n+1) \n\ndef dfs(start) :\n global cnt\n visited[start] = 1 # 해당 컴퓨터 감염 # 방문 체크\n for i in graph[start] : # 방금 감염된 컴퓨터와 인점한 컴퓨터 확인\n if visited[i] == 0 : # 인접한데 감염 안되었다면?\n dfs(i) # 감염시키기\n cnt+=1 # 개수 count \n\n\ndfs(1) \nprint(cnt)\n"
},
{
"alpha_fraction": 0.2791178524494171,
"alphanum_fraction": 0.27980703115463257,
"avg_line_length": 24.034482955932617,
"blob_id": "2d74958b53a887ed921bb2f79235e23228b2d689",
"content_id": "0724262f57986976bab0bd19354705153b3aff0e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1561,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 58,
"path": "/알고리즘/큐&스택&덱&set/스택/균형잡힌 세상.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<string> // getline 이용\n#include<stack>\nusing namespace std;\n\nint k;\nstring input;\nbool res;\nstack <int> stk;\n\nint main() {\n while (1) {\n res = true;\n getline(cin, input); // 한문장씩\n if (input == \".\") break; // 점 \"하나\"만 들어오면\n for (char c : input) {\n if (c == '(') stk.push('(');\n else if (c == '[') stk.push('[');\n else if (c == ')') {\n if (stk.empty()) {\n res = false;\n break;\n }\n else { //비어있지 않아\n if (stk.top() == '(') { //연결 잘될때\n stk.pop();\n }\n else {\n res = false;\n break;\n }\n\n }\n }\n else if (c == ']') {\n if (stk.empty()) {\n res = false;\n break;\n }\n else { //비어있지 않아\n if (stk.top() == '[') { //연결 잘될때\n stk.pop();\n }\n else {\n res = false;\n break;\n }\n\n }\n }\n }\n while (!stk.empty()) { // 혹시라도 남아있다면!\n res = false;\n stk.pop(); // 스택의 재사용을 위해서\n }\n cout << (res ? \"yes\" : \"no\") << \"\\n\";\n }\n}"
},
{
"alpha_fraction": 0.4505183696746826,
"alphanum_fraction": 0.47785109281539917,
"avg_line_length": 18.962265014648438,
"blob_id": "8efa385531d0b5fe56c9ebd8ab54fba63e660a9b",
"content_id": "38e6db53386885ae8736724fc9e70a295dad0bab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1061,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 53,
"path": "/알고리즘/BFS/BFS_단지번호붙이기.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <queue>\n#include <algorithm>\n#include <vector>\nusing namespace std;\n\nint dx[4] = { 1,0,-1,0 };\nint dy[4] = { 0,1,0,-1 };\n\n#define X first\n#define Y second\n\nstring board[26];\nbool visit[26][26];\n\nint main() {\n\tios::sync_with_stdio(0);\n\tcin.tie(0);\n\tint n;\n\tcin >> n;\n\tfor (int i = 0; i < n; i++) cin >> board[i];\n\tqueue<pair<int, int>> Q;\n\tint num = 0;\n\tvector<int> v;\n\tfor (int i = 0; i < n; i++) {\n\t\tfor (int j = 0; j < n; j++) {\n\t\t\tif (board[i][j] == '0' || visit[i][j]) continue;\n\t\t\tnum++;\n\t\t\tQ.push({ i, j });\n\t\t\tvisit[i][j] = true;\n\t\t\tint size = 0;\n\t\t\twhile (!Q.empty()) {\n\t\t\t\tsize++;\n\t\t\t\tpair<int, int> cur = Q.front();\n\t\t\t\tQ.pop();\n\t\t\t\tfor (int i = 0; i < 4; i++) {\n\t\t\t\t\tint nx = cur.X + dx[i];\n\t\t\t\t\tint ny = cur.Y + dy[i];\n\t\t\t\t\tif (nx < 0 || nx >= n || ny < 0 || ny >= n) continue;\n\t\t\t\t\tif (board[nx][ny] == '0' || visit[nx][ny]) continue;\n\t\t\t\t\tQ.push({ nx, ny });\n\t\t\t\t\tvisit[nx][ny] = true;\n\t\t\t\t}\n\n\t\t\t}\n\t\t\tv.push_back(size);\n\t\t}\n\n\t}\n\tsort(v.begin(), v.end());\n\tcout << num << '\\n';\n\tfor (int i : v) cout << i << '\\n';\n}\n\n\n\n"
},
{
"alpha_fraction": 0.42298850417137146,
"alphanum_fraction": 0.4367816150188446,
"avg_line_length": 26.1875,
"blob_id": "cc9abda085a283d85d12ee7eb4f698bfc580e9a1",
"content_id": "77f92d20b18868d48300cb88537f33247c440246",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 523,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 16,
"path": "/programmers/DFS_BFS/네트워크.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "def solution(n, computers):\n \n def dfs(i) : \n vis[i] = 1 \n for a in range(n) : # 모든 컴퓨터를 확인 \n if computers[i][a] and vis[a] == 0 : # 연결되어있고 안가봤다면 \n dfs(a) # 가보자\n answer = 0\n vis = [0 for i in range(len(computers))]\n \n for i in range(n) : # 컴퓨터를 돌면서\n if vis[i] == 0 : # 안가봤으면 \n dfs(i) # 가본다 \n answer += 1 # 한 개의 네트워크\n \n return answer\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5128205418586731,
"avg_line_length": 25,
"blob_id": "defe7e100fb85c7f209144570d014a8f7944aeea",
"content_id": "a64709beded23afd9cc11ff44f00a8d61d2589b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 156,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 6,
"path": "/알고리즘/프로그래머스/n^2배열자르기.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "def solution(n, left, right):\n answer = []\n for i in range(left, right +1 ) :\n answer.append(max(i//n, i%n)+1)\n \n return answer\n"
},
{
"alpha_fraction": 0.489130437374115,
"alphanum_fraction": 0.5018116235733032,
"avg_line_length": 19.44444465637207,
"blob_id": "99751efe257dba41fc7a75fa9b79972053ee6437",
"content_id": "eb98fa8975a0d42967c600f149540bc23f852265",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 552,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 27,
"path": "/알고리즘/BFS/촌수계산.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "from collections import deque\nn = int(input())\np,c = map(int, input().split())\nm = int(input())\narr = [[] for _ in range(n+1)]\n\n\ndist = [0]*(n+1)\n\ndef bfs(n) :\n queue = deque()\n queue.append(n)\n while queue :\n node = queue.popleft()\n for i in arr[node] : \n if dist[i] ==0 :\n dist[i] = dist[node]+1\n queue.append(i)\n else : continue\n\nfor i in range(m) :\n x,y = map(int ,input().split())\n arr[x].append(y)\n arr[y].append(x)\n\nbfs(p)\nprint(dist[c] if dist[c] > 0 else -1)\n"
},
{
"alpha_fraction": 0.3176470696926117,
"alphanum_fraction": 0.36617645621299744,
"avg_line_length": 26.200000762939453,
"blob_id": "b3f38f2061f8e55245cd9895c659303e8efe92f0",
"content_id": "f6dd74ec243feb888c7349c87370e0c92732aeea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 680,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 25,
"path": "/알고리즘/삼성역량테스트/구현_드래곤커브.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "dx = [1,0,-1,0] \ndy = [0,-1,0,1]\n\n \nif __name__==\"__main__\" :\n mp = [[0]*101 for i in range(101)]\n for i in range(int(input())):\n x,y,d,g = map(int,input().split())\n dir = [d]\n for i in range(g) :\n tmp = []\n for j in range(len(dir)) :\n tmp.append((dir[-j-1]+1) %4)\n dir.extend(tmp)\n mp[x][y] = 1 \n for i in dir :\n x,y = x+dx[i],y+dy[i]\n mp[x][y] = 1\n ans = 0 \n for i in range(100) :\n for j in range(100) :\n if mp[i][j] == 1 :\n if mp[i+1][j] and mp[i+1][j+1] and mp[i][j+1] :\n ans +=1 \n print(ans)\n"
},
{
"alpha_fraction": 0.37769079208374023,
"alphanum_fraction": 0.4041095972061157,
"avg_line_length": 26.62162208557129,
"blob_id": "e3e9f01d57a11959dbcae1fd09e38c31ed61a2e6",
"content_id": "f4088b93c7b58dbc12c3cbad6bd9ac9d972b71dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1106,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 37,
"path": "/알고리즘/삼성역량테스트/테트로미노.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "n,m = map(int,input().split())\nmp = [list(map(int,input().split())) for _ in range(n)]\nvis = [[0]*m for i in range(n)]\ndx = [-1,0,1,0]\ndy = [0,1,0,-1]\nans = 0\nmax_val = max(map(max,mp))\n\n\ndef dfs(i,j,idx,total) :\n global ans\n if ans >= total + max_val * (3-idx) : # 더 커질수가 없음 \n return \n if idx == 3 : # 4번 돌았다면 \n ans = max(ans,total)\n return \n else :\n for k in range(4) : # 모든 방향으로 \n nx = i + dx[k]\n ny = j + dy[k]\n if 0<=nx<n and 0<=ny<m and vis[nx][ny]==0 :\n if idx == 1 : # 'ㅗ'모양을 위해 # ㅗ은 연달아 이을수 없다.\n vis[nx][ny] = 1\n dfs(i,j,idx+1, total + mp[nx][ny])\n vis[nx][ny] = 0\n vis[nx][ny] = 1 \n dfs(nx,ny,idx+1, total+mp[nx][ny])\n vis[nx][ny] = 0\n \n\nfor i in range(n) :\n for j in range(m) :\n vis[i][j] = 1 \n dfs(i,j,0,mp[i][j]) # [i,j]에서 시작, 초기값은 mp[i,j]\n vis[i][j] = 0\n \nprint(ans)\n"
},
{
"alpha_fraction": 0.3641732335090637,
"alphanum_fraction": 0.38779526948928833,
"avg_line_length": 19.360000610351562,
"blob_id": "6946494aa14ca211e02dd2feeba046f9ed832e90",
"content_id": "14c96f490069cacdcb3c5a03939fee3b54e1711c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 516,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 25,
"path": "/알고리즘/dp/가장 긴 감소하는 부분 수열.cpp",
"repo_name": "dumi33/world",
"src_encoding": "WINDOWS-1252",
"text": "#include<iostream>\n#include<algorithm>\n#include<vector>\nusing namespace std;\nint n;\nint dp[1001];\nint main() {\n cin >> n;\n vector<int> v(n);\n for (int& i : v) cin >> i;\n int ans = 0;\n\n for (int i = 0; i < n; i++) {\n dp[i] = 1; //±âº»±æÀÌ = 1\n for (int j = 0; j < i; j++) {\n if (v[i] < v[j] && dp[i] < dp[j] + 1) {\n dp[i] = dp[j] + 1;\n }\n }\n }\n for (int i = 0; i < n; i++) {\n ans = max(ans, dp[i]);\n }\n cout << ans;\n}"
},
{
"alpha_fraction": 0.5170187950134277,
"alphanum_fraction": 0.5551643371582031,
"avg_line_length": 20,
"blob_id": "dc1c56815a0e5f9f07f36c467e899a7c804578a5",
"content_id": "7414a9c245833061c8dc312f626f10908e2cea31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1732,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 81,
"path": "/수업/패턴매칭알고리즘.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<stdio.h>\n#include<stdlib.h>\n#include<string.h>\n\n#define scan -1\n#define TRUE 1\n#define FALSE 0\n#define size 100\n\nstruct Deque {\n\tint* deque;\n\tint first, last;\n};\n\nstruct Deque dq;\nchar ch[10] = { ' ','A',' ','B', ' ', ' ', 'A','C','D',' ' };\nint next1[10] = { 5,2,3,4,8,6,7,8,9,0 };\nint next2[10] = { 5,2,1,4,8,2,7,8,9,0 };\n\nvoid inserFirst(int v) { dq.deque[dq.first--] = v; }\nvoid inserLast(int v) { dq.deque[++dq.last] = v; }\nint deleteFirst() {\n\tdq.deque[dq.first] = 0;\n\treturn dq.deque[++dq.first];\n}\nint isempty() {\n\tif (dq.first == dq.last) {\n\t\treturn TRUE;\n\t}\n\telse return FALSE;\n}\nint match(char* t) {\n\tint n1, n2;\n\tint i, j = 0, k, N = strlen(t), state = next1[10];\n\n\tdq.deque = (int*)malloc(sizeof(int) * size);\n\tdq.first = size / 2;\n\tdq.last = size / 2;\n\tinserLast(scan);\n\tprintf(\"%d[%d]\\n\", state, dq.deque[dq.first + 1]);\n\n\twhile (state) {\n\t\tprintf(\"state = %d\\n\", state);\n\t\tif (state == scan) {\n\t\t\tj++;\n\t\t\tif (isempty()) inserFirst(next1[0]);\n\t\t\tinserLast(scan);\n\t\t}\n\t\telse if (ch[state] == t[j]) inserLast(next1[state]);\n\t\telse if (ch[state] == ' ') {\n\t\t\tn1 = next1[state];\n\t\t\tn2 = next2[state];\n\t\t\tinserFirst(n1);\n\t\t\tif (n1 != n2) inserFirst(n2);\n\t\t}\n\t\tfor (k = dq.first + 1; k <= dq.last; k++) {\n\t\t\tprintf(\"[%d]\", dq.deque[k]);\n\t\t}\n\t\tprintf(\"\\n\");\n\t\tif (isempty()) return j;\n\t\tif (j > N) return 0;\n\t\tstate = deleteFirst();\n\t}\n\tfree(dq.deque);\n\treturn j - 1;\n}\nvoid main() {\n\tchar text[100] = \"CDAABCAAABDDACDAACAAAAAAABD\";\n\tint N, pos, previous = 0, i = 0;\n\tN = strlen(text);\n\twhile (1) {\n\t\tpos = match(text + i);\n\t\tif (pos == 0) break;\n\t\tpos += previous;\n\t\ti = pos;\n\t\tif (i <= N) printf(\"패턴이 발생한 위치 : %d\\n\", pos);\n\t\telse break;\n\t\tprevious = i;\n\t}\n\tprintf(\"패턴 매칭 종료.\\n\");\n}\n\n\n\n"
},
{
"alpha_fraction": 0.411827951669693,
"alphanum_fraction": 0.4462365508079529,
"avg_line_length": 30,
"blob_id": "77533908e90df958ba6d2bad1507ab7beb4d63c0",
"content_id": "f8681d25ef3bb389aaeecbb96f3531789faf6b76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 980,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 30,
"path": "/알고리즘/BFS/벽부수고이동하기2.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "from collections import deque\nq = deque()\nfrom sys import stdin\ninput = stdin.readline\n\nn,m,k = map(int, input().split())\nvis = [[[0]*(k+1) for _ in range(m)] for __ in range(n)]\narr = [list(map(int,input().strip())) for _ in range(n)]\ndx = [1,0,-1,0]\ndy = [0,1,0,-1]\n\ndef bfs() :\n q.append([0,0,k]) # k는 벽을 뚫을 수 있는 수\n vis[0][0][k] = 1\n while q :\n x,y,z = q.popleft()\n if x == n-1 and y == m-1 :\n return vis[x][y][z]\n for i in range(4) :\n nx ,ny = dx[i] + x, dy[i]+y\n if 0<=nx<n and 0<=ny<m :\n if arr[nx][ny]==1 and z>0 and vis[nx][ny][z-1]==0: # 여기에서 vis를 이용해 시간단축, z-1임을 유의\n vis[nx][ny][z-1] = vis[x][y][z]+1\n q.append([nx,ny,z-1])\n elif arr[nx][ny]==0 and vis[nx][ny][z]==0:\n vis[nx][ny][z] = vis[x][y][z]+1\n q.append([nx,ny,z]) \n return -1\n\nprint(bfs())\n"
},
{
"alpha_fraction": 0.45673078298568726,
"alphanum_fraction": 0.504807710647583,
"avg_line_length": 23.47058868408203,
"blob_id": "482dd74634aab237902995f3578fda107b148e15",
"content_id": "085ab4560b478604c72cbd119d1f4e73a2e449f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 424,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 17,
"path": "/알고리즘/BFS/숨바꼭질.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "from collections import deque\nx , y= map(int,input().split())\n\ndist = [-1]*100001\ndef bfs(n):\n queue = deque()\n queue.append(n)\n while queue:\n node = queue.popleft()\n for i in (node+1, node-1,node*2) :\n if i < 0 or i > 100000 : continue\n if dist[i] == -1 : # 처음 방문\n dist[i] = dist[node]+1\n queue.append(i) \ndist[x] = 0\nbfs(x)\nprint(dist[y])\n"
},
{
"alpha_fraction": 0.3333333432674408,
"alphanum_fraction": 0.45390069484710693,
"avg_line_length": 9.230769157409668,
"blob_id": "0f298d6d375a15c00d3b97d6e69d023aa0b9fad0",
"content_id": "df980823410349c7cec5a26cb332cf993e5f203a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 149,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 13,
"path": "/알고리즘/그리디/거스름돈.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "n = int(input())\n\nn = 1000-n\ndata = [500,100,50,10,5,1]\n\ncnt = 0\n\nfor i in data :\n cnt+= n // i # 몫\n n %= i # 나머지\n\n\nprint(cnt)\n \n"
},
{
"alpha_fraction": 0.29485756158828735,
"alphanum_fraction": 0.33222344517707825,
"avg_line_length": 29.727272033691406,
"blob_id": "a5b0989131443dc89a99f125c024e0d856cf17af",
"content_id": "b6773cd6f28b65926953bbcb42ce211fb02df6fa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2927,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 88,
"path": "/알고리즘/BFS/연구소.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include <vector>\n#include <queue>\n#include <algorithm>\nusing namespace std;\n\nconst int dy[4] = { 0,0,1,-1 };\nconst int dx[4] = { 1,-1,0,0 };\nint n, m, map[9][9];\nint virus_map[9][9];\ntypedef pair<int, int> P;\nint bfs() {\n queue<P> q;\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < m; j++) {\n virus_map[i][j] = map[i][j]; // 옮기기\n if (virus_map[i][j] == 2) { // 바이러스 있는 곳을 큐에 저장\n q.push({ i,j });\n }\n }\n }\n while (!q.empty()) {\n int x = q.front().first;\n int y = q.front().second;\n q.pop();\n for (int dir = 0; dir < 4; dir++) {\n int nx = x + dx[dir];\n int ny = y + dy[dir];\n if (nx < 0 || nx >= n || ny < 0 || ny >= m) continue;\n if (virus_map[nx][ny] == 0) { //이동가능 지점\n virus_map[nx][ny] = 2; //바이러스 전파\n q.push({ nx,ny });\n }\n }\n }\n int safe = 0;\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < m; j++) {\n if (virus_map[i][j] == 0) { // 안전구역에는\n safe++;\n }\n\n }\n }\n return safe;\n}\nint main() {\n ios::sync_with_stdio(0); cin.tie(0);\n cin >> n >> m;\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < m; j++) {\n cin >> map[i][j];\n }\n }\n int mx_safe = 0; // 안전영역의 크기\n for (int a1 = 0; a1 < n; a1++) { // 1번벽\n for (int a2 = 0; a2 < m; a2++) {\n if (map[a1][a2] != 0) continue; //0이 아니라면 벽을 세울수없으므로\n for (int b1 = 0; b1 < n; b1++) { //2번벽\n for (int b2 = 0; b2 < m; b2++) {\n if (map[b1][b2] != 0) continue; //0이 아니라면 벽을 세울수없으므로\n for (int c1 = 0; c1 < n; c1++) { //3번벽\n for (int c2 = 0; c2 < m; c2++) {\n if (map[c1][c2] != 0) continue; //0이 아니라면 벽을 세울수없으므로\n if (a1 == b1 && a2 == b2) continue; // 같은 자리에 벽을 세울수없으므로\n if (a1 == c1 && a2 == c2) continue;\n if (c1 == b1 && c2 == b2) continue;\n //벽을 세워요\n map[a1][a2] = 1;\n map[b1][b2] = 1;\n map[c1][c2] = 1;\n\n int numofsafe = bfs();\n mx_safe = max(numofsafe, mx_safe);\n\n //벽을 없애요\n map[a1][a2] = 0;\n map[b1][b2] = 0;\n map[c1][c2] = 0;\n }\n }\n }\n }\n }\n }\n cout << mx_safe;\n\n}"
},
{
"alpha_fraction": 0.40611961483955383,
"alphanum_fraction": 0.42002782225608826,
"avg_line_length": 28.95833396911621,
"blob_id": "1402c062624e2f3642613da90b45031297061e3d",
"content_id": "211851fcaa816c1f82a3fdb74318777a41a61932",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 793,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 24,
"path": "/programmers/DFS_BFS/단어변환.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "from collections import deque \ndef solution(begin, target, words):\n answer = 0\n q = deque()\n q.append([begin,0]) # 0은 변화한 횟수\n vis = [0 for i in range(len(words))]\n \n while q :\n word , cnt = q.popleft()\n if word == target : \n answer = cnt \n break\n for i in range(len(words)) : # 단어들을 돌면서\n tmp_cnt = 0\n if vis[i] == 0 : # 이 단어를 안썼다면\n for j in range(len(word)) :\n if word[j] != words[i][j] :\n tmp_cnt+=1 \n if tmp_cnt == 1 : # 만약 한글자만 다르다면\n q.append([words[i],cnt+1])\n vis[i] = 1 # 해당 단어 사용!\n \n \n return answer\n"
},
{
"alpha_fraction": 0.3958333432674408,
"alphanum_fraction": 0.41874998807907104,
"avg_line_length": 23,
"blob_id": "11af212dfed19bfbd3e4b4e7887999738b317796",
"content_id": "953acc966b985d4ccaf0451e34160d751a4f14a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 508,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 20,
"path": "/programmers/힙/디스크 컨드롤러.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "import heapq\ndef solution(jobs):\n answer = 0\n start, now ,i= -1,0,0\n heap = []\n while i < len(jobs) : # 해야할 작업보다 한 작업이 작다면 \n for j in jobs :\n if start <j[0]<=now :\n heapq.heappush(heap,[j[1],j[0]])\n \n if heap :\n cur = heapq.heappop(heap)\n start = now\n now += cur[0]\n answer+=(now-cur[1])\n i+=1 \n else :\n now+=1 \n\n return answer // len(jobs)\n"
},
{
"alpha_fraction": 0.5370370149612427,
"alphanum_fraction": 0.5432098507881165,
"avg_line_length": 12.5,
"blob_id": "c0fa2def070c3f3d5cf211f7367f3fca22368bec",
"content_id": "86af50b1a8d113f6ca8bcf54867f8cb87c0351d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 162,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 12,
"path": "/이코테/그리디/만들 수 없는 금액.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "n = input()\narr = list(map(int, input().split()))\n\ntarget = 1\narr.sort()\nfor i in arr :\n if target < i : \n break\n else : target += i\n\n\nprint(target)\n"
},
{
"alpha_fraction": 0.46875,
"alphanum_fraction": 0.51171875,
"avg_line_length": 18.69230842590332,
"blob_id": "efb7887c76be991c0f4746fb23b316ec907341a0",
"content_id": "0eade6a44c27349ec43d9224073c5ebaf68c27be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 306,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 13,
"path": "/알고리즘/그리디/30.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "arr = input()\narr = sorted(arr, reverse = True)\nsum = 0\n# 30의 배수는 0으로 끝나고 각 자리수의 합이 3의 배수\nif '0' not in arr :\n print(-1)\n\nelse : \n for i in arr :\n sum += int(i) \n if sum %3 == 0 : # 3으로 나눠지면\n print(''.join(arr))\n else : print(-1)\n"
},
{
"alpha_fraction": 0.45719844102859497,
"alphanum_fraction": 0.4678988456726074,
"avg_line_length": 30.18181800842285,
"blob_id": "704606cb9e55cafe9fecd6d61e5052eb94d7909d",
"content_id": "dc2340a7afab795a6208629a11cdf437cb9ecfee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1374,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 33,
"path": "/알고리즘/재귀/재귀함수가 뭔가요.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<string>\nusing namespace std;\nint N;\nstring str = \"____\";\nvoid func(int n) {\n if (n == 0) {\n for (int i = N - n; i > 0; i--) cout << str;\n cout << \"\\\"재귀함수는 자기 자신을 호출하는 함수라네\\\"\\n\";\n for (int i = N - n; i > 0; i--) cout << str;\n cout << \"라고 답변하였지.\\n\";\n return;\n }\n for (int i = N - n; i > 0; i--) cout << str;\n cout << \"\\\"잘 들어보게. 옛날옛날 한 산 꼭대기에 이세상 모든 지식을 통달한 선인이 있었어.\\n\";\n for (int i = N - n; i > 0; i--) cout << str;\n cout << \"마을 사람들은 모두 그 선인에게 수많은 질문을 했고, 모두 지혜롭게 대답해 주었지.\\n\";\n for (int i = N - n; i > 0; i--) cout << str;\n cout << \"그의 답은 대부분 옳았다고 하네. 그런데 어느 날, 그 선인에게 한 선비가 찾아와서 물었어.\\\"\\n\";\n for (int i = N - n + 1; i > 0; i--) cout << str;\n cout << \"\\\"재귀함수가 뭔가요?\\\"\\n\";\n func(n - 1);\n for (int i = N - n; i > 0; i--) cout << str;\n cout << \"라고 답변하였지.\\n\";\n}\nint main() {\n ios::sync_with_stdio(NULL);\n cin.tie(0);\n cin >> N;\n cout << \"어느 한 컴퓨터공학과 학생이 유명한 교수님을 찾아가 물었다.\\n\";\n cout << \"\\\"재귀함수가 뭔가요?\\\"\\n\";\n func(N);\n}"
},
{
"alpha_fraction": 0.34700316190719604,
"alphanum_fraction": 0.37223973870277405,
"avg_line_length": 17.705883026123047,
"blob_id": "dc9dcfe75dc744919847c2aba8c3ce40fb49e254",
"content_id": "fa2f846a37580bf53ef0db6be2980a938491ba46",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 317,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 17,
"path": "/알고리즘/그리디/게임을 만든 동준이.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "#include<iostream>\nusing namespace std;\nint num[102];\nint main() {\n int n, cnt = 0;\n cin >> n;\n for (int i = 1; i <= n; i++) {\n cin >> num[i];\n }\n for (int j = n; j > 0; j--) {\n while (num[j - 1] >= num[j]) {\n num[j - 1]--;\n cnt++;\n }\n }\n cout << cnt;\n}"
},
{
"alpha_fraction": 0.4216787815093994,
"alphanum_fraction": 0.45736947655677795,
"avg_line_length": 19.73972511291504,
"blob_id": "32f0e0b71aa36802fc8ae2338c1e0b3a482c21bd",
"content_id": "8fd79591b066c6fd18e666b7f5d0649d7092d670",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1877,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 73,
"path": "/수업/Floyd.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include <iostream>\n\n#include <algorithm>\n\nusing namespace std;\n#define inf 100000\nconst int MAX = 100;\nint n;\nint D[MAX][MAX] = { //큰값을 inf로 define하였다.\n\t{0,0,0,0,0,0},\n\t{0,0,1,inf,1,5},\n\t{0,9,0,3,2,inf},\n\t{0,inf,inf,0,4,inf},\n\t{0,inf,inf,2,0,3},\n\t{0, 3,inf,inf,inf,0},\n};\nint p[MAX][MAX];\nvoid floyd();\nvoid path(int q, int r);\n\nint main() {\n\tcin >> n;\n\tcout << \"\\n\";\n\tfloyd();\n\tcout << \"D[i][j] is \\n\"; // 최종 D를 출력한다.\n\tfor (int i = 1; i <= n; ++i) {\n\t\tfor (int j = 1; j <= n; ++j) {\n\t\t\tcout << D[i][j] << \" \";\n\t\t}\n\t\tcout << \"\\n\";\n\t}\n\n\tcout << \"\\n\\n\";\n\n\tcout << \"P[i][j] is \\n\"; //PATH를 출력한다.\n\tfor (int i = 1; i <= n; i++) {\n\t\tfor (int j = 1; j <= n; j++) {\n\t\t\tcout << p[i][j]<<\" \";\n\t\t}\n\t\tcout << \"\\n\";\n\t}\n\tcout << \"\\n\\n\";\n\tint a,b;\n\tfor (int i = 0; i < 3; i++) { //3번 반복한다.\n\t\tcout << \"구하고 싶은 최단경로의 시작노드와 끝노드를 입력하시오\\n\";\n\t\tcin >> a >> b;\n\t\tcout << \"The shortest path : \";\n\t\tcout << \"v\" << a; //시작노드\n\t\tpath(a, b);\n\t\tcout << \" v\" << b << \"\\n\\n\"; // 끝노드\n\t}\n\t\n\tcout << \"정보통신공학과_12191728_김두미\";\n}\nvoid floyd() {\n\tfor (int k = 1; k <= n; ++k) {\n\t\tfor (int i = 1; i <= n; ++i) {\n\t\t\tfor (int j = 1; j <= n; ++j) {\n\t\t\t\tif (D[i][j] > D[i][k] + D[k][j]) { // 원래 경로가 새롭게 k노드를 경유할때보다 크다면\n\t\t\t\t\tD[i][j] = D[i][k] + D[k][j]; // 새롭게 k노드를 경유한 비용을 넣는다.\n\t\t\t\t\tp[i][j] = k; //경유점을 P배열에 넣는다\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t}\n}\nvoid path(int q, int r) {\n\tif (p[q][r] != 0) { // 다른 노드를 경유를 했다면\n\t\tpath(q, p[q][r]); //시작노드에서 경유한 노드까지의 경유 경로를 재귀를 이용해 확인한다. \n\t\tcout << \" v\" << p[q][r]; // 출력\n\t\tpath(p[q][r], r); // 경유한 노드부터 마지막 노드까지의 경유 경로를 재귀를 이용해 확인한다.\n\t}\n}"
},
{
"alpha_fraction": 0.41522490978240967,
"alphanum_fraction": 0.4307958483695984,
"avg_line_length": 20.407407760620117,
"blob_id": "d34675c4d2b9d5ede19593a686f473e4e2d505e0",
"content_id": "995d0b6ba888c15edbf4ea48d52da8ba863c03bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 588,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 27,
"path": "/알고리즘/문자열/문자열 단어.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<vector>\nusing namespace std;\nvector<string> v;\nvoid check(string c) {\n for (int i = 0; i < v.size(); i++) {\n for (int j = 0; j < c.size(); j++) {\n if (c == v[i]) return; //같은 단어임\n c += c.at(0);\n c.erase(0, 1);\n }\n \n }\n v.push_back(c);\n}\nint main() {\n ios::sync_with_stdio(0); cin.tie(0);\n int n; cin >> n;\n\n for (int i = 0; i < n; i++) {\n string str;\n cin >> str;\n if (v.size() == 0) v.push_back(str);\n else check(str);\n }\n cout << v.size();\n}\n"
},
{
"alpha_fraction": 0.43115437030792236,
"alphanum_fraction": 0.45757997035980225,
"avg_line_length": 20.75757598876953,
"blob_id": "7313efb81d1cdf2f4723289e093cb78117f3b967",
"content_id": "499b9f0b4b16a44f7b461bce07fe31fd17174b79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 719,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 33,
"path": "/알고리즘/BFS/토마토.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "from collections import deque\nm,n = map(int, input().split())\nmatrix = [list(map(int,input().split()))for _ in range(n)]\n\nqueue = deque([])\n\ndx = [1,0,-1,0]\ndy = [0,1,0,-1]\n\nfor i in range(n):\n for j in range(m) :\n if matrix[i][j] == 1:\n queue.append([i,j])\n\ndef bfs() :\n while queue:\n x,y = queue.popleft()\n\n for i in range(4) :\n nx,ny = x + dx[i], y + dy[i]\n if 0<=nx < n and 0<= ny < m and matrix[nx][ny]==0 : \n queue.append([nx,ny])\n matrix[nx][ny] = matrix[x][y]+1\n\nbfs()\nans = 0\nfor i in matrix :\n for j in i :\n if j == 0:\n print(-1)\n exit(0)\n ans = max(ans,max(i))\nprint(ans-1)\n\n"
},
{
"alpha_fraction": 0.49394938349723816,
"alphanum_fraction": 0.49614962935447693,
"avg_line_length": 26.515151977539062,
"blob_id": "8b36d25cf6c0dda213a2e7f48219090296a87261",
"content_id": "c1110a5436d503e9b09de8a8cde547f214e14e19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 993,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 33,
"path": "/programmers/DFS_BFS/여행경로.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "\nfrom collections import defaultdict\ndef solution(tickets):\n answer = []\n n = len(tickets)\n def init_graph() : \n routes = defaultdict(list) # 디포트값이 list인 딕셔너리 \n for key, value in tickets :\n routes[key].append(value)\n return routes\n \n def dfs(key, footprint) :\n if len(footprint) == n+1 : # 다 경유한 경우 \n return footprint\n \n for idx, country in enumerate(routes[key]) :\n routes[key].pop(idx)\n \n fp = footprint[:]\n fp.append(country)\n \n ret = dfs(country, fp)\n \n if ret : return ret # 다 경유 \n \n routes[key].insert(idx, country)\n \n routes = init_graph()\n for r in routes : # routes의 key가 r으로 \n routes[r].sort() # 경로가 2개 이상일 때 알파벳 순서가 앞서는 경로\n \n answer = dfs(\"ICN\", [\"ICN\"])\n \n return answer\n"
},
{
"alpha_fraction": 0.4297124743461609,
"alphanum_fraction": 0.43769967555999756,
"avg_line_length": 19.899999618530273,
"blob_id": "0088ef6e86eb56151f5ea7ad189367b0014e31f4",
"content_id": "b84210ff7d86985d4f9bbf3486d13b4476adf5ec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 692,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 30,
"path": "/알고리즘/위상정렬/줄세우기.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<vector>\nusing namespace std;\nvector<vector<int> > g;\nvector<int> st, vis;\nvoid dfs(int u) {\n vis[u] = 1;\n for (int v : g[u]) {\n if (!vis[v]) dfs(v);\n }\n st.push_back(u); //더이상 간선이 없을때 //위상이 낮은것 먼저 들어감\n}\nint main() {\n int n, m;\n cin >> n >> m;\n g.resize(n + 1);\n vis.resize(n + 1);\n for (int i = 0; i < m; i++) {\n int a, b;\n cin >> a >> b;\n g[a].push_back(b);\n }\n for (int i = 1; i <= n; i++) {\n if (!vis[i]) dfs(i);\n }\n while (st.size()) { // 위상이 높은것 부터 출력해야함\n cout << st.back() << \" \";\n st.pop_back();\n }\n}"
},
{
"alpha_fraction": 0.42925572395324707,
"alphanum_fraction": 0.46720707416534424,
"avg_line_length": 22.807018280029297,
"blob_id": "683f9dc4481b1185111c0dfcb67de3c12f445ebb",
"content_id": "ef8eb4c1c75bf6202bc15dbae214805a46fba89e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3018,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 114,
"path": "/수업/CRC.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "\n#include <iostream>\nusing namespace std;\n\nstring crc(string data, string gx){\n\tstring crc_data = data;\n\n\tfor (uint8_t i = 0; i < gx.length() - 1; i++) {// 원본 데이터 뒤에 gx-1만큼 0을 추가한다.\n\t\tdata += \"0\";\n\t}\n\tstring q = \"\"; //몫\n\n\tfor (uint8_t i = 0; i < data.length(); i++){ // 사용하는 bit수를 고정하기위해서 uint8사용\n\t\tif (data[i] == '1'){\n\t\t\tq += '1'; // 몫\n\t\t\tfor (uint8_t j = 0; j < gx.length(); j++){\n\t\t\t\tif ((data[i + j] - '0') ^ (gx[j] - '0')){ // xor연산 // string을 int형식으로 반환하기위해 0을 빼준다.\n\t\t\t\t\tdata[i + j] = '1';\n\t\t\t\t}\n\t\t\t\telse data[i + j] = '0';\n\n\t\t\t}\n\t\t}\n\t\telse{\n\t\t\tq += '0';\n\t\t\tfor (uint8_t j = 0; j < gx.length(); j++) {\n\t\t\t\tif ((data[i + j] - '0') ^ 0){ //나눌수 없는 경우 0과 xor\n\t\t\t\t\tdata[i + j] = '1';\n\t\t\t\t}\n\t\t\t\telse data[i + j] = '0';\n\t\t\t}\n\t\t}\n\t\tif (q.length() == data.length() - gx.length() + 1) break; // 나머지가 gx-1의 길이가 될때 멈춤\n\t}\n\t\n\tcrc_data += data.substr(crc_data.length(), gx.length() - 1); // 이어붙인다.\n\treturn crc_data;\n}\n\nstring check(string crc_data, string gx, string& remider) { // 에러 여부 확인\n\tstring q = \"\";\n\n\tfor (uint8_t i = 0; i < crc_data.length(); i++){ // xor연산\n\t\tif (crc_data[i] == '1'){\n\t\t\tq += '1';\n\t\t\tfor (uint8_t j = 0; j < gx.length(); j++){\n\t\t\t\tif ((crc_data[i + j] - '0') ^ (gx[j] - '0')){\n\t\t\t\t\tcrc_data[i + j] = '1';\n\t\t\t\t}\n\t\t\t\telse crc_data[i + j] = '0';\n\t\t\t}\n\t\t}\n\t\telse {\n\t\t\tq += '0';\n\t\t\tfor (uint8_t j = 0; j < gx.length(); j++){\n\t\t\t\tif ((crc_data[i + j] - '0') ^ 0){\n\t\t\t\t\tcrc_data[i + j] = '1';\n\t\t\t\t}\n\t\t\t\telse crc_data[i + j] = '0';\n\t\t\t}\n\t\t}\n\t\tif (q.length() == crc_data.length() - gx.length() + 1) break;\n\t}\n\n\tremider = crc_data.substr(crc_data.length() - gx.length() + 1, gx.length() - 1); // 나머지를 구한다.\n\n\tbool error = false; //에러여부를 저장하는 변수\n\tfor (uint8_t i = 0; i < remider.length(); i++){\n\t\tif (remider[i] != '0'){ // 0이 아니라면 에러가 생긴것이다.\n\t\t\terror = true;\n\t\t\tbreak;\n\t\t}\n\t}\n\tif (error) // 에러가 있다면\n\t\treturn \"error 발견\";\n\telse // 에러가 없다면\n\t\treturn \"error 없음\";\n}\n\nint main()\n{\n\tcout << \"12191728_김두미\\n\";\n\tstring data = \"101110\";\n\tstring gx = \"1001\";\n\tstring remider = \"\";\n\t\n\tcout << \"1번 예시 :\" << \"\\n\";\n\tcout << \"Data:\" << data << \"\\n\";\n\tcout << \"Gx:\" << gx << \"\\n\";\n\tcout << \"CRC code:\" << crc(data, gx) << \"\\n\";\n\tcout << \"오류검출:\" << check(crc(data, gx), gx, remider) << \"\\n\";\n\n\tcout << \"\\n\";\n\n\tdata = \"110011\";\n\tgx = \"1001\";\n\tcout << \"\\n\";\n\tcout << \"2번 예시 :\" << \"\\n\";\n\tcout << \"Data:\" << data << \"\\n\";\n\tcout << \"Gx:\" << gx << \"\\n\";\n\tcout << \"CRC code:\" << crc(data, gx) << \"\\n\";\n\tcout << \"오류검출:\" << check(crc(data, gx), gx, remider) << \"\\n\";\n\t\n\tcout << \"\\n\";\n\n\tdata = \"110011\";\n\tgx = \"1001\";\n\tcout << \"\\n\";\n\tcout << \"3번 예시 :\" << \"\\n\";\n\tcout << \"Data:\" << data << \"\\n\";\n\tcout << \"Gx:\" << gx << \"\\n\";\n\tcout << \"CRC code:\" << crc(data, gx) << \"\\n\";\n\tcout << \"오류검출:\" << check(\"110011100\", gx, remider) << \"\\n\";\n\t\n}"
},
{
"alpha_fraction": 0.3599624037742615,
"alphanum_fraction": 0.37406015396118164,
"avg_line_length": 22.66666603088379,
"blob_id": "994e192848c2c56d98460cf26aea7939eac50c31",
"content_id": "0e26a093398a31f14f127f5b26794c4ec969f37e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1098,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 45,
"path": "/알고리즘/DFS/이분 그래프.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<vector>\n#include<cstring>\nusing namespace std;\n\nvector<vector<int>> adj;\nint vis[20001];\n\nvoid dfs(int cur, int i) {\n vis[cur] = i; // 색깔을 입력\n for (auto k : adj[cur]) {\n if (vis[k] == 0) {\n dfs(k, 3 - i);\n }\n }\n}\nint main() {\n int tc; cin >> tc;\n while (tc--) {\n int v, e; cin >> v >> e;\n memset(vis, 0, sizeof(vis));\n adj.resize(v + 1);\n for (int i = 1; i <= v; i++) {\n adj[i].clear();\n }\n for (int i = 0, a, b; i < e; i++) {\n cin >> a >> b;\n adj[a].push_back(b);\n adj[b].push_back(a);\n }\n for (int i = 1; i <= v; i++) {\n if (vis[i] == 0) {\n dfs(i, 1);\n }\n }\n bool isok = true;\n for (int i = 1; i <= v; i++) {\n if (adj[i].empty()) continue;\n for (int j : adj[i]) {\n if (vis[i] == vis[j]) isok = false; //인접한 노드가 같은 색이라면\n }\n }\n isok ? cout << \"YES\\n\" : cout << \"NO\\n\";\n }\n}"
},
{
"alpha_fraction": 0.4395161271095276,
"alphanum_fraction": 0.47883063554763794,
"avg_line_length": 25.105262756347656,
"blob_id": "8d303bf3b7f5e4ddf896ba792a81a7a4aafa1ee5",
"content_id": "5f22b6ed34faee7b9cc68df678bcd3099f631320",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1166,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 38,
"path": "/알고리즘/그리디/전구와스위치.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "# 0은 1으로 , 1은 0으로 \ndef change(num) :\n return 1 - num\n\n\ndef flip(state,cnt) :\n\t# 첫번째 전구를 킨다. \n if cnt == 1 :\n state[0] = change(state[0])\n state[1] = change(state[1])\n for j in range(1,n) :\n if state[j-1] != goal[j-1] :\n cnt+=1 \n state[j-1] = change(state[j-1])\n state[j] = change(state[j])\n # 마지막 원소가 아니라면 \n # 3개를 변경 \n if j != n-1 : \n state[j+1] = change(state[j+1])\n if state == goal : return cnt \n else : return -1 \n \nif __name__==\"__main__\" :\n n = int(input())\n origin = list(map(int,list(input())))\n goal = list(map(int,list(input())))\n\n\t# 첫번째 전구를 안바꾼다. \n ans1 = flip(origin[:],0)\n # 첫번째 전구를 바꾼다.\n ans2 = flip(origin[:],1)\n \n # 바꿀수있는 방법이 없는경우\n if ans1 == -1 and ans2 == -1 : print(-1)\n # -1일경우에는 그 값이 min이 되어버려서 둘 다 양수라면 min을 , \n # 아니라면 max를 출력 \n else :\n print(min(ans1,ans2)if (ans1>=0 and ans2>=0) else max(ans1,ans2))\n"
},
{
"alpha_fraction": 0.3601398468017578,
"alphanum_fraction": 0.40909090638160706,
"avg_line_length": 21.038461685180664,
"blob_id": "ffd366749a2b4e237ae5fc5cdb771c430c8c52dc",
"content_id": "9242018c69dd77d99e1b83edcfafa92e8ae7f49b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 606,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 26,
"path": "/알고리즘/수학/정답은 이수근이야!!.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<algorithm>\n#include<cmath>\nusing namespace std;\n\nint check[] = {2,4,8,16,32,64};\nint cnt1, cnt2;\nint main() {\n ios::sync_with_stdio(0); cin.tie(0);\n \n int a, b, c;\n cin >> a >> b >>c;\n for (int i = -100; i <= 100; i++) {\n if (a * i * i + b * i + c == 0) {\n cnt1++; // 정수근\n for (int j = 0; j < 6; j++) {\n if (i == check[j]) cnt2++; //이수근\n }\n }\n }\n if (cnt1 != 2) cout << \"둘다틀렸근\";\n else {\n if (cnt2 == 2) cout << \"이수근\";\n else cout<<\"정수근\";\n }\n}"
},
{
"alpha_fraction": 0.3380281627178192,
"alphanum_fraction": 0.3492957651615143,
"avg_line_length": 21.733333587646484,
"blob_id": "2c7624e1a5fc7cbaff55cd68b9da9dc5746736ae",
"content_id": "2a56582c2a7358d6e6ea24fe2b630d1f014f9354",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 393,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 15,
"path": "/알고리즘/dp/가장긴증가하는부분수열.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "if __name__==\"__main__\" :\n n = int(input())\n arr = list(map(int,input().split()))\n \n # 적어도 길이가 1\n dy = [1]*n\n \n for i in range(1,n) :\n # 앞의 원소들을 보며 \n for j in range(i) :\n # 작다면 \n if arr[i] > arr[j] :\n # 갱신\n dy[i] = max(dy[i],dy[j]+1)\n print(max(dy)) \n \n"
},
{
"alpha_fraction": 0.34522560238838196,
"alphanum_fraction": 0.370409220457077,
"avg_line_length": 22.268293380737305,
"blob_id": "cc16092dd49c6f36e84b3754a80073e31f23746a",
"content_id": "65a92b50438b99db86d56d5d3ca9fe94c0e9fe83",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 983,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 41,
"path": "/알고리즘/분할정복/쿼드트리.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\nusing namespace std;\nint arr[64][64];\nvoid compress(int n, int y, int x) { // 시작점\n if (n == 1) {\n cout << arr[y][x];\n return;\n }\n bool iszero = true, isone = true;\n for (int i = y; i < y + n; i++) {\n for (int j = x; j < x + n; j++) {\n if (arr[i][j]) {\n iszero = false;\n }\n else isone = false;\n }\n }\n if (iszero) cout << 0;\n else if (isone) cout << 1;\n else {\n cout << \"(\";\n compress(n / 2, y, x); // 2사분면\n compress(n / 2, y, x + n / 2); // 1사분면\n compress(n / 2, y + n / 2, x); // 3사분면\n compress(n / 2, y + n / 2, x + n / 2); // 4사분면\n cout << \")\";\n }\n}\nint main() {\n int n;\n cin >> n;\n for (int i = 0; i < n; i++) {\n string str;\n cin >> str;\n for (int j = 0; j < n; j++) {\n arr[i][j] = str[j] - '0';\n }\n \n }\n compress(n, 0, 0);\n}"
},
{
"alpha_fraction": 0.4167507588863373,
"alphanum_fraction": 0.4389505684375763,
"avg_line_length": 28.909090042114258,
"blob_id": "60e3d8444c746a3eeadbd7104c85d69cbe8b53cb",
"content_id": "abdee1bac47d14747203717ba617c83545ec4a07",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1041,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 33,
"path": "/알고리즘/Sort/quick_mid.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\nusing namespace std;\nint arr[] = { 4,3,5,34,34,2,425,2,1};\nvoid quick(int st, int en) {\n if (en <= st + 1) return;\n int first = st;\n int mid = (st + en) / 2;\n int rear = en-1;\n if (arr[first] > arr[mid]) swap( arr[first], arr[mid]);\n if (arr[mid] > arr[rear]) swap( arr[mid], arr[rear]);\n if (arr[first] > arr[mid]) swap( arr[first], arr[mid]);//중간값이 중간으로 정렬됨\n swap(arr[mid], arr[first]); //arr[first]가 중간값 \n int p = arr[st]; //피봇을 중간값으로 설정\n int l = st + 1; //\n int r = en - 1;\n while (1) {\n while (l <= r && arr[l] <= p) l++;\n while (l <= r && arr[r] >= p) r--;\n if (l > r) break;\n swap(arr[l], arr[r]);\n }\n swap(arr[r], arr[st]);\n quick(st, r);\n quick(r + 1, en);\n \n}\nint main() {\n int size = sizeof(arr) / sizeof(int);\n quick(0, size);\n for (int i = 0; i < size; i++) {\n cout << arr[i] << \" \";\n }\n}\n\n\n \n"
},
{
"alpha_fraction": 0.48670756816864014,
"alphanum_fraction": 0.4907975494861603,
"avg_line_length": 26.05555534362793,
"blob_id": "b2e24c203e0e564beb0a0dd25104747f03ef6aef",
"content_id": "a34864250a487435ae202d27771233e2223177a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 559,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 18,
"path": "/알고리즘/큐&스택&덱&set/회사에 있는 사람.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<set>\n#include<vector>\nusing namespace std;\nint main() {\n int n; cin >> n;\n set<string> s;\n while (n--) {\n string name, log;\n cin >> name >> log;\n if (log == \"enter\") s.insert(name); // 들어오는 거라면 이름 넣기\n else s.erase(name); // 퇴근하는 사람 이름 지우기\n }\n // for (auto i : s) cout << i << \"\\n\";//역순이 아니라면\n //역순으로 출력\n vector<string> v(s.begin(), s.end());\n for (int i = v.size() - 1; i >= 0; i--) cout << v[i] << \"\\n\";\n}\n\n\n"
},
{
"alpha_fraction": 0.45890411734580994,
"alphanum_fraction": 0.501369833946228,
"avg_line_length": 25.10714340209961,
"blob_id": "04d8bb0b343b632e7989f5322fbc08af75963a3b",
"content_id": "e956df88e04d1ff390093a09fddc50e3819a2d34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 812,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 28,
"path": "/알고리즘/BFS/숨바꼭질.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<queue>\n#include<algorithm>\nusing namespace std;\n#define x first \n#define y second\nint dist[100002];\nint main() { //1차원 BFS\n ios::sync_with_stdio(NULL);\n cin.tie(0);\n int n, k;\n cin >> n >> k; //n은 수빈, K는 동생\n fill(dist, dist + 100001, -1); //-1로 초기화\n dist[n] = 0; //수빈이 자리는 0\n queue<int> Q;\n Q.push(n);\n while (dist[k] == -1) { //동생자리가 비어있을동안\n int cur = Q. front();\n Q.pop();\n for (int next : {cur - 1, cur + 1, 2 * cur}) {\n if (next < 0 || next > 100000) continue; //범위를 나가면 pass\n if (dist[next] != -1) continue; //이미 왔었으면 pass\n dist[next] = dist[cur] + 1;\n Q.push(next);\n }\n }\n cout << dist[k];\n}"
},
{
"alpha_fraction": 0.3437325954437256,
"alphanum_fraction": 0.37827298045158386,
"avg_line_length": 27.967741012573242,
"blob_id": "9a17ecaf3a08e279bf0d2d0168173770f0eea94b",
"content_id": "831c314bb785fa718965b8463b7cbd918a1950e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1951,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 62,
"path": "/알고리즘/BFS/3차원_토마토.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<algorithm>\n#include<queue>\n#include<tuple>\n\nusing namespace std;\nint dx[6] = { 1,-1,0,0,0,0 };\nint dy[6] = { 0,0,1,-1,0,0 };\nint dz[6] = { 0,0,0,0,1,-1 };\nint board[102][102][102];\nint dist[102][102][102];\nqueue<tuple<int, int, int>> Q;\nint main() {\n ios::sync_with_stdio(NULL);\n cin.tie(0);\n int n, m,h;\n cin >> m >> n >> h;\n\n for (int k = 0; k < h; k++) {\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < m; j++) {\n cin >> board[i][j][k]; // 익었는지 안익었는지 없는지 입력받기\n if (board[i][j][k] == 1) { // 익었다면 큐에 넣기\n Q.push({ i,j,k });\n }\n if (board[i][j][k] == 0) { //익지않았다면 \n dist[i][j][k] = -1; // -1넣기\n }\n }\n }\n }\n\n while (!Q.empty()) { //비어있지 않을동안\n tuple<int, int, int> cur = Q.front();\n Q.pop();\n int curx, cury, curz;\n tie(curx, cury, curz) = cur;\n for (int dir = 0; dir < 6; dir++) {\n int nx = curx + dx[dir];\n int ny = cury + dy[dir];\n int nz = curz + dz[dir];\n if (nx < 0 || nx >= n || ny < 0 || ny >= m || nz < 0 || nz >= h) continue; //범위를 벗어난다면 pass\n if (dist[nx][ny][nz] >= 0) continue; //안익은것들만 -1이다. 즉 익었거나 없다면 pass\n dist[nx][ny][nz] = dist[curx][cury][curz] + 1;\n Q.push({ nx,ny,nz });\n }\n }\n int ans = 0;\n for (int k =0 ; k < h; k++) {\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < m; j++) {\n if (dist[i][j][k] == -1) {// 안익은게 존재한다면\n cout << -1;\n return 0; // 여기서 끝냄\n }\n ans = max(ans, dist[i][j][k]);\n }\n }\n }\n\n cout << ans;\n}"
},
{
"alpha_fraction": 0.4178861677646637,
"alphanum_fraction": 0.4642276465892792,
"avg_line_length": 19.180328369140625,
"blob_id": "37bf8c89be09fdba58b385cdabfd886d2e32647f",
"content_id": "2c7c4c8987a9010523cd96181b25d2aaad4222f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1394,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 61,
"path": "/알고리즘/BFS/벽 부수고 이동하기.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<queue>\n\n\nusing namespace std;\nint mp[1001][1001];\nint dis[1001][1001][2]; // 방문표시 + 거리 측정 // 하나의 벽이 부서진 곳을 [1] // 3차원으로 표시\nint n, m;\nint dx[] = { 1,0,-1,0 };\nint dy[] = { 0,1,0,-1 };\nstruct T {\n\tint x, y, wall; //wall 이 0 이면 안깨진, 1이면 깨진\n};\nqueue<T> q;\n\nint bfs() {\n\tdis[0][0][0] = 1; // 시작점 방문 //시작점 부터 count하므로 1을 넣어줌\n\tq.push({ 0,0,0 }); // 큐에 삽입\n\n\twhile (!q.empty()) {\n\t\tint x = q.front().x;\n\t\tint y = q.front().y;\n\t\tint wall = q.front().wall;\n\t\tq.pop();\n\n\n\t\tif (x == n - 1 && y == m - 1) return dis[x][y][wall]; //탈출\n\n\t\tfor (int dir = 0; dir < 4; dir++) {\n\t\t\tint nx = x + dx[dir];\n\t\t\tint ny = y + dy[dir];\n\t\t\tif (ny < 0 || nx < 0 || nx >= n || ny >= m) continue;\n\t\t\tif (dis[nx][ny][wall] == 0) { //안가본곳\n\t\t\t\tif (mp[nx][ny] == 0) { // 갈수있는곳\n\t\t\t\t\tdis[nx][ny][wall] = dis[x][y][wall] + 1;\n\t\t\t\t\tq.push({ nx,ny,wall });\n\t\t\t\t}\n\t\t\t\telse if (wall == 0) { //벽을 깨본적 없다면 // 벽이 있고\n\t\t\t\t\tdis[nx][ny][1] = dis[x][y][0] + 1;\n\t\t\t\t\tq.push({ nx,ny,1 });\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t}\n\treturn -1;\n}\n\n\nint main() {\n\tios::sync_with_stdio(0); cin.tie(0);\n\tcin >> n >> m;\n\tstring tmp;\n\n\tfor (int i = 0; i < n; i++) {\n\t\tcin >> tmp;\n\t\tfor (int j = 0; j < m; j++) {\n\t\t\tmp[i][j] = tmp[j] - '0'; // string을 int 형으로\n\t\t}\n\t}\n\tcout << bfs();\n}"
},
{
"alpha_fraction": 0.3339768350124359,
"alphanum_fraction": 0.3793436288833618,
"avg_line_length": 24.292682647705078,
"blob_id": "5b2f47a9c56fc038abd6688ac6c8b78433d96546",
"content_id": "dac906a988e1701f8a19ff1c151ec3b2d4155d6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1036,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 41,
"path": "/알고리즘/BFS/나이트의_이동.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "#include<iostream>\n#include<queue>\n#include<algorithm>\nint dx[8] = { 2,1,-1,-2,-2,-1,1,2 };\nint dy[8] = { 1,2,2,1,-1,-2,-2,-1 };\nint dis[302][302];\n#define x first\n#define y second\nusing namespace std;\nint main() {\n\n int t, l;\n cin >> t;\n\n while (t--) {\n queue<pair<int, int> >Q;\n cin >> l;\n for (int j = 0; j < l; j++) {\n fill(dis[j], dis[j] + l, -1);\n }\n int x1, y1, x2, y2;\n cin >> x1 >> y1;\n cin >> x2 >> y2;\n dis[x1][y1] = 0;\n Q.push({ x1,y1 });\n\n while (!Q.empty()) {\n pair<int, int> cur = Q.front();\n Q.pop();\n for (int dir = 0; dir < 8; dir++) {\n int nx = cur.x + dx[dir];\n int ny = cur.y + dy[dir];\n if (nx < 0 || nx >= l || ny < 0 || ny >= l) continue;\n if (dis[nx][ny] != -1) continue;\n dis[nx][ny] = dis[cur.x][cur.y] + 1;\n Q.push({ nx,ny });\n }\n }\n cout << dis[x2][y2] << \"\\n\";\n }\n}"
},
{
"alpha_fraction": 0.41304346919059753,
"alphanum_fraction": 0.44021740555763245,
"avg_line_length": 15.727272987365723,
"blob_id": "1f5dc5fc684d0859898bd661caadc8c0ff28fbe7",
"content_id": "e864531139f431c8ac10440a0cd09147a598970d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 200,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 11,
"path": "/이코테/그리디/곱하기혹은더하기.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "n = input()\n\nsum = int(n[0])\n\nfor i in range(1, len(n)) :\n\n if sum <= 1 or int(n[i])<=1 : # 1이어도 덧셈이 유리!!\n sum += int(n[i])\n else : sum *= int(n[i])\n \nprint(sum)\n"
},
{
"alpha_fraction": 0.43266475200653076,
"alphanum_fraction": 0.44412606954574585,
"avg_line_length": 19.52941131591797,
"blob_id": "92d80e3cd13d4087726dcfee6cf5a7581cbbfe7c",
"content_id": "2c236d8098bec6155445c89325b7bf805ef4f5a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 365,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 17,
"path": "/알고리즘/수학/시험감독.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "n = int(input())\narr = list(map(int,input().split()))\nb,c = map(int,input().split())\n\ncnt = 0\nfor student in arr :\n cnt+=1\n if student <= b : # 감독 한명으로 충분 \n continue\n else :\n if (student-b) % c == 0 :\n cnt += (student-b) // c\n else :\n cnt += (student-b) // c\n cnt += 1\n \nprint(cnt)\n"
},
{
"alpha_fraction": 0.4380453824996948,
"alphanum_fraction": 0.44677138328552246,
"avg_line_length": 22.66666603088379,
"blob_id": "4fee834c77bdb1f2f9ebf06ceda5e1b781d98c3b",
"content_id": "8a593c8bc92203e6551f742b50ccc7018bfc4152",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 637,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 24,
"path": "/알고리즘/큐&스택&덱&set/스택/오큰수.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "\n\n#include<iostream>\n#include<stack>\n#include<vector>\nusing namespace std;\nvector<int> v;\nstack <int> s;\nint main() {\n int n; cin >> n;\n for (int i = 0; i < n; i++) {\n int num; cin >> num;\n v.push_back(num);\n }\n\n vector<int> ans(v.size(), -1);// v의 사이즈로 -1로 초기화하여 ans라는 벡터를 생성\n\n for (int i = 0; i < n; i++) {\n while (!s.empty() && v[s.top()] < v[i]) {//v[i]가 무조건 오른쪽\n ans[s.top()] =v[i];\n s.pop();\n }\n s.push(i); // 인덱스를 넣는다.\n }\n for (int i = 0; i < ans.size(); i++) cout << ans[i] << \" \";\n}\n \n"
},
{
"alpha_fraction": 0.38788869976997375,
"alphanum_fraction": 0.40916529297828674,
"avg_line_length": 18.70967674255371,
"blob_id": "4c59193ce2495eabe3cd2b4b007f1573bf7c815b",
"content_id": "f0fe82bb504257073933dad96a4e960e6b0847a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 611,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 31,
"path": "/알고리즘/DFS/ABCDE.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "def dfs(now, depth) :\n global finish \n if depth == 4 : \n finish = 1\n return \n vis[now] = 1 \n for i in mp[now] :\n if vis[i] == 0 :\n dfs(i,depth+1)\n vis[i] = 0 \n\n \n \nif __name__==\"__main__\" :\n n, m = map(int,input().split())\n mp = [[] for _ in range(n)]\n \n for i in range(m) :\n a,b = map(int,input().split())\n mp[a].append(b)\n mp[b].append(a)\n \n vis = [0]*(n+1)\n finish = 0\n \n for i in range(n) :\n dfs(i,0)\n vis[i] = 0 \n if finish : break\n if finish : print(1)\n else : print(0)\n"
},
{
"alpha_fraction": 0.40852129459381104,
"alphanum_fraction": 0.4310776889324188,
"avg_line_length": 19.487178802490234,
"blob_id": "ae46aa1e28bed68b14c1ba62374925adfbba3b1f",
"content_id": "c2bff5025868b7b1701d46121f7b9c4e9d99f7ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 846,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 39,
"path": "/알고리즘/map/대칭 차집합.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include <iostream>\n#include <map>\n\nusing namespace std;\ntypedef long long ll;\nint main() {\n ios::sync_with_stdio(0);\n cin.tie(0);\n\n int n, m; cin >> n >> m;\n map <ll, int> mp;\n map <ll, int> mp_result;\n int sum = 0;\n\n for (int i = 0; i < n; i++) {\n ll num1; cin >> num1;\n if (mp.find(num1) == mp.end()) { // 못찾았다면 //처음 들어왔다면\n mp[num1] = 1;\n }\n }\n\n for (int i = 0; i < m; i++) {\n ll num2; cin >> num2;\n if (mp.find(num2) == mp.end()) { // 못찾았다면 //처음 들어왔다면\n mp_result[num2] = 1;\n }\n else mp[num2] = 0;\n }\n for (auto i : mp) {\n if (i.second != 0) {\n mp_result[i.first] = i.second;\n }\n }\n\n for (auto i : mp_result) {\n sum += i.second;\n }\n cout << sum;\n}"
},
{
"alpha_fraction": 0.47699999809265137,
"alphanum_fraction": 0.503000020980835,
"avg_line_length": 29.15151596069336,
"blob_id": "df20f43286f7f1845652f55860f4f5b956a13343",
"content_id": "9d020a9e972eb4c1c031725db73d49f302ba438b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1028,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 33,
"path": "/알고리즘/Sort/merge_sort.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\nusing namespace std;\nint tmp[1000001];\nint arr[] = { 24,54,78,45,12,6,2,3 };\nvoid merge(int st, int en) {\n int mid = (st + en) / 2;\n int lidx = st; //left 부터 mid 까지 볼생각\n int ridx = mid; // mid부터 right 까지 볼생각\n for (int i = st; i < en; i++) {\n if (ridx == en) tmp[i] = arr[lidx++]; //right index reach end\n else if (lidx == mid) tmp[i] = arr[ridx++]; //left index reach mid\n else if (arr[lidx] <= arr[ridx]) tmp[i] = arr[lidx++];\n else tmp[i] = arr[ridx++];\n }\n for (int i = st; i < en; i++) {\n arr[i] = tmp[i];\n }\n}\nvoid merge_sort(int st, int en) {\n if (en == st + 1) return; //list's length is 1\n int mid = (st + en)/2;\n merge_sort(st, mid); // st:mid_sort\n merge_sort(mid, en); // mid:en_sort\n merge(st, en); // arr[st:en] & arr[mid:en] _ sort\n\n}\nint main() {\n int size = sizeof(arr) / sizeof(int);\n merge_sort(0, size);\n for (int i = 0; i < size; i++) {\n cout << arr[i] << \" \";\n }\n}\n\n \n \n"
},
{
"alpha_fraction": 0.4139966368675232,
"alphanum_fraction": 0.45278245210647583,
"avg_line_length": 29.384614944458008,
"blob_id": "ab5a0a91777ec3e43b1bbd85d59e21a8bfac6994",
"content_id": "cffa41c92064805d19c2cd1ce6384e5e986735e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1384,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 39,
"path": "/알고리즘/BFS/미로탐색.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<queue>\n#include<string>\nusing namespace std;\n#define x first\n#define y second\nint dx[4] = { 1,0,-1,0 };\nint dy[4] = { 0,1,0,-1 };\nstring board[102]; //0과 1을 저장\nint dist[102][102]; //거리저장\nint main() {\n int n, m;\n cin >> n >> m;\n for (int i = 0; i < n; i++) {\n cin >> board[i];\n }\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < m; j++) {\n dist[i][j] = -1; //거리를 -1로 모두 초기화\n }\n }\n queue<pair<int, int> > Q; //2개의 int로 queue를 만든다.\n Q.push({ 0,0 }); //좌측 상단\n dist[0][0] = 0; //가장 처음은 0으로 한다.\n while (!Q.empty()) { //비어있지않을동안 -> (뭔가가 있을동안)\n pair<int, int> cur = Q.front();//2개의 int pair형 변수(?) cur을 만들어 front를 저장한다.\n Q.pop();\n for (int dis = 0; dis < 4; dis++) {\n int nx = cur.x + dx[dis];\n int ny = cur.y + dy[dis];\n if (nx < 0 || nx >= n || ny < 0 || ny >= m) continue; // 0보다 작거나 n,m 보다 클때는 for문의 다음으로 넘어간다.\n if (dist[nx][ny] >= 0 || board[nx][ny] != '1')continue; // 이미 왔던곳이거나 1이 아닐경우 pass\n dist[nx][ny] = dist[cur.x][cur.y] + 1;\n Q.push({ nx,ny });\n }\n\n }\n cout << dist[n - 1][m - 1] + 1;\n}\n\n"
},
{
"alpha_fraction": 0.4151039123535156,
"alphanum_fraction": 0.45565128326416016,
"avg_line_length": 21.43181800842285,
"blob_id": "a3e65076b0532925eaa9f51f446f0a019792b09f",
"content_id": "4b0d3082dbd4fdf71082393c936c8ad1a7c5a58e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2245,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 88,
"path": "/알고리즘/브루트포스/감시.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<vector>\n#include<algorithm>\n#define X first\n#define Y second\nusing namespace std;\nvector<pair<int, int> > cctv; // cctv의 좌표 저장 \n\nint n, m, mn;\nint dx[] = { 1,0,-1,0 };\nint dy[] = { 0,1,0,-1 };\n\nint mp1[10][10]; // 최초에 입력받은\nint mp2[10][10]; // 사각지대의 개수 세기\n\n\nbool Bound(int a, int b) { // 범위를 넘어가면 1을 반환\n\treturn a < 0 || a >= n || b < 0 || b >= m;\n}\n\nvoid upd(int x, int y, int dir) { // (x,y)에서부터 dir방향으로 벽을 만나기 전까지 빈칸을 7로 만듬\n\tdir %= 4; // dir은 0에서 3까지만 \n\twhile (1) {\n\t\tx += dx[dir]; // dir 방향으로 쭉 간다.\n\t\ty += dy[dir];\n\t\tif (Bound(x, y) || mp2[x][y] == 6) return; // 벽이거나, 벗어났다면 upd를 탈출\n\t\tif (mp2[x][y] != 0) continue; // cctv의 경우 pass // cctv는 7으로 만들면 안되니까\n\t\tmp2[x][y] = 7; // 빈칸을 볼수있다는 의미로 7로 만든다.\n\t}\n}\n\nint main() {\n\tios::sync_with_stdio(0); cin.tie(0);\n\tcin >> n >> m;\n\tfor (int i = 0; i < n; i++) {\n\t\tfor (int j = 0; j < m; j++) {\n\t\t\tcin >> mp1[i][j];\n\t\t\tif (mp1[i][j] != 0 && mp1[i][j] != 6) cctv.push_back({ i,j }); // cctv의 위치를 넣는다.\n\t\t\tif (mp1[i][j] == 0) mn++; // 빈칸의 개수 세기\n\t\t}\n\t}\n\tfor (int tmp = 0; tmp < (1 << (2 * cctv.size())); tmp++){ // 4^(cctv.size)만큼\n\t\tfor (int i = 0; i < n; i++) {\n\t\t\tfor (int j = 0; j < m; j++) {\n\t\t\t\tmp2[i][j] = mp1[i][j]; \n\t\t\t}\n\t\t}\n\n\t\tint brute = tmp;\n\t\tfor (int i = 0; i < cctv.size(); i++) {\n\t\t\tint dir = brute % 4; //0~3까지만 \n\t\t\tbrute /= 4;\n\t\t\tint x = cctv[i].X;\n\t\t\tint y = cctv[i].Y;\n\t\t\tif (mp1[x][y] == 1) {\n\t\t\t\tupd(x, y, dir);\n\t\t\t}\n\t\t\telse if (mp1[x][y] == 2) {\n\t\t\t\tupd(x, y, dir); \n\t\t\t\tupd(x, y, dir+2); // 동이면 서로, 북이면 남으로\n\t\t\t}\n\t\t\telse if (mp1[x][y] == 3) {\n\t\t\t\tupd(x, y, dir);\n\t\t\t\tupd(x, y, dir + 1); \n\t\t\t}\n\t\t\telse if (mp1[x][y] == 4) {\n\t\t\t\tupd(x, y, dir);\n\t\t\t\tupd(x, y, dir + 1);\n\t\t\t\tupd(x, y, dir + 2); \n\t\t\t}\n\t\t\telse if (mp1[x][y] == 5) {\n\t\t\t\tupd(x, y, dir);\n\t\t\t\tupd(x, y, dir + 1);\n\t\t\t\tupd(x, y, dir + 2);\n\t\t\t\tupd(x, y, dir + 3);\n\t\t\t}\n\t\t}\n\t\tint val = 0;\n\t\tfor (int i = 0; i < n; i++) {\n\t\t\tfor (int j = 0; j < m; j++) {\n\t\t\t\tif (mp2[i][j] == 0) val++;\n\t\t\t}\n\t\t}\n\t\tmn = min(mn, val);\n\t}\n\tcout << mn;\n\t\n}"
},
{
"alpha_fraction": 0.36838603019714355,
"alphanum_fraction": 0.38868552446365356,
"avg_line_length": 21.593984603881836,
"blob_id": "9c8be16de3ee704beb548707702c8c2023f177ed",
"content_id": "c9ece5b18af37459dda5078f974262321a4edeb9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3347,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 133,
"path": "/알고리즘/삼성역량테스트/구현_마법사 상어와 블리자드.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "from collections import deque\n\n\ndef indexing() :\n x,y = n//2, n//2\n dx = [0,1,0,-1]\n dy = [-1,0,1,0]\n depth = 0\n while True : \n for dir in range(4) :\n if dir %2 ==0 :\n depth+=1 \n for _ in range(depth) :\n x,y = x+dx[dir],y + dy[dir]\n graphIdx.append([x,y])\n if x==0 and y ==0 : return \n \n \ndef magic_shark(dir,dist) :\n x,y = n//2, n//2\n # 북 남 서 동 \n dx = [-1,1,0,0]\n dy = [0,0,-1,1]\n \n # dir 방향으로 dist만큼 \n for i in range(dist) :\n x += dx[dir]\n y += dy[dir]\n # 0으로 만들어줌 \n if 0<=x <n and 0<=y<n :\n mp[x][y] = 0\n # 0을 채워준다. \n fill_blank()\n # 구슬 폭발 \n while bomb() :\n # 폭발한 친구가 있으면 빈칸 채우기 \n fill_blank()\n # 구슬 증식 \n grouping()\n \ndef fill_blank() :\n blankIdx = deque()\n \n # 그래프를 돌면서 \n for x,y in graphIdx :\n # 비어있는 칸 발견 \n if mp[x][y] == 0 :\n blankIdx.append([x,y])\n # 비어있지 않고 비어있는 칸이 존재할 때 \n elif mp[x][y] >0 and blankIdx :\n # 비어있는 칸을 빼서 \n nx,ny = blankIdx.popleft()\n # 비어있는 칸에 넣어준다. \n mp[nx][ny] = mp[x][y]\n mp[x][y] = 0 \n blankIdx.append([x,y])\ndef bomb() :\n vis = deque()\n cnt = 0 \n num = -1 \n flag = False \n for x,y in graphIdx :\n # 연속된 구슬이라면 \n if num == mp[x][y] :\n vis.append([x,y])\n cnt +=1 \n # 연속된 구슬이 아니라면 \n else :\n # 4개 이상 연속 된 경우 \n if cnt >=4 :\n # 폭파된 구슬 개수 저장 \n score[num-1] += cnt \n flag = True \n # 폭파할 구슬들 \n while vis :\n nx,ny = vis.popleft()\n # 4개 이상이었다면 \n if cnt >= 4 :\n mp[nx][ny] = 0\n num = mp[x][y] \n cnt = 1 \n vis.append([x,y])\n return flag\n \ndef grouping() :\n cnt = 1 \n tmpx,tmpy = graphIdx[0]\n num = mp[tmpx][tmpy]\n nums = []\n for i in range(1,len(graphIdx)) :\n x,y = graphIdx[i][0],graphIdx[i][1]\n # 동일한 경우 \n if num == mp[x][y] :\n cnt +=1 \n # 동일하지 않으면 \n else :\n nums.append(cnt)\n nums.append(num)\n num = mp[x][y] \n cnt = 1 \n idx = 0\n for x,y in graphIdx :\n if len(nums)==0 :\n break\n mp[x][y] = nums[idx]\n idx +=1 \n if idx==len(nums) : break\n \n \n \n \n \n\nif __name__==\"__main__\" :\n n,m = map(int,input().split())\n mp = [list(map(int,input().split())) for i in range(n)]\n magic = []\n score = [0]*3\n \n for i in range(m) :\n magic.append(list(map(int,input().split())))\n \n # 그래프를 덱으로 일렬로 늘여뜨려 놓는다고 생각 \n graphIdx = deque()\n indexing()\n \n for d,s in magic :\n magic_shark(d-1,s)\n \n ans = 0\n for i in range(3) :\n ans += (i+1)*score[i]\n print(ans)\n"
},
{
"alpha_fraction": 0.4521739184856415,
"alphanum_fraction": 0.489130437374115,
"avg_line_length": 18.20833396911621,
"blob_id": "412f075b1e78e1eaf410eb6194ec4105b11e437e",
"content_id": "f7eb51ad8edb9abe8ce08f3a2f5b46c08f4fa395",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 460,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 24,
"path": "/알고리즘/Sort/Bubble_sort.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "#include<iostream>\nusing namespace std;\nint arr[] = { 24,51,1,42,23 };\nvoid swap2(int *a, int *b) {\n\tint tmp;\n\ttmp = *a;\n\t*a = *b;\n\t*b = tmp;\n}\nvoid bubble(int *arr, int size) {\n\tfor (int i = 0; i < size; i++) {\n\t\tfor (int j = 0; j < size - 1 - i; j++) {\n\t\t\tif (arr[j] > arr[j + 1]) swap2( &arr[j], &arr[j + 1]);\n\t\t}\n\t}\n}\nint main() {\n\tint size = (sizeof(arr) / sizeof(int));\n\tbubble(arr, size);\n\n\tfor (int i = 0; i < size; i++) {\n\t\tcout << arr[i] << \" \";\n\t}\n}"
},
{
"alpha_fraction": 0.36509206891059875,
"alphanum_fraction": 0.3666933476924896,
"avg_line_length": 23.45098114013672,
"blob_id": "0246500ca9817ee7c3a0d6e230f2ac46ee61add2",
"content_id": "ccb81128606f2e944401de9786ba6c69529a4079",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1301,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 51,
"path": "/알고리즘/큐&스택&덱&set/스택/키로거.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<stack>\n#include<algorithm> // reverse이용하기위해\nusing namespace std;\n\nint main() {\n ios_base::sync_with_stdio(0); cin.tie(0);\n int test_case; cin >> test_case;\n while (test_case--) {\n string str; cin >> str;\n\n stack<char> result;// 결과\n stack<char> temp; // 화살표 저장\n\n for (char c : str) {\n if (c == '<') { // 왼쪽 화살표\n if (!result.empty()) {\n temp.push(result.top());\n result.pop();\n }\n\n }\n else if (c == '>') {\n if (!temp.empty()) {\n result.push(temp.top());\n temp.pop();\n }\n }\n else if (c == '-') {\n if (!result.empty()) {\n result.pop();\n }\n }\n else { // 아무것도 아닐경우\n result.push(c);\n }\n }\n while (!temp.empty()) {\n result.push(temp.top());\n temp.pop();\n }\n string ans;\n while (!result.empty()) {\n ans += result.top();\n result.pop();\n }\n reverse(ans.begin(), ans.end());\n cout << ans << \"\\n\";\n }\n\n}\n\n\n"
},
{
"alpha_fraction": 0.31253859400749207,
"alphanum_fraction": 0.3273625671863556,
"avg_line_length": 21.19178009033203,
"blob_id": "53ac04af5a7686405ae8adf4b6f5be95143ade04",
"content_id": "4db4840e0d85dda4fbb31b7489df4c4944c36974",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1709,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 73,
"path": "/알고리즘/구현/네모네모시력검사.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\nusing namespace std;\nint LEFT, RIGHT, UP, DOWN;\nint arr[101][101];\nchar c;\nint sx, sy, ex, ey;\nint main() {\n int n, m; cin >> n >> m;\n\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < m; j++) {\n char c; cin >> c;\n if (c == '.') arr[i][j] = 0;\n else arr[i][j] = 1; // #일경우\n }\n }\n bool stop = false;\n for (int i = 0; i < n && stop == false; i++) { //break가 바깥쪽은 못끝냄\n for (int j = 0; j < m; j++) {\n if (arr[i][j] == 1) { // #이 나오면\n sy = i; sx = j;\n stop = true;\n break; // 안쪽 루프(for)만 끝낸다. \n }\n }\n }\n stop = false;\n for (int i = n - 1; i >= 0 && stop == false; i--) {\n for (int j = m - 1; j >= 0; j--) {\n if (arr[i][j] == 1) { // #이 나오면\n ey = i; ex = j;\n stop = true;\n break;\n }\n }\n }\n int y = ey - sy + 1;\n int x = ex - sx + 1;\n \n\n //left와 right 확인하기\n for (int i = sy; i <= ey; i++) {\n if (arr[i][sx]) { // #이 있다면\n LEFT++;\n }\n if (arr[i][ex]) {\n RIGHT++;\n }\n }\n \n if (y != LEFT) {\n cout << \"LEFT\"; return 0;\n }\n if (y != RIGHT) {\n cout << \"RIGHT\"; return 0;\n }\n //up와 down 확인하기\n for (int i = sx; i <= ex; i++) {\n if (arr[sy][i]) { // #이 있다면\n UP++;\n }\n if (arr[ey][i]) {\n DOWN++;\n }\n }\n if (x != UP) {\n cout << \"UP\"; return 0;\n }\n if (x != DOWN) {\n cout << \"DOWN\"; return 0;\n }\n\n}"
},
{
"alpha_fraction": 0.5966542959213257,
"alphanum_fraction": 0.6059479713439941,
"avg_line_length": 24.619047164916992,
"blob_id": "37ef86ec353c3084030bcdeda09db38a0f4afe50",
"content_id": "5d871cebba54bd68745461f5bfa1fb6ae74a7889",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 592,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 21,
"path": "/알고리즘/구현/빗물.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "import sys\ninput = sys.stdin.readline\n\nH,W = map(int,input().split())\nheight = list(map(int, input().split())) # 잊어먹었었다. \n\nvolume = 0\nleft, right = 0, len(height)-1\nleft_max, right_max = height[left],height[right]\n\nwhile left < right : \n left_max ,right_max = max(height[left],left_max),max(height[right],right_max)\n\n if left_max < right_max : # 가장 긴 막대에서 만나기 위해 \n volume += left_max - height[left]\n left += 1 # 오른쪽으로\n else :\n volume += right_max - height[right]\n right -= 1 # 왼쪽으로\n \nprint(volume)\n"
},
{
"alpha_fraction": 0.3784615397453308,
"alphanum_fraction": 0.39230769872665405,
"avg_line_length": 21.44827651977539,
"blob_id": "c0fb0729caa110f2e17c99edbdd87acf450874c4",
"content_id": "b8f8e49b10966ff3964448258de645ff877eaba6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 650,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 29,
"path": "/알고리즘/백트래킹/1,2,3 더하기2.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "#include<iostream>\n#include<vector>\nusing namespace std;\nint n, k, cnt;\nvoid func(vector<int>& v, int sum) {\n if (sum > n) return;\n if (sum == n) {\n cnt++;\n if (cnt == k) {\n for (int i = 0; i < v.size(); i++) {\n if (i == v.size() - 1) cout << v[i];\n else cout << v[i] << \"+\";\n }\n }\n return;\n }\n for (int i = 1; i <= 3; i++) {\n v.push_back(i);\n func(v, sum + i);\n v.pop_back();\n }\n}\nint main() {\n ios::sync_with_stdio(0); cin.tie(0);\n cin >> n >> k;\n vector<int> v;\n func(v, 0);\n if (cnt == 0 || cnt < k) cout << \"-1\";\n}"
},
{
"alpha_fraction": 0.48184818029403687,
"alphanum_fraction": 0.5033003091812134,
"avg_line_length": 39.46666717529297,
"blob_id": "119d913c222cef619f1065b589913e92be08ea86",
"content_id": "2702e0eccd130a9c5bd443441ec245fd8d698936",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 732,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 15,
"path": "/알고리즘/재귀/Z.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\nusing namespace std;\nint func(int n, int r, int c) {//r은 행 c는 열\n if (n == 0) return 0;\n int half = 1 << (n - 1);//2^(n-1)을 의미한다.즉 한변/2 이므로 길이의 반\n if (r < half && c < half) return func(n - 1, r, c); //첫번째 네모\n if (r < half && c >= half) return half * half + func(n - 1, r, c - half); //두번째 네모 //열이 반보다 클때 //재귀는 반보다 큰값을 줄여서 다시 부른다.\n if (r >= half && c < half) return 2 * half * half + func(n - 1, r - half, c); //세번째 네모\n return 3 * half * half + func(n - 1, r - half, c - half); //네번째 네모\n}\nint main() {\n int n, r, c;\n cin >> n >> r >> c;\n cout << func(n, r, c);\n}"
},
{
"alpha_fraction": 0.29339098930358887,
"alphanum_fraction": 0.31933292746543884,
"avg_line_length": 33.446807861328125,
"blob_id": "0a63a4179f9d8245ae65a9a51faa0dba5a7d517e",
"content_id": "a031af206c66cc68e1a610a498f8ec832a4e2b19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1635,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 47,
"path": "/알고리즘/삼성역량테스트/시뮬_마법사상어와파이어볼.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "dx = [-1,-1,0,1,1,1,0,-1]\ndy = [0,1,1,1,0,-1,-1,-1]\n \n \n \nif __name__==\"__main__\" :\n n,m,k = map(int,input().split())\n mp = [[[]for i in range(n+1)] for _ in range(n+1)]\n fire_ball = []\n for i in range(m) :\n r,c,m,s,d = map(int,input().split())\n fire_ball.append([r,c,m,s,d])\n \n for _ in range(k) : # k 초 이후에 \n \n # 방향 이동 \n for idx in range(len(fire_ball)) :\n r,c,m,s,d = fire_ball[idx] \n nr,nc = (r + s*dx[d])%n, (c+ s*dy[d])%n \n mp[nr][nc].append([m,s,d])\n \n fire_ball = []\n for i in range(n) :\n for j in range(n) :\n if len(mp[i][j])>=2 :\n sum_m,sum_s,cnt_even,cnt_odd,cnt = 0,0,0,0,len(mp[i][j]) \n while mp[i][j] :\n m,s,d = mp[i][j].pop(0)\n sum_m += m\n sum_s += s \n if d %2 == 0 :\n cnt_even+=1 \n else :\n cnt_odd +=1 \n if cnt == cnt_even or cnt == cnt_odd :\n nd = [0,2,4,6]\n else :\n nd = [1,3,5,7]\n if sum_m//5 :\n for d in nd :\n fire_ball.append([i,j,sum_m//5,sum_s//cnt,d]) \n elif len(mp[i][j])==1 :\n m,s,d=mp[i][j].pop(0)\n fire_ball.append([i,j,m,s,d])\n ans = 0\n ans += sum([f[2] for f in fire_ball])\n print(ans)\n"
},
{
"alpha_fraction": 0.36836835741996765,
"alphanum_fraction": 0.3823823928833008,
"avg_line_length": 26,
"blob_id": "254232689eeceb95aa884ad07be502f40fa07285",
"content_id": "4de09c3c3432ad20624af08e17f2a8e6807a1d7f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1117,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 37,
"path": "/알고리즘/BFS/교환.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "from collections import deque\n \ndef bfs(n,K) :\n # 방문 확인 \n vis = set()\n # n을 0번 변화로 만들 수 있다. \n vis.add((n,0))\n d = deque()\n d.append([n,0])\n ans = 0\n while d :\n num,k = d.popleft()\n if k == K :\n ans = max(ans,num)\n continue \n num = list(str(num))\n # i 와 m 사이에는 j가 있어야하므로 m-1까지 \n for i in range(m-1) : \n for j in range(i+1,m) :\n # 첫번째 자리에 0이 옮겨진다면\n if i == 0 and num[j] == '0' :\n continue\n num[i],num[j] = num[j],num[i]\n # i와 j의 순서를 바꾼 문자열을 합친후 숫자로 만듦\n nn = int(''.join(num))\n if (nn,k+1) not in vis :\n d.append([nn,k+1])\n vis.add((nn,k+1))\n num[i],num[j] = num[j],num[i]\n return ans if ans else -1 \n \n \n\nif __name__==\"__main__\" :\n n,K = map(int,input().split())\n m = len(str(n))\n print(bfs(n,K))\n"
},
{
"alpha_fraction": 0.2927003800868988,
"alphanum_fraction": 0.3093988597393036,
"avg_line_length": 32.27777862548828,
"blob_id": "634f81d3583f89bbcbcf1ff624fd364e2dfa24e1",
"content_id": "cb196a57c2967193c702d2cfcc2be0750d56a295",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4210,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 126,
"path": "/알고리즘/BFS/BFS_적록색약.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<queue>\n#define x first\n#define y second \nusing namespace std;\nint dx[4] = { 1,0,-1,0 };\nint dy[4] = { 0,1,0,-1 };\nstring board[101];\nint vis[101][101];\n\nint main() {\n int n;\n cin >> n;\n for (int i = 0; i < n; i++) {\n cin >> board[i];\n }\n int cnt = 0;\n queue<pair<int, int>> Q;\n for (int i = 0; i < n; i++) { //R의 경우\n for (int j = 0; j < n; j++) {\n if (board[i][j] != 'R' || vis[i][j] == 1) continue;\n cnt++;\n Q.push({ i,j });\n vis[i][j] = 1;\n while (!Q.empty()) {\n pair<int, int> cur = Q.front();\n Q.pop();\n for (int dir = 0; dir < 4; dir++) {\n int nx = cur.x + dx[dir];\n int ny = cur.y + dy[dir];\n if (nx < 0 || nx >= n || ny < 0 || ny >= n) continue;\n if (board[nx][ny] != 'R' || vis[nx][ny] == 1) continue;\n Q.push({ nx,ny });\n vis[nx][ny] = 1;\n }\n }\n }\n }\n \n for (int i = 0; i < n; i++) { //G의 경우\n for (int j = 0; j < n; j++) {\n if (board[i][j] != 'G' || vis[i][j] == 1) continue;\n cnt++;\n Q.push({ i,j });\n vis[i][j] = 1;\n while (!Q.empty()) {\n pair<int, int> cur = Q.front();\n Q.pop();\n for (int dir = 0; dir < 4; dir++) {\n int nx = cur.x + dx[dir];\n int ny = cur.y + dy[dir];\n if (nx < 0 || nx >= n || ny < 0 || ny >= n) continue;\n if (board[nx][ny] != 'G' || vis[nx][ny] == 1) continue;\n Q.push({ nx,ny });\n vis[nx][ny] = 1;\n }\n }\n }\n }\n \n for (int i = 0; i < n; i++) { //B의 경우\n for (int j = 0; j < n; j++) {\n if (board[i][j] != 'B' || vis[i][j] == 1) continue;\n cnt++;\n Q.push({ i,j });\n vis[i][j] = 1;\n while (!Q.empty()) {\n pair<int, int> cur = Q.front();\n Q.pop();\n for (int dir = 0; dir < 4; dir++) {\n int nx = cur.x + dx[dir];\n int ny = cur.y + dy[dir];\n if (nx < 0 || nx >= n || ny < 0 || ny >= n) continue;\n if (board[nx][ny] != 'B' || vis[nx][ny] == 1) continue;\n Q.push({ nx,ny });\n vis[nx][ny] = 1;\n }\n }\n }\n }\n cout << cnt << \" \";\n cnt = 0;\n for (int i = 0; i < n; i++) fill(vis[i], vis[i] + n, 0);\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < n; j++) {\n if (vis[i][j] || board[i][j] == 'B') continue;\n cnt++;\n queue<pair<int, int>> Q;\n vis[i][j] = 1;\n Q.push({ i, j });\n while (!Q.empty()) {\n pair<int, int> cur = Q.front(); Q.pop();\n for (int dir = 0; dir < 4; dir++) {\n int nx = cur.x + dx[dir];\n int ny = cur.y + dy[dir];\n if (nx < 0 || nx >= n || ny < 0 || ny >= n) continue;\n if (vis[nx][ny] || board[nx][ny] == 'B') continue;\n Q.push({ nx, ny });\n vis[nx][ny] = 1;\n }\n }\n }\n }\n \n for (int i = 0; i < n; i++) {\n for (int j = 0; j < n; j++) {\n if (vis[i][j] || board[i][j] != 'B') continue;\n cnt++;\n queue<pair<int, int>> Q;\n vis[i][j] = 1;\n Q.push({ i, j });\n while (!Q.empty()) {\n pair<int, int> cur = Q.front(); Q.pop();\n for (int dir = 0; dir < 4; dir++) {\n int nx = cur.x + dx[dir];\n int ny = cur.y + dy[dir];\n if (nx < 0 || nx >= n || ny < 0 || ny >= n) continue;\n if (vis[nx][ny] || board[nx][ny] != 'B') continue;\n Q.push({ nx, ny });\n vis[nx][ny] = 1;\n }\n }\n }\n }\n cout << cnt << '\\n';\n}"
},
{
"alpha_fraction": 0.4685598313808441,
"alphanum_fraction": 0.5030425786972046,
"avg_line_length": 17.769229888916016,
"blob_id": "a489a4d8db17f7622610dc58af5aff44aff8e685",
"content_id": "bad1d9a280722e71476064c30ade668bc42dc549",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 547,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 26,
"path": "/알고리즘/Sort/insertion_sort.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "#include<iostream>\nusing namespace std;\n\nint arr[] = { 24,51,1,42,23 };\nint key, j;\nvoid insertion(int* arr, int size) {\n\tfor (int i = 1; i < size; i++) { //0번째 원소는 정렬되었다고 가정 //size -1 만큼 돌면서\n\t\tkey = arr[i];\n\t\tfor (j = i - 1; j >= 0; j--) {\n\t\t\tif (arr[j] > key) arr[j + 1] = arr[j]; //큰 수를 나한테 덮는다.\n\t\t\telse break;\n\t\t}\n\t\tarr[j + 1] = key;\n\t}\n}\n\n\n\nint main() {\n\tint size = (sizeof(arr) / sizeof(int));\n\tinsertion(arr, size);\n\n\tfor (int i = 0; i < size; i++) {\n\t\tcout << arr[i] << \" \";\n\t}\n}\n\n \n \n"
},
{
"alpha_fraction": 0.39222222566604614,
"alphanum_fraction": 0.4277777671813965,
"avg_line_length": 27.125,
"blob_id": "350f9ffe15f38f0bb5880b16de67480f01574e72",
"content_id": "f9e784d46b28f3f47e41aeb30937660bd7a3c627",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 934,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 32,
"path": "/알고리즘/BFS/벽부수고이동하기.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "from collections import deque\nimport sys\ninput = sys.stdin.readline\n\ndx = [0,1,0,-1]\ndy = [1,0,-1,0]\n\ndef bfs() :\n q= deque()\n vis = [[[0] * 2 for _ in range(m)] for __ in range(n)]\n q.append([0,0,1])\n vis[0][0][1] = 1\n while q :\n x,y,z = q.popleft()\n if x==n-1 and y == m-1 : \n return vis[x][y][z]\n for i in range(4) :\n nx, ny = dx[i] + x, dy[i] + y\n if 0<=nx<n and 0<=ny<m :\n if arr[nx][ny] == 1 and z == 1 : # 벽을 안뚫은 상태 \n q.append([nx,ny,0])\n vis[nx][ny][0] = vis[x][y][1]+1\n elif arr[nx][ny] == 0 and vis[nx][ny][z]==0: # arr에 갈 수 있고 간적없다면\n vis[nx][ny][z] = vis[x][y][z]+1\n q.append([nx,ny,z])\n return -1\n\n\nn,m = map(int ,input().split())\n\narr = [(list(map(int,list(input().strip()))))for _ in range(n)]\nprint(bfs())\n"
},
{
"alpha_fraction": 0.4351978302001953,
"alphanum_fraction": 0.45975443720817566,
"avg_line_length": 19.36111068725586,
"blob_id": "8c18759e6a34cb3aa1bf8a7015c58a9f4b5a7f5b",
"content_id": "fafe33452fb21d4e5fb6ce4ddab02cd4033ec4d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 763,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 36,
"path": "/알고리즘/heap/보석도둑.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<queue>\n#include<algorithm>\nusing namespace std;\n\nint n, k, ans;\npair<int, int> jew[300001];\nint bag[300001];\npriority_queue<int> pq;\n\nint main() {\n ios_base::sync_with_stdio(0);\n cin.tie(0);\n\n cin >> n >> k;\n\n for (int i = 0; i < n; i++) {\n cin >> jew[i].first >> jew[i].second;\n }\n for (int i = 0; i < k; i++) cin >> bag[i];\n\n sort(jew, jew + n);\n sort(bag, bag + k);\n\n for (int i = 0; i < k; i++) { // 가방의 개수만큼\n int idx = 0;\n while (idx < n && jew[idx].first <= bag[i]) {\n pq.push(jew[idx++].second); // idx를 넣어주고 ++해준다.\n }\n if (!pq.empty()) {\n ans += pq.top();\n pq.pop();\n }\n }\n cout << ans;\n}\n"
},
{
"alpha_fraction": 0.2504892349243164,
"alphanum_fraction": 0.27201566100120544,
"avg_line_length": 26.39285659790039,
"blob_id": "e381004b23865fdc823c57db69b0476c795af984",
"content_id": "badbf4d2818b566b15342ce246644f2af671abaf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1675,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 56,
"path": "/알고리즘/그리디/행렬.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\nusing namespace std;\nint arr[51][51];\nchar c;\nint cnt;\nint main() {\n ios::sync_with_stdio(0); cin.tie(0);\n int n, m; cin >> n >> m;\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < m; j++) {\n cin >> c;\n arr[i][j] = c - '0'; //연속으로 들어올때 이렇게 받아야함\n }\n }\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < m; j++) {\n cin >> c; int temp = c - '0';\n if (temp != arr[i][j]) arr[i][j] = 1;\n else arr[i][j] = 0;\n }\n }\n //크기가 3*3보다 작다면\n if (n < 3 || m < 3) {\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < m; j++) {\n if (arr[i][j]) { // 뒤집을수없는데 다른게 있으먄\n cout << -1;\n return 0;\n }\n }\n }\n cout << 0;\n }\n else { //크기가 3*3보다 크다면\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < m; j++) {\n\n if (arr[i][j]) { // 다를때\n if (i <= n - 3 && j <= m - 3) { // 뒤집을수 있는 상황이라면\n for (int x = i; x < i + 3; x++) {\n for (int y = j; y < j + 3; y++) {\n arr[x][y] = !arr[x][y]; // 뒤집기\n }\n }\n cnt++;\n }\n else { // 다른데 뒤집을 수 없다면?\n cout << -1; return 0;\n }\n }\n }\n }\n cout << cnt;\n }\n\n}"
},
{
"alpha_fraction": 0.41277405619621277,
"alphanum_fraction": 0.43183985352516174,
"avg_line_length": 28.13888931274414,
"blob_id": "9e2fe8b8a625ff2ef3c19a8f7a1c356967ddfae9",
"content_id": "776fa98eb9a9e54ad90dc198a5e3857d41227401",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1069,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 36,
"path": "/알고리즘/삼성역량테스트/구현_이차원배열과연산.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "def oper(a,l):\n for idx, row in enumerate(a) :\n tmp = []\n for n in set(row) :\n if n :\n tmp.append((n,row.count(n)))\n tmp = sorted(tmp, key = lambda x : (x[1],x[0]))\n tmplen = len(tmp)\n if tmplen > 50 : tmplen = 50\n l = max(l,tmplen *2) # 최대 길이 갱신 \n a[idx] = []\n for i in range(tmplen) :\n a[idx].append(tmp[i][0])\n a[idx].append(tmp[i][1])\n \n for idx,row in enumerate(a) :\n for _ in range(l-len(row)) :\n a[idx].append(0)\n \n return a,l\n \nif __name__==\"__main__\" :\n r,c,k = map(int,input().split())\n mp = [list(map(int,input().split())) for _ in range(3)]\n \n rlen,clen = 3,3\n for time in range(101) :\n if r<=rlen and c<=clen and mp[r-1][c-1] == k :\n print(time)\n exit(0)\n if rlen >= clen : # R연산 \n mp,clen = oper(mp,clen)\n else : # C연산\n mp,rlen = oper(list(zip(*mp)), rlen)\n mp = list(zip(*mp))\n print(-1)\n"
},
{
"alpha_fraction": 0.4359756112098694,
"alphanum_fraction": 0.4451219439506531,
"avg_line_length": 17.05555534362793,
"blob_id": "4a7175507022a96b5efac394a0872bb3470b9a2f",
"content_id": "a9342e5da235da5a7445ed96f238db1478bc86f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 328,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 18,
"path": "/알고리즘/큐&스택&덱&set/카드2.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "#include<iostream>\n#include<deque>\nusing namespace std;\ndeque<int> v;\nint main() {\n int n;\n cin >> n;\n for (int i = n; i > 0; i--) {\n v.push_back(i);\n }\n while (v.size() != 1) {\n v.pop_back();\n int cur = v.back();\n v.pop_back();\n v.push_front(cur);\n }\n cout << v[0];\n}\n \n"
},
{
"alpha_fraction": 0.3802083432674408,
"alphanum_fraction": 0.3975694477558136,
"avg_line_length": 27.799999237060547,
"blob_id": "671ed01646675685b8bc6fa8d24bbb04537f1446",
"content_id": "cef276fa7b5384649d01834552a7dbad04aa5c3f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 576,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 20,
"path": "/알고리즘/프로그래머스/DFS/여행경로.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "answer = []\ndef solution(tickets): \n vis = [0]*len(tickets)\n \n def dfs(idx,val,tickets) :\n if idx == len(tickets) :\n answer.append(val[:])\n return\n else :\n for i in range(len(tickets)) :\n if tickets[i][0] == val[-1] and vis[i]==0 :\n vis[i] = 1 \n val.append(tickets[i][1])\n dfs(idx+1, val,tickets)\n vis[i] = 0\n val.pop()\n \n dfs(0,['ICN'],tickets)\n answer.sort() \n return answer[0]\n"
},
{
"alpha_fraction": 0.5318253636360168,
"alphanum_fraction": 0.5633876919746399,
"avg_line_length": 10.248520851135254,
"blob_id": "fb34ea1f0ad9b5e505aa07b7ee4de888039fc426",
"content_id": "23db772d4c2172ced9d3e233aea4bab962343840",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2997,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 169,
"path": "/파이썬문법정리.md",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "# Python 기본 문법 정리 \n// 참고 서적 - 이코테\n\n\n## 연산\n\n나머지\n> a % b [c++ 문법과 동일]<br>\n\n몫\n> a//b\n\n거듭제곱\n> a**b\n\n<br><br>\n\n## 리스트 자료형\n\n파이썬의 리스트는 c언어의 배열 기능포함<br>\n내부적으로는 연결리스트 자료구조를 채택<br>\nc++의 vector와 유사 , 배열 or 테이블이라고 부르기도 한다. \n \n대괄호에 원소를 넣어 초기화, 쉼표로 원소 구분\n```py\na = [1,2,3,4,5,6,7,8,9]\nprint (a)\nprint(a[4]) // 5 출력\n\na = list() // 빈 리스트 생성1\na = [] // 빈 리스트 생성법 2\n```\n\n인덱싱 \n> 인덱스값을 입력하여 리스트의 특정 원소에 접근하는 것\n\n파이썬은 음의 정수도 인덱스값으로 이용가능하다 \n\n-1을 넣으면 가장 마지막 원소가 출력된다. \n\n<br>\n\n슬라이싱\n> 리스트에서 연속적인 위치를 갖는 원소들을 가져오는것 \n\n(문자열에도 사용가능)\n\n대괄호안에 클론(:)을 넣고 시작인덱스, (끝인덱스 -1) 으로 설정할수있다. \n\n```py\na = [1,2,3,4,5,6,7,8,9]\nprint(a[1:4])//[2,3,4]가 출력된다.\n```\n\n리스트 컴프리헨션\n>리스트를 초기화는 방법중 하나<br>대괄호에 조건문과 반복문을 넣는 방식\n\n```py\narray = [i for i in range(20) if i %2==1]\nprint(array)\n```\n\n## 조건문\n\n### if문 \n> if ~ elif ~ else 이용 \n(else if 대신 elif)\n\n```py\nscore = 85\nif score>=90:\n print(\"학점 : A\")\nelif score >= 80:\n print(\"학점 : B\")\nelse:\n print(\"학점 : F\")\n```\n\n<br>\n\n## 반복문\n\n### while\n```py\ni = 1\nresult = 0\n\nwhile i<=9:\n result += i\n i+=1\n\nprint(result)\n```\n\n\n\n### for\n\n>for 변수 in 리스트:<br>\n 실행할 소스코드\n\n<br>\nrange은 (시작값, 끝값 +1 )<br>\nrange(5) 처럼 값 하나만 넣으면 0부터 5번 반복 즉, 0,1,2,3,4\n\n```py\nresult = 0\n\nfor i in range(1,10): // 1부터 9까지\n result += i\n\nprint(result)\n```\n\n\n## 함수 \n\n인자를 지칭해서 넣을수있어서 매개변수의 순서가 달라도 상관없다는특징이 있다. \n\n``` py\ndef add(a,b):\n print(\"함수의 결과는 \", a+b)\n\nadd (3,7)\n```\n\n함수 안에서 함수 밖 변수를 변경하고 싶을때는 global 키워드 이용!\n\n## 입출력\n<br>\n\n### 입력\n\ninput()이용 : 문자열<br>\n정수형으로 이용하고 싶다면 int()함수이용\n\n입력받은 문자열을 띄어쓰기로 구분해서 정수로 저장할때 ->\n```py\nlist(map(int, input().split()))\nn,m,k = map(int, input().split()) # n,m,k로 각자 입력받아 변수 저장\n```\n\n### 숫자를 입력받아 정렬하는 예제\n\n```py\nn = int(input())\ndata = list(map(int,input().split()))\n\ndata.sort(reverse = True)\nprint(data)\n```\n\n### 출력\n\nprint에서 ,로 구분해서 넣으면 띄어쓰기로 출력\n\n기본적으로 출력이후 줄바꿈한다. \n\n\nstr() -> 데이터를 문자열로 바꾼다.\n\n\n### min, max\nlist에서 가장 큰것, 작은것을 구할때 <br>\nlist의 이름을 data라고 하면\n```py\nMIN = min(data)\nMAX = max(data)\n```\n"
},
{
"alpha_fraction": 0.3687150776386261,
"alphanum_fraction": 0.44413408637046814,
"avg_line_length": 16.950000762939453,
"blob_id": "d3c19d15557ef5fd5a841709dedbe9cc806017e5",
"content_id": "d04326ba275da4a8c98356ea94d3bb163774f98a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 358,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 20,
"path": "/알고리즘/dp/설탕 배달.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "#include<iostream>\n#include<algorithm>\nusing namespace std;\nint d[5002];\n\nint dp(int n) {\n fill(d, d + n + 1, 999999);\n d[3] = 1;\n d[5] = 1;\n for (int i = 6; i <= n; i++) {\n d[i] = min(d[i - 3] + 1, d[i - 5] + 1);\n }\n return d[n];\n}\nint main() {\n int n;\n cin >> n;\n if (dp(n) >= 999999) cout << -1;\n else cout << dp(n);\n}"
},
{
"alpha_fraction": 0.3843478262424469,
"alphanum_fraction": 0.40869563817977905,
"avg_line_length": 23.446807861328125,
"blob_id": "4df7e9843b807400c6187494e875ae53f3bf3053",
"content_id": "841ace626a51dfd7ee2753d7e3891de7f0496a68",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1234,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 47,
"path": "/알고리즘/삼성역량테스트/시뮬레이션_뱀.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "from collections import deque\n\n# 하 우 상 좌 \ndx = [1,0,-1,0]\ndy = [0,1,0,-1]\n\n\ndef change(d,c) :\n if c == \"L\" : # 왼쪽으로 방향 틀기 \n d = (d+1) %4 \n else : # 오른쪽으로 방향 틀기 \n d = (d-1) %4 \n return d \n\ndef start() :\n direction = 1 # 초기방향 # 우 \n time = 1\n x,y = 0,0\n vis = deque([[x,y]])\n mp[x][y] = 2 # 뱀이 지나갔던 곳 \n while True :\n x,y = x + dx[direction] , y + dy[direction]\n if 0<=x<n and 0<=y<n and mp[x][y] != 2 : # 갈 수있는 곳 \n if mp[x][y] == 0 :\n tmp_x,tmp_y = vis.popleft() \n mp[tmp_x][tmp_y] = 0 # 꼬리 제거\n mp[x][y] = 2\n vis.append([x,y])\n if time in times.keys() :\n direction = change(direction,times[time])\n time+=1\n else :\n return time \n \nif __name__==\"__main__\" :\n n = int(input())\n k = int(input())\n mp = [[0]*(n) for i in range(n)]\n for i in range(k) :\n x,y = map(int,input().split())\n mp[x-1][y-1] = 1\n L = int(input())\n times = {}\n for i in range(L) :\n x,c = input().split()\n times[int(x)]=c\n print(start()) \n"
},
{
"alpha_fraction": 0.44594594836235046,
"alphanum_fraction": 0.4648648500442505,
"avg_line_length": 11.366666793823242,
"blob_id": "e2654b7bbd8f30bec80a4b3c974ff820798914d7",
"content_id": "ca13bf788eba7d8c2074ff41d232bf601a3d39bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 370,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 30,
"path": "/알고리즘/투포인터/수들의 합2.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "#include<iostream>\n#include<vector>\nusing namespace std;\n\nvector<int> v;\n\nint n, m, cnt;\nint ptr1;\n\nint main() {\n\n\tcin >> n >> m;\n\n\tfor (int i = 0; i < n; i++) {\n\t\tint tmp; cin >> tmp; \n\t\tv.push_back(tmp);\n\t}\n\n\tfor (int i = 0; i < n; i++) {\n\t\tfor (int j = i; j < n; j++) {\n\t\t\tptr1 += v[j];\n\t\t\tif (ptr1 == m) {\n\t\t\t\tcnt++;\n\t\t\t\tbreak;\n\t\t\t}\n\t\t}\n\t\tptr1 = 0;\n\t}\n\tcout<< cnt;\n}"
},
{
"alpha_fraction": 0.3353658616542816,
"alphanum_fraction": 0.4268292784690857,
"avg_line_length": 20.88888931274414,
"blob_id": "7d70d3e568f4008f12f493d20308215c1c735aaf",
"content_id": "03dd3940cdd797e951bec3f81c80a60193c179d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1016,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 45,
"path": "/알고리즘/브루트포스/숫자야구.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\nusing namespace std;\nint n, q, s, b;\nint cnt, num[1000];\n\nint check(int i, int q, int s, int b) {\n\tint s_cnt = 0, b_cnt = 0;\n\tint i_1 = i / 100, i_2 = (i % 100) / 10, i_3 = (i % 100) % 10;\n\tint q_1 = q / 100, q_2 = (q % 100) / 10, q_3 = (q % 100) % 10;\n\n\tif (i_1 == 0 || i_2 == 0 || i_3 == 0 || i_2 == i_1 || i_2 == i_3 || i_1 == i_3) return 1;\n\n\tif (i_1 == q_1) s_cnt++;\n\tif (i_2 == q_2) s_cnt++;\n\tif (i_3 == q_3) s_cnt++;\n\n\tif (q_1 == i_2 || q_1 == i_3) b_cnt++;\n\tif (q_2 == i_1 || q_2 == i_3) b_cnt++;\n\tif (q_3 == i_2 || q_3 == i_1) b_cnt++;\n\n\tif (s_cnt == s && b_cnt == b) return 0; // 맞으면 return 0 \n\n\treturn 1; // 틀리면 return 1\n}\nint main() {\n\tios_base::sync_with_stdio(0); cin.tie(0);\n\n\n\tcin >> n;\n\tfor (int i = 0; i < n; i++) {\n\t\tcin >> q >> s >> b;\n\t\tfor (int i = 123; i <= 987; i++) {\n\t\t\tif (num[i] == 0) { //맞을 가능성이 있는 친구\n\t\t\t\tnum[i] = check(i, q, s, b);\n\t\t\t}\n\n\t\t}\n\t}\n\tfor (int i = 123; i <= 987; i++) {\n\t\tif (num[i] == 0) {\n\t\t\tcnt++;\n\t\t}\n\t}\n\tcout << cnt;\n}"
},
{
"alpha_fraction": 0.3704850375652313,
"alphanum_fraction": 0.3900928795337677,
"avg_line_length": 21.022727966308594,
"blob_id": "2d3a4ffdd7789c912162e3ba30be95896fa32f88",
"content_id": "b2062adfcac96cbef8dd3743c0b916c98dfc832d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2334,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 88,
"path": "/알고리즘/삼성역량테스트/DFS_2048(Easy).py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "from collections import deque\nimport copy\n\ndef get(i,j) :\n if mp[i][j] : \n q.append(mp[i][j])\n mp[i][j] = 0 \n \ndef merge(i,j,di,dj) :\n\t# 보드에 있는 칸들을 돌면서 \n while q :\n x = q.popleft()\n if not mp[i][j] :\n mp[i][j] = x \n # 합쳐질수있다면\n elif mp[i][j] == x :\n \t# 합친다\n mp[i][j] = x*2\n # 상하좌우에 맞춰서 di,dj를 더해준다.\n i,j = i+di,j+dj\n else :\n \t# 다른 값이면 그냥 쌓인다.\n i,j = i + di,j+dj\n mp[i][j] = x \n\ndef move(k) :\n # 상 \n if k == 0 :\n for j in range(n) :\n for i in range(n) :\n # q에 넣고 0으로 만든다. \n get(i,j)\n # 0행 j열에서 부터 시작해서 몰아넣는다. \n # 행이 1씩 증가하도록 한다. \n merge(0,j,1,0) \n # 하 \n elif k == 1 :\n for j in range(n) :\n for i in range(n-1,-1,-1) :\n get(i,j)\n # n-1행 j열에서부터 시작해서 몰아넣는다.\n # 행이 1씩 감소하도록 한다. \n merge(n-1,j,-1,0)\n \n # 좌\n elif k ==2 :\n for i in range(n) :\n for j in range(n) :\n get(i,j)\n # i행 0열에서부터 시작해서 몰아넣는다.\n # 열이 1씩 증가하도록 한다. \n merge(i,0,0,1)\n \n # 우\n else :\n for i in range(n) :\n for j in range(n-1,-1,-1) :\n get(i,j)\n # i행 n-1열 부터 시작해서 몰아넣는다.\n # 열이 1씩 감소하도록 한다. \n merge(i,n-1,0,-1)\n\n\ndef solve(cnt) :\n global mp,ans\n if cnt == 5 :\n ans = max(ans,max(list(map(max,mp))))\n return \n # 방향을 바꾸기전 mp을 저장 \n b = copy.deepcopy(mp)\n \n # 상하좌우 \n for k in range(4) :\n # mp를 변경 \n move(k)\n # 재귀, 한번 움직였으므로 cnt+1 \n solve(cnt+1)\n # 저장해두었던 방향을 바꾸기전 b를 다시 mp로 \n mp = copy.deepcopy(b)\n\n\nif __name__==\"__main__\" :\n n = int(input())\n mp = [list(map(int,input().split()))for _ in range(n)]\n ans, q = 0, deque()\n\n solve(0)\n print(ans)\n"
},
{
"alpha_fraction": 0.32532238960266113,
"alphanum_fraction": 0.3458382189273834,
"avg_line_length": 29.48214340209961,
"blob_id": "22f5bc2e285f02a7fbdf969688a9370f07937322",
"content_id": "07b06a3df70ef2fff0d5fe8bc82f9fec6f95fc8f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1870,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 56,
"path": "/알고리즘/BFS/영역구하기.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<queue>\n#include<vector>\n#include<algorithm>\nusing namespace std;\nint dx[4] = { 1,0,-1,0 };\nint dy[4] = { 0,1,0,-1 };\nvector<int> v;\n#define x first\n#define y second\nint board[101][101];\nvoid fill(int a, int b, int c, int d) { // 주어진 영역을 1로 만든다.\n for (int i = a; i < c; i++) {\n for (int j = b; j < d; j++) {\n board[i][j] = 1;\n }\n }\n}\nint main() {\n\n int n, m, k;\n cin >> m >> n >> k;\n int a, b, c, d;\n for (int i = 0; i < k; i++) {\n cin >> a >> b >> c >> d;\n fill(a, b, c, d); // 1로 변환\n }\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < m; j++) {\n if (board[i][j] == 0) { // 영역이 아닌곳 발견!\n queue<pair<int, int> >Q;\n Q.push({ i,j }); // 큐에 넣는다.\n board[i][j] = 1; // 들렀음\n int cnt = 0;\n while (!Q.empty()) { // 큐가 빌때까지 (즉, 주변에 0이 있는곳이 없을때까지)\n pair<int, int> cur = Q.front();\n Q.pop();\n cnt++; // 0의 개수\n for (int dir = 0; dir < 4; dir++) {\n int nx = cur.x + dx[dir];\n int ny = cur.y + dy[dir];\n if (nx < 0 || nx >= n || ny < 0 || ny >= m) continue; //영역을 나가버림\n if (board[nx][ny] == 0) { // 0인곳 발견\n board[nx][ny] = 1;\n Q.push({ nx,ny });\n }\n }\n } // 그 근방 0 탐색 완료\n v.push_back(cnt); // 개수를 넣는다.\n }\n }\n }\n cout << v.size() << \"\\n\";\n sort(v.begin(), v.end()); // 오름차순 정렬\n for (int t : v) cout << t<<\" \"; \n}"
},
{
"alpha_fraction": 0.3458244204521179,
"alphanum_fraction": 0.35331904888153076,
"avg_line_length": 20.25,
"blob_id": "60fdb2eccbe2ee85acdf8b8846cf4c421da918a4",
"content_id": "4b678144c9b0b352bdca321aae72c8e41f844bb5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 962,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 44,
"path": "/알고리즘/map/I AM IRONMAN.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<map>\nusing namespace std;\nmap<string, string> mp;\nint main() {\n int ans = 0;\n bool iron = false;\n int n, p, w, l, g;\n cin >> n >> p;\n cin >> w >> l >> g;\n for (int i = 0; i < p; i++) {\n string name, log;\n cin >> name >> log;\n mp[name] = log;\n }\n for (int i = 0; i < n; i++) {\n string name;\n cin >> name;\n if (mp.find(name) == mp.end()) { //없다면\n if (ans - l >= 0) {\n ans -= l;\n }\n else ans = 0;\n }\n else if (mp[name] == \"W\") { // 이길사람과 게임을 했다면\n ans += w;\n if (ans >= g) iron = true;\n }\n else if (mp[name] == \"L\") {\n if (ans - l >= 0) {\n ans -= l;\n }\n else ans = 0;\n }\n\n\n }\n if (iron) {\n cout << \"I AM NOT IRONMAN!!\";\n }\n else {\n cout << \"I AM IRONMAN!!\";\n }\n}"
},
{
"alpha_fraction": 0.33922260999679565,
"alphanum_fraction": 0.36890459060668945,
"avg_line_length": 28.29166603088379,
"blob_id": "3dd48a30800c384d27f69bcb589fabb3fba0ed7a",
"content_id": "18871829f65457cff9ac60573b952183cc565b0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1573,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 48,
"path": "/알고리즘/삼성역량테스트/구현_마법사 상어와 비바라기.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "dx = [0,-1,-1,-1,0,1,1,1]\ndy = [-1,-1,0,1,1,1,0,-1]\n \n \n \nif __name__==\"__main__\" :\n diagonal = [1,3,5,7]\n n,m = map(int,input().split())\n water = [list(map(int,input().split())) for i in range(n)]\n # 방향을 입력받음 \n ds = [list(map(int,input().split())) for i in range(m)]\n \n # 구름의 첫 위치 \n cloud = [[n-1,0],[n-1,1],[n-2,0],[n-2,1]]\n \n for d,s in ds :\n vis = [[0]*n for i in range(n)]\n \n next_cloud = []\n for idx in range(len(cloud)) :\n x,y = cloud[idx]\n # d방향으로 s칸 이동 \n nx,ny = (x+dx[d-1]*s)%n, (y+dy[d-1]*s)%n\n # 물의 양 1 증가 \n water[nx][ny] +=1 \n # 이동한 구름의 위치 저장 \n vis[nx][ny] = 1 \n next_cloud.append([nx,ny])\n \n for x,y in next_cloud :\n # 대각선 방향으로 \n cnt = 0 \n for i in diagonal :\n nx,ny = x + dx[i], y + dy[i]\n if 0<=nx<n and 0<=ny<n and water[nx][ny] :\n cnt+=1 \n water[x][y] += cnt \n \n cloud = []\n for i in range(n) :\n for j in range(n) :\n # 바구니에 저장된 물의 양이 2 이상이고 구름이 사리진 칸이 아니여야한다. \n if water[i][j] >=2 and vis[i][j] == 0:\n water[i][j] -=2 \n # 새로운 구름의 위치 \n cloud.append([i,j])\n \n print(sum(sum(water,[])))\n \n"
},
{
"alpha_fraction": 0.45286884903907776,
"alphanum_fraction": 0.4795081913471222,
"avg_line_length": 33.85714340209961,
"blob_id": "7e8182aa10055d33f867010011e67584628919d0",
"content_id": "cbc9f456ac7d1f0f6911ef1e0ef66b9f47449f6b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 502,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 14,
"path": "/programmers/DP/정수삼각형.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "def solution(triangle):\n answer = 0\n \n for i in range(1,len(triangle)) :\n for idx in range(len(triangle[i])) :\n if idx == 0 : # 첫번째 원소\n triangle[i][0] += triangle[i-1][0] \n elif idx == len(triangle[i])-1 : # last 원소 \n triangle[i][idx] += triangle[i-1][idx-1] \n else : \n triangle[i][idx] += max(triangle[i-1][idx-1],triangle[i-1][idx] )\n answer = max(triangle[-1])\n \n return answer\n"
},
{
"alpha_fraction": 0.42574256658554077,
"alphanum_fraction": 0.44059404730796814,
"avg_line_length": 19.200000762939453,
"blob_id": "541f56ce840bd1af446b582c687539ebe83d6ab3",
"content_id": "089421f2b2d7e1054342181955dc1f6a4046e1a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 228,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 10,
"path": "/알고리즘/그리디/잃어버린괄호.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "arr = input().split('-') # '-'로 나누기 \nsum = 0\n\nfor i in arr[0].split('+') : \n sum += int(i)\nfor i in arr[1:] : # 첫번째 이후 => - 기호 이후\n for j in i.split('+') : \n sum-=int(j)\n\nprint(sum)\n"
},
{
"alpha_fraction": 0.47826087474823,
"alphanum_fraction": 0.5140665173530579,
"avg_line_length": 23.978723526000977,
"blob_id": "9d70f4d80537717219888b87141f9ca6db75cf05",
"content_id": "21d7f7c8dc38252b45925aacf3fdf7a9d6c51d2a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1219,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 47,
"path": "/알고리즘/Sort/radix_sort.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<cstring>\n#include<cmath>\nusing namespace std;\nint arr[8] = { 170,45,75,90,2,24,802,66 };\nvoid rxsort(int* data, int size, int p, int k) {\n\tint* count, * temp;\n\tint index, pval, i, j, n;\n\tif ((count = (int*)malloc(k * sizeof(int))) == NULL) return;\n\tif ((temp = (int*) malloc(size * sizeof(int))) == NULL) return;\n\tfor (int n = 0; n < p; n++) {\n\t\tfor (int i = 0; i < k; i++) {\n\t\t\tcount[i] = 0;\n\t\t\tpval = (int)pow((double)k, (double)n);\n\t\t}\n\t\tfor (int j = 0; j < size; j++) {\n\t\t\tindex = (int)(data[j] / pval) % k;\n\t\t\tcount[index] = count[index] + 1;\n\t\t}\n\t\tfor (int i = 1; i < k; i++) {\n\t\t\tcount[i] = count[i] + count[i - 1];\n\t\t}\n\t\tfor (int j = size - 1; j >= 0; j--) {\n\t\t\tindex = (int)(data[j] / pval) % k;\n\t\t\ttemp[count[index] - 1] = data[j];\n\t\t\tcount[index] = count[index] - 1;\n\t\t}\n\t\tmemcpy(data, temp, size * sizeof(int));\n\t\t\n\t}\n\t\n}\nint main() {\n\tint arrsize = sizeof(arr) / sizeof(int);\n\t\n\tcout << \"정렬 전 출력\\n\";\n\tfor (int i = 0; i < arrsize; i++) {\n\t\tcout << arr[i] << \" \";\n\t}\n\trxsort(arr, arrsize, 3, 10); //정렬 \n\tcout << \"\\n정렬 이후 출력\\n\";\n\tfor (int i = 0; i < arrsize; i++) {\n\t\tcout << arr[i] << \" \";\n\t}\n\n\tcout << \"\\n정보통신공학과 / 12191728 / 김두미\";\n}"
},
{
"alpha_fraction": 0.3930269479751587,
"alphanum_fraction": 0.4532487988471985,
"avg_line_length": 19.29032325744629,
"blob_id": "4ea8d8ed2d79b0ae6ebe6008fd0122435eb24f14",
"content_id": "60d742b15aba138b81d81d0a73b42326a8576ab0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 631,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 31,
"path": "/알고리즘/Sort/quick_sort.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "#include <iostream>\nusing namespace std;\n\nint n = 10;\nint arr[1000001] = { 15, 25, 22, 357, 16, 23, -53, 12, 46, 3 };\n\nvoid quick_sort(int st, int en) {\n if (en <= st + 1) return;\n int p = arr[st];\n int l = st+1;\n int r = en - 1;\n\n while (1) {\n while (l <= r && arr[l] <= p) l++;\n while (l <= r && arr[r] >= p) r--;\n if (l > r) break;\n swap(arr[l], arr[r]);\n }\n swap(arr[st], arr[r]);\n quick_sort(st, r);\n quick_sort(r+1, en);\n\n}\n\nint main() {\n ios_base::sync_with_stdio(0);\n cin.tie(0);\n quick_sort(0, n);\n for (int i = 0; i < n; i++) cout << arr[i] << ' ';\n\n}\n \n"
},
{
"alpha_fraction": 0.41124260425567627,
"alphanum_fraction": 0.42603549361228943,
"avg_line_length": 18.823530197143555,
"blob_id": "c71de586e45f4d87ef472df60da7d9858a54d4c7",
"content_id": "a558837e16102a41a5f46f7013722eff9b70fcd8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 338,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 17,
"path": "/알고리즘/그리디/뒤집기.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "#include<iostream>\n#include<algorithm>\nusing namespace std;\nint one, zero;\nstring s;\nint main() {\n cin >> s;\n if (s[0] == '0') zero++;\n else one++;\n for (int i = 1; i < s.size(); i++) {\n if (s[i] != s[i - 1]) {\n if (s[i] == '1') one++;\n else zero++;\n }\n }\n cout << min(zero, one);\n}\n\n"
},
{
"alpha_fraction": 0.2956560254096985,
"alphanum_fraction": 0.31117022037506104,
"avg_line_length": 30.774648666381836,
"blob_id": "5c61f092e3e39806a97566b714342e1237150e18",
"content_id": "5d7b5660c7dbeb1f7e1f443adf94285a83287340",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2402,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 71,
"path": "/알고리즘/삼성역량테스트/구현_원판돌리기.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "from collections import deque\n\n\nif __name__==\"__main__\" :\n n,m,t = map(int,input().split())\n mp = []\n for i in range(n) :\n mp.append(deque(list(map(int,input().split()))))\n \n \n for _ in range(t) :\n \n # 원판 돌리기 \n result = 0 \n x,d,k = map(int,input().split())\n for i in range(n) :\n result += sum(mp[i])\n if (i+1) % x == 0:\n if d == 0 :\n mp[i].rotate(k)\n else :\n mp[i].rotate(-k)\n \n \n if result > 0 : \n # 모두 0이 아닐 때 \n delete = set()\n # 왼쪽 오른쪽 확인 \n for i in range(n) :\n for j in range(m-1) :\n if mp[i][j]!=0 and mp[i][j] == mp[i][j+1] :\n delete.add((i,j))\n delete.add((i,j+1))\n if mp[i][0]!=0 and mp[i][0] == mp[i][m-1] :\n delete.add((i,0))\n delete.add((i,m-1))\n \n # 위, 아래 확인 \n for j in range(m) :\n for i in range(n-1) :\n if mp[i][j]!=0 and mp[i][j] == mp[i+1][j] :\n delete.add((i,j))\n delete.add((i+1,j))\n # 지울 값이 있을 때 \n if len(delete) > 0 :\n for x,y in delete :\n mp[x][y] = 0\n # 지울 값이 없을 때 -> 평균을 구해 빼고 더해준다. \n else :\n zero_cnt = 0\n max_v = 0\n for i in range(n) :\n for j in range(m) :\n if mp[i][j] == 0 :\n zero_cnt +=1 \n else :\n max_v += mp[i][j]\n avg_v = max_v / ((m*n)-zero_cnt)\n for i in range(n) :\n for j in range(m) :\n if mp[i][j]!=0 and mp[i][j]> avg_v : mp[i][j] -=1 \n elif mp[i][j]!=0 and mp[i][j] < avg_v : mp[i][j] +=1 \n # 전부 0일 경우 0을 출력한 후 끝내기 \n else :\n print(0)\n exit(0)\n # 모든 원판의 총합을 출력한다. \n ans = 0\n for i in range(n) :\n ans += sum(mp[i])\n print(ans)\n"
},
{
"alpha_fraction": 0.6379310488700867,
"alphanum_fraction": 0.6724137663841248,
"avg_line_length": 10.600000381469727,
"blob_id": "64c16969ece82139a323abcb7da6421bb0368684",
"content_id": "ddbfe21e5bf5e4c23a3e5f6817cd75d0a4de91b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 117,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 5,
"path": "/README.md",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "# Algorithm 문제풀이 \n\n\n주로 백준 & 프로그래머스 문제를 풉니다\n1일 1커밋할수있도록 😎!\n"
},
{
"alpha_fraction": 0.3534946143627167,
"alphanum_fraction": 0.37365591526031494,
"avg_line_length": 27.615385055541992,
"blob_id": "48ae6ade6f9d197978811507ca542f7b6b96f341",
"content_id": "af5f392b12f0b4f6b86bcf1b0b63158089004e8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 744,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 26,
"path": "/알고리즘/삼성역량테스트/백트래킹_연산자끼워넣기.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "def dfs(idx, val) :\n if idx == len(num) :\n ans.append(val)\n return \n else :\n for i in range(4) :\n if op[i] >= 1 :\n op[i] -=1 \n if i == 0 : dfs(idx+1, val+num[idx])\n elif i == 1 : dfs(idx+1, val-num[idx])\n elif i ==2 : dfs(idx+1, val*num[idx])\n else :\n if val < 0 :\n dfs (idx+1, -((-val) // num[idx]))\n else : dfs(idx+1, val // num[idx])\n op[i] +=1 \n\nif __name__==\"__main__\" :\n n = int(input())\n num = list(map(int,input().split()))\n op = list(map(int,input().split()))\n ans = []\n \n dfs(1,num[0]) \n print(max(ans))\n print(min(ans))\n"
},
{
"alpha_fraction": 0.4157160818576813,
"alphanum_fraction": 0.4499366283416748,
"avg_line_length": 24.45161247253418,
"blob_id": "0ac26b1f77ea4d28d087caace4d23c1ceddc1f88",
"content_id": "e6cee866fdb16578fa5ee4f68c7321afc87b2994",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 975,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 31,
"path": "/알고리즘/BFS/이모티콘.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "from collections import deque\n\nq = deque()\ns = int(input())\ndis = [[-1]*(s+1)for _ in range(s+1)]\n\n\n\ndef bfs() :\n q.append([1,0]) # 화면에 출력된 이모티콘의 개수, 클립보드의 이모티콘의 개수\n dis[1][0] = 0 \n\n while q:\n x,y = q.popleft()\n if dis[x][x]==-1 : # 1번연산 # 클립보드에 복사가 되어있지않다면?\n dis[x][x] = dis[x][y]+1\n q.append([x,x])\n if x+y <= s and dis[x+y][y]==-1: # 2번연산 # 클립보드에 있는 문자만큼 프린트\n dis[x+y][y]=dis[x][y]+1 # 할당하는 것을 ==로 적어서 1시간 넘게 헤맸다. \n q.append([x+y,y])\n if x-1 >= 0 and dis[x-1][y]==-1: # 3번 연산 # 프린트 되어있는 임티 하나 제거\n dis[x-1][y]=dis[x][y]+1\n q.append([x-1,y])\n\nbfs()\nans = -1\nfor i in range(s+1):\n if dis[s][i] != -1:\n if ans == -1 or ans > dis[s][i]:\n ans = dis[s][i]\nprint(ans)\n"
},
{
"alpha_fraction": 0.45271867513656616,
"alphanum_fraction": 0.5236406326293945,
"avg_line_length": 25.46875,
"blob_id": "6d6de620b3c1c4682f037f4970b427aee2f69ede",
"content_id": "f44a12722f2a23fbcb3617030141ff428573a01e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 862,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 32,
"path": "/알고리즘/프로그래머스/1단계/모의고사.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include <string>\n#include <vector>\n#include <iostream>\n#include<algorithm>\nusing namespace std;\n\nvector<int> solution(vector<int> answers) {\n vector<int> answer; // 반환할 정답 \n\n vector<int> answer1{ 1,2,3,4,5 };\n vector<int> answer2{ 2, 1, 2, 3, 2, 4, 2, 5 };\n vector<int> answer3{ 3, 3, 1, 1, 2, 2, 4, 4, 5, 5 };\n\n int cnt1 = 0;\n int cnt2 = 0;\n int cnt3 = 0;\n\n for (int i = 0; i < answers.size(); i++) {\n int i1 = i % 5; // 0~4까지만 \n int i2 = i % 8;\n int i3 = i % 10;\n\n if (answers[i] == answer1[i1]) cnt1++;\n if (answers[i] == answer2[i2]) cnt2++;\n if (answers[i] == answer3[i3]) cnt3++;\n }\n int mx = max(cnt1, (max(cnt2, cnt3)));\n if (mx == cnt1) answer.push_back(1);\n if (mx == cnt2) answer.push_back(2);\n if (mx == cnt3) answer.push_back(3);\n return answer;\n}"
},
{
"alpha_fraction": 0.5098591446876526,
"alphanum_fraction": 0.5160563588142395,
"avg_line_length": 31.272727966308594,
"blob_id": "419748aeef924edcc84923ec38884c44b8645477",
"content_id": "c20bb67934579bb849864a1dc56a620a51d84421",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1833,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 55,
"path": "/Android/화씨_섭씨변환기.java",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "package com.example.for_exer_1;\n\nimport androidx.appcompat.app.AppCompatActivity;\n\nimport android.os.Bundle;\nimport android.view.View;\nimport android.widget.Button;\nimport android.widget.EditText;\nimport android.widget.Switch;\nimport android.widget.TextView;\n\npublic class MainActivity extends AppCompatActivity {\n TextView textView;\n EditText editText;\n Button button;\n Switch sw;\n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n setContentView(R.layout.activity_main);\n\n textView = findViewById(R.id.textView);\n editText = findViewById(R.id.editTextNumberSigned);\n button = findViewById(R.id.button);\n sw = findViewById(R.id.swtich);\n\n button.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View v) {\n //문자열 입력\n if(sw.isChecked()){\n String strF = editText.getText().toString();\n if(strF.equals(\"\"))\n return;\n //처리 : F -> C\n double f = Double.parseDouble(strF); //실수형으로 변환\n double c = (f - 32) * 0.55;\n // text view에 출력\n textView.setText(\"F->C \"+c);\n }\n else{\n String strC = editText.getText().toString();\n if(strC.equals(\"\"))\n return;\n //처리 : C ->F\n double c = Double.parseDouble(strC); //실수형으로 변환\n double f = 9/5.0 * c +32;\n // text view에 출력\n textView.setText(\"C->F \"+f);\n }\n\n }\n });\n }\n}\n"
},
{
"alpha_fraction": 0.3863845467567444,
"alphanum_fraction": 0.4038638472557068,
"avg_line_length": 29.19444465637207,
"blob_id": "0928803a95c9f7122daf862763c44c9ce9cbeced",
"content_id": "a03db0fcdefb6b944c3b275c4346ca35ae094d8a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1223,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 36,
"path": "/알고리즘/삼성역량테스트/구현_경사로.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "def pos(now) : # now는 확인할 배열 \n for j in range(1,n) :\n if abs(now[j] - now[j-1] ) > 1 : return False # 차이가 1이상 나면 False \n \n if now[j] < now[j-1] : # 현재 < 이전 , 오른쪽 스캔\n for k in range(l) :\n # 지도를 나가거나 이미 경사로를 세웠거나 길이가 다르거나 \n if j+k >=n or used[j+k] or now[j] != now[j+k] : return False\n used[j+k] = 1\n \n elif now[j] > now[j-1] :\n for k in range(l) :\n if j-k -1 < 0 or used[j-k-1] or now[j-1] != now[j-k-1] : return False\n used[j-k-1] = 1 \n return True \n\n \nif __name__==\"__main__\" :\n n,l = map(int,input().split())\n mp = [list(map(int,input().split())) for i in range(n)]\n ans = 0\n \n \n # 가로 확인 \n for i in range(n) :\n used = [0 for _ in range(n)]\n if pos(mp[i]) : # 길이 있는지 확인 \n ans+=1 \n\n # 세로 확인 \n for i in range(n) :\n used = [0 for _ in range(n)]\n if pos([mp[j][i] for j in range(n)]) : # 길이 있는지 확인 \n ans += 1\n \n print(ans )\n"
},
{
"alpha_fraction": 0.3734806776046753,
"alphanum_fraction": 0.4000000059604645,
"avg_line_length": 23.45945930480957,
"blob_id": "75d863d4af1f411ec6e568c61797624e40d3f029",
"content_id": "6f73ac94c7248c5e363f630cc013bf5c711e62c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1007,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 37,
"path": "/알고리즘/삼성역량테스트/DFS_치킨배달.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "n,m = map(int,input().split())\nmp = [list(map(int,input().split())) for i in range (n)]\n\nhs = []\nch = []\ncb = [0]*m # 조합 # 선택할 치킨집의 인덱스를 담은 배열 (combination)\nres = int(1e9)\n\n\ndef dfs(L,s) :\n global res\n if L==m: # 치킨집의 개수가 m 개 \n sum = 0 # 도시의 피자거리\n for j in range(len(hs)) : # 집들을 돌면서 \n x1 = hs[j][0]\n y1 = hs[j][1]\n dis = int(1e9)\n for x in cb : # 치킨집 좌표 \n x2 = ch[x][0]\n y2 = ch[x][1]\n dis = min(dis, abs(x2-x1)+abs(y1-y2))\n sum += dis \n if sum <res : res = sum\n \n else :\n for i in range(s,len(ch)) :\n cb[L] = i\n dfs(L+1,i+1) \n \nfor i in range(n) :\n for j in range(n) :\n if mp[i][j] == 1 : # 집 발견 \n hs.append((i,j))\n elif mp[i][j]==2 : # 치킨집 발결 \n ch.append((i,j))\ndfs(0,0)\nprint(res)\n"
},
{
"alpha_fraction": 0.4651162922382355,
"alphanum_fraction": 0.5042839646339417,
"avg_line_length": 18.95121955871582,
"blob_id": "e03bd0f2547e5970fbbcb0303caac514147ac1b3",
"content_id": "992e13e1328eb0a30f4ff8d8a51f28277723206d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 917,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 41,
"path": "/알고리즘/BFS/특정거리의 도시찾기.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<vector>\n#include<queue>\nusing namespace std;\nint n, m, k, x;\n\nvector<int> graph[300001]; //벡터 배열\nvector<int> dist(300001, -1); // -1로 초기화된 300001 개의 원소를 가진 벡터 // 시작점으로부터의 거리 저장\n\n\nint main() {\n\tios_base::sync_with_stdio(0); cin.tie(0);\n\tcin >> n >> m >> k >> x;\n\tfor (int i = 1; i <= m; i++) {\n\t\tint a, b;\n\t\tcin >> a >> b;\n\t\tgraph[a].push_back(b); // 도시끼리 이어진것 저장 \n\t}\n\tdist[x] = 0; //시작점은 dist가 0이다.\n\tqueue<int> q;\n\tq.push(x);\n\twhile (!q.empty()) {\n\t\tint now = q.front();\n\t\tq.pop();\n\t\tfor (int j = 0; j < graph[now].size(); j++) {\n\t\t\tint next = graph[now][j];\n\t\t\tif (dist[next] == -1) { //첫방문\n\t\t\t\tdist[next] = dist[now] + 1;\n\t\t\t\tq.push(next);\n\t\t\t}\n\t\t}\n\t}\n\tint cnt = 0;\n\tfor (int i = 1; i <= n; i++) {\n\t\tif (dist[i] == k) {\n\t\t\tcout << i << \"\\n\";\n\t\t\tcnt++;\n\t\t}\n\t}\n\tif (cnt == 0) cout << -1;\n}"
},
{
"alpha_fraction": 0.4727272689342499,
"alphanum_fraction": 0.5018181800842285,
"avg_line_length": 17.366666793823242,
"blob_id": "9460664428be5ee98145f27c65cc46e5e178ea46",
"content_id": "13df718b7ae2881e98da17073f5672d2917f0735",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 654,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 30,
"path": "/알고리즘/DFS/바이러스.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<vector>\n#include<queue>\nusing namespace std;\nvector<int> adj[101];\nint com, m;\n\nbool vis[101];\nint dfs(int n) {\n int ans = 1; //아무것도 연결되어있지 않아도 1을 반환해야하기때문에\n vis[n] = 1;\n for (int i : adj[n]) {\n if (vis[i] != 1) ans += dfs(i);\n }\n return ans;\n}\n\nint main() {\n\n cin >> com >> m;\n\n for (int i = 0; i < m; i++) {\n int a, b;\n cin >> a >> b;\n adj[a].push_back(b);\n adj[b].push_back(a);\n }\n\n cout << dfs(1) - 1; // 1번째 컴퓨터도 1을 가진다 그러나 첫번째 컴퓨터는 count 하지않아서 -1을 해준다.\n}"
},
{
"alpha_fraction": 0.388579398393631,
"alphanum_fraction": 0.4038997292518616,
"avg_line_length": 18.432432174682617,
"blob_id": "a34e846c684b7390afda6f00d07e6e5e93fa0095",
"content_id": "a1ef018ae04d6e35a954853e60215df20c9df5b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 742,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 37,
"path": "/알고리즘/BFS/바이러스.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<vector>\n#include<queue>\nusing namespace std;\nvector<vector<int> > v;\nint ans = 0;\nint vis[101];\nint bfs() {\n queue<int> q;\n vis[1] = 1;\n q.push(1);\n while (!q.empty()) {\n int cur = q.front();\n q.pop();\n for (int i : v[cur]) {\n if (!vis[i]) {\n vis[i] = 1;\n ans++;\n q.push(i);\n }\n else continue;\n }\n }\n return ans;\n}\nint main() {\n int n, m;\n cin >> n >> m;\n v.resize(n + 1); // 자리가 있어야만 v[i].push_back(3); 이런거 가능\n for (int i = 0,x,y; i < m; i++) {\n cin >> x >> y;\n v[x].push_back(y);\n v[y].push_back(x);\n }\n cout << bfs();\n \n}"
},
{
"alpha_fraction": 0.35014548897743225,
"alphanum_fraction": 0.40155190229415894,
"avg_line_length": 35.82143020629883,
"blob_id": "9f39ebec0467705de6ba82d1aad2aafe99cfd6df",
"content_id": "563547f408048c44846885fae98d56001db78cf5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1031,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 28,
"path": "/알고리즘/삼성역량테스트/시뮬레이션_주사위굴리기.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "dx = [0,0,-1,1] \ndy = [1,-1,0,0]\n\n \nif __name__==\"__main__\" :\n n,m,x,y,k = map(int,input().split())\n mp = [list(map(int,input().split())) for i in range(n)]\n order = list(map(int,input().split()))\n dice = [0 for i in range(6)]\n for i in range(k) :\n dir = order[i] - 1 \n nx,ny = x + dx[dir], y + dy[dir]\n if 0<=nx<n and 0<=ny<m : \n if dir == 0 :\n dice[0],dice[2],dice[3],dice[5] = dice[3],dice[0],dice[5],dice[2]\n elif dir == 1 :\n dice[0],dice[2],dice[3],dice[5] = dice[2],dice[5],dice[0],dice[3]\n elif dir == 2 :\n dice[0],dice[1],dice[4],dice[5] = dice[4],dice[0],dice[5],dice[1]\n else :\n dice[0],dice[1],dice[4],dice[5] = dice[1],dice[5],dice[0],dice[4]\n if mp[nx][ny] == 0 :\n mp[nx][ny] = dice[5]\n else :\n dice[5] = mp[nx][ny]\n mp[nx][ny] = 0\n x,y = nx,ny \n print(dice[0])\n"
},
{
"alpha_fraction": 0.29125475883483887,
"alphanum_fraction": 0.3193916380405426,
"avg_line_length": 28.863636016845703,
"blob_id": "2b82174bcf753e78e0b2c96a71fe281d765afe54",
"content_id": "3e55864bc21cabbe4ea91a5a9a29fe563bed7066",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1323,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 44,
"path": "/알고리즘/삼성역량테스트/구현_상어초등학교.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "dx = [1,0,-1,0]\ndy = [0,-1,0,1]\n \n \nif __name__==\"__main__\" :\n n = int(input())\n dic = {} # 친한 친구 \n for i in range(n**2) :\n a,b,c,d,e = map(int,input().split())\n dic[a] = [b,c,d,e]\n \n mp = [[0]*n for i in range(n)]\n \n for k in dic.keys() :\n tmp = []\n for i in range(n) :\n for j in range(n) :\n empty,friend = 0,0\n if mp[i][j] == 0 : \n for dir in range(4) :\n nx,ny = i + dx[dir], j + dy[dir]\n if 0<=nx<n and 0<=ny<n : \n if mp[nx][ny] in dic[k] :\n friend+=1 \n elif mp[nx][ny] == 0 :\n empty +=1 \n tmp.append([friend,empty,i,j])\n tmp.sort(key = lambda x : (-x[0],-x[1],x[2],x[3]))\n x,y = tmp[0][2],tmp[0][3]\n mp[x][y] = k\n \n \n ans = 0\n for i in range(n) :\n for j in range(n):\n cnt = 0\n for dir in range(4) :\n nx,ny = i + dx[dir], j + dy[dir]\n if 0<=nx<n and 0<=ny<n :\n if mp[nx][ny] in dic[mp[i][j]] :\n cnt+=1 \n if cnt>0 :\n ans += 10**(cnt-1)\n print(ans) \n"
},
{
"alpha_fraction": 0.4062398374080658,
"alphanum_fraction": 0.4491387605667114,
"avg_line_length": 28.028301239013672,
"blob_id": "a05a17e9f9c3b4c72ec8bdf9b00446e919608c03",
"content_id": "d394be3cd32ec9aab0671b0239d44e367df5119b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3739,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 106,
"path": "/수업/편집거리.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream> \n#include<string>\n#include<algorithm>\nusing namespace std;\n\nstring S , T;\nfloat dis[101][101];\nchar A[20], B[20];\nint leven(string s, string t) {\n\tfor (int i = 1; i <= s.size(); i++) { // 0행에 1열부터 1부터 s의 길이만큼 1씩 증가하는수를 0행에 넣어준다.\n\t\tdis[i][0] = i;\n\t}\n\tfor (int j = 1; j<= t.size(); j++) {// 1행에 0열부터 1부터 t의 길이만큼 1씩 증가하는수를 배열에 넣어준다.\n\t\tdis[0][j] = j;\n\t}\n\tfor (int j = 1; j <= t.size(); j++) { // 이차원배열을 모두 돌면서\n\t\tfor (int i = 1; i <= s.size(); i++) {\n\t\t\tif (s[i - 1] == t[j - 1]) dis[i][j] = dis[i - 1][j - 1]; // 비교할 글자가 동일할경우 대각선의 값을 배열에 넣는다.\n\t\t\telse dis[i][j] = min(dis[i - 1][j - 1] + 1, min(dis[i][j - 1] + 1, dis[i - 1][j] + 1)); // 글자가 동일하지 않을경우 (위, 왼쪽,대각선의 값 )+1 중 가장 작은 값을 넣어준다. \n\t\t}\n\t}\n\tfor (int j = 0; j <= t.size(); j++) { // 이차원 배열을 출력한다.\n\t\tfor (int i = 0; i <= s.size(); i++) {\n\t\t\tcout << dis[i][j] << \" \";\n\t\t}\n\t\tcout << \"\\n\";\n\t}\n\tcout << \"\\n\";\n\treturn dis[s.size()][ t.size()]; // 편집하는데 필요한 최소 비용을 출력한다.\n}\nfloat leven2(string s, string t) {// 위의 leven함수와 삽입, 삭제, 교환 비용의 값을 제외하고 동일함\n\tfor (int i = 1; i <= s.size(); i++) {\n\t\tdis[i][0] = i*0.5;\n\t}\n\tfor (int j = 1; j <= t.size(); j++) {\n\t\tdis[0][j] = j * 0.7;\n\t}\n\tfor (int j = 1; j <= t.size(); j++) { \n\t\tfor (int i = 1; i <= s.size(); i++) {\n\t\t\tif (s[i - 1] == t[j - 1]) dis[i][j] = dis[i - 1][j - 1];\n\t\t\telse dis[i][j] = min(dis[i - 1][j - 1] + 0.3, min(dis[i][j - 1] + 0.7, dis[i - 1][j] + 0.5)); // 삽입은 0.7, 교환은 0.3 ,삭제는 0.5로 비용을 설정\n\t\t}\n\t}\n\tfor (int j = 0; j <= t.size(); j++) {\n\t\tfor (int i = 0; i <= s.size(); i++) {\n\t\t\tcout << dis[i][j] << \" \";\n\t\t}\n\t\tcout << \"\\n\";\n\t}\n\tcout << \"\\n\";\n\treturn dis[s.size()][t.size()];\n}\nvoid leven3(string s, string t) {// 위의 leven2함수와 삽입, 삭제, 교환이 발생한 값을 출력하는 것을 제외하고 동일함\n\tint a=0, b=0, c=0;//교환 : a, 삽입 : b ,삭제 : c\n\tfor (int i = 1; i <= s.size(); i++) {\n\t\tdis[i][0] = i * 0.5;\n\t}\n\tfor (int j = 1; j <= t.size(); j++) {\n\t\tdis[0][j] = j * 0.7;\n\t}\n\tfor (int j = 1; j <= t.size(); j++) {\n\t\tfor (int i = 1; i <= s.size(); i++) {\n\t\t\tif (s[i - 1] == t[j - 1]) {//같을경우 -> 아무것도 발생하지않음\n\t\t\t\tdis[i][j] = dis[i - 1][j - 1];\n\t\t\t}\n\t\t\telse {\n\t\t\t\tdis[i][j] = min(dis[i - 1][j - 1] + 0.3, min(dis[i][j - 1] + 0.7, dis[i - 1][j] + 0.5));\n\t\t\t}\n\t\t}\n\t}\n\tfor (int j = 0; j <= t.size(); j++) {\n\t\tfor (int i = 0; i <= s.size(); i++) {\n\t\t\tcout << dis[i][j] << \" \";\n\t\t}\n\t\tcout << \"\\n\";\n\t}\n\tcout << \"\\n\";\n\tif (t.size() > s.size()) { // t가 더 클경우 \n\t\tb = t.size() - s.size(); // 그 차이는 삽입되어야한다.\n\t\tfor (int i = 0; i < s.size(); i++) { // 문자가 다를때 교체\n\t\t\tif (s[i] != t[i]) a++;\n\t\t}\n\t}\n\telse {// s가 더 클경우\n\t\tc = s.size() - t.size(); // 그 차이는 삭제되어야한다.\n\t\tfor (int i = 0; i < t.size(); i++) { // 문자가 다를때 교체\n\t\t\tif (s[i] != t[i]) a++;\n\t\t}\n\t}\n\tcout<<\"교환연산 : \"<<a*0.3 <<\" 삽입연산 : \"<<b*0.7 <<\" 삭제연산 : \"<<c * 0.5 <<\" Levenshtein Distance : \"<<dis[s.size()][t.size()];\n}\n\nint main() {\n\t\n\t\n\tcin >> S >> T;\n\tcout <<\"비용이 모두 1인 경우 Levenshtein Distance : \" << leven(S, T) <<\"입니다\\n\\n\";\n\tcout << \"비용이 다를경우 Levenshtein Distance : \" << leven2(S, T) << \"입니다\\n\";\n\tcout << \"\\n12191728_정보통신공학과_김두미\\n\\n\";\n\tfor (int i = 0; i < 2; i++) {\n\t\tcin >> S >> T;\n\t\tleven3(S, T);\n\t}\n\tcout << \"\\n12191728_정보통신공학과_김두미\\n\\n\";\n\t\n\t}\n"
},
{
"alpha_fraction": 0.328125,
"alphanum_fraction": 0.3645833432674408,
"avg_line_length": 19.84782600402832,
"blob_id": "a84d120f30e928fa39b9d9663e4ce37d202bb0c2",
"content_id": "2ce775d81505384e293fc801eec1d9e34768afeb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 968,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 46,
"path": "/수업/연쇄행렬곱셈.cpp",
"repo_name": "dumi33/world",
"src_encoding": "WINDOWS-1252",
"text": "#include<iostream>\n\nusing namespace std;\n\n#define MIN(A, B) ((A)>(B)?(B):(A))\n#define MAX_VALUE 9999999\n#define MAX_SIZE 101\n\nint M[MAX_SIZE][MAX_SIZE];\nint d[MAX_SIZE];\n\nint main()\n{\n int size = 6;\n\n d[0] = 5, d[1] = 2, d[2] = 3, d[3] = 4, d[4] = 6, d[5] = 7 , d[6] = 8;\n\n for (int diagonal = 0; diagonal < size; diagonal++)\n {\n for (int i = 1; i <= size - diagonal; i++)\n {\n int j = i + diagonal;\n if (j == i)\n {\n M[i][j] = 0;\n continue;\n }\n M[i][j] = MAX_VALUE;\n for (int k = i; k <= j - 1; k++)\n M[i][j] = MIN(M[i][j], M[i][k] + M[k + 1][j] + d[i - 1] * d[k] * d[j]);\n\n }\n }\n\n /*°á°ú Ãâ·Â*/\n cout << M[1][size] << endl;\n for (int i = 1; i <= size; i++)\n {\n for (int j = 1; j <= size; j++)\n {\n cout << M[i][j] << \" \";\n }\n cout << endl;\n }\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.3927125632762909,
"alphanum_fraction": 0.42510122060775757,
"avg_line_length": 17.884614944458008,
"blob_id": "e803e16662100294dfb4bc94c1ea264340af5ed2",
"content_id": "62a46f0f1aa74d5399846e8a0a6d91fa08f5a4af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 508,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 26,
"path": "/알고리즘/큐&스택&덱&set/스택/탑.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<vector>\n#include<stack>\nusing namespace std;\n\nint n, num;\nint arr[500001];\nint ans[500001]; // 0으로 채워져있음\n\nstack<int> s;\n\nint main() {\n cin >> n;\n for (int i = 1; i <= n; i++) {\n cin >> num;\n arr[i] = num;\n }\n for (int i = n; i > 0; i--) {\n while (!s.empty() && arr[s.top()] < arr[i]) {\n ans[s.top()] = i;\n s.pop();\n }\n s.push(i);\n }\n for (int i = 1; i <= n; i++) cout << ans[i] << \" \";\n}\n\n\n\n"
},
{
"alpha_fraction": 0.4505516588687897,
"alphanum_fraction": 0.48445335030555725,
"avg_line_length": 32.2066650390625,
"blob_id": "c7a2dbf4f219b01ba36cb5c4f34094f99a102fdf",
"content_id": "b90395aaaa1034a011880e9b2a71d1a772bfc48c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 6419,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 150,
"path": "/알고리즘/Sort/quick_shell_time.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<ctime>\n\nusing namespace std;\nvoid checksort(int a[], int n) { //알맞게 정렬되었는지 확인 //오름차순정렬확인\n int i;\n int sorted = true;\n for (i = 0; i < n-1; i++) {\n if (a[i] > a[i + 1]) {\n sorted = false;\n }\n if (!sorted) {\n break;\n }\n\n }\n if (sorted) {\n cout << \"정렬이 완벽합니다!\" << \"\\n\";\n }\n else {\n cout << \"정렬에 문제가 발생했습니다..\" << \"\\n\";\n }\n}\nvoid quick(int *arr,int st, int en) {\n if (en <= st + 1) return; //크기가 1보다 작으면 return\n int first = st; \n int mid = (st + en) / 2;\n int rear = en-1; // 배열은 0부터 시작하므로\n if (arr[first] > arr[mid]) swap( arr[first], arr[mid]); //첫값과 중간값 비교\n if (arr[mid] > arr[rear]) swap( arr[mid], arr[rear]); // 중간값과 끝값비교\n if (arr[first] > arr[mid]) swap( arr[first], arr[mid]);//중간값이 중간으로 올바르게 정렬됨\n swap(arr[mid], arr[first]); //arr[first]가 중간값 //pivot을 배열의 첫값으로 설정하기위해 중간값을 first와 swap했음 \n int p = arr[st]; //피봇을 중간값으로 설정\n int l = st + 1; //st는 피봇이므로 +1\n int r = en - 1; //배열은 0부터 시작하므로\n while (1) {\n while (l <= r && arr[l] <= p) l++; //pivot보다 작으면 left 포인터를 증가시킨다.\n while (l <= r && arr[r] >= p) r--;//pivot보다 크면 right 포인터를 감소시킨다.\n if (l > r) break; //left가 right 보다 더 커진다면 while 문 나가기\n swap(arr[l], arr[r]); //left 포인터와 right 포인터가 가리키는 숫자 swap하기\n }\n swap(arr[r], arr[st]); //pivot과 right 포인터가 가리키는 곳 swap\n quick(arr,st, r); //처음부터 r 까지 다시 정렬\n quick(arr,r + 1, en); //r+1 부터 끝까지 다시 quick 정렬\n \n}\nvoid insertion(int* arr, int front, int last, int gap) { //gap을 가지는 삽입정렬\n int key;\n int i, j;\n for (i = front + gap; i < last; i += gap) { //첫값은 정렬되어있는 수로 보기때문에 i = front + gap;\n key = arr[i]; \n for (j = i - gap; j >= front; j -= gap) { \n if (key < arr[j]) {//key 보다 큰것이 있다면\n arr[j + gap] = arr[j]; //i (즉, key였던 곳을 큰값으로 덮어씌운다.\n }\n else break; \n\n }\n\n arr[j + gap] = key; //덮어씌었던 값중 가장 작은 값을 key로 바꾼다.\n }\n\n}\n\nvoid shell_sort(int* arr, int n) {\n int i, gap;\n for (gap = n / 2; gap > 0; gap = gap / 2) {\n if (gap % 2 == 0) { //홀수로 만들어야함//짝수일때는 +1;\n gap++;\n }\n for (i = 0; i < gap; i++) {\n insertion(arr, i, n, gap); //insertion을 기반으로 한 정렬\n }\n }\n}\nfloat start1, start2, end1, end2, res1, res2;\nint arr1[];\n#define mil 100000//십만\n#define mil2 1000000//백만\n#define mil3 10000000//천만\nint arr1[mil];\nint arr2[mil];\nint arr12[mil2];\nint arr22[mil2];\nint arr13[mil3];\nint arr23[mil3];\nint main() {\n \n srand(time(NULL));\n for (int i = 0; i < mil; i++) { //10만까지 난수를 발생하여 arr2에 넣어준다.\n arr1[i] = rand() % mil;\n arr2[i] = arr1[i];//같은 조건에서 소요시간 측정을 위해서 \n }\n \n start1 = clock(); //시작하는 시간\n quick(arr1, 0, mil);\n end1 = clock(); //정렬이 끝나는 시간\n res1 = (float)(end1 - start1); //소요시간\n cout << \"변형된 quick_sort의 십만개 원소의 소요시간은 : \" << res1 << \"ms입니다.\" << \"\\n\"; //소요시간 출력\n checksort(arr1, mil); //정렬이 잘되었나 확인\n\n start2 = clock(); //시작하는 시간\n shell_sort(arr2, mil);\n end2 = clock(); //정렬이 끝나는 시간\n res1 = (float)(end2 - start2); //소요시간\n cout << \"변형된 shell_sort의 십만개 원소의 소요시간은 : \" << res1 << \"ms입니다.\" << \"\\n\"; //소요시간 출력\n checksort(arr2, mil); //정렬이 잘되었나 확인\n/////////////////////////////////////////////////////////////////////////////////////////////////////\n srand(time(NULL));\n for (int i = 0; i < mil2; i++) { //100만까지 난수를 발생하여 arr2에 넣어준다.\n arr12[i] = rand() % mil2;\n arr22[i] = arr12[i]; //같은 조건에서 소요시간 측정을 위해서 \n }\n \n start1 = clock(); //시작하는 시간\n quick(arr12, 0, mil2);\n end1 = clock(); //정렬이 끝나는 시간\n res1 = (float)(end1 - start1); //소요시간\n cout << \"변형된 quick_sort의 백만개 원소의 소요시간은 : \" << res1 << \"ms입니다.\" << \"\\n\"; //소요시간 출력\n checksort(arr1, mil); //정렬이 잘되었나 확인\n\n start2 = clock(); //시작하는 시간\n shell_sort(arr22, mil2);\n end2 = clock(); //정렬이 끝나는 시간\n res1 = (float)(end2 - start2); //소요시간\n cout << \"변형된 shell_sort의 백만개 원소의 소요시간은 : \" << res1 << \"ms입니다.\" << \"\\n\"; //소요시간 출력\n checksort(arr22, mil2); //정렬이 잘되었나 확인\n ///////////////////////////////////////////////////////////////////////////////////////////////////////////////////////\n srand(time(NULL));\n for (int i = 0; i < mil3; i++) { //천만까지 난수를 발생하여 arr2에 넣어준다.\n arr13[i] = rand() % mil3; //난수 넣음\n arr23[i] = arr13[i]; //같은 난수 넣음\n }\n \n start1 = clock(); //시작하는 시간\n quick(arr13, 0, mil3);\n end1 = clock(); //정렬이 끝나는 시간\n res1 = (float)(end1 - start1); //소요시간\n cout << \"변형된 quick_sort의 천만개 원소의 소요시간은 : \" << res1 << \"ms입니다.\" << \"\\n\"; //소요시간 출력\n checksort(arr13, mil3); //정렬이 잘되었나 확인\n\n start2 = clock(); //시작하는 시간\n shell_sort(arr23, mil3);\n end2 = clock(); //정렬이 끝나는 시간\n res1 = (float)(end2 - start2); //소요시간\n cout << \"변형된 shell_sort의 천만개 원소의 소요시간은 : \" << res1 << \"ms입니다.\" << \"\\n\"; //소요시간 출력\n checksort(arr23, mil3); //정렬이 잘되었나 확인\n cout << \"정보통신공학과 12191728 김두미\";\n \n}\n\n\n \n"
},
{
"alpha_fraction": 0.4836956560611725,
"alphanum_fraction": 0.5,
"avg_line_length": 18.421052932739258,
"blob_id": "55e960ee5edd97b9397d81b256294889e9ea1e99",
"content_id": "7152c65ccdc2c3b592852cf0ee83e1806086c436",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 368,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 19,
"path": "/알고리즘/정수론/최대공약수와 최소공배수.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "#include<iostream>\n#include<algorithm>\nusing namespace std;\nint gcd(int n, int m) {\n \n if (m == 0) return n;\n return gcd(m, n % m);\n}\nint lcd(int n, int m, int gcd) {\n return n * m / gcd;\n}\nint main() {\n int n, m;\n cin >> n >> m;\n if (m > n) swap(n, m);\n int gcd1 = gcd(n, m);\n int lcd1 = lcd(n, m, gcd1);\n cout << gcd1 << \"\\n\" << lcd1;\n}"
},
{
"alpha_fraction": 0.4648241102695465,
"alphanum_fraction": 0.4773869216442108,
"avg_line_length": 21.11111068725586,
"blob_id": "69ea9dd5b14e3eb075d82502e485ebc139f2a11a",
"content_id": "a782b96731945bd4290d5b468cd3815cbeded070",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 398,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 18,
"path": "/programmers/stack_queue/프린터.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "from collections import deque\n\ndef solution(priorities, location):\n answer = 0\n d = deque([(v,i) for i,v in enumerate(priorities)])\n \n \n while len(d) :\n tmp = d.popleft()\n if d and max(d)[0] > tmp[0] :\n d.append(tmp)\n else :\n answer+=1 \n if location == tmp[1] : \n return answer\n \n \n return answer\n"
},
{
"alpha_fraction": 0.3712480366230011,
"alphanum_fraction": 0.39336493611335754,
"avg_line_length": 18.212121963500977,
"blob_id": "07725ebd607ae627b431c21238221815cc071a8d",
"content_id": "4212ba9f79d6815514c2c982503f434dcae7078e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 633,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 33,
"path": "/알고리즘/백트래킹/n과m(5).cpp",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "#include<iostream>\n#include<algorithm>\n\nusing namespace std;\nint n, m, a, b, c;\nint use[10];\nint isu[10];\nint arr[10];\nvoid func(int k) {\n if (k == m) {\n for (int i = 0; i < m; i++) cout << arr[i] << \" \";\n cout << \"\\n\";\n return;\n }\n for (int i = 0; i < n; i++) {\n if (!isu[use[i]]) {\n arr[k] = use[i];\n isu[use[i]] = 1;\n func(k + 1);\n isu[use[i]] = 0;\n }\n }\n }\nint main() {\n ios::sync_with_stdio(NULL);\n cin.tie(0);\n cin >> n >> m;\n for (int i = 0; i < n; i++) {\n cin >> use[i];\n }\n sort(use, use + n);\n func(0);\n}"
},
{
"alpha_fraction": 0.27239882946014404,
"alphanum_fraction": 0.29841041564941406,
"avg_line_length": 29.10869598388672,
"blob_id": "72937ec42a4098e5b0e9d779cd2a561e61e63505",
"content_id": "d69051501ef614e54d7db61693076acf714fc9db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1394,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 46,
"path": "/알고리즘/BFS/유기농배추.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<queue>\n#define x first\n#define y second\nint dx[4] = { 1,0,-1,0 };\nint dy[4] = { 0,1,0,-1 };\nusing namespace std;\nint main() {\n queue < pair<int, int> >Q;\n int t, mx = 0;\n cin >> t;\n for (int k = 0; k < t; k++) {\n int board[52][52] = {};\n int vis[52][52] = {}; //0으로 초기화\n int mx = 0;\n int n, m, l;\n cin >> n >> m >> l;\n for (int i = 0; i < l; i++) {\n int a, b;\n cin >> a >> b;\n board[a][b] = 1;\n }\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < m; j++) {\n if (vis[i][j] == 1 || board[i][j] == 0) continue;\n Q.push({ i,j });\n mx++;\n vis[i][j] = 1;\n while (!Q.empty()) {\n pair<int, int> cur = Q.front();\n Q.pop();\n for (int dir = 0; dir < 4; dir++) {\n int nx = cur.x + dx[dir];\n int ny = cur.y + dy[dir];\n if (nx < 0 || nx >= n || ny < 0 || ny >= m || vis[nx][ny] == 1 || board[nx][ny] == 0) {\n continue;\n }\n Q.push({ nx,ny });\n vis[nx][ny] = 1;\n }\n }\n }\n }\n cout << mx << \"\\n\";\n }\n}"
},
{
"alpha_fraction": 0.28727272152900696,
"alphanum_fraction": 0.3292929232120514,
"avg_line_length": 25.90217399597168,
"blob_id": "036e2f0fee354108a1568febdb6e3320a774aace",
"content_id": "db31e780563e1844de02b74ae34359602b28581a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2739,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 92,
"path": "/알고리즘/삼성역량테스트/시뮬레이션_미세먼지안녕!.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "dx = [1,0,-1,0] \ndy = [0,-1,0,1]\n\n \nif __name__==\"__main__\" :\n\n r,c,t = map(int,input().split())\n mp =[list(map(int,input().split())) for i in range(r)]\n \n for i in range(r) : # 공기청정기가 있는 행 알아내기 \n if mp[i][0] == -1 and mp[i+1][0] == -1 : \n now = (i,i+1)\n break\n\n for _ in range(t) :\n \n # 확산 \n \n # 새롭게 확산된 값을 저장할 배열 \n new = [[0]*c for i in range(r)]\n \n for i in range(r) :\n for j in range(c) :\n if mp[i][j] >= 5 : \n each = mp[i][j] // 5 # 확산시킬 값 \n cnt = 0 # 확산시킨 횟수 \n for k in range(4) :\n ndr,ndc = i + dx[k], j +dy[k]\n if 0<=ndr<r and 0<=ndc<c and mp[ndr][ndc]!= -1 :\n new[ndr][ndc] += each\n cnt+=1 \n mp[i][j] = mp[i][j] - (each * cnt)\n \n for i in range(r) :\n for j in range(c) :\n mp[i][j] += new[i][j]\n \n \n # 공기청정기 (순환)\n # 공기청정기의 위쪽 # 반시계 \n \n # 오른쪽으로 \n tmp = mp[now[0]][c-1] # 가장 오른쪽은 위로 올려야하므로 미리 빼준다\n for i in range(c-2,0,-1) : \n mp[now[0]][i+1] = mp[now[0]][i]\n \n # 위로 \n tmp2 = mp[0][c-1]\n for i in range(now[0]-1) :\n mp[i][c-1] = mp[i+1][c-1]\n mp[now[0]-1][c-1] = tmp\n \n # 왼쪽으로 \n tmp = mp[0][0]\n for i in range(c-1) :\n mp[0][i] = mp[0][i+1]\n mp[0][c-2] = tmp2\n \n # 아래쪽으로 \n for i in range(now[0]-1, 1,-1) :\n mp[i][0] = mp[i-1][0]\n mp[now[0]][1] = 0\n mp[1][0] = tmp\n \n # 공기청정기의 아래쪽 \n \n # 오른쪽 \n tmp = mp[now[1]][c-1] # 가장 오른쪽은 위로 올려야하므로 미리 빼준다\n for i in range(c-2,0,-1) : \n mp[now[1]][i+1] = mp[now[1]][i]\n \n # 아래로 \n tmp2 = mp[r-1][c-1]\n for i in range(r-1,now[1],-1) :\n mp[i][c-1] = mp[i-1][c-1]\n mp[now[1]+1][c-1] = tmp\n \n # 왼쪽으로 \n tmp = mp[r-1][0]\n for i in range(c-1) :\n mp[r-1][i] = mp[r-1][i+1]\n mp[r-1][c-2] = tmp2\n \n # 위로 \n for i in range(now[1]+1, r-1) :\n mp[i][0] = mp[i+1][0]\n mp[now[1]][1] = 0\n mp[r-2][0] = tmp\n \n \n ans= sum([sum(mp[i]) for i in range(r)])\n print(ans+2)\n"
},
{
"alpha_fraction": 0.46589258313179016,
"alphanum_fraction": 0.5050798058509827,
"avg_line_length": 21.225807189941406,
"blob_id": "adddff83ca0de76d1bce3203d6edb9e8433c91dd",
"content_id": "4c15892772c58f467ebfac4ed1ed912cbf5e2652",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 689,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 31,
"path": "/알고리즘/삼성역량테스트/DFS_톱니바퀴.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "from collections import deque\n\ndic = {}\nfor i in range(1,5) :\n dic[i] = deque(map(int,input()))\n\ndef rotate_left(x,dir) :\n if x <1 or dic[x][2] == dic[x+1][6] : return \n \n if dic[x][2] != dic[x+1][6] :\n rotate_left(x-1,-dir)\n dic[x].rotate(dir)\n \ndef rotate_right(x,dir) :\n if x >4 or dic[x-1][2] == dic[x][6] : return \n \n if dic[x-1][2] != dic[x][6] :\n rotate_right(x+1,-dir)\n dic[x].rotate(dir)\n\nfor i in range(int(input())) :\n x,dir = map(int,input().split())\n rotate_left(x-1,-dir)\n rotate_right(x+1,-dir)\n dic[x].rotate(dir)\n \nans = 0\nfor i in range(1,5) :\n if dic[i][0] == 1 : \n ans += 2**(i-1)\nprint(ans)\n"
},
{
"alpha_fraction": 0.30733680725097656,
"alphanum_fraction": 0.3304448425769806,
"avg_line_length": 23.394365310668945,
"blob_id": "77162cadec6d9657d714a39247d05d7a423605c1",
"content_id": "ebfb67f73672549bf60b51c5ceebe4b53e89cdea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1731,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 71,
"path": "/알고리즘/BFS/안전영역.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "#include<iostream>\n#include<queue>\n#include<cstring>\n#include<algorithm>\nusing namespace std;\nint dx[] = { 0,-1,1,0 };\nint dy[] = { 1,0,0,-1 };\n#define x first\n#define y second\nint mp[101][101];\nint check[101][101];\nint mx, mn;\nint ans = 0;\npriority_queue < int > pq;\nint n;\n\nint bfs() {\n int cnt = 0;\n queue<pair<int, int> > q;\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < n; j++) {\n if (!check[i][j]) {\n cnt++;\n check[i][j] = 1;\n q.push({ i,j });\n while (!q.empty()) {\n pair<int, int> cur = q.front();\n q.pop();\n\n for (int dir = 0; dir < 4; dir++) {\n int nx = dx[dir] + cur.x;\n int ny = dy[dir] + cur.y;\n if (nx < 0 || nx >= n || ny < 0 || ny >= n) continue;\n if (check[nx][ny] == 1) continue;\n check[nx][ny] = 1;\n q.push({ nx,ny });\n }\n }\n \n }\n }\n }\n return cnt;\n}\nint main() {\n cin >> n;\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < n; j++) {\n cin >> mp[i][j];\n mx = max(mx, mp[i][j]);\n mn = max(mn, mp[i][j]);\n }\n }\n if (mx == 1) cout << 1;\n else {\n for (int k = 1; k <= mx; k++) {\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < n; j++) {\n if (mp[i][j] <= k) check[i][j] = 1;\n\n }\n }\n ans = max(ans, bfs());\n memset(check, 0, sizeof(check));\n }\n\n cout << ans;\n }\n \n \n}"
},
{
"alpha_fraction": 0.372307687997818,
"alphanum_fraction": 0.39846155047416687,
"avg_line_length": 27.88888931274414,
"blob_id": "72069db02b9868435c340a747324d9c3e7e6f666",
"content_id": "7bf0d030593a6f878823d05d09bafd8afdd63020",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1410,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 45,
"path": "/programmers/DFS_BFS/거리두기확인하기.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "from collections import deque \nimport copy \n\ndx = [0,1,0,-1]\ndy = [1,0,-1,0]\n\n\ndef bfs(q,vis,tmp) :\n isTrue = 1 \n while q : \n x,y,cost = q.popleft()\n # 동, 서, 남, 북 다 가봐야죠 \n for dir in range(4) :\n nx,ny = x + dx[dir], y + dy[dir]\n # 대기실 안, 2번만에 이동, 방문한적 없는 \n if 0<=nx<5 and 0<=ny<5 and cost+1 <=2 and vis[nx][ny] == 0:\n \t# 사람이 있다? \n if tmp[nx][ny] == 'P' : \n isTrue=0\n # 빈자리면 덱에 넣어요 \n elif tmp[nx][ny] == 'O' :\n q.append([nx,ny,cost+1])\n vis[nx][ny] = 1\n return isTrue \n\ndef solution(places):\n answer = []\n for room in places :\n tmp = []\n q = deque()\n vis = [[0]*5 for _ in range(5)]\n for i in room :\n tmp.append(list(i))\n ifroomTrue = 1\n for i in range(5) :\n for j in range(5) :\n \t# 사람을 발견해서 q에 넣을 때마다 BFS를 돌린다. \n if tmp[i][j] == 'P' :\n q.append([i,j,0])\n vis[i][j] = 1 \n if bfs(q,copy.deepcopy(vis),tmp)==0 : ifroomTrue = 0 \n vis[i][j] = 0\n answer.append(1) if ifroomTrue else answer.append(0) \n \n return answer\n"
},
{
"alpha_fraction": 0.37849161028862,
"alphanum_fraction": 0.46368715167045593,
"avg_line_length": 28.875,
"blob_id": "c6682182a4c9f3bf207218c0a0077e74ab683d22",
"content_id": "ecd541bb312933c0eacd20d37eae55e4cc9c4d34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 868,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 24,
"path": "/알고리즘/dp/스티커.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include <iostream>\n#include <algorithm>\nusing namespace std;\nint dp[100000][2]; // dp[i][0] : 0~i-1열 전체 + i열 0행에 대해 최댓값, dp[i][1] : 0~i-1열 전체 + i열 1행에 대해 최댓값\nint st[100000][2];\nint main() {\n\tint T;\n\tcin >> T;\n\twhile (T--) {\n\t\tint N;\n\t\tcin >> N;\n\t\tfor (int i = 0; i < N; i++)\n\t\t\tcin >> st[i][0];\n\t\tfor (int i = 0; i < N; i++)\n\t\t\tcin >> st[i][1];\n\t\tdp[0][0] = st[0][0];\n\t\tdp[0][1] = st[0][1];\n\t\tfor (int i = 1; i < N; i++) {\n\t\t\tdp[i][0] = max(st[i][0] + dp[i - 1][1], dp[i - 1][0]);//{i열의 0행의 값 + 이전열(i-1)의 1행의 값} 과 이전열의 0행의 값 중 큰것\n\t\t\tdp[i][1] = max(st[i][1] + dp[i - 1][0], dp[i - 1][1]);//{i열의 1행의 값 + 이전열(i-1)의 0행의 값} 과 이전열의 1행의 값 중 큰것\n\t\t}\n\t\tcout << max(dp[N - 1][0], dp[N - 1][1]) << \"\\n\"; //1행과 0행의 값 중 큰것\n\t}\n}"
},
{
"alpha_fraction": 0.4430479109287262,
"alphanum_fraction": 0.466614305973053,
"avg_line_length": 26.69565200805664,
"blob_id": "63b58dda0ab222a6da91a03b4c22ae49a3089152",
"content_id": "f61471cceb7c4e8110cc4197c6134370cad27404",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1393,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 46,
"path": "/알고리즘/다익스트라/최단경로.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<vector>\n#include<queue>\nusing namespace std;\ntypedef pair<int, int> PI;\n\nint v, e, start,dist[20001],visit[20001];\nvector<vector<pair<int, int>>> V;\npriority_queue<PI,vector<PI>,greater<PI> > q; // firtst -> w, second -> v\n//작은놈부터 나오도록\n//priority_queue<PI > q; 와 같은데 최솟값먼저 나오게 하기위해서\n\nint main() {\n\n cin >> v >> e >> start;\n V.resize(v + 1);\n fill(dist, dist + v + 1, 2e9);\n\n for (int i = 0, p1, p2, p3; i< e; i++) {\n cin >> p1 >> p2 >> p3; // u v w\n V[p1].push_back({ p2,p3 }); \n } \n dist[start] = 0;\n q.push({ 0,start }); /// start는 가중치가 0이므로\n while (!q.empty()) {\n int cur; //현재 정점의 상태\n do {\n cur = q.top().second; // first에는 가중치가있으므로\n q.pop();\n } while (!q.empty() && visit[cur]);\n if (visit[cur]) break;\n visit[cur] = true;\n for (auto& i : V[cur]) {\n int next = i.first; //정점\n int ndist = i.second; // 가중치\n if (dist[next] > dist[cur] + ndist) {\n dist[next] = dist[cur] + ndist; //업데이트\n q.push({ dist[next],next });\n }\n }\n }\n for (int i = 1; i <= v; i++) {\n if (dist[i] == 2e9) cout << \"INF\" << \"\\n\";\n else cout << dist[i] << \"\\n\";\n }\n}"
},
{
"alpha_fraction": 0.3295454680919647,
"alphanum_fraction": 0.41287878155708313,
"avg_line_length": 23,
"blob_id": "d39af9e8338b2f27d832e22c486064b967ca0810",
"content_id": "69e0129ca4efcdfe1b67f6eb9f49b604dd17a8c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 528,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 22,
"path": "/programmers/완전탐색/모의고사.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "def solution(answers):\n answer = []\n supo1 = [1,2,3,4,5]\n supo2 = [2,1,2,3,2,4,2,5]\n supo3 = [3,3,1,1,2,2,4,4,5,5]\n \n cnt = [0,0,0]\n for i in range(len(answers)) :\n if answers[i] == supo1[i%5] :\n cnt[0]+=1 \n if answers[i] == supo2[i%8] :\n cnt[1]+=1 \n if answers[i] == supo3[i%10] :\n cnt[2] += 1\n \n max_cnt = max(cnt)\n \n for i in range(3) :\n if max_cnt == cnt[i] :\n answer.append(i+1)\n \n return answer\n"
},
{
"alpha_fraction": 0.3818565309047699,
"alphanum_fraction": 0.40084388852119446,
"avg_line_length": 19.65217399597168,
"blob_id": "686b045f98db60169efb9668db3948afd2326f4d",
"content_id": "5024f49f0b6d33e0cc808655466cdb737be95110",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 484,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 23,
"path": "/알고리즘/dp/가장 긴 증가하는 부분 수열.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<vector>\n#include<algorithm>\nusing namespace std;\nint dp[1001];\nint main() {\n int n; cin >> n;\n vector<int> v(n);\n for (auto& i : v) cin >> i;\n int ans = 0;\n for (int i = 0; i < n; i++) {\n int mx = 0;\n for (int j = 0; j < i; j++) {\n if (v[i] > v[j]) { // 뒤가 더 크면\n mx = max(mx, dp[j]);\n }\n }\n dp[i] = mx + 1;\n ans = max(ans, dp[i]);\n }\n \n cout << ans;\n}"
},
{
"alpha_fraction": 0.48543688654899597,
"alphanum_fraction": 0.5097087621688843,
"avg_line_length": 24.75,
"blob_id": "b383d1be9a0bd7bca1e61c3eca23268367eb6a7a",
"content_id": "a47e978e55da10d53a1e1e70c82a6daf7c385d4c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 206,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 8,
"path": "/알고리즘/dp/평범한 배낭.py",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "N,K = map(int,input().split())\nitems = []\ndp = [0 for _ in range(K+1)]\nfor i in range(N):\n w,v = map(int,input().split())\n for j in range(K,w-1,-1):\n dp[j] = max(dp[j],dp[j-w]+v)\nprint(dp[-1])\n"
},
{
"alpha_fraction": 0.3549019694328308,
"alphanum_fraction": 0.37843137979507446,
"avg_line_length": 17.925926208496094,
"blob_id": "c39c81ad1fda3bee65aee47b376553eaf4b913df",
"content_id": "4ad1ba14904cba998380051d1e7b760841e7d277",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 510,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 27,
"path": "/알고리즘/백트래킹/n과m(2).cpp",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "#include<iostream>\nint arr[10];\nint iss[10];\nint n, m;\n\nusing namespace std;\nvoid func(int k, int pre) {\n if (k == m) {\n for (int i = 0; i < m; i++) cout << arr[i] << \" \";\n cout << \"\\n\";\n return;\n }\n for (int i = 1; i <= n; i++) {\n if (!iss[i] && pre < i) {\n arr[k] = i;\n iss[i] = 1;\n func(k + 1, i);\n iss[i] = 0;\n }\n }\n}\nint main() {\n ios::sync_with_stdio(NULL);\n cin.tie(0);\n cin >> n >> m;\n func(0, 0);\n}"
},
{
"alpha_fraction": 0.37123745679855347,
"alphanum_fraction": 0.39353400468826294,
"avg_line_length": 21.897436141967773,
"blob_id": "975713236d89387604717a69c8d118d582018cb9",
"content_id": "3ea865d18a47de56bce1b6a2172f17c5b8e9be0e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 923,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 39,
"path": "/알고리즘/Sort/shell_sort.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UTF-8",
"text": "#include<iostream>\nusing namespace std;\nint arr[] = { 343,64,3,5,2,23,4,5 };\nvoid insertion(int *arr, int first, int last, int gap) {\n int key, i,j;\n for (i = first + gap; i <last; i += gap) {\n key = arr[i];\n for ( j = i - gap; j >= first; j -= gap) {\n if (key < arr[j]) {\n arr[j + gap] = arr[j];\n }\n else break;\n \n }\n \n arr[j + gap] = key;\n }\n \n}\n\nvoid shell_sort(int *arr, int n) {\n int i, gap;\n for (gap = n / 2; gap > 0; gap = gap / 2) {\n if (gap % 2 == 0) { //홀수가 좋은가보다//짝수일때는 +1;\n gap++;\n }\n for (i = 0; i < gap; i++) {\n insertion(arr, i, n , gap);\n }\n }\n}\nint main() {\n int size = sizeof(arr) / sizeof(int);\n \n shell_sort(arr, size);\n for (int i = 0; i < size; i++) {\n cout << arr[i] << \" \";\n }\n}\n\n\n \n"
},
{
"alpha_fraction": 0.3457777798175812,
"alphanum_fraction": 0.35644444823265076,
"avg_line_length": 23.39130401611328,
"blob_id": "6dab43feaffc7e7cd0ba5c11a6008c13b8244a6b",
"content_id": "f6b27d7c3429655529d7bcd53538a245e52718dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1189,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 46,
"path": "/알고리즘/큐&스택&덱&set/스택/괄호의 값.cpp",
"repo_name": "dumi33/world",
"src_encoding": "UHC",
"text": "#include<iostream>\n#include<stack>\nusing namespace std;\n\nint tmp = 1, ans = 0;\nbool isok = true;\nstring str;\nstack<char> stk;\n\nint main() {\n\n ios_base::sync_with_stdio(0);\n cin.tie(0); //cin 실행속도 향상\n cin >> str;\n for (int i = 0; i < str.size(); i++) {\n if (str[i] == '(') {\n tmp *= 2;\n stk.push('(');\n }\n else if (str[i] == '[') {\n tmp *= 3;\n stk.push('[');\n }\n else if (str[i] == ')' && (stk.empty() || stk.top() != '(')) {\n isok = false;\n break;\n }\n else if (str[i] == ']' && (stk.empty() || stk.top() != '[')) {\n isok = false;\n break;\n }\n else if (str[i] == ')') {\n if (str[i - 1] == '(') ans += tmp; //바로 이전 글자가 짝궁일경우만\n stk.pop();\n tmp /= 2;\n }\n else if (str[i] == ']') {\n if (str[i - 1] == '[') ans += tmp; //바로 이전 글자가 짝궁일경우만\n stk.pop();\n tmp /= 3;\n }\n }\n\n if (stk.empty() == false || isok == false) cout << 0;\n else cout << ans;\n}\n\n\n\n"
}
] | 145 |
racekiller/Kaggle---Titanic-Python-Pandas
|
https://github.com/racekiller/Kaggle---Titanic-Python-Pandas
|
39d599965f8a972bb54355ea451760339b186860
|
9f80d281a0ce0a6d165bc28376160a6ea1f70f7f
|
1877fc3c2b62adaebbbaf00eb57e7fddf3d9c544
|
refs/heads/master
| 2021-01-12T14:42:14.700888 | 2016-11-10T03:50:45 | 2016-11-10T03:50:45 | 72,064,073 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6757243871688843,
"alphanum_fraction": 0.6856327652931213,
"avg_line_length": 37.287357330322266,
"blob_id": "540f1a5252f275dd62d465645ffe1f4db805f5f0",
"content_id": "544ec875b33d33f94838edb99f8c2d9cbc6a8a0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6661,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 174,
"path": "/KaggleTitanicV2.py",
"repo_name": "racekiller/Kaggle---Titanic-Python-Pandas",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Nov 1 13:12:04 2016\n\n@author: JVivas\n\"\"\"\nimport csv as csv\nimport pandas as pd\nimport numpy as np\nfrom sklearn.preprocessing import OneHotEncoder\n\nWindows_Path = 'C:/Users/jvivas/Dropbox/Private/Personal'\\\n '/Github/Kaggle---Titanic-Python-Pandas'\nMac_Path = '/Users/jvivas/Documents/GitHub/Kaggle - Titanic Python Pandas'\nPath = Windows_Path\ndata = []\n\n# For .read_csv, always use header=0 when you know row 0 is the header row\ndf_original_train = pd.read_csv(Path + '/' + 'train.csv', header=0)\ndf_original_test = pd.read_csv(Path + '/' + 'test.csv', header=0)\ndf_test = pd.read_csv(Path + '/' + 'test.csv', header=0)\ndf_train = pd.read_csv(Path + '/' + 'train.csv', header=0)\ndf = pd.read_csv(Path + '/' + 'train.csv', header=0)\n\ndef measure_perfomance(x,y,tree,show_accuracy=True,\n show_classification_report=False,\n show_confusion_matrix=False):\n y_pred = tree.predict(x)\n if show_accuracy:\n print (\"Accuracy:{0:3f}\".format(metrics.accuracy_score(y,y_pred)),\"/n\")\n if show_classification_report:\n print (\"Classification_report\")\n print (metrics.classification_report(y,y_pred),\"/n\")\n if show_confusion_matrix:\n print (\"Confusion matrix\")\n print (metrics.confusion_matrix(y,y_pred), \"/n\")\n\n\n# let's see the count of missing data aka. null\ndf.isnull().sum()\ndf_test.isnull().sum()\n\n# lets create a new dataframe droping all ages I dont want to come up with\n# fake ages (averages according to the class)\ndf = df.dropna(subset=['Age'])\ndf_test = df_test.dropna(subset=['Age'])\ndf_test = df_test.dropna(subset=['Fare'])\n\n# We need to encode the Sex from the dataframe\n# Next line will assing an integer to each label strin from 0 to n\nclass_mapping = {label: idx for idx,\n label in enumerate(np.unique(df['Sex']))}\n\n# Next we can use the mapping dictionary to transform the class labels\n# into integers\ndf['Sex'] = df['Sex'].map(class_mapping)\ndf_test['Sex'] = df_test['Sex'].map(class_mapping)\n\n# We will get one feature for total family members\ndf['Family'] = df['SibSp'] + df['Parch']\ndf_test['Family'] = df_test['SibSp'] + df_test['Parch']\n\n# Delete the unnecessary features, that dont add values\ndf = df.drop(['Name', 'Ticket', 'Cabin',\n 'Embarked', 'SibSp', 'Parch'], axis=1)\ndf_test = df_test.drop(['Name', 'Ticket', 'Cabin',\n 'Embarked', 'SibSp', 'Parch'], axis=1)\n\n# Another way to do One Hot encoder is using get_dummies using pandas\n# function\n# the function will do the coding automatically and using the dataframe\n# not need to convent to numpy array\n# This function works only for label string to apply one hot encoder\n# to integers we need to do the sklearn one_hot_encoder\n#df = pd.get_dummies(df[['PassengerId', 'Survived', 'Pclass',\n# 'Sex', 'Age', 'Fare']])\n#df_test = pd.get_dummies(df_test[['PassengerId', 'Pclass',\n# 'Sex', 'Age', 'Fare']])\n\n# sklearn one hot encoder works only for numpy arrays\ndfArray = df.values\ndfTestArray = df_test.values\n\n# We use categorical_features to apply the one hot to specific feature\nohe = OneHotEncoder(categorical_features=[2])\ndfArray = ohe.fit_transform(dfArray).toarray()\nohe = OneHotEncoder(categorical_features=[1])\ndfTestArray = ohe.fit_transform(dfTestArray).toarray()\n\n# Here we assign the survived column to the 'y' and the rest to X\nX = np.delete(dfArray, 4, axis=1)\nX = np.delete(X, 3, axis=1)\ny = dfArray[:, [4]]\nX_test_final = np.delete(dfTestArray, 3, axis=1)\n\nfrom sklearn.cross_validation import train_test_split\nX_train, X_test, y_train, y_test = \\\n train_test_split(X, y, test_size=0.25, random_state=0)\n\n# Bringing features onto the same scale this is good to do only for non\n# tree classifier\n# Using normalization\n#from sklearn.preprocessing import MinMaxScaler\n#mms = MinMaxScaler()\n#X_train_norm = mms.fit_transform(X_train)\n#X_test_norm = mms.transform(X_test)\n#\n#from sklearn.preprocessing import StandardScaler\n#stdsc = StandardScaler()\n#X_train_std = stdsc.fit_transform(X_train)\n#X_test_std = stdsc.transform(X_test)\n\n# Train tree decision classifier\nfrom sklearn.tree import DecisionTreeClassifier\ntree = DecisionTreeClassifier(criterion='entropy', max_depth=3,\n min_samples_leaf=5)\ntree = tree.fit(X_train, y_train)\nprint ('Accuracy for Training Data all features: ',\n tree.score(X_train, y_train))\n#tree_norm = tree.fit(X_train_norm, y_train)\n#tree_std = tree.fit(X_train_std, y_train)\n\nfrom sklearn.tree import export_graphviz\nfrom sklearn import metrics\nexport_graphviz(tree, out_file='tree.dot')\n#export_graphviz(tree_norm, out_file='tree_norm.dot')\n#export_graphviz(tree_std, out_file='tree_std.dot')\n\n# Measure performance for Tree Classifier\nmeasure_perfomance(X_test, y_test, tree)\n\nfrom sklearn.ensemble import RandomForestClassifier\nclf = RandomForestClassifier(n_estimators=10000, random_state=33)\nclf = clf.fit(X_train, y_train)\nprint('Random Forest Accuracy Training Dataset with all features: ',\n clf.score(X_test, y_test))\n\n# Meaningful features using Random Forest\nforest = RandomForestClassifier(n_estimators=10000,\n random_state=0,\n n_jobs=1)\nforest.fit(X_train, y_train)\nimportances = forest.feature_importances_\nindices = np.argsort(importances)[::-1]\nfor f in range(X_train.shape[1]):\n print(\"%2d %-*s %f\" % (f + 1, 30,\n 'X_train'+ str([f]), importances[f]))\n\nX_train_new = forest.transform(X_train, threshold=0.10)\n# print(X_train_new.shape)\ntree = tree.fit(X_train, y_train)\nprint('Accuracy Training Dataset All features: ',\n tree.score(X_train, y_train))\ntree = tree.fit(X_test, y_test)\nprint('Accuracy Test Dataset with All Features: ',\n tree.score(X_test, y_test))\n# lets delete the low performance features from the test dataset\nX_test_new = X_test[:, [3, 4, 5]]\ntree = tree.fit(X_train_new, y_train)\nprint('Accuracy Training Dataset with High Performance Features: ',\n tree.score(X_train_new, y_train))\ntree = tree.fit(X_test_new, y_test)\nprint('Accuracy Test Dataset with High Performance Features: ',\n tree.score(X_test_new, y_test))\n\ny_pred_output = tree.predict(X_test_final)\n# Collect the test data's PassengerIds before dropping it\nids = df_test['PassengerId'].values\nKagglePredictionFile = open(\"kagglePredictionTitanicTree_V2.csv\", \"w\")\nopen_file_object = csv.writer(KagglePredictionFile)\nopen_file_object.writerow([\"PassengerId\", \"Survived\"])\nopen_file_object.writerows(zip(ids, y_pred_output))\nKagglePredictionFile.close()\nprint ('Done.')"
},
{
"alpha_fraction": 0.6500273942947388,
"alphanum_fraction": 0.6618418097496033,
"avg_line_length": 36.3684196472168,
"blob_id": "5714779ce097b0c11d9d18fbf4e0b2c15f516aa4",
"content_id": "54d200cd86e375391d155a6862e71b91fe4ec1ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12781,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 342,
"path": "/KaggleTitanic.py",
"repo_name": "racekiller/Kaggle---Titanic-Python-Pandas",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Oct 26 18:34:03 2016\n\n@author: jvivas\n\"\"\"\n\nimport csv as csv\nimport numpy as np\n# Lets do some predictions using Random Forest\n# Import the random forest package\nfrom sklearn.tree import DecisionTreeClassifier\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.cross_validation import train_test_split\nfrom sklearn.metrics import classification_report\nfrom sklearn.pipeline import Pipeline\nfrom sklearn.grid_search import GridSearchCV\nfrom sklearn import tree\nfrom sklearn import metrics\nimport pandas as pd\nfrom sklearn import feature_extraction\n\nWindows_Path = 'C:/Users/jvivas/Dropbox/Private/Personal/Github/Kaggle---Titanic-Python-Pandas'\nMac_Path = '/Users/jvivas/Documents/GitHub/Kaggle - Titanic Python Pandas'\nPath = Windows_Path\ncsv_file_object = csv.reader(open(Path+'/' + 'train.csv'))\nheader = csv_file_object.__next__()\ndata = []\n\n# Lets use different techniques to deal with missing data\n# we create a function called one_hot_dataframe\ndef one_hot_dataframe(data, cols, replace=False):\n vec = feature_extraction.DictVectorizer()\n mkdict = lambda row: dict((col, row(col)) for col in cols)\n vecData = pd.DataFrame(vec.fit_transform( \\\n data[cols].apply(mkdict, axis=1)).toarray())\n vecData.index = data.index\n if replace:\n data = data.drop(cols, axis=1)\n data = data.join(vecData)\n return (data, vecData)\n\n# csv_file_object = csv.reader(open(Path+'/' + 'train.csv'))\n# header = csv_file_object.__next__()\n# data=[]\n#\n# for row in csv_file_object:\n# data.append(row)\n# data = np.array(data)\n\n# Look at the first 15 rows of the Age column:\n# data[0::,5]\n\n# let's see the dataytype\n# type(data[0::5,5])\n\n# So, any slice we take from the data is still a Numpy array. Now let's see if\n# we can take the mean of the passenger ages. They will need to be floats\n# instead of strings, so set this up as:\n\n# ages_onboard = data[0::,5].astype(np.float)\n\n# we will get an error\n# ValueError: could not convert string to float:\n# because there are non numeric values in the column 5\n# using numpy array can not do numerical calculations if there are no\n# numerical types in the set\n# therefore we need to lcean the data\n# or we cna use pandas which offers more tools to do this kind of tasks\n# (data clenasing)\n\n# For .read_csv, always use header=0 when you know row 0 is the header row\ndf_original_train = pd.read_csv(Path + '/' + 'train.csv', header=0)\ndf_original_test = pd.read_csv(Path + '/' + 'test.csv', header=0)\ndf_test = pd.read_csv(Path + '/' + 'test.csv', header=0)\ndf = pd.read_csv(Path + '/' + 'train.csv', header=0)\n# df.head(3)\n# df.tail(3)\n\n# Showing dataframe type\n# type(df)\n# showing elements type\n# df.dtypes\n# Showing additional information for each elemtn (count and type and if tis\n# null)\n# df.info()\n# Showing statistical information such (mean, max, count, min)\n# df.describe()\n\n# Data Munging\n# One step in any data analysis is the data cleaning. Thankfully pandas makes\n# things easier to filter, manipulate, drop out, fill in, transform and\n# replace values inside the dataframe. Below we also learn the syntax that\n# pandas allows for referring to specific columns.\n\n# Referencing and filtering\n# Let's acquire the first 10 rows of the Age column. In pandas this is\n\n# df['Age'][0:10]\n# df.Age[0:10]\n\n# let's do some calculations\n# df['Age'].mean()\n# df['Age'].median()\n\n# How to show specific columns from the df\n# df[['Sex','Pclass','Age']]\n\n# How to filter data\n# Show all rows where age is greater than 60\n# df[df['Age'] > 60]\n\n# Show specific columns that matches the WHERE clause\n# df[df['Age'] > 60][['Pclass','Age','Survived']]\n\n# Lets take a look to the null value in Ages\n\n# df[df['Age'].isnull()][['Sex', 'Pclass', 'Age']]\n\n# here we will go over the dataframe to get the count of male per class\nfor i in range(1,4):\n a = len(df[ (df['Sex'] == 'male') & (df['Pclass'] == i) ])\n print (a)\n\n# let's draw some picture\n# df['Age'].hist()\n# P.show()\n#\n# df['Age'].dropna().hist(bins=16, range=(0,80),alpha = 0.5)\n# P.show()\n\n# Cleaning the data\n# Creating a column into df dataframe\n# df['Gender'] = 4\n\n# Lets use different techniques to deal with missing data\n# we create a function called one_hot_dataframe\ndef one_hot_dataframe(data, cols, replace=False):\n vec = feature_extraction.DictVectorizer()\n mkdict = lambda row: dict((col, row(col)) for col in cols)\n vecData = pd.DataFrame(vec.fit_transform( \\\n data[cols].apply(mkdict, axis=1)).toarray())\n vecData.index = data.index\n if replace:\n data = data.drop(cols, axis=1)\n data = data.join(vecData)\n return (data, vecData)\n\n# titanic, titanic_n = one_hot_dataframe(df, ['Sex', 'Cabin', 'Embarked'], \\\n# replace=True)\n# applying one hot dataframe\n# one hot dataframe will create a feature per categorical value\n# the definition is not working for python 3 I need to update the code to\n# make it work for py3\n# titanic, titanic-n = one_hot_dataframe(df, ['Pclass'])\n\n# Here we take the first letter of the element and convert to Uppercase\ndf['Gender'] = df['Sex'].map(lambda x: x[0].upper())\n\n# Now here we replace each element string with integer number in this case\ndf['Gender'] = df['Sex'].map({'female': 0, 'male': 1}).astype(int)\ndf_test['Gender'] = df_test['Sex'].map({'female': 0, 'male': 1}).astype(int)\n\n# We will do the same than above but this time we will skip the nan (null)\ndf['Embarked_F'] = df['Embarked'].dropna().map({'S': 0, 'Q': 1, 'C': 2}).\\\n astype(int)\ndf_test['Embarked_F'] = df_test['Embarked'].dropna().map({'S': 0, 'Q': 1, 'C': 2}).astype(int)\n# working with missing values, what to do?\n# There are some features that missing values can be converted to null but\n# there are others that can not for example the Age of the passenger in this\n# case what we can do is take the mean by class\n\nmedian_ages = np.zeros((2, 3))\n\nfor i in range(0, 2):\n for j in range(0, 3):\n median_ages[i,j] = df[(df['Gender'] == i) & \\\n (df['Pclass'] == j+1)]['Age'].dropna().median()\n\n# lets create a new column for Age so we can put in there the new values for\n# missing data\ndf['AgeFill'] = df['Age']\n# Lets show the total of passenger with missing Age for specific columns\ndf[ df['Age'].isnull() ][['Gender','Pclass','Age','AgeFill']].head(10)\n\n# Lets populate the dataframe with new ages\n# here we go over the dataframe and will assign the meadian age that matches\n# the Gender and Pclass in order by i and j\nfor i in range(0, 2):\n for j in range(0, 3):\n df.loc[(df.Age.isnull()) & (df.Gender == i) & (df.Pclass == j+1),\n 'AgeFill'] = median_ages[i, j]\n\n# We repeat the process for test dataset\nmedian_ages = np.zeros((2, 3))\n\nfor i in range(0, 2):\n for j in range(0, 3):\n median_ages[i,j] = df_test[(df_test['Gender'] == i) & \\\n (df_test['Pclass'] == j+1)]['Age'].dropna().median()\n\n# lets create a new column for Age so we can put in there the new values for\n# missing data\ndf_test['AgeFill'] = df_test['Age']\n# Lets show the total of passenger with missing Age for specific columns\ndf_test[df_test['Age'].isnull() ][['Gender','Pclass','Age','AgeFill']].head(10)\n\n# Lets populate the dataframe with new ages\n# here we go over the dataframe and will assign the meadian age that matches\n# the Gender and Pclass in order by i and j\nfor i in range(0, 2):\n for j in range(0, 3):\n df_test.loc[(df_test.Age.isnull()) & (df_test.Gender == i) & (df.Pclass == j+1),\n 'AgeFill'] = median_ages[i, j]\n\n# Let's also create a feature that records whether the Age was originally\n# missing.\ndf['AgeIsNull'] = pd.isnull(df.Age).astype(int)\ndf_test['AgeIsNull'] = pd.isnull(df_test.Age).astype(int)\n\ndf['FamilySize'] = df['SibSp'] + df['Parch']\ndf_test['FamilySize'] = df_test['SibSp'] + df_test['Parch']\n\n# Deletig unnecesary columns\n# Here we can show the columns that matches specific criteria as well\ndf.dtypes[df.dtypes.map(lambda x: x=='object')]\ndf_test.dtypes[df_test.dtypes.map(lambda x: x=='object')]\n# We can delete these columns\ndf = df.drop(['Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1)\ndf_test = df_test.drop(['Name', 'Sex', 'Ticket', 'Cabin', 'Embarked'], axis=1)\n# We can delete the Age column as well since we have created the better AgeFill\ndf = df.drop(['Age'],axis = 1)\ndf_test = df_test.drop(['Age'],axis = 1)\n\n#delete null from Embarked column\ndf = df[pd.notnull(df['Embarked_F'])]\n\n#delete null from Fare column (we kept df_test with one null value for a fare record)\n# We need to get the average frpice per class and assign it to the null record\ndf_test2 = df_test[pd.notnull(df_test['Fare'])]\n\nif len(df_test.Fare[df_test.Fare.isnull()]) > 0:\n fare_Average = np.zeros(3)\n for i in range(0, 3):\n fare_Average[i] =\\\n df_test[df_test.Pclass == i+1]['Fare'].dropna().median()\n for i in range(0, 3):\n df_test.loc[(df_test.Fare.isnull()) &\n (df_test.Pclass == i+1),\n ['Fare']] = fare_Average[i]\n\n# Collect the test data's PassengerIds before dropping it\nids = df_test['PassengerId'].values\n# The final step is to convert it into a Numpy array. Pandas can always\n# send back an array using the .values method. Assign to a new variable\n# train_data:\n\nx_train_data = df.ix[:, df.columns != 'Survived'].values\ny_train_data = df['Survived'].values\nx_test_data = df_test.values\n\nx_Train, x_test, y_train, y_test = train_test_split(x_train_data,\\\n y_train_data,\\\n test_size = 0.25, \\\n random_state = 33)\n\n# Lets do feature selection following the book packt ...\n\n# Lets create the pipeline\npipeline = Pipeline([\n ('clf', DecisionTreeClassifier(criterion='entropy'))\n ])\n\n# Next we specify the hyperparameter psace for the grid seach\nparameters = {'clf__max_depth': (100, 125, 150),\n 'clf__min_samples_leaf': (5,6,7)}\n\n# We the set the GridSeacrhCV() to amximize the models F1 score:\ngrid_search = GridSearchCV(pipeline, parameters, n_jobs=-1,\n verbose=1, scoring='f1')\ngrid_search.fit(x_Train, y_train)\n\nprint ('Best score: %0.3f' % grid_search.best_score_)\nprint ('Best parameters set:')\n\nbest_parameters = grid_search.best_estimator_.get_params()\nfor param_name in sorted(parameters.keys()):\n print ('\\t%s: %r' % (param_name, best_parameters[param_name]))\n\n\nclf = tree.DecisionTreeClassifier(criterion='entropy')\nclf = clf.fit(x_Train, y_train)\ny_pred = clf.predict(x_test)\nprint (\"Accuracy: {0:.3f}\".format(metrics.accuracy_score(y_test, y_pred)), \"/n\")\n\nclf_RF = RandomForestClassifier(n_estimators = 10, random_state = 33)\nclf_RF = clf_RF.fit(x_Train, y_train)\ny_pred_RF = clf_RF.predict(x_test)\nprint (\"Accuracy: {0:.3f}\".format(metrics.accuracy_score(y_test, y_pred_RF)), \"/n\")\n\n# Applying Feature selection\nfrom sklearn import feature_selection\nfs = feature_selection.SelectPercentile(feature_selection.chi2,\\\n percentile=20)\nX_train_fs = fs.fit_transform(x_Train, y_train)\nclf_fs = tree.DecisionTreeClassifier(criterion='entropy')\nclf_fs = clf_fs.fit(X_train_fs, y_train)\nX_test_fs = fs.transform(x_test)\ny_pred_fs = clf_fs.predict(X_test_fs)\n\nprint (\"Accuracy: {0:.3f}\".format(metrics.accuracy_score(y_test, y_pred_fs)), \"/n\")\n\ndef measure_perfomance(x,y,clf,show_accuracy=True\\\n ,show_classification_report=True\\\n ,show_confusion_matrix=True):\n y_pred = clf.predict(x)\n if show_accuracy:\n print (\"Accuracy:{0:3f}\".format(metrics.accuracy_score(y,y_pred)),\"/n\")\n if show_classification_report:\n print (\"Classification_report\")\n print (metrics.classification_report(y,y_pred),\"/n\")\n if show_confusion_matrix:\n print (\"Confusion matrix\")\n print (metrics.confusion_matrix(y,y_pred), \"/n\")\n\n# Measure performance for Tree Classifier\nmeasure_perfomance(x_test,y_test, clf,show_classification_report=True, \\\n show_confusion_matrix=True)\n\n# Measure performance for Randomr FOrest Classifier\nmeasure_perfomance(x_test,y_test, clf_RF,show_classification_report=True, \\\n show_confusion_matrix=True)\n\ny_pred_RF_output = clf_RF.predict(x_test_data).astype(int)\n\n# Sending data to CSV file using Kaggle code\nKagglePredictionFile = open(\"kagglePredictionTitanicTree.csv\", \"w\")\nopen_file_object = csv.writer(KagglePredictionFile)\nopen_file_object.writerow([\"PassengerId\",\"Survived\"])\nopen_file_object.writerows(zip(ids, y_pred_RF_output))\nKagglePredictionFile.close()\nprint ('Done.')\n\n"
},
{
"alpha_fraction": 0.7268232107162476,
"alphanum_fraction": 0.7398022413253784,
"avg_line_length": 34.15217208862305,
"blob_id": "a656797e9b45b849361a6ff362526b3e58b5a64c",
"content_id": "44bc8498c2e222b54a55cb6f8d2f153cfbc8eaf2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1618,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 46,
"path": "/KaggleTitanicAdvanceTechniques.py",
"repo_name": "racekiller/Kaggle---Titanic-Python-Pandas",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Oct 26 18:34:03 2016\n\n@author: jvivas\n\"\"\"\n\nimport csv as csv\nimport numpy as np\n# Lets do some predictions using Random Forest\n# Import the random forest package\nfrom sklearn.tree import DecisionTreeClassifier\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.cross_validation import train_test_split\nfrom sklearn.metrics import classification_report\nfrom sklearn.pipeline import Pipeline\nfrom sklearn.grid_search import GridSearchCV\nfrom sklearn import tree\nfrom sklearn import metrics\nimport pandas as pd\nfrom sklearn import feature_extraction\n\nWindows_Path = 'C:/Users/jvivas/Dropbox/Private/Personal/Github/Kaggle---Titanic-Python-Pandas'\nMac_Path = '/Users/jvivas/Documents/GitHub/Kaggle - Titanic Python Pandas'\nPath = Mac_Path\n\n# For .read_csv, always use header=0 when you know row 0 is the header row\ndf_original_train = pd.read_csv(Path + '/' + 'train.csv', header=0)\ndf_original_test = pd.read_csv(Path + '/' + 'test.csv', header=0)\ndf_test = pd.read_csv(Path + '/' + 'test.csv', header=0)\ndf = pd.read_csv(Path + '/' + 'train.csv', header=0)\n\n# Lets fill the missing age with the average according to the class where\n# they were\n\n# Let see how many missing values we have per feature\ndf.isnull().sum()\n\n# Lets delete the column we dont need\ndf = df.drop(['Name', 'Ticket', 'Cabin', 'Embarked'], axis=1)\ndf_test = df_test.drop(['Name', 'Ticket', 'Cabin', 'Embarked'], axis=1)\n\n# Now lets delete the entire row for the passenger with missing age\n# I dont want to come up with a fake age which might lead to unaccurate\n# predictions\ndf = df.dropna()\n\n"
}
] | 3 |
kathrine-swe/elsa
|
https://github.com/kathrine-swe/elsa
|
efebff4070549da6bf7eaf1173b703c7eda8681e
|
140a0674158f69fb57eaa36f37ad6d00f8a1bdf3
|
03231bff2cfa0b99398dabf60e0f80308986f967
|
refs/heads/master
| 2020-04-10T23:55:33.731993 | 2019-09-20T16:00:39 | 2019-09-20T16:00:39 | 161,369,055 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.349071204662323,
"alphanum_fraction": 0.35681113600730896,
"avg_line_length": 35.85714340209961,
"blob_id": "47eb28201bde351d7c42d546955c13cfb7bbe030",
"content_id": "fef9355b6385d6dd79b3c5d07139414d50aa62b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1292,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 35,
"path": "/README.md",
"repo_name": "kathrine-swe/elsa",
"src_encoding": "UTF-8",
"text": "_________________________________________________________________________\n \n\n W E L C O M E T O\n\n\nT h e E d u c a t i o n a l L a b e l i n g S y s t e m\n A t m o s p h e r e s\n \n\n\n .. .k+=:. \n k .eLS\" a` ^% \n ELSAk . <k \n .k 'LSAk .ATmosP\" \n pdELSA. LSAk .pDSATMO\" pdsATM. \n :PDS'ELSA. LSAk pDS: `)Ek. .@LS \"ELSA\" \n atmo 'ELS\" LSAk ATMOS=*ELSA ELSA ELSA \n atmo.+\" LSAk %4\" PDS ELSA ELSA \n atmos LSAk @elsa 4% ELSA ELSA \n 'atmos. .+ .LSAk . .888888P` ELSA ELSA \n \"atmos% ^*SAk ` ^\"F \"PDS4\"\"\"PDS\" \n \"PD' \"A ^K\" ^K' \n\n\n------------------------------------------------------------------------\n\nWHAT IS ELSA?\n\nELSA is a web application created to help streamline the process of\nmaking metadata labels for atmospheric planetary scientists such that\nthere metadata is in accordance with PDS4 standard, an international\nmetadata standard used for archiving planetary data.\n\n________________________________________________________________________\n\n\n"
},
{
"alpha_fraction": 0.565822958946228,
"alphanum_fraction": 0.5713644027709961,
"avg_line_length": 31.396440505981445,
"blob_id": "785b4e7b0ede1265a12ff274157b77e6f77724e3",
"content_id": "1227e91920104bd41e1ff74d3796e02abf5f23fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 20031,
"license_type": "no_license",
"max_line_length": 178,
"num_lines": 618,
"path": "/context/models.py",
"repo_name": "kathrine-swe/elsa",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom django.db import models\nfrom django.conf import settings\nfrom django.contrib.auth.models import User\nfrom django.http import HttpResponseRedirect\nfrom django.shortcuts import render, redirect, render_to_response\nfrom django.urls import reverse\nfrom django.utils.encoding import python_2_unicode_compatible\nfrom shutil import copyfile\n#from .chocolate import *\nimport datetime\nimport shutil\nimport os\n\n\n# Final Variables --------------------------------------------------------------------------------\nMAX_CHAR_FIELD = 100\nMAX_LID_FIELD = 255\nMAX_TEXT_FIELD = 1000\n\nPDS4_LABEL_TEMPLATE_DIRECTORY = os.path.join(settings.TEMPLATE_DIR, 'pds4_labels')\n\n\n\n\n# Notes about models before you get started:\n# \n# When an object has a name, the name is in the format specified in the lid, not the title.\n# It is important to keep it this way because that is how it is used in the urls on starbase\n# minus a little formatting for vids.\n#\n\n\n# Create your models here.\n\n\"\"\"\n10.21 Investigation_Area\n\nRoot Class:Product_Components\nRole:Concrete\n\nClass Description:The Investigation_Area class provides information about an investigation (mission, observing campaign or other coordinated, large-scale data collection effort).\n\nSteward:pds\nNamespace Id:pds\nVersion Id:1.1.0.0\n \tEntity \tCard \tValue/Class \tInd\n\nHierarchy\tProduct_Components\t \t \t \n \t . Investigation_Area\t \t \t \nSubclass\tnone\t \t \t \nAttribute\tname\t1\t \t \n \t type\t1\tIndividual Investigation\t \n \t \t \t Mission\t \n \t \t \tObserving Campaign\t \n \t \t \tOther Investigation\t \nInherited Attribute\tnone\t \t \t \nAssociation\t internal_reference\t1..*\tInternal_Reference\t \nInherited Association\tnone\t \t \t \n\nReferenced from\tContext_Area\t \t \t \n \tObservation_Area\t \t \t \n\"\"\"\nclass InvestigationManager(models.Manager):\n def update_version(self, product_dict):\n self.vid = product_dict['vid']\n self.lid = product_dict['lid']\n self.starbase_label = product_dict['url']\n self.save()\n\n\nclass Investigation(models.Model):\n INVESTIGATION_TYPES = [\n ('individual','individual'),\n ('mission','mission'),\n ('observing_campaign','observing_campaign'),\n ('other_investigation','other_investigation'),\n ]\n\n # Attributes used for crawler\n name = models.CharField(max_length=MAX_CHAR_FIELD)\n type_of = models.CharField(max_length=MAX_CHAR_FIELD, choices=INVESTIGATION_TYPES)\n lid = models.CharField(max_length=MAX_CHAR_FIELD)\n vid = models.FloatField(default=1.0)\n internal_references = []\n starbase_label = models.CharField(max_length=MAX_CHAR_FIELD) \n\n # Attributes used to manage Investigation object\n #objects = InvestigationManager()\n\n\n\n def update_version(self, product_dict):\n self.vid = product_dict['vid']\n self.lid = product_dict['lid']\n self.starbase_label = product_dict['url']\n self.save()\n\n def __str__(self):\n return self.name\n\n\n\n\n\"\"\"\n14.3 Instrument\n\nRoot Class:Tagged_NonDigital_Object\nRole:Concrete\n\nClass Description:The Instrument class provides a description of a physical object that collects data.\n\nSteward:pds\nNamespace Id:pds\nVersion Id:1.3.0.0\n \tEntity \tCard \tValue/Class \tInd\nHierarchy\tTagged_NonDigital_Object\t \t \t \n \t. TNDO_Context\t \t \t \n \t . . Instrument\t \t \t \nSubclass\tnone\t \t \t \n\nAttribute\tdescription\t 1\t \t \n \tmodel_id\t 0..1\t \t \n naif_instrument_id\t0..1\t \t \n \tname\t 0..1\t \t \n \t serial_number\t 0..1\t \t \n \t subtype\t 0..*\t \t \n \t type\t 1..*\tAccelerometer\t \n \t \t \tAlpha Particle Detector\t \n \t \t \tAlpha Particle X-Ray Spectrometer\t \n \t \t \tAltimeter\t \n \t \t \tAnemometer\t \n \t \t \tAtmospheric Sciences\t \n \t \t \tAtomic Force Microscope\t \n \t \t \tBarometer\t \n \t \t \tBiology Experiments\t \n \t \t \tBolometer\t \n \t \t \tCamera\t \n \t \t \tCosmic Ray Detector\t \n \t \t \tDrilling Tool\t \n \t \t \tDust\t \n \t \t \tDust Detector\t \n \t \t \tElectrical Probe\t \n \t \t \tEnergetic Particle Detector\t \n \t \t \tGamma Ray Detector\t \n \t \t \tGas Analyzer\t \n \t \t \tGravimeter\t \n \t \t \tGrinding Tool\t \n \t \t \tHygrometer\t \n \t \t \tImager\t \n \t \t \tImaging Spectrometer\t \n \t \t \tInertial Measurement Unit\t \n \t \t \tInfrared Spectrometer\t \n \t \t \tInterferometer\t \n \t \t \tLaser Induced Breakdown Spectrometer\t \n \t \t \tMagnetometer\t \n \t \t \tMass Spectrometer\t \n \t \t \tMicroscope\t \n \t \t \tMicrowave Spectrometer\t \n \t \t \tMoessbauer Spectrometer\t \n \t \t \tNaked Eye\t \n \t \t \tNeutral Particle Detector\t \n \t \t \tNeutron Detector\t \n \t \t \tParticle Detector\t \n \t \t \tPhotometer\t \n \t \t \tPlasma Analyzer\t \n \t \t \tPlasma Detector\t \n \t \t \tPlasma Wave Spectrometer\t \n \t \t \tPolarimeter\t \n \t \t \tRadar\t \n \t \t \tRadio Science\t \n \t \t \tRadio Spectrometer\t \n \t \t \tRadio Telescope\t \n \t \t \tRadio-Radar\t \n \t \t \tRadiometer\t \n \t \t \tReflectometer\t \n \t \t \tRegolith Properties\t \n \t \t \tRobotic Arm\t \n \t \t \tSeismometer\t \n \t \t \tSmall Bodies Sciences\t \n \t \t \tSpectrograph\t \n \t \t \tSpectrograph Imager\t \n \t \t \tSpectrometer\t \n \t \t \tThermal Imager\t \n \t \t \tThermal Probe\t \n \t \t \tThermometer\t \n \t \t \tUltraviolet Spectrometer\t \n \t \t \tWeather Station\t \n \t \t \tWet Chemistry Laboratory\t \n \t \t \tX-ray Detector\t \n \t \t \tX-ray Diffraction Spectrometer\t \n \t \t \tX-ray Fluorescence Spectrometer\t \nInherited Attribute\tnone\t \t \t \nAssociation \tdata_object\t1\tPhysical_Object\t \nInherited Association\tnone\t \t \t \n\nReferenced from\tProduct_Context\t \t \t \n\"\"\"\nclass InstrumentManager(models.Manager):\n def update_version(self, product_dict):\n self.vid = product_dict['vid']\n self.lid = product_dict['lid']\n self.starbase_label = product_dict['url']\n self.save()\n\nclass Instrument(models.Model):\n INSTRUMENT_TYPES = [\n ('Accelerometer','Accelerometer'),\n ('Alpha Particle Detector','Alpha Particle Detector'),\n ('Alpha Particle X-Ray Spectrometer','Alpha Particle X-Ray Spectrometer'),\n ('Altimeter','Altimeter'),\n ('Anemometer','Anemometer'),\n ('Atmospheric Sciences','Atmospheric Sciences'),\n ('Atomic Force Microscope','Atomic Force Microscope'),\n ('Barometer','Barometer'),\n ('Biology Experiments','Biology Experiments'),\n ('Bolometer','Bolometer'),\n ('Camera','Camera'),\n ('Cosmic Ray Detector','Cosmic Ray Detector'),\n ('Drilling Tool','Drilling Tool'),\n ('Dust','Dust'),\n ('Dust Detector','Dust Detector'),\n ('Electrical Probe','Electrical Probe'),\n ('Energetic Particle Detector','Energetic Particle Detector'),\n ('Gamma Ray Detector','Gamma Ray Detector'),\n ('Gas Analyzer','Gas Analyzer'),\n ('Gravimeter','Gravimeter'),\n ('Grinding Tool','Grinding Tool'),\n ('Hygrometer','Hygrometer'),\n ('Imager','Imager'),\n ('Imaging Spectrometer','Imaging Spectrometer'),\n ('Inertial Measurement Unit','Inertial Measurement Unit'),\n ('Infrared Spectrometer','Infrared Spectrometer'),\n ('Interferometer','Interferometer'),\n ('Laser Induced Breakdown Spectrometer','Laser Induced Breakdown Spectrometer'),\n ('Magnetometer','Magnetometer'),\n ('Mass Spectrometer','Mass Spectrometer'),\n ('Microscope','Microscope'),\n ('Microwave Spectrometer','Microwave Spectrometer'),\n ('Moessbauer Spectrometer','Moessbauer Spectrometer'),\n ('Naked Eye','Naked Eye'),\n ('Neutral Particle Detector','Neutral Particle Detector'),\n ('Neutron Detector','Neutron Detector'),\n ('Particle Detector','Particle Detector'),\n ('Photometer','Photometer'),\n ('Plasma Analyzer','Plasma Analyzer'),\n ('Plasma Detector','Plasma Detector'),\n ('Plasma Wave Spectrometer','Plasma Wave Spectrometer'),\n ('Polarimeter','Polarimeter'),\n ('Radar','Radar'),\n ('Radio Science','Radio Science'),\n ('Radio Spectrometer','Radio Spectrometer'),\n ('Radio Telescope','Radio Telescope'),\n ('Radio-Radar','Radio-Radar'),\n ('Radiometer','Radiometer'),\n ('Reflectometer','Reflectometer'),\n ('Regolith Properties','Regolith Properties'),\n ('Robotic Arm','Robotic Arm'),\n ('Seismometer','Seismometer'),\n ('Small Bodies Sciences','Small Bodies Sciences'),\n ('Spectrograph','Spectrograph'),\n ('Spectrograph Imager','Spectrograph Imager'),\n ('Spectrometer','Spectrometer'),\n ('Thermal Imager','Thermal Imager'),\n ('Thermal Probe','Thermal Probe'),\n ('Thermometer','Thermometer'),\n ('Ultraviolet Spectrometer','Ultraviolet Spectrometer'),\n ('Weather Station','Weather Station'),\n ('Wet Chemistry Laboratory','Wet Chemistry Laboratory'),\n ('X-ray Detector','X-ray Detector'),\n ('X-ray Diffraction Spectrometer','X-ray Diffraction Spectrometer'),\n ('X-ray Fluorescence Spectrometer','X-ray Fluorescence Spectrometer'),\n ]\n # Relational Attributes\n\n # Attributes used for crawler\n lid = models.CharField(max_length=MAX_CHAR_FIELD)\n name = models.CharField(max_length=MAX_CHAR_FIELD)\n type_of = models.CharField(max_length=MAX_CHAR_FIELD, choices=INSTRUMENT_TYPES)\n vid = models.FloatField(default=1.0)\n starbase_label = models.CharField(max_length=MAX_CHAR_FIELD)\n\n # Attributes used to manage Instrument Host object\n #objects = InstrumentManager()\n\n # Meta\n def __str__(self):\n return self.name\n\n def update_version(self, product_dict):\n self.vid = product_dict['vid']\n self.lid = product_dict['lid']\n self.starbase_label = product_dict['url']\n self.save()\n\n\n\n\n\n\n\n\n\"\"\"\n14.8 Target\n\nRoot Class:Tagged_NonDigital_Object\nRole:Concrete\nClass Description:The Target class provides a description of a physical object that is the object of data collection.\nSteward:pds\nNamespace Id:pds\nVersion Id:1.3.0.0\n \tEntity \tCard \tValue/Class \tInd\nHierarchy\tTagged_NonDigital_Object\t \t \t \n \t. TNDO_Context\t \t \t \n \t. . Target\t \t \t \nSubclass\tnone\t \t \t\nAttribute\tdescription\t1\t \t \n \tname\t0..1\t \t \n \ttype\t0..*\tAsteroid\t \n \t \t \tCalibration\t \n \t \t \tCalibration Field\t \n \t \t \tCalibrator\t \n \t \t \tComet\t \n \t \t \tDust\t \n \t \t \tDwarf Planet\t \n \t \t \tEquipment\t \n \t \t \tExoplanet System\t \n \t \t \tGalaxy\t \n \t \t \tGlobular Cluster\t \n \t \t \tLunar Sample\t \n \t \t \tMeteorite\t \n \t \t \tMeteoroid\t \n \t \t \tMeteoroid Stream\t \n \t \t \tNebula\t \n \t \t \tOpen Cluster\t \n \t \t \tPlanet\t \n \t \t \tPlanetary Nebula\t \n \t \t \tPlanetary System\t \n \t \t \tPlasma Cloud\t \n \t \t \tPlasma Stream\t \n \t \t \tRing\t \n \t \t \tSatellite\t \n \t \t \tStar\t \n \t \t \tStar Cluster\t \n \t \t \tSun\t \n \t \t \tSynthetic Sample\t \n \t \t \tTerrestrial Sample\t \n \t \t \tTrans-Neptunian Object\t \nInherited Attribute\tnone\t \t \t \nAssociation\tdata_object\t1\tPhysical_Object\t \nInherited Association\tnone\t \t \t \nReferenced from\tProduct_Context\t \t \t \n\"\"\"\nclass TargetManager(models.Manager):\n def update_version(self, product_dict):\n self.vid = product_dict['vid']\n self.lid = product_dict['lid']\n self.starbase_label = product_dict['url']\n self.save()\n\n@python_2_unicode_compatible\nclass Target(models.Model):\n TARGET_TYPES = [\n ('Asteroid','Asteroid'),\n ('Calibration','Calibration'),\n ('Calibration Field','Calibration Field'),\n ('Calibrator','Calibrator'),\n ('Comet','Comet'),\n ('Dust','Dust'),\n ('Dwarf Planet','Dwarf Planet'),\n ('Equipment','Equipment'),\n ('Exoplanet System','Exoplanet System'),\n ('Galaxy','Galaxy'),\n ('Globular Cluster','Globular Cluster'),\n ('Lunar Sample','Lunar Sample'),\n ('Meteorite','Meteorite'),\n ('Meteoroid','Meteoroid'),\n ('Meteoroid Stream','Meteoroid Stream'),\n ('Nebula','Nebula'),\n ('Open Cluster','Open Cluster'),\n ('Planet','Planet'),\n ('Planetary Nebula','Planetary Nebula'),\n ('Planetary System','Planetary System'),\n ('Plasma Cloud','Plasma Cloud'),\n ('Plasma Stream','Plasma Stream'),\n ('Ring','Ring'),\n ('Satellite','Satellite'),\n ('Star','Star'),\n ('Star Cluster','Star Cluster'),\n ('Sun','Sun'),\n ('Synthetic Sample','Synthetic Sample'),\n ('Target Analog', 'Target Analog'),\n ('Terrestrial Sample','Terrestrial Sample'),\n ('Trans-Neptunian Object','Trans-Neptunian Object'),\n ]\n # Relational Attributes\n\n # Attributes used for crawler\n lid = models.CharField(max_length=MAX_CHAR_FIELD)\n name = models.CharField(max_length=MAX_CHAR_FIELD)\n type_of = models.CharField(max_length=MAX_CHAR_FIELD, choices=TARGET_TYPES)\n vid = models.FloatField(default=1.0)\n starbase_label = models.CharField(max_length=MAX_CHAR_FIELD)\n\n # Attributes used to manage Instrument Host object\n #objects = TargetManager()\n\n # Meta\n def __str__(self):\n return self.name\n\n def update_version(self, product_dict):\n self.vid = product_dict['vid']\n self.lid = product_dict['lid']\n self.starbase_label = product_dict['url']\n self.save()\n\n\n\n\n\n\n\n\n\"\"\"\n14.4 Instrument_Host\n\nRoot Class:Tagged_NonDigital_Object\nRole:Concrete\n\nClass Description:The Instrument Host class provides a description of the physical object upon which an instrument is mounted.\n\nSteward:pds\nNamespace Id:pds\nVersion Id:1.3.0.0\n \tEntity \tCard \tValue/Class \tInd\nHierarchy\tTagged_NonDigital_Object\t \t \t \n \t. TNDO_Context\t \t \t \n \t. . Instrument_Host\t \t \t \nSubclass\tnone\t \t \t \n\nAttribute\tdescription\t 1\t \t \n \tinstrument_host_version_id *Deprecated*\t0..1\t \t \n \tnaif_host_id\t 0..1\t \t \n \tname\t 0..1\t \t \n \tserial_number\t 0..1\t \t \n \ttype\t 1\tEarth Based\t \n \t \t \t Earth-based\t \n \t \t \t Lander\t \n \t \t \t Rover\t \n \t \t \t Spacecraft\t \n \tversion_id *Deprecated*\t 0..1\t \t \n\nInherited Attribute\tnone\t \t \t \nAssociation \tdata_object\t1\tPhysical_Object\t \nInherited Association\tnone\t \t \t \n\nReferenced from\tProduct_Context\t \t \t \n\"\"\"\nclass Instrument_HostManager(models.Manager):\n def update_version(self, product_dict):\n self.vid = product_dict['vid']\n self.lid = product_dict['lid']\n self.starbase_label = product_dict['url']\n self.save()\n\n@python_2_unicode_compatible\nclass Instrument_Host(models.Model):\n INSTRUMENT_HOST_TYPES = [\n ('Earth Based','Earth Based'),\n ('Lander', 'Lander'),\n ('Rover', 'Rover'),\n ('Spacecraft','Spacecraft'),\n ('unk','unk'), # This is only for a fix in Starbase and should be deleted once fixed\n ]\n\n # Relational Attributes\n investigations = models.ManyToManyField(Investigation)\n instruments = models.ManyToManyField(Instrument)\n targets = models.ManyToManyField(Target)\n\n # Attributes used for crawler\n lid = models.CharField(max_length=MAX_CHAR_FIELD)\n name = models.CharField(max_length=MAX_CHAR_FIELD)\n type_of = models.CharField(max_length=MAX_CHAR_FIELD, choices=INSTRUMENT_HOST_TYPES)\n vid = models.FloatField(default=1.0)\n starbase_label = models.CharField(max_length=MAX_CHAR_FIELD)\n\n # Attributes used to manage Instrument Host object\n #objects = Instrument_HostManager()\n\n\n\n # Meta\n def __str__(self):\n return self.name\n\n def update_version(self, product_dict):\n self.vid = product_dict['vid']\n self.lid = product_dict['lid']\n self.starbase_label = product_dict['url']\n self.save()\n\n\n\n\n\n\n\n\"\"\"\n14.2 Facility\n\nRoot Class:Tagged_NonDigital_Object\nRole:Concrete\n\nClass Description:The Facility class provides a name and address for a terrestrial observatory or laboratory.\n\nSteward:pds\nNamespace Id:pds\nVersion Id:1.0.0.0\n \tEntity \tCard \tValue/Class \tInd\nHierarchy\tTagged_NonDigital_Object\t \t \t \n \t. TNDO_Context\t \t \t \n \t . . Facility\t \t \t \nSubclass\tnone\t \t \t \nAttribute\taddress\t 0..1\t \t \n \t country\t 0..1\t \t \n \t description\t0..1\t \t \n \t name\t 0..1\t \t \n \t type\t 1\tLaboratory\t \n \t \t \t Observatory\t \n\nInherited Attribute\tnone\t \t \t \nAssociation\t data_object\t1\tPhysical_Object\t \nInherited Association\tnone\t \t \t \n\nReferenced from\tProduct_Context\t \t \t \n\"\"\"\n@python_2_unicode_compatible\nclass Facility(models.Model):\n FACILITY_TYPES = [\n ('Laboratory','Laboratory'),\n ('Observatory','Observatory'),\n ]\n\n # Relational attribute\n instrument = models.ManyToManyField(Instrument)\n\n # Characteristic attributes\n lid = models.CharField(max_length=MAX_CHAR_FIELD)\n name = models.CharField(max_length=MAX_CHAR_FIELD)\n type_of = models.CharField(max_length=MAX_CHAR_FIELD, choices=FACILITY_TYPES) \n version = models.FloatField(default=1.0)\n\n vid = models.FloatField(default=1.0)\n starbase_label = models.CharField(max_length=MAX_CHAR_FIELD)\n\n # Accessors\n def name_lid_case(self):\n # Convert name to lower case\n name_edit = self.name.lower()\n # Convert spaces to underscores\n name_edit = replace_all(name_edit, ' ', '_')\n\n # Meta\n def __str__(self):\n return self.name\n\n def update_version(self, product_dict):\n self.vid = product_dict['vid']\n self.lid = product_dict['lid']\n self.starbase_label = product_dict['url']\n self.save()\n\n\n\n\n\n\n\n\"\"\"\nTelescope\t \t \n\"\"\"\nclass TelescopeManager(models.Manager):\n def update_version(self, product_dict):\n self.vid = product_dict['vid']\n self.lid = product_dict['lid']\n self.starbase_label = product_dict['url']\n self.save()\n\n@python_2_unicode_compatible\nclass Telescope(models.Model):\n\n # Relational Attributes\n facilities = models.ManyToManyField(Facility)\n\n # Attributes used for crawler\n lid = models.CharField(max_length=MAX_CHAR_FIELD)\n name = models.CharField(max_length=MAX_CHAR_FIELD)\n vid = models.FloatField(default=1.0)\n starbase_label = models.CharField(max_length=MAX_CHAR_FIELD)\n\n # Attributes used to manage Instrument Host object\n #objects = Instrument_HostManager()\n\n\n\n # Meta\n def __str__(self):\n return self.name\n\n def update_version(self, product_dict):\n self.vid = product_dict['vid']\n self.lid = product_dict['lid']\n self.starbase_label = product_dict['url']\n self.save()\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6614837646484375,
"alphanum_fraction": 0.6619280576705933,
"avg_line_length": 37.81034469604492,
"blob_id": "28d809c4d7743f49267fc89cc0227947e0183105",
"content_id": "c0c9a18269d01e4fa95dce78a51a5fd9c772a71f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2251,
"license_type": "no_license",
"max_line_length": 185,
"num_lines": 58,
"path": "/build/urls.py",
"repo_name": "kathrine-swe/elsa",
"src_encoding": "UTF-8",
"text": "# Stdlib imports\n\n# Core Django imports\nfrom django.conf.urls import url, include\n\n# Third-party app imports\n\n# Imports from apps\nfrom . import views\n\n\n\napp_name='build'\nurlpatterns = [\n # Alias\n url(r'^(?P<pk_bundle>\\d+)/alias/$', views.alias, name='alias'),\n\n # Build\n url(r'^$', views.build, name='build'),\n\n # Bundle\n url(r'^(?P<pk_bundle>\\d+)/$', views.bundle, name='bundle'), # Secure\n url(r'^(?P<pk_bundle>\\d+)/confirm_delete/$', views.bundle_delete, name='bundle_delete'), # Secure\n url(r'^(?P<pk_bundle>\\d+)/download/$', views.bundle_download, name='bundle_download'), # Need to secure.\n\n # Citation_Information\n url(r'^(?P<pk_bundle>\\d+)/citation_information/$', views.citation_information, name='citation_information'),\n\n # Collections\n\n\n # Context\n url(r'^(?P<pk_bundle>\\d+)/contextsearch/$', views.context_search, name='context_search'),\n url(r'^(?P<pk_bundle>\\d+)/contextsearch/investigation/$', views.context_search_investigation, name='context_search_investigation'),\n url(r'^(?P<pk_bundle>\\d+)/contextsearch/investigation/(?P<pk_investigation>\\d+)/instrument_host/$', views.context_search_instrument_host, name='context_search_instrument_host'),\n #url(r'^(?P<pk_bundle>\\d+)/contextsearch/mission/(?P<pk_instrument_host>\\d+)/$', views.instrument_host_detail, name='instrument_host_detail'),\n #url(r'^(?P<pk_bundle>\\d+)/contextsearch/mission/(?P<pk_instrument_host>\\d+)/instrument/(?P<pk_instrument>\\d+)/confirm_delete/$', views.instrument_delete, name='instrument_delete'),\n #url(r'^(?P<pk_bundle>\\d+)/contextsearch/facility/$', views.context_search_facility, name='context_search_facility'),\n\n\n # Data\n url(r'^(?P<pk_bundle>\\d+)/data/$', views.data, name='data'),\n url(r'^(?P<pk_bundle>\\d+)/data/(?P<pk_product_observational>\\d+)/$', views.product_observational, name='product_observational'),\n\n # Document\n url(r'^(?P<pk_bundle>\\d+)/document/$', views.document, name='document'),\n url(r'^(?P<pk_bundle>\\d+)/document/product_document/(?P<pk_product_document>\\d+)/$', views.product_document, name='product_document'),\n\n\n # XML_Schema --> A view that no one sees. So no xml_schema url. This might even be removed \n # completely from PDS4\n\n\n\n\n\n # TEST\n]\n"
},
{
"alpha_fraction": 0.6912568211555481,
"alphanum_fraction": 0.6912568211555481,
"avg_line_length": 27.153846740722656,
"blob_id": "fb0b13472fdc8444679eb09959a9a63d5acf5488",
"content_id": "683517d93c2190e4bc0c240b2776cf2d887acf83",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 366,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 13,
"path": "/context/urls.py",
"repo_name": "kathrine-swe/elsa",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\nfrom . import views\n\n\n\napp_name='context'\nurlpatterns = [\n url(r'^$', views.context, name='context'),\n url(r'^investigations/$', views.investigations, name='investigations'),\n url(r'^instruments/$', views.instruments, name='instruments'),\n url(r'^instrument_hosts/$', views.instrument_hosts, name='instrument_hosts'),\n\n]\n"
},
{
"alpha_fraction": 0.7162293195724487,
"alphanum_fraction": 0.7172011733055115,
"avg_line_length": 24.09756088256836,
"blob_id": "4a3fb001e51289063f7d8f16134a93a4564caf57",
"content_id": "9e4c42d58a755851fca79bfbaee70f015bfc8663",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1029,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 41,
"path": "/context/views.py",
"repo_name": "kathrine-swe/elsa",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom django.shortcuts import render\nfrom django.contrib.auth.decorators import login_required\nfrom .models import Investigation, Instrument_Host, Instrument\n\n\n# Create your views here.\n\n@login_required\ndef context(request):\n context_dict = {\n }\n\n return render(request, 'context/repository/repository.html', context_dict)\n\n\n#@login_required\ndef investigations(request):\n context_dict = {\n 'investigations':Investigation.objects.all(),\n }\n\n return render(request, 'context/repository/investigations.html', context_dict)\n\n#@login_required\ndef instrument_hosts(request):\n context_dict = {\n 'instrument_hosts':Instrument_Host.objects.all(),\n }\n\n return render(request, 'context/repository/instrument_hosts.html', context_dict)\n\n#@login_required\ndef instruments(request):\n context_dict = {\n 'instruments':Instrument.objects.all(),\n }\n\n return render(request, 'context/repository/instruments.html', context_dict)\n"
},
{
"alpha_fraction": 0.5297772884368896,
"alphanum_fraction": 0.5308130383491516,
"avg_line_length": 16.445453643798828,
"blob_id": "5dde1e96df96cc821c466cb87b7fa991a46a6702",
"content_id": "22cf55a3788b7166c1cbc61d7c7aadaecd8804ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1931,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 110,
"path": "/context/forms.py",
"repo_name": "kathrine-swe/elsa",
"src_encoding": "UTF-8",
"text": "from django import forms\nfrom django.contrib.auth.models import User\nfrom .chocolate import replace_all\n\nfrom lxml import etree\nimport urllib2, urllib\nimport datetime\n\nfrom .models import *\n# ------------------------------------------------------------------------------------------------------ #\n# ------------------------------------------------------------------------------------------------------ #\n#\n# FORMS\n#\n# The following forms are mostly associated with models. The first form, ConfirmForm, is an example \n# of a form that is not associated with any models. The specification for the PDS4 components \n# (ex: Alias, Bundle, ...) can be found in models.py with the corresponding model object. The comments\n# for the following forms should include the input format rules. This information may or may not need\n# to be in models over forms. I'm not too sure where we will decide to do our data checking as of yet.\n# Some models listed below that have choices do include the specification as a part of data checking.\n#\n# TASK: Add data checking/cleaning to fit ELSA standard.\n#\n# ------------------------------------------------------------------------------------------------------ #\n\n\n\n\n\"\"\"\n Instrument_Host\n\"\"\"\nclass InstrumentHostForm(forms.ModelForm):\n class Meta:\n model = InstrumentHost\n exclude = ('',)\n\n\n\n\n\n\n\n\n\n\n\n\"\"\"\n Instrument\n\"\"\"\nclass InstrumentForm(forms.ModelForm):\n class Meta:\n model = Instrument\n exclude = ('',)\n\n\n\n\n\n\n\n\n\n\n\n\"\"\"\n Mission\n\"\"\"\nclass MissionForm(forms.ModelForm):\n class Meta:\n model = Mission\n exclude = ('',)\n\n\n\n\n\n\n\n\n\n\n\n\n\n\"\"\"\n Target\n\"\"\"\nclass TargetForm(forms.ModelForm):\n class Meta:\n model = Target\n exclude = ('',)\n\n\n\n\n\n\n\n\n\n\n\n\n\"\"\"\n Facility\n\"\"\"\nclass Facility(forms.ModelForm):\n class Meta:\n model = Facility\n exclude = ('',)\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6239168047904968,
"alphanum_fraction": 0.6256499290466309,
"avg_line_length": 26.4761905670166,
"blob_id": "ccd2f60fda7ddfb27ab6318b68f5019daad1dd8f",
"content_id": "8e681aa747bf9b0a3188a7d614385e1abd6593fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 577,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 21,
"path": "/templates/context/repository/instrument_hosts.html",
"repo_name": "kathrine-swe/elsa",
"src_encoding": "UTF-8",
"text": "{% extends 'main/base-k.html' %}\n{% load static %}\n<link rel=\"stylesheet\" href=\"{ % static 'js/context.js' % }\">\n\n{% block title_block %}\nELSA Context Repository - Instrument Hosts\n{% endblock %}\n\n{% block main_header_block %}\nELSA Context Repository - Instrument Hosts\n{% endblock %}\n\n{% block body_block %}\n<table>\n {% for instrument_host in instrument_hosts %}\n <tr><a href=\"{% url 'main:construction' %}\">\n <button class=\"btn btn-indigo mb-3\">{{ instrument_host.name }}<br/>{{ instrument_host.lid }}</button></a></tr>\n {% endfor %}\n\n</table>\n{% endblock %}\n"
}
] | 7 |
bobocaicai/pygame_practice
|
https://github.com/bobocaicai/pygame_practice
|
f82fed87f69954b93d3f6e44da8508df10dfaf55
|
db182198c063cbc42e095b421e1f4ba446e8a8d4
|
767541ed5ef1b0e4780d4ad7ad3de634d7117231
|
refs/heads/master
| 2020-06-11T03:05:59.624803 | 2016-12-15T08:48:33 | 2016-12-15T08:48:33 | 76,017,203 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4145110547542572,
"alphanum_fraction": 0.507255494594574,
"avg_line_length": 29.700000762939453,
"blob_id": "0119c86ce19d38511732461b0a92b71a0d6a0aaf",
"content_id": "12b46aa54fc53aa48a783509bc696c428a34ba0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1585,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 50,
"path": "/test11.py",
"repo_name": "bobocaicai/pygame_practice",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Thu Dec 15 10:23:10 2016\r\n\r\n@author: student\r\n\"\"\"\r\nimport pygame\r\nfrom pygame.locals import *\r\nfrom sys import exit\r\nfrom random import *\r\nfrom math import pi\r\n\r\npygame.init()\r\nscreen=pygame.display.set_mode((640,480),0,32)\r\npoints=[]\r\n\r\nwhile True:\r\n for event in pygame.event.get():\r\n if event.type==QUIT:\r\n exit()\r\n if event.type==KEYDOWN:\r\n points=[]\r\n screen.fill((255,255,255))\r\n if event.type==MOUSEBUTTONDOWN:\r\n screen.fill((255,255,255))\r\n \r\n rc=(randint(0,255),randint(0,255),randint(0,255))\r\n rp=(randint(0,639),randint(0,479))\r\n rs=(639-randint(rp[0],639),479-randint(rp[1],479))\r\n pygame.draw.rect(screen,rc,Rect(rp,rs))\r\n \r\n rp=(randint(0,639),randint(0,479))\r\n rr=randint(1,200)\r\n pygame.draw.circle(screen,rc,rp,rr)\r\n \r\n x,y=pygame.mouse.get_pos()\r\n points.append((x,y))\r\n angle=(x/639.)*pi*2.\r\n pygame.draw.arc(screen,(0,0,0),(0,0,639,479),0,angle,3)\r\n \r\n pygame.draw.ellipse(screen,(0,255,0),(0,0,x,y))\r\n \r\n pygame.draw.line(screen,(0,0,255),(0,0),(x,y))\r\n pygame.draw.line(screen,(255,0,0),(640,480),(x,y))\r\n \r\n if len(points)>1:\r\n pygame.draw.lines(screen,(155,155,0),False,points,2)\r\n for p in points:\r\n pygame.draw.circle(screen,(155,155,155),p,3)\r\n pygame.display.update()\r\n"
},
{
"alpha_fraction": 0.4602150619029999,
"alphanum_fraction": 0.49892473220825195,
"avg_line_length": 21.846153259277344,
"blob_id": "75a3c71abbfeb40c8ca361203c5feb2c59aebb11",
"content_id": "2df28b882db49269d99e668ce4d1194cad9d3ebd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 930,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 39,
"path": "/test4.py",
"repo_name": "bobocaicai/pygame_practice",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Fri Dec 09 17:20:02 2016\r\n\r\n@author: student\r\n\"\"\"\r\nimport pygame\r\nfrom pygame.locals import *\r\nfrom sys import exit\r\n\r\npygame.init()\r\nscreen=pygame.display.set_mode((640,480),0,32)\r\nbackground=pygame.image.load('d:/2/sushiplate.jpg').convert()\r\n\r\nx,y=0,0\r\nmove_x,move_y=0,0\r\n\r\nwhile True:\r\n for event in pygame.event.get():\r\n if event.type==QUIT:\r\n exit()\r\n if event.type==KEYDOWN:\r\n if event.key==K_LEFT:\r\n move_x=-1\r\n elif event.key==K_RIGHT:\r\n move_x=1\r\n elif event.key==K_UP:\r\n move_y=-1\r\n elif event.key==K_DOWN:\r\n move_y=1\r\n elif event.type==KEYUP:\r\n move_x=0\r\n move_y=0\r\n x+=move_x\r\n y+=move_y\r\n \r\n screen.fill((0,0,0))\r\n screen.blit(background,(x,y))\r\n pygame.display.update()\r\n"
},
{
"alpha_fraction": 0.5825825929641724,
"alphanum_fraction": 0.6696696877479553,
"avg_line_length": 23.769229888916016,
"blob_id": "49982ddc792cfe42a95314cca49fc1a92038a4c3",
"content_id": "34136acb5b08e61ca2e4e839bfbdd94dd355c733",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 353,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 13,
"path": "/test6.py",
"repo_name": "bobocaicai/pygame_practice",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Fri Dec 09 20:18:13 2016\r\n\r\n@author: student\r\n\"\"\"\r\nimport pygame\r\nmy_name='Hello World!'\r\npygame.init()\r\nmy_font=pygame.font.SysFont(\"youyuan\",64)\r\n#pygame.font.get_fonts()可以得到系统可用字体\r\nname_surface=my_font.render(my_name,True,(0,0,0),(255,255,255))\r\npygame.image.save(name_surface,\"d:/2/name1.png\")"
},
{
"alpha_fraction": 0.49683257937431335,
"alphanum_fraction": 0.6018099784851074,
"avg_line_length": 24.35714340209961,
"blob_id": "475f2868801e1ddc51a325612c4faa4df0058c08",
"content_id": "40c4cd225d0394843dbd7b408aca1b063ac9b478",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1105,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 42,
"path": "/test9.py",
"repo_name": "bobocaicai/pygame_practice",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Fri Dec 09 21:05:42 2016\r\n\r\n@author: student\r\n\"\"\"\r\n\r\nimport pygame\r\nfrom pygame.locals import *\r\nfrom sys import exit\r\n\r\npygame.init()\r\nscreen=pygame.display.set_mode((640,480),0,32)\r\ncolor1=(0,0,0)\r\ncolor2=(255,255,255)\r\nfactor=0.\r\n\r\ndef blend_color(color1,color2,blend_factor):\r\n r1,g1,b1=color1\r\n r2,g2,b2=color2\r\n r=r1+(r2-r1)*blend_factor\r\n g=g1+(g2-g1)*blend_factor\r\n b=b1+(b2-b1)*blend_factor\r\n return int(r),int(g),int(b)\r\n \r\nwhile True:\r\n for event in pygame.event.get():\r\n if event.type==QUIT:\r\n exit()\r\n \r\n screen.fill((255,255,255))\r\n tri=[(0,120),(639,100),(639,140)]\r\n pygame.draw.polygon(screen,(0,255,0),tri)\r\n pygame.draw.circle(screen,(0,0,0),(int(factor*639.0),120),10)\r\n x,y=pygame.mouse.get_pos()\r\n if pygame.mouse.get_pressed()[0]:\r\n factor=x/639.0\r\n pygame.display.set_caption('Pygame Color Blend Test - %.3f' % factor)\r\n \r\n color=blend_color(color1,color2,factor)\r\n pygame.draw.rect(screen,color,(0,240,640,240))\r\n pygame.display.update()"
},
{
"alpha_fraction": 0.6293888092041016,
"alphanum_fraction": 0.6657997369766235,
"avg_line_length": 26.481481552124023,
"blob_id": "6b63dbed3f64199d353fc63760ff55ad58389a81",
"content_id": "6dd17b252df3e2f4bb9f3557298e493ca1502f9c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 769,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 27,
"path": "/test2.py",
"repo_name": "bobocaicai/pygame_practice",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Fri Dec 09 16:21:44 2016\r\n\r\n@author: student\r\n\"\"\"\r\nimport pygame\r\nfrom pygame.locals import *\r\nfrom sys import exit\r\nbackgound_image_filename='d:/2/sushiplate.jpg'\r\nmouse_image_filename='d:/2/fugu.png'\r\npygame.init()\r\nscreen=pygame.display.set_mode((640,480),0,32)\r\npygame.display.set_caption(\"Hello, World!\")\r\nbackground=pygame.image.load(backgound_image_filename)\r\nmouse_cursor=pygame.image.load(mouse_image_filename)\r\n\r\nwhile True:\r\n for event in pygame.event.get():\r\n if event.type==QUIT:\r\n exit()\r\n screen.blit(background,(0,0))\r\n x,y=pygame.mouse.get_pos()\r\n x-=mouse_cursor.get_width()/2\r\n y-=mouse_cursor.get_height()/2\r\n screen.blit(mouse_cursor,(x,y))\r\n pygame.display.update()\r\n"
},
{
"alpha_fraction": 0.6221786141395569,
"alphanum_fraction": 0.6692836284637451,
"avg_line_length": 24.86842155456543,
"blob_id": "fa030f7dcb5231a18a7afff0b51664c32c29e0c4",
"content_id": "5c559d13a9eab534690e3d0219278eea2e3b2809",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1019,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 38,
"path": "/test14.py",
"repo_name": "bobocaicai/pygame_practice",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Thu Dec 15 14:56:56 2016\r\n\r\n@author: student\r\n\"\"\"\r\nimport pygame\r\nfrom pygame.locals import *\r\nfrom sys import exit\r\nfrom gameobjects.vector2 import Vector2\r\n\r\npygame.init()\r\nscreen=pygame.display.set_mode((640,480),0,32)\r\nbackground=pygame.image.load('D:/2/sushiplate.jpg').convert()\r\nsprite=pygame.image.load('D:/2/fugu.png').convert_alpha()\r\n\r\nclock=pygame.time.Clock()\r\n\r\nposition=Vector2(100.0,100.0)\r\nheading=Vector2()\r\n\r\nwhile True:\r\n for event in pygame.event.get():\r\n if event.type==QUIT:\r\n exit()\r\n screen.blit(background,(0,0))\r\n screen.blit(sprite,position)\r\n \r\n time_passed=clock.tick()\r\n time_passed_seconds=time_passed/1000.0\r\n \r\n destination=Vector2(*pygame.mouse.get_pos())-Vector2(*sprite.get_size())/2\r\n vector_to_mouse=Vector2.from_points(position,destination)\r\n vector_to_mouse.normalize()\r\n \r\n heading=heading+(vector_to_mouse*.6)\r\n position+=heading*time_passed_seconds\r\n pygame.display.update()"
},
{
"alpha_fraction": 0.48245614767074585,
"alphanum_fraction": 0.594298243522644,
"avg_line_length": 23.33333396911621,
"blob_id": "b64a93fc1d0bbba0371f1907ea767818c214a79a",
"content_id": "79e9198454ea95398d6b04744e62bab8485af114",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 456,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 18,
"path": "/test8.py",
"repo_name": "bobocaicai/pygame_practice",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Fri Dec 09 20:53:27 2016\r\n\r\n@author: student\r\n\"\"\"\r\nimport pygame\r\npygame.init()\r\nscreen=pygame.display.set_mode((640,480))\r\nall_colors=pygame.Surface((4096,4096),depth=24)\r\nfor r in xrange(256):\r\n print r+1,'out of 256'\r\n x=(r&15)*256\r\n y=(r>>4)*256\r\n for g in xrange(256):\r\n for b in xrange(256):\r\n all_colors.set_at((x+g,y+b),(r,g,b))\r\npygame.image.save(all_colors,\"allcolors.bmp\")\r\n"
},
{
"alpha_fraction": 0.5665349364280701,
"alphanum_fraction": 0.625823438167572,
"avg_line_length": 22.483871459960938,
"blob_id": "263b4c68ca0499ad7712d193f7b3316bb59a12e7",
"content_id": "caa35d03bf440a012af98dfb7feb7ae815579133",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 763,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 31,
"path": "/test7.py",
"repo_name": "bobocaicai/pygame_practice",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Fri Dec 09 20:26:08 2016\r\n\r\n@author: student\r\n\"\"\"\r\nimport pygame\r\nfrom pygame.locals import *\r\nfrom sys import exit\r\n\r\npygame.init()\r\nscreen=pygame.display.set_mode((640,480),0,32)\r\nbackground=pygame.image.load('d:/2/sushiplate.jpg').convert()\r\nfont_all=pygame.font.get_fonts()\r\nfont=pygame.font.SysFont(font_all[55],40)\r\ntext_surface=font.render(u'你好',True,(0,0,255))\r\n\r\nx=0\r\ny=(480-text_surface.get_height())/2\r\n\r\nwhile True:\r\n for event in pygame.event.get():\r\n if event.type==QUIT:\r\n exit()\r\n screen.blit(background,(0,0))\r\n x-=0.05\r\n if x<-text_surface.get_width():\r\n x=640-text_surface.get_width()\r\n \r\n screen.blit(text_surface,(x,y))\r\n pygame.display.update()\r\n"
},
{
"alpha_fraction": 0.8157894611358643,
"alphanum_fraction": 0.8157894611358643,
"avg_line_length": 18,
"blob_id": "2d9fd417d3a22ed8f24789bf064a79e5a0c8dd42",
"content_id": "8c0dd7ac36b2148834d9da9f7ba99986b669fddd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 38,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 2,
"path": "/README.md",
"repo_name": "bobocaicai/pygame_practice",
"src_encoding": "UTF-8",
"text": "# pygame_practice\npractice the pygame\n"
},
{
"alpha_fraction": 0.5171537399291992,
"alphanum_fraction": 0.5705209374427795,
"avg_line_length": 27.074073791503906,
"blob_id": "4013d11f3fd3b40a1ce10ff1dbd4292ad85f3638",
"content_id": "2e13bfdc664dc2a0b78fddc56c39b6ab84b55deb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 787,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 27,
"path": "/test5.py",
"repo_name": "bobocaicai/pygame_practice",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Fri Dec 09 17:33:46 2016\r\n\r\n@author: student\r\n\"\"\"\r\nimport pygame\r\nfrom pygame.locals import *\r\nfrom sys import exit\r\n\r\npygame.init()\r\nscreen=pygame.display.set_mode((640,480),0,32)\r\nbackground=pygame.image.load('d:/2/sushiplate.jpg').convert()\r\nFullscreen=False\r\nwhile True:\r\n for event in pygame.event.get():\r\n if event.type==QUIT:\r\n exit()\r\n if event.type==KEYDOWN:\r\n if event.key==K_f:\r\n Fullscreen=not Fullscreen\r\n if Fullscreen:\r\n screen=pygame.display.set_mode((640,480),FULLSCREEN,32)\r\n else:\r\n screen=pygame.display.set_mode((640,480),0,32)\r\n screen.blit(background,(0,0))\r\n pygame.display.update()\r\n\r\n"
},
{
"alpha_fraction": 0.4776119291782379,
"alphanum_fraction": 0.5417910218238831,
"avg_line_length": 18.363636016845703,
"blob_id": "278aad6e9971659495516be9a46b16df51f1a70f",
"content_id": "3dbb4786bf76ed4f23e8834bb146e2463a2e4d93",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 670,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 33,
"path": "/test12.py",
"repo_name": "bobocaicai/pygame_practice",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Thu Dec 15 10:52:14 2016\r\n\r\n@author: student\r\n\"\"\"\r\n\r\nimport pygame\r\nfrom pygame.locals import *\r\nfrom sys import exit\r\n\r\npygame.init()\r\nscreen=pygame.display.set_mode((640,480),0,32)\r\n\r\nbackground=pygame.image.load('D:/2/sushiplate.jpg').convert()\r\nsprite=pygame.image.load('D:/2/fugu.png')\r\n\r\nx=0.\r\ny=100.\r\nwhile True:\r\n for event in pygame.event.get():\r\n if event.type==QUIT:\r\n exit()\r\n screen.blit(background,(0,0))\r\n screen.blit(sprite,(x,y))\r\n x+=10\r\n y+=1\r\n \r\n if x>640.:\r\n x=0\r\n if y>480.:\r\n y=100\r\n pygame.display.update()"
}
] | 11 |
kevinsa5/KevinOS
|
https://github.com/kevinsa5/KevinOS
|
2ae318125878ebcab891b9b08a07633afef08987
|
857cb171fbb4de54906f1e4c924164738f34290a
|
a1b7fea25dcf7a91cc08f441c8112ed8a6bbdd17
|
refs/heads/master
| 2021-01-02T09:34:23.989536 | 2015-11-11T02:30:42 | 2015-11-11T02:30:42 | 11,396,282 | 6 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7785714268684387,
"alphanum_fraction": 0.7785714268684387,
"avg_line_length": 22.33333396911621,
"blob_id": "a1d945ba226445fa4f9e036e1bbc42dd3bb97853",
"content_id": "a2f54bc55d8834139ae72594ad25aebd77be2246",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 140,
"license_type": "permissive",
"max_line_length": 44,
"num_lines": 6,
"path": "/editor.h",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "#ifndef EDITOR_H\n#define EDITOR_H\nvoid editor_initialize();\nvoid editor_updateScreen();\nvoid editor_keyPressed(unsigned char, char);\n#endif\n"
},
{
"alpha_fraction": 0.5875551700592041,
"alphanum_fraction": 0.5975962281227112,
"avg_line_length": 24.67578125,
"blob_id": "d7a147ce83bbd484655bee6635f939bfc084743a",
"content_id": "2fe2cdae812db628da94332d4ebf1187bbad08b0",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6573,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 256,
"path": "/sh_lisp.c",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "#include \"util.h\"\n#include \"malloc.h\"\n#include \"kernel.h\"\n\n#define T_EXPR 0\n#define T_INT 1\n#define T_FLOAT 2\n#define T_STRING 3\n#define T_BOOL 4\n\nstruct ExprListNode\n{\n struct expr *expr;\n struct ExprListNode *next;\n struct ExprListNode *prev;\n};\n\n\nstruct expr\n{\n int type;\n void* data;\n};\n\nint atomic(struct expr *e){\n\treturn e->type == T_INT ||\n\t\t e->type == T_FLOAT ||\n\t\t e->type == T_STRING ||\n\t\t e->type == T_BOOL;\n}\n\nstruct expr* makeIntExpr(int i){\n\tstruct expr* ex = (struct expr*) malloc(sizeof(struct expr));\n\tex->type = T_INT;\n\tint *p = (int*)malloc(sizeof(int));\n\t*p = i;\n\tex->data = p;\n\treturn ex;\n}\nstruct expr* makeFloatExpr(double d){\n\tstruct expr* ex = (struct expr*) malloc(sizeof(struct expr));\n\tex->type = T_FLOAT;\n\tdouble *p = (double*)malloc(sizeof(double));\n\t*p = d;\n\tex->data = p;\n\treturn ex;\n}\nstruct expr* makeStringExpr(char *str){\n\tstruct expr* ex = (struct expr*) malloc(sizeof(struct expr));\n\tex->type = T_STRING;\n\tchar *p = (char*)malloc(strLen(str));\n\tmemCopy(str,p,strLen(str));\n\tex->data = p;\n\treturn ex;\n}\nstruct expr* makeBoolExpr(char b){\n\tstruct expr* ex = (struct expr*) malloc(sizeof(struct expr));\n\tex->type = T_BOOL;\n\tchar *p = (char*)malloc(1);\n\t*p = b;\n\tex->data = p;\n\treturn ex;\n}\n\nvoid lispError(char *message){\n\tttprintln(\"-------------------------\");\n\tttprintln(message);\n\tttprintln(\"-------------------------\");\n}\n\nchar* toString(struct expr *e){\n\tif(atomic(e)){\n\t\tif(e->type == T_INT){\n\t\t\tint i = (int) *((int*)e->data);\n\t\t\tchar *str = (char*)malloc(numDigits(i)+1);\n\t\t\tintToString(i, str);\n\t\t\tstr[numDigits(i)] = 0;\n\t\t\treturn str;\n\t\t} else if(e->type == T_FLOAT){\n\t\t\t// print 5 decimal points\n\t\t\tdouble d = (double) *((double*)e->data);\n\t\t\tint intlen = numDigits((int)d);\n\t\t\tchar *str = (char*)malloc(intlen + 5 + 1 + 1);\n\t\t\tintToString((int)d, str);\n\t\t\tstr[intlen] = '.';\n\t\t\tint i;\n\t\t\tdouble rem = d - (int)d;\n\t\t\tfor(i = intlen+1; i < intlen+6; i++){\n\t\t\t\trem *= 10;\n\t\t\t\tstr[i] = '0' + (int)rem;\n\t\t\t\trem = rem - (int)rem;\n\t\t\t}\n\t\t\tstr[i] = 0;\n\t\t\treturn str;\n\t\t} else if(e->type == T_STRING){\n\t\t\tchar* from = (char*) e->data;\n\t\t\tint len = strLen(from);\n\t\t\tchar* to = (char*) malloc(len);\n\t\t\tmemCopy(from,to,len);\n\t\t\treturn to;\n\t\t} else if(e->type == T_BOOL){\n\t\t\tchar* str = malloc(3);\n\t\t\tstr[0] = '#';\n\t\t\tstr[1] = *((char*) e->data) ? 't' : 'f';\n\t\t\tstr[2] = 0;\n\t\t\treturn str;\n\t\t} else {\n\t\t\tchar msg[] = \"unknown type:\";\n\t\t\tint len = strLen(msg);\n\t\t\tint typelen = numDigits(e->type);\n\t\t\tchar *str = (char*) malloc(len + typelen);\n\t\t\tmemCopy(msg,str,len-1);\n\t\t\tchar *temp = (char*) malloc(typelen+1);\n\t\t\tintToString(e->type, temp);\n\t\t\tmemCopy(temp, str+len-1, typelen);\n\t\t\tfree(temp, typelen + 1);\n\t\t\treturn str;\n\t\t}\n\t} else {\n\t\tif(e->type == T_EXPR){\n\t\t\tstruct StringListNode *listHead = (struct StringListNode*) malloc(sizeof(struct StringListNode));\n\t\t\tstruct StringListNode *iter = listHead;\n\t\t\tstruct ExprListNode * n = (struct ExprListNode*) e->data;\n\t\t\tint totalLen = 0;\n\t\t\t\n\t\t\twhile(n){\n\t\t\t\tchar* tempString = toString(n->expr);\n\t\t\t\ttotalLen += strLen(tempString) - 1;\n\t\t\t\titer->str = tempString;\n\t\t\t\t\n\t\t\t\tif(n->next){\n\t\t\t\t\tstruct StringListNode* next = (struct StringListNode*) malloc(sizeof(struct StringListNode));\n\t\t\t\t\titer->next = next;\n\t\t\t\t\tnext->prev = iter;\n\t\t\t\t\titer = next;\n\t\t\t\t}\n\t\t\t\tn = n->next;\n\t\t\t}\n\t\t\t\n\t\t\tchar* str = (char*) malloc(totalLen+1);\n\t\t\titer = listHead;\n\t\t\tint i = 0; \n\t\t\twhile(iter){\n\t\t\t\tint len = strLen(iter->str);\n\t\t\t\tmemCopy(iter->str, str+i, len-1);\n\t\t\t\t//free(iter->str, strLen(iter->str));\n\t\t\t\titer = iter->next;\n\t\t\t\ti += len;\n\t\t\t}\n\t\t\tstr[totalLen] = 0;\n\t\t\treturn str;\n\t\t} else {\n\t\t\tchar msg[] = \"unknown type:\";\n\t\t\tint len = strLen(msg);\n\t\t\tint typelen = numDigits(e->type);\n\t\t\tchar *str = (char*) malloc(len + typelen);\n\t\t\tmemCopy(msg,str,len-1);\n\t\t\tchar *temp = (char*) malloc(typelen+1);\n\t\t\tintToString(e->type, temp);\n\t\t\tmemCopy(temp, str+len-1, typelen);\n\t\t\tfree(temp, typelen + 1);\n\t\t\treturn str;\n\t\t}\n\t}\n}\n\nstruct StringListNode* tokenize(struct StringListNode* list){\n\tchar** ptr;\n\tint totalLength = flattenStringList(list, ptr);\n\tchar* str = *ptr;\n\tif(*str != '('){\n\t\tlispError(\"Improper format: code must begin with `(`\");\n\t\treturn (struct StringListNode*) 0;\n\t}\n\tchar insideString = 0;\n\tint numLeft = 1, numRight = 0, i = 1;\n\tstruct StringListNode *tokenHead = (struct StringListNode*)malloc(sizeof(struct StringListNode));\n\ttokenHead->prev = 0;\n\ttokenHead->next = 0;\n\t\n\ttokenHead->str = (char*) malloc(2);\n\t*(tokenHead->str) = '(';\n\t*(tokenHead->str+1) = 0;\n\tstruct StringListNode *tokenTail = tokenHead;\n\n\twhile(i < totalLength){\n\t\tsleep(100);\n\t\tttprint(\"current char:\");\n\t\tttprintChar(str[i]);\n\t\tttprintChar('\\n');\n\t\tif(str[i] == '('){\n\t\t\tttprintln(\"found (\");\n\t\t\t// necessary or else it crashes:\n\t\t\tttprintln(\"hello\");\n\t\t\tfor(;0 == 1;);\n\t\t\tttprintln(\"here\");\n\t\t\t// very strange.\n\t\t\tnumLeft++;\n\t\t\tstruct StringListNode *temp = (struct StringListNode*)malloc(sizeof(struct StringListNode));\n\t\t\ttemp->str = (char*) malloc(2);\n\t\t\t*(temp->str) = '(';\n\t\t\t*(temp->str+1) = 0;\n\t\t\ttemp->prev = tokenTail;\n\t\t\ttemp->next = 0;\n\t\t\ttokenTail->next = temp;\n\t\t\ttokenTail = temp;\n\t\t} else if(str[i] == ')'){\n\t\t\tttprintln(\"found )\");\n\t\t\tnumRight++;\n\t\t\tstruct StringListNode *temp = (struct StringListNode*)malloc(sizeof(struct StringListNode));\n\t\t\ttemp->str = (char*) malloc(2);\n\t\t\t*(temp->str) = ')';\n\t\t\t*(temp->str+1) = 0;\n\t\t\ttemp->prev = tokenTail;\n\t\t\ttemp->next = 0;\n\t\t\ttokenTail->next = temp;\n\t\t\ttokenTail = temp;\n\t\t} else if(str[i] == ' '){\n\t\t\tttprintln(\"found space\");\n\t\t} else {\n\t\t\tttprintln(\"found otherrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrawefwaefwaefwaefawfewaferrrrrrrrrrrrrrrr\");\n\t\t\tttprintln(\"current other char:\");\n\t\t\tttprintChar(str[i]);\n\t\t\tttprintChar('\\n');\n\t\t\tint start = i;\n\t\t\twhile(str[i] != ' ' && str[i] != '(' && str[i] != ')'){\n\t\t\t\ti++; \n\t\t\t\tttprint(\"current other char:\");\n\t\t\t\tttprintChar(str[i]);\n\t\t\t\tttprintChar('\\n');\n\t\t\t\tif(i >= totalLength) {\n\t\t\t\t\tlispError(\"Improper format: code must end with `)`\");\n\t\t\t\t\treturn (struct StringListNode*) 0;\n\t\t\t\t}\n\t\t\t}\n\t\t\ti--;\n\t\t\tint len = i - start + 1;\n\t\t\tstruct StringListNode *temp = (struct StringListNode*)malloc(sizeof(struct StringListNode));\n\t\t\ttemp->str = (char*)malloc(len+1);\n\t\t\tmemCopy(str+start, temp->str, len);\n\t\t\t(temp->str)[len] = 0;\n\t\t\ttemp->prev = tokenTail;\n\t\t\ttemp->next = 0;\n\t\t\ttokenTail->next = temp;\n\t\t\ttokenTail = temp;\n\t\t}\n\t\tttprint(\"tokenTail: \");\n\t\tttprintln(tokenTail->str);\n\t\ti++;\n\t}\n\tif(numRight != numRight){\n\t\tlispError(\"Improper format: open and close parenthesis counts must match\");\n\t\treturn (struct StringListNode*) 0;\n\t}\n\treturn tokenHead;\n}\n"
},
{
"alpha_fraction": 0.6114226579666138,
"alphanum_fraction": 0.6379023790359497,
"avg_line_length": 21.13793182373047,
"blob_id": "5013138b482ddf6612a7d8929cce16274bb68ef0",
"content_id": "52501d004d071827c3c2891d0630b6f1ea202cb5",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 9630,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 435,
"path": "/kernel.c",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "extern char _binary_KFS_bin_start[];\nchar* vidmem;\nchar prompt;\nint promptColor;\n\nvolatile unsigned long int ticks;\nchar counter;\n\n#include \"kernel.h\"\n#include \"malloc.h\"\n#include \"driver.h\"\n#include \"util.h\"\n#include \"IDT.c\"\n#include \"shell_commands.h\"\n#include \"editor.h\"\n#include \"sh_exec.h\"\n#include \"buildData.h\"\n\nchar modifier[6];\n\nint ttx;\nint tty;\nint terminalMode;\nchar* KFS;\nstruct File *fileBuffer;\nstruct StringListNode *historyHead;\nstruct StringListNode *historyTemp;\n\nchar* message;\n\nvoid main(){\n\tvidmem = (char*) 0xb8000;\n\tclearAllocationTable();\n\t\n\thistoryHead = (struct StringListNode *) malloc(sizeof(struct StringListNode));\n\t\n\thistoryHead->prev = 0;\n\thistoryHead->next = 0;\n\thistoryHead->str = (char*) malloc(2);\n\thistoryHead->str[0] = 0;\n\thistoryTemp = historyHead;\n\tKFS = _binary_KFS_bin_start;\n\tttx = 0;\n\ttty = 0;\n\tticks = 0;\n\tsetSeed(5);\n\tmodifier[5] = 0;\n\tmessage = (char*) malloc(3);\n\tmemCopy(\"OK\",message,3);\n\tint i = 0;\n\n\tcounter = '0';\n\tmemFill(modifier, 0, 5);\n\tmodifier[INSERT] = 1;\n\tmodifier[CAPSLOCK] = 0;\n\tterminalMode = TERMINAL;\n\tprompt = 21;\n\tpromptColor = 0x02;\n\tclearScreen(0x0F);\n\t//ttprintln(\"I am a computer! I am running Kevin's OS!\"); \n\tttprint(\"KevinOS build \");\n\tttprintIntln(getBuildID());\n\tttprint(\"Setting up interrupt descriptor table...\");\n\tidt_init();\n\tsetTimerFreq(1000);\n\tttprintln(\"done\");\n\t\n\t//turn on bit 6 of register B:\n\tdisableInterrupts();\n\twriteByteToPort(0x70,0x8B);\n\tchar prev=readByteFromPort(0x71);\n\twriteByteToPort(0x70,0x8B);\n\twriteByteToPort(0x71, prev | 0x40);\t\n\tenableInterrupts();\n\n\tsh_shell(\"startup.sh\");\n\t\n\tprintPrompt();\n\tprintStatus(0x00);\n}\n//left: E0 4B E0 CB\n//right: E0 4D E0 CD\n//up: E0 48 E0 C8\n//down: E0 50 E0 D0\n\nvoid printNode(struct StringListNode *node){\n\tttprint(\"node:\");\n\tttprintInt((int)node);\n\tttprint(\" prev:\");\n\tttprintInt((int)node->prev);\n\tttprint(\" next:\");\n\tttprintInt((int)node->next);\n\tttprint(\" str:\");\n\tttprintln(node->str);\n}\n\nvoid keyPressed(unsigned char code){\n\tchar c = scancodeToAscii(code, modifier[SHIFT], modifier[CTRL], modifier[CAPSLOCK]);\n\tif(terminalMode == TERMINAL){\n\t\tterminal_keyPressed(code, c);\n\t} else if(terminalMode == EDITOR){\n\t\teditor_keyPressed(code, c);\n\t} else if(terminalMode == INTERPRETER){\n\t\tinterpreter_keyPressed(code, c);\n\t}\n\tif(code == 0x01) setMessage(\"ESC\");\n}\n\nvoid terminal_keyPressed(unsigned char code, char c){\n\tif(code == 0x0E){ // backspace\n\t\tif(getChar(ttx-1,tty) == prompt) return;\n\t\tcursorBackwards();\n\t\tint i = 0;\n\t\twhile(getChar(ttx + i, tty) != 0){\n\t\t\tprintChar(ttx+i,tty,getChar(ttx+i+1,tty),0x0F);\n\t\t\ti++;\n\t\t}\n\t} else if(code == 0x4B){ // left arrow\n\t\tcursorBackwards();\n\t} else if(code == 0x4D){ // right arrow\n\t\tcursorForwards();\n\t} else if(code == 0x48){ // up arrow\n\t\twhile(getChar(ttx-1,tty) != prompt){\n\t\t\tttprintChar(' ');\n\t\t\tcursorBackwards();\n\t\t\tcursorBackwards();\n }\n\t\tttprint(historyTemp->str);\n\t\tif(historyTemp->next != 0)\n\t\t\thistoryTemp = historyTemp->next;\n\t} else if(code == 0x50){ // down arrow\n\t\twhile(getChar(ttx-1,tty) != prompt){\n\t\t\tttprintChar(' ');\n\t\t\tcursorBackwards();\n\t\t\tcursorBackwards();\n }\n\t\tttprint(historyTemp->str);\n\t\tif(historyTemp->prev != 0)\n\t\t\thistoryTemp = historyTemp->prev;\n\t} else if(code == 0x1D){ // control on\n\t\tmodifier[CTRL] = 1;\n\t} else if(code == 0x9D){ //control off\n\t\tmodifier[CTRL] = 0;\n\t} else if(code == 0x36 || code == 0x2A){ //shift on\n\t\tmodifier[SHIFT] = 1;\n\t} else if(code == 0xB6 || code == 0xAA){ //shift off\n\t\tmodifier[SHIFT] = 0;\n\t} else if(code == 0x38){ // alt on\n\t\tmodifier[ALT] = 1;\n\t} else if(code == 0xB8){ // alt off\n\t\tmodifier[ALT] = 0;\n\t} else if(code == 0x52){ // insert\n\t\tmodifier[INSERT]++;\n\t\tmodifier[INSERT] %= 2;\n\t} else if(code == 0x3A){ // capslock\n\t\tmodifier[CAPSLOCK]++;\n\t\tmodifier[CAPSLOCK] %= 2;\n\t}\n\tprintStatus(code);\n\tif(c == 0) return;\n\tif(c != '\\n'){\n\t\tif(modifier[INSERT]){\n\t\t\tint i = 0;\n\t\t\twhile(getChar(ttx + i, tty) != 0){\n\t\t\t\ti++;\n\t\t\t}\n\t\t\twhile(i > 0){\n\t\t\t\tprintChar(ttx+i,tty,getChar(ttx+i-1,tty),0x0F);\n\t\t\t\ti--;\n\t\t\t}\n\t\t}\n\t\tttprintChar(c);\n\t} else {\n\t\tint i = offset(ttx,tty); //find beginning of command (ie the prompt)\n\t\twhile(vidmem[i] != prompt && vidmem[i+1] != promptColor){\n\t\t\ti= i-2;\n\t\t}\n\t\ti+=2;\n\t\tchar command[(offset(ttx,tty)-i+2)/2];\n\t\tcommand[(offset(ttx,tty)-i)/2] = 0;\n\t\tint j;\n\t\tfor(j = 0; j < (offset(ttx,tty)-i)/2; j++) command[j] = vidmem[i+2*j];\n\t\tttprintChar('\\n');\n\n\t\tstruct StringListNode *new = (struct StringListNode *)malloc(sizeof(struct StringListNode));\n\t\t\n\t\tnew->str = (char*) malloc(strLen(command));\n\t\tmemCopy(command,new->str, strLen(command));\n\t\tnew->next = historyHead;\n\t\tnew->prev = 0;\n\n\t\thistoryHead->prev = new;\n\t\thistoryHead = new;\n\t\thistoryTemp = historyHead;\n\n\t\tsh_handler(command);\n\t\tif(terminalMode == TERMINAL){\n\t\t\t//ttprintChar(c);\n\t\t\tprintPrompt();\n\t\t}\n\t}\n}\n\nvoid setMessage(char *new){\n\tfree(message,strLen(message));\n\tint len = strLen(new);\n\tmessage = (char*) malloc(len);\n\tmemCopy(new,message,len);\n}\nvoid printPrompt(){\n\tttprintCharColor(prompt,promptColor);\n}\nvoid sleep(int mS){\n\tenableInterrupts();\n\tunsigned long int start = ticks;\n\twhile(ticks - start < mS){;}\n\t//ttprint(\"done\");\n}\nvoid rtcCall(){\n\tcounter++;\n\tif(counter > '9') counter = '1';\n\tprintChar(width-1,absolute_height,counter,0x0F);\n}\nvoid pitCall(){\n\tticks++;\n\tif(ticks % PITfreq == 0) printStatus(0);\n}\nunsigned long int millis(){\n\treturn ticks;\n}\nvoid printStatus(unsigned char code){\n\tint i;\n\tfor(i = 0; i < width; i++){\n\t\tprintChar(i,height,'-',0x0F);\n\t\tprintChar(i,absolute_height,' ',0x0F);\n\t}\n\tint statusX = 0;\n\tchar str[10];\n\t\n\tprint(statusX, absolute_height, message);\n\tstatusX += strLen(message);\n\t\n\tprint(statusX, absolute_height, \"Code:\");\n\tstatusX += 5;\n\tcharToString(code,str);\n\tif(code != -1) print(statusX, absolute_height, str);\n\tstatusX += 4;\n\n\tprint(statusX, absolute_height, \" Ins:\");\n\tstatusX += 5;\n\tprintChar(statusX, absolute_height, modifier[INSERT]+'0', 0x0F);\n\tstatusX += 1;\n\n\tprint(statusX, absolute_height, \" Shift:\");\n\tstatusX += 7;\n\tprintChar(statusX, absolute_height, modifier[SHIFT]+'0', 0x0F);\n\tstatusX += 1;\n\n\tprint(statusX, absolute_height, \" Caps:\");\n\tstatusX += 6;\n\tprintChar(statusX, absolute_height, modifier[CAPSLOCK]+'0', 0x0F);\n\tstatusX += 1;\n\n\tprint(statusX, absolute_height, \" Ctrl:\");\n\tstatusX += 6;\n\tprintChar(statusX, absolute_height, modifier[CTRL]+'0', 0x0F);\n\tstatusX += 1;\n\n\tprint(statusX, absolute_height, \" Alt:\");\n\tstatusX += 5;\n\tprintChar(statusX, absolute_height, modifier[ALT]+'0', 0x0F);\n\tstatusX += 1;\n\n\t//print(statusX, absolute_height, \" Last:\");\n\t//statusX += 6;\n\t//intToString(commandLength,str);\n\t//print(statusX, absolute_height, str);\n\t//statusX += strLen(str)-1;\n\t\n\tprint(statusX, absolute_height, \" Mode:\");\n\tstatusX += 6;\n\tprintChar(statusX, absolute_height, terminalMode+'0', 0x0F);\n\tstatusX += 1;\t\n\n\t//print(statusX, absolute_height, \" ttx:\");\n\t//statusX += 5;\n\t//intToString(ttx, str);\n\t//print(statusX, absolute_height, str);\n\t//statusX += strLen(str)-1;\n\t\n\tprint(statusX, absolute_height, \" mem:\");\n\tstatusX += 5;\n\tdoubleToString(heapUsage(), str);\n\tprint(statusX, absolute_height, str);\n\tstatusX += strLen(str)-1;\n\t\n\tprint(statusX, absolute_height, \"%\");\n\tstatusX++;\n\t\n\tprint(statusX, absolute_height, \" Time:\");\n\tstatusX += 6;\n\tintToString(ticks/PITfreq,str);\n\tprint(statusX, absolute_height,str);\n\tstatusX += strLen(str)-1;\n}\nvoid ttprint(char *string){\n\tint i;\n\tfor(i = 0; string[i] != 0; i++){\n\t\tttprintChar(string[i]);\n\t}\n}\nvoid ttprintInt(int n){\n\tint len = numDigits(n) + 1;\n\tif(n < 0) len++; // minus sign\n\tchar *str = (char*) malloc(len);\n\tintToString(n,str);\n\tttprint(str);\n\tfree(str,len);\n}\nvoid ttprintIntln(int n){\n\tttprintInt(n);\n\tttprintChar('\\n');\n}\nvoid ttprintCharColor(char c, int col){\n\tif(c == 0) return;\n\tint printable = 1;\n\tif(ttx >= width){\n\t\tttx = 0;\n\t\ttty++;\n\t}\n\tif(c == '\\n'){\n\t\tttx = 0;\n\t\ttty++;\n\t\tc = 0;\n\t}\n\tif(c == '\\t'){\n\t\tint i;\n\t\tfor(i = 0; i < 4; i++) ttprintChar(' ');\n\t\tprintable = 0;\t\n\t}\n\tif(tty >= height){\n\t\tscrollUp();\n\t}\n\tif(c != 0 && printable){\n\t\tprintChar(ttx,tty,c,col);\n\t\tttx++;\n\t}\n\tsetCursor(ttx,tty);\n}\nvoid ttprintChar(char c){\n\tttprintCharColor(c,0x0F);\n}\nvoid cursorForwards(){\n\tif(getChar(ttx,tty) == 0) return;\n\tttx++;\n\tif(ttx >= width){\n\t\tttx = 0;\n\t\ttty++;\n\t}\n\tif(tty >= height){\n\t\tscrollUp();\n\t}\n\tsetCursor(ttx,tty);\n}\nvoid cursorBackwards(){\n\tttx--;\n\tif(ttx < 0){\n\t\tttx = width-1;\n\t\ttty--;\n\t}\n\tsetCursor(ttx,tty);\n\tif(getChar(ttx,tty) == prompt && getColor(ttx,tty) == promptColor){\n\t\tttx++;\n\t\tsetCursor(ttx,tty);\n\t}\n}\n\t\nvoid scrollUp(){\n\tint j;\n\tfor(j = 0; j < height-1; j++){\n\t\tmemCopy(vidmem+(j+1)*(2*width),vidmem+j*(2*width),2*width);\n\t}\n\tfor(j = 0; j < 2*width; j++){\n\t\tprintChar(j,height-1,0,0x0F);\n\t}\n\ttty--;\n}\nvoid ttprintln(char *string){\n\tttprint(string);\n\tttprintChar('\\n');\n}\nvoid print(int x, int y, char *string){\n\tint i = 0;\n\twhile(string[i] != 0) printChar(x++,y,string[i++],0x0f);\n}\nvoid printChar(int x, int y, char c, int col){\n\tvidmem[offset(x,y)] = c;\n\tvidmem[offset(x,y)+1] = col;\n}\nchar getChar(int x, int y){\n\treturn vidmem[offset(x,y)];\n}\nint getColor(int x, int y){\n\treturn vidmem[offset(x,y)+1];\n}\nvoid setCursor(int x, int y){\n\tchar high, low;\n\tlow = (char)((x+y*width) % 256);\n\thigh = (char)((x+y*width) / 256);\n\twriteByteToPort(REG_SCREEN_CTRL, 14);\n\twriteByteToPort(REG_SCREEN_DATA, high);\n\twriteByteToPort(REG_SCREEN_CTRL, 15);\n\twriteByteToPort(REG_SCREEN_DATA, low);\n\tttx = x;\n\ttty = y;\n}\nint offset(int x, int y){\n\treturn 2*(y*width+x);\n}\nvoid clearScreen(int color){\n\tint i;\n\tint j;\n\tfor(i = 0; i < width; i++){\n\t\tfor(j = 0; j < height; j++){\n\t\t\tprintChar(i,j,0,color);\n\t\t}\n\t}\n}\n\nvoid disableInterrupts(){\n\tasm volatile(\"cli\");\n}\nvoid enableInterrupts(){\n\tasm volatile(\"sti; nop\");\n}\n"
},
{
"alpha_fraction": 0.610520601272583,
"alphanum_fraction": 0.6299765706062317,
"avg_line_length": 24,
"blob_id": "ab5bb4e0eb3b30189bbbd1ace34859da9ac34760",
"content_id": "7e3eb56f934f3ccc5adb0009238cb7e0ca7b9368",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5551,
"license_type": "permissive",
"max_line_length": 204,
"num_lines": 222,
"path": "/sh_exec.c",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "#include \"util.h\"\n#include \"kernel.h\"\n#include \"malloc.h\"\n#include \"sh_exec.h\"\n\nint iregisters[10];\nchar cregisters[10];\nint cmp1, cmp2;\n\nvoid exec_sleep(char*);\nvoid exec_seti(char*);\nvoid exec_setc(char*);\nvoid exec_printi(char*);\nvoid exec_printc(char*);\nvoid exec_addi(char*);\nvoid exec_multi(char*);\nvoid exec_null(char*);\nvoid exec_randi(char*);\nvoid exec_inc(char*);\nvoid exec_dec(char*);\nvoid exec_setcmp1(char*);\nvoid exec_setcmp2(char*);\nvoid exec_status(char*);\nstruct StringListNode * exec_findLine(int);\nchar userQuit = 0;\n\nchar *execCommandList[] = { \"sleep\", \"seti\", \"setc\", \"printi\", \"printc\", \"addi\", \"multi\", \"randi\", \"inc\", \"dec\", \"setcmp1\", \"setcmp2\", \"status\" , \"\"};\nvoid (*execFunctionList[])(char*) = {exec_sleep, exec_seti, exec_setc, exec_printi, exec_printc, exec_addi, exec_multi, exec_randi, exec_inc, exec_dec, exec_setcmp1, exec_setcmp2, exec_status, exec_null};\n\nvoid sh_exec(char* unused_params){\n\tterminalMode = INTERPRETER;\n\tchar line[width+1];\n\tline[width] = 0;\n\tint index = 0;\n\tfor(index = 0; index < 10; index++){\n\t\tiregisters[index] = 0;\n\t\tcregisters[index] = 0;\n\t}\n\t//iterate through the buffer\n\tstruct StringListNode *execLine = fileBuffer->firstLine;\n\twhile(execLine){\n\t\tif(userQuit){\n\t\t\tttprintln(\"ESC interrupt\");\n\t\t\tbreak;\n\t\t}\n\t\tif((execLine->str)[0] == 0 || (execLine->str)[0] == '#'){\n\t\t\texecLine = execLine->next;\n\t\t\tcontinue;\n\t\t}\n\t\tint len = strLen(execLine->str);\n\t\tint j = 0;\n\t\twhile(j < len && (execLine->str)[j] != ' ' && (execLine->str)[j] != ';') j++;\n\t\tchar *function = (char*) malloc(j+1);\n\t\tchar *params = (char*) malloc(len-j);\n\t\tmemCopy(execLine->str, function, j);\n\t\tfunction[j] = 0;\n\t\tint k = j;\n\t\twhile(k < len && (execLine->str)[k] != ';') k++;\n\t\tmemCopy(execLine->str + j + 1, params, k-j-1);\n\n\t\tif(strEquals(function, \"jeq\")){\n\t\t\tif(cmp1 == cmp2) execLine = exec_findLine(strToInt(params) - 1);\n\t\t\telse execLine = execLine->next;\n\t\t\tcontinue;\n\t\t}\n\t\tif(strEquals(function, \"jne\")){\n\t\t\tif(cmp1 != cmp2) execLine = exec_findLine(strToInt(params) - 1);\n\t\t\telse execLine = execLine->next;\n\t\t\tcontinue;\n\t\t}\n\t\tif(strEquals(function, \"jge\")){\n\t\t\tif(cmp1 >= cmp2) execLine = exec_findLine(strToInt(params) - 1);\n\t\t\telse execLine = execLine->next;\n\t\t\tcontinue;\n\t\t}\n\t\tif(strEquals(function, \"jle\")){\n\t\t\tif(cmp1 <= cmp2) execLine = exec_findLine(strToInt(params) - 1);\n\t\t\telse execLine = execLine->next;\n\t\t \tcontinue;\n\t\t}\n\t\tif(strEquals(function, \"jlt\")){\n\t\t\tif(cmp1 < cmp2) execLine = exec_findLine(strToInt(params) - 1);\n\t\t\telse execLine = execLine->next;\n\t\t\tcontinue;\n\t\t}\n\t\tif(strEquals(function, \"jgt\")){\n\t\t\tif(cmp1 > cmp2) execLine = exec_findLine(strToInt(params) - 1);\n\t\t\telse execLine = execLine->next;\n\t\t\tcontinue;\n\t\t}\n\t\tj = 0;\n\t\twhile(!strEquals(execCommandList[j],function) && !strEquals(execCommandList[j],\"\")) j++;\n\t\tif(!strEquals(execCommandList[j],\"\")) (*execFunctionList[j])(params);\n\t\telse {\n\t\t\tttprint(\"err: no such function: `\");\n\t\t\tttprint(function);\n\t\t\tttprint(\"` of length:\");\n\t\t\tttprintIntln(strLen(function));\n\t\t\tbreak;\n\t\t}\n\t\texecLine = execLine->next;\n\t}\n\tterminalMode = TERMINAL;\n\treturn;\n}\n\nvoid interpreter_keyPressed(unsigned char code, char c){\n\t//this doesn't work, key presses aren't registered while a function is running\n\tif(code == 0x01){ // escape\n\t\tuserQuit = 1;\n\t}\n}\n\nstruct StringListNode* exec_findLine(int lineNum){\n\tstruct StringListNode *iter = fileBuffer->firstLine;\n\twhile(lineNum-- > 1 && iter) iter = iter->next;\n\treturn iter;\n}\n\n// `sleep milliseconds`\nvoid exec_sleep(char* params){\n\tsleep(strToInt(params));\n}\n\n// `seti registerIndex value`\nvoid exec_seti(char* params){\n\tint index = params[0] - '0';\n\tiregisters[index] = strToInt( (params + 2) );\n}\n\n// `setc registerIndex value`\nvoid exec_setc(char* params){\n\tint index = params[0] - '0';\n\tcregisters[index] = params[2];\n}\n\n// `printi registerIndex`\nvoid exec_printi(char* params){\n\t//printf(\"%d\\n\", iregisters[params[0] - '0']);\n\tttprintIntln(iregisters[params[0] - '0']);\n}\n\n// `printc registerIndex`\nvoid exec_printc(char* params){\n\t//printf(\"%c\\n\", cregisters[params[0] - '0']);\n\tttprintChar(cregisters[params[0] - '0']);\n\tttprintChar('\\n');\n}\n\n// `addi operand operand destination\nvoid exec_addi(char* params){\n\tchar a = params[0] - '0';\n\tchar b = params[2] - '0';\n\tchar c = params[4] - '0';\n\tiregisters[c] = iregisters[a] + iregisters[b];\n}\n\n// `multi operand operand destination\nvoid exec_multi(char* params){\n\tchar a = params[0] - '0';\n\tchar b = params[2] - '0';\n\tchar c = params[4] - '0';\n\tiregisters[c] = iregisters[a] * iregisters[b];\n}\n\n// `randi limit destination\nvoid exec_randi(char* params){\n\tint i;\n\tint limit = 10;\n\tchar index = 0; \n\tfor(i = 0; i < strLen(params); i++){\n\t\tif(params[i] == ' '){\n\t\t\tparams[i] = 0;\n\t\t\tlimit = strToInt(params);\n\t\t\tparams[i] = ' ';\n\t\t\tindex = params[i+1] - '0';\n\t\t\tbreak;\n\t\t}\n\t}\n\tiregisters[index] = (int)rand(limit);\n}\n\nvoid exec_inc(char* params){\n\tiregisters[params[0] - '0'] += 1;\n}\n\nvoid exec_dec(char* params){\n\tiregisters[params[0] - '0'] -= 1;\n}\n\nvoid exec_setcmp1(char* params){\n\tcmp1 = iregisters[params[0] - '0'];\n}\nvoid exec_setcmp2(char* params){\n\tcmp2 = iregisters[params[0] - '0'];\n}\n\nvoid exec_status(char* params){\n\tint i;\n\tttprint(\"ireg:\");\n\tfor(i = 0; i < 10; i++){\n\t\tttprintInt(iregisters[i]);\n\t\tttprintChar(',');\n\t}\n\tttprintln(\"\");\n\tttprint(\"creg:\");\n\tfor(i = 0; i < 10; i++){\n\t\tttprintChar(cregisters[i]);\n\t\tttprintChar(',');\n\t}\n\tttprintln(\"\");\n\tttprint(\"cmp:\");\n\tttprintInt(cmp1);\n\tttprintChar(',');\n\tttprintInt(cmp2);\n\tttprintln(\"\");\n}\n\n\nvoid exec_null(char * params){\n\t\n}\n\n"
},
{
"alpha_fraction": 0.5964955687522888,
"alphanum_fraction": 0.6213736534118652,
"avg_line_length": 22.491262435913086,
"blob_id": "fb3d461d0f628043f393585fcf32a17adc2e0d98",
"content_id": "2b2c88e7d3b7572c667ceabb6418866fa5f7c4d8",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 12099,
"license_type": "permissive",
"max_line_length": 395,
"num_lines": 515,
"path": "/shell_commands.c",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "\nstruct File *readFile(char*);\n\n#include \"shell_commands.h\"\n#include \"kernel.h\"\n#include \"sh_exec.c\"\n#include \"util.h\"\n#include \"sh_lisp.c\"\n#include \"buildData.h\"\n#include \"driver.h\"\n#include \"editor.h\"\n\nchar *shCommandList[] = {\"shell\", \"read\", \"exec\", \"edit\", \"ls\", \"head\",\"cat\", \"textdump\", \"memdump\", \"help\", \"glissando\", \"mario\",\"sleep\", \"beep\", \"htoi\", \"itoh\", \"int\", \"rand\", \"colortable\", \"chartable\", \"hextable\", \"datatypes\", \"sti\", \"cli\", \"builddata\", \"memalloc\", \"memfree\", \"poke\", \"history\", \"memusg\",\"millis\",\"echo\",\"foo\",\"msg\",\"null\"};\nvoid (*shFunctionList[])(char*) = {sh_shell, sh_read, sh_exec, sh_edit, sh_ls, sh_head, sh_cat, sh_textDump, sh_memDump, sh_help, sh_glissando, sh_mario, sh_sleep, sh_beep, sh_htoi, sh_itoh, sh_int, sh_rand, sh_colorTable, sh_charTable, sh_hexTable, sh_dataTypes, sh_sti, sh_cli, sh_buildData, sh_memalloc, sh_memfree, sh_poke, sh_history, sh_memusg,sh_millis, sh_echo, sh_foo, sh_msg, sh_null};\n\nvoid sh_foo(char* command){\n\tstruct expr * testexpr;\n\ttestexpr = makeIntExpr((int) millis());\n\tttprintln(toString(testexpr));\n\ttestexpr = makeFloatExpr(3.14159265358979);\n\tttprintln(toString(testexpr));\n\ttestexpr = makeStringExpr(\"Hello, world!\");\n\tttprintln(toString(testexpr));\n\ttestexpr = makeBoolExpr(1);\n\tttprintln(toString(testexpr));\n\ttestexpr = makeBoolExpr(0);\n\tttprintln(toString(testexpr));\n\t/*\n\tstruct StringListNode* tokens = tokenize(fileBuffer->firstLine);\n\tttprintln(\"printing tokens:\");\n\twhile(tokens){\n\t\tttprintln(tokens->str);\n\t\ttokens = tokens->next;\n\t}*/\n}\n\nvoid sh_handler(char* command){\n\tint i=0;\n\twhile(command[i]!=' ' && command[i]!=0) i++;\n\tif(i == 0) return;\n\tchar program[i+1];\n\tmemCopy(command,program,i);\n\tprogram[i] = 0;\n\tchar params[strLen(command)-i];\n\tmemCopy(command+i+1,params,strLen(command)-i+1);\n\tparams[strLen(command)-i-1] = 0;\n\ti = 0;\n\twhile(!strEquals(shCommandList[i],program) && !strEquals(shCommandList[i],\"null\")) i++;\n\tif(!strEquals(shCommandList[i],\"null\")) (*shFunctionList[i])(params);\n\telse {\n\t\tttprint(\"Command not found: \");\n\t\tttprintln(program);\n\t}\n}\n\nvoid sh_echo(char* params){\n\tttprintln(params);\n}\n\nvoid sh_msg(char* params){\n\tsetMessage(params);\n}\n\n\n// run sh_handler on each line of a file (or the buffer)\nvoid sh_shell(char* params){\n\tstruct StringListNode *temp;\n\tif(strEquals(params,\"buffer\")){\n\t\ttemp = fileBuffer->firstLine;\n\t} else {\n\t\tstruct File *f = readFile(params);\n\t\ttemp = f->firstLine;\n\t}\n\twhile(temp){\n\t\tint len = strLen(temp->str)-1;\n\t\tif((temp->str)[len-1] == '\\n'){ // lines ends with \\n\n\t\t\tchar* line = (char*) malloc(len);\n\t\t\tmemCopy(temp->str, line, len);\n\t\t\tline[len-1] = 0;\n\t\t\tsh_handler(line);\n\t\t\tfree(line, len);\n\t\t} else { // line doesn't end with \\n (last line in file)\n\t\t\tsh_handler(temp->str);\n\t\t}\n\t\ttemp = temp->next;\n\t}\n}\n\nvoid sh_edit(char* params){\n\tterminalMode = EDITOR;\n\teditor_initialize();\n\teditor_updateScreen();\n}\n\nvoid sh_ls(char* params){\n\tint i;\n\t//char firstTime = 1;\n char* pointer = KFS;\n char* KFS_sig = \"KFS Begin\";\n for(i=0; i<strLen(KFS_sig)-1; i++){\n if(pointer[i] != KFS_sig[i]){\n ttprint(\"Error! File system does not start with:\");\n ttprintln(KFS_sig);\n return;\n }\n }\n pointer += 25;\n // 25 is filesystem header, 94 is max # files\n for(i=0; i < 94; i++){\n\t\tif(pointer[0] == 0) continue;\n\t int c;\n\t\tfor(c = 0; c < 10 && pointer[c] != 0; c++){\n\t\t\tttprintChar(pointer[c]);\n\t\t}\n pointer += 16;\n ttprint(\"\\n\");\n }\n}\nvoid sh_head(char* params){\n\tif(strLen(params) == 1){\n\t\tttprintln(\"Must pass a filename.\");\n\t\treturn;\n\t}\n\tint lines = 10;\n\tstruct File *f = readFile(params);\n\tstruct StringListNode* line = f->firstLine;\n\twhile(line && lines > 0){\n\t\tttprint(line->str);\n\t\tline = line->next;\n\t\tlines--;\n\t}\n}\n\n\nvoid sh_read(char* params){\n\tfileBuffer = readFile(params);\n}\n\nvoid sh_cat(char* params){\n\tstruct StringListNode *temp;\n\tif(strEquals(params,\"buffer\")){\n\t\ttemp = fileBuffer->firstLine;\n\t} else {\n\t\tstruct File *f = readFile(params);\n\t\ttemp = f->firstLine;\n\t}\n\twhile(temp){\n\t\tttprint(temp->str);\n\t\ttemp = temp->next;\n\t}\n}\n\nvoid clearBuffer(){\n\tstruct StringListNode *temp = fileBuffer->firstLine;\n\tstruct StringListNode *next;\n\twhile(temp){\n\t\tfree(temp->str, strLen(temp->str));\n\t\tnext = temp->next;\n\t\tfree(temp, sizeof(struct StringListNode));\n\t\ttemp = next;\n\t}\n\tfree(fileBuffer->filename, strLen(fileBuffer->filename));\n\tfileBuffer->filename = 0;\n\tfileBuffer->filesize = 0;\t\n}\n\n/*\n\tparse a file into a linked list of lines separated by \\n\n*/\n\nstruct File *readFile(char* params){\n\tchar** pointer;\n\tint len = getFilePointer(params,pointer);\n\tstruct File *file;\n\tfile = (struct File*)malloc(sizeof(struct File));\n\tfile->filename = (char*)malloc(strLen(params));\n\tmemCopy(params,file->filename,strLen(params));\n\tfile->filesize = len;\n\tint i;\n\tstruct StringListNode *line = (struct StringListNode*) malloc(sizeof(struct StringListNode));\n\tfile->firstLine = line;\n\tline->prev = 0;\n\tline->next = 0;\n\tint lineStart = 0;\n\t// split the file into separate lines\n\tfor(i = 0; i < len; i++){\n\t\tif((*pointer)[i] == '\\n' || i == len-1){\n\t\t\tline->str = (char*) malloc(i-lineStart+2);\n\t\t\tmemCopy((*pointer+lineStart), line->str, i-lineStart+1);\n\t\t\t(line->str)[i-lineStart+1] = 0;\n\t\t\t//set up the next line\n\t\t\tstruct StringListNode *tline;\n\t\t\ttline = (struct StringListNode*) malloc(sizeof(struct StringListNode));\n\t\t\ttline->prev = line;\n\t\t\tline->next = tline;\n\t\t\tline = tline;\n\t\t\tlineStart = i+1;\n\t\t}\n\t\tif(i == len-1){\n\t\t\t//nix the next line, since there isn't one\n\t\t\tline = line->prev;\n\t\t\tfree(line->next, sizeof(struct StringListNode));\n\t\t\tline->next = 0;\n\t\t}\n\t}\n\treturn file;\n}\n\n/* \n* stores pointer to file in param2, returns filesize\n*/\n\nint getFilePointer(char* params, char** pointerParam){\n\n\tint i;\n\t*pointerParam = KFS;\n\tunsigned char** pointer = (unsigned char**) pointerParam;\n\tchar* KFS_sig = \"KFS Begin\";\n\tfor(i=0; i<strLen(KFS_sig)-1; i++){\n\t\tif((*pointer)[i] != KFS_sig[i]){\n\t\t\tttprint(\"Error! KFS does not start with:\");\n\t\t\tttprint(KFS_sig);\n\t\t\treturn -1;\n\t\t}\n\t}\n\n\t*pointer += 25;\n\t// 25 is filesystem header, 94 is max # files\n\tfor(i=0; i < 94; i++){\n\t\t//ttprintln(*pointer);\n\t\tif(strEquals(params,*pointer) || strLen(params) == 11 && strBeginsWith(*pointer,params)) break;\n\t\t*pointer += 16;\n\t}\n\tif(i == 94){\n\t\tttprint(\"File not found:\");\n\t\tttprint(params);\n\t\treturn -2;\n\t}\n\ti = 0;\n\t*pointer += 10;\n\tint sec,off,len;\n\tsec = (*pointer)[i++];\n\n\toff = (*pointer)[i++] << 8 ;\n\toff |= (*pointer)[i++];\n\t\n\tlen = (*pointer)[i++] << 16;\n\tlen |= ((*pointer)[i++] << 8);\n\tlen |= (*pointer)[i++];\n\n\t*pointer = KFS + (sec+3)*512 + off;\n\treturn len;\n}\n\nvoid sh_glissando(char* params){\n\tint i = 220;\n\t//xxxx 50\n\tchar param[8];\n\twhile(i < 220*8){\n\t\tintToString(i,param);\n\t\tif(i < 1000){\n\t\t\tparam[3] = ' ';\n\t\t\tparam[4] = '5';\n\t\t\tparam[5] = '0';\n\t\t\tparam[6] = 0;\n\t\t} else {\n\t\t\tparam[4] = ' ';\n\t\t\tparam[5] = '5';\n\t\t\tparam[6] = '0';\n\t\t\tparam[7] = 0;\n\t\t}\n\t\tsh_beep(param);\n\t\ti = i + 20;\n\t}\n\tsh_beep(\"0 0\");\n}\n\nvoid sh_mario(char* params){\n\tsh_beep(\"659 100\");\n\tsleep(100);\n\tsh_beep(\"659 100\");\n\tsleep(150);\n\tsh_beep(\"659 100\");\n\tsleep(200);\n\tsh_beep(\"523 100\");\n\tsleep(75);\n\tsh_beep(\"659 100\");\n\tsleep(200);\n\tsh_beep(\"784 100\");\n\tsleep(500);\n\tsh_beep(\"392 100\");\n}\nvoid sh_sleep(char* params){\n\tsleep(strToInt(params));\n}\nvoid sh_beep(char* params){\n\t//\"beep freq duration\"\n\tint i,freq = 440, dur = 1000;\n\tfor(i=0;i<strLen(params);i++){\n\t\tif(params[i] == ' ') break;\n\t}\n\tchar frequency[i+1];\n\tmemCopy(params,frequency,i);\n\tfrequency[i] = 0;\n\tfreq = strToInt(frequency);\n\tif(i != strLen(params)){\n\t\tchar duration[strLen(params)-i];\n\t\tmemCopy(params+i+1,duration,strLen(params)-i);\n\t\tdur = strToInt(duration);\n\t}\n\tplay_sound(freq);\n\tsleep(dur);\n\tplay_sound(0);\n}\nvoid sh_htoi(char* params){\n\tint len = strLen(params)-1;\n\tif(len < 3 || params[0] != '0' || params[1] != 'x'){\n\t\tttprintln(\"htoi param must start with `0x`\");\n\t\treturn;\n\t}\n\treverseInPlace(params+2);\n\tlen -= 2;\n\tint i;\n\tint sum = 0;\n\tfor(i = 0; i < len; i++){\n\t\tif(isAlpha(params[i+2])){\n\t\t\tif(isLower(params[i+2]) && params[i+2] <= 'f'){\n\t\t\t\tsum += pow(16,i) * (params[i+2]-'a'+10);\n\t\t\t}\n\t\t\telse if(isUpper(params[i+2]) && params[i+2] <= 'F'){\n\t\t\t\tsum += pow(16,i) * (params[i+2]-'A'+10);\n\t\t\t}\n\t\t\telse {\n\t\t\t\tttprintln(\"improperly formed hex\");\n\t\t\t\treturn;\n\t\t\t}\n\t\t}\n\t\telse sum += pow(16,i) * (params[i+2]-'0');\n\t}\n\tttprintIntln(sum);\n}\nvoid sh_itoh(char* params){\n\tchar s[3];\n\ts[2] = 0;\n\titoh(strToInt(params),s);\n\tttprintln(s);\n}\nvoid sh_int(char* params){\n\tttprintIntln(strToInt(params));\n}\n\nvoid sh_textDump(char* params){\n\t// textDump pointer length\n\tint i;\n\tfor(i=0;i<strLen(params);i++){\n\t\tif(params[i] == ' ') break;\n\t}\n\tchar substr[i+1];\n\tmemCopy(params,substr,i);\n\tsubstr[i] = 0;\n\tchar* pointer = (char*) ((int*)strToInt(substr));\n\tchar substr2[strLen(params)-i];\n\tmemCopy(params+i+1,substr2,strLen(params)-i);\n\tint length = strToInt(substr2);\n\tfor(i=0;i<length;i++){\n\t\tttprintChar(pointer[i]);\n\t}\n\tttprint(\"\\n\");\n}\n\nvoid sh_memDump(char* params){\n\t// textDump pointer length\n\tint i;\n\tfor(i=0;i<strLen(params);i++){\n\t\tif(params[i] == ' ') break;\n\t}\n\tchar substr[i+1];\n\tmemCopy(params,substr,i);\n\tsubstr[i] = 0;\n\tchar* pointer = (char*) ((int*)strToInt(substr));\n\tchar substr2[strLen(params)-i];\n\tmemCopy(params+i+1,substr2,strLen(params)-i);\n\tint length = strToInt(substr2);\n\tchar hex[3];\n\thex[2] = 0;\n\tfor(i=0;i<length;i++){\n\t\titoh(pointer[i], hex);\n\t\tttprint(hex);\n\t\tttprint(\" \");\n\t}\n\tttprint(\"\\n\");\n}\n\nvoid sh_rand(char* params){\n\tint i;\n\tfor(i = 0; i < strLen(params)-1; i++){\n\t\tif(params[i] < '0' || params[i] > '9'){\n\t\t\tttprint(\"parameter must be numeric:\");\n\t\t\tttprintChar(params[i]);\n\t\t\treturn;\n\t\t}\n\t}\n\tif(strLen(params) == 1) ttprintIntln(rand(10));\n\telse ttprintIntln(rand(strToInt(params)));\n\treturn;\n}\nvoid sh_colorTable(char* params){\n\tchar a;\n\tttprint(\"high byte:\");\n\tfor(a = 0; a < 16; a++){\n\t\tttprintCharColor('+',a*16 + 15);\n\t}\n\tttprintChar('\\n');\n\tttprint(\"low byte: \");\n\tfor(a = 0; a < 16; a++){\n\t\tttprintCharColor('+',15*16+a);\n\t}\n\tttprint(\"\\n\");\n}\nvoid sh_charTable(char* params){\n\tchar i;\n\tfor(i = -128; i < 127; i++){\n\t\tttprintChar(i);\n\t}\n\tttprint(\"\\n\");\n}\nvoid sh_hexTable(char* params){\n\tchar str[5];\n\tint a,b;\n\tfor(a = 0; a < 16; a++){\n\t\tfor(b = 0; b < 16; b++){\n\t\t\tcharToString(a*16+b,str);\n\t\t\tttprint(str);\n\t\t\tttprint(\" \");\n\t\t}\n\t}\n}\nvoid sh_dataTypes(char* params){\n\tttprint(\"char:\"); ttprintIntln(sizeof(char));\n\tttprint(\"short:\"); ttprintIntln(sizeof(short));\n\tttprint(\"int:\"); ttprintIntln(sizeof(int));\n\tttprint(\"long:\"); ttprintIntln(sizeof(long));\n}\nvoid sh_sti(char* params){\n\tenableInterrupts();\n}\nvoid sh_cli(char* params){\n\tdisableInterrupts();\n}\nvoid sh_buildData(char* params){\n\tttprint(\"Build ID:\");\n\tttprintIntln(getBuildID());\n}\nvoid sh_help(char* params){\n\tint i = 0;\n\tttprint(\"Available commands are:\");\n\twhile(!strEquals(shCommandList[i],\"null\")){\n\t\tttprint(\" \");\n\t\tttprint(shCommandList[i]);\n\t\ti++;\n\t}\n\tttprint(\"\\n\");\n}\nvoid sh_memalloc(char* params){\n\tchar* ptr = (char*) malloc(strToInt(params));\n\tttprintIntln((int)ptr);\n}\nvoid sh_memfree(char* params){\n\tint i;\n\tfor(i=0;i<strLen(params);i++){\n\t\tif(params[i] == ' ') break;\n\t}\n\tparams[i] = 0;\n\tvoid* pointer = (void*) ((int*)strToInt(params));\n\tint value = strToInt(params+i+1);\n\tfree(pointer, value);\n}\nvoid sh_poke(char* params){\n\t// poke pointer byte(decimal)\n\tint i;\n\tfor(i=0;i<strLen(params);i++){\n\t\tif(params[i] == ' ') break;\n\t}\n\tchar substr[i+1];\n\tmemCopy(params,substr,i);\n\tsubstr[i] = 0;\n\tchar* pointer = (char*) ((int*)strToInt(substr));\n\t\n\tchar substr2[strLen(params)-i];\n\tmemCopy(params+i+1,substr2,strLen(params)-i);\n\tint value = strToInt(substr2);\n\t*pointer = value;\n}\n\nvoid sh_history(char* params){\n\tstruct StringListNode *conductor = historyHead;\n\twhile(conductor->next){\n\t\tttprintln(conductor->str);\n\t\tconductor = conductor->next;\n\t}\n}\nvoid sh_memusg(char* params){\n\tint bytes = getBytesAllocated();\n\tint avail = getAvailableMemory();\n\tttprint(\"Allocated \");\n\tttprintInt(bytes);\n\tttprint(\" of \");\n\tttprintInt(avail);\n\tttprintln(\" bytes\");\n}\nvoid sh_millis(char* params){\n\tttprintIntln(millis());\n}\nvoid sh_null(char* params){\n\tttprintln(\"wtf\");\n}\n"
},
{
"alpha_fraction": 0.7821782231330872,
"alphanum_fraction": 0.7821782231330872,
"avg_line_length": 24.5,
"blob_id": "7205f9543d4aa500a798fda9e800a5c1fa9fa66d",
"content_id": "edb57e8093d5baea1ed70caf20dba6c10b98aaa7",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 101,
"license_type": "permissive",
"max_line_length": 41,
"num_lines": 4,
"path": "/files/startup.sh",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "echo Hello from the startup shell script!\necho Type 'help' for a list of commands.\nread first.l\nmario"
},
{
"alpha_fraction": 0.7575757503509521,
"alphanum_fraction": 0.7575757503509521,
"avg_line_length": 10.166666984558105,
"blob_id": "b7cd9e8c4e096d500a858a2637f1534afb42034f",
"content_id": "4a77aecb361ae7930e7efe1947fc58a40c0dea28",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 66,
"license_type": "permissive",
"max_line_length": 19,
"num_lines": 6,
"path": "/buildData.h",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "#ifndef BUILDDATA_H\n#define BUILDDATA_H\n\nint getBuildID();\n\n#endif"
},
{
"alpha_fraction": 0.6315789222717285,
"alphanum_fraction": 0.6842105388641357,
"avg_line_length": 12.75,
"blob_id": "93a643e6ba5191eb644f5daab838dee81b15fe18",
"content_id": "eda2b265688ff38227202b78e4c474459d0b0dd4",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 57,
"license_type": "permissive",
"max_line_length": 18,
"num_lines": 4,
"path": "/buildData.c",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "\nint getBuildID(){\nint buildID = 508;\nreturn buildID;\n}\n\n"
},
{
"alpha_fraction": 0.5669044256210327,
"alphanum_fraction": 0.6825487613677979,
"avg_line_length": 23.62295150756836,
"blob_id": "4105da0dfb0ab41f5952ca732f7743c656d23cf8",
"content_id": "72c4eece08b2808f1e618779a81b1bc89b7640b3",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 10515,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 427,
"path": "/IDT.c",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "extern void int_general();\t\t// Default interrupt routine\nextern void int_0();\nextern void int_1();\nextern void int_2();\nextern void int_3();\nextern void int_4();\nextern void int_5();\nextern void int_6();\nextern void int_7();\nextern void int_8();\nextern void int_9();\nextern void int_10();\nextern void int_11();\nextern void int_12();\nextern void int_13();\nextern void int_14();\nextern void int_15();\nextern void int_16();\nextern void int_17();\nextern void int_18();\nextern void int_19();\nextern void int_20();\nextern void int_21();\nextern void int_22();\nextern void int_23();\nextern void int_24();\nextern void int_25();\nextern void int_26();\nextern void int_27();\nextern void int_28();\nextern void int_29();\nextern void int_30();\nextern void int_31();\nextern void int_32();\nextern void int_33();\t\t\t// Keyboard interrupt\nextern void int_34();\nextern void int_35();\nextern void int_36();\nextern void int_37();\nextern void int_38();\nextern void int_39();\nextern void int_40();\nextern void int_41();\nextern void int_42();\nextern void int_43();\nextern void int_44();\nextern void int_45();\nextern void int_46();\nextern void int_47();\n\nstruct idtstruct {\n\tunsigned short offset1;\n\tunsigned short selector;\n\tunsigned char unused;\n\tunsigned char flag;\n\tunsigned short offset2;\n} __attribute__((packed));\t\t// Packed to avoid padding\n\nstruct idtpointer {\n\tunsigned short size;\n\tunsigned int offset;\t\n} __attribute__((packed));\t\t// Packed to avoid padding\n\n\nstatic struct idtstruct idttable[256];\t// Define the idt struct\n\nvoid remappic();\nvoid isr_general();\nvoid isr_0();\nvoid isr_1();\nvoid isr_2();\nvoid isr_3();\nvoid isr_4();\nvoid isr_5();\nvoid isr_6();\nvoid isr_7();\nvoid isr_8();\nvoid isr_9();\nvoid isr_10();\nvoid isr_11();\nvoid isr_12();\nvoid isr_13();\nvoid isr_14();\nvoid isr_15();\nvoid isr_16();\nvoid isr_17();\nvoid isr_18();\nvoid isr_19();\nvoid isr_20();\nvoid isr_21();\nvoid isr_22();\nvoid isr_23();\nvoid isr_24();\nvoid isr_25();\nvoid isr_26();\nvoid isr_27();\nvoid isr_28();\nvoid isr_29();\nvoid isr_30();\nvoid isr_31();\nvoid isr_32();\nvoid isr_33();\nvoid isr_34();\nvoid isr_35();\nvoid isr_36();\nvoid isr_37();\nvoid isr_38();\nvoid isr_39();\nvoid isr_40();\nvoid isr_41();\nvoid isr_42();\nvoid isr_43();\nvoid isr_44();\nvoid isr_45();\nvoid isr_46();\nvoid isr_47();\nvoid idt_entry(unsigned int entry, void* offset, unsigned short selector, unsigned char flag);\n\nvoid idt_init()\n{\n\tunsigned int i;\n\tremappic();\n\tstruct idtpointer idt;\t\t\t// Contains the struct being loaded by lidt\n\n\tidt_entry(0, &int_0, 0x08, 0x8E);\t// Flag indicates an interrupt gate\n\tidt_entry(1, &int_1, 0x08, 0x8E);\n\tidt_entry(2, &int_2, 0x08, 0x8E);\n\tidt_entry(3, &int_3, 0x08, 0x8E);\n\tidt_entry(4, &int_4, 0x08, 0x8E);\n\tidt_entry(5, &int_5, 0x08, 0x8E);\n\tidt_entry(6, &int_6, 0x08, 0x8E);\n\tidt_entry(7, &int_7, 0x08, 0x8E);\n\tidt_entry(8, &int_8, 0x08, 0x8E);\n\tidt_entry(9, &int_9, 0x08, 0x8E);\n\tidt_entry(10, &int_10, 0x08, 0x8E);\n\tidt_entry(11, &int_11, 0x08, 0x8E);\n\tidt_entry(12, &int_12, 0x08, 0x8E);\n\tidt_entry(13, &int_13, 0x08, 0x8E);\n\tidt_entry(14, &int_14, 0x08, 0x8E);\n\tidt_entry(15, &int_15, 0x08, 0x8E);\n\tidt_entry(16, &int_16, 0x08, 0x8E);\n\tidt_entry(17, &int_17, 0x08, 0x8E);\n\tidt_entry(18, &int_18, 0x08, 0x8E);\n\tidt_entry(19, &int_19, 0x08, 0x8E);\n\tidt_entry(20, &int_20, 0x08, 0x8E);\n\tidt_entry(21, &int_21, 0x08, 0x8E);\n\tidt_entry(22, &int_22, 0x08, 0x8E);\n\tidt_entry(23, &int_23, 0x08, 0x8E);\n\tidt_entry(24, &int_24, 0x08, 0x8E);\n\tidt_entry(25, &int_25, 0x08, 0x8E);\n\tidt_entry(26, &int_26, 0x08, 0x8E);\n\tidt_entry(27, &int_27, 0x08, 0x8E);\n\tidt_entry(28, &int_28, 0x08, 0x8E);\n\tidt_entry(29, &int_29, 0x08, 0x8E);\n\tidt_entry(30, &int_30, 0x08, 0x8E);\n\tidt_entry(31, &int_31, 0x08, 0x8E);\n\tidt_entry(32, &int_32, 0x08, 0x8E);\n\tidt_entry(33, &int_33, 0x08, 0x8E);\n\tidt_entry(34, &int_34, 0x08, 0x8E);\n\tidt_entry(35, &int_35, 0x08, 0x8E);\n\tidt_entry(36, &int_36, 0x08, 0x8E);\n\tidt_entry(37, &int_37, 0x08, 0x8E);\n\tidt_entry(38, &int_38, 0x08, 0x8E);\n\tidt_entry(39, &int_39, 0x08, 0x8E);\n\tidt_entry(40, &int_40, 0x08, 0x8E);\n\tidt_entry(41, &int_41, 0x08, 0x8E);\n\tidt_entry(42, &int_42, 0x08, 0x8E);\n\tidt_entry(43, &int_43, 0x08, 0x8E);\n\tidt_entry(44, &int_44, 0x08, 0x8E);\n\tidt_entry(45, &int_45, 0x08, 0x8E);\n\tidt_entry(46, &int_46, 0x08, 0x8E);\n\tidt_entry(47, &int_47, 0x08, 0x8E);\n\n\tfor(i = 48; i < 256; i++)\t// Fill in the remaining entries with a standard isr\n\t{\n\t\tidt_entry(i, &int_general, 0x08, 0x8E);\n\t}\n\n\tidt.size = sizeof(idttable) - 1;\t\t// Size of the IDT\n\tidt.offset = (unsigned int)&idttable;\t\t// Pointer to the IDT\n\n\tasm(\"lidt (%0)\" : : \"p\"(&idt));\t\t\t// Load the IDT struct\n\tasm(\"sti\" : :);\t\t\t\t\t// Activate interrupts\n}\n\nvoid idt_entry(unsigned int entry, void* offset, unsigned short selector, unsigned char flag)\n{\n\tunsigned int offsetinteger = (unsigned int)offset;\n\tidttable[entry].offset1 = offsetinteger & 0xFFFF;\t\t\n\tidttable[entry].selector = selector;\n\tidttable[entry].unused = 0;\n\tidttable[entry].flag = flag;\n\tidttable[entry].offset2 = (offsetinteger >> 16) & 0xFFFF;\n}\n\nvoid isr_general(){\n\twriteByteToPort(0x20, 0x20);\n\tttprintln(\"isr_general was called\");\n}\nvoid isr_0(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_0 : Divide Error was called\");\n}\nvoid isr_1(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_1 : Debug Exceptions was called\");\n}\nvoid isr_2(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_2 : Intel Reserved was called\");\n}\nvoid isr_3(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_3 : Breakpoint was called\");\n}\nvoid isr_4(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_4 : Overflow was called\");\n}\nvoid isr_5(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_5 : Bounds Check was called\");\n}\nvoid isr_6(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_6 : Invalid Opcode was called\");\n}\nvoid isr_7(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_7 : Coprocessor Not Available was called\");\n}\nvoid isr_8(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_8 : Double Fault was called\");\n}\nvoid isr_9(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_9 : Coprocessor Segment Overrun was called\");\n}\nvoid isr_10(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_10 : Invalid TSS was called\");\n}\nvoid isr_11(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_11 : Segment Not Present was called\");\n}\nvoid isr_12(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_12 : Stack Exception was called\");\n}\nvoid isr_13(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_13 : General Protection Exception (Triple Fault) was called\");\n}\nvoid isr_14(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_14 Page Fault was called\");\n}\nvoid isr_15(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_15 Intel Reserved was called\");\n}\nvoid isr_16(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_16 Coprocessor Error was called\");\n}\nvoid isr_17(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_17 was called\");\n}\nvoid isr_18(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_18 was called\");\n}\nvoid isr_19(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_19 was called\");\n}\nvoid isr_20(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_20 was called\");\n}\nvoid isr_21(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_21 was called\");\n}\nvoid isr_22(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_22 was called\");\n}\nvoid isr_23(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_23 was called\");\n}\nvoid isr_24(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_24 was called\");\n}\nvoid isr_25(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_25 was called\");\n}\nvoid isr_26(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_26 was called\");\n}\nvoid isr_27(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_27 was called\");\n}\nvoid isr_28(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_28 was called\");\n}\nvoid isr_29(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_29 was called\");\n}\nvoid isr_30(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_30 was called\");\n}\nvoid isr_31(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_31 was called\");\n}\n\nvoid isr_32(){\n\twriteByteToPort(0x20,0x20);\n\tpitCall();\n\t//ttprintln(\"isr_32 (IRQ 0: Programmable Interrupt Timer) was called\");\n}\n\nvoid isr_33(){\n\t//keyboard\n\tunsigned char scancode = readByteFromPort(0x60);\n\tkeyPressed(scancode);\n\twriteByteToPort(0x20, 0x20);\n}\nvoid isr_34(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_34 (IRQ 2: Cascade [used by PICS]) was called\");\n}\nvoid isr_35(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_35 (IRQ 3: COM2) was called\");\n}\nvoid isr_36(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_36 (IRQ 4: COM1) was called\");\n}\nvoid isr_37(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_37 (IRQ 5: LPT2) was called\");\n}\nvoid isr_38(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_38 (IRQ 6: Floppy Disk) was called\");\n}\nvoid isr_39(){\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_39 (IRQ 7: LPT1 / spurious interrupt) was called\");\n}\nvoid isr_40(){\n\twriteByteToPort(0xA0,0x20);\n\twriteByteToPort(0x20,0x20);\n\t//by reading register C, the interrupt will happen again\n\twriteByteToPort(0x70,0x0C);\n\treadByteFromPort(0x71);\n\trtcCall();\n}\nvoid isr_41(){\n\twriteByteToPort(0xA0,0x20);\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_41 (IRQ 9: Free for peripherals) was called\");\n}\nvoid isr_42(){\n\twriteByteToPort(0xA0,0x20);\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_42 (IRQ 10: Free for peripherals) was called\");\n}\nvoid isr_43(){\n\twriteByteToPort(0xA0,0x20);\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_43 (IRQ 11: Free for peripherals) was called\");\n}\nvoid isr_44(){\n\twriteByteToPort(0xA0,0x20);\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_44 (IRQ 12: PS2 Mouse) was called\");\n}\nvoid isr_45(){\n\twriteByteToPort(0xA0,0x20);\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_45 (IRQ 13: FPU / Coprocessor / Inter-processor) was called\");\n}\nvoid isr_46(){\n\twriteByteToPort(0xA0,0x20);\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_46 (IRQ 14: Primary ATA Hard Disk) was called\");\n}\nvoid isr_47(){\n\twriteByteToPort(0xA0,0x20);\n\twriteByteToPort(0x20,0x20);\n\tttprintln(\"isr_47 (IRQ 15: Secondary ATA Hard Disk) was called\");\n}\n\n\nvoid remappic(){\n\twriteByteToPort(0x20, 0x11);\t\t// Initilisation instruction\n\twriteByteToPort(0xA0, 0x11);\n\t\t\n\twriteByteToPort(0x21, 0x20);\t\t// Map the first 8 interrupts to 0x20\n\twriteByteToPort(0xA1, 0x28);\t\t// Map 8 - 15 interrupts to 0x28\n\n\twriteByteToPort(0x21, 0x04);\t\t// Tell the pic how its connected \n\twriteByteToPort(0xA1, 0x02);\t\t\n\t\n\twriteByteToPort(0x21, 0x01);\t\t// Tell the mode it is operating in\n\twriteByteToPort(0xA1, 0x01);\n\n\t//writeByteToPort(0x21, 0xfd);\n\t//writeByteToPort(0xA1, 0xff);\n\twriteByteToPort(0x21, 0x0);\n\twriteByteToPort(0xA1, 0x0);\n}\n\n"
},
{
"alpha_fraction": 0.4323420822620392,
"alphanum_fraction": 0.5013197064399719,
"avg_line_length": 20.93822479248047,
"blob_id": "a537934b37cf182175959ce55a0c7417bce812e7",
"content_id": "e1a9619d2f71021efdec71225681bb7ed0212f21",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5683,
"license_type": "permissive",
"max_line_length": 316,
"num_lines": 259,
"path": "/util.c",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "\n#include \"util.h\"\n#include \"malloc.h\"\n/*\nstruct StringListNode* makeStringBuilder(char* s){\n\tstruct StringListNode* node = (struct StringListNode*) malloc(sizeof(struct StringListNode));\n\tnode->prev = 0;\n\tnode->next = 0;\n\tchar* str = (char*)malloc(strLen(s));\n\tmemCopy(s,str,strLen(s));\n\tnode->str = str;\n\treturn s;\n}\n*/\n\nint flattenStringList(struct StringListNode* head, char** str){\n\tint length = 0, index = 0;\n\tstruct StringListNode *temp = head;\n\twhile(temp){\n\t\tlength += strLen(temp->str)-1;\n\t\ttemp = temp->next;\t\n\t}\n\t*str = (char*)malloc(length+1);\n\ttemp = head;\n\twhile(temp){\n\t\tmemCopy(temp->str, (*str)+index, strLen(temp->str)-1);\n\t\tindex += strLen(temp->str)-1;\n\t\ttemp = temp->next;\n\t}\n\t(*str)[index] = 0;\n\treturn length;\n}\n\nvoid strReplace(char* str, char from, char to){\n\twhile(*str){\n\t\tif(*str == from)\n\t\t\t*str = to;\n\t\tstr++;\n\t}\n}\n\n\nvoid memFill(char* to, char filler, int len){\n\tint i;\n\tfor(i = 0; i < len; i++) to[i] = filler;\n}\nvoid memCopy(char* from, char* to, int len){\n\tint i;\n\tfor(i = 0; i < len; i++){\n\t\tto[i] = from[i];\n\t}\n}\n\nint strLen(char* str){\n\tint i = 0;\n\twhile(str[i++] != 0);\n\treturn i;\n}\n\nvoid doubleToString(double n, char* s){\n\t//default to two decimal places\n\tint intpart = (int) n;\n\tint floatpart = (int)(100*n) % 100;\n\tintToString(intpart, s);\n\tint len = strLen(s)-1;\n\ts[len] = '.';\n\tintToString(floatpart, (s+len+1));\n}\n\nvoid intToString(int n, char s[]){\n\tint num = n;\n\tif(n == 0){\n\t\ts[0] = '0';\n\t\ts[1] = 0;\n\t\treturn;\n\t}\n\tif(num < 0){\n\t\ts++;\n\t\tn*=-1;\n\t}\n\tint i;\n\tfor(i = 0; n != 0; i++){\n\t\ts[i] = '0'+(n % 10);\n\t\tn/=10;\n\t}\n\ts[i] = 0;\n\treverseInPlace(s);\n\tif(num < 0){\n\t\ts--;\n\t\ts[0] = '-';\n\t}\n}\n\nint strToInt(char* s){\n\tint sign = 1;\n\tif(s[0] == '-') sign = -1;\n\tint n = 0;\n\tint i = (sign == 1 ? 0 : 1);\n\tint len = strLen(s);\n\tint power = pow(10,len-i-2);\n\twhile(s[i] != 0){\n\t\tn += (s[i] - '0') * power;\n\t\ti++;\n\t\tpower /= 10;\n\t}\n\treturn n*sign;\n}\n\nvoid itoh(char n, char* s){\n\tunsigned char c = n;\n\tchar upper = (c / 16);\n\tchar lower = (c % 16);\n\ts[0] = upper < 10 ? '0' + upper : 'A' + (upper-10);\n\ts[1] = lower < 10 ? '0' + lower : 'A' + (lower-10);\n}\n\nchar table[2][49] = {{0x0B, 0x02, 0x03, 0x04, 0x05, 0x06, 0x07, 0x08, 0x09, 0x0A, 0x1E, 0x30, 0x2E, 0x20, 0x12, 0x21, 0x22, 0x23, 0x17, 0x24, 0x25, 0x26, 0x32, 0x31, 0x18, 0x19, 0x10, 0x13, 0x1F, 0x14, 0x16, 0x2F, 0x11, 0x2D, 0x15, 0x2C, 0x39, 0x1C, 0x34, 0x33, 0x35, 0x0D, 0x0C, 0x29, 0x1A, 0x1B, 0x2B, 0x28, 0x27},\n\t\t\t\t\t {'0' , '1' , '2' , '3' , '4' , '5' , '6' , '7' , '8' , '9' , 'A' , 'B' , 'C' , 'D' , 'E' , 'F' , 'G' , 'H' , 'I' , 'J' , 'K' , 'L' , 'M' , 'N' , 'O' , 'P' , 'Q' , 'R' , 'S' , 'T' , 'U' , 'V' , 'W' , 'X' , 'Y' , 'Z' , ' ' , '\\n', '.' , ',' , '/', '=' , '-' , '`' , '[' , ']' , '\\\\', '\\'', ';' }};\n\nchar scancodeToAscii(unsigned char scan, char shift, char ctrl, char caps){\n\tint i;\n\tfor(i = 0; i < sizeof(table[0]); i++){\n\t\tif(scan == table[0][i]){\n\t\t\tif(!(shift || caps) && table[1][i]>='A' && table[1][i]<='Z') return table[1][i]-'A'+'a';\n\t\t\tif(shift || caps){\n\t\t\t\tif(table[1][i] == '1') return '!';\n\t\t\t\tif(table[1][i] == '2') return '@';\n\t\t\t\tif(table[1][i] == '3') return '#';\n\t\t\t\tif(table[1][i] == '4') return '$';\n\t\t\t\tif(table[1][i] == '5') return '%';\n\t\t\t\tif(table[1][i] == '6') return '^';\n\t\t\t\tif(table[1][i] == '7') return '&';\n\t\t\t\tif(table[1][i] == '8') return '*';\n\t\t\t\tif(table[1][i] == '9') return '(';\n\t\t\t\tif(table[1][i] == '0') return ')';\n\t\t\t\tif(table[1][i] == ',') return '<';\n\t\t\t\tif(table[1][i] == '.') return '>';\n\t\t\t\tif(table[1][i] == '/') return '?';\n\t\t\t\tif(table[1][i] == '=') return '+';\n\t\t\t\tif(table[1][i] == '-') return '_';\n\t\t\t\tif(table[1][i] == '`') return '~';\n\t\t\t\tif(table[1][i] == '[') return '{';\n\t\t\t\tif(table[1][i] == ']') return '}';\n\t\t\t\tif(table[1][i] == '\\\\') return '|';\n\t\t\t\tif(table[1][i] == '\\'') return '\"';\n\t\t\t\tif(table[1][i] == ';') return ':';\n\t\t\t}\n\t\t\treturn table[1][i];\n\t\t}\n\t}\n\treturn 0;\n}\nvoid charToString(unsigned char c, char* str){\n\tchar high = c >> 4;\n\tchar low = c%16;\n\tstr[0] = '0';\n\tstr[1] = 'x';\n\tstr[2] = '0' + high; \n\tif(str[2] > '9'){\n\t\tstr[2] += 'A' - '9' - 1;\n\t}\n\tstr[3] = '0' + low;\n\tif(str[3] > '9'){\n\t\tstr[3] += 'A' - '9' - 1;\n\t}\n\tstr[4] = 0;\n}\nint strEquals(char* a, char* b){\n\tint i = 0;\n\twhile(a[i] == b[i]){\n\t\tif(a[i++] == 0) return 1;\n\t}\n\treturn 0;\n}\n\nint strBeginsWith(char* a, char*b){\n\tif(strLen(a) < strLen(b)) return 0;\n\tint i = 0;\n\twhile(a[i] == b[i]) i++;\n\tif(b[i] == 0) return 1;\n\treturn 0;\n}\n\nvoid reverseInPlace(char s[]){\n\tif(strLen(s) <= 1){\n\t\treturn;\n\t}\n\tint i,j;\n\tchar c;\n\tfor(i = 0, j = strLen(s)-2; i < j; i++, j--){\n\t\tc = s[i];\n\t\ts[i] = s[j];\n\t\ts[j] = c;\n\t}\n}\n\nint isLower(char c){\n\treturn c >= 'a' && c <= 'z';\n}\nint isUpper(char c){\n\treturn c >= 'A' && c <= 'Z';\n}\n\nint isAlpha(char c){\n\treturn (c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z');\n}\n\nint isNumeric(char c){\n\treturn c >= '0' && c <= '9';\n}\n\nint isAlphaNumeric(char c){\n\treturn isAlpha(c) || isNumeric(c);\n}\nstatic unsigned long int rNum;\nvoid setSeed(unsigned int seed){\n\trNum = seed;\n}\nunsigned int rand(unsigned int max){\n\trNum = rNum * 1103515245+12345;\n\treturn (unsigned int)(rNum/65536) % max;\n}\n\nint pow(int base, int exp)\n{\n\t// exponentiation by squaring\n int result = 1;\n while (exp)\n {\n if (exp & 1)\n result *= base;\n exp >>= 1;\n base *= base;\n }\n return result;\n}\nint numDigits(int num){\n\tif(num < 0) num *= -1;\n\tif ( num < 10 )\n\t\treturn 1;\n\tif ( num < 100 )\n\t\treturn 2;\n\tif ( num < 1000 )\n\t\treturn 3;\n\tif ( num < 10000 )\n\t\treturn 4;\n\tif ( num < 100000 )\n\t\treturn 5;\n\tif ( num < 1000000 )\n\t\treturn 6;\n\tif ( num < 10000000 )\n\t\treturn 7;\n\tif ( num < 100000000 )\n\t\treturn 8;\n\tif ( num < 1000000000 )\n\t\treturn 9;\n\tif ( num < 10000000000 )\n\t\treturn 10;\n\treturn 11;\n}\n"
},
{
"alpha_fraction": 0.6692330241203308,
"alphanum_fraction": 0.6902576088905334,
"avg_line_length": 29.700000762939453,
"blob_id": "5301c3c2764ba7bf60a2743c9bffbadfcb029844",
"content_id": "d81aa3c29341dce479fbdbf7a1bea271bd469ecb",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 3377,
"license_type": "permissive",
"max_line_length": 310,
"num_lines": 110,
"path": "/compile.sh",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nbuildstatus='unsuccessful'\nfunction finish {\n echo \"Build was $buildstatus!\"\n}\ntrap finish EXIT\nset -e\n\nrm -f os-image || true\n\necho 'Running assembler'\nnasm kernel_entry.asm -f elf -o kernel_entry.o\nnasm int.asm -f elf -o int.o\n\necho 'Building KFS'\n./KFS_builder.py\nnasm KFS_gen.asm -f bin -o KFS.bin\nld -melf_i386 -r -b binary -o KFS.o KFS.bin\n\necho \"Compiling kernel files:\"\nprintf \"Compiling malloc.c... \"\ngcc -ffreestanding -m32 -c malloc.c -o malloc.o\nprintf \"ok\\n\"\nprintf \"Compiling shell_commands.c... \"\ngcc -ffreestanding -m32 -c shell_commands.c -o shell_commands.o\nprintf \"ok\\n\"\nprintf \"Compiling util.c... \"\ngcc -ffreestanding -m32 -c util.c -o util.o\nprintf \"ok\\n\"\nprintf \"Compiling kernel.c... \"\ngcc -ffreestanding -m32 -c kernel.c -o kernel.o\nprintf \"ok\\n\"\nprintf \"Compiling driver.c... \"\ngcc -ffreestanding -m32 -c driver.c -o driver.o\nprintf \"ok\\n\"\nprintf \"Compiling editor.c... \"\ngcc -ffreestanding -m32 -c editor.c -o editor.o\nprintf \"ok\\n\"\nprintf \"Compiling buildData.c... \"\ngcc -ffreestanding -m32 -c buildData.c -o buildData.o\nprintf \"ok\\n\"\nprintf \"Linking kernel files... \"\nld -melf_i386 -o kernel.bin -Ttext 0x8000 kernel_entry.o int.o malloc.o shell_commands.o util.o driver.o editor.o buildData.o kernel.o KFS.o --oformat binary --entry main\nprintf \"ok\\n\"\n\nsectorcount=100\nsize=$(wc -c < kernel.bin)\nif ((size<$(($sectorcount*512)))) ; then\n\techo \"Creating kernel image\"\n\tdd if=kernel.bin count=$sectorcount of=padded_kernel.bin conv=sync &> /dev/null && sync\nelse\n\techo \"kernel image is truncated, you must increase the padding count!\"\n\texit 1\nfi\n\nprintf \"Assembling bootloader... \"\nnasm bootloader_stage1.asm -f bin -o stage1.bin\nnasm bootloader_stage2.asm -f bin -o stage2.bin\ncat stage1.bin stage2.bin > boot_sect.bin\ncat boot_sect.bin padded_kernel.bin > os-image\nprintf \"ok\\n\"\n\nprintf \"Checking sector counts... \"\nactual=$(ls -l | grep \"os-image\" | awk '{print $5}')\nactual=$((actual/512-1))\n\nloaded=$(grep \"NUM_SECTORS equ\" < bootloader_stage2.asm |awk '{print $3}')\n\nif [ \"$loaded\" -ne $((actual)) ]; then\n\techo \"\"\n echo \"In bootloader: $loaded\"\n echo \"Filesize: $actual\"\n exit 1\nelse\n\techo \"Sector count ok\"\nfi\n\necho 'Building floppy image'\nrm floppy.img || true\ndd if=/dev/zero of=floppy.img bs=512 count=2880 &> /dev/null && sync\ndd if=os-image of=floppy.img conv=notrunc &> /dev/null && sync\nif [ \"$1\" == \"write\" ]; then\n\techo \"You will overwrite /dev/sdb:\" \n\tls -l /dev/disk/by-id | grep sdb | awk '{print $9}'\n\tread -p \"Are you sure? (y/n)\" -n 1 -r\n\techo \n\tif [[ $REPLY =~ ^[Yy]$ ]]\n\tthen\n\t\tsudo dd if=floppy.img of=/dev/sdb conv=notrunc && sync\n\telse\n\t\tbuildstatus=\"canceled\"\n\t\texit 2\n\tfi\nelse\n\tqemu-system-i386 floppy.img -soundhw pcspk &\nfi\n\n# increment buildData.c values\ncp buildData.c buildData-temp.c\nawk '/int buildID = [0-9]+;/ { printf \"int buildID = %d;\\n\", $4+1 };!/int buildID = [0-9]+;/{print}' < buildData-temp.c > buildData.c\nrm buildData-temp.c\n\necho \"Build #$(grep 'buildID = ' < buildData.c | awk '{ print $4; }' | rev | cut -c 2- | rev)\"\n\nbuildstatus=\"successful\"\nrm *.o\nrm *.bin\n\necho \"SLOC:$(wc -l bootloader_stage1.asm bootloader_stage2.asm boot.sh buildData.c compile.sh driver.c driver.h editor.c editor.h IDT.c int.asm kernel.c kernel_entry.asm kernel.h KFS_builder.py KFS_template.asm malloc.c malloc.h shell_commands.c shell_commands.h sh_exec.c sh_lisp.c util.c util.h | tail -n 1)\"\n"
},
{
"alpha_fraction": 0.6937229633331299,
"alphanum_fraction": 0.6937229633331299,
"avg_line_length": 19.53333282470703,
"blob_id": "97a1cc6cf968f779a699cb1fb813f7c18d8029db",
"content_id": "c19d685671cf3febfec5e1caf30e680f25e5f379",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 924,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 45,
"path": "/shell_commands.h",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "#ifndef SHELL_COMMANDS_H\n#define SHELL_COMMANDS_H\n\nvoid sh_handler(char*);\n\nvoid sh_readKFS(char*);\nvoid sh_textDump(char*);\nvoid sh_memDump(char*);\nvoid sh_help(char*);\nvoid sh_null(char*);\nvoid sh_cat(char*);\nvoid sh_head(char*);\nvoid sh_ls(char*);\nvoid sh_edit(char*);\nvoid sh_read(char*);\nvoid sh_glissando(char*);\nvoid sh_mario(char*);\nvoid sh_sleep(char*);\nvoid sh_beep(char*);\nvoid sh_htoi(char*);\nvoid sh_itoh(char*);\nvoid sh_int(char*);\nvoid sh_rand(char*);\nvoid sh_colorTable(char*);\nvoid sh_charTable(char*);\nvoid sh_hexTable(char*);\nvoid sh_dataTypes(char*);\nvoid sh_sti(char*);\nvoid sh_cli(char*);\nvoid sh_buildData(char*);\nvoid sh_memalloc(char*);\nvoid sh_memfree(char*);\nvoid sh_poke(char*);\nvoid sh_history(char*);\nvoid sh_memusg(char*);\nvoid sh_millis(char*);\nvoid sh_echo(char*);\nvoid sh_shell(char*);\nvoid sh_foo(char*);\nvoid sh_msg(char*);\n\nvoid clearBuffer();\nint getFilePointer(char*, char**);\n\n#endif\n"
},
{
"alpha_fraction": 0.5507411360740662,
"alphanum_fraction": 0.5877993106842041,
"avg_line_length": 32.730770111083984,
"blob_id": "5f263fb42a87e43e2a606a917a5cc4270006825e",
"content_id": "2b119e37c62e912518a5144c963ef5d816a1cf9f",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1754,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 52,
"path": "/KFS_builder.py",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\nimport os\nfiles = os.listdir(\"./files\")\ncontents = {}\nif len(files) > 94: \n\tprint \"Too many files! Max number is 94, but {0} are present.\".format(len(files))\n\texit()\nfor i in files:\n\tif len(i) > 10:\n\t\tprint \"Filename is too long! Can only be ten characters, is currently {0} :{1}\".format(len(i),i)\n\t\texit(1)\nwith open(\"KFS_template.asm\",\"r\") as template, open(\"KFS_gen.asm\",\"w\") as out:\n\tfor line in template:\n\t\tif \"insert file data here\" in line:\n\t\t\tsector = 0\n\t\t\toffset = 0\n\t\t\tfor entry in files:\n\t\t\t\t#if entry.endswith(\".bin\"):\n\t\t\t\t#\twith open(\".files/{0}\".format(entry), \"rb\") as temp:\n\t\t\t\t#\t\t\n\t\t\t\t#\t\n\t\t\t\t#\tcontinue\n\t\t\t\twith open(\"./files/{0}\".format(entry), \"r\") as temp:\n\t\t\t\t\t#contents[entry] = temp.read().rstrip().encode('string_escape')\n\t\t\t\t\t#contents[entry] = temp.read().rstrip().replace('\\n','\\\\n').replace('\\t','\\\\t')\n\t\t\t\t\tcontents[entry] = temp.read().replace('\\n','\\\\n').replace('\\t','\\\\t')\n\t\t\t\tpaddingZeroes = \",0\" * (10-len(entry))\n\t\t\t\tout.write(\"db '{0}'{1}\\n\".format(entry,paddingZeroes))\n\t\t\t\tout.write(\"db {0}\\n\".format(sector))\n\t\t\t\thb = offset >> 8\n\t\t\t\tlb = offset - hb*256\n\t\t\t\tout.write(\"db {0},{1}\\n\".format(hb,lb))\n\t\t\t\tfilesize = os.path.getsize(\"./files/\" + entry) #len(contents[entry])\n\t\t\t\thhb = filesize >> 16\n\t\t\t\thb = (filesize-hhb*256*256) >>8\n\t\t\t\tlb = (filesize-hhb*256*256-hb*256)\n\t\t\t\tout.write(\"db {0},{1},{2}\\n\".format(hhb,hb,lb))\n\t\t\t\toffset += filesize\n\t\t\t\tif offset >= 512:\n\t\t\t\t\tsector += offset / 512\n\t\t\t\t\toffset %= 512\n\t\t\t\t#sector += filesize / 256\n\t\t\t\tout.write(\"\\n\")\n\t\t\tout.write(\"times ({0}*16) db 0\".format(94-len(files)))\n\t\telif \"insert file contents here\" in line:\n\t\t\tfor entry in files:\n\t\t\t\tout.write(\"db `\")\n\t\t\t\tout.write(contents[entry])\n\t\t\t\tout.write(\"`\\n\")\n\t\t\t\n\t\telse:\n\t\t\tout.write(line)\n"
},
{
"alpha_fraction": 0.774193525314331,
"alphanum_fraction": 0.774193525314331,
"avg_line_length": 14.5,
"blob_id": "cf3bcb5159e66b71904b7ae8bf1a1b2690950ab4",
"content_id": "6be32e6ac64616b8cbb5cc13ba508cfdfbcb036e",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 93,
"license_type": "permissive",
"max_line_length": 49,
"num_lines": 6,
"path": "/sh_exec.h",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "#ifndef SHEXEC_H\n#define SHEXEC_H\n\nvoid interpreter_keyPressed(unsigned char, char);\n\n#endif\n"
},
{
"alpha_fraction": 0.6084229350090027,
"alphanum_fraction": 0.6306451559066772,
"avg_line_length": 21.682926177978516,
"blob_id": "1f2c5f4eaaf9fc306db9408bd30263059e37390a",
"content_id": "9c11f23beb8eb063482b324af9ef8297fc35e983",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5580,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 246,
"path": "/editor.c",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "void editor_up();\nvoid editor_down();\n\n#include \"editor.h\"\n#include \"kernel.h\"\n#include \"util.h\"\n#include \"malloc.h\"\n\n// first line displayed in the editor window\nstruct StringListNode *highestLine;\n// line currently being edited\nstruct StringListNode *activeLine;\n\nvoid editor_initialize(){\n\tclearScreen(0x0F);\n\thighestLine = fileBuffer->firstLine;\n\tactiveLine = fileBuffer->firstLine;\n\tsetCursor(0,0);\n}\n\nvoid editor_updateScreen(){\n\tclearScreen(0x7F);\n\tint pushTTX = ttx, pushTTY = tty;\n\tttx = 0;\n\ttty = 0;\n\tstruct StringListNode *temp = highestLine;\n\tint i;\n\tfor(i = 0; i < height -1 && temp; i++){\n\t\tttprint(temp->str);\n\t\ttemp = temp->next;\n\t}\n\tsetCursor(pushTTX,pushTTY);\n}\n\nvoid editor_left(){\n\tttx--;\n\tif(ttx < 0){\n\t\tif(activeLine->prev){\n\t\t\tttx = strLen((activeLine->prev)->str)-2;\n\t\t\teditor_up();\n\t\t} else {\n\t\t\tttx++;\n\t\t}\n\t} else {\n\t\tsetCursor(ttx,tty);\n\t\teditor_updateScreen();\n\t}\n}\n\nvoid editor_right(){\n\tttx++;\n\tif(ttx > strLen(activeLine->str)-2){\n\t\tif(activeLine->next){\n\t\t\tttx = 0;\n\t\t\teditor_down();\n\t\t} else {\n\t\t\tttx--;\n\t\t}\n\t} else {\n\t\tsetCursor(ttx,tty);\n\t\teditor_updateScreen();\n\t}\n}\n\nvoid editor_up(){\n\tif(activeLine->prev){\n\t\tactiveLine = activeLine->prev;\n\t\tif(tty > 0){\n\t\t\ttty--;\n\t\t\tint len = strLen(activeLine->str);\n\t\t\tif(ttx > len-2)\n\t\t\t\tttx = len-2;\n\t\t\tsetCursor(ttx,tty);\n\t\t} else {\n\t\t\thighestLine = highestLine->prev;\n\t\t\teditor_updateScreen();\n\t\t}\n\t}\n}\n\nvoid editor_down(){\n\tif(activeLine->next){\n\t\tactiveLine = activeLine->next;\n\t\tif(tty < height-2){\n\t\t\ttty++;\n\t\t\tint len = strLen(activeLine->str);\n\t\t\tif(ttx > len-2)\n\t\t\t\tttx = len-2;\n\t\t\tsetCursor(ttx,tty);\n\t\t} else {\n\t\t\thighestLine = highestLine->next;\n\t\t\teditor_updateScreen();\n\t\t}\n\t}\n}\n\nvoid editor_backspace(){\n\tif(ttx < 0){\n\t\tsetMessage(\"-1\");\n\t} else if(ttx == 0){\n\t\tif(activeLine->prev){\n\t\t\tchar* previous = activeLine->prev->str;\n\t\t\tint prevLength = strLen(previous);\n\t\t\tchar* current = activeLine->str; \n\t\t\tint currLength = strLen(current); \n\t\t\t// -2 to kill the newline and null\n\t\t\tchar* combined = (char*) malloc(prevLength + currLength - 2);\n\t\t\tmemCopy(previous, combined, prevLength-2);\n\t\t\tmemCopy(current, combined + prevLength-2, currLength);\n\t\t\tstruct StringListNode *next = activeLine->next;\n\t\t\tactiveLine = activeLine->prev;\n\t\t\tfree(current, currLength);\n\t\t\tfree(activeLine->next, sizeof(struct StringListNode));\n\t\t\tfree(previous, prevLength);\n\t\t\tactiveLine->next = next;\n\t\t\tactiveLine->str = combined;\n\n\t\t\tnext->prev = activeLine;\n\t\t\tttx = prevLength-2;\n\t\t\ttty--;\n\t\t\tsetCursor(ttx,tty);\n\t\t\teditor_updateScreen();\n\t\t}\n\t} else {\n\t\tttx--;\n\t\tint len = strLen(activeLine->str);\n\t\tchar *new = (char*)malloc(len-1);\n\t\tmemCopy(activeLine->str,new,ttx);\n\t\tmemCopy(activeLine->str + ttx+1, new+ttx,(len-ttx-1));\n\t\tfree(activeLine->str,len);\n\t\tactiveLine->str = new;\n\n\t\tsetCursor(ttx,tty);\n\t\teditor_updateScreen();\n\t}\n}\n\nvoid editor_keyPressed(unsigned char code, char c){\n\tchar printable = 1;\n\tif(code == 0x0E){ // backspace\n\t\teditor_backspace();\n\t\tprintable = 0;\n\t} else if(code == 0x4B){ // left arrow\n\t\teditor_left();\n\t\tprintable = 0;\n\t} else if(code == 0x4D){ // right arrow\n\t\teditor_right();\n\t\tprintable = 0;\n\t} else if(code == 0x48){ // up arrow\n\t\teditor_up();\n\t\tprintable = 0;\n\t} else if(code == 0x50){ // down arrow\n\t\teditor_down();\n\t\tprintable = 0;\n\t} else if(code == 0xCB){ // left arrow release\n\t\tprintable = 0;\n\t} else if(code == 0xCD){ // right arrow release\n\t\tprintable = 0;\n\t} else if(code == 0xC8){ // up arrow release\n\t\tprintable = 0;\n\t} else if(code == 0xD0){ // down arrow release\n\t\tprintable = 0;\n\t} else if(code == 0x1D){ // control on\n\t\tmodifier[CTRL] = 1;\n\t\tprintable = 0;\n\t} else if(code == 0x9D){ //control off\n\t\tmodifier[CTRL] = 0;\n\t\tprintable = 0;\n\t} else if(code == 0x36 || code == 0x2A){ //shift on\n\t\tmodifier[SHIFT] = 1;\n\t\tprintable = 0;\n\t} else if(code == 0xB6 || code == 0xAA){ //shift off\n\t\tmodifier[SHIFT] = 0;\n\t\tprintable = 0;\n\t} else if(code == 0x38){ // alt on\n\t\tmodifier[ALT] = 1;\n\t\tprintable = 0;\n\t} else if(code == 0xB8){ // alt off\n\t\tmodifier[ALT] = 0;\n\t\tprintable = 0;\n\t} else if(code == 0x52){ // insert\n\t\tmodifier[INSERT]++;\n\t\tmodifier[INSERT] %= 2;\n\t\tprintable = 0;\n\t} else if(code == 0x3A){ // capslock\n\t\tmodifier[CAPSLOCK]++;\n\t\tmodifier[CAPSLOCK] %= 2;\n\t\tprintable = 0;\n\t}\n\tprintStatus(code);\n\tif(modifier[CTRL] && c == 's'){\n\t\tclearScreen(0x00);\n\t\tterminalMode = TERMINAL;\n\t\tttx = 0; tty = 0;\n\t\tsetCursor(ttx,tty);\n\t\tprintPrompt();\n\t\tprintStatus(0x00);\n\t\treturn;\n\t}\n\t\n\tif(c == 0 || !printable) return;\n\tchar str[2];\n\tstr[0] = c;\n\tstr[1] = 0;\n\tsetMessage(str);\n\t\n\tif(c == '\\n'){\n\t\tint lineLength = strLen(activeLine->str);\n\t\tchar* new1 = (char*) malloc(ttx+2);\n\t\tchar* new2 = (char*) malloc(lineLength-ttx);\n\t\tmemCopy(activeLine->str,new1,ttx);\n\t\tnew1[ttx] = '\\n';\n\t\tnew1[ttx+1] = 0;\n\t\tmemCopy(activeLine->str+ttx,new2,lineLength-ttx);\n\t\tstruct StringListNode *newline = (struct StringListNode*) malloc(sizeof(struct StringListNode));\n\t\tnewline->prev = activeLine;\n\t\tnewline->next = activeLine->next;\n\t\tnewline->next->prev = newline;\n\t\tactiveLine->next = newline;\n\t\tfree(activeLine->str, lineLength);\n\t\tactiveLine->str = new1;\n\t\tnewline->str = new2;\n\t\tactiveLine = newline;\n\t\tttx = 0;\n\t\ttty++;\n\t\tsetCursor(ttx,tty);\n\t\teditor_updateScreen();\n\t\treturn;\n\t}\n\n\t\n\tif(modifier[INSERT]){\n\t\t// split the line in twain, reassemble.\n\t\tint len = strLen(activeLine->str);\n\t\tchar *new = (char*)malloc(len+1);\n\t\tmemCopy(activeLine->str,new,ttx);\n\t\tnew[ttx] = c;\n\t\tmemCopy(activeLine->str + ttx, new+ttx+1,(len-ttx));\n\t\tfree(activeLine->str,len);\n\t\tactiveLine->str = new;\n\t} else {\n\t\t(activeLine->str)[ttx] = c;\n\t}\n\teditor_right();\n\teditor_updateScreen();\n}\n"
},
{
"alpha_fraction": 0.7585111260414124,
"alphanum_fraction": 0.763050377368927,
"avg_line_length": 49.068180084228516,
"blob_id": "903cdf908222ccc71f99d7c25d602efb603586f4",
"content_id": "7371898e234f4dadc755fc07ce1962abcc61452b",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2203,
"license_type": "permissive",
"max_line_length": 557,
"num_lines": 44,
"path": "/README.md",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "KevinOS Notes:\n==============\n\nCompilation:\n------------\n\n+ `$ ./compile.sh write` overwrites the filesystem of `/dev/sdb` -- be careful!\n\n+ `$ qemu-system-i386 os-image` can be used for quicker testing, if recompilation is not necessary. \n\n+ Testing is done with QEMU on a Lenovo T430. Development done on 64-bit Linux Mint Debian Edition with the standard GNU toolchain (GCC, LD, etc).\n\nFeatures:\n---------\n\nKevinOS currently loads a 32-bit C kernel in Protected Mode. It detects all interrupt calls and has basic PIT-handling code. Keypress detection for a standard laptop keyboard is more or less complete and the OS boots to a _very_ basic shell. A basic text-buffer editor is available with `edit`, and code in a pseudo-assembly language can be run with `exec`. A very naive `malloc` is in place, perhaps someday it'll be more than the bare minimum. The shell has a few odds and ends (beeps, PRNG, etc). A custom file system (KFS) is used, just for kicks. \n\nUnlicense:\n----------\n\nThis is free and unencumbered software released into the public domain.\n\nAnyone is free to copy, modify, publish, use, compile, sell, or\ndistribute this software, either in source code form or as a compiled\nbinary, for any purpose, commercial or non-commercial, and by any\nmeans.\n\nIn jurisdictions that recognize copyright laws, the author or authors\nof this software dedicate any and all copyright interest in the\nsoftware to the public domain. We make this dedication for the benefit\nof the public at large and to the detriment of our heirs and\nsuccessors. We intend this dedication to be an overt act of\nrelinquishment in perpetuity of all present and future rights to this\nsoftware under copyright law.\n\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND,\nEXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF\nMERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.\nIN NO EVENT SHALL THE AUTHORS BE LIABLE FOR ANY CLAIM, DAMAGES OR\nOTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE,\nARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR\nOTHER DEALINGS IN THE SOFTWARE.\n\nFor more information, please refer to <http://unlicense.org/>\n"
},
{
"alpha_fraction": 0.6724137663841248,
"alphanum_fraction": 0.7241379022598267,
"avg_line_length": 18.33333396911621,
"blob_id": "7e15d6e7002bd8a50ab58db9490bd34b56954270",
"content_id": "303786c71ae2945f932ddff9942b5dfeb33912c6",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 58,
"license_type": "permissive",
"max_line_length": 44,
"num_lines": 3,
"path": "/boot.sh",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nqemu-system-i386 floppy.img -soundhw pcspk &\n"
},
{
"alpha_fraction": 0.5876951217651367,
"alphanum_fraction": 0.641873300075531,
"avg_line_length": 26.923076629638672,
"blob_id": "fcc470e514283f0f1af1b3b6f2d2f57fca70e33c",
"content_id": "2e848815484d6a4a41a844dacab535b693f97939",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1089,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 39,
"path": "/driver.c",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "#include \"driver.h\"\n\nvoid writeByteToPort(unsigned short port, unsigned char data){\n\t__asm__(\"out %%al, %%dx\" : :\"a\" (data), \"d\" (port));\n}\nunsigned char readByteFromPort(unsigned short port){\n\tunsigned char data;\n\t__asm__(\"in %%dx, %%al\" : \"=a\" (data) : \"d\" (port));\n\treturn data;\n}\nint PITfreq;\nvoid setTimerFreq(int hz){\n\tPITfreq = hz;\n\tint divisor = 1193180 / hz; \n\twriteByteToPort(0x43, 0x36); /* Set our command byte 0x36 */\n\twriteByteToPort(0x40, divisor & 0xFF); /* Set low byte of divisor */\n\twriteByteToPort(0x40, divisor >> 8); /* Set high byte of divisor */\n}\nvoid play_sound(int nFrequency) {\n\tif(nFrequency == 0){\n\t\tchar tmp = (readByteFromPort(0x61) & 0xFC);\n\t\twriteByteToPort(0x61, tmp);\n\t\treturn;\n \t}\n \tint Div;\n \tchar tmp;\n \n //Set the PIT to the desired frequency\n\tDiv = 1193180 / nFrequency;\n\twriteByteToPort(0x43, 0xb6);\n\twriteByteToPort(0x42, (char) (Div) );\n\twriteByteToPort(0x42, (char) (Div >> 8));\n\n\t//And play the sound using the PC speaker\n\ttmp = readByteFromPort(0x61);\n\tif (tmp != (tmp | 3)) {\n\t\twriteByteToPort(0x61, tmp | 3);\n\t}\n}\n"
},
{
"alpha_fraction": 0.5637732744216919,
"alphanum_fraction": 0.6337466835975647,
"avg_line_length": 21.808080673217773,
"blob_id": "ad8e485161c8fad46dc483f53eecd528088917f1",
"content_id": "d820f748b5c41efa3bacd95224f623ef16980901",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2258,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 99,
"path": "/malloc.c",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "/*\n\thttp://wiki.osdev.org/Memory_Map_%28x86%29\n\troughly 30 KiB of free memory from 0x0500 to 0x7BFF\n\tthe stack grows down from 0x7c00, so we'll leave that alone.\n\t\n\tupper memory: 0x00100000 -> 0x00EFFFFF (14 MiB)\n\t0x100000 : 0x28E390 allocation table (1631120 bytes, 1.55 MiB)\n\t0x28E391 : 0xEFFFFF heap (13048942 bytes, 12.44 MiB)\n\t\n\theaptable is a usage table, where the nth bit in the\n\ttable is on or off to show if the nth byte in the heapblock \n\tis allocated or not\n*/\n\n#include \"malloc.h\"\n#include \"kernel.h\"\n\n#define TOTAL_HEAP_MEMORY (0xEFFFFF - 0x100000)\n#define TOTAL_ALLOCATABLE_MEMORY (0xEFFFFF - 0x28E391)\n#define TOTAL_TABLE_MEMORY (0x28E391 - 0x100000)\n\nchar* heapTable1 = (char*) 0x100000;\nchar* heapBlock1 = (char*) 0x28E391;\nint bytesAllocated = 0;\n\nvoid* malloc(int size){\n\tint i,j;\n\tint n_consecutive_bytes = 0;\n\tint block_start = 0;\n\tfor(i = 0; i < TOTAL_ALLOCATABLE_MEMORY; i++){\n\t\tfor(j = 0; j < 8; j++){\n\t\t\tif(!(heapTable1[i] & (1 << j))){\n\t\t\t\tn_consecutive_bytes++;\n\t\t\t} else {\n\t\t\t\tn_consecutive_bytes = 0;\n\t\t\t\tblock_start = i*8 + j + 1;\n\t\t\t}\n\t\t\tif(n_consecutive_bytes == size){\n\t\t\t\tgoto end;\n\t\t\t}\n\t\t}\n\t}\n\tend:\n\tif(i*8+j >= TOTAL_ALLOCATABLE_MEMORY){\n\t\treturn (void*) 0;\n\t} else {\n\t\tbytesAllocated += size;\n\t\ti = block_start/8;\n\t\tj = block_start - i*8;\n\t\twhile(i*8 + j < block_start + size){\n\t\t\twhile(i*8 + j < block_start + size && j < 8){\n\t\t\t\theapTable1[i] |= (1 << j);\n\t\t\t\tj++;\n\t\t\t}\n\t\t\tj = 0;\n\t\t\ti++;\n\t\t}\n\t\treturn (void*) (heapBlock1 + block_start);\n\t}\n}\n\nvoid free(void* pointer, int size){\n\tchar* ptr = (char*) pointer;\n\tif(ptr < heapBlock1 || heapBlock1 + TOTAL_ALLOCATABLE_MEMORY < ptr){\n\t\tttprintln(\"Invalid pointer passed to free()\");\n\t\treturn;\n\t}\n\tint i, j, block_start;\n\tbytesAllocated -= size;\n\tblock_start = ptr - heapBlock1;\n\ti = block_start/8;\n\tj = block_start - i*8;\n\twhile(i*8 + j < block_start + size){\n\t\twhile(i*8 + j < block_start + size && j < 8){\n\t\t\theapTable1[i] &= ~(1 << j);\n\t\t\tj++;\n\t\t}\n\t\tj = 0;\n\t\ti++;\n\t}\n}\n\nvoid clearAllocationTable(){\n\tint i;\n\tfor(i = 0; i < TOTAL_TABLE_MEMORY; i++){\n\t\theapTable1[i] = 0;\n\t}\n}\n\nint getBytesAllocated(){\n\treturn bytesAllocated;\n}\nint getAvailableMemory(){\n\treturn TOTAL_ALLOCATABLE_MEMORY;\n}\n\ndouble heapUsage(){\n\treturn (100.0*bytesAllocated)/TOTAL_ALLOCATABLE_MEMORY;\n}\n"
},
{
"alpha_fraction": 0.7554348111152649,
"alphanum_fraction": 0.7554348111152649,
"avg_line_length": 15.727272987365723,
"blob_id": "124bc1e152b40bb6fb007eb25dafb061d40dcbf2",
"content_id": "616364c9b75d9e1a0dffc5985d13f3eb91defab3",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 184,
"license_type": "permissive",
"max_line_length": 28,
"num_lines": 11,
"path": "/malloc.h",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "#ifndef MALLOC_H\n#define MALLOC_H\n\nvoid* malloc(int);\nvoid free(void*,int);\nvoid clearAllocationTable();\nint getBytesAllocated();\nint getAvailableMemory();\ndouble heapUsage();\n\n#endif\n"
},
{
"alpha_fraction": 0.7250000238418579,
"alphanum_fraction": 0.7250000238418579,
"avg_line_length": 19.909090042114258,
"blob_id": "bf23892f53e9c2b5b9808e3b136f0e8f7d59ddca",
"content_id": "2fe23c07b692d6d1021ccda04806e56268b27c2e",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 920,
"license_type": "permissive",
"max_line_length": 54,
"num_lines": 44,
"path": "/util.h",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "#ifndef UTIL_H\n#define UTIL_H\n\n\nstruct StringListNode\n{\n char* str;\n struct StringListNode *next;\n struct StringListNode *prev;\n};\n\nstruct File\n{\n char* filename;\n int filesize;\n struct StringListNode *firstLine;\n};\n\nint flattenStringList(struct StringListNode*, char**);\nvoid strReplace(char*, char, char);\nvoid memFill(char*, char, int);\nvoid memCopy(char*, char*, int);\nint strLen(char*);\nvoid intToString(int, char*);\nint strToInt(char*);\nchar scancodeToAscii(unsigned char, char, char, char);\nvoid charToString(unsigned char, char*);\nint strEquals(char*, char*);\nint strBeginsWith(char*, char*);\nvoid reverseInPlace(char*);\nvoid setSeed(unsigned int);\nunsigned int rand(unsigned int);\nint pow(int, int);\nint numDigits(int);\nint isLower(char);\nint isUpper(char);\nint isAlpha(char);\nint isNumeric(char);\nint isAlphaNumeric(char);\nvoid itoh(char, char*);\nvoid doubleToString(double, char*);\n\n\n#endif\n"
},
{
"alpha_fraction": 0.7505900859832764,
"alphanum_fraction": 0.7671124935150146,
"avg_line_length": 19.8360652923584,
"blob_id": "b10c56bc4bd089373bd81edf5345fd8301cda614",
"content_id": "d88e0144c3dde831a0f52a33f6731e934a566972",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1271,
"license_type": "permissive",
"max_line_length": 46,
"num_lines": 61,
"path": "/kernel.h",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "#ifndef KERNEL_H\n#define KERNEL_H\n\n//terminal modes:\n#define TERMINAL 0\n#define EDITOR 1\n#define INTERPRETER 2\n\n#define width 80\n#define height 23\n#define absolute_height 24\n#define REG_SCREEN_CTRL 0x3D4\n#define REG_SCREEN_DATA 0x3D5\n#define SHIFT 0\n#define CTRL 1\n#define ALT 2\n#define INSERT 3\n#define CAPSLOCK 4\nextern char modifier[6];\n\nextern int ttx;\nextern int tty;\n\nextern int terminalMode;\nextern char* KFS;\nextern struct File *fileBuffer;\n\nextern struct StringListNode *historyHead;\nextern struct StringListNode *historyTemp;\n\nvoid sleep(int);\nvoid printChar(int, int, char, int);\nchar getChar(int, int);\nint getColor(int, int);\nvoid ttprintCharColor(char,int);\nvoid print(int,int,char*);\nvoid ttprintChar(char);\nvoid ttprint(char *);\nvoid ttprintInt(int);\nvoid ttprintln(char *);\nvoid ttprintIntln(int);\nint offset(int, int);\nvoid setCursor(int, int);\nvoid clearScreen(int);\nvoid scrollUp();\nvoid cursorBackwards();\nvoid cursorForwards();\n\nvoid keyPressed(unsigned char);\nvoid terminal_keyPressed(unsigned char, char);\nvoid editor_keyPressed(unsigned char, char);\nvoid pitCall();\nvoid rtcCall();\nvoid printStatus(unsigned char);\nvoid enableInterrupts();\nvoid disableInterrupts();\nvoid printPrompt();\nunsigned long int millis();\nvoid setMessage(char*);\n\n#endif\n"
},
{
"alpha_fraction": 0.7892156839370728,
"alphanum_fraction": 0.7892156839370728,
"avg_line_length": 19.399999618530273,
"blob_id": "f43e46bd42535eaa5a097e313dfa329f146b715f",
"content_id": "a24d8664aad86139d5f9b82870132804afb5faab",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 204,
"license_type": "permissive",
"max_line_length": 53,
"num_lines": 10,
"path": "/driver.h",
"repo_name": "kevinsa5/KevinOS",
"src_encoding": "UTF-8",
"text": "#ifndef DRIVER_H\n#define DRIVER_H\n\nvoid writeByteToPort(unsigned short, unsigned char );\nunsigned char readByteFromPort(unsigned short);\n\nvoid setTimerFreq(int);\nvoid play_sound(int);\nint PITfreq;\n#endif\n"
}
] | 23 |
danhamraj7/CS-Build-Week-2
|
https://github.com/danhamraj7/CS-Build-Week-2
|
c06c55abe7da1b84551576d22cced23f5aa2f22c
|
662f0db0f3d0848d1a528339fbe8e49b0c5029b0
|
9601a9e6ee1042c422864e5c66ce3ce66984c7b8
|
refs/heads/master
| 2022-12-25T00:32:33.058374 | 2020-10-06T16:47:32 | 2020-10-06T16:47:32 | 290,629,623 | 0 | 0 | null | 2020-08-26T23:52:34 | 2020-08-21T22:45:58 | 2020-08-26T18:21:12 | null |
[
{
"alpha_fraction": 0.4598698616027832,
"alphanum_fraction": 0.47288504242897034,
"avg_line_length": 24.61111068725586,
"blob_id": "7bb1143ecf34cb9d1a517726615a093b5776d82c",
"content_id": "577dff7b054c6dfb21cdaf3fffe8a6fd3c88e116",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 461,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 18,
"path": "/leetcode/longest_substring_without_rep_char.py",
"repo_name": "danhamraj7/CS-Build-Week-2",
"src_encoding": "UTF-8",
"text": "class Solution:\n def lengthOfLongestSubstring(self, s: str) -> int:\n dictionary = {}\n left = 0\n right = 0\n ans = 0\n string = len(s)\n\n while(left < string and right < string):\n ele = s[right]\n if(ele in dictionary):\n left = max(left, dictionary[ele] + 1)\n\n dictionary[ele] = right\n ans = max(ans, right - left + 1)\n right += 1\n\n return ans\n"
}
] | 1 |
dhruvagg987/ReVote
|
https://github.com/dhruvagg987/ReVote
|
56302eba82899a452a55fc5f0808e9741d8aed26
|
a8aa6cd008a789d39c1bddce12094a648f381b53
|
181b52bc679b8b9d497c4183547a6d8226bc8fbb
|
refs/heads/main
| 2023-01-04T05:37:20.642718 | 2020-10-18T15:22:31 | 2020-10-18T15:22:31 | 303,486,043 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7150259017944336,
"alphanum_fraction": 0.7253885865211487,
"avg_line_length": 26.714284896850586,
"blob_id": "3a97941201b07dec6fb170c3eca063410d22a075",
"content_id": "756fa2c31836990203e7da01556f968029c61751",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 193,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 7,
"path": "/voter/models.py",
"repo_name": "dhruvagg987/ReVote",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n# Create your models here.\nclass Voter(models.Model):\n # id=models.AutoField()\n username = models.CharField(max_length=20)\n number = models.IntegerField()"
},
{
"alpha_fraction": 0.6800000071525574,
"alphanum_fraction": 0.6800000071525574,
"avg_line_length": 24.14285659790039,
"blob_id": "2f579cb8c5757786857408804350a59f5e311563",
"content_id": "aed982f1f280bb94add7166ce432ca6057c5cde6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 175,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 7,
"path": "/voter/urls.py",
"repo_name": "dhruvagg987/ReVote",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom . import views\n\nurlpatterns = [\n path('',views.home,name=\"home\"),\n path('db/<int:pk>/',views.view_candidates,name=\"view_candidates\"),\n]"
},
{
"alpha_fraction": 0.6767895817756653,
"alphanum_fraction": 0.6941431760787964,
"avg_line_length": 29.799999237060547,
"blob_id": "a1fae3bfa7e0806b955d5464f38491bea4c8041c",
"content_id": "27d97f1a3b5f8c70394caf6b453637762206a701",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 461,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 15,
"path": "/voter/views.py",
"repo_name": "dhruvagg987/ReVote",
"src_encoding": "UTF-8",
"text": "from django.http import HttpResponse,Http404\nfrom django.shortcuts import render\nfrom .models import Voter\n# Create your views here.\n\ndef home(request):\n # return HttpResponse(\"<h1>hiyah !</h1>\")\n return render(request,\"home.html\",{})\n\ndef view_candidates(request,pk):\n try:\n obj = Voter.objects.get(pk=pk)\n except Voter.DoesNotExist:\n raise Http404\n return HttpResponse(f\"username : {obj.username}\"+\"<br>\"+f\"number : {obj.number}\")"
}
] | 3 |
huklee/weddingDayBot
|
https://github.com/huklee/weddingDayBot
|
5327d4fda8a10ac20702f9e40f00ee38108704df
|
86e654ce4d8520fb0f57092391c44865c5694559
|
c41abfe54b8a40929863a2283069a5c0e848f2f9
|
refs/heads/master
| 2020-04-14T02:40:09.647761 | 2019-05-28T13:58:17 | 2019-05-28T13:58:17 | 163,588,340 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7178612351417542,
"alphanum_fraction": 0.744027316570282,
"avg_line_length": 29.310344696044922,
"blob_id": "8cddabb66635f6918eec27401eaa1c0e4f925532",
"content_id": "30a9b8a4ce0a53276f3641d6a1d7953f20c4a6f3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 879,
"license_type": "permissive",
"max_line_length": 135,
"num_lines": 29,
"path": "/README.md",
"repo_name": "huklee/weddingDayBot",
"src_encoding": "UTF-8",
"text": "# bawiBot\nbawi Crawling bot for Python3\n\n## Python Package Requirements\n * pip3 install selenium\n * pip3 install bs4\n * pip3 install Slacker\n\n## For Ubuntu\n * Download Chrome Driver from below\n https://sites.google.com/a/chromium.org/chromedriver/downloads\n\n\n## For Raspberry Pi 3\n * sudo apt-get update\n * sudo apt-get install iceweasel\n * sudo apt-get install xvfb\n * sudo pip3 install selenium==2.53.6\n * sudo pip3 install PyVirtualDisplay\n * sudo pip3 install xvfbwrapper\n\n * (in case of geckodriver Error) selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable needs to be in PATH.\n * wget https://github.com/mozilla/geckodriver/releases/download/v0.19.1/geckodriver-v0.19.1-arm7hf.tar.gz\n * tar -xvf gecko~.tar.gz\n * chmod +x geckodriver\n * sudo cp geckodriver /usr/local/bin/\n\n## Usage\n * python3 main.py [uid] [passwd] [slackbotToken]\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5332167744636536,
"avg_line_length": 22.930233001708984,
"blob_id": "d6895c1b9373d50dc077b283be6080586cd85f26",
"content_id": "7709f4b2d64ae4a85b774be673444b8849f9ac9a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1144,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 43,
"path": "/main.py",
"repo_name": "huklee/weddingDayBot",
"src_encoding": "UTF-8",
"text": "import pickle\nimport sys\nfrom weddingDayBot.weddingDayBot import *\nimport time\n\nfrom datetime import datetime\n\ncheckMonth = [\"2019\", \"9\"]\n\ncheckList = [\n [\"9/7\", \"14:00\"]\n ,[\"9/8\", \"14:00\"]\n ,[\"9/28\", \"14:00\"]\n ,[\"9/29\", \"14:00\"]\n]\n\ndef run(slackToken, showAll=False):\n global checkMonth, checkList, dateIndexMap \n \n # Run the agent\n driver = getWeddingDayDriver()\n\n checkNewPosts(driver, checkMonth, checkList, slackToken, showAll)\n driver.quit()\n \nif __name__ == \"__main__\":\n if len(sys.argv) < 2:\n print(\"usage : python main.py [slackbotToken] [showAllCheck]\")\n exit()\n\n # show option for ShowAll\n if len(sys.argv) >= 3 and sys.argv[2] == \"Y\":\n showAll = True\n else:\n showAll = False\n\n # showAll when the start of the day\n h, m = datetime.now().hour, datetime.now().minute\n if h == 7 and m == 0:\n showAll = True\n\n run(sys.argv[1], showAll)\n sendSlackMsgSimple(sys.argv[1], \"#test\", \"CHECKED \"+time.strftime(\"%Y-%m-%d %l:%M%p %Z\")) \n"
},
{
"alpha_fraction": 0.5605252385139465,
"alphanum_fraction": 0.569757878780365,
"avg_line_length": 31.597314834594727,
"blob_id": "77eae67538470494ec2d6c15df82d79d4243927e",
"content_id": "1edecc3b23e1351b9524e8cab784e1d529700d2c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4908,
"license_type": "permissive",
"max_line_length": 132,
"num_lines": 149,
"path": "/weddingDayBot/weddingDayBot.py",
"repo_name": "huklee/weddingDayBot",
"src_encoding": "UTF-8",
"text": "import re\nimport time\nimport platform \nfrom selenium import webdriver\nfrom slacker import Slacker\nfrom bs4 import BeautifulSoup \n\nfrom selenium.webdriver.common.by import By\nfrom selenium.webdriver.support.ui import WebDriverWait as wait\nfrom selenium.webdriver.support import expected_conditions as EC\nfrom selenium.webdriver.common.desired_capabilities import DesiredCapabilities\n \ndateIndexMap = {\"11:00\":1, \"14:00\":2, \"17:00\":3}\nchannel = \"wedding\"\n\nif \"armv7\" in platform.platform():\n isRPi = True\n from pyvirtualdisplay import Display\nelse:\n isRPi = False\n\nclass HarryPorterBot():\n def getHarryPorterDriver():\n global isRPi\n \n caps = DesiredCapabilities().CHROME\n caps[\"pageLoadStrategy\"] = \"none\"\n \n chrome_options = webdriver.ChromeOptions() \n chrome_options.add_argument('--no-sandbox') \n chrome_options.add_argument('--window-size=1420,1080') \n chrome_options.add_argument('--headless') \n chrome_options.add_argument('--disable-gpu')\n \n driver = webdriver.Chrome(\"/home/huklee/Downloads/chromedriver\", desired_capabilities=caps, chrome_options = chrome_options)\n \n return driver\n \n # Return new Posts from the boardTail\n def getNewPosts(driver, checkMonth):\n # 1. load the initial page\n year, month = checkMonth[0], checkMonth[1]\n driver.get(\"https://eng.snu.ac.kr/enghouse_reserve?tab=3&year={0}&month={1}\".format(year, month))\n \n # wait for loading components\n time.sleep(5)\n \n # 2.\n from selenium.webdriver.common.action_chains import ActionChains\n elem = driver.find_element_by_xpath(\"//input[@id='agree']\")\n actions = ActionChains(driver)\n actions.click(elem).perform()\n elem = driver.find_element_by_xpath(\"//button[@id='enghouse_w']\").click()\n actions = ActionChains(driver)\n actions.click(elem).perform() \n \n # 3. \n time.sleep(5)\n from bs4 import BeautifulSoup \n html = driver.page_source\n soup = BeautifulSoup(html, \"html.parser\")\n posts = soup.select(\"div.reserve_calendar > table\")\n elems = posts[0].findAll(\"td\") \n \n return elems\n \n \n \"\"\"\n assume that current page is a board post page\n return (authorKi, authorName)\n \"\"\"\n def getAuthorInfo(driver):\n # get author Name\n urlHead = \"https://www.bawi.org/\"\n html = driver.page_source\n soup = BeautifulSoup(html, \"html.parser\")\n pasts = soup.select(\"#content > ul > li.author > a.user-profile\")\n \n authorName = pasts[0].text \n \n # get author Ki\n urlTail = pasts[0][\"href\"]\n driver.get(urlHead + urlTail)\n html = driver.page_source\n soup = BeautifulSoup(html, \"html.parser\")\n posts = soup.select(\"body > div > table > tbody > tr > td > h2 > a\")\n authorKi = posts[0].text\n \n return (authorKi, authorName)\n \n def init():\n pass \n \n def checkNewPosts(driver, checkMonth, checkList, slackToken, showAll=False):\n global dateIndexMap, channel\n newPosts = getNewPosts(driver, checkMonth)\n \n result = {}\n for i, e in enumerate(newPosts):\n for (date, cTime) in checkList:\n if date in e.text:\n timeIndex = dateIndexMap[cTime]\n item = newPosts[i+timeIndex].text\n result[(date, cTime)] = item\n \n print(date, cTime, item)\n \n # show all check\n if showAll == False and \"예약완료\" in item: continue\n \n notifySlack(driver, channel, [\"{} {}\".format(date,cTime), item], slackToken)\n \n return result\n \n def sendSlackMsgSimple(token, channel, pretext):\n slack = Slacker(token)\n nowTime = time.time() # unix_time_stamp\n \n att = [{\n \"pretext\": pretext,\n }]\n \n slack.chat.post_message(channel, attachments=att) \n \n def sendSlackMsg(token, channel, pretext, title, text, color=\"good\"):\n slack = Slacker(token)\n nowTime = time.time() # unix_time_stamp\n \n att = [{\n \"pretext\": pretext,\n \"title\": title,\n \"text\": text,\n \"color\": color, # good(green)\n \"mrkdwn_in\": [\n \"text\",\n \"pretext\"\n ],\n \n \"ts\":nowTime\n }]\n \n slack.chat.post_message(channel, attachments=att) \n \n def notifySlack(driver, channel, posts, slackToken):\n title = posts[0]\n text = posts[1]\n \n # 02. send the msg through slack\n sendSlackMsg(slackToken, channel, \"라쿠치나 웨딩홀 예약 업데이트\", title, text)\n \n"
}
] | 3 |
jbga/Behaviour-Cloning
|
https://github.com/jbga/Behaviour-Cloning
|
b4c11fbedafcb926214d52bb104eeeeb6c86af39
|
c59f8b90b7e61fd32886bef1bd18a9bc0b6836b5
|
92221293227ec9b634921a82d940f708e3eaf778
|
refs/heads/master
| 2020-03-02T13:29:28.958301 | 2017-09-05T22:19:03 | 2017-09-05T22:19:03 | 102,534,616 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7402328252792358,
"alphanum_fraction": 0.7600063681602478,
"avg_line_length": 49.98373794555664,
"blob_id": "df2f0beb8f57593a619c7b7663a1928db0a17715",
"content_id": "5cf2a2334b56c116265fd50f45b8d3559fd811f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6271,
"license_type": "no_license",
"max_line_length": 343,
"num_lines": 123,
"path": "/report.md",
"repo_name": "jbga/Behaviour-Cloning",
"src_encoding": "UTF-8",
"text": "# Behavioral Cloning\n\n## Behavioral Cloning Project\n\nThe goals of this project are the following:\n* Use the simulator to collect data of good driving behavior\n* Build, a convolution neural network in Keras that predicts steering angles from images\n* Train and validate the model with a training and validation set\n* Test that the model successfully drives around track one without leaving the road\n* Summarize the results with a written report\n\n\n[//]: # (Image References)\n\n[image1]: ./images/NVidia_net.png \"Model Visualization\"\n[image2]: ./images/Center.jpg \"Center driving\"\n[image3]: ./images/wrong.jpg \"Recovery Image\"\n[image4]: ./images/recover.jpg \"Recovery Image\"\n[image5]: ./images/right.jpg \"Recovery Image\"\n[image6]: ./images/normal.png \"Normal Image\"\n[image7]: ./images/flipped.png \"Flipped Image\"\n\n### Files Submitted & Code Quality\n\n#### 1. Submission includes all required files and can be used to run the simulator in autonomous mode\n\nMy project includes the following files:\n* modelTraining.py containing the script to create and train the model\n* drive.py for driving the car in autonomous mode\n* model.h5 containing a trained convolution neural network\n* report.md summarizing the results\n\n#### 2. Submission includes functional code\nUsing the Udacity provided simulator and my drive.py file, the car can be driven autonomously around the track by executing\n```sh\npython drive.py model.h5\n```\n\n#### 3. Submission code is usable and readable\n\nThe model.py file contains the code for training and saving the convolution neural network. The file shows the pipeline I used for training and validating the model and it contains comments to explain how the code works.\n\n### Model Architecture and Training Strategy\n\n#### 1. An appropriate model architecture has been employed\n\nMy model consists of a convolution neural network with 5x5 filter sizes and depths between 24 and 48 (model.py lines 62-64).\nAfter these layers I have two filters with 3x3 filter sizes and depth 64 (model.py lines 65-66).\nThe model includes RELU layers to introduce nonlinearity (code line 62-66), and the data is normalized in the model using a Keras lambda layer (code line 60)\nAfter these convolutional layers I have four fully connected layers with 100, 50, 10 and 1 units respectively. (code line 68-71)\n\n#### 2. Attempts to reduce overfitting in the model\n\nThe model contains l2 regularization in order to reduce overfitting (model.py lines 68-70).\n\nThe model was trained and validated on different data sets to ensure that the model was not overfitting (code line 13-50). The model was tested by running it through the simulator and ensuring that the vehicle could stay on the track.\n\n#### 3. Model parameter tuning\n\nThe model used an adam optimizer, so the learning rate was not tuned manually (model.py line 74).\n\n#### 4. Appropriate training data\n\nTraining data was chosen to keep the vehicle driving on the road. I used a combination of center lane driving, recovering from the left and right sides of the road and driving counter-clockwise\n\nFor details about how I created the training data, see the next section.\n\n### Model Architecture and Training Strategy\n\n#### 1. Solution Design Approach\n\nThe overall strategy for deriving a model architecture was to iteratively add more complexity to the network while the results kept improving.\n\nMy first step was to use a convolution neural network model similar to the LeNet architecture. I thought this model might be appropriate because it could classify the numbers correctly in the mnist dataset.\n\nThen I use a convolution neural network model similar to an architecture used by nvidia, used to drive a car in real life.\n\nThe final step was to run the simulator to see how well the car was driving around track one. There were a few spots where the vehicle fell off the track. To improve the driving behavior in these cases, I spot where the car was misbehaving and added more training data with recovery behaviours.\n\nAt the end of the process, the vehicle is able to drive autonomously around the track without leaving the road.\n\n#### 2. Final Model Architecture\n\nThe final model architecture (model.py lines 58-71) consisted of a convolution neural network with the following layers and layer sizes:\n\n| Layer Type | Numbers of filters | Kernel size | Stride | Number of units |\n| ------------- |\n| Convolutional | 24 | 5x5 | 2x2 | -- |\n| Convolutional | 36 | 5x5 | 2x2 | -- |\n| Convolutional | 48 | 5x5 | 2x2 | -- |\n| Convolutional | 64 | 3x3 | 1x1 | -- |\n| Convolutional | 64 | 3x3 | 1x1 | -- |\n| Fully connected | -- | -- | -- | 100 |\n| Fully connected | -- | -- | -- | 50 |\n| Fully connected | -- | -- | -- | 10 |\n| Fully connected | -- | -- | -- | 1 |\n\nHere is a visualization of the architecture:\n\n![alt text][image1]\n\n#### 3. Creation of the Training Set & Training Process\n\nTo capture good driving behavior, I first recorded two laps on track one using center lane driving. Here is an example image of center lane driving:\n\n![alt text][image2]\n\nI then recorded the vehicle recovering from the left side and right sides of the road back to center so that the vehicle would learn to recover from getting away from the center of the road. These images show what a recovery looks like starting from a position when the car is on top of the lane marker until the car is in middle of the road :\n\n![alt text][image3]\n![alt text][image4]\n![alt text][image5]\n\nTo augment the data sat, I also flipped images and angles thinking that this would increase the number of training examples and because of that the model would perform better. For example, here is an image that has then been flipped:\n\n![alt text][image6]\n![alt text][image7]\n\nAfter the collection process, I had 24468 number of data points. I then preprocessed this data by making portions of a predetermined number of images and normalizing it's values.\n\nI finally randomly shuffled the data set and put 20% of the data into a validation set.\n\nI used this training data for training the model. The validation set helped determine if the model was over or under fitting. The ideal number of epochs was 4 because the validation loss reach a minimum in epoch 4. I used an adam optimizer so that manually training the learning rate wasn't necessary.\n"
},
{
"alpha_fraction": 0.6535474061965942,
"alphanum_fraction": 0.6882444620132446,
"avg_line_length": 49.81578826904297,
"blob_id": "506e9685bc195ab8ea2d75d8fed568b1650d3770",
"content_id": "34b56a6f8e315192731b40ea53704eb82751f94e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3862,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 76,
"path": "/modelTraining.py",
"repo_name": "jbga/Behaviour-Cloning",
"src_encoding": "UTF-8",
"text": "import csv\nimport cv2\nimport numpy as np\n\nsamples = []\nwith open('./data/driving_log.csv') as csvfile:\n csvfile.readline()\n reader = csv.reader(csvfile)\n for line in reader:\n samples.append(line)\n\nfrom sklearn.model_selection import train_test_split\ntrain_samples, validation_samples = train_test_split(samples, test_size = 0.2)\n\nimport cv2\nimport numpy as np\nimport sklearn\n#Function to generate data on demand (load data as needed)\ndef generator(samples, batch_size=32):\n num_samples = len(samples)\n while 1: # Loop forever so the generator never terminates\n np.random.shuffle(samples)\n for offset in range(0, num_samples, batch_size):\n batch_samples = samples[offset:offset+batch_size]\n\n images = []\n measurements = []\n correction_factors = [0.0, 0.25, -0.25] #Array to correct labels from left and right images\n for batch_sample in batch_samples:\n for i in range(3): #Loop to get center (index 0), left (index 1), and right(index 2) images\n source_path = batch_sample[i]\n filename = source_path.split('/')[-1]\n current_path = './data/IMG/' + filename\n image = cv2.imread(current_path)\n images.append(image)\n measurement = float(batch_sample[3]) + correction_factors[i] #Correct measurement based on camera position\n measurements.append(measurement)\n image_flipped = np.fliplr(image)\n images.append(image_flipped)\n measurement_flipped = -measurement\n measurements.append(measurement_flipped)\n\n X_train = np.array(images)\n y_train = np.array(measurements)\n yield sklearn.utils.shuffle(X_train, y_train)\n\n# compile and train the model using the generator function\ntrain_generator = generator(train_samples, batch_size=32)\nvalidation_generator = generator(validation_samples, batch_size=32)\n\nfrom keras.models import Sequential\nfrom keras.layers import Flatten, Dense,Lambda, Cropping2D\nfrom keras.layers.convolutional import Convolution2D\nfrom keras.layers.pooling import MaxPooling2D\nfrom keras import regularizers\n\nmodel = Sequential()\n\nmodel.add(Lambda(lambda x: x / 255.0 - 0.5, input_shape=(160,320,3))) #normalize data\nmodel.add(Cropping2D(cropping=((70,25), (0,0)))) #Crop data to remove unnecessary parts and speed up training\nmodel.add(Convolution2D(24,(5,5), strides=(2,2), activation=\"relu\")) #Convolution Layer with 24 filters and kernel size 5 with stride 2\nmodel.add(Convolution2D(36,(5,5), strides=(2,2), activation=\"relu\")) #Convolution Layer with 36 filters and kernel size 5 with stride 2\nmodel.add(Convolution2D(48,(5,5), strides=(2,2), activation=\"relu\")) #Convolution Layer with 48 filters and kernel size 5 with stride 2\nmodel.add(Convolution2D(64,(3,3), activation=\"relu\")) #Convolution Layer with 64 filters and kernel size 3 with stride 1\nmodel.add(Convolution2D(64,(3,3), activation=\"relu\")) #Convolution Layer with 64 filters and kernel size 3 with stride 1\nmodel.add(Flatten()) #Flat to get vector\nmodel.add(Dense(100, kernel_regularizer=regularizers.l2(0.01))) #Fully connected layer with 100 hidden units\nmodel.add(Dense(50, kernel_regularizer=regularizers.l2(0.01))) #Fully connected layer with 50 hidden units\nmodel.add(Dense(10, kernel_regularizer=regularizers.l2(0.01))) #Fully connected layer with 10 hidden units\nmodel.add(Dense(1)) #Logits\n\nmodel.compile(loss = 'mse',optimizer='adam') #Mean square error with Adam optimizer\nmodel.fit_generator(train_generator, steps_per_epoch= len(train_samples)/32, validation_data=validation_generator,\n validation_steps=len(validation_samples)/32, epochs=4) #Train model\n\nmodel.save('model.h5') #save model\n"
}
] | 2 |
ColeGoodnight/InsertionAnalysis
|
https://github.com/ColeGoodnight/InsertionAnalysis
|
4dd69b540a82f0abf0fb01c5102e72a375859776
|
546d076a2c96ec58b385467cf4a1e57f4505d60c
|
dcd1b9a711eaf9c8dd03579d061139ce1bac4ad9
|
refs/heads/main
| 2023-04-23T23:43:47.686647 | 2021-05-11T06:54:06 | 2021-05-11T06:54:06 | 366,284,663 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5902777910232544,
"alphanum_fraction": 0.5972222089767456,
"avg_line_length": 23.16666603088379,
"blob_id": "54020c0ad8e4574ae93fad591612ce6f1f807b4a",
"content_id": "6c7f9efbb4845609c61eea8e742d2d92b08350dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 144,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 6,
"path": "/testing.py",
"repo_name": "ColeGoodnight/InsertionAnalysis",
"src_encoding": "UTF-8",
"text": "def isOrdered(list):\n for previous,current in zip(list, list[1:]):\n if (previous > current):\n return False\n\n return True"
},
{
"alpha_fraction": 0.5830115675926208,
"alphanum_fraction": 0.6164736151695251,
"avg_line_length": 34.34090805053711,
"blob_id": "fdad5321680d7ba026116f4aeed709611f915636",
"content_id": "53328b4aff8d0015fd9cbd7a1f2fe68658441321",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1554,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 44,
"path": "/analysis.py",
"repo_name": "ColeGoodnight/InsertionAnalysis",
"src_encoding": "UTF-8",
"text": "from generate import generateSorted, generatePercentageSorted, generateRandomPercentageSorted, generateReverseSorted, generateRandomSorted\nfrom sorting import shannonSort, shellSort, insertionSort\nfrom testing import isOrdered\nfrom visualization import test\nfrom numpy.polynomial import Polynomial as P\nimport matplotlib.pyplot as plt\nimport sympy as sp\nfrom sympy.abc import x\n\ndef main():\n sortNames = (\"shellSort\", \"shannonSort\", \"insertionSort\")\n x = [0, 1, 5, 10, 100, 500, 1000, 3000, 5000, 7000, 10000, 15000]\n y = []\n unsorted = []\n sortingAlgos = [shellSort, shannonSort, insertionSort]\n\n for j in range(0,3):\n for i in range(0,len(x)):\n unsorted = generateRandomPercentageSorted(x[i], 0.8)\n sortedArr, comparisons, assignments = sortingAlgos[j](unsorted)\n y.append(comparisons + assignments)\n \n p = P.fit(x,y,2)\n plt.scatter(x,y)\n\n modi = str(p)\n modlist = modi.split('+')\n postfix = [\"x^2 + \", \"x + \", \"\"]\n for n in range(0,3):\n modlist[n] = \"{:.2e}\".format(int(modlist[n][:modlist[n].find('.')])) + postfix[n]\n \n legendLabel = sortNames[j] + \" - \" + ' '.join(modlist)\n plt.plot(*p.linspace(), label = legendLabel)\n plt.legend()\n y = []\n\n plt.xlabel(\"size of N\")\n plt.ylabel(\"# of comparisons + assignments\")\n plt.title(\"Runtime of O^2 Sorting Algos Using a 80% Randomly Sorted List\")\n plt.gcf().set_size_inches(8,5)\n plt.show()\n\nif __name__ == \"__main__\":\n main()"
},
{
"alpha_fraction": 0.545998752117157,
"alphanum_fraction": 0.5636420845985413,
"avg_line_length": 24.80487823486328,
"blob_id": "1d04d1dc00bba39a7f7ceba539b92e5a4dc828e5",
"content_id": "a038886a6783fe55745681f00cd58d9b641c06d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3174,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 123,
"path": "/sorting.py",
"repo_name": "ColeGoodnight/InsertionAnalysis",
"src_encoding": "UTF-8",
"text": "\ndef insertionSort(arr):\n \n comparisons = 0\n assignments = 0\n # Traverse through 1 to len(arr)\n for i in range(1, len(arr)):\n comparisons += 1\n assignments += 2\n\n key = arr[i]\n \n # Move elements of arr[0..i-1], that are\n # greater than key, to one position ahead\n # of their current position\n j = i-1\n while j >=0 and key < arr[j] :\n comparisons += 2\n assignments += 2\n arr[j+1] = arr[j]\n j -= 1\n assignments+=1\n arr[j+1] = key\n \n return arr, comparisons, assignments\n\ndef shellSort(arr):\n \n comparisons = 0\n assignments = 0\n # Start with a big gap, then reduce the gap\n n = len(arr)\n gap = int(n/2)\n gap = int(gap)\n\n assignments += 2\n\n # Do a gapped insertion sort for this gap size.\n # The first gap elements a[0..gap-1] are already in gapped \n # order keep adding one more element until the entire array\n # is gap sorted\n while gap > 0:\n comparisons += 1\n \n for i in range(gap,n):\n comparisons += 1\n \n # add a[i] to the elements that have been gap sorted\n # save a[i] in temp and make a hole at position i\n temp = arr[i]\n \n # shift earlier gap-sorted elements up until the correct\n # location for a[i] is found\n j = i\n\n assignments+=2\n\n comparisons += 2\n while j >= gap and arr[j-gap] >temp:\n\n comparisons += 2\n assignments += 2\n\n arr[j] = arr[j-gap]\n j -= gap\n \n assignments+=1\n\n # put temp (the original a[i]) in its correct location\n arr[j] = temp\n \n assignments+=1\n gap /= 2\n gap = int(gap)\n \n return arr, comparisons, assignments\n\ndef shannonSort(arr):\n comparions = 0\n assignments = 0\n loopcompare = 0\n loopassign = 0\n\n div5 = int(len(arr)/5)\n rem = len(arr) % 5\n\n rowSortedList = []\n\n looplist = []\n\n # sort list by mulitiple of 5 lists\n for i in range (0,div5):\n looplist, loopcompare, loopassign = insertionSort(arr[i*5:i*5 + 4])\n rowSortedList += looplist\n comparions += loopcompare\n assignments += loopassign\n \n if rem > 1:\n looplist, loopcompare, loopassign = insertionSort(arr[-rem:])\n rowSortedList += looplist\n comparions += loopcompare\n assignments += loopassign\n\n threeSortedList = []\n\n # sort list by 3 lists\n div3 = int(len(arr)/3)\n for i in range (0,1):\n looplist, loopcompare, loopassign = insertionSort(arr[div3*i:div3*i+div3])\n threeSortedList += looplist\n comparions += loopcompare\n assignments += loopassign\n\n looplist, loopcompare, loopassign = insertionSort(arr[2*div3:])\n threeSortedList += looplist\n comparions += loopcompare\n assignments += loopassign\n\n finalSortedList = []\n finalSortedList, loopcompare, loopassign = insertionSort(threeSortedList)\n comparions += loopcompare\n assignments += loopassign\n\n return finalSortedList, comparions, assignments"
},
{
"alpha_fraction": 0.47706422209739685,
"alphanum_fraction": 0.5321100950241089,
"avg_line_length": 11.222222328186035,
"blob_id": "5c9328521d5269bd97c1ccf47eb9dcf646131912",
"content_id": "dd2cdf6ac7b3f84631f518bcd8f3e9b64a26684b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 109,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 9,
"path": "/visualization.py",
"repo_name": "ColeGoodnight/InsertionAnalysis",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\n\ndef test():\n x = [1,2,3]\n y = [2,4,1]\n\n plt.plot(x,y)\n\n plt.show"
},
{
"alpha_fraction": 0.6323202252388,
"alphanum_fraction": 0.650111198425293,
"avg_line_length": 26.5510196685791,
"blob_id": "3c5428329855ec344a23ad0a806f6e92920f1e1b",
"content_id": "64c14bcbea7da779fa1ee1e0084e593203523c40",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1349,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 49,
"path": "/shannonSort.py",
"repo_name": "ColeGoodnight/InsertionAnalysis",
"src_encoding": "UTF-8",
"text": "from insertionSort import insertionSort\n\ndef shannonSort(arr):\n comparions = 0\n assignments = 0\n loopcompare = 0\n loopassign = 0\n\n div5 = int(len(arr)/5)\n rem = len(arr) % 5\n\n rowSortedList = []\n\n looplist = []\n\n # sort list by mulitiple of 5 lists\n for i in range (0,div5):\n looplist, loopcompare, loopassign = insertionSort(arr[i*5:i*5 + 4])\n rowSortedList += looplist\n comparions += loopcompare\n assignments += loopassign\n \n if rem > 1:\n looplist, loopcompare, loopassign = insertionSort(arr[-rem:])\n rowSortedList += looplist\n comparions += loopcompare\n assignments += loopassign\n\n threeSortedList = []\n\n # sort list by 3 lists\n div3 = int(len(arr)/3)\n for i in range (0,1):\n looplist, loopcompare, loopassign = insertionSort(arr[div3*i:div3*i+div3])\n threeSortedList += looplist\n comparions += loopcompare\n assignments += loopassign\n\n looplist, loopcompare, loopassign = insertionSort(arr[2*div3:])\n threeSortedList += looplist\n comparions += loopcompare\n assignments += loopassign\n\n finalSortedList = []\n finalSortedList, loopcompare, loopassign = insertionSort(threeSortedList)\n comparions += loopcompare\n assignments += loopassign\n\n return finalSortedList, comparions, assignments"
},
{
"alpha_fraction": 0.6474654674530029,
"alphanum_fraction": 0.6532257795333862,
"avg_line_length": 21.86842155456543,
"blob_id": "74dc2b351aed7b818ee7733836fa382265f547a9",
"content_id": "d1355b196587886106538fbaf89962823bded7dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 868,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 38,
"path": "/generate.py",
"repo_name": "ColeGoodnight/InsertionAnalysis",
"src_encoding": "UTF-8",
"text": "import random\n\ndef generateSorted(n):\n retList = []\n for i in range(0,n):\n retList.append(i)\n return retList\n\ndef generateReverseSorted(n):\n retList = []\n for i in range(0,n):\n retList.append(n-i)\n \n return retList\n\n# sort is a percentage value to determine \n# where the sorted array will be split for shuffling\ndef generateRandomPercentageSorted(n, sort):\n retList = []\n retList = generateSorted(n)\n split = int(n*sort)+1\n copy = retList[:split]\n random.shuffle(copy)\n retList[:split] = copy\n return retList\n\ndef generatePercentageSorted(n, sort):\n retList = []\n retList = generateSorted(n)\n split = int(n*sort)+1\n retList[:split] = retList[:split][::-1]\n return retList\n\ndef generateRandomSorted(n):\n retList = []\n retList = generateSorted(n)\n random.shuffle(retList)\n return retList"
}
] | 6 |
sum187/263project
|
https://github.com/sum187/263project
|
0355759abf3c50aa4d136a3ceb86fb7ab38d0111
|
c80f7a11990fe0f722277fe9308ca8f574629a39
|
a4e0e18c965cd5137625d72e712fea44ce06de87
|
refs/heads/main
| 2023-07-08T23:33:10.397018 | 2021-08-16T12:02:54 | 2021-08-16T12:02:54 | 396,774,278 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5769230723381042,
"alphanum_fraction": 0.7307692170143127,
"avg_line_length": 25,
"blob_id": "3d3900d72804be5683e8cc4e198dae1e4fb16d63",
"content_id": "2a33e5e73489d088f69e4b5d07dc4c395247b855",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 52,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 2,
"path": "/263-Group-5-main/README.md",
"repo_name": "sum187/263project",
"src_encoding": "UTF-8",
"text": "# 263-Group-5\nCM Project for ENGSCI 263 by group 5.\n"
},
{
"alpha_fraction": 0.5033711791038513,
"alphanum_fraction": 0.5244854688644409,
"avg_line_length": 25.30373764038086,
"blob_id": "1a91e95468585c08bcca434ea3ee573f0fc2f77a",
"content_id": "65d7f75719de86e8872ef663d16fb1b413ec18bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5636,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 214,
"path": "/263-Group-5-main/functions.py",
"repo_name": "sum187/263project",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nfrom os import sep\nfrom functools import reduce\nimport numpy as np\nfrom matplotlib import pyplot as plt\n\n\ndef odePressure(t, P, a, b, q, P0):\n ''' Return the derivative dP/dt at a time, t for given parameters.\n\n Parameters:\n -----------\n t : float\n Independent variable.\n P : float\n Dependent varaible.\n a : float\n Source/sink strength parameter.\n b : float\n Recharge strength parameter.\n q : float\n Source/sink rate.\n P0 : float\n Initial Pressure values.\n\n Returns:\n --------\n dPdt : float\n Derivative of dependent variable with respect to independent variable.\n\n Notes:\n ------\n None\n\n Examples:\n ---------\n >>> \n\n '''\n\n dPdt = -a*q - b*(P - P0)\n return dPdt\n\ndef odeTemp(t, T, P, T0, P0, Tsteam, Tdash, a, b, c):\n ''' Return the derivative dT/dt at a time, t for given parameters.\n dT/dt = a(Tsteam - T) - b(P - P0)(Tdash - T) - c(T - T0)\n\n Parameters:\n -----------\n t : float\n Independent variable.\n T : float\n Dependent varaible.\n P : float\n Pressure values.\n T0 : float\n initial Temperature\n P0 : float\n initial Pressure\n Tdash : float\n function returning values for T'(t)\n a : float\n superparameter 1.\n b : float\n superparameter 2.\n c: float\n superparameter 3.\n Returns:\n --------\n dTdt : float\n Derivative of dependent variable with respect to independent variable.\n\n Notes:\n ------\n None\n\n Examples:\n ---------\n >>> ADD EXAMPLES\n\n '''\n Tprime = Tdash(t, P, T, P0, T0)\n dTdt = a*(Tsteam - T) - b*(P - P0)*(Tprime - T0) - c*(T - T0)\n\n return dTdt\n\ndef Tprime(t, P, T, P0, T0):\n ''' Return the current Temperature if current Pressure is more than initial Pressure, initial Temperature otherwise\n\n Parameters:\n -----------\n t : float\n current time\n P : float\n current Pressure\n T : float\n current Temperature\n P0 : float\n initial Pressure\n T0 : float\n initial Temperature\n \n Returns:\n --------\n Tprime : float\n Returns the required values for temperature depending on directin of flow.\n '''\n if (P > P0):\n return T\n else: \n return T0\n\n\ndef loadGivenData():\n oil = pd.read_csv(\"data\" + sep + \"tr_oil.txt\")\n pressure = pd.read_csv(\"data\" + sep + \"tr_p.txt\")\n steam = pd.read_csv(\"data\" + sep + \"tr_steam.txt\")\n temp = pd.read_csv(\"data\" + sep + \"tr_T.txt\")\n water = pd.read_csv(\"data\" + sep + \"tr_water.txt\")\n\n dataArray = [oil, pressure, steam, temp, water]\n dataArray = [df.set_index('days') for df in dataArray]\n\n data = reduce(lambda left, right: pd.merge(left, right, on = ['days'], how = 'outer'), dataArray).sort_index()\n\n return data\n\ndef loadData():\n oil = np.genfromtxt(\"data\" + sep + \"tr_oil.txt\",delimiter=',',skip_header=1).T\n pressure = np.genfromtxt(\"data\" + sep + \"tr_p.txt\",delimiter=',',skip_header=1).T\n steam = np.genfromtxt(\"data\" + sep + \"tr_steam.txt\",delimiter=',',skip_header=1).T\n temp = np.genfromtxt(\"data\" + sep + \"tr_T.txt\",delimiter=',',skip_header=1).T\n water = np.genfromtxt(\"data\" + sep + \"tr_water.txt\",delimiter=',',skip_header=1).T\n\n return oil, pressure, steam, temp, water\n\ndef objective():\n\n pass\n\ndef interpolate(values,t):\n\n n=len(values[1])\n m=np.zeros(n-1)\n c=np.zeros(n-1)\n for i in range(n-1):\n # q=m*time+c\n m[i]=(values[1][i+1]-values[1][i])/(values[0][i+1]-values[0][i])\n if m[i]==float('inf'):\n m[i]=0\n c[i]=values[1][i]-m[i]*values[0][i]\n\n idx=0\n value=np.zeros(len(t))\n for i in range(len(t)-1):\n while not (t[i]>=values[0][idx] and t[i]<=values[0][idx+1]):\n idx+=1\n value[i]=m[idx]*t[i]+c[idx]\n \n return value\n\ndef solve_ode(f, t, dt, x0, pars,q):\n '''solve ODE numerically with forcing term is altering\n Parameters:\n -----------\n f : callable\n Function that returns dxdt given variable and parameter inputs.\n t0 : float\n Initial time of solution.\n t1 : float\n Final time of solution.\n dt : float\n Time step length.\n x0 : float\n Initial value of solution.\n pars : array-like\n List of parameters passed to ODE function f.\n '''\n x1=np.zeros(len(t))\n x1[0]=x0\n x=np.zeros(len(t))\n x[0]=x0\n # improved euler method\n for i in range(len(t)-1):\n k1=f(t[i],x1[i],q[i],*pars)\n x1[i+1]=k1*dt+x1[i]\n k2=f(t[i+1],x1[i+1],q[i],*pars)\n x[i+1]=dt*(k1+k2)*0.5+x1[i]\n return t,x \n\n\nif __name__ == \"__main__\":\n data = loadGivenData()\n oil, pressure, steam, temp, water=loadData()\n oil=np.concatenate(([[0],[0]], oil),axis=1)\n water=np.concatenate(([[0],[0]], water),axis=1)\n steam=np.concatenate((steam,[[216],[0]]),axis=1)\n \n t=np.linspace(0,216,101)\n oil1=interpolate(oil,t)\n water1=interpolate(water,t)\n steam1=interpolate(steam,t)\n q=water1+oil1-steam1\n\n\n pars=0.6,0.5,1291.76\n p=solve_ode(odePressure,t,t[1],1291.76,pars,q)\n print('')\n\n \n f,axe = plt.subplots(1)\n axe.plot(t,p[1],'k--')\n axe.plot(pressure[0],pressure[1],'r.')\n plt.show()\n \n\n\n"
},
{
"alpha_fraction": 0.4480550289154053,
"alphanum_fraction": 0.5066413879394531,
"avg_line_length": 30.55813980102539,
"blob_id": "8372b38a580e66fa7abf65f11483c0a0105f8415",
"content_id": "941c682b23ede8afb4cb11a3abdab17f6bd0a67f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4216,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 129,
"path": "/263 lab/gradient_descent/annex.py",
"repo_name": "sum187/263project",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nimport matplotlib.pyplot as plt\r\n\r\nJ_scale = .1\r\n\r\ndef objectif_function(theta):\r\n [x, y] = theta\r\n x0 = -.2\r\n y0 = .35\r\n sigma_x = 1.2\r\n sigma_y = .8\r\n return 1-np.exp(-(x-x0)**2/sigma_x**2-(y-y0)**2/sigma_y**2)\r\n \r\ndef line_search(f, theta, J):\r\n gamma = 0.\r\n f_0 = f(theta)\r\n fgamma = lambda g: f(theta-g*J)\r\n j = (fgamma(.01)-f_0)/0.01\r\n N_max = 500\r\n N_it = 0\r\n while abs(j) > 1.e-5 and N_it<N_max:\r\n gamma += -j\r\n f_i = fgamma(gamma)\r\n j = (fgamma(gamma+0.01)-f_i)/0.01\r\n N_it += 1\r\n return gamma\r\n \r\n \r\n \r\ndef plot_J0(f, theta0, J0):\r\n\r\n N = 501\r\n x = np.linspace(-1, 1., N)\r\n y = np.linspace(-1., 1., N)\r\n xv, yv = np.meshgrid(x, y)\r\n Z = np.zeros(xv.shape)\r\n for i in range(len(y)):\r\n for j in range(len(x)):\r\n Z[i][j] = f([xv[i][j], yv[i][j]])\r\n\r\n plt.clf()\r\n ax1 = plt.axes()\r\n ax1.contourf(xv, yv, Z, 21, alpha = .8)\r\n ax1.scatter(theta0[0], theta0[1], color='k', s = 20.)\r\n ax1.arrow(theta0[0], theta0[1], -J_scale*J0[0], -J_scale*J0[1])\r\n ax1.set_xlim(-1.,1.)\r\n ax1.set_ylim(-1.,1.)\r\n ax1.set_xlabel('x')\r\n ax1.set_ylabel('y')\r\n ax1.set_aspect('equal')\r\n plt.savefig('1plot_J.png', bbox_inches = 'tight')\r\n plt.show()\r\n \r\ndef plot_step(f, theta0, J, theta1):\r\n\r\n N = 501\r\n x = np.linspace(-1, 1., N)\r\n y = np.linspace(-1., 1., N)\r\n xv, yv = np.meshgrid(x, y)\r\n Z = np.zeros(xv.shape)\r\n for i in range(len(y)):\r\n for j in range(len(x)):\r\n Z[i][j] = f([xv[i][j], yv[i][j]])\r\n\r\n plt.clf()\r\n ax1 = plt.axes()\r\n ax1.contourf(xv, yv, Z, 21, alpha = .8)\r\n ax1.scatter([theta0[0], theta1[0]], [theta0[1], theta1[1]], color='k', s = 20.)\r\n ax1.plot([theta0[0], theta1[0]], [theta0[1], theta1[1]], color='k', linestyle = '--')\r\n ax1.arrow(theta0[0], theta0[1], -J_scale*J[0], -J_scale*J[1])\r\n ax1.set_xlim(-1.,1.)\r\n ax1.set_ylim(-1.,1.)\r\n ax1.set_xlabel('x')\r\n ax1.set_ylabel('y')\r\n ax1.set_aspect('equal')\r\n plt.savefig('2plot_step.png', bbox_inches = 'tight')\r\n plt.show()\r\n \r\ndef plot_J1(f, theta0, J0, theta1, J1):\r\n \r\n N = 501\r\n x = np.linspace(-1, 1., N)\r\n y = np.linspace(-1., 1., N)\r\n xv, yv = np.meshgrid(x, y)\r\n Z = np.zeros(xv.shape)\r\n for i in range(len(y)):\r\n for j in range(len(x)):\r\n Z[i][j] = f([xv[i][j], yv[i][j]])\r\n\r\n plt.clf()\r\n ax1 = plt.axes()\r\n ax1.contourf(xv, yv, Z, 21, alpha = .8)\r\n ax1.scatter([theta0[0], theta1[0]], [theta0[1], theta1[1]], color='k', s = 20.)\r\n ax1.plot([theta0[0], theta1[0]], [theta0[1], theta1[1]], color='k', linestyle = '--')\r\n ax1.arrow(theta0[0], theta0[1], -J_scale*J0[0], -J_scale*J0[1])\r\n ax1.arrow(theta1[0], theta1[1], -J_scale*J1[0], -J_scale*J1[1])\r\n ax1.set_xlim(-1.,1.)\r\n ax1.set_ylim(-1.,1.)\r\n ax1.set_aspect('equal')\r\n plt.savefig('3plot_J1.png', bbox_inches = 'tight')\r\n plt.show()\r\n \r\ndef plot_Ji(f, list_theta, list_J):\r\n \r\n N = 501\r\n x = np.linspace(-1, 1., N)\r\n y = np.linspace(-1., 1., N)\r\n xv, yv = np.meshgrid(x, y)\r\n Z = np.zeros(xv.shape)\r\n for i in range(len(y)):\r\n for j in range(len(x)):\r\n Z[i][j] = f([xv[i][j], yv[i][j]])\r\n\r\n plt.clf()\r\n # fig = plt.figure(figsize = [10., 10.])\r\n # ax1 = fig.add_subplot(111)\r\n ax1 = plt.axes()\r\n ax1.contourf(xv, yv, Z, 21, alpha = .8)\r\n ax1.scatter([theta[0] for theta in list_theta[1:-1]], [theta[1] for theta in list_theta[1:-1]], color='k', linestyle = '--')\r\n ax1.scatter(list_theta[0][0], list_theta[0][1], color='b', linestyle = '--', label = 'Initial values')\r\n ax1.scatter(list_theta[-1][0], list_theta[-1][1], color='g', linestyle = '--', label = 'Final values')\r\n ax1.plot([theta[0] for theta in list_theta], [theta[1] for theta in list_theta], color='k', linestyle = '--')\r\n for i in range(len(list_theta)-1):\r\n ax1.arrow(list_theta[i][0], list_theta[i][1], -J_scale*list_J[i][0], -J_scale*list_J[i][1])\r\n ax1.set_xlim(-1.,1.)\r\n ax1.set_ylim(-1.,1.)\r\n ax1.set_aspect('equal')\r\n plt.savefig('4plot_J_i.png', bbox_inches = 'tight')\r\n plt.show()\r\n\r\n\r\n\r\n \r\n "
},
{
"alpha_fraction": 0.5425457954406738,
"alphanum_fraction": 0.5601669549942017,
"avg_line_length": 25.967533111572266,
"blob_id": "7290f1019d27f8e6dc0c3da16e969ffeacf7acbe",
"content_id": "88c0d7b61e8c64a75949bf44a6ca472cb30d38cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4313,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 154,
"path": "/263 lab/gradient_descent/gradient_descent.py",
"repo_name": "sum187/263project",
"src_encoding": "UTF-8",
"text": "# ENGSCI263: Gradient Descent Calibration\r\n# gradient_descent.py\r\n\r\n# PURPOSE:\r\n# IMPLEMENT gradient descent functions.\r\n\r\n# PREPARATION:\r\n# Notebook calibration.ipynb.\r\n\r\n# SUBMISSION:\r\n# Show the instructor that you can produce the final figure in the lab document.\r\n\r\n# import modules\r\nimport numpy as np\r\n\r\n\r\n# **this function is incomplete**\r\n#\t\t\t\t\t ----------\r\ndef obj_dir(obj, theta0, model=None):\r\n \"\"\" Compute a unit vector of objective function sensitivities, dS/dtheta0.\r\n\r\n Parameters\r\n ----------\r\n obj: callable\r\n Objective function.\r\n theta0: array-like\r\n Parameter vector at which dS/dtheta0 is evaluated.\r\n \r\n Returns\r\n -------\r\n s : array-like\r\n Unit vector of objective function derivatives.\r\n\r\n \"\"\"\r\n # empty list to store components of objective function derivative \r\n s = np.zeros(len(theta0))\r\n \r\n # compute objective function at theta0\r\n # **uncomment and complete the command below**\r\n s0 = obj(theta0)\r\n\r\n # amount by which to increment parameter\r\n dtheta0 = 1.e-2\r\n \r\n # for each parameter\r\n for i in range(len(theta0)):\r\n # basis vector in parameter direction \r\n eps_i = np.zeros(len(theta0))\r\n eps_i[i] = 1\r\n \r\n # compute objective function at incremented parameter\r\n # **uncomment and complete the command below**\r\n si = obj(theta0+eps_i*dtheta0) \r\n\r\n # compute objective function sensitivity\r\n # **uncomment and complete the command below**\r\n s[i] = (si-s0)/dtheta0\r\n\r\n # return sensitivity vector\r\n return s\r\n\r\n\r\n# **this function is incomplete**\r\n#\t\t\t\t\t ----------\r\ndef step(theta0, s, alpha):\r\n \"\"\" Compute parameter update by taking step in steepest descent direction.\r\n\r\n Parameters\r\n ----------\r\n theta00 : array-like\r\n Current parameter vector.\r\n s : array-like\r\n Step direction.\r\n alpha : float\r\n Step size.\r\n \r\n Returns\r\n -------\r\n theta01 : array-like\r\n Updated parameter vector.\r\n \"\"\"\r\n \r\n return -s*alpha+theta0\r\n\r\n# this function is complete\r\ndef line_search(obj, theta0, s):\r\n \"\"\" Compute step length that minimizes objective function along the search direction.\r\n\r\n Parameters\r\n ----------\r\n obj : callable\r\n Objective function.\r\n theta0 : array-like\r\n Parameter vector at start of line search.\r\n s : array-like\r\n Search direction (objective function sensitivity vector).\r\n \r\n Returns\r\n -------\r\n alpha : float\r\n Step length.\r\n \"\"\"\r\n # initial step size\r\n alpha = 0.\r\n # objective function at start of line search\r\n s0 = obj(theta0)\r\n # anonymous function: evaluate objective function along line, parameter is a\r\n sa = lambda a: obj(theta0-a*s)\r\n # compute initial Jacobian: is objective function increasing along search direction?\r\n j = (sa(.01)-s0)/0.01\r\n # iteration control\r\n N_max = 500\r\n N_it = 0\r\n # begin search\r\n # exit when (i) Jacobian very small (optimium step size found), or (ii) max iterations exceeded\r\n while abs(j) > 1.e-5 and N_it<N_max:\r\n # increment step size by Jacobian\r\n alpha += -j\r\n # compute new objective function\r\n si = sa(alpha)\r\n # compute new Jacobian\r\n j = (sa(alpha+0.01)-si)/0.01\r\n # increment\r\n N_it += 1\r\n # return step size\r\n return alpha\r\n\r\n# this function is complete\r\ndef gaussian2D(theta0, model=None):\r\n \"\"\" Evaluate a 2D Gaussian function at theta0.\r\n\r\n Parameters\r\n ----------\r\n theta0 : array-like \r\n [x, y] coordinate pair.\r\n model : callable\r\n This input always ignored, but required for consistency with obj_dir.\r\n \r\n Returns\r\n -------\r\n z : float\r\n Value of 2D Gaussian at theta0.\r\n \"\"\"\r\n # unpack coordinate from theta0\r\n [x, y] = theta0\r\n # function parameters (fixed)\r\n # centre\r\n x0 = -.2 \t\t\r\n y0 = .35\r\n # widths\r\n sigma_x = 1.2\r\n sigma_y = .8\r\n # evaluate function\r\n return 1-np.exp(-(x-x0)**2/sigma_x**2-(y-y0)**2/sigma_y**2)\r\n\r\n "
},
{
"alpha_fraction": 0.6144927740097046,
"alphanum_fraction": 0.6811594367027283,
"avg_line_length": 38.43571472167969,
"blob_id": "ea5a3b33e0204963ee119810b738542ab752e2a3",
"content_id": "f7017f89ef82e642792e511306adf97e831004e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5524,
"license_type": "no_license",
"max_line_length": 179,
"num_lines": 140,
"path": "/263-Group-5-main/Given_data_visualisation.py",
"repo_name": "sum187/263project",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport os\nfrom matplotlib import pyplot as plt\nimport datetime\nfrom functools import reduce\n\n# Reading in pilot study exp2 and exp3 files.\nexp2Oil = pd.read_csv(\"pilot_project_data_2012\" + os.sep + \"exp2_oil.csv\")\nexp2Pressure = pd.read_csv(\"pilot_project_data_2012\" + os.sep + \"exp2_Pressure.csv\")\nexp2Steam = pd.read_csv(\"pilot_project_data_2012\" + os.sep + \"exp2_Steam.csv\")\nexp2Temp = pd.read_csv(\"pilot_project_data_2012\" + os.sep + \"exp2_Temp.csv\")\nexp2Water = pd.read_csv(\"pilot_project_data_2012\" + os.sep + \"exp2_Water.csv\")\n\nexp3Oil = pd.read_csv(\"pilot_project_data_2012\" + os.sep + \"exp3_oil.csv\")\nexp3Pressure = pd.read_csv(\"pilot_project_data_2012\" + os.sep + \"exp3_Pressure.csv\")\nexp3Steam = pd.read_csv(\"pilot_project_data_2012\" + os.sep + \"exp3_Steam.csv\")\nexp3Temp = pd.read_csv(\"pilot_project_data_2012\" + os.sep + \"exp3_Temp.csv\")\nexp3Water = pd.read_csv(\"pilot_project_data_2012\" + os.sep + \"exp3_Water.csv\")\n\n\njan2012 = datetime.datetime(2012, 1, 1)\n# Joining exp2 dfs\ndfs2 = [exp2Oil, exp2Pressure, exp2Steam, exp2Temp, exp2Water]\n\ndfs2 = [df.set_index('days since jan 2012') for df in dfs2]\ndfs2merged = reduce(lambda left,right: pd.merge(left, right, on = ['days since jan 2012'], how = 'outer'), dfs2)\n\ndfs2merged.insert(1, \"date\", value=0)\n\nfor i, row in dfs2merged.iterrows():\n dfs2merged.at[i, 'date'] = jan2012 + datetime.timedelta(days = i)\n\n\njun2012 = datetime.datetime(2012, 6, 1)\n# Joining exp3 dfs\ndfs3 = [exp3Oil, exp3Pressure, exp3Steam, exp3Temp, exp3Water]\n\ndfs3 = [df.set_index('days since jun 2012') for df in dfs3]\ndfs3merged = reduce(lambda left,right: pd.merge(left, right, on = ['days since jun 2012'], how = 'outer'), dfs3)\n\ndfs3merged.insert(1, \"date\", value=0)\n\nfor i, row in dfs3merged.iterrows():\n dfs3merged.at[i, 'date'] = jun2012 + datetime.timedelta(days = i)\n\n\n# Controls the colors of the plots:\nsteamCol = 'black'\nwaterCol = 'blue'\noilCol = '#EACE09'\npressureCol = 'green'\ntempCol = 'red'\n\n# exp2 plots\nf2 = plt.figure()\ng2 = f2.add_gridspec(3, hspace=0.1)\nax2 = g2.subplots(sharex=True)\nf2.suptitle('Experiment 2 Data')\n\nax2[0].plot(dfs2merged['date'], dfs2merged['steam rate (t/d)'], marker = 'o', linestyle = 'none', color = steamCol ,fillstyle = 'none' ,label = 'Steam Rate (t/d)')\nax2[0].set_ylabel('Steam Rate (t/d)')\nax2[0].legend()\n\nl2_1a = ax2[1].plot(dfs2merged['date'], dfs2merged['water rate (m^3/day)'], marker = 'x', linestyle = 'none', color = waterCol, fillstyle = 'none', label = 'Water Rate (m^3/day)')\nax2[1].set_ylabel(\"Water Rate (m^3/day)\", color = waterCol)\nax2[1].tick_params(axis='y', colors = waterCol)\nax2[1].title.set_color(waterCol)\n\nax2twin1 = ax2[1].twinx()\nl2_1b = ax2twin1.plot(dfs2merged['date'], dfs2merged['oil rate (m^3/day)'], marker = '^', linestyle = 'none', color = oilCol, fillstyle = 'none',label = 'oil rate (m^3/day)')\nax2twin1.set_ylabel(\"Oil Rate (m^3/day)\", color = oilCol)\nax2twin1.tick_params(axis='y', colors = oilCol)\nax2twin1.title.set_color(oilCol)\n\nl2_1 = l2_1a + l2_1b\nlab2_1 = [l.get_label() for l in l2_1]\nax2[1].legend(l2_1, lab2_1)\n\nl2_2a = ax2[2].plot(dfs2merged['date'], dfs2merged['pressure (kPa)'], color = pressureCol, label = 'pressure (kPa)')\nax2[2].set_ylabel(\"Pressure (kPa)\", color = pressureCol)\nax2[2].tick_params(axis='y', colors = pressureCol)\nax2[2].title.set_color(pressureCol)\n\nax2twin2 = ax2[2].twinx()\nl2_2b = ax2twin2.plot(dfs2merged['date'], dfs2merged['temperature (degC)'], color = tempCol, label = 'Temperature (°C)')\nax2twin2.set_ylabel(\"Temperature (°C)\", color = tempCol)\nax2twin2.tick_params(axis='y', colors = tempCol)\nax2twin2.title.set_color(tempCol)\n\nl2_2 = l2_2a + l2_2b\nlab2_2 = [l.get_label() for l in l2_2]\nax2[2].legend(l2_2, lab2_2)\n\n[ax.grid() for ax in ax2] \n\n\n# exp3 plots\nf3 = plt.figure()\ng3 = f3.add_gridspec(3, hspace=0.1)\nax3 = g3.subplots(sharex=True)\nf3.suptitle('Experiment 3 Data')\n\nax3[0].plot(dfs3merged['date'], dfs3merged['steam rate (t/d)'], marker = 'o', linestyle = 'none', color = steamCol,fillstyle = 'none' ,label = 'Steam Rate (t/d)')\nax3[0].set_ylabel('Steam Rate (t/d)')\nax3[0].legend()\n\n\nl3_1a = ax3[1].plot(dfs3merged['date'], dfs3merged['water rate (m^3/d)'], marker = 'x', linestyle = 'none', color = waterCol, fillstyle = 'none', label = 'Water Rate (m^3/day)')\nax3[1].set_ylabel(\"Water Rate (m^3/day)\", color = waterCol)\nax3[1].tick_params(axis='y', colors = waterCol)\nax3[1].title.set_color(waterCol)\n\nax3twin1 = ax3[1].twinx()\nl3_1b = ax3twin1.plot(dfs3merged['date'], dfs3merged['oil rate (m^3/d)'], marker = '^', linestyle = 'none', color = oilCol, fillstyle = 'none',label = 'oil rate (m^3/day)')\nax3twin1.set_ylabel(\"Oil Rate (m^3/day)\", color = oilCol)\nax3twin1.tick_params(axis='y', colors = oilCol)\nax3twin1.title.set_color(oilCol)\n\nl3_1 = l3_1a + l3_1b\nlab3_1 = [l.get_label() for l in l3_1]\nax3[1].legend(l3_1, lab3_1)\n\nl3_2a = ax3[2].plot(dfs3merged['date'], dfs3merged['pressure (kPa)'], color = pressureCol, label = 'pressure (kPa)')\nax3[2].set_ylabel(\"Pressure (kPa)\", color = pressureCol)\nax3[2].tick_params(axis='y', colors = pressureCol)\nax3[2].title.set_color(pressureCol)\n\nax3twin2 = ax3[2].twinx()\nl3_2b = ax3twin2.plot(dfs3merged['date'], dfs3merged['temperature (degC)'], color = tempCol, label = 'Temperature (°C)')\nax3twin2.set_ylabel(\"Temperature (°C)\", color = tempCol)\nax3twin2.tick_params(axis='y', colors = tempCol)\nax3twin2.title.set_color(tempCol)\n\nl3_2 = l3_2a + l3_2b\nlab3_2 = [l.get_label() for l in l3_2]\nax3[2].legend(l3_2, lab3_2)\n\n[ax.grid() for ax in ax3] \n\nplt.show()"
}
] | 5 |
swarlik/GradeCalc
|
https://github.com/swarlik/GradeCalc
|
87c03c4b983179df1466545efa2d180c9f23e132
|
e21b3d3a9d433501703f68ffa4d40d90f7a83e8e
|
8bae3ff8ab91be3136f98d61fe39c18fcd5b164c
|
refs/heads/master
| 2021-05-29T10:18:42.866017 | 2014-06-04T17:50:03 | 2014-06-04T17:50:03 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.49789029359817505,
"alphanum_fraction": 0.7046413421630859,
"avg_line_length": 15.928571701049805,
"blob_id": "26bce427997d81b24df3d78fcaa9997f2467f133",
"content_id": "46d624b00983d98a8c79847736a985417623c315",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 237,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 14,
"path": "/requirements.txt",
"repo_name": "swarlik/GradeCalc",
"src_encoding": "UTF-8",
"text": "Flask==0.10.1\nJinja2==2.7.2\nMarkupSafe==0.23\nPyRSS2Gen==1.0.0\nTwisted==12.2.0\nWerkzeug==0.9.4\naltgraph==0.10.1\nbdist-mpkg==0.4.4\nitsdangerous==0.24\nmodulegraph==0.10.1\nvirtualenv==1.11.2\nwsgiref==0.1.2\nxattr==0.6.4\nzope.interface==3.8.0\n"
},
{
"alpha_fraction": 0.6669387817382812,
"alphanum_fraction": 0.6783673763275146,
"avg_line_length": 20.89285659790039,
"blob_id": "1491d8b55d1e59430d880de3bfef6e098006f730",
"content_id": "75a7a90f700e15b87eb13f48d0a16622ba9014e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1225,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 56,
"path": "/gradecalc.py",
"repo_name": "swarlik/GradeCalc",
"src_encoding": "UTF-8",
"text": "import os\nimport sqlite3\nfrom flask import Flask, request, session, g, redirect, url_for, abort, render_template, flash\n\napp = Flask(__name__)\napp.config.from_object(__name__)\n\napp.config.update(dict(\n\tDATABASE=os.path.join(app.root_path, 'gradecalc.db'),\n\tDEBUG=True,\n\tSECRET_KEY='development key',\n\tUSERNAME='admin',\n\tPASSWORD='default'\n))\napp.config.from_envvar('FLASKR_SETTINGS', silent=True)\n\nversion = '1.0.1'\n\ndef connect_db():\n\trv = sqlite3.connect(app.config['DATABASE'])\n\trv.row_factory = sqlite3.Row\n\treturn rv\n\ndef init_db():\n\twith app.app_context():\n\t\tdb = get_db()\n\t\twith app.open_resource('schema.sql', mode='r') as f:\n\t\t\tdb.cursor().executescript(f.read())\n\t\tdb.commit()\n\ndef get_db():\n\n\tif not hasattr(g, 'sqlite_db'):\n\t\tg.sqlite_db = connect_db()\n\treturn g.sqlite_db\n\[email protected]_appcontext\ndef close_db(error):\n\tif hasattr(g, 'sqlite_db'):\n\t\tg.sqlite_db.close()\n\[email protected]('/')\ndef homepage():\n\treturn render_template('index.html')\n\[email protected]('/info')\ndef info():\n\treturn render_template('info.html', version=version)\n\[email protected]('/signin')\ndef signin():\n\treturn render_template('signin.html')\n\nif __name__ == '__main__':\n\tport = int(os.environ.get(\"PORT\", 5000))\n\tapp.run(host='0.0.0.0', port=port)"
},
{
"alpha_fraction": 0.770370364189148,
"alphanum_fraction": 0.770370364189148,
"avg_line_length": 21.66666603088379,
"blob_id": "a4d91d6358de454a2abaa4b15cbcda13592bf7e1",
"content_id": "c6e62d1d94f1aa8424bbbe1f69224022a8aa2289",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 135,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 6,
"path": "/schema.sql",
"repo_name": "swarlik/GradeCalc",
"src_encoding": "UTF-8",
"text": "drop table if exists users;\ncreate table users (\n\tid integer primary key autoincrement,\n\tuser text not null,\n\tpassword text not null\n);"
}
] | 3 |
yeetzus/MLTests
|
https://github.com/yeetzus/MLTests
|
5f0eab0ceb6227f7620a338d177f6d745717759f
|
7971f1689c0a60ae394280e92de1327fff942745
|
0e98c410258ca597c8e63d116f3a5917947070a4
|
refs/heads/master
| 2021-05-24T08:07:03.218014 | 2020-04-06T10:23:54 | 2020-04-06T10:23:54 | 253,462,141 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6412935256958008,
"alphanum_fraction": 0.6701492667198181,
"avg_line_length": 31.419355392456055,
"blob_id": "54945624710709aba3a29dd5d54cace6f5b47c03",
"content_id": "7ea33f4b4e91dfcf72622e1cffbb28b47a5719e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2010,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 62,
"path": "/ML6 (Machine Learning Engineer)/trainer/data.py",
"repo_name": "yeetzus/MLTests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\"\"\"This file contains the method that creates data and labels from a directory\"\"\"\n\nimport os\nimport cv2\nimport numpy as np\nimport tensorflow as tf\n\ndef create_data_with_labels(image_dir):\n\t\"\"\"Gets numpy data and label array from images that are in the folders that are\n\tin the folder which was given as a parameter. The folders that are in that folder\n\tare identified by the mug they represent and the folder name starts with the label.\"\"\"\n\tmug_dirs = [f for f in os.listdir(image_dir) if not f.startswith('.')]\n\tmug_files = []\n\n\tfor mug_dir in mug_dirs:\n\t\tmug_image_files = [image_dir + mug_dir + '/' + '{0}'.format(f)\n\t\t\t\t\t\t for f in os.listdir(image_dir + mug_dir) if not f.startswith('.')]\n\t\tmug_files += [mug_image_files]\n\n\tnum_images = len(mug_files[0])\n\timages_np_arr = np.empty([len(mug_files), num_images, 64, 64, 3], dtype=np.float32)\n\n\tfor mug, _ in enumerate(mug_files):\n\t\tfor mug_image in range(num_images):\n\t\t\timg = cv2.imread(mug_files[mug][mug_image])\n\t\t\timg = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)\n\t\t\timg = img.astype(np.float32)\n\t\t\timages_np_arr[mug][mug_image] = img / 255.\n\n\tdata = images_np_arr[0]\n\tlabels = np.full(num_images, int(mug_dirs[0][0]))\n\n\tfor i in range(1, len(mug_dirs)):\n\t\tdata = np.append(data, images_np_arr[i], axis=0)\n\t\tlabels = np.append(labels, np.full(num_images, int(mug_dirs[i][0])), axis=0)\n\n\n\t# Data augmentation\n\t# To-do:\n\t# 1) Add noisy/textured augmentation to images\n\t#####\n\n\t#Undersample class 3\n\tif image_dir == 'data/train/':\n\t\tdata = data[:1600]\n\t\tlabels = labels[:1600]\n\t\tfor _ in range(2):\n\t\t\tdata = np.concatenate((data, data[1000:1500]), axis=0)\n\t\t\tlabels = np.concatenate((labels, labels[1000:1500]), axis=0)\n\n\t\tflipped_images = np.flip(data, axis=2)\n\t\tdata = np.concatenate((data, flipped_images), axis=0)\n\t\tlabels = np.concatenate((labels, labels), axis=0)\n\t#####\n\t\n\treturn data, labels\n\n# if __name__ == '__main__':\n# \timport sys\n# \tnp.set_printoptions(threshold=sys.maxsize)\n# \td, l = create_data_with_labels(\"data/train/\")\n"
},
{
"alpha_fraction": 0.707602322101593,
"alphanum_fraction": 0.7105262875556946,
"avg_line_length": 33.20000076293945,
"blob_id": "8744a7736d8c8e2d1ed2872fba31ca529f500008",
"content_id": "f2ecb8e8e827daf19ba92524048d42572a746793",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 342,
"license_type": "no_license",
"max_line_length": 179,
"num_lines": 10,
"path": "/README.md",
"repo_name": "yeetzus/MLTests",
"src_encoding": "UTF-8",
"text": "# ML CodingTests\n\nIf you're like me, you're sick of b***-s*** ML take-home tests that b***-s*** companies keep making you do. So, to fight the man, I'm putting up the assignments and my solutions. \n\nWant to contribute? Pull-request.\n\nCompanies done so far:\n* FiveAI (Cambridge, UK)\n* ML6 (Amsterdam, the Netherlands)\n* ZebraTech (London, UK)\n"
},
{
"alpha_fraction": 0.7638376355171204,
"alphanum_fraction": 0.7778598070144653,
"avg_line_length": 84.75949096679688,
"blob_id": "f4637b679d0554ea118b195dc87a92134e4b998d",
"content_id": "ddf8466ba541154640ae1e14194afd066ce80b41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6775,
"license_type": "no_license",
"max_line_length": 719,
"num_lines": 79,
"path": "/ML6 (Machine Learning Engineer)/README.md",
"repo_name": "yeetzus/MLTests",
"src_encoding": "UTF-8",
"text": "Hello potential ML6 colleague!\n\nIf you are reading this, you are probably applying for an ML engineering job at ML6. This test will evaluate if you have the right skills for this job. The test should approximately take 2 hours.\n\nIn the test, you will try to classify the mugs we drink from at ML6. If you are able to complete this test in a decent way, you might soon be drinking coffee from the black ML6 mug (which is also in the data) together with us.\n\n## The data\n\nAs you can see, all data can be found in the data folder. For your purposes, the data has already been split in training data and test data. They are respectively in the train folder and test folder. In those folders, you can find four folders which represent the mugs you'll need to classify. There are four kind of mugs: the white mug, the black mug (the ML6 mug), the blue mug and the transparent mug (the glass). The white mug is class 0, the black mug class 1, the blue mug class 2 and the transparent mug class 3. These class numbers are necessary to create a correct classifier. If you want, you can inspect the data, however, the code to load the data of the images into numpy arrays is already written for you.\n\n## The model\n\nIn the trainer folder, you will be able to see several python files. The data.py, task.py and final_task.py files are already coded for you. The only file that needs additional code is the model.py file. The comments in this file will indicate which code has to be written.\n\nTo test how your model is doing you can execute the following command (you will need to [install](https://cloud.google.com/sdk/docs/) the gcloud command):\n\n```\ngcloud ml-engine local train --module-name trainer.task --package-path trainer/ -- --eval-steps 5\n```\n\nIf you run this command before you wrote any code in the model.py file, you will notice that it returns errors. Your goal is to write code that does not return errors and achieves an accuracy that is as high as possible.\n\nThe command above will perform 5 evaluation steps during the training. If you want to change this, you only have to change the 5 at the end of the command to the number of evaluation steps you like. The batch size and the number of training steps should be defined in the model.py file.\n\nMake sure you'll think about the solution you will submit for this coding test. If you want the code written by us can be changed to your needs. It is however important that we can still perform our automated evaluation when you submit your solution so make sure you test your solution thoroughly before you submit it. How you can test your solution will be explained later in this README.md file.\n\n\n\nThe command above uses the task.py file. As you can see in the figure above, this file only uses the mug images in the training folder of this repository and uses the test folder to evaluate the model. This is excellent to test how the model performs but to obtain a better evaluation one can also train upon all available data which should increase the performance on the dataset you will be evaluated. After you finished coding up model.py, you can read on and you'll notice how to train your model on the full dataset.\n\n## Deploying the model\n\nOnce you've got the code working you will need to deploy the model to Google Cloud to turn it into an API that can receive new images of mugs and returns its prediction for this mug. Don't worry, the code for this is already written in the final_task.py file. To deploy the model you've just written, you only have to run a few commands in your command line.\n\nTo export your trained model and to train your model on the training folder and the test folder you have to execute the following command (only do this once you've completed coding the model.py file):\n\n```\ngcloud ml-engine local train --module-name trainer.final_task --package-path trainer/\n```\n\nOnce you've executed this command, you will notice that the output folder was created in the root directory of this repository. This folder contains your saved model that you'll be able to deploy on Google Cloud ML-engine.\n\nTo be able to deploy the model on a Google Cloud ML-engine you will need to create a [Google Cloud account](https://cloud.google.com/). You will need a credit card for this, but you'll get free credit from Google to run your ML-engine instance.\n\nOnce you've created your Google Cloud account, you'll need to deploy your model on a project you've created. You can follow a [Google guideline](https://cloud.google.com/ml-engine/docs/tensorflow/getting-started-training-prediction) for this.\n\n## Checking your deployed model\n\nBefore you submit your test, you can check if your deployed model works the way it should by executing the following commands:\n\n```\nMODEL_NAME=<your_model_name>\nVERSION=<your_version_of_the_model>\ngcloud ml-engine predict --model $MODEL_NAME --version $VERSION --json-instances check_deployed_model/test.json\n```\n\nCheck if you are able to get a prediction out of the gcloud command. If you get errors, you should try to resolve them before submitting the project. The output of the command should look something like this (the numbers will probably be different):\n\n```\nCLASSES PROBABILITIES\n1 [2.0589146706995187e-12, 1.0, 1.7370329621294728e-13, 1.2870057122347237e-32]\n```\n\nThe values you use for the $MODEL_NAME variable and the $VERSION variable can be found in your project on the Google Cloud web interface. You will need these values and your Google Cloud project id to submit your coding test.\n\nTo be able to pass the coding test. You should be able to get an accuracy of 75% on our secret dataset of mugs (which you don't have access to). If your accuracy however seems to be less than 75% after we evaluated it, you can just keep submitting solutions until you are able to get an accuracy of 75%.\n\n### Submitting your coding test\n\nOnce you are able to execute the command above without errors, you can add us to your project:\n\n* Go to the menu of your project\n* Click IAM & admin\n* Click Add\n* Add [email protected] with the Project Owner role\n\nIf you added us to your project you should fill in [this form](https://docs.google.com/forms/d/1A6LgwK6zoZVZG3vkDE823jpSc1Cw6VQ4aTd_07ILqwI) so we are able to automatically evaluate your test. Once you've filled in the form you should receive an email with the results of your coding test within 2 hours. We'll hope with you that your results are good enough to land an interview at ML6. If however you don't, you can resubmit a new coding test solution as many times you want so don't give up!\n\nIf you are invited for an interview at ML6 afterwards, you'll have to make sure that you bring your laptop with the code that you've wrote on it, so you can explain your model.py file to us.\n"
},
{
"alpha_fraction": 0.6731234788894653,
"alphanum_fraction": 0.6997578740119934,
"avg_line_length": 28.5,
"blob_id": "e09952349069acd4a3d13080804ffaa23123deff",
"content_id": "ae4879a7c167553068081e6d33c8629c4a054a9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 826,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 28,
"path": "/FiveAI (Computer Vision Engineer)/data.py",
"repo_name": "yeetzus/MLTests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env Python3\n\nimport tensorflow as tf\nimport tensorflow_datasets as tfds\n\nimport matplotlib.pyplot as plt\nimport numpy as np\n\nclass LoadMNIST:\n\tdef __init__(self):\n\t\tself._mnist_train = tfds.load(name='mnist', split='train')\n\t\tself._mnist_test = tfds.load(name='mnist', split='test')\n\n\tdef _create_trains_set(self):\n\t\tdef preprocess(example):\n\t\t\timage, label = example['image'], example['label']\n\t\t\timage = tf.cast(image, tf.float32)\n\t\t\timage = tf.reshape(image, shape=(28 * 28, 1))\n\t\t\timage = image / 255.0\n\t\t\tlabel = tf.one_hot(label, depth=10)\n\t\t\treturn image, label\n\n\t\tself._mnist_train = self._mnist_train.map(preprocess)\n\t\tself._mnist_train = self._mnist_train.repeat(20).shuffle(1024).batch(32)\n\t\t\n\tdef create_data_fetcher(self):\n\t\titerator = self._mnist_train.make_initializable_iterator()\n\t\treturn iterator\n"
},
{
"alpha_fraction": 0.6882471442222595,
"alphanum_fraction": 0.7118871808052063,
"avg_line_length": 50.351722717285156,
"blob_id": "2e461b08198f8b32def5085a56e8827367e67899",
"content_id": "582df4277f6cfa2d7ee5b86c12247c7993ccf29e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7445,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 145,
"path": "/ML6 (Machine Learning Engineer)/trainer/model.py",
"repo_name": "yeetzus/MLTests",
"src_encoding": "UTF-8",
"text": "# #!/usr/bin/env python\n# \"\"\"This file contains all the model information: the training steps, the batch size and the model iself.\"\"\"\n# import numpy as np\n# import tensorflow as tf\n# tf.enable_eager_execution()\n\n# def get_training_steps():\n# \t\"\"\"Returns the number of batches that will be used to train your solution.\n# \tIt is recommended to change this value.\"\"\"\n# \treturn 2000\n\n# def get_batch_size():\n# \t\"\"\"Returns the batch size that will be used by your solution.\n# \tIt is recommended to change this value.\"\"\"\n# \treturn 64\n\n# def solution(features, labels, mode):\n# \t\"\"\"Returns an EstimatorSpec that is constructed using the solution that you have to write below.\"\"\"\n# \t# Input Layer (a batch of images that have 64x64 pixels and are RGB colored (3)\n# \t# learning_rate = tf.Variable(1e-4, name='learning_rate:0')\n# \tinput_layer = tf.reshape(features[\"x\"], [-1, 64, 64, 3])\n# \tinput_layer = tf.image.adjust_contrast(input_layer, 5)\n# \tinput_layer = tf.image.adjust_saturation(input_layer, 5)\n\n# \t# TODO: Code of your solution\n# \tregularizer = tf.contrib.layers.l2_regularizer(scale=0.0)\n# \tnet = tf.image.central_crop(input_layer, 0.40)\n# \tnet = tf.layers.conv2d(input_layer, filters=8, kernel_size=(4, 4), strides=(2,2), padding='VALID', kernel_regularizer=regularizer)\n# \tnet = tf.layers.max_pooling2d(net, pool_size=(2,2), strides=(1,1))\n# \tnet = tf.layers.conv2d(net, filters=12, kernel_size=(4, 4), strides=(2, 2), padding='VALID', kernel_regularizer=regularizer)\n# \tnet = tf.layers.max_pooling2d(net, pool_size=(2, 2), strides=(1,1))\n# \tnet = tf.nn.dropout(net, rate=0.50)\n# \tnet = tf.contrib.layers.flatten(net)\n# \tnet = tf.layers.dense(net, units=256, kernel_regularizer=regularizer, activation=tf.nn.relu)\n# \tnet = tf.nn.dropout(net, rate=0.5)\n# \tnet = tf.layers.dense(net, units=256, kernel_regularizer=regularizer, activation=tf.nn.relu)\n# \tnet = tf.nn.dropout(net, rate=0.5)\n# \tnet = tf.layers.dense(net, units=64, kernel_regularizer=regularizer, activation=tf.nn.relu)\n# \tnet = tf.nn.dropout(net, rate=0.5)\n# \tout = tf.layers.dense(net, units=4)\n\n# \tif mode == tf.estimator.ModeKeys.PREDICT:\n# \t\t# TODO: return tf.estimator.EstimatorSpec with prediction values of all classes\n# \t\t# predictions = {'top_1': tf.argmax(out, -1),\n# \t\t# \t\t\t 'logits':out}\n# \t\tpredictions = {'CLASSES': tf.argmax(out, -1), 'PROBABILITIES':tf.nn.softmax(out)}\n# \t\treturn tf.estimator.EstimatorSpec(mode, predictions=predictions)\n# \telse:\n# \t\tlabels = tf.one_hot(labels, depth=4)\n# \t\treg_loss = tf.losses.get_regularization_loss()\n# \t\tloss = tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=out)\n# \t\tloss = tf.reduce_mean(loss)\n# \t\tloss += reg_loss\n# \t\teval_metric_ops = {\"accuracy\": tf.metrics.accuracy(labels=tf.argmax(labels, axis=-1), predictions=tf.argmax(out, axis=-1))}\n\t\t\n# \t\tif mode == tf.estimator.ModeKeys.TRAIN:\n# \t\t\t# TODO: Let the model train here\n# \t\t\t# TODO: return tf.estimator.EstimatorSpec(mode=mode, loss=loss, train_op=train_op)\n# \t\t\tglobal_step = tf.train.get_or_create_global_step()\n# \t\t\tboundaries = [1000]\n# \t\t\tvalues = [1e-4, 8e-5]\n# \t\t\tlearning_rate = tf.train.piecewise_constant(global_step, boundaries, values)\n# \t\t\ttrain_op = tf.compat.v1.train.RMSPropOptimizer(1e-4).minimize(loss, global_step = global_step)\n# \t\t\treturn tf.estimator.EstimatorSpec(mode=mode, loss=loss, train_op=train_op)\n\n# \t\telif mode == tf.estimator.ModeKeys.EVAL:\n# \t\t\t# The classes variable below exists of an tensor that contains all the predicted classes in a batch\n# \t\t\t# TODO: eval_metric_ops = {\"accuracy\": tf.metrics.accuracy(labels=labels, predictions=classes)}\n# \t\t\t# TODO: return tf.estimator.EstimatorSpec(mode=mode, loss=loss, eval_metric_ops=eval_metric_ops)\n# \t\t\treturn tf.estimator.EstimatorSpec(mode=mode, loss=loss, eval_metric_ops=eval_metric_ops)\n# \t\telse:\n# \t\t\traise NotImplementedError()\n\n#!/usr/bin/env python\n\"\"\"This file contains all the model information: the training steps, the batch size and the model iself.\"\"\"\nimport numpy as np\nimport tensorflow as tf\ntf.enable_eager_execution()\n\ndef get_training_steps():\n\t\"\"\"Returns the number of batches that will be used to train your solution.\n\tIt is recommended to change this value.\"\"\"\n\treturn 1000\n\ndef get_batch_size():\n\t\"\"\"Returns the batch size that will be used by your solution.\n\tIt is recommended to change this value.\"\"\"\n\treturn 64\n\ndef solution(features, labels, mode):\n\t\"\"\"Returns an EstimatorSpec that is constructed using the solution that you have to write below.\"\"\"\n\t# Input Layer (a batch of images that have 64x64 pixels and are RGB colored (3)\n\t# learning_rate = tf.Variable(1e-4, name='learning_rate:0')\n\tinput_layer = tf.reshape(features[\"x\"], [-1, 64, 64, 3])\n\t# input_layer = tf.image.adjust_brightness(input_layer, -50)\n\tinput_layer = tf.image.adjust_contrast(input_layer, 5)\t\n\n\t# TODO: Code of your solution\n\tregularizer = tf.contrib.layers.l2_regularizer(scale=0.085)\n\tnet = tf.image.central_crop(input_layer, 0.40)\n\tnet = tf.layers.conv2d(input_layer, filters=12, kernel_size=(4, 4), strides=(2,2), padding='VALID', kernel_regularizer=regularizer)\n\tnet = tf.layers.max_pooling2d(net, pool_size=(2,2), strides=(1,1))\n\tnet = tf.layers.conv2d(net, filters=12, kernel_size=(4, 4), strides=(2, 2), padding='VALID', kernel_regularizer=regularizer)\n\tnet = tf.layers.max_pooling2d(net, pool_size=(2, 2), strides=(1,1))\n\tnet = tf.nn.dropout(net, rate=0.50)\n\tnet = tf.contrib.layers.flatten(net)\n\tnet = tf.layers.dense(net, units=256, kernel_regularizer=regularizer)\n\tnet = tf.nn.dropout(net, rate=0.5)\n\tnet = tf.layers.dense(net, units=256, kernel_regularizer=regularizer)\n\tnet = tf.nn.dropout(net, rate=0.5)\n\tnet = tf.layers.dense(net, units=64, kernel_regularizer=regularizer)\n\tnet = tf.nn.dropout(net, rate=0.5)\n\tout = tf.layers.dense(net, units=4)\n\n\tif mode == tf.estimator.ModeKeys.PREDICT:\n\t\t# TODO: return tf.estimator.EstimatorSpec with prediction values of all classes\n\t\t# predictions = {'top_1': tf.argmax(out, -1),\n\t\t# \t\t\t 'logits':out}\n\t\tpredictions = {'CLASSES': tf.argmax(out, -1), 'PROBABILITIES':tf.nn.softmax(out)}\n\t\treturn tf.estimator.EstimatorSpec(mode, predictions=predictions)\n\telse:\n\t\tlabels = tf.one_hot(labels, depth=4)\n\t\treg_loss = tf.losses.get_regularization_loss()\n\t\tloss = tf.nn.softmax_cross_entropy_with_logits(labels=labels, logits=out)\n\t\tloss = tf.reduce_mean(loss)\n\t\tloss += reg_loss\n\t\teval_metric_ops = {\"accuracy\": tf.metrics.accuracy(labels=tf.argmax(labels, axis=-1), predictions=tf.argmax(out, axis=-1))}\n\t\t\n\t\tif mode == tf.estimator.ModeKeys.TRAIN:\n\t\t\t# TODO: Let the model train here\n\t\t\t# TODO: return tf.estimator.EstimatorSpec(mode=mode, loss=loss, train_op=train_op)\n\t\t\tglobal_step = tf.train.get_or_create_global_step()\n\t\t\tboundaries = [1000]\n\t\t\tvalues = [1e-4, 8e-5]\n\t\t\tlearning_rate = tf.train.piecewise_constant(global_step, boundaries, values)\n\t\t\ttrain_op = tf.compat.v1.train.RMSPropOptimizer(1e-4).minimize(loss, global_step = global_step)\n\t\t\treturn tf.estimator.EstimatorSpec(mode=mode, loss=loss, train_op=train_op)\n\n\t\telif mode == tf.estimator.ModeKeys.EVAL:\n\t\t\t# The classes variable below exists of an tensor that contains all the predicted classes in a batch\n\t\t\t# TODO: eval_metric_ops = {\"accuracy\": tf.metrics.accuracy(labels=labels, predictions=classes)}\n\t\t\t# TODO: return tf.estimator.EstimatorSpec(mode=mode, loss=loss, eval_metric_ops=eval_metric_ops)\n\t\t\treturn tf.estimator.EstimatorSpec(mode=mode, loss=loss, eval_metric_ops=eval_metric_ops)\n\t\telse:\n\t\t\traise NotImplementedError()"
},
{
"alpha_fraction": 0.4524714946746826,
"alphanum_fraction": 0.46768060326576233,
"avg_line_length": 31.625,
"blob_id": "8463ee36933ccb7c07ac17c6c5430b688f480c21",
"content_id": "40cbf55cb417b5b3420d64adf757a9a64666cf2d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 263,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 8,
"path": "/FiveAI (Computer Vision Engineer)/MNIST_test_variants/load_test_set.py",
"repo_name": "yeetzus/MLTests",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nif __name__ == \"__main__\":\n\n for tst in [\"clean\", \"t1\", \"t2\", \"t3\", \"t4\"]:\n data = np.load(\"test_sets/\" + tst + \".npy\", allow_pickle=True).item()\n x, y = data['x'], data['y']\n print(tst, '\\t', x.shape, '\\t', y.shape)\n\n\n"
},
{
"alpha_fraction": 0.5938018560409546,
"alphanum_fraction": 0.613724410533905,
"avg_line_length": 31.125,
"blob_id": "dadd3fa0d6798cd228f792f89b4248dc33fe2f29",
"content_id": "79d7725f078839645f214eb3c8cd2ce69f9eb739",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1807,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 56,
"path": "/FiveAI (Computer Vision Engineer)/model.py",
"repo_name": "yeetzus/MLTests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env Python3\n\nimport tensorflow as tf\n\nclass MNISTClassifier:\n\tdef __init__(self):\n\t\tself._inputs = tf.placeholder(tf.float32, shape=[None, 28 * 28, 1])\n\t\tself._targets = tf.placeholder(tf.uint8, shape=[None, 10])\n\t\tself._create_network()\n\n\tdef _create_network(self):\n\t\tnet = tf.layers.dense(self._inputs, \n\t\t\t\t\t\t\t units=500, \n\t\t\t\t\t\t\t kernel_initializer='glorot_uniform',\n\t\t\t\t\t\t\t bias_initializer='zeros',\n\t\t\t\t\t\t\t activation=tf.nn.relu)\n\t\tnet = tf.layers.dense(net, \n\t\t\t\t\t\t\t units=500, \n\t\t\t\t\t\t\t kernel_initializer='glorot_uniform',\n\t\t\t\t\t\t\t bias_initializer='zeros',\n\t\t\t\t\t\t\t activation=tf.nn.relu)\n\t\tnet = tf.layers.dense(net, \n\t\t\t\t\t\t\t units=500, \n\t\t\t\t\t\t\t kernel_initializer='glorot_uniform',\n\t\t\t\t\t\t\t bias_initializer='zeros',\n\t\t\t\t\t\t\t activation=tf.nn.relu)\n\t\tnet = tf.layers.dense(net, \n\t\t\t\t\t\t\t units=200, \n\t\t\t\t\t\t\t kernel_initializer='glorot_uniform',\n\t\t\t\t\t\t\t bias_initializer='zeros',\n\t\t\t\t\t\t\t activation=tf.nn.relu)\n\t\tnet = tf.layers.dense(net, \n\t\t\t\t\t\t\t units=200, \n\t\t\t\t\t\t\t kernel_initializer='glorot_uniform',\n\t\t\t\t\t\t\t bias_initializer='zeros',\n\t\t\t\t\t\t\t activation=tf.nn.relu)\n\t\tnet = tf.layers.dense(net, \n\t\t\t\t\t\t\t units=50, \n\t\t\t\t\t\t\t kernel_initializer='glorot_uniform',\n\t\t\t\t\t\t\t bias_initializer='zeros',\n\t\t\t\t\t\t\t activation=tf.nn.relu)\n\t\tnet = tf.layers.dense(net, \n\t\t\t\t\t\t\t units=100, \n\t\t\t\t\t\t\t kernel_initializer='glorot_uniform',\n\t\t\t\t\t\t\t bias_initializer='zeros',\n\t\t\t\t\t\t\t activation=tf.nn.relu)\n\t\tself._net = tf.layers.dense(net, \n\t\t\t\t\t\t\t units=10, \n\t\t\t\t\t\t\t kernel_initializer='glorot_uniform',\n\t\t\t\t\t\t\t bias_initializer='zeros')\n\n\tdef _create_loss(self):\n\t\tself._loss = tf.nn.softmax_cross_entropy_with_logits(labels=self._targets, logits=self._net)\n\n\tdef _create_optimizer(self):\n\t\tself._train = tf.compat.v1.train.AdamOptimizer(1e-4).minimize(self._loss)\n\n\n\n\n\t\t\n\n"
},
{
"alpha_fraction": 0.6205378174781799,
"alphanum_fraction": 0.652461051940918,
"avg_line_length": 35.55172348022461,
"blob_id": "3e3c7ac618d8899ec7f79f7e2c9abfa2cf5a5da5",
"content_id": "29888c8b0ffbd7141592a418cd27eda2342ccd25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6359,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 174,
"path": "/FiveAI (Computer Vision Engineer)/train.py",
"repo_name": "yeetzus/MLTests",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport torch as t\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torch.optim as optim\nfrom torchvision import datasets, transforms\n\nfrom absl import app\nfrom absl import flags\n\nFLAGS = flags.FLAGS\n\n# Network flags\nflags.DEFINE_integer('input_dimensions', 784, 'Dimensions of input observation')\nflags.DEFINE_spaceseplist('units_per_layer', [500, 500, 500, 200, 200, 100, 50, 10], 'Dimensions of input observation')\n\n# Experiment flags\nflags.DEFINE_integer('seed', 0, 'Random seed')\nflags.DEFINE_integer('train_batch_size', 150, 'Batch size of train')\nflags.DEFINE_integer('test_batch_size', 500, 'Batch size of test')\nflags.DEFINE_integer('epochs', 5, 'Number of epochs to run')\n\ndef load_mnist_train_test_data():\n\ttrain_loader = t.utils.data.DataLoader(\n\t\t\tdatasets.MNIST('./data/', train=True, download=True, \n\t\t\t\t\t\t\ttransform=transforms.Compose([\n\t\t\t\t\t\t\t\ttransforms.ToTensor(),\n\t\t\t\t\t\t\t\ttransforms.Normalize((0.1307,), (0.3081,))])),\n\t\t\tbatch_size=FLAGS.train_batch_size, shuffle=True)\n\ttest_loader = t.utils.data.DataLoader(\n\t\t\tdatasets.MNIST('./data/', train=False, download=True,\n\t\t\t\t\t\t\ttransform=transforms.Compose([\n\t\t\t\t\t\t\t\ttransforms.ToTensor(),\n\t\t\t\t\t\t\t\ttransforms.Normalize((0.1307,), (0.3081,))])),\n\t\t\tbatch_size=FLAGS.test_batch_size, shuffle=True)\n\n\treturn train_loader, test_loader\n\nclass MNISTClassifier(nn.Module):\n\tdef __init__(self):\n\t\tsuper(MNISTClassifier, self).__init__()\n\n\t\tself._create_net()\n\t\tself._create_optimizer()\n\n\tdef _create_net(self):\n\t\tself._fc1 = nn.Linear(in_features=FLAGS.input_dimensions, out_features=FLAGS.units_per_layer[0]) \t\t\t\t \n\t\tself._fc2 = nn.Linear(in_features=FLAGS.units_per_layer[0], out_features=FLAGS.units_per_layer[1]) \n\t\tself._fc3 = nn.Linear(in_features=FLAGS.units_per_layer[1], out_features=FLAGS.units_per_layer[2]) \n\t\tself._fc4 = nn.Linear(in_features=FLAGS.units_per_layer[2], out_features=FLAGS.units_per_layer[3]) \n\t\tself._fc5 = nn.Linear(in_features=FLAGS.units_per_layer[3], out_features=FLAGS.units_per_layer[4]) \n\t\tself._fc6 = nn.Linear(in_features=FLAGS.units_per_layer[4], out_features=FLAGS.units_per_layer[5]) \n\t\tself._fc7 = nn.Linear(in_features=FLAGS.units_per_layer[5], out_features=FLAGS.units_per_layer[6]) \n\t\tself._fc8 = nn.Linear(in_features=FLAGS.units_per_layer[6], out_features=FLAGS.units_per_layer[7])\n\t\t\n\tdef forward(self, X):\n\t\tX = self._fc1(X)\n\t\tX = F.relu(X)\n\t\tX = self._fc2(X)\n\t\tX = F.relu(X)\n\t\tX = self._fc3(X)\n\t\tX = F.relu(X)\n\t\tX = self._fc4(X)\n\t\tX = F.relu(X)\n\t\tX = self._fc5(X)\n\t\tX = F.relu(X)\n\t\tX = self._fc6(X)\n\t\tX = F.relu(X)\n\t\tX = self._fc7(X)\n\t\tX = F.relu(X)\n\t\tX = self._fc8(X)\n\t\toutput = F.log_softmax(X, dim=1)\n\t\treturn output\n\n\tdef _create_optimizer(self):\n\t\tself.loss = nn.CrossEntropyLoss()\n\t\tself.optimizer = optim.SGD(self.parameters(), lr=0.01, momentum=0.9)\n\ndef train(argv):\n\ttrain_data_fetcher, test_data_fetcher = load_mnist_train_test_data()\n\ttest_data_fetcher = iter(test_data_fetcher)\n\tnet = MNISTClassifier()\n\t\n\tfor epoch in range(FLAGS.epochs):\n\t\tfor i, data in enumerate(train_data_fetcher, 0):\n\t\t\tX, y = data\n\t\t\tX = X.view(X.shape[0], -1)\n\t\t\ty_hat = net(X)\n\t\t\tnet.optimizer.zero_grad()\n\t\t\tloss = net.loss(y_hat, y)\n\t\t\tloss.backward()\n\t\t\tnet.optimizer.step()\t\n\t\tX_test, y_test = test_data_fetcher.next()\n\t\tX_test = X_test.view(X_test.shape[0], -1)\n\t\ty_hat_test = net(X_test)\n\t\t_, y_hat_test = t.max(y_hat_test, 1)\n\t\tacc = (y_hat_test == y_test).sum().item()\n\t\tprint(acc)\n\n\t# Load test sets\n\tfor tst in [\"clean\", \"t1\", \"t2\", \"t3\", \"t4\"]:\n\t\tdata = np.load(\"./MNIST_test_variants/test_sets/\" + tst + \".npy\", allow_pickle=True).item()\n\t\tX_test, y_test = data['x'], data['y']\n\t\tX_test, y_test = t.from_numpy(X_test), t.from_numpy(y_test)\n\t\tX_test = X_test - t.mean(X_test)\n\t\tX_test = X_test / t.std(X_test)\n\t\tX_test = X_test.view(X_test.shape[0], -1)\n\t\ty_hat_test = net(X_test)\n\t\t_, y_hat_test = t.max(y_hat_test, 1)\n\t\tacc = (y_hat_test == y_test).sum().item()\n\t\tprint(acc)\n\ndef train_all_data(argv):\n\t# Load t3 and t4\n\tt3 = np.load(\"./MNIST_test_variants/test_sets/\" + 't3' + \".npy\", allow_pickle=True).item()\n\tt3_X, t3_y = t3['x'], t3['y']\n\tt3_X_train, t3_y_train = t3_X[:8000], t3_y[:8000]\n\tt3_X_test, t3_y_test = t3_X[8000:], t3_y[8000:]\n\tt4 = np.load(\"./MNIST_test_variants/test_sets/\" + 't4' + \".npy\", allow_pickle=True).item()\n\tt4_X, t4_y = t4['x'], t4['y']\n\tt4_X_train, t4_y_train = t4_X[:8000], t4_y[:8000]\n\tt4_X_test, t4_y_test = t4_X[8000:], t4_y[8000:]\n\tvariants_X_train = np.concatenate((t3_X_train, t4_X_train), axis=0)\n\tvariants_y_train = np.concatenate((t3_y_train, t4_y_train), axis=0)\n\tvariants_X_test = np.concatenate((t3_X_test, t4_X_test), axis=0)\n\tvariants_y_test = np.concatenate((t3_y_test, t4_y_test), axis=0)\n\n\tvariants_X_train = t.from_numpy(variants_X_train).float()\n\tvariants_y_train = t.from_numpy(variants_y_train).float()\n\tvariants_dataset_train = t.utils.data.TensorDataset(variants_X_train, variants_y_train)\n\tvariants_dataset_train_loader = t.utils.data.DataLoader(variants_dataset_train, batch_size=20, shuffle=True)\n\t\n\ttrain_data_fetcher, _ = load_mnist_train_test_data()\n\tvariants_data_fetcher = iter(variants_dataset_train_loader)\n\tnet = MNISTClassifier()\n\t\n\tfor epoch in range(FLAGS.epochs):\n\t\tfor i, data in enumerate(train_data_fetcher, 0):\n\t\t\tX, y = data\n\t\t\ttry: \n\t\t\t\tX_v, y_v = variants_data_fetcher.next()\n\t\t\texcept:\n\t\t\t\tvariants_dataset_train_loader = t.utils.data.DataLoader(variants_dataset_train, batch_size=20, shuffle=True)\n\t\t\t\tvariants_data_fetcher = iter(variants_dataset_train_loader)\n\t\t\t\tX_v, y_v = variants_data_fetcher.next()\n\t\t\tX_v = X_v - 0.1307\n\t\t\tX_v = X_v / 0.3081\n\t\t\ty_v = y_v.long()\n\t\t\tX = t.cat((X, X_v), 0)\n\t\t\ty = t.cat((y, y_v), 0)\n\t\t\tX = X.view(X.shape[0], -1)\n\t\t\ty_hat = net(X)\n\t\t\tnet.optimizer.zero_grad()\n\t\t\tloss = net.loss(y_hat, y)\n\t\t\tloss.backward()\n\t\t\tnet.optimizer.step()\t\n\t\t\tprint(loss)\n\n\n\t# Load test sets\n\tfor tst in [\"clean\", \"t1\", \"t2\", \"t3\", \"t4\"]:\n\t\tdata = np.load(\"./MNIST_test_variants/test_sets/\" + tst + \".npy\", allow_pickle=True).item()\n\t\tX_test, y_test = data['x'], data['y']\n\t\tX_test, y_test = t.from_numpy(X_test), t.from_numpy(y_test)\n\t\tX_test = X_test - t.mean(X_test)\n\t\tX_test = X_test / t.std(X_test)\n\t\tX_test = X_test.view(X_test.shape[0], -1)\n\t\ty_hat_test = net(X_test)\n\t\t_, y_hat_test = t.max(y_hat_test, 1)\n\t\tacc = (y_hat_test == y_test).sum().item()\n\t\tprint(acc)\n\nif __name__ == '__main__':\n\tapp.run(train_all_data)"
}
] | 8 |
offshoreproj-Ghana/Offshore-Ghana2
|
https://github.com/offshoreproj-Ghana/Offshore-Ghana2
|
0008c2de4fb02b5ea8ed5786f61c464d001d6d87
|
3054866cd99d7a0382798ea921aee8c88d3b3d43
|
fe223311c11b15596df866fb5ea6b68a9843f93f
|
refs/heads/master
| 2022-12-27T10:43:58.274729 | 2020-10-13T05:44:33 | 2020-10-13T05:44:33 | 303,095,263 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.745398759841919,
"alphanum_fraction": 0.745398759841919,
"avg_line_length": 22.285715103149414,
"blob_id": "b5142a7719fa59955b8017876b87b1bf3e2fa4fc",
"content_id": "b58150ed3a963452ed1346e8d4fcc63ee1f859a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 326,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 14,
"path": "/aboutuser/urls.py",
"repo_name": "offshoreproj-Ghana/Offshore-Ghana2",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom django.urls import path, include\nfrom rest_framework import routers\nfrom .views import Aboutuserviewset\nfrom . import views \n\n\nrouter = routers.DefaultRouter()\nrouter.register('Person', Aboutuserviewset)\n\nurlpatterns = [\n #path('', views.first),\n path('', include(router.urls)),\n]\n"
},
{
"alpha_fraction": 0.7383720874786377,
"alphanum_fraction": 0.7383720874786377,
"avg_line_length": 14.727272987365723,
"blob_id": "dc7304a49763251504f08119b866509674072896",
"content_id": "f433d37d6d3d73a893871339afb90003edf6ff4a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 172,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 11,
"path": "/frontend/src/reducers/index.js",
"repo_name": "offshoreproj-Ghana/Offshore-Ghana2",
"src_encoding": "UTF-8",
"text": "import { combineReducers } from 'redux';\nimport personReducer from './personReducer'\n\n\n//THIS IS THE rootReducer,\n\nexport default combineReducers({\n\n personReducer,\n\n});"
},
{
"alpha_fraction": 0.8007518649101257,
"alphanum_fraction": 0.8007518649101257,
"avg_line_length": 21.16666603088379,
"blob_id": "0043df21557327e5872851fdd77657a5e034ad8e",
"content_id": "b4e8d60ab6340dc5168ce478ff0c6f1809a13e0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 266,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 12,
"path": "/aboutuser/api.py",
"repo_name": "offshoreproj-Ghana/Offshore-Ghana2",
"src_encoding": "UTF-8",
"text": "from .models import Person\nfrom rest_framework import viewsets, permissions\n\nfrom .serializers import AboutUserSerializer\n\n\n# perosn viewset\n\nclass PersonViewSet(viewsets.ModelViewSet):\n queryset = Person.objects.all()\n\n serializer_class = AboutUserSerializer\n"
},
{
"alpha_fraction": 0.5883095264434814,
"alphanum_fraction": 0.5975610017776489,
"avg_line_length": 45.6274528503418,
"blob_id": "9e8ff0a7864d7b1ca229f08e77174b1cfc9d90bb",
"content_id": "71436c7cad140c16ce653708ba0407e8242c93c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2378,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 51,
"path": "/aboutuser/tests.py",
"repo_name": "offshoreproj-Ghana/Offshore-Ghana2",
"src_encoding": "UTF-8",
"text": "from django.test import TestCase\nclass PersonModelTest(TestCase):\n \n def setUp(self):\n Person.objects.create(First_name='Masahudu', Last_name='Sulemana',Email='[email protected]',Age=29,Income=9.00)\n #Person.objects.create(First_name='sam', Last_name='Quans',Email='[email protected]',Age=24,Income=500)\n \n def test_First_name(self): \n #TESTING IF FIELD NAME HAS REALLY BEEN CREATED AS 'First_name'>>>EXPECTED TO PASS \n person = Person.objects.get(First_name ='Masahudu')\n field_label = person._meta.get_field('First_name').verbose_name\n self.assertEquals(field_label, 'First name')\n \n \n def test_First_name_len(self): \n #TESTING IF LENGTH OF FIRST NAME IS GREATER THAN 250 >>>EXPECTED TO PASS \n person = Person.objects.get(First_name ='Masahudu')\n if len(person.First_name) > 250:\n print('failed test')\n else:\n print('\\n \\n')\n print('=====================test_First_name_len===========================')\n print('The length of First name column is ok>>>passed!!!') \n #self.assertTrue()\n \n \n def test_Last_name_len(self):\n #TESTING IF LENGTH OF LAST NAME IS GREATER THAN 250EXPECTED TO PASS \n person = Person.objects.get(First_name ='Masahudu')\n if len(person.Last_name) > 250:\n print('failed test')\n else:\n print('\\n \\n')\n print('=====================test_Last_name_len===========================')\n print('The length of Last name column is ok>>>passed!!!') \n #self.assertTrue()\n \n \n def test_Last_name(self):\n #TESTING IF LAST NAME IS CREATED AS 'Last_name\" EXPECTED TO PASS\n person = Person.objects.get(Last_name = 'Sulemana')\n field_label = person._meta.get_field('Last_name').verbose_name\n self.assertEquals(field_label, 'Last name') \n\n \n ''' \n Even though i could run various test such as confirming if a field input is an integer, i left that out for now because \n i believe django integer field would really take care of it. but i tested for name of fields since the are developers decisions and can be \n changed and are subject to breaking and the same goes for length of inputs. not withstanding the above reasons, subsequently the field types \n will also be tested.\n '''\n"
},
{
"alpha_fraction": 0.4684385359287262,
"alphanum_fraction": 0.48947951197624207,
"avg_line_length": 22.763158798217773,
"blob_id": "fcf9e4955ffd713866bc552017b3bdea1344327b",
"content_id": "3a379fe7ba85600a45be41baf195e34236d297cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 903,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 38,
"path": "/aboutuser/migrations/0002_auto_20201009_1410.py",
"repo_name": "offshoreproj-Ghana/Offshore-Ghana2",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.2 on 2020-10-09 14:10\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('aboutuser', '0001_initial'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='person',\n old_name='age',\n new_name='Age',\n ),\n migrations.RenameField(\n model_name='person',\n old_name='email',\n new_name='Email',\n ),\n migrations.RenameField(\n model_name='person',\n old_name='fName',\n new_name='First_name',\n ),\n migrations.RenameField(\n model_name='person',\n old_name='income',\n new_name='Income',\n ),\n migrations.RenameField(\n model_name='person',\n old_name='lName',\n new_name='Last_name',\n ),\n ]\n"
},
{
"alpha_fraction": 0.8130564093589783,
"alphanum_fraction": 0.8130564093589783,
"avg_line_length": 27,
"blob_id": "4f30b8eb3b8e3964daef4a0ee63b040e17a2d49c",
"content_id": "a59db408caf0edf3917b7d7c7971cedcd1f0dd20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 337,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 12,
"path": "/aboutuser/views.py",
"repo_name": "offshoreproj-Ghana/Offshore-Ghana2",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom rest_framework import viewsets\nfrom .serializers import AboutUserSerializer\nfrom .models import Person\nfrom django.http import HttpResponse\n\n\n\n# Create your views here.\nclass Aboutuserviewset(viewsets.ModelViewSet):\n serializer_class = AboutUserSerializer\n queryset = Person.objects.all()\n\n"
},
{
"alpha_fraction": 0.5837320685386658,
"alphanum_fraction": 0.5837320685386658,
"avg_line_length": 18.904762268066406,
"blob_id": "02f8ad623f59370c4ef92aef5cdb3213192d29ea",
"content_id": "44da9d0f7c13c5cb27cfadb26eed09d77cf27a8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 418,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 21,
"path": "/frontend/src/Components/App.js",
"repo_name": "offshoreproj-Ghana/Offshore-Ghana2",
"src_encoding": "UTF-8",
"text": "import React, { Fragment } from 'react';\nimport ReactDOM from 'react-dom';\nimport Person from './Person';\nimport { Provider } from 'react-redux';\nimport store from '../store'\n\nexport default function App() {\n return (\n <Provider store={store}>\n <Fragment>\n\n <Person />\n </Fragment>\n </Provider>\n )\n\n}\n\n\n\nReactDOM.render(<App />, document.getElementById('app'))\n"
},
{
"alpha_fraction": 0.6903225779533386,
"alphanum_fraction": 0.7193548679351807,
"avg_line_length": 27.18181800842285,
"blob_id": "ea725fd926d01b52ea5bbc01ca03d402429e6710",
"content_id": "fbe558710a464c1894359876e4c47141824a44e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 310,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 11,
"path": "/aboutuser/models.py",
"repo_name": "offshoreproj-Ghana/Offshore-Ghana2",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n# Create your models here.\n\n\nclass Person(models.Model):\n First_name = models.CharField(max_length=250)\n Last_name = models.CharField(max_length=250)\n Email = models.EmailField(max_length=250, unique=True)\n Age = models.IntegerField()\n Income = models.FloatField()\n"
},
{
"alpha_fraction": 0.44059041142463684,
"alphanum_fraction": 0.44059041142463684,
"avg_line_length": 35.119998931884766,
"blob_id": "4f56f0979892586ef40600f4ebf6c2f403ff6441",
"content_id": "6b62838226adf5b15bbbec23d24cb77de3debe08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2710,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 75,
"path": "/frontend/src/Components/layouts/PersonList.js",
"repo_name": "offshoreproj-Ghana/Offshore-Ghana2",
"src_encoding": "UTF-8",
"text": "import React, { Component } from 'react'\nimport { Button, Table } from 'semantic-ui-react';\nimport { connect } from 'react-redux';\nimport PropTypes from 'prop-types';\nimport { getPersons, deletePerson } from '../../actions/apiAction'\n\n\nclass PersonList extends Component {\n\n static propTypes = {\n persons: PropTypes.array.isRequired,\n getPersons: PropTypes.func.isRequired,\n deletePerson: PropTypes.func.isRequired,\n }\n\n componentDidMount() {\n this.props.getPersons();\n }\n render() {\n\n return (\n <>\n <div className=\"persons-table\">\n <Table celled striped unstackable>\n <Table.Header>\n <Table.Row>\n <Table.HeaderCell> ID</Table.HeaderCell>\n\n <Table.HeaderCell> First Name</Table.HeaderCell>\n <Table.HeaderCell>Last Name</Table.HeaderCell>\n <Table.HeaderCell>Age</Table.HeaderCell>\n <Table.HeaderCell>Email</Table.HeaderCell>\n <Table.HeaderCell>Income</Table.HeaderCell>\n <Table.HeaderCell>Action</Table.HeaderCell>\n\n </Table.Row>\n </Table.Header>\n\n <Table.Body>\n {this.props.persons.map(person => (\n\n\n <Table.Row key={person.id}>\n <Table.Cell>{person.id}</Table.Cell>\n <Table.Cell>{person.First_name}</Table.Cell>\n <Table.Cell>{person.Last_name}</Table.Cell>\n <Table.Cell>{person.Age}</Table.Cell>\n <Table.Cell>{person.Email}</Table.Cell>\n <Table.Cell>{person.Income}</Table.Cell>\n <Table.Cell>\n <Button.Group basic size='small'>\n <Button icon='delete' onClick={this.props.deletePerson.bind(this, person.id)} />\n </Button.Group>\n </Table.Cell>\n\n\n </Table.Row>\n\n ))}\n\n\n\n </Table.Body>\n </Table>\n </div>\n </>\n )\n }\n}\n\nconst mapStateToProps = state => ({\n persons: state.personReducer.persons\n})\n\nexport default connect(mapStateToProps, { getPersons, deletePerson })(PersonList); \n"
},
{
"alpha_fraction": 0.4398766756057739,
"alphanum_fraction": 0.4409044086933136,
"avg_line_length": 19.27083396911621,
"blob_id": "e38439ad8ae3833c9baf239641e3875b13951998",
"content_id": "1b483753f44c0ceb46758a37618f410439bc4815",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 973,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 48,
"path": "/frontend/src/Components/Person.js",
"repo_name": "offshoreproj-Ghana/Offshore-Ghana2",
"src_encoding": "UTF-8",
"text": "import React, { Fragment } from 'react'\nimport { Container, Grid } from 'semantic-ui-react';\nimport '../styles/PersonForm.css';\nimport Footer from './layouts/Footer';\nimport FormCard from './layouts/FormCard';\nimport PersonList from './layouts/PersonList';\n\nfunction Person() {\n return (\n <Fragment>\n <Container fluid >\n\n <div className=\"top-header\">\n\n </div>\n\n <Grid divided='vertically' doubling stackable>\n <Grid.Row columns={2}>\n <Grid.Column>\n <FormCard />\n\n </Grid.Column>\n\n {/* TABLE LIST */}\n\n\n <Grid.Column>\n\n <PersonList />\n\n </Grid.Column>\n\n\n </Grid.Row>\n\n </Grid>\n\n <Footer />\n\n\n\n </Container>\n </Fragment>\n\n )\n}\n\nexport default Person\n"
},
{
"alpha_fraction": 0.746835470199585,
"alphanum_fraction": 0.746835470199585,
"avg_line_length": 25.66666603088379,
"blob_id": "41a8a13b7bc03192d2afb21c428cf42b72a910d4",
"content_id": "0e9b33fcf370783b5acfd58f81babb491954a5c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 79,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 3,
"path": "/frontend/src/index.js",
"repo_name": "offshoreproj-Ghana/Offshore-Ghana2",
"src_encoding": "UTF-8",
"text": "import App from './Components/App';\n\nimport 'semantic-ui-css/semantic.min.css';"
},
{
"alpha_fraction": 0.7235022783279419,
"alphanum_fraction": 0.735023021697998,
"avg_line_length": 15.037036895751953,
"blob_id": "9959bfb730056e93005d3b50f969858612f9d388",
"content_id": "27a56fabe7c602ea4908c4aa85c065dbf9489213",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 434,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 27,
"path": "/README.md",
"repo_name": "offshoreproj-Ghana/Offshore-Ghana2",
"src_encoding": "UTF-8",
"text": "# Offshore-Ghana2\n\nOffshore-Ghana is a test project for the offshore team based in Ghana. Development is still going on, \n\n\n## Installation\n\ncd into frontend folder and run\n```bash\nnpm install\n\n```\nIn root folder run to install django and djangorestframework\n```bash\npipenv install django djangorestframework\n```\n\n## Serve API on localhost:8000\n\n```\npython manage.py runserver\n```\n\n## Run webpack (from frontend)\n```\nnpm run dev\n```\n\n"
}
] | 12 |
anzy03/Air-Hockey-using-Color-Recognition
|
https://github.com/anzy03/Air-Hockey-using-Color-Recognition
|
b75a90069803742ec8818508a06a46ffdc4ec731
|
68d952e2528c676031c46f674e6c1383c032fe4a
|
21bb4d29f25e2c82a1f90efcd0527d527996d377
|
refs/heads/master
| 2020-05-05T02:01:55.998793 | 2019-10-21T21:26:10 | 2019-10-21T21:26:10 | 179,622,140 | 0 | 2 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5783059000968933,
"alphanum_fraction": 0.6410725116729736,
"avg_line_length": 25.047618865966797,
"blob_id": "1869c52623ab903d01595e715da55108c16f1a28",
"content_id": "82a1a7bbfa83d3e7870019c2776a540cff460ad4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1641,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 63,
"path": "/colorrec.py",
"repo_name": "anzy03/Air-Hockey-using-Color-Recognition",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport cv2\nimport keyboard\nimport pyautogui\n\ndef keykey(center):\n\tx = int(center[0])\n\ty = int(center[1])\n\tif(x>200 and x<400 and y<200):\n\t\tkeyboard.press_and_release('w')\n\telif(x<200 and y>200 and y<400):\n\t\tkeyboard.press_and_release('a')\n\telif(x>200 and x<400 and y>200):\n\t\tkeyboard.press_and_release('s')\n\telif(x>400 and y>200 and y<400):\n\t\tkeyboard.press_and_release('d')\n\n\t\n\ncam = cv2.VideoCapture(0)\ncam.set(cv2.CAP_PROP_FRAME_WIDTH,3840)\ncam.set(cv2.CAP_PROP_FRAME_HEIGHT,2160)\nwhile True:\n ret,img = cam.read()\n\n\n # red color boundaries (BGR) just rearrange rgb\n upper = [173, 164, 255]\n lower = [37, 21, 186]\n\n # create NumPy arrays from the boundaries\n lower = np.array(lower, dtype=\"uint8\")\n upper = np.array(upper, dtype=\"uint8\")\n\n# find the colors within the specified boundaries and apply\n# the mask\n mask = cv2.inRange(img, lower, upper)\n output = cv2.bitwise_and(img, img, mask=mask)\n\n ret,thresh = cv2.threshold(mask, 40, 255, 0)\n contours,hierarchy = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)\n\n\n if len(contours) != 0:\n # draw in blue the contours that were founded\n cv2.drawContours(output, contours, -1, 255, 3)\n\n #find the biggest area\n c = max(contours, key = cv2.contourArea)\n\n x,y,w,h = cv2.boundingRect(c)\n center = (x,y)\n print(center)\n #pyautogui.moveTo(center)\n # draw the book contour (in green)\n cv2.rectangle(output,(x,y),(x+w,y+h),(0,255,0),2)\n\n# show the imgs\n cv2.imshow(\"Result\", np.hstack([output]))\n\n k = cv2.waitKey(33)\n if k==27:\n break\n"
},
{
"alpha_fraction": 0.6578699350357056,
"alphanum_fraction": 0.6578699350357056,
"avg_line_length": 28.47222137451172,
"blob_id": "a022f8a8bbd6a04b5f3d8570cc7b7c1b193f3623",
"content_id": "1f4ee0543c03117f4c6ef11b476dd3c98cc42d64",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 1063,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 36,
"path": "/Assets/Scripts/pythonCord.cs",
"repo_name": "anzy03/Air-Hockey-using-Color-Recognition",
"src_encoding": "UTF-8",
"text": "using System.Collections;\nusing System.Collections.Generic;\nusing UnityEngine;\n\npublic class pythonCord : MonoBehaviour\n{\n // Start is called before the first frame update\n System.Diagnostics.Process process = new System.Diagnostics.Process();\n System.Diagnostics.ProcessStartInfo startInfo = new System.Diagnostics.ProcessStartInfo();\n void Start()\n {\n //var p = new System.Diagnostics.Process();\n \n startInfo.WindowStyle = System.Diagnostics.ProcessWindowStyle.Hidden;\n startInfo.FileName = \"cmd.exe\";\n startInfo.Arguments = \"/c python \" + @\"colorrec.py\";\n process.StartInfo = startInfo;\n //showed error about this.\n process.StartInfo.UseShellExecute = false;\n process.StartInfo.RedirectStandardOutput = true;\n process.Start();\n \n // Debug.Log(process.StandardOutput.ReadToEnd());\n }\n\n // Update is called once per frame\n void Update()\n {\n Debug.Log(process.StandardOutput.ReadToEnd());\n }\n\n /* async void Colorrec()\n {\n\n } */\n}\n"
},
{
"alpha_fraction": 0.6046660542488098,
"alphanum_fraction": 0.6168105006217957,
"avg_line_length": 30.290000915527344,
"blob_id": "0689e9372ee37f91e149b3eba22a8bbc9ac759a8",
"content_id": "44cbce7d044df2b749fbf780e0d083f483484a2d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 3131,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 100,
"path": "/Assets/Scripts/AI.cs",
"repo_name": "anzy03/Air-Hockey-using-Color-Recognition",
"src_encoding": "UTF-8",
"text": "using System.Collections;\nusing System.Collections.Generic;\nusing UnityEngine;\n\npublic class AI : MonoBehaviour\n{\n public BoxCollider2D detectDice;\n\n private Vector3 offset;\n private float minX, maxX, minY, maxY;\n private float playerRadius;\n public float moveSpeed = 1f;\n public GameObject dice;\n public float dashSpeed = 3f;\n private bool hitDice;\n\n Vector2 startPos;\n Rigidbody2D rb;\n\n\n // Start is called before the first frame update\n void Start()\n {\n rb = GetComponent<Rigidbody2D>();\n\n BoxCollider2D playerCollider = GetComponent<BoxCollider2D>();\n playerRadius = playerCollider.bounds.extents.x;\n\n // Getting Bottom Corner & Top Corner Of the Screen.\n float camDistance = Vector3.Distance(transform.position, Camera.main.transform.position);\n Vector2 bottomCorner = Camera.main.ViewportToWorldPoint(new Vector3(0, 0, camDistance));\n Vector2 topCorner = Camera.main.ViewportToWorldPoint(new Vector3(1, 1, camDistance));\n\n // Giving Contrains Accoring to the Screen Size.\n minX = bottomCorner.x + playerRadius + 0.2f;\n maxX = topCorner.x - playerRadius - 0.2f;\n //Bottom Half\n minY = 0;\n maxY = topCorner.y - playerRadius - 0.2f;\n\n startPos = transform.position;\n }\n\n // Update is called once per frame\n void Update()\n {\n\n if (GameObject.FindGameObjectWithTag(\"AICollider\").GetComponent<AIZone>().AiActive == true)//Gets bool from AI Zone Script.\n {\n if (dice.transform.position.y < transform.position.y && !hitDice)\n {\n //move towords the dice.\n transform.position = Vector2.MoveTowards(transform.position, dice.transform.position, moveSpeed * Time.deltaTime);\n }\n else\n {\n //move towords the goal.\n transform.position = Vector2.MoveTowards(transform.position, new Vector2(0, 4f), moveSpeed * Time.deltaTime);\n }\n\n }\n else\n {\n //Moves back to Start Position.\n transform.position = Vector2.MoveTowards(transform.position, startPos, moveSpeed * Time.deltaTime);\n }\n if (hitDice == true)\n {\n StartCoroutine(WaitTime(2f));\n }\n // Horizontal contraint\n if (transform.position.x < minX)\n transform.position = new Vector3(minX, transform.position.y);\n if (transform.position.x > maxX)\n transform.position = new Vector3(maxX, transform.position.y); \n\n // vertical contraint\n if (transform.position.y < minY)\n transform.position = new Vector3(transform.position.x, minY);\n if (transform.position.y > maxY)\n transform.position = new Vector3(transform.position.x, maxY); \n\n\n }\n\n private void OnCollisionEnter2D(Collision2D collision)\n {\n if (collision.gameObject.tag == \"Dice\")\n {\n hitDice = true;\n }\n }\n\n IEnumerator WaitTime(float time)\n {\n yield return new WaitForSeconds(time);\n hitDice = false;\n }\n\n}\n"
},
{
"alpha_fraction": 0.6244099736213684,
"alphanum_fraction": 0.641267716884613,
"avg_line_length": 35.17073059082031,
"blob_id": "220f5ac0f025b2bd547fa311fccb9e61389bc886",
"content_id": "892baca93a8a7e5ba4ba8686011cedcc1d5f3430",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 2968,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 82,
"path": "/Assets/Scripts/Player.cs",
"repo_name": "anzy03/Air-Hockey-using-Color-Recognition",
"src_encoding": "UTF-8",
"text": "using System.Collections;\nusing System.Collections.Generic;\nusing UnityEngine;\n\n[RequireComponent(typeof(BoxCollider2D))]\npublic class Player : MonoBehaviour\n{\n public float moveSpeed = 1;\n private float minX, maxX, minY, maxY;\n private float playerRadius;\n public bool player2;\n Rigidbody2D rb;\n public float dashSpeed = 3f;\n private Vector3 offset;\n Vector3 newPosition;\n float mousePositionX,mousePositionY;\n Vector3 paddlePosition;\n\n\n private void Start()\n {\n rb = GetComponent<Rigidbody2D>();\n CapsuleCollider2D playerCollider = GetComponent<CapsuleCollider2D>();\n //BoxCollider2D playerCollider = GetComponent<BoxCollider2D>();\n playerRadius = playerCollider.bounds.extents.x;\n\n // Getting Bottom Corner & Top Corner Of the Screen.\n float camDistance = Vector3.Distance(transform.position, Camera.main.transform.position);\n Vector2 bottomCorner = Camera.main.ViewportToWorldPoint(new Vector3(0, 0, camDistance));\n Vector2 topCorner = Camera.main.ViewportToWorldPoint(new Vector3(1, 1, camDistance));\n\n // Giving Contrains Accoring to the Screen Size.\n minX = bottomCorner.x + playerRadius + 0.2f;\n maxX = topCorner.x - playerRadius - 0.2f;\n if (!player2)\n { //Upper Half\n minY = bottomCorner.y + playerRadius + 0.2f;\n maxY = 0;\n }\n else\n { //Lower Half\n minY = 0;\n maxY = topCorner.y - playerRadius - 0.2f;\n }\n\n offset = gameObject.transform.position - Camera.main.ScreenToWorldPoint(new Vector3(Input.mousePosition.x, Input.mousePosition.y, 10.0f));\n }\n\n private void Update()\n {\n /* Player Movement */\n /* transform.Translate(Input.GetAxis (\"Horizontal\") * moveSpeed * Time.deltaTime,\n Input.GetAxis (\"Vertical\") * moveSpeed * Time.deltaTime,0f) ;*/\n\n mousePositionX = Input.mousePosition.x;\n mousePositionY = Input.mousePosition.y;\n \n\n newPosition = new Vector3(mousePositionX, mousePositionY , 10.0f);\n paddlePosition = Camera.main.ScreenToWorldPoint(newPosition) + offset;\n \n if(Time.timeScale == 1)\n {\n Vector2 moveLocation = new Vector2(-paddlePosition.x,paddlePosition.y);\n transform.position = Vector2.MoveTowards(transform.position,moveLocation,moveSpeed);\n }\n // Horizontal contraint\n if (transform.position.x < minX)\n transform.position = new Vector3(minX, transform.position.y);\n if (transform.position.x > maxX)\n transform.position = new Vector3(maxX, transform.position.y); \n\n // vertical contraint\n if (transform.position.y < minY)\n transform.position = new Vector3(transform.position.x , minY );\n if (transform.position.y > maxY)\n transform.position = new Vector3(transform.position.x, maxY); \n }\n\n \n \n}\n"
},
{
"alpha_fraction": 0.5473527312278748,
"alphanum_fraction": 0.5518270134925842,
"avg_line_length": 26.9375,
"blob_id": "409120a2859b935014ed6f3b76865fe42f5a1ba3",
"content_id": "f1ef9760bcbc54d1101f2c16d66654e8294df685",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 1343,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 48,
"path": "/Assets/Scripts/Goal.cs",
"repo_name": "anzy03/Air-Hockey-using-Color-Recognition",
"src_encoding": "UTF-8",
"text": "using System.Collections;\nusing System.Collections.Generic;\nusing UnityEngine;\nusing TMPro;\n\npublic class Goal : MonoBehaviour\n{\n public TextMeshProUGUI PointText;\n public TextMeshProUGUI pauseText;\n int redPoints;\n int bluePoints;\n GameObject Dice;\n private void OnTriggerEnter2D(Collider2D collision)\n {\n \n if(collision.gameObject.tag == \"Dice\")\n {\n Dice = collision.gameObject;\n Dice.SetActive(false);\n Dice.transform.position = new Vector2(0, 0);\n // WaitTime(5);\n Dice.SetActive(true);\n if(gameObject.name ==\"BlueGoal\")\n {\n bluePoints++;\n Debug.Log(\"BluePoint = \"+ bluePoints);\n PointText.SetText(bluePoints.ToString());\n pauseText.SetText(bluePoints.ToString());\n }\n if(gameObject.name ==\"RedGoal\")\n {\n redPoints++;\n Debug.Log(\"RedPoint = \"+ redPoints);\n PointText.SetText(redPoints.ToString());\n pauseText.SetText(redPoints.ToString());\n }\n\n }\n }\n\n IEnumerable WaitTime(float time)\n {\n Debug.Log(\"Wait Start\");\n yield return new WaitForSeconds(time);\n Dice.SetActive(true);\n Debug.Log(\"Wait Over\");\n }\n}\n"
},
{
"alpha_fraction": 0.6106590628623962,
"alphanum_fraction": 0.625711977481842,
"avg_line_length": 31.342105865478516,
"blob_id": "4193fc847bf54392e6b1520c430f89e257a3501a",
"content_id": "0627c1b22e8a134907a158100f20e28c0a43b650",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 2460,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 76,
"path": "/Assets/Scripts/Dice.cs",
"repo_name": "anzy03/Air-Hockey-using-Color-Recognition",
"src_encoding": "UTF-8",
"text": "using System.Collections;\nusing System.Collections.Generic;\nusing UnityEngine;\n\npublic class Dice : MonoBehaviour\n{\n float paddleHit = 3.5f;\n// float wallHit = 0.2f;\n// float diceDrag = 0.1f;\n float velocityMulti = 0.2f;\n float minVelocity = 3.5f;\n Vector2 lastRecordedVelocity;\n CircleCollider2D diceCollider;\n BoxCollider2D[] wallCollider;\n Rigidbody2D rb;\n\n // Start is called before the first frame update\n void Start()\n {\n rb = gameObject.GetComponent<Rigidbody2D>();\n diceCollider = gameObject.GetComponent<CircleCollider2D>();\n \n GameObject[] pWalls = GameObject.FindGameObjectsWithTag(\"Pwall\");\n wallCollider = new BoxCollider2D[pWalls.Length];\n for(int i =0;i<pWalls.Length;i++)\n {\n wallCollider[i] = pWalls[i].GetComponent<BoxCollider2D>();\n Physics2D.IgnoreCollision(diceCollider,wallCollider[i],true);\n }\n\n }\n\n // Update is called once per frame\n void Update()\n {\n\n lastRecordedVelocity = rb.velocity;\n\n\n }\n\n private void OnCollisionEnter2D(Collision2D col)\n {\n if (col.gameObject.tag == \"paddle\")\n {\n Vector2 transformVector = transform.position - col.transform.position;\n Vector2 paddleVelocity = velocityMulti * col.relativeVelocity;\n float movingVelocity = col.gameObject.GetComponent<Player>().dashSpeed;\n minVelocity += movingVelocity;\n paddleHit = minVelocity;\n paddleHit = Mathf.Clamp(paddleHit, 0.1f, 3.0f);\n rb.velocity = (transformVector + paddleVelocity) * paddleHit;\n }\n\n if (col.gameObject.tag == \"AIpaddle\")\n {\n Vector2 transformVector = transform.position - col.transform.position;\n Vector2 paddleVelocity = velocityMulti * col.relativeVelocity;\n float movingVelocity = col.gameObject.GetComponent<AI>().dashSpeed;\n minVelocity += movingVelocity;\n paddleHit = minVelocity;\n paddleHit = Mathf.Clamp(paddleHit, 0.1f, 3.0f);\n rb.velocity = (transformVector + paddleVelocity) * paddleHit;\n }\n\n if (col.gameObject.tag == \"Vwall\")\n {\n\n Vector2 reflect = Vector2.Reflect(lastRecordedVelocity, col.contacts[0].normal);\n\n //rb.velocity = reflect.normalized * paddleHit;\n rb.velocity = reflect;\n }\n // Debug.Log(col.gameObject.tag);\n }\n}\n"
},
{
"alpha_fraction": 0.560693621635437,
"alphanum_fraction": 0.5682525634765625,
"avg_line_length": 26.765432357788086,
"blob_id": "2b3127ebfd9129418e690547d73abe097f9984f5",
"content_id": "7374149f05bb5e4670456667f843d90f81494b2f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 2251,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 81,
"path": "/Assets/Scripts/SceanChanger.cs",
"repo_name": "anzy03/Air-Hockey-using-Color-Recognition",
"src_encoding": "UTF-8",
"text": "using System.Collections;\nusing System.Collections.Generic;\nusing UnityEngine;\nusing UnityEngine.SceneManagement;\nusing UnityEngine.UI;\n\npublic class SceanChanger : MonoBehaviour\n{\n public GameObject pauseCanvas;\n public GameObject gameCanvas;\n Scene currentScene;\n int sceneBuildIndex;\n\n // Start is called before the first frame update\n void Start()\n {\n int width = 1080; \n int height= 1920; \n bool isFullScreen = false; // should be windowed to run in arbitrary resolution\n Screen.SetResolution (width , height, isFullScreen );\n currentScene = SceneManager.GetActiveScene();\n sceneBuildIndex = currentScene.buildIndex;\n\n Cursor.visible = false;\n }\n\n // Update is called once per frame\n void Update()\n {\n /* currentScene = SceneManager.GetActiveScene();\n sceneBuildIndex = currentScene.buildIndex; */\n if(sceneBuildIndex == 1)\n {\n if(Input.GetKeyDown(KeyCode.Escape) && pauseCanvas.activeSelf == false )\n {\n Time.timeScale = 0;\n pauseCanvas.SetActive(true);\n gameCanvas.SetActive(false);\n }\n else if(Input.GetKeyDown(KeyCode.Escape) && pauseCanvas.activeSelf == true )\n {\n PauseExitButton();\n }\n else if(Input.GetKeyDown(KeyCode.Return) && pauseCanvas.activeSelf == true )\n {\n ResumeButton();\n }\n }\n else if(sceneBuildIndex == 0)\n {\n if(Input.GetKeyDown(KeyCode.Return) && sceneBuildIndex == 0)\n {\n StartButton();\n }\n\n if(Input.GetKeyDown(KeyCode.Escape) && sceneBuildIndex == 0)\n {\n Application.Quit();\n }\n }\n \n }\n \n public void ResumeButton()\n {\n Time.timeScale = 1;\n pauseCanvas.SetActive(false);\n gameCanvas.SetActive(true);\n }\n public void PauseExitButton()\n {\n Time.timeScale = 1;\n pauseCanvas.SetActive(false);\n gameCanvas.SetActive(true);\n SceneManager.LoadScene(0);\n }\n public void StartButton()\n {\n SceneManager.LoadScene(1);\n }\n}\n"
},
{
"alpha_fraction": 0.7319316864013672,
"alphanum_fraction": 0.737187922000885,
"avg_line_length": 30.66666603088379,
"blob_id": "4a67d1d66f20bb6552738452e01211c6dcb27574",
"content_id": "f457e5a1a6b52ed399c14893dfc003212c33131c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 761,
"license_type": "no_license",
"max_line_length": 205,
"num_lines": 24,
"path": "/README.md",
"repo_name": "anzy03/Air-Hockey-using-Color-Recognition",
"src_encoding": "UTF-8",
"text": "# Air-Hockey-using-Color-Recognition\nThis is a 2D Air Hockey game where the contorl of the player is handled by color recognition using Python based OpenCV. The opponent is controlled by A.I which will prevent the dice from reaching the goal.\n\n### Programs Used\n- OpenCV (Python)\n- Unity3D\n- Photoshop cc\n\n### Installation & Running\n\n1. Install OpenCV for Python using `pip install opencv-python` make sure pip is upto date.\n\n2. Run the `app.py`file in the `builds` folder.\n\n### Screenshots\n\n- **Main Menu**\n\n\n- **Play Screen**\n\n\n- **Color Recognition Screen**\n\n\n"
}
] | 8 |
bill0119/python
|
https://github.com/bill0119/python
|
4f3331230f0e91b7e1d537413d815dd666e6672b
|
fc3ad2a696d5103e5ec90c86c64306a211200d75
|
112e8a4ab22dd7f6642ebb26aef5bfd748e068d9
|
refs/heads/master
| 2019-05-25T02:00:43.223023 | 2017-03-15T07:26:33 | 2017-03-15T07:26:33 | 85,041,863 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.42134830355644226,
"alphanum_fraction": 0.5112359523773193,
"avg_line_length": 11.84615421295166,
"blob_id": "78f1c8d43eca081e2ea30444bbdad5c79b0a31e2",
"content_id": "386f0e89e4bd0ca067cef3d8b84a70e3174037c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 178,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 13,
"path": "/test.py",
"repo_name": "bill0119/python",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Wed Mar 15 15:25:35 2017\r\n\r\n@author: BILL.C.LI\r\n\"\"\"\r\n\r\nfor i in range(1, 10) :\r\n print(i)\r\n ++i\r\n \r\nimport os\r\nprint(os.times())"
}
] | 1 |
tro9lh/simpleFlaskApi
|
https://github.com/tro9lh/simpleFlaskApi
|
d57b4530943170d02112c9d9ccd3943da0438f25
|
a362e6a1d3f76bd6fb147d2309013e1515022b7e
|
9cb23b141cc7e243ee06a092a86d751ddbc8f298
|
refs/heads/master
| 2020-04-02T17:20:32.338840 | 2018-10-25T11:02:41 | 2018-10-25T11:02:41 | 154,653,869 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.484437495470047,
"alphanum_fraction": 0.5117371082305908,
"avg_line_length": 39.07857131958008,
"blob_id": "ef6e0b3175e02d7ecdbc3f17a14d945faf9c64b7",
"content_id": "166f36f80ca16346302c254cda6a83a878abc03d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6255,
"license_type": "no_license",
"max_line_length": 218,
"num_lines": 140,
"path": "/strongApp.py",
"repo_name": "tro9lh/simpleFlaskApi",
"src_encoding": "UTF-8",
"text": "from flask import request, url_for\r\nfrom flask_api import FlaskAPI, status, exceptions\r\nfrom datetime import datetime\r\nfrom copy import deepcopy\r\n\r\n\r\napp = FlaskAPI(__name__)\r\n\r\nhash_sums = ('8dfe7942aeb0d65782d76726e960baff', # admin:1337Aa\r\n '899419e103e065a5ca934b9576437f44', # admin:1337Ab\r\n 'ffde69ede2c393fb5a120cd277c25e16') # admin:1337Ac\r\nnotes = {\r\n 0: { # меню\r\n 'gam': 12, # актуальная цена за единицу товара\r\n 'cola': 8,\r\n 'cheez': 13\r\n },\r\n 1: 'build the codez',\r\n 2: 'paint the door',\r\n 3: {'gam':# позиция в меню\r\n {\r\n 'count': 3,# количество в заказе\r\n 'price': 3, # цена за единицу на момент заказа\r\n 'total_cost': 'здесь будет здесь будет стоимость позиции' # произведение количества на цену\r\n },\r\n 'cola':\r\n {\r\n 'count': 3,\r\n 'price': 3,\r\n 'total_cost': 'здесь будет здесь будет стоимость позиции'\r\n },\r\n 'cheez': # позиция в меню\r\n {\r\n 'count': 3,\r\n 'price': 3,\r\n 'total_cost': 'здесь будет здесь будет стоимость позиции'\r\n },\r\n 'datatime': 'здесь будет дата и время заказа',\r\n 'total_cost': 'здесь будет общая стоимость',\r\n 'restaurant': 2, # номер ресторана\r\n 'operator': 5, #номер оператора в ресторане\r\n 'status': 1 # 1 - оплачен и действителен, 0 отменен\r\n }\r\n\r\n\r\n}\r\n\r\ndef note_repr(key):\r\n return {\r\n 'url': request.host_url.rstrip('/') + url_for('notes_detail', key=key),\r\n 'order': notes[key]\r\n }\r\n\r\ndef menu_repr():\r\n return\r\n\r\[email protected](\"/\", methods=['GET', 'POST', 'PUT'])\r\ndef notes_list():\r\n\r\n if request.method == 'POST': # при POST запросе необходимо передать строку, в которой через пробел будут указаны числовые передаваемые параметры и токен кассы : \"text\":\"1 2 3 4 5 6 ffde69ede2c393fb5a120cd277c25e16\"\r\n note = str(request.data.get('text',''))\r\n args_list = note.split(' ')\r\n if args_list[6] in hash_sums:\r\n idx = max(notes.keys()) + 1\r\n notes[idx] = deepcopy(notes[3])\r\n notes[idx]['gam']['count'] = int(args_list[0])\r\n notes[idx]['cola']['count'] = int(args_list[1])\r\n notes[idx]['cheez']['count'] = int(args_list[2])\r\n notes[idx]['gam']['price'] = notes[0]['gam']\r\n notes[idx]['cola']['price'] = notes[0]['cola']\r\n notes[idx]['cheez']['price'] = notes[0]['cheez']\r\n notes[idx]['gam']['total_cost'] = (notes[idx]['gam']['count']) * (notes[idx]['gam']['price'])\r\n notes[idx]['cola']['total_cost'] = (notes[idx]['cola']['count']) * (notes[idx]['cola']['price'])\r\n notes[idx]['cheez']['total_cost'] = (notes[idx]['cheez']['count']) * (notes[idx]['cheez']['price'])\r\n notes[idx]['datatime'] = str(datetime.now().strftime(\"%Y-%m-%d %H:%M:%S\"))\r\n notes[idx]['total_cost'] = (notes[idx]['gam']['total_cost']) + (notes[idx]['cola']['total_cost']) + (notes[idx]['cheez']['total_cost'])\r\n notes[idx]['restaurant'] = int(args_list[3])\r\n notes[idx]['operator'] = int(args_list[4])\r\n notes[idx]['status'] = int(args_list[5])\r\n\r\n\r\n return note_repr(idx), status.HTTP_201_CREATED\r\n else:\r\n return status.HTTP_403_FORBIDDEN\r\n\r\n\r\n elif request.method == 'PUT': # при выполнении метода PUT выполняется изменение цен в меню\r\n note = str(request.data.get('text',''))\r\n args_list = note.split(' ')\r\n notes[0]['gam'] = int(args_list[0])\r\n notes[0]['cola'] = int(args_list[1])\r\n notes[0]['cheez'] = int(args_list[2])\r\n return notes[0]\r\n\r\n # request.method == 'GET'\r\n return [note_repr(idx) for idx in sorted(notes.keys())]\r\n\r\n\r\n\r\[email protected](\"/<int:key>/\", methods=['GET', 'PUT', 'DELETE'])\r\ndef notes_detail(key):\r\n\r\n if request.method == 'PUT':\r\n \r\n note = str(request.data.get('text',''))\r\n args_list = note.split(' ')\r\n if args_list[6] in hash_sums:\r\n idx = key\r\n notes[idx]['gam']['count'] = int(args_list[0])\r\n notes[idx]['cola']['count'] = int(args_list[1])\r\n notes[idx]['cheez']['count'] = int(args_list[2])\r\n notes[idx]['gam']['price'] = notes[0]['gam']\r\n notes[idx]['cola']['price'] = notes[0]['cola']\r\n notes[idx]['cheez']['price'] = notes[0]['cheez']\r\n notes[idx]['gam']['total_cost'] = (notes[idx]['gam']['count']) * (notes[idx]['gam']['price'])\r\n notes[idx]['cola']['total_cost'] = (notes[idx]['cola']['count']) * (notes[idx]['cola']['price'])\r\n notes[idx]['cheez']['total_cost'] = (notes[idx]['cheez']['count']) * (notes[idx]['cheez']['price'])\r\n notes[idx]['datatime'] = str(datetime.now().strftime(\"%Y-%m-%d %H:%M:%S\"))\r\n notes[idx]['total_cost'] = (notes[idx]['gam']['total_cost']) + (notes[idx]['cola']['total_cost']) + (notes[idx]['cheez']['total_cost'])\r\n notes[idx]['restaurant'] = int(args_list[3])\r\n notes[idx]['operator'] = int(args_list[4])\r\n notes[idx]['status'] = int(args_list[5])\r\n\r\n\r\n return note_repr(idx)\r\n else:\r\n return status.HTTP_403_FORBIDDEN\r\n elif request.method == 'DELETE':\r\n notes.pop(key, None)\r\n return '', status.HTTP_204_NO_CONTENT\r\n\r\n # request.method == 'GET'\r\n if key not in notes:\r\n raise exceptions.NotFound()\r\n return note_repr(key)\r\n\r\n\r\n\r\nif __name__ == \"__main__\":\r\n app.run(debug=True)\r\n"
}
] | 1 |
ABHISHEK1105DS/Projects
|
https://github.com/ABHISHEK1105DS/Projects
|
8405df4edd86708f841374e593a8f8379f7b9763
|
01853fb2ae286a30069604fe0f835c2351682b8d
|
15f9f3465189be1da9798557b04d188724fcaaab
|
refs/heads/master
| 2021-06-25T23:20:21.720757 | 2021-02-22T18:16:49 | 2021-02-22T18:16:49 | 203,061,879 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6617871522903442,
"alphanum_fraction": 0.676934003829956,
"avg_line_length": 19.442827224731445,
"blob_id": "71dd2759fda0d78aab7b125d07932850c4fad198",
"content_id": "52514101c1934ea2062d1dcef3eafef5944b219c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9837,
"license_type": "no_license",
"max_line_length": 426,
"num_lines": 481,
"path": "/tweets-sentiment-analysis/tweets-sentiment-analysis.py",
"repo_name": "ABHISHEK1105DS/Projects",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# In[7]:\n\n\nimport numpy as np\nimport pandas as pd\n\n# This is for making some large tweets to be displayed\npd.options.display.max_colwidth = 100\n\n\n# In[12]:\n\n\ntrain_data= pd.read_csv(r'D:\\ml\\tweets-sentiment-analysis/train.csv',encoding='ISO-8859-1')\n\n\n# In[13]:\n\n\ntrain_data\n\n\n# In[14]:\n\n\n# We will now take a look at random tweets to gain more insights\nrand_indexs = np.random.randint(1,len(train_data),50).tolist()\n\n\n# In[18]:\n\n\ntrain_data[\"SentimentText\"][rand_indexs]\n\n\n# In[ ]:\n\n\n\"\"\"\nYou will not have the same results at each execution because of the randomization. For me, after some execution, I noticed this:\n\nThere is tweets with a url (like tweet 35546): we must think about a way to handle URLs, I thought about deleting them because a domain name or the protocol used will not make someone happy or sad unless the domain name is 'food.com'.\nThe use of hashtags: we should keep only the words without '#' so words like python and the hashtag '#python' can be seen as the same word, and of course they are.\nWords like 'as', 'to' and 'so' should be deleted, because they only serve as a way to link phrases and words\n\n\"\"\"\n\n\n# In[19]:\n\n\n# emoticons=>make sure anlaysis to classify emoticon as happy and sad\n\n\n# In[22]:\n\n\nimport re\ntweets_text = train_data.SentimentText.str.cat()\n\n\n# In[24]:\n\n\nemos = set(re.findall(r\" ([xX:;][-']?.) \",tweets_text))\nemos_count = []\n\n\n# In[25]:\n\n\nemos\n\n\n# In[26]:\n\n\nfor emo in emos:\n emos_count.append((tweets_text.count(emo), emo))\nsorted(emos_count,reverse=True)\n\n\n# In[27]:\n\n\nHAPPY_EMO = r\" ([xX;:]-?[dD)]|:-?[\\)]|[;:][pP]) \"\nSAD_EMO = r\" (:'?[/|\\(]) \"\nprint(\"Happy emoticons:\", set(re.findall(HAPPY_EMO, tweets_text)))\nprint(\"Sad emoticons:\", set(re.findall(SAD_EMO, tweets_text)))\n\n\n# In[ ]:\n\n\n# Most used words \n# (What we are going to do next is to define a function that will show us top words, so we may fix things before running our learning algorithm. This function takes as input a text and output words sorted according to their frequency, starting with the most used word.)\n\n\n# In[28]:\n\n\nimport nltk\nfrom nltk.tokenize import word_tokenize\n\n\n# In[29]:\n\n\ndef most_used_words(text):\n tokens = word_tokenize(text)\n frequency_dist = nltk.FreqDist(tokens)\n print(\"There is %d different words\" % len(set(tokens)))\n return sorted(frequency_dist,key=frequency_dist.__getitem__, reverse=True)\n\n\n# In[30]:\n\n\nmost_used_words(train_data.SentimentText.str.cat())[:100]\n\n\n# In[31]:\n\n\n# Stop words\n# (What we can see is that stop words are the most used, but in fact they don't help us determine if a tweet is happy/sad, however, they are consuming memory and they are making the learning process slower, so we really need to get rid of them.)\n\n\n# In[32]:\n\n\nfrom nltk.corpus import stopwords\n\n\n# In[33]:\n\n\nmw = most_used_words(train_data.SentimentText.str.cat())\nmost_words = []\n\n\n# In[34]:\n\n\nfor w in mw:\n if len(most_words) == 1000:\n break\n if w in stopwords.words(\"english\"):\n continue\n else:\n most_words.append(w)\n\n\n# In[35]:\n\n\nsorted(most_words)\n\n\n# In[ ]:\n\n\n# Stemming\n# ( You should have noticed something, right? There are words that have the same meaning, but written in a different manner, sometimes in the plural and sometimes with a suffix (ing, es ...), this will make our model think that they are different words and also make our vocabulary bigger (waste of memory and time for the learning process). The solution is to reduce those words with the same root, this is called stemming. )\n\n\n# In[36]:\n\n\nfrom nltk.stem.snowball import SnowballStemmer\nfrom nltk.stem import WordNetLemmatizer\n\n\n# In[37]:\n\n\ndef stem_tokenize(text):\n stemmer = SnowballStemmer(\"english\")\n stemmer = WordNetLemmatizer()\n return [stemmer.lemmatize(token) for token in word_tokenize(text)]\n\n\n# In[38]:\n\n\ndef lemmatize_tokenize(text):\n lemmatizer = WordNetLemmatizer()\n return [lemmatizer.lemmatize(token) for token in word_tokenize(text)]\n\n\n# In[ ]:\n\n\n# Prepare the data\n# (Bag of Words)\n# We are going to use the Bag of Words algorithm, which basically takes a text as input, extract words from it (this is our vocabulary) to use them in the vectorization process. When a tweet comes in, it will vectorize it by counting the number of occurrences of each word in our vocabulary.)\n\n\n# In[39]:\n\n\nfrom sklearn.feature_extraction.text import TfidfVectorizer\n\n\n# In[ ]:\n\n\n# Building the pipeline\n# It's always a good practice to make a pipeline of transformation for your data, it will make the process of data transformation really easy and reusable. We will implement a pipeline for transforming our tweets to something that our ML models can digest (vectors).\n\n\n# In[40]:\n\n\nfrom sklearn.base import TransformerMixin, BaseEstimator\nfrom sklearn.pipeline import Pipeline\n\n\n# In[41]:\n\n\n# We need to do some preprocessing of the tweets.\n# We will delete useless strings (like @, # ...)\n\n\n# In[42]:\n\n\nclass TextPreProc(BaseEstimator,TransformerMixin):\n def __init__(self, use_mention=False):\n self.use_mention = use_mention\n \n def fit(self, X, y=None):\n return self\n \n def transform(self, X, y=None):\n # We can choose between keeping the mentions\n # or deleting them\n if self.use_mention:\n X = X.str.replace(r\"@[a-zA-Z0-9_]* \", \" @tags \")\n else:\n X = X.str.replace(r\"@[a-zA-Z0-9_]* \", \"\")\n \n # Keeping only the word after the #\n X = X.str.replace(\"#\", \"\")\n X = X.str.replace(r\"[-\\.\\n]\", \"\")\n # Removing HTML garbage\n X = X.str.replace(r\"&\\w+;\", \"\")\n # Removing links\n X = X.str.replace(r\"https?://\\S*\", \"\")\n # replace repeated letters with only two occurences\n # heeeelllloooo => heelloo\n X = X.str.replace(r\"(.)\\1+\", r\"\\1\\1\")\n # mark emoticons as happy or sad\n X = X.str.replace(HAPPY_EMO, \" happyemoticons \")\n X = X.str.replace(SAD_EMO, \" sademoticons \")\n X = X.str.lower()\n return X\n\n\n# In[43]:\n\n\n# This is the pipeline that will transform our tweets to something eatable.\n# You can see that we are using our previously defined stemmer, it will\n# take care of the stemming process.\n# For stop words, we let the inverse document frequency do the job\nfrom sklearn.model_selection import train_test_split\n\nsentiments = train_data['Sentiment']\ntweets = train_data['SentimentText']\n\n\n# In[44]:\n\n\nvectorizer = TfidfVectorizer(tokenizer=lemmatize_tokenize, ngram_range=(1,2))\npipeline = Pipeline([\n ('text_pre_processing', TextPreProc(use_mention=True)),\n ('vectorizer', vectorizer),\n])\n\n# Let's split our data into learning set and testing set\n# This process is done to test the efficency of our model at the end.\n# You shouldn't look at the test data only after choosing the final model\nlearn_data, test_data, sentiments_learning, sentiments_test = train_test_split(tweets, sentiments, test_size=0.3)\n\n# This will tranform our learning data from simple text to vector\n# by going through the preprocessing tranformer.\nlearning_data = pipeline.fit_transform(learn_data)\n\n\n# In[45]:\n\n\n# Select a model\n\n\n# In[47]:\n\n\nfrom sklearn.model_selection import cross_val_score\nfrom sklearn.metrics import accuracy_score\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.naive_bayes import BernoulliNB, MultinomialNB\n\nlr = LogisticRegression()\nbnb = BernoulliNB()\nmnb = MultinomialNB()\n\nmodels = {\n 'logitic regression': lr,\n 'bernoulliNB': bnb,\n 'multinomialNB': mnb,\n}\n\n\n# In[48]:\n\n\nfor model in models.keys():\n scores = cross_val_score(models[model], learning_data, sentiments_learning, scoring=\"f1\", cv=10)\n print(\"===\", model, \"===\")\n print(\"scores = \", scores)\n print(\"mean = \", scores.mean())\n print(\"variance = \", scores.var())\n models[model].fit(learning_data, sentiments_learning)\n print(\"score on the learning data (accuracy) = \", accuracy_score(models[model].predict(learning_data), sentiments_learning))\n print(\"\")\n\n\n# In[49]:\n\n\n# GridSearchCV to choose the best parameters to use.\n\n\n# In[50]:\n\n\n# what the GridSearchCV does is trying different set of parameters, and for each one, it runs a cross validation and estimate the score. At the end we can see what are the best parameter and use them to build a better classifier.\n\n\n# In[51]:\n\n\nfrom sklearn.model_selection import GridSearchCV\n\ngrid_search_pipeline = Pipeline([\n ('text_pre_processing', TextPreProc()),\n ('vectorizer', TfidfVectorizer()),\n ('model', MultinomialNB()),\n])\n\n\n# In[52]:\n\n\nparams = [\n {\n 'text_pre_processing__use_mention': [True, False],\n 'vectorizer__max_features': [1000, 2000, 5000, 10000, 20000, None],\n 'vectorizer__ngram_range': [(1,1), (1,2)],\n },\n]\ngrid_search = GridSearchCV(grid_search_pipeline, params, cv=5, scoring='f1')\ngrid_search.fit(learn_data, sentiments_learning)\nprint(grid_search.best_params_)\n\n\n# In[53]:\n\n\nmnb.fit(learning_data, sentiments_learning)\n\n\n# In[54]:\n\n\ntesting_data = pipeline.transform(test_data)\nmnb.score(testing_data, sentiments_test)\n\n\n# In[56]:\n\n\nsub_data= pd.read_csv(r'D:\\ml\\tweets-sentiment-analysis/test.csv',encoding='ISO-8859-1')\nsub_learning = pipeline.transform(sub_data.SentimentText)\nsub = pd.DataFrame(sub_data.ItemID, columns=(\"ItemID\", \"Sentiment\"))\nsub[\"Sentiment\"] = mnb.predict(sub_learning)\nprint(sub)\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\nmodel = MultinomialNB()\nmodel.fit(learning_data, sentiments_learning)\ntweet = pd.Series([input(),])\ntweet = pipeline.transform(tweet)\nproba = model.predict_proba(tweet)[0]\nprint(\"The probability that this tweet is sad is:\", proba[0])\nprint(\"The probability that this tweet is happy is:\", proba[1])dsa\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n"
},
{
"alpha_fraction": 0.6542313694953918,
"alphanum_fraction": 0.6753416061401367,
"avg_line_length": 17.965394973754883,
"blob_id": "1b0d477fca029304d6272927fb92310bc643f7fa",
"content_id": "80e67b5fd389d2a50e971d1b05d2a281adcca6fa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 26859,
"license_type": "no_license",
"max_line_length": 632,
"num_lines": 1416,
"path": "/adult-census-income/census (1).py",
"repo_name": "ABHISHEK1105DS/Projects",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# In[1]:\n\n\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nimport statsmodels.api as sm\nimport statsmodels.formula.api as smf\nimport sklearn.metrics\nfrom sklearn import ensemble\nfrom scipy import stats as st \nfrom sklearn import linear_model,datasets\n\nfrom sklearn.metrics import mean_squared_error\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[2]:\n\n\ndata=pd.read_csv(r\"D:\\ml\\adult-census-income\\adult.csv\")\n\n\n# In[ ]:\n\n\n\n\n\n# In[3]:\n\n\ndata.isnull().sum()\n\n\n# In[4]:\n\n\n# Setting all the categorical columns to type category\nfor col in set(data.columns) - set(data.describe().columns):\n data[col] = data[col].astype('category')\n \nprint('## 1.1. Columns and their types')\nprint(data.info())\n\n\n# In[ ]:\n\n\n\n\n\n# In[5]:\n\n\ndata.head()\n\n\n# In[ ]:\n\n\n\n\n\n# In[7]:\n\n\ncorrmat = data.corr()\nfig,ax = plt.subplots(figsize = (12,9))\nsns.heatmap(corrmat, vmax=.8, square=True)\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[9]:\n\n\ndata.describe()\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[10]:\n\n\nprint('## 1.4. Missing values')\nfor i,j in zip(data.columns,(data.values.astype(str) == '?').sum(axis = 0)):\n if j > 0:\n print(str(i) + ': ' + str(j) + ' records')\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[11]:\n\n\n\"\"\"Treating Missing Values by predicting them\nI fill the missing values in each of the three columns by predicting their values. For each of the three columns, I use all the attributes (including 'income') as independent variables and treat that column as the dependent variable, making it a multi-class classification task. I use three classification algorithms, namely, logistic regression, decision trees and random forest to predict the class when the value is missing (in this case a '?'). I then take a majority vote amongst the three classifiers to be the class of the missing value. In case of a tie, I pick the majority class of that column using the entire dataset.\"\"\"\n\n\n# In[12]:\n\n\ndef oneHotCatVars(df, df_cols):\n \n df_1 = adult_data = df.drop(columns = df_cols, axis = 1)\n df_2 = pd.get_dummies(df[df_cols])\n \n return (pd.concat([df_1, df_2], axis=1, join='inner'))\n\n\n# In[ ]:\n\n\n\n\n\n# In[13]:\n\n\n\nprint('## 1.5. Correlation Matrix')\n\ndisplay(data.corr())\n\nprint('We see that none of the columns are highly correlated.')\nprint('### 1.4.1. Filling in missing values for Attribute workclass')\n\n\n# In[ ]:\n\n\n\n\n\n# In[14]:\n\n\ncorrmat = data.corr()\nfig,ax = plt.subplots(figsize = (12,9))\nsns.heatmap(corrmat, vmax=.8, square=True)\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[15]:\n\n\ntest_data = data[(data.workclass.values == '?')].copy()\ntest_label = test_data.workclass\n\n\n# In[ ]:\n\n\n\n\n\n# In[16]:\n\n\ntrain_data = data[(data.workclass.values != '?')].copy()\ntrain_label = train_data.workclass\n\n\n# In[17]:\n\n\ntest_data.drop(columns = ['workclass'], inplace = True)\n\n\n# In[18]:\n\n\ntrain_data.drop(columns = ['workclass'], inplace = True)\n\n\n# In[19]:\n\n\ntrain_data = oneHotCatVars(train_data, train_data.select_dtypes('category').columns)\n\n\n# In[20]:\n\n\ntest_data = oneHotCatVars(test_data, test_data.select_dtypes('category').columns)\n\n\n# In[ ]:\n\n\n\n\n\n# In[21]:\n\n\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn import tree\n\n\n# In[22]:\n\n\n\ntest_data = data[(data.workclass.values == '?')].copy()\ntest_label = test_data.workclass\n\ntrain_data = data[(data.workclass.values != '?')].copy()\ntrain_label = train_data.workclass\n\ntest_data.drop(columns = ['workclass'], inplace = True)\ntrain_data.drop(columns = ['workclass'], inplace = True)\n\ntrain_data = oneHotCatVars(train_data, train_data.select_dtypes('category').columns)\ntest_data = oneHotCatVars(test_data, test_data.select_dtypes('category').columns)\n\nlog_reg = LogisticRegression()\nlog_reg.fit(train_data, train_label)\nlog_reg_pred = log_reg.predict(test_data)\n\n\nclf = tree.DecisionTreeClassifier()\nclf = clf.fit(train_data, train_label)\nclf_pred = clf.predict(test_data)\n\nr_forest = RandomForestClassifier(n_estimators=10)\nr_forest.fit(train_data, train_label)\nr_forest_pred = r_forest.predict(test_data)\n\nmajority_class = data.workclass.value_counts().index[0]\n\npred_df = pd.DataFrame({'RFor': r_forest_pred, 'DTree' : clf_pred, 'LogReg' : log_reg_pred})\noverall_pred = pred_df.apply(lambda x: x.value_counts().index[0] if x.value_counts()[0] > 1 else majority_class, axis = 1)\n\ndata.loc[(data.workclass.values == '?'),'workclass'] = overall_pred.values\nprint(data.workclass.value_counts())\nprint(data.workclass.unique())\n\n\n# In[23]:\n\n\noverall_pred \n\n\n# In[24]:\n\n\nmajority_class \n\n\n# In[25]:\n\n\npred_df \n\n\n# In[26]:\n\n\nprint('### 1.4.2. Filling in missing values for Occupation occupation')\n\ntest_data = data[(data.occupation.values == '?')].copy()\ntest_label = test_data.occupation\n\ntrain_data = data[(data.occupation.values != '?')].copy()\ntrain_label = train_data.occupation\n\ntest_data.drop(columns = ['occupation'], inplace = True)\ntrain_data.drop(columns = ['occupation'], inplace = True)\n\ntrain_data = oneHotCatVars(train_data, train_data.select_dtypes('category').columns)\ntest_data = oneHotCatVars(test_data, test_data.select_dtypes('category').columns)\n\nlog_reg = LogisticRegression()\nlog_reg.fit(train_data, train_label)\nlog_reg_pred = log_reg.predict(test_data)\n\n\nclf = tree.DecisionTreeClassifier()\nclf = clf.fit(train_data, train_label)\nclf_pred = clf.predict(test_data)\n\nr_forest = RandomForestClassifier(n_estimators=10)\nr_forest.fit(train_data, train_label)\nr_forest_pred = r_forest.predict(test_data)\n\n\nmajority_class = data.occupation.value_counts().index[0]\n\npred_df = pd.DataFrame({'RFor': r_forest_pred, 'DTree' : clf_pred, 'LogReg' : log_reg_pred})\noverall_pred = pred_df.apply(lambda x: x.value_counts().index[0] if x.value_counts()[0] > 1 else majority_class, axis = 1)\n\ndata.loc[(data.occupation.values == '?'),'occupation'] = overall_pred.values\nprint(data.occupation.value_counts())\nprint(data.occupation.unique())\n\n\n# In[27]:\n\n\nprint('### 1.4.3. Filling in missing values for Native Country')\n\ntest_data = data[(data['native.country'].values == '?')].copy()\ntest_label = test_data['native.country']\n\ntrain_data = data[(data['native.country'].values != '?')].copy()\ntrain_label = train_data['native.country']\n\ntest_data.drop(columns = ['native.country'], inplace = True)\ntrain_data.drop(columns = ['native.country'], inplace = True)\n\ntrain_data = oneHotCatVars(train_data, train_data.select_dtypes('category').columns)\ntest_data = oneHotCatVars(test_data, test_data.select_dtypes('category').columns)\n\nlog_reg = LogisticRegression()\nlog_reg.fit(train_data, train_label)\nlog_reg_pred = log_reg.predict(test_data)\n\n\nclf = tree.DecisionTreeClassifier()\nclf = clf.fit(train_data, train_label)\nclf_pred = clf.predict(test_data)\n\nr_forest = RandomForestClassifier(n_estimators=10)\nr_forest.fit(train_data, train_label)\nr_forest_pred = r_forest.predict(test_data)\n\n\nmajority_class = data['native.country'].value_counts().index[0]\n\npred_df = pd.DataFrame({'RFor': r_forest_pred, 'DTree' : clf_pred, 'LogReg' : log_reg_pred})\noverall_pred = pred_df.apply(lambda x: x.value_counts().index[0] if x.value_counts()[0] > 1 else majority_class, axis = 1)\n\ndata.loc[(data['native.country'].values == '?'),'native.country'] = overall_pred.values\nprint(data['native.country'].value_counts())\nprint(data['native.country'].unique())\n\n\n# In[28]:\n\n\ndata.head()\n\n\n# In[29]:\n\n\nprint('## 1.5. Correlation Matrix')\n\ndisplay(data.corr())\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[30]:\n\n\n# Resetting the categories\n\ndata['workclass'] = data['workclass'].cat.remove_categories('?')\ndata['occupation'] = data['occupation'].cat.remove_categories('?')\ndata['native.country'] = data['native.country'].cat.remove_categories('?')\n\n\n# In[ ]:\n\n\n\n\n\n# In[31]:\n\n\ndata.head()\n\n\n# In[32]:\n\n\nprint('## 1.5. Correlation Matrix')\n\ndisplay(data.corr())\n\n\n# In[33]:\n\n\ncity_category = np.unique(data['education.num'])\ncity_category\n\n\n# In[34]:\n\n\ncity_category = np.unique(data['education'])\ncity_category\n\n\n# In[35]:\n\n\n# Creating a dictionary that contain the education and it's corresponding education level\nedu_level = {}\nfor x,y in data[['education.num','education']].drop_duplicates().itertuples(index=False):\n edu_level[y] = x\n\n\n# In[36]:\n\n\nprint('## 2.1. Education vs Income')\neducation = round(pd.crosstab(data.education, data.income).div(pd.crosstab(data.education, data.income).apply(sum,1),0),2)\neducation = education.reindex(sorted(edu_level, key=edu_level.get, reverse=False))\n\nax = education.plot(kind ='bar', title = 'Proportion distribution across education levels', figsize = (10,8))\nax.set_xlabel('Education level')\nax.set_ylabel('Proportion of population')\n\n\n# In[37]:\n\n\nprint('As the education increase income also increased')\n\n\n# In[38]:\n\n\ndata.head()\n\n\n# In[39]:\n\n\nprint('## 2.2 Sex vs Income')\n\ngender = round(pd.crosstab(data.sex, data.income).div(pd.crosstab(data.sex, data.income).apply(sum,1),0),2)\ngender.sort_values(by = '>50K', inplace = True)\nax = gender.plot(kind ='bar', title = 'Proportion distribution across gender levels')\nax.set_xlabel('Gender level')\nax.set_ylabel('Proportion of population')\n\n\n# In[40]:\n\n\nprint(\"from this we can infere that the there is wage gap between male and female but we dont know any fixed value \")\n\n\n# In[41]:\n\n\ngender_workclass = round(pd.crosstab(data.workclass, [data.income, data.sex]).div(pd.crosstab(data.workclass, [data.income, data.sex]).apply(sum,1),0),2)\ngender_workclass[[('>50K','Male'), ('>50K','Female')]].plot(kind = 'bar', title = 'Proportion distribution across gender for each workclass', figsize = (10,8), rot = 30)\nax.set_xlabel('Gender level')\nax.set_ylabel('Proportion of population')\n\n\n# In[42]:\n\n\nprint(\"varius distribution of money on different platform where money is greater than 50k\")\n\n\n# In[43]:\n\n\ngender_workclass = round(pd.crosstab(data.workclass, [data.income, data.sex]).div(pd.crosstab(data.workclass, [data.income, data.sex]).apply(sum,1),0),2)\ngender_workclass[[('<=50K','Male'), ('<=50K','Female')]].plot(kind = 'bar', title = 'Proportion distribution across gender for each workclass', figsize = (10,8), rot = 30)\nax.set_xlabel('Gender level')\nax.set_ylabel('Proportion of population')\nprint(\"varius distribution of money on different platform where money is less than 50k\")\n\n\n# In[44]:\n\n\nprint(' 2.3. Occupation vs Income')\n\noccupation = round(pd.crosstab(data.occupation, data.income).div(pd.crosstab(data.occupation, data.income).apply(sum,1),0),2)\noccupation.sort_values(by = '>50K', inplace = True)\nax = occupation.plot(kind ='bar', title = 'Proportion distribution across Occupation levels', figsize = (10,8))\nax.set_xlabel('Occupation level')\nax.set_ylabel('Proportion of population')\nprint(\"Occupation category having ='private-house-servant 'has higher percentage of people more than 50 k\")\nprint(\"Occupation category having ='exec-managerical 'has higher percentage of people more than 50 k\")\n\n\n# In[45]:\n\n\nprint(' 2.4. Workclass vs Income')\n\nworkclass = round(pd.crosstab(data.workclass, data.income).div(pd.crosstab(data.workclass, data.income).apply(sum,1),0),2)\nworkclass.sort_values(by = '>50K', inplace = True)\nax = workclass.plot(kind ='bar', title = 'Proportion distribution across workclass levels', figsize = (10,8))\nax.set_xlabel('Workclass level')\nax.set_ylabel('Proportion of population')\n\n\n# In[46]:\n\n\nprint('## 2.5. Race vs Income')\n\nrace = round(pd.crosstab(data.race, data.income).div(pd.crosstab(data.race, data.income).apply(sum,1),0),2)\nrace.sort_values(by = '>50K', inplace = True)\nax = race.plot(kind ='bar', title = 'Proportion distribution across race levels', figsize = (10,8))\nax.set_xlabel('Race level')\nax.set_ylabel('Proportion of population')\n\nprint()\n\n\n# In[47]:\n\n\nprint('## 2.6. Native Country')\n\nnative_country = round(pd.crosstab(data['native.country'], data.income).div(pd.crosstab(data['native.country'], data.income).apply(sum,1),0),2)\nnative_country.sort_values(by = '>50K', inplace = True)\nax = native_country.plot(kind ='bar', title = 'Proportion distribution across Native Country levels', figsize = (20,12))\nax.set_xlabel('Native country')\nax.set_ylabel('Proportion of population')\nprint(\"From the graph, we notice a trend in positioning of the country. South American country are at the left end of the plot, with low proportion of population that make more than 50k a year. The United States is located somewhat centrally, and at the right are countries from Europe and Asia, with higher proportion of population that make more than 50k a year.\")\n\n\n# In[48]:\n\n\ncorrmat = data.corr()\nfig,ax = plt.subplots(figsize = (12,9))\nsns.heatmap(corrmat, vmax=.8, square=True)\n\n\n# In[49]:\n\n\ndata.head()\n\n\n# In[50]:\n\n\nfor col in set(data.columns) - set(data.describe().columns):\n data[col] = data[col].astype('category')\n \nprint('## 1.1. Columns and their types')\nprint(data.info())\n\n\n# In[59]:\n\n\ndata.drop(columns = ['education','fnlwgt','hours.per.week'], inplace = True)\n\nprint('* For education level, we have 2 features that convey the same meaning, \\'education\\' and \\'educational-num\\'. To avoid the effect of this attribute on the models to be overstated, I am not going to use the categorical education attribute.')\nprint('* I use the categorical Hours work column and drop the \\'hour-per-week\\' column')\nprint( '*Also, I chose not to use the \\'Fnlwgt\\' attribute that is used by the census, as the inverse of sampling fraction adjusted for non-response and over or under sampling of particular groups. This attribute does not convey individual related meaning.')\n\n\n# In[60]:\n\n\nprint('## Box plot')\ndata.select_dtypes(exclude = 'category').plot(kind = 'box', figsize = (10,8))\n\n\n# In[65]:\n\n\nprint('Normalization happens on the training dataset, by removing the mean and scaling to unit variance. These values are stored and then later applied to the test data before the test data is passed to the model for prediction. ')\n\n\n# In[ ]:\n\n\n\"\"\"\n4. Model Development & Classification\n4.1. Data Preparation'\nOne-hot encoding is the process of representing multi-class categorical features as binary features, one for each class. Although this process increases the dimensionality of the dataset, classification algorithms tend to work better on this format of data.\n\nI use one-hot encoding to represent all the categorical features in the dataset.\"\"\"\n\n\n# In[66]:\n\n\n# Data Prep\nadult_data = data.drop(columns = ['income'])\nadult_label = data.income\n\n\nadult_cat_1hot = pd.get_dummies(data.select_dtypes('category'))\nadult_non_cat = data.select_dtypes(exclude = 'category')\n\nadult_data_1hot = pd.concat([adult_non_cat, adult_cat_1hot], axis=1, join='inner')\n\n\n# In[69]:\n\n\n# Train - Test split\nfrom sklearn.model_selection import train_test_split\ntrain_data, test_data, train_label, test_label = train_test_split(adult_data_1hot, adult_label, test_size = 0.25)\n\n\n# In[70]:\n\n\n# Normalization\nfrom sklearn.preprocessing import StandardScaler \nscaler = StandardScaler() \n\n# Fitting only on training data\nscaler.fit(train_data) \ntrain_data = scaler.transform(train_data) \n\n# Applying same transformation to test data\ntest_data = scaler.transform(test_data)\n\n\n# In[71]:\n\n\ndef model_eval(actual, pred):\n \n confusion = pd.crosstab(actual, pred, rownames=['Actual'], colnames=['Predicted'])\n TP = confusion.loc['>50K','>50K']\n TN = confusion.loc['<=50K','<=50K']\n FP = confusion.loc['<=50K','>50K']\n FN = confusion.loc['>50K','<=50K']\n\n accuracy = ((TP+TN))/(TP+FN+FP+TN)\n precision = (TP)/(TP+FP)\n recall = (TP)/(TP+FN)\n f_measure = (2*recall*precision)/(recall+precision)\n sensitivity = TP / (TP + FN)\n specificity = TN / (TN + FP)\n error_rate = 1 - accuracy\n \n out = {}\n out['accuracy'] = accuracy\n out['precision'] = precision\n out['recall'] = recall\n out['f_measure'] = f_measure\n out['sensitivity'] = sensitivity\n out['specificity'] = specificity\n out['error_rate'] = error_rate\n \n return out\n\n\n# In[72]:\n\n\n\"\"\"4.2. Model Development\n4.2.1. Decision Tree\nFor the decision tree classifier, I experimented with the splitting criteria, minimum samples required to split, max depth of the tree, minimum samples required at the leaf level and the maximum features to consider when looking for the best split. The following values of the parameters attained the best accuracy during classification. Results in the table below.\n\nSplitting criteria: Gini Index (Using Gini Index marginally outperformed Entropy with a higher accuracy.)\nMin samples required to split: 5% (Best amongst 1%, 10% and 5%.)\nMax Depth: None\nMin samples required at leaf: 0.1 % (Best amongst 1%, 5% and 0.1%.)\nMax features: number of features (Performs better than 'auto', 'log2' and 'sqrt'.)\n\"\"\"\n\n\n# In[73]:\n\n\nprint('### 3.1.1. Model Development ')\n\n# Gini \nclf_gini = tree.DecisionTreeClassifier(criterion = 'gini', min_samples_split = 0.05, min_samples_leaf = 0.001, max_features = None)\nclf_gini = clf_gini.fit(train_data, train_label)\nclf_gini_pred = clf_gini.predict(test_data)\nDTree_Gini = model_eval(test_label, clf_gini_pred)\nprint('Desicion Tree using Gini Index : %.2f percent.' % (round(DTree_Gini['accuracy']*100,2)))\n\n\n# Entropy\nclf_entropy = tree.DecisionTreeClassifier(criterion = 'entropy', min_samples_split = 0.05, min_samples_leaf = 0.001)\nclf_entropy = clf_entropy.fit(train_data, train_label)\nclf_entropy_pred = clf_entropy.predict(test_data)\nDTree_Entropy = model_eval(test_label, clf_entropy_pred)\nprint('Desicion Tree using Entropy : %.2f percent.' % (round(DTree_Entropy['accuracy']*100,2)))\n\nprint('### 3.1.2. Model Evaulation ')\novl_dtree = round(pd.DataFrame([DTree_Entropy, DTree_Gini], index = ['DTree_Entropy','DTree_Gini']),4)\ndisplay(ovl_dtree)\n\n\n# In[ ]:\n\n\n\"\"\"For the ANN classifier, I experimented with the activation function, the solver for weight optimization, regularization term and learning schedule for weight updates. The following values of the parameters attained the best accuracy during classification. Other parameters were neither applicable to the 'adam' solver nor did it improve the performance of the model. Results in the table below.\n\nActivation: Logistic (Marginally outperformed 'relu', 'tanh' and 'identity' functions.)\nSolver: Adam (Works well on relatively large datasets with thousands of training samples or more)\nAlpha: 1e-4 (Best amongst 1, 1e-1, 1e-2, 1e-3, 1e-4 and 1e-5)\nLearning Rate: 'invscaling' (Gradually decreases the learning rate at each time step 't' using an inverse scaling exponent of 'power_t'.)\"\"\"\n\n\n# In[81]:\n\n\nfrom sklearn.neural_network import MLPClassifier\nann_tanh = MLPClassifier(activation = 'tanh', solver='lbfgs', alpha=1e-1, hidden_layer_sizes=(10, 2), random_state=1, warm_start=True)\nann_tanh.fit(train_data, train_label) \nann_tanh_pred = ann_tanh.predict(test_data)\nANN_TanH = model_eval(test_label, ann_tanh_pred)\nprint('ANN using TanH and lbfgs solver : %.2f percent.' % (round(ANN_TanH['accuracy']*100,2)))\n\n\n# Relu\nann_relu = MLPClassifier(activation = 'relu', solver='adam', alpha=1e-1, \n hidden_layer_sizes=(5, 2), random_state=1,\n learning_rate = 'invscaling',\n warm_start = True)\nann_relu.fit(train_data, train_label) \nann_relu_pred = ann_relu.predict(test_data)\nANN_relu = model_eval(test_label, ann_relu_pred)\nprint('ANN using relu and adam solver : %.2f percent.' % (round(ANN_relu['accuracy']*100,2)))\n\n# Log\nann_log = MLPClassifier(activation = 'logistic', solver='adam', \n alpha=1e-4, hidden_layer_sizes=(5, 2),\n learning_rate = 'invscaling', \n random_state=1, warm_start = True)\nann_log.fit(train_data, train_label) \nann_log_pred = ann_log.predict(test_data)\nANN_log = model_eval(test_label, ann_log_pred)\nprint('ANN using logistic and adam solver : %.2f percent.' % (round(ANN_log['accuracy']*100,2)))\n\n# Identity\nann_identity = MLPClassifier(activation = 'identity', solver='adam', alpha=1e-1, hidden_layer_sizes=(5, 2), random_state=1, warm_start = True)\nann_identity.fit(train_data, train_label) \nann_identity_pred = ann_identity.predict(test_data)\nANN_identity = model_eval(test_label, ann_identity_pred)\nprint('ANN using identity and adam solver : %.2f percent.' % (round(ANN_identity['accuracy']*100,2)))\n\n#printmd('### 3.2.2. Model Evaulation ')\novl_ann = round(pd.DataFrame([ANN_TanH, ANN_relu, ANN_log, ANN_identity], index = ['ANN_TanH','ANN_relu', 'ANN_log', 'ANN_identity']),4)\ndisplay(ovl_ann)\n\n\n# In[ ]:\n\n\n\"\"\"4.2.3. Support Vector Machine\nFor the SVM classifier, I experimented with the various available kernels, the penalty of the error term and the tolerance for stopping criteria. The following values of the parameters attained the best accuracy during classification. Results in the table below.\n\nKernel: rbf (Marginally outperformed 'linear, 'poly' and 'sigmoid' kernels.)\nC, penalty of the error term: 1 (Best amongst 0.1, 0.5, 1 and 10)\nTolerance for stopping criteria: 1e-3 (Best amongst 1e-1, 1e-2, 1e-3, 1e-4 and 1e-5)\"\"\"\n\n\n# In[83]:\n\n\nfrom sklearn import svm\n# rbf kernal\nsvm_clf_rbf = svm.SVC(kernel = 'rbf', C = 1, tol = 1e-3)\nsvm_clf_rbf.fit(train_data, train_label)\nsvm_clf_rbf_pred = svm_clf_rbf.predict(test_data)\nSVM_rbf = model_eval(test_label, svm_clf_rbf_pred)\nprint('SVM using rbf kernel : %.2f percent.' % (round(SVM_rbf['accuracy']*100,2)))\n\n# Linear kernel\nsvm_clf_linear = svm.SVC(kernel = 'linear')\nsvm_clf_linear.fit(train_data, train_label)\nsvm_clf_linear_pred = svm_clf_linear.predict(test_data)\nSVM_linear = model_eval(test_label, svm_clf_linear_pred)\nprint('SVM using linear kernel : %.2f percent.' % (round(SVM_linear['accuracy']*100,2)))\n\n\n# Poly kernal\nsvm_clf_poly = svm.SVC(kernel = 'poly')\nsvm_clf_poly.fit(train_data, train_label)\nsvm_clf_poly_pred = svm_clf_poly.predict(test_data)\nSVM_poly = model_eval(test_label, svm_clf_poly_pred)\nprint('SVM using poly kernel : %.2f percent.' % (round(SVM_poly['accuracy']*100,2)))\n\n\nsvm_clf_sigmoid = svm.SVC(kernel = 'sigmoid')\nsvm_clf_sigmoid.fit(train_data, train_label)\nsvm_clf_sigmoid_pred = svm_clf_sigmoid.predict(test_data)\nSVM_sigmoid = model_eval(test_label, svm_clf_sigmoid_pred)\nprint('SVM using sigmoid kernel : %.2f percent.' % (round(SVM_sigmoid['accuracy']*100,2)))\n\n\n\n#printmd('### 3.3.2. Model Evaulation ')\novl_svm = round(pd.DataFrame([SVM_rbf, SVM_linear, SVM_poly, SVM_sigmoid], index = ['SVM_rbf','SVM_linear', 'SVM_poly', 'SVM_sigmoid']),4)\ndisplay(ovl_svm)\n\n\n# In[ ]:\n\n\n\"\"\"\n4.2.4. Ensemble Models\n4.2.4.1. Random Forest\nFor the random forests classifier, I experimented with the number of trees, splitting criteria, minimum samples required to split, max depth of the tree, minimum samples required at the leaf level and the maximum features to consider when looking for the best split. The following values of the parameters attained the best accuracy during classification. Results in the table below.\n\nNum estimators: 100 (Best amongst 10, 50 and 100)\nSplitting criteria: Gini Index (Using Gini Index marginally outperformed Entropy with a higher accuracy.)\nMin samples required to split: 5% (Best amongst 1%, 10% and 5%.)\nMax Depth: None\nMin samples required at leaf: 0.1 % (Best amongst 1%, 5% and 0.1%.)\nMax features: number of features (Performs better than 'auto', 'log2' and 'sqrt'.)\"\"\"\n\n\n# In[84]:\n\n\n# Gini\nr_forest_gini = RandomForestClassifier(n_estimators=100, criterion = 'gini', max_features = None, min_samples_split = 0.05, min_samples_leaf = 0.001)\nr_forest_gini.fit(train_data, train_label)\nr_forest_gini_pred = r_forest_gini.predict(test_data)\nrforest_gini = model_eval(test_label, r_forest_gini_pred)\nprint('Random Forest using Gini Index : %.2f percent.' % (round(rforest_gini['accuracy']*100,2)))\n\n# Entropy\nr_forest_entropy = RandomForestClassifier(n_estimators=100, criterion = 'entropy', max_features = None, min_samples_split = 0.05, min_samples_leaf = 0.001)\nr_forest_entropy.fit(train_data, train_label)\nr_forest_entropy_pred = r_forest_entropy.predict(test_data)\nrforest_entropy = model_eval(test_label, r_forest_entropy_pred)\nprint('Random Forest using Entropy : %.2f percent.' % (round(rforest_entropy['accuracy']*100,2)))\n\n#printmd('### 3.4.1.2. Model Evaulation ')\novl_rf = round(pd.DataFrame([rforest_gini, rforest_entropy], index = ['rforest_gini','rforest_entropy']),4)\ndisplay(ovl_rf)\n\n\n# In[ ]:\n\n\n\"\"\"4.2.4.2. Adaboost\nFor the adaboost classifier, I experimented with base estimator from which the boosted ensemble is built and number of estimators. The following values of the parameters attained the best accuracy during classification. Results in the table below.\n\nBase Estimator: DecisionTreeClassifier\n\nNum estimators: 100 (Best amongst 10, 50 and 100.)\"\"\"\n\n\n# In[85]:\n\n\nfrom sklearn.ensemble import AdaBoostClassifier\nada = AdaBoostClassifier(n_estimators=100) \nada.fit(train_data, train_label)\nada_pred = ada.predict(test_data)\nadaboost = model_eval(test_label, ada_pred)\nprint('Adaboost : %.2f percent.' % (round(adaboost['accuracy']*100,2)))\n\n#printmd('### 3.4.2.2. Model Evaulation ')\novl_ada = round(pd.DataFrame([adaboost], index = ['adaboost']),4)\ndisplay(ovl_ada)\n\n\n# In[86]:\n\n\n\"\"\"4.2.5. Logistic Regression\"\"\"\nlog_reg = LogisticRegression(penalty = 'l2', dual = False, tol = 1e-4, fit_intercept = True, \n solver = 'liblinear')\nlog_reg.fit(train_data, train_label)\nlog_reg_pred = log_reg.predict(test_data)\nlogistic_reg = model_eval(test_label, log_reg_pred)\nprint('Logistic Regression : %.2f percent.' % (round(logistic_reg['accuracy']*100,3)))\n\n#printmd('### 3.5.2. Model Evaulation ')\novl_logreg = round(pd.DataFrame([logistic_reg], index = ['logistic_reg']),4)\ndisplay(ovl_logreg)\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n# roc curve\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n# Overall Performance Statistics\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n"
},
{
"alpha_fraction": 0.7386411428451538,
"alphanum_fraction": 0.7526664733886719,
"avg_line_length": 32.72804641723633,
"blob_id": "ee4c8f80c6db8ff136c13b1bec19aae0cfc27a05",
"content_id": "1880b357893270c94783f89d85f5a0dd953aa4c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11907,
"license_type": "no_license",
"max_line_length": 576,
"num_lines": 353,
"path": "/Text-Classification-classifier/Text Classification and classifier.py",
"repo_name": "ABHISHEK1105DS/Projects",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# In[1]:\n\n\n\"\"\"\nThe goal with text classification can be pretty broad. Maybe we're trying to classify text as about politics or the military. Maybe we're trying to classify it by the gender of the author who wrote it. A fairly popular text classification task is to identify a body of text as either spam or not spam, for things like email filters. In our case, we're going to try to create a sentiment analysis algorithm.\n\nTo do this, we're going to start by trying to use the movie reviews database that is part of the NLTK corpus. From there we'll try to use words as \"features\" which are a part of either a positive or negative movie review. The NLTK corpus movie_reviews data set has the reviews, and they are labeled already as positive or negative. This means we can train and test with this data. First, let's wrangle our data.\n\n\n\"\"\"\n\n\n# In[6]:\n\n\nimport nltk\nimport random\nfrom nltk.corpus import movie_reviews\n\ndocuments = [(list(movie_reviews.words(fileid)), category)\n for category in movie_reviews.categories()\n for fileid in movie_reviews.fileids(category)]\n\nrandom.shuffle(documents)\n# document for training\nprint(documents[1])\n\"\"\"\nBasically, in plain English, the above code is translated to: In each category (we have pos or neg), take all of the file IDs (each review has its own ID), then store the word_tokenized version (a list of words) for the file ID, followed by the positive or negative label in one big list.\n\nNext, we use random to shuffle our documents. This is because we're going to be training and testing. If we left them in order, chances are we'd train on all of the negatives, some positives, and then test only against positives. We don't want that, so we shuffle the data.\"\"\"\n\n\n# In[ ]:\n\n\n\"\"\"\n\nNext, we use random to shuffle our documents. This is because we're going to be training and testing. If we left them in order, chances are we'd train on all of the negatives, some positives, and then test only against positives. We don't want that, so we shuffle the data.\"\"\"\n\"\"\"\n\n\n# In[7]:\n\n\n# common word used most time\nall_words = []\nfor w in movie_reviews.words():\n all_words.append(w.lower())\n# list to freqcy distribution most common word to least common\nall_words = nltk.FreqDist(all_words)\nprint(all_words.most_common(15))\n\n\n# In[8]:\n\n\n# stupid appear 253 time\nprint(all_words[\"stupid\"])\n\n\n# In[11]:\n\n\n\nword_features = list(all_words.keys())[:3000]\n\"\"\"\nMostly the same as before, only with now a new variable, word_features, which contains the top 3,000 most common words. Next, we're going to build a quick function that will find these top 3,000 words in our positive and negative documents, marking their presence as either positive or negative:\n\n\"\"\"\n\n\n# In[13]:\n\n\ndef find_features(document):\n# one basically iteration mean set from document mean unique \n words = set(document) \n features = {}\n for w in word_features:\n features[w] = (w in words)\n# win words boolean value top 3000 words in document true or false\n\n return features\n\n\n# In[14]:\n\n\nprint((find_features(movie_reviews.words('neg/cv000_29416.txt'))))\n\n\n# In[15]:\n\n\nfeaturesets = [(find_features(rev), category) for (rev, category) in documents]\n\n\n# In[21]:\n\n\n\"\"\"\n\nNow it is time to choose an algorithm, separate our data into training and testing sets, and press go! The algorithm that we're going to use first is the Naive Bayes classifier. This is a pretty popular algorithm used in text classification, so it is only fitting that we try it out first. Before we can train and test our algorithm, however, we need to go ahead and split up the data into a training set and a testing set.\n\nYou could train and test on the same dataset, but this would present you with some serious bias issues, so you should never train and test against the exact same data. To do this, since we've shuffled our data set, we'll assign the first 1,900 shuffled reviews, consisting of both positive and negative reviews, as the training set. Then, we can test against the last 100 to see how accurate we are.\n\n\"\"\"\n\n\n# In[24]:\n\n\nprint(featuresets[190])\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[17]:\n\n\n# set that we'll train our classifier with first 1900 wordfs\ntraining_set = featuresets[:1900]\n\n# set that we'll test against.after 1900 words\ntesting_set = featuresets[1900:]\n\n\n# In[18]:\n\n\nclassifier = nltk.NaiveBayesClassifier.train(training_set)\n\n\n# In[19]:\n\n\nprint(\"Classifier accuracy percent:\",(nltk.classify.accuracy(classifier, testing_set))*100)\n\n\n# In[20]:\n\n\nclassifier.show_most_informative_features(15)\n\n\n# In[ ]:\n\n\n\"\"\"\n\nWhat this tells you is the ratio of occurences in negative to positive, or visa versa, for every word. So here, we can see that the term \"insulting\" appears 10.6 more times as often in negative reviews as it does in positive reviews. Ludicrous, 10.1.\n\nNow, let's say you were totally content with your results, and you wanted to move forward, maybe using this classifier to predict things right now. It would be very impractical to train the classifier, and retrain it every time you needed to use it. As such, you can save the classifier using the pickle module. Let's do that next.\n\"\"\"\n\n\n# In[ ]:\n\n\n# pickle\n\"\"\"\nTraining classifiers and machine learning algorithms can take a very long time, especially if you're training against a larger data set. Ours is actually pretty small. Can you imagine having to train the classifier every time you wanted to fire it up and use it? What horror! Instead, what we can do is use the Pickle module to go ahead and serialize our classifier object, so that all we need to do is load that file in real quick.\n\nSo, how do we do this? The first step is to save the object. To do this, first you need to import pickle at the top of your script, then, after you have trained with .train() the classifier, you can then call the following lines:\n\n\"\"\"\n\n\n# \n\n# In[25]:\n\n\n\nimport pickle\n\n\n# In[26]:\n\n\n# write in byte=wb\nsave_classifier = open(\"naivebayes.pickle\",\"wb\")\n# what we want to dump and where want to dump\npickle.dump(classifier, save_classifier)\nsave_classifier.close()\n\n\n# In[27]:\n\n\n\"\"\"\n\nThis opens up a pickle file, preparing to write in bytes some data. Then, we use pickle.dump() to dump the data. The first parameter to pickle.dump() is what are you dumping, the second parameter is where are you dumping it.\n\nAfter that, we close the file as we're supposed to, and that is that, we now have a pickled, or serialized, object saved in our script's directory!\n\nNext, how would we go about opening and using this classifier? The .pickle file is a serialized object, all we need to do now is read it into memory, which will be about as quick as reading any other ordinary file. To do this:\n\"\"\"\n\n\n# In[30]:\n\n\nclassifier_f = open(\"naivebayes.pickle\", \"rb\")\nclassifier = pickle.load(classifier_f)\nclassifier_f.close()\n\n\n# In[31]:\n\n\nprint(\"Classifier accuracy percent:\",(nltk.classify.accuracy(classifier, testing_set))*100)\n\n\n# In[32]:\n\n\nclassifier.show_most_informative_features(15)\n\n\n# In[ ]:\n\n\n\n\n\n# In[29]:\n\n\n\"\"\"\nHere, we do a very similar process. We open the file to read as bytes. Then, we use pickle.load() to load the file, and we save the data to the classifier variable. Then we close the file, and that is that. We now have the same classifier object as before!\n\nNow, we can use this object, and we no longer need to train our classifier every time we wanted to use it to classify.\n\nWhile this is all fine and dandy, we're probably not too content with the 60-75% accuracy we're getting. What about other classifiers? Turns out, there are many classifiers, but we need the scikit-learn (sklearn) module. Luckily for us, the people at NLTK recognized the value of incorporating the sklearn module into NLTK, and they have built us a little API to do it. That's what we'll be doing in the next tutorial.\n\n\"\"\"\n\n\n# In[33]:\n\n\n\"\"\"\nWe've seen by now how easy it can be to use classifiers out of the box, and now we want to try some more! The best module for Python to do this with is the Scikit-learn (sklearn) module.\n\nIf you would like to learn more about the Scikit-learn Module, I have some tutorials on machine learning with Scikit-Learn.\n\n\n \nLuckily for us, the people behind NLTK forsaw the value of incorporating the sklearn module into the NLTK classifier methodology. As such, they created the SklearnClassifier API of sorts. To use that, you just need to import it like:\n\"\"\"\n\n\n# In[34]:\n\n\nfrom nltk.classify.scikitlearn import SklearnClassifier\n\n\n# In[35]:\n\n\nfrom sklearn.naive_bayes import MultinomialNB,BernoulliNB\n\n\n# In[36]:\n\n\nMNB_classifier = SklearnClassifier(MultinomialNB())\nMNB_classifier.train(training_set)\nprint(\"MultinomialNB accuracy percent:\",nltk.classify.accuracy(MNB_classifier, testing_set))\n\nBNB_classifier = SklearnClassifier(BernoulliNB())\nBNB_classifier.train(training_set)\nprint(\"BernoulliNB accuracy percent:\",nltk.classify.accuracy(BNB_classifier, testing_set))\n\n\n# In[37]:\n\n\nfrom sklearn.linear_model import LogisticRegression,SGDClassifier\nfrom sklearn.svm import SVC, LinearSVC, NuSVC\n\n\n# In[38]:\n\n\nprint(\"Original Naive Bayes Algo accuracy percent:\", (nltk.classify.accuracy(classifier, testing_set))*100)\nclassifier.show_most_informative_features(15)\n\nMNB_classifier = SklearnClassifier(MultinomialNB())\nMNB_classifier.train(training_set)\nprint(\"MNB_classifier accuracy percent:\", (nltk.classify.accuracy(MNB_classifier, testing_set))*100)\n\nBernoulliNB_classifier = SklearnClassifier(BernoulliNB())\nBernoulliNB_classifier.train(training_set)\nprint(\"BernoulliNB_classifier accuracy percent:\", (nltk.classify.accuracy(BernoulliNB_classifier, testing_set))*100)\n\nLogisticRegression_classifier = SklearnClassifier(LogisticRegression())\nLogisticRegression_classifier.train(training_set)\nprint(\"LogisticRegression_classifier accuracy percent:\", (nltk.classify.accuracy(LogisticRegression_classifier, testing_set))*100)\n\nSGDClassifier_classifier = SklearnClassifier(SGDClassifier())\nSGDClassifier_classifier.train(training_set)\nprint(\"SGDClassifier_classifier accuracy percent:\", (nltk.classify.accuracy(SGDClassifier_classifier, testing_set))*100)\n\nSVC_classifier = SklearnClassifier(SVC())\nSVC_classifier.train(training_set)\nprint(\"SVC_classifier accuracy percent:\", (nltk.classify.accuracy(SVC_classifier, testing_set))*100)\n\nLinearSVC_classifier = SklearnClassifier(LinearSVC())\nLinearSVC_classifier.train(training_set)\nprint(\"LinearSVC_classifier accuracy percent:\", (nltk.classify.accuracy(LinearSVC_classifier, testing_set))*100)\n\nNuSVC_classifier = SklearnClassifier(NuSVC())\nNuSVC_classifier.train(training_set)\nprint(\"NuSVC_classifier accuracy percent:\", (nltk.classify.accuracy(NuSVC_classifier, testing_set))*100)\n\n\n# In[ ]:\n\n\n\"\"\"\n\nIn this tutorial, we discuss a few issues. The most major issue is that we have a fairly biased algorithm. You can test this yourself by commenting-out the shuffling of the documents, then training against the first 1900, and leaving the last 100 (all positive) reviews. Test, and you will find you have very poor accuracy.\n\nConversely, you can test against the first 100 data sets, all negative, and train against the following 1900. You will find very high accuracy here. This is a bad sign. It could mean a lot of things, and there are many options for us to fix it.\n\n\n \nThat said, the project I have in mind for us suggests we go ahead and use a different data set anyways, so we will do that. In the end, we will find this new data set still contains some bias, and that is that it picks up negative things more often. The reason for this is that negative reviews tend to be \"more negative\" than positive reviews are positive. Handling this can be done with some simple weighting, but it can also get complex fast. Maybe a tutorial for another day. For now, we're going to just grab a new dataset, which we'll be discussing in the next tutorial.\n\n\n\"\"\"\n\n"
},
{
"alpha_fraction": 0.6432656049728394,
"alphanum_fraction": 0.6596909761428833,
"avg_line_length": 12.994889259338379,
"blob_id": "365db611f9b1d59a3dc35dcab56ca8a6f6279811",
"content_id": "96e6348dcddb26287d1f132b0e5e741dd7acf076",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8219,
"license_type": "no_license",
"max_line_length": 343,
"num_lines": 587,
"path": "/movierating/movies_Content_Based_Recommendation_Model.py",
"repo_name": "ABHISHEK1105DS/Projects",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# In[1]:\n\n\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n\n# In[2]:\n\n\n# Reading ratings file\nratings = pd.read_csv(r'D:\\ml\\movierating/ratings.csv', sep='\\t')\n# Reading users file\nusers = pd.read_csv(r'D:\\ml\\movierating/users.csv', sep='\\t', encoding='latin-1', usecols=['user_id', 'gender', 'zipcode', 'age_desc', 'occ_desc'])\n\n# Reading movies file\nmovies = pd.read_csv(r'D:\\ml\\movierating/movies.csv', sep='\\t', encoding='latin-1', usecols=['movie_id', 'title', 'genres'])\n\n\n# In[3]:\n\n\nratings.head()\n\n\n# In[4]:\n\n\n# Reading ratings file\n# Ignore the timestamp column,user_emb_id,movie_emb_id and Unnamed\nratings = pd.read_csv(r'D:\\ml\\movierating/ratings.csv', sep='\\t', encoding='latin-1', usecols=['user_id', 'movie_id', 'rating'])\n\n\n# In[5]:\n\n\nratings.head()\n\n\n# In[6]:\n\n\nratings.info()\n\n\n# In[7]:\n\n\nusers.head()\n\n\n# In[8]:\n\n\nusers.info()\n\n\n# In[9]:\n\n\nmovies.head()\n\n\n# In[10]:\n\n\nmovies.info()\n\n\n# In[11]:\n\n\n# Data Exploration\n\n\n# In[12]:\n\n\n# Titles\n# Are there certain words that feature more often in Movie Titles? I'll attempt to figure this out using a word-cloud visualization.\n\n\n# In[13]:\n\n\n# Import new libraries\nget_ipython().run_line_magic('matplotlib', 'inline')\nimport wordcloud\nfrom wordcloud import WordCloud, STOPWORDS\n\n\n# In[14]:\n\n\n# Create a wordcloud of the movie titles\nmovies['title'] = movies['title'].fillna(\"\").astype('str')\ntitle_corpus = ' '.join(movies['title'])\ntitle_wordcloud = WordCloud(stopwords=STOPWORDS, background_color='black', height=2000, width=4000).generate(title_corpus)\n\n\n# In[15]:\n\n\n# Plot the wordcloud\nplt.figure(figsize=(16,8))\nplt.imshow(title_wordcloud)\nplt.axis('off')\nplt.show()\n\n\n# In[16]:\n\n\n# rating\nratings['rating'].describe()\n\n\n# In[17]:\n\n\n# Import seaborn library\nimport seaborn as sns\nsns.set_style('whitegrid')\nsns.set(font_scale=1.5)\nget_ipython().run_line_magic('matplotlib', 'inline')\n\n# Display distribution of rating\nsns.distplot(ratings['rating'].fillna(ratings['rating'].median()))\n\n\n# In[18]:\n\n\n# Import seaborn library\nimport seaborn as sns\nsns.set_style('whitegrid')\nsns.set(font_scale=1.5)\nget_ipython().run_line_magic('matplotlib', 'inline')\n\n# Display distribution of rating\nsns.distplot(ratings['rating'].fillna(ratings['rating'].mean()))\n\n\n# In[19]:\n\n\n# Join all 3 files into one dataframe\ndataset = pd.merge(pd.merge(movies, ratings),users)\n# Display 20 movies with highest ratings\ndataset[['title','genres','rating']].sort_values('rating', ascending=False).head(20)\n\n\n# In[20]:\n\n\n# genres\n# The genres variable will surely be important while building the recommendation engines since it describes the content of the film (i.e. Animation, Horror, Sci-Fi). A basic assumption is that films in the same genre should have similar contents. I'll attempt to see exactly which genres are the most popular.\n\n\n# In[21]:\n\n\n# Make a census of the genre keywords\ngenre_labels = set()\nfor s in movies['genres'].str.split('|').values:\n genre_labels = genre_labels.union(set(s))\n\n\n# In[22]:\n\n\n# Function that counts the number of times each of the genre keywords appear\ndef count_word(dataset, ref_col, census):\n \"\"\"dataset=>movies,ref_col=genres row in movie,census=genres label\"\"\"\n keyword_count = dict()\n for s in census: \n keyword_count[s] = 0\n for census_keywords in dataset[ref_col].str.split('|'): \n if type(census_keywords) == float and pd.isnull(census_keywords): \n continue \n for s in [s for s in census_keywords if s in census]:\n \"\"\"2 for loop with if statement\"\"\"\n if pd.notnull(s): \n keyword_count[s] += 1\n #______________________________________________________________________\n # convert the dictionary in a list to sort the keywords by frequency\n keyword_occurences = []\n for k,v in keyword_count.items():\n keyword_occurences.append([k,v])\n keyword_occurences.sort(key = lambda x:x[1], reverse = True)\n return keyword_occurences\n\n# Calling this function gives access to a list of genre keywords which are sorted by decreasing frequency\nkeyword_occurences= count_word(movies, 'genres', genre_labels)\nkeyword_occurences\n\n\n# In[ ]:\n\n\n\n\n\n# In[23]:\n\n\n# Define the dictionary used to produce the genre wordcloud\ngenres = dict()\ntrunc_occurences = keyword_occurences[0:18]\n\n\n# In[24]:\n\n\nfor s in trunc_occurences:\n \n genres[s[0]] = s[1]\n\n\n# In[25]:\n\n\n# Create the wordcloud\ngenre_wordcloud = WordCloud(width=1000,height=400, background_color='white')\ngenre_wordcloud.generate_from_frequencies(genres)\n\n# Plot the wordcloud\nf, ax = plt.subplots(figsize=(16, 8))\nplt.imshow(genre_wordcloud, interpolation=\"bilinear\")\nplt.axis('off')\nplt.show()\n\n\n# In[30]:\n\n\n# Content-Based Recommendation Model\n# \"\"\"With all that theory in mind, I am going to build a Content-Based Recommendation Engine that computes similarity between movies based on movie genres. It will suggest movies that are most similar to a particular movie based on its genre. To do so, I will make use of the file movies.csv.\"\"\"\n\n\n# In[27]:\n\n\n# Break up the big genre string into a string array\nmovies['genres'] = movies['genres'].str.split('|')\n# Convert genres to string value\nmovies['genres'] = movies['genres'].fillna(\"\").astype('str')\n\n\n# In[28]:\n\n\nmovies['genres']\n\n\n# In[31]:\n\n\n# do not have a quantitative metric to judge our machine's performance so this will have to be done qualitatively. In order to do so, I'll use TfidfVectorizer function from scikit-learn, which transforms text to feature vectors that can be used as input to estimator.\n# to convert text into integer\n# \"\"\"convert text to word count vectors with CountVectorizer.\n# to convert text to word frequency vectors with TfidfVectorizer.to convert text to unique integers with HashingVectorizer.\"\"\"\n\n\n# In[32]:\n\n\nfrom sklearn.feature_extraction.text import TfidfVectorizer\ntf = TfidfVectorizer(analyzer='word',ngram_range=(1, 2),min_df=0, stop_words='english')\ntfidf_matrix = tf.fit_transform(movies['genres'])\ntfidf_matrix.shape\n\n\n# In[ ]:\n\n\n# I will be using the Cosine Similarity to calculate a numeric quantity that denotes the similarity between two movies. Since we have used the TF-IDF Vectorizer, calculating the Dot Product will directly give us the Cosine Similarity Score. Therefore, we will use sklearn's linear_kernel instead of cosine_similarities since it is much faster.\n\n\n# In[33]:\n\n\nfrom sklearn.metrics.pairwise import linear_kernel\ncosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)\ncosine_sim[:4, :4]\n\n\n# In[34]:\n\n\n# I now have a pairwise cosine similarity matrix for all the movies in the dataset. The next step is to write a function that returns the 20 most similar movies based on the cosine similarity score.\n\n\n# In[36]:\n\n\n# Build a 1-dimensional array with movie titles\ntitles = movies['title']\nindices = pd.Series(movies.index, index=movies['title'])\n\n\n# In[37]:\n\n\nindices\n\n\n# In[38]:\n\n\n# Function that get movie recommendations based on the cosine similarity score of movie genres\n\n\n# In[39]:\n\n\ndef genre_recommendations(title):\n idx = indices[title]\n sim_scores = list(enumerate(cosine_sim[idx]))\n sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)\n sim_scores = sim_scores[1:21]\n movie_indices = [i[0] for i in sim_scores]\n return titles.iloc[movie_indices]\n\n\n# In[40]:\n\n\ngenre_recommendations('Good Will Hunting (1997)').head(20)\n\n\n# In[44]:\n\n\ngenre_recommendations('Freejack (1992)').head(20)\n\n\n# In[ ]:\n\n\n\"\"\"Disadvantages\nFinding the appropriate features is hard.\nDoes not recommend items outside a user's content profile.\nUnable to exploit quality judgments of other users.\n\n\"\"\"\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\ngenres\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n"
},
{
"alpha_fraction": 0.5449160933494568,
"alphanum_fraction": 0.5772732496261597,
"avg_line_length": 9.136818885803223,
"blob_id": "3e3ca29f368f99a2ac33ade796f642c0acca5158",
"content_id": "f47aca02f0f6e92d447938c06d0f67c82a498aae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9117,
"license_type": "no_license",
"max_line_length": 195,
"num_lines": 899,
"path": "/blackfridayt/Untitled6.py",
"repo_name": "ABHISHEK1105DS/Projects",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# In[115]:\n\n\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nimport statsmodels.api as sm\nimport statsmodels.formula.api as smf\nimport sklearn.metrics\nfrom sklearn import ensemble\nfrom scipy import stats as st \nfrom sklearn import linear_model,datasets\nfrom sklearn.metrics import mean_squared_error\n\n\n# In[212]:\n\n\nfrom xgboost import XGBRegressor\nfrom hyperopt import hp,fmin,tpe\nfrom sklearn.model_selection import cross_val_score, KFold\n\n\n# In[ ]:\n\n\n\n\n\n# In[211]:\n\n\nget_ipython().system('pip install hyperopt')\n\n\n# In[ ]:\n\n\n\n\n\n# In[209]:\n\n\nget_ipython().system('pip install xgboost')\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[198]:\n\n\ndata=pd.read_csv(r\"D:\\ml\\blackfridayt\\train.csv\")\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[199]:\n\n\ndata.head()\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[118]:\n\n\n# data cleanning\n\n\n# In[119]:\n\n\nmissing_values = data.isnull().sum().sort_values(ascending = False)\n\n\n# In[120]:\n\n\nmissing_values\n\n\n# In[121]:\n\n\nmissing_values = missing_values[missing_values > 0]/data.shape[0]\nprint(f'{missing_values *100} %')\n\n\n# In[122]:\n\n\n\"\"\"believe that the NaN values for Product_Category_2 and Product_Categrory_3 would mean that the concerned person did not buy the products from these categories.\n\nHence, I believe that it would be safe to replace them with 0.\"\"\"\n\n\n# In[123]:\n\n\ndata = data.fillna(0)\n\n\n# In[124]:\n\n\nmissing_values = data.isnull().sum().sort_values(ascending = False)\nmissing_values = missing_values[missing_values > 0]/data.shape[0]\nprint(f'{missing_values *100} %')\n\n\n# In[125]:\n\n\ndata.dtypes\n\n\n# In[126]:\n\n\n# So, the available datatypes are : int64, float64 and objects. We will leave the numeric datatypes alone and focus on object datatypes as the cannot be directly fen into a Machine Learning Model\n\n\n# In[200]:\n\n\ngender = np.unique(data['Gender'])\ngender\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[128]:\n\n\n# So, we do not have any 'Other' gender type. I will create a fuction and map M=1 and F=0. No sexism intended.\ndef map_gender(gender):\n if gender == 'M':\n return 1\n else:\n return 0\ndata['Gender'] = data['Gender'].apply(map_gender)\n\n\n# In[195]:\n\n\nage = np.unique(data['Age'])\nage\n\n\n# In[ ]:\n\n\n\n\n\n# In[130]:\n\n\ndef map_age(age):\n if age == '0-17':\n return 0\n elif age == '18-25':\n return 1\n elif age == '26-35':\n return 2\n elif age == '36-45':\n return 3\n elif age == '46-50':\n return 4\n elif age == '51-55':\n return 5\n else:\n return 6\ndata['Age']=data['Age'].apply(map_age) \n\n\n# In[131]:\n\n\ncity_category = np.unique(data['City_Category'])\ncity_category\n\n\n# In[132]:\n\n\ndef map_city_categories(city_category):\n if city_category == 'A':\n return 2\n elif city_category == 'B':\n return 1\n else:\n return 0\ndata['City_Category'] = data['City_Category'].apply(map_city_categories)\n\n\n# In[133]:\n\n\ncity_stay = np.unique(data['Stay_In_Current_City_Years'])\ncity_stay\n\n\n# In[134]:\n\n\ndef map_stay(stay):\n if stay == '4+':\n return 4\n else:\n return int(stay)\ndata['Stay_In_Current_City_Years'] = data['Stay_In_Current_City_Years'].apply(map_stay) \n\n\n# In[135]:\n\n\ncols = ['User_ID','Product_ID']\ndata.drop(cols, inplace = True, axis =1)\n\n\n# In[136]:\n\n\ndata.describe()\n\n\n# In[137]:\n\n\ndata.head()\n\n\n# In[138]:\n\n\n# eda\ndata[['Gender','Purchase']].groupby('Gender').mean().plot.bar()\nsns.barplot('Gender', 'Purchase', data = data)\nplt.show()\n\n\n# In[201]:\n\n\ndata[['Age','Purchase']].groupby('Age').mean().plot.bar()\nsns.barplot('Age', 'Purchase', data = data)\nplt.show()\n\n\n# In[ ]:\n\n\n\n\n\n# In[140]:\n\n\nsns.boxplot('Age','Purchase', data = data)\nplt.show()\n\n\n# In[141]:\n\n\n# Not much of a deciation there. We can say that no matter what age group you belong to, you are gonna make full use of your purchasing power on a Black Friday\n\n\n# In[142]:\n\n\ndata[['City_Category','Purchase']].groupby('City_Category').mean().plot.bar()\nsns.barplot('City_Category', 'Purchase', data = data)\nplt.show()\n\n\n# In[143]:\n\n\n# Okay so, the people belonging to category 0 tend to spend a little more. These may be the more developed cities that we are talking about here.\n\n\n# In[144]:\n\n\ncorrmat = data.corr()\nfig,ax = plt.subplots(figsize = (12,9))\nsns.heatmap(corrmat, vmax=.8, square=True)\n\n\n# In[145]:\n\n\nmean_cat_1 = data['Product_Category_1'].mean()\nmean_cat_2 = data['Product_Category_2'].mean()\nmean_cat_3= data['Product_Category_3'].mean()\nprint(f\"PC1: {mean_cat_1} \\n PC2: {mean_cat_2} \\n PC3 : {mean_cat_3}\")\n\n\n# In[146]:\n\n\nprint(data.skew())\n\n\n# In[159]:\n\n\ndef skewness_check(data):\n # Find the skewness in the dataset\n skew_value = list(st.skew(data))\n skew_string = []\n # Looping through the skew value to find the Skew category\n for skew in skew_value:\n if skew >= -.5 and skew <= .5:\n skew_string.append(\"Light Skewed\")\n elif skew <= -.5 and skew >= -1 and skew <= .5 and skew >= 1:\n skew_string.append(\"Moderately Skewed\")\n else:\n skew_string.append(\"Heavily Skewed\")\n # Ctreating data frame\n skew_df = pd.DataFrame({'Column': data.columns, 'Skewness': skew_value, 'Skew Category': skew_string})\n return skew_df\n\n# Skewness for Red Wine\nskewness_check(data.iloc[:, :-1])\n\n\n# In[173]:\n\n\n# boxcox Transformation\ndata[[\"Gender\"]] += 0.1\ndata[[\"Age\"]] += 0.1\ndata[[\"Occupation\"]] += 0.1\ndata[[\"City_Category\"]] += 0.1\ndata[[\"Stay_In_Current_City_Years\"]]+=.1\ndata[[\"Marital_Status\"]]+=.1\ndata[[\"Product_Category_2\"]] += 0.1\n\ndata[[\"Product_Category_3\"]] += 0.1\ndef boxcox_trans(data):\n for i in range(data.shape[1]):\n data.iloc[:, i], _ = st.boxcox(data.iloc[:, i])\n return data\n# Subset the predcitors\nred_trans = data.copy(deep = True)\nred_trans.iloc[:, :-1] = boxcox_trans(red_trans.iloc[:, :-1])\nskewness_check(red_trans.iloc[:, :-1])\n\n\n# In[ ]:\n\n\n\n\n\n# In[174]:\n\n\ndef subplot_hist(data, row = 4, column = 3, title = \"Subplots\", height = 20, width = 19):\n # Create a figure instance, and the two subplots\n fig = plt.figure(figsize = (width, height))\n fig.suptitle(title, fontsize=25, y = 0.93)\n # Run loop over the all the variables\n for i in range(data.shape[1]):\n # Create the axis line\n ax = fig.add_subplot(row, column, i + 1)\n fig.subplots_adjust(hspace = .5)\n # Create histogram for each variable\n sns.distplot(data.iloc[:, i], ax=ax)\n\n # Show the plot\n plt.show()\n \nsubplot_hist(data.iloc[:, :-1], row = 4, column = 3, title = \"Histogram of the Black Predictors\")\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[175]:\n\n\nage = np.unique(data['Age'])\nage\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[176]:\n\n\ncity_stay = np.unique(data['Stay_In_Current_City_Years'])\ncity_stay\n\n\n# In[ ]:\n\n\n\n\n\n# In[177]:\n\n\ncity_category = np.unique(data['City_Category'])\ncity_category\n\n\n# In[ ]:\n\n\n\n\n\n# In[178]:\n\n\ngender = np.unique(data['Gender'])\ngender\n\n\n# In[ ]:\n\n\n\n\n\n# In[179]:\n\n\nY = data[\"Purchase\"]\n\n\n# In[ ]:\n\n\n\n\n\n# In[180]:\n\n\nfrom sklearn.preprocessing import StandardScaler\nSS = StandardScaler()\n\n\n# In[ ]:\n\n\n\n\n\n# In[181]:\n\n\nX = data.drop([\"Purchase\"], axis=1)\nX\n\n\n# In[184]:\n\n\nX.iloc[:, :-3],\n\n\n# In[206]:\n\n\nfrom sklearn.model_selection import train_test_split\nx_over_train,x_over_test,y_over_train,y_over_test = train_test_split(X,Y,test_size=0.2,random_state=3)\n\n\n# In[214]:\n\n\nfrom sklearn.metrics import mean_squared_error\n\ndef rmse(y_,y):\n return mean_squared_error(y_,y)**0.5\n\ndef rmse_scorer(model,X,Y):\n y_ = model.predict(X)\n return rmse(y_,Y)\nfrom xgboost import XGBRegressor\nfrom hyperopt import hp,fmin,tpe\nfrom sklearn.model_selection import cross_val_score, KFold\n\ndef objective(params):\n params = {\n 'n_estimators' : int(params['n_estimators']),\n 'max_depth' : int(params['max_depth']),\n 'learning_rate' : float(params['learning_rate'])\n }\n \n clf = XGBRegressor(**params,n_jobs=4)\n score = cross_val_score(clf, X, Y, scoring = rmse_scorer, cv=KFold(n_splits=3)).mean()\n print(\"Parmas {} - {}\".format(params,score))\n return score\n\nspace = {\n 'n_estimators': hp.quniform('n_estimators', 50, 1000, 50),\n 'max_depth': hp.quniform('max_depth', 4, 20, 4),\n 'learning_rate' : hp.uniform('learning_rate',0.05, 0.2) \n}\n\nbest = fmin(fn=objective,\n space=space,\n algo=tpe.suggest,\n max_evals=10)\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[157]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n"
},
{
"alpha_fraction": 0.5434572100639343,
"alphanum_fraction": 0.5661185383796692,
"avg_line_length": 7.371527671813965,
"blob_id": "f422d39775cd587ecf941df3529b6056160b1a62",
"content_id": "78a2767f2fd40de63de1748f80560631149ea2e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7237,
"license_type": "no_license",
"max_line_length": 289,
"num_lines": 864,
"path": "/turkish/kurkiye_Done.py",
"repo_name": "ABHISHEK1105DS/Projects",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# In[1]:\n\n\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nimport statsmodels.api as sm\nimport statsmodels.formula.api as smf\nimport sklearn.metrics\nfrom sklearn import ensemble\nfrom sklearn import linear_model,datasets\nfrom sklearn.metrics import mean_squared_error\n\n\n# In[5]:\n\n\nda = pd.read_csv(r\"D:\\ml\\turkish\\turkiye.csv\")\n\n\n# In[7]:\n\n\nda\n\n\n# In[8]:\n\n\nda.head()\n\n\n# In[10]:\n\n\ndef missing_percentage(data1, col_name = \"Missing value (%)\"):\n # Calculating the missing percentage\n missing_df1 = pd.DataFrame(data1.isnull().sum() /len(data1)*100, columns = [col_name])\n # Forming the output dataframe\n missing_df = pd.DataFrame({'Data': missing_df1.iloc[:, 0]})\n return missing_df\n\nmissing_percentage(da)\n\n\n# In[11]:\n\n\n\"\"\"\nExploratory Data Analysis\nAs we have checked our data for the missing values, let shift our focus in understanding the data in much better way. Ww will be using visualization in order to do Exploratory Data Analysis(EDA). EDA is an approach for data analysis that employs a variety of techniques mostly graphical to\n\nMaximize insight into a data set\nUncover underlying structure\nExtract important variables\nDetect outliers and anomalies\nTest underlying assumptions\nDevelop parsimonious models\nDetermine optimal factor settings\"\"\"\n\n\n# In[15]:\n\n\n\nda.isnull().sum()\n\n\n# In[16]:\n\n\nda.head()\n\n\n# In[17]:\n\n\nda['instr'].value_counts().plot.bar()\n\n\n# In[46]:\n\n\n\nda['class'].value_counts().plot.bar()\n\n\n# In[84]:\n\n\ndef subplot_hist(data, row = 4, column = 3, title = \"Subplots\", height = 20, width = 19):\n # Create a figure instance, and the two subplots\n fig = plt.figure(figsize = (width, height))\n fig.suptitle(title, fontsize=25, y = 0.93)\n # Run loop over the all the variables\n for i in range(data.shape[1]):\n # Create the axis line\n ax = fig.add_subplot(row, column, i + 1)\n fig.subplots_adjust(hspace = .5)\n # Create histogram for each variable\n sns.distplot(da.iloc[:, i], ax=ax)\n\n # Show the plot\n plt.show()\n \nsubplot_hist(da.iloc[:, :5], row = 4, column = 3, title = \"Histogram of Dataset\")\n\n\n# In[ ]:\n\n\n\n\n\n# In[86]:\n\n\n# for finding skew value\nfrom scipy import stats as st \n\n# Computing the skewness into dataFrame\ndef skewness_check(data):\n # Find the skewness in the dataset\n skew_value = list(st.skew(data))\n skew_string = []\n # Looping through the skew value to find the Skew category\n for skew in skew_value:\n if skew >= -.5 and skew <= .5:\n skew_string.append(\"Light Skewed\")\n elif skew <= -.5 and skew >= -1 and skew <= .5 and skew >= 1:\n skew_string.append(\"Moderately Skewed\")\n else:\n skew_string.append(\"Heavily Skewed\")\n # Ctreating data frame\n skew_df = pd.DataFrame({'Column': data.columns, 'Skewness': skew_value, 'Skew Category': skew_string})\n return skew_df\n\n# Skewness for Red Wine\nskewness_check(da.iloc[:, :5])\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[116]:\n\n\nda[[\"attendance\"]] += 0.1\nda[[\"nb.repeat\"]]+=.1\ndef boxcox_trans(data):\n for i in range(data.shape[1]):\n data.iloc[:, i], _ = st.boxcox(data.iloc[:, i])\n return data\n# Subset the predcitors\nred_trans = da.copy(deep = True)\nred_trans.iloc[:, :-1] = boxcox_trans(red_trans.iloc[:, :5])\nskewness_check(red_trans.iloc[:, :5])\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[101]:\n\n\nprint('Skewness',red_trans['nb.repeat'].skew())\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[115]:\n\n\nprint('Skewness',red_trans['nb.repeat'].skew())\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[67]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[117]:\n\n\n\nred_trans['nb.repeat'].plot()\nprint('Skewness',red_trans['nb.repeat'].skew())\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[120]:\n\n\ndataset_questions = da.iloc[:,5:33]\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[121]:\n\n\n\ndataset_questions\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[114]:\n\n\n#lets do a PCA for feature dimensional reduction\nfrom sklearn.decomposition import PCA\npca = PCA(n_components = 2)\ndataset_questions_pca = pca.fit_transform(dataset_questions)\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[75]:\n\n\nfrom sklearn.cluster import KMeans\nres=[]\nfor i in range(1, 7):\n kmeans = KMeans(n_clusters = i, init = 'k-means++', random_state = 42)\n kmeans.fit(dataset_questions_pca)\n res.append(kmeans.inertia_)\nplt.figure(figsize=(12,6))\nplt.plot(range(1, 7), res,marker = \"o\")\nplt.title('The Elbow Method')\nplt.xlabel('Number of clusters')\nplt.ylabel('res')\nplt.show()\n\n\n# In[ ]:\n\n\n\n\n\n# In[76]:\n\n\nkmeans = KMeans(n_clusters = 3, init = 'k-means++')\ny_kmeans = kmeans.fit_predict(dataset_questions_pca)\n\n\n# In[ ]:\n\n\n\n\n\n# In[77]:\n\n\n# Visualising the clusters\nplt.scatter(dataset_questions_pca[y_kmeans == 0, 0], dataset_questions_pca[y_kmeans == 0, 1], s = 100, c = 'yellow', label = 'Cluster 1')\nplt.scatter(dataset_questions_pca[y_kmeans == 1, 0], dataset_questions_pca[y_kmeans == 1, 1], s = 100, c = 'green', label = 'Cluster 2')\nplt.scatter(dataset_questions_pca[y_kmeans == 2, 0], dataset_questions_pca[y_kmeans == 2, 1], s = 100, c = 'red', label = 'Cluster 3')\nplt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s = 300, c = 'blue', label = 'Centroids')\nplt.title('Clusters of students')\nplt.xlabel('PCA 1')\nplt.ylabel('PCA 2')\nplt.legend()\nplt.show()\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[43]:\n\n\ndataset_questions_pca.shape\n\n\n# In[78]:\n\n\nda.skew()\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[30]:\n\n\nimport collections\ncollections.Counter(y_kmeans)\n\n\n# In[32]:\n\n\nimport scipy.cluster.hierarchy as sch\ndendrogram = sch.dendrogram(sch.linkage(dataset_questions_pca, method = 'ward'))\nplt.title('Dendrogram')\nplt.xlabel('questions')\nplt.ylabel('Euclidean distances')\nplt.show()\n\n\n# In[33]:\n\n\nfrom sklearn.cluster import AgglomerativeClustering\nhc = AgglomerativeClustering(n_clusters = 2, affinity = 'euclidean', linkage = 'ward')\ny_hc = hc.fit_predict(dataset_questions_pca)\nX = dataset_questions_pca\n# Visualising the clusters\nplt.scatter(X[y_hc == 0, 0], X[y_hc == 0, 1], s = 100, c = 'yellow', label = 'Cluster 1')\nplt.scatter(X[y_hc == 1, 0], X[y_hc == 1, 1], s = 100, c = 'red', label = 'Cluster 2')\nplt.title('Clusters of STUDENTS')\nplt.xlabel('PCA 1')\nplt.ylabel('PCA 2')\nplt.legend()\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n"
},
{
"alpha_fraction": 0.6756078004837036,
"alphanum_fraction": 0.7135682106018066,
"avg_line_length": 22.22231674194336,
"blob_id": "f1068516c0e7d54f7a7330e95a393d1d76a90833",
"content_id": "bb0e271b748d7c8d2c5ea7e1843953e15ef94dc7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 27543,
"license_type": "no_license",
"max_line_length": 632,
"num_lines": 1183,
"path": "/TIME-ANALYSIS-SERIES/time_series_analysis.py",
"repo_name": "ABHISHEK1105DS/Projects",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# In[3]:\n\n\n# Importing libraries\nfrom plotly import tools\n\nfrom plotly.offline import init_notebook_mode, iplot\ninit_notebook_mode(connected=True)\nimport plotly.graph_objs as go\nimport plotly.figure_factory as ff\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[4]:\n\n\nimport warnings\nwarnings.filterwarnings('ignore')\nimport numpy as np \nimport pandas as pd\nimport matplotlib.pyplot as plt\nplt.style.use('fivethirtyeight') \n# Above is a special style template for matplotlib, highly useful for visualizing time series data\nget_ipython().run_line_magic('matplotlib', 'inline')\nfrom pylab import rcParams\n\nimport statsmodels.api as sm\nfrom numpy.random import normal, seed\nfrom scipy.stats import norm\nfrom statsmodels.tsa.arima_model import ARMA\nfrom statsmodels.tsa.stattools import adfuller\nfrom statsmodels.graphics.tsaplots import plot_acf, plot_pacf\nfrom statsmodels.tsa.arima_process import ArmaProcess\nfrom statsmodels.tsa.arima_model import ARIMA\nimport math\nfrom sklearn.metrics import mean_squared_error\n\n\n# In[5]:\n\n\n# importing data\n# Google Stocks Data,Humidity in different world cities,Microsoft Stocks Data,Pressure in different world cities\n\n\n# In[6]:\n\n\ngoogle = pd.read_csv('D:/ml/stock-time-series-20050101-to-20171231/GOOGL_2006-01-01_to_2018-01-01.csv', index_col='Date', parse_dates=['Date'])\ngoogle.head()\n\n\n# In[7]:\n\n\nhumidity = pd.read_csv('D:/ml/historical-hourly-weather-data/humidity.csv', index_col='datetime', parse_dates=['datetime'])\nhumidity.tail()\n\n\n# In[8]:\n\n\nhumidity.describe()\n\n\n# In[9]:\n\n\ngoogle.describe()\n\n\n# In[10]:\n\n\ngoogle.info()\n\n\n# In[11]:\n\n\nhumidity.info()\n\n\n# In[12]:\n\n\n# Cleaning and preparing time series data\n#Google stocks data doesn't have any missing values but humidity data does have its fair share of missing values. It is cleaned using fillna() method with ffill parameter which propagates last valid observation to fill gaps \n\n\n# In[13]:\n\n\nhumidity.tail()\n\n\n# In[14]:\n\n\nhumidity = humidity.iloc[1:]\n\n\n# In[15]:\n\n\nhumidity = humidity.fillna(method='ffill')\n\n\n# In[129]:\n\n\nhumidity[\"Montreal\"].diff().iloc[1:].values.shape\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[17]:\n\n\n# Visualizing the datasets\nhumidity[\"Kansas City\"].asfreq('M').plot() # asfreq method is used to convert a time series to a specified frequency. Here it is monthly frequency.\nplt.title('Humidity in Kansas City over time(Monthly frequency)')\nplt.show()\n\n\n# In[18]:\n\n\ngoogle['2008':'2010'].plot(subplots=True, figsize=(10,12))\nplt.title('Google stock attributes from 2008 to 2010')\nplt.savefig('stocks.png')\nplt.show()\n# if sublot paramater is false no open high low andd close graph will be there\n\n\n# In[19]:\n\n\n# Timestamps and Periods\n# Timestamps are used to represent a point in time. Periods represent an interval in time. Periods can used to check if a specific event in the given period. They can also be converted to each other's form.\n\n\n# In[20]:\n\n\n# Creating a Timestamp\ntimestamp = pd.Timestamp(2017, 1, 1, 12)\ntimestamp\n\n\n# In[21]:\n\n\n# Creating a period\nperiod = pd.Period('2017-01-01')\nperiod\n\n\n# In[22]:\n\n\n# Checking if the given timestamp exists in the given period\nperiod.start_time < timestamp < period.end_time\n\n\n# In[23]:\n\n\n# Converting timestamp to period\nnew_period = timestamp.to_period(freq='H')\nnew_period\n\n\n# In[24]:\n\n\n# Converting period to timestamp\nnew_timestamp = period.to_timestamp(freq='H', how='start')\nnew_timestamp\n\n\n# In[25]:\n\n\n# date_range is a method that returns a fixed frequency datetimeindex. It is quite useful when creating your own time series attribute for pre-existing data or arranging the whole data around the time series attribute created by you.\n\n\n# In[26]:\n\n\n# Creating a datetimeindex with daily frequency\ndr1 = pd.date_range(start='1/1/18', end='1/9/18')\ndr1\n\n\n# In[27]:\n\n\n# Creating a datetimeindex with monthly frequency\ndr2 = pd.date_range(start='1/1/18', end='1/1/19', freq='M')\ndr2\n\n\n# In[28]:\n\n\n# Creating a datetimeindex without specifying start date and using periods\ndr3 = pd.date_range(end='1/4/2014', periods=8)\ndr3\n\n\n# In[29]:\n\n\n# Creating a datetimeindex specifying start date , end date and periods\ndr4 = pd.date_range(start='2013-04-24', end='2014-11-27', periods=3)\ndr4\n\n\n# In[30]:\n\n\n# Using to_datetime\n# pandas.to_datetime() is used for converting arguments to datetime. Here, a DataFrame is converted to a datetime series.\n\n\n# In[31]:\n\n\ndf = pd.DataFrame({'year': [2015, 2016], 'month': [2, 3], 'day': [4, 5]})\ndf\n\n\n# In[32]:\n\n\ndf = pd.to_datetime(df)\ndf\n\n\n# In[33]:\n\n\ndf = pd.to_datetime('01-01-2017')\ndf\n\n\n# In[35]:\n\n\n# Shifting and lags\n# We can shift index by desired number of periods with an optional time frequency. This is useful when comparing the time series with a past of itself\nhumidity[\"Vancouver\"].asfreq('M').plot(legend=True)\nshifted = humidity[\"Vancouver\"].asfreq('M').shift(10).plot(legend=True)\nshifted.legend(['Vancouver','Vancouver_lagged'])\nplt.show()\n\n\n# In[41]:\n\n\n# Resampling\n# Upsampling - Time series is resampled from low frequency to high frequency(Monthly to daily frequency). It involves filling or interpolating missing data\n# Downsampling - Time series is resampled from high frequency to low frequency(Weekly to monthly frequency). It involves aggregation of existing data.\n# First, we used ffill parameter which propagates last valid observation to fill gaps. Then we use bfill to propogate next valid observation to fill gaps.\n\n\n# In[37]:\n\n\n# # Let's use pressure data to demonstrate this\npressure = pd.read_csv('D:/ml/historical-hourly-weather-data/pressure.csv', index_col='datetime', parse_dates=['datetime'])\npressure.tail()\n\n\n# In[39]:\n\n\npressure = pressure.iloc[1:]\npressure = pressure.fillna(method='ffill')\n# ffil mean previously filled value along that axis\npressure.tail()\n\n\n# In[40]:\n\n\n# bfil mean next filled value along that axis\n\npressure = pressure.fillna(method='bfill')\npressure.head()\n\n\n# In[42]:\n\n\n# Shape before resampling(downsampling)\npressure.shape\n\n\n# In[43]:\n\n\npressure.head()\n\n\n# In[44]:\n\n\n# We downsample from hourly to 3 day frequency aggregated using mean\npressure = pressure.resample('3D').mean()\npressure.head()\n\n\n# In[45]:\n\n\n# Shape after resampling(downsampling)\npressure.shape\n\n\n# In[46]:\n\n\n# Much less rows are left. Now, we will upsample from 3 day frequency to daily frequency\n\n\n# In[47]:\n\n\npressure = pressure.resample('D').pad()\npressure.head()\n\n\n# In[48]:\n\n\n# Shape after resampling(upsampling)\npressure.shape\n\n\n# In[49]:\n\n\n# Finance and statistics\n\n\n# In[55]:\n\n\n# Percent change\ngoogle['Change'] = google.High.div(google.High.shift())\ngoogle['Change'].plot(figsize=(20,8))\n\n\n# In[57]:\n\n\n# Stock returns\ngoogle['Return'] = google.Change.sub(1).mul(100)\ngoogle['Return'].plot(figsize=(20,8))\n\n\n# In[58]:\n\n\ngoogle.High.pct_change().mul(100).plot(figsize=(20,6)) # Another way to calculate returns\n\n\n# In[59]:\n\n\n# Absolute change in successive rows\ngoogle.High.diff().plot(figsize=(20,6))\n\n\n# In[60]:\n\n\n# Comaring two or more time series\n# We will compare 2 time series by normalizing them. This is achieved by dividing each time series element of all time series by the first element. This way both series start at the same point and can be easily compared.\n\n\n# In[61]:\n\n\n# # We choose microsoft stocks to compare them with google\nmicrosoft = pd.read_csv('D:/ml/stock-time-series-20050101-to-20171231/MSFT_2006-01-01_to_2018-01-01.csv', index_col='Date', parse_dates=['Date'])\n\n\n# In[62]:\n\n\n# Plotting before normalization\ngoogle.High.plot()\nmicrosoft.High.plot()\nplt.legend(['Google','Microsoft'])\nplt.show()\n\n\n# In[63]:\n\n\n# Normalizing and comparison\n# Both stocks start from 100\nnormalized_google = google.High.div(google.High.iloc[0]).mul(100)\nnormalized_microsoft = microsoft.High.div(microsoft.High.iloc[0]).mul(100)\nnormalized_google.plot()\nnormalized_microsoft.plot()\nplt.legend(['Google','Microsoft'])\nplt.show()\n\n\n# In[64]:\n\n\n# You can clearly see how google outperforms microsoft over time.\n# Window functions\n# Window functions are used to identify sub periods, calculates sub-metrics of sub-periods.\n# Rolling - Same size and sliding\n# Expanding - Contains all prior values\n\n\n# In[65]:\n\n\n# Rolling window functions\nrolling_google = google.High.rolling('90D').mean()\ngoogle.High.plot()\nrolling_google.plot()\nplt.legend(['High','Rolling Mean'])\n# Plotting a rolling mean of 90 day window with original High attribute of google stocks\nplt.show()\n\n\n# In[66]:\n\n\n# Now, observe that rolling mean plot is a smoother version of the original plot.\n\n\n# In[67]:\n\n\n# Expanding window functions\nmicrosoft_mean = microsoft.High.expanding().mean()\nmicrosoft_std = microsoft.High.expanding().std()\nmicrosoft.High.plot()\nmicrosoft_mean.plot()\nmicrosoft_std.plot()\nplt.legend(['High','Expanding Mean','Expanding Standard Deviation'])\nplt.show()\n\n\n# In[68]:\n\n\n# OHLC charts\n\n\n# In[69]:\n\n\n\"\"\"\nAn OHLC chart is any type of price chart that shows the open, high, low and close price of a certain time period. Open-high-low-close Charts (or OHLC Charts) are used as a trading tool to visualise and analyse the price changes over time for securities, currencies, stocks, bonds, commodities, etc. OHLC Charts are useful for interpreting the day-to-day sentiment of the market and forecasting any future price changes through the patterns produced.\n\nThe y-axis on an OHLC Chart is used for the price scale, while the x-axis is the timescale. On each single time period, an OHLC Charts plots a symbol that represents two ranges: the highest and lowest prices traded, and also the opening and closing price on that single time period (for example in a day). On the range symbol, the high and low price ranges are represented by the length of the main vertical line. The open and close prices are represented by the vertical positioning of tick-marks that appear on the left (representing the open price) and on right (representing the close price) sides of the high-low vertical line.\nColour can be assigned to each OHLC Chart symbol, to distinguish whether the market is \"bullish\" (the closing price is higher then it opened) or \"bearish\" (the closing price is lower then it opened).\n\"\"\"\n\n\n# In[70]:\n\n\n# OHLC chart of June 2008\ntrace = go.Ohlc(x=google['06-2008'].index,\n open=google['06-2008'].Open,\n high=google['06-2008'].High,\n low=google['06-2008'].Low,\n close=google['06-2008'].Close)\ndata = [trace]\niplot(data, filename='simple_ohlc')\n\n\n# In[71]:\n\n\n# OHLC chart of 2008\ntrace = go.Ohlc(x=google['2008'].index,\n open=google['2008'].Open,\n high=google['2008'].High,\n low=google['2008'].Low,\n close=google['2008'].Close)\ndata = [trace]\niplot(data, filename='simple_ohlc')\n\n\n# In[72]:\n\n\n# Candlestick charts\n\"\"\"This type of chart is used as a trading tool to visualise and analyse the price movements over time for securities, derivatives, currencies, stocks, bonds, commodities, etc. Although the symbols used in Candlestick Charts resemble a Box Plot, they function differently and therefore, are not to be confused with one another.\n\nCandlestick Charts display multiple bits of price information such as the open price, close price, highest price and lowest price through the use of candlestick-like symbols. Each symbol represents the compressed trading activity for a single time period (a minute, hour, day, month, etc). Each Candlestick symbol is plotted along a time scale on the x-axis, to show the trading activity over time.\n\nThe main rectangle in the symbol is known as the real body, which is used to display the range between the open and close price of that time period. While the lines extending from the bottom and top of the real body is known as the lower and upper shadows (or wick). Each shadow represents the highest or lowest price traded during the time period represented. When the market is Bullish (the closing price is higher than it opened), then the body is coloured typically white or green. But when the market is Bearish (the closing price is lower than it opened), then the body is usually coloured either black or red.\nCandlestick Charts are great for detecting and predicting market trends over time and are useful for interpreting the day-to-day sentiment of the market, through each candlestick symbol's colouring and shape. For example, the longer the body is, the more intense the selling or buying pressure is. While, a very short body, would indicate that there is very little price movement in that time period and represents consolidation.\n\nCandlestick Charts help reveal the market psychology (the fear and greed experienced by sellers and buyers) through the various indicators, such as shape and colour, but also by the many identifiable patterns that can be found in Candlestick Charts. In total, there are 42 recognised patterns that are divided into simple and complex patterns. These patterns found in Candlestick Charts are useful for displaying price relationships and can be used for predicting the possible future movement of the market. You can find a list and description of each pattern here.\n\nPlease bear in mind, that Candlestick Charts don't express the events taking place between the open and close price - only the relationship between the two prices. So you can't tell how volatile trading was within that single time period.\n\"\"\"\n\n\n# In[73]:\n\n\n# Candlestick chart of march 2008\ntrace = go.Candlestick(x=google['03-2008'].index,\n open=google['03-2008'].Open,\n high=google['03-2008'].High,\n low=google['03-2008'].Low,\n close=google['03-2008'].Close)\ndata = [trace]\niplot(data, filename='simple_candlestick')\n\n\n# In[74]:\n\n\n# Candlestick chart of 2008\ntrace = go.Candlestick(x=google['2008'].index,\n open=google['2008'].Open,\n high=google['2008'].High,\n low=google['2008'].Low,\n close=google['2008'].Close)\ndata = [trace]\niplot(data, filename='simple_candlestick')\n\n\n# In[75]:\n\n\n# Candlestick chart of 2006-2018\ntrace = go.Candlestick(x=google.index,\n open=google.Open,\n high=google.High,\n low=google.Low,\n close=google.Close)\ndata = [trace]\niplot(data, filename='simple_candlestick')\n\n\n# In[ ]:\n\n\n# Autocorrelation and Partial Autocorrelation¶\n# Autocorrelation - The autocorrelation function (ACF) measures how a series is correlated with itself at different lags.\n# Partial Autocorrelation - The partial autocorrelation function can be interpreted as a regression of the series against its past lags. The terms can be interpreted the same way as a standard linear regression, that is the contribution of a change in that particular lag while holding others constant.\n\n\n# In[76]:\n\n\n# Autocorrelation of humidity of San Diego\nplot_acf(humidity[\"San Diego\"],lags=25,title=\"San Diego\")\nplt.show()\n\n\n# In[77]:\n\n\n# As all lags are either close to 1 or at least greater than the confidence interval, they are statistically significant.\n\n\n# In[78]:\n\n\n# Partial Autocorrelation of humidity of San Diego\nplot_pacf(humidity[\"San Diego\"],lags=25)\nplt.show()\n\n\n# In[79]:\n\n\n# Though it is statistically signficant, partial autocorrelation after first 2 lags is very low.\n\n\n# In[80]:\n\n\n# Partial Autocorrelation of closing price of microsoft stocks\nplot_pacf(microsoft[\"Close\"],lags=25)\nplt.show()\n\n\n# In[81]:\n\n\n# Here, only 0th, 1st and 20th lag are statistically significan\n\n\n# In[82]:\n\n\n# Time series decomposition and Random walks\n\n\n# In[ ]:\n\n\n# Trends, seasonality and noise\n# These are the components of a time series\n# Trend - Consistent upwards or downwards slope of a time series\n# Seasonality - Clear periodic pattern of a time series(like sine funtion)\n# Noise - Outliers or missing values\n\n\n# In[83]:\n\n\n# Let's take Google stocks High for this\ngoogle[\"High\"].plot(figsize=(16,8))\n\n\n# In[84]:\n\n\n# Now, for decomposition...\nrcParams['figure.figsize'] = 11, 9\ndecomposed_google_volume = sm.tsa.seasonal_decompose(google[\"High\"],freq=360) # The frequncy is annual\nfigure = decomposed_google_volume.plot()\nplt.show()\n\n\n# In[ ]:\n\n\n# There is clearly an upward trend in the above plot.\n# You can also see the uniform seasonal change.\n# Non-uniform noise that represent outliers and missing values\n\n\n# In[85]:\n\n\n# White noise\n# White noise has...\n# Constant mean\n# Constant variance\n# Zero auto-correlation at all lags\n\n\n# In[86]:\n\n\n# Plotting white noise\nrcParams['figure.figsize'] = 16, 6\nwhite_noise = np.random.normal(loc=0, scale=1, size=1000)\n# loc is mean, scale is variance\nplt.plot(white_noise)\n\n\n# In[87]:\n\n\n# Plotting autocorrelation of white noise\nplot_acf(white_noise,lags=20)\nplt.show()\n\n\n# In[ ]:\n\n\n# See how all lags are statistically insigficant as they lie inside the confidence interval(shaded portion).\n\n\n# In[ ]:\n\n\n# Random Walk\n\"\"\"\nA random walk is a mathematical object, known as a stochastic or random process, that describes a path that consists of a succession of random steps on some mathematical space such as the integers.\n\nIn general if we talk about stocks, Today's Price = Yesterday's Price + Noise\n\nPt = Pt-1 + εt\nRandom walks can't be forecasted because well, noise is random.\n\nRandom Walk with Drift(drift(μ) is zero-mean)\n\nPt - Pt-1 = μ + εt\n\nRegression test for random walk\n\nPt = α + βPt-1 + εt\nEquivalent to Pt - Pt-1 = α + βPt-1 + εt\n\nTest:\n\nH0: β = 1 (This is a random walk)\nH1: β < 1 (This is not a random walk)\n\nDickey-Fuller Test:\n\nH0: β = 0 (This is a random walk)\nH1: β < 0 (This is not a random walk)\nAugmented Dickey-Fuller test\nAn augmented Dickey–Fuller test (ADF) tests the null hypothesis that a unit root is present in a time series sample. It is basically Dickey-Fuller test with more lagged changes on RHS\n\n\n# In[88]:\n\n\n# Augmented Dickey-Fuller test on volume of google and microsoft stocks \nadf = adfuller(microsoft[\"Volume\"])\nprint(\"p-value of microsoft: {}\".format(float(adf[1])))\nadf = adfuller(google[\"Volume\"])\nprint(\"p-value of google: {}\".format(float(adf[1])))\n\n\n# In[ ]:\n\n\n# both are rejected as p value less than 0.05 so null ypothesis is rejected and this is not a random walk.\n\n\n# In[ ]:\n\n\n# Generating a random walk\n\n\n# In[89]:\n\n\nseed(42)\nrcParams['figure.figsize'] = 16, 6\nrandom_walk = normal(loc=0, scale=0.01, size=1000)\nplt.plot(random_walk)\nplt.show()\n\n\n# In[90]:\n\n\nfig = ff.create_distplot([random_walk],['Random Walk'],bin_size=0.001)\niplot(fig, filename='Basic Distplot')\n\n\n# In[ ]:\n\n\n\"\"\"\nStationarity\nA stationary time series is one whose statistical properties such as mean, variance, autocorrelation, etc. are all constant over time.\n\nStrong stationarity: is a stochastic process whose unconditional joint probability distribution does not change when shifted in time. Consequently, parameters such as mean and variance also do not change over time.\nWeak stationarity: is a process where mean, variance, autocorrelation are constant throughout the time\n\nStationarity is important as non-stationary series that depend on time have too many parameters to account for when modelling the time series. diff() method can easily convert a non-stationary series to a stationary series.\n\nWe will try to decompose seasonal component of the above decomposed time series.\n\"\"\"\n\n\n# In[94]:\n\n\n# The original non-stationary plot\ndecomposed_google_volume.trend.plot()\n\n\n# In[92]:\n\n\n# The new stationary plot\ndecomposed_google_volume.trend.diff().plot()\n\n\n# In[95]:\n\n\n# Modelling using statstools¶\n\n\n# In[96]:\n\n\n# AR modelS\n# An autoregressive (AR) model is a representation of a type of random process; as such, it is used to describe certain time-varying processes in nature, economics, etc. The autoregressive model specifies that the output variable depends linearly on its own previous values and on a stochastic term (an imperfectly predictable term); thus the model is in the form of a stochastic difference equation.\n\n# AR(1) model\n# Rt = μ + ϕRt-1 + εt\n\n# As RHS has only one lagged value(Rt-1)this is called AR model of order 1 where μ is mean and ε is noise at time t\n# If ϕ = 1, it is random walk. Else if ϕ = 0, it is white noise. Else if -1 < ϕ < 1, it is stationary. If ϕ is -ve, there is men reversion. If ϕ is +ve, there is momentum.\n\n# AR(2) model\n# Rt = μ + ϕ1Rt-1 + ϕ2Rt-2 + εt\n\n# AR(3) model\n# Rt = μ + ϕ1Rt-1 + ϕ2Rt-2 + ϕ3Rt-3 + εt\n\n\n# In[97]:\n\n\n# Simulating AR(1) model\nrcParams['figure.figsize'] = 16, 12\nplt.subplot(4,1,1)\nar1 = np.array([1, -0.9]) # We choose -0.9 as AR parameter is +0.9\nma1 = np.array([1])\nAR1 = ArmaProcess(ar1, ma1)\nsim1 = AR1.generate_sample(nsample=1000)\nplt.title('AR(1) model: AR parameter = +0.9')\nplt.plot(sim1)\n# We will take care of MA model later\n# AR(1) MA(1) AR parameter = -0.9\nplt.subplot(4,1,2)\nar2 = np.array([1, 0.9]) # We choose +0.9 as AR parameter is -0.9\nma2 = np.array([1])\nAR2 = ArmaProcess(ar2, ma2)\nsim2 = AR2.generate_sample(nsample=1000)\nplt.title('AR(1) model: AR parameter = -0.9')\nplt.plot(sim2)\n# AR(2) MA(1) AR parameter = 0.9\nplt.subplot(4,1,3)\nar3 = np.array([2, -0.9]) # We choose -0.9 as AR parameter is +0.9\nma3 = np.array([1])\nAR3 = ArmaProcess(ar3, ma3)\nsim3 = AR3.generate_sample(nsample=1000)\nplt.title('AR(2) model: AR parameter = +0.9')\nplt.plot(sim3)\n# AR(2) MA(1) AR parameter = -0.9\nplt.subplot(4,1,4)\nar4 = np.array([2, 0.9]) # We choose +0.9 as AR parameter is -0.9\nma4 = np.array([1])\nAR4 = ArmaProcess(ar4, ma4)\nsim4 = AR4.generate_sample(nsample=1000)\nplt.title('AR(2) model: AR parameter = -0.9')\nplt.plot(sim4)\nplt.show()\n\n\n# In[98]:\n\n\n# Forecasting a simulated model\nmodel = ARMA(sim1, order=(1,0))\nresult = model.fit()\nprint(result.summary())\nprint(\"μ={} ,ϕ={}\".format(result.params[0],result.params[1]))\n\n\n# In[100]:\n\n\n# ϕ is around 0.9 which is what we chose as AR parameter in our first simulated model.\n\n\n# In[101]:\n\n\n# Predicting the models\n\n\n# In[102]:\n\n\n# Predicting simulated AR(1) model \nresult.plot_predict(start=900, end=1010)\nplt.show()\n\n\n# In[103]:\n\n\nrmse = math.sqrt(mean_squared_error(sim1[900:1011], result.predict(start=900,end=999)))\nprint(\"The root mean squared error is {}.\".format(rmse))\n\n\n# In[122]:\n\n\n# Predicting humidity level of Montreal\nhumid = ARMA(humidity[\"Montreal\"].diff().iloc[1:].values, order=(1,0))\nres = humid.fit()\nres.plot_predict(start=1000, end=1100)\nplt.show()\nres.predict(start=27,end=36)\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n\n# In[105]:\n\n\nrmse = math.sqrt(mean_squared_error(humidity[\"Montreal\"].diff().iloc[900:1000].values, result.predict(start=900,end=999)))\nprint(\"The root mean squared error is {}.\".format(rmse))\n\n\n# In[106]:\n\n\n# Predicting closing prices of google\nhumid = ARMA(google[\"Close\"].diff().iloc[1:].values, order=(1,0))\nres = humid.fit()\nres.plot_predict(start=900, end=1010)\nplt.show()\n\n\n# In[107]:\n\n\n# The moving-average (MA) model is a common approach for modeling univariate time series. The moving-average model specifies that the output variable depends linearly on the current and various past values of a stochastic (imperfectly predictable) term.\n\n# MA(1) model\n# Rt = μ + ϵt1 + θϵt-1\n\n# It translates to Today's returns = mean + today's noise + yesterday's noise\n\n# As there is only 1 lagged value in RHS, it is an MA model of order 1\n\n\n# In[108]:\n\n\nrcParams['figure.figsize'] = 16, 6\nar1 = np.array([1])\nma1 = np.array([1, -0.5])\nMA1 = ArmaProcess(ar1, ma1)\nsim1 = MA1.generate_sample(nsample=1000)\nplt.plot(sim1)\n\n\n# In[109]:\n\n\n# Forecasting the simulated MA model\n\n\n# In[110]:\n\n\nmodel = ARMA(sim1, order=(0,1))\nresult = model.fit()\nprint(result.summary())\nprint(\"μ={} ,θ={}\".format(result.params[0],result.params[1]))\n\n\n# In[172]:\n\n\n#### Prediction using MA models¶\n\n\n# In[ ]:\n\n\n\n\n\n# In[112]:\n\n\n# Forecasting and predicting montreal humidity\nmodel = ARMA(humidity[\"Montreal\"].diff().iloc[1:].values, order=(0,3))\nresult = model.fit()\nprint(result.summary())\nprint(\"μ={} ,θ={}\".format(result.params[0],result.params[1]))\nresult.plot_predict(start=1000, end=1100)\nplt.show()\n\n\n# In[113]:\n\n\nrmse = math.sqrt(mean_squared_error(humidity[\"Montreal\"].diff().iloc[1000:1101].values, result.predict(start=1000,end=1100)))\nprint(\"The root mean squared error is {}.\".format(rmse))\n\n\n# In[ ]:\n\n\n# ARMA models\n# Autoregressive–moving-average (ARMA) models provide a parsimonious description of a (weakly) stationary stochastic process in terms of two polynomials, one for the autoregression and the second for the moving average. It's the fusion of AR and MA models.\n\n# ARMA(1,1) model\n# Rt = μ + ϕRt-1 + ϵt + θϵt-1\n# Basically, Today's return = mean + Yesterday's return + noise + yesterday's noise.\n\n\n# In[ ]:\n\n\n# Prediction using ARMA models\n# I am not simulating any model because it's quite similar to AR and MA models. Just forecasting and predictions for this one.\n\n\n# In[115]:\n\n\n# Forecasting and predicting microsoft stocks volume\nmodel = ARMA(microsoft[\"Volume\"].diff().iloc[1:].values, order=(3,3))\nresult = model.fit()\nprint(result.summary())\nprint(\"μ={}, ϕ={}, θ={}\".format(result.params[0],result.params[1],result.params[2]))\nresult.plot_predict(start=1000, end=1100)\nplt.show()\n\n\n# In[117]:\n\n\nrmse = math.sqrt(mean_squared_error(microsoft[\"Volume\"].diff().iloc[1000:1101].values, result.predict(start=1000,end=1100)))\nprint(\"The root mean squared error is {}.\".format(rmse))\n\n\n# In[ ]:\n\n\n\"\"\"\n ARIMA models\nAn autoregressive integrated moving average (ARIMA) model is a generalization of an autoregressive moving average (ARMA) model. Both of these models are fitted to time series data either to better understand the data or to predict future points in the series (forecasting). ARIMA models are applied in some cases where data show evidence of non-stationarity, where an initial differencing step (corresponding to the \"integrated\" part of the model) can be applied one or more times to eliminate the non-stationarity. ARIMA model is of the form: ARIMA(p,d,q): p is AR parameter, d is differential parameter, q is MA parameter\n\nARIMA(1,0,0)\nyt = a1yt-1 + ϵt\n\nARIMA(1,0,1)\nyt = a1yt-1 + ϵt + b1ϵt-1\n\nARIMA(1,1,1)\nΔyt = a1Δyt-1 + ϵt + b1ϵt-1 where Δyt = yt - yt-1\n\n\"\"\"\n\n\n# In[118]:\n\n\n# Predicting the microsoft stocks volume\nrcParams['figure.figsize'] = 16, 6\nmodel = ARIMA(microsoft[\"Volume\"].diff().iloc[1:].values, order=(2,1,0))\nresult = model.fit()\nprint(result.summary())\nresult.plot_predict(start=700, end=1000)\nplt.show()\n\n\n# In[135]:\n\n\nrmse = math.sqrt(mean_squared_error(microsoft[\"Volume\"].diff().iloc[700:1001].values, result.predict(start=700,end=1000)))\nprint(\"The root mean squared error is {}.\".format(rmse))\n\n\n# In[168]:\n\n\nresult.predict(start=700, end=1000)[240]\n\n\n# In[171]:\n\n\nmicrosoft[\"Volume\"].diff().iloc[1:][940]\n\n\n# In[ ]:\n\n\n\"\"\"\n\n1. Introduction to date and time\n 1.1 Importing time series data\n 1.2 Cleaning and preparing time series data\n 1.3 Visualizing the datasets\n 1.4 Timestamps and Periods\n 1.5 Using date_range\n 1.6 Using to_datetime\n 1.7 Shifting and lags\n 1.8 Resampling\n2. Finance and Statistics\n 2.1 Percent change\n 2.2 Stock returns\n 2.3 Absolute change in successive rows\n 2.4 Comaring two or more time series\n 2.5 Window functions\n 2.6 OHLC charts\n 2.7 Candlestick charts\n 2.8 Autocorrelation and Partial Autocorrelation\n3. Time series decomposition and Random Walks\n 3.1 Trends, Seasonality and Noise\n 3.2 White Noise\n 3.3 Random Walk\n 3.4 Stationarity\n4. Modelling using statsmodels\n 4.1 AR models\n 4.2 MA models\n 4.3 ARMA models\n 4.4 ARIMA models\n\"\"\"\n\n\n# In[ ]:\n\n\n\n\n\n# In[ ]:\n\n\n\n\n"
}
] | 7 |
marcoag/failover_cluster
|
https://github.com/marcoag/failover_cluster
|
52cd46ec25e98a43ec7bbe4582bc5008936c8cab
|
beb9485641ee87728073938d766723f763d369a5
|
80305e54a6cca0df64a51fa36ddd30097e64de8a
|
refs/heads/main
| 2023-03-26T18:00:09.119499 | 2021-03-03T07:21:41 | 2021-03-03T07:21:41 | 341,440,935 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6710396409034729,
"alphanum_fraction": 0.6749894022941589,
"avg_line_length": 37.1129035949707,
"blob_id": "d931d1f2c81354ddf88f38b9ed84d3d9768eb678",
"content_id": "08bde42fd05154ecfab86b5dc181a6eca1327cdb",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 7089,
"license_type": "permissive",
"max_line_length": 278,
"num_lines": 186,
"path": "/src/lifecycle_heartbeat.cpp",
"repo_name": "marcoag/failover_cluster",
"src_encoding": "UTF-8",
"text": "// Copyright (c) 2020 Mapless AI, Inc.\n//\n// Licensed under the Apache License, Version 2.0 (the \"License\");\n// you may not use this file except in compliance with the License.\n// You may obtain a copy of the License at\n//\n// http://www.apache.org/licenses/LICENSE-2.0\n//\n// Unless required by applicable law or agreed to in writing, software\n// distributed under the License is distributed on an \"AS IS\" BASIS,\n// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n// See the License for the specific language governing permissions and\n// limitations under the License.\n\n#include \"fail_demo/lifecycle_heartbeat.hpp\"\n\nusing namespace std::chrono_literals;\n\n\nconstexpr std::chrono::milliseconds LEASE_DELTA = 20ms; ///< Buffer added to heartbeat to define lease.\nconstexpr char DEFAULT_HEARTBEAT_NAME[] = \"heartbeat\";\nconstexpr char DEFAULT_WATCHDOGS_HEARTBEAT_NAME[] = \"watchdogs_heartbeat\";\n\nnamespace {\n\nvoid print_usage()\n{\n std::cout <<\n \"Usage: lifecycle_heartbeat [-h] --ros-args -p heartbeat_period:=value [...]\\n\\n\"\n \"required arguments:\\n\"\n \"\\tperiod: Period in positive integer milliseconds of the heartbeat signal.\\n\"\n \"optional arguments:\\n\"\n \"\\t-h : Print this help message.\" <<\n std::endl;\n}\n\n} // anonymous ns\n\nnamespace lifecycle_heartbeat\n{\n\n/// SimpleWatchdog inheriting from rclcpp_lifecycle::LifecycleNode\n/**\n * Internally relies on the QoS liveliness policy provided by rmw implementation (e.g., DDS).\n * The lease passed to this watchdog has to be > the period of the heartbeat signal to account\n * for network transmission times.\n */\nLifecycleHeartbeat::LifecycleHeartbeat(const rclcpp::NodeOptions& options)\n : rclcpp_lifecycle::LifecycleNode(\"lifecycle_heartbeat\", options),\n active_node_(false), heartbeat_topic_(DEFAULT_HEARTBEAT_NAME), \n qos_profile_(1), wakeup_topic_ (\"status_hd\"),\n watchdog_heartbeat_topic_(DEFAULT_WATCHDOGS_HEARTBEAT_NAME)\n{\n \n declare_parameter(\"heartbeat_period\");\n declare_parameter(\"active_node\");\n\n // Lease duration must be >= heartbeat's lease duration\n try {\n heartbeat_period_ = std::chrono::milliseconds(get_parameter(\"heartbeat_period\").as_int());\n active_node_ = get_parameter(\"active_node\").as_bool();\n } catch (...) {\n print_usage();\n // TODO: Update the rclcpp_components template to be able to handle\n // exceptions. Raise one here, so stack unwinding happens gracefully.\n std::exit(-1);\n }\n\n configure();\n activate();\n}\n\nvoid LifecycleHeartbeat::timer_callback()\n{\n\n auto message = sw_watchdog_msgs::msg::Heartbeat();\n rclcpp::Time now = this->get_clock()->now();\n message.stamp = now;\n RCLCPP_INFO(this->get_logger(), \"Publishing heartbeat sent at [%f]\", now.seconds());\n publisher_->publish(message);\n \n}\n\n/// Transition callback for state configuring\nrclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn LifecycleHeartbeat::on_configure(\n const rclcpp_lifecycle::State &)\n{\n // Initialize and configure node\n qos_profile_\n .liveliness(RMW_QOS_POLICY_LIVELINESS_MANUAL_BY_TOPIC)\n .liveliness_lease_duration(heartbeat_period_ + LEASE_DELTA)\n .deadline(heartbeat_period_ + LEASE_DELTA);\n \n //publish on /heartbeat if active node otherwise publish on /watchdogs_heartbeat\n if(active_node_)\n {\n publisher_ = this->create_publisher<sw_watchdog_msgs::msg::Heartbeat>(heartbeat_topic_, qos_profile_);\n }\n else\n {\n publisher_ = this->create_publisher<sw_watchdog_msgs::msg::Heartbeat>(watchdog_heartbeat_topic_, qos_profile_);\n }\n\n if(!status_sub_) {\n status_sub_ = this->create_subscription<sw_watchdog_msgs::msg::Status>(\n\n wakeup_topic_,\n 10,\n [this](const typename sw_watchdog_msgs::msg::Status::SharedPtr msg) -> void {\n if(!active_node_)\n {\n RCLCPP_INFO(get_logger(), \"Watchdog raised, self activation triggered\", msg->stamp.sec);\n std::flush(std::cout);\n deactivate();\n cleanup();\n active_node_=!active_node_;\n configure();\n activate();\n }\n else\n {\n system(\"ros2 run failover_cluster linktime_composition --ros-args -p heartbeat_period:=200 -p watchdog_period:=300 -p active_node:=false -r lifecycle_heartbeat:__node:=hb_bkp -r lifecycle_watchdog:__node:=wd_bkp -r lifecycle_talker:__node:=talker_bkp&\");\n }\n });\n }\n\n RCUTILS_LOG_INFO_NAMED(get_name(), \"on_configure() is called.\");\n return rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn::SUCCESS;\n}\n\n/// Transition callback for state activating\nrclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn LifecycleHeartbeat::on_activate(\n const rclcpp_lifecycle::State &)\n{\n \n timer_ = this->create_wall_timer(heartbeat_period_, std::bind(&LifecycleHeartbeat::timer_callback, this));\n \n publisher_->on_activate();\n\n //If it's the active_node start the watchdog node\n if(active_node_)\n system(\"ros2 run failover_cluster linktime_composition --ros-args -p heartbeat_period:=200 -p watchdog_period:=220 -p active_node:=false&\");\n\n // Starting from this point, all messages are sent to the network.\n RCUTILS_LOG_INFO_NAMED(get_name(), \"on_activate() is called.\");\n return rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn::SUCCESS;\n}\n \n/// Transition callback for state deactivating\nrclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn LifecycleHeartbeat::on_deactivate(\n const rclcpp_lifecycle::State &)\n{\n\n // Starting from this point, all messages are no longer sent to the network.\n publisher_->on_deactivate();\n\n RCUTILS_LOG_INFO_NAMED(get_name(), \"on_deactivate() is called.\");\n\n return rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn::SUCCESS;\n}\n\n/// Transition callback for state cleaningup\nrclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn LifecycleHeartbeat::on_cleanup(\n const rclcpp_lifecycle::State &)\n{\n publisher_.reset();\n status_sub_.reset();\n RCUTILS_LOG_INFO_NAMED(get_name(), \"on cleanup() is called.\");\n\n return rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn::SUCCESS;\n}\n\n/// Transition callback for state shutting down\nrclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn LifecycleHeartbeat::on_shutdown(\n const rclcpp_lifecycle::State &state)\n{\n publisher_.reset();\n\n RCUTILS_LOG_INFO_NAMED(get_name(), \"on shutdown is called from state %s.\", state.label().c_str());\n\n return rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn::SUCCESS;\n}\n \n} // namespace sw_watchdog\n\nRCLCPP_COMPONENTS_REGISTER_NODE(lifecycle_heartbeat::LifecycleHeartbeat)\n"
},
{
"alpha_fraction": 0.8260869383811951,
"alphanum_fraction": 0.8260869383811951,
"avg_line_length": 56.5,
"blob_id": "d955767391fc9008bfaa62118aff6227c359f941",
"content_id": "13183f254ad8a4b6a44afb441c2e8f578e6e2f96",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 115,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 2,
"path": "/README.md",
"repo_name": "marcoag/failover_cluster",
"src_encoding": "UTF-8",
"text": "# failover_cluster\nDemo that uses node composition of lifecycle nodes to achieve fail-over robustness on ROS nodes\n"
},
{
"alpha_fraction": 0.6271428465843201,
"alphanum_fraction": 0.6357142925262451,
"avg_line_length": 40.05882263183594,
"blob_id": "cda9a745649649e0b0e7d499d7b82faa741dc6c6",
"content_id": "a8555b7abc51e275fa54bad50d529c5eac815c6a",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 700,
"license_type": "permissive",
"max_line_length": 131,
"num_lines": 17,
"path": "/launch/failover_demo.launch.py",
"repo_name": "marcoag/failover_cluster",
"src_encoding": "UTF-8",
"text": "\n\nimport launch\nimport launch.actions\nimport launch.substitutions\nimport launch_ros.actions\n\ndef generate_launch_description():\n \n return launch.LaunchDescription([\n launch.actions.DeclareLaunchArgument('autostart', default_value=True, description='Auto start for the node and heartbeat'),\n launch_ros.actions.Node(\n package='failover_cluster', \n executable='linktime_composition', \n output='screen',\n name='linktime_composition',\n parameters=[{'heartbeat_period': 200,\n 'watchdog_period': 220,\n 'acitive_node': launch.substitutions.LaunchConfiguration('autostart')}])])\n"
},
{
"alpha_fraction": 0.6518483757972717,
"alphanum_fraction": 0.6538371443748474,
"avg_line_length": 37.85454559326172,
"blob_id": "ae7d999d04d9af01a2105cd57c8c2494a699f345",
"content_id": "759463edd79402734d99a15a2f57e70a0c45abea",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 8548,
"license_type": "permissive",
"max_line_length": 137,
"num_lines": 220,
"path": "/src/lifecycle_watchdog.cpp",
"repo_name": "marcoag/failover_cluster",
"src_encoding": "UTF-8",
"text": "// Copyright (c) 2020 Mapless AI, Inc.\n//\n// Licensed under the Apache License, Version 2.0 (the \"License\");\n// you may not use this file except in compliance with the License.\n// You may obtain a copy of the License at\n//\n// http://www.apache.org/licenses/LICENSE-2.0\n//\n// Unless required by applicable law or agreed to in writing, software\n// distributed under the License is distributed on an \"AS IS\" BASIS,\n// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n// See the License for the specific language governing permissions and\n// limitations under the License.\n\n#include \"fail_demo/lifecycle_watchdog.hpp\"\n\nusing namespace std::chrono_literals;\n\nconstexpr char OPTION_AUTO_START[] = \"--activate\";\nconstexpr char OPTION_PUB_STATUS[] = \"--publish\";\nconstexpr char DEFAULT_TOPIC_NAME[] = \"heartbeat\";\nconstexpr char DEFAULT_WATCHDOGS_HB_TOPIC_NAME[] = \"watchdogs_heartbeat\";\n\nnamespace {\n\nvoid print_usage()\n{\n std::cout <<\n \"Usage: lifecycle_watchdog lease [\" << OPTION_AUTO_START << \"] [-h]\\n\\n\"\n \"required arguments:\\n\"\n \"\\tlease: Lease in positive integer milliseconds granted to the watched entity.\\n\"\n \"optional arguments:\\n\"\n \"\\t\" << OPTION_AUTO_START << \": Start the watchdog on creation. Defaults to false.\\n\"\n \"\\t\" << OPTION_PUB_STATUS << \": Publish lease expiration of the watched entity. \"\n \"Defaults to false.\\n\"\n \"\\t-h : Print this help message.\" <<\n std::endl;\n}\n\n} // anonymous ns\n\nnamespace lifecycle_watchdog\n{\n\n/// LifecycleWatchdog inheriting from rclcpp_lifecycle::LifecycleNode\n/**\n * Internally relies on the QoS liveliness policy provided by rmw implementation (e.g., DDS).\n * The lease passed to this watchdog has to be > the period of the heartbeat signal to account\n * for network transmission times.\n */\nLifecycleWatchdog::LifecycleWatchdog(const rclcpp::NodeOptions& options)\n : rclcpp_lifecycle::LifecycleNode(\"lifecycle_watchdog\", options),\n active_node_(false), enable_pub_(true), hb_topic_name_(DEFAULT_TOPIC_NAME), \n watchdogs_hb_topic_name_(DEFAULT_WATCHDOGS_HB_TOPIC_NAME), qos_profile_(10)\n{\n \n declare_parameter(\"watchdog_period\");\n declare_parameter(\"active_node\");\n\n // Lease duration must be >= heartbeat's lease duration\n try {\n lease_duration_ = std::chrono::milliseconds(get_parameter(\"watchdog_period\").as_int());\n active_node_ = get_parameter(\"active_node\").as_bool();\n } catch (...) {\n print_usage();\n // TODO: Update the rclcpp_components template to be able to handle\n // exceptions. Raise one here, so stack unwinding happens gracefully.\n std::exit(-1);\n }\n \n configure();\n activate();\n \n}\n\n/// Publish lease expiry of the watched entity\nvoid LifecycleWatchdog::publish_status()\n{\n auto msg = std::make_unique<sw_watchdog_msgs::msg::Status>();\n rclcpp::Time now = this->get_clock()->now();\n msg->stamp = now;\n msg->missed_number = 1;\n\n // Print the current state for demo purposes\n if (!status_pub_->is_activated()) {\n RCLCPP_INFO(get_logger(),\n \"Lifecycle publisher is currently inactive. Messages are not published.\");\n } else {\n RCLCPP_INFO(get_logger(),\n \"Publishing lease expiry (missed count: %u) at [%f]\",\n msg->missed_number, now.seconds());\n status_pub_->publish(std::move(msg));\n }\n\n // Only if the publisher is in an active state, the message transfer is\n // enabled and the message actually published.\n}\n\nvoid LifecycleWatchdog::hb_missing_callback(rclcpp::QOSLivelinessChangedInfo &event)\n{\n printf(\"Reader Liveliness changed event: \\n\");\n// printf(\" alive_count: %d\\n\", event.alive_count);\n// printf(\" not_alive_count: %d\\n\", event.not_alive_count);\n// printf(\" alive_count_change: %d\\n\", event.alive_count_change);\n// printf(\" not_alive_count_change: %d\\n\", event.not_alive_count_change);\n if(event.alive_count == 0) {\n publish_status();\n // Transition lifecycle to deactivated state\n// RCUTILS_LOG_INFO_NAMED(get_name(), \"calling for deactivate, cleanup, configure, activate\");\n deactivate();\n /*cleanup()*/;\n active_node_=!active_node_;\n// configure();\n activate();\n }\n}\n\nusing std::placeholders::_1;\n\n /// Transition callback for state configuring\nrclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn LifecycleWatchdog::on_configure(\n const rclcpp_lifecycle::State &)\n{ \n // Initialize and configure node\n qos_profile_\n .liveliness(RMW_QOS_POLICY_LIVELINESS_MANUAL_BY_TOPIC)\n .liveliness_lease_duration(lease_duration_);\n \n heartbeat_sub_options_.event_callbacks.liveliness_callback = \n std::bind(&LifecycleWatchdog::hb_missing_callback, this, _1);\n \n\n status_pub_ = create_publisher<sw_watchdog_msgs::msg::Status>(\"status_hd\", 10);\n\n RCUTILS_LOG_INFO_NAMED(get_name(), \"on_configure() is called.\");\n return rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn::SUCCESS;\n}\n\n/// Transition callback for state activating\nrclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn LifecycleWatchdog::on_activate(\n const rclcpp_lifecycle::State &)\n{\n if(!active_node_){\n if(!heartbeat_sub_) {\n heartbeat_sub_ = create_subscription<sw_watchdog_msgs::msg::Heartbeat>(\n hb_topic_name_,\n qos_profile_,\n [this](const typename sw_watchdog_msgs::msg::Heartbeat::SharedPtr msg) -> void {\n RCLCPP_INFO(get_logger(), \"Watching %s, heartbeat sent at [%d.x]\", hb_topic_name_.c_str(), msg->stamp.sec);\n },\n heartbeat_sub_options_);\n }\n }\n else{\n if(!heartbeat_sub_) {\n heartbeat_sub_ = create_subscription<sw_watchdog_msgs::msg::Heartbeat>(\n watchdogs_hb_topic_name_,\n qos_profile_,\n [this](const typename sw_watchdog_msgs::msg::Heartbeat::SharedPtr msg) -> void {\n RCLCPP_INFO(get_logger(), \"Watching %s, heartbeat sent at [%d.x]\", watchdogs_hb_topic_name_.c_str(), msg->stamp.sec);\n },\n heartbeat_sub_options_);\n }\n }\n\n // Starting from this point, all messages are sent to the network.\n// if (enable_pub_)\n status_pub_->on_activate();\n\n // Starting from this point, all messages are sent to the network.\n RCUTILS_LOG_INFO_NAMED(get_name(), \"on_activate() is called.\");\n return rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn::SUCCESS;\n}\n\n/// Transition callback for state deactivating\nrclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn LifecycleWatchdog::on_deactivate(\n const rclcpp_lifecycle::State &)\n{\n\n heartbeat_sub_.reset(); // XXX there does not seem to be a 'deactivate' for subscribers.\n heartbeat_sub_ = nullptr;\n \n // Starting from this point, all messages are no longer sent to the network.\n if(enable_pub_)\n status_pub_->on_deactivate();\n\n RCUTILS_LOG_INFO_NAMED(get_name(), \"on_deactivate() is called.\");\n\n return rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn::SUCCESS;\n}\n\n/// Transition callback for state cleaningup\nrclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn LifecycleWatchdog::on_cleanup(\n const rclcpp_lifecycle::State &)\n{ \n heartbeat_sub_.reset(); // XXX there does not seem to be a 'deactivate' for subscribers.\n heartbeat_sub_ = nullptr;\n \n status_pub_.reset();\n RCUTILS_LOG_INFO_NAMED(get_name(), \"on cleanup() is called.\");\n\n return rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn::SUCCESS;\n}\n\n/// Transition callback for state shutting down\nrclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn LifecycleWatchdog::on_shutdown(\n const rclcpp_lifecycle::State &state)\n{\n heartbeat_sub_.reset();\n heartbeat_sub_ = nullptr;\n status_pub_.reset();\n\n RCUTILS_LOG_INFO_NAMED(get_name(), \"on shutdown is called from state %s.\", state.label().c_str());\n\n return rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn::SUCCESS;\n}\n\n} // namespace sw_watchdog\n\nRCLCPP_COMPONENTS_REGISTER_NODE(lifecycle_watchdog::LifecycleWatchdog)\n"
},
{
"alpha_fraction": 0.7441860437393188,
"alphanum_fraction": 0.7468064427375793,
"avg_line_length": 38.649349212646484,
"blob_id": "60ed84fd07b7b9971a7ff13b29f3b6b4e5c98bcd",
"content_id": "a43ceddc32b031e75887cacd5959d395cd1f0e26",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3053,
"license_type": "permissive",
"max_line_length": 105,
"num_lines": 77,
"path": "/include/fail_demo/lifecycle_watchdog.hpp",
"repo_name": "marcoag/failover_cluster",
"src_encoding": "UTF-8",
"text": "// Copyright 2016 Open Source Robotics Foundation, Inc.\n//\n// Licensed under the Apache License, Version 2.0 (the \"License\");\n// you may not use this file except in compliance with the License.\n// You may obtain a copy of the License at\n//\n// http://www.apache.org/licenses/LICENSE-2.0\n//\n// Unless required by applicable law or agreed to in writing, software\n// distributed under the License is distributed on an \"AS IS\" BASIS,\n// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n// See the License for the specific language governing permissions and\n// limitations under the License.\n\n#ifndef FAILOVER__LIFECYCLE_WATCHDOG_HPP_\n#define FAILOVER__LIFECYCLE_WATCHDOG_HPP_\n\n#include <chrono>\n#include <atomic>\n#include <iostream>\n\n#include \"fail_demo/visibility_control.h\"\n\n#include \"rclcpp/rclcpp.hpp\"\n#include \"rcutils/cmdline_parser.h\"\n#include \"rclcpp_components/register_node_macro.hpp\"\n\n#include \"rclcpp_lifecycle/lifecycle_node.hpp\"\n\n#include \"rcutils/logging_macros.h\"\n\n#include \"sw_watchdog_msgs/msg/heartbeat.hpp\"\n#include \"sw_watchdog_msgs/msg/status.hpp\"\n\n#include <unistd.h>\n\nnamespace lifecycle_watchdog\n{\n\nclass LifecycleWatchdog : public rclcpp_lifecycle::LifecycleNode\n{\npublic:\n COMPOSITION_PUBLIC\n explicit LifecycleWatchdog(const rclcpp::NodeOptions& options);\n void publish_status();\n rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn on_configure(\n const rclcpp_lifecycle::State &);\n rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn on_activate(\n const rclcpp_lifecycle::State &);\n rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn on_deactivate(\n const rclcpp_lifecycle::State &);\n rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn on_cleanup(\n const rclcpp_lifecycle::State &);\n rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn on_shutdown(\n const rclcpp_lifecycle::State &state);\nprivate:\n void hb_missing_callback(rclcpp::QOSLivelinessChangedInfo &event);\n\n /// The lease duration granted to the remote (heartbeat) publisher\n std::chrono::milliseconds lease_duration_;\n rclcpp::Subscription<sw_watchdog_msgs::msg::Heartbeat>::SharedPtr heartbeat_sub_ = nullptr;\n /// Publish lease expiry for the watched entity\n // By default, a lifecycle publisher is inactive by creation and has to be activated to publish.\n rclcpp_lifecycle::LifecyclePublisher<sw_watchdog_msgs::msg::Status>::SharedPtr status_pub_ = nullptr;\n /// Whether to enable the watchdog on startup will only be done if we are not the active node.\n bool active_node_;\n /// Whether a lease expiry should be published\n bool enable_pub_;\n /// Topic name for heartbeat signal by the watched entity\n const std::string hb_topic_name_;\n const std::string watchdogs_hb_topic_name_;\n rclcpp::QoS qos_profile_;\n rclcpp::SubscriptionOptions heartbeat_sub_options_;\n};\n\n}\n#endif // COMPOSITION__LIFECYCLE_WATCHDOG_HPP_\n"
},
{
"alpha_fraction": 0.6852952241897583,
"alphanum_fraction": 0.6880801916122437,
"avg_line_length": 34.90666580200195,
"blob_id": "5c8ff385dd62fbd243292d95622a412ae5d03e9e",
"content_id": "94c5e709522a4f9505e3dfe1c9b5c0a5ee64e556",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5386,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 150,
"path": "/src/lifecycle_talker.cpp",
"repo_name": "marcoag/failover_cluster",
"src_encoding": "UTF-8",
"text": "// Copyright (c) 2020 Mapless AI, Inc.\n//\n// Licensed under the Apache License, Version 2.0 (the \"License\");\n// you may not use this file except in compliance with the License.\n// You may obtain a copy of the License at\n//\n// http://www.apache.org/licenses/LICENSE-2.0\n//\n// Unless required by applicable law or agreed to in writing, software\n// distributed under the License is distributed on an \"AS IS\" BASIS,\n// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n// See the License for the specific language governing permissions and\n// limitations under the License.\n\n#include \"fail_demo/lifecycle_talker.hpp\"\n\nusing namespace std::chrono_literals;\n\nnamespace lifecycle_talker\n{\n\nvoid print_usage()\n{\n std::cout <<\n \"Usage: lifecycle [-h] --ros-args -p active_node:=value [...]\\n\\n\"\n \"required arguments:\\n\"\n \"\\tperiod: Period in positive integer milliseconds of the heartbeat signal.\\n\"\n \"optional arguments:\\n\"\n \"\\t-h : Print this help message.\" <<\n std::endl;\n}\n \n/// SimpleWatchdog inheriting from rclcpp_lifecycle::LifecycleNode\n/**\n * Internally relies on the QoS liveliness policy provided by rmw implementation (e.g., DDS).\n * The lease passed to this watchdog has to be > the period of the heartbeat signal to account\n * for network transmission times.\n */\nLifecycleTalker::LifecycleTalker(const rclcpp::NodeOptions& options)\n : rclcpp_lifecycle::LifecycleNode(\"lifecycle_talker\", options),\n active_node_(false), count_(0), wakeup_topic_ (\"status_hd\")\n{\n declare_parameter(\"active_node\");\n \n // Lease duration must be >= heartbeat's lease duration\n try {\n active_node_ = get_parameter(\"active_node\").as_bool();\n } catch (...) {\n print_usage();\n // TODO: Update the rclcpp_components template to be able to handle\n // exceptions. Raise one here, so stack unwinding happens gracefully.\n std::exit(-1);\n }\n \n configure();\n\n if(active_node_) \n {\n RCLCPP_INFO(get_logger(), \"Activation selected\");\n activate();\n }\n else\n RCLCPP_INFO(get_logger(), \"No activation selected\");\n}\n\nvoid LifecycleTalker::timer_callback()\n{\n auto message = std::make_unique<std_msgs::msg::String>();\n message->data = \"Hello World: \" + std::to_string(++count_);\n RCLCPP_INFO(this->get_logger(), \"Publishing: '%s'\", message->data.c_str());\n std::flush(std::cout);\n\n // Put the message into a queue to be processed by the middleware.\n // This call is non-blocking.\n publisher_->publish(std::move(message));\n}\n\n/// Transition callback for state configuring\nrclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn LifecycleTalker::on_configure(\n const rclcpp_lifecycle::State &)\n{\n \n status_sub_ = this->create_subscription<sw_watchdog_msgs::msg::Status>(\n wakeup_topic_,\n 10,\n [this](const typename sw_watchdog_msgs::msg::Status::SharedPtr msg) -> void {\n if(!active_node_)\n {\n RCLCPP_INFO(get_logger(), \"Watchdog raised, self activation triggered\", msg->stamp.sec);\n activate();\n }\n });\n \n\n publisher_ = this->create_publisher<std_msgs::msg::String>(\"chatter\", 10);\n\n RCUTILS_LOG_INFO_NAMED(get_name(), \"on_configure() is called.\");\n return rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn::SUCCESS;\n}\n\n/// Transition callback for state activating\nrclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn LifecycleTalker::on_activate(\n const rclcpp_lifecycle::State &)\n{\n timer_ = this->create_wall_timer(1s, std::bind(&LifecycleTalker::timer_callback, this));\n publisher_->on_activate();\n\n // Starting from this point, all messages are sent to the network.\n RCUTILS_LOG_INFO_NAMED(get_name(), \"on_activate() is called.\");\n return rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn::SUCCESS;\n}\n\n \n/// Transition callback for state deactivating\nrclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn LifecycleTalker::on_deactivate(\n const rclcpp_lifecycle::State &)\n{\n\n // Starting from this point, all messages are no longer sent to the network.\n publisher_->on_deactivate();\n\n RCUTILS_LOG_INFO_NAMED(get_name(), \"on_deactivate() is called.\");\n\n return rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn::SUCCESS;\n}\n\n/// Transition callback for state cleaningup\nrclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn LifecycleTalker::on_cleanup(\n const rclcpp_lifecycle::State &)\n{\n publisher_.reset();\n RCUTILS_LOG_INFO_NAMED(get_name(), \"on cleanup is called.\");\n\n return rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn::SUCCESS;\n}\n\n/// Transition callback for state shutting down\nrclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn LifecycleTalker::on_shutdown(\n const rclcpp_lifecycle::State &state)\n{\n publisher_.reset();\n\n RCUTILS_LOG_INFO_NAMED(get_name(), \"on shutdown is called from state %s.\", state.label().c_str());\n\n return rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn::SUCCESS;\n}\n \n} // namespace sw_watchdog\n\nRCLCPP_COMPONENTS_REGISTER_NODE(lifecycle_talker::LifecycleTalker)\n"
},
{
"alpha_fraction": 0.7540766596794128,
"alphanum_fraction": 0.7576024532318115,
"avg_line_length": 33.378787994384766,
"blob_id": "9788ab30098561bd8262f76a979eeadd059f166f",
"content_id": "93e0ac942a0fc8aa1ceed5fd9fdc47ef8d933e34",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2269,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 66,
"path": "/include/fail_demo/lifecycle_talker.hpp",
"repo_name": "marcoag/failover_cluster",
"src_encoding": "UTF-8",
"text": "// Copyright 2016 Open Source Robotics Foundation, Inc.\n//\n// Licensed under the Apache License, Version 2.0 (the \"License\");\n// you may not use this file except in compliance with the License.\n// You may obtain a copy of the License at\n//\n// http://www.apache.org/licenses/LICENSE-2.0\n//\n// Unless required by applicable law or agreed to in writing, software\n// distributed under the License is distributed on an \"AS IS\" BASIS,\n// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n// See the License for the specific language governing permissions and\n// limitations under the License.\n\n#ifndef FAILOVER__TALKER_COMPONENT_HPP_\n#define FAILOVER__TALKER_COMPONENT_HPP_\n\n#include <chrono>\n\n#include \"fail_demo/visibility_control.h\"\n\n#include \"rclcpp/rclcpp.hpp\"\n#include \"rcutils/cmdline_parser.h\"\n#include \"rclcpp_components/register_node_macro.hpp\"\n\n#include \"std_msgs/msg/string.hpp\"\n#include \"sw_watchdog_msgs/msg/status.hpp\"\n\n#include \"rclcpp_lifecycle/lifecycle_node.hpp\"\n\nnamespace lifecycle_talker\n{\n\nclass LifecycleTalker : public rclcpp_lifecycle::LifecycleNode\n{\npublic:\n COMPOSITION_PUBLIC\n\n explicit LifecycleTalker(const rclcpp::NodeOptions& options);\n rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn \n on_configure(const rclcpp_lifecycle::State &);\n rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn\n on_activate(const rclcpp_lifecycle::State &);\n rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn\n on_deactivate(const rclcpp_lifecycle::State &);\nrclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn \n on_cleanup(const rclcpp_lifecycle::State &);\n rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn \n on_shutdown(const rclcpp_lifecycle::State &state);\n\nprivate:\n void timer_callback();\n \n rclcpp::Subscription<sw_watchdog_msgs::msg::Status>::SharedPtr status_sub_ = nullptr;\n std::shared_ptr<rclcpp_lifecycle::LifecyclePublisher<std_msgs::msg::String>> publisher_ = nullptr;\n \n rclcpp::TimerBase::SharedPtr timer_;\n bool active_node_;\n size_t count_;\n const std::string wakeup_topic_;\n\n};\n\n} // namespace composition\n\n#endif // COMPOSITION__TALKER_COMPONENT_HPP_\n"
},
{
"alpha_fraction": 0.7540673613548279,
"alphanum_fraction": 0.7570942044258118,
"avg_line_length": 35.20547866821289,
"blob_id": "92042992be4081799545a19285e1c314743e6430",
"content_id": "aa30658bc8610401921b18ea48ca8fe303957780",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2643,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 73,
"path": "/include/fail_demo/lifecycle_heartbeat.hpp",
"repo_name": "marcoag/failover_cluster",
"src_encoding": "UTF-8",
"text": "// Copyright 2016 Open Source Robotics Foundation, Inc.\n//\n// Licensed under the Apache License, Version 2.0 (the \"License\");\n// you may not use this file except in compliance with the License.\n// You may obtain a copy of the License at\n//\n// http://www.apache.org/licenses/LICENSE-2.0\n//\n// Unless required by applicable law or agreed to in writing, software\n// distributed under the License is distributed on an \"AS IS\" BASIS,\n// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n// See the License for the specific language governing permissions and\n// limitations under the License.\n\n#ifndef FAILOVER__LIFECYCLE_HEARTBEAT_HPP_\n#define FAILOVER__LIFECYCLE_HEARTBEAT_HPP_\n\n#include <chrono>\n\n#include \"fail_demo/visibility_control.h\"\n\n#include \"rclcpp/rclcpp.hpp\"\n#include \"rcutils/cmdline_parser.h\"\n#include \"rclcpp_components/register_node_macro.hpp\"\n\n#include \"sw_watchdog_msgs/msg/heartbeat.hpp\"\n#include \"sw_watchdog_msgs/msg/status.hpp\"\n\n#include \"std_msgs/msg/string.hpp\"\n\n#include \"rclcpp_lifecycle/lifecycle_node.hpp\"\n\nnamespace lifecycle_heartbeat\n{\n\nclass LifecycleHeartbeat : public rclcpp_lifecycle::LifecycleNode\n{\npublic:\n COMPOSITION_PUBLIC\n\n explicit LifecycleHeartbeat(const rclcpp::NodeOptions& options);\n rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn \n on_configure(const rclcpp_lifecycle::State &);\n rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn\n on_activate(const rclcpp_lifecycle::State &);\n rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn\n on_deactivate(const rclcpp_lifecycle::State &);\n rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn \n on_cleanup(const rclcpp_lifecycle::State &);\n rclcpp_lifecycle::node_interfaces::LifecycleNodeInterface::CallbackReturn \n on_shutdown(const rclcpp_lifecycle::State &state);\n\nprivate: \n\n void timer_callback();\n \n std::shared_ptr<rclcpp_lifecycle::LifecyclePublisher<sw_watchdog_msgs::msg::Heartbeat>> publisher_ = nullptr;\n rclcpp::Subscription<sw_watchdog_msgs::msg::Status>::SharedPtr status_sub_ = nullptr;\n rclcpp::Subscription<sw_watchdog_msgs::msg::Status>::SharedPtr subscription_ = nullptr;\n \n bool active_node_;\n const std::string heartbeat_topic_;\n const std::string wakeup_topic_;\n const std::string wakeup_watchdog_topic_;\n const std::string watchdog_heartbeat_topic_;\n rclcpp::TimerBase::SharedPtr timer_;\n rclcpp::QoS qos_profile_;\n std::chrono::milliseconds heartbeat_period_;\n};\n\n} // namespace lifecycle_heartbeat\n\n#endif // COMPOSITION__LIFECYCLE_HEARTBEAT_HPP_\n"
}
] | 8 |
claimsecond/my-first-blog
|
https://github.com/claimsecond/my-first-blog
|
5cb412dcaa2cb8bfecf0f119cdbf632290fafdbb
|
cfdc6dd6391527e4f3302b2517cfcb73cfd04d79
|
c79226cacbf8b1eb501be57c7d4bcffa49afbf6a
|
refs/heads/master
| 2022-01-08T09:16:05.282674 | 2018-05-15T11:22:35 | 2018-05-15T11:22:35 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6657431721687317,
"alphanum_fraction": 0.6711455583572388,
"avg_line_length": 36.409324645996094,
"blob_id": "516981e09e78d1383bb3748951fdbd91099683cc",
"content_id": "1b9242c6d48d3c0dbc2372fc02e1f9f162d72cfb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7219,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 193,
"path": "/blog/views.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.contrib.auth.decorators import login_required\nfrom django.shortcuts import render\nfrom django.shortcuts import render, get_object_or_404\nfrom django.shortcuts import redirect\nfrom django.utils import timezone\nfrom .models import Post, Comment, Category, CategoryBundle\nfrom .forms import PostForm, CommentForm, CategoryForm, CategoryBundleForm\n\n\n#Post actions section\n\ndef post_list(request):\n categories = get_category_list()\n bundles = get_category_bundle_list()\n posts = Post.objects.filter(published_date__isnull=False).order_by('-published_date')\n return render(request, 'blog/post_list.html', {'posts': posts, 'categories': categories, 'category_bundles': bundles})\n\ndef post_detail(request, pk):\n categories = get_category_list()\n bundles = get_category_bundle_list()\n post = get_object_or_404(Post, pk=pk)\n return render(request, 'blog/post_detail.html', {'post': post, 'categories': categories, 'category_bundles': bundles})\n\n@login_required\ndef post_new(request):\n categories = get_category_list()\n bundles = get_category_bundle_list()\n if request.method == \"POST\":\n form = PostForm(request.POST)\n if (form.is_valid):\n post = form.save(commit=False)\n post.author = request.user\n post.save()\n return redirect('post_detail', pk=post.pk)\n else:\n form = PostForm()\n return render(request, 'blog/post_edit.html', {'form': form})\n\n@login_required\ndef post_draft_list(request):\n categories = get_category_list()\n bundles = get_category_bundle_list()\n posts = Post.objects.filter(published_date__isnull=True).order_by('-created_date')\n return render(request, 'blog/post_draft_list.html', {'posts': posts, 'categories': categories, 'category_bundles': bundles})\n\n@login_required\ndef post_publish(request, pk):\n post = get_object_or_404(Post, pk=pk)\n post.publish()\n return redirect('post_detail', pk=pk)\n\n@login_required\ndef post_remove(request, pk):\n post = get_object_or_404(Post, pk=pk)\n post.delete()\n return redirect('post_list')\n\n@login_required\ndef post_edit(request, pk):\n post = get_object_or_404(Post, pk=pk)\n categories = get_category_list()\n bundles = get_category_bundle_list()\n if request.method == \"POST\":\n form = PostForm(request.POST, instance=post)\n if (form.is_valid()):\n post = form.save(commit=False)\n post.author = request.user\n post.save()\n return redirect('post_detail', pk=post.pk)\n else:\n form = PostForm(instance=post)\n return render(request, 'blog/post_edit.html', {'form': form, 'categories': categories, 'category_bundles': bundles})\n\n#comment actions section\n\ndef add_comment_to_post(request, pk):\n post = get_object_or_404(Post, pk=pk)\n categories = get_category_list()\n bundles = get_category_bundle_list()\n\n if request.method == \"POST\":\n form = CommentForm(request.POST)\n if form.is_valid():\n comment = form.save(commit=False)\n comment.post = post\n comment.save()\n return redirect('post_detail', pk=post.pk)\n else:\n form = CommentForm()\n return render(request, 'blog/add_comment_to_post.html', {'form': form, 'categories': categories, 'category_bundles': bundles})\n\n@login_required\ndef comment_approve(request, pk):\n comment = get_object_or_404(Comment, pk=pk)\n comment.approve()\n return redirect('post_detail', pk=comment.post.pk)\n\n@login_required\ndef comment_remove(request, pk):\n comment = get_object_or_404(Comment, pk=pk)\n comment.delete()\n return redirect('post_detail', pk=comment.post.pk)\n\n#category actions section\n@login_required\ndef category_new(request):\n categories = get_category_list()\n bundles = get_category_bundle_list()\n if request.method == \"POST\":\n form = CategoryForm(request.POST)\n if (form.is_valid):\n category = form.save(commit=False)\n category.save()\n return redirect('post_list')\n else:\n form = CategoryForm()\n return render(request, 'blog/category_edit.html',{'form': form,'categories': categories,'category_bundles': bundles})\n \n@login_required\ndef category_bundle_new(request):\n categories = get_category_list()\n bundles = get_category_bundle_list()\n if request.method == \"POST\":\n form = CategoryBundleForm(request.POST)\n if (form.is_valid):\n category_bundle = form.save(commit=False)\n category_bundle.save()\n return redirect('post_list')\n else:\n form = CategoryBundleForm()\n return render(request, 'blog/category_bundle_edit.html',{'form': form,'categories': categories,'category_bundles': bundles})\n\n@login_required\ndef category_edit(request, pk):\n category = get_object_or_404(Category, pk=pk)\n categories = get_category_list()\n bundles = get_category_bundle_list()\n if request.method == \"POST\":\n form = CategoryForm(request.POST, instance=category)\n if (form.is_valid()):\n category = form.save(commit=False)\n category.save()\n return redirect('post_list')\n else:\n form = CategoryForm(instance=category)\n return render(request, 'blog/category_edit.html', {'is_update':True,'form': form, 'categories': categories, 'category_bundles': bundles})\n\n@login_required\ndef category_bundle_edit(request, pk):\n category_bundle = get_object_or_404(CategoryBundle, pk=pk)\n categories = get_category_list()\n bundles = get_category_bundle_list()\n if request.method == \"POST\":\n form = CategoryBundleForm(request.POST, instance=category_bundle)\n if (form.is_valid()):\n category_bundle = form.save(commit=False)\n category_bundle.save()\n return redirect('post_list')\n else:\n form = CategoryBundleForm(instance=category_bundle)\n return render(request, 'blog/category_bundle_edit.html', {'is_update':True,'form': form, 'categories': categories, 'category_bundles': bundles})\n\n@login_required\ndef category_remove(request, pk):\n category = get_object_or_404(Category, pk=pk)\n category.delete()\n return redirect('post_list')\n\n@login_required\ndef category_bundle_remove(request, pk):\n category_bundle = get_object_or_404(CategoryBundle, pk=pk)\n category_bundle.delete()\n return redirect('post_list')\n\ndef category_list(request):\n categories = get_category_list()\n bundles = get_category_bundle_list()\n return render(request, 'blog/category_list.html', {'categories': categories, 'category_bundles': bundles})\n\ndef get_category_list():\n categories = list(Category.objects.order_by('created_date'))\n return categories\n\ndef get_category_bundle_list():\n bundles = list(CategoryBundle.objects.order_by('created_date'))\n return bundles\n\ndef category_posts(request, pk):\n categories = get_category_list()\n bundles = get_category_bundle_list()\n category = get_object_or_404(Category, pk=pk)\n posts = Post.objects.filter(category=category,published_date__isnull=False).order_by('-published_date')\n return render(request, 'blog/post_list.html', {'categories': categories, 'category_bundles': bundles, 'posts': posts})"
},
{
"alpha_fraction": 0.6435272097587585,
"alphanum_fraction": 0.6435272097587585,
"avg_line_length": 17.379310607910156,
"blob_id": "4f3808a9aaaecbacbf38b7e1ec1aab2ca7b32b4b",
"content_id": "298f5a4156a9500f5836006507ca94094a0222f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 533,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 29,
"path": "/mysite/settings/prod.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from .base import *\n\nMG_APP_LOCATION = 'prod'\n\nDEBUG=False\n\nSECRET_KEY = 'prod secret key'\n\nSECURE_SSL_REDIRECT = True\n\nINSTALLED_APPS = (\n 'django.db.models',\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'django.contrib.humanize',\n 'rest_framework',\n 'rest_framework.authtoken',\n 'blog',\n 'landing',\n 'dashboard',\n 'todo',\n 'bots',\n)\n\nTELEGRAM_BOT_ALLOWED = True\n"
},
{
"alpha_fraction": 0.6384882926940918,
"alphanum_fraction": 0.64644455909729,
"avg_line_length": 30.904762268066406,
"blob_id": "602e601b5988215a886c7e2a48ae38b129ce657b",
"content_id": "aa71e705cd6d22a5680613a15a94c22c28e4d94a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2011,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 63,
"path": "/dashboard/dashes/news/Radiot.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.utils import timezone\n\nimport json\nimport urllib\nfrom datetime import timedelta\nfrom datetime import datetime, timezone\n\nfrom django.shortcuts import get_object_or_404\n\nfrom dashboard.models import RadiotArticle\n\nLATENCY_DAYS=1\nSECONDS_IN_DAY=86400\n\nBASE_API_URL = 'https://news.radio-t.com/api/v1/'\nLAST_NEWS_API_SUFFIX = 'news/last/100'\n\ndef update_info():\n test_article = None\n try:\n if (len(RadiotArticle.objects.filter()) > 0):\n test_article = RadiotArticle.objects.filter()[0]\n except RadiotArticle.DoesNotExist:\n test_article = None\n\n if (test_article == None):\n get_info()\n else:\n last_updated = test_article.last_updated\n from_last_update = (datetime.now(timezone.utc) - last_updated).total_seconds()\n from_last_update = int(from_last_update / SECONDS_IN_DAY)\n if (from_last_update >= LATENCY_DAYS):\n get_info()\n\ndef get_info():\n news = get_raw_info()\n RadiotArticle.objects.filter().delete()\n for article in news:\n db_article = RadiotArticle.objects.create()\n db_article.title = article['title']\n db_article.content = article['content']\n db_article.snippet = article['snippet']\n db_article.main_pic = article['pic']\n db_article.link = article['link']\n db_article.author = article['author']\n db_article.original_ts = article['ts']\n db_article.radiot_ts = article['ats']\n db_article.feed = article['feed']\n db_article.slug = article['slug']\n db_article.comments = article['comments']\n db_article.likes = article['likes']\n db_article.save()\n\ndef get_raw_info():\n json_content = []\n try:\n content = urllib.request.urlopen(BASE_API_URL + LAST_NEWS_API_SUFFIX).read().decode('utf-8')\n json_content = json.loads(content)\n except urllib.error.HTTPError as e:\n print(\"error during fetching radiot news\")\n print(e)\n return json_content\n\n"
},
{
"alpha_fraction": 0.5968169569969177,
"alphanum_fraction": 0.6379310488700867,
"avg_line_length": 29.15999984741211,
"blob_id": "1a6d80f37b1eaf618071513f449a59a09f6c3af0",
"content_id": "5e5a4aeb750e1f8ebb45c4031da1f74e8228ce88",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 754,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 25,
"path": "/todo/migrations/0003_auto_20180220_1206.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.2 on 2018-02-20 09:06\n\nfrom django.conf import settings\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('todo', '0002_auto_20180216_1835'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='action',\n name='category',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='todo.ActionCategory'),\n ),\n migrations.AlterField(\n model_name='actioncategory',\n name='author',\n field=models.ForeignKey(default=None, null=True, on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7625624537467957,
"alphanum_fraction": 0.763150155544281,
"avg_line_length": 39.03529357910156,
"blob_id": "b3af3016373d16be8a3a8b984db7e850f7b495fb",
"content_id": "22fd704d4db5504e71695b9bce4afdd3df6f817e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3403,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 85,
"path": "/rest/views.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom django.contrib.auth.decorators import login_required\nfrom django.contrib.auth.models import User\n\n\nfrom rest_framework.decorators import api_view\nfrom rest_framework.authtoken.models import Token\nfrom rest_framework.response import Response\n\nfrom dashboard.models import Weather, WeatherForecast\nfrom dashboard.models import Currency\nfrom dashboard.models import CryptoMarket\nfrom dashboard.models import CryptoCurrency\nfrom dashboard.models import CurrencyConversion\nfrom dashboard.models import CurrencyStatistics\nfrom dashboard.models import RadiotArticle\n\nfrom dashboard.dashes.news import Radiot\nfrom dashboard.dashes.weather import OpenWeather\nfrom dashboard.dashes.currency import NBRBCurrency\nfrom dashboard.dashes.crypto_currency import CryptoCurrencyInfo\n\nfrom .serializers import WeatherSerializer, WeatherForecastSerializer\nfrom .serializers import CurrencySerializer, CurrencyConversionSerializer, CurrencyStatisticsSerializer\nfrom .serializers import CryptoCurrencySerializer, CryptoMarketSerializer\n\n\n@api_view()\n@login_required\ndef obtain_token(request):\n token = Token.objects.get_or_create(user=request.user)\n return Response({'token': token[0].key})\n\n\n@api_view()\ndef obtain_weather(request):\n requested_city = 'minsk'\n OpenWeather.update_info(requested_city)\n weather = Weather.objects.filter(requested_city=requested_city)[0]\n weather = WeatherSerializer(weather).data\n forecast_db = WeatherForecast.objects.filter(city='Minsk').order_by('date_time')\n forecast = []\n for forecast_item in forecast_db:\n forecast.append(WeatherForecastSerializer(forecast_item).data)\n return Response({'weather': weather, 'forecast': forecast})\n\n@api_view()\ndef obtain_currencies(request):\n NBRBCurrency.update_info()\n currencies_db = Currency.objects.filter(scale__isnull=False)\n statistics_eur_db = CurrencyStatistics.objects.filter(abbreviation='EUR').order_by('date')\n statistics_usd_db = CurrencyStatistics.objects.filter(abbreviation='USD').order_by('date')\n conversions_db = CurrencyConversion.objects.filter(value__isnull=False)\n currencies = []\n conversions = []\n statistics_usd = []\n statistics_eur = []\n for currency_db in currencies_db:\n currencies.append(CurrencySerializer(currency_db).data)\n for conversion_db in conversions_db:\n conversions.append(CurrencyConversionSerializer(conversion_db).data)\n for statistic_usd_db in statistics_usd_db:\n statistics_usd.append(CurrencyStatisticsSerializer(statistic_usd_db).data)\n for statistic_eur_db in statistics_eur_db:\n statistics_eur.append(CurrencyStatisticsSerializer(statistic_eur_db).data)\n return Response({\n 'currencies': currencies, \n 'conversions': conversions, \n 'statistics_eur': statistics_eur,\n 'statistics_usd': statistics_usd\n })\n\n@api_view()\ndef obtain_crypto_currencies(request):\n CryptoCurrencyInfo.update_info()\n crypto_currencies_db = CryptoCurrency.objects.order_by('rank')\n crypto_market_db = CryptoMarket.objects.get()\n crypto_currencies = []\n crypto_market = CryptoMarketSerializer(crypto_market_db).data\n for item in crypto_currencies_db:\n crypto_currencies.append(CryptoCurrencySerializer(item).data)\n return Response({\n 'market' : crypto_market,\n 'crypto_currencies' : crypto_currencies\n })\n"
},
{
"alpha_fraction": 0.8246753215789795,
"alphanum_fraction": 0.8344155550003052,
"avg_line_length": 42.71428680419922,
"blob_id": "7866d36e791e17bed196d53660a2d454972cefee",
"content_id": "cc3388465b54e5946e01a9c9e3b3083bd8af4e0c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 308,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 7,
"path": "/blog/utils.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.contrib.auth.decorators import login_required\nfrom django.shortcuts import render\nfrom django.shortcuts import render, get_object_or_404\nfrom django.shortcuts import redirect\nfrom django.utils import timezone\nfrom .models import Post, Comment, Category\nfrom .forms import PostForm, CommentForm\n\n\n"
},
{
"alpha_fraction": 0.5776566863059998,
"alphanum_fraction": 0.5945504307746887,
"avg_line_length": 41.67441940307617,
"blob_id": "f52442e9b3b3e585d0897bff9d4d82fc408f2dba",
"content_id": "c869910e0323eb696d3b339f50293563b2a05a19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1835,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 43,
"path": "/todo/migrations/0001_initial.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.2 on 2018-02-08 16:54\n\nfrom django.conf import settings\nfrom django.db import migrations, models\nimport django.db.models.deletion\nimport django.utils.timezone\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n migrations.swappable_dependency(settings.AUTH_USER_MODEL),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Action',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('text', models.CharField(default='', max_length=200)),\n ('date', models.DateTimeField(default=django.utils.timezone.now)),\n ('last_updated', models.DateTimeField(default=django.utils.timezone.now)),\n ('status', models.IntegerField(choices=[(0, 'to do'), (1, 'in progress'), (2, 'done')], default=0)),\n ('priority', models.IntegerField(choices=[(0, 'trivial'), (1, 'minor'), (2, 'normal'), (3, 'high'), (4, 'critical')], default=2)),\n ],\n ),\n migrations.CreateModel(\n name='ActionCategory',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(default='', max_length=200)),\n ('last_updated', models.DateTimeField(default=django.utils.timezone.now)),\n ('author', models.ForeignKey(default=None, on_delete=django.db.models.deletion.PROTECT, to=settings.AUTH_USER_MODEL)),\n ],\n ),\n migrations.AddField(\n model_name='action',\n name='category',\n field=models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, to='todo.ActionCategory'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6609195470809937,
"alphanum_fraction": 0.6609195470809937,
"avg_line_length": 23.885713577270508,
"blob_id": "8fb1d816b59a585bf7a04ae5562be15983b184ea",
"content_id": "d7ab321884c48b328101e1b2ef3e090c18cee51f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 870,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 35,
"path": "/dashboard/forms.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django import forms\nfrom .models import UtilitiesRecord, LivingPlace\nfrom .models import IncomeRecord, ExpensesRecord, ExpensesCategory\n\n\nclass ExpensesCategoryForm(forms.ModelForm):\n\n class Meta:\n model = ExpensesCategory\n fields = ('name',)\n\nclass ExpensesRecordForm(forms.ModelForm):\n\n class Meta:\n model = ExpensesRecord\n fields = ('amount', 'date', 'name', 'comment', 'category',)\n\nclass IncomeRecordForm(forms.ModelForm):\n\n class Meta:\n model = IncomeRecord\n fields = ('amount', 'date', 'name', 'comment',)\n\nclass UtilityRecordForm(forms.ModelForm):\n\n class Meta:\n model = UtilitiesRecord\n fields = ('hot_water', 'cold_water', 'electricity', 'gas', 'date', 'place',)\n\n\nclass LivingPlaceForm(forms.ModelForm):\n\n class Meta:\n model = LivingPlace\n fields = ('name', 'address',)"
},
{
"alpha_fraction": 0.6754176616668701,
"alphanum_fraction": 0.6754176616668701,
"avg_line_length": 41,
"blob_id": "ef8e80e0f9198317828687c8b4cbb9c91a6b6f6c",
"content_id": "7b91f44299de5f8687e6f5b247460ec95b34f76b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 419,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 10,
"path": "/landing/urls.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\nfrom . import views\n\nurlpatterns = [\n url(r'^$', views.show_greeting, name='show_greeting'),\n url(r'^landing/messages/$', views.secret_message_list, name='secret_message_list'),\n url(r'^landing/about/$', views.info_about, name='info_about'),\n url(r'^landing/register/$', views.register, name='register'),\n url(r'^landing/greeting/$', views.apps_list, name='apps_list'),\n]"
},
{
"alpha_fraction": 0.7308003306388855,
"alphanum_fraction": 0.7324171662330627,
"avg_line_length": 43.154762268066406,
"blob_id": "2a8a7cc657904c56b3735122f24d0342cfa71c5a",
"content_id": "ed6fa6178c422703581f1ca68ee297e10bbf72f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4071,
"license_type": "no_license",
"max_line_length": 193,
"num_lines": 84,
"path": "/dashboard/telegrambot.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from telegram.ext import CommandHandler, MessageHandler, Filters, JobQueue\nfrom django_telegrambot.apps import DjangoTelegramBot\nfrom dashboard.dashes.weather import OpenWeather\nfrom dashboard.dashes.currency import NBRBCurrency\nfrom dashboard.dashes.crypto_currency import CryptoCurrencyInfo\n\nfrom .model import Weather\nfrom .model import Currency\nfrom .model import CryptoCurrency\n\nimport logging\n\nlogger = logging.getLogger(__name__)\n\nhelp_message = 'Добро пожаловать в гости к mgbot!\\nПо сути - это бот-комбайн\\nПоясню. Одной тематикой он не ограничен. Информация, которая здесь может быть получена довольно разнообразна.\\n'\nhelp_message_commands = 'На данный момент присутствуют следующие комманды:\\nweather - информация о погоде\\ncurrency - курсы валют НБРБ\\nconversion - конверсия валют\\ncrypto - курсы криптовалют'\n\nchat_ids = set()\n\ndef get_weather_message():\n OpenWeather.update_info()\n weather = Weather.objects.filter(city_name='Minsk')\n final_string = ''\n header_string = 'Погода в городе {0} \\n'.format(weather.city_name)\n temperature_string = 'Температура: {0} \\n'.format(weather.temperature)\n humidity_string = 'Влажность: {0} \\n'.format(weather.humidity)\n weather_string = weather.description\n final_string = final_string + header_string + temperature_string + humidity_string + weather_string\n return final_string\n\ndef start(bot, update):\n bot.sendMessage(update.message.chat_id, text='Hi!')\n\ndef help(bot, update):\n bot.sendMessage(update.message.chat_id, text=help_message + help_message_commands)\n\ndef error(bot, update, error):\n logger.warn('Update \"%s\" caused error \"%s\"' % (update, error))\n\ndef weather(bot, update):\n bot.sendMessage(update.message.chat_id, text=get_weather_message())\n\ndef currency(bot, update):\n NBRBCurrency.update_info()\n currencies = Currency.objects.filter(rate__isnull=False)\n final_string = 'Курсы валют от НБРБ: \\n'\n for currency in currencies:\n final_string = final_string + '{0} {1} = {2} BYN \\n'.format(currency.scale, currency.abbreviation, currency.rate)\n bot.sendMessage(update.message.chat_id, text=final_string)\n\ndef currency_conversions(bot, update):\n NBRBCurrency.update_info()\n conversions = CurrencyConversion.objects.filter(currency_from__isnull=False)\n final_string = 'Конверсия курсов валют от НБРБ\\n'\n for conversion in conversions:\n final_string = final_string + conversion.currency_from + ' / ' + conversion.currency_to + ': ' + str(conversion.value) + '\\n'\n bot.sendMessage(update.message.chat_id, text=final_string)\n\ndef crypto(bot, update):\n print('crypto debug info')\n CryptoCurrencyInfo.update_info()\n currencies = CryptoCurrency.objects.order_by('rank')\n final_string = 'Курсы криптовалют:\\n'\n for currency in currencies:\n final_string = final_string + currency.rank + '. ' + currency.name + ': ' + currency.price_usd + '$\\n'\n bot.sendMessage(update.message.chat_id, text=final_string)\n\ndef main():\n logger.info(\"Loading handlers for telegram bot\")\n\n print('telegrambot init')\n dp = DjangoTelegramBot.dispatcher\n dp.add_handler(CommandHandler(\"start\", start))\n dp.add_handler(CommandHandler(\"help\", help))\n dp.add_handler(CommandHandler(\"weather\", weather))\n dp.add_handler(CommandHandler(\"погода\", weather))\n dp.add_handler(CommandHandler(\"currency\", currency))\n dp.add_handler(CommandHandler(\"курсы\", currency))\n dp.add_handler(CommandHandler(\"crypto\", crypto))\n dp.add_handler(CommandHandler(\"криптовалюты\", crypto))\n dp.add_handler(CommandHandler(\"conversion\", currency_conversions))\n dp.add_handler(CommandHandler(\"конверсия\", currency_conversions))\n\n dp.add_error_handler(error)\n\n\n"
},
{
"alpha_fraction": 0.5374175310134888,
"alphanum_fraction": 0.5560791492462158,
"avg_line_length": 49.04716873168945,
"blob_id": "3a706151e3263348e7d9c39c2eb933a0ebc927b5",
"content_id": "565a82c63bc831bf7f5d551733df12d3dcc1b5dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5305,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 106,
"path": "/dashboard/migrations/0001_initial.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.2 on 2018-02-05 10:03\n\nfrom django.db import migrations, models\nimport django.utils.timezone\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='CryptoCurrency',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(default='', max_length=200)),\n ('symbol', models.CharField(default='', max_length=200)),\n ('rank', models.IntegerField(default=0)),\n ('price_usd', models.FloatField(default=0.0)),\n ('price_btc', models.FloatField(default=0.0)),\n ('change_24h', models.FloatField(default=0.0)),\n ],\n ),\n migrations.CreateModel(\n name='CryptoMarket',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('total_usd', models.IntegerField(default=0.0)),\n ('total_usd_day_volume', models.IntegerField(default=0.0)),\n ('active_markets', models.IntegerField(default=0.0)),\n ('active_currencies', models.IntegerField(default=0)),\n ('bitcoin_percent', models.FloatField(default=0.0)),\n ('last_updated', models.DateTimeField(default=django.utils.timezone.now)),\n ],\n ),\n migrations.CreateModel(\n name='Currency',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('scale', models.FloatField(default=0.0)),\n ('rate', models.FloatField(default=0.0)),\n ('abbreviation', models.CharField(default='', max_length=200)),\n ('last_updated', models.DateTimeField(default=django.utils.timezone.now)),\n ],\n ),\n migrations.CreateModel(\n name='CurrencyConversion',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('value', models.FloatField(default=0.0)),\n ('currency_from', models.CharField(default='', max_length=200)),\n ('currency_to', models.CharField(default='', max_length=200)),\n ],\n ),\n migrations.CreateModel(\n name='CurrencyStatistics',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('abbreviation', models.CharField(default='', max_length=200)),\n ('rate', models.FloatField(default=0.0)),\n ('date', models.DateTimeField(default=django.utils.timezone.now)),\n ],\n ),\n migrations.CreateModel(\n name='Weather',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('main_info', models.CharField(default='', max_length=200)),\n ('description', models.CharField(default='', max_length=200)),\n ('icon_name', models.CharField(default='', max_length=200)),\n ('city_name', models.CharField(default='', max_length=200)),\n ('temperature', models.IntegerField(default=0)),\n ('humidity', models.IntegerField(default=0)),\n ('pressure', models.IntegerField(default=0)),\n ('visibility', models.IntegerField(default=0)),\n ('temperature_min', models.IntegerField(default=0)),\n ('temperature_max', models.IntegerField(default=0)),\n ('wind_speed', models.FloatField(default=0.0)),\n ('wind_deg', models.FloatField(default=0.0)),\n ('sunrise', models.DateTimeField(default=django.utils.timezone.now)),\n ('sunset', models.DateTimeField(default=django.utils.timezone.now)),\n ('last_updated', models.DateTimeField(default=django.utils.timezone.now)),\n ('date', models.DateTimeField(default=django.utils.timezone.now)),\n ],\n ),\n migrations.CreateModel(\n name='WeatherForecast',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('temperature', models.IntegerField(default=0)),\n ('temperature_min', models.IntegerField(default=0)),\n ('temperature_max', models.IntegerField(default=0)),\n ('pressure', models.IntegerField(default=0)),\n ('humidity', models.IntegerField(default=0)),\n ('main_info', models.CharField(max_length=200)),\n ('description', models.CharField(max_length=200)),\n ('icon_name', models.CharField(max_length=200)),\n ('wind_speed', models.FloatField(default=0.0)),\n ('wind_deg', models.FloatField(default=0.0)),\n ('date_time', models.DateTimeField(default=django.utils.timezone.now)),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.6561899781227112,
"alphanum_fraction": 0.6636982560157776,
"avg_line_length": 42.725189208984375,
"blob_id": "3cb192a07ff2aaee947fcd0175af69d23f0a228e",
"content_id": "739753cc52bff384af5b6f5071d1c4e8e233cd7f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5727,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 131,
"path": "/dashboard/dashes/weather/OpenWeather.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.utils import timezone\n\nimport json\nimport urllib\nfrom datetime import datetime, timezone\nfrom dashboard.models import Weather, WeatherForecast\n\nbase_context = 'http://api.openweathermap.org/data/2.5/'\nweather_suffix = 'weather'\nforecast_suffix = 'forecast'\napi_key = '0502d0f1f744a28dd8065598094fa1db'\nunits = 'metric'\nlang = 'ru'\nLATENCY = 600\n\n\ndef update_info(requested_city='minsk'):\n test_weather = None\n try:\n test_weather = Weather.objects.filter(requested_city=requested_city).get()\n except Weather.DoesNotExist:\n test_weather = None\n\n if (test_weather == None):\n get_current_weather(requested_city)\n get_db_forecast(requested_city)\n else:\n last_updated = test_weather.last_updated\n from_last_update = (datetime.now(timezone.utc) - last_updated).total_seconds()\n if (from_last_update >= LATENCY):\n get_current_weather(requested_city)\n get_db_forecast(requested_city)\n\ndef forecast():\n json_content = []\n\n for city in cities:\n weather_query = base_context + weather_suffix + '?' + 'q=' + city + '&appid=' + api_key + '&units=' + units + '&lang=' + lang\n forecast_query = base_context + forecast_suffix + '?' + 'q=' + city + '&appid=' + api_key + '&units=' + units + '&lang=' + lang\n weather_content_raw = urllib.request.urlopen(weather_query).read().decode('utf-8')\n forecast_content_raw = urllib.request.urlopen(forecast_query).read().decode('utf-8')\n\n weather_content = json.loads(weather_content_raw)\n forecast_content = json.loads(forecast_content_raw)\n for item in forecast_content['list']:\n item['dt'] = datetime.fromtimestamp(item['dt'])\n json_content.append([weather_content, forecast_content])\n\n return json_content\n\ndef get_current_weather_raw(city):\n context = base_context + weather_suffix\n query = '?' + 'q=' + city + '&appid=' + api_key + '&units=' + units + '&lang=' + lang\n json_content = urllib.request.urlopen(context + query).read().decode('utf-8')\n raw_object = json.loads(json_content)\n\n raw_object['sys']['sunrise'] = datetime.fromtimestamp(raw_object['sys']['sunrise'])\n raw_object['sys']['sunset'] = datetime.fromtimestamp(raw_object['sys']['sunset'])\n raw_object['dt'] = datetime.fromtimestamp(raw_object['dt'])\n return raw_object\n\ndef get_forecast_raw(city):\n context = base_context + forecast_suffix\n query = '?' + 'q=' + city + '&appid=' + api_key + '&units=' + units + '&lang=' + lang\n json_content = urllib.request.urlopen(context + query).read().decode('utf-8')\n raw_list = json.loads(json_content)['list']\n\n for list_unit in raw_list:\n list_unit['dt'] = datetime.fromtimestamp(list_unit['dt'])\n list_unit['city'] = json.loads(json_content)['city']['name']\n print(json.loads(json_content)['city'])\n\n return raw_list\n\ndef get_current_weather(requested_city='minsk'):\n weather_raw = get_current_weather_raw(requested_city)\n default_string = ''\n default_int = -1\n default_float = -1.0\n\n Weather.objects.filter(requested_city=requested_city).delete()\n weather = Weather.objects.create()\n weather.main_info = weather_raw['weather'][0].get('main', default_string)\n weather.description = weather_raw['weather'][0].get('description', default_string)\n weather.icon_name = weather_raw['weather'][0].get('icon', default_string)\n weather.city_name = weather_raw.get('name', default_string)\n weather.requested_city = requested_city\n weather.temperature = int(weather_raw['main'].get('temp', default_int))\n weather.humidity = int(weather_raw['main'].get('humidity', default_int))\n weather.pressure = int(weather_raw['main'].get('pressure', default_int))\n weather.visibility = int(weather_raw.get('visibility', default_int))\n weather.temperature_min = int(weather_raw['main'].get('temp_min', default_int))\n weather.temperature_max = int(weather_raw['main'].get('temp_max', default_int))\n weather.wind_speed = float(weather_raw['wind'].get('speed', default_float))\n weather.wind_deg = float(weather_raw['wind'].get('deg', default_float))\n weather.sunrise = weather_raw['sys']['sunrise']\n weather.sunset = weather_raw['sys']['sunset']\n weather.date = weather_raw['dt']\n\n weather.save()\n\n return Weather.objects\n\ndef get_db_forecast(requested_city='minsk'):\n forecasts_raw = get_forecast_raw(requested_city)\n default_string = ''\n default_int = -1\n default_float = -1.0\n\n WeatherForecast.objects.filter(requested_city=requested_city).delete()\n for forecast_raw in forecasts_raw:\n forecast = WeatherForecast.objects.create()\n\n forecast.city = forecast_raw['city']\n forecast.requested_city = requested_city\n forecast.main_info = forecast_raw['weather'][0].get('main', default_string)\n forecast.description = forecast_raw['weather'][0].get('description', default_string)\n forecast.icon_name = forecast_raw['weather'][0].get('icon', default_string)\n forecast.temperature = forecast_raw['main'].get('temp', default_int)\n forecast.temperature_min = forecast_raw['main'].get('temp_min', default_int)\n forecast.temperature_max = forecast_raw['main'].get('temp_max', default_int)\n forecast.pressure = forecast_raw['main'].get('pressure', default_int)\n forecast.humidity = forecast_raw['main'].get('humidity', default_int)\n forecast.wind_speed = forecast_raw['wind'].get('speed', default_float)\n forecast.wind_deg = forecast_raw['wind'].get('deg', default_float)\n forecast.date_time = forecast_raw['dt']\n\n forecast.save()\n\n return WeatherForecast.objects"
},
{
"alpha_fraction": 0.8573216795921326,
"alphanum_fraction": 0.8573216795921326,
"avg_line_length": 37.095237731933594,
"blob_id": "0e35d071dcac08df9370cadcf9a4716f4d6b92b5",
"content_id": "884b5ed2a29b2319b17b23906ac90bff3088354c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 799,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 21,
"path": "/dashboard/admin.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import Weather, WeatherForecast\nfrom .models import Currency, CurrencyStatistics, CurrencyConversion\nfrom .models import CryptoCurrency, CryptoMarket\nfrom .models import DevByEvent\nfrom .models import LivingPlace, UtilitiesRecord\nfrom .models import IncomeRecord, ExpensesRecord, ExpensesCategory\n\nadmin.site.register(Weather)\nadmin.site.register(WeatherForecast)\nadmin.site.register(Currency)\nadmin.site.register(CurrencyConversion)\nadmin.site.register(CurrencyStatistics)\nadmin.site.register(CryptoCurrency)\nadmin.site.register(CryptoMarket)\nadmin.site.register(DevByEvent)\nadmin.site.register(LivingPlace)\nadmin.site.register(UtilitiesRecord)\nadmin.site.register(IncomeRecord)\nadmin.site.register(ExpensesRecord)\nadmin.site.register(ExpensesCategory)"
},
{
"alpha_fraction": 0.5851393342018127,
"alphanum_fraction": 0.6080495119094849,
"avg_line_length": 41.5,
"blob_id": "c32280494ee5715e1eae1b5cc546b387dec9f392",
"content_id": "e8a6610a02f72cb43612c963c759995a3d263025",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1615,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 38,
"path": "/dashboard/migrations/0006_livingplace_utilitiesrecord.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.2 on 2018-04-04 14:23\n\nfrom django.conf import settings\nfrom django.db import migrations, models\nimport django.db.models.deletion\nimport django.utils.timezone\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n migrations.swappable_dependency(settings.AUTH_USER_MODEL),\n ('dashboard', '0005_auto_20180315_1332'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='LivingPlace',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(default='', max_length=200)),\n ('address', models.TextField(default='')),\n ('last_updated', models.DateTimeField(default=django.utils.timezone.now)),\n ('author', models.ForeignKey(default=None, null=True, on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL)),\n ],\n ),\n migrations.CreateModel(\n name='UtilitiesRecord',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('hot_water', models.IntegerField(default=0)),\n ('cold_water', models.IntegerField(default=0)),\n ('electricity', models.IntegerField(default=0)),\n ('date', models.DateTimeField(default=django.utils.timezone.now)),\n ('place', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='dashboard.LivingPlace')),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.7351822853088379,
"alphanum_fraction": 0.737866222858429,
"avg_line_length": 44.141414642333984,
"blob_id": "d7364b0d35d948b1bebcc973f753d039530626fd",
"content_id": "2f394c573a67a9b6a4d5501945df91ebe8b8c3bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4838,
"license_type": "no_license",
"max_line_length": 193,
"num_lines": 99,
"path": "/bots/telegram_handlers.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.utils import timezone\n\nfrom dashboard.models import Weather\nfrom dashboard.models import Currency\nfrom dashboard.models import CryptoMarket\nfrom dashboard.models import CryptoCurrency\nfrom dashboard.models import CurrencyConversion\nfrom dashboard.models import CurrencyStatistics\nfrom dashboard.models import RadiotArticle\n\nfrom dashboard.dashes.weather import OpenWeather\nfrom dashboard.dashes.currency import NBRBCurrency\nfrom dashboard.dashes.crypto_currency import CryptoCurrencyInfo\nfrom dashboard.dashes.news import Radiot\n\n\nfrom telegram.ext import CommandHandler, MessageHandler, Filters, JobQueue\n\nhelp_message = 'Добро пожаловать в гости к mgbot!\\nПо сути - это бот-комбайн\\nПоясню. Одной тематикой он не ограничен. Информация, которая здесь может быть получена довольно разнообразна.\\n'\nhelp_message_commands = 'На данный момент присутствуют следующие комманды:\\nweather - информация о погоде\\ncurrency - курсы валют НБРБ\\nconversion - конверсия валют\\ncrypto - курсы криптовалют'\n\nchat_ids = set()\n\n\n\ndef news(bot, update):\n final_string = ''\n Radiot.update_info()\n news = RadiotArticle.objects.order_by('-radiot_ts')\n for article in news[0:5:1]:\n final_string = final_string + article.title + '\\n'\n final_string = final_string + article.link + '\\n\\n'\n bot.sendMessage(update.message.chat_id, text=final_string)\n\ndef get_weather_message(requested_city='minsk'):\n OpenWeather.update_info(requested_city)\n weather = Weather.objects.filter(requested_city=requested_city)[0]\n final_string = ''\n header_string = 'Погода в городе {0} \\n'.format(weather.city_name)\n temperature_string = 'Температура: {0} \\n'.format(weather.temperature)\n humidity_string = 'Влажность: {0} \\n'.format(weather.humidity)\n weather_string = weather.description\n final_string = final_string + header_string + temperature_string + humidity_string + weather_string\n return final_string\n\ndef start(bot, update):\n bot.sendMessage(update.message.chat_id, text='Hi!')\n\ndef help(bot, update):\n bot.sendMessage(update.message.chat_id, text=help_message + help_message_commands)\n\ndef weather(bot, update, args):\n text = ''\n if (len(args) == 0):\n text = get_weather_message()\n else:\n text = get_weather_message(args[0])\n bot.sendMessage(update.message.chat_id, text=text)\n\ndef currency(bot, update):\n NBRBCurrency.update_info()\n currencies = Currency.objects.filter(rate__isnull=False)\n final_string = 'Курсы валют от НБРБ: \\n'\n for currency in currencies:\n final_string = final_string + '{0} {1} = {2} BYN \\n'.format(currency.scale, currency.abbreviation, currency.rate)\n bot.sendMessage(update.message.chat_id, text=final_string)\n\ndef currency_conversions(bot, update):\n NBRBCurrency.update_info()\n conversions = CurrencyConversion.objects.filter(currency_from__isnull=False)\n final_string = 'Конверсия курсов валют от НБРБ\\n'\n for conversion in conversions:\n final_string = final_string + conversion.currency_from + ' / ' + conversion.currency_to + ': ' + str(conversion.value) + '\\n'\n bot.sendMessage(update.message.chat_id, text=final_string)\n\ndef crypto(bot, update):\n print('crypto debug info')\n CryptoCurrencyInfo.update_info()\n currencies = CryptoCurrency.objects.order_by('rank')\n final_string = 'Курсы криптовалют:\\n'\n for currency in currencies:\n final_string = final_string + str(currency.rank) + '. ' + currency.name + ': ' + str(currency.price_usd) + '$\\n'\n bot.sendMessage(update.message.chat_id, text=final_string)\n\ndef promote_handlers(dispatcher):\n print('telegrambot init')\n dispatcher.add_handler(CommandHandler(\"start\", start))\n dispatcher.add_handler(CommandHandler(\"help\",help))\n dispatcher.add_handler(CommandHandler(command=\"weather\", callback=weather, pass_args=True))\n dispatcher.add_handler(CommandHandler(\"погода\", weather))\n dispatcher.add_handler(CommandHandler(\"currency\", currency))\n dispatcher.add_handler(CommandHandler(\"курсы\", currency))\n dispatcher.add_handler(CommandHandler(\"crypto\", crypto))\n dispatcher.add_handler(CommandHandler(\"криптовалюты\", crypto))\n dispatcher.add_handler(CommandHandler(\"conversion\", currency_conversions))\n dispatcher.add_handler(CommandHandler(\"конверсия\", currency_conversions))\n dispatcher.add_handler(CommandHandler(\"news\", news))\n dispatcher.add_handler(CommandHandler(\"новости\", news))\n\n\n"
},
{
"alpha_fraction": 0.49367088079452515,
"alphanum_fraction": 0.5822784900665283,
"avg_line_length": 20.94444465637207,
"blob_id": "493e1f17fa4ef7b2b1863412a55da81be2159283",
"content_id": "5c38edcf4c97487db49d9d55a3691a3bc0582472",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 395,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 18,
"path": "/todo/migrations/0004_auto_20180222_1248.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.2 on 2018-02-22 09:48\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('todo', '0003_auto_20180220_1206'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='action',\n name='text',\n field=models.CharField(default='', max_length=1000),\n ),\n ]\n"
},
{
"alpha_fraction": 0.8368794322013855,
"alphanum_fraction": 0.8368794322013855,
"avg_line_length": 27.200000762939453,
"blob_id": "70edef532a8df5c162fbdf96f2ca00138eb7010e",
"content_id": "f13cd33b2492c4b161631395adde32cef48319db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 141,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 5,
"path": "/todo/admin.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import Action, ActionCategory\n\nadmin.site.register(Action)\nadmin.site.register(ActionCategory)\n"
},
{
"alpha_fraction": 0.7061101794242859,
"alphanum_fraction": 0.7061101794242859,
"avg_line_length": 79.10344696044922,
"blob_id": "a4af98039494b2cb8dbc5ffdab5715d9c234da34",
"content_id": "25cc155f909271d7a9ff39dd42b6aea9f0421488",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2324,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 29,
"path": "/dashboard/urls.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\nfrom django.urls import path, re_path, include\n\nfrom . import views\n\nurlpatterns = [\n url(r'^dashboard/weather/$', views.weather_info, name='weather_info'),\n url(r'^dashboard/currencies/$', views.currency_info, name='currency_info'),\n url(r'^dashboard/crypto_currencies/$', views.crypto_currency_info, name='crypto_currency_info'),\n url(r'^dashboard/events/$', views.deb_by_events_info, name='deb_by_events_info'),\n url(r'^dashboard/news/$', views.radiot_news, name='radiot_news'),\n url(r'^dashboard/utilities/list/$', views.utilities_list, name='utilities_list'),\n url(r'^dashboard/utilities/new/$', views.utilities_create, name='utilities_create'),\n url(r'^dashboard/utilities/update/(?P<pk>\\d+)$', views.utilities_update, name='utilities_update'),\n url(r'^dashboard/utilities/delete/(?P<pk>\\d+)$', views.utilities_delete, name='utilities_delete'),\n url(r'^dashboard/living_place/new/$', views.living_place_create, name='living_place_create'),\n url(r'^dashboard/living_place/update/(?P<pk>\\d+)$', views.living_place_update, name='living_place_update'),\n url(r'^dashboard/living_place/delete/(?P<pk>\\d+)$', views.living_place_delete, name='living_place_delete'),\n url(r'^dashboard/expenses/list/$', views.expenses_list, name='expenses_list'),\n url(r'^dashboard/expenses/new/$', views.expenses_record_create, name='expenses_record_create'),\n url(r'^dashboard/expenses/update/(?P<pk>\\d+)$', views.expenses_record_update, name='expenses_record_update'),\n url(r'^dashboard/expenses/delete/(?P<pk>\\d+)$', views.expenses_record_delete, name='expenses_record_delete'),\n url(r'^dashboard/expenses_category/new/$', views.expenses_category_create, name='expenses_category_create'),\n url(r'^dashboard/expenses_category/update/(?P<pk>\\d+)$', views.expenses_category_update, name='expenses_category_update'),\n url(r'^dashboard/expenses_category/delete/(?P<pk>\\d+)$', views.expenses_category_delete, name='expenses_category_delete'),\n url(r'^dashboard/income/new/$', views.income_record_create, name='income_record_create'),\n url(r'^dashboard/income/update/(?P<pk>\\d+)$', views.income_record_update, name='income_record_update'),\n url(r'^dashboard/income/delete/(?P<pk>\\d+)$', views.income_record_delete, name='income_record_delete'),\n]\n\n"
},
{
"alpha_fraction": 0.5356321930885315,
"alphanum_fraction": 0.5609195232391357,
"avg_line_length": 39.78125,
"blob_id": "3db76ba77fb03d1aa6b1e7104afd29425950ea11",
"content_id": "98d10f3341220595ba3ca5b8c735f4d766fbb015",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1305,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 32,
"path": "/dashboard/migrations/0002_radiotarticle.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.2 on 2018-02-23 16:57\n\nfrom django.db import migrations, models\nimport django.utils.timezone\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('dashboard', '0001_initial'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='RadiotArticle',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('title', models.CharField(default='', max_length=400)),\n ('content', models.TextField(default='')),\n ('snippet', models.TextField(default='')),\n ('main_pic', models.CharField(default='', max_length=200)),\n ('link', models.CharField(default='', max_length=200)),\n ('author', models.CharField(default='', max_length=200)),\n ('original_ts', models.DateTimeField(default=django.utils.timezone.now)),\n ('radiot_ts', models.DateTimeField(default=django.utils.timezone.now)),\n ('feed', models.TextField(default='')),\n ('slug', models.TextField(default='')),\n ('comments', models.IntegerField(default=0)),\n ('likes', models.IntegerField(default=0)),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.6209362745285034,
"alphanum_fraction": 0.6280884146690369,
"avg_line_length": 26.464284896850586,
"blob_id": "74f352fe703bea6b1999a1ae2a19291bb009c550",
"content_id": "6a6aba355e6f7d3b6bbcb053cb28cd8254913c40",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1538,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 56,
"path": "/dashboard/dashes/events/DevBy.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.utils import timezone\n\nimport json\nimport urllib\nimport feedparser\n\nfrom datetime import timedelta\nfrom datetime import datetime, timezone\nfrom django.shortcuts import get_object_or_404\n\nfrom dashboard.models import DevByEvent\n\n\nRSS_URL = 'https://events.dev.by/rss'\nLATENCY_DAYS=1\nSECONDS_IN_DAY=86400\n\n\n\ndef update_info():\n test_event = None\n try:\n if (len(DevByEvent.objects.filter())>0):\n test_event = DevByEvent.objects.filter()[0]\n except DevByEvent.DoesNotExist:\n test_event = None\n\n if test_event != None :\n last_updated = test_event.last_updated\n from_last_update = (datetime.now(timezone.utc) - last_updated).total_seconds()\n from_last_update = int(from_last_update / SECONDS_IN_DAY)\n if (from_last_update >= LATENCY_DAYS):\n get_info()\n else:\n get_info()\n\ndef get_info():\n feed = get_raw_info()\n DevByEvent.objects.filter().delete()\n if (feed != None):\n for entry in feed:\n event_db = DevByEvent.objects.create()\n event_db.title = str(entry['title'])\n event_db.content = str(entry['description']).replace('<em>','').replace('<strong>', '').replace('</strong>', '')\n event_db.link = str(entry['link'])\n event_db.save()\n\ndef get_raw_info():\n feed = None\n try:\n feed = feedparser.parse(RSS_URL)\n return feed['entries']\n except Exception as e:\n print('error during fetching dev by feed')\n return feed\n"
},
{
"alpha_fraction": 0.6765463948249817,
"alphanum_fraction": 0.6765463948249817,
"avg_line_length": 58.769229888916016,
"blob_id": "e92176fad991814362b588dbb02519fa884a1663",
"content_id": "d3cae05cebe490b896911fa50c9e6368ebf7311b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 776,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 13,
"path": "/todo/urls.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\nfrom . import views\n\nurlpatterns = [\n url(r'^todo/$', views.action_list, name='action_list'),\n url(r'^todo/task/new/$', views.create_action, name='create_action'),\n url(r'^todo/task/(?P<pk>\\d+)$',views.update_action, name='update_action'),\n url(r'^todo/task/delete/(?P<pk>\\d+)$',views.delete_action, name='delete_action'),\n url(r'^todo/category/new/', views.create_action_category, name='create_action_category'),\n url(r'^todo/category/(?P<pk>\\d+)$',views.category_action_list, name='category_action_list'),\n url(r'^todo/category/update/(?P<pk>\\d+)$',views.update_action_category, name='update_action_category'),\n url(r'^todo/category/delete/(?P<pk>\\d+)$',views.delete_action_category, name='delete_action_category'),\n]"
},
{
"alpha_fraction": 0.6365422606468201,
"alphanum_fraction": 0.6365422606468201,
"avg_line_length": 17.851852416992188,
"blob_id": "f20c551c7904b8ea19f72cb5c96bfcb2df091f4a",
"content_id": "8cb957c8575a265a874563e8d4f25121f883d934",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 509,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 27,
"path": "/mysite/settings/local.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from .base import *\n\nMG_APP_LOCATION = 'local'\n\nDEBUG = True\n\nSECRET_KEY = 'local secret key'\n\nINSTALLED_APPS = (\n 'django.db.models',\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'django.contrib.humanize',\n 'rest_framework',\n 'rest_framework.authtoken',\n 'blog',\n 'landing',\n 'dashboard',\n 'todo',\n 'bots',\n)\n\nTELEGRAM_BOT_ALLOWED = False\n"
},
{
"alpha_fraction": 0.616314172744751,
"alphanum_fraction": 0.616314172744751,
"avg_line_length": 29,
"blob_id": "1a3e13a6afe0c139519ea85289f07a560d0d061c",
"content_id": "f7c556f09b286f5d11d7dc7fac87c0ae5e3066e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 331,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 11,
"path": "/static/js/scrolling.js",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "$(document).ready(function(){\n var headingScroll = document.getElementById('block-heading-scroll');\n var appsScroll = document.getElementById('block-apps-scroll');\n\n headingScroll.onclick = function(e){\n appsScroll.scrollIntoView({\n block: \"start\",\n behavior: \"smooth\"\n });\n };\n});\n\n"
},
{
"alpha_fraction": 0.7954545617103577,
"alphanum_fraction": 0.7954545617103577,
"avg_line_length": 44,
"blob_id": "e3d1d2df7747737852c334b832ca8ba2d83bb5d8",
"content_id": "957a7818aa8ebd08f234c3f46030b1ecbeebb2e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 44,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 1,
"path": "/bots/__init__.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "default_app_config = 'bots.apps.TelegramBot'"
},
{
"alpha_fraction": 0.7471513748168945,
"alphanum_fraction": 0.7504069209098816,
"avg_line_length": 31.910715103149414,
"blob_id": "d19d8fbc304c582ab53e518856e6d52d09a19098",
"content_id": "80a887a4c4e13d02c3b634b55a30a317294b281c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1843,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 56,
"path": "/landing/views.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.contrib.auth.models import User\nfrom django.contrib.auth.decorators import login_required\nfrom django.contrib.auth.forms import UserCreationForm\n\nfrom django.shortcuts import render\nfrom django.shortcuts import render, get_object_or_404\nfrom django.shortcuts import redirect\nfrom django.utils import timezone\n\nfrom rest_framework.authtoken.models import Token\n\nfrom .models import SecretMessage\nfrom .common_settings import versions\n\nfrom dashboard.models import Weather\nfrom dashboard.models import Currency\n\nfrom dashboard.dashes.weather import OpenWeather\nfrom dashboard.dashes.currency import NBRBCurrency\nfrom dashboard.dashes.crypto_currency import CryptoCurrencyInfo\n\n\nimport urllib.request\n\n\ndef show_greeting(request):\n OpenWeather.update_info()\n NBRBCurrency.update_info()\n weather = get_object_or_404(Weather, city_name='Minsk')\n currencies = Currency.objects.filter(scale__isnull=False)\n return render(request, 'landing/greeting.html', {'weather': weather, 'currencies': currencies})\n\ndef apps_list(request):\n return render(request, 'landing/main.html')\n\n@login_required\ndef secret_message_new(request):\n return render(request, 'landing/main.html')\n\n@login_required\ndef secret_message_list(request):\n messages = SecretMessage.objects.filter(text__isnull=False).order_by('date')\n return render(request, 'landing/messages.html', {'secret_messages': messages})\n\ndef info_about(request):\n return render(request, 'about/base.html', {'versions' : versions})\n\ndef register(request):\n form = UserCreationForm()\n if request.method == 'POST':\n form = UserCreationForm(request.POST)\n if form.is_valid:\n new_user = form.save()\n new_user.save()\n return redirect('apps_list')\n return render(request, 'registration/register.html', {'form': form})\n"
},
{
"alpha_fraction": 0.7014546394348145,
"alphanum_fraction": 0.7246278524398804,
"avg_line_length": 42.463233947753906,
"blob_id": "10707d22fb2513889ab99d2311b59f10629e7887",
"content_id": "8af500d069bf28e5ede3392752d3ddb53703be13",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5912,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 136,
"path": "/dashboard/models.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.utils import timezone\n\nclass IncomeRecord(models.Model):\n amount = models.IntegerField(default=0)\n date = models.DateTimeField(default=timezone.now)\n name = models.CharField(max_length=400, default='')\n comment = models.CharField(max_length=400, default='')\n author = models.ForeignKey('auth.User', on_delete=models.CASCADE, default=None, null=True)\n\n def __str__(self):\n return self.name\n\nclass ExpensesRecord(models.Model):\n amount = models.IntegerField(default=0)\n date = models.DateTimeField(default=timezone.now)\n name = models.CharField(max_length=400, default='')\n comment = models.CharField(max_length=400, default='')\n category = models.ForeignKey('dashboard.ExpensesCategory', on_delete=models.CASCADE)\n author = models.ForeignKey('auth.User', on_delete=models.CASCADE, default=None, null=True)\n\n def __str__(self):\n return self.name\n\nclass ExpensesCategory(models.Model):\n name = models.CharField(max_length=400, default='')\n date = models.DateTimeField(default=timezone.now)\n author = models.ForeignKey('auth.User', on_delete=models.CASCADE, default=None, null=True)\n\n def __str__(self):\n return self.name\n\nclass UtilitiesRecord(models.Model):\n hot_water = models.IntegerField(default=0)\n cold_water = models.IntegerField(default=0)\n electricity = models.IntegerField(default=0)\n gas = models.IntegerField(default=0)\n date = models.DateTimeField(default=timezone.now)\n place = models.ForeignKey('dashboard.LivingPlace', on_delete=models.CASCADE)\n\nclass LivingPlace(models.Model):\n name = models.CharField(max_length=200, default='')\n address = models.TextField(default='')\n author = models.ForeignKey('auth.User', on_delete=models.CASCADE, default=None, null=True)\n last_updated = models.DateTimeField(default=timezone.now)\n\n def __str__(self):\n return self.name\n\nclass RadiotArticle(models.Model):\n title = models.CharField(max_length=400, default='')\n content = models.TextField(default='')\n snippet = models.TextField(default='')\n main_pic = models.CharField(max_length=200, default='')\n link = models.CharField(max_length=200, default='')\n author = models.CharField(max_length=200, default='')\n original_ts = models.DateTimeField(default=timezone.now)\n radiot_ts = models.DateTimeField(default=timezone.now)\n feed = models.TextField(default='')\n slug = models.TextField(default='')\n comments = models.IntegerField(default=0)\n likes = models.IntegerField(default=0)\n last_updated = models.DateTimeField(default=timezone.now)\n\nclass DevByEvent(models.Model):\n title = models.CharField(max_length=400, default='')\n content = models.TextField(default='')\n link = models.CharField(max_length=400, default='')\n last_updated = models.DateTimeField(default=timezone.now)\n\nclass CryptoMarket(models.Model):\n total_usd = models.IntegerField(default=0.0)\n total_usd_day_volume = models.IntegerField(default=0.0)\n active_markets = models.IntegerField(default=0.0)\n active_currencies = models.IntegerField(default=0)\n bitcoin_percent = models.FloatField(default=0.0)\n last_updated = models.DateTimeField(default=timezone.now)\n\nclass CryptoCurrency(models.Model):\n name = models.CharField(max_length=200, default='')\n symbol = models.CharField(max_length=200, default='')\n rank = models.IntegerField(default=0)\n price_usd = models.FloatField(default=0.0)\n price_btc = models.FloatField(default=0.0)\n change_24h = models.FloatField(default=0.0)\n\nclass Currency(models.Model):\n scale = models.FloatField(default=0.0)\n rate = models.FloatField(default=0.0)\n abbreviation = models.CharField(default='', max_length=200)\n last_updated = models.DateTimeField(default=timezone.now)\n\nclass CurrencyConversion(models.Model):\n value = models.FloatField(default=0.0)\n currency_from = models.CharField(default='', max_length=200)\n currency_to = models.CharField(default='', max_length=200)\n\nclass CurrencyStatistics(models.Model):\n abbreviation = models.CharField(default='', max_length=200)\n rate = models.FloatField(default=0.0)\n date = models.DateTimeField(default=timezone.now)\n\nclass Weather(models.Model):\n main_info = models.CharField(max_length=200, default='')\n description = models.CharField(max_length=200, default='')\n icon_name = models.CharField(max_length=200, default='')\n city_name = models.CharField(max_length=200, default='')\n requested_city = models.CharField(max_length=200, default='')\n temperature = models.IntegerField(default=0)\n humidity = models.IntegerField(default=0)\n pressure = models.IntegerField(default=0)\n visibility = models.IntegerField(default=0)\n temperature_min = models.IntegerField(default=0)\n temperature_max = models.IntegerField(default=0)\n wind_speed = models.FloatField(default=0.0)\n wind_deg = models.FloatField(default=0.0)\n sunrise = models.DateTimeField(default=timezone.now)\n sunset = models.DateTimeField(default=timezone.now)\n last_updated = models.DateTimeField(default=timezone.now)\n date = models.DateTimeField(default=timezone.now)\n\n\nclass WeatherForecast(models.Model):\n city = models.CharField(max_length=200, default='')\n requested_city = models.CharField(max_length=200, default='')\n temperature = models.IntegerField(default=0)\n temperature_min = models.IntegerField(default=0)\n temperature_max = models.IntegerField(default=0)\n pressure = models.IntegerField(default=0)\n humidity = models.IntegerField(default=0)\n main_info = models.CharField(max_length=200)\n description = models.CharField(max_length=200)\n icon_name = models.CharField(max_length=200)\n wind_speed = models.FloatField(default=0.0)\n wind_deg = models.FloatField(default=0.0)\n date_time = models.DateTimeField(default=timezone.now)\n\n"
},
{
"alpha_fraction": 0.6888168454170227,
"alphanum_fraction": 0.6888168454170227,
"avg_line_length": 34.228572845458984,
"blob_id": "31057549e34cf5a5b0ddd2368723863fed030ea3",
"content_id": "37792af2f7a27871c33d882a9b3cbf1a34d0c98c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1234,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 35,
"path": "/bots/apps.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\nfrom django.conf import settings\n\nimport telegram\n\nfrom telegram.ext import Updater\nfrom telegram.ext import CommandHandler\n\nfrom telegram.error import InvalidToken, TelegramError, BadRequest\n\nTELEGRAM_BOT_TOKEN = '460933242:AAEh67xQVBeT37EwN84iudv80tbYBsOY1QA'\nTELEGRAM_BOT_SUFFIX = 'bots/telegram/'\nTELEGRAM_BOT_WEBHOOK_ADDR = 'https://mgelios.pythonanywhere.com/'\n\nclass TelegramBot(AppConfig):\n name = 'bots'\n verbose_name = 'Telegram bot'\n updater = None\n bot = None\n dispatcher = None\n webhook_started = False\n\n def ready(self):\n from bots import telegram_handlers\n TelegramBot.updater = Updater(token=TELEGRAM_BOT_TOKEN)\n TelegramBot.bot = TelegramBot.updater.bot\n TelegramBot.dispatcher = TelegramBot.updater.dispatcher\n if settings.TELEGRAM_BOT_ALLOWED:\n try:\n telegram_handlers.promote_handlers(TelegramBot.dispatcher)\n TelegramBot.bot.setWebhook(url=TELEGRAM_BOT_WEBHOOK_ADDR+TELEGRAM_BOT_SUFFIX+TELEGRAM_BOT_TOKEN+'/')\n TelegramBot.webhook_started = True\n print('### webhook successfuly started')\n except BadRequest as er:\n print('### error occured during setting webhook')\n\n"
},
{
"alpha_fraction": 0.654374361038208,
"alphanum_fraction": 0.6607324481010437,
"avg_line_length": 28.5563907623291,
"blob_id": "57e5797026017f632e372c3cb33841164a28795e",
"content_id": "d8b7403c10870f03562e6c33c9d5dcd6779c62ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3932,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 133,
"path": "/dashboard/dashes/crypto_currency/CryptoCurrencyInfo.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.utils import timezone\n\nimport json\nimport urllib\n\nfrom datetime import timedelta\nfrom datetime import datetime, timezone\n\nfrom django.shortcuts import get_object_or_404\n\nfrom dashboard.models import CryptoCurrency, CryptoMarket\n\nAPI_URL = 'https://api.coinmarketcap.com/v1/'\nAPI_TYPE_TICKER = 'ticker/'\nAPI_TYPE_GLOBAL = 'global/'\nLIMIT_SUFFIX = '?limit='\nLIMIT_AMOUNT = '10'\n\nSPECIAL_IDS = [\n'nem', \n'stellar', \n'zcash', \n'siacoin', \n'golem-network-tokens', \n'pivx', \n'expanse',\n'ethereum-classic',\n'steem',\n'dogecoin',\n'dash',\n'omisego',\n'stratis',\n'qtum'\n]\n\nLATENCY = 300\n\ndef update_info():\n test_market = None\n try:\n test_market = CryptoMarket.objects.get()\n except CryptoMarket.DoesNotExist:\n test_market = None\n\n if (test_market == None):\n update_db()\n else:\n last_updated = test_market.last_updated\n from_last_update = (datetime.now(timezone.utc) - last_updated).total_seconds()\n if (from_last_update >= LATENCY):\n update_db()\n\ndef update_db():\n raw_currencies = get_info()\n raw_market = get_market_info()\n CryptoCurrency.objects.filter(name__isnull=False).delete()\n CryptoMarket.objects.filter(total_usd__isnull=False).delete()\n for raw_currency in raw_currencies:\n currency = CryptoCurrency.objects.create()\n currency.name = raw_currency['name']\n currency.symbol = raw_currency['symbol']\n currency.rank = raw_currency['rank']\n currency.price_btc = raw_currency['price_btc']\n currency.price_usd = raw_currency['price_usd']\n currency.change_24h = raw_currency['percent_change_24h']\n currency.save()\n print(raw_market)\n market = CryptoMarket.objects.create()\n market.total_usd = int(raw_market[0]['total_market_cap_usd'])\n market.total_usd_day_volume = int(raw_market[0]['total_24h_volume_usd'])\n market.active_markets = int(raw_market[0]['active_markets'])\n market.active_currencies = int(raw_market[0]['active_currencies'])\n market.bitcoin_percent = float(raw_market[0]['bitcoin_percentage_of_market_cap'])\n market.save()\n\n\n\ndef get_market_info():\n json_content = []\n try:\n content = urllib.request.urlopen(API_URL + API_TYPE_GLOBAL + LIMIT_SUFFIX + LIMIT_AMOUNT).read().decode('utf-8')\n json_content.append(json.loads(content))\n except urllib.error.HTTPError:\n print('error during fetching crypto currency market info')\n return json_content\n\n#get both top and special currencies\ndef get_info():\n content = get_currencies()[0]\n special_content = get_special_currencies()\n for special_currency in special_content:\n content.append(special_currency[0])\n\n content = remove_duplicates(content)\n content.sort(key=get_key)\n return content\n\n#get top currencies\ndef get_currencies():\n json_content = []\n try:\n content = urllib.request.urlopen(API_URL + API_TYPE_TICKER + LIMIT_SUFFIX + LIMIT_AMOUNT).read().decode('utf-8')\n json_content.append(json.loads(content))\n except urllib.error.HTTPError:\n print(\"error during fetching crypto currency\")\n return json_content\n\n#get special currencies from list\ndef get_special_currencies():\n json_content = []\n try:\n for special_id in SPECIAL_IDS:\n content = urllib.request.urlopen(API_URL + API_TYPE_TICKER + special_id).read().decode('utf-8')\n json_content.append(json.loads(content))\n except urllib.error.HTTPError:\n print(\"error during fetching crypto currency\")\n return json_content\n\n#get sort key \ndef get_key(item):\n return int(item['rank'])\n\ndef remove_duplicates(content):\n result = []\n for i in range(len(content)):\n found = False\n for j in range(i):\n if (content[i]['id'] == content[j]['id']):\n found = True\n if (not found):\n result.append(content[i])\n return result\n\n"
},
{
"alpha_fraction": 0.6683780550956726,
"alphanum_fraction": 0.6730455160140991,
"avg_line_length": 37.5945930480957,
"blob_id": "1ed7a8e4ff9946ad31666c78c428aba8c6a6ddb9",
"content_id": "ead61de96d3672de08a672351d259964b087f4d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4285,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 111,
"path": "/todo/views.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.contrib.auth.decorators import login_required\nfrom django.shortcuts import render\nfrom django.shortcuts import render, get_object_or_404\nfrom django.shortcuts import redirect\nfrom django.utils import timezone\n\n\nfrom .models import Action, ActionCategory\nfrom .forms import ActionForm, ActionCategoryForm\n\n@login_required\ndef action_list(request):\n first_category = None\n categories = None\n actions = None\n if (len(ActionCategory.objects.filter(author=request.user))>0):\n categories = ActionCategory.objects.filter(author=request.user)\n first_category = categories[0]\n if (first_category != None):\n actions = Action.objects.filter(category=first_category).order_by('-priority')\n return render(\n request, \n 'todo/sheet.html',\n { 'actions': actions,\n 'categories': categories,\n 'active_category': first_category })\n\n@login_required\ndef category_action_list(request, pk):\n category = get_object_or_404(ActionCategory, pk=pk)\n categories = ActionCategory.objects.filter(author=request.user)\n actions = Action.objects.filter(category=category).order_by('-priority')\n return render(\n request,\n 'todo/sheet.html',\n { 'actions': actions,\n 'categories': categories,\n 'active_category': category\n })\n\n@login_required\ndef update_action(request, pk):\n action = get_object_or_404(Action, pk=pk)\n categories = ActionCategory.objects.filter(author=request.user)\n if request.method == 'POST':\n form = ActionForm(request.POST, instance=action)\n if (form.is_valid):\n action = form.save()\n action.save()\n return redirect('category_action_list', pk=action.category.pk)\n else:\n form = ActionForm(instance=action)\n form.fields['category'].queryset = ActionCategory.objects.filter(author=request.user)\n return render(request, 'todo/action_edit.html', {'form': form, 'is_update': True, 'categories': categories})\n\n@login_required\ndef create_action(request):\n categories = ActionCategory.objects.filter(author=request.user)\n if request.method == 'POST':\n form = ActionForm(request.POST)\n if (form.is_valid):\n action = form.save()\n action.save()\n return redirect('category_action_list', pk=action.category.pk)\n else:\n form = ActionForm()\n form.fields['category'].queryset = ActionCategory.objects.filter(author=request.user)\n return render(request, 'todo/action_edit.html', {'form': form, 'categories': categories})\n\n@login_required\ndef create_action_category(request):\n categories = ActionCategory.objects.filter(author=request.user)\n if request.method == 'POST':\n form = ActionCategoryForm(request.POST)\n if (form.is_valid):\n action_category = form.save()\n action_category.author = request.user\n action_category.save()\n return redirect('category_action_list', pk=action_category.pk)\n else:\n form = ActionCategoryForm()\n return render(request, 'todo/category_edit.html', {'form': form, 'categories': categories})\n\n@login_required\ndef update_action_category(request, pk):\n action_category = get_object_or_404(ActionCategory, pk=pk)\n categories = ActionCategory.objects.filter(author=request.user)\n if request.method == 'POST':\n form = ActionCategoryForm(request.POST, instance=action_category)\n if (form.is_valid):\n action_category = form.save()\n action_category.author = request.user\n action_category.save()\n return redirect('category_action_list', pk=action_category.pk)\n else:\n form = ActionCategoryForm(instance=action_category)\n return render(request, 'todo/category_edit.html', {'form': form, 'categories': categories, 'is_update': True})\n\n\n@login_required\ndef delete_action(request, pk):\n action = get_object_or_404(Action, pk=pk)\n category_pk = action.category.pk\n action.delete()\n return redirect('category_action_list', pk=category_pk)\n\n@login_required\ndef delete_action_category(request, pk):\n action_category = get_object_or_404(ActionCategory, pk=pk)\n action_category.delete()\n return redirect('action_list')\n\n"
},
{
"alpha_fraction": 0.7720588445663452,
"alphanum_fraction": 0.7720588445663452,
"avg_line_length": 26.200000762939453,
"blob_id": "2070f556ee79d2d9fce009df0e1e57b5db8151a4",
"content_id": "1b4bc0c491eb6d446b5667be8cbba49325603620",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 272,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 10,
"path": "/dashboard/viber_mgbot.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from viberbot import Api\nfrom viberbot.api.bot_configuration import BotConfiguration\n\nbot_configuration = BotConfiguration(\n name='mgbot',\n auth_token='46f8cbe1dee7d22a-2654d549e59d8703-5d9a149e324492c0'\n)\n\nviber = Api(bot_configuration)\nviber.set_webhook('https://mgelios.pythonanywhere.com/viber/mgbot')\n"
},
{
"alpha_fraction": 0.6535130143165588,
"alphanum_fraction": 0.669874906539917,
"avg_line_length": 27.86111068725586,
"blob_id": "9be975d22f34eed22c5ba34d0e5586692fdeb4e5",
"content_id": "98d2cdab2dc4a65462c690245a12f177d9436a56",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1039,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 36,
"path": "/todo/models.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.utils import timezone\n\nACTION_STATUSES = (\n (0, 'to do'),\n (1, 'in progress'),\n (2, 'done'),\n)\n\nACTION_PRIORITIES = (\n (0, 'trivial'),\n (1, 'minor'),\n (2, 'normal'),\n (3, 'high'),\n (4, 'critical')\n)\n\nclass Action(models.Model):\n text = models.CharField(default='', max_length=1000)\n date = models.DateTimeField(default=timezone.now)\n last_updated = models.DateTimeField(default=timezone.now)\n category = models.ForeignKey('todo.ActionCategory', on_delete=models.CASCADE)\n status = models.IntegerField(default=0, choices=ACTION_STATUSES)\n priority = models.IntegerField(default=2, choices=ACTION_PRIORITIES)\n\n def __str__(self):\n return self.text\n\n\nclass ActionCategory(models.Model):\n author = models.ForeignKey('auth.User', on_delete=models.CASCADE, default=None, null=True)\n name = models.CharField(default='', max_length=200)\n last_updated = models.DateTimeField(default=timezone.now)\n\n def __str__(self):\n return self.name\n"
},
{
"alpha_fraction": 0.638617217540741,
"alphanum_fraction": 0.6458949446678162,
"avg_line_length": 31.562963485717773,
"blob_id": "1c5e8a3b79909f15d83188204b46445b365449cf",
"content_id": "c05a6141e5cb16c17b6a85d9767485e87d763efb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4397,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 135,
"path": "/dashboard/dashes/currency/NBRBCurrency.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.utils import timezone\n\nimport json\nimport urllib\nfrom datetime import timedelta\nfrom datetime import datetime, timezone\n\nfrom django.shortcuts import get_object_or_404\n\nfrom dashboard.models import Currency, CurrencyConversion, CurrencyStatistics\n\ncurrency_list = ['USD', 'EUR', 'RUB', 'UAH', 'CNY']\n\ncurrency_values = {'USD': 0, 'EUR': 0, 'RUB': 0, 'UAH': 0, 'CNY': 0}\n\ncurrency_conversion = [\n ['USD','EUR'],\n ['EUR','USD'],\n ['USD','RUB'],\n ['USD','UAH'],\n ['USD','CNY']\n]\n\nLATENCY_DAYS=1\nSECONDS_IN_DAY=86400\n\ndef update_info():\n test_currency = None\n try:\n test_currency = Currency.objects.filter(abbreviation='USD')[0]\n except Currency.DoesNotExist:\n test_currency = None\n\n if (test_currency == None):\n get_currencies()\n get_statistics_list()\n get_conversions()\n else:\n last_updated = test_currency.last_updated\n from_last_update = (datetime.now(timezone.utc) - last_updated).total_seconds()\n from_last_update = int(from_last_update / SECONDS_IN_DAY)\n if (from_last_update >= LATENCY_DAYS):\n get_currencies()\n get_statistics_list()\n get_conversions()\n\n\ndef get_statistics_list():\n raw_content = get_raw_statistics_list()\n CurrencyStatistics.objects.filter(rate__isnull=False).delete()\n for content in raw_content[0]:\n currency_statistics = CurrencyStatistics.objects.create()\n currency_statistics.rate = content['Cur_OfficialRate']\n currency_statistics.abbreviation = 'USD'\n currency_statistics.date = datetime.strptime(content['Date'], '%Y-%m-%dT%H:%M:%S')\n currency_statistics.save()\n\n for content in raw_content[1]:\n currency_statistics = CurrencyStatistics.objects.create()\n currency_statistics.rate = content['Cur_OfficialRate']\n currency_statistics.abbreviation = 'EUR'\n currency_statistics.date = datetime.strptime(content['Date'], '%Y-%m-%dT%H:%M:%S')\n currency_statistics.save()\n\n\ndef get_conversions():\n CurrencyConversion.objects.filter(value__isnull=False).delete()\n for conversion in currency_conversion:\n conversion_db = CurrencyConversion.objects.create()\n conversion_db.value = currency_values[conversion[0]] / currency_values[conversion[1]]\n conversion_db.currency_from = conversion[0]\n conversion_db.currency_to = conversion[1]\n conversion_db.save()\n\ndef get_currencies():\n raw_content = get_raw_currencies()\n Currency.objects.filter(scale__isnull=False).delete()\n for content in raw_content:\n currency = Currency.objects.create()\n currency.scale = content['Cur_Scale']\n currency.rate = content['Cur_OfficialRate']\n currency.abbreviation = content['Cur_Abbreviation']\n currency.save()\n\n\ndef get_raw_currencies():\n json_content = []\n for currency_id in currency_list:\n currency = get_currency(currency_id)\n if currency and currency != '':\n value = json.loads(currency)\n json_content.append(value)\n currency_values[value['Cur_Abbreviation']] = value['Cur_OfficialRate']/value['Cur_Scale']\n\n return json_content\n\ndef get_currency(id):\n base_url = 'http://www.nbrb.by/API/'\n query = 'ExRates/Rates/' + id + '?ParamMode=2'\n content = ''\n try:\n content = urllib.request.urlopen(base_url + query).read().decode('utf-8')\n except urllib.error.HTTPError as e:\n print(\"error during fetching currency\")\n print(e)\n return content\n\ndef get_raw_statistics_list():\n json_content = []\n id='145'\n json_content.append(get_statistics(id))\n id='292'\n json_content.append(get_statistics(id))\n return json_content\n\n\ndef get_statistics(id):\n to_date = datetime.now()\n delta = timedelta(days=30)\n from_date = to_date - delta\n end_date = to_date.strftime('%d+%b+%Y')\n start_date = from_date.strftime('%d+%b+%Y')\n\n base_url = 'http://www.nbrb.by/API/'\n query = 'ExRates/Rates/Dynamics/' + id + '?startDate='+ start_date + '&endDate=' + end_date\n json_content = ''\n try:\n content = urllib.request.urlopen(base_url + query).read().decode('utf-8')\n json_content = json.loads(content)\n except urllib.error.HTTPError as e:\n print(\"error during fetching currency\")\n print(e)\n\n return json_content\n\n"
},
{
"alpha_fraction": 0.6783940196037292,
"alphanum_fraction": 0.7206125855445862,
"avg_line_length": 68.05714416503906,
"blob_id": "c13263333bc6a811dc61b9350c4987af6fb283e5",
"content_id": "1f0719a07b673212f8600363b3d72c9d7f22e9db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4038,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 35,
"path": "/landing/common_settings.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "versions = [\n '0.8.0 - Стартовала имплементация api v1 для этого сайта, добавлены погода и валюты',\n '0.7.1 - Добавлена круговая диаграмма для категорий трат',\n '0.7.0 - Добавлен раздел учета расходов, категории, прибыль',\n '0.6.1 - Добавлен вывод среднего расхода за день за все время учета коммунальных',\n '0.6.0 - Добавлен раздел коммунальных услуг, учет, разбивка по местам проживания',\n '0.5.4 - Расширен блог, добавлена работа с категориями',\n '0.5.3 - Изменен дизайн стартовой страницы сайта',\n '0.5.2 - Изменены страницы на дэшборде с применением графиков, переход на новую библиотеку',\n '0.5.1 - Расширен дэшборд. Добавлен раздел новостей',\n '0.5.0 - Добавлено новое приложение - список задач. Добавлены метатеги на все приложения',\n '0.4.3 - Поднят из мертвых бот, команды переведены на использование кеширования',\n '0.4.2 - Обновлен дизайн блога на кофейное нечто. Переработана внутренняя структура стиля',\n '0.4.1 - Обновлен дизайн дэшборда на бумажно-хипстерский',\n '0.4.0 - Большое обновление: добавлено кеширование на дэшборд',\n '0.3.7 - Обновлен бот: добавлены команды просмотра криптовалют, добавлена помощь',\n '0.3.6 - Обновлен стиль главной страницы сайта, применена новая цветовая схема, новые лого',\n '0.3.5 - Добавлена колонка конверсии валют на виджет валют',\n '0.3.4 - Добавлены графики изменения валют на виджет валют',\n '0.3.3 - Обновлен стиль списков на дэшборде',\n '0.3.2 - На дэшборд добавлены топ-10 криптовалют',\n '0.3.1 - Бот расширен коммандами курсов валют и прогноза погоды',\n '0.3.0 - Добавлен телеграм-бот, сайт переведен на https, конфигурация разделена на локальную и серверную',\n '0.2.4 - Добавлен прогноз погоды, обновлен стиль погодного виджета, добавлена медиа',\n '0.2.3 - Разделение дэшборда на приложения, выносимые на разные страницы',\n '0.2.2 - На дэшборд добавлена информация о курсе валют по НБРБ',\n '0.2.1 - На дэшборд добавлена информация о текущей погоде',\n '0.2.0 - Добавлено новое приложение - Дэшборд',\n '0.1.1 - Обновлен отзывчивый стиль для стартовой страницы',\n '0.1.0 - Добавлено новое приложение, перетягивающее на себя стартовую страницу сайта',\n '0.0.8 - Полнофункциональный блог с кастомным стилем',\n '0.0.5 - Добавлены комментарии',\n '0.0.2 - Добавлена работа с формами, аутентификация',\n '0.0.1 - Стартовало прохождение курса, начато написание блога'\n]"
},
{
"alpha_fraction": 0.6860759258270264,
"alphanum_fraction": 0.6962025165557861,
"avg_line_length": 43,
"blob_id": "347bee37babfbeb5b9317a8fd26c7d86a93f2731",
"content_id": "514476241c6d6c17836c1db5ad246b5a3eb34305",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 395,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 9,
"path": "/rest/urls.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\nfrom . import views\n\nurlpatterns = [\n url(r'^api/v1/token/$', views.obtain_token, name='obtain_token'),\n url(r'^api/v1/weather/$', views.obtain_weather, name='obtain_weather'),\n url(r'^api/v1/currency/$', views.obtain_currencies, name='obtain_currencies'),\n url(r'^api/v1/crypto/$', views.obtain_crypto_currencies, name='obtain_crypto_currencies'),\n]"
},
{
"alpha_fraction": 0.7282850742340088,
"alphanum_fraction": 0.7282850742340088,
"avg_line_length": 36.5,
"blob_id": "f99a7fdfa6af39aafa706ff665c15dbb5b75e087",
"content_id": "7d621c93a3c62bb6c547055deeb30af54abc1758",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 449,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 12,
"path": "/landing/models.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.utils import timezone\n\n\nclass SecretMessage(models.Model):\n sender = models.ForeignKey('auth.User', related_name='sender', on_delete=models.PROTECT)\n recepient = models.ForeignKey('auth.User', default=None, null=True, related_name='recepient', on_delete=models.PROTECT)\n text = models.TextField()\n date = models.DateTimeField(default=timezone.now)\n\n def __str__(self):\n return self.text"
},
{
"alpha_fraction": 0.663246214389801,
"alphanum_fraction": 0.6703182458877563,
"avg_line_length": 37.76612854003906,
"blob_id": "4af69bd9068bb389036cd121cafa9c79a55913f3",
"content_id": "257f17b69ebf6a4b7e100bf3c0b7b3fa2cc70a89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14423,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 372,
"path": "/dashboard/views.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.conf import settings\nfrom django.contrib.auth.decorators import login_required\nfrom django.shortcuts import render\nfrom django.shortcuts import render, get_object_or_404\nfrom django.shortcuts import redirect\nfrom django.utils import timezone\n\nfrom django.http import HttpResponse\n\nfrom datetime import datetime, timedelta\n\nfrom dashboard.dashes.weather import OpenWeather\nfrom dashboard.dashes.currency import NBRBCurrency\nfrom dashboard.dashes.crypto_currency import CryptoCurrencyInfo\nfrom dashboard.dashes.events import DevBy\nfrom dashboard.dashes.news import Radiot\n\nfrom .models import Weather, WeatherForecast\nfrom .models import Currency, CurrencyStatistics, CurrencyConversion\nfrom .models import CryptoCurrency, CryptoMarket\nfrom .models import DevByEvent\nfrom .models import RadiotArticle\nfrom .models import LivingPlace, UtilitiesRecord\nfrom .models import IncomeRecord, ExpensesRecord, ExpensesCategory\n\nfrom .forms import UtilityRecordForm, LivingPlaceForm\nfrom .forms import ExpensesCategoryForm, ExpensesRecordForm, IncomeRecordForm\n\nfrom viberbot import Api\nfrom viberbot.api.messages.text_message import TextMessage\nfrom viberbot.api.bot_configuration import BotConfiguration\n\nfrom viberbot.api.viber_requests import ViberMessageRequest\n\nbot_configuration = BotConfiguration(\n name='mgbot',\n avatar='https://pp.userapi.com/c840332/v840332973/24399/5gjeGVXaiWE.jpg',\n auth_token='46f8cbe1dee7d22a-2654d549e59d8703-5d9a149e324492c0'\n)\n\nviber = Api(bot_configuration)\n\ndef radiot_news(request):\n Radiot.update_info()\n news = RadiotArticle.objects.order_by('-radiot_ts')\n return render(request, 'news.html', {'news': news})\n\ndef deb_by_events_info(request):\n DevBy.update_info()\n events = DevByEvent.objects.order_by('last_updated')\n return render(request, 'events.html', {'events': events})\n\ndef weather_info(request):\n OpenWeather.update_info()\n weather = get_object_or_404(Weather, city_name='Minsk')\n forecast = WeatherForecast.objects.filter(city='Minsk').order_by('date_time')\n dates = []\n dates_forecast = []\n for info in forecast:\n if len(dates) == 0 or info.date_time.day != dates[len(dates) - 1]:\n dates.append(info.date_time.day)\n max_temp = -200\n min_temp = 1000\n for date in dates:\n date_min = None\n date_max = None\n for info in forecast:\n if (info.date_time.day==date and (date_min==None or date_min.temperature > info.temperature)):\n date_min = info\n if (info.date_time.day==date and (date_max==None or date_max.temperature < info.temperature)):\n date_max = info\n if (max_temp < info.temperature):\n max_temp = info.temperature\n if (min_temp > info.temperature):\n min_temp = info.temperature\n dates_forecast.append([date_min, date_max])\n\n print(dates)\n return render(request, 'weather.html', {'weather': weather, 'forecast': dates_forecast, 'min_temp': min_temp, 'max_temp': max_temp})\n\ndef currency_info(request):\n NBRBCurrency.update_info()\n currencies = Currency.objects.filter(scale__isnull=False)\n statistics_eur = CurrencyStatistics.objects.filter(abbreviation='EUR').order_by('date')\n statistics_usd = CurrencyStatistics.objects.filter(abbreviation='USD').order_by('date')\n conversions = CurrencyConversion.objects.filter(value__isnull=False)\n return render(request, 'currency.html', {\n 'currencies': currencies, \n 'statistics_eur': statistics_eur,\n 'statistics_usd': statistics_usd,\n 'conversions': conversions \n })\n\ndef viber_mgbot(request):\n if request.method == \"POST\":\n viber_request = viber.parse_request(request.get_data())\n if isinstanse(viber_request, ViberMessageRequest):\n message = viber_request.message\n viber.send_message(viber_request.sender.id, [\n message\n ])\n return HttpResponse(status=200)\n\ndef crypto_currency_info(request):\n CryptoCurrencyInfo.update_info()\n crypto_currencies = CryptoCurrency.objects.order_by('rank')\n crypto_market = CryptoMarket.objects.get()\n return render(request, 'crypto_currency.html', \n {\n 'crypto_currencies': crypto_currencies,\n 'crypto_market': crypto_market\n })\n\n# \n# place for utilities section\n# \n\n@login_required\ndef utilities_list(request):\n utilities_records = UtilitiesRecord.objects.order_by('-date')\n living_places = LivingPlace.objects.filter(author=request.user).order_by('-last_updated')\n electricity_in_one_day = 0.0\n hot_water_in_one_day = 0.0\n cold_water_in_one_day = 0.0\n electricity_scale = 10.0\n water_scale = 1000.0\n first_utilities_record = utilities_records[len(utilities_records) - 1]\n last_utilities_record = utilities_records[0]\n days = (last_utilities_record.date - first_utilities_record.date).days\n electricity_in_one_day = (last_utilities_record.electricity - first_utilities_record.electricity)\n hot_water_in_one_day = (last_utilities_record.hot_water - first_utilities_record.hot_water)\n cold_water_in_one_day = (last_utilities_record.cold_water - first_utilities_record.cold_water)\n electricity_in_one_day = electricity_in_one_day / (electricity_scale * days)\n hot_water_in_one_day = hot_water_in_one_day / (water_scale * days)\n cold_water_in_one_day = cold_water_in_one_day / (water_scale * days)\n return render(request, 'utilities.html', \n {\n 'utilities': utilities_records,\n 'living_places': living_places,\n 'cold_water_in_one_day' : cold_water_in_one_day,\n 'hot_water_in_one_day' : hot_water_in_one_day,\n 'electricity_in_one_day' : electricity_in_one_day\n })\n\n@login_required\ndef utilities_create(request):\n if request.method == 'POST':\n form = UtilityRecordForm(request.POST)\n if (form.is_valid):\n utility_record = form.save()\n utility_record.save()\n return redirect('utilities_list')\n else:\n form = UtilityRecordForm()\n form.fields['place'].queryset = LivingPlace.objects.filter(author=request.user)\n return render(request, 'utilities_edit.html', {'form': form})\n\n@login_required\ndef utilities_update(request, pk):\n utilities = get_object_or_404(UtilitiesRecord, pk=pk)\n if request.method == 'POST':\n form = UtilityRecordForm(request.POST)\n if (form.is_valid):\n utility_record = form.save()\n utility_record.save()\n return redirect('utilities_list')\n else:\n form = UtilityRecordForm(instance=utilities)\n form.fields['place'].queryset = LivingPlace.objects.filter(author=request.user)\n return render(request, 'utilities_edit.html', {'form': form, 'is_update': True})\n\n@login_required\ndef utilities_delete(request, pk):\n utilities = get_object_or_404(UtilitiesRecord, pk=pk)\n utilities.delete()\n return redirect('utilities_list')\n\n@login_required\ndef living_place_create(request):\n if request.method == 'POST':\n form = LivingPlaceForm(request.POST)\n if (form.is_valid):\n living_place_record = form.save()\n living_place_record.author = request.user\n living_place_record.save()\n return redirect('utilities_list')\n else:\n form = LivingPlaceForm()\n return render(request, 'living_place_edit.html', {'form': form})\n\n@login_required\ndef living_place_update(request, pk):\n living_place = get_object_or_404(LivingPlace, pk=pk)\n if request.method == 'POST':\n form = LivingPlaceForm(request.POST)\n if (form.is_valid):\n living_place_record = form.save()\n living_place_record.author = request.user\n living_place_record.save()\n return redirect('utilities_list')\n else:\n form = LivingPlaceForm(instance=living_place)\n return render(request, 'living_place_edit.html', {'form': form, 'is_update': True})\n\n@login_required\ndef living_place_delete(request, pk):\n living_place = get_object_or_404(LivingPlace, pk=pk)\n living_place.delete()\n return redirect('utilities_list')\n\n#\n#\n# expenses part\n#\n#\n\n@login_required\ndef expenses_list(request):\n scale = 100.0\n fromDate = datetime.today() - timedelta(days=30)\n expenses_records = ExpensesRecord.objects.filter(author=request.user).filter(date__gte=fromDate).order_by('-date')\n expenses_categories = ExpensesCategory.objects.filter(author=request.user)\n income_records = IncomeRecord.objects.filter(author=request.user).filter(date__gte=fromDate).order_by('-date')\n summary = 0.0\n for expenses_record in expenses_records:\n summary = summary + expenses_record.amount\n summary = summary / scale\n category_info = []\n for expenses_category in expenses_categories:\n category_summary = 0.0\n for expenses_record in expenses_records:\n if expenses_record.category == expenses_category:\n category_summary = category_summary + expenses_record.amount\n category_summary = category_summary / scale\n category_info.append({'name': expenses_category.name, 'amount': category_summary})\n return render(request, 'expenses.html', \n {\n 'expenses': expenses_records,\n 'expenses_categories': expenses_categories,\n 'incomes' : income_records,\n 'scale' : 100,\n 'summary' : summary,\n 'category_info' : category_info\n })\n\n@login_required\ndef expenses_record_delete(request, pk):\n expenses_record = get_object_or_404(ExpensesRecord, pk=pk)\n expenses_record.delete()\n return redirect('expenses_list')\n\n@login_required\ndef expenses_category_delete(request, pk):\n expenses_category = get_object_or_404(ExpensesCategory, pk=pk)\n expenses_category.delete()\n return redirect('expenses_list')\n\n@login_required\ndef income_record_delete(request, pk):\n income_record = get_object_or_404(IncomeRecord, pk=pk)\n income_record.delete()\n return redirect('expenses_list')\n\n@login_required\ndef expenses_category_create(request):\n if request.method == 'POST':\n form = ExpensesCategoryForm(request.POST)\n if (form.is_valid):\n expenses_category = form.save()\n expenses_category.author = request.user\n expenses_category.save()\n return redirect('utilities_list')\n else:\n form = ExpensesCategoryForm()\n return render(request, 'expenses_category_edit.html', {'form': form})\n\n@login_required\ndef expenses_category_update(request, pk):\n expenses_category = get_object_or_404(ExpensesCategory, pk=pk)\n if request.method == 'POST':\n form = ExpensesCategoryForm(request.POST)\n if (form.is_valid):\n expenses_category_record = form.save()\n expenses_category_record.author = request.user\n expenses_category_record.save()\n return redirect('utilities_list')\n else:\n form = ExpensesCategoryForm(instance=expenses_category)\n return render(request, 'expenses_category_edit.html', {'form': form, 'is_update': True})\n\n@login_required\ndef expenses_category_create(request):\n if request.method == 'POST':\n form = ExpensesCategoryForm(request.POST)\n if (form.is_valid):\n expenses_category = form.save()\n expenses_category.author = request.user\n expenses_category.save()\n return redirect('expenses_list')\n else:\n form = ExpensesCategoryForm()\n return render(request, 'expenses_category_edit.html', {'form': form})\n\n@login_required\ndef expenses_category_update(request, pk):\n expenses_category = get_object_or_404(ExpensesCategory, pk=pk)\n if request.method == 'POST':\n form = ExpensesCategoryForm(request.POST)\n if (form.is_valid):\n expenses_category_record = form.save()\n expenses_category_record.author = request.user\n expenses_category_record.save()\n return redirect('expenses_list')\n else:\n form = ExpensesCategoryForm(instance=expenses_category)\n return render(request, 'expenses_category_edit.html', {'form': form, 'is_update': True})\n\n@login_required\ndef expenses_record_create(request):\n if request.method == 'POST':\n form = ExpensesRecordForm(request.POST)\n if (form.is_valid):\n expenses_record = form.save()\n expenses_record.author = request.user\n expenses_record.save()\n return redirect('expenses_list')\n else:\n form = ExpensesRecordForm()\n form.fields['category'].queryset = ExpensesCategory.objects.filter(author=request.user)\n return render(request, 'expenses_record_edit.html', {'form': form})\n\n@login_required\ndef expenses_record_update(request, pk):\n expenses_record = get_object_or_404(ExpensesRecord, pk=pk)\n if request.method == 'POST':\n form = ExpensesRecordForm(request.POST)\n if (form.is_valid):\n expenses_form_record = form.save()\n expenses_form_record.author = request.user\n expenses_form_record.save()\n return redirect('expenses_list')\n else:\n form = ExpensesRecordForm(instance=expenses_record)\n form.fields['category'].queryset = ExpensesCategory.objects.filter(author=request.user)\n return render(request, 'expenses_record_edit.html', {'form': form, 'is_update': True})\n\n@login_required\ndef income_record_create(request):\n if request.method == 'POST':\n form = IncomeRecordForm(request.POST)\n if (form.is_valid):\n income_record = form.save()\n income_record.author = request.user\n income_record.save()\n return redirect('expenses_list')\n else:\n form = IncomeRecordForm()\n return render(request, 'income_record_edit.html', {'form': form})\n\n@login_required\ndef income_record_update(request, pk):\n income_record = get_object_or_404(IncomeRecord, pk=pk)\n if request.method == 'POST':\n form = IncomeRecordForm(request.POST)\n if (form.is_valid):\n income_form_record = form.save()\n income_form_record.author = request.user\n income_form_record.save()\n return redirect('expenses_list')\n else:\n form = IncomeRecordForm(instance=expenses_record)\n return render(request, 'income_record_edit.html', {'form': form, 'is_update': True})\n\n\n"
},
{
"alpha_fraction": 0.7594971060752869,
"alphanum_fraction": 0.7731620669364929,
"avg_line_length": 52.02898406982422,
"blob_id": "305b22056a5726f2b533d6d771785bb0950c8fb6",
"content_id": "1b50ec962ad021005c135e69774310c1298ded09",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3659,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 69,
"path": "/rest/serializers.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from datetime import datetime\n\nfrom rest_framework import serializers\n\nclass CryptoMarketSerializer(serializers.Serializer):\n total_usd = serializers.IntegerField(read_only=True)\n total_usd_day_volume = serializers.IntegerField(read_only=True)\n active_markets = serializers.IntegerField(read_only=True)\n active_currencies = serializers.IntegerField(read_only=True)\n bitcoin_percent = serializers.FloatField(read_only=True)\n last_updated = serializers.DateTimeField(read_only=True)\n\nclass CryptoCurrencySerializer(serializers.Serializer):\n name = serializers.CharField(max_length=200, read_only=True)\n symbol = serializers.CharField(max_length=200, read_only=True)\n rank = serializers.IntegerField(read_only=True)\n price_usd = serializers.FloatField(read_only=True)\n price_btc = serializers.FloatField(read_only=True)\n change_24h = serializers.FloatField(read_only=True)\n\nclass CurrencyStatisticsSerializer(serializers.Serializer):\n abbreviation = serializers.CharField(max_length=200, read_only=True)\n rate = serializers.FloatField(read_only=True)\n date = serializers.DateTimeField(read_only=True)\n\nclass CurrencyConversionSerializer(serializers.Serializer):\n value = serializers.FloatField(read_only=True)\n currency_from = serializers.CharField(max_length=200, read_only=True)\n currency_to = serializers.CharField(max_length=200, read_only=True)\n\nclass CurrencySerializer(serializers.Serializer):\n scale = serializers.FloatField(read_only=True)\n rate = serializers.FloatField(read_only=True)\n abbreviation = serializers.CharField(max_length=200, read_only=True)\n last_updated = serializers.DateTimeField(read_only=True)\n\nclass WeatherSerializer(serializers.Serializer):\n main_info = serializers.CharField(max_length=200, read_only=True)\n description = serializers.CharField(max_length=200, read_only=True)\n icon_name = serializers.CharField(max_length=200, read_only=True)\n city_name = serializers.CharField(max_length=200, read_only=True)\n requested_city = serializers.CharField(max_length=200, read_only=True)\n temperature = serializers.IntegerField(read_only=True)\n humidity = serializers.IntegerField(read_only=True)\n pressure = serializers.IntegerField(read_only=True)\n visibility = serializers.IntegerField(read_only=True)\n temperature_min = serializers.IntegerField(read_only=True)\n temperature_max = serializers.IntegerField(read_only=True)\n wind_speed = serializers.FloatField(read_only=True)\n wind_deg = serializers.FloatField(read_only=True)\n sunrise = serializers.DateTimeField(read_only=True)\n sunset = serializers.DateTimeField(read_only=True)\n last_updated = serializers.DateTimeField(read_only=True)\n date = serializers.DateTimeField(read_only=True)\n\nclass WeatherForecastSerializer(serializers.Serializer):\n city = serializers.CharField(max_length=200, read_only=True)\n requested_city = serializers.CharField(max_length=200, read_only=True)\n temperature = serializers.IntegerField(read_only=True)\n temperature_min = serializers.IntegerField(read_only=True)\n temperature_max = serializers.IntegerField(read_only=True)\n pressure = serializers.IntegerField(read_only=True)\n humidity = serializers.IntegerField(read_only=True)\n main_info = serializers.CharField(max_length=200, read_only=True)\n description = serializers.CharField(max_length=200, read_only=True)\n icon_name = serializers.CharField(max_length=200, read_only=True)\n wind_speed = serializers.FloatField(read_only=True)\n wind_deg = serializers.FloatField(read_only=True)\n date_time = serializers.DateTimeField(read_only=True)\n"
},
{
"alpha_fraction": 0.5737704634666443,
"alphanum_fraction": 0.5856930017471313,
"avg_line_length": 20.677419662475586,
"blob_id": "8763e50fd9ab8b8656f840b544466ce0cc8f4144",
"content_id": "bd9841e460643181a1ece12ff8583a45ccadf02d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 671,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 31,
"path": "/landing/static/js/clock.js",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "var animate, day, month, year, hours, minutes, seconds, date;\n\nfunction init(){\n clock();\n};\n\nfunction bind(id, value){\n if (value < 10){\n value = '0' + value;\n }\n document.getElementById(id).innerHTML = value;\n};\n\nfunction clock(){\n date = new Date();\n seconds = date.getSeconds();\n minutes = date.getMinutes();\n hours = date.getHours();\n day = date.getDate();\n month = date.getMonth()+1;\n year = date.getFullYear();\n bind('sec', seconds);\n bind('min', minutes);\n bind('hours', hours);\n bind('day', day);\n bind('month', month);\n bind('year', year);\n animate = setTimeout(clock, 1000);\n}\n\nwindow.onload = init;"
},
{
"alpha_fraction": 0.6675951480865479,
"alphanum_fraction": 0.6768802404403687,
"avg_line_length": 26.615385055541992,
"blob_id": "0c77965019247f06886949e59e36750e6ca0afc2",
"content_id": "e645c84da469b5e994534686a77c8eb737a080b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1077,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 39,
"path": "/bots/views.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom django.http import HttpResponse, JsonResponse\n\nfrom django.views.decorators.csrf import csrf_exempt\n\nimport telegram\nimport json\nfrom telegram.error import InvalidToken, TelegramError, BadRequest\n\nfrom .apps import TelegramBot\n\n\nmy_telegram_nickname = '@mgelios'\nmy_telegram_id = 396394358\n\n@csrf_exempt\ndef test_endpoint(request):\n bot = TelegramBot.bot\n bot.send_message(chat_id=my_telegram_id, text='LOLed')\n return JsonResponse({})\n\n@csrf_exempt\ndef telegram_bot(request, bot_token):\n if TelegramBot.webhook_started:\n bot = TelegramBot.bot\n updater = TelegramBot.updater\n dispatcher = TelegramBot.dispatcher\n data = {}\n try:\n data = json.loads(request.body.decode(\"utf-8\"))\n except:\n print('### error during fetching json data')\n\n try:\n update = telegram.Update.de_json(data, bot)\n dispatcher.process_update(update)\n except TelegramError as er:\n print('### error during dispatch')\n return JsonResponse({})\n"
},
{
"alpha_fraction": 0.8285714387893677,
"alphanum_fraction": 0.8285714387893677,
"avg_line_length": 19.799999237060547,
"blob_id": "89dde6990d724ca07d5bfb755499d40cca8c401d",
"content_id": "bfab54614404b09dd96ed3678157beb12ef6411e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 105,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 5,
"path": "/landing/admin.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import SecretMessage\n\n\nadmin.site.register(SecretMessage)\n\n"
},
{
"alpha_fraction": 0.6946107745170593,
"alphanum_fraction": 0.6946107745170593,
"avg_line_length": 26.91666603088379,
"blob_id": "7ff1885f0254f63a1e11c7e72d835eec84c17aeb",
"content_id": "5158bf34071d912a1533aa72cf03be23711ad1e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 334,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 12,
"path": "/bots/urls.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\nfrom django.urls import path, re_path, include\n\nfrom . import views\nfrom . import apps\n\nsuffix = apps.TELEGRAM_BOT_SUFFIX\n\nurlpatterns = [\n url(r'{}(?P<bot_token>.+?)/$'.format(suffix), views.telegram_bot, name='telegram_bot'),\n url(r'^bots/test/$', views.test_endpoint, name='test_endpoint'),\n]"
},
{
"alpha_fraction": 0.6228955984115601,
"alphanum_fraction": 0.624579131603241,
"avg_line_length": 33.94117736816406,
"blob_id": "ed6a9566ab271f15ff4e4e5f7934f5caa6c356e4",
"content_id": "df2e07e7b9e79fb19e70757269aea76d4ccd6b8c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 594,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 17,
"path": "/mysite/urls.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import include, url\nfrom django.contrib import admin\n\nfrom django.contrib.auth import views\n\nurlpatterns = [\n url(r'^api/v1/', include('rest_framework.urls')),\n url(r'^admin/', admin.site.urls),\n url(r'^accounts/login/$', views.login, name='login'),\n url(r'^accounts/logout$', views.logout, name='logout', kwargs={'next_page': '/'}),\n url(r'', include('blog.urls')),\n url(r'', include('landing.urls')),\n url(r'', include('dashboard.urls')),\n url(r'', include('todo.urls')),\n url(r'', include('bots.urls')),\n url(r'', include('rest.urls')),\n]\n"
},
{
"alpha_fraction": 0.5325520634651184,
"alphanum_fraction": 0.5690104365348816,
"avg_line_length": 26.428571701049805,
"blob_id": "e4ecbf103972768a343daeb1c6488d06b1fd32fe",
"content_id": "16c97ee942b1b76107f0046a4a2f2127bd31670f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 768,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 28,
"path": "/dashboard/migrations/0005_auto_20180315_1332.py",
"repo_name": "claimsecond/my-first-blog",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.2 on 2018-03-15 10:32\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('dashboard', '0004_radiotarticle_last_updated'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='weather',\n name='requested_city',\n field=models.CharField(default='', max_length=200),\n ),\n migrations.AddField(\n model_name='weatherforecast',\n name='city',\n field=models.CharField(default='', max_length=200),\n ),\n migrations.AddField(\n model_name='weatherforecast',\n name='requested_city',\n field=models.CharField(default='', max_length=200),\n ),\n ]\n"
}
] | 43 |
zapier/oauthlib
|
https://github.com/zapier/oauthlib
|
dc3cb94dee61a45ac2281a577e2bddde98bd1d71
|
351edb37d8de79bd7d04a47d992d99ab8bec3df7
|
831acd6a00cdef53c6c933aa07a8cdbe39b4bc6e
|
refs/heads/master
| 2020-03-22T22:05:48.494720 | 2018-07-12T15:41:41 | 2018-07-12T15:41:47 | 140,733,105 | 0 | 0 |
NOASSERTION
| 2018-07-12T15:39:09 | 2018-07-12T15:41:55 | 2020-03-05T17:49:36 |
Python
|
[
{
"alpha_fraction": 0.5517241358757019,
"alphanum_fraction": 0.6896551847457886,
"avg_line_length": 13.5,
"blob_id": "5960d8052de4ec241b2a0839302f376920dfafab",
"content_id": "5bf6e065b2d7f0d0cc0b6557864480353f07f2dc",
"detected_licenses": [
"BSD-2-Clause",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 58,
"license_type": "permissive",
"max_line_length": 19,
"num_lines": 4,
"path": "/requirements-test.txt",
"repo_name": "zapier/oauthlib",
"src_encoding": "UTF-8",
"text": "-r requirements.txt\ncoverage>=3.7.1\nnose==1.3.7\nmock>=2.0\n"
},
{
"alpha_fraction": 0.7008524537086487,
"alphanum_fraction": 0.7008524537086487,
"avg_line_length": 42.651161193847656,
"blob_id": "fffe42f0a2b15044fb83d737ecb6530c838479bf",
"content_id": "2c334063a59f1d6e9271b942c53ec1753ab8fd7b",
"detected_licenses": [
"BSD-2-Clause",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3754,
"license_type": "permissive",
"max_line_length": 127,
"num_lines": 86,
"path": "/oauthlib/openid/connect/core/grant_types/dispatchers.py",
"repo_name": "zapier/oauthlib",
"src_encoding": "UTF-8",
"text": "import logging\nlog = logging.getLogger(__name__)\n\n\nclass AuthorizationCodeGrantDispatcher(object):\n \"\"\"\n This is an adapter class that will route simple Authorization Code requests, those that have response_type=code and a scope\n including 'openid' to either the default_auth_grant or the oidc_auth_grant based on the scopes requested.\n \"\"\"\n def __init__(self, default_auth_grant=None, oidc_auth_grant=None):\n self.default_auth_grant = default_auth_grant\n self.oidc_auth_grant = oidc_auth_grant\n\n def _handler_for_request(self, request):\n handler = self.default_auth_grant\n\n if request.scopes and \"openid\" in request.scopes:\n handler = self.oidc_auth_grant\n\n log.debug('Selecting handler for request %r.', handler)\n return handler\n\n def create_authorization_response(self, request, token_handler):\n return self._handler_for_request(request).create_authorization_response(request, token_handler)\n\n def validate_authorization_request(self, request):\n return self._handler_for_request(request).validate_authorization_request(request)\n\n\nclass ImplicitTokenGrantDispatcher(object):\n \"\"\"\n This is an adapter class that will route simple Authorization Code requests, those that have response_type=code and a scope\n including 'openid' to either the default_auth_grant or the oidc_auth_grant based on the scopes requested.\n \"\"\"\n def __init__(self, default_implicit_grant=None, oidc_implicit_grant=None):\n self.default_implicit_grant = default_implicit_grant\n self.oidc_implicit_grant = oidc_implicit_grant\n\n def _handler_for_request(self, request):\n handler = self.default_implicit_grant\n\n if request.scopes and \"openid\" in request.scopes and 'id_token' in request.response_type:\n handler = self.oidc_implicit_grant\n\n log.debug('Selecting handler for request %r.', handler)\n return handler\n\n def create_authorization_response(self, request, token_handler):\n return self._handler_for_request(request).create_authorization_response(request, token_handler)\n\n def validate_authorization_request(self, request):\n return self._handler_for_request(request).validate_authorization_request(request)\n\n\nclass AuthorizationTokenGrantDispatcher(object):\n \"\"\"\n This is an adapter class that will route simple Token requests, those that authorization_code have a scope\n including 'openid' to either the default_token_grant or the oidc_token_grant based on the scopes requested.\n \"\"\"\n def __init__(self, request_validator, default_token_grant=None, oidc_token_grant=None):\n self.default_token_grant = default_token_grant\n self.oidc_token_grant = oidc_token_grant\n self.request_validator = request_validator\n\n def _handler_for_request(self, request):\n handler = self.default_token_grant\n scopes = ()\n parameters = dict(request.decoded_body)\n client_id = parameters.get('client_id', None)\n code = parameters.get('code', None)\n redirect_uri = parameters.get('redirect_uri', None)\n\n # If code is not pressent fallback to `default_token_grant` wich will\n # raise an error for the missing `code` in `create_token_response` step.\n if code:\n scopes = self.request_validator.get_authorization_code_scopes(client_id, code, redirect_uri, request)\n\n if 'openid' in scopes:\n handler = self.oidc_token_grant\n\n log.debug('Selecting handler for request %r.', handler)\n return handler\n\n def create_token_response(self, request, token_handler):\n handler = self._handler_for_request(request)\n return handler.create_token_response(request, token_handler)\n"
},
{
"alpha_fraction": 0.7397003769874573,
"alphanum_fraction": 0.7509363293647766,
"avg_line_length": 30.41176414489746,
"blob_id": "f8e37affc9c7ae59bda3ee9c936d40a126c22917",
"content_id": "7fc183d6632631882352713a76f2762239282caf",
"detected_licenses": [
"BSD-2-Clause",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 534,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 17,
"path": "/oauthlib/openid/connect/core/grant_types/__init__.py",
"repo_name": "zapier/oauthlib",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\noauthlib.oauth2.rfc6749.grant_types\n~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\n\"\"\"\nfrom __future__ import unicode_literals, absolute_import\n\nfrom .authorization_code import AuthorizationCodeGrant\nfrom .implicit import ImplicitGrant\nfrom .base import GrantTypeBase\nfrom .hybrid import HybridGrant\nfrom .exceptions import OIDCNoPrompt\nfrom oauthlib.openid.connect.core.grant_types.dispatchers import (\n AuthorizationCodeGrantDispatcher,\n ImplicitTokenGrantDispatcher,\n AuthorizationTokenGrantDispatcher\n)\n"
}
] | 3 |
atulshgl/Reversi
|
https://github.com/atulshgl/Reversi
|
94b8b0ab18c3d94f1fb45cd735783eb17f3d2c0e
|
a516f893a15ddca475bcec569feab4b0e71a95b9
|
c0ddd0131fb88aef66979bafd8f6cd3ac0cf67a0
|
refs/heads/master
| 2021-01-09T09:37:36.822017 | 2017-02-20T03:38:57 | 2017-02-20T03:38:57 | 81,183,087 | 3 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8025078177452087,
"alphanum_fraction": 0.8025078177452087,
"avg_line_length": 105.33333587646484,
"blob_id": "a41ff195f9ede439a5b3c861df8652bc71fe99b7",
"content_id": "81d4e35d00fcf2c56b262d0382d00882a51e7e85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 319,
"license_type": "no_license",
"max_line_length": 307,
"num_lines": 3,
"path": "/README.md",
"repo_name": "atulshgl/Reversi",
"src_encoding": "UTF-8",
"text": "# Reversi\n\nA program to get the best next move for a player in Reversi. The program takes current board state, current player and depth as input then apply minimax algorithm and alpha-beta pruning till the given depth to get the next board state. It also generates logs for all the decisions made by minimax algorithm.\n"
},
{
"alpha_fraction": 0.40884774923324585,
"alphanum_fraction": 0.45236626267433167,
"avg_line_length": 41.6315803527832,
"blob_id": "7ced46344680eff43450f9c1c415808cd4a081a5",
"content_id": "43ae3362eda40ae7f3753965daca966fc092854a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9720,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 228,
"path": "/hw1cs561s2017.py",
"repo_name": "atulshgl/Reversi",
"src_encoding": "UTF-8",
"text": "import os, sys, copy\n\n#inputFilePath = sys.argv[1]\ninputFilePath = os.path.dirname(os.path.realpath(__file__)) + \"/SampleTestCases/input1.txt\"\noutputFilePath = os.path.dirname(os.path.realpath(__file__)) + \"/SampleTestCases/output.txt\"\n\ns = dict()\nfor i in range(-5999,6000):\n s[i] = str(i)\ns[-6000],s[6000] = '-Infinity','Infinity'\n\ndef convertBoard(boardState):\n state = dict()\n for i in range(0,8):\n for j in range(0,8):\n if boardState[i][j] == 'X':\n state[(i,j)] = 1\n elif boardState[i][j] == 'O':\n state[(i,j)] = -1\n return state\n\ndef readInput(filePath):\n player,depth = -1,0\n boardState = []\n with open(inputFilePath,'r') as f:\n lines = f.readlines()\n plyr = lines[0].strip()\n if plyr == 'X':\n player = 1\n depth = int(lines[1].strip())\n for i in range(2,10):\n boardState.append(list(lines[i]))\n state = convertBoard(boardState)\n return (player,depth,state)\n\ndef outputState(filePath,state):\n with open(filePath,'w') as doc:\n for i in range(0,8):\n line = ''\n for j in range(0,8):\n if (i,j) not in state:\n line = line + '*'\n elif state[(i,j)] == 1:\n line = line + 'X'\n elif state[(i,j)] == -1:\n line = line + 'O'\n print line\n doc.write(line + '\\n')\n \n# piece location\n# 1 2 3\n# 4 X 5\n# 6 7 8\n\ndef addToMoves(moves,i,j,direction):\n if (i,j) not in moves:\n moves[(i,j)] = [direction]\n else:\n moves[(i,j)].append(direction)\n return moves\n\ndef getMoves(player,state):\n moves = dict()\n for i in range(0,8):\n for j in range(0,8):\n if (i,j) not in state:\n if i+1<8 and j+1<8 and ((i+1,j+1) in state) and state[(i+1,j+1)] == player*-1:#location 1\n p,q = i,j\n while p+1<8 and q+1<8 and ((p+1,q+1) in state) and state[(p+1,q+1)] == player*-1:\n p,q = p+1,q+1\n if p+1<8 and q+1<8 and ((p+1,q+1) in state) and state[(p+1,q+1)] == player:\n addToMoves(moves,i,j,1)\n if i+1<8 and ((i+1,j) in state) and state[(i+1,j)] == player*-1:#location 2\n p,q = i,j\n while p+1<8 and ((p+1,q) in state) and state[(p+1,q)] == player*-1:\n p = p+1\n if p+1<8 and ((p+1,q) in state) and state[(p+1,q)] == player:\n addToMoves(moves,i,j,2)\n if i+1<8 and j-1>=0 and ((i+1,j-1) in state) and state[(i+1,j-1)] == player*-1:#location 3\n p,q = i,j\n while p+1<8 and q-1>=0 and ((p+1,q-1) in state) and state[(p+1,q-1)] == player*-1:\n p,q = p+1,q-1\n if p+1<8 and q-1>=0 and ((p+1,q-1) in state) and state[(p+1,q-1)] == player:\n addToMoves(moves,i,j,3)\n if j+1<8 and ((i,j+1) in state) and state[(i,j+1)] == player*-1:#location 4\n p,q = i,j\n while q+1<8 and ((p,q+1) in state) and state[(p,q+1)] == player*-1:\n q = q+1\n if q+1<8 and ((p,q+1) in state) and state[(p,q+1)] == player:\n addToMoves(moves,i,j,4)\n if j-1>=0 and ((i,j-1) in state) and state[(i,j-1)] == player*-1:#location 5\n p,q = i,j\n while q-1>=0 and ((p,q-1) in state) and state[(p,q-1)] == player*-1:\n q = q-1\n if q-1>=0 and ((p,q-1) in state) and state[(p,q-1)] == player:\n addToMoves(moves,i,j,5)\n if i-1>=0 and j+1<8 and ((i-1,j+1) in state) and state[(i-1,j+1)] == player*-1:#location 6\n p,q = i,j\n while p-1>=0 and q+1<8 and ((p-1,q+1) in state) and state[(p-1,q+1)] == player*-1:\n p,q = p-1,q+1\n if p-1>=0 and q+1<8 and ((p-1,q+1) in state) and state[(p-1,q+1)] == player:\n addToMoves(moves,i,j,6)\n if i-1>=0 and ((i-1,j) in state) and state[(i-1,j)] == player*-1:#location 7\n p,q = i,j\n while p-1>=0 and ((p-1,q) in state) and state[(p-1,q)] == player*-1:\n p = p-1\n if p-1>=0 and ((p-1,q) in state) and state[(p-1,q)] == player:\n addToMoves(moves,i,j,7)\n if i-1>=0 and j-1>=0 and ((i-1,j-1) in state) and state[(i-1,j-1)] == player*-1:#location 8\n p,q = i,j\n while p-1>=0 and q-1>=0 and ((p-1,q-1) in state) and state[(p-1,q-1)] == player*-1:\n p,q = p-1,q-1\n if p-1>=0 and q-1>=0 and ((p-1,q-1) in state) and state[(p-1,q-1)] == player:\n addToMoves(moves,i,j,8)\n return moves\n\ndef placePiece(player,move,directions,state):\n res = copy.copy(state)\n res[(move[0],move[1])] = player\n for direct in directions:\n i,j = move[0],move[1]\n if direct == 1:\n while i+1<8 and j+1<8 and ((i+1,j+1) in state) and state[(i+1,j+1)] == player*-1:\n i,j = i+1,j+1\n res[(i,j)] = player\n elif direct == 2:\n while i+1<8 and ((i+1,j) in state) and state[(i+1,j)] == player*-1:\n i = i+1\n res[(i,j)] = player\n elif direct == 3:\n while i+1<8 and j-1>=0 and ((i+1,j-1) in state) and state[(i+1,j-1)] == player*-1:\n i,j = i+1,j-1\n res[(i,j)] = player\n elif direct == 4:\n while j+1<8 and ((i,j+1) in state) and state[(i,j+1)] == player*-1:\n j = j+1\n res[(i,j)] = player\n elif direct == 5:\n while j-1>=0 and ((i,j-1) in state) and state[(i,j-1)] == player*-1:\n j = j-1\n res[(i,j)] = player\n elif direct == 6:\n while i-1>=0 and j+1<8 and ((i-1,j+1) in state) and state[(i-1,j+1)] == player*-1:\n i,j = i-1,j+1\n res[(i,j)] = player\n elif direct == 7:\n while i-1>=0 and ((i-1,j) in state) and state[(i-1,j)] == player*-1:\n i = i-1\n res[(i,j)] = player\n elif direct == 8:\n while i-1>=0 and j-1>=0 and ((i-1,j-1) in state) and state[(i-1,j-1)] == player*-1:\n i,j = i-1,j-1\n res[(i,j)] = player\n return res\n \nweights = [[99,-8,8,6,6,8,-8,99],[-8,-24,-4,-3,-3,-4,-24,-8],[8,-4,7,4,4,7,-4,8],[6,-3,4,0,0,4,-3,6],\n [6,-3,4,0,0,4,-3,6],[8,-4,7,4,4,7,-4,8],[-8,-24,-4,-3,-3,-4,-24,-8],[99,-8,8,6,6,8,-8,99]]\n\ndef evaluateState(player,state):\n val = 0\n for pos,s in state.iteritems(): \n val += s*weights[pos[0]][pos[1]]\n return val*player\n\ndef getLocation(move):\n col = ['a','b','c','d','e','f','g','h']\n return col[move[1]] + str(move[0]+1)\n\nlogs = []\npl = 1\ndef play(dad,node,player,depth,maxDepth,state,minmax,alpha,beta):\n val = minmax*-6000\n if depth == maxDepth:\n val = evaluateState(pl,state)\n logs.append(node+','+str(depth)+','+s[val]+','+s[alpha]+','+s[beta])\n return (val,state)\n res = copy.copy(state)\n moves = getMoves(player,state)\n if dad == 'pass' and len(moves) == 0:\n val = evaluateState(pl,state)\n logs.append(node+','+str(depth)+','+s[val]+','+s[alpha]+','+s[beta])\n return (val,state)\n logs.append(node+','+str(depth)+','+s[val]+','+s[alpha]+','+s[beta])\n if len(moves) == 0: ### Pass the move\n (result,st) = play(node,'pass',player*-1,depth+1,maxDepth,copy.copy(state),minmax*-1,alpha,beta)\n if minmax == 1:\n val = max(val,result)\n if val >= beta:\n logs.append(node+','+str(depth)+','+s[val]+','+s[alpha]+','+s[beta])\n return (val,res)\n alpha = max(alpha,val)\n elif minmax == -1:\n val = min(val,result)\n if val<= alpha:\n logs.append(node+','+str(depth)+','+s[val]+','+s[alpha]+','+s[beta])\n return (val,res)\n beta = min(beta,val)\n logs.append(node+','+str(depth)+','+s[val]+','+s[alpha]+','+s[beta])\n else:\n for move,directions in sorted(moves.iteritems()):\n cur = placePiece(player,move,directions,state)\n (result,st) = play(node,getLocation(move),player*-1,depth+1,maxDepth,copy.copy(cur),minmax*-1,alpha,beta)\n if minmax == 1:\n if val < result:\n val,res = result, copy.copy(cur)\n if val >= beta:\n logs.append(node+','+str(depth)+','+s[val]+','+s[alpha]+','+s[beta])\n return (val,res)\n alpha = max(alpha,val)\n elif minmax == -1:\n if val > result:\n val,res = result, copy.copy(cur)\n if val <= alpha:\n logs.append(node+','+str(depth)+','+s[val]+','+s[alpha]+','+s[beta])\n return (val,res)\n beta = min(beta,val)\n logs.append(node+','+str(depth)+','+s[val]+','+s[alpha]+','+s[beta])\n return (val,res)\n\n(player, depth, state) = readInput(inputFilePath)\npl = player\n(val,resState) = play('null','root',player,0,depth,state,1,-6000,6000)\n\noutputState(outputFilePath,resState)\nwith open(outputFilePath,'a') as doc:\n doc.write('Node,Depth,Value,Alpha,Beta\\n')\n for log in logs:\n doc.write(log+'\\n')\n"
}
] | 2 |
chenyi852/python_study
|
https://github.com/chenyi852/python_study
|
71b8bdb4df699fb4418eb2cd0bd3a1937672bbeb
|
7a1e383cea0e14fc61524b9535440fd4d536bbc6
|
53955df2dbe4a8c2137df65381e109978fdd6e46
|
refs/heads/master
| 2021-01-12T02:54:31.477040 | 2019-09-12T21:45:19 | 2019-09-12T21:45:19 | 78,130,722 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5576131939888,
"alphanum_fraction": 0.5713306069374084,
"avg_line_length": 27.58823585510254,
"blob_id": "6fde9d0b5ade8febd3ac58fbe70aa32b944d0901",
"content_id": "fd0d3006e495d270a99510655d8f4a98aecbf83b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1476,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 51,
"path": "/rename.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\nimport os\nimport sys\nimport re\nimport shutil\n\npath=\"/home/chenyi/音乐\"\nwindows_path=\"D:\\03_personal\\01_music\"\ncygwin_path=\"/cygdrive/d/03_personal/01_music\"\n\ndef modify_name(file_path):\n list_file = os.listdir(file_path)\n for item in list_file :\n #将文件名中\"[mqms2](1)\"去掉\n filename=file_path + '/' + item\n\n newname=re.sub(r'\\[\\w*\\]\\(*\\d*\\)*', \"\", filename)\n print(\"%s --> %s\" %(filename, newname))\n \"\"\"\n\t ewname=filename.replace(\"[mqms2](1)\", '')\n\t newname=newname.replace(\"[mqms2]\", '')\n\t newname=newname.replace(\"[mqms]\", '')\n\t newname=newname.replace(' ', '')\n\t\"\"\"\n if not (os.path.normcase(filename) == os.path.normcase(newname)):\n print (\"move \" + filename + \"to \" + newname)\n shutil.move(filename, newname)\n\ndef cleanup_filename(myfile):\n new = re.sub(r'\\[\\w*\\]\\(*\\d*\\)*', \"\", myfile)\n print(\"file is %s, new file name is %s\" %(myfile, new))\n\nif __name__ == '__main__':\n if os.path.exists(path):\n print(\"%s exists\" %(path))\n modify_name(path)\n if os.path.exists(windows_path):\n print(\"%s exists\" %(windows_path))\n modify_name(windows_path)\n if os.path.exists(cygwin_path):\n print(\"%s exists\" %(cygwin_path))\n modify_name(cygwin_path)\n \"\"\" \n for test\n\tcleanup_filename(\"my[mqms2].mp3\")\n\tcleanup_filename(\"my[mqms2](1).mp3\")\n\tcleanup_filename(\"my[mqms].mp3\")\n \"\"\"\n"
},
{
"alpha_fraction": 0.36580517888069153,
"alphanum_fraction": 0.39297547936439514,
"avg_line_length": 24.149999618530273,
"blob_id": "ccba68947b760c7729f00dd5ce8e165c12fc8a24",
"content_id": "7bcef6b4083799f1295fe478b0fab4014bc95f8f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1509,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 60,
"path": "/py3/max_rectangle.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nclass Solution:\n def maximalRectangle(self, matrix) -> int:\n \"\"\"\n :type matrix: list[list[str]]\n :rtype int\n \"\"\"\n # len for row\n n = len(matrix)\n if n == 0:\n return n\n # len for column\n m = len(matrix[0])\n self.ans = 0\n \n heights = [0] * (m + 1)\n for i in range(n):\n for j in range(m):\n \n if matrix[i][j] == '1':\n heights[j] += 1\n else:\n heights[j] = 0\n \n self.ans = max(self.ans, self.robot(heights))\n \n return self.ans\n \n def robot(self, heights):\n i = 0\n stack = []\n max_area = 0\n while i < len(heights):\n if len(stack) == 0 or heights[stack[-1]] <= heights[i]:\n stack.append(i)\n i += 1\n else:\n top = stack.pop()\n max_area = max(max_area, heights[top] * ((i - 1 - stack[-1]) if stack else i))\n \n while stack:\n top = stack.pop()\n max_area = max(max_area, heights[top] * ((i - 1 - stack[-1]) if stack else i))\n \n return max_area\n \nmatrix = [\n [\"1\",\"0\",\"1\",\"0\",\"0\"],\n [\"1\",\"0\",\"1\",\"1\",\"1\"],\n [\"1\",\"1\",\"1\",\"1\",\"1\"],\n [\"1\",\"0\",\"0\",\"1\",\"0\"]\n] \nmatrix=[]\nmatrix=[\n [\"0\",\"1\"],\n [\"1\",\"0\"]\n]\nx = Solution()\nprint(\"max area is %d\" %(x.maximalRectangle(matrix)))\n"
},
{
"alpha_fraction": 0.5675675868988037,
"alphanum_fraction": 0.5795795917510986,
"avg_line_length": 20.483871459960938,
"blob_id": "577f15b2e051ae406f0fd7fec0ce0c497088b15f",
"content_id": "35014dd7075591d1c9ad26fcaa6e63c487bd842b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 666,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 31,
"path": "/py3/task_queue.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\nfrom queue import Queue \n\nclass taskq():\n def __init__(self):\n self.q=Queue(128)\n self.consume_hook = None\n\n def produce(self, data):\n self.q.put(data)\n\n def consume(self):\n if not self.q.empty():\n msg = self.q.get()\n self.consume_hook(msg)\n\n def register_consume_hook(self, consume_hook):\n self.consume_hook = consume_hook\n\ndef process_data(data):\n print(data)\n\nif __name__ == \"__main__\":\n t = taskq()\n t.register_consume_hook(process_data)\n msg1=\"ci fail\"\n msg2=\"compile sucessfully\"\n t.produce(msg1)\n t.produce(msg2)\n t.consume()\n t.consume()\n"
},
{
"alpha_fraction": 0.48711657524108887,
"alphanum_fraction": 0.5490797758102417,
"avg_line_length": 23.696969985961914,
"blob_id": "d5ca708f6bc7a68f280d8373b219dd8bb650958b",
"content_id": "6ec5b11ad37fc2147227ae0d6d9bfbe4a7b7ac08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1630,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 66,
"path": "/py3/sum_of_2nums.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n#leetcode 2\n\n#Definition for singly-linked list.\nclass ListNode:\n def __init__(self, x):\n self.val = x\n self.next = None\n\n## two non-empty link listes are given to represent two non-negative integers.\n## Among them, their respective digits are stored in reverse order, and each\n## node of them can only store one digit.\nclass Solution:\n def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode:\n val1 = self.caculate_val_of_list(l1)\n val2 = self.caculate_val_of_list(l2)\n\n sum = val1 + val2\n sum = str(sum)[::-1]\n\n res = [ListNode(int(ch)) for ch in sum]\n \n for i in (range(len(res) - 1)):\n res[i].next = res[i + 1]\n return res[0]\n\n def caculate_val_of_list(self, l: ListNode)->int:\n idx = 0\n num= 0\n while l:\n num += l.val * 10 ** idx\n idx += 1\n l = l.next\n return num\n \nif __name__ == \"__main__\":\n#(2 -> 4 -> 3) + (5 -> 6 -> 4)\n\tl1 = [1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1]\n\tl2 = [5,6,4]\n\tx1 = ListNode(2)\n\tx2 = ListNode(4)\n\tx3 = ListNode(3)\n\tx1.next = x2\n\tx2.next = x3\n\t\n\tx4 = ListNode(5)\n\tx5 = ListNode(6)\n\tx6 = ListNode(4)\n\tx4.next = x5\n\tx5.next = x6\n\tx = Solution()\n\tres = x.addTwoNumbers(x1, x4)\n\twhile res:\n\t\tprint(res.val)\n\t\tres = res.next\n\t\t\n\tx1 = [ListNode(i) for i in l1]\n\tx2 = [ListNode(i) for i in l2]\n\tfor i in range(len(x1) - 1):\n\t\tx1[i].next = x1[i+1]\n\tfor i in range(len(x2) - 1):\n\t\tx2[i].next = x2[i+1]\n\tres = x.addTwoNumbers(x1[0], x2[0])\n\twhile res:\n\t\tprint(res.val, end=\" \")\n\t\tres = res.next\n"
},
{
"alpha_fraction": 0.5513937473297119,
"alphanum_fraction": 0.5644599199295044,
"avg_line_length": 25.090909957885742,
"blob_id": "4652e1eddd545fe9f3966c1e0a7372347697d72b",
"content_id": "02c75a367d5199323f70b12e434372db04f956d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1152,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 44,
"path": "/file/rm_redundant.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding:utf-8-*-\n\nimport os\nimport hashlib\n\n\ntarget_dir=\"/home/chenyi/音乐\"\n\ndef filecount():\n command = 'ls -lR ' + target_dir + '| grep \"^-\" | wc -l'\n print ('the command to be executed is : ', command)\n filecount = os.popen(command).read()\n return int(filecount)\n\ndef md5sum(filename):\n f = open(filename, 'rb')\n md5 = hashlib.md5()\n while True:\n fb = f.read(8096)\n if not fb:\n break\n md5.update(fb)\n f.close()\n return (md5.hexdigest())\n\ndef delfile():\n all_md5={}\n filedir = os.walk(target_dir)\n for root, dirs, files in filedir:\n for tlie in files:\n path=os.path.join(root, tlie)\n if md5sum(path) in all_md5.values():\n os.remove(path)\n print('remove', path)\n else:\n all_md5[tlie] = md5sum(path)\n\nif __name__ == '__main__':\n oldf = filecount()\n print('the file count before redundant files removed', oldf)\n delfile()\n print('After removing redundant files, there are only', filecount(), 'files')\n print(oldf - filecount(), ' files has been removed')\n"
},
{
"alpha_fraction": 0.5818036794662476,
"alphanum_fraction": 0.5977653861045837,
"avg_line_length": 37.1875,
"blob_id": "431fb2919a4fb1170f88cdc147a56c01a03333a2",
"content_id": "9976fa6da6b7ac0735d8e266b86421898da96259",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2772,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 64,
"path": "/sync_file.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "GB18030",
"text": "# -*- coding: utf-8 -*-\r\n\r\nimport os\r\nimport shutil\r\nimport time\r\nimport logging\r\nimport filecmp\r\n#日志文件配置\r\nlog_filename ='synchro.log'\r\n#日志输出格式化\r\nlog_format = '%(filename)s [%(asctime)s] [%(levelname)s] %(message)s'\r\nlogging.basicConfig(format=log_format,datefmt='%Y-%m-%d %H:%M:%S %p',level=logging.DEBUG) \r\n#日志输出到日志文件\r\nfileLogger = logging.getLogger('fileLogger')\r\nfh = logging.FileHandler(log_filename)\r\nfh.setLevel(logging.INFO)\r\nfileLogger.addHandler(fh);\r\n#需要同步的文件夹路径,可以使用绝对路径,也可以使用相对路径\r\n#synchroPath1 = r'/home/xxx/image1'\r\n#synchroPath2 = r'/home/xxx/image2'\r\nsynchroPath1 = r'D:\\03_personal\\01_music'\r\nsynchroPath2 = r'\\\\192.168.2.176\\chenyi\\音乐'\r\n\r\n#同步方法\r\ndef synchro(synchroPath1,synchroPath2):\r\n leftDiffList = filecmp.dircmp(synchroPath1,synchroPath2).left_only\r\n rightDiffList = filecmp.dircmp(synchroPath1,synchroPath2).right_only\r\n commondirsList =filecmp.dircmp(synchroPath1,synchroPath2).common_dirs\r\n for item in leftDiffList:\r\n copyPath = synchroPath1 + '\\\\' + item\r\n pastePath = synchroPath2 + '\\\\' + item\r\n if(os.path.isdir(copyPath)):\r\n copyDir(copyPath,pastePath)\r\n else :\r\n shutil.copy2(copyPath,pastePath)\r\n fileLogger.info('copy '+copyPath +\" to \"+pastePath)\r\n for item in rightDiffList:\r\n copyPath = synchroPath2 + '\\\\' + item\r\n pastePath = synchroPath1 +'\\\\' + item\r\n if(os.path.isdir(copyPath)):\r\n copyDir(copyPath,pastePath)\r\n else :\r\n shutil.copy2(copyPath,pastePath)\r\n fileLogger.info('copy '+copyPath +\" to \"+pastePath)\r\n for item in commondirsList:\r\n copyPath = synchroPath2 + '\\\\' + item\r\n pastePath = synchroPath1 +'\\\\' + item\r\n syncDir(copyPath,pastePath)\r\n#拷贝文件夹,如果文件夹不存在创建之后直接拷贝全部,如果文件夹已存在那么就同步文件夹 \r\ndef copyDir(copyPath,pastePath):\r\n if(os.path.exists(pastePath)):\r\n synchro(copyPath,pastePath)\r\n else :\r\n os.mkdir(pastePath)\r\n shutil.copytree(copyPath,pastePath)\r\n#子文件夹左右两侧文件夹都包含,就同步两侧子文件夹\r\ndef syncDir(copyPath,pastePath):\r\n copyDir(copyPath,pastePath)\r\n copyDir(pastePath,copyPath)\r\nwhile(True):\r\n synchro(synchroPath1,synchroPath2)\r\n logging.debug('synchro run')\r\n #阻塞方法,上一步执行结束后等待五秒\r\n time.sleep(5)"
},
{
"alpha_fraction": 0.5763195157051086,
"alphanum_fraction": 0.5905848741531372,
"avg_line_length": 17.52777862548828,
"blob_id": "e966c4e4bbae29f58c31b67f21b376da4c35994f",
"content_id": "9e4f77287a9fb8ff4b4dbaff7e26832e6dcc8c73",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 701,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 36,
"path": "/func_alone.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\r\n# coding=utf-8\r\nimport string\r\n\r\ndef tuple_test():\r\n\td = {'a':10, 'b':1, 'c':22}\r\n\tt = list()\r\n\tfor key, val in d.items():\r\n\t\tt.append((val, key))\r\n\tt.sort(reverse = True)\r\n\tprint t\r\n\r\ndef largest_count(fname):\r\n\ttry:\r\n\t\tfhand = open(fname)\r\n\texcept:\r\n\t\tprint \"open %s fail\" %fname\r\n\t\t\r\n\tcounts = dict()\r\n\t\r\n\tfor line in fhand:\r\n\t\tline = line.translate(None, string.punctuation)\r\n\t\tline = line.lower()\r\n\t\twords = line.split()\r\n\t\tfor word in words:\r\n\t\t\tcounts[word] = counts.get(word, 0) + 1\r\n\tt = list()\r\n\tfor key, val in counts.items():\r\n\t\tt.append((val, key))\r\n\tt.sort(reverse = True)\r\n\t\t\r\n\tfor key,val in t[:10]:\r\n\t\tprint key, val\r\n\t\t\r\ntuple_test()\r\nlargest_count('mbox.txt')"
},
{
"alpha_fraction": 0.6373056769371033,
"alphanum_fraction": 0.6433506011962891,
"avg_line_length": 23.217391967773438,
"blob_id": "30c93561fcaa6cef00b131e0fc9aa4d18d29d631",
"content_id": "45eea3900c712489621917e5588d4ae855470f4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1158,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 46,
"path": "/class_study.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\r\n#coding:utf-8\r\n\r\n__metaclass__=type\t#new style classs\r\n\r\nclass person:\r\n\tdef __init__(self, name):\r\n\t\tself.name = name\r\n\t\r\n\tdef get_name(self):\r\n\t\treturn self.name\r\n\t\t\r\n\tdef set_height(self,height):\r\n\t\tprint \"person set height : {height}\" .format(height=height)\r\n\t\t\r\nclass girl(person):\r\n\tdef __init__(self, name):\r\n\t\tsuper(girl, self).__init__(name) # need to deliver the paramenter to base class\r\n\t\tself.breast=90\r\n\t\tself.__name=name #private variable value\r\n\t\r\n\t#@property\r\n\tdef get_personal_name(self):\r\n\t\tprint \"my name is : {name}\" .format(name=self.__name)\r\n\t\t\r\n\tdef set_height(self, height):\r\n\t\tself.height=height\r\n\t\t\r\n\tdef get_height(self):\r\n\t\treturn self.height\r\n\t\t\r\n\tdef about(self):\r\n\t\tprint \"this girl's breat is {breast}, heigh is {height}\" .format(breast=self.breast, height=self.height)\r\nif __name__ == '__main__':\r\n\tcang = person('cang')\r\n\tcang.set_height(13)\r\n\tmali = girl('mali')\r\n\tmali.get_personal_name()\r\n\tname = mali.get_name()\r\n\tprint \"the person name is : {name}\" .format(name=name)\r\n\t\r\n\tmali.set_height(19)\r\n\theight = mali.get_height()\r\n\tprint \"mali height is : {height}\" .format(height=height)\r\n\t\r\n\tmali.about()"
},
{
"alpha_fraction": 0.6541628837585449,
"alphanum_fraction": 0.6683440208435059,
"avg_line_length": 23.288888931274414,
"blob_id": "7a76caf146b214e79486b0f6091da94ee5e914a2",
"content_id": "357622b4e9d1eec134e003182d4d8df440ba9df4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2346,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 90,
"path": "/baidu.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding=utf-8\n\nimport urllib2\nfrom bs4 import BeautifulSoup\nclass BDTB:\n\tdef __init__(self,baseurl,seeLZ,floorTag):\n\t\tself.baseurl=baseurl\n\t\tself.seeLZ='?see_lz='+str(seeLZ)\n\t\tself.file=None\n\t\tself.floor=1\n\t\tself.floorTag=floorTag\n\t\tself.defaultTitle=u\"百度贴吧\"\n\tdef getpage(self,pagenum):\n\t\ttry:\n\t\t\turl = self.baseurl + self.seeLZ + '&pn=' + str(pagenum)\n\t\t\trequest = urllib2.Request(url)\n\t\t\tresponse = urllib2.urlopen(request)\n\t\t\tpage = BeautifulSoup(response, \"html5lib\")\n#\tprint page.prettify()\n\t\t\treturn page\n\t\n\t\texcept urllib2.URLError,e:\n\t\t\tif hasattr(e,'reason'):\n\t\t\t\tprint u\"连接百度贴吧失败,错误原因\",e.reason\n\t\t\t\treturn None\n\n\tdef getTitle(self):\n\t\tpage=self.getpage(1)\n\t\tprint page.title.string\n\t\treturn page.title.string\n#tag=page.h3\n#\t\ttitle=tag['title']\n#\t\tprint title\n#\t\treturn title\n\n\tdef getPageNum(self):\n\t\t\tpage=self.getpage(1)\n\t\t\tnum=page.find_all(attrs={\"class\":\"red\"})\n\t\t\tpagenum=num[1].string\n\t\t\treturn int(pagenum)\n\n\tdef getcontent(self):\n\t\tpagenum=self.getPageNum()+1\n\t\tcontents=[]\n\t\tfor num in range(1,pagenum):\n\t\t\tpage = self.getpage(num)\n\t\t\tnum = page.find_all('cc')\n\t\t\tfor item in num:\n\t\t\t\tcontent=item.get_text()\n\t\t\t\tcontents.append(content.encode('utf-8'))\n\t\t\t\treturn contents\n\n\tdef getFileTitle(self):\n\t\ttitle=self.getTitle()\n\t\tif title is not None:\n\t\t\tself.file=open(title+\".txt\",\"w+\")\n\t\telse:\n\t\t\tself.file=open(self.defaultTitle+\".txt\",\"w+\")\n\n\tdef writeData(self):\n\t\tcontents=self.getcontent()\n\t\tfor item in contents:\n\t\t\tif self.floorTag =='1':\n\t\t\t\tfloorLine='\\n'+str(self.floor)+u'---------------------------------------------\\n'\n\t\t\t\tself.file.write(floorLine)\n\t\t\t\tself.file.write(item)\n\t\t\t\tself.floor +=1\n\n\tdef start(self):\n\t\tself.getFileTitle()\n\t\tpagenum=self.getPageNum()\n\t\tif pagenum == None:\n\t\t\tprint \"URL已失效,请重试\"\n\t\t\treturn\n\t\ttry:\n\t\t\tprint \"该帖子共有\"+str(pagenum)+\"页\"\n\t\t\tself.writeData()\n\t\texcept IOError,e:\n\t\t\tprint \"写入异常,原因\"+e.message\n\t\tfinally:\n\t\t\tprint \"写入成功\"\n\nprint u\"请输入帖子代号\"\n#baseurl='http://tieba.baidu.com/p/'+str(raw_input(u'http://tieba.baidu.com/p/'))\nbaseurl='http://tieba.baidu.com/p/4995679029'\nseeLZ=raw_input(\"是否只获取楼主发言,是输入1,否输入0\\n\")\nfloorTag=raw_input(\"是否写入楼层信息,是输入1否输入0\\n\")\nbdtb=BDTB(baseurl,seeLZ,floorTag)\nbdtb.start()\n"
},
{
"alpha_fraction": 0.5856643319129944,
"alphanum_fraction": 0.6153846383094788,
"avg_line_length": 19.39285659790039,
"blob_id": "728a39dc978e1af7d193919b7ffdfcb779fc06bf",
"content_id": "582c9a769f29a58dfb367cdf9e61d8b3bb504ac9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 572,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 28,
"path": "/py3/py3_homework.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding=utf-8\n\nlst=[]\n\ndef print_lst(mlst):\n for i in range(len(mlst)):\n print (i, mlst[i])\n\nfor i in range(30):\n lst.insert(i, i)\n\n#print_lst(lst)\nprint (lst)\n## there are 30 people in total. every whose number is 9, then poplulated from\n## the queue. After 15 guys are populated from the queue, then the game is \n## finished.\ntotal=30\nidx=0\nnlst=[]\nwhile total > 15:\n idx += 8\n idx %= total\n nlst.insert((30-total), lst[idx])\n lst.pop(idx)\n total -= 1\n print (\"new list :\", nlst)\n print (\"original list :\", lst)\n\n"
},
{
"alpha_fraction": 0.6148267388343811,
"alphanum_fraction": 0.6430298089981079,
"avg_line_length": 22.372549057006836,
"blob_id": "a094305fec3ae2d210b3cef9e14cf8041f1bc7d9",
"content_id": "fb45bb5add57a61b74a9341193724f3e34f95adf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1241,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 51,
"path": "/network.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\r\n# encoding=utf-8\r\n\r\nimport socket\r\nimport time\r\n\r\ndef http_test():\r\n\tmysock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\r\n\tmysock.connect(('www.py4inf.com', 80))\r\n\tmysock.send('GET /code/romeo.txt HTTP/1.0\\r\\nHost: www.py4inf.com\\r\\n\\r\\n')\r\n\r\n\twhile True:\r\n\t\tdata = mysock.recv(512)\r\n\t\tif ( len(data) < 1 ) :\r\n\t\t\tbreak\r\n\t\tprint data\r\n\t\r\n\tmysock.close()\r\n\t\r\ndef http_picture():\r\n\tmysock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\r\n\tmysock.connect(('www.py4inf.com', 80))\r\n#\tmysock.send('GET http://www.py4inf.com/cover.jpg HTTP/1.0\\n\\n')\r\n#Absolute is acceptable with HTTP/1.1 but you use HTTP/1.0.\r\n\tmysock.send('GET /cover.jpg HTTP/1.0\\r\\nHost:www.py4inf.com\\r\\n\\r\\n')\r\n\r\n\r\n\tcount = 0\r\n\tpicture = \"\";\r\n\twhile True:\r\n\t\tdata = mysock.recv(5120)\r\n\t\tif ( len(data) < 1 ) : break\r\n\t\t# time.sleep(0.25)\r\n\t\tcount = count + len(data)\r\n\t\tprint len(data),count\r\n\t\tpicture = picture + data\r\n\r\n\tmysock.close()\r\n\r\n\t# Look for the end of the header (2 CRLF)\r\n\tpos = picture.find(\"\\r\\n\\r\\n\");\r\n\tprint 'Header length',pos\r\n\tprint picture[:pos]\r\n\r\n\t# Skip past the header and save the picture data\r\n\tpicture = picture[pos+4:]\r\n\tfhand = open(\"stuff.jpg\",\"wb\")\r\n\tfhand.write(picture);\r\n\tfhand.close()\r\n\t\t\r\nhttp_picture()"
},
{
"alpha_fraction": 0.6235207319259644,
"alphanum_fraction": 0.6309171319007874,
"avg_line_length": 21.719297409057617,
"blob_id": "bce20ac7d792ab756cab677b3d5e6f168b2070a7",
"content_id": "b3ed97a4b6d5e289eed143e02227083722483062",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1352,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 57,
"path": "/url_study.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\r\n# coding=utf-8\r\n\r\nimport urllib\r\nimport re\r\n\r\nfrom bs4 import BeautifulSoup\r\n\r\ndef urlib_test():\r\n\tcounts = dict()\r\n\tfhand = urllib.urlopen('http://www.py4inf.com/code/romeo.txt')\r\n\tfor line in fhand:\r\n\t\twords = line.split()\r\n\t\tfor word in words:\r\n\t\t\tcounts[word] = counts.get(word, 0) + 1\r\n\t\tprint counts\r\n\r\ndef url_re(url):\r\n\thtml = urllib.urlopen(url).read()\r\n\tlinks = re.findall('href=\"(http://.*?)\"', html)\r\n\tfor link in links:\r\n\t\tprint link\r\n\r\n\r\ndef bs_test(url):\r\n\thtml = urllib.urlopen(url).read()\r\n\tsoup = BeautifulSoup(html, \"html.parser\")\r\n\r\n\t# Retrieve all of the anchor tags\r\n\ttags = soup('a')\r\n\tfor tag in tags:\r\n\t print tag.get('href', None)\r\n\r\n\thtml = urllib.urlopen(url).read()\r\n\tsoup = BeautifulSoup(html, \"html.parser\")\r\n\r\n\t# Retrieve all of the anchor tags\r\n\ttags = soup('a')\r\n\tfor tag in tags:\r\n\t\t# look at the parts of a tag\r\n\t\tprint 'TAG:', tag\r\n\t\tprint 'URL:', tag.get('herf', None)\r\n\t\tprint 'Content:', tag.contents[0]\r\n\t\tprint 'Attrs:', tag.attrs\r\n\r\ndef bs_pic(url):\r\n\timg = urllib.urlopen(url).read()\r\n\tfhand = open(\"cover.jpg\", 'w')\r\n\tfhand.write(img)\r\n\tfhand.close()\r\n\r\n#urlib_test()\r\n#url_re(\"http://www.dr-chuck.com/page1.htm\")\r\n#url_re(\"http://www.py4inf.com/book.htm\")\r\n#print \"-----BeautifulSoup test---\"\r\n#bs_test(\"http://www.py4inf.com/book.htm\")\r\nbs_pic('http://www.py4inf.com/cover.jpg')\r\n"
},
{
"alpha_fraction": 0.45883941650390625,
"alphanum_fraction": 0.46693655848503113,
"avg_line_length": 18.5,
"blob_id": "4a8fe34422e8fc6d2cccbba5db10c61994bf4ac9",
"content_id": "4623a33cbd6950315c5dc69ece56a3842c45e1f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 741,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 38,
"path": "/py3/mg_queue.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nclass mg_queue:\n def __init__(self):\n self.l=[]\n\n def empty(self):\n \"\"\"\n return True, if the queue is empty.\n return False, if the queue is no empty.\n \"\"\"\n return len(self.l) == 0\n\n def put(self, item):\n return self.l.append(item)\n\n def get(self):\n if not self.empty():\n return self.l.pop(0)\n else:\n return None\n\n def peek(self):\n \"\"\"\n return the head without pop.\n \"\"\"\n if not self.empty():\n return self.l[0]\n else:\n return None\n\nif __name__ == \"__main__\":\n q=mg_queue()\n q.put(1)\n print(q.peek())\n q.put(2)\n print(q.get())\n print(q.get())\n"
},
{
"alpha_fraction": 0.5391620993614197,
"alphanum_fraction": 0.562841534614563,
"avg_line_length": 17.678571701049805,
"blob_id": "e932f61f766204f3e5f557888fe479a18dad5eff",
"content_id": "ca5733a1e1426cf06e4ed8b7cb3ea546ab2c4a11",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 549,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 28,
"path": "/regular_express.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\r\n# coding=utf-8\r\nimport re\r\n\r\ndef re_all(fname):\r\n\ts = 'Hello from [email protected] to [email protected] about the meeting @2PM'\r\n\tlst = re.findall('\\S+@\\S+', s)\r\n\tprint lst\r\n\tx = 'We just received $10.00 for cookies.'\r\n\ty = re.findall(\"\\$[0-9.]+\", x)\r\n\tprint y\r\n\t\r\n\tcount = 0\r\n\ttry:\r\n\t\tfhand = open(fname)\r\n\r\n\texcept:\r\n\t\tprint \"open %s fail\" %fname\r\n\r\n\tfor line in fhand:\r\n\t\tline = line.rstrip()\r\n\t\tx = re.findall(\"^X\\S+: ([0-9.]+)\", line)\r\n\t\tif len(x) > 0:\r\n\t\t\tcount += 1\r\n\tprint \"match number is \", count\r\n\tfhand.close()\r\n\t\r\nre_all(\"mbox.txt\")"
},
{
"alpha_fraction": 0.6184738874435425,
"alphanum_fraction": 0.6626505851745605,
"avg_line_length": 30.125,
"blob_id": "bdf85ea3135dad8882dc55e40de706516d07f552",
"content_id": "2979dfa7d3042923079fa64376df422bc02ed494",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 249,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 8,
"path": "/web/weather.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\nimport requests\n\nr = requests.get('http://www.weather.com.cn/data/sk/101020100.html')\nr.encoding = 'utf-8'\nprint(r.json()['weatherinfo']['city'], r.json()['weatherinfo']['WD'], r.json()['weatherinfo']['temp'])\n"
},
{
"alpha_fraction": 0.5904683470726013,
"alphanum_fraction": 0.6117185950279236,
"avg_line_length": 19.033058166503906,
"blob_id": "eb4593821d6735b9fe9927437dc03ea074747ca5",
"content_id": "fbc16ab9391d525eb379952e5b113c3af4a8a17c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4847,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 242,
"path": "/homework.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding=utf-8\nimport random\nimport string\n\ndef random_test():\n\tprint \"----\"\n\tfor i in range(10):\n\t\t#x=random.random()\n\t\tx=random.randint(2,9)\n\tprint x\n\tt=[1,2,3]\n\tprint \"choice :%d\" %random.choice(t)\n\n\ndef computepay(hour, rate):\n\ttry:\n\t\tif hours > 40 :\n\t\t\tpay = 40 * rate\n\t\t\tpay += (hours - 40) * rate*1.5\n\n\t\tprint 'Pay:%.2f' %pay\n\n\texcept:\n\n\t\tprint \"Error, please enter numeric input\"\n\ndef while_test():\n\tn = 0\n\twhile n < 5:\n\t\tprint n\n\t\tn = n + 1\n\n\twhile True :\n\t\tif n > 10:\n\t\t\tbreak;\n\t\tn = n + 1\n\t\tprint n\n\ndef for_test():\n\tfriends = ['chenyi', 'lilin', 'liuhong']\n\tfor friend in friends:\n\t\tprint 'Happy new year', friend\n\tprint \"done!\"\n\n\ttotal = 0\n\tfor itervar in [3,4,5,6,7]:\n\t\ttotal =total + itervar\n\tprint \"total : \", total\n\ndef str_test(fruit):\n\tprint fruit[0:len(fruit)]\n\tprint \"empty: \", fruit[:]\n\n\tprint 'index of a in the %s from third letter : ' %fruit, fruit.find('a', 3)\n\tindex = len(fruit)\n\twhile index > 0:\n\t\tindex = index - 1\n\t\tprint fruit[index]\n\ndef find_test():\n\t data = 'From [email protected] Sat Jan 5 09:14:16 2008'\n\t atpos = data.find('@')\n\t sppos = data.find(' ', atpos)\n\t host = data[atpos + 1 : sppos]\n\t print host\n\n\t str = 'X-DSPAM-Confidence: 0.8475'\n\t sppos = str.find(' ')\n\t num = str[sppos + 1 :]\n\t print \"number is %.2f\" %float(num)\n\ndef file_count(filename):\n\ttry :\n\t\tfhand = open(filename)\n\texcept:\n\t\tprint \"%s can't be opened\" %filename\n\t\texit()\n\tcount = 0\n\tweeks = dict()\n\tfor line in fhand: \n\t\tcount = count + 1\n\t\tif line.lower().startswith('from:') and line.find('edu') == -1:\n\t\t\tline.rstrip()\n\t\t\tt = line.split()\n\t\t\tprint t[1]\n\tprint \"%s has %d line\" %(filename, count)\n\tfhand.close()\n\ndef listtable_test(t):\n\n\tfor i in range(len(t)):\n\t\tt[i] = t[i] * 2\n\n\t\tprint t[i]\n\tprint \"max one is %d : \" %max(t)\n\tt.pop(1)\n\tdel t[len(t) - 1]\n\t#mylist.remove(6)\n\tmylist.sort()\n\tprint mylist\n\ndef dict_test():\n\tword = 'brontosaurus'\n\td = dict()\n\tfor c in word:\n\t\td[c] = d.get(c, 0) + 1\n\tprint d\n\tfor key in d:\n\t\tprint key, d[key]\n\t\t\n\t\t\ndef dict_file_test(fname):\n\ttry:\n\t\tfhand = open(fname)\n\texcept:\n\t\tprint \"%s can't open\" %fname\n\t\texit()\n\tcounts = dict()\n\tfor line in fhand:\n\t\tline = line.translate(None, string.punctuation)\n\t\tline = line.lower()\n\t\t# dict to list\n\t\twords = line. split()\n\t\tfor word in words:\n\t\t\t# get retrurn default value/0 if word is not in counts\n\t\t\tcounts[word] = counts.get(word, 0) + 1\n\tprint counts\n\ndef file_count(filename):\n\ttry :\n\t\tfhand = open(filename)\n\texcept:\n\t\tprint \"%s can't be opened\" %filename\n\t\texit()\n\tcount = 0\n\tweeks = dict()\n\tfor line in fhand: \n\t\tcount = count + 1\n\t\tif line.lower().startswith('from') and line.lower().find('from:') == -1:\n\t\t\tline.rstrip()\n\t\t\tt = line.split(' ')\n\t\t\tweeks[t[2]] = weeks.get(t[2], 0) + 1\n\tprint weeks\n\tfor key in weeks:\n\t\tprint key, weeks[key]\n\tprint max(weeks)\t\t\n\tprint \"%s has %d line\" %(filename, count)\n\tfhand.close()\n\t\n\ndef week_count(filename):\n\ttry :\n\t\tfhand = open(filename)\n\texcept:\n\t\tprint \"%s can't be opened\" %filename\n\t\texit()\n\tcount = 0\n\tweeks = {'Wed': 0, 'Sun': 0, 'Fri': 0, 'Thu': 0, 'Mon': 0, 'Tue': 0, 'Sat': 0}\n\tfor line in fhand: \n\t\tcount = count + 1\n\t\tif line.lower().startswith('from') and line.lower().find('from:') == -1:\n\t\t\tline.rstrip()\n\t\t\tt = line.split(' ')\n\t\t\tif t[2] in weeks :\n\t\t\t\tweeks[t[2]] += 1\n\tprint weeks\n\tfor key in weeks:\n\t\tprint key, weeks[key]\n\t#find the maximun of the dict\n\tprint max(weeks.keys(), key=(lambda k: weeks[k]))\t\t\n\tprint \"%s has %d line\" %(filename, count)\n\tfhand.close()\n\t\n\ndef max_account(fname):\n\ttry:\n\t\tfhand = open(fname)\n\texcept:\n\t\tprint \"%s can't be opened\" %fname\n\t\texit()\n\tweeks = dict()\t\n\taccount = 0\n\t\n\tfor line in fhand:\n\t\tif line.lower().startswith('from') and line.lower().find('from:') == -1:\n\t\t\tline.rstrip()\n\t\t\tt=line.split()\n\t\t\taccount = t[1]\n\t\t\tweeks[account] = weeks.get(account, 0) + 1\n\t\t\t\n\taccount = max(weeks.keys(), key=(lambda k: weeks[k]))\n\tname, domain = account.split('@')\n\tprint domain\n\tprint account, weeks[account]\t\n\ndef tuple_test():\n\td = {'a':10, 'b':1, 'c':22}\n\tt = list()\n\tfor key, val in d.items():\n\t\tt.append((val, key))\n\tt.sort(reverse = True)\n\tprint t\n\ndef largest_count(fname):\n\ttry:\n\t\tfhand = open(fname)\n\texcept:\n\t\tprint \"open %s fail\" %fname\n\t\t\n\tcounts = dict()\n\t\n\tfor line in fhand:\n\t\tline = line.translate(None, string.punctuation)\n\t\tline = line.lower()\n\t\twords = line.split()\n\t\tfor word in words:\n\t\t\tcounts[word] = counts.get(word, 0) + 1\n\tt = list()\n\tfor key, val in counts.items():\n\t\tt.append((val, key))\n\tt.sort(reverse = True)\n\t\t\n\tfor key,val in t[:10]:\n\t\tprint key, val\n\t\nrandom_test()\n#hours=float(raw_input(\"Enter Housr:\"))\n#rate=float(raw_input(\"Enter Rate:\"))\n#computepay(hours, rate)\nwhile_test()\nfor_test()\nstr_test(\"banana\")\nfind_test()\nfile_count(\"mbox.txt\")\nmylist = [6,2,3,4]\nlisttable_test(mylist)\ndict_test()\ndict_file_test(\"memo.txt\")\nmax_account(\"mbox.txt\")\ntuple_test()\nlargest_count('mbox.txt')"
},
{
"alpha_fraction": 0.5027888417243958,
"alphanum_fraction": 0.5123506188392639,
"avg_line_length": 18.57377052307129,
"blob_id": "df44687ea77175b98a53094e2f645b86a6730498",
"content_id": "ad246f6f768068df3b97eaad48ba03b9cd501501",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1303,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 61,
"path": "/express.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\r\n# conding=utf-8\r\n\r\nimport re\r\nimport sys\r\n\r\ndef re_test(fname):\r\n try:\r\n fhand = open(fname)\r\n except:\r\n print (\"open %s fail\" %(fname))\r\n exit()\r\n for line in fhand:\r\n if re.search('^F..m', line):\r\n print (line)\r\n\r\ndef findall_test(fname):\r\n try:\r\n fhand = open(fname)\r\n except:\r\n print (\"open %s fail\" %(fname))\r\n exit()\r\n for line in fhand:\r\n line = line.rstrip()\r\n lst = re.findall('[a-zA-Z0-9]\\S+@\\S+[a-zA-Z0-9]', line)\r\n if len(lst) > 0:\r\n print (lst)\r\n\r\n'''\r\ndef find_book(fname):\r\n\ttry:\r\n\t\tfhand = open(fname)\r\n\texcept:\r\n\t\tprint (\"open %s fail\" %(fname))\r\n\t\texit()\r\n\r\n\tfor line in fhand:\r\n\t\tline = line.rstrip()\r\n\t\tlst = re.findall('as', line)\r\n\tprint (lst)\r\n'''\r\ndef find_book(fname):\r\n try:\r\n fhand = open(fname)\r\n except:\r\n print (\"open %s fail!\" %(fname))\r\n exit()\r\n\r\n for line in fhand:\r\n ## rstrip 删除string末尾的字符,默认为空格\r\n line = line.rstrip()\r\n print (line)\r\n\r\n#reload(sys)\r\n#sys.setdefaultencoding('utf8')\r\n\r\nre_test(\"mbox.txt\")\r\n#findall_test(\"mbox.txt\")\r\nprint (\"====下面为安全图书清单=====\")\r\nfind_book('booklist.txt')\r\n#print re.match(ur\"[\\u4e00-\\u9fa5]+\",\"��\")\r\n"
},
{
"alpha_fraction": 0.5980197787284851,
"alphanum_fraction": 0.6158415675163269,
"avg_line_length": 21.9761905670166,
"blob_id": "21d56647430a5f3a7036120a6b4cf6a0c334dc21",
"content_id": "99e7b180c3246590bce89edb49b7a5cffdb405f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1010,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 42,
"path": "/music_file.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\r\n#coding=utf-8\r\n\r\nimport os\r\nimport shutil\r\nimport filecmp\r\n#dl_path=r'E:\\BaiduYunDownload'\r\ndl_path=r'D:\\Users\\c00200500.CHINA\\Downloads'\r\n#msc_path=r'E:\\music'\r\nmsc_path=r'D:\\03_personal\\01_music'\r\n\r\ndef endwith(*endstring):\r\n\tends = endstring\r\n\tdef run(s):\r\n\t\tf = map(s.endswith,ends)\r\n\t\tif True in f: return s\r\n\treturn run\r\n\r\ndef rm_suffix(item):\r\n\tfile=item.replace(\"[mqms2](1)\", \"\")\r\n\tnew=file.replace(\"[mqms2]\", \"\")\r\n\tnfile=new.replace(' ', '')\r\n\treturn nfile\r\n\t\r\ndef cp_download(src_path, dst_path):\r\n\tfiles=filecmp.dircmp(src_path, dst_path).left_only\r\n\ta=endwith('.mp3','.flac', 'm4a', 'ape','wav')\r\n\tf_files=filter(a, files)\r\n\t\r\n\tfor item in f_files:\r\n\t\tfile=rm_suffix(item)\r\n\t\tsrc_file=src_path + '\\\\' + item\r\n\t\tdst_file=dst_path + '\\\\' + file\r\n\t\tif not ((os.path.isdir(src_file)) or (os.path.exists(dst_file))):\r\n\t\t\tprint \"copy \" + src_file +\" to \" + dst_file\r\n\t\t\tshutil.move(src_file, dst_file)\r\n\t\t\r\n\t\r\n\t\r\n\t\r\nif __name__ == \"__main__\":\r\n\tcp_download(dl_path, msc_path)\r\n\t\r\n"
},
{
"alpha_fraction": 0.6512641906738281,
"alphanum_fraction": 0.6734960675239563,
"avg_line_length": 24.21977996826172,
"blob_id": "1b2b26424a4e88cd5f719b7874208ee7f067adad",
"content_id": "b4da0a8ec176429c3fddcb5c0b42041122a482ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2294,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 91,
"path": "/web/bs_study.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nimport re\nimport urllib.request\nimport chardet\nimport sys\n\nfrom bs4 import BeautifulSoup\n\ndef bs_pic(url):\n\timg = urllib.urlopen(url).read()\n\tfhand = open('cover.jpg', 'w')\n\tfhand.write(img)\n\tfhand.close()\n\ndef bs_picx(url):\n\timg = urllib.urlopen(url)\n\tfhand = open('cover.jpg', 'w')\n\tsize = 0\n\n\twhile True:\n\t\tinfo = img.read(100*1024)\n\t\tif len(info) < 1:\n\t\t\tbreak\n\t\tsize = size + len(info)\n\t\tfhand.write(info)\n\n\tprint (size, 'charatcters copied.')\t\n\tfhand.close()\n\ndef bs_test(url):\n\tlst = list()\n\tindex = url.rfind('/')\n\tprint (index, \"index\\n\")\n\troot_url = url[0:index+1]\n\turl = urllib.urlopen(url).read()\n\tsoup = BeautifulSoup(url, 'html.parser')\n\n\t#Retrieve all of the anchor tags\n\ttags = soup('a')\n\tcount = 0\n\tfor tag in tags:\n\t\t#if re.search('[0-9]', tag.get('href', None)[:1]):\n\t\tif tag.get('href', None)[0].isnumeric():\n\t\t\tpage = root_url + tag.get('href', None)\n\t\t\tlst.append(page)\n\t\t\tprint (page)\n\t\tcount += 1\n\t\t#print tag.get('href', None)\n\tprint (\"count is : \", count)\n\ndef processText(webpage):\n\t# EMPTY LIST TO STORE PROCESSED TEXT\n\n\thtml = urllib.request.urlopen(webpage).read() \n\tencoding = chardet.detect(html)\n\tprint (encoding)\n\n\tsoup = BeautifulSoup(html, 'html.parser') \n\t# kill all script and style elements\n\tfor script in soup([\"script\", \"style\"]):\n\t\tscript.extract()\t# rip it out\n\t\t\n\ttext = soup.get_text()\n\t# break into lines and remove leading and trailing space on each\n\tlines = (line.strip() for line in text.splitlines())\n\t# break multi-headlines into a line each\n\tchunks = (phrase.strip() for line in lines for phrase in line.split(\" \"))\n\t# drop blank lines\n\ttext = '\\n'.join(chunk for chunk in chunks if chunk)\n\t#print text\n\ttitleUni = text.decode(\"GB18030\", \"ignore\")\n\tprint (titleUni)\n\tfhand = open(\"touxiang.txt\", 'w')\n\tfhand.write(titleUni)\n\tfhand.close()\n\t\n\t\n\t\nprint (\"bs test\")\nprint (sys.getdefaultencoding())\n#reload(sys) \n#sys.setdefaultencoding('utf8') \nprint (sys.getdefaultencoding())\n#bs_pic('http://www.py4inf.com/cover.jpg')\n#bs_picx('http://www.py4inf.com/cover.jpg')\n#bs_test('http://www.piaotian.com/html/7/7794/index.html')\nprocessText(\"http://www.google.com\")\n#processText('http://www.piaotian.com/html/7/7794/4671004.html')\n#processText('http://blog.csdn.net/hfahe/article/details/5494895')"
},
{
"alpha_fraction": 0.5628318786621094,
"alphanum_fraction": 0.6017699241638184,
"avg_line_length": 15.142857551574707,
"blob_id": "ceba22d8c78bedc997c5ec381f8206000dba5c10",
"content_id": "6c467ab37751508c9e11e6b78a2b1867e4594b49",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 565,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 35,
"path": "/py3/py3_print.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding=utf-8\n\nimport math\nimport sys\nstr='helloworld'\nprint(str)\nprint(\"this lenth of (%s) is (%d)\" %(str, len(str)))\n\nnhex=0xff\nprint(\"nhex=%x, ndec=%d, noct=%o\" %(nhex, nhex, nhex))\n\n\n## float\nprint(\"PI=%f, PI=%10.3f, PI=%06d\" %(math.pi, math.pi, math.pi))\n\n## string\nprint(\"%.3s\" %(str))\nprint(\"%.*s\" %(6,str))\nprint(\"%10.4s\" %(str))\n\n# list\nlst=[1,2,3,4,'python']\nprint(lst)\n\n# dictonary\nd={1:'a',2:'b',3:'c',4:'d'}\nprint(d)\n\n# new line\nfor i in range(0,6):\n print(i)\n\n# usind system function directly\nsys.stdout.write(\"hello world\")\n"
},
{
"alpha_fraction": 0.5653333067893982,
"alphanum_fraction": 0.5973333120346069,
"avg_line_length": 16.85714340209961,
"blob_id": "5cbc257773a00936f5b9163e67ea6d6ba850eb98",
"content_id": "638f3b21231a9f5fbb1b08c53b4450dc16ea385e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 375,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 21,
"path": "/xml_study.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding=utf-8\n\nimport xml.etree.ElementTree as ET\n\ndef xml_test():\n data = \"\"\"\n<person>\n <name>Chuck</name>\n <phone type=\"intl\">\n +1 734 303 4456\n </phone>\n <email hide=\"yes\"/>\n</person>\"\"\"\n\n print data\n tree = ET.fromstring(data)\n print 'Name', tree.find('name').text\n print 'Attr', tree.find('email').get('hide')\n\nxml_test()\n"
},
{
"alpha_fraction": 0.4379977285861969,
"alphanum_fraction": 0.4562002420425415,
"avg_line_length": 26.354839324951172,
"blob_id": "d34eb2c2519b98f294a6a057e793781bb474d69c",
"content_id": "65164d74a56d2eb55ab6a90a61064f3fa6517d08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 879,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 31,
"path": "/py3/max_histogram.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\r\n#coding:utf-8\r\n\r\nclass Solution:\r\n def largestRectangleArea(self, heights):\r\n \"\"\"\r\n :type heights: list[int]\r\n :rtype int\r\n \"\"\"\r\n i = 0\r\n stack = []\r\n max_value = 0\r\n\r\n while (i < len(heights)):\r\n if len(stack) == 0 or heights[stack[-1]] < heights[i]:\r\n stack.append(i)\r\n i += 1\r\n else:\r\n top = stack.pop()\r\n max_value = max(max_value, heights[top] * ((i - stack[-1] - 1 ) if stack else i ))\r\n\r\n while stack:\r\n top = stack.pop()\r\n max_value = max(max_value, heights[top] * ((i - stack[-1] - 1) if stack else i))\r\n\r\n return max_value\r\n\r\nif __name__ == '__main__':\r\n heights = [2,1,5,6,2,3]\r\n x = Solution()\r\n print(\"max area is %d\" %(x.largestRectangleArea(heights)))\r\n"
},
{
"alpha_fraction": 0.5299999713897705,
"alphanum_fraction": 0.5666666626930237,
"avg_line_length": 15.142857551574707,
"blob_id": "7e7f7b66a8bf76cce13267c9d2b0baddd36dfb18",
"content_id": "5b9d9b884762ff86a040d183f05df63914c82902",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 600,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 35,
"path": "/py3_print.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\r\n# coding=utf-8\r\n\r\nimport math\r\nimport sys\r\nstr='helloworld'\r\nprint(str)\r\nprint(\"this lenth of (%s) is (%d)\" %(str, len(str)))\r\n\r\nnhex=0xff\r\nprint(\"nhex=%x, ndec=%d, noct=%o\" %(nhex, nhex, nhex))\r\n\r\n\r\n## float\r\nprint(\"PI=%f, PI=%10.3f, PI=%06d\" %(math.pi, math.pi, math.pi))\r\n\r\n## string\r\nprint(\"%.3s\" %(str))\r\nprint(\"%.*s\" %(6,str))\r\nprint(\"%10.4s\" %(str))\r\n\r\n# list\r\nlst=[1,2,3,4,'python']\r\nprint(lst)\r\n\r\n# dictonary\r\nd={1:'a',2:'b',3:'c',4:'d'}\r\nprint(d)\r\n\r\n# new line\r\nfor i in range(0,6):\r\n print(i)\r\n\r\n# usind system function directly\r\nsys.stdout.write(\"hello world\")\r\n"
},
{
"alpha_fraction": 0.5602094531059265,
"alphanum_fraction": 0.6492146849632263,
"avg_line_length": 10.875,
"blob_id": "d53607f00ba3934ae374ab7e1b2b7ed355df3288",
"content_id": "0c81160278a8a33fa0e0cff5d5f5fd02d28a40cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 191,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 16,
"path": "/zero_learning_2.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n#coding=utf-8\nimport random\n\n\nprint id(3)\nprint type(3)\nprint 2+3\n\n\"\"\"\nplease caculate 19+2*4-8/2\n\"\"\"\na=19+2*4-8/2\nprint a\nprint 'what\\'s your name?'\nprint 'py'+'thon'\n\n"
},
{
"alpha_fraction": 0.7300613522529602,
"alphanum_fraction": 0.7300613522529602,
"avg_line_length": 31,
"blob_id": "c08d6ae0dcb1e5bcba83204306d79957effd397a",
"content_id": "fe5e9b415fd49a4411847e108eddb6d71dafe1fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 167,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 5,
"path": "/my_imports.py",
"repo_name": "chenyi852/python_study",
"src_encoding": "WINDOWS-1252",
"text": "import sys, cgi, os, re, subprocess \r\nimport cx_Oracle as oracle \r\nfrom rdkit import Chem \r\nsys.path.append(¡°/home/python/my_python_modules/¡±) \r\nimport my_module"
}
] | 25 |
sounghyun890/-
|
https://github.com/sounghyun890/-
|
7ae637cf2eb5f94375ede016d40da14c1287a4e8
|
df7f74fa6cb941c1437f261bee6fa4dc3c965036
|
e5a19e19ff4b73ac2cf8e194d3dc59f6ecdef71b
|
refs/heads/main
| 2023-05-25T20:29:48.303544 | 2021-06-09T14:17:23 | 2021-06-09T14:17:23 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6092379093170166,
"alphanum_fraction": 0.6185581088066101,
"avg_line_length": 38.53333282470703,
"blob_id": "b2cb46948e63bf7faf1dfb61b1fde8d616beb27a",
"content_id": "0fd1b49ce501da1022f49faacec1c555c14af036",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8184,
"license_type": "no_license",
"max_line_length": 193,
"num_lines": 180,
"path": "/bot.py",
"repo_name": "sounghyun890/-",
"src_encoding": "UTF-8",
"text": "import asyncio\r\nimport discord,os\r\nimport datetime\r\n\r\nclient = discord.Client()\r\n \r\n \r\[email protected]\r\nasync def on_ready():\r\n print(\"로그인 된 봇:\") #화면에 봇의 아이디, 닉네임이 출력되는 코드\r\n print(client.user.name)\r\n print(client.user.id)\r\n print(\"===========\")\r\n \r\[email protected]\r\nasync def on_ready():\r\n await client.change_presence(status=discord.Status.offline)\r\n game = discord.Game(\"시작하는 중...\")\r\n await client.change_presence(status=discord.Status.online, activity=game)\r\n while True:\r\n game = discord.Game(\"!도움 찾기\")#상태 메세지\r\n await client.change_presence(status=discord.Status.online, activity=game)\r\n await asyncio.sleep(2)\r\n game = discord.Game(\"!도움 듣기\")\r\n await client.change_presence(status=discord.Status.online, activity=game)\r\n await asyncio.sleep(2) \r\n# 디스코드에는 현재 본인이 어떤 게임을 플레이하는지 보여주는 기능이 있습니다.\r\n# 이 기능을 사용하여 봇의 상태를 간단하게 출력해줄 수 있습니다.\r\n \r\nnow = datetime.datetime.now()\r\ntime = f\"{str(now.year)}년 {str(now.month)}월 {str(now.day)}일 {str(now.hour)}시 {str(now.minute)}분\"\r\n\r\[email protected]\r\nasync def on_message_delete(message):#메세지가 삭제 되면\r\n if message.author.bot:return\r\n channel = client.get_channel(849536197273059338)\r\n embed = discord.Embed(title=f\"삭제됨\", description=f\"유저 : {message.author.display_name} \\n유저ID : {message.author} \\n서버 : {message.guild.name} \\n채널 : {message.channel.mention}\", color=0xFF0000)\r\n embed.add_field(name=\"삭제된 내용\", value=f\"내용 : {message.content}\", inline=False)\r\n embed.set_footer(text=f\"TNS 봇 | {time}\")\r\n await channel.send(embed=embed)\r\n\r\n\r\[email protected] \r\nasync def on_message_edit(before, after):#메세지 수정 되면(작동 안함)\r\n if message.author.bot:return\r\n channel = client.get_channel(849536197273059338)\r\n embed = discord.Embed(title=f\"수정됨\", description=f\"유저 : {before.author.mention} 채널 : {before.channel.mention}\", color=0xFF9900)\r\n embed.add_field(name=\"수정 전 내용\", value=before.content, inline=True)\r\n embed.add_field(name=\"수정 후 내용\", value=after.content, inline=True)\r\n embed.set_footer(text=f\"{before.guild.name} | {time}\")\r\n await channel.send(embed=embed)\r\n\r\n# 봇이 새로운 메시지를 수신했을때 동작되는 코드입니다.\r\[email protected]\r\nasync def on_message(message):\r\n if message.author.bot:\r\n return None \r\n\r\n id = message.author.id\r\n channel = message.channel\r\n\r\n if message.content == \"!도움\":\r\n embed = discord.Embed(title = \"TNS 봇의 도움말\", description = '''\r\n 욕 검열 봇입니다\r\n욕 추가 및 수정을 원하시면 로그 서버의 문의 채팅방을 이용해주세요\r\n\r\n봇 로그 보러가기 https://discord.gg/hFryJ4zYyw''', color = 0x08FFFA)\r\n await message.author.send(embed = embed)\r\n await message.delete()\r\n if message.author.bot:\r\n \r\n await message.author.send(embed = embed) # message.channel.send를 message.author.send로\r\n message_content = message.content\r\n \r\n bad = message_content.find(\"ㅅㅂ\")\r\n bad = bad + message_content.find(\"ㅂㅅ\")\r\n bad = bad + message_content.find(\"ㅄ\")\r\n bad = bad + message_content.find(\"씨발\")\r\n bad = bad + message_content.find(\"닥쳐\")\r\n bad = bad + message_content.find(\"꺼져\")\r\n bad = bad + message_content.find(\"느금마\")\r\n bad = bad + message_content.find(\"잘생김\")\r\n bad = bad + message_content.find(\"니 엄마\")\r\n bad = bad + message_content.find(\"지랄\")\r\n bad = bad + message_content.find(\"싸발\")\r\n bad = bad + message_content.find(\"좇\")\r\n bad = bad + message_content.find(\"ㅈㄴ\")\r\n bad = bad + message_content.find(\"ㅈㄹ\")\r\n bad = bad + message_content.find(\"ㄴㄱㅁ\")\r\n bad = bad + message_content.find(\"좆\")\r\n bad = bad + message_content.find(\"시발\")\r\n bad = bad - message_content.find(\"시발점\")\r\n bad = bad + message_content.find(\"ㄲㅈ\")\r\n bad = bad + message_content.find(\"쌔끼\")\r\n bad = bad + message_content.find(\"fuck\")\r\n bad = bad + message_content.find(\"Tlqkf\")\r\n bad = bad + message_content.find(\"tlqkf\")\r\n bad = bad + message_content.find(\"병신\")\r\n bad = bad + message_content.find(\"박근혜\")\r\n bad = bad + message_content.find(\"섹스\")\r\n bad = bad + message_content.find(\"보지\")\r\n bad = bad - message_content.find(\"보지마\")\r\n bad = bad + message_content.find(\"쉣\")\r\n bad = bad + message_content.find(\"너의 어머니\")\r\n bad = bad + message_content.find(\"샤발\")\r\n bad = bad + message_content.find(\"섹 스\")\r\n bad = bad + message_content.find(\"씨 발\")\r\n bad = bad + message_content.find(\"닥ㅊ\")\r\n bad = bad + message_content.find(\"ㅈㄹㄴ\")\r\n bad = bad + message_content.find(\"병 신\")\r\n bad = bad + message_content.find(\"*발\")\r\n bad = bad + message_content.find(\"*신\")\r\n bad = bad + message_content.find(\"야발\")\r\n bad = bad + message_content.find(\"ㅅ1ㅂ\")#35\r\n bad = bad + message_content.find(\"조까\")\r\n bad = bad + message_content.find(\"퍽큐\")\r\n bad = bad + message_content.find(\"ㅗ\")\r\n bad = bad + message_content.find(\"븅신\")\r\n bad = bad + message_content.find(\"따까리\")\r\n bad = bad + message_content.find(\"새끼\")\r\n bad = bad + message_content.find(\"찐따\")\r\n bad = bad + message_content.find(\"porn\")\r\n bad = bad + message_content.find(\"빠큐\")\r\n bad = bad + message_content.find(\"시놈발\")\r\n bad = bad + message_content.find(\"시이발\")\r\n bad = bad + message_content.find(\"ㅅ ㅂ\")#47\r\n bad = bad + message_content.find(\"미친\")\r\n bad = bad + message_content.find(\"ㄷㅊ\")\r\n bad = bad + message_content.find(\"ㄷ ㅊ\")#51\r\n bad = bad + message_content.find(\"자지\")\r\n bad = bad - message_content.find(\"자지마\")#50\r\n bad = bad + message_content.find(\"폐륜\")\r\n bad = bad + message_content.find(\"불알\")\r\n bad = bad + message_content.find(\"ㅈ같\")\r\n bad = bad + message_content.find(\"ㅈ랄\")\r\n bad = bad + message_content.find(\"기모찌\")\r\n bad = bad + message_content.find(\"자위\")\r\n bad = bad + message_content.find(\"딸딸이\")\r\n bad = bad + message_content.find(\"TLQKF\")\r\n bad = bad + message_content.find(\"SEX\")\r\n bad = bad + message_content.find(\"Sex\")\r\n bad = bad + message_content.find(\"섹슥\")\r\n bad = bad + message_content.find(\"미친놈\")\r\n bad = bad + message_content.find(\"싸가지\")\r\n bad = bad - message_content.find(\"ㅗㅜㅑ\")\r\n bad = bad + message_content.find(\"개세끼\")\r\n bad = bad + message_content.find(\"게세끼\")\r\n bad = bad + message_content.find(\"씌발\")\r\n bad = bad - message_content.find(\"자위대\")#64\r\n bad = bad + message_content.find(\"FUCK\")\r\n bad = bad + message_content.find(\"Fuck\")\r\n bad = bad + message_content.find(\"씹발\")\r\n bad = bad + message_content.find(\"느그어미\")\r\n bad = bad + message_content.find(\"포르노\")\r\n bad = bad - message_content.find(\"자지말\")#68\r\n bad = bad + message_content.find(\"씌발\")\r\n bad = bad + message_content.find(\"씹창\")\r\n bad = bad + message_content.find(\"시이이벌\")\r\n bad = bad + message_content.find(\"뒤져\")\r\n bad = bad + message_content.find(\"존나\")\r\n bad = bad + message_content.find(\"ファック\")\r\n bad = bad + message_content.find(\"他妈的\")\r\n bad = bad + message_content.find(\"ㅣ발\")\r\n bad = bad + message_content.find(\"sibar\")\r\n bad = bad + message_content.find(\"Sibar\")\r\n bad = bad + message_content.find(\"SIBAR\")\r\n bad = bad + message_content.find(\"싯팔\")\r\n \r\n\r\n \r\n \r\n if bad >= -80 :\r\n a = await message.channel.send(message.author.mention+\"님의 메세지가 삭제 되었습니다.\\n[사유:부적절한 언어 포함]\")\r\n await message.delete() \r\n await asyncio.sleep(7)\r\n await a.delete()\r\n await bot.process_commands(messsage)\r\n\r\naccess_token = os.environ[\"token\"]\r\nclient.run(access_token)\r\n"
}
] | 1 |
85496/weather
|
https://github.com/85496/weather
|
2b06a9c8c65cffaa44a3cca977a19f903baf3f16
|
6225dc54011b97d678855d339fea91cc2228fc1f
|
c70b20cbefa8642205d3e84668b63fb26525ee76
|
refs/heads/master
| 2021-08-07T05:46:22.917684 | 2017-11-07T16:41:06 | 2017-11-07T16:41:06 | 109,859,925 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6319797039031982,
"alphanum_fraction": 0.703045666217804,
"avg_line_length": 54.57143020629883,
"blob_id": "6b273d6fcd253d70ebba06904ba7c38c370b5f6f",
"content_id": "761edcf7fe063b17e63eb7ed9be63c03a38552a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 394,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 7,
"path": "/WeatherForcast/WeeklyForcast.py",
"repo_name": "85496/weather",
"src_encoding": "UTF-8",
"text": "print(\"Monday: Cloudy, High of 45, Low of 35\")\r\nprint(\"Tuesday: Partly Cloudy High of 46, Low of 36\")\r\nprint(\"Wednesday: Partly Cloudy High of 46, Low of 32\")\r\nprint(\"Thursday: Scattered Showers, High of 45, Low of 22\")\r\nprint(\"Friday: Cloudy, High of 31, Low of 22\")\r\nprint(\"Saturday: Partly Cloudy, High of 43, Low of 35\")\r\nprint(\"Sunday: Cloudy with a chance of rain, High of 47, Low of 36\")"
}
] | 1 |
andreymal/tabun_feed
|
https://github.com/andreymal/tabun_feed
|
b4c3ace736e59a23f2360da4fb1e189b2b3a2c31
|
ba388ad15f4f30e4a4d0f2f9af169f9ddc4ac98f
|
4f715531504532af48d333406ad159400bed16c1
|
refs/heads/master
| 2020-12-24T04:26:39.881513 | 2019-06-07T17:41:54 | 2019-06-07T17:41:54 | 12,870,865 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6404440402984619,
"alphanum_fraction": 0.6472007632255554,
"avg_line_length": 24.371429443359375,
"blob_id": "a33c5e9888d1ea8c67219e80a5fd34f7b2fe1526",
"content_id": "70d82f715fe1798043f470c2512f000acd7c628f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6479,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 245,
"path": "/tabun_feed/core.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nimport io\nimport os\nimport sys\nimport logging\nimport importlib\nimport traceback\n\nfrom tabun_api.compat import PY2, text, binary\n\n\ndefault_config = '''\\\n[tabun_feed]\nloglevel = WARNING\nlogformat = [%(asctime)s] [%(levelname)s] %(message)s\ndb = tabun_feed.db\nplugins_dir = plugins\nplugins\nfailures_to_db = 0\ngevent_threads = 0\npidfile\nalivefile\nstarted_at_file\nusername\npassword\nsession_id\nkey\nhttp_host\nssl_params\nsession_cookie_name = TABUNSESSIONID\niterations_interval = 10\nquery_interval = 1.5\ntimeout = 15\ntries_if_unauthorized = 60\ntries_if_error = 10\n\n[email]\nfrom = [email protected]\nhost = 127.0.0.1\nport = 25\nuser\npassword\nredirect_to\ndont_edit_subject_on_redirect = 0\ntimeout = 3\nuse_ssl = 0\nuse_tls = 0\nssl_keyfile\nssl_certfile\nnotify_to\nnotify_subject = tabun_feed notify\nnotify_from\nerrors_to\nerrors_subject = tabun_feed error\nerrors_from\n\n[posts]\nurls = /index/newall/#3\nrequest_full_posts = 0\n\n[comments]\nurls = /comments/#5\n'''\n\narguments = {'--': []}\n\nif PY2:\n from ConfigParser import RawConfigParser\n config = RawConfigParser(allow_no_value=True)\n config.readfp(io.BytesIO(default_config.encode('utf-8')))\nelse:\n from configparser import RawConfigParser\n config = RawConfigParser(allow_no_value=True)\n config.read_file([x for x in default_config.split('\\n')])\n\nconfig_files = []\n\nlogger = logging.getLogger('tabun_feed')\nloglevel = logging.WARNING\nplugins = {}\nnotify_func = None\ngevent_used = False\n\n\nclass PluginError(Exception):\n pass\n\n\ndef parse_arguments(args):\n for arg in args:\n if not arg.startswith('-') or arg[1] != '-' and len(arg) != 2:\n arguments['--'].append(arg)\n continue\n if '=' in arg:\n key, value = arg.split('=', 1)\n else:\n key = arg\n value = None\n key = key.lstrip('-')\n arguments[key] = value\n\n\ndef load_config(config_file=None, with_includes=True):\n config_file = os.path.abspath(config_file)\n if config_file in config_files:\n raise RuntimeError('Recursive config: {}'.format(config_files))\n if not os.path.isfile(config_file):\n raise OSError('Config not found: {}'.format(config_file))\n config.read([config_file])\n config_files.append(config_file)\n\n # Загружаем конфиги в алфавитном порядке, а дальше в порядке загрузки конфигов\n # Пути относительно текущего конфига\n if with_includes and config.has_section('includes'):\n dirn = os.path.dirname(config_file)\n incl = sorted(config.items('includes'))\n config.remove_section('includes')\n for _, path in incl:\n load_config(os.path.join(dirn, path))\n\n\ndef init_config(config_file=None):\n global loglevel, gevent_used\n\n if not config_file:\n config_file = os.path.join(os.getcwd(), 'config.cfg')\n load_config(config_file, with_includes=True)\n\n # Инициализируем логгер\n loglevel = text(config.get('tabun_feed', 'loglevel')).upper()\n log_format = config.get('tabun_feed', 'logformat')\n\n if loglevel == 'DEBUG':\n loglevel = logging.DEBUG\n elif loglevel == 'INFO':\n loglevel = logging.INFO\n elif loglevel == 'WARNING':\n loglevel = logging.WARNING\n elif loglevel == 'ERROR':\n loglevel = logging.ERROR\n elif loglevel == 'FATAL':\n loglevel = logging.FATAL\n else:\n raise ValueError(\"Incorrect loglevel\")\n\n logging.basicConfig(level=loglevel, format=log_format)\n\n if config.getboolean('tabun_feed', 'gevent_threads') and not gevent_used:\n import gevent.monkey\n gevent.monkey.patch_all()\n gevent_used = True\n\n # проверка, что это правда boolean (дабы не ловить ошибки потом в обработчике)\n config.getboolean('tabun_feed', 'failures_to_db')\n\n # Добавляем каталоги с плагинами в sys.path для импорта плагинов\n plugins_dir = config.get('tabun_feed', 'plugins_dir')\n if plugins_dir:\n plugins_dir = os.path.abspath(plugins_dir)\n if plugins_dir not in sys.path:\n sys.path.insert(0, plugins_dir)\n\n\ndef load_plugins():\n for module in text(config.get('tabun_feed', 'plugins') or '').split(','):\n if module.strip():\n try:\n load_plugin(module.strip())\n except PluginError as exc:\n logger.fatal(exc.args[0])\n return False\n return True\n\n\ndef load_plugin(module):\n module = get_full_module_name(module)\n\n if module in plugins:\n return plugins[module]\n\n logger.debug('load_plugin %s', module)\n\n try:\n if PY2:\n module = module.encode('utf-8')\n moduleobj = importlib.import_module(module)\n if hasattr(moduleobj, 'init_tabun_plugin'):\n moduleobj.init_tabun_plugin()\n\n except PluginError as exc:\n raise PluginError('Dependence for %s: %s' % (module, exc))\n\n except Exception:\n logger.error(traceback.format_exc())\n raise PluginError('Cannot load module %s' % module)\n\n plugins[module.decode('utf-8') if PY2 else module] = moduleobj\n return moduleobj\n\n\ndef get_full_module_name(module):\n module = text(module)\n if module.startswith(':'):\n module = 'tabun_feed.plugins.' + module[1:]\n elif module.startswith('r:'):\n module = 'tabun_feed.readers.' + module[2:]\n return module\n\n\ndef is_plugin_loaded(module):\n return get_full_module_name(module) in plugins\n\n\ndef notify(body):\n body = text(body)\n (notify_func or default_notify_func)(body)\n\n\ndef default_notify_func(body):\n if config.get('email', 'notify_to'):\n sendmail(\n config.get('email', 'notify_to'),\n config.get('email', 'notify_subject'),\n body,\n fro=config.get('email', 'notify_from') or None\n )\n else:\n logger.warning(body)\n\n\ndef set_notify_func(func):\n global notify_func\n if notify_func:\n raise ValueError('Conflict')\n notify_func = func\n\n\ndef sendmail(to, subject, items, fro=None):\n # Обратная совместимость; лучше использовать tabun_feed.mail.sendmail напрямую\n from tabun_feed.mail import sendmail as new_sendmail\n return new_sendmail(to, subject, body=items, fro=fro)\n"
},
{
"alpha_fraction": 0.6137787103652954,
"alphanum_fraction": 0.6184759736061096,
"avg_line_length": 26.371429443359375,
"blob_id": "0e0d4681a11566f424a6124883c13ee608b6e3f2",
"content_id": "e80128877404edd62f39600d6f64667211c89b51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1916,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 70,
"path": "/tabun_feed/remote_commands.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nimport time\n\nfrom . import worker\nfrom .remote_server import remote_command\n\n\n@remote_command('get_status')\ndef cmd_get_status(packet, client):\n if not isinstance(packet.get('items'), list):\n return {'error': 'Invalid items'}\n items = [str(x) for x in packet['items']]\n\n if items == ['all']:\n result = worker.status.get_json_status()\n else:\n result = {}\n for key in items:\n result[key] = worker.status.get_json_key(key)\n\n return {'cmd': 'status', 'status': result}\n\n\n@remote_command('set_status')\ndef cmd_set_status(packet, client):\n key = packet.get('key')\n if key not in worker.status.editables:\n return {'error': 'This status is not editable'}\n if 'value' not in packet:\n return {'error': 'Value is not defined'}\n worker.status[key] = packet['value']\n return {'cmd': 'set_status_ok', 'value': worker.status[key]}\n\n\n@remote_command('ping')\ndef cmd_ping(packet, client):\n return {'cmd': 'pong', 'time': time.time()}\n\n\n@remote_command('failures')\ndef cmd_failures(packet, client):\n try:\n offset = max(0, int(packet.get('offset', 0)))\n count = max(0, min(500, int(packet.get('count', 20))))\n except Exception:\n return {'error': 'Invalid parameters'}\n return {'cmd': 'failures', 'failures': worker.get_failures(offset, count)}\n\n\n@remote_command('get_failure')\ndef cmd_get_failure(packet, client):\n try:\n fail_id = int(packet['id'])\n except ValueError:\n return {'error': 'Invalid id'}\n return {'cmd': 'failure', 'failure': worker.get_failure(fail_id)}\n\n\n@remote_command('solve_failure')\ndef cmd_solve_failure(packet, client):\n try:\n fail_id = int(packet['id'])\n except ValueError:\n return {'error': 'Invalid id'}\n worker.solve_failure(fail_id)\n return {'cmd': 'ok'}\n"
},
{
"alpha_fraction": 0.6021409630775452,
"alphanum_fraction": 0.6060065627098083,
"avg_line_length": 38.33333206176758,
"blob_id": "d9b1deac79219c84c2e0febd99de2a1c4b7e4d40",
"content_id": "f82d231793504ae12902e66afe5232a4d460338b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8096,
"license_type": "no_license",
"max_line_length": 166,
"num_lines": 171,
"path": "/tabun_feed/user.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nimport json\n\nimport tabun_api as api\n\nfrom . import core, worker\n\n\nuser = None\nanon = None\nlast_requests = []\n\n\ndef auth(username=None, password=None, session_id=None, key=None, http_host=None, session_cookie_name=None, query_interval=None, timeout=None, ssl_params=None):\n \"\"\"Проходит авторизацию на табуне по указанным параметрам и возвращает пользователя.\n Число попыток не ограничено: подвиснет интернет, упадёт сайт — функция дождётся, пока всё починится.\n Может вернуть None, если в процессе авторизации процесс решили остановить.\n \"\"\"\n if query_interval is None:\n query_interval = core.config.getfloat('tabun_feed', 'query_interval')\n if timeout is None:\n timeout = core.config.getfloat('tabun_feed', 'timeout')\n\n u = None\n errors = 0\n\n # Авторизация пользователя\n while not worker.quit_event.is_set():\n try:\n u = None\n # при наличии session_id логиниться, возможно, и не надо\n if session_id and password:\n tmpuser = api.User(session_id=session_id, key=key, http_host=http_host, ssl_params=ssl_params)\n if tmpuser.username:\n if username == tmpuser.username:\n core.logger.info('Fast login %s!', username)\n u = tmpuser\n del tmpuser\n\n if u is None:\n u = api.User(\n session_id=session_id,\n key=key,\n login=username,\n passwd=password,\n http_host=http_host,\n session_cookie_name=session_cookie_name or 'TABUNSESSIONID',\n ssl_params=ssl_params,\n )\n break\n except api.TabunError as exc:\n core.logger.error(\"user %s auth error: %s\", username, exc.message)\n errors += 1\n # избегаем удара банхаммером от fail2ban\n if errors % 3 == 0 or 'пароль' in exc.message:\n worker.quit_event.wait(60)\n else:\n worker.quit_event.wait(5)\n\n if not u:\n return\n\n if query_interval is not None:\n u.query_interval = query_interval\n if timeout is not None:\n u.timeout = timeout\n return u\n\n\ndef auth_global():\n \"\"\"Проходит авторизацию на табуне с указанными в конфигурации параметрами и записывает результат в переменную user.\n Число попыток не ограничено: подвиснет интернет, упадёт сайт — функция дождётся, пока всё починится.\n Попутно создаёт анонима для запроса постов через него, чтобы не сбивать подсветку комментариев.\n После завершения вызывает группу обработчиков relogin_user (если процесс не решили остановить).\n \"\"\"\n global user, anon\n ssl_params = json.loads(core.config.get('tabun_feed', 'ssl_params') or '{}')\n user = auth(\n session_id=core.config.get('tabun_feed', 'session_id'),\n key=core.config.get('tabun_feed', 'key'),\n username=core.config.get('tabun_feed', 'username'),\n password=core.config.get('tabun_feed', 'password'),\n http_host=core.config.get('tabun_feed', 'http_host'),\n session_cookie_name=core.config.get('tabun_feed', 'session_cookie_name'),\n ssl_params=ssl_params,\n )\n if user is None:\n return\n\n if not user.username:\n anon = user\n else:\n anon = auth(\n http_host=core.config.get('tabun_feed', 'http_host'),\n session_cookie_name=core.config.get('tabun_feed', 'session_cookie_name'),\n ssl_params=ssl_params,\n )\n if anon is None:\n return\n\n core.logger.info(\"Logged in as %s\", user.username or '[anonymous]')\n worker.call_handlers_now(\"relogin_user\")\n\n\ndef open_with_check(url, timeout=None):\n \"\"\"Загружает URL, попутно проверяя, что авторизация на месте, и перелогиниваясь при её слёте.\n Если за 10 попыток скачать не получилось, кидает исключение.\n Если за 60 попыток не получилось залогиниться, возвращает то что есть.\n \"\"\"\n\n # Забираем таймеры из конфига (вызов тут, а не при запуске, позволяет\n # менять таймеры налету через удалённое управление)\n max_tries = max(1, core.config.getint('tabun_feed', 'tries_if_unauthorized'))\n max_error_tries = max(1, core.config.getint('tabun_feed', 'tries_if_error'))\n\n raw_data = None\n tries = 0\n # узнаём, можем ли мы вообще перелогиниться\n can_auth = core.config.get('tabun_feed', 'username') and core.config.get('tabun_feed', 'password')\n\n # Делаем вторую и последующую попытки, пока:\n # 1) tabun_feed не выключили (первую попытку всё равно качаем);\n # 2) Попыток меньше шестидеяти (по умолчанию; вроде достаточный срок,\n # чтобы лежачий мускуль Табуна успевал проболеть);\n # 3) Мы не авторизованы, если в конфиге прописана авторизация.\n while raw_data is None or (not worker.quit_event.is_set() and tries < max_tries and can_auth and user.update_userinfo(raw_data) is None):\n if raw_data is not None:\n # если мы попали сюда, то нас разлогинило\n worker.status['request_error'] = 'need relogin'\n # перелогиниваться не торопимся, а то забанит fail2ban\n if tries > 1:\n worker.quit_event.wait(30)\n if worker.quit_event.is_set():\n break\n\n # перелогиниваемся\n try:\n user.login(core.config.get('tabun_feed', 'username'), core.config.get('tabun_feed', 'password'))\n except api.TabunError as exc:\n worker.status['request_error'] = exc.message\n core.logger.warning(\"Relogin error: %s\", exc.message)\n else:\n core.logger.info(\"Re logged in as %s\", user.username or '[anonymous]')\n\n tries += 1\n # скачиваем (несколько попыток)\n for i in range(max_error_tries):\n # бросаем всё, если нужно завершить работу\n if raw_data is not None and worker.quit_event.is_set():\n break\n\n try:\n raw_data = user.urlread(url, timeout=timeout)\n if worker.status['request_error']:\n worker.status['request_error'] = ''\n break # залогиненность проверяем в условии while\n except api.TabunError as exc:\n worker.status['request_error'] = exc.message\n # после последней попытки или при выходе сдаёмся\n if i >= max_error_tries - 1 or worker.quit_event.is_set():\n raise\n worker.quit_event.wait(3)\n\n if raw_data:\n user.update_userinfo(raw_data)\n\n return raw_data\n"
},
{
"alpha_fraction": 0.5615640878677368,
"alphanum_fraction": 0.578203022480011,
"avg_line_length": 29.820512771606445,
"blob_id": "91395d4ad49cdcff1cf5a4ce63cfb8f11e59aa87",
"content_id": "aad7bb55ebf213eee06cf7378db982c7781f59fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1202,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 39,
"path": "/setup.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom setuptools import setup, find_packages\n\n\nsetup(\n name='tabun_feed',\n version='0.6.2',\n description='Watcher of new content on tabun.everypony.ru',\n author='andreymal',\n author_email='[email protected]',\n license='MIT',\n url='https://github.com/andreymal/tabun_feed',\n platforms=['linux', 'osx', 'bsd'],\n packages=find_packages(),\n include_package_data=True,\n install_requires=['tabun_api>=0.7.7'],\n zip_safe=False,\n entry_points={\n 'console_scripts': [\n 'tabun_feed=tabun_feed.runner:main',\n 'tf_manage=tabun_feed.manage:main',\n ],\n },\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'License :: OSI Approved :: MIT License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n ],\n)\n"
},
{
"alpha_fraction": 0.5645843744277954,
"alphanum_fraction": 0.5686473846435547,
"avg_line_length": 29.137754440307617,
"blob_id": "cc096e37cbd7a6cb7eddb0b7970db5b644e0914a",
"content_id": "ec8764a1f2ad759874f05063786f64f8cd9ba952",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6427,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 196,
"path": "/tabun_feed/mail.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nimport smtplib\nimport traceback\nfrom email.header import Header\nfrom email.utils import formataddr\nfrom email.mime.base import MIMEBase\nfrom email.mime.text import MIMEText\nfrom email.mime.multipart import MIMEMultipart\n\nfrom tabun_api.compat import text, PY2\n\n\ndef smtp_connect():\n from tabun_feed import core\n\n if core.config.getboolean('email', 'use_ssl'):\n s = smtplib.SMTP_SSL(\n core.config.get('email', 'host'),\n core.config.getint('email', 'port'),\n timeout=core.config.getint('email', 'timeout'),\n keyfile=core.config.get('email', 'ssl_keyfile'),\n certfile=core.config.get('email', 'ssl_certfile'),\n )\n else:\n s = smtplib.SMTP(\n core.config.get('email', 'host'),\n core.config.getint('email', 'port'),\n timeout=core.config.getint('email', 'timeout'),\n )\n\n if not core.config.getboolean('email', 'use_ssl') and core.config.getboolean('email', 'use_tls'):\n s.ehlo()\n s.starttls(keyfile=core.config.get('email', 'ssl_keyfile'), certfile=core.config.get('email', 'ssl_certfile'))\n s.ehlo()\n\n if core.config.get('email', 'user'):\n s.login(core.config.get('email', 'user'), core.config.get('email', 'password'))\n\n return s\n\n\ndef build_email_body(body):\n prep_body = []\n\n for item in body:\n if isinstance(item, text):\n item = item.encode('utf-8')\n\n if isinstance(item, bytes):\n # text/plain\n prep_body.append(MIMEText(item, 'plain', 'utf-8'))\n continue\n\n if isinstance(item, dict):\n # multipart/alternative\n item = item.copy()\n alt = []\n\n if 'plain' in item:\n # text/plain\n p = item.pop('plain')\n if isinstance(p, text):\n p = p.encode('utf-8')\n alt.append(MIMEText(p, 'plain', 'utf-8'))\n\n if 'html' in item:\n # text/html\n p = item.pop('html')\n if isinstance(p, text):\n p = p.encode('utf-8')\n alt.append(MIMEText(p, 'html', 'utf-8'))\n\n if item:\n raise NotImplementedError('non-text emails are not implemeneted')\n\n # build alternative\n if len(alt) == 1:\n m = alt[0]\n else:\n m = MIMEMultipart('alternative')\n for x in alt:\n m.attach(x)\n\n prep_body.append(m)\n continue\n\n if isinstance(item, MIMEBase):\n prep_body.append(item)\n continue\n\n raise ValueError('Incorrect body type: {}'.format(type(item)))\n\n if len(prep_body) == 1:\n return prep_body[0]\n\n m = MIMEMultipart('mixed')\n for x in prep_body:\n m.attach(x)\n return m\n\n\ndef sendmail(to, subject, body, fro=None, headers=None, conn=None):\n '''Отправляет письмо по электронной почте на указанные адреса.\n\n В качестве отправителя ``fro`` может быть указана как просто почта, так и\n список из двух элементов: имени отправителя и почты.\n\n Тело письма ``body`` может быть очень произвольным:\n\n - str или bytes: отправляется простое text/plain письмо;\n - словарь: если элементов больше одного, то будет multipart/alternative,\n если элемент один, то только он и будет:\n - plain: простое text/plain письмо;\n - html: HTML-письмо;\n - что-то наследующееся от MIMEBase;\n - всё перечисленное в списке: будет отправлен multipart/mixed со всем\n перечисленным.\n\n :param to: получатели (может быть переопределено настройкой\n email.redirect_to)\n :type to: str или list\n :param str subject: тема письма\n :param body: содержимое письма\n :param fro: отправитель (по умолчанию email.from)\n :type fro: str, list, tuple\n :param dict headers: дополнительные заголовки (значения — строки\n или списки)\n :rtype: bool\n '''\n\n from tabun_feed import core\n\n if fro is None:\n fro = core.config.get('email', 'from')\n\n if PY2 and isinstance(fro, str):\n fro = fro.decode('utf-8')\n\n if not isinstance(fro, text):\n if isinstance(fro, (tuple, list)) and len(fro) == 2:\n # make From: =?utf-8?q?Name?= <e@mail>\n fro = formataddr((Header(fro[0], 'utf-8').encode(), fro[1]))\n else:\n raise ValueError('Non-string from address must be [name, email] list')\n\n if not core.config.get('email', 'host') or not body:\n return False\n\n if core.config.get('email', 'redirect_to') is not None:\n if not core.config.getboolean('email', 'dont_edit_subject_on_redirect'):\n subject = '[To: {!r}] {}'.format(to, subject or '').rstrip()\n to = core.config.get('email', 'redirect_to')\n\n if not isinstance(to, (tuple, list, set)):\n to = [to]\n\n if not isinstance(body, (list, tuple)):\n body = [body]\n\n msg = build_email_body(body)\n\n msg['From'] = fro\n msg['Subject'] = Header(subject, 'utf-8').encode()\n\n prep_headers = {}\n if headers:\n prep_headers.update(headers)\n\n for header, value in prep_headers.items():\n if not isinstance(value, (list, tuple, set)):\n value = [value]\n for x in value:\n msg[header] = x\n\n try:\n close_conn = False\n if not conn:\n conn = smtp_connect()\n close_conn = True\n\n for x in to:\n del msg['To']\n msg['To'] = x.encode('utf-8') if PY2 and isinstance(x, text) else x\n conn.sendmail(fro, x, msg.as_string() if PY2 else msg.as_string().encode('utf-8'))\n\n if close_conn:\n conn.quit()\n except Exception:\n core.logger.error(traceback.format_exc())\n return False\n\n return True\n"
},
{
"alpha_fraction": 0.5020087361335754,
"alphanum_fraction": 0.5063755512237549,
"avg_line_length": 26.392345428466797,
"blob_id": "2b928a409f1e61c383d46852cbe9ba301a079511",
"content_id": "701c9ca1d24d47ef69af134bbf2712ff5d390fbe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6347,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 209,
"path": "/tabun_feed/remote_connection.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nimport json\nimport socket\nimport threading\n\n\nclass RemoteConnection(object):\n def __init__(self):\n \"\"\"Базовый класс для клиентов с используемым в tabun_feed протоколом.\"\"\"\n self._sock = None\n self._closed = True\n self._parser = None\n\n self._lock = threading.Lock()\n self._handlers = []\n\n def __del__(self):\n self.close()\n\n @property\n def sock(self):\n return self._sock\n \n @property\n def closed(self):\n return self._closed\n \n @property\n def lock(self):\n return self._lock\n\n def fileno(self):\n return self._sock.fileno() if self._sock else None\n\n def connect(self, addr, timeout=None):\n \"\"\"Подключается к серверу по указанному адресу.\"\"\"\n with self._lock:\n if not self._closed:\n self.close()\n self._sock = open_socket_by_addr(addr, timeout=timeout)\n self._closed = False\n self._parser = start_parser()\n self._parser.send(None)\n\n def accept(self, sock):\n \"\"\"Привязывается и переданному в аргументе сокету.\"\"\"\n with self._lock:\n if not self._closed:\n self.close()\n self._sock = sock\n self._closed = False\n self._parser = start_parser()\n self._parser.send(None)\n\n def add_onclose_handler(self, func):\n \"\"\"Добавляет обработчик отключения клиента.\"\"\"\n if func not in self._handlers:\n self._handlers.append(func)\n\n def close(self):\n \"\"\"Закрывает сокет.\"\"\"\n if self._closed:\n return\n if self._sock:\n with self._lock:\n self._closed = True\n try:\n self._sock.shutdown(socket.SHUT_RDWR)\n self._sock.close()\n except Exception:\n pass\n self._sock = None\n if self._parser:\n try:\n self._parser.send(None)\n except StopIteration:\n pass\n self._parser = None\n for func in self._handlers:\n func(self)\n\n def get(self):\n \"\"\"Возвращает следующий полученный пакет. Берёт из буфера, сокет не трогает.\n Но в случае ошибки при парсинге закрывает соединение и возвращает None.\n \"\"\"\n if self._closed:\n return\n try:\n return self._parser.send(b'')\n except StopIteration:\n self.close()\n return\n\n def wait(self, one_pass=False):\n \"\"\"Возвращает следующий пакет, ожидая его получения при необходимости.\n При one_pass=True чтение из сокета будет произведено однократно, а если\n пакет придёт не целиком, вместо дальнейшего ожидания вернётся None.\n \"\"\"\n packet = self._parser.send(b'')\n if packet:\n return packet\n\n while packet is None:\n try:\n data = self._sock.recv(65536)\n except Exception:\n data = b''\n if not data:\n self.close()\n break\n packet = self._parser.send(data)\n if one_pass:\n break\n\n return packet\n\n def send(self, packet):\n \"\"\"Отправляет пакет и возвращает число отправленных байт (в том числе 0 при закрытии соединения или ошибке сокета).\"\"\"\n if self.closed:\n return 0\n data = json.dumps(packet).encode('utf-8')\n data = str(len(data)).encode('utf-8') + b'\\n' + data + b'\\n'\n with self._lock:\n try:\n self._sock.send(data)\n except Exception:\n self.close()\n return 0\n\n\ndef parse_addr(addr):\n if addr.startswith('unix://'):\n return 'unix', addr[7:]\n else:\n # TODO: TCP\n raise ValueError(\"Invalid addr\")\n\n\ndef open_socket_by_addr(addr, timeout=None):\n typ, addr = parse_addr(addr)\n if typ == 'unix':\n sock = socket.socket(socket.AF_UNIX)\n sock.connect(addr)\n if timeout is not None:\n sock.settimeout(timeout)\n return sock\n\n\ndef start_parser():\n buf = b''\n packet_size = None\n\n jd = json.JSONDecoder()\n\n while True:\n # 1) Читаем длину пакета\n while b'\\n' not in buf:\n data = yield\n if data is None:\n break\n buf += data\n if data is None:\n break\n packet_size, buf = buf.split(b'\\n', 1)\n if len(packet_size) > 7 or not packet_size.isdigit():\n break\n packet_size = int(packet_size)\n\n # 2) Качаем сам пакет\n while len(buf) <= packet_size:\n data = yield\n if data is None:\n break\n buf += data\n\n # 3) Проверяем целостность\n if buf[packet_size] not in (b'\\n', 10): # py2/3, ага\n break\n\n # 4) Декодируем пакет\n packet = buf[:packet_size]\n buf = buf[packet_size + 1:]\n\n try:\n packet = jd.decode(packet.decode('utf-8'))\n except Exception:\n break\n\n # 5) Отдаём его\n if packet.get('cmd') == 'many' and isinstance(packet.get('items'), list):\n packets = packet['items']\n else:\n packets = [packet]\n\n ok = True\n for packet in packets:\n if not isinstance(packet, dict):\n ok = False\n break\n data = yield packet\n if data is None:\n break\n buf += data\n if not ok:\n break\n"
},
{
"alpha_fraction": 0.5328533053398132,
"alphanum_fraction": 0.5377537608146667,
"avg_line_length": 29.484756469726562,
"blob_id": "2d1497e871ce713e58a745c45ef673e0a8bf10af",
"content_id": "46a2314102d2b17f1b26fca9d51be09f1b5f9fc2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10540,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 328,
"path": "/tabun_feed/remote_server.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nimport os\nimport time\nimport socket\nimport logging\nimport threading\n\nfrom tabun_api.compat import text, PY2\n\nif PY2:\n from Queue import Queue, Empty as QueueEmpty\nelse:\n from queue import Queue, Empty as QueueEmpty\n\nfrom . import core, worker, remote_connection\n\n\nserver = None\n\n\nclass RemoteControlHandler(logging.Handler):\n # FIXME: it is too dirty\n _lock = None\n onemit = None\n\n def emit(self, record):\n if self._lock is None:\n self._lock = threading.RLock()\n\n with self._lock:\n msg = logging.root.handlers[0].format(record)\n if self.onemit:\n self.onemit(msg)\n\n\nclass RemoteClient(remote_connection.RemoteConnection):\n commands = {}\n\n def __init__(self, *args, **kwargs):\n super(RemoteClient, self).__init__(*args, **kwargs)\n self.authorized = False\n self.subscriptions = []\n\n @classmethod\n def add_command(cls, command, func):\n command = text(command)\n if command in cls.commands:\n raise RuntimeError('Conflict')\n cls.commands[command] = func\n\n def close(self):\n super(RemoteClient, self).close()\n server.client_onclose(self)\n\n def process_client(self):\n try:\n while not self.closed:\n packet = self.wait()\n if packet is None:\n break\n\n result = self.process_packet(packet)\n if result is not None:\n self.send(result)\n except Exception:\n worker.fail()\n\n def process_packet(self, packet):\n if packet is None:\n return\n\n # Авторизация при необходимости\n if not self.authorized:\n if not server.password or packet.get('authorize') == server.password:\n self.authorized = True\n else:\n return {'error': 'Authorization required'}\n\n # ищем команду\n cmd = packet.get('cmd')\n if not cmd:\n return {'error': 'No command'}\n cmd = text(cmd)\n\n func = self.commands.get(cmd)\n if func is None:\n func = getattr(self, 'cmd_' + cmd, None)\n\n if func is None:\n return {'error': 'Unknown command `{}`'.format(cmd)}\n\n # и выполняем её\n try:\n result = func(packet, self)\n except Exception:\n worker.fail()\n return {'error': 'Internal server error'}\n\n if isinstance(result, (list, tuple)) and result:\n return {'cmd': 'many', 'items': result} if len(result) > 1 else result[0]\n return result\n\n def cmd_subscribe(self, packet, client):\n if not isinstance(packet.get('items'), list):\n return {'error': 'Invalid items'}\n if len(self.subscriptions) + len(packet['items']) > 1000:\n return {'error': 'Too many items'}\n\n subs = set(text(x) for x in packet['items'] if x in ('log', 'status'))\n\n for x in subs:\n if x not in client.subscriptions:\n client.subscriptions.append(x)\n\n packets = [{'cmd': 'subscribed', 'items': client.subscriptions}]\n\n if 'status' in packet['items']:\n packets.append({'cmd': 'status', 'status': worker.status.get_json_status()})\n\n if 'log' in packet['items']:\n packets.append({'cmd': 'log', 'lines': server.get_log_buffer()})\n\n return packets\n\n\nclass RemoteServer(object):\n def __init__(self, addr, password=None, unix_mode=0o770):\n self.password = password or None\n self.typ, self.addr = remote_connection.parse_addr(addr)\n\n self.lock = threading.Lock()\n self.clients = []\n\n if self.typ == 'unix':\n if os.path.exists(self.addr):\n # Процесс после смерти может не прибрать за собой UNIX-сокет\n s = socket.socket(socket.AF_UNIX)\n try:\n s.connect(self.addr)\n except Exception:\n # Не подключились — прибираем самостоятельно\n os.remove(self.addr)\n else:\n # Ой, процесс жив ещё — bind ниже выкинет исключение\n s.close()\n del s\n\n self.sock = socket.socket(socket.AF_UNIX)\n self.sock.bind(self.addr)\n os.chmod(self.addr, unix_mode)\n # TODO: chown, chgrp\n self.sock.listen(64)\n\n self.log_handler = RemoteControlHandler()\n self.log_handler.onemit = self.onemit\n core.logger.addHandler(self.log_handler)\n self.nolog = False\n self._log_buffer = []\n\n self._pubsub_queue = Queue()\n\n def __del__(self):\n self.close()\n\n def onupdate(self, key, old_value, new_value):\n if key != 'event_id':\n self.send_pubsub('status', {key: new_value})\n\n def onemit(self, msg):\n if self.nolog:\n return\n try:\n self.send_pubsub('log', msg)\n except Exception:\n self.nolog = True # избегаем рекурсии\n try:\n worker.fail()\n finally:\n self.nolog = False\n\n def get_log_buffer(self, count=50):\n return self._log_buffer[-count:]\n\n def close(self, tm=None):\n if not self.sock:\n return\n\n self.close_pubsub()\n\n self.sock.shutdown(socket.SHUT_RDWR)\n self.sock.close()\n self.sock = None\n\n for c in self.clients:\n c.close()\n self.clients = []\n\n if self.typ == 'unix' and os.path.exists(self.addr):\n os.remove(self.addr)\n if self.log_handler:\n core.logger.removeHandler(self.log_handler)\n self.log_handler = None\n\n def client_onclose(self, client):\n if client.closed and client in self.clients:\n self.clients.remove(client)\n worker.status.add('clients_count', -1)\n\n def run(self):\n while self.sock is not None and not worker.quit_event.is_set():\n try:\n csock = self.sock.accept()[0]\n except Exception:\n continue\n c = RemoteClient()\n c.accept(csock)\n self.clients.append(c)\n worker.status.add('clients_count', 1)\n threading.Thread(target=c.process_client).start()\n\n def pubsub_thread(self):\n while not worker.quit_event.is_set():\n # ожидаем новые события\n try:\n item = self._pubsub_queue.get()\n except QueueEmpty:\n continue\n\n if item is None:\n break\n\n # ожидаем новые события ещё чуть-чуть, чтобы отослать всё одним пакетом\n items = [item]\n tm = time.time()\n while time.time() - tm < 0.05:\n try:\n item = self._pubsub_queue.get(timeout=0.03)\n except QueueEmpty:\n break\n if item is None:\n break\n items.append(item)\n\n # собираем события в один пакет\n status = {}\n log_lines = []\n for name, value in items:\n if name == 'status':\n status.update(value)\n elif name == 'log':\n log_lines.append(value)\n\n with self.lock:\n # собираем буфер для свежеподключившихся клиентов\n if self.log_handler:\n for x in log_lines:\n self._log_buffer.append(x)\n if len(self._log_buffer) > 300:\n self._log_buffer = self._log_buffer[-250:]\n\n # и рассылаем\n if not self.clients:\n continue\n\n for x in self.clients:\n data = []\n if status and 'status' in x.subscriptions:\n data.append({'cmd': 'status', 'status': status})\n if log_lines and 'log' in x.subscriptions:\n data.append({'cmd': 'log', 'lines': log_lines})\n if len(data) > 1:\n x.send({'cmd': 'many', 'items': data})\n elif data:\n x.send(data[0])\n\n def send_pubsub(self, name, data):\n self._pubsub_queue.put((name, data))\n\n def close_pubsub(self):\n self._pubsub_queue.put(None)\n\n\ndef remote_command(cmd):\n def decorator(func):\n RemoteClient.add_command(cmd, func)\n return func\n return decorator\n\n\ndef start():\n global server\n # читаем конфиг\n if not core.config.has_option('tabun_feed', 'remote_bind') or not core.config.get('tabun_feed', 'remote_bind'):\n core.logger.info('Remote control is disabled')\n return\n\n bind = core.config.get('tabun_feed', 'remote_bind')\n if core.config.has_option('tabun_feed', 'remote_password'):\n password = core.config.get('tabun_feed', 'remote_password')\n else:\n password = None\n\n # стартуем сервер и цепляем необходимые обработчики\n unix_mode = '770'\n if core.config.has_option('tabun_feed', 'remote_unix_mode'):\n unix_mode = core.config.get('tabun_feed', 'remote_unix_mode')\n if len(unix_mode) == 3:\n try:\n unix_mode = int(unix_mode, 8)\n except ValueError:\n unix_mode = 0o770\n else:\n unix_mode = 0o770\n server = RemoteServer(bind, password, unix_mode=unix_mode)\n worker.add_handler('exit', server.close)\n worker.add_handler(\"update_status\", server.onupdate)\n worker.status['clients_count'] = 0\n\n # этот поток получает данные от клиентов\n worker.start_thread(server.run)\n\n # этот поток нужен, чтобы собирать кучку идущих подряд сообщений в один пакет\n # и отсылать всё разом, а не флудить кучей мелких пакетов\n worker.start_thread(server.pubsub_thread)\n"
},
{
"alpha_fraction": 0.6631054282188416,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 29.521739959716797,
"blob_id": "b56d2fbe9be5fc7c2c2c61cbf9ae5306a900d738",
"content_id": "bba11690a865242f9c26c3d05f132be8aa3cbba3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2808,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 92,
"path": "/tabun_feed/plugins/api_reader.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nimport time\nfrom threading import RLock\n\nimport tabun_api as api\nfrom tabun_api.compat import text, binary\nfrom tabun_feed import worker\n\n\ndefault_send_request = None\ndefault_get_posts = None\ndefault_get_comments = None\ndefault_get_profile = None\n\nlock = RLock()\nlast_requests = []\n\n\ndef normalize_url(user, url):\n if isinstance(url, (text, binary)):\n norm_url = url if isinstance(url, text) else url.decode('utf-8', 'replace')\n else:\n norm_url = url.get_full_url()\n if norm_url.startswith('/'):\n norm_url = (user.http_host or api.http_host) + norm_url\n return norm_url\n\n\ndef patched_send_request(user, request, *args, **kwargs):\n global last_requests\n\n url = request.get_full_url()\n if isinstance(url, binary):\n url = url.decode('utf-8', 'replace')\n\n http_host = user.http_host or api.http_host\n if url.startswith(http_host):\n url = url[len(http_host):]\n\n with lock:\n tm = time.time()\n last_requests = [x for x in last_requests if x[0] > time.time() - 60]\n last_requests.append((tm, url))\n worker.status['last_requests'] = '\\n'.join(text(x[0]) + ' ' + text(x[1]) for x in last_requests)\n\n worker.status['request_counter'] += 1\n try:\n worker.status['request_now'] = url\n return default_send_request(user, request, *args, **kwargs)\n finally:\n if worker.status['request_now'] == url:\n worker.status['request_now'] = None\n\n\ndef patched_get_posts(user, url='/index/newall/', raw_data=None):\n posts = default_get_posts(user, url, raw_data)\n worker.call_handlers_here('request_posts', normalize_url(user, url), posts)\n return posts\n\n\ndef patched_get_comments(user, url='/comments/', raw_data=None):\n comments = default_get_comments(user, url, raw_data)\n worker.call_handlers_here('request_comments', normalize_url(user, url), comments)\n return comments\n\n\ndef patched_get_profile(user, username=None, raw_data=None):\n profile = default_get_profile(user, username, raw_data)\n worker.call_handlers_here('request_profile', profile)\n return profile\n\n\ndef init_tabun_plugin():\n global default_send_request, default_get_posts, default_get_comments, default_get_profile\n\n worker.status['request_counter'] = 0\n worker.status['request_now'] = None\n worker.status['last_requests'] = ''\n\n default_send_request = api.User.send_request\n default_get_posts = api.User.get_posts\n default_get_comments = api.User.get_comments\n default_get_profile = api.User.get_profile\n\n api.User.send_request = patched_send_request\n api.User.get_posts = patched_get_posts\n api.User.get_comments = patched_get_comments\n api.User.get_profile = patched_get_profile\n"
},
{
"alpha_fraction": 0.6531791687011719,
"alphanum_fraction": 0.6630883812904358,
"avg_line_length": 22.98019790649414,
"blob_id": "894a2fbb097d79877dc247144856ea4d483ad85a",
"content_id": "a7d5940548792dafc4f6ca0e25fea886dead4475",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2746,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 101,
"path": "/tabun_feed/runner.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nimport sys\nimport signal\nimport inspect\nimport logging\n\nimport tabun_api as api\n\n\ntf_user_agent = api.http_headers[\"user-agent\"] + ' tabun_feed/0.6.2'\napi.http_headers[\"user-agent\"] = tf_user_agent\n\ngo_thread = None\n\n\ndef sigterm(signo, frame):\n # Получать просьбу завершиться должен получать только основной поток и только один раз\n signal.signal(signal.SIGTERM, signal.SIG_IGN)\n signal.signal(signal.SIGINT, signal.SIG_IGN)\n if go_thread:\n go_thread.kill(SystemExit, False)\n else:\n raise SystemExit\n\n\ndef patch_encoding():\n if sys.version_info[0] == 2:\n reload(sys).setdefaultencoding('utf-8')\n\n\ndef patch_iso8601():\n try:\n from iso8601.iso8601 import LOG\n except ImportError:\n pass\n else:\n LOG.setLevel(logging.INFO)\n\n\ndef go():\n from . import core, user, worker, remote_server, remote_commands\n remote_server.start()\n worker.start_handlers()\n\n core.logger.info('Starting %s', tf_user_agent)\n try:\n user.auth_global()\n except (KeyboardInterrupt, SystemExit):\n print('')\n worker.stop()\n return\n\n return worker.run()\n\ndef main(args=None, config_file=None):\n global go_thread\n\n # Запускаем костыли\n patch_encoding()\n patch_iso8601()\n\n # Загружаемся\n if args is None:\n args = sys.argv[1:]\n\n from . import core\n\n core.parse_arguments(args)\n core.init_config(core.arguments.get('config', config_file))\n\n # Всё остальное запускам только после gevent, чтобы применился monkey patching\n from . import worker, db\n\n # Записывам состояние для удобства отладки\n worker.status['gevent_used'] = core.gevent_used\n worker.status.append('threads', (repr(main), inspect.getfile(main)))\n\n db.init()\n worker.touch_pidfile()\n worker.touch_started_at_file()\n\n # Инициализируем плагины (здесь уже могут появляться новые потоки)\n if not core.load_plugins():\n return False\n\n # worker сам не выключается, мы его выключаем\n signal.signal(signal.SIGTERM, sigterm)\n signal.signal(signal.SIGINT, sigterm)\n\n # worker ничего не знает про gevent, разруливаем его запуск и корректное выключение\n if core.gevent_used:\n import gevent\n go_thread = gevent.spawn(go)\n go_thread.join()\n return go_thread.value\n else:\n return go()\n"
},
{
"alpha_fraction": 0.5858098864555359,
"alphanum_fraction": 0.5911646485328674,
"avg_line_length": 27.953489303588867,
"blob_id": "09150511b4c576de71da6af94a0e262fb35f1ac1",
"content_id": "317327dda2cbe4e441e82685bee9a2a996eaf3e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3894,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 129,
"path": "/tabun_feed/plugins/vk_suggestions.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nimport time\n\nfrom tabun_feed import core, worker\n\n\nvk_plug = core.load_plugin('tabun_feed.plugins.vk')\nvk = None\n\ntargets = tuple(set(-x['id'] for x in vk_plug.targets.values() if x is not None and x['id'] < 0))\niter_current = -1\nlast_posts = []\n\n\ndef reader():\n global iter_current\n iter_current += 1\n\n n = (iter_current * 2) % len(targets)\n for i, group_id in enumerate(targets[n:n + 2]):\n if i > 0:\n time.sleep(0.4)\n worker.status['vk_suggestions'] = 'Processing {}'.format(group_id)\n try:\n process_suggestions(group_id)\n except Exception:\n worker.fail()\n worker.status['vk_suggestions'] = ''\n\n\ndef process_suggestions(group_id):\n global last_posts\n\n try:\n result = vk.api(\n 'wall.get',\n {'owner_id': -group_id, 'offset': 0, 'count': 100, 'extended': 1, 'filter': 'suggests'}\n )\n except Exception as exc:\n core.logger.warning('VK Suggestions %d fail: %s', group_id, exc)\n return\n\n if not result.get('response'):\n return\n\n profiles = {x['id']: x for x in result['response'].get('profiles', [])}\n profiles.update({-x['id']: x for x in result['response'].get('groups', [])})\n\n if len(last_posts) > 150:\n last_posts = last_posts[-100:]\n\n posts = result['response'].get('items', [])\n for post in posts:\n post_id = (post['owner_id'], post['id'])\n if post_id in last_posts:\n continue\n last_posts.append(post_id)\n notify_post(post, profiles)\n\n\ndef notify_post(post, profiles=None):\n profiles = profiles or {}\n\n # Информация о паблике\n owner_id = post['owner_id']\n if owner_id in profiles:\n owner_name = profiles[owner_id].get('name') or profiles[owner_id].get('screen_name', '')\n else:\n owner_name = str(owner_id)\n\n if owner_id in profiles and profiles[owner_id].get('screen_name'):\n owner_link = 'https://vk.com/' + profiles[owner_id].get('screen_name')\n else:\n owner_link = 'https://vk.com/public{}'.format(-owner_id)\n\n # Информация об авторе предложенной новости\n user_id = post['from_id']\n if user_id in profiles:\n user_name = profiles[user_id].get('name') or '{} {}'.format(profiles[user_id].get('first_name'), profiles[user_id].get('last_name'))\n else:\n user_name = str(user_id)\n\n if user_id in profiles and profiles[user_id].get('screen_name'):\n user_link = 'https://vk.com/' + profiles[user_id].get('screen_name')\n else:\n user_link = 'https://vk.com/id{}'.format(user_id)\n\n # Собираем прикрепления к посту\n attachments = []\n\n for att in post.get('attachments', []):\n if att.get('type') == 'photo':\n attachments.append('Фотография {}'.format(vk_plug.get_photo_url(att['photo'])))\n else:\n attachments.append('Прикрепление {}'.format(att.get('type')))\n\n # Собираем и отправляем уведомление\n msg = '''{owner_name} {owner_link} — новая предложенная новость\n\n{body}\n\n{attachments}\n\n{user_name} {user_link}'''.format(\n owner_id=owner_id,\n owner_name=owner_name,\n owner_link=owner_link,\n body=post.get('text', ''),\n user_id=user_id,\n user_name=user_name,\n user_link=user_link,\n attachments='\\n'.join(attachments),\n )\n\n core.notify(msg)\n\n\ndef init_tabun_plugin():\n global vk\n if not targets or not core.config.has_option('vk', 'access_token'):\n core.logger.warning('VK is not available; vk_suggestions disabled')\n return\n vk = vk_plug.App()\n worker.status['vk_suggestions'] = ''\n worker.add_reader(reader)\n"
},
{
"alpha_fraction": 0.6754468679428101,
"alphanum_fraction": 0.6763876080513,
"avg_line_length": 26.256410598754883,
"blob_id": "b8994f03f92eab353aa14121118987d59d87b3ba",
"content_id": "583b09831a270fc71c7756223b3bd62c5499825c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1063,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 39,
"path": "/tabun_feed/plugins/monitor.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nfrom tabun_feed import core, worker, user\n\n\ndef new_post(post, full_post):\n core.logger.info('New post %d: %s', (full_post or post).post_id, (full_post or post).title)\n\n\ndef edit_post(post, full_post):\n core.logger.info('Edited post %d: %s', (full_post or post).post_id, (full_post or post).title)\n\n\ndef new_comment(comment):\n core.logger.info('New comment %d/%d', comment.post_id, comment.comment_id)\n\n\ndef edit_comment(comment):\n core.logger.info('Edited comment %d/%d', comment.post_id, comment.comment_id)\n\n\ndef new_blog(blog):\n core.logger.info('New blog %s', blog.name)\n\n\ndef new_user(ppl):\n core.logger.info('New user %s', ppl.username)\n\n\ndef init_tabun_plugin():\n worker.add_handler('new_post', new_post)\n worker.add_handler('edit_post', edit_post)\n worker.add_handler('new_comment', new_comment)\n worker.add_handler('edit_comment', edit_comment)\n worker.add_handler('new_blog', new_blog)\n worker.add_handler('new_user', new_user)\n"
},
{
"alpha_fraction": 0.5877013802528381,
"alphanum_fraction": 0.5972316861152649,
"avg_line_length": 29.1849308013916,
"blob_id": "d46a23e2a472a018814bfcccb5bf86b5384c1a35",
"content_id": "0087dc1a441aa49d71796fbbcf17902b3a6bbf25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4878,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 146,
"path": "/tabun_feed/plugins/telegram_feed/utils.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals, absolute_import\n\nimport time\n\nimport tabun_api as api\nfrom tabun_api.compat import PY2, text\n\nfrom tabun_feed import core, user, worker\n\nif PY2:\n from urllib2 import quote\nelse:\n from urllib.parse import quote\n\n\ndef html_escape(s):\n s = s.replace('&', '&')\n s = s.replace('<', '<')\n s = s.replace('>', '>')\n s = s.replace('\"', '"')\n return s\n\n\ndef build_body(post, short=False):\n # type: (api.Post) -> text\n fmt = api.utils.HTMLFormatter()\n\n # Заголовок\n tg_body = '<b>{}</b>\\n'.format(html_escape(post.title.strip()))\n\n # Блог и информация об авторе под заголовком\n tg_body += '#{} (<a href=\"{}{}\">{}</a>)'.format(\n quote(post.blog or 'blog').replace('-', '_'),\n\n post.context['http_host'],\n '/profile/{}/'.format(quote(post.author)),\n html_escape(post.author),\n )\n\n # Подпись к фоточкам у телеграма может быть не более 1024 символов\n # И ещё 120 символов резервируем про запас под ссылку и прочий хлам\n max_len = (1024 if short else 8200) - len(tg_body) - 120\n\n # Собственно текст поста (перед катом)\n post_body = fmt.format(post.body, with_cutted=False)[:max_len + 1]\n if len(post_body) >= max_len:\n post_body = post_body[:post_body.rfind(' ')] + '… ->'\n\n while '\\n\\n\\n' in post_body:\n post_body = post_body.replace('\\n\\n\\n', '\\n\\n')\n\n if post_body.endswith('\\n====='):\n post_body = post_body[:-6]\n\n tg_body += '\\n\\n'\n # FIXME: злоупотребление html-сущностями позволяет здесь превысить\n # телеграмный лимит 1024 символа, но мне лень это фиксить\n tg_body += html_escape(post_body)\n\n return tg_body.strip()\n\n\ndef find_image(post):\n # type: (api.Post) -> Tuple[Optional[text], Optional[bytes]]\n\n # Для начала поищем картинку, явно заданную пользователем\n img_forced = None\n for i in post.body.xpath('.//img')[:20]:\n alt = i.get('alt')\n if not alt:\n continue\n if alt.startswith('tf:http://') or alt.startswith('tf:https://'):\n img_forced = alt[3:]\n break\n elif alt == 'tf:this' and i.get('src') and (i.get('src').startswith('http://') or i.get('src').startswith('https://')):\n img_forced = i.get('src')\n break\n\n if img_forced:\n return img_forced, None\n\n # приоритет картинок: нормальные в посте, нормальные в заголовках спойлеров, вообще какие-нибудь\n urls_clean = api.utils.find_images(post.body, spoiler_title=(post.blog == \"Analiz\"), no_other=True)[0]\n urls_spoilers = api.utils.find_images(post.body, spoiler_title=True, no_other=True)[0]\n urls_other = api.utils.find_images(post.body, spoiler_title=True, no_other=False)[0]\n\n # Если не нашлось вообще ничего, то делать нечего\n if not urls_clean and not urls_spoilers and not urls_other:\n return None, None\n\n for x in urls_clean:\n if x in urls_spoilers:\n urls_spoilers.remove(x)\n for x in urls_clean + urls_spoilers:\n if x in urls_other:\n urls_other.remove(x)\n\n # Среди найденных картинок выбираем лучшую\n url = None # type: Optional[text]\n data = None # type: Optional[bytes]\n for urls in (urls_clean, urls_spoilers, urls_other):\n url, data = api.utils.find_good_image(urls[:5])\n if url:\n break\n\n return url, data\n\n\ndef build_photo_attachment(post, full_post):\n # type: (api.Post, Optional[api.Post]) -> Optional[text]\n\n try:\n image, idata = find_image(post)\n except Exception:\n worker.fail()\n image = None\n idata = None\n\n if image is None:\n return None\n\n if image.startswith('//'):\n image = 'https:' + image\n elif image.startswith('/'):\n image = post.context['http_host'] + image\n elif not image.startswith('http://') and not image.startswith('https://'):\n image = None\n\n return image\n\n\ndef get_post_author(author):\n # type: (text) -> api.UserInfo\n for i in range(10):\n try:\n author = user.anon.get_profile(author)\n break\n except api.TabunError as exc:\n if i >= 9 or exc.code == 404 or worker.quit_event.is_set():\n raise\n core.logger.warning('telegram_feed: get author profile error: %s', exc.message)\n time.sleep(3)\n return author\n"
},
{
"alpha_fraction": 0.5861628651618958,
"alphanum_fraction": 0.589737057685852,
"avg_line_length": 29.364341735839844,
"blob_id": "db6bd6fdd42fae7f4b3d6618a3aaad56724b198b",
"content_id": "23b3efb9ddec786e6f940c8c5be824dccd92039c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4039,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 129,
"path": "/tabun_feed/db.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nimport os\nimport sqlite3\nfrom threading import RLock\n\nfrom . import core\n\n\ndb = None\n\n\nclass Database(object):\n def __init__(self, path):\n self.path = os.path.abspath(path) if path != ':memory:' else path\n self.db = sqlite3.connect(self.path, check_same_thread=False)\n self.lock = RLock()\n self.allow_commit = True\n self._cur = None\n self._tables = None\n self.created = bool(self.tables)\n\n def __enter__(self):\n self.lock.acquire()\n self._cur = self.db.cursor()\n self.allow_commit = False\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n self.allow_commit = True\n if exc_type is None:\n self.commit()\n else:\n self.db.rollback()\n self._cur = None\n self.lock.release()\n\n @property\n def tables(self):\n if self._tables is None:\n self._tables = tuple(x[0] for x in self.query(\"select name from sqlite_master where type = ?\", (\"table\",)))\n return self._tables\n\n def create_table(self, name, data):\n with self.lock:\n self._tables = None\n return (self._cur or self.db).execute('create table `{}` {}'.format(name, data))\n\n def init_table(self, name, data):\n if name in self.tables:\n return False\n self.create_table(name, data)\n return True\n\n def execute(self, *args):\n with self.lock:\n return (self._cur or self.db).execute(*args)\n\n def execute_unsafe(self, *args):\n # no locking\n return (self._cur or self.db).execute(*args)\n\n def executemany(self, *args):\n with self.lock:\n return (self._cur or self.db).executemany(*args)\n\n def query(self, *args):\n with self.lock:\n return (self._cur or self.db).execute(*args).fetchall()\n\n def commit(self):\n with self.lock:\n if not self.allow_commit:\n return\n try:\n self.db.commit()\n except (KeyboardInterrupt, SystemExit):\n print(\"commit break!\")\n raise\n\n\ndef load_page_cache(page):\n \"\"\"Возвращает список упорядоченных айдишников каких-то элементов (постов или комментариев, например).\"\"\"\n return [x[0] for x in db.query('select item_id from page_dumps where page = ? order by order_id', (page,))]\n\n\ndef save_page_cache(page, items):\n \"\"\"Сохраняет список упорядоченных айдишников.\"\"\"\n with db:\n db.execute('delete from page_dumps where page = ?', (page,))\n for index, item in enumerate(items):\n db.execute('insert into page_dumps values(?, ?, ?)', (page, index, item))\n\n\ndef get_db_last(name, default=0):\n last = db.query(\"select value from lasts where name = ?\", (name,))\n if last:\n return last[0][0]\n db.query(\"insert into lasts values(?, ?)\", (name, default))\n return default\n\n\ndef set_db_last(name, value):\n db.execute(\"replace into lasts values(?, ?)\", (name, value))\n\n\ndef init():\n global db\n db = Database(core.config.get('tabun_feed', 'db'))\n\n db.init_table('lasts', \"(name text not null primary key, value int not null default 0)\")\n\n if db.init_table('page_dumps', \"(page char(16) not null, order_id int not null default 0, item_id int not null, primary key(page, item_id))\"):\n db.execute(\"create index page_dump_key on page_dumps(page)\")\n\n if db.init_table('failures', '''(\n id integer primary key autoincrement not null,\n hash text not null,\n first_time int not null,\n last_time int not null,\n occurrences int not null default 1,\n solved int not null default 0,\n error text not null,\n desc text default null,\n status_json text not null default \"{}\"\n )'''):\n db.execute(\"create index failures_hash on failures(hash)\")\n"
},
{
"alpha_fraction": 0.5996131300926208,
"alphanum_fraction": 0.6073501110076904,
"avg_line_length": 23.046510696411133,
"blob_id": "0180909c8b335a63a4c19f22fca2c65ff9d6da16",
"content_id": "558d7c93fa113211c4cf6ddefeaee883305c276e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1109,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 43,
"path": "/tabun_feed/readers/blogs.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nfrom .. import core, user, worker\nfrom ..db import db, get_db_last, set_db_last\n\n\ntic = 9\n\n\ndef reader():\n global tic\n tic += 1\n if tic < 10:\n return # Блоги появляются редко, не тратим время зазря\n tic = 0\n\n blogs = user.user.get_blogs_list(order_by='blog_id', order_way='desc')\n\n if core.loglevel == core.logging.DEBUG:\n core.logger.debug('Downloaded %d blogs, last 5: %r', len(blogs), blogs[:5])\n\n last_blog_id = get_db_last('blog_id')\n new_last_id = None\n\n for blog in blogs:\n if blog.blog_id <= last_blog_id:\n break # сортировка по айдишнику в обратном порядке\n worker.call_handlers(\"new_blog\", blog)\n if new_last_id is None:\n new_last_id = blog.blog_id\n\n if new_last_id is not None:\n set_db_last('blog_id', new_last_id)\n db.commit()\n\n worker.call_handlers(\"blogs_list\", blogs)\n\n\ndef init_tabun_plugin():\n worker.add_reader(reader)\n"
},
{
"alpha_fraction": 0.6007847189903259,
"alphanum_fraction": 0.6022560000419617,
"avg_line_length": 27.31944465637207,
"blob_id": "ab5bb154a59f639cab687afd1ac365fd23bca98c",
"content_id": "e2a4d0d176de394892cf03d2cc01d897db07ba8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2092,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 72,
"path": "/tabun_feed/plugins/telegram_feed/queue.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals, absolute_import\n\nimport time\n\nfrom tabun_api.compat import PY2\n\nfrom tabun_feed import core\n\nif PY2:\n from Queue import Queue\nelse:\n from queue import Queue\n\n\nclass FeedQueueItem(object):\n def __init__(self, post, full_post=None, extra_params=None, tm=None):\n if not post:\n raise ValueError('Post is required')\n self.tm = float(tm) if tm is not None else time.time()\n self.post = post # type: api.Post\n self.full_post = full_post # type: Optional[api.Post]\n self.extra_params = dict(extra_params or {}) # type: Dict[str, Any]\n\n\nclass FeedQueue(object):\n def __init__(self):\n self._queue = Queue()\n\n # low level api\n\n def put(self, item):\n # type: (Optional[FeedQueueItem]) -> None\n if item is not None and not isinstance(item, FeedQueueItem):\n raise TypeError\n self._queue.put(item)\n\n def get(self, block=True, timeout=None):\n return self._queue.get(block, timeout)\n\n def has_post(self, post_id):\n # Здесь никто не отменял гонку, так что это просто защита от дурака\n for item in list(self._queue.queue):\n post = item.full_post or item.post\n if post.post_id == post_id:\n return True\n return False\n\n # high level api\n\n def add_post(self, post=None, full_post=None, tm=None, extra_params=None):\n # type: (Optional[api.Post], Optional[api.Post], Optional[float], Optional[Dict[str, Any]]) -> None\n\n post = post or full_post\n if post is None:\n core.logger.error('telegram_feed: add_post_to_queue received empty post, this is a bug')\n return\n\n item = FeedQueueItem(\n post=post,\n full_post=full_post,\n extra_params=extra_params,\n tm=tm,\n )\n\n self._queue.put(item)\n core.logger.debug('telegram_feed: post %d added to queue', post.post_id)\n\n\nqueue = FeedQueue()\n"
},
{
"alpha_fraction": 0.4998599886894226,
"alphanum_fraction": 0.5138616561889648,
"avg_line_length": 26.46923065185547,
"blob_id": "37f5fffd08f78da2651c1aa06d1b1e27bb327e03",
"content_id": "f0b351c9e759072fbe4cffe529a63d20cac95956",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3611,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 130,
"path": "/tabun_feed/plugins/vk.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nimport sys\nimport json\nimport time\n\nif sys.version_info.major == 2:\n text = unicode\n import urllib2 as urequest\n def quote(s):\n return urequest.quote(text(s).encode('utf-8'))\nelse:\n text = str\n import urllib.request as urequest\n quote = urequest.quote\n\nfrom .. import core\n\n\ntargets = {}\n\n\nclass App(object):\n def __init__(self, access_token=None, v='5.40'):\n if access_token is None and core.config.has_option('vk', 'access_token'):\n access_token = core.config.get('vk', 'access_token')\n self.access_token = access_token\n self.v = v\n\n def api(self, method_name, args, method=\"POST\", timeout=30):\n args = dict(args)\n link = \"https://api.vk.com/method/\" + quote(method_name)\n if self.access_token and 'access_token' not in args:\n args['access_token'] = self.access_token\n if self.v and 'v' not in args:\n args['v'] = self.v\n\n params = ''\n\n for key, data in args.items():\n if isinstance(data, (list, tuple)):\n data = ','.join(text(x) for x in data)\n else:\n data = text(data)\n params += quote(key) + '=' + quote(data) + '&'\n params = params[:-1]\n\n if method == \"GET\":\n link += \"?\" + params\n\n if sys.version_info.major == 2:\n link = link.encode('utf-8')\n\n req = urequest.Request(link, method)\n\n if method == \"POST\":\n req.data = params.encode('utf-8')\n\n for _ in range(10):\n try:\n resp = urequest.urlopen(req, timeout=timeout)\n break\n except IOError as exc:\n if 'handshake operation' not in text(exc):\n raise\n time.sleep(2)\n data = resp.read()\n\n try:\n answer = json.loads(data.decode('utf-8'))\n except Exception:\n answer = {\"error\": {\n \"error_code\": 0,\n \"error_msg\": \"Unparsed VK answer\",\n \"data\": data\n }}\n\n return answer\n\n\ndef get_photo_url(photo, max_level='photo_2560', levels=('photo_2560', 'photo_1280', 'photo_807', 'photo_604', 'photo_130', 'photo_75')):\n try:\n pos = levels.index(max_level)\n except Exception:\n return\n\n for x in levels[pos:]:\n url = photo.get(x)\n if url:\n return url\n\n\ndef parse_vk_targets(line):\n line = [x.strip() for x in line.split(';') if x and ':' in x]\n result = {}\n for target in line:\n # blog1,blog2,blog3: owner_id, prefix\n blogs, owner = [x.split(',') for x in target.split(':')]\n blogs = [x.strip() for x in blogs if x.strip()]\n\n # Пустой owner_id — значит не постить посты из этих блогов\n if owner[0].strip() == '_':\n owner = ['0']\n owner_id = int(owner[0])\n prefix = None\n if len(owner) > 1:\n prefix = owner[1].strip()\n\n if not prefix:\n if owner_id < 0:\n prefix = \"public\" + str(-owner_id)\n else:\n prefix = \"id\" + str(owner_id)\n\n for blog in blogs:\n if owner_id:\n result[blog] = {'id': owner_id, 'prefix': prefix}\n else:\n result[blog] = None\n\n return result\n\n\ndef init_tabun_plugin():\n global targets\n if core.config.has_option('vk', 'targets'):\n targets = parse_vk_targets(core.config.get('vk', 'targets'))\n"
},
{
"alpha_fraction": 0.5467458963394165,
"alphanum_fraction": 0.5498450398445129,
"avg_line_length": 23.98064422607422,
"blob_id": "65242ab8f60517e36465c25d45af8725f34d0a2e",
"content_id": "ade9267444fba59e76b7279f8f3a5e5a02df67f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3872,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 155,
"path": "/tabun_feed/manage.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nimport os\nimport sys\nimport json\nimport readline # pylint: disable=unused-import\nfrom threading import Thread, Event\n\nfrom tabun_feed.remote_connection import RemoteConnection\n\ntry:\n from ConfigParser import RawConfigParser\nexcept ImportError:\n from configparser import RawConfigParser\n\nPY2 = sys.version_info.major == 2\n\nconfig = RawConfigParser(allow_no_value=True)\n\nmodes = {}\n\npy_prompt = None\npy_event = Event()\n\n\ndef print_help():\n modes_str = ', '.join(sorted(modes.keys()))\n print('Modes: {}'.format(modes_str))\n\n\ndef tail_log(client, args):\n client.send({'cmd': 'subscribe', 'items': ['log', 'status']})\n while True:\n packet = client.wait()\n if packet is None:\n break\n if packet.get('error'):\n print(packet)\n break\n if packet.get('cmd') == 'log':\n for x in packet.get('lines', []):\n print(x)\n elif packet.get('cmd') == 'status':\n pass # print(packet)\n\n\ndef raw_connect(client, args):\n Thread(target=raw_read_thread, args=(client,)).start()\n while not client.closed:\n try:\n if PY2:\n data = raw_input().decode('utf-8')\n else:\n data = input()\n except (EOFError, KeyboardInterrupt, SystemError):\n break\n if not data:\n break\n client.send(json.loads(data))\n client.close()\n\n\ndef raw_read_thread(client):\n while not client.closed:\n print(client.wait())\n\n\ndef python(client, args):\n import getpass\n passwd = getpass.getpass('Password: ')\n client.send({'cmd': 'python', 'password': passwd})\n Thread(target=python_thread, args=(client,)).start()\n while not client.closed:\n py_event.wait()\n py_event.clear()\n if client.closed:\n break\n try:\n if PY2:\n data = raw_input(py_prompt or '>>> ').decode('utf-8')\n else:\n data = input(py_prompt or '>>> ')\n except KeyboardInterrupt:\n client.send({'cmd': 'python', 'interrupt': True})\n continue\n except EOFError:\n data = None\n\n client.send({'cmd': 'python', 'data': data})\n client.close()\n\n\ndef python_thread(client):\n global py_prompt\n while not client.closed:\n data = client.wait()\n if data is None:\n continue\n if data.get('cmd') == 'python_write' and data.get('data') is not None:\n sys.stdout.write(data['data'].encode('utf-8') if PY2 else data['data'])\n elif data.get('cmd') == 'python_input':\n py_prompt = data.get('prompt')\n py_event.set()\n elif data.get('cmd') == 'python_closed':\n client.close()\n break\n elif data.get('error'):\n print(data)\n client.close()\n break\n else:\n print(data)\n\n py_prompt = None\n py_event.set()\n\n\ndef main(args=None):\n if args is None:\n args = sys.argv[1:]\n if not args:\n print_help()\n return\n\n config_path = 'config.cfg'\n for x in tuple(args):\n if x.startswith('--config='):\n config_path = x[9:]\n args.remove(x)\n break\n config.read(config_path)\n\n if not config.has_option('tabun_feed', 'remote_bind'):\n print('Cannot find bind in config')\n return\n\n client = RemoteConnection()\n client.connect(config.get('tabun_feed', 'remote_bind'))\n\n try:\n cmd = args.pop(0)\n if cmd in modes:\n modes[cmd](client, args)\n else:\n print('Unknown command {}'.format(cmd))\n except (KeyboardInterrupt, SystemExit):\n print()\n finally:\n client.close()\n\n\nmodes['log'] = tail_log\nmodes['raw'] = raw_connect\nmodes['python'] = python\n"
},
{
"alpha_fraction": 0.5466932654380798,
"alphanum_fraction": 0.5529190897941589,
"avg_line_length": 29.187942504882812,
"blob_id": "919bb4420d1e18892b3b2a283de12dc69c68e90d",
"content_id": "d4349d396eec92e2ae781c48939daf59bb94e12c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17738,
"license_type": "no_license",
"max_line_length": 206,
"num_lines": 564,
"path": "/tabun_feed/worker.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nimport os\nimport sys\nimport json\nimport time\nimport inspect\nimport traceback\nfrom hashlib import md5\nfrom socket import timeout as socket_timeout\nfrom threading import Thread, RLock, Event, local, current_thread\n\nimport tabun_api as api\nfrom tabun_api.compat import text, binary, PY2\n\nfrom . import core, db\n\nif PY2:\n from Queue import PriorityQueue, Empty as QueueEmpty\nelse:\n from queue import PriorityQueue, Empty as QueueEmpty\n\n\nthreads = []\nreaders = []\nhandlers = {}\nevents = PriorityQueue()\nhandlers_thread = None\nquit_event = Event()\n\n\nclass Status(object):\n def __init__(self, state=None, onupdate=None, onupdate_ignore_for=(), debug=False):\n \"\"\"Объект, хрнящий информацию о текущем состоянии tabun_feed (часть используется в работе, часть только для отладки).\"\"\"\n self._state = dict(state) if state else {}\n self._state['workers'] = 0\n self._lock = RLock()\n self._editables = [] # for remote control\n self._subscriptions = {}\n\n self._local = local()\n if debug:\n self._debug = True\n self._state['workers_list'] = []\n else:\n self._debug = False\n self._state['workers_list'] = None\n\n self.onupdate = onupdate\n self.onupdate_ignore_for = onupdate_ignore_for\n\n @property\n def state(self):\n return dict(self._state)\n\n @property\n def editables(self):\n return tuple(self._editables)\n\n @property\n def debug(self):\n return self._debug\n\n @property\n def lock(self):\n return self._lock\n\n def __enter__(self):\n if self._debug:\n if not hasattr(self._local, 'workers_queue'):\n self._local.workers_queue = []\n st = inspect.stack()\n st = '{1}:{2} ({3})'.format(*st[1]) if len(st) > 1 else None\n self._local.workers_queue.append(st)\n\n with self._lock:\n if self._debug:\n self._state['workers_list'].append(st)\n old = self._state['workers']\n self._state['workers'] = old + 1\n\n if self.onupdate and 'workers' not in self.onupdate_ignore_for:\n self.onupdate('workers', old, old + 1)\n\n def __exit__(self, typ, value, tb):\n if self._debug:\n st = self._local.workers_queue.pop() if self._local.workers_queue else None\n\n with self._lock:\n if self._debug and st in self._state['workers_list']:\n self._state['workers_list'].remove(st)\n old = self._state['workers']\n self._state['workers'] = old - 1\n\n if self.onupdate and 'workers' not in self.onupdate_ignore_for:\n self.onupdate('workers', old, old - 1)\n\n def __getitem__(self, key):\n return self._state.get(key)\n\n def __setitem__(self, key, value):\n with self._lock:\n old = self._state.get(key, None)\n self._state[key] = value\n if self._subscriptions.get(key):\n for x in self._subscriptions[key]:\n try:\n x(key, old, value)\n except Exception:\n fail()\n if self.onupdate and 'workers' not in self.onupdate_ignore_for:\n try:\n self.onupdate(key, old, value)\n except Exception:\n fail()\n\n def add(self, key, value=1, loop_on=None):\n with self._lock:\n old = self._state.get(key, 0)\n if loop_on is not None and old >= loop_on:\n new = 0\n else:\n new = old + value\n self[key] = new\n return new\n\n def append(self, key, item):\n with self._lock:\n value = self._state.get(key)\n if value is None or item in value:\n return False\n value.append(item)\n self[key] = value # call onupdate\n return True\n\n def remove(self, key, item):\n with self._lock:\n value = self._state.get(key)\n if value is None or item not in value:\n return False\n value.remove(item)\n self[key] = value # call onupdate\n return True\n\n def add_editable_item(self, key):\n if key not in self._editables:\n self._editables.append(key)\n\n def subscribe(self, key, func):\n if key not in self._subscriptions:\n self._subscriptions[key] = []\n if func not in self._subscriptions[key]:\n self._subscriptions[key].append(func)\n\n def get_json_key(self, key):\n with self._lock:\n value = self._state.get(key)\n if value is not None and not isinstance(value, (text, int, bool, float)):\n try:\n json.dumps(value, ensure_ascii=False) # checking\n return value\n except Exception:\n return text(value)\n return value\n\n def get_json_status(self):\n with self._lock:\n state = dict(self._state)\n\n for key in tuple(state.keys()):\n value = state[key]\n if value is not None and not isinstance(value, (text, int, bool, float)):\n try:\n json.dumps(value, ensure_ascii=False) # checking\n state[key] = value\n except Exception:\n state[key] = text(value)\n return state\n\n\nstatus = Status(\n {\n 'started_at': time.time(),\n 'counter': 0,\n 'iter': 0,\n 'request_error': None,\n 'alivetime': 0,\n 'event_id': 0,\n 'threads': [],\n 'readers_count': 0,\n 'reader_current': 0,\n 'iterations_interval': 0,\n },\n onupdate=lambda key, old_value, new_value: call_handlers_here(\"update_status\", key, old_value, new_value),\n onupdate_ignore_for=('event_id', 'alivetime', 'last_requests', 'workers_list'),\n debug=True\n)\n\n\ndef add_reader(func):\n \"\"\"Добавляет читалку Табуна. Она будет вызываться в цикле в основном потоке.\"\"\"\n if func not in readers:\n readers.append(func)\n\n\ndef add_handler(name, func, priority=1):\n \"\"\"Добавляет обработчик в группу с указанным названием.\"\"\"\n funcs = handlers.get(name)\n if not funcs:\n funcs = ([], [], [])\n handlers[name] = funcs\n if priority < 0 or priority > 2:\n raise ValueError('Invalid priority %d' % priority)\n funcs[priority].append(func)\n\n\ndef call_handlers(name, *args):\n \"\"\"Вызывает группу обработчиков. Выполняются в отдельном потоке.\"\"\"\n if current_thread() is handlers_thread:\n call_handlers_here(name, *args)\n else:\n events.put((10, status.add('event_id', loop_on=1000000), name, args))\n\n\ndef call_handlers_now(name, *args):\n \"\"\"Вызывает группу обработчиков с повышенным приоритетом. Выполняются в отдельном потоке.\"\"\"\n if current_thread() is handlers_thread:\n call_handlers_here(name, *args)\n else:\n events.put((0, status.add('event_id', loop_on=1000000), name, args))\n\n\ndef call_handlers_here(name, *args):\n \"\"\"Вызывает группу обработчиков в текущем потоке. Аккуратнее с использованием!\n Возвращает число всего вызванных обработчиков и число упавших из них.\n \"\"\"\n name = text(name)\n\n called = 0\n errors = 0\n prs = handlers.get(name, ())\n for pr in prs:\n for func in pr:\n try:\n if name != 'update_status': # избегаем рекурсии из-за следующей строки\n with status:\n called += 1\n func(*args)\n else:\n func(*args)\n except Exception:\n core.logger.error('Handler %s (%s) failed:', name, func)\n fail()\n errors += 1\n finally:\n if name != 'update_status':\n touch_alivefile()\n\n if not prs:\n if name != 'update_status':\n touch_alivefile()\n\n return called, errors\n\n\ndef touch_alivefile():\n tm = time.time()\n if tm - status['alivetime'] < 1:\n return\n status['alivetime'] = tm\n\n path = core.config.get('tabun_feed', 'alivefile')\n if not path:\n return\n\n try:\n with open(path, 'wb') as fp:\n fp.write((text(int(status['alivetime'])) + '\\n').encode('utf-8'))\n except Exception as exc:\n core.logger.error('Cannot touch alive file %s: %s', path, exc)\n\n\ndef touch_pidfile():\n status['pid'] = os.getpid()\n\n path = core.config.get('tabun_feed', 'pidfile')\n if not path:\n return\n\n try:\n with open(path, 'wb') as fp:\n fp.write(text(status['pid']).encode('utf-8') + b'\\n')\n except Exception as exc:\n core.logger.error('Cannot write pid file: %s', exc)\n\n\ndef touch_started_at_file():\n path = core.config.get('tabun_feed', 'started_at_file')\n if not path:\n return\n\n try:\n with open(path, 'wb') as fp:\n fp.write(text(status['started_at']).encode('utf-8') + b'\\n')\n except Exception as exc:\n core.logger.error('Cannot write started_at file: %s', exc)\n\n\ndef clear_runfiles():\n for path in (core.config.get('tabun_feed', 'pidfile'), core.config.get('tabun_feed', 'started_at_file')):\n if not path or not os.path.isfile(path):\n continue\n try:\n os.remove(path)\n except Exception as exc:\n core.logger.error(\"Cannot remove %s: %s\", path, exc)\n\n\ndef run_handlers_thread():\n while not events.empty() or not quit_event.is_set():\n try:\n priority, event_id, name, args = events.get(timeout=1)\n except QueueEmpty:\n continue\n\n if not name:\n continue\n\n try:\n call_handlers_here(name, *args)\n except Exception:\n fail()\n quit_event.wait(5)\n\n\ndef run_reader():\n status['iterations_interval'] = core.config.getfloat('tabun_feed', 'iterations_interval')\n\n while not quit_event.is_set():\n with status:\n core.logger.debug('Watcher iteration start')\n status['iter'] += 1\n\n rs = tuple(readers)\n status['readers_count'] = len(rs)\n\n for i, func in enumerate(tuple(readers)):\n if quit_event.is_set():\n break\n status['reader_current'] = i\n\n try:\n func()\n except api.TabunError as exc:\n core.logger.warning('Tabun error: %s', exc.message)\n status['error'] = exc.message\n except socket_timeout as exc:\n core.logger.warning('Tabun result read error: timeout')\n status['error'] = 'timeout'\n except Exception:\n fail()\n quit_event.wait(5)\n\n if events.empty():\n touch_alivefile()\n\n db.db.commit()\n status['readers_count'] = 0\n status['reader_current'] = 0\n core.logger.debug('Watcher iteration ok')\n\n quit_event.wait(status['iterations_interval'])\n\n\ndef format_failure_email(data):\n from email.mime.text import MIMEText\n from email.mime.multipart import MIMEMultipart\n\n def e(x):\n return x.replace('&', '&').replace('<', '<').replace('>', '>').replace('\"', '"')\n\n plain_text = 'tabun_feed worker failed at {}:\\n\\n{}\\n\\nStatus:'.format(\n time.strftime('%Y-%m-%d %H:%M:%S'),\n data\n )\n\n for key, value in sorted(status.state.items()):\n plain_text += '\\n- {}: {}'.format(key, text(value))\n plain_text += '\\n'\n\n html_text = '<strong>tabun_feed worker failed at {}:</strong><br/>\\n<pre style=\"font-family: \\'DejaVu Mono\\', monospace; background-color: #f5f5f5;\">{}</pre>\\n<hr/>\\n<em>Status:</em><br/>\\n<ul>'.format(\n time.strftime('%Y-%m-%d %H:%M:%S'),\n e(data)\n )\n\n for key, value in sorted(status.state.items()):\n html_text += '\\n <li><strong>{}:</strong> <span style=\"white-space: pre-wrap\">{}</span></li>'.format(key, e(text(value)))\n html_text += '\\n</ul>'\n\n html_text = '<html><head></head><body>{}</body></html>'.format(html_text)\n\n mpart = MIMEMultipart('alternative')\n mpart.attach(MIMEText(plain_text.encode('utf-8'), 'plain', 'utf-8'))\n mpart.attach(MIMEText(html_text.encode('utf-8'), 'html', 'utf-8'))\n return [mpart]\n\n\ndef fail(desc=None):\n # Печатаем ошибку в лог\n exc = traceback.format_exc().strip()\n if isinstance(exc, binary):\n exc = exc.decode('utf-8', 'replace')\n if desc:\n core.logger.error(desc)\n core.logger.error(exc)\n\n # Отправляем на почту\n if core.config.get('email', 'errors_to'):\n try:\n core.sendmail(\n core.config.get('email', 'errors_to'),\n core.config.get('email', 'errors_subject'),\n format_failure_email(exc),\n fro=core.config.get('email', 'errors_from') or None\n )\n except Exception:\n core.logger.error(traceback.format_exc())\n\n try:\n if not core.config.getboolean('tabun_feed', 'failures_to_db'):\n return\n\n # считаем какой-нибудь хэш, чтобы не завалить админку одинаковыми ошибками\n ex_type, ex, tb = sys.exc_info()\n fail_hash = text(tb.tb_frame.f_code.co_filename) + '\\x00' + text(tb.tb_lineno)\n fail_hash += '\\x00' + text(ex_type) + '\\x00' + text(ex)\n fail_hash = md5(fail_hash.encode('utf-8')).hexdigest()\n del ex_type, ex, tb\n\n st = json.dumps(status.get_json_status())\n\n # инкрементируем число случаев, если ошибка с таким хэшем уже есть\n fail_id = db.db.query('select id from failures where hash = ? and solved = 0 order by last_time desc limit 1', (fail_hash,))\n if fail_id:\n fail_id = fail_id[0][0]\n db.db.execute('update failures set occurrences = occurrences + 1, last_time = ? where id = ?', (int(time.time()), fail_id))\n return fail_id\n\n # создаём новую запись, если это первая такая нерешённая ошибка\n return db.db.execute(\n 'insert into failures(hash, first_time, last_time, error, desc, status_json) values (?, ?, ?, ?, ?, ?)',\n (fail_hash, int(time.time()), int(time.time()), exc, desc or None, st)\n ).lastrowid\n\n except Exception:\n traceback.print_exc()\n return None\n\n\ndef get_failures(offset=0, count=20):\n return [{\n 'id': x[0],\n 'first_time': x[1],\n 'last_time': x[2],\n 'occurrences': x[3],\n 'solved': x[4],\n 'error': x[5],\n 'desc': x[6]\n } for x in db.db.execute('select id, first_time, last_time, occurrences, solved, error, desc from failures order by id desc limit ?, ?', (offset, count)).fetchall()]\n\n\ndef get_failure(fail_id):\n x = db.db.query('select id, first_time, last_time, occurrences, solved, error, desc, status_json from failures where id = ?', (int(fail_id),))\n if not x:\n return\n x = x[0]\n return {\n 'id': x[0],\n 'first_time': x[1],\n 'last_time': x[2],\n 'occurrences': x[3],\n 'solved': x[4],\n 'error': x[5],\n 'desc': x[6],\n 'status': json.loads(x[7])\n }\n\n\ndef solve_failure(fail_id):\n db.db.execute('update failures set solved=1 where id=?', (fail_id,))\n\n\ndef start_handlers():\n global handlers_thread\n handlers_thread = start_thread(run_handlers_thread)\n\n\ndef start_thread(func, *args, **kwargs):\n try:\n item = (repr(func), inspect.getfile(func))\n except TypeError:\n item = (repr(func), None)\n\n def start_thread_func():\n threads.append(thread)\n status.append('threads', item)\n try:\n func(*args, **kwargs)\n except: # pylint: disable=W0702\n # KeyobardInterrupt и SystemExit в неосновном потоке — тоже ошибка\n fail()\n finally:\n status.remove('threads', item)\n threads.remove(thread)\n\n thread = Thread(target=start_thread_func)\n thread.start()\n return thread\n\n\ndef stop():\n quit_event.set()\n call_handlers('stop')\n if handlers_thread is not None:\n if status['workers'] > 0 or not events.empty():\n core.logger.info('Waiting for shutdown workers (%s)', status['workers'])\n events.put((20, status.add('event_id'), 'exit', [time.time()]))\n try:\n handlers_thread.join()\n except (KeyboardInterrupt, SystemExit):\n traceback.print_exc()\n\n for t in tuple(threads):\n t.join()\n\n try:\n db.db.commit()\n except Exception:\n pass\n\n core.logger.info('Exiting')\n clear_runfiles()\n\n\n# entry point: #\n\n\ndef run():\n call_handlers('start')\n\n try:\n run_reader()\n except (KeyboardInterrupt, SystemExit):\n print('')\n except Exception:\n fail()\n return False\n else:\n return True\n finally:\n stop()\n"
},
{
"alpha_fraction": 0.5566232204437256,
"alphanum_fraction": 0.5655456185340881,
"avg_line_length": 33.282352447509766,
"blob_id": "aba2139d1075e150e188bf8b26669eb69b700db5",
"content_id": "755204a7ac96662310f75a2830786e7a5e33aa37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8965,
"license_type": "no_license",
"max_line_length": 152,
"num_lines": 255,
"path": "/tabun_feed/plugins/vk_online.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nimport time\n\nfrom tabun_feed import core, worker\nfrom tabun_feed.db import db\nfrom tabun_feed.remote_server import remote_command\n\n\nvk_plug = core.load_plugin('tabun_feed.plugins.vk')\nvk = None\n\ntargets = tuple(set(-x['id'] for x in vk_plug.targets.values() if x is not None and x['id'] < 0))\n\ninterval = 300\nlast_align_time = None\niter_current = -1\n\n\ncode = r\"\"\"var count = -1;\nvar users = [];\nwhile((count == -1 || users.length < count - %OFFSET%) && users.length < 10000){\n var members = API.groups.getMembers( {\"group_id\": \"%GROUP_ID%\", \"sort\": \"time_asc\", \"count\": 1000, \"offset\": users.length + %OFFSET%} );\n if(members.items.length == 0) return {\"count\": count, \"users\": users};\n count = members.count;\n users = users + API.users.get( {\"user_ids\": members.items, \"fields\": \"online\"} );\n}\nreturn {\"count\": count, \"users\": users};\"\"\"\n\n\ndef reader():\n global last_align_time, iter_current\n\n iter_current += 1\n new_align_time = int(time.time()) // interval * interval\n\n if new_align_time - last_align_time < interval:\n n = (iter_current * 2) % len(targets)\n for i, group_id in enumerate(targets[n:n + 2]):\n if i > 0:\n time.sleep(0.4)\n process_if_needed(group_id)\n return\n\n last_align_time = new_align_time\n core.logger.debug('VK Online: %s %s', time.strftime('%H:%M:%S', time.localtime(last_align_time)), time.strftime('%H:%M:%S'))\n\n for i, group_id in enumerate(targets):\n if i > 0:\n time.sleep(0.5)\n worker.status['vk_online'] = 'Processing {}'.format(group_id)\n try:\n process_group(group_id)\n except Exception:\n worker.fail()\n core.logger.error('VK Online %d fail', group_id)\n worker.status['vk_online'] = ''\n\n worker.status['vk_online_last'] = int(time.time())\n db.commit()\n\n\ndef process_if_needed(group_id):\n try:\n result = vk.api('groups.getMembers', {'group_id': group_id, 'count': 0})\n except Exception as exc:\n core.logger.warning('VK Online %d fail: %s', group_id, exc)\n return\n\n if not result.get('response'):\n return\n\n old_count = db.query(\n 'select count from vk_online where group_id = ? order by time desc limit 1',\n (group_id,)\n )\n old_count = old_count[0][0] if old_count else -1\n\n count = result['response'].get('count')\n if count is not None and count != old_count:\n time.sleep(0.3)\n worker.status['vk_online'] = 'Processing {}'.format(group_id)\n try:\n process_group(group_id)\n except Exception as exc:\n worker.fail()\n core.logger.error('VK Online %d fail', group_id)\n worker.status['vk_online'] = ''\n\n\ndef process_group(group_id):\n count = -1\n users = []\n usersdict = {}\n queries = 0\n\n # так как у метода execute ограничение в 25 запросов API, собираем-таки инфу через несколько таких запросов\n while count == -1 or len(users) < count:\n queries += 1\n if queries > 50:\n core.logger.error('VK Online: too many queries! Maybe %d members in group %d is too many for plugin', count, group_id)\n count = -1\n break\n\n if count != -1:\n time.sleep(0.4)\n\n # 10 - запас на тех, кто отписался в процессе скачивания\n # (не совсем надёжно, потому что могут отписаться и при\n # выполнении VKScript, но лучше чем ничего)\n offset = max(0, len(users) - 10)\n rcode = code.replace('%GROUP_ID%', str(group_id)).replace('%OFFSET%', str(offset))\n try:\n result = vk.api('execute', {'code': rcode})\n except Exception as exc:\n core.logger.warning('VK Online %d fail: %s', group_id, exc)\n count = -1\n break\n\n resp = result.get('response')\n if not resp:\n count = -1\n break\n\n count = resp['count']\n if not resp['users']:\n break\n for x in resp['users']:\n usersdict[x['id']] = x\n if x['id'] not in users:\n users.append(x['id'])\n\n if count == -1:\n return\n\n online = len([True for x in usersdict.values() if x['online']])\n\n # подгружаем сохранённый список участников\n q = db.query('select user_id, leave_time from vk_members where group_id = ?', (group_id,))\n dbusers = [x[0] for x in q]\n dbcurrent = [x[0] for x in q if x[1] is None]\n del q\n\n if not dbusers:\n core.logger.info('VK Online: init members for group %d', group_id)\n j = 0\n chunklen = 500\n while j * chunklen < len(users):\n chunk = [(group_id, x, None, None) for x in users[j * chunklen:j * chunklen + chunklen]]\n db.executemany('insert into vk_members(group_id, user_id, join_time, leave_time) values(?, ?, ?, ?)', chunk)\n j += 1\n joined = set()\n leaved = set()\n\n else:\n joined = set(users) - set(dbcurrent)\n leaved = set(dbcurrent) - set(users)\n for x in joined:\n core.logger.debug('join %d (target %d)', x, group_id)\n if x not in dbusers:\n db.execute('insert into vk_members(group_id, user_id, join_time, leave_time) values(?, ?, ?, ?)', (group_id, x, int(time.time()), None))\n elif x not in dbcurrent:\n db.execute('update vk_members set leave_time = ? where group_id = ? and user_id = ?', (None, group_id, x))\n\n for x in leaved:\n core.logger.debug('leave %d (target %d)', x, group_id)\n if x in dbcurrent:\n db.execute('update vk_members set leave_time = ? where group_id = ? and user_id = ?', (int(time.time()), group_id, x))\n\n if joined or leaved:\n diff = '|' + '|'.join(['+' + str(x) for x in joined] + ['-' + str(x) for x in leaved]) + '|'\n else:\n diff = None\n db.execute(\n 'insert into vk_online(group_id, time, online, count, diff) values(?, ?, ?, ?, ?)',\n (group_id, int(time.time()), online, count, diff)\n )\n\n\n@remote_command('vk_stat')\ndef cmd_vk_stat(packet, client):\n try:\n groups = [int(x) for x in packet.get('groups', ())]\n except Exception:\n return {'error': 'Invalid groups'}\n if not groups:\n groups = [x[0] for x in db.query('select distinct group_id from vk_online')]\n\n try:\n start_time = int(packet['start_time']) if packet.get('start_time') is not None else None\n except Exception:\n return {'error': 'Invalid start time'}\n\n try:\n end_time = int(packet['end_time']) if packet.get('end_time') is not None else int(time.time())\n except Exception:\n return {'error': 'Invalid end time'}\n\n result = {}\n for group_id in groups:\n if start_time is None:\n items = reversed(db.query(\n 'select time, count, online from vk_online where group_id = ? and time <= ? order by time desc limit 1200',\n (group_id, end_time)\n ))\n else:\n items = db.query(\n 'select time, count, online from vk_online where group_id = ? and time >= ? and time <= ? order by time limit 1200',\n (group_id, start_time, end_time)\n )\n result[str(group_id)] = [{\n 'time': x[0],\n 'count': x[1],\n 'online': x[2]\n } for x in items]\n\n return {'cmd': 'vk_stat', 'groups': result}\n\n\ndef init_tabun_plugin():\n global vk, interval, last_align_time\n if not targets or not core.config.has_option('vk', 'access_token'):\n core.logger.warning('VK is not available; vk_online disabled')\n return\n vk = vk_plug.App()\n\n if db.init_table('vk_online', '''(\n group_id int not null,\n time int not null,\n online int not null,\n count int not null,\n diff text default null,\n primary key(group_id, time)\n )'''):\n db.execute('create index vk_group on vk_online(group_id)')\n\n if db.init_table('vk_members', '''(\n id integer primary key autoincrement not null,\n group_id int not null,\n user_id int not null,\n join_time int default null,\n leave_time int default_null\n )'''):\n db.execute('create unique index vk_member on vk_members(group_id, user_id)')\n\n if core.config.has_option('vk_online', 'query_interval'):\n interval = max(30, core.config.getint('vk_online', 'query_interval'))\n last_align_time = int(time.time()) // interval * interval\n\n worker.status['vk_online_last'] = db.query('select max(time) from vk_online')[0][0] or None\n worker.status['vk_online'] = ''\n worker.add_reader(reader)\n"
},
{
"alpha_fraction": 0.5543695688247681,
"alphanum_fraction": 0.5602068305015564,
"avg_line_length": 32.127071380615234,
"blob_id": "eb4e9a36c1a4564bbe9d31c16a9412b48e379cbb",
"content_id": "37c97f78976341d96947e95e5770f62ff8198788",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6130,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 181,
"path": "/tabun_feed/plugins/mysql.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nimport time\nimport logging\nfrom threading import RLock\n\nimport MySQLdb\nfrom tabun_api.compat import PY2, text, binary\n\nif PY2:\n from urlparse import urlparse\nelse:\n from urllib.parse import urlparse\n\nfrom .. import core\n\n\ndb = None\ndebug_by_default = False\n\n\nclass DB(object):\n def __init__(self, path, user=None, password=None, database=None, autocommit=True):\n self.path = text(path)\n self.user = text(user) if user else None\n self.password = text(password) if password else None\n self.database = text(database) if database else None\n self.autocommit = bool(autocommit)\n\n self._lock = RLock()\n self._conn = None\n self._with_count = 0 # число захватов блокировки в текущем потоке\n self._transaction_started = False # дабы не запускать транзакцию когда не требуется\n\n self.debug = debug_by_default\n\n self.connect()\n\n def __enter__(self):\n self._lock.acquire()\n self._with_count += 1\n if self._with_count == 1:\n self._transaction_started = False\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n try:\n if not self.autocommit and self._with_count == 1 and self._transaction_started:\n if exc_type is None:\n if self.debug:\n logging.debug('MySQL commit')\n self._conn.commit()\n else:\n if self.debug:\n logging.debug('MySQL rollback')\n self._conn.rollback()\n finally:\n self._with_count -= 1\n self._lock.release()\n\n @property\n def lock(self):\n return self._lock\n\n @property\n def connection(self):\n return self._conn\n\n def set_debug(self, debug):\n self.debug = bool(debug)\n\n def connect(self):\n data = urlparse(self.path)\n\n kwargs = {\n 'user': data.username or self.user,\n 'passwd': data.password or self.password,\n 'charset': 'utf8'\n }\n if self.database:\n kwargs['db'] = self.database\n\n if data.scheme == 'unix':\n if data.hostname:\n raise ValueError(\n 'hostname must be empty for unix socket; '\n 'use unix:/path/to/socket or unix:///path/to/socket '\n 'or unix://username:password@/path/to/socket'\n )\n kwargs['host'] = 'localhost'\n kwargs['unix_socket'] = data.path\n else:\n kwargs['host'] = data.hostname\n if data.port is not None:\n kwargs['port'] = data.port\n\n with self._lock:\n self._conn = MySQLdb.connect(**kwargs)\n self._conn.ping(True)\n self._conn.cursor().execute('set autocommit=%d' % (1 if self.autocommit else 0))\n\n def disconnect(self):\n if not self._conn:\n return False\n with self._lock:\n self._conn.close()\n self._conn = None\n return True\n\n def escape(self, obj):\n # _conn.escape method is shit\n if isinstance(obj, text):\n result = self._conn.escape(obj.encode('utf-8'))\n else:\n result = self._conn.escape(obj)\n return result.decode('utf-8') if isinstance(result, binary) else text(result)\n\n def execute(self, sql, args=(), tries=15, _start_transaction=True):\n if _start_transaction and not self.autocommit and self._with_count > 0 and not self._transaction_started:\n # При выключенном автокоммите в конструкции `with` запускаем транзакцию\n self.execute('start transaction', _start_transaction=False)\n self._transaction_started = True\n\n if isinstance(sql, binary):\n sql = sql.decode('utf-8')\n\n if self.debug:\n logging.debug('MySQL Query: %s %s', sql, args)\n\n for i in range(tries):\n try:\n if i > 0:\n self.connect()\n c = self._conn.cursor()\n c.execute(sql, args)\n return c\n except MySQLdb.OperationalError as exc:\n if self._transaction_started or i >= tries or exc.args[0] not in (2013, 2002, 2006):\n raise\n c = None\n time.sleep(0.3)\n\n def execute_in(self, sql, in_args, args=(), binary_args=False):\n # select * from sometable where somecolumn = %s and somecolumn2 in (%s)\n if isinstance(sql, binary):\n sql = sql.decode('utf-8')\n # FIXME: binary_args?\n in_args = ((('binary ' if binary else '') + self.escape(x)) for x in in_args)\n in_args = ', '.join(in_args)\n sql = sql.replace('(%s)', '(' + in_args.replace('%', '%%') + ')')\n\n return self.execute(sql, args)\n\n def query(self, sql, args=()):\n with self._lock:\n return self.execute(sql, args).fetchall()\n\n def query_in(self, sql, in_args, args=(), binary_args=False):\n with self._lock:\n return self.execute_in(sql, in_args, args, binary_args).fetchall()\n\n\ndef connection_from_config(section='mysql', prefix=''):\n return DB(\n core.config.get(section, prefix + 'uri'),\n core.config.get(section, prefix + 'username') if core.config.has_option(section, prefix + 'username') else None,\n core.config.get(section, prefix + 'password') if core.config.has_option(section, prefix + 'password') else None,\n core.config.get(section, prefix + 'database') if core.config.has_option(section, prefix + 'database') else None,\n autocommit=False,\n )\n\n\ndef init_tabun_plugin():\n global db, debug_by_default\n if not core.config.has_section('mysql'):\n return\n if core.config.has_option('mysql', 'debug'):\n debug_by_default = core.config.getboolean('mysql', 'debug')\n db = connection_from_config()\n"
},
{
"alpha_fraction": 0.6038665771484375,
"alphanum_fraction": 0.6152388453483582,
"avg_line_length": 30.035293579101562,
"blob_id": "b254921caccee35c134046007d59f322e86965e7",
"content_id": "d207c45847242d9495233888b2b8721f8f20c198",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3019,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 85,
"path": "/tabun_feed/readers/activity.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nimport time\n\nimport tabun_api as api\n\nfrom .. import core, user, worker\nfrom ..db import db, get_db_last, set_db_last\n\n\ndef pack_item(item):\n # надёжного красивого способа сохранить и сравнить активность нет, поэтому костыляем\n return '%d\\x00%d\\x00%s\\x00%s\\x00%s\\x00%s\\x00%s\\x00%s\\x00' % (\n item.type, time.mktime(item.date),\n item.post_id, item.comment_id,\n item.blog, item.username,\n item.title, item.data,\n )\n\n\ndef reader():\n last_id = get_db_last(\"activity_id\")\n last_loaded_id = None\n first_loaded_id = None\n items = []\n new_items = []\n\n # ограничиваем число загрузок на случай багов\n for i in range(50):\n if i >= 49:\n core.logger.error(\"Infinity activity loading! Break.\")\n break\n\n # качаем активность\n if last_loaded_id is None:\n last_loaded_id, raw_items = user.user.get_activity()\n else:\n try:\n last_loaded_id, raw_items = user.user.get_more_activity(last_loaded_id)\n except api.TabunError as exc:\n core.logger.warning(\"Activity loading error: %s\", exc)\n break\n items.extend(raw_items)\n\n # запоминаем самый свежий айдишник\n if first_loaded_id is None:\n first_loaded_id = last_loaded_id\n\n # выходим, если точно скачали всё новое\n # (можно и + 20, но пусть будет десяток про запас)\n if not last_id or not raw_items or last_loaded_id <= last_id + 10:\n break\n\n # подгружаем кэш, с которым будем сравнивать активность\n last_items = [x[0] for x in db.execute('select data from last_activity').fetchall()]\n\n # выбираем только новую активность\n new_items = []\n for item in items:\n if pack_item(item) in last_items:\n break\n new_items.append(item)\n if not new_items:\n return\n new_items = list(reversed(new_items))\n\n for item in new_items:\n worker.call_handlers(\"new_activity\", item)\n\n worker.call_handlers(\"activity_list\", items, len(new_items))\n\n # сохраняем кэш активности (10 штук про запас, ибо активность может пропадать, например, с удалёнными постами)\n with db:\n db.execute('delete from last_activity')\n for item in items[:10]:\n db.execute('insert into last_activity values(?)', (pack_item(item),))\n set_db_last(\"activity_id\", max(first_loaded_id, last_loaded_id, last_id))\n\n\ndef init_tabun_plugin():\n db.init_table('last_activity', '(data text not null)')\n worker.add_reader(reader)\n"
},
{
"alpha_fraction": 0.5408788323402405,
"alphanum_fraction": 0.5448734760284424,
"avg_line_length": 29.52845573425293,
"blob_id": "4593039d20c02274619b5d14b60e77cc01cb7b6b",
"content_id": "3fac42e5f7daa5dd3021bbdf41ecd598d312f0f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3755,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 123,
"path": "/tabun_feed/plugins/interpreter.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nimport sys\nfrom io import StringIO, BytesIO\nfrom code import InteractiveConsole\n\nfrom tabun_api.compat import PY2, text, binary\n\nfrom tabun_feed import core, worker, db, user\nfrom tabun_feed.remote_server import remote_command\n\n\nclients = {}\n\n\nclass AsyncConsole(InteractiveConsole):\n def __init__(self, locals=None, filename=\"<console>\", client=None):\n InteractiveConsole.__init__(self, locals, filename)\n self.client = client\n\n def interact_async(self, banner=None):\n try:\n sys.ps1\n except AttributeError:\n sys.ps1 = \">>> \"\n try:\n sys.ps2\n except AttributeError:\n sys.ps2 = \"... \"\n cprt = 'Type \"help\", \"copyright\", \"credits\" or \"license\" for more information.'\n if banner is None:\n self.write(\"Python %s on %s\\n%s\\n(%s)\\n\" %\n (sys.version, sys.platform, cprt,\n InteractiveConsole.__name__))\n elif banner:\n self.write(\"%s\\n\" % text(banner))\n more = 0\n while 1:\n try:\n if more:\n prompt = sys.ps2\n else:\n prompt = sys.ps1\n try:\n line = yield prompt\n except EOFError:\n self.write(\"\\n\")\n break\n else:\n more = self.push(line)\n except KeyboardInterrupt:\n self.write(\"\\nKeyboardInterrupt\\n\")\n self.resetbuffer()\n more = 0\n\n def write(self, data):\n if isinstance(data, binary):\n data = data.decode('utf-8', 'replace')\n elif not isinstance(data, text):\n data = text(data)\n if self.client is None:\n sys.stderr.write(data.encode('utf-8') if PY2 else data)\n else:\n self.client.send({'cmd': 'python_write', 'data': data})\n\n\ndef onclose(client):\n if client in clients:\n del clients[client]\n\n\n@remote_command('python')\ndef cmd_python(packet, client):\n if client in clients:\n if packet.get('interrupt'):\n prompt = clients[client].interpreter.throw(KeyboardInterrupt())\n return {'cmd': 'python_input', 'prompt': prompt}\n\n data = packet.get('data')\n if not isinstance(data, text):\n try:\n clients[client].interpreter.throw(EOFError())\n except StopIteration:\n pass\n del clients[client]\n return {'cmd': 'python_closed'}\n\n # FIXME: this shit is not thread-safety\n old_stdout = sys.stdout\n try:\n s = BytesIO() if PY2 else StringIO\n sys.stdout = s\n prompt = clients[client].interpreter.send(data)\n finally:\n sys.stdout = old_stdout\n\n clients[client].write(s.getvalue())\n return {'cmd': 'python_input', 'prompt': prompt}\n\n passwd = None\n if core.config.has_option('tabun_feed', 'remote_console_password'):\n passwd = text(core.config.get('tabun_feed', 'remote_console_password'))\n if not passwd:\n return {'error': 'unavailable'}\n if packet.get('password') != passwd:\n return {'error': 'unauthorized'}\n\n new_locals = {\n 'core': core,\n 'worker': worker,\n 'db': db,\n 'user': user,\n 'sys': None\n }\n\n client.add_onclose_handler(onclose)\n clients[client] = AsyncConsole(locals=new_locals, client=client)\n clients[client].interpreter = clients[client].interact_async()\n prompt = clients[client].interpreter.send(None)\n return {'cmd': 'python_input', 'prompt': prompt}\n"
},
{
"alpha_fraction": 0.7945205569267273,
"alphanum_fraction": 0.7945205569267273,
"avg_line_length": 72,
"blob_id": "67ba20dc411d755fefb991cda7a2b3feadd72e19",
"content_id": "aa75622305416f41fa13d65ea929920c0f98c4f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 73,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 1,
"path": "/requirements.txt",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "git+https://github.com/andreymal/tabun_api.git#egg=tabun_api[imageutils]\n"
},
{
"alpha_fraction": 0.6239700317382812,
"alphanum_fraction": 0.6274656653404236,
"avg_line_length": 28.448530197143555,
"blob_id": "e0b4291e435461bfb5a8a5543bc9f2bfa5416c34",
"content_id": "05d7849800a786b92bc4b7830f0b3a8333aec5ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4620,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 136,
"path": "/tabun_feed/plugins/telegram_feed/store.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals, absolute_import\n\nimport time\n\nfrom tabun_api.compat import text\n\nfrom tabun_feed import db\n\n\n# Статусы:\n# всё успешно сделано\nOK = 0\n# ещё в очереди лежит (храним для восстановления состояния очереди после перезапуска бота)\nPENDING = 1\n# закрытый блог (или черновик, но это уже не норма), ничего не сделано\nCLOSED = -1\n# какая-то ошибка, будет повторная попытка в будущем\nFAILED = -2\n# не получилось скачать пост с Табуна, ничего не сделано\nNODOWNLOAD = -3\n# какая-то ошибка была много раз подряд, будет повтор только после перезапуска бота\nPENDING_FAILED = -4\n# не запостилось из-за упора в лимит (для телеграма ещё не реализовано)\nLIMIT = -5\n# пост отфильтрован пользовательскими правилами, ничего не сделано (ещё не реализовано)\nFILTERED = -6\n# пост проигнорирован по иным причинам (тоже ещё не реализовано)\nIGNORED = -7\n\n\n# Значение по умолчанию для аргументов save_post_status;\n# означает не обновлять значение такого-то столбца в базе\n# (если его в базе нет, то будет создано значение по умолчанию)\nKEEP = object()\n\n\ndef check_db():\n # type: () -> None\n\n db.db.init_table('tg_posts', '''(\n post_id int not null primary key,\n processed_at int not null,\n status int not null,\n status_text text default null,\n process_duration int not null,\n tg_chat_id int default null,\n tg_message_id int default null\n )''')\n\n\ndef get_rows_by_status(statuses):\n # type: (Iterable[int]) -> List[tuple]\n statuses = tuple(set(statuses))\n if not statuses:\n return []\n rows = db.db.query((\n 'select post_id, processed_at, status, status_text, process_duration, tg_chat_id, tg_message_id '\n 'from tg_posts where status in ({})'\n ).format(', '.join('?' for _ in statuses)), statuses)\n return rows\n\n\ndef save_post_status(\n post_id,\n processed_at=KEEP,\n status=KEEP,\n status_text=KEEP,\n process_duration=KEEP,\n tg_chat_id=KEEP,\n tg_message_id=KEEP,\n commit=True,\n):\n post_id = int(post_id)\n exists = bool(db.db.query('select post_id from tg_posts where post_id = ?', (post_id,)))\n\n args = {} # type: Dict[str, Any]\n\n if processed_at is not KEEP:\n args['processed_at'] = int(processed_at if processed_at is not None else int(time.time()))\n elif not exists:\n args['processed_at'] = int(time.time())\n\n if status is not KEEP:\n args['status'] = int(status)\n elif not exists:\n args['status'] = PENDING\n\n if status_text is not KEEP:\n args['status_text'] = text(status_text) if status_text else None\n elif not exists:\n args['status_text'] = None\n\n if process_duration is not KEEP:\n args['process_duration'] = int(process_duration)\n elif not exists:\n args['process_duration'] = 0\n\n if tg_chat_id is not KEEP:\n args['tg_chat_id'] = int(tg_chat_id) if tg_chat_id is not None else None\n elif not exists:\n args['tg_chat_id'] = None\n\n if tg_message_id is not KEEP:\n args['tg_message_id'] = int(tg_message_id) if tg_message_id is not None else None\n elif not exists:\n args['tg_message_id'] = None\n\n if not args:\n return\n\n args_fields = [] # type: List[text]\n args_values = [] # type: List[text]\n\n if exists:\n sql = 'update tg_posts set {0} where post_id = ?'\n for k, v in args.items():\n args_fields.append('{} = ?'.format(k))\n args_values.append(v)\n args_values.append(post_id)\n sql = sql.format(', '.join(args_fields))\n\n else:\n sql = 'insert into tg_posts ({0}) values ({1})'\n for k, v in args.items():\n args_fields.append(k)\n args_values.append(v)\n args_fields.append('post_id')\n args_values.append(post_id)\n sql = sql.format(', '.join(args_fields), ', '.join('?' for _ in args_values))\n\n db.db.execute(sql, tuple(args_values))\n if commit:\n db.db.commit()\n"
},
{
"alpha_fraction": 0.6523053646087646,
"alphanum_fraction": 0.6538170576095581,
"avg_line_length": 23.962265014648438,
"blob_id": "e78c24a5dd7bf27a28a8cbeb464a89542a96d67b",
"content_id": "be26921dc25f88882c56cd8aa3343888ceb3151d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1444,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 53,
"path": "/tabun_feed/readers/talk.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nfrom .. import worker, user\n\n\ntalk_handler = None\nprocess_talk = False\n\n\ndef update_unread_count():\n worker.status['talk_unread'] = user.user.talk_unread\n\n\ndef handler_raw_data(url, raw_data):\n # предполагается скачивание данных через user.open_with_check,\n # а там всегда вызывается update_userinfo\n if process_talk:\n return\n if user.user.talk_unread == worker.status['talk_unread']:\n return\n\n old_unread = worker.status['talk_unread']\n worker.status['talk_unread'] = user.user.talk_unread\n if talk_handler and user.user.talk_unread > old_unread:\n worker.call_handlers('_talk_new')\n\n\ndef set_talk_handler(func):\n # В обработчиках тоже стоит использовать open_with_check,\n # чтобы talk_unread обновлялось само\n # И не забывайте update_unread_count()\n global talk_handler\n if talk_handler:\n raise ValueError('Conflict')\n talk_handler = func\n\n def decorator():\n global process_talk\n process_talk = True\n try:\n func()\n finally:\n process_talk = False\n\n worker.add_handler('_talk_new', decorator)\n\n\ndef init_tabun_plugin():\n worker.status['talk_unread'] = 0\n worker.add_handler('raw_data', handler_raw_data)\n"
},
{
"alpha_fraction": 0.5952568054199219,
"alphanum_fraction": 0.5993186831474304,
"avg_line_length": 37.54545593261719,
"blob_id": "f3529fb51602a99a40b6398f8ee84a3ca38399e4",
"content_id": "12fe3e515735dc3ee16e8bf3967cd79c8dae44e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8408,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 198,
"path": "/tabun_feed/readers/posts.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nimport time\nfrom datetime import datetime\n\nfrom tabun_api.compat import text\n\nfrom .. import core, worker, user\nfrom ..db import db, get_db_last, set_db_last\n\n\ndef reader():\n last_post_time = get_db_last('last_post_time')\n\n # скачиваем посты\n posts, pages = load_posts(last_post_time)\n\n if core.loglevel == core.logging.DEBUG:\n core.logger.debug('Downloaded posts: %s', ', '.join(text(x.post_id) for x in posts))\n\n new_posts = []\n\n # подгружаем из базы информацию о последних постах\n post_infos = get_posts_info(x.post_id for x in posts)\n oldest_post_time = get_db_last('oldest_post_time')\n new_oldest_post_time = None\n new_last_post_time = None\n\n status_changed = False\n\n for post in posts:\n # слишком старые посты игнорируем\n tm = (post.utctime - datetime(1970, 1, 1)).total_seconds()\n if tm < oldest_post_time:\n continue\n\n if new_oldest_post_time is None:\n new_oldest_post_time = tm\n if new_last_post_time is None or tm > new_last_post_time:\n new_last_post_time = tm\n\n # проверяем, был ли обработан этот пост\n short_hash, full_hash = post_infos.get(post.post_id, (None, None))\n if short_hash or full_hash:\n # пост уже был обработан\n new_short_hash = post.hashsum()\n if new_short_hash != short_hash:\n # Упс, пост изменили\n if not post.short:\n full_post = post\n elif worker.status['request_full_posts'] and post.short:\n full_post = (user.user if post.private else user.anon).get_post(post.post_id, post.blog)\n if post.vote_total is not None and full_post.vote_total is None:\n full_post.vote_total = post.vote_total\n full_post.vote_count = post.vote_count\n else:\n full_post = None\n new_full_hash = full_post.hashsum() if full_post else 'N/A'\n set_post_info(post.post_id, tm, new_short_hash, new_full_hash)\n worker.call_handlers('edit_post', post, full_post)\n continue\n\n if not post.short:\n full_post = post\n elif worker.status['request_full_posts'] and post.short:\n full_post = (user.user if post.private else user.anon).get_post(post.post_id, post.blog)\n if post.vote_total is not None and full_post.vote_total is None:\n full_post.vote_total = post.vote_total\n full_post.vote_count = post.vote_count\n else:\n full_post = None\n\n short_hash = post.hashsum()\n full_hash = full_post.hashsum() if full_post else 'N/A'\n\n set_post_info(post.post_id, tm, short_hash, full_hash)\n\n # отправляем в другой поток на обработку\n worker.call_handlers(\"new_post\", post, full_post)\n if not status_changed:\n worker.status['iter_last_with_post'] = worker.status['iter']\n status_changed = True\n new_posts.append((post, full_post))\n\n if worker.status['request_full_posts'] and post.short:\n time.sleep(2) # не DDoS'им\n\n # Для плагинов, желающих обработать все новые посты в одном обработчике\n worker.call_handlers(\"new_posts\", new_posts)\n\n if core.loglevel == core.logging.DEBUG:\n core.logger.debug('New posts: %s', ', '.join(text(x[0].post_id) for x in new_posts))\n\n # стираем слишком старые посты\n if new_oldest_post_time is not None and new_oldest_post_time != oldest_post_time:\n set_db_last('oldest_post_time', new_oldest_post_time)\n clear_post_info_older(new_oldest_post_time)\n\n if new_last_post_time is not None and new_last_post_time != last_post_time:\n set_db_last('last_post_time', new_last_post_time)\n\n worker.call_handlers(\"posts_list\", posts)\n\n # считалка постов, ушедших в сервис-зону и восставших из черновиков\n # old_page = load_page_cache('posts')\n # new_page = [x.post_id for x in posts]\n # posts_dict = dict(((x.post_id, x) for x in posts))\n\n # if old_page == new_page:\n # return\n\n # added, removed, restored, displaced = calc_page_diff(old_page, new_page)\n # print old_page\n # print new_page\n # print added, removed, restored, displaced, time.strftime(\"%Y-%m-%d %H:%M:%S\")\n\n # save_page_cache('posts', new_page)\n\n\ndef load_posts(last_post_time=None):\n \"\"\"Скачивалка постов согласно конфигурации. Попутно качает список блогов, если имеется.\"\"\"\n urls = [x.strip() for x in core.config.get('posts', 'urls').split(',') if x.strip()]\n raw_posts = []\n pages = []\n\n for url in urls:\n # узнаём, сколько страниц нам разрешено качать\n if '#' in url:\n url, pages_count = url.split('#', 1)\n if ':' in pages_count:\n min_pages_count, pages_count = pages_count.split(':', 1)\n min_pages_count = max(1, int(min_pages_count))\n pages_count = max(1, int(pages_count))\n else:\n min_pages_count = 1\n pages_count = max(1, int(pages_count))\n else:\n min_pages_count = 1\n pages_count = 1\n\n for page_num in range(1, pages_count + 1):\n current_url = (url.rstrip('/') + ('/page%d/' % page_num)) if page_num > 1 else url\n raw_data = user.open_with_check(current_url)\n worker.call_handlers('raw_data', current_url, raw_data)\n\n posts = user.user.get_posts(url, raw_data=raw_data)\n raw_posts.extend(posts)\n if page_num < 2:\n pages.append(posts)\n\n # не качаем то, что качать не требуется\n tm = (posts[0].utctime - datetime(1970, 1, 1)).total_seconds()\n if page_num >= min_pages_count and last_post_time and tm < last_post_time:\n # ^ посты отсортированы в API по времени в прямом порядке\n break\n\n post_ids = []\n posts = []\n for post in sorted(raw_posts, key=lambda x: x.utctime):\n if post.post_id not in post_ids:\n # ^ исключаем возможные дубликаты (ориентируемся по айдишникам, а не содержимому целиком)\n posts.append(post)\n post_ids.append(post.post_id)\n\n return posts, pages\n\n\ndef get_posts_info(post_ids):\n \"\"\"Возвращает словарь хэшей постов (один хэш - пост до ката, второй хэш - пост целиком). Хэши могут быть None.\"\"\"\n query = ', '.join(text(int(x)) for x in post_ids)\n hashes = db.query(\"select post_id, short_hash, full_hash from posts where post_id in (%s)\" % query)\n return dict((x[0], x[1:]) for x in hashes)\n\n\ndef set_post_info(post_id, tm, short_hash, full_hash):\n \"\"\"Сохраняет хэши поста. Время поста нужно передавать для последующей чистки базы.\"\"\"\n db.execute(\"replace into posts values(?, ?, ?, ?)\", (int(post_id), int(tm), short_hash, full_hash))\n\n\ndef clear_post_info_older(tm):\n \"\"\"Чистит базу от слишком старых постов, чтобы место не забивать.\"\"\"\n db.execute('delete from posts where tm < ?', (int(tm),))\n\n\ndef update_status(key, old, new):\n core.logger.debug('status: %s (%s -> %s)', key, old, new)\n\n\ndef init_tabun_plugin():\n db.init_table('posts', '(post_id int not null primary key, tm int not null, short_hash text default null, full_hash text default null)')\n\n if not worker.status['request_full_posts']:\n worker.status['request_full_posts'] = core.config.getboolean('posts', 'request_full_posts')\n worker.status['iter_last_with_post'] = 0\n worker.add_reader(reader)\n"
},
{
"alpha_fraction": 0.625,
"alphanum_fraction": 0.7678571343421936,
"avg_line_length": 17.66666603088379,
"blob_id": "1ac09e4ea43d45a90f2bbce7b2c9d318a35f1ed7",
"content_id": "1874914de1067061a663b0f8849c6a830f8d63c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 56,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 3,
"path": "/optional-requirements.txt",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "gevent\nmysqlclient>=1.3.6\npython-telegram-bot==12.0.0b1\n"
},
{
"alpha_fraction": 0.6058370471000671,
"alphanum_fraction": 0.6132135987281799,
"avg_line_length": 37.974998474121094,
"blob_id": "016f9e75365a325243c879bbf998bea12fb429e1",
"content_id": "853119a5bd1991c40a90e7ca2d24f2507b192417",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6842,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 160,
"path": "/tabun_feed/readers/comments.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nfrom datetime import datetime\n\nimport tabun_api as api\nfrom tabun_api.compat import text\n\nfrom .. import core, user, worker\nfrom ..db import db, get_db_last, set_db_last\n\n\ndef reader():\n last_comment_time = get_db_last('last_comment_time')\n\n # скачиваем комментарии\n comments, pages = load_comments(last_comment_time)\n\n if core.loglevel == core.logging.DEBUG:\n core.logger.debug('Downloaded %d comments, last 10: %s', len(comments), \", \".join(text(x.comment_id) for x in comments[-10:]))\n \n new_comments = []\n\n comment_infos = get_comments_info(x.comment_id for x in comments)\n\n oldest_comment_time = get_db_last('oldest_comment_time')\n new_oldest_comment_time = None\n new_last_comment_time = None\n\n for comment in comments:\n tm = (comment.utctime - datetime(1970, 1, 1)).total_seconds()\n # слишком старые комментарии игнорируем\n if tm < oldest_comment_time:\n continue\n\n if new_oldest_comment_time is None:\n new_oldest_comment_time = tm\n if new_last_comment_time is None or tm > new_last_comment_time:\n new_last_comment_time = tm\n\n comment_hash = comment_infos.get(comment.comment_id, (None,))[0]\n if comment_hash:\n # комментарий уже был обработан\n new_comment_hash = comment.hashsum()\n if new_comment_hash != comment_hash:\n # Упс, коммент изменили\n set_comment_info(comment.comment_id, tm, new_comment_hash)\n worker.call_handlers('edit_comment', comment)\n continue\n\n comment_hash = comment.hashsum()\n set_comment_info(comment.comment_id, tm, comment_hash)\n\n # отправляем в другой поток на обработку\n if comment.deleted:\n worker.call_handlers(\"new_deleted_comment\", comment)\n else:\n worker.call_handlers(\"new_comment\", comment)\n new_comments.append(comment)\n\n # Для плагинов, желающих обработать все новые комменты в одном обработчике\n worker.call_handlers(\"new_comments\", new_comments)\n\n if core.loglevel == core.logging.DEBUG:\n core.logger.debug('New comments: %s', ', '.join(text(x.comment_id) for x in new_comments))\n\n # стираем слишком старые комментарии\n if new_oldest_comment_time is not None and new_oldest_comment_time != oldest_comment_time:\n set_db_last('oldest_comment_time', new_oldest_comment_time)\n clear_comment_info_older(new_oldest_comment_time)\n\n if new_last_comment_time is not None and new_last_comment_time != last_comment_time:\n set_db_last('last_comment_time', new_last_comment_time)\n\n worker.call_handlers(\"comments_list\", comments)\n\n\ndef load_comments(last_comment_time=None):\n \"\"\"Скачивалка комментариев согласно конфигурации.\"\"\"\n urls = [x.strip() for x in core.config.get('comments', 'urls').split(',') if x.strip()]\n raw_comments = []\n pages = []\n\n for url in urls:\n # узнаём, сколько страниц нам разрешено качать\n if '#' in url:\n url, pages_count = url.split('#', 1)\n if ':' in pages_count:\n min_pages_count, pages_count = pages_count.split(':', 1)\n min_pages_count = max(1, int(min_pages_count))\n pages_count = max(1, int(pages_count))\n else:\n min_pages_count = 1\n pages_count = max(1, int(pages_count))\n else:\n min_pages_count = 1\n pages_count = 1\n\n for page_num in range(1, pages_count + 1):\n current_url = (url.rstrip('/') + ('/page%d/' % page_num)) if page_num > 1 else url\n # комменты грузятся ОЧЕНЬ долго:\n try:\n raw_data = user.open_with_check(current_url, timeout=max(120, user.user.timeout))\n except api.TabunError as exc:\n # Лента может быть убита удалённым блогом; вытаскиваем что получится\n if exc.code != 500:\n raise\n raw_data = exc.exc.read()\n if raw_data.rstrip().endswith(b'<a href=\"') and b'<li class=\"comment-link\">' in raw_data[-100:]:\n core.logger.error('Comments error 500, trying to parse partially')\n else:\n raise\n worker.call_handlers('raw_data', current_url, raw_data)\n\n comments = sorted(user.user.get_comments(current_url, raw_data=raw_data).values(), key=lambda x: x.utctime)\n raw_comments.extend(comments)\n if page_num < 2:\n pages.append(comments)\n\n if not comments:\n core.logger.error('Comments feed returned 0 comments, looks like impossible situation')\n break\n\n # не качаем то, что качать не требуется\n tm = (comments[0].utctime - datetime(1970, 1, 1)).total_seconds()\n if page_num >= min_pages_count and last_comment_time and tm < last_comment_time:\n break\n\n comment_ids = []\n comments = []\n for comment in sorted(raw_comments, key=lambda x: x.utctime):\n if comment.comment_id not in comment_ids:\n comments.append(comment)\n comment_ids.append(comment.comment_id)\n\n return comments, pages\n\n\ndef get_comments_info(comment_ids):\n \"\"\"Возвращает словарь хэшей комментариев. Хэши не могут быть None, в отличие от постов.\"\"\"\n query = ', '.join(text(int(x)) for x in comment_ids)\n hashes = db.query(\"select comment_id, hash from comments where comment_id in (%s)\" % query)\n return dict((x[0], x[1:]) for x in hashes)\n\n\ndef set_comment_info(comment_id, tm, comment_hash):\n \"\"\"Сохраняет хэш комментария. Время нужно передавать для последующей чистки базы.\"\"\"\n db.execute(\"replace into comments values(?, ?, ?)\", (int(comment_id), int(tm), comment_hash))\n\n\ndef clear_comment_info_older(tm):\n \"\"\"Чистит базу от слишком старых комментариев, чтобы место не забивать.\"\"\"\n db.execute('delete from comments where tm < ?', (int(tm),))\n\n\ndef init_tabun_plugin():\n db.init_table('comments', '(comment_id int not null primary key, tm int not null, hash text not null)')\n worker.add_reader(reader)\n"
},
{
"alpha_fraction": 0.6057851314544678,
"alphanum_fraction": 0.6140496134757996,
"avg_line_length": 23.693878173828125,
"blob_id": "1e0ff553be542561b02006c5990695d791a67381",
"content_id": "bd54afba90e350189c6c1a1aea258a3ec8e1537b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1255,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 49,
"path": "/tabun_feed/readers/new_users.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals\n\nimport time\n\nfrom .. import core, user, worker\nfrom ..db import db\n\n\ntic = 4\nuser_list = None\n\n\ndef reader():\n global tic, user_list\n tic += 1\n if tic < 5:\n return # Пользователи появляются редко, не тратим время зазря\n tic = 0\n\n users = user.user.get_people_list(order_by='user_id', order_way='desc')\n\n if core.loglevel == core.logging.DEBUG:\n core.logger.debug('Downloaded %d new users, last 5: %r', len(users), users[:5])\n\n users.reverse()\n\n if user_list is None:\n user_list = [x[0] for x in db.query('select username from new_users')]\n\n for new_user in users:\n if new_user.username in user_list:\n continue\n worker.call_handlers(\"new_user\", new_user)\n db.execute(\n 'insert into new_users values(?, ?)',\n (new_user.username, int(time.time()))\n )\n user_list.append(new_user.username)\n db.commit()\n\n worker.call_handlers(\"users_list\", users)\n\n\ndef init_tabun_plugin():\n db.init_table('new_users', '(username char(32) not null primary key, grabbed_at int not null)')\n worker.add_reader(reader)\n"
},
{
"alpha_fraction": 0.7524219751358032,
"alphanum_fraction": 0.7524219751358032,
"avg_line_length": 24.108108520507812,
"blob_id": "2e8845cd46fc8da94d1d0c22e3d803a2c1e78240",
"content_id": "dade78a1e887a09f537baa6cf582dfc811e2980e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1411,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 37,
"path": "/README.md",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "tabun_feed\n==========\n\nСледилка за Табуном. В стандартной поставке умеет:\n\n* Следить за постами (с учётом публикации из черновиков), комментами, блогами, пользователями, активностью, личными сообщениями;\n\n* Не падать от падений Табуна, перелогиниваться по необходимости;\n\n* Работать в два потока для большей производительности, а также дружить с gevent;\n\n* Предоставлять удалённое управление для более удобного администрирования;\n\n* Подключаться к MySQL и ВКонтакте для работы самописных плагинов.\n\nОстаётся лишь написать ко всему этому нужные вам плагины.\n\n\n#### Установка через pip\n\n```\npip install git+https://github.com/andreymal/tabun_feed.git#egg=tabun_feed\n```\n\n\n#### Пример плагина, печатающего заголовки новых постов\n\n```\nimport time\nfrom tabun_feed import worker\n\ndef new_post(post, full_post):\n print(time.strftime('%H:%M:%S'), post.title)\n\ndef init_tabun_plugin():\n worker.add_handler('new_post', new_post)\n```\n"
},
{
"alpha_fraction": 0.6261886358261108,
"alphanum_fraction": 0.627519965171814,
"avg_line_length": 31.060976028442383,
"blob_id": "6cb7b9a301e65f67d9dbe718e119fb9be0109e66",
"content_id": "0abd47366a24d779c8d4b7a81a7174da72ab98ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12047,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 328,
"path": "/tabun_feed/plugins/telegram_feed/__init__.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals, absolute_import\n\nimport time\n\nimport tabun_api as api\nfrom tabun_api.compat import PY2, text\nfrom telegram import ParseMode\n# from telegram.message import Message\n\nfrom tabun_feed import core, worker, user, db\nfrom tabun_feed.plugins.telegram_feed.queue import FeedQueueItem, queue\nfrom tabun_feed.plugins.telegram_feed import store as tg_store, utils as tg_utils\n\nif PY2:\n from Queue import Empty as QueueEmpty\nelse:\n from queue import Empty as QueueEmpty\n\n\n# config\ndefault_target = None # type: Union[int, str, None]\nallowed_closed_blogs = {'NSFW'} # TODO: настройка списка допустимых закрытых блогов\n\n# variables\ntg = core.load_plugin('tabun_feed.plugins.telegram')\n\n# Здесь хранится число попыток постинга. При превышении определённого значения\n# попытки прекращаются, чтобы не дудосить телеграм зазря\n# Сбрасывается при перезапуске бота\npost_tries = {} # type: Dict[int, int]\nmax_post_tries = 5\n\n\n# Функция, делающая основную работу (работает в отдельном потоке)\n\n\ndef process_new_post(item):\n # type: (FeedQueueItem) -> None\n\n target = default_target\n assert target is not None\n\n start_time = time.time()\n\n # Скачиваем профиль автора для анализа\n # TODO: спискота известных юзеров, чтоб время на скачивание не тратить\n worker.status['telegram_feed'] = 'Getting post author'\n author = tg_utils.get_post_author(item.post.author)\n\n worker.status['telegram_feed'] = 'Process post'\n\n with_attachments = True\n with_link = True # TODO: выпилить?\n\n n = item.post.body\n if author.rating < 30.0:\n # Защищаемся от бризюкового понева\n with_attachments = False\n\n if item.post.private:\n # Не палим награнный контент из (полу)закрытых блогов\n with_link = False\n with_attachments = False\n\n if not with_attachments and with_link and (\n n.xpath('//img') or n.xpath('//embed') or\n n.xpath('//object') or n.xpath('//iframe')\n ):\n # Таким образом прячется картинка из превьюшки ссылки\n with_link = False\n\n with_link = False # А зачем превьюшка в телеграме-то?\n\n # Крепим фоточку\n photo_url = None # type: Optional[text]\n if with_attachments:\n photo_url = tg_utils.build_photo_attachment(item.post, item.full_post)\n\n # Собираем текст поста со всем оформлением\n # (его содержимое зависит от наличия или отсутствия фоточки)\n tg_body = tg_utils.build_body(item.post, short=photo_url is not None)\n tg_body += '\\n\\n' + item.post.url\n\n worker.status['telegram_feed'] = 'Sending post'\n\n # Постим\n result = None # type: Optional[Message]\n if photo_url:\n try:\n # Делаем попытку оптравки с фоточкой\n result = tg.dispatcher.bot.send_photo(\n chat_id=target,\n photo=photo_url,\n caption=tg_body,\n parse_mode=ParseMode.HTML,\n )\n except Exception as exc:\n # Если не получилось — попробуем второй раз без фоточки\n core.logger.warning('telegram_feed: cannot send post with photo: %s', exc)\n time.sleep(1)\n\n if result is None:\n result = tg.dispatcher.bot.send_message(\n chat_id=target,\n text=tg_body,\n parse_mode=ParseMode.HTML,\n disable_web_page_preview=not with_link,\n )\n\n assert result is not None\n end_time = time.time()\n\n # Сохраняем результат в базе\n tg_store.save_post_status(\n item.post.post_id,\n processed_at=end_time,\n status=tg_store.OK,\n status_text=None,\n process_duration=int(round(end_time - start_time)),\n tg_chat_id=result.chat.id,\n tg_message_id=result.message_id,\n )\n\n\n# Обработчики событий\n\n\ndef new_post(post, full_post=None):\n # type: (api.Post, Optional[api.Post]) -> None\n\n if post.private and post.blog not in api.halfclosed and post.blog not in allowed_closed_blogs:\n core.logger.debug('telegram_feed: post %d is closed', post.post_id)\n tg_store.save_post_status(post.post_id, status=tg_store.CLOSED, status_text=None, processed_at=None)\n return\n\n if post.draft:\n core.logger.debug('telegram_feed: post %d is draft', post.post_id)\n tg_store.save_post_status(post.post_id, status=tg_store.CLOSED, status_text=None, processed_at=None)\n return\n\n tg_store.save_post_status(post.post_id, status=tg_store.PENDING, status_text=None, processed_at=None)\n queue.add_post(post, full_post)\n\n\ndef new_blog(blog):\n # с блогами со всякими там очередями и надёжностями не церемонимся, потребность в этом не особо есть\n worker.status['telegram_feed'] = 'Sending blog'\n target = default_target\n\n if blog.status != api.Blog.OPEN:\n tg_body = 'Новый закрытый блог: ' + tg_utils.html_escape(blog.name)\n else:\n tg_body = 'Новый блог: ' + tg_utils.html_escape(blog.name)\n tg_body += '\\n#' + blog.blog.replace('-', '_')\n tg_body += '\\n\\n' + blog.url\n\n notify = False\n try:\n # Постим\n # (TODO: нормальная обработка ошибок)\n tg.dispatcher.bot.send_message(\n chat_id=target,\n text=tg_body,\n parse_mode=ParseMode.HTML,\n disable_web_page_preview=True,\n )\n except Exception:\n notify = True\n\n if notify:\n core.notify('Не удалось запостить новый блог: ' + blog.url)\n\n worker.status['vk'] = None\n\n\n# Основной поток, запускающий постилку постов из очереди\n\n\ndef new_post_thread():\n while not worker.quit_event.is_set():\n # Достаём пост из очереди\n try:\n item = queue.get() # type: Optional[FeedQueueItem]\n except QueueEmpty:\n continue\n\n if item is None:\n # None обычно пихается при выключении бота, так что continue может выйти из цикла\n continue\n\n # Пашем\n post_id = item.post.post_id\n worker.status['telegram_feed_post'] = post_id\n notify_msg = None\n post_tries[post_id] = post_tries.get(post_id, 0) + 1\n\n try:\n with worker.status:\n process_new_post(item)\n\n except (KeyboardInterrupt, SystemExit):\n raise\n\n except Exception as exc:\n worker.fail()\n notify_msg = 'Внутренняя ошибка сервера: {}'.format(text(exc))\n\n if post_tries[post_id] >= max_post_tries:\n # Если было слишком много попыток — расстраиваемся и забиваем болт на пост\n core.logger.warning('telegram_feed: post %d is too failed! Retrying only after restart.', post_id)\n tg_store.save_post_status(\n post_id,\n status=tg_store.PENDING_FAILED,\n status_text=None,\n processed_at=None,\n )\n\n else:\n # Если было не очень много попыток, то попробуем ещё раз попозже\n queue.put(item)\n core.logger.warning('telegram_feed: post %d failed', post_id)\n tg_store.save_post_status(\n post_id,\n status=tg_store.FAILED,\n status_text=None,\n processed_at=None,\n )\n\n finally:\n worker.status['telegram_feed_post'] = None\n worker.status['telegram_feed'] = None\n\n # Если что-то сломалось или отменилось, то уведомляем админа\n if notify_msg is not None:\n # TODO: нормальное исключение, из которого можно достать причину ошибки\n nbody = 'Не удалось запостить пост ' + item.post.url\n if notify_msg:\n nbody += '\\n' + notify_msg\n core.notify(nbody)\n del nbody\n\n # Немного спим между постами, чтоб не флудить\n worker.quit_event.wait(10)\n\n\ndef download_post_to_queue(post_id, reset_tries=False, check_exist=False, extra_params=None):\n # type: (int, bool bool, Optional[Dict[str, Any]], Optional[FeedStoreItem]) -> bool\n\n # Скачивает пост с Табуна и вызывает add_post_to_queue. Проверки\n # на закрытость блога не выполняет.\n\n if check_exist:\n # Здесь никто не отменял гонку данных, так что это проверка выполняет\n # роль просто защиты от дурака\n if queue.has_post(post_id):\n core.logger.debug('telegram_feed: Pending post %d already in queue', post_id)\n return True\n\n try:\n full_post = user.user.get_post(post_id)\n\n except api.TabunError as exc:\n core.logger.warning('telegram_feed: Cannot download post %d: %s', post_id, exc.message)\n tg_store.save_post_status(post_id, status=tg_store.NODOWNLOAD, status_text=None, processed_at=None)\n\n return False\n\n if reset_tries:\n post_tries.pop(post_id, None)\n queue.add_post(full_post=full_post, extra_params=extra_params)\n return True\n\n\ndef restore_queue_from_store(with_failed=False, with_pending_failed=False, reset_tries=False):\n # Загружает PENDING и опционально FAILED и PENDING_FAILED посты\n # из базы данных, в первую очередь чтобы восстановить очередь постов\n # после перезапуска бота.\n\n statuses = {tg_store.PENDING}\n if with_failed:\n statuses |= {tg_store.FAILED}\n if with_pending_failed:\n statuses |= {tg_store.PENDING_FAILED}\n\n items = tg_store.get_rows_by_status(statuses)\n if not items:\n return\n core.logger.info('telegram_feed: process %d pending posts', len(items))\n\n for item in items:\n if worker.quit_event.is_set():\n break\n post_id = item[0]\n download_post_to_queue(post_id, reset_tries, check_exist=True)\n worker.quit_event.wait(2)\n\n\ndef init_tabun_plugin():\n global default_target\n\n if not core.config.has_option('telegram_feed', 'channel') or not core.config.get('telegram_feed', 'channel'):\n return\n default_target = core.config.get('telegram_feed', 'channel')\n\n tg_store.check_db()\n\n core.logger.debug('telegram_feed started')\n core.logger.debug('default target: %s', default_target)\n\n worker.status['telegram_feed'] = None\n worker.status['telegram_feed_post'] = None\n\n worker.add_handler('start', start)\n worker.add_handler('stop', stop)\n worker.add_handler('new_post', new_post)\n worker.add_handler('new_blog', new_blog)\n\n\ndef start():\n worker.start_thread(new_post_thread)\n restore_queue_from_store(with_failed=True, with_pending_failed=True)\n\n\ndef stop():\n queue.put(None)\n"
},
{
"alpha_fraction": 0.6567164063453674,
"alphanum_fraction": 0.65903240442276,
"avg_line_length": 27.573530197143555,
"blob_id": "cb866f733bc289de88501222bac0bf218ce826a1",
"content_id": "c39f90cc4775fd7c5e00f3697de49cfc7b476a88",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3910,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 136,
"path": "/tabun_feed/plugins/telegram.py",
"repo_name": "andreymal/tabun_feed",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import unicode_literals, absolute_import\n\nimport sys\n\nfrom telegram.ext import Updater, CommandHandler, MessageHandler, Filters\n# from telegram.ext.dispatcher import Dispatcher\n# from telegram.message import Message\n# from telegram.update import Update\n# from telegram.ext.callbackcontext import CallbackContext\n\nfrom tabun_feed import core, worker\n\nif sys.version_info.major == 2:\n text = unicode\nelse:\n text = str\n\n# config\n\nread_updates = True\nlog_incoming_messages = True\nfallback_message_text = 'Прости, я не знаю, что ответить.' # type: Optional[str]\n\n# variables\nmessage_handlers = {0: [], 1: [], 2: []}\nupdater = None # type: Optional[Updater]\ndispatcher = None # type: Optional[Dispatcher]\n\n\n# public api\n\n\ndef add_message_handler(handler, priority=1):\n message_handlers[priority].append(handler)\n\n\ndef add_command_handler(command, handler):\n assert dispatcher is not None\n h = CommandHandler(command, handler)\n dispatcher.add_handler(h)\n\n\n# worker\n\n\ndef default_message_handler(update, context):\n # type: (Update, CallbackContext) -> None\n if fallback_message_text:\n context.bot.send_message(chat_id=update.message.chat_id, text=fallback_message_text)\n\n\ndef message_handler(update, context):\n # type: (Update, CallbackContext) -> None\n try:\n message = update.message # type: Optional[Message]\n if message is None:\n # it means update.edited_message is not None\n return\n\n if log_incoming_messages:\n core.logger.info(\n 'Telegram message from %s (%s): %s',\n message.from_user.username if message.from_user else None,\n message.from_user.id if message.from_user else None,\n message.text,\n )\n\n for priority in [0, 1, 2]:\n for handler in message_handlers[priority]:\n if handler(update, context):\n return\n default_message_handler(update, context)\n\n except Exception:\n worker.fail()\n\n\n# init\n\n\ndef start_telegram():\n if updater is None:\n return\n assert dispatcher is not None\n\n if read_updates:\n core.logger.info('Starting Telegram updater thread')\n updater.start_polling()\n else:\n core.logger.info('Telegram started (updater thread is disabled)')\n\n me = dispatcher.bot.get_me()\n core.logger.info('Telegram bot logged in as @%s', me.username or '?')\n\n\ndef stop_telegram():\n if updater is None:\n return\n assert dispatcher is not None\n\n if read_updates:\n core.logger.info('Stopping Telegram updater thread...')\n updater.stop()\n core.logger.info('Telegram stopped')\n\n\ndef init_tabun_plugin():\n global updater, dispatcher, fallback_message_text, read_updates, log_incoming_messages\n\n if not core.config.has_option('telegram', 'bot_token') or not core.config.get('telegram', 'bot_token'):\n return\n\n if core.config.has_option('telegram', 'read_updates'):\n read_updates = core.config.getboolean('telegram', 'read_updates')\n if core.config.has_option('telegram', 'log_incoming_messages'):\n log_incoming_messages = core.config.getboolean('telegram', 'log_incoming_messages')\n\n bot_token = text(core.config.get('telegram', 'bot_token'))\n updater = Updater(token=bot_token, use_context=True)\n dispatcher = updater.dispatcher\n\n h = MessageHandler(Filters.all, message_handler)\n dispatcher.add_handler(h)\n\n worker.add_handler('start', start_telegram)\n worker.add_handler('stop', stop_telegram)\n\n if core.config.has_option('telegram', 'fallback_message_text'):\n fallback_message_text = (\n text(core.config.get('telegram', 'fallback_message_text'))\n if core.config.get('telegram', 'fallback_message_text')\n else None\n )\n"
}
] | 32 |
ng-dat/Webdevelopment.Flask.Base
|
https://github.com/ng-dat/Webdevelopment.Flask.Base
|
f550873b5b84e78613a218e761717ae34220b61f
|
231a53e9b902b33087714b194a98124a3dc06841
|
22744a4f5031db99bcc4aa41b21cc4e1af141680
|
refs/heads/master
| 2022-05-04T23:35:29.944164 | 2018-10-09T08:56:53 | 2018-10-09T08:56:53 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7160839438438416,
"alphanum_fraction": 0.7209790349006653,
"avg_line_length": 35.69230651855469,
"blob_id": "ac3a19bfbb4c7856e3d63fe7d756d667ae818099",
"content_id": "18474848d6d27d9f37dddc67d7ab05124152cd6b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1430,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 39,
"path": "/controllers/account_controller.py",
"repo_name": "ng-dat/Webdevelopment.Flask.Base",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint, session, render_template, abort, request, redirect, jsonify, url_for\nfrom database.database_connector import AccountConnector\n\naccount_controller = Blueprint('account_controller', __name__, template_folder='/templates')\n\n\n@account_controller.route('/showlogin', methods=['GET', 'POST'])\ndef show_login():\n\terror_message = request.args.get('error_message', None)\n\tnext_page = request.args.get('next_page', '/home')\n\treturn render_template('login.html', error_message = error_message, next_page = next_page)\n\n\n@account_controller.route('/checklogin', methods=['POST'])\ndef check_login():\n\tif request.method == 'POST':\n\t\tif request.form['account'] and request.form['password'] and request.form['next_page']:\n\t\t\taccount = request.form['account']\n\t\t\tpassword = request.form['password']\n\t\t\tnext_page = request.form['next_page']\n\t\telse:\n\t\t\tabort(401)\n\telse:\n\t\tabort(401)\n\taccount_connector = AccountConnector()\n\tif account_connector.validate_password(account, password):\n\t\tsession['logged_in'] = True\n\t\tsession['account_info'] = account_connector.get_one(account)[0]\t\t\n\t\treturn redirect(next_page)\n\telse:\n\t\treturn redirect(url_for('account_controller.show_login', error_message = 'Invalid account or password', next_page = next_page))\n\n\n@account_controller.route('/logout', methods=['GET', 'POST'])\ndef logout():\n\tsession['logged_in'] = False\n\tsession['account_info'] = None\n\n\treturn redirect('/showlogin')"
},
{
"alpha_fraction": 0.7121576070785522,
"alphanum_fraction": 0.7126381397247314,
"avg_line_length": 31.03076934814453,
"blob_id": "9f1a623fd897841f0de6dc25d8b69398eb8aa3f4",
"content_id": "a9f7cf166a0f4b61f9d43cac703183377926ff97",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2081,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 65,
"path": "/database/database_connector.py",
"repo_name": "ng-dat/Webdevelopment.Flask.Base",
"src_encoding": "UTF-8",
"text": "from sqlalchemy import create_engine\nfrom sqlalchemy.orm import sessionmaker\nfrom sqlalchemy.orm import load_only\n\nfrom database.database_setup import Base, Account\n\n\nclass DatabaseConnectorBase(object):\n\t\n\tdef __init__(self):\n\t\t# Create session and connect to DB\n\t\tengine = create_engine('sqlite:///flaskserverbase.db')\n\t\tBase.metadata.bind = engine\n\t\tDBSession = sessionmaker(bind=engine)\n\t\tself.session = DBSession()\n\n\nclass AccountConnector(DatabaseConnectorBase):\n\n\tdef __init__(self):\n\t\tsuper( AccountConnector, self).__init__()\n\n\tdef insert_one(self, account, password, role):\n\t\t#check duplicate:\n\t\tif len(self.get_one(account)) > 0:\n\t\t\tprint('Duplicated when inserting account: ' + account)\n\t\t\treturn None\n\n\t\tnew_account = Account(account = account, password = password, role = role)\n\t\tself.session.add(new_account)\n\t\tself.session.commit()\n\n\tdef update_one_role(self, account, new_role):\n\t\t\n\t\tself.session.query(Account).filter_by(account = account).update({'role': new_role})\t\t\n\t\tself.session.commit()\t\n\n\tdef delete_one(self, account):\n\t\tself.session.query(Account).filter_by(account = account).delete()\n\t\tself.session.commit()\n\n\tdef get_one(self, account):\n\t\tlist_accouts = []\n\t\tfor x in self.session.query(Account).filter_by(account = account):\n\t\t\tlist_accouts.append(dict(account = x.account, password = x.password, role = x.role))\n\t\treturn list_accouts\n\n\tdef get_all(self):\n\t\tlist_account = []\n\t\tfor x in self.session.query(Account):\n\t\t\tlist_account.append(dict(account = x.account, password = x.password, role = x.role))\n\t\treturn list_account\n\n\tdef get_by_role(self, role):\t\t\n\t\tlist_accouts = []\t\n\t\tfor x in self.session.query(Account).filter_by(role = role):\n\t\t\tlist_accouts.append(dict(account = x.account, password = x.password, role = x.role))\n\t\treturn list_accouts\n\n\tdef validate_password(self, account, password):\n\t\tdata = self.session.query(Account.account, Account.password).filter_by(account = account)\n\t\tif data == None or data.first() == None:\n\t\t\treturn False\n\t\tdata_acc, data_pass = data.first()\n\t\treturn (account == data_acc and password == data_pass)"
},
{
"alpha_fraction": 0.7326057553291321,
"alphanum_fraction": 0.7489768266677856,
"avg_line_length": 27.230770111083984,
"blob_id": "537fb55fd2e849bb8765a490529f2339d79f6380",
"content_id": "e4d01bfb337215e3a9c9b3de416ebd94f106a984",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 733,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 26,
"path": "/database_initialize.py",
"repo_name": "ng-dat/Webdevelopment.Flask.Base",
"src_encoding": "UTF-8",
"text": "from database.database_connector import AccountConnector\n\naccountConnector = AccountConnector()\n\n#insert\naccountConnector.insert_one(account = 'account1', password = '1', role = 'admin')\naccountConnector.insert_one(account = 'account2', password = '1', role = 'user')\naccountConnector.insert_one(account = 'account3', password = '1', role = 'user')\n\n#query\nfor x in accountConnector.get_all():\n\tprint (x)\n\n#update \naccountConnector.update_one_role(2, 'admin')\nfor x in accountConnector.get_all():\n\tprint (x)\n\n#delete\naccountConnector.delete_one(2)\nfor x in accountConnector.get_all():\n\tprint (x)\n\n#validate password\nprint(accountConnector.validate_password('account1', '1'))\nprint(accountConnector.validate_password('account1', '2'))"
},
{
"alpha_fraction": 0.613043487071991,
"alphanum_fraction": 0.613043487071991,
"avg_line_length": 21.299999237060547,
"blob_id": "bd8bb23a25bf75bbc62f16049d224846141d7ac0",
"content_id": "a99405b6d02f316d6a8dd79fc77bfb21b2fe12ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 230,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 10,
"path": "/readme.md",
"repo_name": "ng-dat/Webdevelopment.Flask.Base",
"src_encoding": "UTF-8",
"text": "#Demo server\n\n#Install:\n - Install docker\n - Build flask image:\n \t- Go to folder ./flask-image\n - Run command: docker build -t flask .\n - Run service: \n - Go to main folder ./\n - Run command: docker-compose up\n\n \n"
},
{
"alpha_fraction": 0.6875687837600708,
"alphanum_fraction": 0.7040703892707825,
"avg_line_length": 25.735294342041016,
"blob_id": "1a0a3227d0dd7fc680c2fc8262437b5000762482",
"content_id": "824031ef0c78e7dcb64140ccab373fb83bae3499",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 909,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 34,
"path": "/database/database_setup.py",
"repo_name": "ng-dat/Webdevelopment.Flask.Base",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nfrom sqlalchemy import Column, ForeignKey, Integer, String\nfrom sqlalchemy.ext.declarative import declarative_base\nfrom sqlalchemy.orm import relationship\nfrom sqlalchemy import create_engine\n\nBase = declarative_base()\n\n\n# class MenuItem(Base):\n# __tablename__ = 'menu_item'\n\n# name = Column(String(80), nullable=False)\n# id = Column(Integer, primary_key=True)\n# description = Column(String(250))\n# price = Column(String(8))\n# course = Column(String(250))\n# restaurant_id = Column(Integer, ForeignKey('restaurant.id'))\n# restaurant = relationship(Restaurant)\n\n\nclass Account(Base):\n __tablename__ = 'account'\n\n account = Column(String(80), nullable=False, primary_key=True)\n password = Column(String(80), nullable=False)\n role = Column(String(80))\n \n\nengine = create_engine('sqlite:///flaskserverbase.db')\n\n\nBase.metadata.create_all(engine)\n"
},
{
"alpha_fraction": 0.6657276749610901,
"alphanum_fraction": 0.6910797953605652,
"avg_line_length": 26.33333396911621,
"blob_id": "5f58377db58b885aa098e16bedeb2d44e9ffb302",
"content_id": "e859645e97a706cba4e4162ccf5e03ad3a76716c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1065,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 39,
"path": "/app.py",
"repo_name": "ng-dat/Webdevelopment.Flask.Base",
"src_encoding": "UTF-8",
"text": "from flask import Flask, session, render_template, abort, request, redirect, jsonify, url_for\nfrom functools import wraps\n\nfrom controllers.account_controller import account_controller\n\napp = Flask(__name__)\napp.register_blueprint(account_controller)\n\n\ndef login_required(f):\n @wraps(f)\n def decorated_function(*args, **kwargs):\n if (not session.get('logged_in')) or (not session['logged_in']):\n return redirect(url_for('account_controller.show_login', next_page = request.url[7:]))\n return f(*args, **kwargs)\n return decorated_function\n\n\[email protected](401)\ndef page_not_found(e):\n\treturn render_template('401.html'), 401\n\n\[email protected](404)\ndef page_not_found(e):\n\treturn render_template('404.html'), 404\n\n\[email protected]('/home', methods=['GET', 'POST'])\n@login_required\ndef home():\n\taccount_info = session.get('account_info', None)\n\treturn render_template('home.html', account = account_info['account'])\n\n\nif __name__ == '__main__':\n\tapp.secret_key = 'super secret key'\n\tapp.debug = True\n\tapp.run(host='0.0.0.0', port=5000)"
},
{
"alpha_fraction": 0.8888888955116272,
"alphanum_fraction": 0.8888888955116272,
"avg_line_length": 10.5,
"blob_id": "108bdfad84443374f981e311ed96facfad9be259",
"content_id": "d227e59a89768871a0ed209c3aefab1330e8686f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 45,
"license_type": "no_license",
"max_line_length": 16,
"num_lines": 4,
"path": "/flask-image/python_requirement.txt",
"repo_name": "ng-dat/Webdevelopment.Flask.Base",
"src_encoding": "UTF-8",
"text": "flask\nflask_sqlalchemy\nrequests\nFlask-Session"
}
] | 7 |
Ming-is/pyFEpX
|
https://github.com/Ming-is/pyFEpX
|
e153925de9f9267aac082c3080fdb06c980b9fc7
|
f95851e41025fb57893041d0395d53a5745b7e6c
|
77bc5842163f31a05698e14ea97bad87373e1a2b
|
refs/heads/master
| 2023-04-14T16:35:07.350082 | 2021-05-03T01:13:46 | 2021-05-03T01:13:46 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5528913140296936,
"alphanum_fraction": 0.5688953399658203,
"avg_line_length": 24.151472091674805,
"blob_id": "371e2a9b113479ffa3a924b1f66e1c6542b89b45",
"content_id": "aedf4131fda73c6e819a830ee3f2e011666e7c1e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17933,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 713,
"path": "/PythonScripts/Sphere.py",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport scipy as sci\nimport scipy.spatial as scisp\nimport Utility as utl\nimport FiniteElement as fem\nimport importlib\n\n'''\nThis program was written by Robert Carson on June 10th, 2015.\nIt is based upon the OdfPf library that the Deformation Processing Lab has written in MATLAB.\n\nThe following functions are available in this module:\n\nEqualArea\nProjStereo\nPSphDistance\nPSphGaussian\nSphBaseMesh\nXYZOfThetaPhi\nSphCrdMesh\nSpherePz\nSphDistanceFunc\n\n'''\n\n\ndef EqualArea(p3d, *args):\n '''\n EqualArea - Equal area projection on sphere.\n \n USAGE:\n\n p2d = EqualArea(p3d)\n p2d = EqualArea(p3d, basis)\n\n INPUT:\n\n p3d is 3 x n,\n a list of n unit vectors\n basis is a 3 x 3 matrix, (optional)\n it's columns form an orthonormal basis used to find the\n projection; defaults to the identity\n\n OUTPUT:\n\n p2d is a real 2 x n array:\n the equal area projections of points in `p3d'\n\n NOTES:\n\n * The equal area projection is computed using the \n third basis vector as the pole. Planar components\n are given relative to the first two basis vectors.\n\n\n '''\n p3d = np.atleast_2d(p3d)\n\n if len(args) == 0:\n pcrd = p3d\n else:\n pcrd = args[0].T * p3d\n\n zfac = np.sqrt(2 / (1 + pcrd[2, :]))\n p2d = np.tile(zfac, (2, 1)) * pcrd[0:2, :]\n\n return p2d\n\n\ndef ProjStereo(p3d, *args):\n '''\n ProjStereo - stereographic projection\n \n USAGE:\n\n p2d = ProjStereo(p3d)\n p2d = ProjStereo(p3d, basis)\n\n INPUT:\n\n p3d is 3 x n,\n a list of n unit vectors\n basis is a 3 x 3 matrix, (optional)\n it's columns form an orthonormal basis used to find the\n projection; defaults to the identity\n\n OUTPUT:\n\n p2d is a real 2 x n array:\n the stereographic projections of points in `p3d'\n\n NOTES:\n\n * The projection is computed from the south pole relative\n to the basis.\n * Also not that there are many stereographic projections depending on\n where the projection plane is put relative to the pole.\n\n\n '''\n p3d = np.atleast_2d(p3d)\n\n if len(args) == 0:\n pcrd = p3d\n else:\n pcrd = args[0].T * p3d\n\n zfac = 1 + pcrd[2, :]\n p2d = np.concatenate((np.atleast_2d(pcrd[0, :] / zfac),\n np.atleast_2d(pcrd[1, :] / zfac)), axis=0)\n\n return p2d\n\n\ndef PSphDistance(pt, ptlist):\n '''\n PSphDistance - Distance on projective sphere.\n\n USAGE:\n\n dist = PSphDistance(pt, ptlist)\n\n INPUT:\n\n pt is 3 x 1, \n a point on the unit sphere (S^2)\n ptlist is 3 x n, \n a list of points on the unit sphere\n\n OUTPUT:\n\n dist is 1 x n, \n the distance from `pt' to each point in the list\n\n NOTES:\n\n * The distance between two points on the sphere is the angle\n in radians between the two vectors. On the projective\n sphere, antipodal points are considered equal, so the \n distance is the minimum of the distances obtained by\n including the negative of pt as well.\n\n '''\n\n pt = np.atleast_2d(pt)\n ptlist = np.atleast_2d(ptlist)\n\n n = ptlist.shape[1]\n ptmat = np.tile(pt, (1, n))\n\n pt1 = np.arccos(np.sum(ptmat.conj() * ptlist, axis=0))\n pt2 = np.arccos(np.sum((-1 * ptmat.conj()) * ptlist, axis=0))\n\n dist2 = np.concatenate((np.atleast_2d(pt1), np.atleast_2d(pt2)), axis=0)\n\n dist = np.min(dist2, axis=0)\n\n return dist\n\n\ndef PSphGaussian(center, pts, stdev):\n '''\n PSphGaussian - Gaussian distribution for smoothing on projective sphere.\n \n USAGE:\n\n fsm = PSphGaussian(center, pts, stdev)\n\n INPUT:\n\n center is 3 x 1, \n the center of the distribution\n pts is 3 x n, \n a list of points on the sphere; antipodal\n points are considered equal\n stdev is 1 x 1, \n the (1D) standard deviation\n\n OUTPUT:\n\n fsm is 1 x n, \n the list of values at each point of pts\n\n Notes: \n\n * The result is not normalized, so this may have to be\n done after the fact.\n * The distribution is a 1-D normal distribution applied\n to the distance function on the projective sphere.\n * The actual scaling factor to give unit integral over \n the projective sphere is not computed; the result\n is not normalized.\n\n\n '''\n\n twosigsq = 2 * (stdev ** 2)\n theta = PSphDistance(center, pts)\n minusthetasq = -1 * theta * theta\n fsm = (1 / (stdev * np.sqrt(2 * np.pi))) * np.exp(minusthetasq / twosigsq)\n\n return fsm\n\n\ndef SphBaseMesh(dim, **kwargs):\n '''\n SphBaseMesh - Generate base mesh for spheres.\n \n USAGE:\n\n mesh = SphBaseMesh(dim)\n mesh = SphBaseMesh(dim, 'param', 'value')\n\n INPUT:\n\n dim is a positive integer,\n the dimension of the sphere (2 for the usual sphere S^2)\n\n These arguments can be followed by a list of\n parameter/value pairs which specify keyword options.\n Available options include:\n\n 'Hemisphere' 'True | False'\n to mesh only the upper hemisphere\n\n\n OUTPUT:\n\n mesh is a MeshStructure,\n on the sphere of the specified dimension\n\n NOTES:\n\n * For S^2, the normals may be mixed, some outer, some inner. \n This needs to be fixed.\n\n\n '''\n\n if len(kwargs) == 0:\n\n HEMI = False\n\n else:\n\n HEMI = kwargs['Hemisphere']\n\n n = dim\n\n caxes = np.diag(np.arange(1, n + 2))\n pts = np.concatenate((np.zeros((n + 1, 1)), caxes, -caxes), axis=1)\n\n conlen = 2 ** (n + 1)\n\n if HEMI:\n pts = pts[:, 0:-1]\n conlen = 2 ** n\n\n tcon = scisp.Delaunay(np.transpose(pts), qhull_options='QJ').simplices.T\n con = tcon - 1\n con = np.atleast_2d(con[con > -1]).reshape((n + 1, conlen))\n\n mesh = {}\n\n mesh['con'] = con\n mesh['crd'] = utl.UnitVector(pts[:, 1:])\n mesh['simplices'] = tcon\n\n return mesh\n\n\ndef XYZOfThetaPhi(thetaphi):\n '''\n XYZOfThetaPhi - Map spherical coordinates to sphere.\n\n USAGE:\n\n xyz = XYZOfThetaPhi(thetaphi)\n\n INPUT:\n\n thetaphi is 2 x n, \n the spherical coordinates for a list of n points; \n theta is the angle that the projection onto x-y plane \n makes with the x-axis, and phi is the angle with z-axis\n\n OUTPUT:\n\n xyz is 3 x n, \n the Cartesian coordinates of the points described by (theta, phi)\n\n\n '''\n\n thetaphi = np.atleast_2d(thetaphi)\n\n if thetaphi.shape[0] == 1:\n thetaph = thetaphi.T\n\n theta = thetaphi[0, :]\n phi = thetaphi[1, :]\n\n ct = np.cos(theta)\n st = np.sin(theta)\n\n sp = np.sin(phi)\n\n xyz = np.concatenate((np.atleast_2d(sp * ct), np.atleast_2d(sp * st), np.atleast_2d(np.cos(phi))), axis=0)\n return xyz\n\n\ndef SphCrdMesh(ntheta, nphi, **kwargs):\n '''\n SphCrdMesh - Generate a hemisphere mesh based on spherical coordinates.\n \n USAGE:\n\n smesh = SphCrdMesh(ntheta, nphi)\n\n INPUT:\n\n ntheta is a positive integer,\n the number of subdivisions in theta\n nphi is a positive integer,\n the number of subdivisions in phi\n\n These arguments can be followed by a list of\n parameter/value pairs which specify keyword options.\n Available options are listed below with default values\n shown in brackets.\n\n 'MakeL2ip' {'on'}|'off'\n computes the L2 inner product matrix and \n adds it to the mesh structure as a field .l2ip\n 'QRule' string {'qr_trid06p12'}\n name of a quadrature rule for triangles, to be used\n in building the l2ip matrix\n 'PhiMax' scalar\n largest angle with the vertical z-axis, i.e. for \n incomplete pole figure data\n\n OUTPUT:\n\n smesh is a MeshStructure,\n on the hemisphere (H^2)\n\n NOTES:\n\n * No equivalence array is produced.\n \n '''\n makel2ip = kwargs.get('MakeL2ip', True)\n qrule = kwargs.get('QRule', 'qr_trid06p12')\n phimax = kwargs.get('PhiMax', np.pi / 2)\n\n tdiv = 2 * np.pi * np.arange(ntheta + 1) / ntheta\n pdiv = phimax * np.arange(nphi + 1) / nphi\n\n phi, theta = np.meshgrid(pdiv, tdiv)\n npts = (ntheta + 1) * (nphi + 1)\n\n thetaphi = np.concatenate((theta.T.reshape((1, npts)), phi.T.reshape((1, npts))), axis=0)\n\n xyz = XYZOfThetaPhi(thetaphi)\n\n nt1 = ntheta + 1\n np1 = nphi + 1\n\n leftedge = np.arange(0, 1 + nt1 * nphi, nt1)\n rightedge = leftedge + ntheta\n\n SeeNodes = np.arange(npts)\n SeeNodes[rightedge] = leftedge\n SeeNodes[0:nt1] = 0\n\n UseThese = SeeNodes >= np.arange(npts)\n nreduced = sum(UseThese)\n\n scrd = xyz[:, UseThese]\n\n NewNode = np.arange(npts)\n Masters = NewNode[UseThese]\n NewNode[Masters] = np.arange(nreduced)\n\n top = np.arange(nt1 * nphi, npts)\n OldNodes = np.arange(npts)\n OldNodes[rightedge] = -1\n OldNodes[top] = -1\n NodeOne = np.atleast_2d(OldNodes[OldNodes > -1])\n\n tcon1 = np.concatenate((NodeOne, NodeOne + 1, NodeOne + nt1 + 1))\n tcon2 = np.concatenate((NodeOne, NodeOne + nt1 + 1, NodeOne + nt1))\n tmpind = np.concatenate((tcon1, tcon2), axis=1)\n tmpcon = NewNode[SeeNodes[tmpind]]\n\n Eq12 = (tmpcon[1, :] - tmpcon[0, :]) == 0\n Eq13 = (tmpcon[2, :] - tmpcon[0, :]) == 0\n Eq23 = (tmpcon[1, :] - tmpcon[2, :]) == 0\n\n Degenerate = np.any([Eq12, Eq13, Eq23], axis=0)\n\n scon = tmpcon[:, np.logical_not(Degenerate)]\n smesh = {'crd': scrd, 'con': scon, 'eqv': []}\n\n '''\n Need to still add section where L2ip is calculated for the sphere\n and then added to mesh dict:\n Uncomment with all of this is implemented\n if makel2ip:\n smesh['l2ip'] = SphGQRule(smesh, LoadQuadrature(qrule))\n '''\n\n return smesh\n\n\n'''\nWon't be able to test this part just quite yet\n'''\n\n\ndef SphDifferential(mesh, refpts): # not finished yet need to work on this later\n '''\n SphDifferential - Compute differential of mapping to sphere.\n \n USAGE:\n\n diff = SphDifferential(mesh, refpts)\n\n INPUT:\n\n mesh is a mesh,\n on a sphere of any dimension\n refpts is d x n, \n a list of points in the reference element,\n usually the quadrature points, given in barycentric\n coordinates\n\n OUTPUT:\n\n diff is d x (d-1) x nq, \n a list of tangent vectors at each reference\n point for each element; nq is the number of global \n quadrature points, that is n x ne, where ne is the\n number of elements\n\n '''\n\n crd = mesh['crd']\n con = mesh['con']\n\n dr = refpts.shape\n dc = crd.shape\n d = con.shape\n\n if dc[0] != d[0]:\n raise ValueError('dimension mismatch: coords and elements')\n if dr[0] != d[0]:\n raise ValueError('dimension mismatch: ref pts and elements')\n\n dm1 = d - 1\n\n '''\n \n First compute tangent vectors at intermediate\n mapping to inscribed simplex. Make a copy for \n each quadrature point.\n\n\n '''\n \n \ndef SpherePz(x, nargout=1):\n '''\n \n SpherePZ - Generate point, gradients and Hessians of map to sphere.\n \n USAGE:\n \n sk = SpherePZ(x)\n [sk, gk] = SpherePZ(x)\n [sk, gk, Hk] = SpherePZ(x)\n \n INPUT:\n \n x is d x 1, \n a vector with norm <= 1\n \n nargaout is number of outputted arguments and this is needed since python\n does not have it's own equivalent of nargout from matlab and defaults\n to 1 nargout\n \n OUTPUT:\n \n sk is e x 1, \n a point on the sphere (sqrt(1-x^2), x)\n gk is d x e, \n the gradients of each component of sk\n Hk is d x d x e, \n the Hessians of each component of sk\n\n '''\n x = np.atleast_2d(x)\n if x.shape[0] == 1:\n x = x.T\n d = x.shape[0]\n \n Nx = np.sqrt(1-np.dot(x.T, x))\n \n sk = np.concatenate((Nx,x), axis=0)\n\n \n if nargout == 1:\n return sk\n \n mNxi = -1/Nx\n gN = mNxi*x\n\n gk = np.concatenate((gN, np.identity(d)), axis=1)\n \n if nargout == 2:\n return (sk, gk)\n \n dzero = np.zeros((d,d*d))\n lmat = np.identity(d)+np.dot(gN, gN.T)\n Hk = np.concatenate((mNxi*lmat, dzero), axis=1)\n \n Hk = Hk.T.reshape((d+1,d,d)).T\n \n return (sk, gk, Hk)\n \ndef SphDistanceFunc(x, pts, Sofx, nargout=1):\n '''\n \n SphDistanceFunc - Return half sum of squared distances on sphere.\n \n USAGE:\n \n f = SphDistanceFunc(x, pts, @Sofx)\n [f, gf] = SphDistanceFunc(x, pts, @Sofx)\n [f, gf, Hf] = SphDistanceFunc(x, pts, @Sofx)\n \n INPUT:\n \n x is d x 1, \n a point in parameter space \n pts is (d+1) x n, \n a list of n points on the sphere\n Sofx is a function handle and is a string, \n returning parameterization component quantities \n (function, gradient and Hessian) \n nargaout is number of outputted arguments and this is needed since python\n does not have it's own equivalent of nargout from matlab and defaults\n to 1 nargout\n \n OUTPUT:\n \n f is a scalar, \n the objective function at x\n gf is a vector, \n the gradient of f at x\n Hf is a matrix, \n the Hessian of f at x\n \n NOTES:\n \n * See MisorientationStats\n \n '''\n \n x = np.atleast_2d(x)\n \n if x.shape[0] == 1:\n x = x.T\n \n pts = np.atleast_2d(pts)\n \n if pts.shape[0] == 1:\n pts = pts.T\n d1, n = pts.shape\n d = d1 - 1 # dimension of parameter space\n \n # this part creates a function evaluation handle to behave like matlab's \n # feval \n modStr = utl.findModule(Sofx)\n feval = getattr(importlib.import_module(modStr), Sofx)\n \n if nargout == 1:\n s = feval(x, nargout) # function value only\n elif nargout == 2:\n s, gs = feval(x, nargout) # gradient now included\n else:\n s, gs, Hs = feval(x, nargout) # hessian now included\n Hs = Hs.T.reshape((d1, d*d)).T # more efficient form for later use\n \n # Return function value \n ctheta = np.minimum(1, np.dot(s.T, pts))\n ctheta = np.atleast_2d(ctheta)\n thetai = np.arccos(ctheta)\n \n f = 0.5*np.dot(thetai,thetai.T)\n \n if nargout == 1:\n return f\n \n # Compute gradient\n \n gc = np.dot(gs, pts)\n \n stheta = np.sin(thetai)\n \n limit = (thetai <= np.finfo(float).eps) # below machine eps\n nlimit = (thetai > np.finfo(float).eps) # above machine eps\n \n thfac1 = np.zeros(stheta.shape)\n \n thfac1[nlimit] = thetai[nlimit]/stheta[nlimit]\n thfac1[limit] = 1\n \n gf = -1*np.dot(gc, thfac1.T)\n \n if nargout == 2:\n return (f, gf)\n \n # Compute Hessian\n \n Hc = np.dot(Hs, pts)\n \n limit = (thetai <= np.power(np.finfo(float).eps,1.0/3.0)) # below machine eps\n nlimit = (thetai > np.power(np.finfo(float).eps,1.0/3.0)) # above machine eps\n \n thfac3 = np.zeros(stheta.shape)\n \n thfac3[nlimit] = (stheta[nlimit] - thetai[nlimit]*ctheta[nlimit])/(stheta[nlimit]*stheta[nlimit]*stheta[nlimit])\n thfac3[limit] = 1.0/3.0\n \n gcgct = utl.RankOneMatrix(gc).T.reshape((n, d*d)).T\n \n Hf = np.dot(gcgct, thfac3.T) - np.dot(Hc, thfac1.T)\n \n Hf = Hf.T.reshape(d,d).T\n \n return (f, gf, Hf)\n \ndef SphereAverage(pts, **kwargs):\n '''\n SphereAverage - Find `average' of list of points on sphere.\n \n USAGE:\n \n avg = SphereAverage(pts)\n [avg, optdat] = SphereAverage(pts, Pzation, nlopts)\n \n INPUT:\n \n pts is m x n, \n a list of n points in R^m of unit length\n kwargs:\n x0 is the initial guess,\n in given parameterization\n nlopts are options to be passed to the nonlinear minimizer.\n \n OUTPUT:\n \n avg is m x 1, \n is a unit vector representing the \"average\" of `pts'\n optdat is a cell array, \n with three members, {fval, exitflag, output}\n (see documentation for `fminunc')\n \n NOTES:\n \n * If only one argument is given, the average returned is \n the arithmetic average of the points. If all three arguments\n are given, then the average is computed using unconstrained\n minimization of the sum of squared angles from the data points,\n using the parameterization specified and the options given.\n \n * See the matlab builtin `fminunc' for details.\n \n * This routine needs to be fixed. Currently it uses the\n parameterization given by `SpherePZ' instead of the \n function handle `PZation'.\n \n '''\n \n pts = np.atleast_2d(pts)\n \n if pts.shape[0] == 1:\n pts = pts.T\n \n avg = utl.UnitVector(np.sum(pts, axis=1)) # all that misorienataionstats uses\n if len(kwargs) == 0:\n return avg\n else:\n wts = kwargs.get('wts', None)\n if wts is not None:\n# wts = np.tile(wts, (m,1))\n avg = utl.UnitVector(np.sum(pts*wts, axis=1))\n return avg\n \n #==============================================================================\n # x0 = kwargs.get('x0',None)\n # nlopts = kwargs.get('nlopts',None)\n # \n # fun = 'SphDistanceFunc'\n #==============================================================================\n \n '''\n optimization part maybe have it feed in the average from above as an\n initial guess for where the center should be located though the avg values\n should only be the vector values and not the scalar so avg[1:4] and not \n avg[:]\n '''\n"
},
{
"alpha_fraction": 0.5595152974128723,
"alphanum_fraction": 0.586600124835968,
"avg_line_length": 28.23958396911621,
"blob_id": "74dbf72736bc762a1ae5d60cc96017ff1620e120",
"content_id": "d0bccdf06b62273ff98dd98d1898aaacc60abbe7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2806,
"license_type": "permissive",
"max_line_length": 137,
"num_lines": 96,
"path": "/PythonScripts/lofem_post_processing_test.py",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat Apr 22 13:30:15 2017\n\n@author: robertcarson\n\"\"\"\n\nimport FePX_Data_and_Mesh as fepxDM\nimport numpy as np\nimport FiniteElement as fe\nfrom latorifem import mainlatprogram as latfem\n\n\nfloc = '/Users/robertcarson/Research_Local_Code/fepx_master/Examples/ControlMode/'\nfname = 'n2_small'\n#fBname = 'gr_agamma'\n\nmesh = fepxDM.readMesh(floc,fname)\n#\nnproc = 2\nnframe = 14\nngrains = 1\n\n#%%\n\ndata = fepxDM.readData(floc, nproc, None, ['stress_q', 'adx'])\n#\n##%%\n#ncrds = mesh['crd'].shape[1]\nnslip = data['stress_q'].shape[1]\n\n\nNsf = fe.sfmat()\n\nNTNsf, NT = fe.sftsfmat()\n\n#ag_nodal = np.zeros((nslip, ncrds, nframe))\n#residuals = np.zeros((nslip, nframe))\n#\nfor grnum in range(ngrains):\n print(\"Starting grain number: \"+str(grnum+1))\n lcon, lcrd, upts, uelem = fe.localConnectCrd(mesh, grnum+1)\n indlog = mesh['grains'] == grnum+1\n agamma = data['stress_q'][:,:,indlog,:]\n ncrds = lcrd.shape[1]\n \n nel = lcon.shape[1]\n \n amat2 = fe.gr_lstq_amat(lcon, Nsf, ncrds)\n \n ag_nodal = np.zeros((nslip, ncrds, nframe))\n ag_nodal2 = np.zeros((nslip, ncrds, nframe))\n residuals = np.zeros((nslip, nframe))\n \n ncrd = lcrd.shape[1]\n ngdot = 12\n ncvec = ncrd*3\n dim = 3\n nnpe = 9\n kdim1 = 29\n \n gdot = np.zeros((nel,12))\n vel = np.zeros((ncrd, 3))\n strain = np.zeros((nel,3,3))\n gdot = np.zeros((nel,12))\n density = np.zeros((12, nel))\n grod0 = np.zeros((ncvec, 1))\n ang = np.zeros((ncrd, 3))\n crd = np.zeros((ncrd, 3))\n \n latfem.initializeall(nel, ngdot, ncrd)\n \n for j in range(nframe):\n \n print(\"Starting frame: \"+str(j)+\" out of:\" + str(nframe))\n \n crd[:,:] = np.squeeze(data['coord'][:,upts, j]).T\n latfem.setdata(strain, gdot, vel, lcon.T, crd, grod0, nel1=nel-1, dim1=dim-1, ngd1=ngdot-1, ncr1=ncrd-1, nnp=nnpe, ncvc1=ncvec-1)\n qpt_det = latfem.getjacobiandet(nel1=nel-1, nqp1=14)\n amat = fe.superconvergence_mat(NTNsf, qpt_det, lcon.T, ncrds)\n bvec = fe.superconvergence_vec(NT, qpt_det, lcon.T, agamma[:, :, :, j], ncrds)\n ag_nodal[:,:,j] = fe.superconvergnce_solve(amat, bvec)\n ag_nodal2[:, :, j], residuals[:, j] = fe.gr_lstq_solver(amat2, agamma[:, :, :, j], ncrds)\n## \n## \n latfem.deallocate_vars() \n# strgrnum = np.char.mod('%4.4d', np.atleast_1d(grnum+1))[0]\n# with open(floc+fBname+strgrnum+'.data','ab') as f_handle:\n# for j in range(nframe):\n# f_handle.write(bytes('%Frame Number'+str(j)+'\\n','UTF-8'))\n# for k in range(ncrds):\n# np.savetxt(f_handle,np.squeeze(ag_nodal[:, k, j]), newline = ' ')\n# f_handle.write(bytes('\\n','UTF-8'))\n# \n# print(\"Finished grain number: \"+str(grnum+1))"
},
{
"alpha_fraction": 0.5546375513076782,
"alphanum_fraction": 0.5661266446113586,
"avg_line_length": 46.22256088256836,
"blob_id": "1b0f8e2a17e10a916e8d6912e54571675aab76e1",
"content_id": "0950dd01af034c75b2492e505f139e284a2a5951",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15493,
"license_type": "permissive",
"max_line_length": 121,
"num_lines": 328,
"path": "/PythonScripts/graph_cc_dfs.py",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Thu Jun 29 10:53:05 2017\n\n@author: robertcarson\n\"\"\"\n\nimport numpy as np\n\ndef graph_DFS(graph, set_true, set_false):\n '''\n Terminology needs to be worked on to be more in line with the\n actual math terms...\n \n A graph traversal to find all connected components in the graph\n using a DFS method. Connected components are determined by if a\n node is true or false, which is determined from the logical array\n passed into the function. If it is true two nodes are said to be\n connected.\n \n It should be noted that this nodes here could be an element or a\n node in a finite element type mesh. The node just refers to a\n vertex in an undirected graph.\n \n The graph inputed is a list of each node and the nodes connected\n to it by a vertex. In a finite element mesh there are a large\n number of ways in which the connected nodes could be determined.\n If one is examining connected elements, the connected codes could\n be other elements that share a common face, edge, or node with the\n element. If one is examining a node this could vary quite a bit\n from nodes that are connected to nodes that share the same element\n as the parent node. It is up to the user to determine how they want\n these graphs to be formed.\n \n The method will require two stacks. One where we traverse through\n the graph which is a list of nodes and their \"local graph\". The\n second stack is required for the DFS.\n \n Input:\n graph: a list of sets that contain each nodes neighbor in the\n global graph/mesh\n set_true: a set of nodes that are true\n set_false: a set of nodes that are false\n Output:\n con_comp: a list of sets that has all the various connected\n components in the global graph/mesh\n '''\n \n #Creating the stack of nodes to go through \n stack_node = []\n #We already know which ones are good so no need to do extra work\n stack_node.extend(set_true)\n #This stack is initially empty\n stack_DFS = []\n #We want the nodes that have been seen to be a set for fast look ups\n #We are setting it equal to our false set to start off with\n seen = set_false\n #We want to make a con_comp to be an empty list but will have sets\n #in it later as we go through the nodal stack.\n con_comp = []\n \n \n while stack_node:\n #Pop off an element from our nodal stack to examine the data\n i = stack_node.pop()\n #Check to see if that node has already been seen\n if i not in seen:\n #Go ahead and add that node to seen \n seen.add(i)\n #We now create an empty set for our connected components\n tmp_con_comp = set()\n #Go ahead and add the node we are starting off with\n tmp_con_comp.add(i)\n #Form the stack for our stack_DFS with node I's nodal neighbors\n stack_DFS.extend(graph[i])\n while stack_DFS:\n j = stack_DFS.pop()\n #We already know it must be true and it hasn't been seen yet\n if j not in seen: \n #Add to j to tmp_con_comp\n tmp_con_comp.add(j)\n #Add node j to seen\n seen.add(j)\n #Extend our stack_DFS with node J's nodal neighbors\n stack_DFS.extend(graph[j])\n #We can now add the temporary connected component set to our \n #connected components list\n con_comp.append(tmp_con_comp)\n\n #We can now return all of the connected components in the global \n #graph/mesh\n return con_comp\n\ndef tf_sets(logical_array):\n '''\n A simple helper function that takes in a numpy logical array and\n turns it into two sets. One set corresponds to all of the indices\n in the logical array that are true. The other set corresponds to\n all of the indices in the logical array that are false.\n \n Input: logical_array - a numpy logical array\n Output: tr_set - a set of all the indices that correspond to true\n values in logical_array\n f_set - a set of all the indices that correspond to false\n values in logical_array\n '''\n \n tr_set = set()\n f_set = set()\n \n i = 0\n \n for log in logical_array:\n if log:\n tr_set.add(i)\n else:\n f_set.add(i)\n i += 1\n \n return (tr_set, f_set)\n \ndef global_conn_comps_rss(conn_comps, gb_inter_rss, gb_elem_conn, grains):\n '''\n This file takes in the connected component dictionary created earlier.\n It then using the conditions set by the resolved shear stress slip boundary\n criterions to create the global connected component set. It therefore\n requires the grain boundary connectivity array and the grains associated\n with each element. From this data it will construct a list of sets that contain\n tuples that says what grain number our set is from, the slip system number of that set,\n and finally the set from that slip system that has our connected components.\n Initially, the list contains all of the connected components in it before we've started\n combining sets. We'll go through our gb_inter_rss and use that to determine if any of our sets are\n connected. The nice thing here is we only have to check one node from each grain element to see if\n we have any sets that can be combined. If they are connected we go and find where our\n two tuples are located. We combine the sets that both belong to and replace the first set we came\n across with the new set. We delete the latter set from our list. By constructing everything this way,\n when we finish going through all of the grain boundary interaction list we will have our final list\n of global connected components.\n Input:\n conn_comps - a dictionary of dictionarys that has the following keys:\n the first key is our grain number and the second key is our slip system number.\n In our innermost dictionary we store a list of sets of all of the connected components associated\n with that slip system for a particular grain.\n gb_inter_rss - A similar structure to gr_inter_list. \n A dictionary that contains all of the possible GB element\n interactions. The keys are a tuple of (GB_e1, GB_e2) where\n GB_e1 and GB_e2 are the sorted grain elements. \n The contents of the dictionary at a specific key are a list\n with two numpy arrays. The first array contains the permutations\n of all of the xtal_sn indices. It also contains which slip systems have the\n highest resolved shear stress for that slip normal. The order goes perms and then\n corresponds ss num for GB_e1 and GB_e2 respectively. The second array is a numpy\n boolean array that tells us if slip transferal is even possible there.\n This dictionary will have to be recreated at each simulation step due to there\n being new stress values. The nice thing it also will tell us what the \n structure of our global connected component list will look like.\n gb_elem_conn - The element connectivity array for each grain boundary\n element. It allows for the reconstruction of the triangular\n prism elements. It is given as a numpy array. The last\n two elements in the array tell us what elements correspond\n to that particular connectivity array. It has dimensions of 14x#GB elements\n grains - The grain number that each element corresponds to. It is represented as \n a 1D numpy int array.\n Output - \n gl_conn_comp_rss_list - A list of sets that contain tuples with the following info: grain number our\n set is from, the slip system number of that set, and finally the set from \n that slip system that has our connected components. It is our global connected\n component list that corresponds with the resolved shear stress GB slip transferal\n requirements.\n '''\n \n \n gl_conn_comp_rss_list = list()\n #Create the initial structure of gl_conn_comp_list\n for ngrains in conn_comps:\n for nss in conn_comps[ngrains]:\n nelems = len(conn_comps[ngrains][nss])\n if nelems > 0:\n for i in range(nelems):\n temp_t = tuple([ngrains, nss, i])\n #Need to create an empty set first and then we can\n #add our tuple to it. If we try and add this directly\n #We'll just get the objects in the set.\n temp_set = set()\n temp_set.add(temp_t)\n gl_conn_comp_rss_list.append(temp_set.copy())\n \n nelems = gb_elem_conn.shape[1]\n \n for ielem in range(nelems):\n elems = np.squeeze(gb_elem_conn[12:14, ielem]) \n elem_list = sorted(elems.tolist())\n #We'll use this for our first index to our conn_comp\n grns = grains[elem_list]\n #The key for gb_inter_rss\n keydict = tuple(elem_list)\n data = gb_inter_rss[keydict]\n #Grab our boolean array that tells us what we need to look at\n bool_arr = data[1]\n #Only need to look at the below so now we know what ss we need\n #We might end up with an empty array here\n interact = data[0][bool_arr, 2:4]\n #We'll be able to from here figure out if we have an empty array or not\n nss_exam = interact.shape[0]\n \n #Grab our nodes to check if our sets are connected or not later on\n if(elems[0] == elem_list[0]):\n #We actually needed all 6 nodes for each element\n nd0 = gb_elem_conn[0, ielem]\n nd1 = gb_elem_conn[1, ielem]\n nd2 = gb_elem_conn[2, ielem]\n nd6 = gb_elem_conn[6, ielem]\n nd7 = gb_elem_conn[7, ielem]\n nd8 = gb_elem_conn[8, ielem]\n \n nd3 = gb_elem_conn[3, ielem]\n nd4 = gb_elem_conn[4, ielem]\n nd5 = gb_elem_conn[5, ielem]\n nd9 = gb_elem_conn[9, ielem]\n nd10 = gb_elem_conn[10, ielem] \n nd11 = gb_elem_conn[11, ielem]\n \n else:\n #We actually needed all 6 nodes for each element\n nd3 = gb_elem_conn[0, ielem]\n nd4 = gb_elem_conn[1, ielem]\n nd5 = gb_elem_conn[2, ielem]\n nd9 = gb_elem_conn[6, ielem]\n nd10 = gb_elem_conn[7, ielem]\n nd11 = gb_elem_conn[8, ielem]\n \n nd0 = gb_elem_conn[3, ielem]\n nd1 = gb_elem_conn[4, ielem]\n nd2 = gb_elem_conn[5, ielem]\n nd6 = gb_elem_conn[9, ielem]\n nd7 = gb_elem_conn[10, ielem] \n nd8 = gb_elem_conn[11, ielem]\n \n for i in range(nss_exam):\n #We can now use these to check if they are in our sets or not\n len1 = len(conn_comps[grns[0]][interact[i, 0]])\n len2 = len(conn_comps[grns[1]][interact[i, 1]])\n #Want to make sure that both sets are greater than 0 or we shouldn't bother doing anything\n if (len1 > 0) & (len2 > 0):\n #Setting flags to assume no element is any of our sets\n flag1 = False\n flag2 = False\n #Testing the first set\n tmp = conn_comps[grns[0]][interact[i, 0]]\n nsets = len(tmp)\n for j in range(nsets):\n #If we found our node in a set we update our flag to true.\n #Then we create our tuple to search our sets, and finally\n #we can just exit the loop.\n surf_elem_test = (nd0 in tmp[j]) | (nd1 in tmp[j]) | (nd2 in tmp[j])\n surf_elem_test = surf_elem_test | (nd6 in tmp[j]) | (nd7 in tmp[j]) | (nd8 in tmp[j])\n if surf_elem_test:\n flag1 = True\n tup1 = tuple([grns[0], interact[i, 0], j])\n break\n #Now testing second sets\n tmp = conn_comps[grns[1]][interact[i, 1]]\n nsets = len(tmp)\n for j in range(nsets):\n #Temporary logical variable\n surf_elem_test = (nd3 in tmp[j]) | (nd4 in tmp[j]) | (nd5 in tmp[j])\n surf_elem_test = surf_elem_test | (nd9 in tmp[j]) | (nd10 in tmp[j]) | (nd11 in tmp[j])\n if surf_elem_test:\n #If we found our node in a set we update our flag to true.\n #Then we create our tuple to search our sets, and finally\n #we can just exit the loop.\n flag2 = True\n tup2 = tuple([grns[1], interact[i, 1], j])\n break\n #If we had the nodes in both sets then we can find where our conn comp are in our\n #large list\n if flag1 & flag2:\n ind1, ind2 = find_gl_conn_comp_list_loc(gl_conn_comp_rss_list, tup1, tup2)\n #Need to make sure they aren't in the same set if they are we don't do anything\n if ind1 != ind2:\n #Update our set in place\n gl_conn_comp_rss_list[ind1].update(gl_conn_comp_rss_list[ind2])\n del gl_conn_comp_rss_list[ind2]\n \n \n \n return gl_conn_comp_rss_list\n\n\ndef find_gl_conn_comp_list_loc(gl_conn_comp_list, tup1, tup2):\n '''\n Helper function to find where our tuples are located in our huge global connected component list.\n The returned indices ind1 and ind2 are sorted so ind1 <= ind2.\n Input:\n gl_conn_comp_list - a list of sets with tuple elements\n tup1 - One tuple to find in our list of sets\n tup2 - Another tuple to find in our list of sets\n Output:\n ind1 - the minimum location of our tuples in the list\n ind2 - the maximum location of our tuples in the list\n '''\n \n ind1 = 0\n ind2 = 0\n \n nelems = len(gl_conn_comp_list)\n \n #We're just going to do one loop\n flag1 = False\n flag2 = False\n \n for i in range(nelems):\n if tup1 in gl_conn_comp_list[i]:\n ind1 = i\n flag2 = True\n \n if tup2 in gl_conn_comp_list[i]:\n ind2 = i\n flag2 = True\n \n if flag1 & flag2:\n indices = sorted([ind1, ind2])\n ind1 = indices[0]\n ind2 = indices[1]\n break \n \n return (ind1, ind2)\n "
},
{
"alpha_fraction": 0.7020254135131836,
"alphanum_fraction": 0.7260556221008301,
"avg_line_length": 39.95774459838867,
"blob_id": "5d2251d2f17c66876843586c1117d4aef1e630e8",
"content_id": "8782e282307c29191a28de2900e9eb1d53818736",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2913,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 71,
"path": "/PythonScripts/lofem_job_script.py",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Jan 9 14:59:18 2018\n\n@author: robertcarson\n\"\"\"\n\nimport numpy as np\nimport FePX_Data_and_Mesh as fepxDM\n\n#Where the mesh, grain, and phase info is located\n\nfileLoc = '/Users/robertcarson/OneDrive/LOFEM_Study/n456_cent/mid/'\nfileName = 'n456-cent-rcl04'\n#fileName = 'n456_nf_raster_L2_r1_v2_rcl05'\n#Mesh is read\nmesh = fepxDM.readMesh(fileLoc,fileName)\n#Getting the initial mesh\nconn = mesh['con']\n#Finding out how many crds, nodes, and nelems there are\nncrds = np.unique(np.ravel(conn)).size\nncvec = ncrds * 3\nnelems = conn.shape[1]\nnnode = conn.shape[0]\n#Getting the grain and phases for each element\n#The phase information should be changed later onto to be either\n#1 == FCC, 2 == BCC, and 3 == HCP\ngrains = mesh['grains']\nphases = mesh['phases']\n#We now get the nodal connectivity array\nndconn = fepxDM.mesh_node_conn(conn, ncrds)\n#We now fix the connectivity such that all of the grain boundary nodes have\n#a unique index for every grain that it is shared between.\n#If we didn't do this all of the grains would be connected. We don't want this.\n#We want each grain to be its own mesh for the LOFEM method. \nconn2 = fepxDM.grain_conn_mesh(ndconn, conn, grains, ncrds)\n#We now find the new number of coords\nncrds = np.unique(np.ravel(conn2)).size\n#We find the final nodal connectivity array which will be used for the\n#coord phase and grain info\nndconn2 = fepxDM.mesh_node_conn(conn2, ncrds)\n#We offset this by one just for LOFEM method since it assumes a 1 base for\n#its connectivity arrays.\nconn2 = conn2 + 1\n#Initiallizing the grain and phase arrays\ngrains2 = np.zeros((ncrds,1), dtype='int32') - 1\nphase2 = np.zeros((ncrds,1), dtype='int32') - 1\n#We now loop through all of the nodes\nfor i in range(len(ndconn2)):\n #We find all of the elements that a node is connected to\n ind = np.array(list(ndconn2[i]), dtype='int32')\n #All elements that a node are connected to should have the same\n #grain and phase info, so we just set that nodes grain and phase\n #to the same value as the first elements value\n grains2[i,0] = grains[ind[0]]\n phase2[i,0] = phases[ind[0]]\n\n#Finally we can write out our new connectivity array for the global\n#LOFEM mesh. The first thing for that files requirements is the number of\n#coords in the entire system.\nwith open(fileLoc+fileName+'2.cmesh','wb') as f_handle:\n f_handle.write(bytes(str(ncrds)+'\\n','UTF-8'))\n np.savetxt(f_handle, np.squeeze(conn2).T, fmt='%d')\n#We now write out the coord grain file that follows the same format as the\n#traditional one from FEpX. The one difference is we don't write out how\n#many grains or phases there are since this is just repeated information\n#from the elemental grain file. \ntmp = np.concatenate((grains2, phase2), axis=1) \nwith open(fileLoc+fileName+'2.cgrain','wb') as f_handle:\n np.savetxt(f_handle, np.squeeze(tmp), fmt='%d')\n \n"
},
{
"alpha_fraction": 0.49763327836990356,
"alphanum_fraction": 0.5676622986793518,
"avg_line_length": 35.28561782836914,
"blob_id": "255e1760bd217497bdd8b86ed2bd24dcbcdc87f2",
"content_id": "f9621bc687f924e578a96810993429685c00364e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 54506,
"license_type": "permissive",
"max_line_length": 125,
"num_lines": 1502,
"path": "/PythonScripts/FiniteElement.py",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "import os\nimport numpy as np\nimport scipy as sci\nimport Misori as mis\nimport Rotations as rot\nimport Utility as utl\nfrom scipy import optimize as sciop\n\n'''\nList of all functions available in this module\nLoadQuadrature(qname)\ncalcVol(crd, con)\ncentroidTet(crd, con)\nlocalConnectCrd(mesh, grNum)\nconcatConnArray(gconn, lconn, gupts, lupts, guelem, luelem)\ndeformationStats(defgrad, wts, crd, con, misrot,xtalrot, strain, kor)\nnearvertex(sigs, vert, nverts, xtalrot, wts)\nelem_fe_cen_val(crds, conn)\nsurface_quad_tet()\nsurfaceLoadArea(scrds, sconn, sig, wt2d, sfgdt)\nsfmat()\ngr_lstq_amat(conn, nsf, ncrds)\ngr_lstq_solver(amat, q_mat, ncrds)\ngr_nnlstq(amat, q_mat, ncrds)\n\n'''\n\n\n\ndef LoadQuadrature(qname):\n '''\n LoadQuadrature - Load quadrature data rule.\n\n USAGE:\n\n qrule = LoadQuadrature(qname)\n\n INPUT:\n\n qname is a string, \n the basename of the quadrature data files\n\n OUTPUT:\n\n qrule is a QRuleStructure, \n it consists of the quadrature point locations and weights\n\n NOTES:\n\n * It is expected that the quadrature rules are for simplices,\n and the last barycentric coordinate is appended to the file\n read from the data.\n\n * Expected suffixes are .qps for the location and .qpw for\n the weights.\n\n '''\n path = os.getcwd()\n pathFile = path+'/data/Quadrature/'+qname\n \n try:\n pts = np.loadtxt(pathFile+'.qps').T\n wts = np.loadtxt(pathFile+'.qpw').T\n except FileNotFoundError as e:\n z = e\n print(z)\n \n raise ValueError('File name is wrong')\n\n n = pts.shape[1]\n\n pts = np.concatenate((pts, np.ones((1,n))-np.sum(pts, axis = 0)), axis = 0)\n\n qrule = {'pts':pts, 'wts':np.atleast_2d(wts)}\n\n return qrule\n \ndef calcVol(crd, con):\n '''\n Calculates the volume of an arbitary polyhedron made up of tetrahedron elems\n It also calculates the relative volume of each element compared to the\n polyhedron's volume, so elVol/polyVol and returns that as weight\n \n Input: crd - 3xn numpy array coordinate of the elements of the mesh\n con - 10xn numpy array connectivity array that says which nodes go\n with what elements\n Output: vol - scalar value, total volume of the polyhedron\n wts - 1xn numpy array relative weight of each element for the polyhedron\n '''\n \n nelems = con.shape[1]\n wts = np.zeros((nelems,))\n \n for i in range(nelems):\n coord = np.squeeze(crd[:, con[[0, 2, 4, 9], i]])\n coord = np.concatenate((coord, [[1, 1, 1, 1]]), axis=0)\n wts[i] = 1.0/6.0*np.abs(np.linalg.det(coord))\n \n vol = np.sum(wts)\n wts = wts/vol\n \n return (vol, wts)\n \ndef centroidTet(crd, con):\n '''\n Calculates the centroid of a tetrahedron\n \n Input: crd - 3xn numpy array coordinate of the elements of the mesh\n con - 10xn numpy array connectivity array that says which nodes go\n with what elements\n Output: cen - 3x1 numpy array centroid of the tetrahedron\n '''\n \n nelems = con.shape[1]\n centroid = np.zeros((3, nelems))\n for i in range(nelems):\n coord = np.squeeze(crd[:, con[[0, 2, 4, 9],i]])\n centroid[:, i] = np.sum(coord, axis=1)/4.0\n \n return centroid\n \ndef localConnectCrd(mesh, grNum):\n '''\n Calculates the local connectivity based upon the grain number provided\n \n Input: mesh - a dict structure given by the FePX_Data_and_Mesh module'\n grNum - an integer that corresponds to the grain of interest\n \n Output:con - 10xn numpy array connectivity array that says which nodes go\n with what elements and that have corrected the node numbers to\n correspond to only be 0 - (nelem-1) in the grain\n crd - 3xn numpy array of coordinates that correspond to this grain\n ''' \n \n logInd = mesh['grains'] == grNum\n \n lenlogInd = len(logInd)\n elemInd = np.r_[0:lenlogInd]\n uElem = elemInd[logInd]\n con = mesh['con'][:, logInd]\n nelem = con.shape[1]\n vecCon = con.reshape((10*nelem,1))\n uPts = np.int32(np.unique(vecCon))\n crd = mesh['crd'][:, uPts]\n count = 0\n for i in uPts:\n vecCon[vecCon == i] = count\n count +=1\n \n con = np.int_(vecCon.reshape((10, nelem)))\n \n return (con, crd, uPts, uElem)\n\ndef localGrainConnectCrd(mesh, grNum):\n '''\n Calculates the local connectivity based upon the grain number provided\n \n Input: mesh - a dict structure given by the FePX_Data_and_Mesh module'\n grNum - an integer that corresponds to the grain of interest\n \n Output:con - 10xn numpy array connectivity array that says which nodes go\n with what elements and that have corrected the node numbers to\n correspond to only be 0 - (nelem-1) in the grain\n crd - 3xn numpy array of coordinates that correspond to this grain\n ''' \n \n logInd = mesh['grains'] == grNum\n \n lenlogInd = len(logInd)\n elemInd = np.r_[0:lenlogInd]\n uElem = elemInd[logInd]\n con = mesh['crd_con'][:, logInd]\n nelem = con.shape[1]\n vecCon = con.reshape((10*nelem,1))\n uPts = np.int32(np.unique(vecCon))\n count = 0\n for i in uPts:\n vecCon[vecCon == i] = count\n count +=1\n \n con = np.int_(vecCon.reshape((10, nelem)))\n \n return (con, uPts, uElem)\n\ndef concatConnArray(gconn, lconn, gupts, lupts, guelem, luelem):\n '''\n Takes in a \"global\" connectivity array and adds one with local node\n values to it after offsetting by the previous highest node number.\n This function essentially gives us multiple connectivity arrays\n glued together but not necessarily connected with each other.\n The main purpose of it is to have a number of grains containg their\n own mesh, but overall it looks like one big mesh.\n It also takes in a global and local unique pts array and just\n concatentate them together. Thus it is possible in this new array\n to have multiples of the same pts listed in it. The same concat\n is down with the unique element arrays but here we should not see\n the possibilities of multiple elements repeated.\n \n Input:\n gconn - a \"global\" connectivity array and it's 0 based\n lconn - a local connectivity array that needs to be offset using\n the largest value in gconn and it's 0 based\n gupts - a 1D numpy array that contains all the \"unique\" pts in\n in the conn array, but will really be used in rearranging\n nodal data from the original mesh.\n lupts - a 1D numpy array that is going to be added to gupts\n guelem - a 1D numpy array that contains all of the unique elem\n numbers. It's use is to rearrange the data matrix\n luelem - a 1D numpy array that is going to be added to gulem\n \n Output:\n fconn - the final connectivity array\n fupts - the final \"unique\" pts list\n fuelem - the final unique elements list\n '''\n \n if gconn.size == 0:\n mconn = 0\n fconn = lconn\n else:\n mconn = np.max(np.max(gconn))\n lconn[:,:] = lconn[:,:] + mconn + 1\n fconn = np.hstack((gconn, lconn))\n \n fupts = np.hstack((gupts, lupts))\n fuelem = np.hstack((guelem, luelem))\n \n return (fconn, fupts, fuelem)\n \ndef lofem_elas_stretch_stats(wts, xtalrot_l, xtalrot_d, strain_l, strain_d):\n '''\n A function to compare the elastic left stretch tensor metric for both\n a LOFEM and discrete lattice orientation evolution method. It also\n returns a metric that shows the difference between the two sets of\n elastic stretch.\n \n Input: wts - a n numpy vec of relative wts of the elements\n xtralrot_l - a rodrigues vector of 3xnelem of the lattice orientation for LOFEM update\n xtralrot_d - a kocks vector of 3xnelem of the lattice orientation for discrete update\n strain_l - the crystal frame strain for the LOFEM update as a nelemx3x3\n strain_d - the crystal frame strain for the discrete update as a nelemx3x3\n \n Output:data - a dict that contains the following\n veSpread_L - the elastic left stretch tensor metric for a grain for LOFEM update\n veSpread_D - the elastic left stretch tensor metric for a grain for discrete update\n veSpread_Diff - the elastic left stretch tensor metric for the difference\n between the lofem and discrete method. In other words, the difference\n of the stretch at each element is used for its calculations.\n \n '''\n\n nelems = wts.shape[0]\n \n vevec_l = np.zeros((6, nelems))\n vevec_d = np.zeros((6, nelems))\n vevec = np.zeros((6, nelems))\n \n wts = wts/np.sum(wts)\n wts1 = np.tile(wts, (6, 1))\n \n\n for i in range(wts.shape[0]): \n \n xtalrmat = np.squeeze(rot.OrientConvert(xtalrot_l[:, i], 'rod', 'rmat', 'degrees', 'degrees'))\n velas_l = np.eye(3) + xtalrmat.dot(strain_l[:, :, i].dot(xtalrmat.T)) #convert strain from lattice to sample\n \n xtalrmat = np.squeeze(rot.OrientConvert(xtalrot_d[:, i], 'kocks', 'rmat', 'degrees', 'degrees'))\n velas_d = np.eye(3) + xtalrmat.dot(strain_d[:, :, i].dot(xtalrmat.T))\n \n \n vevec_l[0, i] = velas_l[0,0]\n vevec_l[1, i] = velas_l[1,1]\n vevec_l[2, i] = velas_l[2,2]\n vevec_l[3, i] = velas_l[1,2]\n vevec_l[4, i] = velas_l[0,2]\n vevec_l[5, i] = velas_l[0,1]\n \n vevec_d[0, i] = velas_d[0,0]\n vevec_d[1, i] = velas_d[1,1]\n vevec_d[2, i] = velas_d[2,2]\n vevec_d[3, i] = velas_d[1,2]\n vevec_d[4, i] = velas_d[0,2]\n vevec_d[5, i] = velas_d[0,1]\n \n vevec = vevec_l - vevec_d\n \n \n cen = utl.mat2d_row_order(np.sum(vevec*wts1, axis=1)) \n vi = vevec - np.tile(cen, (1, nelems)) \n vinv = np.sum(utl.RankOneMatrix(vi*wts1, vi), axis=2) \n diff_vespread = np.atleast_2d(np.sqrt(np.trace(vinv[:, :])))\n \n \n cen = utl.mat2d_row_order(np.sum(vevec_l*wts1, axis=1)) \n vi = vevec_l - np.tile(cen, (1, nelems)) \n vinv = np.sum(utl.RankOneMatrix(vi*wts1, vi), axis=2) \n vespread_l = np.atleast_2d(np.sqrt(np.trace(vinv[:, :])))\n \n cen = utl.mat2d_row_order(np.sum(vevec_d*wts1, axis=1)) \n vi = vevec_d - np.tile(cen, (1, nelems)) \n vinv = np.sum(utl.RankOneMatrix(vi*wts1, vi), axis=2) \n vespread_d = np.atleast_2d(np.sqrt(np.trace(vinv[:, :])))\n \n \n\n data = {'veSpread_L':vespread_l, 'veSpread_D':vespread_d, 'veSpread_Diff':diff_vespread,}\n \n return data\n \ndef deformationStats(defgrad, wts, crd, con, misrot, xtalrot, strain, kor):\n '''\n Performs statistics on the deformation gradient for a particular mesh\n So, it gets the mean difference in minimum and maximum principle eig. vals.\n of the V matrix. Then it also returns the std. of the matrix\n It also gets the spread of the rotation matrix based on the values sent to\n the misorientationstats function\n \n Input:defgrad - a nx3x3 numpy array of the deformation gradient for the mesh\n wts - a n numpy vec of relative wts of the elements\n crd - a nx3 numpy array of the crd of the mesh (used in getting rSpread)\n con - a nx10 numpy array of the connectivity of the mesh (used in getting rSpread)\n \n Output:data - a dict that contains the following\n mFgrad - mean deformation gradient of the mesh\n mVpr - mean difference in the principal components of the\n right stretch tensor, V, of the mesh\n sdVpr - standard deviation of the difference in the principal components\n of the right stretch tensor, V, of the mesh\n rSpread - the mean kernal average of the spread of the rotation matrix\n across the mesh\n '''\n\n vvec = np.zeros((6, defgrad.shape[2]))\n velasvec = np.zeros((6, defgrad.shape[2]))\n fvec = np.zeros((9, defgrad.shape[2]))\n fevec = np.zeros((9, defgrad.shape[2]))\n rkocks = np.zeros((defgrad.shape[0], defgrad.shape[2]))\n \n kocks = rot.OrientConvert(np.eye(3), 'rmat', 'kocks', 'degrees', 'degrees')\n \n wts = wts/np.sum(wts)\n wts1 = np.tile(wts, (6, 1))\n wts2 = np.tile(wts, (9, 1))\n \n fvec[0, :] = defgrad[0, 0, :]\n fvec[1, :] = defgrad[1, 1, :]\n fvec[2, :] = defgrad[2, 2, :]\n \n fvec[3, :] = defgrad[1, 2, :]\n fvec[4, :] = defgrad[0, 2, :]\n fvec[5, :] = defgrad[0, 1, :]\n \n fvec[6, :] = defgrad[2, 1, :]\n fvec[7, :] = defgrad[2, 0, :]\n fvec[8, :] = defgrad[1, 0, :]\n \n# V = np.zeros((defgrad.shape[1], defgrad.shape[2], defgrad.shape[0]))\n# R = np.zeros((defgrad.shape[1], defgrad.shape[2], defgrad.shape[0])) \n# eV = np.zeros((1, defgrad.shape[0]))\n# eVe = np.zeros((1, defgrad.shape[0]))\n# rchange = np.zeros((1, defgrad.shape[0]))\n# print(defgrad.shape)\n# rpm = np.zeros((defgrad.shape[0], 3, 3))\n# Fpm = np.zeros((defgrad.shape[0], 3, 3))\n# veinv = np.zeros((defgrad.shape[0], 3, 3))\n# vem = np.zeros((defgrad.shape[0], 3, 3))\n# rpkocks = np.zeros((defgrad.shape[1], defgrad.shape[0]))\n# Rm = np.zeros((defgrad.shape[0], 3, 3))\n# Vm = np.zeros((defgrad.shape[0], 3, 3))\n# upm = np.zeros((defgrad.shape[0], 3, 3))\n# reye = np.zeros((defgrad.shape[0], 3, 3))\n# defplgrad = np.zeros((defgrad.shape[0], 3, 3))\n\n for i in range(defgrad.shape[2]): \n \n R, V = sci.linalg.polar(defgrad[:, :, i], 'left')\n rkocks[:,i] = np.squeeze(rot.OrientConvert(R, 'rmat', 'kocks', 'degrees', 'degrees'))\n \n vvec[0, i] = V[0,0]\n vvec[1, i] = V[1,1]\n vvec[2, i] = V[2,2]\n vvec[3, i] = V[1,2]\n vvec[4, i] = V[0,2]\n vvec[5, i] = V[0,1]\n\n rxtal = np.squeeze(rot.OrientConvert(misrot[:, i], 'quat', 'rmat', 'degrees', 'degrees'))\n xtalrmat = np.squeeze(rot.OrientConvert(xtalrot[:, i], kor, 'rmat', 'degrees', 'degrees'))\n velas = np.eye(3) + xtalrmat.dot(strain[:, :, i].dot(xtalrmat.T)) #convert strain from lattice to sample\n\n elasdefgrad = velas.dot(rxtal)\n \n velasvec[0, i] = velas[0,0]\n velasvec[1, i] = velas[1,1]\n velasvec[2, i] = velas[2,2]\n velasvec[3, i] = velas[1,2]\n velasvec[4, i] = velas[0,2]\n velasvec[5, i] = velas[0,1]\n \n fevec[0, i] = elasdefgrad[0, 0]\n fevec[1, i] = elasdefgrad[1, 1]\n fevec[2, i] = elasdefgrad[2, 2]\n \n fevec[3, i] = elasdefgrad[1, 2]\n fevec[4, i] = elasdefgrad[0, 2]\n fevec[5, i] = elasdefgrad[0, 1]\n \n fevec[6, i] = elasdefgrad[2, 1]\n fevec[7, i] = elasdefgrad[2, 0]\n fevec[8, i] = elasdefgrad[1, 0]\n \n# velasinv = sci.linalg.inv(velas)\n# vem[i, :, :] = velas\n# veinv[i, :, :] = velasinv\n# reye[i, :, :] = xtalrmat.T.dot(xtalrmat)\n# ftemp = sci.linalg.inv(velas).dot(defgrad[i, :, :]) \n# ftemp = velasinv.dot(defgrad[i, :, :])\n# Fp = rxtal.T.dot(ftemp)\n# defplgrad[i, :, :] = Fp \n# Fpm[i, :, :] = Fp\n# Rp, Up = sci.linalg.polar(Fp, 'right')\n# Rp = np.around(Rp, decimals=7)\n# Fpm[i, :, :] = Fp\n# rpm[i, :, :] = Rp\n# upm[i, :, :] = Up\n# rdecomp = rxtal.dot(Rp)\n# rdiff = R.T.dot(rdecomp)\n# rchange[:, i] = np.trace(rdiff-np.eye(3))\n# rpkocks[:,i] = np.squeeze(rot.OrientConvert(Rp, 'rmat', 'kocks', 'degrees', 'degrees'))\n# eV[:, i] = np.max(temp) - np.min(temp)\n# temp, junk = np.linalg.eig(velas)\n# eVe[:, i] = np.max(temp) - np.min(temp)\n# print(R.shape)\n \n cen = utl.mat2d_row_order(np.sum(velasvec*wts1, axis=1))\n vi = velasvec - np.tile(cen, (1, defgrad.shape[2]))\n vinv = np.sum(utl.RankOneMatrix(vi*wts1, vi), axis=2)\n vespread = np.atleast_2d(np.sqrt(np.trace(vinv[:, :])))\n \n cen = utl.mat2d_row_order(np.sum(vvec*wts1, axis=1))\n vi = vvec - np.tile(cen, (1, defgrad.shape[2]))\n vinv = np.sum(utl.RankOneMatrix(vi*wts1, vi), axis=2)\n vspread = np.atleast_2d(np.sqrt(np.trace(vinv[:, :])))\n \n cen = utl.mat2d_row_order(np.sum(fvec*wts2, axis=1))\n vi = fvec - np.tile(cen, (1, defgrad.shape[2]))\n vinv = np.sum(utl.RankOneMatrix(vi*wts2, vi), axis=2)\n fSpread = np.atleast_2d(np.sqrt(np.trace(vinv[:, :])))\n \n cen = utl.mat2d_row_order(np.sum(fevec*wts2, axis=1))\n vi = fevec - np.tile(cen, (1, defgrad.shape[2]))\n vinv = np.sum(utl.RankOneMatrix(vi*wts2, vi), axis=2)\n feSpread = np.atleast_2d(np.sqrt(np.trace(vinv[:, :])))\n \n misAngs, misQuats = mis.misorientationGrain(kocks, rkocks, [0], kor)\n stats = mis.misorientationTensor(misQuats, crd, con, crd, [0])\n rSpread = stats['gSpread']\n \n# misAngs, misQuats = mis.misorientationGrain(kocks, rpkocks, [0], kor)\n# stats2 = mis.misorientationBartonTensor(misQuats, crd, con, crd, [0])\n# indG = np.squeeze(misAngs > 0.0001)\n# rpSpread = stats2['gSpread']\n# mFgrad = np.average(defgrad, axis=0, weights=wts)\n# mVpr = np.atleast_2d(np.average(eV, axis=1, weights=wts)).T\n# var = np.atleast_2d(np.average((eV-mVpr)**2, axis=1, weights=wts)).T\n# sdVpr = np.sqrt(var)\n# \n# mVpre = np.atleast_2d(np.average(eVe, axis=1, weights=wts)).T\n# var = np.atleast_2d(np.average((eVe-mVpre)**2, axis=1, weights=wts)).T\n# sdVpre = np.sqrt(var)\n# mFpgrad = np.average(defplgrad, axis=0, weights=wts)\n# rchg = np.atleast_2d(np.average(rchange,axis=1, weights=wts)).T\n# data = {'mVpr':mVpr, 'sdVpr':sdVpr, 'rSpread':rSpread, 'mFgrad':mFgrad, \n# 'rchg':rchg, 'mVpre':mVpre, 'sdVpre':sdVpre, 'rpSpread':rpSpread, 'mFpgrad':mFpgrad,\n# 'vespread':vespread, 'vspread':vspread}\n\n data = {'veSpread':vespread, 'vSpread':vspread, 'rSpread':rSpread, 'fSpread':fSpread, 'feSpread':feSpread}\n \n return data\n \ndef nearvertex(sigs, vert, nverts, xtalrot, wts):\n '''\n Finds angle of nearest nearest vertice to the deviatoric stress of the crystal.\n The stress should be in the crystal reference frame first, since the vertices\n are based upon crystal reference frame values and not sample frame values.\n \n Input:\n sig = nelemx3x3 stress in the sample frame\n vert = nverts*3 x 3 vertice values taken from the FEPX vertice file\n nverts = number of vertices depends on xtal type\n angs = nelemx3 kocks angles of xtal in grain\n Output:\n angs = mean smallest absolute angle value from zero and shows how close\n the stress is from one of the initial vertices across grain.\n '''\n \n nelem = sigs.shape[0]\n\n xtalsig = np.zeros((nelem, 3, 3)) \n \n ind = np.r_[0, 3, 5]\n \n \n for i in range(nelem):\n maxang = np.pi/2\n xtalrmat = np.squeeze(rot.OrientConvert(xtalrot[:, i], 'kocks', 'rmat', 'degrees', 'degrees'))\n xtalsig[i, :, :] = xtalrmat.T.dot(sigs[i, :, :].dot(xtalrmat)) # convert stress from sample to xtal basis\n \n xtalsig = np.average(xtalsig, axis=0, weights=wts) \n sig = np.atleast_2d(np.ravel(xtalsig)[np.r_[0,1,2,4,5,8]])\n \n for j in range(nverts):\n dsig = sig[0, :] - 1/3*np.sum(sig[0, ind])*np.asarray([1,0,0,1,0,1])\n tvert = np.ravel(vert[np.r_[j*3:(j+1)*3], :])\n dotp = np.sum(dsig*tvert[np.r_[0,1,2,4,5,8]])\n ang = np.arccos(dotp/(np.linalg.norm(dsig)*np.linalg.norm(tvert[np.r_[0,1,2,4,5,8]])))\n \n if abs(ang) < maxang:\n maxang = ang\n \n mangs = maxang\n \n return mangs\n\n\ndef elem_fe_cen_val(crds, conn):\n '''\n Takes in the raw values at the coordinates and gives the value at\n the centroid of a quadratic tetrahedral element using finite\n element shape functions.\n \n Input: crds - the 3d vector at each node of the mesh\n conn - the connectivity array that takes the crd values and\n gives the elemental values\n Output: ecrds - the elemental 3d vector at the centroid of each\n element in the mesh\n \n '''\n \n nelems = conn.shape[1]\n ecrds = np.zeros((3, nelems))\n tcrds = np.zeros((3, 10))\n \n loc_ptr = np.ones(3) * 0.25\n \n sfvec_ptr = np.zeros((10))\n \n NT = np.zeros((10,1))\n \n sfvec_ptr[0] = 2.0e0 * (loc_ptr[0] + loc_ptr[1] + loc_ptr[2] - 1.0e0) * (loc_ptr[0] + loc_ptr[1] +loc_ptr[2] - 0.5e0)\n sfvec_ptr[1] = -4.0e0 * (loc_ptr[0] + loc_ptr[1] + loc_ptr[2] - 1.0e0) * loc_ptr[0]\n sfvec_ptr[2] = 2.0e0 * loc_ptr[0] * (loc_ptr[0] - 0.5e0)\n sfvec_ptr[3] = 4.0e0 * loc_ptr[1] * loc_ptr[0]\n sfvec_ptr[4] = 2.0e0 * loc_ptr[1] * (loc_ptr[1] - 0.5e0)\n sfvec_ptr[5] = -4.0e0 * (loc_ptr[0] + loc_ptr[1] + loc_ptr[2] - 1.0e0) * loc_ptr[1]\n sfvec_ptr[6] = -4.0e0 * (loc_ptr[0] + loc_ptr[1] + loc_ptr[2] - 1.0e0) * loc_ptr[2]\n sfvec_ptr[7] = 4.0e0 * loc_ptr[0] * loc_ptr[2]\n sfvec_ptr[8] = 4.0e0 * loc_ptr[1] * loc_ptr[2]\n sfvec_ptr[9] = 2.0e0 * loc_ptr[2] * (loc_ptr[2] - 0.5e0)\n \n NT[:, 0] = sfvec_ptr[:]\n \n \n for i in range(nelems):\n tcrds = crds[:, conn[:, i]]\n ecrds[:, i] = np.squeeze(np.dot(tcrds, NT))\n\n return ecrds\n\ndef surface_quad_tet():\n '''\n Outputs: quadrature points for quad tet surface\n quadrature weights for quad tet surface\n sf for quad tet surface\n grad sf for quad tet surface\n '''\n \n # ** 6-noded triangular element **\n\n # quadrature points\n \n qp2d = np.zeros((2,7))\n wt2d = np.zeros(7)\n sf = np.zeros((6, 7))\n sfgd = np.zeros((2, 6, 7))\n\n qp2d[0, 0] = 0.33333333333333 \n qp2d[0, 1] = 0.05971587178977 \n qp2d[0, 2] = 0.47014206410512 \n qp2d[0, 3] = 0.47014206410512 \n qp2d[0, 4] = 0.79742698535309 \n qp2d[0, 5] = 0.10128650732346 \n qp2d[0, 6] = 0.10128650732346 \n\n qp2d[1, 0] = 0.33333333333333\n qp2d[1, 1] = 0.47014206410512\n qp2d[1, 2] = 0.05971587178977\n qp2d[1, 3] = 0.47014206410512\n qp2d[1, 4] = 0.10128650732346\n qp2d[1, 5] = 0.79742698535309\n qp2d[1, 6] = 0.10128650732346\n\n # weight\n\n wt2d[0] = 0.1125\n wt2d[1] = 0.06619707639425\n wt2d[2] = 0.06619707639425\n wt2d[3] = 0.06619707639425\n wt2d[4] = 0.06296959027241\n wt2d[5] = 0.06296959027241\n wt2d[6] = 0.06296959027241\n \n for i in range(7):\n xi = qp2d[0, i]\n eta = qp2d[1, i]\n zeta = 1.0 - xi - eta\n # nodal locations:\n #\n # 3\n # 42\n # 561\n #\n #\n sf[0, i] = (2.0 * xi - 1.0) * xi\n sf[1, i] = 4.0 * eta * xi\n sf[2, i] = (2.0 * eta - 1.0) * eta\n sf[3, i] = 4.0 * eta * zeta\n sf[4, i] = (2.0 * zeta - 1.0) * zeta\n sf[5, i] = 4.0 * xi * zeta\n \n sfgd[0, 0, i] = 4.0 * xi - 1.0\n sfgd[0, 1, i] = 4.0 *eta\n sfgd[0, 2, i] = 0.0\n sfgd[0, 3, i] = -4.0 * eta\n sfgd[0, 4, i] = -4.0 * zeta + 1.0\n sfgd[0, 5, i] = 4.0 * zeta - 4.0 * xi\n \n sfgd[1, 0, i] = 0.0\n sfgd[1, 1, i] = 4.0 * xi\n sfgd[1, 2, i] = 4.0 * eta - 1.0\n sfgd[1, 3, i] = 4.0 * zeta - 4.0 * eta\n sfgd[1, 4, i] = -4.0 * zeta + 1.0\n sfgd[1, 5, i] = -4.0 * xi\n \n return (qp2d, wt2d, sf, sfgd)\n\ndef surfaceConn(scrds, sconn, surf):\n '''\n All of the surface nodes and connectivity matrix are taken in and\n only the ones related to the surface of interest are returned.\n This function assummes a cubic/rectangular mesh for now.\n The surf number of interest is given where:\n z1 = min z surface\n z2 = max z surface\n y1 = min y surface\n y2 = max y surface\n x1 = min x surface\n x2 = max x surface\n Input: scrds = a 3xnsurf_crds size array where all of the surface\n coords are given\n sconn = a 7xnsurf_elem size array where all of the surface\n conn are given. It should also be noted that the 1st elem\n is the element number that the surface can be found on\n surf = a string with the above surf numbers as its values\n Output: gconn = the global surface connectivity array for the\n surface of interest\n lconn = the local surface connectivity array for the\n surface of interest\n '''\n \n nelems = sconn.shape[1]\n \n logInd = np.zeros(nelems, dtype=bool)\n\n if surf == 'x1':\n ind = 0\n val = np.min(scrds[ind,:])\n elif surf == 'x2':\n ind = 0\n val = np.max(scrds[ind,:])\n elif surf == 'y1':\n ind = 1\n val = np.min(scrds[ind,:])\n elif surf == 'y2':\n ind = 1\n val = np.max(scrds[ind,:])\n elif surf == 'z1':\n ind = 2\n val = np.min(scrds[ind,:])\n else:\n ind = 2\n val = np.max(scrds[ind,:])\n \n for i in range(nelems):\n ecrds = scrds[ind, sconn[1:7, i]]\n logInd[i] = np.all(ecrds == val)\n \n gconn = sconn[:, logInd]\n \n lconn = np.copy(gconn)\n \n nelem = lconn.shape[1]\n \n vecCon = lconn[0, :]\n uCon = np.int32(np.unique(vecCon))\n count = 0\n for i in uCon:\n vecCon[vecCon == i] = count\n count +=1\n \n lconn[0, :] = np.int_(vecCon)\n \n vecCon = lconn[1:7, :].reshape((6*nelem,1))\n uCon = np.int32(np.unique(vecCon))\n count = 0\n for i in uCon:\n vecCon[vecCon == i] = count\n count +=1\n \n lconn[1:7, :] = np.int_(vecCon.reshape((6, nelem)))\n \n return (gconn, lconn) \n \ndef surfaceLoadArea(scrds, sconn, sig, wt2d, sfgdt):\n '''\n Takes in the surface coordinates and surface element centroidal stress\n Then computes the area on the surface and load on the surface\n Input: scrds = a 3xnsurf_coords\n sconn = a 6xnsurf_elems vector of the surface connectivity\n sig = a 6xnsurf_elems vector of the Cauchy stress\n wt2d = a n length vector of the surface quad pt weights\n sfgdt = a 6x2xn length vector of the trans grad surf interp array \n Output: load = a vector of size 3 equal to the load on the surface\n area = a scalar value equal to the surface area\n '''\n \n load = np.zeros(3)\n area = 0.0\n \n nselem = sig.shape[1]\n nqpts = wt2d.shape[0]\n \n tangent = np.zeros((3, 2))\n normal = np.zeros(3)\n sjac = 0.0\n \n nmag = 0.0\n \n for i in range(nselem):\n tangent = 0.0\n normal = 0.0\n #Get an array of the element surface crds\n ecrds = scrds[:, sconn[:, i]]\n for j in range(nqpts):\n #The two tangent vectors are just ecrds*sfgdt\n tangent = ecrds.dot(sfgdt[:, :, j])\n #The normal is just t1 x t2\n normal = np.cross(tangent[:, 0], tangent[:, 1])\n #The normal is just the L2 norm of n\n nmag = np.sqrt(np.inner(normal, normal[:]))\n #sjac is just the L2 norm of the normal vec\n sjac = nmag\n #Normalize the normal vec\n normal = normal / nmag\n #Now compute the loads and area given above info\n load[0] += wt2d[j] * sjac * (sig[0, i]*normal[0] +\\\n sig[1, i]*normal[1] + sig[2, i]*normal[2])\n load[1] += wt2d[j] * sjac * (sig[1, i]*normal[0] +\\\n sig[3, i]*normal[1] + sig[4, i]*normal[2])\n load[2] += wt2d[j] * sjac * (sig[2, i]*normal[0] +\\\n sig[4, i]*normal[1] + sig[5, i]*normal[2])\n area += wt2d[j] * sjac\n \n return (load, area)\n \ndef sfmat():\n '''\n Outputs the shape function matrix for a 10 node tetrahedral element\n Pretty much just using FEpX\n Output: N - The isoparametric shape functions for all 15 quadrature points\n '''\n NDIM = 3\n \n qp3d_ptr = np.zeros((NDIM*15))\n \n qp3d_ptr[0] = 0.333333333333333333e0\n qp3d_ptr[1 * NDIM] = 0.333333333333333333e0\n qp3d_ptr[2 * NDIM] = 0.333333333333333333e0\n qp3d_ptr[3 * NDIM] = 0.0e0\n qp3d_ptr[4 * NDIM] = 0.25e0\n qp3d_ptr[5 * NDIM] = 0.909090909090909091e-1\n qp3d_ptr[6 * NDIM] = 0.909090909090909091e-1\n qp3d_ptr[7 * NDIM] = 0.909090909090909091e-1\n qp3d_ptr[8 * NDIM] = 0.727272727272727273e0\n qp3d_ptr[9 * NDIM] = 0.665501535736642813e-1\n qp3d_ptr[10 * NDIM] = 0.665501535736642813e-1\n qp3d_ptr[11 * NDIM] = 0.665501535736642813e-1\n qp3d_ptr[12 * NDIM] = 0.433449846426335728e0\n qp3d_ptr[13 * NDIM] = 0.433449846426335728e0\n qp3d_ptr[14 * NDIM] = 0.433449846426335728e0\n \n qp3d_ptr[1] = 0.333333333333333333e0\n qp3d_ptr[1 + 1 * NDIM] = 0.333333333333333333e0\n qp3d_ptr[1 + 2 * NDIM] = 0.0e0\n qp3d_ptr[1 + 3 * NDIM] = 0.333333333333333333e0\n qp3d_ptr[1 + 4 * NDIM] = 0.25e0\n qp3d_ptr[1 + 5 * NDIM] = 0.909090909090909091e-1\n qp3d_ptr[1 + 6 * NDIM] = 0.909090909090909091e-1\n qp3d_ptr[1 + 7 * NDIM] = 0.727272727272727273e0\n qp3d_ptr[1 + 8 * NDIM] = 0.909090909090909091e-1\n qp3d_ptr[1 + 9 * NDIM] = 0.665501535736642813e-1\n qp3d_ptr[1 + 10 * NDIM] = 0.433449846426335728e0\n qp3d_ptr[1 + 11 * NDIM] = 0.433449846426335728e0\n qp3d_ptr[1 + 12 * NDIM] = 0.665501535736642813e-1\n qp3d_ptr[1 + 13 * NDIM] = 0.665501535736642813e-1\n qp3d_ptr[1 + 14 * NDIM] = 0.433449846426335728e0\n \n qp3d_ptr[2] = 0.333333333333333333e0\n qp3d_ptr[2 + 1 * NDIM] = 0.0e0\n qp3d_ptr[2 + 2 * NDIM] = 0.333333333333333333e0\n qp3d_ptr[2 + 3 * NDIM] = 0.333333333333333333e0\n qp3d_ptr[2 + 4 * NDIM] = 0.25e0\n qp3d_ptr[2 + 5 * NDIM] = 0.909090909090909091e-1\n qp3d_ptr[2 + 6 * NDIM] = 0.727272727272727273e0\n qp3d_ptr[2 + 7 * NDIM] = 0.909090909090909091e-1\n qp3d_ptr[2 + 8 * NDIM] = 0.909090909090909091e-1\n qp3d_ptr[2 + 9 * NDIM] = 0.433449846426335728e0\n qp3d_ptr[2 + 10 * NDIM] = 0.665501535736642813e-1\n qp3d_ptr[2 + 11 * NDIM] = 0.433449846426335728e0\n qp3d_ptr[2 + 12 * NDIM] = 0.665501535736642813e-1\n qp3d_ptr[2 + 13 * NDIM] = 0.433449846426335728e0\n qp3d_ptr[2 + 14 * NDIM] = 0.665501535736642813e-1\n \n sfvec_ptr = np.zeros((10))\n N = np.zeros((15,10))\n \n for i in range(15):\n loc_ptr = qp3d_ptr[i*3:(i+1)*3]\n sfvec_ptr[0] = 2.0e0 * (loc_ptr[0] + loc_ptr[1] + loc_ptr[2] - 1.0e0) * (loc_ptr[0] + loc_ptr[1] +loc_ptr[2] - 0.5e0)\n sfvec_ptr[1] = -4.0e0 * (loc_ptr[0] + loc_ptr[1] + loc_ptr[2] - 1.0e0) * loc_ptr[0]\n sfvec_ptr[2] = 2.0e0 * loc_ptr[0] * (loc_ptr[0] - 0.5e0)\n sfvec_ptr[3] = 4.0e0 * loc_ptr[1] * loc_ptr[0]\n sfvec_ptr[4] = 2.0e0 * loc_ptr[1] * (loc_ptr[1] - 0.5e0)\n sfvec_ptr[5] = -4.0e0 * (loc_ptr[0] + loc_ptr[1] + loc_ptr[2] - 1.0e0) * loc_ptr[1]\n sfvec_ptr[6] = -4.0e0 * (loc_ptr[0] + loc_ptr[1] + loc_ptr[2] - 1.0e0) * loc_ptr[2]\n sfvec_ptr[7] = 4.0e0 * loc_ptr[0] * loc_ptr[2]\n sfvec_ptr[8] = 4.0e0 * loc_ptr[1] * loc_ptr[2]\n sfvec_ptr[9] = 2.0e0 * loc_ptr[2] * (loc_ptr[2] - 0.5e0)\n N[i, :] = sfvec_ptr[:]\n \n return N\n\ndef iso_dndx():\n '''\n Returns the isoparametric dndx matrix\n '''\n \n NDIM = 3\n \n qp3d_ptr = np.zeros((NDIM*15))\n \n qp3d_ptr[0] = 0.333333333333333333e0\n qp3d_ptr[1 * NDIM] = 0.333333333333333333e0\n qp3d_ptr[2 * NDIM] = 0.333333333333333333e0\n qp3d_ptr[3 * NDIM] = 0.0e0\n qp3d_ptr[4 * NDIM] = 0.25e0\n qp3d_ptr[5 * NDIM] = 0.909090909090909091e-1\n qp3d_ptr[6 * NDIM] = 0.909090909090909091e-1\n qp3d_ptr[7 * NDIM] = 0.909090909090909091e-1\n qp3d_ptr[8 * NDIM] = 0.727272727272727273e0\n qp3d_ptr[9 * NDIM] = 0.665501535736642813e-1\n qp3d_ptr[10 * NDIM] = 0.665501535736642813e-1\n qp3d_ptr[11 * NDIM] = 0.665501535736642813e-1\n qp3d_ptr[12 * NDIM] = 0.433449846426335728e0\n qp3d_ptr[13 * NDIM] = 0.433449846426335728e0\n qp3d_ptr[14 * NDIM] = 0.433449846426335728e0\n \n qp3d_ptr[1] = 0.333333333333333333e0\n qp3d_ptr[1 + 1 * NDIM] = 0.333333333333333333e0\n qp3d_ptr[1 + 2 * NDIM] = 0.0e0\n qp3d_ptr[1 + 3 * NDIM] = 0.333333333333333333e0\n qp3d_ptr[1 + 4 * NDIM] = 0.25e0\n qp3d_ptr[1 + 5 * NDIM] = 0.909090909090909091e-1\n qp3d_ptr[1 + 6 * NDIM] = 0.909090909090909091e-1\n qp3d_ptr[1 + 7 * NDIM] = 0.727272727272727273e0\n qp3d_ptr[1 + 8 * NDIM] = 0.909090909090909091e-1\n qp3d_ptr[1 + 9 * NDIM] = 0.665501535736642813e-1\n qp3d_ptr[1 + 10 * NDIM] = 0.433449846426335728e0\n qp3d_ptr[1 + 11 * NDIM] = 0.433449846426335728e0\n qp3d_ptr[1 + 12 * NDIM] = 0.665501535736642813e-1\n qp3d_ptr[1 + 13 * NDIM] = 0.665501535736642813e-1\n qp3d_ptr[1 + 14 * NDIM] = 0.433449846426335728e0\n \n qp3d_ptr[2] = 0.333333333333333333e0\n qp3d_ptr[2 + 1 * NDIM] = 0.0e0\n qp3d_ptr[2 + 2 * NDIM] = 0.333333333333333333e0\n qp3d_ptr[2 + 3 * NDIM] = 0.333333333333333333e0\n qp3d_ptr[2 + 4 * NDIM] = 0.25e0\n qp3d_ptr[2 + 5 * NDIM] = 0.909090909090909091e-1\n qp3d_ptr[2 + 6 * NDIM] = 0.727272727272727273e0\n qp3d_ptr[2 + 7 * NDIM] = 0.909090909090909091e-1\n qp3d_ptr[2 + 8 * NDIM] = 0.909090909090909091e-1\n qp3d_ptr[2 + 9 * NDIM] = 0.433449846426335728e0\n qp3d_ptr[2 + 10 * NDIM] = 0.665501535736642813e-1\n qp3d_ptr[2 + 11 * NDIM] = 0.433449846426335728e0\n qp3d_ptr[2 + 12 * NDIM] = 0.665501535736642813e-1\n qp3d_ptr[2 + 13 * NDIM] = 0.433449846426335728e0\n qp3d_ptr[2 + 14 * NDIM] = 0.665501535736642813e-1\n \n iso_dndx = np.zeros((3,10,15))\n dndx_ptr = np.zeros((30)) \n \n for i in range(15):\n loc_ptr = qp3d_ptr[i*3:(i+1)*3]\n dndx_ptr[0] = 4.0e0 * (loc_ptr[0] + loc_ptr[1] + loc_ptr[2]) - 3.0e0;\n dndx_ptr[1] = 4.0e0 * (loc_ptr[0] + loc_ptr[1] + loc_ptr[2]) - 3.0e0;\n dndx_ptr[2] = 4.0e0 * (loc_ptr[0] + loc_ptr[1] + loc_ptr[2]) - 3.0e0;\n dndx_ptr[3] = -4.0e0 * (2.0e0 * loc_ptr[0] + loc_ptr[1] +loc_ptr[2] - 1.0e0);\n dndx_ptr[4] = -4.0e0 * loc_ptr[0];\n dndx_ptr[5] = -4.0e0 * loc_ptr[0];\n dndx_ptr[6] = 4.0e0 * loc_ptr[0] - 1.0e0;\n dndx_ptr[7] = 0.0e0;\n dndx_ptr[8] = 0.0e0;\n dndx_ptr[9] = 4.0e0 * loc_ptr[1];\n dndx_ptr[10] = 4.0e0 * loc_ptr[0];\n dndx_ptr[11] = 0.0e0;\n dndx_ptr[12] = 0.0e0;\n dndx_ptr[13] = 4.0e0 * loc_ptr[1] - 1.0e0;\n dndx_ptr[14] = 0.0e0;\n dndx_ptr[15] = -4.0e0 * loc_ptr[1];\n dndx_ptr[16] = -4.0e0 * (loc_ptr[0] + 2.0e0 * loc_ptr[1] + loc_ptr[2] - 1.0e0);\n dndx_ptr[17] = -4.0e0 * loc_ptr[1];\n dndx_ptr[18] = -4.0e0 * loc_ptr[2];\n dndx_ptr[19] = -4.0e0 * loc_ptr[2];\n dndx_ptr[20] = -4.0e0 * (loc_ptr[0] + loc_ptr[1] + 2.0e0 * loc_ptr[2] - 1.0e0);\n dndx_ptr[21] = 4.0e0 * loc_ptr[2];\n dndx_ptr[22] = 0.0e0;\n dndx_ptr[23] = 4.0e0 * loc_ptr[0];\n dndx_ptr[24] = 0.0e0;\n dndx_ptr[25] = 4.0e0 * loc_ptr[2];\n dndx_ptr[26] = 4.0e0 * loc_ptr[1];\n dndx_ptr[27] = 0.0e0;\n dndx_ptr[28] = 0.0e0;\n dndx_ptr[29] = 4.0e0 * loc_ptr[2] - 1.0e0;\n iso_dndx[:,:,i] = np.reshape(dndx_ptr, (3, 10), order='F')\n\n return iso_dndx\n\ndef local_gradient_shape_func(iso_dndx, elem_crd, iqpt):\n '''\n This function takes in element coordinates, and then using the parent\n gradient shape functions that are constant through out the simulation\n it calculates the local gradient shape functions for each element at\n each quadrature point.\n Input:\n iso_dndx - the isoparametric dndx matrix.\n elem_crd - the elemental coordinate array - nnpex3xnelems\n iqpt - the quadrature point are we interested in examining\n \n Output: \n loc_dndx - The local gradient shape functions at the quadrature point\n for each element. It has a shape of 3xnnpexnelems\n qpt_det - The determinant at the quadrature point for each element.\n It has a shape of nelems\n '''\n \n nelems = elem_crd.shape[2]\n nnpe = elem_crd.shape[0]\n \n loc_dndx = np.zeros((3, nnpe, nelems), dtype='float64', order='F')\n qpt_det = np.zeros((nelems), dtype='float64', order='F')\n jac = np.zeros((3,3), dtype='float64', order='F')\n ijac = np.zeros((3,3), dtype='float64', order='F')\n \n \n for i in range(nelems):\n jac = np.dot(iso_dndx[:,:,iqpt], elem_crd[:,:,i])\n ijac = np.linalg.inv(jac)\n qpt_det[i] = ((ijac[0,0]*ijac[1,1]*ijac[2,2] + ijac[0,1]*ijac[1,2]*ijac[2,0] + ijac[0,2]*ijac[1,0]*ijac[2,1])\n - (ijac[0,2]*ijac[1,1]*ijac[2,0] + ijac[0,1]*ijac[1,0]*ijac[2,2] + ijac[0,0]*ijac[1,2]*ijac[2,1]))\n loc_dndx[:,:,i] = np.dot(ijac, iso_dndx[:,:,iqpt])\n \n return (loc_dndx, qpt_det)\n \ndef get_scalar_grad(scalar, loc_dndx):\n '''\n This function uses the local gradient shape functions from each element\n to calculate the gradient of a scalar field.\n \n Input:\n scalar - the scalar field which is a nnpexnelem\n loc_dndx - the local gradient shape function which is a 3xnnpexnelems\n Output:\n scalar_grad - the scalar gradient at some quadrature point within the\n element. It has a size of 3xnelems\n '''\n \n nelems = scalar.shape[1]\n \n scalar_grad = np.zeros((3, nelems), dtype='float64', order='F')\n \n for i in range(nelems):\n scalar_grad[:, i] = np.dot(scalar[:, i], loc_dndx[:,:,i].T)\n\n return scalar_grad \n\n\ndef get_vec_grad(vec, loc_dndx):\n '''\n This function uses the local gradient shape functions from each element\n to calculate the gradient of a vector field.\n \n Input:\n vec - the vector field which is a 3xnnpexnelem\n loc_dndx - the local gradient shape function which is a 3xnnpexnelems\n Output:\n scalar_grad - the vector gradient at some quadrature point within the\n element. It has a size of 3x3xnelems\n '''\n \n nelems = vec.shape[2]\n \n vec_grad = np.zeros((3, 3, nelems), dtype='float64', order='F')\n \n for i in range(nelems):\n vec_grad[:, :, i] = vec[:,:,i].dot(loc_dndx[:,:,i].T)\n\n return vec_grad \n\ndef get_nye_tensor(vec_grad):\n '''\n This function uses the lattice orientation gradient field\n and computes the nye tensor.\n \n Input:\n vec_grad - the vector field which is a 3x3xnelem\n Output:\n nye_ten - the nye tensor which is a 3x3xnelem\n '''\n nelems = vec_grad.shape[2]\n vec_gradT = np.swapaxes(vec_grad, 0, 1)\n trT = np.zeros((3,3,nelems), dtype='float64', order='F')\n for i in range(nelems):\n trT[:,:,i] = 0.5 * np.eye(3)*np.trace(np.squeeze(vec_gradT[:,:,i]))\n nye_ten = vec_gradT - trT\n \n return nye_ten\n\ndef get_l2_norm_dd(nye_ten, l2mat):\n '''\n It takes in the nye tensor and outputs the dislocation density using\n the L2 norm method. It also takes in the L2 matrix from Arsenlis 1999 paper.\n \n Input: nye_ten - the nye tensor as calculated in the above function which is\n a 3x3xnelem\n l2mat - the L2 mat as given in Arsenlis 1999 paper for FCC materials. If\n you had a different system then the L2 matrix would need to be calculated\n ahead of time. The size is nslip x 9\n \n Output: dd - the dislocation density for the 12 main slip systems in an FCC material if\n the L2 mat is from the 1999 Arsenlis paper. If it isn't then it is however\n many main slip systems in your material. The size is nslip x nelems\n \n '''\n \n nelems = nye_ten.shape[2]\n dd = np.zeros((12, nelems), dtype='float64', order='F')\n alpha = nye_ten.reshape(9, nelems)\n \n for i in range(nelems):\n dd[:, i] = l2mat.dot(alpha[:,i])\n \n return dd\n\ndef get_l2_matrix():\n '''\n The L2 mat from Arsenlis 1999 paper for GND calculations for an FCC material\n Output: l2mat - The l2mat as given in the paper which is 12 x 9.\n '''\n \n a = np.sqrt(3.0)/9.0\n c = np.sqrt(3.0)/84.0\n z = 0.0\n \n l2mat = np.zeros((12, 9), dtype='float64', order='F')\n \n l2mat[:, 0] = [a, -a, z, a, -a, z, a, -a, z, a, -a, z]\n l2mat[:, 1] = [7.0*c, 13.0*c, c, -7.0*c, -13.0*c, -c, -7.0*c, -13.0*c, -c, 7.0*c, 13.0*c, c]\n l2mat[:, 2] = [-13.0*c, -7.0*c, -c, 13.0*c, 7.0*c, c,-13.0*c, -7.0*c, -c, 13.0*c, 7.0*c, c]\n l2mat[:, 3] = [7.0*c, c, 13.0*c, -7.0*c, -c, -13.0*c, -7.0*c, -c, -13.0*c, 7.0*c, c, 13.0*c]\n l2mat[:, 4] = [-a, z, a, -a, z, a, -a, z, a, -a, z, a]\n l2mat[:, 5] = [13.0*c, c, 7.0*c, 13.0*c, c, 7.0*c, -13.0*c, -c, -7.0*c, -13.0*c, -c, -7.0*c]\n l2mat[:, 6] = [c, 7.0*c, 13.0*c, -c, -7.0*c, -13.0*c, c, 7.0*c, 13.0*c, -c, -7.0*c, -13.0*c]\n l2mat[:, 7] = [-c, -13.0*c, -7.0*c, -c, -13.0*c, -7.0*c, -c, 13.0*c, 7.0*c, c, 13.0*c, 7.0*c]\n l2mat[:, 8] = [z, a, -a, z, a, -a, z, a, -a, z, a, -a]\n \n return l2mat\n\ndef sf_qpt_wts():\n '''\n Quadrature point weights for a 10 node tet\n '''\n \n wtqp = np.zeros(15)\n wtqp[0:4] = 0.602678571428571597e-2\n wtqp[4] = 0.302836780970891856e-1\n wtqp[5:9] = 0.116452490860289742e-1\n wtqp[9:15] = 0.109491415613864534e-1\n\n return wtqp \n\ndef sftsfmat():\n '''\n Creates a NTN array that has the appropriate weights applied at\n each quadratutre point.\n Also return NT with appropriate weight applied to it\n '''\n qpt_wts = sf_qpt_wts()\n N = sfmat()\n NT = N.T\n \n NTN = np.zeros((10,10,15))\n \n for i in range(15):\n NTN[:,:,i] = np.outer(N[i,:], N[i,:]) * qpt_wts[i]\n NT[:,i] = NT[:,i] * qpt_wts[i]\n\n return (NTN, NT) \n\ndef gr_lstq_amat(conn, nsf, ncrds):\n '''\n Inputs:\n conn - the local connectivity array a nelem x 10 size array\n nsf - the shape function matrix\n ncrds - number of coordinates/nodal points in the grain\n Output:\n amat - the matrix used in our least squares problem for the grain\n It will be constant through out the solution.\n '''\n \n nelems = conn.shape[1]\n nqpts = nsf.shape[0]\n amat = np.zeros((nelems*nqpts, ncrds))\n #Build up our A matrix to be used in a least squares solution\n j = 0\n k = 0\n for i in range(nelems):\n j = i * nqpts\n k = (i + 1) * nqpts\n ecrds = np.squeeze(conn[:, i])\n amat[j:k, ecrds] = nsf\n \n return amat\n \ndef gr_lstq_solver(amat, q_mat, ncrds):\n '''\n Inputs:\n conn - the local connectivity array a nelem x 10 size array\n q_mat - vector at each quad point\n size = nqpts x nvec x nelems\n ncrds - number of coordinates/nodal points in the grain\n Output:\n nod_mat - the nodal values of a grain for the q_mat\n residual - the residual from the least squares\n \n A least squares routine is used to solve for the solution. \n It'll find the nodal values of the points at the quadrature mat for\n a grain.\n '''\n \n nvec = q_mat.shape[1]\n nqpts = q_mat.shape[0]\n nelems = q_mat.shape[2]\n nod_mat = np.zeros((nvec,ncrds), dtype='float64')\n b = np.zeros((nqpts*nelems))\n residual = np.zeros(nvec)\n \n for i in range(nvec):\n b[:] = np.ravel(q_mat[:, i, :], order = 'F')\n nod_mat[i, :], residual[i], t1, t2 = np.linalg.lstsq(amat, b)\n \n return (nod_mat, residual)\n\ndef gr_nnlstq(amat, q_mat, ncrds):\n '''\n Inputs:\n conn - the local connectivity array a nelem x 10 size array\n q_mat - vector at each quad point\n size = nqpts x nvec x nelems\n ncrds - number of coordinates/nodal points in the grain\n Output:\n nod_agamma - the nodal values of a grain for the q_mat\n residual - the residual from the least squares\n \n A nonnegative nonlinear least squares optimization routine is used to solve for\n the solution. It'll find the nodal values of the absolute q_mat for\n a grain.\n '''\n \n nvec = q_mat.shape[1]\n nqpts = q_mat.shape[0]\n nelems = q_mat.shape[2]\n nod_mat = np.zeros((nvec,ncrds), dtype='float64')\n b = np.zeros((nqpts*nelems))\n residual = np.zeros(nvec)\n \n for i in range(nvec):\n b[:] = np.ravel(q_mat[:, i, :], order = 'F')\n nod_mat[i, :], residual[i] = sciop.nnls(amat, b)\n \n return (nod_mat, residual)\n\ndef superconvergence_mat(NTN, qpt_det, conn, ncrds):\n '''\n Input:\n NTN - the shape function transpose shape function outer product\n matrix with dimensions - nnpe x nnpe x nqpts\n qpt_det - the determinate of the jacobian matrix for each\n quadrature point of an element - dimensions nelem x nqpts\n conn - the connectivity array\n ncrds - the number of coordinates\n Output:\n amat - the superconvergence matrix\n '''\n nelems = conn.shape[0]\n nqpts = NTN.shape[2]\n nnpe = NTN.shape[0]\n amat = np.zeros((ncrds, ncrds), dtype='float64', order='F')\n \n for i in range(nelems):\n for j in range(nqpts):\n for k in range(nnpe):\n ind = conn[i, k]\n amat[ind, conn[i, :]] = amat[ind, conn[i, :]] + NTN[k,:,j] * qpt_det[i,j] \n \n return amat \n\ndef superconvergence_vec(NT, qpt_det, conn, qpt_vec, ncrds):\n '''\n Input\n NT - the transpose shape function\n qpt_det - the determinate of the jacobian matrix for each\n quadrature point of an element - dimensions nelem x nqpts\n conn - the connectivity array\n qpt_vec - vector at each quad point for nvecs\n size = nqpts x nvec x nelems\n ncrds - the number of coordinates\n \n Output:\n bvec - the integration of NT*qpt_vec over the domain product\n size is ncrds x nvec\n '''\n \n nqpts = qpt_det.shape[1]\n nelems = conn.shape[0]\n nvec = qpt_vec.shape[1]\n nnpe = conn.shape[1]\n \n bvec = np.zeros((ncrds, nvec), dtype='float64', order='F')\n tarr = np.zeros((nqpts), dtype='float64', order='F')\n tind = np.zeros((nnpe), dtype='int32', order='F')\n \n for i in range(nvec):\n for j in range(nelems):\n tind[:] = conn[j, :]\n tarr[:] = qpt_vec[:,i,j]*qpt_det[j, :]\n bvec[tind, i] = bvec[tind, i] + NT.dot(tarr)\n \n return bvec\n\ndef superconvergence_gr_nnlstq(amat, bvec, ncrds):\n '''\n Inputs:\n conn - the local connectivity array a nelem x 10 size array\n q_mat - vector at each quad point\n size = nqpts x nvec x nelems\n ncrds - number of coordinates/nodal points in the grain\n Output:\n nod_agamma - the nodal values of a grain for the q_mat\n residual - the residual from the least squares\n \n A nonnegative nonlinear least squares optimization routine is used to solve for\n the solution. It'll find the nodal values of the absolute q_mat for\n a grain.\n '''\n \n nvec = bvec.shape[1]\n\n nod_mat = np.zeros((ncrds, nvec), dtype='float64', order='F')\n b = np.zeros((ncrds), dtype='float64', order='C')\n residual = np.zeros((nvec), dtype='float64', order='F')\n \n for i in range(nvec):\n b[:] = bvec[:, i]\n nod_mat[:, i], residual[i] = sciop.nnls(amat, b)\n \n return (nod_mat.T, residual)\n \n\ndef superconvergence_solve(amat, bvec):\n '''\n Solves the superconvergence patch test problem to obtain values at the\n nodal coordinates\n Input:\n amat - our superconvergence matrix\n bvec - our superconvergence bvec with a size of ncrds x nvec\n Output\n xvec - our superconvergence nodal solutions with a size of ncrds x nvec\n '''\n \n xvec = np.linalg.solve(amat, bvec)\n\n return xvec.T\n\ndef superconvergence_solve_cg(NTN, qpt_det, bvec, conn, ncrds):\n '''\n Solves the superconvergence patch test problem to obtain values at the\n nodal coordinates using a preconditioned conjugate gradient solver.\n Input:\n NTN - the shape function transpose shape function outer product\n matrix with dimensions - nnpe x nnpe x nqpts\n qpt_det - the determinate of the jacobian matrix for each\n quadrature point of an element - dimensions nelem x nqpts\n bvec - the integration of NT*qpt_vec over the domain product\n size is ncrds x nvec\n conn - the connectivity array\n ncrds - the number of coordinates\n Output:\n xvec - our superconvergence nodal solutions with a size of ncrds x nvec\n '''\n\n nelems = conn.shape[0]\n nvec = bvec.shape[1]\n nnpe = conn.shape[1]\n nqpts = NTN.shape[2] \n mvec = np.zeros((ncrds, 1), dtype='float64', order='F')\n tind = np.zeros((nnpe), dtype='int32')\n xvec = np.zeros((ncrds, nvec), dtype='float64', order='F')\n \n# We need to first form our preconditioner. A simple Jacobi is good enough\n# for our use since our elements results in a pretty sparse and blocked\n# series of events of our elements.\n for i in range(nelems):\n tind[:] = conn[i, :]\n for j in range(nqpts):\n #The diagonal of our element series\n diag_NTN = np.diag(NTN[:, :, j])\n mvec[tind] = mvec[tind] + diag_NTN[:] * qpt_det[i, j]\n \n #The inverse of our preconditioner \n inv_mvec = 1.0/mvec[:]\n #Here we're going to start our pcg solver\n for i in range(nvec):\n xvec[:, i] = superconvergence_block_pcg(NTN, qpt_det, inv_mvec, bvec[:, i], conn, ncrds)\n \n return xvec\n \n \n \ndef superconvergence_block_pcg(NTN, qpt_det, inv_mvec, bvec, conn, ncrds):\n '''\n Solves the superconvergence patch test problem to obtain values at the\n nodal coordinates using a preconditioned conjugate gradient solver.\n Input:\n NTN - the shape function transpose shape function outer product\n matrix with dimensions - nnpe x nnpe x nqpts\n qpt_det - the determinate of the jacobian matrix for each\n quadrature point of an element - dimensions nelem x nqpts\n bvec - the integration of NT*qpt_vec over the domain product\n size is ncrds x 1\n conn - the connectivity array\n ncrds - the number of coordinates\n Output:\n xvec - our superconvergence nodal solutions with a size of ncrds x 1\n '''\n \n tol = 1.0e-14\n \n nelems = conn.shape[0]\n nnpe = conn.shape[1]\n nqpts = NTN.shape[2] \n \n tind = np.zeros((nnpe), dtype='int32')\n tmat = np.zeros((nnpe), dtype='float64', order='F')\n \n rk = np.zeros((ncrds, 1), dtype='float64', order='F')\n rk1 = np.zeros((ncrds, 1), dtype='float64', order='F')\n zk = np.zeros((ncrds, 1), dtype='float64', order='F')\n zk1 = np.zeros((ncrds, 1), dtype='float64', order='F')\n pk = np.zeros((ncrds, 1), dtype='float64', order='F')\n xk = np.zeros((ncrds, 1), dtype='float64', order='F')\n pak = np.zeros((ncrds, 1), dtype='float64', order='F') \n \n rk[:, 0] = bvec[:]\n \n k = 0\n \n err = np.zeros((1), dtype='float64', order='F')\n mu = np.zeros((1), dtype='float64', order='F')\n tau = np.zeros((1), dtype='float64', order='F')\n \n #The below should return 0 the first time its called subsequent trials\n #won't result in a zero value though\n for i in range(nelems):\n tind[:] = conn[i, :]\n tmat[:, :] = 0.0\n for j in range(nqpts):\n tmat[:, :] = tmat[:, :] + NTN[:, :, j] * qpt_det[i, j]\n rk[tind, 0] = rk[tind, 0] - tmat.dot(xk[tind, 0])\n \n zk[:] = inv_mvec[:] * rk[:]\n pk[:] = zk[:]\n \n \n #We will break out of this if the error is below the tolerance value \n for i in range(ncrds):\n pak[:] = 0.0\n #The Apk product is calculated here\n for j in range(nelems):\n tind[:] = conn[j, :]\n tmat[:, :] = 0.0\n for k in range(nqpts):\n tmat[:, :] = tmat[:, :] + NTN[:, :, k] * qpt_det[j, k]\n pak[tind, 0] = pak[tind, 0] + tmat.dot(pk[tind, 0])\n #We should only perform the top operation once\n #We use it down below as rk1.T.dot(zk1)\n mu = (rk.T.dot(zk))/(pk.T.dot(pak))\n \n xk[:] = xk[:] - mu * pk[:]\n \n rk1[:] = rk[:]\n rk[:] = rk[:] - mu * pak[:]\n \n zk1[:] = zk[:]\n zk[:] = inv_mvec[:] * rk[:]\n #We should set this top part as the new operation that's used above\n tau = (rk.T.dot(zk))/(rk1.T.dot(zk1))\n pk[:] = zk[:] + tau * pk[:]\n \n err = np.squeeze(rk.T.dot(rk))\n \n if np.abs(err) < tol:\n break\n \n return np.squeeze(xk)\n \n \n\ndef jacobian_lin(mesh):\n '''\n jacobian_lin - Compute Jacobian of linear mesh mappings.\n \n USAGE:\n \n jac = jacobian_lin(mesh)\n \n INPUT:\n \n mesh is a MeshStructure,\n with simplicial element type\n \n OUTPUT:\n \n jac is 1 x m, \n the Jacobian of each element\n \n NOTES:\n \n * The mesh may be embedded in a space of higher \n dimension than the reference element. In that\n case, the Jacobian is computed as (sqrt(det(J'*J))\n and is always positive. When the target space is\n of the same dimension as the reference element,\n the Jacobian is computed as usual and can be\n positive or negative.\n \n * Only simplicial (linear) element types are allowed. \n '''\n \n crd = mesh['crd']\n con = mesh['con']\n \n e = con.shape[0]\n ddom = e - 1\n dtar = crd.shape[0]\n \n nels = con.shape[1]\n \n jac = np.zeros(nels)\n \n if (ddom == dtar):\n for i in range(nels):\n simp = crd[:, con[:, i].T]\n mat = simp[:, 0:ddom] - np.tile(simp[:, e] (1, ddom))\n jac[i] = np.linalg.det(mat)\n else:\n for i in range(nels):\n simp = crd[:, con[:, i].T]\n mat = simp[:, 0:ddom] - np.tile(simp[:, e] (1, ddom))\n mat = mat.T.dot(mat)\n jac[i] = np.sqrt(np.linalg.det(mat))\n \n return jac\n \n"
},
{
"alpha_fraction": 0.522486686706543,
"alphanum_fraction": 0.538601279258728,
"avg_line_length": 39.18730163574219,
"blob_id": "a0b86eeca4d0a09695d36228e5e4e2efef7e983a",
"content_id": "1cbf01666e237822d6e0848958488453b1ce830a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 37978,
"license_type": "permissive",
"max_line_length": 160,
"num_lines": 945,
"path": "/PythonScripts/FePX_Data_and_Mesh.py",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport textadapter as ta\n#import iopro\nimport Utility as util\n\n'''\nList of functions available:\nreadMesh(fileLoc, fileName)\nmesh_node_neigh(conn, nd_conn)\nmesh_node_conn(conn, nnode)\nwordParser(listVals)\nreadData(fileLoc, nProc, frames=None, fepxData=None, restart=False)\nreadGrainData(fileLoc, grainNum, frames=None, grData=None)\nreadLOFEMData(fileLoc, nProc, nqpts=15, frames=None, lofemData=None)\nfixStrain(epsVec)\nfindComments(fileLoc)\nselectFrameTxt(fileLoc, frames, comments='%')\n'''\ndef readMesh(fileLoc, fileName, LOFEM=False):\n ''' \n Takes in the file location and file name and it then generates a dictionary structure from those files for the mesh.\n Input: fileLoc = a string of the loaction of file on your computer\n fileName = a string of the name of the file assuming they are all equal for .mesh, .kocks, and .grain\n Outpute: mesh = a dictionary that contains the following fields in it:\n name = file location\n eqv = any equivalence nodes currently this is an empty nest\n grains = what grain each element corresponds to\n con = connectivity of the mesh for each element\n crd = coordinates of each node\n surfaceNodes = surface nodes of the mesh\n kocks = kocks angles for each grain\n phases = phase number of each element\n '''\n surfaceNodes = []\n con = []\n crd = []\n eqv = []\n name = fileLoc\n meshLoc = fileLoc + fileName + '.mesh'\n grainLoc = fileLoc + fileName + '.grain'\n kockLoc = fileLoc + fileName + '.kocks' \n grains = []\n phases = []\n kocks = []\n mesh = {}\n mesh['name'] = name\n mesh['eqv'] = []\n\n with open(meshLoc) as f:\n # data = f.readlines()\n for line in f:\n words = line.split()\n # print(words)\n lenWords = len(words)\n if not words:\n continue\n if lenWords == 4:\n nums = wordParser(words)\n crd.append(nums[1:4])\n if lenWords == 7:\n nums = wordParser(words)\n surfaceNodes.append(nums[0:7])\n if lenWords == 11:\n nums = wordParser(words)\n con.append(nums[1:11])\n\n grains = np.genfromtxt(grainLoc, usecols=(0), skip_header=1, skip_footer=0)\n ugrains = np.unique(grains)\n phases = np.genfromtxt(grainLoc, usecols=(1), skip_header=1, skip_footer=0)\n kocks = np.genfromtxt(kockLoc, usecols=(0, 1, 2), skip_header=2, skip_footer=1)\n if not kocks.shape[0] == ugrains.shape[0]:\n kocks = np.genfromtxt(kockLoc, usecols=(0, 1, 2), skip_header=2, skip_footer=0)\n mesh['con'] = np.require(np.asarray(con, order='F', dtype=np.int32).transpose(), requirements=['F'])\n mesh['crd'] = np.require(np.asarray(crd, order='F').transpose(), requirements=['F'])\n mesh['surfaceNodes'] = np.require(np.asarray(surfaceNodes, order='F',dtype=np.int32).transpose(), requirements=['F'])\n mesh['grains'] = np.asfortranarray(grains.transpose(), dtype=np.int32)\n mesh['kocks'] = util.mat2d_row_order(np.asfortranarray(kocks.transpose()))\n mesh['phases'] = np.asfortranarray(phases.transpose(),dtype=np.int8)\n \n if (LOFEM):\n crd_meshLoc = fileLoc + fileName + '.cmesh'\n crd_grainLoc = fileLoc + fileName + '.cgrain'\n \n cgrains = ta.genfromtxt(crd_grainLoc, usecols=(0))\n cphases = ta.genfromtxt(crd_grainLoc, usecols=(1))\n ccon = ta.genfromtxt(crd_meshLoc, skip_header=1)\n \n mesh['crd_con'] = np.asfortranarray(ccon.transpose(), dtype=np.int32) - 1\n mesh['crd_grains'] = np.asfortranarray(cgrains.transpose(), dtype=np.int32)\n mesh['crd_phases'] = np.asfortranarray(cphases.transpose(), dtype=np.int8)\n\n return mesh\n\ndef mesh_node_neigh(conn, nd_conn):\n '''\n Creates a list of all of a nodes neighbors given the connectivity\n array and the node elem connectivity array. \n \n Input: conn = a numpy array of the mesh connectivity array\n nd_conn = a list of sets for each node and what elems they\n are connected to\n \n Output: nd_neigh = a list of sets of a nodes neighbors\n \n Note: This should work but it still needs a slightly more extensive testing\n '''\n\n nnode = len(nd_conn)\n nd_neigh = [set() for _ in range(nnode)]\n ncrds = conn.shape[0]\n\n #There's got to be a faster way to do this... \n for i in range(nnode):\n for j in nd_conn[i]:\n for k in range(ncrds):\n tmp = conn[k,j]\n nd_neigh[i].add(tmp)\n #Get rid of your own node... \n nd_neigh[i].discard(i)\n \n return nd_neigh\n \ndef mesh_node_conn(conn, nnode):\n '''\n Takes in the element connectivity array and computes the inverse\n array or the nodal connectivity array.\n \n Input: conn = a numpy array of the mesh element connectivity array\n nnode = the number of nodes in the mesh\n \n Output: nd_conn = a list of sets for each node and what elems they\n are connected to\n \n Note: This should work but it still needs more extensive testing\n '''\n \n nd_conn = [set() for _ in range(nnode)]\n \n ncrds, nelems = conn.shape\n \n for i in range(nelems):\n for j in range(ncrds):\n tmp = conn[j,i]\n nd_conn[tmp].add(i)\n \n return nd_conn\n\ndef grain_conn_mesh(ndconn, conn, grains, nnode):\n '''\n Takes in the nodal and elemental connectivity arrays. It then goes through\n the list of nodes and increments the node count for those in different grains\n in the elemental connectivity array. It also will update all of the other\n nodes by the most current incremental count.\n \n Input: ndconn = a list of sets for each node and what elems they are\n connected to\n conn = a numpy array of the mesh element connectivity array\n grains = a numpy array corresponding to what grain each element is\n in\n nnode = the number of nodes in the mesh\n Output: conn = a numpy array that is the updated connectivity array\n '''\n #We don't increment anything to start off with\n incr = 0\n nodes = np.zeros(10, dtype='int32')\n #Really wish I didn't have to make a copy of this...\n conn_orig = np.copy(conn)\n conn2 = np.copy(conn)\n \n for i in range(nnode):\n #We want a numpy array of all the elements connected to that node\n ndelems = np.array(list(ndconn[i]), dtype='int32')\n #We also want to know how many unique grains we actually have\n ugrns = np.unique(grains[ndelems])\n #Our inner loop that were going to use to go through the data\n for j in ndelems:\n #First we get all the nodes\n nodes[:] = conn_orig[:, j]\n #Then we simply get the index of our node\n ind = nodes == i\n #Finally we increment the conn array\n conn2[ind, j] = incr + i + np.where(ugrns == grains[j])[0][0]\n \n #We don't need to increment anything if there is only one grain for\n #that node\n nincr = ugrns.shape[0] - 1\n incr = incr + nincr\n \n return conn2\n\ndef grain_boundary_nodes(ndconn, grains, nnode):\n '''\n Takes in the nodal and elemental connectivity arrays. It then goes through\n the list of nodes and finds all of the nodes that belong to a GB.\n Later we would need to find what elements share that surface. We would\n need elements with 6 or more elements on a surface to be connected to\n the other elements. This would be used in our global nodal connectivity\n matrix.\n \n Input: ndconn = a list of sets for each node and what elems they are\n connected to\n conn = a numpy array of the mesh element connectivity array\n grains = a numpy array corresponding to what grain each element is\n in\n nnode = the number of nodes in the mesh\n Output: gbnodes = a dictionary of dictionary. The first key is the original\n node number and the second key is the grain number for that\n node. It will then return the new node number\n nincr = a numpy array containing the number of increments made\n for each node. This can be used for many things and one\n such thing is finding the GB elements by finding the elements\n with 6 or more GB nodes\n '''\n \n nincr = np.zeros(nnode, dtype='int32')\n incr = 0\n \n for i in range(nnode):\n #We want a numpy array of all the elements connected to that node\n ndelems = np.array(list(ndconn[i]), dtype='int32')\n #We also want to know how many unique grains we actually have\n ugrns = np.unique(grains[ndelems])\n #Our inner loop that were going to use to go through the data\n #The node doesn't need to be incremented if it isn't on a GB.\n nincr[i] = ugrns.shape[0] - 1\n \n nodes = np.int32(np.where(nincr > 0)[0])\n #Going ahead and initiallizing our set all at once\n# gbnodes = [np.zeros((3, nincr[i]+1), dtype='int32') for i in nodes]\n gbnodes = dict.fromkeys(nodes, {})\n\n\n #Cycle through the index of all the nodes that were on the boundary\n for i in nodes:\n #We want a numpy array of all the elements connected to that node\n ndelems = np.array(list(ndconn[i]), dtype='int32')\n #We also want to know how many unique grains we actually have\n ugrns = np.unique(grains[ndelems])\n gbnodes[i] = dict.fromkeys(ugrns, None)\n tmp = set()\n for j in ndelems:\n #Finally we increment the conn array\n new_index = incr + i + np.where(ugrns == grains[j])[0][0]\n tmp.add((i, new_index, grains[j]))\n \n for item in tmp:\n gbnodes[i][np.int32(item[2])] = np.int32(item[1])\n \n incr = incr + nincr[i]\n\n return (gbnodes, nincr)\n\ndef grain_boundary_elements(nincr, gbnodes, nd_conn, nd_conn_gr, conn, grain):\n '''\n It takes in the number of grains a coord originally belongs to. It takes\n in the list of grain boundary coordinates and there respectively updated\n coords. It takes in the original nd_conn array before the nodes on the\n grain boundary were updated with new values. It finally takes in the \n updated nodal connectivity array which will be used to generate the\n connectivity array for the surface grain boundary elements. Finally,\n it will output a list of the GB element index and its paired element.\n Input:\n gbnodes = a dictionary of dictionary. The first key is the original\n node number and the second key is the grain number for that\n node. It will then return the new node number \n nincr = a numpy array containing the number of increments made\n for each node. This can be used for many things and one\n such thing is finding the GB elements by finding the elements\n with 6 or more GB nodes\n ndconn = a list of sets for each node and what elems they are\n connected to\n conn = a numpy array of the mesh element connectivity array\n grain = a numpy array corresponding to what grain each element is\n in\n ndconn_gr = a list of sets for each node after being renumbered for \n so that gb nodes are on seperate nodes \n and what elems they are connected to\n \n Output:\n gb_elems = A numpy array of all of the elements on the grain boundary with\n 6 or more nodes on the surface. In other words we want\n to know what elements have an element face on the grain\n boundary.\n gb_conn = The element connectivity array for each grain boundary\n element. It allows for the reconstruction of the triangular\n prism elements. It is given as a numpy array. The last\n two elements in the array tell us what elements correspond\n to that particular connectivity array.\n gb_elem_set = A set of frozen sets that contains all of grain boundary\n element pairs. One can then use this in conjunction with\n the gb_conn to build up our grain boundary surface elements.\n It could also be used in a number of different areas. \n '''\n \n nelems = conn.shape[1]\n \n gb_elem_set = set()\n nsurfs = np.zeros(nelems, dtype='int8')\n \n for i in range(nelems):\n tconn = np.squeeze(conn[:, i])\n tincr = np.sum(nincr[tconn] > 0)\n nsurfs[i] = tincr\n \n gb_elems = np.where(nsurfs > 5)[0]\n gb_elems_iter = np.where(nsurfs > 5)[0]\n surf_index = np.zeros((gb_elems.shape[0], 5), dtype=np.int32)\n \n j = 0\n for i in gb_elems_iter:\n tconn = np.squeeze(conn[:, i])\n index = np.where(nincr[tconn] > 0)[0]\n surf_index[j, 4] = i\n tmp = 0\n #surface 1 of 10 node tet\n if(np.any(index == 1) & np.any(index == 5)):\n i0 = tconn[0]\n i1 = tconn[1]\n i2 = tconn[2]\n i3 = tconn[3]\n i4 = tconn[4]\n i5 = tconn[5]\n #All need to be on the surface\n gb_surf_test = (i0 in gbnodes) & (i1 in gbnodes) & (i2 in gbnodes) & (i3 in gbnodes) & (i4 in gbnodes) & (i5 in gbnodes)\n if gb_surf_test:\n #Finds the intersection of the 6 different node set\n s1 = nd_conn[i0] & nd_conn[i1] & nd_conn[i2] & nd_conn[i3] & nd_conn[i4] & nd_conn[i5]\n #We need to check that the length is greater than 1 if it isn't than we toss\n #that point\n ugrns = np.unique(grain[list(s1)])\n if(len(s1) > 1) & (ugrns.shape[0] > 1):\n tmp = tmp + 1\n surf_index[j, 0] = list(s1 - {i})[0]\n gb_elem_set.add(frozenset(s1))\n #surface 2 of 10 node tet\n if(np.any(index == 1) & np.any(index == 9)):\n i0 = tconn[0]\n i1 = tconn[1]\n i2 = tconn[2]\n i3 = tconn[7]\n i4 = tconn[9]\n i5 = tconn[6]\n #All need to be on the surface\n gb_surf_test = (i0 in gbnodes) & (i1 in gbnodes) & (i2 in gbnodes) & (i3 in gbnodes) & (i4 in gbnodes) & (i5 in gbnodes)\n if gb_surf_test:\n #Finds the intersection of the 6 different node set\n s1 = nd_conn[i0] & nd_conn[i1] & nd_conn[i2] & nd_conn[i3] & nd_conn[i4] & nd_conn[i5]\n #We need to check that the length is greater than 1 if it isn't than we toss\n #that point. It also turns out that somehow we could end up with elements that are on the\n #same grain. I'm not sure how since they should all be unique.\n ugrns = np.unique(grain[list(s1)])\n if(len(s1) > 1) & (ugrns.shape[0] > 1):\n tmp = tmp + 1\n surf_index[j, 1] = list(s1 - {i})[0]\n gb_elem_set.add(frozenset(s1))\n #surface 3 of 10 node tet\n if(np.any(index == 3) & np.any(index == 9)):\n i0 = tconn[2]\n i1 = tconn[3]\n i2 = tconn[4]\n i3 = tconn[8]\n i4 = tconn[9]\n i5 = tconn[7]\n #All need to be on the surface\n gb_surf_test = (i0 in gbnodes) & (i1 in gbnodes) & (i2 in gbnodes) & (i3 in gbnodes) & (i4 in gbnodes) & (i5 in gbnodes)\n if gb_surf_test:\n #Finds the intersection of the 6 different node set \n s1 = nd_conn[i0] & nd_conn[i1] & nd_conn[i2] & nd_conn[i3] & nd_conn[i4] & nd_conn[i5]\n #We need to check that the length is greater than 1 if it isn't than we toss\n #that point\n ugrns = np.unique(grain[list(s1)])\n if(len(s1) > 1) & (ugrns.shape[0] > 1):\n tmp = tmp + 1\n surf_index[j, 2] = list(s1 - {i})[0]\n gb_elem_set.add(frozenset(s1))\n #surface 4 of 10 node tet\n if(np.any(index == 5) & np.any(index == 9)):\n i0 = tconn[4]\n i1 = tconn[5]\n i2 = tconn[0]\n i3 = tconn[6]\n i4 = tconn[9]\n i5 = tconn[8]\n #All need to be on the surface\n gb_surf_test = (i0 in gbnodes) & (i1 in gbnodes) & (i2 in gbnodes) & (i3 in gbnodes) & (i4 in gbnodes) & (i5 in gbnodes)\n if gb_surf_test:\n #Finds the intersection of the 6 different node set\n s1 = nd_conn[i0] & nd_conn[i1] & nd_conn[i2] & nd_conn[i3] & nd_conn[i4] & nd_conn[i5]\n #We need to check that the length is greater than 1 if it isn't than we toss\n #that point\n ugrns = np.unique(grain[list(s1)])\n if(len(s1) > 1) & (ugrns.shape[0] > 1):\n tmp = tmp + 1\n surf_index[j, 3] = list(s1 - {i})[0] \n gb_elem_set.add(frozenset(s1))\n #We need to check and make sure that if a grain boundary element\n #is actually a grain boundary element.\n #If it did not share a face at all then we remove it from the grain\n #boundary element array\n if(tmp > 0):\n j = j + 1\n else:\n gb_elems = gb_elems[gb_elems != i]\n \n nsurf_elems = len(gb_elem_set)\n \n gb_conn = np.zeros((14, nsurf_elems), dtype=np.int32)\n \n# nb_gbnodes = len(gbnodes)\n \n j = 0\n for gb_els in gb_elem_set:\n elems = np.asarray(list(gb_els), dtype=np.int32)\n gb_conn[12:14, j] = elems\n tgrains = np.int32(grain[elems])\n \n ind2 = np.where(elems[0] == np.squeeze(surf_index[:,4]))[0]\n surf = np.where(elems[1] == np.squeeze(surf_index[ind2, 0:4]))[0]\n tconn = np.squeeze(conn[:, elems[0]])\n \n if(surf == 0):\n ind = np.asarray([0,1,2,3,4,5])\n elif(surf == 1):\n ind = np.asarray([0,1,2,7,9,6]) \n elif(surf == 2):\n ind = np.asarray([2,3,4,8,9,7]) \n else:\n ind = np.asarray([4,5,5,6,9,8]) \n \n nodes_orig = np.int32(np.squeeze(tconn[ind]))\n \n i1 = nodes_orig[0]\n i2 = nodes_orig[1]\n i3 = nodes_orig[2]\n i4 = nodes_orig[3]\n i5 = nodes_orig[4]\n i6 = nodes_orig[5]\n \n #Manual creation of the index since there's no easy way to do this\n #through the use of a loop with the current ordering of the conn\n #array\n gb_conn[0, j] = gbnodes[i1][tgrains[0]]\n gb_conn[6, j] = gbnodes[i2][tgrains[0]] \n gb_conn[1, j] = gbnodes[i3][tgrains[0]] \n gb_conn[7, j] = gbnodes[i4][tgrains[0]] \n gb_conn[2, j] = gbnodes[i5][tgrains[0]] \n gb_conn[8, j] = gbnodes[i6][tgrains[0]]\n \n gb_conn[3, j] = gbnodes[i1][tgrains[1]] \n gb_conn[9, j] = gbnodes[i2][tgrains[1]] \n gb_conn[4, j] = gbnodes[i3][tgrains[1]]\n gb_conn[10, j] = gbnodes[i4][tgrains[1]]\n gb_conn[5, j] = gbnodes[i5][tgrains[1]] \n gb_conn[11, j] = gbnodes[i6][tgrains[1]]\n \n j = j + 1\n \n \n return (gb_elems, gb_conn, gb_elem_set)\n\ndef wordParser(listVals):\n '''\n Read in the string list and parse it into a floating list\n Input: listVals = a list of strings\n Output: numList = a list of floats\n '''\n numList = []\n for str in listVals:\n num = float(str)\n numList.append(num)\n\n return numList\n\n\ndef readData(fileLoc, nProc, frames=None, fepxData=None, restart=False):\n '''\n Reads in the data files that you are interested in across all the processors\n and only for the frames that you are interested in as well\n Input: fileLoc = a string of the file location\n nProc = an integer of the number of processors used in the simulation\n frames = what frames you are interested in, default value is all of them\n fepxData = what data files you want to look at, default value is:\n .ang, .strain, .stress, .adx, .advel, .dpeff, .eqplstrain, .crss\n Output: data = a dictionary that contains a list/ndarray of all read in data files. If other files other than default are wanted than the keys for those\n values will be the file location. The default files have the following key\n values:\n coord_0: a float array of original coordinates\n hard_0: a float array of original crss_0/g_0 for each element\n angs_0: a float array of original kocks angles for each element\n vel_0: a float array of original velocity at each node\n coord: a float array of deformed coordinates\n hard: a float array of crss/g for each element\n angs: a float array of evolved kocks angles for each element\n stress: a float array of the crystal stress for each element\n strain: a float array of the sample strain for each element\n pldefrate: a float of the plastic deformation rate for each element\n plstrain: a float of the plastic strain for each element\n vel: a float array of the velocity at each node\n '''\n flDflt = False\n frDflt = False\n data = {}\n proc = np.arange(nProc)\n\n if fepxData is None:\n fepxData = ['ang', 'strain', 'stress', 'adx', 'advel', 'dpeff', 'eqplstrain', 'crss']\n flDflt = True\n if frames is None:\n fName = fepxData[0]\n file = fileLoc + 'post.' + fName + '.0'\n nFrames = findComments(file)\n if fName == 'ang' or fName == 'adx' or fName == 'advel' or fName == 'crss' or fName == 'rod':\n if restart:\n frames = np.arange(1, nFrames + 1)\n else:\n frames = np.arange(1, nFrames)\n nFrames = nFrames - 1\n else: \n frames = np.arange(1, nFrames + 1)\n frDflt = True\n else:\n nFrames = np.size(frames)\n frames = np.asarray(frames) + 1\n\n for fName in fepxData:\n print(fName)\n tmp = []\n tproc = []\n temp = []\n tFrames = []\n if fName == 'ang' or fName == 'adx' or fName == 'advel' or fName == 'crss' or fName == 'rod':\n tnf = nFrames + 1\n if restart:\n tnf = nFrames\n tFrames = frames.copy()\n if (not frDflt):\n tFrames = np.concatenate(([1], tFrames))\n\n else:\n tnf = nFrames\n tFrames = frames.copy()\n npf = 0\n for p in proc:\n# print(p)\n tmp = []\n tmp1 = []\n fLoc = fileLoc + 'post.' + fName + '.' + str(p)\n\n if frDflt:\n tmp = ta.genfromtxt(fLoc, comments='%')\n else:\n tmp = selectFrameTxt(fLoc, tFrames, comments='%')\n\n vec = np.atleast_2d(tmp).shape\n if vec[0] == 1:\n vec = (vec[1], vec[0])\n npf += vec[0] / tnf\n tmp1 = np.reshape(np.ravel(tmp),(tnf, np.int32(vec[0] / tnf), vec[1])).T\n tproc.append(tmp1)\n\n temp = np.asarray(np.concatenate(tproc, axis=1))\n\n# temp = tproc.reshape(vec[1], npf, tnf, order='F').copy()\n\n # Multiple setup for the default data names have to be changed to keep comp saved\n # First two if and if-else statements are for those that have default values\n if fName == 'ang':\n if restart:\n data['angs'] = np.atleast_3d(temp[1:4, :, :])\n else:\n data['angs_0'] = np.atleast_3d(temp[1:4, :, 0])\n data['angs'] = np.atleast_3d(temp[1:4, :, 1::1])\n\n elif fName == 'adx' or fName == 'advel' or fName == 'crss' or fName == 'rod':\n if fName == 'adx':\n tName = 'coord'\n elif fName == 'advel':\n tName = 'vel'\n elif fName == 'rod':\n tName = 'rod'\n else:\n tName = 'crss'\n if restart:\n data[tName] = np.atleast_3d(temp)\n else:\n data[tName + '_0'] = np.atleast_3d(temp[:, :, 0])\n data[tName] = np.atleast_3d(temp[:, :, 1::1])\n\n elif fName == 'dpeff':\n tName = 'pldefrate'\n data[tName] = np.atleast_3d(temp)\n\n elif fName == 'eqplstrain':\n tName = 'plstrain'\n data[tName] = np.atleast_3d(temp)\n elif fName == 'stress_q':\n nvec = temp.shape[0]\n nqpts = 15\n nelems = np.int32(temp.shape[1]/nqpts)\n temp1d = np.ravel(temp)\n temp4d = temp1d.reshape(nvec, nelems, nqpts, nFrames)\n data[fName] = np.swapaxes(np.swapaxes(temp4d, 0, 2), 1, 2)\n\n else:\n data[fName] = np.atleast_3d(temp)\n\n return data\n\ndef mpi_partioner(nprocs, ncrds, nelems):\n '''\n Returns the ncrd and nelem partion per processor\n '''\n \n proc_elems = np.zeros((nprocs), dtype='int32')\n proc_crds = np.zeros((nprocs), dtype='int32')\n \n for i in range(nprocs):\n nlocal = np.int(nelems / nprocs)\n s = i * nlocal + 1\n deficit = nelems%nprocs\n s = s + min(i, deficit)\n if (i < deficit):\n nlocal = nlocal + 1\n e = s + nlocal - 1\n if ((e > nelems) or (i == (nprocs - 1))):\n e = nelems\n \n proc_elems[i] = e - s + 1\n \n nlocal = np.int(ncrds / nprocs)\n s = i * nlocal + 1\n deficit = ncrds%nprocs\n s = s + min(i, deficit)\n if (i < deficit):\n nlocal = nlocal + 1\n e = s + nlocal - 1\n if ((e > ncrds) or (i == (nprocs - 1))):\n e = ncrds\n \n proc_crds[i] = e - s + 1\n \n return (proc_elems, proc_crds)\n\ndef readGrainData(fileLoc, grainNum, frames=None, grData=None):\n '''\n Reads in the grain data that you are interested in. It can read the\n specific rod, gammadot, and gamma files.\n Input: fileLoc = a string of the file location\n grainNum = an integer of the grain number\n frames = what frames you are interested in, default value is all of them\n lofemData = what data files you want to look at, default value is:\n ang, gamma, gammadot\n Output: data a dictionary that contains an ndarray of all the values\n read in the above file.\n rod_0: a float array of the original orientation at\n each nodal point of the grain.\n rod: a float array of the orientation at each nodal point\n of the grain through each frame.\n gamma: a float array of the integrated gammadot at each nodal\n point of the grain through each frame.\n gdot: a float array of the gammadot at each nodal point\n of the grain through each frame.\n '''\n \n flDflt = False\n frDflt = False\n data = {}\n \n if grData is None:\n grData = ['ang', 'gamma', 'gdot']\n flDflt = True\n if frames is None:\n strgrnum = np.char.mod('%4.4d', np.atleast_1d(grainNum))[0]\n if grData[0] == 'ang':\n fend = '.rod'\n else:\n fend = '.data'\n file = fileLoc + 'gr_' + grData[0] + strgrnum + fend\n nFrames = findComments(file)\n if grData[0] == 'ang':\n nFrames = nFrames - 1\n frames = np.arange(1, nFrames + 1)\n frDflt = True\n else:\n nFrames = np.size(frames)\n frames = np.asarray(frames) + 1\n \n for fName in grData:\n print(fName)\n tFrames = []\n if fName == 'ang':\n tnf = nFrames + 1\n tFrames = frames.copy()\n fend = 'rod'\n if (not frDflt):\n tFrames = np.concatenate(([1], tFrames)) \n \n else:\n tnf = nFrames\n tFrames = frames.copy()\n fend = 'data'\n \n tmp = []\n strgrnum = np.char.mod('%4.4d', np.atleast_1d(grainNum))[0]\n fLoc = fileLoc + 'gr_' + fName + strgrnum + '.' + fend\n\n if frDflt:\n tmp = ta.genfromtxt(fLoc, comments='%')\n else:\n tmp = selectFrameTxt(fLoc, tFrames, comments='%')\n\n vec = np.atleast_2d(tmp).shape\n if vec[0] == 1:\n vec = (vec[1], vec[0])\n temp = np.reshape(np.ravel(tmp),(tnf, np.int32(vec[0] / tnf), vec[1])).T\n \n if fName == 'ang':\n data['angs_0'] = np.atleast_3d(temp[:,:,0])\n data['angs'] = np.atleast_3d(temp[:, :, 1::1])\n else:\n data[fName] = np.atleast_3d(temp)\n \n return data\n\ndef readLOFEMData(fileLoc, nProc, nstps=None, nelems=None, ncrds=None, nqpts=15, frames=None, lofemData=None, restart=False):\n '''\n Reads in the data files that you are interested in across all the processors\n and only for the frames that you are interested in as well\n Input: fileLoc = a string of the file location\n nProc = an integer of the number of processors used in the simulation\n frames = what frames you are interested in, default value is all of them\n lofemData = what data files you want to look at, default value is:\n .strain, .stress,.crss, .agamma\n Output: data = a dictionary that contains a list/ndarray of all read in data files. If other files other than default are wanted than the keys for those\n values will be the file location. The default files have the following key\n values:\n coord_0: a float array of original coordinates\n hard_0: a float array of original crss_0/g_0 for each element\n angs_0: a float array of original kocks angles for each element\n vel_0: a float array of original velocity at each node\n coord: a float array of deformed coordinates\n hard: a float array of crss/g for each element\n angs: a float array of evolved kocks angles for each element\n stress: a float array of the crystal stress for each element\n strain: a float array of the sample strain for each element\n pldefrate: a float of the plastic deformation rate for each element\n plstrain: a float ofp the plastic strain for each element\n vel: a float array of the velocity at each node\n '''\n flDflt = False\n frDflt = False\n data = {}\n proc = np.arange(nProc)\n\n if lofemData is None:\n lofemData = ['strain', 'stress', 'crss', 'agamma', 'ang']\n flDflt = True\n if frames is None:\n if nstps is None:\n fName = lofemData[0]\n if fName == 'ang':\n strgrnum = np.char.mod('%4.4d', np.atleast_1d(0))[0]\n file = fileLoc + 'gr_' + fName + strgrnum + '.rod'\n else:\n file = fileLoc + 'lofem.' + fName + '.0'\n nFrames = findComments(file)\n if fName == 'ang' or fName == 'adx' or fName == 'advel' or fName == 'crss' or fName == 'rod':\n if restart:\n frames = np.arange(1, nFrames + 1)\n else:\n frames = np.arange(1, nFrames)\n nFrames = nFrames - 1\n else: \n frames = np.arange(1, nFrames + 1)\n frDflt = True\n \n else:\n if nstps is None:\n fName = lofemData[0]\n if fName == 'ang':\n strgrnum = np.char.mod('%4.4d', np.atleast_1d(0))[0]\n file = fileLoc + 'gr_' + fName + strgrnum + '.rod'\n else:\n file = fileLoc + 'lofem.' + fName + '.0'\n nstps = findComments(file)\n if fName == 'ang' or fName == 'adx' or fName == 'advel' or fName == 'crss' or fName == 'rod':\n if not restart:\n nstps = nstps - 1\n# frames = np.arange(1, nstps + 1)\n proc_elems, proc_crds = mpi_partioner(nProc, ncrds, nelems)\n nFrames = np.size(frames)\n frames = np.asarray(frames) + 1\n for fName in lofemData:\n print(fName)\n tmp = []\n tproc = []\n temp = []\n tFrames = []\n if fName == 'ang' or fName == 'adx' or fName == 'advel' or fName == 'crss' or fName == 'rod':\n tnf = nFrames + 1\n if restart:\n tnf = nFrames\n tFrames = frames.copy()\n if (not frDflt):\n tFrames = np.concatenate(([1], tFrames))\n else:\n tnf = nFrames\n tFrames = frames.copy()\n npf = 0\n for p in proc:\n# print(p)\n tmp = []\n tmp1 = []\n if fName == 'ang':\n strgrnum = np.char.mod('%4.4d', np.atleast_1d(p))[0]\n fLoc = fileLoc + 'gr_' + fName + strgrnum + '.rod'\n else:\n fLoc = fileLoc + 'lofem.' + fName + '.' + str(p)\n\n if frDflt:\n tmp = ta.genfromtxt(fLoc, comments='%')\n else:\n if fName == 'ang' or fName == 'adx' or fName == 'advel' or fName == 'rod':\n skipst = proc_crds[p] * (tFrames[0] - 1)\n skipft = proc_crds[p] * (nstps - (tFrames[0]))\n elif fName == 'agamma_q' or fName == 'gamma_q' or fName == 'gammadot_q':\n skipst = proc_elems[p] * (tFrames[0] - 1) * nqpts\n skipft = proc_elems[p] * tFrames[0] * nqpts\n else:\n skipst = proc_elems[p] * (tFrames[0] - 1)\n skipft = proc_elems[p] * (nstps - (tFrames[0]))\n nvals = skipft - skipst\n nvals = skipft - skipst\n tmp = np.genfromtxt(fLoc, comments='%', skip_header=skipst, max_rows=nvals)\n# tmp = selectFrameTxt(fLoc, tFrames, comments='%')\n\n vec = np.atleast_2d(tmp).shape\n if vec[0] == 1:\n vec = (vec[1], vec[0])\n npf += vec[0] / tnf\n tmp1 = np.reshape(np.ravel(tmp),(tnf, np.int32(vec[0] / tnf), vec[1])).T\n tproc.append(tmp1)\n\n temp = np.asarray(np.concatenate(tproc, axis=1))\n\n\n# temp = tproc.reshape(vec[1], npf, tnf, order='F').copy()\n\n # Multiple setup for the default data names have to be changed to keep comp saved\n # First two if and if-else statements are for those that have default values\n\n if fName == 'adx' or fName == 'advel' or fName == 'crss' or fName == 'ang':\n if fName == 'adx':\n tName = 'coord'\n elif fName == 'advel':\n tName = 'vel'\n elif fName == 'ang':\n tName = 'angs'\n else:\n tName = 'crss'\n if restart:\n data[tName] = np.atleast_3d(temp)\n else: \n data[tName + '_0'] = np.atleast_3d(temp[:, :, 0])\n data[tName] = np.atleast_3d(temp[:, :, 1::1])\n\n elif fName == 'dpeff':\n tName = 'pldefrate'\n data[tName] = np.atleast_3d(temp)\n\n elif fName == 'eqplstrain':\n tName = 'plstrain'\n data[tName] = np.atleast_3d(temp)\n elif fName == 'agamma_q' or fName == 'gamma_q' or fName == 'gammadot_q':\n nslip = temp.shape[0]\n nqpts = 15\n nelems = np.int32(temp.shape[1]/nqpts)\n temp1d = np.ravel(temp)\n temp4d = temp1d.reshape(nslip, nelems, nqpts, nFrames)\n data[fName] = np.swapaxes(np.swapaxes(temp4d, 0, 2), 1, 2)\n else:\n data[fName] = np.atleast_3d(temp)\n\n return data\n\n\ndef fixStrain(epsVec):\n '''\n Converts the strain vector into a strain tensor\n ''' \n vec = epsVec.shape\n \n indices = [0, 1, 2, 1, 3, 4, 2, 4, 5] \n \n strain = np.zeros((3, 3, vec[1]))\n\n strain = np.reshape(epsVec[indices, :], (3, 3, vec[1]))\n \n return strain\n \n\ndef findComments(fileLoc):\n '''\n Takes in a file path and then returns the number of fortran comments in that file\n Input: fileLoc-a string of the file path way\n Output: an integer of the number of comments in that file\n '''\n i = 0\n with open(fileLoc) as f:\n for line in f:\n tmp = line.split()\n if tmp[0][0] == '%':\n i += 1\n return i\n\n\ndef selectFrameTxt(fileLoc, frames, comments='%'):\n '''\n Takes in a file name and frames that one wants to examine and collects the data that\n relates to those frames\n Input: fileLoc=a string of the file path\n frames=a ndarray of the frames that one is interested in\n comments=a string containing the comments starting character\n Output: a list of the data refering to those frames\n '''\n i = 0\n count = 0\n nList = []\n tframes = frames.tolist()\n\n with open(fileLoc) as f:\n for line in f:\n tmp = line.split()\n count += 1\n# if len(tmp) > 3:\n# print(tmp)\n# print(count)\n if tmp[0] == comments:\n count = 0\n i += 1\n continue\n if i in tframes:\n nList.append(np.float_(tmp))\n# print(count)\n return np.asarray(nList)\n\n"
},
{
"alpha_fraction": 0.5672268867492676,
"alphanum_fraction": 0.5840336084365845,
"avg_line_length": 34.70000076293945,
"blob_id": "fa62a2a6287978376e7be2135dacaaac167c8d63",
"content_id": "c254734b705cfd78d6de4bed20b433463f360424",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11424,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 320,
"path": "/PythonScripts/Graphics.py",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\nfrom mpl_toolkits.mplot3d import Axes3D\nimport matplotlib.tri as mtri\nfrom mpl_toolkits.mplot3d.art3d import Poly3DCollection\nfrom matplotlib import cm\nfrom matplotlib.ticker import LinearLocator, FormatStrFormatter\n\n\ndef plotTriangleMesh(mesh, **kwargs):\n '''\n It requires a mesh with a connectivity in it and the coordinates.\n If singular values are needed to be plotted that those must be specified in the\n dictionary as 'spatial' those will than be added to the plot as well\n \n Input: mesh['crd'] should be 3xn where n > = 3\n '''\n\n if len(kwargs) == 0:\n scalar = np.ones((mesh['crd'].shape[1], 1))\n else:\n scalar = kwargs['spatial']\n\n fig = plt.figure()\n ax = fig.gca(projection='3d')\n\n triang = mtri.Triangulation(x=mesh['crd'][0, :].T, y=mesh['crd'][1, :].T, triangles=mesh['con'].T)\n\n ax.plot_trisurf(triang, mesh['crd'][2, :])\n\n plt.show()\n\n\ndef plotSurface(mesh, **kwargs):\n '''\n It will plot the surface of any polygon that has been meshed up. Plotting of spatial data is also\n allowed and this is accomplished by providing a set of singular data points for each being plotted of\n the surface of the polygon. If spatial data is not provided than the surface will all be plotted the\n same color 'blue'\n \n Input: mesh a dictionary containing a set of coordinates/nodal value and a set of connectivity of \n each face\n \n mesh['crd'] should be a 3xn where n > = 3. The x, y, and z coords are located at \n mesh['crd'][0,:], mesh['crd'][1,:], and mesh['crd'][2,:] respectively. If a 2d surface is to\n be plotted other matplotlib functions might be more appropriate, but one can do it here by\n setting all of the out of plane coordinates to be equal to a singular constant.\n \n mesh['con'] should be a a 3xn where n >= 1. The connectivity should follow a standard clockwise\n or counter-clockwise order around the face of the surface polygon. If it is not then no\n insurance can be made that junk won't be plotted that doesn't represent what one was hoping to\n get out.\n \n kwargs input: \"scalar\" - the spatial data corresponding to what one wants to plot on each fac\n of the surface.\n \"colorMap\" - the color map that one wants to use with the scalar values, default\n value is jet\n Other inputs are the same as those used in the Poly3DCollection object, so\n \"facecolors\", \"edgecolors\", \"alpha\", \"zsort\".\n The facecolors arg is replaced with the scalar data mapping if that is \n provided.\n \n Output: a poly3dcollection is outputted \n '''\n\n if mesh['crd'].shape[0] != 3 or mesh['crd'].shape[1] < 3:\n print('The inputted mesh[''crd''] is not correct. mesh[''crd''] needs to have dim of 3xn where n>=3')\n raise ValueError('The inputted mesh[''crd''] is not correct. mesh[''crd''] needs to have dim of 3xn where n>=3')\n\n if mesh['con'].shape[0] is not 3:\n print('The inputted mesh[''con''] is not correct. mesh[''con''] needs to have dim of 3x1 where n>=3')\n raise ValueError('The inputted mesh[''con''] is not correct. mesh[''con''] needs to have dim of 3xn where n>=1')\n\n condim = np.atleast_2d(mesh['con']).shape\n\n # Check to see if connectivity was originally one dimension\n # and fix it if it to be 2d and in the right order\n if condim[0] == 1 and condim[1] == 3:\n condim = condim([1,0])\n mesh['con'] = np.atleast_2d(mesh['con']).T\n\n scalars = kwargs.pop('scalar', None)\n colormap = kwargs.pop('colorMap', None)\n facecolors = kwargs.pop('facecolors', None)\n\n # set up the color options\n\n if colormap is None:\n colormap = cm.jet\n\n if scalars is None and facecolors is None:\n facecolors = colormap(np.zeros(condim[1]))\n elif scalars is not None and facecolors is None:\n N = scalars / scalars.max()\n facecolors = colormap(N)\n elif scalars is None and facecolors is not None:\n N = np.random.rand(condim[1])\n print(N.shape)\n facecolors = colormap(N)\n \n print(facecolors)\n\n '''\n Creating the polygon/surface vertices\n poly_verts is initially initiallized to be a zeros 3d matrix\n '''\n\n poly_verts = np.zeros((condim[1], 3, 3))\n\n ind = 0\n \n minx = np.max(mesh['crd'][0, :])\n maxx = np.min(mesh['crd'][0, :])\n miny = np.max(mesh['crd'][1, :])\n maxy = np.min(mesh['crd'][1, :])\n minz = np.max(mesh['crd'][2, :])\n maxz = np.min(mesh['crd'][2, :])\n\n for con in mesh['con'].T:\n \n x = mesh['crd'][0, np.int_(con)]\n y = mesh['crd'][1, np.int_(con)]\n z = mesh['crd'][2, np.int_(con)]\n \n tminx = np.min(x)\n tmaxx = np.max(x)\n tminy = np.min(y)\n tmaxy = np.max(y)\n tminz = np.min(z)\n tmaxz = np.max(z)\n \n if tminx < minx:\n minx = tminx\n if tminy < miny:\n miny = tminy\n if tminz < minz:\n minz = tminz\n \n if tmaxx > minx:\n maxx = tmaxx\n if tmaxy > maxy:\n maxy = tmaxy\n if tmaxz > maxz:\n maxz = tmaxz\n \n\n vertices = np.asarray(list(zip(x, y, z)))\n\n poly_verts[ind, :, :] = vertices\n\n ind += 1\n\n coll = Poly3DCollection(poly_verts, facecolors=facecolors, **kwargs)\n\n fig = plt.figure()\n ax = fig.gca(projection='3d')\n ax.add_collection(coll)\n\n xlim = [minx * 1.1, maxx * 1.1]\n ylim = [miny * 1.1, maxy * 1.1]\n zlim = [minz * 1.1, maxz * 1.1]\n\n ax.set_xlim(xlim[0], xlim[1])\n ax.set_ylim(ylim[0], ylim[1])\n ax.set_zlim(zlim[0], zlim[1])\n ax.elev = 50\n\n plt.show()\n\n return coll\n\ndef plotPolygon(mesh, **kwargs):\n '''\n It will plot the surface of any polygon that has been meshed up. Plotting of spatial data is also\n allowed and this is accomplished by providing a set of singular data points for each being plotted of\n the surface of the polygon. If spatial data is not provided than the surface will all be plotted the\n same color 'blue'. Currently, only the following element types are taken in: standard linear\n tetrahedral, standard quadratic tetrahedral, and FePX quadratic tetrahedral element order. In the \n future, the following element types will be added standard 8 node brick element and 20 node brick \n element order.\n \n Input: mesh a dictionary containing a set of coordinates/nodal value and a set of connectivity of \n each face\n \n mesh['crd'] should be a 3xn where n > = 3. The x, y, and z coords are located at \n mesh['crd'][0,:], mesh['crd'][1,:], and mesh['crd'][2,:] respectively. If a 2d surface is to\n be plotted other matplotlib functions might be more appropriate, but one can do it here by\n setting all of the out of plane coordinates to be equal to a singular constant.\n \n mesh['con'] should be a a 4xn where n >= 1. The connectivity should follow a standard clockwise\n or counter-clockwise order around the face of the surface polygon. If it is not then no\n insurance can be made that junk won't be plotted that doesn't represent what one was hoping to\n get out.\n \n kwargs input: \"scalar\" - the spatial data corresponding to what one wants to plot on each\n element\n \"colorMap\" - the color map that one wants to use with the scalar values, default\n value is jet\n \"fepx\" - the element type used is fepx type\n Other inputs are the same as those used in the Poly3DCollection object, so\n \"facecolors\", \"edgecolors\", \"alpha\", \"zsort\".\n The facecolors arg is replaced with the scalar data mapping if that is \n provided.\n \n Output: a poly3dcollection is outputted \n '''\n \n condim = np.atleast_2d(mesh['con']).shape\n\n # Check to see if connectivity was originally one dimension\n # and fix it if it to be 2d and in the right order\n if condim[0] == 1 and condim[1] > 1:\n mesh['con'] = np.atleast_2d(mesh['con']).T\n\n numnode = mesh['con'].shape[0]\n \n print(numnode)\n \n if numnode == 4:\n elem = 'ltet'\n elif numnode == 10:\n etype = kwargs.pop('fepx', None)\n if etype is None:\n elem = 'qtet'\n else:\n elem = 'fepx'\n \n# scalar = kwargs.pop('scalars', None)\n \n mesh['con'] = getelemface(mesh['con'], elem)\n \n coll = plotSurface(mesh, **kwargs)\n \n return coll \n \n \ndef getelemface(con, eltype):\n '''\n It takes in the connectivity of the nodes of the element and returns the appropriate surface\n connectivity of the element. So if a tetrahedral element is taken in then the surface connectivity\n now is a [3 x 4n] array where n is the number of elements.\n \n Input: con - a [m x n] array where m is atleast 4 and corresponds to the number of nodes in the\n element. Then n is the number of elements\n eltype - a string that describes the element type and is one of the following:\n 'ltet' - a standard linear tetrahedral element\n 'qtet' - a standard quadratic tetrahedral element\n 'fepx' - a quadratic tetrahedral element that corresponds to fepx propram input\n '''\n \n nelem = con.shape[1]\n \n surfcon = np.zeros((3, nelem*4))\n \n print(eltype)\n \n j = 0\n ind = 0\n \n for i in con.T:\n \n if eltype == 'ltet' or eltype == 'qtet':\n surfcon[:, j] = i[[0, 1, 2]]\n surfcon[:, j+1] = i[[0, 1, 3]]\n surfcon[:, j+2] = i[[1, 2, 3]]\n surfcon[:, j+3] = i[[2, 0, 3]]\n elif eltype == 'fepx':\n surfcon[:, j] = i[[0, 2, 4]]\n surfcon[:, j+1] = i[[0, 2, 9]]\n surfcon[:, j+2] = i[[2, 4, 9]]\n surfcon[:, j+3] = i[[4, 0, 9]]\n \n ind +=1\n j = ind*4\n \n return surfcon\n\n\n \n\n'''\nExample of the above function:\n\nimport Graphics\nimport Sphere\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom mpl_toolkits.mplot3d import Axes3D\nimport matplotlib.tri as mtri\nfrom mpl_toolkits.mplot3d.art3d import Poly3DCollection\nfrom matplotlib import cm\nfrom matplotlib.ticker import LinearLocator, FormatStrFormatter\n\nplt.close('All')\nmesh = Sphere.SphBaseMesh(2)\n\nG=np.ones((8,))*10\nG[3]=5\nG[2]=0.1\nN=G/G.max()\n\ncoll = Graphics.plotSurface(mesh, **{'scalar':N,'colorMap':cm.Blues,'edgecolors':'none'})\n\n\nfig = plt.figure()\nax = fig.gca(projection='3d')\nax.add_collection(coll)\n\nxlim=[mesh['crd'][0,:].min()*1.5,mesh['crd'][0,:].max()*1.5]\nylim=[mesh['crd'][1,:].min()*1.5,mesh['crd'][1,:].max()*1.5]\nzlim=[mesh['crd'][2,:].min()*1.5,mesh['crd'][2,:].max()*1.5]\n\nax.set_xlim(xlim[0], xlim[1])\nax.set_ylim(ylim[0], ylim[1])\nax.set_zlim(zlim[0], zlim[1])\nax.elev = 50\n\nplt.show()\n\n'''\n"
},
{
"alpha_fraction": 0.5636546015739441,
"alphanum_fraction": 0.5749678015708923,
"avg_line_length": 48.84642791748047,
"blob_id": "7737dfc772ee4bf61578056c610abdc2a8936f77",
"content_id": "53a13af7843b62cbba98b81eb3f7a9b4658b8f84",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13966,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 280,
"path": "/PythonScripts/gb_slip_transferal.py",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Apr 3 16:06:47 2018\n\n@author: robertcarson\n\"\"\"\n\nimport numpy as np\n#import graph_cc_dfs as gccd\nimport pickle\nfrom itertools import product\n\n'''\nThe gb_slip_transferal module will contain all of the necessary functions to find\nwhat grains can allow slip transferal. Next, it will contain all of the necessary\nfunctions that allow us to create our grain boundary element interaction matrix.\n\n'''\n\ndef gb_interaction_rss_list(gr_angs, gr_neigh_list, xtal_sn, fLoc):\n '''\n It attempts to find grains that have slip plane normals within 20 degs\n of their neighboring grains. If they don't then we don't have to worry\n about slip transferal between those two grains.\n \n It also saves all of the grain boundary interactions off to a Python pickle\n file. These calculations should not need to change between different mesh\n resolutions or from different loading conditions ideally. \n \n Input:\n gr_angs - The orientations for each grain represented as rotation matrix.\n It should be a numpy array of 3x3xngrains\n gr_neigh_list - A list of all of the neighbors for each grain. It should\n be a list of sets that has ngrain elements in it.\n xtal_sn - The xtal slip plane normals for the specified xtal type.\n This is currently limited to single phase materials, but it\n should be extendable to multiple phase materials.\n It is a numpy array of 3xnslip_normals.\n fLoc - The location for where one wants all of the grain boundary\n interactions saved off to. It should be a valid path string.\n Output:\n grain_inter_rss - A dictionary that contains all of the possible GB\n interactions. The keys are a tuple of (GA#, GC#) where\n GA# and GC# are the sorted grain numbers that describe a specific\n GB. The contents of the dictionary at a specific key are a list\n with two numpy arrays. The first array contains the permutations\n of all of the xtal_sn indices. The second array is a numpy\n boolean array that tells us if slip transferal is even possible there.\n '''\n \n \n grain_inter_rss = dict()\n nsn = xtal_sn.shape[1]\n ngrains = len(gr_neigh_list)\n \n tmp = np.r_[0:nsn]\n \n p=list(product(tmp,repeat=2))\n #This is going to be a constant numpy array that goes into the list of\n #which resides in p.\n arr1 = np.array([p[i:i+nsn] for i in range(0,len(p),nsn)])\n\n nperms = nsn*nsn \n arr1 = arr1.reshape((nperms, 2))\n #We are preallocating our boolean array for when it's used in our inner loop\n bool_arr = np.full((nperms), False, dtype=bool)\n \n mindeg = 20 * np.pi/180\n \n \n #Looping through all of the \n for i in range(ngrains):\n #The current grain that we are on\n pr_grain = i + 1\n for gr in gr_neigh_list[i]:\n #We need our dictionary keys to be placed in order \n #ganum and gbnum are our keys\n ganum = np.min([gr, pr_grain])\n gbnum = np.max([gr, pr_grain])\n #Figuring out which way we need to do our multiplications for our\n #permutation matrices\n if ganum == pr_grain:\n pr_loc = 0\n ngh_loc = 1\n else:\n pr_loc = 1\n ngh_loc = 0\n \n dict_key = tuple([ganum, gbnum])\n #We only need to go through the calculations steps if this grain\n #boundary interaction has not already been seen\n if dict_key not in grain_inter_rss:\n bool_arr[:] = False\n #Getting the rotated slip plane normals\n pr_gr_sn = np.squeeze(gr_angs[:,:,i]).dot(xtal_sn)\n #Python is a little dumb so this is now and we can't just\n #subtract the number inside the index.\n ngh_gr_sn = np.squeeze(gr_angs[:,:,(gr - 1)]).dot(xtal_sn)\n for j in range(nperms):\n pr_perm = arr1[j, pr_loc]\n ngh_perm = arr1[j, ngh_loc]\n #Calculating the dot product and angle\n dp = np.squeeze(pr_gr_sn[:,pr_perm]).dot(np.squeeze(ngh_gr_sn[:, ngh_perm]))\n if np.abs(dp) > 1.0:\n dp = 0.99999 * np.sign(dp)\n ang = np.arccos(dp)\n #Checking to see if our degree is below the minimum 20 degs\n if ang <= mindeg:\n bool_arr[j] = True\n \n #We are now assigning our data to our dictionary with the provided key\n #The copy is required due to numpy wanting to just have shallow copies everywhere\n grain_inter_rss[dict_key] = [arr1.copy(), bool_arr.copy()]\n \n \n #We now pickle all of our grain interactions so we don't need to constantly\n #recalculate this on subsequent simulations \n #Later on we can just reread all of this in by doing something like\n #with open(fileLoc + 'gb_inter_rss_dict.pickle', 'rb') as f_handle:\n # grain_neigh_list2 = pickle.load(f_handle) \n with open(fLoc + 'grain_inter_rss_dict.pickle', 'wb') as f_handle:\n pickle.dump(grain_inter_rss, f_handle, protocol=pickle.HIGHEST_PROTOCOL)\n \n return grain_inter_rss\n\ndef gb_inter_rss_selection(gr_angs, gr_inter_list, grains, gb_elem_set, xtal_ss, stress, xtal_type, step, fLoc):\n '''\n It goes through all of the allowable grain boundary interactions in order\n to find the slip system that has the largest allowable resolved shear\n stress. The final structure is saved off for future post processing incase\n one wants to try and look at various different grain \n \n Input:\n gr_angs - The orientations elemental orientations for all elements. It should\n be a numpy array of 3x3xnelems.\n \n gr_inter_list - A dictionary that contains all of the possible GB\n interactions. The keys are a tuple of (GA#, GC#) where\n GA# and GC# are the sorted grain numbers that describe a specific\n GB. The contents of the dictionary at a specific key are a list\n with two numpy arrays. The first array contains the permutations\n of all of the xtal_sn indices. The second array is a numpy\n boolean array that tells us if slip transferal is even possible there.\n grains - The grain number that each element corresponds to. It is represented as \n a 1D numpy int array.\n gb_elem_set - A set of frozen sets that contains all of grain boundary\n element pairs. \n xtal_ss - The xtal slip systems schmid tensors for the specified xtal type.\n This is currently limited to single phase materials, but it\n should be extendable to multiple phase materials.\n It is a numpy array of 3x3xnslip_systems.\n stress - The Caucgy stress for every element. It should be a numpy array\n with dimensions 3x3xnelems.\n xtal_type - It tells us what crystal type we are dealing with to allow\n for easier post processing. Once again this is currently single\n phase. However, it could be easily extended to multiple\n phases. The possible values are \"FCC\", \"BCC\", or \"HCP\"\n step - The load step you're on. It's used in pickle file for indexing purposes.\n fLoc - The location for where one wants all of the grain element\n interactions saved off to. It should be a valid path string.\n Output:\n gb_inter_rss - A similar structure to gr_inter_list. \n A dictionary that contains all of the possible GB element\n interactions. The keys are a tuple of (GB_e1, GB_e2) where\n GB_e1 and GB_e2 are the sorted grain elements. \n The contents of the dictionary at a specific key are a list\n with two numpy arrays. The first array contains the permutations\n of all of the xtal_sn indices. It also contains which slip systems have the\n highest resolved shear stress for that slip normal. The order goes perms and then\n corresponds ss num for GB_e1 and GB_e2 respectively. The second array is a numpy\n boolean array that tells us if slip transferal is even possible there.\n This dictionary will have to be recreated at each simulation step due to there\n being new stress values. The nice thing it also will tell us what the \n structure of our global connected component list will look like.\n '''\n #A list of lists that tells us for each slip normal what slip systems to examine \n if xtal_type == 'FCC':\n ss_list = [[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 10, 11]]\n nsn = 4\n elif xtal_type == 'BCC':\n ss_list = [[0, 9], [1, 7], [2, 5], [3, 6], [4, 10], [8, 11]]\n nsn = 6\n elif xtal_type == 'HCP':\n ss_list = [[0, 1, 2], [3], [4], [5], [6, 7], [8, 9], [10, 11], [12, 13], [14, 15], [16, 17]]\n nsn = 10\n else:\n raise ValueError('Provided xtal type is not a valid type. FCC, BCC, and HCP are only accepted values')\n \n gb_inter_rss = dict()\n \n tmp = np.r_[0:nsn]\n \n p=list(product(tmp,repeat=2))\n #This is going to be a constant numpy array that goes into the list of\n #which resides in p.\n arr1 = np.array([p[i:i+nsn] for i in range(0,len(p),nsn)])\n nperms = nsn*nsn \n arr1 = arr1.reshape((nperms, 2))\n \n nind = np.r_[0:nperms]\n #This is going to be the first item going into our list\n #It contains all of the permuations of slip normals and the rss with the highest\n #value only for those systems with a true value. If isn't true its value is\n #zero.\n arr3 = np.zeros((nperms, 4), dtype='int32', order='F')\n arr3[:,0:2] = arr1.copy() \n \n #We are going to loop through all of the elements of the gb_elem_set\n for felems in gb_elem_set:\n arr3[:,2:4] = 0\n #We need to convert from a frozenset to a list\n elems = list(felems)\n #Now find the min and max values we will use this as our dict_key\n min_elem = min(elems)\n max_elem = max(elems)\n dict_key = tuple([min_elem, max_elem])\n #We want to find the grains associatted with the min and max elements\n min_gr = grains[min_elem]\n max_gr = grains[max_elem]\n #Now we want to sort our min_gr and max_gr for our dict_key\n in_dict_key = tuple(sorted([min_gr, max_gr]))\n bool_arr = gr_inter_list[in_dict_key][1]\n #The normals of interest if any\n if np.any(bool_arr):\n #Go ahead and retrieve our stress and oritation values\n min_rot = np.squeeze(gr_angs[:,:,min_elem])\n max_rot = np.squeeze(gr_angs[:,:,max_elem])\n min_stress = np.squeeze(stress[:,:,min_elem])\n max_stress = np.squeeze(stress[:,:,max_elem])\n #Get the indices of all of those of interest\n ind = nind[bool_arr]\n for i in ind:\n #Get the necessary permutation we're looking at currently\n perm = arr1[i, :]\n #See if the smallest grain number is the minimum angle\n #We then assign the correct permutation number to it\n if in_dict_key[0] == min_gr:\n min_ss = perm[0]\n max_ss = perm[1]\n else:\n min_ss = perm[1]\n max_ss = perm[0]\n #Find the index corresponding to the minimum resolved shear stress \n min_rss_ind = -1\n max_rss = 0\n for ss in ss_list[min_ss]:\n #Rotating from crystal to sample frame for the xtal schmid tensor\n rxtal_ss = min_rot.dot(np.squeeze(xtal_ss[:,:,ss]).dot(min_rot.T))\n #We now are finding the resolved shear stress on the system.\n #We want the absolute maximum value.\n rss = np.abs(np.trace(min_stress.dot(rxtal_ss.T)))\n if rss > max_rss:\n max_rss = rss\n min_rss_ind = ss\n #Find the index corresponding to the maximum resolved shear stress\n max_rss_ind = -1\n max_rss = 0\n for ss in ss_list[max_ss]:\n #Rotating from crystal to sample frame for the xtal schmid tensor\n rxtal_ss = max_rot.dot(np.squeeze(xtal_ss[:,:,ss]).dot(max_rot.T))\n #We now are finding the resolved shear stress on the system.\n #We want the absolute maximum value.\n rss = np.abs(np.trace(max_stress.dot(rxtal_ss.T)))\n if rss > max_rss:\n max_rss = rss\n max_rss_ind = ss \n #Now save off the min and max rss ind for that permutation\n arr3[i, 2] = min_rss_ind\n arr3[i, 3] = max_rss_ind\n \n gb_inter_rss[dict_key] = [arr3.copy(), bool_arr.copy()]\n \n \n \n #We are now going to pickle all of this data to be used later on possibly.\n with open(fLoc + 'gb_inter_rss_s'+str(step)+'dict.pickle', 'wb') as f_handle:\n pickle.dump(gb_inter_rss, f_handle, protocol=pickle.HIGHEST_PROTOCOL)\n \n return gb_inter_rss\n \n "
},
{
"alpha_fraction": 0.6741982698440552,
"alphanum_fraction": 0.6825801730155945,
"avg_line_length": 33.212501525878906,
"blob_id": "f4e05161a93b3ad333f551658b83241550422c3d",
"content_id": "2a4fe6549b12e844e769b0c14e5e27dcca0fc16b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2744,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 80,
"path": "/PythonScripts/gb_node_elem_example.py",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Mar 23 14:54:56 2018\n\n@author: robertcarson\n\"\"\"\n\nimport numpy as np\nimport FePX_Data_and_Mesh as fepxDM\nimport FiniteElement as fe\n\n#The location of our mesh/data\nfileLoc = '/Users/robertcarson/Research_Local_Code/fepx_robert/Source/LOFEM/'\n#The name of our mesh\nfileName = 'n6'\n\nmesh = fepxDM.readMesh(fileLoc,fileName)\n#How many grains we have\nngrains = 6\n\nmesh = fepxDM.readMesh(fileLoc,fileName)\n\nconn = mesh['con']\n\nncrds = np.unique(np.ravel(conn)).size\nnelems = conn.shape[1]\n\ngrains = mesh['grains']\n#The list of all of our grains\nugrains = np.unique(grains)\n#Here we're creating our nodal connectivity array\nndconn = fepxDM.mesh_node_conn(conn, ncrds)\n#This gets all of the grain boundary nodes\ngbnodes, nincr = fepxDM.grain_boundary_nodes(ndconn, grains, ncrds)\n\ngrain_gbnode_list = list()\ngrain_neigh_list = list()\n#%%\nfor igrain in ugrains:\n print('###### Starting Grain Number '+str(igrain)+' ######')\n tmp = set()\n tmp2 = set()\n for inode in gbnodes:\n if igrain in gbnodes[inode]:\n tmp.add(inode)\n tmp2.update(list(gbnodes[inode].keys()))\n #Once we've iterated through all of the grain boundary nodes we append\n #our temporary set to the grain gb node list \n tmp2.remove(igrain) \n grain_gbnode_list.append(tmp)\n grain_neigh_list.append(tmp2)\n \nfor i in ugrains:\n print('###### Starting Grain Number '+str(i)+' ######')\n #Create a set that will hold all of the elements that have a GB node\n grain_set = set()\n #We might be doing work where we need the local connectivity and etc.\n #If we don't we could create an index array and from there use a logical\n #array to get the unique elements belonging to the array\n #so something along the lines of:\n # ind = np.r_[0:nelems]\n # uelem = ind[mesh['grains'] == i]\n lcon, lcrd, ucon, uelem = fe.localConnectCrd(mesh, i)\n #We're going to need to perform the intersection between two nodal\n #connectivity set and the unique element set for the grain\n #This will allow us a quick way to obtain the elements that are on the\n #grain boundary\n uelem_set = set(uelem.tolist())\n \n for inode in grain_gbnode_list[i-1]:\n #The intersection of our two sets\n tmp = ndconn[inode].intersection(uelem_set)\n #Adding the values from this set to our grain set\n #We used a set here because we don't want any duplicate values\n grain_set.update(tmp)\n #Append our set for this grain to our list\n grain_gbelem_list.append(grain_set)\n#Now that we have all of our grain boundary elements and nodes we split up\n#we can do what ever analysis we need to on our data located there. "
},
{
"alpha_fraction": 0.7241746783256531,
"alphanum_fraction": 0.7263045907020569,
"avg_line_length": 54.235294342041016,
"blob_id": "6e9d5955e73a5ce7fd9bf334bf7f2825c4f22a7f",
"content_id": "9a740d19f5c813f2d9ffa1470ed2ee4e2241c8ad",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 939,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 17,
"path": "/PythonFortranCode/ModuleDependencies.mk",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "$(LIBRARY)(ConstantsModule.o):\t$(LIBRARY)(IntrinsicTypesModule.o)\n$(LIBRARY)(units.o): $(LIBRARY)(IntrinsicTypesModule.o)\n$(LIBRARY)(shape_3d.o): $(LIBRARY)(IntrinsicTypesModule.o)\n$(LIBRARY)(matrixMath.o): $(LIBRARY)(IntrinsicTypesModule.o)\n$(LIBRARY)(matrixMath.o): $(LIBRARY)(units.o)\n$(LIBRARY)(quadrature.o): $(LIBRARY)(IntrinsicTypesModule.o)\n$(LIBRARY)(femVariables.o): $(LIBRARY)(IntrinsicTypesModule.o)\n$(LIBRARY)(femVariables.o): $(LIBRARY)(units.o)\n$(LIBRARY)(schmidTensor.o): $(LIBRARY)(IntrinsicTypesModule.o)\n$(LIBRARY)(schmidTensor.o): $(LIBRARY)(ConstantsModule.o)\n$(LIBRARY)(schmidTensor.o): $(LIBRARY)(matrixMath.o)\n$(LIBRARY)(LatOriFEM.o): $(LIBRARY)(IntrinsicTypesModule.o)\n$(LIBRARY)(LatOriFEM.o): $(LIBRARY)(quadrature.o)\n$(LIBRARY)(LatOriFEM.o): $(LIBRARY)(shape_3d.o)\n$(LIBRARY)(LatOriFEM.o): $(LIBRARY)(units.o)\n$(LIBRARY)(LatOriFEM.o): $(LIBRARY)(femVariables.o)\n$(LIBRARY)(LatOriFEM.o): $(LIBRARY)(matrixMath.o)\n"
},
{
"alpha_fraction": 0.5595653653144836,
"alphanum_fraction": 0.5987582206726074,
"avg_line_length": 27.285715103149414,
"blob_id": "fd6aed61fceb460170c919eb2f67d7c5014bfe7c",
"content_id": "1d53a3f98d38799ebc58cbed49a9160ffb7c72a8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2577,
"license_type": "permissive",
"max_line_length": 137,
"num_lines": 91,
"path": "/PythonScripts/dislocation_density.py",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon Sep 18 10:49:20 2017\n\n@author: robertcarson\n\"\"\"\n\nimport numpy as np\nimport FePX_Data_and_Mesh as fepxDM\nimport FiniteElement as fe\nfrom latorifem import mainlatprogram as latfem\n\nfileLoc = '/Users/robertcarson/Research_Local_Code/Output/LOFEM_STUDY/n456_cent/low/'\n#fileLoc = '/Volumes/My Passport for Mac/Simulations//LOFEM_Study/n456_cent_c10/low_txt/'\nfileLoc = '/media/robert/My Passport for Mac/Simulations/LOFEM_Study/n456_cent_c03/low_txt/'\nfileLoc = '/media/robert/DataDrives/LOFEM_Study/n456_NF/mono/low_txt/'\nfileName = 'n456-cent-rcl05'\nfileName = 'n456_nf_raster_L2_r1_v2_rcl075'\nfBname = 'gr_dd'\n\nnproc = 64\nnsteps = 42\n\nframes = np.arange(0,nsteps)\n\nmesh = fepxDM.readMesh(fileLoc,fileName)\n\nngrains = 456\n\ngrains = np.r_[1:(ngrains+1)]\n\n#%%\n\nprint('About to start processing data')\nkor = 'rod'\nprint('Starting to read DISC data')\ndata = fepxDM.readData(fileLoc, nproc, fepxData=['adx'])\nprint('Finished Reading DISC data')\n\n#%%\n\nfor i in grains:\n print('###### Starting Grain Number '+str(i)+' ######')\n \n gdata = fepxDM.readGrainData(fileLoc, i, frames=None, grData=['ang'])\n \n lcon, lcrd, ucon, uelem = fe.localConnectCrd(mesh, i)\n \n nel = lcon.shape[1]\n \n indlog = mesh['grains'] == i\n strgrnum = np.char.mod('%4.4d', np.atleast_1d(i))[0]\n\n ncrd = lcrd.shape[1]\n ngdot = 12\n ncvec = ncrd*3\n dim = 3\n nnpe = 9\n kdim1 = 29\n \n gdot = np.zeros((nel,12))\n vel = np.zeros((ncrd, 3))\n strain = np.zeros((nel,3,3))\n gdot = np.zeros((nel,12))\n density = np.zeros((12, nel))\n grod0 = np.zeros((ncvec, 1))\n ang = np.zeros((ncrd, 3))\n crd = np.zeros((ncrd, 3))\n \n latfem.initializeall(nel, ngdot, ncrd)\n \n for j in range(nsteps):\n \n crd[:,:] = np.squeeze(data['coord'][:,ucon, j]).T\n ang[:,:] = np.squeeze(gdata['angs'][:,:,j]).T\n \n latfem.setdata(strain, gdot, vel, lcon.T, crd, grod0, nel1=nel-1, dim1=dim-1, ngd1=ngdot-1, ncr1=ncrd-1, nnp=nnpe, ncvc1=ncvec-1)\n \n density = latfem.get_disc_dens(nel-1, ang, nc1=ncrd-1, dim1=dim-1)\n \n with open(fileLoc+fBname+strgrnum+'.data','ab') as f_handle:\n f_handle.write(bytes('%Grain step'+str(j)+'\\n','UTF-8'))\n for k in range(nel):\n np.savetxt(f_handle,density[:, k], newline=' ')\n f_handle.write(bytes('\\n','UTF-8'))\n \n print('Grain #'+str(i)+'% done: {:.3f}'.format(((j+1)/nsteps)))\n \n \n latfem.deallocate_vars() \n"
},
{
"alpha_fraction": 0.6701754331588745,
"alphanum_fraction": 0.7029239535331726,
"avg_line_length": 20.375,
"blob_id": "bd2bb0be170aab814ef1352593190b3ec705369b",
"content_id": "5c3144fca2279c2874b71aa8a6b1e78ad8701234",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 855,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 40,
"path": "/PythonFortranCode/makefile",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "CFLAGS\t =\nFFLAGS =\nCPPFLAGS =\nFPPFLAGS =\nSOURCEF = \nLOCDIR = ~/Source/PythonFortranCode\n\ninclude Sources.mk\ninclude Rules-fortran.mk\ninclude ModuleDependencies.mk\n\nFOPTS = -O3 -funroll-loops -ftree-vectorize -m64 -fPIC\n\nF90 = gfortran\nF90FLAGS = $(FOPTS) -JModules -IModules\nf2py = f2py -c --fcompiler=gnu95 -L. -l$(LIBBASE) -IModules\n\ndefault: $(LIBRARY)\n#\n$(LIBRARY): Modules $(f90OBJECTS) $(mOBJECTS)\n\tar crs $@ $(f90OBJECTS) $(mOBJECTS)\n\trm -r *.o\n\npython: mainLatProgram.f90\n\t$(f2py) mainLatProgram.f90 -m latorifem\n#\tcp latorifem.so ~/Research_Local_Code/PythonScripts/\n\nModules: force\n\tmkdir -p Modules\n#\n# Need to define \"DIRT\" for \"clean\" target\n#\nDIRT=$(LIBRARY) Modules/*.mod\n\ndebug:\n\t@echo Fortran linker $(F90)\n\t@echo Fortran lib $(PETSC_KSP_LIB)\n\t@echo f90objects $(f90OBJECTS)\n\t@echo Library $(LIBRARY)\n\t@echo python $(f2py3)\n"
},
{
"alpha_fraction": 0.5750535130500793,
"alphanum_fraction": 0.6117395162582397,
"avg_line_length": 29.055299758911133,
"blob_id": "c542c7f208ecde6d5bb8545bf0e66a9a3fccad4c",
"content_id": "a607daa86e80db9f164fb3246720490dd3474dc2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6542,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 217,
"path": "/PythonScripts/dislocation_density_pyv.py",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon Sep 18 10:49:20 2017\n\n@author: robertcarson\n\"\"\"\n\nimport numpy as np\nimport Rotations as rot\nimport FePX_Data_and_Mesh as fepxDM\nimport FiniteElement as fe\n\n#%%\n#fileLoc = '/Users/robertcarson/Research_Local_Code/Output/LOFEM_STUDY/n456_cent/low/'\n#fileLoc = '/media/robert/My Passport for Mac/Simulations/LOFEM_Study/n456_cent_m15/mid_txt/'\n#fileLoc = '/home/rac428/Outputs/LOFEM_Study/n456_cent_uori_m15/low_txt/'\n#fileLoc = '/media/robert/DataDrives/LOFEM_Study/n456_NF/mono/low_txt/'\n#fileLoc = '/Users/robertcarson/Research_Local_Code/fepx_robert/Examples/ControlMode/LOFEM_REFACTOR2/data/'\nfileLoc = '/Volumes/My Passport for Mac/Simulations/LOFEM_Study/n456_cent_m15/mid_txt/'\nfileName = 'n456-cent-rcl04'\n#fileName = 'n456_nf_raster_L2_r1_v2_rcl075'\n#fileName = 'n6'\n#This will be the base name that you want all of your data saved off to.\n#The file name will look something like gr_dd####.data where the #### are the actual\n#grain numbers\nfBname = 'gr_dd'\n\n#fileLoc = '/media/robert/DataDrives/n1k_pois_iso_reg_pt2/'\n#fileName = 'n1k-id6k-rcl05'\n\n#Here we have our number of processors and number of steps in our simulation\nnproc = 64\n#nsteps = 19\n#nsteps = 46\n#nsteps = 19\n#nsteps = 43\nnsteps = 44\n#nsteps = 52\n#nsteps = 64\n#nsteps = 86\n\nframes = np.arange(0,nsteps)\n\nmesh = fepxDM.readMesh(fileLoc, fileName, LOFEM = True)\n\n\n#ngrains = 6\nngrains = 456\n#ngrains = 1000\n\ngrains = np.r_[1:(ngrains+1)]\n\n#%%\n#From here on uncomment commented lines to run code on the LOFEM Refactored\n#data\nprint('About to start processing data')\nkor = 'rod'\nldata = fepxDM.readLOFEMData(fileLoc, nproc, lofemData=['ang'])\nprint('Starting to read DISC data')\ndata = fepxDM.readData(fileLoc, nproc, fepxData=['adx'])\nprint('Finished Reading DISC data')\n\n#%%\n#\n#gconn = np.asarray([], dtype='float64')\n#gconn = np.atleast_2d(gconn)\n#gupts = np.asarray([], dtype=np.int32)\n#guelem = np.asarray([], dtype=np.int32)\n#\n#se_bnds = np.zeros((ngrains*2), dtype='int32')\n#se_el_bnds = np.zeros((ngrains*2), dtype='int32')\n#\n#st_bnd = 0\n#en_bnd = 0\n#\n#st_bnd2 = 0\n#en_bnd2 = 0\n#\n#for i in grains:\n# \n# lcon, lcrd, lupts, luelem = fe.localConnectCrd(mesh, i)\n# st_bnd = en_bnd\n# en_bnd = st_bnd + lupts.shape[0]\n# \n# j = (i - 1) * 2\n# \n# se_bnds[j] = st_bnd\n# se_bnds[j+1] = en_bnd\n# \n# st_bnd2 = en_bnd2\n# en_bnd2 = st_bnd2 + luelem.shape[0]\n# \n# j = (i - 1) * 2\n# \n# se_el_bnds[j] = st_bnd2\n# se_el_bnds[j+1] = en_bnd2\n# \n# gconn, gupts, guelem = fe.concatConnArray(gconn, lcon, gupts, lupts, guelem, luelem) \n#\n#npts = gupts.shape[0]\n#nelem = guelem.shape[0]\n#\n##%%\n#\n#gconn2 = np.asarray([], dtype='float64')\n#gconn2 = np.atleast_2d(gconn2)\n#gupts2 = np.asarray([], dtype=np.int32)\n#guelem2 = np.asarray([], dtype=np.int32)\n#\n#se_bnds2 = np.zeros((ngrains*2), dtype='int32')\n#se_el_bnds2 = np.zeros((ngrains*2), dtype='int32')\n#\n#st_bnd = 0\n#en_bnd = 0\n#\n#st_bnd2 = 0\n#en_bnd2 = 0\n#\n#for i in grains:\n# \n# lcon, lupts, luelem = fe.localGrainConnectCrd(mesh, i)\n# st_bnd = en_bnd\n# en_bnd = st_bnd + lupts.shape[0]\n# \n# j = (i - 1) * 2\n# \n# se_bnds2[j] = st_bnd\n# se_bnds2[j+1] = en_bnd\n# \n# st_bnd2 = en_bnd2\n# en_bnd2 = st_bnd2 + luelem.shape[0]\n# \n# j = (i - 1) * 2\n# \n# se_el_bnds2[j] = st_bnd2\n# se_el_bnds2[j+1] = en_bnd2\n# \n# gconn2, gupts2, guelem2 = fe.concatConnArray(gconn2, lcon, gupts2, lupts, guelem2, luelem) \n#\n#npts2 = gupts2.shape[0]\n#nelem2 = guelem2.shape[0]\n#\n##%%\n## \n#gr_angs = np.zeros((1, npts, nsteps), dtype='float64')\n#lofem_angs = np.zeros((1, nelem, nsteps), dtype='float64')\n#disc_angs = np.zeros((1, nelem, nsteps), dtype='float64')\n##\n#origin = np.zeros((3,1), dtype='float64')\n\n#%%\n\niso_dndx = fe.iso_dndx()\nlmat = fe.get_l2_matrix()\nnnpe = 10\ndim = 3\nngdot = 12\n\nfor i in grains:\n print('###### Starting Grain Number '+str(i)+' ######')\n \n lcon, lcrd, ucon, uelem = fe.localConnectCrd(mesh, i)\n lcon2, ucon2, uelem2 = fe.localGrainConnectCrd(mesh, i)\n \n nel = lcon.shape[1]\n ncrd = ucon.shape[0]\n \n indlog = mesh['grains'] == i\n indlog2 = mesh['crd_grains'] == i\n \n strgrnum = np.char.mod('%4.4d', np.atleast_1d(i))[0]\n \n elem_crd = np.zeros((nnpe, dim, nel), dtype='float64', order='F')\n crd = np.zeros((ncrd, dim), dtype='float64', order='F')\n \n el_vec = np.zeros((dim, nnpe, nel), dtype='float64', order='F')\n vec_grad = np.zeros((dim, dim, nel), dtype='float64', order='F')\n nye_ten = np.zeros((dim, dim, nel), dtype='float64', order='F')\n density = np.zeros((ngdot, nel), dtype='float64', order='F')\n loc_dndx = np.zeros((dim, nnpe, nel), dtype='float64', order='F')\n det_qpt = np.zeros((nel), dtype='float64', order='F')\n \n \n ang_axis = np.zeros((dim, ncrd, nsteps), dtype='float64', order='F')\n \n #The Nye Tensor is based on our angle axis representation so we need\n #to rotate from a rod vec to angle axis\n for j in range(nsteps):\n ang_axis[:,:,j] = rot.AngleAxisOfRod(ldata['angs'][:,indlog2,j])\n \n for j in range(nsteps):\n \n crd[:,:] = np.squeeze(data['coord'][:,ucon, j]).T \n #Creating an array that contains our coords for each element\n #Creates an array that has an array of our orientations for each element\n for k in range(nel):\n elem_crd[:, :, k] = crd[lcon[:, k], :]\n el_vec[:, :, k] = ang_axis[:, lcon2[:, k], j]\n #Here we're obtaining our local dN/dX versions of our shape function along with our\n # jacobian at the middle quadrature point \n loc_dndx[:,:,:], det_qpt[:] = fe.local_gradient_shape_func(iso_dndx, elem_crd, 4)\n #Here we're getting the gradient of our vector data and from that the Nye tensor\n vec_grad = fe.get_vec_grad(el_vec, loc_dndx)\n nye_ten = fe.get_nye_tensor(vec_grad)\n #Here we're calculating the Nye tensor using the L2 norm method given in\n #the 1999 Arsenlis paper of dislocations\n density = fe.get_l2_norm_dd(nye_ten, lmat)\n \n #Here we're just saving our data off\n with open(fileLoc+fBname+strgrnum+'.data','ab') as f_handle:\n f_handle.write(bytes('%Grain step'+str(j)+'\\n','UTF-8'))\n for k in range(nel):\n np.savetxt(f_handle,density[:, k], newline=' ')\n f_handle.write(bytes('\\n','UTF-8'))\n \n print('Grain #'+str(i)+'% done: {:.3f}'.format(((j+1)/nsteps)))\n \n "
},
{
"alpha_fraction": 0.5591581463813782,
"alphanum_fraction": 0.5964163541793823,
"avg_line_length": 33.47058868408203,
"blob_id": "2a9415e6b06837899e7de131a98d794c68c971b4",
"content_id": "21c206b0e1cbfa57a874289a733a48f7544bb881",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3516,
"license_type": "permissive",
"max_line_length": 309,
"num_lines": 102,
"path": "/PythonScripts/PlotStressStrain.py",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "import numpy as np\n#import numpy.matlib as npm\n#import scipy.io as sio\nimport matplotlib.pyplot as plt\nfrom matplotlib import rc\nimport matplotlib.patches as mpatches\n\nrc('mathtext', default='regular')\n\nfont = {'size' : 14}\n\nrc('font', **font)\n\nfileLoc = ['/Users/robertcarson/OneDrive/n500_pois_iso_A/post.force2', '/Users/robertcarson/OneDrive/n500_pois_dg_0_all14_A/hires/post.force2', '/Users/robertcarson/OneDrive/n500_pois_dg_1_all_1_A/post.force2'] #, '/Volumes/My Passport for Mac/Simulations/midres/aniStudy/A/n500_pois_dg_1_all0_A/post.force2']\n\nii = 0\n\nclrs = ['red', 'blue', 'green', 'black']\nmrks = ['-.', ':', '--', 'solid']\n\nfig, ax = plt.subplots(1)\n\ns = ['A','E','F','H','I']\n\nMSize2 = 3\n\nfor fLoc in fileLoc:\n\n data = np.loadtxt(fLoc, comments='%')\n \n # simname='LoadControl'\n simname = 'DispControl'\n l0 = 1\n epsdot = 1e-3\n MSize = 2\n \n nincr = data.shape[0]\n nind = np.arange(0,nincr+1)\n istep = np.concatenate((np.array([1]), data[:, 0]))\n sig = np.concatenate((np.array([0]), data[:, 4])) / (l0 ** 2)\n time = np.concatenate((np.array([0]), data[:, 6]))\n eps = np.zeros((nincr + 1))\n \n ind = np.squeeze(np.asarray([nind[time==3.0], nind[time==6.0], nind[time==9.0], nind[time==12.0], nind[time==15.0]]))\n \n for i in range(1, nincr + 1):\n dtime = time[i] - time[i - 1]\n if sig[i] - sig[i - 1] > 0:\n eps[i] = eps[i - 1] + epsdot * dtime\n else:\n eps[i] = eps[i - 1] - epsdot * dtime\n \n if simname == 'LoadControl':\n# fig = plt.figure()\n # \tax=plt.axis([0,0.10,0,200])\n ax.plot(eps, sig, color=clrs[ii], marker='*', markersize=MSize)\n elif simname == 'DispControl':\n# fig = plt.figure()\n # \tplt.axis([0,0.10,0,200])\n if ii == 0:\n ax.plot(eps, sig, color=clrs[ii], linestyle=mrks[ii], linewidth=MSize2)\n else:\n ax.plot(eps, sig, color=clrs[ii], linestyle=mrks[ii], linewidth=MSize)\n# if (ii==0):\n# for i, txt in enumerate(s):\n# if (i==0) or (i==4):\n# ax.annotate(txt,(np.squeeze(eps[ind[i]]+eps[ind[i]]*0.07), np.squeeze(sig[ind[i]]-sig[ind[i]]*0.07)))\n# else:\n# ax.annotate(txt,(np.squeeze(eps[ind[i]]+eps[ind[i]]*0.05), np.squeeze(sig[ind[i]]+sig[ind[i]]*0.2)))\n# [print(j) for j in eps]\n ii += 1\n \nfLoc = '/Users/robertcarson/OneDrive/n500_pois_iso_A/post.force'\ndata = np.loadtxt(fLoc, comments='%')\nax.plot(data[:,0], data[:,1], color=clrs[ii], linestyle=mrks[ii], linewidth=MSize)\nax.grid()\n\nbox = ax.get_position()\nax.set_position([box.x0, box.y0 + box.height * 0,\n box.width, box.height * 1])\n \nax.axis([-0.0035, 0.0035, -300, 300])\n\nax.set_ylabel('Macroscopic engineering stress [MPa]')\nax.set_xlabel('Macroscopic engineering strain [-]')\n#plt.title('Macroscopic Stress-Strain Curve')\n\nred_patch = mpatches.Patch(color='red', label='Isotropic hardening')\nblue_patch = mpatches.Patch(color='blue', label='Latent hardening with direct hardening off')\ngreen_patch = mpatches.Patch(color='green', label='Latent hardening with direct hardening on')\nblack_patch = mpatches.Patch(color='black', label='Experimental OMC copper')\n\nax.legend(handles=[red_patch, blue_patch, green_patch, black_patch], loc='upper center', bbox_to_anchor=(0.5, -0.1),\n fancybox=True, ncol=1)\n\nfig.show()\nplt.show()\n\n\n\npicLoc = 'SS_strain_hires_exp.png'\nfig.savefig(picLoc, dpi = 300, bbox_inches='tight')\n"
},
{
"alpha_fraction": 0.6284075975418091,
"alphanum_fraction": 0.6494348645210266,
"avg_line_length": 38.709571838378906,
"blob_id": "5d29ba6cc3756db273eae9d692037ac779dd4818",
"content_id": "7ea251b17b085389fff65719fbf8b876cc1b749b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12032,
"license_type": "permissive",
"max_line_length": 136,
"num_lines": 303,
"path": "/PythonScripts/lofem_post_processing-linux.py",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sun Aug 20 15:20:49 2017\n\n@author: robertcarson\n\"\"\"\n\nimport numpy as np\nimport FePX_Data_and_Mesh as fepxDM\nimport FiniteElement as fe\n#from latorifem import mainlatprogram as latfem\nimport Rotations as rot\nimport Misori as mis\n#%%\n#Getting the location of all of our simulation data and then the mesh file name\n#fileLoc = '/Users/robertcarson/Research_Local_Code/Output/LOFEM_STUDY/n456_cent/low/'\n#fileLoc = '/media/robert/My Passport for Mac/Simulations/LOFEM_Study/n456_cent_m15/mid_txt/'\nfileLoc = '/home/rac428/Outputs/LOFEM_Study/n456_cent_uori_m15/low_txt/'\n#fileLoc = '/media/robert/DataDrives/LOFEM_Study/n456_NF/mono/low_txt/'\n#fileLoc = '/Users/robertcarson/Research_Local_Code/fepx_robert/Examples/ControlMode/LOFEM_REFACTOR2/data/'\nfileName = 'n456-cent-rcl05'\n#fileName = 'n456_nf_raster_L2_r1_v2_rcl075'\n#fileName = 'n6'\n#What we want the basename of the file where we save our kinematic metrics saved along with a few other variables.\nfBname = 'grainData'\n\n#fileLoc = '/media/robert/DataDrives/n1k_pois_iso_reg_pt2/'\n#fileName = 'n1k-id6k-rcl05'\n\n#The number of processors and steps within the simulation.\nnproc = 64\n#nsteps = 16\nnsteps = 46\n#nsteps = 19\n#nsteps = 43\n#nsteps = 44\n#nsteps = 52\n#nsteps = 64\n#nsteps = 86\n\nframes = np.arange(0,nsteps)\n#Reading in our mesh data\nmesh = fepxDM.readMesh(fileLoc, fileName, LOFEM = True)\n#How many grains that our polycrystal had\n#ngrains = 6\nngrains = 456\n#ngrains = 1000\n\ngrains = np.r_[1:(ngrains+1)]\n#Misorientation difference variable that shows the relative angle of rotation between the discrete and smooth lattice methods\n#from element to element\nmisoriD = np.zeros((mesh['grains'].shape[0], nsteps))\n\n#%%\n\nprint('About to start processing data')\n#Tells us what our angle file data is whether its a rod vec or kocks angles\nkor = 'rod'\n#Reading in our LOFEM data\nldata = fepxDM.readLOFEMData(fileLoc, nproc, lofemData=['strain', 'ang'])\nprint('Finished Reading LOFEM data')\nprint('Starting to read DISC data')\ndata = fepxDM.readData(fileLoc, nproc, fepxData=['ang', 'adx', 'strain'], restart=False)\nprint('Finished Reading DISC data')\n\n#%%\n#Global connectivity array reordered such that it goes grain by grain\ngconn = np.asarray([], dtype='float64')\ngconn = np.atleast_2d(gconn)\n#The unique pts and elements that correspond to the above\ngupts = np.asarray([], dtype=np.int32)\nguelem = np.asarray([], dtype=np.int32)\n#Finding the nodal points and elements upper and lowere bounds for all of the grain data\nse_bnds = np.zeros((ngrains*2), dtype='int32')\nse_el_bnds = np.zeros((ngrains*2), dtype='int32')\n\nst_bnd = 0\nen_bnd = 0\n\nst_bnd2 = 0\nen_bnd2 = 0\n\nfor i in grains:\n \n lcon, lcrd, lupts, luelem = fe.localConnectCrd(mesh, i)\n st_bnd = en_bnd\n en_bnd = st_bnd + lupts.shape[0]\n \n j = (i - 1) * 2\n \n se_bnds[j] = st_bnd\n se_bnds[j+1] = en_bnd\n \n st_bnd2 = en_bnd2\n en_bnd2 = st_bnd2 + luelem.shape[0]\n \n j = (i - 1) * 2\n \n se_el_bnds[j] = st_bnd2\n se_el_bnds[j+1] = en_bnd2\n \n gconn, gupts, guelem = fe.concatConnArray(gconn, lcon, gupts, lupts, guelem, luelem) \n\nnpts = gupts.shape[0]\nnelem = guelem.shape[0]\n\n#%%\n#The below is the same as the above but here we just use the LOFEM connectivity array\ngconn2 = np.asarray([], dtype='float64')\ngconn2 = np.atleast_2d(gconn2)\ngupts2 = np.asarray([], dtype=np.int32)\nguelem2 = np.asarray([], dtype=np.int32)\n\nse_bnds2 = np.zeros((ngrains*2), dtype='int32')\nse_el_bnds2 = np.zeros((ngrains*2), dtype='int32')\n\nst_bnd = 0\nen_bnd = 0\n\nst_bnd2 = 0\nen_bnd2 = 0\n\nfor i in grains:\n \n lcon, lupts, luelem = fe.localGrainConnectCrd(mesh, i)\n st_bnd = en_bnd\n en_bnd = st_bnd + lupts.shape[0]\n \n j = (i - 1) * 2\n \n se_bnds2[j] = st_bnd\n se_bnds2[j+1] = en_bnd\n \n st_bnd2 = en_bnd2\n en_bnd2 = st_bnd2 + luelem.shape[0]\n \n j = (i - 1) * 2\n \n se_el_bnds2[j] = st_bnd2\n se_el_bnds2[j+1] = en_bnd2\n \n gconn2, gupts2, guelem2 = fe.concatConnArray(gconn2, lcon, gupts2, lupts, guelem2, luelem) \n\nnpts2 = gupts2.shape[0]\nnelem2 = guelem2.shape[0]\n\n#%%\n#\n#These are variables telling us the relative rotation away from the current grain average orientation for either\n#nodal or elemental data \ngr_angs = np.zeros((1, npts, nsteps), dtype='float64')\nlofem_angs = np.zeros((1, nelem, nsteps), dtype='float64')\ndisc_angs = np.zeros((1, nelem, nsteps), dtype='float64')\n#Telling us the origin in 3D space\norigin = np.zeros((3,1), dtype='float64')\n#%%\n#\nfor i in grains:\n print('###### Starting Grain Number '+str(i)+' ######')\n \n #Reading in our local connectivity arrays in terms of our regular connectivity array and the one generated for the LOFEM simulations\n lcon, lcrd, ucon, uelem = fe.localConnectCrd(mesh, i)\n lcon2, ucon2, uelem2 = fe.localGrainConnectCrd(mesh, i)\n # # of elements and nodes in a grain\n nel = lcon.shape[1]\n npts = ucon.shape[0]\n #Tells us globally what points correspond to the grain we're examing\n indlog = mesh['grains'] == i\n indlog2 = mesh['crd_grains'] == i\n #Here we're getting the misorientation angle and quaternion for our angles when taken with respect the original orientation\n #for the discrete method\n misAngs, misQuats = mis.misorientationGrain(mesh['kocks'][:,i-1], data['angs'][:,indlog,:], frames, 'kocks')\n #Legacy code but just setting our deformation gradient to the identity array\n defgrad = np.tile(np.atleast_3d(np.identity(3)), (1,1,nel))\n #A list holding our deformation stats for the discrete and lofem methods\n deflist = []\n ldeflist = []\n #el_angs is a temporary variable that will hold the grain values that go into misoriD\n el_angs = np.zeros((3,nel,nsteps))\n #Our difference quats, lofem quaternion at nodes, lofem quaternion at the centroid of the element, and discrete method quats\n diff_misQuats = np.zeros((4,nel,nsteps))\n lQuats = np.zeros((4, npts, nsteps))\n leQuats = np.zeros((4, nel, nsteps))\n dQuats = np.zeros((4, nel, nsteps))\n #Just converting from our inputted orientation data to quaternions\n for j in range(nsteps): \n el_angs[:,:,j] = fe.elem_fe_cen_val(ldata['angs'][:,indlog2,j], lcon2)\n lQuats[:,:,j] = rot.QuatOfRod(np.squeeze(ldata['angs'][:,indlog2,j]))\n leQuats[:,:,j] = rot.QuatOfRod(np.squeeze(el_angs[:,:,j]))\n dQuats[:,:,j] = rot.OrientConvert(np.squeeze(data['angs'][:,indlog,j]), 'kocks', 'quat', 'degrees', 'radians')\n #Here we're getting the misorientation angle and quaternion for our angles when taken with respect the original orientation\n #for the lofem method\n lemisAngs, lemisQuats = mis.misorientationGrain(mesh['kocks'][:,i-1], el_angs, frames, kor)\n \n for j in range(nsteps):\n #Getting misorientation between the lofem and disc elements\n temp2, tempQ = mis.misorientationGrain(data['angs'][:,indlog, j], el_angs[:,:,j], [0], kor)\n diff_misQuats[:,:,j] = np.squeeze(tempQ)\n misoriD[indlog, j] = np.squeeze(temp2)\n \n crd = np.squeeze(data['coord'][:,ucon, j])\n #Getting strain data\n epsVec = np.squeeze(ldata['strain'][:, indlog, j])\n #Taking the strain data and putting it into the tensorial view\n #FEpX saves strain data off as 11, 21, 31, 22, 32, 33 so we also have to do some other\n #fanagling of the data\n strain = fepxDM.fixStrain(epsVec)\n #Calculating the volume and wts of the element assumming no curvature to the element\n #The wts are used in all of the calculations and these are relative wts where each element wts is based on\n #vol_elem/vol_grain\n vol, wts = fe.calcVol(crd, lcon)\n #Getting our deformation data but this method is old so we can actually update it a bit\n ldefdata = fe.deformationStats(defgrad, wts, crd, lcon, lemisQuats[:, :, j], el_angs[:,:,j], strain, kor)\n ldeflist.append(ldefdata)\n #Doing the same as the above but now for the discrete data case\n epsVec = np.squeeze(data['strain'][:, indlog, j])\n strain = fepxDM.fixStrain(epsVec)\n \n defdata = fe.deformationStats(defgrad, wts, crd, lcon, misQuats[:, :, j], data['angs'][:, indlog, j], strain, 'kocks')\n deflist.append(defdata)\n \n print('Grain #'+str(i)+'% done: {:.3f}'.format(((j+1)/nsteps)))\n #Saving off all of the data now\n with open(fileLoc+fBname+'LOFEM'+'.vespread','ab') as f_handle:\n f_handle.write(bytes('%Grain number'+str(i)+'\\n','UTF-8'))\n for j in range(nsteps):\n np.savetxt(f_handle,ldeflist[j]['veSpread'])\n \n with open(fileLoc+fBname+'DISC'+'.vespread','ab') as f_handle:\n f_handle.write(bytes('%Grain number'+str(i)+'\\n','UTF-8'))\n for j in range(nsteps):\n np.savetxt(f_handle,deflist[j]['veSpread'])\n \n with open(fileLoc+fBname+'LOFEM'+'.fespread','ab') as f_handle:\n f_handle.write(bytes('%Grain number'+str(i)+'\\n','UTF-8'))\n for j in range(nsteps):\n np.savetxt(f_handle,ldeflist[j]['feSpread'])\n \n with open(fileLoc+fBname+'DISC'+'.fespread','ab') as f_handle:\n f_handle.write(bytes('%Grain number'+str(i)+'\\n','UTF-8'))\n for j in range(nsteps):\n np.savetxt(f_handle,deflist[j]['feSpread'])\n #Calculating all of our misorientation data now\n stats = mis.misorientationTensor(lQuats, lcrd, lcon, data['coord'][:, ucon, :], i, True)\n lmisAngs, lmisQuats = mis.misorientationGrain(origin, stats['angaxis'], frames, 'axis', True)\n \n with open(fileLoc+fBname+'LOFEM'+'.misori','ab') as f_handle:\n f_handle.write(bytes('%Grain number '+str(i)+'\\n','UTF-8'))\n np.savetxt(f_handle,stats['gSpread'])\n\n stats = mis.misorientationTensor(dQuats, lcrd, lcon, data['coord'][:, ucon, :], i, False)\n misAngs, misQuats = mis.misorientationGrain(origin, stats['angaxis'], frames, 'axis', True)\n \n with open(fileLoc+fBname+'DISC'+'.misori','ab') as f_handle:\n f_handle.write(bytes('%Grain number '+str(i)+'\\n','UTF-8'))\n np.savetxt(f_handle,stats['gSpread'])\n\n stats = mis.misorientationTensor(leQuats, lcrd, lcon, data['coord'][:, ucon, :], i, False)\n lemisAngs, lemisQuats = mis.misorientationGrain(origin, stats['angaxis'], frames, 'axis', True)\n with open(fileLoc+fBname+'LOFEM_ELEM'+'.misori','ab') as f_handle:\n f_handle.write(bytes('%Grain number '+str(i)+'\\n','UTF-8'))\n np.savetxt(f_handle,stats['gSpread'])\n\n stats = mis.misorientationTensor(diff_misQuats, lcrd, lcon, data['coord'][:, ucon, :], i, False)\n with open(fileLoc+fBname+'DIFF_LOFEM'+'.misori','ab') as f_handle:\n f_handle.write(bytes('%Grain number '+str(i)+'\\n','UTF-8'))\n np.savetxt(f_handle,stats['gSpread'])\n\n l = (i - 1) * 2\n k = l + 2\n \n ind = se_bnds[l:k]\n ind2 = se_el_bnds[l:k]\n #Saving off the relative misori data mentioned earlier\n gr_angs[:, ind[0]:ind[1], :] = lmisAngs\n disc_angs[:, ind2[0]:ind2[1], :] = misAngs\n lofem_angs[:, ind2[0]:ind2[1], :] = lemisAngs\n \n#%%\n#Writing those misori data off to a file\nwith open(fileLoc+fBname+'diff'+'.emisori','ab') as f_handle:\n for i in range(nsteps):\n f_handle.write(bytes('%Step number '+str(i)+'\\n','UTF-8'))\n np.savetxt(f_handle, np.squeeze(misoriD[:, i]))\n\n\n#%%\nwith open(fileLoc+fBname+'.cmisori','ab') as f_handle:\n for i in range(nsteps):\n f_handle.write(bytes('%Step number '+str(i)+'\\n','UTF-8'))\n np.savetxt(f_handle, np.squeeze(gr_angs[:, :, i]))\n \n#%%\nwith open(fileLoc+fBname+'_DISC'+'.cmisori','ab') as f_handle:\n for i in range(nsteps):\n f_handle.write(bytes('%Step number '+str(i)+'\\n','UTF-8'))\n np.savetxt(f_handle, np.squeeze(disc_angs[:, :, i]))\n#%%\nwith open(fileLoc+fBname+'_LOFEM_ELEM'+'.cmisori','ab') as f_handle:\n for i in range(nsteps):\n f_handle.write(bytes('%Step number '+str(i)+'\\n','UTF-8'))\n np.savetxt(f_handle, np.squeeze(lofem_angs[:, :, i]))\n"
},
{
"alpha_fraction": 0.4663536846637726,
"alphanum_fraction": 0.5399060845375061,
"avg_line_length": 13.860465049743652,
"blob_id": "a4b2fd011fa7155421ac6b2c6922b247e3c6b3c1",
"content_id": "51e3f803182a4426f6c7856e907a8ee45171e3f9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 639,
"license_type": "permissive",
"max_line_length": 44,
"num_lines": 43,
"path": "/PythonFortranCode/Rules-fortran.mk",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "#\n# Suffix rules for fortran-90/95 files.\n# \n# * includes \"clean\" and \"force\"\n#\n.SUFFIXES: .f90 .F90 .ff .INC .inc .f95 .F95\n#\n.f90.o:\n\t$(F90) -c $(F90FLAGS) $<\n.f90:\n\t$(F90) -o $@ $(F90FLAGS) $<\n.f95.o:\n\t$(F95) -c $(F95FLAGS) $<\n.f95:\n\t$(F95) -o $@ $(F95FLAGS) $<\n.F90.o:\n\t$(F90) -c $(F90FLAGS) $<\n.INC.inc:\n\t/bin/rm -f $@\n\t$(CPP) $(CPPFLAGS) $< > $@\n\tchmod 444 $@\n.ff.o:\n\t$(F90) -c $(FFLAGS) $<\n\n#\n# Rules for `clean' target.\n#\n# TARGETS: clean\n# NEEDS: DIRT\n# DEFINES: REMOVE\n# USES: force\n#\nREMOVE=/bin/rm -f\n#\nclean: force\n\t$(REMOVE) $(DIRT)\n#\n#\n# Rule to force execution of another rule.\n#\n# TARGETS: force\n#\nforce:\n"
},
{
"alpha_fraction": 0.6878980994224548,
"alphanum_fraction": 0.7129777073860168,
"avg_line_length": 34.104896545410156,
"blob_id": "af47d5c84de40c270eb54ebabd2d3a2f7ee6429d",
"content_id": "61e9003c9baa8532a4b087ce81cedac3bc77334a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5024,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 143,
"path": "/PythonScripts/calc_load_surf_script.py",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Aug 8 09:56:35 2017\n\n@author: robertcarson\n\"\"\"\n\nimport numpy as np\nimport FePX_Data_and_Mesh as fepxDM\nimport FiniteElement as fe\nimport matplotlib.pyplot as plt\nimport matplotlib.ticker as ticker\nfrom scipy import stats\n\n#The file locations that we'll be pulling from\nfileLoc = '/Users/robertcarson/Research_Local_Code/Output/LOFEM_STUDY/n456_cent/low/'\nfileLoc = '/Volumes/My Passport for Mac/Simulations/LOFEM_Study/n456_cent_c10/low_txt/'\nfileLoc = '/media/robert/My Passport for Mac/Simulations/LOFEM_Study/n456_cent_c10/low_txt/'\nfileLoc = '/media/robert/DataDrives/LOFEM_Study/n456_NF/mono/low_txt/'\nfileName = 'n456-cent-rcl05'\nfileName = 'n456_nf_raster_L2_r1_v2_rcl075'\n\n#Getting info about the number of processors and steps in the simulation\nnproc = 64\nnsteps = 42\n\nmesh = fepxDM.readMesh(fileLoc, fileName)\n#Reading in where the macroscopic strain spots should be. This is assumming that the simulation\n#was conducted in displacement control. If it wasn't then one would need to calculate that from the post.force\n#series of files where the time step is provided. \nmstrain = np.genfromtxt(fileLoc+'mstrain.txt', comments = '%')\n\n#%%\n#Here we need to read in our stress and nodal coordinate data.\ndata = fepxDM.readData(fileLoc, nproc, None, ['adx','stress'], False) #,'gammadot', 'crss'\n\n#%%\n#Getting our 2D element quadrature point data in order to find surface info from our elemental data\nqp2d, wt2d, sf, sfgd = fe.surface_quad_tet()\n#Creating the transpose of the shape function gradient \nsfgdt = np.swapaxes(sfgd, 0, 1)\n#\n##%%\n#Getting out what the coords for our mesh and the surface connectivity\nscrds = mesh['crd']\nsconn = mesh['surfaceNodes']\n#Telling it what surface that we want to be dealing with\nsurf = 'z2'\n#Getting the connectivity array of our sample surface in terms of our global coords and then a local version\n#where the global connectivity array is renumbered such that our first index is now 0.\n#See the function to see how things are laid out in the arrays\ngconn, lconn = fe.surfaceConn(scrds, sconn, surf)\n\n#%%\n#Initializing a load and surface arrays\nload = np.zeros((3, nsteps))\narea = np.zeros(nsteps) \n#Going through all of the steps and finding our surface elements\nfor i in range(nsteps):\n vec = np.unique(gconn[1:7, :])\n #Getting all of the coords that we need in our current frame\n scrds = data['coord'][:, vec, i]\n #Grabbing the stress state from the elements that are along that surface\n sig = data['stress'][:, gconn[0, :], i]\n #We calculate the load and area of the surface here\n load[:, i], area[i] = fe.surfaceLoadArea(scrds, lconn[1:7,:], sig, wt2d, sfgdt)\n \n# %%\n#This is now doing the same as the above but just calculating it for our LOFEM method\nldata = fepxDM.readLOFEMData(fileLoc, nproc, 15, None, ['stress']) # 'stress',,'gammadot','crss'\n\n#%%\nloload = np.zeros((3, nsteps))\nloarea = np.zeros(nsteps) \n\nfor i in range(nsteps):\n vec = np.unique(gconn[1:7, :])\n scrds = data['coord'][:, vec, i]\n sig = ldata['stress'][:, gconn[0, :], i]\n loload[:, i], loarea[i] = fe.surfaceLoadArea(scrds, lconn[1:7,:], sig, wt2d, sfgdt)\n \n#%%\n\n#mstrain = mstrain[0:nsteps]\n#mstrain[nsteps-1] = 0.128\n#Calculating our engineering strain. The area should really be the initial area, but\n#I've decided to use my first step instead since I know it's pretty early on in the elastic regime where\n#I'm at less than 0.01% strain so we should see very small differences in the two areas.\nestress = loload[2,:]/area[0]\nestress2 = load[2,:]/area[0]\n#Here we're calculating the true stress\ntstress = loload[2,:]/area[:]\ntstress2 = load[2,:]/area[:]\n\n#%%\n\nfig, ax = plt.subplots(1)\n\nbox = ax.get_position()\nax.set_position([box.x0, box.y0 + box.height * 0.1,\n box.width*1.4, box.height*1.4])\n\nax.plot(mstrain, estress2, label='Discrete Xtal Lattice Orientation Update')\n\nax.plot(mstrain, estress, label='LOFEM Xtal Lattice Orientation Update')\n\nax.set_ylabel('Macroscopic engineering stress [MPa]')\nax.set_xlabel('Macroscopic engineering strain [-]')\n\nax.legend(loc='upper center', bbox_to_anchor=(0.5, -0.15),fancybox=True, ncol=1)\n\nfig.show()\nplt.show()\n\npicLoc = 'lofem_ss_nf_mono_curve.png'\nfig.savefig(picLoc, dpi = 300, bbox_inches='tight')\n\n#%%\n\nfig, ax = plt.subplots(1)\n\nbox = ax.get_position()\nax.set_position([box.x0, box.y0 + box.height * 0.1,\n box.width*1.4, box.height*1.4])\n#Calculating the true strain here\ntstrain = np.log(mstrain + 1)\n\nax.plot(tstrain, tstress2, label='Discrete Xtal Lattice Orientation Update')\n\nax.plot(tstrain, tstress, label='LOFEM Xtal Lattice Orientation Update')\n\nax.set_ylabel('Macroscopic true stress [MPa]')\nax.set_xlabel('Macroscopic true strain [-]')\n\nax.legend(loc='upper center', bbox_to_anchor=(0.5, -0.15),fancybox=True, ncol=1)\n\nfig.show()\nplt.show()\n\n#We can save off our stress-strain curve if we'd like\npicLoc = 'lofem_true_ss_nf_mono_curve.png'\nfig.savefig(picLoc, dpi = 300, bbox_inches='tight')\n\n\n\n\n"
},
{
"alpha_fraction": 0.645054280757904,
"alphanum_fraction": 0.676417350769043,
"avg_line_length": 22.188810348510742,
"blob_id": "68658ba901d5aa843a8a7fafdac64c6e9bde69d7",
"content_id": "c1bf69164c3ea3dc031c6b4c085ff989da899a1e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3316,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 143,
"path": "/PythonScripts/LoadBCSGenerator.py",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "import math\n\ndef readMesh(fileLoc):\n\t''' Takes in the file location of the FEpX mesh file. It then goes through and reads\n\t\tand parses the data to only return the relevant Surface Nodes as a list with each\n\t\tsurface seperated into their own respected surface subsection. If they are located\n\t\ton multiple surfaces than the nodes go to the multiple surface subsection.\n\t'''\n\tnodes=[]\n\tsurfaceNodes=[]\n\twith open(fileLoc) as f:\n\t\tdata = f.readlines()\n \t\n\tfor line in data:\n\t\twords=line.split()\n#\t\tprint(words)\n\t\tlenWords=len(words)\n\t\tif not words:\n\t\t\tcontinue\n\t\tif lenWords==4:\n\t\t\tnums=wordParser(words)\n\t\t\t#print(nums)\n\t\t\tlenNums=len(nums)\n\t\t\tnodes.append(nums)\n\t\n\tsurfaceNodes=nodeSurface(nodes)\n\treturn surfaceNodes\n\t\ndef wordParser(listVals):\n\t'''\n\tRead in the string list and parse it into a floating list\n\t'''\n\tnumList=[]\n\tfor str in listVals:\n\t\tnum=float(str)\n\t\tnumList.append(num)\n\t\t#print(num)\n\treturn numList\n\t\ndef nodeSurface(nodes):\n\t'''\n\tRead in all the nodes and then determines which ones are on a surface. It returns a\n\tset of surface nodes\n\t'''\n\tsurfaceNodes=[]\n\tfor nod in nodes:\n\t\tloc=nod[1:]\n\t\tif 0.0 in loc:\n\t\t\tsurfaceNodes.append(nod)\n\t\telif 1.0 in loc:\n\t\t\tsurfaceNodes.append(nod)\n\treturn surfaceNodes\n\t\ndef createBCSFile(sNodes,vel,bcsCond,fileName,fileLoc):\n\t'''\n\tRead in surfaceNodes, strain rate/vel, and boundary bounded condition.\n\tIt outputs a file in the following format\n\t#Nodes\n\t\tNode\tT/F\t\tT/F\t\tT/F\t\tvelX velY velZ\n\t\t...\n\tThe file name is specified by the user without the .bcs and so is the location\n\tto save it at.\n\t'''\n\toutputList=[]\n\tdirct=fileLoc+fileName+'.bcs'\n\tfor nod in sNodes:\n\t\toutput=outputStruct(nod,vel,bcsCond)\n\t\toutputList.append(output)\n\twriteOutput(outputList,dirct)\n\t\ndef outputStruct(nod,vel,bcsCond):\n\t'''\n\tTakes in node, velocity, and boundary condition setting.\n\tCreates an output list from the above\n\t'''\n\tisGrip=False\n\toutput=[0]*7\n\tif bcsCond=='grip':\n\t\tisGrip=True\n\toutput[0]=int(nod[0])\n\tloc=nod[1:]\n\tif isGrip:\n\t\toutput[1]='F'\n\t\toutput[2]='F'\n\t\toutput[4]=0.000000000\n\t\toutput[5]=0.000000000\n\telse:\n\t\tfor i in range(0,2):\n\t\t\tif loc[i]==0:\n\t\t\t\toutput[i+1]='T'\n\t\t\telse:\n\t\t\t\toutput[i+1]='F'\n\t\t\toutput[i+4]=0.000000000\n\t\n\tif loc[2]==0 or loc[2]==1:\n\t\toutput[3]='T'\n\t\tif loc[2]==1:\n\t\t\toutput[6]=vel\n\t\telse:\n\t\t\toutput[6]=0.000000000\n\telse:\n\t\toutput[3]='F'\n\t\toutput[6]=0.000000000\n\treturn output\n\ndef writeOutput(outputList,dirct):\n\t'''\n\tWrites the actual .bcs file in the directory file provided\n\t'''\n\tlenOutput=len(outputList)\n\tmaxVal=outputList[lenOutput-1]\n\tlogMax=math.floor(math.log10(maxVal[0]))\n\twith open(dirct,'w') as f:\n\t\tf.write(str(lenOutput)+'\\n')\n\t\tfor list in outputList:\n\t\t\ts=''\n\t\t\tfor i in range(0,7):\n\t\t\t\tif i<4:\n\t\t\t\t\tif i==0:\n\t\t\t\t\t\tval=list[i]\n\t\t\t\t\t\t\n\t\t\t\t\t\tif val==0:\n\t\t\t\t\t\t\tval=1\n\t\t\t\t\t\t\t\t\n\t\t\t\t\t\tlogCur=math.floor(math.log10(val))\n\t\t\t\t\t\ts+=' '*(logMax-logCur)\n\t\t\t\t\ts+=' '+str(list[i])\n\t\t\t\telif i==4:\n\t\t\t\t\ts+=' '+'{0:.6e}'.format(list[i])\n\t\t\t\telse:\n\t\t\t\t\ts+=' '+'{0:.6e}'.format(list[i])\n\t\t\tprint(s)\n\t\t\tf.write(s+'\\n')\n\t\n\t\t\n\nfileLoc='/Users/robertcarson/Research_Local_Code/fepx-devl/Examples/ControlMode/n2.mesh'\nvel=0.005;\nbcsCondition='symmetric'\nfileName='example'\nfileLocation='/Users/robertcarson/Research_Local_Code/fepx/Jobs/'\nsurfaceNodes=readMesh(fileLoc)\n#createBCSFile(surfaceNodes,vel,bcsCondition,fileName,fileLocation)\n"
},
{
"alpha_fraction": 0.5919185876846313,
"alphanum_fraction": 0.6029742956161499,
"avg_line_length": 26.098142623901367,
"blob_id": "463e21a1b9daeba1ead90e51a9f895ef5f5a029e",
"content_id": "e586c7e2b3f4bbfe8aed560d38c3a927189978db",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10221,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 377,
"path": "/PythonScripts/Utility.py",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport scipy as sci\nimport glob\nimport re\nimport os\nimport importlib\n\n'''\nVarious different utility functions have been implemented from the Deformation Processing Lab OdfPf \nlibrary plus an additional function to help evaluate unknown functions\n\nThe following functions are available in this module:\n\nfindModule\n\nAggregrateFunction\nMetricGij\nRankOneMatrix\nUniqueVectors\nUnitVector\n\nOther functions available in there are not rewritten here because of the fact they are not implemented\nin any of the other codes. They could be added if the need for them exists.\n'''\n\n\ndef findModule(fhandle, fileDir=None):\n '''\n When trying to evaluate a function and the module is not known where it's located this function\n will search the current active directory to see if it can find the module in that directory.\n The directory can also be specified if one is using this package out side of the current directory.\n The module is then returned in which that function is located. It will also only work with Unix and \n Windows machines, since those have well defined path directories\n\n Input: fhandle - a string of the function handle being examined\n (optional) fileDir - a string of the directory to look in\n Output: modS - a string of the module that the function is located in\n\n If the function can not be found then a value error is thrown\n '''\n\n if fileDir is None:\n\n fileDir = os.getcwd()\n sysName = os.name\n\n if sysName == 'nt': # Windows operating systems \n dSep = '\\\\'\n else: # Unix operating systems\n dSep = '/'\n fileDir += dSep\n\n fPath = fileDir + '*.py'\n files = glob.glob(fPath) # Get all of the python files in the current directory\n phrase = 'def ' + fhandle # Looks for the function handle in the file\n\n count = 0\n\n for f in files: # Search all of the files\n with open(f) as fpy:\n data = fpy.readlines()\n for line in data: # Search line by line of the file opened\n flag = re.search(phrase, line)\n if flag:\n count += 1\n break\n\n if count > 0:\n outS = re.sub(r'{}.*?'.format(re.escape(fileDir)), '', f)\n modS = re.sub(r'{}.*?'.format(re.escape('.py')), '', outS)\n break\n\n count = 0\n\n if count == 0:\n print('Function could not be found in the current working directory')\n raise ValueError('Function not in current directory')\n\n return modS\n\n\ndef AggregrateFunction(pts, agg, wts, pointFun, varargin):\n '''\n AggregateFunction - Create a function from an aggregate of points.\n\n USAGE:\n\n aggf = AggregateFunction(pts, agg, wts, PointFun)\n aggf = AggregateFunction(pts, agg, wts, PointFun, args)\n\n INPUT:\n\n pts is d x n, \n the set of points on which to evaluate the aggregate function\n agg is d x m, \n a collection of points (the aggregate)\n wts is 1 x m, \n the weighting associated with points in `agg'\n pointFun is a function handle string,\n the function which evaluates the distribution associated \n with each point of the aggregate;\n the required interface to PointFun is:\n\n PointFun(center, points [, args])\n center is d x 1, the center of the distribution\n points is d x n, a list of points to evaluate\n args are function-specific arguments\n\n Remaining arguments are passed to PointFun and should be inputed as a\n dictionary whose keys are the same name as the functions input name\n\n OUTPUT:\n\n aggf is 1 x n, \n the values of the aggregate function at each point in `pts';\n\n NOTES:\n\n * Each point in the aggregate is the center of a distribution\n over the whole space, given by PointFun; all of these \n distributions are superposed to give the resulting \n aggregate function, which is then evaluated at the \n specified point.\n\n\n '''\n\n keys = varargin.keys()\n pts = mat2d_row_order(pts)\n agg = mat2d_row_order(agg)\n wts = np.atleast_1d(wts)\n n = pts.shape\n m = agg.shape\n wtscheck = len(wts)\n\n if m[1] != wtscheck:\n print('dimension mismatch: wts and agg (length)')\n raise ValueError('dimension mismatch between wts and agg (length)')\n\n if n[0] != m[0]:\n print('dimension mismatch: pts and agg (first dimension)')\n raise ValueError('dimension mismatch between pts and agg (1st dim)')\n\n aggf = np.zeros((1, n[1]))\n\n modStr = findModule(pointFun)\n feval = getattr(importlib.import_module(modStr), pointFun)\n\n for i in range(m[1]):\n aggf = aggf + wts[i] * feval(agg[:, i], pts, **varargin)\n\n return aggf\n\n\ndef MetricGij(diff):\n '''\n MetricGij - Compute components of metric from differential.\n\n USAGE:\n\n gij = MetricGij(diff)\n\n INPUT:\n\n diff is m x n x l,\n the array of n tangent vectors of dimension m at each \n of l points\n\n OUTPUT:\n\n gij is n x n x l, \n the metric components (dot(ti, tj)) at each of the l points\n\n '''\n\n m = diff.shape\n gij = np.zeros((m[0], m[0], m[2]))\n\n for i in range(m[2]):\n gij[:, :, i] = np.dot(np.transpose(diff[:, :, i], (1, 0, 2)), diff[:, :, i])\n\n return gij\n\n\ndef RankOneMatrix(vec1, *args):\n '''\n RankOneMatrix - Create rank one matrices (dyadics) from vectors. It therefore simply computes the \n outer product between two vectors, $v_j \\otimes v_i$\n\n USAGE:\n\n r1mat = RankOneMatrix(vec1)\n r1mat = RankOneMatrix(vec1, vec2)\n\n INPUT:\n\n vec1 is m1 x n, \n an array of n m1-vectors \n vec2 is m2 x n, (optional) \n an array of n m2-vectors\n\n OUTPUT:\n\n r1mat is m1 x m2 x n, \n an array of rank one matrices formed as c1*c2' \n from columns c1 and c2\n\n With one argument, the second vector is taken to\n the same as the first.\n\n NOTES:\n\n * This routine can be replaced by MultMatArray.\n\n\n '''\n\n vec1 = mat2d_row_order(vec1)\n\n if len(args) == 0:\n vec2 = vec1.copy()\n else:\n vec2 = np.atleast_2d(args[0])\n\n m = vec1.shape\n n = vec2.shape[0]\n\n if m[0] != n:\n print('dimension mismatch: vec1 and vec2 (first dimension)')\n raise ValueError('dimension mismatch between vec1 and vec2 (1st dim)')\n\n rrom = np.zeros((m[0], n, m[1]))\n\n for i in range(m[1]):\n rrom[:, :, i] = np.outer(vec1[:, i], vec2[:, i])\n\n return rrom\n\n\ndef UniqueVectors(vec, *args):\n '''\n UniqueVectors - Remove near duplicates from a list of vectors.\n \n USAGE:\n\n [uvec, ord, iord] = UniqueVectors(vec)\n [uvec, ord, iord] = UniqueVectors(vec, tol)\n\n INPUT:\n\n vec is d x n, \n an array of n d-vectors\n tol is a scalar, (optional) \n the tolerance for comparison; it defaults to 1.0e-14\n\n OUTPUT:\n\n uvec is d x m, \n the set of unique vectors; two adjacent vectors are considered\n equal if each component is within the given tolerance\n ord is an m-vector, (integer)\n which relates the input vector to the output vector, \n i.e. uvec = vec(:, ord)\n iord is an n-vector, (integer)\n which relates the reduced vector to the original vector, \n i.e. vec = uvec(:, iord)\n\n NOTES:\n\n * After sorting, only adjacent entries are tested for equality\n within the tolerance. For example, if x1 and x2 are within\n the tolerance, and x2 and x3 are within the tolerance, then \n all 3 will be considered the same point, even though x1 and\n x3 may not be within the tolerance. Consequently, if you\n make the tolerance too large, all the points will be\n considered the same. Nevertheless, this routine should be \n adequate for the its intended application (meshing), where\n the points fall into well-separated clusters.\n\n\n '''\n\n vec = mat2d_row_order(vec)\n\n if len(args) == 0:\n tol = 1.0e-14\n else:\n tol = args[0]\n\n d = vec.shape\n n = d[1]\n\n ivec = np.zeros((d[0], d[1]))\n\n for row in range(d[0]):\n tmpsrt = np.sort(vec[row, :])\n tmpord = np.argsort(vec[row, :])\n\n tmpcmp = np.abs(tmpsrt[1:n] - tmpsrt[0:n - 1])\n\n indep = np.hstack((True, tmpcmp > tol))\n\n rowint = np.cumsum(indep)\n\n ivec[row, tmpord] = rowint\n\n utmp, orde, iord = np.unique(ivec.T, return_index=True, return_inverse=True)\n\n orde = np.int_(np.floor(orde / 3))\n\n uvec = vec[:, orde]\n orde = orde.T\n iord = iord.T\n\n return (uvec, orde, iord)\n\n\ndef UnitVector(vec, *args):\n '''\n UnitVector - Normalize an array of vectors.\n\n USAGE:\n\n uvec = UnitVector(vec)\n uvec = UnitVector(vec, ipmat)\n\n INPUT:\n\n vec is m x n, \n an array of n nonzero vectors of dimension m\n ipmat is m x m, (optional)\n this is a (SPD) matrix which defines the inner product\n on the vectors by the rule: \n norm(v)^2 = v' * ipmat * v\n\n If `ipmat' is not specified, the usual Euclidean \n inner product is used.\n\n OUTPUT:\n\n uvec is m x n,\n the array of unit vectors derived from `vec'\n\n\n '''\n\n vec = mat2d_row_order(vec)\n\n m = vec.shape[0]\n\n if len(args) > 0:\n ipmat = args[0]\n nrm2 = np.sum(vec.conj() * np.dot(ipmat, vec), axis=0)\n else:\n nrm2 = np.sum(vec.conj() * vec, axis=0)\n\n nrm = np.tile(np.sqrt(nrm2), (m, 1))\n uvec = vec / nrm\n\n return uvec\n \ndef mat2d_row_order(mat):\n '''\n It takes in a mat nxm or a vec of n length and returns a 2d numpy array\n that is nxm where m is a least 1 instead of mxn where m is 1 like the \n numpy.atleast_2d() will do if a vec is entered\n \n Input: mat - a numpy vector or matrix with dimensions of n or nxm\n output: mat - a numpy matrix with dimensions nxm where m is at least 1 \n \n '''\n \n mat = np.atleast_2d(mat) \n if mat.shape[0] == 1:\n mat = mat.T\n \n return mat\n \n"
},
{
"alpha_fraction": 0.6001507639884949,
"alphanum_fraction": 0.6089469790458679,
"avg_line_length": 40.77193069458008,
"blob_id": "582e5169027f95f115817a928cffc16025161902",
"content_id": "fb60e48485e6dde723711b72a9ea1c7f2cf6c853",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11937,
"license_type": "permissive",
"max_line_length": 162,
"num_lines": 285,
"path": "/PythonScripts/fepx_vtk.py",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Jun 30 10:39:13 2017\n\n@author: robertcarson\n\"\"\"\n\nimport numpy as np\nimport evtk.vtk\nfrom evtk.hl import unstructuredGridToVTK\n\n'''\nList of functions available in this module\nfepxconn_2_vtkconn(conn)\nevtk_conn_offset_type_creation(conn, wedge_conn = None)\nevtk_elem_data_creation(data, uconn, nelems, wedge_nelems)\nevtk_pts_data_creation(data, uorder)\nevtk_xyz_crd_creation(coords, uorder)\nevtk_fileCreation(fileLoc, xcrd, ycrd, zcrd, conn, offsets, cell_types, cellData=None, cellKeys=None, ptsData=None, ptsKeys=None)\nevtk_groupVTKData(fileLoc, fOutList, simTimes)\n'''\n\n\ndef fepxconn_2_vtkconn(conn):\n '''\n Takes in the fepx connectivity array and switches it to the vtk\n format.\n \n Input:\n conn - a numpy array of the elemental connectivity array for a\n quadratic tetrahedral element with FePX nodal ordering\n Output:\n vtk_conn - a numpy array of the elemental connectivity array\n given in the vtk nodal order for a quadratic tetrahedral \n element\n \n '''\n \n #Rearrangement of array\n \n vtko = np.array([0, 2, 4, 9, 1, 3, 5, 6, 7, 8], dtype = np.int8)\n \n vtk_conn = conn[vtko, :]\n \n \n return vtk_conn\n\ndef evtk_conn_offset_type_creation(conn, wedge_conn = None):\n '''\n Takes in an elemental connectivity array and if given a wedge \n element connectivity array and outputs the EVTK conn and offset\n arrays.\n \n Input:\n conn - a 2D numpy array of the elemental connectivity array\n for a quadratic tetrahedral element given in the vtk format\n (Optional) wedge_conn - a 2D numpy array of the elemental wedge\n connectivity array. It is an optional input and is not\n needed.\n Output: evtk_conn - 1D array that defines the vertices associated \n to each element. Together with offset define the \n connectivity or topology of the grid. It is assumed \n that vertices in an element are listed consecutively. \n evtk_offset - 1D array with the index of the last vertex of\n each element in the connectivity array. It should have \n length nelem, where nelem is the number of cells or \n elements in the grid.\n evtk_cell_types - 1D array with an integer that defines the\n cell type of each element in the grid. It should have \n size nelem. This should be assigned from \n evtk.vtk.VtkXXXX.tid, where XXXX represent the type of \n cell. Please check the VTK file format specification \n for allowed cell types. \n \n '''\n \n tet_off = 10\n wedge_off = 12\n \n conn_nelem = conn.shape[1]\n \n conn1D = conn.flatten(order = 'F')\n \n conn_off = np.arange(9, conn_nelem*tet_off, tet_off)\n \n quadTet = evtk.vtk.VtkQuadraticTetra.tid\n quadLinWedge = evtk.vtk.VtkQuadraticLinearWedge.tid \n \n cell_type = quadTet*np.ones(conn_nelem, dtype=np.uint8, order='F')\n \n if wedge_conn is not None:\n wedge_nelem = wedge_conn.shape[1]\n wedge1D = wedge_conn.flatten(order = 'F')\n wedge_off = np.arange(0, wedge_nelem*wedge_off, wedge_off)\n wedge_type = quadLinWedge * np.ones(wedge_nelem, dtype=np.uint8, order='F')\n else:\n wedge1D = np.array([], dtype=np.int32)\n wedge_off = np.array([], dtype=np.int32)\n wedge_type = np.array([], dtype=np.uint8)\n \n \n evtk_conn = np.hstack((conn1D, wedge1D))\n evtk_offset = np.hstack((conn_off, wedge_off)) + 1\n evtk_cell_type = np.hstack((cell_type, wedge_type))\n \n return (evtk_conn, evtk_offset, evtk_cell_type)\n\ndef evtk_elem_data_creation(data, uconn, nelems, wedge_nelems):\n '''\n Arranges the data given in the global numbers to the unique\n connectivity array if there's a difference in how things are numbered.\n This would help if one has each grain as it's own \"mesh\" without having\n their nodes connected to the main mesh. Therefore, the data would\n need to be rearranged to account for this new difference.\n If one does have connectivity to other grains through a wedge element\n then the wedge elements have a data value of 0.\n \n Input: data - global data that we're going to rearrange. It should\n be a 2D numpy array with the 2 axis having a length equal\n to the number of elements\n \n uconn - a 1D numpy array with the unique indices corresponding\n to how the data should be rearranged to fit the new order\n of the global connectivity array\n \n nelems - a scalar value telling us how many elements are in\n data. We will use it as a sanity check to make sure the data\n doesn't have a shape that conforms to what we expect it to.\n \n wedge_nelems - a scalar value telling us how many wedge\n elements are going to end up being in the connectivity array\n \n Output: evtk_data - the rearranged data array that can now be used\n in our visualizations using paraview. \n '''\n if(data.ndim == 1):\n data = np.atleast_2d(data)\n \n dlen = data.shape[0]\n \n dnelems = nelems + wedge_nelems\n \n evtk_data = np.zeros((dlen, dnelems), dtype='float64')\n \n evtk_data[:,0:nelems] = data[:, uconn]\n \n if(dlen == 6):\n vec = evtk_data.shape\n indices = [0, 1, 2, 1, 3, 4, 2, 4, 5] \n# temp = np.zeros((3, 3, vec[1]))\n temp = np.reshape(evtk_data[indices, :], (3, 3, vec[1]))\n evtk_data = temp\n \n return evtk_data\n\ndef evtk_pts_data_creation(data, uorder):\n '''\n Arranges the data given in the global numbers to the unique\n connectivity array if there's a difference in how things are numbered.\n This would help if one has each grain as it's own \"mesh\" without having\n their nodes connected to the main mesh. Therefore, the data would\n need to be rearranged to account for this new difference. \n \n Input: data - global data that we're going to rearrange. It should\n be a 2D numpy array with the 2nd axis having a length equal\n to the number of number of nodal positions in the mesh.\n \n uorder - a 1D numpy array with the indices corresponding\n to how the crds should be rearranged to the new nodal\n arrangment of the mesh. It's possible that there are repeated\n indices in this array that would correspond to the nodes that\n were lying on the grain boundary.\n \n Output: evtk_pts - the rearranged data array that can now be used\n in our visualizations using paraview\n \n '''\n \n epts_len = uorder.shape[0]\n \n evtk_pts = np.zeros((3, epts_len), dtype='float64')\n \n evtk_pts[:,:] = data[:, uorder]\n\n return evtk_pts\n\ndef evtk_xyz_crd_creation(coords, uorder):\n '''\n Arranges the coords given in the global numbers to the unique\n connectivity array if there's a difference in how things are numbered.\n This would help if one has each grain as it's own \"mesh\" without having\n their nodes connected to the main mesh. Therefore, the data would\n need to be rearranged to account for this new difference. \n \n Input: coords - global coords that we're going to rearrange. It should\n be a 2D numpy array with the 2nd axis having a length equal\n to the number of number of nodal positions in the mesh.\n \n uorder - a 1D numpy array with the indices corresponding\n to how the crds should be rearranged to the new nodal\n arrangment of the mesh. It's possible that there are repeated\n indices in this array that would correspond to the nodes that\n were lying on the grain boundary.\n \n Output: evtk_x - the rearranged x coords that can now be used\n in our visualizations using paraview\n evtk_y - the rearranged y coords that can now be used\n in our visualizations using paraview\n evtk_z - the rearranged z coords that can now be used\n in our visualizations using paraview\n \n '''\n \n epts_len = uorder.shape[0]\n \n evtk_x = np.zeros((epts_len), dtype='float64')\n evtk_y = np.zeros((epts_len), dtype='float64')\n evtk_z = np.zeros((epts_len), dtype='float64')\n \n evtk_x[:] = coords[0, uorder]\n evtk_y[:] = coords[1, uorder]\n evtk_z[:] = coords[2, uorder]\n \n return(evtk_x, evtk_y, evtk_z)\n\ndef evtk_fileCreation(fileLoc, xcrd, ycrd, zcrd, conn, offsets, cell_types, cellData=None, cellKeys=None, ptsData=None, ptsKeys=None):\n '''\n Wrapper around the unstructuredGridToVTK function \n Export unstructured grid and associated data.\n\n Inputs:\n fileLoc: name of the file without extension where data should be saved.\n xcrd, ycrd, zcrd: 1D arrays with coordinates of the vertices of cells.\n It is assumed that each element has diffent number of vertices.\n conn: 1D array that defines the vertices associated to \n each element. Together with offset define the connectivity\n or topology of the grid. It is assumed that vertices in \n an element are listed consecutively.\n offsets: 1D array with the index of the last vertex of each element\n in the connectivity array. It should have length nelem,\n where nelem is the number of cells or elements in the grid.\n cell_types: 1D array with an integer that defines the cell type\n of each element in the grid. It should have size nelem.\n This should be assigned from evtk.vtk.VtkXXXX.tid,\n where XXXX represent the type of cell. Please check the\n VTK file format specification for allowed cell types. \n cellData: Dictionary with variables associated to each line.\n Keys should be the names of the variable stored in each array.\n All arrays must have the same number of elements. \n pointData: Dictionary with variables associated to each vertex.\n Keys should be the names of the variable stored in each array.\n All arrays must have the same number of elements.\n\n Output:\n fOut: Full path to saved file.\n '''\n fOut = unstructuredGridToVTK(fileLoc, xcrd, ycrd, zcrd, conn, offsets, cell_types, cellData=cellData, cellKeys=cellKeys, pointData=ptsData, pointKeys=ptsKeys)\n \n return fOut\n \ndef evtk_groupVTKData(fileLoc, fOutList, simTimes):\n '''\n A wrapper function that creates a VTK group to visualize time\n dependent data in Paraview.\n \n Input:\n fileLoc - name of the file without extension where the group\n file should be saved.\n fOutList - a list of all of the vtk files that are to be grouped\n together\n simTimes - a numpy 1D array of the simulation times that each\n vtk corresponds to\n \n \n '''\n \n ltime = simTimes.shape[0]\n \n gclass = evtk.vtk.VtkGroup(fileLoc)\n \n for i in range(ltime):\n gclass.addFile(filepath = fOutList[i], sim_time=simTimes[i])\n \n gclass.save()\n\n \n \n \n "
},
{
"alpha_fraction": 0.6083064675331116,
"alphanum_fraction": 0.6364124417304993,
"avg_line_length": 37,
"blob_id": "230b50ed5e082452bc8f9e407a51e90fab998f5b",
"content_id": "f257e781c86da71ddbe9ab915fecd9b2906b689b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11172,
"license_type": "permissive",
"max_line_length": 170,
"num_lines": 294,
"path": "/PythonScripts/lofem_vtk_script.py",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Sep 1 13:52:05 2017\n\n@author: robertcarson\n\"\"\"\n\nimport numpy as np\nimport fepx_vtk as fvtk\n#import graph_cc_dfs as gcdfs\nimport FePX_Data_and_Mesh as fepxDM\nimport textadapter as ta\nimport FiniteElement as fe\n#import sklearn.preprocessing as sklpp\n\n#fileLoc = '/Users/robertcarson/Research_Local_Code/Output/n1k_pois_iso_reg/'\n#fileLoc = '/Volumes/My Passport for Mac/Simulations/hires/n500_pois_iso/'\n#fileName = 'n1k-id6k-rcl05'\n#fileName = 'n500-id6k'\n\n#nproc = 64\n#nsteps = 44\n#fileLoc = '/Users/robertcarson/Research_Local_Code/Output/LOFEM_STUDY/n456_cent/low/'\n#fileLoc = '/Volumes/My Passport for Mac/Simulations/LOFEM_Study/n456_cent_c10/low_txt/'\nfileLoc = '/media/robert/My Passport for Mac/Simulations/LOFEM_Study/n456_cent_m15/low_txt/'\n#fileLoc = '/media/robert/DataDrives/LOFEM_Study/n456_NF/mono/low_txt/'\nfileName = 'n456-cent-rcl05'\n#fileName = 'n456_nf_raster_L2_r1_v2_rcl075'\nfBname = 'grainData'\n\n#fileVTK = '/Users/robertcarson/Research_Local_Code/Output/LOFEM_STUDY/n456_cent/'\nfileVTK = '/media/robert/Data/SimulationData/LOFEM_Data/n456_cent/mono/'\n#fileVTK = '/Users/robertcarson/Research_Local_Code/Output/'\n#fileVTK = '/media/robert/Data/SimulationData/LOFEM_Data/n456_NF/mono/'\nfVTKLOFEM = fileVTK + 'lofem_mono'\nfVTKDISC = fileVTK + 'disc_mono'\n\nfVTKLGROUP = fVTKLOFEM + '_group'\nfVTKDGROUP = fVTKDISC + '_group'\n#\nnproc = 64\nnsteps = 44\n\nframes = np.arange(0,nsteps)\n\nmesh = fepxDM.readMesh(fileLoc,fileName)\n\nngrains = 456\nnangs = 3\nnss = 12\n#ngrains = 1000\n#ngrains = 500\n\ngrains = np.r_[1:(ngrains+1)]\n\nnels = mesh['grains'].shape[0]\n\n\n#%%\nr2d = 180/np.pi\nprint('About to start processing data')\nkor = 'rod'\nldata = fepxDM.readLOFEMData(fileLoc, nproc, lofemData=['strain','stress','crss'])\n#print('Finished Reading LOFEM data')\nprint('Starting to read DISC data')\ndata = fepxDM.readData(fileLoc, nproc, fepxData=['adx', 'strain','stress','crss'], restart=False)#, 'ang'])\nprint('Finished Reading DISC data')\n#%%\nmisori = ta.genfromtxt(fileLoc+fBname+'diff.emisori', comments='%')\ndmisori = ta.genfromtxt(fileLoc+fBname+'_DISC.cmisori', comments='%')\ngr_cmisori = ta.genfromtxt(fileLoc+fBname+'.cmisori', comments='%')\n#alpha = ta.genfromtxt(fileLoc+fBname+'.alpha', comments='%')\n\ndmisori = dmisori.reshape((nsteps, nels)).T*r2d\nmisori = misori.reshape((nsteps, nels)).T*r2d\n#gr_cmisori = gr_misori.reshape((nsteps, nels)).T*r2d\n#alpha = alpha.reshape((nsteps, nels)).T\nprint('Finished Reading in Misori, Gr Misori, and Alpha')\n\n#%%\n\ngconn = np.asarray([], dtype='float64')\ngconn = np.atleast_2d(gconn)\ngupts = np.asarray([], dtype=np.int32)\nguelem = np.asarray([], dtype=np.int32)\n\ngrains_elem = np.asarray([], dtype=np.int32)\ngrains_pts = np.asarray([], dtype=np.int32)\n\nse_bnds = np.zeros((ngrains*2), dtype='int32')\nse_el_bnds = np.zeros((ngrains*2), dtype='int32')\n\nst_bnd = 0\nen_bnd = 0\n\nst_bnd2 = 0\nen_bnd2 = 0\n\nfor i in grains:\n \n lcon, lcrd, lupts, luelem = fe.localConnectCrd(mesh, i)\n st_bnd = en_bnd\n en_bnd = st_bnd + lupts.shape[0]\n \n j = (i - 1) * 2\n \n se_bnds[j] = st_bnd\n se_bnds[j+1] = en_bnd\n \n st_bnd2 = en_bnd2\n en_bnd2 = st_bnd2 + luelem.shape[0]\n \n j = (i - 1) * 2\n \n se_el_bnds[j] = st_bnd2\n se_el_bnds[j+1] = en_bnd2\n \n lcon = fvtk.fepxconn_2_vtkconn(lcon)\n gconn, gupts, guelem = fe.concatConnArray(gconn, lcon, gupts, lupts, guelem, luelem) \n\nnpts = gupts.shape[0]\nnelem = guelem.shape[0]\n\n \ngr_angs = np.zeros((nangs, npts, nsteps), dtype='float64')\ngr_gdot = np.zeros((nss, npts, nsteps), dtype='float64')\ngr_gamma = np.zeros((nss, npts, nsteps), dtype='float64')\ngr_dd = np.zeros((nss, nelem, nsteps), dtype='float64')\ngr_cmisori = gr_cmisori.reshape((nsteps, npts)).T*r2d\n \n#%% \n\nfor i in grains:\n print('###### Starting Grain Number '+str(i)+' ######')\n \n gdata = fepxDM.readGrainData(fileLoc, i, frames=None, grData=['ang','gdot','gamma','dd'])\n j = (i - 1) * 2\n k = j + 2\n ind = se_bnds[j:k]\n ind2 = se_el_bnds[j:k]\n gr_gamma[:, ind[0]:ind[1], :] = gdata['gamma']\n gr_gdot[:, ind[0]:ind[1], :] = gdata['gdot']\n gr_angs[:, ind[0]:ind[1], :] = gdata['angs']\n gr_dd[:, ind2[0]:ind2[1], :] = gdata['dd']\n#%% \nevtk_conn, evtk_offset, evtk_type = fvtk.evtk_conn_offset_type_creation(gconn)\n#\nnelems = guelem.shape[0]\n#\ngrains_elem = np.atleast_2d(mesh['grains'])\ngrains_elem = np.atleast_2d(grains_elem)\n#nelems = grains_elem.shape[1]\n#grains_pts = np.atleast_2d(grains_pts)\n\n\n#%%\n\nlofem_file = []\ndisc_file = []\n#%%\n#\nsgr_gamma = np.zeros((4, gr_gamma.shape[1], nsteps))\n\nsgr_gamma[0, :, :] = np.sum(gr_gamma[0:3, :, :], axis = 0)\nsgr_gamma[1, :, :] = np.sum(gr_gamma[3:6, :, :], axis = 0)\nsgr_gamma[2, :, :] = np.sum(gr_gamma[6:9, :, :], axis = 0)\nsgr_gamma[3, :, :] = np.sum(gr_gamma[9:12, :, :], axis = 0)\n\nsgr_gdot = np.zeros((4, gr_gamma.shape[1], nsteps))\n\nsgr_gdot[0, :, :] = np.sum(gr_gdot[0:3, :, :], axis = 0)\nsgr_gdot[1, :, :] = np.sum(gr_gdot[3:6, :, :], axis = 0)\nsgr_gdot[2, :, :] = np.sum(gr_gdot[6:9, :, :], axis = 0)\nsgr_gdot[3, :, :] = np.sum(gr_gdot[9:12, :, :], axis = 0)\n\nss_rho = np.zeros((4, gr_dd.shape[1], nsteps))\n\nss_rho[0, :, :] = np.sum(np.abs(gr_dd[0:3, :, :]), axis = 0)\nss_rho[1, :, :] = np.sum(np.abs(gr_dd[3:6, :, :]), axis = 0)\nss_rho[2, :, :] = np.sum(np.abs(gr_dd[6:9, :, :]), axis = 0)\nss_rho[3, :, :] = np.sum(np.abs(gr_dd[9:12, :, :]), axis = 0)\n\n#%%\nmStress = np.zeros((nels,nsteps), dtype=\"float64\")\neffStress = np.zeros((nels,nsteps), dtype=\"float64\")\ntriax = np.zeros((nels,nsteps), dtype=\"float64\")\n\nfor j in range(nsteps):\n stress = fepxDM.fixStrain(np.squeeze(ldata['stress'][:,:,j]))\n for i in range(nels):\n mStress[i,j] = 1/3*np.trace(stress[:,:,i])\n devStress = stress[i,:,:] - mStress[i,j]*np.eye(3)\n effStress[i,j] = np.sqrt(3/2*np.trace(np.dot(devStress,devStress.T)))\n triax[i,j] = mStress[i,j]/effStress[i,j]\n#%%\n#ngr_angs = np.zeros((gr_angs.shape))\n#for i in range(nsteps):\n# ngr_angs[:,:,i] = sklpp.normalize(gr_angs[:,:,i], axis=0)\n\n#%%\n#npts = data['coord'].shape[1]\n#guelem = np.r_[0:nelems]\n#gupts = np.r_[0:npts]\n#nsteps = 44\n\n#cDict = {'grain_elem':'Scalars', 'misorientation':'Scalars', 'alpha':'Scalars', 'Grain_misorientation':'Scalars'}\n\nloDict = {'stress':'Tensors', 'strain':'Tensors', 'grain_elem':'Scalars', 'crss':'Scalars', 'misorientation':'Scalars',\n 'rho_n1':'Scalars', 'rho_n2':'Scalars', 'rho_n3':'Scalars', 'rho_n4':'Scalars', 'disc_misori':'Scalars',\n 'mean_stress':'Scalars','deff_stress':'Scalars', 'triaxiality':'Scalars'}\ncDict = {'stress':'Tensors', 'strain':'Tensors', 'grain_elem':'Scalars', 'crss':'Scalars'}\npDict = {'grain_rod':'Vectors', 'gr_gamma_n1':'Scalars', 'gr_gamma_n2':'Scalars', 'gr_gamma_n3':'Scalars', 'gr_gamma_n4':'Scalars',\n 'gr_gdot_n1':'Scalars', 'gr_gdot_n2':'Scalars', 'gr_gdot_n3':'Scalars', 'gr_gdot_n4':'Scalars', 'gr_misori':'Scalars'}\n\n\n\nfor i in range(nsteps):\n print('##########Starting Step # '+str(i)+'##########')\n ldict = {}\n ddict = {}\n ldict2 = {}\n ddict2 = {}\n \n ldict2['grain_rod'] = np.ascontiguousarray(gr_angs[:,:,i])\n ldict2['gr_misori'] = np.ascontiguousarray(gr_cmisori[:,i])\n ldict2['gr_gamma_n1'] = np.ascontiguousarray(sgr_gamma[0,:,i])\n ldict2['gr_gamma_n2'] = np.ascontiguousarray(sgr_gamma[1,:,i])\n ldict2['gr_gamma_n3'] = np.ascontiguousarray(sgr_gamma[2,:,i])\n ldict2['gr_gamma_n4'] = np.ascontiguousarray(sgr_gamma[3,:,i])\n ldict2['gr_gdot_n1'] = np.ascontiguousarray(sgr_gdot[0,:,i])\n ldict2['gr_gdot_n2'] = np.ascontiguousarray(sgr_gdot[1,:,i])\n ldict2['gr_gdot_n3'] = np.ascontiguousarray(sgr_gdot[2,:,i])\n ldict2['gr_gdot_n4'] = np.ascontiguousarray(sgr_gdot[3,:,i])\n \n ldict['disc_misori'] = np.ascontiguousarray(dmisori[:,i])\n ldict['rho_n1'] = np.ascontiguousarray(ss_rho[0,:,i])\n ldict['rho_n2'] = np.ascontiguousarray(ss_rho[1,:,i])\n ldict['rho_n3'] = np.ascontiguousarray(ss_rho[2,:,i])\n ldict['rho_n4'] = np.ascontiguousarray(ss_rho[3,:,i])\n ddict['grain_elem'] = fvtk.evtk_elem_data_creation(grains_elem, guelem, nelems, 0)\n ldict['misorientation'] = fvtk.evtk_elem_data_creation(misori[:,i], guelem, nelems, 0)\n# ddict['alpha'] = fvtk.evtk_elem_data_creation(alpha[:,i], guelem, nelems, 0)\n# ddict['Grain_misorientation'] = fvtk.evtk_elem_data_creation(gr_misori[:,i], guelem, nelems, 0)\n# lkeys = {}\n# ddict['grain_elem'] = fvtk.evtk_elem_data_creation(grains_elem, guelem, nelems, 0)\n# lkeys['grain_elem'] = 'Scalars' \n ldict['grain_elem'] = fvtk.evtk_elem_data_creation(grains_elem, guelem, nelems, 0)\n# ddict2['grain_pts'] = fvtk.evtk_pts_data_creation(grains_pts, gupts)\n# ldict2['grain_pts'] = fvtk.evtk_pts_data_creation(grains_pts, gupts)\n xcrd, ycrd, zcrd = fvtk.evtk_xyz_crd_creation(data['coord'][:,:,i], gupts)\n ddict['stress'] = fvtk.evtk_elem_data_creation(data['stress'][:,:,i], guelem, nelems, 0)\n ddict['strain'] = fvtk.evtk_elem_data_creation(data['strain'][:,:,i], guelem, nelems, 0)\n ddict['crss'] = fvtk.evtk_elem_data_creation(data['crss'][:,:,i], guelem, nelems, 0)\n# ddict['dpeff'] = fvtk.evtk_elem_data_creation(data['dpeff'][:,:,i], guelem, nelems, 0)\n ldict['stress'] = fvtk.evtk_elem_data_creation(ldata['stress'][:,:,i], guelem, nelems, 0)\n ldict['strain'] = fvtk.evtk_elem_data_creation(ldata['strain'][:,:,i], guelem, nelems, 0)\n ldict['crss'] = fvtk.evtk_elem_data_creation(ldata['crss'][:,:,i], guelem, nelems, 0)\n# ldict['dpeff'] = fvtk.evtk_elem_data_creation(ldata['dpeff'][:,:,i], guelem, nelems, 0)\n \n ldict['mean_stress'] = fvtk.evtk_elem_data_creation(mStress[:,i], guelem, nelems, 0)\n ldict['deff_stress'] = fvtk.evtk_elem_data_creation(effStress[:,i], guelem, nelems, 0)\n ldict['triaxiality'] = fvtk.evtk_elem_data_creation(triax[:,i], guelem, nelems, 0)\n temp = fvtk.evtk_fileCreation(fVTKLOFEM+str(i), xcrd, ycrd, zcrd, evtk_conn, evtk_offset, evtk_type, cellData=ldict, cellKeys = loDict, ptsData=ldict2, ptsKeys=pDict)\n lofem_file.append(temp)\n print('######## Printed LOFEM File #########')\n temp = fvtk.evtk_fileCreation(fVTKDISC+str(i), xcrd, ycrd, zcrd, evtk_conn, evtk_offset, evtk_type, cellData=ddict, cellKeys = cDict)#, ptsData=ddict2)\n disc_file.append(temp)\n print('######## Printed DISC File #########')\n\n#%%\n\nsimTimes = np.r_[0:nsteps]\n#\nfvtk.evtk_groupVTKData(fVTKLGROUP, lofem_file, simTimes)\nfvtk.evtk_groupVTKData(fVTKDGROUP, disc_file, simTimes)\n\n#%%\n\nsmstress = np.mean(np.abs(mStress), axis=0)\nseffstress = np.mean(np.abs(effStress), axis=0)\nstriax = np.mean(np.abs(triax), axis=0)\n\nwith open(fileLoc+fBname+'mean_mstress.text','wb') as f_handle:\n# f_handle.write(bytes('%Grain number'+str(grnum)+'\\n','UTF-8'))\n np.savetxt(f_handle, smstress)\n \nwith open(fileLoc+fBname+'mean_deffstress.text','wb') as f_handle:\n# f_handle.write(bytes('%Grain number'+str(grnum)+'\\n','UTF-8'))\n np.savetxt(f_handle, seffstress)\n \nwith open(fileLoc+fBname+'mean_triax.text','wb') as f_handle:\n# f_handle.write(bytes('%Grain number'+str(grnum)+'\\n','UTF-8'))\n np.savetxt(f_handle, striax)\n"
},
{
"alpha_fraction": 0.8112566471099854,
"alphanum_fraction": 0.8190199136734009,
"avg_line_length": 113.38888549804688,
"blob_id": "a76f9111d27290dcc18bff0e75d0d1c7aa7367f1",
"content_id": "1a1972b9b18d5fd82044661c70eefa5de5c1b4d5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2061,
"license_type": "permissive",
"max_line_length": 386,
"num_lines": 18,
"path": "/README.md",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "# Note: This repo was related to the old Cornell DPLab FEpX code. I am no longer maintaining this. I am now focusing on the development of the open-source LLNL ExaConstit and ExaCMech crystal plasticity modeling and finite element libraries/application codes. Since these libraries are being heavily focused on running on next-gen exascale computers such as Frontier and El Capitan. \n\n# pyFEpX\nPython tools to process FEpX data and some OdfPF capabilities built in. The library provides a number of features including orientation convertions, misorientation metrics, orientation-spatial metrics, intragrain deformation metrics, superconvergence methods, dislocation density methods, and finally binary vtk preparation scripts. \n\nYou will need scipy, numpy, and TextAdapter obtained from Anaconda.\nThe easiest way to install these is using the Anaconda software conda. You can obtain TextAdapter at https://github.com/ContinuumIO/TextAdapter as a replacement to iopro. It's the renamed and open sourced version of iopro. It does include some installations steps on your own.\n\nI've also include a few example scripts to process the FEpX data. I'm open to also including support for other simulation result readers and conversions processess from their method to the ones used here.\n\nIncluded in the OdfPF package are complete versions of the rotation and misorientation modules from the matlab code. The creation and examination of pole figures and inverse pole figures are still a work in progress.\n\nThe intragrain deformation metrics provided in https://doi.org/10.1088/1361-651X/aa6dc5 are also provided under the FiniteElement.lofem_elas_stretch_stats and FiniteElement.deformationStats functions.\n\n\n\nContains a modified version of Paulo Herrera's PyEVTK library found at https://bitbucket.org/pauloh/pyevtk/overview. The license for PyEVTK hosted here can be found at https://github.com/rcarson3/pyFEpX/blob/master/PythonScripts/pyevtk/src/LICENSE \nThe PyEVTK library allows for the creation of binary VTK files to be used in either VisIT or Paraview.\n\n\n"
},
{
"alpha_fraction": 0.5423105955123901,
"alphanum_fraction": 0.5675077438354492,
"avg_line_length": 22.50587272644043,
"blob_id": "e3ab43776501eb5ea7a8182bb98c9cea1c478b0a",
"content_id": "56c73a05b4b1eab4cbbc03c675613e2ac2c49a87",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 28019,
"license_type": "permissive",
"max_line_length": 185,
"num_lines": 1192,
"path": "/PythonScripts/Rotations.py",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport scipy.linalg as scila\n# from Misori import Misorientation\nimport mesh as msh # not yet written\nimport PolytopeStructure as PStruc # not yet written\nimport Utility as utl\nfrom sklearn.preprocessing import normalize\n\n'''\nThis program was written by Robert Carson on June 10th, 2015.\nIt is based upon the OdfPf library that the Deformation Processing Lab has written in MATLAB.\n\nThe following functions are available in this module:\n\n*Orientation Conversion functions\n\nBungeOfKocks\nBungeOfRMat\nKocksOfBunge\nRMatOfBunge\nRMatOfQuat\nQuatOfRMat\nRodOfQuat\nQuatOfRod\nQuatOfAngleAxis\nOrientConvert\n\n*Quaternion math functions\n\nQuatProd\nMeanQuat\n\n*Fundamental region functions\n\nToFundamentalRegionQ\nToFundamentalRegion\n\n*Crystal symmetry functions\n\nCubSymmetries\nHexSymmetries\nOrtSymmetries\n\n*Rodrigues space math functions\n\nMisorientations *used to be inside Misori module but had to move here for comp\n reasons\nRodDistance\nRodGaussian # needs to be tested but showed work\n\n\n\nThe following rotations functions are missing or need to be worked on from that matlab library:\n\nCubBaseMesh*\nCubPolytope*\n\nHexBaseMesh*\nHexPolytope*\nOrtBaseMesh*\nOrtPolytope*\n\nQuatGradient # quite a bit\nQuatReorVel # quite a bit\nRodDifferential # quite a bit\nRodMetric # quite a bit\n\n*The functions need to have their dependent libraries added\n\nFunctions not ported over due to their lack of dependencies/general use:\n\nQuatOfLaueGroup - several of the xtal sym already included\nRMatOfGRAINDEXU\nRotConvert - OrientConvert replaced it\nRodDistance - dependencies no longer included in OdfPf\n\n\n'''\n\n\n'''\nVarious orientation convertion functions in this first section\n'''\n\n\ndef BungeOfKocks(kocks=None, units=None):\n '''\n BungeOfKocks - Bunge angles from Kocks angles.\n \n USAGE:\n \n bunge = BungeOfKocks(kocks, units)\n \n INPUT:\n \n kocks is n x 3,\n the Kocks angles for the same orientations\n units is a string,\n either 'degrees' or 'radians'\n \n OUTPUT:\n \n bunge is n x 3,\n the Bunge angles for n orientations\n \n NOTES:\n \n * The angle units apply to both input and output.\n \n '''\n if kocks is None or kocks.__len__() == 0 or units is None or units.__len__() == 0:\n print('need two arguments: kocks, units')\n raise ValueError('need two arguments: kocks, units')\n\n if units == 'degrees':\n pi_over_2 = 90\n else:\n pi_over_2 = np.pi/2\n\n kocks = utl.mat2d_row_order(kocks)\n\n bunge = np.copy(kocks)\n bunge[0, :] = kocks[0, :]+pi_over_2\n bunge[2, :] = pi_over_2 - kocks[2, :]\n\n return bunge\n\n\ndef BungeOfRMat(rmat=None, units=None):\n '''\n BungeOfRMat - Bunge angles from rotation matrices.\n \n USAGE:\n \n bunge = BungeOfRMat(rmat, units)\n \n INPUT:\n \n rmat is 3 x 3 x n,\n an array of rotation matrices\n units is a string,\n either 'degrees' or 'radians' specifying the output\n angle units\n \n OUTPUT:\n \n bunge is n x 3,\n the array of Euler angles using Bunge convention\n \n '''\n if rmat is None or rmat.__len__() == 0 or units is None or units.__len__() == 0:\n print('need two arguments: kocks, units')\n raise ValueError('need two arguments: kocks, units')\n if units == 'degrees':\n indeg = True\n elif units == 'radians':\n indeg = False\n else:\n print('units needs to be either radians or degrees')\n raise ValueError('angle units need to be specified: ''degrees'' or ''radians''')\n\n rmat = np.atleast_3d(rmat)\n\n if rmat.shape[0] != 3:\n rmat = rmat.T\n\n n = rmat.shape[2]\n\n c2 = np.copy(rmat[2, 2, :])\n c2 = np.minimum(c2[:], 1.0)\n c2 = np.maximum(c2[:], -1.0)\n\n myeps = np.sqrt(np.finfo(float).eps)\n near_pole = (np.absolute(c2) > 1-myeps)\n not_near_pole = (np.absolute(c2) < 1-myeps)\n\n s2 = np.zeros((n))\n c1 = np.zeros((n))\n s1 = np.zeros((n))\n c3 = np.zeros((n))\n s3 = np.zeros((n))\n\n s2[not_near_pole] = np.sqrt(1 - c2[not_near_pole]*c2[not_near_pole])\n\n c1[not_near_pole] = -1.0*rmat[1, 2, not_near_pole]/s2[not_near_pole]\n s1[not_near_pole] = rmat[0, 2, not_near_pole]/s2[not_near_pole]\n c3[not_near_pole] = rmat[2, 1, not_near_pole]/s2[not_near_pole]\n s3[not_near_pole] = rmat[2, 0, not_near_pole]/s2[not_near_pole]\n\n c1[near_pole] = rmat[0, 0, near_pole]\n s1[near_pole] = rmat[1, 0, near_pole]\n c3[near_pole] = 1.0\n s3[near_pole] = 0.0\n\n bunge = np.array([np.arctan2(s1, c1), np.arccos(c2), np.arctan2(s3, c3)])\n\n bunge[bunge < 0] = bunge[bunge < 0] + 2*np.pi\n\n if indeg:\n bunge = bunge*180/np.pi\n\n return bunge\n\n\ndef KocksOfBunge(bunge=None, units=None):\n '''\n KocksOfBunge - Kocks angles from Bunge angles.\n\n USAGE:\n\n kocks = KocksOfBunge(bunge, units)\n\n INPUT:\n\n bunge is 3 x n,\n the Bunge angles for n orientations \n units is a string,\n either 'degrees' or 'radians'\n\n OUTPUT:\n\n kocks is 3 x n,\n the Kocks angles for the same orientations\n\n NOTES:\n\n * The angle units apply to both input and output.\n '''\n\n if bunge is None or units is None:\n print('need two arguments: bunge, units')\n raise ValueError('need two arguments: bunge, units')\n\n if units == 'degrees':\n indeg = True\n elif units == 'radians':\n indeg = False\n else:\n print('units needs to be either radians or degrees')\n raise ValueError('angle units need to be specified: ''degrees'' or ''radians''')\n\n if indeg:\n pi_over_2 = 90\n else:\n pi_over_2 = np.pi/2\n\n bunge = utl.mat2d_row_order(bunge)\n\n\n kocks = bunge.copy()\n\n kocks[0, :] = bunge[0, :] - pi_over_2\n kocks[2, :] = pi_over_2 - bunge[2, :]\n\n return kocks\n\n\ndef RMatOfBunge(bunge, units):\n '''\n RMatOfBunge - Rotation matrix from Bunge angles.\n\n USAGE:\n\n rmat = RMatOfBunge(bunge, units)\n\n INPUT:\n\n bunge is 3 x n,\n the array of Bunge parameters\n units is a string,\n either 'degrees' or 'radians'\n\n OUTPUT:\n\n rmat is 3 x 3 x n,\n the corresponding rotation matrices\n\n\n '''\n\n if bunge is None or units is None:\n print('need two arguments: bunge, units')\n raise ValueError('need two arguments: bunge, units')\n\n if units == 'degrees':\n indeg = True\n bunge = bunge*(np.pi/180)\n elif units == 'radians':\n indeg = False\n else:\n print('units needs to be either radians or degrees')\n raise ValueError('angle units need to be specified: ''degrees'' or ''radians''')\n \n bunge = utl.mat2d_row_order(bunge)\n n = bunge.shape[1]\n cbun = np.cos(bunge)\n sbun = np.sin(bunge)\n\n rmat = np.asarray([[cbun[0, :]*cbun[2, :]-sbun[0, :]*cbun[1, :]*sbun[2, :]],\n [sbun[0, :]*cbun[2, :] + cbun[0, :]*cbun[1, :]*sbun[2, :]],\n [sbun[1, :]*sbun[2, :]],\n [-1*cbun[0, :]*sbun[2, :] - sbun[0, :]*cbun[1, :]*cbun[2, :]],\n [-1*sbun[0, :]*sbun[2, :] + cbun[0, :]*cbun[1, :]*cbun[2, :]],\n [sbun[1, :]*cbun[2, :]],\n [sbun[0, :]*sbun[1, :]],\n [-1*cbun[0, :]*sbun[1, :]],\n [cbun[1, :]]])\n\n rmat = rmat.T.reshape((n, 3, 3)).T\n\n return rmat\n\n\ndef RMatOfQuat(quat):\n '''\n RMatOfQuat - Convert quaternions to rotation matrices.\n\n USAGE:\n\n rmat = RMatOfQuat(quat)\n\n INPUT:\n\n quat is 4 x n, \n an array of quaternion parameters\n\n OUTPUT:\n\n rmat is 3 x 3 x n, \n the corresponding array of rotation matrices\n\n NOTES:\n\n * This is not optimized, but still does okay\n (about 6,700/sec on intel-linux ~2GHz)\n '''\n quat = utl.mat2d_row_order(quat)\n n = quat.shape[1]\n rmat = np.zeros((3, 3, n), order='F')\n\n zeroTol = 1.0e-7 # sqrt(eps) due to acos()\n\n for i in range(0, n):\n\n theta = 2*np.arccos(quat[0, i])\n\n if theta > zeroTol:\n w = theta/np.sin(theta/2)*quat[1:4, i]\n else:\n w = np.asarray([0, 0, 0]).T\n\n wSkew = [[0, -1*w[2], w[1]], [w[2], 0, -1*w[0]], [-1*w[1], w[0], 0]]\n rmat[:, :, i] = scila.expm(wSkew)\n\n return rmat\n\n\ndef QuatOfRMat(rmat):\n '''\n QuatOfRMat - Quaternion from rotation matrix\n\n USAGE:\n\n quat = QuatOfRMat(rmat)\n\n INPUT:\n\n rmat is 3 x 3 x n,\n an array of rotation matrices\n\n OUTPUT:\n\n quat is 4 x n,\n the quaternion representation of `rmat'\n\n '''\n rmat = np.atleast_3d(rmat)\n if rmat.shape[0] != 3:\n rmat = rmat.T\n rsize = rmat.shape\n\n ca = 0.5*(rmat[0, 0, :]+rmat[1, 1, :]+rmat[2, 2, :]-1)\n ca = np.minimum(ca, 1)\n ca = np.maximum(ca, -1)\n angle = np.squeeze(np.arccos(ca)).T\n\n '''\n \n Three cases for the angle: \n\n * near zero -- matrix is effectively the identity\n * near pi -- binary rotation; need to find axis\n * neither -- general case; can use skew part\n\n\n '''\n tol = 1.0e-4\n anear0 = angle < tol\n nnear0 = np.sum(anear0)\n angle[anear0] = 0\n\n raxis = [[rmat[2, 1, :]-rmat[1, 2, :]], [rmat[0, 2, :]-rmat[2, 0, :]], [rmat[1, 0, :]-rmat[0, 1, :]]]\n raxis = utl.mat2d_row_order(np.squeeze(raxis)) \n \n if nnear0 > 0:\n if rsize[2] == 1:\n raxis[:, 0] = 1\n else:\n raxis[:, anear0] = 1\n\n special = np.squeeze(angle > np.pi-tol)\n nspec = np.sum(special)\n\n if nspec > 0:\n angle[special] = np.tile(np.pi, (nspec))\n if rsize[2] == 1:\n tmp = np.atleast_3d(rmat[:, :, 0])+np.tile(np.atleast_3d(np.identity(3)), (1, 1, nspec))\n else:\n tmp = rmat[:, :, special]+np.tile(np.atleast_3d(np.identity(3)), (1, 1, nspec))\n tmpr = tmp.T.reshape(3, 3*nspec)\n dp = np.sum(tmpr.conj()*tmpr, axis=0)\n tmpnrm = dp.reshape(3, nspec)\n ind = np.argmax(tmpnrm, axis=0)\n ind = ind + list(range(0, 3*nspec-1, 3))\n saxis = np.atleast_2d(np.squeeze(tmpr[:, ind]))\n\n if rsize[2] == 1:\n raxis[:, 0] = saxis\n else:\n# print(special.shape)\n if saxis.shape[0] == 1:\n raxis[:, special] = saxis.T\n else:\n raxis[:, special] = saxis\n \n\n quat = QuatOfAngleAxis(angle, raxis)\n\n return quat\n\n\ndef RodOfQuat(quat):\n ''' \n RodOfQuat - Rodrigues parameterization from quaternion.\n\n USAGE:\n\n rod = RodOfQuat(quat)\n\n INPUT:\n\n quat is 4 x n, \n an array whose columns are quaternion paramters; \n it is assumed that there are no binary rotations \n (through 180 degrees) represented in the input list\n\n OUTPUT:\n\n rod is 3 x n, \n an array whose columns form the Rodrigues parameterization \n of the same rotations as quat\n\n '''\n \n rod = quat[1:4, :]/np.tile(quat[0, :], (3, 1))\n\n return rod\n\n\ndef QuatOfRod(rod):\n '''\n QuatOfRod - Quaternion from Rodrigues vectors.\n\n USAGE:\n\n quat = QuatOfRod(rod)\n\n INPUT:\n\n rod is 3 x n, \n an array whose columns are Rodrigues parameters\n\n OUTPUT:\n\n quat is 4 x n, \n an array whose columns are the corresponding unit\n quaternion parameters; the first component of \n `quat' is nonnegative\n\n '''\n\n rod = utl.mat2d_row_order(rod) \n \n cphiby2 = np.cos(np.arctan(np.linalg.norm(rod, axis=0)))\n\n quat = np.asarray([[cphiby2], np.tile(cphiby2, (3, 1))*rod])\n\n quat = np.concatenate(quat, axis=0)\n\n return quat\n\n'''\nVarious Quaternion functions thourh still missing: QuatReorVel, QuatGradient going to leave Laue group out\n'''\n\ndef QuatProd(q2, q1):\n '''\n QuatProd - Product of two unit quaternions.\n\n USAGE:\n\n qp = QuatProd(q2, q1)\n\n INPUT:\n\n q2, q1 are 4 x n, \n arrays whose columns are quaternion parameters\n\n OUTPUT:\n\n qp is 4 x n, \n the array whose columns are the quaternion parameters of \n the product; the first component of qp is nonnegative\n\n NOTES:\n\n * If R(q) is the rotation corresponding to the\n quaternion parameters q, then \n\n R(qp) = R(q2) R(q1)\n\n\n '''\n\n a = np.atleast_2d(q2[0, :])\n a3 = np.tile(a, (3, 1))\n b = np.atleast_2d(q1[0, :])\n b3 = np.tile(b, (3, 1))\n\n avec = np.atleast_2d(q2[1:4, :])\n bvec = np.atleast_2d(q1[1:4, :])\n\n qp1 = np.atleast_2d(a*b - np.sum(avec.conj()*bvec, axis=0))\n if q1.shape[1] == 1:\n qp2 = np.atleast_2d(np.squeeze(a3*bvec + b3*avec + np.cross(avec.T, bvec.T).T)).T\n else:\n qp2 = np.atleast_2d(np.squeeze(a3*bvec + b3*avec + np.cross(avec.T, bvec.T).T))\n\n qp = np.concatenate((qp1, qp2), axis=0)\n\n q1neg = np.nonzero(qp[0, :] < 0)\n\n qp[:, q1neg] = -1*qp[:, q1neg]\n\n return qp\n\ndef QuatMean(quats):\n '''\n QuatMean finds the average quaternion based upon the methodology defined in\n Quaternion Averaging by Markley, Cheng, Crassidis, and Oshman\n \n Input:\n quats - A list of quaternions of that we want to find the average quaternion\n Output:\n mquats - the mean quaternion of the system\n '''\n if(quats.shape[0] == 4):\n n = quats.shape[1]\n mmat = 1/n*quats.dot(quats.T)\n else:\n n = quats.shape[0]\n mmat = 1/n*quats.T.dot(quats)\n bmmat = mmat - np.eye(4)\n \n eig, eigvec = np.linalg.eig(bmmat)\n mquats = np.squeeze(eigvec[:, np.argmax(eig)])\n \n return mquats\n \n\ndef QuatOfAngleAxis(angle, raxis):\n '''\n QuatOfAngleAxis - Quaternion of angle/axis pair.\n\n USAGE:\n\n quat = QuatOfAngleAxis(angle, axis)\n\n INPUT:\n\n angle is an n-vector, \n the list of rotation angles\n axis is 3 x n, \n the list of rotation axes, which need not\n be normalized (e.g. [1 1 1]'), but must be nonzero\n\n OUTPUT:\n\n quat is 4 x n, \n the quaternion representations of the given\n rotations. The first component of quat is nonnegative.\n '''\n\n tol = 1.0e-5\n\n #Errors can occur when this is near pi or negative pi\n limit = np.abs(np.abs(angle) - np.pi) < tol\n \n angle[limit] = np.pi * np.sign(angle[limit])\n \n halfAngle = 0.5*angle.T\n cphiby2 = np.atleast_2d(np.cos(halfAngle))\n sphiby2 = np.sin(halfAngle)\n scaledAxis = normalize(raxis, axis=0)*np.tile(sphiby2, (3,1))\n# rescale = sphiby2/np.sqrt(np.sum(raxis.conj()*raxis, axis=0))\n# scaledAxis = np.tile(rescale, (3, 1))*raxis\n quat = np.concatenate((cphiby2, scaledAxis), axis=0)\n q1neg = np.nonzero(quat[0, :] < 0)\n quat[:, q1neg] = -1*quat[:, q1neg]\n\n return quat\n\ndef AngleAxisOfRod(rod):\n '''\n Takes in a Rodrigues Vector and returns the angle axis pair\n '''\n \n rod = utl.mat2d_row_order(rod) \n \n angle = 2*np.arctan(np.linalg.norm(rod, axis=0))\n\n ang_axis = angle*normalize(rod, axis=0)\n \n return ang_axis\n \n \n\n'''\nUniversal convertion function\n'''\n\n\ndef OrientConvert(inOri, inConv, outConv, inDeg=None, outDeg=None):\n '''\n OrientConvert - Convert among orientation conventions.\n\n STATUS: in development\n\n USAGE:\n\n out = OrientConvert(in, inConv, outConv)\n out = OrientConvert(in, inConv, outConv, inDeg, outDeg)\n\n INPUT:\n\n in is d x n \n input parameters (e.g. Euler angles)\n inConv is a string\n input convention\n outConv is a string\n output convention\n inDeg is a string\n either 'degrees' or 'radians'\n outDeg is a string\n either 'degrees' or 'radians'\n\n OUTPUT:\n\n out is e x n \n output parameters\n NOTES:\n\n * Conventions are 'kocks', 'bunge', 'rmat', 'quat', 'rod'\n * If any Euler angle conventions are specified, then the\n degrees convention must also be specified\n\n\n\n Convert input to rotation matrices.\n\n '''\n\n if inConv == 'kocks':\n rmat = RMatOfBunge(BungeOfKocks(inOri, inDeg), inDeg)\n elif inConv == 'bunge':\n rmat = RMatOfBunge(inOri, inDeg)\n elif inConv == 'rmat':\n rmat = inOri\n elif inConv == 'rod' or inConv == 'rodrigues':\n rmat = RMatOfQuat(QuatOfRod(inOri))\n elif inConv == 'quat' or inConv == 'quaternion':\n rmat = RMatOfQuat(inOri)\n else:\n print('input convention not matched')\n raise ValueError('input convention not matched')\n\n if outConv == 'kocks':\n out = KocksOfBunge(BungeOfRMat(rmat, outDeg), outDeg)\n elif outConv == 'bunge':\n out = BungeOfRMat(rmat, outDeg)\n elif outConv == 'rmat':\n out = rmat\n elif outConv == 'rod' or outConv == 'rodrigues':\n out = RodOfQuat(QuatOfRMat(rmat))\n elif outConv == 'quat' or outConv == 'quaternion':\n out = QuatOfRMat(rmat)\n else:\n print('output convention not matched')\n raise ValueError('output convention not matched')\n\n return np.require(out, requirements=['F'])\n\n'''\nFunctions used to bring orientations back into the fundamental region\nThe OrientConvert function can be used to bring them back into any other space other than Rod or Quat space\n'''\n\n\ndef ToFundamentalRegionQ(quat, qsym):\n '''\n ToFundamentalRegionQ - To quaternion fundamental region.\n\n USAGE:\n\n q = ToFundamentalRegionQ(quat, qsym)\n\n INPUT:\n\n quat is 4 x n, \n an array of n quaternions\n qsym is 4 x m, \n an array of m quaternions representing the symmetry group\n\n OUTPUT:\n\n q is 4 x n, the array of quaternions lying in the\n fundamental region for the symmetry group \n in question\n\n NOTES: \n\n * This routine is very memory intensive since it \n applies all symmetries to each input quaternion.\n\n\n '''\n quat = utl.mat2d_row_order(quat) \n qsym = utl.mat2d_row_order(qsym)\n n = quat.shape[1]\n m = qsym.shape[1]\n\n qMat = np.tile(quat, (m, 1))\n\n qSymMat = np.tile(qsym, (1, n))\n\n qeqv = QuatProd(qMat.T.reshape(m*n, 4).T, qSymMat)\n\n q0_abs = np.abs(np.atleast_2d(qeqv[0, :]).T.reshape(n, m)).T\n\n imax = np.argmax(q0_abs, axis=0)\n\n ind = np.arange(n)*m + imax\n\n q = qeqv[:, ind]\n\n return q\n\n\ndef ToFundamentalRegion(quat, qsym):\n '''\n ToFundamentalRegion - Put rotation in fundamental region.\n\n USAGE:\n\n rod = ToFundamentalRegion(quat, qsym)\n\n INPUT:\n\n quat is 4 x n, \n an array of n quaternions\n qsym is 4 x m, \n an array of m quaternions representing the symmetry group\n\n OUTPUT:\n\n rod is 3 x n, \n the array of Rodrigues vectors lying in the fundamental \n region for the symmetry group in question\n\n NOTES: \n\n * This routine is very memory intensive since it \n applies all symmetries to each input quaternion.\n\n\n '''\n\n q = ToFundamentalRegionQ(quat, qsym)\n rod = RodOfQuat(q)\n\n return rod\n\n'''\nThe cubic, hexagonal, and orthorhombic symmetry groups for rotations necessary to form a fundamental region around the origin in rodrigues space, and they are given here as quaternions.\n\nIf any other symmetries groups are desired they would need to be programmed in\n\n'''\n\n\ndef CubSymmetries():\n ''' CubSymmetries - Return quaternions for cubic symmetry group.\n\n USAGE:\n\n csym = CubSymmetries\n\n INPUT: none\n\n OUTPUT:\n\n csym is 4 x 24, \n quaternions for the cubic symmetry group\n '''\n\n '''\n array index 1 = identity\n array index 2-4 = fourfold about x1\n array index 5-7 = fourfold about x2\n array index 8-9 = fourfold about x9\n array index 10-11 = threefold about 111\n array index 12-13 = threefold about 111\n array index 14-15 = threefold about 111\n array index 16-17 = threefold about 111\n array index 18-24 = twofold about 110\n \n '''\n angleAxis = [\n [0.0, 1, 1, 1],\n [np.pi*0.5, 1, 0, 0],\n [np.pi, 1, 0, 0],\n [np.pi*1.5, 1, 0, 0],\n [np.pi*0.5, 0, 1, 0],\n [np.pi, 0, 1, 0],\n [np.pi*1.5, 0, 1, 0],\n [np.pi*0.5, 0, 0, 1],\n [np.pi, 0, 0, 1],\n [np.pi*1.5, 0, 0, 1],\n [np.pi*2/3, 1, 1, 1],\n [np.pi*4/3, 1, 1, 1],\n [np.pi*2/3, -1, 1, 1],\n [np.pi*4/3, -1, 1, 1],\n [np.pi*2/3, 1, -1, 1],\n [np.pi*4/3, 1, -1, 1],\n [np.pi*2/3, -1, -1, 1],\n [np.pi*4/3, -1, -1, 1],\n [np.pi, 1, 1, 0],\n [np.pi, -1, 1, 0],\n [np.pi, 1, 0, 1],\n [np.pi, 1, 0, -1],\n [np.pi, 0, 1, 1],\n [np.pi, 0, 1, -1]]\n #\n angleAxis = np.asarray(angleAxis).transpose()\n angle = angleAxis[0, :]\n axis = angleAxis[1:4, :]\n #\n # Axis does not need to be normalized it is done\n # in call to QuatOfAngleAxis.\n #\n csym = QuatOfAngleAxis(angle, axis)\n\n return csym\n\n\ndef HexSymmetries():\n '''\n HexSymmetries - Quaternions for hexagonal symmetry group.\n\n USAGE:\n\n hsym = HexSymmetries\n\n INPUT: none\n\n OUTPUT:\n\n hsym is 4 x 12,\n it is the hexagonal symmetry group represented\n as quaternions\n\n\n '''\n p3 = np.pi/3\n p6 = np.pi/6\n ci = np.atleast_2d(np.cos(p6*(np.arange(6))))\n si = np.atleast_2d(np.sin(p6*(np.arange(6))))\n z6 = np.zeros((1, 6))\n w6 = np.ones((1, 6))\n pi6 = np.tile(np.pi, [1, 6])\n p3m = np.atleast_2d(p3*(np.arange(6)))\n\n sixfold = np.concatenate((p3m, z6, z6, w6))\n twofold = np.concatenate((pi6, ci, si, z6))\n\n angleAxis = np.asarray(np.concatenate((sixfold, twofold), axis=1))\n angle = angleAxis[0, :]\n axis = angleAxis[1:4, :]\n #\n # Axis does not need to be normalized it is done\n # in call to QuatOfAngleAxis.\n #\n hsym = QuatOfAngleAxis(angle, axis)\n\n return hsym\n\n\ndef OrtSymmetries():\n '''\n OrtSymmetries - Orthorhombic symmetry group.\n\n USAGE:\n\n osym = OrtSymmetries\n\n INPUT: none\n\n OUTPUT:\n\n osym is 4 x 4, \n the quaternions for the symmetry group\n\n\n '''\n angleAxis = [\n [0.0, 1, 1, 1],\n [np.pi, 1, 0, 0],\n [np.pi, 0, 1, 0],\n [np.pi, 0, 0, 1]]\n\n angleAxis = np.asarray(angleAxis).transpose()\n angle = angleAxis[0, :]\n axis = angleAxis[1:4, :]\n #\n # Axis does not need to be normalized it is done\n # in call to QuatOfAngleAxis.\n #\n osym = QuatOfAngleAxis(angle, axis)\n\n return osym\n\n'''\nUnfinished code that don't yet have their dependencies programmed in yet\n'''\n\n\ndef CubBaseMesh():\n '''\n \n CubBaseMesh - Return base mesh for cubic symmetries\n \n USAGE:\n \n m = CubBaseMesh\n \n INPUT: no inputs\n \n OUTPUT:\n \n m is a MeshStructure,\n on the cubic fundamental region\n \n \n '''\n m = msh.LoadMesh('cub-base')\n m['symmetries'] = CubSymmetries()\n\n return m\n\ndef HexBaseMesh():\n '''\n \n HexBaseMesh - Return base mesh for hexagonal symmetries\n \n USAGE:\n \n m = HexBaseMesh\n \n INPUT: no inputs\n \n OUTPUT:\n \n m is a MeshStructure,\n on the hexagonal fundamental region\n \n \n '''\n m = msh.LoadMesh('hex-base')\n m['symmetries'] = HexSymmetries()\n\n return m\n\ndef OrtBaseMesh():\n '''\n \n OrtBaseMesh - Return base mesh for orthorhombic symmetries\n \n USAGE:\n \n m = OrtBaseMesh\n \n INPUT: no inputs\n \n OUTPUT:\n \n m is a MeshStructure,\n on the orthorhombic fundamental region\n \n \n '''\n m = msh.LoadMesh('ort-base')\n m['symmetries'] = OrtSymmetries()\n\n return m\n\ndef CubPolytope():\n\n '''\n CubPolytope - Polytope for cubic fundamental region.\n \n USAGE:\n \n cubp = CubPolytope\n \n INPUT: none\n \n OUTPUT:\n \n cubp is a PolytopeStructure:\n it gives the polytope for the cubic\n fundamental region including the vertex\n list and the faces component (for plotting)\n \n \n \n Compute faces (constraints).\n '''\n\n b1 = np.tan(np.pi/8)\n b2 = np.tan(np.pi/6)\n\n utmp = np.array([[1, 1, 1], [1, -1, 1], [-1, 1, 1], [-1, -1, 1]]).T\n\n n111 = utl.UnitVector(utmp)\n matrix = np.concatenate((np.identity(3), n111.T), axis=0)\n matrix = np.concatenate((matrix, -1.0*matrix), axis=0)\n\n pass\n\n'''\nDifferent Rodrigues functions\n'''\n\n\ndef RodDistance(pt, ptlist, sym):\n '''\n RodDistance - Find angular distance between rotations.\n \n USAGE:\n\n dist = RodDistance(pt, ptlist, sym)\n\n INPUT:\n\n pt is 3 x 1, \n a point given in Rodrigues parameters\n ptlist is 3 x n, \n a list of points, also Rodrigues \n sym is 4 x m, \n the symmetry group in quaternions\n\n OUTPUT:\n\n dist is 1 x n, \n the distance between `pt' and each point in `ptlist'\n\n\n '''\n pt = utl.mat2d_row_order(pt)\n ptlist = utl.mat2d_row_order(ptlist)\n\n q1 = QuatOfRod(pt)\n q2 = QuatOfRod(ptlist)\n\n dist, mis = Misorientation(q1, q2, sym)\n\n return dist\n\n\ndef Misorientation(q1, q2, sym):\n '''\n Misorientation - Return misorientation data for quaternions.\n\n USAGE:\n\n angle = Misorientation(q1, q2, sym)\n [angle, mis] = Misorientation(q1, q2, sym)\n\n INPUT:\n\n q1 is 4 x n1, \n is either a single quaternion or a list of n quaternions\n q2 is 4 x n, \n a list of quaternions\n\n OUTPUT:\n\n angle is 1 x n, \n the list of misorientation angles between q2 and q1\n mis is 4 x n, (optional) \n is a list of misorientations in the fundamental region \n (there are many equivalent choices)\n\n NOTES:\n\n * The misorientation is the linear tranformation which\n takes the crystal basis given by q1 to that given by\n q2. The matrix of this transformation is the same\n in either crystal basis, and that is what is returned\n (as a quaternion). The result is inverse(q1) * q2.\n In the sample reference frame, the result would be\n q2 * inverse(q1). With symmetries, the result is put\n in the fundamental region, but not into the Mackenzie cell.\n\n\n '''\n q1 = utl.mat2d_row_order(q1)\n q2 = utl.mat2d_row_order(q2)\n\n f1 = q1.shape\n f2 = q2.shape\n\n if f1[1] == 1:\n q1 = np.tile(q1, (1, f2[1]))\n\n q1i = np.concatenate((np.atleast_2d(-1*q1[0, :]), np.atleast_2d(q1[1:4, :])), axis=0)\n\n mis = ToFundamentalRegionQ(QuatProd(q1i, q2), sym)\n\n angle = 2*np.arccos(np.minimum(1, mis[0, :]))\n\n return (angle, mis)\n\n\ndef RodGaussian(cen, pts, stdev, sym):\n '''\n RODGAUSSIAN - Gaussian distribution on angular distance.\n\n USAGE:\n\n gauss = RodGaussian(cen, pts, stdev, sym)\n\n INPUT:\n\n cen is 3 x 1, \n the center of the distribution (in Rodrigues parameters)\n pts is 3 x n, \n a list of points (Rodrigues parameters)\n stdev is 1 x 1, \n the standard deviation of the distribution\n sym is 4 x k, \n the symmetry group (quaternions)\n\n OUTPUT:\n\n gauss is 1 x n, \n the list of values at each input point\n\n NOTES:\n\n * This returns the values of a (not normalized) 1D Gaussian \n applied to angular distance from the center point \n * The result is not normalized to have unit integral.\n\n\n '''\n twosigsq = 2*(stdev**2)\n theta = RodDistance(cen, pts, sym)\n minusthetasq = -1*theta*theta\n gauss = np.exp(minusthetasq, twosigsq)\n\n return gauss\n"
},
{
"alpha_fraction": 0.6678321957588196,
"alphanum_fraction": 0.7692307829856873,
"avg_line_length": 14.94444465637207,
"blob_id": "bf6eafc2fa52a141e48d7410811b95135ef4a392",
"content_id": "5243a2997fd2d5d2f4f969abd01d15c827651768",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 286,
"license_type": "permissive",
"max_line_length": 32,
"num_lines": 18,
"path": "/PythonFortranCode/Sources.mk",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "LIBBASE = orifem\nLIBRARY = lib$(LIBBASE).a\n\nf90SOURCES=\\\nIntrinsicTypesModule.f90\\\nunits.f90\\\nConstantsModule.f90\\\nquadrature.f90\\\nmatrixMath.f90\\\nshape_3d.f90\\\nfemVariables.f90\\\nschmidTensor.f90\\\n\nmSOURCES=\\\nLatOriFEM.f90\\\n\nf90OBJECTS=$(f90SOURCES:.f90=.o)\nmOBJECTS=$(mSOURCES:.f90=.o)"
},
{
"alpha_fraction": 0.5519295930862427,
"alphanum_fraction": 0.5659627914428711,
"avg_line_length": 35.49275207519531,
"blob_id": "2a86cd6945621211d07354fe8e33fb335e92eeaf",
"content_id": "826d0c0d0f2996604796361903ed92f9d5a7d326",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15107,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 414,
"path": "/PythonScripts/Misori.py",
"repo_name": "Ming-is/pyFEpX",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport scipy as sci\nimport Utility as utl\nimport Sphere as sph\nimport Rotations as rot\nimport FiniteElement as fe\nfrom sklearn.preprocessing import normalize\n\n'''\nThis program was written by Robert Carson on June 10th, 2015.\nIt is based upon the OdfPf library that the Deformation Processing Lab has written in MATLAB.\n\nThe following functions are available in this module:\nmisorientationStats\nmisorientationGrain\nmisorientationBartonTensor\n\n\n'''\n\ndef bartonStats(misorient, locations, *wts):\n '''\n MisorientationStats - Misorientation correlation statistics.\n\n USAGE:\n\n stats = MisorientationStats(misorient, locations)\n stats = MisorientationStats(misorient, locations, wts)\n\n INPUT:\n\n misorient is 4 x n, \n a list of misorientation quaternions,\n assumed to have been derived from properly clustered \n orientation data\n locations is d x n, (d <= 3) \n a list of spatial locations corresponding to the \n misorientations\n wts is 1 x n, (optional)\n a list of weights; if not specified, uniform weights are used\n\n OUTPUT:\n\n stats is a structure with five components:\n\n W is a 3 x 3 matrix (A in Barton paper)\n X is a d x d matrix (M in Barton paper)\n WX is a 3 x d matrix (cross-correlation\n of normalized variables; X in\n Barton paper)\n wi is 3 x n, the unnormalized axial vectors\n xi is d x n, the unnormalized spatial directions\n from the centroid\n\n REFERENCE: \n\n \"A Methodology for Determining Average Lattice Orientation and \n Its Application to the Characterization of Grain Substructure\",\n\n Nathan R. Barton and Paul R. Dawson,\n\n Metallurgical and Materials Transactions A,\n Volume 32A, August 2001, pp. 1967--1975\n \n\n '''\n locations = utl.mat2d_row_order(locations)\n misorient = utl.mat2d_row_order(misorient)\n d, n = misorient.shape \n if len(wts) == 0:\n wts = np.tile(1.0/n, (3, n))\n else:\n wts = np.tile(wts, (3, 1))\n \n wts1 = np.tile(wts[0, :], (4, 1))\n misOriCen = sph.SphereAverage(misorient, **{'wts':wts1})\n misorient = misorient - np.tile(misOriCen, (1, n))\n\n ang = utl.mat2d_row_order(2*np.arccos(misorient[0, :]))\n wsc = np.zeros(ang.shape)\n \n limit = (ang < np.finfo(float).eps)\n nlimit = (ang > np.finfo(float).eps)\n \n angn = ang[nlimit]\n \n wsc[nlimit]= angn/np.sin(angn/2)\n wsc[limit] = 2\n \n wi = misorient[1:4, :]*np.tile(wsc.T, (3, 1))\n \n wi = wi*np.tile(ang.T, (3,1))\n\n \n cen = utl.mat2d_row_order(np.sum(locations*wts, axis=1))\n \n xi = locations - np.tile(cen, (1, n))\n \n Winv = np.sum(utl.RankOneMatrix(wi*wts, wi), axis=2)\n Xinv = np.sum(utl.RankOneMatrix(xi*wts, xi), axis=2)\n #We needed to scale this up if it was close to being ill-conditioned\n if(np.abs(np.linalg.det(Winv)) < 1e-6):\n if(np.abs(np.linalg.det(Winv)) < 1e-16):\n W = np.zeros((3,3))\n else:\n Wtemp = np.multiply(1e9, Winv)\n W = np.multiply(1e9, np.linalg.inv(Wtemp))\n else:\n W = np.linalg.inv(Winv)\n Whalf = sci.linalg.sqrtm(W)\n \n if(np.abs(np.linalg.det(Xinv)) < 1e-6):\n Xtemp = np.multiply(1e9, Xinv)\n X = np.multiply(1e9, np.linalg.inv(Xtemp))\n else:\n X = np.linalg.inv(Xinv)\n Xhalf = sci.linalg.sqrtm(X)\n \n wibar = np.dot(Whalf, wi)\n xibar = np.dot(Xhalf, xi)\n \n WX = np.sum(utl.RankOneMatrix(wibar*wts, xibar), axis=2)\n \n stat = {'W':W, 'Winv':Winv, 'Xinv':Xinv, 'X':X, 'WX':WX, 'wi':wi, 'xi':xi}\n \n return stat\n \n \ndef misorientationGrain(kocks, angs, frames, kor, gr_mis=False):\n '''\n It takes in the mesh, the grain number of interest, the angles output from\n FePX and then the number of frames.\n \n It outputs the misorientations angles calculated for that specific grain\n by using the built in misorientation function within the ODFPF library.\n \n Input: kocks - the kocks angle of the the grain being examined\n grNum - an integer of the grain that you want to find the \n misorientation for each element\n angs - a numpy array 3xnxnframes of the angles output from FePX\n frames - list of frames your interested in examining\n \n Output: misAngs - a numpy array of nxframes that contains the angle of\n misorientation for each element with respect to the\n original orientation of the grain\n misQuat - a numpy array of 4xnxnframes that contains the\n misorientation quaternion for each element with respect to\n the original orientation of the grain\n '''\n angs = np.atleast_3d(angs)\n if angs.shape[0] == 1:\n angs = angs.T\n lenQuat = angs.shape[1]\n deg = 'degrees'\n misAngs = np.zeros((lenQuat,len(frames)))\n misQuat = np.zeros((4,lenQuat, len(frames)))\n misQuat[0, :, :] = 1\n if(gr_mis):\n origQuat = rot.OrientConvert(kocks, 'rod', 'quat', deg, deg)\n else:\n origQuat = rot.OrientConvert(kocks, 'kocks', 'quat', deg, deg)\n csym = rot.CubSymmetries()\n j = 0\n for i in frames:\n if kor == 'axis' or kor == 'axisangle':\n tQuat = rot.QuatOfAngleAxis(np.squeeze(angs[0, :, i]), np.squeeze(angs[1:4, :, i])) \n else:\n tQuat = rot.OrientConvert(np.squeeze(angs[:, :, i]), kor, 'quat', deg, deg)\n misAngs[:, j], misQuat[:, :, j] = rot.Misorientation(origQuat, tQuat, csym)\n j +=1\n \n return (misAngs, misQuat)\n \n\ndef misorientationBartonTensor(misori, lcrd, lcon, crd , grnum, crdOpt = False):\n '''\n misOrientationBartonTensor takes in the misorientation quaternions\n for the grain of interest and finds the various quantities located in\n Barton's paper \"A Methodology for Determining Average Lattice Orientation and \n Its Application to the Characterization of Grain Substructure.\" \n\n Inputs:\n misOri: the misorientation quaternions for all of the\n frames of interest as calculated for the grain of interest.\n lcrd: the local crd of the grain mesh\n lcon: the local con of the grain mesh\n crd: the coordinates of each node at each time step\n crdOpt: if crdOpt is to be used\n\n grNum: The grain number of interest\n Outputs:\n stats: A structure with 14 different elements:\n W is a 3 x 3 x nframe matrix (A in Barton paper)\n X is a d x d x nframe matrix (M in Barton paper)\n !WX is a 3 x d x nframe matrix (cross-correlation\n of normalized variables; X in\n Barton paper)\n wi is 3 x n x nframe, the unnormalized axial vectors\n xi is d x n x nframe, the unnormalized spatial directions\n from the centroid\n Winv is a 3 x 3 x nframe matrix (A inv in Barton Paper)\n Xinv is a 3 x 3 x nframe matrix (M inv in Barton Paper)\n U is a 3 x 3 x nframe matrix (U in Barton Paper)\n Also the orientation eigenvectors of WX\n V is a 3 x 3 x nframe matrix (V in Barton Paper)\n Also the spatial eigenvectors of WX\n S is a 3 x 3 x nframe matrix (S in Barton Paper)\n Also the eigenvalues of WX\n !xV is 3 x n x nframe, a spatial correlation used in\n Barton's titanium paper and is a scalar value\n !wU is 3 x n x nframe, a misorientation\n correlation used in Barton's titanium paper and is a\n scalar value\n GrainVol is nframe, the volume of the grain during each\n frame\n gSpread is nframe, the grain spread as calculated from\n Barton's paper using Winv. It is a scalar spread of\n the misorientation blob.\n ! - vars are currently commented out inorder to save total space\n used by the outputted dictionary\n\n '''\n \n misori = np.atleast_3d(misori)\n if misori.shape[0] == 1:\n misori = misori.T\n crd = np.atleast_3d(crd)\n if crd.shape[0] == 1:\n crd = crd.T\n \n tVol, wts = fe.calcVol(lcrd, lcon)\n cen = np.sum(fe.centroidTet(lcrd, lcon)*wts, axis=1)\n \n jk, nelems, nframes = misori.shape\n realMisori = np.zeros((3, 3, nframes))\n xs = np.zeros((3, 3, nframes))\n winv = np.zeros((3, 3, nframes))\n xsinv = np.zeros((3, 3, nframes))\n realBar = np.zeros((3, 3, nframes))\n us = np.zeros((3, 3, nframes))\n vs = np.zeros((3, 3, nframes))\n ss = np.zeros((3, 3, nframes))\n tVol = np.zeros((nframes,))\n gspread = np.zeros((nframes,))\n \n for i in range(nframes):\n tcrd = crd[:, :, i]\n tVol[i], wts = fe.calcVol(tcrd, lcon)\n elcen = fe.centroidTet(tcrd, lcon)\n if crdOpt:\n tstat = bartonStats(misori[:, :, i], tcrd)\n else:\n tstat = bartonStats(misori[:, :, i], elcen, *wts)\n realMisori[:, :, i] = tstat['W']\n xs[:, :, i] = tstat['X']\n winv[:, :, i] = tstat['Winv']\n xsinv[:, :, i] = tstat['Xinv']\n realBar[:, :, i] = tstat['WX']\n us[:, :, i], ss[:, :, i], vs[:, :, i] =np.linalg.svd(realBar[:, :, i])\n gspread[i] = np.sqrt(np.trace(winv[:, :, i]))\n \n stats = {'W':realMisori, 'X':xs, 'Winv':winv, 'Xinv':xsinv, 'WX':realBar,\n 'U':us, 'S':ss, 'V':vs, 'GrainVol':tVol, 'centroid':cen, 'gSpread':gspread}\n \n return stats\n \n \ndef misorientationStats(misorient, *wts):\n '''\n MisorientationStats - Misorientation correlation statistics.\n\n USAGE:\n\n stats = MisorientationStats(misorient, locations)\n stats = MisorientationStats(misorient, locations, wts)\n\n INPUT:\n\n misorient is 4 x n, \n a list of misorientation quaternions,\n assumed to have been derived from properly clustered \n orientation data\n wts is 1 x n, (optional)\n a list of weights; if not specified, uniform weights are used\n\n OUTPUT:\n\n stats is a structure with five components:\n\n W is a 3 x 3 matrix (A in Barton paper)\n Winv is a 3 x 3 matrix (A^-1 in Barton paper)\n wi is 3 x n, the unnormalized axial vectors\n\n REFERENCE: \n\n \"A Methodology for Determining Average Lattice Orientation and \n Its Application to the Characterization of Grain Substructure\",\n\n Nathan R. Barton and Paul R. Dawson,\n\n Metallurgical and Materials Transactions A,\n Volume 32A, August 2001, pp. 1967--1975\n \n\n '''\n misorient = utl.mat2d_row_order(misorient)\n d, n = misorient.shape \n if len(wts) == 0:\n wts = np.tile(1.0/n, (3, n))\n else:\n wts = np.tile(wts, (3, 1))\n \n wts1 = np.tile(wts[0, :], (4, 1))\n misOriCen = sph.SphereAverage(misorient, **{'wts':wts1})\n misorient = misorient - np.tile(misOriCen, (1, n))\n \n ang = utl.mat2d_row_order(2*np.arccos(misorient[0, :]))\n wsc = np.zeros(ang.shape)\n \n limit = (ang < np.finfo(float).eps)\n nlimit = (ang > np.finfo(float).eps)\n \n angn = ang[nlimit]\n \n wsc[nlimit]= angn/np.sin(angn/2)\n wsc[limit] = 2\n \n wi = misorient[1:4, :]*np.tile(wsc.T, (3, 1))\n \n angax = np.zeros((4, n))\n angax[0, :] = np.linalg.norm(wi, axis = 0)\n angax[1:4, :] = normalize(wi, axis = 0)\n \n Winv = np.sum(utl.RankOneMatrix(wi*wts, wi), axis=2)\n \n #We needed to scale this up if it was close to being ill-conditioned\n if(np.abs(np.linalg.det(Winv)) < 1e-6):\n if(np.abs(np.linalg.det(Winv)) < 1e-16):\n W = np.zeros((3,3))\n else:\n Wtemp = np.multiply(1e9, Winv)\n W = np.multiply(1e9, np.linalg.inv(Wtemp))\n else:\n W = np.linalg.inv(Winv)\n \n stat = {'W':W, 'Winv':Winv, 'wi':wi, 'angaxis':angax}\n \n return stat\n \n \ndef misorientationTensor(misori, lcrd, lcon, crd , grnum, crdOpt = False):\n '''\n misOrientationTensor takes in the misorientation quaternions\n for the grain of interest and finds the various quantities located in\n Barton's paper \"A Methodology for Determining Average Lattice Orientation and \n Its Application to the Characterization of Grain Substructure.\" \n\n Inputs:\n misOri: the misorientation quaternions for all of the\n frames of interest as calculated for the grain of interest.\n lcrd: the local crd of the grain mesh\n lcon: the local con of the grain mesh\n crd: the coordinates of each node at each time step\n crdOpt: if crdOpt is to be used\n\n grNum: The grain number of interest\n Outputs:\n stats: A structure with 4 different elements:\n W is a 3 x 3 x nframe matrix (A in Barton paper)\n wi is 3 x n x nframe, the unnormalized axial vectors\n Winv is a 3 x 3 x nframe matrix (A inv in Barton Paper)\n gSpread is nframe, the grain spread as calculated from\n Barton's paper using Winv. It is a scalar spread of\n the misorientation blob.\n angaxis is 4 x n x nframe, the normalized axial vectors with \n the ang being 1st index \n \n ! - vars are currently commented out inorder to save total space\n used by the outputted dictionary\n\n '''\n \n misori = np.atleast_3d(misori)\n if misori.shape[0] == 1:\n misori = misori.T\n crd = np.atleast_3d(crd)\n if crd.shape[0] == 1:\n crd = crd.T\n \n tVol, wts = fe.calcVol(lcrd, lcon)\n \n jk, nelems, nframes = misori.shape\n realMisori = np.zeros((3, 3, nframes))\n winv = np.zeros((3, 3, nframes))\n wi = np.zeros((3, nelems, nframes))\n angaxis = np.zeros((4, nelems, nframes))\n gspread = np.zeros((nframes,))\n \n for i in range(nframes):\n tcrd = crd[:, :, i]\n tVol, wts = fe.calcVol(tcrd, lcon)\n if crdOpt:\n tstat = misorientationStats(misori[:, :, i])\n else:\n tstat = misorientationStats(misori[:, :, i], *wts)\n realMisori[:, :, i] = tstat['W']\n winv[:, :, i] = tstat['Winv']\n wi[:,:,i] = tstat['wi']\n angaxis[:,:,i] = tstat['angaxis']\n gspread[i] = np.sqrt(np.trace(winv[:, :, i]))\n \n stats = {'W':realMisori, 'wi':wi, 'angaxis':angaxis, 'Winv':winv, 'gSpread':gspread}\n \n return stats"
}
] | 25 |
wyk9787/D-MAP
|
https://github.com/wyk9787/D-MAP
|
b80ad005374fe8dc09e6923674abdb0cac215d87
|
34dd29a7afed152a2e6b411db2cbea311d87d91c
|
783939d7bcbaf4d6d7ae22d6a4358ac96581632a
|
refs/heads/master
| 2020-03-12T19:58:18.218570 | 2018-05-14T20:57:57 | 2018-05-14T20:57:57 | 130,795,411 | 2 | 0 | null | 2018-04-24T04:18:53 | 2018-04-24T04:18:55 | 2018-04-24T21:00:42 | null |
[
{
"alpha_fraction": 0.6062196493148804,
"alphanum_fraction": 0.6153547167778015,
"avg_line_length": 26.367021560668945,
"blob_id": "363234119ae2b3888374e070f7b2d9947c372841",
"content_id": "c16aada3be1dd06afe658d96c4cdbc5b36e9091f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 10290,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 376,
"path": "/src/server/server.cpp",
"repo_name": "wyk9787/D-MAP",
"src_encoding": "UTF-8",
"text": "#include <pthread.h>\n#include <stdbool.h>\n#include <stdio.h>\n#include <string.h>\n#include <stdlib.h>\n#include <time.h>\n#include <unistd.h>\n#include <iostream>\n#include <vector>\n#include <sys/types.h>\n#include <sys/socket.h>\n#include <netinet/in.h>\n#include <arpa/inet.h>\n#include <unordered_map>\n#include <algorithm>\n#include <time.h>\n#include <assert.h>\n#include <sys/stat.h>\n#include \"worker-server.hpp\"\n\n// define function pointers \nusing has_next_t = bool (*)(void);\nusing get_next_t = char* (*)(void);\n\n// check if there is a user\nbool user_exist = false;\nint user_socket;\n\nint num_of_workers;\nstd::unordered_map<int, bool> list_of_workers;\n\ntypedef struct thread_args {\n int socket_fd;\n}thread_arg_t;\n\npthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;\n\nvoid * user_thread_fn (void* u) {\n // Unpack thread arguments\n thread_arg_t* args = (thread_arg_t*)u;\n int socket_fd = args->socket_fd;\n\n // 1.Read the size of the executable file first. The number will be sent as a 10-byte string.\n char executable_size[10];\n if((read(socket_fd, (void*)executable_size, 10)) == -1) {\n perror(\"read\");\n return NULL;\n }\n long filesize = strtol(executable_size, NULL, 10);\n\n // 2.Then get the executable file from the user (this file should be of filesize).\n char executable[filesize];\n int bytes_to_read = filesize;\n int prev_read = 0;\n\n // Keep reading bytes until the entire file is read.\n while(bytes_to_read > 0){\n // Executable_read indicates the bytes already read by the read function.\n int executable_read = read(socket_fd, executable + prev_read, bytes_to_read);\n if(executable_read < 0) {\n perror(\"read executable\");\n return NULL;\n }\n bytes_to_read -= executable_read;\n prev_read += executable_read;\n }\n\n // Set up the filename for shared library\n char shared_library[40];\n int rand_num = rand();\n sprintf(shared_library, \"./temp%d.so\", rand_num);\n \n // Open a temp file in the \"write-binary\" mode.\n FILE * exe_lib = fopen(shared_library, \"wb\");\n if(exe_lib == NULL) { \n perror(\"Failed: \");\n exit(1);\n }\n \n // Write the read bytes to the file.\n if (fwrite(executable, filesize, 1, exe_lib) != 1){\n fprintf(stderr, \"fwrite\\n\");\n exit(1);\n }\n\n // Close file stream.\n fclose(exe_lib);\n\n // Make shared object executable\n if(chmod(shared_library, S_IRUSR | S_IWUSR | S_IXUSR | S_IXGRP | S_IRGRP | S_IWGRP | S_IXOTH | S_IROTH | S_IWOTH) != 0) {\n perror(\"chmod\");\n exit(2);\n }\n \n // 3.Finally get the arguments from user.\n task_arg_user_t task_args;\n int bytes = read(socket_fd, &task_args, sizeof(task_arg_user_t));\n if(bytes != sizeof(task_arg_user_t)) {\n fprintf(stderr, \"Read: Not reading enough bytes. Expected: %lu; Actual: %d.\\n\", sizeof(task_arg_user_t), bytes);\n return NULL;\n }\n \n \n // Unpack arguments from the user\n int num_args = task_args.num_args;\n char function_name[256];\n strcpy(function_name, task_args.function_name);\n char inputs[256];\n strcpy(inputs, task_args.inputs); // TODO: will change to a list of inputs in the future\n\n // Load the shared library\n dlerror();\n void* program = dlopen(shared_library, RTLD_LAZY | RTLD_GLOBAL);\n if(program == NULL) {\n fprintf(stderr, \"dlopen: %s\\n\", dlerror());\n exit(EXIT_FAILURE);\n }\n\n // Get the iterator functions\n dlerror();\n has_next_t has_next = (has_next_t)dlsym(program, \"has_next\");\n char* error = dlerror();\n if(error != NULL) {\n fprintf(stderr, \"has_next error: %s\\n\", error);\n exit(1);\n }\n\n dlerror();\n get_next_t get_next = (get_next_t)dlsym(program, \"get_next\");\n if(error != NULL) {\n fprintf(stderr, \"get_next error: %s\\n\", error);\n exit(1);\n }\n\n // Loop through all workers\n for(auto cur : list_of_workers) {\n int socket = cur.first;\n char temp[filesize];\n memcpy(temp, executable, filesize);\n \n //First send the size of the executable file\n if(write(socket, executable_size, 10) != 10) {\n perror(\"write\");\n exit(2);\n }\n\n // Send the executable file to the worker\n if(write(socket, temp, filesize) != filesize) {\n perror(\"Write executable\");\n exit(2);\n }\n }\n\n // Pack arguments for the worker\n task_arg_worker_t* task_arg_worker = (task_arg_worker_t*)malloc(sizeof(task_arg_worker_t));\n task_arg_worker->num_args = num_args;\n strcpy(task_arg_worker->function_name, function_name);\n strcpy(task_arg_worker->inputs, inputs);\n \n while(has_next()) {\n int worker_socket;\n // Check if the worker is free. If so, give it a task; otherwise, skip it.\n bool found = false;\n while(true) {\n for(auto cur : list_of_workers) {\n if(cur.second) { // This worker is available\n list_of_workers[cur.first] = false;\n worker_socket = cur.first;\n found = true;\n break;\n }\n }\n if(found) break; // If we found an avaialble worker, break from the while loop\n }\n\n // Copy the new chunk into the struct\n strcpy(task_arg_worker->chunk, get_next());\n\n // Set up the continue command\n char to_go[2];\n sprintf(to_go, \"%d\", 1);\n\n // Tell the worker there is more work on this task\n if(write(worker_socket, to_go, 2) < 0) {\n perror(\"write\");\n exit(2);\n }\n \n // Send the task_arg_worker_t to the worker\n if(write(worker_socket, (void*)task_arg_worker, sizeof(task_arg_worker_t)) < 0) {\n perror(\"write\");\n exit(2);\n }\n }\n\n // Wait until all workers done with their tasks\n while(!std::all_of(list_of_workers.begin(), list_of_workers.end(), [](std::pair<int, bool> cur){ return cur.second == true; }));\n\n // Set up the finishing message\n char to_go[2];\n sprintf(to_go, \"%d\", 0);\n \n for(auto cur : list_of_workers) {\n int socket = cur.first;\n // Tell the worker there is no more work on this task\n if(write(socket, to_go, 2) < 0) {\n perror(\"write\");\n exit(2);\n }\n }\n\n // Close the socket to the user so user know the task is finished\n if (close(socket_fd) < 0){\n perror(\"Close in user thread\");\n exit(2);\n }\n\n if(dlclose(program) != 0) {\n dlerror();\n exit(1);\n }\n\n printf(\"Got all the done workers.\\n\");\n \n return NULL;\n}\n\n\nvoid* worker_thread_fn(void* w) {\n // Unpack thread arguments\n thread_arg_t* args = (thread_arg_t*)w;\n int worker_socket = args->socket_fd;\n\n while(true) { \n char buffer[10];\n // Read output size from the worker\n int bytes_read = read(worker_socket, buffer, 10);\n \n // Save the size of the output\n int bytes_to_read = atoi(buffer);\n \n //not sending to the user if chunk is size 0\n if (bytes_to_read == 0) {\n list_of_workers[worker_socket] = true;\n continue;\n }\n\n pthread_mutex_lock(&mutex);\n // Write output size to the user\n if(write(user_socket, buffer, 10) < 0) {\n perror(\"write\");\n return NULL;\n }\n \n char output_buffer[256] = {0};\n int prev_read = 0;\n \n while(bytes_to_read > 0) {\n // Read actual output from the worker\n int output_read = read(worker_socket, output_buffer + prev_read, bytes_to_read);\n if(output_read < 0) {\n perror(\"read failed\");\n exit(2);\n }\n if (output_read == 0)\n break;\n output_buffer[output_read] = '\\0';\n\n // Write output to the user\n if(write(user_socket, output_buffer, output_read) < 0) {\n perror(\"write\");\n return NULL;\n }\n bytes_to_read -= output_read;\n prev_read += output_read;\n }\n list_of_workers[worker_socket] = true;\n pthread_mutex_unlock(&mutex);\n }\n \n // Close the socket\n if (close(worker_socket) < 0){\n perror(\"Close in worker thread\");\n exit(2);\n }\n\n return NULL;\n}\n\nint main() {\n srand(time(NULL));\n // Set up a socket\n int s = socket(AF_INET, SOCK_STREAM, 0);\n if(s == -1) {\n perror(\"socket\");\n exit(2);\n }\n\n // Listen for any address on port 60519.\n struct sockaddr_in addr;\n addr.sin_addr.s_addr = INADDR_ANY;\n addr.sin_family = AF_INET;\n addr.sin_port = htons(PORT_NUMBER);\n\n // Bind to the specified address\n if(bind(s, (struct sockaddr*)&addr, sizeof(struct sockaddr_in))) {\n perror(\"bind\");\n exit(2);\n }\n\n // Become a server socket\n listen(s, 2);\n\n // Initialize the number of workers\n int num_of_workers = 0;\n // Repeatedly accept client connections\n while(true) {\n // Accept a client connection\n struct sockaddr_in client_addr;\n socklen_t client_addr_len = sizeof(struct sockaddr_in);\n\n // Blocking call: accepts connection from a user/worker and gets its socket\n int client_socket = accept(s, (struct sockaddr*)&client_addr, &client_addr_len);\n\n printf(\"Accept a connection.\\n\");\n // Getting IP address of the client\n char ipstr[INET_ADDRSTRLEN];\n inet_ntop(AF_INET, &client_addr.sin_addr, ipstr, INET_ADDRSTRLEN);\n\n char buffer[256];\n int bytes_read = read(client_socket, buffer, 256);\n if(bytes_read < 0) {\n perror(\"read failed\");\n exit(2);\n }\n // Get the integer at the beginning of the message\n char* token = strtok(buffer, \"\\n\");\n int sig = atoi(token);\n\n // Checks if the client is a user or a worker\n if(sig == WORKER_JOIN) {\n // Create the thread for worker\n thread_arg_t* args = (thread_arg_t*)malloc(sizeof(thread_arg_t));\n args->socket_fd = client_socket;\n\n pthread_t thread_worker;\n if(pthread_create(&thread_worker, NULL, worker_thread_fn, args)) {\n perror(\"pthread_create failed\");\n exit(EXIT_FAILURE);\n }\n printf(\"Worker %d connected from %s\\n\", num_of_workers, ipstr);\n\n // Add worker to the list\n list_of_workers.insert({client_socket, true});\n num_of_workers++;\n } else if(sig == USER_JOIN) {\n if(!user_exist){\n printf(\"A user joined.\\n\");\n // Create the thread for user\n thread_arg_t* args = (thread_arg_t*)malloc(sizeof(thread_arg_t));\n args->socket_fd = client_socket;\n\n // Let the server know the user socket\n user_socket = client_socket;\n pthread_t thread_user;\n if(pthread_create(&thread_user, NULL, user_thread_fn, args)) {\n perror(\"pthread_create failed\");\n exit(EXIT_FAILURE);\n }\n }else{\n char* message = (char*)\"Server is busy.\\n\";\n write(client_socket, message, strlen(message));\n }\n }\n }\n}\n"
},
{
"alpha_fraction": 0.6351351141929626,
"alphanum_fraction": 0.6351351141929626,
"avg_line_length": 13.800000190734863,
"blob_id": "56cbe36679270311cb7bbfd38cb24885853ae489",
"content_id": "c09a7b88e70e9b95838a60e1279b83f114085241",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 74,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 5,
"path": "/src/user/Makefile",
"repo_name": "wyk9787/D-MAP",
"src_encoding": "UTF-8",
"text": "ROOT = ../../\nTARGETS = user\nLIBS = pthread dl\n\ninclude $(ROOT)/common.mk\n"
},
{
"alpha_fraction": 0.6447368264198303,
"alphanum_fraction": 0.6447368264198303,
"avg_line_length": 14.199999809265137,
"blob_id": "4a2a1170c1197a8c739f5f9486cd524e3e42508e",
"content_id": "49f3cb9d3ef5ff759ea8fa8a48391bf2d339e5d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 76,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 5,
"path": "/src/server/Makefile",
"repo_name": "wyk9787/D-MAP",
"src_encoding": "UTF-8",
"text": "ROOT = ../../\nTARGETS = server\nLIBS = pthread dl\n\ninclude $(ROOT)/common.mk\n"
},
{
"alpha_fraction": 0.598376989364624,
"alphanum_fraction": 0.6090950965881348,
"avg_line_length": 27.519651412963867,
"blob_id": "f5ba385d0ed660a5607ec8c698c1c87d456b277e",
"content_id": "a5023a6b0f66f197d407838047b1aeb1f7f56808",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 6531,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 229,
"path": "/src/worker/worker.cpp",
"repo_name": "wyk9787/D-MAP",
"src_encoding": "UTF-8",
"text": "#include <stdbool.h>\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n#include <unistd.h>\n#include <sys/types.h>\n#include <sys/socket.h>\n#include <sys/stat.h>\n#include <netinet/in.h>\n#include <netdb.h>\n#include <pthread.h>\n#include <arpa/inet.h>\n#include <dlfcn.h>\n#include <errno.h>\n#include <vector>\n#include <string>\n#include <time.h>\n#include \"worker-server.hpp\"\n\n// The pointer to the function in the library that will be executed\ntypedef int (*real_main_t)(int argc, char** argv);\n\n/**\n * Makes a socket and connect to another with the given address on the given port.\n * @param server_address, a string that represents the name of the server\n * @param port, an integer that represents the port number\n * * @returns file descriptor for the socket that is connected to server_address on port.\n */\nint socket_connect(char * server_address, int port) {\n // Turn the server name into an IP address\n struct hostent* server = gethostbyname(server_address);\n if(server == NULL) {\n fprintf(stderr, \"Unable to find host %s\\n\", server_address);\n return -1;\n }\n\n // Set up a socket\n int sock = socket(AF_INET, SOCK_STREAM, 0);\n if(sock == -1) {\n perror(\"socket failed\");\n return -1;\n }\n\n // Initialize the socket address\n struct sockaddr_in addr_client = {\n .sin_family = AF_INET,\n .sin_port = htons(port)\n };\n\n // Fill in the address from the server variable we declared earlier\n bcopy((char*)server->h_addr, (char*)&addr_client.sin_addr.s_addr, server->h_length);\n\n // Connect to the server\n if(connect(sock, (struct sockaddr*)&addr_client, sizeof(struct sockaddr_in))) {\n perror(\"connect failed in socket_connect\");\n return -1;\n }\n \n return sock;\n}\n\nint main(int argc, char** argv) {\n srand(time(NULL));\n if(argc != 2) {\n fprintf(stderr, \"Usage: %s <server address>\\n\", argv[0]);\n exit(EXIT_FAILURE);\n }\n \n // Connect to server\n char* server_address = argv[1];\n int server_socket = socket_connect(server_address, PORT_NUMBER);\n\n // Send a worker-join message to the server\n char result[50];\n sprintf(result, \"%d\\n\", WORKER_JOIN);\n int ret = write(server_socket, result, strlen(result));\n if(ret != strlen(result)) {\n perror(\"write\");\n exit(2);\n }\n while(1) {\n // First get the size of the executable\n char executable_size[10];\n if(read(server_socket, executable_size, 10) != 10) {\n perror(\"exectuable size\");\n exit(2); \n }\n long filesize = strtol(executable_size, NULL, 10);\n // Then get the executable file and save it locally\n char executable[filesize];\n int bytes_to_read = filesize;;\n\n char shared_library[40];\n int rand_num = rand();\n sprintf(shared_library, \"./injection%d.so\", rand_num);\n\n int executable_read;\n int prev_read = 0;\n // Keep reading bytes until the entire file is read.\n while (bytes_to_read > 0) {\n executable_read = read(server_socket, executable+prev_read, bytes_to_read);\n if(executable_read < 0) {\n perror(\"read executable\");\n exit(2);\n }\n bytes_to_read -= executable_read;\n prev_read += executable_read;\n }\n \n // Open a temp file in the \"write-binary\" mode.\n FILE * exe_lib = fopen(shared_library, \"wb\");\n if (exe_lib == NULL) { \n perror(\"Failed: \");\n exit(1);\n }\n\n // Write the read bytes to the file.\n if (fwrite(executable, filesize, 1, exe_lib) != 1){\n fprintf(stderr, \"fwrite\\n\");\n exit(1);\n }\n\n fclose(exe_lib);\n \n if(chmod(shared_library, S_IRUSR | S_IWUSR | S_IXUSR | S_IXGRP | S_IRGRP | S_IWGRP | S_IXOTH | S_IROTH | S_IWOTH) != 0) {\n perror(\"chmod\");\n exit(2);\n }\n\n // Load the shared library (actual program resides here)\n void* injection = dlopen(shared_library, RTLD_LAZY | RTLD_GLOBAL);\n if(injection == NULL) {\n fprintf(stderr, \"dlopen: %s\\n\", dlerror());\n exit(EXIT_FAILURE);\n }\n \n while(1) {// Keep looping until finish this task\n char result[2];\n if(read(server_socket, result, 2) < 0) {\n perror(\"read\");\n exit(1);\n }\n int cmd = atoi(result);\n if(cmd == 0) { // We are done with this task\n break;\n }\n \n // Get function arguments from the server\n task_arg_worker_t* buffer = (task_arg_worker_t*)malloc(sizeof(task_arg_worker_t));\n int bytes_read = read(server_socket, (void*)buffer, sizeof(task_arg_worker_t));\n if(bytes_read < sizeof(task_arg_worker_t)) {\n fprintf(stderr,\"Read: Not reading enough bytes. Expected: %lu; Actual: %d\", sizeof(task_arg_worker_t), bytes_read);\n exit(2);\n }\n \n // Unpack the function arguments sent from the server\n int num_args = buffer->num_args;\n char function_name[256];\n strcpy(function_name, buffer->function_name);\n char inputs[256];\n strcpy(inputs, buffer->inputs);\n char chunk[256];\n strcpy(chunk, buffer->chunk);\n\n dlerror();\n // Get the entrance function\n real_main_t real_main = (real_main_t)dlsym(injection, function_name);\n char* error = dlerror();\n if(error != NULL) {\n fprintf(stderr, \"Error: %s\\n\", error);\n exit(1);\n }\n \n // Initialize the arguments to the program\n char* func_args[num_args];\n int index = 0;\n\n // The first argument to the function will be the name of the function\n func_args[0] = function_name;\n index++;\n\n // The next argument[s] are the input(s) to the function\n // TODO: Will change it to a list of inputs\n func_args[index] = inputs;\n index++;\n\n // The last argument to the function will be the chunk of work.\n func_args[index] = chunk;\n\n char output_buffer[4096] = {0};\n fclose(stdout);\n stdout = fmemopen(output_buffer, sizeof(output_buffer), \"w\");\n setbuf(stdout, NULL);\n \n // Execute the program\n real_main(num_args+2, func_args);\n fflush(stdout);\n\n int size_buffer = strlen(output_buffer);\n char size_msg[10];\n sprintf(size_msg, \"%d\", size_buffer);\n \n if(write(server_socket, size_msg, 10) != 10) {\n perror(\"write\");\n exit(2);\n }\n\n if(write(server_socket, output_buffer, size_buffer) != size_buffer) {\n perror(\"write\");\n exit(2);\n }\n\n free(buffer);\n }\n\n // Close the shared library\n if(dlclose(injection) != 0) {\n dlerror();\n exit(1);\n }\n }\n \n //close the connection to the socket\n if (close(server_socket) < 0) {\n perror(\"Close in worker\");\n exit(2);\n }\n //end\n}\n"
},
{
"alpha_fraction": 0.6363636255264282,
"alphanum_fraction": 0.6363636255264282,
"avg_line_length": 14.399999618530273,
"blob_id": "0c77b449d88bc72a5b13e5d4049d69302872a9c5",
"content_id": "07b6d88cf373527c57203a0eadbc2906fdc99690",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 77,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 5,
"path": "/src/worker/Makefile",
"repo_name": "wyk9787/D-MAP",
"src_encoding": "UTF-8",
"text": "ROOT = ../../\nTARGETS = worker \nLIBS = pthread dl\n\ninclude $(ROOT)/common.mk\n"
},
{
"alpha_fraction": 0.6287533044815063,
"alphanum_fraction": 0.6463263034820557,
"avg_line_length": 26.375,
"blob_id": "454b82e7ac6d678ba1d5808dcadd9d667672590c",
"content_id": "448278d033e13a033902f4a61032a33680a0b310",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 7227,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 264,
"path": "/src/password_6char/password_6char.c",
"repo_name": "wyk9787/D-MAP",
"src_encoding": "UTF-8",
"text": "#include <math.h>\n#include <openssl/md5.h>\n#include <pthread.h>\n#include <stdbool.h>\n#include <stdint.h>\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n#include <unistd.h>\n\n\n#define NUM_THREAD 4\n#define MAX_USERNAME_LENGTH 24\n#define PASSWORD_LENGTH 6\n#define NUM_WORKERS 4\n\nsize_t TOTAL_PASSWORDS = 308915776; // 26^6 \n\nsize_t PROCESS_SO_FAR = 0;\nsize_t STEP = 38614472; // 26^6/8\n\n// Use this struct to pass arguments to our threads\ntypedef struct thread_args { \n long pos_begin;\n size_t offset; \n} thread_args_t;\n\n// use this struct to receive results from our threads\ntypedef struct thread_result { int result; } thread_result_t;\n\ntypedef struct password_entry {\n char username[MAX_USERNAME_LENGTH + 1];\n uint8_t password_md5[MD5_DIGEST_LENGTH + 1];\n bool cracked;\n struct password_entry *next;\n} password_entry_t;\n\nvoid crack_passwords(char *plaintext);\nvoid generate_all_possibilities(long pos_begin, size_t offset);\nint md5_string_to_bytes(const char *md5_string, uint8_t *bytes);\npassword_entry_t *read_password_file(const char *filename);\nvoid print_md5_bytes(const uint8_t *bytes);\nchar* get_next();\nbool has_next();\n\nchar* get_next() {\n char* ret = malloc(10 * sizeof(char));\n if(ret == NULL) {\n perror(\"malloc\");\n exit(1);\n }\n sprintf(ret, \"%zu\", PROCESS_SO_FAR);\n PROCESS_SO_FAR += STEP;\n return ret; \n}\n\nbool has_next() {\n return PROCESS_SO_FAR < TOTAL_PASSWORDS;\n}\n\npassword_entry_t *passwords;\n\n// pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER;\n\n/**\n * This is our thread function. When we call pthread_create with this as an\n * argument\n * a new thread is created to run this thread in parallel with the program's\n * main\n * thread. When passing parameters to thread functions or accepting return\n * values we\n * have to jump through a few hoops because POSIX threads can only take and\n * return\n * a void*.\n */\nvoid *thread_fn(void *void_args) {\n // Case the args pointer to the appropriate type and print our argument\n thread_args_t *args = (thread_args_t *)void_args;\n generate_all_possibilities(args->pos_begin, args->offset);\n // Return the pointer to allocated memory to our parent thread.\n return NULL;\n}\n\nint entrance(int argc, char **argv) {\n\n if (argc != 3) {\n fprintf(stderr, \"Usage: %s <path to password directory file> <starting position for the chunk>\\n\", argv[0]);\n exit(1);\n }\n\n // Read in the password file\n passwords = read_password_file(argv[1]);\n long pos_begin = strtol(argv[2], NULL, 10); \n\n // Initilization\n password_entry_t *current = passwords;\n while (current != NULL) {\n current->cracked = false;\n current = current->next;\n }\n\n pthread_t threads[NUM_THREAD];\n\n // Make NUM_THREAD amount of structs so we can pass arguments to our threads\n thread_args_t thread_args[NUM_THREAD];\n\n // Create threads\n for (size_t i = 0; i < NUM_THREAD; i++) {\n thread_args[i].pos_begin = pos_begin; \n thread_args[i].offset = i * STEP / NUM_THREAD;\n if (pthread_create(&threads[i], NULL, thread_fn, &thread_args[i]) != 0) {\n perror(\"Error creating thread 1\");\n exit(2);\n }\n }\n\n // Make pointers to the thread result structs that our threads will write into\n // thread_result_t *thread_result[NUM_THREAD];\n\n // Wait threads to join\n for (size_t i = 0; i < NUM_THREAD; i++) {\n if (pthread_join(threads[i], NULL) != 0) {\n perror(\"Error joining with thread 1\");\n exit(2);\n }\n }\n\n return 0;\n}\n\nvoid generate_all_possibilities(long pos_begin, size_t offset) {\n int cur_digit = PASSWORD_LENGTH - 1;\n size_t len = STEP / NUM_THREAD;\n char guess[7] = \"aaaaaa\";\n size_t start = pos_begin + offset;\n size_t end = start + len;\n for (size_t i = start; i < end; i++) {\n size_t num = i;\n while (num > 0) {\n guess[cur_digit--] = num % 26 + 'a';\n num /= 26;\n }\n cur_digit = PASSWORD_LENGTH - 1;\n\n crack_passwords(guess);\n }\n}\n\nvoid crack_passwords(char *plaintext) {\n uint8_t password_hash[MD5_DIGEST_LENGTH];\n MD5((unsigned char *)plaintext, strlen(plaintext), password_hash);\n\n // Check if the two hashes are equal\n password_entry_t *current = passwords;\n bool all_true = true;\n while (current != NULL) {\n if (!current->cracked) { // Has not been cracked yet\n if (memcmp(current->password_md5, password_hash, MD5_DIGEST_LENGTH) ==\n 0) {\n printf(\"%s \", current->username);\n printf(\"%s\\n\", plaintext);\n // pthread_mutex_lock(&m);\n current->cracked = true;\n // pthread_mutex_unlock(&m);\n } else {\n all_true = false;\n }\n }\n current = current->next;\n }\n if (all_true) {\n exit(0);\n }\n}\n\n/**\n * Read a file of username and MD5 passwords. Return a linked list\n * of entries.\n * \\param filename The path to the password file\n * \\returns A pointer to the first node in the password list\n */\npassword_entry_t *read_password_file(const char *filename) {\n // Open the password file\n FILE *password_file = fopen(filename, \"r\");\n if (password_file == NULL) {\n fprintf(stderr, \"opening password file: %s\\n\", filename);\n exit(2);\n }\n\n // Keep track of the current list\n password_entry_t *list = NULL;\n\n // Read until we hit the end of the file\n while (!feof(password_file)) {\n // Make space for a new node\n password_entry_t *newnode =\n (password_entry_t *)malloc(sizeof(password_entry_t));\n\n // Make space to hold the MD5 string\n char md5_string[MD5_DIGEST_LENGTH * 2 + 1];\n\n // Try to read. The space in the format string is required to eat the\n // newline\n if (fscanf(password_file, \"%s %s \", newnode->username, md5_string) != 2) {\n fprintf(stderr, \"Error reading password file: malformed line\\n\");\n exit(2);\n }\n\n // Convert the MD5 string to MD5 bytes in our new node\n if (md5_string_to_bytes(md5_string, newnode->password_md5) != 0) {\n fprintf(stderr, \"Error reading MD5\\n\");\n exit(2);\n }\n\n // Add the new node to the front of the list\n newnode->next = list;\n list = newnode;\n }\n\n return list;\n}\n\n/**\n * Convert a string representation of an MD5 hash to a sequence\n * of bytes. The input md5_string must be 32 characters long, and\n * the output buffer bytes must have room for MD5_DIGEST_LENGTH\n * bytes.\n *\n * \\param md5_string The md5 string representation\n * \\param bytes The destination buffer for the converted md5 hash\n * \\returns 0 on success, -1 otherwise\n */\nint md5_string_to_bytes(const char *md5_string, uint8_t *bytes) {\n // Check for a valid MD5 string\n if (strlen(md5_string) != 2 * MD5_DIGEST_LENGTH)\n return -1;\n\n // Start our \"cursor\" at the start of the string\n const char *pos = md5_string;\n\n // Loop until we've read enough bytes\n for (size_t i = 0; i < MD5_DIGEST_LENGTH; i++) {\n // Read one byte (two characters)\n int rc = sscanf(pos, \"%2hhx\", &bytes[i]);\n if (rc != 1)\n return -1;\n\n // Move the \"cursor\" to the next hexadecimal byte\n pos += 2;\n }\n\n return 0;\n}\n\n/**\n * Print a byte array that holds an MD5 hash to standard output.\n *\n * \\param bytes An array of bytes from an MD5 hash function\n */\nvoid print_md5_bytes(const uint8_t *bytes) {\n for (size_t i = 0; i < MD5_DIGEST_LENGTH; i++) {\n printf(\"%02hhx\", bytes[i]);\n }\n}\n"
},
{
"alpha_fraction": 0.6643677949905396,
"alphanum_fraction": 0.6931034326553345,
"avg_line_length": 21.894737243652344,
"blob_id": "781da0c1c7edc0e607a7bc113fe111b1440d09e6",
"content_id": "4e3601398570b2f2cf416957f540a7be29e241b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 870,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 38,
"path": "/include/worker-server.hpp",
"repo_name": "wyk9787/D-MAP",
"src_encoding": "UTF-8",
"text": "#include <stdbool.h>\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n#include <unistd.h>\n#include <sys/types.h>\n#include <sys/socket.h>\n#include <netinet/in.h>\n#include <netdb.h>\n#include <pthread.h>\n#include <arpa/inet.h>\n#include <dlfcn.h>\n#include <errno.h>\n#include <vector>\n\n#define PORT_NUMBER 1406\n#define WORKER_JOIN -1\n#define USER_JOIN -2\n\n/**\n * The server will provide each worker with three types of arguments:\n * 1. the number of inputs\n * 2. the name of the function to execute\n * 3. (at most) one input to the function\n * 4. a chunk of task\n */\ntypedef struct __attribute__((packed)) task_args_worker {\n int num_args;\n char function_name[256];\n char inputs[256];\n char chunk[256];\n}task_arg_worker_t;\n\ntypedef struct __attribute__((packed)) task_args_user {\n int num_args;\n char function_name[256];\n char inputs[256];\n}task_arg_user_t;\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 13.399999618530273,
"blob_id": "88a05f4da739b11af6ef3308360a9f6963f109c3",
"content_id": "efbc1d6136431028fa37c0dc1c629bf9c1ef8380",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 72,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 5,
"path": "/tests/Makefile",
"repo_name": "wyk9787/D-MAP",
"src_encoding": "UTF-8",
"text": "ROOT = ..\nTARGETS = password_test \nLIBS = dl\n\ninclude $(ROOT)/common.mk\n"
},
{
"alpha_fraction": 0.720588207244873,
"alphanum_fraction": 0.732758641242981,
"avg_line_length": 26,
"blob_id": "1cc8b820845f64b94005e31d075fcac50991b19f",
"content_id": "d8072d3a4e5f712b25b96b8fb1ac7f5eccec5102",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1972,
"license_type": "no_license",
"max_line_length": 158,
"num_lines": 73,
"path": "/README.md",
"repo_name": "wyk9787/D-MAP",
"src_encoding": "UTF-8",
"text": "# D-MAP\nA distributed version of map procedure that distributes task to multiple\nthreads running on multiple machines\n\n## Usage\n\n* Run `make` in the root directory, it will compile each program inside of each\ndirectory.\n\n### User\n\n0. To use this system, you need to compile your program into a shared object (.so file) and implement two functions:\n - `bool has_next();` return true of false to indicate if there is more work that needs to be done\n - `char* get_next();` return the next chunk of inputs to the entrance function\n \n See `src/password_6char/` and `src/password_7char` for examples.\n1. `cd src/user/`\n2. `./user <server_adress>`\n3. Answering the prompts by entering the request information. You can find example input file in `src/user/input-6.in` and `src/user/input-7.in`\n4. The user program will send information to server and will wait for output of the\n program sent back.\n\n### Server\n\n1. `cd src/server`\n2. `./server`\n3. The server will then start listening for connection from both workers and\n user\n\n### Worker\n\n1. `cd src/worker`\n2. `./worker <server_address>`\n3. The worker will then connect to the server and then wait for jobs\n\n## Example\n\nBelow is a simple walkthrough of the password cracker program:\n\n1. Compile the system by running `make`.\n\n2. Server needs to start first: `./src/server/server`\n\n3. For each available worker machine to join the server: \n\n```\ncd ./src/worker/\n./worker <SERVER_ADDRESS>\n```\n\n4. Then user joins the system and sends the password cracker program (**You need to change the input file (e.g. input-6.in and input-7.in to your own path**):\n\n```\ncd ./src/user/\n./user <SERVER_ADDRESS> < input-6.in\n```\n\n5. Wait for workers to complete the result and send output back to the server then from server to the user\n\n6. Expected output(Order may differ): \n\n```\nvostinar cached\nstone chmcls\nkington divest\ncurtsinger evlprf\nrebelsky glimmr\nwolz oliver\nwalker robots\nosera snthtc\nweinman vizwiz\nklinge xaqznl\n```\n\n"
},
{
"alpha_fraction": 0.5696576237678528,
"alphanum_fraction": 0.5743801593780518,
"avg_line_length": 30.962265014648438,
"blob_id": "6ec4120dc21344c6e7a65ca1e0343c9f9f92781d",
"content_id": "9ce04f0d630f4479b4038df2e7abf32f7ed616f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1694,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 53,
"path": "/src/user/test.py",
"repo_name": "wyk9787/D-MAP",
"src_encoding": "UTF-8",
"text": "import subprocess\nimport sys\nimport time\nimport csv\n\nINPUT_FILES = ['input-6.in', 'input-7.in']\nNUM_ITERATION = 5\nOUTPUT_FILE = '../../result/result.csv'\n\nif len(sys.argv) < 3:\n print ('Usage: python3 test.py <SERVER_ADDRESS> <NUM_MACHINE>');\n sys,exit()\n\nSERVER_ADDR = sys.argv[1]\nNUM_MACHINE = sys.argv[2]\n\n# with open(OUTPUT_FILE, 'w', newline='') as csv_file:\n# writer = csv.writer(csv_file, delimiter=',')\n# data = [\"Input\", \"NUM_ITERATION\", \"AVERAGE_TIME\", \"NUM_MACHINE\"]\n# writer.writerow(data)\n\n\n# Iterate through every input file\nfor f in INPUT_FILES:\n # Set commands\n cmd = './user ' + SERVER_ADDR + ' < ' + f \n \n print (\"++++++++++++++++++++++++++++++++++++++++\")\n print (\"START RUNNNING ON INPUT FILE:\" + f)\n print (\"++++++++++++++++++++++++++++++++++++++++\")\n\n sum_time = 0\n # Iterate through NUM_ITERATION times\n for i in range(NUM_ITERATION):\n print(\"Start running \" + str(i) +\"th time\")\n # Record starting time\n start_time = time.time()\n # Run the program\n process = subprocess.Popen(cmd, shell=True)\n # Get output\n out, err = process.communicate()\n # Record ending time\n end_time = time.time()\n print(\"Running for \" + str(end_time - start_time))\n sum_time += end_time - start_time\n average_time = sum_time / NUM_ITERATION\n print (\"Running on average: \" + str(average_time)) \n # Write to a csv file \n with open(OUTPUT_FILE, 'a', newline='') as csv_file:\n writer = csv.writer(csv_file, delimiter=',')\n data = [f, NUM_ITERATION, average_time, NUM_MACHINE]\n writer.writerow(data)\n print(\"Finishing writing to the file\")\n"
},
{
"alpha_fraction": 0.609262228012085,
"alphanum_fraction": 0.6202886700630188,
"avg_line_length": 24.844558715820312,
"blob_id": "dff83bb447a9238508a6d5b3aeb1bd5818795410",
"content_id": "87475c5cc8b6f981baa9cbc74dc743b747c3121e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4988,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 193,
"path": "/src/user/user.cpp",
"repo_name": "wyk9787/D-MAP",
"src_encoding": "UTF-8",
"text": "#include <stdbool.h>\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n#include <unistd.h>\n#include <sys/types.h>\n#include <sys/socket.h>\n#include <netinet/in.h>\n#include <netdb.h>\n#include <pthread.h>\n#include <arpa/inet.h>\n#include <dlfcn.h>\n#include <errno.h>\n#include <vector>\n#include <string>\n#include \"worker-server.hpp\"\n\n#define MAX_COMMAND_WIDTH 100\n#define MAX_NUM_COMMAND 100\n\nint socket_connect(char* server_address, int port) {\n struct hostent* server = gethostbyname(server_address);\n if(server == NULL) {\n fprintf(stderr, \"Unable to find host %s\\n\", server_address);\n exit(EXIT_FAILURE);\n }\n\n // Set up a socket\n int sock = socket(AF_INET, SOCK_STREAM, 0);\n if(sock == -1) {\n perror(\"socket failed\");\n exit(EXIT_FAILURE);\n }\n\n // Initialize the socket address\n struct sockaddr_in addr_client = {\n .sin_family = AF_INET,\n .sin_port = htons(port)\n };\n\n bcopy((char*)server->h_addr, (char*)&addr_client.sin_addr.s_addr, server->h_length);\n\n // Connect to the server\n if(connect(sock, (struct sockaddr*)&addr_client, sizeof(struct sockaddr_in))) {\n perror(\"connect failed in socket_connect\");\n return -1;\n }\n\n char join[5];\n sprintf(join, \"%d\", USER_JOIN);\n\n // Send join message\n if(write(sock, join, strlen(join)) == -1) {\n perror(\"write\");\n exit(EXIT_FAILURE);\n }\n return sock;\n}\n\n\nint main(int argc, char** argv) {\n if (argc != 2) {\n fprintf(stderr, \"Usage: %s <server address>\\n\", argv[0]);\n exit(EXIT_FAILURE);\n }\n\n char* server_address = argv[1];\n int server_socket = socket_connect(server_address, PORT_NUMBER);\n\n char* program_path = NULL;\n size_t program_len;\n printf(\"Please enter the path of the program (.so file): \\n\");\n if (getline(&program_path, &program_len, stdin) == -1) {\n fprintf(stderr, \"getline() failed\\n\");\n exit(EXIT_FAILURE); \n }\n program_path[strlen(program_path)-1] = '\\0';\n\n printf(\"Please enter the function name:\\n\");\n char* function_name = NULL;\n size_t function_name_len;\n if (getline(&function_name, &function_name_len, stdin) == -1) {\n fprintf(stderr, \"getline() failed\\n\");\n exit(EXIT_FAILURE); \n }\n function_name[strlen(function_name)-1] = '\\0';\n \n char* line = NULL;\n size_t line_size;\n \n printf(\"Please enter all the command line arguments for each program\\n\");\n printf(\"Enter 'NULL' when you are done.\\n\");\n if (getline(&line, &line_size, stdin) == -1) {\n fprintf(stderr, \"getline() failed\\n\");\n exit(EXIT_FAILURE); \n }\n line[strlen(line)-1] = '\\0';\n\n char commands[MAX_NUM_COMMAND][MAX_COMMAND_WIDTH];\n int num_args = 0; // Index for the commands\n while(strcmp(line, \"NULL\") != 0) { // Still have more commands\n // We need to get rid of the newline character\n strncpy(commands[num_args], line, strlen(line)); \n\n num_args++;\n\n line = NULL;\n line_size = 0;\n if (getline(&line, &line_size, stdin) == -1) {\n fprintf(stderr, \"getline() failed\\n\");\n exit(EXIT_FAILURE); \n }\n line[strlen(line)-1] = '\\0';\n }\n\n // Open the exectuable file\n FILE* exec_file = fopen(program_path, \"rb\");\n if(exec_file == NULL) {\n fprintf(stderr, \"Read file %s failed\\n\", program_path);\n exit(EXIT_FAILURE);\n }\n\n // Jump to the end of the file\n fseek(exec_file, 0, SEEK_END); \n // Get the current byte offset in the file\n long filelen = ftell(exec_file); \n // Go back to the beginning of the file \n rewind(exec_file);\n\n // Create space for the file \n char* buffer = (char *)malloc((filelen+1)*sizeof(char)); // Enough memory for file + \\0\n // Read file into the buffer\n fread(buffer, filelen, 1, exec_file); // Read in the entire file\n fclose(exec_file); // Close the file\n\n // Send file size\n char size_message[10];\n sprintf(size_message, \"%ld\", filelen);\n if(write(server_socket, size_message, 10) == -1) {\n perror(\"write\");\n exit(EXIT_FAILURE);\n }\n \n // Send actual file (exectuable)\n int write_bytes;\n write_bytes = write(server_socket, buffer, filelen); \n if(write_bytes== -1) {\n perror(\"write\");\n exit(EXIT_FAILURE);\n }\n\n // Send arguments\n task_arg_user_t args = {\n .num_args = num_args \n };\n strncpy(args.function_name, function_name, strlen(function_name));\n strncpy(args.inputs, commands[0], strlen(commands[0]));\n\n if(write(server_socket, &args, sizeof(task_arg_user_t)) == -1) {\n perror(\"write\");\n exit(EXIT_FAILURE);\n }\n \n \n // Reading program's output\n char size_buffer[10];\n\n while (true) {\n int bytes_read = read(server_socket, size_buffer, 10);\n\n //if there is nothing left to read\n if (bytes_read == 0)\n break;\n \n // Save the size of the output\n int bytes_to_read = atoi(size_buffer);\n\n \n char print_buffer[256] = {0};\n \n while(bytes_to_read > 0) {\n int ret = read(server_socket, print_buffer, bytes_to_read);\n if(ret < 0) {\n perror(\"read\");\n exit(2);\n }\n printf(\"%s\", print_buffer);\n bytes_to_read -= ret;\n }\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5947063565254211,
"alphanum_fraction": 0.6029776930809021,
"avg_line_length": 20.210525512695312,
"blob_id": "605e844c02c8852b4551ad9369c639d906a73357",
"content_id": "ad905e4be877a5ce5ce5556ff285c99b7c154c49",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1209,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 57,
"path": "/tests/password_test.c",
"repo_name": "wyk9787/D-MAP",
"src_encoding": "UTF-8",
"text": "#define _GNU_SOURCE\n#include <stdio.h>\n#include <stdlib.h>\n#include <dlfcn.h>\n#include <errno.h>\n#include <stdint.h>\n#include <stdio.h>\n#include <stdlib.h>\n#include <fcntl.h>\n#include <unistd.h>\n#include <stdbool.h>\n\ntypedef int (*real_main_t)(int argc, char** argv);\ntypedef bool (*has_next_t)();\ntypedef char* (*get_next_t)();\n\nconst char* shared_library = \"../src/password_7char/password_7char.so\";\n\nint main(int argc, char** argv) {\n errno = 0;\n void* injection = dlopen(shared_library, RTLD_LAZY | RTLD_GLOBAL);\n if(injection == NULL) {\n perror(\"dlopen\");\n exit(1);\n }\n\n dlerror();\n has_next_t has_next = (has_next_t)dlsym(injection, \"has_next\");\n char* error = dlerror();\n if(error != NULL) {\n printf(\"Error: %s\\n\", error);\n exit(1);\n }\n \n dlerror();\n get_next_t get_next = (get_next_t)dlsym(injection, \"get_next\");\n error = dlerror();\n if(error != NULL) {\n printf(\"Error: %s\\n\", error);\n exit(1);\n }\n\n dlerror();\n real_main_t real_main = (real_main_t)dlsym(injection, \"entrance\");\n error = dlerror();\n if(error != NULL) {\n printf(\"Error: %s\\n\", error);\n exit(1);\n }\n\n while(has_next()) {\n argv[2] = get_next(); \n real_main(3, argv);\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.7352941036224365,
"alphanum_fraction": 0.75,
"avg_line_length": 26.200000762939453,
"blob_id": "d27b7330a9b83a53c19553d40babf275f6d0b6ad",
"content_id": "4a8760633deb00d60fd400149b7173a3f5d0501e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 136,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 5,
"path": "/Makefile",
"repo_name": "wyk9787/D-MAP",
"src_encoding": "UTF-8",
"text": "ROOT = .\nDIRS = tests src/password_7char src/user src/password_6char src/server src/worker\nLIBS = pthread dl\n\ninclude $(ROOT)/common.mk\n"
},
{
"alpha_fraction": 0.5882353186607361,
"alphanum_fraction": 0.615686297416687,
"avg_line_length": 14.9375,
"blob_id": "c1315110186d2f88f172c1a806560269377e464b",
"content_id": "ddd4be5b41f16f3659566644f8d533aee192c697",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 255,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 16,
"path": "/tests/deploy.sh",
"repo_name": "wyk9787/D-MAP",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n# A script to see when is the port unbounded any more\n\noutput=\"bind\"\n\nlsof ti:60519 | xargs kill -9\n\nwhile [ -n `./src/server/server | grep -q \"bind\"` ]\n do\t\n echo trying!\t\n espeak \"trying!\"\n sleep 2\n done \n \necho \"Ready to run!\"\n"
},
{
"alpha_fraction": 0.6703296899795532,
"alphanum_fraction": 0.6813187003135681,
"avg_line_length": 17.200000762939453,
"blob_id": "035cc637d69a03a6180d1d69a6678cfeef91bfcc",
"content_id": "ce78cacff5d98bff11aed9feff1773876510bea9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 91,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 5,
"path": "/src/password_6char/Makefile",
"repo_name": "wyk9787/D-MAP",
"src_encoding": "UTF-8",
"text": "ROOT = ../../\nTARGETS = password_6char.so\nLIBS = crypto pthread\n\ninclude $(ROOT)/common.mk\n"
},
{
"alpha_fraction": 0.6703296899795532,
"alphanum_fraction": 0.6813187003135681,
"avg_line_length": 17.200000762939453,
"blob_id": "b3a35ec516984ed49ff8ecdb73dc0c6196d2d7e6",
"content_id": "c5216a86ac9ebdaa0b79179f987ea8b36d3f0fbe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 91,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 5,
"path": "/src/password_7char/Makefile",
"repo_name": "wyk9787/D-MAP",
"src_encoding": "UTF-8",
"text": "ROOT = ../../\nTARGETS = password_7char.so\nLIBS = crypto pthread\n\ninclude $(ROOT)/common.mk\n"
}
] | 16 |
WFGQAAUTOMATION/Learn-Python-the-Hard-Way
|
https://github.com/WFGQAAUTOMATION/Learn-Python-the-Hard-Way
|
ca9541f093febded1b5a818ecf95421767406d7c
|
8acf15de9bcd15a5d3342aabc30f1eedc00f2719
|
585743caccee386fffd1fbfe7d8c10b72a280d30
|
refs/heads/master
| 2016-08-12T09:54:22.366633 | 2015-12-04T13:12:40 | 2015-12-04T13:12:40 | 45,990,669 | 0 | 0 | null | 2015-11-11T15:39:48 | 2015-11-11T15:46:13 | 2015-12-03T21:05:19 |
Python
|
[
{
"alpha_fraction": 0.7309644818305969,
"alphanum_fraction": 0.7309644818305969,
"avg_line_length": 23.66666603088379,
"blob_id": "91c758ac4b88335b8ba9f3cb8893ef7b783e43ed",
"content_id": "2341b2d5edcf98ff9653a53745caaf66541bd4c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 591,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 24,
"path": "/Exercise_15.py",
"repo_name": "WFGQAAUTOMATION/Learn-Python-the-Hard-Way",
"src_encoding": "UTF-8",
"text": "from sys import argv\n\nscript, filename = argv\n\n# Packs the variable with the contents\n# of the file.\ntxt = open(filename)\n\n# Prints the file name on the screen\nprint \"Here's your file %r:\" % filename\n# Prints the content of the variable\nprint txt.read()\n# Close the file\ntxt.close()\n# Asks for the name of the file again.\nprint \"Type the filename again:\"\n# User types in the file name\nfile_again = raw_input(\"> \")\n# Pack the new variable with the contents of the file\ntxt_again = open(file_again)\n# Print the contents of the variable\nprint txt_again.read()\n# Close the file\ntxt_again.close()"
},
{
"alpha_fraction": 0.5890052318572998,
"alphanum_fraction": 0.5994764566421509,
"avg_line_length": 18.100000381469727,
"blob_id": "3114cb2a9df11c56e9cb217785d0a864d17d6b6c",
"content_id": "c2ec6a1234633201b54d3e87c9cb224c48854be6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 382,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 20,
"path": "/Exercise_10.py",
"repo_name": "WFGQAAUTOMATION/Learn-Python-the-Hard-Way",
"src_encoding": "UTF-8",
"text": "tabby_cat = \"\\tI'm tabbed in.\"\npersian_cat = \"I'm split\\non a line.\"\nbackslash_cat = \"I'm \\\\ a \\\\ cat.\"\n\nfat_cat = \"\"\"\nI'll do a list:\n\\t1 Cat food\n\\t2 Fishies\n\\t3 Catnip\\n\\t4 Grass\n\"\"\"\n\nprint tabby_cat\nprint persian_cat\nprint backslash_cat\nprint fat_cat\n\n# This loop will not end and makes a cool graphic.\nwhile True:\n for i in [\"/\",\"-\",\"|\",\"\\\\\",\"|\"]:\n print \"%s\\r\" % i,\n"
},
{
"alpha_fraction": 0.7058823704719543,
"alphanum_fraction": 0.7133917212486267,
"avg_line_length": 20.594594955444336,
"blob_id": "960ff7c2f5ae653410eb3b1e4d4a9ef991e2bacf",
"content_id": "2dfc7d83d246ff9159840c0f9a746f2488ecc4c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 799,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 37,
"path": "/Exercise_20.py",
"repo_name": "WFGQAAUTOMATION/Learn-Python-the-Hard-Way",
"src_encoding": "UTF-8",
"text": "from sys import argv\n\nscript, input_file = argv\n\n# Func to print contents of file\ndef print_all(f):\n print f.read()\n\n# Func to move to the beginning of the file\ndef rewind(f):\n f.seek(0)\n\n# Func to print the given line from the file\ndef print_a_line(line_count, f):\n print line_count, f.readline()\n\n# Opens file and loads the variable\ncurrent_file = open(input_file)\n\nprint \"First let's print the whole file:\\n\"\nprint_all(current_file)\n\nprint \"\\nNow let's rewind, kind of like a tape.\\n\"\nrewind(current_file)\n\nprint \"Let's print three lines:\\n\"\ncurrent_line = 1\nprint_a_line(current_line, current_file)\n\n#current_line = current_line + 1\ncurrent_line += 1\nprint_a_line(current_line, current_file)\n\n\n#current_line = current_line + 1\ncurrent_line += 1\nprint_a_line(current_line, current_file)\n"
},
{
"alpha_fraction": 0.698051929473877,
"alphanum_fraction": 0.7077922224998474,
"avg_line_length": 24.66666603088379,
"blob_id": "cee63579306c6e5ccdc179722a6736b0c3cec839",
"content_id": "3aad393dea3626458aa3cd432758a33e2e961f20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 308,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 12,
"path": "/Exercise_13.py",
"repo_name": "WFGQAAUTOMATION/Learn-Python-the-Hard-Way",
"src_encoding": "UTF-8",
"text": "from sys import argv\n\nfirst = raw_input('1st Variable?' )\nsecond = raw_input('2nd Variable?' )\nthird = raw_input('3rd Variable?' )\n\nscript = argv\n\nprint \"The script is called: %s\" % script\nprint \"Your first variable is:\", first\nprint \"Your second variable is:\", second\nprint \"Your third variable is:\", third\n"
}
] | 4 |
mojtabah/6_23_git
|
https://github.com/mojtabah/6_23_git
|
55b398756fa5ee5cdd552776993a9b3f2a38520c
|
a0be6f3295c434e8bb9ac1983633dd86686b26dc
|
10bcb8070da4eb27bb3a171333271b0e06db6e91
|
refs/heads/master
| 2021-01-17T06:33:52.066094 | 2015-06-23T16:08:10 | 2015-06-23T16:08:10 | 37,926,506 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6857143044471741,
"alphanum_fraction": 0.7285714149475098,
"avg_line_length": 16.25,
"blob_id": "8b10de6734a680d60bb01d6935c34829e8524e50",
"content_id": "9ff94c2b33605e7a3bbdb4d81fed98d4eb363fad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 70,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 4,
"path": "/README.md",
"repo_name": "mojtabah/6_23_git",
"src_encoding": "UTF-8",
"text": "This is a project for s2i2 teaching Git.\n\n-bullet\n -nested bullet 1\n\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.6835442781448364,
"avg_line_length": 18.75,
"blob_id": "9fb053e85ead2123b597682c2005ff4a748665d4",
"content_id": "f0e14e8c256a08e90b913d66a509a7da6d2c749a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 158,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 8,
"path": "/README.md.BACKUP.4371.md",
"repo_name": "mojtabah/6_23_git",
"src_encoding": "UTF-8",
"text": "This is a project for s2i2 teaching Git.\n\n-bullet\n<<<<<<< HEAD\n -nested bullet 2\n=======\n -nested bullet 1\n>>>>>>> 4e12ba903e82195d1d977b671bf5faf3d6c71a09\n"
},
{
"alpha_fraction": 0.5454545617103577,
"alphanum_fraction": 0.6115702390670776,
"avg_line_length": 18,
"blob_id": "f1ab98f8f786861b760f568b6cc1192b36aee8be",
"content_id": "a3007f18095d8be0a2ef1c627c1a2b95cd9e24a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 363,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 19,
"path": "/src/temp.py",
"repo_name": "mojtabah/6_23_git",
"src_encoding": "UTF-8",
"text": "#! /anaconda/bin python\n\"\"\"This is a python module that converts temperatures\n\"\"\"\n\ndef f_to_k(temp):\n converted = ((temp - 32) * (5./9)) + 273.15\n return converted\n\ndef k_to_c(temp):\n return temp-273.15\n\ndef f_to_c(temp):\n temp_k = f_to_k(temp)\n result = k_to_c(temp_k) \n return result\n\nprint f_to_k(212)\nprint k_to_c(273.15)\nprint f_to_c(32)\n \n"
}
] | 3 |
alejjjano/ExcelEdit
|
https://github.com/alejjjano/ExcelEdit
|
6613507e97a6482d0d37e53a40faa1ebc6ee7bde
|
6bb55cf9f310d8d076e99651ebdb1126ee125a94
|
d1c3cf198126e168dbec0015a194035282270812
|
refs/heads/master
| 2021-05-08T20:01:40.115059 | 2018-01-30T20:52:08 | 2018-01-30T20:52:08 | 119,592,484 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5968955755233765,
"alphanum_fraction": 0.6015992760658264,
"avg_line_length": 24.575000762939453,
"blob_id": "2073401d091ce8902641a11e5ca24a3fadd08a04",
"content_id": "e1085194bb12b11c4010087a3ccb5074f1635655",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2126,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 80,
"path": "/XLS to KML.py",
"repo_name": "alejjjano/ExcelEdit",
"src_encoding": "UTF-8",
"text": "import openpyxl\r\nimport simplekml\r\nimport os\r\n\r\n\r\ndef exceltodict(filename, sheetname):\r\n \"\"\"\r\n filename is a string\r\n sheet is a string\r\n returns geodict:\r\n names as keys strings\r\n coordinates as values strings\r\n \"\"\"\r\n\r\n book = openpyxl.load_workbook(filename)\r\n sheet = book.get_sheet_by_name(sheetname)\r\n\r\n colm = {}\r\n\r\n j = 1\r\n while (sheet.cell(row=1, column=j).value) is not None:\r\n if str(sheet.cell(row=1, column=j).value) in [\"Name\", \"Nombre\", \"NAME\", \"NOMBRE\", \"IE\"]:\r\n colm[\"NAMES\"] = j\r\n elif str(sheet.cell(row=1, column=j).value) in [\"LAT\", \"Lat\"]:\r\n colm[\"LATS\"] = j\r\n elif str(sheet.cell(row=1, column=j).value) in [\"LONG\", \"Long\"]:\r\n colm[\"LONGS\"] = j\r\n elif \"NAMES\" in colm and \"LATS\" in colm and \"LONGS\" in colm: # If all columns are in colm then stop\r\n break\r\n j += 1\r\n\r\n geodict = {}\r\n\r\n i = 2\r\n while (sheet.cell(row=i, column=1).value) is not None:\r\n name = str(sheet.cell(row=i, column=colm[\"NAMES\"]).value)\r\n lat = str(sheet.cell(row=i, column=colm[\"LATS\"]).value)\r\n long = str(sheet.cell(row=i, column=colm[\"LONGS\"]).value)\r\n geodict[name] = long + \",\" + lat\r\n i += 1\r\n\r\n return geodict\r\n\r\n\r\ndef dicttoKMLfolder(datadict):\r\n \"\"\"\r\n datadict is a dictionary with:\r\n names as keys, strings\r\n lat and log as values, strings\r\n returns KMLfolder with points\r\n \"\"\"\r\n\r\n\r\ndef KMLfldtofile(KMLfolder, filename):\r\n \"\"\"\r\n filename is a string\r\n transforms KMLfolder into a KML file\r\n and writes it with namef: filename\r\n \"\"\"\r\n\r\n\r\n# Enter main program\r\n# Set files to read and write\r\nfiletoread = input(\"Insert filename to read\")\r\nfiletoread = filetoread+\".xlsx\"\r\nfiletowrite = filetoread\r\n\r\ndata = exceltodict(filetoread, \"Hoja1\")\r\n\r\n# Print log of exported data\r\nprint(\"Generate points:\")\r\nfor key in data.keys():\r\n print(key, \":\", data[key])\r\n\r\nfolder = dicttoKMLfolder(data)\r\nKMLfldtofile(folder, filetowrite)\r\n\r\n# Messages to end program\r\nprint(\"KML wrote with name\", filetowrite)\r\ninput(\"Press key to end\")\r\n"
},
{
"alpha_fraction": 0.6348884105682373,
"alphanum_fraction": 0.6348884105682373,
"avg_line_length": 22.75,
"blob_id": "5a6d500bafe1227893d5b16e8b5298971537d30e",
"content_id": "76556c27a1dfc5d25aa5101a030786c61805d43e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 493,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 20,
"path": "/Read_Excel_row.py",
"repo_name": "alejjjano/ExcelEdit",
"src_encoding": "UTF-8",
"text": "def countDiffValues(texttoread):\r\n # Elaborates a list from numbers in texttoread\r\n valuelist = [num for num in texttoread.split(\"\t\")]\r\n\r\n # Elaborates a list from different numbers\r\n\r\n items = []\r\n for i in valuelist:\r\n if i not in items:\r\n items.append(i)\r\n\r\n # Prints all different values in the row\r\n print(items)\r\n\r\n # Prints the total amount of different values in the row\r\n print(len(items))\r\n\r\n\r\nx = input(\"Insert Data\")\r\ncountDiffValues(x)"
},
{
"alpha_fraction": 0.7039473652839661,
"alphanum_fraction": 0.7138158082962036,
"avg_line_length": 19.761905670166016,
"blob_id": "89572d23c53ad6db982f3a6d7fe76cd8bdd80e9d",
"content_id": "4755ef90ff623c2baa0a015bdf47371146c824b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 912,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 42,
"path": "/CollapseColumns.py",
"repo_name": "alejjjano/ExcelEdit",
"src_encoding": "UTF-8",
"text": "import openpyxl\r\nimport string\r\n\r\nfilename = \"CONSOLIDADOV3_TEST.xlsx\"\r\n\r\n# Load book and sheet\r\nbook = openpyxl.load_workbook(filename)\r\nsheet = book.active\r\n\r\n# Define column list\r\ncolumns = [char for char in string.ascii_uppercase]\r\n\r\nfor i in string.ascii_uppercase:\r\n for j in string.ascii_uppercase:\r\n columns.append(i+j)\r\n\r\n\r\n# Define start and stop points to edit\r\ncolumnToStart = \"B\" # Guide value should be in this column\r\ncolumnToEnd = \"Z\"\r\n\r\nstart = 4 # Label values should be in this column\r\nstop = 1070\r\n\r\n# Define list of columns\r\nindexToStart = columns.index(columnToStart)\r\nindexToEnd = columns.index(columnToEnd)\r\n\r\ncolumnList = columns[indexToStart:indexToEnd+1]\r\n\r\n# Initiate data structure to store\r\n\r\n\r\n\r\n# Read row by row and store non-repeating data\r\nfor i in range(start, stop + 1):\r\n\r\n#Write data in new book\r\n\r\n\r\n# Save book to file\r\nbook.save(\"CONSOLIDADOV3_TEST_EDIT.xlsx\")"
},
{
"alpha_fraction": 0.6348484754562378,
"alphanum_fraction": 0.6648989915847778,
"avg_line_length": 22.762500762939453,
"blob_id": "eb433394640a5bf024e3828b7a2c78376bec8325",
"content_id": "1a499b82b32799d9785601589124bad78bcb5573",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3961,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 160,
"path": "/MergeData Tests.py",
"repo_name": "alejjjano/ExcelEdit",
"src_encoding": "UTF-8",
"text": "# Test search Col\r\n\r\n# Case 1: List contains real columns\r\n\r\nprint(\"Test Case 1\")\r\n\r\nfilenameC1 = \"CONSOLIDADO_C1.xlsx\"\r\nbookC1 = openpyxl.load_workbook(filenameC1)\r\nsheetC1 = bookC1.get_sheet_by_name(\"CONSOLIDADO\")\r\n\r\nheaderNum = 4\r\n\r\ncolumnsToEdit = [\"CODIGO LOCAL\",\r\n \"TOTAL MODULOS\",\r\n \"ESTADO DE LOS TRABAJOS\"]\r\n\r\nindexes = []\r\nfor column in columnsToEdit:\r\n indexes.append(searchCol(column, sheetC1, headerNum))\r\n print(\" Column \", column, \"in index\", searchCol(column, sheetC1, headerNum))\r\n\r\n\r\nprint(indexes)\r\n\r\n# Case 2: List is empty\r\n\r\nprint(\"Test Case 2\")\r\n\r\nfilenameC1 = \"CONSOLIDADO_C1.xlsx\"\r\nbookC1 = openpyxl.load_workbook(filenameC1)\r\nsheetC1 = bookC1.get_sheet_by_name(\"CONSOLIDADO\")\r\n\r\nheaderNum = 4\r\n\r\ncolumnsToEdit = []\r\n\r\nindexes = []\r\nfor column in columnsToEdit:\r\n indexes.append(searchCol(column, sheetC1, headerNum))\r\n\r\n\r\nprint(indexes)\r\n\r\n# Case 3: List contains non valid columns\r\n\r\nprint(\"Test Case 3\")\r\n\r\nfilenameC1 = \"CONSOLIDADO_C1.xlsx\"\r\nbookC1 = openpyxl.load_workbook(filenameC1)\r\nsheetC1 = bookC1.get_sheet_by_name(\"CONSOLIDADO\")\r\n\r\nheaderNum = 4\r\n\r\ncolumnsToEdit = [\"CODIGO LOCAL\",\r\n \"TOTAL MODULOS\",\r\n \"ESTADO DE LOS TRABAJOS\",\r\n \"Hola\"]\r\n\r\nindexes = []\r\nfor column in columnsToEdit:\r\n try:\r\n indexes.append(searchCol(column, sheetC1, headerNum))\r\n print(\" Column \", column, \"in index\", searchCol(column, sheetC1, headerNum))\r\n except:\r\n print(\"Test 3 successfull\")\r\n\r\nprint(indexes)\r\n\r\n\r\n# Case 4: List contains accented text\r\n\r\nprint(\"Test Case 4\")\r\n\r\nfilenameC1 = \"CONSOLIDADO_C1.xlsx\"\r\nbookC1 = openpyxl.load_workbook(filenameC1)\r\nsheetC1 = bookC1.get_sheet_by_name(\"CONSOLIDADO\")\r\n\r\nheaderNum = 4\r\n\r\ncolumnsToEdit = [\"TIPO DE INSPECCIÓN\"]\r\n\r\nindexes = []\r\nfor column in columnsToEdit:\r\n indexes.append(searchCol(column, sheetC1, headerNum))\r\n print(\" Column \", column, \"in index\", searchCol(column, sheetC1, headerNum))\r\n\r\nprint(indexes)\r\n\r\n\r\n\r\n\r\n\r\n\r\n# Test cases for checkCol\r\n\r\n# Test 1: When both columns have equal values\r\n\r\nsheet1 = openpyxl.load_workbook(\"TESTS.xlsx\").get_sheet_by_name(\"T1-1\")\r\nsheet2 = openpyxl.load_workbook(\"TESTS.xlsx\").get_sheet_by_name(\"T1-2\")\r\nprint(checkCol(sheet1,sheet2,\"COLUMNA\",1))\r\n\r\n# Test 2: When both columns have different values\r\n\r\nsheet1 = openpyxl.load_workbook(\"TESTS.xlsx\").get_sheet_by_name(\"T2-1\")\r\nsheet2 = openpyxl.load_workbook(\"TESTS.xlsx\").get_sheet_by_name(\"T2-2\")\r\nprint(checkCol(sheet1,sheet2,\"COLUMNA\",1))\r\n\r\n# Test 3: When one column is empty\r\n\r\nsheet1 = openpyxl.load_workbook(\"TESTS.xlsx\").get_sheet_by_name(\"T3-1\")\r\nsheet2 = openpyxl.load_workbook(\"TESTS.xlsx\").get_sheet_by_name(\"T3-2\")\r\nprint(checkCol(sheet1,sheet2,\"COLUMNA\",1))\r\n\r\n# Test 4: When both columns are empty\r\n\r\nsheet1 = openpyxl.load_workbook(\"TESTS.xlsx\").get_sheet_by_name(\"T4-1\")\r\nsheet2 = openpyxl.load_workbook(\"TESTS.xlsx\").get_sheet_by_name(\"T4-2\")\r\nprint(checkCol(sheet1,sheet2,\"COLUMNA\",1))\r\n\r\n\r\n\r\n\r\n\r\n# Test cases for searchRow\r\n\r\n# Test 1: value in column\r\n\r\nsheet = openpyxl.load_workbook(\"TESTS.xlsx\").get_sheet_by_name(\"T1-1\")\r\nif searchRow(20, \"COLUMNA\", sheet, 1) == 21:\r\n print(\"Test 1 successfull\")\r\nelse:\r\n print(\"Test 1 wrong\")\r\n\r\n# Test 2: value not in column\r\n\r\nsheet = openpyxl.load_workbook(\"TESTS.xlsx\").get_sheet_by_name(\"T1-1\")\r\ntry:\r\n print(searchRow(50, \"COLUMNA\", sheet, 1))\r\nexcept ValueError:\r\n print(\"Test 2 succesfull\")\r\nelse:\r\n print(\"Test 2 wrong\")\r\n\r\n# Test 3: value multiple times in column\r\n\r\nsheet = openpyxl.load_workbook(\"TESTS.xlsx\").get_sheet_by_name(\"T5-B\")\r\nif searchRow(20, \"COLUMNA\", sheet, 1) == 21:\r\n print(\"Test 3 successfull\")\r\nelse:\r\n print(\"Test 3 wrong\")\r\n\r\n# Test 4: Empty column\r\n\r\nsheet = openpyxl.load_workbook(\"TESTS.xlsx\").get_sheet_by_name(\"T4-2\")\r\ntry:\r\n print(searchRow(50, \"COLUMNA\", sheet, 1))\r\nexcept ValueError:\r\n print(\"Test 4 succesfull\")\r\nelse:\r\n print(\"Test 4 wrong\")"
},
{
"alpha_fraction": 0.6574585437774658,
"alphanum_fraction": 0.6726519465446472,
"avg_line_length": 21.354839324951172,
"blob_id": "5d4089755b8ab5eed7a496ec35b3b249bee5669b",
"content_id": "baf325271003f0ef7317732dbb8519a35e910507",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 724,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 31,
"path": "/GruposInspeccion.py",
"repo_name": "alejjjano/ExcelEdit",
"src_encoding": "UTF-8",
"text": "import openpyxl\r\n\r\n\r\nfilename = \"CONSOLIDADOV3.xlsx\"\r\n\r\n# Load book and sheet\r\nbook = openpyxl.load_workbook(filename)\r\nsheet = book.active\r\n\r\n# Define start and stop points to edit\r\ncolumnToRead = \"Y\"\r\nstart = 5\r\nstop = 1070\r\n\r\n# Define column to write\r\ncolumnToWrite = \"AA\"\r\n\r\n# Start counter\r\ncounter = 0\r\n\r\n# Read every cell in range, by rows\r\nfor i in range(start, stop+1):\r\n # Evaluates if the value has changed\r\n if sheet[columnToRead+str(i)].value != sheet[columnToRead+str(i-1)].value:\r\n counter += 1\r\n # Write counter value in column to write\r\n sheet[columnToWrite+str(i)] = counter\r\n print(\"Cell \"+columnToWrite+str(i)+\" updated to \"+str(counter))\r\n\r\n\r\nbook.save(\"CONSOLIDADOV3_EDIT.xlsx\")\r\n"
},
{
"alpha_fraction": 0.795918345451355,
"alphanum_fraction": 0.795918345451355,
"avg_line_length": 23.5,
"blob_id": "3a0acd0411d60f6eff8818f0fa803be7276175ea",
"content_id": "f0ff556d7c7e442c44d115ac5a5bdd9434936143",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 49,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 2,
"path": "/README.md",
"repo_name": "alejjjano/ExcelEdit",
"src_encoding": "UTF-8",
"text": "# ExcelEdit\nPython scripts to edit data in Excel\n"
},
{
"alpha_fraction": 0.6325844526290894,
"alphanum_fraction": 0.6474438309669495,
"avg_line_length": 28.5567569732666,
"blob_id": "12e298c2ac8fb7b6fd8d812b4e1499014a37af25",
"content_id": "2c005dc611274460624f6fd1a7710fb225c245c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5659,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 185,
"path": "/MergeData.py",
"repo_name": "alejjjano/ExcelEdit",
"src_encoding": "UTF-8",
"text": "import openpyxl\r\nimport string\r\n\r\n\r\n# Definir caracteres de columnas\r\n\r\ncolumnChars = [char for char in string.ascii_uppercase]\r\nfor i in string.ascii_uppercase:\r\n for j in string.ascii_uppercase:\r\n columnChars.append(i+j)\r\nprint(columnChars)\r\n\r\n\r\ndef searchCol(columnName, sheet, header):\r\n \"\"\"\r\n :param columnName: string, column to search\r\n :param sheet: sheet to look into\r\n :param header: the index of the header row\r\n :return: Index of column to search, as a letter\r\n \"\"\"\r\n\r\n index = 0\r\n cursor = sheet[columnChars[index] + str(header)]\r\n while cursor.value is not None:\r\n if cursor.value == columnName:\r\n return columnChars[index]\r\n index += 1\r\n cursor = sheet[columnChars[index] + str(header)]\r\n raise ValueError(\"Column \" + columnName + \" not in Worksheet\")\r\n\r\n\r\ndef searchRow(id, columnName, sheet, header):\r\n \"\"\"\r\n :param columnName: the name of the column, as a string\r\n :param sheet: sheet to look at\r\n :param header: the index of header of the columns\r\n :param id: the value to look at in the column\r\n :return: the index of the row where id is found\r\n \"\"\"\r\n columnIndex = searchCol(columnName, sheet, header)\r\n\r\n i = header + 1\r\n cursor = sheet[columnIndex+str(i)]\r\n while cursor.value is not None:\r\n if cursor.value == id:\r\n return i\r\n i += 1\r\n cursor = sheet[columnIndex + str(i)]\r\n raise ValueError(\"Value \" + str(id) + \" is not in column \" + columnName)\r\n\r\n\r\ndef checkCol(sheet1, sheet2, columnToCheck, header):\r\n \"\"\"\r\n :param sheet1: first sheet to check\r\n :param sheet2: second sheet to check\r\n :param columnToCheck: the column column to check, by name as a str\r\n :param header: the index of the header row\r\n :return: Boolean. True if the columns contain the same values in both sheets\r\n \"\"\"\r\n\r\n columnIndex1 = searchCol(columnToCheck, sheet1, header)\r\n columnIndex2 = searchCol(columnToCheck, sheet2, header)\r\n\r\n # Track all values in sheet1\r\n listSheet1=[]\r\n i = header + 1\r\n cursor = sheet1[columnIndex1+str(i)]\r\n while cursor.value is not None:\r\n listSheet1.append(cursor.value)\r\n i += 1\r\n cursor = sheet1[columnIndex1 + str(i)]\r\n\r\n # Track all values in sheet2\r\n listSheet2=[]\r\n i = header + 1\r\n cursor = sheet2[columnIndex2+str(i)]\r\n while cursor.value is not None:\r\n listSheet2.append(cursor.value)\r\n i += 1\r\n cursor = sheet2[columnIndex2 + str(i)]\r\n\r\n #Check if items are repeated in both lists\r\n flag = True\r\n\r\n for item in listSheet1:\r\n if listSheet1.count(item) > 1:\r\n print(\"Repeated items in Sheet 1\")\r\n flag = False\r\n\r\n for item in listSheet2:\r\n if listSheet2.count(item) > 1:\r\n print(\"Repeated items in Sheet 2\")\r\n flag = False\r\n\r\n return sorted(listSheet1) == sorted(listSheet2) and flag\r\n\r\n\r\ndef columnList(sheet, columnName,header):\r\n \"\"\"\r\n :param sheet: sheet to read\r\n :param columnName: column to read\r\n :param header: header of columns\r\n :return: list of all values in column\r\n \"\"\"\r\n\r\n columnIndex = searchCol(columnName,sheet,header)\r\n colList = []\r\n\r\n i = header+1\r\n cursor = sheet[columnIndex + str(i)]\r\n while cursor.value is not None:\r\n colList.append(cursor.value)\r\n i += 1\r\n cursor = sheet[columnIndex + str(i)]\r\n\r\n return colList\r\n\r\n\r\ndef replaceValue(sheet1, sheet2, columnToEdit, tagColumn, id, header):\r\n \"\"\"\r\n :param sheet1: sheet to replace values\r\n :param sheet2: sheet to get values from\r\n :param columnToEdit: columnToEdit, by Name\r\n :param tagColumn: name of the tag Column, as text\r\n :param id: id of the tag column to replace, wich is in both sheets\r\n :param header: the header of the columns\r\n :return: None, just replaces the value in the sheet1\r\n \"\"\"\r\n\r\n rowIndexWrite = searchRow(id, tagColumn, sheet1, header)\r\n rowIndexRead = searchRow(id, tagColumn, sheet2, header)\r\n\r\n columnIndexWrite = searchCol(columnToEdit, sheet1, header)\r\n columnIndexRead = searchCol(columnToEdit, sheet2, header)\r\n\r\n sheet1[columnIndexWrite + str(rowIndexWrite)] = sheet2[columnIndexRead + str(rowIndexRead)].value\r\n\r\n print(\"Cell \"+ columnIndexWrite + str(rowIndexWrite) + \" updated to \" + str(sheet2[columnIndexRead + str(rowIndexRead)].value))\r\n\r\n\r\n\r\n# Leer Tablas C1 - C2\r\n\r\nfilenameC1 = \"CONSOLIDADO_C21.xlsx\"\r\nfilenameC2 = \"CONSOLIDADO_C22.xlsx\"\r\n\r\nbookC1 = openpyxl.load_workbook(filenameC1)\r\nbookC2 = openpyxl.load_workbook(filenameC2)\r\n\r\nsheetC1 = bookC1.get_sheet_by_name(\"CONSOLIDADO\")\r\nsheetC2 = bookC2.get_sheet_by_name(\"CONSOLIDADO\")\r\n\r\n# Buscar columnas C1 - tag, A, B, C ... C2 - tag, A, B, C ...\r\n# Almacenar ubicación de columnas\r\n\r\ntagColumn = \"N°\"\r\n\r\nheaderNum = 4\r\n\r\ncolumnsToEdit = [\"AREA RESPONSABLE DE INSPECCIÓN\",\r\n \"RESPONSABLE DE INSPECCIÓN\",\r\n \"FECHA DE INSPECCIÓN\"]\r\n\r\n# Revisar los valores de tag C1 y C2 para que:\r\n# No se repitan y coincidan entre sí\r\n\r\nif not checkCol(sheetC1, sheetC2, tagColumn, headerNum):\r\n raise ValueError(\"Values from \" + tagColumn + \" are repeated or not coherent in both tables\")\r\n\r\n# Reemplazar datos de C1 por los de C2 para\r\n# las columnas A, B, C ...\r\n\r\ntagColumnList = columnList(sheetC2,tagColumn,headerNum)\r\n\r\nfor column in columnsToEdit:\r\n for id in tagColumnList:\r\n replaceValue(sheetC1, sheetC2, column, tagColumn, id, headerNum)\r\n\r\n# Guardar tabla con nuevo nombre\r\n\r\nfilenameCF = \"CONSOLIDADO_CF2.xlsx\"\r\n\r\nbookC1.save(filenameCF)\r\n\r\nprint(\"Edited file saved as \" + filenameCF)\r\n"
}
] | 7 |
hexiaoxiao-cs/CS211-FALL18
|
https://github.com/hexiaoxiao-cs/CS211-FALL18
|
5530f7f6b173181f387dafd4488feae127afd349
|
033d604e62bb02bbee58c648acb6eb3cac06ff32
|
b23f4ba7fe408609115e68747bccc1208b7bb7a3
|
refs/heads/master
| 2022-03-21T09:17:01.561349 | 2019-12-09T17:14:17 | 2019-12-09T17:14:17 | 149,375,379 | 0 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.49381017684936523,
"alphanum_fraction": 0.5577716827392578,
"avg_line_length": 17.87013053894043,
"blob_id": "ff476b36bf32ab98bf82b648cabeaa6c6ac6b02e",
"content_id": "ac294fbf914e4877acfa2974e32369be18490847",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1454,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 77,
"path": "/pa2-old/src/mexp/mexp.c",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<stdlib.h>\n\nint** toexp(int m,int**matrix1, int**matrix2)\n{\n\tint tmp1,tmp2,tmp3,sum=0;\n\tint **ansmat=(int **)malloc(m*sizeof(int *));\n\tfor(tmp1=0;tmp1<m;tmp1++)\n\t{\n\t\tansmat[tmp1]=(int*)malloc(m*sizeof(int));\n\t}\n\tfor(tmp1=0;tmp1<m;tmp1++){\n\t\tfor(tmp2=0;tmp2<m;tmp2++){\n\t\t\tfor(tmp3=0;tmp3<m;tmp3++){\n\t\t\t\tsum+=matrix1[tmp1][tmp3]*matrix2[tmp3][tmp2];\n\t\t\t\t//\tprintf(\"%d * %d = %d\\n\",matrix1[tmp1][tmp3],matrix2[tmp3][tmp2],sum);\n\t\t\t}\n\t\t\tansmat[tmp1][tmp2]=sum;\n\t\t\tsum=0;\n\t\t}\n\t}\n\treturn ansmat;\n}\n\nint main(int argc, char* argv[])\n{\n\tfreopen(argv[1],\"r\",stdin);\n\tint m,tmp1=0,tmp2=0,exp;\n\tscanf(\"%d\\n\",&m);\n\tint **matrix=(int**)malloc(m*sizeof(int*));\n\tint **ans;\n\t//printf(\"%s\\n\",argv[1]);\n\t//freopen(argv[1],\"r\",stdin);\n\tfor(tmp1=0;tmp1<m;tmp1++)\n\t{\n\t\tmatrix[tmp1]=(int*)malloc(m*sizeof(int));\n\t}\n\n\tfor(tmp1 = 0 ; tmp1<m; tmp1++){\n\t\tfor(tmp2=0;tmp2<m;tmp2++){\n\t\t\tscanf(\"%d \",&matrix[tmp1][tmp2]);\n\t\t}\n\t\tscanf(\"\\n\");\n\t}\n\tscanf(\"%d\",&exp);\n\tans=matrix;\n\tif(exp==0){\n\t\tfor(tmp1=0;tmp1<m;tmp1++)\n\t\t{\n\t\t\tif(tmp1==0){\n\t\t\tprintf(\"1\");}\n\t\t\telse{printf(\"0\");}\n\t\t\tfor(tmp2=1;tmp2<m;tmp2++)\n\t\t\t{\n\t\t\t\tif(tmp1==tmp2){printf(\" 1\");}\n\t\t\t\telse{printf(\" 0\");}\n\t\t\t}\n\t\t\tprintf(\"\\n\");\n\t\t}\n\t\treturn EXIT_SUCCESS;\n\t}\n\tfor(tmp1=1;tmp1<exp;tmp1++)\n\t{\n\t\tans=toexp(m,ans,matrix);\n\t}\n\tfor(tmp1=0;tmp1<m;tmp1++)\n\t{\n\t\tprintf(\"%d\",ans[tmp1][0]);\n\t\tfor(tmp2=1;tmp2<m;tmp2++)\n\t\t{\n\t\t\tprintf(\" %d\",ans[tmp1][tmp2]);\n\t\t}\n\t\tprintf(\"\\n\");\n\t}\n\n\treturn EXIT_SUCCESS;\n}\n\n"
},
{
"alpha_fraction": 0.6931818127632141,
"alphanum_fraction": 0.6931818127632141,
"avg_line_length": 21,
"blob_id": "903e34dcf8f2002fdef253fe00a5315e09f3691b",
"content_id": "e2697b1018da2707dd95e9a5a9d4232a45aa9874",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 88,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 4,
"path": "/pa2/src/life/Makefile",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "life: life.c\n\tgcc -g -Wall -Werror -fsanitize=address -o life life.c\nclean:\n\trm -r life\n"
},
{
"alpha_fraction": 0.5919645428657532,
"alphanum_fraction": 0.6216387152671814,
"avg_line_length": 24.867429733276367,
"blob_id": "a004afbd87797b7385518bc1b9b8bdb0ce2576aa",
"content_id": "c61d4dd7dff41aac2085e5bb434cdc33e0073048",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 15805,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 611,
"path": "/pa4/src/truthtable.c",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n\n#include <ctype.h>\n\nint DEBUG=0;\nint powy(int x,int y)\n{\n\tint tmp=0,toret=x;\n\tif(y==0){return 1;}\n\tfor(tmp=1;tmp<y;tmp++)\n\t{\n\t\ttoret*=x;\n\t}\n\treturn toret;\n}\n\ntypedef struct instrblk{\n\tint instr;\n\tint *inputs;\n\tint *outputs;\n\tstruct instrblk *next;\n} instrblk;\n\ntypedef struct strarr{\n\tchar *name;\n\tint num;\n\tstruct strarr *next;\n} strarr;\n\nint insert_var(char *varn,strarr *curr)\n{\n\tint numc;\n\tstrarr *haha=curr;\n\tif(curr==NULL){numc=0;}else{while(haha->next!=NULL){haha=haha->next;}numc=haha->num;}\n\tstrarr *new=(strarr*)malloc(sizeof(strarr));\n\tnew->name=varn;\n\tnumc++;\n\tnew->num=numc;\n\tnew->next=NULL;\n\tif(curr==NULL){curr=new;return 1;}\n\thaha->next=new;\n\treturn numc;\n}\n\nchar* get_name(strarr* head, int target)\n{\n\tstrarr *curr=head;\n\twhile(curr!=NULL){\n\t\tif(curr->num==target){break;}\n\t\tcurr=curr->next;}\n\tif(curr==NULL){return NULL;}\n\treturn curr->name;\n}\n\nint get_num(strarr* head, char* val)\n{\n\tstrarr *curr=head;\n\twhile(curr!=NULL)\n\t{\n\t\tif(strcmp(curr->name,val)==0){break;}\n\t\tcurr=curr->next;\n\t}\n\tif(curr==NULL){return -1;}\n\treturn curr->num;\n\t\n}\n\n/*void create_instr(instrblk *curr, int func, int *input,int *output)\n{\n\tinstrblk new= (instrblk *)malloc(sizeof(instrblk));\n\tnew->instr=func;\n\tnew->inputs=input;\n\tnew->outputs=output;\n\tif(curr==NULL){curr=new;return;}\n\tcurr->next=new;\n\treturn;\n}*/\n\nint chkdep(instrblk *curr, int *varin)\n{\n\tint tempvar=0;\n\tint size=0;\n\tif(curr==NULL){return -1;}\n\tif(curr->instr==2){size=1;}\n\tif(curr->instr>=3&&curr->instr<=6){size=2;}\n\tif(curr->instr==7){size=-(curr->inputs[0])+1;tempvar=1;}\n\tif(curr->instr==8){tempvar=1;size=powy(2,-curr->inputs[0])+1-curr->inputs[0];}\n\tif(curr->instr==9){size=1;}\n\tif(DEBUG==1){printf(\"CHKDEP START\\n\");}\n\tfor(;tempvar<size;tempvar++)\n\t{\n\t\tif(DEBUG==1){\n\t\tprintf(\"Checking %d\\n\",tempvar);}\n\t\tif (curr->inputs[tempvar] > 0) {\n\t\t\tif (varin[curr->inputs[tempvar]] == -1) { \n\t\t\t\tif(DEBUG==1){\n\t\t\t\t\tprintf(\"We need: %d, do we have?:%d\",curr->inputs[tempvar],varin[curr->inputs[tempvar]]);}\n\t\t\treturn -1; }\n\t\t}else\n\t\t{ }\n\n\t}\n\tif(DEBUG==1){printf(\"CHKDEP STOPPED\\n\");}\n\treturn 0;\n}\nvoid printarr(int* a,int valnums)\n{\n\tint tmp=1;\n\tprintf(\"PRINT CURR ARR\\n\");\n\tfor(tmp=1;tmp<valnums;tmp++)\n\t{\n\t\tprintf(\"%d:%d\\n\",tmp,a[tmp]);\n\t}\n\tprintf(\"\\n\");\n}\nvoid instrsort(instrblk *head,int valnums)\n{\n\tint *a,tempvar=0,size=0;\n\tint counter=0;\n\tint flag=0;\n\tinstrblk *curr=head,*before=head,*currbefore=head;\n\ta=(int*)malloc(valnums*sizeof(int));\n\tmemset(a,-1,sizeof(int)*valnums);\n\tif(DEBUG==1){\n\t\tprintf(\"\\nSTARTSORT\\n\");}\n\twhile(curr!=NULL){\n\t\tif(curr==NULL){break;}\n\t\tif(DEBUG==1){\n\t\tprintf(\"%d\\n\",counter);}\n\t\tcounter++;\n\t\tif(curr->instr==0){//inputblock\n\t\t\tfor(tempvar=1;tempvar<=-(curr->outputs[0]);tempvar++){\n\t\t\t\ta[curr->outputs[tempvar]]=1;\n\t\t\t}\n\t\t\tbefore=curr;\n\t\t\tcurrbefore=curr;\n\t\t\tcurr=curr->next;\n\t\t\tcontinue;\n\t\t}\n\t\t//check if satisfy dependence\n\t\tif(chkdep(curr,a)==-1){\n\t\t\tif(DEBUG==1){\n\t\t\tprintf(\"%d Block Not Pass, Continue to next block\\n\",curr->instr);\n\t\t\tprintarr(a,valnums);}\n\t\t\tcurrbefore=curr;\n\t\t\tcurr=curr->next;\n\t\t\tflag=1;\n\t\t\tcontinue;}\n\t\t//dependence satisfied\n\t\tif(DEBUG==1){\n\t\tprintf(\"%d DEPENDENCE SATISFIED\\n\",curr->instr);\n\t\t\n\t\tprintarr(a,valnums);\n\t\t}\n\t\tif(curr->instr==1){tempvar=0;size=1;}\n\t\tif(curr->instr==2){tempvar=0;size=1;}\n\t\tif(curr->instr>=3&&curr->instr<=6){tempvar=0;size=1;}\n\t\tif(curr->instr==7){size=powy(2,-(curr->inputs[0]));tempvar=0;}\n\t\tif(curr->instr==8){tempvar=0;size=1;}\n\t\tif(curr->instr==9){tempvar=0;size=1;}\n\t\tfor(;tempvar<size;tempvar++)\n\t\t{\n\t\t\tif (curr->outputs[tempvar] > 0) {\n\t\t\t\ta[curr->outputs[tempvar]] = 1;\n\t\t\t}\n\t\t}\n\t\tif(flag==1){\n\t\t\tif(DEBUG==1){\n\t\t\t\tprintf(\"We need to switch two block from: %d, to %d\\n\",curr->instr,before->instr);}\t\n\t\t\tcurrbefore->next=curr->next;\n\t\t\tcurr->next=before->next;\n\t\t\tbefore->next=curr;\n\t\t\tbefore=curr;\n\t\t\tcurrbefore=curr;\n\t\t\tcurr=curr->next;\n\t\t\tflag=0;}\n\t\telse\n\t\t{\n\t\t\tif(DEBUG==1){\n\t\t\tprintf(\"CONTINUE TO NEXT\\n\");}\n\t\t\tbefore=curr;\n\t\t\tcurrbefore=curr;\n\t\t\tcurr=curr->next;\n\t\t}\n\n\t\t/*if(curr->next==NULL){//last member in the list\n\t\t\tcurr=before->next;\n\t\t\tbefore=curr;\n\t\t}\n\t\telse{//not the last member in the list\n\t\t\tcurr=curr->next;\n\t\t}*/\n\t}\n\tif(DEBUG==1){\n\t\tprintf(\"EXIT SORT\\n\");}\n\treturn;\n}\nint NOT(int input)\n{\n\tif(DEBUG==1){\n\t\tprintf(\"Not\\n%d\\n\",input);}\n\treturn !input;\n}\nint AND(int input1,int input2)\n{\n\tif(DEBUG==1){\n\t\tprintf(\"AND\\n%d %d\\n\",input1,input2);}\n\treturn input1&&input2;\n}\nint OR(int input1,int input2)\n{\n\tif(DEBUG==1){\n\tprintf(\"OR\\n%d %d\\n\",input1,input2);}\n\treturn input1||input2;\n}\nint NAND(int input1,int input2)\n{\n\tif(DEBUG==1){\n\tprintf(\"NAND\\n%d %d\\n\",input1,input2);}\n\treturn !(input1&&input2);\n}\nint NOR(int input1,int input2)\n{\n\tif(DEBUG==1){\n\tprintf(\"NOR\\n%d %d\\n\",input1,input2);}\n\treturn !(input1||input2);\n}\nint XOR(int input1,int input2)\n{\n\tif(DEBUG==1){\n\tprintf(\"XOR\\n%d %d\\n\",input1,input2);}\n\tif((input1||input2)==1&&!(input1&&input2)){return 1;}\n\telse{return 0;}\n}\nint DECODER(int n, int* input1) //return the place of the digit with 1\n{\n\tint miku,hatsune=0;\n\tint temp = n-2;\n\tif(DEBUG==1){\n\tprintf(\"Decoder Block:\\n\");}\n\tfor(miku=1;miku<n;miku++)\n\t{\n\t\thatsune+=input1[miku]*powy(2,temp);\n\t\tif(DEBUG==1){\n\t\t\t\tprintf(\"%d %d %d Curr Sum:%d\\n\",temp,input1[miku],powy(2,temp),hatsune);}\n\t\ttemp--;\n\t}\n\treturn hatsune;\n}\nint MUX(int n, int* input1)\n//input1 is the \"selector\"\n//input2 is to be selected\n{\n\tint miku,hatsune=0;\n\tint temp = n-1;\n\tif(DEBUG==1){\n\t\tprintf(\"MUX:\\n\");}\n\tfor(miku= powy(2, n)+1;miku<powy(2, n)+n+1;miku++)\n\t{\n\t\tif(DEBUG==1){\n\t\t\t\tprintf(\"Digit:%d,Place:%d,Datainarray:%d\\n\", temp, miku, input1[miku]);\n\t\t\t\tprintf(\"power of digit: %d\\n\", powy(2, temp));}\n\t\thatsune+=input1[miku]*powy(2,temp);\n\t\ttemp--;\n\t\t\n\t}\n\tif(DEBUG==1){\n\tprintf(\"Adder:%d THis should give the place of the output\\n\", hatsune);}\n\treturn input1[hatsune+1];\n}\t\nvoid LOAD_EFFECTIVE_VALUE(int* vals, instrblk *curr, int* hatsune,int size) //hatsune is the return array, size \n{\n\tint miku = 0;\n\t\n\t\n\tfor(;miku<size;miku++)\n\t{\n\t\tif (curr->inputs[miku] <= 0) { hatsune[miku] = -curr->inputs[miku]; continue; }\n\t\thatsune[miku]=vals[curr->inputs[miku]];\n\t\t\n\t}\n\treturn;\n}\nint* operation(instrblk *curr, int* vals)\n{\n\tint *hatsune,miku;\n\tint temp = 0;\n\tswitch(curr->instr){\n\t\tcase 0: break;\n\t\tcase 1: //NOT\n\t\t\thatsune = (int*)malloc(sizeof(int));\n\t\t\tLOAD_EFFECTIVE_VALUE(vals, curr, hatsune, 1);\n\t\t\tvals[curr->outputs[0]]=NOT(hatsune[0]);\n\t\t\tbreak;\n\t\tcase 2: //AND\n\t\t\thatsune = (int*)malloc(2 * sizeof(int));\n\t\t\tLOAD_EFFECTIVE_VALUE(vals, curr, hatsune, 2);\n\t\t\tvals[curr->outputs[0]]=AND(hatsune[0],hatsune[1]);\n\t\t\tbreak;\n\t\tcase 3: //OR\n\t\t\thatsune = (int*)malloc(2 * sizeof(int));\n\t\t\tLOAD_EFFECTIVE_VALUE(vals, curr, hatsune, 2);\n\t\t\tvals[curr->outputs[0]]=OR(hatsune[0],hatsune[1]);\n\t\t\tbreak;\n\t\tcase 4: //NAND\n\t\t\thatsune = (int*)malloc(2 * sizeof(int));\n\t\t\tLOAD_EFFECTIVE_VALUE(vals, curr, hatsune, 2);\n\t\t\tvals[curr->outputs[0]]=NAND(hatsune[0],hatsune[1]);\n\t\t\tbreak;\n\t\tcase 5: //NOR\n\t\t\thatsune = (int*)malloc(2 * sizeof(int));\n\t\t\tLOAD_EFFECTIVE_VALUE(vals, curr, hatsune, 2);\n\t\t\tvals[curr->outputs[0]]=NOR(hatsune[0],hatsune[1]);\n\t\t\tbreak;\n\t\tcase 6: //XOR\n\t\t\thatsune = (int*)malloc(2 * sizeof(int));\n\t\t\tLOAD_EFFECTIVE_VALUE(vals, curr, hatsune, 2);\n\t\t\tvals[curr->outputs[0]]=XOR(hatsune[0],hatsune[1]);\n\t\t\tbreak;\n\t\tcase 7: //DECODER\n\t\t\thatsune=(int*)malloc((1-curr->inputs[0])*sizeof(int));\n\t\t\tLOAD_EFFECTIVE_VALUE(vals,curr,hatsune,1-curr->inputs[0]);\n\t\t\ttemp = DECODER(1-curr->inputs[0], hatsune);\n\t\t\tvals[curr->outputs[temp]]=1;\n\t\t\tbreak;\n\t\tcase 8://MUX\n\t\t\thatsune = (int*)malloc((1 - curr->inputs[0] + powy(2, -curr->inputs[0])) * sizeof(int));\n\t\t\tLOAD_EFFECTIVE_VALUE(vals,curr,hatsune, 1 - curr->inputs[0] + powy(2, -curr->inputs[0]));\n\t\t\tmiku=hatsune[0];\n\t\t\tvals[curr->outputs[0]]=MUX(miku,hatsune);\n\t\t\tbreak;\n\t\tcase 9://PASS\n\t\t\thatsune = (int*)malloc(sizeof(int));\n\t\t\tLOAD_EFFECTIVE_VALUE(vals,curr,hatsune, 1);\n\t\t\tif(DEBUG==1){printf(\"PASS BLOCK\\nPassing from %d:%d to %d\\n\",curr->inputs[0],hatsune[0],curr->outputs[0]);}\n\t\t\tvals[curr->outputs[0]]=hatsune[0];\n\t\t\tbreak;\n\t}\n\tif(curr->next==NULL){if(curr->instr!=0){free(hatsune);}return vals;}\n\telse{if(curr->instr!=0){free(hatsune);}return operation(curr->next,vals);}\n}\n\nvoid printTruth(instrblk *instr,int *outputs,int valnums){\n\tint numinput=-instr->outputs[0],numoutput=-outputs[0],pos=0;\n\tint *a,*mask;\n\ta=(int*)malloc(valnums*sizeof(int));\n\tmask = (int*)malloc(valnums * sizeof(int));\n\n\tint size=powy(2,numinput),tempvar,tempvar1,OF=0;\n\tmemset(a,0,sizeof(int)*valnums);\n\tmemset(mask, 0, sizeof(int)*valnums);\n\tfor (tempvar = 1; tempvar <= numinput; tempvar++) {\n\t\tmask[instr->outputs[tempvar]] = 1;\n\t}\n\tfor(tempvar1=1;tempvar1<=numinput;tempvar1++){\n\tprintf(\"%d \",a[instr->outputs[tempvar1]]);\n\t}\n\toperation(instr,a);\n\tprintf(\"|\");\n\tfor(tempvar1=1;tempvar1<=numoutput;tempvar1++){\n\t\tprintf(\" %d\",a[outputs[tempvar1]]);\n\t}\n\tprintf(\"\\n\");\n\tfor(tempvar=1;tempvar<size;tempvar++)\n\t{\n\t\tOF=0;\n\t\ta[instr->outputs[numinput]]++;\n\t\tif(a[instr->outputs[numinput]]==2){\n\t\t\ta[instr->outputs[numinput]]=0;\n\t\t\tOF=1;\n\t\t\tpos=numinput-1;\n\t\t\twhile(OF!=0){\n\t\t\t\t\n\t\t\t\ta[instr->outputs[pos]]++;\n\t\t\t\tOF=0;\n\t\t\t\tif(a[instr->outputs[pos]]==2){\n\t\t\t\t\ta[instr->outputs[pos]]=0;\n\t\t\t\t\tOF=1;\n\t\t\t\t\tpos--;\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t\t//set all other values to zero\n\t\tfor (tempvar1 = 0; tempvar1 < valnums; tempvar1++)\n\t\t{\n\t\t\ta[tempvar1] *= mask[tempvar1];\n\n\t\t}\n\t\tfor(tempvar1=1;tempvar1<=numinput;tempvar1++){\n\t\t\tprintf(\"%d \",a[instr->outputs[tempvar1]]);\n\t\t}\n\t\toperation(instr,a);\n\t\tprintf(\"|\");\n\t\tfor(tempvar1=1;tempvar1<=numoutput;tempvar1++){\n\t\t\tprintf(\" %d\",a[outputs[tempvar1]]);\n\t\t}\n\t\tprintf(\"\\n\");\n\t}\n\tif(DEBUG==1){\n\tprintf(\"%d %d\",numoutput,valnums);}\n\treturn;\n}\n\nint* scanstring(strarr **vars)\n{\n\tchar* tmp;\n\tchar temp;\n\tint nowint=0,last=0,*output,tt;\n\tint stop=0;\n\tint isDigit=1;//1 is true 0 is false\n\toutput=(int*)malloc(sizeof(int));\n\ttmp=(char*)malloc(sizeof(char));\n\twhile(1)\n\t{\t\t\n\t\tif(stop==1){\n\t\t\t//printf(\"\\n%d\\n\",(int)(sizeof(output)/sizeof(int)));\n\t\t\t//printf(\"%d\\n\",(int)sizeof(output));\n\t\t\t//printf(\"%d\\n\",output[nowint-1]);\n\t\t\treturn output;}\n\t\tif(scanf(\"%c\",&temp)==EOF){\n\t\t\tstop = 1;\n\n\t\t}\n\n\t\tif(temp==':'){continue;}\n\t\tif(temp==' '||temp=='\\n'||stop==1){\n\t\t\tif(temp=='\\n'){stop=1;}\n\t\t\tif(last==0){if(temp=='\\n'){return output;}continue;}\n\t\t\telse{last=0;\n\t\t\t\tif(isDigit==1){output=(int*)realloc(output,(nowint+1)*sizeof(int));\n\t\t\t\toutput[nowint]=-atoi(tmp);\n\t\t\t\tlast=0;\n\t\t\t\tnowint++;\n\t\t\t\tisDigit=1;\n\t\t\t\ttmp=(char*)malloc(sizeof(char));if(temp=='\\n'){return output;}\n\t\t\t\tcontinue;}\n\t\t\t\telse{\n\t\t\t\t//printf(\"%s:\",tmp);\n\t\t\t\ttt=get_num(*vars,tmp);\n\t\t\t\t//printf(\"%d\\n\",tt);\n\t\t\t\tif(tt==-1){\n\t\t\t\t\tif(*vars==NULL){\n\t\t\t\t\t\tstrarr *new=(strarr*)malloc(sizeof(strarr));\n\t\t\t\t\t\tnew->name=tmp;\n\t\t\t\t\t\tnew->num=1;\n\t\t\t\t\t\tnew->next=NULL;\n\t\t\t\t\t\t*vars=new;\n\t\t\t\t\t\ttt=1;\n\t\t\t\t\t}else{\n\t\t\t\t\ttt=insert_var(tmp,*vars);}\n\t\t\t\t\t}\n\t\t\t\toutput=(int*)realloc(output,(nowint+1)*sizeof(int));\n\t\t\t\t//printf(\"nowint:%d\\nintsize:%d\",nowint,(int)sizeof(int));\n\t\t\t\t//printf(\"output:%d\",(int)sizeof(output));\n\t\t\t\toutput[nowint]=tt;\n\t\t\t\tnowint++;\n\t\t\t\tlast=0;\n\t\t\t\tisDigit=1;\n\t\t\t\ttmp=(char*)malloc(sizeof(char));if(temp=='\\n'){return output;}continue;\n\t\t\t\t\t}\n\t\t\t\t\n\t\t\t}\n\t\t}\n\t\t\n\t\tif(isdigit(temp)==0){isDigit=0;}\n\t\ttmp=(char*)realloc(tmp,(last+2)*sizeof(char));\n\t\ttmp[last]=temp;\n\t\ttmp[last+1]='\\0';\n\t\t//printf(\"%s\\n\",tmp);\n\t\tif(nowint==0){}else{\n\t\t//printf(\"%d\\n\",output[nowint-1]);\n\t\t}\n\t\tlast++;\n\t}\n\n}\n\nvoid toinout(int* orig,instrblk *instr,int where,int length){\n\tint ptr=0;\n\tinstr->inputs=(int*)malloc(sizeof(int)*(where));\n\tinstr->outputs=(int*)malloc(sizeof(int)*(length-where));\n\twhile(ptr<length){\n\t\tif(ptr<where){//\"FOR WHERE GIVE RIGHT POINT\"\n\t\t\n\t\tinstr->inputs[ptr]=orig[ptr];}\n\t\telse{\n\t\t\tinstr->outputs[ptr-where]=orig[ptr];}\n\t\tptr++;\n\t}\n\treturn;\n}\n\nvoid print_instrblk(instrblk *instr){\n\tint temp;\n\tswitch(instr->instr)\n\t{\n\t\tcase 0: printf(\"Input Block\\n Outputs:\");for(temp=1;temp<=-(instr->outputs[0]);temp++){printf(\"%d \",instr->outputs[temp]);}printf(\"\\n\");break;\n\t\tcase 1: printf(\"NOT Block\\n Inputs:%d\\nOutputs:%d\\n\\n\",instr->inputs[0],instr->outputs[0]);break;\n\t\tcase 2: printf(\"AND Block\\n Inputs:%d,%d\\nOutputs:%d\\n\\n\",instr->inputs[0],instr->inputs[1],instr->outputs[0]);break;\n\t\tcase 3: printf(\"OR Block\\n Inputs:%d,%d\\nOutputs:%d\\n\\n\",instr->inputs[0],instr->inputs[1],instr->outputs[0]);break;\n\t\tcase 4: printf(\"NAND Block\\n Inputs:%d,%d\\nOutputs:%d\\n\\n\",instr->inputs[0],instr->inputs[1],instr->outputs[0]);break;\n\t\tcase 5: printf(\"NOR Block\\n Inputs:%d,%d\\nOutputs:%d\\n\\n\",instr->inputs[0],instr->inputs[1],instr->outputs[0]);break;\n\t\tcase 6: printf(\"XOR Block\\n Inputs:%d,%d\\nOutputs:%d\\n\\n\",instr->inputs[0],instr->inputs[1],instr->outputs[0]);break;\n\t\tcase 7: printf(\"DECODER\\n Numbers:%d\\n\", -instr->inputs[0]);\n\t\t\tprintf(\"Inputs:\\n\");\n\t\t\tfor (temp = 1; temp <= -instr->inputs[0]; temp++)\n\t\t\t{\n\t\t\t\tprintf(\"%d \", instr->inputs[temp]);\n\t\t\t}\n\t\t\tprintf(\"\\nOutputs:\\n\");\n\t\t\tfor (temp = 0; temp <powy(2,-instr->inputs[0]); temp++)\n\t\t\t{\n\t\t\t\tprintf(\"%d \", instr->outputs[temp]);\n\t\t\t}\n\t\t\tprintf(\"\\n\");\n\t\t\tbreak;\n\t\tcase 8: printf(\"MUX\\n Numbers:%d\\n\", -instr->inputs[0]);\n\t\t\tprintf(\"Inputs:\\n\");\n\t\t\tfor (temp = 1; temp <powy(2, -instr->inputs[0])-instr->inputs[0]+1; temp++)\n\t\t\t{\n\t\t\t\tprintf(\"%d \", instr->inputs[temp]);\n\t\t\t}\n\t\t\tprintf(\"\\nOutputs:\\n\");\n\t\t\tprintf(\"%d\", instr->outputs[0]);\n\t\t\tprintf(\"\\n\");\n\t\t\tbreak;\n\t\tcase 9: printf(\"PASS BLOCK\\n Passing %d to %d\\n\",instr->inputs[0],instr->outputs[0]);break;\n\t}\n\treturn;\n}\n\nint* parse(strarr **vars, instrblk **instr)\n{\n\tchar ins[100];\n\tinstrblk *tmp1,*tmp2;\n\tint *output;\n\tint *tmp3;\n\t//int hh;\n\twhile(scanf(\" %s \",ins)!=EOF)\n\t{\n\t\ttmp1=(instrblk*) malloc(sizeof(instrblk));\n\t\tif(strcmp(ins,\"INPUT\")==0){tmp1->instr=0;tmp1->inputs=NULL;tmp1->outputs=scanstring(vars);}\n\t\tif(strcmp(ins,\"OUTPUT\")==0){output=scanstring(vars);continue;}\n\t\tif(strcmp(ins,\"NOT\")==0){tmp1->instr=1;tmp3=scanstring(vars);toinout(tmp3,tmp1,1,2);}\n\t\tif(strcmp(ins,\"AND\")==0){tmp1->instr=2;tmp3=scanstring(vars);toinout(tmp3,tmp1,2,3);}\n\t\tif(strcmp(ins,\"OR\")==0){tmp1->instr=3;tmp3=scanstring(vars);toinout(tmp3,tmp1,2,3);}\n\t\tif(strcmp(ins,\"NAND\")==0){tmp1->instr=4;tmp3=scanstring(vars);toinout(tmp3,tmp1,2,3);}\n\t\tif(strcmp(ins,\"NOR\")==0){tmp1->instr=5;tmp3=scanstring(vars);toinout(tmp3,tmp1,2,3);}\n\t\tif(strcmp(ins,\"XOR\")==0){tmp1->instr=6;tmp3=scanstring(vars);toinout(tmp3,tmp1,2,3);}\n\t\tif(strcmp(ins,\"DECODER\")==0){tmp1->instr=7;\n\t\ttmp3=scanstring(vars);\n\t\ttoinout(tmp3,tmp1,-tmp3[0]+1,1-tmp3[0]+powy(2,-tmp3[0]));}\n\t\tif(strcmp(ins,\"MULTIPLEXER\")==0){tmp1->instr=8;tmp3=scanstring(vars);toinout(tmp3,tmp1,powy(2,-tmp3[0])+1-tmp3[0],2-tmp3[0]+powy(2,-tmp3[0]));}\n\t\tif(strcmp(ins,\"PASS\")==0){tmp1->instr=9;tmp3=scanstring(vars);toinout(tmp3,tmp1,1,2);}\n/* \t\tprintf(\"%d\\n\",tmp1->instr);\n\t\tprintf(\"Inputs:\\n\");\n\t\tif(tmp1->inputs==NULL){printf(\"No Inputs\\n\");}\n\t\telse{\n\t\t\tfor(hh=0;hh<sizeof(tmp1->inputs)/sizeof(int);hh++)\n\t\t\t{\n\t\t\t\tprintf(\"%d \",tmp1->inputs[hh]);\n\t\t\t}\n\t\t}\n\t\tprintf(\"\\nOutputs:\\n\");\n\t\tif(tmp1->outputs==NULL){printf(\"No Outputs\\n\");}\n\t\telse{\n\t\t\tfor(hh=0;hh<(sizeof(tmp1->outputs)/sizeof(int));hh++)\n\t\t\t{\n\t\t\t\tprintf(\"%d \",tmp1->outputs[hh]);\n\t\t\t}\n\t\t}\n\t\tprintf(\"\\n\\n\"); */\n\t\tif(DEBUG==1){\n\t\t\t\tprint_instrblk(tmp1);}\n\t\ttmp1->next=NULL;\n\t\tif(*instr==NULL){*instr=tmp1;tmp2=tmp1;}\n\t\telse{tmp2->next=tmp1;tmp2=tmp2->next;}\n\n\t}\t\n\t\n\treturn output;\n}\n\n\n\nint main(int argc,char* argv[])\n{\n\tstrarr *vars=NULL,*tempstrarr;\n\tinstrblk *a=NULL,*b=NULL;\n\tint cntarg=0,*output;\n\t//\n\t//initializing vals\n\t//\n\tif(argc>1){freopen(argv[1],\"r\",stdin);}\n\toutput=parse(&vars,&a);\n\ttempstrarr=vars;\n\twhile(tempstrarr!=NULL){cntarg++;tempstrarr=tempstrarr->next;}\n\t//printf(\"There are %d variables in the instruction\",cntarg);\n\tinstrsort(a,cntarg+1);\n\tif(DEBUG==1){\n\t\tprintf(\"Execute Print INSTRBLK After Sort\\n\");\n\t\tb=a;\n\t\twhile(b!=NULL){print_instrblk(b);b=b->next;}\n\t\t}\n\tprintTruth(a,output,cntarg+1);\n\t\n\treturn EXIT_SUCCESS;\n\n}\n"
},
{
"alpha_fraction": 0.5414012670516968,
"alphanum_fraction": 0.5636942386627197,
"avg_line_length": 15.526315689086914,
"blob_id": "78ec639fae48722be86103d37f214559e023a052",
"content_id": "9d2909cf2c42d6422ff27885601ea70867e79de4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 314,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 19,
"path": "/pa1/src/rle/test.c",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<stdlib.h>\n#include<string.h>\nint main()\n{\n\tchar *a,*b;\n\tchar *z;\n\tint c =0;\n\ta=\"asdkjfhaksjdh\";\n\tb=(char *)malloc((strlen(a)+2)*sizeof(char));\n\tfor(c=0;c<strlen(a);c++){\n\tb[c]=a[c];\n\t}\n\tz=(char*)malloc(2*sizeof(char));\n\tz[0]='a';\n\tb[c]='\\0';\n\tprintf(\"%d\",(int)(strlen(z)));\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.4000000059604645,
"alphanum_fraction": 0.7333333492279053,
"avg_line_length": 14,
"blob_id": "933d5b5922f82aa4aeff5d2daeb2a97294bdef54",
"content_id": "ead86d549719a939cdd3dfc0385821f96f580c03",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 15,
"license_type": "no_license",
"max_line_length": 14,
"num_lines": 1,
"path": "/README.md",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "# CS211-FALL18\n"
},
{
"alpha_fraction": 0.7096773982048035,
"alphanum_fraction": 0.7096773982048035,
"avg_line_length": 22.25,
"blob_id": "c227db9636f6bb2c7cb7d03ad1440e91cbf36df8",
"content_id": "1637c0e153249130de26cca4a75576adafff8795",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 93,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 4,
"path": "/pa2/src/llist/Makefile",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "llist: llist.c\n\tgcc -g -Wall -Werror -fsanitize=address -o llist llist.c\nclean:\n\trm -f llist\n"
},
{
"alpha_fraction": 0.7244898080825806,
"alphanum_fraction": 0.7244898080825806,
"avg_line_length": 23.5,
"blob_id": "51c635c7f4107f131c2441ea632f29eb76fbd63a",
"content_id": "607d2153c85c853e5010a8f201c7f19055c00c9a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 98,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 4,
"path": "/pa2/src/queens/Makefile",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "queens: queens.c\n\tgcc -g -Wall -Werror -fsanitize=address -o queens queens.c\nclean:\n\trm -r queens\n"
},
{
"alpha_fraction": 0.708737850189209,
"alphanum_fraction": 0.708737850189209,
"avg_line_length": 24.5,
"blob_id": "9a85e95f10c1adfbe173f2b3cd4d3d26894ad1bd",
"content_id": "24becb10d7ceb328b3d75aef1d57d9f0d5a39178",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 103,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 4,
"path": "/pa2-old/src/stddev/Makefile",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "stddev: stddev.c\n\tgcc -g -lm -Wall -Werror -fsanitize=address -o stddev stddev.c\nclean:\n\trm -f stddev\n\n"
},
{
"alpha_fraction": 0.6440042853355408,
"alphanum_fraction": 0.6456102728843689,
"avg_line_length": 18.755556106567383,
"blob_id": "8c7709f443af82aa95c9f5ec3e8a26699bd19a56",
"content_id": "f4cfa00382f4401829674dbfe255f8c35398564c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1868,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 90,
"path": "/pa2/src/llist/llist.c",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <stdlib.h>\r\n#include <string.h>\r\ntypedef struct llnode{\r\n\tint num;\r\n\tstruct llnode *next;\r\n}llnode;\r\nllnode* insert(llnode *p, int x)\r\n{\r\n\tstruct llnode *currhead,*beforehead=NULL,*temp;\r\n\tcurrhead=p;\r\n\tif(currhead==NULL)\r\n\t{\r\n\t\tcurrhead=(llnode*)malloc(sizeof(llnode));\r\n\t\tcurrhead->num=x;\r\n\t\tcurrhead->next=NULL;\r\n\t\treturn currhead;\r\n\t}\r\n\twhile(currhead!=NULL&&currhead->num<=x)\r\n\t{\r\n\t\tif(currhead->num==x){return p;}\r\n\t\tbeforehead=currhead;\r\n\t\tcurrhead=currhead->next;\r\n\t}\r\n\tif(beforehead==NULL){\r\n\t\tbeforehead=(llnode*)malloc(sizeof(llnode));\r\n\t\tbeforehead->num=x;\r\n\t\tbeforehead->next=currhead;\r\n\t\treturn beforehead;\r\n\t}\r\n\ttemp=(llnode*)malloc(sizeof(llnode));\r\n\ttemp->num=x;\r\n\ttemp->next=currhead;\r\n\tbeforehead->next=temp;\r\n\treturn p;\r\n}\r\nint checklength(llnode *p)\r\n{\r\n\tint a=0;\r\n\tstruct llnode *head=p;\r\n\twhile (head!=NULL)\r\n\t{\r\n\t\ta++;\r\n\t\thead=head->next;\r\n\t}\r\n\treturn a;\r\n}\r\nllnode* delete(llnode *p, int target)\r\n{\r\n\tstruct llnode *currhead,*beforehead;\r\n\tcurrhead=p;\r\n\twhile(currhead!=NULL&&currhead->num!=target)\r\n\t{\r\n\t\tbeforehead=currhead;\r\n\t\tcurrhead=currhead->next;\r\n\t}\r\n\tif(beforehead==NULL&&currhead!=NULL){beforehead=p;p=p->next;free(beforehead);return p;}\r\n\tif(currhead==NULL){return p;}\r\n\tbeforehead->next=currhead->next;\r\n\tfree(currhead);\r\n\treturn p;\r\n}\r\nvoid printllist(llnode *p,int counter)\r\n{\r\n\tstruct llnode *curr;\r\n\tprintf(\"%d :\",counter);\r\n\tcurr=p;\r\n\twhile(curr!=NULL){\r\n\t\tprintf(\" %d\",curr->num);\r\n\t\t\r\n\t\tcurr=curr->next;\r\n\t}\r\n\tprintf(\"\\n\");\r\n\treturn;\r\n}\r\n\r\n\r\n\r\nint main(int argc,char* argv[])\r\n{\r\n\tstruct llnode* head=NULL;\r\n\tint counter=0,num=0;\r\n\tchar input;\r\n\t\r\n\twhile(scanf(\"%c %d\",&input,&num)!=EOF){\r\n\t\tif(input=='i'){head=insert(head,num);counter++;printllist(head,checklength(head));}\r\n\t\tif(input=='d'){head=delete(head,num);counter--;printllist(head,checklength(head));}\r\n\t}\r\n\treturn EXIT_SUCCESS;\r\n}\r\n"
},
{
"alpha_fraction": 0.6292017102241516,
"alphanum_fraction": 0.644957959651947,
"avg_line_length": 16,
"blob_id": "84d310b99e0d442acd8b06ff3c36e462b335b2a3",
"content_id": "3e27bb29c6d9a4271acfa06894b6b4b5918f2b06",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 952,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 56,
"path": "/pa2-old/src/stddev/stddev.c",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<stdlib.h>\n#include<math.h>\ntypedef struct llnode{\n\tdouble num;\n\tstruct llnode *next;\n}llnode;\n\nint main(int argc,char* argv[])\n{\n\tstruct llnode *head=NULL;\n\tstruct llnode *temp=NULL;\n\tstruct llnode *curr=NULL;\n\tdouble currnum=0;\n\tdouble mean=0;\n\tdouble standdev=0;\n\tdouble temp2=0;\n\tint count=0;\n\twhile(scanf(\"%lf\",&currnum)==1)\n\t{\n\t\tif(head==NULL){\n\t\t\thead=(llnode *) malloc(sizeof(llnode));\n\t\t\thead->num=currnum;\n\t\t\thead->next=NULL;\n\t\t\tcurr=head;\n\t\t\t}\n\t\telse{\n\t\t\ttemp=(llnode*)malloc(sizeof(llnode));\n\t\t\ttemp->num=currnum;\n\t\t\ttemp->next=NULL;\n\t\t\tcurr->next=temp;\n\t\t\tcurr=temp;\n\t\t}\n\t\tcurrnum=0;\n\t\tcount++;\n\t}\n\tcurr=head;\n\twhile(curr!=NULL)\n\t{\n\t\tmean+=curr->num;\n\t\tcurr=curr->next;\n\t}\n\tmean=mean/count;\n\tcurr=head;\n\tprintf(\"mean: %.0f\\n\",mean);\n\twhile(curr!=NULL)\n\t{\n\t\ttemp2+=pow(curr->num-mean,2);\n\t\tcurr=curr->next;\n\t}\n\ttemp2=temp2/count;\n\tstanddev=sqrt(temp2);\n\tprintf(\"stddev: %.0f\\n\",standdev);\n\treturn EXIT_SUCCESS;\n\n}\n"
},
{
"alpha_fraction": 0.6790123581886292,
"alphanum_fraction": 0.6790123581886292,
"avg_line_length": 19,
"blob_id": "99bf175e068d1c03577734ad1f1797cf3bb48b8e",
"content_id": "d2e6ef04640e539af1ac613e20aa9b79f3c2b5ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 81,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 4,
"path": "/pa1/src/rle/Makefile",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "rle: rle.c\n\tgcc -Wall -Werror -fsanitize=address -o rle rle.c\nclean:\n\trm -f rle\n\n"
},
{
"alpha_fraction": 0.5678327679634094,
"alphanum_fraction": 0.6097838282585144,
"avg_line_length": 26.255813598632812,
"blob_id": "5122c3d6ba095641dbed5c502106d0872f54214a",
"content_id": "9e513c7c6aea1e13376efce7fc2b04fc51b7812c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 7032,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 258,
"path": "/pa5/src/cachesim.c",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <ctype.h>\n#include <string.h>\nint DEBUG=0;\nint log2base(int x)\n{\n\tint tmp=0,tmp2=x;\n\tunsigned nbit=0;\n\twhile(tmp2!=0){\n\t\ttmp2=tmp2>>1;\n\t\ttmp++;\n\t}\n\tnbit=(1<<tmp)&x;\n\tif(nbit==0){\n\treturn tmp-1;}\n\telse{return -1;}\n}\n\nvoid print(int mr,int mw,int ch,int cm)\n{\n\tprintf(\"Memory reads: %d\\n\",mr);\n\tprintf(\"Memory writes: %d\\n\",mw);\n\tprintf(\"Cache hits: %d\\n\",ch);\n\tprintf(\"Cache misses: %d\\n\",cm);\n\treturn;\n}\nint checkpriority(int **priority,int sets,int assoc)\n{\n\t//return least priority or the entry with zero\n\tint tmp1=0,min=0,zerofl=0,max=0,mini=100000000;\n\tfor(tmp1=0;tmp1<assoc;tmp1++)\n\t{\n\t\tif(priority[sets][tmp1]==0&&zerofl!=1){min=tmp1;zerofl=1;}\n\t\tif(priority[sets][tmp1]<mini&&zerofl!=1){min=tmp1;mini=priority[sets][tmp1];}\n\t\tif(priority[sets][tmp1]>max){max=priority[sets][tmp1];}\n\t}\n\tpriority[sets][min]=max+1;\n\tif(zerofl==0){\n\t\tfor(tmp1=0;tmp1<assoc;tmp1++)\n\t\t{\n\t\t\tpriority[sets][tmp1]--;\n\t\t}\n\t}\n\treturn min;\n}\nvoid accesslru(int **priority,int sets,int assoc,int line)\n{\n\tint tmp=0,max=0;\n\tfor(tmp=0;tmp<assoc;tmp++)\n\t{\n\t\tif(priority[sets][tmp]>max){max=priority[sets][tmp];}\n\t}\n\tpriority[sets][line]=max+1;\n\treturn; \n}\nint main(int argc, char *argv[])\n{\n\tint cache_size=0,prefetch=0,replacement=0,block_size=0,assoc=0;//parameters by reading the string\n\tint sets=0;//parameters by calculating\n\tunsigned long int **tag,**valid;\n\tchar tmp[1000];\n\tint **priority;\n\tunsigned long int addr=0;\n\tint memr=0,memw=0,ch=0,cm=0;\n\tint setb=0,blsb=0;\n\tunsigned long tmp1=0,tmp2=0,tmp3=0,tt=0;\n\tint miku=0,match=0,match_prefetch=0,wline=0;\n\t//reading argument\n\tif(argc!=7){printf(\"Invalid arguments\\n\");}\n\tcache_size=atoi(argv[1]);\n\tblock_size=atoi(argv[5]);\n\tif(strcmp(argv[4],\"lru\")==0){replacement=1;}\n\tif(strcmp(argv[3],\"p1\")==0){prefetch=1;}\n\tif(strcmp(argv[2],\"direct\")==0){assoc=1;}\n\telse{\n\t\tif(strcmp(argv[2],\"assoc\")==0){assoc=(int)cache_size/block_size;}\n\t\telse{assoc=argv[2][6]-'0';if(log2base(assoc)==-1){printf(\"CRITICAL ERROR: ASSOC NOT POW OF 2!\\n\");return EXIT_SUCCESS;}\n\t\t}\n\t}\n\tif(log2base(cache_size)==-1 || log2base(block_size)==-1){printf(\"CRITICAL ERROR: PARAMETER NOT CORRECT!\\n\");return EXIT_SUCCESS;}\n\tcache_size=cache_size;\n\tblock_size=block_size;\n\tsets=(int)cache_size/(block_size*assoc);\n\t\n\tfreopen(argv[6],\"r\",stdin);\n\t//prefetch 0 no 1 one above\n\t//replacement 0 FIFO 1 lru\n\t//assoc 1 direct other \n\ttag=(unsigned long int**) malloc(sets*sizeof(unsigned long int*));\n\tfor(tmp1=0;tmp1<sets;tmp1++)\n\t{\n\t\ttag[tmp1]=(unsigned long int *) malloc(assoc*sizeof(unsigned long int));\n\t\tmemset(tag[tmp1],0,assoc*sizeof(unsigned long int));\n\t}\n\t\n\t\n\tvalid=(unsigned long int**)malloc(sets*sizeof(unsigned long int*));\n\tfor(tmp1=0;tmp1<sets;tmp1++)\n\t{\n\t\tvalid[tmp1]=(unsigned long int *)malloc(assoc*sizeof(unsigned long int));\n\t\tmemset(valid[tmp1],0,assoc*sizeof(unsigned long int));\n\t}\n\t\n\tsetb=log2base(sets);\n\tblsb=log2base(block_size);\n\tif(DEBUG==1){\n\t\tprintf(\"There are %d sets, %d lines, %d block size\\n\",sets,assoc,block_size);\n\t\tprintf(\"prefetch: %d, assoc: %d replacement: %d\\n\",prefetch,assoc,replacement);\n\t\tprintf(\"Bit Shifter Argument: %d set shift, %d block shift\",setb,blsb);\n\t\t}\n\tif(replacement==0){\n\n\t\tpriority=(int **)malloc(sizeof(int*));\n\t\tpriority[0]=(int *)calloc(sets,sizeof(int));\n\t\t\n\t}\n\telse{\n\t\tpriority=(int **)malloc(sets*sizeof(int*));\n\t\tfor(tmp1=0;tmp1<sets;tmp1++)\n\t\t{\n\t\t\tpriority[tmp1]=(int *)calloc(assoc,sizeof(int));\n\t\t\t\n\t\t}\n\t\n\n\t}\n\n\t//Start procesing the file\n\twhile(1)\n\t{\n\t\tscanf(\" %s \",tmp);\n\t\tif(DEBUG==1){\n\t\tprintf(\"%s\\n\",tmp);}\n\t\tif(strcmp(tmp,\"#eof\")==0){//print sth\n\t\t\tprint(memr,memw,ch,cm);\n\t\t\tbreak;\n\t\t}\n\t\tscanf(\" %s %lx\",tmp,&addr);\n\t\tif(DEBUG==1){printf(\"%s %lx\\n\",tmp,addr);}\n\t\ttmp1=addr-(addr>>blsb)*(1<<blsb);\n\t\taddr=addr>>blsb;//delete block info\n\n\t\ttmp3=addr>>setb;//tag info\n\t\ttmp2=addr-tmp3*(1<<setb);//set info\n\t\tif(DEBUG==1){printf(\"Block Index: %lx, Set Index: %lx, Tag: %lx\\n\",tmp1,tmp2,tmp3);}\n\t\tmatch=0;\n\t\tfor(miku=0;miku<assoc;miku++)\n\t\t{\n\t\t\tif(tag[tmp2][miku]==tmp3&&valid[tmp2][miku]==1){match=1;wline=miku;break;}\n\t\t}\n\t\tif(match==0){\n\t\t\tif(DEBUG==1){printf(\"CACHE MISS!!\\n\");\n\t\t\t\tif(replacement==0){\n\t\t\t\t\tprintf(\"Curr Priority: %d, Curr valid: %ld, Curr tag: %lx\\n\",priority[0][tmp2],valid[tmp2][priority[0][tmp2]],tag[tmp2][priority[0][tmp2]]);\n\t\t\t\t}\n\n\t\t\t}\n\t\t\tif(replacement==0){\n\t\t\t\tmatch_prefetch=0;\n\t\t\t\ttag[tmp2][priority[0][tmp2]]=tmp3;\n\t\t\t\tvalid[tmp2][priority[0][tmp2]]=1;\n\t\t\t\tif(priority[0][tmp2]==assoc-1){priority[0][tmp2]=0;}\n\t\t\t\telse{priority[0][tmp2]++;}\n\t\t\t\tif(prefetch==1){\n\t\t\t\t\t//if(((tmp1+block_size)>>blsb)>0){tmp2++;}\n\t\t\t\t\tif(DEBUG==1){\n\t\t\t\t\t\tprintf(\"Entering Prefetching\\n\");\n\t\t\t\t\t}\n\t\t\t\t\ttmp2++;\n\t\t\t\t\tif((tmp2>>setb)>0){tmp2=0;\n\t\t\t\t\t\ttmp3++;\n\t\t\t\t\t\tif(DEBUG==1){\n\t\t\t\t\t\tprintf(\"Tag Number Before Check %lx\\n\",tmp3);}\n\t\t\t\t\t\t\n\t\t\t\t\tif(DEBUG==1){printf(\"To Check : %lx\\n\",(tmp3>>(48-setb-blsb)));\n\t\t\t\t\tprintf(\"Shifting %d to left\\n\",48-setb-blsb);}\n\t\t\t\t\tif((tmp3>>(48-setb-blsb))>1){tmp3=0;\n\t\t\t\t\t}\n\t\t\t\t\t}\n\t\t\t\t\t\n\t\t\t\t\tfor(miku=0;miku<assoc;miku++)\n\t\t\t\t\t{\n\t\t\t\t\t\tif(tag[tmp2][miku]==tmp3&&valid[tmp2][miku]==1){match_prefetch=1;break;}\n\t\t\t\t\t}\n\t\t\t\t\tif(DEBUG==1){\n\t\t\t\t\t\tprintf(\"Prefetching Set Number: %lx, Tag Number %lx, Target? %d\\n\",tmp2,tmp3,match_prefetch);\n\t\t\t\t\t}\n\n\t\t\t\t\tif(match_prefetch==0){\n\t\t\t\t\ttag[tmp2][priority[0][tmp2]]=tmp3;\n\t\t\t\t\tvalid[tmp2][priority[0][tmp2]]=1;\n\t\t\t\t\tif(priority[0][tmp2]==assoc-1){priority[0][tmp2]=0;}\n\t\t\t\t\telse{priority[0][tmp2]++;}\n\t\t\t\t\tmemr++;\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t}\n\t\t\tif(replacement==1){//LRU\n\t\t\t\tmatch_prefetch=0;\n\t\t\t\ttt=checkpriority(priority,tmp2,assoc);//The Place For inserting\n\t\t\t\tif(DEBUG==1){\n\t\t\t\t\tprintf(\"Returned Place For inserting: %lu\\n\",tt);\n\t\t\t\t\tprintf(\"Curr Priority: %d, Curr valid: %ld, Curr tag: %lx\\n\",priority[tmp2][tt],valid[tmp2][tt],tag[tmp2][tt]);\n\t\t\t\t}\n\t\t\t\ttag[tmp2][tt]=tmp3;\n\t\t\t\tvalid[tmp2][tt]=1;\n\t\t\t\tif(prefetch==1){\n\t\t\t\t\tif(DEBUG==1){\n\t\t\t\t\t\tprintf(\"Entering Prefetching\\n\");\n\t\t\t\t\t}\n\t\t\t\t\ttmp2++;\n\t\t\t\t\tif((tmp2>>setb)>0){tmp2=0;\n\t\t\t\t\t\ttmp3++;\n\t\t\t\t\t\tif(DEBUG==1){\n\t\t\t\t\t\tprintf(\"Tag Number Before Check %lx\\n\",tmp3);}\n\t\t\t\t\t\t\n\t\t\t\t\tif(DEBUG==1){printf(\"To Check : %lx\\n\",(tmp3>>(48-setb-blsb)));\n\t\t\t\t\tprintf(\"Shifting %d to left\\n\",48-setb-blsb);}\n\t\t\t\t\tif((tmp3>>(48-setb-blsb))>1){tmp3=0;\n\t\t\t\t\t}\n\t\t\t\t\t}\n\t\t\t\t\tfor(miku=0;miku<assoc;miku++)\n\t\t\t\t\t{\n\t\t\t\t\t\tif(tag[tmp2][miku]==tmp3&&valid[tmp2][miku]==1){match_prefetch=1;break;}\n\t\t\t\t\t}\n\n\t\t\t\t\tif(match_prefetch==0){\n\t\t\t\t\t\ttt=checkpriority(priority,tmp2,assoc);\n\t\t\t\t\t\tif(DEBUG==1){\n\t\t\t\t\t\t\tprintf(\"Returned Place For inserting: %lu\\n\",tt);\n\t\t\t\t\t\t\tprintf(\"Curr Priority: %d, Curr valid: %ld, Curr tag: %lx\\n\",priority[tmp2][tt],valid[tmp2][tt],tag[tmp2][tt]);\n\t\t\t\t\t\t}\n\t\t\t\t\t\ttag[tmp2][tt]=tmp3;\n\t\t\t\t\t\tvalid[tmp2][tt]=1;\n\t\t\t\t\t\tmemr++;\n\t\t\t\t\t}\n\t\t\t\t}\t\n\t\t\t}\n\t\t}\n\t\tif(match==1&&replacement==1){accesslru(priority,tmp2,assoc,wline);}\n\t\tif(strcmp(tmp,\"W\")==0){//do writing\n\t\t\tif(match==1){ch++;memw++;}\n\t\t\telse{cm++;memr++;memw++;}\n\t\t}\n\t\tif(strcmp(tmp,\"R\")==0){//do reading\n\t\t\tif(match==1){ch++;}\n\t\t\telse{\n\t\t\t\tcm++;\n\t\t\t\tmemr++;\n\t\t\t}\n\t\t}\n\t\tif(DEBUG==1){print(memr,memw,ch,cm);}\n\n\t}\n\n\treturn EXIT_SUCCESS;\n}\n"
},
{
"alpha_fraction": 0.7520661354064941,
"alphanum_fraction": 0.7520661354064941,
"avg_line_length": 22.799999237060547,
"blob_id": "2474649d57011eff2061cdcd63574979d25724c3",
"content_id": "26793db15f3873afd92dc7de5b3b1f4e3337ebe9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 121,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 5,
"path": "/pa4/src/Makefile",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "truthtable: truthtable.c\n\tgcc -g -Wall -Werror -fsanitize=address -o truthtable truthtable.c\n\nclean:\n\trm -f truthtable\n\n\n"
},
{
"alpha_fraction": 0.5906133651733398,
"alphanum_fraction": 0.6231412887573242,
"avg_line_length": 24.927711486816406,
"blob_id": "e5f097a35da4b11dbb34e111394bf571a00d8457",
"content_id": "00bbe255f59f69f9d1dd46b532743c688e7da7cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2152,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 83,
"path": "/pa2/src/life/life.c",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<stdlib.h>\nint check(int **board,int x, int y,int height,int width)\n{\n\tint x_up=0,x_down=0,y_right=0,y_left=0;\n\tint counter=0;\n\tif(x==0){x_up=height-1;x_down=1;}else{\n\tif(x==height-1){x_down=0;x_up=x-1;}else\n\t{x_up=x-1;x_down=x+1;}\n\t}\n\n\tif(y==0){y_left=width-1;y_right=1;}else{\n\tif(y==width-1){y_right=0;y_left=y-1;}else{\n\t\ty_right=y+1;y_left=y-1;}\n\t}\n\tif(board[x_up][y_left]==1){counter++;}\n\tif(board[x_up][y]==1){counter++;}\n\tif(board[x_up][y_right]==1){counter++;}\n\tif(board[x][y_left]==1){counter++;}\n\tif(board[x][y_right]==1){counter++;}\n\tif(board[x_down][y_left]==1){counter++;}\n\tif(board[x_down][y]==1){counter++;}\n\tif(board[x_down][y_right]==1){counter++;}\n\tif(board[x][y]==1&&(counter!=3&&counter!=2)){return 0;}\n\tif(board[x][y]==0&&counter==3){return 1;}\n\treturn board[x][y];\n}\nvoid printboard(int **board, int height,int width){\n\tint temp1,temp2;\n\tfor(temp1=0;temp1<height;temp1++){\n\t\tfor(temp2=0;temp2<width;temp2++)\n\t\t{\n\t\t\tif(board[temp1][temp2]==1){printf(\"*\");}\n\t\t\telse{printf(\".\");\n\t\t\t}\n\t\t}\n\t\tprintf(\"\\n\");\n\t}\n\n\treturn;\n}\nint main(int argc, char* argv[])\n{\n\tint times,**board,***tempboard;\n\tchar tempchar;\n\tint height,width,temp,temp2,counter;\n\tif(argc!=3){printf(\"ARGUMENT MISSING!!!\\n\");return EXIT_SUCCESS;}\n\tfreopen(argv[2],\"r\",stdin);\n\ttimes=atoi(argv[1]);\n\tscanf(\"%d %d \",&height,&width);\n\tboard=(int**)malloc(height*sizeof(int*));\n\ttempboard=(int***)malloc(times*sizeof(int**));\n\t\n\tfor(temp=0;temp<height;temp++)\n\t{\n\t\t\n\t\tboard[temp]=(int*)malloc(width*sizeof(int*));\n\n\t\tfor(temp2=0;temp2<width;temp2++)\n\t\t{\n\t\t\tscanf(\" %c \",&tempchar);\n\t\t\tif(tempchar=='.'){board[temp][temp2]=0;}\n\t\t\telse{if(tempchar=='*'){board[temp][temp2]=1;}\n\t\t\t\telse{printf(\"INPUT ERROR\\n\");return EXIT_SUCCESS;}\n\t\t\t}\n\t\t}\n\t}\n\tcounter=0;\n\twhile(counter<times){\n\t\ttempboard[counter]=(int**)malloc(height*sizeof(int*));\n\n\t\tfor(temp=0;temp<height;temp++)\n\t\t{\n\t\t\ttempboard[counter][temp]=(int*)malloc(width*sizeof(int));\n\t\t\tfor(temp2=0;temp2<width;temp2++){\n\t\t\t\ttempboard[counter][temp][temp2]=check(board,temp,temp2,height,width);\n\t}\n\t\t}\n\t\tboard=tempboard[counter];\n\t\tcounter++;}\n\tprintboard(board,height,width);\n\treturn EXIT_SUCCESS;\n}\n"
},
{
"alpha_fraction": 0.4651639461517334,
"alphanum_fraction": 0.5081967115402222,
"avg_line_length": 22.238094329833984,
"blob_id": "18c19070804663e0d39917cd48a19830806f7427",
"content_id": "85ea6a65b6e958b5d2d951589cf9202af8d91dc5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 488,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 21,
"path": "/pa1/src/rot13/rot13.c",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\nint main(int argc,char *argv[])\n{\n\tint a = 0,len;\n\tif(argc!=2){printf(\"%d ARGUMENTS MISSING\\n\",2-argc);return EXIT_FAILURE;}\n\tlen=strlen(argv[1]);\n\tfor(a=0;a<len;a++){\n\t\tif((argv[1][a]>='A' && argv[1][a]<='M')||(argv[1][a]>='a' && argv[1][a]<='m')){\n\t\t\targv[1][a]+=13;\n\t\t}else{\n\t\tif((argv[1][a]>='N' && argv[1][a]<='Z')||(argv[1][a]>='n' && argv[1][a]<='z')){\n\t\t\targv[1][a]-=13;\n\t\t}\n\t\t}\n\t}\n\tprintf(\"%s\\n\",argv[1]);\n\treturn 0;\n\n}\n"
},
{
"alpha_fraction": 0.5809898972511292,
"alphanum_fraction": 0.586614191532135,
"avg_line_length": 29.65517234802246,
"blob_id": "bf63462cf5920c7719f9a46dbcc8fb6999549218",
"content_id": "bbd5ac31a98a5218118ac55d3413f5e81fc31911",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1778,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 58,
"path": "/pa5/grader.py",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\nimport autograde\nimport os, os.path\n\nassignment_name = 'PA5'\nrelease='1'\n\nclass CacheTests(autograde.FileTests):\n def __init__(self, ref_suffix='.txt', **kws):\n super(CacheTests, self).__init__(ref_suffix=ref_suffix, **kws)\n\n repl,pref = kws['id'].split('.')\n\n self.repl = repl\n self.pref = pref\n\n def get_tests(self, prog, data_dir):\n\n # gather the names of the reference files\n fnames = [fname for fname in os.listdir(data_dir)\n if fname.startswith(self.prefix)\n and fname.endswith(self.ref_suffix)]\n fnames.sort()\n\n autograde.logger.debug('Tests for %s: %s', self.id, fnames)\n\n # for each reference name, determine the corresponding trace file\n for ref_name in fnames:\n id = ref_name[len(self.prefix):-len(self.ref_suffix)]\n trace, csize, assoc, bsize = id.split('.')\n\n tracefile = os.path.join(data_dir,\n 'trace' + trace + '.txt')\n\n if not os.path.exists(tracefile):\n autograde.logger.warning('Unmatched reference file: %r', ref_name)\n continue\n\n ref = os.path.join(data_dir, ref_name)\n\n yield autograde.FileRefTest(\n cmd = [prog, csize, assoc, self.pref, self.repl, bsize, tracefile],\n ref_file = ref,\n )\n\nassignment = autograde.Project('cachesim',\n CacheTests(id='fifo.p0', weight=2.5),\n CacheTests(id='fifo.p1', weight=2.5),\n CacheTests(id='lru.p0', category=autograde.EXTRA),\n CacheTests(id='lru.p1', category=autograde.EXTRA),\n user_class=None,\n)\n\n\n\nif __name__ == '__main__':\n autograde.set_asan_symbolizer()\n autograde.main(assignment_name, assignment, release)\n"
},
{
"alpha_fraction": 0.5012072920799255,
"alphanum_fraction": 0.5986546874046326,
"avg_line_length": 27.009662628173828,
"blob_id": "e47c3894de8cf6ad049a714430c259763f2fab27",
"content_id": "f8de38a0a842a49207ff5b51afd08279283c716d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5798,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 207,
"path": "/pa2/src/queens/queens.bak.c",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<stdlib.h>\n#include<string.h>\nvoid getconflictmap(int board[8][8], int conflict[8][8])\n{\n\tint temp1=0,temp2=0,temp3=0;\n\t//int deb1=0,deb2=0;\n\tfor(temp1=0;temp1<8;temp1++){\n\t\tfor(temp2=0;temp2<8;temp2++){\n\t\t\tconflict[temp1][temp2]=0;}}\n\n\tfor(temp1=0;temp1<8;temp1++){\n\t\tfor(temp2=0;temp2<8;temp2++)\n\t\t{\n\t\t//\tfor(deb1=0;deb1<8;deb1++){\n\t\t//\tfor(deb2=0;deb2<8;deb2++){\n\t\t//\tprintf(\"%d\",conflict[deb1][deb2]);}\n\t\t//\tprintf(\"\\n\");\n\t\t//\t}\n\t\t//\tprintf(\"-----------------------\\n\");\t\n\t\t\tif(board[temp1][temp2]!=0){\n\t\t\t\tfor(temp3=1;temp3<8;temp3++)\n\t\t\t\t{\n\t\t\t\t\tif(temp1-temp3>=0){conflict[temp1-temp3][temp2]=1;}\n\t\t\t\t\tif(temp1+temp3<8){conflict[temp1+temp3][temp2]=1;}\n\t\t\t\t\tif(temp2-temp3>=0){conflict[temp1][temp2-temp3]=1;}\n\t\t\t\t\tif(temp2+temp3<8){conflict[temp1][temp2+temp3]=1;}\n\t\t\t\t\tif(temp1-temp3>=0&&temp2-temp3>=0){conflict[temp1-temp3][temp2-temp3]=1;}\n\t\t\t\t\tif(temp1+temp3<8&&temp2+temp3<8){conflict[temp1+temp3][temp2+temp3]=1;}\n\t\t\t\t\tif(temp1+temp3<8&&temp2-temp3>=0){conflict[temp1+temp3][temp2-temp3]=1;}\n\t\t\t\t\tif(temp1-temp3>=0&&temp2+temp3<8){conflict[temp1-temp3][temp2+temp3]=1;}\n\t\t\t\t}\n\t\t\t}\n\t\t\tif(board[temp1][temp2]==3){\n\t\t\t\tif(temp1-2>=0){\n\t\t\t\t\tif(temp2-1>=0){conflict[temp1-2][temp2-1]=1;}\n\t\t\t\t\t//else{conflict[temp1-2][8+temp2-1]=1;}\n\t\t\t\t\tif(temp2+1<8){conflict[temp1-2][temp2+1]=1;}\n\t\t\t\t\t//else{conflict[temp1-2][temp2+1-8]=1;}\n\t\t\t\t}\n\t\t\t\telse{\n\t\t\t\t\tif(temp2-1>=0){conflict[temp1-2+8][temp2-1]=1;}\n\t\t\t\t\t//else{conflict[temp1-2+8][8+temp2-1]=1;}\n\t\t\t\t\tif(temp2+1<8){conflict[temp1-2+8][temp2+1]=1;}\n\t\t\t\t\t//else{conflict[temp1-2+8][temp2+1-8]=1;}\n\t\t\t\t}\n\t\t\t\tif(temp1+2<8){\n\t\t\t\t\tif(temp2-1>=0){conflict[temp1+2][temp2-1]=1;}\n\t\t\t\t\t//else{conflict[temp1+2][8+temp2-1]=1;}\n\t\t\t\t\tif(temp2+1<8){conflict[temp1+2][temp2+1]=1;}\n\t\t\t\t\t//else{conflict[temp1+2][temp2+1-8]=1;}\n\t\t\t\t}\n\t\t\t\telse{\n\t\t\t\t\tif(temp2-1>=0){conflict[temp1+2-8][temp2-1]=1;}\n\t\t\t\t\t//else{conflict[temp1+2-8][8+temp2-1]=1;}\n\t\t\t\t\tif(temp2+1<8){conflict[temp1+2-8][temp2+1]=1;}\n\t\t\t\t\t//else{conflict[temp1+2-8][temp2+1-8]=1;}\n\t\t\t\t}\n\t\t\t\tif(temp1-1>=0){\n\t\t\t\t\tif(temp2-2>=0){conflict[temp1-1][temp2-2]=1;}\n\t\t\t\t\t//else{conflict[temp1-1][8+temp2-2]=1;}\n\t\t\t\t\tif(temp2+2<8){conflict[temp1-1][temp2+2]=1;}\n\t\t\t\t\t//else{conflict[temp1-1][temp2+2-8]=1;}\n\t\t\t\t}\n\t\t\t\telse{\n\t\t\t\t\tif(temp2-2>=0){conflict[temp1-1+8][temp2-2]=1;}\n\t\t\t\t\t//else{conflict[temp1-1+8][8+temp2-2]=1;}\n\t\t\t\t\tif(temp2+2<8){conflict[temp1-1+8][temp2+2]=1;}\n\t\t\t\t\t//else{conflict[temp1-1+8][temp2+2-8]=1;}\n\t\t\t\t}\n\t\t\t\tif(temp1+1<8){\n\t\t\t\t\tif(temp2-2>=0){conflict[temp1+1][temp2-2]=1;}\n\t\t\t\t\t//else{conflict[temp1+1][8+temp2-2]=1;}\n\t\t\t\t\tif(temp2+2<8){conflict[temp1+1][temp2+2]=1;}\n\t\t\t\t\t//else{conflict[temp1+1][temp2+2-8]=1;}\n\t\t\t\t}\n\t\t\t\telse{\n\t\t\t\t\tif(temp2-2>=0){conflict[temp1+1-8][temp2-2]=1;}\n\t\t\t\t\t//else{conflict[temp1+1-8][8+temp2-2]=1;}\n\t\t\t\t\tif(temp2+2<8){conflict[temp1+1-8][temp2+2]=1;}\n\t\t\t\t\t//else{conflict[temp1+1-8][temp2+2-8]=1;}\n\t\t\t\t}\n\n\n\n\t\t\t}\n\t\t}\n\t}\n\treturn;\n}\nint check(int conflictmap[8][8],int board[8][8]){\n\tint temp1,temp2;\n\tfor(temp1=0;temp1<8;temp1++){\n\t\tfor(temp2=0;temp2<8;temp2++){\n\t\t\tif(conflictmap[temp1][temp2]!=0&&board[temp1][temp2]!=0){\n\t\t\t\treturn 1;\n\t\t\t}\n\t\t}\n\t}\n\treturn 0;\n\n}\nint printmatrix(int board[8][8],int conflictmap[8][8])\n{\n\tint tmp1,tmp2;\n\tfor(tmp1=0;tmp1<8;tmp1++){\n\t\tfor(tmp2=0;tmp2<8;tmp2++)\n\t\t{\n\t\t\tif(conflictmap[tmp1][tmp2]!=1){\n\t\t\t\tif(board[tmp1][tmp2]==2){printf(\"Q\");continue;}\n\t\t\t\tif(board[tmp1][tmp2]==0){printf(\"q\");continue;}\n\t\t\t}\n\t\t\telse{printf(\".\");}\n\t\t}\n\t\tprintf(\"\\n\");\n\t}\n\t\n\n\treturn 0;\n}\nint printmatrix_withwarrier(int board[8][8],int conflictmap[8][8])\n{\n\tint tmp1,tmp2;\n\tint tmpb[8][8],tmpc[8][8];\n\tfor(tmp1=0;tmp1<8;tmp1++){\n\t\tfor(tmp2=0;tmp2<8;tmp2++)\n\t\t{\n\t\t\tif(conflictmap[tmp1][tmp2]!=1){\n\t\t\t\tif(board[tmp1][tmp2]==2){printf(\"Q\");continue;}\n\t\t\t\tif(board[tmp1][tmp2]==3){printf(\"W\");continue;}\n\t\t\t\tif(board[tmp1][tmp2]==0){\n\t\t\t\t\tmemcpy(tmpb,board,8*8*sizeof(int));\n\t\t\t\t\ttmpb[tmp1][tmp2]=3;\n\t\t\t\t\tgetconflictmap(tmpb,tmpc);\n\t\t\t\t\tif(check(tmpc,tmpb)==1){printf(\"q\");continue;}\n\t\t\t\t\telse{printf(\"w\");continue;}\n\t\t\t\t}\n\t\t\t}\n\t\t\telse{printf(\".\");}\n\t\t}\n\t\tprintf(\"\\n\");\n\t}\n\t\n\n\treturn 0;\n}\nint addqueen(int board[8][8],int conflictmap[8][8],int depth)\n{\n\tint t1=0,t2=0,flag=0,tmpf=0;\n\tint tempconf[8][8],tempboard[8][8];\n\tif(depth>2){return 0;}\n\tfor(t1=0;t1<8;t1++)\n\t{\n\t\tfor(t2=0;t2<8;t2++)\n\t\t{\n\t\t\tif(conflictmap[t1][t2]!=1&&board[t1][t2]==0)\n\t\t\t{\n\t\t\t\tmemcpy(tempboard,board,8*8*sizeof(int));\n\t\t\t\ttempboard[t1][t2]=2;\n\t\t\t\tgetconflictmap(tempboard,tempconf);\n\t\t\t\t//if(check(tempconf,tempboard)==1){return flag;}\n\t\t\t\t//printf(\"LOOP\\n\");\n\t\t\t\ttmpf=addqueen(tempboard,tempconf,depth+1);\n\t\t\t\tif(tmpf+1>flag){flag=tmpf+1;}\n\t\t\t}\n\t\t}\n\t}\n\n\treturn flag;\n\t\t\t\n}\nint main(int argc,char* argv[])\n{\n\tint isWarrier=0,isaddQueen=0;\n\tif(argc<2){printf(\"INSUFFICIENT ARGUMENT\\n\");return EXIT_SUCCESS;}\n\tif(argc==2){}else{\n\tif(strcmp(argv[argc-2],\"-w\")==0 || strcmp(argv[argc-3],\"-w\")==0){isWarrier=1;}\n\tif(strcmp(argv[argc-2],\"+2\")==0 || strcmp(argv[argc-3],\"+2\")==0){isaddQueen=1;}}\n\tfreopen(argv[argc-1],\"r\",stdin);\n\tint board[8][8],conflictbd[8][8];\n\tchar tempchar;\n\tint temp1,temp2;\n\tint status=0;\n\tint howmanyqueens=0;\n\tfor(temp1=0;temp1<8;temp1++){\n\t\tfor(temp2=0;temp2<8;temp2++){\n\t\t\tscanf(\" %c \",&tempchar);\n\t\t\tif(tempchar=='Q'){board[temp1][temp2]=2;}\n\t\t\telse{if(tempchar=='W'){board[temp1][temp2]=3;}\n\t\t\t\telse{board[temp1][temp2]=0;}}\n\t\t}\n\t}\n\tgetconflictmap(board,conflictbd);\n\tstatus=check(conflictbd,board);\n\t\n\t\n\tif(status==1){printf(\"Invalid\\n\"); return EXIT_SUCCESS;}\n\telse{if(isWarrier==1){printmatrix_withwarrier(board,conflictbd);}else{printmatrix(board,conflictbd);}}\n\tif(isaddQueen==1){howmanyqueens=addqueen(board,conflictbd,0);\n\t//printf(\"%d\",howmanyqueens);\n\tif(howmanyqueens==0){printf(\"Zero\\n\");}\n\tif(howmanyqueens==1){printf(\"One\\n\");}\n\tif(howmanyqueens>=2){printf(\"Two or more\\n\");}}\n\t\n\t\n\treturn EXIT_SUCCESS;\n}\n"
},
{
"alpha_fraction": 0.6790123581886292,
"alphanum_fraction": 0.6790123581886292,
"avg_line_length": 19,
"blob_id": "a39bfd9c61aeb4741577b04395ab127f09b49874",
"content_id": "c3f5ac1fe141e092bdfd3c010c37bb4e3a3b472e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 81,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 4,
"path": "/src/gcd/Makefile",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "gcd: gcd.c\n\tgcc -Wall -Werror -fsanitize=address -o gcd gcd.c\nclean:\n\trm -f gcd\n\n"
},
{
"alpha_fraction": 0.6167094111442566,
"alphanum_fraction": 0.6203737854957581,
"avg_line_length": 18.919708251953125,
"blob_id": "674d458efededf30d3e589d8654fddcaec124da3",
"content_id": "979d1e2be6af55fd3ec5c277f3e884877fe6bbe9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2729,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 137,
"path": "/pa2/src/bst/bst.c",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<stdlib.h>\ntypedef struct node{\n\tint num;\n\tstruct node *left,*right;\n}node;\nnode* insert(node *root,int num){\n\tstruct node *before,*curr,*rt,*temp;\n\trt=root;\n\tcurr=root;\n\twhile(curr!=NULL)\n\t{\n\t\tif(curr->num==num){printf(\"duplicate\\n\");return root;}\n\t\tif(curr->num<num){before=curr;curr=curr->right;}\n\t\telse{before=curr;curr=curr->left;}\n\t}\n\tif(rt==NULL){\n\t\trt=(node *)malloc(sizeof(node));\n\t\trt->num=num;\n\t\trt->right=NULL;\n\t\trt->left=NULL;\n\t\tprintf(\"inserted\\n\");\n\t\treturn rt;\n\t}\n\tif(before->num<num){\n\t\ttemp=(node*)malloc(sizeof(node));\n\t\ttemp->num=num;\n\t\tprintf(\"inserted\\n\");\n\t\ttemp->left=NULL;\n\t\ttemp->right=NULL;\n\t\tbefore->right=temp;\n\t}\n\telse{\n\t\ttemp=(node*)malloc(sizeof(node));\n\t\ttemp->num=num;\n\t\tprintf(\"inserted\\n\");\n\t\ttemp->left=NULL;\n\t\ttemp->right=NULL;\n\t\tbefore->left=temp;\n\t}\n\treturn rt;\n}\nnode* delete(node *root,int num){\n\tstruct node *rt=NULL,*curr=NULL,*temp=NULL,*temp2=NULL,*before=NULL;\n\tint toc=0;\n\trt=root;\n\tcurr=rt;\n\tif(rt==NULL){printf(\"absent\\n\");return NULL;}\n\twhile(curr!=NULL){\n\t\tif(curr->num==num){break;}\n\t\tif(curr->num>num){before=curr;curr=curr->left;}\n\t\telse{before=curr;curr=curr->right;}\t\n\t}\n\tif(curr==NULL){printf(\"absent\\n\");return rt;}\n\ttemp=curr;\n\tif(curr->left==NULL){\n\t\tif(curr->right==NULL){\n\t\t\tif(before!=NULL){\n\t\t\tif(before->num>num){before->left=NULL;}\n\t\t\telse{\n\t\t\tbefore->right=NULL;}\n\t\t\tfree(curr);\n\t\t\tprintf(\"deleted\\n\");\n\t\t\treturn rt;}\n\t\t\telse{printf(\"deleted\\n\");free(rt);return NULL;}\n\t\t\t}\t\n\t\telse{\n\t\t\ttemp=curr->right;\n\t\t\tcurr->right=curr->right->right;\n\t\t\tcurr->num=temp->num;\n\t\t\tprintf(\"deleted\\n\");\n\t\t\tfree(temp);\n\t\t\treturn rt;\n\t\t}\n\t}\n\tbefore=temp;\n\n\ttemp2=temp->left;\t\n\twhile(temp2->right!=NULL){\n\t\tbefore=temp2;\n\t\ttemp2=temp2->right;\n\t}\n\ttoc=temp2->num;\n\tif(before==temp){before->left=NULL;}else{\n\tbefore->right=NULL;}\n\tfree(temp2);\n\tprintf(\"deleted\\n\");\n\tcurr->num=toc;\n\treturn rt;\n}\nvoid search(node *root,int num)\n{\n\tstruct node *rt=root;\n\twhile(rt!=NULL)\n\t{\n\t\tif(rt->num==num){printf(\"present\\n\");return;}\n\t\tif(rt->num>num){rt=rt->left;}\n\t\telse{rt=rt->right;}\n\t}\n\tprintf(\"absent\\n\");\n\treturn;\n}\nvoid printnode(node *root)\n{\n\tif(root==NULL)return;\n\tprintf(\"(\");\n\tif(root->left!=NULL){printnode(root->left);\n\t}\n\tprintf(\"%d\",root->num);\n\tif(root->right!=NULL){printnode(root->right);}\n\tprintf(\")\");\n\treturn;\n}\nint main(int argc,char* argv[])\n{\n\tchar a;\n\tint curr;\n\tstruct node *root=NULL;\n\twhile(scanf(\" %c\",&a)==1){\n\t\tif(a=='i'){\n\t\t\tscanf(\" %d\",&curr);\n\t\t\troot=insert(root,curr);\n\t\t\tcontinue;\n\t\t}\n\t\tif(a=='s'){\n\t\t\tscanf(\" %d\",&curr);\n\t\t\tsearch(root,curr);\n\t\t\tcontinue;}\n\t\tif(a=='d'){\n\t\t\tscanf(\" %d\",&curr);\n\t\t\troot=delete(root,curr);\n\t\t\tcontinue;}\n\t\tif(a=='p'){printnode(root);printf(\"\\n\");continue;}\n\t\telse{break;}\n\t}\n\treturn EXIT_SUCCESS;\n}\n"
},
{
"alpha_fraction": 0.611940324306488,
"alphanum_fraction": 0.646766185760498,
"avg_line_length": 19.100000381469727,
"blob_id": "fe593909d22f46837701a49980ecf4133cb1cc3a",
"content_id": "908423bbc23fd1034fb8cfe35f90b1bbc4f140a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 402,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 20,
"path": "/pa1/src/gcd/gcd.c",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\nint gcd(int x,int y)\n{\n\n\tif(x==0){return y;}\n\treturn gcd(y%x,x); \n}\n\nint main(int argc, char *argv[])\n{\n\tint number1,number2,result;\n\tif(argc!=3){printf(\"%d ARGUMENT(S) MISSING\",3-argc);return EXIT_FAILURE;}\n\tnumber1=atoi(argv[1]);\n\tnumber2=atoi(argv[2]);\n\t/*printf(\"%d %d\\n\",number1,number2);*/\n\tresult=gcd(number1,number2);\n\tprintf(\"%d\\n\",result);\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.5430266857147217,
"alphanum_fraction": 0.5875371098518372,
"avg_line_length": 13.65217399597168,
"blob_id": "d76e7436caca0ea81545afa1d5a8c420a22785d0",
"content_id": "57dea8033ed67053603350aa0852101f931aec00",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 337,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 23,
"path": "/pa1/src/gcd/troublemaker.c",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<stdlib.h>\n#define MAXTESTCASES 100\nint gcd(int a,int b){\n\tif(b==0){return a;}\n\treturn gcd(b,a%b);\n}\nint main()\n{\n\tint a=0,b=0,ct=0;\n\tfreopen(\"./tests/tests.txt\",\"w\",stdout);\n\tfor(ct=0;ct<MAXTESTCASES;ct++)\n\t{\n\ta=rand()%100;\n\tb=rand()%100;\n\t\n\tprintf(\"%d %d\\n\",a,b);\n\tprintf(\"%d\\n\",gcd(a,b));\n\t\n\t}\n\treturn 0;\n\n}\n"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.6241071224212646,
"avg_line_length": 26.317073822021484,
"blob_id": "e9fae9990160cb5779b51a1a9f6d63758d378985",
"content_id": "73fec4620a7862baf4c4156bd8111b118b4d2421",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1120,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 41,
"path": "/pa1/src/rle/rle.c",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n\nint main(int argc,char *argv[])\n{\n\tchar *input,temp='\\0';\n\tint a=0,counter=0,len=0,outlen=0,intlen=0;\n\tif(argc!=2){printf(\"%d ARGUMENTS MISSING!!!\",2-argc);return EXIT_FAILURE;}\n\tinput=argv[1];\n\tlen=strlen(input);\n\tchar *output,*qq;\n\toutput=(char *)malloc((len*2+1)*sizeof(char));\n\t\tfor(a=0;a<len;a++){\n\t\tif(input[a]>='0' && input[a]<='9'){printf(\"error\\n\");return 0;}\n\t\tif(temp=='\\0'){\n\t\t\t\ttemp=input[a];\n\t\t\t\t\n \t\t\t\tcounter++;\n\t\t\t\tcontinue;}\n\t\telse{if(temp==input[a]){counter++;continue;}\n\t\t\telse{\n\t\t\t\toutput[outlen]=temp;\n\t\t\t\tintlen=snprintf(NULL,0,\"%s%d\",output,counter);\n\t\t\t\tqq=(char *)malloc((intlen+1)*sizeof(char));\n\t\t\t\tsnprintf( qq, intlen + 1, \"%s%d\", output,counter);\n\t\t\t\toutput=qq;\n\t\t\t\tintlen=snprintf(NULL,0,\"%d\",counter);\n\t\t\t\tcounter=1;temp=input[a];outlen+=1+intlen;}}\n\t}\n\toutput[outlen]=temp;\n\tintlen=snprintf(NULL,0,\"%s%d\",output,counter);\n\tqq=(char *)malloc((intlen+1)*sizeof(char));\n\tsnprintf(qq,intlen+1,\"%s%d\",output,counter);\n\toutput=qq;\n\n\tif(strlen(output)>strlen(input)){printf(\"%s\",input);return 0;}\n\tprintf(\"%s\",output);\n\t\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6931818127632141,
"alphanum_fraction": 0.6931818127632141,
"avg_line_length": 21,
"blob_id": "cc9a8fbc9244b42a56f9af1cb727acf6754bc448",
"content_id": "79492e57c0fcb7ad600a884afa54f43cc83c79cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 88,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 4,
"path": "/pa2-old/src/mexp/Makefile",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "mexp: mexp.c\n\tgcc -g -Wall -Werror -fsanitize=address -o mexp mexp.c\nclean:\n\trm -f mexp\n"
},
{
"alpha_fraction": 0.7407407164573669,
"alphanum_fraction": 0.7407407164573669,
"avg_line_length": 12.5,
"blob_id": "4bef9d3df9c23ee82612e969b14ffb81a88ee08a",
"content_id": "196d86a436252699bb74c0aa86f827d0488b6832",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 27,
"license_type": "no_license",
"max_line_length": 17,
"num_lines": 2,
"path": "/pa2-old/src/llist/stupid.c",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include\n"
},
{
"alpha_fraction": 0.5220483541488647,
"alphanum_fraction": 0.5597439408302307,
"avg_line_length": 15.160919189453125,
"blob_id": "fc6225ab60ff334d8e64c84082ac40b7cb9a15ae",
"content_id": "ea353a4d5f82757739792b1e42f3214fd9d6d411",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1406,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 87,
"path": "/pa1/src/rle/troublemaker.c",
"repo_name": "hexiaoxiao-cs/CS211-FALL18",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<stdlib.h>\n#define MAXTESTCASES 100\n/*int gcd(int a,int b){\n\tif(b==0){return a;}\n\treturn gcd(b,a%b);\n}*/\nvoid rle()\n{\n\tint MAXLENGTH=100;\n\tint a=0;\n\tint b[85];\n\tint c=0,target;\n\tint temp=0;\n\tint stuff=0;\n\tint str[100];\n\tint place=0,len;\n\tint occurance[100];\n\tfor(a=33;a<=47;a++)\n\t{\n\t\tb[c]=a;\n\t\tc++;\n\t}\n\tfor(a=58;a<=126;a++)\n\t{\n\t\tb[c]=a;\n\t\tc++;\n\t}\n\tfor(a=0;a<MAXTESTCASES;a++)\n\t{\n\t\tc=0;\n\t\tplace=0;\n\t\twhile(c<MAXLENGTH)\n\t\t{\n\t\t\t\t\n\t\t\ttarget=rand()%MAXLENGTH;\n\t\t\tstuff=rand()%84;\n\t\t\tfor(temp=0;temp<target;temp++)\n\t\t\t{\n\t\t\t\tprintf(\"%c\",b[stuff]);\n\t\t\t}\n\t\t\tstr[place]=stuff;\n\t\t\toccurance[place]=target;\n\t\t\tplace++;\n\t\t\tc+=target;\n\t\t}\n\t\tlen=c;\n\t\tprintf(\"\\n\");\n\t\tfor(c=place-1;c>0;c--)\n\t\t{\n\t\t\tif(str[c]==str[c-1]){occurance[c-1]+=occurance[c];occurance[c]=0;}\n\t\t}\n\t\t\n\t\tif(place*2<len){\n\t\tfor(c=0;c<place;c++)\n\t\t\t{\n\t\t\tif(occurance[c]==0){continue;}\n\t\t\t//if(str[c]==str[c+1]){printf(\"%c%d\",b[str[c]],occurance[c]+occurance[c+1]);c++;continue;}\n\t\t\tprintf(\"%c%d\",b[str[c]],occurance[c]);\n\t\t\t}}\n\t\telse{\n\t\t/* I don't want to write how to print the whole string again and this program will most likely to generate string which are worth compressing*/\n\t\t}\n\t\tprintf(\"\\n\");\n\t\t\n\t\t}\n\t\n\t\n\treturn;\n}\nint main()\n{\n\t\n\tfreopen(\"./tests/tests.txt\",\"w\",stdout);\n\t/*for(ct=0;ct<MAXTESTCASES;ct++)\n\t{\n\ta=rand()%100;\n\tb=rand()%100;\n\t\n\tprintf(\"%d %d\\n\",a,b);\n\tprintf(\"%d\\n\",gcd(a,b));\n\t\n\t}*/\n\trle();\n\treturn 0;\n\n}\n"
}
] | 25 |
MTS-Strathclyde/PC_plus
|
https://github.com/MTS-Strathclyde/PC_plus
|
47e850f4d688b639c928e707df2935d09ddd52da
|
832d347c2549be14a1b136432a929621fd90a659
|
7e52a2c4160bf75d007b2b80bc3b10e76f30364c
|
refs/heads/master
| 2021-01-10T17:04:08.930277 | 2020-07-29T14:38:05 | 2020-07-29T14:38:05 | 49,525,966 | 5 | 4 | null | 2016-01-12T20:09:48 | 2017-09-06T16:32:52 | 2018-04-18T04:42:11 |
Python
|
[
{
"alpha_fraction": 0.5284770131111145,
"alphanum_fraction": 0.548880398273468,
"avg_line_length": 37.04231262207031,
"blob_id": "e4ef23a3615ac81f435b4662b37f146f2517f610",
"content_id": "a5c47550adedc8a3bac55271d1cda3c24cad79f2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 46757,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 1229,
"path": "/rism3d_pc.py",
"repo_name": "MTS-Strathclyde/PC_plus",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\"\"\"\nCreated on Thu Jan 30 16:04:49 2014\n\n@author: Maksim Misin ([email protected])\n\nCompute solvation free energy with rism3d.singlpnt and apply PC corrections.\nThe script also can prepare topology, minimize solute and run generate\nsusceptibility files using 1D-RISM. The output is written to separate .log and\nresults.txt files.\n\nAs an input takes pdb file compatible with antechamber. For example:\nATOM 1 C1 MOL 1 3.537 1.423 0.000 1.00 0.00\nATOM 2 H1 MOL 1 4.089 2.224 0.496 1.00 0.00\nATOM 3 H2 MOL 1 4.222 0.611 -0.254 1.00 0.00\nATOM 4 H3 MOL 1 2.759 1.049 0.669 1.00 0.00\nATOM 5 H4 MOL 1 3.077 1.810 -0.912 1.00 0.00\nTER\nEND\n\nTo run the simmulation simply type:\npython rism3d_pc.py molecule.pdb\n\nThe script requires working installations of python2.7 and AmberTools 12+\n\nFor more information run:\npython rism3d_pc.py -h\n\nIf you find the script useful, please cite:\n\nMisin, M.; Fedorov, M.; Palmer, D. Hydration Free Energies of Ionic Species\nby Molecular Theory and Simulation, J. Phys. Chem. B. 2016.\nhttp://dx.doi.org/10.1021/acs.jpcb.5b10809\n\nMisin, M.; Fedorov, M. V.; Palmer, D. S. Accurate Hydration Free Energies at\na Wide Range of Temperatures from 3D-RISM. J. Chem. Phys. 2015, 142, 091105.\nhttp://dx.doi.org/10.1063/1.4914315\n\nan article where PC+ correction was originally proposed:\n\nSergiievskyi, V.; Jeanmairet, G.; Levesque, M.; Borgis, D. Solvation\nFree-Energy Pressure Corrections in the Three Dimensional Reference Interaction\nSite Model. J. Chem. Phys. 2015, 143, 184116.\nhttp://dx.doi.org/10.1063/1.4935065\n\nas well all related AmberTools' RISM programs.\n\"\"\"\n\nimport sys\nimport argparse\nimport subprocess\nimport distutils.spawn\nimport shutil\nimport os\nimport glob\nimport datetime\nimport time\nimport threading\nimport signal\nimport numpy as np\n\n\n## Non RISM globals ##\n__version__ = '2020.1'\n\nREQUIRED_EXECUTABLES = ['antechamber', 'parmchk2', 'tleap', 'rism3d.snglpnt',\n 'rism1d', 'sander', 'ambpdb']\n\n## Constants ##\nK_B = 1.9872041E-3 # boltzmann const in kcal/mol/K\nN_A = 6.022141e23 # avogadro's constant\n\n\n## RISM-related globals ##\n\nSOLV_SUCEPT_SCRPT = \"\"\"#!/bin/bash\n\ncat > {name1d}.inp <<EOF\n&PARAMETERS\n THEORY='{rism1d}', CLOSUR='{closure}', !Theory\n NR=16384, DR=0.025, !Grid\n OUTLST='xCGT', rout=0, !Output\n NIS=20, DELVV=0.3, TOLVV=1.e-12, !MDIIS\n KSAVE=-1, KSHOW=1, maxstep=10000, !Check pointing and iterations\n SMEAR=1, ADBCOR=0.5, !Electrostatics\n TEMPER={temp}, DIEps={diel}, !bulk solvent properties\n NSP=1\n/\n &SPECIES !SPC water\n DENSITY={conc}d0,\n MODEL=\"$AMBERHOME/dat/rism1d/mdl/{smodel}.mdl\"\n/\nEOF\n\nrism1d {name1d} > {name1d}.out\n\"\"\"\n\nRUNLEAP = \"\"\"source leaprc.gaff2\nmol = loadmol2 \"{name}.mol2\"\ncheck mol\nloadamberparams \"{name}.frcmod\"\nSaveAmberParm mol \"{name}.prmtop\" \"{name}.incrd\"\nSavePdb mol \"{name}.pdb\"\nquit\n\"\"\"\n\nMIN_SCRIPT = \"\"\"Normal minimization\n &cntrl\n imin=1, ! perform minimization\n maxcyc=200, ! The maximum number of cycles of minimization\n drms=1e-3, ! RMS force\n ntmin=3, ! xmin algorithm\n ntb=0, ! no periodic boundary\n cut=999., ! non-bonded cutoff\n ntpr=5 ! printing frequency\n /\n\"\"\"\nMIN_SCRIPT_RISM = \"\"\"Minimization with rism\n &cntrl\n\timin=1, maxcyc=200, drms=1e-3, ntmin=3,ntb=0,cut=999.,\n\tntpr=5, irism=1\n /\n &rism\n\tclosure='{closure}', buffer=25, tolerance=1e-4,solvcut=9999\n /\n\"\"\"\n\n\nMIN_SCRIPT_NAME = 'min.input'\nRISM1D_NAME = '{smodel}_{temp}'\nRESULTS_NAME = 'results.txt'\n\nRESULTS = \"\"\"dGsolv(closure)= {exchem} kcal/mol\nPMV= {pmv} A^3\n\ndGsolv(PC+)= {PC_plus} kcal/mol\ndGsolv(PC)= {PC} kcal/mol\n\nP_minus_ideal_gas_pressure= {pressure_plus} kcal/mol/A^3\nP= {pressure} kcal/mol/A^3\n\n\"\"\"\n\n\ndef process_command_line(argv):\n \"\"\"Processes arguments\n\n Parameters\n ----------\n argv : list\n Command line arguments.\n\n Returns\n -------\n out : argparse.Namespace\n Namespace of command line arguments.\n \"\"\"\n parser = argparse.ArgumentParser(description=\"\"\"Run 3D-RISM single point\n calculation. This script is a wrapper around Amber rism3d.snglpnt program,\n designed to simplify calculations. It also computes pressure corrections\n to RISM solvation free energy.\n \"\"\")\n #molecule options\n molecule_options = parser.add_argument_group('Solute options',\n \"\"\"Options related to a solute molecule.\n Calculation requires only pdb and prmtop files.\n If prmtop file is not present, script will try to\n create this file using antechamber and\n tleap. By default AM1-BCC charges and GAFF\n will be used.\"\"\")\n molecule_options.add_argument('file', metavar='molec.pdb',\n help=\"\"\"Input solute file. Must be in a format\n acceptable by Antechamber. The extension must\n indicate the format (e.g. pdb or mol2).\"\"\")\n molecule_options.add_argument('-p', '--prmtop',\n help=\"\"\"Path to parameters and topology (prmtop) file\n of solute.\"\"\")\n molecule_options.add_argument('--scale_chg',\n help=\"\"\"Scale all solute by this value prmtop file [1.0].\"\"\",\n default=1.0, type=float)\n molecule_options.add_argument('-c', '--molcharge',\n help=\"\"\"Charge of the solute [0].\"\"\", default=\"0\")\n molecule_options.add_argument('--multiplicity',\n help=\"\"\"Multiplicity of the solute [1].\"\"\", default=1,\n type=int)\n molecule_options.add_argument('--minimize',\n help=\"\"\" Minimize solute before performing\n 3D-RISM calculation using either gradient descent (min) or\n RISM minimization using sander (rism, not recommended).\n If no keywords are provided minimization is not performed.\n \"\"\")\n #1drism\n rism1d_options = parser.add_argument_group('1D-RISM options',\n \"\"\"3D-RISM calculation requires xvv file\n (site-site susceptibilities) to run.\n If such file is not provided script can run a\n 1D-RISM to try to genrate it, but will asume that\n the solvent is pure water. Some of the 1D-RISM related\n options are in 3D-RISM group. \"\"\")\n rism1d_options.add_argument('-x', '--xvv',\n help=\"\"\"Path to an existing xvv file. This will skip 1D-RISM\n calculation and all related parameters\n will be ignored. Solvent density as well as calculation\n temeprature will be read from this file.\"\"\")\n rism1d_options.add_argument('--smodel',\n help=\"\"\"Solvent model for 1D-RISM calculation available in\n \"$AMBERHOME/dat/rism1d/mdl/{smodel}.mdl\" [cSPCE].\"\"\",\n default=\"cSPCE\")\n rism1d_options.add_argument('--rism1d',\n help=\"\"\"Type of 1D-RISM theory. Only DRISM has been\n extensively tested [DRISM].\"\"\",\n default=\"DRISM\")\n #3drism\n rism3d_options = parser.add_argument_group('3D-RISM options',\n \"\"\"Options related to the main calculation.\"\"\")\n rism3d_options.add_argument('--closure',\n help=\"\"\"Brdige closure for 3D-RISM and 1D-RISM calculation\n if it is necessary. Either hnc, kh, or pseN\n (N in pseN should be an integer) [pse3].\"\"\",\n default=\"pse3\")\n rism3d_options.add_argument('-t', '--temperature',\n help=\"\"\"Temperature in K at which calculation will be\n preformed. If xvv file was provided, this option will be\n used only for naming directory [298.15].\"\"\",\n default=298.15, type=float)\n rism3d_options.add_argument('--clean_up',\n help=\"\"\" How should auxiliary files be treated:\n 0 - delete nothing;\n 1 - delete some [default];\n 2 - delete all but input, results, and log.\n \"\"\", default=1, type=int)\n rism3d_options.add_argument('--dir_name',\n help=\"\"\"Custom name for produced calculation\n directory. The default one is:\n {mol_name}_{temperature}.\"\"\")\n rism3d_options.add_argument('--timeout',\n help=\"\"\" Minutes after which 3D-RISM calculation\n will be killed. Use 0 for no timeout. [0]. Only works\n on Unix-like system.\n \"\"\", default=0, type=float)\n rism3d_options.add_argument('--tolerance',\n help=\"\"\" Maximum residual values for 3D-RISM solution\n convergence. If many closures a list of closures\n can be supplied [1E-5].\"\"\",\n default=['1e-5'], nargs='*')\n rism3d_options.add_argument('--write_g',\n help=\"\"\"Write radial distribution functions produced\n in 3D-RISM calculation.\"\"\",\n action='store_true')\n rism3d_options.add_argument('--write_c',\n help=\"\"\"Write direct correlation function produced\n in 3D-RISM calculation.\"\"\",\n action='store_true')\n rism3d_options.add_argument('--write_u',\n help=\"\"\"Write solute solvent potential energy grid.\"\"\",\n action='store_true')\n rism3d_options.add_argument('--write_h',\n help=\"\"\"Write total correlation function in k space.\"\"\",\n action='store_true')\n rism3d_options.add_argument('--write_asymp',\n help=\"\"\"Write asymptotics of total and direct\n correlation fuctions in real space.\"\"\",\n action='store_true')\n rism3d_options.add_argument('--noasympcorr',\n help=\"\"\" Thermodynamics of 3D-RISM is calculated without\n long-range asymptotics.\"\"\",\n action='store_true')\n rism3d_options.add_argument('--buffer',\n help=\"\"\"Minimum distance between the solute and the\n edge of the solvent box in A for 3D-RISM\n calculation [25].\"\"\",\n default=25, type=float)\n rism3d_options.add_argument('--solvbox',\n help=\"\"\"Size of the x, y, and z dimensions of the box in\n Angstroms. Specifying this parameter overrides buffer.\"\"\",\n nargs=3)\n rism3d_options.add_argument('--grdsp',\n help=\"\"\"Linear grid spacings for x, y and z\n dimensions. Should be separated with spaces. Units: A\n [0.5 0.5 0.5].\"\"\",\n default=(.5, .5, .5), nargs=3)\n rism3d_options.add_argument('--polar_decomp',\n help=\"\"\"Decomposes solvation free energy into polar\n and non-polar components.\"\"\",\n action='store_true')\n rism3d_options.add_argument('--verbose3d',\n help=\"\"\"Verbosity of 3D-RISM calculation. 0 - print\n nothing; 1 - print iterations; 2 - print all [2].\"\"\",\n default=2, type=int)\n rism3d_options.add_argument('--maxstep3d',\n help=\"\"\"Maximum number of iterations in 3D-RISM\n calculation [500].\"\"\",\n default=500, type=int)\n rism3d_options.add_argument('--rism3d_path',\n help=\"\"\"Specify absolute path or exact name of rism3d.sngpnt\n [rism3d.snglpnt].\"\"\", default='rism3d.snglpnt')\n return parser.parse_args(argv)\n\n\ndef water_dielectric_const(T):\n \"\"\"Return water dielectric constant for temperature 253.15K < T < 383.15K.\n Uses interpolation equation (eq. 9) for static dielectri constant found in\n the doucment by The International Association for the Properties of\n Water and Steam from 2011\n <http://www.iapws.org/relguide/LiquidWater.pdf>`__.\n Pressure = 0.1 MPa\n\n Parameters\n ----------\n T : float\n Temperature in K\n\n Returns\n -------\n e : float\n Water dielectric constant at T\n\n Examples\n --------\n >>> round(water_dielectric_const(273.15), 3)\n 87.927\n >>> round(water_dielectric_const(298.15), 3)\n 78.375\n >>> round(water_dielectric_const(375), 3)\n 55.266\n \"\"\"\n if not 253.15 <= T <= 383.15:\n raise ValueError(\"Temperature is outside of allowed range.\")\n T_star = T/300.0\n coefs = [-43.7527, 299.504, -399.364, 221.327]\n exp_f = [-0.05, -1.47, -2.11, -2.31]\n e = 0\n for i in range(4):\n e += coefs[i]*T_star**(exp_f[i])\n return e\n\n\ndef water_concentration(T):\n \"\"\"Return water concentration for temperature range 253.15K < T < 383.15K.\n Uses interpolation equation (eq. 2) for specific volume found in\n the doucment by The International Association for the Properties of\n Water and Steam from 2011\n <http://www.iapws.org/relguide/LiquidWater.pdf>`__.\n Pressure = 0.1 MPa\n\n Parameters\n ----------\n T : float\n Temperature in K\n\n Returns\n -------\n conc : float\n Water conentration at T in mol/l\n\n Examples\n --------\n >>> round(water_concentration(273.15), 3)\n 55.498\n >>> round(water_concentration(298.15), 3)\n 55.343\n \"\"\"\n if not 253.15 <= T <= 383.15:\n raise ValueError(\"Temperature is outside of allowed range.\")\n p0 = 10.0**5 # Pa\n R = 8.31464 # J/mol/K\n Tr = 10.0\n Ta = 593.0\n Tb = 232.0\n a = [1.93763157E-2,\n 6.74458446E+3,\n -2.22521604E+5,\n 1.00231247E+8,\n -1.63552118E+9,\n 8.32299658E+9]\n b = [5.78545292E-3,\n -1.53195665E-2,\n 3.11337859E-2,\n -4.23546241E-2,\n 3.38713507E-2,\n -1.19946761E-2]\n n = [None, 4., 5., 7., 8., 9.]\n m = [1., 2., 3., 4., 5., 6.]\n def alpha(T):\n return Tr/(Ta - T)\n def beta(T):\n return Tr/(T - Tb)\n coef = a[0] + b[0]*beta(T)**m[0]\n for i in range(1, 6):\n coef += a[i]*alpha(T)**n[i] + b[i]*beta(T)**m[i]\n v0 = R*Tr/p0*coef # m3/mol\n return 1/(v0*1000) # mol/L\n\n\nclass Xvv(object):\n \"\"\" Wrapper around xvvfile used to compute 3d-rism pressure \"\"\"\n def __init__(self, fname):\n \"\"\" Read xvvfile and set instance attributes\n\n Parameters\n ----------\n\n fname : string\n Path to a valid xvv file\n \"\"\"\n self.fname = fname\n self.ngrid = None\n self.nsites = None\n self.nspecies = None\n self.temperature = None\n self.dr = None\n self.atom_names = None\n self.densities = None\n self.xvv_data = None\n self.multiplicities = None\n self.unique_sites_per_species = None\n self.total_sites_per_species = None\n self.species_densities = None\n self.normalized_densities = None\n self._read_xvvfile()\n self._compute_species_properties()\n\n def _read_xvvfile(self):\n with open(self.fname) as f:\n lines = f.readlines()\n tot_lines = len(lines)\n for i, line in enumerate(lines):\n line = line.split()\n if len(line) <= 1:\n continue\n if line[1] == 'POINTERS':\n data = list(map(int, lines[i+2].split()))\n self.ngrid, self.nsites, self.nspecies = data\n if line[1] == 'MTV':\n self.multiplicities = list(map(int, lines[i+2].split()))\n if line[1] == 'NVSP':\n self.unique_sites_per_species = list(map(int, lines[i+2].split()))\n if line[1] == 'THERMO':\n data = lines[i+2].split()\n self.temperature = float(data[0]) # K\n self.dr = float(data[4]) # Angstrom\n if line[1] == 'ATOM_NAME':\n data = lines[i+2].strip()\n #split into groups of 4\n self.atom_names = [data[i:i+4].strip() for i in range(0, len(data), 4)]\n if line[1] == 'RHOV' and len(line) == 2:\n self.densities = list(map(float, lines[i+2].split()))\n #are there more lines with density?\n counter = 3\n while lines[i+counter].startswith(' '):\n self.densities.extend(list(map(float, lines[i+counter].split())))\n counter += 1\n try:\n assert len(self.densities) == len(self.atom_names)\n except AssertionError:\n print('Inconsistent number of densities and atom names')\n print(self.densities)\n print(self.atom_names)\n raise ValueError\n if line[1] == 'XVV' and len(line) == 2:\n self.xvv_data = []\n xvv_ind = i + 2\n while xvv_ind < tot_lines and not lines[xvv_ind].startswith('%'):\n self.xvv_data.extend(lines[xvv_ind].split())\n xvv_ind += 1\n break\n assert len(self.xvv_data) == self.ngrid*self.nsites*self.nsites\n self.xvv_data = np.array(self.xvv_data, dtype=float)\n self.xvv_data = np.reshape(self.xvv_data,\n (self.ngrid, self.nsites, self.nsites),\n order='F')\n\n def _compute_species_properties(self):\n self.normalized_densities = []\n for density, multiplicity in zip(self.densities, self.multiplicities):\n self.normalized_densities.append(density/multiplicity)\n self.species_densities = []\n self.total_sites_per_species = []\n pointer = 0\n for sp_sites in self.unique_sites_per_species:\n pointer += sp_sites\n total_sites = sum(self.multiplicities[pointer - sp_sites:pointer])\n self.total_sites_per_species.append(total_sites)\n self.species_densities.append(self.normalized_densities[pointer - 1])\n assert len(self.species_densities) == self.nspecies\n\n def compute_3drism_pressures(self, k=0):\n \"\"\" Compute 3drism pressure using loaded xvv file.\n Uses equation 20 from the article by Sergiievskyi et al.\n (http://dx.doi.org/10.1063/1.4935065).\n\n Parameters\n ----------\n k : int\n Which k value to use to compute pressure. The pressure can be pretty\n sensitive to it. It is recommended to experiment with a couple of\n k values or better, plot dependency of pressure on it to see\n which value works best.\n\n Return\n ------\n pressures : tuple of floats\n Tuple containeing two pressures.\n First element is 3D-RISM pressure (used in PC), second element is\n 3D-RISM pressure minus ideal gas pressure (used in PC+).\n Both have units of kcal/mol/A^3.\n \"\"\"\n xvv_k = self.xvv_data[k,:,:]\n density_vec = np.array(self.normalized_densities)\n mult_vec = np.array(self.multiplicities)\n # Z_k from sergievskyi's article\n z_k = mult_vec/density_vec*(np.identity(self.nsites) - np.linalg.inv(xvv_k))\n z_k_sum_densities2 = np.sum(density_vec*z_k*density_vec.T)\n densities_times_sites = [sites*dens for sites, dens in zip(self.total_sites_per_species,\n self.species_densities)]\n pressure = sum(densities_times_sites) - .5*z_k_sum_densities2\n pressure = pressure*self.temperature*K_B\n ideal_pressure = sum(self.species_densities)*K_B*self.temperature\n return pressure, pressure - ideal_pressure\n\n\ndef prepare_calc_directory(mol_path, T, dir_name=None):\n \"\"\"Copy pdb file into the directory with the same name. If such directory\n doesn't exist it will try to create it.\n\n Parameters\n ----------\n mol_path : string\n Path to solute\n\n T : float\n A calculation temperature\n\n dir_name : string or None\n A name of directory in which calculation is produced. If None is\n supplied a default value will be used.\n\n Returns\n -------\n dir_name: string\n Name of the calculation directory\n name: string\n Full path to input file without extension\n ext: string\n Extension of the file (everything after last '.').\n \"\"\"\n pdb_path, name_without_path = os.path.split(mol_path)\n if not dir_name:\n dir_name = os.path.join(pdb_path,\n name_without_path.rsplit('.',1)[0] + '_' + str(T))\n try:\n os.mkdir(dir_name)\n except OSError as e:\n if e.errno == 17:\n pass\n else:\n raise e\n name = os.path.join(dir_name, name_without_path)\n shutil.copy(mol_path, name)\n name, ext = name.rsplit('.', 1)\n return dir_name, name, ext\n\n\ndef prepare_logfile(name, argv):\n \"\"\"Create a logfile which will be used throught the calculation.\n\n Parameters\n ----------\n name : string\n Full path to calculation directory/name\n\n argv : list\n Command used to start script\n\n Returns\n -------\n out: file object\n Returns logfile.\n \"\"\"\n p, _ = os.path.split(name)\n if p == '':\n p = '.'\n log_name = '{}.log'.format(name)\n logfile = open(log_name, 'w')\n logfile.write(str(datetime.datetime.now())+'\\n') # timestamp\n logfile.write(' '.join(argv) + '\\n')\n logfile.flush()\n return logfile\n\n\ndef generate_prmtop(name, ext, logfile, molcharge=0, multiplicity=1):\n \"\"\"Generate topology file using GAFF and AM1-BCC charges, scaled by the supplied\n factor.\n\n Parameters\n ----------\n name : string\n Full path to molecule structure file\n\n ext : string\n Structre file extension (indicating structure type)\n\n logfile : A writable file object\n A file to which calculation std. output will be written\n\n molcharge : int | filename (string)\n Charge of the solute\n\n multiplicity : int\n Multiplicty of the solute\n\n Returns\n -------\n out: string\n Returns the name of prepared topology file\n \"\"\"\n p, no_p_name = os.path.split(name)\n if p == '':\n p = '.'\n #Firstly we use antechamber to recognize atom and bonding types, and\n #generate topology\n if isinstance(molcharge, int):\n chg = ['-c', 'bcc', #charge method (AM1-BCC)\n '-nc', str(molcharge), #Net molecule charge\n '-m', str(multiplicity) #Multiplicity\n ]\n else:\n chg = ['-c', 'rc', #charge method (read)\n '-cf', molcharge #charge file\n ]\n ante_out = subprocess.check_output(['antechamber',\n '-i', '{}.{}'.format(no_p_name, ext),\n '-fi', ext,\n '-o', '{}.mol2'.format(no_p_name), # output file\n '-fo', 'mol2', # output format describing each residue\n '-at','amber', # atom types (gaff2)\n '-s', '2' # status info ; 2 means verbose\n ] + chg,\n cwd=p)\n logfile.write(ante_out.decode('utf8'))\n #Run parmchk to generate missing gaff force field parameters\n parm_out = subprocess.check_output(['parmchk2',\n '-i', '{}.mol2'.format(no_p_name),\n '-f', 'mol2',\n '-o', '{}.frcmod'.format(no_p_name)], #file with missing FF params\n cwd=p)\n logfile.write(parm_out.decode('utf8'))\n logfile.flush()\n #Run tleap to generate topology and coordinates for the molecule\n leap_input_name = os.path.join(p, 'runleap.in')\n with open(leap_input_name, 'w') as f:\n f.write(RUNLEAP.format(name=no_p_name))\n leap_out = subprocess.check_output(['tleap', '-f', 'runleap.in'], cwd=p)\n logfile.write(leap_out.decode('utf8'))\n logfile.flush()\n prmtop_name = '{}.prmtop'.format(no_p_name)\n return prmtop_name\n\n\ndef check_consistency(prmtop_name, name):\n \"\"\" Check if the ordering of atoms is the same both in pdb file and in\n prmtop file.\n\n Parameters\n ----------\n\n prmtop_name : string\n Path to prmtop file\n\n name : string\n Calculation name\n \"\"\"\n p, no_p_name = os.path.split(name)\n if p == '':\n p = '.'\n pdb_atom_list = []\n with open(name + '.pdb') as f:\n for line in f:\n if line[:6] in [\"ATOM \", \"HETATM\"]:\n pdb_atom_list.append(line[12:16]) # atom name field\n with open(os.path.join(p, prmtop_name)) as f:\n prmtop_atom_string = ''\n n=4 # number of columns for each atname in prmtop\n lastcol=80 # last column in each prmtop line\n for line in f:\n if line.startswith('%FLAG ATOM_NAME'):\n next(f) # skip one line\n atom_name_row = next(f).strip('\\n')\n while not atom_name_row.startswith('%'):\n prmtop_atom_string += atom_name_row[:lastcol+1]\n atom_name_row = next(f).strip('\\n')\n # split string into characters of length n\n prmtop_atom_list = [prmtop_atom_string[i:i+n] \\\n for i in range(0, len(prmtop_atom_string), n)]\n for i, (pdb_aname, prmtop_aname) in \\\n enumerate(zip(pdb_atom_list, prmtop_atom_list)):\n if pdb_aname.strip() != prmtop_aname.strip():\n raise ValueError(\"The name of atom number {} in pdb file is: {} and \\\nin prmtop file: {}. Check the consistency between two files.\".format(i,\n pdb_aname.strip(), prmtop_aname.strip()))\n\n\ndef prepare_prmtop(args, name, ext, dir_name, logfile):\n \"\"\" Places appropriate prmtop file into the calculation folder and scales\n it's charges if necessary.\n\n Parameters\n ----------\n\n args : Namespace\n Command line arguments\n\n name : string\n Calculation name\n\n ext : string\n Structure type (extension).\n\n dir_name : string\n Name of calculation directory\n\n logfile : File_object\n Calculation log\n\n Returns\n -------\n\n out : string\n Path to prmtop file.\n\n \"\"\"\n # Copy prmtop file, because we might want to change it (change charges)\n if not args.prmtop:\n try:\n chg = int(args.molcharge)\n print('Running AM1-BCC calculation...')\n except ValueError:\n chg = \"../\" + args.molcharge\n print('Reading chargs from {}...'.format(chg))\n prmtop_name = generate_prmtop(name, ext, logfile, chg, args.multiplicity)\n else:\n if ext != 'pdb':\n raise ValueError(\"Use of prmtop requires a pdb format.\")\n print('Reading user provided prmtop file')\n try:\n shutil.copy(args.prmtop, dir_name)\n prmtop_name = os.path.split(args.prmtop)[1] # names are relative to calc directory\n except shutil.Error:\n # most likely error is due to src = destination\n prmtop_name = os.path.split(args.prmtop)[1]\n check_consistency(prmtop_name, name)\n #Open file and scale all the charges\n prm_lines = []\n with open(os.path.join(dir_name, prmtop_name), 'r') as f:\n for line in f:\n if line.startswith('%FLAG CHARGE'):\n prm_lines.append(line)\n prm_lines.append(next(f)) # skip format line\n next_line = next(f)\n while next_line.startswith(' '):\n chrgs = next_line.split()\n new_chrgs = ['{: .8E}'.format(float(chg)*args.scale_chg) for chg in chrgs]\n prm_lines.append( ' ' + ' '.join(new_chrgs) + '\\n')\n next_line = next(f)\n prm_lines.append(next_line)\n else:\n prm_lines.append(line)\n with open(os.path.join(dir_name, prmtop_name), 'w') as f:\n f.writelines(prm_lines)\n return prmtop_name\n\n\ndef minimize_solute(name, logfile, prmtop_name, args, xvv):\n \"\"\" Minimize the solute structure using Sander.\n The pdb file in the calculation directory **will** be overwritten.\n\n Parameters\n ----------\n\n name : string\n Calculation name\n\n logfile : File_object\n Calculation log\n\n prmtop_name : string, default None\n Topology file for calculation. Path should be given\n relative to the directory in which pdb file is located.\n\n args : Namespace\n Command line arguments\n\n xvv: string\n Name of an existing xvv file.\n\n \"\"\"\n p, no_p_name = os.path.split(name)\n if p == '':\n p = '.'\n if args.minimize == 'min':\n min_script = MIN_SCRIPT\n elif args.minimize == 'rism':\n min_script = MIN_SCRIPT_RISM\n else:\n raise ValueError('Unknown minimization type. Use either rism or min.')\n print('Minimizing solute structure')\n # use or create restart (incrd) file\n rst_name = os.path.join(name + '.incrd')\n if not os.path.isfile(rst_name):\n conv_out = subprocess.check_output(['antechamber',\n '-i', '{}.pdb'.format(no_p_name),\n '-fi', 'pdb',\n '-o', '{}.incrd'.format(no_p_name), #output file\n '-fo', 'rst', #output format\n ],\n cwd=p)\n logfile.write(conv_out.decode('utf8'))\n with open(os.path.join(p, MIN_SCRIPT_NAME), 'w') as f:\n f.write(min_script.format(closure=args.closure))\n # minimize solute and overwrite restart file\n min_out = subprocess.check_output(['sander',\n '-O', #overwrite files\n '-i', MIN_SCRIPT_NAME,\n '-p', prmtop_name,\n '-c', '{}.incrd'.format(no_p_name),\n '-r', '{}.incrd'.format(no_p_name),\n '-xvv', os.path.relpath(xvv, p)\n ],\n cwd=p)\n logfile.write(min_out.decode('utf8'))\n # converst restart file to pdb and write\n p = subprocess.Popen(['ambpdb', '-c', '{}.incrd'.format(no_p_name),\n '-p', prmtop_name], stdout=subprocess.PIPE,\n stderr=subprocess.PIPE, cwd=p)\n pdb_min,err = p.communicate()\n #print(err)\n #print(pdb_min)\n with open(name + '.pdb', 'w') as f:\n f.write(pdb_min)\n\n\ndef run_rism1d(name, logfile, T=298.15, smodel=\"SPC\", rism1d=\"DRISM\",\n closure=\"PSE3\", xvv=None):\n \"\"\"Generate xvv file at a given temperature.\n\n Parameters\n ----------\n name : string\n Full path to pdb file without extension\n\n T : float, default 298.15\n A calculation temperature\n\n smodel : string, default SPC\n Water model available in $AMBERHOME/dat/rism1d/mdl/{smodel}.mdl\n\n rism1d : string, default DRISM\n Type of 1D-RISM theory. Only DRISM has been extensively tested\n\n closure : string, default HNC\n Brdige closure which will be used in both 1D-RISM simmulation\n\n xvv : string\n Path to an existing xvv file. If supplied, 1D-RISM calulation will\n be skipped. Otherwise, returned path will be changed relative\n to the 3D-RISM calculation directory.\n\n Returns\n -------\n xvv : string\n Path to a created (existing) xvv file relative to calculation dir.\n \"\"\"\n p, _ = os.path.split(name)\n rism1d_name = None\n if p == '':\n p = '.'\n if not xvv:\n #Generate solvent susceptibility file\n print('Running 1D-RISM calculation...')\n rism1d_name = RISM1D_NAME.format(smodel=smodel, temp=T)\n xvv_script_name_no_p = '{}.sh'.format(rism1d_name)\n xvv_script_name = os.path.join(p, xvv_script_name_no_p)\n diel = round(water_dielectric_const(T), 3)\n conc = round(water_concentration(T), 3)\n succ_srcirpt = SOLV_SUCEPT_SCRPT.format(temp=T, diel=diel, conc=conc,\n smodel=smodel, rism1d=rism1d,\n closure=closure.upper(),\n name1d=rism1d_name)\n with open(xvv_script_name, 'w') as f:\n f.write(succ_srcirpt)\n xvv_out = subprocess.check_output(['bash', xvv_script_name_no_p],\n cwd=p)\n logfile.write(xvv_out.decode('utf8'))\n logfile.flush()\n xvv = '{}.xvv'.format(rism1d_name)\n else:\n if abs(T - 298.15) > 1.0e-4:\n print('Warning: xvv file submitted')\n print('Temperature passed from command line will be ignored!')\n print('Using provided xvv file...')\n xvv = os.path.relpath(xvv, p) # path relative to the calc. directory\n return xvv\n\n\nclass RISM3D_Singlpnt(object):\n \"\"\" A class used to assist setting up 3D-RISM calculation.\n\n Init is used to specify temperature as well as non-standard names for\n topology (prmtop) or water susceptibility (xvv) files.\n\n The calculation details like closure or tolerance are defined in\n setup_calculation method.\n \"\"\"\n def __init__(self, name, T, logfile, prmtop_name=None, xvv=None):\n \"\"\" Create a class for running rism3d.snglpnt.\n\n Parameters\n ----------\n name : string\n Full path to pdb file without extension\n\n T : float\n A calculation temperature\n\n logfile : A writable file object\n A file to which calculation std. output will be written\n\n prmtop_name : string, default None\n A name of topology file for calculation. If\n it is not specified defaults to name.prmtop. Path should be given\n relative to the directory in which pdb file is located.\n\n xvv : string, default None\n A name of susceptibility file for this calculation. Defaults\n to water_T.xvv, where T is calculation temperature rounded to\n two digits. Path should be given relative to the directory in\n which pdb file is located.\n\n \"\"\"\n self.name = name\n self.T = T\n self.p, self.no_p_name = os.path.split(name)\n self.logfile = logfile\n if prmtop_name:\n self.prmtop_name = prmtop_name\n else:\n self.prmtop_name = '{}.prmtop'.format(self.no_p_name)\n if xvv:\n self.xvv_name = xvv\n else:\n self.xvv_name = 'water_{temp}.xvv'.format(temp=self.T)\n self.run_flags_list = None\n\n def setup_calculation(self, closure='hnc', write_g=False, write_h=False,\n write_c=False,\n write_u=False, write_asymp=False,\n noasympcorr=False,\n buffer_distance=25.0,\n solvbox=False,\n grdspc=(0.5, 0.5, 0.5),\n tolerance=1e-5, polar_decomp=False,\n verbose=0, maxstep=500,\n rism3d_path='rism3d.snglpnt'):\n \"\"\" Setup calculation rism3d.snglpnt. calculation.\n\n More details on each of the parameter can be found in AmberTools\n manual RISM section.\n\n Parameters\n ----------\n closure : string, default hnc\n Allowed closure values are kh, hnc, pseN. Here N is an\n integer.\n\n write_g : boolean, default False\n Specifies whether program will write radial distribution\n functions.\n\n write_h : boolean, default False\n Specifies whether program will write total correlation\n functions in k space.\n\n write_c : boolean, default False\n Specifies wheter program will write direct correlation\n functions.\n\n write_u : boolean, default False\n Specifies wheter program will write potential energy\n grid.\n\n write_asymp : boolean, default False\n Write asymptotics of total and direct correlation fuctions in\n real space.\n\n noasympcorr : boolean, default False\n Don't use long range corrections to compute thermodynamics.\n\n buffer_distance : float, default 25.0\n Minimum distance between the solute and the edge of\n the solvent box in A.\n\n solvbox : array-like (should contain 3 floats)\n Size of the box in x y and z directions. Overrides buffer_distance.\n\n grdsp: array-like (should contain 3 floats), default (0.5, 0.5, 0.5)\n Comma separated linear grid spacings for x, y and z dimensions.\n\n tolerance: float, default 1e-10\n Maximum residual values for solution convergence.\n\n polar_decomp: boolean, default False\n Decomposes solvation free energy into polar and non-polar\n components\n\n verbose: int, default 0\n Either 0, 1 or 2. Determines verbosity of caluclation.\n\n maxstep: int, default 1000\n Number of iterations in 3D-RISM calculation.\n\n rism3d_path : str, default rism3d.snglpnt\n Absolute path or exact name of rism3d.snglpnt program\n \"\"\"\n grdspc = ','.join(map(str, grdspc))\n if solvbox:\n solvbox = ','.join(map(str, solvbox))\n self.run_flags_list = [rism3d_path,\n '--pdb', '{}.pdb'.format(self.no_p_name),\n '--prmtop', self.prmtop_name,\n '--rst', '{}.incrd'.format(self.no_p_name),\n '--xvv', self.xvv_name,\n '--grdspc', grdspc,]\n self.run_flags_list.extend(['--tolerance'] + tolerance)\n self.run_flags_list.extend(['--closure', closure])\n if solvbox:\n self.run_flags_list.extend(['--solvbox', solvbox])\n else:\n self.run_flags_list.extend(['--buffer', str(buffer_distance)])\n if write_g:\n self.run_flags_list.extend(['--guv',\n 'g_{}'.format(self.no_p_name)])\n if write_h:\n self.run_flags_list.extend(['--huv',\n 'h_{}'.format(self.no_p_name)])\n if write_c:\n self.run_flags_list.extend(['--cuv',\n 'c_{}'.format(self.no_p_name)])\n if write_u:\n self.run_flags_list.extend(['--uuv',\n 'u_{}'.format(self.no_p_name)])\n if write_asymp:\n self.run_flags_list.extend(['--asymp',\n 'a_{}'.format(self.no_p_name)])\n if noasympcorr:\n self.run_flags_list.extend(['--noasympcorr'])\n if polar_decomp:\n self.run_flags_list.extend(['--polarDecomp'])\n if verbose:\n self.run_flags_list.extend(['--verbose'])\n self.run_flags_list.extend(['{}'.format(verbose)])\n if maxstep:\n self.run_flags_list.extend(['--maxstep'])\n self.run_flags_list.extend(['{}'.format(maxstep)])\n\n def run_calculation_and_log(self, timeout=30):\n \"\"\"Run 3D-RISM single point calculation and log.\n\n Parameters\n ----------\n timeout : float, defult 30\n When HNC calculations get stuck they tend\n to run for a long amount of time. If calculation is\n running more than 30min most likely it is stuck.\n This option records 3D-RISM caclulation PID and\n kills it after supplied number of minutes. Doesn't work\n on windows. And in some other cases as well.\n \"\"\"\n start_time = time.time()\n #print(self.run_flags_list)\n self.logfile.write('3D-RISM command: {}\\n'.format(self.run_flags_list))\n rism_out = subprocess.check_output(self.run_flags_list, cwd=self.p)\n self.logfile.write(rism_out.decode('utf8'))\n self.logfile.flush()\n #write timestamp and close\n end_time = time.time()\n self.logfile.write(str(datetime.datetime.now()) + '\\n')\n runtime = end_time - start_time\n self.logfile.write('3D-RISM runtime: {:.0f}'.format(runtime))\n self.logfile.flush()\n self.logfile.close()\n\n\ndef clean_up(name, T, level):\n \"\"\"Delete junk.\n\n Parameters\n ----------\n name : string\n Full path to pdb file without extension\n\n T: float\n A calculation temperature\n\n level : {0, 1, 2}\n 0 - delete nothing;\n 1 - delete ANTECHAMBER*, all water but .sh and .therm,\n .frcmod, .mol2, NEWPDB.PDB, PREP.INF, ATOMTYPE.INF, runleap.in\n sqm*, leap.log;\n 2 - delete ALL but RESULTS_NAME and logfile - not recommended.\n \"\"\"\n p, no_p_name = os.path.split(name)\n water_name = 'water_{}'.format(T)\n to_del1_glob = ['ANTECHAMBER*', 'sqm*', 'water*vv*']\n to_del1_files = [no_p_name + '.mol2', no_p_name + '.frcmod',\n water_name + '.inp', water_name + '.out',\n water_name + '.sav', 'ATOMTYPE.INF',\n 'leap.log', 'NEWPDB.PDB', 'PREP.INF', 'runleap.in',\n MIN_SCRIPT_NAME, 'mdout', 'mdinfo']\n will_be_deleted_list = []\n if level == 1:\n for wildcard in to_del1_glob:\n will_be_deleted_list.extend(glob.glob(os.path.join(p, wildcard)))\n will_be_deleted_list.extend([os.path.join(p, f) for f in \\\n to_del1_files])\n if level == 2:\n all_files = os.listdir(p)\n all_files.remove(RESULTS_NAME)\n log_name = '{}.log'.format(no_p_name)\n all_files.remove(log_name)\n will_be_deleted_list.extend([os.path.join(p, f) for f in all_files])\n for f in will_be_deleted_list:\n try:\n os.unlink(f)\n except OSError as e:\n if e.errno == 2:\n pass\n else:\n raise e\n\n\ndef write_results(name, xvv_obj):\n \"\"\" Parses log file and writes free energies and corrections to\n results.txt.\n\n Parameters\n ----------\n name : string\n Full path to pdb file without extension\n\n xvv_obj : Xvv class instance\n Wrapper around xvv file used for calculation\n \"\"\"\n p, _ = os.path.split(name)\n log_name = '{}.log'.format(name)\n exchem = None\n pmv = None\n with open(log_name, 'r') as f:\n for line in f:\n if line[0:11] == \"rism_exchem\":\n exchem = float(line.split()[1])\n if line[0:11] == \"rism_volume\":\n pmv = float(line.split()[1])\n # supporting new versions of amber\n if line.startswith('rism_excessChemicalPotential'):\n exchem = float(line.split()[1])\n if line.startswith(\"rism_partialMolarVolume\"):\n pmv = float(line.split()[1])\n if not pmv:\n print(open(log_name).read())\n raise ValueError(\"Cannot find pmv value in log file. Most likely calculation didn't converge.\")\n # compute PC\n pres, pres_plus = xvv_obj.compute_3drism_pressures() # [kcal/mol/A^3]\n PC = exchem - pres*pmv # pressure correction [kcal/mol]\n PC_plus = exchem - pres_plus*pmv # pressure correction plus [kcal/mol]\n #Write and print results\n results = RESULTS.format(exchem=exchem, pmv=pmv, PC=PC, PC_plus=PC_plus,\n pressure=pres, pressure_plus=pres_plus)\n with open(os.path.join(p, RESULTS_NAME), 'w') as f:\n f.write(results)\n print('Calculation has finished')\n print('RISM exchem={} kcal/mol'.format(exchem))\n print('PC+ dG*(solv)={} kcal/mol'.format(PC_plus))\n print('Detailed output can be found in {}.log'.format(name))\n return PC_plus\n\n\ndef main(argv):\n args = process_command_line(argv)\n for executable in REQUIRED_EXECUTABLES:\n if not distutils.spawn.find_executable(executable):\n raise NameError(\"{} is not found!\".format(executable))\n print('Starting SFE calculation for {}'.format(args.file))\n dir_name, name, ext = prepare_calc_directory(args.file, args.temperature, args.dir_name)\n logfile = prepare_logfile(name, argv)\n prmtop_name = prepare_prmtop(args, name, ext, dir_name, logfile)\n #xvv is the path to xvv file relative to calc directory\n xvv = run_rism1d(name, logfile, args.temperature, args.smodel,\n args.rism1d, args.closure, xvv=args.xvv)\n xvv_obj = Xvv(os.path.join(dir_name, xvv))\n if args.minimize:\n print(\"Minimizing solute.\")\n minimize_solute(name, logfile, prmtop_name, args, xvv)\n rism_calc = RISM3D_Singlpnt(name, xvv_obj.temperature,\n logfile, prmtop_name=prmtop_name,\n xvv=xvv)\n rism_calc.setup_calculation(args.closure,\n write_g=args.write_g,\n write_h=args.write_h,\n write_c=args.write_c,\n write_u=args.write_u,\n write_asymp=args.write_asymp,\n noasympcorr=args.noasympcorr,\n buffer_distance=args.buffer,\n solvbox=args.solvbox,\n grdspc=args.grdsp,\n tolerance=args.tolerance,\n polar_decomp=args.polar_decomp,\n verbose=args.verbose3d,\n maxstep=args.maxstep3d,\n rism3d_path=args.rism3d_path)\n print('Running 3D-RISM calculation...')\n rism_calc.run_calculation_and_log(args.timeout)\n pc_plus = write_results(name, xvv_obj)\n clean_up(name, xvv_obj.temperature, args.clean_up)\n return pc_plus\n\n\nif __name__ == '__main__':\n main(sys.argv[1:])\n\n\n\n"
},
{
"alpha_fraction": 0.5561980605125427,
"alphanum_fraction": 0.595205545425415,
"avg_line_length": 44.93236541748047,
"blob_id": "b4d20e4ce2f9e9c34bda8fb61eed1e696a7e18e8",
"content_id": "eb01b65fe6130d024a62051e73d97c812963cca0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 9511,
"license_type": "permissive",
"max_line_length": 227,
"num_lines": 207,
"path": "/README.md",
"repo_name": "MTS-Strathclyde/PC_plus",
"src_encoding": "UTF-8",
"text": "PC+\n===\n\n_Note: dockerized version of this script is available here: https://github.com/MTS-Strathclyde/pcplus-docker_\n\n\n\nPython script to simplify computation of 3D-RISM pressure corrected (PC+/PC) hydration free energy. The 3D-RISM pressure is computed using the equation 20. from the following article:\n\n_Sergiievskyi, V.; Jeanmairet, G.; Levesque, M.; Borgis, D. Solvation Free-Energy Pressure Corrections in the Three Dimensional Reference Interaction Site Model. J. Chem. Phys. 2015, 143, 184116. http://dx.doi.org/10.1063/1.4935065_\n\nIf you find the script useful please cite the following works:\n\n_Misin, M.; Fedorov, M.; Palmer, D. Hydration Free Energies of Ionic Species by Molecular Theory and Simulation, J. Phys. Chem. B. 2016. http://dx.doi.org/10.1021/acs.jpcb.5b10809_\n\nand\n\n_Misin, M.; Fedorov, M. V.; Palmer, D. S. Accurate Hydration Free Energies at a Wide Range of Temperatures from 3D-RISM. J. Chem. Phys. 2015, 142, 091105. http://dx.doi.org/10.1063/1.4914315_\n\n\n\nAuthors\n-------\nMaksim Mišin <[email protected]>\n\nUsage examples\n--------------\n\nAs an input script takes a pdb file with single solute. For example (methane.pdb):\n```text\nATOM 1 C1 MOL 1 3.537 1.423 0.000 1.00 0.00\nATOM 2 H1 MOL 1 4.089 2.224 0.496 1.00 0.00\nATOM 3 H2 MOL 1 4.222 0.611 -0.254 1.00 0.00\nATOM 4 H3 MOL 1 2.759 1.049 0.669 1.00 0.00\nATOM 5 H4 MOL 1 3.077 1.810 -0.912 1.00 0.00\nTER\nEND\n```\n\n1) 298.15 K methane hydration free energy calculation:\n\n```\n$ python rism3d_pc.py methane.pdb\nStarting SFE calculation for methane.pdb at T=298.15 K\nRunning AM1-BCC calculation...\nRunning 1D-RISM calculation...\nRunning 3D-RISM calculation...\nCalculation has finished\nRISM exchem=8.57636028 kcal/mol\nPC+ dG*(hyd)=1.07928069898 kcal/mol\nDetailed output can be found in methane_298.15/methane.log\n```\n\n2) 350 K calculation with tip3p water\n\n```\n$ python rism3d_pc.py methane.pdb -t 350 --smodel TP3\nStarting SFE calculation for methane.pdb at T=350.0 K\nRunning AM1-BCC calculation...\nRunning 1D-RISM calculation...\nRunning 3D-RISM calculation...\nCalculation has finished\nRISM exchem=9.01341914 kcal/mol\nPC+ dG*(hyd)=1.35551076507 kcal/mol\nDetailed output can be found in methane_350.0/methane.log\n```\n\n3) Using existing topology and susceptibility (xvv) files\n\n```\n$ python rism3d_pc.py methane.pdb -p methane.prmtop -x water_nacl.xvv\nStarting SFE calculation for methane.pdb at T=298.15 K\nReading user provided prmtop file\nUsing provided xvv file...\nRunning 3D-RISM calculation...\nCalculation has finished\nRISM exchem=8.67168499 kcal/mol\nPC+ dG*(hyd)=1.1103088454 kcal/mol\nDetailed output can be found in methane_298.15/methane.log\n```\n\nPrerequisites\n-------------\n\nThe script requires:\n\n* Python 3.6 or later: http://www.python.org/\n* AmberTools18 or later: http://ambermd.org/\n\n\nGet some help\n-------------\n\n $ python rism3d_pc.py -h\n usage: rism3d_pc.py [-h] [-p PRMTOP] [--scale_chg SCALE_CHG] [-c MOLCHARGE]\n [--multiplicity MULTIPLICITY] [--minimize MINIMIZE]\n [-x XVV] [--smodel SMODEL] [--rism1d RISM1D]\n [--closure [CLOSURE [CLOSURE ...]]] [-t TEMPERATURE]\n [--clean_up CLEAN_UP] [--dir_name DIR_NAME]\n [--timeout TIMEOUT]\n [--tolerance [TOLERANCE [TOLERANCE ...]]] [--write_g]\n [--write_c] [--write_u] [--write_asymp] [--noasympcorr]\n [--buffer BUFFER] [--solvbox SOLVBOX SOLVBOX SOLVBOX]\n [--grdsp GRDSP GRDSP GRDSP] [--polar_decomp]\n [--verbose3d VERBOSE3D] [--maxstep3d MAXSTEP3D]\n molec.pdb\n\n Run 3D-RISM single point calculation. This script is a wrapper around Amber\n rism3d.snglpnt program, designed to simplify calculations. It also computes\n pressure corrections to RISM solvation free energy.\n\n optional arguments:\n -h, --help show this help message and exit\n\n Solute options:\n Options related to a solute molecule. Calculation requires only pdb and\n prmtop files. If prmtop file is not present, script will try to create\n this file using antechamber and tleap. By default AM1-BCC charges and GAFF\n will be used.\n\n molec.pdb Input solute file. Must be in pdb format acceptable by\n Antechamber. Must have a .pdb extension.\n -p PRMTOP, --prmtop PRMTOP\n Path to parameters and topology (prmtop) file of\n solute.\n --scale_chg SCALE_CHG\n Scale all solute by this value prmtop file [1.0].\n -c MOLCHARGE, --molcharge MOLCHARGE\n Charge of the solute [0].\n --multiplicity MULTIPLICITY\n Multiplicity of the solute [1].\n --minimize MINIMIZE Minimize solute before performing 3D-RISM calculation\n using either gradient descent (min) or RISM\n minimization using sander (rism, not recommended). If\n no keywords are provided minimization is not\n performed.\n\n 1D-RISM options:\n 3D-RISM calculation requires xvv file (site-site susceptibilities) to run.\n If such file is not provided script can run a 1D-RISM to try to genrate\n it, but will asume that the solvent is pure water. Some of the 1D-RISM\n related options are in 3D-RISM group.\n\n -x XVV, --xvv XVV Path to an existing xvv file. This will skip 1D-RISM\n calculation and all related parameters will be\n ignored. Solvent density as well as calculation\n temeprature will be read from this file.\n --smodel SMODEL Solvent model for 1D-RISM calculation available in\n \"$AMBERHOME/dat/rism1d/mdl/{smodel}.mdl\" [SPC].\n --rism1d RISM1D Type of 1D-RISM theory. Only DRISM has been\n extensively tested [DRISM].\n\n 3D-RISM options:\n Options related to the main calculation.\n\n --closure [CLOSURE [CLOSURE ...]]\n Brdige closure for 3D-RISM and 1D-RISM calculation if\n it is necessary. Either HNC, KH, PSEn (n in PSEn\n should be an integer) or a list of them for sequential\n convergence. For 1D-RISM calculation only last closure\n will be used [PSE3].\n -t TEMPERATURE, --temperature TEMPERATURE\n Temperature in K at which calculation will be\n preformed. If xvv file was provided, this option will\n be used only for naming directory [298.15].\n --clean_up CLEAN_UP How should auxiliary files be treated: 0 - delete\n nothing; 1 - delete some [default]; 2 - delete all but\n input, results, and log.\n --dir_name DIR_NAME Custom name for produced calculation directory. The\n default one is: {mol_name}_{temperature}.\n --timeout TIMEOUT Minutes after which 3D-RISM calculation will be\n killed. Use 0 for no timeout. [0]. Only works on Unix-\n like system.\n --tolerance [TOLERANCE [TOLERANCE ...]]\n Maximum residual values for 3D-RISM solution\n convergence. If many closures a list of closures can\n be supplied [1E-5].\n --write_g Write radial distribution functions produced in 3D-\n RISM calculation.\n --write_c Write direct correlation function produced in 3D-RISM\n calculation.\n --write_u Write solute solvent potential energy grid.\n --write_asymp Write asymptotics of total and direct correlation\n fuctions in real space.\n --noasympcorr Thermodynamics of 3D-RISM is calculated without long-\n range asymptotics.\n --buffer BUFFER Minimum distance between the solute and the edge of\n the solvent box in A for 3D-RISM calculation [25].\n --solvbox SOLVBOX SOLVBOX SOLVBOX\n Size of the x, y, and z dimensions of the box in\n Angstroms. Specifying this parameter overrides buffer.\n --grdsp GRDSP GRDSP GRDSP\n Linear grid spacings for x, y and z dimensions. Should\n be separated with spaces. Units: A [0.5 0.5 0.5].\n --polar_decomp Decomposes solvation free energy into polar and non-\n polar components.\n --verbose3d VERBOSE3D\n Verbosity of 3D-RISM calculation. 0 - print nothing; 1\n - print iterations; 2 - print all [2].\n --maxstep3d MAXSTEP3D\n Maximum number of iterations in 3D-RISM calculation\n [500].\n\n\nNotes\n-----\nThe script has been tested only on Ubuntu, but it should work on most Linux distributions and on Mac OS X. To make it Windows-friendly one would probably need to change the names of executable programs and add them to the PATH.\n\n\n\n"
},
{
"alpha_fraction": 0.5091331601142883,
"alphanum_fraction": 0.5178880095481873,
"avg_line_length": 37.45738220214844,
"blob_id": "06bbe61b4c58969b6e41589fc94d8ac2893d0601",
"content_id": "95c80912e864fd7640c582f485360803d5542415",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18504,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 481,
"path": "/gen_prmtop.py",
"repo_name": "MTS-Strathclyde/PC_plus",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python2\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri May 22 17:48:40 2015\n\n@author: max\n\"\"\"\n\nfrom __future__ import print_function, division\n\nimport os\nimport argparse\nimport sys\nimport glob\nimport shlex\ntry:\n import pybel\nexcept ImportError:\n print(\"Pybel not found, some features may not work correctly!\")\nimport subprocess\ntry:\n import parmed.tools as pact\n from parmed.amber import AmberParm\nexcept ImportError as e:\n print('Make sure you are using AmberTools17!')\n raise e\n\nMIN_SCRIPT = \"\"\"Normal minimization\n &cntrl\n imin=1, ! perform minimization\n maxcyc=10000, ! The maximum number of cycles of minimization\n drms=1e-3, ! RMS force\n ntmin=3, ! xmin algorithm\n ntb=0, ! no periodic boundary\n cut=999., ! non-bonded cutoff\n ntpr=5 ! printing frequency\n /\n\"\"\"\n\n\n\nRUNLEAP = \"\"\"source {leaprc}\nmol = loadmol2 \"{name}.mol2\"\ncheck mol\nloadamberparams \"{name}.frcmod\"\nSaveAmberParm mol \"{name}.prmtop\" \"{name}.incrd\"\nSavePdb mol \"{name}.pdb\"\nquit\n\"\"\"\n#loadamberparams {name}.frcmod\ndef process_command_line(argv):\n \"\"\"Processes arguments\n\n Parameters\n ----------\n argv : list\n Command line arguments.\n\n Returns\n -------\n out : argparse.Namespace\n Namespace of command line arguments.\n \"\"\"\n parser = argparse.ArgumentParser(description=\"\"\" Prepare AMBER prmtop file.\"\"\")\n #Positional args\n parser.add_argument('file', metavar='molec.pdb',\n help=\"\"\"Input file. Either structure file [pdb or mol2]\n or existing prmtop file.\"\"\")\n #Optional args\n parser.add_argument('-f', '--moltype',\n help=\"\"\"Molecule type [pdb]\"\"\", default='pdb')\n parser.add_argument('-c', '--molcharge',\n help=\"\"\"Charge of the solute [0]\"\"\", default=0,\n type=int)\n parser.add_argument('-cm', '--charge_model',\n help=\"\"\"Charge model to use. All antechamber options as\n well as opls will work [bcc].\"\"\", default='bcc') \n parser.add_argument('-lj', '--lennard_jones',\n help=\"\"\"Lennard jones parameters to use (opls, gaff, gaff2, sybyl)\n [gaff]\"\"\", default='gaff') \n parser.add_argument('--scale_r',\n help=\"\"\"Scale all lennard jones radiuses . [1.0]\"\"\",\n default=1.0, type=float)\n parser.add_argument('--scale_eps',\n help=\"\"\"Scale all epsilon values. [1.0]\"\"\",\n default=1.0, type=float)\n parser.add_argument('--multiplicity',\n help=\"\"\"Multiplicity of the solute [1]\"\"\", default=1,\n type=int)\n parser.add_argument('--clean_up',\n help=\"\"\" How should auxiliary files be treated:\n 0 - delete nothing;\n 1 - delete all [default];\n \"\"\", default=1, type=int)\n parser.add_argument('--charge_f',\n help=\"\"\"Supply a charge file to the antechamber. A\n file should contain a list of atomic partial charges\n appearing in the same ordear as are atoms in tge pdb\n file. One row shouldn't contain more than 8 charges.\n \"\"\")\n parser.add_argument('--scale_chg',\n help=\"\"\"Scale all charges predicted by the\n antechamber by a certain value . [1.0]\"\"\",\n default=1.0, type=float)\n parser.add_argument('--input_chg',\n help=\"\"\"Manually input charge for every atom type\"\"\",\n action='store_true')\n parser.add_argument('--input_lj',\n help=\"\"\"Manually input LJ parameters for every atom type\"\"\",\n action='store_true')\n parser.add_argument('--lj_radius_type',\n help=\"\"\"Specify type of LJ radius to input (rmin/2 or \n sigma) [rmin/2]\"\"\",\n default='rmin/2')\n parser.add_argument('-n', '--new_name',\n help=\"\"\"Name of the new prmtop. By default will overwrite\n existing one.\"\"\")\n parser.add_argument('--nomod',\n help=\"\"\" Use this to simply run antechamber (and \n minimization) and exit. Doesn't change default\n atomtypes.\"\"\",\n action='store_true')\n parser.add_argument('--minimize',\n help=\"\"\" Minimize solute using gradient descent.\"\"\",\n action='store_true')\n parser.add_argument('--ffld_out',\n help=\"\"\" File containing ffld server output that script\n will use to assign opls radii and charges. lj option \n must be set to opls for this to work!\"\"\")\n return parser.parse_args(argv)\n\n\n\ndef minimize_solute(name, prmtop_name, args):\n \"\"\" Minimize the solute structure using Sander. \n The pdb file in the calculation directory **will** be overwritten.\n \n Parameters\n ----------\n\n name : string\n Calculation name\n \n prmtop_name : string, default None\n Topology file for calculation. Path should be given\n relative to the directory in which pdb file is located.\n \n args : Namespace\n Command line arguments\n\n \"\"\"\n min_script_name = 'min_script.input'\n p, no_p_name = os.path.split(name)\n if p == '':\n p = '.'\n print('Minimizing solute structure')\n # use or create restart (incrd) file\n rst_name = os.path.join(name + '.incrd')\n if not os.path.isfile(rst_name):\n subprocess.check_output(['antechamber',\n '-i', '{}.pdb'.format(no_p_name),\n '-fi', 'pdb',\n '-o', '{}.incrd'.format(no_p_name), #output file\n '-fo', 'rst', #output format\n ],\n cwd=p)\n with open(os.path.join(p, min_script_name), 'w') as f:\n f.write(MIN_SCRIPT)\n # minimize solute and overwrite restart file\n print(subprocess.check_output(['sander',\n '-O', #overwrite files\n '-i', min_script_name,\n '-p', prmtop_name,\n '-c', '{}.incrd'.format(no_p_name),\n '-r', '{}.incrd'.format(no_p_name)],\n cwd=p))\n with open(rst_name) as f:\n rst_text = f.read()\n # converst restart file to pdb and write\n p = subprocess.Popen(['ambpdb',\n '-p', prmtop_name], stdout=subprocess.PIPE,\n stderr=subprocess.PIPE, stdin=subprocess.PIPE)\n pdb_min = p.communicate(input=rst_text)[0]\n #print(pdb_min)\n with open(name + '.pdb', 'w') as f:\n f.write(pdb_min)\n\n\n\ndef generate_prmtop(name, args):\n \"\"\"Generate topology file using GAFF charges scaled by the supplied\n factor.\n\n Parameters\n ----------\n name : string\n Full path to pdb file without extension\n\n logfile : A writable file object\n A file to which calculation std. output will be written\n\n molcharge : int\n Charge of the solute\n\n multiplicity : int\n Multiplicty of the solute\n\n charge_f : string\n A name of the file containing atomic partial charges readable by\n antechamber. The file will be supplied to the antechamber through\n the option rc. It should contain partial charges appearing in the\n same order as in the pdb file with not more than 8 charges per row.\n\n Returns\n -------\n out: string\n Returns the name of prepared topology file\n \"\"\"\n p, no_p_name = os.path.split(name)\n if p == '':\n p = '.'\n #Firstly we use antechamber to recognize atom and bonding types, and\n #generate topology. Even if we want opls lj paramters, we still need\n #to assign atom types first to generate .prmtop file and only then\n #change them.\n if args.input_chg or args.charge_model == 'opls':\n subprocess.check_output([\"antechamber\",\n '-i', args.file,\n '-fi', args.moltype,\n '-at', args.lennard_jones, \n '-o', '{}.mol2'.format(no_p_name), #output file\n '-fo', 'mol2', #output format describing each residue\n '-s', '2', #status info ; 2 means verbose\n '-dr', 'n' #do not check molecule for \"correctness\"\n ],\n cwd=p)\n elif args.charge_f:\n raise ValueError('This option is bugged - needs fixing')\n args.charge_f = os.path.relpath(args.charge_f, p) #path relative to calc dir\n subprocess.check_output(['antechamber',\n '-i', args.file,\n '-fi', args.moltype,\n '-at', args.lennard_jones,\n '-o', '{}.mol2'.format(no_p_name), #output file\n '-fo', 'mol2', #output format describing each residue\n '-c', 'rc', #charge method: read in charge\n '-cf', args.charge_f, #file with charges\n '-s', '2', #status info ; 2 means verbose\n ],\n cwd=p)\n else:\n subprocess.check_output(['antechamber',\n '-i', args.file,\n '-fi', args.moltype,\n '-at', args.lennard_jones,\n '-o', '{}.mol2'.format(no_p_name), #output file\n '-fo', 'mol2', #output format\n '-c', args.charge_model, #charge method \n '-s', '2', #status info ; 2 means verbose\n '-nc', str(args.molcharge), #Net molecule charge\n '-m', str(args.multiplicity) #Multiplicity\n ],\n cwd=p)\n# #Run parmchk to generate missing gaff force field parameters\n try:\n subprocess.check_output(['parmchk2',\n '-i', '{}.mol2'.format(no_p_name),\n '-f', 'mol2',\n '-o', '{}.frcmod'.format(no_p_name)], #file with missing FF params\n cwd=p)\n except subprocess.CalledProcessError:\n # try falling back on parmchk1\n subprocess.check_output(['parmchk',\n '-i', '{}.mol2'.format(no_p_name),\n '-f', 'mol2',\n '-o', '{}.frcmod'.format(no_p_name)], #file with missing FF params\n cwd=p)\n #Run tleap to generate topology and coordinates for the molecule\n if args.lennard_jones == 'gaff2':\n leaprc = 'leaprc.gaff2'\n else:\n leaprc = 'leaprc.gaff'\n leap_input_name = os.path.join(p, 'runleap.in')\n with open(leap_input_name, 'w') as f:\n f.write(RUNLEAP.format(name=no_p_name, leaprc=leaprc))\n subprocess.check_output(['tleap', '-f', 'runleap.in'], cwd=p)\n prmtop_name = '{}.prmtop'.format(no_p_name)\n return prmtop_name\n\n\ndef run_ffld_server(args, name):\n p, no_p_name = os.path.split(name)\n if p == '':\n p = '.'\n if args.ffld_out:\n with open(args.ffld_out) as f:\n out = f.readlines()\n else:\n schrod_path = os.environ['SCHRODINGER']\n command = \"\"\"{}/utilities/ffld_server -ipdb {}.pdb -print_parameters\"\"\"\\\n .format(schrod_path,name)\n out = subprocess.check_output(shlex.split(command)).splitlines()\n # check if ff parms were generated \n parm_data_start = None\n for i, l in enumerate(out):\n if l.startswith('OPLSAA FORCE FIELD TYPE ASSIGNED'):\n parm_data_start = i + 4\n if not parm_data_start:\n # try to use mol2 for generation\n print('Failed to assigne parameters for pdb, trying mol2')\n # gen mol2 using babel - it recognizes atoms\n mol = pybel.readfile('pdb', name + '.pdb').next()\n mol_mol2 = mol.write('mol2')\n # in babel mol2 there is a problem atoms called CLx are regarded as\n # carbons, not as clorines\n fixed_mol2 = []\n for l in mol_mol2.splitlines():\n ls = l.split()\n if len(ls) == 9: # atom row\n if ls[1].startswith('CL') or ls[1].startswith('Cl'):\n ls[5] = 'Cl'\n l = '{:>7} {:<7}{:>10}{:>10}{:>10} {:<8}{:<3}{:<8}{:>10}'.format(*ls)\n if ls[1].startswith('BR') or ls[1].startswith('Br'):\n ls[5] = 'Br'\n l = '{:>7} {:<7}{:>10}{:>10}{:>10} {:<8}{:<3}{:<8}{:>10}'.format(*ls) \n fixed_mol2.append(l)\n fixed_mol2 = '\\n'.join(fixed_mol2)\n with open(name + '.mol2', 'w') as f:\n f.write(fixed_mol2)\n command = \"\"\"{}/utilities/ffld_server -imol2 {}.mol2 -print_parameters\"\"\"\\\n .format(schrod_path,name)\n out = subprocess.check_output(shlex.split(command)).splitlines()\n # check again\n for i, l in enumerate(out):\n if l.startswith('OPLSAA FORCE FIELD TYPE ASSIGNED'):\n parm_data_start = i + 4\n if not parm_data_start:\n raise ValueError('Failed to assign oplsaa parameters to {}'.format(name))\n return out, parm_data_start\n\n\ndef get_opls_parameters(args, name):\n out, parm_data_start = run_ffld_server(args, name)\n radii = []\n epss = []\n chgs = [] \n for l in out[parm_data_start:]:\n if not l.startswith('-----'):\n l = l.split()\n radii.append(float(l[5])/2*2**(1./6)) # rmin/2, A\n epss.append(float(l[6])) # kcal/mol \n chgs.append(float(l[4])) # e\n else:\n break\n return radii, epss, chgs\n \n\ndef get_usr_input(parm_name, atname, old_value):\n usr_value = raw_input('Provide new {} for {} (blank=keep old) [{:f}]: '.\\\n format(parm_name, atname, old_value))\n if usr_value:\n return float(usr_value)\n else:\n return old_value \n \n \ndef get_chargef_charges(charge_f):\n with open(charge_f) as f:\n charges = f.read().split()\n return charges\n \n\ndef prepare_prmtop(args, name):\n \"\"\" Places appropriate prmtop file into the calculation folder and scales\n it's charges if necessary.\n\n Parameters\n ----------\n\n args : Namespace\n Command line arguments\n\n Returns\n -------\n\n out : string\n Path to prmtop file.\n\n \"\"\"\n # The atom specification in ParmedActions is terrible and requires the use\n # of masks. A good description of what it is can be found in Amber14 manual\n # section 28.2.3\n if args.file.endswith('.prmtop'):\n prmtop_name = args.file\n else:\n prmtop_name = generate_prmtop(name, args)\n if args.new_name:\n new_name = args.new_name\n else:\n new_name = prmtop_name\n if args.minimize:\n minimize_solute(name, prmtop_name, args)\n if args.nomod:\n # we are done\n return 0\n parm = AmberParm(prmtop_name)\n if args.charge_model == 'opls' or args.lennard_jones == 'opls':\n opls_radii, opls_epss, opls_chgs = get_opls_parameters(args, name)\n # account for scenario when charge_f is submitted along with existing prmtop\n if args.charge_f and args.file.endswith('.prmtop'):\n chargef_charges = get_chargef_charges(args.charge_f)\n #iterate over atoms\n for i, atom in enumerate(parm.atoms):\n attyp, atname, attchg = atom.type, atom.name, float(atom.charge)\n #print(attchg)\n nbidx = parm.LJ_types[attyp]\n lj_r = float(parm.LJ_radius[nbidx - 1])\n lj_eps = float(parm.LJ_depth[nbidx - 1])\n # change attyp to atnmae\n act = pact.change(parm, '@{} AMBER_ATOM_TYPE {}'.format(atname, atname))\n act.execute()\n # deal with chgs\n if args.input_chg:\n print()\n attchg = get_usr_input('charge', atname, attchg)\n elif args.charge_model == 'opls':\n attchg = opls_chgs[i]\n elif args.charge_f and args.file.endswith('.prmtop'):\n attchg = float(chargef_charges[i])\n attchg = attchg * args.scale_chg\n act = pact.change(parm, '@{} charge {:f}'.format(atname, float(attchg)))\n act.execute()\n # deal with lj\n if args.input_lj:\n if args.lj_radius_type == 'sigma':\n lj_r = lj_r*2./(2**(1./6)) # convert to sigma\n lj_r = get_usr_input('lj_r', atname, lj_r)\n if args.lj_radius_type == 'sigma':\n lj_r = lj_r/2.*(2**(1./6))\n lj_eps = get_usr_input('lj_eps', atname, lj_eps)\n elif args.lennard_jones== 'opls':\n lj_r = opls_radii[i]\n lj_eps = opls_epss[i]\n lj_r = lj_r * args.scale_r\n lj_eps = lj_eps * args.scale_eps\n #print(lj_r, lj_eps)\n act = pact.changeLJSingleType(parm, '@{} {:f} {:f}'.format(atname, lj_r, lj_eps))\n act.execute()\n #parm.overwrite = True\n parm.write_parm(new_name)\n\n\ndef main(argv):\n args = process_command_line(argv)\n name = os.path.splitext(args.file)[0]\n prepare_prmtop(args, name)\n #clean\n level = args.clean_up\n p, no_p_name = os.path.split(name)\n to_del1_glob = ['ANTECHAMBER*', 'sqm*']\n to_del1_files = [ no_p_name + '.frcmod',\n 'ATOMTYPE.INF',\n 'leap.log', 'NEWPDB.PDB', 'PREP.INF', 'runleap.in']\n will_be_deleted_list = []\n if level == 1:\n for wildcard in to_del1_glob:\n will_be_deleted_list.extend(glob.glob(os.path.join(p, wildcard)))\n will_be_deleted_list.extend([os.path.join(p, f) for f in \\\n to_del1_files])\n for f in will_be_deleted_list:\n try:\n os.unlink(f)\n except OSError as e:\n if e.errno == 2:\n pass\n else:\n raise e\n\n\nif __name__ == '__main__':\n main(sys.argv[1:])\n \n\n"
},
{
"alpha_fraction": 0.5150662660598755,
"alphanum_fraction": 0.5302497148513794,
"avg_line_length": 39.675418853759766,
"blob_id": "b7cf34cb419c4e08d5e6b467c872a9ef57dd1a72",
"content_id": "5951dad9c2db66135ae736170d05faa4aedb5d31",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17058,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 419,
"path": "/rism3d_pressure.py",
"repo_name": "MTS-Strathclyde/PC_plus",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Jan 12 14:57:09 2016\n\nCompute pressure using varous methods.\n@author: max\n\"\"\"\n\nimport numpy as np\nimport sys\nimport pubfft\nfrom scipy import fftpack\nimport matplotlib.pyplot as plt\nimport argparse\n\nK_B = 1.9872041E-3 # boltzmann const in kcal/mol/K\nN_A = 6.022141e23 # avogadro's constant\n\n\ndef process_command_line(argv):\n \"\"\"Processes arguments\n\n Parameters\n ----------\n argv : list\n Command line arguments.\n\n Returns\n -------\n out : argparse.Namespace\n Namespace of command line arguments.\n \"\"\"\n parser = argparse.ArgumentParser(description=\"\"\"Calculate 3D-RISM \n pressure and a number of related quantities.\"\"\")\n #Positional args\n parser.add_argument('xvv', metavar='solvent.xvv',\n help=\"\"\"Site-site susceptibility file in Amber\n 1D-RISM format.\"\"\")\n #Optional args\n parser.add_argument('-t', '--therm',\n help=\"\"\" File with 1D-RISM thermodynamic output\"\"\") \n parser.add_argument('-c', '--cvv',\n help=\"\"\" File with 1D-RISM cvv functions\"\"\") \n parser.add_argument('-k', '--k_number',\n help=\"\"\" Compute pressure at k = dk*k_number [0]\"\"\",\n default=0, type=int)\n parser.add_argument('--plot_xvvk',\n help=\"\"\" Create a plot of X_{ij} (k) for each i and j\"\"\",\n action='store_true')\n parser.add_argument('--save_xvvk',\n help=\"\"\" Name of the file in which xvv_{ij} (k) will be\n stored\"\"\")\n parser.add_argument('--plot_xvvr',\n help=\"\"\" Create a plot of X_{ij} (r) for each i and j\"\"\",\n action='store_true')\n parser.add_argument('--save_xvvr',\n help=\"\"\" Name of the file in which xvv_{ij} (r) will be\n stored\"\"\")\n parser.add_argument('--plot_zr',\n help=\"\"\" Create a plot of z_{ij} (r) for each i and j\"\"\",\n action='store_true')\n parser.add_argument('--plot_zk',\n help=\"\"\" Create a plot of z_{ij} (k) for each i and j\"\"\",\n action='store_true')\n parser.add_argument('--save_zr',\n help=\"\"\" Name of the file in which z_{ij} (r) will be\n stored\"\"\")\n parser.add_argument('--save_zk',\n help=\"\"\" Name of the file in which z_{ij} (k) will be\n stored\"\"\")\n return parser.parse_args(argv)\n\n\n\nclass Xvv(object):\n \"\"\" Wrapper around xvvfile used to compute 3d-rism pressure \"\"\"\n def __init__(self, fname):\n \"\"\" Read xvvfile and set instance attributes \n \n Parameters\n ----------\n \n fname : string\n Path to a valid xvv file\n \"\"\"\n self.fname = fname\n self.ngrid = None\n self.nsites = None\n self.nspecies = None\n self.temperature = None\n self.dr = None\n self.atom_names = None\n self.densities = None\n self.xvv_data = None\n self.multiplicities = None\n # Unique sites per species\n self.unique_sites_per_species = None\n # Actual number of sites per species\n self.total_sites_per_species = None\n # Density of each species\n self.species_densities = None\n # Sites from the same species have densities equal to densities of species\n self.normalized_densities = None\n self._read_xvvfile()\n self._compute_species_properties()\n\n def _read_xvvfile(self):\n with open(self.fname) as f:\n lines = f.readlines()\n tot_lines = len(lines)\n for i, line in enumerate(lines):\n line = line.split()\n if len(line) <= 1:\n continue\n if line[1] == 'POINTERS':\n data = map(int, lines[i+2].split())\n self.ngrid, self.nsites, self.nspecies = data\n if line[1] == 'MTV':\n self.multiplicities = map(int, lines[i+2].split())\n if line[1] == 'NVSP':\n self.unique_sites_per_species = map(int, lines[i+2].split())\n if line[1] == 'THERMO':\n data = lines[i+2].split()\n self.temperature = float(data[0]) # K\n self.dr = float(data[4]) # Angstrom\n if line[1] == 'ATOM_NAME':\n data = lines[i+2].strip()\n #split into groups of 4\n self.atom_names = [data[i:i+4].strip() for i in range(0, len(data), 4)]\n if line[1] == 'RHOV' and len(line) == 2:\n self.densities = map(float, lines[i+2].split())\n #are there more lines with density?\n counter = 3\n while lines[i+counter].startswith(' '):\n self.densities.extend(map(float, lines[i+counter].split()))\n counter += 1\n try:\n assert len(self.densities) == len(self.atom_names)\n except AssertionError:\n print('Inconsistent number of densities and atom names')\n print(self.densities)\n print(self.atom_names)\n raise ValueError\n if line[1] == 'XVV' and len(line) == 2:\n self.xvv_data = []\n xvv_ind = i + 2\n while xvv_ind < tot_lines and not lines[xvv_ind].startswith('%'):\n self.xvv_data.extend(lines[xvv_ind].split())\n xvv_ind += 1\n break\n assert len(self.xvv_data) == self.ngrid*self.nsites*self.nsites\n self.xvv_data = np.array(self.xvv_data, dtype=float)\n self.xvv_data = np.reshape(self.xvv_data,\n (self.ngrid, self.nsites, self.nsites),\n order='F')\n\n def get_k(self):\n \"\"\" Return array of k values\"\"\"\n dk = np.pi/(self.ngrid*self.dr)\n return np.array([i*dk for i in range(self.ngrid)])\n\n\n def _compute_species_properties(self):\n self.normalized_densities = []\n for density, multiplicity in zip(self.densities, self.multiplicities):\n self.normalized_densities.append(density/multiplicity)\n self.species_densities = []\n self.total_sites_per_species = []\n pointer = 0 \n for sp_sites in self.unique_sites_per_species:\n pointer += sp_sites\n total_sites = sum(self.multiplicities[pointer - sp_sites:pointer])\n self.total_sites_per_species.append(total_sites)\n self.species_densities.append(self.normalized_densities[pointer - 1])\n assert len(self.species_densities) == self.nspecies\n\n\n def _get_compressibility_from_therm(self, therm_p):\n \"\"\" Return solvent compressibility.\n \n Parameters\n ----------\n therm_p : string\n path to .therm file\n \n Returns\n -------\n compres : float\n Units: 1/MPa\n \"\"\"\n with open(therm_p, 'r') as f:\n therm_lines = f.readlines()\n compres = float(therm_lines[2].split()[-1])\n units = therm_lines[2].split()[-2]\n if units == '[10e-4/MPa]':\n # Old version of Ambertools\n return compres*10e-4\n if units == '[1/kPa]':\n # # !! This is ambertools 14, where compressiblity is bugged.\n # Units are shown to be [1/kPa], while in reality compres thea are in [1/MPa]\n # http://archive.ambermd.org/201503/0651.html\n return compres\n if units == '[1/MPa]':\n # This is ambertools 15\n # All is good\n return compres\n else:\n raise ValueError('Unknown compressiblity format, check *.therm file')\n\n\n def compute_3drism_pressures(self, k=0):\n \"\"\" Compute 3drism pressure using loaded xvv file.\n Uses equation 20 from the article by Sergiievskyi et al. \n (http://dx.doi.org/10.1063/1.4935065). \n\n Parameters\n ----------\n k : int\n Which k value to use to compute pressure. 1 is recommended.\n \n Return\n ------\n pressures : tuple of floats\n Tuple containeing two pressures.\n First element is 3D-RISM pressure (used in PC), second element is\n 3D-RISM pressure minus ideal gas pressure (used in PC+).\n Both have units of kcal/mol/A^3.\n \"\"\"\n xvv_k = self.xvv_data[k,:,:]\n density_vec = np.array(self.normalized_densities)\n mult_vec = np.array(self.multiplicities)\n # Z_k from sergievskyi's article\n z_k = mult_vec/density_vec*(np.identity(self.nsites) - np.linalg.inv(xvv_k))\n z_k_sum_densities2 = np.sum(density_vec*z_k*density_vec.T)\n densities_times_sites = [sites*dens for sites, dens in zip(self.total_sites_per_species,\n self.species_densities)]\n pressure = sum(densities_times_sites) - .5*z_k_sum_densities2\n pressure = pressure*self.temperature*K_B\n #print self.total_sites_per_species\n ideal_pressure = sum(self.species_densities)*K_B*self.temperature\n #print 'under_pressure',pressure - 2*ideal_pressure\n return pressure - ideal_pressure, pressure\n \n def compute_compres_pressure(self, therm_p):\n \"\"\" Compute 3drism pressure using loaded xvv file.\n Uses equation 21 from the article by Sergiievskyi et al. \n (http://dx.doi.org/10.1063/1.4935065). \n\n Parameters\n ----------\n therm_p : string\n path to .therm file\n \n Return\n ------\n pressures : tuple of floats\n Tuple containeing two pressures.\n First element is 3D-RISM pressure minus ideal gas pressure (used in PC+),\n second is 3D-RISM pressure (used in PC).\n Both have units of kcal/mol/A^3.\n \"\"\"\n compres = self._get_compressibility_from_therm(therm_p) # 1/MPa\n # 4.184e24 A^3 = kcal/MPa\n# C_k0_rho2 = sum(self.species_densities) - \\\n# (4.184e24*self.temperature*K_B/N_A*compres)**(-1) #density**2*c(k=0)\n C_k0_rho = 1 - \\\n (sum(self.species_densities)*1.0e24*self.temperature*K_B/N_A*compres*4184)**(-1) #density**2*c(k=0)\n C_k0_rho2 = C_k0_rho*sum(self.species_densities)\n # pressure using eq. 21\n # works for mixtures as well!\n pressure = K_B*self.temperature*sum(np.array(self.species_densities)\\\n *(np.array(self.total_sites_per_species)+1))/2.\\\n - K_B*self.temperature/2.*C_k0_rho2\n ideal_pressure = sum(self.species_densities)*K_B*self.temperature\n return pressure - ideal_pressure, pressure\n \n def compute_cvv_pressure(self, cvv_fname):\n cvv = np.loadtxt(cvv_fname).astype(float)\n dr = cvv[1,0] - cvv[0,0]\n C_k0_rho2 = 0\n for i in range(self.nsites):\n for j in range(i, self.nsites):\n interaction = i + j + 1\n integral = np.sum(cvv[:, interaction]*cvv[:, 0]**2*4*np.pi)*dr\n if i != j:\n integral = integral*2\n rho2 = self.multiplicities[i]*self.multiplicities[j]*\\\n self.normalized_densities[i]*self.normalized_densities[j]\n C_k0_rho2 += rho2*integral\n pressure = K_B*self.temperature*sum(np.array(self.species_densities)\\\n *(np.array(self.total_sites_per_species)+1))/2.\\\n - K_B*self.temperature/2.*C_k0_rho2\n ideal_pressure = sum(self.species_densities)*K_B*self.temperature\n return pressure - ideal_pressure, pressure\n \n def compute_zk(self):\n \"\"\" Return z(k) matrix \"\"\"\n zk = []\n dk = np.pi/(self.ngrid*self.dr)\n k = np.array([i*dk for i in range(self.ngrid)])\n mult_vec = np.array(self.multiplicities)\n density_vec = np.array(self.normalized_densities)\n# print density_vec\n# for k in range(self.ngrid):\n# if k%100 == 0:\n# print k\n# xvv_k = self.xvv_data[k,:,:]\n# # Z_k from sergievskyi's article\n# zk_i = mult_vec/density_vec*(np.identity(self.nsites) - np.linalg.inv(xvv_k))\n# #print zk_i.shape\n# zk.append(zk_i)\n zk = [mult_vec/density_vec*(np.identity(self.nsites) - \\\n np.linalg.inv(self.xvv_data[i,:,:])) \\\n for i in range(self.ngrid)]\n zk = np.array(zk)\n return k, np.array(zk)\n \n def compute_xvvr(self):\n \"\"\" Return xvv(r) matrix \"\"\"\n r = np.array([i*self.dr for i in range(self.ngrid)])\n k = self.get_k()\n xvvr = [[\"\" for i in range(self.nsites)] for j in range(self.nsites)]\n for i in range(self.nsites):\n for j in range(self.nsites):\n xvvk_ij = self.xvv_data[:,i,j]\n xvvr_ij = pubfft.sinfti(xvvk_ij*k, self.dr, -1)/r\n# n_pots_for_interp = 6\n# r_for_interp = r[1:n_pots_for_interp+1]\n# xvvr_for_interp = xvvr_ij[:n_pots_for_interp]\n# poly_coefs = np.polyfit(r_for_interp, xvvr_for_interp, 3)\n# poly_f = np.poly1d(poly_coefs)\n# xvvr[i][j] = [poly_f(0)]\n xvvr[i][j] = xvvr_ij\n return r, np.swapaxes(xvvr, 0, 2)\n\n def compute_zr(self):\n \"\"\" Return z(r) matrix \"\"\"\n r = np.array([i*self.dr for i in range(self.ngrid)])\n k, zk = self.compute_zk()\n print 'computed zk',zk.shape\n zr = [[\"\" for i in range(self.nsites)] for j in range(self.nsites)]\n for i in range(self.nsites):\n for j in range(self.nsites):\n zk_ij = zk[1:,i,j]\n zr_ij = pubfft.sinfti(zk_ij*k[1:], self.dr, -1)/r[1:]\n #zr_ij = np.abs(fftpack.fft(zk_ij))\n n_pots_for_interp = 6\n r_for_interp = r[1:n_pots_for_interp+1]\n zr_for_interp = zr_ij[:n_pots_for_interp]\n poly_coefs = np.polyfit(r_for_interp, zr_for_interp, 3)\n poly_f = np.poly1d(poly_coefs)\n zr[i][j] = [poly_f(0)]\n zr[i][j].extend(zr_ij)\n return r, np.swapaxes(zr, 0, 2)\n \n \ndef plot_and_save(x, func, xvv_inst, plot=False, fname=False):\n mat = x.T\n for m in range(xvv_inst.nsites):\n for n in range(m+1):\n if fname:\n mat = np.c_[mat, func[:,m,n].T]\n if plot:\n plt.plot(x, func[:,m,n], \n label='{}-{}'.format(xvv_inst.atom_names[m], \n xvv_inst.atom_names[n]))\n if fname:\n np.savetxt(fname, mat)\n if plot:\n plt.legend()\n plt.savefig('graph.png', dpi=300)\n plt.show() \n \n\ndef main(argv):\n args = process_command_line(argv)\n xvv_inst = Xvv(args.xvv)\n pres_plus, pres = xvv_inst.compute_3drism_pressures(args.k_number)\n print 'Pressure+: {:.6f} kcal/mol/A^3'.format(pres_plus)\n print 'Pressure: {:.6f} kcal/mol/A^3'.format(pres)\n kcal_per_a_cubed_to_bar = 4.184e28/N_A\n print 'Pressure+: {:.6f} bar'.format(pres_plus*kcal_per_a_cubed_to_bar)\n print 'Pressure: {:.6f} bar'.format(pres*kcal_per_a_cubed_to_bar)\n if args.therm:\n cpres_plus, cpres = xvv_inst.compute_compres_pressure(args.therm)\n print 'compres Pressure+: {:.6f} kcal/mol/A^3'.format(cpres_plus)\n print 'compres Pressure: {:.6f} kcal/mol/A^3'.format(cpres)\n if args.cvv:\n cvvpres_plus, cvvpres = xvv_inst.compute_cvv_pressure(args.cvv)\n print 'cvv Pressure+: {:.6f} kcal/mol/A^3'.format(cvvpres_plus)\n print 'cvv Pressure: {:.6f} kcal/mol/A^3'.format(cvvpres)\n analyze_xvvr = args.plot_xvvr or args.save_xvvr\n if analyze_xvvr:\n r, xvvr = xvv_inst.compute_xvvr()\n plot_and_save(r, xvvr, xvv_inst, args.plot_xvvr, args.save_xvvr) \n analyze_xvvk = args.plot_xvvk or args.save_xvvk\n if analyze_xvvk:\n k = xvv_inst.get_k()\n plot_and_save(k, xvv_inst.xvv_data, xvv_inst, args.plot_xvvk, args.save_xvvk)\n analyze_zr = args.plot_zr or args.save_zr\n if analyze_zr:\n r, zr = xvv_inst.compute_zr()\n plot_and_save(r, zr, xvv_inst, args.plot_zr, args.save_zr)\n analyze_zk = args.plot_zk or args.save_zk\n if analyze_zk:\n k, zk = xvv_inst.compute_zk()\n plot_and_save(k, zk, xvv_inst, args.plot_zk, args.save_zk)\n \n #\n #pressures = []\n #for i in range(40):\n # pressures.append(xvv_inst.compute_3drism_pressures(i))\n #plt.plot(pressures, '-o')\n #plt.show()\n \n \nif __name__ == '__main__':\n main(sys.argv[1:])\n \n \n \n"
},
{
"alpha_fraction": 0.5521656274795532,
"alphanum_fraction": 0.5734132528305054,
"avg_line_length": 25.594202041625977,
"blob_id": "69e35c3dd25cf23ef81f0bfbabbf7e1f3ff16ecc",
"content_id": "5d79dbb726b157aff439c98e1ae74185d6dbd6a5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3671,
"license_type": "permissive",
"max_line_length": 128,
"num_lines": 138,
"path": "/pqr2prmtop.py",
"repo_name": "MTS-Strathclyde/PC_plus",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python2\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon, 16 Apr, 2018\n\n@author: David M. Rogers\n\"\"\"\n\nfrom __future__ import print_function, division\nfrom math import floor\n\nimport os\nimport argparse\nimport sys\nimport glob\n\ntry:\n #import parmed.tools as pact\n from parmed.topologyobjects import Atom,ResidueList,AtomType\n from parmed.structure import Structure\n from parmed.charmm import CharmmPsfFile\nexcept ImportError as e:\n print('Make sure you are using AmberTools17!')\n raise e\n\ndef process_command_line(argv):\n \"\"\"Processes arguments\n\n Parameters\n ----------\n argv : list\n Command line arguments.\n\n Returns\n -------\n out : argparse.Namespace\n Namespace of command line arguments.\n \"\"\"\n parser = argparse.ArgumentParser(description=\"\"\" Prepare Simple AMBER prmtop file.\"\"\")\n #Positional args\n parser.add_argument('pqr', metavar='molec.pqr',\n help=\"\"\"Input file, a PDB with all atoms followed by\n 3 space-delimited columns containing charge,\n radius (Rmin), and epsilon params in units of\n electrons, Angstrom, and kcal/mol (respectively).\"\"\")\n parser.add_argument('out', metavar='molec.prmtop',\n help=\"\"\"Name of the prmtop file to output.\n No bonded interactions will be added.\n \"\"\")\n return parser.parse_args(argv)\n\ndef read_pqr(filename):\n \"\"\" Read the atom/residue/chain names, coordinates and extra fields\n from a pqr file.\n\n Parameters\n ----------\n\n filename : PDB filename\n Path to the input file\n\n Returns\n -------\n\n name \n [4-char]\n\n res\n [4-char]\n\n resn\n [int]\n\n chain\n [1-char]\n\n x\n [3-float]\n\n qre\n [float*] -- all remaining space-delimited floats\n\n \"\"\"\n name = [] # 4-char\n res = [] # 4-char\n resn = [] # int\n chain = [] # 1-char\n x = [] # 3-float\n qre = [] # float*\n with open(filename) as f:\n for line in f.xreadlines():\n if line[0:6] not in [\"ATOM \", \"HETATM\"]:\n continue\n\n name.append(line[12:16])\n res.append(line[17:21])\n chain.append(line[21])\n resn.append(int(line[22:26]))\n x.append( [ float(line[30:38]), float(line[38:46]),\n float(line[46:54]) ] )\n qre.append(map(float, line[54:].split()))\n return name,res,resn,chain,x,qre\n\ndef mk_structure(args, name):\n name, res, resn, chain, x, qre = read_pqr(name)\n assert all(len(z) == 3 for z in qre), \"All ATOM lines must end with 3 parameters: chg / e0, Rmin / Ang, and eps / kcal/mol.\"\n Q = sum(z[0] for z in qre)\n if abs(Q - floor(Q+0.5)) > 1e-6:\n print(\"Warning! Total charge on molecule is not an integer: %e\"%Q)\n\n s = Structure()\n for n,(q,r,e) in zip(name, qre):\n s.add_atom(atom(n, q, e, r), 'MOL', 1, 'A')\n\n return s\n\ndef main(argv):\n args = process_command_line(argv)\n s = mk_structure(args, args.pqr)\n s.save(args.out, format='amber', overwrite=True)\n\ntype_serial = 0\n\n# Create an atom type especially for this chg/LJ parameter combo\n# Uses global parameter, type_serial!\ndef atom(name, chg, eps, rmin):\n global type_serial\n type_serial += 1\n at = AtomType(name, type_serial, 1.0, 1)\n at.set_lj_params(eps, rmin)\n a = Atom(name=name, type=name, charge=chg, mass=1.0,# Below 2 choices are\n solvent_radius=0.5*(rmin + 3.5537)/1.7, # not clearly defined.\n screen=0.8)\n a.atom_type = at\n return a\n\nif __name__ == '__main__':\n main(sys.argv[1:])\n\n"
}
] | 5 |
pwlandoll/cs470-image-processing
|
https://github.com/pwlandoll/cs470-image-processing
|
a13ab376b9d7d6c050b23d84177377df1a904221
|
6d344fdd7764fb6d84bcc37c30c6884d8368b0c9
|
fb1039649f54aae17ba3e17e278dd25b36a9ae4f
|
refs/heads/master
| 2021-01-10T22:28:29.419799 | 2015-12-18T15:46:46 | 2015-12-18T15:46:46 | 42,326,222 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6941853761672974,
"alphanum_fraction": 0.6971932053565979,
"avg_line_length": 40.659149169921875,
"blob_id": "9bbbaf3e67df2be5d1effd8080f091b7e1c98f43",
"content_id": "a0a817276b3085e7c4f3144ff2fc73a61246e15a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 66161,
"license_type": "no_license",
"max_line_length": 194,
"num_lines": 1552,
"path": "/plugin/Medical_Image_Processing.py",
"repo_name": "pwlandoll/cs470-image-processing",
"src_encoding": "UTF-8",
"text": "import os\r\nimport re\r\n\r\nfrom csv import reader\r\n\r\nfrom datetime import datetime\r\n\r\nfrom ij import IJ\r\nfrom ij import Menus\r\nfrom ij import WindowManager\r\nfrom ij.gui import GenericDialog\r\nfrom ij.io import LogStream\r\nfrom ij.macro import Interpreter\r\nfrom ij.macro import MacroRunner\r\n\r\nfrom java.awt import BorderLayout\r\nfrom java.awt import Color\r\nfrom java.awt import Container\r\nfrom java.awt import Dimension\r\nfrom java.awt import Robot\r\nfrom java.awt.event import ActionListener\r\nfrom java.awt.event import KeyEvent\r\nfrom java.awt.event import WindowAdapter\r\n\r\nfrom java.io import BufferedReader\r\nfrom java.io import BufferedWriter\r\nfrom java.io import File\r\nfrom java.io import FileReader\r\nfrom java.io import FileWriter\r\nfrom java.io import IOException\r\n\r\nfrom java.lang import System\r\nfrom java.lang import Thread\r\nfrom java.lang import Runnable\r\n\r\nfrom javax.swing import BorderFactory\r\nfrom javax.swing import BoxLayout\r\nfrom javax.swing import JFrame\r\nfrom javax.swing import JCheckBox\r\nfrom javax.swing import JLabel\r\nfrom javax.swing import JComboBox\r\nfrom javax.swing import JPanel\r\nfrom javax.swing import JTextField\r\nfrom javax.swing import JButton\r\nfrom javax.swing import JFileChooser\r\nfrom javax.swing import JMenu\r\nfrom javax.swing import JMenuBar\r\nfrom javax.swing import JMenuItem\r\nfrom javax.swing import JPopupMenu\r\nfrom javax.swing import JProgressBar\r\nfrom javax.swing import JOptionPane\r\nfrom javax.swing import JSeparator\r\nfrom javax.swing import SwingConstants\r\nfrom javax.swing import SwingUtilities\nfrom javax.swing.border import Border\r\nfrom javax.swing.filechooser import FileNameExtensionFilter\r\n\r\nfrom java.util import Scanner\r\nfrom java.util import Timer\r\nfrom java.util import TimerTask\r\n\r\nfrom loci.plugins import BF\r\n\r\nfrom os.path import join\r\n\r\nfrom subprocess import call\r\n\r\nfrom urllib import urlretrieve\r\n\r\n\r\n# This plugin creates a menu to batch process images using imagej's macro files.\r\n# This pluign requires the user to have R installed on their machine.\r\n# This plugin requires the user to have created a macro file with imagej's macro recorder\r\n#\tor to have hand crafted one.\r\n# The plugin will then take that macro that was created from one specific image, and \r\n#\tgeneralize it so that it can be used for batch processing of images.\r\n# The user can select either a directory containing images, or a text file containing \r\n#\ta list of urls to images. Then they select an output folder, where any new files\r\n#\twill be saved. Then they select one of the generalized macro files they have created.\r\n#\tThey can then press start and it will perform the macro operation on all images found\r\n#\tin the directory or in the text file. When finished the results will be fed into an R\r\n#\tscript for analyzing (need to implement)\r\n\r\n\r\n# Wraps a method call to allow static methods to be called from ImageProcessorMenu\r\nclass CallableWrapper:\r\n\tdef __init__(self, any):\r\n\t\tself.__call__ = any\r\n\r\n\r\n# ActionListener for DelimiterComboBox\r\nclass DelimiterActionListener(ActionListener):\r\n\tdef actionPerformed(self,event):\r\n\t\t# Get DelimiterComboBox object\r\n\t\tbox = event.getSource()\r\n\t\t# Enable/Disable extension textfield based on selected delimiter\r\n\t\tImageProcessorMenu.setExtensionTextfieldEnabled(box.getSelectedItem())\r\n\r\n\r\n# Main class\r\nclass ImageProcessorMenu:\r\n\tdef __init__(self):\r\n\t\t# Creates a variable for the directory instead of hard coding it\r\n\t\tself.directoryName = \"Medical_Image\"\r\n\t\t# String of accepted file types for use throughout application\r\n\t\tself.defaultValidFileExtensionsString = \".png, .gif, .dcm, .jpg, .jpeg, .jpe, .jp2, .ome.fif, .ome.tiff, .ome.tf2, .ome.tf8, .ome.bft, .ome, .mov, .tif, .tiff, .tf2, .tf8, .btf, .v3draw, .wlz\"\r\n\t\t# This will be set depending on the contents of the users acceptedFileExtensions.txt\r\n\t\tself.validFileExtensionsString = \"\"\r\n\t\t# Path for the stored accepted extension file\r\n\t\tself.acceptedExtensionFile = IJ.getDir(\"plugins\") + self.directoryName + \"/acceptedFileExtensions.txt\"\r\n\r\n\t\t# Path for the stored text file\r\n\t\tself.pathFile = IJ.getDir(\"plugins\") + self.directoryName + \"/user_paths.txt\"\r\n\r\n\t\t# Set frame size\r\n\t\tframeWidth, frameHeight = 550, 350\r\n\t\t# Set button size\r\n\t\tbuttonWidth, buttonHeight = 130, 25\r\n\r\n\t\t# Create frame\r\n\t\tself.frame = JFrame(\"Medical Image Processing\")\r\n\t\tself.frame.setSize(frameWidth, frameHeight)\r\n\t\tself.frame.setDefaultCloseOperation(JFrame.DISPOSE_ON_CLOSE)\r\n\r\n\t\t# Add a panel to the frame\r\n\t\tpnl = JPanel()\r\n\t\tpnl.setBounds(10,10,frameWidth,frameHeight)\r\n\t\t#pnl.setLayout(BoxLayout(BoxLayout.LINE_AXIS)\r\n\t\tself.frame.add(pnl)\r\n\r\n\t\t# Add a textfield to the frame to display the input directory\r\n\t\tself.inputTextfield = JTextField(30)\r\n\t\tself.inputTextfield.setText(\"Select Import Directory\")\r\n\t\tpnl.add(self.inputTextfield)\r\n\r\n\t\t# Add a browse button to the frame for an input directory\r\n\t\tinputButton = JButton('Select Input',actionPerformed=self.optionMenuPopup)\r\n\t\tinputButton.setPreferredSize(Dimension(buttonWidth, buttonHeight))\r\n\t\tpnl.add(inputButton)\r\n\r\n\t\t# Add a textfield to the frame to display the output directory\r\n\t\tself.outputTextfield = JTextField(30)\r\n\t\tself.outputTextfield.setText(\"Select Output Directory\")\r\n\t\tpnl.add(self.outputTextfield)\r\n\r\n\t\t# Add a browse button to the frame to search for an output directory\r\n\t\toutputButton = JButton('Select Output',actionPerformed=self.setOutputDirectory)\r\n\t\toutputButton.setPreferredSize(Dimension(buttonWidth, buttonHeight))\r\n\t\tpnl.add(outputButton)\r\n\r\n\t\t# Add a textfield to the frame to display the macro file directory\r\n\t\tself.macroSelectTextfield = JTextField(30)\r\n\t\tself.macroSelectTextfield.setText(\"Select Macro File\")\r\n\t\tself.macroSelectTextfield.setName(\"Macro File\")\r\n\t\tpnl.add(self.macroSelectTextfield)\r\n\r\n\t\t# Add a browse button to the frame to search for a macro file\r\n\t\tmacroFileSelectButton = JButton('Select Macro',actionPerformed=self.setMacroFileDirectory)\r\n\t\tmacroFileSelectButton.setPreferredSize(Dimension(buttonWidth, buttonHeight))\r\n\t\tpnl.add(macroFileSelectButton)\r\n\r\n\t\t# Add a textfield to the frame to display the R Script directory\r\n\t\tself.rScriptSelectTextfield = JTextField(30)\r\n\t\tself.rScriptSelectTextfield.setText(\"Select R Script\")\r\n\t\tself.rScriptSelectTextfield.setName(\"R Script\")\r\n\t\tpnl.add(self.rScriptSelectTextfield)\r\n\r\n\t\t# Add a browse button to the frame to search for an R Script\r\n\t\trScriptSelectButton = JButton('Select R Script',actionPerformed=self.setRScriptDirectory)\r\n\t\trScriptSelectButton.setPreferredSize(Dimension(buttonWidth, buttonHeight))\r\n\t\tpnl.add(rScriptSelectButton)\r\n\r\n\t\t# Add separator line for user friendliness\r\n\t\tsep = JSeparator(SwingConstants.HORIZONTAL)\r\n\t\tsep.setPreferredSize(Dimension(frameWidth - 35,5))\r\n\t\tpnl.add(sep)\r\n\r\n\t\t# Save south-most panel as globally accessible object in order to iterate through pertinent components\r\n\t\tImageProcessorMenu.fileSpecificationsPanel = pnl\r\n\r\n\t\t# Label for textfield below\r\n\t\tself.extensionLabel = JLabel(\"File Extensions:\")\r\n\t\tpnl.add(self.extensionLabel)\r\n\r\n\t\t# ComboBox for selected file extension delimeter\r\n\t\tself.delimeterComboBox = JComboBox()\r\n\t\tself.delimeterComboBox.addItem(\"All File Types\")\r\n\t\tself.delimeterComboBox.addItem(\"Include\")\r\n\t\tself.delimeterComboBox.addItem(\"Exclude\")\r\n\t\tself.delimeterComboBox.addActionListener(DelimiterActionListener())\r\n\t\tpnl.add(self.delimeterComboBox)\r\n\r\n\t\t# Add a textfield to the frame to get the user's selected file extensions\r\n\t\tself.extensionTextfield = JTextField()\r\n\t\tself.extensionTextfield.setPreferredSize(Dimension(175,25))\r\n\t\tself.extensionTextfield.setText(\"Example: .jpg, .png\")\r\n\t\tself.extensionTextfield.setName(\"Extensions\")\r\n\t\tself.extensionTextfield.setToolTipText(\"Valid File Types: [\" + self.validFileExtensionsString + \"]\")\r\n\t\tpnl.add(self.extensionTextfield)\r\n\r\n\t\t# Blank spaces for alignment purposes\r\n\t\tself.blankLbl = JLabel(\" \")\r\n\t\tpnl.add(self.blankLbl)\r\n\r\n\t\t# Label for textfield below\r\n\t\tself.containsLabel = JLabel(\"File Name Contains:\")\r\n\t\tpnl.add(self.containsLabel)\r\n\r\n\t\t# Add a textfield to the frame to get the specified text that a filename must contain\r\n\t\tself.containsTextfield = JTextField(30)\r\n\t\tpnl.add(self.containsTextfield)\r\n\r\n\t\t# Add a checkbox which determines whether or not to copy the original image file(s) to the newly created directory/directories\r\n\t\tself.copyImageToNewDirectoryCheckBox = JCheckBox(\"Copy Original Image(s) to Output Directory\")\r\n\t\tpnl.add(self.copyImageToNewDirectoryCheckBox)\r\n\r\n\t\t#Add separator line for user friendliness\r\n\t\tsep2 = JSeparator(SwingConstants.HORIZONTAL)\r\n\t\tsep2.setPreferredSize(Dimension(frameWidth - 35,5))\r\n\t\tpnl.add(sep2)\r\n\r\n\t\t# Add a start button to the frame\r\n\t\tself.startButton = JButton('Start', actionPerformed=self.start)\r\n\t\tself.startButton.setEnabled(False)\r\n\t\tself.startButton.setPreferredSize(Dimension(150,40))\r\n\t\tpnl.add(self.startButton)\r\n\r\n\t\t# Add a menu to the frame\r\n\t\tmenubar = JMenuBar()\r\n\t\tfile = JMenu(\"File\")\r\n\r\n\t\t# Create a generalize macro menu option\r\n\t\tcreateGeneralMacro = JMenuItem(\"Create Generalized Macro File\", None, actionPerformed=self.generalizePrompts)\r\n\t\tcreateGeneralMacro.setToolTipText(\"Create a macro file that can be used in the processing pipeline using an existings macro file\")\r\n\t\tfile.add(createGeneralMacro)\r\n\r\n\t\t# Create menu option to change the path to RScript.exe\r\n\t\tchangeRPath = JMenuItem(\"Change R Path\", None, actionPerformed=self.changeRPath)\r\n\t\tchangeRPath.setToolTipText(\"Specify The Location of RScript.exe (Contained in the R Installation Directory by Default)\")\r\n\t\tfile.add(changeRPath)\r\n\r\n\t\t# Create menu option to run the r script on the csv files in the output directory\r\n\t\trunRWithoutImageProcessing = JMenuItem(\"Run R Script Without Processing Images\", None, actionPerformed=self.runRWithoutImageProcessing)\r\n\t\trunRWithoutImageProcessing.setToolTipText(\"Runs the selected R script on already created .csv files\")\r\n\t\tfile.add(runRWithoutImageProcessing)\r\n\r\n\t\t# Create menu option to modify the default r script\r\n\t\tbasicRModifier = JMenuItem(\"Create basic R Script\",None, actionPerformed=self.basicRModifier)\r\n\t\tbasicRModifier.setToolTipText(\"Load a csv file and select two categories to be used in a scatter plot\")\r\n\t\tfile.add(basicRModifier)\r\n\r\n\t\t# Create menu option to add file extensions to the list of accepted types\r\n\t\taddAcceptedFileExtension = JMenuItem(\"Add Accepted File Extension\", None, actionPerformed=AddFileExtensionMenu)\r\n\t\taddAcceptedFileExtension.setToolTipText(\"Add a Specified File Extension to the List of Accepted Types\")\r\n\t\tfile.add(addAcceptedFileExtension)\r\n\r\n\t\t# Create an exit menu option, Will close all windows associated with fiji\r\n\t\tfileExit = JMenuItem(\"Exit\", None, actionPerformed=self.onExit)\r\n\t\tfileExit.setToolTipText(\"Exit application\")\r\n\t\tfile.add(fileExit)\r\n\r\n\t\t# Add the menu to the frame\r\n\t\tmenubar.add(file)\r\n\t\tself.frame.setJMenuBar(menubar)\r\n\r\n\t\t# Disable file extension textfield off the bat\r\n\t\tself.setExtensionTextfieldEnabled(\"All File Types\")\r\n\r\n\t\t# Show the frame, done last to show all components\r\n\t\tself.frame.setResizable(False)\r\n\t\tself.frame.setVisible(True)\r\n\r\n\t\t# Find the R executable\r\n\t\tself.findR(False)\r\n\r\n\t\t# Check if user has file containing accepted file extensions\r\n\t\tself.checkAcceptedExtensionsFile()\r\n\r\n\t# Closes the program\r\n\tdef onExit(self, event):\r\n\t\tself.frame.dispose()\r\n\t\t# Using the line below will close the entire Fiji program, not just the plugin\r\n\t\t#System.exit(0)\r\n\r\n\tdef checkPathFile(self):\r\n\t\tif not os.path.exists(self.pathFile):\r\n\t\t\t# Create the user path file, and write empty file paths\r\n\t\t\ttry:\r\n\t\t\t\tpathFile = open(self.pathFile, \"w\")\r\n\t\t\t\tpathFile.write(\"inputPath\\t\\r\\n\")\r\n\t\t\t\tpathFile.write(\"outputPath\\t\\r\\n\")\r\n\t\t\t\tpathFile.write(\"macroPath\\t\\r\\n\")\r\n\t\t\t\tpathFile.write(\"rPath\\t\\r\\n\")\r\n\t\t\t\tpathFile.write(\"rScriptPath\\t\\r\\n\")\r\n\t\t\t\tpathFile.close()\r\n\t\t\texcept IOError:\r\n\t\t\t\tself.showErrorDialog(\"Permissions Error\", \"Insufficient read/write access to %s\\r\\nPlease correct this issue and restart the plugin.\" % self.pathFile)\r\n\r\n\t# Checks to see if the file self.directoryName + /acceptedFileExtensions.txt exists within FIJI's plugins directory\r\n\tdef checkAcceptedExtensionsFile(self):\r\n\t\t# File does not exist\r\n\t\tif not os.path.exists(self.acceptedExtensionFile):\r\n\t\t\t# Create the user path file, and write empty file paths\r\n\t\t\textFile = open(self.acceptedExtensionFile, \"w\")\r\n\t\t\t# Get default accepted file extensions\r\n\t\t\tdefaultExtensions = self.defaultValidFileExtensionsString.split(',')\r\n\t\t\tfor ext in defaultExtensions:\r\n\t\t\t\textFile.write(ext.strip() + \", \")\r\n\t\t\tself.validFileExtensionsString = self.defaultValidFileExtensionsString\r\n\t\t\textFile.close()\r\n\t\t# File exists\r\n\t\telse:\r\n\t\t\ttry:\r\n\t\t\t\tfile = open(self.acceptedExtensionFile, \"r\")\r\n\t\t\t\t# Temporary string for concatenation of file contents\r\n\t\t\t\ttmp = \"\"\r\n\t\t\t\t# Get extensions from file, concatenate to string\r\n\t\t\t\tfor line in file:\r\n\t\t\t\t\ttmp = tmp + line\r\n\t\t\t\tself.validFileExtensionsString = tmp\r\n\t\t\t\tfile.close()\r\n\t\t\texcept IOError:\r\n\t\t\t\tself.showErrorDialog(\"Permissions Error\", \"Insufficient read/write access to %s\\r\\nPlease correct this issue and restart the plugin.\" % self.acceptedExtensionFile)\r\n\r\n\t\t# Update tool tip text to reflect all valid file extensions\r\n\t\tself.extensionTextfield.setToolTipText(\"Valid File Types: [\" + self.validFileExtensionsString + \"]\")\r\n\r\n\t# Read in the data from the path file, return as a dictionary\r\n\tdef readPathFile(self):\r\n\t\treturnDictionary = {\r\n\t\t\t\"inputPath\": \"\",\r\n\t\t\t\"outputPath\": \"\",\r\n\t\t\t\"macroPath\": \"\",\r\n\t\t\t\"rPath\": \"\",\r\n\t\t\t\"rScriptPath\": \"\"}\r\n\t\ttry:\r\n\t\t\t# Open the file as read-only\r\n\t\t\tpathFile = open(self.pathFile, 'r')\r\n\t\t\t# Take each line, split along delimeter, and store in dictionary\r\n\t\t\tfor line in pathFile:\r\n\t\t\t\t# Split on tab character\r\n\t\t\t\tsplit = line.split(\"\\t\")\r\n\t\t\t\t# Update the dictionary only if splitting shows there was a value stored\r\n\t\t\t\tif len(split) > 1:\r\n\t\t\t\t\treturnDictionary[split[0]] = split[1].strip()\r\n\t\t\tpathFile.close()\r\n\t\texcept IOError:\r\n\t\t\tself.showErrorDialog(\"Permissions Error\", \"Insufficient read/write access to %s\\r\\nPlease correct this issue and restart the plugin.\" % self.pathFile)\r\n\t\treturn returnDictionary\r\n\r\n\tdef findR(self, change):\r\n\t\t# Get rPath from the path file\r\n\t\t# Requires that the path file exists\r\n\t\tself.checkPathFile()\r\n\t\trPath = self.readPathFile()[\"rPath\"]\r\n\t\t# If it found one, set the global variable and prepopulate directories, else further the search\r\n\t\tif rPath and rPath.strip() != \"\" and not change:\r\n\t\t\trcmd = rPath\r\n\t\t\tself.prepopulateDirectories()\r\n\t\telse:\r\n\t\t\trcmd = None\r\n\t\t\t# Look for the Rscript command. First, try known locations for OS X, Linux, and Windows\r\n\t\t\tosxdir, linuxdir, windowsdir = \"/usr/local/bin/Rscript\", \"/usr/bin/Rscript\", \"C:/Program Files/R\"\r\n\t\t\tif os.path.exists(osxdir) and not change:\r\n\t\t\t\trcmd = osxdir\r\n\t\t\telif os.path.exists(linuxdir) and not change:\r\n\t\t\t\trcmd = linuxdir\r\n\t\t\telif os.path.exists(windowsdir) and not change:\r\n\t\t\t\t# Set the R command to the latest version in the C:\\Program Files\\R folder\r\n\t\t\t\ttry:\r\n\t\t\t\t\trcmd = '\"' + windowsdir + \"/\" + os.listdir(windowsdir)[-1] + '/bin/Rscript.exe\"'\r\n\t\t\t\texcept IndexError:\r\n\t\t\t\t\t# If the R directory exists, but has no subdirectories, then an IndexError happens\r\n\t\t\t\t\t# We don't care at this point, we'll just pass it over without setting rcmd.\r\n\t\t\t\t\tpass\r\n\t\t\t# If none of those work\r\n\t\t\tif not rcmd:\r\n\t\t\t\tmessage = (\"No R path found. You will be asked to select the Rscript executable.\\n\"\r\n\t\t\t\t\t\"On Windows systems, RScript.exe is found in the \\\\bin\\\\ folder of the R installation.\\n\"\r\n\t\t\t\t\t\"On OS X, Rscript is usually found in /usr/local/bin/.\\n\"\r\n\t\t\t\t\t\"On Linux, Rscript is usually found in /usr/bin.\")\r\n\t\t\t\tif not change:\r\n\t\t\t\t\tJOptionPane.showMessageDialog(self.frame, message)\r\n\t\t\t\tchooseFile = JFileChooser()\r\n\t\t\t\tchooseFile.setFileSelectionMode(JFileChooser.FILES_ONLY)\r\n\t\t\t\t# Verify that the selected file is \"Rscript\" or \"Rscript.exe\"\r\n\t\t\t\tnotR = True\r\n\t\t\t\twhile notR:\r\n\t\t\t\t\tret = chooseFile.showDialog(self.frame, \"Select\")\r\n\t\t\t\t\tif chooseFile.getSelectedFile() is not None and ret == JFileChooser.APPROVE_OPTION:\r\n\t\t\t\t\t\tr = chooseFile.getSelectedFile().getPath()\r\n\t\t\t\t\t\tif r[-7:] == \"Rscript\" or r[-11:] == \"Rscript.exe\":\r\n\t\t\t\t\t\t\trcmd = r\r\n\t\t\t\t\t\t\tnotR = False\r\n\t\t\t\t\t\telse:\r\n\t\t\t\t\t\t\tJOptionPane.showMessageDialog(self.frame, \"The selected file must be Rscript or Rscript.exe\")\r\n\t\t\t\t\t# If 'cancel' is selected then the loop breaks\r\n\t\t\t\t\tif ret == JFileChooser.CANCEL_OPTION:\r\n\t\t\t\t\t\tnotR = False\r\n\t\tself.rcommand = rcmd\r\n\r\n\t# Enables/Disables the file extension textfield based on the user's selected delimiter\r\n\tdef setExtensionTextfieldEnabled(selectedDelimiter):\r\n\t\textTextfield = JTextField()\r\n\t\t# Iterate through JPanel to find the extension textfield\r\n\t\tfor c in ImageProcessorMenu.fileSpecificationsPanel.getComponents():\r\n\t\t\tif (isinstance(c,JTextField)):\r\n\t\t\t\tif (c.getName() == \"Extensions\"):\r\n\t\t\t\t\textTextfield = c\r\n\r\n\t\t# Disable the textfield\r\n\t\tif (selectedDelimiter == \"All File Types\"):\r\n\t\t\tborder = BorderFactory.createLineBorder(Color.black)\r\n\t\t\textTextfield.setEnabled(False)\r\n\t\t\textTextfield.setDisabledTextColor(Color.black)\r\n\t\t\textTextfield.setBackground(Color.lightGray)\r\n\t\t\textTextfield.setBorder(border)\r\n\t\t\textTextfield.setText(\"Example: .jpg, .png\")\r\n\t\t# Enable the textfield\r\n\t\telse:\r\n\t\t\tborder = BorderFactory.createLineBorder(Color.gray)\r\n\t\t\textTextfield.setEnabled(True)\r\n\t\t\textTextfield.setBackground(Color.white)\r\n\t\t\textTextfield.setBorder(border)\r\n\t\t\t# Text will not clear if the user has specified extensions and has changed delimiter category\r\n\t\t\tif (extTextfield.getText() == \"Example: .jpg, .png\"):\r\n\t\t\t\textTextfield.setText(\"\")\r\n\r\n\t# Wrap method call so that it is callable outside this class' scope\r\n\tsetExtensionTextfieldEnabled = CallableWrapper(setExtensionTextfieldEnabled)\r\n\r\n\t# Launches file chooser dialog boxes to select a macro to generalize, and when file was used to create it\r\n\tdef generalizePrompts(self, event):\r\n\t\t# Creates a file chooser object\r\n\t\tchooseFile = JFileChooser()\r\n\r\n\t\t# Allow for selection of files or directories\r\n\t\tchooseFile.setFileSelectionMode(JFileChooser.FILES_ONLY)\r\n\r\n\t\t# Filter results to only .ijm files\r\n\t\tfilter = FileNameExtensionFilter(\"Macro File\", [\"ijm\"])\r\n\t\tchooseFile.addChoosableFileFilter(filter)\r\n\r\n\t\t# Show the chooser to select a .ijm file\r\n\t\tret = chooseFile.showDialog(self.inputTextfield, \"Choose file\")\r\n\r\n\t\t# If a file is chosen continue to allow user to choose where to save the generalized file\r\n\t\tif chooseFile.getSelectedFile() is not None and ret == JFileChooser.APPROVE_OPTION:\r\n\t\t\tname = self.getName()\r\n\t\t\tif name != None:\r\n\t\t\t\tself.generalize(chooseFile.getSelectedFile(), name)\r\n\r\n\t# Prompts the user for the name of a file, if the user leaves the field black, informs the user a name is required\r\n\t# If user clicks cancel on error, None is returned\r\n\t# If user enters a name, that name is returned\r\n\tdef getName(self):\r\n\t\t# Creates a prompt asking the user of the name of the file used in creating the original macro\r\n\t\tresult = JOptionPane.showInputDialog(None, \"Enter image name used to create macro (including extension):\")\r\n\t\tif result == None or result ==\"\":\r\n\t\t\tself.showErrorDialog(\"Error\",\"Must enter a name. If no name exists, enter NONAME\")\r\n\t\t\t# If user clicks cancel on error message, don't continue\r\n\t\t\tif not self.frameToDispose.wasCanceled():\r\n\t\t\t\treturn self.getName()\r\n\t\t\telse:\r\n\t\t\t\treturn None\r\n\t\telse:\r\n\t\t\treturn result\r\n\r\n\t# Takes a specific macro file and generalizes it to be used in the processing pipeline\r\n\t# macroFile, type=File, The specific macro file\r\n\t# file,\ttype=Sting, The name of the file used when creating the specific macro\r\n\tdef generalize(self, macroFile, file):\r\n\t\t# Name of the file without the file extension\r\n\t\tfileName = file\r\n\t\tif fileName.find(\".\") > 0:\r\n\t\t\tfileName = fileName[0: fileName.find(\".\")]\r\n\r\n\t\ttry:\r\n\t\t\tfileContents = \"\"\r\n\t\t\tstring = \"\"\r\n\r\n\t\t\t# Read in the original macro file using a buffered reader\r\n\t\t\tbr = BufferedReader(FileReader(macroFile))\r\n\t\t\tstring = br.readLine()\r\n\t\t\twhile string is not None:\r\n\t\t\t\tfileContents = fileContents + string\r\n\t\t\t\tstring = br.readLine()\r\n\r\n\t\t\t# Replace anywhere text in the macro file where the images name is used with IMAGENAME\r\n\t\t\tfileContents = fileContents.replace(file, \"IMAGENAME\")\r\n\r\n\t\t\t# Replace the bio-formats importer directory path with INPUTPATH\r\n\t\t\tfileContents = re.sub(\"open=[^\\\"]*IMAGENAME\", \"open=[INPUTPATH]\", fileContents)\r\n\r\n\t\t\t# Replace the bio-formats exporter directory path with FILEPATH\r\n\t\t\tfileContents = re.sub(r\"save=[^\\\"]*\\\\\",r\"save=FILEPATH/\", fileContents)\r\n\r\n\t\t\t# Replace the bio-formats exporter directory path with FILPEPATH followed by text used to inidcate\r\n\t\t\t# \twhat processing was done on the image and IMAGENAME\r\n\t\t\tfileContents = re.sub(r\"save=FILEPATH/([^\\\"]*)IMAGENAME\",r\"save=[FILEPATH/\\1IMAGENAME]\", fileContents)\r\n\r\n\t\t\t# Replace the save results directory path with nothing, we handle our own saving of results\r\n\t\t\t#fileContents = re.sub(\"saveAs\\(\\\"Results\\\", \\\".*\\\\\\\\\", r'saveAs(\"Results\", \"FILEPATH/../', fileContents)\n\t\t\tfileContents = re.sub(r'saveAs\\(\"Results\",[^;]*\\);', '', fileContents)\n\r\n\t\t\t# Replace the save text directory path with FILEPATH\r\n\t\t\tfileContents = re.sub(\"saveAs\\(\\\"Text\\\", \\\".*\\\\\\\\\", r'saveAs(\"Text\", \"FILEPATH/../', fileContents)\r\n\r\n\t\t\t# Replace all places where the image name without a file extension appears with NOEXTENSION\r\n\t\t\tfileContents = re.sub(fileName, \"NOEXTENSION\", fileContents)\r\n\r\n\t\t\t# Used to handle instances of bio-formats exporter that change file extensions\n\t\t\tfileContents = re.sub(r\"save=FILEPATH/([^\\\"]*)NOEXTENSION([^\\s\\\"]*)\",r\"save=[FILEPATH/\\1NOEXTENSION\\2]\", fileContents)\r\n\r\n\t\t\t# Replace all paths found in the open command with INPUTPATH\\\\IMAGENAME\r\n\t\t\tfileContents = re.sub('open\\(\"[^\"]*\\\\IMAGENAME\"','open(\"INPUTPATH\"', fileContents)\r\n\r\n\t\t\t# Replace all paths found using run(\"save\") with path FILEPATH\\\\IMAGENAME for instances that use the same file extension and FILEPATH\\\\NOEXTENSION for different file extensions\r\n\t\t\tfileContents = re.sub(r'run\\(\"Save\", \"save=[^\"]*\\\\([^\"]*)IMAGENAME\"', 'run(\"Save\", \"save=[FILEPATH/\\1IMAGENAME]\"', fileContents)\r\n\t\t\tfileContents = re.sub(r'run\\(\"Save\", \"save=[^\"]*\\\\([^\"]*)NOEXTENSION([^\"]*)\"', 'run(\"Save\", \"save=[FILEPATH/\\1NOEXTENSION\\2]\"', fileContents)\r\n\r\n\t\t\t# Replace all paths found using saveAs with path FILEPATH\\\\IMAGENAME for instances that use the same file extension and FILEPATH\\\\NOEXTENSION for different file extensions\r\n\t\t\tfileContents = re.sub(r'saveAs\\([^,]*, \"[^\"]*\\\\([^\"]*)IMAGENAME\"\\)', 'saveAs(\\1, \"FILEPATH/\\2IMAGENAME\")', fileContents)\r\n\t\t\tfileContents = re.sub(r'saveAs\\([^,]*, \"[^\"]*\\\\([^\"]*)NOEXTENSION([^\"]*)\"\\)', 'saveAs(\\1,\"FILEPATH/\\2NOEXTENSION\\3\")', fileContents)\r\n\r\n\t\t\t# Inserts code to save the images if no save commands are found in the original macro file\r\n\t\t\tif fileContents.find(\"Bio-Formats Exporter\") == -1 and fileContents.find(\"saveAs(\") == -1 and fileContents.find('run(\"Save\"') == -1:\r\n\t\t\t\t# Split the macro by ; and add the text ;saveChanges(); inbetween each split to save any images changes that might have occured\r\n\t\t\t\t# This calls the function saveChanges() defined in the macro\r\n\t\t\t\tlistOfLines = fileContents.split(\";\")\r\n\t\t\t\tfileContents = \"\"\r\n\t\t\t\tfor line in listOfLines:\r\n\t\t\t\t\tif re.match(\"run.*\",line):\r\n\t\t\t\t\t\tcommand = re.sub(r'run\\(\"([^\"]*)\"[^\\)]*\\)', r'\\1',line).replace(\".\",\"\").replace(\" \",\"_\")\r\n\t\t\t\t\telse:\r\n\t\t\t\t\t\tcommand = \"unknown\"\r\n\t\t\t\t\tfileContents = fileContents + line + \";\" + \"saveChanges(\\\"\" + command + \"\\\");\"\r\n\t\t\telse:\n\t\t\t\tfileContents = fileContents.replace(\";\",';saveResults();')\n\r\n\r\n\t\t\t# Inserts in import function if the user did not use one\r\n\t\t\tif fileContents.find(\"Bio-Formats Importer\") == -1 and fileContents.find(\"open(\") == -1:\r\n\t\t\t\t# Import the image using the bio-formats importer\r\n\t\t\t\timportCode = ('IJ.redirectErrorMessages();'\r\n\t\t\t\t\t\t\t 'open(\"INPUTPATH\");'\r\n\t\t\t\t\t\t\t 'if(nImages < 1){'\r\n\t\t\t\t\t\t\t\t 'run(\"Bio-Formats Importer\", \"open=[INPUTPATH] autoscale color_mode=Default view=Hyperstack stack_order=XYCZT\");'\r\n\t\t\t\t\t\t\t\t 'if(is(\"composite\") == 1){'\r\n\t\t\t\t\t\t\t\t \t # Merge the image into one channel, instead of three seperate red, green, and blue channels\r\n\t\t\t\t\t\t\t\t\t 'run(\"Stack to RGB\");'\r\n\t\t\t\t\t\t\t\t\t # Remember the id of the new image\r\n\t\t\t\t\t\t\t\t\t 'selectedImage = getImageID();'\r\n\t\t\t\t\t\t\t\t\t # Close the seperate channel images\r\n\t\t\t\t\t\t\t\t\t 'for (i=0; i < nImages; i++){ '\r\n\t\t\t\t\t\t\t\t\t \t'selectImage(i+1);'\r\n\t\t\t\t\t\t\t\t\t \t'if(!(selectedImage == getImageID())){'\r\n\t\t\t\t\t\t\t\t\t \t\t'close();'\r\n\t\t\t\t\t\t\t\t\t \t\t'i = i - 1;'\r\n\t\t\t\t\t\t\t\t\t \t'}'\r\n\t\t\t\t\t\t\t\t\t '}'\r\n\t\t\t\t\t\t\t\t\t # Reselect the new image\r\n\t\t\t\t\t\t\t\t\t 'selectImage(selectedImage);'\r\n\t\t\t\t\t\t\t\t\t # Rename window the file name (removes (RGB) from the end of the file window)\r\n\t\t\t\t\t\t\t\t\t 'rename(getInfo(\"image.filename\"));'\r\n\t\t\t\t\t\t\t\t '}'\r\n\t\t\t\t\t\t\t '}')\r\n\r\n\t\t\t\tfileContents = importCode + fileContents\r\n\r\n\t\t\t\t\t\t\t # Checks if image is has a valid extension, if not, replace it with .tif\r\n\t\t\tfunctionToSave = ('function getSaveName(image){'\r\n\t\t\t\t\t\t\t\t# Name of the file\r\n\t\t\t\t\t\t\t\t'name = substring(image, 0, indexOf(image,\".\"));'\r\n\t\t\t\t\t\t\t\t# Extension\r\n\t\t\t\t\t\t\t\t'ext = substring(image, indexOf(image,\".\"));'\r\n\t\t\t\t\t\t\t\t# Extensions supported by Bio-Formats-Exporter\r\n\t\t\t\t\t\t\t\t'validExts = \".jpg, .jpeg, .jpe, .jp2, .ome.fif, .ome.tiff, .ome.tf2, .ome.tf8, .ome.bft, .ome, .mov, .tif, .tiff, .tf2, .tf8, .btf, .v3draw, .wlz\";'\r\n\t\t\t\t\t\t\t\t# Checks if ext is in validExts\r\n\t\t\t\t\t\t\t\t'if(indexOf(validExts, ext) == -1){'\r\n\t\t\t\t\t\t\t\t\t'image = name + \".tif\";'\r\n\t\t\t\t\t\t\t\t'}'\r\n\t\t\t\t\t\t\t\t# Return same string passed in, or same name with .tif extension\r\n\t\t\t\t\t\t\t\t'return image;'\r\n\t\t\t\t\t\t\t '}'\r\n\t\t\t\t\t\t\t # Creates the column name in the results window and adds the imageName to each record\r\n\t\t\t\t\t\t\t 'function saveResults(){'\r\n\t\t\t\t\t\t\t # Checks if a results window is open\r\n\t\t\t\t\t\t\t\t'if (isOpen(\"Results\")) {'\r\n\t\t\t\t\t\t\t\t\t# Loop for every record in the results window\r\n\t\t\t\t\t\t\t\t\t'for(i=0;i<getValue(\"results.count\");i++){'\r\n\t\t\t\t\t\t\t\t\t\t# Add the imagename to the record\r\n\t\t\t\t\t\t\t\t\t\t'if(List.size() > 0){'\n\t\t\t\t\t\t\t\t\t\t\t'setResult(\"Image Name\", i, List.get(getImageID()));'\n\t\t\t\t\t\t\t\t\t\t'}'\n\t\t\t\t\t\t\t\t\t\t'else{'\n\t\t\t\t\t\t\t\t\t\t\t'setResult(\"Image Name\", i, getTitle());'\n\t\t\t\t\t\t\t\t\t\t'}'\n\t\t\t\t\t\t\t\t\t\t'setResult(\"Base Image\", i, \"IMAGENAME\");'\r\n\t\t\t\t\t\t\t\t\t'}'\r\n\t\t\t\t\t\t\t\t\t'selectWindow(\"Results\");'\r\n\t\t\t\t\t\t\t\t\t# Strip the extension from the file name and save the results as the imagename.csv\r\n\t\t\t\t\t\t\t\t\t'if(List.size() > 0){'\n\t\t\t\t\t\t\t\t\t\t'saveAs(\"Results\", \"FILEPATH/../\" + substring(List.get(getImageID()),0,indexOf(List.get(getImageID()),\".\")) +\".csv\");'\n\t\t\t\t\t\t\t\t\t'}'\n\t\t\t\t\t\t\t\t\t'else{'\n\t\t\t\t\t\t\t\t\t\t'saveAs(\"Results\", \"FILEPATH/../\" + substring(getTitle(),0,indexOf(getTitle(),\".\")) +\".csv\");'\n\t\t\t\t\t\t\t\t\t'}'\n\t\t\t\t\t\t\t\t\t# Close the results window\r\n\t\t\t\t\t\t\t\t\t'run(\"Close\");'\r\n\t\t\t\t\t\t\t\t'}'\r\n\t\t\t\t\t\t\t '}'\r\n\t\t\t\t\t\t\t # Add the function saveChanges() to the macro to check for any changes in the images that need to be saved\r\n\t\t\t\t\t\t\t 'function saveChanges(command){'\r\n\t\t\t\t\t\t\t\t# Checks if an image is open\r\n\t\t\t\t\t\t\t\t'if(nImages != 0){'\r\n\t\t\t\t\t\t\t\t\t# Store the id of the open image to reselect it once the process is over\r\n\t\t\t\t\t\t\t\t\t'selectedImage = getImageID();'\r\n\t\t\t\t\t\t\t\t\t'for (i=0; i < nImages; i++){ '\r\n\t\t\t\t\t\t\t\t\t\t'selectImage(i+1);'\r\n\t\t\t\t\t\t\t\t\t\t# Get the id of the image\r\n\t\t\t\t\t\t\t\t\t\t'imageID = getImageID();'\r\n\t\t\t\t\t\t\t\t\t\t# Checks if the imageID exists in the list, if not we need to create an entry for it\r\n\t\t\t\t\t\t\t\t\t\t# List uses key,value pairs, in this use case, the key is the imageID, the value is the imageName\r\n\t\t\t\t\t\t\t\t\t\t'if(List.get(imageID) == \"\"){'\r\n\t\t\t\t\t\t\t\t\t\t\t# If there was no previous image set the name of the file to its window title\r\n\t\t\t\t\t\t\t\t\t\t\t'if(List.get(\"previousImage\") == \"\"){'\r\n\t\t\t\t\t\t\t\t\t\t\t\t'List.set(imageID,getTitle());'\r\n\t\t\t\t\t\t\t\t\t\t\t'}'\r\n\t\t\t\t\t\t\t\t\t\t\t# Otherwise make it its window title stripped of the extension, followed by the name of the previous image\r\n\t\t\t\t\t\t\t\t\t\t\t'else{'\r\n\t\t\t\t\t\t\t\t\t\t\t\t'title = replace(getTitle(), \" \", \"_\");'\r\n\t\t\t\t\t\t\t\t\t\t\t\t'if(indexOf(title, \"_\", indexOf(title, \".\")) != -1){'\r\n\t\t\t\t\t\t\t\t\t\t\t\t\t'title = substring(title, indexOf(title, \"_\", indexOf(title, \".\")) + 1) + substring(title, 0, indexOf(title, \"_\", indexOf(title, \".\")));'\r\n\t\t\t\t\t\t\t\t\t\t\t\t'}'\r\n\t\t\t\t\t\t\t\t\t\t\t\t'List.set(imageID, substring(title,0,indexOf(title,\".\")) + \"_\" + List.get(List.get(\"previousImage\")));'\r\n\t\t\t\t\t\t\t\t\t\t\t'}'\r\n\t\t\t\t\t\t\t\t\t\t'}'\r\n\t\t\t\t\t\t\t\t\t\t'title = replace(List.get(imageID), \" \", \"_\");'\r\n\t\t\t\t\t\t\t\t\t\t# If anything exists after the extension, move it to the front of the image name instead\r\n\t\t\t\t\t\t\t\t\t\t'if(indexOf(title, \"_\", indexOf(title, \".\")) != -1){'\r\n\t\t\t\t\t\t\t\t\t\t\t'title = substring(title, indexOf(title, \"_\", indexOf(title, \".\")) + 1) + substring(title, 0, indexOf(title, \"_\", indexOf(title, \".\")));'\r\n\t\t\t\t\t\t\t\t\t\t'}'\r\n\t\t\t\t\t\t\t\t\t\t'title = getSaveName(title);'\r\n\t\t\t\t\t\t\t\t\t\t# If file doesn't exist, save it\r\n\t\t\t\t\t\t\t\t\t\t'if(File.exists(\"FILEPATH/\" + title) != 1){'\r\n\t\t\t\t\t\t\t\t\t\t\t'run(\"Bio-Formats Exporter\", \"save=[FILEPATH/\" + title + \"]\" + \" export compression=Uncompressed\");'\r\n\t\t\t\t\t\t\t\t\t\t\t'setOption(\"Changes\", false);'\r\n\t\t\t\t\t\t\t\t\t\t'}'\r\n\t\t\t\t\t\t\t\t\t\t# If changes have been made to the image, save it\r\n\t\t\t\t\t\t\t\t\t\t'if(is(\"changes\")){'\r\n\t\t\t\t\t\t\t\t\t\t\t'title = command + \"_\" + title;'\r\n\t\t\t\t\t\t\t\t\t\t\t'if(File.exists(\"FILEPATH/\" + title) == 1){'\r\n\t\t\t\t\t\t\t\t\t\t\t\t# Name without extension\r\n\t\t\t\t\t\t\t\t\t\t\t\t'name = substring(title, 0, indexOf(title,\".\"));'\r\n\t\t\t\t\t\t\t\t\t\t\t\t# Filename counter\r\n\t\t\t\t\t\t\t\t\t\t\t\t'titleIteration = 0;'\r\n\t\t\t\t\t\t\t\t\t\t\t\t# File extension\r\n\t\t\t\t\t\t\t\t\t\t\t\t'ext = substring(title, indexOf(title, \".\"));'\r\n\t\t\t\t\t\t\t\t\t\t\t\t# While the file exists, increment the counter to produce a different name\r\n\t\t\t\t\t\t\t\t\t\t\t\t'while(File.exists(\"FILEPATH/\" + name + \"(\" + titleIteration + \")\" + ext) == 1){'\r\n\t\t\t\t\t\t\t\t\t\t\t\t\t'titleIteration = titleIteration + 1;'\r\n\t\t\t\t\t\t\t\t\t\t\t\t'}'\r\n\t\t\t\t\t\t\t\t\t\t\t\t# Name of the file to export\r\n\t\t\t\t\t\t\t\t\t\t\t\t'title = name + \"(\" + titleIteration + \")\" + ext;'\r\n\t\t\t\t\t\t\t\t\t\t\t\t'run(\"Bio-Formats Exporter\", \"save=[FILEPATH/\" + title + \"]\" + \" export compression=Uncompressed\");'\r\n\t\t\t\t\t\t\t\t\t\t\t'}'\r\n\t\t\t\t\t\t\t\t\t\t\t'else{'\r\n\t\t\t\t\t\t\t\t\t\t\t\t'run(\"Bio-Formats Exporter\", \"save=[FILEPATH/\" + title + \"]\" + \" export compression=Uncompressed\");'\r\n\t\t\t\t\t\t\t\t\t\t\t'}'\r\n\t\t\t\t\t\t\t\t\t\t\t# Change the name of the image in the List\r\n\t\t\t\t\t\t\t\t\t\t\t'List.set(imageID, title);'\r\n\t\t\t\t\t\t\t\t\t\t\t# Mark file has no changes\r\n\t\t\t\t\t\t\t\t\t\t\t'setOption(\"Changes\", false);'\r\n\t\t\t\t\t\t\t\t\t\t'}'\r\n\t\t\t\t\t\t\t\t\t'}'\r\n\t\t\t\t\t\t\t\t\t# Select the image that was originally selected\r\n\t\t\t\t\t\t\t\t\t'selectImage(selectedImage);'\r\n\t\t\t\t\t\t\t\t\t# Save the results windows if its open\r\n\t\t\t\t\t\t\t\t\t'saveResults();'\r\n\t\t\t\t\t\t\t\t\t# Set the previous image to the selectedImage id\r\n\t\t\t\t\t\t\t\t\t'List.set(\"previousImage\", selectedImage);'\r\n\t\t\t\t\t\t\t\t'}'\r\n\t\t\t\t\t\t\t'}')\r\n\t\t\tfileContents = functionToSave + fileContents\r\n\r\n\t\t\t# Closes any open images\r\n\t\t\tfileContents = fileContents + 'if(nImages != 0){for (i=0; i < nImages; i++){selectImage(i+1);close();i=i-1;}'\r\n\n\t\t\t# Regular expressions sometimes create double ]], need to replace them with just ]\n\t\t\tfileContents = fileContents.replace(']]',']')\n\r\n\t\t\t# Create the general macro file and write the generalized text to it, use a file browswer to select where to save file\r\n\t\t\tfileChooser = JFileChooser();\r\n\t\t\tif fileChooser.showSaveDialog(self.frame) == JFileChooser.APPROVE_OPTION:\r\n\t\t\t\tpath = fileChooser.getSelectedFile().getPath()\r\n\t\t\t\tif path[-4:] != \".ijm\":\r\n\t\t\t\t\tpath = path + \".ijm\"\r\n\t\t\t\tnewMacro = File(path)\r\n\r\n\t\t\t\t# Write genearalized macro using a buffered writer\r\n\t\t\t\twriter = BufferedWriter(FileWriter(newMacro))\r\n\t\t\t\twriter.write(fileContents)\r\n\t\t\t\twriter.close()\r\n\t\texcept IOException:\r\n\t\t\tprint \"IO exception\"\r\n\r\n\t# Creates a menu popup for the select input directory button, select input directory or url csv file\r\n\tdef optionMenuPopup(self, event):\r\n\t\t# Create the menu\r\n\t\tmenu = JPopupMenu()\r\n\r\n\t\t# Select directory item\r\n\t\tdirectoryItem = JMenuItem(\"Select Directory\", actionPerformed=self.setInputDirectory)\r\n\t\tdirectoryItem.setToolTipText(\"Browse for the directory containing the images to process\")\r\n\t\tmenu.add(directoryItem)\r\n\r\n\t\t# Select url csv file item\r\n\t\turlItem = JMenuItem(\"Select URL File\", actionPerformed=self.selectURLFile)\r\n\t\turlItem.setToolTipText(\"Browse for the file containing a comma seperated list of urls that point to images to process\")\r\n\t\tmenu.add(urlItem)\r\n\r\n\t\t# Show the menu\r\n\t\tmenu.show(event.getSource(), event.getSource().getWidth(), 0)\r\n\r\n\t# Creates a file chooser to select a file with a list of urls that link to images\r\n\tdef selectURLFile(self, event):\r\n\t\t# Creates a file chooser object\r\n\t\tchooseFile = JFileChooser()\r\n\r\n\t\t# Allow for selection of only files\r\n\t\tchooseFile.setFileSelectionMode(JFileChooser.FILES_ONLY)\r\n\t\t# Show the chooser\r\n\t\tret = chooseFile.showDialog(self.inputTextfield, \"Choose url file\")\r\n\t\tif chooseFile.getSelectedFiles() is not None:\r\n\r\n\t\t\t# Save the selection to attributed associated with input or output\r\n\t\t\tif ret == JFileChooser.APPROVE_OPTION:\r\n\t\t\t\t# Save the path to the file\r\n\t\t\t\tself.urlLocation = chooseFile.getSelectedFile().getPath()\r\n\t\t\t\t# Change the text of the input textbox to the path to the url file\r\n\t\t\t\tself.inputTextfield.setText(chooseFile.getSelectedFile().getPath())\r\n\t\t\t\tself.shouldEnableStart()\r\n\r\n\t# Sets the input directory\r\n\tdef setInputDirectory(self, event):\r\n\t\tself.setDirectory(\"Input\", None)\r\n\r\n\t# Sets the output directory\r\n\tdef setOutputDirectory(self, event):\r\n\t\tself.setDirectory(\"Output\", None)\r\n\r\n\t# Sets the macro file directory\r\n\tdef setMacroFileDirectory(self,event):\r\n\t\tself.setDirectory(\"Macro File\", None)\r\n\r\n\t# Sets the R script directory\r\n\tdef setRScriptDirectory(self, event):\r\n\t\tself.setDirectory(\"R Script\", None)\r\n\r\n\t# Sets the R Path (RScript.exe) directory\r\n\tdef setRPathDirectory(self, event):\r\n\t\tself.setDirectory(\"R Path\", None)\r\n\r\n\t# Action listener for Change R Path menu option\r\n\tdef changeRPath(self, event):\r\n\t\tself.findR(True)\r\n\r\n\t# Creates a filechooser for the user to select a directory for input or output\r\n\t# @param directoryType\tDetermines whether or not to be used to locate the input, output, macro file, or R script directory\r\n\tdef setDirectory(self, directoryType, savedFilePath):\r\n\t\t# User has no previously saved directory paths, open the file chooser\r\n\t\tif savedFilePath is None:\r\n\t\t\t# Creates a file chooser object\r\n\t\t\tchooseFile = JFileChooser()\r\n\r\n\t\t\tif (directoryType == \"Input\" or directoryType == \"Output\"):\r\n\t\t\t\t# Allow for selection of directories\r\n\t\t\t\tchooseFile.setFileSelectionMode(JFileChooser.DIRECTORIES_ONLY)\r\n\t\t\t\t# Jump to the user's previously selected directory location\r\n\t\t\t\tif (directoryType == \"Input\" and not self.inputTextfield.getText() == \"Select Input Directory\"):\r\n\t\t\t\t\tchooseFile.setCurrentDirectory(File(self.inputTextfield.getText()))\r\n\t\t\t\telif (directoryType == \"Output\" and not self.outputTextfield.getText() == \"Select Output Directory\"):\r\n\t\t\t\t\tchooseFile.setCurrentDirectory(File(self.outputTextfield.getText()))\r\n\t\t\telse:\r\n\t\t\t\t# Allow for selection of files\r\n\t\t\t\tchooseFile.setFileSelectionMode(JFileChooser.FILES_ONLY)\r\n\t\t\t\t# Jump to the user's previously selected directory location\r\n\t\t\t\tif (directoryType == \"Macro File\" and not self.macroSelectTextfield.getText() == \"Select Macro File\"):\r\n\t\t\t\t\tchooseFile.setCurrentDirectory(File(self.macroSelectTextfield.getText()))\r\n\t\t\t\telif (directoryType == \"R Script\" and not self.rScriptSelectTextfield.getText() == \"Select R Script\"):\r\n\t\t\t\t\tchooseFile.setCurrentDirectory(File(self.rScriptSelectTextfield.getText()))\r\n\r\n\t\t\t# Show the chooser\r\n\t\t\tret = chooseFile.showDialog(self.inputTextfield, \"Choose \" + directoryType + \" directory\")\r\n\t\t\tif chooseFile.getSelectedFiles() is not None:\r\n\t\t\t\t# Save the selection to attributed associated with input or output\r\n\t\t\t\tif ret == JFileChooser.APPROVE_OPTION:\r\n\t\t\t\t\tif directoryType == \"Input\":\r\n\t\t\t\t\t\tself.inputDirectory = chooseFile.getSelectedFile()\r\n\t\t\t\t\t\tself.inputTextfield.setText(chooseFile.getSelectedFile().getPath())\r\n\t\t\t\t\t\tself.urlLocation = None\r\n\t\t\t\t\telif directoryType == \"Output\":\r\n\t\t\t\t\t\tself.outputDirectory = chooseFile.getSelectedFile()\r\n\t\t\t\t\t\tself.outputTextfield.setText(chooseFile.getSelectedFile().getPath())\r\n\t\t\t\t\telif directoryType == \"Macro File\":\r\n\t\t\t\t\t\tself.macroDirectory = chooseFile.getSelectedFile()\r\n\t\t\t\t\t\tself.macroSelectTextfield.setText(chooseFile.getSelectedFile().getPath())\r\n\t\t\t\t\telif directoryType == \"R Script\":\r\n\t\t\t\t\t\tself.rScriptDirectory = chooseFile.getSelectedFile()\r\n\t\t\t\t\t\tself.rScriptSelectTextfield.setText(chooseFile.getSelectedFile().getPath())\r\n\t\t\t\t\tself.shouldEnableStart()\r\n\t\t# User has data for previously saved directories, populate the text fields and global variables with pertinent information\r\n\t\telse:\r\n\t\t\t# Get the file from specified path\r\n\t\t\tfile = File(savedFilePath)\r\n\r\n\t\t\t# Only populate the path to the directory if the directory itself actually exists (user may have deleted it)\r\n\t\t\tif (os.path.exists(file.getPath())):\r\n\t\t\t\t# Set directory based on type\r\n\t\t\t\tif (directoryType == \"Input\"):\r\n\t\t\t\t\tself.inputDirectory = file\r\n\t\t\t\t\tself.inputTextfield.setText(file.getPath())\r\n\t\t\t\t\tself.urlLocation = None\r\n\t\t\t\telif directoryType == \"Output\":\r\n\t\t\t\t\tself.outputDirectory = file\r\n\t\t\t\t\tself.outputTextfield.setText(savedFilePath)\r\n\t\t\t\telif directoryType == \"Macro File\":\r\n\t\t\t\t\tself.macroDirectory = file\r\n\t\t\t\t\tself.macroSelectTextfield.setText(savedFilePath)\r\n\t\t\t\telif directoryType == \"R Path\":\r\n\t\t\t\t\tself.rcommand = savedFilePath\r\n\t\t\t\telif directoryType == \"R Script\":\r\n\t\t\t\t\tself.rScriptDirectory = file\r\n\t\t\t\t\tself.rScriptSelectTextfield.setText(savedFilePath)\r\n\r\n\t\t\t\tself.shouldEnableStart()\r\n\r\n\tdef shouldEnableStart(self):\r\n\t\t# Enable the start button if both an input and output have been selected\r\n\t\ttry:\r\n\t\t\tif ((self.inputDirectory is not None or self.urlLocation is not None) and (self.outputDirectory is not None)):\r\n\t\t\t\tself.startButton.setEnabled(True)\r\n\t\texcept AttributeError:\r\n\t\t\tpass\r\n\r\n\t# Downloads the images from the url file\r\n\tdef start(self, event):\r\n\t\ttry:\r\n\t\t\tif self.urlLocation is not None:\r\n\t\t\t\tself.downloadFiles(self.urlLocation)\r\n\t\texcept AttributeError:\r\n\t\t\tpass\r\n\r\n\t\t#Do not start running if directory contains no images\r\n\t\tif (len(self.inputDirectory.listFiles()) > 0):\r\n\t\t\tself.runMacro()\r\n\t\telse:\r\n\t\t\tself.showErrorDialog(\"ERROR - Directory Contains No Images\", \"Selected Directory is Empty. Please Choose a Directory That Contains At Least One Image\")\r\n\r\n\t# Downloads each image in the file of image urls\r\n\tdef downloadFiles(self, filename):\r\n\t\t# Make the input directory the location of the downloaded images\r\n\t\tself.inputDirectory = self.outputDirectory.getPath() + \"/originalImages/\"\r\n\t\tself.inputDirectory = File(self.inputDirectory)\r\n\t\tself.inputDirectory.mkdirs()\r\n\t\ttry:\r\n\t\t\tinputFile = open(filename, 'w')\r\n\t\t\t# Save each image in the file\r\n\t\t\tfor line in inputFile:\r\n\t\t\t\ttry:\r\n\t\t\t\t\tpath = self.inputDirectory.getPath().replace(\"\\\\\",\"/\") + '/' + line[line.rfind('/') + 1:].replace(\"/\",\"//\")\r\n\t\t\t\t\turlretrieve(line.strip(), path.strip())\r\n\t\t\t\texcept:\r\n\t\t\t\t\t# JAVA 7 and below will not authenticate with SSL Certificates of length 1024 and above\r\n\t\t\t\t\t# no workaround I can see as fiji uses its own version of java\r\n\t\t\t\t\tprint \"unable to access server\"\r\n\t\texcept IOError:\r\n\t\t\tself.showErrorDialog(\"Permissions Error\", \"Insufficient read/write access to %s\\r\\nPlease correct this issue and restart the plugin.\" % filename)\r\n\r\n\t# Runs the R script selected by the user\r\n\t# If no R script was selected, do nothing\r\n\tdef runRScript(self, scriptFilename, outputDirectory):\r\n\t\t# If the path to Rscript is not set, set it\r\n\t\tif not self.rcommand:\r\n\t\t\tfindR(False)\r\n\r\n\t\tpath = scriptFilename.getPath()\r\n\t\t# Checks if the path to RScript includes a quote as the first character\r\n\t\t# If it does, then the scriptFilename must be encapsulated in quotes\r\n\t\t# This is necessary for filepaths with spaces in them in windows\r\n\r\n\t\t# Makes sure rcommand is surrounded by quotes on windows\r\n\t\tif \".exe\" in self.rcommand and self.rcommand[0:1] != '\"':\r\n\t\t\tself.rcommand = '\"' + self.rcommand + '\"'\r\n\r\n\t\t# Makes sure arguments for the command line command are in quotes on windows\r\n\t\tif \".exe\" in self.rcommand:\r\n\t\t\tscriptFilename = '\"' + scriptFilename.getPath() + '\"'\r\n\t\t\toutputDirectory = '\"' + outputDirectory.getPath() + '\"'\r\n\r\n\t\t# Runs the command line command to execute the r script\r\n\t\t# shell=True parameter necessary for *nix systems\r\n\t\tLogStream.redirectSystem()\r\n\t\tcall(\"%s %s %s\" % (self.rcommand, scriptFilename, outputDirectory), shell = True)\r\n\t\tif re.match(\".*is not recognized.*\",IJ.getLog()):\r\n\t\t\tcall(\"%s %s %s\" % (self.rcommand, scriptFilename, outputDirectory))\r\n\r\n\t# Runs the macro file for each image in the input directory\r\n\tdef runMacro(self):\r\n\t\t# Accepted file types\r\n\t\tself.validFileExtensions = self.validFileExtensionsString.replace(\" \",\"\").split(\",\")\r\n\t\t# Add blank string to list in case user does not specify file extensions\r\n\t\tself.validFileExtensions.append(\"\")\r\n\t\t# Get the user's selected delimiter\r\n\t\tself.choice = self.delimeterComboBox.getSelectedItem()\r\n\r\n\t\t# Get user's desired file extensions\r\n\t\t# No need to get selected extensions if user wants all file types or has not specified any extensions\r\n\t\tif (self.choice == \"All File Types\" or (self.extensionTextfield.getText() == \"\")):\r\n\t\t\tself.selectedExtensions = self.validFileExtensions\r\n\t\t# User has chosen to include/exclude files of certain types\r\n\t\telse:\r\n\t\t\tself.selectedExtensions = self.extensionTextfield.getText()\r\n\t\t\tself.selectedExtensions = self.selectedExtensions.lower()\r\n\t\t\tself.selectedExtensions = self.selectedExtensions.split(\",\")\r\n\r\n\t\t\t# Validation routine to ensure selected file extensions are valid and comma seperated\r\n\t\t\tif not (self.validateUserInput(self.extensionTextfield.getName(), self.selectedExtensions, self.validFileExtensions)):\r\n\t\t\t\treturn\r\n\r\n\t\t# Get file name contains pattern\r\n\t\tself.containString = self.containsTextfield.getText()\r\n\r\n\t\t# Location of the generalized macro function, this will be a prompt where the user selects the file\r\n\t\tself.macroFile = File(self.macroDirectory.getPath())\r\n\r\n\t\t# Validation routine to ensure selected macro file is actually a macro file (file extension = '.ijm')\r\n\t\tif not (self.validateUserInput(self.macroSelectTextfield.getName(), [self.macroFile.getName()[-4:]], [\".ijm\"])):\r\n\t\t\treturn\r\n\r\n\t\t# Location of R Script\r\n\t\tif not (self.rScriptSelectTextfield.getText() == \"Select R Script\"):\r\n\t\t\trScript = File(self.rScriptDirectory.getPath())\r\n\r\n\t\t\t# Validation routine to ensure selected R Script is actually an R Script (file extension = '.R')\r\n\t\t\tif not (self.validateUserInput(self.rScriptSelectTextfield.getName(), [rScript.getName()[-2:]], [\".R\"])):\r\n\t\t\t\treturn\r\n\r\n\t\t# Gets an array of all the images in the input directory\r\n\t\tlistOfPictures = self.inputDirectory.listFiles()\r\n\r\n\t\t# Returns images as specified by the user and adds them to a list\r\n\t\tlistOfPicturesBasedOnUserSpecs = self.getImagesBasedOnUserFileSpecications(listOfPictures)\r\n\r\n\t\t# Save the array of images to the instance\r\n\t\tself.pictures = listOfPicturesBasedOnUserSpecs\r\n\r\n\t\t# Read in the macro file with a buffered reader\r\n\t\tself.readInMacro()\r\n\r\n\t\t# Create an index indicating which image in the array is next to be processed\r\n\t\tself.index = 0\r\n\t\tself.process()\r\n\r\n\t#Reads in the macro file and stores it as a string to be modified during process\r\n\tdef readInMacro(self):\r\n\t\tfileContents = \"\"\r\n\t\tstring = \"\"\r\n\t\t# Read in the general macro\r\n\t\tbr = BufferedReader(FileReader(self.macroFile))\r\n\t\tstring = br.readLine()\r\n\t\twhile string is not None:\r\n\t\t\tfileContents = fileContents + string\r\n\t\t\tstring = br.readLine()\r\n\t\tself.macroString = fileContents\r\n\r\n\t# Gets the next image to process and creates a specific macro for that file\r\n\t# Creates an instance of macroRunner to run the macro on a seperate thread\r\n\tdef process(self):\r\n\t\t# True when processing the first image\r\n\t\tif self.index == 0:\r\n\t\t\t# Save data to the user path file\r\n\t\t\tself.updateUserPathFile()\r\n\t\t\t# Hide the main menu\r\n\t\t\tself.frame.setVisible(False)\r\n\r\n\t\t\t# Create the progress menu and pass it a reference to the main menu\r\n\t\t\tself.macroMenu = MacroProgressMenu()\r\n\t\t\tself.macroMenu.setMenuReference(self)\r\n\r\n\t\t\tself.enterPresser = PressEnterRunner()\r\n\t\t\tThread(self.enterPresser).start()\r\n\r\n\t\t# Checks that there is another image to process\r\n\t\tif self.index < len(self.pictures):\r\n\t\t\t# Increase the progress bar's value\r\n\t\t\tself.macroMenu.setProgressBarValue(int(((self.index * 1.0) / len(self.pictures)) * 100))\r\n\r\n\t\t\t# Image to process\r\n\t\t\tfile = self.pictures[self.index]\r\n\r\n\t\t\t# Increase the index indicating which file to be processed next\r\n\t\t\tself.index = self.index + 1\r\n\r\n\t\t\t# The name of the image without a file extension\r\n\t\t\tfileName = file.getName()\r\n\t\t\tif fileName.index(\".\") > 0:\r\n\t\t\t\tfileName = fileName[0: fileName.index(\".\")]\r\n\r\n\t\t\t# Will determine if user has specified an output directory or url location\r\n\t\t\tlogFileDir = \"\"\r\n\r\n\t\t\t# Create a folder with the name of the image in the output folder to house any outputs of the macro\r\n\t\t\tif (self.outputDirectory is not None):\r\n\t\t\t\toutputDir = File(self.outputDirectory.getPath() + \"/\" + fileName)\r\n\t\t\t\tlogFileDir = self.outputDirectory.getPath() + \"/Log.txt\"\r\n\t\t\telse:\r\n\t\t\t\toutputDir = File(self.urlLocation.getPath() + \"/\" + fileName)\r\n\t\t\t\tlogFileDir = self.urlLocation.getPath() + \"/Log.txt\"\r\n\r\n\t\t\toutputDir.mkdir()\r\n\r\n\t\t\t# INPUTPATH: Replaced with the path to the file to be processed (path includes the file with extension)\r\n\t\t\t# FILEPATH: Replaced with the path where any outputs from the macro will be saved\r\n\t\t\t# IMAGENAME: Replaced with the name of the file with file extension\r\n\t\t\t# NOEXTENSION: Replaced with the name of the file without file extension\r\n\t\t\t# run(\"View Step\"): Replaced with macro command to wait for user input to contine, allow user to make\r\n\t\t\t#\tsure the macro is working correctly\r\n\t\t\ttry:\r\n\t\t\t\t# Copy the macro string to be modified, leaving the original\r\n\t\t\t\tfileContents = self.macroString\r\n\r\n\t\t\t\t# Replace all the generalized strings with specifics\r\n\t\t\t\tfileContents = fileContents.replace(\"INPUTPATH\", file.getPath().replace(\"\\\\\",\"\\\\\\\\\"))\r\n\t\t\t\tfileContents = fileContents.replace(\"FILEPATH\", outputDir.getPath().replace(\"\\\\\",\"/\"))\r\n\t\t\t\tfileContents = fileContents.replace(\"IMAGENAME\", file.getName().replace(\"\\\\\",\"/\"))\r\n\t\t\t\tfileContents = fileContents.replace(\"NOEXTENSION\", fileName.replace(\"\\\\\",\"/\"))\r\n\t\t\t\tfileContents = fileContents.replace('run(\"View Step\")','waitForUser(\"Press ok to continue\")')\r\n\r\n\t\t\texcept IOException:\r\n\t\t\t\tprint \"IOException\"\r\n\r\n\t\t\t# Create a macroRunner object to run the macro on a seperate thread\r\n\t\t\tself.runner = macroRunner()\r\n\r\n\t\t\t# Give the macroRunner object the macro to run\r\n\t\t\tself.runner.setMacro(fileContents)\r\n\r\n\t\t\t# Give the macroRunner object a reference to this menu so it can call process\r\n\t\t\t# \ton this instance when it finishes running the macro so the next image can\r\n\t\t\t# \tbe processed\r\n\t\t\tself.runner.setReference(self)\r\n\r\n\t\t\t# Start the macro\r\n\t\t\tthread = Thread(self.runner)\r\n\t\t\tthread.start()\r\n\r\n\t\t\t# Make a copy of the original image if the user has chosen to do so\r\n\t\t\tif (self.copyImageToNewDirectoryCheckBox.isSelected()):\r\n\t\t\t\tself.copyOriginalImageToNewDirectory(file, outputDir)\r\n\r\n\t\t\t#Creates a log file (or appends to it if one already exists) which will record processing procedures and other pertinent information\r\n\t\t\tself.createLogFile(file, logFileDir, outputDir, fileContents)\r\n\t\telse:\r\n\t\t\t# Macros are finished running, so show the main menu and dispose\r\n\t\t\t#\tof the progress menu.\r\n\t\t\tself.frame.setVisible(True)\r\n\t\t\tself.macroMenu.disposeMenu()\r\n\t\t\tself.enterPresser.stop()\r\n\t\t\t# Run the R script if one has been selected\r\n\t\t\ttry:\r\n\t\t\t\tself.runRScript(self.rScriptDirectory, self.outputDirectory)\r\n\t\t\texcept AttributeError:\r\n\t\t\t\tprint \"No R Script Selected\"\r\n\r\n\t# Creates a generic dialog window to display error messages\r\n\tdef showErrorDialog(self, title, message):\r\n\t\tself.frameToDispose = GenericDialog(\"\")\r\n\t\tself.frameToDispose.setTitle(title)\r\n\t\tself.frameToDispose.addMessage(message)\r\n\t\tself.frameToDispose.showDialog()\r\n\r\n\tdef validateUserInput(self, inputCategory, userInput, validInputs):\r\n\t\tisValid = True\r\n\t\terrorTitle = \"\"\r\n\t\terrorMessage = \"\"\r\n\r\n\t\tfor ext in userInput:\r\n\t\t\tif not (ext in validInputs):\r\n\t\t\t\tisValid = False\r\n\r\n\t\tif not(isValid):\r\n\t\t\tif (inputCategory == \"Extensions\"):\r\n\t\t\t\terrorTitle = \"ERROR - Invalid File Extension Format(s)\"\r\n\t\t\t\terrorMessage = \"Error: One or More of Your Selected File Extensions is Invalid. \\n\" + \"Ensure All Selected File Extensions Are Valid and Seperated by Commas.\"\r\n\t\t\telif (inputCategory == \"Macro File\"):\r\n\t\t\t\terrorTitle = \"ERROR - Invalid Macro File\"\r\n\t\t\t\terrorMessage = \"Error: You Have Selected an Invalid Macro File. Please Ensure Your Selected File Ends With '.ijm'.\"\r\n\t\t\telif (inputCategory == \"R Script\"):\r\n\t\t\t\terrorTitle = \"ERROR - Invalid R Script\"\r\n\t\t\t\terrorMessage = \"Erro: You Have Selected an Invalid R Script. Please Ensure Your Selected File Ends With '.R'.\"\r\n\t\t\telif (inputCategory == \"R Path\"):\r\n\t\t\t\terrorTitle = \"ERROR - Invalid R Path\"\r\n\t\t\t\terrorMessage = \"Error: \" + \"'\" + userInput[0] + \"'\" + \" is Not the Correct File. Please Ensure You Have Navigated to the R Installation Directory and Have Selected 'Rscript.exe'\"\r\n\r\n\t\t\tself.showErrorDialog(errorTitle, errorMessage)\r\n\t\treturn isValid\r\n\r\n\t# Copies the original image from the existing directory to the newly created one\r\n\tdef copyOriginalImageToNewDirectory(self, fileToSave, outputDir):\r\n\t\ttry:\r\n\t\t\tshutil.copy(self.inputDirectory.getPath() + \"/\" + fileToSave.getName(), outputDir.getPath() + \"/\" + fileToSave.getName())\r\n\t\texcept:\r\n\t\t\t\"some error\"\r\n\r\n\t# Gets values from file specification components within the JPanel and returns images based on user's specifications\r\n\tdef getImagesBasedOnUserFileSpecications(self, images):\r\n\t\timagesToReturn = []\r\n\t\tfor file in images:\r\n\t\t\tfileName = file.getName()\r\n\t\t\t# Check for file extensions\r\n\t\t\tif (fileName[-4:].lower() in self.selectedExtensions):\r\n\t\t\t\tif ((self.choice == \"Include\" or self.choice == \"All File Types\") or (self.choice == \"Exclude\" and self.selectedExtensions == self.validFileExtensions)):\r\n\t\t\t\t\tif not (self.containString == \"\"):\r\n\t\t\t\t\t\tif (self.containString in fileName):\r\n\t\t\t\t\t\t\timagesToReturn.append(file)\r\n\t\t\t\t\telse:\r\n\t\t\t\t\t\timagesToReturn.append(file)\r\n\t\t\tif not (fileName[-4:].lower() in self.selectedExtensions):\r\n\t\t\t\tif (self.choice == \"Exclude\" and fileName[-4:].lower() in self.validFileExtensions):\r\n\t\t\t\t\tif not (self.containString == \"\"):\r\n\t\t\t\t\t\t# Check for file name pattern\r\n\t\t\t\t\t\tif (self.containString in fileName):\r\n\t\t\t\t\t\t\timagesToReturn.append(file)\r\n\t\t\t\t\t# No file name pattern specified\r\n\t\t\t\t\telse:\r\n\t\t\t\t\t\timagesToReturn.append(file)\r\n\t\treturn imagesToReturn\r\n\r\n\t# Creates/appends to a log file in the user's specified output directory which will record all processing done on selected images\r\n\tdef createLogFile(self, img, logFileDir, outputDir, fileContents):\r\n\t\ttry:\r\n\t\t\t# Create a txt file for log info\r\n\t\t\tlog = open(logFileDir, 'a')\r\n\t\t\tlog.write(str(datetime.now()) +' - Results for image: ' + img.getPath() + '\\n')\r\n\r\n\t\t\t# If the user has chosen to copy over the original image, record it in log file\r\n\t\t\tif (self.copyImageToNewDirectoryCheckBox.isSelected()):\r\n\t\t\t\t\tlog.write(str(datetime.now()) +'Copied image to: ' + outputDir.getPath() + '\\n')\r\n\r\n\t\t\t# Append each processing operation to the log file\r\n\t\t\tlog.write('Process performed: ' + '\\n')\r\n\t\t\toperationsPerformed = fileContents.split(\";\")\r\n\t\t\tfor i in operationsPerformed:\r\n\t\t\t\tlog.write('\\t' + str(datetime.now()) + ' - ' + i + '\\n')\r\n\t\t\tlog.write('\\n')\r\n\t\t\tlog.write('\\n')\r\n\r\n\t\t\t# Close the file\r\n\t\t\tlog.close()\r\n\t\texcept IOError:\r\n\t\t\tself.showErrorDialog(\"Permissions Error\", \"Insufficient read/write access to %s\\r\\nPlease correct this issue and restart the plugin.\" % logFileDir)\r\n\r\n\t# Updates a text file containing the file paths for the user's selected input, output, macro file, R installation (.exe) path, and R Script directories\r\n\t# This file's data will be used to prepopulate the text fields with the user's last selected directories\r\n\tdef updateUserPathFile(self):\r\n\t\ttry:\r\n\t\t\t# Create the file to house the path\r\n\t\t\tfile = File(self.pathFile)\r\n\t\t\twriter = BufferedWriter(FileWriter(file))\r\n\r\n\t\t\t# Create the contents of the file\r\n\t\t\t# rPath: Path to R.exe on the users system\r\n\t\t\t# inputPath: Last used input directory path\r\n\t\t\t# outputPath: Last used output directory path\r\n\t\t\t# macroPath: Last used macro file path\r\n\t\t\t# rScriptPath: Last used r script file path\r\n\t\t\tcontents = \"rPath\\t\" + self.rcommand + \"\\r\\n\"\r\n\t\t\tcontents = contents + \"inputPath\\t\" + self.inputDirectory.getPath() + \"\\r\\n\"\r\n\t\t\tcontents = contents + \"outputPath\\t\" + self.outputDirectory.getPath() + \"\\r\\n\"\r\n\t\t\tcontents = contents + \"macroPath\\t\" + self.macroDirectory.getPath() + \"\\r\\n\"\r\n\r\n\t\t\tif not(self.rScriptDirectory is None):\r\n\t\t\t\tcontents = contents + \"rScriptPath\\t\" + self.rScriptDirectory.getPath() + \"\\r\\n\"\r\n\t\t\telse:\r\n\t\t\t\tcontents = contents + \"rScriptPath\\t\\r\\n\"\r\n\r\n\t\t\twriter.write(contents)\r\n\t\t\twriter.close()\r\n\t\texcept IOError:\r\n\t\t\tself.showErrorDialog(\"Permissions Error\", \"Insufficient read/write access to %s\\r\\nPlease correct this issue and restart the plugin.\" % self.pathFile)\r\n\r\n\t# Assign each global path variable to corresponding path from array. Also change text of each textfield.\r\n\tdef prepopulateDirectories(self):\r\n\t\t# Get user paths file\r\n\t\tpaths = self.readPathFile()\r\n\r\n\t\t# Populate R Path\r\n\t\tif paths['rPath'] != \"\":\r\n\t\t\tself.setDirectory(\"R Path\", paths['rPath'])\r\n\t\t# Populate Input Directory Path\r\n\t\tif paths['inputPath'] != \"\":\r\n\t\t\tself.setDirectory(\"Input\", paths['inputPath'])\r\n\t\t# Populate Output Directory Path\r\n\t\tif paths['outputPath'] != \"\":\r\n\t\t\tself.setDirectory(\"Output\", paths['outputPath'])\r\n\t\t# Populate Macro File Path\r\n\t\tif paths['macroPath'] != \"\":\r\n\t\t\tself.setDirectory(\"Macro File\", paths['macroPath'])\r\n\t\t# Populate R Script Path\r\n\t\tif paths['rScriptPath'] != \"\":\r\n\t\t\tself.setDirectory(\"R Script\", paths['rScriptPath'])\r\n\r\n\t\tself.shouldEnableStart()\r\n\r\n\t# Adds selected extension(s) to the text file containing the lsit of accepted file types. Also updates the global list variable for valid file types.\r\n\tdef updateUserAcceptedExtensions(self,extensions):\r\n\t\ttry:\r\n\t\t\tfile = open(self.acceptedExtensionFile, 'a')\r\n\r\n\t\t\tfor ext in extensions:\r\n\t\t\t\t# Boolean to indicate specified extension is already in the list - no need to add it again\r\n\t\t\t\tduplicate = False\r\n\t\t\t\tif ext.strip() in self.validFileExtensionsString:\r\n\t\t\t\t\tduplicate = True\r\n\t\t\t\tif not (duplicate):\r\n\t\t\t\t\t# write extension to file\r\n\t\t\t\t\tfile.write(ext.strip() + \", \")\r\n\t\t\t\t\t# add new extensions to global list\r\n\t\t\t\t\tself.validFileExtensionsString = self.validFileExtensionsString + \", \" + ext.strip()\r\n\r\n\t\t\t# Update tool tip text to reflect all valid file extensions\r\n\t\t\tself.extensionTextfield.setToolTipText(\"Valid File Types: [\" + self.validFileExtensionsString + \"]\")\r\n\t\t\t# Close the file\r\n\t\t\tfile.close()\r\n\n\t\texcept IOError:\r\n\t\t\tself.showErrorDialog(\"Permissions Error\", \"Insufficient read/write access to %s\\r\\nPlease correct this issue and restart the plugin.\" % self.acceptedExtensionFile)\r\n\r\n\tupdateUserAcceptedExtensions = CallableWrapper(updateUserAcceptedExtensions)\r\n\r\n\t# Runs the r script without having to process the images first\r\n\t# requires both the r script directory and output directory\r\n\t# If these are not set, will notify user, and prompt user for the locations\r\n\tdef runRWithoutImageProcessing(self,event):\r\n\t\ttry:\r\n\t\t\t# If the rScriptDirectory and outputDirectory are set, run the r script\r\n\t\t\tif self.rScriptDirectory != None and self.outputDirectory != None:\r\n\t\t\t\tself.runRScript(self.rScriptDirectory, self.outputDirectory)\r\n\t\texcept:\r\n\t\t\t# One of the two directories was not set, show user the error\r\n\t\t\tself.showErrorDialog(\"Error\",\"Both an output directory and R script must be selected\")\r\n\t\t\t# If user clicks cancel on error message, don't continue\r\n\t\t\tif not self.frameToDispose.wasCanceled():\r\n\t\t\t\t# Checks if it was the output directory not set, if so prompt the user to set it\r\n\t\t\t\ttry:\r\n\t\t\t\t\tself.outputDirectory\r\n\t\t\t\texcept:\r\n\t\t\t\t\tself.setDirectory(\"Output\",None)\r\n\t\t\t\t# Checks if it was the r script directory not set, if so prompt the user to set it\r\n\t\t\t\ttry:\r\n\t\t\t\t\tself.rScriptDirectory\r\n\t\t\t\texcept:\r\n\t\t\t\t\tself.setDirectory(\"R Script\",None)\r\n\t\t\t\t# Run the method again\r\n\t\t\t\tself.runRWithoutImageProcessing(self)\r\n\r\n\t# Prompts the user to select a .csv file\r\n\t# Creates a frame that has two drop down menus, one for an x variable and one for a y variable\r\n\t# Drop down menus are populated with the column names from the csv file\r\n\t# Creates a basic R script using the selected variables\r\n\tdef basicRModifier(self,event):\r\n\t\t# Creates file chooser to select a .csv file\r\n\t\tchooseFile = JFileChooser()\r\n\t\tchooseFile.setFileSelectionMode(JFileChooser.FILES_ONLY)\r\n\t\tret = chooseFile.showDialog(self.frame, \"Select csv file\")\r\n\t\tif chooseFile.getSelectedFile() is not None and ret == JFileChooser.APPROVE_OPTION:\r\n\t\t\t# Checks if file selected is a .csv file\r\n\t\t\tif chooseFile.getSelectedFile().getPath()[-4:] == \".csv\":\r\n\t\t\t\t# Open the file\r\n\t\t\t\tcsvFile = open(chooseFile.getSelectedFile().getPath(), \"rt\")\r\n\t\t\t\ttry:\r\n\t\t\t\t\tcsvreader = reader(csvFile)\r\n\t\t\t\t\t# Read in the columns as an array\r\n\t\t\t\t\tcolumns = csvreader.next()\r\n\t\t\t\t\t# Create a basic menu with two drop downs\r\n\t\t\t\t\tframe = JFrame(\"Create Basic R Script\")\r\n\t\t\t\t\tframe.setSize(400,150)\r\n\t\t\t\t\tframe.setDefaultCloseOperation(JFrame.DISPOSE_ON_CLOSE)\r\n\t\t\t\t\tpanel = JPanel()\r\n\t\t\t\t\tpanel.setBounds(10,10,400,150)\r\n\t\t\t\t\tframe.add(panel)\r\n\t\t\t\t\txLabel = JLabel(\"X Variable:\")\r\n\t\t\t\t\tyLabel = JLabel(\"Y Variable:\")\r\n\t\t\t\t\tself.xComboBox = JComboBox()\r\n\t\t\t\t\tself.yComboBox = JComboBox()\r\n\r\n\t\t\t\t\t#Fill in drop downs with the column names\r\n\t\t\t\t\tfor column in columns:\r\n\t\t\t\t\t\tself.xComboBox.addItem(column)\r\n\t\t\t\t\t\tself.yComboBox.addItem(column)\r\n\t\t\t\t\tself.xComboBox.setSelectedIndex(0)\r\n\t\t\t\t\tself.yComboBox.setSelectedIndex(0)\r\n\t\t\t\t\tbutton = JButton(\"Ok\", actionPerformed=self.errorCheckSelected)\r\n\t\t\t\t\tpanel.add(xLabel)\r\n\t\t\t\t\tpanel.add(self.xComboBox)\r\n\t\t\t\t\tpanel.add(yLabel)\r\n\t\t\t\t\tpanel.add(self.yComboBox)\r\n\t\t\t\t\tpanel.add(button)\r\n\t\t\t\t\tframe.add(panel)\r\n\t\t\t\t\tframe.show()\r\n\t\t\t\texcept IOError:\r\n\t\t\t\t\tself.showErrorDialog(\"Permissions Error\", \"Insufficient read/write access to %s\\r\\nPlease correct this issue and restart the plugin.\" % csvFile)\r\n\t\t\t\texcept:\r\n\t\t\t\t\tprint \"Error\"\r\n\t\t\telse:\r\n\t\t\t\tself.showErrorDialog(\"Error\",\"Must be a .csv file\")\r\n\t\t\t\t# If user clicks cancel on error message, don't continue\r\n\t\t\t\tif not self.frameToDispose.wasCanceled():\r\n\t\t\t\t\tself.basicRModifier(None)\r\n\r\n\t# Checks is both an x and y have been selected\r\n\t# If not, show error message\r\n\t# If so, create a basic r script\r\n\tdef errorCheckSelected(self,event):\r\n\t\tif self.xComboBox.getSelectedItem() == \" \" or self.yComboBox.getSelectedItem() == \" \":\r\n\t\t\tself.showErrorDialog(\"Error\",\"Both an x and y variable must be selected\")\r\n\t\telse:\r\n\t\t\tSwingUtilities.getWindowAncestor(event.getSource().getParent()).dispose()\n\t\t\tself.generateBasicRScript(self.xComboBox.getSelectedItem(), self.yComboBox.getSelectedItem())\r\n\r\n\t# Reads in a basic r script and does a relace on the variables that make up the x and y axis\n\t# Then it writes the new file to a new file based on the users selection with a file chooser\r\n\t# xVariable\t\tThe varaible the user wants on the x axis\n\t# yVariable \tThe variable the user wants on the y axis\n\tdef generateBasicRScript(self, xVariable, yVariable):\r\n\t\ttry:\r\n\t\t\t# Ask user where to save and what to call file using a file chooser\n\t\t\tfileChooser = JFileChooser();\n\t\t\tif fileChooser.showSaveDialog(self.frame) == JFileChooser.APPROVE_OPTION:\n\t\t\t\tpath = fileChooser.getSelectedFile().getPath()\n\t\t\t\t# Error checking to include extension\n\t\t\t\tif path[-4:] != \".R\":\n\t\t\t\t\tpath = path + \".R\"\n\t\t\t\t# Open the file used for creating the basic r script\n\t\t\t\tdefaultR = open(IJ.getDir(\"plugins\") + self.directoryName + \"/Compare2Script.R\", \"r\")\r\n\t\t\t\tnewR = \"\"\r\n\t\t\t\t# Read in each line of the file\n\t\t\t\tfor line in defaultR:\r\n\t\t\t\t\tnewR = newR + line\r\n\t\t\t\t# Replace the XVARAIABLE and YVARIABLE text with the values selected by the user\n\t\t\t\tnewR = newR.replace(\"XVARIABLE\", xVariable)\n\t\t\t\tnewR = newR.replace(\"YVARIABLE\", yVariable)\n\n\t\t\t\t# Write the text to a new file that the user selected\n\t\t\t\tout = open(path, \"w\")\r\n\t\t\t\tout.write(newR)\r\n\t\t\t\tout.close()\r\n\t\texcept IOError:\r\n\t\t\tself.showErrorDialog(\"Permissions Error\", \"Insufficient read/write access to %s\\r\\nPlease correct this issue and restart the plugin.\" % \"files\")\r\n\r\n\t### End of ImageProcessorMenu\r\n\r\n\r\n# Creates a Window which prompts the user to enter their desired file types to be added to the list of accepted file types\r\nclass AddFileExtensionMenu():\r\n\n\t# Gets the user's specified extension(s)\r\n\tdef getUserInput(self, event):\r\n\t\t# Split each extension to array\r\n\t\textensions = self.addExtTextfield.getText().split(',')\r\n\t\tImageProcessorMenu.updateUserAcceptedExtensions(ImageProcessorMenu(), extensions)\r\n\t\tself.disposeAddMenuExtensionFrame()\n\r\n\t# Window Constructor\r\n\tdef __init__(self, event):\r\n\t\t# Create frame\r\n\t\tframeWidth, frameHeight = 600, 300\r\n\t\tself.addExtMenuFrame = JFrame(\"Add File Extension\")\r\n\t\tself.addExtMenuFrame.setSize(frameWidth, frameHeight)\r\n\t\tself.addExtMenuFrame.setDefaultCloseOperation(JFrame.DISPOSE_ON_CLOSE)\r\n\r\n\t\tcontent = self.addExtMenuFrame.getContentPane()\r\n\r\n\t\t# Add a panel to the frame\r\n\t\tpnl = JPanel()\r\n\t\tpnl.setBounds(10,10,frameWidth,frameHeight)\r\n\t\tself.addExtMenuFrame.add(pnl)\r\n\r\n\t\t# Add labels to prompt the user\r\n\t\tself.promptUserLbl1 = JLabel(\"Enter All File Extensions That You Wish to Add to the List of Accepted File Extnensions Below.\")\r\n\t\tpnl.add(self.promptUserLbl1)\r\n\t\tself.promptUserLbl2 = JLabel(\"Ensure that Each Extension is Comma-Seperated: \")\r\n\t\tpnl.add(self.promptUserLbl2)\r\n\r\n\t\t# Add a textfield to the frame to get the user's selected file extensions to add\r\n\t\tself.addExtTextfield = JTextField()\r\n\t\tself.addExtTextfield.setPreferredSize(Dimension(175,25))\r\n\t\tself.addExtTextfield.setText(\"Example: .jpg, .png\")\r\n\t\tpnl.add(self.addExtTextfield)\r\n\r\n\t\t# Add an 'Add' button to the frame to execute adding the specified extension to the accepted list\r\n\t\tself.addExtBtn = JButton('Add', actionPerformed=self.getUserInput)\r\n\t\tself.addExtBtn.setEnabled(True)\r\n\t\tself.addExtBtn.setPreferredSize(Dimension(150,40))\r\n\t\tpnl.add(self.addExtBtn)\r\n\r\n\t\t# Show the frame and disable resizing of it\r\n\t\tself.addExtMenuFrame.setResizable(False)\r\n\t\tself.addExtMenuFrame.setVisible(True)\n\n\tdef disposeAddMenuExtensionFrame(self):\n\t\tself.addExtMenuFrame.dispose()\n\r\n\r\n# Extends the WindowAdapter class: does this to overide the windowClosing method\r\n#\tto create a custom close operation.\r\n# Creates a progress bar indicating what percentage of images have been processed\r\n# Closing the menu will stop the images from being processed\r\nclass MacroProgressMenu(WindowAdapter):\r\n\tdef __init__(self):\r\n\t\t# Create a frame as backbone for the menu, add listener for custom close operation\r\n\t\tself.macroMenuFrame = JFrame(\"Processing Images...\")\r\n\t\tself.macroMenuFrame.setDefaultCloseOperation(JFrame.DO_NOTHING_ON_CLOSE)\r\n\t\tself.macroMenuFrame.addWindowListener(self)\r\n\r\n\t\tcontent = self.macroMenuFrame.getContentPane()\r\n\r\n\t\t# Create the progess bar\r\n\t\tself.progressBar = JProgressBar()\r\n\t\tself.setProgressBarValue(0)\r\n\t\tself.progressBar.setStringPainted(True)\r\n\r\n\t\t# Add a border\r\n\t\tborder = BorderFactory.createTitledBorder(\"Processing...\");\r\n\t\tself.progressBar.setBorder(border)\r\n\t\tcontent.add(self.progressBar, BorderLayout.NORTH)\r\n\r\n\t\t# Set size and show frame\r\n\t\tself.macroMenuFrame.setSize(300, 100)\r\n\t\tself.macroMenuFrame.setVisible(True)\r\n\r\n\t# Sets a reference to the main menu\r\n\t# Would put in constructor, but cannot get variables to be passed in that way\r\n\tdef setMenuReference(self, ref):\r\n\t\tself.ref = ref\r\n\r\n\t# Sets the progress bar's value\r\n\tdef setProgressBarValue(self, value):\r\n\t\tself.progressBar.setValue(value)\r\n\r\n\t# Override\r\n\t# Custom on close opperation\r\n\tdef windowClosing(self, event):\r\n\t\t# Prevents more macros from running\r\n\t\tself.ref.runner.run = False\r\n\t\t# Stops currently ruuing macro\r\n\t\tself.ref.runner.abortMacro()\r\n\t\t# Shows the main menu\r\n\t\tself.ref.frame.setVisible(True)\r\n\r\n\t\t# Disposes of this progress menu\r\n\t\tself.disposeMenu()\r\n\r\n\t# Disposes of this progress menu\r\n\tdef disposeMenu(self):\r\n\t\tself.macroMenuFrame.dispose()\r\n\r\n\r\n# Extends the class runnable to run on a seperate thread\r\n# Recieves a macro file from the ImageProcessorMenu instance\r\n# \tand runs the macro. After the macro is executed, it calls\r\n#\tthe process method of the ImageProcessorMenu instance to\r\n#\tcreate a macro for the next file.\r\n# Cannot get a new constuctor to work otherwise the set\r\n# \tmethods would just be part of the constructor\r\nclass macroRunner(Runnable):\r\n\t# Overides the run method of the Runnable class\r\n\t# Creates an instance of Interpreter to run the macro\r\n\t# Runs the macro in the instance and calls process on\r\n\t#\tthe ImageProcessorMenu instance\r\n\tdef run(self):\r\n\t\tself.run = True\r\n\t\tself.inter = Interpreter()\r\n\t\ttry:\r\n\t\t\tself.inter.run(self.macroString)\r\n\t\texcept:\r\n\t\t\tself.enterPresser.stop()\r\n\t\t# Prevents future macros from running if current macro was aborted\r\n\t\tif self.run:\r\n\t\t\tWindowManager.closeAllWindows()\r\n\t\t\tself.ref.process()\r\n\r\n\t# Sets the macro file\r\n\t# string, the macro file to be run\r\n\tdef setMacro(self, string):\r\n\t\tself.macroString = string\r\n\r\n\t# Sets the ImageProcessMenu instance that is processing images\r\n\t# ref, the ImageProcessMenu instance\r\n\tdef setReference(self, ref):\r\n\t\tself.ref = ref\r\n\r\n\t# Aborts the currently running macro\r\n\tdef abortMacro(self):\r\n\t\tself.inter.abort()\r\n\r\n\r\nclass PressEnterRunner(Runnable):\r\n\tdef run(self):\r\n\t\tself.timer = Timer()\r\n\t\tself.start()\r\n\r\n\tdef start(self):\r\n\t\ttry:\r\n\t\t\tself.task = PressEnterTask()\r\n\t\t\tself.task.setRef(self)\r\n\t\t\tself.timer.schedule(self.task, 10000)\r\n\t\texcept AttributeError:\r\n\t\t\tpass\r\n\r\n\tdef stop(self):\r\n\t\ttry:\r\n\t\t\tself.timer.cancel()\r\n\t\texcept AttributeError:\r\n\t\t\tpass\r\n\r\n\tdef reset(self):\r\n\t\ttry:\r\n\t\t\tself.stop()\r\n\t\t\tself.start()\r\n\t\texcept AttributeError:\r\n\t\t\tpass\r\n\r\n\r\nclass PressEnterTask(TimerTask):\r\n\tdef run(self):\r\n\t\trobot = Robot()\r\n\t\trobot.keyPress(KeyEvent.VK_ENTER)\r\n\t\ttry:\r\n\t\t\tself.ref.start()\r\n\t\texcept:\r\n\t\t\tprint \"Error\"\r\n\r\n\tdef setRef(self, ref):\r\n\t\tself.ref = ref\r\n\r\n\r\nif __name__ == '__main__':\r\n\t# Start things off.\r\n\tImageProcessorMenu()\r\n"
},
{
"alpha_fraction": 0.6908283829689026,
"alphanum_fraction": 0.692307710647583,
"avg_line_length": 34.55263137817383,
"blob_id": "259db3b67177c312a9b0065b9a97ec44dad42e4a",
"content_id": "e1fcd4d9a393af137b5985290a39a3ec49dcd53c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 2704,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 76,
"path": "/plugin/Compare2Script.R",
"repo_name": "pwlandoll/cs470-image-processing",
"src_encoding": "UTF-8",
"text": "\n\n#Clear global enviornment\nrm(list = ls(all.names = TRUE))\n\n#Libraries should now install to /Users/\"you\"/R/win-library/x.y, \n#for which you have the appropriate permissions.\ndir.create(Sys.getenv(\"R_LIBS_USER\"), recursive = TRUE)\n\n# Retrieve Date and Time\n# Date will be used to create a new directory\n# Time will be used to save files into that new directory. (Timestamp)\ncurDate <- Sys.Date()\ncurDate_Time <- Sys.time()\ncurTime <- format(Sys.time(), \"%I_%M %p\")\n\n\n\n# Function to install packages if not installed.\n# If you create a method that requires a different package along with the ones listed below, \n#simply add a comma followed by \"your package name\", after \"plyr\" below.It will automatically test if it \n#is installed and if not will install it.\n#This will keep r from restarting everytime the package is already installed.\ncheckPackage <- function(x){\n for( i in x ){\n # require returns TRUE invisibly if it was able to load package\n if( ! require( i , character.only = TRUE ) ){\n # If package was not able to be loaded then re-install\n install.packages( i , dependencies = TRUE )\n }\n }\n}\n\n# Then try/install packages...Insert any more packages that may be needed here\ncheckPackage( c(\"ggplot2\") )\n\n\noutputDirectory <- commandArgs(trailingOnly = TRUE)[1]\n\n# This is the code to read all csv files into R.\n# Create One data frame.\npath <- paste0(outputDirectory, \"/\", sep=\"\")\nprint(path)\nfile_list <- list.files(path = path, pattern=\"*.csv\")\ndata <- do.call(\"rbind\", lapply(file_list, function(x) \n read.csv(paste(path, x, sep = \"\"), stringsAsFactors = FALSE)))\n\n# Create a subdirectory based on the curDate variable for saving plots.\n# A Folder is created with the current date as it's name\ndir.create(file.path(path,curDate), showWarnings = FALSE)\n# Set newly created folder as working directory. Now all files saved will be\n# saved into that location\nsetwd(paste(path,curDate,\"/\",sep = \"\"))\n\n#Pass in selected variables\nvariableX <- \"XVARIABLE\"\nvariableY <- \"YVARIABLE\"\n\n#Create labels\nlabelX = variableX\nlabelY = variableY\n\n#Return column index\nvarX <- which(colnames(data)==variableX)\nvarY <- which(colnames(data)==variableY)\n\n#Selects all rows based on the column index\nvariableX <- data[[varX]]\nvariableY <- data[[varY]]\n\n#Scatterplot\nscatterPlot <- function(xVar, yVar){\n library(ggplot2)\n plot <- qplot(xVar, yVar, xlab = labelX, ylab = labelY) + geom_smooth(method=lm, # Add linear regression line\n se=FALSE)\n ggsave(filename = paste(labelX, \" \", labelY, \" Test_ScatterPlot\", curTime, \".jpg\", sep=\"\"), plot = plot)\n}\nwith(data, scatterPlot(variableX, variableY))\n"
},
{
"alpha_fraction": 0.6865770816802979,
"alphanum_fraction": 0.6908909678459167,
"avg_line_length": 39.72297286987305,
"blob_id": "75f1e8cefa34b8fb6ce21b6e2f6eb4aba56023f6",
"content_id": "04ace6ed95aea580406a06ba7591733bdda364d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 6027,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 148,
"path": "/plugin/Sample_Script.R",
"repo_name": "pwlandoll/cs470-image-processing",
"src_encoding": "UTF-8",
"text": "#Clear global enviornment\nrm(list = ls(all.names = TRUE))\n\n#Libraries should now install to /Users/\"you\"/R/win-library/x.y, \n#for which you have the appropriate permissions.\ndir.create(Sys.getenv(\"R_LIBS_USER\"), recursive = TRUE)\n\n# Retrieve Date and Time\n# Date will be used to create a new directory\n# Time will be used to save files into that new directory. (Timestamp)\ncurDate <- Sys.Date()\ncurDate_Time <- Sys.time()\ncurTime <- format(Sys.time(), \"%I_%M %p\")\n\n\n\n# Function to install packages if not installed.\n# If you create a method that requires a different package along with the ones listed below, \n#simply add a comma followed by \"your package name\", after \"plyr\" below.It will automatically test if it \n#is installed and if not will install it.\n#This will keep r from restarting everytime the package is already installed.\ncheckPackage <- function(x){\n for( i in x ){\n # require returns TRUE invisibly if it was able to load package\n if( ! require( i , character.only = TRUE ) ){\n # If package was not able to be loaded then re-install\n install.packages( i , dependencies = TRUE )\n }\n }\n}\n\n# Then try/install packages...Insert any more packages that may be needed here\ncheckPackage( c(\"ggplot2\",\"psych\",\"corrgram\", \"plyr\", \"car\", \"reshape2\", \"vcd\", \"hexbin\") )\n\noutputDirectory <- commandArgs(trailingOnly = TRUE)[1]\n\n# This is the code to read all csv files into R.\n# Create One data frame.\npath <- paste0(outputDirectory, \"/\", sep=\"\")\nprint(path)\nfile_list <- list.files(path = path, pattern=\"*.csv\")\ndata <- do.call(\"rbind\", lapply(file_list, function(x) \n read.csv(paste(path, x, sep = \"\"), stringsAsFactors = FALSE)))\n\n#Add a column specifying ct or xray\ndata$Image.Type <- \"\"\n\n#Create data frames based on CT in the Image.Name variable\nCT_Data <-data[grep(\"ct\", data$Image.Name, ignore.case = TRUE),]\n#Change row in Image Type to CT\nCT_Data$Image.Type = \"CT\"\n\n#Create data frames based on XRAY in the Image.Name variable\nXRay_Data <- data[grep(\"xr\", data$Image.Name, ignore.case = TRUE),]\n#Change row in Image Type to XRAY\n#nonCT_XRay <- data[grep(\"xr|ct\", data$Image.Name, ignore.case = TRUE, invert = TRUE),]\nXRay_Data$Image.Type = \"XRAY\"\n\n#Merge two tables into new data frame\ndata_merge <- rbind(CT_Data, XRay_Data)\n\n#Remove Image.Type column from data frame to retain original data\ndata$Image.Type = NULL\n\n# Create a subdirectory based on the curDate variable for saving plots.\n# (If today is 4/4/14, then a new folder will be created with that date and any work done on that day will be \n# saved into that folder.)Will then set current directory to the new direcory created. \n# This way all the data has already been loaded into the global enviornment per the previous directory. \n# Now all new plots will be saved to the new directory.\ndir.create(file.path(path,curDate), showWarnings = FALSE)\nsetwd(paste(path,curDate,\"/\",sep = \"\"))\n\n\n\n# This function should return a proper list with all the data.frames as elements.\n# Has a new column added specifying which data frame it is from (labeling purposes)\ndfs <- Filter(function(x) is(x, \"data.frame\"), mget(ls()))\ndfNames <- names(dfs)\nfor(x in 1: length(dfs)){\n df.name <- dfNames[x]\n print(df.name)\n colnames(dfs[[x]])[1]\n dfs[[x]]$fromDF <- df.name\n}\n\n# Kernel density plots \n# grouped by CT and XRay\ndensityPlot<- function(dataFrame, Variable, VariableLabel, Fill){\n library(ggplot2)\n plot <- qplot(Variable, data=dataFrame, geom=\"density\", fill=Fill, alpha=I(.5),\n xlab = VariableLabel)\n ggsave(filename = paste0(VariableLabel, \"_DensityPlot\", curTime, \".jpg\", sep = \"\"), plot = plot)\n}\nwith(data_merge, densityPlot(data_merge,StdDev, \"StdDev\", Image.Type))\nwith(data_merge, densityPlot(data_merge,Skew, \"Skew\", Image.Type))\nwith(data_merge, densityPlot(data_merge,X.Area,\"X.Area\", Image.Type))\n\n#Scatterplot\nscatterPlot <- function(label,xVar, xString, yVar, yString){\n library(ggplot2)\n #Will specify CT or XRay\n label_1 <- label[[1]]\n plot <- qplot(xVar, yVar, xlab = xString, ylab = yString, main = label) + geom_smooth(method=lm, # Add linear regression line\n se=FALSE)\n ggsave(filename = paste(label_1,\"_\", xString, \" vs \", yString, \"_ScatterPlot\", curTime, \".jpg\", sep=\"\"), plot = plot)\n}\nwith(CT_Data, scatterPlot(Image.Type,StdDev, \"StdDev\", Mean, \"Mean\"))\nwith(XRay_Data, scatterPlot(Image.Type,StdDev, \"StdDev\", Mean, \"Mean\"))\n\n#Regression\nregressionPlot <- function(fillVar, xVar, xLabel, yVar, yLabel){\n library(ggplot2)\n plot <- qplot(xVar, yVar,geom=c(\"point\", \"smooth\"), \n method=\"lm\", formula=y~x, color=fillVar, main = \"Regression Plot\")\n ggsave(filename = paste0(xLabel,\" vs \", yLabel, \"_Regression\", curTime, \".jpg\", sep = \"\"), plot = plot)\n}\n\nwith(data_merge, regressionPlot(Image.Type,StdDev, \"StdDev\", Mean, \"Mean\"))\n\n# Boxplot\n# observations (points) are overlayed and jittered\nboxPlot <- function(xVar, xLabel, yVar, yLabel){\n library(ggplot2)\n plot <- qplot(xVar, yVar,geom=c(\"boxplot\", \"jitter\"), \n fill=xVar, ylab = yLabel, xlab = \"\", main = xLabel)\n ggsave(filename = paste0(xLabel, \" vs \", yLabel, \"_BoxPlot\", curTime, \".jpg\", sep = \"\"), plot = plot)\n}\n with(data_merge, boxPlot(Image.Type, \"Image Type\", StdDev, \"StdDev\"))\n with(data_merge, boxPlot(Image.Type, \"Image Type\", StdDev, \"Mean\"))\n \nscatterplotMatrix<- function(){\n jpeg(paste(\"Merged Data Matrices\", curTime, \".jpg\", sep=\"\"), width = 850)\n library(car)\n scatterplot.matrix(~Area+Mean+StdDev+X.Area|Image.Type, data = data_merge)\n dev.off()\n}\nscatterplotMatrix()\n\nsink(file=paste0(\"Complete Data Summary_\",curTime, \".txt\", sep = \"\")) \nsummary(data_merge)\nsink(NULL)\n\n#Create a new data frame based on if the word area is found in any of the columns\n#If this is the case, a new data frame will be created based on those area columns\nareaCol <- data[grep(\"area\", names(data), value = TRUE,ignore.case = TRUE)]\nsink(file=paste0(\"Area Summary_\",curTime, \".txt\", sep = \"\")) \nsummary(areaCol)\nsink(NULL)\n"
},
{
"alpha_fraction": 0.705804169178009,
"alphanum_fraction": 0.7095702290534973,
"avg_line_length": 41.18691635131836,
"blob_id": "dda4f48c485e46ec44adc2205f7a55cee9825232",
"content_id": "52301f5292f19c67d1f2b9921eb8e6256ac68b9f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 4514,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 107,
"path": "/plugin/Template_Script.R",
"repo_name": "pwlandoll/cs470-image-processing",
"src_encoding": "UTF-8",
"text": "# Template R Script\n# Use this script to create custom R scripts\n# The call to checkPackage at the end can be changed to install a custom list of package\n\n#Clear global enviornment\nrm(list = ls(all.names = TRUE))\n\n#Libraries should now install to /Users/\"you\"/R/win-library/x.y, \n#for which you have the appropriate permissions.\ndir.create(Sys.getenv(\"R_LIBS_USER\"), recursive = TRUE)\n\n# Retrieve Date and Time\n# Date will be used to create a new directory\n# Time will be used to save files into that new directory. (Timestamp)\ncurDate <- Sys.Date()\ncurDate_Time <- Sys.time()\ncurTime <- format(Sys.time(), \"%I_%M %p\")\n\n# Function to install packages if not installed.\n# If you create a method that requires a different package along with the ones listed below, \n#simply add a comma followed by \"your package name\", after \"plyr\" below.It will automatically test if it \n#is installed and if not will install it.\n#This will keep r from restarting everytime the package is already installed.\ncheckPackage <- function(x){\n for( i in x ){\n # require returns TRUE invisibly if it was able to load package\n if( ! require( i , character.only = TRUE ) ){\n # If package was not able to be loaded then re-install\n install.packages( i , dependencies = TRUE )\n }\n }\n}\n# Try/install packages...Insert any more packages that may be needed here\ncheckPackage( c(\"methods\", \"ggplot2\") )\n\noutputDirectory <- commandArgs(trailingOnly = TRUE)[1]\n\n# This is the code to read all csv files into R.\n# Create One data frame.\npath <- paste0(outputDirectory, \"/\", sep=\"\")\nprint(path)\nfile_list <- list.files(path = path, pattern=\"*.csv\")\ndata <- do.call(\"rbind\", lapply(file_list, function(x) \n read.csv(paste(path, x, sep = \"\"), stringsAsFactors = FALSE)))\n\n# Create a subdirectory based on the curDate variable for saving plots.\n# A Folder is created with the current date as it's name\ndir.create(file.path(path,curDate), showWarnings = FALSE)\n# Set newly created folder as working directory. Now all files saved will be\n# saved into that location\nsetwd(paste(path,curDate,\"/\",sep = \"\"))\n\n#Create a new data frame based on if the word area is found in any of the columns\n#If this is the case, a new data frame will be created based on those area columns\n#This can similarily be done with other variables. Simply substitue area with a new word/subset of letters.\nareaCol <- data[grep(\"area\", names(data), value = TRUE,ignore.case = TRUE)]\nsink(file=paste0(\"Area Summary_\",curTime, \".txt\", sep = \"\")) \nsummary(areaCol)\nsink(NULL)\n\n#Check if initial data frame is null. If that is the case the lines below will not run.\n# This function should return a proper list with all the data.frames as elements.\ndfs <- Filter(function(x) is(x, \"data.frame\"), mget(ls()))\ndfNames <- names(dfs)\nfor(x in 1: length(dfs)){\n df.name <- dfNames[x]\n print(df.name)\n colnames(dfs[[x]])[1]\n # Has a new column created specifying which data frame it is from (labeling purposes)\n dfs[[x]]$fromDF <- df.name\n}\n\n#Create a text file summarizing the data from all the csv files\nsink(file=paste0(\"Complete Data Summary_\",curTime, \".txt\", sep = \"\")) \nsummary(data)\nsink(NULL)\n\n# Return each unique variable from Base.Image Column. (No Repeats)\ncount <- unique(data$Base.Image)\n# Return the count of the number of rows in the previous variable count\ncount <- length(count)\n# Create a color palette with the amount return from count.\n# R palette is only set to 8 different colors to begin with\ncol.rainbow <- rainbow(count)\n# Set current palette to col.rainbow created above\npalette(col.rainbow)\n\n#Plot All indexes for One Variable at a time.\nfor ( i in seq(1,length( data ),1) ){\n #Plotting numerical data. Will only look for variables that are either integer or double\n if(typeof(data[[i]]) == \"integer\" | typeof(data[[i]]) == \"double\"){\n #ScatterPlot\n jpeg(paste(\"Scatter Plot \",names(data[i]),\" \", curTime, \".jpg\", sep=\"\"), width = 1500, height = 900)\n # Type B will output both points and lines.Base.Image must be included from FIJI Macro.\n # Plots index of image vs. Variable Column. *Columns are not compared against one another\n plot(data[,i],ylab=names(data[i]), type = \"b\", col = factor(data$Base.Image))\n dev.off()\n #BoxPlot\n jpeg(paste(\"Box Plot \",names(data[i]),\" \", curTime, \".jpg\", sep=\"\"))\n boxplot(data[,i],ylab=names(data[i]))\n dev.off()\n #BarPlot\n jpeg(paste(\"Bar Plot \",names(data[i]),\" \", curTime, \".jpg\", sep=\"\"))\n barplot(data[,i],ylab=names(data[i]), col = factor(data$Base.Image))\n dev.off()\n }\n}\n"
},
{
"alpha_fraction": 0.7508756518363953,
"alphanum_fraction": 0.7626970410346985,
"avg_line_length": 57.53845977783203,
"blob_id": "c10bc269fd67bb73d90c78de0b537b4189ec5641",
"content_id": "0826c4b5930b61537084bc8122983bddd32e8be6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2316,
"license_type": "no_license",
"max_line_length": 360,
"num_lines": 39,
"path": "/README.md",
"repo_name": "pwlandoll/cs470-image-processing",
"src_encoding": "UTF-8",
"text": "# MIPPy - Medical Image Processing in Python\nProject for John Carroll University CS470 Fall 2015\n\n## Purpose\nThe goal of the software is to perform post-processing and statistical analysis on a set of images through the Fiji platform. The plugin allows any number of images to be opened and sent through an arbitrary pipeline of processes. After processing, the results will be passed on to statistical software that will provide a final analysis from the image input. \n\n## Installation Instructions\n1. **Install the Prerequisites:**\n\t* Fiji (Fiji Is Just ImageJ)\n\t\t* [Download here](http://fiji.sc/Downloads#Fiji)\n\t\t* Requires [Java](http://www.oracle.com/technetwork/java/javase/downloads/jre8-downloads-2133155.html)\n\t\t* After installing Fiji, update to the latest version by opening the ‘Help’ menu and selecting ‘Update ImageJ…’\n\t\t* NOTE: Reading the documentation and instructions on Fiji’s website is recommended \n\t* R\n\t\t* Required for statistical analysis\n\t\t* To download, click [here](https://cran.r-project.org/mirrors.html) and select a mirror site.\n\t\t* IMPORTANT: Windows users should take note of where R is installed\n2. **Download the Software:** To install the plugin, download the [Medical_Image.zip file](https://github.com/pwlandoll/cs470-image-processing/raw/master/Medical_Image.zip) and extract to the ‘plugins’ folder in Fiji. \n\t* Windows/Linux\n\t\t1. Extract the zip file to the ‘plugins’ folder of the Fiji.app folder downloaded earlier. If there is an option to create a new folder for the extracted files, do not select it.\n\t\t2. Restart Fiji\n\t* OS X\n\t\t1. Double-click/extract the zip file\n\t\t2. Open a Finder window, and from the ‘Go’ menu, select ‘Go to Folder’\n\t\t3. In the text field, type ‘/Applications/Fiji.app/plugins’\n\t\t4. Drag the extracted folder into the open plugins folder\n\t\t5. Restart Fiji\n\nFor more information on installation, usage, and troubleshooting, see `MIPPyUserGuide.pdf`. \n\n## Medical_Image.zip File\nThe software is delivered as a .zip file that will contain:\n* The main plugin file `Medical_Image_Processing.py`\n* Another Python file, `View_Step.py`\n* A sample macro file\n* A sample R script\n* A basic R script with functionality to compare variables\n* An R template that the user can use to make custom R scripts\n* A copy of the User Guide\n\n"
}
] | 5 |
kuanweih/QFSolver
|
https://github.com/kuanweih/QFSolver
|
de692c9cd24fa4264093f170d8b02d736d689c70
|
548ec9511d2c6c193526883a660d654e057c12c4
|
54108730e35cd633edd916f9456b7c7d8dbaeba0
|
refs/heads/master
| 2020-04-01T03:30:31.305038 | 2018-10-13T02:59:54 | 2018-10-13T02:59:54 | 152,824,400 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8064516186714172,
"alphanum_fraction": 0.8064516186714172,
"avg_line_length": 14.5,
"blob_id": "df5429594e6f4c53e6a9f43fdd351a9089dd023a",
"content_id": "aa9bcf702e9b853ace878e906a9ceb58d2ad9b18",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 31,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 2,
"path": "/README.md",
"repo_name": "kuanweih/QFSolver",
"src_encoding": "UTF-8",
"text": "# QFSolve\nQuantum Fluid Solver\n"
},
{
"alpha_fraction": 0.5237287878990173,
"alphanum_fraction": 0.5677965879440308,
"avg_line_length": 19.34482765197754,
"blob_id": "62c7aed8d13c90095d0d5722e7974bda399f7512",
"content_id": "78b52bc6d194f0bb31cd4629e25bb06cc1f330d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 590,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 29,
"path": "/solver.py",
"repo_name": "kuanweih/QFSolver",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\n\nN_1D = 20 # number of grids on a side\nETA = 1. # mass/hbar: particle mass over Planck const.\nBOXSIZE = 1. # simulation box size\nCFL = 1. # Caurant constrain for a time step\n\n\n# 1D perturbation wave\nrho_0 = 1.\nrho_1 = 1e-4\nk = 2. * np.pi\nphi_0 = 0.\nv_0 = 1.\nv_1 = np.pi * 1e-4\n\nprint(np.linspace(0,BOXSIZE,num=N_1D))\n\n# fluid_ic = [[],\n# []] # ic arrays\n#\n#\n# dh = BOXSIZE / N_1D # grid size\n# dts = ETA * dh**2 # time step for Schrodinger\n# dtf = dh / vmax # time step for fluid dynamics\n# dt = CFL / (1. / dts + 1. / dtf)\n#\n# fluid\n"
}
] | 2 |
hemantjhil/python
|
https://github.com/hemantjhil/python
|
f9eda04e9437b5405a384eeb2ced6d8707cb1d82
|
e0e51fdae07a8a908147a972115b7f32fc74a12f
|
ac89cd4afb6bb75f26746c9a96838dfa0dcc4fb8
|
refs/heads/master
| 2020-05-24T17:17:15.657714 | 2019-08-31T05:07:08 | 2019-08-31T05:07:08 | 187,380,508 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6283687949180603,
"alphanum_fraction": 0.6368794441223145,
"avg_line_length": 27.200000762939453,
"blob_id": "3ba6f38105774d67dfe8faf3d9dacc3b54ac68fd",
"content_id": "30431b24fa5c7005cfef26db4976e644f22654aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 705,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 25,
"path": "/prime_number_in_least_time.py",
"repo_name": "hemantjhil/python",
"src_encoding": "UTF-8",
"text": "{\n#Initial Template for Python 3\n//Position this line where user code will be pasted.\nimport math ##You will need this for prime checking\n \ndef main():\n testcases=int(input()) #testcases\n while(testcases>0):\n number=int(input())\n print(isPrime(number)) ##This isPrime is function that you need to create\n testcases-=1\n \nif __name__=='__main__':\n main()\n}\n''' This is a function problem.You only need to complete the function given below '''\n#User function Template for python3\n##Write the function completely\ndef isPrime(number):\n b=True;\n for i in range(2,int(math.sqrt(number))):\n if(number%i==0):\n b=False\n break;\n return b\n"
},
{
"alpha_fraction": 0.5395833253860474,
"alphanum_fraction": 0.550000011920929,
"avg_line_length": 23,
"blob_id": "676d33fed267c05537e55507f3d6de91b0f30373",
"content_id": "4b4c7b79eaded7b902c2b58e6416683f7a23d76f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 960,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 40,
"path": "/sorting_in_list.py",
"repo_name": "hemantjhil/python",
"src_encoding": "UTF-8",
"text": "{\n#Initial Template for Python 3\n//Position this line where user code will be pasted.\n \n# Driver Code\ndef main():\n \n # Testcase input\n testcases = int(input())\n \n # Looping through testcases\n while(testcases > 0):\n size_arr = int(input())\n \n name = input().split()\n marks = input().split()\n arr = list()\n for i in range(0, size_arr, 1):\n arr.append((name[i], marks[i]))\n \n arr.sort(key = customSort)\n \n for i in arr:\n print (i[0], i[1], end = \" \")\n \n print ()\n testcases -= 1\n \nif __name__ == '__main__':\n main()\n}\n''' This is a function problem.You only need to complete the function given below '''\n#User function Template for python3\n# Function to sort using comparator\ndef customSort(arr):\n \n # Your code here\n # Hint : Should be a return statement\n getkey=arr[-1]\n return sorted(arr,key=lambda x:x[-1])\n"
},
{
"alpha_fraction": 0.6495176553726196,
"alphanum_fraction": 0.6623794436454773,
"avg_line_length": 31.736841201782227,
"blob_id": "0f2f3718f9072a221def9d36ad264fc830077061",
"content_id": "bd0d2026e5692710957f0773359e2cd6db625504",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 622,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 19,
"path": "/var_argument.py",
"repo_name": "hemantjhil/python",
"src_encoding": "UTF-8",
"text": "{\n#Initial Template for Python 3\n//Position this line where user code will be pasted.\ndef main():\n testcases=int(input()) #testcases\n while(testcases>0):\n single=int(input())\n multivar(single,4,5,6,7) ## The single argument and multiarguments are passed to multivar function\n testcases-=1\n \nif __name__=='__main__':\n main()\n}\n''' This is a function problem.You only need to complete the function given below '''\n#User function Template for python3\ndef multivar(a, *var): \n ##*var takes multiple arguments inside it\n ## print the sum of a + elements of var\n print (a+sum(var))\n"
},
{
"alpha_fraction": 0.2927120625972748,
"alphanum_fraction": 0.31182795763015747,
"avg_line_length": 23.617647171020508,
"blob_id": "d0eef05de880112ee10b32892354ff706492bb26",
"content_id": "e4b42da5f7db58cd0d59492a2f1826a95478a7ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 837,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 34,
"path": "/matrix_in_spiral.py",
"repo_name": "hemantjhil/python",
"src_encoding": "UTF-8",
"text": "#code\nimport numpy as np\ndef main():\n t=int(input())\n while(t>0):\n m,n=[int(x) for x in input().split()]\n #a=[]\n e=list(map(int,input().split()))\n a=np.array(e).reshape(m,n)\n k=0;l=0\n while(k<m and l<n):\n for i in range(l,n):\n print(a[k][i],end=\" \")\n \n k+=1;\n for i in range(k,m):\n print(a[i][n-1],end=\" \")\n \n n-=1\n if(k<m):\n for i in range(n-1,l-1,-1):\n print(a[m-1][i],end=\" \")\n \n m-=1;\n if(l<n):\n for i in range(m-1,k-1,-1):\n print(a[i][l],end=\" \")\n \n l+=1\n \n t-=1;\n print()\nif __name__=='__main__':\n main()\n"
},
{
"alpha_fraction": 0.5648415088653564,
"alphanum_fraction": 0.5763688683509827,
"avg_line_length": 25.769229888916016,
"blob_id": "09066a92fe7bd961d3e3c644023a1f044d6e2d0e",
"content_id": "38f062339edc4004be5101c071e00405375175c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 347,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 13,
"path": "/count_substring.py",
"repo_name": "hemantjhil/python",
"src_encoding": "UTF-8",
"text": "def count_substring(string, sub_string):\n k=0\n for i in range(0,len(string)-len(sub_string)+1):\n if(sub_string in string[i:i+len(sub_string)]):\n k=k+1\n return k\n\nif __name__ == '__main__':\n string = input().strip()\n sub_string = input().strip()\n \n count = count_substring(string, sub_string)\n print(count)"
},
{
"alpha_fraction": 0.6378676295280457,
"alphanum_fraction": 0.6452205777168274,
"avg_line_length": 29.22222137451172,
"blob_id": "1f1556a53ae7250602cda172c6f1a117c7a7e0ff",
"content_id": "7dbbda6d825e07c878ad0b30d1b5218c6e9aef7f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 544,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 18,
"path": "/lambda_power.py",
"repo_name": "hemantjhil/python",
"src_encoding": "UTF-8",
"text": "{\n#Initial Template for Python 3\n//Position this line where user code will be pasted. \ndef main():\n testcases=int(input()) #testcases\n while(testcases>0):\n base=int(input())\n exp=int(input())\n print(power(base,exp)) ##calling the anonymous function\n testcases-=1\n \nif __name__=='__main__':\n main()\n}\n''' This is a function problem.You only need to complete the function given below '''\n#User function Template for python3\n \npower = lambda a,b:a**b##write the lambda expression in one line here\n"
},
{
"alpha_fraction": 0.49383804202079773,
"alphanum_fraction": 0.5017605423927307,
"avg_line_length": 22.183673858642578,
"blob_id": "43949e07c483990da35e13cb2dfc6f1460c03f83",
"content_id": "c2c44a0c24f5dcc4190b4c5704ddfaaf86752f54",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1136,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 49,
"path": "/dict_in_python.py",
"repo_name": "hemantjhil/python",
"src_encoding": "UTF-8",
"text": "{\n#Initial Template for Python 3\n//Position this line where user code will be pasted.\n# Driver code\ndef main():\n \n # testcase input\n testcase = int(input())\n \n # looping through testcases\n while(testcase > 0):\n \n n = int(input())\n sum = int(input())\n dict = {}\n x = n\n p = [int(i) for i in (input().split())]\n \n for i in p:\n dict[i] = 0\n \n for i in p:\n dict[i] +=1\n \n if pair_sum(dict, n, p, sum) is True:\n print (\"Yes\")\n else:\n print (\"No\")\n \n testcase -= 1\nif __name__ == '__main__':\n main()\n}\n''' This is a function problem.You only need to complete the function given below '''\n#User function Template for python3\n# Function to check if pair \n# with given sum exists\ndef pair_sum(dict, n, arr, sum):\n \n # Your code here\n # Hint: You can use 'in' to find if any key is in dict\n for i in dict.keys():\n dict2=dict.copy()\n dict2.pop(i)\n if((sum-i)in dict2.keys()):\n return True\n break\n \n return False\n"
}
] | 7 |
siriusi/BGA_ML
|
https://github.com/siriusi/BGA_ML
|
61ae7aa34b623baa90fa7cd587d7c0827046a757
|
8d2e8ed9b7a1657738a816396a92648a2e143990
|
31e34920ea48ac3fd4ba3b1e27470125276b0db9
|
refs/heads/master
| 2020-03-13T18:16:42.570255 | 2018-09-18T15:36:54 | 2018-09-18T15:36:54 | 131,232,567 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.49813929200172424,
"alphanum_fraction": 0.5220627188682556,
"avg_line_length": 30.88135528564453,
"blob_id": "345e5c5cdd368540f00c64105440bae59acf8225",
"content_id": "367e2ff7019adcca958724973faa17b9cc63f53c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2045,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 59,
"path": "/MyMoiveRateInDouban.py",
"repo_name": "siriusi/BGA_ML",
"src_encoding": "UTF-8",
"text": "# coding:utf-8\nimport urllib.request\nfrom lxml import html\nfrom importlib import reload\nimport sys\n\nreload(sys)\n#sys.setdefaultencoding(\"utf-8\")\n\nk = 1\nfor j in range(0,11):\n\n url = 'https://movie.douban.com/people/47048452/collect?sort=time&start='+str(j * 30)\n url += '&filter=all&mode=list&tags_sort=count'\n #url = 'https://movie.douban.com/top250?start={}&filter='.format(i * 25)\n response = urllib.request.urlopen(url)\n con = response.read()\n\n sel = html.fromstring(con)\n\n rateMapping = ['rating1-t','rating2-t','rating3-t','rating4-t','rating5-t']\n # 所有的信息都在class属性为info的div标签里,可以先把这个节点取出来\n for i in sel.xpath('//div[@class=\"item-show\"]'):\n # 影片名称\n title = i.xpath('div[@class=\"title\"]/a/text()')[0]\n title = title.lstrip()\n title = title.lstrip('\\n')\n title = title.rstrip()\n title = title.rstrip('\\n')\n rateStr = i.xpath('div[@class=\"date\"]/span/@class')[0]\n\n rate = rateMapping.index(rateStr) + 1\n # 导演演员信息\n #info_1 = info[0].replace(\" \", \"\").replace(\"\\n\", \"\")\n # 上映日期\n #date = info[1].replace(\" \", \"\").replace(\"\\n\", \"\").split(\"/\")[0]\n # 制片国家\n #country = info[1].replace(\" \", \"\").replace(\"\\n\", \"\").split(\"/\")[1]\n # 影片类型\n #geners = info[1].replace(\" \", \"\").replace(\"\\n\", \"\").split(\"/\")[2]\n # 评分\n #rate = i.xpath('//span[@class=\"rating_num\"]/text()')[0]\n # 评论人数\n #comCount = i.xpath('//div[@class=\"star\"]/span[4]/text()')[0]\n\n # 打印结果看看\n print(\"No.%s\" % str(k))\n print(title, \" \",rate)\n\n k += 1\n'''\n # 写入文件\n with open(\"top250.txt\", \"a\") as f:\n f.write(\n \"TOP%s\\n影片名称:%s\\n评分:%s %s\\n上映日期:%s\\n上映国家:%s\\n%s\\n\" % (k, title, rate, comCount, date, country, info_1))\n\n f.write(\"==========================\\n\")\n \n'''\n"
},
{
"alpha_fraction": 0.6885572075843811,
"alphanum_fraction": 0.7263681888580322,
"avg_line_length": 27.714284896850586,
"blob_id": "611da48a9edff7e5c832656b57014941021bc629",
"content_id": "799e27dc3d3a70c13abab36d4dacbcde33b5a7c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1121,
"license_type": "no_license",
"max_line_length": 163,
"num_lines": 35,
"path": "/Translates_From_CNTW_To_CNZH.py",
"repo_name": "siriusi/BGA_ML",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Thu May 3 11:06:12 2018\n想写一个从繁体翻译成简体的脚本,不过没有成功,目前卡在翻译模块module_url的解析没有成功,不知道什么原因\n@author: Z\n\"\"\"\nimport urllib.request\nfrom lxml import etree\nfrom importlib import reload\nimport sys\nimport codecs\nfrom langconv import Converter\n\nreload(sys)\n#sys.setdefaultencoding(\"utf-8\")\n\n\n#module_url = 'https://zh-cn.boardgamearena.com/translation?module_id=1126&source_locale=zh_TW&dest_locale=zh_CN&refreshtemplate=1&dojo.preventCache=1525318818027'\nurl = 'https://zh-cn.boardgamearena.com/#!translation?module_id=1119&source_locale=en_US&dest_locale=zh_CN&page=1'\n\nresponse = urllib.request.urlopen(url)\n\ncon = response.read().decode('UTF-8',errors=\"ignore\") \nprint(con)\n#sel = etree.XML(con)\n#sel = sel.xpath('//div[@style=\"display:block\"]/div')[0]\n#for i in sel.xpath('/div'):\n# print(\"????\")\n# print(i)\n \n \nsimplified = \"${player_name} 使用了骰子 (${dice_numeric}) 和移動了一個棋\"\nprint(simplified)\ntraditional = Converter('zh-hans').convert(simplified)\nprint(traditional)\n"
},
{
"alpha_fraction": 0.5666879415512085,
"alphanum_fraction": 0.5845564603805542,
"avg_line_length": 26.491228103637695,
"blob_id": "5905f02e33c907e2cda0cc6f105d920adece5630",
"content_id": "94359115a98788f5f688ffe171dff9d982ff86d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1731,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 57,
"path": "/IncanGold.py",
"repo_name": "siriusi/BGA_ML",
"src_encoding": "UTF-8",
"text": "# coding:utf-8\nimport urllib.request\nfrom lxml import html\nfrom lxml import etree\nfrom importlib import reload\nimport sys\nimport codecs\n\nreload(sys)\n#sys.setdefaultencoding(\"utf-8\")\n\n\nurl = 'https://zh-cn.1.boardgamearena.com/incangold?table=39625878'\n\n\n#\nresponse = urllib.request.urlopen(url)\ncon = response.read().decode('UTF-8',errors=\"ignore\") \nsel = html.fromstring(con)\n#从文件打开,注意对有中文字符的网页要编码转换\n#url = 'D:\\\\Z\\\\BGA\\\\Incan_Gold_Test.html'\n#file = codecs.open(url,'r','utf-8').read()\n#sel = etree.HTML(file)\n\n \n# 所有的信息都在class属性为info的div标签里,可以先把这个节点取出来\nfor i in sel.xpath('//div[@id=\"overall-content\"]//table[@id = \"playArea\"] \\\n //div[@id = \"table_wrap\"]/div[@id=\"tablecards\"]/div'):\n # 影片名称\n print(i.xpath(\"@style\")[0])\n #pic_loc = i.xpath('@style')\n #print(pic_loc)\n #title = title.lstrip()\n #title = title.lstrip('\\n')\n #title = title.rstrip()\n #title = title.rstrip('\\n')\n #rateStr = i.xpath('div[@class=\"date\"]/span/@class')[0]\n\n #rate = rateMapping.index(rateStr) + 1\n # 导演演员信息\n #info_1 = info[0].replace(\" \", \"\").replace(\"\\n\", \"\")\n # 上映日期\n #date = info[1].replace(\" \", \"\").replace(\"\\n\", \"\").split(\"/\")[0]\n # 制片国家\n #country = info[1].replace(\" \", \"\").replace(\"\\n\", \"\").split(\"/\")[1]\n # 影片类型\n #geners = info[1].replace(\" \", \"\").replace(\"\\n\", \"\").split(\"/\")[2]\n # 评分\n #rate = i.xpath('//span[@class=\"rating_num\"]/text()')[0]\n # 评论人数\n #comCount = i.xpath('//div[@class=\"star\"]/span[4]/text()')[0]\n\n # 打印结果看看\n #print(\"No.%s\" % str(k))\n #print(title, \" \",rate)\n\n #k += 1\n"
},
{
"alpha_fraction": 0.5325610637664795,
"alphanum_fraction": 0.5579211115837097,
"avg_line_length": 31.26262664794922,
"blob_id": "1125aff1e5340aee8f6a01e8e34feff743d6f020",
"content_id": "a0161aac72ceb6cd4633bcc48f8ce18bab046fa7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3442,
"license_type": "no_license",
"max_line_length": 160,
"num_lines": 99,
"path": "/TranslatesMovieNameFromBaidu.py",
"repo_name": "siriusi/BGA_ML",
"src_encoding": "UTF-8",
"text": "# /usr/bin/env python\n# coding=utf8\nimport http\nimport hashlib\nimport urllib.request\nimport random\nimport json\n\nwhile True:\n fin = open(r'G:\\MachineLearning\\Coursera\\machine-learning-ex8\\machine-learning-ex8\\ex8\\movie_ids.txt', 'r') #以读的方式打开输入文件\n fout = open(r'G:\\MachineLearning\\Coursera\\machine-learning-ex8\\machine-learning-ex8\\ex8\\2.txt', 'w') #以写的方式打开输出文件\n for eachLine in fin:\n appid = '20180110000113508' #参考百度翻译后台,申请appid和secretKey\n secretKey = 'icVksvKMHTNASJ8bWw7u'\n httpClient = None\n myurl = '/api/trans/vip/translate'\n q = eachLine.strip() #文本文件中每一行作为一个翻译源\n fromLang = 'en' #中文\n toLang = 'zh' #英文\n salt = random.randint(32768, 65536)\n sign = appid+q+str(salt)+secretKey\n sign = sign.encode('UTF-8')\n m1 = hashlib.md5()\n m1.update(sign)\n sign = m1.hexdigest()\n myurl = myurl+'?appid='+appid+'&q='+urllib.parse.quote(q)+'&from='+fromLang+'&to='+toLang+'&salt='+str(salt)+'&sign='+sign\n httpClient = http.client.HTTPConnection('api.fanyi.baidu.com')\n httpClient.request('GET', myurl)\n #response是HTTPResponse对象\n response = httpClient.getresponse()\n html= response.read().decode('UTF-8')\n #print(html)\n target2 = json.loads(html)\n src = target2[\"trans_result\"][0][\"dst\"]\n #print(src)#取得翻译后的文本结果,测试可删除注释\n outStr = src\n fout.write(outStr.strip() + '\\n')\n fin.close()\n fout.close()\n print('翻译成功,请查看文件')\n break\n'''\nreload(sys)\n\nimport requests\n\n\ndef fanyi():\n while True:\n context = input(\"请输入翻译的内容(退出q):\")\n\n if context in ['q', 'Q']:\n break\n else:\n url = 'http://fanyi.baidu.com/v2transapi/'\n data = {\n 'from': 'en',\n 'to': 'zh',\n 'query': context,\n 'transtype': 'translang',\n 'simple_means_flag': '3',\n }\n headers = {\n 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.153 Safari/537.36 SE 2.X MetaSr 1.0'}\n response = requests.post(url, data, headers=headers)\n head = response.headers\n\n # text = response.text\n # text = json.loads(text)\n # res = text['trans_result']['data'][0]['dst']\n # print(res)\n print(head['Content-Type'])\n print(response.json()['trans_result']['data'][0]['dst'])\n\n\nfanyi()\n'''\n\n'''\nurl = 'http://fanyi.baidu.com/?aldtype=85#en/zh/Clerks'\n\nresponse = urllib.request.urlopen(url)\ncon = response.read()\n\nsel = html.fromstring(con)\n\nword = sel.xpath('//div[@id=\"transOtherResutl\"]//strong[@class=\"dict-comment-mean\"]/text()')\nprint(word)\n# 所有的信息都在class属性为info的div标签里,可以先把这个节点取出来\n\nfor i in sel.xpath('//div[@class=\"item-show\"]'):\n # 影片名称\n title = i.xpath('div[@class=\"title\"]/a/text()')[0]\n title = title.lstrip()\n title = title.lstrip('\\n')\n title = title.rstrip()\n title = title.rstrip('\\n')\n rateStr = i.xpath('div[@class=\"date\"]/span/@class')[0]\n'''\n"
},
{
"alpha_fraction": 0.7647058963775635,
"alphanum_fraction": 0.7647058963775635,
"avg_line_length": 16,
"blob_id": "3d11e6a03ce15eb5866cffd6728cc813704e5b8c",
"content_id": "daa88394d1c41f3856c23c0d810f5b5f6183734d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 34,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 2,
"path": "/README.md",
"repo_name": "siriusi/BGA_ML",
"src_encoding": "UTF-8",
"text": "# BGA_ML\nmachine learning for BGA\n"
},
{
"alpha_fraction": 0.5403387546539307,
"alphanum_fraction": 0.5627390146255493,
"avg_line_length": 30.924419403076172,
"blob_id": "761c6d6caa15b021ac4f98991fa1daac0b04d18b",
"content_id": "03a43ef0b00ef8dcbfe3e4be8c5e368919a87296",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5791,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 172,
"path": "/DownLoadFiles.py",
"repo_name": "siriusi/BGA_ML",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding:utf-8 -*-\n\nfrom gevent import monkey\n\nmonkey.patch_all()\nfrom gevent.pool import Pool\nimport gevent\nfrom lxml import html\nimport urllib.request\nimport requests\nimport sys\nimport threading\nimport os\nimport time\n\n\ndef Handler(start, end, url, filename):\n headers = {'Range': 'bytes=%d-%d' % (start, end)}\n r = requests.get(url, headers=headers, stream=True)\n\n # 写入文件对应位置\n with open(filename, \"r+b\") as fp:\n fp.seek(start)\n var = fp.tell()\n fp.write(r.content)\n\n\ndef download_file(url, oriURL, dirName, num_thread=5):\n\n #如果文件夹不存在则新建\n if not os.path.exists(dirName):\n os.makedirs(dirName)\n\n #整理URL,是之正确\n url = url.replace('./', oriURL, 1)\n #print(url)\n if url[0:4] != 'http':\n url = oriURL + url\n #print(url)\n url = url[0:len(url)-1] if url[-1] == '/' else url\n file_DirAndName = dirName + '\\\\' + url.split('/')[-1].strip()\n\n r = requests.head(url)\n try:\n file_size = int(\n r.headers['content-length']) # Content-Length获得文件主体的大小,当http服务器使用Connection:keep-alive时,不支持Content-Length\n except:\n print(\"检查URL,或不支持多线程下载\")\n return\n\n # 创建一个和要下载文件一样大小的文件\n fp = open(file_DirAndName, \"wb\")\n fp.truncate(file_size)\n fp.close()\n\n # 启动多线程写文件\n part = file_size // num_thread # 如果不能整除,最后一块应该多几个字节\n for i in range(num_thread):\n start = part * i\n if i == num_thread - 1: # 最后一块\n end = file_size\n else:\n end = start + part\n\n t = threading.Thread(target=Handler, kwargs={'start': start, 'end': end, 'url': url, 'filename': file_DirAndName})\n t.setDaemon(True)\n t.start()\n\n # 等待所有线程下载完成\n main_thread = threading.current_thread()\n for t in threading.enumerate():\n if t is main_thread:\n continue\n t.join()\n print('%s 下载完成' % file_DirAndName)\n\n\ndef download(url, oriURL, dirName):\n chrome = 'Mozilla/5.0 (X11; Linux i86_64) AppleWebKit/537.36 ' + '(KHTML, like Gecko) Chrome/41.0.2272.101 Safari/537.36'\n headers = {'User-Agent': chrome}\n\n #如果文件夹不存在则新建\n if not os.path.exists(dirName):\n os.makedirs(dirName)\n\n #整理URL,是之正确\n url = url.replace('./', oriURL, 1)\n #print(url)\n if url[0:4] != 'http':\n url = oriURL + url\n #print(url)\n url = url[0:len(url)-1] if url[-1] == '/' else url\n file_DirAndName = dirName + '\\\\' + url.split('/')[-1].strip()\n\n r = requests.get(url.strip(), headers=headers, stream=True)\n start_time = time.time()\n with open(file_DirAndName, 'wb') as f:\n\n block_size = 1024\n '''\n count = 1\n try:\n total_size = int(r.headers.get('content-length'))\n print('file total size :', total_size)\n except TypeError:\n print('using dummy length !!!')\n total_size = 10000000\n '''\n for chunk in r.iter_content(chunk_size=block_size):\n if chunk:\n '''\n duration = time.time() - start_time\n progress_size = int(count * block_size)\n if duration >= 2:\n speed = int(progress_size / (1024 * duration))\n percent = int(count * block_size * 100 / total_size)\n sys.stdout.write(\"\\r...%d%%, %d MB, %d KB/s, %d seconds passed\" %\n (percent, progress_size / (1024 * 1024), speed, duration))\n '''\n f.write(chunk)\n f.flush()\n # count += 1\n\n print(file_DirAndName, \" 完成!\")\n\nif __name__ == \"__main__\":\n #url = 'http://vision.stanford.edu/teaching/cs131_fall1415/schedule.html'\n url = 'http://cvgl.stanford.edu/teaching/cs231a_winter1415/schedule.html'\n #dirName = 'G:\\\\MachineLearning\\\\CS131_ComputerVision_FoundationsAndApplications'\n dirName = 'G:\\\\MachineLearning\\\\CS231A_ComputerVision_From3DReconstructionToRecognition'\n #oriURL = 'http://vision.stanford.edu/teaching/cs131_fall1415/'\n oriURL = 'http://cvgl.stanford.edu/teaching/cs231a_winter1415/'\n response = urllib.request.urlopen(url)\n con = response.read()\n sel = html.fromstring(con)\n\n # 定位到TR\n #tempTable = sel.xpath('//div[@id=\"content\"]/div/table/tbody/tr')\n tempTable = sel.xpath('//div[@class=\"panel panel-default\"]/table//tr')\n p = Pool(5)\n lastLectureNo = 1\n for i in range(0, len(tempTable)):\n tempTR = tempTable[i]\n tdList = tempTR.xpath('td//a/@href')\n\n #找出第几章节\n #lectureNoList = tempTR.xpath('td')[0].xpath('strong/text()')\n lectureNoList = tempTR.xpath('td')[0].xpath('text()')\n lectureNo = lastLectureNo if (len(lectureNoList) == 0 or not lectureNoList[0].isdigit()) else lectureNoList[0]\n lastLectureNo = lectureNo\n\n for downURL in tdList:\n print(downURL)\n subDirName = dirName + '\\\\Lecture' + lectureNo\n #download_file(downURL, oriURL, subDirName, 5)\n p.spawn(download, downURL, oriURL, subDirName)\n p.join()\n # if len(sys.argv) == 2:\n # filename = sys.argv[1]\n # f = open(filename, \"r\")\n'''\n for line in f.readlines():\n if line:\n p.spawn(download, line.strip())\n key = line.split('/')[-1].strip()\n removeLine(key, filename)\n f.close()\n p.join()\n else:\n print('Usage: python %s urls.txt' % sys.argv[0])\n'''\n"
}
] | 6 |
kb0rg/hb_hw06
|
https://github.com/kb0rg/hb_hw06
|
60e2588da120548ecc640e25d89ee6c293fbf4f8
|
7104a181137f73706b28edb0b16182aafc22b7a6
|
14d60531d9e90085fc84643cc3d0155786d5504b
|
refs/heads/master
| 2021-01-18T17:28:29.770215 | 2015-01-23T07:31:41 | 2015-01-23T07:31:41 | 29,721,869 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6950464248657227,
"alphanum_fraction": 0.7012383937835693,
"avg_line_length": 22.962963104248047,
"blob_id": "b5873da70c88267992a2c959ecea4b6921ba9cc3",
"content_id": "9fadde43da7da1ec6be818b3bd6b85fdc3944909",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 646,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 27,
"path": "/melon_info.py",
"repo_name": "kb0rg/hb_hw06",
"src_encoding": "UTF-8",
"text": "\"\"\"\nmelon_info.py - Prints out all the melons in our inventory\n\n\"\"\"\n\n\"\"\"\n-> add ability to keep track of the flesh\ncolor, rind color and average weight.\n-> make script easier to manage, for flexibilty\nto change what is being tracked\n-> Hint 1: You can change the format of the melons.py file\n-> Hint 2: Dictionaries\n\"\"\"\n\nfrom melons import melon_name, melon_seedless, melon_price\n\n\ndef print_melon(name, seedless, price):\n\thashasnot = 'have'\n\tif seedless:\n\t\thashasnot = 'do not have'\n\t\n\tprint \"%ss %s seeds and are $%0.2f\" % ( name, hashasnot, price)\n\n\nfor i in melon_name.keys():\n print_melon(melon_name[i], melon_seedless[i], melon_price[i])"
}
] | 1 |
khalilm1906/SimpleRecursion
|
https://github.com/khalilm1906/SimpleRecursion
|
d9dd1a714b032abb929215141f42a80611ee3f57
|
77df923c14aba253b43dc52d148d2f2ff0eaca13
|
2ffeda4d9a7fe424fefe04ef449fa7dc402b1922
|
refs/heads/master
| 2021-09-01T12:20:07.409917 | 2017-12-27T00:22:41 | 2017-12-27T00:22:41 | 115,463,280 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5596153736114502,
"alphanum_fraction": 0.5826923251152039,
"avg_line_length": 31.5,
"blob_id": "43168f82d1d5358bc7a818597032655b0a38c36b",
"content_id": "4a4cf08975855c5208ebba273f05dbebbe793079",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 520,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 16,
"path": "/find_char.py",
"repo_name": "khalilm1906/SimpleRecursion",
"src_encoding": "UTF-8",
"text": "def find_character_index(character, index=0):\n i = index\n c = str.upper(character)\n alphabet = [chr(x) for x in range(65, 91)]\n\n if i < 26:\n if alphabet[i] == c:\n print(\"FOUND CHARACTER %s in English Alphabet at %d\" % (character, i+1))\n return i+1\n else:\n print(\"count %d does not equal %s so recursing\" % (i+1, character))\n i += 1\n find_character_index(character,i)\n else:\n print(\"CHARACTER %s Not Found in English Alphabet\" % character)\n return -1\n"
},
{
"alpha_fraction": 0.8604651093482971,
"alphanum_fraction": 0.8604651093482971,
"avg_line_length": 20.5,
"blob_id": "6a5a13175ece152e732afcb354e540f3a50142b4",
"content_id": "87a8d4b24fec6cf6b0bb233e4d9e202a8c0d2320",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 43,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 2,
"path": "/README.md",
"repo_name": "khalilm1906/SimpleRecursion",
"src_encoding": "UTF-8",
"text": "# SimpleRecursion\nSimple Recursion Example\n"
}
] | 2 |
EgorZhuchkov/code_to_docstring
|
https://github.com/EgorZhuchkov/code_to_docstring
|
e8dd0653b0c804068a796384c1efa06d30c5bf57
|
9c27157c18da28747e51d045029de94d4b29789c
|
c9019efee05bfc88196f7f0d741d229b13e0a751
|
refs/heads/master
| 2023-06-18T12:54:41.723857 | 2021-07-13T10:55:55 | 2021-07-13T10:55:55 | 380,783,841 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4761904776096344,
"alphanum_fraction": 0.682539701461792,
"avg_line_length": 14.75,
"blob_id": "5f31e697ade513b2ee09700aee4beea414f717f7",
"content_id": "17f62800a0f955be107c386aa30e66a572935018",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 63,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 4,
"path": "/requirements.txt",
"repo_name": "EgorZhuchkov/code_to_docstring",
"src_encoding": "UTF-8",
"text": "torch==1.8.1\ntransformers==4.8.1\nrequests==2.25.1\nflask==2.0.1\n"
},
{
"alpha_fraction": 0.6179039478302002,
"alphanum_fraction": 0.6299126744270325,
"avg_line_length": 35.63999938964844,
"blob_id": "794b62ea754d80f4013ce42a6196a8963b6bf14a",
"content_id": "8b9348d711858ae27739b12da7e6babd666b5685",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 916,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 25,
"path": "/app.py",
"repo_name": "EgorZhuchkov/code_to_docstring",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template, request\nfrom model import DocstringGenerator\n\napp = Flask(__name__)\ncomment_generator = DocstringGenerator()\n\nGENERATED_COMMENT_SIZE = 200\nLINE_BREAK_WORDS = ['Returns:', 'Args:', 'Parameters:', 'Returns -', 'Args -', 'Parameters -']\n\[email protected]('/', methods=('GET', 'POST'))\ndef index():\n if request.method == 'POST':\n code = request.form['code']\n if code:\n generated_comment = comment_generator.generate(code, GENERATED_COMMENT_SIZE)\n for item in LINE_BREAK_WORDS:\n generated_comment = generated_comment.replace(item, '\\n' + item)\n return render_template('index.html', comment=generated_comment)\n else:\n return render_template('index.html', error='Empty code input')\n else:\n return render_template('index.html')\n\nif __name__ == '__main__':\n app.run(host='0.0.0.0', port=5000)\n"
},
{
"alpha_fraction": 0.5702990889549255,
"alphanum_fraction": 0.5788930654525757,
"avg_line_length": 39.98591613769531,
"blob_id": "c6f3c2ebde911eb1c8a81785f72c2c226d593861",
"content_id": "131b07c5124238324b6ec96d447008e7b0a62b9a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2909,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 71,
"path": "/model.py",
"repo_name": "EgorZhuchkov/code_to_docstring",
"src_encoding": "UTF-8",
"text": "import io\nimport os\nimport re\nimport torch\nimport tokenize\nfrom download import download_file_from_google_drive\nfrom transformers import BartTokenizerFast\nfrom transformers.models.bart import BartForConditionalGeneration\n\n# Constants\nCHECKPOINT_PATH = 'bart_based'\nCHECKPOINT_REMOTE_ID = \"1P6Evc4LP5RzULq63kYHdsWNb4utO2Avj\"\nMAX_CODE_LEN = 340\n\nclass DocstringGenerator:\n def __init__(self):\n if(not os.path.exists(CHECKPOINT_PATH)):\n print(\"Downloading model checkpoint\")\n download_file_from_google_drive(CHECKPOINT_REMOTE_ID, CHECKPOINT_PATH)\n\n device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')\n model_data = torch.load(CHECKPOINT_PATH, map_location=device)\n\n self.tokenizer = BartTokenizerFast.from_pretrained('facebook/bart-base')\n self.model = BartForConditionalGeneration.from_pretrained(\"facebook/bart-base\")\n self.model.load_state_dict(model_data['model_state'])\n\n def _remove_comments_and_docstrings_(self, source):\n io_obj = io.StringIO(source)\n out = \"\"\n prev_toktype = tokenize.INDENT\n last_lineno = -1\n last_col = 0\n for tok in tokenize.generate_tokens(io_obj.readline):\n token_type = tok[0]\n token_string = tok[1]\n start_line, start_col = tok[2]\n end_line, end_col = tok[3]\n if start_line > last_lineno:\n last_col = 0\n if start_col > last_col:\n out += (\" \" * (start_col - last_col))\n if token_type == tokenize.COMMENT:\n pass\n elif token_type == tokenize.STRING:\n if prev_toktype != tokenize.INDENT:\n if prev_toktype != tokenize.NEWLINE:\n if start_col > 0:\n out += token_string\n else:\n out += token_string\n prev_toktype = token_type\n last_col = end_col\n last_lineno = end_line\n out = '\\n'.join(l for l in out.splitlines() if l.strip())\n return out\n\n def generate(self, code, max_length):\n with torch.no_grad():\n code = self._remove_comments_and_docstrings_(code)\n code = re.sub(\"\\s+\", \" \", code)\n inp = self.tokenizer(code)['input_ids']\n inp = torch.tensor(inp).view(1,-1)[:,:MAX_CODE_LEN].clone()\n generated = self.model.generate(input_ids=inp.to(self.model.device), \n decoder_start_token_id=self.tokenizer.bos_token_id, \n num_beams=10,\n max_length=max_length, no_repeat_ngram_size=4)\n generated = generated[0].cpu().tolist()\n generated.remove(self.tokenizer.bos_token_id)\n generated.remove(self.tokenizer.eos_token_id)\n return self.tokenizer.decode(generated)"
},
{
"alpha_fraction": 0.7793618440628052,
"alphanum_fraction": 0.7929396033287048,
"avg_line_length": 42.32352828979492,
"blob_id": "f264171abb2729f29e52809f291c06a679f857a1",
"content_id": "6e2f73700ad404a0e1d94a023d8120851546b9a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2317,
"license_type": "no_license",
"max_line_length": 353,
"num_lines": 34,
"path": "/README.md",
"repo_name": "EgorZhuchkov/code_to_docstring",
"src_encoding": "UTF-8",
"text": "# [Обученные модели, презентация проекта](https://drive.google.com/drive/folders/1PHxNSUsENyCu6xSXdWpkcjOaom5zMhpn?usp=sharing)\n\n# Генерация комментариев к методам\n**Участники проекта:**<br>\n* Жучков Е.А. ИДБ-18-09<br>\n* Жучкова Т.Г. ИДБ-18-09\n\n## Краткое описание проекта\nПриложение получает от пользователя метод или функцию на одном из поддерживаемых языков программирования. Обученная модель генерирует комментарий на основе данного кода, описывающий его функционал.\n\n## Детали реализации\nПоскольку данная проблема сводится к задаче машинного перевода, была выбрана seq2seq архитектура на основе трансформера BART. Для обучения были взяты данные из [датасета CodeSearchNet](https://github.com/github/CodeSearchNet). На данный момент для генерации доступны только функции на языке Python. Приложение использует Flask в качестве веб-фреймворка.\n\n## Инструкция по запуску на локальном компьютере\n1. Клонировать проект на локальный компьютер.\n```\ngit clone https://github.com/EgorZhuchkov/code_to_docstring\ncd code_to_docstring\n```\n2. Убедиться, что на компьютере установлены необходимые зависимости, указанные в [requirements.txt](requirements.txt).\n```\npip install -r requirements.txt\n```\n3. Запустить файл app.py в корне проекта.\n```\npython app.py\n```\n4. Перейти по адресу указанному в консоли. Например:\n```\nRunning on http://localhost:5000/\n```\n\n**Предупреждение:**<br>\n*При запуске приложение загружает из облака модель и чекпоинт. Это может занять некоторое время.*\n"
}
] | 4 |
goinghlf/mnist-with-tensorflow
|
https://github.com/goinghlf/mnist-with-tensorflow
|
be5b329f4ca11cbd144ce9734b5dd4d2204c2c79
|
5655a5309890633b90335040cc22a3466b3d9096
|
35264f5f7f5f58e2d2bf9c1dc15a64de24361616
|
refs/heads/master
| 2021-04-27T00:23:40.193752 | 2018-03-08T17:11:30 | 2018-03-08T17:11:30 | 123,804,690 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7700381875038147,
"alphanum_fraction": 0.7719465494155884,
"avg_line_length": 36.42856979370117,
"blob_id": "1e6a22a5c23cdb227e784bb267123d5d5568f8d3",
"content_id": "74cd26011f75081efa5a4a5327ae5ed345e6b813",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1048,
"license_type": "no_license",
"max_line_length": 242,
"num_lines": 28,
"path": "/README.md",
"repo_name": "goinghlf/mnist-with-tensorflow",
"src_encoding": "UTF-8",
"text": "# mnist-with-tensorflow\n### overview\n This project implements a classic example of MNIST, which is designed to help the novice get a quick introduction of artificial intelligence and tensorflow through the program.This example comes from http://www.tensorfly.cn/.\n\n### langrage\npython\n### tool\ntensorflow\n### files\ntrain.py: The main code for training.\n\ninput_data.py: Code to read and decompress data from MNIST_data. \n\nMNIST_data: The folder for train data and test data. \n\ntest.py: Used to identify a given picture\n\n4.png: An example picture (number 4)\n\n### notice\nThe first time you use this project, you need to install tensorflow and python.In addition, you need to follow the prompts to install missing programs (such as numpy).\n\nFirst you need to run train.py to create a folder named \"weight\" that contains the training results.Then,if you need to identify a given picture, you need to run test.py and you may need to modify the parameters of the ImageToMatrix function.\n\n### contact\nany questions please contact [email protected]. \n\nbest regards.\n"
},
{
"alpha_fraction": 0.6527736783027649,
"alphanum_fraction": 0.6973877549171448,
"avg_line_length": 38.160919189453125,
"blob_id": "79d6f42a0a9a550352a9eccce2058f32cc662589",
"content_id": "61b580d6902ef4850e97224b3f45d9b2ba870f65",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3411,
"license_type": "no_license",
"max_line_length": 266,
"num_lines": 87,
"path": "/train.py",
"repo_name": "goinghlf/mnist-with-tensorflow",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport tensorflow as tf\n\n# Read the training data set from the file\nimport input_data\nmnist = input_data.read_data_sets('MNIST_data', one_hot=True)\n\n# Define the x to be entered and y_ to be expected, just two placeholders, similar to two variables that need to be entered at training time\nx = tf.placeholder(\"float\", shape=[None, 784])\ny_ = tf.placeholder(\"float\", shape=[None, 10])\n\n# Define two functions for variable initialization\ndef weight_variable(shape):\n initial = tf.truncated_normal(shape, stddev=0.1)\n return tf.Variable(initial)\n\ndef bias_variable(shape):\n initial = tf.constant(0.1, shape=shape)\n return tf.Variable(initial)\n\n# Define convolution OP\ndef conv2d(x, W):\n return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')\n\n# Define pooling OP\ndef max_pool_2x2(x):\n return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],\n strides=[1, 2, 2, 1], padding='SAME')\n\n# Define the weight and bias of the first layer convolution\nW_conv1 = weight_variable([5, 5, 1, 32])\nb_conv1 = bias_variable([32])\n\n# Make a length of 784 one-dimensional x to a 28x28 matrix, this is the size of the original image.\nx_image = tf.reshape(x, [-1,28,28,1])\n\n# After Relu activation function, then pooling.\nh_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)\n# After this pooling, the image size becomes half of the original, that is 14 × 14\nh_pool1 = max_pool_2x2(h_conv1)\n\n# The output of Relu function, and then through a layer of convolutional neural network, which is similar to the first layer of convolutional neural network.\nW_conv2 = weight_variable([5, 5, 32, 64])\nb_conv2 = bias_variable([64])\n\nh_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)\n# After this pooling, the image size is further reduced by half, that is, 7 × 7\nh_pool2 = max_pool_2x2(h_conv2)\n\n# Now that the image size is reduced to 7x7, we add a fully connected layer of 1024 neurons to process the entire image. We reshape the tensor output from the pooling layer into a one-dimensional vector, multiply the weight matrix, and add bias, then use ReLU on it.\nW_fc1 = weight_variable([7 * 7 * 64, 1024])\nb_fc1 = bias_variable([1024])\n\nh_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])\nh_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)\n\n# Dropout,to prevent overfitting\nkeep_prob = tf.placeholder(\"float\")\nh_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)\n\n# Add a softmax layer at last\nW_fc2 = weight_variable([1024, 10])\nb_fc2 = bias_variable([10])\n\ny_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)\n\ncross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))\ntrain_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)\ncorrect_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))\naccuracy = tf.reduce_mean(tf.cast(correct_prediction, \"float\"))\n\nsaver = tf.train.Saver()\n\n# Create Session,start training\nwith tf.Session() as sess:\n\tsess.run(tf.initialize_all_variables())\n\tfor i in range(20000):\n\t batch = mnist.train.next_batch(50)\n\t if i%100 == 0:\n\t train_accuracy = accuracy.eval(feed_dict={\n\t\tx:batch[0], y_: batch[1], keep_prob: 1.0})\n print \"step %d, training accuracy %g\"%(i, train_accuracy)\n\t train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})\n\n\tsave_path = saver.save(sess, \"./weight/model.ckpt\")\n\tprint \"test accuracy %g\"%accuracy.eval(feed_dict={\n\t x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0})\n"
},
{
"alpha_fraction": 0.6329268217086792,
"alphanum_fraction": 0.6487804651260376,
"avg_line_length": 31.799999237060547,
"blob_id": "fd5017b1f6769af3de0db1ee0d7ccf6e995e74a4",
"content_id": "87fc491ee045d91fcb23c29016ec8236ab386e60",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 820,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 25,
"path": "/test.py",
"repo_name": "goinghlf/mnist-with-tensorflow",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport tensorflow as tf\nfrom PIL import Image\nimport numpy as np\n\ndef ImageToMatrix(filename):\n im = Image.open(filename) \n #im.show()\n width,height = im.size\n im = im.convert(\"L\") \n data = im.getdata()\n data = np.array(data,dtype=\"float\")/255.0\n return data\n\nprint \"Recognition..., please wait!\"\nwith tf.Session() as sess:\n saver = tf.train.import_meta_graph('./weight/model.ckpt.meta')\n graph = tf.get_default_graph()\n x_input = graph.get_tensor_by_name(\"Placeholder:0\")\n y_conv = graph.get_tensor_by_name(\"Softmax:0\")\n keep_prob = graph.get_tensor_by_name(\"Placeholder_2:0\")\n saver.restore(sess, \"./weight/model.ckpt\")\n output = sess.run(y_conv, {x_input: ImageToMatrix(\"4.png\"), keep_prob: 1.0})\n print \"The num is\", tf.argmax(output, 1).eval()\n"
}
] | 3 |
freemanwyz/probabilistic-synapse-detection
|
https://github.com/freemanwyz/probabilistic-synapse-detection
|
08fcf648c11ff70e16f5b86bd5ea21c5fc2456ec
|
355217bc67beee8957b7eb0529f23226f2b0d874
|
2e6b1e6f45db3637d7c76270cc353a46da47c15e
|
refs/heads/master
| 2020-04-16T00:28:08.003528 | 2018-04-19T17:20:34 | 2018-04-19T17:20:34 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7956204414367676,
"alphanum_fraction": 0.8248175382614136,
"avg_line_length": 44.66666793823242,
"blob_id": "5db911dbffc8ea151ab1ec5f74b96ee4029c7e02",
"content_id": "dd686531615d2decd0cdfd09cef2fc2aa5114196",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 137,
"license_type": "permissive",
"max_line_length": 127,
"num_lines": 3,
"path": "/runme/collman_runme/readme.md",
"repo_name": "freemanwyz/probabilistic-synapse-detection",
"src_encoding": "UTF-8",
"text": "readme \n\nCode necessary for running the synapse detection method on the conjugate array tomography data described in Collman et al 2015. "
},
{
"alpha_fraction": 0.7575528621673584,
"alphanum_fraction": 0.7741692066192627,
"avg_line_length": 76.52941131591797,
"blob_id": "a3c55335cb33f03ba05b21832c77badc4106b932",
"content_id": "f61720c47da58f1ffcb2fadaad2123eead05bda2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1324,
"license_type": "permissive",
"max_line_length": 339,
"num_lines": 17,
"path": "/README.md",
"repo_name": "freemanwyz/probabilistic-synapse-detection",
"src_encoding": "UTF-8",
"text": "## Readme for Probabilistic fluorescence-based synapse detection\n\n[note] I rewrote the method in python and it's the most current version of the codebase. If you're interested in that, please visit <https://aksimhal.github.io/SynapseAnalysis/SynapseDetection>. \n\nThank you for visiting the paper's code repository. Here, you'll find links to download the data and the necessary code needed to run the synapse detection code yourself. \n\nIf you'd like to explore the algorithm itself, run /runme/sample_runme/run_sample.m This runme runs a few example queries on sample data (a tiny portion of data from Weiler et al, 2014) inlcuded in the repository. \n\nTo download the conjugate array tomography data or the chessboard data, navigate to /ndio for instructions. \n\n#### Original Data references. \nThe conjugate array tomography data was originally published here: http://www.jneurosci.org/content/35/14/5792. It can be downloaded here: https://neurodata.io/data/collman15. The chessboard dataset was originally published here: http://www.nature.com/articles/sdata201446 and can be downloaded here: https://neurodata.io/data/weiler14. \n\n\n\n#### Questions?\nI'm excited to see how folks are going to use this! Drop me a line if you have any questions, or if you'd like to talk about anything in the paper - [email protected]\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.8219178318977356,
"alphanum_fraction": 0.8219178318977356,
"avg_line_length": 72,
"blob_id": "e96e064d1ac526d3ebf3d55b3ba093731509b422",
"content_id": "9e36a12ac1161a0da266080fe90f5bab5e6ca3ff",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 73,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 1,
"path": "/analysis_scripts/cAT_evaluation/README.md",
"repo_name": "freemanwyz/probabilistic-synapse-detection",
"src_encoding": "UTF-8",
"text": "To evaluate the silane dataset, please look at evaluate_silane_results.m\n"
},
{
"alpha_fraction": 0.8360655903816223,
"alphanum_fraction": 0.8360655903816223,
"avg_line_length": 19.33333396911621,
"blob_id": "f31f9b70d5d5205ef1228b29ce7a1c70f715d545",
"content_id": "326fd68bb5fef105a055db763f55bcf41357e54d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 61,
"license_type": "permissive",
"max_line_length": 51,
"num_lines": 3,
"path": "/runme/weiler_runme/readme.md",
"repo_name": "freemanwyz/probabilistic-synapse-detection",
"src_encoding": "UTF-8",
"text": "readme \n\nScripts necessary to analyze the chessboard dataset "
},
{
"alpha_fraction": 0.6112785339355469,
"alphanum_fraction": 0.6405510306358337,
"avg_line_length": 21.77450942993164,
"blob_id": "98e8be6e1aed007a6b95f3b58684cab634a2c0d6",
"content_id": "bb9bfd2a5c922fa39d0acec1528512b6a7e8b604",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2323,
"license_type": "permissive",
"max_line_length": 127,
"num_lines": 102,
"path": "/ndio/nd_download_conjugateAT_gelatin.py",
"repo_name": "freemanwyz/probabilistic-synapse-detection",
"src_encoding": "UTF-8",
"text": "import ndio\nimport scipy.io as io\nimport os\nimport ndio.remote.neurodata as neurodata\n\n\nnd = neurodata(hostname='synaptomes.neurodata.io')\nvolumeList = ['collman14v2'];\n#'Ex2R18C1', 'Ex2R18C2', 'Ex3R43C1', 'Ex3R43C2', 'Ex3R43C3', 'Ex6R15C1', 'Ex6R15C2', 'Ex10R55','Ex12R75', 'Ex12R76', 'Ex13R51',\n\n#\n#baseStr = \"/data/anish/Synaptome/kristina15/rawVolumes/\";\nbaseStr = \"/Users/anish/Documents/Connectome/Synaptome-Duke/\";\n\nfolderStrBoolean = os.path.isdir(baseStr);\nif (folderStrBoolean == False):\n\tos.mkdir(baseStr)\n\tprint \"Folder Created\"\n\nfor token in volumeList:\n\tprint token\n\tchannels = nd.get_channels(token)\n\tx_stop, y_stop, z_stop = nd.get_image_size(token, resolution=0)\n\tprint x_stop, y_stop, z_stop\n\n\n\t# See if directory exists\n\tfolderStr = baseStr + token + os.path.sep;\n\tfolderStrBoolean = os.path.isdir(folderStr);\n\tif (folderStrBoolean == False):\n\t\tos.mkdir(folderStr)\n\t\tprint \"Folder Created\"\n\n\tprint \"Folder check completed\"\n\ttokenList = channels.keys();\n\n\tz_pt = z_stop / 3;\n\n\tquery = {\n\t 'token': token,\n\t 'channel': 'PSD95_1',\n\t 'x_start': 0,\n\t 'x_stop': x_stop,\n\t 'y_start': 0,\n\t 'y_stop': y_stop,\n\t 'z_start': 0,\n\t 'z_stop': z_pt,\n\t 'resolution': 0\n\t}\n\n\tfor x in xrange(0, len(tokenList)):\n\n\t c = tokenList[x]\n\t print \"{}\".format(c),\n\t print \"\"\n\n\t query['channel'] = c\n\t channelName = \"{}\".format(c)\n\t print x;\n\t fullFileName = folderStr + channelName + \"_p1\";\n\t cutout = nd.get_cutout(**query)\n\t io.savemat(fullFileName,{channelName:cutout})\n\t print \"file saved\"\n\n\tzpt2 = z_pt * 2;\n\tquery['z_start'] = z_pt;\n\tquery['z_stop'] = zpt2;\n\n\tfor x in xrange(0, len(tokenList)):\n\n\t c = tokenList[x]\n\t print \"{}\".format(c),\n\t print \"\"\n\n\t query['channel'] = c\n\t channelName = \"{}\".format(c)\n\t print x;\n\t fullFileName = folderStr + channelName + \"_p2\";\n\t cutout = nd.get_cutout(**query)\n\t io.savemat(fullFileName,{channelName:cutout})\n\t print \"file saved\"\n\n\tquery['z_start'] = zpt2;\n\tquery['z_stop'] = z_stop;\n\n\tfor x in xrange(0, len(tokenList)):\n\n\t c = tokenList[x]\n\t print \"{}\".format(c),\n\t print \"\"\n\n\t query['channel'] = c\n\t channelName = \"{}\".format(c)\n\t print x;\n\t fullFileName = folderStr + channelName + \"_p3\";\n\t cutout = nd.get_cutout(**query)\n\t io.savemat(fullFileName,{channelName:cutout})\n\t print \"file saved\"\n\n\n\n\tprint(\"download completed\")\n"
},
{
"alpha_fraction": 0.7956204414367676,
"alphanum_fraction": 0.7956204414367676,
"avg_line_length": 136,
"blob_id": "ff2d388ebad3de68a423d918c4c245603d54a005",
"content_id": "23a59514782453fb4b6eaec7f58fb4a9d5adea22",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 137,
"license_type": "permissive",
"max_line_length": 136,
"num_lines": 1,
"path": "/runme/sample_runme/readme.txt",
"repo_name": "freemanwyz/probabilistic-synapse-detection",
"src_encoding": "UTF-8",
"text": "Prior to running the sample, please change the path directories to match your computer. If you have any questions, please email [email protected]\n"
},
{
"alpha_fraction": 0.8518518805503845,
"alphanum_fraction": 0.8518518805503845,
"avg_line_length": 26,
"blob_id": "f661172fbb55e2daa8d2f8940eda2daad66890a2",
"content_id": "761ec1f94816ab50331498650e42f702f1a0c106",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 81,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 3,
"path": "/analysis_scripts/cb_evaluation/readme.md",
"repo_name": "freemanwyz/probabilistic-synapse-detection",
"src_encoding": "UTF-8",
"text": "readme \n\nscripts for determining biological properties reported in syanpse-paper "
},
{
"alpha_fraction": 0.8571428656578064,
"alphanum_fraction": 0.8571428656578064,
"avg_line_length": 27.33333396911621,
"blob_id": "f1fbe114586654219044eae79acf7df5d89ff813",
"content_id": "dd1f326de19e0547cee33084275fa25e8964f162",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 84,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 3,
"path": "/analysis_scripts/CB_DataAnalysis/readme.md",
"repo_name": "freemanwyz/probabilistic-synapse-detection",
"src_encoding": "UTF-8",
"text": "readme \n\nscripts for testing various biological properties of the chessboard dataset"
},
{
"alpha_fraction": 0.7694483995437622,
"alphanum_fraction": 0.7913720011711121,
"avg_line_length": 77.5,
"blob_id": "4e219dc459e345d36cbc9d146939ccafc6e0d276",
"content_id": "14486b8ff36ecdcdaf2d6f4dba16582506c181e7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1414,
"license_type": "permissive",
"max_line_length": 338,
"num_lines": 18,
"path": "/ndio/readme.md",
"repo_name": "freemanwyz/probabilistic-synapse-detection",
"src_encoding": "UTF-8",
"text": "### Downloading the data \n\nThe original data is hosted by Neurodata.io and they provide the offical support to access and download the data. I've provided scripts which I've used to download the data, but they may not work in the future. If you run into any issues, feel free to create either a github issue or email me directly at [email protected]. \n\n\nPrior to running the scripts, the 'ndio' python package must be installed: 'pip install ndio==1.1.5'\n\nTo download the larger conjugate array tomography dataset, use this script: nd_download_conjugateAT_gelatin.py. The manual synapse annotations: https://drive.google.com/file/d/0B-klet4qHv35NVJYSDI1WUFiVHM/view?usp=drive_web\n\n\nTo download the smaller conjugate array tomography dataset, use this script: nd_download_conjugateAT_silane.py. The manual synapse annotations: https://drive.google.com/file/d/0B-klet4qHv35blJTbkI1OVRSeTg/view?usp=drive_web \n\nTo download the chessboard dataset, nd_download_chessboard.py\n\nFor each script, change the local download locations to your own machine. \n\n#### Original Data references. \nThe conjugate array tomography data was originally published here: http://www.jneurosci.org/content/35/14/5792. It can be downloaded here: https://neurodata.io/data/collman15. The chessboard dataset was originally published here: http://www.nature.com/articles/sdata201446 and can be downloaded here: https://neurodata.io/data/weiler14. \n"
}
] | 9 |
nic-savelyev/exel
|
https://github.com/nic-savelyev/exel
|
c647d070919afe2b5608f80803525324530fe76a
|
d6987736a76f1c94590365e5e0bfd7cfac5d4b05
|
fce14db510ef7b6d68553fac91e730eee97430ca
|
refs/heads/master
| 2021-06-23T16:50:13.649631 | 2017-08-17T18:12:58 | 2017-08-17T18:12:58 | 100,425,613 | 0 | 0 | null | 2017-08-15T22:50:24 | 2017-08-22T22:19:07 | 2017-08-22T22:19:55 |
Python
|
[
{
"alpha_fraction": 0.5078750252723694,
"alphanum_fraction": 0.5441518425941467,
"avg_line_length": 35.02790832519531,
"blob_id": "a560ed471e9633229cd6857677f7b86db8a879f4",
"content_id": "83e1915e1b19df663eb749124d379658bbdb5a7c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8583,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 215,
"path": "/try_to_xlsx.py",
"repo_name": "nic-savelyev/exel",
"src_encoding": "UTF-8",
"text": "from openpyxl import Workbook\nimport random\n\nwb = Workbook()\n\n# grab the active worksheet\nws = wb.active\n\n#количество траифка по позициям\ntraffic = [1, 0.85, 0.75, 0.65, 0.06, 0.05, 0.04, 0.03, 0.02]\n\n#ценность клика\nclick_value = 800\n\n\nver_conv = [0]*50\namount_traff = [0]*50\n\n \ncost_click = [25]*50 #массив ставок по ключам. начальная ставка 20 руб.\nbase_cost_click = 25 #контрольная фиксированная ставка для всех ключей - 20 руб\ncost_pos = [[0]*9 for i in range(50)] #массив стоимости позиций\nall_count_conv = 0\nall_money = 0\nall_money_fix = 0\nu = 0\nl = 50\ncount_conv = [0]*50\nall_key_conv = [0]*50\nall_key_costs = [0]*50\ncosts_per_key = [0]*50\nfull_money = 0\nfull_conv = 0\n\nfull_money_fix = 0\nfull_conv_fix = 0\nfull_costs_per_key = [0]*50\nfull_conv_per_key = [0]*50\n\nfull_full_money = 0\nfull_full_conv = 0\n \nfull_full_money_fix = 0\nfull_full_conv_fix = 0\n\nfor q in range(10):\n random.seed\n\n #задаем вероятности конверсий и количетсво трафика ключам\n for i in range(50): \n ver_conv[i] = round(random.uniform(0.5, 5)/100, 2)\n amount_traff[i] = random.randint(1, 50)\n\n for x in range (1, 10):\n all_count_conv = 0\n all_count_conv_fix = 0\n money = 0\n money_fix = 0\n traff_period = [0]*50\n for v in range(1, 50):\n #генерируем стоимость позиций для ключа\n cost_pos[v][8] = round(random.uniform(1, 3), 2)\n cost_pos[v][7] = cost_pos[v][8] + round(random.uniform(0.5, 2), 2)\n cost_pos[v][6] = cost_pos[v][7] + round(random.uniform(0.5, 2), 2)\n cost_pos[v][5] = cost_pos[v][6] + round(random.uniform(0.5, 2), 2)\n cost_pos[v][4] = cost_pos[v][5] + round(random.uniform(0.5, 3), 2)\n cost_pos[v][3] = cost_pos[v][4] + round(random.uniform(4, 10), 2)\n cost_pos[v][2] = cost_pos[v][3] + round(random.uniform(2, 10), 2)\n cost_pos[v][1] = cost_pos[v][2] + round(random.uniform(1, 15), 2)\n cost_pos[v][0] = cost_pos[v][1] + round(random.uniform(2, 10), 2)\n\n #записываем в excel цены \n #for i in range(1, 10):\n # ws.cell(row=v+u, column=i).value = cost_pos[v][i-1]\n\n #ищем максимальную доступную позицию и стоимость клика для оптимизатора\n cpc = [0]*50\n for i in range(9):\n if cost_pos[v][i] <= cost_click[v]:\n cpc[v] = cost_pos[v][i]+0.01\n num_pos = i\n break\n\n #максимальная позиция и стоимость клика для фиксированной ставки\n cpc_fix = [0]*50\n for j in range(9):\n if cost_pos[v][j] <= base_cost_click:\n cpc_fix[v] = cost_pos[v][j]+0.01\n num_pos_fix = j\n break\n \n #считаем количество трафика за период для оптимизатора\n traff_period[v] = round(amount_traff[v] * traffic [num_pos], 0)\n\n #считаем количество трафика за период для фиксированной ставки\n traff_period_fix = round(amount_traff[v] * traffic [num_pos_fix], 0)\n\n #расходы по ключу оптимизатора\n costs_per_key[v] = traff_period[v] * cpc[v]\n full_costs_per_key[v] += costs_per_key[v]\n\n #расходы по ключу фикс\n costs_per_key_fix = traff_period_fix * cpc_fix[v]\n\n #количество конверсий оптимизатора\n count_conv[v] = round(traff_period[v] * ver_conv[v], 0)\n all_count_conv += count_conv[v]\n full_conv_per_key[v] += count_conv[v]\n\n #количество конверсий с фикс ставкой\n count_conv_fix = round(traff_period_fix * ver_conv[v], 0)\n all_count_conv_fix += count_conv_fix\n\n conv_cost = [0]*50\n #стоимость конверсии по ключам с опитимизатором\n if count_conv[v] > 0:\n conv_cost[v] = costs_per_key[v] / count_conv[v]\n\n conv_cost_fix = [0]*50\n #стоимость конверсии по ключам с фискированной ставкой\n if count_conv_fix > 0:\n conv_cost_fix[v] = costs_per_key_fix / count_conv_fix\n \n #расходы за период\n money += costs_per_key[v]\n money_fix += costs_per_key_fix\n \n #фиксированная ставка \n #ws.cell(row=v+u, column=11).value = cpc_fix[v]\n #ws.cell(row=v+u, column=12).value = num_pos_fix\n #ws.cell(row=v+u, column=13).value = traff_period_fix\n #ws.cell(row=v+u, column=14).value = costs_per_key_fix\n #ws.cell(row=v+u, column=15).value = count_conv_fix\n #ws.cell(row=v+u, column=16).value = conv_cost_fix[v]\n\n #оптимизированная ставка\n #ws.cell(row=v+u, column=18).value = cpc[v]\n #ws.cell(row=v+u, column=19).value = num_pos\n #ws.cell(row=v+u, column=20).value = traff_period[v]\n #ws.cell(row=v+u, column=21).value = costs_per_key[v]\n #ws.cell(row=v+u, column=22).value = count_conv[v]\n #ws.cell(row=v+u, column=23).value = conv_cost[v]\n #ws.cell(row=v+u, column=24).value = cost_click[v]\n #ws.cell(row=v+u, column=28).value = full_costs_per_key[v]\n #ws.cell(row=v+u, column=29).value = full_conv_per_key[v]\n #if full_conv_per_key[v] > 0:\n # ws.cell(row=v+u, column=30).value = full_costs_per_key[v] / full_conv_per_key[v]\n\n\n #считаем расходы и конверсии у фиксированной ставки\n cost_conv_period_fix = money_fix / all_count_conv\n all_money_fix += money_fix\n\n #считаем расходы и конверсии у оптимизатора\n cost_conv_period = money / all_count_conv\n all_money += money\n\n '''#ввывод итоговых цифр за период\n ws.cell(row=l, column=14).value = money_fix\n ws.cell(row=l, column=21).value = money\n ws.cell(row=l, column=15).value = all_count_conv_fix\n ws.cell(row=l, column=22).value = all_count_conv\n ws.cell(row=l, column=16).value = cost_conv_period_fix\n ws.cell(row=l, column=23).value = cost_conv_period'''\n\n U = 0\n full_money += money\n full_conv += all_count_conv\n \n full_money_fix += money_fix\n full_conv_fix += all_count_conv_fix\n #выставляем ставки\n for i in range(1, 50):\n if full_conv_per_key[i] > 0:\n if full_costs_per_key[i] / full_conv_per_key[i] < click_value*1.15:\n cost_click[i] = cost_click[i] + cost_click[i]*0.1\n else:\n cost_click[i] = cost_click[i] - cost_click[i]*0.1\n \n if full_costs_per_key[i] / full_conv_per_key[i] > click_value*1.5:\n cost_click[i] = 0\n else:\n if full_costs_per_key[i] > 1700:\n cost_click[i] = 0\n\n u += 52\n l += 52 \n\n\n # U = traff_period[i] * ver_conv[i]\n #\n # if U * cpc[i] < click_value:\n # cost_click[i] = cost_click[i] + cost_click[i]*0.1\n # else:\n # cost_click[i] = cost_click[i] - cost_click[i]*0.1\n \n\n full_full_money += full_money\n full_full_conv += full_conv\n \n full_full_money_fix += full_money_fix\n full_full_conv_fix += full_conv_fix\n\nws.cell(row=1, column=32).value = full_full_money\nws.cell(row=1, column=33).value = full_full_conv\nws.cell(row=1, column=34).value = full_full_money / full_full_conv\n\nws.cell(row=2, column=32).value = full_full_money_fix\nws.cell(row=2, column=33).value = full_full_conv_fix\nws.cell(row=2, column=34).value = full_full_money_fix / full_full_conv_fix\n\n# Save the file\nwb.save(\"sample1.xlsx\")\n\nprint (\"Done\")\n"
}
] | 1 |
Maciek1200/underdeveloped-countries
|
https://github.com/Maciek1200/underdeveloped-countries
|
9bd5311d2be6e682e5bd65f238227677dfa0b7e1
|
ea988766e000ac57236a8e528801229f4150d770
|
7c5eff0588cb115696e6d40d01ea1e969abeef7d
|
refs/heads/master
| 2022-04-23T06:22:14.793909 | 2020-04-23T20:50:54 | 2020-04-23T20:50:54 | 258,325,723 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7848911881446838,
"alphanum_fraction": 0.8072983622550964,
"avg_line_length": 77.05000305175781,
"blob_id": "90fe1a6398c7c476dbfacb4cc5e54016656e0267",
"content_id": "4fc3753a1c96531de303315903504ef069dd4e82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1564,
"license_type": "no_license",
"max_line_length": 312,
"num_lines": 20,
"path": "/README.md",
"repo_name": "Maciek1200/underdeveloped-countries",
"src_encoding": "UTF-8",
"text": "# underdeveloped-countries\nCOVID-19 \nProject to connect patients to doctors dummy data on the incidence of the new coronavirus or COVID-19 in Spanish territory. These data will be used exclusively in an educational and didactic way for right now. \n\nTables of values Nationally: https://github.com/ivanhtemp/covid19/blob/master/totales_espana.csv The Ministry of Health did not publish reports on February 29, March 1, March 7, and March 8. \nThe data was extracted from the Department of Homeland Security, under the Cabinet of the Presidency of the Government. \nData sources: Ministry of Health, Consumption and Social Welfare: https://www.mscbs.gob.es/profesionales/saludPublica/ccayes/alertasActual/nCov-China/situacionActual.htm Department of Homeland Security: https://www.dsn.gob.es/es/actualidad/sala-prensa COVID-19 situation in Spain: https://covid19.isciii.es/ \n\nEpidemiological analysis: https://www.isciii.es/QueHacemos/Servicios/VigilanciaSaludPublicaRENAVE/EnfermedadesTransmisibles/Paginas/InformesCOVID-19.aspx Health | \n\n\nCommunity of Madrid: https://www.comunidad.madrid/servicios/salud/covid-19-comunicados \n\nJunta de Castilla y León: https://comunicacion.jcyl.es/web/es/coronavirus.html \n\nOpen data of the Junta de Castilla y León: https://analisis.datosabierto.jcyl.es/pages/coronavirus/ \n\nMinistry of Health and Public Health - Generalitat Valenciana: http://www.san.gva.es/comunicados-coronavirus \n\nOfficial sources from Italy: http://opendatadpc.maps.arcgis.com/apps/opsdashboard/index.html#/b0c68bce2cce478eaac82fe38d4138b1 \n"
},
{
"alpha_fraction": 0.6485148668289185,
"alphanum_fraction": 0.6732673048973083,
"avg_line_length": 32.66666793823242,
"blob_id": "b5030bfcc52dc53d1a0b53be89ccd684d14d8616",
"content_id": "f64ad3abd471940e1e08333c74f0d4d9b7428c44",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 202,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 6,
"path": "/covid19_madrid.py",
"repo_name": "Maciek1200/underdeveloped-countries",
"src_encoding": "UTF-8",
"text": "import pandas as pd\n\ndef get_sorted_dataframe(filename):\n df = pd.read_csv(filename, sep=';', encoding='ISO-8859-1')\n df = df.sort_values(by=['municipio_distrito', 'fecha_informe'])\n return df\n"
}
] | 2 |
ForgeFlow/croston
|
https://github.com/ForgeFlow/croston
|
d51c0660b4789d385c9a12c3ec9eb68ecd5c5fbe
|
5d287ede6b43159432a0ec7271db8c83b5793e2d
|
87c2340c976f30592c861781975258df9c82c481
|
refs/heads/master
| 2021-01-26T07:45:34.100343 | 2020-02-26T21:38:19 | 2020-02-26T21:38:19 | 243,370,780 | 1 | 2 | null | 2020-02-26T21:35:48 | 2020-02-26T20:45:50 | 2019-11-20T18:11:56 | null |
[
{
"alpha_fraction": 0.5652173757553101,
"alphanum_fraction": 0.5652173757553101,
"avg_line_length": 16.125,
"blob_id": "e4be9da5e39b4ab74f286263531bf2efc5735d58",
"content_id": "a87245b9d8722db213b9b6b00269713f1bdaa33d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 138,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 8,
"path": "/docs/croston/croston.rst",
"repo_name": "ForgeFlow/croston",
"src_encoding": "UTF-8",
"text": "croston\n=============================\n\n.. automodule:: croston.croston\n\t:members:\n\t:undoc-members:\n\t:private-members:\n\t:special-members:\n\n"
},
{
"alpha_fraction": 0.6774193644523621,
"alphanum_fraction": 0.774193525314331,
"avg_line_length": 7,
"blob_id": "e6ce99910bd3d6ca43cea82cea6553d62f9f2306",
"content_id": "0c1c5d70126c784f71eac83c39d835a982df8119",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 31,
"license_type": "no_license",
"max_line_length": 12,
"num_lines": 4,
"path": "/requirements.txt",
"repo_name": "ForgeFlow/croston",
"src_encoding": "UTF-8",
"text": "numpy\npandas\nscipy\ntwine==2.0.0"
},
{
"alpha_fraction": 0.707317054271698,
"alphanum_fraction": 0.7351916432380676,
"avg_line_length": 20.259260177612305,
"blob_id": "dc885002fbb1f5fee85a817af378595fd48670d9",
"content_id": "72d5cfae27577cd73b52215604425a071dd6100c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 574,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 27,
"path": "/README.md",
"repo_name": "ForgeFlow/croston",
"src_encoding": "UTF-8",
"text": "# croston\nA package to forecast intermittent time series using croston's method\n\n[readthedocs: croston](https://newell-brands-croston.readthedocs-hosted.com/en/latest/)\n\nexample:\n```\n\nimport numpy as np\nimport random\nfrom croston import croston\nimport matplotlib.pyplot as plt\n\n\na = np.zeros(50)\nval = np.array(random.sample(range(100,200), 10))\nidxs = random.sample(range(50), 10)\n\nts = np.insert(a, idxs, val)\n\nfit_pred = croston.fit_croston(ts, 10)\n\nyhat = np.concatenate([fit_pred['croston_fittedvalues'], fit_pred['croston_forecast']])\n\nplt.plot(ts)\nplt.plot(yhat)\n```\n"
},
{
"alpha_fraction": 0.6342943906784058,
"alphanum_fraction": 0.664643406867981,
"avg_line_length": 22.535715103149414,
"blob_id": "263f040c92a82b67fb4aeff262cc35f8c308e72a",
"content_id": "93c431bbb73a4299410bb91f58850f85d9a66fcb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": true,
"language": "reStructuredText",
"length_bytes": 659,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 28,
"path": "/docs/_build/html/_sources/croston/example.rst.txt",
"repo_name": "ForgeFlow/croston",
"src_encoding": "UTF-8",
"text": "example\n=============================\n.. code-block:: python\n :linenos:\n\n\timport numpy as np\n\timport random\n\tfrom croston import croston\n\timport matplotlib.pyplot as plt\n\n\n\ta = np.zeros(50)\n\tval = np.array(random.sample(range(100,200), 10))\n\tidxs = random.sample(range(50), 10)\n\n\tts = np.insert(a, idxs, val)\n\n\n\tfit_pred = croston.fit_croston(ts, 10, 'original') # croston's method\n\n\t#fit_pred = croston.fit_croston(ts, 10, 'sba') # Syntetos-Boylan approximation\n\t#fit_pred = croston.fit_croston(ts, 10, 'sbj') # Shale-Boylan-Johnston\n\n\n\tyhat = np.concatenate([fit_pred['croston_fittedvalues'], fit_pred['croston_forecast']])\n\n\tplt.plot(ts)\n\tplt.plot(yhat)\n"
},
{
"alpha_fraction": 0.40274566411972046,
"alphanum_fraction": 0.40910404920578003,
"avg_line_length": 31.952381134033203,
"blob_id": "0e6dfececc2d7eb2f5d3b5ef398f3544fd69e913",
"content_id": "7faa55ea6404ee048bca4b83f79c8aae4f9c4ef9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6920,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 210,
"path": "/build/lib/croston/croston.py",
"repo_name": "ForgeFlow/croston",
"src_encoding": "UTF-8",
"text": "\"\"\"\ncroston model for intermittent time series\n\"\"\"\n\nimport numpy as np\nimport pandas as pd\nfrom scipy.optimize import minimize\n\ndef fit_croston(\n input_endog,\n forecast_length,\n croston_variant = 'original'\n ):\n \"\"\"\n\n :param input_endog: numpy array of intermittent demand time series\n :param forecast_length: forecast horizon\n :param croston_variant: croston model type\n :return: dictionary of model parameters, in-sample forecast, and out-of-sample forecast\n \"\"\"\n \n input_series = np.asarray(input_endog)\n epsilon = 1e-7\n input_length = len(input_series)\n nzd = np.where(input_series != 0)[0]\n \n if list(nzd) != [0]:\n \n try:\n w_opt = _croston_opt(\n input_series = input_series,\n input_series_length = input_length,\n croston_variant = croston_variant,\n epsilon = epsilon, \n w = None,\n nop = 1\n )\n \n croston_training_result = _croston(\n input_series = input_series, \n input_series_length = input_length,\n croston_variant = croston_variant,\n w = w_opt, \n h = forecast_length,\n epsilon = epsilon,\n )\n croston_model = croston_training_result['model']\n croston_fittedvalues = croston_training_result['in_sample_forecast']\n \n croston_forecast = croston_training_result['out_of_sample_forecast']\n\n except Exception as e:\n \n croston_model = None\n croston_fittedvalues = None\n croston_forecast = None\n print(str(e))\n \n else:\n \n croston_model = None\n croston_fittedvalues = None\n croston_forecast = None \n \n \n return {\n 'croston_model': croston_model,\n 'croston_fittedvalues': croston_fittedvalues,\n 'croston_forecast': croston_forecast\n }\n\ndef _croston(\n input_series, \n input_series_length,\n croston_variant,\n w, \n h, \n epsilon\n ):\n \n # Croston decomposition\n nzd = np.where(input_series != 0)[0] # find location of non-zero demand\n \n k = len(nzd)\n z = input_series[nzd] # demand\n \n x = np.concatenate([[nzd[0]], np.diff(nzd)]) # intervals\n\n # initialize\n \n init = [z[0], np.mean(x)]\n \n zfit = np.array([None] * k)\n xfit = np.array([None] * k)\n\n # assign initial values and prameters\n \n zfit[0] = init[0]\n xfit[0] = init[1]\n\n if len(w) == 1:\n a_demand = w[0]\n a_interval = w[0]\n \n else:\n a_demand = w[0]\n a_interval = w[1]\n \n # compute croston variant correction factors\n # sba: syntetos-boylan approximation\n # sbj: shale-boylan-johnston\n # tsb: teunter-syntetos-babai \n \n if croston_variant == 'sba':\n correction_factor = 1 - (a_interval / 2)\n \n elif croston_variant == 'sbj':\n correction_factor = (1 - a_interval / (2 - a_interval + epsilon))\n \n else:\n correction_factor = 1\n \n # fit model\n \n for i in range(1,k):\n zfit[i] = zfit[i-1] + a_demand * (z[i] - zfit[i-1]) # demand\n xfit[i] = xfit[i-1] + a_interval * (x[i] - xfit[i-1]) # interval\n \n cc = correction_factor * zfit / (xfit + epsilon)\n \n croston_model = {\n 'a_demand': a_demand,\n 'a_interval': a_interval,\n 'demand_series': pd.Series(zfit),\n 'interval_series': pd.Series(xfit),\n 'demand_process': pd.Series(cc),\n 'correction_factor': correction_factor\n }\n \n # calculate in-sample demand rate\n \n frc_in = np.zeros(input_series_length)\n tv = np.concatenate([nzd, [input_series_length]]) # Time vector used to create frc_in forecasts\n \n for i in range(k):\n frc_in[tv[i]:min(tv[i+1], input_series_length)] = cc[i]\n\n # forecast out_of_sample demand rate\n \n if h > 0:\n frc_out = np.array([cc[k-1]] * h)\n \n else:\n frc_out = None\n \n return_dictionary = {\n 'model': croston_model,\n 'in_sample_forecast': frc_in,\n 'out_of_sample_forecast': frc_out\n }\n \n return return_dictionary\n\ndef _croston_opt(\n input_series, \n input_series_length, \n croston_variant,\n epsilon,\n w = None,\n nop = 1\n ):\n \n p0 = np.array([0.1] * nop)\n \n wopt = minimize(\n fun = _croston_cost, \n x0 = p0, \n method='Nelder-Mead',\n args=(input_series, input_series_length, croston_variant, epsilon)\n )\n \n constrained_wopt = np.minimum([1], np.maximum([0], wopt.x)) \n \n return constrained_wopt\n \n\ndef _croston_cost(\n p0,\n input_series,\n input_series_length,\n croston_variant,\n epsilon\n ):\n \n # cost function for croston and variants\n \n frc_in = _croston(\n input_series = input_series,\n input_series_length = input_series_length,\n croston_variant = croston_variant,\n w=p0,\n h=0,\n epsilon = epsilon\n )['in_sample_forecast']\n \n E = input_series - frc_in\n E = E[E != np.array(None)]\n E = np.mean(E ** 2)\n\n return E\n"
}
] | 5 |
warreny11/log_processes
|
https://github.com/warreny11/log_processes
|
809be55e216db35db271ec2eb027af8273d0ca98
|
80982ab4fa3acf27a3b95675915df47bea96ddc5
|
40cbabf86e7a73a7436d0dc89b9fa9f874aca6e7
|
refs/heads/specific_data_selection
| 2020-03-24T05:29:27.967888 | 2018-08-13T05:56:29 | 2018-08-13T05:56:29 | 142,491,181 | 0 | 0 | null | 2018-07-26T20:31:58 | 2018-08-07T18:46:59 | 2018-08-09T17:57:29 |
Python
|
[
{
"alpha_fraction": 0.49767979979515076,
"alphanum_fraction": 0.5069605708122253,
"avg_line_length": 19.452381134033203,
"blob_id": "9b988256e2be42a14b31b7aedd24532c55150e64",
"content_id": "97ac99ab576bc54229a4b05ad82a07d60dc02826",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 862,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 42,
"path": "/GUI/serialcom.py",
"repo_name": "warreny11/log_processes",
"src_encoding": "UTF-8",
"text": "import serial\nimport time\nimport sys\nimport os\nimport re\nfrom data_sort import convert\n\nport = \"/dev/tty.usbserial\"\nbaud = 9600\n\nser = serial.Serial(port, baud)\n\ncmdstate = \"\"\n\nclass commandline(object):\n def __init__(self, my_input):\n commandline.my_input = raw_input()\n\n\ndef connect(a,b): \n \n \n ser = serial.Serial(str(a), b)\n while ser.is_open:\n return 0\n else:\n return -1 #0 is connected, -1 is not connected \n \ndef commands():\n \n \n if commandline.my_input== \"a\":\n print(\"entering auto printout mode\\n\")\n cmdstate = \"autoprint\"\n \n if commandline.my_input== \"e\": \n cmdstate = \"exiting\"\n\n else :\n cmdstate = \"commandin\"\n\n return cmdstate\n\n\n\n"
},
{
"alpha_fraction": 0.4521276652812958,
"alphanum_fraction": 0.4654255211353302,
"avg_line_length": 16.136363983154297,
"blob_id": "4a93537b8da7cfbdc5afcb82a3efc285f11702a3",
"content_id": "21c8d249c62185560e3159ff6a5879aa7a7d738e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 376,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 22,
"path": "/GUI/print.py",
"repo_name": "warreny11/log_processes",
"src_encoding": "UTF-8",
"text": "import serial\nfrom data_sort import convert\n\nport = \"/dev/tty.usbserial\"\nbaud = 9600\n\nser = serial.Serial(port, baud)\n\ndef autoprint():\n rxstr = ''\n while (1):\n \n out = ''\n out += ser.read()\n rxstr += out\n #if out != '':\n# print (out)\n if out == ';':\n convert(rxstr)\n rxstr = ''\n \nautoprint()"
},
{
"alpha_fraction": 0.5083100199699402,
"alphanum_fraction": 0.5542483925819397,
"avg_line_length": 29.2598876953125,
"blob_id": "61288fe3ed372b39c387398a407d73499f66d1b8",
"content_id": "0d935deef1ac434f75a16f9a60a9b34929d180e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5355,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 177,
"path": "/GUI_python.py",
"repo_name": "warreny11/log_processes",
"src_encoding": "UTF-8",
"text": "import serial\nimport io\nimport Tkinter\nfrom Tkinter import*\nimport ttk\nimport threading\nimport time\n\n\nserial_data = ''\nfilter_data = ''\nupdate_period = 5\nserial_object = None\ngui = Tk()\ngui.title(\"Seatrec Serial Interface\")\n\n\ndef connect(): \n version_ = button_var.get()\n print version_\n global serial_object\n port = port_entry.get()\n baud = baud_entry.get() \n \n try:\n if version_ == 2:\n try:\n serial_object = serial.Serial('/dev/tty' + str(port), baud)\n \n except:\n print \"Cant Open Specified Port\"\n\n elif version_ == 1:\n serial_object = serial.Serial('COM' + str(port), baud)\n\n elif version_ == 3:\n serial_object = serial.Serial('/dev/tty.' + str(port), baud)\n\n except ValueError:\n print \"Enter Baud and Port\"\n return\n\n t1 = threading.Thread(target = get_data)\n t1.daemon = True\n t1.start()\n\ndef get_data():\n \"\"\"basic data reading and filtering, eliminates newlines from n and r and seperates with commas\"\"\"\n global serial_object\n global filter_data\n global serial_object\n global filter_data\n\n while(1): \n try:\n serial_data = serial_object.readline().strip('\\n').strip('\\r')\n filter_data = serial_data.split(',')\n print filter_data\n except TypeError:\n pass\n\ndef update_gui(): \n \"\"\"data collection and presentation\"\"\"\n global filter_data\n global update_period\n text.place(x = 15, y = 10)\n \n progress_1.place(x = 150, y = 50)\n progress_2.place(x = 60, y = 130)\n progress_3.place(x = 60, y = 160)\n progress_4.place(x = 60, y = 190)\n progress_5.place(x = 60, y = 220)\n new = time.time()\n \n while(1):\n if filter_data: \n text.insert(END, filter_data)\n text.insert(END,\"\\n\")\n try:\n progress_1[\"value\"] = filter_data[0]\n progress_2[\"value\"] = filter_data[1]\n progress_3[\"value\"] = filter_data[2]\n progress_4[\"value\"] = filter_data[3]\n progress_5[\"value\"] = filter_data[4] \n except :\n pass \n \n if time.time() - new >= update_period:\n text.delete(\"1.0\", END)\n progress_1[\"value\"] = 0\n progress_2[\"value\"] = 0\n progress_3[\"value\"] = 0\n progress_4[\"value\"] = 0\n progress_5[\"value\"] = 0\n new = time.time()\n\ndef send(): \n send_data = data_entry.get() \n if not send_data:\n print \"Sent Nothing\"\n \n serial_object.write(send_data)\n\ndef disconnect(): \n try:\n serial_object.close() \n \n except AttributeError:\n print \"Closed without Using it -_-\"\n\n gui.quit()\n\nif __name__ == \"__main__\":\n\n \"\"\"\n The main loop consists of all the GUI objects and its placement.\n The Main loop handles all the widget placements.\n \"\"\" \n\n #frames\n frame_1 = Frame(height = 285, width = 480, bd = 3, relief = 'groove').place(x = 7, y = 5)\n frame_2 = Frame(height = 150, width = 480, bd = 3, relief = 'groove').place(x = 7, y = 300)\n text = Text(width = 65, height = 5)\n\n \n #threads\n t2 = threading.Thread(target = update_gui)\n t2.daemon = True\n t2.start()\n\n \n #Labels\n pressuregauge_ = Label(text = \"Pressure(psi):\").place(x = 15, y= 100)\n data2_ = Label(text = \"Data2:\").place(x = 15, y= 130)\n data3_ = Label(text = \"Data3:\").place(x = 15, y= 160)\n data4_ = Label(text = \"Data4:\").place(x = 15, y= 190)\n data5_ = Label(text = \"Data5:\").place(x = 15, y= 220)\n\n baud = Label(text = \"Baud\").place(x = 100, y = 348)\n port = Label(text = \"Port (without tty)\").place(x = 200, y = 348)\n contact = Label(text = \"[email protected]\").place(x = 250, y = 437)\n\n #progress_bars\n progress_1 = ttk.Progressbar(orient = HORIZONTAL, mode = 'determinate', length = 200, max = 255)\n progress_2 = ttk.Progressbar(orient = HORIZONTAL, mode = 'determinate', length = 200, max = 255)\n progress_3 = ttk.Progressbar(orient = HORIZONTAL, mode = 'determinate', length = 200, max = 255)\n progress_4 = ttk.Progressbar(orient = HORIZONTAL, mode = 'determinate', length = 200, max = 255)\n progress_5 = ttk.Progressbar(orient = HORIZONTAL, mode = 'determinate', length = 200, max = 255)\n\n\n\n #Entry\n data_entry = Entry()\n data_entry.place(x = 100, y = 255)\n \n baud_entry = Entry(width = 7)\n baud_entry.place(x = 100, y = 365)\n \n port_entry = Entry(width = 7)\n port_entry.place(x = 200, y = 365)\n\n\n\n #radio button\n button_var = IntVar()\n radio_1 = Radiobutton(text = \"Windows\", variable = button_var, value = 1).place(x = 10, y = 315)\n radio_2 = Radiobutton(text = \"Linux\", variable = button_var, value = 2).place(x = 110, y = 315)\n radio_3 = Radiobutton(text = \"Mac\", variable = button_var, value = 3).place(x = 210, y = 315)\n\n #button\n button1 = Button(text = \"Send\", command = send, width = 6).place(x = 15, y = 250)\n connect = Button(text = \"Connect\", command = connect).place(x = 15, y = 360)\n disconnect = Button(text = \"Disconnect\", command = disconnect).place(x =370, y = 360)\n \n #mainloop\n gui.geometry('500x500')\n gui.mainloop()"
},
{
"alpha_fraction": 0.347517728805542,
"alphanum_fraction": 0.6362715363502502,
"avg_line_length": 59.875,
"blob_id": "9c06093f2f7be0fb9e94a61314d5a4e88d38c3a9",
"content_id": "bd69b1c258d20435af02939422ca90be3a76adc7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 987,
"license_type": "no_license",
"max_line_length": 749,
"num_lines": 16,
"path": "/GUI/reciever.py",
"repo_name": "warreny11/log_processes",
"src_encoding": "UTF-8",
"text": "import serial\n\nser = serial.Serial(\"COM3\", 9600)\nwhile ser.is_open:\n\n x = ser.read()\n\n if x == \"RN\":\n ser.write(\":EV=01;:PR=0000;:PM=0000;:IP=0006130A;:RN=0000;:VB=0000;:VG=0000;:VC1=0000;:VC2=0000;:VC3=0000;:VC4=0000;:VC5=0000;:VC6=0000;:CB=0000;:CH=0000;:CG=0000;:SCD=0000;:ST=00000000;:RT=0000;:RS=00;:TS=00003BB4;:T16=0039;:TN=FFFE;:TH=FFFE;:TG=FFFE;:TB2=0000;:TB1=0000;:TC=0198;:ML=0000;:EC=0000;:ET=0000;:EI=0000;:FF=000558C0;:QC=FFFFFFFF;:CVB=00;:UB=0012;:QG=0000;:QB=0000;:EE=01;:HE=00;:BT=00152509;:BD=00180518;:FR=0101;:CVT=FFFFFFFF;:RE=0000;:SE=0000;:TIM=0000;:DE=07;:DEC=0050;:HEC=0057;:IO=0010;:SU=94;:EV=02;:PR=0000;:RN=0000;:SCD=0000;:ST=00000000;:RT=0000;:TS=00008640;:TC=0198;:EC=0000;:ET=0000;:EI=0000;:FF=00055AC6;:QC=FFFFFFFF;:CVB=00;:EE=03;:CVT=FFFFFFFF;:DEC=00A2;:HEC=00A9;:SU=90;download complete; checksum = 0x0000A035\")\n \n elif x == \"e\":\n ser.close()\n \n else :\n command = raw_input()\n ser.write(command)\n \n "
},
{
"alpha_fraction": 0.6290322542190552,
"alphanum_fraction": 0.6290322542190552,
"avg_line_length": 22.799999237060547,
"blob_id": "8aaae77dfe5bc817f2eb47c510de42f75bca1c0f",
"content_id": "f1073e86b9d8c1c317bc0c67ff6073ca5f126109",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 124,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 5,
"path": "/GUI/class_tests.py",
"repo_name": "warreny11/log_processes",
"src_encoding": "UTF-8",
"text": "import serial\n\nclass commandline(object):\n def __init__(self, my_input):\n commandline.my_input = raw_input()\n\n "
},
{
"alpha_fraction": 0.5280373692512512,
"alphanum_fraction": 0.5467289686203003,
"avg_line_length": 14.285714149475098,
"blob_id": "44236096862caca11323656effdfa7a0ee5aa8b5",
"content_id": "c04f7b42917088423581c8346ad2284c63d56b15",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 214,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 14,
"path": "/GUI/commandinput.py",
"repo_name": "warreny11/log_processes",
"src_encoding": "UTF-8",
"text": "import serial\nimport time\n\nport = \"/dev/tty.usbserial\"\nbaud = 9600\n\nser = serial.Serial(port, baud)\n\ndef commandin(my_input):\n ser.write(my_input + '\\r\\n')\n \n \n \n#commandin()\n"
},
{
"alpha_fraction": 0.5375816822052002,
"alphanum_fraction": 0.5457516312599182,
"avg_line_length": 22.423076629638672,
"blob_id": "44f5bc2543c2380ead9e64d46232400b6f112aa1",
"content_id": "f8d5dc48c352c26459135e86f87c1298e485b9e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 612,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 26,
"path": "/GUI/liveline.py",
"repo_name": "warreny11/log_processes",
"src_encoding": "UTF-8",
"text": "import serial\nimport time\n\n#port = raw_input(\"Enter Port Name: \")\n#baud = raw_input(\"Enter Baud Rate: \")\n\ndef connect(): \n global serial_object\n \n try:\n serial_object = serial.Serial(\"/dev/tty.usbserial\", 9600)\n serial_object.write(b'this is me')\n except:\n print \"Cant Open Specified Port\"\n\n if serial_object.is_open:\n while True:\n size = serial_object.inWaiting()\n if size:\n data = serial_object.read(size)\n print data\n else:\n print 'no data'\n time.sleep(1) \n\nprint connect()\n\n\n\n"
},
{
"alpha_fraction": 0.6731517314910889,
"alphanum_fraction": 0.688715934753418,
"avg_line_length": 16.133333206176758,
"blob_id": "893b5d585fdc96520ae748cd3628760e7561c68c",
"content_id": "b196f47f78d168de8711f189c294034a2604d52d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 257,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 15,
"path": "/GUI/test_serialscript.py",
"repo_name": "warreny11/log_processes",
"src_encoding": "UTF-8",
"text": "import os, pty, serial\n\nmaster, slave = pty.openpty()\ns_name = os.ttyname(slave)\n\nser = serial.Serial(s_name)\n\n# To Write to the device\nser.write('Your text')\nprint(\"hi\")\nif ser.is_open:\n print \"hey\"\n\n# To read from the device\nprint os.read(master,1000)\n"
},
{
"alpha_fraction": 0.37816646695137024,
"alphanum_fraction": 0.5615199208259583,
"avg_line_length": 39.43902587890625,
"blob_id": "32b57600127bf34eb171928d55187320cae23744",
"content_id": "66638e9498137d80d95f97b80d303b2c6b9f0947",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1658,
"license_type": "no_license",
"max_line_length": 741,
"num_lines": 41,
"path": "/GUI/data_sort.py",
"repo_name": "warreny11/log_processes",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nimport re\n\ndef convert(liveline):\n \n pattern = re.compile(r'\\:([^;]*)\\;')\n split_line = pattern.findall(liveline)\n data = []\n key = []\n\n for i in range(len(split_line)):\n \n brokendata = split_line[i].split('=')\n data.append(brokendata[1])\n key.append(brokendata[0])\n \n try:\n data[i] = int(data[i],16)\n err = \"\"\n \n except:\n data[i] = 0\n err = \"NaN\"\n \n\n if key[i] == \"VB\" : \n print(\"Voltage : \" + str(data[i]*0.001+0) + err + \" Volts\")\n \n\n if key[i] == \"PR\" :\n print(\"Pressure : \" + str(data[i]*1+0) + err + \" Pascals\")\n\n if key[i] == \"IP\" :\n print(\"Internal Pressure : \" + str((data[i]*.25+0)*0.00750062) + err + \" mm of mercury\")\n \n \n\n#wish list: db connection to data_sort for pulling the \n\n#convert(\":EV=01;:PR=0000;:PM=0000;:IP=0006130A;:RN=0000;:VB=0000;:VG=0000;:VC1=0000;:VC2=0000;:VC3=0000;:VC4=0000;:VC5=0000;:VC6=0000;:CB=0000;:CH=0000;:CG=0000;:SCD=0000;:ST=00000000;:RT=0000;:RS=00;:TS=00003BB4;:T16=0039;:TN=FFFE;:TH=FFFE;:TG=FFFE;:TB2=0000;:TB1=0000;:TC=0198;:ML=0000;:EC=0000;:ET=0000;:EI=0000;:FF=000558C0;:QC=FFFFFFFF;:CVB=00;:UB=0012;:QG=0000;:QB=0000;:EE=01;:HE=00;:BT=00152509;:BD=00180518;:FR=0101;:CVT=FFFFFFFF;:RE=0000;:SE=0000;:TIM=0000;:DE=07;:DEC=0050;:HEC=0057;:IO=0010;:SU=94;:EV=02;:PR=0000;:RN=0000;:SCD=0000;:ST=00000000;:RT=0000;:TS=00008640;:TC=0198;:EC=0000;:ET=0000;:EI=0000;:FF=00055AC6;:QC=FFFFFFFF;:CVB=00;:EE=03;:CVT=FFFFFFFF;:DEC=00A2;:HEC=00A9;:SU=90;download complete; checksum = 0x0000A035\")\n"
},
{
"alpha_fraction": 0.47861355543136597,
"alphanum_fraction": 0.48156341910362244,
"avg_line_length": 21.93220329284668,
"blob_id": "e7ed46c196a3441e4e391e4d4e4d264abadb8441",
"content_id": "80eff61a36d5718094af6d08595f6abc40da7a8c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1356,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 59,
"path": "/GUI/ser_interface.py",
"repo_name": "warreny11/log_processes",
"src_encoding": "UTF-8",
"text": "import serial\nimport time\nimport sys\nimport os\nimport re\nfrom data_sort import convert\n\nclass commandline(object):\n def __init__(self, my_input):\n self.my_input = raw_input\n\n\ncmdstate = \"\"\n\ndef connect(a,b): \n\n global serial_object\n serial_object = serial.Serial(str(a), b)\n while serial_object.is_open:\n return 0\n else:\n return -1 #0 is connected, -1 is not connected \n \n\n\ndef commands():\n global serial_object\n \n \n cmd = raw_input()\n\n\n if cmd == \" \":\n print(\"updating data\\n\")\n serial_object.write(\"RN\")\n if serial_object.in_waiting():\n livedata = serial_object.read()\n print convert(livedata)\n else:\n print(\"no data\")\n cmd = raw_input()\n \n \n elif cmd == \"a\":\n print(\"entering auto printout mode\\n\")\n cmdstate = \"autoprint\"\n \n \n \n \n elif cmd == \"e\": \n print(\"exiting program and disconnecting from serial\") #e: exit hotkey\n serial_object.close() \n sys.exit()\n\n else: #all other commands are sent to serial\n serial_object.write(cmd)\n\n return cmdstate\n\n\n\n"
},
{
"alpha_fraction": 0.6293103694915771,
"alphanum_fraction": 0.6465517282485962,
"avg_line_length": 17.91666603088379,
"blob_id": "ff3e69d72b8194387da47b52b15d6fd9a6ef53ae",
"content_id": "72d669d6c2e4c69089a232446499fb85c053d127",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 232,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 12,
"path": "/GUI/exiting.py",
"repo_name": "warreny11/log_processes",
"src_encoding": "UTF-8",
"text": "import serial\nimport sys \n\nport = \"/dev/tty.usbserial\"\nbaud = 9600\n\nser = serial.Serial(port, baud)\n\ndef leave(): \n print(\"exiting program and disconnecting from serial\") #e: exit hotkey\n ser.close() \n sys.exit()\n \n"
},
{
"alpha_fraction": 0.5913461446762085,
"alphanum_fraction": 0.6019230484962463,
"avg_line_length": 25.66666603088379,
"blob_id": "3ff69ffa14571d59810484caed02396ae2534c4f",
"content_id": "81cf070f9d4cbc00fda92f37a3e06bfa74e56dbc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1040,
"license_type": "no_license",
"max_line_length": 178,
"num_lines": 39,
"path": "/GUI/serialscript.py",
"repo_name": "warreny11/log_processes",
"src_encoding": "UTF-8",
"text": "from serialcom import connect, commands, serial, commandline\nimport re\nimport time\nimport sys\nfrom autoprint import autoprint\nfrom commandinput import commandin\nfrom exiting import leave\n\ndebug = 1\n\nif debug == 1:\n port = \"/dev/tty.usbserial\"\n baud = 9600\n\nelif debug == 0:\n port = raw_input(\"Enter Port Name: \")\n baud = raw_input(\"Enter Baud Rate: \")\n\nif connect(port,baud)==0:\n print \"Connected...\" \n print \"To switch to auto mode, press a and Enter\\nTo type commands, type then enter\\nTo disconnect and exit, press e and Enter\" #if connected\n if debug == 1:\n print port, baud\n \n while connect(port,baud)==0:\n \n cmdauto = commands()\n if cmdauto == \"autoprint\":\n autoprint()\n if cmdauto == \"commandin\":\n commandin(commandline.my_input)\n if cmdauto == \"exiting\":\n leave()\n \n else: \n print \"Connection Broken...\"\n\nelif connect(port,baud)==-1:\n print \"Connection not established...\"\n"
},
{
"alpha_fraction": 0.6029411554336548,
"alphanum_fraction": 0.6764705777168274,
"avg_line_length": 14.222222328186035,
"blob_id": "01588c7db24bb232d071afce8f2b0bdb360dc12b",
"content_id": "050954134840b6992c717f75ad6a2c2e90072889",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 136,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 9,
"path": "/GUI/data_import.py",
"repo_name": "warreny11/log_processes",
"src_encoding": "UTF-8",
"text": "def hex2dec(hexnum):\n \n num = int(hexnum,16)\n return num\n\n#data import apply conversion \n\ntest = \"00003BB4\"\nprint hex2dec(test)"
},
{
"alpha_fraction": 0.5882353186607361,
"alphanum_fraction": 0.5989304780960083,
"avg_line_length": 17.299999237060547,
"blob_id": "9472133c2cb89bb4f7c397d6d4a05bff867ee09f",
"content_id": "2f2216732b1c2619f3d64746af3ee0ace22b2357",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 187,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 10,
"path": "/GUI/connect.py",
"repo_name": "warreny11/log_processes",
"src_encoding": "UTF-8",
"text": "import serial\n\ndef connect(a,b): \n\n global serial_object\n serial_object = serial.Serial(str(a), b)\n while serial_object.is_open:\n return 0\n else:\n return -1 \n\n\n\n"
}
] | 14 |
ilsenatorov/DeadZhenyaR8
|
https://github.com/ilsenatorov/DeadZhenyaR8
|
b264747708a2bc82ac1fc393434c2e0a1dfe401d
|
ba311c408eae2db92e5a731849a2996d4cfad06a
|
ba01fef1da8263b4071c9d0fdf4b0b2192204361
|
refs/heads/master
| 2022-01-24T06:57:30.914079 | 2022-01-19T12:30:37 | 2022-01-19T12:30:37 | 143,179,922 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6662059426307678,
"alphanum_fraction": 0.6706979870796204,
"avg_line_length": 29.463157653808594,
"blob_id": "0d9580c49881ea23fdccb8670061f7d5b0c5b264",
"content_id": "330c2b2b4d12023563331402175d539445b463d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3080,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 95,
"path": "/Dead_Zhenya.py",
"repo_name": "ilsenatorov/DeadZhenyaR8",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nThe Degenerate Bot, Zhenya. Parse the token into the start_zhenya function or with -q if launching as script.\n\"\"\"\nimport markovify\nimport pandas as pd\nimport logging\nimport argparse\nfrom telegram import Update\nfrom telegram.ext import CallbackContext, Updater, CommandHandler\n\n\ndef start(update: Update, context: CallbackContext):\n context.bot.send_message(\n chat_id=update.effective_chat.id,\n text=\"\"\"\nДобро пожаловать к самому дегенеративному боту.\n/olo чтобы сгенерировать рандомную дегенеративность.\n/with _word_, чтобы сгенерировать дегенеративность начинающуюся c _word_\"\"\",\n )\n\n\ndef olo(update: Update, context: CallbackContext):\n \"\"\"\n Generate random message (/start command)\n \"\"\"\n context.bot.send_message(\n chat_id=update.message.chat_id, text=text_model.make_short_sentence(140).lower()\n )\n\n\ndef error(update, error):\n \"\"\"\n Print warnings in case of errors\n \"\"\"\n \"\"\"Log Errors caused by Updates.\"\"\"\n logger.warning('Update \"%s\" caused error \"%s\"', update, error)\n\n\ndef OLO_start(update: Update, context: CallbackContext):\n \"\"\"\n Generate random message starting from words given (/with command)\n \"\"\"\n argument = \" \".join(context.args)\n try:\n reply = text_model.make_sentence_with_start(argument.lower(), strict=False)\n except:\n context.bot.send_message(\n chat_id=update.message.chat_id, text=\"Недостаточно дегенеративности(((99((9\"\n )\n return\n if reply is None:\n context.bot.send_message(\n chat_id=update.message.chat_id, text=\"Недостаточно дегенеративности(((99((9\"\n )\n else:\n context.bot.send_message(chat_id=update.message.chat_id, text=reply)\n\n\n\ndef start_zhenya(token):\n updater = Updater(token=token)\n dispatcher = updater.dispatcher\n\n # Read the data\n\n # Config the logger\n logging.basicConfig(\n format=\"%(asctime)s - %(name)s - %(levelname)s - %(message)s\",\n level=logging.INFO,\n )\n logger = logging.getLogger(__name__)\n\n # Create the text model\n # Add all the handlers\n dispatcher.add_handler(CommandHandler(\"start\", start))\n dispatcher.add_handler(CommandHandler(\"olo\", olo))\n dispatcher.add_handler(CommandHandler(\"with\", OLO_start, pass_args=True))\n dispatcher.add_error_handler(error)\n\n # Start the bot\n updater.start_polling()\n # idle is better than just polling, because of Ctrl+c\n updater.idle()\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser(formatter_class=argparse.RawTextHelpFormatter)\n parser.add_argument(\"-t\", help=\"your bot API token\", type=str)\n args = parser.parse_args()\n print(args.t)\n df = pd.read_csv(\"./OLO.tsv\", sep=\"\\t\", index_col=0)\n text_model = markovify.NewlineText(df.Clean.astype(str).str.lower(), state_size=2)\n start_zhenya(token=args.t)\n"
},
{
"alpha_fraction": 0.774193525314331,
"alphanum_fraction": 0.7849462628364563,
"avg_line_length": 61,
"blob_id": "93ee08670101ecbf8c73fbba52cf30d6c6d5a87a",
"content_id": "a8b4e28339a4cea71973fe24f5b3a7bcd3939909",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 186,
"license_type": "no_license",
"max_line_length": 167,
"num_lines": 3,
"path": "/README.md",
"repo_name": "ilsenatorov/DeadZhenyaR8",
"src_encoding": "UTF-8",
"text": "# Dead Zhenya R8\n\nUses HMM from `markovify` and the messages from some degenerate friends to generate degenerate messages in Telegram. Can be found in Telegram at **@DeadZhenyaR8_bot**.\n"
}
] | 2 |
AmayruN5/chat
|
https://github.com/AmayruN5/chat
|
b2e1972d7f77d1f95c4afd38204f0cd2d2a3bf9a
|
fc616e48db455e5a8dfee4bc5ee4b97db3dd3877
|
da1b23de9ca0e3020f7a1ccb0f717b6548841f19
|
refs/heads/master
| 2020-04-14T18:15:11.511236 | 2019-01-07T09:39:55 | 2019-01-07T09:39:55 | 164,011,730 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7157490253448486,
"alphanum_fraction": 0.7183098793029785,
"avg_line_length": 36.238094329833984,
"blob_id": "6921c85cfecdd820859da0f227ff11309db49f90",
"content_id": "10ac1d25d9531cc8e917e48503ba97b3fc53bb9d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 781,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 21,
"path": "/chat_app/models.py",
"repo_name": "AmayruN5/chat",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.contrib.auth.models import User\nfrom django.utils import timezone\n\n# Create your models here.\nclass Chat(models.Model):\n first_user = models.ForeignKey(User, on_delete=models.CASCADE, related_name='first_user')\n second_user = models.ForeignKey(User, on_delete=models.CASCADE, related_name='secod_user')\n\n def __str__(self):\n return self.first_user.username + '&' + self.second_user.username\n\n\nclass Message(models.Model):\n chat = models.ForeignKey('chat_app.Chat', on_delete=models.CASCADE, related_name='messages')\n text = models.TextField()\n author = models.ForeignKey(User, on_delete=models.CASCADE)\n send_date = models.DateTimeField(default=timezone.now)\n\n def __str__(self):\n return self.text[:30]"
},
{
"alpha_fraction": 0.5776397585868835,
"alphanum_fraction": 0.5869565010070801,
"avg_line_length": 28.363636016845703,
"blob_id": "f7a0d4e1d02b62a6b24883bbde02f5a64d6098d9",
"content_id": "8675e8fbea55c81735685068275627c886c84bde",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 322,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 11,
"path": "/chat_app/forms.py",
"repo_name": "AmayruN5/chat",
"src_encoding": "UTF-8",
"text": "from django import forms\nfrom .models import Message\n\nclass MessageForm(forms.ModelForm):\n\n class Meta:\n model = Message\n fields= ('text',)\n labels = {'text': 'Send message'}\n widgets = {'text': forms.Textarea(attrs={'colls': 50,\n 'rows': 4, 'id': 'mess-text', 'required': True})}"
},
{
"alpha_fraction": 0.6388206481933594,
"alphanum_fraction": 0.6388206481933594,
"avg_line_length": 36,
"blob_id": "70b701bc9e34956e55fde4cea45d28bed0dd6695",
"content_id": "c162b0be2be8288af1b8bdfb50bce6d010f2023f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 407,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 11,
"path": "/chat_app/urls.py",
"repo_name": "AmayruN5/chat",
"src_encoding": "UTF-8",
"text": "from django.urls import path, include\n\nfrom . import views\n\nurlpatterns = [\n path('', views.index, name='index'),\n path('signup/', views.signup, name='signup'),\n path('chat/<int:f_user>/<int:s_user>/', views.chat, name='chat'),\n path('chat/<int:f_user>/<int:s_user>/send', views.send_mes, name='send_mes'),\n path('chat/<int:f_user>/<int:s_user>/messages', views.messages, name='messages'),\n]\n"
},
{
"alpha_fraction": 0.5756457448005676,
"alphanum_fraction": 0.5756457448005676,
"avg_line_length": 37.85714340209961,
"blob_id": "4dda12b5522b24a39475d1f678d86e00e363783a",
"content_id": "f12e6ca317e38a609ce4f6a550a66a3f3c5e5074",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 271,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 7,
"path": "/chat_app/templates/chat_app/messages.html",
"repo_name": "AmayruN5/chat",
"src_encoding": "UTF-8",
"text": "{% comment %} <div class=\"chat-area\" id=\"chat\"> {% endcomment %}\n {% for message in messages %}\n <div class=\"well sell-sm\">\n <p><strong>{{message.author}}:</strong> {{ message.text|linebreaks }}</p><hr>\n </div>\n {% endfor %}\n{% comment %} </div> {% endcomment %}"
},
{
"alpha_fraction": 0.6394335627555847,
"alphanum_fraction": 0.6410675644874573,
"avg_line_length": 37.26041793823242,
"blob_id": "c0e9d37db13588738abcdcecd7a0928fd72f07a0",
"content_id": "2fff17129350a1c55f008b22d3cfb2f412aa6446",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3672,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 96,
"path": "/chat_app/views.py",
"repo_name": "AmayruN5/chat",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, redirect\nfrom django.contrib.auth import login, authenticate\nfrom django.contrib.auth.forms import UserCreationForm\nfrom django.http import HttpResponseRedirect, Http404\nfrom django.urls import reverse\nfrom django.utils import timezone\nfrom django.contrib.auth.decorators import login_required\nfrom django.http import JsonResponse, HttpResponse\nimport json\n\nfrom django.contrib.auth.models import User\nfrom .models import Chat, Message\nfrom .forms import MessageForm\n\n\ndef index(request):\n users = User.objects.all()\n return render(request, 'chat_app/index.html', {'users': users})\n\ndef signup(request):\n if request.method == 'POST':\n form = UserCreationForm(request.POST)\n if form.is_valid():\n form.save()\n username = form.cleaned_data.get('username')\n raw_password = form.cleaned_data.get('password1')\n user = authenticate(username=username, password=raw_password)\n login(request, user)\n create_chats(user)\n return HttpResponseRedirect(reverse('chat_app:index'))\n else:\n form = UserCreationForm()\n return render(request, 'chat_app/signup.html', {'form': form})\n\n@login_required\ndef chat(request, f_user, s_user):\n check_user(request, f_user, s_user)\n chat = get_chat(f_user, s_user)\n messages = Message.objects.filter(chat_id=chat.id).order_by('send_date')\n return render(request, 'chat_app/chat.html', {'messages': messages, 'f_user': f_user, 's_user': s_user})\n\n# @login_required\n# def send_mes(request, f_user, s_user):\n# # chat_id = get_chat_id(f_user, s_user)\n# # chat = Chat.objects.get(id=chat_id)\n# chat = get_chat(f_user, s_user)\n# messages = Message.objects.filter(chat_id=chat.id).order_by('send_date')\n# if request.method == 'POST':\n# form = MessageForm(request.POST)\n# if form.is_valid():\n# new_mes = form.save(commit=False)\n# new_mes.chat = chat\n# new_mes.author = request.user\n# new_mes.send_date = timezone.now()\n# new_mes.save()\n# return redirect('chat_app:chat', f_user, s_user)\n# else:\n# form = MessageForm()\n# return render(request, 'chat_app/chat.html', {'form': form, 'messages': messages, 'f_user': f_user, 's_user': s_user})\n\ndef send_mes(request, f_user, s_user):\n if request.method == 'POST':\n chat = get_chat(f_user, s_user)\n mess_text = request.POST.get('mess')\n new_mess = Message(chat=chat, text=mess_text, author=request.user)\n new_mess.save()\n return JsonResponse({'mess_text': new_mess.text, 'author': new_mess.author.username})\n else:\n return HttpResponse('Request must be POST')\n\n\ndef messages(request, f_user, s_user):\n check_user(request, f_user, s_user)\n chat = get_chat(f_user, s_user)\n messages = Message.objects.filter(chat_id=chat.id).order_by('send_date')\n return render(request, 'chat_app/messages.html', {'messages': messages})\n\n\ndef get_chat(f_user, s_user):\n users = (User.objects.get(id=f_user), User.objects.get(id=s_user))\n chat = Chat.objects.get(first_user__in=users, second_user__in=users)\n return chat\n\ndef create_chats(user):\n users = User.objects.all()\n for u in users:\n if u.id != user.id:\n chat = Chat()\n chat.first_user = user\n chat.second_user = u\n chat.save()\n\ndef check_user(request, f_user, s_user):\n # if request.user != User.objects.get(id=f_user) and request.user.id != User.objects.get(id=s_user):\n if request.user.id != f_user and request.user.id != s_user:\n raise Http404"
},
{
"alpha_fraction": 0.6161011457443237,
"alphanum_fraction": 0.6260811686515808,
"avg_line_length": 40.75,
"blob_id": "a1e8d9d0b86a51ce0eb0bf15b345156e6f4ed2be",
"content_id": "adf21c0d99fa7bd5c0d5a6cec2958dc9de8a61b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1503,
"license_type": "no_license",
"max_line_length": 152,
"num_lines": 36,
"path": "/chat_app/migrations/0001_initial.py",
"repo_name": "AmayruN5/chat",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.4 on 2019-01-03 10:58\n\nfrom django.conf import settings\nfrom django.db import migrations, models\nimport django.db.models.deletion\nimport django.utils.timezone\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n migrations.swappable_dependency(settings.AUTH_USER_MODEL),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Chat',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('first_user', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, related_name='first_user', to=settings.AUTH_USER_MODEL)),\n ('second_user', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, related_name='secod_user', to=settings.AUTH_USER_MODEL)),\n ],\n ),\n migrations.CreateModel(\n name='Message',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('text', models.TextField()),\n ('send_date', models.DateTimeField(default=django.utils.timezone.now)),\n ('author', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL)),\n ('chat', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, related_name='messages', to='chat_app.Chat')),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.7914110422134399,
"alphanum_fraction": 0.7914110422134399,
"avg_line_length": 17.11111068725586,
"blob_id": "e06ab5319951e1603f85005c8b82217020ab4e0c",
"content_id": "0aba80ec01e44f24d57220f0be61bf26680bbbd1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 163,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 9,
"path": "/chat_app/admin.py",
"repo_name": "AmayruN5/chat",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\n\nfrom chat_app.models import Chat, Message\n\nadmin.site.register(Chat)\nadmin.site.register(Message)\n\n\n# Register your models here.\n"
}
] | 7 |
po1ng/Spider-zhihu
|
https://github.com/po1ng/Spider-zhihu
|
eb78c804bbce6093e8af1aa2bf35352e74fb5342
|
a935aba5350cb446b92d67b8abbf145342697aac
|
f67eb603c35d22ebe9553ee7c87ab6090edba24b
|
refs/heads/master
| 2021-06-14T12:41:29.917266 | 2017-02-16T04:16:48 | 2017-02-16T04:16:48 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5436456799507141,
"alphanum_fraction": 0.5564826726913452,
"avg_line_length": 33.622222900390625,
"blob_id": "f9d0fcb03c1d4a187139afe6becffcdd99758791",
"content_id": "ef3c1ac76960b457128d2c4d5c36a98c321b7374",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3338,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 90,
"path": "/login.py",
"repo_name": "po1ng/Spider-zhihu",
"src_encoding": "UTF-8",
"text": "from selenium import webdriver\nimport time\nimport information\nfrom MongodbConn import MongoPipeline\ndef captcha1():#验证码输入\n try:\n driver.find_element_by_id('captcha')\n return True\n except:\n return False\ndef captcha2():#倒立的字\n try:\n driver.find_element_by_class_name('Captcha-imageConatiner')\n return True\n except:\n return False\n\nif __name__ ==\"__main__\":\n# def send(urllist):\n# info = input(\"请输入搜索内容:\\n\")\n url1 = 'https://www.zhihu.com/people/wan-shi-xian-3/activities'\n\n\n driver = webdriver.Chrome(r'chromedriver.exe')\n url = 'https://www.zhihu.com/#signin'\n driver.get(url)\n driver.find_element_by_name('account').clear()\n driver.find_element_by_name('account').send_keys('') #账户\n driver.find_element_by_name('password').clear()\n driver.find_element_by_name('password').send_keys('')#密码\n time.sleep(3)\n flag1 = captcha1()\n flag2 = captcha2()\n if flag1==True:\n k = input(\"请输入验证码,若无验证码,请输入“OK”:\\n\")\n try:\n driver.find_element_by_id('captcha').clear()\n driver.find_element_by_id('captcha').send_keys(k)\n driver.find_element_by_xpath('/html/body/div[1]/div/div[2]/div[2]/form/div[2]/button').click()\n except:\n driver.find_element_by_xpath('/html/body/div[1]/div/div[2]/div[2]/form/div[2]/button').click()\n elif flag2==True:\n k = input(\"请输入倒立的字,点击完成以后请输入“OK”,若无字,请直接输入“ok”\\n\")\n driver.find_element_by_xpath('/html/body/div[1]/div/div[2]/div[2]/form/div[2]/button').click()\n time.sleep(4)\n\n # driver.find_element_by_class_name('Icon Button-icon Icon--comments').click()\n # driver.find_element_by_css_selector('.MemberButtonGroup ProfileButtonGroup ProfileHeader-buttons').click()\n\n #开始发送私信\n # urllist = information.solve(info)\n conn = MongoPipeline()\n conn.open_connection('zhihu')\n ids = conn.getIds('info',{'type': 'url'})\n\n _id = next(ids, None)\n\n while _id:\n print(_id)\n url1 = _id['url']\n flag = _id['flag']\n _id = next(ids, None)\n if flag==False:\n time.sleep(2)\n driver.get(url1)\n time.sleep(5)\n mylist = driver.find_elements_by_tag_name('button') #比较难定位,只能遍历所有标签,找到相同名字的\n for each in mylist:\n if each.text=='发私信':\n each.click()\n break\n mylist2 = driver.find_elements_by_tag_name('textarea')\n print(len(mylist2))\n print(mylist2[0].text)\n mylist2[0].clear()\n mylist2[0].send_keys('hello')\n # for each in mylist2:\n # print(each.text)\n # if each.text =='私信内容':\n # each.clear()\n # each.send_keys('hello')\n # break\n mylist3 = driver.find_elements_by_tag_name('button')\n for each in mylist3:\n if each.text == '发送':\n each.click()\n break\n print('发送完成!...')\n\n conn.update_item({'url':url1},{\"$set\":{\"flag\":True}},'info')\n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 11.5,
"blob_id": "cdf4734d3f0eae1e7afb071715ad93ec5a10da04",
"content_id": "ea9da9b863300ec200d0a1fe8b621c06eba166fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 43,
"license_type": "no_license",
"max_line_length": 14,
"num_lines": 2,
"path": "/README.md",
"repo_name": "po1ng/Spider-zhihu",
"src_encoding": "UTF-8",
"text": "# Spider-zhihu\n爬取用户和发送私信\n"
},
{
"alpha_fraction": 0.532866358757019,
"alphanum_fraction": 0.5511853694915771,
"avg_line_length": 30.474576950073242,
"blob_id": "4e122c9dcbae28b17d6c200702d55e5a617cfb39",
"content_id": "34fd6c19a9096905ea8d977bf2ae29281baf18f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1934,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 59,
"path": "/information.py",
"repo_name": "po1ng/Spider-zhihu",
"src_encoding": "UTF-8",
"text": "import requests\nimport re\nimport login\nfrom MongodbConn import MongoPipeline\n# def solve(info):\nif __name__ ==\"__main__\":\n conn = MongoPipeline()\n conn.open_connection('zhihu')\n info = input(\"请输入搜索内容:\\n\")\n url = 'https://www.zhihu.com/r/search?q=' + str(info) + '&type=people&offset=10'\n\n #请求头\n header = {\n 'Host':\"www.zhihu.com\",\n 'User-Agent':\"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:51.0) Gecko/20100101 Firefox/51.0\",\n 'Accept':\"*/*\",\n 'Accept-Language':\"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3\",\n 'Accept-Encoding':\"gzip, deflate, br\",\n 'X-Requested-With':\"XMLHttpRequest\",\n 'Connection':\"keep-alive\"\n }\n\n finallyUrlList = [] #用于存入所有的用户url\n\n #处理第一页的信息\n html = requests.get(url,headers = header).text\n nexturl = re.findall('\"next\":\"(.*?)\"}',html,re.S)[0].replace(\"\\\\\",'')\n urllist = re.findall(\"data-id=(.*?)>\",html,re.S)\n for each in urllist:\n k = each.replace('\\\\', '').replace('\\\"', '')\n k = 'https://www.zhihu.com/people/'+k\n finallyUrlList.append(k)\n print(k)\n\n #循环,直到下一页为空为止\n while (nexturl!=None):\n\n nexturl = 'https://www.zhihu.com'+ nexturl\n html2 = requests.get(nexturl, headers=header).text\n\n print(nexturl)\n urllist = re.findall(\"data-id=(.*?)>\",html2,re.S)\n for each in urllist:\n k = each.replace('\\\\','').replace('\\\"','')\n k = 'https://www.zhihu.com/people/' + k\n finallyUrlList.append(k)\n print(k)\n try:\n nexturl = re.findall('\"next\":\"(.*?)\"}',html2,re.S)[0].replace(\"\\\\\",'')\n except:\n nexturl = None\n for each in finallyUrlList:\n dic = {}\n dic['url'] = each\n dic['flag'] = False\n dic['type'] = 'url'\n conn.process_item(dic,'info')\n # return finallyUrlList\n # login.send(finallyUrlList)"
}
] | 3 |
Renkar/Spider_robot
|
https://github.com/Renkar/Spider_robot
|
01cf766737e295b12d6c868711e9ab530ca12132
|
f6fd5dd2553343b3683b792dc72c975f0caaf6ad
|
cb3cbfb703ba3432f008954d59c5085df1b5debe
|
refs/heads/master
| 2018-01-08T06:09:35.107850 | 2016-03-16T16:42:26 | 2016-03-16T16:42:26 | 53,496,578 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5421108603477478,
"alphanum_fraction": 0.5447761416435242,
"avg_line_length": 25.00719451904297,
"blob_id": "a3b2d406f33920aef1a61a8a8e113197cc78a287",
"content_id": "4af0dfb131b2f2b2d0610c7f1503e87b9aca8ae2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3752,
"license_type": "no_license",
"max_line_length": 156,
"num_lines": 139,
"path": "/Spider_robot.py",
"repo_name": "Renkar/Spider_robot",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\nimport requests\r\nimport urlparse\r\nfrom bs4 import BeautifulSoup\r\nimport json\r\nimport re\r\nimport pymysql\r\n\r\npatern_email = r'\\b[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,6}\\b'\r\nbase_url = 'http://stroy-design.net/'\r\nTAG_RE = re.compile(r'<[^>]+>')\r\n\r\n\r\n\r\n\r\n\r\ndef get_task():\r\n task_dict =[]\r\n tasks =[]\r\n s = requests.Session()\r\n get = s.get('https://api.github.com/repos/Renkar/For_spider/issues?access_token=73850f62a6556bc7f016222ce88c612e6bf7c0d2')\r\n body = json.dumps({'labels':[\"Error\"]})\r\n issue = json.loads(get.text)\r\n for i in issue:\r\n name = i['labels'][0]['name']\r\n if name == 'Ready' and \"email\" in i[\"body\"] and \"phone\" in i[\"body\"]:\r\n number =['']\r\n number = i['number']\r\n options = i[\"body\"]\r\n tasks.append(options)\r\n else:\r\n number = i['number']\r\n post = s.post(url='https://api.github.com/repos/Renkar/For_spider/issues/%s?access_token=73850f62a6556bc7f016222ce88c612e6bf7c0d2' %(str(number)), data=body)\r\n for task in tasks:\r\n task = json.loads(task)\r\n task_dict.append(task)\r\n return task_dict\r\n\r\n\r\n\r\ndef remove_tags(text):\r\n return TAG_RE.sub('', text)\r\n\r\ndef get_page(url):\r\n r = requests.get(url)\r\n page = r.text\r\n return page\r\n\r\ndef get_links_on_page(data,url):\r\n visited = []\r\n soup = BeautifulSoup(data,\"html.parser\")\r\n domen = urlparse.urlparse(url).hostname\r\n shema = urlparse.urlparse(url).scheme\r\n host = shema +'://' + domen\r\n try:\r\n for i in soup('a'):\r\n i = i['href']\r\n frag = urlparse.urlparse(i).path\r\n path = re.sub(patern_email,'',frag)\r\n link = host + path\r\n if link not in visited:\r\n visited.append(link)\r\n except KeyError:\r\n print \"key eror\"\r\n\r\n return visited\r\n\r\ndef get_all_iternal_links(links_on_start_page):\r\n addet_links =[]\r\n for link in links_on_start_page:\r\n pages = get_page(link)\r\n foundet_links = get_links_on_page(pages,link)\r\n for links in foundet_links:\r\n if links not in addet_links and 'jpeg' not in links and 'pdf' not in links and 'png' not in links and 'swf' not in links and 'jpg' not in links:\r\n addet_links.append(links)\r\n return addet_links\r\n\r\ndef get_all_content(links):\r\n visited = []\r\n content = []\r\n try:\r\n for link in links:\r\n if link not in visited:\r\n\r\n visited.append(link)\r\n contents = get_page(link)\r\n \r\n content.append(contents)\r\n\r\n except EOFError:\r\n print \"warning\"\r\n\r\n return content\r\n\r\ndef search_email(content):\r\n emails = []\r\n for page in content:\r\n page = remove_tags(page)\r\n emails_on_page = re.findall(patern_email, page)\r\n for email in emails_on_page:\r\n if email not in emails:\r\n emails.append(email)\r\n return emails\r\n\r\ndef search_phone(content):\r\n phones = []\r\n for page in content:\r\n page = remove_tags(page)\r\n page = page.encode('UTF-8')#.replace(' ','').replace(\"\\n\", '').replace('\\t','').replace('(','').replace(')','').replace('-','')\r\n print phones\r\n print page\r\n\r\n\r\ndef option_to_scrap(content,email,phone):\r\n if email == \"True\":\r\n emails = search_email(content)\r\n print emails\r\n\r\n if phone == 'True':\r\n print phone\r\n\r\n\r\n\r\ndef start(url,email,phone):\r\n data = get_page(url)\r\n links = get_links_on_page(data,url)\r\n all_links = get_all_iternal_links(links)\r\n all_content = get_all_content(all_links)\r\n option_to_scrap(all_content,email=email,phone=phone)\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\nif __name__ =='__main__':\r\n for i in get_task():\r\n start(i['url'],i['email'],i['phone'])"
}
] | 1 |
wangwei-cmd/CT-image-reconstruction
|
https://github.com/wangwei-cmd/CT-image-reconstruction
|
3edfb02aae23d680fe8d17bece079a9196ae192f
|
82799480a4f552502237b4af975822f417679f36
|
87cf95c2a853913fc0b48fe4f13dd6ff2b847198
|
refs/heads/master
| 2023-05-13T03:49:55.824233 | 2023-04-28T16:04:28 | 2023-04-28T16:04:28 | 258,703,877 | 9 | 4 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7961630821228027,
"alphanum_fraction": 0.8105515837669373,
"avg_line_length": 68.33333587646484,
"blob_id": "360b373fa139e7b54860401f96d64a4534439068",
"content_id": "2bf1faf4ef6b72d8459998ee092ed9795daba30b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 417,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 6,
"path": "/README.md",
"repo_name": "wangwei-cmd/CT-image-reconstruction",
"src_encoding": "UTF-8",
"text": "# CT-image-reconstruction\nThe codes implement the CT reconstruction networks described in our peer-reviwed work\n\"An end-to-end deep network for reconstructing CT images directly from sparse sinograms\" submited to IEEE TCI.\nThe code was written based on tensorflow2.0.\n\nThe sparse matrix AT and inputted sinograms can be downloaded from the baiduyun link: https://pan.baidu.com/s/1Vey42hWPz-myxnHZOZFnVQ code: jaj2.\n\n"
},
{
"alpha_fraction": 0.5395308136940002,
"alphanum_fraction": 0.5586446523666382,
"avg_line_length": 39.578311920166016,
"blob_id": "499f75662393253df2c565c4d0d5114789294d4a",
"content_id": "8e81218a1ac38aa5b852157a6dc75d1cc7b32614",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3453,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 83,
"path": "/parabeam/make_ini.py",
"repo_name": "wangwei-cmd/CT-image-reconstruction",
"src_encoding": "UTF-8",
"text": "import glob\r\nimport matplotlib.pyplot as plt\r\nimport numpy as np\r\nimport tensorflow as tf\r\nfrom skimage.transform import radon,iradon\r\nfrom make_sin_noise import add_sin_noise\r\nfrom utilize import CT_uitil\r\nimport os\r\nfrom skimage.measure import compare_psnr\r\nimport matplotlib.pyplot as plt\r\n\r\n\r\ndef make_ini(u_img,angles,udir):\r\n # u_img = readimage(dir, ux, uy)\r\n # np.save(udir + '/npy/' + '/u_CT_img_'+str(np.max(u_img)), u_img)\r\n print('shape of u_img:', u_img.shape)\r\n print('maximum of u_img:', np.max(u_img))\r\n # np.save(udir + '/npy/' + '/u_CT_img_no_scale', u_img)\r\n theta = np.linspace(0, 180, angles, endpoint=False)\r\n ini_u_img = np.zeros(u_img.shape)\r\n temp = radon(u_img[0, :, :, 0], theta=theta, circle=False)\r\n shape = temp.shape\r\n ct_sin_img = np.zeros([u_img.shape[0], shape[0], shape[1], u_img.shape[3]])\r\n ct_sin_img_noisy = np.zeros([u_img.shape[0], shape[0], shape[1], u_img.shape[3]])\r\n\r\n var=0.5\r\n inter=54\r\n iter=list(range(0,u_img.shape[0],inter))\r\n ct = CT_uitil(u_img.shape, theta)\r\n for i in range(len(iter)):\r\n ct_sin_img[iter[i]:iter[i]+inter] = ct.radon(u_img[iter[i]:iter[i]+inter]).numpy()\r\n # ct_sin_img_noisy[iter[i]:iter[i]+inter] = add_sin_noise(ct_sin_img[iter[i]:iter[i]+inter],var=var)\r\n ct_sin_img_noisy[iter[i]:iter[i]+inter] = ct_sin_img[iter[i]:iter[i]+inter] #%no noise\r\n ini_u_img[iter[i]:iter[i]+inter] = ct.iradon(ct_sin_img_noisy[iter[i]:iter[i]+inter]).numpy()\r\n print(i)\r\n\r\n\r\n # np.save(udir + '/npy//512x512/' + '/ini,angle=' + str(angles) + '_no_scale_' + '_' + str(var),\r\n # ini_u_img)\r\n # np.save(udir + '/npy//512x512/' + '/f,angle=' + str(angles) + '_no_scale_' + '_' + str(var),\r\n # ct_sin_img)\r\n # np.save(udir + '/npy//512x512/' + '/f_noisy,angle=' + str(angles) + '_no_scale_' + '_' + str(var),\r\n # ct_sin_img_noisy)\r\n\r\n np.save(udir + '/ini,angle=' + str(angles) + '_no_scale_' + '_' + str(var),\r\n ini_u_img)\r\n np.save(udir + '/f,angle=' + str(angles) + '_no_scale_' + '_' + str(var),\r\n ct_sin_img)\r\n np.save(udir + '/f_noisy,angle=' + str(angles) + '_no_scale_' + '_' + str(var),\r\n ct_sin_img_noisy)\r\n\r\n print('save_complete')\r\n print('min of ct_sin_img_noisy:', np.min(ct_sin_img_noisy))\r\n psnr=np.zeros([1,u_img.shape[0]])\r\n psnr1=np.zeros([1,u_img.shape[0]])\r\n for i in range( u_img.shape[0]):\r\n psnr[0,i]=compare_psnr(u_img[i],ini_u_img[i],np.max(u_img[i]))\r\n # psnr1[0, i] = compare_psnr(ct_sin_img[i], ct_sin_img_noisy[i], np.max(ct_sin_img[i]))\r\n print('psnr:',psnr)\r\n print('psnr1:', psnr1)\r\n\r\n # print(tf.image.psnr(u_img, ini_u_img, np.max(u_img)).numpy())\r\n # print(tf.image.psnr(ct_sin_img, ct_sin_img_noisy, np.max(ct_sin_img)).numpy())\r\n\r\nif __name__ == \"__main__\":\r\n os.environ[\"CUDA_VISIBLE_DEVICES\"] = \"0\"\r\n # set='train'\r\n set = 'test'\r\n udir = 'E:\\CT_image\\AMP\\sparse_angles\\\\'+set+'/npy'\r\n ux, uy = 512, 512\r\n # u_img=CT.make_CT(udir,ux,uy)\r\n # u_img=np.load(udir+'/npy/'+'u_CT_img_test_no_scale.npy')\r\n u_img = np.load(udir + '/u_CT_img_no_scale.npy')\r\n if set=='train':\r\n L=1000\r\n if set=='test':\r\n L=500\r\n L = np.minimum(L, len(u_img))\r\n u_img=u_img[0:L]\r\n np.save(udir + '//u_CT_img_no_scale', u_img)\r\n # print('shape of u_img:', u_img.shape)\r\n angles = 60\r\n make_ini(u_img, angles,udir)\r\n\r\n"
},
{
"alpha_fraction": 0.49268150329589844,
"alphanum_fraction": 0.5564940571784973,
"avg_line_length": 44.721622467041016,
"blob_id": "f0afb066c0234a22a652017639f4a4f987b86ae7",
"content_id": "4adbed0d32b4f297cabdda95867a21adf14d3a2c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17285,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 370,
"path": "/compared_networks/DD_Net_tf2.py",
"repo_name": "wangwei-cmd/CT-image-reconstruction",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\r\nimport numpy as np\r\nimport datetime\r\nimport os\r\nimport glob\r\n\r\n\r\ndef BN(img):\r\n # batch_mean, batch_var = tf.nn.moments(img, [0, 1, 2], name='moments')\r\n # img = tf.nn.batch_normalization(img, batch_mean, batch_var, 0, 1, 1e-3)\r\n img=tf.keras.layers.BatchNormalization()(img)\r\n return img\r\n\r\n# def conv2d(x, W):\r\n# tf.keras.layers.Conv2D(64, 3, strides=[1, 1, 1, 1], padding='same')(output)\r\n# return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')\r\n\r\n\r\ndef max_pool_2x1(x):\r\n return tf.keras.layers.MaxPool2D([1, 2], strides=[1, 2], padding='same')(x)\r\n # return tf.nn.max_pool(x, ksize=[1, 1, 2, 1], strides=[1, 1, 2, 1], padding='SAME')\r\n\r\n\r\ndef max_pool_2x2(x):\r\n # return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')\r\n return tf.keras.layers.MaxPool2D([2, 2], strides=[2, 2], padding='same')(x)\r\n\r\n\r\ndef max_pool(x, n):\r\n return tf.keras.layers.MaxPool2D([n, n], strides=[1, 2], padding='same')(x)\r\n # return tf.nn.max_pool(x, ksize=[1, n, n, 1], strides=[1, n, n, 1], padding='VALID')\r\n\r\n\r\ndef build_unpool(source, kernel_shape):\r\n # input_shape = source.get_shape().as_list()\r\n input_shape=tf.shape(source)\r\n # return tf.reshape(source,[input_shape[1] * kernel_shape[1], input_shape[2] * kernel_shape[2]])\r\n return tf.image.resize(source, [input_shape[1] * kernel_shape[1], input_shape[2] * kernel_shape[2]])\r\n\r\n\r\n\r\ndef DenseNet(input, growth_rate=16, nb_filter=16, filter_wh=5):\r\n # shape = input.get_shape().as_list()\r\n shape=tf.shape(input)\r\n with tf.name_scope('layer1'):\r\n input = BN(input)\r\n input = tf.nn.relu(input)\r\n\r\n # w1_1 = weight_variable([1, 1, shape[3], nb_filter * 4])\r\n # b1_1 = bias_variable([nb_filter * 4])\r\n # c1_1 = tf.nn.conv2d(input, w1_1, strides=[1, 1, 1, 1], padding='SAME') + b1_1\r\n c1_1 = tf.keras.layers.Conv2D(nb_filter * 4, [1,1],1, padding='same')(input)\r\n ##\r\n\r\n c1_1 = BN(c1_1)\r\n c1_1 = tf.nn.relu(c1_1)\r\n\r\n # w1 = weight_variable([filter_wh, filter_wh, nb_filter * 4, nb_filter])\r\n # b1 = bias_variable([nb_filter])\r\n # c1 = tf.nn.conv2d(c1_1, w1, strides=1, padding='SAME') + b1\r\n c1 = tf.keras.layers.Conv2D(nb_filter,[filter_wh, filter_wh], 1, padding='same')(c1_1)\r\n\r\n h_concat1 = tf.concat([input, c1], 3)\r\n\r\n with tf.name_scope('layer2'):\r\n h_concat1 = BN(h_concat1)\r\n h_concat1 = tf.nn.relu(h_concat1)\r\n\r\n # w2_1 = weight_variable([1, 1, shape[3] + nb_filter, nb_filter * 4])\r\n # b2_1 = bias_variable([nb_filter * 4])\r\n # c2_1 = tf.nn.conv2d(h_concat1, w2_1, strides=[1, 1, 1, 1], padding='SAME') + b2_1\r\n c2_1 = tf.keras.layers.Conv2D(nb_filter * 4, [1, 1], 1, padding='same')(h_concat1)\r\n ##\r\n\r\n c2_1 = BN(c2_1)\r\n c2_1 = tf.nn.relu(c2_1)\r\n\r\n # w2 = weight_variable([filter_wh, filter_wh, nb_filter * 4, nb_filter])\r\n # b2 = bias_variable([nb_filter])\r\n # c2 = tf.nn.conv2d(c2_1, w2, strides=[1, 1, 1, 1], padding='SAME') + b2\r\n c2 = tf.keras.layers.Conv2D(nb_filter, [filter_wh, filter_wh], 1, padding='same')(c2_1)\r\n\r\n h_concat2 = tf.concat([input, c1, c2], 3)\r\n\r\n with tf.name_scope('layer3'):\r\n h_concat2 = BN(h_concat2)\r\n h_concat2 = tf.nn.relu(h_concat2)\r\n\r\n # w3_1 = weight_variable([1, 1, shape[3] + nb_filter + nb_filter, nb_filter * 4])\r\n # b3_1 = bias_variable([nb_filter * 4])\r\n # c3_1 = tf.nn.conv2d(h_concat2, w3_1, strides=[1, 1, 1, 1], padding='SAME') + b3_1\r\n c3_1 = tf.keras.layers.Conv2D(nb_filter * 4, [1, 1], 1, padding='same')(h_concat2)\r\n ##\r\n\r\n c3_1 = BN(c3_1)\r\n c3_1 = tf.nn.relu(c3_1)\r\n\r\n # w3 = weight_variable([filter_wh, filter_wh, nb_filter * 4, nb_filter])\r\n # b3 = bias_variable([nb_filter])\r\n # c3 = tf.nn.conv2d(c3_1, w3, strides=[1, 1, 1, 1], padding='SAME') + b3\r\n c3 = tf.keras.layers.Conv2D(nb_filter, [filter_wh, filter_wh], 1, padding='same')(c3_1)\r\n\r\n h_concat3 = tf.concat([input, c1, c2, c3], 3)\r\n\r\n with tf.name_scope('layer4'):\r\n h_concat3 = BN(h_concat3)\r\n h_concat3 = tf.nn.relu(h_concat3)\r\n\r\n # w4_1 = weight_variable([1, 1, shape[3] + nb_filter + nb_filter + nb_filter, nb_filter * 4])\r\n # b4_1 = bias_variable([nb_filter * 4])\r\n # c4_1 = tf.nn.conv2d(h_concat3, w4_1, strides=[1, 1, 1, 1], padding='SAME') + b4_1\r\n c4_1 = tf.keras.layers.Conv2D(nb_filter * 4, [1, 1], 1, padding='same')(h_concat3)\r\n ##\r\n\r\n c4_1 = BN(c4_1)\r\n c4_1 = tf.nn.relu(c4_1)\r\n\r\n # w4 = weight_variable([filter_wh, filter_wh, nb_filter * 4, nb_filter])\r\n # b4 = bias_variable([nb_filter])\r\n # c4 = tf.nn.conv2d(c4_1, w4, strides=[1, 1, 1, 1], padding='SAME') + b4\r\n c4 = tf.keras.layers.Conv2D(nb_filter, [filter_wh, filter_wh], 1, padding='same')(c4_1)\r\n\r\n return tf.concat([input, c1, c2, c3, c4], 3)\r\n\r\ndef mix(input_image):\r\n nb_filter = 16\r\n # W_conv1 = weight_variable([7, 7, 1, nb_filter])\r\n # b_conv1 = bias_variable([nb_filter])\r\n # h_conv1 = (tf.nn.conv2d(input_image, W_conv1, strides=[1, 1, 1, 1],\r\n # padding='SAME') + b_conv1) # 256*256**(nb_filter)\r\n h_conv1 =tf.keras.layers.Conv2D(nb_filter, [7, 7], 1, padding='same')(input_image)\r\n\r\n h_pool1 = tf.nn.max_pool(h_conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],\r\n padding='SAME') # 128*128*(nb_filter)\r\n\r\n\r\n D1 = DenseNet(h_pool1, growth_rate=16, nb_filter=nb_filter, filter_wh=5) # 128*128*(nb_filter*4+nb_filter)\r\n\r\n D1 = BN(D1)\r\n D1 = tf.nn.relu(D1)\r\n # W_conv1_T = weight_variable([1, 1, nb_filter + nb_filter * 4, nb_filter])\r\n # b_conv1_T = bias_variable([nb_filter])\r\n # h_conv1_T = (\r\n # tf.nn.conv2d(D1, W_conv1_T, strides=[1, 1, 1, 1], padding='SAME') + b_conv1_T) # 128*128*(nb_filter)\r\n h_conv1_T = tf.keras.layers.Conv2D(nb_filter, [1, 1], 1, padding='same')(D1)\r\n\r\n h_pool1_T = tf.nn.max_pool(h_conv1_T, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1],\r\n padding='SAME') # 64*64*(nb_filter)\r\n\r\n ##\r\n D2 = DenseNet(h_pool1_T, growth_rate=16, nb_filter=nb_filter, filter_wh=5) # 64*64*(4*nb_filter + nb_filter)\r\n D2 = BN(D2)\r\n D2 = tf.nn.relu(D2)\r\n\r\n # W_conv2_T = weight_variable([1, 1, nb_filter + nb_filter * 4, nb_filter])\r\n # b_conv2_T = bias_variable([nb_filter])\r\n # h_conv2_T = (\r\n # tf.nn.conv2d(D2, W_conv2_T, strides=[1, 1, 1, 1], padding='SAME') + b_conv2_T) # 64*64*(nb_filter)\r\n\r\n h_conv2_T = tf.keras.layers.Conv2D(nb_filter, [1, 1], 1, padding='same')(D2)\r\n h_pool2_T = tf.nn.max_pool(h_conv2_T, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1],\r\n padding='SAME') # 32*32*(nb_filter)\r\n\r\n ##\r\n D3 = DenseNet(h_pool2_T, growth_rate=16, nb_filter=nb_filter, filter_wh=5) # 32*32*(4*nb_filter + nb_filter)\r\n D3 = BN(D3)\r\n D3 = tf.nn.relu(D3)\r\n # W_conv3_T = weight_variable([1, 1, nb_filter + nb_filter * 4, nb_filter])\r\n # b_conv3_T = bias_variable([nb_filter])\r\n # h_conv3_T = (\r\n # tf.nn.conv2d(D3, W_conv3_T, strides=[1, 1, 1, 1], padding='SAME') + b_conv3_T) # 32*32*(nb_filter)\r\n\r\n h_conv3_T = tf.keras.layers.Conv2D(nb_filter, [1, 1], 1, padding='same')(D3)\r\n h_pool3_T = tf.nn.max_pool(h_conv3_T, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1],\r\n padding='SAME') # 16*16*(nb_filter)\r\n\r\n ##\r\n D4 = DenseNet(h_pool3_T, growth_rate=16, nb_filter=nb_filter, filter_wh=5) # 16*16*(4*nb_filter + nb_filter)\r\n D4 = BN(D4)\r\n D4 = tf.nn.relu(D4)\r\n # W_conv4_T = weight_variable([1, 1, nb_filter + nb_filter * 4, nb_filter])\r\n # b_conv4_T = bias_variable([nb_filter])\r\n # h_conv4_T = (\r\n # tf.nn.conv2d(D4, W_conv4_T, strides=[1, 1, 1, 1], padding='SAME') + b_conv4_T) # 16*16*(nb_filter)\r\n h_conv4_T = tf.keras.layers.Conv2D(nb_filter, [1, 1], 1, padding='same')(D4)\r\n\r\n ##\r\n\r\n # W_conv40 = weight_variable([5, 5, 2 * nb_filter, 2 * nb_filter])\r\n # b_conv40 = bias_variable([2 * nb_filter])\r\n # h_conv40 = tf.nn.relu(\r\n # tf.nn.conv2d_transpose(tf.concat([build_unpool(h_conv4_T, [1, 2, 2, 1]), h_conv3_T], 3), W_conv40,\r\n # [batch, 64, 64, 2 * nb_filter], strides=[1, 1, 1, 1],\r\n # padding='SAME') + b_conv40) # 32*32*40\r\n h_conv40 = tf.concat([build_unpool(h_conv4_T, [1, 2, 2, 1]), h_conv3_T], 3)\r\n h_conv40 = tf.keras.layers.Conv2DTranspose(2 * nb_filter,[5,5],strides=1,padding='SAME')(h_conv40)\r\n h_conv40 = tf.nn.relu(h_conv40)\r\n batch_mean, batch_var = tf.nn.moments(h_conv40, [0, 1, 2], name='moments')\r\n h_conv40 = tf.nn.batch_normalization(h_conv40, batch_mean, batch_var, 0, 1, 1e-3) # 32*32\r\n\r\n # W_conv40_T = weight_variable([1, 1, nb_filter, (2 * nb_filter)])\r\n # b_conv40_T = bias_variable([nb_filter])\r\n # h_conv40_T = tf.nn.relu(\r\n # tf.nn.conv2d_transpose(h_conv40, W_conv40_T, [batch, 64, 64, nb_filter], strides=[1, 1, 1, 1],\r\n # padding='SAME') + b_conv40_T) # 32*32*40\r\n h_conv40_T = tf.keras.layers.Conv2DTranspose(nb_filter, [1, 1], strides=1, padding='SAME')(h_conv40)\r\n h_conv40_T = tf.nn.relu(h_conv40_T)\r\n batch_mean, batch_var = tf.nn.moments(h_conv40_T, [0, 1, 2], name='moments')\r\n h_conv40_T = tf.nn.batch_normalization(h_conv40_T, batch_mean, batch_var, 0, 1, 1e-3)\r\n\r\n ##\r\n # W_conv5 = weight_variable([5, 5, 2 * nb_filter, 2 * nb_filter])\r\n # b_conv5 = bias_variable([2 * nb_filter])\r\n # h_conv5 = tf.nn.relu(\r\n # tf.nn.conv2d_transpose(tf.concat([build_unpool(h_conv40_T, [1, 2, 2, 1]), h_conv2_T], 3), W_conv5,\r\n # [batch, 128, 128, 2 * nb_filter], strides=[1, 1, 1, 1],\r\n # padding='SAME') + b_conv5) # 64*64*20\r\n h_conv5 = tf.concat([build_unpool(h_conv40_T, [1, 2, 2, 1]), h_conv2_T], 3)\r\n h_conv5 = tf.keras.layers.Conv2DTranspose(2 * nb_filter, [5, 5], strides=1, padding='SAME')(h_conv5)\r\n h_conv5 = tf.nn.relu(h_conv5)\r\n batch_mean, batch_var = tf.nn.moments(h_conv5, [0, 1, 2], name='moments')\r\n h_conv5 = tf.nn.batch_normalization(h_conv5, batch_mean, batch_var, 0, 1, 1e-3)\r\n\r\n # W_conv5_T = weight_variable([1, 1, nb_filter, 2 * nb_filter])\r\n # b_conv5_T = bias_variable([nb_filter])\r\n # h_conv5_T = tf.nn.relu(\r\n # tf.nn.conv2d_transpose(h_conv5, W_conv5_T, [batch, 128, 128, nb_filter], strides=[1, 1, 1, 1],\r\n # padding='SAME') + b_conv5_T) # 64*64*20\r\n h_conv5_T = tf.keras.layers.Conv2DTranspose(nb_filter, [1, 1], strides=1, padding='SAME')(h_conv5)\r\n h_conv5_T = tf.nn.relu(h_conv5_T)\r\n batch_mean, batch_var = tf.nn.moments(h_conv5_T, [0, 1, 2], name='moments')\r\n h_conv5_T = tf.nn.batch_normalization(h_conv5_T, batch_mean, batch_var, 0, 1, 1e-3)\r\n\r\n ##\r\n # W_conv6 = weight_variable([5, 5, 2 * nb_filter, 2 * nb_filter])\r\n # b_conv6 = bias_variable([2 * nb_filter])\r\n # h_conv6 = tf.nn.relu(\r\n # tf.nn.conv2d_transpose(tf.concat([build_unpool(h_conv5_T, [1, 2, 2, 1]), h_conv1_T], 3), W_conv6,\r\n # [batch, 256, 256, 2 * nb_filter], strides=[1, 1, 1, 1],\r\n # padding='SAME') + b_conv6)\r\n h_conv6 = tf.concat([build_unpool(h_conv5_T, [1, 2, 2, 1]), h_conv1_T], 3)\r\n h_conv6 = tf.keras.layers.Conv2DTranspose(2 * nb_filter, [5, 5], strides=1, padding='SAME')(h_conv6)\r\n h_conv6 = tf.nn.relu(h_conv6)\r\n batch_mean, batch_var = tf.nn.moments(h_conv6, [0, 1, 2], name='moments')\r\n h_conv6 = tf.nn.batch_normalization(h_conv6, batch_mean, batch_var, 0, 1, 1e-3)\r\n\r\n # W_conv6_T = weight_variable([1, 1, nb_filter, 2 * nb_filter])\r\n # b_conv6_T = bias_variable([nb_filter])\r\n # h_conv6_T = tf.nn.relu(\r\n # tf.nn.conv2d_transpose(h_conv6, W_conv6_T, [batch, 256, 256, nb_filter], strides=[1, 1, 1, 1],\r\n # padding='SAME') + b_conv6_T) # 64*64*20\r\n h_conv6_T = tf.keras.layers.Conv2DTranspose(nb_filter, [1, 1], strides=1, padding='SAME')(h_conv6)\r\n h_conv6_T = tf.nn.relu(h_conv6_T)\r\n batch_mean, batch_var = tf.nn.moments(h_conv6_T, [0, 1, 2], name='moments')\r\n h_conv6_T = tf.nn.batch_normalization(h_conv6_T, batch_mean, batch_var, 0, 1, 1e-3)\r\n\r\n # W_conv7 = weight_variable([5, 5, 2 * nb_filter, 2 * nb_filter])\r\n # b_conv7 = bias_variable([2 * nb_filter])\r\n # h_conv7 = tf.nn.relu(\r\n # tf.nn.conv2d_transpose(tf.concat([build_unpool(h_conv6_T, [1, 2, 2, 1]), h_conv1], 3), W_conv7,\r\n # [batch, 512, 512, 2 * nb_filter], strides=[1, 1, 1, 1],\r\n # padding='SAME') + b_conv7)\r\n h_conv7 = tf.concat([build_unpool(h_conv6_T, [1, 2, 2, 1]), h_conv1], 3)\r\n h_conv7 = tf.keras.layers.Conv2DTranspose(2 * nb_filter, [5, 5], strides=1, padding='SAME')(h_conv7)\r\n h_conv7 = tf.nn.relu(h_conv7)\r\n\r\n # W_conv8 = weight_variable([1, 1, 1, 2 * nb_filter])\r\n # b_conv8 = bias_variable([1])\r\n # h_conv8 = tf.nn.relu(tf.nn.conv2d_transpose(h_conv7, W_conv8, [batch, 512, 512, 1], strides=[1, 1, 1, 1],\r\n # padding='SAME') + b_conv8)\r\n h_conv8 = tf.keras.layers.Conv2DTranspose(1, [1, 1], strides=1, padding='SAME')(h_conv7)\r\n h_conv8 = tf.nn.relu(h_conv8)\r\n return h_conv8\r\n\r\ndef make_model(batch,ux=None,uy=None):\r\n inputs = tf.keras.Input(shape=(ux,uy,1),batch_size=batch)\r\n outputs=mix(inputs)\r\n model=tf.keras.Model(inputs=inputs,outputs=outputs)\r\n return model\r\n\r\ndef train(epoch, udir,batch, theta, iternum, restore=0, ckpt='./weights/CT_tf2_4'):\r\n u_img = np.load(udir + 'u_CT_img_no_scale.npy')\r\n print('shape of u_img:', u_img.shape)\r\n # f_img = np.load(udir + '/f,angle=' + str(angles) + '_255.0_0.002.npy')\r\n ini_u_img = np.load(udir + 'ini,angle=60_no_scale__0.5.npy')\r\n\r\n M = np.max(np.max(ini_u_img, 1), 1)\r\n M = np.reshape(M, [np.shape(M)[0], 1, 1, 1])\r\n u_img = u_img / M * 255\r\n ini_u_img = ini_u_img / M * 255\r\n\r\n\r\n current_time = datetime.datetime.now().strftime(\"%Y%m%d-%H%M%S\")\r\n train_log_dir = 'logs/gradient_tape/' + current_time + '/train'\r\n test_log_dir = 'logs/gradient_tape/' + current_time + '/test'\r\n\r\n optimizer = tf.keras.optimizers.Adagrad(learning_rate=0.001)\r\n Model = make_model(batch,ux=256,uy=256)\r\n if restore == 1:\r\n # call the build function in the layers since do not use tf.keras.Input\r\n ##maybe move the functions in build function to _ini_ need not do this\r\n _=Model(ini_u_img[0:1])\r\n Model.load_weights(ckpt)\r\n print('load weights, done')\r\n tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=train_log_dir)\r\n\r\n u_img=tf.cast(u_img,tf.float32)\r\n ini_u_img = tf.cast(ini_u_img, tf.float32)\r\n N=tf.shape(u_img)[0]\r\n vx=ini_u_img[N-5:N]\r\n vy=u_img[N-5:N]\r\n # vx=tf.cast(vx,tf.float32)\r\n # vy = tf.cast(vy, tf.float32)\r\n train_data = tf.data.Dataset.from_tensor_slices((u_img[0:N-5], ini_u_img[0:N-5])).batch(batch)\r\n for i in range(epoch):\r\n for iter, ufini in enumerate(train_data):\r\n u, ini_u = ufini\r\n Loss, m1, m2,m3 = train_step(ini_u, Model, u, loss, psnr, optimizer,vx,vy)\r\n print(iter, \"/\", i, \":\", Loss.numpy(),\r\n \"psnr1:\", m1.numpy(),\r\n \"psnr2:\", m2.numpy(),\r\n 'psnr3:', m3.numpy()\r\n )\r\n if i%10==0:\r\n Model.save_weights(ckpt)\r\n # Model.compile(optimizer=optimizer, loss=[loss], metrics=[psnr])\r\n # Model.fit(x, y, batch_size=batch, epochs=epoch, callbacks=[tensorboard_callback],\r\n # validation_split=1/80)\r\n Model.save_weights(ckpt)\r\n # tf.keras.utils.plot_model(Model, 'multi_input_and_output_model.png', show_shapes=True)\r\n\r\n\r\[email protected]\r\ndef train_step(inputs, model, labels, Loss, Metric, optimizer,vx,vy):\r\n with tf.GradientTape() as tape:\r\n predictions = model(inputs, training=1)\r\n loss = Loss(labels, predictions)\r\n grads = tape.gradient(loss, model.trainable_variables)\r\n optimizer.apply_gradients(zip(grads, model.trainable_variables))\r\n m1 = Metric(labels, inputs)\r\n m2 = Metric(labels, model(inputs, training=0))\r\n m3 = Metric(vy, model(vx, training=0))\r\n return loss, m1, m2, m3\r\n\r\n\r\ndef loss(x, y):\r\n x1 = tf.cast(x, tf.float32)\r\n y1 = tf.cast(y, tf.float32)\r\n shape = tf.cast(tf.shape(x), tf.float32)\r\n return tf.reduce_sum(tf.math.square(x1 - y1)) / shape[0] / shape[1] / shape[2] / shape[3]\r\n\r\n\r\ndef psnr(x, y,max_val=255):\r\n x = tf.cast(x, tf.float32)\r\n y = tf.cast(y, tf.float32)\r\n batch = tf.cast(tf.shape(x)[0], tf.float32)\r\n return tf.reduce_sum(tf.image.psnr(x, y, max_val=tf.reduce_max(x))) / batch\r\n\r\n\r\n\r\nif __name__ == '__main__':\r\n os.environ[\"CUDA_VISIBLE_DEVICES\"] = \"0\"\r\n iternum = 20\r\n epoch = 200\r\n batch = 5\r\n angles = 180\r\n theta = np.linspace(0, 180, angles, endpoint=False)\r\n udir = \"./train/\"\r\n vdir = \"validate\"\r\n train(epoch, udir, batch, theta, iternum, restore=0, ckpt='./512x512/weights/DD_NET')"
},
{
"alpha_fraction": 0.48833274841308594,
"alphanum_fraction": 0.528678297996521,
"avg_line_length": 42.507938385009766,
"blob_id": "8e482886d3504f534a3b0f9cacb591e8df6f22db",
"content_id": "7e48d05eac92e97dd55e31f15353be3c782cfa65",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11228,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 252,
"path": "/parabeam/utilize.py",
"repo_name": "wangwei-cmd/CT-image-reconstruction",
"src_encoding": "UTF-8",
"text": "\r\nimport numpy as np\r\nfrom scipy.fftpack import fft, ifft, fftfreq,fftshift\r\nfrom functools import partial\r\nfrom scipy.interpolate import interp1d\r\nfrom skimage.transform import radon,iradon,rotate\r\nimport pydicom\r\nimport tensorflow as tf\r\nfrom skimage.measure import compare_psnr\r\nimport math\r\nimport glob\r\nimport os\r\nimport matplotlib.pyplot as plt\r\nclass CT_uitil:\r\n def __init__(self,img_size,theta=None,filter=\"ramp\"):\r\n self.img_size=img_size\r\n if theta is None:\r\n theta=np.arange(180)\r\n self.theta = theta * np.pi / 180.0\r\n else:\r\n self.theta = theta * np.pi / 180.0\r\n self.filter=filter\r\n self.pad_width, self.diagonal = self.shape_radon()\r\n self.sin_size = [img_size[0], self.diagonal, len(self.theta), img_size[3]]\r\n self.fourier_filter=self.get_fourier_filter()\r\n self.index_w=self.make_cor_rotate()\r\n\r\n def get_fourier_filter(self):\r\n img_shape=self.sin_size[1]\r\n size = max(64, int(2 ** np.ceil(np.log2(2 * img_shape))))\r\n filter_name=self.filter\r\n filter_types = ('ramp', 'shepp-logan', 'cosine', 'hamming', 'hann', None)\r\n if filter_name not in filter_types:\r\n raise ValueError(\"Unknown filter: %s\" % filter)\r\n n = np.concatenate((np.arange(1, size / 2 + 1, 2, dtype=np.int),\r\n np.arange(size / 2 - 1, 0, -2, dtype=np.int)))\r\n f = np.zeros(size)\r\n f[0] = 0.25\r\n f[1::2] = -1 / (np.pi * n) ** 2\r\n\r\n fourier_filter = 2 * np.real(fft(f)) # ramp filter\r\n if filter_name == \"ramp\":\r\n pass\r\n elif filter_name == \"shepp-logan\":\r\n # Start from first element to avoid divide by zero\r\n omega = np.pi * fftfreq(size)[1:]\r\n fourier_filter[1:] *= tf.sin(omega) / omega\r\n elif filter_name == \"cosine\":\r\n freq = np.linspace(0, np.pi, size, endpoint=False)\r\n cosine_filter = tf.signal.fftshift(tf.sin(freq))\r\n fourier_filter *= cosine_filter\r\n elif filter_name == \"hamming\":\r\n fourier_filter *= tf.signal.fftshift(np.hamming(size))\r\n elif filter_name == \"hann\":\r\n fourier_filter *= tf.signal.fftshift(np.hanning(size))\r\n elif filter_name is None:\r\n fourier_filter[:] = 1\r\n fourier_filter=fourier_filter[:, np.newaxis]\r\n fourier_filter = np.expand_dims(np.transpose(fourier_filter, [1, 0]).astype(np.complex128), 0)\r\n fourier_filter = np.expand_dims(fourier_filter, 0)\r\n return fourier_filter\r\n\r\n # @tf.function\r\n def iradon(self, radon_image, output_size=None,interpolation=\"linear\"):\r\n shape = self.sin_size\r\n fourier_filter = self.fourier_filter\r\n theta=self.theta\r\n angles_count = len(theta)\r\n if angles_count != shape[2]:\r\n raise ValueError(\"The given ``theta`` does not match the number of \"\r\n \"projections in ``radon_image``.\")\r\n\r\n img_shape = shape[1]\r\n if output_size is None:\r\n # If output size not specified, estimate from input radon image\r\n output_size = int(np.floor(np.sqrt((img_shape) ** 2 / 2.0)))\r\n\r\n projection_size_padded = max(64, int(2 ** np.ceil(np.log2(2 * img_shape))))\r\n pad_width = ((0, 0), (0, projection_size_padded - img_shape), (0, 0), (0, 0))\r\n img = tf.pad(radon_image, pad_width, mode='constant', constant_values=0)\r\n # fourier_filter = get_fourier_filter(projection_size_padded, filter)\r\n projection = tf.signal.fft(tf.cast(tf.transpose(img, [0, 3, 2, 1]), tf.complex128)) * fourier_filter\r\n radon_filtered = tf.math.real(tf.signal.ifft(projection)[:, :, :, :img_shape])\r\n #\r\n radon_filtered = tf.transpose(radon_filtered, [3, 2, 0, 1])\r\n radon_filtered = tf.cast(radon_filtered, tf.float64)\r\n\r\n # Reconstruct image by interpolation\r\n reconstructed = tf.zeros((tf.shape(radon_image)[0], output_size, output_size, tf.shape(radon_image)[3]))\r\n reconstructed = tf.cast(reconstructed,tf.float64)\r\n radius = output_size // 2\r\n xpr, ypr = np.mgrid[:output_size, :output_size] - radius\r\n x = np.arange(img_shape) - img_shape // 2\r\n\r\n thetad = tf.cast(theta, tf.float64)\r\n # for col, angle in dd:\r\n for i in range(len(theta)):\r\n col, angle = radon_filtered[:, i, :, :], thetad[i]\r\n t = ypr * tf.math.cos(angle) - xpr * tf.math.sin(angle)\r\n temp = tf.gather(col, tf.cast(tf.math.ceil(t), tf.int32) + img_shape // 2)\r\n temp1 = tf.gather(col, tf.cast(tf.math.floor(t), tf.int32) + img_shape // 2)\r\n w = t - tf.math.floor(t)\r\n w = tf.expand_dims(w, -1)\r\n w = tf.expand_dims(w, -1)\r\n w = tf.broadcast_to(w, tf.shape(temp))\r\n temp2 = w * temp + (1 - w) * temp1\r\n temp3 = tf.transpose(temp2, [2, 0, 1, 3])\r\n reconstructed += temp3\r\n return reconstructed * np.pi / (2 * angles_count)\r\n\r\n # @tf.function\r\n def radon(self, img):\r\n input_shape=self.img_size\r\n # assert tf.constant(input_shape)==tf.shape(img)\r\n theta=self.theta\r\n numAngles = len(theta)\r\n pad_width, diagonal = self.pad_width, self.diagonal\r\n img=tf.cast(img,tf.float64)\r\n img1 = tf.pad(img, pad_width, mode='constant', constant_values=0)\r\n # sinogram = np.zeros((input_shape[0], diagonal, len(theta), input_shape[3]))\r\n pp=[]\r\n for n in range(numAngles):\r\n rotated = self.imrotate(img1, n)\r\n # sinogram[:, :, n, :] = tf.reduce_sum(rotated, axis=1)\r\n pp.append(tf.reduce_sum(rotated, axis=1))\r\n # pp=np.array(pp)\r\n pp=tf.stack(pp)\r\n sinogram = tf.transpose(pp,[1,2,0,3])\r\n return sinogram\r\n\r\n def shape_radon(self):\r\n # numAngles = len(theta)\r\n # shape = tf.shape(img)\r\n # shape1 = tf.cast(shape, tf.float32)\r\n shape=shape1 = self.img_size\r\n diagonal = np.sqrt(2) * np.max([shape1[1],shape1[2]])\r\n pad = [np.ceil(diagonal - shape1[1]), np.ceil(diagonal - shape1[2])]\r\n # pad = tf.cast(pad, tf.int32)\r\n pad = np.array(pad).astype(np.int32)\r\n new_center = [(shape[1] + pad[0]) // 2, (shape[2] + pad[1]) // 2]\r\n old_center = [shape[1] // 2, shape[2] // 2]\r\n pad_before = [new_center[0] - old_center[0], new_center[1] - old_center[1]]\r\n pad_width = [(0, 0), (pad_before[0], pad[0] - pad_before[0]), (pad_before[1], pad[1] - pad_before[1]), (0, 0)]\r\n # img1 = np.pad(img, pad_width, mode='constant', constant_values=0)\r\n assert pad[0]+shape[1]==pad[1]+shape[2]\r\n pad_width = np.array(pad_width).astype(np.int32)\r\n return pad_width, pad[0] + shape[1]\r\n\r\n def imrotate(self, img, theta_i):\r\n index11, index12, index21, index22, w11, w12, w21, w22 = self.index_w[theta_i]\r\n img1 = tf.cast(tf.transpose(img, [1, 2, 3, 0]),tf.float64)\r\n f11, f12, f21, f22 = tf.gather_nd(img1, index11), tf.gather_nd(img1, index12), tf.gather_nd(img1,\r\n index21), tf.gather_nd(\r\n img1, index22)\r\n bilinear = w11 * tf.transpose(f11, [2, 1, 0]) + w12 * tf.transpose(f12, [2, 1, 0]) + w21 * tf.transpose(f21,\r\n [2, 1,\r\n 0]) + w22 * tf.transpose(\r\n f22, [2, 1, 0])\r\n rotate = tf.reshape(bilinear,\r\n [tf.shape(bilinear)[0], tf.shape(bilinear)[1], tf.shape(img)[1], tf.shape(img)[2]])\r\n rotate = tf.transpose(rotate, [0, 2, 3, 1])\r\n\r\n return rotate\r\n\r\n def cor_rotate(self, theta_i):\r\n theta=self.theta[theta_i]\r\n cos = math.cos(theta)\r\n sin = math.sin(theta)\r\n ux=uy=self.diagonal\r\n semicorx = math.floor(ux / 2)\r\n semicory = math.floor(uy / 2)\r\n x = np.arange(ux) - semicorx\r\n y = np.arange(uy) - semicory\r\n XY = np.meshgrid(x, y)\r\n X, Y = XY[0], XY[1]\r\n sx = (cos * Y - sin * X) + semicorx\r\n sy = (sin * Y + cos * X) + semicory\r\n sx = np.reshape(sx, [-1])\r\n sy = np.reshape(sy, [-1])\r\n x1 = np.floor(sx)\r\n x2 = x1+1\r\n y1 = np.floor(sy)\r\n y2 = y1+1\r\n # index = np.stack([sx, sy], 1)\r\n index11 = np.stack([x1, y1], 1).astype(np.int32)\r\n index12 = np.stack([x1, y2], 1).astype(np.int32)\r\n index21 = np.stack([x2, y1], 1).astype(np.int32)\r\n index22 = np.stack([x2, y2], 1).astype(np.int32)\r\n w11 = ((x2 - sx) * (y2 - sy)).astype(np.float64)\r\n w12 = ((x2 - sx) * (sy - y1)).astype(np.float64)\r\n w21 = ((sx - x1) * (y2 - sy)).astype(np.float64)\r\n w22 = ((sx - x1) * (sy - y1)).astype(np.float64)\r\n return index11, index12, index21, index22, w11, w12, w21, w22\r\n\r\n def make_cor_rotate(self):\r\n cor=[]\r\n theta=self.theta\r\n for i in range(len(theta)):\r\n cor.append(self.cor_rotate(i))\r\n return cor\r\n\r\n\r\nif __name__=='__main__':\r\n os.environ[\"CUDA_VISIBLE_DEVICES\"] = \"0\"\r\n # udir = '/home/wangwei/ct-compare/CT_image/Pancreas-CT/PANCREAS_0002//11-24-2015-PANCREAS0002-Pancreas-23046/Pancreas-63502'\r\n udir='E:/CT_image/Pancreas-CT/PANCREAS_0002//11-24-2015-PANCREAS0002-Pancreas-23046/Pancreas-63502'\r\n # udir='/home/wangwei/ct-compare/CPTAC-LUAD/CPTAC-LUAD'\r\n dd = glob.glob(udir + \"/**/*.dcm\", recursive=True)\r\n dd.sort()\r\n L = len(dd)\r\n L = min(5000, L)\r\n f = []\r\n for i in range(L):\r\n name = dd[i]\r\n dc = pydicom.dcmread(name)\r\n temp = dc.pixel_array\r\n temp = temp.astype(np.float32)\r\n divider = np.max(temp) - np.min(temp)\r\n if divider == 0:\r\n print('divider being zero: index ', i)\r\n pass\r\n temp = (temp - np.min(temp)) / divider\r\n f.append(temp)\r\n f = np.array(f)\r\n f = np.expand_dims(f, -1)\r\n cen=f.shape[1]//2\r\n # f=f[0:10,:,:,:]\r\n batch = 2\r\n M = N = 256\r\n LL=M//2\r\n f = f[0:batch, cen-LL:cen+LL, cen-LL:cen+LL, :]*255\r\n angles = 180\r\n theta = np.linspace(0, 180, angles, endpoint=False)\r\n\r\n s = radon(f[0, :, :, 0], circle=False,theta=theta)\r\n rf = iradon(s, theta)\r\n pp = compare_psnr(f[0, :, :, 0], rf, np.max(f[0, :, :, 0]))\r\n\r\n shape=f.shape\r\n ct=CT_uitil([0,shape[1],shape[2],0],theta=theta)\r\n s1=ct.radon(f)\r\n ss=tf.expand_dims(tf.expand_dims(s,0),-1)\r\n rf1=ct.iradon(ss)\r\n # rf1 = ct.iradon(s1)\r\n pp1=tf.image.psnr(f[:1,:,:,:],rf1,np.max(f))\r\n print('f_shap:', f.shape)\r\n print('s-s1:', np.sum(np.abs(s - s1[0, :, :, 0])))\r\n print('rf-rf1:', np.sum(np.abs(rf-rf1[0, :, :, 0])))\r\n print('f-rf:', np.sum(np.abs(f[0, :, :, 0] - rf)))\r\n print('f-rf1:', np.sum(np.abs(f[0,:,:,0] - rf1[0, :, :, 0])))\r\n print('psnr beween f and rf:', pp)\r\n print('psnr beween f1 and rf1:',pp1.numpy())\r\n print('debug')\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5285078883171082,
"alphanum_fraction": 0.5742013454437256,
"avg_line_length": 30.460525512695312,
"blob_id": "613d8438bed650d15fab9b5174a64913eee16c1f",
"content_id": "ae530183399c24d0867cac9a22da9e1267f56f4e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2473,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 76,
"path": "/fan2para/testnew1.py",
"repo_name": "wangwei-cmd/CT-image-reconstruction",
"src_encoding": "UTF-8",
"text": "import new1 as net\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\nimport tensorflow as tf\r\nimport os\r\n\r\ndef interp(f,xp,x):\r\n # f_img=f[:,:,::2,:]\r\n f_img=f\r\n shape=f.shape\r\n L=len(x)\r\n f_interp = np.zeros(shape=[shape[0],shape[1],L,shape[3]])\r\n idL = np.where(x <= xp[0])[0]\r\n idR = np.where(x >= xp[-1])[0]\r\n xx = x[idL[-1] + 1:idR[0]]\r\n id = np.searchsorted(xp, xx)\r\n L = xx - xp[id - 1]\r\n R = xp[id] - xx\r\n w1 = R / (L + R)\r\n w2 = 1 - w1\r\n val1 = f_img[:, :, id - 1, :]\r\n val2 = f_img[:, :, id, :]\r\n val1 = val1.transpose([0, 1, 3, 2])\r\n val2 = val2.transpose([0, 1, 3, 2])\r\n temp = val1 * w1 + val2 * w2\r\n f_interp[:, :, idL[-1] + 1:idR[0], :] = temp.transpose([0, 1, 3, 2])\r\n for i in idL:\r\n f_interp[:, :, i, :] = f_img[:, :, 0, :]\r\n for j in idR:\r\n f_interp[:, :, j, :] = f_img[:, :, -1, :]\r\n return f_interp\r\nos.environ[\"CUDA_VISIBLE_DEVICES\"] = \"1\"\r\nAangles=180\r\nAT = np.load('AT_' + str(Aangles) + '_512x512' + '.npz')\r\nval = AT['name1'].astype('float32')\r\nindex = AT['name2']\r\nshape = AT['name3']\r\nAT = tf.sparse.SparseTensor(index, val, shape)\r\n# AT = tf.cast(AT, tf.float32)\r\ntheta=np.linspace(0, 180, Aangles, endpoint=False)\r\nModel=net.make_model_3(AT,(725, 180),(512, 512))\r\nckpt='./weights'+'/new1_model_lambda=0.5'\r\nbatch=5\r\ndata = np.load('test' + '_fan2para.npz')\r\nf_noisy_img = data['f_noisy'].astype('float32')\r\nL=500\r\nf_noisy_img=f_noisy_img[0:L]\r\ndef inimodel(f_noisy,Model,ckpt=ckpt):\r\n _ = Model(f_noisy[0:1])\r\n Model.load_weights(ckpt)\r\n\r\n\r\ndef evaluate(f_noisy, batch, Model):\r\n _ = inimodel(f_noisy, Model)\r\n prediction = np.zeros([L,512,512,1])\r\n iter = list(range(0, L, batch))\r\n for i in range(len(iter)):\r\n prediction[iter[i]:iter[i] + batch] = Model(f_noisy[iter[i]:iter[i] + batch])[1].numpy()\r\n print(i)\r\n return prediction\r\n\r\nprediction=evaluate(f_noisy_img,batch,Model)\r\nii=np.random.randint(0,L)\r\nprint('show figure:',ii)\r\nplt.imshow(f_noisy_img[ii,:,:,0],cmap='gray')\r\nplt.figure()\r\nplt.imshow(prediction[ii,:,:,0],cmap='gray')\r\nplt.show()\r\n\r\n# vy=data['u'].astype('float32')\r\n# vy=vy[0:L]\r\n# vy=tf.cast(vy,tf.float32)\r\n# pp=tf.image.psnr(tf.cast(prediction,tf.float32),vy,tf.reduce_max(prediction)).numpy()\r\n# qq=tf.image.ssim(tf.cast(prediction,tf.float32),vy,tf.reduce_max(prediction)).numpy()\r\n# print('average psnr:',tf.reduce_mean(pp).numpy())\r\n# print('average ssim:',tf.reduce_mean(qq).numpy())\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5208107233047485,
"alphanum_fraction": 0.5808903574943542,
"avg_line_length": 30.7738094329834,
"blob_id": "3a4578d5efb915a166b23c66d896236c3bff1b61",
"content_id": "bfba68fda2e665864c0b956b64f4680898c3d424",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2763,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 84,
"path": "/fan-beam/testnew2.py",
"repo_name": "wangwei-cmd/CT-image-reconstruction",
"src_encoding": "UTF-8",
"text": "import new2 as net\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\nimport tensorflow as tf\r\nimport os\r\ndef interp(f,xp,x):\r\n # f_img=f[:,:,::2,:]\r\n f_img=f\r\n shape=f.shape\r\n L=len(x)\r\n f_interp = np.zeros(shape=[shape[0],shape[1],L,shape[3]])\r\n idL = np.where(x <= xp[0])[0]\r\n idR = np.where(x >= xp[-1])[0]\r\n xx = x[idL[-1] + 1:idR[0]]\r\n id = np.searchsorted(xp, xx)\r\n L = xx - xp[id - 1]\r\n R = xp[id] - xx\r\n w1 = R / (L + R)\r\n w2 = 1 - w1\r\n val1 = f_img[:, :, id - 1, :]\r\n val2 = f_img[:, :, id, :]\r\n val1 = val1.transpose([0, 1, 3, 2])\r\n val2 = val2.transpose([0, 1, 3, 2])\r\n temp = val1 * w1 + val2 * w2\r\n f_interp[:, :, idL[-1] + 1:idR[0], :] = temp.transpose([0, 1, 3, 2])\r\n for i in idL:\r\n f_interp[:, :, i, :] = f_img[:, :, 0, :]\r\n for j in idR:\r\n f_interp[:, :, j, :] = f_img[:, :, -1, :]\r\n return f_interp\r\nos.environ[\"CUDA_VISIBLE_DEVICES\"] = \"0\"\r\n#AT = np.load('AT_fan_512x512_theta=0_0.5_175.5_alpha=-40:0.05:40_beta=0:1:359_R=600.npz')\r\nAT = np.load('AT_fan_512x512_theta=0_0.5_175.5_alpha=-40_0.05_40_beta=0_1_359_R=600.npz')\r\nval = AT['val'].astype('float32')\r\nindex = AT['index']\r\nshape = AT['shape']\r\nw_c = AT['w_c'].astype('float32')\r\nAT = tf.sparse.SparseTensor(index, val, shape)\r\nAT = tf.sparse.reorder(AT)#######\r\ndel val\r\ndel index\r\n\r\nbatch=5\r\ns_shape = (360, 1601)\r\nout_size = (512, 512)\r\nmax_alpha = 40\r\nn1=1601\r\nalpha = np.linspace(-max_alpha, max_alpha, n1) * np.pi / 180\r\nalpha = alpha.astype('float32')\r\nModel=net.make_model_3(AT, alpha, w_c, s_shape, out_size)\r\ndata=np.load('test'+'_fan_data.npz')\r\nf_noisy_img=data['sin_fan_ini'].astype('float32')\r\nckpt='./fan-beam/weights'+'/new2_model_lambda=0.5'\r\nL=500\r\nf_noisy=f_noisy_img[0:L]\r\ndef inimodel(f_noisy,Model,ckpt=ckpt):\r\n _ = Model(f_noisy[0:1])\r\n Model.load_weights(ckpt)\r\n\r\n\r\ndef evaluate(f_noisy, batch, Model):\r\n _ = inimodel(f_noisy, Model)\r\n prediction = np.zeros([L,512,512,1])\r\n iter = list(range(0, L, batch))\r\n for i in range(len(iter)):\r\n prediction[iter[i]:iter[i] + batch] = Model(f_noisy[iter[i]:iter[i] + batch])[1].numpy()\r\n print(i)\r\n return prediction\r\n\r\nprediction=evaluate(f_noisy,batch,Model)\r\nii=np.random.randint(0,L)\r\nprint('show figure:',ii)\r\nplt.imshow(f_noisy[ii,:,:,0],cmap='gray')\r\nplt.figure()\r\nplt.imshow(prediction[ii,:,:,0],cmap='gray')\r\nplt.show()\r\n\r\n# vy=data['u'].astype('float32')\r\n# vy=vy[0:L]\r\n# vy=tf.cast(vy,tf.float32)\r\n# pp=tf.image.psnr(tf.cast(prediction,tf.float32),vy,tf.reduce_max(prediction)).numpy()\r\n# qq=tf.image.ssim(tf.cast(prediction,tf.float32),vy,tf.reduce_max(prediction)).numpy()\r\n# print('average psnr:',tf.reduce_mean(pp).numpy())\r\n# print('average ssim:',tf.reduce_mean(qq).numpy())\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5387083888053894,
"alphanum_fraction": 0.5654833316802979,
"avg_line_length": 37.88800048828125,
"blob_id": "3b4641d8df403c99f5f1b5dd27141cc8e676d883",
"content_id": "875d39c151ee656992e6b0e3fea7488919fc6c50",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9972,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 250,
"path": "/compared_networks/fbpconv.py",
"repo_name": "wangwei-cmd/CT-image-reconstruction",
"src_encoding": "UTF-8",
"text": "\r\nimport tensorflow as tf\r\nfrom collections import OrderedDict\r\nimport numpy as np\r\nimport datetime\r\nimport os\r\n\r\n\r\ndef crop_and_concat(x1,x2):\r\n x1_shape = tf.shape(x1)\r\n x2_shape = tf.shape(x2)\r\n # offsets for the top left corner of the crop\r\n offsets = [0, (x1_shape[1] - x2_shape[1]) // 2, (x1_shape[2] - x2_shape[2]) // 2, 0]\r\n size = [x1_shape[0], x2_shape[1], x2_shape[2], x1_shape[3]]\r\n x1_crop = tf.slice(x1, offsets, size)\r\n # return tf.concat([x1_crop, x2], 3)\r\n return tf.keras.layers.Concatenate(3)([x1_crop, x2])\r\n\r\n\r\ndef create_conv_net(x, channels=1, n_class=1, layers=3, features_root=16, filter_size=3, pool_size=2, Ngpu=1,\r\n maxpool=True, summaries=True):\r\n \"\"\"\r\n Creates a new convolutional unet for the given parametrization.\r\n\r\n :param x: input tensor, shape [?,nx,ny,channels]\r\n :param keep_prob: dropout probability tensor\r\n :param channels: number of channels in the input image\r\n :param n_class: number of output labels\r\n :param layers: number of layers in the net\r\n :param features_root: number of features in the first layer\r\n :param filter_size: size of the convolution filter\r\n :param pool_size: size of the max pooling operation\r\n :param summaries: Flag if summaries should be created\r\n \"\"\"\r\n\r\n # Placeholder for the input image\r\n nx = tf.shape(x)[1]\r\n ny = tf.shape(x)[2]\r\n x_image = tf.reshape(x, [-1, nx, ny, channels])\r\n in_node = x_image\r\n # batch_size = tf.shape(x_image)[0]\r\n\r\n # weights = []\r\n # weights_d = []\r\n # biases = []\r\n # biases_d = []\r\n dw_h_convs = OrderedDict()\r\n\r\n in_size = 1000\r\n size = in_size\r\n padding = 'same'\r\n if Ngpu == 1:\r\n gname = '0'\r\n else:\r\n gname = '1'\r\n # down layers\r\n with tf.device('/gpu:0'):\r\n for layer in range(0, layers):\r\n features = 2 ** layer * features_root\r\n filters = features\r\n if layer == 0:\r\n # w1 = weight_variable([filter_size, filter_size, channels, features], stddev)\r\n w1_kernel_size=[filter_size, filter_size]\r\n else:\r\n # w1 = weight_variable([filter_size, filter_size, features // 2, features], stddev)\r\n w1_kernel_size = [filter_size, filter_size]\r\n\r\n # w2 = weight_variable([filter_size, filter_size, features, features], stddev)\r\n w2_kernel_size=[filter_size, filter_size]\r\n # b1 = bias_variable([features])\r\n # b2 = bias_variable([features])\r\n\r\n # conv = conv2d(in_node, w1, keep_prob, padding)\r\n # in_node = tf.nn.relu(conv + b1)\r\n conv=tf.keras.layers.Conv2D(filters,w1_kernel_size,padding=padding)(in_node)\r\n in_node=tf.keras.layers.ReLU()(conv)\r\n\r\n # conv = conv2d(in_node, w2, keep_prob, padding)\r\n # in_node = tf.nn.relu(conv + b2)\r\n conv = tf.keras.layers.Conv2D(filters, w2_kernel_size, padding=padding)(in_node)\r\n in_node = tf.keras.layers.ReLU()(conv)\r\n\r\n dw_h_convs[layer] = in_node\r\n # dw_h_convs[layer] = tf.nn.relu(conv2 + b2)\r\n # convs.append((conv1, conv2))\r\n\r\n size -= 4\r\n if layer < layers - 1:\r\n if maxpool:\r\n in_node = tf.keras.layers.MaxPool2D(pool_size)(dw_h_convs[layer])\r\n else:\r\n in_node = tf.keras.layers.AveragePooling2D(pool_size)(dw_h_convs[layer])\r\n\r\n # pools[layer] = max_pool(dw_h_convs[layer], pool_size)\r\n # in_node = pools[layer]\r\n size /= 2\r\n\r\n in_node = dw_h_convs[layers - 1]\r\n\r\n with tf.device('/gpu:0'):\r\n # up layers\r\n for layer in range(layers - 2, -1, -1):\r\n features = 2 ** (layer + 1) * features_root\r\n # stddev = np.sqrt(2 / (filter_size ** 2 * features))\r\n\r\n # wd = weight_variable_devonc([pool_size, pool_size, features // 2, features], stddev)\r\n # bd = bias_variable([features // 2])\r\n # in_node = tf.nn.relu(deconv2d(in_node, wd, pool_size, padding) + bd)\r\n in_node = tf.keras.layers.Conv2DTranspose(features, pool_size,strides=2, padding=padding)(in_node)\r\n in_node = tf.keras.layers.ReLU()(in_node)\r\n\r\n conv = crop_and_concat(dw_h_convs[layer], in_node)\r\n\r\n # w1 = weight_variable([filter_size, filter_size, features, features // 2], stddev)\r\n # w2 = weight_variable([filter_size, filter_size, features // 2, features // 2], stddev)\r\n # b1 = bias_variable([features // 2])\r\n # b2 = bias_variable([features // 2])\r\n filters=features // 2\r\n w1_kernel_size=[filter_size, filter_size]\r\n w2_kernel_size=[filter_size, filter_size]\r\n\r\n # conv = conv2d(conv, w1, keep_prob, padding)\r\n conv=tf.keras.layers.Conv2D(filters, w1_kernel_size, padding=padding)(conv)\r\n # conv = tf.nn.relu(conv + b1)\r\n conv=tf.keras.layers.ReLU()(conv)\r\n\r\n # conv = conv2d(conv, w2, keep_prob, padding)\r\n # in_node = tf.nn.relu(conv + b2)\r\n conv = tf.keras.layers.Conv2D(filters, w2_kernel_size, padding=padding)(conv)\r\n in_node =tf.keras.layers.ReLU()(conv)\r\n\r\n # weights.append((w1, w2))\r\n # weights_d.append((wd))\r\n # biases.append((b1, b2))\r\n # biases_d.append((bd))\r\n\r\n # convs.append((conv1, conv2))\r\n\r\n size *= 2\r\n size -= 4\r\n\r\n # with tf.device('/gpu:1'):\r\n # Output Map\r\n # weight = weight_variable([1, 1, features_root, n_class], stddev)\r\n # bias = bias_variable([n_class])\r\n # conv = conv2d(in_node, weight, tf.constant(1.0), padding)\r\n conv=tf.keras.layers.Conv2D(n_class, [1, 1], padding=padding)(in_node)\r\n # output_map = conv + bias + x_image # tf.nn.relu(conv + bias)\r\n output_map = conv + x_image\r\n return output_map\r\n\r\n\r\ndef make_model(batch,ux=256,uy=256):\r\n inputs = tf.keras.Input(shape=(ux,uy,1),batch_size=batch)\r\n outputs=create_conv_net(inputs)\r\n model=tf.keras.Model(inputs=inputs,outputs=outputs)\r\n return model\r\n\r\ndef train(epoch, udir,batch, theta, iternum, restore=0, ckpt='./weights/CT_tf2_4'):\r\n max_val = 255\r\n angles = np.shape(theta)[0]\r\n u_img = np.load(udir + 'u_CT_img_no_scale.npy')\r\n print('shape of u_img:', u_img.shape)\r\n # f_img = np.load(udir + '/f,angle=' + str(angles) + '_255.0_0.002.npy')\r\n ini_u_img = np.load(udir + 'ini,angle=60_no_scale__0.5.npy')\r\n\r\n M = np.max(np.max(ini_u_img, 1), 1)\r\n M = np.reshape(M, [np.shape(M)[0], 1, 1, 1])\r\n u_img = u_img / M * 255\r\n ini_u_img = ini_u_img / M * 255\r\n\r\n\r\n current_time = datetime.datetime.now().strftime(\"%Y%m%d-%H%M%S\")\r\n train_log_dir = 'logs/gradient_tape/' + current_time + '/train'\r\n test_log_dir = 'logs/gradient_tape/' + current_time + '/test'\r\n\r\n optimizer = tf.keras.optimizers.Adagrad(learning_rate=0.001)\r\n Model = make_model(batch)\r\n if restore == 1:\r\n # call the build function in the layers since do not use tf.keras.Input\r\n ##maybe move the functions in build function to _ini_ need not do this\r\n _=Model(ini_u_img[0:1])\r\n Model.load_weights(ckpt)\r\n print('load weights, done')\r\n tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=train_log_dir)\r\n\r\n u_img = tf.cast(u_img, tf.float32)\r\n ini_u_img = tf.cast(ini_u_img, tf.float32)\r\n N=tf.shape(u_img)[0]\r\n vx=ini_u_img[N-5:N]\r\n vy=u_img[N-5:N]\r\n # vx=tf.cast(vx,tf.float32)\r\n # vy = tf.cast(vy, tf.float32)\r\n train_data = tf.data.Dataset.from_tensor_slices((u_img[0:N-5], ini_u_img[0:N-5])).batch(batch)\r\n for i in range(epoch):\r\n for iter, ufini in enumerate(train_data):\r\n u, ini_u = ufini\r\n Loss, m1, m2,m3 = train_step(ini_u, Model, u, loss, psnr, optimizer,vx,vy)\r\n print(iter, \"/\", i, \":\", Loss.numpy(),\r\n \"psnr1:\", m1.numpy(),\r\n \"psnr2:\", m2.numpy(),\r\n 'psnr3:', m3.numpy()\r\n )\r\n if i%10==0:\r\n Model.save_weights(ckpt)\r\n # Model.compile(optimizer=optimizer, loss=[loss], metrics=[psnr])\r\n # Model.fit(x, y, batch_size=batch, epochs=epoch, callbacks=[tensorboard_callback],\r\n # validation_split=1/80)\r\n Model.save_weights(ckpt)\r\n # tf.keras.utils.plot_model(Model, 'multi_input_and_output_model.png', show_shapes=True)\r\n\r\n\r\n# @tf.function\r\ndef train_step(inputs, model, labels, Loss, Metric, optimizer,vx,vy):\r\n with tf.GradientTape() as tape:\r\n predictions = model(inputs, training=1)\r\n loss = Loss(labels, predictions)\r\n grads = tape.gradient(loss, model.trainable_variables)\r\n optimizer.apply_gradients(zip(grads, model.trainable_variables))\r\n m1 = Metric(labels, inputs)\r\n m2 = Metric(labels, model(inputs, training=0))\r\n m3 = Metric(vy, model(vx, training=0))\r\n return loss, m1, m2, m3\r\n\r\n\r\ndef loss(x, y):\r\n x1 = tf.cast(x, tf.float32)\r\n y1 = tf.cast(y, tf.float32)\r\n shape = tf.cast(tf.shape(x), tf.float32)\r\n return tf.reduce_sum(tf.math.square(x1 - y1)) / shape[0] / shape[1] / shape[2] / shape[3]\r\n\r\n\r\ndef psnr(x, y,max_val=255):\r\n x = tf.cast(x, tf.float32)\r\n y = tf.cast(y, tf.float32)\r\n batch = tf.cast(tf.shape(x)[0], tf.float32)\r\n return tf.reduce_sum(tf.image.psnr(x, y, max_val=tf.reduce_max(x))) / batch\r\n\r\n\r\nif __name__ == '__main__':\r\n # tf.debugging.set_log_device_placement(True)\r\n os.environ[\"CUDA_VISIBLE_DEVICES\"] = \"1\"\r\n iternum = 20\r\n epoch = 200\r\n batch = 5\r\n angles = 180\r\n theta = np.linspace(0, 180, angles, endpoint=False)\r\n # udir = \"/home/wangwei/ct-compare/CPTAC-LUAD//npy/\"\r\n udir = \"./train/\"\r\n vdir = \"validate\"\r\n train(epoch, udir, batch, theta, iternum, restore=0, ckpt='./512x512/weights/fbpconv')"
},
{
"alpha_fraction": 0.5878605246543884,
"alphanum_fraction": 0.6213950514793396,
"avg_line_length": 38.58503341674805,
"blob_id": "35942b299aa3c6e8d3b5fc2463d014d022334031",
"content_id": "1553fc2fd45d5f8a7db1226491aba9454c448b99",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5964,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 147,
"path": "/compared_networks/red_cnn.py",
"repo_name": "wangwei-cmd/CT-image-reconstruction",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\r\nimport cv2 as cv\r\nimport numpy as np\r\nimport os\r\nimport datetime\r\n\r\n\r\ndef redcnn(in_image, kernel_size=[5, 5], filter_size=96, conv_stride=1, initial_std=0.01):\r\n # conv layer1\r\n conv1 = tf.keras.layers.Conv2D(filter_size, kernel_size, conv_stride, padding='valid')(in_image)\r\n conv1=tf.keras.layers.ReLU()(conv1)\r\n # conv layer2\r\n conv2 = tf.keras.layers.Conv2D( filter_size, kernel_size, conv_stride, padding='valid')(conv1)\r\n conv2 = shortcut_deconv8 = tf.keras.layers.ReLU()(conv2)\r\n # conv layer3\r\n conv3 = tf.keras.layers.Conv2D(filter_size, kernel_size, conv_stride, padding='valid')(conv2)\r\n conv3 = tf.keras.layers.ReLU()(conv3)\r\n # conv layer4\r\n conv4 = tf.keras.layers.Conv2D(filter_size, kernel_size, conv_stride, padding='valid')(conv3)\r\n conv4 = shortcut_deconv6 = tf.keras.layers.ReLU()(conv4)\r\n # conv layer5\r\n conv5 = tf.keras.layers.Conv2D(filter_size, kernel_size, conv_stride, padding='valid')(conv4)\r\n conv5 = tf.keras.layers.ReLU()(conv5)\r\n\r\n \"\"\"\r\n decoder\r\n \"\"\"\r\n # deconv 6 + shortcut (residual style)\r\n deconv6 = tf.keras.layers.Conv2DTranspose(filter_size, kernel_size, conv_stride, padding='valid')(conv5)\r\n deconv6 += shortcut_deconv6\r\n deconv6 = tf.keras.layers.ReLU()(deconv6)\r\n # deconv 7\r\n deconv7 = tf.keras.layers.Conv2DTranspose(filter_size, kernel_size, conv_stride, padding='valid')(deconv6)\r\n deconv7 = tf.keras.layers.ReLU()(deconv7)\r\n # deconv 8 + shortcut\r\n deconv8 = tf.keras.layers.Conv2DTranspose(filter_size, kernel_size, conv_stride, padding='valid')(deconv7)\r\n deconv8 += shortcut_deconv8\r\n deconv8 = tf.keras.layers.ReLU()(deconv8)\r\n # deconv 9\r\n deconv9 = tf.keras.layers.Conv2DTranspose(filter_size, kernel_size, conv_stride, padding='valid')(deconv8)\r\n deconv9 = tf.keras.layers.ReLU()(deconv9)\r\n # deconv 10 + shortcut\r\n deconv10 = tf.keras.layers.Conv2DTranspose(1, kernel_size, conv_stride, padding='valid')(deconv9)\r\n deconv10 += in_image\r\n output = tf.keras.layers.ReLU()(deconv10)\r\n return output\r\n\r\n\r\ndef make_model(batch):\r\n inputs = tf.keras.Input(shape=(None,None,1),batch_size=batch)\r\n outputs=redcnn(inputs)\r\n model=tf.keras.Model(inputs=inputs,outputs=outputs)\r\n return model\r\n\r\ndef train(epoch, udir,batch, theta, iternum, restore=0, ckpt='./weights/CT_tf2_4'):\r\n max_val = 255\r\n angles = np.shape(theta)[0]\r\n u_img = np.load(udir + 'u_CT_img_no_scale.npy')\r\n print('shape of u_img:', u_img.shape)\r\n # f_img = np.load(udir + '/f,angle=' + str(angles) + '_255.0_0.002.npy')\r\n ini_u_img = np.load(udir + 'ini,angle=60_no_scale__0.5.npy')\r\n\r\n M = np.max(np.max(ini_u_img, 1), 1)\r\n M = np.reshape(M, [np.shape(M)[0], 1, 1, 1])\r\n u_img = u_img / M * 255\r\n ini_u_img = ini_u_img / M * 255\r\n\r\n\r\n current_time = datetime.datetime.now().strftime(\"%Y%m%d-%H%M%S\")\r\n train_log_dir = 'logs/gradient_tape/' + current_time + '/train'\r\n test_log_dir = 'logs/gradient_tape/' + current_time + '/test'\r\n\r\n optimizer = tf.keras.optimizers.Adagrad(learning_rate=0.001)\r\n Model = make_model(batch)\r\n if restore == 1:\r\n # call the build function in the layers since do not use tf.keras.Input\r\n ##maybe move the functions in build function to _ini_ need not do this\r\n _=Model(ini_u_img[0:1])\r\n Model.load_weights(ckpt)\r\n print('load weights, done')\r\n tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=train_log_dir)\r\n\r\n u_img = tf.cast(u_img, tf.float32)\r\n ini_u_img = tf.cast(ini_u_img, tf.float32)\r\n N=tf.shape(u_img)[0]\r\n vx=ini_u_img[N-5:N]\r\n vy=u_img[N-5:N]\r\n vx=tf.cast(vx,tf.float32)\r\n vy = tf.cast(vy, tf.float32)\r\n train_data = tf.data.Dataset.from_tensor_slices((u_img[0:N-5], ini_u_img[0:N-5])).batch(batch)\r\n for i in range(epoch):\r\n for iter, ufini in enumerate(train_data):\r\n u, ini_u = ufini\r\n Loss, m1, m2,m3 = train_step(ini_u, Model, u, loss, psnr, optimizer,vx,vy)\r\n print(iter, \"/\", i, \":\", Loss.numpy(),\r\n \"psnr1:\", m1.numpy(),\r\n \"psnr2:\", m2.numpy(),\r\n 'psnr3:', m3.numpy()\r\n )\r\n if i%2==0:\r\n Model.save_weights(ckpt)\r\n # Model.compile(optimizer=optimizer, loss=[loss], metrics=[psnr])\r\n # Model.fit(x, y, batch_size=batch, epochs=epoch, callbacks=[tensorboard_callback],\r\n # validation_split=1/80)\r\n Model.save_weights(ckpt)\r\n # tf.keras.utils.plot_model(Model, 'multi_input_and_output_model.png', show_shapes=True)\r\n\r\n\r\[email protected]\r\ndef train_step(inputs, model, labels, Loss, Metric, optimizer,vx,vy):\r\n with tf.GradientTape() as tape:\r\n predictions = model(inputs, training=1)\r\n loss = Loss(labels, predictions)\r\n grads = tape.gradient(loss, model.trainable_variables)\r\n optimizer.apply_gradients(zip(grads, model.trainable_variables))\r\n m1 = Metric(labels, inputs)\r\n m2 = Metric(labels, model(inputs, training=0))\r\n m3 = Metric(vy, model(vx, training=0))\r\n return loss, m1, m2, m3\r\n\r\n\r\ndef loss(x, y):\r\n x1 = tf.cast(x, tf.float32)\r\n y1 = tf.cast(y, tf.float32)\r\n shape = tf.cast(tf.shape(x), tf.float32)\r\n return tf.reduce_sum(tf.math.square(x1 - y1)) / shape[0] / shape[1] / shape[2] / shape[3]\r\n\r\n\r\ndef psnr(x, y,max_val=255):\r\n x = tf.cast(x, tf.float32)\r\n y = tf.cast(y, tf.float32)\r\n batch = tf.cast(tf.shape(x)[0], tf.float32)\r\n return tf.reduce_sum(tf.image.psnr(x, y, max_val=tf.reduce_max(x))) / batch\r\n\r\n\r\n\r\nif __name__ == '__main__':\r\n os.environ[\"CUDA_VISIBLE_DEVICES\"] = \"2\"\r\n iternum = 20\r\n epoch = 200\r\n batch = 5\r\n angles = 60\r\n theta = np.linspace(0, 180, angles, endpoint=False)\r\n # udir = \"/home/wangwei/ct-compare/CPTAC-LUAD//npy/\"\r\n udir = \"./train/\"\r\n vdir = \"validate\"\r\n train(epoch, udir, batch, theta, iternum, restore=0, ckpt='./512x512/weights/red_cnn')"
},
{
"alpha_fraction": 0.5385996699333191,
"alphanum_fraction": 0.5845601558685303,
"avg_line_length": 31.963415145874023,
"blob_id": "8cb3ceb043fec6e7eac26178bb85bb2bec75c73f",
"content_id": "8682090359355ac37c87aac809ef01008e6b82e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2785,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 82,
"path": "/parabeam/testnew.py",
"repo_name": "wangwei-cmd/CT-image-reconstruction",
"src_encoding": "UTF-8",
"text": "import newmodel as net4\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\nimport tensorflow as tf\r\nimport os\r\nimport cv2 as cv\r\n\r\ndef interp(f,xp,x):\r\n # f_img=f[:,:,::2,:]\r\n f_img=f\r\n shape=f.shape\r\n L=len(x)\r\n f_interp = np.zeros(shape=[shape[0],shape[1],L,shape[3]])\r\n idL = np.where(x <= xp[0])[0]\r\n idR = np.where(x >= xp[-1])[0]\r\n xx = x[idL[-1] + 1:idR[0]]\r\n id = np.searchsorted(xp, xx)\r\n L = xx - xp[id - 1]\r\n R = xp[id] - xx\r\n w1 = R / (L + R)\r\n w2 = 1 - w1\r\n val1 = f_img[:, :, id - 1, :]\r\n val2 = f_img[:, :, id, :]\r\n val1 = val1.transpose([0, 1, 3, 2])\r\n val2 = val2.transpose([0, 1, 3, 2])\r\n temp = val1 * w1 + val2 * w2\r\n f_interp[:, :, idL[-1] + 1:idR[0], :] = temp.transpose([0, 1, 3, 2])\r\n for i in idL:\r\n f_interp[:, :, i, :] = f_img[:, :, 0, :]\r\n for j in idR:\r\n f_interp[:, :, j, :] = f_img[:, :, -1, :]\r\n return f_interp\r\nos.environ[\"CUDA_VISIBLE_DEVICES\"] = \"0\"\r\nAangles=180\r\nAT = np.load('AT_' + str(Aangles) + '_512x512' + '.npz')\r\nval = AT['name1'].astype('float32')\r\nindex = AT['name2']\r\nshape = AT['name3']\r\nAT = tf.sparse.SparseTensor(index, val, shape)\r\n# AT = tf.cast(AT, tf.float32)\r\ntheta=np.linspace(0, 180, Aangles, endpoint=False)\r\nckpt='./weights'+'/new_model_lambda=0.5'\r\nbatch=5\r\nModel=net4.make_model_3(AT,(725, 180),(512, 512))\r\nudir = \"./test/\"\r\nangles=60\r\nsuperangles=180\r\nf_noisy_img = np.load(udir + '/f_noisy,angle=' + str(angles) + '_no_scale__0.5.npy')\r\nf_noisy_img=interp(f_noisy_img, np.linspace(0, 180, angles, endpoint=False), np.linspace(0, 180, superangles, endpoint=False))\r\nL=500\r\nf_noisy_img=f_noisy_img[0:L]\r\nf_noisy=tf.cast(f_noisy_img,tf.float32)\r\ndef inimodel( f_noisy, Model,ckpt=ckpt):\r\n _ = Model(f_noisy[0:1])\r\n Model.load_weights(ckpt)\r\n\r\n\r\ndef evaluate(f_noisy, batch, Model):\r\n _ = inimodel(f_noisy, Model)\r\n prediction = np.zeros([tf.shape(f_noisy).numpy()[0],512,512,1])\r\n iter = list(range(0, tf.shape(f_noisy).numpy()[0], batch))\r\n for i in range(len(iter)):\r\n prediction[iter[i]:iter[i] + batch] = Model(f_noisy_img[iter[i]:iter[i] + batch])[\r\n 1].numpy()\r\n print(i)\r\n return prediction\r\n\r\nprediction=evaluate(f_noisy,batch,Model)\r\nii=np.random.randint(0,L)\r\nprint('show figure:',ii)\r\nplt.imshow(f_noisy[ii,:,:,0],cmap='gray')\r\nplt.figure()\r\nplt.imshow(prediction[ii,:,:,0],cmap='gray')\r\nplt.show()\r\n\r\n# vy=np.load(udir+ 'u_CT_img_no_scale.npy')\r\n# vy=vy[0:L]\r\n# vy=tf.cast(vy,tf.float32)\r\n# pp=tf.image.psnr(tf.cast(prediction,tf.float32),vy,tf.reduce_max(prediction)).numpy()\r\n# qq=tf.image.ssim(tf.cast(prediction,tf.float32),vy,tf.reduce_max(prediction)).numpy()\r\n# print('average psnr:',tf.reduce_mean(pp).numpy())\r\n# print('average ssim:',tf.reduce_mean(qq).numpy())\r\n"
},
{
"alpha_fraction": 0.5227566957473755,
"alphanum_fraction": 0.5661974549293518,
"avg_line_length": 39.65827178955078,
"blob_id": "7cabdf2e17048bf18a75e5fbada5010818f4a7dd",
"content_id": "0e8abf248fd30a1af3d01250124b8780d2c839fa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11579,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 278,
"path": "/fan2para/new1.py",
"repo_name": "wangwei-cmd/CT-image-reconstruction",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\r\nimport cv2 as cv\r\nimport matplotlib.pyplot as plt\r\nimport numpy as np\r\nimport os\r\nimport datetime\r\nfrom skimage.transform import radon,iradon,rotate\r\nfrom scipy.fftpack import fft, ifft, fftfreq, fftshift\r\nclass sinLayer(tf.keras.Model):\r\n def __init__(self, AT,s_shape = (725, 360),out_size=(512,512)):\r\n super(sinLayer, self).__init__()\r\n self.AT = AT\r\n self.s_shape=s_shape\r\n self.out_size = out_size\r\n w_b=w_bfunction(np.pi,np.linspace(-np.floor(s_shape[0]/2),s_shape[0]-np.floor(s_shape[0]/2)-1,s_shape[0]))\r\n self.w_b =w_b.astype('float32')\r\n self.sinLayer=[]\r\n self.sinLayer_1 = []\r\n\r\n self.ctLayer=[]\r\n self.ctLayer_1 = []\r\n ###sinLayer###\r\n self.sinLayer.append(tf.keras.layers.Conv2D(64, 5, padding='same', name='sinconv1', activation=tf.nn.relu))\r\n self.M1=4\r\n for layers in range(1,self.M1+1):\r\n self.sinLayer.append(tf.keras.layers.Conv2D(64, 5, padding='same', name='sinconv%d' % layers, use_bias=False))\r\n self.sinLayer.append(tf.keras.layers.BatchNormalization())\r\n self.sinLayer.append(tf.keras.layers.ReLU())\r\n self.sinLayer.append(tf.keras.layers.Conv2D(1, 5, name='sinconv6',padding='same'))\r\n ###CTLayer###\r\n self.ctLayer.append(tf.keras.layers.Conv2D(64, 5, padding='same', name='ctconv1', activation=tf.nn.relu))\r\n self.M2=5\r\n for layers in range(1,self.M2+1):\r\n self.ctLayer.append(tf.keras.layers.Conv2D(64, 5, padding='same', name='ctconv%d' % layers, use_bias=False))\r\n self.ctLayer.append(tf.keras.layers.BatchNormalization())\r\n self.ctLayer.append(tf.keras.layers.ReLU())\r\n self.ctLayer.append(tf.keras.layers.Conv2D(1, 5, name='ctconv6', padding='same'))\r\n\r\n def decode(self, sin_fan):\r\n # AT, alpha, h, w_c=self.AT,self.alpha,self.h,self.w_c\r\n AT, w_b = self.AT, self.w_b\r\n sin_fan = tf.transpose(sin_fan, perm=[0, 2, 1, 3])\r\n # cos_alpha = tf.math.cos(alpha)\r\n s_fan_shape = sin_fan.shape\r\n batch = tf.shape(sin_fan)[0]\r\n sin_fan1 = tf.reshape(sin_fan, [-1, s_fan_shape[2], 1])\r\n filter_s_fan = tf.nn.conv1d(sin_fan1, tf.expand_dims(tf.expand_dims(w_b, -1), -1), stride=1, padding='SAME')\r\n # filter_s_fan1=tf.reshape(filter_s_fan,s_fan_shape)\r\n filter_s_fan2 = tf.reshape(filter_s_fan, [batch, -1])\r\n filter_s_fan2 = tf.transpose(filter_s_fan2)\r\n rf = tf.sparse.sparse_dense_matmul(AT, filter_s_fan2)\r\n rf = tf.transpose(rf)\r\n rf = tf.reshape(rf, [batch, 512, 512, 1])\r\n return 4 * rf\r\n\r\n # @tf.function\r\n def call(self, inputs):\r\n de_sin = self.sinLayer[0](inputs)\r\n pp = de_sin\r\n for i in range(1, self.M1 + 1):\r\n for j in range(0, 3):\r\n de_sin = self.sinLayer[3 * i + j - 2](de_sin)\r\n pp = de_sin + pp\r\n de_sin = self.sinLayer[3 * self.M1 + 1](pp/self.M1) + inputs\r\n\r\n fbp = self.decode(de_sin)\r\n\r\n outputs = self.ctLayer[0](fbp)\r\n qq = outputs\r\n for i in range(1, self.M2 + 1):\r\n for j in range(0, 3):\r\n outputs = self.ctLayer[3 * i + j - 2](outputs)\r\n qq = qq + outputs\r\n outputs = self.ctLayer[3 * self.M2 + 1](qq/self.M2) + fbp\r\n return [de_sin, outputs, fbp]\r\n\r\ndef interp(f,xp,x):\r\n # f_img=f[:,:,::2,:]\r\n f_img=f\r\n shape=f.shape\r\n L=len(x)\r\n f_interp = np.zeros(shape=[shape[0],shape[1],L,shape[3]])\r\n idL = np.where(x <= xp[0])[0]\r\n idR = np.where(x >= xp[-1])[0]\r\n xx = x[idL[-1] + 1:idR[0]]\r\n id = np.searchsorted(xp, xx)\r\n L = xx - xp[id - 1]\r\n R = xp[id] - xx\r\n w1 = R / (L + R)\r\n w2 = 1 - w1\r\n val1 = f_img[:, :, id - 1, :]\r\n val2 = f_img[:, :, id, :]\r\n val1 = val1.transpose([0, 1, 3, 2])\r\n val2 = val2.transpose([0, 1, 3, 2])\r\n temp = val1 * w1 + val2 * w2\r\n f_interp[:, :, idL[-1] + 1:idR[0], :] = temp.transpose([0, 1, 3, 2])\r\n for i in idL:\r\n f_interp[:, :, i, :] = f_img[:, :, 0, :]\r\n for j in idR:\r\n f_interp[:, :, j, :] = f_img[:, :, -1, :]\r\n return f_interp\r\n\r\ndef u_function(s):\r\n u=np.zeros(s.shape)\r\n index_1=np.where(s==0)[0]\r\n u[index_1]=1/2\r\n index=np.where(s!=0)[0]\r\n v=s[index]\r\n u[index]=(np.cos(v)-1)/(v**2)+np.sin(v)/v\r\n return u\r\ndef w_bfunction(b,s):\r\n return u_function(b*s)*(b**2)/(4*np.pi**2)\r\n\r\ndef decode(sin_fan,AT,w_b):\r\n # AT, alpha, h, w_c=self.AT,self.alpha,self.h,self.w_c\r\n sin_fan=tf.transpose(sin_fan,perm=[0,2,1,3])\r\n # cos_alpha = tf.math.cos(alpha)\r\n s_fan_shape =sin_fan.shape\r\n batch=tf.shape(sin_fan)[0]\r\n sin_fan1 = tf.reshape(sin_fan, [-1, s_fan_shape[2], 1])\r\n filter_s_fan = tf.nn.conv1d(sin_fan1, tf.expand_dims(tf.expand_dims(w_b,-1),-1), stride=1, padding='SAME')\r\n # filter_s_fan1=tf.reshape(filter_s_fan,s_fan_shape)\r\n filter_s_fan2 = tf.reshape(filter_s_fan, [batch, -1])\r\n filter_s_fan2 = tf.transpose(filter_s_fan2)\r\n rf = tf.sparse.sparse_dense_matmul(AT, filter_s_fan2)\r\n rf = tf.transpose(rf)\r\n rf = tf.reshape(rf, [batch, 512, 512, 1])\r\n return 4*rf\r\n\r\n\r\n\r\n\r\ndef make_model_3(AT,s_shape=(725, 360),out_size=(512,512)):\r\n CT=sinLayer(AT,s_shape,out_size)\r\n inputs = tf.keras.Input(shape=(s_shape[0],s_shape[1],1))\r\n [de_sin, outputs, fbp]=CT(inputs)\r\n model = tf.keras.Model(inputs=inputs, outputs=[de_sin, outputs, fbp])\r\n return model\r\n\r\n\r\ndef train(epoch, udir,batch, theta, iternum, restore=0, ckpt='./weights/CT_tf2_4'):\r\n angles = np.shape(theta)[0]\r\n\r\n s_shape = (725, 180)\r\n out_size = (512, 512)\r\n AT = np.load('AT_' + str(180) + '_512x512' + '.npz')\r\n\r\n data = np.load('train' + '_fan2para.npz')\r\n u_img = data['u'].astype('float32')\r\n f_noisy_img = data['f_noisy'].astype('float32')\r\n f_img = data['f'].astype('float32')\r\n # u_ini = data['ini_u'].astype('float32')\r\n # M = np.max(np.max(u_ini, 1), 1)\r\n # M=np.reshape(M, [np.shape(M)[0],1,1,1])\r\n # u_img=u_img/M*255\r\n # f_noisy_img=f_noisy_img/M*255\r\n # f_img=f_img/M*255\r\n # u_ini=u_ini/M*255\r\n\r\n val = AT['name1'].astype('float32')\r\n index = AT['name2']\r\n shape = AT['name3']\r\n # del u_ini\r\n\r\n AT = tf.sparse.SparseTensor(index, val, shape)\r\n # AT = tf.cast(AT, tf.float32)\r\n del val\r\n del index\r\n\r\n # u_img = np.load(udir + 'u_CT_img_no_scale.npy')\r\n print('shape of u_img:', u_img.shape)\r\n # f_noisy_img = np.load(udir + '/f_noisy,angle=' + str(180) + '_ no_scale__0.5.npy')\r\n\r\n # f_img=np.load(udir + '/f,angle=' + str(180) + '_ no_scale__0.5.npy')\r\n # ini_u_img = np.load(udir + '/ini,angle=' + str(angles) + '_255.0_0.002.npy')\r\n\r\n\r\n current_time = datetime.datetime.now().strftime(\"%Y%m%d-%H%M%S\")\r\n train_log_dir = 'logs/gradient_tape/' + current_time + '/train'\r\n test_log_dir = 'logs/gradient_tape/' + current_time + '/test'\r\n\r\n optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)\r\n # Model = make_model(batch, AT,w_b,s_shape,out_size)\r\n # Model=sinLayer(AT,s_shape,out_size)\r\n Model=make_model_3(AT,s_shape,out_size)\r\n tf.keras.backend.clear_session()\r\n # tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=train_log_dir)\r\n\r\n # u_img = tf.cast(u_img, tf.float32)\r\n # f_noisy_img = tf.cast(f_noisy_img, tf.float32)\r\n # f_img=tf.cast(f_img, tf.float32)\r\n\r\n N=tf.shape(u_img)[0]\r\n vx=f_noisy_img[N-5:N]\r\n vy=[f_img[N-5:N],u_img[N-5:N]]\r\n train_data = tf.data.Dataset.from_tensor_slices((u_img[0:N-5],f_img[0:N-5], f_noisy_img[0:N-5])).shuffle(tf.cast(N-5,tf.int64)).batch(batch)\r\n # _ = Model(vx[0:1])\r\n if restore == 1:\r\n # call the build function in the layers since do not use tf.keras.Input\r\n ##maybe move the functions in build function to _ini_ need not do this\r\n _=Model(vx[0:1])\r\n Model.load_weights(ckpt)\r\n print('load weights, done')\r\n for i in range(epoch):\r\n for iter, ufini in enumerate(train_data):\r\n u,f, f_noisy = ufini\r\n # Loss, m1, m2, m3 = train_step(f_noisy, Model, [f, u], loss, psnr, optimizer, vx, vy,epochnum=i)\r\n Loss, m1, m2, m3 = train_step(f_noisy, Model, [f, u], loss_1, psnr, optimizer, vx, vy, epochnum=i)\r\n print(iter, \"/\", i, \":\", Loss.numpy(),\r\n \"psnr_f_fnoisy:\", m1.numpy(),\r\n \"psnr1\", [m2[0].numpy(), m2[1].numpy(), m2[2].numpy()],\r\n ###psnr of f and f_noisy, u and fbp, u and reconstructe,respectively\r\n 'psnr3:', [m3[0].numpy(), m3[1].numpy(), m3[2].numpy()]\r\n )\r\n\r\n if i%2==0:\r\n Model.save_weights(ckpt)\r\n # Model.compile(optimizer=optimizer, loss=[loss], metrics=[psnr])\r\n # Model.fit(x, y, batch_size=batch, epochs=epoch, callbacks=[tensorboard_callback],\r\n # validation_split=1/80)\r\n Model.save_weights(ckpt)\r\n # tf.keras.utils.plot_model(Model, 'multi_input_and_output_model.png', show_shapes=True)\r\n\r\n\r\[email protected]\r\ndef train_step(inputs, model, labels, Loss, Metric, optimizer,vx,vy,epochnum):\r\n # if epochnum<1000:\r\n # weights = 0.9999\r\n # else:\r\n # weights = 0.0001\r\n with tf.GradientTape() as tape:\r\n predictions = model(inputs, training=1)\r\n loss = Loss(labels, predictions)\r\n grads = tape.gradient(loss, model.trainable_variables)\r\n optimizer.apply_gradients(zip(grads, model.trainable_variables))\r\n # m1 = Metric(labels, inputs)\r\n m1 = tf.reduce_sum(tf.image.psnr(labels[0], inputs, max_val=tf.reduce_max(labels[0]))) / tf.cast(tf.shape(inputs)[0],tf.float32)\r\n m2 = Metric(labels, model(inputs, training=0))\r\n m3 = Metric(vy, model(vx, training=0))\r\n return loss, m1, m2, m3\r\n\r\n\r\ndef loss_1(x, y,weights=0.5):\r\n x0 = tf.cast(x[0], tf.float32)\r\n x1 = tf.cast(x[1], tf.float32)\r\n y0 = tf.cast(y[0], tf.float32)\r\n y1 = tf.cast(y[1], tf.float32)\r\n shape = tf.cast(tf.shape(x[0]), tf.float32)\r\n shape1 = tf.cast(tf.shape(x[1]), tf.float32)\r\n return weights*tf.reduce_sum(tf.math.square(x0 - y0)) / shape[0] / shape[1] / shape[2] / shape[3]\\\r\n +(1-weights)*tf.reduce_sum(tf.math.square(x1 - y1))/shape1[0] / shape1[1] / shape1[2] / shape1[3]\r\n # return tf.reduce_sum(tf.math.square(x0 - y0)) / shape[0] / shape[1] / shape[2] / shape[3]\r\n # return tf.reduce_sum(tf.math.square(x1 - y1))/shape1[0] / shape1[1] / shape1[2] / shape1[3]\r\n\r\ndef psnr(x, y,max_val=255):\r\n x0 = tf.cast(x[0], tf.float32)\r\n x1 = tf.cast(x[1], tf.float32)\r\n y0 = tf.cast(y[0], tf.float32)\r\n y1 = tf.cast(y[1], tf.float32)\r\n y2 = tf.cast(y[2], tf.float32)\r\n batch = tf.cast(tf.shape(x[1])[0], tf.float32)\r\n psnr1=tf.reduce_sum(tf.image.psnr(x0, y0, max_val=tf.reduce_max(x0))) / batch######psnr of f and de_sin\r\n psnr2=tf.reduce_sum(tf.image.psnr(x1, y2, max_val=tf.reduce_max(x1))) / batch######psnr of u and fbp\r\n psnr3 = tf.reduce_sum(tf.image.psnr(x1, y1, max_val=tf.reduce_max(x1))) / batch#####psnr of u and reconstructed\r\n return [psnr1,psnr2,psnr3]\r\n\r\n\r\nif __name__ == '__main__':\r\n os.environ[\"CUDA_VISIBLE_DEVICES\"] = \"2\"\r\n iternum = 20\r\n epoch = 100\r\n\r\n batch = 5\r\n theta = np.linspace(0, 180, 180, endpoint=False)\r\n udir = \"./train/\"\r\n vdir = \"validate\"\r\n # train(epoch, udir, batch, theta, iternum, restore=0, ckpt='./weights/two_stage_4_2')\r\n train(epoch, udir, batch, theta, iternum, restore=0, ckpt='./512x512/weights/new1_model_lambda=0.5')"
}
] | 10 |
geranium12/EmoReco
|
https://github.com/geranium12/EmoReco
|
91d951e585a1fb1e8d6ec730be74433ddc3a0595
|
7b2a2dc29cda1f3f2c80eb7fbe732a4d6f3d6930
|
f21ba2294c5d7baaf3506b4c946745bd1301cec8
|
refs/heads/master
| 2022-12-07T22:29:09.891170 | 2020-08-23T20:53:41 | 2020-08-23T20:53:41 | 288,728,431 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5344418287277222,
"alphanum_fraction": 0.5581947565078735,
"avg_line_length": 23.264705657958984,
"blob_id": "bee7a6caa1d5cf0331b3b3bb67b3c0270024fc9f",
"content_id": "bb74d76e5aba7a49593b8ba70f54628dcc46b9b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 842,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 34,
"path": "/data/server/kogerocommander.py",
"repo_name": "geranium12/EmoReco",
"src_encoding": "UTF-8",
"text": "\"\"\"\n KOGERO TEAM\n\"\"\"\nimport kogeroserver\n\n# startserver HOST PORT \n# closeserver\n#\n# startserver 192.168.0.116 60606\n\n \nIS_ACTIVE = False\n\ndef getCommand(message):\n fragmented_message = list(message.split(' '))\n return fragmented_message\n \nif __name__ == '__main__':\n \n command_pipe = None\n \n while True:\n message = input()\n command = getCommand(message)\n \n if (command[0] == 'startserver' and IS_ACTIVE == False):\n command_pipe = kogeroserver.initializeServer(command[1], command[2])\n if (command_pipe != -1):\n IS_ACTIVE = True\n elif (command[0] == 'closeserver' and IS_ACTIVE == True):\n kogeroserver.closeServer(command_pipe)\n IS_ACTIVE = False\n else:\n print('Invalid commmand.')\n \n "
},
{
"alpha_fraction": 0.30927833914756775,
"alphanum_fraction": 0.44329896569252014,
"avg_line_length": 20.66666603088379,
"blob_id": "faa5b75d90b0b75049217371025e06fdd7748982",
"content_id": "58215238562a4aac1c2cf50bc227be37b29f26c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 194,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 9,
"path": "/data/server/bye.py",
"repo_name": "geranium12/EmoReco",
"src_encoding": "UTF-8",
"text": "import pickle\n\nwith open('emo_to_diseases.pkl', 'wb') as f:\n w1 = [[0] * 16] * 7\n w2 = [[1] * 11] * 16\n b1 = [0] * 16\n b2 = [1] * 11\n \n pickle.dump((w1, w2, b1, b2, '0.01'), f)"
},
{
"alpha_fraction": 0.5460756421089172,
"alphanum_fraction": 0.5643051266670227,
"avg_line_length": 33.43032455444336,
"blob_id": "c00ce2c94233b3e153c7fb2e53f964eb1d2737aa",
"content_id": "a12ca1b2fcf06159017db67d8bab384a5be94b1c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 31304,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 897,
"path": "/Emoreco.py",
"repo_name": "geranium12/EmoReco",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3.6 \n\nimport time\nimport os\nimport pyodbc\n\nimport sys\nimport threading\nimport queue\nimport socket\nimport pickle\nfrom azure.storage.file import FileService\n\nimport math, random\nimport sys\n\nfrom PyQt5.QtWidgets import QApplication, QWidget, QPushButton, QHBoxLayout, QVBoxLayout, QDesktopWidget, QLabel, QMainWindow, QGridLayout\nfrom PyQt5.QtGui import QIcon, QPixmap, QImage, QPalette, QBrush, QPainter, QPen, QColor, QGradient, QLinearGradient\nfrom PyQt5 import QtCore, uic, QtGui\nfrom PyQt5.QtCore import Qt, QPointF, QRectF\nfrom PyQt5.QtChart import QChart, QChartView, QLineSeries, QPieSeries, QPieSlice, QBarSet, QBarSeries, QBarCategoryAxis\nfrom PyQt5.QtGui import QPolygonF, QPainter\nfrom PyQt5.QtCore import (QCoreApplication, QObject, QRunnable, QThread,\n QThreadPool, pyqtSignal)\n\nimport urllib.request as urllib2\nimport dlib\nimport tensorflow as tf\nimport numpy as np\nimport cv2\n\n\n#########################################################\n#########################################################\n#########################################################\n#########################################################\n#########################################################\n\nLAST_LAUNCH = 0\nHOST = '127.0.01'\nPORT = 60607\nnumber_of_steps = 3001\nbeta = 0.005\nsigma = 5e-2\ninit_learning_rate = 0.002\ndropout_value_1 = 0.75\ndropout_value_2 = 0.85\ndropout_value_3 = 0.9\nhidden_layer_1 = 600\nhidden_layer_2 = 600\nhidden_layer_3 = 400\nbatch_size = 128\ndecay_steps = 1000\npoints_count = 68-17\nlabels_count = 7\ndecay_rate = 0.9\nINF = 1e9 + 7\nmINF = -1e9 - 7\npower = 4\nblank_opened = False\nsys_n = 11\nlandmarks_n = 68\nroot = \"./data/\"\ndangerous_asymmetry = 25\nasymmetry_time = 330000\nprefix_to_edit = ''\n\nwith open(root+'mean_shape.pkl', 'rb') as f:\n mean_face = pickle.load(f)\n f.close()\n \ntext = ['Anger', 'Neutral', 'Disgust', 'Fear', 'Happiness', 'Sadness', 'Surprise']\n\ndef internet_on():\n try:\n urllib2.urlopen('http://216.58.192.142', timeout=1)\n return True\n except urllib2.URLError as err: \n return False\n\nclass SomeObject(QObject):\n connection_failed = pyqtSignal()\n finished = pyqtSignal()\n\n def sendStatistic(self):\n if ex.emo_sum == 0:\n self.finished.emit()\n return\n\n if not(internet_on()):\n self.connection_failed.emit()\n return\n\n emo_stat = (ex.emo_stat / ex.emo_sum).tolist()\n answer = BlankAnswer\n try:\n cnxn = pyodbc.connect('DRIVER={SQL Server};SERVER=emorecodb.database.windows.net', user='EmoRecoLogin@EmoRecoDB', password='EmoRecoPass1.', database='EmoRecoDB')\n cursor = cnxn.cursor()\n cursor.execute(\"INSERT INTO EmotionsStatistics VALUES \" + str(tuple(emo_stat + answer)))\n cnxn.commit()\n global form_completed\n form_completed = True\n self.finished.emit()\n except Exception as e:\n self.connection_failed.emit()\n #raise e\n\n def loadMatrix(self):\n if not(internet_on()):\n self.finished.emit()\n ex.StateLabel.setText('Connection failed. Please, try again.')\n return\n\n with open(prefix_to_edit+'data/emo_to_diseases.pkl', 'rb') as f:\n old_version, matrices = pickle.load(f)\n f.close()\n \n file_service = None\n try:\n file_service = FileService(account_name='emorecostorage', account_key='H6W60c0sP214/4iEeKPhiXcXxmMUzI6mSpwJslb3CD49hmI5pL1+/cNLkQm8zrCkGLFza7qd5pWwaydHA2QbJQ==')\n file_service.get_file_to_path('emorecofiles', None, 'emo_to_diseases.pkl', prefix_to_edit+'data/emo_to_diseases_temp.pkl')\n except Exception:\n #raise\n #ex.StateLabel.setText('The version you have is the newest.')\n ex.StateLabel.setText('Connection failed. Please, try again.')\n self.finished.emit()\n return\n\n with open(prefix_to_edit+'data/emo_to_diseases_temp.pkl', 'rb') as f:\n nv, matrices = pickle.load(f)\n f.close()\n\n if nv == old_version:\n ex.StateLabel.setText('The version you have is the newest.')\n else:\n with open(prefix_to_edit+'data/emo_to_diseases.pkl', 'wb') as f:\n pickle.dump((nv, matrices), f)\n f.close()\n ex.StateLabel.setText('The model was updated successfully.')\n self.finished.emit()\n return\n\ncap = cv2.VideoCapture(0)\npredictor_model = root+\"shape_predictor_68_face_landmarks.dat\"\nface_detector = dlib.get_frontal_face_detector()\nface_pose_predictor = dlib.shape_predictor(predictor_model)\nnum_points = 68\npoints_to_delete = 17\n\ngraph = tf.Graph()\n\nwith graph.as_default():\n # Инициализируем матрицы весов\n weights1 = tf.Variable(\n tf.truncated_normal([points_count * 2, hidden_layer_1], stddev = sigma))\n weights2 = tf.Variable(\n tf.truncated_normal([hidden_layer_1, hidden_layer_2], stddev = sigma))\n weights3 = tf.Variable(\n tf.truncated_normal([hidden_layer_2, labels_count], stddev = sigma))\n \n # Инициализируем веса для нейронов смещения\n biases1 = tf.Variable(\n tf.constant(0.1, shape = (hidden_layer_1,)))\n biases2 = tf.Variable(\n tf.constant(0.1, shape = (hidden_layer_2,)))\n biases3 = tf.Variable(\n tf.constant(0.1, shape = (labels_count,)))\n \n # Описываем модель\n def model(input, p1, p2):\n hidden1 = tf.nn.dropout(tf.nn.relu(tf.matmul(input, weights1) + biases1), p1)\n hidden2 = tf.nn.dropout(tf.nn.relu(tf.matmul(hidden1, weights2) + biases2), p2)\n logits = tf.nn.bias_add(tf.matmul(hidden2, weights3), biases3)\n return logits\n \n td = tf.placeholder(tf.float32, shape = [1, points_count * 2])\n model_saver = tf.train.Saver()\n \n check_prediction = tf.nn.softmax(model(td, 1, 1))\n \ndef find_rotation(array):\n '''Единственный аргумент функции - numpy-массив \n из 68*2 элементов - координат точек'''\n \n nose_index = 27\n chin_index = 8 \n '''Углом поворота лица будем считать угол между вектором, \n проведённым от верхней точки переносицы\n до нижней точки подбородка, и вертикалью'''\n \n nose = np.array([array[2*nose_index], array[2*nose_index+1]])\n chin = np.array([array[2*chin_index], array[2*chin_index+1]])\n \n vector = chin-nose\n length = math.sqrt(vector[0]**2 + vector[1]**2)\n \n if vector[1]>0:\n return math.acos(vector[0]/length) - math.pi/2\n return math.acos(-vector[0]/length) + math.pi/2\n\ndef rotate(alpha, array): \n '''Принимает на вход угол поворота (в радианах) и массив \n точек, который надо повернуть'''\n \n landmarks = array\n nose_index = 27\n nose = np.array([landmarks[2*nose_index], landmarks[2*nose_index+1]]) \n #Координаты верхней точки переносицы (точки отсчёта)\n \n cos = math.cos(alpha)\n sin = math.sin(alpha)\n \n # Матрица поворота\n rotation_matrix = np.array([[cos, -sin], [sin, cos]])\n \n for point in range(num_points):\n vector = np.array([landmarks[2*point], landmarks[2*point+1]]) - nose\n vector = np.dot(vector, rotation_matrix) + nose #Умножение на матрицу поворота\n \n landmarks[2*point] = vector[0]\n landmarks[2*point+1] = vector[1]\n \n return landmarks\n\ndef normalize_dataset(array):\n modif_array = array\n \n modif_array = rotate(find_rotation(modif_array), modif_array)\n \n max_y = -1e9\n max_x = -1e9\n min_y = 1e9\n min_x = 1e9\n \n for coord in range(num_points):\n min_y = min(min_y, modif_array[coord*2])\n min_x = min(min_x, modif_array[coord*2+1])\n \n for coord in range(num_points):\n modif_array[coord*2] -= min_y\n modif_array[coord*2+1] -= min_x\n \n for coord in range(num_points):\n max_y = max(max_y, modif_array[coord*2])\n max_x = max(max_x, modif_array[coord*2+1])\n \n for coord in range(num_points):\n modif_array[coord*2] /= max_y\n modif_array[coord*2+1] /= max_x\n\n return np.array(modif_array)#[points_to_delete*2:]\n\nsession = tf.Session(graph=graph)\nmodel_saver.restore(session, root+\"saved_models/EmoReco.ckpt\")\nprint(\"Model restored.\") \nprint('Initialized')\n\n\n#########################################################\n#########################################################\n#########################################################\n#########################################################\n#########################################################\n#########################################################\n\ndef predictDiseases(emotions):\n with open(prefix_to_edit+root+'emo_to_diseases.pkl', 'rb') as f:\n version, model = pickle.load(f)\n f.close()\n layer = np.array(emotions)\n for W, B, activation_f in model:\n layer = np.dot(layer, W) + B\n if (activation_f == 'sigmoid'):\n layer = 1/(1+np.exp(-layer))\n elif (activation_f == 'relu'):\n for i in range(layer.shape[0]):\n layer[i] = max(layer[i], 0)\n return layer\n\n#win = dlib.image_window()\n\ndef count_points(box, shape):\n counter = 0\n for i in range(landmarks_n):\n if shape.part(i).x <= box.right() and shape.part(i).x >= box.left() and shape.part(i).y <= box.bottom() and shape.part(i).y >= box.top():\n counter += 1\n return counter\n\nclass Example(QWidget):\n window_width = 600\n window_height = 720\n update_clicked = False\n \n def __init__(self):\n super().__init__()\n uic.loadUi(root+'MainWindow.ui', self)\n self.initUI()\n\n def initUI(self):\n # GETTING CURRENT YEAR AND MONTH\n # PEREDELAT!\n\n #self.status_txt.setLayout(QtGui.QHBoxLayout())\n\n self.cur_year = int(time.strftime('%Y', time.gmtime(time.time())))\n self.cur_month = int(time.strftime('%m', time.gmtime(time.time())))\n ######################################\n\n self.NN_file = prefix_to_edit+root+'emo_to_diseases.pkl'\n global form_completed\n\n self.stat_pickle_file = prefix_to_edit+root+'emotion_statistics.pkl'\n if os.path.exists(self.stat_pickle_file):\n with open(self.stat_pickle_file, 'rb') as openfile:\n launch_year, launch_month, self.emo_stat, self.emo_sum, form_completed, self.asymmetry_sum = pickle.load(openfile)\n if (launch_year != self.cur_year) or (launch_month != self.cur_month) or not(form_completed):\n form_completed = False\n self.ShowBlanque()\n else:\n self.emo_stat = np.zeros(labels_count)\n self.emo_sum = 0\n self.asymmetry_sum = 0\n form_completed = True\n\n print(self.asymmetry_sum / max(self.emo_sum, 1))\n if (self.emo_sum >= asymmetry_time) and (self.asymmetry_sum / max(self.emo_sum, 1) >= dangerous_asymmetry):\n self.ShowWarning()\n \n self.setGeometry(300, 300, self.window_width, self.window_height)\n self.setFixedSize(self.window_width, self.window_height)\n\n # Set icon\n self.setWindowTitle('Emoreco')\n self.setWindowIcon(QIcon(root+'Logo.ico'))\n\n # Set background image\n oImage = QImage(root+\"Body.png\")\n palette = QPalette()\n palette.setBrush(QPalette.Window, QBrush(oImage))\n #self.setPalette(palette)\n \n # Set Update and Predict buttons\n oImage = QPixmap(root+\"Predict.png\")\n palette = QPalette()\n palette.setBrush(self.buttonPredict.backgroundRole(), QBrush(oImage))\n \n self.buttonPredict.setFlat(1)\n self.buttonPredict.setAutoFillBackground(1)\n self.buttonPredict.setPalette(palette)\n self.buttonPredict.clicked.connect(self.OnPredictClick)\n \n oImage = QPixmap(root+\"Update.png\")\n palette = QPalette()\n palette.setBrush(self.buttonUpdate.backgroundRole(), QBrush(oImage))\n \n self.buttonUpdate.setFlat(1)\n self.buttonUpdate.setAutoFillBackground(1)\n self.buttonUpdate.setPalette(palette)\n self.buttonUpdate.clicked.connect(self.OnUpdateClick)\n \n self.smoothed = np.zeros(labels_count)\n self.previous_predictions = list()\n self.smoothed_asymmetry = 0\n self.previous_asymmetries = list()\n self.previous_asymmetries_for_graph = list()\n \n self.prev_face = 0\n self.can_normalize = False\n self.frames_unrecognized = 0\n\n self.blinking_freq = list()\n self.results_n = 7\n self.counter = 0\n \n self.timer = QtCore.QBasicTimer()\n self.timer.start(10, self)\n self.prev_eyes_state = True #Opened or closed\n self.points_counter = 0\n self.tremor = 100\n self.show()\n \n def timerEvent(self, e):\n self.update() \n\n def resizeEvent(self, event):\n palette = QPalette()\n img = QImage(root+'Body.png')\n scaled = img.scaled(self.size(), Qt.KeepAspectRatioByExpanding, transformMode = Qt.SmoothTransformation)\n palette.setBrush(QPalette.Window, QBrush(scaled))\n self.setPalette(palette) \n \n def paintEvent(self, e):\n qp = QPainter()\n qp.begin(self)\n \n if blank_opened:\n self.drawDiagram(self.emo_stat, qp)\n self.drawAsymmetry(qp) \n return\n \n ret, frame = cap.read()\n frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)\n #win.clear_overlay()\n #win.set_image(frame)\n #print(self.tremor)\n nose_index = 27\n if self.tremor >= 20 or not(self.faces_found) or self.points_counter <= 60:\n image = cv2.resize(frame, (320, 240))\n self.detected_faces = face_detector(image, 1)\n\n #print(type(self.detected_faces))\n self.faces_found = False\n for i, face_rect in enumerate(self.detected_faces):\n if not(self.faces_found):\n \n self.faces_found = True\n \n face_rect = dlib.rectangle(face_rect.left() * 2, \n face_rect.top() * 2, \n face_rect.right() * 2, \n face_rect.bottom() * 2)\n\n pose_landmarks = face_pose_predictor(frame, face_rect)\n #win.add_overlay(pose_landmarks)\n #win.add_overlay(face_rect)\n self.points_counter = count_points(face_rect, pose_landmarks)\n #print(count_points(face_rect, pose_landmarks))\n\n face = list()\n for i in range(landmarks_n):\n face.append(pose_landmarks.part(i).x)\n face.append(pose_landmarks.part(i).y)\n\n face_unnormalized = np.array(face)\n face = normalize_dataset(np.array(face, dtype=float))\n \n self.predictEmotion(face)\n self.CalcAsymmetry(face)\n \n self.drawDiagram(self.emo_stat, qp)\n self.drawAsymmetry(qp) \n \n if self.faces_found:\n if self.can_normalize:\n self.tremor = np.linalg.norm((face_unnormalized - self.prev_face_unnormalized)[:32])\n #print(np.linalg.norm((face_unnormalized - self.prev_face_unnormalized)[:32]))\n face = (face + self.prev_face)/2\n \n self.drawPoints(face, qp)\n self.prev_face = face * 1\n self.prev_face_unnormalized = face_unnormalized * 1\n self.can_normalize = True\n self.frames_unrecognized = 0\n else:\n self.frames_unrecognized += 1\n \n if self.frames_unrecognized < 10:\n face = (mean_face + self.prev_face)/2\n self.drawPoints(face, qp)\n self.prev_face = face * 1\n else:\n self.can_normalize = False\n self.labelEmotion.setText('')\n self.labelPercent.setText('')\n \n #print(-start_time + time.time())\n self.counter += 1\n if self.counter == 5:\n self.counter = 0 \n\n def drawAsymmetry(self, qp):\n graph_w = 232\n graph_h = 104\n corner_x = 17\n corner_y = 678\n \n scale = 1\n circles_r = 10\n \n pen = QPen(Qt.SolidLine)\n pen.setColor(QColor(255, 255, 255))\n pen.setWidth (2)\n qp.setPen(pen)\n \n brush = QBrush(Qt.NoBrush)\n qp.setBrush(brush)\n \n #qp.drawLine(corner_x, corner_y + graph_h, corner_x + graph_w, corner_y + graph_h)\n #qp.drawLine(corner_x, corner_y + graph_h, corner_x, corner_y)\n \n interval = graph_w // (power*2)\n for i in range(len(self.previous_asymmetries_for_graph)):\n y = max(-(self.previous_asymmetries_for_graph[i])*scale + corner_y, corner_y - graph_h)\n #qp.drawEllipse(corner_x + interval * (i-1), \n #y, circles_r, circles_r) \n if i>=1:\n y_prev = max(-(self.previous_asymmetries_for_graph[i-1])*scale + corner_y, corner_y - graph_h)\n qp.drawLine(corner_x + interval * (i-1),\n y_prev,\n corner_x + interval * (i),\n y)\n #print('({})'.format(self.blinking_freq[i] - self.blinking_freq[i-1]))\n \n def predictEmotion(self, face): \n feed_dict = {\n td:np.array([face[34:]])\n }\n predictions = session.run(check_prediction, feed_dict=feed_dict)\n predictions.shape = labels_count\n \n self.smoothed += predictions\n self.previous_predictions.append(predictions)\n \n if len(self.previous_predictions) > power:\n self.smoothed -= self.previous_predictions[0]\n del self.previous_predictions[0]\n \n predictions_to_show = self.smoothed/len(self.previous_predictions)\n \n self.labelEmotion.setText(text[np.argmax(predictions_to_show)])\n self.labelPercent.setText(str(math.floor(np.max(predictions_to_show)*100)) + '%')\n \n self.emo_stat += predictions_to_show\n self.emo_sum += 1\n \n def CalcAsymmetry(self, face):\n left_corner = 48\n right_corner = 54\n left_eye = 36\n right_eye = 45\n nose = 30\n K = 2500 * 7\n \n v1 = [face[left_corner*2] - face[left_eye*2], face[left_corner*2+1] - face[left_eye*2+1]]\n v2 = [face[right_corner*2] - face[right_eye*2], face[right_corner*2+1] - face[right_eye*2+1]]\n\n asymmetry = abs((v1[0]*v1[0] + v1[1]*v1[1]) / (v2[0]*v2[0] + v2[1]*v2[1]) * 100 - 100)\n asymmetry -= abs(face[66]*100 - 50) * 0.7\n asymmetry = max(min(asymmetry*1.5, 100), 0)\n \n self.asymmetry_sum += asymmetry\n self.smoothed_asymmetry += asymmetry\n self.previous_asymmetries.append(asymmetry)\n self.previous_asymmetries_for_graph.append(asymmetry)\n \n if len(self.previous_asymmetries) > power:\n self.smoothed_asymmetry -= self.previous_asymmetries[0]\n del self.previous_asymmetries[0]\n\n if len(self.previous_asymmetries_for_graph) > power*2:\n del self.previous_asymmetries_for_graph[0]\n \n asymmetry_to_show = self.smoothed_asymmetry/len(self.previous_asymmetries)\n #self.labelAsymmetry.setText(str(int(face[66]*100)/100.))\n self.labelAsymmetry.setText(str(int(asymmetry_to_show)) + '%')# + ' ' + str(face[nose*2]))\n\n \n def drawDiagram(self, vector, qp):\n vector_t = vector[[1, 6, 4, 2, 0, 3, 5]]\n if self.emo_sum == 0:\n return\n \n # ДОБАВИТЬ ОБОДОЧЕК\n \n R = 250\n r = 200\n \n half_pi = 90*16\n \n pen = QPen(Qt.NoPen)\n qp.setPen(pen)\n brush = QBrush(Qt.SolidPattern)\n rectangle = QRectF(self.window_width - R, self.window_height - R, 2*R, 2*R)\n rectangle_small = QRectF(self.window_width - r, self.window_height - r, 2*r, 2*r)\n \n startAngle = half_pi\n colors = [QColor(128, 157, 249), QColor(85, 131, 242), QColor(114, 210, 172), \n QColor(223, 147, 249), QColor(207, 115, 252), QColor(158, 47, 205), \n QColor(124, 38, 163)]\n \n for i in range(len(vector)):\n brush.setColor(colors[i])\n qp.setBrush(brush)\n \n phi = int(vector_t[i] / self.emo_sum * half_pi)\n qp.drawPie(rectangle, startAngle, startAngle + phi)\n startAngle += phi\n \n brush.setColor(QColor(61, 56, 63))\n qp.setBrush(brush)\n qp.drawPie(rectangle_small, half_pi, half_pi*2)\n \n def drawPoints(self, face, qp):\n brush = QBrush(Qt.SolidPattern)\n brush.setColor(QColor(232, 241, 240))\n qp.setBrush(brush)\n pen = QPen(Qt.NoPen)\n qp.setPen(pen)\n\n w_x = 350\n w_y = 30\n w_width = 201\n w_height = 230\n \n for i in range (landmarks_n):\n qp.drawEllipse(face[2*i]*w_width+w_x, face[2*i+1]*w_height+w_y, 7, 7) \n \n def updateFinished(self):\n self.objThread.quit()\n self.LoadingAnimation.stop()\n self.LoadingLabel.hide()\n self.update_clicked = False\n self.objThread.wait()\n del self.obj\n del self.objThread\n\n def OnUpdateClick(self):\n if not(self.update_clicked):\n self.LoadingLabel.show()\n self.LoadingAnimation = QtGui.QMovie(root+\"LoadingAnimationSmall.gif\")\n self.LoadingLabel.setMovie(self.LoadingAnimation)\n self.LoadingAnimation.start()\n self.update_clicked = True\n self.objThread = QThread()\n self.obj = SomeObject()\n self.obj.moveToThread(self.objThread)\n self.obj.finished.connect(self.updateFinished)\n self.objThread.started.connect(self.obj.loadMatrix)\n self.objThread.start()\n\n def ShowBlanque(self):\n global blank_opened\n blank_opened = True\n self.secondWin = SecondWindow(self)\n self.secondWin.show()\n\n def ShowWarning(self):\n global blank_opened\n blank_opened = True\n self.warning = WarningWindow(self)\n self.warning.show()\n \n def OnPredictClick(self):\n global blank_opened\n global dis_prediction\n \n dis_prediction = predictDiseases(self.emo_stat / self.emo_sum) * 100\n \n blank_opened = True\n self.secondWin = PredictWindow(self)\n self.secondWin.show()\n \n def closeEvent(self, event):\n with open(self.stat_pickle_file, 'wb') as f:\n pickle.dump((self.cur_year, self.cur_month, self.emo_stat, self.emo_sum, form_completed, self.asymmetry_sum), f)\n \nBlankAnswer = list()\nclass SecondWindow(QWidget):\n agreed = False\n def __init__(self, parent=None):\n super().__init__(parent, QtCore.Qt.Window)\n uic.loadUi(root+'Blank.ui', self)\n self.build()\n\n def build(self):\n self.setWindowTitle('Emoreco')\n self.setWindowIcon(QIcon(root+'Logo.ico'))\n \n oImage = QPixmap(root+\"NextButton.png\")\n palette = QPalette()\n palette.setBrush(self.nextButton.backgroundRole(), QBrush(oImage))\n self.nextButton.setFlat(1)\n self.nextButton.setAutoFillBackground(1)\n self.nextButton.setPalette(palette)\n self.load_label.hide()\n \n self.boxes_list = [\n self.Circulatory,\n self.Digestive,\n self.Endocrine,\n self.Integumentary,\n self.Lymphatic,\n self.Muscular,\n self.Nervous,\n self.Excretory,\n self.Reproductive,\n self.Respiratory,\n self.Skeletal]\n \n self.stages_texts = [\n 'Please tick here those body systems that made you consult a doctor this month',\n 'Please tick here those body systems that made you take drugs this month',\n 'Please tick here those body systems with which minor problems occurred this month',\n 'Thanks you! Your response is now being sent to the server'\n ]\n \n self.sys_n = sys_n\n global BlankAnswer\n BlankAnswer = [0] * self.sys_n\n self.stages_n = 3\n self.cur_stage = 0\n self.stages_power = [3, 2, 1]\n self.nextButton.setStyleSheet('color: white;')\n self.nextButton.clicked.connect(self.nextStage)\n self.show()\n self.Heading.setStyleSheet('color: white;')\n \n def nextStage(self):\n if self.cur_stage == 4:\n self.close_window()\n return\n\n for box in range(self.sys_n):\n if self.boxes_list[box].isChecked():\n BlankAnswer[box] = max(BlankAnswer[box], self.stages_power[self.cur_stage])\n self.boxes_list[box].nextCheckState()\n \n print(BlankAnswer)\n self.cur_stage += 1\n self.Heading.setText(self.stages_texts[self.cur_stage])\n if self.cur_stage == 2:\n self.nextButton.setText('Send!')\n if self.cur_stage == 3:\n self.agreed = True\n self.send_and_close()\n\n def connection_failed(self):\n self.load_label.hide()\n self.nextButton.show()\n self.nextButton.setText('Close')\n self.Heading.setText(\"Connection failed. This form will be suggested next time.\")\n self.cur_stage = 4\n\n def close_window(self):\n global blank_opened\n blank_opened = False\n ex.emo_stat = np.zeros(labels_count)\n ex.emo_sum = 0\n self.objThread.quit()\n self.hide()\n self.objThread.wait()\n del self.objThread\n del self.obj\n\n def send_and_close(self):\n movie = QtGui.QMovie(root+\"LoadingAnimation.gif\")\n self.load_label.setMovie(movie)\n movie.start()\n self.load_label.show()\n\n self.nextButton.hide()\n self.objThread = QThread()\n self.obj = SomeObject()\n self.obj.moveToThread(self.objThread)\n self.obj.finished.connect(self.close_window)\n self.obj.connection_failed.connect(self.connection_failed)\n self.objThread.started.connect(self.obj.sendStatistic)\n self.objThread.start()\n \n def closeEvent(self, e):\n global blank_opened\n blank_opened = False\n ex.emo_stat = np.zeros(labels_count)\n ex.emo_sum = 0\n global form_completed\n if not(self.agreed):\n form_completed = True\n \ndis_prediction = list()\nclass PredictWindow(QWidget):\n def __init__(self, parent=None):\n super().__init__(parent, QtCore.Qt.Window)\n uic.loadUi(root+'Predict interface.ui', self)\n self.build()\n \n def build(self):\n self.setWindowTitle('Emoreco')\n self.setWindowIcon(QIcon(root+'Logo.ico'))\n \n oImage = QImage(root+\"Background.png\")\n palette = QPalette()\n palette.setBrush(QPalette.Window, QBrush(oImage))\n self.setPalette(palette)\n \n oImage = QPixmap(root+\"Ok.png\")\n palette = QPalette()\n palette.setBrush(self.OkButton.backgroundRole(), QBrush(oImage))\n \n self.OkButton.setFlat(1)\n self.OkButton.setAutoFillBackground(1)\n self.OkButton.setPalette(palette)\n self.OkButton.clicked.connect(self.closeWindow)\n set_list = [\n QBarSet('Circulatory'),\n QBarSet('Digestive'),\n QBarSet('Endocrine'),\n QBarSet('Integumentary'),\n QBarSet('Lymphatic'),\n QBarSet('Muscular'),\n QBarSet('Nervous'),\n QBarSet('Excretory'),\n QBarSet('Reproductive'),\n QBarSet('Respiratory'),\n QBarSet('Skeletal')]\n \n categories = ['']\n \n series = QBarSeries()\n chart = QChart()\n axis = QBarCategoryAxis()\n \n for i in range(sys_n):\n set_list[i].append([dis_prediction[i]])\n series.append(set_list[i])\n \n chart.addSeries(series)\n axis.append(categories)\n\n chart.setTitle('Our prediction (%)')\n \n chart.createDefaultAxes()\n chart.setAxisX(axis, series)\n chart.legend().setAlignment(Qt.AlignLeft)\n chart.setBackgroundBrush(QColor(61, 56, 63, 0))\n \n chartView = QChartView(chart)\n chartView.chart().setAnimationOptions(QChart.AllAnimations)\n \n base = self.gridLayout\n base.addWidget(chartView)\n self.show()\n \n def closeWindow(self):\n global blank_opened\n blank_opened = False\n self.hide()\n \n def closeEvent(self, e):\n global blank_opened\n blank_opened = False\n\nclass WarningWindow(QWidget):\n def __init__(self, parent=None):\n super().__init__(parent, QtCore.Qt.Window)\n uic.loadUi(root+'Warning interface.ui', self)\n self.build()\n \n def build(self):\n self.setWindowTitle('Emoreco')\n self.setWindowIcon(QIcon(root+'Logo.ico'))\n \n oImage = QPixmap(root+\"NextButton.png\")\n palette = QPalette()\n palette.setBrush(self.OkButton.backgroundRole(), QBrush(oImage))\n \n self.OkButton.setFlat(1)\n self.OkButton.setAutoFillBackground(1)\n self.OkButton.setPalette(palette)\n self.OkButton.clicked.connect(self.closeWindow)\n self.OkButton.setStyleSheet('color: white;')\n self.show()\n \n def closeWindow(self):\n global blank_opened\n blank_opened = False\n self.hide()\n \n def closeEvent(self, e):\n global blank_opened\n blank_opened = False\n\ndef initialize_app():\n if not(os.path.exists(prefix_to_edit + 'data')):\n os.makedirs(prefix_to_edit + 'data')\n with open('data/emo_to_diseases.pkl', 'rb') as f:\n data = pickle.load(f)\n f.close()\n\n with open(prefix_to_edit+'data/emo_to_diseases.pkl', 'wb') as f:\n pickle.dump(data, f)\n f.close()\n\n if not(os.path.exists(prefix_to_edit + 'data/emo_to_diseases.pkl')):\n with open('data/emo_to_diseases.pkl', 'rb') as f:\n data = pickle.load(f)\n f.close()\n\n with open(prefix_to_edit+'data/emo_to_diseases.pkl', 'wb') as f:\n pickle.dump(data, f)\n f.close() \n\n\nif __name__ == '__main__':\n initialize_app()\n app = QApplication(sys.argv)\n ex = Example()\n sys.exit(app.exec_())\n"
},
{
"alpha_fraction": 0.7910959124565125,
"alphanum_fraction": 0.7996575236320496,
"avg_line_length": 72,
"blob_id": "cdcf5baedb9159bd63cb5c253c1fb8bb2b49bcca",
"content_id": "a7e8f419308c6fa4e1b30d830d444933213c1661",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 584,
"license_type": "no_license",
"max_line_length": 304,
"num_lines": 8,
"path": "/README.md",
"repo_name": "geranium12/EmoReco",
"src_encoding": "UTF-8",
"text": "# EmoReco\n### Spring - Summer 2018\n\nIt is a source code of our team project which won first prize in the National Computer Science Conference and second prize in the BelSEF. This project was represented by Belarus at the EUCYS in Dublin, Ireland. \n\nThe program recognises your facial features and emotions by webcam. It collects your emotional statistics every month and send it to our server. The project uses Python, Tensorflow and PyQT. There are implementations of the random forest for facial alignment and a neural network for emotion recognition.\n\n\n"
},
{
"alpha_fraction": 0.5510955452919006,
"alphanum_fraction": 0.5698509812355042,
"avg_line_length": 26.97058868408203,
"blob_id": "907597fe2f201ab187efbd596e9ec8e496c6b521",
"content_id": "38d409a53607bafd16dcd4bf1bc6a905e879f0c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5705,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 204,
"path": "/data/server/kogeroclient.py",
"repo_name": "geranium12/EmoReco",
"src_encoding": "UTF-8",
"text": "\"\"\"\n KOGERO TEAM\n (!!!) Warning: USE ONLY updateClient & sendStatistic functions!\n\"\"\"\n\nimport sys\nimport threading\nimport queue\nimport socket\nimport pickle\n\nPACKET_SIZE = 4096\nCURRENT_VERSION = '0.1'\nRECV_TIMEOUT = 10\nSEND_TIMEOUT = 10\nSTR_ENCODING = 'UTF-8'\n\n\n#----------------------------------\n# Function to establish connection with server\n#----------------------------------\n\n\ndef establishConnection(host, port):\n \n connection_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n connection_socket.settimeout(10)\n try:\n connection_socket.connect((host, port))\n except:\n sys.exit(0)\n return connection_socket\n\n\n#----------------------------------\n# Functions for sending data\n#----------------------------------\n\n\ndef sendString(connection, string, timeout = SEND_TIMEOUT):\n \n encoded_string = bytes(string, STR_ENCODING)\n sendRaw(connection, encoded_string, timeout)\n return 1\n\ndef sendRaw(connection, bytes_stream, timeout = SEND_TIMEOUT):\n \n connection.settimeout(timeout)\n try:\n connection.sendall(bytes_stream)\n except:\n connection.close()\n sys.exit(0)\n return 1\n\n\n#----------------------------------\n# Functions for receiving data\n#----------------------------------\n\n\ndef getString(connection, timeout = RECV_TIMEOUT):\n \n encoded_string = getRaw(connection, timeout)\n return str(encoded_string, STR_ENCODING)\n\ndef getRaw(connection, timeout = RECV_TIMEOUT):\n \n data = b''\n connection.settimeout(timeout)\n while(True):\n try:\n fragment = connection.recv(PACKET_SIZE)\n except:\n connection.close()\n sys.exit(0)\n data += fragment\n if (len(fragment) < PACKET_SIZE):\n break\n if (data == b''):\n connection.close()\n sys.exit(0)\n return data\n\n\n#----------------------------------\n# Fucntions for handling types of connections in specialized Thread\n#----------------------------------\n\n\ndef sendStatisticThread(host, port, form_array, emotions_array, result_queue):\n \n connection_socket = establishConnection(host, port)\n sendString(connection_socket, 'STATS')\n answer = getString(connection_socket)\n if (answer == 'READY'):\n send_dict = {\n 'form' : form_array,\n 'emotions' : emotions_array\n }\n pickled_dict = pickle.dumps(send_dict)\n sendRaw(connection_socket, pickled_dict)\n answer = getString(connection_socket)\n if (answer == 'END'):\n result_queue.get()\n result_queue.put(1)\n connection_socket.close()\n\ndef updateClientThread(host, port, current_version, result_queue):\n \n pickled_data = None\n unpickled_dictionary = None\n matrix_7_16 = None\n matrix_16_12 = None\n connection_socket = establishConnection(host, port)\n sendString(connection_socket, 'UPDATE')\n server_version = getString(connection_socket)\n if (float(server_version) > float(current_version)):\n sendString(connection_socket, 'NEXT')\n answer = getString(connection_socket)\n if (answer != 'READY'):\n connection_socket.close()\n sys.exit(0)\n else:\n sendString(connection_socket, 'READY')\n pickled_data = getRaw(connection_socket)\n sendString(connection_socket, 'END')\n else:\n sendString(connection_socket, 'END')\n result_queue.get()\n result_queue.put(2)\n sys.exit(0)\n connection_socket.close()\n \n try:\n unpickled_dictionary = pickle.loads(pickled_data)\n matrix_7_16 = unpickled_dictionary['matrix_7_16']\n matrix_16_12 = unpickled_dictionary['matrix_16_11']\n bias_1 = unpickled_dictionary['bias_1']\n bias_2 = unpickled_dictionary['bias_2']\n except:\n sys.exit(0)\n\n\n result_queue.get()\n result_queue.put(1)\n result_queue.put(matrix_7_16)\n result_queue.put(matrix_16_12)\n result_queue.put(bias_1)\n result_queue.put(bias_2)\n result_queue.put(str(server_version))\n \n \n#----------------------------------\n# Functions for calling <SendFunction>Thread\n#----------------------------------\n\n\ndef sendStatistic(host, port, form_array, emotions_array):\n \n result_queue = queue.Queue()\n result_queue.put(0)\n connection_thread = threading.Thread(target = sendStatisticThread,\n args = (host, port, form_array,\n emotions_array, result_queue))\n connection_thread.start()\n connection_thread.join()\n \n send_status = result_queue.get()\n return send_status\n \ndef updateClient(host, port, current_version):\n \n matrix_7_16 = None\n matrix_16_12 = None\n bias_1 = None\n bias_2 = None\n new_version = current_version\n result_queue = queue.Queue()\n result_queue.put(0)\n connection_thread = threading.Thread(target = updateClientThread,\n args = (host, port,\n current_version, result_queue))\n connection_thread.start()\n connection_thread.join()\n \n update_status = result_queue.get()\n if (update_status == 1):\n try:\n matrix_7_16 = result_queue.get()\n matrix_16_12 = result_queue.get()\n bias_1 = result_queue.get()\n bias_2 = result_queue.get()\n new_version = result_queue.get()\n except:\n pass\n return update_status, matrix_7_16, matrix_16_12, bias_1, bias_2, new_version\n \n\nif __name__ == '__main__':\n\tinput()\n\tres = sendStatistic('10.97.91.153', 64000, [1, 2], [3, 4])\n\tprint(res)\n\tinput()"
},
{
"alpha_fraction": 0.5509339570999146,
"alphanum_fraction": 0.5545178055763245,
"avg_line_length": 26.468656539916992,
"blob_id": "4aa63858fc9d59dd4318ff91659d28d926a52164",
"content_id": "7daa78ba3673dfe573aa3c52708baafedf3dec04",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9208,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 335,
"path": "/data/server/kogeroserver.py",
"repo_name": "geranium12/EmoReco",
"src_encoding": "UTF-8",
"text": "\"\"\"\n KOGERO TEAM\n\"\"\"\n\nimport sys\nimport multiprocessing as mulpro\nimport time\nimport socket\nimport pickle\n\nMAX_CONNECTIONS = 10\nPACKET_SIZE = 4096\nACCEPT_TIMEOUT = 0.5\nCURRENT_VERSION = '0.3'\nRECV_TIMEOUT = 30\nSEND_TIMEOUT = 30\nERROR_TIMEOUT = 5\nSTR_ENCODING = 'UTF-8'\n\n\n#----------------------------------\n# Functions for manipulation with [ADMIN ~ SERVER] command pipe\n#----------------------------------\n \n\ndef closeServer(input_pipe):\n \n input_pipe.send('#CS')\n print('Server Closed.')\n\ndef checkPipe(read_pipe):\n \n if (read_pipe.poll()):\n message = read_pipe.recv()\n if (message == '#CS'):\n return True\n return False\n\n\n#----------------------------------\n# Old function for getting message\n#----------------------------------\n \n\n\"\"\"\ndef getMessage(connection, adress):\n \n data = b''\n \n while (True):\n \n try:\n fragment = connection.recv(PACKET_SIZE)\n except:\n return ERROR_MSG\n \n data += fragment\n if (len(fragment) < PACKET_SIZE):\n break\n \n if (data == b''):\n data = ERROR_MSG\n \n return data\n\"\"\"\n\n\n#----------------------------------\n# Functions for closing connections\n#----------------------------------\n\n\ndef closeConnectionError(connection, adress):\n \n print('Error. ERROR connection closing with {}.'.format(adress))\n connection.settimeout(ERROR_TIMEOUT)\n try:\n connection.sendall(bytes('ERROR', STR_ENCODING))\n except:\n pass\n connection.close()\n sys.exit(0)\n\ndef closeConnectionSuccess(connection, adress):\n \n print('Successfull talk with {}. Closing Connection.'.format(adress))\n connection.settimeout(SEND_TIMEOUT)\n try:\n connection.sendall(bytes('END', STR_ENCODING))\n except:\n closeConnectionError(connection, adress)\n connection.close()\n sys.exit(0)\n \n#----------------------------------\n# Functions for sending data\n#----------------------------------\n\n\ndef sendString(connection, adress, string, timeout = SEND_TIMEOUT):\n \n encoded_string = bytes(string, STR_ENCODING)\n sendRaw(connection, adress, encoded_string, timeout)\n return 1\n\ndef sendRaw(connection, adress, bytes_stream, timeout = SEND_TIMEOUT):\n \n connection.settimeout(timeout)\n try:\n connection.sendall(bytes_stream)\n except:\n closeConnectionError(connection, adress)\n return 1\n\n#----------------------------------\n# Functions for receiving data\n#----------------------------------\n\n\ndef getString(connection, adress, timeout = RECV_TIMEOUT):\n \n encoded_string = getRaw(connection, adress, timeout)\n return str(encoded_string, STR_ENCODING)\n\ndef getRaw(connection, adress, timeout = RECV_TIMEOUT):\n \n data = b''\n connection.settimeout(timeout)\n while(True):\n try:\n fragment = connection.recv(PACKET_SIZE)\n except:\n closeConnectionError(connection, adress)\n data += fragment\n if (len(fragment) < PACKET_SIZE):\n break\n if (data == b''):\n closeConnectionError(connection, adress)\n return data\n\n\n#----------------------------------\n# Functions for handling types of connections\n#----------------------------------\n \n \n#New\ndef receiveStatistic(connection, adress):\n \n sendString(connection, adress, 'READY')\n pickled_stats = getRaw(connection, adress)\n with open('{} {} {}.pickle'.format(time.strftime('%Y.%m.%d %H.%M.%S',\n time.gmtime(time.time())),\n adress[0], adress[1]), 'wb') as openfile:\n openfile.write(pickled_stats)\n \n received_dict = pickle.loads(pickled_stats)\n print('Received stats from {}.'.format(adress))\n print(str(received_dict['form']).replace('], ', '],\\n'))\n print(str(received_dict['emotions']).replace('], ', '],\\n'))\n print('-------------------------------------------')\n closeConnectionSuccess(connection, adress)\n return 1\n \n\"\"\"\n# Old\ndef receiveStatistic_OLD(connection, adress):\n \n connection.sendall(bytes('READY', 'UTF-8'))\n \n data = getMessage(connection, adress)\n \n if (data == ERROR_MSG):\n closeConnectionError(connection, adress)\n return ;\n \n received_object = pickle.loads(data)\n \n with open('{} {} {}.pickle'.format(time.strftime('%Y_%m_%d %H_%M_%S', time.gmtime(time.time())),\n adress[0], adress[1]), 'wb') as openfile:\n pickle.dump(received_object, openfile)\n \n connection.sendall(bytes('END', 'UTF-8'))\n connection.close()\n print('Received STATS from {}'.format(adress))\n\"\"\"\n \ndef updateClient(connection, adress):\n\n data = b''\n sendString(connection, adress, CURRENT_VERSION)\n answer = getString(connection, adress)\n if (answer == 'NEXT'):\n try:\n with open('UPDATE {}.pickle'.format(str(CURRENT_VERSION)), 'rb') as openfile:\n data = openfile.read()\n except FileNotFoundError:\n print('UPDATE {}.pickle do not insist.'.format(CURRENT_VERSION))\n closeConnectionError(connection, adress)\n sendString(connection, adress, 'READY')\n answer = getString(connection, adress)\n if (answer != 'READY'):\n closeConnectionError(connection, adress)\n sendRaw(connection, adress, data)\n answer = getString(connection, adress)\n if (answer == 'END'):\n print('Successfull update for {}'.format(adress))\n else:\n print(\"Undefined response from {}, but update package has been sent.\".format(adress))\n elif (answer == 'END'):\n print('{} has newer version of Network or client is Up-to-date. Aborting UPDATE.'.format(adress))\n else:\n closeConnectionError(connection, adress)\n closeConnectionSuccess(connection, adress)\n return 1\n \n\"\"\"\n#Old\ndef updateClient_OLD(connection, adress):\n \n connection.sendall(bytes(CURRENT_VERSION, 'UTF-8'))\n \n message = getMessage(connection, adress)\n if (message == ERROR_MSG):\n closeConnectionError(connection, adress)\n return ;\n \n elif (str(message, 'UTF-8') == 'NEXT'):\n \n with open('UPDATE {}.pickle'.format(CURRENT_VERSION), 'rb') as openfile:\n data = pickle.load(openfile)\n \n pickle_data = pickle.dumps(data)\n \n try:\n connection.sendall(pickle_data)\n except:\n closeConnectionError(connection, adress)\n return ;\n \n message = getMessage(connection, adress)\n if (str(message, 'UTF-8') == 'END'):\n print('Newer version of network sent to {}'.format(adress))\n else:\n print('Undefined error with {}, but looks like newer version of network was sent'.format(adress))\n \n else:\n print('{} have higher version'.format(adress))\n \n connection.close()\n\"\"\" \n\n\n#----------------------------------\n# Function for transfering each type of REQUEST for specialized function\n#----------------------------------\n\n \ndef serveClient(connection, adress):\n \n connection.settimeout(RECV_TIMEOUT)\n connection_type = getString(connection, adress)\n \n try:\n CONN_DICT[connection_type](connection, adress)\n except KeyError:\n closeConnectionError(connection, adress)\n\n\n#----------------------------------\n# Main server connection accepting process\n#---------------------------------- \n\n\ndef acceptConnections(server_socket, server_pipe):\n \n server_socket.listen(MAX_CONNECTIONS)\n server_socket.settimeout(ACCEPT_TIMEOUT)\n \n print('Starting Connections Acceptation...')\n \n while (True):\n \n if (checkPipe(server_pipe)):\n break\n \n try:\n connection, adress = server_socket.accept()\n except: \n continue\n \n print('Connection Accepted from ADR {}.'.format(adress))\n client_process = mulpro.Process(target = serveClient,\n args = (connection, adress))\n client_process.daemon = False\n client_process.start()\n \n server_socket.close()\n return 1\n\n\n#----------------------------------\n# Function for __init__ server from ServerCommander\n#----------------------------------\n \n\ndef initializeServer(host, port):\n\n parent_end, child_end = mulpro.Pipe()\n \n try:\n server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n server_socket.bind((str(host), int(port)))\n except:\n print(\"Can't bind to ({}, {}). Aborting server __init__.\".format(host, port))\n return -1\n \n server_process = mulpro.Process(target = acceptConnections,\n args = (server_socket, child_end))\n server_process.daemon = False\n server_process.start()\n \n print('Server Initialized.')\n \n return parent_end\n\n\n#----------------------------------\n# DICTIONARY which contains references to ServeClient functions\n#----------------------------------\n\nCONN_DICT = {\n 'UPDATE' : updateClient,\n 'STATS': receiveStatistic\n }\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5897097587585449,
"alphanum_fraction": 0.6068601608276367,
"avg_line_length": 28.480520248413086,
"blob_id": "f6fd56071e3ed2c35343ac1c5297c55ce1b6233d",
"content_id": "c1ba933d5ded8858651f59fe60f3461618cbc3e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2274,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 77,
"path": "/data/server/untitled0.py",
"repo_name": "geranium12/EmoReco",
"src_encoding": "UTF-8",
"text": "# library\nimport matplotlib.pyplot as plt\n \n# create data\nsize_of_groups=[3,1]\n \n# Create a pieplot\nplt.pie(size_of_groups)\n#plt.show()\n \n# add a circle at the center\nmy_circle=plt.Circle( (0,0), 0.7, color='white')\np=plt.gcf()\np.gca().add_artist(my_circle)\n \nplt.show()\n\n '''\n m_brushTool = new BrushTool(\"Slice brush\", this);\n m_brushTool->setBrush(m_slice->originalBrush());\n m_brush.setColor(dialog.selectedColor());\n m_slice->setBrush(m_brushTool->brush());\n \n Series->setHoleSize(0.35);\n series->append(\"Protein 4.2%\", 4.2);\n QPieSlice *slice = series->append(\"Fat 15.6%\", 15.6);\n slice->setExploded();\n slice->setLabelVisible();\n series->append(\"Other 23.8%\", 23.8);\n series->append(\"Carbs 56.4%\", 56.4);\n \n QChartView *chartView = new QChartView();\n chartView->setRenderHint(QPainter::Antialiasing);\n chartView->chart()->setTitle(\"Donut with a lemon glaze (100g)\");\n chartView->chart()->addSeries(series);\n chartView->chart()->legend()->setAlignment(Qt::AlignBottom);\n chartView->chart()->setTheme(QChart::ChartThemeBlueCerulean);\n chartView->chart()->legend()->setFont(QFont(\"Arial\", 7));'''\n \n \n \n#QChart::ChartTheme theme = static_cast<QChart::ChartTheme>(m_themeComboBox->itemData(\n # m_themeComboBox->currentIndex()).toInt());\n # m_chartView->chart()->setTheme(theme);\n \n #m_startAngle = new QDoubleSpinBox();\n \n # m_startAngle->setValue(m_series->pieStartAngle());\n \n #_series->setPieEndAngle(m_endAngle->value());\n \n '''m_slice->setExploded(m_sliceExploded->isChecked());\n \n CustomSlice::CustomSlice(QString label, qreal value)\n : QPieSlice(label, value)\n{\n connect(this, &CustomSlice::hovered, this, &CustomSlice::showHighlight);\n}\n\nQBrush CustomSlice::originalBrush()\n{\n return m_originalBrush;\n}\n\nvoid CustomSlice::showHighlight(bool show)\n{\n if (show) {\n QBrush brush = this->brush();\n m_originalBrush = brush;\n brush.setColor(brush.color().lighter());\n setBrush(brush);\n } else {\n setBrush(m_originalBrush);\n }\n}\n \n *m_series << new CustomSlice(\"Slice 1\", 10.0);'''\n "
}
] | 7 |
suhas-iyer-au7/Predicting_heart_disease
|
https://github.com/suhas-iyer-au7/Predicting_heart_disease
|
287669c7f732c44402f34fe52f9b3d00f47c42f6
|
c3ac98d8752acf22d5347be12276d6bb1ddf01ba
|
2cc9645479fdf5e7d54ed69cbe2a968dcfbe8ea2
|
refs/heads/master
| 2022-11-15T02:41:49.268065 | 2020-07-14T12:07:10 | 2020-07-14T12:07:10 | 279,574,165 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6044735312461853,
"alphanum_fraction": 0.6115657687187195,
"avg_line_length": 29.065574645996094,
"blob_id": "7ff489fd92a2deaf1df1ce04f9808407d702533c",
"content_id": "8ba5c4dd016fc7377ba990c1273243cf78606e9c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1833,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 61,
"path": "/app.py",
"repo_name": "suhas-iyer-au7/Predicting_heart_disease",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom flask import Flask, request, jsonify, render_template\nimport pickle\n\napp = Flask(__name__)\nmodel = pickle.load(open('model.pkl', 'rb'))\n\[email protected]('/')\ndef home():\n return render_template('index.html')\n\n\ndef ValuePredictor(to_predict_list): \n to_predict = np.array(to_predict_list).reshape(1, 13) \n result = model.predict(to_predict) \n return result[0]\[email protected]('/predict',methods=['POST'])\ndef predict():\n '''\n For rendering results on HTML GUI\n '''\n int_features = [float(x) for x in request.form.values()]\n final_features = [np.array(int_features)]\n prediction = model.predict(final_features)\n\n output = round(prediction[0], 2)\n if int(output)== 1: \n prediction ='High chances of heart disease'\n else: \n prediction ='Chances of heart disease is less' \n return render_template('index.html', prediction_text='{}'.format(prediction))\n\n\n\n\n# @app.route('/result', methods = ['POST']) \n# def result(): \n# if request.method == 'POST': \n# to_predict_list = request.form.to_dict() \n# to_predict_list = list(to_predict_list.values()) \n# to_predict_list = list(map(int, to_predict_list)) \n# result = ValuePredictor(to_predict_list) \n# if int(result)== 1: \n# prediction ='Income more than 50K'\n# else: \n# prediction ='Income less that 50K' \n# return render_template(\"result.html\", prediction = prediction)\n\[email protected]('/predict_api',methods=['POST'])\ndef predict_api():\n '''\n For direct API calls trought request\n '''\n data = request.get_json(force=True)\n prediction = model.predict([np.array(list(data.values()))])\n\n output = prediction[0]\n return jsonify(output)\n\nif __name__ == \"__main__\":\n app.run(debug=True)"
},
{
"alpha_fraction": 0.36714738607406616,
"alphanum_fraction": 0.40102726221084595,
"avg_line_length": 24.8925838470459,
"blob_id": "4a1932100af0503d04e6743ad82d701a4171466b",
"content_id": "208cf76de2affb90a3bcadc87b366cfd2b9a16a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10124,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 391,
"path": "/heart.py",
"repo_name": "suhas-iyer-au7/Predicting_heart_disease",
"src_encoding": "UTF-8",
"text": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"# Heart Disease Prediction\\n\",\n \"\\n\",\n \"\\n\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 31,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"import numpy as np\\n\",\n \"import pandas as pd\\n\",\n \"import matplotlib.pyplot as plt\\n\",\n \"from matplotlib import rcParams\\n\",\n \"from matplotlib.cm import rainbow\\n\",\n \"%matplotlib inline\\n\",\n \"import warnings\\n\",\n \"warnings.filterwarnings('ignore')\\n\",\n \"import pickle\\n\",\n \"from sklearn.neighbors import KNeighborsClassifier\\n\",\n \"from sklearn.tree import DecisionTreeClassifier\\n\",\n \"from sklearn.ensemble import RandomForestClassifier\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 44,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"dataset = pd.read_csv('G:/suhas/Predicting-Heart-Disease-master/dataset.csv')\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 45,\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/html\": [\n \"<div>\\n\",\n \"<style scoped>\\n\",\n \" .dataframe tbody tr th:only-of-type {\\n\",\n \" vertical-align: middle;\\n\",\n \" }\\n\",\n \"\\n\",\n \" .dataframe tbody tr th {\\n\",\n \" vertical-align: top;\\n\",\n \" }\\n\",\n \"\\n\",\n \" .dataframe thead th {\\n\",\n \" text-align: right;\\n\",\n \" }\\n\",\n \"</style>\\n\",\n \"<table border=\\\"1\\\" class=\\\"dataframe\\\">\\n\",\n \" <thead>\\n\",\n \" <tr style=\\\"text-align: right;\\\">\\n\",\n \" <th></th>\\n\",\n \" <th>age</th>\\n\",\n \" <th>sex</th>\\n\",\n \" <th>cp</th>\\n\",\n \" <th>trestbps</th>\\n\",\n \" <th>chol</th>\\n\",\n \" <th>fbs</th>\\n\",\n \" <th>restecg</th>\\n\",\n \" <th>thalach</th>\\n\",\n \" <th>exang</th>\\n\",\n \" <th>oldpeak</th>\\n\",\n \" <th>slope</th>\\n\",\n \" <th>ca</th>\\n\",\n \" <th>thal</th>\\n\",\n \" <th>target</th>\\n\",\n \" </tr>\\n\",\n \" </thead>\\n\",\n \" <tbody>\\n\",\n \" <tr>\\n\",\n \" <th>0</th>\\n\",\n \" <td>63</td>\\n\",\n \" <td>1</td>\\n\",\n \" <td>3</td>\\n\",\n \" <td>145</td>\\n\",\n \" <td>233</td>\\n\",\n \" <td>1</td>\\n\",\n \" <td>0</td>\\n\",\n \" <td>150</td>\\n\",\n \" <td>0</td>\\n\",\n \" <td>2.3</td>\\n\",\n \" <td>0</td>\\n\",\n \" <td>0</td>\\n\",\n \" <td>1</td>\\n\",\n \" <td>1</td>\\n\",\n \" </tr>\\n\",\n \" <tr>\\n\",\n \" <th>1</th>\\n\",\n \" <td>37</td>\\n\",\n \" <td>1</td>\\n\",\n \" <td>2</td>\\n\",\n \" <td>130</td>\\n\",\n \" <td>250</td>\\n\",\n \" <td>0</td>\\n\",\n \" <td>1</td>\\n\",\n \" <td>187</td>\\n\",\n \" <td>0</td>\\n\",\n \" <td>3.5</td>\\n\",\n \" <td>0</td>\\n\",\n \" <td>0</td>\\n\",\n \" <td>2</td>\\n\",\n \" <td>1</td>\\n\",\n \" </tr>\\n\",\n \" <tr>\\n\",\n \" <th>2</th>\\n\",\n \" <td>41</td>\\n\",\n \" <td>0</td>\\n\",\n \" <td>1</td>\\n\",\n \" <td>130</td>\\n\",\n \" <td>204</td>\\n\",\n \" <td>0</td>\\n\",\n \" <td>0</td>\\n\",\n \" <td>172</td>\\n\",\n \" <td>0</td>\\n\",\n \" <td>1.4</td>\\n\",\n \" <td>2</td>\\n\",\n \" <td>0</td>\\n\",\n \" <td>2</td>\\n\",\n \" <td>1</td>\\n\",\n \" </tr>\\n\",\n \" <tr>\\n\",\n \" <th>3</th>\\n\",\n \" <td>56</td>\\n\",\n \" <td>1</td>\\n\",\n \" <td>1</td>\\n\",\n \" <td>120</td>\\n\",\n \" <td>236</td>\\n\",\n \" <td>0</td>\\n\",\n \" <td>1</td>\\n\",\n \" <td>178</td>\\n\",\n \" <td>0</td>\\n\",\n \" <td>0.8</td>\\n\",\n \" <td>2</td>\\n\",\n \" <td>0</td>\\n\",\n \" <td>2</td>\\n\",\n \" <td>1</td>\\n\",\n \" </tr>\\n\",\n \" <tr>\\n\",\n \" <th>4</th>\\n\",\n \" <td>57</td>\\n\",\n \" <td>0</td>\\n\",\n \" <td>0</td>\\n\",\n \" <td>120</td>\\n\",\n \" <td>354</td>\\n\",\n \" <td>0</td>\\n\",\n \" <td>1</td>\\n\",\n \" <td>163</td>\\n\",\n \" <td>1</td>\\n\",\n \" <td>0.6</td>\\n\",\n \" <td>2</td>\\n\",\n \" <td>0</td>\\n\",\n \" <td>2</td>\\n\",\n \" <td>1</td>\\n\",\n \" </tr>\\n\",\n \" </tbody>\\n\",\n \"</table>\\n\",\n \"</div>\"\n ],\n \"text/plain\": [\n \" age sex cp trestbps chol fbs restecg thalach exang oldpeak slope \\\\\\n\",\n \"0 63 1 3 145 233 1 0 150 0 2.3 0 \\n\",\n \"1 37 1 2 130 250 0 1 187 0 3.5 0 \\n\",\n \"2 41 0 1 130 204 0 0 172 0 1.4 2 \\n\",\n \"3 56 1 1 120 236 0 1 178 0 0.8 2 \\n\",\n \"4 57 0 0 120 354 0 1 163 1 0.6 2 \\n\",\n \"\\n\",\n \" ca thal target \\n\",\n \"0 0 1 1 \\n\",\n \"1 0 2 1 \\n\",\n \"2 0 2 1 \\n\",\n \"3 0 2 1 \\n\",\n \"4 0 2 1 \"\n ]\n },\n \"execution_count\": 45,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"dataset.head()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"### Data Processing\\n\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 46,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"dataset = pd.get_dummies(df, columns = ['sex', 'cp', 'fbs', 'restecg', 'exang', 'slope', 'ca', 'thal'])\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 47,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from sklearn.model_selection import train_test_split\\n\",\n \"from sklearn.preprocessing import StandardScaler\\n\",\n \"standardScaler = StandardScaler()\\n\",\n \"columns_to_scale = ['age', 'trestbps', 'chol', 'thalach', 'oldpeak']\\n\",\n \"dataset[columns_to_scale] = standardScaler.fit_transform(dataset[columns_to_scale])\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 48,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"y = dataset['target']\\n\",\n \"X = dataset.drop(['target'], axis = 1)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 49,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from sklearn.model_selection import cross_val_score\\n\",\n \"knn_scores = []\\n\",\n \"for k in range(1,21):\\n\",\n \" knn_classifier = KNeighborsClassifier(n_neighbors = k)\\n\",\n \" score=cross_val_score(knn_classifier,X,y,cv=10)\\n\",\n \" knn_scores.append(score.mean())\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 50,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"knn_classifier = KNeighborsClassifier(n_neighbors = 12)\\n\",\n \"score=cross_val_score(knn_classifier,X,y,cv=10)\\n\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 51,\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"0.8448387096774195\"\n ]\n },\n \"execution_count\": 51,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"score.mean()\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"## Random Forest Classifier\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 52,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"from sklearn.ensemble import RandomForestClassifier\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 53,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \" RandomForestClassifier(n_estimators=10)\\n\",\n \"\\n\",\n \"score=cross_val_score(randomforest_classifier,X,y,cv=10)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 54,\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"0.8082795698924731\"\n ]\n },\n \"execution_count\": 54,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"score.mean()\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 55,\n \"metadata\": {},\n \"outputs\": [\n {\n \"data\": {\n \"text/plain\": [\n \"RandomForestClassifier(bootstrap=True, ccp_alpha=0.0, class_weight=None,\\n\",\n \" criterion='gini', max_depth=None, max_features='auto',\\n\",\n \" max_leaf_nodes=None, max_samples=None,\\n\",\n \" min_impurity_decrease=0.0, min_impurity_split=None,\\n\",\n \" min_samples_leaf=1, min_samples_split=2,\\n\",\n \" min_weight_fraction_leaf=0.0, n_estimators=10,\\n\",\n \" n_jobs=None, oob_score=False, random_state=None,\\n\",\n \" verbose=0, warm_start=False)\"\n ]\n },\n \"execution_count\": 55,\n \"metadata\": {},\n \"output_type\": \"execute_result\"\n }\n ],\n \"source\": [\n \"randomforest_classifier.fit(X,y)\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": 56,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# Saving model to disk\\n\",\n \"pickle.dump(randomforest_classifier, open('model.pkl','wb'))\\n\",\n \"\\n\",\n \"# Loading model to compare the results\\n\",\n \"model = pickle.load(open('model.pkl','rb'))\\n\",\n \"# print(model.predict([[2, 9, 6]]))\"\n ]\n }\n ],\n \"metadata\": {\n \"kernelspec\": {\n \"display_name\": \"Python 3\",\n \"language\": \"python\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\",\n \"version\": \"3.7.6\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 2\n}\n"
}
] | 2 |
leonardocasini/LeapGesturalCar
|
https://github.com/leonardocasini/LeapGesturalCar
|
851ef9bf0db1561b5802ce2eb5d511e836bf4d66
|
2571e91cad7d338d5430a557caa96cf8a33d8c29
|
939f3da009e5674a81ab2d0f70ba7b9ec43ac10e
|
refs/heads/master
| 2021-09-17T15:39:41.589024 | 2018-07-03T09:48:29 | 2018-07-03T09:48:29 | 125,860,247 | 0 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6088680624961853,
"alphanum_fraction": 0.6499639749526978,
"avg_line_length": 16.0864200592041,
"blob_id": "dfd2903409f88f4240e0bb25a813992313e2d0f9",
"content_id": "5ed9c019dcda3df18894218fd81cd7990c8f578c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2774,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 162,
"path": "/test.py",
"repo_name": "leonardocasini/LeapGesturalCar",
"src_encoding": "UTF-8",
"text": "import os, sys\nimport time\nimport RPi.GPIO as GPIO\n# to use Raspberry Pi board pin numbers\nGPIO.setmode(GPIO.BCM)\n\n# set up the GPIO channels\nr1 = 16 #DX Anteriore\nr2 = 26 #DX Posteriore\nr3 = 21 #SX Anteriore\nr4 = 20 #SX Posteriore\nr5 = 12 #DX Anteriore 2\nr6 = 19 #Dx Posteriore 2\nr7 = 13 #SX Anteriore 2\nr8 = 6 #SX Posteriore 2\nGPIO.setup(r1, GPIO.OUT) # GPIO 0\nGPIO.setup(r2, GPIO.OUT) # GPIO 1\nGPIO.setup(r3, GPIO.OUT) # GPIO 2\nGPIO.setup(r4, GPIO.OUT) # GPIO 3\nGPIO.setup(r5, GPIO.OUT) # GPIO 4\nGPIO.setup(r6, GPIO.OUT) # GPIO 5\nGPIO.setup(r7, GPIO.OUT) # GPIO 6\nGPIO.setup(r8, GPIO.OUT) # GPIO 7\n\n\ndef halt():\n\tGPIO.output(r1, True) #GPI O a 1 Led acceso\n\tGPIO.output(r2, True) #GPI 1 a 1 Led acceso\n\tGPIO.output(r3, True) #GPI 2 a 1 Led acceso\n\tGPIO.output(r4, True) #GPI 3 a 1 Led acceso\n\tGPIO.output(r5, False) #GPI 4 a 1 Led acceso\n\tGPIO.output(r6, False) #GPI 5 a 1 Led acceso\n\tGPIO.output(r7, False) #GPI 6 a 1 Led acceso\n\tGPIO.output(r8, False) #GPI 7 a 1 Led acceso\n\n#Pin setting for each wheels\ndef DxAnt():\n\tGPIO.output(r3, True)\n\tGPIO.output(r7, True)\ndef DxPost():\n\tGPIO.output(r1, True)\n\tGPIO.output(r5, True)\ndef SxAnt():\n\tGPIO.output(r4, True)\n\tGPIO.output(r8, True)\ndef SxPost():\n\tGPIO.output(r2, True)\n\tGPIO.output(r6, True)\ndef DxAnt2():\n\tGPIO.output(r4, False)\ndef DxPost2():\n\tGPIO.output(r3, False)\ndef SxAnt2():\n\tGPIO.output(r2, False)\ndef SxPost2():\n\tGPIO.output(r1, False)\n\n\n#Once the pins have been set, we made the turning methods \ndef goAhead():\n\thalt()\n\tDxAnt()\n\tSxAnt()\n\tDxPost()\n\tSxPost()\n\ndef goBack():\n\thalt()\n\tDxAnt2()\n\tSxAnt2()\n\tDxPost2()\n\tSxPost2()\n\ndef DxSoft():\n\thalt()\n\tSxAnt()\n\tDxPost()\n\tSxPost()\n\ndef DxHard():\n\thalt()\n\tSxAnt()\n\tSxPost()\n\ndef SxSoft():\n\thalt()\n\tDxAnt()\n\tDxPost()\n\tSxPost()\n\ndef SxHard():\n\thalt()\n\tDxAnt()\n\tDxPost()\n\ndef SxSoft2():\n\thalt()\n\tSxAnt2()\n\tDxPost2()\n\tDxAnt2()\n\ndef SxHard2():\n\thalt()\n\tDxAnt2()\n\tDxPost2()\n\ndef DxSoft2():\n\thalt()\n\tDxAnt2()\n\tSxPost2()\n\tSxAnt2()\n\ndef DxHard2():\n\thalt()\n\tDxAnt2()\n\tDxPost2()\n\n\nif __name__ == '__main__':\n\n\n\tif len(sys.argv) > 1:\n\t\tbehavior = str(sys.argv[1])\n\t#Behavior set on LeapMotionWidget decide which pins active\n\tif behavior == \"halt\":\n\t\thalt()\n\telif behavior == \"goAhead\":\n\t\tgoAhead()\n\telif behavior == \"goBack\":\n\t\tgoBack()\n\telif behavior == \"SxSoft\":\n\t\tSxSoft()\n\telif behavior == \"SxHard\":\n\t\tSxHard()\n\telif behavior == \"DxSoft\":\n\t\tDxSoft()\n\telif behavior == \"DxHard\":\n\t\tDxHard()\n\telif behavior == \"SxSoft2\":\n\t\tSxSoft2()\n\telif behavior == \"SxHard2\":\n\t\tSxHard2()\n\telif behavior == \"DxSoft2\":\n\t\tDxSoft2()\n\telif behavior == \"DxHard2\":\n\t\tDxHard2()\n\t\n\telif behavior == \"test\":\n\t\t#Some command to check if working\n\t\thalt()\n\t\tSxAnt()\n\t\ttime.sleep(1)\n\t\thalt()\n\t\tSxPost()\n\t\ttime.sleep(1)\n\t\thalt()\n\t\tDxPost()\n\t\ttime.sleep(1)\n\t\thalt()\n\t\tDxAnt()\n\t\ttime.sleep(1)\n\t\thalt()\n\t\n\n\n\t\n"
},
{
"alpha_fraction": 0.6492537260055542,
"alphanum_fraction": 0.6492537260055542,
"avg_line_length": 18.14285659790039,
"blob_id": "937a5753f6287b438dac22c1fa98c78709acaac2",
"content_id": "ee8e96794d30e4dc77879466325bfbf6ca64d42e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 134,
"license_type": "permissive",
"max_line_length": 67,
"num_lines": 7,
"path": "/scriptHalt.php",
"repo_name": "leonardocasini/LeapGesturalCar",
"src_encoding": "UTF-8",
"text": "\n<?php\n$behavior = $_GET['behavior'];\necho $behavior;\n$a- exec(\"sudo python /var/www/html/apiLeorio/test.py \".$behavior);\necho $a;\n\n?>"
},
{
"alpha_fraction": 0.5806555151939392,
"alphanum_fraction": 0.5931073427200317,
"avg_line_length": 38.517459869384766,
"blob_id": "1a5ccd605b7e532f1b9baf6cac3ce786fefce7c9",
"content_id": "e7b82bad6d5d8db0589f840f2bdb59d44da04d44",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12448,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 315,
"path": "/main.PY",
"repo_name": "leonardocasini/LeapGesturalCar",
"src_encoding": "UTF-8",
"text": "from Tkinter import *\nfrom time import *\nimport timeit\nimport tkMessageBox\nimport urllib2\nimport cv2\nimport Tkinter as tk\nfrom PIL import ImageTk, Image\n\nimport os, sys, inspect, thread, time\nsrc_dir = os.path.dirname(inspect.getfile(inspect.currentframe()))\narch_dir = os.path.abspath(os.path.join(src_dir, 'lib'))\nsys.path.insert(0, os.path.abspath(os.path.join(src_dir, arch_dir)))\n\nimport Leap\n\nfrom LeapMotionWidget import DriveListener2\n\nclass DriveListener(Leap.Listener):\n newBehavior='Try' \n behavior = 'None'\n #Below attributes is used to chose event gestures\n chooseXDirection=None#3\n chooseYDirection=None#0\n window = None\n #Boolean attributes used to check hand's presence\n defaultLeft = False\n defaultRight = False\n\n def setFrame(self, caller):\n #It is necessary to call method that chnage appearance of window\n self.window = caller\n \n def on_connect(self, controller):\n print \"Connected\"\n\n def on_frame(self, controller):\n boolLeft = False\n boolRight = False\n frame = controller.frame()\n #Initilize boolean false\n self.window.setSwitchColorLeft(False)\n self.window.setSwitchColorRight(False)\n #No Hands\n if len(frame.hands) ==0:\n self.chooseXDirection=0\n #One hand\n elif len(frame.hands) == 1: \n if frame.hands[0].is_left == False : \n self.chooseXDirection=0\n \n for hand in frame.hands:\n #handType = \"Left hand\" if hand.is_left else \"Right hand\" CI STA DA BUTTARE\n if hand.is_left: \n boolLeft = True\n #Set direction of car \n #postive go a head\n if hand.palm_position[2] > 40 : \n self.chooseXDirection= 2 \n #negative go back\n elif hand.palm_position[2] < -40 :\n self.chooseXDirection = 1\n\n #Normal of hand\n normal = hand.palm_normal\n\n #Detect right hand\n if not hand.is_left:\n boolRight = True\n\n #Right hand's roll decide the direction of car\n #Positive \n if normal.roll* Leap.RAD_TO_DEG < 30 and normal.roll* Leap.RAD_TO_DEG>-30:\n self.chooseYDirection=0 \n if normal.roll* Leap.RAD_TO_DEG < -40 :\n self.chooseYDirection=1\n if normal.roll* Leap.RAD_TO_DEG < -70 :\n self.chooseYDirection=3\n if normal.roll* Leap.RAD_TO_DEG > 60 : \n self.chooseYDirection=2\n if normal.roll* Leap.RAD_TO_DEG > 90 :\n self.chooseYDirection=4\n \n #Based on the previous checks the attribute newBehavior is set\n if self.chooseXDirection== 0:\n self.newBehavior='halt'\n elif self.chooseXDirection== 1 and self.chooseYDirection==0:\n self.newBehavior='goAhead'\n elif self.chooseXDirection==1 and self.chooseYDirection==1:\n self.newBehavior='DxSoft'\n elif self.chooseXDirection==1 and self.chooseYDirection==3:\n self.newBehavior='DxHard'\n elif self.chooseXDirection==1 and self.chooseYDirection==2:\n self.newBehavior='SxSoft'\n elif self.chooseXDirection==1 and self.chooseYDirection==4:\n self.newBehavior='SxHard' \n elif self.chooseXDirection==2 and self.chooseYDirection==0:\n self.newBehavior= 'goBack'\n elif self.chooseXDirection==2 and self.chooseYDirection==1:\n self.newBehavior= 'DxSoft2'\n elif self.chooseXDirection==2 and self.chooseYDirection==2:\n self.newBehavior= 'SxSoft2'\n\n #Below if statement check if there are a changes on bahavior car\n if self.behavior != self.newBehavior:\n #If newBehavior is different from behavior call method and reload attribute behavior \n self.behavior = self.newBehavior\n if self.behavior == 'DxSoft':\n self.window.turnDXsoft()\n elif self.behavior == 'goAhead':\n self.window.GoAhead()\n elif self.behavior == 'SxSoft':\n self.window.turnSXsoft()\n elif self.behavior == 'SxHard':\n self.window.turnSXhard()\n elif self.behavior == 'goBack':\n self.window.goBack()\n elif self.behavior == 'DxHard':\n self.window.turnDXhard()\n elif self.behavior == 'SxSoft2':\n self.window.turnDXback()\n elif self.behavior == 'DxSoft2':\n self.window.turnSXback()\n #Send Http Request with the new behavior \n contents = urllib2.urlopen(\"http://bernice.local/apiLeorio/scriptHalt.php?behavior=\"+self.behavior).read()\n\n #if there is a change in hand presence/absent\n if self.defaultLeft != boolLeft:\n #LeftHand founded\n if boolLeft == True:\n self.window.change_color_left_green()\n self.defaultLeft = boolLeft\n #LeftHand not founded\n else:\n self.window.change_color_left_white()\n self.defaultLeft = boolLeft\n #Stop driving car\n contents = urllib2.urlopen(\"http://bernice.local/apiLeorio/scriptHalt.php?behavior=\"+'halt').read() \n if self.defaultRight != boolRight:\n #RightHand founded\n if boolRight == True:\n self.window.change_color2_right_white()\n self.defaultRight = boolRight \n #RightHand not founded\n else:\n self.window.change_color2_right_white()\n self.defaultRight = boolRight \n\n\nclass Window:\n def __init__(self):\n #Initialize a window\n self.window = tk.Tk()\n self.window.configure(background='gray13')\n self.window.protocol('WM_DELETE_WINDOW',self.on_closing)\n self.window.grid()\n self.window.resizable(False,False)\n\n #Initialize Leap Controller\n self.leap = Leap.Controller()\n \n #Boolen check if start drive\n self.checkStart = False\n \n #Initialize listener and linked to Frame\n self.listener = DriveListener2()#DriveListener()\n self.listener.setFrame(self)\n \n #Two boolean for check state of hands\n self.switchColorLeft = False\n self.switchColorRight = False\n\n #Set window title and size\n self.window.title( \"Control Panel\" )\n self.window.geometry( \"472x650\" )\n\n #Open image of car go a head\n self.imgGoAhead = Image.open('images/carw.jpg')\n #resize to content of window\n self.imgGoAhead = self.imgGoAhead.resize((461, 507),Image.ANTIALIAS)\n img = ImageTk.PhotoImage(self.imgGoAhead)\n #Set the image on panel\n self.panel = tk.Label(self.window, image = img)\n self.panel.pack(side = \"bottom\", fill = \"both\", expand = \"yes\")\n self.panel.configure(background='black')\n self.panel.grid()\n #Canvas where put two label\n self.canvas = Canvas(self.window, width = 464 ,height = 100, bg = \"gray13\",highlightbackground= \"gray13\")\n self.canvas.grid()\n #Two Label initiliza with color white, became green wheen detect hands\n self.textRightHand = self.canvas.create_text(100,50,fill = \"white\",text='Left hand',font=(\"Purisa\",20))\n self.textLeftHand = self.canvas.create_text(365,50,fill = \"white\",text='Right hand', font=(\"Purisa\",20))\n\n #Button connect event start drive\n self.startButton = Button(self.window,text=\"Start Drive\", command= self.startClick,foreground = \"red\",highlightbackground = \"gray13\")\n self.startButton.grid()\n\n #PreCalculate image of rotation car\n self.imgDxSoft = self.imgGoAhead.rotate(-30)\n self.imgSxSoft = self.imgGoAhead.rotate(30)\n self.imgDxHard = self.imgGoAhead.rotate(-60)\n self.imgSxHard = self.imgGoAhead.rotate(60)\n\n #Open image of car go back with an arrow point down\n self.imgGoBack = Image.open('images/carwback.jpg')\n self.imgGoBack = self.originalGoBack.resize((461, 507),Image.ANTIALIAS)\n\n #PreCalculate image of rotation car on inversion mode\n self.resizedDxBack = self.resizedGoBack.rotate(-30)\n self.resizedSxBack = self.resizedGoBack.rotate(30)\n\n self.window.mainloop()\n \n def on_closing(self):\n #if there isn't connection only destroy window else send a comand of halt\n if urllib2.URLError:\n self.window.destroy() \n else:\n contents = urllib2.urlopen(\"http://bernice.local/apiLeorio/scriptHalt.php?behavior=\"+'halt').read() \n self.leap.remove_listener(self.listener)\n self.window.destroy() \n\n #Methods change value of booleans\n def setSwitchColorLeft(self,value):\n self.switchColorLeft=value\n def setSwitchColorRight(self,value):\n self.switchColorRight=value \n \n #Methods change color of Labels\n def change_color_left_green(self):\n self.canvas.itemconfig(1,fill =\"green\")\n def change_color_left_white(self):\n self.canvas.itemconfig(1,fill =\"white\") \n def change_color_right_green(self):\n self.canvas.itemconfig(2,fill =\"green\")\n def change_color2_right_white(self):\n self.canvas.itemconfig(2,fill =\"white\")\n\n #Events on start drive\n def startClick(self):\n #boolen controll if there some errors\n error = False\n #First click\n if self.checkStart == False:\n self.leap.add_listener(self.listener)\n #check if leap motion device is connected to computer\n if self.leap.is_connected == False:\n tkMessageBox.showerror(\"Error\", 'Connect Leap Motion controller')\n error = True\n else:\n #Try to connect to raspberry sending a commang of halt\n try:\n contents = urllib2.urlopen(\"http://bernice.local/apiLeorio/scriptHalt.php?behavior=\"+'halt').read()\n except urllib2.URLError,e:\n tkMessageBox.showerror(\"Error\", e.reason)\n error = True\n \n if error == False:\n self.startButton[\"text\"] = \"pause\"\n self.checkStart = True\n else:\n self.quitClick()\n #remove listener\n self.leap.remove_listener(self.listener)\n #Change text of button\n self.startButton[\"text\"] = \"Restart\"\n self.checkStart = False\n\n #event on close program\n def quitClick(self):\n try:\n contents = urllib2.urlopen(\"http://bernice.local/apiLeorio/scriptHalt.php?behavior=\"+'halt').read() \n except urllib2.URLError,e:\n tkMessageBox.showerror(\"Error\", e.reason)\n\n #The methods below implements image change\n def turnDXsoft(self):\n img2 = ImageTk.PhotoImage(self.imgDxSoft)\n self.panel.configure(image=img2)\n self.panel.image = img2\n def turnSXsoft(self):\n img2 = ImageTk.PhotoImage(self.imgSxSoft)\n self.panel.configure(image=img2)\n self.panel.image = img2 \n def GoAhead(self):\n img2 = ImageTk.PhotoImage(self.imgGoAhead)\n self.panel.configure(image=img2)\n self.panel.image = img2 \n def goBack(self):\n img2 = ImageTk.PhotoImage(self.imgGoBack)\n self.panel.configure(image=img2)\n self.panel.image = img2\n def turnDXhard(self):\n img2 = ImageTk.PhotoImage(self.imgDxHard)\n self.panel.configure(image=img2)\n self.panel.image = img2\n def turnSXhard(self):\n img2 = ImageTk.PhotoImage(self.imgSxHard)\n self.panel.configure(image=img2)\n self.panel.image = img2\n def turnDXback(self):\n img2 = ImageTk.PhotoImage(self.imgDxBack)\n self.panel.configure(image=img2)\n self.panel.image = img2\n def turnSXback(self):\n img2 = ImageTk.PhotoImage(self.imgSxBack)\n self.panel.configure(image=img2)\n self.panel.image = img2\n \n\ndef main():\n Window()\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.5436473488807678,
"alphanum_fraction": 0.5538461804389954,
"avg_line_length": 41.5,
"blob_id": "b4cfc2d5524def72eaa148a68f1d10006d0b2ee5",
"content_id": "8a5efa69e84fc065fc38241355158daa2198dd2d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5785,
"license_type": "permissive",
"max_line_length": 127,
"num_lines": 136,
"path": "/LeapMotionWidget.py",
"repo_name": "leonardocasini/LeapGesturalCar",
"src_encoding": "UTF-8",
"text": "import os, sys, inspect, thread, time\nsrc_dir = os.path.dirname(inspect.getfile(inspect.currentframe()))\narch_dir = os.path.abspath(os.path.join(src_dir, 'lib'))\nsys.path.insert(0, os.path.abspath(os.path.join(src_dir, arch_dir)))\n\nimport Leap\n\nclass DriveListener2(Leap.Listener):\n newBehavior='Try' \n behavior = 'None'\n #Below attributes is used to chose event gestures\n chooseXDirection=None#3\n chooseYDirection=None#0\n window = None\n #Boolean attributes used to check hand's presence\n defaultLeft = False\n defaultRight = False\n\n def setFrame(self, caller):\n #It is necessary to call method that chnage appearance of window\n self.window = caller\n \n def on_connect(self, controller):\n print \"Connected\"\n\n def on_frame(self, controller):\n boolLeft = False\n boolRight = False\n frame = controller.frame()\n #Initilize boolean false\n self.window.setSwitchColorLeft(False)\n self.window.setSwitchColorRight(False)\n #No Hands\n if len(frame.hands) ==0:\n self.chooseXDirection=0\n #One hand\n elif len(frame.hands) == 1: \n if frame.hands[0].is_left == False : \n self.chooseXDirection=0\n \n for hand in frame.hands:\n #handType = \"Left hand\" if hand.is_left else \"Right hand\" CI STA DA BUTTARE\n if hand.is_left: \n boolLeft = True\n #Set direction of car \n #postive go a head\n if hand.palm_position[2] > 40 : \n self.chooseXDirection= 2 \n #negative go back\n elif hand.palm_position[2] < -40 :\n self.chooseXDirection = 1\n\n #Normal of hand\n normal = hand.palm_normal\n\n #Detect right hand\n if not hand.is_left:\n boolRight = True\n\n #Right hand's roll decide the direction of car\n #Positive \n if normal.roll* Leap.RAD_TO_DEG < 30 and normal.roll* Leap.RAD_TO_DEG>-30:\n self.chooseYDirection=0 \n if normal.roll* Leap.RAD_TO_DEG < -40 :\n self.chooseYDirection=1\n if normal.roll* Leap.RAD_TO_DEG < -70 :\n self.chooseYDirection=3\n if normal.roll* Leap.RAD_TO_DEG > 60 : \n self.chooseYDirection=2\n if normal.roll* Leap.RAD_TO_DEG > 90 :\n self.chooseYDirection=4\n \n #Based on the previous checks the attribute newBehavior is set\n if self.chooseXDirection== 0:\n self.newBehavior='halt'\n elif self.chooseXDirection== 1 and self.chooseYDirection==0:\n self.newBehavior='goAhead'\n elif self.chooseXDirection==1 and self.chooseYDirection==1:\n self.newBehavior='DxSoft'\n elif self.chooseXDirection==1 and self.chooseYDirection==3:\n self.newBehavior='DxHard'\n elif self.chooseXDirection==1 and self.chooseYDirection==2:\n self.newBehavior='SxSoft'\n elif self.chooseXDirection==1 and self.chooseYDirection==4:\n self.newBehavior='SxHard' \n elif self.chooseXDirection==2 and self.chooseYDirection==0:\n self.newBehavior= 'goBack'\n elif self.chooseXDirection==2 and self.chooseYDirection==1:\n self.newBehavior= 'DxSoft2'\n elif self.chooseXDirection==2 and self.chooseYDirection==2:\n self.newBehavior= 'SxSoft2'\n\n #Below if statement check if there are a changes on bahavior car\n if self.behavior != self.newBehavior:\n #If newBehavior is different from behavior call method and reload attribute behavior \n self.behavior = self.newBehavior\n if self.behavior == 'DxSoft':\n self.window.turnDXsoft()\n elif self.behavior == 'goAhead':\n self.window.GoAhead()\n elif self.behavior == 'SxSoft':\n self.window.turnSXsoft()\n elif self.behavior == 'SxHard':\n self.window.turnSXhard()\n elif self.behavior == 'goBack':\n self.window.goBack()\n elif self.behavior == 'DxHard':\n self.window.turnDXhard()\n elif self.behavior == 'SxSoft2':\n self.window.turnDXback()\n elif self.behavior == 'DxSoft2':\n self.window.turnSXback()\n #Send Http Request with the new behavior \n contents = urllib2.urlopen(\"http://bernice.local/apiLeorio/scriptHalt.php?behavior=\"+self.behavior).read()\n\n #if there is a change in hand presence/absent\n if self.defaultLeft != boolLeft:\n #LeftHand founded\n if boolLeft == True:\n self.window.change_color_left_green()\n self.defaultLeft = boolLeft\n #LeftHand not founded\n else:\n self.window.change_color_left_white()\n self.defaultLeft = boolLeft\n #Stop driving car\n contents = urllib2.urlopen(\"http://bernice.local/apiLeorio/scriptHalt.php?behavior=\"+'halt').read() \n if self.defaultRight != boolRight:\n #RightHand founded\n if boolRight == True:\n self.window.change_color2_right_white()\n self.defaultRight = boolRight \n #RightHand not founded\n else:\n self.window.change_color2_right_white()\n self.defaultRight = boolRight \n\n"
}
] | 4 |
KaiHsuan-Liu/Coding-practice
|
https://github.com/KaiHsuan-Liu/Coding-practice
|
9fef666f84d46380f43edd7775970689afce9076
|
9a8810c9d7379e97c732dcc62e3715c576fd565f
|
ff9c632641ec3b7755a3e1d1778332e2475b569f
|
refs/heads/master
| 2022-11-25T08:24:09.137406 | 2020-07-21T09:12:25 | 2020-07-21T09:12:25 | 278,520,722 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4285714328289032,
"alphanum_fraction": 0.5630252361297607,
"avg_line_length": 22.399999618530273,
"blob_id": "07e726ef7308bcb430794508cc00fda2f1a7d305",
"content_id": "9dc834d590454f52a8c885819729116e3a911746",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 119,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 5,
"path": "/Codility_Practice/Lesson_5/python_MinAvgTwoSlice.py",
"repo_name": "KaiHsuan-Liu/Coding-practice",
"src_encoding": "UTF-8",
"text": "\n\n# Codility Lesson 5-3 # [4, 2, 2, 5, 1, 5, 8]\ndef MinAvgTwoSlice(A):\n\n\nprint(MinAvgTwoSlice([4, 2, 2, 5, 1, 5, 8]))\n"
},
{
"alpha_fraction": 0.42219802737236023,
"alphanum_fraction": 0.4744287133216858,
"avg_line_length": 21.975000381469727,
"blob_id": "ba2744d5627378c31b2e3d30142428d8171f864b",
"content_id": "e17f90179241d87a46f9c4281c6be2ce1c0cebd8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 919,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 40,
"path": "/Codility_Practice/Lesson_4/python_FrogRiverOne.py",
"repo_name": "KaiHsuan-Liu/Coding-practice",
"src_encoding": "UTF-8",
"text": "# Codility Lesson 4-1 # 5, [1, 3, 1, 4, 2, 3, 5, 4]\ndef FrogRiverOne(X, A):\n pos = set()\n for i, j in enumerate(A):\n pos.add(j)\n print(i, j, pos)\n if len(pos) == X:\n return i\n return -1\n\n# Codility Lesson 4-2 #5, [3, 4, 4, 6, 1, 4, 4])\ndef MaxCounters(N, A):\n counter = [0]*N\n for item in A:\n if 1 <= item <= N:\n counter[item-1] += 1\n else:\n counter[:] = [max(counter)]*N\n\n return counter\n\n# Codility Lesson 4-3 # [1, 3, 6, 4, 1, 2]\ndef MissingInteger(A):\n for idx in range(1, len(A)):\n print(idx)\n if idx not in A:\n return idx\n if A[idx] < 0:\n return 1\n return idx + 1\n\n# Codility Lesson 4-4 # [4, 1, 3, 2]\ndef PermCheck(A):\n # write your code in Python 3.6\n S = set(A)\n print(S)\n if max(S) == len(A) and len(S) == len(A):\n return 1\n else:\n return 0\n"
},
{
"alpha_fraction": 0.4056224822998047,
"alphanum_fraction": 0.4618473947048187,
"avg_line_length": 23.799999237060547,
"blob_id": "5b3992b06ade7f1f1de8080d2f548bd8c0dabe02",
"content_id": "acd0591dc3fc3c03c9530e9df86d3cb65d6b6fd1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 249,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 10,
"path": "/Codility_Practice/Lesson_4/python_MaxCounters.py",
"repo_name": "KaiHsuan-Liu/Coding-practice",
"src_encoding": "UTF-8",
"text": "\n# Codility Lesson 4-2 #5, [3, 4, 4, 6, 1, 4, 4])\ndef MaxCounters(N, A):\n counter = [0]*N\n for item in A:\n if 1 <= item <= N:\n counter[item-1] += 1\n else:\n counter[:] = [max(counter)]*N\n\n return counter\n"
},
{
"alpha_fraction": 0.42424243688583374,
"alphanum_fraction": 0.4761904776096344,
"avg_line_length": 24.55555534362793,
"blob_id": "591da389016ba0bb4888e4b3c1f85e887a9f12c5",
"content_id": "af3c4884aa8452d35de6eaf1e9dd9692b068c628",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 231,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 9,
"path": "/Codility_Practice/Lesson_4/python_MissingInteger.py",
"repo_name": "KaiHsuan-Liu/Coding-practice",
"src_encoding": "UTF-8",
"text": "\n# Codility Lesson 4-3 # [1, 3, 6, 4, 1, 2]\ndef MissingInteger(A):\n for idx in range(1, len(A)):\n print(idx)\n if idx not in A:\n return idx\n if A[idx] < 0:\n return 1\n return idx + 1\n"
},
{
"alpha_fraction": 0.41726619005203247,
"alphanum_fraction": 0.4748201370239258,
"avg_line_length": 20.230770111083984,
"blob_id": "06efded97a47444a7ce71ec3b81869d9bbe98104",
"content_id": "432f7d8ff65824894a188a01c29a869ea74a56ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 278,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 13,
"path": "/Codility_Practice/Lesson_5/python_PassingCars.py",
"repo_name": "KaiHsuan-Liu/Coding-practice",
"src_encoding": "UTF-8",
"text": "\n\n# Codility Lesson 5-4 # [0, 1, 0, 1, 1]\ndef PassingCars(A):\n temp = 0\n total = 0\n for number in A:\n if number == 0:\n temp += 1\n else:\n total += temp\n print(temp, total)\n\n return total\nprint(PassingCars([0, 1, 0, 1, 1]))\n"
},
{
"alpha_fraction": 0.46125462651252747,
"alphanum_fraction": 0.48154982924461365,
"avg_line_length": 23.590909957885742,
"blob_id": "cc298d936714ac8ce224eb7fe9579fac8a87b683",
"content_id": "d24e5e49f3b7da8e85034196540485d2e4b798a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 554,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 22,
"path": "/Sorting/quick_sort.py",
"repo_name": "KaiHsuan-Liu/Coding-practice",
"src_encoding": "UTF-8",
"text": "def quick_sort(data, left, right):\n if left >= right:\n return\n i = left\n j = right\n key = data[left]\n print(data, i, j, key)\n while i != j:\n while data[j] > key and i < j: #找比key小\n j -= 1\n while data[i] <= key and i < j: #找比key大\n i += 1\n if i < j:\n data[i], data[j] = data[j], data[i]\n data[left] = data[i]\n data[i] = key\n quick_sort(data, left, i-1)\n quick_sort(data, i+1, right)\n\ndata = [8, 9, 2, 5, 1]\nquick_sort(data, 0 ,len(data)-1)\nprint(data)\n\n"
},
{
"alpha_fraction": 0.5022624731063843,
"alphanum_fraction": 0.5339366793632507,
"avg_line_length": 23.55555534362793,
"blob_id": "fbc306db90055277e956f382cd197180d9c06298",
"content_id": "2cd9b2c9c712222f5bb15a4cf87eb9a8dd242718",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 221,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 9,
"path": "/Codility_Practice/Lesson_3/python_PermMissingElem.py",
"repo_name": "KaiHsuan-Liu/Coding-practice",
"src_encoding": "UTF-8",
"text": "# Codility Lesson 3-2 #[2, 3, 1, 5]\ndef PermMissingElem(A):\n lenA = len(A)\n should_be = max(A)\n sum_is = sum(A)\n for i in range(lenA):\n # print(i)\n should_be += i+1\n return should_be - sum_is\n"
},
{
"alpha_fraction": 0.4252631664276123,
"alphanum_fraction": 0.4673684239387512,
"avg_line_length": 21.619047164916992,
"blob_id": "a8569e96ab11d84a097e4b8e73ac6324d3fea302",
"content_id": "6287274d00a4a9bea7f3ab8174415348000dd136",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 475,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 21,
"path": "/Codility_Practice/Lesson_2/python_odd_occurrencesIn_array.py",
"repo_name": "KaiHsuan-Liu/Coding-practice",
"src_encoding": "UTF-8",
"text": "# Codility Lesson 2-2 #[9, 3, 9, 3, 9, 7, 9]\ndef OddOccurrencesInArray1(A):\n print(A)\n if len(A) == 1:\n return A[0]\n A = sorted(A)\n print(A)\n for i in range(0, len(A), 2):\n print(i, '-', A[i])\n if i+1 == len(A):\n return A[i]\n if A[i] != A[i+1]:\n return A[i]\n\n# Codility Lesson 2-2\ndef OddOccurrencesInArray2(A):\n odd = 0\n for i in A:\n odd ^= i #odd = odd^i\n print(i, '-', odd)\n return odd\n"
},
{
"alpha_fraction": 0.46063652634620667,
"alphanum_fraction": 0.5041875839233398,
"avg_line_length": 26.136363983154297,
"blob_id": "46a60553e303c525e42b0675414c3790b26afc63",
"content_id": "202c35722a3a083bbf0ef50029093d10c41a059b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 597,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 22,
"path": "/Codility_Practice/Lesson_3/python_TapeEquilibrium.py",
"repo_name": "KaiHsuan-Liu/Coding-practice",
"src_encoding": "UTF-8",
"text": "# Codility Lesson 3-3 #[3, 1, 2, 4, 3]\ndef TapeEquilibrium1(A):\n head = A[0] #3\n tail = sum(A[1:]) #10\n diff = abs(head - tail) #7\n for idx in range(1, len(A)-1):\n head += A[idx]\n tail -= A[idx]\n print(idx, head, tail) #idx 1-4, 4, 9\n if abs(head - tail) < diff:\n diff = abs(head - tail)\n return diff\n\n# Codility Lesson 3-3\ndef TapeEquilibrium2(A):\n head, tail, tmp = 0, 0, []\n for i in range(len(A)):\n head += A[i]\n tail = sum(A[i+1:])\n print(i, head, tail)\n tmp.append(abs(head - tail))\n return min(tmp)\n"
},
{
"alpha_fraction": 0.46179401874542236,
"alphanum_fraction": 0.514950156211853,
"avg_line_length": 19,
"blob_id": "156d9132ef70da62fd06a0df22f3ec64d4e21ead",
"content_id": "de360a2edb6378a89c9aab65e964db33d0f31b95",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 301,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 15,
"path": "/Codility_Practice/Lesson_3/python_FrogJmp.py",
"repo_name": "KaiHsuan-Liu/Coding-practice",
"src_encoding": "UTF-8",
"text": "\n# Codility Lesson 3-1 #10, 85, 30\ndef FrogJmp1(X, Y, D):\n count = 0\n while (X < Y):\n X+=D\n count+=1\n return count\n\n# Codility Lesson 3-1\ndef FrogJmp2(X, Y, D):\n distance = Y-X\n if distance % D == 0:\n return distance // D\n else:\n return distance // D + 1\n"
},
{
"alpha_fraction": 0.46133682131767273,
"alphanum_fraction": 0.5058977603912354,
"avg_line_length": 22.8125,
"blob_id": "8b682d396465e3dede066be966fcee189412da1a",
"content_id": "0c7a5cf771e120de4207a4f85fd149999ffbbfb8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 763,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 32,
"path": "/Codility_Practice/Lesson_1/python_binary_gap.py",
"repo_name": "KaiHsuan-Liu/Coding-practice",
"src_encoding": "UTF-8",
"text": "# Codility Lesson 1 #1041, 32\ndef BinaryGap1(N):\n # print(len(max(format(N, 'b').strip('0').split('1'))))\n toBin = bin(N)[2:]\n list1 = toBin.split('1')\n print(toBin, list1, len(list1))\n if toBin.endswith('0'):\n len1 = len(list1) - 1\n else:\n len1 = len(list1)\n\n max_number = 0\n for i in range(len1):\n print(i,list1[i])\n if max_number < len(list1[i]):\n max_number = len(list1[i])\n print('Result: ', max_number)\n\n# Codility Lesson 1\ndef BinaryGap2(N):\n B = bin(N)\n B = B[2:]\n print(B)\n maxCount = 0\n count = 0\n for i in range(len(B)):\n if B[i] == '1':\n maxCount = max(maxCount,count)\n count = 0\n else:\n count += 1\n print(maxCount)\n\n"
},
{
"alpha_fraction": 0.45497629046440125,
"alphanum_fraction": 0.5023696422576904,
"avg_line_length": 22.33333396911621,
"blob_id": "fac110954e3af14ede3e991e29b621796c7c5608",
"content_id": "7f6fdc0b75bde57686d6123a5fd1b4c14bf3cd9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 211,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 9,
"path": "/Codility_Practice/Lesson_4/python_PermCheck.py",
"repo_name": "KaiHsuan-Liu/Coding-practice",
"src_encoding": "UTF-8",
"text": "\n# Codility Lesson 4-4 # [4, 1, 3, 2]\ndef PermCheck(A):\n # write your code in Python 3.6\n S = set(A)\n print(S)\n if max(S) == len(A) and len(S) == len(A):\n return 1\n else:\n return 0\n"
},
{
"alpha_fraction": 0.49554139375686646,
"alphanum_fraction": 0.5273885130882263,
"avg_line_length": 25.200000762939453,
"blob_id": "bb8ba9af7ee23992cde06fb5bdeb65b6c5321945",
"content_id": "fde130f96ecc9d7e4db6e17afc00e1f81c962f06",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 785,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 30,
"path": "/Sorting/merge_sort.py",
"repo_name": "KaiHsuan-Liu/Coding-practice",
"src_encoding": "UTF-8",
"text": "def merge_sort(array):\n print('Default', array)\n N = len(array)\n if N <= 1:\n return array\n mid = N//2\n left_array = array[:mid]\n right_array = array[mid:]\n print('L:', left_array, 'R:',right_array)\n return (merge(merge_sort(left_array), merge_sort(right_array)))\n\ndef merge(left, right):\n print('Merge L', left, 'Merge R', right)\n tmp = []\n while len(left) != 0 and len(right) != 0:\n if left[0] < right[0]:\n tmp.append(left[0])\n left.remove(left[0])\n else:\n tmp.append(right[0])\n right.remove(right[0])\n if len(left) == 0:\n tmp = tmp + right\n else:\n tmp = tmp + left\n print('tmp:', tmp)\n return tmp\n\narray = [64, 34, 25, 12, 22, 11, 90]\nprint(merge_sort(array))"
},
{
"alpha_fraction": 0.4171122908592224,
"alphanum_fraction": 0.47058823704719543,
"avg_line_length": 22.375,
"blob_id": "f334f2fd756b3747b10ebea4cf23dc54cd609481",
"content_id": "6e82ca0ca923906c984b294c2785adcca06d3578",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 187,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 8,
"path": "/Codility_Practice/Lesson_5/python_CountDiv.py",
"repo_name": "KaiHsuan-Liu/Coding-practice",
"src_encoding": "UTF-8",
"text": "# Codility Lesson 5-1 # 6, 11, 2\ndef CountDiv(A, B, K):\n count = 0\n for idx in range(A, B+1):\n # print(idx)\n if idx % K == 0:\n count += 1\n return count\n"
},
{
"alpha_fraction": 0.5263158082962036,
"alphanum_fraction": 0.6052631735801697,
"avg_line_length": 18,
"blob_id": "57d730a801f3cada89aafa07da35d7da1cbb69a2",
"content_id": "5b409a84c1331be622728eb32ceeb6f802c5ecd2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 38,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 2,
"path": "/README.md",
"repo_name": "KaiHsuan-Liu/Coding-practice",
"src_encoding": "UTF-8",
"text": "# Coding-practice\n###### Python 3.6.8\n"
},
{
"alpha_fraction": 0.4501510560512543,
"alphanum_fraction": 0.48942598700523376,
"avg_line_length": 26.58333396911621,
"blob_id": "13d41787b84b35d65a5b8800e1648314c4c04341",
"content_id": "5cc899d075087e675cb1dd027f74a3dd0adc6b99",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 331,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 12,
"path": "/Sorting/bubble_sort.py",
"repo_name": "KaiHsuan-Liu/Coding-practice",
"src_encoding": "UTF-8",
"text": "def bubble_sort(array):\n # print(array)\n N = len(array) - 1\n for i in range(N):\n for j in range(N-i):\n # print(j, array[j], j+1, array[j+1])\n if array[j] > array[j+1]:\n array[j],array[j+1] = array[j+1], array[j]\n print(array)\n\narray = [19,2,45,31]\nbubble_sort(array)\n"
},
{
"alpha_fraction": 0.39388489723205566,
"alphanum_fraction": 0.4316546618938446,
"avg_line_length": 28.263158798217773,
"blob_id": "60fd9bace33690e9f7fb0b60dafd3a04f3697373",
"content_id": "cc1a8223d45c5981ad8c32309d06853e6391155c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 556,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 19,
"path": "/Codility_Practice/Lesson_5/python_GenomicRangeQuery.py",
"repo_name": "KaiHsuan-Liu/Coding-practice",
"src_encoding": "UTF-8",
"text": "# Codility Lesson 5-2 # S = \"CAGCCTA\",P = [2, 5, 0], Q = [4, 5, 6]\ndef GenomicRangeQuery(S = \"CAGCCTA\",P = [2, 5, 0], Q = [4, 5, 6]):\n lenP = len(P)\n result = [0]*lenP\n for i in range(lenP):\n print(i)\n Pi = P[i]\n Qi = Q[i]\n tmp = S[Pi:Qi+1] #slice end need to -1\n if 'A' in tmp:\n result[i] = 1\n elif 'C' in tmp:\n result[i] = 2\n elif 'G' in tmp:\n result[i] = 3\n elif 'T' in tmp:\n result[i] = 4\n print(Pi, Qi, tmp, result)\n return result\n"
},
{
"alpha_fraction": 0.38009050488471985,
"alphanum_fraction": 0.42081448435783386,
"avg_line_length": 23.55555534362793,
"blob_id": "f58ed2800e56f15f88f590f1f8f29d7971fd663f",
"content_id": "8eaa89d5d23b37ff0eeb1f5f3be689dea6f75b94",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 221,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 9,
"path": "/Codility_Practice/Lesson_2/python_cyclic_rotation.py",
"repo_name": "KaiHsuan-Liu/Coding-practice",
"src_encoding": "UTF-8",
"text": "# Codility Lesson 2-1 # L = [3, 8, 9, 7, 6], K = 3\ndef CyclicRotation(L, K):\n if len(L) == 0:\n return L\n K = K%len(L)\n print(L[K:], L[:K])\n print(L[-K:], L[:-K])\n L = L[-K:] + L[:-K]\n return L\n"
},
{
"alpha_fraction": 0.4360313415527344,
"alphanum_fraction": 0.4725848436355591,
"avg_line_length": 21.58823585510254,
"blob_id": "52812b7df1650933b1121dff9ff0e4715acc90f9",
"content_id": "c80b88b903e1a39eba50ed91b97891f0f1c1e391",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 383,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 17,
"path": "/Sorting/insertion_sort.py",
"repo_name": "KaiHsuan-Liu/Coding-practice",
"src_encoding": "UTF-8",
"text": "def insertion_sort(array):\n print(array)\n N = len(array)\n for i in range(1, N):\n key = array[i]\n j = i-1\n print(i, j ,key)\n while j >= 0 and key < array[j]:\n array[j+1] = array[j]\n j -= 1\n print(array, j)\n array[j+1] = key\n print(array)\n\narray = [12, 11, 13, 5, 6]\ninsertion_sort(array)\nprint(array)"
}
] | 19 |
IrinaNizova/11_duplicates
|
https://github.com/IrinaNizova/11_duplicates
|
59ef01b2752eedd4de20fb9e6448ad8f5e3dfc33
|
65cb39258f7920984f037de6705b4e474aa07985
|
087571588741e043bee00b92f0f406dd4b8c46c5
|
refs/heads/master
| 2021-07-16T14:38:49.409990 | 2017-10-21T18:49:45 | 2017-10-21T18:49:45 | 105,794,473 | 0 | 0 | null | 2017-10-04T17:01:03 | 2016-09-09T17:36:54 | 2017-10-01T11:43:15 | null |
[
{
"alpha_fraction": 0.5956284403800964,
"alphanum_fraction": 0.5965391397476196,
"avg_line_length": 33.3125,
"blob_id": "3991bbfa932d405b0163a8c605240f2d5472d55d",
"content_id": "d8b593a7cf618ab6aa82429c4ae582c8aec78b61",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1098,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 32,
"path": "/duplicates.py",
"repo_name": "IrinaNizova/11_duplicates",
"src_encoding": "UTF-8",
"text": "import os\nimport argparse\n\n\ndef find_duplicates(root_dir_path):\n files_in_folder = []\n duplicates = []\n for root, dir, file_names in os.walk(root_dir_path):\n for file_name in file_names:\n file_path = os.path.join(root, file_name)\n if os.path.islink(file_path):\n continue\n file_size = os.path.getsize(file_path)\n if (file_name, file_size) in files_in_folder:\n duplicates.append((file_path, file_name))\n else:\n file_size = os.path.getsize(file_path)\n files_in_folder.append((file_name, file_size))\n duplicates.sort(key=lambda x: x[1])\n return duplicates\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser()\n parser.add_argument(\"dir_path\", help=\"write name of json file\")\n duplicates = find_duplicates(parser.parse_args().dir_path)\n if duplicates:\n print(\"This files have duplicates: \")\n for duplicate_name, _ in duplicates:\n print(duplicate_name)\n else:\n print(\"There are no duplicates in this folder\")\n"
},
{
"alpha_fraction": 0.7290909290313721,
"alphanum_fraction": 0.7454545497894287,
"avg_line_length": 22.913043975830078,
"blob_id": "65641914e384f3f64b24116c3660f0b17e5a7cc7",
"content_id": "28a499ef0aa064f3ecc2a6b577efd8caa7c96157",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 550,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 23,
"path": "/README.md",
"repo_name": "IrinaNizova/11_duplicates",
"src_encoding": "UTF-8",
"text": "# Anti-Duplicator\nScript that takes an input folder, looks through all the files in it (and all subfolders and sub-folders ...)\nand reports if it finds duplicates.\n\n# How to run\n```python\npython duplicates.py [folder]\n```\nExample:\n```python\npython3 duplicates.py /var/log\n```\n\n# Example of output\n```\nThis files have duplicates:\ntest/my/java_error_in_PYCHARM_2742.log\ntest/my/less/java_error_in_PYCHARM_2742.log\n```\n\n# Project Goals\n\nThe code is written for educational purposes. Training course for web-developers - [DEVMAN.org](https://devman.org)\n"
}
] | 2 |
suyash/char-rnn
|
https://github.com/suyash/char-rnn
|
7d28f5baaf6eb8a600eb0e43aaf83f1cefdb746a
|
a41022d7cb03c95d421007c6f20882db402ab8ca
|
3d3aa9bdd6458951f1937f92b3badf5ac83a8fdd
|
refs/heads/master
| 2020-03-27T20:02:47.336396 | 2019-02-15T04:40:07 | 2019-02-15T04:40:07 | 147,033,391 | 2 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6642335653305054,
"alphanum_fraction": 0.6712811589241028,
"avg_line_length": 32.108333587646484,
"blob_id": "167c89611b8e2b050c0a7af2a1f972fb20550b7a",
"content_id": "5dd562b77eaf71d75d82e4885068477fc7216fed",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 3973,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 120,
"path": "/web/src/index.ts",
"repo_name": "suyash/char-rnn",
"src_encoding": "UTF-8",
"text": "import * as tf from \"@tensorflow/tfjs\";\nimport debug from \"debug\";\n\nimport { decode, encode, sample, sleep } from \"./utils\";\n\ndebug.enable(\"*\");\n\nconst INITIAL_TEXT: string = \"Immortal longings in me: now no more\";\n\nlet speed: number = 38;\nlet playing: boolean = false;\nlet text: string = INITIAL_TEXT;\n\nlet predictionContainer: HTMLElement;\nlet speedElement: HTMLInputElement;\nlet textElement: HTMLPreElement;\nlet button: HTMLButtonElement;\n\nwindow.addEventListener(\"DOMContentLoaded\", main);\n\nasync function main(): Promise<void> {\n const log: debug.IDebugger = debug(\"main\");\n\n predictionContainer = document.querySelector(\"#predictionContainer\") as HTMLElement;\n speedElement = document.querySelector(\"#speedControlSlider\") as HTMLInputElement;\n textElement = document.querySelector(\"pre\") as HTMLInputElement;\n button = document.querySelector(\"#controls button\") as HTMLButtonElement;\n\n (speedElement as any).value = speed;\n speedElement.addEventListener(\"change\", onSpeedChange);\n\n button.addEventListener(\"click\", () => onButtonClick(model));\n\n textElement.innerText = text;\n\n let model: tf.Model;\n\n try {\n model = await tf.loadModel(\"indexeddb://model_shakespeare\");\n log(\"loaded from idb\");\n } catch (err) {\n model = await tf.loadModel(\"model/shakespeare/v1/model.json\");\n const result: tf.io.SaveResult = await model.save(\"indexeddb://model_shakespeare\");\n log(\"saving to idb:\", result);\n }\n\n model.summary();\n\n (document.querySelector(\"#loadingMessage\") as HTMLElement).classList.add(\"hidden\");\n (document.querySelector(\"#controls\") as HTMLElement).classList.remove(\"hidden\");\n predictionContainer.classList.remove(\"hidden\");\n\n setTimeout(() => textElement.focus(), 0);\n}\n\nfunction onSpeedChange(e: Event): void {\n const log: debug.IDebugger = debug(\"onSpeedChange\");\n speed = (e.target as any).value;\n log(\"speed changed to\", speed);\n}\n\nfunction onButtonClick(model: tf.Model): void {\n if (playing) {\n playing = false;\n button.innerText = \"Start\";\n } else {\n playing = true;\n\n button.classList.add(\"hidden\");\n predictionContainer.classList.remove(\"editable\");\n textElement.removeAttribute(\"contenteditable\");\n\n predict(model);\n }\n}\n\nasync function predict(model: tf.Model): Promise<void> {\n while (playing) {\n const [nc]: [string, void] = await Promise.all([\n next(text, model),\n sleep((41 - speed) * 6),\n ]);\n\n textElement.innerText += nc;\n text = text.substr(1) + nc;\n }\n}\n\nasync function next(c: string, model: tf.Model): Promise<string> {\n const predictions: tf.Tensor<tf.Rank.R1> = tf.tidy(() => generatePredictions(c, model));\n const data: Float32Array = await predictions.data() as Float32Array;\n predictions.dispose();\n\n const nextCode: number = sample(data);\n return decode(nextCode);\n}\n\nfunction generatePredictions(c: string, model: tf.Model): tf.Tensor<tf.Rank.R1> {\n const batchSize: number = (model.input as tf.SymbolicTensor).shape[0];\n const sequenceLength: number = c.length;\n const vocabSize: number = (model.input as tf.SymbolicTensor).shape[2];\n\n const inp: tf.Tensor<tf.Rank.R3> = tf.tidy(() => generateInput(c, batchSize, vocabSize));\n\n const predictions: tf.Tensor<tf.Rank> = model.predict(inp, { batchSize }) as tf.Tensor<tf.Rank>;\n\n const lastPrediction: tf.Tensor<tf.Rank.R3> = tf.slice3d(\n predictions as tf.Tensor<tf.Rank.R3>,\n [0, sequenceLength - 1, 0],\n [batchSize, 1, vocabSize],\n );\n\n return lastPrediction.reshape([batchSize, vocabSize]).sum(0);\n}\n\nfunction generateInput(c: string, batchSize: number, vocabSize: number): tf.Tensor<tf.Rank.R3> {\n const code: number[] = encode(c);\n const tensor: tf.Tensor<tf.Rank.R2> = tf.oneHot(code, vocabSize);\n return tf.stack(Array.from({ length: batchSize }).map(() => tensor)) as tf.Tensor<tf.Rank.R3>;\n}\n"
},
{
"alpha_fraction": 0.5178236365318298,
"alphanum_fraction": 0.5562852025032043,
"avg_line_length": 22.688888549804688,
"blob_id": "82fad05d0a940e0948b54dd9767d3dcc63b82cfa",
"content_id": "9c6f3e00f6284da8e03f8f8bf50fade570a01348",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 1066,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 45,
"path": "/web/src/utils.ts",
"repo_name": "suyash/char-rnn",
"src_encoding": "UTF-8",
"text": "import { discrete } from \"./sampling\";\n\nfunction codeToVocab(code: number): number {\n if (code === 9) {\n return 1;\n } else if (code === 10) {\n return 127 - 30;\n } else if (32 <= code && code <= 126) {\n return code - 30;\n }\n\n return 0;\n}\n\nexport function encode(s: string): number[] {\n const ans: number[] = Array.from({ length: s.length });\n\n for (let i: number = 0 ; i < s.length ; i++) {\n ans[i] = codeToVocab(s.charCodeAt(i));\n }\n\n return ans;\n}\n\nexport function decode(code: number): string {\n if (code === 1) {\n return String.fromCharCode(9);\n } else if (code === 127 - 30) {\n return String.fromCharCode(10);\n } else if (32 <= (code + 30) && (code + 30) <= 126) {\n return String.fromCharCode(code + 30);\n }\n\n return String.fromCharCode(0);\n}\n\nexport function sample(p: Float32Array): number {\n return discrete(p);\n}\n\nexport function sleep(ms: number): Promise<void> {\n return new Promise((resolve: () => void): void => {\n setTimeout(resolve, ms);\n });\n}\n"
},
{
"alpha_fraction": 0.37473684549331665,
"alphanum_fraction": 0.46526315808296204,
"avg_line_length": 17.269229888916016,
"blob_id": "1d82a3863bd59a4f5dc212c3c5431b08c36c5af4",
"content_id": "26623687b1dc969bcc1ad33340308838a7c7fe6c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 475,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 26,
"path": "/trainer/utils.py",
"repo_name": "suyash/char-rnn",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\ndef decode(c):\n if c == 1:\n return 9\n elif c == 127 - 30:\n return 10\n elif 32 <= c + 30 <= 126:\n return c + 30\n else:\n return 0\n\ndef encode(c):\n if c == 9:\n return 1\n elif c == 10:\n return 127 - 30\n elif 32 <= c <= 126:\n return c - 30\n else:\n return 0\n\ndef sample(p, topn=98):\n p[np.argsort(p)[:-topn]] = 0\n p = p / np.sum(p)\n return np.random.choice(98, 1, p=p)[0]\n"
},
{
"alpha_fraction": 0.5091384053230286,
"alphanum_fraction": 0.5274151563644409,
"avg_line_length": 26.35714340209961,
"blob_id": "e3fcff87654882423505fad2d19b2504d21682b7",
"content_id": "066247aaf934f2a02c0af4ebee205e89c1cb30ad",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 383,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 14,
"path": "/web/src/sampling.ts",
"repo_name": "suyash/char-rnn",
"src_encoding": "UTF-8",
"text": "export function bernoulli(p: number): number {\n return (Math.random() < p) ? 1 : 0;\n}\n\nexport function discrete(p: Float32Array): number {\n for (let i: number = 0 ; i < p.length ; i++) {\n const x: number = p[i] / p.slice(i).reduce((a: number, b: number): number => a + b, 0);\n if (bernoulli(x)) {\n return i;\n }\n }\n\n return p.length - 1;\n}\n"
},
{
"alpha_fraction": 0.5600000023841858,
"alphanum_fraction": 0.5694267749786377,
"avg_line_length": 23.685535430908203,
"blob_id": "816562ad971ab58b94349576c952a49396edf89c",
"content_id": "095dca8c6586f7399ec25a0dda9a6b13d36ee7d0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3925,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 159,
"path": "/trainer/task.py",
"repo_name": "suyash/char-rnn",
"src_encoding": "UTF-8",
"text": "import argparse\n\nimport numpy as np\nimport tensorflow as tf\nfrom tensorflow.keras.callbacks import LambdaCallback, TensorBoard\nfrom tensorflowjs.converters import save_keras_model\n\nfrom input import create_iterator\nfrom model import create_model\nfrom utils import encode, decode, sample\n\nVOCAB_SIZE = 98\n\ndef run(\n train_files,\n batch_size,\n epochs,\n steps_per_epoch,\n learning_rate,\n learning_rate_decay,\n layers,\n rnn_sequence_length,\n dropout_pdrop,\n predict_length,\n export_dir,\n job_dir,\n):\n model = create_model(layers, VOCAB_SIZE, learning_rate, learning_rate_decay, batch_size, dropout_pdrop)\n print(model.summary())\n\n def on_epoch_end(epoch, logs):\n c = \"S\"\n\n print(\"\\n\", end=\"\")\n\n for _ in range(predict_length):\n print(c, end=\"\")\n inp = np.zeros([batch_size, 1, VOCAB_SIZE])\n for i in range(batch_size):\n inp[i][0][encode(ord(c))] = 1.0\n prob = model.predict(inp, batch_size=batch_size)\n prob = np.reshape(prob, [batch_size, VOCAB_SIZE])\n prob = np.sum(prob, axis=0)\n rc = sample(prob)\n c = chr(decode(rc))\n\n print(\"\\n\")\n\n train_iterator = create_iterator(train_files, batch_size, rnn_sequence_length, VOCAB_SIZE, True)\n eval_iterator = create_iterator(train_files, batch_size, rnn_sequence_length, VOCAB_SIZE, True)\n\n model.fit(\n train_iterator,\n shuffle=False,\n steps_per_epoch=steps_per_epoch,\n epochs=epochs,\n validation_data=eval_iterator,\n validation_steps=1,\n callbacks=[\n TensorBoard(log_dir=job_dir),\n LambdaCallback(on_epoch_end=on_epoch_end),\n ],\n )\n\n if export_dir is not None:\n model.save(\"%s/model.h5\" % export_dir)\n save_keras_model(model, \"%s/web\" % export_dir)\n\ndef main():\n parser = argparse.ArgumentParser()\n\n parser.add_argument(\n '--train-files',\n help=\"\"\"Local or GCS path to training data\"\"\",\n required=True\n )\n\n parser.add_argument(\n '--batch-size',\n help=\"\"\"Batch size for training and eval steps\"\"\",\n default=32,\n type=int\n )\n\n parser.add_argument(\n '--epochs',\n help=\"\"\"Number of epochs\"\"\",\n default=200,\n type=int\n )\n\n parser.add_argument(\n '--steps-per-epoch',\n help=\"\"\"Number of training steps in an epoch\"\"\",\n default=100,\n type=int\n )\n\n parser.add_argument(\n '--learning-rate',\n help=\"\"\"Learning rate value for the optimizers\"\"\",\n default=0.001,\n type=float\n )\n\n parser.add_argument(\n '--learning-rate-decay',\n help=\"\"\"Learning rate decay value for the optimizers\"\"\",\n default=1e-5,\n type=float\n )\n\n parser.add_argument(\n '--layers',\n help=\"\"\"List of recurrent layers with sizes\"\"\",\n nargs=\"+\",\n default=[64, 64, 64],\n type=int\n )\n\n parser.add_argument(\n '--rnn-sequence-length',\n help=\"\"\"Mumber of times the RNN is unrolled\"\"\",\n default=40,\n type=int\n )\n\n parser.add_argument(\n '--dropout-pdrop',\n help=\"\"\"The fraction of input units to drop\"\"\",\n default=0.25,\n type=float\n )\n\n parser.add_argument(\n '--predict-length',\n help=\"\"\"Length of generated prediction\"\"\",\n default=500,\n type=int\n )\n\n parser.add_argument(\n '--export-dir',\n help=\"\"\"Local/GCS location to export model, if None, the model is not exported\"\"\",\n default=None,\n required=False\n )\n\n parser.add_argument(\n '--job-dir',\n help=\"\"\"Local/GCS location to write checkpoints and export models\"\"\",\n required=True\n )\n\n HYPERPARAMS, _ = parser.parse_known_args()\n run(**HYPERPARAMS.__dict__)\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.7023661136627197,
"alphanum_fraction": 0.7384806871414185,
"avg_line_length": 24.90322494506836,
"blob_id": "d1c248cef4c666be65f052aed2b488c431f6e735",
"content_id": "74264f6d655217a643015e1dc3ec43336f90c240",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 803,
"license_type": "permissive",
"max_line_length": 140,
"num_lines": 31,
"path": "/README.md",
"repo_name": "suyash/char-rnn",
"src_encoding": "UTF-8",
"text": "# char-rnn\n\nSmall character-based language model implementation in TensorFlow with tf.data and keras APIs along with a browser demo using TensorFlow.js.\n\nThe task file takes hidden state sizes as a parameter and generates a neural network with stateful GRU cells of the specified layer sizes.\n\n### Running\n\n```\npython trainer/task.py \\\n --train-files $DATA_DIR \\\n --epochs 100 \\\n --steps-per-epoch 100 \\\n --layers 64 64 64 \\\n --job-dir $OUTPUT_DIR \\\n --export-dir $OUTPUT_DIR\n```\n\n### Other Art\n\n- https://github.com/martin-gorner/tensorflow-rnn-shakespeare\n\n- https://karpathy.github.io/2015/05/21/rnn-effectiveness/\n\n- https://arxiv.org/abs/1506.02078\n\n### TODO\n\n- make `VOCAB_LENGTH` a configurable hyperparameter to allow fitting arbitrary vocab sizes\n\n- distribution without data parallelism\n"
},
{
"alpha_fraction": 0.5702564120292664,
"alphanum_fraction": 0.5723077058792114,
"avg_line_length": 29.46875,
"blob_id": "6cc02d26dbaa6a3829413208aa427accbfe0ff89",
"content_id": "ff80d9508504bb8d5c0eee393701283f726fdc9a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 975,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 32,
"path": "/web/rollup.config.js",
"repo_name": "suyash/char-rnn",
"src_encoding": "UTF-8",
"text": "import commonjs from \"rollup-plugin-commonjs\";\nimport copy from \"rollup-plugin-copy\";\nimport resolve from \"rollup-plugin-node-resolve\";\nimport typescript from \"rollup-plugin-typescript2\";\nimport { terser } from \"rollup-plugin-terser\";\n\nconst tsconfig = process.env.NODE_ENV === \"production\" ? \"tsconfig.json\" : \"tsconfig.dev.json\";\n\nexport default {\n input: \"./src/index.ts\",\n output: {\n file: \"./lib/index.js\",\n format: \"iife\",\n globals: {\n \"@tensorflow/tfjs\": \"tf\",\n },\n sourcemap: process.env.NODE_ENV !== \"production\",\n },\n external: [\n \"@tensorflow/tfjs\",\n ],\n plugins: [\n typescript({ tsconfig, tsconfigOverride: { compilerOptions: { module: \"es6\" } } }),\n resolve({ browser: true }),\n commonjs(),\n copy({\n verbose: true,\n \"./src/html/index.html\": \"./lib/index.html\",\n }),\n process.env.NODE_ENV === \"production\" && terser(),\n ],\n}\n"
},
{
"alpha_fraction": 0.7321428656578064,
"alphanum_fraction": 0.7359693646430969,
"avg_line_length": 40.26315689086914,
"blob_id": "0347f553939476b01eaec3ac5342396698e3c23e",
"content_id": "9ae9082a00b631ec9819e57cb3863461e06f6ea5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 784,
"license_type": "permissive",
"max_line_length": 134,
"num_lines": 19,
"path": "/trainer/model.py",
"repo_name": "suyash/char-rnn",
"src_encoding": "UTF-8",
"text": "from tensorflow.keras.models import Sequential\nfrom tensorflow.keras.layers import Activation, Dense, GRU\nfrom tensorflow.keras.optimizers import Adam\n\ndef create_model(layers, vocab_size, learning_rate, learning_rate_decay, batch_size, dropout):\n model = Sequential()\n\n model.add(GRU(layers[0], stateful=True, return_sequences=True, dropout=dropout, batch_input_shape=(batch_size, None, vocab_size)))\n\n for i in range(len(layers) - 1):\n model.add(GRU(layers[i + 1], stateful=True, return_sequences=True, dropout=dropout))\n\n model.add(Dense(vocab_size))\n model.add(Activation(\"softmax\"))\n\n optimizer = Adam(lr=learning_rate, decay=learning_rate_decay)\n model.compile(loss=\"categorical_crossentropy\", optimizer=optimizer, metrics=[\"acc\"])\n\n return model\n"
},
{
"alpha_fraction": 0.5524093508720398,
"alphanum_fraction": 0.5732737183570862,
"avg_line_length": 29.5,
"blob_id": "4b148ff07a25e4afd72917dfc42314395ecac990",
"content_id": "3b5ffbe506b2dbba1b432baec766c31df070881d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2013,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 66,
"path": "/trainer/input.py",
"repo_name": "suyash/char-rnn",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\n\ndef create_iterator(pattern, batch_size, sequence_length, vocab_size, repeat=False):\n \"\"\"\n Parameters\n ----------\n pattern : string\n glob pattern with files to read\n\n batch_size : integer\n batch size for input\n\n sequence_length : integer\n unroll size for rnn\n\n vocab_size : integer\n number of chars in vocab\n\n repeat : bool\n repeat if reached end\n \"\"\"\n def encode(c):\n return tf.case({\n tf.equal(c, 9): lambda: 1,\n tf.equal(c, 10): lambda: 127 - 30,\n tf.logical_and(tf.greater_equal(c, 32), tf.less_equal(c, 126)): lambda: c - 30,\n }, default=lambda: 0, exclusive=True)\n\n def split(row):\n row = tf.decode_raw(row, out_type=tf.uint8)\n row = tf.cast(row, tf.int32)\n row = tf.map_fn(encode, row)\n l = tf.size(row)\n return tf.slice(row, [0], [l - 1]), tf.slice(row, [1], [l - 1])\n\n def pad(row):\n l = tf.size(row)\n p = batch_size * sequence_length\n r = l % p\n return tf.cond(\n tf.not_equal(r, 0),\n lambda: tf.concat([row, tf.zeros(p - r, dtype=tf.int32)], 0),\n lambda: row,\n )\n\n def transpose(row):\n row = tf.reshape(row, [batch_size, -1, sequence_length])\n row = tf.transpose(row, [1, 0, 2])\n return row\n\n dataset = tf.data.Dataset.list_files(pattern)\n dataset = dataset.shuffle(buffer_size=64)\n dataset = dataset.flat_map(lambda file: tf.data.Dataset.from_tensors(tf.read_file(file)))\n dataset = dataset.map(split)\n dataset = dataset.map(lambda f, l: (pad(f), pad(l)))\n dataset = dataset.map(lambda f, l: (transpose(f), transpose(l)))\n dataset = dataset.apply(tf.contrib.data.unbatch())\n\n dataset = dataset.map(lambda f, l: (tf.one_hot(f, vocab_size, 1.0, 0.0), tf.one_hot(l, vocab_size, 1.0, 0.0)))\n\n if repeat:\n dataset = dataset.repeat()\n\n iterator = dataset.make_one_shot_iterator()\n\n return iterator\n"
}
] | 9 |
andrewhead/ICTD17-Paper
|
https://github.com/andrewhead/ICTD17-Paper
|
4287e64874685686259dfc3cca8bcd6043bbb8c4
|
7b518c2fb2f26b349670e580111235ac3c815801
|
483b1db9f84f22a12efa6b7b1095565d5d70ea8f
|
refs/heads/master
| 2021-07-08T16:28:09.396726 | 2017-08-29T04:20:34 | 2017-08-29T04:20:34 | 88,106,094 | 2 | 2 | null | null | null | null | null |
[
{
"alpha_fraction": 0.647198498249054,
"alphanum_fraction": 0.6490978002548218,
"avg_line_length": 34.099998474121094,
"blob_id": "b978a10e9ae4e2160f73a285bfeec1847104fddc",
"content_id": "a4b12289d7b62ecc6b9daf523423e60d2995a363",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2106,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 60,
"path": "/util/predict_index.py",
"repo_name": "andrewhead/ICTD17-Paper",
"src_encoding": "UTF-8",
"text": "\"\"\"\nGiven a pickled model and a set of examples in an `npz` file (already split\ninto `X_train` and `X_test`, output predicted and actual results. Print\nout one line for each example, with the first column containing the\nactual output and the second containing the predicted output.\n\"\"\"\n\nimport argparse\nimport numpy as np\nfrom sklearn.externals import joblib\n\n\ndef get_expected_values(y_train, y_test):\n \"\"\" Concatenate `y` data into single list of expected y values \"\"\"\n y_all = np.concatenate((y_train, y_test))\n return y_all\n\n\ndef get_predictions(model, x_train, x_test):\n \"\"\" Predict `y` values for all input X \"\"\"\n x_all = np.concatenate((x_train, x_test))\n y_predicted = model.predict(x_all)\n return y_predicted\n\n\nif __name__ == '__main__':\n\n parser = argparse.ArgumentParser(\n description=\"Output expected and predicted values for a set of \" +\n \"examples and a model\")\n parser.add_argument(\"model\", help=\"pkl file containing model\")\n parser.add_argument(\n \"data\",\n help=\".npz file. Expected to contain the following fields: \" +\n \"X_train, X_test, y_train, y_test\")\n parser.add_argument(\n \"--report-r2\",\n action=\"store_true\",\n help=\"Whether to print out R^2 value before expected and \" +\n \"predicted values\")\n args = parser.parse_args()\n\n model_loaded = joblib.load(args.model)\n data = np.load(args.data)\n X_train_loaded = data['X_train']\n X_test_loaded = data['X_test']\n y_train_loaded = data['y_train']\n y_test_loaded = data['y_test']\n\n y_expected_results = get_expected_values(y_train_loaded, y_test_loaded)\n y_predicted_results = get_predictions(model_loaded, X_train_loaded, X_test_loaded)\n\n if args.report_r2:\n x_all_loaded = np.concatenate((X_train_loaded, X_test_loaded))\n print(\"R^2:\", model_loaded.score(x_all_loaded, y_expected_results))\n\n print(\"Example Index,Expected,Predicted\")\n for i in range(len(y_expected_results)):\n print(\",\".join([str(_) for _ in\n [i, y_expected_results[i], y_predicted_results[i]]]))\n"
},
{
"alpha_fraction": 0.44680851697921753,
"alphanum_fraction": 0.5531914830207825,
"avg_line_length": 22.5,
"blob_id": "55445714f17305d5c78859e0c3fdd07697efe3bd",
"content_id": "40f1f4279fd7fc9844657d3e245e41998b3706ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 47,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 2,
"path": "/.pylintrc",
"repo_name": "andrewhead/ICTD17-Paper",
"src_encoding": "UTF-8",
"text": "[BASIC]\nconst-rgx=[a-zA-Z_][a-zA-Z0-9_]{2,30}$\n"
},
{
"alpha_fraction": 0.684326708316803,
"alphanum_fraction": 0.6865342259407043,
"avg_line_length": 40.1363639831543,
"blob_id": "acd8c05ecdc2ba2960e33c02443b10ef161fe6e9",
"content_id": "ae3be345d68c1577072fccde4493234e23e78f08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 906,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 22,
"path": "/util/get_test_indexes.py",
"repo_name": "andrewhead/ICTD17-Paper",
"src_encoding": "UTF-8",
"text": "import random\nfrom argparse import ArgumentParser\nimport os\n\n\nif __name__ == \"__main__\":\n\n argument_parser = ArgumentParser(description=\"Make list of image indexes for test set\")\n argument_parser.add_argument(\"input_dir\", help=\"Directory containing images\")\n argument_parser.add_argument(\"ratio\", type=float, default=0.1,\n help=\"Proportion of original images to add to test set. \" +\n \"If images don't divide evenly by the proportion, the number of images \" +\n \"is rounded down to the nearest whole number.\")\n args = argument_parser.parse_args()\n\n filenames = os.listdir(args.input_dir)\n image_indexes = [int(filename.replace(\".jpg\", \"\")) for filename in filenames]\n\n test_sample_size = int(len(image_indexes) * args.ratio)\n test_image_indexes = random.sample(image_indexes, test_sample_size)\n for index in test_image_indexes:\n print(index)\n\n"
},
{
"alpha_fraction": 0.6331706643104553,
"alphanum_fraction": 0.6369182467460632,
"avg_line_length": 45.45344161987305,
"blob_id": "12d690a906b836276579bb33c6fce17f8b814de5",
"content_id": "b6793a6a1345677ca03a8f21adc7a41191accd8f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11474,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 247,
"path": "/train_index_water.py",
"repo_name": "andrewhead/ICTD17-Paper",
"src_encoding": "UTF-8",
"text": "\"\"\" REUSE: A substantial amount of the code in this file was reused from\nProblem Set 1 teacher-provided boilerplate and our code. There's a lot\nof logic for clustering images that we didn't want to invent twice. \"\"\"\n\nimport argparse\nfrom osgeo import gdal, ogr, osr\nimport numpy as np\nimport csv\nimport os.path\nfrom tqdm import tqdm\n\nfrom sklearn.linear_model import Ridge\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.model_selection import cross_val_predict, cross_val_score\nfrom sklearn.externals import joblib\n\nfrom util.geometry import MapGeometry\nfrom util.load_data import read_wealth_records, read_education_records,\\\n read_water_records, get_map_from_i_j_to_example_index\n\n\ndef get_features_for_clusters(records, features_dir, i_j_to_example_index_map, map_geometry):\n # Returns a numpy array, where each row corresponds to one of the entries\n # in `wealth_records`. Each row contains the average of the features for\n # all images in that record's cluster.\n # Also returns a list of all clusters for which *no* images were found\n # (may be those right on the border). The prediction data for these ones\n # should probably be discarded.\n\n avg_feature_arrays = tuple()\n missing_records = {}\n records_without_any_images = []\n for record_index, record in tqdm(enumerate(records), \n desc=\"Loading features for records\", total=len(records)):\n \n # Find the neighborhood of images for this record's location\n # Latitude and longitude are more precise, so if they're available, use\n # them for finding the closest set of images in the neighborhood\n if 'longitude' in record and 'latitude' in record:\n neighborhood = map_geometry.get_image_rect_from_long_lat(\n record['longitude'], record['latitude'])\n else:\n neighborhood = map_geometry.get_image_rect_from_cell_indexes(\n record['i'], record['j'])\n centroid_longitude, centroid_latitude = (\n map_geometry.get_centroid_long_lat(record['i'], record['j']))\n # Save references to tthe approximate latitude and longitude,\n # in case we want to use it for printing out debugging info later.\n record['longitude'] = centroid_longitude\n record['latitude'] = centroid_latitude\n \n # Collect features for all images in the neighborhood\n feature_arrays = tuple()\n count_missing = 0\n for image_i in range(neighborhood['left'], neighborhood['left'] + neighborhood['width']):\n for image_j in range(neighborhood['top'], neighborhood['top'] + neighborhood['height']):\n if (image_i, image_j) not in i_j_to_example_index_map:\n count_missing += 1\n continue\n example_index = i_j_to_example_index_map[(image_i, image_j)]\n example_features = np.load(os.path.join(\n features_dir, str(example_index) + \".npz\"))[\"data\"]\n feature_arrays += (example_features,)\n\n # Compute the average of all features over all neighbors\n if len(feature_arrays) > 0:\n cluster_features = np.stack(feature_arrays)\n avg_feature_arrays += (np.average(cluster_features, axis=0),)\n \n if count_missing > 0:\n missing_records[record_index] = count_missing\n if len(feature_arrays) == 0:\n records_without_any_images.append(record_index)\n\n if len(missing_records.keys()) > 0:\n print(\"Missing images for %d clusters. \" % (len(missing_records.keys())) +\n \". This might not be a bad thing as some clusters may be near a \" +\n \"border. These clusters are:\")\n for record_index, missing_count in missing_records.items():\n print(\"Record %d (%f, %f): %d images\" % \n (record_index, records[record_index]['latitude'],\n records[record_index]['longitude'], missing_count))\n\n avg_features = np.stack(avg_feature_arrays)\n return avg_features, records_without_any_images\n\n\ndef predict(features, y, output_filename):\n # This method assumes you have already split the data into\n # test data and training data, and are only passing in training data.\n\n # Do cross-validation for this model\n ridge = Ridge()\n r2_values = cross_val_score(ridge, features, y, cv=10, scoring='r2')\n print(\"Cross-validation results:\")\n print(\"All R^2:\", r2_values)\n print(\"Average R^2:\", np.average(r2_values))\n\n # Retrain the model on all training data, and dump it to a file for later\n ridge = Ridge()\n ridge.fit(features, y)\n print(\"Saving trained model to file \", output_filename)\n joblib.dump(ridge, output_filename)\n\n return ridge\n\n\nif __name__ == '__main__':\n\n parser = argparse.ArgumentParser(description=\"Train models to predict \" +\n \"wealth, water and education indexes from arbitrary features\")\n parser.add_argument(\"features_dir\", help=\"directory containing features, \" +\n \"with one file containing a flat numpy array (.npz) per image\")\n parser.add_argument(\"wealth_csv\", help=\"CSV file where \" +\n \"the top row is a header, col 1 (zero-indexed) is the wealth index, \" +\n \"col 7 is the latitude, and col 8 is the longitude.\")\n parser.add_argument(\"education_csv\", help=\"CSV file where \" +\n \"the top row is a header, col 3 (zero-indexed) is the education index, \" +\n \"col 1 is the cell's 'i' coordinate, and col 2 is the 'j' coordinate.\")\n parser.add_argument(\"water_csv\", help=\"CSV file where \" +\n \"the top row is a header, col 4 (zero-indexed) is the water index, \" +\n \"col 2 is the cell's 'i' coordinate, and col 3 is the 'j' coordinate.\")\n\n parser.add_argument(\"nightlights_csv\", help=\"CSV file where \" +\n \"the top row is a header, col 0 (zero-indexed) is the index of the \" +\n \"example (basename of eature file), and cols 2 and 3 are the \" +\n \"i and j of the cell in the nightlights data\")\n parser.add_argument(\"nightlights_raster\", help=\"Raster file of \" +\n \"nightlights, used for making a map from latitude and longitude \" +\n \"to cell indexes on the map.\")\n parser.add_argument(\"--show-test-results\", action='store_true',\n help=\"Whether to present test results at the end of training. For \" +\n \"good practice, you should only set this flag when this is the last \" +\n \"time to measure performance.\")\n parser.add_argument(\"--prediction-output-basename\",\n help=\"If you're running test results, set this flag and you can \" +\n \"output the test predictions to file\")\n parser.add_argument(\"output_basename\", help=\"Basename of files to which \" +\n \"to output the created models.\")\n parser.add_argument(\"-v\", action=\"store_true\", help=\"verbose\")\n args = parser.parse_args()\n\n if args.v:\n print(\"Loading map geometry...\", end=\"\")\n map_geometry = MapGeometry(args.nightlights_raster)\n if args.v:\n print(\".\")\n i_j_to_example_index_map = get_map_from_i_j_to_example_index(args.nightlights_csv)\n \n # Predict wealth\n if args.v:\n print(\"Preparing for wealth predictions.\")\n wealth_records = read_wealth_records(args.wealth_csv)\n y_wealth = [r['wealth'] for r in wealth_records]\n X_wealth, records_to_discard = get_features_for_clusters(\n records=wealth_records,\n features_dir=args.features_dir,\n i_j_to_example_index_map=i_j_to_example_index_map,\n map_geometry=map_geometry,\n )\n # Some of the clusters might not have any images. Just discard the\n # prediction for these ones, don't factor it into the model. Make\n # sure to discard in reverse, so we don't mess up the indexing\n # for discarding later records after discarding earlier records.\n for i in reversed(records_to_discard):\n del(y_wealth[i])\n X_wealth_train, X_wealth_test, y_wealth_train, y_wealth_test = (\n train_test_split(X_wealth, y_wealth, test_size=0.33, random_state=1))\n print(\"Now predicting wealth...\")\n wealth_model = predict(X_wealth_train, y_wealth_train,\n args.output_basename + \"_wealth.pkl\")\n\n # Predict education\n if args.v:\n print(\"Preparing for education predictions.\")\n education_records = read_education_records(args.education_csv)\n y_education = [r['education_index'] for r in education_records]\n X_education, records_to_discard = get_features_for_clusters(\n records=education_records,\n features_dir=args.features_dir,\n i_j_to_example_index_map=i_j_to_example_index_map,\n map_geometry=map_geometry,\n )\n for i in reversed(records_to_discard):\n del(y_education[i])\n X_education_train, X_education_test, y_education_train, y_education_test = (\n train_test_split(X_education, y_education, test_size=0.33, random_state=2))\n print(\"Now predicting education...\")\n education_model = predict(X_education_train, y_education_train,\n args.output_basename + \"_education.pkl\")\n \n # Predict Water\n if args.v:\n print(\"Preparing for water predictions.\")\n water_records = read_water_records(args.water_csv)\n y_water = [r['water_index'] for r in water_records]\n X_water, records_to_discard = get_features_for_clusters(\n records=water_records,\n features_dir=args.features_dir,\n i_j_to_example_index_map=i_j_to_example_index_map,\n map_geometry=map_geometry,\n )\n for i in reversed(records_to_discard):\n del(y_water[i])\n X_water_train, X_water_test, y_water_train, y_water_test = (\n train_test_split(X_water, y_water, test_size=0.33, random_state=2))\n print(\"Now predicting water...\")\n water_model = predict(X_water_train, y_water_train,\n args.output_basename + \"_water.pkl\")\n\n\n if args.show_test_results:\n \n print(\"Evaluating performance on test set.\")\n\n if args.prediction_output_basename is not None:\n wealth_predictions = wealth_model.predict(X_wealth_test)\n np.savez_compressed(\n args.prediction_output_basename + \"_wealth.npz\",\n X_train=X_wealth_train,\n y_train=y_wealth_train,\n X_test=X_wealth_test,\n y_test=y_wealth_test,\n y_test_predictions=wealth_predictions,\n )\n education_predictions = education_model.predict(X_education_test)\n np.savez_compressed(\n args.prediction_output_basename + \"_education.npz\",\n X_train=X_education_train,\n y_train=y_education_train,\n X_test=X_education_test,\n y_test=y_education_test,\n y_test_predictions=education_predictions,\n )\n water_predictions = water_model.predict(X_water_test)\n np.savez_compressed(\n args.prediction_output_basename + \"_water.npz\",\n X_train=X_water_train,\n y_train=y_water_train,\n X_test=X_water_test,\n y_test=y_water_test,\n y_test_predictions=water_predictions,\n )\n\n print(\"Wealth R^2:\", wealth_model.score(X_wealth_test, y_wealth_test))\n print(\"Education R^2:\", education_model.score(X_education_test, y_education_test))\n print(\"Water R^2:\", water_model.score(X_water_test, y_water_test))\n"
},
{
"alpha_fraction": 0.614701509475708,
"alphanum_fraction": 0.6285940408706665,
"avg_line_length": 35.33546447753906,
"blob_id": "01ef12602d0e3041f85b57b1c5e03e3561d8a4e1",
"content_id": "7c64afb2232b72a52cb55d55b42b5a40486ae230",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11373,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 313,
"path": "/train.py",
"repo_name": "andrewhead/ICTD17-Paper",
"src_encoding": "UTF-8",
"text": "import keras\nfrom keras import backend as K\nfrom keras.models import Model\nfrom keras.layers import Activation, Dense, Dropout, Flatten, Reshape\nfrom keras.layers.convolutional import Conv2D\nfrom keras.layers.pooling import AveragePooling2D\nfrom keras.preprocessing import image\nfrom keras_models.vgg16 import VGG16\nfrom keras.optimizers import SGD\n\nimport numpy as np\n\nimport math\nimport csv\nfrom argparse import ArgumentParser\nimport os.path\nfrom time import gmtime, strftime\n\n\n# This method assumes that all labels are a string representing an integer\ndef load_labels(csv_filename, test_indexes, num_classes=3):\n\n labels = []\n with open(csv_filename) as csvfile:\n rows = csv.reader(csvfile)\n first_row = True\n for row in rows:\n if first_row:\n first_row = False\n continue\n index = int(row[0])\n if index not in test_indexes:\n labels.append(row[6])\n label_vector = np.array(labels)\n label_array = keras.utils.to_categorical(label_vector, num_classes)\n\n # Compute class weights inversely proportional to class frequency\n class_counts = {}\n for label in labels:\n if label not in class_counts.keys():\n class_counts[label] = 0\n class_counts[label] += 1\n max_class_count = max(class_counts.values())\n class_weights = {}\n for (label, class_count) in class_counts.items():\n # The label in the class weights dictionary needs to be an\n # integer for Keras to make use of it.\n class_weights[int(label)] = max_class_count / float(class_count)\n\n return label_array, class_weights\n\n\ndef load_test_indexes(test_index_filename):\n test_indexes = []\n with open(test_index_filename) as test_index_file:\n for line in test_index_file:\n test_indexes.append(int(line.strip()))\n return test_indexes\n\n\ndef get_image_paths(input_dir, test_image_indexes):\n image_paths = []\n for filename in os.listdir(input_dir):\n image_index = int(filename.replace(\".jpg\", \"\"))\n if image_index not in test_image_indexes:\n image_paths.append(os.path.join(input_dir, filename))\n return image_paths\n\n\ndef load_images(image_paths, verbose=False):\n\n WIDTH = 400\n HEIGHT = 400\n\n if verbose:\n print(\"Loading images...\")\n\n X = np.zeros((len(image_paths), WIDTH, HEIGHT, 3))\n for img_index, img_path in enumerate(image_paths, start=0):\n img = image.load_img(img_path)\n img_array = image.img_to_array(img)\n X[img_index, :, :, :] = img_array\n if verbose and img_index > 0 and (img_index % 1000) == 0:\n print(\"Loaded %d of %d images...\" % (img_index, len(image_paths)))\n\n if verbose:\n print(\"Loaded all images.\")\n\n return X\n\n\n# Written using the guidance from this Stack Overflow post:\n# http://stackoverflow.com/questions/41458859/keras-custom-metric-for-single-class-accuracy/41717938\ndef per_class_recall(class_id):\n\n def compute_recall(y_true, y_pred):\n true_classes = K.argmax(y_true, axis=-1)\n pred_classes = K.argmax(y_pred, axis=-1)\n recall_mask = K.cast(K.equal(true_classes, class_id), 'int32')\n classes_matching_target = K.cast(K.equal(true_classes, pred_classes), 'int32') * recall_mask\n recall = K.sum(classes_matching_target) / K.maximum(K.sum(recall_mask), 1)\n return recall\n \n # XXX: We use this hack of renaming the metric because Keras only shows the metrics\n # for a function with one name once (won't show this metric for 3 classes otherwise),\n # and this also makes the output look prettier.\n compute_recall.__name__ = \"recall (C%d)\" % class_id\n return compute_recall\n\n\ndef per_class_count_expected(class_id, batch_size):\n\n def compute_count_expected(y_true, y_pred):\n true_classes = K.argmax(y_true, axis=-1)\n expected_mask = K.cast(K.equal(true_classes, class_id), 'int32')\n return K.sum(expected_mask) / batch_size\n\n compute_count_expected.__name__ = \"%% examples (C%d)\" % class_id\n return compute_count_expected\n\n\ndef train(image_paths, y, class_weights, num_classes=3, batch_size=16, epochs=4, kfolds=3, verbose=False):\n\n # Load baseline model (ImageNet)\n if verbose:\n print(\"Loading ImageNet model...\", end=\"\")\n model = VGG16(\n # Initialize with ImageNet weights\n weights=\"imagenet\",\n # Continue training on 400x400 images. We'll have to update the final\n # layers of the model to be fully convolutional.\n include_top=False,\n input_shape=(400, 400, 3),\n )\n if verbose:\n print(\"done.\")\n\n if verbose:\n print(\"Updating final layers...\", end=\"\")\n\n # Add new fully convolutional \"top\" to the model\n # To the best of my ability, this follows the architecture published in\n # the GitHub repository of Neal Jean:\n # https://github.com/nealjean/predicting-poverty/blob/1b072cc418116332abfeea59fea095eaedc15d9a/model/predicting_poverty_deploy.prototxt\n # However, note that the VGG architecture that we initially load\n # varies from that described in Neal's `prototxt` file, even though we\n # try to make sure that the top layers are identical.\n layer = model.layers[-1].output\n layer = Dropout(0.5, name=\"conv6_dropout\")(layer)\n layer = Conv2D(\n filters=4096,\n kernel_size=(6, 6),\n strides=6,\n activation='relu',\n name=\"conv6\",\n kernel_initializer=keras.initializers.glorot_normal(),\n bias_initializer=keras.initializers.Constant(value=0.1),\n )(layer)\n layer = Dropout(0.5, name=\"conv7_dropout\")(layer)\n layer = Conv2D(\n filters=4096,\n kernel_size=(1, 1),\n strides=1,\n activation='relu',\n name=\"conv7\",\n kernel_initializer=keras.initializers.glorot_normal(),\n bias_initializer=keras.initializers.Constant(value=0.1),\n )(layer)\n layer = Dropout(0.5, name=\"conv8_dropout\")(layer)\n layer = Conv2D(\n filters=3,\n kernel_size=(1, 1),\n strides=1,\n name=\"conv8\",\n kernel_initializer=keras.initializers.glorot_normal(),\n bias_initializer=keras.initializers.Constant(value=0.1),\n )(layer)\n layer = AveragePooling2D(\n pool_size=(2, 2),\n strides=1,\n name=\"predictions_pooling\"\n )(layer)\n # XXX: I'm not sure this is correct (Neal's model may have created\n # a softmax for each pool individually) but it's good enough for now.\n layer = Flatten(name=\"predictions_flatten\")(layer)\n layer = Dense(num_classes, name=\"predictions_dense\")(layer)\n layer = Activation('softmax', name=\"predictions\")(layer)\n\n # Reset the model with the new top\n model = Model(model.input, layer)\n if verbose:\n print(\"done.\")\n\n if verbose:\n print(\"Compiling model...\", end=\"\")\n # The `loss` came from the MNIST example (may be incorrect)\n # and the learning rate came from the Xie et al. paper,\n # \"Transfer learning from deep features for remote sening and \n # poverty mapping\".\n metrics = ['accuracy']\n for class_index in range(num_classes):\n metrics.append(per_class_recall(class_index))\n metrics.append(per_class_count_expected(class_index, batch_size))\n model.compile(\n loss=keras.losses.categorical_crossentropy,\n optimizer=SGD(lr=1e-6),\n metrics=metrics,\n )\n if verbose:\n print(\"done.\")\n\n # Shuffle the images and labels\n index_order = np.array(list(range(len(image_paths))))\n np.random.shuffle(index_order)\n # X_shuffled = np.zeros(X.shape, dtype=K.floatx())\n image_paths_shuffled = np.zeros((len(image_paths),), dtype=object)\n y_shuffled = np.zeros(y.shape, dtype=K.floatx())\n for new_index, old_index in enumerate(index_order, start=0):\n image_paths_shuffled[new_index] = image_paths[old_index]\n y_shuffled[new_index] = y[old_index]\n\n image_paths = image_paths_shuffled\n y = y_shuffled\n\n # Train the model\n for fold_index in range(kfolds):\n\n # fold_size = math.ceil(len(X) / kfolds)\n fold_size = math.ceil(len(image_paths) / kfolds)\n val_fold_start = fold_size * fold_index\n val_fold_end = fold_size * (fold_index + 1)\n\n # Get the validation set\n # Using a trick from http://stackoverflow.com/questions/25330959/\n val_mask = np.zeros(len(image_paths), np.bool)\n val_mask[val_fold_start:val_fold_end] = 1\n image_paths_val = image_paths[val_mask]\n y_val = y[val_mask]\n\n # Get the training set\n train_mask = np.invert(val_mask)\n image_paths_train = image_paths[train_mask]\n y_train = y[train_mask]\n\n if verbose:\n print(\"Training on fold %d of %d\" % (fold_index + 1, kfolds))\n print(\"Training set size: %d\" % (len(image_paths_train)))\n print(\"Validation set size: %d\" % (len(image_paths_val)))\n\n class Generator(object):\n\n def __init__(self, image_paths, labels, batch_size=16):\n self.index = 0\n self.image_paths = image_paths\n self.labels = labels\n self.batch_size = batch_size\n\n def __iter__(self):\n return self\n\n def __next__(self):\n return self.next()\n\n def next(self):\n\n # Retrieve next batch\n batch_image_paths = self.image_paths[self.index:self.index + self.batch_size]\n batch_labels = self.labels[self.index:self.index + self.batch_size]\n batch_images = load_images(batch_image_paths.tolist(), verbose=False)\n\n # Advance pointer for next batch\n self.index += batch_size\n if self.index >= len(self.image_paths):\n self.index = 0\n\n return (batch_images, batch_labels)\n\n if verbose:\n print(\"Now fitting the model.\")\n print(\"Using class weights: \" + str(class_weights))\n model.fit_generator(\n Generator(image_paths_train, y_train),\n steps_per_epoch=math.ceil(float(len(image_paths_train)) / batch_size),\n epochs=epochs,\n class_weight=class_weights,\n verbose=(1 if verbose else 0),\n validation_data=Generator(image_paths_val, y_val),\n validation_steps=math.ceil(float(len(image_paths_val)) / batch_size),\n )\n\n # Save the model after each fold\n model.save(os.path.join(\n \"models\", \"model-\" + strftime(\"%Y%m%d-%H%M%S\", gmtime()) + \".h5\"))\n \n\nif __name__ == \"__main__\":\n\n argument_parser = ArgumentParser(description=\"Preprocess images for training\")\n argument_parser.add_argument(\"csvfile\", help=\"CSV containing labels\")\n argument_parser.add_argument(\"input_dir\")\n argument_parser.add_argument(\n \"test_index_file\",\n help=\"Name of file that has index of test sample on each line\")\n argument_parser.add_argument(\n \"-v\", action=\"store_true\",\n help=\"Print out detailed info about progress.\")\n args = argument_parser.parse_args()\n\n test_indexes = load_test_indexes(args.test_index_file)\n image_paths = get_image_paths(args.input_dir, test_indexes)\n y, class_weights = load_labels(args.csvfile, test_indexes)\n\n train(image_paths, y, class_weights, verbose=args.v)\n"
},
{
"alpha_fraction": 0.7129360437393188,
"alphanum_fraction": 0.7377491593360901,
"avg_line_length": 28.18787956237793,
"blob_id": "696a56480e167f2cb4a50f006858b8e9e3191092",
"content_id": "c67e671180ed07637f3464559fd06952635cfe90",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 9635,
"license_type": "no_license",
"max_line_length": 385,
"num_lines": 330,
"path": "/README.md",
"repo_name": "andrewhead/ICTD17-Paper",
"src_encoding": "UTF-8",
"text": "# DiiD-Predictor\n\nYou can use the following commands to do training and testing for our DiiD final project.\nBefore you run any of these commands, do this:\n\n```bash\nsudo -u andrew bash # Change user to Andrew\ncd ~/DiiD-Predictor # Change directory to this directory\nsource venv/bin/activate # Start Python virtual environment (load dependencies)\n```\n\nMost of these commands will take a *really long* time to run. To make sure that they\nstill run even after your SSH session has ended, use `nohup` at the beginning\nof every command. You can start off a command with `nohup` and then watch it's\nprogress with the following recipe:\n\n```bash\nnohup <command> & # run the command, don't terminate when SSH session is closed\ntail -f nohup.log # view the output of the program\n```\n\nFor example, to extract features, run:\n```bash\nnohup python extract_features.py \\\n images/Rwanda_simple/ \\\n block5_pool \\\n --output-dir features/rwanda_vgg16_block5_pool/ &\ntail -f nohup.log\n```\n\n## Preprocess images to have the expected indexes\n\n*Note*: The `rwanda_TL.csv` file comes will have to be uploaded securely (it's protected data).\nBefore doing this, create a `csv` directory in the `DiiD-Predictor` directory.\nFor uploading this file with `scp`, see related instructions for connecting over `ssh` (here)[https://cloud.google.com/compute/docs/instances/connecting-to-instance#standardssh].\nThen, run the `copy_images.py` script.\n\n```bash\npython copy_images.py \\\n images/Rwanda/ \\\n csv/rwanda_TL.csv \\\n --output-dir images/Rwanda_simple/\n```\n\n## Split into the test set\n\n```bash\npython util/get_test_indexes.py \\\n images/Rwanda_simple/ 0.1 > indexes/Rwanda_test_indexes.txt\n```\n\n## Extract features from an arbitrary layer of a neural network model\n\n```bash\npython extract_features.py \\\n images/Rwanda_simple/ \\\n block5_pool \\\n --output-dir features/rwanda_vgg16_block5_pool/\n```\n\nThe `--flatten` flag is optional, and it flattens the feature array for each image. Replace `\"block5_conv3\"` with the name of the layer you want to extract features for. You can also set the number of images to process together with the `--batch-size` argument. While this extracts features from an ImageNet VGG16 model, you can also provide another model with the `--model` option.\n\n## Train the top layers of the neural network\n\nTo train the top layers:\n```bash\npython train_top.py \\\n features/rwanda_vgg16_block5_pool \\\n csv/rwanda_TL.csv \\\n indexes/Rwanda_test_indexes.txt \\\n --learning-rate 0.01 \\\n --batch-size=100 \\\n --epochs=6 \\\n -v\n```\n\nNote that this steps depends on having run the previous steps to have the CSV file for Rwanda data, having the images moved into simple indexing form (single integer in the title), and having generated the test set image indexes.\n\n## Get final layer features (can be used for predicting ed and wealth index)\n\nWe rely on the `extract_features` script once again:\n\n```bash\npython extract_features.py \\\n features/rwanda_vgg16_block5_pool \\\n conv7 \\\n --flatten \\\n --model models/rwanda_vgg16_trained_top.h5 \\\n --input-type=features \\\n --batch-size=16 \\\n --output-dir=features/rwanda_vgg16_trained_top_conv7_flattened/\n```\n\n## Train a model for predicting wealth and education index\n\n```bash\npython train_index.py \\\n features/rwanda_vgg16_trained_top_conv7_flattened/ \\\n csv/rwanda_DHS_wealth.csv \\\n csv/rwanda_cluster_avg_educ_nightlights.csv \\\n csv/rwanda_TL.csv \\\n nightlights/F182010.v4d_web.stable_lights.avg_vis.tif \\\n models/indexes/rwanda_vgg16_trained_top \\\n -v\n```\n\nAdd the `--show-test-results` flag, and optionally set the\n`--prediction-output-basename` option, to see and save the\nmodel performance on the test set.\n\n## Train a model for predicting wealth, education and water index\n```\npython train_index_water.py \\\n features/rwanda_vgg16_trained_top_conv7_flattened/ \\\n csv/rwanda_DHS_wealth.csv \\\n csv/rwanda_cluster_avg_educ_nightlights.csv \\\n csv/rwanda_cluster_avg_water_nightlights.csv \\\n csv/rwanda_TL.csv \\\n nightlights/F182010.v4d_web.stable_lights.avg_vis.tif \\\n models/indexes/rwanda_vgg16_trained_top \\\n -v\n ```\n\n## Retrain convolutional layers\n\nExtract the features in block 4:\n\n```bash\npython extract_features.py \\\n images/Rwanda_simple/ \\\n block4_pool \\\n --output-dir features/rwanda_vgg16_block4_pool/\n```\n\nThen retrain only the end of top of the net and the last convolutional block.\n(At the time of writing this, this step wasn't yet implemented.)\n\n```bash\npython tune_block5.py \\\n features/rwanda_vgg16_block4_pool \\\n models/rwanda_vgg16_trained_top.h5 \\\n csv/rwanda_TL.csv \\\n indexes/Rwanda_test_indexes.txt \\\n --batch-size=100 \\\n --learning-rate=.0001 \\\n --epochs=6 \\\n -v\n```\n\n### And then extract the final layer features...\n\nFirst, by flattening the learned model:\n```bash\npython flatten_tuned_model.py \\\n models/rwanda_vgg16_tuned.h5 \\\n models/rwanda_vgg16_tuned_flattened.h5\n```\n\nAnd then by extracting flattened final layer features:\n```bash\npython extract_features.py \\\n features/rwanda_vgg16_block5_pool \\\n conv7 \\\n --flatten \\\n --model models/rwanda_vgg16_tuned_flattened.h5 \\\n --input-type=features \\\n --batch-size=16 \\\n --output-dir=features/rwanda_vgg16_tuned_conv7/\n```\n\n### And then retrain the index predictors!\n\n```bash\npython train_index.py \\\n features/rwanda_vgg16_tuned_conv7_flattened/ \\\n csv/rwanda_DHS_wealth.csv \\\n csv/rwanda_cluster_avg_educ_nightlights.csv \\\n csv/rwanda_TL.csv \\\n nightlights/F182010.v4d_web.stable_lights.avg_vis.tif \\\n models/indexes/rwanda_vgg16_tuned \\\n -v\n```\n\n## Getting images that cause activation in later layers\n\nExtract the features of a convolutional layer:\n\n```bash\npython extract_features.py \\\n features/rwanda_vgg16_block4_pool/ \\\n block5_conv3 \\\n --model models/rwanda_vgg16_tuned.h5\n --input-type=features\n --batch-size=16\n --output-dir=features/rwanda_vgg16_tuned_block5_conv3/\n```\n\nCompute which images activate each filter in that layer:\n\n```bash\npython get_activations.py \\\n features/rwanda_vgg16_tuned_block5_conv3/ \\\n activations/rwanda_vgg16_tuned_block5_conv3.txt \\\n --exemplar-count=10\n```\n\nVisualize which images maximize each filter:\n\n```bash\npython visualize_activations.py \\\n activations/rwanda_vgg16_tuned_block5_conv3.txt \\\n images/Rwanda_simple/ \\\n activations/rwanda_vgg16_tuned_block5_conv3.pdf\n```\n\n## Restricting feature extraction and training to a subset of images\n\nRun this command twice. Once to produce training indexes \nfor training the top\n(`indexes/Rwanda_train_top_training_indexes.txt`), and once\nto produce indexes for fine-tuning\n(`indexes/Rwanda_tuning_training_indexes.txt`).\n\n```bash\npython util/sample.py \\\n images/Rwanda_simple/ \\\n csv/rwanda_TL.csv \\\n indexes/Rwanda_test_indexes.txt \\\n 10000 > indexes/Rwanda_train_top_training_indexes.txt\n```\n\nYou can also precompute the indexes of features that are\nclose to the DHS clusters:\n\n```bash\npython util/geometry.py \\\n csv/rwanda_DHS_wealth.csv \\\n csv/rwanda_cluster_avg_educ_nightlights.csv \\\n csv/rwanda_cluster_avg_water_nightlights.csv \\\n csv/rwanda_TL.csv \\\n nightlights/F182010.v4d_web.stable_lights.avg_vis.tif > indexes/Rwanda_dhs_cluster_indexes.txt\n```\n\nYou can restric feature extraction to just examples with\nindexes defined in a set of files:\n\n```bash\npython extract_features.py \\\n images/Rwanda_simple/ \\\n block5_pool \\\n --output-dir features/rwanda_vgg16_block5_pool/ \\\n --filter-indexes indexes/Rwanda_test_indexes.txt indexes/Rwanda_train_top_training_indexes.txt\n```\n\nNote that you can provide multiple files from which to read\nthe indexes for feature extraction!\n\nThen, you can train the top or do fine-tuning with these\nprecomputed training indexes, for example:\n\n```bash\npython train_top.py \\\n features/rwanda_vgg16_block5_pool \\\n csv/rwanda_TL.csv \\\n indexes/Rwanda_test_indexes.txt \\\n --learning-rate 0.01 \\\n --batch-size=100 \\\n --epochs=6 \\\n --training-indexes-file=indexes/Rwanda_train_top_training_indexes.txt \\\n -v\n```\n\n## Setup\n\nIf you're setting up a machine from scratch, you'll need to follow these steps.\n\n### GPU setup\n\nIt's critical that you work with a GPU for this to have any\nreasonable performance on training and feature extraction.\n\nOn a Google Cloud compute instance:\n\nInstall the GPU (instructions based on those from (Google Cloud docs)[https://cloud.google.com/compute/docs/gpus/add-gpus]):\n\n```bash\necho \"Checking for CUDA and installing.\"\nif ! dpkg-query -W cuda; then\n # The 16.04 installer works with 16.10.\n curl -O http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_8.0.61-1_amd64.deb\n sudo dpkg -i ./cuda-repo-ubuntu1604_8.0.61-1_amd64.deb\n sudo apt-get update\n sudo apt-get install cuda -y\nfi\n```\n\nAdd the CudNN library:\nFrom your main development computer (not Google Cloud), transfer the `deb` that you download from [here](https://developer.nvidia.com/cudnn) (make sure to download version 5.1).\n```bash\nscp -i ~/.ssh/google_compute_engine ~/Downloads/libcudnn6_6.0.20-1+cuda8.0_amd64.deb [email protected]:/home/andrew/\n```\n\nThen from the compute machine, install it with `dpkg`:\n```bash\nsudo dkpg -i libcudnn6_6.0.20-1+cuda8.0_amd64.deb\n```\n\n### Other Project dependencies\n\n```bash\ngit clone <link to this repository>\n\nsudo apt-get update\nsudo apt-get install python-pip --fix-missing\npip install virtualenv\nsudo apt-get install python-gdal\n\ncd DiiD-Predictor\nvirtualenv --system-site-packages venv -p python3 # lets you access system-wide python3-gdal\nsource venv/bin/activate\npip install -I -r requirements.txt\n```\n\n## Get images for a country\n\n```bash\nmkdir images\ncd images/\ngsutil -m cp -r gs://diid/Rwanda .\n```\n"
},
{
"alpha_fraction": 0.6595481634140015,
"alphanum_fraction": 0.662725031375885,
"avg_line_length": 33.54268264770508,
"blob_id": "e852684bc38f74c9890ddc0da52ec6d12fd13865",
"content_id": "df60d52576cc489d10c894b0b1ee25c95fc6f9df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5666,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 164,
"path": "/util/sample.py",
"repo_name": "andrewhead/ICTD17-Paper",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nimport math\nimport csv\nfrom argparse import ArgumentParser\nimport os.path\nfrom time import gmtime, strftime\n\nfrom util.load_data import load_labels, load_test_indexes\n\n\n# Use this to get an equal representation of all classes in the\n# set of examples that you'll be training on.\ndef sample_by_class(example_indexes, labels, sample_size):\n\n all_examples = np.array([], dtype=np.int32)\n\n # Sort examples by class\n class_examples = {}\n for example_index in example_indexes:\n class_ = labels[example_index]\n if class_ not in class_examples:\n class_examples[class_] = []\n class_examples[class_].append(example_index)\n\n # For each class...\n for class_, examples in class_examples.items():\n\n # Repeat the array as many times as it will take to get\n # enough examples for the sample. Stack a bunch of shuffled\n # repeats on top of each other. This sampling method lets us\n # avoid repeat sampling until all items have been sampled once.\n examples_array = np.array(examples, dtype=np.int32)\n repeats = math.ceil(float(sample_size) / len(examples))\n repeated_examples = np.array([], dtype=np.int32)\n for _ in range(repeats):\n repeat = examples_array.copy()\n np.random.shuffle(repeat)\n repeated_examples = np.concatenate((repeated_examples, repeat))\n\n # Truncate the repeated randomized lists to the sample size\n # and append to the shared list of output examples\n repeated_examples = repeated_examples[:sample_size]\n all_examples = np.concatenate((all_examples, repeated_examples))\n\n # Shuffle one more time at the end, as before this, all\n # examples have incidentally been sorted by class\n np.random.shuffle(all_examples)\n return all_examples\n\n\n# Return a list of fold specs, where each one includes\n# \"train\": a list of indexes of training examples\n# \"validation\": a list of indexes of validation examples\n# All test indexes will be omitted from all folds\ndef get_folds(example_indexes, num_folds=3):\n\n indexes_shuffled = np.array(example_indexes, dtype=np.int32)\n np.random.shuffle(indexes_shuffled)\n\n folds = []\n fold_size = math.ceil(len(indexes_shuffled) / num_folds)\n for fold_index in range(num_folds):\n\n fold_start = fold_size * fold_index\n fold_end = fold_start + fold_size\n\n validation_mask = np.zeros(len(indexes_shuffled), np.bool)\n validation_mask[fold_start:fold_end] = 1\n validation_indexes = indexes_shuffled[validation_mask]\n\n training_mask = np.invert(validation_mask)\n training_indexes = indexes_shuffled[training_mask]\n\n folds.append({\n \"validation\": validation_indexes,\n \"training\": training_indexes,\n })\n\n return folds\n\n\ndef get_training_examples(features_dir, labels, test_indexes, sample_size):\n\n # Get list of indexes for all examples. Assume that every file starts\n # with its index as its basename when making this list.\n example_indexes = []\n for feature_filename in os.listdir(features_dir):\n index = int(os.path.splitext(feature_filename)[0])\n example_indexes.append(index)\n\n # Filter to the indexes that can be used for training\n example_indexes_set = set(example_indexes)\n test_indexes_set = set(test_indexes)\n training_indexes = example_indexes_set.difference(test_indexes_set)\n\n # Sample for equal representation of each class\n sampled_examples = sample_by_class(training_indexes, labels, sample_size)\n return sampled_examples\n\n\nclass FeatureExampleGenerator(object):\n\n def __init__(self, indexes, feature_dir, labels, batch_size):\n self.indexes = indexes\n self.feature_dir = feature_dir\n self.labels = labels\n self.batch_size = batch_size\n self.pointer = 0\n\n def __iter__(self):\n return self\n\n def __next__(self):\n return self.next()\n\n def next(self):\n\n # Get the list of example indexes in this batch\n batch_indexes = self.indexes[self.pointer:self.pointer + self.batch_size]\n\n # Load features for examples from file\n data_file_names = [\n os.path.join(self.feature_dir, str(i) + \".npz\")\n for i in batch_indexes]\n examples = tuple()\n for filename in data_file_names:\n examples += (np.load(filename)[\"data\"],)\n example_array = np.stack(examples)\n\n # Grab the labels for this batch\n labels = self.labels[batch_indexes]\n\n # Advance pointer for next batch\n self.pointer += self.batch_size\n if self.pointer >= len(self.indexes):\n self.pointer = 0\n\n return (example_array, labels)\n\n\nif __name__ == \"__main__\":\n\n argument_parser = ArgumentParser(description=\"Compute indexes for training set\")\n argument_parser.add_argument(\"features_dir\")\n argument_parser.add_argument(\"csvfile\", help=\"CSV containing labels\")\n argument_parser.add_argument(\n \"test_index_file\",\n help=\"Name of file that has index of test sample on each line\")\n argument_parser.add_argument(\n \"sample_size\", default=10000, type=int,\n help=\"Number of images to sample from each class (avoid biasing smaller classes).\")\n args = argument_parser.parse_args()\n\n test_indexes = load_test_indexes(args.test_index_file)\n labels = load_labels(args.csvfile)\n examples = get_training_examples(\n features_dir=args.features_dir,\n labels=labels,\n test_indexes=test_indexes,\n sample_size=args.sample_size\n )\n for example in examples:\n print(example)\n\n"
},
{
"alpha_fraction": 0.644374430179596,
"alphanum_fraction": 0.6493930816650391,
"avg_line_length": 41.41584014892578,
"blob_id": "9772df6c8f3a89aab2b13f957f20dbb895b3c2e0",
"content_id": "7e01a6ad91bbbcc1e3f6d0ad9102ae08d733a0e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8568,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 202,
"path": "/extract_features.py",
"repo_name": "andrewhead/ICTD17-Paper",
"src_encoding": "UTF-8",
"text": "from keras import backend as K\nfrom keras.models import load_model, Model\nfrom keras.preprocessing import image\nfrom keras.utils.generic_utils import get_custom_objects\nfrom keras_models.vgg16 import VGG16\nimport numpy as np\n\nimport math\nimport os.path\nimport argparse\nfrom tqdm import tqdm\n\n\ndef get_features_for_input_features(model, filenames, batch_size):\n\n # Load first features to get its shape\n feature_array = np.load(filenames[0])[\"data\"]\n input_shape = feature_array.shape\n\n batch_start = 0\n while batch_start < len(filenames):\n\n num_rows = min(batch_size, len(filenames) - batch_start)\n X = np.zeros((num_rows,) + input_shape)\n batch_filenames = filenames[batch_start:batch_start + batch_size]\n batch_example_indexes = []\n\n for input_index, input_path in enumerate(batch_filenames):\n\n # Make each image a single 'row' of a tensor\n input_ = np.load(input_path)[\"data\"]\n X[input_index] = input_\n\n # Save the index of the the example we just loaded\n example_index = int(os.path.splitext(os.path.basename(input_path))[0])\n batch_example_indexes.append(example_index)\n\n # Find the output of the final layer\n # Borrowed from https://github.com/fchollet/keras/issues/41\n features = model.predict([X])\n features_array = np.array(features)\n yield (batch_example_indexes, features_array)\n batch_start += batch_size\n\n yield StopIteration\n\n\ndef get_features_for_input_images(model, img_paths, batch_size):\n\n # Load first image to get image dimensions\n img = image.load_img(img_paths[0])\n width = img.width\n height = img.height\n\n batch_start = 0\n while batch_start < len(img_paths):\n\n num_rows = min(batch_size, len(img_paths) - batch_start)\n # XXX: I'm not sure if the order of height and width is correct here,\n # but it doesn't matter for us right now as we're using square images\n X = np.zeros((num_rows, width, height, 3))\n batch_img_paths = img_paths[batch_start:batch_start + batch_size]\n batch_example_indexes = []\n\n for img_index, img_path in enumerate(batch_img_paths):\n\n # Make each image a single 'row' of a tensor\n img = image.load_img(img_path)\n img_array = image.img_to_array(img)\n X[img_index, :, :, :] = img_array\n\n # Save the index of the the example we just loaded\n example_index = int(os.path.splitext(os.path.basename(img_path))[0])\n batch_example_indexes.append(example_index)\n\n # Find the output of the final layer\n features = model.predict([X])\n features_array = np.array(features)\n yield (batch_example_indexes, features_array)\n batch_start += batch_size\n\n yield StopIteration\n\n\ndef extract_features(model_path, input_dir, layer_name, output_dir,\n flatten, batch_size, input_type, example_indexes):\n\n # Add records for the custom metrics we attached to the models,\n # pointing them to no-op metrics methods.\n custom_objects = get_custom_objects()\n custom_objects.update({\"recall (C0)\": lambda x, y: K.constant(0)})\n custom_objects.update({\"% examples (C0)\": lambda x, y: K.constant(0)})\n custom_objects.update({\"recall (C1)\": lambda x, y: K.constant(0)})\n custom_objects.update({\"% examples (C1)\": lambda x, y: K.constant(0)})\n custom_objects.update({\"recall (C2)\": lambda x, y: K.constant(0)})\n custom_objects.update({\"% examples (C2)\": lambda x, y: K.constant(0)})\n\n # Create a model that only outputs the requested layer\n if model_path:\n print(\"Loading model %s...\" % (model_path), end=\"\")\n model = load_model(model_path)\n else:\n print(\"Loading VGG16...\", end=\"\")\n model = VGG16(weights='imagenet', include_top=False)\n print(\"done.\")\n\n print(\"Adjusting model to output feature layer...\" , end=\"\")\n output_layer = model.get_layer(layer_name)\n input_layer = model.layers[0]\n model = Model(input_layer.input, output_layer.output)\n print(\"done.\")\n\n print(\"Now computing features for all batches of images...\")\n filename = lambda image_index: os.path.join(\n output_dir, str(image_index) + \".npz\")\n if not os.path.exists(output_dir):\n os.makedirs(output_dir)\n\n # Load in the filenames. Filter down to a subset if the caller provided\n # a list of indexes they wanted features for.\n basenames = os.listdir(input_dir)\n selected_basenames = []\n for basename in basenames:\n if example_indexes is None:\n selected_basenames.append(basename)\n else:\n example_index = int(os.path.splitext(basename)[0])\n if example_index in example_indexes:\n selected_basenames.append(basename)\n filenames = [os.path.join(input_dir, f) for f in selected_basenames]\n \n # Compute the features in batches\n expected_batches = math.ceil(len(filenames) / float(batch_size))\n if input_type == \"images\":\n input_generator = get_features_for_input_images(model, filenames, batch_size)\n elif input_type == \"features\":\n input_generator = get_features_for_input_features(model, filenames, batch_size)\n\n for (example_indexes, feature_batch) in tqdm(input_generator, total=expected_batches):\n if flatten:\n feature_batch = feature_batch.reshape(feature_batch.shape[0], -1)\n for example_index, image_features in zip(example_indexes, feature_batch):\n # It's important to store using `compressed` if you want to save more than\n # a few hundred images. Without compression, every 1,000 images will take\n # about 1GB of memory, which might not scale well for most datasets\n # Each record is saved to its own file to enable efficient loading without\n # needing to load all image features into memory during later training.\n np.savez_compressed(filename(example_index), data=image_features)\n\n print(\"All features have been computed and saved.\")\n print(\"Reload features for each image with: `np.load(<filename>)['data']`\")\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(description=\n \"Extract features for a set of images from a layer of \" +\n \"a neural network model.\"\n )\n parser.add_argument(\"input_dir\", help=\"Directory containing all inputs\")\n parser.add_argument(\"layer_name\", help=\"Layer from which to extract features\")\n parser.add_argument(\"--input-type\", default=\"images\",\n choices=[\"images\", \"features\"], help=\"Input to the model. If features, \" +\n \"the input directory should contain 'npz' files created with this \" +\n \"script. If images, the input directory should contain images.\")\n parser.add_argument(\"--model\", help=\"H5 file containing model. If not \" +\n \"provided, then features are extracted using VGG16\")\n parser.add_argument(\"--flatten\", action=\"store_true\", help=\n \"Whether to flatten the extracted features. This is useful if you \" +\n \"want to train regression using the extracted features.\"\n )\n parser.add_argument(\"--batch-size\", default=32, help=\"Number of images to \" + \n \"extract features for at a time.\", type=int)\n parser.add_argument(\"--output-dir\", default=\"features/output/\",\n help=\"Name of directory to write features to.\")\n parser.add_argument(\"--filter-indexes\", nargs=\"+\",\n help=\"Files containing indexes of the examples for which features \" +\n \"should be extracted. A different index should appear on each \" +\n \"line, and you can specify multiple files.\")\n args = parser.parse_args()\n\n # Make list of the examples for which we want to extract features. If no\n # indexes files were provided, we set `example_indexes` to None, which\n # means we'll extract features for all files in the input directory.\n if args.filter_indexes:\n example_indexes = set()\n for indexes_filename in args.filter_indexes:\n with open(indexes_filename) as indexes_file:\n for line in indexes_file:\n example_indexes.add(int(line.strip()))\n else:\n example_indexes = None\n\n extract_features(\n model_path=args.model,\n input_dir=args.input_dir,\n layer_name=args.layer_name,\n output_dir=args.output_dir,\n flatten=args.flatten,\n batch_size=args.batch_size,\n input_type=args.input_type,\n example_indexes=example_indexes,\n )\n"
},
{
"alpha_fraction": 0.6432088017463684,
"alphanum_fraction": 0.6581233739852905,
"avg_line_length": 37.36666488647461,
"blob_id": "344a87bb2f3b642c46a8539a23df2ae7ede39a80",
"content_id": "bc1ed9b6f37940186f1c3d81ace9f88fea9e8979",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6906,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 180,
"path": "/train_top.py",
"repo_name": "andrewhead/ICTD17-Paper",
"src_encoding": "UTF-8",
"text": "import keras\nfrom keras import backend as K\nfrom keras.callbacks import EarlyStopping\nfrom keras.models import Sequential, load_model\nfrom keras.layers import Activation, Dense, Dropout, Flatten, Reshape\nfrom keras.layers.convolutional import Conv2D\nfrom keras.layers.pooling import AveragePooling2D\nfrom keras.preprocessing import image\nfrom keras_models.vgg16 import VGG16\nfrom keras.optimizers import SGD\n\nimport numpy as np\n\nimport math\nimport csv\nfrom argparse import ArgumentParser\nimport os.path\nfrom time import gmtime, strftime\n\nfrom util.load_data import load_labels, load_test_indexes\nfrom util.sample import get_folds, get_training_examples, FeatureExampleGenerator\n\n\n# To the best of my ability, this creates the top layers of a neural network\n# as demonstrated in the GitHub repository of Neal Jean at\n# https://github.com/nealjean/predicting-poverty/blob/1b072cc418116332abfeea59fea095eaedc15d9a/model/predicting_poverty_deploy.prototxt\n# This function returns the first layer and the last layer of that top.\ndef make_jean_top(num_classes=3):\n\n model = Sequential()\n model.add(Dropout(0.5, name=\"conv6_dropout\", input_shape=(12, 12, 512)))\n model.add(Conv2D(\n filters=4096,\n kernel_size=(6, 6),\n strides=6,\n activation='relu',\n name=\"conv6\",\n kernel_initializer=keras.initializers.glorot_normal(),\n bias_initializer=keras.initializers.Constant(value=0.1),\n ))\n model.add(Dropout(0.5, name=\"conv7_dropout\"))\n model.add(Conv2D(\n filters=4096,\n kernel_size=(1, 1),\n strides=1,\n activation='relu',\n name=\"conv7\",\n kernel_initializer=keras.initializers.glorot_normal(),\n bias_initializer=keras.initializers.Constant(value=0.1),\n ))\n model.add(Dropout(0.5, name=\"conv8_dropout\"))\n model.add(Conv2D(\n filters=3,\n kernel_size=(1, 1),\n strides=1,\n name=\"conv8\",\n kernel_initializer=keras.initializers.glorot_normal(),\n bias_initializer=keras.initializers.Constant(value=0.1),\n ))\n model.add(AveragePooling2D(\n pool_size=(2, 2),\n strides=1,\n name=\"predictions_pooling\"\n ))\n # XXX: I'm not sure this is correct (Neal's model may have created\n # a softmax for each pool individually) but it's good enough for now.\n model.add(Flatten(name=\"predictions_flatten\"))\n model.add(Dense(num_classes, name=\"predictions_dense\"))\n model.add(Activation('softmax', name=\"predictions\"))\n \n return model\n\n\ndef train(features_dir, top_model_filename, labels, batch_size, sample_size,\n learning_rate, epochs, kfolds, training_indexes_filename,\n verbose=False, num_classes=3):\n\n if top_model_filename is not None:\n if verbose:\n print(\"Loading model of top of net...\", end=\"\")\n model = load_model(top_model_filename)\n else:\n if verbose:\n print(\"Building model of top of net...\", end=\"\")\n model = make_jean_top()\n if verbose:\n print(\"done.\")\n\n if verbose:\n print(\"Compiling model...\", end=\"\")\n model.compile(\n loss=keras.losses.categorical_crossentropy,\n optimizer=SGD(lr=learning_rate),\n metrics=['accuracy'],\n )\n if verbose:\n print(\"done.\")\n\n # Sample for training indexes, or load from file\n if training_indexes_filename is not None:\n sampled_examples = []\n with open(training_indexes_filename) as training_indexes_file:\n for line in training_indexes_file:\n sampled_examples.append(int(line.strip()))\n else:\n sampled_examples = get_training_examples(\n features_dir, labels, test_indexes, sample_size)\n\n # Divide the sampled training data into folds\n folds = get_folds(sampled_examples, kfolds)\n\n # Convert labels to one-hot array for use in training.\n label_array = keras.utils.to_categorical(labels, num_classes)\n\n # Only train for one of the fold, to better replicate Xie et al.\n for i, fold in enumerate(folds, start=1):\n\n training_examples = fold[\"training\"]\n validation_examples = fold[\"validation\"]\n\n if verbose:\n print(\"Training on fold %d of %d\" % (i, len(folds)))\n print(\"Training set size: %d\" % (len(training_examples)))\n print(\"Validation set size: %d\" % (len(validation_examples)))\n\n # Do the actual fitting here\n model.fit_generator(\n FeatureExampleGenerator(training_examples, features_dir, label_array, batch_size),\n steps_per_epoch=math.ceil(float(len(training_examples)) / batch_size),\n epochs=epochs,\n verbose=(1 if verbose else 0),\n validation_data=FeatureExampleGenerator(validation_examples, features_dir, label_array, batch_size),\n validation_steps=math.ceil(float(len(validation_examples)) / batch_size),\n callbacks=[EarlyStopping(monitor='val_loss', patience=2)],\n )\n if not os.path.exists(\"models\"):\n os.makedirs(\"models\")\n model.save(os.path.join(\n \"models\", \"model-\" + strftime(\"%Y%m%d-%H%M%S\", gmtime()) + \".h5\"))\n\n break\n \n\nif __name__ == \"__main__\":\n\n argument_parser = ArgumentParser(description=\"Train top layers of neural net\")\n argument_parser.add_argument(\"features_dir\")\n argument_parser.add_argument(\"csvfile\", help=\"CSV containing labels\")\n argument_parser.add_argument(\n \"-v\", action=\"store_true\",\n help=\"Print out detailed info about progress.\")\n argument_parser.add_argument(\"--top-model\", help=\"H5 for previously trained \" +\n \"top layers of the neural network.\")\n argument_parser.add_argument(\n \"--batch-size\", default=16, type=int, help=\"Number of training examples at a time. \" +\n \"More than 16 at a time seems to lead to out-of-memory errors on K80\")\n argument_parser.add_argument(\n \"--sample-size\", default=10000, type=int,\n help=\"Number of images to sample from each class (avoid biasing smaller classes).\")\n argument_parser.add_argument(\"--learning-rate\", default=0.01, type=float)\n argument_parser.add_argument(\"--epochs\", default=50, type=int)\n argument_parser.add_argument(\"--num-folds\", default=10, type=int)\n argument_parser.add_argument(\"--training-indexes-file\", help=\"File containing \" +\n \"an index of a training example on each line. Useful if you only have \" +\n \"features extracted for a subset of the examples.\")\n args = argument_parser.parse_args()\n\n labels = load_labels(args.csvfile)\n train(\n args.features_dir,\n args.top_model,\n labels,\n epochs=args.epochs,\n sample_size=args.sample_size,\n batch_size=args.batch_size,\n kfolds=args.num_folds,\n learning_rate=args.learning_rate,\n training_indexes_filename=args.training_indexes_file,\n verbose=args.v,\n )\n"
},
{
"alpha_fraction": 0.6731588840484619,
"alphanum_fraction": 0.6755934357643127,
"avg_line_length": 38.590362548828125,
"blob_id": "5c4777a05af38cd0c6ba9919a82234d94f3a9825",
"content_id": "0b2da20d83d35dcb3674988b0d5690fab0e7f9bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3286,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 83,
"path": "/get_activations.py",
"repo_name": "andrewhead/ICTD17-Paper",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport argparse\nimport os.path\nimport gc\nfrom tqdm import tqdm\n\n\ndef get_activations(features_dir, exemplar_count, output_filename):\n\n output_file = open(output_filename, 'w')\n\n # Get number of examples and shape of features\n num_examples = len(os.listdir(features_dir))\n features_instance = np.load(os.path.join(features_dir, os.listdir(features_dir)[0]))[\"data\"]\n features_shape = features_instance.shape\n\n # Find out how many filters we'll be averaging over, and the\n # axes of the features over which to average to get the average intensity\n # within each filter as the filter \"activations\"\n num_filters = features_shape[-1]\n within_filter_axes = tuple(range(len(features_shape) - 1))\n\n # Make an array of zeros, with one row for each example and one\n # and one column for the \"activation\" in each filter\n filter_activations = np.zeros((num_examples, num_filters))\n\n # Load in this batch of features for all examples\n example_indexes = []\n for i, filename in tqdm(enumerate(os.listdir(features_dir)),\n total=num_examples, desc=\"Loading features\"):\n\n # Store a link from the example's index in the numpy array\n # and the index of the example in the features directory. \n example_index = int(os.path.splitext(filename)[0])\n example_indexes.append(example_index)\n\n # Load the features for this example\n path = os.path.join(features_dir, filename)\n features = np.load(path)[\"data\"]\n\n # Compute the activations for the example's features\n example_filter_averages = np.average(features, axis=within_filter_axes)\n filter_activations[i] = example_filter_averages\n\n # Iterate through each filter, with a sorted list of which rows maximize each one.\n # Remember that these row indexes need to be mapped back to example indexes\n # in the original feature directory.\n print(\"Writing exemplars to file...\", end=\"\")\n for filter_index, example_ranks in enumerate(filter_activations.argsort(axis=0).T):\n\n # Extract the top N exemplars that maximize each filter\n exemplar_rows = example_ranks[::-1][:exemplar_count]\n\n # Find out the example indexes for each row in the maximizing rows\n exemplars = [example_indexes[row_index] for row_index in exemplar_rows]\n\n # Write list of exemplars to file\n output_file.write(\"%d: [\" % (filter_index,))\n for exemplar in exemplars:\n output_file.write(\"%d \" % (exemplar,))\n output_file.write(\"]\\n\")\n\n print(\"done.\")\n output_file.close()\n\n\nif __name__ == \"__main__\":\n\n parser = argparse.ArgumentParser(description=\n \"Get indexes of images that most activate individual \" +\n \"filters in a set of provided features\")\n parser.add_argument(\"features_dir\", help=\"directory containing \" +\n \"features processed for each image.\")\n parser.add_argument(\"output\", help=\"file to output the results\")\n parser.add_argument(\"--exemplar-count\", default=10, type=int,\n help=\"How many exemplars of each feature to save\")\n\n args = parser.parse_args()\n get_activations(\n features_dir=args.features_dir,\n exemplar_count=args.exemplar_count,\n output_filename=args.output,\n )\n"
},
{
"alpha_fraction": 0.6402468681335449,
"alphanum_fraction": 0.6473862528800964,
"avg_line_length": 46.4942512512207,
"blob_id": "577cf3301ad22bb491b9a20339b69846ea7882a1",
"content_id": "f1e412b15b397e56ce8b68ec9d7abfbb17e6970c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8264,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 174,
"path": "/util/geometry.py",
"repo_name": "andrewhead/ICTD17-Paper",
"src_encoding": "UTF-8",
"text": "import argparse\n\nfrom osgeo import gdal\nimport numpy as np\n\nfrom util.load_data import read_wealth_records, read_education_records,\\\n read_water_records, get_map_from_i_j_to_example_index\n\n\nclass MapGeometry(object):\n \"\"\"\n This class is an eyesore, but unfortunately it's necessary for finding\n images within the vicinity of a latitude and longitude, so that we can\n predict a `y` using average features over a larger spatial area.\n \"\"\"\n def __init__(self, raster_filename):\n self.load_raster(raster_filename)\n\n def load_raster(self, raster_filename):\n\n raster_dataset = gdal.Open(raster_filename, gdal.GA_ReadOnly)\n\n # get project coordination\n proj = raster_dataset.GetProjectionRef()\n bands_data = []\n\n # Loop through all raster bands\n for b in range(1, raster_dataset.RasterCount + 1):\n band = raster_dataset.GetRasterBand(b)\n bands_data.append(band.ReadAsArray())\n no_data_value = band.GetNoDataValue()\n bands_data = np.dstack(bands_data)\n rows, cols, n_bands = bands_data.shape\n\n # Get the metadata of the raster\n geo_transform = raster_dataset.GetGeoTransform()\n (upper_left_x, x_size, x_rotation, upper_left_y, y_rotation, y_size) = geo_transform\n \n # Get location of each pixel\n x_size = 1.0 / int(round(1 / float(x_size)))\n y_size = - x_size\n y_index = np.arange(bands_data.shape[0])\n x_index = np.arange(bands_data.shape[1])\n top_left_x_coords = upper_left_x + x_index * x_size\n top_left_y_coords = upper_left_y + y_index * y_size\n\n # Add half of the cell size to get the centroid of the cell\n centroid_x_coords = top_left_x_coords + (x_size / 2)\n centroid_y_coords = top_left_y_coords + (y_size / 2)\n\n self.x_size = x_size\n self.top_left_x_coords = top_left_x_coords\n self.top_left_y_coords = top_left_y_coords\n self.centroid_x_coords = centroid_x_coords\n self.centroid_y_coords = centroid_y_coords\n\n def get_cell_idx(self, lon, lat):\n lon_idx = np.where(self.top_left_x_coords < lon)[0][-1]\n lat_idx = np.where(self.top_left_y_coords > lat)[0][-1]\n return lon_idx, lat_idx\n\n def get_image_rect_from_cell_indexes(self, image_i, image_j):\n return self.get_image_rect_from_long_lat(\n self.centroid_x_coords[image_i],\n self.centroid_y_coords[image_j])\n\n def get_image_rect_from_long_lat(self, longitude, latitude):\n \"\"\"\n We want to get a 10x10 matrix of images around this image. All we have is the \n center cell indexes and latitude and longitude of the center. We can't just \n expand to 5 on either side, as this will give us an 11x11 matrix of images.\n So we can create this 11x11 matrix, and truncate whichever sides are\n farthest away from the center latitude and longitude.\n\n In practice, I compute this as follows. I pick the image 5 to the left of\n the center image (the left image). Then I compute the longitude of the\n ideal left boundary of the matrix, if the center coordinates were right in \n the middle of the 10x10 cell. If the ideal left boundary is closer to right \n side of the left image than the left side, then less than half of this \n column of images would fit within the ideal image matrix: we truncate the\n left side. Otherwise, less than half of the right column would fit in the\n ideal image matrix; we truncate the right side. We use the same logic to\n decide whether to truncate the top or bottom of the 11x11 matrix.\n \"\"\"\n (image_i, image_j) = self.get_cell_idx(longitude, latitude)\n left_image_i = image_i - 5\n left_image_center_longitude = self.centroid_x_coords[left_image_i]\n ideal_left_longitude = longitude - self.x_size * 5\n truncate_left = (ideal_left_longitude > left_image_center_longitude)\n \n top_image_j = image_j - 5\n top_image_center_latitude = self.centroid_y_coords[top_image_j]\n ideal_top_latitude = latitude + self.x_size * 5 # (latitude gets more positive as we go up)\n truncate_top = (ideal_top_latitude < top_image_center_latitude)\n \n rect = {'width': 10, 'height': 10}\n rect['left'] = image_i - 4 if truncate_left else image_i - 5\n rect['top'] = image_j - 4 if truncate_top else image_j - 5\n return rect\n\n def get_centroid_long_lat(self, image_i, image_j):\n return self.centroid_x_coords[image_i], self.centroid_y_coords[image_j]\n\n\ndef get_indexes_for_clusters(records, i_j_to_example_index_map, map_geometry):\n\n example_indexes = set()\n\n for record_index, record in enumerate(records):\n \n # Find the neighborhood of images for this record's location\n # Latitude and longitude are more precise, so if they're available, use\n # them for finding the closest set of images in the neighborhood\n if 'longitude' in record and 'latitude' in record:\n neighborhood = map_geometry.get_image_rect_from_long_lat(\n record['longitude'], record['latitude'])\n else:\n neighborhood = map_geometry.get_image_rect_from_cell_indexes(\n record['i'], record['j'])\n \n # Collect features for all images in the neighborhood\n for image_i in range(neighborhood['left'], neighborhood['left'] + neighborhood['width']):\n for image_j in range(neighborhood['top'], neighborhood['top'] + neighborhood['height']):\n if (image_i, image_j) not in i_j_to_example_index_map:\n continue\n example_index = i_j_to_example_index_map[(image_i, image_j)]\n example_indexes.add(example_index)\n\n return example_indexes\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(description=\"Compute indexes of images\" + \n \"that will be used for computing indexes in clusters\")\n parser.add_argument(\"wealth_csv\", help=\"CSV file where \" +\n \"the top row is a header, col 1 (zero-indexed) is the wealth index, \" +\n \"col 7 is the latitude, and col 8 is the longitude.\")\n parser.add_argument(\"education_csv\", help=\"CSV file where \" +\n \"the top row is a header, col 3 (zero-indexed) is the education index, \" +\n \"col 1 is the cell's 'i' coordinate, and col 2 is the 'j' coordinate.\")\n parser.add_argument(\"water_csv\", help=\"CSV file where \" +\n \"the top row is a header, col 4 (zero-indexed) is the water index, \" +\n \"col 2 is the cell's 'i' coordinate, and col 3 is the 'j' coordinate.\")\n parser.add_argument(\"nightlights_csv\", help=\"CSV file where \" +\n \"the top row is a header, col 0 (zero-indexed) is the index of the \" +\n \"example (basename of eature file), and cols 2 and 3 are the \" +\n \"i and j of the cell in the nightlights data\")\n parser.add_argument(\"nightlights_raster\", help=\"Raster file of \" +\n \"nightlights, used for making a map from latitude and longitude \" +\n \"to cell indexes on the map.\")\n args = parser.parse_args()\n\n map_geometry = MapGeometry(args.nightlights_raster)\n i_j_to_example_index_map = get_map_from_i_j_to_example_index(args.nightlights_csv)\n \n # Read in records for wealth, education, and water\n wealth_records = read_wealth_records(args.wealth_csv)\n education_records = read_education_records(args.education_csv)\n water_records = read_water_records(args.water_csv)\n\n # Get indexes of images that we need to load for all three data types\n example_indexes = set()\n wealth_example_indexes = get_indexes_for_clusters(\n wealth_records, i_j_to_example_index_map, map_geometry)\n education_example_indexes = get_indexes_for_clusters(\n education_records, i_j_to_example_index_map, map_geometry)\n water_example_indexes = get_indexes_for_clusters(\n water_records, i_j_to_example_index_map, map_geometry)\n\n # Print example indexes to STDOUT\n example_indexes = example_indexes.union(wealth_example_indexes,\n education_example_indexes, water_example_indexes)\n for index in example_indexes:\n print(index)\n"
},
{
"alpha_fraction": 0.48469388484954834,
"alphanum_fraction": 0.6900510191917419,
"avg_line_length": 15.333333015441895,
"blob_id": "6602a09d732cb38d4000cfca6ab77f336205c0d8",
"content_id": "f07a293dab32843b4cb4042456c9f011aea44661",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 784,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 48,
"path": "/requirements.txt",
"repo_name": "andrewhead/ICTD17-Paper",
"src_encoding": "UTF-8",
"text": "appdirs==1.4.3\nappnope==0.1.0\nastroid==1.5.2\ncycler==0.10.0\nCython==0.25.2\ndecorator==4.0.11\nflake8==3.3.0\nh5py==2.7.0\nipython==5.3.0\nipython-genutils==0.2.0\nisort==4.2.5\nKeras==2.0.3\nlazy-object-proxy==1.3.1\nMako==1.0.6\nMarkupSafe==1.0\nmatplotlib==2.0.0\nmccabe==0.6.1\nnumpy==1.12.1\nolefile==0.44\npackaging==16.8\npexpect==4.2.1\npickleshare==0.7.4\nPillow==4.1.0\nprompt-toolkit==1.0.14\nprotobuf==3.2.0\nptyprocess==0.5.1\npycodestyle==2.3.1\npycosat==0.6.1\npyflakes==1.5.0\nPygments==2.2.0\npylint==1.7.1\npyparsing==2.2.0\npython-dateutil==2.6.0\npytz==2017.2\nPyYAML==3.12\nrequests==2.13.0\nruamel.yaml==0.14.10\nscikit-learn==0.18.1\nscipy==0.19.0\nsimplegeneric==0.8.1\nsix==1.10.0\ntensorflow==1.0.1\ntensorflow-gpu==1.0.1\nTheano==0.9.0\ntqdm==4.11.2\ntraitlets==4.3.2\nwcwidth==0.1.7\nwrapt==1.10.10\n"
},
{
"alpha_fraction": 0.5885416865348816,
"alphanum_fraction": 0.5929487347602844,
"avg_line_length": 31.828947067260742,
"blob_id": "068ca4a1d78ded5a3c7f1d8b30e7a4fe50bf0864",
"content_id": "744d0423aacbe13cca776256e0a74f5767620e1d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2496,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 76,
"path": "/copy_images.py",
"repo_name": "andrewhead/ICTD17-Paper",
"src_encoding": "UTF-8",
"text": "from argparse import ArgumentParser\nimport csv\nimport shutil\nimport os.path\nimport glob\nimport re\n\n\ndef make_cell_to_index_lookup(csv_filename):\n lookup = {}\n with open(csv_filename) as csvfile:\n reader = csv.reader(csvfile)\n # Skip the first row (headers)\n first_row = True\n for row in reader:\n if first_row:\n first_row = False\n continue\n index = int(row[0])\n i = int(row[2])\n j = int(row[3])\n lookup[(i, j)] = index\n return lookup\n\n\ndef make_cell_to_file_lookup(input_dir):\n lookup = {}\n for (dirpath, dirnames, filenames) in os.walk(input_dir):\n for filename in filenames:\n match = re.match(r\"(\\d+)_(\\d+).jpg\", filename)\n if match:\n i = int(match.group(1))\n j = int(match.group(2))\n lookup[(i, j)] = os.path.join(dirpath, filename)\n return lookup\n\n\ndef move_files(cell_to_index_dict, cell_to_file_dict, output_dir, move):\n\n # Create the output directory\n if not os.path.exists(output_dir):\n os.mkdir(output_dir)\n\n copy_count = 0\n for (i, j), index in cell_to_index_dict.items():\n\n # Only transfer a file if there's a record for it in the\n # nightlights data, and the image actually exists\n if not (i, j) in cell_to_file_dict:\n continue\n source_filename = cell_to_file_dict[(i, j)]\n if not os.path.exists(source_filename):\n continue\n\n # Copy or move the file\n copy_function = shutil.copyfile if not move else shutil.move\n copy_function(\n source_filename,\n os.path.join(output_dir, str(index) + \".jpg\")\n )\n copy_count += 1\n print(\".\", end=\"\")\n if copy_count % 100 == 0:\n print()\n\n\nif __name__ == \"__main__\":\n argument_parser = ArgumentParser(description=\"Rename image files\")\n argument_parser.add_argument(\"input_dir\")\n argument_parser.add_argument(\"csvfile\", help=\"Name of file with image indexes\")\n argument_parser.add_argument(\"--output-dir\", default=\"images\")\n argument_parser.add_argument(\"--move\", help=\"Move images instead of copying\", action=\"store_true\")\n args = argument_parser.parse_args()\n cell_to_index_dict = make_cell_to_index_lookup(args.csvfile)\n cell_to_file_dict = make_cell_to_file_lookup(args.input_dir)\n move_files(cell_to_index_dict, cell_to_file_dict, args.output_dir, args.move)\n\n"
},
{
"alpha_fraction": 0.6234607696533203,
"alphanum_fraction": 0.6491683125495911,
"avg_line_length": 35.44881820678711,
"blob_id": "e08c1797277071ae0ba85e6a2ccabba4c67541cd",
"content_id": "84e2141d6fc4a6ae8814e303e7b013f102311d0a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4629,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 127,
"path": "/flatten_tuned_model.py",
"repo_name": "andrewhead/ICTD17-Paper",
"src_encoding": "UTF-8",
"text": "import keras\nfrom keras.models import Sequential, save_model, load_model\nfrom keras.optimizers import SGD\nfrom keras.layers import Activation, Dense, Dropout, Flatten, Reshape\nfrom keras.layers.convolutional import Conv2D\nfrom keras.layers.pooling import MaxPooling2D, AveragePooling2D\n\nfrom argparse import ArgumentParser\n\n\ndef flatten(tuned_model_filename, output_filename):\n\n # Load the top of the past model. We'll need this for manually\n # transferring over the weights of each of those layers.\n tuned_model = load_model(tuned_model_filename)\n tuned_model_top = tuned_model.layers[-1]\n\n # XXX: Here we clone the model architecture. `tune_block5.py` creates\n # a hierarchical version of this, which we want to flatten so that we\n # can easily access the output of intermediate layers.\n # Replication of block 5 of VGG16 (See `tune_block5.py`)\n model = Sequential()\n model.add(Conv2D(\n filters=512,\n kernel_size=(3, 3),\n activation='relu',\n padding='same',\n name='block5_conv1',\n # Hard-coded input size. This is the output size of `block4_pool` when\n # the input images are 400x400.\n input_shape=(25, 25, 512)\n ))\n model.add(Conv2D(\n filters=512,\n kernel_size=(3, 3),\n activation='relu',\n padding='same',\n name='block5_conv2'\n ))\n model.add(Conv2D(\n filters=512,\n kernel_size=(3, 3),\n activation='relu',\n padding='same',\n name='block5_conv3'\n ))\n model.add(MaxPooling2D(\n pool_size=(2, 2),\n strides=(2, 2),\n name='block5_pool'\n ))\n # This is a replication of the prediction layers from Jean et al.\n # Originally defined in `train_top.py` file.\n conv6_layer_index = len(model.layers)\n model.add(Dropout(0.5, name=\"conv6_dropout\", input_shape=(12, 12, 512)))\n model.add(Conv2D(\n filters=4096,\n kernel_size=(6, 6),\n strides=6,\n activation='relu',\n name=\"conv6\",\n kernel_initializer=keras.initializers.glorot_normal(),\n bias_initializer=keras.initializers.Constant(value=0.1),\n ))\n model.add(Dropout(0.5, name=\"conv7_dropout\"))\n model.add(Conv2D(\n filters=4096,\n kernel_size=(1, 1),\n strides=1,\n activation='relu',\n name=\"conv7\",\n kernel_initializer=keras.initializers.glorot_normal(),\n bias_initializer=keras.initializers.Constant(value=0.1),\n ))\n model.add(Dropout(0.5, name=\"conv8_dropout\"))\n model.add(Conv2D(\n filters=3,\n kernel_size=(1, 1),\n strides=1,\n name=\"conv8\",\n kernel_initializer=keras.initializers.glorot_normal(),\n bias_initializer=keras.initializers.Constant(value=0.1),\n ))\n model.add(AveragePooling2D(\n pool_size=(2, 2),\n strides=1,\n name=\"predictions_pooling\"\n ))\n model.add(Flatten(name=\"predictions_flatten\"))\n model.add(Dense(3, name=\"predictions_dense\"))\n model.add(Activation('softmax', name=\"predictions\"))\n\n # This loads weights into the block5 layers.\n for layer_index in range(conv6_layer_index):\n model.layers[layer_index].set_weights(\n tuned_model.layers[layer_index].get_weights())\n # model.load_weights(tuned_model_filename, by_name=True)\n\n # We still need to manually load weights into all the layers after block5\n # which were nested in the original tuned model.\n for layer_index in range(len(tuned_model_top.layers)):\n model.layers[conv6_layer_index + layer_index].set_weights(\n tuned_model_top.layers[layer_index].get_weights())\n\n # We compile this here so that when we load it later, it will already\n # be compiled (which our `extract_features` script expects). Though\n # this step could be taken out if we don't need to reload pre-compiled\n # models in later scripts.\n model.compile(\n loss=keras.losses.categorical_crossentropy,\n optimizer=SGD(lr=0.0001, momentum=0.9),\n metrics=['accuracy'],\n )\n\n model.save(output_filename)\n\n\nif __name__ == \"__main__\":\n argument_parser = ArgumentParser(description=\"Flatten tuned net.\" +\n \"The net is expected to start a block 4 of VGG16 and end with \" +\n \"predictions from the top we train for nightlights prediction.\")\n argument_parser.add_argument(\"tuned_model\",\n help=\"Name of file containing hierarchical tuned model\")\n argument_parser.add_argument(\"output_file\",\n help=\"Name of file to write flattened model to\")\n args = argument_parser.parse_args()\n flatten(args.tuned_model, args.output_file)\n"
},
{
"alpha_fraction": 0.6378527283668518,
"alphanum_fraction": 0.6509290933609009,
"avg_line_length": 38.27027130126953,
"blob_id": "446e5942d31ec8349ece692024e6f2b31b5485e5",
"content_id": "b73aaac14d56fc0d3f7488e0855a747cd57bc977",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7265,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 185,
"path": "/tune_block5.py",
"repo_name": "andrewhead/ICTD17-Paper",
"src_encoding": "UTF-8",
"text": "import keras\nfrom keras.models import Sequential, load_model\nfrom keras.layers.convolutional import Conv2D\nfrom keras.layers.pooling import MaxPooling2D\nfrom keras.optimizers import SGD\nfrom keras.utils.data_utils import get_file\n\nimport numpy as np\n\nimport math\nfrom argparse import ArgumentParser\nimport os.path\nfrom time import gmtime, strftime\n\nfrom util.load_data import load_labels, load_test_indexes\nfrom util.sample import get_folds, get_training_examples, FeatureExampleGenerator\n\n\nBLOCK5_WEIGHTS = 'https://github.com/fchollet/deep-learning-models/releases/download/v0.1/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5'\n\n\ndef train(features_dir, top_model_filename, labels, test_indexes, batch_size, sample_size,\n learning_rate, momentum, epochs, kfolds, training_indexes_filename,\n verbose=False, num_classes=3):\n\n if verbose:\n print(\"Creating block 5 of VGG16..\", end=\"\")\n\n # Replication of block 5 of VGG16. This is the layer that we're going\n # to retrain to become more attuned to daytime imagery.\n model = Sequential()\n model.add(Conv2D(\n filters=512,\n kernel_size=(3, 3),\n activation='relu',\n padding='same',\n name='block5_conv1',\n # Hard-coded input size. This is the output size of `block4_pool` when\n # the input images are 400x400.\n input_shape=(25, 25, 512)\n ))\n model.add(Conv2D(\n filters=512,\n kernel_size=(3, 3),\n activation='relu',\n padding='same',\n name='block5_conv2'\n ))\n model.add(Conv2D(\n filters=512,\n kernel_size=(3, 3),\n activation='relu',\n padding='same',\n name='block5_conv3'\n ))\n model.add(MaxPooling2D(\n pool_size=(2, 2),\n strides=(2, 2),\n name='block5_pool'\n ))\n\n if verbose:\n print(\"done.\")\n\n # Initialize the layers of block 5 with the VGG16 ImageNet weights.\n # Note: we should load weights *before* adding the top of the model,\n # as we might clobber some of the previously trained weights in the\n # top if we load weights after the top has been added.\n if verbose:\n print(\"Loading ImageNet weights into block 5...\", end=\"\")\n weights_path = get_file('vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5',\n BLOCK5_WEIGHTS, cache_subdir='models')\n model.load_weights(weights_path, by_name=True)\n if verbose:\n print(\"done.\")\n\n # Load the previously trained top model, and add it to the top of the net.\n if verbose:\n print(\"Loading the top of the model from %s...\" % (top_model_filename,), end=\"\")\n top_model = load_model(top_model_filename)\n model.add(top_model)\n if verbose:\n print(\"done.\")\n\n if verbose:\n print(\"Compiling model...\", end=\"\")\n model.compile(\n loss=keras.losses.categorical_crossentropy,\n # Note: this learning rate should be pretty low (e.g., 1e-4, as\n # recommended in the referenced blog post, to keep previously-\n # learned features in tact. Reference:\n # https://blog.keras.io/building-powerful-image-classification-models-using-very-little-data.html\n optimizer=SGD(lr=learning_rate, momentum=momentum),\n metrics=['accuracy'],\n )\n if verbose:\n print(\"done.\")\n\n # Sample for training indexes, or load from file\n if training_indexes_filename is not None:\n sampled_examples = []\n with open(training_indexes_filename) as training_indexes_file:\n for line in training_indexes_file:\n sampled_examples.append(int(line.strip()))\n else:\n sampled_examples = get_training_examples(\n features_dir, labels, test_indexes, sample_size)\n\n # Divide the sampled training data into folds\n folds = get_folds(sampled_examples, kfolds)\n\n # Convert labels to one-hot array for use in training.\n label_array = keras.utils.to_categorical(labels, num_classes)\n\n # Here, we fit the neural network for each fold\n for i, fold in enumerate(folds, start=1):\n\n training_examples = fold[\"training\"]\n validation_examples = fold[\"validation\"]\n\n if verbose:\n print(\"Training on fold %d of %d\" % (i, len(folds)))\n print(\"Training set size: %d\" % (len(training_examples)))\n print(\"Validation set size: %d\" % (len(validation_examples)))\n\n # Do the actual fitting here\n model.fit_generator(\n FeatureExampleGenerator(training_examples, features_dir, label_array, batch_size),\n steps_per_epoch=math.ceil(float(len(training_examples)) / batch_size),\n epochs=epochs,\n verbose=(1 if verbose else 0),\n validation_data=FeatureExampleGenerator(validation_examples, features_dir, label_array, batch_size),\n validation_steps=math.ceil(float(len(validation_examples)) / batch_size),\n )\n if not os.path.exists(\"models\"):\n os.makedirs(\"models\")\n model.save(os.path.join(\n \"models\", \"tuned-\" + strftime(\"%Y%m%d-%H%M%S\", gmtime()) + \".h5\"))\n \n\nif __name__ == \"__main__\":\n\n argument_parser = ArgumentParser(description=\"Train top layers of neural net\")\n argument_parser.add_argument(\"features_dir\")\n argument_parser.add_argument(\"top_model\", help=\"H5 for previously trained \" +\n \"top layers of the neural network.\")\n argument_parser.add_argument(\"csvfile\", help=\"CSV containing labels\")\n argument_parser.add_argument(\n \"test_index_file\",\n help=\"Name of file that has index of test sample on each line\")\n argument_parser.add_argument(\n \"-v\", action=\"store_true\",\n help=\"Print out detailed info about progress.\")\n argument_parser.add_argument(\n \"--batch-size\", default=16, type=int, help=\"Number of training examples at a time. \" +\n \"More than 16 at a time seems to lead to out-of-memory errors on K80\")\n argument_parser.add_argument(\n \"--sample-size\", default=10000, type=int,\n help=\"Number of images to sample from each class (avoid biasing smaller classes).\")\n argument_parser.add_argument(\"--learning-rate\", default=0.0001, type=float,\n help=\"(Should be low, to keep previously learned features in tact.)\")\n argument_parser.add_argument(\"--momentum\", default=0.9, type=float)\n argument_parser.add_argument(\"--epochs\", default=10, type=int)\n argument_parser.add_argument(\"--num-folds\", default=3, type=int)\n argument_parser.add_argument(\"--training-indexes-file\", help=\"File containing \" +\n \"an index of a training example on each line. Useful if you only have \" +\n \"features extracted for a subset of the examples.\")\n args = argument_parser.parse_args()\n\n test_indexes = load_test_indexes(args.test_index_file)\n labels = load_labels(args.csvfile)\n train(\n features_dir=args.features_dir,\n top_model_filename=args.top_model,\n labels=labels,\n test_indexes=test_indexes,\n epochs=args.epochs,\n sample_size=args.sample_size,\n batch_size=args.batch_size,\n kfolds=args.num_folds,\n learning_rate=args.learning_rate,\n momentum=args.momentum,\n training_indexes_filename=args.training_indexes_file,\n verbose=args.v,\n )\n"
},
{
"alpha_fraction": 0.6597753763198853,
"alphanum_fraction": 0.6653904914855957,
"avg_line_length": 33.3684196472168,
"blob_id": "a325186799b26dc30bdca7cb4cb91d6bf3efdd01",
"content_id": "947cbd8d607f8cd3d6dc666073e8eea00ced8168",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3918,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 114,
"path": "/evaluate_model.py",
"repo_name": "andrewhead/ICTD17-Paper",
"src_encoding": "UTF-8",
"text": "from keras.models import load_model\nfrom keras.utils import to_categorical\n\nimport numpy as np\nfrom sklearn.metrics import classification_report\n\nimport math\nfrom argparse import ArgumentParser\nimport os.path\n\nfrom train import load_test_indexes\nfrom train_top import load_labels\n\n\nclass FeatureExampleGenerator(object):\n\n def __init__(self, indexes, feature_dir, batch_size):\n self.indexes = indexes\n self.feature_dir = feature_dir\n self.batch_size = batch_size\n self.pointer = 0\n\n def __iter__(self):\n return self\n\n def __next__(self):\n return self.next()\n\n def next(self):\n\n # Get the list of example indexes in this batch\n batch_indexes = self.indexes[self.pointer:self.pointer + self.batch_size]\n\n # Load features for examples from file\n data_file_names = [\n os.path.join(self.feature_dir, str(i) + \".npz\")\n for i in batch_indexes]\n examples = tuple()\n for filename in data_file_names:\n examples += (np.load(filename)[\"data\"],)\n example_array = np.stack(examples)\n\n # Advance pointer for next batch\n self.pointer += self.batch_size\n if self.pointer >= len(self.indexes):\n self.pointer = 0\n\n return example_array\n\n\ndef predict(model_filename, features_dir, test_indexes, all_labels, batch_size, verbose):\n\n # Convert list of expected labels to one-hot array\n expected_labels = to_categorical(all_labels[test_indexes])\n\n # Load model from file\n model = load_model(model_filename)\n\n # Compute predictions for all test examples\n predictions = model.predict_generator(\n FeatureExampleGenerator(test_indexes, features_dir, batch_size),\n steps=math.ceil(float(len(test_indexes)) / batch_size),\n verbose=(1 if verbose else 0),\n )\n\n # Predictions are scores for each class, for each example\n # We convert them into a one-hot matrix of labels as follows:\n # 1. Identify all prediction scores below .5. We mark these as\n # incapable of resulting in a classifcation as that class\n below_threshold_mask = np.where(predictions < .5)\n\n # 2. Identify the position of all predictions that aren't the\n # max in their row. These also can't be the predicted label.\n not_max_mask = np.ones(predictions.shape, dtype=np.bool_)\n not_max_mask[range(predictions.shape[0]), predictions.argmax(axis=1)] = 0\n\n # 3. Make one-hot matrix with a one at all locations where the\n # score is greater than the threshold and the max\n labels = np.ones(predictions.shape, dtype=np.uint8)\n labels[not_max_mask] = 0\n labels[below_threshold_mask] = 0\n\n print(classification_report(expected_labels, labels))\n\n\n\nif __name__ == \"__main__\":\n\n argument_parser = ArgumentParser(description=\"Train top layers of neural net\")\n argument_parser.add_argument(\"features_dir\")\n argument_parser.add_argument(\"model\", help=\"H5 for previously trained \" +\n \"model of the neural network.\")\n argument_parser.add_argument(\"csvfile\", help=\"CSV containing labels\")\n argument_parser.add_argument(\n \"test_index_file\",\n help=\"Name of file that has index of test sample on each line\")\n argument_parser.add_argument(\n \"-v\", action=\"store_true\",\n help=\"Print out detailed info about progress.\")\n argument_parser.add_argument(\n \"--batch-size\", default=16, type=int, help=\"Number of training examples at a time. \" +\n \"More than 16 at a time seems to lead to out-of-memory errors on K80\")\n args = argument_parser.parse_args()\n\n test_indexes = load_test_indexes(args.test_index_file)\n labels = load_labels(args.csvfile)\n predict(\n model_filename=args.model,\n features_dir=args.features_dir,\n test_indexes=test_indexes,\n all_labels=labels,\n batch_size=args.batch_size,\n verbose=args.v,\n )\n"
},
{
"alpha_fraction": 0.6098531484603882,
"alphanum_fraction": 0.6123011112213135,
"avg_line_length": 39.345680236816406,
"blob_id": "0c4b5e372c924fa349f0972800c9779818f62cc4",
"content_id": "e960feead3768127b05861ba5469f955b95841ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3268,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 81,
"path": "/visualize_activations.py",
"repo_name": "andrewhead/ICTD17-Paper",
"src_encoding": "UTF-8",
"text": "import argparse\nimport re\nimport os.path\nimport math\nfrom tqdm import tqdm\n\n# These two lines allow us to use headless matplotlib (e.g., without Tkinter or\n# some other display front-end)\nimport matplotlib\nmatplotlib.use('Agg')\n\nimport matplotlib.image as mpimg\nimport matplotlib.pyplot as plt\nfrom matplotlib.backends.backend_pdf import PdfPages\n\n\ndef visualize_activations(activations_filename, image_dir, output_filename):\n\n # Open file first time just to get the number of filters\n activations_file = open(activations_filename)\n num_filters = sum(1 for line in activations_file)\n activations_file.close()\n\n with open(activations_filename) as activations_file:\n\n # We use PdfPages as it will let us make a multi-page PDF. If there\n # are a lot of images in it, then PDF readers should be able to load\n # just the content on one page at a time, instead of taking a very\n # long time initializing to load one huge page of figures. This\n # use of PdfPages is based on the code example at:\n # https://matplotlib.org/examples/pylab_examples/multipage_pdf.html\n with PdfPages(output_filename) as output_file:\n\n for line in tqdm(activations_file, total=num_filters):\n\n # For each line, find the filter and exemplar images\n match = re.match(r\"(\\d+): \\[(.*)\\]$\", line.strip())\n filter_index = int(match.group(1))\n image_indexes = [int(n) for n in match.group(2).split()]\n\n # Make array of subplots for showing exemplars \n rows = 4\n cols = math.ceil(len(image_indexes) / rows)\n f, axarr = plt.subplots(rows, cols, figsize=(24, 18))\n f.suptitle(\"Images activating filter %d\" % (filter_index))\n\n # Hide axes, make it look prettier\n for ax in axarr.flatten():\n ax.axis('off')\n\n # Show each image in each cell\n for i, image_index in enumerate(image_indexes):\n image = mpimg.imread(os.path.join(\n image_dir, str(image_index) + \".jpg\"))\n row = int(i / cols)\n col = i % cols\n axarr[row, col].imshow(image)\n\n # These two lines save the figure to a page of the PDF\n output_file.savefig()\n plt.close()\n \n\nif __name__ == \"__main__\":\n\n parser = argparse.ArgumentParser(description=\"Create a PDF with the images \" +\n \"that maximize the activation of each filter\")\n parser.add_argument(\"activations\", help=\"File mapping filter indexes \" +\n \"to indexes of images that maximize their activation. Produced by the \" +\n \"`get_activations` script\")\n parser.add_argument(\"image_dir\", help=\"Directory that contains all of the \" +\n \"images for whcih activations were previously measured\")\n parser.add_argument(\"output\", help=\"Title of a PDF file to which to output \" +\n \"the resulting visualizations\")\n args = parser.parse_args()\n\n visualize_activations(\n activations_filename=args.activations,\n image_dir=args.image_dir,\n output_filename=args.output,\n )\n"
},
{
"alpha_fraction": 0.5529268980026245,
"alphanum_fraction": 0.555959939956665,
"avg_line_length": 31.643564224243164,
"blob_id": "22b46371e11bc9375d688398d5c019338d40eab1",
"content_id": "a84620b544f6e95b2bb780547310e68e885baf75",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3297,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 101,
"path": "/util/load_data.py",
"repo_name": "andrewhead/ICTD17-Paper",
"src_encoding": "UTF-8",
"text": "import csv\nimport numpy as np\n\n\n# This method assumes that all labels are a string representing an integer\ndef load_labels(csv_filename):\n labels = []\n with open(csv_filename) as csvfile:\n rows = csv.reader(csvfile)\n first_row = True\n for row in rows:\n if first_row:\n first_row = False\n continue\n labels.append(row[6])\n return np.array(labels)\n\n\ndef load_test_indexes(test_index_filename):\n test_indexes = []\n with open(test_index_filename) as test_index_file:\n for line in test_index_file:\n if len(line.strip()) > 0:\n test_indexes.append(int(line.strip()))\n return test_indexes\n\n\ndef read_wealth_records(csv_path):\n\n records = []\n\n with open(csv_path) as csv_file:\n csv_reader = csv.DictReader(csv_file)\n for row in csv_reader:\n # Support multiple formats of wealth index file (we have\n # inconsistent internal formats).\n if \"wealth_index\" in row:\n row['wealth'] = float(row['wealth_index'])\n row['i'] = int(row['xcoord'].replace(\".0\", \"\"))\n row['j'] = int(row['ycoord'].replace(\".0\", \"\"))\n else:\n row['wealth'] = float(row['wealth'])\n row['latitude'] = float(row['LATNUM'])\n row['longitude'] = float(row['LONGNUM'])\n records.append(row)\n\n return records\n\n\ndef read_education_records(csv_path):\n\n records = []\n\n with open(csv_path) as csv_file:\n csv_reader = csv.DictReader(csv_file)\n for row in csv_reader:\n # Cast cell i, j, and wealth to numbers\n # In the current data, all i's and j's end with an\n # unnecessary .0, so we strip it off\n row['i'] = int(row['xcoord'].replace(\".0\", \"\"))\n row['j'] = int(row['ycoord'].replace(\".0\", \"\"))\n row['education_index'] = float(row['avg_educ_index'])\n records.append(row)\n\n return records\n\n\ndef read_water_records(csv_path):\n\n records = []\n\n with open(csv_path) as csv_file:\n csv_reader = csv.DictReader(csv_file)\n for row in csv_reader:\n # Cast cell i, j, and wealth to numbers\n # In the current data, all i's and j's end with an\n # unnecessary .0, so we strip it off\n row['i'] = int(row['xcoord'].replace(\".0\", \"\"))\n row['j'] = int(row['ycoord'].replace(\".0\", \"\"))\n row['water_index'] = float(row['avg_water_index'])\n records.append(row)\n\n return records\n\n\ndef get_map_from_i_j_to_example_index(nightlights_csv_path):\n # Later on, we're going to have to go from an `i` and `j` of a cell\n # in the raster map to an example index. We've luckily already\n # stored the relationship between these in a CSV file. We just have\n # to hydrate it into a map.\n i_j_to_example_dict = {}\n with open(nightlights_csv_path) as csv_file:\n csv_reader = csv.DictReader(csv_file)\n for row in csv_reader:\n # Cast longitude, latitude, and wealth to numbers\n id_ = int(row['id'])\n i = int(row['full_i'])\n j = int(row['full_j'])\n i_j_to_example_dict[(i, j)] = id_\n\n return i_j_to_example_dict\n"
}
] | 18 |
monir0908/django_custom_authentication
|
https://github.com/monir0908/django_custom_authentication
|
f2c649ef4fe10b0235ec5cf732c9b89b166d0f7b
|
1d76280d22982a01e5b9b50c86bb09466b559803
|
eb94c3a27e79babf2516de8155628b9339159fa4
|
refs/heads/master
| 2022-12-10T20:57:53.321134 | 2020-09-13T16:27:25 | 2020-09-13T16:27:25 | 295,185,988 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6783369779586792,
"alphanum_fraction": 0.6783369779586792,
"avg_line_length": 31.071428298950195,
"blob_id": "2bfb6e72aee384f065a68e87f1db12fda800d877",
"content_id": "8d4f1b34283e9bf1f4d7af14e95a3da0797c82e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 457,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 14,
"path": "/student/backends.py",
"repo_name": "monir0908/django_custom_authentication",
"src_encoding": "UTF-8",
"text": "from django.conf import settings\nfrom django.contrib.auth.backends import BaseBackend\nfrom django.contrib.auth.hashers import check_password\nfrom .models import Student\n\nclass MyBackend(BaseBackend):\n \n def authenticate(self, request, username=None, password=None):\n try:\n user = Student.objects.get(username=username)\n #print(user)\n except User.DoesNotExist:\n return None \n return user\n "
},
{
"alpha_fraction": 0.6273148059844971,
"alphanum_fraction": 0.6631944179534912,
"avg_line_length": 20.549999237060547,
"blob_id": "04c54cbd3bc264a6c9f57308f4d16504a57e9bfe",
"content_id": "ffe3efc6f2b1f0ffda8857583c4b2f659fb47efe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 864,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 40,
"path": "/README.md",
"repo_name": "monir0908/django_custom_authentication",
"src_encoding": "UTF-8",
"text": "# django_custom_authentication\nThe repo illustrates how django custom authentication can be created along with multiple user-types\n\n# create a virtual-environment\n~pip freeze <br />\n~mkvirtualenv django-custom-authentication\n\n# install requirements.txt\npip install -r requirements.txt\n\n# check multiple user models registration and login\nFor user (get and post) <br/>\nhttp://127.0.0.1:8000/api/users/ <br/>\n\nWhile registering user: <br/>\n\n{ <br/>\n \"email\":\"[email protected]\", <br/>\n \"username\":\"monir1\" <br/>\n}\n\n\nFor student (register) <br/>\nhttp://127.0.0.1:8000/api/student/register/ <br/>\n\nWhile registering: <br/>\n\n{ <br/>\n \"username\":\"[email protected]\", <br/>\n \"password\":\"12345678\" <br/>\n}\n\nFor student (login) <br/>\nhttp://127.0.0.1:8000/student/login/ <br/>\n\nWhile loging in: <br/>\n{ <br/>\n \"username\":\"[email protected]\", <br/>\n \"password\":\"12345678\" <br/>\n}\n\n\n"
},
{
"alpha_fraction": 0.7533556818962097,
"alphanum_fraction": 0.7583892345428467,
"avg_line_length": 32.79999923706055,
"blob_id": "8043223bd3db42383d1f0af844b6e0d5020ef448",
"content_id": "adad7f1b1a1b06119051e680c00288d71ad7dd73",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1192,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 35,
"path": "/student/views.py",
"repo_name": "monir0908/django_custom_authentication",
"src_encoding": "UTF-8",
"text": "from student.serializers import StudentResigtrationSerializer, StudentLoginSerializer\nfrom student.models import Student\nfrom rest_framework import generics, filters\nfrom rest_framework.permissions import AllowAny,IsAuthenticated\nfrom rest_framework.views import APIView\nfrom django.http import JsonResponse\nfrom rest_framework.response import Response\nfrom rest_framework import status\nfrom rest_framework import serializers\nfrom student.models import Student\n\n\n\nclass StudentRegistration(APIView):\n permission_classes = (AllowAny,)\n serializer_class = StudentResigtrationSerializer\n\n def post(self, request): \n \n serializer = self.serializer_class(data=request.data)\n serializer.is_valid(raise_exception=True)\n serializer.save()\n\n return Response(serializer.data, status=status.HTTP_201_CREATED)\n\nclass StudentLoginView(APIView):\n permission_classes = (AllowAny,)\n serializer_class = StudentLoginSerializer\n\n \n def post(self, request): \n serializer = self.serializer_class(data=request.data)\n serializer.is_valid(raise_exception=True)\n\n return Response(serializer.data, status=status.HTTP_200_OK) "
},
{
"alpha_fraction": 0.6436781883239746,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 22.81818199157715,
"blob_id": "da5e69a1b9f529ecb798574f921a0af1bc51b5ef",
"content_id": "617cd06d832baab01f5e6ca781bf9d5af987d0ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 261,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 11,
"path": "/student/models.py",
"repo_name": "monir0908/django_custom_authentication",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n\nclass Student(models.Model):\n username = models.EmailField(max_length=255, unique=True)\n password = models.CharField(max_length=255, unique=True)\n \n \n\n def __str__(self):\n return self.username + \"- a student\""
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.6091185212135315,
"avg_line_length": 25.983606338500977,
"blob_id": "52b07e42fada040f108ef7ca191140045a1b91d3",
"content_id": "478f45a04b670af668b4ecb1d0934779dedee6df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1645,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 61,
"path": "/student/serializers.py",
"repo_name": "monir0908/django_custom_authentication",
"src_encoding": "UTF-8",
"text": "from rest_framework import serializers\nfrom student.models import Student\nfrom rest_framework.serializers import (\n ModelSerializer,\n Serializer,\n ValidationError,\n HyperlinkedModelSerializer,\n)\n\nfrom django.contrib.auth import authenticate\n\nclass StudentResigtrationSerializer(serializers.ModelSerializer):\n \n password = serializers.CharField(\n max_length=128,\n min_length=8,\n write_only=True\n )\n\n class Meta:\n model = Student \n fields = ['username','password']\n\n # def create(self, validated_data): \n # return Student.objects.create_user(**validated_data)\n\n\n\nclass StudentLoginSerializer(serializers.Serializer):\n username = serializers.CharField(max_length=255, read_only=True)\n # mobile = serializers.CharField(max_length=255)\n\n #https://github.com/encode/django-rest-framework/blob/3.9.0/rest_framework/serializers.py#L86\n \n def validate(self, attrs):\n \n \n username = self.initial_data['username']\n password = self.initial_data['password']\n\n \n if username is None:\n raise serializers.ValidationError(\n 'An username is required to log in.'\n )\n \n \n user = authenticate(username=username, password=password)\n\n print(\"-------------\")\n print(user)\n \n if user is None:\n raise serializers.ValidationError(\n 'A user with this email and password was not found.'\n )\n \n return {\n 'password': user.password,\n 'username': user.username\n }"
},
{
"alpha_fraction": 0.6848635077476501,
"alphanum_fraction": 0.6848635077476501,
"avg_line_length": 32.625,
"blob_id": "f397d736d2b26a324171e5dfd2700216a6a3bc7a",
"content_id": "8f5a853821ec734979ee211f63fc1f72218c3ec8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 806,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 24,
"path": "/authentication/serializers.py",
"repo_name": "monir0908/django_custom_authentication",
"src_encoding": "UTF-8",
"text": "from rest_framework import serializers\n\nfrom .models import User\n\n\nclass RegistrationSerializer(serializers.ModelSerializer): \n\n class Meta:\n model = User\n # List all of the fields that could possibly be included in a request\n # or response, including fields specified explicitly above.\n fields = ['email', 'username']\n\n def create(self, validated_data):\n # Use the `create_user` method we wrote earlier to create a new user.\n return User.objects.create_user(**validated_data)\n\nclass UserSerializer(serializers.ModelSerializer): \n\n class Meta:\n model = User\n # List all of the fields that could possibly be included in a request\n # or response, including fields specified explicitly above.\n fields = ['email', 'username']"
},
{
"alpha_fraction": 0.7152103781700134,
"alphanum_fraction": 0.7152103781700134,
"avg_line_length": 27.18181800842285,
"blob_id": "1a31e6bdc6d49382c2cc852a1023425b6ac11e56",
"content_id": "66692eefc340b4f8ef1fdcd02e56d3c86be23853",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 309,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 11,
"path": "/student/urls.py",
"repo_name": "monir0908/django_custom_authentication",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\nfrom . import views\nfrom student.views import StudentRegistration, StudentLoginView\n\n\napp_name = 'student'\nurlpatterns = [\n # register\n url(r'^register/$', StudentRegistration.as_view(), name='register'),\n url(r'^login/$', StudentLoginView.as_view(), name='login'),\n]"
}
] | 7 |
genescn/basic
|
https://github.com/genescn/basic
|
44066c148ff4c145748714361ff4b1be2073957a
|
191a6e90ea1a765e5db805a89e210e6a69e038a2
|
d9f0c2a4aa20fe6ffdd8e4ad5d75b1afdc2c820e
|
refs/heads/master
| 2022-02-01T02:49:07.958656 | 2022-01-12T00:12:18 | 2022-01-12T00:12:18 | 137,259,940 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5058274865150452,
"alphanum_fraction": 0.5081585049629211,
"avg_line_length": 19.285715103149414,
"blob_id": "ad79af9ee7494b68e5d7803b9e8feacc248c6125",
"content_id": "b9463c0177ae16289b7b762bf950442ae6c9b1b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 429,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 21,
"path": "/teste.py",
"repo_name": "genescn/basic",
"src_encoding": "UTF-8",
"text": "content = 'We are not what we should be \\\nWe are not what we need to be \\\nBut at least we are not what we used to be \\\n -- Football Coach'\n\nl = content.split()\nwords = set(l)\n\ndict = {}\n\nfor w in words:\n lw = []\n for count, d in enumerate(l):\n if d == w:\n try:\n lw.append(l[count+1])\n except IndexError: \n continue\n dict[w] = lw\n\nprint(dict) "
},
{
"alpha_fraction": 0.739130437374115,
"alphanum_fraction": 0.782608687877655,
"avg_line_length": 17.399999618530273,
"blob_id": "dced05defd2c8f875af1b0df372015596f19200a",
"content_id": "f984147c4a68700f140af226008721de1baec8d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 97,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 5,
"path": "/README.md",
"repo_name": "genescn/basic",
"src_encoding": "UTF-8",
"text": "# basic\n\nRepósitorio do curso WTTD para o módulo I\n\nAtualização do repositório em Jan/2022.\n"
}
] | 2 |
VforV93/VABLUT
|
https://github.com/VforV93/VABLUT
|
def7d7bfc3e3382e371842628b14046808d7284f
|
32add559ba03468f8dfa098cdec7f5c132c4b3dc
|
4b22dd05ede5ec48ac609d55d96314d420d5c56f
|
refs/heads/master
| 2021-06-21T17:13:46.863440 | 2020-12-29T15:20:59 | 2020-12-29T15:20:59 | 179,646,288 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6070460677146912,
"alphanum_fraction": 0.6070460677146912,
"avg_line_length": 22.125,
"blob_id": "e89df449923b5067dfe403d698691e9054593be7",
"content_id": "0a6d18d0ffbbbb1e99f4400059754b3bb74a23ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 369,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 16,
"path": "/vablut/engine/rand.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "import random\nimport time\nfrom vablut.engine.base import Engine\n\nclass RandomEngine(Engine):\n def __init__(self, delay=None):\n self.delay = delay\n \n def choose(self, board):\n moves = board.get_all_moves()\n if self.delay:\n time.sleep(self.delay)\n return random.choice(moves)\n\n def __str__(self):\n return 'Random'"
},
{
"alpha_fraction": 0.5637393593788147,
"alphanum_fraction": 0.5741265416145325,
"avg_line_length": 31.090909957885742,
"blob_id": "55d7c9addb30412a65eebca7bebfa97a6bbd1c40",
"content_id": "3c81cc4c7882e4bbf42e5e48edc2122a4a5a6bf5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1059,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 33,
"path": "/vablut/evaluate/evaluate_gl_esc.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom vablut.board import PLAYER1, PLAYER2, DRAW\nfrom vablut.evaluate.base import Evaluator, INF\nfrom vablut.evaluate.evaluate_glutton import Evaluator_glutton\nfrom vablut.evaluate.evaluate_escapist import Evaluator_escapist\n\nclass Evaluator_gl_esc(Evaluator):\n def __init__(self, weights=[None,None]):\n super(Evaluator_gl_esc, self).__init__(weights)\n if weights[0]:\n self._eg = Evaluator_glutton(weights[0])\n else:\n self._eg = Evaluator_glutton()\n \n if weights[1]:\n self._ee = Evaluator_escapist(weights[1])\n else:\n self._ee = Evaluator_escapist()\n \n def evaluate(self, board):\n if board.end is not None:\n if board.end == DRAW:\n return 0\n elif board.end == board.stm:\n return INF\n else:\n return -INF\n\n score1 = self._eg.evaluate(board)\n score2 = self._ee.evaluate(board)\n \n score = score1 + score2\n return score\n"
},
{
"alpha_fraction": 0.5643749833106995,
"alphanum_fraction": 0.5762500166893005,
"avg_line_length": 35.7931022644043,
"blob_id": "a61fa1078aa2742fd9cd6b06a8dd052ce0766950",
"content_id": "d89e7159d2f5961fbdb7eaff4d9d22b23235dfee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3202,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 87,
"path": "/vablut/gameJava.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport socket\nimport json\n\nimport numpy as np\nfrom vablut.modules.Utils import utils\nfrom vablut.board import Board, PLAYER1, PLAYER2, KING_VALUE, DRAW\n\nHOST = \"localhost\"\nWHITEPORT = 5800\nBLACKPORT = 5801\nNAME = \"TABRUTT\"\n\nplayers = {\"BLACK\": PLAYER1, \"WHITE\": PLAYER2}\n\n#deve poter accettare un parametro che definisce se sei nero o bianco, nel costruttore chiamato engine\nclass GameJavaHandler(object): \n def __init__(self, engine, playerType, verbose=False):\n self.engine = engine\n self.verbose = verbose\n self.playerType = playerType\n\n def play(self):\n#1 \n print('%s PLAY started'%self.playerType)\n sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n print('%s mi provo a collegare'%self.playerType)\n\n if(self.playerType.upper() == 'WHITE'): #l'idea è quella di estrarre una property dall'engine che mi dica chi è\n sock.connect((HOST, WHITEPORT))\n else:\n sock.connect((HOST, BLACKPORT))\n\n print('%s CONNESSO!'%self.playerType)\n#2\n x = json.dumps(NAME + '_' + self.playerType)\n utils.write_utf8(x, sock)\n#3\n state = utils.read_utf8(sock)\n state = json.loads(state)\n state_pos = self.from_json_to_pos(state)\n b = Board(state_pos, draw_dic={})\n while(True):\n print(b)\n print(b._draw_dic)\n if(players[self.playerType.upper()] == b.stm):\n move = self.engine.choose(b)\n print(move)\n temp = {}\n temp['from'] = move[0]\n temp['to'] = move[1]\n temp['turn'] = self.playerType.upper()\n move = json.dumps(temp)\n utils.write_utf8(move, sock)\n state = utils.read_utf8(sock)\n b = self.draw_board_from_server(state, b)\n else:\n #state = utils.read_utf8(sock)\n print(\"In attesa dell'avversario\")\n \n state = utils.read_utf8(sock)\n b = self.draw_board_from_server(state, b)\n\n @classmethod\n def from_json_to_pos(cls, gson_state):\n pos = np.asarray(gson_state['board']).flatten()\n pos[pos=='EMPTY'] = 0\n pos[pos=='THRONE'] = 0\n pos[pos=='BLACK'] = int(PLAYER1)\n pos[pos=='WHITE'] = int(PLAYER2)\n pos[pos=='KING'] = int(KING_VALUE)\n pos = np.asarray(pos, dtype=int)\n return Board.from_pos_to_dic(pos) \n \n @classmethod\n def draw_board_from_server(cls, state: str, b: Board):\n state = json.loads(state)\n state_pos = cls.from_json_to_pos(state)\n return Board(state_pos, players[state['turn']], draw_dic=b._draw_dic)\n \n#cosa fare?\n #1-connettersi a localhost (andare a vedere le porte)\n #2-inviare nome es. \"TABRUTT\"\n #3-mettersi in lettura (che restituisce lo stato) con un while. Se whitewin, bw o draw esce da while, altrimenti\n #3.1-ricostruire lo stato\n #3.2-valutare il turno (capire a chi tocca)\n #3.3-agire di conseguenza chiamando i metodi dell'engine / se non tocca a me ripetere read bloccante (punto 3)"
},
{
"alpha_fraction": 0.5561665296554565,
"alphanum_fraction": 0.5820895433425903,
"avg_line_length": 36.47058868408203,
"blob_id": "3b036771f9f47eae7b2549926fb6542d3e444c11",
"content_id": "bd6fb962fea46068b2adbe9342587c5ed0c3a280",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1273,
"license_type": "no_license",
"max_line_length": 161,
"num_lines": 34,
"path": "/vablut/evaluate/evaluate_glesc_ks.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom vablut.board import Board, PLAYER1, PLAYER2, DRAW\nfrom vablut.evaluate.base import Evaluator, INF\nfrom vablut.evaluate.evaluate_gl_esc import Evaluator_gl_esc\n\nclass Evaluator_glesc_ks(Evaluator_gl_esc):\n def __init__(self, weights=[None,None,{PLAYER1: np.array([0, 4, 1, 0, 1, 0, 1, 0], dtype=int), PLAYER2: np.array([0, -15, -1, 1, -1, 2, 0, 1], dtype=int)}]):\n super(Evaluator_glesc_ks, self).__init__(weights)\n\n def evaluate(self, board):\n if board.end is not None:\n if board.end == DRAW:\n return 0\n elif board.end == board.stm:\n return INF\n else:\n return -INF\n\n king_stats = board.king_stats(board.pos)\n\n s1 = (self.weights[2][PLAYER1] * king_stats).sum()\n s2 = (self.weights[2][PLAYER2] * king_stats).sum()\n\n score = s1 - s2\n if board.stm == PLAYER1:\n return super(Evaluator_glesc_ks, self).evaluate(board) + score\n else:\n return super(Evaluator_glesc_ks, self).evaluate(board) - score\n\n'''\n# [**escape distance** , capturable , # move for capturing, \n# free els around k , # b pieces around k , w pieces around k, \n# b 1 move to king , w 1 move to king]\n'''"
},
{
"alpha_fraction": 0.535018265247345,
"alphanum_fraction": 0.5560292601585388,
"avg_line_length": 33.20833206176758,
"blob_id": "7c477960b68a6e80f2f7528de11f2bf287c83301",
"content_id": "da0157b78edf070075d54b130969b02a06ddc9c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3284,
"license_type": "no_license",
"max_line_length": 191,
"num_lines": 96,
"path": "/vablut/evaluate/evaldiff.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport numpy as np\nfrom vablut.board import Board, PLAYER1, PLAYER2, KING_VALUE\nfrom vablut.evaluate.base import INF\nfrom vablut.modules.tables import move_segments, _indices, cross_center_segments, possible_move_segments\nfrom vablut.modules.ashton import winning_el\n\n#TO TEST\n\ndef board_blocking(pos, move_seg, enemy):\n count = 0\n for seg in move_seg:\n if (np.isin(pos[seg], winning_el)).any():\n flag = False\n for el in pos[seg]:\n if not flag and el == -1:\n flag = True\n elif flag and el == enemy:\n count += 1\n break\n elif el != 0:\n break\n flag = False\n for el in pos[seg][::-1]:\n if not flag and el == -1:\n flag = True\n elif flag and el == enemy:\n count += 1\n break\n elif el != 0:\n break\n return count\n\n\"\"\"\n [# vie di uscita che blocco - precedenti bloccate, # pezzi neri vicini, # pezzi bianchi vicini, # Re di fianco, # avversari attaccabili 1 mossa, # Re attaccabile 1 mossa, is moving king?]\n\"\"\"\ndef evaldiff(board: Board, m, weights=None):\n #I use the default weights\n if weights is None:\n weights = {\n PLAYER1:np.array([ 10, 2, 4, 15, 5, 12, 0 ], dtype=int),\n PLAYER2:np.array([ 3, 4, 2, 10, 5, 1, 15], dtype=int)}\n else:\n weights = {board.stm: weights}\n\n score = np.asarray(np.zeros(7), dtype=int)\n\n if len(weights[board.stm]) != len(score):\n raise ValueError('weights must be contain %s elements like score'%len(score))\n\n #First element of score\n m = board.coordinates_string_to_int(m)\n FROM = m[0]\n TO = m[1]\n #print('selected move: %s->%s'%(FROM,TO))\n original_pos = board.pos.flatten()\n\n if board.stm == PLAYER2 and original_pos[FROM] == KING_VALUE:\n score[6] = 1\n\n pos_prima = board.pos_update_capturing(original_pos, FROM)\n pos_prima[pos_prima==KING_VALUE] = PLAYER2\n pos_prima[FROM] = -1\n #print(pos_prima.reshape((9,9)))\n blocco = board_blocking(pos_prima, move_segments[FROM], board.other)\n\n moved_pos = original_pos.copy()\n moved_pos[TO] = moved_pos[FROM]\n moved_pos[FROM] = 0\n\n pos_dopo = board.pos_update_capturing(moved_pos, TO)\n pos_dopo[TO] = -1\n blocco_dopo = board_blocking(pos_dopo, move_segments[TO], board.other)\n\n\n score[0] = blocco_dopo - blocco\n\n # pezzi neri vicini, # pezzi bianchi vicini, # Re di fianco\n c = np.bincount(moved_pos[cross_center_segments[TO]][1:], minlength=4)\n score[1], score[2], score[3] = c[1], c[2], c[3]\n \n \n pos_dopo = board.pos_update_capturing(moved_pos, TO)\n\n # avversari attaccabili 1 mossa, # Re attaccabile 1 mossa\n for seg in possible_move_segments[TO]:\n line = pos_dopo[seg]\n if line[0] == board.stm and (line[-1] == board.other or line[-1] == KING_VALUE):\n c = np.bincount(line[1:], minlength=4)\n if c[1:].sum() == 1:\n if line[-1] == board.other:\n score[4] += 1\n else:\n score[5] += 1\n\n return np.dot(weights[board.stm],score)\n"
},
{
"alpha_fraction": 0.5216820240020752,
"alphanum_fraction": 0.5236530900001526,
"avg_line_length": 29.459999084472656,
"blob_id": "23bf218b4f42ee3bf6ce433e68c61868f5f6430b",
"content_id": "996bd71baa3afa0a3452780d2b5278834cbf6759",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1522,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 50,
"path": "/vablut/engine/cached.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport time\n\nfrom vablut.evaluate.base import INF\nfrom vablut.modules.cache import Cache, CacheSimm\n\n\nclass CachedEngineMixin(object):\n def __init__(self, *args, cache=None, **kwargs):\n super(CachedEngineMixin, self).__init__(*args, **kwargs)\n if not cache:\n self._cache = CacheSimm()\n else:\n self._cache = cache\n\n def showstats(self, pv, score):\n t = time.time() - self._startt\n if t:\n nps = (self._counters['nodes'] + self._counters['hits'])/ t\n else:\n nps = 0\n\n pv = ', '.join(str(x) for x in pv)\n\n ctx = self._counters.copy()\n ctx['pv'] = pv\n ctx['nps'] = nps\n ctx['score'] = score\n ctx['time'] = t\n \n print(self.FORMAT_STAT.format(**ctx))\n \n def search(self, board, depth, ply=1, alpha=-INF, beta=INF):\n\n if board.end is not None:\n return self.endscore(board, ply)\n\n hit, move, score = self._cache.lookup(board, depth, ply, alpha, beta)\n if hit:\n self.inc('hits')\n if move is not None:\n move = [move]\n else:\n move = []\n return move, score\n else:\n move, score = super(CachedEngineMixin, self).search(board, depth, ply, alpha, beta, hint=move)\n self._cache.put(board, move, depth, ply, score, alpha, beta)\n self._counters['cache_len'] = len(self._cache._cache)\n return move, score"
},
{
"alpha_fraction": 0.5066033005714417,
"alphanum_fraction": 0.5419968366622925,
"avg_line_length": 43.046512603759766,
"blob_id": "ad6bc92c8c35eadfb5864d3a514acd6314625fd3",
"content_id": "53002ee46c7d07692ab8a34207efff20ecccc64d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1893,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 43,
"path": "/vablut/evaluate/evaluate_escapist.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom vablut.board import PLAYER1, PLAYER2, DRAW\nfrom vablut.evaluate.base import Evaluator, INF\n\nclass Evaluator_escapist(Evaluator):\n def __init__(self, weights={1:np.asarray([2,1,-3,0,0, 0, 0,1,12,0,0,-2, 0,0,0,-15, 0,-5]),\n 2:np.asarray([0,0,1,0,150,150,0,0,0, 2,0,-10,0,0,0,15,-5,0])}):\n super(Evaluator_escapist, self).__init__(weights)\n\n def evaluate(self, board): \n scores = {PLAYER1: np.zeros(len(self.weights[PLAYER1]), dtype=int),\n PLAYER2: np.zeros(len(self.weights[PLAYER2]), dtype=int)}\n \n if board.end is not None:\n if board.end == DRAW:\n return 0\n elif board.end == board.stm:\n return INF\n else:\n return -INF\n\n stats, block_stats, free_esc_seg = board.escape_el_stats(board.pos)\n\n scores[PLAYER1] = np.concatenate((stats.flatten(), block_stats.flatten(), free_esc_seg))\n scores[PLAYER2] = np.concatenate((stats.flatten(), block_stats.flatten(), free_esc_seg))\n \n s1 = (self.weights[PLAYER1] * scores[PLAYER1]).sum()\n s2 = (self.weights[PLAYER2] * scores[PLAYER2]).sum()\n \n score = s1 - s2\n if board.stm == PLAYER1:\n return score\n else:\n return -score\n\n'''\n# winning els occupied from B , 1 move to occupied for B , # winning els occupied from W, \n# 1 move to occupied for W , # winning els occupied from K , 1 move to occupied for K, \n# B block B to w_e , B block W to w_e , B block K to w_e, \n# W block B to w_e , W block W to w_e , W block K to w_e, \n# K block B to w_e , K block W to w_e , K block K to w_e, \n# free muerte escape line , # muerte line with just B , # muerte line with just W\n'''"
},
{
"alpha_fraction": 0.6105263233184814,
"alphanum_fraction": 0.6647773385047913,
"avg_line_length": 43.10714340209961,
"blob_id": "0df83b15f60c0f060ab187bcc1a62b8fee4c00ac",
"content_id": "79da8c17d4ea56cd608b3009c1037274a27ad178",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1235,
"license_type": "no_license",
"max_line_length": 174,
"num_lines": 28,
"path": "/runny.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "#da linea di comando leggere se BLACK o WHITE. \n#Istanziare poi l'engine associato e passarlo al gamehandler\n#from sys import getsizeof\nimport numpy as np\nfrom vablut.board import PLAYER1, PLAYER2, DRAW\nfrom vablut.engine.pvs import PVSCachedTimeEngine, PVSCachedTimeThreadsEngine\n\nfrom vablut.evaluate.moveorder import MoveOrder\nfrom vablut.game import GameHandler\n\nfrom vablut.evaluate.evaluate_glutton import Evaluator_glutton\nfrom vablut.evaluate.evaluate_glesc_ks import Evaluator_glesc_ks\n\ndef main():\n ev_g = Evaluator_glutton({1:[1], 2:[1]})\n ege_w = Evaluator_glesc_ks([{1:[50], 2:[2]}, None, {PLAYER1: np.array([0, 4, 1, -1, 1, 0, 1, 0], dtype=int), PLAYER2: np.array([0, -15, -1, 1, -1, 2, 0, 1], dtype=int)}])\n ege_b = Evaluator_glesc_ks([{1:[5], 2:[15]}, None, {PLAYER1: np.array([0, 4, 1, -1, 2, 0, 1, 0], dtype=int), PLAYER2: np.array([0, -15, -1, 1, -1, 2, 0, 1], dtype=int)}])\n mo = MoveOrder('diff')\n \n #pn = NegamaxEngine(ev_g, 1)\n p1 = PVSCachedTimeThreadsEngine(ege_b, mo, 3, 4, max_sec=60, verbose=True) #NERO\n p2 = PVSCachedTimeThreadsEngine(ege_w, mo, 3, 4, max_sec=60, verbose=True) #BIANCO\n gh = GameHandler(p1,p2,True)\n gh.play()\n\n \nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.591549277305603,
"alphanum_fraction": 0.668008029460907,
"avg_line_length": 34.14285659790039,
"blob_id": "5bd3740deb81d49e496631d7c17ca16335edf6ea",
"content_id": "735630473f783c25311a8a0858478e822d5069af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 497,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 14,
"path": "/vablut/tests/test_evaluate_escapist.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "# coding=utf-8\nimport numpy as np\nfrom vablut.board import Board\nfrom vablut.evaluate import evaluate_escapist\nfrom vablut.evaluate.evaluate_escapist import Evaluator_escapist\nimport pytest\nfrom vablut.tests.test_board import pos1\n\n#b = Board(pos1, PLAYER1)\nev = Evaluator_escapist(weights={1:np.asarray([1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1]),\n 2:np.asarray([1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1])})\n#def test_evaluate():\n# scores = ev.evaluate(b)\n# print(scores)\n \n"
},
{
"alpha_fraction": 0.637436032295227,
"alphanum_fraction": 0.6601762175559998,
"avg_line_length": 61.83035659790039,
"blob_id": "f7648ce474bfaeb15b0825681721c9ab06d7c138",
"content_id": "33e29df85f7b5f4dabbd950405bd9ff170f5cad2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7036,
"license_type": "no_license",
"max_line_length": 212,
"num_lines": 112,
"path": "/vablut/tests/test_ashton.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom vablut.modules.ashton import *\nfrom vablut.modules.tables import _indices\nfrom random import randint\n\nimport pytest\n\ndef test_colrow():\n #ashton rules required 9x9 board\n assert col == 9,\"Ashton rules: col must be 9 not %s\"%col\n assert row == 9,\"Ashton rules: row must be 9 not %s\"%row\n\ndef test_camps():\n assert len(camps) == 4,\"camps must contains 4 arrays not %s\"%len(camps)\n for c in camps:\n assert len(c) == 4,\"every camp must contins 4 elements[%s]\"%c\n assert len(set(c)) == 4,\"camps elements must be different from each other\"\n assert len(np.bincount(c)) < col*row,\"each element in every camps must be an index < %s\"%(col*row)\n\ndef test_campsegments():\n assert len(camp_segments) == 9*9,\"camp_segments must be an index square with %s elements index\"%(9*9)\n for c in camps:\n for ec in c:\n assert ec in camp_segments[ec],\"camp:%s - element:%s must be in camp_segments[%s]:%s\"%(c,ec,ec,camp_segments[ec])\n assert set(camp_segments[ec]) == set(c),\"camp_segments[%s] should be %s instead of %s\"%(ec,c,camp_segments[ec])\n \ndef test_throneel():\n assert throne_el == 40,\"throne_el must be 40 not %s\"%throne_el\n \ndef test_kingcapturesegments():\n corners = {_indices[0][0]}\n corners.add(_indices[0][-1])\n corners.add(_indices[-1][0])\n corners.add(_indices[-1][-1])\n \n assert len(king_capture_segments) == 9*9,\"king_capture_segments must be an index square with %s elements index\"%(9*9)\n for c in corners:\n assert len(king_capture_segments[c]) == 0,\"king_capture_segments[%s] must be empty because the King can not get to the corners\"%c\n \n for i_kc in cross_center_segments[throne_el]:\n assert len(king_capture_segments[i_kc]) == 1,\"the capture segments with king starteing index must be just one and not %s\"%len(king_capture_segments[i_kc])\n assert len(set(king_capture_segments[i_kc][0])) == 5,\"in the throne_el or neighborhood king_capture_segments[%s] must contains 5 elements\"%i_kc\n assert set(cross_center_segments[i_kc]) == set(king_capture_segments[i_kc][0]),\"king_capture_segments[%s] should be %s instead of %s\"%(i_kc,cross_center_segments[i_kc],king_capture_segments[i_kc])\n\n horizontal_per = []\n horizontal_per.append(_indices[0][1:-1])\n horizontal_per.append(_indices[-1][1:-1])\n \n for hp in horizontal_per:\n for hpe in hp:\n assert (king_capture_segments[hpe] == np.asarray([hpe-1,hpe,hpe+1])).all(),\"king_capture_segments[%s] should be %s instead of %s\"%(hpe,np.asarray([hpe-1,hpe,hpe+1]),king_capture_segments[hpe])\n \n vertical_per = []\n vertical_per.append(_indices.transpose()[0][1:-1])\n vertical_per.append(_indices.transpose()[-1][1:-1])\n \n for vp in vertical_per:\n for vpe in vp:\n assert (king_capture_segments[vpe] == np.asarray([vpe-col,vpe,vpe+col])).all(),\"king_capture_segments[%s] should be %s instead of %s\"%(vpe,np.asarray([vpe-col,vpe,vpe+col]),king_capture_segments[vpe])\n \n for ins in _indices[1:-1].transpose()[1:-1].transpose().flatten():\n if ins not in cross_center_segments[throne_el]:\n assert [ins-1,ins,ins+1] in king_capture_segments[ins].tolist(),\"king_capture_segments[%s]:%s should contain %s\"%(ins,king_capture_segments[ins],np.asarray([ins-1,ins,ins+1]))\n assert [ins-col,ins,ins+col] in king_capture_segments[ins].tolist(),\"king_capture_segments[%s]:%s should contain %s\"%(ins,king_capture_segments[ins],np.asarray([ins-col,ins,ins+col]))\n \ndef test_winningel():\n per = []\n per.append(_indices[0][1:-1])\n per.append(_indices[-1][1:-1])\n per.append(_indices.transpose()[0][1:-1])\n per.append(_indices.transpose()[-1][1:-1])\n\n assert (len(winning_el) == ((col-2)*2 + (row-2)*2)-12),\"winning_el must contain %s elements instead of %s\"%(((col-2)*2 + (row-2)*2)-12,len(winning_el))\n for p in per:\n assert p[0] in winning_el,\"%s should be in winning_el:%s\"%(p[0],winning_el)\n assert p[1] in winning_el,\"%s should be in winning_el:%s\"%(p[1],winning_el)\n assert p[-1] in winning_el,\"%s should be in winning_el:%s\"%(p[-1],winning_el)\n assert p[-2] in winning_el,\"%s should be in winning_el:%s\"%(p[-2],winning_el)\n\ndef test_prohibitedsegments():\n #testing black prohibited elements\n for c in camps.flatten():\n assert c in prohibited_segments[PLAYER1][0],\"the camp element %s should be prohibited for the Black Player moving FROM:%s\"%(c,0)\n assert c in prohibited_segments[PLAYER1][2],\"the camp element %s should be prohibited for the Black Player moving FROM:%s\"%(c,2)\n assert c in prohibited_segments[PLAYER1][7],\"the camp element %s should be prohibited for the Black Player moving FROM:%s\"%(c,7)\n assert c in prohibited_segments[PLAYER1][11],\"the camp element %s should be prohibited for the Black Player moving FROM:%s\"%(c,11)\n assert c in prohibited_segments[PLAYER1][12],\"the camp element %s should be prohibited for the Black Player moving FROM:%s\"%(c,12)\n assert c in prohibited_segments[PLAYER1][16],\"the camp element %s should be prohibited for the Black Player moving FROM:%s\"%(c,16)\n assert c in prohibited_segments[PLAYER1][31],\"the camp element %s should be prohibited for the Black Player moving FROM:%s\"%(c,31)\n assert c in prohibited_segments[PLAYER1][39],\"the camp element %s should be prohibited for the Black Player moving FROM:%s\"%(c,39)\n assert c in prohibited_segments[PLAYER1][41],\"the camp element %s should be prohibited for the Black Player moving FROM:%s\"%(c,41)\n assert c in prohibited_segments[PLAYER1][49],\"the camp element %s should be prohibited for the Black Player moving FROM:%s\"%(c,49)\n assert c in prohibited_segments[PLAYER1][58],\"the camp element %s should be prohibited for the Black Player moving FROM:%s\"%(c,58)\n assert c in prohibited_segments[PLAYER1][68],\"the camp element %s should be prohibited for the Black Player moving FROM:%s\"%(c,68)\n assert c in prohibited_segments[PLAYER1][69],\"the camp element %s should be prohibited for the Black Player moving FROM:%s\"%(c,69)\n\n for i in _indices.flatten():\n for cs in camp_segments[i]:\n assert cs not in prohibited_segments[PLAYER1][i],\"the camp element %s should not be prohibited for the Black Player moving FROM:%s\"%(cs,i)\n\n #testing black prohibited elements\n\ndef test_capturingdic():\n for i,cd in capturing_dic.items():\n assert throne_el in cd,\"throne element:%s should count always in capturing. It must be in %s\"%(throne_el,cd)\n for c in camps:\n assert c[0] in cd,\"camp element:%s should count always in capturing. It must be in %s\"%(c[0],cd)\n assert c[2] in cd,\"camp element:%s should count always in capturing. It must be in %s\"%(c[2],cd)\n assert c[3] in cd,\"camp element:%s should count always in capturing. It must be in %s\"%(c[3],cd)\n\n\ntest_kingcapturesegments()"
},
{
"alpha_fraction": 0.28679555654525757,
"alphanum_fraction": 0.4274708926677704,
"avg_line_length": 51.31216812133789,
"blob_id": "13b6a2553c0c31cf685769a418fb2305768e41b3",
"content_id": "e8ab32e153438194c99beb29cda4064b56fe8a4a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 59321,
"license_type": "no_license",
"max_line_length": 219,
"num_lines": 1134,
"path": "/vablut/tests/test_board.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport numpy as np\nfrom vablut.board import *\nimport pytest\n\n#several test position\nblacks = np.array([[0,0,0,1,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,1,0,0,0,0,0,1,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,1,1,0],\n [0,0,0,0,0,0,0,0,0]])\nwhites = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,1,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,1,0,0,0],\n [0,0,0,0,0,0,0,1,0],\n [0,0,0,0,0,0,0,0,0],\n [0,1,0,0,0,0,0,0,1],\n [0,0,0,0,0,0,0,0,0]])\nking = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\npos1 = {PLAYER1:blacks, PLAYER2: (whites,king)}\n\nblacks = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,1,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,1,0,1,0,0,1],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0]])\nwhites = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,1,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,1,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,1,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,1,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\nking = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\npos2 = {PLAYER1:blacks, PLAYER2: (whites,king)}\n\nblacks = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [1,0,0,0,0,1,0,0,0],\n [1,1,0,0,0,0,1,0,0],\n [0,0,0,0,0,1,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,1,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\nwhites = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,1,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,1,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\nking = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,1,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\npos3 = {PLAYER1:blacks, PLAYER2: (whites,king)}\n\nblacks = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,1,0,0,0,0,0,0,0],\n [0,1,0,0,0,0,1,1,0],\n [0,1,0,0,0,1,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\nwhites = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,1,0,1,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,1,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,1,1,1,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\nking = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,1,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\npos4 = {PLAYER1:blacks, PLAYER2: (whites,king)}\n\nblacks = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,1,0],\n [0,0,0,0,0,0,0,0,0],\n [0,1,0,1,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\nwhites = np.array([[0,0,0,0,0,0,0,0,0],\n [0,1,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,1,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,1,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\nking = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,1,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\npos5 = {PLAYER1:blacks, PLAYER2: (whites,king)}\n\nblacks = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,1,0,0,0,0,0,0,0],\n [1,0,0,0,0,0,0,0,1],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,1],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,1,0,1,1,0,0,0]])\nwhites = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,1,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,1,0,0,0],\n [0,1,1,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\nking = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,1,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\npos6 = {PLAYER1:blacks, PLAYER2: (whites,king)}\n\nblacks = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,1,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,1,0,0,1],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0]])\nwhites = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,1,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,1,0,0,0,0,0,0,0],\n [0,0,0,1,0,0,1,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,1,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\nking = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\npos7 = {PLAYER1:blacks, PLAYER2: (whites,king)}\n\nblacks = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,1,0,1,0,1,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\nwhites = np.array([[0,0,0,0,0,0,0,0,0],\n [0,1,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,1,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,1,0,0],\n [0,0,0,0,0,0,0,0,0]])\nking = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\npos8 = {PLAYER1:blacks, PLAYER2: (whites,king)}\n\nblacks = np.array([[0,0,0,0,0,0,0,1,0],\n [1,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [1,0,0,0,0,0,0,0,0],\n [1,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,1,0,1,0,0,0,0]])\nwhites = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,1,0,1,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\nking = np.array([[0,0,0,0,0,0,1,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\npos9 = {PLAYER1:blacks, PLAYER2: (whites,king)}\n\nblacks = np.array([[0,0,0,0,0,0,0,1,0],\n [1,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [1,0,0,0,0,0,0,0,0],\n [1,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,1,0,1,0,0,0,0]])\nwhites = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,1,0,1,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\nking = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [1,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\npos10 = {PLAYER1:blacks, PLAYER2: (whites,king)}\n\nblacks = np.array([[0,0,0,0,0,0,0,1,0],\n [1,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [1,0,0,0,0,0,0,0,0],\n [1,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,1,0,1,0,0,0,0]])\nwhites = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,1,0,1,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\nking = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,1,0,0,0,0,0,0,0]])\npos11 = {PLAYER1:blacks, PLAYER2: (whites,king)}\n\n\ndef test_properties():\n boardP1 = Board(pos1, PLAYER1)\n boardP2 = Board(pos1, PLAYER2)\n assert boardP1.end is None,\"board.end should be None\"\n assert boardP2.end is None,\"board.end should be None\"\n\n assert boardP1.stm == PLAYER1,\"board.stm should be PLAYER1\"\n assert boardP1.stm != PLAYER2,\"board.stm should be PLAYER1\"\n assert boardP2.stm == PLAYER2,\"board.stm should be PLAYER2\"\n assert boardP2.stm != PLAYER1,\"board.stm should be PLAYER2\"\n\n assert boardP1.other == PLAYER2,\"board.other should be PLAYER2\"\n assert boardP2.other == PLAYER1,\"board.other should be PLAYER1\"\n\n pos = np.array([[0,0,0,1,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,2,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,1,0,0,0,2,0,1,0],\n [0,0,0,0,0,0,0,2,0],\n [0,0,0,0,3,0,0,0,0],\n [0,2,0,0,0,0,1,1,2],\n [0,0,0,0,0,0,0,0,0]])\n\n assert (boardP1.pos==pos).all(),\"boardP1 should have %s like pos\"%(pos)\n assert (boardP2.pos==pos).all(),\"boardP2 should have %s like pos\"%(pos)\n\ndef test_checkend():\n board1_1 = Board(pos1, PLAYER1, COMPUTE, 41)\n board1_2 = Board(pos1, PLAYER2, COMPUTE, 58)\n board1_3 = Board(pos1, PLAYER2, COMPUTE, 70)\n assert board1_1.end is None,\"\\n%s \\n the end should be None\"%(board1_1)\n assert board1_2.end is None,\"\\n%s \\n the end should be None\"%(board1_2)\n assert board1_3.end is None,\"\\n%s \\n the end should be None\"%(board1_3)\n \n board2_1 = Board(pos2, PLAYER2, COMPUTE, 31)\n board2_2 = Board(pos2, PLAYER2, COMPUTE, 39)\n board2_3 = Board(pos2, PLAYER2, COMPUTE, 41)\n board2_4 = Board(pos2, PLAYER2, COMPUTE, 49)\n assert board2_1.end is PLAYER1,\"\\n%s \\n the end should be %s(PLAYER1)\"%(board2_1,PLAYER1)\n assert board2_2.end is PLAYER1,\"\\n%s \\n the end should be %s(PLAYER1)\"%(board2_2,PLAYER1)\n assert board2_3.end is PLAYER1,\"\\n%s \\n the end should be %s(PLAYER1)\"%(board2_3,PLAYER1)\n assert board2_4.end is PLAYER1,\"\\n%s \\n the end should be %s(PLAYER1)\"%(board2_4,PLAYER1)\n\n board3_1 = Board(pos3, PLAYER2, COMPUTE, 32)\n board3_2 = Board(pos3, PLAYER2, COMPUTE, 42)\n board3_3 = Board(pos3, PLAYER2, COMPUTE, 50)\n board3_4 = Board(pos3, PLAYER1, COMPUTE, 41)\n board3_5 = Board(pos3, PLAYER1, COMPUTE, 12)\n board3_6 = Board(pos3, PLAYER2, COMPUTE, 37)\n assert board3_1.end is PLAYER1,\"\\n%s \\n the end should be %s(PLAYER1)\"%(board3_1,PLAYER1)\n assert board3_2.end is PLAYER1,\"\\n%s \\n the end should be %s(PLAYER1)\"%(board3_2,PLAYER1)\n assert board3_3.end is PLAYER1,\"\\n%s \\n the end should be %s(PLAYER1)\"%(board3_3,PLAYER1)\n assert board3_4.end is None,\"\\n%s \\n the end should be None\"%(board3_4)\n assert board3_5.end is None,\"\\n%s \\n the end should be None\"%(board3_5)\n assert board3_6.end is None,\"\\n%s \\n the end should be None\"%(board3_6)\n\n board4_1 = Board(pos4, PLAYER1, COMPUTE, 32)\n board4_2 = Board(pos4, PLAYER2, COMPUTE, 42)\n board4_3 = Board(pos4, PLAYER2, COMPUTE, 50)\n board4_4 = Board(pos4, PLAYER1, COMPUTE, 41)\n board4_5 = Board(pos4, PLAYER1, COMPUTE, 46)\n assert board4_1.end is None,\"\\n%s \\n the end should be None\"%(board4_1)\n assert board4_2.end is None,\"\\n%s \\n the end should be None\"%(board4_2)\n assert board4_3.end is None,\"\\n%s \\n the end should be None\"%(board4_3)\n assert board4_4.end is None,\"\\n%s \\n the end should be None\"%(board4_4)\n assert board4_5.end is None,\"\\n%s \\n the end should be None\"%(board4_5)\n \n draw_dic = {}\n board5_1 = Board(pos5, PLAYER2, COMPUTE, 55)\n board5_2 = Board(pos5, PLAYER2, COMPUTE, 57)\n board5_3 = Board(pos5, PLAYER1, COMPUTE, 47)\n board5_4 = Board(pos5, PLAYER1, COMPUTE, 65, draw_dic)\n board5_5 = Board(pos5, PLAYER1, COMPUTE, 56)\n assert board5_1.end is PLAYER1,\"\\n%s \\n the end should be %s(PLAYER1)\"%(board5_1,PLAYER1)\n assert board5_2.end is PLAYER1,\"\\n%s \\n the end should be %s(PLAYER1)\"%(board5_2,PLAYER1)\n assert board5_3.end is None,\"\\n%s \\n the end should be None\"%(board5_3)\n assert board5_4.end is None,\"\\n%s \\n the end should be None\"%(board5_4)\n board5_4again = Board(pos5, PLAYER1, COMPUTE, 65, draw_dic)\n assert board5_4again.end is DRAW,\"\\n%s \\n the end should be DRAW\"%(board5_4again)\n assert board5_5.end is None,\"\\n%s \\n the end should be None\"%(board5_5)\n \n board6_1 = Board(pos6, PLAYER2, COMPUTE, 19)\n board6_2 = Board(pos6, PLAYER2, COMPUTE, 27)\n board6_3 = Board(pos6, PLAYER1, COMPUTE, 28)\n board6_4 = Board(pos6, PLAYER2, COMPUTE, 49)\n board6_5 = Board(pos6, PLAYER1, COMPUTE, 46)\n assert board6_1.end is PLAYER1,\"\\n%s \\n the end should be %s(PLAYER1)\"%(board6_1,PLAYER1)\n assert board6_2.end is None,\"\\n%s \\n the end should be None\"%(board6_2)\n assert board6_3.end is None,\"\\n%s \\n the end should be None\"%(board6_3)\n assert board6_4.end is None,\"\\n%s \\n the end should be None\"%(board6_4)\n assert board6_5.end is None,\"\\n%s \\n the end should be None\"%(board6_5)\n draw_dic = {}\n board7_1 = Board(pos7, PLAYER2, COMPUTE, 31, draw_dic)\n board7_2 = Board(pos7, PLAYER2, COMPUTE, 41)\n board7_3 = Board(pos7, PLAYER1, COMPUTE, 39)\n board7_4 = Board(pos7, PLAYER1, COMPUTE, 49)\n assert board7_1.end is None,\"\\n%s \\n the end should be None\"%(board7_1)\n assert board7_2.end is None,\"\\n%s \\n the end should be None\"%(board7_2)\n assert board7_3.end is None,\"\\n%s \\n the end should be None\"%(board7_3)\n assert board7_4.end is None,\"\\n%s \\n the end should be None\"%(board7_4)\n board7_1again = Board(pos7, PLAYER2, COMPUTE, 41, draw_dic)\n assert board7_1again.end is DRAW,\"\\n%s \\n the end should be DRAW\"%(board7_1again)\n\n board8_1 = Board(pos8, PLAYER2, COMPUTE, 32)\n board8_2 = Board(pos8, PLAYER2, COMPUTE, 34)\n assert board8_1.end is PLAYER1,\"\\n%s \\n the end should be %s(PLAYER1)\"%(board8_1,PLAYER1)\n assert board8_2.end is PLAYER1,\"\\n%s \\n the end should be %s(PLAYER1)\"%(board8_2,PLAYER1)\n\n board9 = Board(pos9, PLAYER1, COMPUTE, 6)\n board10 = Board(pos10, PLAYER1, COMPUTE, 18)\n board11 = Board(pos11, PLAYER1, COMPUTE, 73)\n assert board9.end is PLAYER2,\"\\n%s \\n the end should be %s(PLAYER2)\"%(board9,PLAYER2)\n assert board10.end is PLAYER2,\"\\n%s \\n the end should be %s(PLAYER2)\"%(board10,PLAYER2)\n assert board11.end is PLAYER2,\"\\n%s \\n the end should be %s(PLAYER2)\"%(board11,PLAYER2)\n\ndef test_orthogonalsegment():\n board1 = Board(pos1, PLAYER1, COMPUTE, 41)\n board3 = Board(pos3, PLAYER1, COMPUTE, 41)\n board6 = Board(pos6, PLAYER2, COMPUTE, 27)\n #b1: moving B FROM 31 TO 29, FROM 37 TO 39, FROM 43 TO 70\n #b1: invalid moving FROM 69 TO 57, FROM 3 TO 78\n r1_1 = np.asarray([0,0,1])\n r1_2 = np.asarray([1,0,0])\n r1_3 = np.asarray([1,2,0,1])\n assert (board1.orthogonal_segment(board1.pos, 31, 29)==r1_1).all(),\"the orthogonal segment FROM %s TO %s should be %s and not %s\"%(31,29,r1_1,board1.orthogonal_segment(board1.pos, 31, 29))\n assert (board1.orthogonal_segment(board1.pos, 37, 39)==r1_2).all(),\"the orthogonal segment FROM %s TO %s should be %s and not %s\"%(37,39,r1_2,board1.orthogonal_segment(board1.pos, 37, 39))\n assert (board1.orthogonal_segment(board1.pos, 43, 70)==r1_3).all(),\"the orthogonal segment FROM %s TO %s should be %s and not %s\"%(47,70,r1_3,board1.orthogonal_segment(board1.pos, 47, 70))\n with pytest.raises(ValueError):\n assert board1.orthogonal_segment(board1.pos, 69, 57)\n assert board1.orthogonal_segment(board1.pos, 3, 78)\n\n #b3: moving FROM 42 TO 38, FROM 65 TO 20\n #b3: invalid moving FROM 69 TO 57\n r3_1 = np.asarray([0,0,0,3,1])\n r3_2 = np.asarray([0,0,0,0,0,1])\n assert (board3.orthogonal_segment(board3.pos, 42, 38)==r3_1).all(),\"the orthogonal segment FROM %s TO %s should be %s and not %s\"%(42,38,r3_1,board3.orthogonal_segment(board3.pos, 42, 38))\n assert (board3.orthogonal_segment(board3.pos, 65, 20)==r3_2).all(),\"the orthogonal segment FROM %s TO %s should be %s and not %s\"%(65,20,r3_2,board3.orthogonal_segment(board3.pos, 65, 20))\n with pytest.raises(ValueError):\n assert board3.orthogonal_segment(board1.pos, 69, 57)\n\n #b6: moving FROM 46 TO 51, FROM 74 TO 20\n #b6: invalid moving FROM 77 TO 17\n r6_1 = np.asarray([2,2,0,1,0,0])\n r6_2 = np.asarray([0,0,0,2,0,0,1])\n assert (board6.orthogonal_segment(board6.pos, 46, 51)==r6_1).all(),\"the orthogonal segment FROM %s TO %s should be %s and not %s\"%(46,51,r6_1,board6.orthogonal_segment(board6.pos, 46, 51))\n assert (board6.orthogonal_segment(board6.pos, 74, 20)==r6_2).all(),\"the orthogonal segment FROM %s TO %s should be %s and not %s\"%(74,20,r6_2,board6.orthogonal_segment(board6.pos, 74, 20))\n with pytest.raises(ValueError):\n assert board6.orthogonal_segment(board6.pos, 77, 17)\n\ndef test_frompostodic():\n check_pos = pos5[PLAYER1] + 2*pos5[PLAYER2][0] + 3*pos5[PLAYER2][1]\n board5 = Board(pos5, PLAYER1, COMPUTE, 47)\n c_pos_dic = Board.from_pos_to_dic(check_pos)\n\n assert (board5._pos[PLAYER1].flatten()==c_pos_dic[PLAYER1].flatten()).all()\n assert (board5._pos[PLAYER2][0].flatten()==c_pos_dic[PLAYER2][0].flatten()).all()\n assert (board5._pos[PLAYER2][1].flatten()==c_pos_dic[PLAYER2][1].flatten()).all()\n \n board7 = Board(pos7, PLAYER2, COMPUTE, 41)\n assert not (board7._pos[PLAYER1].flatten()==c_pos_dic[PLAYER1].flatten()).all()\n assert not (board7._pos[PLAYER2][0].flatten()==c_pos_dic[PLAYER2][0].flatten()).all()\n\ndef test_posupdate():\n board5 = Board(pos5, PLAYER1, COMPUTE, 47)\n pos5_up_b = np.array([[0,0,0,1,1,1,0,0,0],\n [0,2,0,0,1,0,0,0,0],\n [0,0,0,0,2,0,0,0,0],\n [1,0,0,0,2,0,0,0,1],\n [1,1,0,0,1,0,0,1,1],\n [1,0,2,0,0,0,0,0,1],\n [0,1,3,1,0,0,0,0,0],\n [0,0,2,0,1,0,0,0,0],\n [0,0,0,1,1,1,0,0,0]])\n pos5_up_w = np.array([[0,0,0,2,2,2,0,0,0],\n [0,2,0,0,2,0,0,0,0],\n [0,0,0,0,2,0,0,0,0],\n [2,0,0,0,2,0,0,0,2],\n [2,2,0,0,2,0,0,2,2],\n [2,0,2,0,0,0,0,0,2],\n [0,1,3,1,0,0,0,0,0],\n [0,0,2,0,2,0,0,0,0],\n [0,0,0,2,2,2,0,0,0]])\n assert (board5.pos_update(board5.pos, 57).flatten() == pos5_up_b.flatten()).all(),\"the updated pos should be \\n%s instead of \\n%s\"%(pos5_up_b,board5.pos_update(board5.pos, 57).reshape((ROW,COL)))\n assert (board5.pos_update(board5.pos, 31).flatten() == pos5_up_w.flatten()).all(),\"the updated pos should be \\n%s instead of \\n%s\"%(pos5_up_w,board5.pos_update(board5.pos, 31).reshape((ROW,COL)))\n \n board7 = Board(pos7, PLAYER2, COMPUTE, 41)\n pos7_up_w = np.array([[0,0,0,2,2,2,0,0,0],\n [0,0,0,1,2,2,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [2,2,0,0,1,0,0,0,2],\n [2,2,0,2,2,1,2,2,2],\n [2,0,0,0,1,0,0,0,2],\n [0,0,0,0,0,0,0,0,0],\n [0,2,0,0,2,0,0,0,0],\n [0,0,0,2,2,2,0,0,0]])\n pos7_up_b = np.array([[0,0,0,1,1,1,0,0,0],\n [0,0,0,1,1,2,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [1,2,0,0,1,0,0,0,1],\n [1,1,0,2,1,1,2,1,1],\n [1,0,0,0,1,0,0,0,1],\n [0,0,0,0,0,0,0,0,0],\n [0,2,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0]])\n assert (board7.pos_update(board7.pos, 42).flatten() == pos7_up_w.flatten()).all(),\"the updated pos should be \\n%s instead of \\n%s\"%(pos7_up_w,board7.pos_update(board7.pos, 42).reshape((ROW,COL)))\n assert (board7.pos_update(board7.pos, 67).flatten() == pos7_up_b.flatten()).all(),\"the updated pos should be \\n%s instead of \\n%s\"%(pos7_up_b,board7.pos_update(board7.pos, 67).reshape((ROW,COL)))\n assert (board7.pos_update(board7.pos, 76).flatten() == pos7_up_b.flatten()).all(),\"the updated pos should be \\n%s instead of \\n%s\"%(pos7_up_b,board7.pos_update(board7.pos, 76).reshape((ROW,COL)))\n\n board9 = Board(pos9, PLAYER1, COMPUTE, 6)\n pos9_up_b = np.array([[0,0,0,1,1,1,3,1,0],\n [1,0,0,0,1,2,0,2,0],\n [0,0,0,0,0,0,0,0,0],\n [1,0,0,0,0,0,0,0,1],\n [1,0,0,0,1,0,0,1,1],\n [0,0,0,0,2,0,0,0,1],\n [0,0,0,0,2,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,1,1,1,1,0,0,0]])\n pos9_up_w = np.array([[0,0,0,2,2,2,3,1,0],\n [1,0,0,0,2,2,0,2,0],\n [0,0,0,0,0,0,0,0,0],\n [2,0,0,0,0,0,0,0,2],\n [2,2,0,0,2,0,0,2,2],\n [2,0,0,0,2,0,0,0,2],\n [0,0,0,0,2,0,0,0,0],\n [0,0,0,0,2,0,0,0,0],\n [0,0,1,2,2,2,0,0,0]])\n pos9_up_k = np.array([[0,0,0,3,3,3,3,1,0],\n [1,0,0,0,3,2,0,2,0],\n [0,0,0,0,0,0,0,0,0],\n [3,0,0,0,0,0,0,0,3],\n [3,3,0,0,3,0,0,3,3],\n [3,0,0,0,2,0,0,0,3],\n [0,0,0,0,2,0,0,0,0],\n [0,0,0,0,3,0,0,0,0],\n [0,0,1,3,3,3,0,0,0]])\n assert (board9.pos_update(board9.pos, 36).flatten() == pos9_up_b.flatten()).all(),\"the updated pos should be \\n%s instead of \\n%s\"%(pos9_up_b,board9.pos_update(board9.pos, 36).reshape((ROW,COL)))\n assert (board9.pos_update(board9.pos, 14).flatten() == pos9_up_w.flatten()).all(),\"the updated pos should be \\n%s instead of \\n%s\"%(pos9_up_w,board9.pos_update(board9.pos, 14).reshape((ROW,COL)))\n assert (board9.pos_update(board9.pos, 6).flatten() == pos9_up_k.flatten()).all(),\"the updated pos should be \\n%s instead of \\n%s\"%(pos9_up_k,board9.pos_update(board9.pos, 6).reshape((ROW,COL)))\n\ndef test_posupdatecapturing():\n board5 = Board(pos5, PLAYER1, COMPUTE, 47)\n pos5_up_b = np.array([[0,0,0,1,0,1,0,0,0],\n [0,2,0,0,1,0,0,0,0],\n [0,0,0,0,2,0,0,0,0],\n [1,0,0,0,2,0,0,0,1],\n [0,1,0,0,1,0,0,1,0],\n [1,0,2,0,0,0,0,0,1],\n [0,1,3,1,0,0,0,0,0],\n [0,0,2,0,1,0,0,0,0],\n [0,0,0,1,0,1,0,0,0]])\n pos5_up_w = np.array([[0,0,0,2,0,2,0,0,0],\n [0,2,0,0,2,0,0,0,0],\n [0,0,0,0,2,0,0,0,0],\n [2,0,0,0,2,0,0,0,2],\n [0,2,0,0,2,0,0,2,0],\n [2,0,2,0,0,0,0,0,2],\n [0,1,3,1,0,0,0,0,0],\n [0,0,2,0,2,0,0,0,0],\n [0,0,0,2,0,2,0,0,0]])\n assert (board5.pos_update_capturing(board5.pos, 57).flatten() == pos5_up_b.flatten()).all(),\"the updated pos should be \\n%s instead of \\n%s\"%(pos5_up_b,board5.pos_update_capturing(board5.pos, 57).reshape((ROW,COL)))\n assert (board5.pos_update_capturing(board5.pos, 31).flatten() == pos5_up_w.flatten()).all(),\"the updated pos should be \\n%s instead of \\n%s\"%(pos5_up_w,board5.pos_update_capturing(board5.pos, 31).reshape((ROW,COL)))\n \n board7 = Board(pos7, PLAYER2, COMPUTE, 41)\n pos7_up_w = np.array([[0,0,0,2,0,2,0,0,0],\n [0,0,0,1,2,2,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [2,2,0,0,1,0,0,0,2],\n [0,2,0,2,2,1,2,2,1],\n [2,0,0,0,1,0,0,0,2],\n [0,0,0,0,0,0,0,0,0],\n [0,2,0,0,2,0,0,0,0],\n [0,0,0,2,1,2,0,0,0]])\n pos7_up_b = np.array([[0,0,0,1,0,1,0,0,0],\n [0,0,0,1,1,2,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [1,2,0,0,1,0,0,0,1],\n [0,1,0,2,1,1,2,1,1],\n [1,0,0,0,1,0,0,0,1],\n [0,0,0,0,0,0,0,0,0],\n [0,2,0,0,1,0,0,0,0],\n [0,0,0,1,1,1,0,0,0]])\n assert (board7.pos_update_capturing(board7.pos, 42).flatten() == pos7_up_w.flatten()).all(),\"the updated pos should be \\n%s instead of \\n%s\"%(pos7_up_w,board7.pos_update_capturing(board7.pos, 42).reshape((ROW,COL)))\n assert (board7.pos_update_capturing(board7.pos, 67).flatten() == pos7_up_b.flatten()).all(),\"the updated pos should be \\n%s instead of \\n%s\"%(pos7_up_b,board7.pos_update_capturing(board7.pos, 67).reshape((ROW,COL)))\n assert (board7.pos_update_capturing(board7.pos, 76).flatten() == pos7_up_b.flatten()).all(),\"the updated pos should be \\n%s instead of \\n%s\"%(pos7_up_b,board7.pos_update_capturing(board7.pos, 76).reshape((ROW,COL)))\n \n board9 = Board(pos9, PLAYER1, COMPUTE, 6)\n pos9_up_b = np.array([[0,0,0,1,0,1,3,1,0],\n [1,0,0,0,1,2,0,2,0],\n [0,0,0,0,0,0,0,0,0],\n [1,0,0,0,0,0,0,0,1],\n [1,1,0,0,1,0,0,1,0],\n [1,0,0,0,2,0,0,0,1],\n [0,0,0,0,2,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,1,1,1,1,0,0,0]])#36\n pos9_up_w = np.array([[0,0,0,2,0,2,3,1,0],\n [1,0,0,0,2,2,0,2,0],\n [0,0,0,0,0,0,0,0,0],\n [2,0,0,0,0,0,0,0,2],\n [1,2,0,0,2,0,0,2,0],\n [2,0,0,0,2,0,0,0,2],\n [0,0,0,0,2,0,0,0,0],\n [0,0,0,0,2,0,0,0,0],\n [0,0,1,2,1,2,0,0,0]])#14\n pos9_up_k = np.array([[0,0,0,3,0,3,3,1,0],\n [1,0,0,0,3,2,0,2,0],\n [0,0,0,0,0,0,0,0,0],\n [3,0,0,0,0,0,0,0,3],\n [1,3,0,0,3,0,0,3,0],\n [3,0,0,0,2,0,0,0,3],\n [0,0,0,0,2,0,0,0,0],\n [0,0,0,0,3,0,0,0,0],\n [0,0,1,3,1,3,0,0,0]])#6\n assert (board9.pos_update_capturing(board9.pos, 36).flatten() == pos9_up_b.flatten()).all(),\"the updated pos should be \\n%s instead of \\n%s\"%(pos9_up_b,board9.pos_update_capturing(board9.pos, 36).reshape((ROW,COL)))\n assert (board9.pos_update_capturing(board9.pos, 14).flatten() == pos9_up_w.flatten()).all(),\"the updated pos should be \\n%s instead of \\n%s\"%(pos9_up_w,board9.pos_update_capturing(board9.pos, 14).reshape((ROW,COL)))\n assert (board9.pos_update_capturing(board9.pos, 6).flatten() == pos9_up_k.flatten()).all(),\"the updated pos should be \\n%s instead of \\n%s\"%(pos9_up_k,board9.pos_update_capturing(board9.pos, 6).reshape((ROW,COL)))\n\ndef test_coordinatesinttostring():\n assert Board.coordinates_int_to_string((19,25)) == ('B3','H3'),\"the coordinate: %s should correspond to %s instead of %s\"%('(19,25)',\"('B3','H3')\",Board.coordinates_int_to_string((19,25)))\n assert Board.coordinates_int_to_string((31,58)) == ('E4','E7'),\"the coordinate: %s should correspond to %s instead of %s\"%('(31,58)',\"('E4','E7')\",Board.coordinates_int_to_string((31,58)))\n assert Board.coordinates_int_to_string((78,15)) == ('G9','G2'),\"the coordinate: %s should correspond to %s instead of %s\"%('(78,15)',\"('G9','G2')\",Board.coordinates_int_to_string((78,15)))\n assert Board.coordinates_int_to_string((8,0)) == ('I1','A1'),\"the coordinate: %s should correspond to %s instead of %s\"%('(8,0)',\"('I1','A1')\",Board.coordinates_int_to_string((8,0)))\n assert Board.coordinates_int_to_string((54,13)) == ('A7','E2'),\"the coordinate: %s should correspond to %s instead of %s\"%('(54,13)',\"('A7','E2')\",Board.coordinates_int_to_string((54,13)))\n\ndef test_coordinatesstringtoint():\n assert Board.coordinates_string_to_int(('B3','H3')) == (19,25),\"the coordinate: %s should correspond to %s instead of %s\"%(\"('B3','H3')\",'(19,25)',Board.coordinates_string_to_int(('B3','H3')))\n assert Board.coordinates_string_to_int(('E5','A9')) == (40,72),\"the coordinate: %s should correspond to %s instead of %s\"%(\"('E5','A9')\",'(40,72)',Board.coordinates_string_to_int(('E5','A9')))\n assert Board.coordinates_string_to_int(('G2','G6')) == (15,51),\"the coordinate: %s should correspond to %s instead of %s\"%(\"('G2','G6')\",'(15,51)',Board.coordinates_string_to_int(('G2','G6')))\n assert Board.coordinates_string_to_int(('E6','A6')) == (49,45),\"the coordinate: %s should correspond to %s instead of %s\"%(\"('E6','A6')\",'(49,45)',Board.coordinates_string_to_int(('E6','A6')))\n assert Board.coordinates_string_to_int(('F9','I9')) == (77,80),\"the coordinate: %s should correspond to %s instead of %s\"%(\"('F9','I9')\",'(77,80)',Board.coordinates_string_to_int(('F9','I9')))\n\ndef test_getallmoves():\n board1 = Board(pos1, PLAYER1, COMPUTE, 41)#B move\n b1_pm = board1.get_all_moves()\n assert ('E1','F1') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('E1','F1'),board1)\n assert ('E1','E2') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('E1','E2'),board1)\n assert ('H5','I5') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('H5','I5'),board1)\n assert ('E4','B4') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('E4','B4'),board1)\n assert ('E4','E3') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('E4','E3'),board1)\n assert ('E4','H4') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('E4','H4'),board1)\n assert ('E4','F4') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('E4','F4'),board1)\n assert ('G8','G1') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('G8','G1'),board1)\n assert ('H8','H9') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('H8','H9'),board1)\n assert ('H8','H7') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('H8','H7'),board1)\n \n assert ('E4','E2') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('E4','E2'),board1)\n assert ('E4','A4') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('E4','A4'),board1)\n assert ('E4','I4') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('E4','I4'),board1)\n assert ('E4','E5') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('E4','E5'),board1)\n assert ('E4','E6') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('E4','E6'),board1)\n assert ('D1','F1') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('D1','F1'),board1)\n assert ('D1','D9') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('D1','D9'),board1)\n assert ('E1','E6') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('E1','E6'),board1)\n assert ('B5','E5') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('B5','E5'),board1)\n assert ('H5','D5') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('H5','D5'),board1)\n assert ('H5','H6') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('H5','H6'),board1)\n assert ('H5','H7') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('H5','H7'),board1)\n assert ('G8','E8') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('G8','E8'),board1)\n assert ('G8','C8') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('G8','C8'),board1)\n assert ('G8','I8') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('G8','I8'),board1)\n assert ('H8','F8') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('H8','F8'),board1)\n assert ('H8','H4') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('H8','H4'),board1)\n assert ('H8','H1') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('H8','H1'),board1)\n \n assert len(b1_pm) == 49,\"the following board:\\n%s\\nshould have %s possible moves instead of %s per Player:%s\"%(board1,49,len(b1_pm),board1.stm)\n\n board1 = Board(pos1, PLAYER2, COMPUTE, 69)#W move\n b1_pm = board1.get_all_moves()\n assert ('C3','B3') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('C3','B3'),board1)\n assert ('C3','D3') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('C3','D3'),board1)\n assert ('C3','C1') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('C3','C1'),board1)\n assert ('C3','C8') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('C3','C8'),board1)\n assert ('C3','I3') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('C3','I3'),board1)\n assert ('F5','G5') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('F5','G5'),board1)\n assert ('F5','F2') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('F5','F2'),board1)\n assert ('F5','F3') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('F5','F3'),board1)\n assert ('F5','F6') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('F5','F6'),board1)\n assert ('B8','B6') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('B8','B6'),board1)\n assert ('B8','B9') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('B8','B9'),board1)\n assert ('B8','D8') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('B8','D8'),board1)\n assert ('H6','B6') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('H6','B6'),board1)\n assert ('H6','H7') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('H6','H7'),board1)\n assert ('I8','I7') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('I8','I7'),board1)\n assert ('I8','I9') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('I8','I9'),board1)\n assert ('E7','E6') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('E7','E6'),board1)\n assert ('E7','B7') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('E7','B7'),board1)\n assert ('E7','I7') in b1_pm,\"%s should be a possibile move for\\n%s\"%(('E7','I7'),board1)\n \n assert ('B8','B4') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('B8','B4'),board1)\n assert ('B8','E8') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('B8','E8'),board1)\n assert ('B8','F8') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('B8','F8'),board1)\n assert ('F5','E5') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('B8','E5'),board1)\n assert ('F5','I5') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('B8','I5'),board1)\n assert ('F5','D5') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('B8','D5'),board1)\n assert ('H6','I6') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('H6','I6'),board1)\n assert ('H6','A6') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('H6','A6'),board1)\n assert ('H6','H3') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('H6','H3'),board1)\n assert ('H6','H9') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('H6','H9'),board1)\n assert ('I8','I6') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('I8','I6'),board1)\n assert ('I8','I2') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('I8','I2'),board1)\n assert ('I8','F8') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('I8','F8'),board1)\n assert ('I8','C8') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('I8','C8'),board1)\n assert ('I8','G8') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('I8','G8'),board1)\n assert ('E7','E5') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('E7','E5'),board1)\n assert ('E7','E8') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('E7','E8'),board1)\n assert ('E7','E9') not in b1_pm,\"%s should NOT be a possibile move for\\n%s\"%(('E7','E9'),board1)\n \n assert len(b1_pm) == 47,\"the following board:\\n%s\\nshould have %s possible moves instead of %s per Player:%s\"%(board1,38,len(b1_pm),board1.stm)\n \ndef test_move_b3():\n b3 = Board(pos3, PLAYER2, COMPUTE, 65, {})#W move\n \n b3_1 = b3.move(('F8','F7'))\n b3_1_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,2,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [1,0,0,0,2,1,0,0,0],\n [1,1,0,0,0,3,1,0,0],\n [0,0,0,0,2,0,0,0,0],\n [0,0,0,0,0,2,0,0,0],\n [0,0,1,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\n assert (b3_1.pos.flatten() == b3_1_pos.flatten()).all()\n \n b3_2 = b3_1.move(('C8','C7'))\n b3_2_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,2,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [1,0,0,0,2,1,0,0,0],\n [1,1,0,0,0,3,1,0,0],\n [0,0,0,0,2,0,0,0,0],\n [0,0,1,0,0,2,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\n assert (b3_2.pos.flatten() == b3_2_pos.flatten()).all()\n \n b3_3 = b3_2.move(('E4','E3'))\n b3_3_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,2,0,1,0,0,0,0],\n [0,0,0,0,2,0,0,0,0],\n [1,0,0,0,0,1,0,0,0],\n [1,1,0,0,0,3,1,0,0],\n [0,0,0,0,2,0,0,0,0],\n [0,0,1,0,0,2,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\n assert (b3_3.pos.flatten() == b3_3_pos.flatten()).all(),\"\\n%s\\n%s\"%(b3_3, b3_3_pos)\n \n b3_4 = b3_3.move(('G5','G7'))\n b3_4_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,2,0,1,0,0,0,0],\n [0,0,0,0,2,0,0,0,0],\n [1,0,0,0,0,1,0,0,0],\n [1,1,0,0,0,3,0,0,0],\n [0,0,0,0,2,0,0,0,0],\n [0,0,1,0,0,2,1,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\n assert (b3_4.pos.flatten() == b3_4_pos.flatten()).all()\n \n b3_5 = b3_4.move(('E3','F3'))\n b3_5_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,2,0,1,0,0,0,0],\n [0,0,0,0,0,2,0,0,0],\n [1,0,0,0,0,0,0,0,0],\n [1,1,0,0,0,3,0,0,0],\n [0,0,0,0,2,0,0,0,0],\n [0,0,1,0,0,2,1,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\n assert (b3_5.pos.flatten() == b3_5_pos.flatten()).all()\n \n b3_6 = b3_5.move(('C7','E7'))\n b3_6_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,2,0,1,0,0,0,0],\n [0,0,0,0,0,2,0,0,0],\n [1,0,0,0,0,0,0,0,0],\n [1,1,0,0,0,3,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,1,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\n assert (b3_6.pos.flatten() == b3_6_pos.flatten()).all()\n \n b3_7 = b3_6.move(('F5','F7'))\n b3_7_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,2,0,1,0,0,0,0],\n [0,0,0,0,0,2,0,0,0],\n [1,0,0,0,0,0,0,0,0],\n [1,1,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,3,1,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\n assert (b3_7.pos.flatten() == b3_7_pos.flatten()).all()\n \n b3_8 = b3_7.move(('G7','H7'))\n b3_8_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,2,0,1,0,0,0,0],\n [0,0,0,0,0,2,0,0,0],\n [1,0,0,0,0,0,0,0,0],\n [1,1,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,3,0,1,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\n assert (b3_8.pos.flatten() == b3_8_pos.flatten()).all()\n\n b3_9 = b3_8.move(('F7','G7'))\n b3_9_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,2,0,1,0,0,0,0],\n [0,0,0,0,0,2,0,0,0],\n [1,0,0,0,0,0,0,0,0],\n [1,1,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,3,1,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]]) \n assert (b3_9.pos.flatten() == b3_9_pos.flatten()).all()\n\n b3_10 = b3_9.move(('E7','F7'))\n b3_10_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,2,0,1,0,0,0,0],\n [0,0,0,0,0,2,0,0,0],\n [1,0,0,0,0,0,0,0,0],\n [1,1,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,1,3,1,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]]) \n assert (b3_10.pos.flatten() == b3_10_pos.flatten()).all()\n assert b3_10.end == PLAYER1,\"\\n%s \\n the end should be %s(PLAYER1)\"%(b3_10,PLAYER1)\n\ndef test_move_b6():\n b6 = Board(pos6, PLAYER1, COMPUTE, 28, {})\n\n b6_ended = b6.move(('I4','C4'))\n b6_ended_pos = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,1,0,0,0,0,0,2,0],\n [1,3,1,0,0,0,0,0,0],\n [0,0,0,0,0,2,0,0,0],\n [0,2,2,0,1,0,0,0,1],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,1,0,1,1,0,0,0]])\n assert (b6_ended.pos.flatten() == b6_ended_pos.flatten()).all()\n assert b6_ended.end == PLAYER1,\"\\n%s \\n the end should be %s(PLAYER1)\"%(b6_ended,PLAYER1)\n\ndef test_move():\n b = Board(draw_dic = {})\n\n b_1 = b.move(('F5','F8'))\n b_1_pos = np.array([[0,0,0,1,1,1,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,2,0,0,0,0],\n [1,0,0,0,2,0,0,0,1],\n [1,1,2,2,3,0,2,1,1],\n [1,0,0,0,2,0,0,0,1],\n [0,0,0,0,2,0,0,0,0],\n [0,0,0,0,1,2,0,0,0],\n [0,0,0,1,1,1,0,0,0]])\n assert (b_1.pos.flatten() == b_1_pos.flatten()).all()\n\n b_2 = b_1.move(('F1','F5'))\n b_2_pos = np.array([[0,0,0,1,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,2,0,0,0,0],\n [1,0,0,0,2,0,0,0,1],\n [1,1,2,2,3,1,0,1,1],\n [1,0,0,0,2,0,0,0,1],\n [0,0,0,0,2,0,0,0,0],\n [0,0,0,0,1,2,0,0,0],\n [0,0,0,1,1,1,0,0,0]])\n assert (b_2.pos.flatten() == b_2_pos.flatten()).all()\n\n b_3 = b_2.move(('D5','D8'))\n b_3_pos = np.array([[0,0,0,1,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,2,0,0,0,0],\n [1,0,0,0,2,0,0,0,1],\n [1,1,2,0,3,1,0,1,1],\n [1,0,0,0,2,0,0,0,1],\n [0,0,0,0,2,0,0,0,0],\n [0,0,0,2,0,2,0,0,0],\n [0,0,0,1,1,1,0,0,0]])\n assert (b_3.pos.flatten() == b_3_pos.flatten()).all()\n\n b_4 = b_3.move(('D1','D7'))\n b_4_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,2,0,0,0,0],\n [1,0,0,0,2,0,0,0,1],\n [1,1,2,0,3,1,0,1,1],\n [1,0,0,0,2,0,0,0,1],\n [0,0,0,1,2,0,0,0,0],\n [0,0,0,0,0,2,0,0,0],\n [0,0,0,1,1,1,0,0,0]])\n assert (b_4.pos.flatten() == b_4_pos.flatten()).all()\n\n b_5 = b_4.move(('E3','G3'))\n b_5_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,2,0,0],\n [1,0,0,0,2,0,0,0,1],\n [1,1,2,0,3,1,0,1,1],\n [1,0,0,0,2,0,0,0,1],\n [0,0,0,1,2,0,0,0,0],\n [0,0,0,0,0,2,0,0,0],\n [0,0,0,1,1,1,0,0,0]])\n assert (b_5.pos.flatten() == b_5_pos.flatten()).all()\n\n b_6 = b_5.move(('F5','F3'))\n b_6_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,1,2,0,0],\n [1,0,0,0,2,0,0,0,1],\n [1,1,2,0,3,0,0,1,1],\n [1,0,0,0,2,0,0,0,1],\n [0,0,0,1,2,0,0,0,0],\n [0,0,0,0,0,2,0,0,0],\n [0,0,0,1,1,1,0,0,0]])\n assert (b_6.pos.flatten() == b_6_pos.flatten()).all()\n\n b_7 = b_6.move(('E4','E3'))\n b_7_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,2,0,2,0,0],\n [1,0,0,0,0,0,0,0,1],\n [1,1,2,0,3,0,0,1,1],\n [1,0,0,0,2,0,0,0,1],\n [0,0,0,1,2,0,0,0,0],\n [0,0,0,0,0,2,0,0,0],\n [0,0,0,1,1,1,0,0,0]])\n assert (b_7.pos.flatten() == b_7_pos.flatten()).all()\n\n b_8 = b_7.move(('A4','E4'))\n b_8_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,2,0,0],\n [0,0,0,0,1,0,0,0,1],\n [1,1,2,0,3,0,0,1,1],\n [1,0,0,0,2,0,0,0,1],\n [0,0,0,1,2,0,0,0,0],\n [0,0,0,0,0,2,0,0,0],\n [0,0,0,1,1,1,0,0,0]])\n assert (b_8.pos.flatten() == b_8_pos.flatten()).all()\n\n b_9 = b_8.move(('E7','G7'))\n b_9_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,2,0,0],\n [0,0,0,0,1,0,0,0,1],\n [1,1,2,0,3,0,0,1,1],\n [1,0,0,0,2,0,0,0,1],\n [0,0,0,1,0,0,2,0,0],\n [0,0,0,0,0,2,0,0,0],\n [0,0,0,1,1,1,0,0,0]])\n assert (b_9.pos.flatten() == b_9_pos.flatten()).all()\n \n b_10 = b_9.move(('H5','H7'))\n b_10_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,2,0,0],\n [0,0,0,0,1,0,0,0,1],\n [1,1,2,0,3,0,0,0,1],\n [1,0,0,0,2,0,0,0,1],\n [0,0,0,1,0,0,2,1,0],\n [0,0,0,0,0,2,0,0,0],\n [0,0,0,1,1,1,0,0,0]])\n assert (b_10.pos.flatten() == b_10_pos.flatten()).all()\n\n b_11 = b_10.move(('E6','E7'))\n b_11_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,2,0,0],\n [0,0,0,0,1,0,0,0,1],\n [1,1,2,0,3,0,0,0,1],\n [1,0,0,0,0,0,0,0,1],\n [0,0,0,1,2,0,2,1,0],\n [0,0,0,0,0,2,0,0,0],\n [0,0,0,1,1,1,0,0,0]])\n assert (b_11.pos.flatten() == b_11_pos.flatten()).all()\n\n b_12 = b_11.move(('I5','F5'))\n b_12_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,2,0,0],\n [0,0,0,0,1,0,0,0,1],\n [1,1,2,0,3,1,0,0,0],\n [1,0,0,0,0,0,0,0,1],\n [0,0,0,1,2,0,2,1,0],\n [0,0,0,0,0,2,0,0,0],\n [0,0,0,1,1,1,0,0,0]])\n assert (b_12.pos.flatten() == b_12_pos.flatten()).all()\n\n b_13 = b_12.move(('G3','G6'))\n b_13_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,1],\n [1,1,2,0,3,1,0,0,0],\n [1,0,0,0,0,0,2,0,1],\n [0,0,0,1,2,0,2,1,0],\n [0,0,0,0,0,2,0,0,0],\n [0,0,0,1,1,1,0,0,0]])\n assert (b_13.pos.flatten() == b_13_pos.flatten()).all()\n\n b_14 = b_13.move(('F5','F7'))\n b_14_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,1],\n [1,1,2,0,3,0,0,0,0],\n [1,0,0,0,0,0,2,0,1],\n [0,0,0,1,0,1,0,1,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,1,1,1,0,0,0]])\n assert (b_14.pos.flatten() == b_14_pos.flatten()).all()\n\n b_15 = b_14.move(('E5','E7'))\n b_15_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,1],\n [1,1,2,0,0,0,0,0,0],\n [1,0,0,0,0,0,2,0,1],\n [0,0,0,1,3,1,0,1,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,1,1,1,0,0,0]])\n assert (b_15.pos.flatten() == b_15_pos.flatten()).all()\n\n b_16 = b_15.move(('A6','E6'))\n b_16_pos = np.array([[0,0,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,1],\n [1,1,2,0,0,0,0,0,0],\n [0,0,0,0,1,0,2,0,1],\n [0,0,0,1,3,1,0,1,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,1,1,1,0,0,0]])\n assert (b_16.pos.flatten() == b_16_pos.flatten()).all()\n print(b_16)\n\ndef test_coordinate_transformation():\n m1 = ('H5','H2')\n assert Board.coordinates_transformation(m1,'VF') == ('B5','B2'),\"the move: %s with the %s transformation should be %s\"%(m1,'VF',('B5','B2'))\n assert Board.coordinates_transformation(m1,'HF') == ('H5','H8'),\"the move: %s with the %s transformation should be %s\"%(m1,'HF',('H5','H8'))\n assert Board.coordinates_transformation(m1,'LR') == ('E2','B2'),\"the move: %s with the %s transformation should be %s\"%(m1,'LR',('E2','B2'))\n assert Board.coordinates_transformation(m1,'LRVF') == ('E2','H2'),\"the move: %s with the %s transformation should be %s\"%(m1,'LRVF',('E2','H2'))\n assert Board.coordinates_transformation(m1,'LRHF') == ('E8','B8'),\"the move: %s with the %s transformation should be %s\"%(m1,'LRHF',('E8','B8'))\n assert Board.coordinates_transformation(m1,'LRLR') == ('B5','B8'),\"the move: %s with the %s transformation should be %s\"%(m1,'LRLR',('B5','B8'))\n assert Board.coordinates_transformation(m1,'LRLRLR') == ('E8','H8'),\"the move: %s with the %s transformation should be %s\"%(m1,'LRLRLR',('E8','H8'))\n\n m2 = ('E5','G5')\n assert Board.coordinates_transformation(m2,'VF') == ('E5','C5'),\"the move: %s with the %s transformation should be %s\"%(m2,'VF',('E5','C5'))\n assert Board.coordinates_transformation(m2,'HF') == ('E5','G5'),\"the move: %s with the %s transformation should be %s\"%(m2,'HF',('E5','G5'))\n assert Board.coordinates_transformation(m2,'LR') == ('E5','E3'),\"the move: %s with the %s transformation should be %s\"%(m2,'LR',('E5','E3'))\n assert Board.coordinates_transformation(m2,'LRVF') == ('E5','E3'),\"the move: %s with the %s transformation should be %s\"%(m2,'LRVF',('E5','E3'))\n assert Board.coordinates_transformation(m2,'LRHF') == ('E5','E7'),\"the move: %s with the %s transformation should be %s\"%(m2,'LRHF',('E5','E7'))\n assert Board.coordinates_transformation(m2,'LRLR') == ('E5','C5'),\"the move: %s with the %s transformation should be %s\"%(m2,'LRLR',('E5','C5'))\n assert Board.coordinates_transformation(m2,'LRLRLR') == ('E5','E7'),\"the move: %s with the %s transformation should be %s\"%(m2,'LRLRLR',('E5','E7'))\n\n m3 = ('A8','C8')\n assert Board.coordinates_transformation(m3,'VF') == ('I8','G8'),\"the move: %s with the %s transformation should be %s\"%(m3,'VF',('I8','G8'))\n assert Board.coordinates_transformation(m3,'HF') == ('A2','C2'),\"the move: %s with the %s transformation should be %s\"%(m3,'HF',('A2','C2'))\n assert Board.coordinates_transformation(m3,'LR') == ('H9','H7'),\"the move: %s with the %s transformation should be %s\"%(m3,'LR',('H9','H7'))\n assert Board.coordinates_transformation(m3,'LRVF') == ('B9','B7'),\"the move: %s with the %s transformation should be %s\"%(m3,'LRVF',('B9','B7'))\n assert Board.coordinates_transformation(m3,'LRHF') == ('H1','H3'),\"the move: %s with the %s transformation should be %s\"%(m3,'LRHF',('H1','H3'))\n assert Board.coordinates_transformation(m3,'LRLR') == ('I2','G2'),\"the move: %s with the %s transformation should be %s\"%(m3,'LRLR',('E5','C5'))\n assert Board.coordinates_transformation(m3,'LRLRLR') == ('B1','B3'),\"the move: %s with the %s transformation should be %s\"%(m3,'LRLRLR',('E5','E7'))\n\n'''\nblacks = np.array([[0,0,0,0,1,0,0,0,1],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,1,1,0,0],\n [0,0,0,1,0,0,0,0,0],\n [1,1,0,0,0,0,0,0,1],\n [0,0,0,0,0,0,0,0,0],\n [0,0,1,0,0,0,0,1,0],\n [0,0,0,0,1,0,1,0,0],\n [1,0,0,0,0,1,0,0,1]])\nwhites = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,1,0,0],\n [0,0,0,0,0,1,1,0,0],\n [0,0,0,1,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\nking = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,1,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\npos = {PLAYER1:blacks, PLAYER2: (whites,king)}\nb = Board(pos, PLAYER1)\nprint(b)\nb.king_stats(b.pos)\n'''"
},
{
"alpha_fraction": 0.7023809552192688,
"alphanum_fraction": 0.7023809552192688,
"avg_line_length": 27.33333396911621,
"blob_id": "638a731a6a6af2eb89a9e8299bce5720f820c4f3",
"content_id": "7f3f9318281f86164b7ace112573d364a293ee42",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 84,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 3,
"path": "/vablut/engine/base.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "class Engine(object):\n def choose(self, board):\n raise NotImplementedError"
},
{
"alpha_fraction": 0.6203081607818604,
"alphanum_fraction": 0.6351903080940247,
"avg_line_length": 45.30487823486328,
"blob_id": "c396aeafde29723c349323cbf474b6bc3d22e417",
"content_id": "0f77cb14081ee42c079614db95b9dfce9d395064",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7593,
"license_type": "no_license",
"max_line_length": 158,
"num_lines": 164,
"path": "/vablut/tests/test_tables.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom vablut.modules.tables import *\nfrom vablut.modules.tables import _indices\nfrom random import randint\n\nimport pytest\nimport numpy as np\n\ndef test_tables_indices():\n assert col>0,\"impossible to work with col<=0\"\n assert row>0,\"impossible to work with row<=0\"\n assert 0 in _indices.flatten(),\"0 not in _indices\"\n assert col in _indices.flatten(),\"col not in _indices\"\n assert row in _indices.flatten(),\"row not in _indices\"\n assert col*row-1 in _indices.flatten(),\"%s(last element) not in _indices\"%(col*row-1)\n assert col*row == len(_indices.flatten()),\"_indices must contains col(%s)*row(%s) elements\"%(col,row)\n \[email protected](1)\ndef test_tables_capturesegments():\n assert capture_segments.size != 0,\"capture_segments.size is equal to 0, so why are you using this module/package with a table board without captures?\"\n r = randint(0,row-1)\n if _indices[:][r].size > 3:\n c = randint(0,row-3)\n assert _indices[:][r][c:c+3] in capture_segments,\"%s not in capture_segments\"%_indices[:][r][c:c+3]\n \n c = randint(0,col-1)\n if _indices.transpose()[:][c].size > 3:\n r = randint(0,row-3)\n assert _indices.transpose()[:][c][r:r+3] in capture_segments,\"%s not in capture_segments\"%_indices[:][c][r:r+3]\n \n assert len(capture_segments) == ((col-2)*row + (row-2)*col),\"col:%s row:%s capture_segments does not have %s elements\"%(col,row,(col-2)*row + (row-2)*col)\n \n\ndef test_tables_revsegments():\n assert len(rev_segments)==col*row,\"rev_segments len is non equal to %s(col*row)\"%(col*row)\n for i,v in enumerate(rev_segments):\n assert len(v)>1,\"rev_segments[%s] empty\"%i\n \ndef test_tables_movesegments():\n assert len(rev_segments)==col*row,\"move_segments len is non equal to %s(col*row)\"%(col*row)\n for i,v in enumerate(move_segments):\n assert len(v)==2,\"move_segments[%s] does not have exatly 2 items\"%i\n assert len(set(v[0]).intersection(set(v[1])))==1,'0 or 2 and more elements are in the %s-i of move_segments'%i\n\n\ndef test_tables_possiblemovesegments_init():\n assert len(possible_move_segments)==col*row,\"possible_move_segments len is non equal to %s(col*row)\"%(col*row)\n max_moves_pos = len(possible_move_segments[0])\n for i,v in enumerate(possible_move_segments):\n assert len(v)==max_moves_pos,\"possible_move_segments[%s] does not have the same amount of moves than others(%s)\"%(i,max_moves_pos)\n for m in v:\n assert len(m)>1,\"1 move element not allowed. The move %s inside the possible_move_segments[%s](%s) has just 1 element.\"%(m,i,v)\n \n\[email protected](1)\ndef test_tables_possiblemovesegments():\n #Horizontal random check\n r = randint(0,row-1)\n lung = randint(2,col)\n start_el = randint(0,col-lung)\n check_move = _indices[r][start_el:start_el+lung]\n assert len(check_move)<=col,\"Horizontal move can not be longer than cols\"\n i = check_move[0]\n ret = False\n for move in possible_move_segments[i]:\n if(len(check_move) == move.size and (check_move==move).all()):\n ret = True\n assert ret,\"horizontal move %s is not in possible_move_segments[%s]\"%(check_move, i)\n\n #Vertical random check\n r = randint(0,col-1)\n lung = randint(2,row)\n start_el = randint(0,row-lung)\n check_move = _indices.transpose()[r][start_el:start_el+lung]\n assert len(check_move)<=row,\"Vertical move can not be longer than rows\"\n i = check_move[0]\n ret = False\n for move in possible_move_segments[i]:\n if(len(check_move) == move.size and (check_move==move).all()):\n ret = True\n assert ret,\"vertical move %s is not in possible_move_segments[%s]\"%(check_move, i)\n \ndef test_tables_crosscentersegments():\n count = np.zeros(6,dtype=int)\n assert len(cross_center_segments) == col*row,\"cross_center_segments must be an index square with %s elements index\"%(col*row)\n for cross in cross_center_segments:\n assert cross.size>1,\"Every cross must contain at least 2 elements\"\n assert cross.size<=5,\"Every cross must contain less or equal 5 elements\"\n count[cross.size] += 1\n \n corners = 4\n per = ((col-2)*2) + ((row-2)*2)\n oths = col * row - per - corners\n assert count[3]==corners,\"the 4 corners must contains 3 cross elements\"\n assert count[4]==per,\"the perimeters cross elements must be %s\"%per\n assert count[5]==oths,\"the inside elements must be %s\"%oths\n\n left_corners = {_indices[0][0]}\n right_corners = {_indices[0][-1]}\n left_corners.add(_indices[-1][0])\n right_corners.add(_indices[-1][-1])\n \n uppper_per = set([])\n bottom_per = set([])\n left_per = set([])\n right_per = set([])\n uppper_per.update(_indices[0][1:-1])\n bottom_per.update(_indices[-1][1:-1])\n left_per.update(_indices.transpose()[0][1:-1])\n right_per.update(_indices.transpose()[-1][1:-1])\n \n oths = set(_indices.flatten())\n oths -= uppper_per\n oths -= bottom_per\n oths -= left_per\n oths -= right_per\n oths -= left_corners\n oths -= right_corners\n\n for lc in left_corners:\n assert lc == cross_center_segments[lc][0],\"index %s must be also in the array contained in cross_center_segments[%s]\"%(lc,lc)\n assert len(cross_center_segments[lc]) == 3\n assert (lc+1 in cross_center_segments[lc])\n \n for rc in right_corners:\n assert rc == cross_center_segments[rc][0],\"index %s must be also in the array contained in cross_center_segments[%s]\"%(rc,rc)\n assert len(cross_center_segments[rc]) == 3\n assert (rc-1 in cross_center_segments[rc])\n \n for up in uppper_per:\n assert up == cross_center_segments[up][0],\"index %s must be also in the array contained in cross_center_segments[%s]\"%(up,up)\n assert len(cross_center_segments[up]) == 4\n assert (up-1 in cross_center_segments[up])\n assert (up+1 in cross_center_segments[up])\n assert (up+col in cross_center_segments[up])\n \n for bp in bottom_per:\n assert bp == cross_center_segments[bp][0],\"index %s must be also in the array contained in cross_center_segments[%s]\"%(up,up)\n assert len(cross_center_segments[bp]) == 4\n assert (bp-1 in cross_center_segments[bp])\n assert (bp+1 in cross_center_segments[bp])\n assert (bp-col in cross_center_segments[bp])\n \n for lp in left_per:\n assert lp == cross_center_segments[lp][0],\"index %s must be also in the array contained in cross_center_segments[%s]\"%(up,up)\n assert len(cross_center_segments[lp]) == 4\n assert (lp-col in cross_center_segments[lp])\n assert (lp+1 in cross_center_segments[lp])\n assert (lp+col in cross_center_segments[lp])\n \n for rp in right_per:\n assert rp == cross_center_segments[rp][0],\"index %s must be also in the array contained in cross_center_segments[%s]\"%(up,up)\n assert len(cross_center_segments[rp]) == 4\n assert (rp-col in cross_center_segments[rp])\n assert (rp-1 in cross_center_segments[rp])\n assert (rp+col in cross_center_segments[rp])\n \n for ot in oths:\n assert ot == cross_center_segments[ot][0],\"index %s must be also in the array contained in cross_center_segments[%s]\"%(ot,ot)\n assert len(cross_center_segments[ot]) == 5\n assert (ot+1 in cross_center_segments[ot])\n assert (ot-1 in cross_center_segments[ot])\n assert (ot+col in cross_center_segments[ot])\n assert (ot-col in cross_center_segments[ot])"
},
{
"alpha_fraction": 0.5100753903388977,
"alphanum_fraction": 0.5262708067893982,
"avg_line_length": 38.55390930175781,
"blob_id": "d30419f29ea3a500f58312c70d1531992938a7fb",
"content_id": "6112876c340125e49e501cfa097ea5849008b34c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18709,
"license_type": "no_license",
"max_line_length": 193,
"num_lines": 473,
"path": "/vablut/board.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport numpy as np\nfrom vablut.modules.tables import _indices, move_segments, capture_segments, rev_segments, possible_move_segments, near_center_segments, cross_center_segments\nfrom vablut.modules.ashton import PLAYER1, PLAYER2, DRAW, COMPUTE, KING_VALUE, throne_el, blacks, whites, king, king_capture_segments, winning_el, prohibited_segments, capturing_dic\n\nCOL = int(len(_indices[0]))\nROW = int(len(_indices.transpose()[0]))\n\nclass WrongMoveError(Exception):\n pass\n\nclass Board(object):\n def __init__(self, pos=None, stm=PLAYER2, end=COMPUTE, last_move=None, draw_dic=None):\n if pos is None:\n pos = {PLAYER1:blacks, PLAYER2: (whites,king)}\n \n self._pos = pos\n self._stm = stm\n self._draw_dic = draw_dic\n if end == COMPUTE:\n self._end = self._check_end(self.pos, last_move, draw_dic)\n else:\n self._end = end\n\n @property\n def end(self):\n return self._end\n \n @property\n def stm(self):\n return self._stm\n \n @property\n def other(self):\n return PLAYER1 if self._stm != PLAYER1 else PLAYER2\n \n @property\n def pos(self):\n return (PLAYER1*self._pos[PLAYER1]+PLAYER2*self._pos[PLAYER2][0]+KING_VALUE*self._pos[PLAYER2][1])\n \n def _check_end(self, pos, last_move=None, draw_dic=None):\n if draw_dic is not None:\n if self.hashkey() in draw_dic:\n return DRAW\n else:\n draw_dic[self.hashkey()] = True\n \n if KING_VALUE in self.win_segments(pos):\n return PLAYER2\n \n if len(self.get_all_moves()) == 0:\n return self.other\n \n if last_move is not None:\n pos = pos.flatten()\n if pos[pos==KING_VALUE].sum() == 0:#if in the previous black movement the king is been captured\n return PLAYER1\n \n if self.stm == PLAYER2: \n #pos drug\n i_king = _indices.flatten()[pos == KING_VALUE][0]\n pos = self.pos_update(pos, last_move)\n pos[i_king] = KING_VALUE\n for seg in king_capture_segments[i_king]:\n if last_move in seg:\n c = np.bincount(pos[seg])\n if c[PLAYER1] == len(seg)-1:\n return PLAYER1\n return None\n \n @classmethod\n def win_segments(cls, pos):\n if isinstance(pos, Board):\n return cls.win_segments(pos.pos)\n else:\n pos = pos.flatten()\n return pos[winning_el]\n \n def __str__(self):\n disc = {\n 0: '_',\n 1: 'B',\n 2: 'W',\n 3: 'K'\n }\n \n s = []\n for row in self.pos:\n s.append(' | '.join(disc[x] for x in row))\n s.append(' | '.join('.'*COL))\n s.append(' | '.join(map(str, 'ABCDEFGHI')))\n s = ['| ' + x + ' |' for x in s]\n s = [i + ' ' + x for i, x in zip('123456789 ', s)]\n s = '\\n'.join(s)\n \n if self.end is DRAW:\n s += '\\n<<< Game over: draw'\n elif self.end is not None:\n s += '\\n<<< Game over: %s win' % disc[self.end]\n else:\n s += '\\n<<< Move to %s' % disc[self.stm]\n \n return s\n \n #m must be a tuple (FROM, TO). es ('D1', 'F1')\n def move(self, m):\n if not isinstance(m, tuple):\n raise ValueError(m)\n \n check_pos = self.pos\n\n #Conversation from ('letter''number', 'letter''number') to ('0-48', '0-48')\n FROM, TO = self.coordinates_string_to_int(m)\n \n #FROM piece must be a self.stm piece(if stm == PLAYER2, FROM can be W or K)\n if not ((self.stm == PLAYER1 and check_pos.flatten()[FROM] == self.stm) or (self.stm == PLAYER2 and (check_pos.flatten()[FROM] == self.stm or check_pos.flatten()[FROM] == KING_VALUE))):\n raise WrongMoveError('move:%s Not Permitted: FROM Value not Player_%s'%(str(m),str(self.stm)))\n #TO must be empty to move on a piece\n if not (check_pos.flatten()[TO] == 0):\n raise WrongMoveError('move:%s Not Permitted: TO Value not empty'%(str(m)))\n \n check_drug_pos = self.pos_update(check_pos, FROM)\n\n #Free space in movement(FROM-TO)\n try:\n mov = self.orthogonal_segment(check_drug_pos,FROM,TO)\n except:\n raise WrongMoveError('Not Permitted: FROM-TO movement can not be oblique')\n \n if not mov.sum()==check_drug_pos[FROM]:\n raise WrongMoveError('Not Permitted: FROM-TO movement not free')\n \n #\"move\" the piece FROM -> TO\n check_pos_ret = check_pos.flatten()\n check_pos_ret[TO] = check_pos_ret[FROM]\n check_pos_ret[FROM] = 0\n check_pos = check_pos_ret.copy()\n \n check_drug_pos = self.pos_update_capturing(check_pos, TO)\n \n #Captures Check\n for s in rev_segments[TO]:\n seg = check_drug_pos[s].copy()\n seg_pos = check_pos[s].copy()\n if seg[1] != self.other and seg_pos[1] != self.other:\n continue\n \n seg[seg==KING_VALUE] = PLAYER2\n c = np.bincount(seg)\n if c[0] or len(c)!=3:\n continue\n if c[self.stm]==2 and seg[0] == self.stm and seg[2] == self.stm:\n seg_pos[1]=0\n check_pos[s] = seg_pos\n \n seg_pos_cpy = seg_pos.copy()\n seg_pos_cpy[seg_pos_cpy==KING_VALUE] = PLAYER2\n c = np.bincount(seg_pos_cpy)\n if c[0] or len(c)!=3:\n continue\n if c[self.stm]==2 and seg[0] == self.stm and seg[2] == self.stm:\n seg_pos[1]=0\n check_pos[s] = seg_pos\n \n future_pos = self.from_pos_to_dic(check_pos, COL, ROW)\n future_draw_dic = None\n if self._draw_dic:\n future_draw_dic =self._draw_dic.copy()\n \n return Board(future_pos, self.other, COMPUTE, TO, draw_dic = future_draw_dic)\n \n #Return the vector between FROM and TO\n @classmethod\n def orthogonal_segment(cls, pos, FROM, TO):\n i_to, i_from, line = None, None, None\n if TO in move_segments[FROM][0]:#mi muovo in una riga\n line = move_segments[FROM][0]\n i_from = int(FROM%len(line))\n i_to = int(TO%len(line))\n elif TO in move_segments[FROM][1]:#mi muovo in una colonna\n line = move_segments[FROM][1]\n i_from = int(FROM/len(line))\n i_to = int(TO/len(line))\n\n if i_to is None or i_from is None:\n raise ValueError('FROM and TO not in the same orthogonal segment')\n \n if i_to < i_from:\n line = line[i_to:i_from+1]\n else:\n line = line[i_from:i_to+1]\n ret = pos.flatten()\n \n return ret[line]\n \n #Transform a compact board's raffiguration(2-Dmatric with 0,1,2,3 elements) to the corresponding dictionary raffiguration \n @classmethod\n def from_pos_to_dic(cls, pos, col=COL, row=ROW):\n ret = {PLAYER1:np.asarray([],dtype=int), PLAYER2: (np.asarray([],dtype=int),np.asarray([],dtype=int))}\n b, w, k = pos.copy(), pos.copy()-1, pos.copy()-2\n \n b[b!=1] = 0 \n w[w!=1] = 0 \n k[k!=1] = 0\n\n ret[PLAYER1] = b.reshape((col,row))\n ret[PLAYER2] = (w.reshape((col,row)),k.reshape((col,row)))\n return ret\n \n @classmethod\n def pos_update_capturing(cls, pos, TO):\n pos = pos.flatten() \n piece = pos[TO] #1:black 2:white 3:king\n if piece == 0:\n return pos\n pos[capturing_dic[piece]] = piece\n #pos[throne_el] = piece #THRONE always considerated friend, the camp's elements(the center one not included) friends if they are not occupied\n return pos\n \n #the actual and real pos(board configuration) is updated setting the prohibited elements for piece = piece if the element is empty\n @classmethod\n def pos_update(cls, pos, FROM):\n pos = pos.flatten() \n piece = pos[FROM] #1:black 2:white 3:king\n if piece == 0:\n return pos\n #NO -> TO DRUG ALWAYS mask = pos[prohibited_segments[piece][FROM]] == 0 #elements to modified just if in pos the el is empty\n #seg = prohibited_segments[piece][FROM]\n pos[prohibited_segments[piece][FROM]] = piece\n return pos\n \n def get_all_moves(self):\n ret = []\n moving = self.stm\n original_board = self.pos.flatten()\n \n pos = {PLAYER1: self._pos[PLAYER1].copy(), PLAYER2: self._pos[PLAYER2][0].copy()+self._pos[PLAYER2][1].copy()}\n \n y = pos[moving].flatten()\n indices = _indices.flatten()\n yi = y*indices\n yi = yi[yi>0]#tutti gli indici in cui il player moving ha delle pedine\n for imoves in possible_move_segments[yi]:\n for smove in imoves:#smove[0] FROM index element\n board = original_board.copy()\n board = self.pos_update(board, smove[0])\n if board[smove].sum() == original_board[smove[0]]:\n ret.append(self.coordinates_int_to_string((smove[0], smove[-1])))\n return ret\n \n #Conversion from ('0-48', '0-48') to ('letter''number', 'letter''number')\n @classmethod\n def coordinates_int_to_string(cls, m, col=COL, row=ROW):\n if not isinstance(m, tuple):\n raise ValueError('Move conversion Error: m is not a tuple')\n \n FROM, TO = int(m[0]), int(m[1])\n alp = { 1:'A', 2:'B', 3:'C', 4:'D', 5:'E', 6:'F', 7:'G', 8:'H', 9:'I' }\n \n if ((FROM not in range(0, int(col*row))) or (TO not in range(0, int(col*row)))):\n raise ValueError(m)\n \n FROM = alp[int(FROM%col)+1]+str(int(FROM/col)+1)\n TO = alp[int(TO%col)+1]+str(int(TO/col)+1)\n return (FROM, TO)\n #===---===---===---===---===---===---===---===---===---===---===---===\n #Conversion from ('letter''number', 'letter''number') to ('0-48', '0-48')\n @classmethod\n def coordinates_string_to_int(cls, m, col=COL, row=ROW):\n if not isinstance(m, tuple):\n raise ValueError('Move conversion Error: m is not a tuple')\n\n FROM, TO = m[0], m[1]\n alp = {'A': 1, 'B': 2, 'C': 3, 'D': 4, 'E': 5, 'F': 6, 'G': 7, 'H': 8, 'I': 9}\n \n if ((FROM[0] not in alp) or (TO[0] not in alp) or (int(FROM[1]) not in range(1,row+1)) or (int(TO[1]) not in range(1,row+1))):\n raise ValueError(m)\n \n FROM, TO = ((int(FROM[1])-1)*col)+alp[FROM[0]]-1, ((int(TO[1])-1)*col)+alp[TO[0]]-1 \n return (FROM, TO)\n #===---===---===---===---===---===---===---===---===---===---===---===\n @classmethod\n def coordinates_transformation(cls, move, t):\n tran = {\n 'VF': cls.VF,\n 'HF': cls.HF,\n 'LR': cls.LR,\n 'LRVF': cls.LRVF,\n 'LRHF': cls.LRHF,\n 'LRLR': cls.LRLR,\n 'LRLRLR':cls.LRLRLR\n }\n if t not in tran:\n raise ValueError(t)\n\n indices = _indices.copy()\n move_int = cls.coordinates_string_to_int(move)\n tran_indices = tran[t](indices).flatten()\n FROM = indices.flatten()[tran_indices == move_int[0]] #[tran_indices == ]\n TO = indices.flatten()[tran_indices == move_int[1]] #[tran_indices == move_int[1]]\n return cls.coordinates_int_to_string((FROM[0],TO[0]))\n\n def hashkey(self):\n return hash(str(self.pos))\n \n def cachehashkey(self):\n return hash(str(self.pos)+str(self.stm))\n\n @classmethod\n def VF(cls, pos):\n return np.flip(pos, 1)\n\n @classmethod\n def HF(cls, pos):\n return np.flip(pos, 0)\n \n @classmethod\n def LR(cls, pos):\n return np.rot90(pos)\n\n @classmethod\n def LRVF(cls, pos):\n return cls.VF(cls.LR(pos))\n \n @classmethod\n def LRHF(cls, pos):\n return cls.HF(cls.LR(pos))\n\n @classmethod\n def LRLR(cls, pos):\n return np.rot90(pos,2)\n \n @classmethod\n def LRLRLR(cls, pos):\n return np.rot90(pos,3)\n\n def cachehashsimmkey(self):\n tran = {\n 'VF': self.VF,\n 'HF': self.HF,\n 'LR': self.LR,\n 'LRVF': self.LRVF,\n 'LRHF': self.LRHF,\n 'LRLR': self.LRLR,\n 'LRLRLR':self.LRLRLR\n }\n\n yield self.cachehashkey(), False\n for tp, func in tran.items():\n yield hash(str(func(self.pos))+str(self.stm)), tp\n \n \n # === === === Method for Evaluator purpose === === ===\n #Return [# black pieces, # white pieces(king excluded)]\n @classmethod\n def number_pieces(cls, pos):\n c = np.bincount(pos.flatten(), minlength=3)\n return np.asarray([c[PLAYER1], c[PLAYER2]], dtype=int)\n \n #Return black pieces - white pieces(king excluded)\n @classmethod\n def pieces_difference(cls, pos):\n c = np.bincount(pos.flatten(), minlength=3)\n return c[PLAYER1]-c[PLAYER2]\n \n #Number of winning elements that are blocked from w/b and number of w/b pieces that can get with 1 movement\n @classmethod\n def escape_el_stats(cls, pos): #[OCCUPIED from w, OCCUPIED from b, 1 move w to occupied, 1 move b to occupied, free muerte escape line, # muerte line with just B, # muerte line with just W]\n stats = {PLAYER1: np.zeros(2, dtype=int), PLAYER2: np.zeros(2, dtype=int), KING_VALUE: np.zeros(2, dtype=int)}\n block_stats = {PLAYER1: np.zeros(3, dtype=int), PLAYER2: np.zeros(3, dtype=int), KING_VALUE: np.zeros(3, dtype=int)} # b:[blocking black, blocking white, blocking king] w:same k:same\n free_esc_seg= np.zeros(3, dtype=int)\n possible_free_line = [_indices[2], _indices[-3], _indices.transpose()[2], _indices.transpose()[-3]]\n\n pos = pos.flatten()\n for w in winning_el:\n if pos[w]: #if w pos is full it will be impossible get it on\n stats[pos[w]][0] += 1\n continue\n for pms in possible_move_segments[w]:\n segment = pos[pms]\n if not segment.sum(): #avoid board segment filtered\n continue\n c = np.bincount(segment, minlength=4)\n if c[1:].sum()==1 and segment[-1]!=0: #1 move check\n if cls.pos_update(pos,pms[-1])[pms[1:-1]].sum() == 0:\n stats[segment[-1]][1] += 1\n elif c[1:].sum()==2 and segment[-1]!=0: #Direct Blocking check [win_el, 0, ..., ->#<-, 0, ..., #]\n cutted_seg = segment[1:-1]\n if (cutted_seg == cls.pos_update(pos,pms[-1])[pms[1:-1]]).all():\n cutted_seg = cutted_seg[cutted_seg>0]\n if len(cutted_seg) == 1:\n block_stats[cutted_seg[0]][segment[-1]-1] += 1\n \n for pfl in possible_free_line:\n ln_seg = pos[pfl]\n if ln_seg.sum() == 0:\n free_esc_seg[0] += 1\n else:\n ln_seg[ln_seg==KING_VALUE]=PLAYER2\n c = np.bincount(ln_seg, minlength = 3)\n if c[PLAYER1] == 0:\n free_esc_seg[2] += 1\n elif c[PLAYER2] == 0:\n free_esc_seg[1] += 1\n\n\n return np.asarray([np.asarray(stats[x], dtype=int) for x in stats]), np.asarray([np.asarray(block_stats[x], dtype=int) for x in block_stats]), free_esc_seg\n \"\"\"[winning els occupied from B, 1 move to occupied for B, # winning els occupied from W, \n 1 move to occupied for W, # winning els occupied from K, 1 move to occupied for K, \n B block B to w_e, B block W to w_e, B block K to w_e, \n W block B to w_e, W block W to w_e, W block K to w_e, \n K block B to w_e, K block W to w_e, K block K to w_e, free line seg]\"\"\"\n\n # get stats about the king position\n # [escape distance, capturable, # move for capturing, free els around k, b pieces around k, w pieces around k, b 1 move to king, w 1 move to king]\n @classmethod\n def king_stats(cls, pos):\n pos = pos.flatten()\n stats = np.zeros(8, dtype=int)\n king_i = int(_indices.flatten()[pos == 3])\n # 1-capturable) The king is capturable if the black player can move his pieces next to the king\n for k_capture_s in king_capture_segments[king_i]:\n k_capture_s = k_capture_s[k_capture_s!=king_i]\n ret = np.zeros(len(k_capture_s), dtype=bool)\n num_moves = 0\n for i,nex_to_k in enumerate(k_capture_s):\n if pos[nex_to_k] == PLAYER1:\n ret[i] = True\n elif cls.pos_reachable_by_player(pos, nex_to_k, PLAYER1):\n ret[i] = True\n num_moves += 1\n if (ret == True).all():\n stats[1] = True\n if (stats[2]== 0 or stats[2]>num_moves) and num_moves>0:\n stats[2]=num_moves\n\n # 3,4,5\n pos_drug = cls.pos_update(pos, king_i)\n c = np.bincount(pos[cross_center_segments[king_i]][1:], minlength = 4)\n stats[3] = c[0]\n stats[4] = c[1]\n stats[5] = c[2]\n\n for ind_near in cross_center_segments[king_i][1:]:\n if not pos_drug[ind_near]:\n stats[6] += cls.pos_reachable_by_player(pos, ind_near, PLAYER1)\n stats[7] += cls.pos_reachable_by_player(pos, ind_near, PLAYER2)\n\n return stats\n\n \n # True if the board index is empty and reachable in 1 move by the player[PLAYER1, PLAYER2 or KING_VALUE]\n @classmethod\n def pos_reachable_by_player(cls, pos, index, player):\n pos = pos.flatten()\n ret = 0\n if pos[index]:#index already occupied, return False\n return ret \n for move in possible_move_segments[index]:\n segment = pos[move]\n if segment[-1] and np.bincount(segment[segment!=0]).sum() == 1:\n drug_pos = cls.pos_update(pos, move[-1])\n drug_segment = drug_pos[move]\n if (segment == drug_segment).all() and segment[-1]==player:\n ret += 1\n return ret\n\n # Returns the number of empty boxes, white pieces, black pieces and eventually the king in the 8 blocks around the cell reached by a possible move\n @classmethod\n def pieces_around(cls, pos, index):\n pos = pos.flatten()\n c = np.bincount(pos[near_center_segments[index][1:]], minlength=4)\n return c\n"
},
{
"alpha_fraction": 0.5320250988006592,
"alphanum_fraction": 0.5417582392692566,
"avg_line_length": 37.84756088256836,
"blob_id": "0a08443d6006e4372079fd946409b61cd53ff441",
"content_id": "76ba933e2402ef135212252608fff8583fc7d7e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6370,
"license_type": "no_license",
"max_line_length": 244,
"num_lines": 164,
"path": "/vablut/engine/pvs.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "import time\nfrom multiprocessing import Queue, Pool, Manager, Process\n\nfrom vablut.evaluate.base import INF\nfrom vablut.engine.alphabeta import AlphaBetaEngine\nfrom vablut.engine.cached import CachedEngineMixin\nfrom vablut.engine.base import Engine\nfrom vablut.engine.negamax import NegamaxEngine\n\nfrom vablut.modules.cache import Cache, CacheSimm\n\n\nclass PVSEngine(AlphaBetaEngine):\n def search(self, board, depth, ply=1, alpha=-INF, beta=INF, hint=None):\n self.inc('nodes')\n\n if board.end is not None:\n return self.endscore(board, ply)\n\n if depth <= 0:\n self.inc('leaves')\n return [], self.evaluate(board)\n\n bestmove = []\n bestscore = alpha\n for i, m in enumerate(self.moveorder(board, board.get_all_moves(), hint, self._evaluator)):\n if i == 0 or depth == 1 or (beta-alpha) == 1:\n nextmoves, score = self.search(board.move(m), depth-1, ply+1, -beta, -bestscore)\n else:\n # pvs uses a zero window for all the other searches\n _, score = self.search(board.move(m), depth-1, ply+1, -bestscore-1, -bestscore)\n score = -score\n if score > bestscore:\n nextmoves, score = self.search(board.move(m), depth-1, ply+1, -beta, -bestscore)\n else:\n continue\n\n score = -score\n if score > bestscore:\n bestscore = score\n bestmove = [m] + nextmoves\n elif not bestmove:\n bestmove = [m] + nextmoves\n\n if self._verbose and self._counters['nodes']%1000==0:\n self.showstats(bestmove, bestscore)\n\n if bestscore >= beta:\n self.inc('betacuts')\n break\n\n return bestmove, bestscore\n\n def __str__(self):\n return 'PVS(%s)' % self._maxdepth\n\nclass PVSCachedEngine(CachedEngineMixin, PVSEngine):\n FORMAT_STAT = (\n 'score: {score} [time: {time:0.3f}s, pv: {pv}]\\n' +\n 'nps: {nps}, nodes: {nodes}, betacuts: {betacuts}\\n' +\n 'hits: {hits}[{cache_len}], leaves: {leaves}, draws: {draws}, mates: {mates}'\n )\n\n def initcnt(self):\n super(PVSCachedEngine, self).initcnt()\n self._counters['hits'] = 0\n self._counters['cache_len'] = len(self._cache._cache)\n \n def __str__(self):\n return 'PVSCache(%s)' % self._maxdepth\n\nclass PVSCachedTimeEngine(PVSCachedEngine):\n def __init__(self, *args, max_sec=None, **kwargs):\n super(PVSCachedTimeEngine, self).__init__(*args, **kwargs)\n self._max_sec = max_sec-2\n\n def search(self, board, depth, ply=1, alpha=-INF, beta=INF, max_sec=None):\n if self._max_sec and (time.time() - self._startt) > (self._max_sec-1):\n return [], self.evaluate(board)\n\n return super(PVSCachedTimeEngine, self).search(board, depth, ply, alpha, beta)\n\ndef func_thread(*args, **kwargs):\n q = args[5]\n c = CacheSimm(initial = args[7])\n engine = PVSCachedTimeEngine(args[0], args[1], args[2], max_sec = args[3], verbose = args[4], cache = c)\n\n engine.initcnt()\n pv, score = engine.search(args[6], args[2], ply=2, alpha=args[8], beta=args[9])\n m = [args[10]]\n m = m + pv\n q.put((m, score, c))\n\nclass PVSCachedTimeThreadsEngine(PVSEngine):\n def __init__(self, evaluator, moveorder, maxdepth, max_thread, max_sec=None, verbose=True):\n super(PVSCachedTimeThreadsEngine, self).__init__(evaluator, moveorder, maxdepth, verbose)\n self._max_thread = max_thread\n self._max_sec = max_sec-2\n self._depthLB = maxdepth\n self._depthUP = maxdepth + 1\n self._moveorder = moveorder\n self._res = Queue()\n self._cache = CacheSimm()\n self._pool = Pool(processes=max_thread)\n self._threshold = 25\n\n\n def search(self, board, depth, ply=1, alpha=-INF, beta=INF, max_sec=None):\n q = Manager().Queue()\n count = 0\n #tot = 0\n if board.end is not None:\n return self.endscore(board, ply)\n\n if depth <= 0:\n return [], self.evaluate(board)\n\n bestmove = []\n bestscore = alpha\n\n if len(board.get_all_moves()) <= self._threshold and self._threshold < self._depthUP:\n self._maxdepth += 1\n\n for i, m in enumerate(self.moveorder(board, board.get_all_moves(), None, self._evaluator)):\n max_sec = self._max_sec - (time.time() - self._startt)\n res = self._pool.apply_async(func_thread, (self._evaluator, self._moveorder, self._maxdepth-1, max_sec, False, q, board.move(m), self._cache._cache.copy(), -beta, -bestscore, m)) # ...Instantiate a thread and pass a unique ID to it\n count += 1\n #tot += 1\n\n if i == 0:\n bestmove = [m]\n \n if count >= self._max_thread:\n try:\n ti = self._max_sec - (time.time() - self._startt)\n entry = q.get(timeout=ti)\n count -= 1\n self._cache._cache.update(entry[2]._cache)\n nextmoves = entry[0]\n score = -entry[1]\n if score > bestscore:\n bestscore = score\n bestmove = nextmoves\n elif not bestmove:\n bestmove = nextmoves\n except Exception as e: \n print(e)\n print('**HO FINITO IL TEMPO** mosse [%s/%s] - maxdepth:%s'%(i+1,len(board.get_all_moves()), self._maxdepth))\n if self._maxdepth > self._depthLB:\n self._maxdepth -= 1\n self._threshold -= 2\n return bestmove, bestscore\n\n if (time.time() - self._startt) > self._max_sec:\n print('mosse [%s/%s] - maxdepth:%s'%(i+1,len(board.get_all_moves()), self._maxdepth))\n if self._maxdepth > self._depthLB:\n self._maxdepth -= 1\n self._threshold -= 2\n return bestmove, bestscore\n\n\n print('**FINITE LE MOSSE** mosse [%s/%s] - maxdepth:%s ts:%s'%(i+1,len(board.get_all_moves()), self._maxdepth, self._threshold))\n #self._maxdepth += 1 \n return bestmove, bestscore"
},
{
"alpha_fraction": 0.5054054260253906,
"alphanum_fraction": 0.5081080794334412,
"avg_line_length": 26.44444465637207,
"blob_id": "17957f332539393613e46ba28746ead52ab4f600",
"content_id": "2bbe3158b5597902cf661c0679662451289e0144",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 740,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 27,
"path": "/vablut/engine/human.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "from vablut.board import WrongMoveError\nfrom vablut.engine.base import Engine\n\nclass HumanEngine(Engine):\n def __init__(self, name):\n self.name = name\n\n def choose(self, board):\n \"\"\"Ask the user to choose the move\"\"\"\n\n print(board)\n while True:\n try:\n FROM = input('Your move: ')\n TO = input('Your move: ')\n move = (FROM.upper(),TO.upper())\n return move\n except ValueError:\n print('Wrong move! Must be an integer between 1-8.')\n except WrongMoveError as e:\n print(e.message)\n else:\n break\n return move\n\n def __str__(self):\n return self.name"
},
{
"alpha_fraction": 0.7332071661949158,
"alphanum_fraction": 0.7634815573692322,
"avg_line_length": 35.44827651977539,
"blob_id": "4a2a3fe959d56cb479eb6de873293155613b614e",
"content_id": "8ea9083fe98af3dc53ed94b65ef3d424c1574f12",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1057,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 29,
"path": "/README.md",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "# Intelligent Agent for the [AI @ Unibo Competition](http://ai.unibo.it/games/boardgamecompetition/tablut/1819INF)\nVABLUT project made for the AI competition - Master Degree in Computer Engineering - Bologna 2018-2019\n\nInstructions to install the Vablut Agent\nrequired packages:\n- python 3.5.# o higher\n[\n sudo apt update\n sudo apt install python3-pip\n pip3 --version #pip 9.0.1 ... (python 3.5)\n]\n- pip3\n\nin TABBRUTT folder:\n- pip3 install -r requirements.txt\n- pip3 install pytest\n- py.test\n\nInstructions to use the Vablut Agent\nThis project doesn't include any web interface, the Server project is possible to download here: https://github.com/AGalassi/TablutCompetition.git\n- Download the java Server project and open it in eclipse(or similar)\n- Run the Server.java(more information about the server's execution in the github project description)\n- Run the Human.java agent\n\n- Run the Vablut AI\n - python/python3 tabbrutt.py black|white [max_sec_mossa=60 max_thread=4 verbose=False]\n[\n\tes: python3 tabbrutt.py black|white 60 4 False|True\n]\n"
},
{
"alpha_fraction": 0.5365703701972961,
"alphanum_fraction": 0.585279643535614,
"avg_line_length": 38.21084213256836,
"blob_id": "2d099d8d86846341d0b6c911dbed1e4db7e7509d",
"content_id": "1b22fc2aa0b884290b7bf31e823705b50e507ba8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6508,
"license_type": "no_license",
"max_line_length": 218,
"num_lines": 166,
"path": "/vablut/modules/ashton.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# camp_segments is an index square -> group of board's elements that represents a camp\n# king_capture_segments is an index square -> group of 1 or more segments(3 or 5 elements) to check the king camptures\nimport numpy as np\nfrom vablut.modules.tables import col, row, capture_segments, cross_center_segments, _indices\n\n\nPLAYER1 = 1\nPLAYER2 = 2\nDRAW = 0\nCOMPUTE = -1\nKING_VALUE = 3 #MUST be different from PLAYER1 and PLAYER2\n\ncamps = []\ncamp_segments = [[] for x in range(col*row)]\nking_capture_segments = [[] for x in range(col*row)]\n\nwinning_el = [] #King goal\nprohibited_black_el = [] #throne\nprohibited_white_el = [] #corners and throne\nprohibited_king_el = [] #throne if king leaves the position\n\ncapturing_dic = {PLAYER1: [], PLAYER2: [], KING_VALUE: []} # dictionary used to \"drug\" the board position for the capture's purpose\n\n#DEFAULT: Starting position of the game\nblacks = np.array([[0,0,0,1,1,1,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [1,0,0,0,0,0,0,0,1],\n [1,1,0,0,0,0,0,1,1],\n [1,0,0,0,0,0,0,0,1],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,1,1,1,0,0,0]])\n\nwhites = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,1,1,0,1,1,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\n\nking = np.array([[0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,1,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0],\n [0,0,0,0,0,0,0,0,0]])\n\nthrone_el = 40#king.flatten().dot(_indices.flatten())\n\n\ndef add_camp(line1, line2):\n seg = line1[int(len(line1)/2)-1:int(len(line1)/2)+2]\n seg = np.append(seg, line2[int(len(line2)/2)])\n camps.append(seg)\n for c in seg:\n camp_segments[c] = seg\n\nadd_camp(_indices[0], _indices[1])\nadd_camp(_indices.transpose()[-1], _indices.transpose()[-2])\nadd_camp(_indices[-1], _indices[-2])\nadd_camp(_indices.transpose()[0], _indices.transpose()[1])\n\n# --- WINNING WHITE ELEMENTS ---\ndef add_winning_el(line):\n for x in line:\n if x not in winning_el and len(camp_segments[x]) == 0:\n winning_el.append(x)\n#every border elements\nadd_winning_el(_indices[0][1:-1])\nadd_winning_el(_indices[-1][1:-1])\nadd_winning_el(_indices.transpose()[0][1:-1])\nadd_winning_el(_indices.transpose()[-1][1:-1])\n# === === === === === === === === === === === === === === === === === === === === === === === === === === \n \n#Black pieces can not never take throne position. The black prohibited elements are dynamic with an evaluation that depends on FROM moving index.(checked in Board.py)\nprohibited_black_el.append(throne_el)\n\n\n#White prohibited elements. Whites can not go to the throne(even if it is empty) and camps\nprohibited_white_el = list(prohibited_black_el)\nfor c in camps:\n for el in c:\n prohibited_white_el.append(el)\n\n\nprohibited_king_el = list(prohibited_white_el)\n\n\n# capturing_dic generation - the same for each kind of piece\ncap_el = []\ncap_el.append(throne_el)\nfor c in camps:\n cap_el.append(c[0])\n cap_el.append(c[2])\n cap_el.append(c[3])\ncapturing_dic[PLAYER1] = np.asarray(cap_el[:])\ncapturing_dic[PLAYER2] = np.asarray(cap_el[:])\ncapturing_dic[KING_VALUE] = np.asarray(cap_el[:])\n\n# king_capture_segments\nfor tc in capture_segments:\n king_capture_segments[tc[1]].append(tc)\n# different camptures rule in throne and adjacent elements\nking_capture_segments[throne_el] = [cross_center_segments[throne_el]]\nfor adjacent in king_capture_segments[throne_el][0][1:]:\n king_capture_segments[adjacent] = [cross_center_segments[adjacent]]\n# === === === === === === === === === === === === === === === === === === === === === === === === === === \n\n#np.asarray Trasformation\ncamps = np.asarray(camps)\n#winning_el.remove(1)\n#winning_el.append(40)\nwinning_el = np.asarray(winning_el)\n\nprohibited_black_el = np.asarray(prohibited_black_el)\nprohibited_white_el = np.asarray(prohibited_white_el)\nprohibited_king_el = np.asarray(prohibited_king_el)\n\n\ncamp_segments = np.asarray([np.asarray(x, dtype=int) for x in camp_segments])\nking_capture_segments = np.asarray([np.asarray(x, dtype=int) for x in king_capture_segments])\n# prohibited_segments is a dictionary containing an index square for every kind of pieces(white, king and black) -> group of prohibited indices used to modify the pos game board to generate all moves or check camptures\nprohibited_segments = {PLAYER1: [[] for x in range(col*row)], PLAYER2: [[] for x in range(col*row)], KING_VALUE: [[] for x in range(col*row)]}\n\nmask = np.ones(col*row, dtype=bool)\n\nw_mask = mask.copy()\nw_mask[prohibited_white_el] = False\niw = _indices.flatten()*whites.flatten() #whites starting indices\niw=iw[iw>0]\nw_mask[iw] = True\nfor pwe in _indices.flatten()[w_mask]:\n prohibited_segments[PLAYER2][pwe] = prohibited_white_el.copy()\n\n\nk_mask = mask.copy()\nk_mask[prohibited_king_el] = False\nik = _indices.flatten()*king.flatten() #king starting indices\nik=ik[ik>0]\nk_mask[ik] = True\nfor pwe in _indices.flatten()[k_mask]:\n prohibited_segments[KING_VALUE][pwe] = prohibited_king_el.copy()\nprohibited_segments[KING_VALUE][_indices.flatten().dot(king.flatten())] = prohibited_king_el.copy()\n\nb_mask = mask.copy()\nb_mask[prohibited_black_el] = False\nib = _indices.flatten()*blacks.flatten() #king starting indices\nib=ib[ib>0]\nb_mask[ib] = True\nfor pwe in _indices.flatten()[b_mask]:\n prohibited_segments[PLAYER1][pwe] = np.concatenate((prohibited_black_el, camps.flatten()))#for each elements, default prohibited are all camps el...\nfor i,x in enumerate(camps):#...prohibited camp elements update\n for el in x: \n prohibited_segments[PLAYER1][el] = np.concatenate((prohibited_black_el, camps[:i].flatten(), camps[i+1:].flatten()))\n# === === === === === === === === === === === === === === === === === === === === === === === === === === \n\n#prohibited_segments[1][3][1] = 3\ndel c, el, i, pwe, tc, x, cap_el"
},
{
"alpha_fraction": 0.5742681622505188,
"alphanum_fraction": 0.5807734131813049,
"avg_line_length": 34.487178802490234,
"blob_id": "125d2c21d30bdb1911326d07223f9b9d141d8ad3",
"content_id": "a6ad2874cca4573a4e5b9045e166aa35dc6ba076",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2767,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 78,
"path": "/vablut/engine/alphabeta.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "import time\nfrom vablut.evaluate.base import INF\nfrom vablut.engine.negamax import NegamaxEngine\nfrom vablut.engine.cached import CachedEngineMixin\n\nclass AlphaBetaEngine(NegamaxEngine):\n FORMAT_STAT = (\n 'score: {score} [time: {time:0.3f}s, pv: {pv}]\\n' +\n 'nps: {nps}, nodes: {nodes}, betacuts: {betacuts}\\n' +\n 'leaves: {leaves}, draws: {draws}, mates: {mates}'\n )\n\n def __init__(self, evaluator, moveorder, maxdepth=2, verbose=True):\n super(AlphaBetaEngine, self).__init__(evaluator, maxdepth, verbose)\n self.moveorder = moveorder.order\n\n def initcnt(self):\n super(AlphaBetaEngine, self).initcnt()\n self._counters['betacuts'] = 0\n\n def search(self, board, depth, ply=1, alpha=-INF, beta=INF, hint=None):\n self.inc('nodes')\n if board.end is not None:\n return self.endscore(board, ply)\n\n if depth <= 0:\n self.inc('leaves')\n return [], self.evaluate(board)\n\n bestmove = []\n bestscore = alpha\n for m in self.moveorder(board, board.get_all_moves(), hint, self._evaluator):\n nextmoves, score = self.search(board.move(m), depth-1, ply+1, -beta, -bestscore)\n score = -score\n if score > bestscore:\n bestscore = score\n bestmove = [m] + nextmoves\n elif not bestmove:\n bestmove = [m] + nextmoves\n\n if self._counters['nodes']%1000==0 and self._verbose:\n self.showstats(bestmove, bestscore)\n\n if bestscore >= beta:\n self.inc('betacuts')\n break\n\n return bestmove, bestscore\n\n def __str__(self):\n return 'AlphaBeta(%s)' % self._maxdepth\n\nclass ABCachedEngine(CachedEngineMixin, AlphaBetaEngine):\n FORMAT_STAT = (\n 'score: {score} [time: {time:0.3f}s, pv: {pv}]\\n' +\n 'nps: {nps}, nodes: {nodes}, betacuts: {betacuts}\\n' +\n 'hits: {hits}[{cache_len}], leaves: {leaves}, draws: {draws}, mates: {mates}'\n )\n\n def initcnt(self):\n super(ABCachedEngine, self).initcnt()\n self._counters['hits'] = 0\n self._counters['cache_len'] = len(self._cache._cache)\n\n def __str__(self):\n return 'ABCache(%s)' % self._maxdepth\n\n\nclass ABCachedTimeEngine(ABCachedEngine):\n def __init__(self, *args, max_sec=None, **kwargs):\n super(ABCachedTimeEngine, self).__init__(*args, **kwargs)\n self._max_sec = max_sec\n\n def search(self, board, depth, ply=1, alpha=-INF, beta=INF, max_sec=None):\n if self._max_sec and (time.time() - self._startt) > (self._max_sec-1):\n return [], self.evaluate(board) \n\n return super(ABCachedTimeEngine, self).search(board, depth, ply, alpha, beta)"
},
{
"alpha_fraction": 0.5834353566169739,
"alphanum_fraction": 0.6128110885620117,
"avg_line_length": 39.83333206176758,
"blob_id": "ea447c34a164e3f5edc2c5db873b0fb981b2a018",
"content_id": "399955b1526b2a1a6169557fc40779f02de48b3c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2451,
"license_type": "no_license",
"max_line_length": 176,
"num_lines": 60,
"path": "/tabbrutt.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "\n#da linea di comando leggere se BLACK o WHITE. \n#Istanziare poi l'engine associato e passarlo al gamehandler\n#from vablut.game import GameHandler\nimport sys\nimport numpy as np\nfrom vablut.board import PLAYER1, PLAYER2, DRAW\n\nfrom vablut.evaluate.moveorder import MoveOrder\nfrom vablut.evaluate.evaluate_glesc_ks import Evaluator_glesc_ks\nfrom vablut.engine.pvs import PVSCachedTimeEngine, PVSCachedTimeThreadsEngine\nfrom vablut.gameJava import GameJavaHandler\n\ndef main(): #python tabbrutt.py player_type [max_sec_mossa max_thread verbose] es: python tabbrutt.py black|white 60 4 False|True\n max_sec_mossa = 60\n max_thread = 4\n player_type = None\n ege = None\n engine = None\n mo = MoveOrder('diff')\n verbose = True\n\n try:\n if sys.argv[1]:\n player_type = str(sys.argv[1]).lower()\n if player_type not in ['black','white']:\n raise ValueError('!Wrong argv[player_type]! the first required argument[player_type] is different from black|white')\n else:\n raise ValueError('!Required argv[player_type] missing! run the script with at least one input argument black|white')\n\n if sys.argv[2]:\n max_sec_mossa = int(sys.argv[2])\n if sys.argv[3]:\n max_thread = int(sys.argv[3])\n if sys.argv[4]:\n verbose = bool(sys.argv[2])\n except Exception as e: \n print(e)\n\n if max_sec_mossa <= 0:\n raise ValueError('!Thinking seconds can not be <= 0!')\n if max_thread < 0:\n raise ValueError('!Thinking seconds can not be <= 0!')\n \n if player_type == 'black':\n ege = Evaluator_glesc_ks([{1:[2], 2:[10]}, None, {PLAYER1: np.array([0, 4, 1, 0, 1, 0, 1, 0], dtype=int), PLAYER2: np.array([0, -15, -1, 1, -1, 2, 0, 1], dtype=int)}])\n elif player_type == 'white':\n ege = Evaluator_glesc_ks([{1:[150], 2:[3]}, None, {PLAYER1: np.array([0, 4, 1, 0, 1, 0, 1, 0], dtype=int), PLAYER2: np.array([0, -15, -1, 1, -1, 2, 0, 1], dtype=int)}])\n else:\n raise ValueError('!IMPOSSIBLE!')\n\n if max_thread == 0:\n engine = PVSCachedTimeEngine(ege, mo, 3, max_sec=max_sec_mossa, verbose=verbose)\n else:\n engine = PVSCachedTimeThreadsEngine(ege, mo, 3, max_thread, max_sec=max_sec_mossa, verbose=verbose)\n\n gh = GameJavaHandler(engine, player_type, verbose)\n gh.play()\n \nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5625717639923096,
"alphanum_fraction": 0.5763490200042725,
"avg_line_length": 31.296297073364258,
"blob_id": "9cfd5dfff52dcc882ceac5e0f20621160780300d",
"content_id": "b579fc485098c2ceac829065bd9b67be5f02eac4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 871,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 27,
"path": "/vablut/modules/Utils.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport struct\nimport socket\n\nclass utils(object):\n def recvall(sock, size):\n received_chunks = []\n buf_size = 4096\n remaining = size\n while remaining > 0:\n received = sock.recv(min(remaining, buf_size))\n if not received:\n raise Exception('unexcepted EOF')\n received_chunks.append(received)\n remaining -= len(received)\n return b''.join(received_chunks)\n \n def write_utf8(s: str, sock: socket.socket):\n encoded = s.encode(encoding='utf-8')\n sock.sendall(struct.pack('>i', len(encoded)))\n sock.sendall(encoded)\n \n def read_utf8(sock):\n len_bytes = utils.recvall(sock, 4)\n length = struct.unpack('>i', len_bytes)[0]\n encoded = utils.recvall(sock, length)\n return str(encoded, encoding='utf-8')"
},
{
"alpha_fraction": 0.5203989148139954,
"alphanum_fraction": 0.5457842350006104,
"avg_line_length": 32.45454406738281,
"blob_id": "449312c50e5ca68da0531f1f68dd627e1fbe1799",
"content_id": "801f37442b4ee86b3f11f100fdccd03788e3eff1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1103,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 33,
"path": "/vablut/evaluate/evaluate_glutton.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom vablut.board import Board, PLAYER1, PLAYER2, DRAW\nfrom vablut.evaluate.base import Evaluator, INF\n\nclass Evaluator_glutton(Evaluator):\n def __init__(self, weights={PLAYER1:[1],PLAYER2:[3]}):\n super(Evaluator_glutton, self).__init__(weights)\n \n def evaluate(self, board):\n scores = {PLAYER1: np.zeros(len(self.weights[PLAYER1]), dtype=int),\n PLAYER2: np.zeros(len(self.weights[PLAYER2]), dtype=int)}\n \n if board.end is not None:\n if board.end == DRAW:\n return 0\n elif board.end == board.stm:\n return INF\n else:\n return -INF\n \n n_pieces = board.number_pieces(board.pos)\n\n scores[PLAYER1][0] = n_pieces[0]\n scores[PLAYER2][0] = n_pieces[1]\n \n s1 = (self.weights[PLAYER1] * scores[PLAYER1]).sum()\n s2 = (self.weights[PLAYER2] * scores[PLAYER2]).sum()\n #print(s1,s2)\n score = s1 - s2\n if board.stm == PLAYER1:\n return score\n else:\n return -score"
},
{
"alpha_fraction": 0.5600722432136536,
"alphanum_fraction": 0.5645889639854431,
"avg_line_length": 28.932432174682617,
"blob_id": "1f6aa8296e7df2eed90fba4f3aa2596661498ea9",
"content_id": "6c95f5a9751431ae79aa094e063537be51d2379e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2214,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 74,
"path": "/vablut/engine/greedy.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport numpy as np\nfrom vablut.engine.base import Engine\nfrom vablut.evaluate.base import INF\nfrom vablut.evaluate.evaldiff import evaldiff\n\nclass GreedyEngine(Engine):\n def __init__(self, evaluator, verbose=True):\n self._verbose = verbose\n self._evaluator = evaluator\n self.evaluate = self._evaluator.evaluate\n\n def choose(self, board):\n moves = board.get_all_moves()\n m = moves[0]\n moves = moves[1:]\n\n bestmove = m\n bestscore = -self.evaluate(board.move(m))\n\n for m in moves:\n score = -self.evaluate(board.move(m))\n #print(\"move: %s score:%d\"%(m,score))\n if score > bestscore:\n bestmove = m\n bestscore = score\n\n if self._verbose:\n print('Selected move %d with score %s' % (bestscore, bestmove))\n \n return bestmove\n\n def __str__(self):\n return 'Greedy'\n\nclass WeightedGreedyEngine(Engine):\n \"\"\"Same as GreedyEngine but move randomly using scores as weights\"\"\"\n\n def __init__(self, evaluator, verbose=True):\n self._evaluator = evaluator\n self._verbose = verbose\n self.evaluate = self._evaluator.evaluate\n\n def choose(self, board):\n moves = board.get_all_moves()\n\n # nothing to weigh\n if len(moves) < 2:\n return moves[0]\n\n # winning move or threat blocking?\n scores = [evaldiff(board, m) for m in moves]\n if max(scores) >= INF - 1:\n return max(zip(scores, moves))[1]\n\n weights = np.array(scores, dtype=float) + 1\n\n if weights.sum() == 0:\n weights = np.array([1 / len(moves)] * len(moves), dtype=float)\n else:\n weights /= weights.sum()\n\n selected_move = np.random.choice(range(len(moves)), p=weights)\n selected_move = moves[selected_move]\n\n if self._verbose:\n selected_score = scores[list(moves).index(selected_move)]\n print('Selected move %s with score %s' % (str(selected_move),\n selected_score))\n\n return selected_move\n\n def __str__(self):\n return 'Weighted Greedy'"
},
{
"alpha_fraction": 0.5568420886993408,
"alphanum_fraction": 0.574526309967041,
"avg_line_length": 35.5461540222168,
"blob_id": "4b465ccfb7098d5b94e937e3536d4823d80c329c",
"content_id": "513bdd70be654b78d57b8f3db58affd94ed3495e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4750,
"license_type": "no_license",
"max_line_length": 162,
"num_lines": 130,
"path": "/vablut/modules/tables.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "# coding=utf-8\nimport numpy as np\n#\n# Segment tables\n#\n# Capture_Segments are trios of indices that represent three squares aligned and\n# consecutive in the board(Vertical or Horizontal).\n#\n# rev_segments is an index square -> group of trios-segments to ckeck for captures\n# move_segments is an index square -> group of line-segments that pass by the square(the row and the column that pass from a i-j element of the board)\n# possible_move_segments is an index square -> group of variable-segments used to get all possible moves\n# cross_center_segments is an index square -> group of 1 segments to check the cross capture of the king. 1st element is the middle elemente of the cross.\n# near_center_segments is an index square -> given one position it returns all the near positions\n\ncol = row = 9\n\ncapture_segments = []\nall_cross = []\nall_near = []\nnear_center_segments = [[] for x in range(col*row)]\ncross_center_segments = [[] for x in range(col*row)]\nrev_segments = [[] for x in range(col*row)]\nmove_segments = [[] for x in range(col*row)]\npossible_move_segments = [[] for x in range(col*row)]\n\n_indices = np.arange(col*row).reshape((row, col))\n\ndef add_rev(line):\n for x in range(len(line)-2):\n seg = line[x:x+3]\n capture_segments.append(seg)\n rev_segments[seg[0]].append(seg)\n rev_segments[seg[-1]].append(seg)\n \ndef add_near(*lines):\n if len(lines) == 2:\n for x in range(len(lines[0])):\n seg = lines[0][x:x+2]\n if x > 0:\n seg = np.append(seg, lines[0][x-1])\n seg = np.append(seg, lines[1][x-1])\n seg = np.append(seg, lines[1][x])\n if x < col-1:\n seg = np.append(seg, lines[1][x+1])\n all_near.append(seg)\n near_center_segments[seg[0]] = seg\n if len(lines) == 3:\n for x in range(len(lines[1])):\n seg = lines[1][x:x+2]\n if x > 0:\n seg = np.append(seg, lines[1][x-1])\n seg = np.append(seg, lines[0][x-1])\n seg = np.append(seg, lines[2][x-1])\n seg = np.append(seg, [lines[0][x], lines[2][x]])\n if x < col-1:\n seg = np.append(seg, [lines[0][x+1], lines[2][x+1]])\n all_near.append(seg)\n near_center_segments[seg[0]] = seg\n #print(near_center_segments)\n \n\ndef add_possible_move(line):\n for x in range(len(line)-1):\n for f in range(1,len(line[x:])):\n seg = line[x:x+f+1]\n possible_move_segments[seg[0]].append(seg)\n\n\ndef add_cross(*lines):\n if len(lines) == 2:\n for x in range(len(lines[0])):\n seg = lines[0][x:x+2]\n if x > 0:\n seg = np.append(seg, lines[0][x-1])\n seg = np.append(seg, lines[1][x])\n all_cross.append(seg)\n cross_center_segments[seg[0]] = seg\n if len(lines) == 3:\n for x in range(len(lines[1])):\n seg = lines[1][x:x+2]\n if x > 0:\n seg = np.append(seg, lines[1][x-1])\n seg = np.append(seg, [lines[0][x],lines[2][x]])\n all_cross.append(seg)\n cross_center_segments[seg[0]] = seg\n\ndef add_move(line):\n for n in line:\n move_segments[n].append(line)\n\nfor l_row in _indices:\n add_rev(l_row)\n add_move(l_row)\n add_possible_move(l_row)\n add_possible_move(l_row[::-1])\n #missing\n \nfor l_col in _indices.transpose():\n add_rev(l_col) \n add_move(l_col)\n add_possible_move(l_col)\n add_possible_move(l_col[::-1])\n #missing\n \n#section to check the cross capture of the king-NOT USED IN THIS VERSION OF TABLUT\nadd_cross(_indices[0], _indices[1])\nadd_cross(_indices[-1], _indices[-2])\nfor t in range(len(_indices)-2):\n trios = _indices[t:t+3]\n add_cross(trios[0],trios[1],trios[2])\n \n#adding all nears in the proper arrays\nadd_near(_indices[0], _indices[1])\nadd_near(_indices[-1], _indices[-2])\nfor t in range(len(_indices)-2):\n trios = _indices[t:t+3]\n add_near(trios[0], trios[1], trios[2])\n\n#np.asarray Trasformation\ncapture_segments = np.asarray(capture_segments)\nall_cross = np.asarray(all_cross)\nall_near = np.asarray(all_near)\n\ncross_center_segments = np.asarray([np.asarray(x) for x in cross_center_segments])\nrev_segments = np.asarray([np.asarray(x) for x in rev_segments])\nmove_segments = np.asarray([np.asarray(x) for x in move_segments])\npossible_move_segments = np.asarray([np.asarray(x) for x in possible_move_segments])\nnear_center_segments = np.asarray([np.asarray(x) for x in near_center_segments])\n\ndel trios, t"
},
{
"alpha_fraction": 0.6250787377357483,
"alphanum_fraction": 0.6250787377357483,
"avg_line_length": 45.70588302612305,
"blob_id": "7e25e59fbbf6723097f236d386b568eb298cecaf",
"content_id": "eb1a718a621bad358723d958ba262319b1c3d45e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1587,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 34,
"path": "/compile.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "from distutils.core import setup\nfrom distutils.extension import Extension\nfrom Cython.Distutils import build_ext\n\next_modules = [\n Extension(\"tables\", [\"vablut\\modules\\\\tables.py\"]),\n Extension(\"ashton\", [\"vablut\\modules\\\\ashton.py\"]),\n Extension(\"cache\", [\"vablut\\modules\\\\cache.py\"]),\n Extension(\"Utils\", [\"vablut\\modules\\\\Utils.py\"]),\n Extension(\"base\", [\"vablut\\evaluate\\\\base.py\"]),\n Extension(\"evaldiff\", [\"vablut\\evaluate\\\\evaldiff.py\"]),\n Extension(\"evaluate_escapist\", [\"vablut\\evaluate\\\\evaluate_escapist.py\"]),\n Extension(\"evaluate_gl_esc\", [\"vablut\\evaluate\\\\evaluate_gl_esc.py\"]),\n Extension(\"evaluate_glesc_ks\", [\"vablut\\evaluate\\\\evaluate_glesc_ks.py\"]),\n Extension(\"evaluate_glutton\", [\"vablut\\evaluate\\\\evaluate_glutton.py\"]),\n Extension(\"moveorder\", [\"vablut\\evaluate\\\\moveorder.py\"]),\n Extension(\"base\", [\"vablut\\engine\\\\base.py\"]),\n Extension(\"alphabeta\", [\"vablut\\engine\\\\alphabeta.py\"]),\n Extension(\"cached\", [\"vablut\\engine\\\\cached.py\"]),\n Extension(\"greedy\", [\"vablut\\engine\\\\greedy.py\"]),\n Extension(\"human\", [\"vablut\\engine\\\\human.py\"]),\n Extension(\"negamax\", [\"vablut\\engine\\\\negamax.py\"]),\n Extension(\"pvs\", [\"vablut\\engine\\\\pvs.py\"]),\n Extension(\"rand\", [\"vablut\\engine\\\\rand.py\"]),\n Extension(\"board\", [\"vablut\\\\board.py\"]),\n Extension(\"game\", [\"vablut\\game.py\"]),\n Extension(\"runny\", [\"vablut\\\\runny.pyx\"])\n]\n\nsetup(\n name = 'test',\n cmdclass = {'build_ext': build_ext},\n ext_modules = ext_modules\n)"
},
{
"alpha_fraction": 0.5703448057174683,
"alphanum_fraction": 0.5717241168022156,
"avg_line_length": 28.020000457763672,
"blob_id": "409fa2f475d804188558ceda6722548627bed924",
"content_id": "692359a6ef40b13ffd096efb2e560c97f57f1440",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1450,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 50,
"path": "/vablut/evaluate/moveorder.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "import random\nfrom functools import partial\n\nfrom vablut.evaluate.base import Evaluator\nfrom vablut.evaluate.evaldiff import evaldiff\n\nclass MoveOrder(object):\n def __init__(self, name):\n name = name.lower()\n dispatcher = {\n 'seq': self._order_seq,\n 'random': self._order_random,\n 'diff': self._order_diff,\n 'eval': self._order_eval\n }\n\n if name not in dispatcher:\n raise NotImplemented()\n\n self._order = dispatcher[name.lower()]\n\n def _order_seq(self, board, moves, evaluator = None):\n return moves\n\n def _order_random(self, board, moves, evaluator = None):\n random.shuffle(moves)\n return moves\n\n def _order_diff(self, board, moves, evaluator = None):\n if len(moves) <= 1:\n return moves\n\n return sorted(moves, key=partial(evaldiff, board), reverse=True)\n\n def _order_eval(self, board, moves, evaluator: Evaluator):\n if not hasattr(self, 'evaluate'):\n self.evaluate = evaluator.evaluate\n if len(moves) <= 1:\n return moves\n \n return sorted(moves, key=lambda m: -self.evaluate(board.move(m)), reverse=True)\n\n def order(self, board, moves, hint=None, ev = None):\n if hint is not None:\n yield hint\n\n for x in self._order(board, moves, ev):\n if x == hint:\n continue\n yield x"
},
{
"alpha_fraction": 0.5987842082977295,
"alphanum_fraction": 0.6170212626457214,
"avg_line_length": 19.625,
"blob_id": "5ac5614e6740d3ccec55c42fcd8ef1f77fc584f4",
"content_id": "63c9c28efe7809561a492560099378bcb7c77366",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 329,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 16,
"path": "/vablut/evaluate/base.py",
"repo_name": "VforV93/VABLUT",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport numpy as np\nfrom vablut.board import Board\n\nINF = 10000\n\nclass Evaluator(object):\n def __init__(self, weights):\n self._weights = weights\n \n @property\n def weights(self):\n return self._weights\n \n def evaluate(self, board: Board):\n raise NotImplementedError"
}
] | 27 |
deqing/download-agent
|
https://github.com/deqing/download-agent
|
08861e8d06d1a5280fe0006c7ac787cf37c9d429
|
3326230d3fddd95b1b2527d37377d5f5e2306ad3
|
d29adcd217d53eca0670cfe4e537b18b0206200f
|
refs/heads/master
| 2021-01-06T20:42:28.245035 | 2013-08-01T11:46:10 | 2013-08-01T11:46:10 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6808858513832092,
"alphanum_fraction": 0.6820183992385864,
"avg_line_length": 24.308917999267578,
"blob_id": "bef18c2e0cf4806714421af6f836af5c94fefbb7",
"content_id": "cf3ad5247108ab94d94275d0647b404cfe8bacf8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 7947,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 314,
"path": "/download-agent-dl-mgr.c",
"repo_name": "deqing/download-agent",
"src_encoding": "UTF-8",
"text": "/*\n * Copyright (c) 2012 Samsung Electronics Co., Ltd All Rights Reserved\n *\n * Licensed under the Apache License, Version 2.0 (the License);\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an AS IS BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n\n#include \"download-agent-client-mgr.h\"\n#include \"download-agent-debug.h\"\n#include \"download-agent-dl-mgr.h\"\n#include \"download-agent-utils.h\"\n#include \"download-agent-http-mgr.h\"\n#include \"download-agent-file.h\"\n#include \"download-agent-plugin-conf.h\"\n\n\nstatic da_result_t __cancel_download_with_slot_id(int slot_id);\nstatic da_result_t __suspend_download_with_slot_id(int slot_id);\n\n\nda_result_t requesting_download(stage_info *stage)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\treq_dl_info *request_session = DA_NULL;\n\n\tDA_LOG_FUNC_START(Default);\n\n\tif (!stage) {\n\t\tDA_LOG_ERR(Default, \"stage is null..\");\n\t\tret = DA_ERR_INVALID_ARGUMENT;\n\t\tgoto ERR;\n\t}\n\n\tret = make_req_dl_info_http(stage, GET_STAGE_TRANSACTION_INFO(stage));\n\tif (ret != DA_RESULT_OK)\n\t\tgoto ERR;\n\n\trequest_session = GET_STAGE_TRANSACTION_INFO(stage);\n\tret = request_http_download(stage);\n\tif (DA_RESULT_OK == ret) {\n\t\tDA_LOG(Default, \"Http download is complete.\");\n\t} else {\n\t\tDA_LOG_ERR(Default, \"Http download is failed. ret = %d\", ret);\n\t\tgoto ERR;\n\t}\nERR:\n\treturn ret;\n}\n\nda_result_t handle_after_download(stage_info *stage)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\tda_mime_type_id_t mime_type = DA_MIME_TYPE_NONE;\n\n\tDA_LOG_FUNC_START(Default);\n\n\tmime_type = get_mime_type_id(\n\t GET_CONTENT_STORE_CONTENT_TYPE(GET_STAGE_CONTENT_STORE_INFO(stage)));\n\n\tswitch (mime_type) {\n\t\tcase DA_MIME_TYPE_NONE:\n\t\t\tDA_LOG(Default, \"DA_MIME_TYPE_NONE\");\n\t\t\tret = DA_ERR_MISMATCH_CONTENT_TYPE;\n\t\t\tbreak;\n\t\tdefault:\n\t\t\tCHANGE_DOWNLOAD_STATE(DOWNLOAD_STATE_FINISH, stage);\n\t\t\tbreak;\n\t} /* end of switch */\n\n\treturn ret;\n}\n\nstatic da_result_t __cancel_download_with_slot_id(int slot_id)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\tdownload_state_t download_state;\n\tstage_info *stage = DA_NULL;\n\n\tDA_LOG_FUNC_START(Default);\n\n\t_da_thread_mutex_lock (&mutex_download_state[slot_id]);\n\tdownload_state = GET_DL_STATE_ON_ID(slot_id);\n\tDA_LOG(Default, \"download_state = %d\", GET_DL_STATE_ON_ID(slot_id));\n\n\tif (download_state == DOWNLOAD_STATE_FINISH ||\n\t\t\tdownload_state == DOWNLOAD_STATE_CANCELED) {\n\t\tDA_LOG_CRITICAL(Default, \"Already download is finished. Do not send cancel request\");\n\t\t_da_thread_mutex_unlock (&mutex_download_state[slot_id]);\n\t\treturn ret;\n\t}\n\t_da_thread_mutex_unlock (&mutex_download_state[slot_id]);\n\n\tstage = GET_DL_CURRENT_STAGE(slot_id);\n\tif (!stage)\n\t\treturn DA_RESULT_OK;\n\n\tret = request_to_cancel_http_download(stage);\n\tif (ret != DA_RESULT_OK)\n\t\tgoto ERR;\n\tDA_LOG(Default, \"Download cancel Successful for download id - %d\", slot_id);\nERR:\n\treturn ret;\n}\n\nda_result_t cancel_download(int dl_id)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\n\tint slot_id = DA_INVALID_ID;\n\n\tDA_LOG_FUNC_START(Default);\n\n\tret = get_slot_id_for_dl_id(dl_id, &slot_id);\n\tif (ret != DA_RESULT_OK) {\n\t\tDA_LOG_ERR(Default, \"dl req ID is not Valid\");\n\t\tgoto ERR;\n\t}\n\n\tif (DA_FALSE == is_valid_slot_id(slot_id)) {\n\t\tDA_LOG_ERR(Default, \"Download ID is not Valid\");\n\t\tret = DA_ERR_INVALID_ARGUMENT;\n\t\tgoto ERR;\n\t}\n\n\tret = __cancel_download_with_slot_id(slot_id);\n\nERR:\n\treturn ret;\n\n}\n\nstatic da_result_t __suspend_download_with_slot_id(int slot_id)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\tdownload_state_t download_state;\n\tstage_info *stage = DA_NULL;\n\n\tDA_LOG_FUNC_START(Default);\n\n\t_da_thread_mutex_lock (&mutex_download_state[slot_id]);\n\tdownload_state = GET_DL_STATE_ON_ID(slot_id);\n\tDA_LOG(Default, \"download_state = %d\", GET_DL_STATE_ON_ID(slot_id));\n\t_da_thread_mutex_unlock (&mutex_download_state[slot_id]);\n\n\tstage = GET_DL_CURRENT_STAGE(slot_id);\n\tif (!stage)\n\t\treturn DA_ERR_CANNOT_SUSPEND;\n\n\tret = request_to_suspend_http_download(stage);\n\tif (ret != DA_RESULT_OK)\n\t\tgoto ERR;\n\tDA_LOG(Default, \"Download Suspend Successful for download id-%d\", slot_id);\nERR:\n\treturn ret;\n}\n\nda_result_t suspend_download(int dl_id, da_bool_t is_enable_cb)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\tint slot_id = DA_INVALID_ID;\n\n\tDA_LOG_FUNC_START(Default);\n\n\tret = get_slot_id_for_dl_id(dl_id, &slot_id);\n\tif (ret != DA_RESULT_OK) {\n\t\tDA_LOG_ERR(Default, \"dl req ID is not Valid\");\n\t\tgoto ERR;\n\t}\n\tGET_DL_ENABLE_PAUSE_UPDATE(slot_id) = is_enable_cb;\n\tif (DA_FALSE == is_valid_slot_id(slot_id)) {\n\t\tDA_LOG_ERR(Default, \"Download ID is not Valid\");\n\t\tret = DA_ERR_INVALID_ARGUMENT;\n\t\tgoto ERR;\n\t}\n\n\tret = __suspend_download_with_slot_id(slot_id);\n\nERR:\n\treturn ret;\n\n}\n\nstatic da_result_t __resume_download_with_slot_id(int slot_id)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\tdownload_state_t download_state;\n\tstage_info *stage = DA_NULL;\n\n\tDA_LOG_FUNC_START(Default);\n\n\t_da_thread_mutex_lock (&mutex_download_state[slot_id]);\n\tdownload_state = GET_DL_STATE_ON_ID(slot_id);\n\tDA_LOG(Default, \"download_state = %d\", GET_DL_STATE_ON_ID(slot_id));\n\t_da_thread_mutex_unlock (&mutex_download_state[slot_id]);\n\n\tstage = GET_DL_CURRENT_STAGE(slot_id);\n\n\tret = request_to_resume_http_download(stage);\n\tif (ret != DA_RESULT_OK)\n\t\tgoto ERR;\n\tDA_LOG(Default, \"Download Resume Successful for download id-%d\", slot_id);\nERR:\n\treturn ret;\n}\n\nda_result_t resume_download(int dl_id)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\tint slot_id = DA_INVALID_ID;\n\n\tDA_LOG_FUNC_START(Default);\n\n\tret = get_slot_id_for_dl_id(dl_id, &slot_id);\n\tif (ret != DA_RESULT_OK)\n\t\tgoto ERR;\n\n\tif (DA_FALSE == is_valid_slot_id(slot_id)) {\n\t\tDA_LOG_ERR(Default, \"Download ID is not Valid\");\n\t\tret = DA_ERR_INVALID_DL_REQ_ID;\n\t\tgoto ERR;\n\t}\n\n\tret = __resume_download_with_slot_id(slot_id);\n\nERR:\n\treturn ret;\n}\n\nda_result_t send_user_noti_and_finish_download_flow(\n\t\tint slot_id, char *installed_path, char *etag)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\tdownload_state_t download_state = DA_NULL;\n\tda_bool_t need_destroy_download_info = DA_FALSE;\n\n\tDA_LOG_FUNC_START(Default);\n\n\t_da_thread_mutex_lock (&mutex_download_state[slot_id]);\n\tdownload_state = GET_DL_STATE_ON_ID(slot_id);\n\tDA_LOG(Default, \"state = %d\", download_state);\n\t_da_thread_mutex_unlock (&mutex_download_state[slot_id]);\n\n\tswitch (download_state) {\n\tcase DOWNLOAD_STATE_FINISH:\n\t\tsend_client_finished_info(slot_id, GET_DL_ID(slot_id),\n\t\t installed_path, DA_NULL, DA_RESULT_OK,\n\t\t get_http_status(slot_id));\n\t\tneed_destroy_download_info = DA_TRUE;\n\t\tbreak;\n\tcase DOWNLOAD_STATE_CANCELED:\n\t\tsend_client_finished_info(slot_id, GET_DL_ID(slot_id),\n\t\t\t\tinstalled_path, etag, DA_RESULT_USER_CANCELED,\n\t\t\t\tget_http_status(slot_id));\n\t\tneed_destroy_download_info = DA_TRUE;\n\t\tbreak;\n#ifdef PAUSE_EXIT\n\tcase DOWNLOAD_STATE_PAUSED:\n\t\tneed_destroy_download_info = DA_TRUE;\n\t\tbreak;\n#endif\n\tdefault:\n\t\tDA_LOG(Default, \"download state = %d\", download_state);\n\t\tbreak;\n\t}\n\n\tif (need_destroy_download_info == DA_TRUE) {\n\t\tdestroy_download_info(slot_id);\n\t} else {\n\t\tDA_LOG_CRITICAL(Default, \"download info is not destroyed\");\n\t}\n\n\treturn ret;\n}\n\nda_bool_t is_valid_download_id(int dl_id)\n{\n\n\tda_bool_t ret = DA_TRUE;\n\tint slot_id = DA_INVALID_ID;\n\n\tDA_LOG_VERBOSE(Default, \"[is_valid_download_id]download_id : %d\", dl_id);\n\n\tret = get_slot_id_for_dl_id(dl_id, &slot_id);\n\tif (ret != DA_RESULT_OK) {\n\t\tDA_LOG_ERR(Default, \"dl req ID is not Valid\");\n\t\tret = DA_FALSE;\n\t\tgoto ERR;\n\t} else {\n\t\tret = DA_TRUE;\n\t}\n\n\tif (DA_FALSE == is_valid_slot_id(slot_id)) {\n\t\tDA_LOG_ERR(Default, \"Download ID is not Valid\");\n\t\tret = DA_FALSE;\n\t\tgoto ERR;\n\t}\n\tif (GET_DL_THREAD_ID(slot_id) < 1) {\n\t\tDA_LOG_ERR(Default, \"Download thread is not alive\");\n\t\tret = DA_FALSE;\n\t\tgoto ERR;\n\t}\n\nERR:\n\treturn ret;\n}\n"
},
{
"alpha_fraction": 0.6685489416122437,
"alphanum_fraction": 0.670773446559906,
"avg_line_length": 23.658227920532227,
"blob_id": "f7e5851eedfd8adb09b087b7d7404a73fba68442",
"content_id": "2ac32dd6643c18d503c1d597ca1ac013485e24e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5844,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 237,
"path": "/download-agent-interface.c",
"repo_name": "deqing/download-agent",
"src_encoding": "UTF-8",
"text": "/*\n * Copyright (c) 2012 Samsung Electronics Co., Ltd All Rights Reserved\n *\n * Licensed under the Apache License, Version 2.0 (the License);\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an AS IS BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n\n#include \"download-agent-interface.h\"\n#include \"download-agent-debug.h\"\n#include \"download-agent-utils.h\"\n#include \"download-agent-http-mgr.h\"\n#include \"download-agent-http-misc.h\"\n#include \"download-agent-client-mgr.h\"\n#include \"download-agent-dl-mgr.h\"\n#include \"download-agent-basic.h\"\n#include \"download-agent-file.h\"\n\nint da_init(\n da_client_cb_t *da_client_callback)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\n\tDA_LOG_FUNC_START(Default);\n\n\tif (!da_client_callback) {\n\t\tret = DA_ERR_INVALID_ARGUMENT;\n\t\treturn ret;\n\t}\n\n\tret = init_log_mgr();\n\tif (ret != DA_RESULT_OK)\n\t\tgoto ERR;\n\n\tret = init_client_app_mgr();\n\tif (ret != DA_RESULT_OK)\n\t\tgoto ERR;\n\n\tret = reg_client_app(da_client_callback);\n\tif (ret != DA_RESULT_OK)\n\t\tgoto ERR;\n\n\tret = init_http_mgr();\n\tif (ret != DA_RESULT_OK)\n\t\tgoto ERR;\n\n\tret = init_download_mgr();\n\tif (ret != DA_RESULT_OK)\n\t\tgoto ERR;\n\n\tret = create_saved_dir();\n\tif (ret != DA_RESULT_OK)\n\t\tgoto ERR;\n\nERR:\n\tif (DA_RESULT_OK != ret)\n\t\tda_deinit();\n\n\tDA_LOG_CRITICAL(Default, \"Return ret = %d\", ret);\n\n\treturn ret;\n}\n\n/* TODO:: deinit should clean up all the clients... */\nint da_deinit()\n{\n\tda_result_t ret = DA_RESULT_OK;\n\n\tDA_LOG_FUNC_START(Default);\n\n\tdeinit_http_mgr();\n\tdeinit_download_mgr();\n\t/* Do not clean temporary download path\n\t * The client can resume or restart download with temporary file in case of failed download.\n\t */\n\tdereg_client_app();\n\tDA_LOG(Default, \"====== da_deinit EXIT =====\");\n\n\treturn ret;\n}\n\nint da_start_download(\n const char *url,\n int *download_id)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\n\tDA_LOG_FUNC_START(Default);\n\n\t*download_id = DA_INVALID_ID;\n\n\tif (DA_FALSE == is_valid_url(url, &ret))\n\t\tgoto ERR;\n\n\tDA_LOG(Default, \"url = %s\", url);\n\n\tret = start_download(url, download_id);\n\tif (ret != DA_RESULT_OK)\n\t\tgoto ERR;\n\nERR:\n\tDA_LOG_CRITICAL(Default, \"Return: Dl req id = %d, ret = %d\", *download_id, ret);\n\treturn ret;\n}\n\nint da_start_download_with_extension(\n\tconst char\t\t*url,\n\textension_data_t *extension_data,\n\tint\t*download_id\n)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\tint req_header_count = 0;\n\tint i = 0;\n\n\tDA_LOG_FUNC_START(Default);\n\n\t*download_id = DA_INVALID_ID;\n\n\tif (DA_FALSE == is_valid_url(url, &ret))\n\t\tgoto ERR;\n\n\tDA_LOG(Default, \"url = %s\", url);\n\n\tif (ret != DA_RESULT_OK)\n\t\tgoto ERR;\n\tif (!extension_data) {\n\t\tret = DA_ERR_INVALID_ARGUMENT;\n\t\tgoto ERR;\n\t}\n\n\tif (extension_data->request_header_count > 0) {\n\t\tDA_LOG_VERBOSE(Default, \"input request_header_count = [%d]\",\n\t\t\textension_data->request_header_count);\n\t\tfor (i = 0; i < extension_data->request_header_count; i++) {\n\t\t\tif (extension_data->request_header[i]) {\n\t\t\t\treq_header_count++;\n\t\t\t\tDA_LOG_VERBOSE(Default, \"request_header = [%s]\",\n\t\t\t\t\textension_data->request_header[i]);\n\t\t\t}\n\t\t}\n\t\tDA_LOG(Default, \"actual request_header_count = [%d]\", req_header_count);\n\t\tif (extension_data->request_header_count != req_header_count) {\n\t\t\tDA_LOG_ERR(Default, \"Request header count is not matched with number of request header array\");\n\t\t\textension_data->request_header = NULL;\n\t\t\textension_data->request_header_count = 0;\n\t\t\tret = DA_ERR_INVALID_ARGUMENT;\n\t\t\tgoto ERR;\n\t\t}\n\t}\n\n\tif (extension_data->install_path) {\n\t\tif (!is_dir_exist(extension_data->install_path))\n\t\t\treturn DA_ERR_INVALID_INSTALL_PATH;\n\t\tDA_LOG_VERBOSE(Default, \"install_path = [%s]\", extension_data->install_path);\n\t}\n\n\tif (extension_data->file_name)\n\t\tDA_LOG_VERBOSE(Default, \"file_name = [%s]\", extension_data->file_name);\n\tif (extension_data->temp_file_path)\n\t\tDA_LOG_VERBOSE(Default, \"temp_file_path = [%s]\", extension_data->temp_file_path);\n\tif (extension_data->etag)\n\t\tDA_LOG_VERBOSE(Default, \"etag = [%s]\", extension_data->etag);\n\n\tif (extension_data->user_data)\n\t\tDA_LOG_VERBOSE(Default, \"user_data = [%p]\", extension_data->user_data);\n\n\tret = start_download_with_extension(url, download_id, extension_data);\n\nERR:\n\tDA_LOG_CRITICAL(Default, \"Return: Dl req id = %d, ret = %d\", *download_id, ret);\n\treturn ret;\n}\n\nint da_cancel_download(int download_id)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\n\tDA_LOG_VERBOSE(Default, \"Cancel for dl_id = %d\", download_id);\n\n\tret = cancel_download(download_id);\n\n\tDA_LOG_CRITICAL(Default, \"Return: Cancel id = %d, ret = %d\", download_id, ret);\n\treturn ret;\n}\n\nint da_suspend_download(int download_id)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\n\tDA_LOG_VERBOSE(Default, \"Suspend for dl_id = %d\", download_id);\n\n\tret = suspend_download(download_id, DA_TRUE);\n\n\tDA_LOG_CRITICAL(Default, \"Return: Suspend id = %d, ret = %d\", download_id, ret);\n\treturn ret;\n}\n\nint da_suspend_download_without_update(int download_id)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\n\tDA_LOG_VERBOSE(Default, \"Suspend for dl_id = %d\", download_id);\n\n\tret = suspend_download(download_id, DA_FALSE);\n\n\tDA_LOG_CRITICAL(Default, \"Return: Suspend id = %d, ret = %d\", download_id, ret);\n\treturn ret;\n}\n\n\nint da_resume_download(int download_id)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\n\tDA_LOG_VERBOSE(Default, \"Resume for dl_id = %d\", download_id);\n\n\tret = resume_download(download_id);\n\n\tDA_LOG_CRITICAL(Default, \"Return: Resume id = %d, ret = %d\", download_id, ret);\n\treturn ret;\n}\n\nint da_is_valid_download_id(int download_id)\n{\n\tda_bool_t ret = DA_FALSE;\n\tret = is_valid_download_id(download_id);\n\treturn ret;\n}\n"
},
{
"alpha_fraction": 0.7377266883850098,
"alphanum_fraction": 0.7412649393081665,
"avg_line_length": 38.66666793823242,
"blob_id": "522bddf78002afbff5f8ef2df7c0bbb26511f6e0",
"content_id": "3200aa4e8a630f1dbb88cefc6da2d20abaa0a8a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2261,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 57,
"path": "/include/download-agent-file.h",
"repo_name": "deqing/download-agent",
"src_encoding": "UTF-8",
"text": "/*\n * Copyright (c) 2012 Samsung Electronics Co., Ltd All Rights Reserved\n *\n * Licensed under the Apache License, Version 2.0 (the License);\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an AS IS BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n\n#ifndef _Download_Agent_File_H\n#define _Download_Agent_File_H\n\n#include <stdio.h>\n#include <sys/types.h>\n#include <sys/stat.h>\n\n#include \"download-agent-type.h\"\n#include \"download-agent-dl-mgr.h\"\n\n#define DA_DEFAULT_FILE_DIR_PATH \"/tmp\" //\"/opt/usr/media/.tmp_download\"\n#define DA_DEFAULT_INSTALL_PATH_FOR_PHONE \"/tmp\" //\"/opt/usr/media/Downloads\"\n#define DA_DEFAULT_INSTALL_PATH_FOR_MMC \"/tmp\" //\"/opt/storage/sdcard/Downloads\"\n\nda_bool_t is_file_exist(const char *file_path);\nda_bool_t is_dir_exist(const char *dir_path);\n\nvoid get_file_size(char *file_path, unsigned long long *out_file_size);\n\nda_result_t clean_files_from_dir(char *dir_path);\nda_result_t create_saved_dir(void);\n\nda_result_t file_write_ongoing(stage_info *stage, char *body, int body_len);\nda_result_t file_write_complete(stage_info *stage);\nda_result_t start_file_writing(stage_info *stage);\nda_result_t start_file_writing_append(stage_info *stage);\nda_result_t start_file_writing_append_with_new_download(stage_info *stage);\n\nda_result_t get_mime_type(stage_info *stage, char **out_mime_type);\nda_result_t discard_download(stage_info *stage) ;\nvoid clean_paused_file(stage_info *stage);\nda_result_t replace_content_file_in_stage(stage_info *stage, const char *dest_dd_file_path);\nda_result_t decide_tmp_file_path(stage_info *stage);\nchar *get_full_path_avoided_duplication(char *in_dir, char *in_candidate_file_name, char *in_extension);\n\nda_result_t copy_file(const char *src, const char *dest);\nda_result_t create_dir(const char *install_dir);\nda_result_t get_default_dir(char **out_path);\nda_result_t get_default_install_dir(char **out_path);\n\n#endif\n"
},
{
"alpha_fraction": 0.7316209077835083,
"alphanum_fraction": 0.7387068271636963,
"avg_line_length": 31.257143020629883,
"blob_id": "f51731d419cab459c623b75864b968db409b4401",
"content_id": "3e3204808ef9429186ca6cd3e6b825a2c24bd789",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1129,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 35,
"path": "/include/download-agent-utils-dl-id-history.h",
"repo_name": "deqing/download-agent",
"src_encoding": "UTF-8",
"text": "/*\n * Copyright (c) 2012 Samsung Electronics Co., Ltd All Rights Reserved\n *\n * Licensed under the Apache License, Version 2.0 (the License);\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an AS IS BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n\n#ifndef _Download_Agent_Utils_Hash_Table_H\n#define _Download_Agent_Utils_Hash_Table_H\n\n#include \"download-agent-pthread.h\"\n\ntypedef struct _dl_id_history_t dl_id_history_t;\nstruct _dl_id_history_t {\n\tint starting_num;\n\tint cur_dl_id;\n\tpthread_mutex_t mutex;\n};\n\nda_result_t init_dl_id_history(dl_id_history_t *dl_id_history);\nda_result_t deinit_dl_id_history(dl_id_history_t *dl_id_history);\n\nint get_available_dl_id(dl_id_history_t *dl_id_history);\n\n\n#endif /* _Download_Agent_Utils_Hash_Table_H */\n"
},
{
"alpha_fraction": 0.7018557786941528,
"alphanum_fraction": 0.7030116319656372,
"avg_line_length": 31.78105354309082,
"blob_id": "60f73a767c61bed521010a3a27a7a10bced761e8",
"content_id": "83d6a0f3be08694498757c18edbcec84abc194c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 15573,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 475,
"path": "/include/download-agent-interface.h",
"repo_name": "deqing/download-agent",
"src_encoding": "UTF-8",
"text": "/*\n * Copyright (c) 2012 Samsung Electronics Co., Ltd All Rights Reserved\n *\n * Licensed under the Apache License, Version 2.0 (the License);\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an AS IS BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n\n#ifndef _Download_Agent_Interface_H\n#define _Download_Agent_Interface_H\n\n#ifndef EXPORT_API\n#define EXPORT_API __attribute__((visibility(\"default\")))\n#endif\n\n#ifdef __cplusplus\nextern \"C\"\n{\n#endif\n\n#include \"download-agent-defs.h\"\n#include <stdarg.h>\n\n/**\n * @struct user_paused_info_t\n * @brief Download Agent will send its state through this structure.\n * @see da_paused_info_cb\n * @par\n * This is used only by callback /a user_paused_info_t. \\n\n */\ntypedef struct {\n\t/// download request id for this notification\n\tint download_id;\n} user_paused_info_t;\n\n/**\n * @struct user_progress_info_t\n * @brief Download Agent will send current downloading file's information through this structure.\n * @see da_progress_info_cb\n * @par\n * This is used only by callback /a da_progress_info_cb. \\n\n */\ntypedef struct {\n\t/// download request id for this updated download information\n\tint download_id;\n\t/// received size of chunked data.\n\tunsigned long int received_size;\n} user_progress_info_t;\n\n/**\n * @struct user_download_info_t\n * @brief Download Agent will send current download's information through this structure.\n * @see da_started_info_cb\n * @par\n * This is used only by callback /a da_started_info_cb. \\n\n */\ntypedef struct {\n\t/// download request id for this updated download information\n\tint download_id;\n\t/// file's mime type from http header.\n\tchar *file_type;\n\t/// file size from http header.\n\tunsigned long int file_size;\n\t/// This is temporary file path.\n\tchar *tmp_saved_path;\n\t/// This is the file name for showing to user.\n\tchar *content_name;\n\t/// etag string value for resume download,\n\tchar *etag;\n} user_download_info_t;\n\ntypedef struct {\n\t/// download request id for this updated download information\n\tint download_id;\n\t/// This has only file name for now.\n\tchar *saved_path;\n\t/// etag string value for resume download,\n\t/// This is returned when the download is failed and the etag is received from content server\n\tchar *etag;\n\t/// convey error code if necessary, or it is zero.\n\tint err;\n\t/// http status code if necessary, or it is zero.\n\tint http_status;\n} user_finished_info_t;\n\ntypedef struct {\n\tconst char **request_header;\n\tint request_header_count;\n\tconst char *install_path;\n\tconst char *file_name;\n\tconst char *temp_file_path; /* For resume download, the \"etag\" value should be existed together */\n\tconst char *etag; /* For resume download */\n\tvoid *user_data;\n} extension_data_t;\n\n/**\n * @typedef da_paused_cb\n * @brief Download Agent will call this function to paused its state.\n *\n * This is user callback function registered on \\a da_init. \\n\n *\n * @remarks For the most of time, this state is just informative, so, user doesn't need to do any action back to Download Agent.\n *\n * @warning Download will be holding until getting user confirmation result through the function.\n *\n * @param[in]\t\tstate\t\tstate from Download Agent\n * @param[in]\t\tuser_param\tuser parameter which is set with \\a DA_FEATURE_USER_DATA\n *\n * @see da_init\n * @see da_client_cb_t\n */\ntypedef void (*da_paused_info_cb) (user_paused_info_t *paused_info, void *user_param);\n\n/**\n * @brief Download Agent will call this function to update received size of download-requested file.\n *\n * This is user callback function registered on \\a da_init. \\n\n * This is informative, so, user doesn't need to do any action back to Download Agent.\\n\n *\n * @param[in]\t\tprogress_info\t\tupdated downloading information\n * @param[in]\t\tuser_param\tuser parameter which is set with \\a DA_FEATURE_USER_DATA\n *\n * @see da_init\n * @see da_client_cb_t\n */\ntypedef void (*da_progress_info_cb) (user_progress_info_t *progress_info, void *user_param);\n\n/**\n * @brief Download Agent will call this function to update mime type, temp file name, total file sizeand installed path.\n *\n * This is user callback function registered on \\a da_init. \\n\n * This is informative, so, user doesn't need to do any action back to Download Agent.\\n\n *\n * @param[in]\t\tdownload_info\t\tupdated download information\n * @param[in]\t\tuser_param\tuser parameter which is set with \\a DA_FEATURE_USER_DATA\n *\n * @see da_init\n * @see da_client_cb_t\n */\ntypedef void (*da_started_info_cb) (user_download_info_t *download_info, void *user_param);\n\ntypedef void (*da_finished_info_cb) (user_finished_info_t *finished_info, void *user_param);\n /**\n * @struct da_client_cb_t\n * @brief This structure convey User's callback functions for \\a da_init\n * @see da_init\n */\ntypedef struct {\n\t/// callback to convey download information\n\tda_started_info_cb update_dl_info_cb;\n\t/// callback to convey downloading information while downloading including received file size\n\tda_progress_info_cb update_progress_info_cb;\n\t/// callback to convey saved path\n\tda_finished_info_cb finished_info_cb;\n\t/// callback to convey etag value\n\tda_paused_info_cb paused_info_cb;\n} da_client_cb_t;\n\n/**\n * @fn int da_init (da_client_cb_t *da_client_callback)\n * @brief This function initiates Download Agent and registers user callback functions.\n * @warning This should be called at once when client application is initialized before using other Download Agent APIs\n * @warning This function is paired with da_deinit function.\n *\n * @pre None.\n * @post None.\n *\n * @param[in]\tda_client_callback\tUser callback function structure. The type is struct data pointer.\n * @return\t\tDA_RESULT_OK for success, or DA_ERR_XXX for fail. DA_ERR_XXX is defined at download-agent-def.h.\n * @remarks\t\tUser MUST call this function first rather than any other DA APIs. \\n\n * \t\t\t\tPlease do not call UI code at callback function in direct. \\n\n * \t\t\t\tIt is better that it returns as soon as copying the data of callback functon. \\n\n * @see da_deinit\n * @par Example\n * @code\n * #include <download-agent-interface.h>\n *\n * void da_started_info_cb(user_download_info_t *download_info,void *user_param);\n * void da_progress_info_cb(user_downloading_info_t *downloading_info,void *user_param);\n * void da_finished_cb(user_finished_info_t *complted_info, void *user_param);\n * void da_paused_info_cb(user_paused_info_t *paused_info, void *user_param);\n *\n * int download_initialize()\n * {\n *\tint da_ret;\n *\tda_client_cb_t da_cb = {0};\n *\n *\tda_cb.update_dl_info_cb = &update_download_info_cb;\n *\tda_cb.update_progress_info_cb = &progress_info_cb;\n *\tda_cb.finished_info_cb = &finished_info_cb;\n *\tda_cb.paused_info_cb = &paused_cb;\n *\n *\tda_ret = da_init (&da_cb, 0);\n *\tif (da_ret == DA_RESULT_OK) {\n *\t\t// printf(\"successed\\n\");\n *\t\treturn true;\n *\t} else {\n *\t\t// printf(\"failed with error code %d\\n\", da_ret);\n *\t\treturn fail;\n *\t}\n * }\n * @endcode\n */\nEXPORT_API int da_init(da_client_cb_t *da_client_callback);\n\n /**\n * @fn int da_deinit ()\n * @brief This function deinitiates Download Agent.\n *\n * This function destroys all infomation for client manager.\n * When Download Agent is not used any more, please call this function.\n * Usually when client application is destructed, this is needed.\n *\n * @remarks This is paired with da_init. \\n\n * \t\t\tThe client Id should be the one from /a da_init(). \\n\n * \t\t\tOtherwise, it cannot excute to deinitialize. \\n\n *\n * @pre da_init() must be called in advance.\n * @post None.\n *\n * @return\t\tDA_RESULT_OK for success, or DA_ERR_XXX for fail. DA_ERR_XXX is defined at download-agent-def.h.\n * @see da_init\n * @par Example\n * @code\n * #include <download-agent-interface.h>\n *\n *\n * int download_deinitialize()\n * {\n *\tint da_ret;\n *\tda_ret = da_deinit();\n *\tif(da_ret == DA_RESULT_OK) {\n *\t\t// printf(\"successed\\n\");\n *\t\treturn true;\n *\t} else {\n *\t\t// printf(\"failed with error code %d\\n\", da_ret);\n *\t\treturn fail;\n *\t}\n * }\n @endcode\n */\nEXPORT_API int da_deinit();\n\n /**\n * @fn int da_start_download(const char *url, int *download_id)\n * @brief This function starts to download a content on passed URL.\n *\n * Useful information and result are conveyed through following callbacks.\n * @li da_started_info_cb\n * @li da_progress_cb\n *\n * @pre da_init() must be called in advance.\n * @post None.\n * @remarks\n * \tDownloaded file is automatically registered to system. (e.g. File DB) \\n\n * \tIf there is another file has same name on registering directory, new one's name would have numbering postfix. \\n\n * \t(e.g. abc.mp3 to abc_1.mp3)\n *\n * @param[in]\turl\t\t\t\turl to start download\n * @param[out]\tdownload_id\t\tassigned download request id for this URL\n * @return\t\tDA_RESULT_OK for success, or DA_ERR_XXX for fail. DA_ERR_XXX is defined at download-agent-def.h.\n *\n * @see None.\n *\n * @par Example\n * @code\n * #include <download-agent-interface.h>\n *\n * int da_ret;\n * int download_id;\n * char *url = \"http://www.test.com/sample.mp3\";\n *\n * da_ret = da_start_download(url,&download_id);\n * if (da_ret == DA_RESULT_OK)\n *\tprintf(\"download requesting is successed\\n\");\n * else\n *\tprintf(\"download requesting is failed with error code %d\\n\", da_ret);\n * @endcode\n */\nEXPORT_API int da_start_download(const char *url, int *download_id);\n\n/**\n* @fn int da_start_download_with_extension(const char *url, extension_data_t ext_data, int *download_id)\n* @brief This function starts to download a content on passed URL with passed extension.\n*\n* Useful information and result are conveyed through following callbacks.\n* @li da_started_info_cb\n* @li da_progress_cb\n*\n* @pre da_init() must be called in advance.\n* @post None.\n* @remarks This API operation is exactly same with da_start_download(), except for input properties.\t\\n\n*\n* @param[in]\turl\turl to start download\n* @param[in]\text_data extension data\n* @param[out]\tdownload_id\tassigned download request id for this URL\n* @return\tDA_RESULT_OK for success, or DA_ERR_XXX for fail. DA_ERR_XXX is defined at download-agent-def.h.\n*\n*\n* @par Example\n* @code\n #include <download-agent-interface.h>\n\n\tint da_ret;\n\tint download_id;\n\textension_data_t ext_data = {0,};\n\tconst char *url = \"https://www.test.com/sample.mp3\";\n\tconst char *install_path = \"/myFiles/music\";\n\tconst char *my_data = strdup(\"data\");\n\text_data.install_path = install_path;\n\text_data.user_data = (void *)my_data;\n\n\tda_ret = da_start_download_with_extension(url, &download_id, &ext_data);\n\tif (da_ret == DA_RESULT_OK)\n printf(\"download requesting is successed\\n\");\n\telse\n printf(\"download requesting is failed with error code %d\\n\", da_ret);\n @endcode\n*/\nEXPORT_API int da_start_download_with_extension(const char *url,\n\textension_data_t *ext_data,\n\tint *download_id\n);\n\n\n/**\n * @fn int da_cancel_download(int download_id)\n * @brief This function cancels a download for passed download_id.\n *\n * Client can use this function if user wants to cancel already requested download.\n *\n * @remarks Should check return value. \\n\n * \t\t\tIf return value is not DA_RESULT_OK, then previous requested download can be keep downloading.\n * @remarks After calling this function, all information for the download_id will be deleted. So, client cannot request anything for the download_id.\n *\n * @pre There should be exist ongoing or suspended download for download_id.\n * @post None.\n *\n * @param[in]\t\tdownload_id\t\tdownload request id\n * @return\t\tDA_RESULT_OK for success, or DA_ERR_XXX for fail\n *\n * @see None.\n *\n * @par Example\n * @code\n #include <download-agent-interface.h>\n\n int da_ret;\n int download_id;\n\n da_ret = da_cancel_download(download_id);\n if(da_ret == DA_RESULT_OK) {\n\t\t// printf(\"download with [%d] is successfully canceled.\\n\", download_id);\n }\n else {\n\t\t// in this case, downloading with download_id is keep ongoing.\n\t\tprintf(\"failed to cancel with error code %d\\n\", da_ret);\n }\n @endcode\n */\nEXPORT_API int da_cancel_download(int download_id);\n\n\n/**\n * @fn int da_suspend_download(int download_id)\n * @brief This function suspends downloading for passed download_id.\n *\n * Client can use this function if user wants to suspend already requested download.\n *\n * @remarks Should check return value. \\n\n * \t\t\tIf return value is not DA_RESULT_OK, then previous requested download can be keep downloading.\n * @remarks After calling this function, all information for the download_id will be remained. So, client can request resume for the download_id.\n * @remarks Client should cancel or resume for this download_id, or all information for the download_id will be leaved forever.\n *\n * @pre There should be exist ongoing download for download_id.\n * @post None.\n *\n * @param[in]\t\tdownload_id\t\tdownload request id\n * @return\t\tDA_RESULT_OK for success, or DA_ERR_XXX for fail\n *\n * @see da_resume_download()\n * @see da_cancel_download()\n *\n * @par Example\n * @code\n #include <download-agent-interface.h>\n\n int da_ret;\n int download_id;\n\n da_ret = da_suspend_download(download_id);\n if(da_ret == DA_RESULT_OK) {\n\t\t// printf(\"download with [%d] is successfully suspended.\\n\", download_id);\n }\n else {\n\t\t// in this case, downloading with download_id is keep ongoing.\n\t\tprintf(\"failed to suspend with error code %d\\n\", da_ret);\n }\n @endcode\n */\nEXPORT_API int da_suspend_download(int download_id);\n\nEXPORT_API int da_suspend_download_without_update(int download_id);\n/**\n * @fn int da_resume_download(int download_id)\n * @brief This function resumes downloading for passed download_id.\n *\n * Client can use this function if user wants to resume suspended download.\n *\n * @remarks Should check return value. \\n\n * \t\t\tIf return value is not DA_RESULT_OK, then requested download can be not to resume.\n *\n * @pre There should be exist suspended download for download_id.\n * @post None.\n *\n * @param[in]\t\tdownload_id\t\tdownload request id\n * @return\t\tDA_RESULT_OK for success, or DA_ERR_XXX for fail\n *\n * @see da_suspend_download()\n *\n * @par Example\n * @code\n #include <download-agent-interface.h>\n\n int da_ret;\n int download_id;\n\n da_ret = da_resume_download(download_id);\n if(da_ret == DA_RESULT_OK) {\n\t\t// printf(\"download with [%d] is successfully resumed.\\n\", download_id);\n }\n else {\n\t\t// in this case, downloading with download_id is keep suspended.\n\t\tprintf(\"failed to resume with error code %d\\n\", da_ret);\n }\n @endcode\n */\nEXPORT_API int da_resume_download(int download_id);\n\n/**\n * @fn int da_is_valid_download_id(int download_id)\n * @brief This function return the download id is valid and the download thread is still alive.\n *\n * Client can use this function if user wants to resume download.\n * If the download id is vaild and the download thread is alive, it can resume download with using da_resume_download()\n * If the the download thread was already terminated due to restarting the process,\n * it can resume download with using da_start_download_with_extension()\n *\n *\n *\n * @remarks Should check return value. \\n\n * \t\t\tIf return value is not DA_RESULT_OK, then requested download can be not to resume.\n *\n * @pre There should be exist suspended download for download_id.\n * @post None.\n *\n * @param[in]\t\tdownload_id\t\tdownload request id\n * @return\t\t1 for success, or 0 for fail\n *\n */\nEXPORT_API int da_is_valid_download_id(int download_id);\n\n#ifdef __cplusplus\n}\n#endif\n\n#endif //_Download_Agent_Interface_H\n\n\n"
},
{
"alpha_fraction": 0.665755033493042,
"alphanum_fraction": 0.6670172810554504,
"avg_line_length": 28.98895835876465,
"blob_id": "434eb4968eaa31c50b0738432c451eb860ccd44e",
"content_id": "e4268acf838300ee06a3ed65123b3a680b88b363",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 19013,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 634,
"path": "/download-agent-client-mgr.c",
"repo_name": "deqing/download-agent",
"src_encoding": "UTF-8",
"text": "/*\n * Copyright (c) 2012 Samsung Electronics Co., Ltd All Rights Reserved\n *\n * Licensed under the Apache License, Version 2.0 (the License);\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an AS IS BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n\n#include <unistd.h>\n\n#include \"download-agent-client-mgr.h\"\n#include \"download-agent-debug.h\"\n#include \"download-agent-utils.h\"\n#include \"download-agent-file.h\"\n\n#define IS_CLIENT_Q_HAVING_DATA(QUEUE)\t(QUEUE->having_data)\n\nstatic client_app_mgr_t client_app_mgr;\n\nstatic da_result_t __launch_client_thread(void);\nstatic void *__thread_for_client_noti(void *data);\nvoid __thread_clean_up_handler_for_client_thread(void *arg);\nstatic void __pop_client_noti(client_noti_t **out_client_noti);\n\nvoid __client_q_goto_sleep_without_lock(void);\nvoid __client_q_wake_up_without_lock(void);\nvoid destroy_client_noti(client_noti_t *client_noti);\n\nda_result_t init_client_app_mgr()\n{\n\tDA_LOG_FUNC_START(ClientNoti);\n\n\tif(client_app_mgr.is_init)\n\t\treturn DA_RESULT_OK;\n\n\tclient_app_mgr.is_init = DA_TRUE;\n\tclient_app_mgr.client_app_info.client_user_agent = DA_NULL;\n\tclient_app_mgr.is_thread_init = DA_FALSE;\n\n\treturn DA_RESULT_OK;\n}\n\nda_bool_t is_client_app_mgr_init(void)\n{\n\treturn client_app_mgr.is_init;\n}\n\nda_result_t reg_client_app(\n\t\tda_client_cb_t *da_client_callback)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\tclient_queue_t *queue = DA_NULL;\n\tclient_noti_t *client_noti = DA_NULL;\n\n\tDA_LOG_FUNC_START(ClientNoti);\n\n\tmemset(&(client_app_mgr.client_app_info.client_callback),\n\t\t\t0, sizeof(da_client_cb_t));\n\tmemcpy(&(client_app_mgr.client_app_info.client_callback),\n\t\t\tda_client_callback, sizeof(da_client_cb_t));\n\n\t_da_thread_mutex_init(&(client_app_mgr.mutex_client_mgr), DA_NULL);\n\n\t/* If some noti is existed at queue, delete all */\n\tdo {\n\t\t__pop_client_noti(&client_noti);\n\t\tdestroy_client_noti(client_noti);\n\t} while(client_noti != DA_NULL);\n\n\tqueue = &(client_app_mgr.client_queue);\n\tDA_LOG_VERBOSE(ClientNoti, \"client queue = %p\", queue);\n\t_da_thread_mutex_init(&(queue->mutex_client_queue), DA_NULL);\n\t_da_thread_cond_init(&(queue->cond_client_queue), DA_NULL);\n\n\tret = __launch_client_thread();\n\n\treturn ret;\n}\n\nda_result_t dereg_client_app(void)\n{\n\tclient_noti_t *client_noti = DA_NULL;\n\n\tDA_LOG_FUNC_START(ClientNoti);\n\n\tclient_noti = (client_noti_t *)calloc(1, sizeof(client_noti_t));\n\tif (!client_noti) {\n\t\tDA_LOG_ERR(ClientNoti, \"calloc fail\");\n\t\treturn DA_ERR_FAIL_TO_MEMALLOC;\n\t}\n\n\tclient_noti->slot_id = DA_INVALID_ID;\n\tclient_noti->noti_type = Q_CLIENT_NOTI_TYPE_TERMINATE;\n\tclient_noti->next = DA_NULL;\n\n\t_da_thread_mutex_lock(&(client_app_mgr.mutex_client_mgr));\n\tif (client_app_mgr.is_thread_init != DA_TRUE) {\n\t\tDA_LOG_CRITICAL(ClientNoti, \"try to cancel client mgr thread id[%lu]\", client_app_mgr.thread_id);\n\t\tif (pthread_cancel(client_app_mgr.thread_id) < 0) {\n\t\t\tDA_LOG_ERR(ClientNoti, \"cancel thread is failed!!!\");\n\t\t}\n\t\tfree(client_noti);\n\t} else {\n\t\tvoid *t_return = NULL;\n\t\tDA_LOG_VERBOSE(ClientNoti, \"pushing Q_CLIENT_NOTI_TYPE_TERMINATE\");\n\t\tpush_client_noti(client_noti);\n\t\tDA_LOG_CRITICAL(Thread, \"===try to join client mgr thread id[%lu]===\", client_app_mgr.thread_id);\n\t\tif (pthread_join(client_app_mgr.thread_id, &t_return) < 0) {\n\t\t\tDA_LOG_ERR(Thread, \"join client thread is failed!!!\");\n\t\t}\n\t\tDA_LOG_CRITICAL(Thread, \"===thread join return[%d]===\", (char*)t_return);\n\t}\n\t_da_thread_mutex_unlock(&(client_app_mgr.mutex_client_mgr));\n\n\t/* ToDo: This clean up should be done at the end of client_thread. */\n\tif(client_app_mgr.client_app_info.client_user_agent) {\n\t\tfree(client_app_mgr.client_app_info.client_user_agent);\n\t\tclient_app_mgr.client_app_info.client_user_agent = DA_NULL;\n\t}\n\t_da_thread_mutex_lock(&(client_app_mgr.mutex_client_mgr));\n\tclient_app_mgr.is_thread_init = DA_FALSE;\n\t_da_thread_mutex_unlock(&(client_app_mgr.mutex_client_mgr));\n\t_da_thread_mutex_destroy(&(client_app_mgr.mutex_client_mgr));\n\treturn DA_RESULT_OK;\n}\n\nda_result_t send_client_paused_info(int slot_id)\n{\n\tclient_noti_t *client_noti = DA_NULL;\n\tuser_paused_info_t *paused_info = DA_NULL;\n\tdownload_state_t state = GET_DL_STATE_ON_ID(slot_id);\n\n\tDA_LOG_FUNC_START(ClientNoti);\n\n\tif (!GET_DL_ENABLE_PAUSE_UPDATE(slot_id)) {\n\t\tDA_LOG(ClientNoti, \"Do not call pause cb\");\n\t\treturn DA_RESULT_OK;\n\t}\n\tif (!is_valid_slot_id(slot_id)) {\n\t\tDA_LOG_ERR(ClientNoti, \"Download ID is not valid\");\n\t\treturn DA_RESULT_OK;\n\t}\n\n\tDA_LOG_VERBOSE(ClientNoti, \"slot_id[%d]\", slot_id);\n\tif ((DOWNLOAD_STATE_PAUSED != state)) {\n\t\tDA_LOG(ClientNoti, \"The state is not paused. state:%d\", state);\n\t\treturn DA_ERR_INVALID_STATE;\n\t}\n\n\tclient_noti = (client_noti_t *)calloc(1, sizeof(client_noti_t));\n\tif (!client_noti) {\n\t\tDA_LOG_ERR(ClientNoti, \"calloc fail\");\n\t\treturn DA_ERR_FAIL_TO_MEMALLOC;\n\t}\n\n\tclient_noti->slot_id = slot_id;\n\tclient_noti->user_data = GET_DL_USER_DATA(slot_id);\n\tclient_noti->noti_type = Q_CLIENT_NOTI_TYPE_PAUSED_INFO;\n\tclient_noti->next = DA_NULL;\n\n\tpaused_info = (user_paused_info_t *)&(client_noti->type.paused_info);\n\tpaused_info->download_id= GET_DL_ID(slot_id);\n\tDA_LOG(ClientNoti, \"pushing paused info. slot_id=%d, dl_id=%d\",\n\t\t\tslot_id, GET_DL_ID(slot_id));\n\n\tpush_client_noti(client_noti);\n\n\treturn DA_RESULT_OK;\n}\n\nda_result_t send_client_update_progress_info (\n\t\tint slot_id,\n\t\tint dl_id,\n\t\tunsigned long int received_size\n\t\t)\n{\n\tclient_noti_t *client_noti = DA_NULL;\n\tuser_progress_info_t *progress_info = DA_NULL;\n\n\t//DA_LOG_FUNC_START(ClientNoti);\n\n\tif (!is_valid_slot_id(slot_id)) {\n\t\tDA_LOG_ERR(ClientNoti, \"Download ID is not valid\");\n\t\treturn DA_ERR_INVALID_DL_REQ_ID;\n\t}\n\n\tclient_noti = (client_noti_t *)calloc(1, sizeof(client_noti_t));\n\tif (!client_noti) {\n\t\tDA_LOG_ERR(ClientNoti, \"calloc fail\");\n\t\treturn DA_ERR_FAIL_TO_MEMALLOC;\n\t}\n\n\tclient_noti->slot_id = slot_id;\n\tclient_noti->user_data = GET_DL_USER_DATA(slot_id);\n\tclient_noti->noti_type = Q_CLIENT_NOTI_TYPE_PROGRESS_INFO;\n\tclient_noti->next = DA_NULL;\n\n\tprogress_info = (user_progress_info_t *)&(client_noti->type.update_progress_info);\n\tprogress_info->download_id= dl_id;\n\tprogress_info->received_size = received_size;\n\n\tDA_LOG_VERBOSE(ClientNoti, \"pushing received_size=%lu, slot_id=%d, dl_id=%d\",\n\t\t\treceived_size, slot_id, dl_id);\n\n\tpush_client_noti(client_noti);\n\n\treturn DA_RESULT_OK;\n}\n\nda_result_t send_client_update_dl_info (\n\t\tint slot_id,\n\t\tint dl_id,\n\t\tchar *file_type,\n\t\tunsigned long int file_size,\n\t\tchar *tmp_saved_path,\n\t\tchar *pure_file_name,\n\t\tchar *etag,\n\t\tchar *extension)\n{\n\tclient_noti_t *client_noti = DA_NULL;\n\tuser_download_info_t *update_dl_info = DA_NULL;\n\tint len = 0;\n\n\tDA_LOG_FUNC_START(ClientNoti);\n\n\tif (!is_valid_slot_id(slot_id)) {\n\t\tDA_LOG_ERR(ClientNoti, \"Download ID is not valid\");\n\t\treturn DA_ERR_INVALID_DL_REQ_ID;\n\t}\n\n\tclient_noti = (client_noti_t *)calloc(1, sizeof(client_noti_t));\n\tif (!client_noti) {\n\t\tDA_LOG_ERR(ClientNoti, \"calloc fail\");\n\t\treturn DA_ERR_FAIL_TO_MEMALLOC;\n\t}\n\n\tclient_noti->slot_id = slot_id;\n\tclient_noti->user_data = GET_DL_USER_DATA(slot_id);\n\tclient_noti->noti_type = Q_CLIENT_NOTI_TYPE_STARTED_INFO;\n\tclient_noti->next = DA_NULL;\n\n\tupdate_dl_info = (user_download_info_t *)&(client_noti->type.update_dl_info);\n\tupdate_dl_info->download_id = dl_id;\n\tupdate_dl_info->file_size = file_size;\n\tif (pure_file_name && extension) {\n\t\tlen = strlen(pure_file_name) + strlen(extension) + 1;\n\t\tupdate_dl_info->content_name = (char *)calloc(len + 1, sizeof(char));\n\t\tif (!update_dl_info->content_name) {\n\t\t\tfree(client_noti);\n\t\t\treturn DA_ERR_FAIL_TO_MEMALLOC;\n\t\t}\n\t\tsnprintf(update_dl_info->content_name, len + 1, \"%s.%s\",\n\t\t\t\tpure_file_name, extension);\n\t}\n\n\t/* These strings MUST be copied to detach __thread_for_client_noti from download_info */\n\tif (file_type)\n\t\tupdate_dl_info->file_type = strdup(file_type);\n\n\tif (tmp_saved_path)\n\t\tupdate_dl_info->tmp_saved_path = strdup(tmp_saved_path);\n\n\tif (etag)\n\t\tupdate_dl_info->etag = strdup(etag);\n\tDA_LOG(ClientNoti, \"pushing file_size=%lu, slot_id=%d, dl_id=%d\",\n\t\t\tfile_size, slot_id, dl_id);\n\n\tpush_client_noti(client_noti);\n\n\treturn DA_RESULT_OK;\n}\n\nda_result_t send_client_finished_info (\n\t\tint slot_id,\n\t\tint dl_id,\n\t\tchar *saved_path,\n\t\tchar *etag,\n\t\tint error,\n\t\tint http_status\n\t\t)\n{\n\tclient_noti_t *client_noti = DA_NULL;\n\tuser_finished_info_t *finished_info = DA_NULL;\n\n\tDA_LOG_FUNC_START(ClientNoti);\n\n\tif (!is_valid_slot_id(slot_id)) {\n\t\tDA_LOG_ERR(ClientNoti, \"Download ID is not valid\");\n\t\treturn DA_ERR_INVALID_DL_REQ_ID;\n\t}\n\n\tclient_noti = (client_noti_t *)calloc(1, sizeof(client_noti_t));\n\tif (!client_noti) {\n\t\tDA_LOG_ERR(ClientNoti, \"calloc fail\");\n\t\treturn DA_ERR_FAIL_TO_MEMALLOC;\n\t}\n\n\tclient_noti->slot_id = slot_id;\n\tclient_noti->user_data = GET_DL_USER_DATA(slot_id);\n\tclient_noti->noti_type = Q_CLIENT_NOTI_TYPE_FINISHED_INFO;\n\tclient_noti->next = DA_NULL;\n\n\tfinished_info = (user_finished_info_t *)&(client_noti->type.finished_info);\n\tfinished_info->download_id = dl_id;\n\tfinished_info->err = error;\n\tfinished_info->http_status = http_status;\n\n\tif (saved_path) {\n\t\tfinished_info->saved_path = strdup(saved_path);\n\t\tDA_LOG(ClientNoti, \"saved path=%s\", saved_path);\n\t}\n\tif (etag) {\n\t\tfinished_info->etag = strdup(etag);\n\t\tDA_LOG(ClientNoti, \"pushing finished info. etag[%s]\", etag);\n\t}\n\tDA_LOG(ClientNoti, \"user_data=%p\", client_noti->user_data);\n\tDA_LOG(ClientNoti, \"http_status=%d\", http_status);\n\tDA_LOG(ClientNoti, \"pushing slot_id=%d, dl_id=%d err=%d\", slot_id, dl_id, error);\n\n\tpush_client_noti(client_noti);\n\n\treturn DA_RESULT_OK;\n}\n\nda_result_t __launch_client_thread(void)\n{\n\tpthread_t thread_id = DA_NULL;\n\n\tDA_LOG_FUNC_START(Thread);\n\n\tif (pthread_create(&thread_id,DA_NULL,__thread_for_client_noti,DA_NULL) < 0) {\n\t\tDA_LOG_ERR(Thread, \"making thread failed..\");\n\t\treturn DA_ERR_FAIL_TO_CREATE_THREAD;\n\t}\n\tDA_LOG(Thread, \"client mgr thread id[%d]\", thread_id);\n\tclient_app_mgr.thread_id = thread_id;\n\treturn DA_RESULT_OK;\n}\n\nvoid destroy_client_noti(client_noti_t *client_noti)\n{\n\tif (client_noti) {\n\t\tif (client_noti->noti_type == Q_CLIENT_NOTI_TYPE_STARTED_INFO) {\n\t\t\tuser_download_info_t *update_dl_info = DA_NULL;\n\t\t\tupdate_dl_info = (user_download_info_t*)&(client_noti->type.update_dl_info);\n\t\t\tif (update_dl_info->file_type) {\n\t\t\t\tfree(update_dl_info->file_type);\n\t\t\t\tupdate_dl_info->file_type = DA_NULL;\n\t\t\t}\n\t\t\tif (update_dl_info->tmp_saved_path) {\n\t\t\t\tfree(update_dl_info->tmp_saved_path);\n\t\t\t\tupdate_dl_info->tmp_saved_path = DA_NULL;\n\t\t\t}\n\t\t\tif (update_dl_info->etag) {\n\t\t\t\tfree(update_dl_info->etag);\n\t\t\t\tupdate_dl_info->etag = DA_NULL;\n\t\t\t}\n\t\t} else if (client_noti->noti_type ==\n\t\t\t\tQ_CLIENT_NOTI_TYPE_FINISHED_INFO) {\n\t\t\tuser_finished_info_t *finished_info = DA_NULL;\n\t\t\tfinished_info = (user_finished_info_t*)\n\t\t\t\t&(client_noti->type.finished_info);\n\t\t\tif (finished_info->saved_path) {\n\t\t\t\tfree(finished_info->saved_path);\n\t\t\t\tfinished_info->saved_path = DA_NULL;\n\t\t\t}\n\t\t\tif (finished_info->etag) {\n\t\t\t\tfree(finished_info->etag);\n\t\t\t\tfinished_info->etag = DA_NULL;\n\t\t\t}\n\t\t}\n\t\tfree(client_noti);\n\t}\n}\n\n\nvoid push_client_noti(client_noti_t *client_noti)\n{\n\tclient_queue_t *queue = DA_NULL;\n\tclient_noti_t *head = DA_NULL;\n\tclient_noti_t *pre = DA_NULL;\n\tclient_noti_t *cur = DA_NULL;\n\n\t/* DA_LOG_FUNC_START(ClientNoti); */\n\n\tqueue = &(client_app_mgr.client_queue);\n\t_da_thread_mutex_lock (&(queue->mutex_client_queue));\n\n\thead = queue->client_q_head;\n\tif (!head) {\n\t\tqueue->client_q_head = client_noti;\n\t} else {\n\t\tcur = head;\n\t\twhile (cur->next) {\n\t\t\tpre = cur;\n\t\t\tcur = pre->next;\n\t\t}\n#if 0\n\t\tif (cur->noti_type == Q_CLIENT_NOTI_TYPE_PROGRESS_INFO) {\n\t\t\t/* For UI performance. If the update noti info is existed at queue,\n\t\t\t replace it with new update noti info */\n\t\t\tif (cur->slot_id == client_noti->slot_id) {\n\t\t\t\t/* DA_LOG(ClientNoti, \"exchange queue's tail and pushing item\"); */\n\t\t\t\tif (pre == DA_NULL)\n\t\t\t\t\tqueue->client_q_head = client_noti;\n\t\t\t\telse\n\t\t\t\t\tpre->next = client_noti;\n\t\t\t\tdestroy_client_noti(cur);\n\t\t\t} else {\n\t\t\t\tcur->next = client_noti;\n\t\t\t}\n\t\t} else {\n\t\t\tcur->next = client_noti;\n\t\t}\n#else\n\tcur->next = client_noti;\n#endif\n\t}\n\n\tqueue->having_data = DA_TRUE;\n\n\t__client_q_wake_up_without_lock();\n\tif (queue->client_q_head->next) {\n\t\tDA_LOG_VERBOSE(ClientNoti, \"client noti[%p] next noti[%p]\",\n\t\t\t\tqueue->client_q_head, queue->client_q_head->next);\n\t} else {\n\t\tDA_LOG_VERBOSE(ClientNoti, \"client noti[%p] next noti is NULL\",\n\t\t\t\tqueue->client_q_head);\n\t}\n\n\t_da_thread_mutex_unlock (&(queue->mutex_client_queue));\n}\n\nvoid __pop_client_noti(client_noti_t **out_client_noti)\n{\n\tclient_queue_t *queue = DA_NULL;\n\n\t/* DA_LOG_FUNC_START(ClientNoti); */\n\n\tqueue = &(client_app_mgr.client_queue);\n\n\t_da_thread_mutex_lock (&(queue->mutex_client_queue));\n\n\tif (queue->client_q_head) {\n\t\t*out_client_noti = queue->client_q_head;\n\t\tqueue->client_q_head = queue->client_q_head->next;\n\t\tif (queue->client_q_head) {\n\t\t\tDA_LOG_VERBOSE(ClientNoti, \"client noti[%p] next noti[%p]\",\n\t\t\t\t\t*out_client_noti, queue->client_q_head);\n\t\t} else {\n\t\t\tDA_LOG_VERBOSE(ClientNoti, \"client noti[%p] next noti is NULL\",\n\t\t\t\t\t*out_client_noti);\n\t\t}\n\t} else {\n\t\t*out_client_noti = DA_NULL;\n\t}\n\n\tif (queue->client_q_head == DA_NULL) {\n\t\tqueue->having_data = DA_FALSE;\n\t}\n\n\t_da_thread_mutex_unlock (&(queue->mutex_client_queue));\n}\n\nvoid __client_q_goto_sleep_without_lock(void)\n{\n\tclient_queue_t *queue = DA_NULL;\n\n\t/* DA_LOG_FUNC_START(ClientNoti); */\n\n\tqueue = &(client_app_mgr.client_queue);\n\t_da_thread_cond_wait(&(queue->cond_client_queue), &(queue->mutex_client_queue));\n}\n\nvoid __client_q_wake_up_without_lock(void)\n{\n\tclient_queue_t *queue = DA_NULL;\n\n\t/* DA_LOG_FUNC_START(ClientNoti); */\n\n\tqueue = &(client_app_mgr.client_queue);\n\t_da_thread_cond_signal(&(queue->cond_client_queue));\n}\n\nvoid __thread_clean_up_handler_for_client_thread(void *arg)\n{\n\tDA_LOG_CRITICAL(Thread, \"cleanup for thread id = %d\", pthread_self());\n}\n\nstatic void *__thread_for_client_noti(void *data)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\tda_bool_t need_wait = DA_TRUE;\n\tclient_queue_t *queue = DA_NULL;\n\tclient_noti_t *client_noti = DA_NULL;\n\n\t//DA_LOG_FUNC_START(Thread);\n\n\t_da_thread_mutex_lock(&(client_app_mgr.mutex_client_mgr));\n\tclient_app_mgr.is_thread_init = DA_TRUE;\n\t_da_thread_mutex_unlock(&(client_app_mgr.mutex_client_mgr));\n\n\tqueue = &(client_app_mgr.client_queue);\n\tDA_LOG_VERBOSE(ClientNoti, \"client queue = %p\", queue);\n\n\tpthread_setcancelstate(PTHREAD_CANCEL_DISABLE, DA_NULL);\n\tpthread_cleanup_push(__thread_clean_up_handler_for_client_thread, (void *)DA_NULL);\n\n\tdo {\n\t\t_da_thread_mutex_lock(&(queue->mutex_client_queue));\n\t\tif (DA_FALSE == IS_CLIENT_Q_HAVING_DATA(queue)) {\n\t\t\tDA_LOG_VERBOSE(Thread, \"Sleep @ thread_for_client_noti!\");\n\t\t\t__client_q_goto_sleep_without_lock();\n\t\t\tDA_LOG_VERBOSE(Thread, \"Woke up @ thread_for_client_noti\");\n\t\t}\n\t\t_da_thread_mutex_unlock(&(queue->mutex_client_queue));\n\n\t\tdo {\n\t\t\t__pop_client_noti(&client_noti);\n\t\t\tif (client_noti == DA_NULL) {\n\t\t\t\tDA_LOG_ERR(ClientNoti, \"There is no data on client queue!\");\n\t\t\t\tret = DA_ERR_INVALID_STATE;\n\t\t\t\tneed_wait = DA_FALSE;\n\t\t\t} else {\n\t\t\t\tDA_LOG_VERBOSE(ClientNoti, \"noti type[%d]\",\n\t\t\t\t\t\tclient_noti->noti_type);\n\t\t\t\tswitch (client_noti->noti_type) {\n\t\t\t\tcase Q_CLIENT_NOTI_TYPE_STARTED_INFO:\n\t\t\t\t{\n\t\t\t\t\tuser_download_info_t *update_dl_info = DA_NULL;;\n\t\t\t\t\tupdate_dl_info = (user_download_info_t*)(&(client_noti->type.update_dl_info));\n\t\t\t\t\tif (client_app_mgr.client_app_info.client_callback.update_dl_info_cb) {\n\t\t\t\t\t\tclient_app_mgr.client_app_info.client_callback.update_dl_info_cb(update_dl_info, client_noti->user_data);\n\t\t\t\t\t\tif (update_dl_info->etag)\n\t\t\t\t\t\t\tDA_LOG(ClientNoti, \"Etag:[%s]\", update_dl_info->etag);\n\t\t\t\t\t\tDA_LOG(ClientNoti, \"Update download info for slot_id=%d, dl_id=%d, received size=%lu- DONE\",\n\t\t\t\t\t\t\t\tclient_noti->slot_id,\n\t\t\t\t\t\t\t\tupdate_dl_info->download_id,\n\t\t\t\t\t\t\t\tupdate_dl_info->file_size\n\t\t\t\t\t\t\t\t);\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t\tbreak;\n\t\t\t\tcase Q_CLIENT_NOTI_TYPE_PROGRESS_INFO:\n\t\t\t\t{\n\t\t\t\t\tuser_progress_info_t *progress_info = DA_NULL;;\n\t\t\t\t\tprogress_info = (user_progress_info_t*)(&(client_noti->type.update_progress_info));\n\t\t\t\t\tif (client_app_mgr.client_app_info.client_callback.update_progress_info_cb) {\n\t\t\t\t\t\tclient_app_mgr.client_app_info.client_callback.update_progress_info_cb(progress_info, client_noti->user_data);\n\t\t\t\t\t\tDA_LOG_VERBOSE(ClientNoti, \"Update downloading info for slot_id=%d, dl_id=%d, received size=%lu - DONE\",\n\t\t\t\t\t\t\t\tclient_noti->slot_id,\n\t\t\t\t\t\t\t\tprogress_info->download_id,\n\t\t\t\t\t\t\t\tprogress_info->received_size);\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t\tbreak;\n\t\t\t\tcase Q_CLIENT_NOTI_TYPE_FINISHED_INFO:\n\t\t\t\t{\n\t\t\t\t\tuser_finished_info_t *finished_info = DA_NULL;;\n\t\t\t\t\tfinished_info = (user_finished_info_t*)(&(client_noti->type.finished_info));\n\t\t\t\t\tif (client_app_mgr.client_app_info.client_callback.finished_info_cb) {\n\t\t\t\t\t\tclient_app_mgr.client_app_info.client_callback.finished_info_cb(\n\t\t\t\t\t\t\tfinished_info, client_noti->user_data);\n\t\t\t\t\t\tDA_LOG(ClientNoti, \"Completed info for slot_id=%d, dl_id=%d, saved_path=%s etag=%s err=%d http_state=%d user_data=%p- DONE\",\n\t\t\t\t\t\t\t\tclient_noti->slot_id,\n\t\t\t\t\t\t\t\tfinished_info->download_id,\n\t\t\t\t\t\t\t\tfinished_info->saved_path,\n\t\t\t\t\t\t\t\tfinished_info->etag,\n\t\t\t\t\t\t\t\tfinished_info->err,\n\t\t\t\t\t\t\t\tfinished_info->http_status,\n\t\t\t\t\t\t\t\tclient_noti->user_data);\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t\tbreak;\n\t\t\t\tcase Q_CLIENT_NOTI_TYPE_PAUSED_INFO:\n\t\t\t\t{\n\t\t\t\t\tuser_paused_info_t *da_paused_info = DA_NULL;\n\t\t\t\t\tda_paused_info = (user_paused_info_t *)(&(client_noti->type.paused_info));\n\n\t\t\t\t\tif (client_app_mgr.client_app_info.client_callback.paused_info_cb) {\n\t\t\t\t\t\tDA_LOG(ClientNoti, \"User Paused info for slot_id=%d, dl_id=%d - Done\",\n\t\t\t\t\t\t\t\tclient_noti->slot_id,\n\t\t\t\t\t\t\t\tda_paused_info->download_id);\n\t\t\t\t\t\tclient_app_mgr.client_app_info.client_callback.paused_info_cb(\n\t\t\t\t\t\t\tda_paused_info, client_noti->user_data);\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t\tbreak;\n\t\t\t\tcase Q_CLIENT_NOTI_TYPE_TERMINATE:\n\t\t\t\t\tDA_LOG_CRITICAL(ClientNoti, \"Q_CLIENT_NOTI_TYPE_TERMINATE\");\n\t\t\t\t\tneed_wait = DA_FALSE;\n\t\t\t\t\tbreak;\n\t\t\t\t}\n\t\t\t\tdestroy_client_noti(client_noti);\n\t\t\t}\n\n\t\t\tif(DA_TRUE == need_wait) {\n\t\t\t\t_da_thread_mutex_lock(&(queue->mutex_client_queue));\n\t\t\t\tif (DA_FALSE == IS_CLIENT_Q_HAVING_DATA(queue)) {\n\t\t\t\t\t_da_thread_mutex_unlock (&(queue->mutex_client_queue));\n\t\t\t\t\tbreak;\n\t\t\t\t} else {\n\t\t\t\t\t_da_thread_mutex_unlock (&(queue->mutex_client_queue));\n\t\t\t\t}\n\t\t\t} else {\n\t\t\t\tbreak;\n\t\t\t}\n\t\t} while (1);\n\t} while (DA_TRUE == need_wait);\n\n\t_da_thread_mutex_destroy(&(queue->mutex_client_queue));\n\t_da_thread_cond_destroy(&(queue->cond_client_queue));\n\n\tpthread_cleanup_pop(0);\n\tDA_LOG_CRITICAL(Thread, \"=====thread_for_client_noti- EXIT=====\");\n\tpthread_exit((void *)NULL);\n\treturn DA_NULL;\n}\n\nchar *get_client_user_agent_string(void)\n{\n\tif (!client_app_mgr.is_init)\n\t\treturn DA_NULL;\n\n\treturn client_app_mgr.client_app_info.client_user_agent;\n}\n"
},
{
"alpha_fraction": 0.7328072190284729,
"alphanum_fraction": 0.7361894249916077,
"avg_line_length": 28.566667556762695,
"blob_id": "5017c8962eb9b230f34de4ce240c65ac4ed5cc14",
"content_id": "f4c62344b71c70b1c01fbca079293929103a0e3b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2661,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 90,
"path": "/include/download-agent-client-mgr.h",
"repo_name": "deqing/download-agent",
"src_encoding": "UTF-8",
"text": "/*\n * Copyright (c) 2012 Samsung Electronics Co., Ltd All Rights Reserved\n *\n * Licensed under the Apache License, Version 2.0 (the License);\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an AS IS BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n\n#ifndef _Download_Agent_Client_Mgr_H\n#define _Download_Agent_Client_Mgr_H\n\n#include <string.h>\n\n#include \"download-agent-type.h\"\n#include \"download-agent-interface.h\"\n\n#include \"download-agent-pthread.h\"\n\ntypedef enum {\n\tQ_CLIENT_NOTI_TYPE_STARTED_INFO = 0,\n\tQ_CLIENT_NOTI_TYPE_PROGRESS_INFO,\n\tQ_CLIENT_NOTI_TYPE_PAUSED_INFO,\n\tQ_CLIENT_NOTI_TYPE_FINISHED_INFO,\n\tQ_CLIENT_NOTI_TYPE_TERMINATE,\n} client_noti_type;\n\ntypedef struct _client_noti_t client_noti_t;\nstruct _client_noti_t {\n\tint slot_id;\n\tvoid *user_data;\n\tclient_noti_type noti_type;\n\tunion _client_type {\n\t\tuser_download_info_t update_dl_info;\n\t\tuser_progress_info_t update_progress_info;\n\t\tuser_paused_info_t paused_info;\n\t\tuser_finished_info_t finished_info;\n\t} type;\n\n\tclient_noti_t *next;\n};\n\ntypedef struct _client_queue_t {\n\tda_bool_t having_data;\n\tclient_noti_t *client_q_head;\n\tpthread_mutex_t mutex_client_queue;\n\tpthread_cond_t cond_client_queue;\n} client_queue_t;\n\ntypedef struct _client_app_info_t {\n\tda_client_cb_t client_callback;\n\tchar *client_user_agent;\n} client_app_info_t;\n\ntypedef struct _client_app_mgr_t {\n\tda_bool_t is_init;\n\tclient_queue_t client_queue;\n\tclient_app_info_t client_app_info;\n\tpthread_t thread_id;\n\tda_bool_t is_thread_init;\n\tpthread_mutex_t mutex_client_mgr;\n} client_app_mgr_t;\n\nda_result_t init_client_app_mgr(void);\nda_bool_t is_client_app_mgr_init(void);\n\nda_result_t reg_client_app(da_client_cb_t *da_client_callback);\nda_result_t dereg_client_app(void);\n\nda_result_t send_client_paused_info (int slot_id);\nda_result_t send_client_update_dl_info (int slot_id, int dl_id,\n\t\tchar *file_type, unsigned long int file_size, char *tmp_saved_path,\n\t\tchar *pure_file_name, char *etag, char *extension);\nda_result_t send_client_update_progress_info (int slot_id, int dl_id,\n\t\tunsigned long int received_size);\nda_result_t send_client_finished_info (int slot_id, int dl_id,\n\t\tchar *saved_path, char *etag, int error, int http_status);\n\nchar *get_client_user_agent_string(void);\n\nvoid push_client_noti(client_noti_t *client_noti);\n\n#endif\n"
},
{
"alpha_fraction": 0.698113203048706,
"alphanum_fraction": 0.6995645761489868,
"avg_line_length": 26.540000915527344,
"blob_id": "febb66abd817764267633621c7d12c7bac338d68",
"content_id": "ce48e7d72bc2891112e054c3ec0c5cb88e487ce7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1378,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 50,
"path": "/README.md",
"repo_name": "deqing/download-agent",
"src_encoding": "UTF-8",
"text": "\nIntroduction\n------------\n\nThis download agent was part of download-provider in Tizen framework.\nIt provides basic download functionalities based on libsoup.\n\nIt is now separated and can be built into an independent library for external use.\n\nExample\n-------\n\n```C\n#include <pthread.h>\n#include \"download-agent-interface.h\"\n\nstatic GMainLoop* loop = NULL;\nstatic void update_download_info_cb(user_download_info_t *download_info, void *user_param) { }\nstatic void progress_info_cb(user_progress_info_t *progress_info, void *user_param) { }\nstatic void paused_info_cb(user_paused_info_t *paused_info, void *user_param) { }\nstatic void finished_info_cb(user_finished_info_t *finished_info, void *user_param) {\n da_deinit();\n if (g_main_loop_is_running(loop)) {\n g_main_loop_quit(loop);\n }\n}\n\nstatic void* thread_func(void *arg) {\n da_client_cb_t da_cb;\n da_cb.update_dl_info_cb = &update_download_info_cb;\n da_cb.update_progress_info_cb = &progress_info_cb;\n da_cb.finished_info_cb = &finished_info_cb;\n da_cb.paused_info_cb = &paused_info_cb;\n da_init(&da_cb);\n\n int id;\n da_start_download(\"http://test.com/sample.mp3\", &id);\n loop = g_main_loop_new(NULL, 0);\n g_main_loop_run(loop);\n}\n\nint main()\n{\n g_type_init();\n\n pthread_t pt;\n pthread_create(&pt, NULL, &thread_func, NULL);\n}\n```\n\nFor details of usage, please refer to include/download-agent-interface.h\n"
},
{
"alpha_fraction": 0.7356418967247009,
"alphanum_fraction": 0.7423986196517944,
"avg_line_length": 34.878787994384766,
"blob_id": "173f73e2f4d2f33b727c04935c7a3d643b6f6c49",
"content_id": "b273fd8353ab8d44dcc81c23cdb78ab07968a2cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1184,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 33,
"path": "/include/download-agent-dl-mgr.h",
"repo_name": "deqing/download-agent",
"src_encoding": "UTF-8",
"text": "/*\n * Copyright (c) 2012 Samsung Electronics Co., Ltd All Rights Reserved\n *\n * Licensed under the Apache License, Version 2.0 (the License);\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an AS IS BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n\n#ifndef _Download_Agent_Dl_Mgr_H\n#define _Download_Agent_Dl_Mgr_H\n\n#include \"download-agent-type.h\"\n#include \"download-agent-dl-info-util.h\"\n\nda_result_t cancel_download(int dl_id);\nda_result_t suspend_download(int dl_id, da_bool_t is_enable_cb);\nda_result_t resume_download (int dl_id);\n\nda_result_t requesting_download(stage_info *stage);\nda_result_t handle_after_download(stage_info *stage);\nda_result_t send_user_noti_and_finish_download_flow(\n\t\tint slot_id, char *installed_path, char *etag);\n\nda_bool_t is_valid_download_id(int dl_id);\n#endif\n"
},
{
"alpha_fraction": 0.5704934597015381,
"alphanum_fraction": 0.5715004801750183,
"avg_line_length": 36.47169876098633,
"blob_id": "2909b7433637fae5f4c196c840a7c0316d5af369",
"content_id": "86a7648459e7812868a0fd63c9bf3330987ea25d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1986,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 53,
"path": "/download-agent.gyp",
"repo_name": "deqing/download-agent",
"src_encoding": "UTF-8",
"text": "{\n 'targets': [\n {\n 'target_name': 'agent',\n 'type': 'static_library',\n 'include_dirs': [ 'include' ],\n 'variables': { 'packages': ['libsoup-2.4'] },\n 'includes': [ '../../pkg-config.gypi' ],\n 'cflags': [ '-fPIC' ],\n 'ldflags': [ '-fPIC' ],\n 'sources': [\n 'download-agent-basic.c',\n 'download-agent-client-mgr.c',\n 'download-agent-debug.c',\n 'download-agent-dl-info-util.c',\n 'download-agent-dl-mgr.c',\n 'download-agent-encoding.c',\n 'download-agent-file.c',\n 'download-agent-http-mgr.c',\n 'download-agent-http-misc.c',\n 'download-agent-http-msg-handler.c',\n 'download-agent-http-queue.c',\n 'download-agent-interface.c',\n 'download-agent-mime-util.c',\n 'download-agent-plugin-conf.c',\n 'download-agent-plugin-libsoup.c',\n 'download-agent-utils.c',\n 'download-agent-utils-dl-id-history.c',\n 'include/download-agent-basic.h',\n 'include/download-agent-client-mgr.h',\n 'include/download-agent-debug.h',\n 'include/download-agent-defs.h',\n 'include/download-agent-dl-info-util.h',\n 'include/download-agent-dl-mgr.h',\n 'include/download-agent-encoding.h',\n 'include/download-agent-file.h',\n 'include/download-agent-http-mgr.h',\n 'include/download-agent-http-misc.h',\n 'include/download-agent-http-msg-handler.h',\n 'include/download-agent-http-queue.h',\n 'include/download-agent-interface.h',\n 'include/download-agent-mime-util.h',\n 'include/download-agent-plugin-conf.h',\n 'include/download-agent-plugin-http-interface.h',\n 'include/download-agent-plugin-libsoup.h',\n 'include/download-agent-pthread.h',\n 'include/download-agent-type.h',\n 'include/download-agent-utils-dl-id-history.h',\n 'include/download-agent-utils.h',\n ],\n },\n ],\n}\n"
},
{
"alpha_fraction": 0.6940804123878479,
"alphanum_fraction": 0.6999548077583313,
"avg_line_length": 30.16901397705078,
"blob_id": "584ff36446d6b667480aa4bdfdac342ee4623c98",
"content_id": "1d067223e46260ad4fc754ab9344fd35731062d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2213,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 71,
"path": "/download-agent-utils-dl-id-history.c",
"repo_name": "deqing/download-agent",
"src_encoding": "UTF-8",
"text": "/*\n * Copyright (c) 2012 Samsung Electronics Co., Ltd All Rights Reserved\n *\n * Licensed under the Apache License, Version 2.0 (the License);\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an AS IS BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n\n#include \"download-agent-type.h\"\n#include \"download-agent-utils.h\"\n#include \"download-agent-utils-dl-id-history.h\"\n\nda_result_t init_dl_id_history(dl_id_history_t *dl_id_history)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\n\t/* Initial dl_id_history will be starting number for dl_id.\n\t * dl_id will be sequentially increased from the dl_id_history,\n\t * then dl_id_history will be updated. */\n\t_da_thread_mutex_init(&(dl_id_history->mutex), DA_NULL);\n\t_da_thread_mutex_lock(&(dl_id_history->mutex));\n\tget_random_number(&(dl_id_history->starting_num));\n\tdl_id_history->cur_dl_id = DA_INVALID_ID;\n\t_da_thread_mutex_unlock(&(dl_id_history->mutex));\n\n\tDA_LOG_CRITICAL(Default,\"starting num = %d\", dl_id_history->starting_num);\n\treturn ret;\n}\n\nda_result_t deinit_dl_id_history(dl_id_history_t *dl_id_history)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\n\t_da_thread_mutex_lock(&(dl_id_history->mutex));\n\tdl_id_history->starting_num = DA_INVALID_ID;\n\tdl_id_history->cur_dl_id = DA_INVALID_ID;\n\t_da_thread_mutex_unlock(&(dl_id_history->mutex));\n\n\t_da_thread_mutex_destroy(&(dl_id_history->mutex));\n\n\treturn ret;\n}\n\nint get_available_dl_id(dl_id_history_t *dl_id_history)\n{\n\tint dl_id = 0;\n\n\t_da_thread_mutex_lock(&(dl_id_history->mutex));\n\n\tif (dl_id_history->cur_dl_id == DA_INVALID_ID)\n\t\tdl_id_history->cur_dl_id = dl_id_history->starting_num;\n\telse if (dl_id_history->cur_dl_id > 254)\n\t\tdl_id_history->cur_dl_id = 1;\n\telse\n\t\tdl_id_history->cur_dl_id++;\n\n\tdl_id = dl_id_history->cur_dl_id;\n\n\t_da_thread_mutex_unlock(&(dl_id_history->mutex));\n\n\tDA_LOG_CRITICAL(Default,\"dl_id = %d\", dl_id);\n\treturn dl_id;\n}\n"
},
{
"alpha_fraction": 0.6653435230255127,
"alphanum_fraction": 0.6681679487228394,
"avg_line_length": 25.200000762939453,
"blob_id": "095d41f260fd4118dd3ffc870a56a4d2d0b7d9a9",
"content_id": "8e3bb7821af041bd525a6c6cd2d30136ca8d5565",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 13100,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 500,
"path": "/download-agent-dl-info-util.c",
"repo_name": "deqing/download-agent",
"src_encoding": "UTF-8",
"text": "/*\n * Copyright (c) 2012 Samsung Electronics Co., Ltd All Rights Reserved\n *\n * Licensed under the Apache License, Version 2.0 (the License);\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an AS IS BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n\n#include <string.h>\n\n#include \"download-agent-client-mgr.h\"\n#include \"download-agent-dl-info-util.h\"\n#include \"download-agent-debug.h\"\n#include \"download-agent-utils.h\"\n#include \"download-agent-file.h\"\n#include \"download-agent-http-mgr.h\"\n#include \"download-agent-plugin-conf.h\"\n\npthread_mutex_t mutex_download_state[DA_MAX_DOWNLOAD_ID];\nstatic pthread_mutex_t mutex_download_mgr = PTHREAD_MUTEX_INITIALIZER;\ndownload_mgr_t download_mgr;\n\nvoid cleanup_source_info_basic_download(source_info_basic_t *source_info_basic);\nvoid cleanup_req_dl_info_http(req_dl_info *http_download);\nvoid destroy_file_info(file_info *file);\n\nda_result_t init_download_mgr() {\n\tda_result_t ret = DA_RESULT_OK;\n\tint i = 0;\n\n\tDA_LOG_FUNC_START(Default);\n\n\t_da_thread_mutex_lock(&mutex_download_mgr);\n\n\tif (download_mgr.is_init == DA_FALSE) {\n\t\tdownload_mgr.is_init = DA_TRUE;\n\n\t\tfor (i = 0; i < DA_MAX_DOWNLOAD_ID; i++) {\n\t\t\t_da_thread_mutex_init(&mutex_download_state[i], DA_NULL);\n\t\t\tinit_download_info(i);\n\t\t}\n\t\tinit_dl_id_history(&(download_mgr.dl_id_history));\n\t}\n\n\t_da_thread_mutex_unlock(&mutex_download_mgr);\n\n\treturn ret;\n}\n\nda_result_t deinit_download_mgr(void) {\n\tda_result_t ret = DA_RESULT_OK;\n\n\tDA_LOG_FUNC_START(Default);\n\n\t_da_thread_mutex_lock(&mutex_download_mgr);\n\tif (download_mgr.is_init == DA_TRUE) {\n\t\tint i = 0;\n\t\tdl_info_t *dl_info = DA_NULL;\n\t\tvoid *t_return = NULL;\n\t\tfor (i = 0; i < DA_MAX_DOWNLOAD_ID; i++) {\n\t\t\tdl_info = &(download_mgr.dl_info[i]);\n\t\t\tif (dl_info && dl_info->is_using) {\n\t\t\t\trequest_to_abort_http_download(GET_DL_CURRENT_STAGE(i));\n\t\t\t\tDA_LOG_CRITICAL(Thread, \"===download id[%d] thread id[%lu] join===\",i, GET_DL_THREAD_ID(i));\n/* Because the download daemon can call the deinit function, the resources of pthread are not freed\n FIXME later : It is needed to change the termination flow again.\n\t\tif (pthread_join(GET_DL_THREAD_ID(i), &t_return) < 0) {\n\t\t\tDA_LOG_ERR(Thread, \"join client thread is failed!!!\");\n\t\t}\n*/\n\t\tDA_LOG_CRITICAL(Thread, \"===download id[%d] thread join return[%d]===\",i, (char*)t_return);\n\t\t\t}\n\t\t}\n\t\tdownload_mgr.is_init = DA_FALSE;\n\t\tdeinit_dl_id_history(&(download_mgr.dl_id_history));\n\t}\n\t_da_thread_mutex_unlock(&mutex_download_mgr);\n\treturn ret;\n}\n\nvoid init_download_info(int slot_id)\n{\n\tdl_info_t *dl_info = DA_NULL;\n\n//\tDA_LOG_FUNC_START(Default);\n\n\t_da_thread_mutex_lock(&mutex_download_state[slot_id]);\n//\tDA_LOG_VERBOSE(Default, \"Init slot_id [%d] Info\", slot_id);\n\tdl_info = &(download_mgr.dl_info[slot_id]);\n\n\tdl_info->is_using = DA_FALSE;\n\tdl_info->state = DOWNLOAD_STATE_IDLE;\n\tdl_info->download_stage_data = DA_NULL;\n\tdl_info->dl_id = 0;\n\tdl_info->http_status = 0;\n\tdl_info->enable_pause_update = DA_FALSE;\n\tdl_info->user_install_path = DA_NULL;\n\tdl_info->user_file_name = DA_NULL;\n\tdl_info->user_etag = DA_NULL;\n\tdl_info->user_temp_file_path = DA_NULL;\n\tdl_info->user_data = DA_NULL;\n\n\tQ_init_queue(&(dl_info->queue));\n\n\tDA_LOG_VERBOSE(Default, \"Init slot_id [%d] Info END\", slot_id);\n\t_da_thread_mutex_unlock(&mutex_download_state[slot_id]);\n\n\treturn;\n}\n\nvoid destroy_download_info(int slot_id)\n{\n\tdl_info_t *dl_info = DA_NULL;\n\n\tDA_LOG_FUNC_START(Default);\n\n\tDA_LOG(Default, \"Destroying slot_id [%d] Info\", slot_id);\n\n\tif (slot_id == DA_INVALID_ID) {\n\t\tDA_LOG_ERR(Default, \"invalid slot_id\");\n\t\treturn;\n\t}\n\n\tdl_info = &(download_mgr.dl_info[slot_id]);\n\tif (DA_FALSE == dl_info->is_using) {\n/*\t\tDA_LOG_ERR(Default, \"invalid slot_id\"); */\n\t\treturn;\n\t}\n\n\t_da_thread_mutex_lock (&mutex_download_state[slot_id]);\n\tdl_info->state = DOWNLOAD_STATE_IDLE;\n\tDA_LOG(Default, \"Changed download_state to - [%d] \", dl_info->state);\n\n\tdl_info->active_dl_thread_id = 0;\n\n\tif (dl_info->download_stage_data != DA_NULL) {\n\t\tremove_download_stage(slot_id, dl_info->download_stage_data);\n\t\tdl_info->download_stage_data = DA_NULL;\n\t}\n\tdl_info->dl_id = 0;\n\tdl_info->enable_pause_update = DA_FALSE;\n\tif (dl_info->user_install_path) {\n\t\tfree(dl_info->user_install_path);\n\t\tdl_info->user_install_path = DA_NULL;\n\t}\n\n\tif (dl_info->user_file_name) {\n\t\tfree(dl_info->user_file_name);\n\t\tdl_info->user_file_name = DA_NULL;\n\t}\n\n\tif (dl_info->user_etag) {\n\t\tfree(dl_info->user_etag);\n\t\tdl_info->user_etag = DA_NULL;\n\t}\n\n\tif (dl_info->user_temp_file_path ) {\n\t\tfree(dl_info->user_temp_file_path );\n\t\tdl_info->user_temp_file_path = DA_NULL;\n\t}\n\n\tdl_info->user_data = DA_NULL;\n\n\tQ_destroy_queue(&(dl_info->queue));\n\tdl_info->http_status = 0;\n\n\tdl_info->is_using = DA_FALSE;\n\n\tDA_LOG(Default, \"Destroying slot_id [%d] Info END\", slot_id);\n\t_da_thread_mutex_unlock (&mutex_download_state[slot_id]);\n\treturn;\n}\n\nvoid *Add_new_download_stage(int slot_id)\n{\n\tstage_info *download_stage_data = NULL;\n\tstage_info *new_download_stage_data = NULL;\n\n\tDA_LOG_FUNC_START(Default);\n\n\tnew_download_stage_data = (stage_info*)calloc(1, sizeof(stage_info));\n\tif (!new_download_stage_data)\n\t\tgoto ERR;\n\n\tnew_download_stage_data->dl_id = slot_id;\n\tdownload_stage_data = GET_DL_CURRENT_STAGE(slot_id);\n\tif (download_stage_data) {\n\t\twhile (download_stage_data->next_stage_info) {\n\t\t\tdownload_stage_data\n\t\t\t = download_stage_data->next_stage_info;\n\t\t};\n\t\tdownload_stage_data->next_stage_info = new_download_stage_data;\n\t} else {\n\t\tGET_DL_CURRENT_STAGE(slot_id) = new_download_stage_data;\n\t}\n\tDA_LOG(Default, \"NEW STAGE ADDED FOR DOWNLOAD ID[%d] new_stage[%p]\", slot_id,new_download_stage_data);\n\nERR:\n\treturn new_download_stage_data;\n}\n\nvoid remove_download_stage(int slot_id, stage_info *in_stage)\n{\n\tstage_info *stage = DA_NULL;\n\n\tDA_LOG_FUNC_START(Default);\n\n\tstage = GET_DL_CURRENT_STAGE(slot_id);\n\tif (DA_NULL == stage) {\n\t\tDA_LOG_VERBOSE(Default, \"There is no stage field on slot_id = %d\", slot_id);\n\t\tgoto ERR;\n\t}\n\n\tif (DA_NULL == in_stage) {\n\t\tDA_LOG_VERBOSE(Default, \"There is no in_stage to remove.\");\n\t\tgoto ERR;\n\t}\n\n\tif (in_stage == stage) {\n\t\tDA_LOG_VERBOSE(Default, \"Base stage will be removed. in_stage[%p]\",in_stage);\n\t\tDA_LOG_VERBOSE(Default, \"next stage[%p]\",stage->next_stage_info);\n\t\tGET_DL_CURRENT_STAGE(slot_id) = stage->next_stage_info;\n\t\tempty_stage_info(in_stage);\n\t\tfree(in_stage);\n\t\tin_stage = DA_NULL;\n\t} else {\n\t\twhile (in_stage != stage->next_stage_info) {\n\t\t\tstage = stage->next_stage_info;\n\t\t}\n\t\tif (in_stage == stage->next_stage_info) {\n\t\t\tstage->next_stage_info\n\t\t\t\t= stage->next_stage_info->next_stage_info;\n\t\t\tDA_LOG_VERBOSE(Default, \"Stage will be removed. in_stage[%p]\",in_stage);\n\t\t\tDA_LOG_VERBOSE(Default, \"next stage[%p]\",stage->next_stage_info);\n\t\t\tempty_stage_info(in_stage);\n\t\t\tfree(in_stage);\n\t\t\tin_stage = DA_NULL;\n\t\t}\n\t}\n\nERR:\n\treturn;\n}\n\nvoid empty_stage_info(stage_info *in_stage)\n{\n\tsource_info_t *source_information = NULL;\n\treq_dl_info *request_download_info = NULL;\n\tfile_info *file_information = NULL;\n\n\tDA_LOG_FUNC_START(Default);\n\n\tDA_LOG(Default, \"Stage to Remove:[%p]\", in_stage);\n\tsource_information = GET_STAGE_SOURCE_INFO(in_stage);\n\n\tcleanup_source_info_basic_download(\n\t GET_SOURCE_BASIC(source_information));\n\n\trequest_download_info = GET_STAGE_TRANSACTION_INFO(in_stage);\n\n\tcleanup_req_dl_info_http(request_download_info);\n\n\tfile_information = GET_STAGE_CONTENT_STORE_INFO(in_stage);\n\tdestroy_file_info(file_information);\n}\n\nvoid cleanup_source_info_basic_download(source_info_basic_t *source_info_basic)\n{\n\tif (NULL == source_info_basic)\n\t\tgoto ERR;\n\n\tDA_LOG_FUNC_START(Default);\n\n\tif (NULL != source_info_basic->url) {\n\t\tfree(source_info_basic->url);\n\t\tsource_info_basic->url = DA_NULL;\n\t}\n\nERR:\n\treturn;\n\n}\n\nvoid cleanup_req_dl_info_http(req_dl_info *http_download)\n{\n\tDA_LOG_FUNC_START(Default);\n\n\tif (http_download->http_info.http_msg_request) {\n\t\thttp_msg_request_destroy(\n\t\t &(http_download->http_info.http_msg_request));\n\t}\n\n\tif (http_download->http_info.http_msg_response) {\n\t\thttp_msg_response_destroy(\n\t\t &(http_download->http_info.http_msg_response));\n\t}\n\n\tif (DA_NULL != http_download->location_url) {\n\t\tfree(http_download->location_url);\n\t\thttp_download->location_url = DA_NULL;\n\t}\n\tif (DA_NULL != http_download->content_type_from_header) {\n\t\tfree(http_download->content_type_from_header);\n\t\thttp_download->content_type_from_header = DA_NULL;\n\t}\n\n\tif (DA_NULL != http_download->etag_from_header) {\n\t\tfree(http_download->etag_from_header);\n\t\thttp_download->etag_from_header = DA_NULL;\n\t}\n\n\thttp_download->invloved_transaction_id = DA_INVALID_ID;\n\thttp_download->content_len_from_header = 0;\n\thttp_download->downloaded_data_size = 0;\n\n\t_da_thread_mutex_destroy(&(http_download->mutex_http_state));\n\n\treturn;\n}\n\nvoid destroy_file_info(file_info *file_information)\n{\n//\tDA_LOG_FUNC_START(Default);\n\n\tif (!file_information)\n\t\treturn;\n\n\tif (file_information->file_name_final) {\n\t\tfree(file_information->file_name_final);\n\t\tfile_information->file_name_final = NULL;\n\t}\n\n\tif (file_information->content_type) {\n\t\tfree(file_information->content_type);\n\t\tfile_information->content_type = NULL;\n\t}\n\n\tif (file_information->pure_file_name) {\n\t\tfree(file_information->pure_file_name);\n\t\tfile_information->pure_file_name = NULL;\n\t}\n\n\tif (file_information->extension) {\n\t\tfree(file_information->extension);\n\t\tfile_information->extension = NULL;\n\t}\n\treturn;\n}\n\nvoid clean_up_client_input_info(client_input_t *client_input)\n{\n\tDA_LOG_FUNC_START(Default);\n\n\tif (client_input) {\n\t\tclient_input->user_data = NULL;\n\n\t\tif (client_input->install_path) {\n\t\t\tfree(client_input->install_path);\n\t\t\tclient_input->install_path = DA_NULL;\n\t\t}\n\n\t\tif (client_input->file_name) {\n\t\t\tfree(client_input->file_name);\n\t\t\tclient_input->file_name = DA_NULL;\n\t\t}\n\n\t\tif (client_input->etag) {\n\t\t\tfree(client_input->etag);\n\t\t\tclient_input->etag = DA_NULL;\n\t\t}\n\n\t\tif (client_input->temp_file_path) {\n\t\t\tfree(client_input->temp_file_path);\n\t\t\tclient_input->temp_file_path = DA_NULL;\n\t\t}\n\n\t\tclient_input_basic_t *client_input_basic =\n\t\t &(client_input->client_input_basic);\n\n\t\tif (client_input_basic && client_input_basic->req_url) {\n\t\t\tfree(client_input_basic->req_url);\n\t\t\tclient_input_basic->req_url = DA_NULL;\n\t\t}\n\n\t\tif (client_input_basic && client_input_basic->user_request_header) {\n\t\t\tint i = 0;\n\t\t\tint count = client_input_basic->user_request_header_count;\n\t\t\tfor (i = 0; i < count; i++)\n\t\t\t{\n\t\t\t\tif (client_input_basic->user_request_header[i]) {\n\t\t\t\t\tfree(client_input_basic->user_request_header[i]);\n\t\t\t\t\tclient_input_basic->user_request_header[i] = DA_NULL;\n\t\t\t\t}\n\t\t\t}\n\n\t\t\tfree(client_input_basic->user_request_header);\n\t\t\tclient_input_basic->user_request_header = DA_NULL;\n\t\t\tclient_input_basic->user_request_header_count = 0;\n\t\t}\n\t} else {\n\t\tDA_LOG_ERR(Default, \"client_input is NULL.\");\n\t}\n\n\treturn;\n}\n\nda_result_t get_slot_id_for_dl_id(\n int dl_id,\n int* slot_id)\n{\n\tda_result_t ret = DA_ERR_INVALID_DL_REQ_ID;\n\tint iter = 0;\n\n\tif (dl_id < 0) {\n\t\tDA_LOG_ERR(Default, \"dl_id is less than 0 - %d\", dl_id);\n\t\treturn DA_ERR_INVALID_DL_REQ_ID;\n\t}\n\n\t_da_thread_mutex_lock(&mutex_download_mgr);\n\tfor (iter = 0; iter < DA_MAX_DOWNLOAD_ID; iter++) {\n\t\tif (download_mgr.dl_info[iter].is_using == DA_TRUE) {\n\t\t\tif (download_mgr.dl_info[iter].dl_id ==\n\t\t\t\tdl_id) {\n\t\t\t\t*slot_id = iter;\n\t\t\t\tret = DA_RESULT_OK;\n\t\t\t\tbreak;\n\t\t\t}\n\t\t}\n\t}\n\t_da_thread_mutex_unlock(&mutex_download_mgr);\n\n\treturn ret;\n}\n\n\nda_result_t get_available_slot_id(int *available_id)\n{\n\tda_result_t ret = DA_ERR_ALREADY_MAX_DOWNLOAD;\n\tint i;\n\n\t_da_thread_mutex_lock(&mutex_download_mgr);\n\tfor (i = 0; i < DA_MAX_DOWNLOAD_ID; i++) {\n\t\tif (download_mgr.dl_info[i].is_using == DA_FALSE) {\n\t\t\tinit_download_info(i);\n\n\t\t\tdownload_mgr.dl_info[i].is_using = DA_TRUE;\n\n\t\t\tdownload_mgr.dl_info[i].dl_id\n\t\t\t\t= get_available_dl_id(&(download_mgr.dl_id_history));\n\n\t\t\t*available_id = i;\n\t\t\tDA_LOG_CRITICAL(Default, \"available download id = %d\", *available_id);\n\t\t\tret = DA_RESULT_OK;\n\n\t\t\tbreak;\n\t\t}\n\t}\n\t_da_thread_mutex_unlock(&mutex_download_mgr);\n\n\treturn ret;\n}\n\nda_bool_t is_valid_slot_id(int slot_id)\n{\n\tda_bool_t ret = DA_FALSE;\n\n\tif (slot_id >= 0 && slot_id < DA_MAX_DOWNLOAD_ID) {\n\t\tif (download_mgr.dl_info[slot_id].is_using == DA_TRUE)\n\t\t\tret = DA_TRUE;\n\t}\n\n\treturn ret;\n}\n\nvoid store_http_status(int dl_id, int status)\n{\n\tif (status < 100 || status > 599) {\n\t\tDA_LOG_ERR(Default, \"Invalid status code [%d]\", status);\n\t\treturn;\n\t}\n\tDA_LOG_VERBOSE(Default, \"store_http_status id[%d]status[%d] \",dl_id, status);\n\tdownload_mgr.dl_info[dl_id].http_status = status;\n}\n\nint get_http_status(int slot_id)\n{\n\tif (!download_mgr.dl_info[slot_id].is_using) {\n\t\tDA_LOG_ERR(Default, \"Invalid slot_id [%d]\", slot_id);\n\t\treturn 0;\n\t}\n\treturn download_mgr.dl_info[slot_id].http_status;\n}\n"
},
{
"alpha_fraction": 0.6724014282226562,
"alphanum_fraction": 0.7283154129981995,
"avg_line_length": 30.337078094482422,
"blob_id": "c5ccb809c3adbf1db756b53fa944ca9a2131c069",
"content_id": "0a24e1419da2a4bed84eab42b1b3729d3a766c45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2790,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 89,
"path": "/include/download-agent-defs.h",
"repo_name": "deqing/download-agent",
"src_encoding": "UTF-8",
"text": "/*\n * Copyright (c) 2012 Samsung Electronics Co., Ltd All Rights Reserved\n *\n * Licensed under the Apache License, Version 2.0 (the License);\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an AS IS BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n\n#ifndef _Download_Agent_Defs_H\n#define _Download_Agent_Defs_H\n\n#ifndef DEPRECATED\n#define DEPRECATED __attribute__((deprecated))\n#endif\n\n/**\n * Max count to download files simultaneously. \\n\n * Main reason for this restriction is because of Network bandwidth.\n */\n#define DA_MAX_DOWNLOAD_REQ_AT_ONCE\t50\n\n#define DA_RESULT_OK\t0\n#define DA_RESULT_FAIL\t-1\n\n#define DA_TRUE\t\t1\n#define DA_FALSE \t\t0\n#define DA_NULL \t\t0\n#define DA_INVALID_ID\t-1\n\n#define DA_RESULT_USER_CANCELED -10 \n\n// InputError Input error (-100 ~ -199)\n// Client passed wrong parameter\n#define DA_ERR_INVALID_ARGUMENT\t\t-100\n#define DA_ERR_INVALID_DL_REQ_ID\t-101\n#define DA_ERR_INVALID_URL\t\t\t-103\n#define DA_ERR_INVALID_INSTALL_PATH\t-104\n#define DA_ERR_INVALID_MIME_TYPE\t-105\n\n// Client passed correct parameter, but Download Agent rejects the request because of internal policy.\n#define DA_ERR_ALREADY_CANCELED\t\t-160\n#define DA_ERR_ALREADY_SUSPENDED\t-161\n#define DA_ERR_ALREADY_RESUMED\t\t-162\n#define DA_ERR_CANNOT_SUSPEND \t-170\n#define DA_ERR_CANNOT_RESUME \t-171\n#define DA_ERR_INVALID_STATE\t\t-190\n#define DA_ERR_ALREADY_MAX_DOWNLOAD\t-191\n#define DA_ERR_UNSUPPORTED_PROTOCAL\t-192\n\n// System error (-200 ~ -299)\n#define DA_ERR_FAIL_TO_MEMALLOC\t\t-200\n#define DA_ERR_FAIL_TO_CREATE_THREAD\t\t-210\n#define DA_ERR_FAIL_TO_OBTAIN_MUTEX\t\t-220\n#define DA_ERR_FAIL_TO_ACCESS_FILE\t-230\n#define DA_ERR_DISK_FULL \t-240\n\n// Platform error (-300 ~ -399)\n#define DA_ERR_FAIL_TO_GET_CONF_VALUE\t\t-300\n#define DA_ERR_FAIL_TO_ACCESS_STORAGE\t-310\n#define DA_ERR_DLOPEN_FAIL \t\t-330\n\n// Network error (-400 ~ -499)\n#define DA_ERR_NETWORK_FAIL\t\t\t\t-400\n#define DA_ERR_UNREACHABLE_SERVER\t\t-410\n#define DA_ERR_HTTP_TIMEOUT \t-420\n#define DA_ERR_SSL_FAIL\t\t\t\t\t-430\n#define DA_ERR_TOO_MANY_REDIECTS\t\t-440\n\n// HTTP error - not conforming with HTTP spec (-500 ~ -599)\n#define DA_ERR_MISMATCH_CONTENT_TYPE\t-500\n#define DA_ERR_MISMATCH_CONTENT_SIZE\t-501\n#define DA_ERR_SERVER_RESPOND_BUT_SEND_NO_CONTENT\t-502\n\n// DRM error - not conforming with DRM spec (-700 ~ -799)\n#define DA_ERR_DRM_FAIL\t\t\t-700\n#define DA_ERR_DRM_FILE_FAIL\t-710\n\n// install error (-800 ~ -899)\n#define DA_ERR_FAIL_TO_INSTALL_FILE\t-800\n\n#endif\n\n"
},
{
"alpha_fraction": 0.7078254222869873,
"alphanum_fraction": 0.7251278162002563,
"avg_line_length": 33.364864349365234,
"blob_id": "e95633f81863d3ebf6039d9ea9de473bbcec63aa",
"content_id": "4361ad52a91720e432ff163c9883178c4ae26ef7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2543,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 74,
"path": "/include/download-agent-utils.h",
"repo_name": "deqing/download-agent",
"src_encoding": "UTF-8",
"text": "/*\n * Copyright (c) 2012 Samsung Electronics Co., Ltd All Rights Reserved\n *\n * Licensed under the Apache License, Version 2.0 (the License);\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an AS IS BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n\n#ifndef _Download_Agent_Utils_H\n#define _Download_Agent_Utils_H\n\n#include <time.h>\n#include \"download-agent-defs.h\"\n#include \"download-agent-interface.h\"\n#include \"download-agent-dl-mgr.h\"\n\n/* Todo : move these to mime-util.c */\n#define MIME_DRM_MESSAGE\t\"application/vnd.oma.drm.message\"\n#define MIME_ODF \t\t\t\t\"application/vnd.oasis.opendocument.formula\"\n#define MIME_OMA_DD \t\t\t\"application/vnd.oma.dd+xml\"\n#define MIME_MIDP_JAR\t\t\"application/vnd.sun.j2me.java-archive\"\n#define MIME_MULTIPART_MESSAGE\t\"multipart/related\"\n#define MIME_TEXT_PLAIN \t\t\"text/plain\"\n\n#define SAVE_FILE_BUFFERING_SIZE_50KB (50*1024)\n#define SAVE_FILE_BUFFERING_SIZE_5MB (5*1024*1024)\n\n#define DA_SLEEP(x) \\\n\tdo \\\n\t{ \\\n\t\tstruct timespec interval,remainder; \\\n\t\tinterval.tv_sec = (unsigned int)((x)/1000); \\\n\t\tinterval.tv_nsec = (((x)-(interval.tv_sec*1000))*1000000); \\\n\t\tnanosleep(&interval,&remainder); \\\n\t} while(0)\n\ntypedef enum {\n\tDA_STORAGE_PHONE,\t\t\t/*To Store in Phone memory*/\n\tDA_STORAGE_MMC,\t\t\t /*To Store in MMC */\n\tDA_STORAGE_SYSTEM\t\t\t/*To Store in both Phone and MMC*/\n} da_storage_type_t;\n\ntypedef struct _da_storage_size_t {\n\tunsigned long b_available;\n\tunsigned long b_size;\n} da_storage_size_t;\n\ntypedef enum {\n\tDA_MIME_TYPE_NONE,\n\tDA_MIME_TYPE_DRM1_MESSATE,\n\tDA_MIME_TYPE_END\n} da_mime_type_id_t;\n\nvoid get_random_number(int *out_num);\nda_result_t get_available_dd_id(int *available_id);\nda_result_t get_extension_from_mime_type(char *mime_type, char **extension);\nda_mime_type_id_t get_mime_type_id(char *content_type);\nda_result_t get_available_memory(da_storage_type_t storage_type, da_storage_size_t *avail_memory);\nda_bool_t is_valid_url(const char *url, da_result_t *err_code);\n\nint read_data_from_file(char *file, char**out_buffer);\nda_result_t move_file(const char *from_path, const char *to_path);\nvoid remove_file(const char *file_path);\nchar *_stristr(const char *long_str, const char *find_str);\n\n#endif\n"
},
{
"alpha_fraction": 0.682442843914032,
"alphanum_fraction": 0.6849135160446167,
"avg_line_length": 29.985645294189453,
"blob_id": "72db93ed262f2a08cf459ad99aed248980727bf1",
"content_id": "8a7681c43e972cc74570d66d1ebfd9b6e13f67fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 12952,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 418,
"path": "/download-agent-basic.c",
"repo_name": "deqing/download-agent",
"src_encoding": "UTF-8",
"text": "/*\n * Copyright (c) 2012 Samsung Electronics Co., Ltd All Rights Reserved\n *\n * Licensed under the Apache License, Version 2.0 (the License);\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an AS IS BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n\n#include <stdlib.h>\n\n#include \"download-agent-basic.h\"\n#include \"download-agent-debug.h\"\n#include \"download-agent-client-mgr.h\"\n#include \"download-agent-utils.h\"\n#include \"download-agent-http-mgr.h\"\n#include \"download-agent-http-misc.h\"\n#include \"download-agent-dl-mgr.h\"\n#include \"download-agent-pthread.h\"\n#include \"download-agent-file.h\"\n\nstatic void* __thread_start_download(void* data);\nvoid __thread_clean_up_handler_for_start_download(void *arg);\n\nstatic da_result_t __make_source_info_basic_download(\n\t\tstage_info *stage,\n\t\tclient_input_t *client_input);\nstatic da_result_t __download_content(stage_info *stage);\n\nda_result_t start_download(const char *url , int *dl_id)\n{\n\tDA_LOG_FUNC_START(Default);\n\treturn start_download_with_extension(url, dl_id, NULL);\n}\n\nda_result_t start_download_with_extension(\n\t\tconst char *url,\n\t\tint *dl_id,\n\t\textension_data_t *extension_data)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\tint slot_id = 0;\n\tconst char **request_header = DA_NULL;\n\tconst char *install_path = DA_NULL;\n\tconst char *file_name = DA_NULL;\n\tconst char *etag = DA_NULL;\n\tconst char *temp_file_path = DA_NULL;\n\tint request_header_count = 0;\n\tvoid *user_data = DA_NULL;\n\tclient_input_t *client_input = DA_NULL;\n\tclient_input_basic_t *client_input_basic = DA_NULL;\n\tdownload_thread_input *thread_info = DA_NULL;\n\tpthread_attr_t thread_attr;\n\n\tDA_LOG_FUNC_START(Default);\n\n\tif (extension_data) {\n\t\trequest_header = extension_data->request_header;\n\t\tif (extension_data->request_header_count)\n\t\t\trequest_header_count = extension_data->request_header_count;\n\t\tinstall_path = extension_data->install_path;\n\t\tfile_name = extension_data->file_name;\n\t\tuser_data = extension_data->user_data;\n\t\tetag = extension_data->etag;\n\t\ttemp_file_path = extension_data->temp_file_path;\n\t}\n\n\tret = get_available_slot_id(&slot_id);\n\tif (DA_RESULT_OK != ret)\n\t\treturn ret;\n\n\t*dl_id = GET_DL_ID(slot_id);\n\n\tclient_input = (client_input_t *)calloc(1, sizeof(client_input_t));\n\tif (!client_input) {\n\t\tDA_LOG_ERR(Default, \"DA_ERR_FAIL_TO_MEMALLOC\");\n\t\tret = DA_ERR_FAIL_TO_MEMALLOC;\n\t\tgoto ERR;\n\t} else {\n\t\tclient_input->user_data = user_data;\n\t\tif (install_path) {\n\t\t\tint install_path_len = strlen(install_path);\n\t\t\tif (install_path[install_path_len-1] == '/')\n\t\t\t\tinstall_path_len--;\n\n\t\t\tclient_input->install_path = (char *)calloc(install_path_len+1, sizeof(char));\n\t\t\tif (client_input->install_path)\n\t\t\t\tstrncpy(client_input->install_path, install_path, install_path_len);\n\t\t}\n\n\t\tif (file_name) {\n\t\t\tclient_input->file_name = (char *)calloc(strlen(file_name)+1, sizeof(char));\n\t\t\tif (client_input->file_name)\n\t\t\t\tstrncpy(client_input->file_name, file_name, strlen(file_name));\n\t\t}\n\n\t\tif (etag) {\n\t\t\tclient_input->etag = (char *)calloc(strlen(etag)+1, sizeof(char));\n\t\t\tif (client_input->etag)\n\t\t\t\tstrncpy(client_input->etag, etag, strlen(etag));\n\n\t\t}\n\n\t\tif (temp_file_path) {\n\t\t\tclient_input->temp_file_path = (char *)calloc(strlen(temp_file_path)+1, sizeof(char));\n\t\t\tif (client_input->temp_file_path)\n\t\t\t\tstrncpy(client_input->temp_file_path, temp_file_path, strlen(temp_file_path));\n\t\t}\n\n\t\tclient_input_basic = &(client_input->client_input_basic);\n\t\tclient_input_basic->req_url = (char *)calloc(strlen(url)+1, sizeof(char));\n\t\tif(DA_NULL == client_input_basic->req_url) {\n\t\t\tDA_LOG_ERR(Default, \"DA_ERR_FAIL_TO_MEMALLOC\");\n\t\t\tret = DA_ERR_FAIL_TO_MEMALLOC;\n\t\t\tgoto ERR;\n\t\t}\n\t\tstrncpy(client_input_basic->req_url ,url,strlen(url));\n\n\t\tif (request_header_count > 0) {\n\t\t\tint i = 0;\n\t\t\tclient_input_basic->user_request_header =\n\t\t\t\t(char **)calloc(1, sizeof(char *)*request_header_count);\n\t\t\tif(DA_NULL == client_input_basic->user_request_header) {\n\t\t\t\tDA_LOG_ERR(Default, \"DA_ERR_FAIL_TO_MEMALLOC\");\n\t\t\t\tret = DA_ERR_FAIL_TO_MEMALLOC;\n\t\t\t\tgoto ERR;\n\t\t\t}\n\t\t\tfor (i = 0; i < request_header_count; i++)\n\t\t\t{\n\t\t\t\tclient_input_basic->user_request_header[i] = strdup(request_header[i]);\n\t\t\t}\n\t\t\tclient_input_basic->user_request_header_count = request_header_count;\n\t\t}\n\t}\n\n\tthread_info = (download_thread_input *)calloc(1, sizeof(download_thread_input));\n\tif (!thread_info) {\n\t\tDA_LOG_ERR(Default, \"DA_ERR_FAIL_TO_MEMALLOC\");\n\t\tret = DA_ERR_FAIL_TO_MEMALLOC;\n\t\tgoto ERR;\n\t} else {\n\t\tthread_info->slot_id = slot_id;\n\t\tthread_info->client_input = client_input;\n\t}\n\tif (pthread_attr_init(&thread_attr) != 0) {\n\t\tret = DA_ERR_FAIL_TO_CREATE_THREAD;\n\t\tgoto ERR;\n\t}\n\n\tif (pthread_attr_setdetachstate(&thread_attr, PTHREAD_CREATE_DETACHED) != 0) {\n\t\tret = DA_ERR_FAIL_TO_CREATE_THREAD;\n\t\tgoto ERR;\n\t}\n\n\tif (pthread_create(&GET_DL_THREAD_ID(slot_id), &thread_attr,\n\t\t\t__thread_start_download, thread_info) < 0) {\n\t\tDA_LOG_ERR(Thread, \"making thread failed..\");\n\t\tret = DA_ERR_FAIL_TO_CREATE_THREAD;\n\t} else {\n\t\tif (GET_DL_THREAD_ID(slot_id) < 1) {\n\t\t\tDA_LOG_ERR(Thread, \"The thread start is failed before calling this\");\n// When http resource is leaked, the thread ID is initialized at error handling section of thread_start_download()\n// Because the thread ID is initialized, the ptrhead_detach should not be called. This is something like timing issue between threads.\n// thread info and basic_dl_input is freed at thread_start_download(). And it should not returns error code in this case.\n\t\t\tgoto ERR;\n\t\t}\n\t}\n\tDA_LOG_CRITICAL(Thread, \"download thread create slot_id[%d] thread id[%lu]\",\n\t\t\tslot_id,GET_DL_THREAD_ID(slot_id));\n\nERR:\n\tif (DA_RESULT_OK != ret) {\n\t\tif (client_input) {\n\t\t\tclean_up_client_input_info(client_input);\n\t\t\tfree(client_input);\n\t\t\tclient_input = DA_NULL;\n\t\t}\n\t\tif (thread_info) {\n\t\t\tfree(thread_info);\n\t\t\tthread_info = DA_NULL;\n\t\t}\n\t\tdestroy_download_info(slot_id);\n\t}\n\treturn ret;\n}\n\nda_result_t __make_source_info_basic_download(\n\t\tstage_info *stage,\n\t\tclient_input_t *client_input)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\tclient_input_basic_t *client_input_basic = DA_NULL;\n\tsource_info_t *source_info = DA_NULL;\n\tsource_info_basic_t *source_info_basic = DA_NULL;\n\n\tDA_LOG_FUNC_START(Default);\n\n\tif (!stage) {\n\t\tDA_LOG_ERR(Default, \"no stage; DA_ERR_INVALID_ARGUMENT\");\n\t\tret = DA_ERR_INVALID_ARGUMENT;\n\t\tgoto ERR;\n\t}\n\n\tclient_input_basic = &(client_input->client_input_basic);\n\tif (DA_NULL == client_input_basic->req_url) {\n\t\tDA_LOG_ERR(Default, \"DA_ERR_INVALID_URL\");\n\t\tret = DA_ERR_INVALID_URL;\n\t\tgoto ERR;\n\t}\n\n\tsource_info_basic = (source_info_basic_t*)calloc(1, sizeof(source_info_basic_t));\n\tif (DA_NULL == source_info_basic) {\n\t\tDA_LOG_ERR(Default, \"DA_ERR_FAIL_TO_MEMALLOC\");\n\t\tret = DA_ERR_FAIL_TO_MEMALLOC;\n\t\tgoto ERR;\n\t}\n\n\tsource_info_basic->url = client_input_basic->req_url;\n\tclient_input_basic->req_url = DA_NULL;\n\n\tif (client_input_basic->user_request_header) {\n\t\tsource_info_basic->user_request_header =\n\t\t\tclient_input_basic->user_request_header;\n\t\tsource_info_basic->user_request_header_count =\n\t\t\tclient_input_basic->user_request_header_count;\n\t\tclient_input_basic->user_request_header = DA_NULL;\n\t\tclient_input_basic->user_request_header_count = 0;\n\t}\n\n\tsource_info = GET_STAGE_SOURCE_INFO(stage);\n\tmemset(source_info, 0, sizeof(source_info_t));\n\n\tsource_info->source_info_type.source_info_basic = source_info_basic;\n\n\tDA_LOG(Default, \"BASIC HTTP STARTED: URL=%s\",\n\t\t\tsource_info->source_info_type.source_info_basic->url);\nERR:\n\treturn ret;\n}\n\nvoid __thread_clean_up_handler_for_start_download(void *arg)\n{\n DA_LOG_CRITICAL(Default, \"cleanup for thread id = %d\", pthread_self());\n}\n\nstatic void *__thread_start_download(void *data)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\tdownload_thread_input *thread_info = DA_NULL;\n\tclient_input_t *client_input = DA_NULL;\n\tstage_info *stage = DA_NULL;\n\tdownload_state_t download_state = 0;\n\n\tint slot_id = DA_INVALID_ID;\n\n\tDA_LOG_FUNC_START(Thread);\n\n\tpthread_setcancelstate(PTHREAD_CANCEL_DISABLE, DA_NULL);\n\n\tthread_info = (download_thread_input*)data;\n\tif (DA_NULL == thread_info) {\n\t\tDA_LOG_ERR(Thread, \"thread_info is NULL..\");\n\t\tret = DA_ERR_INVALID_ARGUMENT;\n\t\treturn DA_NULL;\n\t} else {\n\t\tslot_id = thread_info->slot_id;\n\t\tclient_input = thread_info->client_input;\n\n\t\tif(thread_info) {\n\t\t\tfree(thread_info);\n\t\t\tthread_info = DA_NULL;\n\t\t}\n\t}\n\n\tpthread_cleanup_push(__thread_clean_up_handler_for_start_download, (void *)NULL);\n\n\tif (DA_FALSE == is_valid_slot_id(slot_id)) {\n\t\tret = DA_ERR_INVALID_ARGUMENT;\n\t\tDA_LOG_ERR(Default, \"Invalid Download ID\");\n\t\tgoto ERR;\n\t}\n\n\tif (!client_input) {\n\t\tret = DA_ERR_INVALID_ARGUMENT;\n\t\tDA_LOG_ERR(Default, \"Invalid client_input\");\n\t\tgoto ERR;\n\t}\n\n\tstage = Add_new_download_stage(slot_id);\n\tif (!stage) {\n\t\tret = DA_ERR_FAIL_TO_MEMALLOC;\n\t\tDA_LOG_ERR(Default, \"STAGE ADDITION FAIL!\");\n\t\tgoto ERR;\n\t}\n\tDA_LOG(Default, \"new added Stage : %p\", stage);\n\n\tGET_DL_USER_DATA(slot_id) = client_input->user_data;\n\tclient_input->user_data = DA_NULL;\n\tGET_DL_USER_INSTALL_PATH(slot_id) = client_input->install_path;\n\tclient_input->install_path = DA_NULL;\n\tGET_DL_USER_FILE_NAME(slot_id) = client_input->file_name;\n\tclient_input->file_name = DA_NULL;\n\tGET_DL_USER_ETAG(slot_id) = client_input->etag;\n\tclient_input->etag = DA_NULL;\n\tGET_DL_USER_TEMP_FILE_PATH(slot_id) = client_input->temp_file_path;\n\tclient_input->temp_file_path = DA_NULL;\n\tret = __make_source_info_basic_download(stage, client_input);\n\t/* to save memory */\n\tif (client_input) {\n\t\tclean_up_client_input_info(client_input);\n\t\tfree(client_input);\n\t\tclient_input = DA_NULL;\n\t}\n\n\tif (ret == DA_RESULT_OK)\n\t\tret = __download_content(stage);\n\nERR:\n\tif (client_input) {\n\t\tclean_up_client_input_info(client_input);\n\t\tfree(client_input);\n\t\tclient_input = DA_NULL;\n\t}\n\n\tif (DA_RESULT_OK == ret) {\n\t\tchar *installed_path = NULL;\n\t\tchar *etag = DA_NULL;\n\t\treq_dl_info *request_info = NULL;\n\t\tfile_info *file_storage = NULL;\n\t\tDA_LOG_CRITICAL(Default, \"Whole download flow is finished.\");\n\t\t_da_thread_mutex_lock (&mutex_download_state[GET_STAGE_DL_ID(stage)]);\n\t\tdownload_state = GET_DL_STATE_ON_STAGE(stage);\n\t\t_da_thread_mutex_unlock (&mutex_download_state[GET_STAGE_DL_ID(stage)]);\n\t\tif (download_state == DOWNLOAD_STATE_ABORTED) {\n\t\t\tDA_LOG(Default, \"Abort case. Do not call client callback\");\n#ifdef PAUSE_EXIT\n\t\t} else if (download_state == DOWNLOAD_STATE_PAUSED) {\n\t\t\tDA_LOG(Default, \"Finish case from paused state\");\n\t\t\tdestroy_download_info(slot_id);\n#endif\n\t\t} else {\n\t\t\trequest_info = GET_STAGE_TRANSACTION_INFO(stage);\n\t\t\tetag = GET_REQUEST_HTTP_HDR_ETAG(request_info);\n\t\t\tfile_storage = GET_STAGE_CONTENT_STORE_INFO(stage);\n\t\t\tinstalled_path = GET_CONTENT_STORE_ACTUAL_FILE_NAME(file_storage);\n\t\t\tsend_user_noti_and_finish_download_flow(slot_id, installed_path,\n\t\t\t\t\tetag);\n\t\t}\n\t} else {\n\t\tchar *etag = DA_NULL;\n\t\treq_dl_info *request_info = NULL;\n\t\trequest_info = GET_STAGE_TRANSACTION_INFO(stage);\n\t\tDA_LOG_CRITICAL(Default, \"Download Failed -Return = %d\", ret);\n\t\tif (request_info) {\n\t\t\tetag = GET_REQUEST_HTTP_HDR_ETAG(request_info);\n\t\t\tsend_client_finished_info(slot_id, GET_DL_ID(slot_id),\n\t\t\t\t\tDA_NULL, etag, ret, get_http_status(slot_id));\n\t\t}\n\t\tdestroy_download_info(slot_id);\n\t}\n\n\tpthread_cleanup_pop(0);\n\tDA_LOG_CRITICAL(Thread, \"=====thread_start_download - EXIT=====\");\n\tpthread_exit((void *)NULL);\n\treturn DA_NULL;\n}\n\nda_result_t __download_content(stage_info *stage)\n{\n\tda_result_t ret = DA_RESULT_OK;\n\tdownload_state_t download_state = 0;\n\tda_bool_t isDownloadComplete = DA_FALSE;\n\tint slot_id = DA_INVALID_ID;\n\n\tDA_LOG_FUNC_START(Default);\n\n\tslot_id = GET_STAGE_DL_ID(stage);\n\tCHANGE_DOWNLOAD_STATE(DOWNLOAD_STATE_NEW_DOWNLOAD, stage);\n\n\tdo {\n\t\tstage = GET_DL_CURRENT_STAGE(slot_id);\n\t\t_da_thread_mutex_lock (&mutex_download_state[GET_STAGE_DL_ID(stage)]);\n\t\tdownload_state = GET_DL_STATE_ON_STAGE(stage);\n\t\tDA_LOG(Default, \"download_state to - [%d] \", download_state);\n\t\t_da_thread_mutex_unlock (&mutex_download_state[GET_STAGE_DL_ID(stage)]);\n\n\t\tswitch(download_state) {\n\t\tcase DOWNLOAD_STATE_NEW_DOWNLOAD:\n\t\t\tret = requesting_download(stage);\n\n\t\t\t_da_thread_mutex_lock (&mutex_download_state[GET_STAGE_DL_ID(stage)]);\n\t\t\tdownload_state = GET_DL_STATE_ON_STAGE(stage);\n\t\t\t_da_thread_mutex_unlock (&mutex_download_state[GET_STAGE_DL_ID(stage)]);\n\t\t\tif (download_state == DOWNLOAD_STATE_CANCELED ||\n\t\t\t\t\tdownload_state == DOWNLOAD_STATE_ABORTED ||\n\t\t\t\t\tdownload_state == DOWNLOAD_STATE_PAUSED) {\n\t\t\t\tbreak;\n\t\t\t} else {\n\t\t\t\tif (DA_RESULT_OK == ret) {\n\t\t\t\t\tret = handle_after_download(stage);\n\t\t\t\t}\n\t\t\t}\n\t\t\tbreak;\n\t\tdefault:\n\t\t\tisDownloadComplete = DA_TRUE;\n\t\t\tbreak;\n\t\t}\n\t}while ((DA_RESULT_OK == ret) && (DA_FALSE == isDownloadComplete));\n\n\treturn ret;\n}\n"
}
] | 15 |
pfjob09/datascience
|
https://github.com/pfjob09/datascience
|
d8848548f3be0486260908e24ce6c8fcb692c5cc
|
57c4ba208bffc2de20e44759e3858dec9620f8ca
|
ff8d713448e8de680f3a9d459df3af0e24bd56f1
|
refs/heads/master
| 2021-01-22T00:10:31.214421 | 2015-05-22T21:12:33 | 2015-05-22T21:12:33 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6807909607887268,
"avg_line_length": 31.18181800842285,
"blob_id": "b9242f925f9bd61fac37fbe78f165f80ce48b3ea",
"content_id": "f98a814ebff961b201d78c01776b3be6be6e6cf4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 354,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 11,
"path": "/datascience/tests.py",
"repo_name": "pfjob09/datascience",
"src_encoding": "UTF-8",
"text": "from numpy.random import permutation\n\n\ndef permutation_test(observed, expected, stat_func, n_samples=10000):\n all_samples = observed.append(expected)\n n_obs = len(observed)\n values = []\n for i in range(n_samples):\n samples = permutation(all_samples)\n values.append(stat_func(samples[:n_obs], samples[n_obs:]))\n return values\n"
},
{
"alpha_fraction": 0.6629213690757751,
"alphanum_fraction": 0.7640449404716492,
"avg_line_length": 21.25,
"blob_id": "81059c6a79d06d78c31db22558bd0078c51af221",
"content_id": "2a402e7fc72af5c0ca6b9601f1c72ee4aeaea304",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 178,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 8,
"path": "/requirements.txt",
"repo_name": "pfjob09/datascience",
"src_encoding": "UTF-8",
"text": "pandas==0.16.0\nscipy==0.15.1\nseaborn==0.5.1\nscikit-learn==0.16.0\nstatsmodels==0.6.1\ngit+https://github.com/jordanh/neurio-python.git@master#egg=neurio-master\nnetworkx\npygraphviz\n"
}
] | 2 |
kitokyo/grapl
|
https://github.com/kitokyo/grapl
|
8e2e6446addd679a317b07b07f2574532285089a
|
bc36db28e9f05824c44ee94f5b751e87e784db0f
|
93b37778216e5586fc902a9698b5f71cb35b33f3
|
refs/heads/master
| 2020-06-25T17:28:53.520710 | 2019-07-19T05:23:26 | 2019-07-19T05:23:26 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6538018584251404,
"alphanum_fraction": 0.6549538969993591,
"avg_line_length": 33.039215087890625,
"blob_id": "b7785f7b755446d1dd39fda0dad899dd2ae3dd53",
"content_id": "963392c95ed15416587376107705ea34eca745ea",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1736,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 51,
"path": "/analyzer_executor/src/svchost_unexpected_parent.py",
"repo_name": "kitokyo/grapl",
"src_encoding": "UTF-8",
"text": "import os\n\nfrom multiprocessing.connection import Connection\n\nfrom grapl_analyzerlib.entities import SubgraphView, ProcessQuery, ProcessView\nfrom grapl_analyzerlib.entity_queries import Not\nfrom grapl_analyzerlib.execution import ExecutionFailed, ExecutionComplete, ExecutionHit\n\nfrom pydgraph import DgraphClient, DgraphClientStub\n\n\n# Look for processes with svchost.exe in their name with non services.exe parents\ndef query(dgraph_client: DgraphClient, node_key: str) -> ProcessView:\n\n return (\n ProcessQuery()\n .with_process_name(contains=[Not(\"services.exe\"), Not(\"lsass.exe\")])\n .with_children(ProcessQuery().with_process_name(contains=\"svchost\"))\n .query_first(dgraph_client, node_key)\n )\n\n\ndef _analyzer(client: DgraphClient, graph: SubgraphView, sender: Connection):\n print(f'Analyzing {len(graph.nodes)} nodes')\n for node in graph.nodes.values():\n node = node.node\n if not isinstance(node, ProcessView):\n continue\n print('Analyzing Process Node')\n response = query(client, node.node_key)\n print(response)\n if response:\n print(f\"Got a response {response.node_key}\")\n print(f\"Debug view: {response.to_dict(root=True)}\")\n sender.send(\n ExecutionHit(\n analyzer_name=\"svchost_unusual_parent\",\n node_view=response,\n risk_score=50,\n )\n )\n\n sender.send(ExecutionComplete())\n\n\ndef analyzer(client: DgraphClient, graph: SubgraphView, sender: Connection):\n try:\n _analyzer(client, graph, sender)\n except Exception as e:\n print(f\"analyzer failed: {e}\")\n sender.send(ExecutionFailed())\n"
},
{
"alpha_fraction": 0.7021276354789734,
"alphanum_fraction": 0.8085106611251831,
"avg_line_length": 10.75,
"blob_id": "f4fd346fa6736e017cf951bdd12dd1d44d221535",
"content_id": "e13ef49fb936f81b5520b8d442936501b7e3e1fd",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 47,
"license_type": "permissive",
"max_line_length": 25,
"num_lines": 4,
"path": "/analyzer_executor/requirements.txt",
"repo_name": "kitokyo/grapl",
"src_encoding": "UTF-8",
"text": "pydgraph\nboto3\ngrapl-analyzerlib==0.1.72\nredis\n"
}
] | 2 |
RodrigoHernan/applied-databases
|
https://github.com/RodrigoHernan/applied-databases
|
2a7436cceb4adb10e8f61c538ab1dfcc2dbc8ff4
|
aeac3b9b5c8fd5f4de743402dfc291a00706f509
|
ac86db946d81fc6a87ec68fd10114cded4b186f2
|
refs/heads/master
| 2023-08-02T13:02:51.344155 | 2021-09-15T23:19:35 | 2021-09-15T23:19:35 | 406,156,696 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8529411554336548,
"alphanum_fraction": 0.8823529481887817,
"avg_line_length": 7.75,
"blob_id": "4ee19e8c32baa048f8c91644a7258833b515b8a6",
"content_id": "0c6f24a152b9f598cf08db7f58e2b15aa6a3ebf4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 34,
"license_type": "no_license",
"max_line_length": 15,
"num_lines": 4,
"path": "/src/requirements.txt",
"repo_name": "RodrigoHernan/applied-databases",
"src_encoding": "UTF-8",
"text": "luigi\npandas\nnumpy\npsycopg2-binary"
},
{
"alpha_fraction": 0.6034318208694458,
"alphanum_fraction": 0.6034318208694458,
"avg_line_length": 24.585365295410156,
"blob_id": "d0714cdd01477413801b0bec7aed7a654562ca4e",
"content_id": "3cdd6ca75aa1bf828df42d5fe89b0e44cd18f8b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1049,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 41,
"path": "/src/utils.py",
"repo_name": "RodrigoHernan/applied-databases",
"src_encoding": "UTF-8",
"text": "from luigi.contrib.postgres import CopyToTable, PostgresQuery, PostgresTarget\n\n\n\nclass PostgresTargetWithRows(PostgresTarget):\n\n rows = []\n\n def __init__(self, host, database, user, password, table, update_id, port=None, rows=[]):\n super(PostgresTargetWithRows, self).__init__(host, database, user, password, table, update_id, port)\n self.rows = rows\n\nclass PostgresQueryWithRows(PostgresQuery):\n\n rows = []\n\n def run(self):\n connection = self.output().connect()\n cursor = connection.cursor()\n sql = self.query\n\n cursor.execute(sql)\n\n for row in cursor.fetchall():\n self.rows.append(row)\n\n self.output().touch(connection)\n\n connection.commit()\n connection.close()\n\n def output(self):\n return PostgresTargetWithRows(\n host=self.host,\n database=self.database,\n user=self.user,\n password=self.password,\n table=self.table,\n update_id=self.update_id,\n rows=self.rows\n )\n"
},
{
"alpha_fraction": 0.6378718614578247,
"alphanum_fraction": 0.6401602029800415,
"avg_line_length": 25.08955192565918,
"blob_id": "fbe43335ca7370f3bcdfdbce53ec89f9bb715322",
"content_id": "5b1f7df931f50b893d57a85110fece671890a02d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1748,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 67,
"path": "/src/main.py",
"repo_name": "RodrigoHernan/applied-databases",
"src_encoding": "UTF-8",
"text": "import luigi\nimport luigi.contrib.postgres\nfrom luigi.contrib.postgres import CopyToTable, PostgresQuery, PostgresTarget\nimport time\nimport random\nfrom utils import PostgresQueryWithRows\n\n\nclass Config(luigi.Config):\n host = 'db'\n database = 'dw'\n user = 'postgres'\n password = 'postgres'\n\n\nclass CopyToTableBase(CopyToTable):\n host = Config.host\n database = Config.database\n user = Config.user\n password = Config.password\n\n def rows(self):\n for row in self.input().rows:\n yield row\n\n\nclass GetTracktSoldData(PostgresQueryWithRows):\n version = luigi.IntParameter()\n\n host = Config.host\n database = \"postgres\"\n user = Config.user\n password = Config.password\n table = \"Artist\"\n query = '''SELECT t.\"Name\" as \"Name\", t.\"AlbumId\" as \"AlbumId\", il.\"UnitPrice\" as \"InvoiceUnitPrice\"\n FROM \"source\".\"Track\" as t\n inner join \"source\".\"InvoiceLine\" as il ON t.\"TrackId\" = il.\"TrackId\";'''\n\n\nclass PopulateTracktSold(CopyToTableBase):\n database = \"dw\"\n version = luigi.IntParameter()\n\n table = 'fact_track_sold'\n\n columns = (('Name', 'text'),\n ('AlbumId', 'int'),\n ('InvoiceUnitPrice', 'int'))\n\n def create_table(self, connection):\n connection.cursor().execute(\n \"\"\"CREATE TABLE {table} (id SERIAL PRIMARY KEY, \"Name\" TEXT, \"AlbumId\" INT, \"InvoiceUnitPrice\" FLOAT);\"\"\"\n .format(table=self.table))\n\n def requires(self):\n return GetTracktSoldData(self.version)\n\n\nclass MainFlow(luigi.Task):\n version = luigi.IntParameter()\n\n def requires(self):\n return PopulateTracktSold(self.version)\n\n\nif __name__ == '__main__':\n luigi.build([MainFlow(random.randint(0, 100))])\n"
},
{
"alpha_fraction": 0.6926229596138,
"alphanum_fraction": 0.7254098653793335,
"avg_line_length": 17.846153259277344,
"blob_id": "c6a8a9afe215137922ba2cddb64db68279fe0c9d",
"content_id": "1f780f140668234a02e2feda544bba1e322b4d9c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 244,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 13,
"path": "/README.md",
"repo_name": "RodrigoHernan/applied-databases",
"src_encoding": "UTF-8",
"text": "### Pre requisitos\n - docker\n - docker-compose\n\n## Instrucciones\n\nSe debe ejecutar en la raiz del proyecto:\n~~~\ndocker-compose up\n~~~\nPD: La primera vez que se ejecuta puede llegar a demorar\n\nAbrir [http://localhost:8082](http://localhost:8082)"
},
{
"alpha_fraction": 0.6412825584411621,
"alphanum_fraction": 0.6593186259269714,
"avg_line_length": 19.79166603088379,
"blob_id": "bfee162a8600dfff0d0d804e3eec1b204f72e53a",
"content_id": "09ba6b95af66befae536c10541dc330f078cbdc1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 499,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 24,
"path": "/src/Dockerfile",
"repo_name": "RodrigoHernan/applied-databases",
"src_encoding": "UTF-8",
"text": "FROM python:rc-alpine3.9\n\nENV PYTHONUNBUFFERED 1\n\nWORKDIR /src/\n\nCOPY requirements.txt .\n\nRUN \\\n apk add --no-cache postgresql-libs && \\\n apk add --no-cache jpeg-dev zlib-dev zlib python3-dev && \\\n apk add --no-cache libmagic && \\\n apk add --no-cache --virtual .build-deps gcc musl-dev postgresql-dev && \\\n apk add --no-cache bash\n\nRUN apk add build-base\n\nRUN \\\n python3 -m pip install -r requirements.txt --no-cache-dir && \\\n apk --purge del .build-deps\n\nCOPY . .\n\nEXPOSE 8082\n"
},
{
"alpha_fraction": 0.5702917575836182,
"alphanum_fraction": 0.5981432199478149,
"avg_line_length": 18.33333396911621,
"blob_id": "789ae4c475561d2a9afac878513e4d44e9780025",
"content_id": "83ec16b5be31fffd13bb1ba11a4c6650ca539455",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "YAML",
"length_bytes": 754,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 39,
"path": "/docker-compose.yml",
"repo_name": "RodrigoHernan/applied-databases",
"src_encoding": "UTF-8",
"text": "version: '3.7'\n\nservices:\n db:\n image: postgres:11-alpine\n restart: unless-stopped\n environment:\n - POSTGRES_DB=postgres\n - POSTGRES_USER=postgres\n - POSTGRES_PASSWORD=postgres\n - POSTGRES_HOST_AUTH_METHOD=trust\n volumes:\n - postgres_data:/var/lib/postgresql/data/\n ports:\n - 5432:5432\n\n luigi:\n build: ./src\n command: python3 main.py\n volumes:\n - ./src:/src\n # - static_volume:/src/staticfiles\n # - media_volume:/src/media\n depends_on:\n - luigid\n - db\n\n luigid:\n build: ./src\n command: luigid --pidfile /tmp/luigid.pid --state-path /tmp/luigi-state.pickle\n volumes:\n - ./src:/src\n ports:\n - 8082:8082\n\n\nvolumes:\n postgres_data:\n static_volume:\n"
}
] | 6 |
arnaudhugo/scraping
|
https://github.com/arnaudhugo/scraping
|
2d344e26a8d30dd2bf16838929df3f7e6fdd4990
|
bfc56d0fa5ff74e18887aca66e3dc64bd23d27ec
|
e8aec2c634a4c4a3bd764567526feaf4fe55c771
|
refs/heads/master
| 2021-09-07T08:44:26.110293 | 2018-02-20T14:32:01 | 2018-02-20T14:32:01 | 122,209,926 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4641439616680145,
"alphanum_fraction": 0.48028579354286194,
"avg_line_length": 39.20212936401367,
"blob_id": "084bb240c7be1d4e2e4b5ce07355772284d3fc08",
"content_id": "0256d91844d3babad1bb8ab1af62769726cf29b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3779,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 94,
"path": "/scrapy.py",
"repo_name": "arnaudhugo/scraping",
"src_encoding": "UTF-8",
"text": "import re\nimport datetime\nfrom urllib2 import urlopen\nfrom bs4 import BeautifulSoup as soup\n\n# Url de la page contenant les 10 annonces les plus recentes\nurl = 'https://www.pap.fr/annonce/location-appartement-maison-ile-de-france-g471-a-partir-de-2-chambres'\nhtml = urlopen(url)\ncontent = html.read()\nhtml.close()\npage_soup = soup(content, \"html.parser\")\n\n# Recuperer tout les liens vers les 10 annonces les plus recentes\nlink_to_annonce = page_soup.findAll(\"div\",{\"class\":\"search-results-list\"})\nmatches = re.findall('href=\"(.*?)\"', str(link_to_annonce))\n\n# Nommer le fichier json de la date_heure du scaping\nnow = datetime.datetime.now()\nname_file = now.strftime(\"%Y-%m-%d_%H-%M\")\n\nfile = open(\"./json_file/\" + name_file + \".json\", \"w\")\nfile.write(\"{\\n\")\nvar2 = 0\ntmp = \"\"\nfor link in matches:\n if link.find(\"annonce/\") == 1:\n if link != tmp and link.split(\"-\")[12][0] == \"r\":\n var2 = var2 + 1\n tmp = link\n url_annonce = \"https://www.pap.fr/\" + link\n html2 = urlopen(url_annonce)\n content2 = html2.read()\n html2.close()\n page_soup2 = soup(content2, \"html.parser\")\n\n # Numero annonce (format : rXXXXXXXXX)\n file.write(\"\\t\\\"\" + str(var2) + \"\\\": {\\n\")\n \n # Trouver le titre\n title = page_soup2.findAll(\"span\",{\"class\":\"h1\"})\n if not title:\n file.write(\"\\t\\t\\\"titre\\\": \\\"\" + \"no title\" + \"\\\",\\n\")\n print(\"no title\")\n else:\n file.write(\"\\t\\t\\\"titre\\\": \\\"\" + title[0].text.encode('utf-8') + \"\\\",\\n\")\n print(title[0].text.encode('utf-8'))\n\n # Trouver le numero\n num = page_soup2.findAll(\"strong\",{\"class\":\"tel-wrapper\"})\n if not num:\n file.write(\"\\t\\t\\\"numero\\\": \\\"\" + \"no num\" + \"\\\",\\n\")\n print(\"no num\")\n else:\n file.write(\"\\t\\t\\\"numero\\\": \\\"\" + num[1].text.strip().encode('utf-8') + \"\\\",\\n\")\n print(num[1].text.strip().encode('utf-8'))\n\n # Trouver le prix\n price = page_soup2.findAll(\"span\",{\"class\":\"item-price\"})\n if not price:\n file.write(\"\\t\\t\\\"prix\\\": \\\"\" + \"no price\" + \"\\\",\\n\")\n print(\"no price\")\n else:\n file.write(\"\\t\\t\\\"prix\\\": \\\"\" + price[0].text.encode('utf-8') + \"\\\",\\n\")\n print(price[0].text.encode('utf-8'))\n\n # Trouver la description\n desc = page_soup2.findAll(\"div\",{\"class\":\"item-description margin-bottom-30\"})\n if not desc:\n file.write(\"\\t\\t\\\"desc\\\": \\\"\" + \"no description\" + \"\\\",\\n\")\n print(\"no description\")\n else:\n file.write(\"\\t\\t\\\"desc\\\": \\\"\" + desc[0].div.p.text.strip().encode('utf-8').replace('\\n',' ').replace('\\r','') + \"\\\",\\n\")\n print(desc[0].div.p.text.strip().encode('utf-8').replace('\\n',' ').replace('\\r',''))\n\n # Trouver la/les photo(s)\n img = page_soup2.findAll(\"img\")\n file.write(\"\\t\\t\\\"images\\\": {\\n\")\n file.write(\"\\t\\t\\t\\\"image0\\\": \\\"\" + \"no image\" + \"\\\",\\n\")\n var = 0\n for image in img:\n photo = str(image).split(\"\\\"\")[3]\n if photo.split(\":\")[0] == \"https\":\n var = var + 1\n file.write(\"\\t\\t\\t\\\"image\" + str(var) + \"\\\": \\\"\" + photo.encode('utf-8') + \"\\\",\\n\")\n print(photo.encode('utf-8'))\n else:\n file.write(\"\\t\\t\\t\\\"image\" + str(var + 1) + \"\\\": \\\"\" + \"Fin\" + \"\\\"\\n\")\n file.write(\"\\t\\t}\\n\")\n if var2 < 10:\n file.write(\"\\t},\\n\")\nelse:\n file.write(\"\\t}\\n\")\nfile.write(\"}\\n\")\nfile.close()\n"
},
{
"alpha_fraction": 0.46700143814086914,
"alphanum_fraction": 0.47919654846191406,
"avg_line_length": 27.4489803314209,
"blob_id": "4856b87f958b240373bf3edc5395faf3da2fa1cf",
"content_id": "73155687bb461cc98b181cb285c277821cbe487a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 1394,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 49,
"path": "/index.php",
"repo_name": "arnaudhugo/scraping",
"src_encoding": "UTF-8",
"text": "<!DOCTYPE html>\n<?php\n $last_ctime = 0;\n $good_file = \"\";\n if ($handle = opendir('./json_file')) {\n while (false !== ($entry = readdir($handle))) {\n if ($entry != \"..\") {\n if ($entry != \".\") {\n if ((filectime(\"./json_file/\" . $entry)) > $last_ctime) {\n\t $good_file = $entry;\n\t $last_ctime = filectime(\"./json_file/\" . $entry);\n }\n }\n }\n }\n closedir($handle);\n }\n $j_file = \"./json_file/\" . $good_file;\n $json = file_get_contents($j_file);\n $json_data = json_decode($json, true);\n?>\n<html>\n <header>\n <meta charset=\"utf-8\">\n <title>Dashboard</title>\n </header>\n <body>\n <?php\n $var = 1;\n while ($var <= 10) {\n ?>\n <div style='border:1px solid black'>\n <h1><?php echo $json_data[$var]['titre']; ?></h1>\n <p>Numero : <?php echo $json_data[$var]['numero']; ?></p>\n <p>Prix : <?php echo $json_data[$var]['prix']; ?></p>\n <p>Description : <?php echo $json_data[$var]['desc']; ?></p>\n <img src='<?php echo $json_data[$var]['images']['image1']; ?>' style='height: 56px;'/>\n <img src='<?php echo $json_data[$var]['images']['image2']; ?>' style='height: 56px;'/>\n <img src='<?php echo $json_data[$var]['images']['image3']; ?>' style='height: 56px;'/>\n </div>\n <?php\n $var++;\n }\n ?>\n </body>\n <footer>\n Arnaud_h\n </footer>\n</html>\n"
}
] | 2 |
tmconnors/SallieMaeScrapper
|
https://github.com/tmconnors/SallieMaeScrapper
|
f768cf3a6b3e2570839fbd26cf5a32ec2a6a45ef
|
a3c592756ec63ff1e79708a477a327f2a91ad2e5
|
184632f4528fef6f7103e7fae555baaa85afe51f
|
refs/heads/master
| 2016-08-05T07:51:13.551802 | 2015-01-08T20:35:23 | 2015-01-08T20:35:23 | 24,863,421 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6405063271522522,
"alphanum_fraction": 0.6860759258270264,
"avg_line_length": 25.33333396911621,
"blob_id": "4aafc36c993269b278cb7296afe76e7e6fc28349",
"content_id": "b8e95cc6dc7af3cf24578c0f3f70059712a14dd7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 395,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 15,
"path": "/README.md",
"repo_name": "tmconnors/SallieMaeScrapper",
"src_encoding": "UTF-8",
"text": "SallieMaeScrapper\n=================\n\nFind out when you'll be free from Sallie Mae and your student loan debt. \n\n\n-ssn SSN, -s SSN your social security number\n\n-dob DOB, -d DOB your date of birth MM/DD/YYYY\n\n-usr USR, -u USR your Sallie Mae username\n\n-pwd PWD, -p PWD your Sallie Mae password\n\nusuage: python main.py monthly_payment -s [123456789] -d [02/29/2012] -u [AZNSENPAI] -p [P0WERTHIRST]\n"
},
{
"alpha_fraction": 0.5609756112098694,
"alphanum_fraction": 0.577095627784729,
"avg_line_length": 44.445858001708984,
"blob_id": "5ff3a175c4f63aa956077a043568d7c7ad88f46e",
"content_id": "611892181f82280d672ff66d6674c08a03b7d31b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7134,
"license_type": "no_license",
"max_line_length": 160,
"num_lines": 157,
"path": "/main.py",
"repo_name": "tmconnors/SallieMaeScrapper",
"src_encoding": "UTF-8",
"text": "__author__ = 'thomas.connors'\n\nfrom selenium import webdriver\nimport time\nimport datetime\nimport numpy as np\nimport sys\nimport locale\nimport argparse\n\ndef monthly_interest(loanAmount, intRate, current_monthly_interest):\n for x in range(0, 30):\n daily_interest = float(((intRate / (365 * 100)) * loanAmount))\n current_monthly_interest.append(daily_interest)\n loanAmount += daily_interest\n return round(loanAmount,2)\n\ndef total_monthly_interest(loanAmounts, intRates):\n current_monthly_interest = []\n for i in range(0, len(loanAmounts)):\n loanAmounts[i] = monthly_interest(loanAmounts[i], intRates[i], current_monthly_interest)\n return sum(current_monthly_interest)\n\ndef make_payment(payment, loanAmounts, intRates):\n payment_remainder = payment\n while( payment_remainder > 0):\n max_rate = np.array(intRates)\n max_rate_i = np.where(max_rate == max_rate.max())[0][0]\n loanAmounts[max_rate_i] -= payment_remainder\n if( loanAmounts[max_rate_i] < 0 ):\n payment_remainder = abs(loanAmounts[max_rate_i])\n loanAmounts.pop(max_rate_i)\n intRates.pop(max_rate_i)\n if( len(intRates) == 0 or len(loanAmounts) == 0):\n break\n else:\n payment_remainder = 0\n\ndef print_metadata():\n totalLoan = sum(loanAmounts)\n loanPercents = []\n for i in xrange(0, len(loanAmounts)):\n loanPercents.append((loanAmounts[i]/totalLoan)*100)\n totalLoanPercent = 0\n for i in xrange(0, len(loanPercents)):\n totalLoanPercent += loanPercents[i]*intRates[i]/100\n print(\"Balance\".rjust(9) + \"\\t\" + \"Interest Rate\" + \"\\t \" + \"Percent\".rjust(13) + \" |\")\n print(\"-----------------------------------------------|\")\n for i in xrange(0, len(loanAmounts)):\n print( '${0:,.2f}'.format(loanAmounts[i]).rjust(10) + \"\\t\" + (\"%.2f\" % intRates[i]).rjust(8) + \"%\\t\\t\" + (\"%.2f\" % loanPercents[i]).rjust(5) + \"% |\")\n print(\"-----------------------------------------------|\")\n print(\"Total Loan: \" + \"\\t\\t\\t\" + '${0:,.2f}'.format(totalLoan).rjust(14) + \" |\")\n print(\"Weighted Average Interest Rate: \" + \"\\t\" + (\"%.2f\" % totalLoanPercent).rjust(5) + \"% |\" )\n print(\"-----------------------------------------------|\")\n print(\" |\")\n print( \"Monthly Payment: \" + \"\\t\\t\" + '${0:,.2f}'.format(monthly_payment).rjust(13) + \"% |\")\n print(\"-----------------------------------------------|\")\n print(\" |\")\n print(\"Month\" + \"\\t\\t\" + \"Balance\" + \"\\t \" + \"Monthly Interest\".rjust(21) + \" |\")\n print(\"-----------------------------------------------|\")\n\n\ndef print_post_metadata(totalLoan, totalInterest, totalPayments):\n print(\"-----------------------------------------------|\")\n print(\"Final Payment: \" + \"\\t\\t\\t\" + '${0:,.2f}'.format(totalLoan).rjust(14)+\" |\")\n print(\"Total Interest Paid:\" + \"\\t\\t\" + '${0:,.2f}'.format(totalInterest).rjust(14) +\" |\")\n print(\"Total Payment: \" + \"\\t\\t\\t\" + '${0:,.2f}'.format(totalPayments).rjust(14)+ \" |\")\n print(\"-----------------------------------------------|\")\n\ndef sanitize_data(loanAmounts, intRates):\n loanAmounts.pop()\n loanAmounts.pop(0)\n\n loanAmountsI = []\n for i in xrange(0, len(loanAmounts)):\n loanAmounts[i] = loanAmounts[i].replace(\"$\", \"\")\n loanAmounts[i] = loanAmounts[i].replace(\",\", \"\")\n loanAmountsI.append(float(loanAmounts[i]))\n loanAmounts = loanAmountsI\n intRatesI = []\n for i in xrange(0, len(intRates)):\n intRates[i] = intRates[i].replace(\"%\", \"\")\n intRatesI.append(float(intRates[i]))\n intRates = intRatesI\n\n\ndef scrape(ssn, dob, usr, pwd):\n driver = webdriver.Firefox()\n driver.get(\"http://www.salliemae.com\")\n driver.switch_to.frame(driver.find_element_by_id(\"ctl16_frLogin\"))\n driver.find_element_by_xpath(\".//*[@id='lblUserId']\").send_keys(usr)\n driver.find_element_by_xpath(\".//*[@id='lblPassword']\").send_keys(pwd)\n driver.find_element_by_xpath(\".//*[@id='LogInSubmit']\").click()\n time.sleep(2)\n driver.find_element_by_name('tSSN1').send_keys(ssn[0:3])\n driver.find_element_by_name('tSSN2').send_keys(ssn[3:5])\n driver.find_element_by_name('tSSN3').send_keys(ssn[5:9])\n driver.find_element_by_name('tmonth').send_keys(dob.split('/')[0])\n driver.find_element_by_name('tday').send_keys(dob.split('/')[1])\n driver.find_element_by_name('tyear').send_keys(dob.split('/')[2])\n driver.find_element_by_xpath(\".//*[@id='Submit']\").click()\n time.sleep(5)\n driver.close()\n\n loanAmountsW = []\n for element in driver.find_elements_by_class_name('loan-balance'):\n loanAmountsW.append(element)\n\n for i in range(0, len(loanAmountsW)):\n loanAmounts.append(loanAmountsW[i].text)\n\n interestRatesW = []\n for element in driver.find_elements_by_class_name('int-rate'):\n interestRatesW.append(element)\n\n for i in range(0, len(interestRatesW)):\n intRates.append(interestRatesW[i].text)\n\nif __name__ == \"__main__\":\n\n parser = argparse.ArgumentParser(description='Sallie MAE')\n parser.add_argument('payment', metavar='Monthly Payment', type=int, nargs='+',\n help='how much you will pay each month')\n parser.add_argument('-ssn','-s', help='your social security number', required=True)\n parser.add_argument('-dob','-d', help='your date of birth MM/DD/YYYY', required=True)\n parser.add_argument('-usr','-u', help='your Sallie Mae username', required=True)\n parser.add_argument('-pwd','-p', help='your Sallie Mae password', required=True)\n args = parser.parse_args()\n loanAmounts = []\n intRates = []\n scrape(args.ssn, args.dob, args.usr, args.pwd)\n monthly_payment = args.payment[0]\n sanitize_data(loanAmounts, intRates)\n loanAmounts = map(float, loanAmounts)\n intRates = map(float, intRates)\n print_metadata()\n totalLoan = sum(loanAmounts)\n totalInterest = 0\n totalPayments = 0\n if len(intRates) == len(loanAmounts):\n d = datetime.date.today()\n while( totalLoan > 0 ):\n d = d + datetime.timedelta(365/12)\n monthly_interest_total = total_monthly_interest(loanAmounts, intRates)\n totalInterest += monthly_interest_total\n make_payment(monthly_payment, loanAmounts, intRates)\n totalPayments += monthly_payment\n print( d.strftime(\"%m/%y\") +\"\\t\\t\" + '${0:,.2f}'.format(totalLoan).rjust(10) + \"\\t\" + '${0:,.2f}'.format(monthly_interest_total).rjust(14)+\" |\")\n totalLoan = sum(loanAmounts)\n if( (totalLoan - monthly_payment) < 0 ):\n d = d + datetime.timedelta(365/12)\n monthly_interest_total = total_monthly_interest(loanAmounts, intRates)\n totalInterest += monthly_interest_total\n totalPayments += totalLoan\n print( d.strftime(\"%m/%y\") +\"\\t\\t\" + '${0:,.2f}'.format(totalLoan).rjust(10) + \"\\t\" + '${0:,.2f}'.format(monthly_interest_total).rjust(14)+\" |\")\n break\n print_post_metadata(totalLoan, totalInterest, totalPayments)"
}
] | 2 |
elfadly/CNN-with-tensorflow-for-emotion-recognition
|
https://github.com/elfadly/CNN-with-tensorflow-for-emotion-recognition
|
144eb5dc5a162a9a84b3d79a3959749ab8a3783a
|
1fd6a8fbd8908f5ce93675c774ca4cf20a73a1f0
|
57a610f5f0e522478cc32f7b3bd35b19d6ca031b
|
refs/heads/master
| 2021-01-20T06:43:43.368663 | 2017-05-02T09:16:34 | 2017-05-02T09:16:34 | 89,918,172 | 9 | 4 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4656212329864502,
"alphanum_fraction": 0.49336549639701843,
"avg_line_length": 26.633333206176758,
"blob_id": "e086c4e594754064fc49a51f18094b27401cdba6",
"content_id": "294036f4afc72e44f9d76e50c1546303d503bf90",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 829,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 30,
"path": "/uint8-to-image.py",
"repo_name": "elfadly/CNN-with-tensorflow-for-emotion-recognition",
"src_encoding": "UTF-8",
"text": "# Converts pixels in fer2013.csv (data set) to images\n\nimport csv\nfrom PIL import Image\n\n#image parameters\nsize = 48,48\nmode = 'RGB'\nfile = 'private-test-150.csv'\n\nwith open(file,'r') as csvin:\n traindata=csv.reader(csvin, delimiter=',', quotechar='\"')\n rowcount=0\n for row in traindata:\n if rowcount > 0:\n print 'rows ' + str(rowcount) + \"\\n\"\n x=0\n y=0\n pixels=row[1].split()\n img = Image.new(mode,size)\n for pixel in pixels:\n colour=(int(pixel),int(pixel),int(pixel))\n img.putpixel((x,y), colour)\n x+=1\n if x >= 48:\n x=0\n y+=1\n imgfile='img-'+str(rowcount)+'-'+str(row[0])+'.png'\n img.save(imgfile,'png')\n rowcount+=1\n"
},
{
"alpha_fraction": 0.5458898544311523,
"alphanum_fraction": 0.5889864563941956,
"avg_line_length": 21.35714340209961,
"blob_id": "7359aafb0a996f24ed0ac49178e08a49fb461088",
"content_id": "0cc879c2f721515470bf477691fa370e06b03e54",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1253,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 56,
"path": "/uint8-to-binary.rb",
"repo_name": "elfadly/CNN-with-tensorflow-for-emotion-recognition",
"src_encoding": "UTF-8",
"text": "# Converts array of image pixels to binary format\n# Run separately for Training Set and Test Set\n\nrequire 'CSV'\n\nclass Integer\n def to_bin(width)\n '%0*b' % [width, self]\n end\nend\n\nDATA_SET_UINT8 = \"/Users/aman/Desktop/Synapse/fer2013/fer2013.csv\"\nDATA_SET_BIN = \"/Users/aman/Desktop/Synapse/fer2013/fer2013.bin\"\n# DATA_SET_BIN = \"/Users/aman/Desktop/Synapse/fer2013/test_batch.bin\" # Test data\n\n\nputs \"Reading csv ...\"\n\nFile.open(DATA_SET_BIN, 'wb') do |output|\n ctr = 1\n\n CSV.foreach(DATA_SET_UINT8, headers: true) do |row|\n emotion = row[\"emotion\"]\n pixels = row[\"pixels\"]\n usage = row[\"Usage\"]\n\n\n if usage == 'Training'\n # if usage == 'PublicTest' # Test data\n arr = [emotion.to_i.to_bin(8)] + pixels.split(' ').map { |i| i.to_i.to_bin(8) }\n puts \"#{ctr} : #{emotion} | #{pixels[0..10]} ... | #{usage} | bytes=#{arr.count}\"\n output.write [arr.join].pack(\"B*\")\n\n ctr += 1\n else\n break\n end\n\n end\nend\n\nputs \"Done!\"\n\n\n# Sample Code\n#\n# a = [6, 59]\n# b = [9, 32]\n# # a = [\"00000110\", \"00111011\"]\n#\n# File.open(\"sample-out.bin\", 'wb') do |output|\n# output.write [a.map { |i| i.to_bin(8) }.join].pack(\"B*\")\n# output.write [b.map { |i| i.to_bin(8) }.join].pack(\"B*\")\n# end\n#\n# puts \"Done!\"\n\n"
},
{
"alpha_fraction": 0.7142857313156128,
"alphanum_fraction": 0.7714285850524902,
"avg_line_length": 28.85714340209961,
"blob_id": "e6dba545bcc266b375f9605a9d27a2f22ffa67ff",
"content_id": "b9cfc2639576e88a28a28bb655e141dea2ac6a17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 210,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 7,
"path": "/__init__.py",
"repo_name": "elfadly/CNN-with-tensorflow-for-emotion-recognition",
"src_encoding": "UTF-8",
"text": "\"\"\"Makes helper libraries available in the fer2013 package.\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport fer2013\nimport fer2013_input\n\n"
},
{
"alpha_fraction": 0.64420485496521,
"alphanum_fraction": 0.7068732976913452,
"avg_line_length": 43.969696044921875,
"blob_id": "95059aaaf5a4c6fc17e540e641de0383ca270f29",
"content_id": "3a309852534d28df4c9e272cf7a2ecb6c3b040bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1484,
"license_type": "no_license",
"max_line_length": 184,
"num_lines": 33,
"path": "/README.md",
"repo_name": "elfadly/CNN-with-tensorflow-for-emotion-recognition",
"src_encoding": "UTF-8",
"text": "Facial Emotion Recognition using TensorFlow!\n\nDATA SET:\n---------\n- Download Data Set: `fer2013.bin` (63M) and `test_batch.bin` (7.9M) from https://goo.gl/ffmy2h\n\n Image Properties: `Size of an image` - 48 x 48 pixels (2304 bytes), `Size of a label` - number in (0..6) (1 byte) (0=Angry, 1=Fear, 2=Happy, 3=Sad, 4=Disgust, 5=Surprise, 6=Neutral).\n\n Data Set Format: `1st byte` is the label number and the `next 2304 bytes` are the image pixels.\n\n- Create a data directory in your system: `/tmp/fer2013_data/`\n\n- Put the training data set (28,709 images) in: `/tmp/fer2013_data/fer2013-batches-bin/fer2013.bin`\n\n- Put the testing data set (3,589 images) in: `/tmp/fer2013_data/fer2013-batches-bin/test_batch.bin`\n\nHOW TO RUN:\n-----------\n- Install `TensorFlow`: https://www.tensorflow.org/versions/r0.7/get_started/os_setup.html#pip-installation\n- Run `python fer2013_train.py` (Takes ~20hrs on a quad core laptop!)\n- Run `python fer2013_eval.py` on fer2013.bin data (Training Precision)\n- Run `python fer2013_eval.py` on test_batch.bin data (Evaluation Precision)\n\nSTATS DASHBOARD:\n----------------\n- Run `tensorboard --logdir \"/tmp\"`\n- Go to `http://0.0.0.0:6006/`\n- This displays `events`, `images`, `graphs` and `histograms` for the train and eval runs on the model.\n\nREFERENCES:\n-----------\n- Code references and examples from https://www.tensorflow.org\n- Data Set from https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge/data\n"
}
] | 4 |
danielEbanks/TensorJST_Public
|
https://github.com/danielEbanks/TensorJST_Public
|
a4c3ce1561b999f53dc5a606e412bf25b90cb7e5
|
46a6d187bfd44920a8cda81f74e161f6c4374f3e
|
44ab5d2b16241f8de4aa5640d240913859cba4ce
|
refs/heads/main
| 2023-06-04T23:03:43.716968 | 2021-06-22T19:20:43 | 2021-06-22T19:20:43 | 379,377,629 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6199207305908203,
"alphanum_fraction": 0.6253716349601746,
"avg_line_length": 41.0625,
"blob_id": "345c61a3e004035750e9ea12b4018658297d1921",
"content_id": "c97092ac62108ba2de0d9d4a711acc9105c38f51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2018,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 48,
"path": "/pca.py",
"repo_name": "danielEbanks/TensorJST_Public",
"src_encoding": "UTF-8",
"text": "import tensorly as tl\nfrom sklearn.decomposition import IncrementalPCA\n\nclass PCA():\n def __init__(self, n_eigenvec, alpha_0, batch_size): # n_eigenvec here corresponds to n_topic in the LDA\n self.n_eigenvec = n_eigenvec\n self.alpha_0 = alpha_0\n self.batch_size = batch_size\n self.pca = IncrementalPCA(n_components = self.n_eigenvec, batch_size = self.batch_size)\n\n def fit(self, X):\n '''Fit the entire data to get the projection weights (singular vectors) and\n whitening weights (scaled explained variance) of a centered input dataset X.\n Parameters\n ----------\n X : tensor containing all input documents\n '''\n self.pca.fit(X*tl.sqrt(self.alpha_0+1))\n self.projection_weights_ = tl.transpose(self.pca.components_)\n self.whitening_weights_ = self.pca.explained_variance_*(X.shape[0] - 1)/(X.shape[0])\n\n def partial_fit(self, X_batch):\n '''Fit a batch of data and update the projection weights (singular vectors) and\n whitening weights (scaled explained variance) accordingly using a centered\n batch of the input dataset X.\n Parameters\n ----------\n X_batch : tensor containing a batch of input documents\n '''\n self.pca.partial_fit(X_batch)\n self.projection_weights_ = tl.transpose(self.pca.components_)\n self.whitening_weights_ = self.pca.explained_variance_*(X.shape[0] - 1)/(X.shape[0])\n\n def transform(self, X):\n '''Whiten some centered tensor X using the fitted PCA model.\n Parameters\n ----------\n X : centered input tensor\n '''\n return tl.dot(X, (self.projection_weights_ / tl.sqrt(self.whitening_weights_)[None, :]))\n\n def reverse_transform(self, X):\n '''Unwhiten some whitened tensor X using the fitted PCA model.\n Parameters\n ----------\n X : whitened input tensor\n '''\n return tl.dot(X, (self.projection_weights_ * tl.sqrt(self.whitening_weights_)).T)"
},
{
"alpha_fraction": 0.6565533876419067,
"alphanum_fraction": 0.6699029207229614,
"avg_line_length": 38.28571319580078,
"blob_id": "8f84fccca50600a8200dfca91d606f880a3ca34f",
"content_id": "9cc78da0eb754c94552e8b392fcbafe0e29a2111",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 824,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 21,
"path": "/cumulant_gradient.py",
"repo_name": "danielEbanks/TensorJST_Public",
"src_encoding": "UTF-8",
"text": "import tensorly as tl\n# This should work with any backend\n# tl.set_backend('pytorch')\nfrom tensorly.cp_tensor import cp_mode_dot\nimport tensorly.tenalg as tnl\nfrom tensorly.tenalg.core_tenalg import tensor_dot, batched_tensor_dot, outer, inner\n\ndef cumulant_gradient(phi, y_batch, alpha=1, theta=1):\n \"\"\"Computes the average gradient for a batch of whitened samples\n phi : (n_features, rank)\n factor to be optimized\n y_batch : (n_samples, n_features)\n each row is one whitened sample\n Returns\n -------\n phi_gradient : gradient of the loss with respect to Phi\n of shape (n_features, rank)\n \"\"\"\n gradient = 3*(1 + theta)*tl.dot(phi, tl.dot(phi.T, phi)**2)\n gradient -= 3*(1 + alpha)*(2 + alpha)/(2*y_batch.shape[0])*tl.dot(y_batch.T, tl.dot(y_batch, phi)**2)\n return gradient"
},
{
"alpha_fraction": 0.6169759631156921,
"alphanum_fraction": 0.6294493675231934,
"avg_line_length": 31.554454803466797,
"blob_id": "7dc708f6f9e0b94978754388fdab7a378a3032eb",
"content_id": "6dd2005c6aa21f7238a1cc115ff185661fcc05c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3287,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 101,
"path": "/tensor_lda_util.py",
"repo_name": "danielEbanks/TensorJST_Public",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nfrom scipy.special import comb, digamma, gammaln\nfrom scipy.stats import gamma\nimport sparse\nimport scipy\n\n# Import TensorLy\nimport tensorly as tl\nfrom tensorly import norm\nfrom tensorly.tenalg.core_tenalg.tensor_product import batched_tensor_dot\n\ntl.set_backend('numpy')\ndevice = 'cpu'#cuda\n\ndef get_ei(length, i):\n '''Get the ith standard basis vector of a given length'''\n e = tl.zeros(length)\n e[i] = 1\n return e\n\ndef dirichlet_expectation(alpha):\n '''Normalize alpha using the dirichlet distribution'''\n return digamma(alpha) - digamma(sum(alpha))\n\ndef smooth_beta(beta, smoothing = 0.01):\n '''Smooth the existing beta so that it all positive (no 0 elements)'''\n smoothed_beta = beta * (1 - smoothing)\n smoothed_beta += (np.ones((beta.shape[0], beta.shape[1])) * (smoothing/beta.shape[0]))\n\n assert np.all(abs(np.sum(smoothed_beta, axis=0) - 1) <= 1e-6), 'sum not close to 1'\n assert smoothing <= 1e-4 or np.all(smoothed_beta > 1e-10), 'zero values'\n return smoothed_beta\n\ndef simplex_proj(V):\n '''Project V onto a simplex'''\n v_len = V.size\n U = np.sort(V)[::-1]\n cums = np.cumsum(U, dtype=float) - 1\n index = np.reciprocal(np.arange(1, v_len+1, dtype=float))\n inter_vec = cums * index\n to_befind_max = U - inter_vec\n max_idx = 0\n\n for i in range(0, v_len):\n if (to_befind_max[v_len-i-1] > 0):\n max_idx = v_len-i-1\n break\n theta = inter_vec[max_idx]\n p_norm = V - theta\n p_norm[p_norm < 0.0] = 0.0\n return (p_norm, theta)\n\ndef non_negative_adjustment(M):\n '''Adjust M so that it is not negative by projecting it onto a simplex'''\n M_on_simplex = np.zeros(M.shape)\n M = tl.to_numpy(M)\n\n for i in range(0, M.shape[1]):\n projected_vector, theta = simplex_proj(M[:, i] - np.amin(M[:, i]))\n projected_vector_revsign, theta_revsign = simplex_proj(-1*M[:, i] - np.amin(-1*M[:, i]))\n\n if (theta < theta_revsign):\n M_on_simplex[:, i] = projected_vector\n else:\n M_on_simplex[:, i] = projected_vector_revsign\n return M_on_simplex\n\ndef perplexity (documents, beta, alpha, gamma):\n '''get perplexity of model, given word count matrix (documents)\n topic/word distribution (beta), weights (alpha), and document/topic\n distribution (gamma)'''\n\n elogbeta = np.log(beta)\n\n corpus_part = np.zeros(documents.shape[0])\n for i, doc in enumerate(documents):\n doc_bound = 0.0\n gammad = gamma[i]\n elogthetad = dirichlet_expectation(gammad)\n\n for idx in np.nonzero(doc)[0]:\n doc_bound += doc[idx] * log_sum_exp(elogthetad + elogbeta[idx].T)\n\n doc_bound += np.sum((alpha - gammad) * elogthetad)\n doc_bound += np.sum(gammaln(gammad) - gammaln(alpha))\n doc_bound += gammaln(np.sum(alpha)) - gammaln(np.sum(gammad))\n\n corpus_part[i] = doc_bound\n\n #sum the log likelihood of all the documents to get total log likelihood\n log_likelihood = np.sum(corpus_part)\n total_words = np.sum(documents)\n\n #perplexity is - log likelihood / total number of words in corpus\n return (-1*log_likelihood / total_words)\n\ndef log_sum_exp(x):\n '''calculate log(sum(exp(x)))'''\n a = np.amax(x)\n return a + np.log(np.sum(np.exp(x - a)))"
},
{
"alpha_fraction": 0.5960791110992432,
"alphanum_fraction": 0.6062193512916565,
"avg_line_length": 41.56834411621094,
"blob_id": "18892d5f077faf1024e3396497d92cb17b22da55",
"content_id": "a169e1a502c0c4d8fdddd55f46c8c9f05818783e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5917,
"license_type": "no_license",
"max_line_length": 207,
"num_lines": 139,
"path": "/tlda_final.py",
"repo_name": "danielEbanks/TensorJST_Public",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport math\nfrom scipy.stats import gamma\n\nimport tensorly as tl\nfrom cumulant_gradient import cumulant_gradient\nimport tensor_lda_util as tl_util\n\n\nclass TLDA():\n def __init__(self, n_topic,n_senti ,alpha_0, n_iter_train, n_iter_test, batch_size, learning_rate = 0.001, gamma_shape = 1.0, smoothing = 1e-6): # we could try to find a more informative name for alpha_0\n # set all parameters here\n self.n_topic = n_topic\n self.n_senti = n_senti\n self.alpha_0 = alpha_0\n self.n_iter_train = n_iter_train\n self.n_iter_test = n_iter_test\n self.batch_size = batch_size\n self.learning_rate = learning_rate\n self.gamma_shape = gamma_shape\n self.smoothing = smoothing\n self.weights_ = tl.ones(self.n_topic*self.n_senti)\n self.factors_ = tl.tensor(np.random.randn(self.n_topic, self.n_topic)/10000)\n\n def partial_fit(self, X_batch, verbose = False):\n '''Update the factors directly from the batch using stochastic gradient descent\n Parameters\n ----------\n X_batch : ndarray of shape (number_documents, num_topics) equal to the whitened\n word counts in each document in the documents used to update the factors\n verbose : bool, optional\n if True, print information about every 200th iteration\n '''\n # incremental version\n y_mean = tl.mean(X_batch, axis=0)\n\n for i in range(1, self.n_iter_train):\n for j in range(0, len(X_batch)-(self.batch_size-1), self.batch_size):\n y = X_batch[j:j+self.batch_size]\n\n lr = self.learning_rate*(10/(10+i))\n self.factors_ -= lr*cumulant_gradient(self.factors_, y, self.alpha_0,1)\n if verbose == True and (i % 200) == 0:\n print(\"Epoch: \" + str(i) )\n\n def fit(self, X, verbose = False):\n '''Update the factors directly from X using stochastic gradient descent\n Parameters \n ----------\n X : ndarray of shape (number_documents, num_topics) equal to the whitened\n word counts in each document in the documents used to update the factors\n '''\n\n self.partial_fit(X, verbose = verbose)\n\n def _predict_topic(self, doc, adjusted_factor,w_mat):\n '''Infer the document-topic distribution vector for a given document using variational inference\n Parameters\n ----------\n doc : tensor of length vocab_size equal to the number of occurrences\n of each word in the vocabulary in a document\n adjusted_factor : tensor of shape (number_topics, vocabulary_size) equal to the learned\n document-topic distribution\n Returns\n -------\n gammad : tensor of shape (1, n_cols) equal to the document/topic distribution\n for the doc vector\n '''\n \n n_cols = len(self.factors_)\n if w_mat == False:\n self.weights_ = self.weights_ = tl.ones(self.n_topic*self.n_senti)/(self.n_topic*self.n_senti)\n if w_mat == True:\n self.weights_ = self.weights_ = tl.ones(self.n_topic)/(self.n_topic)\n\n \n\n\n gammad = tl.tensor(gamma.rvs(self.gamma_shape, scale= 1.0/self.gamma_shape, size = n_cols)) # gamma dist. \n exp_elogthetad = tl.tensor(np.exp(tl_util.dirichlet_expectation(gammad)))\n exp_elogbetad = tl.tensor(np.array(adjusted_factor))\n\n phinorm = (tl.dot(exp_elogbetad, exp_elogthetad) + 1e-100)\n mean_gamma_change = 1.0\n\n iter = 0\n while (mean_gamma_change > 1e-2 and iter < self.n_iter_test):\n lastgamma = tl.copy(gammad)\n gammad = ((exp_elogthetad * (tl.dot(exp_elogbetad.T, doc / phinorm))) + self.weights_)\n exp_elogthetad = tl.tensor(np.exp(tl_util.dirichlet_expectation(gammad)))\n phinorm = (tl.dot(exp_elogbetad, exp_elogthetad) + 1e-100)\n\n mean_gamma_change = tl.sum(tl.abs(gammad - lastgamma)) / n_cols\n all_gamma_change = gammad-lastgamma\n iter += 1\n\n return gammad\n\n def predict(self, X_test,w_mat=False,doc_predict=True):\n '''Infer the document/topic distribution from the factors and weights and\n make the factor non-negative\n Parameters\n ----------\n X_test : ndarray of shape (number_documents, vocabulary_size) equal to the word\n counts in each test document\n Returns\n -------\n gammad_norm2 : tensor of shape (number_documents, number_topics) equal to\n the normalized document/topic distribution for X_test\n factor : tensor of shape (vocabulary_size, number_topics) equal to the\n adjusted factor\n '''\n\n adjusted_factor = tl.transpose(self.factors_)\n #adjusted_factor = tl_util.non_negative_adjustment(adjusted_factor)\n #adjusted_factor = tl_util.smooth_beta(adjusted_factor, smoothing=self.smoothing)\n \n \n # set negative part to 0\n adjusted_factor[adjusted_factor < 0.] = 0.\n # smooth beta\n adjusted_factor *= (1. - self.smoothing)\n adjusted_factor += (self.smoothing / adjusted_factor.shape[1])\n\n adjusted_factor /= adjusted_factor.sum(axis=1)[:, np.newaxis]\n \n \n if doc_predict == True:\n\n gammad_l = (np.array([tl.to_numpy(self._predict_topic(doc, adjusted_factor,w_mat)) for doc in X_test]))\n gammad_l = tl.tensor(np.nan_to_num(gammad_l))\n\n #normalize using exponential of dirichlet expectation\n gammad_norm = tl.tensor(np.exp(np.array([tl_util.dirichlet_expectation(g) for g in gammad_l])))\n gammad_norm2 = tl.tensor(np.array([row / np.sum(row) for row in gammad_norm]))\n\n return gammad_norm2, tl.transpose(adjusted_factor)\n else:\n return tl.transpose(adjusted_factor) "
}
] | 4 |
eaudeweb/edw.highcharts
|
https://github.com/eaudeweb/edw.highcharts
|
0d84308339caf9107730e6c74eb39f8d084dbd7f
|
8a4d9a24d7123579cb50cd5d959b1a2910528b26
|
32ce45b3bc2b629b5c6b400d550c6e8c7cceae62
|
refs/heads/master
| 2021-01-20T15:37:01.467141 | 2013-02-18T16:21:29 | 2013-02-18T16:21:29 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6413043737411499,
"alphanum_fraction": 0.6413043737411499,
"avg_line_length": 15.727272987365723,
"blob_id": "7509e9d867e8c2afeb5cef602ec076692250b0d5",
"content_id": "24b1972ea659ebbe5e1181c53c21fd9baed5396b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 368,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 22,
"path": "/edw/highcharts/README.txt",
"repo_name": "eaudeweb/edw.highcharts",
"src_encoding": "UTF-8",
"text": "Overview\n========\nEau de Web Highcharts is a Plone add-on that provides Highcharts JS lib for\nPlone users.\n\n\nInstallation\n============\n * Go to admin > Site Setup > Add-ons\n * Activate Eau de Web Highcharts\n\n\nAuthors\n=======\n\n- `Eau de Web <http://eaudeweb.ro>`_\n\n\nDocumentation\n=============\n\n- `Source code on Github <https://github.com/eaudeweb/edw.highcharts>`_\n"
},
{
"alpha_fraction": 0.6431034207344055,
"alphanum_fraction": 0.6474137902259827,
"avg_line_length": 20.90566062927246,
"blob_id": "a87ab5bdc99de60e7e205d47064a52efbb334d33",
"content_id": "928502a177a8da3ff5feebdd1ae8f38ea1b70847",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 1160,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 53,
"path": "/README.txt",
"repo_name": "eaudeweb/edw.highcharts",
"src_encoding": "UTF-8",
"text": "=====================\nEau de Web Highcharts\n=====================\n\nIntroduction\n============\n\nEau de Web Highcharts provides `Highcharts JS library`_ as zope3 resources.\n\n.. note ::\n\n This add-on doesn't do anything by itself. It needs to be integrated by a\n developer within your own products.\n\nInstallation\n============\n\nzc.buildout\n-----------\nIf you are using `zc.buildout`_ and the `plone.recipe.zope2instance`_\nrecipe to manage your project, you can do this:\n\n* Update your buildout.cfg file:\n\n * Add ``edw.highcharts`` to the list of eggs to install\n * Tell the `plone.recipe.zope2instance`_ recipe to install a ZCML slug\n\n ::\n\n [instance]\n ...\n eggs =\n ...\n edw.highcharts\n\n zcml =\n ...\n edw.highcharts\n\n* Re-run buildout, e.g. with::\n\n $ ./bin/buildout\n\nYou can skip the ZCML slug if you are going to explicitly include the package\nfrom another package's configure.zcml file.\n\nSource code\n===========\n\n- `Eau de Web on Github <https://github.com/eaudeweb/edw.highcharts>`_\n\n.. _`Highcharts JS library`: http://highcharts.com\n.. _`plone.recipe.zope2instance`: http://pypi.python.org/pypi/plone.recipe.zope2instance"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 12,
"blob_id": "b3e16425d909ef8d2f26d7a9dc75efae2a2de3d8",
"content_id": "0e9f20b69f0108d4edefabe3094c29db3a927cba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 25,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 2,
"path": "/edw/highcharts/static/__init__.py",
"repo_name": "eaudeweb/edw.highcharts",
"src_encoding": "UTF-8",
"text": "\"\"\" Highcharts JS lib\n\"\"\""
}
] | 3 |
torpidfox/GeneExpressionMapping
|
https://github.com/torpidfox/GeneExpressionMapping
|
0353b134659dee7554a228a07289e788a6e7f8ed
|
77b9affe8ab9e83adc5a75cb7c55995d6a108f96
|
c98ee0b84cdc305e049a8c0c54c08a58eb0a309a
|
refs/heads/master
| 2020-03-10T08:16:17.210324 | 2019-09-18T18:19:27 | 2019-09-18T18:19:27 | 129,281,466 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5337243676185608,
"alphanum_fraction": 0.5337243676185608,
"avg_line_length": 23.735849380493164,
"blob_id": "b3b3ae7bf5573cc8980e3391d702515c6d108da7",
"content_id": "e0307d9750694a4928ea15dd6518287bad2bd82c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1364,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 53,
"path": "/logger.py",
"repo_name": "torpidfox/GeneExpressionMapping",
"src_encoding": "UTF-8",
"text": "import pathlib\r\nimport datetime\r\nimport json\r\nfrom numpy import shape\r\nfrom numpy import savez\r\n\r\nclass Logger:\r\n def __init__(self,\r\n description):\r\n\r\n \tself.path = '../logs/{}/'.format(description)\r\n \tpathlib.Path(self.path).mkdir(parents=True, exist_ok=True)\r\n \tself.results_file = open('{}log_autoenc_loss.csv'.format(self.path), 'w+')\r\n \t#self.config_file.write(json.dumps(params))\r\n \t#self.config_file.close()\r\n\r\n @staticmethod\r\n def _dump_to_file(filename,\r\n vals): \r\n savez(filename, **vals)\r\n\r\n def dump_res(self,\r\n vals,\r\n vals_description=['original', \r\n 'encoded', \r\n 'squeezed', \r\n 'decoded', \r\n #'labels', \r\n 'second_set',\r\n 'second_set_original'],\r\n attr='train'):\r\n\r\n for ind, el in enumerate(vals):\r\n # add labels to data for convinience\r\n print(len(el))\r\n data = {key : el for key, el in zip(vals_description, el)}\r\n self._dump_to_file('{}model{}_res_{}'.format(self.path, ind, attr), data)\r\n\r\n def log_results(self,\r\n epoch,\r\n losses):\r\n\r\n \tself.results_file.write('%i %s\\n' % (epoch, losses))\r\n\r\n def __exit__(self,\r\n type,\r\n value,\r\n traceback):\r\n \r\n self.results_file.close()\r\n\r\n def __enter__(self):\r\n return self\r\n"
},
{
"alpha_fraction": 0.725806474685669,
"alphanum_fraction": 0.7419354915618896,
"avg_line_length": 13.5,
"blob_id": "0e941c0956b51f75593fe2c6a4117a054851010a",
"content_id": "08e224519e77fdc3d1deb40f1f7ac14c7cb0a9ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 62,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 4,
"path": "/README.md",
"repo_name": "torpidfox/GeneExpressionMapping",
"src_encoding": "UTF-8",
"text": "# GeneExpressionMapping\r\n## Launching\r\n\r\npython3 ref_main.py\r\n"
},
{
"alpha_fraction": 0.6108205914497375,
"alphanum_fraction": 0.6269106864929199,
"avg_line_length": 26.912281036376953,
"blob_id": "2dc8e4c3a9700218438e16afeb858f41407d4488",
"content_id": "f1e96dc105b2abe2594a2616325d7440bfe95529",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4972,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 171,
"path": "/model.py",
"repo_name": "torpidfox/GeneExpressionMapping",
"src_encoding": "UTF-8",
"text": "from subset import PrivateDomain, nn\r\nimport tensorflow as tf\r\nfrom logger import Logger\r\n\r\nimport sys\r\nsys.path.append('./add_libs/')\r\nimport losses as los\r\nsummaries_dir = './summary/'\r\nlogs_dir = 'two_sets_from_one'\r\n\r\ntres_valid_loss = 1\r\niter_count = 1\r\ndropout_prob = tf.get_default_graph().get_tensor_by_name('dropout_prob:0')\r\n\r\nsqueezed_data_ind = -2\r\n\r\n\r\nclass Model:\r\n\tdef __init__(self, sets, split=False):\r\n\t\tself.sets = sets\r\n\t\tself.valid = {dropout_prob : 1}\r\n\t\tself.split = split\r\n\r\n\t\tfor s in self.sets:\r\n\t\t\tself.valid.update(s.feed_valid_dict())\r\n\r\n\tdef losses(self):\r\n\t\t\"\"\" Compute all the losses \"\"\"\r\n\r\n\t\t# private decoders loss\r\n\t\tprivate_loss = [s.loss(self.epoch_step) for s in self.sets]\r\n\r\n\t\t# private classification loss\r\n\t\tclass_loss = [s.class_loss for s in self.sets if s.tagged]\r\n\r\n\t\t# private accuracy\r\n\t\tself.accuracy = [s.accuracy for s in self.sets if s.tagged]\r\n\r\n\t\tdelay_steps = [self.epoch_step % tf.to_int32(s.delay) for s in self.sets]\r\n\t\tdistr_loss = list()\r\n\r\n\t\t# append the result of applying one split's decoder to another split and vice versa\r\n\t\tif self.split:\r\n\t\t\tself.sets[0].result.append(\r\n\t\t\t\tnn(self.sets[0].decoder_v, self.sets[1].result[squeezed_data_ind])\r\n\t\t\t)\r\n\t\t\tself.sets[1].result.append(\r\n\t\t\t\tnn(self.sets[1].decoder_v, self.sets[0].result[squeezed_data_ind - 1])\r\n\t\t\t)\r\n\r\n\t\t# compute distribution losses\r\n\t\tif not self.split:\r\n\t\t\tfor s1, delay_step1 in zip(self.sets, delay_steps):\r\n\t\t\t\t_, var1 = tf.nn.moments(s1.result[0], axes=[0])\r\n\r\n\t\t\t\tfor s2, delay_step2 in zip(self.sets, delay_steps):\r\n\t\t\t\t\tif s1 != s2:\t\r\n\t\t\t\t\t\tshould_add = tf.logical_and(tf.equal(delay_step1, 0),\r\n\t\t\t\t\t\t\ttf.equal(delay_step2, 0))\r\n\r\n\t\t\t\t\t\t_, var2 = tf.nn.moments(s2.result[0], axes=[0])\r\n\t\t\t\t\t\tcoeff = 1.0 / tf.sqrt(tf.reduce_mean(var1) * tf.reduce_mean(var2))\r\n\r\n\t\t\t\t\t\tdistr_loss.append(tf.cond(should_add,\r\n\t\t\t\t\t\t\tlambda: tf.to_float(0.0),\t\r\n\t\t\t\t\t\t\tlambda: tf.losses.mean_squared_error(s2.result[1], s1.result[1]) / 2,\r\n\t\t\t\t\t\t\t))\r\n\r\n\t\t#self.loss = [tf.to_float(0.0), tf.to_float(0.0)] + private_loss\r\n\r\n\t\t#total loss\r\n\t\tself.loss = distr_loss+private_loss+class_loss\r\n\t\ttf.summary.scalar('distribution loss', distr_loss)\r\n\t\t\r\n\t\treturn self.loss\r\n\r\n\tdef feed_dict(self, step):\r\n\t\t\"\"\" returns the dictionary to feed to tensorflow's session to \r\n\t\tParametrs:\r\n\t\t\tstep -- global session step\r\n\r\n\t\t\"\"\" \r\n\t\tfeed_vals = {dropout_prob : 0.8}\r\n\r\n\t\t# add training batch from all the sets\r\n\t\tfor s in self.sets:\r\n\t\t\tfeed_vals.update(s.feed_dict(step))\r\n\r\n\t\treturn feed_vals\r\n\r\n\r\n\tdef build_graph(self):\r\n\t\t\"\"\" Perform all the computations \"\"\"\r\n\r\n\t\tfor s in self.sets:\r\n\t\t\ts.run(s.x)\r\n\r\n\t\t# global step variable\r\n\t\tself.epoch_step = tf.Variable(0,\r\n\t\t\tname='epoch_num',\r\n\t\t\ttrainable=False)\r\n\r\n\t\tstep_inc_op = tf.assign_add(self.epoch_step, 1)\r\n\r\n\t\tlearning_rate = tf.train.exponential_decay(1e-2, self.epoch_step, 100, 0.96)\r\n\r\n\t\twith tf.name_scope('loss'):\r\n\t\t\ttotal_loss = tf.reduce_sum(self.losses())\r\n\r\n\t\ttf.summary.scalar('loss', total_loss)\r\n\r\n\t\topt = tf.train.AdagradOptimizer(learning_rate=1e-3).minimize(total_loss)\r\n\r\n\t\tvalid_op = [self.loss] + [self.accuracy] + [s.result for s in self.sets]\r\n\t\ttrain_op = valid_op + [opt]\r\n\r\n\t\treturn train_op, valid_op, step_inc_op\r\n\r\n\tdef run(self):\r\n\t\t\"\"\" Run training \"\"\"\r\n\r\n\t\ttrain_op, valid_op, step_inc_op = self.build_graph()\r\n\t\tvalid_loss_step = 0\r\n\t\tmin_valid_loss = float('inf')\r\n\t\tvalid_loss = 10\r\n\t\tvalid_acc = 0\r\n\t\tstep = 0\r\n\t\tsaver = tf.train.Saver()\r\n\r\n\t\twith Logger(logs_dir) as logging:\r\n\t\t\twith tf.Session() as sess:\r\n\t\t\t\t#summary_op = tf.merge_all_summaries()\r\n\t\t\t\t#train_writer = tf.train.SummaryWriter(summaries_dir + '/train', sess.graph)\r\n\t\t\t\t#test_writer = tf.train.SummaryWriter(summaries_dir + '/test')\r\n\r\n\t\t\t\tsess.run(tf.global_variables_initializer())\t\r\n\t\t\t\tsess.run(tf.local_variables_initializer())\r\n\r\n\t\t\t\twhile valid_loss_step < tres_valid_loss:\r\n\t\t\t\t\tstep = sess.run(step_inc_op)\r\n\t\t\t\t\tfeed_dict = self.feed_dict(step)\r\n\t\t\t\t\tloss, acc, *result, _ = sess.run(train_op, feed_dict=feed_dict)\r\n\r\n\t\t\t\t\tif not step % 10:\r\n\t\t\t\t\t\tprint(step, loss, acc)\r\n\t\t\t\t\t\tprint('valid', valid_loss, valid_acc, valid_loss_step)\r\n\t\t\t\t\t\tvalid_loss, valid_acc, *valid_result = sess.run(valid_op, feed_dict=self.valid)\r\n\r\n\t\t\t\t\t\tif sum(valid_loss) < min_valid_loss:\r\n\t\t\t\t\t\t\tmin_valid_loss = sum(valid_loss) \r\n\t\t\t\t\t\t\tvalid_loss_step = 0\r\n\r\n\t\t\t\t\t\t\t# append the source data from the second split to compare to the results of decoding\r\n\t\t\t\t\t\t\tvalid_result[0].append(self.sets[0].data.second_split(self.sets[1].data.original_df))\t\r\n\t\t\t\t\t\t\tvalid_result[1].append(self.sets[1].data.second_split(self.sets[0].data.original_df))\t\r\n\t\t\t\t\t\t\tlogging.dump_res(valid_result, attr='valid')\r\n\t\t\t\t\t\t\t\r\n\t\t\t\t\t\t\tif not step % 1000:\r\n\t\t\t\t\t\t\t\tsaver.save(sess, \"../logs/{}/model.ckpt\".format(logs_dir))\r\n\t\t\t\t\t\telse:\r\n\t\t\t\t\t\t\tvalid_loss_step += 1\r\n\r\n\r\n\t\t\t\t\tlogging.log_results(step, [loss, valid_loss])\r\n\t\t\t\t\t\t\r\n\t\t\t\t\t\t\r\n\r\ndef sess_runner(sets):\r\n\tm = Model(sets, split=True)\r\n\r\n\tm.run()\r\n\r\n\r\n\r\n\r\n\r\n\r\n\t\t\r\n\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.6416288018226624,
"alphanum_fraction": 0.6532911658287048,
"avg_line_length": 24.62631607055664,
"blob_id": "62c78558ea96e0b39edc6266580b674dbe893bf7",
"content_id": "8de295eb841cc8c0e9a6997dca5729ec6b1ccb75",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5059,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 190,
"path": "/subset.py",
"repo_name": "torpidfox/GeneExpressionMapping",
"src_encoding": "UTF-8",
"text": "from data_reader_r import Data\r\nimport tensorflow as tf\r\nimport numpy as np \r\n\r\ninit = tf.contrib.layers.xavier_initializer()\r\n\r\nshared_scope = 'shared'\r\ngene_count = 1000\r\nnum_hidden_2 = gene_count // 4\r\nnum_hidden_1 = gene_count // 2\r\nbatch_size = 50\r\nnum_classes = 4 \r\ndropout_prob = tf.placeholder_with_default(1.0, \r\n\tshape=(),\r\n\tname='dropout_prob')\r\n\r\n# neural network's params variables\r\nshared_shape = [num_hidden_1, num_hidden_1, num_hidden_2, num_hidden_2, num_hidden_2]\r\nclassification_shape = [num_hidden_2, num_classes]\r\nactivation = tf.nn.selu\r\ninit_weights = lambda n1, n2: tf.Variable(\r\n tf.random_normal([n1, n2], 0, np.sqrt(2 / n1))\r\n )\r\n\r\ninit_zeros = lambda n1: tf.Variable([0] * n1, dtype = 'float')\r\nlayer = lambda x, v: tf.nn.xw_plus_b(x, v['w'], v['b'])\r\nrecon_loss = lambda x1, x2: tf.losses.mean_squared_error(x1, x2)\r\n\r\ndef init_variables(shape):\r\n\t\"\"\" Init network's variables \"\"\"\r\n\tvariable_list = list()\r\n\r\n\tfor i, dim in enumerate(shape[:-1]):\r\n\t\tl = {'w' : init_weights(dim, shape[i + 1]),\r\n\t\t'b' : init_zeros(shape[i + 1])}\r\n\t\ttf.add_to_collection(tf.GraphKeys.REGULARIZATION_LOSSES, l['w'])\r\n\t\tvariable_list.append(l)\r\n\r\n\treturn variable_list\r\n\r\ndef nn(layers, x, is_enc=False, is_private=True):\r\n\t\"\"\" apply number of layers to the data\r\n\tParameters:\r\n\t\tlayers -- weights and biases of the layers\r\n\t\tx -- data to apply network to\r\n\t\tis_enc -- is this an encoder\r\n\t\tis_private -- is this a non-shared part\r\n\t\t\"\"\"\r\n\r\n\tfor i, l in enumerate(layers):\r\n\t\tif i != len(layers) - 1:\r\n\t\t\tx = activation(layer(x, l))\r\n\t\t\tx = tf.nn.dropout(x, dropout_prob) if i == 0 and is_enc else x \r\n\t\telif is_enc and is_private:\r\n\t\t\tx = activation(layer(x, l))\r\n\t\telse:\r\n\t\t\t# do not apply activation to the very output\r\n\t\t\tx = layer(x, l)\r\n\r\n\treturn x\r\n\r\ndef classify(x, labels):\r\n\t\"\"\" Classification \r\n\tParameters:\r\n\t\tx -- data\r\n\t\tlabels -- computed lables (before the sofrmax)\r\n\t\"\"\"\r\n\r\n\tlogits = classification_layers(x)\r\n\tclass_loss = tf.losses.sigmoid_cross_entropy(multi_class_labels=labels,\r\n\t\t\tlogits=logits)\r\n\r\n\tcorrect_pred = tf.equal(\r\n\t\ttf.argmax(tf.nn.softmax(logits), 1), \r\n\t\ttf.argmax(labels, 1)\r\n\t\t)\r\n\r\n\taccuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))\r\n\r\n\treturn class_loss, accuracy\r\n\r\n\r\nshared_variables = init_variables(shared_shape)\r\nshared_layers = lambda x: nn(shared_variables, x, True, False)\r\n\r\ncalssification_variables = init_variables(classification_shape)\r\nclassification_layers = lambda x: layer(tf.nn.dropout(x, dropout_prob),\r\n calssification_variables[0])\r\n\r\nclass PrivateDomain:\r\n\tdef __init__(self,\r\n\t\tdata,\r\n\t\tind=0,\r\n\t\ttagged=False,\r\n\t\tweight=1,\r\n\t\tdelay=1):\r\n\r\n\t\t\"\"\" Create variables that are private to the set\r\n\t\tParams:\r\n\t\t\tdata -- Data object containing the dataset\r\n\t\t\tind -- index of the set\r\n\t\t\ttagged -- is there classification data\r\n\t\t\tweight -- coefficient for the reconstruction loss\r\n\t\t\tdelay -- how many epochs should be skipped before applying nn to this set\r\n\t\t\"\"\"\r\n\r\n\t\tself.data = data\r\n\t\tself.weight = weight\r\n\t\tself.tagged = tagged\r\n\t\tself.delay = delay\r\n\t\tself.ind = ind\r\n\r\n\t\tself.encoder_shape = [self.data.dim, self.data.dim, num_hidden_1, num_hidden_1]\r\n\t\tself.decoder_shape = shared_shape[::-1] + self.encoder_shape[::-1] \r\n\r\n\t\tself.x = self.data.placeholder\r\n\t\tself.feedable = [self.x]\r\n\r\n\t\tif tagged:\r\n\t\t\tself.labels = tf.placeholder(tf.float32,\r\n\t\t\t\tshape=[batch_size, self.data.num_classes])\r\n\r\n\t\t\tself.feedable.append(self.labels)\r\n\r\n\t\tself.init_vars()\r\n\t\r\n\tdef init_vars(self):\r\n\t\t\"\"\" Initialize network's variables \"\"\"\r\n\r\n\t\tself.encoder_v = init_variables(self.encoder_shape)\r\n\t\tself.decoder_v = init_variables(self.decoder_shape)\r\n\r\n\tdef run(self, x):\r\n\t\t\"\"\" Apply the network to the data \"\"\"\r\n\r\n\t\tencoded = nn(self.encoder_v, x, is_enc=True)\r\n\t\tsqueezed = shared_layers(encoded)\r\n\r\n\t\tif self.tagged:\r\n\t\t\tself.class_loss, self.accuracy = classify(squeezed, self.labels)\r\n\r\n\t\tdecoded = nn(self.decoder_v, squeezed)\r\n\r\n\t\tself.result = [x, encoded, squeezed, decoded]\r\n\r\n\t\tif self.tagged:\r\n\t\t\tself.result.append(self.labels)\r\n\r\n\t\treturn recon_loss(x, decoded)\r\n\r\n\tdef loss(self,\r\n\t\tglobal_step):\r\n\t\t\"\"\" Compute reconstruction and (if applicable) classification losses \r\n\t\tParams:\r\n\t\t\tglobal_step -- global epoch step\r\n\t\t\"\"\"\r\n\r\n\t\tbatch_loss = self.run(self.x)\r\n\r\n\t\testimate_cond = global_step % tf.to_int32(self.delay)\r\n\t\tself.dec_loss = tf.cond(tf.equal(estimate_cond, 0),\r\n\t\t\tlambda: batch_loss,\r\n\t\t\tlambda: tf.to_float(0.0))\r\n\r\n\t\tif not self.tagged:\r\n\t\t\tself.class_loss = 0.0\r\n\r\n\t\treturn tf.reduce_sum([self.weight * self.dec_loss])\r\n\r\n\tdef feed_dict(self, step):\r\n\t\t\"\"\" Construct the dict to feed to the network \"\"\"\r\n\r\n\t\tif not step % self.delay:\r\n\t\t\tvals = next(self.data)\r\n\t\telse:\r\n\t\t\tvals = self.data.placeholders()\r\n\r\n\t\tfeed_dict = {k: v for k, v in zip(self.feedable, vals)}\r\n\r\n\t\treturn feed_dict\r\n\r\n\tdef feed_valid_dict(self):\r\n\t\t\"\"\" Construct the validation dict to feed to the network \"\"\"\r\n\r\n\t\tfeed_dict = {self.x : self.data.valid}\r\n\r\n\t\tif self.tagged:\r\n\t\t\tfeed_dict.update({self.labels : self.data.valid_tags})\r\n\r\n\t\treturn feed_dict\r\n"
},
{
"alpha_fraction": 0.649111270904541,
"alphanum_fraction": 0.6668860912322998,
"avg_line_length": 30.625,
"blob_id": "1057e7bbf9d92ee9c6fbd2162ce927d579c26b23",
"content_id": "47b3c583bbada55803778f9a461063c44da944a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 1519,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 48,
"path": "/preprocess/normalisation.r",
"repo_name": "torpidfox/GeneExpressionMapping",
"src_encoding": "UTF-8",
"text": "# template to normalise raw counts\n\nlibrary(DESeq2)\nmx_samples = read.table('../test_data/GSE80655_GeneExpressionData_Updated_3-26-2018.txt', header=TRUE, sep = '\\t')\n\n# convert to numeric\ncountDataMatrix <- as.matrix(mx_samples[ , -1])\nrownames(countDataMatrix) <- mx_samples[ , 1]\n\n# construct fake design\nsample_names = colnames(countDataMatrix)\nmx_design = as.matrix(rbinom(length(sample_names), 1, 0.5))\ncolnames(mx_design) <- 'disease'\nrownames(mx_design) <- sample_names\n\n\n# create DESeq2 structure\ndds <- DESeqDataSetFromMatrix(countData = countDataMatrix,\n colData = mx_design,\n design =~ disease)\n\nkeep <- rowSums(counts(dds)) >= 20\ndds <- dds[keep,]\n\n# estimate normalising factors\ndds <- estimateSizeFactors(dds)\n\n# get normalised matrix of samples\nmx_samples_normalised = counts(dds, normalized=TRUE)\n\n# convert from Ensembl to Gene Symbol\nlibrary(biomaRt)\n\nmart = useEnsembl(biomart=\"ensembl\", dataset=\"hsapiens_gene_ensembl\")\nnew_names <- getBM(filters = \"ensembl_gene_id\", \n attributes = c(\"ensembl_gene_id\", \"hgnc_symbol\"),\n values=rownames(mx_samples_normalised), \n mart= mart)\n\n#here comes comlete mess\nindices <- which(new_names$hgnc_symbol != \"\")\nfiltered <- mx_samples_normalised[indices,,drop=F]\nnames = new_names[indices,]\nnames <- names[ , 2]\nrow.names(filtered) = names\n\n# SAVE\nwrite.table(t(filtered), file = '../test_data/80655_norm.txt', quote = FALSE, sep = ' ', eol = '\\n')\n\n"
},
{
"alpha_fraction": 0.5717213153839111,
"alphanum_fraction": 0.6152663826942444,
"avg_line_length": 28.53125,
"blob_id": "1f0fee82ffeeb3ea5621c3d6bbd7a00f46e911af",
"content_id": "83664d9bbe1700c253ae0b99c5fdb0cf23589b8d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1952,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 64,
"path": "/scatterplotter.py",
"repo_name": "torpidfox/GeneExpressionMapping",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt \r\nimport numpy as np \r\nfrom mpl_toolkits.mplot3d import Axes3D\r\nfrom sklearn.decomposition import PCA\r\nimport pandas as pd\r\n\r\nfig = plt.gcf()\r\n\r\n\r\ndef plot(x, y, title, pos, xl='Original', yl='Decoded'): \r\n\tsub_coord = 220 + pos \r\n\tax = fig.add_subplot(sub_coord) \r\n\tmse = ((x - y) ** 2).mean()\r\n\tax.scatter(x, y, label=str(mse))\r\n\tplt.xlabel(xl) \r\n\tplt.ylabel(yl) \r\n\tplt.title(title) \r\n\tplt.legend(loc=2)\r\n\t# plt.xlim(left=0, right=14)\r\n\t# plt.ylim(bottom=0, top=14)\r\n\tplt.plot(ax.get_xlim(), ax.get_ylim(), ls=\"--\", c=\".1\") \r\n\r\nwith np.load('../logs/two_sets_from_one/model0_res_valid.npz') as f: \r\n\td1 = f['second_set_original']\r\n\tprint(np.shape(f['original'])) \r\n\tprint(np.shape(d1))\r\n\r\nwith np.load('../logs/two_sets_from_one/model1_res_valid.npz') as f: \r\n\td2_1 = f['second_set'] \r\n\tprint(np.shape(d2_1))\r\n\tmeans = [((x - y) ** 2).mean() for x, y in zip(d1, d2_1)]\r\n\tplot(d1[1], d2_1[1], \"Second split decoder applied to first split data\", 3)\r\n\r\n\r\nwith np.load('../logs/two_sets_from_one/model0_res_valid.npz') as f:\r\n\td1 = f['original'] \r\n\tprint(np.shape(d1))\r\n\tplot(d1[1], d1[15], \"Main dataset random samples\", 1, xl='Sample 1', yl='Sample 2') \r\n\r\nwith np.load('../logs/two_sets_from_one/model1_res_valid.npz') as f: \r\n\td1 = f['original'] \r\n\r\n\tprint(np.shape(d1)) \r\n\tplot(d1[1], d1[10], \"Additional dataset random samples\", 2, xl='Sample 1', yl='Sample 2')\r\n\r\n\r\nwith np.load('../logs/two_sets_from_one/model1_res_valid.npz') as f: \r\n\td2 = f['decoded']\r\n\td1 = f['original'] \r\n\tprint(np.shape(d2)) \r\n\tplot(d1[1], d2[1], \"Additional dataset valid result\", 4)\r\n\r\n\r\n# with np.load('multi_sets2/model2_res_train.npz') as f:\r\n# \td1= f['arr_0']\r\n# \td2 = f['arr_1']\r\n\r\n# plot(d2[0], d1[0], 'dataset 3 train result', 5)\r\n\r\n# with np.load('multi_sets2/model2_res_decoded.npz') as f:\r\n# \td1= f['arr_0']\r\n\r\n# plot(d1, data2_in, 'cross set', 6, xl='3 set\\'s sample decoded by 2\\'s decoder', yl='2\\'s own sample')\r\nplt.show()"
},
{
"alpha_fraction": 0.6360759735107422,
"alphanum_fraction": 0.6835442781448364,
"avg_line_length": 25.41666603088379,
"blob_id": "20979a2462f8bd8e584a56932f7b1821abc52f20",
"content_id": "b7bdf040e48015875c9d9cd734a1970d1c3b89b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 316,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 12,
"path": "/preprocess/concatenate.py",
"repo_name": "torpidfox/GeneExpressionMapping",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nfrom functools import reduce\nimport os\n\npath = \"../test_data/E-GEOD-45642.processed.1\"\nbuf = []\nfor file in os.listdir(path):\n\tbuf.append(pd.read_csv(os.path.join(path, file), sep='\\t'))\n\n\ndf = reduce(lambda df1, df2: pd.merge(df1, df2, on='ID_REF'), buf)\ndf.to_csv('../test_data/45642_conc.csv')"
},
{
"alpha_fraction": 0.6257928013801575,
"alphanum_fraction": 0.6553910970687866,
"avg_line_length": 23.894737243652344,
"blob_id": "0bdec5fb6717aae8e73082b035c993ad6a429e57",
"content_id": "42a26b1327a8fb84955fdb181cb2afe4e54253b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 473,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 19,
"path": "/preprocess/low_counts_filter.py",
"repo_name": "torpidfox/GeneExpressionMapping",
"src_encoding": "UTF-8",
"text": "import pandas as pd\n\ndf = pd.read_csv('../test_data/80655_norm.txt', sep=' ', header=0)\n\ngenes = []\nwith open('../test_data/pathways.txt') as f:\n\tf.readline()\n\n\tfor l in f:\n\t\tgenes += l.split()\n\t\tf.readline()\n\nprint(len(set(genes)))\nheader = list(df)\nsums = df.sum(axis=0)\nintercept = [el for el in set(genes) if el in header and sums[el] > 10]\nfiltered_df = df[['sample'] + intercept]\nprint(len(list(filtered_df)))\nfiltered_df.to_csv('../test_data/GSE80655_filtered.csv')\n"
},
{
"alpha_fraction": 0.5670102834701538,
"alphanum_fraction": 0.6105383634567261,
"avg_line_length": 20.763158798217773,
"blob_id": "cce3dbf5b005ef69f0bfd38b38528909b3bb7cfe",
"content_id": "4583550716eeb41839b2e3a569aabdb42fdd39c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 873,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 38,
"path": "/ref_main.py",
"repo_name": "torpidfox/GeneExpressionMapping",
"src_encoding": "UTF-8",
"text": "from data import Data\r\nfrom subset import PrivateDomain\r\nfrom model import sess_runner\r\n\r\n#main_dataset = Data(log=False,\r\n#\tfilename='../data/3732_filtered.txt',\r\n#\tbatch_size=50,\r\n#\tsep=' ')\r\n\r\nmain_dataset = Data(filename='../data/3732_filtered.txt',\r\n split=True,\r\n split_start=800,\r\n\t#additional_info='../data/gse80655_annotation.txt',\r\n \tbatch_size=50,\r\n\tsep=' ',\r\n \tlog=False)\r\n\r\nsupporting_dataset = Data(filename='../data/3732_filtered.txt',\r\n split=True,\r\n split_end=800,\r\n ind=1,\r\n #additional_info='../data/gse80655_annotation.txt',\r\n batch_size=50,\r\n sep=' ',\r\n log=False)\r\n\r\n\r\ndef runner():\r\n\tmodel = [PrivateDomain(main_dataset, delay=1, tagged=False)]\r\n\r\n\tmodel.append(PrivateDomain(supporting_dataset, \r\n\t \tweight=1, \r\n\t \tind=1, \r\n\t \ttagged=False))\r\n\r\n\tsess_runner(model)\r\n\r\nrunner()\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.6812865734100342,
"alphanum_fraction": 0.7002924084663391,
"avg_line_length": 22.620689392089844,
"blob_id": "6779b6204af125fa83143fc7dea650292dcd4b65",
"content_id": "1d43ed0c068c824aea2fe5a04ceae315c0fece5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 684,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 29,
"path": "/preprocess/preprocess_data.py",
"repo_name": "torpidfox/GeneExpressionMapping",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nimport pandas as pd\nimport numpy as np\nimport json\n\ndef filter_genes(genes, weights):\n\treturn {g1 : {g2 : weights[g1][g2] for g2 in genes} for g1 in genes}\n\ndef create_weights(df, weights):\n\tw = []\n\tgenes = list(df)[2:]\n\tweights_filtered = filter_genes(genes, weights)\n\n\tfor g in genes:\n\t\tw.append(list(weights_filtered[g].values()))\n\n\treturn np.array(w)\n\ndef preprocess(df, weights):\n\tresult = df.iloc[:,2:]\n\tprint(result)\n\tprint(result.dot(weights.T))\n\treturn df.dot(weights)\n\ndf = pd.read_csv('../test_data/GSE80655_filtered.csv')\nwith open('../test_data/weights.txt') as f:\n\tweights = json.load(f)\n\nprint(print(preprocess(df, create_weights(df, weights))))"
},
{
"alpha_fraction": 0.7151162624359131,
"alphanum_fraction": 0.7344961166381836,
"avg_line_length": 29.352941513061523,
"blob_id": "2594ebd5aea4973f99f89ecd6449e864fb4a6260",
"content_id": "780cd5445d63b826a06fed36e59189a2556041d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 516,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 17,
"path": "/preprocess/names_conversion.R",
"repo_name": "torpidfox/GeneExpressionMapping",
"src_encoding": "UTF-8",
"text": "genes = scan('../test_data/gene_names.txt', character())\ngenes\n\nif (!requireNamespace(\"BiocManager\", quietly = TRUE))\n install.packages(\"BiocManager\")\nBiocManager::install(\"hgu133a.db\")\n\nlibrary(hgu133a.db)\nlibrary(annotate)\nx <- hgu133aSYMBOL\nmapped_probes <- mappedkeys(x)\ngenesym.probeid <- as.data.frame(x[mapped_probes])\nhead(genesym.probeid)\n\nlibrary(data.table)\nmapped = setDT(genesym.probeid, key = 'probe_id')[J(genes)]\nwrite.table(mapped, file='../test_data/affy_to_kegg_2', quote=FALSE, row.names=FALSE)\n"
},
{
"alpha_fraction": 0.5509708523750305,
"alphanum_fraction": 0.6165048480033875,
"avg_line_length": 19.549999237060547,
"blob_id": "a327e4cd8bcabb626bf2e13094373606efc757ac",
"content_id": "7dbf32e33f170615e9047c96ab65faa79d01bf71",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 412,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 20,
"path": "/preprocess/transpose_data.py",
"repo_name": "torpidfox/GeneExpressionMapping",
"src_encoding": "UTF-8",
"text": "import pandas as pd\n\n\nprev_i = 1\n\nwith open('3732_transposed.txt', 'w') as f:\n\tpass\n\nwith open('3732_transposed.txt', 'a') as f:\n\tfor i in range(100, 200, 100):\n\t\tdf = pd.read_csv('../data/kegg_filtered.txt', \n\t\t\tsep=' ', \n\t\t\tskiprows=1, \n\t\t\theader=0,\n\t\t\tnames=range(1:27888),\n\t\t\tusecols=lambda x: x in [prev_i:i])\n\n\t\ttransposed = df.T\n\t\ttransposed.to_csv(f, header=True if prev_i == 1 else False)\n\t\tprev_i = i\n\t"
},
{
"alpha_fraction": 0.6586480140686035,
"alphanum_fraction": 0.6656516194343567,
"avg_line_length": 25.909835815429688,
"blob_id": "1ceb8196859f07c2921ccdbd712c3b01c01f8eb7",
"content_id": "d09aab4070f8ccb1a7e37e328508e9022d9df1af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3284,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 122,
"path": "/data.py",
"repo_name": "torpidfox/GeneExpressionMapping",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nimport tensorflow as tf\n\nclass Data: \n\n\tdef __init__(self,\n\t\tfilename,\n\t\tsep=',',\n\t\tind=0,\n\t\tsplit=False,\n\t\tsplit_start=None,\n\t\tsplit_end=None,\n\t\tbatch_size=50,\n\t\tlog=False,\n\t\tadditional_info=None,\n\t\tleft_on='sample',\n\t\tright_on='Sample'):\n\n\t\t\"\"\"Create a new dataset.\n\n\t\tParametrs:\n\t\t\tfilename -- csv file containting gene expression data\n\t\t\tsep -- separator used in the filename (default ',')\n\t\t\tsplit -- whether the dataset is splitted into two datasets with different\n\t\t\t columns (genes)\n\t\t\tsplit_start -- index of the first column of the split\n\t\t\tsplit_end -- index of the last column of the split\n\t\t\tbatch_size -- batch size\n\t\t\tlog -- True if the data should be log transformed\n\t\t\tleft_on -- how the column with sample names is called in dataset\n\t\t\tright_on -- how the column with sample names is called in file with samples descriptions\n\t\t\"\"\"\n\n\n\t\tself.df = pd.read_csv(filename, sep=sep)\n\t\tself.ind = ind\n\t\tself.tagged = True if additional_info else False\n\n\t\tif log:\n\t\t\tself.df.iloc[:, 2:] = self.df.iloc[:, 2:].applymap(lambda x: np.log(x + 1))\n\t\t\n\t\tif additional_info:\n\t\t\ttags_df = pd.read_csv(additional_info,\n\t\t\t\tsep=' ')\n\n\t\t\t#Add the tags to the main dataset\n\t\t\tself.df = pd.merge(self.df, tags_df, \n\t\t\t\tleft_on=left_on, \n\t\t\t\tright_on=right_on,\n\t\t\t\thow='outer').iloc[:,:-1]\n\t\t\tself.num_classes = self.df['Disease'].nunique() - 1\n\n\t\t\t#Convert categorical variables to indicators\n\t\t\tself.df = pd.concat([self.df.drop('Disease', axis=1), \n\t\t\t\tpd.get_dummies(self.df['Disease'],\n\t\t\t\t\tdrop_first=True)], axis=1)\n\n\t\tif split:\n\t\t\tsplitted_df = self.df.iloc[:, split_start:split_end]\n\n\t\t\t#If there is no column with sample names in this split then add one\n\t\t\tif 'sample' not in splitted_df.columns:\n\t\t\t\tsplitted_df.insert(0, 'sample', self.df['sample'])\n\n\t\t\tself.df = splitted_df\n\t\t\t\n\t\tself.batch_size = batch_size\n\t\tself.dim = len(self.df.columns) - 2\n\t\tself.placeholder = tf.placeholder(tf.float32, \n\t\t\tshape=[batch_size, self.dim])\n\t\n\t\tself._create_valid()\n\n\n\tdef _create_valid(self):\n\t\t\"\"\" Create valid batch\"\"\"\n\n\t\tself.valid_indices = np.random.random_integers(0, \n\t\t\tlen(self.df) - 1, \n\t\t\tsize=(self.batch_size, ))\n\t\t\n\t\tself.valid = self.df.iloc[self.valid_indices, 2:-self.num_classes if self.tagged else None]\n\n\t\tif self.tagged:\n\t\t\tself.valid_tags = self.df.iloc[self.valid_indices, -self.num_classes:]\n\n\t\t# Drop the validation data from the training dataset.\n\t\tself.original_df = self.df\n\t\tself.df = self.df.drop(self.valid_indices)\n\n\tdef second_split(self, second_frame):\n\t\t\"\"\" Get validation data from the second part of the dataframe\n\t\tParametrs:\n\t\t\tsecond_frame -- second part of the dataframe\n\t\t\"\"\"\n\t\treturn second_frame.iloc[self.valid_indices, 2:].values \n\n\tdef __next__(self):\n\t\t\"\"\" Return the next batch of training data \"\"\"\n\n\t\tif self.tagged:\n\t\t\tdata = self.df.sample(n=self.batch_size).iloc[:, 2:]\n\t\t\ttags = data.iloc[:,-self.num_classes:].values\n\t\t\tvalues = data.iloc[:, :-self.num_classes]\n\n\t\t\treturn values, tags\n\n\t\treturn [self.df.sample(n=self.batch_size).iloc[:, 2:].values]\n\n\n\tdef placeholders(self):\n\t\t\"\"\" Fake data \"\"\"\n\t\t\n\t\tbatch = [[0 for _ in range(self.dim)]] * self.batch_size\n\n\t\tif self.tagged:\n\t\t\tlabels = [0 for _ in range(self.num_classes) - 1] * self.batch_size\n\n\t\t\treturn batch, labels\n\n\t\treturn batch\n\n"
},
{
"alpha_fraction": 0.6218611598014832,
"alphanum_fraction": 0.6425406336784363,
"avg_line_length": 23.14285659790039,
"blob_id": "649e26590c60bbe98550ec197ae6595c5a03962b",
"content_id": "30e80fe1b5666d010b4db9a3319471672cd068bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 677,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 28,
"path": "/preprocess/kegg_gene_filter.py",
"repo_name": "torpidfox/GeneExpressionMapping",
"src_encoding": "UTF-8",
"text": "import pandas as pd\n\ngenes = []\nwith open('../test_data/pathways.txt') as f:\n\tf.readline()\n\n\tfor l in f:\n\t\tgenes += l.split()\n\t\tf.readline()\n\nkegg_genes = set(genes)\n\nname_mapped = pd.read_csv('../test_data/affy_to_kegg_2', sep=' ')\nname_mapped = dict(zip(name_mapped.probe_id, name_mapped.symbol))\n\ngenes = []\n\nwith open('../test_data/45642_conc.csv') as input_f, open('../test_data/45642_filtered.txt', 'w') as output_f:\n\tsamples = input_f.readline()\n\toutput_f.write(samples)\n\n\tfor l in input_f:\n\t\tgene_data = l.split(',')\n\t\tprint(name_mapped[gene_data[1]])\n\n\t\tif name_mapped[gene_data[1]] in kegg_genes:\n\t\t\tprint(gene_data[1])\n\t\t\toutput_f.write(' '.join(gene_data) + '\\n')\n\n"
},
{
"alpha_fraction": 0.5848708748817444,
"alphanum_fraction": 0.6014760136604309,
"avg_line_length": 15.9375,
"blob_id": "597a7105c4b60e9765eb3bf9c28ea6e12270ff8e",
"content_id": "be94a16314cd2f03d80a22d87e466b1707c2aa81",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 542,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 32,
"path": "/preprocess/weights.py",
"repo_name": "torpidfox/GeneExpressionMapping",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport json\n\nl = 0.5\n\nbuff = []\nwith open('../test_data/pathways.txt') as f:\n\tf.readline()\n\n\tfor line in f:\n\t\tbuff += line.split()\n\t\tf.readline()\n\ngenes = set(buff)\n\n\ngene_to_gene = {gene : {g : 0 for g in genes} for gene in genes}\n\nwith open('../test_data/pathways.txt') as f:\n\tf.readline()\n\n\tfor line in f:\n\t\tpath = line.split()\n\n\t\tfor g1 in path:\n\t\t\tfor i, g2 in enumerate(path):\n\t\t\t\tif g1 != g2:\n\t\t\t\t\tgene_to_gene[g1][g2] += np.exp(-l * i)\n\n\nwith open('../test_data/weights.txt', 'w') as f:\n\tjson.dump(gene_to_gene, f)\n"
}
] | 15 |
Eik1874/EliteQuant_Python
|
https://github.com/Eik1874/EliteQuant_Python
|
f373aac7dc7bff485bacad207b357f6f77a97d88
|
0e0377fcde8759343a24376acaf5d76d44dd7664
|
33ec1613f4be5f0426562a93ee81a04f93daecad
|
refs/heads/master
| 2020-03-30T06:18:58.186428 | 2018-09-27T01:30:27 | 2018-09-27T01:30:27 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5323570966720581,
"alphanum_fraction": 0.5404244065284729,
"avg_line_length": 46.52083206176758,
"blob_id": "ffe5d39d7e184d2f1644c1139b4dca4449f41b57",
"content_id": "6088af4d23337cfac51ed57b9a147422057deb7b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11404,
"license_type": "permissive",
"max_line_length": 131,
"num_lines": 240,
"path": "/source/performance/performance_manager.py",
"repo_name": "Eik1874/EliteQuant_Python",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nimport numpy as np\nimport pandas as pd\nimport re\nimport empyrical as ep\nimport pyfolio as pf\n\nclass PerformanceManager(object):\n \"\"\"\n Record equity, positions, and trades in accordance to pyfolio format\n First date will be the first data start date\n \"\"\"\n def __init__(self, symbols, benchmark=None, batch_tag='0', multi=1, fvp=None):\n self._symbols = []\n self._benchmark = benchmark\n self._batch_tag = batch_tag\n self._multi = multi # root multiplier, for CL1, CL2\n if multi is None:\n self._multi = 1\n self._df_fvp = fvp\n\n if self._multi > 1:\n for sym in symbols:\n self._symbols.extend([sym+str(i+1) for i in range(multi)]) # CL1 CL2\n else:\n self._symbols.extend(symbols)\n\n self._slippage = 0.0\n self._commission_rate = 0.0\n self.reset()\n\n # ------------------------------------ public functions -----------------------------#\n # or each sid\n def reset(self):\n self._realized_pnl = 0.0\n self._unrealized_pnl = 0.0\n\n self._equity = pd.Series() # equity line\n self._equity.name = 'total'\n\n if self._multi > 1:\n self._df_positions = pd.DataFrame(columns=self._symbols * 2 + ['cash', 'total', 'benchmark']) # Position + Symbol\n else:\n self._df_positions = pd.DataFrame(columns=self._symbols + ['cash', 'total', 'benchmark']) # Position + Symbol\n\n self._df_trades = pd.DataFrame(columns=['amount', 'price', 'symbol'])\n\n def set_splippage(self, slippage):\n self._slippage = slippage\n\n def set_commission_rate(self, commission_rate):\n self._commission_rate = commission_rate\n\n def update_performance(self, current_time, position_manager, data_board):\n if self._equity.empty:\n self._equity[current_time] = 0.0\n return\n # on a new time/date, calculate the performances for the last date\n elif current_time != self._equity.index[-1]:\n performance_time = self._equity.index[-1]\n\n equity = 0.0\n self._df_positions.loc[performance_time] = [0] * len(self._df_positions.columns)\n for sym, pos in position_manager.positions.items():\n m = 1\n if self._df_fvp is not None:\n try:\n if '|' in sym:\n ss = sym.split('|')\n match = re.match(r\"([a-z ]+)([0-9]+)?\", ss[0], re.I)\n sym2 = match.groups()[0]\n\n m = self._df_fvp.loc[sym2, 'FVP']\n except:\n m = 1\n\n equity += pos.size * data_board.get_last_price(sym) * m\n if '|' in sym:\n ss = sym.split('|')\n self._df_positions.loc[performance_time, ss[0]] = [pos.size * data_board.get_last_price(sym)*m, ss[1]]\n else:\n self._df_positions.loc[performance_time, sym] = pos.size * data_board.get_last_price(sym) * m\n self._df_positions.loc[performance_time, 'cash'] = position_manager.cash\n self._equity[performance_time] = equity + position_manager.cash\n self._df_positions.loc[performance_time, 'total'] = self._equity[performance_time]\n # calculate benchmark\n if self._benchmark is not None:\n if self._df_positions.shape[0] == 1:\n self._df_positions.at[performance_time, 'benchmark'] = self._equity[performance_time]\n else:\n benchmark_p0 = data_board.get_hist_price(self._benchmark, performance_time)\n periodic_ret = 0\n try:\n periodic_ret = benchmark_p0.iloc[-1]['Close'] / benchmark_p0.iloc[-2]['Close'] - 1\n except:\n periodic_ret = benchmark_p0.iloc[-1]['Price'] / benchmark_p0.iloc[-2]['Price'] - 1\n self._df_positions.at[performance_time, 'benchmark'] = self._df_positions.iloc[-2]['benchmark'] * (\n 1 + periodic_ret)\n\n self._equity[current_time] = 0.0\n\n def on_fill(self, fill_event):\n # self._df_trades.loc[fill_event.timestamp] = [fill_event.fill_size, fill_event.fill_price, fill_event.full_symbol]\n self._df_trades = self._df_trades.append(pd.DataFrame(\n {'amount': [fill_event.fill_size], 'price': [fill_event.fill_price], 'symbol': [fill_event.full_symbol]},\n index=[fill_event.fill_time]))\n\n def update_final_performance(self, current_time, position_manager, data_board):\n \"\"\"\n When a new data date comes in, it calcuates performances for the previous day\n This leaves the last date not updated.\n So we call the update explicitly\n \"\"\"\n performance_time = current_time\n\n equity = 0.0\n self._df_positions.loc[performance_time] = [0] * len(self._df_positions.columns)\n for sym, pos in position_manager.positions.items():\n m = 1\n if self._df_fvp is not None:\n try:\n if '|' in sym:\n ss = sym.split('|')\n match = re.match(r\"([a-z ]+)([0-9]+)?\", ss[0], re.I)\n sym2 = match.groups()[0]\n\n m = self._df_fvp.loc[sym2, 'FVP']\n except:\n m = 1\n equity += pos.size * data_board.get_last_price(sym) * m\n if '|' in sym:\n ss = sym.split('|')\n self._df_positions.loc[performance_time, ss[0]] = [pos.size * data_board.get_last_price(sym) * m, ss[1]]\n else:\n self._df_positions.loc[performance_time, sym] = pos.size * data_board.get_last_price(sym) * m\n self._df_positions.loc[performance_time, 'cash'] = position_manager.cash\n\n self._equity[performance_time] = equity + position_manager.cash\n self._df_positions.loc[performance_time, 'total'] = self._equity[performance_time]\n\n # calculate benchmark\n if self._benchmark is not None:\n if self._df_positions.shape[0] == 1:\n self._df_positions.at[performance_time, 'benchmark'] = self._equity[performance_time]\n else:\n benchmark_p0 = data_board.get_hist_price(self._benchmark, performance_time)\n periodic_ret = 0\n try:\n periodic_ret = benchmark_p0.iloc[-1]['Close'] / benchmark_p0.iloc[-2]['Close'] - 1\n except:\n periodic_ret = benchmark_p0.iloc[-1]['Price'] / benchmark_p0.iloc[-2]['Price'] - 1\n\n self._df_positions.at[performance_time, 'benchmark'] = self._df_positions.iloc[-2]['benchmark'] * (\n 1 + periodic_ret)\n\n def caculate_performance(self):\n # to daily\n try:\n rets = self._equity.resample('D').last().dropna().pct_change()\n if self._benchmark is not None:\n b_rets = self._df_positions['benchmark'].resample('D').last().dropna().pct_change()\n except:\n rets = self._equity.pct_change()\n if self._benchmark is not None:\n b_rets = self._df_positions['benchmark'].pct_change()\n\n rets = rets[1:]\n if self._benchmark is not None:\n b_rets = b_rets[1:]\n perf_stats_all = None\n #rets.index = rets.index.tz_localize('UTC')\n #self._df_positions.index = self._df_positions.index.tz_localize('UTC')\n if not self._df_trades.index.empty:\n if self._benchmark is not None:\n # self._df_trades.index = self._df_trades.index.tz_localize('UTC')\n # pf.create_full_tear_sheet(rets, self._df_positions, self._df_trades)\n rets.index = pd.to_datetime(rets.index)\n b_rets.index = rets.index\n # pf.create_returns_tear_sheet(rets,benchmark_rets=b_rets)\n perf_stats_strat = pf.timeseries.perf_stats(rets)\n perf_stats_benchmark = pf.timeseries.perf_stats(b_rets)\n perf_stats_all = pd.concat([perf_stats_strat, perf_stats_benchmark], axis=1)\n perf_stats_all.columns = ['Strategy', 'Benchmark']\n else:\n # self._df_trades.index = self._df_trades.index.tz_localize('UTC')\n # pf.create_full_tear_sheet(rets, self._df_positions, self._df_trades)\n rets.index = pd.to_datetime(rets.index)\n # pf.create_returns_tear_sheet(rets,benchmark_rets=rets)\n perf_stats_all = pf.timeseries.perf_stats(rets)\n perf_stats_all = perf_stats_all.to_frame(name='Strategy')\n\n drawdown_df = pf.timeseries.gen_drawdown_table(rets, top=5)\n monthly_ret_table = ep.aggregate_returns(rets, 'monthly')\n monthly_ret_table = monthly_ret_table.unstack().round(3)\n ann_ret_df = pd.DataFrame(ep.aggregate_returns(rets, 'yearly'))\n ann_ret_df = ann_ret_df.unstack().round(3)\n return perf_stats_all, drawdown_df, monthly_ret_table, ann_ret_df\n\n def create_tearsheet(self):\n # to daily\n try:\n rets = self._equity.resample('D').last().dropna().pct_change()\n if self._benchmark is not None:\n b_rets = self._df_positions['benchmark'].resample('D').last().dropna().pct_change()\n except:\n rets = self._equity.pct_change()\n if self._benchmark is not None:\n b_rets = self._df_positions['benchmark'].pct_change()\n\n rets = rets[1:]\n if self._benchmark is not None:\n b_rets = b_rets[1:]\n #rets.index = rets.index.tz_localize('UTC')\n #self._df_positions.index = self._df_positions.index.tz_localize('UTC')\n if not self._df_trades.index.empty:\n if self._benchmark is not None:\n # self._df_trades.index = self._df_trades.index.tz_localize('UTC')\n # pf.create_full_tear_sheet(rets, self._df_positions, self._df_trades)\n rets.index = pd.to_datetime(rets.index)\n b_rets.index = rets.index\n pf.create_returns_tear_sheet(rets)\n #pf.create_simple_tear_sheet(rets, benchmark_rets=b_rets)\n else:\n # self._df_trades.index = self._df_trades.index.tz_localize('UTC')\n # pf.create_full_tear_sheet(rets, self._df_positions, self._df_trades)\n rets.index = pd.to_datetime(rets.index)\n pf.create_returns_tear_sheet(rets)\n # pf.create_simple_tear_sheet(rets)\n\n def save_results(self, output_dir):\n '''\n equity and df_posiiton should have the same datetime index\n :param output_dir:\n :return:\n '''\n self._df_positions = self._df_positions[self._symbols+['cash', 'total', 'benchmark']]\n self._df_positions.to_csv('{}{}{}{}'.format(output_dir, '/positions_', self._batch_tag if self._batch_tag else '', '.csv'))\n self._df_trades.to_csv('{}{}{}{}'.format(output_dir, '/trades_', self._batch_tag if self._batch_tag else '', '.csv'))\n # ------------------------------- end of public functions -----------------------------#"
}
] | 1 |
DigitalNatureGroup/TPU-Posenet
|
https://github.com/DigitalNatureGroup/TPU-Posenet
|
b2335e7030ccf2dcf47940d174d92bae1cd2621a
|
2af7a57e456e954f912aff5a3ebc2913bacf30ff
|
8a363c05af3961727c4543e2e83da9c07e2dc92f
|
refs/heads/master
| 2022-11-07T22:27:49.939026 | 2020-06-11T06:25:09 | 2020-06-11T06:25:09 | 271,466,520 | 1 | 0 |
MIT
| 2020-06-11T06:12:45 | 2020-06-09T08:10:12 | 2019-11-12T02:41:39 | null |
[
{
"alpha_fraction": 0.7325335144996643,
"alphanum_fraction": 0.7586449980735779,
"avg_line_length": 60.565216064453125,
"blob_id": "2e4b57631261f889f6df61d9a6dd25a8316b4bf3",
"content_id": "c75f851489a8ee7d2515ea64cc76ec36edf9c36e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1417,
"license_type": "permissive",
"max_line_length": 148,
"num_lines": 23,
"path": "/models/download.sh",
"repo_name": "DigitalNatureGroup/TPU-Posenet",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\ncurl -sc /tmp/cookie \"https://drive.google.com/uc?export=download&id=1feTGCIBtXkLXirnwvZU6oyMUFbLxS3nO\" > /dev/null\nCODE=\"$(awk '/_warning_/ {print $NF}' /tmp/cookie)\"\ncurl -Lb /tmp/cookie \"https://drive.google.com/uc?export=download&confirm=${CODE}&id=1feTGCIBtXkLXirnwvZU6oyMUFbLxS3nO\" -o posenet_mobilenetv1.zip\nunzip posenet_mobilenetv1.zip\nrm posenet_mobilenetv1.zip\n\ncurl -sc /tmp/cookie \"https://drive.google.com/uc?export=download&id=1mdUKcwFTckmoStQpS4SUihGaz7eUt-Xt\" > /dev/null\nCODE=\"$(awk '/_warning_/ {print $NF}' /tmp/cookie)\"\ncurl -Lb /tmp/cookie \"https://drive.google.com/uc?export=download&confirm=${CODE}&id=1mdUKcwFTckmoStQpS4SUihGaz7eUt-Xt\" -o deeplabv3.zip\nunzip deeplabv3.zip\nrm deeplabv3.zip\n\ncurl -sc /tmp/cookie \"https://drive.google.com/uc?export=download&id=1ZYoP824ZBNgpnX-K2LcE7XgjIOBYdcdk\" > /dev/null\nCODE=\"$(awk '/_warning_/ {print $NF}' /tmp/cookie)\"\ncurl -Lb /tmp/cookie \"https://drive.google.com/uc?export=download&confirm=${CODE}&id=1ZYoP824ZBNgpnX-K2LcE7XgjIOBYdcdk\" -o mobilenet_ssd_v2_coco.zip\nunzip mobilenet_ssd_v2_coco.zip\nrm mobilenet_ssd_v2_coco.zip\n\ncurl -sc /tmp/cookie \"https://drive.google.com/uc?export=download&id=1lAbSVsmG9ticeIicHqgDrBFru_pJeyzZ\" > /dev/null\nCODE=\"$(awk '/_warning_/ {print $NF}' /tmp/cookie)\"\ncurl -Lb /tmp/cookie \"https://drive.google.com/uc?export=download&confirm=${CODE}&id=1lAbSVsmG9ticeIicHqgDrBFru_pJeyzZ\" -o colorpalette.png\n\n"
},
{
"alpha_fraction": 0.572277843952179,
"alphanum_fraction": 0.5923028588294983,
"avg_line_length": 28.187213897705078,
"blob_id": "cb8b195e1179f96e8ecd22ccfac8db372045ee35",
"content_id": "fcebceb7de9ca0be9d42287987a9a3cd80fb0a8b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6392,
"license_type": "permissive",
"max_line_length": 151,
"num_lines": 219,
"path": "/pose_picam_multi_tpu.py",
"repo_name": "DigitalNatureGroup/TPU-Posenet",
"src_encoding": "UTF-8",
"text": "import argparse\nimport numpy as np\nimport cv2\nimport time\nfrom PIL import Image\nfrom time import sleep\nimport multiprocessing as mp\nfrom edgetpu.basic import edgetpu_utils\nfrom pose_engine import PoseEngine\nfrom imutils.video.pivideostream import PiVideoStream\nfrom imutils.video.filevideostream import FileVideoStream\nimport imutils\n\nlastresults = None\nprocesses = []\nframeBuffer = None\nresults = None\nfps = \"\"\ndetectfps = \"\"\nframecount = 0\ndetectframecount = 0\ntime1 = 0\ntime2 = 0\n\nEDGES = (\n ('nose', 'left eye'),\n ('nose', 'right eye'),\n ('nose', 'left ear'),\n ('nose', 'right ear'),\n ('left ear', 'left eye'),\n ('right ear', 'right eye'),\n ('left eye', 'right eye'),\n ('left shoulder', 'right shoulder'),\n ('left shoulder', 'left elbow'),\n ('left shoulder', 'left hip'),\n ('right shoulder', 'right elbow'),\n ('right shoulder', 'right hip'),\n ('left elbow', 'left wrist'),\n ('right elbow', 'right wrist'),\n ('left hip', 'right hip'),\n ('left hip', 'left knee'),\n ('right hip', 'right knee'),\n ('left knee', 'left ankle'),\n ('right knee', 'right ankle'),\n)\n\n\ndef camThread(results, frameBuffer, camera_width, camera_height, model_width, model_height, vidfps, video_file_path):\n\n global fps\n global detectfps\n global framecount\n global detectframecount\n global time1\n global time2\n global lastresults\n global cam\n global window_name\n global vs\n\n if video_file_path != \"\":\n vs = FileVideoStream(video_file_path).start()\n window_name = \"Movie File\"\n else:\n vs = PiVideoStream((camera_width, camera_height), vidfps).start()\n window_name = \"PiCamera\"\n time.sleep(2)\n cv2.namedWindow(window_name, cv2.WINDOW_AUTOSIZE)\n\n while True:\n t1 = time.perf_counter()\n\n color_image = vs.read()\n if frameBuffer.full():\n frameBuffer.get()\n frames = cv2.resize(color_image, (model_width, model_height))\n frameBuffer.put(frames.copy())\n res = None\n\n if not results.empty():\n res = results.get(False)\n detectframecount += 1\n imdraw = overlay_on_image(frames, res, model_width, model_height)\n lastresults = res\n else:\n imdraw = overlay_on_image(frames, lastresults, model_width, model_height)\n\n cv2.imshow(window_name, imdraw)\n\n if cv2.waitKey(1)&0xFF == ord('q'):\n break\n\n # FPS calculation\n framecount += 1\n if framecount >= 15:\n fps = \"(Playback) {:.1f} FPS\".format(time1/15)\n detectfps = \"(Detection) {:.1f} FPS\".format(detectframecount/time2)\n framecount = 0\n detectframecount = 0\n time1 = 0\n time2 = 0\n t2 = time.perf_counter()\n elapsedTime = t2-t1\n time1 += 1/elapsedTime\n time2 += elapsedTime\n\n\ndef inferencer(results, frameBuffer, model, camera_width, camera_height):\n\n engine = None\n\n # Acquisition of TPU list without model assignment\n devices = edgetpu_utils.ListEdgeTpuPaths(edgetpu_utils.EDGE_TPU_STATE_UNASSIGNED)\n\n devopen = False\n for device in devices:\n try:\n engine = PoseEngine(model, device)\n devopen = True\n break\n except:\n continue\n\n if devopen == False:\n print(\"TPU Devices open Error!!!\")\n sys.exit(1)\n\n print(\"Loaded Graphs!!! \")\n\n while True:\n\n if frameBuffer.empty():\n continue\n\n # Run inference.\n color_image = frameBuffer.get()\n prepimg = color_image[:, :, ::-1].copy()\n\n tinf = time.perf_counter()\n result, inference_time = engine.DetectPosesInImage(prepimg)\n print(time.perf_counter() - tinf, \"sec\")\n results.put(result)\n\n\ndef draw_pose(img, pose, threshold=0.2):\n xys = {}\n for label, keypoint in pose.keypoints.items():\n if keypoint.score < threshold: continue\n xys[label] = (int(keypoint.yx[1]), int(keypoint.yx[0]))\n img = cv2.circle(img, (int(keypoint.yx[1]), int(keypoint.yx[0])), 5, (0, 255, 0), -1)\n\n for a, b in EDGES:\n if a not in xys or b not in xys: continue\n ax, ay = xys[a]\n bx, by = xys[b]\n img = cv2.line(img, (ax, ay), (bx, by), (0, 255, 255), 2)\n\n\ndef overlay_on_image(frames, result, model_width, model_height):\n\n color_image = frames\n\n if isinstance(result, type(None)):\n return color_image\n img_cp = color_image.copy()\n\n for pose in result:\n draw_pose(img_cp, pose)\n\n cv2.putText(img_cp, fps, (model_width-170,15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA)\n cv2.putText(img_cp, detectfps, (model_width-170,30), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA)\n\n return img_cp\n\nif __name__ == '__main__':\n\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--model\", default=\"models/posenet_mobilenet_v1_075_481_641_quant_decoder_edgetpu.tflite\", help=\"Path of the detection model.\")\n parser.add_argument('--videofile', default=\"\", help='Path to input video file. (Default=\"\")')\n parser.add_argument('--vidfps', type=int, default=30, help='FPS of Video. (Default=30)')\n args = parser.parse_args()\n\n model = args.model\n video_file_path = args.videofile\n vidfps = args.vidfps\n\n camera_width = 320\n camera_height = 240\n model_width = 640\n model_height = 480\n\n try:\n mp.set_start_method('forkserver')\n frameBuffer = mp.Queue(3)\n results = mp.Queue()\n\n # Start streaming\n p = mp.Process(target=camThread,\n args=(results, frameBuffer, camera_width, camera_height, model_width, model_height, vidfps, video_file_path),\n daemon=True)\n p.start()\n processes.append(p)\n\n # Activation of inferencer\n devices = edgetpu_utils.ListEdgeTpuPaths(edgetpu_utils.EDGE_TPU_STATE_UNASSIGNED)\n for devnum in range(len(devices)):\n p = mp.Process(target=inferencer,\n args=(results, frameBuffer, model, model_width, model_height),\n daemon=True)\n sleep(5)\n p.start()\n processes.append(p)\n\n while True:\n sleep(1)\n\n finally:\n for p in range(len(processes)):\n processes[p].terminate()\n"
},
{
"alpha_fraction": 0.5800694227218628,
"alphanum_fraction": 0.6010340452194214,
"avg_line_length": 33.77586364746094,
"blob_id": "0659551ee21548f33fc6a6f478ee3c6d6db0adda",
"content_id": "42b066d707b965fa69a176a4ad1a4600e02dc080",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14119,
"license_type": "permissive",
"max_line_length": 154,
"num_lines": 406,
"path": "/ssd-deeplab-posenet.py",
"repo_name": "DigitalNatureGroup/TPU-Posenet",
"src_encoding": "UTF-8",
"text": "import sys\nimport argparse\nimport numpy as np\nimport cv2\nimport time\nfrom PIL import Image\nfrom time import sleep\nimport multiprocessing as mp\nfrom edgetpu.basic import edgetpu_utils\nfrom pose_engine import PoseEngine\nfrom edgetpu.basic.basic_engine import BasicEngine\nfrom edgetpu.detection.engine import DetectionEngine\n\npose_lastresults = None\ndeep_lastresults = None\nssd_lastresults = None\nprocesses = []\npose_frameBuffer = None\ndeep_frameBuffer = None\nssd_frameBuffer = None\npose_results = None\ndeep_results = None\nssd_results = None\nfps = \"\"\npose_detectfps = \"\"\ndeep_detectfps = \"\"\nssd_detectfps = \"\"\nframecount = 0\npose_detectframecount = 0\ndeep_detectframecount = 0\nssd_detectframecount = 0\ntime1 = 0\ntime2 = 0\n\nbox_color = (255, 128, 0)\nbox_thickness = 1\nlabel_background_color = (125, 175, 75)\nlabel_text_color = (255, 255, 255)\npercentage = 0.0\n\n# COCO Labels\nSSD_LABELS = ['person','bicycle','car','motorcycle','airplane','bus','train','truck','boat','',\n 'traffic light','fire hydrant','stop sign','parking meter','bench','bird','cat','dog','horse','sheep',\n 'cow','elephant','bear','','zebra','giraffe','backpack','umbrella','','',\n 'handbag','tie','suitcase','frisbee','skis','snowboard','sports ball','kite','baseball bat','baseball glove',\n 'skateboard','surfboard','tennis racket','bottle','','wine glass','cup','fork','knife','spoon',\n 'bowl','banana','apple','sandwich','orange','broccoli','carrot','hot dog','pizza','donut',\n 'cake','chair','couch','potted plant','bed','','dining table','','','toilet',\n '','tv','laptop','mouse','remote','keyboard','cell phone','microwave','oven','toaster',\n 'sink','refrigerator','','book','clock','vase','scissors','teddy bear','hair drier','toothbrush']\n\n# Deeplab color palettes\nDEEPLAB_PALETTE = Image.open(\"models/colorpalette.png\").getpalette()\n\n# Posenet Edges\nEDGES = (\n ('nose', 'left eye'),\n ('nose', 'right eye'),\n ('nose', 'left ear'),\n ('nose', 'right ear'),\n ('left ear', 'left eye'),\n ('right ear', 'right eye'),\n ('left eye', 'right eye'),\n ('left shoulder', 'right shoulder'),\n ('left shoulder', 'left elbow'),\n ('left shoulder', 'left hip'),\n ('right shoulder', 'right elbow'),\n ('right shoulder', 'right hip'),\n ('left elbow', 'left wrist'),\n ('right elbow', 'right wrist'),\n ('left hip', 'right hip'),\n ('left hip', 'left knee'),\n ('right hip', 'right knee'),\n ('left knee', 'left ankle'),\n ('right knee', 'right ankle'),\n)\n\n\ndef camThread(pose_results, deep_results, ssd_results,\n pose_frameBuffer, deep_frameBuffer, ssd_frameBuffer,\n camera_width, camera_height, vidfps, usbcamno, videofile):\n\n global fps\n global pose_detectfps\n global deep_detectfps\n global ssd_detectfps\n global framecount\n global pose_detectframecount\n global deep_detectframecount\n global ssd_detectframecount\n global time1\n global time2\n global pose_lastresults\n global deep_lastresults\n global ssd_lastresults\n global cam\n global window_name\n global waittime\n\n if videofile == \"\":\n cam = cv2.VideoCapture(usbcamno)\n cam.set(cv2.CAP_PROP_FPS, vidfps)\n cam.set(cv2.CAP_PROP_FRAME_WIDTH, camera_width)\n cam.set(cv2.CAP_PROP_FRAME_HEIGHT, camera_height)\n waittime = 1\n window_name = \"USB Camera\"\n else:\n cam = cv2.VideoCapture(videofile)\n waittime = vidfps\n window_name = \"Movie File\"\n\n cv2.namedWindow(window_name, cv2.WINDOW_AUTOSIZE)\n\n while True:\n t1 = time.perf_counter()\n\n ret, color_image = cam.read()\n if not ret:\n continue\n\n if pose_frameBuffer.full():\n pose_frameBuffer.get()\n if deep_frameBuffer.full():\n deep_frameBuffer.get()\n if ssd_frameBuffer.full():\n ssd_frameBuffer.get()\n\n frames = cv2.resize(color_image, (camera_width, camera_height)).copy()\n pose_frameBuffer.put(cv2.resize(color_image, (640, 480)).copy())\n deep_frameBuffer.put(cv2.resize(color_image, (513, 513)).copy())\n ssd_frameBuffer.put(cv2.resize(color_image, (640, 480)).copy())\n\n res = None\n\n # Posenet\n if not pose_results.empty():\n res = pose_results.get(False)\n pose_detectframecount += 1\n imdraw = pose_overlay_on_image(frames, res)\n pose_lastresults = res\n else:\n imdraw = pose_overlay_on_image(frames, pose_lastresults)\n\n # MobileNet-SSD\n if not ssd_results.empty():\n res = ssd_results.get(False)\n ssd_detectframecount += 1\n imdraw = ssd_overlay_on_image(imdraw, res)\n ssd_lastresults = res\n else:\n imdraw = ssd_overlay_on_image(imdraw, ssd_lastresults)\n\n # Deeplabv3\n if not deep_results.empty():\n res = deep_results.get(False)\n deep_detectframecount += 1\n imdraw = deep_overlay_on_image(imdraw, res, camera_width, camera_height)\n deep_lastresults = res\n else:\n imdraw = deep_overlay_on_image(imdraw, deep_lastresults, camera_width, camera_height)\n\n cv2.putText(imdraw, fps, (camera_width-170,15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA)\n cv2.putText(imdraw, pose_detectfps, (camera_width-170,30), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA)\n cv2.putText(imdraw, deep_detectfps, (camera_width-170,45), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA)\n cv2.putText(imdraw, ssd_detectfps, (camera_width-170,60), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA)\n cv2.imshow(window_name, imdraw)\n\n if cv2.waitKey(waittime)&0xFF == ord('q'):\n break\n\n # FPS calculation\n framecount += 1\n # Posenet\n if framecount >= 15:\n fps = \"(Playback) {:.1f} FPS\".format(time1/15)\n pose_detectfps = \"(Posenet) {:.1f} FPS\".format(pose_detectframecount/time2)\n deep_detectfps = \"(Deeplab) {:.1f} FPS\".format(deep_detectframecount/time2)\n ssd_detectfps = \"(SSD) {:.1f} FPS\".format(ssd_detectframecount/time2)\n framecount = 0\n pose_detectframecount = 0\n deep_detectframecount = 0\n ssd_detectframecount = 0\n time1 = 0\n time2 = 0\n t2 = time.perf_counter()\n elapsedTime = t2-t1\n time1 += 1/elapsedTime\n time2 += elapsedTime\n\n\ndef pose_inferencer(results, frameBuffer, model, device):\n\n pose_engine = None\n pose_engine = PoseEngine(model, device)\n print(\"Loaded Graphs!!! (Posenet)\")\n\n while True:\n\n if frameBuffer.empty():\n continue\n\n # Run inference.\n color_image = frameBuffer.get()\n prepimg_pose = color_image[:, :, ::-1].copy()\n tinf = time.perf_counter()\n result_pose, inference_time = pose_engine.DetectPosesInImage(prepimg_pose)\n print(time.perf_counter() - tinf, \"sec (Posenet)\")\n results.put(result_pose)\n\n\ndef deep_inferencer(results, frameBuffer, model, device):\n\n deep_engine = None\n deep_engine = BasicEngine(model, device)\n print(\"Loaded Graphs!!! (Deeplab)\")\n\n while True:\n\n if frameBuffer.empty():\n continue\n\n # Run inference.\n color_image = frameBuffer.get()\n prepimg_deep = color_image[:, :, ::-1].copy()\n prepimg_deep = prepimg_deep.flatten()\n tinf = time.perf_counter()\n latency, result_deep = deep_engine.run_inference(prepimg_deep)\n print(time.perf_counter() - tinf, \"sec (Deeplab)\")\n results.put(result_deep)\n\n\ndef ssd_inferencer(results, frameBuffer, model, device):\n\n ssd_engine = None\n ssd_engine = DetectionEngine(model, device)\n print(\"Loaded Graphs!!! (SSD)\")\n\n while True:\n\n if frameBuffer.empty():\n continue\n\n # Run inference.\n color_image = frameBuffer.get()\n prepimg_ssd = color_image[:, :, ::-1].copy()\n prepimg_ssd = Image.fromarray(prepimg_ssd)\n tinf = time.perf_counter()\n result_ssd = ssd_engine.detect_with_image(prepimg_ssd, threshold=0.5, keep_aspect_ratio=True, relative_coord=False, top_k=10)\n print(time.perf_counter() - tinf, \"sec (SSD)\")\n results.put(result_ssd)\n\n\ndef draw_pose(img, pose, threshold=0.2):\n xys = {}\n for label, keypoint in pose.keypoints.items():\n if keypoint.score < threshold: continue\n xys[label] = (int(keypoint.yx[1]), int(keypoint.yx[0]))\n img = cv2.circle(img, (int(keypoint.yx[1]), int(keypoint.yx[0])), 5, (0, 255, 0), -1)\n\n for a, b in EDGES:\n if a not in xys or b not in xys: continue\n ax, ay = xys[a]\n bx, by = xys[b]\n img = cv2.line(img, (ax, ay), (bx, by), (0, 255, 255), 2)\n\n\ndef pose_overlay_on_image(frames, result):\n\n color_image = frames\n\n if isinstance(result, type(None)):\n return color_image\n img_cp = color_image.copy()\n\n for pose in result:\n draw_pose(img_cp, pose)\n\n return img_cp\n\n\ndef deep_overlay_on_image(frames, result, width, height):\n\n color_image = frames\n\n if isinstance(result, type(None)):\n return color_image\n img_cp = color_image.copy()\n\n outputimg = np.reshape(np.uint8(result), (513, 513))\n outputimg = cv2.resize(outputimg, (width, height))\n outputimg = Image.fromarray(outputimg, mode=\"P\")\n outputimg.putpalette(DEEPLAB_PALETTE)\n outputimg = outputimg.convert(\"RGB\")\n outputimg = np.asarray(outputimg)\n outputimg = cv2.cvtColor(outputimg, cv2.COLOR_RGB2BGR)\n img_cp = cv2.addWeighted(img_cp, 1.0, outputimg, 0.9, 0)\n\n return img_cp\n\n\ndef ssd_overlay_on_image(frames, result):\n\n color_image = frames\n\n if isinstance(result, type(None)):\n return color_image\n img_cp = color_image.copy()\n\n for obj in result:\n box = obj.bounding_box.flatten().tolist()\n box_left = int(box[0])\n box_top = int(box[1])\n box_right = int(box[2])\n box_bottom = int(box[3])\n cv2.rectangle(img_cp, (box_left, box_top), (box_right, box_bottom), box_color, box_thickness)\n\n percentage = int(obj.score * 100)\n label_text = SSD_LABELS[obj.label_id] + \" (\" + str(percentage) + \"%)\" \n\n label_size = cv2.getTextSize(label_text, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)[0]\n label_left = box_left\n label_top = box_top - label_size[1]\n if (label_top < 1):\n label_top = 1\n label_right = label_left + label_size[0]\n label_bottom = label_top + label_size[1]\n cv2.rectangle(img_cp, (label_left - 1, label_top - 1), (label_right + 1, label_bottom + 1), label_background_color, -1)\n cv2.putText(img_cp, label_text, (label_left, label_bottom), cv2.FONT_HERSHEY_SIMPLEX, 0.5, label_text_color, 1)\n\n return img_cp\n\n\nif __name__ == '__main__':\n\n parser = argparse.ArgumentParser()\n parser.add_argument(\"--pose_model\", default=\"models/posenet_mobilenet_v1_075_481_641_quant_decoder_edgetpu.tflite\", help=\"Path of the posenet model.\")\n parser.add_argument(\"--deep_model\", default=\"models/deeplabv3_mnv2_dm05_pascal_trainaug_edgetpu.tflite\", help=\"Path of the deeplabv3 model.\")\n parser.add_argument(\"--ssd_model\", default=\"models/mobilenet_ssd_v2_coco_quant_postprocess_edgetpu.tflite\", help=\"Path of the mobilenet-ssd model.\")\n parser.add_argument(\"--usbcamno\", type=int, default=0, help=\"USB Camera number.\")\n parser.add_argument('--videofile', default=\"\", help='Path to input video file. (Default=\"\")')\n parser.add_argument('--vidfps', type=int, default=30, help='FPS of Video. (Default=30)')\n parser.add_argument('--camera_width', type=int, default=640, help='USB Camera resolution (width). (Default=640)')\n parser.add_argument('--camera_height', type=int, default=480, help='USB Camera resolution (height). (Default=480)')\n args = parser.parse_args()\n\n pose_model = args.pose_model\n deep_model = args.deep_model\n ssd_model = args.ssd_model\n usbcamno = args.usbcamno\n vidfps = args.vidfps\n videofile = args.videofile\n camera_width = args.camera_width\n camera_height = args.camera_height\n\n try:\n mp.set_start_method('forkserver')\n pose_frameBuffer = mp.Queue(10)\n deep_frameBuffer = mp.Queue(10)\n ssd_frameBuffer = mp.Queue(10)\n pose_results = mp.Queue()\n deep_results = mp.Queue()\n ssd_results = mp.Queue()\n\n # Start streaming\n p = mp.Process(target=camThread,\n args=(pose_results, deep_results, ssd_results,\n pose_frameBuffer, deep_frameBuffer, ssd_frameBuffer,\n camera_width, camera_height, vidfps, usbcamno, videofile),\n daemon=True)\n p.start()\n processes.append(p)\n\n # Activation of inferencer\n devices = edgetpu_utils.ListEdgeTpuPaths(edgetpu_utils.EDGE_TPU_STATE_UNASSIGNED)\n print(devices)\n\n # Posenet\n if len(devices) >= 1:\n p = mp.Process(target=pose_inferencer,\n args=(pose_results, pose_frameBuffer, pose_model, devices[0]),\n daemon=True)\n p.start()\n processes.append(p)\n\n # DeeplabV3\n if len(devices) >= 2:\n p = mp.Process(target=ssd_inferencer,\n args=(ssd_results, ssd_frameBuffer, ssd_model, devices[1]),\n daemon=True)\n p.start()\n processes.append(p)\n\n # MobileNet-SSD v2\n if len(devices) >= 3:\n p = mp.Process(target=deep_inferencer,\n args=(deep_results, deep_frameBuffer, deep_model, devices[2]),\n daemon=True)\n p.start()\n processes.append(p)\n\n while True:\n sleep(1)\n\n finally:\n for p in range(len(processes)):\n processes[p].terminate()\n"
},
{
"alpha_fraction": 0.6066811680793762,
"alphanum_fraction": 0.6468706130981445,
"avg_line_length": 40.54787063598633,
"blob_id": "bd8748f5521bf6649fb83692a7208a9742d8574a",
"content_id": "356aed900735d5e9dd3b54076a4edbca043d2628",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 7843,
"license_type": "permissive",
"max_line_length": 268,
"num_lines": 188,
"path": "/README.md",
"repo_name": "DigitalNatureGroup/TPU-Posenet",
"src_encoding": "UTF-8",
"text": "# TPU-Posenet\nEdge TPU Accelerator/Multi-TPU/Multi-Model + Posenet/DeeplabV3/MobileNet-SSD + Python + Sync/Async + LaptopPC/RaspberryPi. \nInspired by **[google-coral/project-posenet](https://github.com/google-coral/project-posenet)**. \nThis repository was tuned to speed up Google's sample logic to support multi-TPU. And I replaced the complex Gstreamer implementation with the OpenCV implementation. \n\n## 0. Table of contents\n**1. [Environment](#1-environment)** \n**2. [Inference behavior](#2-inference-behavior)** \n **2-1. [Async, TPU x3, USB Camera, Single Person](#2-1-async-tpu-x3-usb-camera-single-person)** \n **2-2. [Sync, TPU x1, USB Camera, Single Person](#2-2-sync-tpu-x1-usb-camera-single-person)** \n **2-3. [Sync, TPU x1, MP4 (30 FPS), Multi Person](#2-3-sync-tpu-x1-mp4-30-fps-multi-person)** \n **2-4. [Async, TPU x3, USB Camera (30 FPS), Multi-Model, Posenet + DeeplabV3 + MobileNet-SSDv2](#2-4-async-tpu-x3-usb-camera-30-fps-multi-model-posenet--deeplabv3--mobilenet-ssdv2)** \n**3. [Introduction procedure](#3-introduction-procedure)** \n **3-1. [Common procedures for devices](#3-1-common-procedures-for-devices)** \n **3-2-1. [Only Linux](#3-2-1-only-linux)** \n **3-2-2. [Only RaspberryPi (Stretch or Buster)](#3-2-2-only-raspberrypi-stretch-or-buster)** \n**4. [Usage](#4-usage)** \n**5. [Reference articles](#5-reference-articles)** \n\n## 1. Environment\n\n- Ubuntu or RaspberryPi\n - **(Note: Because RaspberryPi3 is a low-speed USB 2.0, multi-TPU operation becomes extremely unstable.)**\n- OpenCV4.1.1-openvino\n- Coral Edge TPU Accelerator (Multi-TPU)\n - Automatically detect the number of multiple TPU accelerators connected to a USB hub to improve performance.\n- USB Camera (Playstationeye)\n- Picamera v2\n- Self-powered USB 3.0 Hub\n- Python 3.5.2+\n\n\n\n## 2. Inference behavior\n### 2-1. Async, TPU x3, USB Camera, Single Person\n**Youtube:https://youtu.be/LBk71RKca1c** \n \n \n### 2-2. Sync, TPU x1, USB Camera, Single Person\n**Youtube:https://youtu.be/GuuXzpLXFJo** \n \n \n### 2-3. Sync, TPU x1, MP4 (30 FPS), Multi Person\n**Youtube:https://youtu.be/ibPuI12bj2w** \n \n \n### 2-4. Async, TPU x3, USB Camera (30 FPS), Multi-Model, Posenet + DeeplabV3 + MobileNet-SSDv2\n**Youtube:https://youtu.be/d946VOE65tU** \n \n\n## 3. Introduction procedure\n### 3-1. Common procedures for devices\n```bash\n$ sudo apt-get update;sudo apt-get upgrade -y\n\n$ sudo apt-get install -y python3-pip\n$ sudo pip3 install pip --upgrade\n$ sudo pip3 install numpy\n\n$ wget https://dl.google.com/coral/edgetpu_api/edgetpu_api_latest.tar.gz -O edgetpu_api.tar.gz --trust-server-names\n$ tar xzf edgetpu_api.tar.gz\n$ sudo edgetpu_api/install.sh\n\n$ git clone https://github.com/PINTO0309/TPU-Posenet.git\n$ cd TPU-Posenet.git\n$ cd models;./download.sh;cd ..\n$ cd media;./download.sh;cd ..\n```\n### 3-2-1. Only Linux\n```bash\n$ wget https://github.com/PINTO0309/OpenVINO-bin/raw/master/Linux/download_2019R2.sh\n$ chmod +x download_2019R2.sh\n$ ./download_2019R2.sh\n$ l_openvino_toolkit_p_2019.2.242/install_openvino_dependencies.sh\n$ ./install_GUI.sh\nOR\n$ ./install.sh\n```\n### 3-2-2. Only RaspberryPi (Stretch or Buster)\n```bash\n### Only Raspbian Buster ############################################################\n$ cd /usr/local/lib/python3.7/dist-packages/edgetpu/swig/\n$ sudo cp \\\n_edgetpu_cpp_wrapper.cpython-35m-arm-linux-gnueabihf.so \\\n_edgetpu_cpp_wrapper.cpython-37m-arm-linux-gnueabihf.so\n### Only Raspbian Buster ############################################################\n\n$ cd ~/TPU-Posenet\n$ sudo pip3 install imutils\n$ sudo raspi-config\n```\n \n \n \n \n \n \n```bash\n$ wget https://github.com/PINTO0309/OpenVINO-bin/raw/master/RaspberryPi/download_2019R2.sh\n$ sudo chmod +x download_2019R2.sh\n$ ./download_2019R2.sh\n$ echo \"source /opt/intel/openvino/bin/setupvars.sh\" >> ~/.bashrc\n$ source ~/.bashrc\n```\n## 3-2-3. Only Windows\nRun Sample\n```\n> python pose_camera_single_tpu.py --model .\\models\\mobilenet\\posenet_mobilenet_v1_075_481_641_quant_decoder_edgetpu.tflite\n```\n\n## 4. Usage\n```bash\nusage: pose_camera_multi_tpu.py [-h] [--model MODEL] [--usbcamno USBCAMNO]\n [--videofile VIDEOFILE] [--vidfps VIDFPS]\n\noptional arguments:\n -h, --help show this help message and exit\n --model MODEL Path of the detection model.\n --usbcamno USBCAMNO USB Camera number.\n --videofile VIDEOFILE\n Path to input video file. (Default=\"\")\n --vidfps VIDFPS FPS of Video. (Default=30)\n```\n```bash\nusage: pose_camera_single_tpu.py [-h] [--model MODEL] [--usbcamno USBCAMNO]\n [--videofile VIDEOFILE] [--vidfps VIDFPS]\n\noptional arguments:\n -h, --help show this help message and exit\n --model MODEL Path of the detection model.\n --usbcamno USBCAMNO USB Camera number.\n --videofile VIDEOFILE\n Path to input video file. (Default=\"\")\n --vidfps VIDFPS FPS of Video. (Default=30)\n```\n```bash\nusage: pose_picam_multi_tpu.py [-h] [--model MODEL] [--videofile VIDEOFILE] [--vidfps VIDFPS]\n\noptional arguments:\n -h, --help show this help message and exit\n --model MODEL Path of the detection model.\n --videofile VIDEOFILE\n Path to input video file. (Default=\"\")\n --vidfps VIDFPS FPS of Video. (Default=30)\n```\n```bash\nusage: pose_picam_single_tpu.py [-h] [--model MODEL] [--videofile VIDEOFILE] [--vidfps VIDFPS]\n\noptional arguments:\n -h, --help show this help message and exit\n --model MODEL Path of the detection model.\n --videofile VIDEOFILE\n Path to input video file. (Default=\"\")\n --vidfps VIDFPS FPS of Video. (Default=30)\n```\n```bash\nusage: ssd-deeplab-posenet.py [-h] [--pose_model POSE_MODEL]\n [--deep_model DEEP_MODEL]\n [--ssd_model SSD_MODEL] [--usbcamno USBCAMNO]\n [--videofile VIDEOFILE] [--vidfps VIDFPS]\n [--camera_width CAMERA_WIDTH]\n [--camera_height CAMERA_HEIGHT]\n\noptional arguments:\n -h, --help show this help message and exit\n --pose_model POSE_MODEL\n Path of the posenet model.\n --deep_model DEEP_MODEL\n Path of the deeplabv3 model.\n --ssd_model SSD_MODEL\n Path of the mobilenet-ssd model.\n --usbcamno USBCAMNO USB Camera number.\n --videofile VIDEOFILE\n Path to input video file. (Default=\"\")\n --vidfps VIDFPS FPS of Video. (Default=30)\n --camera_width CAMERA_WIDTH\n USB Camera resolution (width). (Default=640)\n --camera_height CAMERA_HEIGHT\n USB Camera resolution (height). (Default=480)\n```\n## 5. Reference articles\n1. **[Edge TPU USB Accelerator analysis - I/O data transfer - Qiita - iwatake2222](https://qiita.com/iwatake2222/items/922f02893355b30dab2e)** \n\n2. **[[150 FPS ++] Connect three Coral Edge TPU accelerators and infer in parallel processing to get ultra-fast object detection inference performance ーTo the extreme of useless high performanceー - Qiita - PINTO](https://qiita.com/PINTO/items/63b6f01eb22a5ab97901)** \n\n3. **[[150 FPS ++] Connect three Coral Edge TPU accelerators and infer in parallel processing to get ultra-fast Posenet inference performance ーTo the extreme of useless high performanceー - Qiita - PINTO](https://qiita.com/PINTO/items/e969fa7601d0868e451f)** \n\n4. **[Raspberry Pi Camera Module](https://www.raspberrypi.org/documentation/raspbian/applications/camera.md)** \n"
}
] | 4 |
brevans/srt_converter
|
https://github.com/brevans/srt_converter
|
8567c23e08d44f763d197c2ba8b4f183bcd03ea4
|
214e8c78697f6bb370cb00caa37cdb2097b0dd88
|
051ef60274190855e74b205553062cd7214d36f9
|
refs/heads/master
| 2020-05-29T15:12:54.351706 | 2016-07-28T19:07:23 | 2016-07-28T19:07:23 | 62,896,616 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6502136588096619,
"alphanum_fraction": 0.708760678768158,
"avg_line_length": 34.725189208984375,
"blob_id": "923118692d19efdd4db160fea95d1f536972431b",
"content_id": "8ceb82bdaff17163bf4a101c4b82eff10b48c4a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4680,
"license_type": "no_license",
"max_line_length": 317,
"num_lines": 131,
"path": "/README.md",
"repo_name": "brevans/srt_converter",
"src_encoding": "UTF-8",
"text": "# srt_converter\n\nFor the bird man Sam Snow.\n\nrun this python script in a directory with exported .srt caption files to get more usable data. It tries to mkae sure data are handled correctly, but there are probably bugs. It should complain if there is something obvioulsy wrong. In this case, don't trust output until there are no errors for the file in question.\n\n```bash\npython srt_2_csv.py\n```\nYou need:\n * python 3+\n * the file in this repo, ```stake_coords.csv```\n * .srt files\n\n## SRT File specs\n The srt filename needs to have a date (format YYYYMMDD) in the first field if split by underscores. The date can have extra letters before or after. Each 4-line entry in an srt file looks like:\n\n```\n2\n00:03:53,367 --> 00:06:30,434\nThe quick brown fox\n\n```\nLine 1 is the caption numer, starting with 1. \nLine 2 is the start and stop of the caption, relative to the beginning of the video in Hours:Minutes:Seconds,Milliseconds \nThe third line is the string of text for the caption. \nThe fourth line is always empty, and assumed to be so.\n\n#### Snow Format\n\nThe behavior data is encoded as semicolon separated fields (trailing and leading whitespace is removed) in the text of the captions. The captions that this script pays attention to fall into four categories, others are ignored. Examples and descriptions below.\n\n_**Atomic_Clock:**_ \n```\n1\n00:00:03,667 --> 00:03:53,367\nAtomic_clock; 6:46:11;\n\n```\nText fields (must be exactly two): \n1. The text \"Atomic_clock\" \n2. The local time, measured in Hours:Minutes:Seconds \n\n_**Position:**_\n```\n20\n00:15:00,067 --> 00:15:02,500\nPosition; 705; H5; 2.5; 6.5; 351; H6; 6.5; 1; 315; H5; 7; 9; 710; H6; 9; 0; 340; H5; 9.5; 9.5; 702; I6; 0; 0\n\n```\nText fields (First field, then mutiples of 4): \n1. The text \"Position\" \n2. Bird ID \n3. Grid stake ID \n4. X Offset relative to stake \n5. Y Offset relative to stake \nRepeat 2-5 \n\n_**Interactions:**_ \nThere are two types of interaction captions that get parsed. \n_**start:**_\n```\n12\n00:12:01,567 --> 00:12:03,834\n710; 3; start; 702; H6; 7.5; 1; I6; 0; 0;Y; SI; #strutting interrupted from a distance\n\n```\nText fields (First field, then mutiples of 4): \n1. Initiator ID \n2. Interaction Number \n3. The text \"start\" \n4. Partner ID \n5. Initiator stake \n6. Initiator X offset relative to initiator stake \n7. Initiator Y offset relative to initiator stake \n8. Partner stake \n9. Partner X offset relative to partner stake \n10. Partner Y offset relative to partner stake \n11. Females Present: Y or N \n12. Reaction Code \n13. Other notes \n\n_**end:**_\n```\n11\n00:11:29,300 --> 00:12:01,567\n710; 2; end; 702; 710; 2; FO; #unclear who disengages\n\n```\nText fields (exactly 8): \n1. Initiator ID \n2. Interaction Number \n3. The text \"end\" \n4. Partner ID \n5. Disengager ID \n6. Bouts Of Smacking: a number \n7. Face off: either FO, CH or NA \n8. Other notes \n\n\n## Output\nThe output files are: \n * < input filename >_interactions.csv\n * < input filename >_positions.csv\n\n#### Interactions output file columns:\n1. **Lek_Date_ID**: the first portion of the file name, if split by underscores. e.g. \"CHG20140326\"\n2. **Time_Stamp**: Date and time of interaction _start_, based on atomic clock in video, with no timezone, in [ISO 8601](https://en.wikipedia.org/wiki/ISO_8601) format\n3. **Initiator_ID**: should match between start and end entry\n4. **Interaction_Number**: should match between start and end entry\n5. **Partner_ID**: should match between start and end entry\n6. **Females_Present**: from start entry\n7. **Reaction_Code**: from start entry\n8. **Disengager_ID**: from end entry\n9. **Bouts_O_Smacking**: from end entry\n10. **Face_Off**: either FO, CH or NA\n11. **Duration**: end - start times in seconds\n12. **Initiator_Cartesian_X**: corrected initiator X coordinate, based on stake_coords.csv\n13. **Initiator_Cartesian_Y**: corrected initiator Y coordinate, based on stake_coords.csv\n14. **Partner_Cartesian_X**: corrected partner Y coordinate, based on stake_coords.csv\n15. **Partner_Cartesian_Y**: corrected partner Y coordinate, based on stake_coords.csv\n16. **Other_notes**: notes from both start and end\n\n#### Positions output columns:\n1. **Lek_Date_ID**: the first portion of the file name, if split by underscores. e.g. \"CHG20140326\"\n2. **Time_Stamp**: Date and time, based on atomic clock in video, with no timezone, in [ISO 8601](https://en.wikipedia.org/wiki/ISO_8601) format\n3. **Bird_ID**: Bird Identifier from position entry\n4. **X_Offset**: X offset from position entry\n5. **Y_Offset**: Y offset from position entry\n6. **Cartesian_X**: corrected X coordinate, based on stake_coords.csv\n7. **Cartesian_Y**: corrected y coordinate, based on stake_coords.csv\n"
},
{
"alpha_fraction": 0.573029637336731,
"alphanum_fraction": 0.5771270394325256,
"avg_line_length": 53.24182891845703,
"blob_id": "a81b1fb116909936e68071b1e5807c690985c5a2",
"content_id": "5a85165483c66f57570b39c8fb68311d1ab98cee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8298,
"license_type": "no_license",
"max_line_length": 212,
"num_lines": 153,
"path": "/srt_2_csv.py",
"repo_name": "brevans/srt_converter",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nfrom datetime import datetime\nfrom operator import itemgetter\nfrom glob import glob\nimport os\nimport re\n\n#set up columns\ninteraction_columns = ['Lek_Date_ID', 'Time_Stamp', 'Initiator_ID', \n 'Interaction_Number', 'Partner_ID', 'Females_Present',\n 'Reaction_Code', 'Disengager_ID', 'Bouts_O_Smacking', 'Face_Off',\n 'Duration', 'Initiator_Cartesian_X', 'Initiator_Cartesian_Y',\n 'Partner_Cartesian_X', 'Partner_Cartesian_Y', 'Other_Notes']\n\nstart_columns = ['caption_number', 'Caption_Stamp', 'Initiator_ID', \n 'Interaction_Number', 'Data_Type', 'Partner_ID', \n 'Initiator_Stake', 'Initiator_X', 'Initiator_Y',\n 'Partner_Stake', 'Partner_X', 'Partner_Y', \n 'Females_Present', 'Reaction_Code', 'Other_Notes']\n \n\nend_columns = ['caption_number', 'Caption_Stamp', 'Initiator_ID', \n 'Interaction_Number', 'Data_Type', 'Partner_ID', \n 'Disengager_ID', 'Bouts_O_Smacking', 'Face_Off', 'Other_Notes']\n \nind_pos_columns = ['Bird_ID', 'Grid_Stake', 'X_Offset', 'Y_Offset']\n\npos_columns = ['Lek_Date_ID','Time_Stamp','Caption_Stamp', 'Bird_ID', 'Grid_Stake',\n 'X_Offset', 'Y_Offset', 'Cartesian_X', 'Cartesian_Y']\n\ndef make_stake_dict(fn):\n fh = open(fn)\n d = {}\n header = next(fh)\n for l in fh:\n tmp = l.split(',')\n d[tmp[0]] = [int(x) for x in tmp[1:]]\n return d\n\ndef parse_srt(fn, stake_fn):\n data_in = []\n stake_offset = make_stake_dict(stake_fn)\n fh = open(fn)\n lek_date_id = os.path.basename(fn).split('_')[0]\n while True:\n try:\n caption_number = next(fh).rstrip(\"\\n\")\n #keep start of caption interval, floor to whole seconds\n caption_stamp = next(fh).split(' --> ')[0].split(',')[0]\n data = [x.lstrip().rstrip() for x in next(fh).rstrip().rstrip(';').lstrip().split(';')]\n toss_me = next(fh)\n #every data line is caption number, time_stamp + its fields\n data_in.append([caption_number, caption_stamp]+data)\n except StopIteration:\n break\n\n interactions = []\n start_ints = []\n end_ints = []\n positions = []\n atomic_time = None\n for d in data_in:\n if d[2] == 'Atomic_clock': #get atomic time, offset\n atomic_time = (datetime.strptime(d[3], \"%H:%M:%S\") -\n datetime.strptime(d[1], \"%H:%M:%S\"))\n if d[2].lower()=='position': #parse out individual positions\n assert (len(d)-3)%len(ind_pos_columns)==0, \" Wrong number of bird position fields at caption number {} in file {}\".format(d[0], fn)\n try:\n for (bid, stn, xoff, yoff) in zip(d[3::4],d[4::4],d[5::4],d[6::4]):\n ind_pos = dict(zip(ind_pos_columns, [bid, stn, xoff, yoff]))\n ind_pos['Lek_Date_ID'] = lek_date_id\n ind_pos['Caption_Stamp'] = d[1]\n #convert postions to cartesian\n ind_pos['Cartesian_X'] = str(stake_offset[ind_pos['Grid_Stake']][0]+ float(ind_pos['X_Offset']))\n ind_pos['Cartesian_Y'] = str(stake_offset[ind_pos['Grid_Stake']][1]+ float(ind_pos['Y_Offset']))\n positions.append(ind_pos)\n except Exception as e:\n print(\"something looks wrong with your position data at caption {}: {} \\n in file {}\".format(d[0], e, fn))\n sys.exit(1)\n \n start_stop_loc = 4\n if len(d) > start_stop_loc and (d[start_stop_loc].lower()=='start' or d[start_stop_loc].lower()=='end'):\n try:\n if d[start_stop_loc].lower() == 'start':\n assert len(start_columns) == len(d), \"Number of columns doesn't match.\"\n start_ints.append(dict(zip(start_columns, d)))\n if d[start_stop_loc].lower() == 'end':\n assert len(end_columns) == len(d), \"Number of columns doesn't match.\"\n end_ints.append(dict(zip(end_columns, d)))\n except Exception as e:\n print(\"something looks wrong with your start or stop at caption {}: {} \\n in file {}\".format(d[0], e, fn))\n sys.exit(1)\n \n assert atomic_time is not None, \"Didn't find an atomic time entry in file {}, can't calulate proper Time_Stamp!\".format(fn)\n \n #convert caption times to date time stamps\n for i in [start_ints, end_ints]:\n for j in i:\n caption_string = re.sub(r\"\\D\", \"\", lek_date_id) + j['Caption_Stamp']\n j['Time_Stamp'] = atomic_time+datetime.strptime(caption_string, \"%Y%m%d%H:%M:%S\")\n for p in positions:\n caption_string = re.sub(r\"\\D\", \"\", lek_date_id) + p['Caption_Stamp']\n p['Time_Stamp'] = (atomic_time+datetime.strptime(caption_string, \"%Y%m%d%H:%M:%S\")).strftime(\"%Y-%m-%d %H:%M:%S\")\n \n # stitch together start and end entries, sort each then compare and complain \n for start_int, end_int in zip(sorted(start_ints, key=itemgetter('Initiator_ID', 'Interaction_Number')), \n sorted(end_ints, key=itemgetter('Initiator_ID', 'Interaction_Number'))):\n assert len(start_ints) == len(end_ints), \"error, different number of start ({}) and end ({}) entries in file: {}\".format(len(start_int), len(end_int), fn)\n assert start_int['Initiator_ID'] == end_int['Initiator_ID'], \"Initiator ID mismatch in start&stop captions {}, {}, file {}\".format(start_int['caption_number'], end_int['caption_number'])\n assert start_int['Partner_ID'] == end_int['Partner_ID'], \"Partner ID mismatch in start&stop captions {}, {}, file {}\".format(start_int['caption_number'], end_int['caption_number'])\n assert start_int['Interaction_Number'] == end_int['Interaction_Number'], \"Interaction Number mismatch in start&stop captions {}, {}, file {}\".format(start_int['caption_number'], end_int['caption_number'])\n interact = {}\n interact['Lek_Date_ID'] = lek_date_id\n interact['Time_Stamp'] = start_int['Time_Stamp'].strftime(\"%Y-%m-%d %H:%M:%S\")\n interact['Initiator_ID'] = start_int['Initiator_ID']\n interact['Interaction_Number'] = start_int['Interaction_Number']\n interact['Partner_ID'] = start_int['Interaction_Number']\n interact['Females_Present'] = start_int['Females_Present']\n interact['Reaction_Code'] = start_int['Reaction_Code']\n interact['Disengager_ID'] = end_int['Disengager_ID']\n interact['Bouts_O_Smacking'] = end_int['Bouts_O_Smacking']\n interact['Face_Off'] = end_int['Face_Off']\n interact['Duration'] = str((end_int['Time_Stamp'] - start_int['Time_Stamp']).seconds)\n interact['Initiator_Cartesian_X'] = str(stake_offset[start_int['Initiator_Stake']][0]+ float(start_int['Initiator_X']))\n interact['Initiator_Cartesian_Y'] = str(stake_offset[start_int['Initiator_Stake']][1]+ float(start_int['Initiator_Y']))\n interact['Partner_Cartesian_X'] = str(stake_offset[start_int['Partner_Stake']][0]+ float(start_int['Partner_X']))\n interact['Partner_Cartesian_Y'] = str(stake_offset[start_int['Partner_Stake']][1]+ float(start_int['Partner_Y']))\n interact['Other_Notes'] = start_int['Other_Notes'] + ' ' + end_int['Other_Notes']\n interactions.append(interact)\n \n return sorted(interactions, key=itemgetter('Time_Stamp')), positions\n\ndef data_2_csv(fn, interactions, positions):\n csv_inte = open(fn.replace('.srt','_interactions.tsv'), 'w')\n csv_inte.write('\\t'.join(interaction_columns)+'\\n')\n for inter in interactions:\n csv_inte.write('\\t'.join([inter[x] for x in interaction_columns])+'\\n')\n csv_inte.close()\n \n csv_posi = open(fn.replace('.srt','_positions.tsv'), 'w')\n csv_posi.write('\\t'.join(pos_columns)+'\\n')\n for posi in positions:\n csv_posi.write('\\t'.join([posi[x] for x in pos_columns])+'\\n')\n csv_posi.close()\n \n\nif __name__ == \"__main__\":\n stakes = 'stake_coords.csv'\n for srt in glob('*.srt'):\n print('Working on file {} ...'.format(srt))\n interactions, positions = parse_srt(srt, stakes)\n data_2_csv(srt, interactions, positions)\n print('Done.')"
}
] | 2 |
aryan1384/management_app
|
https://github.com/aryan1384/management_app
|
7feada9bedb60807dfa31b5723635a6846cfe9a0
|
f274eb40c548e52a89f42e24640a81e0c406c332
|
9082d5169ac074f93d1d97eb0d1bc2934bde2237
|
refs/heads/master
| 2023-03-29T03:10:46.202913 | 2021-04-07T08:08:30 | 2021-04-07T08:08:30 | 298,791,533 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6803514957427979,
"alphanum_fraction": 0.6871704459190369,
"avg_line_length": 45.03559875488281,
"blob_id": "55f0d91b4e9c4ecced6f635e3972cb1ce3a24393",
"content_id": "57d8505c129c95aab2cd9d2414304e3eb8dc1630",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14225,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 309,
"path": "/bank_balances - 1.py",
"repo_name": "aryan1384/management_app",
"src_encoding": "UTF-8",
"text": "from PyQt5 import QtCore, QtGui, QtWidgets\nimport functions\nfrom PyQt5.QtWidgets import QApplication, QWidget, QScrollArea, QVBoxLayout, QGroupBox, QLabel, QPushButton, QFormLayout, QFileDialog\nfrom PyQt5.QtWidgets import QApplication, QWidget, QPushButton, QVBoxLayout\nfrom PyQt5.QtGui import QIcon\nfrom PyQt5.QtCore import pyqtSlot\n\nimport sys\nimport tkinter \n\nroot = tkinter.Tk()\n#variables\n#window\nwidth_window = root.winfo_screenwidth()\nheight_window = root.winfo_screenheight()\n#print(width_window , height_window)\n\n#tools\nwidth_tools = width_window // 4\nheight_tools = height_window - (height_window // 7)\nx_tools = width_window // 40\ny_tools = height_window // 25\n\n#detail\nwidth_details = width_window // 5 * 3\nheight_details = height_tools\nx_details = x_tools + width_tools + (width_window // 15)\ny_details = y_tools \n\ny_buttons = 50\n'''class button(object):\n detail = \"\"\n text = \"\"\n def show_text(self):\n pass'''\n \n\n\nclass Ui_MainWindow(object):\n buttons = []\n \n def setupUi(self, MainWindow):\n MainWindow.setObjectName(\"MainWindow\")\n MainWindow.resize(width_window, height_window)\n self.button_file = []\n self.centralwidget = QtWidgets.QWidget(MainWindow)\n self.centralwidget.setObjectName(\"centralwidget\")\n MainWindow.setCentralWidget(self.centralwidget)\n\n self.num=1\n\n #groupBox_tool\n \n self.groupBox_tool = QtWidgets.QGroupBox(self.centralwidget)\n self.groupBox_tool.setGeometry(QtCore.QRect(x_tools, y_tools, width_tools, height_tools))\n self.groupBox_tool.setCursor(QtGui.QCursor(QtCore.Qt.ArrowCursor))\n self.groupBox_tool.setObjectName(\"groupBox_tool\")\n\n self.groupBox_detail = QtWidgets.QGroupBox(self.centralwidget)\n self.groupBox_detail.setGeometry(QtCore.QRect(x_details, y_details, width_details, height_details))\n self.groupBox_detail.setObjectName(\"groupBox_detail\")\n\n self.label_detail = QtWidgets.QLabel(self.groupBox_detail)\n self.label_detail.setGeometry(QtCore.QRect(width_details // 2 - 30, height_details // 2 - 20, 91, 51))\n font = QtGui.QFont()\n font.setPointSize(16)\n self.label_detail.setFont(font)\n self.label_detail.setObjectName(\"label_detail\")\n\n #formLayout =QFormLayout()\n #labelLis = []\n #comboList = []\n #for i in range(50):\n # labelLis.append(QLabel(\"Label\"))\n # comboList.append(QPushButton(\"Click Me\"))\n # formLayout.addRow(labelLis[i], comboList[i])\n #self.groupBox_detail.setLayout(formLayout)\n #scroll = QScrollArea()\n #scroll.setWidget(self.groupBox_detail)\n #scroll.setWidgetResizable(True)\n #scroll.setFixedHeight(400)\n #layout = QVBoxLayout()\n #layout.addWidget(scroll)\n\n '''self.label_tool = QtWidgets.QLabel(self.groupBox_tool)\n self.label_tool.setGeometry(QtCore.QRect(width_tools // 2 - 45, height_tools // 2 - 20, 91, 51))\n font = QtGui.QFont()\n font.setPointSize(16)\n self.label_tool.setFont(font)\n self.label_tool.setObjectName(\"label_tool\")'''\n\n self.addFile_button = QtWidgets.QPushButton(self.groupBox_tool)\n y_addFile_button = len(self.buttons)*70 + 50\n self.addFile_button.setGeometry(QtCore.QRect(70, y_addFile_button, 111, 51))\n font = QtGui.QFont()\n font.setPointSize(20)\n self.addFile_button.setFont(font)\n self.addFile_button.setObjectName(\"addFile_button\")\n \n self.menubar = QtWidgets.QMenuBar(MainWindow)\n self.menubar.setGeometry(QtCore.QRect(0, 0, 1000, 21))\n self.menubar.setObjectName(\"menubar\")\n self.menuFile = QtWidgets.QMenu(self.menubar)\n self.menuFile.setObjectName(\"menuFile\")\n self.menuOpen = QtWidgets.QMenu(self.menuFile)\n self.menuOpen.setObjectName(\"menuOpen\")\n self.menuReccomendation = QtWidgets.QMenu(self.menubar)\n self.menuReccomendation.setObjectName(\"menuReccomendation\")\n self.menuHelp = QtWidgets.QMenu(self.menubar)\n self.menuHelp.setObjectName(\"menuHelp\")\n self.menuLists = QtWidgets.QMenu(self.menubar)\n self.menuLists.setObjectName(\"menuLists\")\n self.menuReports = QtWidgets.QMenu(self.menuLists)\n self.menuReports.setObjectName(\"menuReports\")\n MainWindow.setMenuBar(self.menubar)\n self.statusbar = QtWidgets.QStatusBar(MainWindow)\n self.statusbar.setObjectName(\"statusbar\")\n MainWindow.setStatusBar(self.statusbar)\n self.actionSave = QtWidgets.QAction(MainWindow)\n self.actionSave.setObjectName(\"actionSave\")\n self.actionSave_as = QtWidgets.QAction(MainWindow)\n self.actionSave_as.setObjectName(\"actionSave_as\")\n self.actionNew = QtWidgets.QAction(MainWindow)\n self.actionNew.setObjectName(\"actionNew\")\n self.actionOpen_file = QtWidgets.QAction(MainWindow)\n self.actionOpen_file.setObjectName(\"actionOpen_file\")\n self.actionOpen_file = QtWidgets.QAction(MainWindow)\n self.actionOpen_file.setObjectName(\"actionOpen_file\")\n #self.actionOpen_other = QtWidgets.QAction(MainWindow)\n #self.actionOpen_other.setObjectName(\"actionOpen_other\")\n self.actionBank_balances = QtWidgets.QAction(MainWindow)\n self.actionBank_balances.setObjectName(\"actionBank_balances\")\n self.actionDocuments = QtWidgets.QAction(MainWindow)\n self.actionDocuments.setObjectName(\"actionDocuments\")\n self.actionCrafts_and_Consumption = QtWidgets.QAction(MainWindow)\n self.actionCrafts_and_Consumption.setObjectName(\"actionCrafts_and_Consumption\")\n self.actionChecks_issued = QtWidgets.QAction(MainWindow)\n self.actionChecks_issued.setObjectName(\"actionChecks_issued\")\n self.actionExpenses = QtWidgets.QAction(MainWindow)\n self.actionExpenses.setObjectName(\"actionExpenses\")\n self.actionAssets = QtWidgets.QAction(MainWindow)\n self.actionAssets.setObjectName(\"actionAssets\")\n self.actionStocks = QtWidgets.QAction(MainWindow)\n self.actionStocks.setObjectName(\"actionStocks\")\n self.actionEmployees = QtWidgets.QAction(MainWindow)\n self.actionEmployees.setObjectName(\"actionEmployees\")\n self.actionCustomers = QtWidgets.QAction(MainWindow)\n self.actionCustomers.setObjectName(\"actionCustomers\")\n self.actionBank_balances_Advice = QtWidgets.QAction(MainWindow)\n self.actionBank_balances_Advice.setObjectName(\"actionBank_balances_Advice\")\n self.actionStocks_Advice = QtWidgets.QAction(MainWindow)\n self.actionStocks_Advice.setObjectName(\"actionStocks_Advice\")\n self.actionEmployees_Advice = QtWidgets.QAction(MainWindow)\n self.actionEmployees_Advice.setObjectName(\"actionEmployees_Advice\")\n self.actionCustomers_Advice = QtWidgets.QAction(MainWindow)\n self.actionCustomers_Advice.setObjectName(\"actionCustomers_Advice\")\n #self.menuOpen.addAction(self.actionOpen_other)\n self.menuOpen.addAction(self.actionOpen_file)\n self.menuFile.addAction(self.actionNew)\n self.menuFile.addAction(self.menuOpen.menuAction())\n self.menuFile.addAction(self.actionSave)\n self.menuFile.addAction(self.actionSave_as)\n self.menuReccomendation.addAction(self.actionBank_balances_Advice)\n self.menuReccomendation.addAction(self.actionStocks_Advice)\n self.menuReccomendation.addAction(self.actionEmployees_Advice)\n self.menuReccomendation.addAction(self.actionCustomers_Advice)\n self.menuReports.addAction(self.actionDocuments)\n self.menuReports.addAction(self.actionCrafts_and_Consumption)\n self.menuLists.addAction(self.actionBank_balances)\n self.menuLists.addAction(self.menuReports.menuAction())\n self.menuLists.addAction(self.actionChecks_issued)\n self.menuLists.addAction(self.actionExpenses)\n self.menuLists.addAction(self.actionAssets)\n self.menuLists.addAction(self.actionStocks)\n self.menuLists.addAction(self.actionEmployees)\n self.menuLists.addAction(self.actionCustomers)\n self.menubar.addAction(self.menuFile.menuAction())\n self.menubar.addAction(self.menuLists.menuAction())\n self.menubar.addAction(self.menuReccomendation.menuAction())\n self.menubar.addAction(self.menuHelp.menuAction())\n\n self.retranslateUi(MainWindow)\n QtCore.QMetaObject.connectSlotsByName(MainWindow)\n\n #self.groupBox_detail.setLayout(formLayout)\n #scroll = QScrollArea()\n #scroll.setWidget(self.groupBox_detail)\n #scroll.setWidgetResizable(True)\n #scroll.setFixedHeight(600)\n #layout = QVBoxLayout()\n #layout.addWidget(scroll)\n\n def retranslateUi(self, MainWindow):\n _translate = QtCore.QCoreApplication.translate\n #groupBox_text\n self.groupBox_tool.setTitle(_translate(\"MainWindow\", \"Tools\"))\n self.addFile_button.setText(_translate(\"MainWindow\", \"+\"))\n\n self.label_detail.setText(_translate(\"MainWindow\", \"No detail\"))\n self.label_detail.adjustSize()\n self.groupBox_detail.setTitle(_translate(\"MainWindow\", \"Detail\"))\n\n MainWindow.setWindowTitle(_translate(\"MainWindow\", \"MainWindow\"))\n self.menuFile.setTitle(_translate(\"MainWindow\", \"File\"))\n self.menuOpen.setTitle(_translate(\"MainWindow\", \"Open\"))\n self.menuReccomendation.setTitle(_translate(\"MainWindow\", \"Advice and Predicts\"))\n self.menuHelp.setTitle(_translate(\"MainWindow\", \"Help\"))\n self.menuLists.setTitle(_translate(\"MainWindow\", \"Lists\"))\n self.menuReports.setTitle(_translate(\"MainWindow\", \"Reports\"))\n self.actionSave.setText(_translate(\"MainWindow\", \"Save\"))\n self.actionSave.setStatusTip(_translate(\"MainWindow\", \"Save file\"))\n self.actionSave.setShortcut(_translate(\"MainWindow\", \"Ctrl+S\"))\n self.actionSave_as.setText(_translate(\"MainWindow\", \"Save as\"))\n self.actionSave_as.setStatusTip(_translate(\"MainWindow\", \"Save file as\"))\n self.actionNew.setText(_translate(\"MainWindow\", \"New\"))\n self.actionNew.setStatusTip(_translate(\"MainWindow\", \"New file\"))\n self.actionNew.setShortcut(_translate(\"MainWindow\", \"Ctrl+N\"))\n self.actionOpen_file.setText(_translate(\"MainWindow\", \"Open file\"))\n self.actionOpen_file.setText(_translate(\"MainWindow\", \"Open file\"))\n self.actionOpen_file.setStatusTip(_translate(\"MainWindow\", \"Open main file\"))\n self.actionOpen_file.setShortcut(_translate(\"MainWindow\", \"Ctrl+Shift+O\"))\n #self.actionOpen_other.setText(_translate(\"MainWindow\", \"Open other\"))\n #self.actionOpen_other.setStatusTip(_translate(\"MainWindow\", \"Open partial file\"))\n #self.actionOpen_other.setShortcut(_translate(\"MainWindow\", \"Ctrl+O\"))\n self.actionBank_balances.setText(_translate(\"MainWindow\", \"Bank balances\"))\n self.actionDocuments.setText(_translate(\"MainWindow\", \"Documents\"))\n self.actionCrafts_and_Consumption.setText(_translate(\"MainWindow\", \"Crafts and Consumption\"))\n self.actionChecks_issued.setText(_translate(\"MainWindow\", \"Checks issued\"))\n self.actionExpenses.setText(_translate(\"MainWindow\", \"Expenses\"))\n self.actionAssets.setText(_translate(\"MainWindow\", \"Assets\"))\n self.actionStocks.setText(_translate(\"MainWindow\", \"Stocks\"))\n self.actionEmployees.setText(_translate(\"MainWindow\", \"Employees\"))\n self.actionCustomers.setText(_translate(\"MainWindow\", \"Customers\"))\n self.actionBank_balances_Advice.setText(_translate(\"MainWindow\", \"Bank balances\"))\n self.actionStocks_Advice.setText(_translate(\"MainWindow\", \"Stocks\"))\n self.actionEmployees_Advice.setText(_translate(\"MainWindow\", \"Employees\"))\n self.actionCustomers_Advice.setText(_translate(\"MainWindow\", \"Customers\"))\n\n #click_addFile\n self.layout = QVBoxLayout(self.groupBox_tool) \n self.layout.addWidget(self.addFile_button)\n self.addFile_button.clicked.connect(self.addbutton)\n\n #file\n self.actionNew.triggered.connect(lambda: self.functionNew())\n #self.actionOpen_other.triggered.connect(lambda: self.functionOpen_other())\n self.actionOpen_file.triggered.connect(lambda: self.functionOpen_file())\n self.actionSave.triggered.connect(lambda: self.functionSave())\n self.actionSave_as.triggered.connect(lambda: self.functionSave_as())\n\n #file\n def functionNew(self):\n print('New clicked!')\n pass\n\n '''def functionOpen_other(self):\n pass'''\n\n def functionOpen_file(self):\n print('Open file clicked')\n address = functions.open_file()\n print(address)\n pass\n\n def functionSave(self):\n pass\n\n def functionSave_as(self):\n pass\n \n def addbutton(self):\n option = QFileDialog.Options()\n widget = QWidget()\n myfile = QFileDialog.getOpenFileName(widget,'open file','default.txt','All Files (*.*)', options = option)\n text_file_ = open(myfile[0] , 'r')\n text_file = text_file_.readlines()\n text_file_.close()\n #print(text_file)\n self.show_text(text_file)\n self.button_file.append(text_file)\n print('Button-{} will be created'.format(self.num))\n button2 = QPushButton(str(self.num) , self.groupBox_tool)\n button2.clicked.connect(lambda : self.show_text(self.button_file[int(button2.text()) - 1]))\n# button2.move(100, 200)\n self.layout.addWidget(button2)\n self.num += 1\n \n\n def show_text(self,text_file):\n #print('here')\n mytext = ''\n for i in text_file:\n mytext += i\n self.label_detail.setText(mytext)\n self.label_detail.setGeometry(QtCore.QRect(20, 20, 450, 450))\n font = QtGui.QFont()\n font.setPointSize(14)\n self.label_detail.setFont(font)\n self.label_detail.adjustSize()\n \n\nif __name__ == \"__main__\":\n \n app = QtWidgets.QApplication(sys.argv)\n MainWindow = QtWidgets.QMainWindow()\n ui = Ui_MainWindow()\n ui.setupUi(MainWindow) \n MainWindow.show()\n sys.exit(app.exec_())\n"
},
{
"alpha_fraction": 0.643847644329071,
"alphanum_fraction": 0.650739312171936,
"avg_line_length": 40.27931213378906,
"blob_id": "10b50084bea76fa0e67b159fa186fd473a3b52be",
"content_id": "ad2d7c854be5e54b02857fd4cf82844a8c60952c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 23942,
"license_type": "no_license",
"max_line_length": 187,
"num_lines": 580,
"path": "/main.py",
"repo_name": "aryan1384/management_app",
"src_encoding": "UTF-8",
"text": "\n# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file 'first.ui'\n#\n# Created by: PyQt5 UI code generator 5.15.1\n#\n# WARNING: Any manual changes made to this file will be lost when pyuic5 is\n# run again. Do not edit this file unless you know what you are doing.\n\n\nfrom PyQt5 import QtCore, QtGui, QtWidgets\nfrom PyQt5.QtWidgets import QApplication, QWidget, QScrollArea, QVBoxLayout, QHBoxLayout, QGroupBox, QLabel, QPushButton, QFormLayout, QFileDialog, QLayout, QTableWidget, QTableWidgetItem\n\nimport os\nfrom PIL import Image\n\nimport sys\nimport tkinter\nimport pandas as pd\n\nroot = tkinter.Tk()\n#variables\n#window\nwidth_window = root.winfo_screenwidth() - 15\nheight_window = root.winfo_screenheight() - 78\n#print(width_window , height_window)\n\n#tools\nwidth_tools = width_window // 4\nheight_tools = height_window - (height_window // 9)\nx_tools = width_window // 40\ny_tools = height_window // 25\n\n#detail\nwidth_details = width_window // 5 * 3\nheight_details = height_tools\nx_details = x_tools + width_tools + (width_window // 15)\ny_details = y_tools \nheight_tools = height_tools - (height_tools // 5)\n\n#option\nwidth_option = width_tools\nheight_option = height_details - height_tools - (height_tools // 15)\nx_option = x_tools\ny_option = y_tools + height_tools + (height_tools // 15) \n\n\nclass Ui_MainWindow(object):\n def setupUi(self, MainWindow):\n MainWindow.setObjectName(\"MainWindow\")\n MainWindow.resize(width_window, height_window)\n\n self.centralwidget = QtWidgets.QWidget(MainWindow)\n self.centralwidget.setObjectName(\"centralwidget\")\n MainWindow.setCentralWidget(self.centralwidget)\n\n #groupBox --------------------------------------------------\n '''formLayout =QFormLayout()'''\n\n\n self.groupBox_tool = QtWidgets.QGroupBox(self.centralwidget)\n self.groupBox_tool.setGeometry(QtCore.QRect(x_tools, y_tools, width_tools, height_tools))\n self.groupBox_tool.setCursor(QtGui.QCursor(QtCore.Qt.ArrowCursor))\n self.groupBox_tool.setObjectName(\"groupBox_tool\")\n\n self.groupBox_detail = QtWidgets.QGroupBox(self.centralwidget)\n self.groupBox_detail.setGeometry(QtCore.QRect(x_details, y_details, width_details, height_details))\n self.groupBox_detail.setObjectName(\"groupBox_detail\")\n\n self.groupBox_option = QtWidgets.QGroupBox(self.centralwidget)\n self.groupBox_option.setGeometry(QtCore.QRect(x_option, y_option, width_option, height_option))\n self.groupBox_option.setObjectName(\"groupBox_option\")\n\n '''self.groupBox_detail.setLayout(formLayout)\n scroll = QScrollArea()\n scroll.setWidget(self.groupBox_detail)\n scroll.setWidgetResizable(True)\n scroll.setFixedHeight(400)\n layout = QVBoxLayout()\n layout.addWidget(scroll)'''\n\n #label in groupBox --------------------------------------------\n\n self.label_name = QtWidgets.QLabel(self.centralwidget)\n self.label_name.setGeometry(QtCore.QRect(x_tools, y_tools - 20, 91, 51))\n font = QtGui.QFont()\n font.setPointSize(8)\n self.label_name.setFont(font)\n self.label_name.setObjectName(\"label_name\")\n\n\n self.label_detail = QtWidgets.QLabel(self.groupBox_detail)\n self.label_detail.setGeometry(QtCore.QRect(width_details // 2 - 30, height_details // 2 - 20, 91, 51))\n font = QtGui.QFont()\n font.setPointSize(16)\n self.label_detail.setFont(font)\n self.label_detail.setObjectName(\"label_detail\")\n\n self.label_tool = QtWidgets.QLabel(self.groupBox_tool)\n self.label_tool.setGeometry(QtCore.QRect(width_tools // 2 - 45, height_tools // 2 - 20, 91, 51))\n font = QtGui.QFont()\n font.setPointSize(16)\n self.label_tool.setFont(font)\n self.label_tool.setObjectName(\"label_tool\")\n\n #menu ------------------------------------------------------\n\n self.menubar = QtWidgets.QMenuBar(MainWindow)\n self.menubar.setGeometry(QtCore.QRect(0, 0, 1000, 21))\n self.menubar.setObjectName(\"menubar\")\n self.menuFile = QtWidgets.QMenu(self.menubar)\n self.menuFile.setObjectName(\"menuFile\")\n self.menuOpen = QtWidgets.QMenu(self.menuFile)\n self.menuOpen.setObjectName(\"menuOpen\")\n self.menuReccomendation = QtWidgets.QMenu(self.menubar)\n self.menuReccomendation.setObjectName(\"menuReccomendation\")\n self.menuHelp = QtWidgets.QMenu(self.menubar)\n self.menuHelp.setObjectName(\"menuHelp\")\n self.menuLists = QtWidgets.QMenu(self.menubar)\n self.menuLists.setObjectName(\"menuLists\")\n self.menuReports = QtWidgets.QMenu(self.menuLists)\n self.menuReports.setObjectName(\"menuReports\")\n MainWindow.setMenuBar(self.menubar)\n self.statusbar = QtWidgets.QStatusBar(MainWindow)\n self.statusbar.setObjectName(\"statusbar\")\n MainWindow.setStatusBar(self.statusbar)\n self.actionSave = QtWidgets.QAction(MainWindow)\n self.actionSave.setObjectName(\"actionSave\")\n self.actionSave_as = QtWidgets.QAction(MainWindow)\n self.actionSave_as.setObjectName(\"actionSave_as\")\n self.actionNew = QtWidgets.QAction(MainWindow)\n self.actionNew.setObjectName(\"actionNew\")\n self.actionOpen_file = QtWidgets.QAction(MainWindow)\n self.actionOpen_file.setObjectName(\"actionOpen_file\")\n self.actionOpen_file = QtWidgets.QAction(MainWindow)\n self.actionOpen_file.setObjectName(\"actionOpen_file\")\n '''self.actionOpen_other = QtWidgets.QAction(MainWindow)\n self.actionOpen_other.setObjectName(\"actionOpen_other\")'''\n self.actionBank_balances = QtWidgets.QAction(MainWindow)\n self.actionBank_balances.setObjectName(\"actionBank_balances\")\n self.actionDocuments = QtWidgets.QAction(MainWindow)\n self.actionDocuments.setObjectName(\"actionDocuments\")\n self.actionCrafts_and_Consumption = QtWidgets.QAction(MainWindow)\n self.actionCrafts_and_Consumption.setObjectName(\"actionCrafts_and_Consumption\")\n self.actionChecks_issued = QtWidgets.QAction(MainWindow)\n self.actionChecks_issued.setObjectName(\"actionChecks_issued\")\n self.actionExpenses = QtWidgets.QAction(MainWindow)\n self.actionExpenses.setObjectName(\"actionExpenses\")\n self.actionAssets = QtWidgets.QAction(MainWindow)\n self.actionAssets.setObjectName(\"actionAssets\")\n self.actionStocks = QtWidgets.QAction(MainWindow)\n self.actionStocks.setObjectName(\"actionStocks\")\n self.actionEmployees = QtWidgets.QAction(MainWindow)\n self.actionEmployees.setObjectName(\"actionEmployees\")\n self.actionCustomers = QtWidgets.QAction(MainWindow)\n self.actionCustomers.setObjectName(\"actionCustomers\")\n self.actionBank_balances_Advice = QtWidgets.QAction(MainWindow)\n self.actionBank_balances_Advice.setObjectName(\"actionBank_balances_Advice\")\n self.actionStocks_Advice = QtWidgets.QAction(MainWindow)\n self.actionStocks_Advice.setObjectName(\"actionStocks_Advice\")\n self.actionEmployees_Advice = QtWidgets.QAction(MainWindow)\n self.actionEmployees_Advice.setObjectName(\"actionEmployees_Advice\")\n self.actionCustomers_Advice = QtWidgets.QAction(MainWindow)\n self.actionCustomers_Advice.setObjectName(\"actionCustomers_Advice\")\n #self.menuOpen.addAction(self.actionOpen_other)\n self.menuOpen.addAction(self.actionOpen_file)\n self.menuFile.addAction(self.actionNew)\n self.menuFile.addAction(self.menuOpen.menuAction())\n self.menuFile.addAction(self.actionSave)\n self.menuFile.addAction(self.actionSave_as)\n self.menuReccomendation.addAction(self.actionBank_balances_Advice)\n self.menuReccomendation.addAction(self.actionStocks_Advice)\n self.menuReccomendation.addAction(self.actionEmployees_Advice)\n self.menuReccomendation.addAction(self.actionCustomers_Advice)\n self.menuReports.addAction(self.actionDocuments)\n self.menuReports.addAction(self.actionCrafts_and_Consumption)\n self.menuLists.addAction(self.actionBank_balances)\n self.menuLists.addAction(self.menuReports.menuAction())\n self.menuLists.addAction(self.actionChecks_issued)\n self.menuLists.addAction(self.actionExpenses)\n self.menuLists.addAction(self.actionAssets)\n self.menuLists.addAction(self.actionStocks)\n self.menuLists.addAction(self.actionEmployees)\n self.menuLists.addAction(self.actionCustomers)\n self.menubar.addAction(self.menuFile.menuAction())\n self.menubar.addAction(self.menuLists.menuAction())\n self.menubar.addAction(self.menuReccomendation.menuAction())\n self.menubar.addAction(self.menuHelp.menuAction())\n\n self.retranslateUi(MainWindow)\n QtCore.QMetaObject.connectSlotsByName(MainWindow)\n\n def retranslateUi(self, MainWindow):\n _translate = QtCore.QCoreApplication.translate\n \n #groupBox_text ------------------------------------------------\n\n self.groupBox_tool.setTitle(_translate(\"MainWindow\", \"Tools\"))\n self.label_tool.setText(_translate(\"MainWindow\", \"No tool\"))\n \n self.label_tool.adjustSize()\n self.label_detail.setText(_translate(\"MainWindow\", \"No detail\"))\n self.label_detail.adjustSize()\n self.groupBox_detail.setTitle(_translate(\"MainWindow\", \"Detail\"))\n self.groupBox_option.setTitle(_translate(\"MainWindow\", \"Option\"))\n\n MainWindow.setWindowTitle(_translate(\"MainWindow\", \"MainWindow\"))\n self.menuFile.setTitle(_translate(\"MainWindow\", \"File\"))\n self.menuOpen.setTitle(_translate(\"MainWindow\", \"Open\"))\n self.menuReccomendation.setTitle(_translate(\"MainWindow\", \"Advice and Predicts\"))\n self.menuHelp.setTitle(_translate(\"MainWindow\", \"Help\"))\n self.menuLists.setTitle(_translate(\"MainWindow\", \"Lists\"))\n self.menuReports.setTitle(_translate(\"MainWindow\", \"Reports\"))\n self.actionSave.setText(_translate(\"MainWindow\", \"Save\"))\n self.actionSave.setStatusTip(_translate(\"MainWindow\", \"Save file\"))\n self.actionSave.setShortcut(_translate(\"MainWindow\", \"Ctrl+S\"))\n self.actionSave_as.setText(_translate(\"MainWindow\", \"Save as\"))\n self.actionSave_as.setStatusTip(_translate(\"MainWindow\", \"Save file as\"))\n self.actionNew.setText(_translate(\"MainWindow\", \"New\"))\n self.actionNew.setStatusTip(_translate(\"MainWindow\", \"New file\"))\n self.actionNew.setShortcut(_translate(\"MainWindow\", \"Ctrl+N\"))\n self.actionOpen_file.setText(_translate(\"MainWindow\", \"Open file\"))\n self.actionOpen_file.setText(_translate(\"MainWindow\", \"Open file\"))\n self.actionOpen_file.setStatusTip(_translate(\"MainWindow\", \"Open main file\"))\n self.actionOpen_file.setShortcut(_translate(\"MainWindow\", \"Ctrl+O\"))\n #self.actionOpen_other.setText(_translate(\"MainWindow\", \"Open other\"))\n #self.actionOpen_other.setStatusTip(_translate(\"MainWindow\", \"Open partial file\"))\n #self.actionOpen_other.setShortcut(_translate(\"MainWindow\", \"Ctrl+O\"))\n self.actionBank_balances.setText(_translate(\"MainWindow\", \"Bank balances\"))\n self.actionDocuments.setText(_translate(\"MainWindow\", \"Documents\"))\n self.actionCrafts_and_Consumption.setText(_translate(\"MainWindow\", \"Crafts and Consumption\"))\n self.actionChecks_issued.setText(_translate(\"MainWindow\", \"Checks issued\"))\n self.actionExpenses.setText(_translate(\"MainWindow\", \"Expenses\"))\n self.actionAssets.setText(_translate(\"MainWindow\", \"Assets\"))\n self.actionStocks.setText(_translate(\"MainWindow\", \"Stocks\"))\n self.actionEmployees.setText(_translate(\"MainWindow\", \"Employees\"))\n self.actionCustomers.setText(_translate(\"MainWindow\", \"Customers\"))\n self.actionBank_balances_Advice.setText(_translate(\"MainWindow\", \"Bank balances\"))\n self.actionStocks_Advice.setText(_translate(\"MainWindow\", \"Stocks\"))\n self.actionEmployees_Advice.setText(_translate(\"MainWindow\", \"Employees\"))\n self.actionCustomers_Advice.setText(_translate(\"MainWindow\", \"Customers\"))\n\n #click_menu\n\n #file\n self.actionNew.triggered.connect(lambda: self.functionNew())\n #self.actionOpen_other.triggered.connect(lambda: self.functionOpen_other())\n self.actionOpen_file.triggered.connect(lambda: self.functionOpen_file())\n self.actionSave.triggered.connect(lambda: self.functionSave())\n self.actionSave_as.triggered.connect(lambda: self.functionSave_as())\n #lists\n self.actionBank_balances.triggered.connect(lambda: self.functionBank_balances())\n self.actionDocuments.triggered.connect(lambda: self.functionDucuments())\n self.actionCrafts_and_Consumption.triggered.connect(lambda: self.functionCraft_and_Consumption())\n self.actionChecks_issued.triggered.connect(lambda: self.functionChecks_issued())\n self.actionExpenses.triggered.connect(lambda: self.functionExpenses())\n self.actionAssets.triggered.connect(lambda: self.functionAsset())\n self.actionStocks.triggered.connect(lambda: self.functionStocks())\n self.actionEmployees.triggered.connect(lambda: self.functionEmployees())\n self.actionCustomers.triggered.connect(lambda: self.functionCustomers())\n #advice and predict\n self.actionBank_balances_Advice.triggered.connect(lambda: self.functionBank_balances_Advice())\n self.actionStocks_Advice.triggered.connect(lambda: self.functionStocks_Advice())\n self.actionEmployees_Advice.triggered.connect(lambda: self.functionEmployees_Advice())\n self.actionCustomers_Advice.triggered.connect(lambda: self.functionCustomers_Advice())\n\n #varaible ----------------------------------------\n self.flag_layout_tool = False\n self.flag_layout_option = False\n self.map_option = self.analysis_text\n self.currunt_map = \"text\"\n\n\n def scroll_tools(self):\n pass\n\n #file\n def functionNew(self):\n print('New clicked!')\n pass\n\n def functionOpen_other(self):\n pass\n\n def functionOpen_file(self):\n print('Open file clicked')\n address = functions.open_file()\n print(address)\n pass\n\n def functionSave(self):\n pass\n\n def functionSave_as(self):\n pass\n\n #lists\n\n def functionBank_balances(self):\n self.prepare(\"Bank balances\", ['text','table'])\n \n\n def functionDucuments(self):\n self.prepare(\"Documents\", ['text','pic'])\n \n\n def functionCraft_and_Consumption(self):\n self.prepare(\"Craft and Consumptions\", ['text','pic','table','chart'])\n \n\n def functionChecks_issued(self):\n self.prepare(\"Checks issued\", ['text','pic','table'])\n \n\n def functionExpenses(self):\n self.prepare(\"Expences\", ['text','table','chart','pic'])\n \n\n def functionAsset(self):\n self.prepare(\"Assets\",['text','pic','table','chart'])\n \n\n def functionStocks(self):\n self.prepare(\"Stocks\", ['text','table','stock'])\n \n\n def functionEmployees(self):\n self.prepare(\"Employees\", ['text','pic','table'])\n \n def functionCustomers(self):\n pass\n #advice and predict\n def functionBank_balances_Advice(self):\n pass\n\n def functionStocks_Advice(self):\n pass\n\n def functionEmployees_Advice(self):\n pass\n\n def functionCustomers_Advice(self):\n pass\n\n\n #functions -------------------------------------------------------\n def prepare(self, map_name, list_options):\n self.check_previous()\n \n self.prepare_show(map_name)\n self.show_option(list_options)\n\n def prepare_show(self, map_name):\n self.map_name = map_name\n self.label_name.setText(map_name + \" - \" + self.currunt_map)\n self.label_name.adjustSize()\n\n self.make_plus_button()\n\n #print(self.currunt_map)\n self.shown_file_address = \"information/\" + str(map_name) + \"/\" + str(self.currunt_map) \n #print(os.listdir(\"information/\" + str(map_name)))\n self.shown_file = os.listdir(self.shown_file_address)\n\n for i in range(len(self.shown_file)):\n self.make_tool_button(self.shown_file[i])\n\n \n\n \n def make_plus_button(self):\n self.addFile_button = QtWidgets.QPushButton(self.groupBox_tool)\n #y_addFile_button = len(self.buttons)*70 + 50\n #self.addFile_button.setGeometry(QtCore.QRect(70, y_addFile_button, 111, 51))\n font = QtGui.QFont()\n font.setPointSize(20)\n self.addFile_button.setFont(font)\n self.addFile_button.setObjectName(\"addFile_button\")\n self.button_file = []\n if not self.flag_layout_tool:\n self.make_layout()\n\n self.number_name_toolButton = {}\n\n self.layout_tool.addWidget(self.addFile_button)\n self.addFile_button.clicked.connect(self.addbutton)\n\n self.addFile_button.setText(\"+\")\n self.num=1\n\n\n def make_layout(self):\n #click_addFile\n self.layout_tool = QVBoxLayout(self.groupBox_tool) \n\n self.flag_layout_tool = True\n\n def addbutton(self):\n option = QFileDialog.Options()\n widget = QWidget()\n myfile = QFileDialog.getOpenFileName(widget,'open file','default.txt','All Files (*.*)', options = option)\n self.map_option(myfile[0])\n\n def make_tool_button(self, address):\n self.map_option(address)\n\n\n def change_map(self, new_map):\n if new_map == \"text\":\n self.map_option = self.analysis_text\n\n if new_map == \"pic\":\n self.map_option = self.analysis_pic\n\n if new_map == \"table\":\n self.map_option = self.show_table\n\n if new_map == \"chart\":\n self.map_option = self.show_chart \n\n self.currunt_map = new_map\n self.num = 1\n self.check_previous() \n self.prepare_show(self.map_name)\n\n def analysis_text(self, address):\n try:\n \n text_file_ = open(address , 'r')\n text_file = text_file_.readlines()\n text_file_.close()\n #print(text_file)\n self.show_text(text_file)\n \n self.button_file.append(text_file)\n #print('Button-{} will be created'.format(self.num))\n a = r\"/ \" #related to below line\n address = address.split(a[0])\n address = address[-1]\n address = address.split(\".\")\n self.number_name_toolButton[str(address[0])] = self.num #dic for address and number\n #print(self.number_name_toolButton)\n button_tool = QPushButton(str(address[0]) , self.groupBox_tool)\n button_tool.clicked.connect(lambda : self.show_text(self.button_file[ self.number_name_toolButton[button_tool.text()] - 1]))\n #button2.move(100, 200)\n self.layout_tool.addWidget(button_tool)\n self.num += 1\n\n except:\n pass\n\n def analysis_pic(self, address):\n print(\"enter analysis_pic\")\n img = address\n \n #print(text_file)\n self.show_picture(img)\n self.button_file.append(img)\n print('Button-{} will be created'.format(self.num))\n button2 = QPushButton(str(self.num) , self.groupBox_tool)\n button2.clicked.connect(lambda : self.show_picture(self.button_file[int(button2.text()) - 1]))\n# button2.move(100, 200)\n self.layout_tool.addWidget(button2)\n self.num += 1\n\n\n def show_text(self,text_file):\n #print('here')\n mytext = ''\n for i in text_file:\n mytext += i\n\n self.label_detail.setText(mytext)\n self.label_detail.setGeometry(QtCore.QRect(20, 20, 450, 450))\n font = QtGui.QFont()\n font.setPointSize(14)\n self.label_detail.setFont(font)\n self.label_detail.adjustSize() \n\n\n def show_table(self, address):\n \n # Create table\n self.info = pd.read_csv(address)\n self.tableWidget = QTableWidget()\n self.tableWidget.setRowCount(2)\n self.tableWidget.setColumnCount(6)\n print(self.info.loc[1][1])\n for i in range(2):\n for j in range(5):\n self.tableWidget.setItem(i,j, QTableWidgetItem(self.info.loc[i][j]))\n print(self.info.loc[i][j]) \n self.tableWidget.move(100,0)\n\n # table selection change\n self.tableWidget.doubleClicked.connect(self.on_click)\n\n self.layout = QVBoxLayout(self.groupBox_detail)\n self.layout.addWidget(self.tableWidget) \n\n\n def on_click(self):\n print(\"\\n\")\n for currentQTableWidgetItem in self.tableWidget.selectedItems():\n print(currentQTableWidgetItem.row(), currentQTableWidgetItem.column(), currentQTableWidgetItem.text())\n\n def show_picture(self,img):\n #img.save(\"trash.jpg\")\n image = Image.open(img)\n width_img, height_img = image.size\n while width_img > width_details or height_img > height_details:\n image = image.resize((int(width_img // 1.05), int(height_img // 1.05)))\n width_img, height_img = image.size\n image.save(\"trash.jpg\") \n #print(width_img, height_img)\n self.label_detail.setPixmap(QtGui.QPixmap(\"trash.jpg\"))\n self.label_detail.setGeometry(QtCore.QRect(0, 0, width_img ,height_img))\n os.remove('trash.jpg')\n #self.label_detail.adjustSize()\n\n def show_chart(self):\n print(\"show_chart\")\n\n def deleteLayout(self, cur_lay):\n #QtGui.QLayout(cur_lay)\n \n if cur_lay is not None:\n while cur_lay.count():\n item = cur_lay.takeAt(0)\n widget = item.widget()\n if widget is not None:\n widget.deleteLater()\n else:\n self.deleteLayout(item.layout())\n #delete(cur_lay)\n\n def check_previous(self):\n if not self.flag_layout_tool:\n self.label_tool.clear()\n\n if self.flag_layout_tool:\n self.deleteLayout(self.layout_tool)\n font = QtGui.QFont()\n font.setPointSize(16)\n self.label_detail.setFont(font)\n self.label_detail.setText(\"No detail\")\n self.label_detail.setGeometry(QtCore.QRect(width_details // 2 - 30, height_details // 2 - 20, 91, 51))\n self.label_detail.adjustSize()\n\n def show_option(self, option_list):\n if not self.flag_layout_option:\n self.layout_option = QHBoxLayout(self.groupBox_option)\n self.flag_layout_option = True\n\n self.deleteLayout(self.layout_option)\n #option_list = len(option_list)\n self.option_text = [''] * len(option_list)\n self.option_button = [''] * len(option_list)\n for i in range(len(option_list)):\n self.option_text[i] = option_list[i]\n self.option_button[i] = QPushButton(self.option_text[i], self.groupBox_option)\n self.layout_option.addWidget(self.option_button[i])\n self.option_button[0].clicked.connect(lambda : self.change_map(self.option_button[0].text()))\n self.option_button[1].clicked.connect(lambda : self.change_map(self.option_button[1].text()))\n if len(option_list) > 2:\n self.option_button[2].clicked.connect(lambda : self.change_map(self.option_button[2].text()))\n if len(option_list) > 3:\n self.option_button[3].clicked.connect(lambda : self.change_map(self.option_button[3].text()))\n\n def function_option(self, text_button):\n print(text_button)\n \napp = QtWidgets.QApplication(sys.argv)\nMainWindow = QtWidgets.QMainWindow()\nui = Ui_MainWindow()\nui.setupUi(MainWindow)\n#MainWindow.showMaximized()\n \nMainWindow.show()\nsys.exit(app.exec_())"
},
{
"alpha_fraction": 0.5877145528793335,
"alphanum_fraction": 0.6043360233306885,
"avg_line_length": 21.867769241333008,
"blob_id": "7274ee783e2e366f80b31fe064b0f3820cdc1a2f",
"content_id": "e0a30ef505d586807c1d5676ea0e723a1872eb82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5535,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 242,
"path": "/mytest.py",
"repo_name": "aryan1384/management_app",
"src_encoding": "UTF-8",
"text": "\n#!/usr/bin/python\n\n\"\"\"\nZetCode PyQt5 tutorial\n\nIn this example, we position two push\nbuttons in the bottom-right corner\nof the window.\n\nAuthor: Jan Bodnar\nWebsite: zetcode.com\n\"\"\"\n\nimport sys\nfrom PyQt5.QtWidgets import (QWidget, QPushButton,\n QHBoxLayout, QVBoxLayout, QApplication)\n\n\nclass Example(QWidget):\n\n def __init__(self):\n super().__init__()\n\n self.initUI()\n\n def initUI(self):\n\n okButton = QPushButton(\"OK\", self)\n cancelButton = QPushButton(\"Cancel\")\n\n okButton.clicked.connect(self.p)\n\n hbox = QHBoxLayout()\n hbox.addStretch(1)\n hbox.addWidget(okButton)\n hbox.addWidget(cancelButton)\n\n vbox = QVBoxLayout()\n vbox.addStretch(0)\n vbox.addLayout(hbox)\n\n self.setLayout(vbox)\n\n self.setGeometry(300, 300, 600, 300)\n self.setWindowTitle('Buttons')\n self.show()\n\n def p(self):\n print(1)\n\n\ndef main():\n app = QApplication(sys.argv)\n ex = Example()\n sys.exit(app.exec_())\n\n\nif __name__ == '__main__':\n main()\n\n\n\n\n\n\n\n\n\n#!/usr/bin/python\n\n\"\"\"\nZetCode PyQt5 tutorial\n\nIn this example, we create a bit\nmore complicated window layout using\nthe QGridLayout manager.\n\nAuthor: Jan Bodnar\nWebsite: zetcode.com\n\"\"\"\n\nimport sys\nfrom PyQt5.QtWidgets import (QWidget, QLabel, QLineEdit, QPushButton,\n QTextEdit, QGridLayout, QApplication)\n\n\nclass Example(QWidget):\n\n def __init__(self):\n super().__init__()\n\n self.initUI()\n\n def initUI(self):\n title = QLabel('Title')\n author = QLabel('Author')\n review = QLabel('Review')\n\n self.titleEdit = QLineEdit()\n authorEdit = QLineEdit()\n reviewEdit = QTextEdit()\n self.okButton = QPushButton(\"OK\")\n\n grid = QGridLayout()\n grid.setSpacing(10)\n\n grid.addWidget(title, 1, 0)\n grid.addWidget(self.titleEdit, 1, 1)\n\n grid.addWidget(author, 2, 0)\n grid.addWidget(authorEdit, 2, 1)\n\n grid.addWidget(review, 3, 0)\n grid.addWidget(reviewEdit, 3, 1, 5, 1)\n\n grid.addWidget(self.okButton, 9, 1)\n\n self.setLayout(grid)\n\n self.okButton.clicked.connect(self.p)\n\n self.setGeometry(300, 300, 350, 300)\n self.setWindowTitle('Review')\n self.show()\n\n def p(self):\n print(self.titleEdit.text())\n\n\ndef main():\n app = QApplication(sys.argv)\n ex = Example()\n sys.exit(app.exec_())\n\n\nif __name__ == '__main__':\n main() \n\n\n\n\n\n\n\n\n'''import sys\nfrom PyQt5.QtWidgets import QMainWindow, QApplication, QWidget, QAction, QTableWidget,QTableWidgetItem,QVBoxLayout\nfrom PyQt5.QtGui import QIcon\nfrom PyQt5.QtCore import pyqtSlot\nimport pandas as pd\ndetail = pd.read_csv(\"information/Bank_balances/X.csv\")\nprint(detail.loc[0][4])\n\nclass App(QWidget):\n\n def __init__(self):\n super().__init__()\n self.title = 'PyQt5 table - pythonspot.com'\n self.left = 200\n self.top = 300\n self.width = 700\n self.height = 500\n self.initUI()\n \n def initUI(self):\n self.setWindowTitle(self.title)\n self.setGeometry(self.left, self.top, self.width, self.height)\n \n self.createTable()\n\n # Add box layout, add table to box layout and add box layout to widget\n self.layout = QVBoxLayout()\n self.layout.addWidget(self.tableWidget) \n self.setLayout(self.layout) \n\n # Show widget\n self.show()\n\n def createTable(self):\n # Create table\n self.tableWidget = QTableWidget()\n self.tableWidget.setRowCount(2)\n self.tableWidget.setColumnCount(5)\n for i in range(2):\n for j in range(5):\n self.tableWidget.setItem(i,j, QTableWidgetItem(detail.loc[i][j]))\n print(detail.loc[i][j]) \n self.tableWidget.move(0,0)\n\n # table selection change\n self.tableWidget.doubleClicked.connect(self.on_click)\n\n @pyqtSlot()\n def on_click(self):\n print(\"\\n\")\n for currentQTableWidgetItem in self.tableWidget.selectedItems():\n print(currentQTableWidgetItem.row(), currentQTableWidgetItem.column(), currentQTableWidgetItem.text())\n \nif __name__ == '__main__':\n app = QApplication(sys.argv)\n ex = App()\n sys.exit(app.exec_()) ''' \n\n\n''''''\n\n\n\n'''from PyQt5 import QtGui\nfrom PyQt5.QtWidgets import QApplication, QWidget, QScrollArea, QVBoxLayout, QGroupBox, QLabel, QPushButton, QFormLayout\nimport sys\nclass Window(QWidget):\n def __init__(self, val):\n super().__init__()\n self.title = \"PyQt5 Scroll Bar\"\n self.top = 200\n self.left = 500\n self.width = 400\n self.height = 300\n self.setWindowIcon(QtGui.QIcon(\"icon.png\"))\n self.setWindowTitle(self.title)\n self.setGeometry(self.left, self.top, self.width, self.height)\n formLayout =QFormLayout()\n groupBox = QGroupBox(\"This Is Group Box\")\n labelLis = []\n comboList = []\n for i in range(val):\n labelLis.append(QLabel(\"Label\"))\n comboList.append(QPushButton(\"Click Me\"))\n formLayout.addRow(labelLis[i], comboList[i])\n groupBox.setLayout(formLayout)\n scroll = QScrollArea()\n scroll.setWidget(groupBox)\n scroll.setWidgetResizable(True)\n scroll.setFixedHeight(400)\n layout = QVBoxLayout(self)\n layout.addWidget(scroll)\n self.show()\nApp = QApplication(sys.argv)\nwindow = Window(5)\nsys.exit(App.exec())\n'''\n"
},
{
"alpha_fraction": 0.6724409461021423,
"alphanum_fraction": 0.6763779520988464,
"avg_line_length": 16.175676345825195,
"blob_id": "a9b742302fa3b80428811f727bdfa6bc35b34e7f",
"content_id": "78a6bc344759e093571a4927001cb9e544be370a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1270,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 74,
"path": "/functions.py",
"repo_name": "aryan1384/management_app",
"src_encoding": "UTF-8",
"text": "import sys\nfrom PyQt5.QtWidgets import QApplication, QWidget, QInputDialog, QLineEdit, QFileDialog\nfrom PyQt5.QtGui import QIcon\n\n#def file\ndef new():\n\tpass\n\ndef open_other():\n option = QFileDialog.Options()\n widget = QWidget()\n myfile = QFileDialog.getOpenFileName(widget,'save file','JPEG (*.jpg;*jpeg;*.jpe;*.jfif);;PNG (*.png);;PDF (*.pdf);;', options = option)\n #print(myfile)\n return myfile[0]\n\ndef open_file():\n option = QFileDialog.Options()\n widget = QWidget()\n myfile = QFileDialog.getOpenFileName(widget,'save file','default.jpg','All Files (*.*)', options = option)\n #print(myfile)\n return myfile[0]\n\ndef save():\n\tpass\n\ndef save_as():\n option = QFileDialog.Options()\n widget = QWidget()\n myfile = QFileDialog.getSaveFileName(widget,'save file','default.jpg','All Files (*.*)', options = option)\n #print(myfile)\n return myfile[0]\n\n#lists\n\ndef Bank_balances():\n\tpass\n\ndef Documents():\n\tpass\n\ndef Crafts_and_Consumption():\n\tpass\n\ndef Checks_issued():\n\tpass\n\ndef Expenses():\n\tpass\n\ndef Assets():\n\tpass\n\ndef Stocks():\n\tpass\n\ndef Employees():\n\tpass\n\ndef Customers():\n\tpass\n\n#Advice and predicts\n\ndef Bank_balances_advice():\n\tpass\n\ndef Stocks_advice():\n\tpass\n\ndef Employees_advice():\n\tpass\n\ndef Customers_advice():\n\tpass"
}
] | 4 |
KKhushhalR2405/Face-X
|
https://github.com/KKhushhalR2405/Face-X
|
4704a1f2144c3f71158f885a4e338a572a49e5ac
|
4ffb82d4833b230141c1f8dd5829f9ae6cdb3045
|
0b3344d9f509fd3e63ec4632a381972c95e429f4
|
refs/heads/master
| 2023-04-04T15:32:46.909615 | 2021-04-14T13:59:29 | 2021-04-14T13:59:29 | 355,666,537 | 3 | 0 |
MIT
| 2021-04-07T19:55:12 | 2021-04-07T08:57:41 | 2021-04-07T08:57:38 | null |
[
{
"alpha_fraction": 0.6515620350837708,
"alphanum_fraction": 0.6844919919967651,
"avg_line_length": 35.75531768798828,
"blob_id": "4e06888be5e0c16728036067c549af4c0b5e2207",
"content_id": "6ae10d32e8a68162f03996ab72d9f42c37ab0d91",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3553,
"license_type": "permissive",
"max_line_length": 164,
"num_lines": 94,
"path": "/Cartoonify Image/Cartoonify-GUI/cartoonify-gui.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#Importing the necessary libraries\r\nimport tkinter as tk\r\nimport numpy as np\r\nfrom tkinter import *\r\nfrom tkinter import messagebox\r\nfrom PIL import Image,ImageTk\r\nimport cv2\r\nimport easygui\r\nimport sys\r\nimport os\r\n\r\n#Function Defined for Uploading function:\r\ndef upload():\r\n imagepath = easygui.fileopenbox()\r\n cartoon(imagepath)\r\n\r\n#Function to convert image to cartoon\r\ndef cartoon(imagepath):\r\n #Image variable takes image using imagepath\r\n image = cv2.imread(imagepath)\r\n\r\n if image is None:\r\n print('Choose another file')\r\n sys.exit()\r\n height, width, channels = image.shape\r\n print(width, height, channels)\r\n\r\n #Image_resize\r\n if height >=900 and width >=1200:\r\n resized_image = cv2.resize(image, (800, int(700*0.8)))\r\n else:\r\n resized_image = cv2.resize(image, (width, int(width*0.8)))\r\n #sharpen image\r\n\r\n #Putting a filter using numpy array\r\n filter = np.array([[-1, -1, -1], [-1, 9, -1], [-1, -1, -1]])\r\n #Sharpening Image using Open CV filter2D function\r\n sharpen_image = cv2.filter2D(resized_image, -1, filter)\r\n #Converting to Fray Image Scale\r\n gray_image = cv2.cvtColor(sharpen_image, cv2.COLOR_BGR2GRAY)\r\n #Blurring the Image\r\n blurred = cv2.medianBlur(gray_image, 9)\r\n # For every pixel, the same threshold value is applied. If the pixel value is smaller than the threshold, it is set to 0, otherwise it is set to a maximum value\r\n thresh = cv2.adaptiveThreshold(blurred, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 9, 11)\r\n #Original Image \r\n original_image = cv2.bilateralFilter(resized_image, 13, 150, 150)\r\n\r\n cartoon = cv2.bitwise_and(original_image, original_image, mask=thresh)\r\n if cartoon.shape[0] >=900 and cartoon.shape[1] >=1200:\r\n cartoon_resize = cv2.resize(cartoon, (800, int(700*0.8)))\r\n else:\r\n cartoon_resize = cv2.resize(cartoon, (cartoon.shape[1], int(cartoon.shape[0]*0.8)))\r\n #cartoon_resize = cv2.resize(cartoon, (width, int(width*0.8)))\r\n\r\n #Displaying the Main,Cartoonified and Sharpened Image\r\n cv2.imshow(\"Cartoonified\", cartoon_resize)\r\n cv2.imshow(\"Main Image\", image)\r\n cv2.imshow(\"Sharped Image\", sharpen_image)\r\n save1 = Button(GUI, text=\"Save cartoon image\", command=lambda: save_image(cartoon_resize, imagepath ), padx=30, pady=5)\r\n save1.configure(background='black', foreground='white', font=('calibri', 12, 'bold'))\r\n save1.pack(side=TOP, pady=50)\r\n\r\n#Saving Image \r\ndef save_image(cartoon_resize, imagepath):\r\n name= \"CartooniFied\"\r\n file = os.path.dirname(os.path.realpath(imagepath))\r\n last_name = os.path.splitext(imagepath)[1]\r\n path = os.path.join(file, name + last_name )\r\n cv2.imwrite(path, cartoon_resize)\r\n full_name = \"Image \" + name + \"saved at\" + path\r\n\r\n tk.messagebox.showinfo(message=full_name)\r\n\r\n\r\n#create GUI Interface:\r\n\r\n#Defining the basic structure of the application\r\nGUI = tk.Tk()\r\nGUI.geometry('650x500')\r\nGUI.title(\"Cartoonify Image\")\r\nGUI.configure(background='skyblue')\r\n#Loading the Background Image for the Application\r\nload=Image.open(\"D:\\\\GitRepo\\\\Face-X\\\\Cartoonify Image\\\\Cartoonify-GUI\\\\background.png\")\r\nrender=ImageTk.PhotoImage(load)\r\nimg=Label(GUI,image=render)\r\nimg.place(x=0,y=0)\r\n\r\n#Defining Buttons\r\nlabel=Label(GUI, background='black', font=('calibri',20,'bold'))\r\nupload=Button(GUI, text=\"Cartoonify Image\",command=upload, padx=30,pady=5)\r\nupload.configure(background='black', foreground='white',font=('calibri',12,'bold'))\r\nupload.pack(side=TOP,pady=50)\r\n\r\nGUI.mainloop()\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.7702627182006836,
"alphanum_fraction": 0.7864729166030884,
"avg_line_length": 44.871795654296875,
"blob_id": "67cc726a6198e68de99121340f0dbbf2117bff09",
"content_id": "5d6bc86619081f004f823b88bf4c8697b68e19da",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1791,
"license_type": "permissive",
"max_line_length": 327,
"num_lines": 39,
"path": "/Face-Swapping/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "## Face-Swapping\n\nThis application lets you swap a face in one image with a face from another image. \n\n## Steps used for this project:\n\n1. Taking two images – one as the source and another as a destination.\n2. Using the dlib landmark detector on both these images. \n3. Joining the dots in the landmark detector to form triangles. \n4. Extracting these triangles\n5. Placing the source image on the destination and smoothening the face\n\n## Selecting Images\n\nYou can select any two images of your choice. Both the images are front-facing and are well lit.\n\n## Using the dlib landmark detector on the images\n\nDlib is a python library that provides us with landmark detectors to detect important facial landmarks. These 68 points are important to identify the different features in both faces.\n\n## Joining the dots in the landmark detector to form triangles for the source image.\n\nTo cut a portion of the face and fit it to the other we need to analyse the size and perspective of both the images. To do this, we will split the entire face into smaller triangles by joining the landmarks so that the originality of the image is not lost and it becomes easier to swap the triangles with the destination image.\n\n## Extracting these triangles \n\nOnce we have the triangles in source and destination the next step is to extract them from the source image.\n\n## Placing the source image on the destination\n\nNow, we can reconstruct the destination image and start placing the source image on the destination one.\n\n### Example 1\n\n\n\n### Example 2\n\n\n"
},
{
"alpha_fraction": 0.6303901672363281,
"alphanum_fraction": 0.6478439569473267,
"avg_line_length": 23.9743595123291,
"blob_id": "da2b94d66789b8ae2b7b1d95d1d7e519e36c1bc9",
"content_id": "8f8cf9fad34f9f4c9b935e5df1d03ec7eb1ec1a3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 974,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 39,
"path": "/Face Reconstruction/Face Alignment in Full Pose Range/demo@obama/rendering_demo.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# coding: utf-8\n\n\"\"\"\nA demo for rendering mesh generated by `main.py`\n\"\"\"\n\nfrom rendering import cfg, _to_ctype, RenderPipeline\nimport scipy.io as sio\nimport imageio\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n\ndef test():\n # 1. first, using main.py to generate dense vertices, like emma_input_0.mat\n fp = '../samples/emma_input_0.mat'\n vertices = sio.loadmat(fp)['vertex'].T # 3xm\n print(vertices.shape)\n img = imageio.imread('../samples/emma_input.jpg').astype(np.float32) / 255.\n\n # 2. render it\n # triangles = sio.loadmat('tri_refine.mat')['tri'] # mx3\n triangles = sio.loadmat('../visualize/tri.mat')['tri'].T - 1 # mx3\n print(triangles.shape)\n triangles = _to_ctype(triangles).astype(np.int32) # for type compatible\n app = RenderPipeline(**cfg)\n img_render = app(vertices, triangles, img)\n\n plt.imshow(img_render)\n plt.show()\n\n\ndef main():\n test()\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.7250391840934753,
"alphanum_fraction": 0.7396758794784546,
"avg_line_length": 25.929576873779297,
"blob_id": "d2b3aa007e88bb9f8b7f5f0fa089c81aaea7a9d4",
"content_id": "564790c66e7c458dd364089c8909dcacb70a8e49",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1913,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 71,
"path": "/Recognition-Algorithms/Recognition using PCA/main.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import numpy as np \nfrom sklearn.preprocessing import normalize\nfrom sklearn.datasets import fetch_lfw_people\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.neighbors import KNeighborsClassifier\nimport matplotlib.pyplot as plt\n\nlfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)\n\nimage_data = lfw_people.images #3D matrix (images as 2D vectors)\nno_of_sample, height, width = lfw_people.images.shape\ndata = lfw_people.data #images as 1D arrays (flattened data)\nlabels = lfw_people.target #categories\ntarget_labels = lfw_people.target_names #category names\n\n'''Testing Image data and visualising random image'''\nplt.imshow(image_data[30, :, :])\nplt.show()\n\n'''UNderstanding labels'''\nprint 'these are the label', labels\nprint 'target labels', target_labels\n\n\n'''Seeing image dimensions and number of images'''\nprint 'number of images', no_of_sample\nprint 'image height and width', height, width\n\n\n'''\nNormalising the following matrix\n'''\nsk_norm = normalize(data, axis=0) \nnorm_matrix = (data-np.mean(data, axis=0))/np.var(data, axis=0)\n\nmatrix = sk_norm\n\n\n'''\nPCA\n'''\ncov_matrix = matrix.T.dot(matrix)/(matrix.shape[0]) #finding the covaraince matrix\nvalues, vectors = np.linalg.eig(cov_matrix) #Fiding the eigen vector space\n\nred_dim = 1000\neigen_faces = vectors[:, :red_dim]\n\npca_vectors = matrix.dot(eigen_faces) #obtain our eigen faces\n\n'''\nVisualizing Principal Components\n'''\neigen_vec = np.reshape(eigen_faces[:,1], (50,37))\nplt.imshow(eigen_vec)\n#plt.show()\n\n'''\nUsing machine learning techniques\n'''\n\n\nX_train, X_test, y_train, y_test = train_test_split(pca_vectors, labels, random_state=42) #splitting test data\n\nknn = KNeighborsClassifier(n_neighbors=10) #using a K means Classifier\nknn.fit(X_train, y_train) #training data\n\nprint 'accuracy', knn.score(X_test, y_test) #applying model on test data\n\n\n# cv2.imshow('original image', img)\n# cv2.imshow('grey', grey_img)\n\n"
},
{
"alpha_fraction": 0.7147679328918457,
"alphanum_fraction": 0.7367088794708252,
"avg_line_length": 47.375,
"blob_id": "8f164e58fc50923f5bb1365b20886e9b90ca2333",
"content_id": "0a0007d250f49c45fa6c17a283a1abd6941c7b69",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1185,
"license_type": "permissive",
"max_line_length": 154,
"num_lines": 24,
"path": "/Face-Detection/Facial-Features-and-Face-Detection-CNN/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "## Facial-Features-and-Face-Detection-CNN\r\n**This project is for building CNN architecture for facial features and face detection by plotting points on the facial features and box around the face**\r\n\r\n## Data Source:\r\nIn the following link, there is a dataset from kaggle website and all the necessary information that will be needed to understand the nature of the data:\r\n[**Dataset Source** ](https://www.kaggle.com/jessicali9530/celeba-dataset)\r\n \r\nBut we are going to use only **the data of the first 35000 images** beacuse the data is **very big (1 GB)** for the memory.\r\n\r\n## Performace of the model:\r\nThe accuracy of the model = 90%\r\n\r\n## Content of this repository:\r\n#### 1- data\r\nIn this folder, there are:\r\n* 35000 images\r\n* 60 test images for just showing the performace on the final model\r\n* CSV file contains the keypoints of facial features as (x,y) coordinates and the image_id\r\n#### 2- jupyter notebook of the model.\r\nIn this notebook, i build the CNN architecture of the model. \r\n#### 3- model.h5\r\nThis is the weights of the final model\r\n#### 4- jupyter notebook of the testing.\r\nIn this notebook, we test the model on 60 images to show the performace of the model\r\n"
},
{
"alpha_fraction": 0.5785064101219177,
"alphanum_fraction": 0.5996133089065552,
"avg_line_length": 43.014183044433594,
"blob_id": "f769b1138691abe9475513800f604aad4a1daace",
"content_id": "b3fe8e7416a9b92123c1887aa436c2fd619780d6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 24826,
"license_type": "permissive",
"max_line_length": 146,
"num_lines": 564,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_tfGraph/deep_3dmm_decoder.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n# system\nfrom __future__ import print_function\n\n# python lib\nimport numpy as np\n# tf_render\nimport tensorflow as tf\n\nfrom src_common.net.resnet_v1_3dmm import encoder_resnet50\n\nfrom src_common.net.inception_resnet_v1 import identity_inference\nfrom src_common.geometry.face_align.align_facenet import facenet_align\n\nfrom src_common.geometry.camera_distribute.camera_utils import project3d_batch\nfrom src_common.geometry.render.lighting import vertex_normals_pre_split_fixtopo\nfrom src_common.geometry.render.api_tf_mesh_render import mesh_depthmap_camera, mesh_renderer_camera, mesh_renderer_camera_light, \\\n tone_mapper\n\n\n\n# net\ndef pred_encoder_coeff(opt, defined_pose_main, list_image, is_training=True):\n pred_rank = 2 * opt.gpmm_rank + opt.gpmm_exp_rank + 6 + 27\n\n with tf.name_scope(\"3dmm_coeff\"):\n #\n list_gpmm = []\n list_gpmm_color = []\n list_gpmm_exp = []\n list_gpmm_pose = []\n list_gpmm_lighting = []\n\n for i in range(len(list_image)):\n\n pred_id_src, end_points_src = encoder_resnet50(list_image[i], pred_rank, is_training=is_training, reuse=tf.AUTO_REUSE)\n\n pred_3dmm_src = pred_id_src[:, : opt.gpmm_rank]\n pred_3dmm_color_src = pred_id_src[:, opt.gpmm_rank : 2 * opt.gpmm_rank]\n pred_3dmm_exp_src = pred_id_src[:, 2 * opt.gpmm_rank : 2 * opt.gpmm_rank + opt.gpmm_exp_rank]\n\n list_gpmm.append(pred_3dmm_src)\n list_gpmm_color.append(pred_3dmm_color_src)\n list_gpmm_exp.append(pred_3dmm_exp_src)\n\n pred_pose_render_src = pred_id_src[:, 2 * opt.gpmm_rank + opt.gpmm_exp_rank : 2 * opt.gpmm_rank + opt.gpmm_exp_rank + 6]\n pred_pose_render_src = pred_pose_render_src + defined_pose_main\n pred_lighting_src = pred_id_src[:, 2 * opt.gpmm_rank + opt.gpmm_exp_rank + 6 : 2 * opt.gpmm_rank + opt.gpmm_exp_rank + 6 + 27]\n\n list_gpmm_pose.append(pred_pose_render_src)\n list_gpmm_lighting.append(pred_lighting_src)\n\n return list_gpmm, list_gpmm_color, list_gpmm_exp, list_gpmm_pose, list_gpmm_lighting\n\ndef pred_encoder_coeff_light(opt, defined_pose_main, list_image, is_training=True):\n pred_rank = 2 * opt.gpmm_rank + opt.gpmm_exp_rank + 6 + 27\n\n with tf.name_scope(\"3dmm_coeff\"):\n #\n list_gpmm = []\n for i in range(len(list_image)):\n pred_id_src, end_points_src = encoder_resnet50(list_image[i], pred_rank, is_training=is_training, reuse=tf.AUTO_REUSE)\n list_gpmm.append(pred_id_src)\n return list_gpmm\n\n# id\ndef pred_encoder_id(opt, gpmm_render_tar_align):\n list_gpmm_id_pred_tar = []\n for i in range(len(gpmm_render_tar_align)):\n gpmm_render_de = gpmm_render_tar_align[i] * 255.0\n\n # if opt.mode_depth_pixel_loss == 'clip':\n # gpmm_render_de = tf.clip_by_value(gpmm_render_de, 0.0, 255.0)\n\n gpmm_render_de = facenet_image_process(gpmm_render_de)\n\n gpmm_id_pred_tar = pred_encoder_facenet(gpmm_render_de)\n\n #gpmm_id_pred_tar = tf.Print(gpmm_id_pred_tar, [tf.reduce_mean(gpmm_render_de), tf.reduce_mean(gpmm_id_pred_tar)], message='gpmm_id_pred')\n\n list_gpmm_id_pred_tar.append(gpmm_id_pred_tar[0])\n\n return list_gpmm_id_pred_tar\n\ndef pred_encoder_facenet(image):\n with tf.name_scope(\"3dmm_identity\"):\n #\n list_gpmm_id = []\n\n prelogits, end_points = identity_inference(\n image, 0.8, phase_train=False,\n bottleneck_layer_size=512, weight_decay=0.0, reuse=tf.AUTO_REUSE\n )\n # list_gpmm_id.append(prelogits)\n embeddings = tf.nn.l2_normalize(prelogits, 1, 1e-10, name='embeddings')\n\n list_gpmm_id.append(embeddings)\n\n return list_gpmm_id\n\ndef decoder_similar(opt, defined_lm_facenet_align, render_img, list_img, lm2d, list_lm2d_gt):\n \"\"\"\n Render image align, id\n \"\"\"\n gpmm_render_align = facenet_align(render_img, lm2d, defined_lm_facenet_align, opt.img_height, opt.img_width)\n gpmm_render_tar_id = pred_encoder_id(opt, gpmm_render_align)\n\n \"\"\"\n Ori image align, id\n \"\"\"\n image_align = facenet_align(list_img, list_lm2d_gt, defined_lm_facenet_align, opt.img_height, opt.img_width)\n tgt_image_id = pred_encoder_id(opt, image_align)\n\n return gpmm_render_tar_id, tgt_image_id, gpmm_render_align, image_align\n\n# decode mesh\ndef decoder_colorMesh(h_lrgp, list_gpmm, list_gpmm_color, list_gpmm_exp, list_gpmm_lighting, flag_sgl_mul=None):\n \"\"\"\n :param list_gpmm:\n :param list_gpmm_color:\n :param list_gpmm_exp:\n :param list_gpmm_lighting:\n :return:\n list_gpmm_vertex:\n list_gpmm_vertexNormal: range (0, 1),\n list_gpmm_vertexColor: range (0, 1_NAN),\n list_gpmm_vertexShade: range (0, 1_NAN),\n list_gpmm_vertexColorOrigin: range (0, 1),\n \"\"\"\n list_gpmm_vertex = []\n list_gpmm_vertexNormal = []\n list_gpmm_vertexColor = []\n list_gpmm_vertexShade = []\n list_gpmm_vertexColorOrigin = []\n\n for i in range(len(list_gpmm)):\n\n gpmm_vertex_src = h_lrgp.instance(list_gpmm[i], list_gpmm_exp[i])\n\n # gpmm_vertex_src = tf.Print(gpmm_vertex_src, [tf.reduce_mean(gpmm_vertex_src), tf.reduce_mean(list_gpmm[i]),\n # tf.reduce_mean(list_gpmm_exp[i])], message='coeff, vertex')\n gpmm_vertexColor_ori = h_lrgp.instance_color(list_gpmm_color[i])\n\n gpmm_vertexNormal = vertex_normals_pre_split_fixtopo(\n gpmm_vertex_src, h_lrgp.h_curr.mesh_tri, h_lrgp.h_curr.mesh_vertex_refer_face,\n h_lrgp.h_curr.mesh_vertex_refer_face_index, h_lrgp.h_curr.mesh_vertex_refer_face_num\n )\n gpmm_vertexColor, pred_gpmm_vertexShade = \\\n gpmm_lighting(list_gpmm_lighting[i], gpmm_vertexNormal, gpmm_vertexColor_ori)\n\n list_gpmm_vertex.append(gpmm_vertex_src)\n list_gpmm_vertexNormal.append(gpmm_vertexNormal)\n\n list_gpmm_vertexColor.append(gpmm_vertexColor)\n list_gpmm_vertexShade.append(pred_gpmm_vertexShade)\n list_gpmm_vertexColorOrigin.append(gpmm_vertexColor_ori)\n\n return list_gpmm_vertex, list_gpmm_vertexNormal, list_gpmm_vertexColor, list_gpmm_vertexShade, list_gpmm_vertexColorOrigin\n\ndef decoder_colorMesh_test(h_lrgp, dict_inter_comm, exp=True, full=False):\n \"\"\"\n :param list_gpmm:\n :param list_gpmm_color:\n :param list_gpmm_exp:\n :param list_gpmm_lighting:\n :return:\n list_gpmm_vertex:\n list_gpmm_vertexNormal: range (0, 1),\n list_gpmm_vertexColor: range (0, 1_NAN),\n list_gpmm_vertexShade: range (0, 1_NAN),\n list_gpmm_vertexColorOrigin: range (0, 1),\n \"\"\"\n list_gpmm_vertex = []\n list_gpmm_vertexNormal = []\n list_gpmm_vertexColor = []\n list_gpmm_vertexShade = []\n list_gpmm_vertexColorOrigin = []\n\n # parse\n list_gpmm = dict_inter_comm['pred_coeff_shape']\n list_gpmm_color = dict_inter_comm['pred_coeff_color']\n list_gpmm_exp = dict_inter_comm['pred_coeff_exp']\n list_gpmm_lighting = dict_inter_comm['pred_coeff_light']\n\n #\n for i in range(len(list_gpmm)):\n if full:\n if exp == True:\n gpmm_vertex_src = h_lrgp.instance_full(list_gpmm[i], list_gpmm_exp[i])\n else:\n gpmm_vertex_src = h_lrgp.instance_full(list_gpmm[i])\n\n gpmm_vertexColor_ori = h_lrgp.instance_color_full(list_gpmm_color[i])\n else:\n if exp == True:\n gpmm_vertex_src = h_lrgp.instance(list_gpmm[i], list_gpmm_exp[i])\n else:\n gpmm_vertex_src = h_lrgp.instance(list_gpmm[i])\n\n gpmm_vertexColor_ori = h_lrgp.instance_color(list_gpmm_color[i])\n\n gpmm_vertexNormal = vertex_normals_pre_split_fixtopo(\n gpmm_vertex_src, h_lrgp.h_curr.mesh_tri, h_lrgp.h_curr.mesh_vertex_refer_face,\n h_lrgp.h_curr.mesh_vertex_refer_face_index, h_lrgp.h_curr.mesh_vertex_refer_face_num\n )\n gpmm_vertexColor, pred_gpmm_vertexShade = \\\n gpmm_lighting(list_gpmm_lighting[i], gpmm_vertexNormal, gpmm_vertexColor_ori)\n\n list_gpmm_vertexNormal.append(gpmm_vertexNormal)\n list_gpmm_vertexColor.append(gpmm_vertexColor)\n list_gpmm_vertexShade.append(pred_gpmm_vertexShade)\n\n list_gpmm_vertex.append(gpmm_vertex_src)\n list_gpmm_vertexColorOrigin.append(gpmm_vertexColor_ori)\n\n return list_gpmm_vertex, list_gpmm_vertexNormal, list_gpmm_vertexColor, list_gpmm_vertexShade, list_gpmm_vertexColorOrigin\n\ndef decoder_lm(h_lrgp, list_gpmm_vertex_tar_batch, list_mtx_proj_batch):\n with tf.name_scope(\"3dmm/lm\"):\n list_lm2d = []\n for i in range(len(list_gpmm_vertex_tar_batch)):\n gpmm_vertex_tar_batch = list_gpmm_vertex_tar_batch[i]\n #\n lm3d = h_lrgp.get_lm3d_instance_vertex(h_lrgp.idx_lm68, gpmm_vertex_tar_batch)\n #\n lm2d = project3d_batch(lm3d, list_mtx_proj_batch[i])\n\n list_lm2d.append(lm2d)\n\n return list_lm2d\n\n# render\ndef decoder_renderColorMesh(opt, h_lrgp, list_vertex, list_vertex_normal, list_vertexColor, mtx_perspect_frustrum,\n list_mtx_model_view, list_cam_position, fore=1, tone=True):\n if isinstance(list_vertex, list)==False:\n list_vertex = [list_vertex]\n list_vertex_normal = [list_vertex_normal]\n if isinstance(list_vertexColor, list) == False:\n list_vertexColor = [list_vertexColor]\n if isinstance(list_mtx_model_view, list) == False:\n list_mtx_model_view = [list_mtx_model_view]\n list_cam_position = [list_cam_position]\n\n # render\n gpmm_render = []\n gpmm_render_mask = []\n gpmm_render_tri_ids = []\n for i in range(len(list_vertex)):\n if fore > 0:\n vertex_fore = tf.gather(list_vertex[i], h_lrgp.h_curr.idx_subTopo, axis=1)\n vertex_normal_fore = tf.gather(list_vertex_normal[i], h_lrgp.h_curr.idx_subTopo, axis=1)\n vertex_color_fore = tf.gather(list_vertexColor[i], h_lrgp.h_curr.idx_subTopo, axis=1)\n tri = h_lrgp.h_fore.mesh_tri\n # vertex_fore = tf.Print(vertex_fore, [tf.reduce_mean(vertex_fore), tf.reduce_mean(vertex_normal_fore),\n # tf.reduce_mean(vertex_color_fore),\n # tf.reduce_mean(list_mtx_model_view[0]),\n # tf.reduce_mean(list_cam_position[0])], message='before render')\n else:\n vertex_fore = list_vertex[i]\n vertex_normal_fore = list_vertex_normal[i]\n vertex_color_fore = list_vertexColor[i]\n tri = h_lrgp.h_curr.mesh_tri\n\n if i < len(list_mtx_model_view):\n pred_render, pred_render_mask, pred_render_tri_ids = gpmm_render_image(\n opt, vertex_fore, tri, vertex_normal_fore, vertex_color_fore,\n mtx_perspect_frustrum, list_mtx_model_view[i], list_cam_position[i], tone\n )\n else:\n pred_render, pred_render_mask, pred_render_tri_ids = gpmm_render_image(\n opt, vertex_fore, tri, vertex_normal_fore, vertex_color_fore,\n mtx_perspect_frustrum, list_mtx_model_view[0], list_cam_position[0], tone\n )\n\n gpmm_render.append(pred_render)\n gpmm_render_mask.append(pred_render_mask)\n gpmm_render_tri_ids.append(pred_render_tri_ids)\n return gpmm_render, gpmm_render_mask, gpmm_render_tri_ids\n\ndef decoder_renderColorMesh_gary(opt, h_lrgp, list_vertex, list_vertex_normal, list_vertexColor, mtx_perspect_frustrum,\n list_mtx_model_view, list_cam_position, fore=1, tone=True, background=10.0):\n if isinstance(list_vertex, list)==False:\n list_vertex = [list_vertex]\n list_vertex_normal = [list_vertex_normal]\n if isinstance(list_vertexColor, list) == False:\n list_vertexColor = [list_vertexColor]\n if isinstance(list_mtx_model_view, list) == False:\n list_mtx_model_view = [list_mtx_model_view]\n list_cam_position = [list_cam_position]\n # render\n gpmm_render = []\n gpmm_render_mask = []\n gpmm_render_tri_ids = []\n for i in range(len(list_vertex)):\n if fore > 0:\n vertex_fore = tf.gather(list_vertex[i], h_lrgp.h_curr.idx_subTopo, axis=1)\n vertex_normal_fore = tf.gather(list_vertex_normal[i], h_lrgp.h_curr.idx_subTopo, axis=1)\n vertex_color_fore = tf.gather(list_vertexColor[i], h_lrgp.h_curr.idx_subTopo, axis=1)\n tri = h_lrgp.h_fore.mesh_tri\n else:\n vertex_fore = list_vertex[i]\n vertex_normal_fore = list_vertex_normal[i]\n vertex_color_fore = list_vertexColor[i]\n tri = h_lrgp.h_curr.mesh_tri\n\n if i < len(list_mtx_model_view):\n pred_render, pred_render_mask, pred_render_tri_ids = gpmm_render_image_garyLight(\n opt, vertex_fore, tri, vertex_normal_fore, vertex_color_fore,\n mtx_perspect_frustrum, list_mtx_model_view[i], list_cam_position[i], tone, background\n )\n else:\n pred_render, pred_render_mask, pred_render_tri_ids = gpmm_render_image_garyLight(\n opt, vertex_fore, tri, vertex_normal_fore, vertex_color_fore,\n mtx_perspect_frustrum, list_mtx_model_view[0], list_cam_position[0], tone, background\n )\n\n gpmm_render.append(pred_render)\n gpmm_render_mask.append(pred_render_mask)\n gpmm_render_tri_ids.append(pred_render_tri_ids)\n return gpmm_render, gpmm_render_mask, gpmm_render_tri_ids\n\ndef decoder_depth(opt, h_lrgp, list_vertex, mtx_perspect_frustrum, list_mtx_ext, list_mtx_model_view, list_cam_position, fore=1):\n refine_depths = []\n refine_depths_mask = []\n with tf.name_scope(\"3dmm/depth\"):\n for i in range(len(list_vertex)):\n if fore > 0:\n vertex_fore = tf.gather(list_vertex[i], h_lrgp.h_curr.idx_subTopo, axis=1)\n tri = h_lrgp.h_fore.mesh_tri\n else:\n vertex_fore = list_vertex[i]\n tri = h_lrgp.h_curr.mesh_tri\n\n if i < len(list_mtx_model_view):\n pred_render, mask = gpmm_generate_depthmap(\n opt, vertex_fore, tri,\n mtx_perspect_frustrum, list_mtx_ext[i], list_mtx_model_view[i], list_cam_position[i]\n )\n else:\n pred_render, mask = gpmm_generate_depthmap(\n opt, vertex_fore, tri,\n mtx_perspect_frustrum, list_mtx_ext[0], list_mtx_model_view[0], list_cam_position[0]\n )\n refine_depths.append(pred_render)\n refine_depths_mask.append(mask)\n return refine_depths, refine_depths_mask\n\n#\ndef facenet_image_process(image_batch_float):\n list_img_std = []\n for b in range(image_batch_float.shape[0]):\n image_std = (tf.cast(image_batch_float[b], tf.float32) - 127.5) / 128.0\n # image_std = tf.image.per_image_standardization(image_batch_float[b])\n list_img_std.append(image_std)\n return tf.stack(list_img_std, axis=0)\n\n# detail api\ndef gpmm_lighting(gamma, norm, face_texture):\n # compute vertex color using face_texture and SH function lighting approximation\n # input: face_texture with shape [1,N,3]\n # \t norm with shape [1,N,3]\n #\t\t gamma with shape [1,27]\n # output: face_color with shape [1,N,3], RGB order, range from 0-1\n #\t\t lighting with shape [1,N,3], color under uniform texture, range from 0-1\n batch_size = face_texture.shape[0]\n num_vertex = face_texture.shape[1]\n\n init_lit = tf.constant([0.8, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0])\n init_lit = tf.reshape(init_lit, [1, 1, 9])\n init_lit = tf.tile(init_lit, multiples=[batch_size, 3, 1])\n\n gamma = tf.reshape(gamma, [-1, 3, 9])\n gamma = gamma + init_lit\n\n # parameter of 9 SH function\n a0 = np.pi\n a1 = 2 * np.pi / np.sqrt(3.0)\n a2 = 2 * np.pi / np.sqrt(8.0)\n c0 = 1 / np.sqrt(4 * np.pi)\n c1 = np.sqrt(3.0) / np.sqrt(4 * np.pi)\n c2 = 3 * np.sqrt(5.0) / np.sqrt(12 * np.pi)\n\n Y0 = tf.tile(tf.reshape(a0 * c0, [1, 1, 1]), [batch_size, num_vertex, 1])\n Y0 = tf.cast(Y0, tf.float32)\n Y1 = tf.reshape(-a1 * c1 * norm[:, :, 1], [batch_size, num_vertex, 1])\n Y2 = tf.reshape(a1 * c1 * norm[:, :, 2], [batch_size, num_vertex, 1])\n Y3 = tf.reshape(-a1 * c1 * norm[:, :, 0], [batch_size, num_vertex, 1])\n Y4 = tf.reshape(a2 * c2 * norm[:, :, 0] * norm[:, :, 1], [batch_size, num_vertex, 1])\n Y5 = tf.reshape(-a2 * c2 * norm[:, :, 1] * norm[:, :, 2], [batch_size, num_vertex, 1])\n Y6 = tf.reshape(a2 * c2 * 0.5 / tf.sqrt(3.0) * (3 * tf.square(norm[:, :, 2]) - 1), [batch_size, num_vertex, 1])\n Y7 = tf.reshape(-a2 * c2 * norm[:, :, 0] * norm[:, :, 2], [batch_size, num_vertex, 1])\n Y8 = tf.reshape(a2 * c2 * 0.5 * (tf.square(norm[:, :, 0]) - tf.square(norm[:, :, 1])), [batch_size, num_vertex, 1])\n\n Y = tf.concat([Y0, Y1, Y2, Y3, Y4, Y5, Y6, Y7, Y8], axis=2)\n\n # Y shape:[batch,N,9].\n lit_r = tf.squeeze(tf.matmul(Y, tf.expand_dims(gamma[:, 0, :], 2)), 2) # [batch,N,9] * [batch,9,1] = [batch,N]\n lit_g = tf.squeeze(tf.matmul(Y, tf.expand_dims(gamma[:, 1, :], 2)), 2)\n lit_b = tf.squeeze(tf.matmul(Y, tf.expand_dims(gamma[:, 2, :], 2)), 2)\n\n # shape:[batch,N,3]\n face_color = tf.stack(\n [lit_r * face_texture[:, :, 0], lit_g * face_texture[:, :, 1], lit_b * face_texture[:, :, 2]], axis=2)\n shade_color = tf.stack([lit_r, lit_g, lit_b], axis=2)\n\n # face_color = tf.clip_by_value(face_color, 0.0, 1.0)\n # shade_color = tf.clip_by_value(shade_color, 0.0, 1.0)\n\n return face_color, shade_color # (0, Nan) (0, Nan)\n\n\ndef gpmm_face_replace(list_img, list_gpmm_render_img, list_gpmm_render_mask):\n if isinstance(list_img, list) == False:\n list_img = [list_img]\n if isinstance(list_gpmm_render_img, list) == False:\n list_gpmm_render_img = [list_gpmm_render_img]\n if isinstance(list_gpmm_render_mask, list) == False:\n list_gpmm_render_mask = [list_gpmm_render_mask]\n\n list_gpmm_render_img_replace = []\n for i in range(len(list_img)):\n img = list_img[i]\n gpmm_render_img = list_gpmm_render_img[i]\n gpmm_render_mask = list_gpmm_render_mask[i]\n gpmm_render_mask = tf.tile(gpmm_render_mask, multiples=[1, 1, 1, 3])\n\n img_replace = gpmm_render_img + (1.0 - gpmm_render_mask) * img\n\n list_gpmm_render_img_replace.append(img_replace)\n\n return list_gpmm_render_img_replace\n\n\ndef gpmm_render_image(opt, vertex, tri, vertex_normal, vertex_color, mtx_perspect_frustrum, mtx_model_view,\n cam_position, tone=True):\n \"\"\"\n :param vertex: [bs, num_ver, 3]\n :param tri: [bs, num_tri, 3] or [num_tri, 3]\n :param vertex_normal: [bs, num_ver, 3]\n :param vertex_color: [bs, num_ver, 3]\n :param mtx_perspect_frustrum: [bs, 4, 4]\n :param mtx_model_view: [bs, 4, 4]\n :param cam_position: [bs, 3]\n :return:\n render_image, shape=[batch_size, h, w, 3], dtype=tf_render.float32\n render_image_mask, shape=[batch_size, h, w, 1], dtype=tf_render.float32\n render_tri_ids, shape=[batch_size, h, w, 1], dtype=tf_render.int32\n \"\"\"\n\n # manual light\n # light_positions = tf.constant([[0.0, 0.0, 1000.0]], shape=[1, 1, 3])\n # light_intensities = tf.constant([[1.0, 0.0, 0.0]], shape=[1, 1, 3])\n # ambient_color = tf.constant([[1.0, 1.0, 1.0]], shape=[1, 3])\n # ambient_color = tf.tile(ambient_color, [opt.batch_size, 1])\n\n if len(tri.shape) == 2:\n render_image, render_image_mask, render_tri_ids = \\\n mesh_renderer_camera_light(vertex, tri, vertex_normal, vertex_color, mtx_model_view,\n mtx_perspect_frustrum, cam_position, opt.img_width, opt.img_height)\n if tone:\n tonemapped_renders = tf.concat(\n [\n tone_mapper(render_image[:, :, :, 0:3], 0.7),\n render_image[:, :, :, 3:4]\n ],\n axis=3)\n else:\n tonemapped_renders = tf.clip_by_value(render_image, 0.0, 100000.0)\n\n else:\n list_tonemapped_renders = []\n list_render_image_mask = []\n list_render_tri_ids = []\n for i in range(tri.shape[0]): # bs\n render_image, render_image_mask, render_tri_ids = \\\n mesh_renderer_camera_light(\n vertex[i:i + 1, :, :], tri[i], vertex_normal[i:i + 1, :, :], vertex_color[i:i + 1, :, :],\n mtx_model_view[i:i + 1, :, :], mtx_perspect_frustrum[i:i + 1, :, :], cam_position[i:i + 1, :],\n opt.img_width, opt.img_height)\n\n if tone:\n tonemapped_renders = tf.concat(\n [\n tone_mapper(render_image[:, :, :, 0:3], 0.7),\n render_image[:, :, :, 3:4]\n ],\n axis=3)\n else:\n tonemapped_renders = tf.clip_by_value(render_image, 0.0, 100000.0)\n\n list_tonemapped_renders.append(tonemapped_renders)\n list_render_image_mask.append(render_image_mask)\n list_render_tri_ids.append(render_tri_ids)\n\n tonemapped_renders = tf.concat(list_tonemapped_renders, axis=0)\n render_image_mask = tf.concat(list_render_image_mask, axis=0)\n render_tri_ids = tf.concat(list_render_tri_ids, axis=0)\n\n return tonemapped_renders[:, :, :, 0:3], render_image_mask, render_tri_ids\n\ndef gpmm_render_image_garyLight(opt, vertex, tri, vertex_normal, vertex_color, mtx_perspect_frustrum, mtx_model_view,\n cam_position, tone=True, background=10.999):\n \"\"\"\n :param vertex: [bs, num_ver, 3]\n :param tri: [bs, num_tri, 3] or [num_tri, 3]\n :param vertex_normal: [bs, num_ver, 3]\n :param vertex_color: [bs, num_ver, 3]\n :param mtx_perspect_frustrum: [bs, 4, 4]\n :param mtx_model_view: [bs, 4, 4]\n :param cam_position: [bs, 3]\n :return:\n render_image, shape=[batch_size, h, w, 3], dtype=tf_render.float32\n render_image_mask, shape=[batch_size, h, w, 1], dtype=tf_render.float32\n render_tri_ids, shape=[batch_size, h, w, 1], dtype=tf_render.int32\n \"\"\"\n\n # manual light\n light_positions = tf.constant([[0.0, 0.0, 1000.0, -1000.0, 0.0, 1000.0, 1000.0, 0.0, 1000.0]], shape=[1, 3, 3])\n light_positions = tf.tile(light_positions, [opt.batch_size, 1, 1])\n light_intensities = tf.constant([[0.50, 0.50, 0.50]], shape=[1, 3, 3])\n light_intensities = tf.tile(light_intensities, [opt.batch_size, 1, 1])\n # ambient_color = tf.constant([[1.0, 1.0, 1.0]], shape=[1, 3])\n # ambient_color = tf.tile(ambient_color, [opt.batch_size, 1])\n\n if len(tri.shape) == 2:\n render_image, render_image_mask = \\\n mesh_renderer_camera(vertex, tri, vertex_normal, vertex_color, mtx_model_view,\n mtx_perspect_frustrum, cam_position, light_positions, light_intensities,\n opt.img_width, opt.img_height, background=background)\n\n tonemapped_renders = tf.clip_by_value(render_image, 0.0, 100000.0)\n\n else:\n list_tonemapped_renders = []\n list_render_image_mask = []\n list_render_tri_ids = []\n for i in range(tri.shape[0]): # bs\n render_image, render_image_mask = \\\n mesh_renderer_camera(\n vertex[i:i + 1, :, :], tri[i], vertex_normal[i:i + 1, :, :], vertex_color[i:i + 1, :, :],\n mtx_model_view[i:i + 1, :, :], mtx_perspect_frustrum[i:i + 1, :, :], cam_position[i:i + 1, :],\n light_positions, light_intensities, opt.img_width, opt.img_height, background=10.999)\n\n tonemapped_renders = tf.clip_by_value(render_image, 0.0, 100000.0)\n\n list_tonemapped_renders.append(tonemapped_renders)\n list_render_image_mask.append(render_image_mask)\n list_render_tri_ids.append(1)\n\n tonemapped_renders = tf.concat(list_tonemapped_renders, axis=0)\n render_image_mask = tf.concat(list_render_image_mask, axis=0)\n render_tri_ids = tf.concat(list_render_tri_ids, axis=0)\n\n return tonemapped_renders[:, :, :, 0:3], render_image_mask, render_image_mask\n\n\ndef gpmm_generate_depthmap(opt, mesh, tri, mtx_perspect_frustrum, mtx_ext, mtx_model_view, cam_position):\n depthmap, depthmap_mask = mesh_depthmap_camera(mesh, tri, mtx_ext, mtx_model_view, mtx_perspect_frustrum,\n opt.img_width, opt.img_height)\n\n depthmap = depthmap * tf.squeeze(depthmap_mask, axis=-1)\n depthmap = tf.clip_by_value(depthmap, opt.depth_min, opt.depth_max)\n depthmap = tf.expand_dims(depthmap, axis=-1)\n\n return depthmap, depthmap_mask\n\n"
},
{
"alpha_fraction": 0.2620144784450531,
"alphanum_fraction": 0.6552556753158569,
"avg_line_length": 54.585365295410156,
"blob_id": "0c5c0849c3404fb07cbbcd6340c7b1a2d6cc0af9",
"content_id": "4ecd810ff8ec8ecc5cb9c565394e1505fa10cb27",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4557,
"license_type": "permissive",
"max_line_length": 123,
"num_lines": 82,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/geometry/face_align/align_facenet.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#\nimport numpy as np\nimport tensorflow as tf\n\n# self\nfrom .align import lm2d_trans\n\n# main\ndef get_facenet_align_lm(img_height):\n lm_facenet_align = [\n (0.0792396913815, 0.339223741112), (0.0829219487236, 0.456955367943),\n (0.0967927109165, 0.575648016728), (0.122141515615, 0.691921601066),\n (0.168687863544, 0.800341263616), (0.239789390707, 0.895732504778),\n (0.325662452515, 0.977068762493), (0.422318282013, 1.04329000149),\n (0.531777802068, 1.06080371126), (0.641296298053, 1.03981924107),\n (0.738105872266, 0.972268833998), (0.824444363295, 0.889624082279),\n (0.894792677532, 0.792494155836), (0.939395486253, 0.681546643421),\n (0.96111933829, 0.562238253072), (0.970579841181, 0.441758925744),\n (0.971193274221, 0.322118743967), (0.163846223133, 0.249151738053),\n (0.21780354657, 0.204255863861), (0.291299351124, 0.192367318323),\n (0.367460241458, 0.203582210627), (0.4392945113, 0.233135599851),\n (0.586445962425, 0.228141644834), (0.660152671635, 0.195923841854),\n (0.737466449096, 0.182360984545), (0.813236546239, 0.192828009114),\n (0.8707571886, 0.235293377042), (0.51534533827, 0.31863546193),\n (0.516221448289, 0.396200446263), (0.517118861835, 0.473797687758),\n (0.51816430343, 0.553157797772), (0.433701156035, 0.604054457668),\n (0.475501237769, 0.62076344024), (0.520712933176, 0.634268222208),\n (0.565874114041, 0.618796581487), (0.607054002672, 0.60157671656),\n (0.252418718401, 0.331052263829), (0.298663015648, 0.302646354002),\n (0.355749724218, 0.303020650651), (0.403718978315, 0.33867711083),\n (0.352507175597, 0.349987615384), (0.296791759886, 0.350478978225),\n (0.631326076346, 0.334136672344), (0.679073381078, 0.29645404267),\n (0.73597236153, 0.294721285802), (0.782865376271, 0.321305281656),\n (0.740312274764, 0.341849376713), (0.68499850091, 0.343734332172),\n (0.353167761422, 0.746189164237), (0.414587777921, 0.719053835073),\n (0.477677654595, 0.706835892494), (0.522732900812, 0.717092275768),\n (0.569832064287, 0.705414478982), (0.635195811927, 0.71565572516),\n (0.69951672331, 0.739419187253), (0.639447159575, 0.805236879972),\n (0.576410514055, 0.835436670169), (0.525398405766, 0.841706377792),\n (0.47641545769, 0.837505914975), (0.41379548902, 0.810045601727),\n (0.380084785646, 0.749979603086), (0.477955996282, 0.74513234612),\n (0.523389793327, 0.748924302636), (0.571057789237, 0.74332894691),\n (0.672409137852, 0.744177032192), (0.572539621444, 0.776609286626),\n (0.5240106503, 0.783370783245), (0.477561227414, 0.778476346951)\n ]\n\n TPL_MIN, TPL_MAX = np.min(lm_facenet_align, axis=0), np.max(lm_facenet_align, axis=0)\n lm_facenet_align = (lm_facenet_align - TPL_MIN) / (TPL_MAX - TPL_MIN)\n defined_lm_facenet_align = tf.constant(lm_facenet_align, shape=[1, 68, 2])\n # defined_lm_facenet_align = defined_lm_facenet_align[:, 17:, :]\n # defined_lm_facenet_align = defined_lm_facenet_align[:, 48:, :]\n # defined_lm_facenet_align = lm_dlib_to_celebA(defined_lm_facenet_align)\n\n facenet_scale = float(96) / 110.0\n defined_lm_facenet_align = img_height * defined_lm_facenet_align * facenet_scale + img_height * (1 - facenet_scale) / 2\n defined_lm_facenet_align = tf.cast(defined_lm_facenet_align, dtype=tf.float32)\n\n return defined_lm_facenet_align\n\ndef facenet_align(list_image, list_lm, std_lm, img_height, img_width):\n if isinstance(list_image, list) == False:\n list_image = [list_image]\n if isinstance(list_lm, list) == False:\n list_lm = [list_lm]\n\n list_image_warp = []\n for i in range(len(list_image)):\n images = list_image[i]\n images_pad = tf.pad(images, paddings=[[0, 0], [56, 56], [56, 56], [0, 0]], mode='REFLECT')\n lm2d_align = list_lm[i] # bs, lm_num, xy\n lm2d_align = lm2d_align + 56\n # lm2d_align = lm2d_align[:, 48:, :]\n # lm2d_align = lm_dlib_to_celebA(lm2d_align)\n #\n with tf.device('/cpu:0'):\n trans_mat = lm2d_trans(std_lm, lm2d_align)\n # image_warp = transform(images, trans_mat)\n flat_transforms = tf.contrib.image.matrices_to_flat_transforms(trans_mat)\n image_warp = tf.contrib.image.transform(images_pad, flat_transforms, interpolation='BILINEAR',\n output_shape=[img_height, img_width])\n list_image_warp.append(image_warp)\n return list_image_warp"
},
{
"alpha_fraction": 0.6112805008888245,
"alphanum_fraction": 0.6349085569381714,
"avg_line_length": 23.296297073364258,
"blob_id": "01601ae0c609a603b701672e08dda46962390668",
"content_id": "3b4c2e2bca923afcb9cbf15d6ac03eefab8a0996",
"detected_licenses": [
"BSD-3-Clause",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1312,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 54,
"path": "/Snapchat_Filters/devil_filter/devil.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import cv2\nfrom PIL import Image\nimport numpy as np\n\nsave = True\n\ndef show(image):\n global save\n\n #open filter to apply\n fMask = Image.open('devilFilter.png')\n\n #convert colored image into gray scale image\n gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)\n\n #detection of face(s)\n faceFile = cv2.CascadeClassifier('face.xml')\n faces = faceFile.detectMultiScale(gray,1.3,5)\n\n #convert array into image\n bg = Image.fromarray(image)\n\n #apply filter onto background image\n for (x,y,w,h) in faces:\n cv2.rectangle(image, (y, x), ((y + h), (x + w+70)), (0,0,255 ), 2)\n #resize the filter size\n fMask = fMask.resize((w,h))\n #paste it\n bg.paste(fMask, (x,y-(h//2)), mask=fMask)\n\n #press 's' key to save image\n #then only press 'esc' key to exit window\n if save==True and cv2.waitKey(1) == ord('s'):\n cv2.imwrite('savedPicture.jpg', np.asarray(bg))\n save=False\n\n #return as array\n return np.asarray(bg)\n\n\n#capture live video stream from webcam\nvideo = cv2.VideoCapture(0)\n\nwhile True:\n flag,img = video.read()\n cv2.imshow('Video',show(img))\n #press 'esc' key to exit window\n if cv2.waitKey(1)==27: #27 is ascii value of esc\n break\n\nprint(video)\n#release memory\nvideo.release()\ncv2.destroyAllWindows()\n"
},
{
"alpha_fraction": 0.7285115122795105,
"alphanum_fraction": 0.75052410364151,
"avg_line_length": 33.07143020629883,
"blob_id": "c329b2a237b1048fc67a17693a96e027d7df6d9b",
"content_id": "f19053b190ebbe51bbbebcd0a13bbfbdfd910b7b",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 954,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 28,
"path": "/Awesome-face-operations/Glitter Filter/glitter filter.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from matplotlib import pyplot as plt #imported the required libraries\nimport numpy as np\nimport cv2\nimport os.path \n\n\n# take path of the image as input\nimage_path = input(\"Enter the path here:\") #example -> C:\\Users\\xyz\\OneDrive\\Desktop\\project\\image.jpg \nimg = cv2.imread(image_path)\n\nimage = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)\nimage_small = cv2.pyrDown(image)\n\nimage_rgb = cv2.pyrUp(image_small)\nimage_gray = cv2.cvtColor(image_rgb, cv2.COLOR_RGB2GRAY)\nimage_blur = cv2.medianBlur(image_gray, 13) #applied median blur on image_gray\n\nimage_edge = cv2.cvtColor(image_blur, cv2.COLOR_GRAY2RGB)\n\nfinal_output = cv2.bitwise_or(image_edge, image) #used bitwise or method between the image_edge and image\n\nplt.figure(figsize= (15,15))\nplt.imshow(final_output)\nplt.axis('off')\nfilename = os.path.basename(image_path)\nplt.savefig(\"(Glitter Filtered)\"+filename) #saved file name as (Filtered)image_name.jpg\n\nplt.show() #final glitter filtered photo\n"
},
{
"alpha_fraction": 0.8679245114326477,
"alphanum_fraction": 0.8679245114326477,
"avg_line_length": 9.800000190734863,
"blob_id": "3a79115e0c6d3bc72cff0b3dc4a5925c65ff9c02",
"content_id": "9bba456093c582767fce56c306ac561d7f295249",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 53,
"license_type": "permissive",
"max_line_length": 21,
"num_lines": 5,
"path": "/Recognition-Algorithms/Recognition_using_Xception/requirements.txt",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "numpy\nPillow\ntqdm\nopencv-python\nopencv-contrib-python"
},
{
"alpha_fraction": 0.7224546670913696,
"alphanum_fraction": 0.7364016771316528,
"avg_line_length": 41.235294342041016,
"blob_id": "a2975b4357d40fc016f30e0a769181ef82f40bd9",
"content_id": "808b3e9323911087e1cf9652c400d0649b899263",
"detected_licenses": [
"BSD-3-Clause",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 717,
"license_type": "permissive",
"max_line_length": 127,
"num_lines": 17,
"path": "/Snapchat_Filters/ThugLife/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Thug life Glass,stash and cigar filter with sound using openCV and Haarcascade:\n\n* This project is a trial to imitate snapchat filters with sound.\n\n### Requirements\n* Python 3.7 or more \n* OpenCV - ***To install , type pip install opencv-python in the terminal.\n* Download the Haarcascade file. \n* Pygame - *** To install , type pip install pygame in the terminal\n\n### Running the program !!\n* Clone this repository ` git clone https://github.com/akshitagupta15june/Face-X.git`\n* Change Directory to ` Snapchat_Filters` then to `Thug_Life` (type cd Snapchat_Filters [enter] then type cd Thug_Life [enter])\n* Run code using the cmd ` python thug_life.py`\n\n### Screenshot \n<img src=\"capture.jpg\" height=300 width=300>"
},
{
"alpha_fraction": 0.6319845914840698,
"alphanum_fraction": 0.647398829460144,
"avg_line_length": 18.760000228881836,
"blob_id": "fe7c8d622329154b28f76cab554249218936add8",
"content_id": "9252341a079033be7f5b247baacf4ab4d32564e1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 519,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 25,
"path": "/Recognition-Algorithms/Recognition using KNearestNeighbors/Pre_proccessed_data_collection.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#Pre-Proccessed Images Data Collection\r\nimport cv2\r\nimport numpy as np\r\nimport os\r\nphoto = cv2.imread(\"path of image\") #photo should be of 640x480 pixels and axis must match.\r\nname = input(\"Enter your name : \")\r\n\r\nframes = []\r\noutputs = []\r\n\r\nframes.append(photo.flatten())\r\noutputs.append([name])\r\n\r\nX = np.array(frames)\r\ny = np.array(outputs)\r\n\r\ndata = np.hstack([y, X])\r\n\r\nf_name = \"face_data.npy\"\r\n\r\nif os.path.exists(f_name):\r\n old = np.load(f_name)\r\n data = np.vstack([old, data])\r\n\r\nnp.save(f_name, data)\r\n"
},
{
"alpha_fraction": 0.5242628455162048,
"alphanum_fraction": 0.5356360673904419,
"avg_line_length": 47.65163803100586,
"blob_id": "fab507dd1181c50b86aeda601474495838ccff35",
"content_id": "8fdf26aa91738727f92b3419bdd124c47000b13d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11870,
"license_type": "permissive",
"max_line_length": 131,
"num_lines": 244,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/data/data_loader_semi_unsupervised_skin.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport os\nimport random\nimport tensorflow as tf\nimport numpy as np\n\nfrom src_common.common.tf_io import unpack_image_sequence, data_augmentation_mul\n\nclass DataLoader(object):\n def __init__(self, \n dataset_dir=None,\n batch_size=None,\n img_height=None, \n img_width=None, \n num_source=None,\n aug_crop_size=None,\n read_pose=False,\n match_num=0,\n read_gpmm=False,\n flag_data_aug=False,\n flag_shuffle=True):\n self.dataset_dir = dataset_dir\n self.batch_size = batch_size\n self.img_height = img_height\n self.img_width = img_width\n self.num_source = num_source\n self.aug_crop_size = aug_crop_size\n self.read_pose = read_pose\n self.match_num = match_num\n self.flag_data_aug = flag_data_aug\n self.flag_shuffle = flag_shuffle\n\n def format_file_list(self, data_root, split):\n all_list = {}\n with open(data_root + '/%s.txt' % split, 'r') as f:\n frames = f.readlines()\n flag_slg_mul = [x.split(' ')[0] for x in frames]\n subfolders = [x.split(' ')[1] for x in frames]\n frame_ids = [x.split(' ')[2][:-1] for x in frames]\n\n image_file_list = [os.path.join(data_root, subfolders[i],\n frame_ids[i] + '.jpg') for i in range(len(frames))]\n cam_file_list = [os.path.join(data_root, subfolders[i],\n frame_ids[i] + '_cam.txt') for i in range(len(frames))]\n skin_file_list = [os.path.join(data_root, subfolders[i],\n frame_ids[i] + '_skin.jpg') for i in range(len(frames))]\n\n steps_per_epoch = int(len(image_file_list) // self.batch_size)\n print(\"*************************************************************** format_file_list \")\n img_cam = list(zip(image_file_list, cam_file_list, skin_file_list, flag_slg_mul))\n if self.flag_shuffle:\n random.shuffle(img_cam)\n else:\n print(\"Without shuffle\")\n image_file_list, cam_file_list, skin_file_list, flag_slg_mul = zip(*img_cam)\n\n all_list['image_file_list'] = image_file_list\n all_list['cam_file_list'] = cam_file_list\n all_list['skin_file_list'] = skin_file_list\n all_list['flag_slg_mul'] = flag_slg_mul\n\n self.steps_per_epoch = int(len(all_list['image_file_list']) // self.batch_size)\n print(\"Finish format_file_list\")\n if len(image_file_list) > 10:\n for i in range(10):\n print(image_file_list[i])\n return all_list\n\n def load_train_batch(self, is_test=False):\n \"\"\"\n Load a batch of training instances using the new tensorflow\n Dataset api.\n \"\"\"\n def _parse_train_img(img_path):\n with tf.device('/cpu:0'):\n img_buffer = tf.read_file(img_path)\n image_decoded = tf.image.decode_jpeg(img_buffer)\n # TODO: TW Image sequence structure\n tgt_image, src_image_stack = \\\n unpack_image_sequence(\n image_decoded, self.img_height, self.img_width, self.num_source)\n return tgt_image, src_image_stack\n\n def _batch_preprocessing(stack_images, stack_images_skin, flag_sgl_mul, intrinsics, optional_data1, optional_data2):\n intrinsics = tf.cast(intrinsics, tf.float32)\n image_all = tf.concat([stack_images[0], stack_images[1], stack_images_skin[0], stack_images_skin[1]], axis=3)\n\n if not is_test and self.flag_data_aug: # otherwise matches coords are wrong\n if self.match_num == 0:\n image_all, intrinsics, matches = data_augmentation_mul(\n image_all, intrinsics, self.img_height, self.img_width)\n else:\n image_all, intrinsics, matches = data_augmentation_mul(\n image_all, intrinsics, self.img_height, self.img_width, optional_data2)\n else:\n matches = optional_data2\n\n image = image_all[:, :, :, :3*(self.num_source+1)]\n image_skin = image_all[:, :, :, 3*(self.num_source+1):]\n return image, image_skin, flag_sgl_mul, intrinsics, optional_data1, matches\n\n input_image_names_ph = tf.placeholder(tf.string, shape=[None], name='input_image_names_ph')\n image_dataset = tf.data.Dataset.from_tensor_slices(input_image_names_ph).map(_parse_train_img)\n\n input_skin_names_ph = tf.placeholder(tf.string, shape=[None], name='input_skin_names_ph')\n skin_dataset = tf.data.Dataset.from_tensor_slices(input_skin_names_ph).map(_parse_train_img)\n\n flag_sgl_mul_ph = tf.placeholder(tf.int32, [None], name='flag_sgl_mul_ph')\n flag_sgl_mul_dataset = tf.data.Dataset.from_tensor_slices(flag_sgl_mul_ph)\n\n cam_intrinsics_ph = tf.placeholder(tf.float32, [None, 1+self.num_source, 3, 3], name='cam_intrinsics_ph')\n intrinsics_dataset = tf.data.Dataset.from_tensor_slices(cam_intrinsics_ph)\n\n datasets = (image_dataset, skin_dataset, flag_sgl_mul_dataset, intrinsics_dataset)\n if self.read_pose:\n poses_ph = tf.placeholder(tf.float32, [None, 1+self.num_source, 6], name='poses_ph')\n pose_dataset = tf.data.Dataset.from_tensor_slices(poses_ph)\n datasets = datasets + (pose_dataset,)\n else:\n datasets = datasets + (intrinsics_dataset,)\n if self.match_num > 0:\n matches_ph = tf.placeholder(tf.float32, [None, (1+self.num_source), self.match_num, 2], name='matches_ph')\n match_dataset = tf.data.Dataset.from_tensor_slices(matches_ph)\n datasets = datasets + (match_dataset,)\n else:\n datasets = datasets + (intrinsics_dataset,)\n\n all_dataset = tf.data.Dataset.zip(datasets)\n all_dataset = all_dataset.batch(self.batch_size)\n if self.flag_shuffle:\n all_dataset = all_dataset.shuffle(buffer_size=4000).repeat().prefetch(self.batch_size*4)\n all_dataset = all_dataset.map(_batch_preprocessing)\n iterator = all_dataset.make_initializable_iterator()\n return iterator\n\n def init_data_pipeline(self, sess, batch_sample, file_list):\n #\n def _load_cam_intrinsics(cam_filelist, read_pose, match_num):\n all_cam_intrinsics = []\n all_poses = []\n all_matches = []\n\n for i in range(len(cam_filelist)):\n filename = cam_filelist[i]\n if i % 50000 == 0:\n print(i, ' in all: ', len(cam_filelist))\n f = open(filename)\n one_intrinsic = []\n for i in range(1 + self.num_source):\n line = f.readline()\n #\n cam_intri_vec = [float(num) for num in line.strip().split(',')]\n if len(cam_intri_vec) != 9:\n print(filename, i, line)\n\n cam_intrinsics = np.reshape(cam_intri_vec, [3, 3])\n one_intrinsic.append(cam_intrinsics)\n one_intrinsic = np.stack(one_intrinsic, axis=0)\n all_cam_intrinsics.append(one_intrinsic)\n #\n if read_pose:\n one_sample_pose = []\n for i in range(0, 1 + self.num_source):\n lines = f.readline()\n pose = [float(num) for num in lines.strip().split(',')]\n pose_vec = np.reshape(pose, [6])\n one_sample_pose.append(pose_vec)\n one_sample_pose = np.stack(one_sample_pose, axis=0)\n all_poses.append(one_sample_pose)\n #\n if match_num > 0:\n image_matches = []\n for i in range(1 + self.num_source):\n one_matches = []\n line = f.readline()\n for j in range(self.match_num):\n line = f.readline()\n\n match_coords = [float(num) for num in line.strip().split(',')]\n match_vec = np.reshape(match_coords, [2])\n one_matches.append(match_vec)\n one_matches = np.stack(one_matches, axis=0) # 68\n image_matches.append(one_matches)\n # TODO: Very dangerous\n # if i == self.num_source / 2:\n # image_matches = [one_matches] + image_matches\n # else:\n\n image_matches = np.stack(image_matches, axis=0) # (1 + self.num_source), 68\n\n all_matches.append(image_matches)\n\n f.close()\n all_cam_intrinsics = np.stack(all_cam_intrinsics, axis=0)\n\n if read_pose:\n all_poses = np.stack(all_poses, axis=0)\n if match_num > 0:\n all_matches = np.stack(all_matches, axis=0)\n return all_cam_intrinsics, all_poses, all_matches\n\n # load cam_intrinsics using native python\n print('load camera intrinsics...')\n cam_intrinsics, all_poses, all_matches = _load_cam_intrinsics(file_list['cam_file_list'], self.read_pose, self.match_num)\n\n input_dict = {'data_loading/input_image_names_ph:0': file_list['image_file_list'][:self.batch_size * self.steps_per_epoch],\n 'data_loading/input_skin_names_ph:0': file_list['skin_file_list'][:self.batch_size * self.steps_per_epoch],\n 'data_loading/flag_sgl_mul_ph:0': file_list['flag_slg_mul'][:self.batch_size * self.steps_per_epoch],\n 'data_loading/cam_intrinsics_ph:0': cam_intrinsics[:self.batch_size*self.steps_per_epoch]}\n if self.read_pose:\n print('load pose data...')\n input_dict['data_loading/poses_ph:0'] = all_poses[:self.batch_size*self.steps_per_epoch]\n if self.match_num > 0:\n print('load matches data...')\n input_dict['data_loading/matches_ph:0'] = all_matches[:self.batch_size*self.steps_per_epoch]\n\n sess.run(batch_sample.initializer, feed_dict=input_dict)\n\n def batch_unpack_image_sequence(self, image_seq, img_height, img_width, num_source):\n # Assuming the center image is the target frame\n tgt_start_idx = int(img_width * (num_source//2))\n tgt_image = tf.slice(image_seq, \n [0, 0, tgt_start_idx, 0], \n [-1, -1, img_width, -1])\n # Source frames before the target frame\n src_image_1 = tf.slice(image_seq, \n [0, 0, 0, 0], \n [-1, -1, int(img_width * (num_source//2)), -1])\n # Source frames after the target frame\n src_image_2 = tf.slice(image_seq, \n [0, 0, int(tgt_start_idx + img_width), 0], \n [-1, -1, int(img_width * (num_source//2)), -1])\n src_image_seq = tf.concat([src_image_1, src_image_2], axis=2)\n # Stack source frames along the color channels (i.e. [B, H, W, N*3])\n src_image_stack = tf.concat([tf.slice(src_image_seq, \n [0, 0, i*img_width, 0], \n [-1, -1, img_width, -1]) \n for i in range(num_source)], axis=3)\n return tgt_image, src_image_stack\n\nif __name__ == \"__main__\":\n path_data = \"/home/jshang/SHANG_Data_MOUNT/141/GAFR_semi_bfmAlign_3/11141_300WLP_CelebA_Mpie_tensor_MERGE\"\n h_loader = DataLoader(batch_size=5)\n f = h_loader.format_file_list(path_data, 'train', 3, 2)"
},
{
"alpha_fraction": 0.5704225301742554,
"alphanum_fraction": 0.5957746505737305,
"avg_line_length": 23.482759475708008,
"blob_id": "04ca292fe62c0bceb9da4535bdbb7a85c435f249",
"content_id": "0c57af8b22431eb22aa20923225a5caab54bab97",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1420,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 58,
"path": "/Face Reconstruction/Face Alignment in Full Pose Range/demo@obama/rendering.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# coding: utf-8\n\nimport sys\n\nsys.path.append('../')\nimport os\nimport os.path as osp\nfrom glob import glob\n\nfrom utils.lighting import RenderPipeline\nimport numpy as np\nimport scipy.io as sio\nimport imageio\n\ncfg = {\n 'intensity_ambient': 0.3,\n 'color_ambient': (1, 1, 1),\n 'intensity_directional': 0.6,\n 'color_directional': (1, 1, 1),\n 'intensity_specular': 0.1,\n 'specular_exp': 5,\n 'light_pos': (0, 0, 5),\n 'view_pos': (0, 0, 5)\n}\n\n\ndef _to_ctype(arr):\n if not arr.flags.c_contiguous:\n return arr.copy(order='C')\n return arr\n\n\ndef obama_demo():\n wd = 'obama_res@dense_py'\n if not osp.exists(wd):\n os.mkdir(wd)\n\n app = RenderPipeline(**cfg)\n img_fps = sorted(glob('obama/*.jpg'))\n triangles = sio.loadmat('tri_refine.mat')['tri'] # mx3\n triangles = _to_ctype(triangles).astype(np.int32) # for type compatible\n\n for img_fp in img_fps[:]:\n vertices = sio.loadmat(img_fp.replace('.jpg', '_0.mat'))['vertex'].T # mx3\n img = imageio.imread(img_fp).astype(np.float32) / 255.\n\n # end = time.clock()\n img_render = app(vertices, triangles, img)\n # print('Elapse: {:.1f}ms'.format((time.clock() - end) * 1000))\n\n img_wfp = osp.join(wd, osp.basename(img_fp))\n imageio.imwrite(img_wfp, img_render)\n print('Writing to {}'.format(img_wfp))\n\n\nif __name__ == '__main__':\n obama_demo()\n"
},
{
"alpha_fraction": 0.45306387543678284,
"alphanum_fraction": 0.7535853981971741,
"avg_line_length": 24.566667556762695,
"blob_id": "74a0bf2d1a746c2de23a254fb13fcc22bfc8916b",
"content_id": "4e2f91df33304da55133db820d6b837ecb032aec",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 1534,
"license_type": "permissive",
"max_line_length": 55,
"num_lines": 60,
"path": "/Face Reconstruction/3D Face Reconstruction with Weakly-Supervised Learning/requirements.txt",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# This file may be used to create an environment using:\n# $ conda create --name <env> --file <this file>\n# platform: win-64\nblas=1.0=mkl\nca-certificates=2020.11.8=h5b45459_0\ncertifi=2020.11.8=py38haa244fe_0\nchardet=3.0.4=pypi_0\ncudatoolkit=10.1.243=h74a9793_0\ndocopt=0.6.2=pypi_0\nfreetype=2.10.4=hd328e21_0\nfuture=0.18.2=pypi_0\nfvcore=0.1.2.post20201111=pypi_0\nicc_rt=2020.2=intel_254\nidna=2.10=pypi_0\nintel-openmp=2020.2=254\njpeg=9b=hb83a4c4_2\nlibpng=1.6.37=h2a8f88b_0\nlibtiff=4.1.0=h56a325e_1\nlz4-c=1.9.2=hf4a77e7_3\nmkl=2020.2=256\nmkl-service=2.3.0=py38hb782905_0\nmkl_fft=1.2.0=py38h45dec08_0\nmkl_random=1.1.1=py38h47e9c7a_0\nmsys2-conda-epoch=20160418=1\nninja=1.7.2=0\nnumpy=1.19.2=py38hadc3359_0\nnumpy-base=1.19.2=py38ha3acd2a_0\nolefile=0.46=py_0\nopenssl=1.1.1h=he774522_0\nPillow>=8.1.1=py38h4fa10fc_0\npip=20.2.4=py38haa95532_0\npipreqs=0.4.10=pypi_0\nportalocker=2.0.0=pypi_0\npython=3.8.5=h5fd99cc_1\npython_abi=3.8=1_cp38\npytorch=1.6.0=py3.8_cuda101_cudnn7_0\npytorch3d=0.3.0=pypi_0\npywin32=300=pypi_0\nPyYAML>=5.4=pypi_0\nrequests=2.25.0=pypi_0\nscipy=1.5.2=py38h14eb087_0\nsetuptools=50.3.1=py38haa95532_1\nsix=1.15.0=py38haa95532_0\nsqlite=3.33.0=h2a8f88b_0\ntabulate=0.8.7=pyh9f0ad1d_0\ntermcolor=1.1.0=pypi_0\ntk=8.6.10=he774522_0\ntorchvision=0.7.0=py38_cu101\ntqdm=4.52.0=pyhd3deb0d_0\nurllib3>=1.26.4=pypi_0\nvc=14.1=h0510ff6_4\nvs2015_runtime=14.16.27012=hf0eaf9b_3\nwheel=0.35.1=pyhd3eb1b0_0\nwincertstore=0.2=py38_0\nxz=5.2.5=h62dcd97_0\nyacs=0.1.8=pypi_0\nyaml=0.2.5=he774522_0\nyarg=0.1.9=pypi_0\nzlib=1.2.11=h62dcd97_4\nzstd=1.4.5=h04227a9_0\n"
},
{
"alpha_fraction": 0.5287500023841858,
"alphanum_fraction": 0.581250011920929,
"avg_line_length": 27.571428298950195,
"blob_id": "447c42a00888ee11cfe0c924e4eb39d9f8bcef41",
"content_id": "c1a15fea1604ad6277569f39df0f9dbb103e24ed",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 800,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 28,
"path": "/Face Reconstruction/Face Alignment in Full Pose Range/training/train_pdc.sh",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\nLOG_ALIAS=$1\nLOG_DIR=\"logs\"\nmkdir -p ${LOG_DIR}\n\nLOG_FILE=\"${LOG_DIR}/${LOG_ALIAS}_`date +'%Y-%m-%d_%H:%M.%S'`.log\"\n#echo $LOG_FILE\n\n./train.py --arch=\"mobilenet_1\" \\\n --start-epoch=1 \\\n --loss=vdc \\\n --snapshot=\"snapshot/phase1_pdc\" \\\n --param-fp-train='../train.configs/param_all_norm.pkl' \\\n --param-fp-val='../train.configs/param_all_norm_val.pkl' \\\n --warmup=5 \\\n --opt-style=resample \\\n --batch-size=256 \\\n --base-lr=0.01 \\\n --epochs=50 \\\n --milestones=30,40 \\\n --print-freq=50 \\\n --devices-id=0,1,2,3 \\\n --workers=8 \\\n --filelists-train=\"../train.configs/train_aug_120x120.list.train\" \\\n --filelists-val=\"../train.configs/train_aug_120x120.list.val\" \\\n --root=\"/path/to//train_aug_120x120\" \\\n --log-file=\"${LOG_FILE}\"\n"
},
{
"alpha_fraction": 0.5935373902320862,
"alphanum_fraction": 0.6700680255889893,
"avg_line_length": 28.842105865478516,
"blob_id": "4622ecfc4d4a10d0797e5ea4adf4ee2134378788",
"content_id": "be237b7cc3ca2a454ea2ee2b9e4d4915bca33991",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 588,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 19,
"path": "/Snapchat_Filters/devil_filter/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\r\n<h1>Apply Snapchat Devil filter to your live video stream</h1>\r\n\r\n<h3>Requirements</h3>\r\n<ul>\r\n <li>Python 3.7.x</li>\r\n <li>OpenCV</li>\r\n <li>PIL</li>\r\n <li>numpy</li>\r\n</ul>\r\n\r\n<h3>Instructions</h3>\r\n<ul>\r\n <li>Clone this repository</li>\r\n <li>Change directory to 'Snapchat_Filters' then to 'devil_filter' </li>\r\n <li>Run 'devil.py' </li>\r\n <li>Press 's' key to take snapshot of your filtered image</li>\r\n <li>Then Press 'esc' key to exit window </li>\r\n</ul>\r\n\r\n"
},
{
"alpha_fraction": 0.5605721473693848,
"alphanum_fraction": 0.5996898412704468,
"avg_line_length": 30.032085418701172,
"blob_id": "fc243b2864e18bf74f8a90c93bfa4879f9b97b0a",
"content_id": "cbfc59409a0d9d408ed2e587c4c5b48c17ee95a8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5803,
"license_type": "permissive",
"max_line_length": 148,
"num_lines": 187,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/geometry/camera_distribute/camera_utils.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n# system\nfrom __future__ import print_function\n\n# python lib\nimport math\nfrom copy import deepcopy\n\n\n# tf_render\nimport tensorflow as tf\n\n# self\n\n# tianwei\nfrom src_common.geometry.geo_utils import get_ext_inv, get_relative_pose, projective_inverse_warp, pose_vec2rt, pose_vec2mat, mat2pose_vec, \\\n fundamental_matrix_from_rt, reprojection_error\n\n\"\"\"\nWithout bp\n\"\"\"\ndef build_train_graph_3dmm_frustrum(intrinsic, near=3000.0, far=7000.0):\n batch_size = intrinsic.shape[0]\n # def build_train_graph_3dmm_frustrum(self, intrinsic, near=0.1, far=2000.0):\n # intrinsic\n focal_len_x = tf.slice(intrinsic, [0, 0, 0], [-1, 1, 1])\n focal_len_x = tf.squeeze(focal_len_x, axis=-1)\n\n focal_len_y = tf.slice(intrinsic, [0, 1, 1], [-1, 1, 1])\n focal_len_y = tf.squeeze(focal_len_y, axis=-1)\n\n u = tf.slice(intrinsic, [0, 0, 2], [-1, 1, 1])\n u = tf.squeeze(u, axis=-1)\n\n v = tf.slice(intrinsic, [0, 1, 2], [-1, 1, 1])\n v = tf.squeeze(v, axis=-1)\n\n #\n near = tf.reshape(tf.constant(near), shape=[1, 1])\n far = tf.reshape(tf.constant(far), shape=[1, 1])\n near = tf.tile(near, [batch_size, 1])\n far = tf.tile(far, [batch_size, 1])\n\n #\n mtx_frustrum = projectionFrustrumMatrix_batch(focal_len_x, focal_len_y, u, v, near, far)\n\n return mtx_frustrum\n\ndef build_train_graph_3dmm_camera(intrinsic, pose_6dof):\n if isinstance(pose_6dof, list) == False:\n pose_6dof = [pose_6dof]\n\n list_ext = []\n list_proj = []\n list_mv = []\n list_eye = []\n\n for i in range(len(pose_6dof)):\n mtx_ext = pose_vec2mat(pose_6dof[i], False)\n mtx_rot = tf.slice(mtx_ext, [0, 0, 0], [-1, 3, 3])\n mtx_t = tf.slice(pose_6dof[i], [0, 3], [-1, 3])\n mtx_t = tf.expand_dims(mtx_t, -1)\n\n # ext\n mtx_proj = project_batch(intrinsic, mtx_rot, mtx_t)\n #\n mtx_mv = modelViewMatrix_batch(mtx_rot, mtx_t)\n #\n mtx_eye = ext_to_eye_batch(mtx_rot, mtx_t)\n\n list_ext.append(mtx_ext)\n list_proj.append(mtx_proj)\n list_mv.append(mtx_mv)\n list_eye.append(mtx_eye)\n\n return list_ext, list_proj, list_mv, list_eye\n\n\"\"\"\nWith bp\n\"\"\"\ndef project_batch(mtx_intrinsic, rot_batch, t_batch):\n batch_size = mtx_intrinsic.shape[0]\n\n M = tf.matmul(mtx_intrinsic, rot_batch)\n p4 = tf.matmul(mtx_intrinsic, t_batch)\n proj = tf.concat([M, p4], axis=2)\n\n r4 = tf.constant([0., 0., 0., 1.], shape=[1, 1, 4])\n r4 = tf.tile(r4, [batch_size, 1, 1])\n proj = tf.concat([proj, r4], axis=1)\n\n return proj\n\ndef project3d_batch(pt_batch, mtx_proj_batch):\n batch_size = pt_batch.shape[0]\n\n homo_batch = tf.ones([batch_size, tf.shape(pt_batch)[1], 1], dtype=tf.float32)\n pt_batch_homo = tf.concat([pt_batch, homo_batch], axis=2)\n pt_batch_homo_trans = tf.transpose(pt_batch_homo, perm=[0, 2, 1])\n pt_batch_homo_2d_trans = tf.matmul(mtx_proj_batch, pt_batch_homo_trans)\n pt_batch_homo_2d = tf.transpose(pt_batch_homo_2d_trans, perm=[0, 2, 1])\n\n pt_batch_homo_2d_main = pt_batch_homo_2d[:, :, 0:2]\n pt_batch_homo_2d_w = pt_batch_homo_2d[:, :, 2]\n pt_batch_homo_2d_w = tf.expand_dims(pt_batch_homo_2d_w, -1)\n pt_batch_homo_2d_normal = pt_batch_homo_2d_main / (pt_batch_homo_2d_w + 1e-6)\n\n return pt_batch_homo_2d_normal\n\ndef ext_to_eye_batch(rot_batch, t_batch):\n #mtx_t_trans = tf_render.expand_dims(t_batch, 1)\n t_batch = tf.transpose(t_batch, perm=[0, 2, 1])\n eye_trans = - tf.matmul(t_batch, rot_batch)\n eye = tf.squeeze(eye_trans, axis=1)\n return eye\n\ndef modelViewMatrix_batch(rot_batch, t_batch):\n batch_size = rot_batch.shape[0]\n\n mtx_inv = tf.constant(\n [\n [1., 0., 0.],\n [0., -1., 0.],\n [0., 0., -1.]\n ], shape=[1, 3, 3]\n )\n mtx_inv = tf.tile(mtx_inv, [batch_size, 1, 1])\n\n # Inv rotate\n rot_inv = tf.matmul(mtx_inv, rot_batch)\n c4 = tf.constant([0., 0., 0.], shape=[1, 3, 1])\n c4 = tf.tile(c4, [batch_size, 1, 1])\n rot_inv = tf.concat([rot_inv, c4], axis=2)\n\n r4 = tf.constant([0., 0., 0., 1.], shape=[1, 1, 4])\n r4 = tf.tile(r4, [batch_size, 1, 1])\n rot_inv = tf.concat([rot_inv, r4], axis=1)\n\n eye_inv = -ext_to_eye_batch(rot_batch, t_batch)\n eye_inv_trans = tf.expand_dims(eye_inv, axis=-1)\n trans_id_inv = tf.eye(3, batch_shape=[batch_size])\n trans_inv = tf.concat([trans_id_inv, eye_inv_trans], axis=2)\n trans_inv = tf.concat([trans_inv, r4], axis=1)\n\n mv = tf.matmul(rot_inv, trans_inv)\n\n return mv\n\n\"\"\"\nTheory: https://www.scratchapixel.com/lessons/3d-basic-rendering/perspective-and-orthographic-projection-matrix/opengl-perspective-projection-matrix\n\"\"\"\ndef projectionFrustrumMatrix_batch(focal_len_x, focal_len_y, u, v, near, far):\n image_width_batch = 2 * u\n image_height_batch = 2 * v\n\n # From triangle similarity\n width = image_width_batch * near / focal_len_x\n height = image_height_batch * near / focal_len_y\n\n right = width - (u * near / focal_len_x)\n left = right - width\n\n top = v * near / focal_len_y\n bottom = top - height\n\n vertical_range = right - left\n p00 = 2 * near / vertical_range\n p02 = (right + left) / vertical_range\n\n horizon_range = top-bottom\n p11 = 2 * near / horizon_range\n p12 = (top + bottom) / horizon_range\n\n depth_range = far - near\n p_22 = -(far + near) / depth_range\n p_23 = -2.0 * (far * near / depth_range)\n\n zero_fill = tf.zeros_like(p00)\n minus_one_fill = tf.ones_like(p00)\n\n r1 = tf.stack([p00, zero_fill, p02, zero_fill], axis=2)\n r2 = tf.stack([zero_fill, p11, p12, zero_fill], axis=2)\n r3 = tf.stack([zero_fill, zero_fill, p_22, p_23], axis=2)\n r4 = tf.stack([zero_fill, zero_fill, -minus_one_fill, zero_fill], axis=2)\n\n P = tf.concat([r1, r2, r3, r4], axis=1, name='mtx_fustrum_batch')\n\n return P"
},
{
"alpha_fraction": 0.5857880115509033,
"alphanum_fraction": 0.6032600998878479,
"avg_line_length": 44.42390441894531,
"blob_id": "c8b594003406882370cffa4bd2196b36e2d2bdc2",
"content_id": "06e239535faef824bffe1c70cf0e26d7d8b0b0ea",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 48649,
"license_type": "permissive",
"max_line_length": 180,
"num_lines": 1071,
"path": "/Face Reconstruction/3D Face Reconstruction using Graph Convolution Network/base_model.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import logging\nimport math\nimport os\nimport shutil\nimport time\n\nimport cv2\nimport imageio\nimport numpy as np\nimport scipy.sparse\nimport tensorflow as tf\n\nimport utils\nfrom lib import graph, mesh_renderer\nfrom lib.mesh_io import write_obj\n\nlogger = logging.getLogger('x')\n\n\nclass BaseModel():\n \"\"\"\n Mesh Convolutional Autoencoder which uses the Chebyshev approximation.\n \"\"\"\n\n def __init__(self, args, sess, graphs, refer_mesh, image_paths, img_file):\n self.sess = sess\n self.graph = graphs\n mesh_shape = list(refer_mesh['vertices'].shape)\n self.gan = args.gan\n self.wide = args.wide\n self.root_dir = args.root_dir\n self.img_file = img_file\n self.stage = args.stage\n if args.mode == 'test':\n self.restore = True\n else:\n self.restore = args.restore\n\n self.laplacians, self.downsamp_trans, self.upsamp_trans, self.pool_size = utils.init_sampling(\n refer_mesh, os.path.join(args.root_dir, 'data', 'params', args.name), args.name)\n logger.info(\"Transform Matrices and Graph Laplacians Generated.\")\n self.refer_meshes = utils.get_mesh_list(args.name)\n\n self.bfm = utils.BFM_model(self.root_dir, 'data/bfm2009_face.mat')\n # color = np.ones_like(refer_mesh['vertices'], dtype=np.uint8)\n # color[self.bfm.skin_index] = 0\n # write_obj('tests.obj', refer_mesh['vertices'], refer_mesh['faces'], color)\n # write_obj('test.obj', refer_mesh['vertices'], refer_mesh['faces'], color)\n\n self.buffer_size = args.buffer_size\n self.workers = args.workers\n self.num_filter = [16, 16, 16, 32]\n self.c_k = 6\n self.cam_z = 34\n self.z_dim = args.nz\n self.num_vert = mesh_shape[0]\n self.vert_dim = 6\n self.drop_rate = args.drop_rate\n self.batch_size = args.batch_size\n self.num_epochs = args.epoch\n self.img_size = args.img_size\n self.learning_rate = args.lr\n self.adv_lambda = args.adv_lambda\n if args.suffix is None:\n self.dir_name = args.name\n else:\n self.dir_name = args.name + '_' + args.suffix\n self.brelu = self.b1relu\n self.pool = self.poolwT\n self.unpool = self.poolwT\n\n self.dilation_kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,\n (5, 5)).astype(np.float32)[..., np.newaxis]\n self.erosion_kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE,\n (9, 9)).astype(np.float32)[..., np.newaxis]\n # lm_3d_idx = [\n # int(x)\n # for x in open('data/face_landmarks.txt', 'r').readlines()\n # if len(x.strip()) > 1\n # ]\n # # self.lm_3d_idx = lm_3d_idx[8:9] + lm_3d_idx[17:]\n # self.lm_3d_idx = lm_3d_idx[17:]\n self.lm_3d_idx = self.bfm.landmark[17:]\n\n train_image_paths, self.val_image_paths, self.test_image_paths = utils.make_paths(\n image_paths, os.path.join(self.root_dir, 'data', 'params', args.name, 'image'),\n self.root_dir)\n self.train_image_paths = np.array(train_image_paths, dtype='object')\n\n num_train = len(self.train_image_paths)\n logger.info('Number of train data: %d', num_train)\n self.num_batches = num_train // self.batch_size\n if args.eval == 0:\n self.eval_frequency = self.num_batches\n elif args.eval < 1:\n self.eval_frequency = int(self.num_batches * args.eval)\n else:\n self.eval_frequency = int(args.eval)\n logger.info('Evaluation frequency: %d', self.eval_frequency)\n\n self.vert_mean = np.reshape(self.bfm.shapeMU, [-1, 3])\n\n self.decay_steps = num_train // args.batch_size\n\n self.regularizers = []\n self.regularization = 5e-4\n\n self.ckpt_dir = os.path.join('checkpoints', self.dir_name)\n self.summ_dir = os.path.join('summaries', self.dir_name)\n self.samp_dir = os.path.join('samples', self.dir_name)\n\n self.build_graph()\n\n def build_graph(self):\n \"\"\"Build the computational graph of the model.\"\"\"\n # self.graph = tf.Graph()\n\n # with self.graph.as_default():\n # Inputs.\n with tf.name_scope('inputs'):\n\n data_idxs = [x for x in range(len(self.train_image_paths))]\n image_dataset = tf.data.Dataset.from_tensor_slices(data_idxs)\n # image_dataset = image_dataset.map(\n # lambda start_idx: tf.py_func(self.load_image_bin, [start_idx], [tf.float32, tf.float32]))\n image_dataset = image_dataset.map(\n lambda start_idx: tf.py_func(self.load_image_bin, [start_idx], tf.float32))\n\n image_dataset = image_dataset.shuffle(buffer_size=self.buffer_size)\n image_dataset = image_dataset.batch(self.batch_size)\n image_dataset = image_dataset.repeat()\n image_iterator = image_dataset.make_one_shot_iterator()\n # self.train_rgbas, self.train_2dlms = image_iterator.get_next()\n self.train_rgbas = image_iterator.get_next()\n self.train_rgbas.set_shape([self.batch_size, self.img_size, self.img_size, 4])\n self.train_images = (self.train_rgbas[..., :3] + 1) * 127.5\n # self.train_2dlms.set_shape([self.batch_size, len(self.lm_3d_idx), 2])\n\n self.refer_faces = [\n tf.convert_to_tensor(x['faces'], dtype=tf.int32, name='refer_faces_{}'.format(i))\n for i, x in enumerate(self.refer_meshes)\n ]\n\n self.ph_rgbas = tf.placeholder(tf.float32, (self.batch_size, self.img_size, self.img_size, 4),\n 'input_rgbas')\n self.input_images = (self.ph_rgbas[..., :3] + 1) * 127.5\n # self.input_images = tf.floor((self.ph_rgbas[..., 2::-1] + 1) * 127.5)\n\n self.ph_2dlms = tf.placeholder(tf.float32, (self.batch_size, len(self.lm_3d_idx), 2),\n 'input_2dlm')\n self.ph_ren_lambda = tf.placeholder(tf.float32, (), 'render_lambda')\n self.ph_ref_lambda = tf.placeholder(tf.float32, (), 'refine_lambda')\n # self.ph_adv_lambda = tf.placeholder(tf.float32, (), 'adv_lambda')\n\n with tf.gfile.GFile(os.path.join(self.root_dir, 'data/FaceReconModel.pb'), 'rb') as f:\n face_rec_graph_def = tf.GraphDef()\n face_rec_graph_def.ParseFromString(f.read())\n\n def get_emb_coeff(net_name, inputs):\n resized = tf.image.resize_images(inputs, [224, 224])\n bgr_inputs = resized[..., ::-1]\n tf.import_graph_def(face_rec_graph_def, name=net_name, input_map={'input_imgs:0': bgr_inputs})\n image_emb = self.graph.get_tensor_by_name(net_name + '/resnet_v1_50/pool5:0')\n image_emb = tf.squeeze(image_emb, axis=[1, 2])\n coeff = self.graph.get_tensor_by_name(net_name + '/coeff:0')\n return image_emb, coeff\n\n image_emb, self.coeff = get_emb_coeff('facerec', self.train_images)\n image_emb_test, self.coeff_test = get_emb_coeff('facerec_test', self.input_images)\n\n with tf.gfile.GFile(os.path.join(self.root_dir, 'data/FaceNetModel.pb'), 'rb') as f:\n face_net_graph_def = tf.GraphDef()\n face_net_graph_def.ParseFromString(f.read())\n\n def get_img_feat(net_name, inputs):\n # inputs should be in [0, 255]\n # facenet_input = tf.image.resize_image_with_crop_or_pad(inputs, 160, 160)\n # TODO: fix resize issue!!!\n facenet_input = tf.image.resize_images(inputs, [160, 160])\n\n facenet_input = (facenet_input - 127.5) / 128.0\n tf.import_graph_def(face_net_graph_def, name=net_name, input_map={\n 'input:0': facenet_input,\n 'phase_train:0': False\n })\n image_feat = self.graph.get_tensor_by_name(\n net_name + '/InceptionResnetV1/Logits/AvgPool_1a_8x8/AvgPool:0')\n image_feat = tf.squeeze(image_feat, axis=[1, 2])\n return image_feat\n\n image_feat = get_img_feat('facenet', self.train_images)\n image_feat_test = get_img_feat('facenet_test', self.input_images)\n\n self.image_emb = tf.concat([image_emb, image_feat], axis=-1)\n self.image_emb_test = tf.concat([image_emb_test, image_feat_test], axis=-1)\n\n pred_results = self.inference(self.train_rgbas, self.coeff, self.image_emb)\n self.vert_pred = pred_results['vertice']\n self.pca_text_pred = pred_results['pca_texture']\n self.gcn_text_pred = pred_results['gcn_texture']\n self.pca_color_pred = pred_results['pca_color']\n self.gcn_color_pred = pred_results['gcn_color']\n self.proj_color_pred = pred_results['proj_color']\n self.pca_render_pred = pred_results['pca_render_color']\n self.gcn_render_pred = pred_results['gcn_render_color']\n self.lm_proj_pred = pred_results['lm_project']\n # render_mask = self._erosion2d(self.train_rgbas[..., 3:])\n render_mask = self.pca_render_pred[..., 3:] * self.train_rgbas[..., 3:]\n gcn_render_image = (self.gcn_render_pred[..., :3] + 1) * 127.5\n self.gcn_overlay = gcn_render_image[..., :3] * render_mask +\\\n self.train_images[..., :3] * (1 - render_mask)\n gcn_image_feat = get_img_feat('facenet_gcn', self.gcn_overlay)\n self.all_loss, self.pca_loss, self.gcn_loss, self.proj_loss, self.refine_loss, self.perc_loss, self.var_loss, self.sym_loss = self.compute_loss(\n self.train_rgbas, self.pca_render_pred, self.gcn_render_pred, self.pca_text_pred,\n self.gcn_text_pred, self.proj_color_pred, self.pca_color_pred, self.gcn_color_pred,\n image_feat, gcn_image_feat, self.regularization)\n\n test_results = self.inference(self.ph_rgbas, self.coeff_test, self.image_emb_test,\n is_training=False, reuse=True, get_inter=True)\n self.vert_test = test_results['vertice']\n self.norm_test = test_results['normal']\n self.pca_text_test = test_results['pca_texture']\n self.gcn_text_test = test_results['gcn_texture']\n self.pca_color_test = test_results['pca_color']\n self.gcn_color_test = test_results['gcn_color']\n self.proj_color_test = test_results['proj_color']\n self.pca_ren_tex_test = test_results['pca_render_text']\n self.gcn_ren_tex_test = test_results['gcn_render_text']\n self.pca_ren_clr_test = test_results['pca_render_color']\n self.gcn_ren_clr_test = test_results['gcn_render_color']\n self.lm_proj_test = test_results['lm_project']\n # render_mask_test = self._erosion2d(self.ph_rgbas[..., 3:])\n render_mask_test = self.pca_ren_clr_test[..., 3:] * self.ph_rgbas[..., 3:]\n gcn_ren_image_test = (self.gcn_ren_clr_test[..., :3] + 1) * 127.5\n self.gcn_over_test = gcn_ren_image_test[..., :3] * render_mask_test +\\\n self.input_images[..., :3] * (1 - render_mask_test)\n gcn_image_feat_test = get_img_feat('facenet_gcn_test', self.gcn_over_test)\n self.test_all_loss, self.test_pca_loss, self.test_gcn_loss, self.test_proj_loss, self.test_refine_loss, self.test_perc_loss, _, _ = self.compute_loss(\n self.ph_rgbas, self.pca_ren_clr_test, self.gcn_ren_clr_test, self.pca_text_test,\n self.gcn_text_test, self.proj_color_test, self.pca_color_test, self.gcn_color_test,\n image_feat_test, gcn_image_feat_test, self.regularization, True)\n\n self.d_loss = None\n if self.gan:\n real_image = self.train_rgbas[..., :3]\n fake_image = self.gcn_overlay / 127.5 - 1.0\n self.g_loss, self.d_loss = self.compute_gan_loss(real_image, fake_image)\n self.all_loss = self.all_loss + self.g_loss\n\n real_img_test = self.ph_rgbas[..., :3]\n fake_img_test = self.gcn_over_test / 127.5 - 1.0\n self.test_g_loss, self.test_d_loss = self.compute_gan_loss(real_img_test, fake_img_test,\n reuse=True)\n self.test_all_loss = self.test_all_loss + self.test_g_loss\n\n self.gen_train, self.dis_train = self.training(self.all_loss, self.d_loss)\n # self.op_encoder = self.encoder(self.ph_data, reuse=True)\n # self.op_decoder = self.decoder(self.ph_z, reuse=True)\n\n # Initialize variables, i.e. weights and biases.\n self.op_init = tf.global_variables_initializer()\n\n # Summaries for TensorBoard and Save for model parameters.\n self.op_summary = tf.summary.merge_all()\n\n var_all = tf.global_variables()\n trainable_vars = tf.trainable_variables()\n bn_vars = [x for x in var_all if 'BatchNorm/moving' in x.name]\n global_vars = [x for x in var_all if 'training' in x.name]\n vars_to_save = trainable_vars + bn_vars + global_vars\n self.op_saver = tf.train.Saver(var_list=vars_to_save, max_to_keep=3)\n\n logger.info('Successfully Build Graph')\n\n def inference(self, images, coeff, image_emb, is_training=True, reuse=False, get_inter=False):\n\n shape_coef, exp_coef, color_coef, angles, gamma, translation = utils.split_bfm09_coeff(coeff)\n\n # shapeMU = tf.constant(self.bfm.shapeMU, dtype=tf.float32)\n shapePC = tf.constant(self.bfm.shapePC, dtype=tf.float32)\n # expMU = tf.constant(self.bfm.expressionMU, dtype=tf.float32)\n expPC = tf.constant(self.bfm.expressionPC, dtype=tf.float32)\n colorMU = tf.constant(self.bfm.colorMU, dtype=tf.float32)\n colorPC = tf.constant(self.bfm.colorPC, dtype=tf.float32)\n\n vert_offset = tf.einsum('ij,aj->ai', shapePC, shape_coef) + tf.einsum(\n 'ij,aj->ai', expPC, exp_coef)\n vertice = tf.reshape(vert_offset, [self.batch_size, self.num_vert, 3]) + self.vert_mean\n vertice = vertice - tf.reduce_mean(self.vert_mean, axis=0, keepdims=True)\n # normal = tf.nn.l2_normalize(vertice)\n normal = self.compute_norm(vertice)\n\n rotation = utils.rotation_matrix_tf(angles)\n vert_trans = tf.matmul(vertice, rotation) + tf.reshape(translation, [self.batch_size, 1, 3])\n normal_rot = tf.matmul(normal, rotation)\n\n pca_texture = tf.einsum('ij,aj->ai', colorPC, color_coef) + colorMU\n # outputs of pca is [0, 255]\n pca_texture = tf.clip_by_value(pca_texture, 0.0, 255.0)\n pca_texture = pca_texture / 127.5 - 1\n pca_texture = tf.reshape(pca_texture, [self.batch_size, self.num_vert, 3])\n\n # outputs of mesh_decoder using tanh for activation\n\n with tf.variable_scope('render', reuse=reuse):\n camera_position = tf.constant([0, 0, 10], dtype=tf.float32)\n camera_lookat = tf.constant([0, 0, 0], dtype=tf.float32)\n camera_up = tf.constant([0, 1, 0], dtype=tf.float32)\n light_positions = tf.tile(tf.reshape(tf.constant([0, 0, 0], dtype=tf.float32), [1, 1, 3]),\n [self.batch_size, 1, 1])\n light_intensities = tf.tile(tf.reshape(tf.constant([0, 0, 0], dtype=tf.float32), [1, 1, 3]),\n [self.batch_size, 1, 1])\n fov_y = 12.5936\n ambient_color = tf.tile(tf.reshape(tf.constant([1, 1, 1], dtype=tf.float32), [1, 3]),\n [self.batch_size, 1])\n\n def postprocess(inputs):\n outputs = tf.clip_by_value(inputs, 0.0, 1.0)\n outputs = outputs * [[[[2.0, 2.0, 2.0, 1.0]]]] - [[[[1.0, 1.0, 1.0, 0.0]]]]\n return outputs\n\n # make color between 0 and 1 before rendering\n # outputs will be post processed, [-1, 1] for rgb value\n def neural_renderer(vertices, triangles, normals, diffuse_colors):\n renders, shift_vert = mesh_renderer.mesh_renderer(\n vertices=vertices, triangles=triangles, normals=normals, diffuse_colors=diffuse_colors,\n camera_position=camera_position, camera_lookat=camera_lookat, camera_up=camera_up,\n light_positions=light_positions, light_intensities=light_intensities,\n image_width=self.img_size, image_height=self.img_size, fov_y=fov_y,\n ambient_color=ambient_color)\n return postprocess(renders), shift_vert\n\n pca_render_text, shift_vert = neural_renderer(vertices=vert_trans,\n triangles=self.refer_faces[0],\n normals=normal_rot,\n diffuse_colors=(pca_texture + 1) / 2)\n pca_color = self.illumination((pca_texture + 1) / 2, normal_rot, gamma)\n\n pca_render_color, _ = neural_renderer(vertices=vert_trans, triangles=self.refer_faces[0],\n normals=normal_rot, diffuse_colors=pca_color)\n pca_color = pca_color * 2 - 1\n\n facial = tf.tan(fov_y / 360.0 * math.pi)\n facial = tf.reshape(facial, [-1, 1, 1])\n proj_vert = shift_vert[..., :3] * [[[1, -1, -1]]]\n proj_vert = proj_vert[..., :2] / facial / proj_vert[..., 2:3]\n\n eros_mask = self._erosion2d(images[..., 3:])\n eros_image = tf.concat([images[..., :3], eros_mask], axis=-1)\n lm_project = tf.gather(proj_vert, self.lm_3d_idx, axis=1)\n proj_color = self.project_color(proj_vert, eros_image)\n visiable = tf.cast(normal_rot[..., 2:3] > 0, tf.float32) * proj_color[..., 3:4]\n proj_color = tf.concat([proj_color[..., :3] * visiable, visiable], axis=-1)\n # TODO: \n # refine_input = pca_texture\n # refine_input = tf.concat([pca_texture, proj_color[..., :3]], axis=-1)\n refine_input = tf.concat([pca_texture, proj_color], axis=-1)\n gcn_texture = self.mesh_generator(image_emb, refine_input, reuse=reuse)\n\n with tf.variable_scope('render', reuse=reuse):\n gcn_render_text, _ = neural_renderer(vertices=vert_trans, triangles=self.refer_faces[0],\n normals=normal_rot, diffuse_colors=(gcn_texture + 1) / 2)\n gcn_color = self.illumination((gcn_texture + 1) / 2, normal_rot, gamma)\n gcn_render_color, _ = neural_renderer(vertices=vert_trans, triangles=self.refer_faces[0],\n normals=normal_rot, diffuse_colors=gcn_color)\n gcn_color = gcn_color * 2 - 1\n\n tf.summary.image('pca_render_text', pca_render_text, max_outputs=4)\n tf.summary.image('gcn_render_text', gcn_render_text, max_outputs=4)\n tf.summary.image('pca_render_color', pca_render_color, max_outputs=4)\n tf.summary.image('gcn_render_color', gcn_render_color, max_outputs=4)\n\n logger.info('Successfully Inferenced')\n\n return {\n # 'vertice': vert_trans,\n 'vertice': vertice,\n 'normal': normal,\n 'pca_texture': pca_texture, # [-1, 1]\n 'gcn_texture': gcn_texture, # [-1, 1]\n 'pca_color': pca_color, # [-1, 1]\n 'gcn_color': gcn_color, # [-1, 1]\n 'proj_color': proj_color, # [-1, 1]\n 'pca_render_text': pca_render_text, # [-1, 1]\n 'gcn_render_text': gcn_render_text, # [-1, 1]\n 'pca_render_color': pca_render_color, # [-1, 1]\n 'gcn_render_color': gcn_render_color, # [-1, 1]\n 'lm_project': lm_project\n }\n\n def compute_loss(self, input_image, pca_render, gcn_render, pca_texture, gcn_texture, proj_color,\n pca_color, gcn_color, input_feat, gcn_feat, regularization, get_inter=False):\n \"\"\"Adds to the inference model the layers required to generate loss.\"\"\"\n with tf.name_scope('loss'):\n with tf.name_scope('data_loss'):\n skin_mask = self._erosion2d(input_image[..., 3:])\n gcn_render_mask = tf.round(gcn_render[..., 3:]) * skin_mask\n\n # pca_render_loss = tf.losses.mean_squared_error(\n pca_render_loss = tf.losses.absolute_difference(\n predictions=pca_render[..., :3] * gcn_render_mask, labels=input_image[..., :3] *\n gcn_render_mask, reduction=tf.losses.Reduction.SUM) / tf.reduce_sum(gcn_render_mask)\n\n # gcn_render_loss = tf.losses.mean_squared_error(\n gcn_render_loss = tf.losses.absolute_difference(\n predictions=gcn_render[..., :3] * gcn_render_mask, labels=input_image[..., :3] *\n gcn_render_mask, reduction=tf.losses.Reduction.SUM) / tf.reduce_sum(gcn_render_mask)\n\n # project_loss_image = tf.losses.mean_squared_error(\n project_loss_image = tf.losses.absolute_difference(\n predictions=gcn_color * proj_color[..., 3:],\n labels=proj_color[..., :3] * proj_color[..., 3:], reduction=tf.losses.Reduction.MEAN)\n\n # project_loss_pca = tf.losses.mean_squared_error(\n project_loss_pca = tf.losses.absolute_difference(\n predictions=gcn_color * (1 - proj_color[..., 3:]),\n labels=pca_color * (1 - proj_color[..., 3:]), reduction=tf.losses.Reduction.MEAN)\n\n project_loss = project_loss_image + 0.3 * project_loss_pca\n\n # refine_loss = tf.losses.mean_squared_error(\n refine_loss = tf.losses.absolute_difference(predictions=gcn_texture, labels=pca_texture,\n reduction=tf.losses.Reduction.MEAN)\n\n perception_loss = 1 - tf.reduce_mean(utils.cosine(input_feat, gcn_feat))\n\n var_losses = []\n gcn_skin_texture = tf.gather(gcn_texture, self.bfm.skin_index, axis=1)\n for i in range(3):\n _, variance = tf.nn.moments(gcn_skin_texture[..., i], axes=1)\n var_losses.append(variance)\n var_loss = tf.reduce_mean(var_losses)\n\n sym_diff = tf.gather(gcn_texture, self.bfm.left_index, axis=1) - tf.gather(\n gcn_texture, self.bfm.right_index, axis=1)\n sym_loss = tf.reduce_mean(tf.sqrt(tf.reduce_sum(tf.square(sym_diff) + 1e-16, axis=-1)))\n\n # adj_tensor = tf.constant(self.adjacent.reshape(\n # [1, self.num_vert, self.num_vert, 1]),\n # dtype=tf.int32,\n # shape=[1, self.num_vert, self.num_vert, 1])\n # coo = self.adjacent.tocoo()\n\n # indices = np.mat([0, self.adjacent.row, self.adjacent.col, 0]).transpose()\n # values = np.ones_like(self.adjacent.data, np.float32)\n # adj_tensor = tf.SparseTensor(indices, values, self.adjacent.shape)\n # # adj_tensor = tf.SparseTensor(self.adjacent.indices,\n # # np.clip(self.adjacent.data, 0, 1),\n # # self.adjacent.shape)\n # expand = tf.ones([1, self.num_vert, self.num_vert, 3], dtype=tf.float32)\n # expand = expand * tf.expand_dims(gcn_texture, axis=1)\n # exp_trans = tf.transpose(expand, [0, 2, 1, 3])\n # # vertical = tf.ones([self.num_vert, self.num_vert, 3], dtype=tf.float32)\n # # vertical = vertical * tf.expand_dims(gcn_texture, axis=2)\n # smooth_loss = tf.abs((expand - exp_trans) * adj_tensor)\n # test = tf.sparse_to_dense(smooth_loss.indices, )\n\n #TODO: need attention\n # data_loss = self.ph_ref_lambda * refine_loss + self.ph_ren_lambda * (\n # gcn_render_loss + 0.2 * project_loss +\n # 0.2 * perception_loss) + 0.1 * sym_loss\n data_loss = self.ph_ref_lambda * refine_loss + self.ph_ren_lambda * (\n project_loss + 0.2 * perception_loss + 0.5 * sym_loss + 0.01 * var_loss)\n\n # if not get_inter:\n # self.skin_mask = skin_mask\n # self.gcn_render_mask = gcn_render_mask\n # self.gcn_render_image = gcn_render[..., :3]\n # self.input_image_rgb = input_image[..., :3]\n # self.pca_render_image = pca_render[..., :3]\n\n with tf.name_scope('regularization'):\n regularization *= tf.add_n(self.regularizers)\n loss = data_loss + regularization\n\n tf.summary.scalar('loss/data_loss', data_loss)\n tf.summary.scalar('loss/pca_render_loss', pca_render_loss)\n tf.summary.scalar('loss/gcn_render_loss', gcn_render_loss)\n tf.summary.scalar('loss/project_loss', project_loss)\n tf.summary.scalar('loss/refine_loss', refine_loss)\n tf.summary.scalar('loss/perception_loss', perception_loss)\n tf.summary.scalar('loss/var_loss', var_loss)\n tf.summary.scalar('loss/sym_loss', sym_loss)\n tf.summary.scalar('loss/regularization', regularization)\n\n logger.info('Successfully Computed Losses')\n\n return loss, pca_render_loss, gcn_render_loss, project_loss, refine_loss, perception_loss, var_loss, sym_loss\n\n def compute_gan_loss(self, real_image, fake_image, reuse=False, scale=10.0):\n t = not reuse\n real_score = self.image_disc(real_image, t, reuse=reuse)\n fake_score = self.image_disc(fake_image, t, reuse=True)\n\n epsilon = tf.random_uniform([], 0.0, 1.0)\n hat_image = epsilon * real_image + (1 - epsilon) * fake_image\n hat_score = self.image_disc(hat_image, t, reuse=True)\n hat_gradient = tf.gradients(hat_score, hat_image)[0]\n hat_gradient = tf.sqrt(tf.reduce_sum(tf.square(hat_gradient), axis=[1, 2, 3]))\n hat_gradient = tf.reduce_mean(tf.square(hat_gradient - 1.0) * scale)\n\n g_loss = -self.adv_lambda * tf.reduce_mean(fake_score)\n d_loss = self.adv_lambda * (tf.reduce_mean(fake_score) - tf.reduce_mean(real_score) +\n hat_gradient)\n\n logger.info('Successfully Computed GAN Losses')\n\n return g_loss, d_loss\n\n def training(self, g_loss, d_loss=None, decay_rate=0.98):\n \"\"\"Adds to the loss model the Ops required to generate and apply gradients.\"\"\"\n with tf.name_scope('training'):\n # Learning rate.\n global_step = tf.Variable(0, name='global_step', trainable=False)\n if decay_rate != 1:\n learning_rate = tf.train.exponential_decay(self.learning_rate, global_step,\n self.decay_steps, decay_rate, staircase=True)\n else:\n learning_rate = self.learning_rate\n\n optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)\n\n check_grads = []\n\n def check_gradients(grads):\n for i, (grad, var) in enumerate(grads):\n if grad is None:\n logger.info('warning: %s has no gradient', var.op.name)\n else:\n grads[i] = (tf.clip_by_norm(grad, 5), var)\n check_grads.append(tf.check_numerics(grad, \"error occur\"))\n\n all_vars = tf.trainable_variables()\n mesh_gen_vars = [x for x in all_vars if x.name.startswith('mesh_generator')]\n g_grads = optimizer.compute_gradients(g_loss, var_list=mesh_gen_vars)\n check_gradients(g_grads)\n\n if d_loss is not None:\n image_dis_vars = [x for x in all_vars if x.name.startswith('image_disc')]\n d_grads = optimizer.compute_gradients(d_loss, var_list=image_dis_vars)\n check_gradients(d_grads)\n\n with tf.control_dependencies(check_grads):\n op_g_grad = optimizer.apply_gradients(g_grads, global_step=global_step)\n if d_loss is not None:\n op_d_grad = optimizer.apply_gradients(d_grads, global_step=global_step)\n\n # The op return the learning rate.\n update_bn_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)\n with tf.control_dependencies([op_g_grad] + update_bn_ops):\n gen_train = tf.identity(learning_rate, name='control')\n\n dis_train = None\n if d_loss is not None:\n with tf.control_dependencies([op_d_grad] + update_bn_ops):\n dis_train = tf.identity(learning_rate, name='control')\n\n logger.info('Successfully Build Training Optimizer')\n\n return gen_train, dis_train\n\n def fit(self):\n for d in [self.ckpt_dir, self.summ_dir, self.samp_dir]:\n if not os.path.isdir(d):\n os.makedirs(d)\n\n logger.info('Start Fitting Model')\n t_process, t_wall = time.clock(), time.time()\n shutil.rmtree(self.summ_dir, ignore_errors=True)\n writer = tf.summary.FileWriter(self.summ_dir)\n # shutil.rmtree(self.ckpt_dir, ignore_errors=True)\n if not os.path.isdir(self.ckpt_dir):\n os.makedirs(self.ckpt_dir)\n path = os.path.join(self.ckpt_dir, 'model')\n if not os.path.isdir(self.samp_dir):\n os.makedirs(self.samp_dir)\n self.sess.run(self.op_init)\n\n if self.restore:\n self._restore_ckpt()\n self.restore = False\n\n val_image = utils.load_images(self.val_image_paths, self.img_size, alpha=True, landmark=False)\n\n step = 0\n for epoch in range(self.num_epochs):\n ren_lambda = np.clip(0.2 * epoch, 0, 1).astype(np.float32)\n ref_lambda = np.clip(1 - ren_lambda, 0.2, 1).astype(np.float32)\n logger.info('render_lambda: %f, refine_lambda: %f', ren_lambda, ref_lambda)\n feed_dict = {self.ph_ren_lambda: ren_lambda, self.ph_ref_lambda: ref_lambda}\n fetches = [\n self.gen_train, self.all_loss, self.pca_loss, self.gcn_loss, self.proj_loss,\n self.refine_loss, self.perc_loss, self.var_loss, self.sym_loss\n ]\n if self.gan:\n dis_fetches = fetches + [self.g_loss, self.d_loss]\n for batch in range(self.num_batches):\n try:\n train_dis = self.gan and ren_lambda > 1e-5\n # train_dis = True\n if train_dis:\n for _ in range(5):\n _ = self.sess.run(self.dis_train, feed_dict=feed_dict)\n\n _, all_loss, pca_loss, gcn_loss, proj_loss, refine_loss, perc_loss, var_loss, sym_loss, g_loss, d_loss = self.sess.run(\n dis_fetches, feed_dict=feed_dict)\n else:\n _, all_loss, pca_loss, gcn_loss, proj_loss, refine_loss, perc_loss, var_loss, sym_loss = self.sess.run(\n fetches, feed_dict=feed_dict)\n if batch % 10 == 0:\n log_str = ' all_loss: {:.3e}, pca_loss: {:.3e}, gcn_loss: {:.3e}, proj_loss: {:.3e}, refine_loss: {:.3e}, perc_loss: {:.3e}, var_loss: {:.3e}, sym_loss: {:.3e}'.format(\n all_loss, pca_loss, gcn_loss, proj_loss, refine_loss, perc_loss, var_loss, sym_loss)\n if train_dis:\n log_str += ', g_loss: {:.3e}, d_loss: {:.3e}'.format(g_loss, d_loss)\n logger.info('batch {} / {} (epoch {} / {}):'.format(batch, self.num_batches, epoch,\n self.num_epochs))\n logger.info(log_str)\n except Exception as e:\n logger.info('Error Occured in Sess Run.')\n logger.debug(e)\n\n # Periodical evaluation of the model.\n if batch % self.eval_frequency == 0:\n string, results = self.evaluate(val_image)\n logger.info(' validation {}'.format(string))\n logger.info(' time: {:.0f}s (wall {:.0f}s)'.format(time.clock() - t_process,\n time.time() - t_wall))\n self.save_sample(results, step, val_image, idx=0)\n\n # Summaries for TensorBoard.\n summary = tf.Summary(\n value=[tf.Summary.Value(tag='validation/loss', simple_value=results['all_loss'])])\n writer.add_summary(summary, step)\n\n # Save model parameters (for evaluation).\n self.op_saver.save(self.sess, path, global_step=step)\n step += 1\n\n writer.close()\n\n def save_sample(self, results, step, val_image, val_landmark=None, sample_dir=None, idx=0,\n only_skin=False):\n if sample_dir is None:\n sample_dir = self.samp_dir\n\n input_image = utils.img_denormalize(val_image[idx])\n vertice = results['vertices'][idx]\n normal = results['normals'][idx]\n pca_texture = utils.img_denormalize(results['pca_texts'][idx])\n gcn_texture = utils.img_denormalize(results['gcn_texts'][idx])\n pca_color = utils.img_denormalize(results['pca_colors'][idx])\n gcn_color = utils.img_denormalize(results['gcn_colors'][idx])\n proj_color = utils.img_denormalize(results['proj_color'][idx])\n pca_ren_tex = utils.img_denormalize(results['pca_ren_texs'][idx])\n gcn_ren_tex = utils.img_denormalize(results['gcn_ren_texs'][idx])\n pca_ren_clr = utils.img_denormalize(results['pca_ren_clrs'][idx])\n gcn_ren_clr = utils.img_denormalize(results['gcn_ren_clrs'][idx])\n lm_proj = results['lm_projs'][idx]\n\n # input_image = np.clip(\n # input_image.astype(np.int32) + [[[0, 0, 0, 64]]], 0,\n # 255).astype(np.uint8)\n imageio.imsave(os.path.join(sample_dir, '{}_input.png'.format(step)), input_image[..., :3])\n # imageio.imsave(os.path.join(sample_dir, '{}_mask.png'.format(step)),\n # input_image[..., 3])\n if val_landmark is None:\n lm_image = input_image[..., :3]\n else:\n lm_image = utils.draw_image_with_lm(None, input_image[..., :3], val_landmark[idx],\n self.img_size, (0, 0, 255))\n utils.draw_image_with_lm(os.path.join(sample_dir, '{}_lm_proj.png'.format(step)), lm_image,\n lm_proj, self.img_size)\n\n render_mask = pca_ren_clr[:, :, 3:] // 255\n if only_skin:\n render_mask = render_mask * (input_image[..., 3:] // 255)\n # render_mask = cv2.erode(render_mask, np.ones((5, 5), dtype=np.uint8), iterations=5)\n\n imageio.imsave(os.path.join(sample_dir, '{}_mask.png'.format(step)), render_mask * 255)\n\n def save_render(inputs, name, draw_lm=False):\n image = inputs[:, :, :3] * render_mask + input_image[:, :, :3] * (1 - render_mask)\n if draw_lm:\n utils.draw_image_with_lm(os.path.join(sample_dir, name), image, lm_proj, self.img_size)\n else:\n imageio.imsave(os.path.join(sample_dir, name), image)\n\n # imageio.imsave(os.path.join(sample_dir, '{}_gcn.png'.format(step)), gcn_ren_clr)\n save_render(pca_ren_tex, '{}_pca_ren_tex.png'.format(step))\n save_render(gcn_ren_tex, '{}_gcn_ren_tex.png'.format(step))\n save_render(pca_ren_clr, '{}_pca_ren_clr.png'.format(step))\n save_render(gcn_ren_clr, '{}_gcn_ren_clr.png'.format(step))\n\n write_obj(os.path.join(sample_dir, '{}_pca_texture.obj'.format(step)), vertice,\n self.refer_meshes[0]['faces'], pca_texture, normal)\n write_obj(os.path.join(sample_dir, '{}_gcn_texture.obj'.format(step)), vertice,\n self.refer_meshes[0]['faces'], gcn_texture, normal)\n write_obj(os.path.join(sample_dir, '{}_pca_color.obj'.format(step)), vertice,\n self.refer_meshes[0]['faces'], pca_color, normal)\n write_obj(os.path.join(sample_dir, '{}_gcn_color.obj'.format(step)), vertice,\n self.refer_meshes[0]['faces'], gcn_color, normal)\n write_obj(os.path.join(sample_dir, '{}_proj_color.obj'.format(step)), vertice,\n self.refer_meshes[0]['faces'], proj_color, normal)\n logger.info('Sample %s saved!', step)\n\n def evaluate(self, images):\n # t_process, t_wall = time.clock(), time.time()\n\n size = images.shape[0]\n result_list = []\n\n for begin in range(0, size, self.batch_size):\n end = begin + self.batch_size\n end = min([end, size])\n batch_image = np.zeros((self.batch_size, images.shape[1], images.shape[2], images.shape[3]))\n tmp_image = images[begin:end]\n batch_image[:end - begin] = tmp_image\n # batch_landmark = None\n # if landmarks is not None:\n # batch_landmark = np.zeros((self.batch_size, len(self.lm_3d_idx), 2))\n # tmp_landmark = landmarks[begin:end]\n # batch_landmark[:end - begin] = tmp_landmark\n\n result = self.predict(batch_image)\n result_list.append(result)\n\n results = {\n 'vertices': np.concatenate([x['vertice'] for x in result_list]),\n 'normals': np.concatenate([x['normal'] for x in result_list]),\n 'pca_texts': np.concatenate([x['pca_text'] for x in result_list]),\n 'gcn_texts': np.concatenate([x['gcn_text'] for x in result_list]),\n 'pca_colors': np.concatenate([x['pca_color'] for x in result_list]),\n 'gcn_colors': np.concatenate([x['gcn_color'] for x in result_list]),\n 'proj_color': np.concatenate([x['proj_color'] for x in result_list]),\n 'pca_ren_texs': np.concatenate([x['pca_ren_tex'] for x in result_list]),\n 'gcn_ren_texs': np.concatenate([x['gcn_ren_tex'] for x in result_list]),\n 'pca_ren_clrs': np.concatenate([x['pca_ren_clr'] for x in result_list]),\n 'gcn_ren_clrs': np.concatenate([x['gcn_ren_clr'] for x in result_list]),\n 'lm_projs': np.concatenate([x['lm_proj'] for x in result_list]),\n 'all_loss': np.mean([x['all_loss'] for x in result_list]),\n 'pca_loss': np.mean([x['pca_loss'] for x in result_list]),\n 'gcn_loss': np.mean([x['gcn_loss'] for x in result_list]),\n 'proj_loss': np.mean([x['proj_loss'] for x in result_list]),\n 'refine_loss': np.mean([x['refine_loss'] for x in result_list]),\n 'perc_loss': np.mean([x['perc_loss'] for x in result_list]),\n }\n\n string = 'loss: {:.3e}, pca_loss:{:.3e}, gcn_loss:{:.3e}, proj_loss:{:.3e}, refine_loss:{:.3e}, perc_loss:{:.3e}'.format(\n result['all_loss'], result['pca_loss'], result['gcn_loss'], result['proj_loss'],\n result['refine_loss'], result['perc_loss'])\n\n if self.gan:\n results['g_loss'] = np.mean([x['g_loss'] for x in result_list])\n results['d_loss'] = np.mean([x['d_loss'] for x in result_list])\n string += ', g_loss:{:.3e}, d_loss:{:.3e}'.format(results['g_loss'], results['d_loss'])\n return string, results\n\n def predict(self, images):\n if not isinstance(images, np.ndarray):\n images = np.array(images)\n\n if self.restore:\n self._restore_ckpt()\n self.restore = False\n\n fetches = [\n self.vert_test, self.norm_test, self.pca_text_test, self.gcn_text_test, self.pca_color_test,\n self.gcn_color_test, self.proj_color_test, self.pca_ren_tex_test, self.gcn_ren_tex_test,\n self.pca_ren_clr_test, self.gcn_ren_clr_test, self.lm_proj_test, self.test_all_loss,\n self.test_pca_loss, self.test_gcn_loss, self.test_proj_loss, self.test_refine_loss,\n self.test_perc_loss\n ]\n feed_dict = {\n self.ph_rgbas: images,\n # self.ph_2dlms: landmarks,\n self.ph_ren_lambda: 1,\n self.ph_ref_lambda: 1\n }\n\n # coeff, feat, emb, resize = self.sess.run([\n # self.coeff_test, self.image_feat_test, self.image_emb_test,\n # self.resize_input\n # ],\n # feed_dict=feed_dict)\n # imageio.imwrite('test1.png', resize[0].astype(np.uint8))\n\n if self.gan:\n fetches += [self.test_g_loss, self.test_d_loss]\n vertice, normal, pca_text, gcn_text, pca_color, gcn_color, proj_color, pca_ren_tex,\\\n gcn_ren_tex, pca_ren_clr, gcn_ren_clr, lm_proj, all_loss, pca_loss, gcn_loss,\\\n proj_loss, refine_loss, perc_loss, g_loss, d_loss = self.sess.run(\n fetches, feed_dict)\n else:\n vertice, normal, pca_text, gcn_text, pca_color, gcn_color, proj_color, pca_ren_tex,\\\n gcn_ren_tex, pca_ren_clr, gcn_ren_clr, lm_proj, all_loss, pca_loss, gcn_loss,\\\n proj_loss, refine_loss, perc_loss = self.sess.run(fetches, feed_dict)\n\n result = {\n 'vertice': vertice,\n 'normal': normal,\n 'pca_text': pca_text,\n 'gcn_text': gcn_text,\n 'pca_color': pca_color,\n 'gcn_color': gcn_color,\n 'proj_color': proj_color,\n 'pca_ren_tex': pca_ren_tex,\n 'gcn_ren_tex': gcn_ren_tex,\n 'pca_ren_clr': pca_ren_clr,\n 'gcn_ren_clr': gcn_ren_clr,\n 'lm_proj': lm_proj,\n 'all_loss': all_loss,\n 'pca_loss': pca_loss,\n 'gcn_loss': gcn_loss,\n 'proj_loss': proj_loss,\n 'refine_loss': refine_loss,\n 'perc_loss': perc_loss\n }\n\n if self.gan:\n result['g_loss'] = g_loss\n result['d_loss'] = d_loss\n\n return result\n\n def load_image(self, filename):\n return utils.load_image(filename, self.img_size, True, True)\n\n def load_image_bin(self, start_idx):\n image_len = 4 * self.img_size * self.img_size * 4\n return utils.load_image_bin(start_idx, self.img_file, image_len, self.img_size)\n\n def _erosion2d(self, inputs):\n # outputs = inputs\n outputs = tf.nn.dilation2d(inputs, self.dilation_kernel, [1, 1, 1, 1], [1, 1, 1, 1], 'SAME') - 1\n for _ in range(2):\n outputs = tf.nn.erosion2d(outputs, self.erosion_kernel, [1, 1, 1, 1], [1, 1, 1, 1],\n 'SAME') + 1\n return outputs\n\n def _restore_ckpt(self):\n # if self.serv_restore:\n # filename = tf.train.latest_checkpoint(\n # os.path.join(self.root_dir, self.ckpt_dir))\n # else:\n filename = tf.train.latest_checkpoint(self.ckpt_dir)\n if filename:\n self.op_saver.restore(self.sess, filename)\n logger.info('======================================')\n logger.info('Restored checkpoint from %s', filename)\n logger.info('======================================')\n\n def _weight_variable(self, shape, regularization=True, initial=None):\n # initial = tf.truncated_normal_initializer(0, 0.1)\n if initial is None:\n try:\n initial = tf.initializers.he_normal()\n except AttributeError:\n initial = tf.contrib.layers.variance_scaling_initializer(dtype=tf.float32)\n var = tf.get_variable('weights', shape, tf.float32, initializer=initial)\n if regularization:\n self.regularizers.append(tf.nn.l2_loss(var))\n # tf.summary.histogram(var.op.name, var)\n return var\n\n def _bias_variable(self, shape, regularization=True, initial=tf.zeros_initializer()):\n # initial=tf.constant_initializer(0.1)):\n var = tf.get_variable('bias', shape, tf.float32, initializer=initial)\n if regularization:\n self.regularizers.append(tf.nn.l2_loss(var))\n # tf.summary.histogram(var.op.name, var)\n return var\n\n def chebyshev5(self, inputs, L, Fout, K):\n # if not hasattr(self, 'InterX'):\n # self.InterX = x\n N, M, Fin = inputs.get_shape()\n N, M, Fin = int(N), int(M), int(Fin)\n # Rescale Laplacian and store as a TF sparse tensor. Copy to not modify the shared L.\n L = scipy.sparse.csr_matrix(L)\n L = graph.rescale_L(L, 2)\n L = L.tocoo()\n indices = np.column_stack((L.row, L.col))\n L = tf.SparseTensor(indices, L.data, L.shape)\n L = tf.sparse_reorder(L)\n # Transform to Chebyshev basis\n x0 = tf.transpose(inputs, perm=[1, 2, 0]) # M x Fin x N\n x0 = tf.reshape(x0, [M, Fin * N]) # M x Fin*N\n x = tf.expand_dims(x0, 0) # 1 x M x Fin*N\n\n def concat(x, x_):\n x_ = tf.expand_dims(x_, 0) # 1 x M x Fin*N\n return tf.concat([x, x_], axis=0) # K x M x Fin*N\n\n if K > 1:\n x1 = tf.sparse_tensor_dense_matmul(L, x0)\n x = concat(x, x1)\n for _ in range(2, K):\n x2 = 2 * tf.sparse_tensor_dense_matmul(L, x1) - x0 # M x Fin*N\n x = concat(x, x2)\n x0, x1 = x1, x2\n x = tf.reshape(x, [K, M, Fin, N]) # K x M x Fin x N\n x = tf.transpose(x, perm=[3, 1, 2, 0]) # N x M x Fin x K\n x = tf.reshape(x, [N * M, Fin * K]) # N*M x Fin*K\n # Filter: Fin*Fout filters of order K, i.e. one filterbank per feature pair.\n W = self._weight_variable([Fin * K, Fout], regularization=False)\n x = tf.matmul(x, W) # N*M x Fout\n return tf.reshape(x, [N, M, Fout]) # N x M x Fout\n\n def cheb_res_block(self, inputs, L, Fout, K, relu=True):\n _, _, Fin = inputs.get_shape().as_list()\n if Fin != Fout:\n with tf.variable_scope('shortcut'):\n shortcut = self.chebyshev5(inputs, L, Fout, 1)\n else:\n shortcut = inputs\n\n with tf.variable_scope('filter1'):\n x = self.chebyshev5(inputs, L, Fout, K)\n with tf.variable_scope('bias_relu1'):\n x = self.brelu(x)\n\n with tf.variable_scope('filter2'):\n x = self.chebyshev5(x, L, Fout, K)\n x = tf.add(x, shortcut)\n if relu:\n with tf.variable_scope('bias_relu2'):\n x = self.brelu(x)\n\n # with tf.variable_scope('filter3'):\n # x = self.chebyshev5(x, L, 3, K)\n # if tanh:\n # x = tf.nn.tanh(x)\n\n return x\n\n def b1relu(self, inputs):\n \"\"\"Bias and ReLU. One bias per filter.\"\"\"\n # N, M, F = x.get_shape()\n _, _, F = inputs.get_shape()\n b = self._bias_variable([1, 1, int(F)], regularization=False)\n #TODO replace with tf.nn.elu\n # return tf.nn.relu(inputs + b)\n return tf.nn.elu(inputs + b)\n\n def b2relu(self, inputs):\n \"\"\"Bias and ReLU. One bias per vertex per filter.\"\"\"\n # N, M, F = x.get_shape()\n _, M, F = inputs.get_shape()\n b = self._bias_variable([1, int(M), int(F)], regularization=False)\n return tf.nn.relu(inputs + b)\n\n def poolwT(self, inputs, L):\n Mp = L.shape[0]\n N, M, Fin = inputs.get_shape()\n N, M, Fin = int(N), int(M), int(Fin)\n # Rescale transform Matrix L and store as a TF sparse tensor. Copy to not modify the shared L.\n L = scipy.sparse.csr_matrix(L)\n L = L.tocoo()\n indices = np.column_stack((L.row, L.col))\n L = tf.SparseTensor(indices, L.data, L.shape)\n L = tf.sparse_reorder(L)\n\n x = tf.transpose(inputs, perm=[1, 2, 0]) # M x Fin x N\n x = tf.reshape(x, [M, Fin * N]) # M x Fin*N\n x = tf.sparse_tensor_dense_matmul(L, x) # Mp x Fin*N\n x = tf.reshape(x, [Mp, Fin, N]) # Mp x Fin x N\n x = tf.transpose(x, perm=[2, 0, 1]) # N x Mp x Fin\n\n return x\n\n def fc(self, inputs, Mout, relu=True):\n \"\"\"Fully connected layer with Mout features.\"\"\"\n # N, Min = x.get_shape()\n _, Min = inputs.get_shape()\n W = self._weight_variable([int(Min), Mout], regularization=True)\n b = self._bias_variable([Mout], regularization=True)\n x = tf.matmul(inputs, W) + b\n return tf.nn.relu(x) if relu else x\n\n def conv2d(self, inputs, f_out, kernel, stride, padding='SAME', batch_norm=True, lrelu=True,\n is_training=True, name='conv2d'):\n with tf.variable_scope(name):\n _, _, _, f_in = inputs.get_shape()\n W = self._weight_variable([kernel, kernel, f_in, f_out])\n b = self._bias_variable([f_out])\n # b = self._bias_variable([1, 28, 28, self.F])\n # x_2d = tf.reshape(x, [-1,28,28,1])\n x = tf.nn.conv2d(inputs, W, strides=[1, stride, stride, 1], padding=padding) + b\n if batch_norm:\n x = tf.contrib.layers.batch_norm(x, decay=0.9, zero_debias_moving_mean=True,\n is_training=is_training, trainable=True)\n return tf.nn.leaky_relu(x) if lrelu else x\n\n def compute_norm(self, vertice):\n # vertex index for each triangle face, with shape [F,3], F is number of faces\n face_id = self.refer_faces[0]\n # adjacent face index for each vertex, with shape [N,8], N is number of vertex\n point_id = self.bfm.point_buf - 1\n point_id = tf.reshape(point_id, [-1])\n v1 = tf.gather(vertice, face_id[:, 0], axis=1)\n v2 = tf.gather(vertice, face_id[:, 1], axis=1)\n v3 = tf.gather(vertice, face_id[:, 2], axis=1)\n e1 = v1 - v2\n e2 = v2 - v3\n\n face_norm = tf.cross(e1, e2) # compute normal for each face\n # concat face_normal with a zero vector at the end\n face_norm = tf.concat([face_norm, tf.zeros([self.batch_size, 1, 3], dtype=tf.float32)], axis=1)\n v_norms = tf.gather(face_norm, point_id, axis=1)\n # compute vertex normal using one-ring neighborhood\n v_norm = tf.reduce_sum(tf.reshape(v_norms, [self.batch_size, self.num_vert, 8, 3]), axis=2)\n # normalize normal vectors\n v_norm = v_norm / tf.expand_dims(tf.linalg.norm(v_norm, axis=2), 2)\n\n return v_norm\n\n def project_color(self, proj_vert, image):\n half_size = self.img_size // 2\n vertice = tf.cast(tf.round(proj_vert * half_size + half_size), np.int32)\n flatten_image = tf.reshape(image, [self.batch_size, self.img_size * self.img_size, -1])\n x_coords = tf.clip_by_value(vertice[..., 1], 0, self.img_size - 1)\n y_coords = tf.clip_by_value(vertice[..., 0], 0, self.img_size - 1)\n coords = x_coords * self.img_size + y_coords\n # proj_color = tf.gather_nd(flatten_image, coords)\n proj_color = utils.batch_gather(flatten_image, coords)\n return proj_color\n\n def illumination(self, face_tex, norm, gamma):\n # input face_tex should be [0, 1] with RGB channels\n face_texture = face_tex * 255.0\n\n init_lit = tf.constant([0.8, 0, 0, 0, 0, 0, 0, 0, 0], dtype=tf.float32)\n gamma = tf.reshape(gamma, [-1, 3, 9])\n gamma = gamma + tf.reshape(init_lit, [1, 1, 9])\n\n a0 = np.pi\n a1 = 2 * np.pi / tf.sqrt(3.0)\n a2 = 2 * np.pi / tf.sqrt(8.0)\n c0 = 1 / tf.sqrt(4 * np.pi)\n c1 = tf.sqrt(3.0) / tf.sqrt(4 * np.pi)\n c2 = 3 * tf.sqrt(5.0) / tf.sqrt(12 * np.pi)\n\n Y_shape = [self.batch_size, self.num_vert, 1]\n Y0 = tf.tile(tf.reshape(a0 * c0, [1, 1, 1]), Y_shape)\n Y1 = tf.reshape(-a1 * c1 * norm[:, :, 1], Y_shape)\n Y2 = tf.reshape(a1 * c1 * norm[:, :, 2], Y_shape)\n Y3 = tf.reshape(-a1 * c1 * norm[:, :, 0], Y_shape)\n Y4 = tf.reshape(a2 * c2 * norm[:, :, 0] * norm[:, :, 1], Y_shape)\n Y5 = tf.reshape(-a2 * c2 * norm[:, :, 1] * norm[:, :, 2], Y_shape)\n Y6 = tf.reshape(a2 * c2 * 0.5 / tf.sqrt(3.0) * (3 * tf.square(norm[:, :, 2]) - 1), Y_shape)\n Y7 = tf.reshape(-a2 * c2 * norm[:, :, 0] * norm[:, :, 2], Y_shape)\n Y8 = tf.reshape(a2 * c2 * 0.5 * (tf.square(norm[:, :, 0]) - tf.square(norm[:, :, 1])), Y_shape)\n Y = tf.concat([Y0, Y1, Y2, Y3, Y4, Y5, Y6, Y7, Y8], axis=2)\n\n lit_r = tf.squeeze(tf.matmul(Y, tf.expand_dims(gamma[:, 0, :], 2)), 2)\n # [batch,N,9] * [batch,9,1] = [batch,N]\n lit_g = tf.squeeze(tf.matmul(Y, tf.expand_dims(gamma[:, 1, :], 2)), 2)\n lit_b = tf.squeeze(tf.matmul(Y, tf.expand_dims(gamma[:, 2, :], 2)), 2)\n\n face_color = tf.stack([\n lit_r * face_texture[:, :, 0], lit_g * face_texture[:, :, 1], lit_b * face_texture[:, :, 2]\n ], axis=2)\n # lighting = np.stack([lit_r, lit_g, lit_b], axis=2) * 128\n\n return tf.clip_by_value(face_color / 255.0, 0.0, 1.0)\n\n def mesh_generator(self, *args, **kwargs):\n raise NotImplementedError()\n\n def image_disc(self, *args, **kwargs):\n raise NotImplementedError()\n"
},
{
"alpha_fraction": 0.6658905744552612,
"alphanum_fraction": 0.6670547127723694,
"avg_line_length": 30.814815521240234,
"blob_id": "0659d8207c84731ebd562fc75ed394c60d90513e",
"content_id": "055619c673edf1f5668983672f2ae7697fc39ede",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 859,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 27,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/data/__init__.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n# system\nfrom __future__ import print_function\n\n# python lib\nimport importlib\n\ndef find_dataloader_using_name(dataset_name):\n # Given the option --dataset [datasetname],\n # the file \"datasets/datasetname_dataset.py\"\n # will be imported.\n dataset_filename = \"src_common.data.\" + dataset_name\n datasetlib = importlib.import_module(dataset_filename)\n\n # In the file, the class called DatasetNameDataset() will\n # be instantiated. It has to be a subclass of BaseDataset,\n # and it is case-insensitive.\n dataloader = None\n for name, cls in datasetlib.__dict__.items():\n if name == \"DataLoader\":\n dataloader = cls\n\n if dataloader is None:\n print(\"In %s.py, there should be a right class name that matches %s in lowercase.\" % (\n dataset_filename, \"DataLoader\"))\n exit(0)\n\n return dataloader"
},
{
"alpha_fraction": 0.7132148742675781,
"alphanum_fraction": 0.7368128895759583,
"avg_line_length": 52.761192321777344,
"blob_id": "5baf624c524454be6984e4ba16538919c79fd4fb",
"content_id": "34d1ca64049696412ccf43fd88ab94935eda7d20",
"detected_licenses": [
"MIT",
"GPL-3.0-only"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3608,
"license_type": "permissive",
"max_line_length": 221,
"num_lines": 67,
"path": "/Face-Emotions-Recognition/Eye-Blink-Counter/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Eye Blinking detection\n\n## When is the eye blinking?\n\nIf you think about this question, what possible explanation could you give to describe the blinking of the eyes? Probably more then one answer will be right.\n\nLet’s do some brainstorming to define an eye that is blinking.\n\n<h4>An eye is blinking when:</h4>\n<ul>\n<li>The eyelid is closed\n<li>We can’t see the eyeball anymore\n<li>Bottom and upper eyelashes connect together\n</ul>\n\nAnd also we need to take into account that all this actions must happen for a short amount of time (approximately a blink of an eye takes 0.3 to 0.4 seconds) otherwise it meas that the eye is just closed.\n\nNow that we have found some possible answer to detect the blinking of the eye, we should focus on what’s possible to detect using Opencv, possibly choosing the easiest and most reliable solution with what we already have.\n\n## Detecting the blinking\n\nThis is how the lines look like when the eye is open.\n<img src=\"https://github.com/akshitagupta15june/Face-X/blob/master/Face-Emotions-Recognition/Eye-Blink-Counter/images/eye_open.jpg\" align=\"centre\">\n\nThis when the eye is closed.\n<img src=\"https://github.com/akshitagupta15june/Face-X/blob/master/Face-Emotions-Recognition/Eye-Blink-Counter/images/eye_closed.jpg\" align=\"centre\">\n\n<h4>What can you notice?</h4>\n\nWe can clearly see that the size of the horizontal line is almost identical in the closed eye and in the open eye while the vertical line is much longer in the open eye in coparison with the closed eye.\nIn the closed eye, the vertical line almost disappears.\n\nWe will take then the horizontal line as the point of reference, and from this we calculate the ratio in comparison with the vertical line.\nIf the the ratio goes below a certain number we will consider the eye to be closed, otherwise open.\n\nOn python then we create a function to detect the blinking ratio where we insert the eye points and the facial landmark coordinates and we will get the ratio between these two lines.\n\n```bash\ndef get_blinking_ratio(eye_points, facial_landmarks):\n left_point = (facial_landmarks.part(eye_points[0]).x, facial_landmarks.part(eye_points[0]).y)\n right_point = (facial_landmarks.part(eye_points[3]).x, facial_landmarks.part(eye_points[3]).y)\n center_top = midpoint(facial_landmarks.part(eye_points[1]), facial_landmarks.part(eye_points[2]))\n center_bottom = midpoint(facial_landmarks.part(eye_points[5]), facial_landmarks.part(eye_points[4]))\n\n hor_line = cv2.line(frame, left_point, right_point, (0, 255, 0), 2)\n ver_line = cv2.line(frame, center_top, center_bottom, (0, 255, 0), 2)\n\n hor_line_lenght = hypot((left_point[0] - right_point[0]), (left_point[1] - right_point[1]))\n ver_line_lenght = hypot((center_top[0] - center_bottom[0]), (center_top[1] - center_bottom[1]))\n\n ratio = hor_line_lenght / ver_line_lenght\n return ratio\n```\n\nWe will then use the ratio number later to detect and we can finally define when the eye is blinking or not.\nIn this case I found ratio number 5.7 to be the most reiable threshold, at least for my eye.\n\n```bash\nlandmarks = predictor(gray, face)\n left_eye_ratio = get_blinking_ratio([36, 37, 38, 39, 40, 41], landmarks)\n right_eye_ratio = get_blinking_ratio([42, 43, 44, 45, 46, 47], landmarks)\n blinking_ratio = (left_eye_ratio + right_eye_ratio) / 2\n if blinking_ratio > 5.7:\n cv2.putText(frame, \"BLINKING\", (50, 150), font, 7, (255, 0, 0))\n```\n\n<img src=\"https://github.com/akshitagupta15june/Face-X/blob/master/Face-Emotions-Recognition/Eye-Blink-Counter/images/working.png\" align=\"centre\">\n"
},
{
"alpha_fraction": 0.6900250315666199,
"alphanum_fraction": 0.7912048697471619,
"avg_line_length": 41.3636360168457,
"blob_id": "c9c456da09e92f8db3abc3ea3de0ff2304dd1888",
"content_id": "9b1974c807d9b5497fc07f829b79d7cf75b94cfd",
"detected_licenses": [
"BSD-3-Clause",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2797,
"license_type": "permissive",
"max_line_length": 435,
"num_lines": 66,
"path": "/Awesome-face-operations/Gender_Classification/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Gender Detection\n\n\n#### Table of contents\n\n- Introduction\n- Dataset\n- Implementation\n- Outputs\n- Running procedure\n- Dependencies\n\n\n### Introduction\n\nIn these modern days, gender recognition from facial image has been a crucial topic. To solve \nsuch delicate problem several handy approaches are being studied in Computer Vision. However, \nmost of these approaches hardly achieve high accuracy and precision. Lighting, illumination, \nproper face area detection, noise, ethnicity and various facial expressions hinder the correctness \nof the research. Therefore, we propose a simple gender recognition system from facial image \nwhere we first detect faces from a scene using Haar Feature Based Cascade Classifier then introducing it to the model architecture. The face detection goal is achieved by OpenCV.\n\n\n### Dataset\n\nUTKFace dataset is a large-scale face dataset with long age span (range from 0 to 116 years old). The dataset consists of over 20,000 face images with annotations of age, gender, and ethnicity. The images cover large variation in pose, facial expression, illumination, occlusion, resolution, etc. This dataset could be used on a variety of tasks, e.g., face detection, age estimation, age progression/regression, landmark localization.\n\nlink to download dataset: https://www.kaggle.com/jangedoo/utkface-new\n\n\n\n### Implementation\n\n- ##### Model Architecture\n \n\n- ##### Data Augmentation\n Data augmentation can be used to address both the requirements, the diversity of the training data, and the amount of data. Besides these two, augmented data can also be used to address the class imbalance problem in classification tasks.In order to increase the model ability to detect the gender from different point of views , we decided to use the data augmentation concept.\n\n\n\n\n\n### Outputs\n\n\n\n\n\n\n\n\n\n### Dependencies\n- tensorflow 2.4.1\n- openCV\n- Numpy\n- OS\n- Matplotlib\n\n\n### Running Procedure\n- Clone the Repository \n- Open your notebook\n- check paths for the test data\n- Enjoy the experience \n"
},
{
"alpha_fraction": 0.5208333134651184,
"alphanum_fraction": 0.7166666388511658,
"avg_line_length": 17.461538314819336,
"blob_id": "256b78d324be62fdf4bde376977971e32f308ff2",
"content_id": "9b1e15f0c280341e95466bf9719770f38e8da1bd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 240,
"license_type": "permissive",
"max_line_length": 28,
"num_lines": 13,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/requirements.txt",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "torch==0.4.0\nface-alignment\nh5py==2.10.0\nmatplotlib==2.2.4\nnumpy==1.16.6\nopencv-python==3.4.2.17\nscikit-image==0.14.5\nscikit-learn==0.20.3\nscipy==1.2.2\ntensorboard==1.13.1\ntensorflow-estimator==1.13.0\ntensorflow-gpu==2.4.0\ntrimesh==2.38.40\n"
},
{
"alpha_fraction": 0.6490885615348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 40.5405387878418,
"blob_id": "f79078fc19cf4a8d4750e2bfd837c5636340e164",
"content_id": "3df8d7151591044a68f741d32075afb804c71ed5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1536,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 37,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/geometry/covisible.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# encoding: utf-8\n'''\n@author: Jiaxiang Shang\n@license: (C) Copyright 2013-2017, Node Supply Chain Manager Corporation Limited.\n@contact: [email protected]\n@time: 3/16/20 1:28 PM\n@desc:\n'''\nimport tensorflow as tf\n\ndef mm_covisible_tri(h_lrgp, tri_ids_tar, tri_ids_src):\n batch_size = h_lrgp.batch_size\n\n tri_ids_tar = tf.reshape(tri_ids_tar, [-1])\n ver_ids_tar = tf.gather(h_lrgp.h_fore.mesh_tri, tri_ids_tar) # vertex idx\n ver_ids_tar = tf.reshape(ver_ids_tar, [batch_size, -1])\n\n tri_ids_src = tf.reshape(tri_ids_src, [batch_size, -1])\n ver_ids_src = tf.gather(h_lrgp.h_fore.mesh_tri, tri_ids_src)\n ver_ids_src = tf.reshape(ver_ids_src, [batch_size, -1])\n\n ver_ids_consistency = tf.sets.set_intersection(ver_ids_tar, ver_ids_src, False)\n ver_ids_consistency = tf.sparse_tensor_to_dense(ver_ids_consistency, validate_indices=False) # bs, h*w*3\n\n tri_consistency = []\n for j in range(batch_size):\n # find adjacent triangle for robust\n tri_ids_consistency_b = tf.gather(h_lrgp.h_fore.mesh_vertex_refer_face_pad, ver_ids_consistency[j]) # num, 8\n tri_ids_consistency_b = tf.reshape(tri_ids_consistency_b, [-1])\n tri_consistency_b = tf.gather(h_lrgp.h_fore.mesh_tri, tri_ids_consistency_b) # vertex idx\n # [4w 3]\n # tri_consistency_b = tf.Print(tri_consistency_b, [tf.shape(tri_consistency_b)], message='tri_consistency')\n tri_consistency.append(tri_consistency_b)\n tri_consistency = tf.stack(tri_consistency, axis=0)\n\n return tri_consistency"
},
{
"alpha_fraction": 0.6392157077789307,
"alphanum_fraction": 0.6784313917160034,
"avg_line_length": 24.5,
"blob_id": "9db7051875fcdba1f5e1471309de6f553a43932b",
"content_id": "93c4014b61be28bc31dcc9478b617872f94b94b4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 255,
"license_type": "permissive",
"max_line_length": 40,
"num_lines": 10,
"path": "/Face Reconstruction/Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model/toy_example/mesh_to_vertex.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# To obtain vertices of 3D faces \".obj\"\n\nimport openmesh as om\nimport numpy as np\n\nmesh = om.read_trimesh(\"mean_face.obj\")\nvertex = np.zeros((3,6144), dtype=float)\nfor i in range(6144):\n vertex[:, i] = mesh.points()[i]\nnp.save(\"mean_face.npy\", vertex)\n"
},
{
"alpha_fraction": 0.6831476092338562,
"alphanum_fraction": 0.7090877294540405,
"avg_line_length": 24.524444580078125,
"blob_id": "99e987304a10f83481938b4af874d5d0149d607e",
"content_id": "5e260f7182309444ecf5de1ad860af7cfed9e7a0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5744,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 225,
"path": "/Face-Detection/Face detection using OpenCV/Face-Detection.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# ### Importing Required Liberaries\n# Following libraries must be import first to run the codes \n\n# In[1]:\n\n#import required libraries \nimport numpy as np\nimport cv2\nimport matplotlib.pyplot as plt\nimport time\n\n# In[2]:\n\ndef convertToRGB(img):\n return cv2.cvtColor(img, cv2.COLOR_BGR2RGB)\n\n# In[3]:\n\n#load cascade classifier training file for haarcascade\nhaar_face_cascade = cv2.CascadeClassifier('data/haarcascade_frontalface_alt.xml')\n\n#load test iamge\ntest1 = cv2.imread('data/test1.jpg')\n\n#convert the test image to gray image as opencv face detector expects gray images\ngray_img = cv2.cvtColor(test1, cv2.COLOR_BGR2GRAY)\nplt.imshow(gray_img, cmap='gray')\n\n# In[4]:\n\n#let's detect multiscale (some images may be closer to camera than others) images\nfaces = haar_face_cascade.detectMultiScale(gray_img, scaleFactor=1.1, minNeighbors=5);\n\n#print the number of faces found\nprint('Faces found: ', len(faces))\n\n# In[5]:\n\n#go over list of faces and draw them as rectangles on original colored img\nfor (x, y, w, h) in faces:\n cv2.rectangle(test1, (x, y), (x+w, y+h), (0, 255, 0), 2)\n\n# In[6]:\n\n#conver image to RGB and show image\nplt.imshow(convertToRGB(test1))\n\n# In[7]:\n\ndef detect_faces(f_cascade, colored_img, scaleFactor = 1.1):\n img_copy = np.copy(colored_img)\n #convert the test image to gray image as opencv face detector expects gray images\n gray = cv2.cvtColor(img_copy, cv2.COLOR_BGR2GRAY)\n \n #let's detect multiscale (some images may be closer to camera than others) images\n faces = f_cascade.detectMultiScale(gray, scaleFactor=scaleFactor, minNeighbors=5);\n \n #go over list of faces and draw them as rectangles on original colored img\n for (x, y, w, h) in faces:\n cv2.rectangle(img_copy, (x, y), (x+w, y+h), (0, 255, 0), 2)\n \n return img_copy\n\n\n# Now let's try this function on another test image\n\n# In[8]:\n\n#load another image\ntest2 = cv2.imread('data/test3.jpg')\n\n#call our function to detect faces\nfaces_detected_img = detect_faces(haar_face_cascade, test2)\n\n#conver image to RGB and show image\nplt.imshow(convertToRGB(faces_detected_img))\n\n# In[9]:\n\n#load another image\ntest2 = cv2.imread('data/test4.jpg')\n\n#call our function to detect faces\nfaces_detected_img = detect_faces(haar_face_cascade, test2)\n\n#conver image to RGB and show image\nplt.imshow(convertToRGB(faces_detected_img))\n\n# In[10]:\n\n#load another image\ntest2 = cv2.imread('data/test4.jpg')\n\n#call our function to detect faces\nfaces_detected_img = detect_faces(haar_face_cascade, test2, scaleFactor=1.2)\n\n#conver image to RGB and show image\nplt.imshow(convertToRGB(faces_detected_img))\n\n\n# In[11]:\n\n#load cascade classifier training file for lbpcascade\nlbp_face_cascade = cv2.CascadeClassifier('data/lbpcascade_frontalface.xml')\n\n#load test image\ntest2 = cv2.imread('data/test2.jpg')\n#call our function to detect faces\nfaces_detected_img = detect_faces(lbp_face_cascade, test2)\n\n#conver image to RGB and show image\nplt.imshow(convertToRGB(faces_detected_img))\n\n\n# Let's try it on another test image. \n\n# In[12]:\n\n#load test image\ntest2 = cv2.imread('data/test3.jpg')\n#call our function to detect faces\nfaces_detected_img = detect_faces(lbp_face_cascade, test2)\n\n#conver image to RGB and show image\nplt.imshow(convertToRGB(faces_detected_img))\n\n\n# ## Haar and LBP Results Analysis\n\n# We will run both `Haar` and `LBP` on test images to see accuracy and time delay of each.\n\n# In[13]:\n\n#load cascade classifier training file for haarcascade\nhaar_face_cascade = cv2.CascadeClassifier('data/haarcascade_frontalface_alt.xml')\n#load cascade classifier training file for lbpcascade\nlbp_face_cascade = cv2.CascadeClassifier('data/lbpcascade_frontalface.xml')\n\n#load test image1\ntest1 = cv2.imread('data/test5.jpg')\n#load test image2\ntest2 = cv2.imread('data/test6.jpg')\n\n\n# ### Test-1\n\n# In[16]:\n\n#------------HAAR-----------\n#note time before detection\nt1 = time.time()\n\n#call our function to detect faces\nhaar_detected_img = detect_faces(haar_face_cascade, test1)\n\n#note time after detection\nt2 = time.time()\n#calculate time difference\ndt1 = t2 - t1\n#print the time differene\n\n#------------LBP-----------\n#note time before detection\nt1 = time.time()\n\nlbp_detected_img = detect_faces(lbp_face_cascade, test1)\n\n#note time after detection\nt2 = time.time()\n#calculate time difference\ndt2 = t2 - t1\n#print the time differene\n\n#----------Let's do some fancy drawing-------------\n#create a figure of 2 plots (one for Haar and one for LBP)\nf, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 5))\n\n#show Haar image\nax1.set_title('Haar Detection time: ' + str(round(dt1, 3)) + ' secs')\nax1.imshow(convertToRGB(haar_detected_img))\n\n#show LBP image\nax2.set_title('LBP Detection time: ' + str(round(dt2, 3)) + ' secs')\nax2.imshow(convertToRGB(lbp_detected_img))\n\n# ### Test-2 \n\n# In[17]:\n\n#------------HAAR-----------\n#note time before detection\nt1 = time.time()\n\n#call our function to detect faces\nhaar_detected_img = detect_faces(haar_face_cascade, test2)\n\n#note time after detection\nt2 = time.time()\n#calculate time difference\ndt1 = t2 - t1\n#print the time differene\n\n#------------LBP-----------\n#note time before detection\nt1 = time.time()\n\nlbp_detected_img = detect_faces(lbp_face_cascade, test2)\n\n#note time after detection\nt2 = time.time()\n#calculate time difference\ndt2 = t2 - t1\n#print the time differene\n\n#----------Let's do some fancy drawing-------------\n#create a figure of 2 plots (one for Haar and one for LBP)\nf, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 5))\n\n#show Haar image\nax1.set_title('Haar Detection time: ' + str(round(dt1, 3)) + ' secs')\nax1.imshow(convertToRGB(haar_detected_img))\n\n#show LBP image\nax2.set_title('LBP Detection time: ' + str(round(dt2, 3)) + ' secs')\nax2.imshow(convertToRGB(lbp_detected_img))\n "
},
{
"alpha_fraction": 0.7693121433258057,
"alphanum_fraction": 0.7957671880722046,
"avg_line_length": 93.5,
"blob_id": "3b2710a99c62d0c05a5a326fc2674d6ac0c4e64a",
"content_id": "ae28a81d735ea82afc92d16681af578081b79207",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 945,
"license_type": "permissive",
"max_line_length": 335,
"num_lines": 10,
"path": "/Face-Mask-Detection/face-mask-detection-using-cnn/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "### Introduction:\n- Face mask detection had seen significant progress in the domains of Image processing and Computer vision, since the rise of the Covid-19 pandemic. Many face detection models have been created using several algorithms and techniques. The approach in this project uses deep learning, TensorFlow, Keras, and OpenCV to detect face masks.\n- Convolutional Neural Network, Data augmentation are the key to this project.\n### Example:\n\n\n\n### Methodology used:\n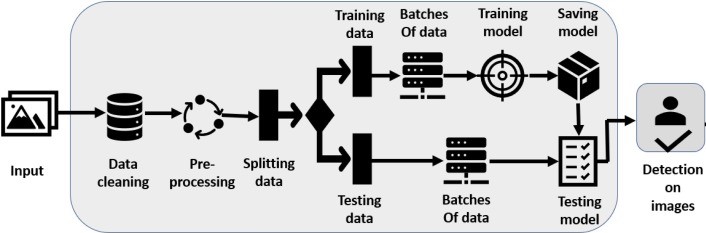\n### This is the step by step methodology of how this project is created..!!\n"
},
{
"alpha_fraction": 0.56153404712677,
"alphanum_fraction": 0.5901545286178589,
"avg_line_length": 29.64912223815918,
"blob_id": "c122f52d35394f39fb2ae0be5bc97de0d386301a",
"content_id": "24dc99b7c5a0090edb5f2e4a37d710e2a5946ade",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1747,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 57,
"path": "/Face Reconstruction/Facial Reconstruction and Dense Alignment/python/demo.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from facerda import FaceRDA\nfrom centerface.centerface import CenterFace\nfrom utils import crop_img, plot_vertices\nimport cv2\n\n\ndef test_facerda():\n frame = cv2.imread(\"00.jpg\")\n cv2.imshow('frame', frame)\n\n h, w = frame.shape[:2]\n centerface = CenterFace(h, w, landmarks=True)\n model_path = \"../model/frda_sim.onnx\"\n facerda = FaceRDA(model_path, True)\n\n dets, _ = centerface(frame, threshold=0.5) # 3. forward\n if dets.shape[0] == 0:\n return\n for det in dets:\n boxes, score = det[:4].astype(\"int32\"), det[4]\n roi_box = centerface.get_crop_box(boxes[0], boxes[1], boxes[2] - boxes[0], boxes[3] - boxes[1], 1.4)\n face, ret_roi = crop_img(frame, roi_box)\n vertices = facerda(face, roi_box)\n frame = plot_vertices(frame, vertices)\n\n cv2.imshow('image', frame)\n cv2.waitKey(0)\n\n\ndef camera_facerda():\n cap = cv2.VideoCapture(0)\n success, frame = cap.read()\n\n h, w = frame.shape[:2]\n centerface = CenterFace(h, w, landmarks=True)\n model_path = \"../model/frda_sim.onnx\"\n facerda = FaceRDA(model_path, True)\n\n while success:\n success, frame = cap.read()\n dets, _ = centerface(frame, threshold=0.5) # 3. forward\n if dets.shape[0] == 0:\n continue\n for det in dets:\n boxes, score = det[:4].astype(\"int32\"), det[4]\n roi_box = centerface.get_crop_box(boxes[0], boxes[1], boxes[2] - boxes[0], boxes[3] - boxes[1], 1.4)\n face, ret_roi = crop_img(frame, roi_box)\n vertices = facerda(face, roi_box)\n frame = plot_vertices(frame, vertices)\n\n cv2.imshow('frame', frame)\n cv2.waitKey(30)\n\n\nif __name__ == \"__main__\":\n # test_facerda()\n camera_facerda()\n"
},
{
"alpha_fraction": 0.6401673555374146,
"alphanum_fraction": 0.6694560647010803,
"avg_line_length": 22.899999618530273,
"blob_id": "c69cd8ffbe7017e7e060727d95ae5152488ef3e2",
"content_id": "95fa6cb0c5d35954ff427c817e990fc61d058643",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 239,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 10,
"path": "/Face Reconstruction/Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model/toy_example/vertex_to_mesh.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# To recover 3D faces from vertices '.npy'\n\nimport openmesh as om\nimport numpy as np\n\nmesh = om.read_trimesh(\"mean_face.obj\")\nvertex = np.load(\"1.npy\")\nfor i in range(6144):\n mesh.points()[i] = vertex[:, i]\nom.write_mesh(\"1.obj\", mesh)\n"
},
{
"alpha_fraction": 0.6937500238418579,
"alphanum_fraction": 0.706250011920929,
"avg_line_length": 29.4761905670166,
"blob_id": "c5f757ff405c7a9cb180a4948e8779ab3231d118",
"content_id": "d5f66077ac4f65a08f17dedf5e141f5031c30780",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 640,
"license_type": "permissive",
"max_line_length": 146,
"num_lines": 21,
"path": "/Face Reconstruction/Face Alignment in Full Pose Range/BFM_Remove_Neck/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "**Todo:** Update the neck-removing processing pipeline from original BFM model.\n\nThe original version with neck:\n<p align=\"center\">\n <img src=\"imgs/bfm.png\" alt=\"neck\" width=\"400px\">\n</p>\n\nThe refined version without neck:\n<p align=\"center\">\n <img src=\"imgs/bfm_refine.png\" alt=\"no neck\" width=\"400px\">\n</p>\n\nThese two images are rendered by MeshLab.\n\n`bfm_show.m` shows how to render it with 68 keypoints in Matlab.\n\n<p align=\"center\">\n <img src=\"imgs/bfm_refine.jpg\" alt=\"no neck\">\n</p>\n\nAttention: the z-axis value of `bfm.ply` and `bfm_refine.ply` file are opposed in `model_refine.mat`, do not use these two `ply` file in training.\n"
},
{
"alpha_fraction": 0.7610579133033752,
"alphanum_fraction": 0.7716978192329407,
"avg_line_length": 42.28947448730469,
"blob_id": "a6e01233d2980d928c7a9d1b325dfd996814c135",
"content_id": "6f7bca94ffe017e3e566907d76f5df0ba9504963",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6579,
"license_type": "permissive",
"max_line_length": 592,
"num_lines": 152,
"path": "/Face-Detection/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "## Requirements\nYou will need on your system:\n\n### *cmake*\nYour system needs CMake installed, an open-source, cross-platform family of tools designed to build, test and package software. CMake is used to control the software compilation process using simple platform and compiler independent configuration files, and generate native makefiles and workspaces that can be used in the compiler environment of your choice. The suite of CMake tools were created by Kitware in response to the need for a powerful, cross-platform build environment for open-source projects such as ITK and VTK.\n\nIf it's not installed in your system, you can run the following commands to install it:\n\n```\n# Update repo\nsudo apt-get update\n\n# Install cmake if it's not installed\nsudo apt-get install build-essential cmake\n```\n\n### *1. Install and compile dlib*\nBefore proceeding with the usage and installation of the face recognition library in Python, you will need the distributable of dlib installed on your system and the python binding as well. Dlib is a modern C++ toolkit containing machine learning algorithms and tools for creating complex software in C++ to solve real world problems. It is used in both industry and academia in a wide range of domains including robotics, embedded devices, mobile phones, and large high performance computing environments. Dlib's open source licensing allows you to use it in any application, free of charge.\n\nTo start with the compilation of dlib in your system, clone the repository in some directory in your system:\n\n```\n# Clone the dlib library in some directory of the system\ngit clone https://github.com/davisking/dlib.git\n```\n\nThen, proceed to build dlib with the following commands:\n\n```\n# get into the cloned directory\ncd dlib\n\n# create build directory inside the cloned directory\nmkdir build\n\n# Switch to the created directory\ncd build\n\n# generate a Makefile in the current directory\ncmake ..\n\n# Build dlib !\ncmake --build .\n```\nThis will start the build process and once it finishes, the native library of dlib will be available in your system. For more information about Dlib, please visit [official website](http://dlib.net/).\n\n### *2. Install Python binding for dlib*\nAfter building dlib, switch again to the cloned directory in the previous step:\n\n```\ncd ..\n```\nAnd proceed with the installation of the python bindings running the `setup.py` file with Python 3 with the following command:\n\n```\npython3 setup.py install\n```\n\nThis will install the binding and you will be able to import dlib later in your Python code. In case that you face the following exception during the execution of the previous command:\n\n```\nTraceback (most recent call last):\n File \"setup.py\", line 42, in <module>\n from setuptools import setup, Extension\nImportError: No module named 'setuptools'\n```\n\nInstall the Python 3 setup tools with the following command:\n\n```\nsudo apt-get install python3-setuptools\n```\n\nAnd now try again to run the `python3 setup.py install` command.\n\n### *3. Install face recognition library*\nNow, we'll use the face recognition library. This library recognize and manipulate faces from Python or from the command line with the world's simplest face recognition library.\n\nThis also provides a simple `face_recognition` command line tool that lets you do face recognition on a folder of images from the command line easily. You can install it with the following command:\n\n### *Note*\nThe installation will take a while to download and install, **so be patient**.\n\n```\npip3 install face_recognition\n```\n\nIf you don't have pip3 installed, install it with the following command:\n\n```\nsudo apt-get -y install python3-pip\n```\n\nFor more information about this library, please visit the [official repository at Github](https://github.com/ageitgey/face_recognition). After installing the library, you will be able to use it either from the CLI or your python scripts.\n\n### *4. How to use*\nWhen you install face_recognition, you get two simple command-line programs:\n\n- `face_recognition` - Recognize faces in a photograph or folder full for photographs.\n- `face_detection` - Find faces in a photograph or folder full for photographs.\n\nYou will have as well the possibility of import the library in your scripts and use it from there !\n\nFor example, with this library you will be able to identify some faces according to some little database as source. Create a directory that contains the possible persons that the script will be able to identify, in this example we'll have a directory with 3 celebrities:\n\n\n\nIn our command, we'll identify this directory as our source of images. In other directory, we'll store the image of the celebrity that we want to identify from our database, obviously we'll use one of the regitered celebrities, but with another image:\n\n\n\nThe logic is the following, the library will use the directory of images `celebrities` as database and we'll search from who's the image(s) stored in the `unknown` directory. You can run the following command to accomplish the mentioned task:\n\n```\nface_recognition ./celebrities/ ./unknown/\n```\n\nThen, the output will be:\n\n```\n./unknown/unknown_celebrity.jpg, Ryan Reynolds\n```\n\nThe command will output the path to the image that was processed, in our case `unknown_celebrity.jpg` and will add the name of the matched image from the `celebrities` directory as suffix. In this case, the library was able to identify the actor Ryan Reynolds from our images. Note that this can work with multiple images as well.\n\n### *Face detection*\nThe face detection allows you to identify the location of faces inside an image. The library will return the coordinates of the images in the image, so you can use those coordinates to draw squares in the images. Exactly like the face recognition tool, the command will print the path of the image in the providen directory followed by the coordinates as suffix, for example:\n\n```\nface_detection ./celebrities/\n```\n\nThis will generate the following output:\n\n```\n./celebrities/Justin Timberlake.jpg,137,424,352,209\n./celebrities/unknown_celebrity.jpg,95,427,244,277\n./celebrities/Barack Obama.jpg,29,141,101,69\n./celebrities/Ryan Reynolds.jpg,94,473,273,293\n```\n\nAs you can see, you can obtain the coordinates of the identified faces in the image after the first comma of the string. You can use it with your code as well:\n\n```\nimport face_recognition\n\nimage = face_recognition.load_image_file(\"Ryan Reynolds.jpg\")\nface_locations = face_recognition.face_locations(image)\n\n# [(98, 469, 284, 283)]\nprint(face_locations)\n```"
},
{
"alpha_fraction": 0.7423181533813477,
"alphanum_fraction": 0.7578247785568237,
"avg_line_length": 57.295833587646484,
"blob_id": "687eef2eaf824c5fdca3eec70808bd7e4b0c4aa3",
"content_id": "6c9f88545d9d80c68290a5d37a6cbcabf5902c2a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 14015,
"license_type": "permissive",
"max_line_length": 840,
"num_lines": 240,
"path": "/Facial_Biometric/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Face Biometric using OpenCV\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Facial_Biometric/Images/Timeattdmain%20(1).png\" hight=\"300px\" width=\"600px\" align=\"left\"/>\n\n## 1.Introduction\n\nFace recognition is the technique in which the identity of a human being can be identified using ones individual face. Such kind of systems can be used in photos, videos, or in real time machines. The objective of this article is to provide a simpler and easy method in machine technology. With the help of such a technology one can easily detect the face by the help of dataset in similar matching appearance of a person. The method in which with the help of python and OpenCV in deep learning is the most efficient way to detect the face of the person. This method is useful in many fields such as the military, for security, schools, colleges and universities, airlines, banking, online web applications, gaming etc. this system uses powerful python algorithm through which the detection and recognition of face is very easy and efficien\n\n This repository detects a human face using Dlib's 68 points model. As the human face is way too complex for a computer to learn, so we have used the 68 points model to ease the process of facial recognition. Facial Biometric uses a two step biometric process for facial recognition. \n These steps are:\n - Facial localization to locate a human face and return `4(x,y)-coordinates` that forms a rectangle bounding the face.\n - Detecting facial structures using Dlib's 68 points model. \n\n## 2.Dlib's 68 points model\n\n The below image is an example of Dlib's 68 points model. This pre-trained facial landmark detector inside the Dlib's library is used to estimate the location of 68(x,y)-coordinates that maps to the different facial structures. \n\n### 1.Facial landmark points detection through Dlib's 68 Model:\n\nThere are mostly two steps to detect face landmarks in an image which are given below:\n- Face detection: Face detection is the first methods which locate a human face and return a value in `x,y,w,h` which is a rectangle.\n- Face landmark: After getting the location of a face in an image, then we have to through points inside of that rectangle.\n\nThere are many methods of face detector but we focus in this post only one which is Dlib's method. Like, Opencv uses methods LBP cascades and HAAR and Dlib's use methods HOG `(Histogram of Oriented Gradients)`and SVM `(Support Vector Machine)`.\n\nNow to draw landmarks on the face of the detected rectangle, we are passing the landmarks values and image to the facePoints. In the below code, we are passing landmarks and image as a parameter to a method called drawPoints which accessing the coordinates(x,y) of the ith landmarks points using the `part(i).x` and `part(i).y`. All landmarks points are saved in a numpy array and then pass these points to in-built `cv2.polyline` method to draw the lines on the face using the startpoint and endpoint parameters.\n\n## 3.What is Face Detection ?\n\nFace detection is a type of computer vision technology that is able to identify people’s faces within digital images. This is very easy for humans, but computers need precise instructions. The images might contain many objects that aren’t human faces, like buildings, cars, animals, and so on.\n\nIt is distinct from other computer vision technologies that involve human faces, like facial recognition, analysis, and tracking : \n\n- `Facial recognition` : involves identifying the face in the image as belonging to person X and not person Y. It is often used for biometric purposes, like unlocking your smartphone.\n\n- `Facial analysis` : tries to understand something about people from their facial features, like determining their age, gender, or the emotion they are displaying.\n\n- `Facial tracking` : is mostly present in video analysis and tries to follow a face and its features (eyes, nose, and lips) from frame to frame. The most popular applications are various filters available in mobile apps like Snapchat.\n\nTo create a complete project on Face Recognition, we must work on 3 very distinct phases:\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Facial_Biometric/Images/0_oJIRaoERCUHoyylG_.png\" align=\"right\"/>\n- Face Detection and Data Gathering\n- Train the Recognizer\n- Face Recognition\nThe below block diagram resumes those phases:\n\n\n## 4.How Do Computers “See” Images? \n\nThe smallest element of an image is called a pixel, or a picture element. It is basically a dot in the picture. An image contains multiple pixels arranged in rows and columns.\nYou will often see the number of rows and columns expressed as the image resolution. For example, an Ultra HD TV has the resolution of 3840x2160, meaning it is 3840 pixels wide and 2160 pixels high.\n\n But a computer does not understand pixels as dots of color. It only understands numbers. To convert colors to numbers, the computer uses various color models. In color images, pixels are often represented in the RGB color model. RGB stands for Red Green Blue. Each pixel is a mix of those three colors. RGB is great at modeling all the colors humans perceive by combining various amounts of red, green, and blue.\n \n Since a computer only understand numbers, every pixel is represented by three numbers, corresponding to the amounts of red, green, and blue present in that pixel. In grayscale (black and white) images, each pixel is a single number, representing the amount of light, or intensity, it carries. In many applications, the range of intensities is from 0 (black) to 255 (white). Everything between 0 and 255 is various shades of gray.\n\nIf each grayscale pixel is a number, an image is nothing more than a matrix (or table) of numbers:\n\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Facial_Biometric/Images/face%20(1).png\" height=\"300px\" align=\"right\"/>\n\nExample 3x3 image with pixel values and colors\n\nIn color images, there are three such matrices representing the red, green, and blue channels.\n\n## 5.Cascading Classifiers\n\nThe definition of a cascade is a series of waterfalls coming one after another. A similar concept is used in computer science to solve a complex problem with simple units. The problem here is reducing the number of computations for each image.\n\nWhen an image subregion enters the cascade, it is evaluated by the first stage. If that stage evaluates the subregion as positive, meaning that it thinks it’s a face, the output of the stage is maybe. If a subregion gets a maybe, it is sent to the next stage of the cascade. If that one gives a positive evaluation, then that’s another maybe, and the image is sent to the third stage:\n\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Facial_Biometric/Images/one_stage.png\" height=\"350px\" align=\"left\"/>\n\n\n### A weak classifier in a cascade : \n\nThis process is repeated until the image passes through all stages of the cascade. If all classifiers approve the image, it is finally classified as a human face and is presented to the user as a detection.\n\nIf, however, the first stage gives a negative evaluation, then the image is immediately discarded as not containing a human face. If it passes the first stage but fails the second stage, it is discarded as well. Basically, the image can get discarded at any stage of the classifier:\n\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Facial_Biometric/Images/Classifier_cascade.png\"/>\n\n### A cascade of n classifiers for face detection : \n\nThis is designed so that non-faces get discarded very quickly, which saves a lot of time and computational resources. Since every classifier represents a feature of a human face, a positive detection basically says, “Yes, this subregion contains all the features of a human face.” But as soon as one feature is missing, it rejects the whole subregion.\n\nTo accomplish this effectively, it is important to put your best performing classifiers early in the cascade. In the Viola-Jones algorithm, the eyes and nose bridge classifiers are examples of best performing weak classifiers.\n\n### Import OpenCV and load the image into memory:\n\n```\nimport cv2 as cv\n\n# Read image from your local file system\noriginal_image = cv.imread('path/to/your-image.jpg')\n\n# Convert color image to grayscale for Viola-Jones\ngrayscale_image = cv.cvtColor(original_image, cv.COLOR_BGR2GRAY)\n\n```\n\nDepending on the version, the exact path might vary, but the folder name will be haarcascades, and it will contain multiple files. The one you need is called `haarcascade_frontalface_alt.xml`.\n\nIf for some reason, your installation of OpenCV did not get the pre-trained classifier,\n```\n# Load the classifier and create a cascade object for face detection\nface_cascade = cv.CascadeClassifier('path/to/haarcascade_frontalface_alt.xml')\n```\nThe face_cascade object has a method `detectMultiScale()`, which receives an image as an argument and runs the classifier cascade over the image. The term MultiScale indicates that the algorithm looks at subregions of the image in multiple scales, to detect faces of varying sizes:\n\n`detected_faces = face_cascade.detectMultiScale(grayscale_image)`\n\nThe variable detected_faces now contains all the detections for the target image. To visualize the detections, you need to iterate over all detections and draw rectangles over the detected faces.\n\nOpenCV’s `rectangle()` draws rectangles over images, and it needs to know the pixel coordinates of the top-left and bottom-right corner. The coordinates indicate the row and column of pixels in the image.\n\nLuckily, detections are saved as pixel coordinates. Each detection is defined by its top-left corner coordinates and width and height of the rectangle that encompasses the detected face.\n\nAdding the width to the row and height to the column will give you the bottom-right corner of the image:\n```\nfor (column, row, width, height) in detected_faces:\n cv.rectangle(\n original_image,\n (column, row),\n (column + width, row + height),\n (0, 255, 0),\n 2\n )\n ```\nrectangle() accepts the following arguments:\n\n- The original image\n- The coordinates of the top-left point of the detection\n- The coordinates of the bottom-right point of the detection\n- The color of the rectangle (a tuple that defines the amount of red, green, and blue (0-255))\n- The thickness of the rectangle lines\n\nFinally, you need to display the image:\n```\ncv.imshow('Image', original_image)\ncv.waitKey(0)\ncv.destroyAllWindows()\n```\n`imshow()` displays the image. `waitKey()` waits for a keystroke. Otherwise, `imshow()` would display the image and immediately close the window. Passing 0 as the argument tells it to wait indefinitely. Finally, `destroyAllWindows()` closes the window when you press a key.\n\n## 6.How to get started\n- Clone this repository-\n`git clone https://github.com/akshitagupta15june/Face-X.git`\n- Change Directory-\n`cd Facial_Biometric`\n\n- Run file-\n`python library.py`\n\n- Input name-\n`Type your name in the input dialogue opened in the terminal`\n\n## Requirements\n\n- python 3.6+\n- opencv\n- dlib\n\n`Note` : This file takes input video from your webcam and detects the points, So you need an inbuilt or externally connected webcam\n\n## Installation \n\n- Create virtual environment-\n```\n- `python -m venv env`\n- `source env/bin/activate` (Linux)\n- `pip install opencv-python==4.4.0.44`\n- `pip install dlib==19.21.1`\n- `pip install opencv-python==4.4.0.44`\n```\n```\nNote : dlib is a library written in c++ that used applications like cmake,boost etc.,if you face any error while installing dlib, don't panic and try to install the extensions required.\n```\n\n\n## 7.Code Overview : \n```\nimport cv2\nimport dlib\n\ndetector = dlib.get_frontal_face_detector()\n\npredictor = dlib.shape_predictor(\"./shape_predictor_68_face_landmarks.dat\")\nname = input(\"Enter your name: \")\ncap = cv2.VideoCapture(0)\n\nwhile True:\n\n ret, frame = cap.read()\n gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)\n\n faces = detector(gray)\n\n for face in faces:\n x1=face.left()\n y1=face.top()\n x2=face.right()\n y2=face.bottom()\n cv2.rectangle(frame, (x1,y1), (x2,y2),(0,255,0),3)\n landmarks = predictor(gray, face)\n # print(landmarks.parts())\n nose = landmarks.parts()[27]\n # print(nose.x, nose.y)\n cv2.putText(frame,str(name),(x1, y1 - 10), cv2.FONT_HERSHEY_COMPLEX, 1, (255, 0, 0), 2)\n for point in landmarks.parts():\n cv2.circle(frame, (point.x, point.y), 2, (0, 0, 255), 3)\n\n # print(faces)\n\n if ret:\n cv2.imshow(\"My Screen\", frame)\n\n key = cv2.waitKey(1)\n\n if key == ord(\"q\"):\n break\n\ncap.release()\ncv2.destroyAllWindows()\n\n```\n## 8.Result Obtain: \n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Facial_Biometric/Images/result.jpg\" height=\"400px\"/>\n\n\n\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Facial_Biometric/Images/face-b3.png\" height=\"450px\" align=\"left\"/>\n<p style=\"clear:both;\">\n<h1><a name=\"contributing\"></a><a name=\"community\"></a> <a href=\"https://github.com/akshitagupta15june/Face-X\">Community</a> and <a href=\"https://github.com/akshitagupta15june/Face-X/blob/master/CONTRIBUTING.md\">Contributing</a></h1>\n<p>Please do! Contributions, updates, <a href=\"https://github.com/akshitagupta15june/Face-X/issues\"></a> and <a href=\" \">pull requests</a> are welcome. This project is community-built and welcomes collaboration. Contributors are expected to adhere to the <a href=\"https://gssoc.girlscript.tech/\">GOSSC Code of Conduct</a>.\n</p>\n<p>\nJump into our <a href=\"https://discord.com/invite/Jmc97prqjb\">Discord</a>! Our projects are community-built and welcome collaboration. 👍Be sure to see the <a href=\"https://github.com/akshitagupta15june/Face-X/blob/master/Readme.md\">Face-X Community Welcome Guide</a> for a tour of resources available to you.\n</p>\n<p>\n<i>Not sure where to start?</i> Grab an open issue with the <a href=\"https://github.com/akshitagupta15june/Face-X/issues\">help-wanted label</a>\n</p>\n\n\n\n"
},
{
"alpha_fraction": 0.6634482741355896,
"alphanum_fraction": 0.7875862121582031,
"avg_line_length": 50.78571319580078,
"blob_id": "0fc835c604ac4dc06b6f68845092f32f937dba77",
"content_id": "30af16535475d3907e94e7b4c760cd88ec593026",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 725,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 14,
"path": "/Snapchat_Filters/Pig_nose_filter/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#85 \n\n**The process**:\n- Using the OpenCV detecting the face in the face\n- For every Face I had to detect the landmarks on the face using the 68 facial landmark coordinates\n- Using the coordinates I had to detect the coordinates 29(top_nose), 30(center_nose), 31(left_nose) and 35(right_nose)\n- After detecting the coordinates, reduce the size of the pig_nose into that area\n- and then mask the pig_nose into the actual frame\n\nThe Facial Landmark Coordinates\n\n\nThe screenshot with the filter\n\n"
},
{
"alpha_fraction": 0.5852687358856201,
"alphanum_fraction": 0.5958858728408813,
"avg_line_length": 49.266666412353516,
"blob_id": "fea81a3ad73e95426cd662a6dad4587c18259422",
"content_id": "a2d3ca448f65e2b4f8cd8992f9ebcde711800042",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1507,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 30,
"path": "/Face Reconstruction/Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model/train.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import cariface\nfrom train_options import TrainOptions\n\nif __name__ == '__main__':\n opt = TrainOptions().parse()\n\n model = cariface.CariFace()\n model.init_numbers(opt.landmark_num, opt.vertex_num, opt.device_num)\n model.init_data(opt.data_path)\n if opt.if_train == True:\n model.load_train_data(opt.train_image_path, opt.train_landmark_path, opt.train_vertex_path,\n opt.batch_size, opt.num_workers)\n model.load_test_data(opt.test_image_path, opt.test_landmark_path,\n opt.test_lrecord_path, opt.test_vrecord_path, opt.num_workers)\n model.load_model(opt.resnet34_lr, opt.mynet1_lr, opt.mynet2_lr, opt.use_premodel,\n opt.model1_path, opt.model2_path)\n model.test()\n for epoch in range(1, opt.total_epoch+1):\n model.train(epoch, opt.lambda_land, opt.lambda_srt)\n if epoch % opt.test_frequency == 0:\n model.test()\n if epoch % opt.save_frequency == 0:\n model.save_model(epoch, opt.save_model_path)\n model.save_model(opt.total_epoch, opt.save_model_path)\n else:\n model.load_test_data(opt.test_image_path, opt.test_landmark_path,\n opt.test_lrecord_path, opt.test_vrecord_path, opt.num_workers)\n model.load_model(opt.resnet34_lr, opt.mynet1_lr, opt.mynet2_lr, opt.use_premodel,\n opt.model1_path, opt.model2_path)\n model.test()"
},
{
"alpha_fraction": 0.6384839415550232,
"alphanum_fraction": 0.7580174803733826,
"avg_line_length": 25.384614944458008,
"blob_id": "7d6fb4e6b9d83dc2b814aa7e14288be6042ea9bf",
"content_id": "5cc4bd2e1a594d8430c7732a9a9e282fd07450b5",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 686,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 26,
"path": "/Snapchat_Filters/mustache and black sunglasses/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "<h1>Make your pictures lively with these mustache and black sunglasses</h1>\n\n\n\n\n\n\n<h1>Requirements: </h1>\n<ul>\nOpenCV\n <br>\nPython 3.7.x\n <br>\nNumpy\n <br>\nHaarcascade classifiers\n </ul>\n \n<h1>Instruction</h1>\n<ul>\nClone this repository git clone https://github.com/akshitagupta15june/Face-X.git\n <br>\nChange Directory to Snapchat_Filters then to mustache and black sunglasses\n <br>\nRun code using the cmd mustache and black sunglasses.py\n </ul>\n"
},
{
"alpha_fraction": 0.5905159711837769,
"alphanum_fraction": 0.6167610883712769,
"avg_line_length": 42.7066650390625,
"blob_id": "73fef03a5c2eff71f07a0923fae82820e3dcd37a",
"content_id": "3891e7306ea344530ffa1344b750b936a9fb23d7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3353,
"license_type": "permissive",
"max_line_length": 194,
"num_lines": 75,
"path": "/Face-Mask-Detection/Recognition using EfficientNetB3/face_detector.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#importing required libraries\r\nimport os\r\nimport numpy as np\r\nimport cv2\r\nfrom keras.models import load_model\r\n\r\n\r\n\r\n#input shape on which we have trained our model\r\n\r\ninput_shape = (120,120,3)\r\nlabels_dict = {0: 'WithMask', 1: 'WithoutMask'}\r\ncolor_dict = {0 : (0,255,0), 1:(0,0,255)} #if 1 - RED color, 0 - GREEN color\r\nmodel = load_model('best_model.hdf5')\r\n\r\n# !pip install mtcnn #toinstall the model mtcnn ## https://machinelearningmastery.com/how-to-perform-face-detection-with-classical-and-deep-learning-methods-in-python-with-keras/\r\nfrom mtcnn.mtcnn import MTCNN #importing the model\r\ndetector = MTCNN() # instatiating the model\r\n\r\n## RESEARCH PAPER LINK: https://arxiv.org/abs/1604.02878\r\n\r\nsize = 4\r\nwebcam = cv2.VideoCapture(0) # Use camera 0 - default webcam\r\n\r\n#\r\nwhile True: #we are reading frame by frame\r\n (rval, im) = webcam.read()\r\n # im = cv2.flip(im, 1, 1) # Flip to act as a mirror\r\n#\r\n# # Resize the image to speed up detection\r\n mini = cv2.resize(im, (im.shape[1] // size, im.shape[0] // size))\r\n\r\n rgb_image = cv2.cvtColor(mini, cv2.COLOR_BGR2RGB) # MTCNN needs the file in RGB format, but cv2 reads in BGR format. Hence we are converting.\r\n faces = detector.detect_faces(mini) # detecting faces---> we will have (x,y,w,h) coordinates\r\n\r\n\r\n#\r\n# # Draw rectangles around each face\r\n for f in faces:\r\n x, y, w, h = [v * size for v in f['box']]\r\n\r\n\r\n# # cropping the face portion from the entire image\r\n face_img = im[y:y + h, x:x + w]\r\n # print(face_img)\r\n resized = cv2.resize(face_img, (input_shape[0],input_shape[1])) # resizing the image to our reuired input size on which we have trained our model\r\n\r\n reshaped = np.reshape(resized, (1, input_shape[0],input_shape[1], 3)) # we have used ImageDatagenerator and we have trained our model in batches\r\n # hence input shape to our model is (batch_size,height,width,color_depth)\r\n # we are converting the image into this format. i.e. (height,width,color_depth) ---> (batch_size,height,width,color_depth)\r\n\r\n result = model.predict(reshaped) #predicting\r\n# # print(result)\r\n#\r\n label = np.argmax(result, axis=1)[0] #getting the index for the maximum value\r\n#\r\n cv2.rectangle(im, (x, y), (x + w, y + h), color_dict[label], 2) # Bounding box (Big rectangle around the face)\r\n cv2.rectangle(im, (x, y - 40), (x + w, y), color_dict[label], -1) # small rectangle above BBox where we will put our text\r\n #Thickness of -1 px will fill the rectangle shape by the specified color.\r\n cv2.putText(im, labels_dict[label], (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (255, 255, 255), 2) # https://www.geeksforgeeks.org/python-opencv-cv2-puttext-method/\r\n#\r\n# # Show the image\r\n cv2.imshow('LIVE FACE DETECTION', im)\r\n key = cv2.waitKey(10)\r\n# # if Esc key is press then break out of the loop\r\n if key == 27: # The Esc key\r\n break\r\n# # Stop video\r\nwebcam.release()\r\n#\r\n# # Close all started windows\r\ncv2.destroyAllWindows()\r\n\r\n## SPECIAL THANKS TO\r\n## https://github.com/mk-gurucharan/Face-Mask-Detection/blob/master/FaceMask-Detection.ipynb\r\n"
},
{
"alpha_fraction": 0.5537683963775635,
"alphanum_fraction": 0.5691225528717041,
"avg_line_length": 46.09321212768555,
"blob_id": "4ad851b9435ff63fe72030c4b00bb2b5fdbe9944",
"content_id": "3d833d9076a1bc478d68e2321301e9ab563e2327",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 52038,
"license_type": "permissive",
"max_line_length": 162,
"num_lines": 1105,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_tfGraph/build_graph.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nfrom __future__ import print_function\n\n#\nimport os\nimport time\n\nfrom src_common.common.format_helper import *\nfrom src_common.common.visual_helper import *\n# data\nfrom src_common.data import find_dataloader_using_name\n# geometry\nfrom src_common.geometry.gpmm.bfm09_tf_uv import BFM_TF\n# common\nfrom src_common.common.parse_encoder import parse_coeff_list\nfrom src_common.geometry.camera_distribute.camera_utils import *\nfrom src_common.geometry.face_align.align_facenet import get_facenet_align_lm\nfrom .deep_3dmm_decoder import *\n# multiview\nfrom src_common.geometry.geo_utils import projective_inverse_warp\nfrom .decoder_multiView import *\n# tf\n#\n# loss\nfrom .deep_3dmm_loss import *\n\nclass MGC_TRAIN(object):\n def __init__(self, opt):\n self.opt = opt\n # 3dmm\n self.h_lrgp = BFM_TF(opt.path_gpmm, opt.gpmm_rank, opt.gpmm_exp_rank, opt.batch_size, full=1)\n\n\n def build_train_graph_dataLoader(self):\n opt = self.opt\n DataLoader = find_dataloader_using_name(opt.dataset_loader)\n #getattr(sys.modules[__name__], self.data_loader_name)\n data_loader = DataLoader(opt.dataset_dir,\n opt.batch_size,\n opt.img_height,\n opt.img_width,\n opt.num_source,\n match_num=opt.match_num,\n flag_data_aug=opt.flag_data_aug,\n flag_shuffle=opt.flag_shuffle)\n\n with tf.name_scope(\"data_loading\"):\n batch_sample = data_loader.load_train_batch()\n # give additional batch_size info since the input is undetermined placeholder\n batch_image_concat, batch_skin_concat, batch_flag_sgl_mul, batch_intrinsic, batch_intrinsic, batch_matches = \\\n batch_sample.get_next()\n\n def process_skin(list_skin):\n list_skin_prop = []\n for skin in list_skin:\n skin = tf.image.convert_image_dtype(skin, dtype=tf.float32)\n skin = tf.image.rgb_to_grayscale(skin)\n\n tgt_skin_add = skin > 0.5\n tgt_skin_add = tf.cast(tgt_skin_add , tf.float32)\n\n tgt_skin_store = 1.0 - tgt_skin_add\n\n tgt_skin_pro = tgt_skin_add + skin * tgt_skin_store\n\n list_skin_prop.append(tgt_skin_pro)\n return list_skin_prop\n\n #\n self.tgt_image = batch_image_concat[:, :, :, :3]\n self.src_image_stack = batch_image_concat[:, :, :, 3:]\n\n self.tgt_image.set_shape([opt.batch_size, opt.img_height, opt.img_width, 3]) # [bs, 128, 416, 3]\n self.src_image_stack.set_shape([opt.batch_size, opt.img_height, opt.img_width, 3 * opt.num_source]) # [bs, 128, 416, 6]\n\n self.tgt_image = preprocess_image(self.tgt_image)\n self.src_image_stack = preprocess_image(self.src_image_stack)\n\n self.list_tar_image = [self.tgt_image]\n self.list_src_image = [self.src_image_stack[:, :, :, i * 3:(i + 1) * 3] for i in range(opt.num_source)]\n self.list_image = self.list_tar_image + self.list_src_image\n\n #\n self.tgt_skin = batch_skin_concat[:, :, :, :3]\n self.tgt_skin = [self.tgt_skin]\n self.list_tar_skin = process_skin(self.tgt_skin)\n\n self.src_skin = batch_skin_concat[:, :, :, 3:]\n self.src_skin.set_shape([opt.batch_size, opt.img_height, opt.img_width, 3*opt.num_source])\n self.src_skin = [self.src_skin[:, :, :, i*3:(i+1)*3] for i in range(opt.num_source)]\n self.list_src_skin = process_skin(self.src_skin)\n self.list_skin = self.list_tar_skin + self.list_src_skin\n\n #\n self.flag_sgl_mul = tf.reshape(batch_flag_sgl_mul, [opt.batch_size]) # [bs, 1]\n self.flag_sgl_mul = tf.cast(self.flag_sgl_mul, dtype=tf.float32) # [0, 1, 2]\n\n\n self.matches = batch_matches\n self.matches.set_shape([opt.batch_size, (opt.num_source+1), opt.match_num, 2])\n\n self.lm2d_weight = np.ones(68, dtype=float)\n self.lm2d_weight[28 - 1:36] = opt.lm_detail_weight\n self.lm2d_weight[61 - 1:] = opt.lm_detail_weight\n self.lm2d_weight = tf.constant(self.lm2d_weight, dtype=tf.float32)\n\n self.list_lm2d_gt_tar = [self.matches[:, 0, :, :]]\n self.list_lm2d_gt_src = [self.matches[:, i, :, :] for i in range(1, self.matches.shape[1])]\n self.list_lm2d_gt = self.list_lm2d_gt_tar + self.list_lm2d_gt_src\n\n return data_loader, batch_sample\n\n\n def set_constant_node(self):\n opt = self.opt\n \"\"\"\n ************************************ data load ************************************\n \"\"\"\n self.global_step = tf.Variable(0, name='global_step', trainable=False)\n\n self.batch_size = self.opt.batch_size\n\n # camera\n defined_pose_main = tf.constant([0.000000, 0.000000, 3.141593, 0.17440447, 9.1053238, 4994.3359], shape=[1, 6])\n self.intrinsics_single = tf.constant([4700.000000, 0., 112.000000, 0., 4700.000000, 112.000000, 0., 0., 1.], shape=[1, 3, 3])\n self.intrinsics_single = tf.tile(self.intrinsics_single, [self.batch_size, 1, 1])\n self.gpmm_frustrum = build_train_graph_3dmm_frustrum(self.intrinsics_single)\n self.defined_pose_main = tf.tile(defined_pose_main, [self.batch_size, 1])\n\n # identity loss\n defined_lm_facenet_align = get_facenet_align_lm(opt.img_height)\n self.defined_lm_facenet_align = tf.tile(defined_lm_facenet_align, [self.batch_size, 1, 1])\n\n \"\"\"\n Train\n \"\"\"\n def build_train_graph(self, list_coeffALL=None):\n '''[summary]\n build training graph\n Returns:\n data loader and batch sample for train() to initialize\n undefined placeholders\n '''\n opt = self.opt\n\n \"\"\"\n ************************************ setting **********************************************\n \"\"\"\n self.set_constant_node()\n self.total_loss = tf.constant(0.0)\n\n # ******************************************** Network\n if list_coeffALL is None:\n list_coeffALL = pred_encoder_coeff_light(self.opt, self.defined_pose_main, self.list_image, is_training=True)\n\n # ******************************************** Common flow\n dict_loss_common, dict_intermedate_common = \\\n self.build_decoderCommon(list_coeffALL, self.list_image, self.list_skin, self.list_lm2d_gt, self.flag_sgl_mul)\n self.dict_inter_comm = dict_intermedate_common\n\n # ******************************************** Intermediate result for(print, visual, tensorboard)\n # weighted loss for each view\n self.gpmm_regular_shape_loss = dict_loss_common['reg_shape_loss']\n self.gpmm_regular_color_loss = dict_loss_common['reg_color_loss']\n self.gpmm_lm_loss = dict_loss_common['lm2d_loss']\n self.gpmm_pixel_loss = dict_loss_common['render_loss']\n self.gpmm_id_loss = dict_loss_common['id_loss']\n\n # visual landmark on the rendered images/shade/render loss error map\n #self.gpmm_pose_tar, self.gpmm_pose_src = parse_seq(dict_intermedate_common['pred_6dof_pose'])\n self.lm2d_tar, self.lm2d_src = parse_seq(dict_intermedate_common['pred_lm2d'])\n self.gpmm_render_tar, self.gpmm_render_src = parse_seq(dict_intermedate_common['3dmm_render'])\n self.gpmm_render_mask_tar, self.gpmm_render_mask_src = parse_seq(dict_intermedate_common['3dmm_render_mask'])\n self.gpmm_render_shade_tar, self.gpmm_render_shade_src = parse_seq(dict_intermedate_common['3dmm_render_shade'])\n self.gpmm_render_tri_ids_tar, self.gpmm_render_tri_ids_src = parse_seq(dict_intermedate_common['3dmm_render_tri_id'])\n self.list_render_loss_error_tar, self.list_render_loss_error_src = parse_seq(dict_intermedate_common['3dmm_render_loss_heat'])\n\n # visual identity facenet input\n self.gpmm_render_tar_align, self.gpmm_render_src_align = parse_seq(dict_intermedate_common['id_render_align'])\n self.tar_image_align, self.src_image_align = parse_seq(dict_intermedate_common['id_image_align'])\n\n # visual depthmap\n self.tar_depths, self.lr_depths = parse_seq(dict_intermedate_common['3dmm_depthmap'])\n\n self.gpmm_consist_pixel_tar = self.list_lm2d_gt_tar\n self.gpmm_consist_pixel_src = self.list_lm2d_gt_src\n\n self.common_loss = dict_loss_common['loss_common']\n self.total_loss += self.common_loss\n\n # ******************************************** Multi-view flow\n dict_loss_mgc, dict_inter_mgc = \\\n self.build_decoderMGC(self.flag_sgl_mul, self.list_image, self.list_lm2d_gt, dict_intermedate_common)\n self.dict_inter_mgc = dict_inter_mgc\n\n # loss\n self.ga_loss = dict_loss_mgc['loss_mgc']\n self.ssim_loss = dict_loss_mgc['ssim_loss']\n self.pixel_loss = dict_loss_mgc['pixel_loss']\n self.epipolar_loss = dict_loss_mgc['epi_loss']\n self.depth_loss = dict_loss_mgc['depth_loss']\n\n self.total_loss += opt.MULTIVIEW_weight * dict_loss_mgc['loss_mgc']\n\n # ******************************************** Training op\n self.build_train_graph_train_op()\n\n\n def build_decoderCommon(self, list_coeff_all, list_image, list_skin=None, list_lm2d_gt=None, flag_sgl_mul=None):\n \"\"\"\n A common mapping function from images to intermediate result\n :param gpmm_frustrum:\n :param list_image:\n 1.can be single image or multi images\n 2.shape: [bs, h, w, c]\n :param list_lm2d_gt:\n :return:\n \"\"\"\n dict_loss_common = dict()\n dict_intermedate_common = dict()\n \"\"\"\n ************************************ Coefficients (clean) *********************************\n \"\"\"\n list_gpmm, list_gpmm_color, list_gpmm_exp, list_gpmm_pose, list_gpmm_light = \\\n parse_coeff_list(self.opt, list_coeff_all, self.defined_pose_main)\n\n dict_intermedate_common['pred_coeff_shape'] = list_gpmm\n dict_intermedate_common['pred_coeff_color'] = list_gpmm_color\n dict_intermedate_common['pred_coeff_exp'] = list_gpmm_exp\n dict_intermedate_common['pred_coeff_light'] = list_gpmm_light\n\n dict_intermedate_common['pred_6dof_pose'] = list_gpmm_pose\n\n \"\"\"\n ************************************ Decoder **********************************************\n \"\"\"\n # bfm\n list_gpmm_vertex, list_gpmm_vertexNormal, list_gpmm_vertexColor, list_gpmm_vertexShade, list_gpmm_vertexColorOri = \\\n decoder_colorMesh(self.h_lrgp, list_gpmm, list_gpmm_color, list_gpmm_exp, list_gpmm_light, flag_sgl_mul)\n\n dict_intermedate_common['gpmm_vertex'] = list_gpmm_vertex\n dict_intermedate_common['gpmm_vertexNormal'] = list_gpmm_vertexNormal\n dict_intermedate_common['gpmm_vertexColor'] = list_gpmm_vertexColor\n # cam\n list_gpmm_ext, list_gpmm_proj, list_gpmm_mv, list_gpmm_eye = \\\n build_train_graph_3dmm_camera(self.intrinsics_single, list_gpmm_pose)\n dict_intermedate_common['pred_cam_mv'] = list_gpmm_mv\n dict_intermedate_common['pred_cam_eye'] = list_gpmm_eye\n \"\"\"\n ************************************ Landmark (clean) *************************************\n \"\"\"\n # loss:lm\n list_lm2d = decoder_lm(self.h_lrgp, list_gpmm_vertex, list_gpmm_proj) # bs, ver_num, xy\n\n dict_intermedate_common['pred_lm2d'] = list_lm2d\n\n \"\"\"\n ************************************ Render **********************************************\n \"\"\"\n list_gpmm_render, list_gpmm_render_mask, list_gpmm_render_tri_ids = decoder_renderColorMesh(\n # gpmm_vertexColor: (0, Nan)\n self.opt, self.h_lrgp, list_gpmm_vertex, list_gpmm_vertexNormal, list_gpmm_vertexColor,\n self.gpmm_frustrum, list_gpmm_mv, list_gpmm_eye, fore= self.opt.flag_fore, tone=False\n )\n list_gpmm_render = gpmm_face_replace(list_image, list_gpmm_render, list_gpmm_render_mask)\n\n \"\"\"\n ************************************ Visualization or Testing *****************************\n \"\"\"\n # render visual\n list_gpmm_render_shade, _, _ = decoder_renderColorMesh( # gpmm_vertexShade: (0, Nan)\n self.opt, self.h_lrgp, list_gpmm_vertex, list_gpmm_vertexNormal, list_gpmm_vertexShade,\n self.gpmm_frustrum, list_gpmm_mv, list_gpmm_eye, fore= self.opt.flag_fore, tone=False\n )\n dict_intermedate_common['3dmm_render_shade'] = list_gpmm_render_shade\n # # main 3 view\n # gpmm_main_ext, gpmm_main_proj, gpmm_main_mv, gpmm_main_eye = \\\n # build_train_graph_3dmm_camera(self.intrinsics_single, self.defined_pose_main)\n # gpmm_render_tar_main, _, _ = decoder_renderColorMesh(\n # opt, self.h_lrgp, gpmm_vertex, gpmm_vertexNormal, gpmm_vertexColorOri, gpmm_frustrum,\n # gpmm_main_mv, gpmm_main_eye)\n\n \"\"\"\n Weighted Loss\n \"\"\"\n if list_lm2d_gt is not None:\n # loss:reg\n gpmm_regular_shape_loss = compute_3dmm_regular_l2_loss(list_gpmm)\n gpmm_regular_shape_loss += 0.8 * compute_3dmm_regular_l2_loss(list_gpmm_exp)\n gpmm_regular_color_loss = 0.0017 * compute_3dmm_regular_l2_loss(list_gpmm_color)\n\n gpmm_lm_loss = compute_lm_eul_square_loss(list_lm2d, list_lm2d_gt, self.lm2d_weight) # clean\n\n gpmm_pixel_loss, list_render_loss_error = \\\n compute_3dmm_render_eul_masknorm_skin_loss(list_gpmm_render, list_gpmm_render_mask, list_skin,\n list_image)\n dict_intermedate_common['3dmm_render'] = list_gpmm_render\n dict_intermedate_common['3dmm_render_mask'] = list_gpmm_render_mask\n dict_intermedate_common['3dmm_render_tri_id'] = list_gpmm_render_tri_ids\n dict_intermedate_common['3dmm_render_loss_heat'] = list_render_loss_error\n\n \"\"\"\n ************************************ Identity ********************************************\n \"\"\"\n\n list_gpmm_render_id, list_image_id, gpmm_render_align, image_align = \\\n decoder_similar(self.opt, self.defined_lm_facenet_align, list_gpmm_render, list_image, list_lm2d,\n list_lm2d_gt)\n gpmm_id_loss, _ = compute_3dmm_id_cos_loss(list_image_id, list_gpmm_render_id)\n dict_intermedate_common['id_render'] = list_gpmm_render_id\n dict_intermedate_common['id_image'] = list_image_id\n dict_intermedate_common['id_render_align'] = gpmm_render_align\n dict_intermedate_common['id_image_align'] = image_align\n\n \"\"\"\n ************************************ Depthmap *********************************************\n \"\"\"\n list_gpmm_depthmap, _ \\\n = decoder_depth(self.opt, self.h_lrgp, list_gpmm_vertex, self.gpmm_frustrum, list_gpmm_ext,\n list_gpmm_mv,\n list_gpmm_eye)\n dict_intermedate_common['3dmm_depthmap'] = list_gpmm_depthmap\n # dict_intermedate_common['3dmm_depthmap_mask'] = list_gpmm_depthmap_mask\n # dict_intermedate_common['3dmm_depthmap_min'] = list_gpmm_depthmap_min\n # dict_intermedate_common['3dmm_depthmap_max'] = list_gpmm_depthmap_max\n\n gpmm_regular_shape_loss = gpmm_regular_shape_loss / (self.opt.num_source + 1)\n gpmm_regular_color_loss = gpmm_regular_color_loss / (self.opt.num_source + 1)\n gpmm_lm_loss = gpmm_lm_loss / (self.opt.num_source + 1)\n gpmm_pixel_loss = gpmm_pixel_loss / (self.opt.num_source + 1)\n gpmm_id_loss = gpmm_id_loss / (self.opt.num_source + 1)\n dict_loss_common['reg_shape_loss'] = gpmm_regular_shape_loss\n dict_loss_common['reg_color_loss'] = gpmm_regular_color_loss\n dict_loss_common['lm2d_loss'] = gpmm_lm_loss\n dict_loss_common['render_loss'] = gpmm_pixel_loss\n dict_loss_common['id_loss'] = gpmm_id_loss\n\n loss_common = tf.constant(0.0)\n\n loss_common += self.opt.gpmm_regular_shape_loss_weight * gpmm_regular_shape_loss\n loss_common += self.opt.gpmm_regular_color_loss_weight * gpmm_regular_color_loss\n\n if self.opt.gpmm_lm_loss_weight > 0:\n loss_common += self.opt.gpmm_lm_loss_weight * gpmm_lm_loss\n if self.opt.gpmm_pixel_loss_weight > 0:\n loss_common += self.opt.gpmm_pixel_loss_weight * gpmm_pixel_loss\n if self.opt.gpmm_id_loss_weight:\n loss_common += self.opt.gpmm_id_loss_weight * gpmm_id_loss\n\n dict_loss_common['loss_common'] = loss_common\n\n return dict_loss_common, dict_intermedate_common\n\n\n def build_decoderMGC(self, flag_sgl_mul, list_image, list_lm2d_gt, dict_inter_common):\n \"\"\"\n :param list_image:\n :param list_lm2d_gt:\n :param dict_intermedate_common:\n :return:\n \"\"\"\n\n # input\n #relative pose from target to source\n list_rel_poses = decoder_warppose(self.opt, dict_inter_common['pred_6dof_pose'])\n\n #\n list_covisible_map = decoder_covisible_map(self.opt, self.h_lrgp, self.gpmm_frustrum, dict_inter_common)\n\n # inter\n list_tarTile_image = []\n list_tarTile_depth = []\n\n list_viewSyn_image = []\n list_viewSyn_depth = []\n list_viewSyn_mask = []\n list_viewSyn_image_masked = []\n list_render_mask = []\n list_viewSyn_ssim_mask = []\n\n # output\n dict_loss_common = dict()\n dict_intermedate_common = dict()\n\n # Start loop all source view\n curr_tar_image = list_image[0]\n curr_tar_depths = dict_inter_common['3dmm_depthmap'][0]\n for i in range(self.opt.num_source):\n list_tarTile_image.append(curr_tar_image)\n list_tarTile_depth.append(curr_tar_depths)\n # Inverse warp the source image to the target image frame\n with tf.name_scope(\"warp\"):\n curr_src_image = list_image[1 + i] # careful of [tar, src_all]\n curr_source_depth = dict_inter_common['3dmm_depthmap'][1 + i]\n warp_pose = list_rel_poses[i]\n # view synthetic\n # curr_src_image = tf.Print(curr_src_image, [tf.reduce_mean(curr_src_image)], message='curr_src_image')\n # curr_tar_depths = tf.Print(curr_tar_depths, [tf.reduce_mean(curr_tar_depths)], message='curr_tar_depths')\n # curr_source_depth = tf.Print(curr_source_depth, [tf.reduce_mean(curr_source_depth)], message='curr_source_depth')\n\n curr_viewSyn_image, curr_viewSyn_depth, viewSyn_mask = projective_inverse_warp(\n curr_src_image, tf.squeeze(curr_tar_depths, axis=-1), curr_source_depth,\n warp_pose, self.intrinsics_single[:, :, :], is_vec=True)\n #\n # curr_viewSyn_image = tf.Print(curr_viewSyn_image,\n # [tf.reduce_sum(curr_viewSyn_image), tf.reduce_sum(curr_tar_depths-852)], message='warp')\n\n #\n list_viewSyn_image.append(curr_viewSyn_image)\n list_viewSyn_depth.append(curr_viewSyn_depth)\n\n # covisible map\n view_syn_mask = viewSyn_mask * list_covisible_map[i]\n #view_syn_mask = tf.Print(view_syn_mask, [tf.reduce_sum(view_syn_mask)], message='view_syn_mask')\n\n # cut bg\n if 0:\n depthRender_min = dict_inter_common['3dmm_depthmap_min'][1 + i]\n depthRender_max = dict_inter_common['3dmm_depthmap_max'][1 + i]\n l_one = tf.ones_like(curr_viewSyn_depth)\n l_zero = tf.zeros_like(curr_viewSyn_depth)\n depthValid_mask = tf.where(tf.greater(viewSyn_depth, depthRender_max), x=l_zero, y=l_one)\n #view_syn_mask = view_syn_mask * depthValid_mask\n\n # mask dict_intermedate_common['3dmm_render_mask']\n list_viewSyn_mask.append(view_syn_mask)\n list_render_mask.append(dict_inter_common['3dmm_render_mask'][0])\n\n curr_viewSyn_image_mask = curr_viewSyn_image * view_syn_mask # (0, 1)\n list_viewSyn_image_masked.append(curr_viewSyn_image_mask)\n\n # 1.pixel\n ssim_mask = slim.avg_pool2d(view_syn_mask, 3, 1, 'VALID') # TODO: Right SSIM\n list_viewSyn_ssim_mask.append(ssim_mask)\n\n # 2.depth\n\n # 3.epipolar\n dict_intermedate_common['list_viewSyn_image'] = list_viewSyn_image\n dict_intermedate_common['list_viewSyn_mask'] = list_viewSyn_mask\n dict_intermedate_common['list_viewSyn_image_masked'] = list_viewSyn_image_masked\n\n\n # 1. pixel loss\n # photo loss\n list_curr_viewSyn_pixel_error, list_curr_viewSyn_pixel_error_visual = \\\n compute_pixel_eul_loss_list(list_viewSyn_image_masked, list_viewSyn_mask, list_render_mask, list_tarTile_image)\n\n flag_sgl_mul_curr = flag_sgl_mul\n flag_sgl_mul_curr = tf.clip_by_value(flag_sgl_mul_curr, 0.0, 1.0)\n pixel_loss = combine_flag_sgl_mul_loss(list_curr_viewSyn_pixel_error, flag_sgl_mul_curr)\n\n dict_intermedate_common['list_curr_viewSyn_pixel_error_visual'] = list_curr_viewSyn_pixel_error_visual\n\n # ssim loss\n list_curr_viewSyn_ssim_error = compute_ssim_loss_list(list_viewSyn_image, list_tarTile_image, list_viewSyn_ssim_mask)\n\n flag_sgl_mul_curr = flag_sgl_mul\n flag_sgl_mul_curr = tf.clip_by_value(flag_sgl_mul_curr, 0.0, 1.0)\n ssim_loss = combine_flag_sgl_mul_loss(list_curr_viewSyn_ssim_error, flag_sgl_mul_curr)\n\n # 2. depth loss\n \"\"\"\n depth: range(0, NAN+)\n proj_mask: range(0, 1)\n \"\"\"\n list_viewSyn_depth_alinged = decoder_align_depthMap(self.opt, list_tarTile_depth, list_viewSyn_depth, list_viewSyn_mask)\n\n list_curr_viewSyn_depth_error, list_curr_viewSyn_depth_visual = \\\n compute_depthmap_l1_loss_list(list_viewSyn_depth_alinged, list_viewSyn_mask, list_tarTile_depth) # TODO: bug!!!\n\n flag_sgl_mul_curr = flag_sgl_mul\n flag_sgl_mul_curr = tf.clip_by_value(flag_sgl_mul_curr, 0.0, 1.0)\n depth_loss = combine_flag_sgl_mul_loss(list_curr_viewSyn_depth_error, flag_sgl_mul_curr, flag_batch_norm=False)\n\n dict_intermedate_common['list_viewSyn_depth_alinged'] = list_viewSyn_depth_alinged\n dict_intermedate_common['list_curr_viewSyn_depth_visual'] = list_curr_viewSyn_depth_visual\n\n # 3. Eipipolar loss (fundamental matrix)\n list_epiLoss_batch, list_reprojLoss_batch, mgc_epi_lines, mgc_epi_distances = compute_match_loss_list(\n list_lm2d_gt, dict_inter_common['3dmm_depthmap'][0], list_rel_poses, self.intrinsics_single\n )\n flag_sgl_mul_curr = flag_sgl_mul - 1\n flag_sgl_mul_curr = tf.clip_by_value(flag_sgl_mul_curr, 0.0, 1.0)\n epi_loss = combine_flag_sgl_mul_loss(list_epiLoss_batch, flag_sgl_mul_curr, flag_batch_norm=False)\n\n\n dict_intermedate_common['mgc_epi_lines'] = mgc_epi_lines\n dict_intermedate_common['mgc_epi_distances'] = mgc_epi_distances\n\n \"\"\"\n Weighted Loss\n \"\"\"\n loss_multiView = tf.constant(0.0)\n if self.opt.photom_weight > 0:\n loss_multiView += self.opt.photom_weight * pixel_loss\n dict_loss_common['pixel_loss'] = pixel_loss\n else:\n dict_loss_common['pixel_loss'] = tf.constant(0.0)\n\n if self.opt.ssim_weight > 0:\n loss_multiView += self.opt.ssim_weight * ssim_loss\n dict_loss_common['ssim_loss'] = ssim_loss\n else:\n dict_loss_common['ssim_loss'] = tf.constant(0.0)\n\n if self.opt.epipolar_weight > 0:\n loss_multiView += self.opt.epipolar_weight * epi_loss\n dict_loss_common['epi_loss'] = epi_loss\n else:\n dict_loss_common['epi_loss'] = tf.constant(0.0)\n\n if self.opt.depth_weight > 0:\n loss_multiView += self.opt.depth_weight * depth_loss\n dict_loss_common['depth_loss'] = depth_loss\n else:\n dict_loss_common['depth_loss'] = tf.constant(0.0)\n\n dict_loss_common['loss_mgc'] = loss_multiView\n\n # inter\n dict_intermedate_common['list_rel_poses'] = list_rel_poses\n\n return dict_loss_common, dict_intermedate_common\n\n\n def build_train_graph_train_op(self):\n opt = self.opt\n\n with tf.name_scope(\"train_op\"):\n #print('Global variables:', tf.global_variables())\n train_vars = [var for var in tf.trainable_variables()]\n #print('Optimized variables:', train_vars)\n\n #print(\"Global variables number: %d\" % (len(tf.global_variables())))\n print(\"Optimized variables number: %d\" % (len(train_vars)))\n \"\"\"\n Clean\n \"\"\"\n train_vars = [(var) for var in train_vars if var.name.find('InceptionResnetV1') == -1]\n #print(\"Optimized variables number(After clean forward var): %d\" % (len(train_vars)))\n\n update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)\n with tf.control_dependencies(update_ops):\n optim0 = tf.train.AdamOptimizer(1.0 * opt.learning_rate, opt.beta1) # face+pose: no constrain\n self.train_op = []\n\n if len(train_vars) != 0:\n #self.total_loss = tf.Print(self.total_loss, [self.total_loss], message='self.total_loss', summarize=4)\n self.grads_and_vars = optim0.compute_gradients(self.total_loss, var_list=train_vars)\n\n for grad, var in self.grads_and_vars:\n if grad is None:\n print(\"Optimized variables grad is None: \", var)\n self.grads_and_vars = [(grad, var) for grad, var in self.grads_and_vars if grad is not None]\n sum_grads = [tf.reduce_sum(grad) for grad, var in self.grads_and_vars]\n self.total_grad = tf.reduce_sum(sum_grads)\n self.train_op.append(optim0.apply_gradients(self.grads_and_vars))\n self.incr_global_step = tf.assign(self.global_step, self.global_step + 1)\n\n\n def collect_summaries(self):\n opt = self.opt\n\n # scalar\n tf.summary.scalar(\"total_loss\", self.total_loss)\n tf.summary.scalar(\"common_loss\", self.common_loss)\n tf.summary.scalar(\"ga_loss\", self.ga_loss)\n # common\n if opt.gpmm_regular_shape_loss_weight > 0:\n tf.summary.scalar(\"gpmm_regular_shape_loss\", self.gpmm_regular_shape_loss)\n if opt.gpmm_regular_color_loss_weight > 0:\n tf.summary.scalar(\"gpmm_regular_color_loss\", self.gpmm_regular_color_loss)\n if opt.gpmm_lm_loss_weight > 0:\n tf.summary.scalar(\"gpmm_lm_loss\", self.gpmm_lm_loss)\n if opt.gpmm_pixel_loss_weight > 0:\n tf.summary.scalar(\"gpmm_pixel_loss\", self.gpmm_pixel_loss)\n if opt.gpmm_id_loss_weight:\n tf.summary.scalar(\"gpmm_id_loss\", self.gpmm_id_loss)\n # multi-view\n if opt.ssim_weight > 0:\n tf.summary.scalar(\"ssim_loss\", self.ssim_loss)\n if opt.photom_weight > 0:\n tf.summary.scalar(\"pixel_loss\", self.pixel_loss)\n if opt.epipolar_weight > 0:\n tf.summary.scalar(\"epipolar_loss\", self.epipolar_loss)\n if opt.depth_weight > 0:\n tf.summary.scalar(\"depth_loss\", self.depth_loss)\n\n if 1:\n\n \"\"\"\n image\n \"\"\"\n self.list_img_tar = deprocess_image_series(self.list_tar_image)\n self.list_img_src = deprocess_image_series(self.list_src_image)\n\n \"\"\"\n image + landmark\n \"\"\"\n list_img_lmDraw_tar = draw_landmark_image(self.list_tar_image, self.lm2d_tar, opt.img_height, opt.img_width, color=1)\n list_img_lmDraw_tar = draw_landmark_image(list_img_lmDraw_tar, self.list_lm2d_gt_tar, opt.img_height, opt.img_width, color=2)\n\n list_img_lmDraw_src = draw_landmark_image(self.list_src_image, self.lm2d_src, opt.img_height, opt.img_width, color=1)\n list_img_lmDraw_src = draw_landmark_image(list_img_lmDraw_src, self.list_lm2d_gt_src, opt.img_height, opt.img_width, color=2)\n\n \"\"\"\n render main pose\n \"\"\"\n #tf.summary.image('gpmm_render_tar_main', deprocess_image(self.gpmm_render_tar_main[0]))\n\n \"\"\"\n render derivatives\n \"\"\"\n # shade\n list_shade_tar = deprocess_image_series(self.gpmm_render_shade_tar)\n list_shade_src = deprocess_image_series(self.gpmm_render_shade_src)\n\n # mask\n list_render_mask_tar = deprocess_gary_image_series(self.gpmm_render_mask_tar)\n list_render_mask_src = deprocess_gary_image_series(self.gpmm_render_mask_src)\n\n # skin\n list_skin_tar = deprocess_gary_image_series(self.list_tar_skin)\n list_skin_src = deprocess_gary_image_series(self.list_src_skin)\n\n \"\"\"\n render\n \"\"\"\n # tar render and ori image\n self.list_render_image_tar = deprocess_image_series(self.gpmm_render_tar)\n self.list_render_image_src = deprocess_image_series(self.gpmm_render_src)\n\n list_render_loss_tar = deprocess_image_series(self.list_render_loss_error_tar)\n list_render_loss_src = deprocess_image_series(self.list_render_loss_error_src)\n\n # Render\n # 1\n show_img_imgLM_tar = concate_image_series(self.list_img_tar, list_img_lmDraw_tar, axis=1)\n show_img_imgLM_src = concate_image_series(self.list_img_src, list_img_lmDraw_src, axis=1)\n\n # 2\n show_light_mask_tar = concate_image_series(list_skin_tar, list_shade_tar, axis=1)\n show_light_mask_src = concate_image_series(list_skin_src, list_shade_src, axis=1)\n\n # fusion\n render_12_tar = concate_image_series(show_img_imgLM_tar, self.list_render_image_tar, axis=1)\n render_23_tar = concate_image_series(show_light_mask_tar, list_render_loss_tar, axis=1)\n render_123_tar = concate_image_series(render_12_tar, render_23_tar, axis=2)\n\n render_12_src = concate_image_series(show_img_imgLM_src, self.list_render_image_src, axis=1)\n render_23_src = concate_image_series(show_light_mask_src, list_render_loss_src, axis=1)\n render_123_src = concate_image_series(render_12_src, render_23_src, axis=2)\n\n self.show_gpmm_render_all = concate_semi_image_series(render_123_tar, render_123_src)\n tf.summary.image('gpmm_render_all', self.show_gpmm_render_all)\n\n \"\"\"\n epipolar:\n image + consistance\n \"\"\"\n self.list_img_lmConsistDraw_tar = draw_landmark_image(self.list_tar_image, self.gpmm_consist_pixel_tar, opt, color=1)\n self.list_img_lmConsistDraw_src = draw_landmark_image(self.list_src_image, self.gpmm_consist_pixel_src, opt, color=1)\n\n # epipolar\n list_img_lmConsistDraw = draw_landmark_image(self.list_image, self.list_lm2d_gt, opt.img_height, opt.img_width, color=1)\n\n # photematric\n list_geo_proj_img_src = deprocess_image_series(self.dict_inter_mgc['list_viewSyn_image'])\n list_geo_proj_img_fore_src = deprocess_image_series(self.dict_inter_mgc['list_viewSyn_image_masked'])\n\n list_geo_proj_mask_src = deprocess_gary_image_series(self.dict_inter_mgc['list_viewSyn_mask'])\n list_geo_proj_img_error_src = deprocess_image_series(self.dict_inter_mgc['list_curr_viewSyn_pixel_error_visual'])\n\n # 1\n show_geo_proj_img_tar = concate_image_series(self.list_tar_image, self.list_tar_image, axis=1)\n show_geo_proj_img_tar = deprocess_image_series(show_geo_proj_img_tar)\n show_geo_proj_img_src = concate_image_series(list_geo_proj_img_src, list_geo_proj_img_fore_src, axis=1)\n\n show_geo_proj_img_me_tar = concate_image_series(self.list_tar_image, self.list_tar_image, axis=1)\n show_geo_proj_img_me_tar = deprocess_image_series(show_geo_proj_img_me_tar)\n show_geo_proj_img_me_src = concate_image_series(list_geo_proj_mask_src, list_geo_proj_img_error_src, axis=1)\n\n # 2\n show_geo_proj_tar = concate_image_series(show_geo_proj_img_tar, show_geo_proj_img_me_tar, axis=1)\n show_geo_proj_src = concate_image_series(show_geo_proj_img_src, show_geo_proj_img_me_src, axis=1)\n\n # 3\n show_geo_epi_tar = concate_image_series(list_img_lmConsistDraw[0:1], show_geo_proj_tar, axis=1)\n show_geo_epi_src = concate_image_series(list_img_lmConsistDraw[1:], show_geo_proj_src, axis=1)\n\n # fusion\n self.show_proj_all = insert_semi_image_series(show_geo_epi_tar, show_geo_epi_src)\n\n tf.summary.image(\"show_warp_proj_all\", self.show_proj_all)\n\n\n def train_pre(self, opt):\n self.opt = opt\n\n \"\"\"\n 1.continue training\n 2.pretrain model\n \"\"\"\n restore_vars = tf.global_variables()\n self.restorer = tf.train.Saver(restore_vars, max_to_keep=None)\n self.saver = tf.train.Saver(tf.global_variables(), max_to_keep=None)\n\n # pretrain model\n if opt.ckpt_face_pretrain is not None:\n face_variables_to_restore = []\n\n\n face_variables_to_restore_all = slim.get_model_variables(\"resnet_v1_50\")\n for var in face_variables_to_restore_all:\n if var.op.name.find('logits') != -1 or var.op.name.find('predictions') != -1:\n pass\n elif var.op.name.find('block1_final') != -1:\n pass\n else:\n face_variables_to_restore.append(var)\n print(\"Face network pretrain, number: %d\" % (len(face_variables_to_restore)))\n self.face_restorer = slim.assign_from_checkpoint_fn(opt.ckpt_face_pretrain, face_variables_to_restore, True)\n\n if opt.ckpt_face_id_pretrain is not None:\n # 1\n # face_variables_to_restore = slim.get_model_variables(\"InceptionResnetV1\")\n # print(\"ID network pretrain, number: %d\" % (len(face_variables_to_restore)))\n # self.face_id_restorer = slim.assign_from_checkpoint_fn(opt.ckpt_face_id_pretrain, face_variables_to_restore, True)\n\n # 2\n face_variables_to_restore = tf.model_variables(\"InceptionResnetV1\")\n print(\"Identity variables number: %d\" % (len(face_variables_to_restore)))\n #saver = tf_render.train.Saver([var for var in test_var])\n self.face_id_restorer = tf.train.Saver(face_variables_to_restore)\n\n\n def train(self, opt):\n # FLAGS\n assert opt.num_source == opt.seq_length - 1\n \"\"\"\n Build Graph\n \"\"\"\n # all the data directly stored in the self.Graph\n data_loader, batch_sample = self.build_train_graph_dataLoader()\n #with tf.device('/cpu:0'):\n self.build_train_graph()\n\n #\n self.collect_summaries()\n\n #\n with tf.name_scope(\"parameter_count\"):\n parameter_count = \\\n tf.reduce_sum([tf.reduce_prod(tf.shape(v)) for v in tf.trainable_variables()])\n\n # model\n self.train_pre(opt)\n\n \"\"\"\n Start Training\n \"\"\"\n # Initialize variables\n sv = tf.train.Supervisor(logdir=opt.checkpoint_dir,\n save_summaries_secs=0,\n saver=None)\n config = tf.ConfigProto(allow_soft_placement=True)\n config.gpu_options.allocator_type = 'BFC' # A \"Best-fit with coalescing\" algorithm, simplified from a version of dlmalloc.\n #config.gpu_options.per_process_gpu_memory_fraction = 0.8\n config.gpu_options.allow_growth = True\n with sv.managed_session(config=config) as sess:\n print(\"Parameter count =\", sess.run(parameter_count))\n\n \"\"\"\n Functional Define\n \"\"\"\n # continue train\n if opt.continue_train:\n if opt.init_ckpt_file is None:\n checkpoint = tf.train.latest_checkpoint(opt.checkpoint_dir)\n else:\n checkpoint = opt.init_ckpt_file\n print(\"Resume training from previous checkpoint: %s\" % checkpoint)\n self.restorer.restore(sess, checkpoint)\n #\n dic_ckpt, name_ckpt = os.path.split(checkpoint)\n gs = name_ckpt.split('-')[1].split('.')[0]\n #\n # self.global_step = tf.Variable(0, name='global_step', trainable=False)\n step_start = int(gs) + 1\n else:\n # pretrain model\n if opt.ckpt_face_pretrain is not None:\n self.face_restorer(sess)\n step_start = 0 + 1\n\n if opt.ckpt_face_id_pretrain is not None:\n self.face_id_restorer.restore(sess, opt.ckpt_face_id_pretrain)\n\n # init global\n #sess.run(tf_render.global_variables_initializer())\n\n \"\"\"\n Loop Start\n \"\"\"\n start_time = time.time()\n # \"\"\"\n # Data init\n # \"\"\"\n sess.graph.finalize()\n for step in range(step_start, opt.max_steps+1):\n \"\"\"\n Data init\n \"\"\"\n if step == 1 or (opt.dataset_name_list == 'train' and step % self.steps_per_epoch == 0) or (opt.continue_train and step == step_start):\n global_all_file_list = data_loader.format_file_list(opt.dataset_dir, opt.dataset_name_list)\n self.steps_per_epoch = data_loader.steps_per_epoch # Step count\n data_loader.init_data_pipeline(sess, batch_sample, global_all_file_list)\n print(\"Update dataloader list: (step %d in all %d)\" % (step, self.steps_per_epoch))\n\n \"\"\"\n Define fetch\n \"\"\"\n fetches = {\n \"total_loss\": self.total_loss,\n #\"total_grad\": self.total_grad,\n \"train\": self.train_op,\n \"global_step\": self.global_step,\n \"incr_global_step\": self.incr_global_step\n }\n if step % opt.summary_freq == 0:\n fetches[\"ga_loss\"] = self.ga_loss\n fetches[\"pixel_loss\"] = self.pixel_loss\n fetches[\"ssim_loss\"] = self.ssim_loss\n fetches[\"depth_loss\"] = self.depth_loss\n fetches[\"epipolar_loss\"] = self.epipolar_loss\n\n fetches[\"gpmm_pixel_loss\"] = self.gpmm_pixel_loss\n fetches[\"gpmm_lm_loss\"] = self.gpmm_lm_loss\n fetches[\"gpmm_id_loss\"] = self.gpmm_id_loss\n fetches[\"gpmm_reg_shape_loss\"] = self.gpmm_regular_shape_loss\n fetches[\"gpmm_reg_color_loss\"] = self.gpmm_regular_color_loss\n\n fetches[\"summary\"] = sv.summary_op\n\n \"\"\"\n ********************************************* Start Trainning *********************************************\n \"\"\"\n results = sess.run(fetches)\n gs = results[\"global_step\"]\n\n if step % opt.summary_freq == 0:\n sv.summary_writer.add_summary(results[\"summary\"], gs)\n train_epoch = math.ceil(gs / self.steps_per_epoch)\n train_step = gs - (train_epoch - 1) * self.steps_per_epoch\n print(\"Epoch %2d: %5d/%5d (time: %4.4f), Step %d:\"\n % (train_epoch, train_step, gs, (time.time() - start_time) / opt.summary_freq, step))\n\n print(\"total: [%.4f]\" % (results[\"total_loss\"]))\n\n print(\"ga/pixel/ssim/depth/epipolar loss: [%.4f/%.4f/%.4f/%.4f/%.4f]\" % (\n results[\"ga_loss\"], results[\"pixel_loss\"], results[\"ssim_loss\"], results[\"depth_loss\"], results[\"epipolar_loss\"]))\n\n print(\"(weight)ga/pixel/ssim/depth/epipolar loss: [%.4f/%.4f/%.4f/%.4f/%.4f]\" % (\n results[\"ga_loss\"] * opt.MULTIVIEW_weight,\n results[\"pixel_loss\"] * (1-opt.ssim_weight),\n results[\"ssim_loss\"] * opt.ssim_weight,\n results[\"depth_loss\"] * opt.depth_weight,\n results[\"epipolar_loss\"] * opt.epipolar_weight)\n )\n\n # 3dmm loss\n print(\"mm_pixel/mm_lm/mm_id/mm_reg_s/mm_reg_c loss: [%.4f/%.4f/%.4f/%.4f/%.4f]\" % (\n results[\"gpmm_pixel_loss\"], results[\"gpmm_lm_loss\"], results[\"gpmm_id_loss\"],\n results[\"gpmm_reg_shape_loss\"], results[\"gpmm_reg_color_loss\"]))\n\n print(\"(weight)mm_pixel/mm_lm/mm_id/mm_reg_s/mm_reg_c loss: [%.4f/%.4f/%.4f/%.4f/%.4f]\\n\" % (\n results[\"gpmm_pixel_loss\"] * opt.gpmm_pixel_loss_weight,\n results[\"gpmm_lm_loss\"] * opt.gpmm_lm_loss_weight,\n results[\"gpmm_id_loss\"] * opt.gpmm_id_loss_weight,\n results[\"gpmm_reg_shape_loss\"] * opt.gpmm_regular_shape_loss_weight,\n results[\"gpmm_reg_color_loss\"] * opt.gpmm_regular_color_loss_weight))\n start_time = time.time()\n \"\"\"\n Save model\n \"\"\"\n if gs % opt.save_freq == 0 and step >= opt.min_steps:\n self.save(sess, opt.checkpoint_dir, gs)\n\n\n def save(self, sess, checkpoint_dir, step):\n model_name = 'model'\n print(\" [*] Saving checkpoint step %d to %s...\" % (step, checkpoint_dir))\n self.saver.save(sess, os.path.join(checkpoint_dir, model_name), global_step=step)\n\n \"\"\"\n Test\n \"\"\"\n def set_constant_test(self):\n # cam\n self.set_constant_node()\n\n # multi pose\n defined_pose_left = tf.constant([-0.000000, -0.392699, -3.141593, 37.504993, 9.1053238, 4994.3359], shape=[1, 6])\n self.defined_pose_left = tf.tile(defined_pose_left, multiples=[self.batch_size, 1])\n defined_pose_right = tf.constant([-0.000000, 0.392699, -3.141593, -37.341232, 9.1053238, 4994.3359], shape=[1, 6])\n self.defined_pose_right = tf.tile(defined_pose_right, multiples=[self.batch_size, 1])\n\n self.define_pose = tf.stack([self.defined_pose_left, self.defined_pose_main, self.defined_pose_right], axis=0)\n\n # print color\n gpmm_vertexColor_gary = tf.constant([0.7529, 0.7529, 0.7529], shape=[1, 1, 3])\n #gpmm_vertexColor_gary = tf.constant([0.5, 0.5, 0.5], shape=[1, 1, 3])\n gpmm_vertexColor_gary = tf.tile(gpmm_vertexColor_gary, [self.batch_size, self.h_lrgp.h_curr.point3d_mean_np.shape[0], 1])\n self.list_vertexColor_gary = [gpmm_vertexColor_gary]\n\n\n def build_test_graph(self, opt, img_height, img_width, batch_size=1):\n self.opt = opt\n\n self.img_height = img_height\n self.img_width = img_width\n\n self.batch_size = batch_size\n self.rank = self.opt.gpmm_rank\n\n # start\n input_uint8 = tf.placeholder(tf.uint8, [self.batch_size, self.img_height, self.img_width, 3], name='pl_input')\n input_float = preprocess_image(input_uint8)\n self.list_input_float = [input_float]\n\n # setting\n self.set_constant_test()\n\n # single view\n list_coeffALL = pred_encoder_coeff_light(self.opt, self.defined_pose_main, self.list_input_float, is_training=False)\n\n dict_loss_common, dict_intermedate_common = \\\n self.build_decoderCommon(list_coeffALL, self.list_input_float)\n self.dict_inter_comm = dict_intermedate_common\n self.dict_loss_common = dict_loss_common\n\n # multi-level\n self.list_vertex, self.list_vertexNormal, self.list_vertexColor, self.list_vertexShade, self.list_vertexColorOri = \\\n decoder_colorMesh_test(self.h_lrgp, self.dict_inter_comm, exp=True)\n\n # visual\n if opt.flag_visual:\n self.build_testVisual_graph()\n\n\n def build_testVisual_graph(self):\n opt = self.opt\n self.gpmm_render_mask = []\n\n self.overlay_255 = []\n self.overlayTex_255 = []\n self.overlayLight_255 = []\n\n self.overlayGeo_255 = []\n self.overlayMain_255 = []\n self.overlayTexMain_255 = []\n self.overlayLightMain_255 = []\n\n self.overlayGeoMain_255 = []\n self.apper_mulPose_255 = []\n\n for v in range(len(self.list_vertex)):\n \"\"\"\n 0. single visual: overlay(color + texture + geometry + illumination)\n \"\"\"\n color_overlay_single = [self.list_vertexColor[0],\n self.list_vertexColorOri[0],\n self.list_vertexShade[0]]\n overlay_single = []\n for i in range(len(color_overlay_single)):\n # render\n texture_color = color_overlay_single[i]\n\n gpmm_render, gpmm_render_mask_v, _ = decoder_renderColorMesh(\n opt, self.h_lrgp, self.list_vertex[0], self.list_vertexNormal[0], texture_color,\n self.gpmm_frustrum, self.dict_inter_comm['pred_cam_mv'][v], self.dict_inter_comm['pred_cam_eye'][v], fore=opt.flag_fore, tone=False\n )\n\n gpmm_render = gpmm_face_replace(self.list_input_float[v], gpmm_render, gpmm_render_mask_v)\n gpmm_render = tf.clip_by_value(gpmm_render, 0.0, 1.0)\n #gpmm_render = tf.Print(gpmm_render, [gpmm_render], message='gpmm_render')\n #\n gpmm_render_visual = tf.image.convert_image_dtype(gpmm_render[0], dtype=tf.uint8)\n overlay_single.append(gpmm_render_visual)\n #\n self.gpmm_render_mask.append(gpmm_render_mask_v[0])\n\n self.overlay_255.append(overlay_single[0])\n self.overlayTex_255.append(overlay_single[1])\n self.overlayLight_255.append(overlay_single[2])\n\n\n # single visual geo\n overlayGeo, _, _ = decoder_renderColorMesh_gary(\n opt, self.h_lrgp, self.list_vertex[0], self.list_vertexNormal[0], self.list_vertexColor_gary,\n self.gpmm_frustrum, self.dict_inter_comm['pred_cam_mv'][v], self.dict_inter_comm['pred_cam_eye'][v], fore=opt.flag_fore, tone=False, background=-1\n )\n overlayGeo = gpmm_face_replace(self.list_input_float[v], overlayGeo, self.gpmm_render_mask[v])\n overlayGeo = tf.clip_by_value(overlayGeo, 0.0, 1.0)\n overlayGeo_255 = tf.image.convert_image_dtype(overlayGeo[0], dtype=tf.uint8)\n self.overlayGeo_255.append(overlayGeo_255)\n\n \"\"\"\n 1. single visual: main(color + texture + geometry + illumination)\n \"\"\"\n if v == 0:\n gpmm_tar_extMain, gpmm_tar_projMain, gpmm_tar_mvMain, gpmm_tar_eyeMain = \\\n build_train_graph_3dmm_camera(self.intrinsics_single, self.define_pose[1])\n\n overlay_single = []\n for i in range(len(color_overlay_single)):\n # render\n texture_color = color_overlay_single[i]\n\n gpmm_render, gpmm_render_mask_v, _ = decoder_renderColorMesh(\n opt, self.h_lrgp, self.list_vertex[0], self.list_vertexNormal[0], texture_color,\n self.gpmm_frustrum, gpmm_tar_mvMain, gpmm_tar_eyeMain, fore=opt.flag_fore, tone=False\n )\n\n gpmm_render = tf.clip_by_value(gpmm_render, 0.0, 1.0)\n\n gpmm_render_visual = tf.image.convert_image_dtype(gpmm_render[0], dtype=tf.uint8)\n overlay_single.append(gpmm_render_visual)\n\n self.overlayMain_255.append(overlay_single[0])\n self.overlayTexMain_255.append(overlay_single[1])\n self.overlayLightMain_255.append(overlay_single[2])\n\n\n #\n overlayGeo, _, _ = decoder_renderColorMesh_gary(\n opt, self.h_lrgp, self.list_vertex[0], self.list_vertexNormal[0], self.list_vertexColor_gary,\n self.gpmm_frustrum, gpmm_tar_mvMain, gpmm_tar_eyeMain, fore=opt.flag_fore, tone=False, background=-1\n )\n #overlayGeo = gpmm_face_replace(self.input_float, overlayGeo, self.gpmm_render_mask)\n overlayGeo = tf.clip_by_value(overlayGeo, 0.0, 1.0)\n overlayGeoMain_255 = tf.image.convert_image_dtype(overlayGeo[0], dtype=tf.uint8)\n self.overlayGeoMain_255.append(overlayGeoMain_255)\n\n \"\"\"\n 2. multi-poses visual: 3 random pose\n \"\"\"\n for i in range(self.define_pose.shape[0]):\n pose = self.define_pose[i]\n #pose = tf.tile(pose, multiples=[self.batch_size, 1])\n\n gpmm_tar_ext, gpmm_tar_proj, gpmm_tar_mv, gpmm_tar_eye = \\\n build_train_graph_3dmm_camera(self.intrinsics_single, pose)\n\n # render\n gpmm_render, gpmm_render_mask, _ = decoder_renderColorMesh(\n opt, self.h_lrgp, self.list_vertex[0], self.list_vertexNormal[0], self.list_vertexColor[0],\n self.gpmm_frustrum, gpmm_tar_mv, gpmm_tar_eye, fore=opt.flag_fore, tone=False\n )\n gpmm_render = tf.clip_by_value(gpmm_render, 0.0, 1.0)\n\n if i == 0:\n apper_mulPose_255 = tf.image.convert_image_dtype(gpmm_render[0], dtype=tf.uint8) # bs, y, x\n else:\n apper_mulPose_255 = tf.concat([apper_mulPose_255, tf.image.convert_image_dtype(gpmm_render[0], dtype=tf.uint8)], axis=2) # bs, y, x\n self.apper_mulPose_255.append(apper_mulPose_255)\n\n\n def inference(self, sess, inputs):\n fetches = {}\n\n # Eval\n # 0. vertex\n fetches['vertex_shape'] = self.list_vertex\n\n # 1. color\n fetches['vertex_color'] = self.list_vertexColor\n fetches['vertex_color_ori'] = self.list_vertexColorOri\n\n # Visual\n if self.opt.flag_visual:\n fetches['gpmm_render_mask'] = self.gpmm_render_mask\n\n fetches['overlay_255'] = self.overlay_255\n fetches['overlayTex_255'] = self.overlayTex_255\n fetches['overlayLight_255'] = self.overlayLight_255\n fetches['overlayGeo_255'] = self.overlayGeo_255\n\n fetches['overlayMain_255'] = self.overlayMain_255\n fetches['overlayTexMain_255'] = self.overlayTexMain_255\n fetches['overlayLightMain_255'] = self.overlayLightMain_255\n fetches['overlayGeoMain_255'] = self.overlayGeoMain_255\n\n fetches['apper_mulPose_255'] = self.apper_mulPose_255\n\n # lm2d, pose\n fetches['lm2d'] = self.dict_inter_comm['pred_lm2d']\n fetches['gpmm_pose'] = self.dict_inter_comm['pred_6dof_pose']\n fetches['gpmm_intrinsic'] = self.intrinsics_single\n\n #\n results = sess.run(fetches, feed_dict={'pl_input:0':inputs})\n\n return results\n"
},
{
"alpha_fraction": 0.7323943376541138,
"alphanum_fraction": 0.7761304378509521,
"avg_line_length": 59.1363639831543,
"blob_id": "33ac1f9d7b77cb9dee03417571391e9d5e964323",
"content_id": "49c5ace1a8b6c8d1a327a813364e4fb259e4083d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1349,
"license_type": "permissive",
"max_line_length": 209,
"num_lines": 22,
"path": "/Recognition-Algorithms/Face Recognition using VGG/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Facial Recognition Using Deep Neural Networks (VGG)\r\n\r\nThis repository includes jupyter notebooks and test pictures of our project.\r\n\r\nWe are trying to predict the name of celebs in a picture provided. \r\n\r\n<img src=\"https://github.com/NEERAJAP2001/Face-X/blob/VGG-Face-Detection/Recognition-Algorithms/Face%20Recognition%20using%20VGG/assets/mg.jpg\" width=\"250\">\r\n\r\n\r\nTo do this, we considered a well-known pre-trained Convolutional Deep Neural Networks, called VGG-FACE.\r\n<img src=\"https://github.com/NEERAJAP2001/Face-X/blob/VGG-Face-Detection/Recognition-Algorithms/Face%20Recognition%20using%20VGG/assets/Dataset.PNG\">\r\n\r\n\r\n## Facial Recognition Using Pre-Trained VGG-Face + OpenCV\r\n#### Jupyter notebook of our project can be found here [Pre_Trained_Vgg_Face.ipynb](https://github.com/NEERAJAP2001/Face-X/blob/VGG-Face-Detection/Face%20Recognition%20using%20VGG/Training%20VGG%20Model.ipynb)\r\n\r\n## Result:\r\n\r\n<img src=\"https://github.com/NEERAJAP2001/Face-X/blob/VGG-Face-Detection/Recognition-Algorithms/Face%20Recognition%20using%20VGG/assets/mgresult.PNG\">\r\n\r\n#### DataSet : http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html\r\n#### Jupyter notebook of our project can be found here [Fine_Tuning_Vgg_Face.ipynb](https://github.com/NEERAJAP2001/Face-X/blob/VGG-Face-Detection/Face%20Recognition%20using%20VGG/Fine_Tuning%20Model.ipynb).\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5093888640403748,
"alphanum_fraction": 0.5401703715324402,
"avg_line_length": 55.71751403808594,
"blob_id": "8b3176bcf3cfe31119f6064877291a6634e13c33",
"content_id": "d76ce6f73ff43f1854101e839fb91bb28285de2f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 20077,
"license_type": "permissive",
"max_line_length": 179,
"num_lines": 354,
"path": "/Face Reconstruction/Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model/cariface.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from datagen import TrainSet, TestSet\n\nimport os\nimport numpy as np\nimport torch\nimport torch.nn as nn\nimport torch.optim as optim\nimport torch.utils.data as data\nimport torchvision\nimport time\n\n\"\"\"\n CalculateLandmark2D:\n 'euler_angle' is a euler_angle tensor with size (batch_size, 3),\n 'scale' is a scale tensor with size (batch_size, 1),\n 'trans' is a translation matrix with size (batch_size, 2),\n 'points' is a point tensor with size (batch_size, 3, vertex_num),\n 'landmark_index' is a long tensor with size (landmark_num),\n 'landmark_num' is the number of landmarks\n\"\"\"\ndef CalculateLandmark2D(euler_angle, scale, trans, points, landmark_index, landmark_num):\n batch_size = euler_angle.shape[0]\n theta = euler_angle[:,0].reshape(-1,1,1)\n phi = euler_angle[:,1].reshape(-1,1,1)\n psi = euler_angle[:,2].reshape(-1,1,1)\n one = torch.ones(batch_size,1,1).to(euler_angle.device)\n zero = torch.zeros(batch_size, 1, 1).to(euler_angle.device)\n rot_x = torch.cat((\n torch.cat((one,zero,zero),1),\n torch.cat((zero,theta.cos(), theta.sin()),1),\n torch.cat((zero,-theta.sin(),theta.cos()),1),\n ),2)\n rot_y = torch.cat((\n torch.cat((phi.cos(),zero,-phi.sin()),1),\n torch.cat((zero,one, zero),1),\n torch.cat((phi.sin(),zero,phi.cos()),1),\n ),2)\n rot_z = torch.cat((\n torch.cat((psi.cos(),psi.sin(),zero),1),\n torch.cat((-psi.sin(),psi.cos(), zero),1),\n torch.cat((zero,zero,one),1),\n ),2)\n rot = torch.bmm(rot_z, torch.bmm(rot_y,rot_x)) \n mu = points\n idx = landmark_index\n vertex = torch.index_select(mu, 2, idx)\n xy_t = torch.bmm(scale.reshape(-1,1,1)*rot[:,0:2,:].reshape(-1,2,3), vertex)\n xy_t += trans.reshape(-1,2,1).expand_as(xy_t)\n landmarks = torch.cat((xy_t[:,0,:].reshape(-1,1), xy_t[:,1,:].reshape(-1,1)), 1).reshape(-1,landmark_num,2)\n\n return landmarks\n\n\"\"\"\n MyNet:\n 'vertex_num' is the number of vertices of 3D meshes,\n 'pca_pri' is the PCA basis to initialize the last FC layer\n\"\"\"\nclass MyNet(nn.Module):\n def __init__(self, vertex_num, pca_pri):\n super(MyNet, self).__init__()\n self.fc1 = nn.Linear(in_features=94, out_features=226, bias=True)\n torch.nn.init.kaiming_normal_(self.fc1.weight.data)\n torch.nn.init.zeros_(self.fc1.bias.data)\n self.fc2 = nn.Linear(in_features=226, out_features=226, bias=True)\n torch.nn.init.kaiming_normal_(self.fc1.weight.data)\n torch.nn.init.zeros_(self.fc2.bias.data)\n self.fc3 = nn.Linear(in_features=226, out_features=vertex_num*9, bias=True)\n self.fc3.weight.data = pca_pri.t()\n torch.nn.init.zeros_(self.fc3.bias.data)\n\n def forward(self, x):\n active_opt = nn.ReLU(True)\n x = active_opt(self.fc1(x))\n x = self.fc2(x)\n x = self.fc3(x)\n return x\n\nclass CariFace():\n def init_numbers(self, landmark_num=68, vertex_num=6144, device_num=0):\n self.landmark_num = landmark_num\n self.vertex_num = vertex_num\n self.device_num = device_num\n\n def init_data(self, data_path=\"data/\"):\n \"\"\"\n related document\n \"\"\"\n pca_pri_path = data_path + \"pca_pri.npy\" # the PCA basis of latent deformation representation (DR)\n logR_S_mean_path = data_path + \"logR_S_mean.npy\" # the mean of DR\n A_pinv_path = data_path + \"A_pinv.npy\" # the matrix for solving vertices' coordinates from DR\n warehouse_vertex_path = data_path + \"P_.npy\" # vertices' coordinates of the mean face\n connect_path = data_path + \"connect.txt\" # the connected relation of vertices\n one_ring_center_ids_path = data_path + \"one_ring_center_ids.txt\" # the ids of 1-ring centers\n one_ring_ids_path = data_path + \"one_ring_ids.txt\" # the ids of vertices connected to 1-ring centers\n one_ring_lbweights_path = data_path + \"one_ring_lbweights.npy\" # the Laplacian weights of each connection\n landmark_index_path = data_path + \"best_68.txt\" # the ids of 68 3D landmarks\n # load pca_pri and logR_S_mean\n self.pca_pri = torch.from_numpy(np.load(pca_pri_path)).float().to(self.device_num)\n self.logR_S_mean = torch.from_numpy(np.load(logR_S_mean_path)).float().to(self.device_num)\n # A_pinv and warehouse_0's vertices\n self.A_pinv = torch.from_numpy(np.load(A_pinv_path)).to(self.device_num).float()\n self.P_ = torch.from_numpy(np.load(warehouse_vertex_path)).to(self.device_num).float()\n # connects and landmarks' indices\n self.one_ring_center_ids = torch.from_numpy(np.loadtxt(one_ring_center_ids_path)).to(self.device_num).long()\n self.one_ring_ids = torch.from_numpy(np.loadtxt(one_ring_ids_path)).to(self.device_num).long()\n self.one_ring_lbweights = torch.from_numpy(np.load(one_ring_lbweights_path)).to(self.device_num).float()\n file = open(connect_path, 'r')\n lines = file.readlines()\n file.close()\n connects = []\n connects_num = 0\n for line in lines:\n line = line.strip('\\n')\n line = line.strip(' ')\n line = line.split(' ')\n connects.append(line)\n for i in range(self.vertex_num):\n connects_num += len(connects[i])\n conn_i = torch.zeros(2,connects_num).long()\n conn_k = 0\n for i in range(self.vertex_num):\n for j in range(len(connects[i])):\n conn_i[:,conn_k] = torch.LongTensor([i, conn_k])\n conn_k += 1\n conn_v = torch.ones(connects_num).long()\n self.connect_ = torch.sparse.FloatTensor(conn_i, conn_v, torch.Size([self.vertex_num,connects_num])).to(self.device_num).float()\n self.landmark_index = torch.from_numpy(np.loadtxt(landmark_index_path)).long().to(self.device_num)\n \n def load_train_data(self, image_path, landmark_path, vertex_path, size=32, workers=6):\n trainset = TrainSet(image_path, landmark_path, vertex_path, self.landmark_num, self.vertex_num)\n self.train_loader = torch.utils.data.DataLoader(trainset, batch_size=size, shuffle=True, num_workers=workers)\n\n def load_test_data(self, image_path, landmark_path, lrecord_path, vrecord_path, workers=6):\n testset = TestSet(image_path, landmark_path, lrecord_path, vrecord_path)\n self.test_loader = torch.utils.data.DataLoader(testset, batch_size=1, shuffle=False, num_workers=workers)\n\n def load_model(self, resnet34_lr=1e-4, mynet1_lr=1e-5, mynet2_lr=1e-8,\n use_premodel=True, model1_path=\"model/resnet34_adam.pth\", model2_path=\"model/mynet_adam.pth\"):\n self.model1 = torchvision.models.resnet34(pretrained=True)\n fc_features = self.model1.fc.in_features\n self.model1.fc = nn.Linear(in_features=fc_features, out_features=100)\n self.model1 = self.model1.to(self.device_num)\n self.model2 = MyNet(self.vertex_num, self.pca_pri).to(self.device_num)\n if use_premodel == True:\n ck1 = torch.load(model1_path)\n ck2 = torch.load(model2_path)\n # ck1 = torch.load(model1_path, map_location={'cuda:0':'cuda:3'})\n # ck2 = torch.load(model2_path, map_location={'cuda:0':'cuda:3'})\n self.model1.load_state_dict(ck1['net'])\n self.model2.load_state_dict(ck2['net'])\n # optimizer\n self.optimizer1 = torch.optim.Adam(self.model1.parameters(), lr = resnet34_lr)\n self.optimizer2 = torch.optim.Adam([\n {'params':self.model2.fc1.parameters(), 'lr':mynet1_lr},\n {'params':self.model2.fc2.parameters(), 'lr':mynet1_lr}])\n self.optimizer3 = torch.optim.Adam(self.model2.fc3.parameters(), lr = mynet2_lr)\n # loss function\n self.loss_fn = nn.MSELoss().to(self.device_num)\n\n def train(self, epoch, lambda_land=1, lambda_srt=1e-1):\n start = time.time()\n self.model1.train()\n self.model2.train()\n total_loss = 0.0\n total_num = 0\n loss_1 = 0.0\n loss_2 = 0.0\n loss_3 = 0.0\n with torch.autograd.set_detect_anomaly(True):\n for batch_idx, (img, landmark, vertex) in enumerate(self.train_loader):\n img, landmark, vertex = img.to(self.device_num).float(), landmark.to(self.device_num).float(), vertex.to(self.device_num).float()\n output = self.model1(img)\n alpha = output[:,0:94] # alpha parameter\n scale = output[:, 94] # scale parameter\n euler_angle = output[:, 95:98] # euler_angle parameter\n trans = output[:, 98:100] # trans parameter\n \n # solve logR_S and T\n delta = self.model2(alpha)\n logR_S = delta + self.logR_S_mean\n logR_S = logR_S.reshape(-1, 9)\n rparas = logR_S[:,0:3]\n sparas = logR_S[:,3:]\n angles = rparas.norm(2,1)\n indices = angles.nonzero()\n tRs = torch.zeros_like(logR_S)\n tRs[:,0::4] = 1.0\n if indices.numel() > 0 and indices.numel() < angles.numel():\n indices = indices[:,0]\n crparas = rparas[indices]/angles[indices].reshape(-1,1)\n temp = (1-torch.cos(angles[indices]).reshape(-1,1))\n tempS = torch.sin(angles[indices]).reshape(-1,1)\n tRs[indices, 0::4] = torch.cos(angles[indices]).reshape(-1,1) + temp * crparas * crparas\n tRs[indices, 1] = temp.view(-1) * crparas[:,0] * crparas[:,1] - tempS.view(-1) * crparas[:,2]\n tRs[indices, 2] = temp.view(-1) * crparas[:,0] * crparas[:,2] + tempS.view(-1) * crparas[:,1]\n tRs[indices, 3] = temp.view(-1) * crparas[:,0] * crparas[:,1] + tempS.view(-1) * crparas[:,2]\n tRs[indices, 5] = temp.view(-1) * crparas[:,1] * crparas[:,2] - tempS.view(-1) * crparas[:,0]\n tRs[indices, 6] = temp.view(-1) * crparas[:,0] * crparas[:,2] - tempS.view(-1) * crparas[:,1]\n tRs[indices, 7] = temp.view(-1) * crparas[:,1] * crparas[:,2] + tempS.view(-1) * crparas[:,0]\n elif indices.numel()==angles.numel():\n rparas = rparas/angles.reshape(-1,1)\n temp = (1-torch.cos(angles).reshape(-1,1))\n tempS = torch.sin(angles).reshape(-1,1)\n tRs[:, 0::4] = torch.cos(angles).reshape(-1,1) + temp * rparas * rparas\n tRs[:, 1] = temp.view(-1) * rparas[:,0] * rparas[:,1] - tempS.view(-1) * rparas[:,2]\n tRs[:, 2] = temp.view(-1) * rparas[:,0] * rparas[:,2] + tempS.view(-1) * rparas[:,1]\n tRs[:, 3] = temp.view(-1) * rparas[:,0] * rparas[:,1] + tempS.view(-1) * rparas[:,2]\n tRs[:, 5] = temp.view(-1) * rparas[:,1] * rparas[:,2] - tempS.view(-1) * rparas[:,0]\n tRs[:, 6] = temp.view(-1) * rparas[:,0] * rparas[:,2] - tempS.view(-1) * rparas[:,1]\n tRs[:, 7] = temp.view(-1) * rparas[:,1] * rparas[:,2] + tempS.view(-1) * rparas[:,0]\n tSs = torch.zeros_like(logR_S)\n tSs[:, 0:3] = sparas[:, 0:3]\n tSs[:, 3] = sparas[:, 1]\n tSs[:, 4:6] = sparas[:, 3:5]\n tSs[:, 6] = sparas[:, 2]\n tSs[:, 7] = sparas[:, 4]\n tSs[:, 8] = sparas[:, 5]\n Ts = torch.bmm(tRs.reshape(-1,3,3), tSs.reshape(-1,3,3)).reshape(-1, self.vertex_num, 9)\n \n # solve points\n Tijs = Ts.index_select(1, self.one_ring_center_ids) + Ts.index_select(1, self.one_ring_ids)\n pijs = self.P_.index_select(0, self.one_ring_center_ids) - self.P_.index_select(0, self.one_ring_ids)\n temp = torch.zeros((Tijs.size()[0],3,Tijs.size()[1]), device=Ts.device)\n temp[:,0,:] = torch.sum(Tijs[:,:,0:3]*(pijs*self.one_ring_lbweights.reshape(-1,1)), 2)\n temp[:,1,:] = torch.sum(Tijs[:,:,3:6]*(pijs*self.one_ring_lbweights.reshape(-1,1)), 2)\n temp[:,2,:] = torch.sum(Tijs[:,:,6:9]*(pijs*self.one_ring_lbweights.reshape(-1,1)), 2)\n temp = temp.reshape(-1, self.one_ring_ids.numel()).t().clone()\n RHS = torch.spmm(self.connect_, temp)\n points = (torch.matmul(self.A_pinv, RHS)).t()\n points_mean = torch.mean(points, 1).reshape(points.shape[0],-1)\n points -= points_mean.expand_as(points)\n points = points.reshape(-1,3,self.vertex_num)\n loss_geo = 10 * self.loss_fn(points, vertex)\n\n # solve landmarks\n lands_2d = CalculateLandmark2D(euler_angle, scale, trans, points, self.landmark_index, self.landmark_num)\n loss_land = 1e-4 * self.loss_fn(lands_2d, landmark)\n lands = CalculateLandmark2D(euler_angle, scale, trans, vertex, self.landmark_index, self.landmark_num)\n loss_srt = 1e-4 * self.loss_fn(lands, landmark)\n loss_land_srt = 0.0\n if (epoch-1) // 500 == 0:\n loss_land_srt = lambda_srt * loss_srt\n else:\n loss_land_srt = lambda_land * loss_land\n\n # back propagation\n self.optimizer1.zero_grad()\n self.optimizer2.zero_grad()\n self.optimizer3.zero_grad()\n loss_geo.backward(retain_graph=True)\n if (epoch-1) // 10000 > 0:\n self.optimizer3.step()\n self.optimizer2.step()\n loss_land_srt.backward()\n self.optimizer1.step()\n\n loss_1 += loss_geo.item() * img.shape[0]\n loss_2 += loss_land.item() * img.shape[0]\n loss_3 += loss_srt.item() * img.shape[0]\n total_loss += (loss_geo.item() + loss_land.item() + loss_srt.item()) * img.shape[0]\n total_num += img.shape[0]\n end = time.time()\n print(\"epoch_\"+str(epoch)+\":\\ttime: \"+str(end-start)+\"s\")\n print(\"\\tloss_geo: \" + \"{:3.6f}\".format(loss_1/total_num) + \"\\tloss_land: \" + \"{:3.6f}\".format(loss_2/total_num) + \"\\tloss_srt: \" + \"{:3.6f}\".format(loss_3/total_num))\n \n def test(self):\n start = time.time()\n self.model1.eval()\n self.model2.eval()\n loss_test = 0.0\n total_num = 0\n with torch.no_grad():\n for img, landmark, lrecord, vrecord in self.test_loader:\n img, landmark = img.to(self.device_num).float(), landmark.to(self.device_num).float()\n output = self.model1(img)\n alpha = output[:, 0:94]\n scale = output[:, 94]\n euler_angle = output[:, 95:98]\n trans = output[:, 98:100]\n\n # solve logR_S and T\n delta = self.model2(alpha)\n logR_S = delta + self.logR_S_mean\n logR_S = logR_S.reshape(-1,9)\n rparas = logR_S[:,0:3]\n sparas = logR_S[:,3:]\n angles = rparas.norm(2,1)\n indices = angles.nonzero()\n tRs = torch.zeros_like(logR_S)\n tRs[:,0::4] = 1.0\n if indices.numel() > 0 and indices.numel() < angles.numel():\n indices = indices[:,0]\n crparas = rparas[indices]/angles[indices].reshape(-1,1)\n temp = (1-torch.cos(angles[indices]).reshape(-1,1))\n tempS = torch.sin(angles[indices]).reshape(-1,1)\n tRs[indices, 0::4] = torch.cos(angles[indices]).reshape(-1,1) + temp * crparas * crparas\n tRs[indices, 1] = temp.view(-1) * crparas[:,0] * crparas[:,1] - tempS.view(-1) * crparas[:,2]\n tRs[indices, 2] = temp.view(-1) * crparas[:,0] * crparas[:,2] + tempS.view(-1) * crparas[:,1]\n tRs[indices, 3] = temp.view(-1) * crparas[:,0] * crparas[:,1] + tempS.view(-1) * crparas[:,2]\n tRs[indices, 5] = temp.view(-1) * crparas[:,1] * crparas[:,2] - tempS.view(-1) * crparas[:,0]\n tRs[indices, 6] = temp.view(-1) * crparas[:,0] * crparas[:,2] - tempS.view(-1) * crparas[:,1]\n tRs[indices, 7] = temp.view(-1) * crparas[:,1] * crparas[:,2] + tempS.view(-1) * crparas[:,0]\n elif indices.numel()==angles.numel():\n rparas = rparas/angles.reshape(-1,1)\n temp = (1 - torch.cos(angles).reshape(-1,1))\n tempS = torch.sin(angles).reshape(-1,1)\n tRs[:, 0::4] = torch.cos(angles).reshape(-1,1) + temp * rparas * rparas\n tRs[:, 1] = temp.view(-1) * rparas[:,0] * rparas[:,1] - tempS.view(-1) * rparas[:,2]\n tRs[:, 2] = temp.view(-1) * rparas[:,0] * rparas[:,2] + tempS.view(-1) * rparas[:,1]\n tRs[:, 3] = temp.view(-1) * rparas[:,0] * rparas[:,1] + tempS.view(-1) * rparas[:,2]\n tRs[:, 5] = temp.view(-1) * rparas[:,1] * rparas[:,2] - tempS.view(-1) * rparas[:,0]\n tRs[:, 6] = temp.view(-1) * rparas[:,0] * rparas[:,2] - tempS.view(-1) * rparas[:,1]\n tRs[:, 7] = temp.view(-1) * rparas[:,1] * rparas[:,2] + tempS.view(-1) * rparas[:,0]\n tSs = torch.zeros_like(logR_S)\n tSs[:, 0:3] = sparas[:, 0:3]\n tSs[:, 3] = sparas[:, 1]\n tSs[:, 4:6] = sparas[:, 3:5]\n tSs[:, 6] = sparas[:, 2]\n tSs[:, 7] = sparas[:, 4]\n tSs[:, 8] = sparas[:, 5]\n Ts = torch.bmm(tRs.reshape(-1,3,3), tSs.reshape(-1,3,3)).reshape(-1, self.vertex_num, 9)\n\n # solve points\n Tijs = Ts.index_select(1, self.one_ring_center_ids) + Ts.index_select(1, self.one_ring_ids)\n pijs = self.P_.index_select(0, self.one_ring_center_ids) - self.P_.index_select(0, self.one_ring_ids)\n temp = torch.zeros((Tijs.size()[0], 3, Tijs.size()[1]), device=Ts.device)\n temp[:,0,:] = torch.sum(Tijs[:,:,0:3]*(pijs*self.one_ring_lbweights.reshape(-1,1)), 2)\n temp[:,1,:] = torch.sum(Tijs[:,:,3:6]*(pijs*self.one_ring_lbweights.reshape(-1,1)), 2)\n temp[:,2,:] = torch.sum(Tijs[:,:,6:9]*(pijs*self.one_ring_lbweights.reshape(-1,1)), 2)\n temp = temp.reshape(-1, self.one_ring_ids.numel()).t().clone()\n RHS = torch.spmm(self.connect_, temp)\n points = (torch.matmul(self.A_pinv, RHS)).t()\n points_mean = torch.mean(points, 1).reshape(points.shape[0], -1)\n points -= points_mean.expand_as(points)\n points = points.reshape(-1,3,self.vertex_num)\n\n # solve landmarks\n lands_2d = CalculateLandmark2D(euler_angle, scale, trans, points, self.landmark_index, self.landmark_num)\n loss_land = 1e-4 * self.loss_fn(lands_2d, landmark)\n\n loss_test += loss_land.item() * img.shape[0]\n total_num += img.shape[0]\n np.save(str(lrecord[0]), lands_2d.reshape(self.landmark_num,2).data.cpu().numpy())\n np.save(str(vrecord[0]), points.reshape(3,self.vertex_num).data.cpu().numpy())\n end = time.time()\n print(\"result: \"+ \"{:3.6f}\".format(loss_test/total_num)+\"\\ttime: \"+str(end-start)+\"s\")\n print(\"\\tloss_land: \" + \"{:3.6f}\".format(loss_test/total_num))\n print('\\n')\n\n def save_model(self, epoch, save_path=\"record/\"):\n state1 = {'net':self.model1.state_dict(), 'optimizer':self.optimizer1.state_dict(), 'epoch':epoch}\n state2 = {'net':self.model2.state_dict(), 'optimizer2':self.optimizer2.state_dict(), 'optimizer3':self.optimizer3.state_dict(), 'epoch':epoch}\n torch.save(state1, save_path+\"resnet34_adam_\"+str(epoch)+\".pth\")\n torch.save(state2, save_path+\"mynet_adam_\"+str(epoch)+\".pth\")"
},
{
"alpha_fraction": 0.7426470518112183,
"alphanum_fraction": 0.748161792755127,
"avg_line_length": 42.560001373291016,
"blob_id": "f52f9ad23da780f3acbab0c6eb3109e1ade04249",
"content_id": "af43e008a409a6cddd8c911e5d80f73c4d5a3cd9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1088,
"license_type": "permissive",
"max_line_length": 411,
"num_lines": 25,
"path": "/Recognition-Algorithms/Recognition Using Dlib/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Overview\n\nDlib's facial recognition functionality is used by Adam Geitgey to build [face_recognition](https://github.com/ageitgey/face_recognition) library. It has an accuracy of **99.38%**. With the help of this library, we can convert the images in a dataset to the face encodings. At the time of face recognization, we can compare the unknown image's face encoding to the encodings present in the dataset to find the person.\n\n# Requirments\n\n- ```pip install dlib```\n- ```pip install numpy```\n- ```pip install git+https://github.com/ageitgey/face_recognition_models```\n\n# Execution\n\n- Clone the repository using-\n```\ngit clone https://github.com/akshitagupta15june/Face-X.git\n```\n- Change Directory\n```\ncd Recognition-Algorithms/Recognition Using Dlib\n```\n- Add all the known images into the folder `images` and follow the steps given in `face.py`.\n\n- Take one unknown image and give it to the program, it will fetch the name of the person present in the image if it's already in the dataset.\n\n> **_NOTE:_** This program can work for images that consist of only one person facing in front."
},
{
"alpha_fraction": 0.7685834765434265,
"alphanum_fraction": 0.7882187962532043,
"avg_line_length": 88.08333587646484,
"blob_id": "02c54bc0dbb363661e8a1ee2230c9640eb9c0691",
"content_id": "f80436e6042b71f74b9bc9ec5165c5ca38e6b073",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2139,
"license_type": "permissive",
"max_line_length": 316,
"num_lines": 24,
"path": "/GUI_for_Face Recognistion_using_LBPH_algo/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n# GUI for face recognition using LBPH Algo\n**Face Recognition:** with the facial images already extracted, cropped, resized, and usually converted to grayscale, the face recognition algorithm is responsible for finding characteristics that best describe the image.\n## Local Binary Patterns Histograms\nThe **Local Binary Pattern Histogram(LBPH)** algorithm is a simple solution to the face recognition problem, which can recognize both front face and side face.\n- LBPH is one of the easiest face recognition algorithms.\n- It can represent local features in the images.\n- It is possible to get great results (mainly in a controlled environment).\n- It is robust against monotonic grayscale transformations.\n- It is provided by the OpenCV library (Open Source Computer Vision Library).\n## Steps of LBPH algorithm\n ### 1. Parameters:\n- Radius\n- Neighbours\n- Grid X\n- Grid Y\n### 2. Training the Algorithm:\nwe need to use a dataset with the facial images of the people we want to recognize. We need to also set an ID (it may be a number or the name of the person) for each image, so the algorithm will use this information to recognize an input image and give you an output. Images of the same person must have the same ID.\n### 3. Applying the LBP operation\nThe first computational step of the LBPH is to create an intermediate image that describes the original image in a better way, by highlighting the facial characteristics. To do so, the algorithm uses a concept of a sliding window, based on the parameters radius and neighbors.\n### 4. Extracting the Histograms\nNow, using the image generated in the last step, we can use the Grid X and Grid Y parameters to divide the image into multiple grids, as can be seen in the following image:\n\n### 5. Performing the face recognition\nIn this step, the algorithm is already trained. Each histogram created is used to represent each image from the training dataset. So, given an input image, we perform the steps again for this new image and creates a histogram that represents the image.\n"
},
{
"alpha_fraction": 0.5508257150650024,
"alphanum_fraction": 0.5985320806503296,
"avg_line_length": 45.186439514160156,
"blob_id": "f1d4c964ca9440767209d0e1f5f401b94653acff",
"content_id": "99248f829f6ae17b895d40ae58ffcb65a34e2a01",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2725,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 59,
"path": "/Face Reconstruction/Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model/update_contour/fit_indices.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import torch\nimport numpy as np\n\n#V_NUM the number of vertices\n#euler_angle a euler_angle tensor with size (m,3)\n#scale a scale tensor with size (m,1)\n#trans a translation matrix with size (m,2)\n#points a point tensor with size (m,3,V_NUM)\n#parallel a long tensor with size (17,4), you can read it from './parallel.txt' file.\n#best_51 a long tensor with size (51), which represents the last 51 landmarks (68-17=51).\ndef FittingIndicesPlus(euler_angle, scale, trans, points, parallel, best_51):\n batch_size = euler_angle.shape[0]\n theta = euler_angle[:,0].reshape(-1,1,1)\n phi = euler_angle[:,1].reshape(-1,1,1)\n psi = euler_angle[:,2].reshape(-1,1,1)\n one = torch.ones(batch_size,1,1).to(euler_angle.device)\n zero = torch.zeros(batch_size, 1, 1).to(euler_angle.device)\n rot_x = torch.cat((\n torch.cat((one,zero,zero),1),\n torch.cat((zero,theta.cos(), theta.sin()),1),\n torch.cat((zero,-theta.sin(),theta.cos()),1),\n ),2)\n rot_y = torch.cat((\n torch.cat((phi.cos(),zero,-phi.sin()),1),\n torch.cat((zero,one, zero),1),\n torch.cat((phi.sin(),zero,phi.cos()),1),\n ),2)\n rot_z = torch.cat((\n torch.cat((psi.cos(),psi.sin(),zero),1),\n torch.cat((-psi.sin(),psi.cos(), zero),1),\n torch.cat((zero,zero,one),1),\n ),2)\n rot = torch.bmm(rot_z, torch.bmm(rot_y,rot_x))\n\n rott_geo = torch.bmm(rot, points)\n mu = points\n\n parallel_ids = parallel.reshape(-1)\n parallels_vertex = torch.index_select(mu, 2, parallel_ids)\n parallels_xy_t = torch.bmm(scale.reshape(-1,1,1)*rot[:,0:2,:].reshape(-1,2,3), parallels_vertex)\n parallels_xy_t += trans.reshape(-1,2,1).expand_as(parallels_xy_t)\n parallels_xy = torch.cat((parallels_xy_t[:,0,:].reshape(-1,1), parallels_xy_t[:,1,:].reshape(-1,1)), 1).reshape(-1,68,2)\n front_part = parallels_xy[:,0:32,0].view(-1,8,parallel.shape[1])\n behind_part = parallels_xy[:,32:68,0].view(-1,9,parallel.shape[1])\n _, min_ids = torch.min(front_part,2)\n _, max_ids = torch.max(behind_part,2)\n ids = torch.cat((min_ids, max_ids), 1)\n parallels_xy = parallels_xy.view(-1, parallel.shape[1],2)\n landmarks = parallels_xy[torch.arange(0, parallels_xy.shape[0]).to(ids.device), ids.view(-1),:].reshape(batch_size,-1,2)\n\n idx_51 = best_51\n vertex = torch.index_select(mu, 2, idx_51)\n xy_t = torch.bmm(scale.reshape(-1,1,1)*rot[:,0:2,:].reshape(-1,2,3), vertex)\n xy_t += trans.reshape(-1,2,1).expand_as(xy_t)\n xy = torch.cat((xy_t[:,0,:].reshape(-1,1), xy_t[:,1,:].reshape(-1,1)), 1).reshape(-1,51,2)\n\n landmarks = torch.cat((landmarks,xy),1)\n\n return rot, landmarks\n"
},
{
"alpha_fraction": 0.3333333432674408,
"alphanum_fraction": 0.4861111044883728,
"avg_line_length": 13.399999618530273,
"blob_id": "514b6b48b54ccd17b2365a6708076b15502ffe1a",
"content_id": "93ad199dc79c1005ec561999eef1bacaea275fbf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 72,
"license_type": "permissive",
"max_line_length": 26,
"num_lines": 5,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/tools/preprocess/__init__.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\"\"\"\n@Author : Jiaxiang Shang\n@Email : [email protected]\n@Time : 2020/7/25 14:21\n\"\"\"\n"
},
{
"alpha_fraction": 0.5451403856277466,
"alphanum_fraction": 0.5796976089477539,
"avg_line_length": 31.16666603088379,
"blob_id": "a1f3f63ebcfce8ae6d2be0946d9404424735f09b",
"content_id": "2516fe7c41043211d821246ec13750b1779931ef",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2315,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 72,
"path": "/Snapchat_Filters/ThugLife/thug_life.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport cv2\nfrom pygame import mixer\n\n\nface_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')\n\nspecs_ori = cv2.imread('glass.png', -1)\ncigar_ori = cv2.imread('cigar.png', -1)\n# Camera Init\ncap = cv2.VideoCapture(0)\ncap.set(cv2.CAP_PROP_FPS, 30)\nmixer.init()\n\n# Loading the song\nmixer.music.load(\"Smoke weed everyday.mp3\")\n# Setting the volume\nmixer.music.set_volume(0.7) \n# Start playing the song\nmixer.music.play()\n\n\ndef transparentOverlay(src, overlay, pos=(0, 0), scale=1):\n overlay = cv2.resize(overlay, (0, 0), fx=scale, fy=scale)\n h, w, _ = overlay.shape # Size of foreground\n rows, cols, _ = src.shape # Size of background Image\n y, x = pos[0], pos[1] # Position of foreground/overlay image\n\n for i in range(h):\n for j in range(w):\n if x + i >= rows or y + j >= cols:\n continue\n alpha = float(overlay[i][j][3] / 255.0) # read the alpha channel\n src[x + i][y + j] = alpha * overlay[i][j][:3] + (1 - alpha) * src[x + i][y + j]\n return src\n\nwhile 1:\n ret, img = cap.read()\n gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)\n faces = face_cascade.detectMultiScale(img, 1.2, 5, 0, (120, 120), (350, 350))\n for (x, y, w, h) in faces:\n if h > 0 and w > 0:\n glass_symin = int(y + 1.5 * h / 5)\n glass_symax = int(y + 2.5 * h / 5)\n sh_glass = glass_symax - glass_symin\n\n cigar_symin = int(y + 4 * h / 6)\n cigar_symax = int(y + 5.5 * h / 6)\n sh_cigar = cigar_symax - cigar_symin\n\n face_glass_roi_color = img[glass_symin:glass_symax, x:x + w]\n face_cigar_roi_color = img[cigar_symin:cigar_symax, x:x + w]\n\n specs = cv2.resize(specs_ori, (int(w), sh_glass), interpolation=cv2.INTER_CUBIC)\n cigar = cv2.resize(cigar_ori, (int(w), sh_cigar), interpolation=cv2.INTER_CUBIC)\n\n transparentOverlay(face_glass_roi_color, specs)\n #transparentOverlay(face_cigar_roi_color, cigar, (int(w / 2), int(sh_cigar / 2)))\n\n cv2.imshow('Thug Life', img)\n key = cv2.waitKey(1) & 0xFF\n if key == ord(\"q\"):\n break\n\n k = cv2.waitKey(30) & 0xff\n if k == 27:\n\n cv2.imwrite('img.jpg', img)\n break\n\ncap.release()\ncv2.destroyAllWindows()"
},
{
"alpha_fraction": 0.7308438420295715,
"alphanum_fraction": 0.7798253893852234,
"avg_line_length": 63.21875,
"blob_id": "cd844d0f770e4f0cb6e1c442faf8311c6dfc995d",
"content_id": "0d78fd3418d800752cbcdb0d5d467d13bb218b46",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2062,
"license_type": "permissive",
"max_line_length": 270,
"num_lines": 32,
"path": "/Cartoonify Image/Cartoonify_face_image/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Cartoonifying a face image.\n\n- To Cartoonify the image we have used Computer vision, Where we apply various filters to the input image to produce a Cartoonified image. To accomplish this we have used Python programming language and opencv a Computer Vision library.<br>\n \n ## Dependencies:\n The Dependencies used are:\n - Opencv :It provides the tool for applying computer vison techniques on the image.\n - Numpy :Images are stored and processed as numbers, These are taken as arrays.\n\n## How to Run:\n- Download the directory.\n- You can use any Editor, Notebook Or IDE's to open the Cartoonify-face_image.py file.\n- Run Cartoonify-face_image.py file.\n- Press Space bar to exit.\n\n## Steps of its working:\n\n- We have imported the cv2 and numpy library.\n- We are capturing the image frames using cv2.VideoCapture().\n- We are reading the image frames by using frame_cap.read().\n- We are applying Gray scale filter to the image frames using cv2.cvtcolor() and the by passing second parameter as cv2.COLOR_BGR2GRAY.\n- We are using MedianBlur on the gray scale image obtained above by setting the kernal size as 5 to blur the image using cv2.medianBlur().\n- We are using adaptive threshold on the image obtained after applying Medianblur, we are using a threshold value of 255 to filter out the pixel and we are using the adaptive method cv2.ADAPTIVE_THRESH_MEAN_C with a threshold type as cv2.THRESH_BINARY and block size 9.\n- We are applying a Bilateral filter on the original image frames using cv2.bilateralFilter() with kernal size 9 and the threshold as 250 to remove the Noise in the image.\n- We are then applying Bitwise and operation on the Bilateral image and the image obtained after using Adaptive threshold which gives the resulting cartoonified image.\n\n## Result:\n ### Input Video\n \n\n ### Output Video\n \n \n \n \n"
},
{
"alpha_fraction": 0.5466758608818054,
"alphanum_fraction": 0.5825008749961853,
"avg_line_length": 30.09677505493164,
"blob_id": "bf62667f37051ad5c1d51c9d8f6cac9bef9c5af1",
"content_id": "70cdb583f9b5f1b3067024822d7dbade13e941cc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2903,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 93,
"path": "/Recognition-Algorithms/Recognition Using LBP_SVM/model.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import cv2\nimport os\nimport glob\nfrom skimage import feature\nimport numpy as np\nfrom sklearn.svm import SVC\nfrom sklearn.model_selection import GridSearchCV\n\n\nclass LocalBinaryPatterns:\n\n def __init__(self, numPoints, radius):\n # store the number of points and radius\n self.numPoints = numPoints\n self.radius = radius\n\n def describe(self, image, eps=1e-7):\n # compute the Local Binary Pattern representation\n # of the image, and then use the LBP representation\n # to build the histogram of patterns\n lbp = feature.local_binary_pattern(image, self.numPoints,\n self.radius, method=\"uniform\")\n (hist, _) = np.histogram(lbp.ravel(),\n bins=np.arange(0, self.numPoints + 3),\n range=(0, self.numPoints + 2))\n # normalize the histogram\n hist = hist.astype(\"float\")\n hist /= (hist.sum() + eps)\n # return the histogram of Local Binary Patterns\n return hist\n\n\ndesc = LocalBinaryPatterns(24, 8)\nimg_folder = 'dataset/'\n\nlabels = []\narray = []\n\ni = 0\ncnt = 0\nmapping = {}\nfor dir1 in os.listdir(img_folder):\n cnt = cnt + 1\n mapping[cnt] = dir1\n\n for file in os.listdir(os.path.join(img_folder, dir1)):\n\n image_path = os.path.join(img_folder, dir1, file)\n image = cv2.imread(image_path)\n gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)\n hist = desc.describe(gray) # get the LBP histogram here.\n hist = np.array(hist).reshape(-1, 1)\n hist = hist.T\n labels.append(cnt)\n if i == 0:\n array = np.vstack(hist)\n else:\n array = np.vstack([array, hist])\n i = i + 1\n\nparam_grid = {'C': [1e3, 5e3, 1e4, 5e4, 1e5],\n 'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1], }\nclf = GridSearchCV(\n SVC(kernel='rbf', class_weight='balanced'), param_grid\n)\nclf = clf.fit(array, labels)\n\ncap = cv2.VideoCapture(0)\ncap.set(3, 640)\ncap.set(4, 480)\n\nwhile True:\n ret, img = cap.read()\n gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)\n face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')\n faces = face_cascade.detectMultiScale(gray, scaleFactor=1.2, minNeighbors=5)\n\n for x, y, w, h in faces:\n cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)\n roi_gray = gray[y:y + h, x:x + w]\n\n hist = desc.describe(roi_gray) # get the LBP histogram here.\n hist = np.array(hist).reshape(-1, 1)\n hist = hist.T\n roi_color = img[y:y + h, x:x + w]\n output = clf.predict(hist)\n cv2.putText(img, str(mapping[output[0]]), (x, y - 10), cv2.FONT_HERSHEY_COMPLEX, 2, (255, 0, 0), 2)\n cv2.imshow('video', img)\n k = cv2.waitKey(30) & 0xff\n if k == 27: # press 'ESC' to quit\n break\ncap.release()\ncv2.destroyAllWindows()\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.8275862336158752,
"alphanum_fraction": 0.8275862336158752,
"avg_line_length": 29,
"blob_id": "fa150e7cef57041927bf753ce29a68542bfaba91",
"content_id": "24d67201809ac7930e9c795f05123cd5f767db07",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 29,
"license_type": "permissive",
"max_line_length": 29,
"num_lines": 1,
"path": "/Recognition-Algorithms/Recognition_using_Xception/models/__init__.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from models.xception import *"
},
{
"alpha_fraction": 0.5599368810653687,
"alphanum_fraction": 0.578864336013794,
"avg_line_length": 20.133333206176758,
"blob_id": "c6184b465dfef45ef132e8d21c033a5304df2584",
"content_id": "235016254d951742d8d766ae7a531c3c43296796",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 634,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 30,
"path": "/Face Reconstruction/Face Alignment in Full Pose Range/demo@obama/convert_imgs_to_video.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# coding: utf-8\n\nimport os\nimport os.path as osp\nimport sys\nfrom glob import glob\nimport imageio\n\n\ndef main():\n assert len(sys.argv) >= 2\n d = sys.argv[1]\n\n fps = glob(osp.join(d, '*.jpg'))\n fps = sorted(fps, key=lambda x: int(x.split('/')[-1].replace('.jpg', '')))\n\n imgs = []\n for fp in fps:\n img = imageio.imread(fp)\n imgs.append(img)\n\n if len(sys.argv) >= 3:\n imageio.mimwrite(sys.argv[2], imgs, fps=24, macro_block_size=None)\n else:\n imageio.mimwrite(osp.basename(d) + '.mp4', imgs, fps=24, macro_block_size=None)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.7909002900123596,
"alphanum_fraction": 0.797676682472229,
"avg_line_length": 41.95833206176758,
"blob_id": "eb1b5841d5720d8c9099cb77dc990c4d897e3f8d",
"content_id": "981072851749127bf61a18bf4d24c7ced12669c8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 1033,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 24,
"path": "/Face-Detection/face and eye detection/readme.txt",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "Face and Eye Detection using Haar Cascade:\n\nFace and Eye detection is done using Haar Cascade. Haar Cascade is a\nMachine Learning based approach where a cascade function is trained\nwith set of input data.It contains pre-trained classifiers for face,\neyes,smile etc. For face detection we have used a face classifier\nand similarly for eye detection we have used an eye classifier.\nUsing Opencv we can detect faces and eyes in images as well as videos.\n\nStep-1:Import all the necessary libraries like opencv.\n\nStep-2:We have then added the path of classifiers(pre-trained) for \nface and eyes as face_cascade and eye_cascade respectively.\n\nStep-3:Then we use a function named VideoCapture() to capture\nour video using our camera.\n\nStep-4:Video contains different frames,which are in BGR format.\nThese frames are coverted to Grey frames using cvtColor() function.\n\nStep-5:Using the classifiers our face and eyes are detected.\n\nStep-5:Using cv2.rectangle() function,a rectangle is created around our face and eyes\nof any color we want.\n\n\n"
},
{
"alpha_fraction": 0.7477253675460815,
"alphanum_fraction": 0.7696443200111389,
"avg_line_length": 37.36507797241211,
"blob_id": "dd3b6eb94319651b774d38da5bab1a9cfd380d8b",
"content_id": "0ed74f8e50b082ea91c3e630f1645f7f844b7ed8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2418,
"license_type": "permissive",
"max_line_length": 806,
"num_lines": 63,
"path": "/Recognition-Algorithms/Recognition using ResNet50/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "## Overview\nFace Recognition Using opencv, keras and tensorflow.\n\nThis model uses ResNet50 model for the recognition of the User face.\n\nProgram is trained for 5 epochs, You can increase the number of epochs and the number of layers accordingly.\n\n## ScreenShots\n\n<img src=\"Screenshot from 2020-12-11 21-40-08.png\" height=\"250px\">\n<img src=\"Screenshot from 2020-12-11 17-59-00.png\" height=\"250px\">\n\n### Dependencies:\n* pip install numpy\n* pip install pandas\n* pip install tensorflow\n* pip install keras\n* pip install opencv-python\n\nDownload haarcascades file from here=> https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml\n\n\n## Quick Start\n\n- Fork and Clone the repository using-\n```\ngit clone https://github.com/akshitagupta15june/Face-X.git\n```\n- Create virtual environment-\n```\n- `python -m venv env`\n- `source env/bin/activate` (Linux)\n- `env\\Scripts\\activate` (Windows)\n```\n- Install dependencies-\n\n- Headover to Project Directory- \n```\ncd Recognition using ResNet50\n```\n- Create dataset using -\n```\n- Run Building_Dataset.py on respective idle(VS Code, PyCharm, Jupiter Notebook, Colab)\n```\nNote: Do split the dataset into Train and Test folders.\n\n- Train the model -\n```\n- Run Training the model.py\n```\nNote: Make sure all dependencies are installed properly.\n\n- Final-output -\n```\n- Run final_output.py\n```\nNote: Make sure you have haarcascade_frontalface_default.xml file \n### Details about Resnet 50\nResNet is a short name for Residual Network. As the name of the network indicates, the new terminology that this network introduces is residual learning. In a deep convolutional neural network, several layers are stacked and are trained to the task at hand. The network learns several low/mid/high level features at the end of its layers. In residual learning, instead of trying to learn some features, we try to learn some residual. Residual can be simply understood as subtraction of feature learned from input of that layer. ResNet does this using shortcut connections (directly connecting input of nth layer to some (n+x)th layer. It has proved that training this form of networks is easier than training simple deep convolutional neural networks and also the problem of degrading accuracy is resolved.\n<br>\nThis is the fundamental concept of ResNet.\n<br>\nResNet50 is a 50 layer Residual Network. There are other variants like ResNet101 and ResNet152 also.\n\n"
},
{
"alpha_fraction": 0.6904672980308533,
"alphanum_fraction": 0.7095327377319336,
"avg_line_length": 29.033708572387695,
"blob_id": "c17059edb658b48071b63c7e0289734153431bfd",
"content_id": "12f8b470ac3f3593fca0d6df48a8bc69d23452b9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2681,
"license_type": "permissive",
"max_line_length": 147,
"num_lines": 89,
"path": "/facex-library/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "## 🎊What's new 🎊\n\nAdded, \n\n- Face mask detection\n- sketch effect [A-kriti](https://github.com/akshitagupta15june/Face-X/tree/master/Awesome-face-operations/Ghost%20Image)\n- mosiac effect [Sudip Ghosh](https://github.com/AdityaNikhil/Face-X/blob/master/Awesome-face-operations/Mosaic-Effect/Mosaic.py)\n- ghost image [iaditichine](https://github.com/akshitagupta15june/Face-X/blob/master/Awesome-face-operations/Pencil%20Sketch/pencil_sketch_code.py)\n\n\n## About\n\nA unified library for **FaceX** to run all the FaceX algorithms using only one line of code. \n\n## Example\n#### Running cartoonify using FaceX library\n from facex import FaceX \n import cv2\n \n img = FaceX.cartoonify('your-img.jpg', method='opencv')\n cv2.imshow(img)\n cv2.waitkey()\n\nSimilarly we can run,\n\n FaceX.face_detect('your-img.jpg', method='opencv') #Face detection\n FaceX.face_mask('your-img.jpg', method='opencv') #Face mask detection\n \n And many more....\n\n## How to use\n\nYou can simply run the `demo.py` file to visualize some examples. Also check the below steps to run your own code,\n\n1) Clone this repo.\n\n2) cd `facex-library` from the command line.\n\n3) open your favourite text editor and place it inside `facex-library` folder. \n\n4) Run the commands of [example](#Example) section.\n\n## Current supported algorithms\n\n### OpenCV\n\n1) **face_detection**\n\t**method** : `facex.face_detect(img_path='your-img.jpg', methods='opencv')`\n\n2) **cartoonify**\n**method** : `facex.cartoonify(img_path='your-img.jpg', methods='opencv')`\n\n3) **blur background**\n**method** : `facex.blur_bg(img_path='your-img.jpg', methods='opencv')`\n\n4) **Ghost image**\n**method** : `facex.ghost_img(img_path='your-img.jpg', methods='opencv')`\n\n5) **mosaic**\n**method** : `facex.mosaic(img_path='your-img.jpg', x=219, y=61, w=460-219, h=412-61)`\nWhere, (x,y,w,h) are co-ordinates to apply mosaic effect on the image.\n\n6) **Sketch**\n**method** : `facex.sketch(img_path='your-img.jpg', methods='opencv')`\n\n### Deep Learning\n\n1) **Face Mask Detection**\n\n**method** : \n\n```\nfacex.face_mask(image='your-img.jpg') (for image)\nfacex.face_mask(image='your-img.jpg') (for video)\n```\n\nMore deep learning algorithms shall be added soon! (Stay put)\n\n## Pending Tasks\n\n1) Release facex library V1.0\n2) Refine the environment for easy access to the algorithms.\n3) Make a **facex pip package**. \n4) Make a clear documentation.\n5) Make clear documentation for the contributors to link the algorithms with the package. \n6) Add more algorithms.\n\n## Contributions are welcome\nFeel free to suggest any changes or fixes for the benefit of the package [here](https://github.com/akshitagupta15june/Face-X/discussions/323).\n\n\n"
},
{
"alpha_fraction": 0.5792929530143738,
"alphanum_fraction": 0.629292905330658,
"avg_line_length": 28.21538543701172,
"blob_id": "fd9e678346ac6960d0db53f89e444506e497042e",
"content_id": "4e9fd8c921b6d2e9d7e6c7b432fa2427e0200220",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1980,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 65,
"path": "/Cartoonify Image/Cartoonification/cartoonify_without_GUI.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import cv2\r\nimport argparse\r\n\r\nvideo_capture = cv2.VideoCapture(0)\r\nfourcc = cv2.VideoWriter_fourcc(*'XVID')\r\nout = cv2.VideoWriter('cartoonised.avi', fourcc, 20.0, (1200, 600))\r\n\r\nwhile (video_capture.isOpened()):\r\n ret, frame = video_capture.read()\r\n\r\n if ret == True:\r\n\r\n gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)\r\n resized_image= cv2.resize(gray, (1200, 600))\r\n blurred = cv2.medianBlur(resized_image, 9)\r\n\r\n thresh = cv2.adaptiveThreshold(blurred, 255, cv2.ADAPTIVE_THRESH_MEAN_C,\r\n cv2.THRESH_MASK, 11,11)\r\n\r\n\r\n original_image = cv2.bilateralFilter(frame,9, 300, 300)\r\n\r\n cartoon = cv2.bitwise_and(original_image, original_image, mask= thresh)\r\n\r\n out.write(cartoon)\r\n\r\n\r\n\r\n cv2.imshow('Cartoon_image', cartoon)\r\n cv2.imshow('Original Image', frame)\r\n\r\n if cv2.waitKey(1) & 0xFF ==27:\r\n break\r\n\r\n else:\r\n print(\"Camera not available, Please upload a photo\")\r\n\r\n\r\nif(video_capture.isOpened() == False):\r\n arg_parse = argparse.ArgumentParser()\r\n arg_parse.add_argument(\"-i\", \"--image\", required=True, help= \"Image Path\")\r\n\r\n args= vars(arg_parse.parse_args())\r\n image = cv2.imread(args['image'])\r\n filename = 'Cartoonified_image.jpg'\r\n resized_image = cv2.resize(image, (600, 450))\r\n gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)\r\n\r\n blurred = cv2.medianBlur(gray_image, 9)\r\n thresh = cv2.adaptiveThreshold(blurred, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 11,11)\r\n\r\n original_image = cv2.bilateralFilter(image, 9, 300, 300)\r\n\r\n cartoon = cv2.bitwise_and(original_image, original_image, mask=thresh)\r\n cartoon_resize= cv2.resize(cartoon, (600,450))\r\n\r\n cv2.imshow(\"Cartoonified\", cartoon_resize)\r\n cv2.imwrite(filename, cartoon)\r\n cv2.imshow(\"Main Image\", resized_image)\r\n\r\ncv2.waitKey(0)\r\n\r\nout.release()\r\nvideo_capture.release()\r\ncv2.destroyAllWindows()\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.7326178550720215,
"alphanum_fraction": 0.7405506372451782,
"avg_line_length": 42.71428680419922,
"blob_id": "2386e3860a44c14b00a29376bd02efa1736b9d85",
"content_id": "6e54fbba03a71ec1e9abbdef55e01ee3bf285ce0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2197,
"license_type": "permissive",
"max_line_length": 334,
"num_lines": 49,
"path": "/Face Reconstruction/3D Face Reconstruction with Weakly-Supervised Learning/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Accurate 3D Face Reconstruction with Weakly-Supervised Learning: From Single Image to Image Set\n\nPytorch version of the repo [Deep3DFaceReconstruction](https://github.com/microsoft/Deep3DFaceReconstruction).\n\nThis repo only contains the **reconstruction** part, so you can use [Deep3DFaceReconstruction-pytorch](https://github.com/changhongjian/Deep3DFaceReconstruction-pytorch) repo to train the network. And the pretrained model is also from this [repo](https://github.com/changhongjian/Deep3DFaceReconstruction-pytorch/tree/master/network).\n\n## Features\n\n### MTCNN\n\nI use mtcnn to crop raw images and detect 5 landmarks. The most code of MTCNN comes from [FaceNet-pytorch](https://github.com/timesler/facenet-pytorch).\n\n### Pytorc3d\n\nIn this repo, I use [PyTorch3d 0.3.0](https://github.com/facebookresearch/pytorch3d) to render the reconstructed images.\n\n### Estimating Intrinsic Parameters\n\nIn the origin repo ([Deep3DFaceReconstruction-pytorch](https://github.com/changhongjian/Deep3DFaceReconstruction-pytorch)), the rendered images is not the same as the input image because of `preprocess`. So, I add the `estimate_intrinsic` to get intrinsic parameters.\n\n## Examples:\n\nHere are some examples:\n\n|Origin Images|Cropped Images|Rendered Images|\n|-------------|---|---|\n||||\n\n\n## File Architecture\n\n```\n├─BFM same as Deep3DFaceReconstruction\n├─dataset storing the corpped images\n│ └─Vladimir_Putin\n├─examples show examples\n├─facebank storing the raw/origin images\n│ └─Vladimir_Putin\n├─models storing the pretrained models\n├─output storing the output images(.mat, .png)\n│ └─Vladimir_Putin\n└─preprocess cropping images and detecting landmarks\n ├─data storing the models of mtcnn\n ├─utils\n```\n\nAlso, this repo can also generate the UV map, and you need download UV coordinates from the following link: \n Download UV coordinates fom STN website: https://github.com/anilbas/3DMMasSTN/blob/master/util/BFM_UV.mat \n Copy BFM_UV.mat to BFM\n\n"
},
{
"alpha_fraction": 0.5218848586082458,
"alphanum_fraction": 0.5774842500686646,
"avg_line_length": 31.9350643157959,
"blob_id": "b4703a7ab98b7578779add37c217569d7395d92f",
"content_id": "cfec102a46c636cc6e2e3790f1e1f8eae66f2a1a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5072,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 154,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/geometry/face_align/align.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#\nimport tensorflow as tf\nimport numpy as np\nimport math\n\n\n\"\"\"\nFrom \n\"\"\"\ndef Quaternion2Mat(quat):\n \"\"\"\n :param quat: 4\n :return: 3x3\n \"\"\"\n quat = tf.squeeze(quat)\n w = quat[0]\n x = quat[1]\n y = quat[2]\n z = quat[3]\n\n val00 = 1 - 2 * y * y - 2 * z * z\n val01 = 2 * x * y - 2 * z * w\n val02 = 2 * x * z + 2 * y * w\n val10 = 2 * x * y + 2 * z * w\n\n val11 = 1 - 2 * x * x - 2 * z * z\n val12 = 2 * y * z - 2 * x * w\n val20 = 2 * x * z - 2 * y * w\n val21 = 2 * y * z + 2 * x * w\n val22 = 1 - 2 * x * x - 2 * y * y\n rotation = tf.stack([val00, val01, val02, val10, val11, val12, val20, val21, val22], axis=0)\n rotation = tf.reshape(rotation, shape=[3,3])\n return rotation\n\ndef CenterOfPoints(points):\n center = tf.reduce_mean(points, axis=1) # 3\n return center\n\ndef UncenterPoints(points):\n point_num = points.get_shape().as_list()[1]\n center = CenterOfPoints(points) # 2\n center = tf.expand_dims(center, axis=-1) # 2x1\n center_tile = tf.tile(center, [1, point_num])\n u_points = points - center_tile\n return u_points\n\ndef ScaleFromPoints(left_points, right_points):\n \"\"\"\n Compute relative scale from left points to right points\n :param left_points: 3xN\n :param right_points: 3xN\n :return:\n \"\"\"\n lefts = UncenterPoints(left_points) # 3xN\n rights = UncenterPoints(right_points)\n\n ## Compute scale\n left_norm_square = tf.reduce_sum(tf.square(tf.norm(lefts, axis=0)))\n right_norm_square = tf.reduce_sum(tf.square(tf.norm(rights, axis=0)))\n scale = tf.sqrt(right_norm_square / left_norm_square)\n return scale\n\ndef TransformFromPointsTF(left_points, right_points):\n \"\"\"\n Tensorflow implementatin of aligning left points to right points\n :param left_points: 3xN\n :param right_points: 3xN\n :return:\n \"\"\"\n\n lefts = UncenterPoints(left_points) # 3xN\n rights = UncenterPoints(right_points)\n # lefts = left_points\n # rights = right_points\n\n ## Compute scale\n left_norm_square = tf.reduce_sum(tf.square(tf.norm(lefts, axis=0)))\n right_norm_square = tf.reduce_sum(tf.square(tf.norm(rights, axis=0)))\n scale = tf.sqrt(right_norm_square / (left_norm_square+1e-6))\n\n ## Compute rotation\n #rights = tf.Print(rights, [rights], message='rights', summarize=2 * 68)\n M = tf.matmul(lefts, rights, transpose_b=True) # 3x3\n #M = tf.Print(M, [M.shape, M], message=\"M\", summarize=64)\n\n N00 = M[0, 0] + M[1, 1] + M[2, 2]\n N11 = M[0, 0] - M[1, 1] - M[2, 2]\n N22 = -M[0, 0] + M[1, 1] - M[2, 2]\n N33 = -M[0, 0] - M[1, 1] + M[2, 2]\n\n N01 = M[1, 2] - M[2, 1]\n N10 = M[1, 2] - M[2, 1]\n N02 = M[2, 0] - M[0, 2]\n N20 = M[2, 0] - M[0, 2]\n\n N03 = M[0, 1] - M[1, 0]\n N30 = M[0, 1] - M[1, 0]\n N12 = M[0, 1] + M[1, 0]\n N21 = M[0, 1] + M[1, 0]\n\n N13 = M[0, 2] + M[2, 0]\n N31 = M[0, 2] + M[2, 0]\n N23 = M[1, 2] + M[2, 1]\n N32 = M[1, 2] + M[2, 1]\n N = tf.stack([N00,N01,N02,N03,N10,N11,N12,N13,N20,N21,N22,N23,N30,N31,N32,N33], axis=0)\n N = tf.reshape(N, [4,4])\n\n #N = tf.Print(N, [N.shape, N], message=\"N\", summarize=64)\n\n eigen_vals, eigen_vecs = tf.self_adjoint_eig(N)\n quaternion = tf.squeeze((tf.slice(eigen_vecs, [0, 3], [4, 1]))) # 4\n #quaternion = tf_render.Print(quaternion, [quaternion], message='quaternion', summarize=4)\n rotation = Quaternion2Mat(quaternion) # 3x3\n\n ## Compute translation\n left_center = CenterOfPoints(left_points)\n right_center = CenterOfPoints(right_points)\n rot_left_center = tf.squeeze(tf.matmul(rotation, tf.expand_dims(left_center, axis=-1))) # 3\n translation = right_center - scale * rot_left_center\n\n return scale, rotation, translation\n\n#\ndef lm2d_trans(lm_src, lm_tar):\n filler_mtx = tf.constant([0.0, 0.0, 1.0], shape=[1, 3])\n list_trans_mtx = []\n for b in range(lm_src.shape[0]):\n filler_z = tf.constant([0.0], shape=[1, 1])\n filler_z = tf.tile(filler_z, multiples=[lm_src.shape[1], 1])\n b_src = lm_src[b]\n b_src = tf.concat([b_src, filler_z], axis=1)\n b_src = tf.transpose(b_src)\n b_tar = lm_tar[b]\n b_tar = tf.concat([b_tar, filler_z], axis=1)\n b_tar = tf.transpose(b_tar)\n\n #b_src = tf.Print(b_src, [b_src], message='b_src', summarize=2 * 68)\n # b_tar = tf_render.Print(b_tar, [b_tar], message='b_tar', summarize=16)\n s, rot_mat, translation = TransformFromPointsTF(b_src, b_tar)\n\n # s = tf_render.Print(s, [s, s.shape], message='s', summarize=1)\n\n # rot_mat = tf_render.Print(rot_mat, [rot_mat], message='rot_mat', summarize=9)\n # translation = tf_render.Print(translation, [translation], message='translation', summarize=3)\n rot_mat = rot_mat[0:2, 0:2] * s\n translation = translation[0:2]\n translation = tf.expand_dims(translation, axis=-1)\n\n ext_mat = tf.concat([rot_mat, translation], axis=1)\n ext_mat = tf.concat([ext_mat, filler_mtx], axis=0)\n list_trans_mtx.append(ext_mat)\n\n trans_mtx = tf.stack(list_trans_mtx)\n return trans_mtx\n"
},
{
"alpha_fraction": 0.713840901851654,
"alphanum_fraction": 0.7296915054321289,
"avg_line_length": 45.74324417114258,
"blob_id": "df5bc078989deeab1207cf406421c47ebc0a1ab8",
"content_id": "fba21f5f23f176fdcaf4d2a085efd555dd22a947",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3533,
"license_type": "permissive",
"max_line_length": 258,
"num_lines": 74,
"path": "/Face Reconstruction/RingNet for Face Reconstruction/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# RingNet\r\n\r\n\r\n\r\nThis is an official repository of the paper Learning to Regress 3D Face Shape and Expression from an Image without 3D Supervision.\r\n```\r\nLearning to Regress 3D Face Shape and Expression from an Image without 3D Supervision\r\nSoubhik Sanyal, Timo Bolkart, Haiwen Feng, Michael J. Black\r\nCVPR 2019\r\n```\r\n\r\n## Download models\r\n\r\n* Download pretrained RingNet weights from the [project website](https://ringnet.is.tue.mpg.de), downloads page. Copy this inside the **model** folder\r\n* Download FLAME 2019 model from [here](http://flame.is.tue.mpg.de/). Copy it inside the **flame_model** folder. This step is optional and only required if you want to use the output Flame parameters to play with the 3D mesh, i.e., to neutralize the pose and\r\nexpression and only using the shape as a template for other methods like [VOCA (Voice Operated Character Animation)](https://github.com/TimoBolkart/voca).\r\n* Download the [FLAME_texture_data](http://files.is.tue.mpg.de/tbolkart/FLAME/FLAME_texture_data.zip) and unpack this into the **flame_model** folder.\r\n\r\n## Demo\r\n\r\nRingNet requires a loose crop of the face in the image. We provide two sample images in the **input_images** folder which are taken from [CelebA Dataset](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html). \r\n\r\n#### Output predicted mesh rendering\r\n\r\nRun the following command from the terminal to check the predictions of RingNet\r\n```\r\npython -m demo --img_path ./input_images/000001.jpg --out_folder ./RingNet_output\r\n```\r\nProvide the image path and it will output the predictions in **./RingNet_output/images/**.\r\n\r\n#### Output predicted mesh\r\n\r\nIf you want the output mesh then run the following command\r\n```\r\npython -m demo --img_path ./input_images/000001.jpg --out_folder ./RingNet_output --save_obj_file=True\r\n```\r\nIt will save a *.obj file of the predicted mesh in **./RingNet_output/mesh/**.\r\n\r\n#### Output textured mesh\r\n\r\nIf you want the output the predicted mesh with the image projected onto the mesh as texture then run the following command\r\n```\r\npython -m demo --img_path ./input_images/000001.jpg --out_folder ./RingNet_output --save_texture=True\r\n```\r\nIt will save a *.obj, *.mtl, and *.png file of the predicted mesh in **./RingNet_output/texture/**.\r\n\r\n#### Output FLAME and camera parameters\r\n\r\nIf you want the predicted FLAME and camera parameters then run the following command\r\n```\r\npython -m demo --img_path ./input_images/000001.jpg --out_folder ./RingNet_output --save_obj_file=True --save_flame_parameters=True\r\n```\r\nIt will save a *.npy file of the predicted flame and camera parameters and in **./RingNet_output/params/**.\r\n\r\n#### Generate VOCA templates\r\n\r\nIf you want to play with the 3D mesh, i.e. neutralize pose and expression of the 3D mesh to use it as a template in [VOCA (Voice Operated Character Animation)](https://github.com/TimoBolkart/voca), run the following command\r\n```\r\npython -m demo --img_path ./input_images/000013.jpg --out_folder ./RingNet_output --save_obj_file=True --save_flame_parameters=True --neutralize_expression=True\r\n```\r\n\r\n## Referencing RingNet\r\n\r\nPlease cite the following paper if you use the code directly or indirectly in your research/projects.\r\n```\r\n@inproceedings{RingNet:CVPR:2019,\r\ntitle = {Learning to Regress 3D Face Shape and Expression from an Image without 3D Supervision},\r\nauthor = {Sanyal, Soubhik and Bolkart, Timo and Feng, Haiwen and Black, Michael},\r\nbooktitle = {Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR)},\r\nmonth = jun,\r\nyear = {2019},\r\nmonth_numeric = {6}\r\n}\r\n```\r\n"
},
{
"alpha_fraction": 0.4642857015132904,
"alphanum_fraction": 0.6785714030265808,
"avg_line_length": 15.800000190734863,
"blob_id": "8c8b339916d96f2a85904a16e67e1143cca6fdc6",
"content_id": "d37b86db16586eac07c4b43894cbd4564a159b17",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 84,
"license_type": "permissive",
"max_line_length": 23,
"num_lines": 5,
"path": "/Face Reconstruction/Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model/requirements.txt",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "numpy==1.18.1\ntorch==1.4.0\ntorchvision==0.5.0\nPillow>=8.1.1\nopencv-python==3.4.2.17\n"
},
{
"alpha_fraction": 0.49065324664115906,
"alphanum_fraction": 0.5197972059249878,
"avg_line_length": 42.3408088684082,
"blob_id": "562a13bf5a5eb9be29fd4e9903a25a5342bda78f",
"content_id": "2008c32e8a9ceb87d8b6caebf798725134fa9438",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 28994,
"license_type": "permissive",
"max_line_length": 195,
"num_lines": 669,
"path": "/Facial Recognition Attendance Management System/run.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\nfrom tkinter import *\nfrom cv2 import cv2\nimport csv\nimport os\nimport numpy as np\nfrom PIL import Image,ImageTk\nimport pandas as pd\nimport datetime\nimport time\n\n#####Window is our Main frame of system\nwindow = tk.Tk()\nwindow.title(\"FAMS-Face Recognition Based Attendance Management System\")\n\nwindow.geometry('1280x720')\nwindow.configure(background='snow')\n\n####GUI for manually fill attendance\n\ndef manually_fill():\n global sb\n sb = tk.Tk()\n sb.iconbitmap('AMS.ico')\n sb.title(\"Enter subject name...\")\n sb.geometry('580x320')\n sb.configure(background='snow')\n\n def err_screen_for_subject():\n\n def ec_delete():\n ec.destroy()\n global ec\n ec = tk.Tk()\n ec.geometry('300x100')\n ec.iconbitmap('AMS.ico')\n ec.title('Warning!!')\n ec.configure(background='snow')\n Label(ec, text='Please enter your subject name!!!', fg='red', bg='white', font=('times', 16, ' bold ')).pack()\n Button(ec, text='OK', command=ec_delete, fg=\"black\", bg=\"lawn green\", width=9, height=1, activebackground=\"Red\",\n font=('times', 15, ' bold ')).place(x=90, y=50)\n\n def fill_attendance():\n ts = time.time()\n Date = datetime.datetime.fromtimestamp(ts).strftime('%Y_%m_%d')\n timeStamp = datetime.datetime.fromtimestamp(ts).strftime('%H:%M:%S')\n Time = datetime.datetime.fromtimestamp(ts).strftime('%H:%M:%S')\n Hour, Minute, Second = timeStamp.split(\":\")\n ####Creatting csv of attendance\n\n ##Create table for Attendance\n date_for_DB = datetime.datetime.fromtimestamp(ts).strftime('%Y_%m_%d')\n global subb\n subb=SUB_ENTRY.get()\n DB_table_name = str(subb + \"_\" + Date + \"_Time_\" + Hour + \"_\" + Minute + \"_\" + Second)\n\n import pymysql.connections\n\n ###Connect to the database\n try:\n global cursor\n connection = pymysql.connect(host='localhost', user='root', password='', db='manually_fill_attendance')\n cursor = connection.cursor()\n except Exception as e:\n print(e)\n\n sql = \"CREATE TABLE \" + DB_table_name + \"\"\"\n (ID INT NOT NULL AUTO_INCREMENT,\n ENROLLMENT varchar(100) NOT NULL,\n NAME VARCHAR(50) NOT NULL,\n DATE VARCHAR(20) NOT NULL,\n TIME VARCHAR(20) NOT NULL,\n PRIMARY KEY (ID)\n );\n \"\"\"\n\n\n try:\n cursor.execute(sql) ##for create a table\n except Exception as ex:\n print(ex) #\n\n if subb=='':\n err_screen_for_subject()\n else:\n sb.destroy()\n MFW = tk.Tk()\n MFW.iconbitmap('AMS.ico')\n MFW.title(\"Manually attendance of \"+ str(subb))\n MFW.geometry('880x470')\n MFW.configure(background='snow')\n\n def del_errsc2():\n errsc2.destroy()\n\n def err_screen1():\n global errsc2\n errsc2 = tk.Tk()\n errsc2.geometry('330x100')\n errsc2.iconbitmap('AMS.ico')\n errsc2.title('Warning!!')\n errsc2.configure(background='snow')\n Label(errsc2, text='Please enter Student & Enrollment!!!', fg='red', bg='white',\n font=('times', 16, ' bold ')).pack()\n Button(errsc2, text='OK', command=del_errsc2, fg=\"black\", bg=\"lawn green\", width=9, height=1,\n activebackground=\"Red\", font=('times', 15, ' bold ')).place(x=90, y=50)\n\n def testVal(inStr, acttyp):\n if acttyp == '1': # insert\n if not inStr.isdigit():\n return False\n return True\n\n ENR = tk.Label(MFW, text=\"Enter Enrollment\", width=15, height=2, fg=\"white\", bg=\"blue2\",\n font=('times', 15, ' bold '))\n ENR.place(x=30, y=100)\n\n STU_NAME = tk.Label(MFW, text=\"Enter Student name\", width=15, height=2, fg=\"white\", bg=\"blue2\",\n font=('times', 15, ' bold '))\n STU_NAME.place(x=30, y=200)\n\n global ENR_ENTRY\n ENR_ENTRY = tk.Entry(MFW, width=20,validate='key', bg=\"yellow\", fg=\"red\", font=('times', 23, ' bold '))\n ENR_ENTRY['validatecommand'] = (ENR_ENTRY.register(testVal), '%P', '%d')\n ENR_ENTRY.place(x=290, y=105)\n\n def remove_enr():\n ENR_ENTRY.delete(first=0, last=22)\n\n STUDENT_ENTRY = tk.Entry(MFW, width=20, bg=\"yellow\", fg=\"red\", font=('times', 23, ' bold '))\n STUDENT_ENTRY.place(x=290, y=205)\n\n def remove_student():\n STUDENT_ENTRY.delete(first=0, last=22)\n\n ####get important variable\n def enter_data_DB():\n ENROLLMENT = ENR_ENTRY.get()\n STUDENT = STUDENT_ENTRY.get()\n if ENROLLMENT=='':\n err_screen1()\n elif STUDENT=='':\n err_screen1()\n else:\n time = datetime.datetime.fromtimestamp(ts).strftime('%H:%M:%S')\n Hour, Minute, Second = time.split(\":\")\n Insert_data = \"INSERT INTO \" + DB_table_name + \" (ID,ENROLLMENT,NAME,DATE,TIME) VALUES (0, %s, %s, %s,%s)\"\n VALUES = (str(ENROLLMENT), str(STUDENT), str(Date), str(time))\n try:\n cursor.execute(Insert_data, VALUES)\n except Exception as e:\n print(e)\n ENR_ENTRY.delete(first=0, last=22)\n STUDENT_ENTRY.delete(first=0, last=22)\n\n def create_csv():\n import csv\n cursor.execute(\"select * from \" + DB_table_name + \";\")\n csv_name='C:/Users/kusha/PycharmProjects/Attendace managemnt system/Attendance/Manually Attendance/'+DB_table_name+'.csv'\n with open(csv_name, \"w\") as csv_file:\n csv_writer = csv.writer(csv_file)\n csv_writer.writerow([i[0] for i in cursor.description]) # write headers\n csv_writer.writerows(cursor)\n O=\"CSV created Successfully\"\n Notifi.configure(text=O, bg=\"Green\", fg=\"white\", width=33, font=('times', 19, 'bold'))\n Notifi.place(x=180, y=380)\n import csv\n import tkinter\n root = tkinter.Tk()\n root.title(\"Attendance of \" + subb)\n root.configure(background='snow')\n with open(csv_name, newline=\"\") as file:\n reader = csv.reader(file)\n r = 0\n\n for col in reader:\n c = 0\n for row in col:\n # i've added some styling\n label = tkinter.Label(root, width=13, height=1, fg=\"black\", font=('times', 13, ' bold '),\n bg=\"lawn green\", text=row, relief=tkinter.RIDGE)\n label.grid(row=r, column=c)\n c += 1\n r += 1\n root.mainloop()\n\n Notifi = tk.Label(MFW, text=\"CSV created Successfully\", bg=\"Green\", fg=\"white\", width=33,\n height=2, font=('times', 19, 'bold'))\n\n\n c1ear_enroll = tk.Button(MFW, text=\"Clear\", command=remove_enr, fg=\"black\", bg=\"deep pink\", width=10,\n height=1,\n activebackground=\"Red\", font=('times', 15, ' bold '))\n c1ear_enroll.place(x=690, y=100)\n\n c1ear_student = tk.Button(MFW, text=\"Clear\", command=remove_student, fg=\"black\", bg=\"deep pink\", width=10,\n height=1,\n activebackground=\"Red\", font=('times', 15, ' bold '))\n c1ear_student.place(x=690, y=200)\n\n DATA_SUB = tk.Button(MFW, text=\"Enter Data\",command=enter_data_DB, fg=\"black\", bg=\"lime green\", width=20,\n height=2,\n activebackground=\"Red\", font=('times', 15, ' bold '))\n DATA_SUB.place(x=170, y=300)\n\n MAKE_CSV = tk.Button(MFW, text=\"Convert to CSV\",command=create_csv, fg=\"black\", bg=\"red\", width=20,\n height=2,\n activebackground=\"Red\", font=('times', 15, ' bold '))\n MAKE_CSV.place(x=570, y=300)\n\n def attf():\n import subprocess\n subprocess.Popen(r'explorer /select,\"C:\\Users\\kusha\\PycharmProjects\\Attendace managemnt system\\Attendance\\Manually Attendance\\-------Check atttendance-------\"')\n\n attf = tk.Button(MFW, text=\"Check Sheets\",command=attf,fg=\"black\" ,bg=\"lawn green\" ,width=12 ,height=1 ,activebackground = \"Red\" ,font=('times', 14, ' bold '))\n attf.place(x=730, y=410)\n\n MFW.mainloop()\n\n\n SUB = tk.Label(sb, text=\"Enter Subject\", width=15, height=2, fg=\"white\", bg=\"blue2\", font=('times', 15, ' bold '))\n SUB.place(x=30, y=100)\n\n global SUB_ENTRY\n\n SUB_ENTRY = tk.Entry(sb, width=20, bg=\"yellow\", fg=\"red\", font=('times', 23, ' bold '))\n SUB_ENTRY.place(x=250, y=105)\n\n fill_manual_attendance = tk.Button(sb, text=\"Fill Attendance\",command=fill_attendance, fg=\"white\", bg=\"deep pink\", width=20, height=2,\n activebackground=\"Red\", font=('times', 15, ' bold '))\n fill_manual_attendance.place(x=250, y=160)\n sb.mainloop()\n\n##For clear textbox\ndef clear():\n txt.delete(first=0, last=22)\n\ndef clear1():\n txt2.delete(first=0, last=22)\ndef del_sc1():\n sc1.destroy()\ndef err_screen():\n global sc1\n sc1 = tk.Tk()\n sc1.geometry('300x100')\n sc1.iconbitmap('AMS.ico')\n sc1.title('Warning!!')\n sc1.configure(background='snow')\n Label(sc1,text='Enrollment & Name required!!!',fg='red',bg='white',font=('times', 16, ' bold ')).pack()\n Button(sc1,text='OK',command=del_sc1,fg=\"black\" ,bg=\"lawn green\" ,width=9 ,height=1, activebackground = \"Red\" ,font=('times', 15, ' bold ')).place(x=90,y= 50)\n\n##Error screen2\ndef del_sc2():\n sc2.destroy()\ndef err_screen1():\n global sc2\n sc2 = tk.Tk()\n sc2.geometry('300x100')\n sc2.iconbitmap('AMS.ico')\n sc2.title('Warning!!')\n sc2.configure(background='snow')\n Label(sc2,text='Please enter your subject name!!!',fg='red',bg='white',font=('times', 16, ' bold ')).pack()\n Button(sc2,text='OK',command=del_sc2,fg=\"black\" ,bg=\"lawn green\" ,width=9 ,height=1, activebackground = \"Red\" ,font=('times', 15, ' bold ')).place(x=90,y= 50)\n\n###For take images for datasets\ndef take_img():\n l1 = txt.get()\n l2 = txt2.get()\n if l1 == '':\n err_screen()\n elif l2 == '':\n err_screen()\n else:\n try:\n cam = cv2.VideoCapture(0)\n detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')\n Enrollment = txt.get()\n Name = txt2.get()\n sampleNum = 0\n while (True):\n ret, img = cam.read()\n gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)\n faces = detector.detectMultiScale(gray, 1.3, 5)\n for (x, y, w, h) in faces:\n cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)\n # incrementing sample number\n sampleNum = sampleNum + 1\n # saving the captured face in the dataset folder\n cv2.imwrite(\"TrainingImage/ \" + Name + \".\" + Enrollment + '.' + str(sampleNum) + \".jpg\",\n gray[y:y + h, x:x + w])\n cv2.imshow('Frame', img)\n # wait for 100 miliseconds\n if cv2.waitKey(1) & 0xFF == ord('q'):\n break\n # break if the sample number is morethan 100\n elif sampleNum > 70:\n break\n cam.release()\n cv2.destroyAllWindows()\n ts = time.time()\n Date = datetime.datetime.fromtimestamp(ts).strftime('%Y-%m-%d')\n Time = datetime.datetime.fromtimestamp(ts).strftime('%H:%M:%S')\n row = [Enrollment, Name, Date, Time]\n with open('StudentDetails\\StudentDetails.csv', 'a+') as csvFile:\n writer = csv.writer(csvFile, delimiter=',')\n writer.writerow(row)\n csvFile.close()\n res = \"Images Saved for Enrollment : \" + Enrollment + \" Name : \" + Name\n Notification.configure(text=res, bg=\"SpringGreen3\", width=50, font=('times', 18, 'bold'))\n Notification.place(x=250, y=400)\n except FileExistsError as F:\n f = 'Student Data already exists'\n Notification.configure(text=f, bg=\"Red\", width=21)\n Notification.place(x=450, y=400)\n\n\n###for choose subject and fill attendance\ndef subjectchoose():\n def Fillattendances():\n sub=tx.get()\n now = time.time() ###For calculate seconds of video\n future = now + 20\n if time.time() < future:\n if sub == '':\n err_screen1()\n else:\n recognizer = cv2.face.LBPHFaceRecognizer_create() # cv2.createLBPHFaceRecognizer()\n try:\n recognizer.read(\"TrainingImageLabel\\Trainner.yml\")\n except:\n e = 'Model not found,Please train model'\n Notifica.configure(text=e, bg=\"red\", fg=\"black\", width=33, font=('times', 15, 'bold'))\n Notifica.place(x=20, y=250)\n\n harcascadePath = \"haarcascade_frontalface_default.xml\"\n faceCascade = cv2.CascadeClassifier(harcascadePath)\n df = pd.read_csv(\"StudentDetails\\StudentDetails.csv\")\n cam = cv2.VideoCapture(0)\n font = cv2.FONT_HERSHEY_SIMPLEX\n col_names = ['Enrollment', 'Name', 'Date', 'Time']\n attendance = pd.DataFrame(columns=col_names)\n while True:\n ret, im = cam.read()\n gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)\n faces = faceCascade.detectMultiScale(gray, 1.2, 5)\n for (x, y, w, h) in faces:\n global Id\n\n Id, conf = recognizer.predict(gray[y:y + h, x:x + w])\n if (conf <70):\n print(conf)\n global Subject\n global aa\n global date\n global timeStamp\n Subject = tx.get()\n ts = time.time()\n date = datetime.datetime.fromtimestamp(ts).strftime('%Y-%m-%d')\n timeStamp = datetime.datetime.fromtimestamp(ts).strftime('%H:%M:%S')\n aa = df.loc[df['Enrollment'] == Id]['Name'].values\n global tt\n tt = str(Id) + \"-\" + aa\n En = '15624031' + str(Id)\n attendance.loc[len(attendance)] = [Id, aa, date, timeStamp]\n cv2.rectangle(im, (x, y), (x + w, y + h), (0, 260, 0), 7)\n cv2.putText(im, str(tt), (x + h, y), font, 1, (255, 255, 0,), 4)\n\n else:\n Id = 'Unknown'\n tt = str(Id)\n cv2.rectangle(im, (x, y), (x + w, y + h), (0, 25, 255), 7)\n cv2.putText(im, str(tt), (x + h, y), font, 1, (0, 25, 255), 4)\n if time.time() > future:\n break\n\n attendance = attendance.drop_duplicates(['Enrollment'], keep='first')\n cv2.imshow('Filling attedance..', im)\n key = cv2.waitKey(30) & 0xff\n if key == 27:\n break\n\n ts = time.time()\n date = datetime.datetime.fromtimestamp(ts).strftime('%Y-%m-%d')\n timeStamp = datetime.datetime.fromtimestamp(ts).strftime('%H:%M:%S')\n Hour, Minute, Second = timeStamp.split(\":\")\n fileName = \"Attendance/\" + Subject + \"_\" + date + \"_\" + Hour + \"-\" + Minute + \"-\" + Second + \".csv\"\n attendance = attendance.drop_duplicates(['Enrollment'], keep='first')\n print(attendance)\n attendance.to_csv(fileName, index=False)\n\n ##Create table for Attendance\n date_for_DB = datetime.datetime.fromtimestamp(ts).strftime('%Y_%m_%d')\n DB_Table_name = str( Subject + \"_\" + date_for_DB + \"_Time_\" + Hour + \"_\" + Minute + \"_\" + Second)\n import pymysql.connections\n\n ###Connect to the database\n try:\n global cursor\n connection = pymysql.connect(host='localhost', user='root', password='', db='Face_reco_fill')\n cursor = connection.cursor()\n except Exception as e:\n print(e)\n\n sql = \"CREATE TABLE \" + DB_Table_name + \"\"\"\n (ID INT NOT NULL AUTO_INCREMENT,\n ENROLLMENT varchar(100) NOT NULL,\n NAME VARCHAR(50) NOT NULL,\n DATE VARCHAR(20) NOT NULL,\n TIME VARCHAR(20) NOT NULL,\n PRIMARY KEY (ID)\n );\n \"\"\"\n ####Now enter attendance in Database\n insert_data = \"INSERT INTO \" + DB_Table_name + \" (ID,ENROLLMENT,NAME,DATE,TIME) VALUES (0, %s, %s, %s,%s)\"\n VALUES = (str(Id), str(aa), str(date), str(timeStamp))\n try:\n cursor.execute(sql) ##for create a table\n cursor.execute(insert_data, VALUES)##For insert data into table\n except Exception as ex:\n print(ex) #\n\n M = 'Attendance filled Successfully'\n Notifica.configure(text=M, bg=\"Green\", fg=\"white\", width=33, font=('times', 15, 'bold'))\n Notifica.place(x=20, y=250)\n\n cam.release()\n cv2.destroyAllWindows()\n\n import csv\n import tkinter\n root = tkinter.Tk()\n root.title(\"Attendance of \" + Subject)\n root.configure(background='snow')\n cs = 'C:/Users/kusha/PycharmProjects/Attendace managemnt system/' + fileName\n with open(cs, newline=\"\") as file:\n reader = csv.reader(file)\n r = 0\n\n for col in reader:\n c = 0\n for row in col:\n # i've added some styling\n label = tkinter.Label(root, width=8, height=1, fg=\"black\", font=('times', 15, ' bold '),\n bg=\"lawn green\", text=row, relief=tkinter.RIDGE)\n label.grid(row=r, column=c)\n c += 1\n r += 1\n root.mainloop()\n print(attendance)\n\n ###window is frame for subject chooser\n windo = tk.Tk()\n windo.iconbitmap('AMS.ico')\n windo.title(\"Enter subject name...\")\n windo.geometry('580x320')\n windo.configure(background='snow')\n Notifica = tk.Label(windo, text=\"Attendance filled Successfully\", bg=\"Green\", fg=\"white\", width=33,\n height=2, font=('times', 15, 'bold'))\n\n def Attf():\n import subprocess\n subprocess.Popen(r'explorer /select,\"C:\\Users\\kusha\\PycharmProjects\\Attendace managemnt system\\Attendance\\-------Check atttendance-------\"')\n\n attf = tk.Button(windo, text=\"Check Sheets\",command=Attf,fg=\"black\" ,bg=\"lawn green\" ,width=12 ,height=1 ,activebackground = \"Red\" ,font=('times', 14, ' bold '))\n attf.place(x=430, y=255)\n\n sub = tk.Label(windo, text=\"Enter Subject\", width=15, height=2, fg=\"white\", bg=\"blue2\", font=('times', 15, ' bold '))\n sub.place(x=30, y=100)\n\n tx = tk.Entry(windo, width=20, bg=\"yellow\", fg=\"red\", font=('times', 23, ' bold '))\n tx.place(x=250, y=105)\n\n fill_a = tk.Button(windo, text=\"Fill Attendance\", fg=\"white\",command=Fillattendances, bg=\"deep pink\", width=20, height=2,\n activebackground=\"Red\", font=('times', 15, ' bold '))\n fill_a.place(x=250, y=160)\n windo.mainloop()\n\ndef admin_panel():\n win = tk.Tk()\n win.iconbitmap('AMS.ico')\n win.title(\"LogIn\")\n win.geometry('880x420')\n win.configure(background='snow')\n\n def log_in():\n username = un_entr.get()\n password = pw_entr.get()\n\n if username == 'kushal' :\n if password == 'kushal14320':\n win.destroy()\n import csv\n import tkinter\n root = tkinter.Tk()\n root.title(\"Student Details\")\n root.configure(background='snow')\n\n cs = 'C:/Users/kusha/PycharmProjects/Attendace managemnt system/StudentDetails/StudentDetails.csv'\n with open(cs, newline=\"\") as file:\n reader = csv.reader(file)\n r = 0\n\n for col in reader:\n c = 0\n for row in col:\n # i've added some styling\n label = tkinter.Label(root, width=8, height=1, fg=\"black\", font=('times', 15, ' bold '),\n bg=\"lawn green\", text=row, relief=tkinter.RIDGE)\n label.grid(row=r, column=c)\n c += 1\n r += 1\n root.mainloop()\n else:\n valid = 'Incorrect ID or Password'\n Nt.configure(text=valid, bg=\"red\", fg=\"black\", width=38, font=('times', 19, 'bold'))\n Nt.place(x=120, y=350)\n\n else:\n valid ='Incorrect ID or Password'\n Nt.configure(text=valid, bg=\"red\", fg=\"black\", width=38, font=('times', 19, 'bold'))\n Nt.place(x=120, y=350)\n\n\n Nt = tk.Label(win, text=\"Attendance filled Successfully\", bg=\"Green\", fg=\"white\", width=40,\n height=2, font=('times', 19, 'bold'))\n # Nt.place(x=120, y=350)\n\n un = tk.Label(win, text=\"Enter username\", width=15, height=2, fg=\"white\", bg=\"blue2\",\n font=('times', 15, ' bold '))\n un.place(x=30, y=50)\n\n pw = tk.Label(win, text=\"Enter password\", width=15, height=2, fg=\"white\", bg=\"blue2\",\n font=('times', 15, ' bold '))\n pw.place(x=30, y=150)\n\n def c00():\n un_entr.delete(first=0, last=22)\n\n un_entr = tk.Entry(win, width=20, bg=\"yellow\", fg=\"red\", font=('times', 23, ' bold '))\n un_entr.place(x=290, y=55)\n\n def c11():\n pw_entr.delete(first=0, last=22)\n\n pw_entr = tk.Entry(win, width=20,show=\"*\", bg=\"yellow\", fg=\"red\", font=('times', 23, ' bold '))\n pw_entr.place(x=290, y=155)\n\n c0 = tk.Button(win, text=\"Clear\", command=c00, fg=\"black\", bg=\"deep pink\", width=10, height=1,\n activebackground=\"Red\", font=('times', 15, ' bold '))\n c0.place(x=690, y=55)\n\n c1 = tk.Button(win, text=\"Clear\", command=c11, fg=\"black\", bg=\"deep pink\", width=10, height=1,\n activebackground=\"Red\", font=('times', 15, ' bold '))\n c1.place(x=690, y=155)\n\n Login = tk.Button(win, text=\"LogIn\", fg=\"black\", bg=\"lime green\", width=20,\n height=2,\n activebackground=\"Red\",command=log_in, font=('times', 15, ' bold '))\n Login.place(x=290, y=250)\n win.mainloop()\n\n\n###For train the model\ndef trainimg():\n recognizer = cv2.face.LBPHFaceRecognizer_create()\n global detector\n detector = cv2.CascadeClassifier(\"haarcascade_frontalface_default.xml\")\n try:\n global faces,Id\n faces, Id = getImagesAndLabels(\"TrainingImage\")\n except Exception as e:\n l='please make \"TrainingImage\" folder & put Images'\n Notification.configure(text=l, bg=\"SpringGreen3\", width=50, font=('times', 18, 'bold'))\n Notification.place(x=350, y=400)\n\n recognizer.train(faces, np.array(Id))\n try:\n recognizer.save(\"TrainingImageLabel\\Trainner.yml\")\n except Exception as e:\n q='Please make \"TrainingImageLabel\" folder'\n Notification.configure(text=q, bg=\"SpringGreen3\", width=50, font=('times', 18, 'bold'))\n Notification.place(x=350, y=400)\n\n res = \"Model Trained\" # +\",\".join(str(f) for f in Id)\n Notification.configure(text=res, bg=\"SpringGreen3\", width=50, font=('times', 18, 'bold'))\n Notification.place(x=250, y=400)\n\ndef getImagesAndLabels(path):\n imagePaths = [os.path.join(path, f) for f in os.listdir(path)]\n # create empth face list\n faceSamples = []\n # create empty ID list\n Ids = []\n # now looping through all the image paths and loading the Ids and the images\n for imagePath in imagePaths:\n # loading the image and converting it to gray scale\n pilImage = Image.open(imagePath).convert('L')\n # Now we are converting the PIL image into numpy array\n imageNp = np.array(pilImage, 'uint8')\n # getting the Id from the image\n\n Id = int(os.path.split(imagePath)[-1].split(\".\")[1])\n # extract the face from the training image sample\n faces = detector.detectMultiScale(imageNp)\n # If a face is there then append that in the list as well as Id of it\n for (x, y, w, h) in faces:\n faceSamples.append(imageNp[y:y + h, x:x + w])\n Ids.append(Id)\n return faceSamples, Ids\n\nwindow.grid_rowconfigure(0, weight=1)\nwindow.grid_columnconfigure(0, weight=1)\nwindow.iconbitmap('AMS.ico')\n\ndef on_closing():\n from tkinter import messagebox\n if messagebox.askokcancel(\"Quit\", \"Do you want to quit?\"):\n window.destroy()\nwindow.protocol(\"WM_DELETE_WINDOW\", on_closing)\n\nmessage = tk.Label(window, text=\"Face-Recognition-Based-Attendance-Management-System\", bg=\"cyan\", fg=\"black\", width=50,\n height=3, font=('times', 30, 'italic bold '))\n\nmessage.place(x=80, y=20)\n\nNotification = tk.Label(window, text=\"All things good\", bg=\"Green\", fg=\"white\", width=15,\n height=3, font=('times', 17, 'bold'))\n\nlbl = tk.Label(window, text=\"Enter Enrollment\", width=20, height=2, fg=\"black\", bg=\"deep pink\", font=('times', 15, ' bold '))\nlbl.place(x=200, y=200)\n\ndef testVal(inStr,acttyp):\n if acttyp == '1': #insert\n if not inStr.isdigit():\n return False\n return True\n\ntxt = tk.Entry(window, validate=\"key\", width=20, bg=\"yellow\", fg=\"red\", font=('times', 25, ' bold '))\ntxt['validatecommand'] = (txt.register(testVal),'%P','%d')\ntxt.place(x=550, y=210)\n\nlbl2 = tk.Label(window, text=\"Enter Name\", width=20, fg=\"black\", bg=\"deep pink\", height=2, font=('times', 15, ' bold '))\nlbl2.place(x=200, y=300)\n\ntxt2 = tk.Entry(window, width=20, bg=\"yellow\", fg=\"red\", font=('times', 25, ' bold '))\ntxt2.place(x=550, y=310)\n\nclearButton = tk.Button(window, text=\"Clear\",command=clear,fg=\"black\" ,bg=\"deep pink\" ,width=10 ,height=1 ,activebackground = \"Red\" ,font=('times', 15, ' bold '))\nclearButton.place(x=950, y=210)\n\nclearButton1 = tk.Button(window, text=\"Clear\",command=clear1,fg=\"black\" ,bg=\"deep pink\" ,width=10 ,height=1, activebackground = \"Red\" ,font=('times', 15, ' bold '))\nclearButton1.place(x=950, y=310)\n\nAP = tk.Button(window, text=\"Check Register students\",command=admin_panel,fg=\"black\" ,bg=\"cyan\" ,width=19 ,height=1, activebackground = \"Red\" ,font=('times', 15, ' bold '))\nAP.place(x=990, y=410)\n\ntakeImg = tk.Button(window, text=\"Take Images\",command=take_img,fg=\"white\" ,bg=\"blue2\" ,width=20 ,height=3, activebackground = \"Red\" ,font=('times', 15, ' bold '))\ntakeImg.place(x=90, y=500)\n\ntrainImg = tk.Button(window, text=\"Train Images\",fg=\"black\",command=trainimg ,bg=\"lawn green\" ,width=20 ,height=3, activebackground = \"Red\" ,font=('times', 15, ' bold '))\ntrainImg.place(x=390, y=500)\n\nFA = tk.Button(window, text=\"Automatic Attendace\",fg=\"white\",command=subjectchoose ,bg=\"blue2\" ,width=20 ,height=3, activebackground = \"Red\" ,font=('times', 15, ' bold '))\nFA.place(x=690, y=500)\n\nquitWindow = tk.Button(window, text=\"Manually Fill Attendance\", command=manually_fill ,fg=\"black\" ,bg=\"lawn green\" ,width=20 ,height=3, activebackground = \"Red\" ,font=('times', 15, ' bold '))\nquitWindow.place(x=990, y=500)\n\nwindow.mainloop()"
},
{
"alpha_fraction": 0.6261246204376221,
"alphanum_fraction": 0.6456181406974792,
"avg_line_length": 42.81386947631836,
"blob_id": "54c35bb5bf0faeb5fc25f4506b1d0726e2369f21",
"content_id": "1a8d29f47f33ed656519001299f85948488bffc1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12004,
"license_type": "permissive",
"max_line_length": 150,
"num_lines": 274,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_tfGraph/deep_3dmm_loss.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# system\nfrom __future__ import print_function\n\n# tf_render\nimport tensorflow as tf\nimport tensorflow.contrib.slim as slim\n\n# self\n# jiaxiang\nfrom src_common.common.visual_helper import pixel_error_heatmap\n# tianwei\nfrom src_common.geometry.geo_utils import fundamental_matrix_from_rt, reprojection_error\n\n# common losses\ndef compute_3dmm_regular_l2_loss(pred_batch_list):\n gpmm_regular_loss = 0.0\n for i in range(len(pred_batch_list)):\n loss_gpmm_src_reg = tf.reduce_sum(tf.square(pred_batch_list[i]))\n gpmm_regular_loss += loss_gpmm_src_reg\n return gpmm_regular_loss\n\ndef compute_lm_eul_square_loss(pred_batch_list, gt_batch_list, weight=None):\n gpmm_lm_loss = 0.0\n for i in range(len(pred_batch_list)):\n lm2d = pred_batch_list[i]\n lm2d_gt = gt_batch_list[i]\n\n lm_loss = tf.reduce_sum(tf.square(lm2d - lm2d_gt), 2)\n if weight is not None:\n lm_loss = lm_loss * weight\n\n gpmm_lm_loss += tf.reduce_mean(lm_loss)\n return gpmm_lm_loss\n\ndef compute_3dmm_render_eul_masknorm_skin_loss(pred_batch_list, pred_mask_batch_list, pred_skin_batch_list, gt_batch):\n \"\"\"\n :param pred_batch_list:\n :param pred_mask_batch_list:\n :param pred_skin_batch_list:\n :param gt_batch:\n :return:\n \"\"\"\n if isinstance(pred_batch_list, list) == False:\n pred_batch_list = [pred_batch_list]\n if isinstance(pred_mask_batch_list, list) == False:\n pred_mask_batch_list = [pred_mask_batch_list]\n\n gpmm_pixel_loss = 0.0\n list_render_loss_error = []\n for i in range(len(pred_batch_list)):\n pred = pred_batch_list[i] * pred_skin_batch_list[i] # (0, 1) * (0, 1)\n gt = gt_batch[i] * pred_skin_batch_list[i]\n\n # l1\n curr_render_error = pred - gt\n curr_render_src_error = tf.reduce_sum(tf.square(curr_render_error), 3) # bs, h, w, c\n curr_render_src_error = tf.sqrt(curr_render_src_error + 1e-6)\n curr_render_src_error = tf.expand_dims(curr_render_src_error, -1) # bs, h, w, 1 # (0, 1) * (0, 1)\n\n list_render_loss_error.append(pixel_error_heatmap(curr_render_src_error))\n\n # loss\n # curr_render_mask_sum = pred_mask_batch_list[i]\n # curr_render_mask_sum = tf.reduce_sum(curr_render_mask_sum, axis=[1, 2, 3])\n\n curr_render_option_sum = pred_skin_batch_list[i] * pred_mask_batch_list[i]\n curr_render_option_sum = tf.reduce_sum(curr_render_option_sum, axis=[1, 2, 3])\n\n curr_render_src_error = tf.reduce_sum(curr_render_src_error, axis=[1, 2, 3])\n curr_render_src_error = curr_render_src_error / (curr_render_option_sum + 1e-6)\n curr_render_src_error = tf.reduce_mean(curr_render_src_error)\n\n gpmm_pixel_loss += curr_render_src_error\n\n return gpmm_pixel_loss, list_render_loss_error\n\ndef compute_3dmm_id_cos_loss(pred_batch_list, gt_batch_list):\n if isinstance(pred_batch_list, list) == False:\n pred_batch_list = [pred_batch_list]\n if isinstance(gt_batch_list, list) == False:\n gt_batch_list = [gt_batch_list]\n\n gpmm_id_loss = 0.0\n list_simi_norm = []\n for i in range(len(pred_batch_list)):\n pred = pred_batch_list[i]\n gt = gt_batch_list[i]\n\n simi = tf.reduce_sum(tf.multiply(pred, gt), axis=1) # bs, 199\n #x_norm = tf_render.sqrt(tf_render.reduce_sum(tf_render.square(pred) + 1e-6, axis=1))\n #y_norm = tf_render.sqrt(tf_render.reduce_sum(tf_render.square(gt) + 1e-6, axis=1))\n #loss = loss / (x_norm*y_norm + 1e-6)\n #simi = tf.Print(simi, [simi], message=\"simi\", summarize=4)\n simi_norm = (simi + 1.0) / 2.0\n list_simi_norm.append(simi_norm)\n\n loss = -simi + 1.0\n loss = tf.reduce_mean(loss)\n gpmm_id_loss += loss\n\n return gpmm_id_loss, list_simi_norm\n\n# MGC losses\ndef combine_flag_sgl_mul_loss(loss_batch_list, flag_sgl_mul_curr, flag_batch_norm=True):\n loss = tf.constant(0.0)\n for i in range(len(loss_batch_list)):\n curr_proj_error = loss_batch_list[i]\n curr_proj_error = tf.expand_dims(curr_proj_error, -1)\n # curr_proj_error = tf.Print(curr_proj_error, [curr_proj_error.shape, self.flag_sgl_mul.shape], message='curr_proj_error', summarize=16)\n curr_proj_error_batch = curr_proj_error * flag_sgl_mul_curr # bs\n #tf.print(curr_proj_error_batch,[tf.reduce_mean(curr_proj_error_batch), flag_sgl_mul_curr],message='flag_curr_proj_error_batch', summarize=12)\n # curr_proj_error_batch = tf.Print(curr_proj_error_batch, [curr_proj_error_batch], message='curr_proj_error_batch', summarize=16)\n # self.pixel_loss += tf.reduce_sum(curr_proj_error_batch) / (tf.reduce_sum(self.flag_sgl_mul) + 1e-6)\n if flag_batch_norm:\n loss += tf.reduce_mean(curr_proj_error_batch)\n else:\n loss += tf.reduce_sum(curr_proj_error_batch) / (tf.reduce_sum(flag_sgl_mul_curr) + 1e-6)\n return loss\n\ndef compute_pixel_eul_loss_list(pred_batch, pred_mask_batch, pred_gpmmmask_batch, gt_batch):\n render_loss = 0.0\n list_render_loss_batch = []\n list_render_loss_visual_batch = []\n for i in range(len(pred_batch)):\n pred = pred_batch[i]\n warp_mask = pred_mask_batch[i]\n render_mask = pred_gpmmmask_batch[i]\n gt = gt_batch[i]\n curr_render_error, curr_render_src_error_visual = compute_pixel_eul_loss(pred, warp_mask, render_mask, gt)\n\n list_render_loss_batch.append(curr_render_error)\n list_render_loss_visual_batch.append(curr_render_src_error_visual)\n return list_render_loss_batch, list_render_loss_visual_batch\n\ndef compute_pixel_eul_loss(pred_batch, pred_mask_batch, pred_gpmmmask_batch, gt_batch):\n # eul\n curr_render_error = pred_batch - gt_batch\n\n curr_render_src_error = tf.reduce_sum(tf.square(curr_render_error), 3)\n\n curr_render_src_error = tf.sqrt(curr_render_src_error + 1e-6)\n curr_render_src_error = tf.expand_dims(curr_render_src_error, -1)\n\n curr_render_src_error = curr_render_src_error * pred_mask_batch\n curr_render_src_error = curr_render_src_error * pred_gpmmmask_batch\n\n curr_render_src_error_visual = pixel_error_heatmap(curr_render_src_error)\n\n curr_render_option_sum = pred_mask_batch * pred_gpmmmask_batch\n curr_render_option_sum = tf.reduce_sum(curr_render_option_sum, axis=[1, 2, 3])\n\n curr_render_src_error = tf.reduce_sum(curr_render_src_error, axis=[1, 2, 3])\n curr_render_src_error = curr_render_src_error / (curr_render_option_sum + 1e-6)\n\n # curr_render_src_error = tf.Print(curr_render_src_error, [tf.reduce_sum(curr_render_src_error), tf.reduce_sum(curr_render_option_sum)],\n # message='error')\n\n return curr_render_src_error, curr_render_src_error_visual\n\ndef compute_ssim_loss_list(list_x, list_y, list_mask):\n list_ssim_error = []\n for i in range(len(list_x)):\n x = list_x[i]\n y = list_y[i]\n\n ssim_error = compute_ssim_loss(x,y) * list_mask[i]\n ssim_error = tf.reduce_mean(ssim_error, axis=[1, 2, 3])\n\n list_ssim_error.append(ssim_error)\n return list_ssim_error\n\ndef compute_ssim_loss(x, y):\n # reference https://github.com/tensorflow/models/tree/master/research/vid2depth/model.py\n \"\"\"Computes a differentiable structured image similarity measure.\"\"\"\n c1 = 0.01 ** 2\n c2 = 0.03 ** 2\n mu_x = slim.avg_pool2d(x, 3, 1, 'VALID')\n mu_y = slim.avg_pool2d(y, 3, 1, 'VALID')\n sigma_x = slim.avg_pool2d(x ** 2, 3, 1, 'VALID') - mu_x ** 2\n sigma_y = slim.avg_pool2d(y ** 2, 3, 1, 'VALID') - mu_y ** 2\n sigma_xy = slim.avg_pool2d(x * y, 3, 1, 'VALID') - mu_x * mu_y\n ssim_n = (2 * mu_x * mu_y + c1) * (2 * sigma_xy + c2)\n ssim_d = (mu_x ** 2 + mu_y ** 2 + c1) * (sigma_x + sigma_y + c2)\n ssim = ssim_n / ssim_d\n return tf.clip_by_value((1 - ssim) / 2, 0, 1)\n\ndef compute_depthmap_l1_loss_list(list_pred_batch, list_pred_mask_batch, list_gt_batch):\n list_curr_viewSyn_depth_error = []\n list_curr_viewSyn_pixel_depth_visual = []\n for i in range(len(list_pred_batch)):\n curr_render_src_error, curr_render_src_error_visual = \\\n compute_depthmap_l1_loss(list_pred_batch[i], list_pred_mask_batch[i], list_pred_mask_batch[i], list_gt_batch[i])\n #curr_render_src_error = tf.Print(curr_render_src_error, [tf.reduce_mean(curr_render_src_error)],message='curr_render_src_error')\n list_curr_viewSyn_depth_error.append(curr_render_src_error)\n list_curr_viewSyn_pixel_depth_visual.append(curr_render_src_error_visual)\n return list_curr_viewSyn_depth_error, list_curr_viewSyn_pixel_depth_visual\n\ndef compute_depthmap_l1_loss(pred_batch, pred_mask_batch, pred_gpmmmask_batch, gt_batch):\n batch_size = pred_batch.shape[0]\n # l1\n curr_render_error = pred_batch - gt_batch\n\n curr_render_src_error = tf.abs(curr_render_error)\n\n curr_render_src_error = curr_render_src_error * pred_mask_batch\n curr_render_src_error = curr_render_src_error * pred_gpmmmask_batch\n\n\n error_max = tf.reduce_max(tf.reshape(curr_render_src_error, [batch_size, -1]), axis=1)\n curr_render_src_error_norm = tf.divide(curr_render_src_error, tf.reshape(error_max, [batch_size, 1, 1, 1]) + 1e-6)\n\n curr_render_src_error_visual = pixel_error_heatmap(curr_render_src_error_norm)\n\n # curr_render_option_sum = pred_mask_batch * pred_gpmmmask_batch\n # curr_render_option_sum = tf.reduce_sum(curr_render_option_sum, axis=[1, 2, 3])\n #\n # curr_render_src_error = tf.reduce_sum(curr_render_src_error, axis=[1, 2, 3])\n # curr_render_src_error = curr_render_src_error / (curr_render_option_sum + 1e-6)\n\n curr_render_src_error = tf.reduce_mean(curr_render_src_error, axis=[1, 2, 3])\n\n return curr_render_src_error, curr_render_src_error_visual\n\ndef compute_match_loss_list(list_points, pred_depth, list_pose, intrinsics):\n list_epiLoss_batch = []\n list_reprojLoss_batch = []\n mgc_epi_lines = []\n mgc_epi_distances = []\n for i in range(len(list_points)-1):\n dist_p2l_aver, reproj_error, epi_lines, dist_p2l = \\\n compute_match_loss(list_points[0], list_points[1+i], pred_depth, list_pose[i], intrinsics)\n list_epiLoss_batch.append(dist_p2l_aver)\n list_reprojLoss_batch.append(reproj_error)\n mgc_epi_lines.append(epi_lines)\n mgc_epi_distances.append(dist_p2l)\n return list_epiLoss_batch, list_reprojLoss_batch, mgc_epi_lines, mgc_epi_distances\n\ndef compute_match_loss(points1, points2, pred_depth, pose, intrinsics):\n batch_size = points1.shape[0]\n match_num = tf.shape(points1)[1]\n\n ones = tf.ones([batch_size, match_num, 1])\n points1 = tf.concat([points1, ones], axis=2) # bs, num, 3\n points2 = tf.concat([points2, ones], axis=2)\n\n # compute fundamental matrix loss\n fmat = fundamental_matrix_from_rt(pose, intrinsics)\n fmat = tf.expand_dims(fmat, axis=1)\n fmat_tiles = tf.tile(fmat, [1, match_num, 1, 1])\n\n list_epi_lines = []\n list_dist_p2l = []\n for i in range(batch_size):\n epi_lines = tf.matmul(fmat_tiles[i], tf.expand_dims(points1, axis=3)[i])\n dist_p2l = tf.abs(tf.matmul(tf.transpose(epi_lines, perm=[0, 2, 1]), tf.expand_dims(points2, axis=3)[i]))\n list_epi_lines.append(epi_lines)\n list_dist_p2l.append(dist_p2l)\n epi_lines = tf.stack(list_epi_lines)\n dist_p2l = tf.stack(list_dist_p2l)\n\n a = tf.slice(epi_lines, [0, 0, 0, 0], [-1, -1, 1, -1])\n b = tf.slice(epi_lines, [0, 0, 1, 0], [-1, -1, 1, -1])\n dist_div = tf.sqrt(a * a + b * b) + 1e-6\n dist_p2l = (dist_p2l / dist_div)\n\n dist_p2l_aver = tf.reduce_mean(dist_p2l, axis=[1, 2, 3])\n #dist_p2l_aver = tf.Print(dist_p2l_aver, [tf.shape(dist_p2l_aver), dist_p2l_aver], message=\"dist_p2l_aver\", summarize=2 * 16)\n\n # compute projection loss\n reproj_error = reprojection_error(points1, points2, pred_depth, pose, intrinsics)\n #reproj_error = tf.Print(reproj_error, [tf.shape(reproj_error), reproj_error], message=\"reproj_error\", summarize=2 * 16)\n\n\n return dist_p2l_aver, reproj_error, epi_lines, dist_p2l"
},
{
"alpha_fraction": 0.585489809513092,
"alphanum_fraction": 0.6099815368652344,
"avg_line_length": 28.643835067749023,
"blob_id": "6540ad77e7d148e9fcd54baa11e5af187216982d",
"content_id": "3af07b3a27e00de62887e422c855cb1cc8aa4f78",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2164,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 73,
"path": "/Face Reconstruction/3D Face Reconstruction using Graph Convolution Network/create_bin.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import argparse\nimport os\nimport time\nfrom glob import glob\n\nimport numpy as np\nfrom tqdm import tqdm\n\nimport utils\n\n\ndef create_bin():\n args = get_args()\n image_paths = glob('{}/data/CelebA_Segment/*.*'.format(args.root_dir))\n train_image_paths, val_image_paths, _ = utils.make_paths(\n image_paths, os.path.join(args.root_dir, 'data', 'params', args.name, 'image'), args.root_dir)\n # with open('data/CelebA_RGBA.bin', 'wb') as img_f, open('data/CelebA_Landmark.bin', 'wb') as lm_f:\n with open('data/CelebA_RGBA.bin', 'wb') as img_f:\n for p in tqdm(train_image_paths):\n try:\n image = utils.load_image(p, 224, True, False)\n img_f.write(image)\n # lm_f.write(landmark)\n img_f.flush()\n # lm_f.flush()\n except Exception as e:\n print(p)\n print(e)\n\n\ndef read_bin():\n # images = open('data/CelebA_RGBA.bin', 'rb')\n # landmarks = open('data/CelebA_Landmark.bin', 'rb')\n # image_array = np.fromstring(images, dtype=np.float32).reshape(\n # (-1, 224, 224, 4))\n # landmark_array = np.fromstring(landmarks, dtype=np.float32).reshape(\n # (-1, 51, 2))\n # print(len(images), len(landmarks))\n batch_size = 4\n with open('data/CelebA_RGBA.bin', 'rb') as im_f, open('data/CelebA_Landmark.bin', 'rb') as lm_f:\n for batch in range(128 // batch_size):\n start = time.time()\n im_len = 4 * batch_size * 224 * 224 * 4\n im_start = batch * im_len\n lm_len = 4 * batch_size * 51 * 2\n lm_start = batch * lm_len\n\n im_f.seek(im_start)\n im_str = im_f.read(im_len)\n lm_f.seek(lm_start)\n lm_str = lm_f.read(lm_len)\n\n images = np.fromstring(im_str, dtype=np.float32).reshape((-1, 224, 224, 4))\n landmarks = np.fromstring(lm_str, dtype=np.float32).reshape((-1, 51, 2))\n print(time.time() - start)\n\n print('Done')\n\n\ndef main():\n create_bin()\n # read_bin()\n\n\ndef get_args():\n parser = argparse.ArgumentParser()\n parser.add_argument('--root_dir', default='/mnt/d/Codes/gcn_face', help='data root directory')\n parser.add_argument('--name', default='bfm09_face', help='dataset name')\n return parser.parse_args()\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5168474316596985,
"alphanum_fraction": 0.538250207901001,
"avg_line_length": 31.772512435913086,
"blob_id": "44fcc04995df42c215fc3511f32ca55cdfca32fd",
"content_id": "5917e462b19978313315b238fee08f9a42ed8eee",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6915,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 211,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/geometry/camera/camera.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n# system\nfrom __future__ import print_function\n\n# python lib\nimport math\nfrom copy import deepcopy\nimport numpy as np\n\n# tf_render\nimport tensorflow as tf\n\n# self\nfrom rotation import RotationMtxBatch\nfrom tfmatchd.face.common.format_helper import batch_size_extract\n\n\"\"\"\n*************************************** Theory ***************************************\n\"\"\"\n\n\"\"\"\nProj:\n mtx_proj\n M, p4(no need now)\n mtx_intrinsic, mtx_rot, mtx_t\nIntrinsic: \n mtx_intrinsic\n focal_len_x, focal_len_y, u, v\nExt:\n mtx_rot, mtx_t\n camera_center\n \n\"\"\"\n\n\"\"\"\n*************************************** Code ***************************************\n\"\"\"\n\n\"\"\"\nnumpy or tensor\nno grad\n\"\"\"\nclass IntrinsicMtxBatch(object):\n \"\"\"\n 0. batch\n 1. broadcast support\n \"\"\"\n def __init__(self, u, v, focal_len_x=None, focal_len_y=None, fov_x=None, fov_y=None):\n \"\"\"\n :param u:\n :param v:\n :param focal_len_x:\n :param focal_len_y:\n :param fov_x: field of view\n *\n * ~\n * |\n * | u\n * ) fov_x |\n * * * * * ~\n {__________________}\n focal_len_x\n\n \"\"\"\n\n # Read information\n if isinstance(u, tf.Tensor) == False:\n self.u = tf.convert_to_tensor(u, dtype=tf.float32)\n self.v = tf.convert_to_tensor(v, dtype=tf.float32)\n else:\n self.u = u\n self.v = v\n self.aspect_ratio = self.u / self.v\n\n if focal_len_x is not None:\n self._create_focal_len(focal_len_x, focal_len_y)\n else:\n assert fov_x is not None or fov_y is not None\n\n if fov_x is not None:\n self._create_fov_x(fov_x)\n else:\n self._create_fov_y(fov_y)\n\n # Normalize [batch_size, data]\n self.u = tf.reshape(self.u, [-1, 1])\n self.v = tf.reshape(self.v, [-1, 1])\n self.aspect_ratio = tf.reshape(self.aspect_ratio, [-1, 1])\n self.focal_len_x = tf.reshape(self.focal_len_x, [-1, 1])\n self.focal_len_y = tf.reshape(self.focal_len_y, [-1, 1])\n\n # 0. Batch\n batch_size = batch_size_extract(self.u, self.v, self.focal_len_x, self.focal_len_y)\n assert batch_size is not None\n\n # 1. Broadcast\n if self.u.shape[0] == 1:\n self.u = tf.tile(self.u, [batch_size, 1])\n self.v = tf.tile(self.v, [batch_size, 1])\n\n if self.focal_len_x.shape[0] == 1:\n self.focal_len_x = tf.tile(self.focal_len_x, [batch_size, 1])\n self.focal_len_y = tf.tile(self.focal_len_y, [batch_size, 1])\n\n zeros = tf.zeros_like(self.focal_len_x, dtype=tf.float32)\n r1 = tf.stack([self.focal_len_x, zeros, self.u], axis=1)\n r1 = tf.reshape(r1, [batch_size, 3])\n r2 = tf.stack([zeros, self.focal_len_y, self.v], axis=1)\n r2 = tf.reshape(r2, [batch_size, 3])\n r3 = tf.constant([0., 0., 1.], shape=[1, 3])\n r3 = tf.tile(r3, [batch_size, 1])\n self.mtx_intrinsic = tf.stack([r1, r2, r3], axis=1) # [batch, r, c] r:axis=1\n\n def _create_focal_len(self, focal_len_x, focal_len_y):\n if isinstance(focal_len_x, tf.Tensor) == False:\n self.focal_len_x = tf.convert_to_tensor(focal_len_x, dtype=tf.float32)\n self.focal_len_y = tf.convert_to_tensor(focal_len_y, dtype=tf.float32)\n else:\n self.focal_len_x = focal_len_x\n self.focal_len_y = focal_len_y\n\n def _create_fov_x(self, fov_x):\n if isinstance(fov_x, tf.Tensor) == False:\n self.fov_x = tf.convert_to_tensor(fov_x, dtype=tf.float32)\n self.focal_len_x = (1.0 * self.u) / tf.tan(fov_x * (math.pi / 360.0))\n self.focal_len_y = self.focal_len_x * self.aspect_ratio\n\n def _create_fov_y(self, fov_y):\n if isinstance(fov_y, tf.Tensor) == False:\n self.fov_y = tf.convert_to_tensor(fov_y, dtype=tf.float32)\n self.focal_len_y = (1.0 * self.v) / tf.tan(fov_y * (math.pi / 360.0))\n self.focal_len_x = self.focal_len_y / self.aspect_ratio\n\n def Get_image_width(self):\n return self.u * 2.0\n\n def Get_image_height(self):\n return self.v * 2.0\n\n def Get_batch_mtx_intrinsic(self):\n return self.mtx_intrinsic\n\n\"\"\"\ntensor only\n\"\"\"\nclass CameraMtxBatch(object):\n \"\"\"\n 0. batch\n 1. broadcast support\n \"\"\"\n def __init__(self, h_intrinsic, h_extenal):\n self.h_intrinsic = h_intrinsic\n self.h_extenal = h_extenal\n\n self.mtx_intrinsic = self.h_intrinsic.Get_batch_mtx_intrinsic()\n self.mtx_rot = self.h_extenal.rot_batch\n self.mtx_t = self.h_extenal.t_batch\n\n # 0. Batch\n self.batch_size = batch_size_extract(self.mtx_intrinsic, self.mtx_rot, self.mtx_t)\n assert self.batch_size is not None\n\n # 1. broadcast\n if self.mtx_intrinsic.shape[0] == 1:\n self.mtx_intrinsic = tf.tile(self.mtx_intrinsic, [self.batch_size, 1, 1])\n\n if self.mtx_rot.shape[0] == 1:\n self.mtx_rot = tf.tile(self.mtx_rot, [self.batch_size, 1, 1])\n self.mtx_t = tf.tile(self.mtx_t, [self.batch_size, 1])\n\n #\n self.mtx_proj = self._Cal_mtxProj()\n\n def _Cal_mtxProj(self):\n M = tf.matmul(self.mtx_intrinsic, self.mtx_rot)\n t_trans = tf.expand_dims(self.mtx_t, -1)\n p4 = tf.matmul(self.mtx_intrinsic, t_trans)\n ext = tf.concat([M, p4], axis=2)\n\n r4 = tf.constant([0., 0., 0., 1.], shape=[1, 1, 4])\n r4 = tf.tile(r4, [self.batch_size, 1, 1])\n ext = tf.concat([ext, r4], axis=1)\n\n return ext\n\n def Project(self, pt_batch, re_grad=False):\n homo_batch = tf.ones([self.batch_size, pt_batch.shape[1], 1])\n pt_batch_homo = tf.concat([pt_batch, homo_batch], axis=2)\n pt_batch_homo_trans = tf.transpose(pt_batch_homo, perm=[0, 2, 1])\n pt_batch_homo_2d_trans = tf.matmul(self.mtx_proj, pt_batch_homo_trans)\n pt_batch_homo_2d = tf.transpose(pt_batch_homo_2d_trans, perm=[0, 2, 1])\n\n pt_batch_homo_2d_main = pt_batch_homo_2d[:, :, 0:2]\n pt_batch_homo_2d_w = pt_batch_homo_2d[:, :, 2]\n pt_batch_homo_2d_w = tf.expand_dims(pt_batch_homo_2d_w, -1)\n pt_batch_homo_2d_normal = pt_batch_homo_2d_main / pt_batch_homo_2d_w\n\n return pt_batch_homo_2d_normal\n\n def Get_rot_t_batch(self):\n return self.mtx_rot, self.mtx_t\n\n def Get_eularAngle_rot_t_batch(self):\n eular_angle_rot = self.h_extenal.eular_rotMtx_batch(self.mtx_rot)\n return eular_angle_rot, self.mtx_t\n\n def Get_eye_batch(self):\n return self.h_extenal.Get_eye_batch()\n\nif __name__ == \"__main__\":\n h_intrMtx = IntrinsicMtxBatch(np.random.random((16,1)), np.random.random((16,1)), 1000, 1000)\n h_intrMtx.Get_batch_mtx_intrinsic()"
},
{
"alpha_fraction": 0.7658450603485107,
"alphanum_fraction": 0.7734741568565369,
"avg_line_length": 67.13999938964844,
"blob_id": "0e8deac961022215706376d40409ccfca85fc12e",
"content_id": "d633c3218ad976cc24f4b00bd6bcf1e8607f25e3",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3408,
"license_type": "permissive",
"max_line_length": 388,
"num_lines": 50,
"path": "/Snapchat_Filters/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Snapchat Filters <img src=\"_images/logo.png\" width=\"40\" >\n\nSnapchat is a popular messaging app that lets users exchange pictures and videos, and it's most catchy and used features are its filters. Face filters are common applications that we use almost every day in our lives. From Snapchat to Instagram there are thousands of filters that allow you to look like an animal, a princess or even another human being.\n\n<p align=\"center\">\n<img align=\"center\" src=\"_images/Face_filter.gif\" width=\"50%\" >\n</p>\n\n[](https://github.com/akshitagupta15june/Face-X.git/issues)\n[](https://github.com/akshitagupta15june/Face-X.git/network/members)\n[](https://github.com/akshitagupta15june/Face-X/stargazers)\n[](https://github.com/akshitagupta15june/Face-X/issues)\n\n\n\n\n\n## Why Use Face Filters ?\n<ul>\n <li>Face filters are now a promising opportunity and powerful marketing tool.</li> \n <li>You can engage the audience, empower people to self-express creatively, create and share marvelous photos and videos on social networks and drastically boost the enjoyment of using the app. </li>\n <li>Inspire consumers to take and share photos with branded filters and spread the word.</li>\n <li>Allow consumers virtually try on glasses, jewellery and make-up at home to see how products look.</li>\n</ul>\n\n## How to create a face filter ?\n<ul>\n <li>Face filters can be easily created using openCV Library.</li> \n <li>OpenCV (Open Source Computer Vision Library) is an open source computer vision and machine learning software library. OpenCV was built to provide a common infrastructure for computer vision applications and to accelerate the use of machine perception in the commercial products. Being a BSD-licensed product, OpenCV makes it easy for businesses to utilize and modify the code. </li>\n <li>First openCV is used to detect the face of the person in an image (usually using haarcascade frontal face algorithm), then extract it's facial features , find the coordinates of those features and superimpose filters over those coordinates.</li>\n</ul>\n\n\n# Want to contribute your own Snapchat Filter?\n You can refer to [CONTRIBUTING.md](`https://github.com/akshitagupta15june/Face-X/blob/master/CONTRIBUTING.md`)\n#### Or follow the below steps - \n- Fork this repository.\n- Clone the forked repository\n` git clone https://github.com/<your-username>/<repo-name>`\n- Change Directory\n` cd Snapchat_Filters`\n- Make a folder and add your code file and a readme file with screenshots or improve existing filters (each folder represents a specific filter, follow the instructions in the folder to run that application).\n- Add your files or changes to staging area\n`git add .`\n- Commit message\n` git commit -m \"Enter message\"`\n- Push your code\n` git push`\n- Make Pull request with the Master branch of `akshitagupta15june/Face-X` repo.\n- Wait for reviewers to review your PR\n\n"
},
{
"alpha_fraction": 0.5671009421348572,
"alphanum_fraction": 0.5958248376846313,
"avg_line_length": 36.92856979370117,
"blob_id": "8e32cec8fd21358c45103de630cefca0959ac563",
"content_id": "dd0fdfbd34b5741f2a15bf7ebd42b87fe17b38b2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6371,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 168,
"path": "/Face Reconstruction/Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model/datagen.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\"\"\"\nThis file is for data preprocessing\n\"\"\"\nimport os\nimport cv2\nfrom PIL import Image\nimport numpy as np\nimport torch\nfrom torch.utils import data\nfrom torchvision import transforms\n\ntrain_transform=transforms.Compose([\n transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5),\n transforms.ToTensor(),\n transforms.Normalize(mean=(0.5,0.5,0.5),std=(0.5,0.5,0.5))\n])\n\ntest_transform=transforms.Compose([\n transforms.ToTensor(),\n transforms.Normalize(mean=(0.5,0.5,0.5),std=(0.5,0.5,0.5))\n])\n\ndef clip_rot_flip_face(image, landmarks, scale, alpha):\n \"\"\"\n given a face and its 68 landmarks,\n clip and rotate it with 'scale' and 'alpha',\n and return scaled and rotated face with new 68 landmarks.\n \"\"\"\n # calculate x_min, x_max, y_min, y_max, center_x, center_y and box_w\n x_min = np.min(landmarks[:,0])\n x_max = np.max(landmarks[:,0])\n y_min = np.min(landmarks[:,1])\n y_max = np.max(landmarks[:,1])\n center_x = (x_min + x_max) / 2\n center_y = (y_min + y_max) / 2\n box_w = max(x_max-x_min, y_max-y_min)\n\n # calculate x_0, y_0, x_1 and y_1\n x_0 = np.random.uniform(center_x-(0.5+0.75*(scale-1.0))*box_w, center_x-(0.5+0.25*(scale-1.0))*box_w)\n y_0 = np.random.uniform(center_y-(0.5+0.75*(scale-1.0))*box_w, center_y-(0.5+0.25*(scale-1.0))*box_w)\n x_0 = round(max(0.0, x_0))\n y_0 = round(max(0.0, y_0))\n x_1 = round(min(image.shape[1], x_0+scale*box_w))\n y_1 = round(min(image.shape[0], y_0+scale*box_w))\n \n \"\"\"\n process image and landmarks\n \"\"\"\n # Random clip for image\n new_image = image[int(y_0):int(y_1), int(x_0):int(x_1)]\n new_image = cv2.resize(new_image, (224,224), interpolation=cv2.INTER_LINEAR)\n # Random rotate for image\n rot_mat = cv2.getRotationMatrix2D((112, 112), alpha, 1) # obtain RotationMatrix2D with fixed center (112, 112)\n new_image = cv2.warpAffine(new_image, rot_mat, (224, 224)) # obtain rotated image\n \n # Random clip for corresponding landmarks\n new_landmarks = landmarks\n new_landmarks[:,0] = (new_landmarks[:,0] - x_0) * 224 / (x_1 - x_0)\n new_landmarks[:,1] = (new_landmarks[:,1] - y_0) * 224 / (y_1 - y_0)\n # Random rotate for corresponding landmarks\n new_landmarks = np.asarray([(rot_mat[0][0]*x+rot_mat[0][1]*y+rot_mat[0][2],\n rot_mat[1][0]*x+rot_mat[1][1]*y+rot_mat[1][2]) for (x, y) in new_landmarks]) # adjust new_landmarks after rotating\n \n return new_image, new_landmarks\n\nclass TrainSet(data.Dataset):\n \"\"\"\n construct trainset, including images, landmarks, and vertices of ground-truth meshes\n \"\"\"\n def __init__(self, image_path, landmark_path, vertex_path, landmark_num=68, vertex_num=6144):\n \"\"\"\n initialize TrainSet\n \"\"\"\n file = open(image_path,'r')\n image = file.readlines()\n file.close()\n file = open(landmark_path,'r')\n landmark = file.readlines()\n file.close()\n file = open(vertex_path,'r')\n vertex = file.readlines()\n file.close()\n self.image = [os.path.join(k.strip('\\n')) for k in image]\n self.landmark = [os.path.join(k.strip('\\n')) for k in landmark]\n self.vertex = [os.path.join(k.strip('\\n')) for k in vertex]\n self.transforms = train_transform\n if len(self.image) == len(self.landmark) == len(self.vertex):\n self.num_samples = len(self.image)\n self.landmark_arrays = np.zeros((self.num_samples, landmark_num, 2), np.float32)\n self.vertex_arrays = np.zeros((self.num_samples, 3, vertex_num), np.float32)\n for i in range(self.num_samples):\n self.landmark_arrays[i,...] = np.load(self.landmark[i])\n self.vertex_arrays[i,...] = np.load(self.vertex[i])\n\n def __getitem__(self,index):\n # get image\n image_path = self.image[index]\n image = cv2.imread(image_path)\n # get landmark\n landmark = self.landmark_arrays[index,...]\n # get vertex\n vertex = self.vertex_arrays[index,...]\n\n \"\"\"\n preprocess image and landmark\n \"\"\"\n # image, landmark = clip_rot_flip_face(image, landmark, 1.2, np.random.uniform(-10.0, 10.0))\n image, landmark = clip_rot_flip_face(image, landmark, 1.2, 5*np.random.randint(-1, 2))\n image = Image.fromarray(cv2.cvtColor(image,cv2.COLOR_BGR2RGB))\n if self.transforms:\n image = self.transforms(image)\n else:\n image = torch.from_numpy(image)\n\n return image, landmark, vertex\n\n def __len__(self):\n return self.num_samples\n\nclass TestSet(data.Dataset):\n \"\"\"\n construct test set,\n including images, landmarks for calculating errors\n and 'lrecord', 'vrecord' for recording estimated landmarks and vertices of recovered meshes.\n \"\"\"\n def __init__(self, image_path, landmark_path, lrecord_path, vrecord_path):\n \"\"\"\n initialize Test Set\n \"\"\"\n file = open(image_path,'r')\n image = file.readlines()\n file.close()\n file = open(landmark_path, 'r')\n landmark = file.readlines()\n file.close()\n file = open(lrecord_path,'r')\n lrecord = file.readlines()\n file.close()\n file = open(vrecord_path,'r')\n vrecord = file.readlines()\n file.close()\n self.image = [os.path.join(k.strip('\\n')) for k in image]\n self.landmark = [os.path.join(k.strip('\\n')) for k in landmark]\n self.lrecord = [os.path.join(k.strip('\\n')) for k in lrecord]\n self.vrecord = [os.path.join(k.strip('\\n')) for k in vrecord]\n self.transforms = test_transform\n if len(self.image) == len(self.landmark) == len(self.lrecord) == len(self.vrecord):\n self.num_samples = len(self.image)\n\n def __getitem__(self,index):\n # get image\n image_path = self.image[index]\n image = Image.open(image_path)\n if self.transforms:\n image = self.transforms(image)\n else:\n image = torch.from_numpy(image)\n # get landmark\n landmark_path = self.landmark[index]\n landmark = np.load(landmark_path)\n # get record\n lrecord = self.lrecord[index]\n vrecord = self.vrecord[index]\n\n return image, landmark, lrecord, vrecord\n\n def __len__(self):\n return self.num_samples"
},
{
"alpha_fraction": 0.7906504273414612,
"alphanum_fraction": 0.7906504273414612,
"avg_line_length": 27.941177368164062,
"blob_id": "263a380ec45173681f926d91323bae3d9b8907fa",
"content_id": "00349dff92065cb440461a315ab6e2053b961693",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": true,
"language": "Markdown",
"length_bytes": 492,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 17,
"path": "/.github/ISSUE_TEMPLATE/readme_improvement.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "---\nname: Documentation\nabout: Suggest documentation improvement for this project\ntitle: Documentation Improvement\nlabels: Documentation\nassignees: ''\n\n---\n\n**Is your documentation request related to a problem? Please describe.**\nA clear and concise description of what the problem is.\n\n**Describe the documentation you want to improved**\nA clear and concise description of what you want to happen.\n\n**Additional context**\nAdd any other context or screenshots about the feature request here.\n"
},
{
"alpha_fraction": 0.5942857265472412,
"alphanum_fraction": 0.6028571724891663,
"avg_line_length": 22.266666412353516,
"blob_id": "b0679093e3931fe76ff4b26bf155027d4ab9229d",
"content_id": "740b6be67436946fdf729737dc890b52bf4b40b5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 700,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 30,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/common/format_helper.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n# system\nfrom __future__ import print_function\n\n# python lib\nimport numpy as np\n\n# tf_render\nimport tensorflow as tf\n\n# self\n\ndef parse_seq(list_seq):\n return list_seq[0:1], list_seq[1:]\n\ndef parse_gpu_list(gpu_list):\n return gpu_list.split(',')\n\ndef batch_size_extract(*object): # TODO: More robust\n \"\"\"\n :param object: np, tensor, scalar\n :return:\n \"\"\"\n batch_size = None\n for inst in object:\n if inst is not None:\n if (isinstance(inst, tf.Tensor) or isinstance(inst, np.ndarray)) and len(inst.shape) > 1:\n batch_size = max(inst.shape[0], batch_size)\n else:\n batch_size = max(1, batch_size)\n return batch_size\n\n"
},
{
"alpha_fraction": 0.5177238583564758,
"alphanum_fraction": 0.5643656849861145,
"avg_line_length": 23.5238094329834,
"blob_id": "e122d5694fd831924f0eb14c886c6fd04f35a65a",
"content_id": "51840fc07884fe596114ada2e79de05a25989fba",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1072,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 42,
"path": "/Facial_Biometric/library.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import cv2\r\nimport dlib\r\n\r\ndetector = dlib.get_frontal_face_detector()\r\n\r\npredictor = dlib.shape_predictor(\"./shape_predictor_68_face_landmarks.dat\")\r\nname = input(\"Enter your name: \")\r\ncap = cv2.VideoCapture(0)\r\n\r\nwhile True:\r\n\r\n ret, frame = cap.read()\r\n gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)\r\n\r\n faces = detector(gray)\r\n\r\n for face in faces:\r\n x1=face.left()\r\n y1=face.top()\r\n x2=face.right()\r\n y2=face.bottom()\r\n cv2.rectangle(frame, (x1,y1), (x2,y2),(0,255,0),3)\r\n landmarks = predictor(gray, face)\r\n # print(landmarks.parts())\r\n nose = landmarks.parts()[27]\r\n # print(nose.x, nose.y)\r\n cv2.putText(frame,str(name),(x1, y1 - 10), cv2.FONT_HERSHEY_COMPLEX, 1, (255, 0, 0), 2)\r\n for point in landmarks.parts():\r\n cv2.circle(frame, (point.x, point.y), 2, (0, 0, 255), 3)\r\n\r\n # print(faces)\r\n\r\n if ret:\r\n cv2.imshow(\"My Screen\", frame)\r\n\r\n key = cv2.waitKey(1)\r\n\r\n if key == ord(\"q\"):\r\n break\r\n\r\ncap.release()\r\ncv2.destroyAllWindows()\r\n"
},
{
"alpha_fraction": 0.6141479015350342,
"alphanum_fraction": 0.6165595054626465,
"avg_line_length": 28.341463088989258,
"blob_id": "0bd8fdba62220e255fed28fd907ca87bf11f8189",
"content_id": "89b657d362b440d5b76b287c11c04d44a7b52a6b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1244,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 41,
"path": "/Recognition-Algorithms/Recognition_using_mtcnn/mtcnn.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import mtcnn\r\nimport matplotlib.pyplot as plt\r\nfilename = \"1.jpg\"\r\npixels = plt.imread(filename)\r\n# print(\"Shape of image/array:\",pixels.shape)\r\nimgplot = plt.imshow(pixels)\r\n# plt.show()\r\n\r\ndetector = mtcnn.MTCNN()\r\nfaces = detector.detect_faces(pixels)\r\n# for face in faces:\r\n # print(face)\r\ndef draw_facebox(filename, result_list):\r\n data = plt.imread(filename)\r\n plt.imshow(data)\r\n ax = plt.gca()\r\n for result in result_list:\r\n x, y, width, height = result['box']\r\n rect = plt.Rectangle((x, y), width, height, fill=False, color='orange')\r\n ax.add_patch(rect)\r\n \r\n plt.show()\r\n \r\nfaces = detector.detect_faces(pixels)\r\ndraw_facebox(filename, faces)\r\ndef draw_facedot(filename, result_list):\r\n data = plt.imread(filename)\r\n plt.imshow(data)\r\n ax = plt.gca()\r\n \r\n for result in result_list:\r\n x, y, width, height = result['box']\r\n rect = plt.Rectangle((x, y), width, height,fill=False, color='orange')\r\n ax.add_patch(rect)\r\n for key, value in result['keypoints'].items():\r\n dot = plt.Circle(value, radius=10, color='red')\r\n ax.add_patch(dot)\r\n plt.show()\r\n \r\nfaces = detector.detect_faces(pixels)\r\ndraw_facedot(filename, faces)\r\n"
},
{
"alpha_fraction": 0.7094869613647461,
"alphanum_fraction": 0.732186496257782,
"avg_line_length": 39.59917449951172,
"blob_id": "01a28f992dce184ea1888e5ab8f84712b26ac3a9",
"content_id": "10386538ce2ae91f5a47a2e23e8de2b9aed6b161",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 9866,
"license_type": "permissive",
"max_line_length": 264,
"num_lines": 242,
"path": "/Face-Emotions-Recognition/Smile Percentage Detection/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "When using OpenCV’s deep neural network module with Caffe models, you’ll need two sets of files:\n\n- The **.prototxt** file(s) which define the model architecture (i.e., the layers themselves)\n- The **.caffemodel** file which contains the weights for the actual layers\n\nOpen up a `detect_faces.py` and see the following lines :\n\n```\n# import the necessary packages\nimport numpy as np\nimport argparse\nimport cv2\n# construct the argument parse and parse the arguments\nap = argparse.ArgumentParser()\nap.add_argument(\"-i\", \"--image\", required=True, help=\"path to input image\")\nap.add_argument(\"-p\", \"--prototxt\", required=True, help=\"path to Caffe 'deploy' prototxt file\")\nap.add_argument(\"-m\", \"--model\", required=True, help=\"path to Caffe pre-trained model\")\nap.add_argument(\"-c\", \"--confidence\", type=float, default=0.5, help=\"minimum probability to filter weak detections\")\nargs = vars(ap.parse_args())\n```\n\nHere we are importing our required packages and parsing command line arguments.\n\nWe have three required arguments:\n\n- `--image` : The path to the input image.\n- `--prototxt` : The path to the Caffe prototxt file.\n- `--model` : The path to the pretrained Caffe model.\n\nAn optional argument, `--confidence` , can overwrite the default threshold of 0.5 if you wish.\n\nFrom there lets load our model and create a blob from our image:\n\n```\n# load our serialized model from disk\nprint(\"[INFO] loading model...\")\nnet = cv2.dnn.readNetFromCaffe(args[\"prototxt\"], args[\"model\"])\n# load the input image and construct an input blob for the image\n# by resizing to a fixed 300x300 pixels and then normalizing it\nimage = cv2.imread(args[\"image\"])\n(h, w) = image.shape[:2]\nblob = cv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 1.0, (300, 300), (104.0, 177.0, 123.0))\n```\n\nFirst, we load our model using our `--prototxt` and `--model` file paths. We store the model as net.\n\nThen we load the `image` , extract the dimensions, and create a `blob`.\n\nThe `dnn.blobFromImage` takes care of pre-processing which includes setting the `blob` dimensions and normalization.\n\nNext, we’ll apply face detection:\n\n```\n# pass the blob through the network and obtain the detections and\n# predictions\nprint(\"[INFO] computing object detections...\")\nnet.setInput(blob)\ndetections = net.forward()\n```\n\nTo detect faces, we pass the `blob` through the net.\nAnd from there we’ll loop over the `detections` and draw boxes around the detected faces:\n\n```\n# loop over the detections\nfor i in range(0, detections.shape[2]):\n\t# extract the confidence (i.e., probability) associated with the prediction\n\tconfidence = detections[0, 0, i, 2]\n\t# filter out weak detections by ensuring the `confidence` is greater than the minimum confidence\n\tif confidence > args[\"confidence\"]:\n\t\t# compute the (x, y)-coordinates of the bounding box for the object\n\t\tbox = detections[0, 0, i, 3:7] * np.array([w, h, w, h])\n\t\t(startX, startY, endX, endY) = box.astype(\"int\")\n \n\t\t# draw the bounding box of the face along with the associated probability\n\t\ttext = \"{:.2f}%\".format(confidence * 100)\n\t\ty = startY - 10 if startY - 10 > 10 else startY + 10\n\t\tcv2.rectangle(image, (startX, startY), (endX, endY), (0, 0, 255), 2)\n\t\tcv2.putText(image, text, (startX, y), cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)\n# show the output image\ncv2.imshow(\"Output\", image)\ncv2.waitKey(0)\n```\n\nWe begin looping over the detections.\n\nFrom there, we extract the confidence and compare it to the confidence threshold. We perform this check to filter out weak detections.\n\nIf the confidence meets the minimum threshold, we proceed to draw a rectangle and along with the *probability* of the detection.\n\nTo accomplish this, we first calculate the *(x, y)*-coordinates of the bounding box.\n\nWe then build our confidence `text` string which contains the probability of the detection.\n\nIn case the our `text` would go off-image (such as when the face detection occurs at the very top of an image), we shift it down by 10 pixels.\n\nOur face rectangle and confidence `text` is drawn on the image.\n\nFrom there we loop back for additional detections following the process again. If no `detections` remain, we’re ready to show our output `image` on the screen.\n\nFrom there, open up a terminal and execute the following command:\n\n```\n$ python detect_faces.py --image rooster.jpg --prototxt deploy.prototxt.txt \\\n\t--model res10_300x300_ssd_iter_140000.caffemodel\n```\n\n\n\nHere you can see face is detected with 74.30% confidence, even though face is at an angle. OpenCV’s Haar cascades are notorious for missing faces that are not at a “straight on” angle, but by using OpenCV’s deep learning face detectors, we are able to detect face.\n\nAnd now we’ll see how another example works, this time with three faces:\n\n```\n$ python detect_faces.py --image iron_chic.jpg --prototxt deploy.prototxt.txt \\\n\t--model res10_300x300_ssd_iter_140000.caffemodel\n```\n\n\n\nAgain, this just goes to show how much better (in terms of accuracy) the deep learning OpenCV face detectors are over their standard Haar cascade counterparts shipped with the library.\n\n## Face detection in video and webcam with OpenCV and deep learning\nLet’s also apply face detection to videos, video streams, and webcams.\n\nLuckily for us, most of our code in the previous section on face detection with OpenCV in single images can be reused here!\n\nOpen up a `detect_faces_video.py` , and see the following code:\n\n```\n# import the necessary packages\nfrom imutils.video import VideoStream\nimport numpy as np\nimport argparse\nimport imutils\nimport time\nimport cv2\n# construct the argument parse and parse the arguments\nap = argparse.ArgumentParser()\nap.add_argument(\"-p\", \"--prototxt\", required=True, help=\"path to Caffe 'deploy' prototxt file\")\nap.add_argument(\"-m\", \"--model\", required=True, help=\"path to Caffe pre-trained model\")\nap.add_argument(\"-c\", \"--confidence\", type=float, default=0.5, help=\"minimum probability to filter weak detections\")\nargs = vars(ap.parse_args())\n```\n\nCompared to above, we will need to import three additional packages: `VideoStream` , `imutils` , and `time` .\n\nIf you don’t have imutils in your virtual environment, you can install it via:\n\n```\n$ pip install imutils\n```\n\nOur command line arguments are mostly the same, except we do not have an `--image` path argument this time. We’ll be using our webcam’s video feed instead.\n\nFrom there we’ll load our model and initialize the video stream:\n\n```\n# load our serialized model from disk\nprint(\"[INFO] loading model...\")\nnet = cv2.dnn.readNetFromCaffe(args[\"prototxt\"], args[\"model\"])\n# initialize the video stream and allow the camera sensor to warm up\nprint(\"[INFO] starting video stream...\")\nvs = VideoStream(src=0).start()\ntime.sleep(2.0)\n```\n\nLoading the model is the same as above.\n\nWe initialize a `VideoStream` object specifying camera with index zero as the source (in general this would be your laptop’s built in camera or your desktop’s first camera detected).\n\nWe then allow the camera sensor to warm up for 2 seconds.\n\nFrom there we loop over the frames and compute face detections with OpenCV:\n\n```\n# loop over the frames from the video stream\nwhile True:\n\t# grab the frame from the threaded video stream and resize it to have a maximum width of 400 pixels\n\tframe = vs.read()\n\tframe = imutils.resize(frame, width=400)\n \n\t# grab the frame dimensions and convert it to a blob\n\t(h, w) = frame.shape[:2]\n\tblob = cv2.dnn.blobFromImage(cv2.resize(frame, (300, 300)), 1.0, (300, 300), (104.0, 177.0, 123.0))\n \n\t# pass the blob through the network and obtain the detections and predictions\n\tnet.setInput(blob)\n\tdetections = net.forward()\n```\n\nThis block should look mostly familiar to the static image version.\n\nIn this block, we’re reading a `frame` from the video stream, creating a `blob` , and passing the blob through the deep neural `net` to obtain face detections.\n\nWe can now loop over the detections, compare to the confidence threshold, and draw face boxes + confidence values on the screen:\n\n```\n# loop over the detections\n\tfor i in range(0, detections.shape[2]):\n\t\t# extract the confidence (i.e., probability) associated with the prediction\n\t\tconfidence = detections[0, 0, i, 2]\n\t\t# filter out weak detections by ensuring the `confidence` is\n\t\t# greater than the minimum confidence\n\t\tif confidence < args[\"confidence\"]:\n\t\t\tcontinue\n\t\t# compute the (x, y)-coordinates of the bounding box for the object\n\t\tbox = detections[0, 0, i, 3:7] * np.array([w, h, w, h])\n\t\t(startX, startY, endX, endY) = box.astype(\"int\")\n \n\t\t# draw the bounding box of the face along with the associated probability\n\t\ttext = \"{:.2f}%\".format(confidence * 100)\n\t\ty = startY - 10 if startY - 10 > 10 else startY + 10\n\t\tcv2.rectangle(frame, (startX, startY), (endX, endY), (0, 0, 255), 2)\n\t\tcv2.putText(frame, text, (startX, y), cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)\n```\n\nFor a detailed review of this code block, please review the above section where we perform face detection to still, static images. The code here is nearly identical.\n\nNow that our OpenCV face detections have been drawn, let’s display the frame on the screen and wait for a keypress:\n\n```\n# show the output frame\n\tcv2.imshow(\"Frame\", frame)\n\tkey = cv2.waitKey(1) & 0xFF\n \n\t# if the `q` key was pressed, break from the loop\n\tif key == ord(\"q\"):\n\t\tbreak\n# do a bit of cleanup\ncv2.destroyAllWindows()\nvs.stop()\n```\n\nWe display the `frame` on the screen until the “q” key is pressed at which point we `break` out of the loop and perform cleanup.\n\nOnce you have downloaded the files, running the deep learning OpenCV face detector with a webcam feed is easy with this simple command:\n\n```\n$ python detect_faces_video.py --prototxt deploy.prototxt.txt \\\n\t--model res10_300x300_ssd_iter_140000.caffemodel\n```"
},
{
"alpha_fraction": 0.6828536987304688,
"alphanum_fraction": 0.7440047860145569,
"avg_line_length": 48.02941131591797,
"blob_id": "d401941dfe00b210cea3ed34c33e714cd6a7408e",
"content_id": "e52e748f00523759910a606032a600570e830acd",
"detected_licenses": [
"BSD-3-Clause",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1668,
"license_type": "permissive",
"max_line_length": 354,
"num_lines": 34,
"path": "/Awesome-face-operations/Blurring image across face/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Blurring Image Across Face <img src=\"https://img.icons8.com/color/48/000000/blur.png\"/> \n\n<p align=\"center\">\n <img style=\"text-align: center;\" src=\"https://user-images.githubusercontent.com/64009389/111880150-51884080-89b2-11eb-80f1-12a1d8e53941.gif\" alt=\"giphy\" style=\"zoom:50%;\" />\n</p>\n\n## Abstract <img src=\"https://img.icons8.com/color/30/000000/help--v1.png\"/>\n\nAn image seems more detailed if we can observe all the objects and their shapes accurately in it. For instance, an image with a face looks clear when we can identify eyes, ears, etc very clear. This shape of an object is due to its edges. So in blurring, we simply reduce the edge content and makes the transition from one color to the other very smooth.\n\nBackground blurring is most often seen as a feature of portrait mode in phone cameras. Another example is zoom and other online platforms that blur the background and not the face. In this model, we provide you with a small code to try this effect out, especially blurring the face.\n\n\n\n## Requirements <img src=\"https://img.icons8.com/color/30/000000/settings.png\"/>\n\n- Python\n- OpenCV\n\n\n\n## Quick Start <img src=\"https://img.icons8.com/color/30/000000/google-code.png\"/>\n\n- Clone the Repository from [Here](https://github.com/akshitagupta15june/Face-X.git)\n- Change the Directory: `cd \"Blurring image across face\"` or `cd Blurring\\ image\\ across\\ face/`\n- Run `main.py`\n\n ##### Note: This code might show error in VScode. PyCharm and jupyter notebook work fine.\n\n\n\n## Result <img src=\"https://img.icons8.com/color/30/000000/image.png\"/>\n\n\n\n"
},
{
"alpha_fraction": 0.7794308066368103,
"alphanum_fraction": 0.795924961566925,
"avg_line_length": 82.56756591796875,
"blob_id": "f1ec4c4cb428463edbf092aa7c3cabc3cdc396df",
"content_id": "2fa94c40767afa1c57222a745be2b0f3b94f0cd5",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3100,
"license_type": "permissive",
"max_line_length": 478,
"num_lines": 37,
"path": "/Snapchat_Filters/Detective Filter/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Detective Filter\n\n\n#### Requirements\n- Python 3.7.x\n- OpenCV\n- Imutils\n- Dlib library\n- Download Face Landmark Detection Model (shape_predictor_68_face_landmarks.dat file) \nfrom [here](https://github.com/italojs/facial-landmarks-recognition/blob/master/shape_predictor_68_face_landmarks.dat).\n\n#### Instruction\n- Clone this repository ` git clone https://github.com/akshitagupta15june/Face-X.git`\n- Change Directory to ` Snapchat_Filters` then to `Detective Filter`\n- Run code using the cmd ` python detective_filter.py`\n\n### Screenshot\n<img height=\"380\" src=\"https://raw.githubusercontent.com/Vi1234sh12/Face-X/4b7e31df8542ecd9331056a9d3c9823b98d9bdcc/Snapchat_Filters/Detective%20Filter/assets/out.jpg\">\n\n### Detail of the Algorithm used in Detective Filter\nWe are using Viola Jones algorithm which is named after two computer vision researchers who proposed the method in 2001, Paul Viola and Michael Jones in their paper, “Rapid Object Detection using a Boosted Cascade of Simple Features”. Despite being an outdated framework, Viola-Jones is quite powerful, and its application has proven to be exceptionally notable in real-time face detection. This algorithm is painfully slow to train but can detect faces in real-time with impressive speed.\n<br>\nGiven an image(this algorithm works on grayscale image), the algorithm looks at many smaller subregions and tries to find a face by looking for specific features in each subregion. It needs to check many different positions and scales because an image can contain many faces of various sizes. Viola and Jones used Haar-like features to detect faces in this algorithm.\n<br>\nThe Viola Jones algorithm has four main steps\n<br>\n\n1. Selecting Haar-like features:<\\strong>Haar-like features are digital image features used in object recognition. All human faces share some universal properties of the human face like the eyes region is darker than its neighbour pixels, and the nose region is brighter than the eye region.\n<br> \n\n2. Creating an integral image:An integral image (also known as a summed-area table) is the name of both a data structure and an algorithm used to obtain this data structure. It is used as a quick and efficient way to calculate the sum of pixel values in an image or rectangular part of an image.\n\n<br>\n3. Running AdaBoost training: we’re training the AdaBoost to identify important features, we’re feeding it information in the form of training data and subsequently training it to learn from the information to predict. So ultimately, the algorithm is setting a minimum threshold to determine whether something can be classified as a useful feature or not.\n<br>\n<br>\n4. Creating classifier cascades:<\\strong>We set up a cascaded system in which we divide the process of identifying a face into multiple stages. In the first stage, we have a classifier which is made up of our best features, in other words, in the first stage, the subregion passes through the best features such as the feature which identifies the nose bridge or the one that identifies the eyes. In the next stages, we have all the remaining features.\n"
},
{
"alpha_fraction": 0.7950000166893005,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 66,
"blob_id": "62adf1d0cb479bf11d7918fe7d39a9b6a404a0d6",
"content_id": "7843521734184205f1f94e7f61ff2e541f8896d2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 200,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 3,
"path": "/Face Reconstruction/Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model/cal_error/README.txt",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "This folder contains a method to calculate landmark detection errors,\nincluding several metrics shown in 'TABLE 1' of our paper.\nYou can have a try at a larger dataset, such as the testset we provide."
},
{
"alpha_fraction": 0.5510540008544922,
"alphanum_fraction": 0.5642622113227844,
"avg_line_length": 32.46131134033203,
"blob_id": "c7d54d4e2659a5243aad985864c8c1ec1f86bd21",
"content_id": "d12ff22a79a711fed81719cb59f126711a8b6479",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 22486,
"license_type": "permissive",
"max_line_length": 131,
"num_lines": 672,
"path": "/Face Reconstruction/3D Face Reconstruction using Graph Convolution Network/lib/mesh_sampling.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#pylint: disable=len-as-condition\nimport heapq\nimport math\nimport os\nfrom random import choice\n\nimport numpy as np\nimport scipy.sparse as sp\n\nimport utils\nfrom lib.mesh_io import write_obj\n\n\ndef vertex_quadrics(vertice, triangle):\n \"\"\"Computes a quadric for each vertex in the Mesh.\n\n Returns:\n v_quadrics: an (N x 4 x 4) array, where N is # vertices.\n \"\"\"\n\n # Allocate quadrics\n v_quadrics = np.zeros((len(vertice), 4, 4))\n\n # For each face...\n for _, tri in enumerate(triangle):\n # Compute normalized plane equation for that face\n vert_idxs = tri\n verts = np.hstack((vertice[vert_idxs], np.array([1, 1, 1]).reshape(-1, 1)))\n _, _, v = np.linalg.svd(verts)\n eq = v[-1, :].reshape(-1, 1)\n eq = eq / (np.linalg.norm(eq[0:3]))\n\n # Add the outer product of the plane equation to the\n # quadrics of the vertices for this face\n for k in range(3):\n v_quadrics[tri[k], :, :] += np.outer(eq, eq)\n\n return v_quadrics\n\n\ndef setup_deformation_transfer(src_vert, src_tri, tgt_vert):\n rows = np.zeros(3 * tgt_vert.shape[0])\n cols = np.zeros(3 * tgt_vert.shape[0])\n coeffs_v = np.zeros(3 * tgt_vert.shape[0])\n # coeffs_n = np.zeros(3 * tgt_vert.shape[0])\n\n # nearest_faces, nearest_parts, nearest_vertices = source.compute_aabb_tree(\n # ).nearest(tgt_vert, True)\n nearest_faces, nearest_parts, nearest_vertices = utils.aabbtree_compute_nearest(\n src_vert, src_tri, tgt_vert, True)\n nearest_faces = nearest_faces.ravel().astype(np.int64)\n nearest_parts = nearest_parts.ravel().astype(np.int64)\n nearest_vertices = nearest_vertices.ravel()\n\n for i in range(tgt_vert.shape[0]):\n # Closest triangle index\n f_id = nearest_faces[i]\n # Closest triangle vertex ids\n nearest_f = src_tri[f_id]\n\n # Closest surface point\n nearest_v = nearest_vertices[3 * i:3 * i + 3]\n # Distance vector to the closest surface point\n # dist_vec = tgt_vert[i] - nearest_v\n\n rows[3 * i:3 * i + 3] = i * np.ones(3)\n cols[3 * i:3 * i + 3] = nearest_f\n\n n_id = nearest_parts[i]\n if n_id == 0:\n # Closest surface point in triangle\n A = np.vstack((src_vert[nearest_f])).T\n coeffs_v[3 * i:3 * i + 3] = np.linalg.lstsq(A, nearest_v, rcond=None)[0]\n elif 0 < n_id <= 3:\n # Closest surface point on edge\n A = np.vstack(\n (src_vert[nearest_f[n_id - 1]], src_vert[nearest_f[n_id % 3]])).T\n tmp_coeffs = np.linalg.lstsq(A, tgt_vert[i], rcond=None)[0]\n coeffs_v[3 * i + n_id - 1] = tmp_coeffs[0]\n coeffs_v[3 * i + n_id % 3] = tmp_coeffs[1]\n else:\n # Closest surface point a vertex\n coeffs_v[3 * i + n_id - 4] = 1.0\n\n # if use_normals:\n # A = np.vstack((vn[nearest_f])).T\n # coeffs_n[3 * i:3 * i + 3] = np.linalg.lstsq(A, dist_vec)[0]\n\n #coeffs = np.hstack((coeffs_v, coeffs_n))\n #rows = np.hstack((rows, rows))\n #cols = np.hstack((cols, source.v.shape[0] + cols))\n matrix = sp.csc_matrix((coeffs_v, (rows, cols)),\n shape=(tgt_vert.shape[0], src_vert.shape[0]))\n return matrix\n\n\ndef qslim_decimator_transformer(vertice,\n triangle,\n factor=None,\n n_verts_desired=None):\n \"\"\"Return a simplified version of this mesh.\n\n A Qslim-style approach is used here.\n\n :param factor: fraction of the original vertices to retain\n :param n_verts_desired: number of the original vertices to retain\n :returns: new_faces: An Fx3 array of faces, mtx: Transformation matrix\n \"\"\"\n\n if factor is None and n_verts_desired is None:\n raise Exception('Need either factor or n_verts_desired.')\n\n if n_verts_desired is None:\n n_verts_desired = math.ceil(len(vertice) * factor) * 1.0\n\n Qv = vertex_quadrics(vertice, triangle)\n\n # fill out a sparse matrix indicating vertex-vertex adjacency\n # from psbody.mesh.topology.connectivity import get_vertices_per_edge\n vert_adj = utils.get_vertices_per_edge(vertice, triangle)\n # vert_adj = sp.lil_matrix((len(vertice), len(vertice)))\n # for f_idx in range(len(triangle)):\n # vert_adj[triangle[f_idx], triangle[f_idx]] = 1\n\n vert_adj = sp.csc_matrix(\n (vert_adj[:, 0] * 0 + 1, (vert_adj[:, 0], vert_adj[:, 1])),\n shape=(len(vertice), len(vertice)))\n vert_adj = vert_adj + vert_adj.T\n vert_adj = vert_adj.tocoo()\n\n def collapse_cost(Qv, r, c, v):\n Qsum = Qv[r, :, :] + Qv[c, :, :]\n p1 = np.vstack((v[r].reshape(-1, 1), np.array([1]).reshape(-1, 1)))\n p2 = np.vstack((v[c].reshape(-1, 1), np.array([1]).reshape(-1, 1)))\n\n destroy_c_cost = p1.T.dot(Qsum).dot(p1)\n destroy_r_cost = p2.T.dot(Qsum).dot(p2)\n result = {\n 'destroy_c_cost': destroy_c_cost,\n 'destroy_r_cost': destroy_r_cost,\n 'collapse_cost': min([destroy_c_cost, destroy_r_cost]),\n 'Qsum': Qsum\n }\n return result\n\n # construct a queue of edges with costs\n queue = []\n for k in range(vert_adj.nnz):\n r = vert_adj.row[k]\n c = vert_adj.col[k]\n\n if r > c:\n continue\n\n cost = collapse_cost(Qv, r, c, vertice)['collapse_cost']\n heapq.heappush(queue, (cost, (r, c)))\n\n # decimate\n collapse_list = []\n nverts_total = len(vertice)\n faces = triangle.copy()\n while nverts_total > n_verts_desired:\n e = heapq.heappop(queue)\n r = e[1][0]\n c = e[1][1]\n if r == c:\n continue\n\n cost = collapse_cost(Qv, r, c, vertice)\n if cost['collapse_cost'] > e[0]:\n heapq.heappush(queue, (cost['collapse_cost'], e[1]))\n # print 'found outdated cost, %.2f < %.2f' % (e[0], cost['collapse_cost'])\n continue\n else:\n\n # update old vert idxs to new one,\n # in queue and in face list\n if cost['destroy_c_cost'] < cost['destroy_r_cost']:\n to_destroy = c\n to_keep = r\n else:\n to_destroy = r\n to_keep = c\n\n collapse_list.append([to_keep, to_destroy])\n\n # in our face array, replace \"to_destroy\" vertidx with \"to_keep\" vertidx\n np.place(faces, faces == to_destroy, to_keep)\n\n # same for queue\n which1 = [\n idx for idx in range(len(queue)) if queue[idx][1][0] == to_destroy\n ]\n which2 = [\n idx for idx in range(len(queue)) if queue[idx][1][1] == to_destroy\n ]\n for k in which1:\n queue[k] = (queue[k][0], (to_keep, queue[k][1][1]))\n for k in which2:\n queue[k] = (queue[k][0], (queue[k][1][0], to_keep))\n\n Qv[r, :, :] = cost['Qsum']\n Qv[c, :, :] = cost['Qsum']\n\n a = faces[:, 0] == faces[:, 1]\n b = faces[:, 1] == faces[:, 2]\n c = faces[:, 2] == faces[:, 0]\n\n # remove degenerate faces\n def logical_or3(x, y, z):\n return np.logical_or(x, np.logical_or(y, z))\n\n faces_to_keep = np.logical_not(logical_or3(a, b, c))\n faces = faces[faces_to_keep, :].copy()\n\n nverts_total = (len(np.unique(faces.flatten())))\n\n new_faces, mtx = _get_sparse_transform(faces, len(vertice))\n return new_faces, mtx\n\n\ndef _get_sparse_transform(faces, num_original_verts):\n verts_left = np.unique(faces.flatten())\n IS = np.arange(len(verts_left))\n JS = verts_left\n data = np.ones(len(JS))\n\n mp = np.arange(0, np.max(faces.flatten()) + 1)\n mp[JS] = IS\n new_faces = mp[faces.copy().flatten()].reshape((-1, 3))\n\n ij = np.vstack((IS.flatten(), JS.flatten()))\n mtx = sp.csc_matrix((data, ij), shape=(len(verts_left), num_original_verts))\n\n return (new_faces, mtx)\n\n\ndef generate_transform_matrices(name, refer_vertices, refer_triangles, factors):\n \"\"\"Generates len(factors) meshes, each of them is scaled by factors[i] and\n computes the transformations between them.\n\n Returns:\n M: a set of meshes downsampled from mesh by a factor specified in factors.\n A: Adjacency matrix for each of the meshes\n D: Downsampling transforms between each of the meshes\n U: Upsampling transforms between each of the meshes\n \"\"\"\n\n factors = [1.0 / x for x in factors]\n # M, A, D, U = [], [], [], []\n # V, T, A, D, U = [], [], [], [], []\n vertices = []\n triangles = []\n adjacencies = []\n downsamp_trans = []\n upsamp_trans = []\n adjacencies.append(\n utils.get_vert_connectivity(refer_vertices, refer_triangles))\n # M.append(mesh)\n vertices.append(refer_vertices)\n triangles.append(refer_triangles)\n\n for factor in factors:\n ds_triangle, ds_transform = qslim_decimator_transformer(vertices[-1],\n triangles[-1],\n factor=factor)\n downsamp_trans.append(ds_transform)\n # new_mesh_v = ds_D.dot(M[-1].v)\n ds_vertice = ds_transform.dot(vertices[-1])\n # new_mesh = Mesh(v=new_mesh_v, f=ds_f)\n # M.append(new_mesh)\n vertices.append(ds_vertice)\n triangles.append(ds_triangle)\n adjacencies.append(utils.get_vert_connectivity(ds_vertice, ds_triangle))\n # U.append(setup_deformation_transfer(M[-1], M[-2]))\n upsamp_trans.append(\n setup_deformation_transfer(vertices[-1], triangles[-1], vertices[-2]))\n\n for i, (vertice, triangle) in enumerate(zip(vertices, triangles)):\n write_obj(\n os.path.join('data', 'reference', name, 'reference{}.obj'.format(i)),\n vertice, triangle)\n\n return adjacencies, downsamp_trans, upsamp_trans\n\n\ndef generate_spirals(\n step_sizes,\n M,\n Adj,\n Trigs,\n reference_points,\n dilation=None,\n random=False,\n # meshpackage='mpi-mesh',\n counter_clockwise=True,\n nb_stds=2):\n Adj_spirals = []\n for i, _ in enumerate(Adj):\n mesh_vertices = M[i]['vertices']\n\n spiral = get_spirals(\n mesh_vertices,\n Adj[i],\n Trigs[i],\n reference_points[i],\n n_steps=step_sizes[i],\n # padding='zero',\n counter_clockwise=counter_clockwise,\n random=random)\n Adj_spirals.append(spiral)\n print('spiral generation for hierarchy %d (%d vertices) finished' %\n (i, len(Adj_spirals[-1])))\n\n ## Dilated convolution\n if dilation:\n for i, _ in enumerate(dilation):\n dil = dilation[i]\n dil_spirals = []\n for j, _ in enumerate(Adj_spirals[i]):\n s = Adj_spirals[i][j][:1] + Adj_spirals[i][j][1::dil]\n dil_spirals.append(s)\n Adj_spirals[i] = dil_spirals\n\n # Calculate the lengths of spirals\n # Use mean + 2 * std_dev, to capture 97% of data\n L = []\n for i, _ in enumerate(Adj_spirals):\n L.append([])\n for j, _ in enumerate(Adj_spirals[i]):\n L[i].append(len(Adj_spirals[i][j]))\n L[i] = np.array(L[i])\n spiral_sizes = []\n for i, _ in enumerate(L):\n sz = L[i].mean() + nb_stds * L[i].std()\n spiral_sizes.append(int(sz))\n print('spiral sizes for hierarchy %d: %d' % (i, spiral_sizes[-1]))\n\n # 1) fill with -1 (index to the dummy vertex, i.e the zero padding) the spirals with length smaller than the chosen one\n # 2) Truncate larger spirals\n spirals_np = []\n for i, _ in enumerate(spiral_sizes): #len(Adj_spirals)):\n S = np.zeros((1, len(Adj_spirals[i]) + 1, spiral_sizes[i])) - 1\n for j, _ in enumerate(Adj_spirals[i]):\n S[0, j, :len(Adj_spirals[i][j])] = Adj_spirals[i][j][:spiral_sizes[i]]\n #spirals_np.append(np.repeat(S,args['batch_size'],axis=0))\n spirals_np.append(S)\n\n return spirals_np, spiral_sizes, Adj_spirals\n\n\ndef get_spirals(\n mesh,\n adj,\n trig,\n reference_points,\n n_steps=1,\n # padding='zero',\n counter_clockwise=True,\n random=False):\n spirals = []\n\n if not random:\n heat_path = None\n dist = None\n for reference_point in reference_points:\n heat_path, dist = single_source_shortest_path(mesh, adj, reference_point,\n dist, heat_path)\n heat_source = reference_points\n\n for i in range(mesh.shape[0]):\n seen = set()\n seen.add(i)\n trig_central = list(trig[i])\n A = adj[i]\n spiral = [i]\n\n # 1) Frist degree of freedom - choose starting pooint:\n if not random:\n if i in heat_source: # choose closest neighbor\n shortest_dist = np.inf\n init_vert = None\n for neighbor in A:\n d = np.sum(np.square(mesh[i] - mesh[neighbor]))\n if d < shortest_dist:\n shortest_dist = d\n init_vert = neighbor\n\n else: # on the shortest path to the reference point\n init_vert = heat_path[i]\n else:\n # choose starting point:\n # random for first ring\n init_vert = choice(A)\n\n # first ring\n if init_vert is not None:\n ring = [init_vert]\n seen.add(init_vert)\n else:\n ring = []\n while len(trig_central) > 0 and init_vert is not None:\n cur_v = ring[-1]\n cur_t = [t for t in trig_central if t in trig[cur_v]]\n if len(ring) == 1:\n orientation_0 = (cur_t[0][0] == i and cur_t[0][1] == cur_v)\\\n or (cur_t[0][1] == i and cur_t[0][2] == cur_v)\\\n or (cur_t[0][2] == i and cur_t[0][0] == cur_v)\n if not counter_clockwise:\n orientation_0 = not orientation_0\n\n # 2) Second degree of freedom - 2nd point/orientation ambiguity\n if len(cur_t) >= 2:\n # Choose the triangle that will direct the spiral counter-clockwise\n if orientation_0:\n # Third point in the triangle - next vertex in the spiral\n third = [p for p in cur_t[0] if p != i and p != cur_v][0]\n trig_central.remove(cur_t[0])\n else:\n third = [p for p in cur_t[1] if p != i and p != cur_v][0]\n trig_central.remove(cur_t[1])\n ring.append(third)\n seen.add(third)\n # 3) Stop if the spiral hits the boundary in the first point\n elif len(cur_t) == 1:\n break\n else:\n # 4) Unique ordering for the rest of the points (3rd onwards)\n if len(cur_t) >= 1:\n # Third point in the triangle - next vertex in the spiral\n third = [p for p in cur_t[0] if p != cur_v and p != i][0]\n # Don't append the spiral if the vertex has been visited already\n # (happens when the first ring is completed and the spiral returns to the central vertex)\n if third not in seen:\n ring.append(third)\n seen.add(third)\n trig_central.remove(cur_t[0])\n # 4) Stop when the spiral hits the boundary (the already visited triangle is no longer in the list): First half of the spiral\n elif len(cur_t) == 0:\n break\n\n rev_i = len(ring)\n if init_vert is not None:\n v = init_vert\n\n if orientation_0 and len(ring) == 1:\n reverse_order = False\n else:\n reverse_order = True\n need_padding = False\n\n # 5) If on the boundary: restart from the initial vertex towards the other direction,\n # but put the vertices in reverse order: Second half of the spiral\n # One exception if the starting point is on the boundary + 2nd point towards the desired direction\n while len(trig_central) > 0 and init_vert is not None:\n cur_t = [t for t in trig_central if t in trig[v]]\n if len(cur_t) != 1:\n break\n else:\n need_padding = True\n\n third = [p for p in cur_t[0] if p != v and p != i][0]\n trig_central.remove(cur_t[0])\n if third not in seen:\n ring.insert(rev_i, third)\n seen.add(third)\n if not reverse_order:\n rev_i = len(ring)\n v = third\n\n # Add a dummy vertex between the first half of the spiral and the second half - similar to zero padding in a 2d grid\n if need_padding:\n ring.insert(rev_i, -1)\n \"\"\"\n ring_copy = list(ring[1:])\n rev_i = rev_i - 1\n for z in range(len(ring_copy)-2):\n if padding == 'zero':\n ring.insert(rev_i,-1) # -1 is our sink node\n elif padding == 'mirror':\n ring.insert(rev_i,ring_copy[rev_i-z-1])\n \"\"\"\n spiral += ring\n\n # Next rings:\n for _ in range(n_steps - 1):\n next_ring = set([])\n next_trigs = set([])\n if len(ring) == 0:\n break\n base_triangle = None\n init_vert = None\n\n # Find next hop neighbors\n for w in ring:\n if w != -1:\n for u in adj[w]:\n if u not in seen:\n next_ring.add(u)\n\n # Find triangles that contain two outer ring nodes. That way one can folllow the spiral ordering in the same way\n # as done in the first ring: by simply discarding the already visited triangles+nodes.\n for u in next_ring:\n for tr in trig[u]:\n if len([x for x in tr if x in seen]) == 1:\n next_trigs.add(tr)\n elif ring[0] in tr and ring[-1] in tr:\n base_triangle = tr\n # Normal case: starting point in the second ring ->\n # the 3rd point in the triangle that connects the 1st and the last point in the 1st ring with the 2nd ring\n if base_triangle is not None:\n init_vert = [x for x in base_triangle if x != ring[0] and x != ring[-1]]\n # Make sure that the the initial point is appropriate for starting the spiral,\n # i.e it is connected to at least one of the next candidate vertices\n if len(list(next_trigs.intersection(set(trig[init_vert[0]])))) == 0:\n init_vert = None\n\n # If no such triangle exists (one of the vertices is dummy,\n # or both the first and the last vertex take part in a specific type of boundary)\n # or the init vertex is not connected with the rest of the ring -->\n # Find the relative point in the the triangle that connects the 1st point with the 2nd, or the 2nd with the 3rd\n # and so on and so forth. Note: This is a slight abuse of the spiral topology\n if init_vert is None:\n for r in range(len(ring) - 1):\n if ring[r] != -1 and ring[r + 1] != -1:\n tr = [t for t in trig[ring[r]] if t in trig[ring[r + 1]]]\n for t in tr:\n init_vert = [v for v in t if v not in seen]\n # make sure that the next vertex is appropriate to start the spiral ordering in the next ring\n if len(init_vert) > 0 and len(\n list(next_trigs.intersection(set(trig[init_vert[0]])))) > 0:\n break\n else:\n init_vert = []\n if len(init_vert) > 0 and len(\n list(next_trigs.intersection(set(trig[init_vert[0]])))) > 0:\n break\n else:\n init_vert = []\n\n # The rest of the procedure is the same as the first ring\n if init_vert is None:\n init_vert = []\n if len(init_vert) > 0:\n init_vert = init_vert[0]\n ring = [init_vert]\n seen.add(init_vert)\n else:\n init_vert = None\n ring = []\n\n # if i == 57:\n # import pdb;pdb.set_trace()\n while len(next_trigs) > 0 and init_vert is not None:\n cur_v = ring[-1]\n cur_t = list(next_trigs.intersection(set(trig[cur_v])))\n\n if len(ring) == 1:\n try:\n orientation_0 = (cur_t[0][0] in seen and cur_t[0][1] == cur_v) \\\n or (cur_t[0][1] in seen and cur_t[0][2] == cur_v) \\\n or (cur_t[0][2] in seen and cur_t[0][0] == cur_v)\n except:\n import pdb\n pdb.set_trace()\n if not counter_clockwise:\n orientation_0 = not orientation_0\n\n # 1) orientation ambiguity for the next ring\n if len(cur_t) >= 2:\n # Choose the triangle that will direct the spiral counter-clockwise\n if orientation_0:\n # Third point in the triangle - next vertex in the spiral\n third = [p for p in cur_t[0] if p not in seen and p != cur_v][0]\n next_trigs.remove(cur_t[0])\n else:\n third = [p for p in cur_t[1] if p not in seen and p != cur_v][0]\n next_trigs.remove(cur_t[1])\n ring.append(third)\n seen.add(third)\n # 2) Stop if the spiral hits the boundary in the first point\n elif len(cur_t) == 1:\n break\n else:\n # 3) Unique ordering for the rest of the points\n if len(cur_t) >= 1:\n third = [p for p in cur_t[0] if p != v and p not in seen]\n next_trigs.remove(cur_t[0])\n if len(third) > 0:\n third = third[0]\n if third not in seen:\n ring.append(third)\n seen.add(third)\n else:\n break\n # 4) Stop when the spiral hits the boundary\n # (the already visited triangle is no longer in the list): First half of the spiral\n elif len(cur_t) == 0:\n break\n\n rev_i = len(ring)\n if init_vert is not None:\n v = init_vert\n\n if orientation_0 and len(ring) == 1:\n reverse_order = False\n else:\n reverse_order = True\n\n need_padding = False\n\n while len(next_trigs) > 0 and init_vert is not None:\n cur_t = [t for t in next_trigs if t in trig[v]]\n if len(cur_t) != 1:\n break\n else:\n need_padding = True\n\n third = [p for p in cur_t[0] if p != v and p not in seen]\n next_trigs.remove(cur_t[0])\n if len(third) > 0:\n third = third[0]\n if third not in seen:\n ring.insert(rev_i, third)\n seen.add(third)\n if not reverse_order:\n rev_i = len(ring)\n v = third\n\n if need_padding:\n ring.insert(rev_i, -1)\n \"\"\"\n ring_copy = list(ring[1:])\n rev_i = rev_i - 1\n for z in range(len(ring_copy)-2):\n if padding == 'zero':\n ring.insert(rev_i,-1) # -1 is our sink node\n elif padding == 'mirror':\n ring.insert(rev_i,ring_copy[rev_i-z-1])\n \"\"\"\n\n spiral += ring\n\n spirals.append(spiral)\n return spirals\n\n\ndef distance(v, w):\n return np.sqrt(np.sum(np.square(v - w)))\n\n\ndef single_source_shortest_path(V, E, source, dist=None, prev=None):\n if dist is None:\n dist = [None for i in range(len(V))]\n prev = [None for i in range(len(V))]\n q = []\n seen = set()\n heapq.heappush(q, (0, source, None))\n while len(q) > 0 and len(seen) < len(V):\n d_, v, p = heapq.heappop(q)\n if v in seen:\n continue\n seen.add(v)\n prev[v] = p\n dist[v] = d_\n for w in E[v]:\n if w in seen:\n continue\n dw = d_ + distance(V[v], V[w])\n heapq.heappush(q, (dw, w, v))\n\n return prev, dist\n"
},
{
"alpha_fraction": 0.8148148059844971,
"alphanum_fraction": 0.8148148059844971,
"avg_line_length": 27,
"blob_id": "1de73be7b4edd0153d159b636fc2b5fd62141698",
"content_id": "bb6e630472ca87521048697bba00cc976962992d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 27,
"license_type": "permissive",
"max_line_length": 27,
"num_lines": 1,
"path": "/Recognition-Algorithms/Recognition_using_NasNet/models/__init__.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from models.nasnet import *"
},
{
"alpha_fraction": 0.6263368129730225,
"alphanum_fraction": 0.654189944267273,
"avg_line_length": 31.288660049438477,
"blob_id": "8935e07ac6bb3ddb238e880c2a839352ead21392",
"content_id": "8a85bb4940d0ae911445168604834c631681762a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12530,
"license_type": "permissive",
"max_line_length": 130,
"num_lines": 388,
"path": "/facex-library/facex.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import imutils\nimport time\nimport cv2\nimport numpy as np\nfrom matplotlib import pyplot as plt\nimport os\n\n\nclass InvalidFile(Exception):\n\tpass\n \ndef cartoonify(img_path, method='opencv'):\n\n\t# Code by : Sagnik Mukherjee\n\t# Link : https://github.com/akshitagupta15june/Face-X/tree/master/Cartoonify%20Image\n\n\tif(os.path.isfile(img_path)):\n\n\t\ttry:\n\n\t\t\tif method=='opencv':\n\t\t\t\t# Reading the Image\n\t\t\t\timage = cv2.imread(img_path)\n\t\t\t\t# Finding the Edges of Image\n\t\t\t\tgray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)\n\t\t\t\tblur = cv2.medianBlur(gray, 5)\n\t\t\t\tedges = cv2.adaptiveThreshold(blur, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 9, 9)\n\t\t\t\t# Making a Cartoon of the image\n\t\t\t\tcolor = cv2.bilateralFilter(image, 9, 250, 250)\n\t\t\t\tcartoon = cv2.bitwise_and(color, color, mask=edges)\n\n\t\t\t\treturn cartoon\n\t\texcept:\n\n\t\t\traise InvalidFile(\"Only image files are supported.(.png, .jpg, .jpeg)\")\n\n\telse:\n\n\t\traise InvalidFile(\"Invalid File!\")\n\n\n\ndef face_detection(img_path, method='opencv'):\t\n\n\t# Code by : Srimoni Dutta\n\t# Link : https://github.com/akshitagupta15june/Face-X/tree/master/Face-Detection/Face%20Detection%20using%20Haar%20Cascade\n\n\tif(os.path.isfile(img_path)):\n\n\t\ttry:\n\n\t\t\tif method=='opencv':\n\t\t\t\tface_cascade=cv2.CascadeClassifier(os.path.join(os.getcwd(),'haarcascade_frontalface_default.xml'))\n\t\t\t\timg=cv2.imread(img_path)\n\t\t\t\tgray=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)\n\t\t\t\tfaces=face_cascade.detectMultiScale(gray,1.1,4)\n\t\t\t\tfor (x,y,w,h) in faces:\n\t\t\t\t\tcv2.rectangle(img,(x,y),(x+w,y+h),(0,255,255),2)\n\n\t\t\t\treturn img\n\t\texcept:\n\n\t\t\traise InvalidFile(\"Only image files are supported.(.png, .jpg, .jpeg)\")\n\n\telse:\n\n\t\traise InvalidFile(\"Invalid File!\")\t\t\t\t\n\ndef blur_bg(img_path, method='opencv'):\n\n\t# Code by : Anas-Issa\n\t# Link : https://github.com/akshitagupta15june/Face-X/tree/master/Blurring%20image%20across%20face\n\n\tif(os.path.isfile(img_path)):\n\n\t\ttry:\n\n\t\t\tif method=='opencv':\n\n\t\t\t\tdetector = cv2.CascadeClassifier(\"haarcascade_frontalface_default.xml\")\n\t\t\t\timg=cv2.imread(img_path)\n\n\t\t\t\tgray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)\n\t\t\t\tfaces = detector.detectMultiScale(gray, 1.3, 5)\n\n\t\t\t\tfor (x, y, w, h) in faces:\n\t\t\t\t\t\tface = img[y:y + h, x:x + w]\n\t\t\t\t\t\tframe = cv2.blur(img, ksize = (10, 10))\n\t\t\t\t\t\tframe[y:y + h, x:x + w] = face\n\n\t\t\t\treturn img\n\t\texcept:\n\n\t\t\traise InvalidFile(\"Only image files are supported.(.png, .jpg, .jpeg)\")\n\n\telse:\n\n\t\traise InvalidFile(\"Invalid File!\")\t\t\t\t\t\t\t\n\ndef ghost_img(img_path, method='opencv'):\n\n\t# Code by : A-kriti\n\t# Link : https://github.com/akshitagupta15june/Face-X/tree/master/Awesome-face-operations/Ghost%20Image\n\n\tif(os.path.isfile(img_path)):\n\n\t\ttry:\t\n\n\t\t\tif method=='opencv':\n\t\t\t\t# take path of the image as input\n\t\t\t\timg_path = img_path \n\t\t\t\timg = cv2.imread(img_path)\n\n\t\t\t\timage = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)\n\n\t\t\t\timg_small = cv2.pyrDown(image)\n\t\t\t\tnum_iter = 5\n\t\t\t\tfor _ in range(num_iter):\n\t\t\t\t\timg_small= cv2.bilateralFilter(img_small, d=9, sigmaColor=9, sigmaSpace=7)\n\t\t\t\timg_rgb = cv2.pyrUp(img_small)\n\n\t\t\t\timg_gray = cv2.cvtColor(img_rgb, cv2.COLOR_RGB2GRAY)\n\t\t\t\timg_blur = cv2.medianBlur(img_gray, 7)\n\t\t\t\timg_edge = cv2.adaptiveThreshold(img_blur, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 7, 2)\n\n\t\t\t\timg_edge = cv2.cvtColor(img_edge, cv2.COLOR_GRAY2RGB)\n\n\t\t\t\tarray = cv2.bitwise_xor(image, img_edge) #used bitwise xor method \n\t\t\t\tplt.figure(figsize=(10,10))\n\t\t\t\tplt.imshow(array)\n\t\t\t\tplt.axis('off')\n\t\t\t\tfilename = os.path.basename(img_path)\n\n\t\t\t\treturn array #final filtered photo\n\n\t\texcept:\n\n\t\t\traise InvalidFile(\"Only image files are supported.(.png, .jpg, .jpeg)\")\n\n\telse:\n\n\t\traise InvalidFile(\"Invalid File!\")\t\t\t\t\t\t\n\n\n\ndef mosaic (img_path, x, y, w, h, neighbor=9):\n\n\t# Code by : Sudip Ghosh\n\t# Link : https://github.com/AdityaNikhil/Face-X/blob/master/Awesome-face-operations/Mosaic-Effect/Mosaic.py\n\n\tif(os.path.isfile(img_path)):\n\n\t\ttry:\n\n\t\t\tframe = cv2.imread(img_path, 1)\t\n\t\t\tfh, fw=frame.shape [0], frame.shape [1]\n\t\t\tif (y + h>fh) or (x + w>fw):\n\t\t\t\treturn\n\t\t\tfor i in range (0, h-neighbor, neighbor):#keypoint 0 minus neightbour to prevent overflow\n\t\t\t\tfor j in range (0, w-neighbor, neighbor):\n\t\t\t\t\trect=[j + x, i + y, neighbor, neighbor]\n\t\t\t\t\tcolor=frame [i + y] [j + x] .tolist () #key point 1 tolist\n\t\t\t\t\tleft_up=(rect [0], rect [1])\n\t\t\t\t\tright_down=(rect [0] + neighbor-1, rect [1] + neighbor-1) #keypoint 2 minus one pixel\n\t\t\t\t\tcv2.rectangle (frame, left_up, right_down, color, -1)\n\n\t\t\treturn frame\n\t\texcept:\n\n\t\t\traise InvalidFile(\"Only image files are supported.(.png, .jpg, .jpeg)\")\n\n\telse:\n\n\t\traise InvalidFile(\"Only image files are supported.(.png, .jpg, .jpeg)\")\n\ndef sketch(img_path, method='opencv'):\n\t\n\t# Code by : iaditichine\n\t# Link : https://github.com/akshitagupta15june/Face-X/blob/master/Awesome-face-operations/Pencil%20Sketch/pencil_sketch_code.py\t\t\n\n\tif(os.path.isfile(img_path)):\n\n\t\ttry:\n\n\t\t\timg=cv2.imread(img_path)\n\t\t\timg_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)\n\t\t\timg_invert = cv2.bitwise_not(img_gray)\n\t\t\timg_smoothing = cv2.GaussianBlur(img_invert, (21, 21),sigmaX=0, sigmaY=0)\n\t\t\t\n\t\t\treturn cv2.divide(img_gray, 255 - img_smoothing, scale=256)\n\t\texcept:\n\n\t\t\traise InvalidFile(\"Only image files are supported.(.png, .jpg, .jpeg)\")\n\n\telse:\n\n\t\traise InvalidFile(\"Only image files are supported.(.png, .jpg, .jpeg)\")\t\n\n\ndef detect_and_predict_mask(frame, faceNet, maskNet):\n\n\t# (Partly taken)Code by : PyImageSearch\n\t# Link : https://www.pyimagesearch.com/2020/05/04/covid-19-face-mask-detector-with-opencv-keras-tensorflow-and-deep-learning/\n\n\t# grab the dimensions of the frame and then construct a blob from it\n\t\n\t(h, w) = frame.shape[:2]\n\tblob = cv2.dnn.blobFromImage(frame, 1.0, (300, 300),\n\t\t(104.0, 177.0, 123.0))\n\t# pass the blob through the network and obtain the face detections\n\tfaceNet.setInput(blob)\n\tdetections = faceNet.forward()\n\t# initialize our list of faces, their corresponding locations,\n\t# and the list of predictions from our face mask network\n\tfaces = []\n\tlocs = []\n\tpreds = []\n\n\t# loop over the detections\n\tfor i in range(0, detections.shape[2]):\n\t\t# extract the confidence (i.e., probability) associated with\n\t\t# the detection\n\t\tconfidence = detections[0, 0, i, 2]\n\t\t# filter out weak detections by ensuring the confidence is\n\t\t# greater than the minimum confidence\n\t\tif confidence > 0.5:\n\t\t\t# compute the (x, y)-coordinates of the bounding box for\n\t\t\t# the object\n\t\t\tbox = detections[0, 0, i, 3:7] * np.array([w, h, w, h])\n\t\t\t(startX, startY, endX, endY) = box.astype(\"int\")\n\t\t\t# ensure the bounding boxes fall within the dimensions of\n\t\t\t# the frame\n\t\t\t# extract the face ROI, convert it from BGR to RGB channel\n\t\t\t# ordering, resize it to 224x224, and preprocess it\n\t\t\tface = frame[startY:endY, startX:endX]\n\t\t\tface = cv2.cvtColor(face, cv2.COLOR_BGR2RGB)\n\t\t\tface = cv2.resize(face, (224, 224))\n\t\t\tface = img_to_array(face)\n\t\t\tface = preprocess_input(face)\n\t\t\t# add the face and bounding boxes to their respective\n\t\t\t# lists\n\t\t\tfaces.append(face)\n\t\t\tlocs.append((startX, startY, endX, endY))\n\t# only make a predictions if at least one face was detected\n\tif len(faces) > 0:\n\t\t# for faster inference we'll make batch predictions on *all*\n\t\t# faces at the same time rather than one-by-one predictions\n\t\t# in the above `for` loop\n\t\tfaces = np.array(faces, dtype=\"float32\")\n\t\tpreds = maskNet.predict(faces, batch_size=32)\n\t# return a 2-tuple of the face locations and their corresponding\n\t# locations\n\treturn (locs, preds)\n\ndef face_mask(image):\n\tfrom tensorflow.keras.applications.mobilenet_v2 import preprocess_input\n\tfrom tensorflow.keras.preprocessing.image import img_to_array\n\tfrom tensorflow.keras.models import load_model\n\tfrom imutils.video import VideoStream\t\n\t# load our serialized face detector model from disk\n\tprint(\"[INFO] loading face detector model...\")\n\tprototxtPath = \"models/deploy.prototxt\"\n\tweightsPath = \"models/res10_300x300_ssd_iter_140000.caffemodel\"\n\tmodel = \"models/mask_detector.model\"\n\tnet = cv2.dnn.readNet(prototxtPath, weightsPath)\n\t# load the face mask detector model from disk\n\tprint(\"[INFO] loading face mask detector model...\")\n\tmodel = load_model(model)\t\n\n\tif(os.path.isfile(image)):\n\t\t#############################################\n\n\t\t## IMAGE MASK DETECTION\n\n\t\t#############################################\t\t\n\t\tif(image.endswith('jpg') or image.endswith('png')):\n\t\t\ttry:\n\t\t\t\t# load the input image from disk, clone it, and grab the image spatial\n\t\t\t\t# dimensions\n\t\t\t\timage = cv2.imread(image)\n\t\t\t\torig = image.copy()\n\t\t\t\t(h, w) = image.shape[:2]\n\t\t\t\t# construct a blob from the image\n\t\t\t\tblob = cv2.dnn.blobFromImage(image, 1.0, (300, 300),\n\t\t\t\t\t(104.0, 177.0, 123.0))\n\t\t\t\t# pass the blob through the network and obtain the face detections\n\t\t\t\tprint(\"[INFO] computing face detections...\")\n\t\t\t\tnet.setInput(blob)\n\t\t\t\tdetections = net.forward()\n\n\t\t\t\t# loop over the detections\n\t\t\t\tfor i in range(0, detections.shape[2]):\n\t\t\t\t\t# extract the confidence (i.e., probability) associated with\n\t\t\t\t\t# the detection\n\t\t\t\t\tconfidence = detections[0, 0, i, 2]\n\t\t\t\t\t# filter out weak detections by ensuring the confidence is\n\t\t\t\t\t# greater than the minimum confidence\n\t\t\t\t\tif confidence > 0.5:\n\t\t\t\t\t\t# compute the (x, y)-coordinates of the bounding box for\n\t\t\t\t\t\t# the object\n\t\t\t\t\t\tbox = detections[0, 0, i, 3:7] * np.array([w, h, w, h])\n\t\t\t\t\t\t(startX, startY, endX, endY) = box.astype(\"int\")\n\t\t\t\t\t\t# ensure the bounding boxes fall within the dimensions of\n\t\t\t\t\t\t# the frame\n\t\t\t\t\t\t# extract the face ROI, convert it from BGR to RGB channel\n\t\t\t\t\t\t# ordering, resize it to 224x224, and preprocess it\n\t\t\t\t\t\tface = image[startY:endY, startX:endX]\n\t\t\t\t\t\tface = cv2.cvtColor(face, cv2.COLOR_BGR2RGB)\n\t\t\t\t\t\tface = cv2.resize(face, (224, 224))\n\t\t\t\t\t\tface = img_to_array(face)\n\t\t\t\t\t\tface = preprocess_input(face)\n\t\t\t\t\t\tface = np.expand_dims(face, axis=0)\n\t\t\t\t\t\t# pass the face through the model to determine if the face\n\t\t\t\t\t\t# has a mask or not\n\t\t\t\t\t\t(mask, withoutMask) = model.predict(face)[0]\n\n\t\t\t\t# determine the class label and color we'll use to draw\n\t\t\t\t\t\t# the bounding box and text\n\t\t\t\t\t\tlabel = \"Mask\" if mask > withoutMask else \"No Mask\"\n\t\t\t\t\t\tcolor = (0, 255, 0) if label == \"Mask\" else (0, 0, 255)\n\t\t\t\t\t\t# include the probability in the label\n\t\t\t\t\t\tlabel = \"{}: {:.2f}%\".format(label, max(mask, withoutMask) * 100)\n\t\t\t\t\t\t# display the label and bounding box rectangle on the output\n\t\t\t\t\t\t# frame\n\t\t\t\t\t\tcv2.putText(image, label, (startX, startY - 10),\n\t\t\t\t\t\t\tcv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2)\n\t\t\t\t\t\tcv2.rectangle(image, (startX, startY), (endX, endY), color, 2)\n\n\t\t\t\t\treturn image\n\n\t\t\texcept:\n\n\t\t\t\traise InvalidFile(\"Files of following format are only supported.(.png, .jpg, .jpeg, .mp4)\")\n\n\n\t\t#############################################\n\n\t\t## VIDEO MASK DETECTION\n\n\t\t#############################################\n\n\t\telif(image.endswith('mp4')):\n\t\t\tprint(\"[INFO] starting video stream...\")\n\t\t\tcap = cv2.VideoCapture(image)\n\n\t\t\t# loop over the frames from the video stream\n\t\t\twhile cap.isOpened():\n\t\t\t\t# grab the frame from the threaded video stream and resize it\n\t\t\t\t# to have a maximum width of 400 pixels\n\t\t\t\tret,frame = cap.read()\n\t\t\t\tframe = imutils.resize(frame, width=400)\n\t\t\t\t# detect faces in the frame and determine if they are wearing a\n\t\t\t\t# face mask or not\n\t\t\t\t(locs, preds) = detect_and_predict_mask(frame, net, model)\n\n\t\t\t\t# loop over the detected face locations and their corresponding\n\t\t\t\t# locations\n\t\t\t\tfor (box, pred) in zip(locs, preds):\n\t\t\t\t\t# unpack the bounding box and predictions\n\t\t\t\t\t(startX, startY, endX, endY) = box\n\t\t\t\t\t(mask, withoutMask) = pred\n\t\t\t\t\t# determine the class label and color we'll use to draw\n\t\t\t\t\t# the bounding box and text\n\t\t\t\t\tlabel = \"Mask\" if mask > withoutMask else \"No Mask\"\n\t\t\t\t\tcolor = (0, 255, 0) if label == \"Mask\" else (0, 0, 255)\n\t\t\t\t\t# include the probability in the label\n\t\t\t\t\tlabel = \"{}: {:.2f}%\".format(label, max(mask, withoutMask) * 100)\n\t\t\t\t\t# display the label and bounding box rectangle on the output\n\t\t\t\t\t# frame\n\t\t\t\t\tcv2.putText(frame, label, (startX, startY - 10),\n\t\t\t\t\t\tcv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2)\n\t\t\t\t\tcv2.rectangle(frame, (startX, startY), (endX, endY), color, 2)\n\n\t\t\t\t# show the output frame\n\t\t\t\tcv2.imshow(\"Frame\", frame)\n\t\t\t\tkey = cv2.waitKey(1) & 0xFF\n\t\t\t\t# if the `q` key was pressed, break from the loop\n\t\t\t\tif key == ord(\"q\"):\n\t\t\t\t\tbreak\n\t\t\t# do a bit of cleanup\n\t\t\tcv2.destroyAllWindows()\n\t\t\tcap.release()\n\n\n\n\telse:\n\n\t\traise InvalidFile(\"Files of following format are only supported.(.png, .jpg, .jpeg, .mp4)\")\n\n\n"
},
{
"alpha_fraction": 0.5374331474304199,
"alphanum_fraction": 0.5935828685760498,
"avg_line_length": 37.47368240356445,
"blob_id": "250ec7dc56f95476f0049b3e4df3a4b8290f0de1",
"content_id": "04825b0d314d6fddb292d3836dc2ac8bd8bd922a",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 748,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 19,
"path": "/Awesome-face-operations/Mosaic-Effect/Mosaic.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import cv2\r\ndef do_mosaic (frame, x, y, w, h, neighbor=9):\r\n fh, fw=frame.shape [0], frame.shape [1]\r\n if (y + h>fh) or (x + w>fw):\r\n return\r\n for i in range (0, h-neighbor, neighbor):#keypoint 0 minus neightbour to prevent overflow\r\n for j in range (0, w-neighbor, neighbor):\r\n rect=[j + x, i + y, neighbor, neighbor]\r\n color=frame [i + y] [j + x] .tolist () #key point 1 tolist\r\n left_up=(rect [0], rect [1])\r\n right_down=(rect [0] + neighbor-1, rect [1] + neighbor-1) #keypoint 2 minus one pixel\r\n cv2.rectangle (frame, left_up, right_down, color, -1)\r\nim=cv2.imread (\"test.jpg\", 1)\r\ndo_mosaic (im, 219, 61, 460-219, 412-61)\r\nwhile 1:\r\n k=cv2.waitkey (10)\r\n if k == 27:\r\n break\r\n cv2.imshow (\"mosaic\", im)"
},
{
"alpha_fraction": 0.7544352412223816,
"alphanum_fraction": 0.7820816040039062,
"avg_line_length": 108.08064270019531,
"blob_id": "46769434a1cc47d1a9efb93958cf095744927dc1",
"content_id": "355680ff2e7d32b02f7f06f0022c914f8902014a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6774,
"license_type": "permissive",
"max_line_length": 470,
"num_lines": 62,
"path": "/Recognition-Algorithms/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "### Demonstration of different algorithms and operations on faces\n\nThere are several approaches for recognizing a face. The algorithm can use statistics, try to find a pattern which represents a specific person or use a convolutional neural network. \n<div align=\"center\">\n<img src=\"https://media.giphy.com/media/AXorq76Tg3Vte/giphy.gif\" width=\"20%\"><br>\n</div>\n\nThe algorithms used for the tests are Eigenfaces, Fisherfacesand local binary patterns histograms which all come from the library OpenCV. Eigenfaces and Fisher faces are used with a Euclidean distance to predict the person. The algorithm which is using a deep convolutional neural network is the project called OpenFace.\n\nThis can be used for automatic face detection attendance system in recent technology.\n\n\n\n`\nRecognition of faces by different algorithms and frameworks. Despite a variety of open-source face recognition frameworks available, there was \nno ready-made solution to implement. So In this project all kind of algorithms are implemented and even with various operations that can be implemented\nin a frontal face. The available algorithms processed only high-resolution static shots and performed insufficiently.\n`\n\n\n### Requirements 👇\n- Python3.6+\n- virtualenv (`pip install virtualenv`)\n\n### Installation 🖥\n- `virtualenvv env`\n- `source venv/bin/activate` (Linux)\n- `venv\\Scripts\\activate` (Windows)\n- `pip install -r requirements.txt`\n- Create an .env file, copy the content from .env.sample and add your data path. Example: `DATA_PATH = \"./foto_reco/\"`\n\n\n## Comparative Study of the Algorithms used here :\n\nThis project holds different type of deep learning models on different frameworks. every single model has it's uniqueness and contribute vastly to the deep learning domain .\nIf we try to compare them, we might find better understanding over those and this would be great for all of us :)\n\nModel | Creator | Published | Description \n--- | --- | --- | --- \nDeepface | Facebook AI | June, 2014 | The accuracy of DeepFace observed with any two random images from the dataset is reported above 99.5 % with using Ensemble Model from the Deepface library. The Library is built on Keras and Tensorflow by Sefik Ilkin Serengil and Alper Ozpinar using several models such as VGG-Face, Google FaceNet, OpenFace, Facebook DeepFace, DeepID, ArcFace and Dlib.\nLBPH | C. Silva | March,2015 | Got the highest accuracy in all experiments, but this algorithm has the higher impact of the negative light exposure and high noise level more than the others that are statistical approach.\nCNN | Yann LeCun | 1980 | The use of Convolutional Neural network architecture is done here to trace the availability of Facial image in the camera frame. An Input image is passed through a series of convolution layers with filters, Pooling, fully connected layers. Softmax function is applied to classify an object with probabilistic values between 0 and 1.\nLBP_SVM | C. Silva | March,2015 | The accuracy is reported at 90.52% using SVM which has a gamma value of 0.0000015 and penalty parameter of the error term C = 2.5 while using the RBF kernel.\nMobileNetV2 | Google AI | April,2018 | Faster for the same accuracy across the entire latency spectrum. In particular, the new models use 2x fewer operations, need 30% fewer parameters and are about 30-40% faster on a Google Pixel phone than MobileNetV1 models, all while achieving higher accuracy.\nEfficientNet | Google AI | May, 2019 | On the ImageNet challenge, with a 66M parameter calculation load, EfficientNet reached 84.4% accuracy and took its place among the state-of-the-art.\nEigenFaceRecogniser | M. Turk and A. Pentland | 1991 | The accuracy of Eigenface is satisfactory (over 90 %) with frontal faces. Eigenface uses PCA. A drawback is that it is very sensitive for lightening conditions and the position of the head. Fisherface is similar to Eigenface but with improvement in better classification of different classes image.\nFisherFaceRecogniser | Aleix Martinez | 2011 | Fisherface is a technique similar to Eigenfaces but it is geared to improve clustering of classes. While Eigenfaces relies on PCA, Fischer faces relies on LDA (aka Fischer’s LDA) for dimensionality reduction.\nGhostNet | Huwayei Noah | Recent | GhostNet can achieve higher recognition performance (75% , top-1 accuracy) than MobileNetV3 with similar computational cost on the ImageNet ILSVRC-2012 classification dataset.\nKNN | Evelyn Fix and Joseph Hodges | 1951 | K-Nearest Neighbor face recognition delivered best accuracy 91.5% on k=1. KNN showed the faster execution time compared with PCA and LDA. Time execution of KNN to recognize face was 0.152 seconds on high-processor. Face detection and recognition only need 2.66 second to recognize on low-power ARM11 based system\nPCA | Karl Pearson | 1901 | Principal Component Analysis (PCA) model is being demonstrated here and the accuracy reported is 63.66 % on the lfw_people dataset by fitting Principal Component Analysis (PCA) algorithm on the above dataset. \nResNet-50 | Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun | Dec,2015 | ResNet-50 is a convolutional neural network that is 50 layers deep. You can load a pretrained version of the network trained on more than a million images from the ImageNet database [1]. The pretrained network can classify images into 1000 object categories, such as keyboard, mouse, pencil, and many animals.\nSIFT | David Lowe | 1999 | Scale-Invariant Feature Transform algorithm is used here which produces a list of good features from the ROI define in two image. The two images are then matched using a Bruteforce matcher with the result of match coming out as negative.\nDenseNet121 | Gao Huang, Zhuang Liu, Laurens van der Maaten, Kilian Q. Weinberger | Jan,2018 | Got Best Paper Award with over 2000 citations. It is jointly invented by Cornwell University, Tsinghua University and Facebook AI Research (FAIR)\nVGG-19 | Karen Simonyan, Andrew Zisserman | April,2015 | This model achieves 75.2% top-1 and 92.5% top-5 accuracy on the ImageNet Large Scale Visual Recognition Challenge 2012 dataset.\nMTCNN | Kaipeng Zhang, Zhanpeng Zhang, Zhifeng Li, Yu Qiao | April,2016 | One of the hottest model used most widely recently for its high precision and outstanding real time performance among the state-of-art algorithms for face detection. Then, the first basic application of portrait classification is researched based on MTCNN and FaceNet. Its direction is one of the most classical and popular area in nowadays AI visual research, and is also the base of many other industrial branches.\n\n \n\n\n\n\nWe can see that the models are very new in this world and also can see the quick evolution of them .Face Recognition with Deep learning has now become **PIECE OF CAKE** with the help of this Benchmark Models. \n"
},
{
"alpha_fraction": 0.5831908583641052,
"alphanum_fraction": 0.6038936376571655,
"avg_line_length": 40.12890625,
"blob_id": "e934aec8c508b7812126db3aa13b87802770dd65",
"content_id": "12e7032900ded9e65018b2cdd069c9ad3ddf296a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10530,
"license_type": "permissive",
"max_line_length": 137,
"num_lines": 256,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/test_image.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from __future__ import division\n\nimport os\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'\nimport sys\nfrom shutil import copyfile\n\n# tf\nimport numpy as np\nimport tensorflow as tf\nimport torch\n\n# save result\nimport face_alignment\nimport cv2\nimport PIL.Image as pil\nimport matplotlib.pyplot as plt\nimport trimesh\n\n# path\n_curr_path = os.path.abspath(__file__) # /home/..../face\n_cur_dir = os.path.dirname(_curr_path) # ./\n\n# save result\nfrom src_common.common.face_io import write_self_camera, write_self_lm\nfrom tools.preprocess.detect_landmark import LM_detector_howfar\nfrom tools.preprocess.crop_image_affine import *\n\n# graph\nfrom src_tfGraph.build_graph import MGC_TRAIN\n\nflags = tf.app.flags\n\n#\nflags.DEFINE_string(\"dic_image\", \"data/test/\", \"Dataset directory\")\nflags.DEFINE_string(\"output_dir\", \"data/output_test_one\", \"Output directory\")\nflags.DEFINE_string(\"ckpt_file\", \"model/model-400000\", \"checkpoint file\")\n#flags.DEFINE_string(\"ckpt_file\", \"/home/jiaxiangshang/Downloads/202008/70_31_warpdepthepi_reg/model-400000\", \"checkpoint file\")\n\n#\nflags.DEFINE_integer(\"batch_size\", 1, \"The size of of a sample batch\")\nflags.DEFINE_integer(\"img_width\", 224, \"Image(square) size\")\nflags.DEFINE_integer(\"img_height\", 224, \"Image(square) size\")\n\n# gpmm\nflags.DEFINE_string(\"path_gpmm\", \"model/bfm09_trim_exp_uv_presplit.h5\", \"Dataset directory\")\nflags.DEFINE_integer(\"light_rank\", 27, \"3DMM coeffient rank\")\nflags.DEFINE_integer(\"gpmm_rank\", 80, \"3DMM coeffient rank\")\nflags.DEFINE_integer(\"gpmm_exp_rank\", 64, \"3DMM coeffient rank\")\n\n#\nflags.DEFINE_boolean(\"flag_eval\", True, \"3DMM coeffient rank\")\nflags.DEFINE_boolean(\"flag_visual\", True, \"\")\nflags.DEFINE_boolean(\"flag_fore\", False, \"\")\n\n# visual\nflags.DEFINE_boolean(\"flag_overlay_save\", True, \"\")\nflags.DEFINE_boolean(\"flag_overlayOrigin_save\", True, \"\")\nflags.DEFINE_boolean(\"flag_main_save\", True, \"\")\n\nFLAGS = flags.FLAGS\n\nif __name__ == '__main__':\n FLAGS.dic_image = os.path.join(_cur_dir, FLAGS.dic_image)\n FLAGS.output_dir = os.path.join(_cur_dir, FLAGS.output_dir)\n\n FLAGS.ckpt_file = os.path.join(_cur_dir, FLAGS.ckpt_file)\n FLAGS.path_gpmm = os.path.join(_cur_dir, FLAGS.path_gpmm)\n \n \n if not os.path.exists(FLAGS.dic_image):\n print(\"Error: no dataset_dir found\")\n\n if not os.path.exists(FLAGS.output_dir):\n os.makedirs(FLAGS.output_dir)\n print(\"Finish copy\")\n\n \"\"\"\n preprocess\n \"\"\"\n lm_d_hf = LM_detector_howfar(lm_type=int(3), device='cpu', face_detector='sfd')\n\n \"\"\"\n build graph\n \"\"\"\n system = MGC_TRAIN(FLAGS)\n system.build_test_graph(\n FLAGS, img_height=FLAGS.img_height, img_width=FLAGS.img_width, batch_size=FLAGS.batch_size\n )\n\n \"\"\"\n load model\n \"\"\"\n test_var = tf.global_variables()#tf.model_variables()\n # this because we need using the\n test_var = [tv for tv in test_var if tv.op.name.find('VertexNormalsPreSplit') == -1]\n saver = tf.train.Saver([var for var in test_var])\n\n #config = tf.ConfigProto()\n config=tf.ConfigProto(device_count={'cpu':0})\n config.gpu_options.allow_growth = True\n with tf.Session(config=config) as sess:\n sess.run(tf.global_variables_initializer())\n sess.graph.finalize()\n saver.restore(sess, FLAGS.ckpt_file)\n #\n import time\n # preprocess\n path_image = os.path.join(FLAGS.dic_image, 'image04275.jpg')\n image_bgr = cv2.imread(path_image)\n image_rgb = image_bgr[..., ::-1]\n if image_bgr is None:\n print(\"Error: can not find \", path_image)\n with torch.no_grad():\n lm_howfar = lm_d_hf.lm_detection_howfar(image_bgr)\n lm_howfar = lm_howfar[:, :2]\n\n # face image align by landmark\n # we also provide a tools to generate 'std_224_bfm09'\n lm_trans, img_warped, tform = crop_align_affine_transform(lm_howfar, image_rgb, FLAGS.img_height, std_224_bfm09)\n image_rgb_b = img_warped[None, ...]\n # M_inv is used to back project the face reconstruction result to origin image\n M_inv = np.linalg.inv(tform.params)\n M = tform.params\n #print(np.matmul(M_inv, M))\n\n \"\"\"\n Start\n \"\"\"\n time_st = time.time()\n pred = system.inference(sess, image_rgb_b)\n time_end = time.time()\n print(\"Time each batch: \", time_end - time_st)\n\n # name\n dic_image, name_image = os.path.split(path_image)\n name_image_pure, _ = os.path.splitext(name_image)\n\n \"\"\"\n Render\n \"\"\"\n image_input = image_rgb_b\n\n \"\"\"\n NP\n \"\"\"\n b = 0\n vertex_shape = pred['vertex_shape'][0][b, :, :]\n vertex_color = pred['vertex_color'][0][b, :, :]\n vertex_color = np.clip(vertex_color, 0, 1)\n #vertex_color_rgba = np.concatenate([vertex_color, np.ones([vertex_color.shape[0], 1])], axis=1)\n vertex_color_ori = pred['vertex_color_ori'][0][b, :, :]\n vertex_color_ori = np.clip(vertex_color_ori, 0, 1)\n\n if FLAGS.flag_eval:\n mesh_tri = trimesh.Trimesh(\n vertex_shape.reshape(-1, 3),\n system.h_lrgp.h_curr.mesh_tri_np.reshape(-1, 3),\n vertex_colors=vertex_color.reshape(-1, 3),\n process=False\n )\n mesh_tri.visual.kind == 'vertex'\n\n path_mesh_save = os.path.join(FLAGS.output_dir, name_image_pure + \".ply\")\n mesh_tri.export(path_mesh_save)\n \"\"\"\n Landmark 3D\n \"\"\"\n path_lm3d_save = os.path.join(FLAGS.output_dir, name_image_pure + \"_lm3d.txt\")\n lm_68 = vertex_shape[system.h_lrgp.h_curr.idx_lm68_np]\n\n write_self_lm(path_lm3d_save, lm_68)\n\n \"\"\"\n Landmark 2D\n\n \"\"\"\n lm2d = pred['lm2d'][0][b, :, :]\n path_lm2d_save = os.path.join(FLAGS.output_dir, name_image_pure + \"_lm2d.txt\")\n write_self_lm(path_lm2d_save, lm2d)\n\n \"\"\"\n Pose\n \"\"\"\n path_cam_save = os.path.join(FLAGS.output_dir, name_image_pure + \"_cam.txt\")\n\n pose = pred['gpmm_pose'][0][b, :]\n intrinsic = pred['gpmm_intrinsic'][b, :, :]\n\n write_self_camera(path_cam_save, FLAGS.img_width, FLAGS.img_height, intrinsic, pose)\n\n \"\"\"\n Common visual\n \"\"\"\n if FLAGS.flag_visual:\n # visual\n result_overlayMain_255 = pred['overlayMain_255'][0][b, :, :]\n result_overlayTexMain_255 = pred['overlayTexMain_255'][0][b, :, :]\n result_overlayGeoMain_255 = pred['overlayGeoMain_255'][0][b, :, :]\n result_overlayLightMain_255 = pred['overlayLightMain_255'][0][b, :, :]\n result_apper_mulPose_255 = pred['apper_mulPose_255'][0][b, :, :]\n\n result_overlay_255 = pred['overlay_255'][0][b, :, :]\n result_overlayTex_255 = pred['overlayTex_255'][0][b, :, :]\n result_overlayGeo_255 = pred['overlayGeo_255'][0][b, :, :]\n result_overlayLight_255 = pred['overlayLight_255'][0][b, :, :]\n\n # common\n visual_concat = np.concatenate([image_input[0], result_overlay_255, result_overlayGeo_255, result_apper_mulPose_255], axis=1)\n path_image_save = os.path.join(FLAGS.output_dir, name_image_pure + \"_mulPoses.jpg\")\n plt.imsave(path_image_save, visual_concat)\n\n if FLAGS.flag_overlayOrigin_save:\n gpmm_render_mask = pred['gpmm_render_mask'][0][b, :, :]\n gpmm_render_mask = np.tile(gpmm_render_mask, reps=(1, 1, 3))\n\n path_image_origin = os.path.join(dic_image, name_image_pure + \".jpg\")\n image_origin = cv2.imread(path_image_origin)\n\n gpmm_render_overlay_wo = inverse_affine_warp_overlay(\n M_inv, image_origin, result_overlay_255, gpmm_render_mask)\n gpmm_render_overlay_texture_wo = inverse_affine_warp_overlay(\n M_inv, image_origin, result_overlayTex_255, gpmm_render_mask)\n gpmm_render_overlay_gary_wo = inverse_affine_warp_overlay(\n M_inv, image_origin, result_overlayGeo_255, gpmm_render_mask)\n gpmm_render_overlay_illu_wo = inverse_affine_warp_overlay(\n M_inv, image_origin, result_overlayLight_255, gpmm_render_mask)\n\n path_image_save = os.path.join(FLAGS.output_dir, name_image_pure + \"_overlayOrigin.jpg\")\n cv2.imwrite(path_image_save, gpmm_render_overlay_wo)\n path_image_save = os.path.join(FLAGS.output_dir, name_image_pure + \"_overlayTexOrigin.jpg\")\n # cv2.imwrite(path_image_save, gpmm_render_overlay_texture_wo)\n path_image_save = os.path.join(FLAGS.output_dir, name_image_pure + \"_overlayGeoOrigin.jpg\")\n cv2.imwrite(path_image_save, gpmm_render_overlay_gary_wo)\n path_image_save = os.path.join(FLAGS.output_dir, name_image_pure + \"_overlayLightOrigin.jpg\")\n # cv2.imwrite(path_image_save, gpmm_render_overlay_illu_wo)\n\n if FLAGS.flag_main_save:\n path_image_save = os.path.join(FLAGS.output_dir, name_image_pure + \"_overlayMain.jpg\")\n plt.imsave(path_image_save, result_overlayMain_255)\n path_image_save = os.path.join(FLAGS.output_dir, name_image_pure + \"_overlayTexMain.jpg\")\n #plt.imsave(path_image_gray_main_overlay, gpmm_render_overlay)\n path_image_save = os.path.join(FLAGS.output_dir, name_image_pure + \"_overlayGeoMain.jpg\")\n plt.imsave(path_image_save, result_overlayGeoMain_255)\n path_image_save = os.path.join(FLAGS.output_dir, name_image_pure + \"_overlayLightMain.jpg\")\n #cv2.imwrite(path_image_save, result_overlayLightMain_255)\n\n if FLAGS.flag_overlay_save:\n path_image_save = os.path.join(FLAGS.output_dir, name_image_pure + \"_overlay.jpg\")\n plt.imsave(path_image_save, result_overlay_255)\n path_image_save = os.path.join(FLAGS.output_dir, name_image_pure + \"_overlayTex.jpg\")\n plt.imsave(path_image_save, result_overlayTex_255)\n path_image_save = os.path.join(FLAGS.output_dir, name_image_pure + \"_overlayGeo.jpg\")\n plt.imsave(path_image_save, result_overlayGeo_255)\n path_image_save = os.path.join(FLAGS.output_dir, name_image_pure + \"_overlayLight.jpg\")\n plt.imsave(path_image_save, result_overlayLight_255)\n\n"
},
{
"alpha_fraction": 0.7444373965263367,
"alphanum_fraction": 0.7628734707832336,
"avg_line_length": 41.513511657714844,
"blob_id": "a67c64f093edb7b4115fe58d612adfe532fe0702",
"content_id": "2cee6e04a7df48e6fb4d76028f6ab8ac52b5a915",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1573,
"license_type": "permissive",
"max_line_length": 159,
"num_lines": 37,
"path": "/Recognition-Algorithms/Recognition using KNearestNeighbors/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Overview\n#### Facial Recognition using Open-cv and sklearn KNearestNeighbour model.\n# Dependencies\n- `pip install numpy`\n- `pip install opencv-python`\n- `pip install sklearn`\n# Quick Start\n- Make a folder and then:\n\n git clone https://github.com/akshitagupta15june/Face-X.git\n cd Recognition using KNearestNeighbors\n\n- To collect live data run below command\n \n python live_data_collection.py (to collect live data)\n\n It will ask to enter name of sample you are showing, after inputing show sample to webcam (Make sure there is sufficient light so that webcam recognises it).\n Then press `C` to capture images, and `Q` to exit screen.\n The data will be saved in `face_data.npy` file in same directory.\n \n \n\n\n\n- For pre-processed data.\n \n python Pre_proccessed_data_collection.py\n \n Make sure the samples should be of 640x480 pixels and axis should match exactly. [Warning:The model should be trained with atleast 5 images.]\n\n- After data collection, run below command to train model and recognising images using webcam.\n \n python image_recogniser.py\n \n # Screenshot\n\n\n"
},
{
"alpha_fraction": 0.6234800219535828,
"alphanum_fraction": 0.6350275278091431,
"avg_line_length": 47.02941131591797,
"blob_id": "08cb809af076106b2bee9a73d0dc0bbe24acee76",
"content_id": "00d36b0b25c63d6eb1843e7dd746df19811d3e73",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11431,
"license_type": "permissive",
"max_line_length": 198,
"num_lines": 238,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/geometry/render/lighting.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\nimport tensorflow as tf\nfrom tensorflow.python.framework import ops\n\n\ndef _repeat_1d(tensor, count):\n\n assert tensor.get_shape().ndims == 1\n return tf.reshape(tf.tile(tensor[:, tf.newaxis], tf.convert_to_tensor([1, count])), [-1])\n\n\ndef _prepare_vertices_and_faces(vertices, faces):\n\n if isinstance(vertices, tf.Tensor) == False:\n vertices = tf.convert_to_tensor(vertices, name='vertices')\n faces = tf.convert_to_tensor(faces, name='faces')\n\n if faces.dtype is not tf.int32:\n assert faces.dtype is tf.int64\n faces = tf.cast(faces, tf.int32)\n\n return vertices, faces\n\n\ndef _get_face_normals(vertices, faces):\n\n vertices_ndim = vertices.get_shape().ndims\n v_trans_axis = [vertices_ndim - 2] + list(range(vertices_ndim - 2)) + [vertices_ndim - 1]\n vertices_by_index = tf.transpose(vertices, v_trans_axis) # indexed by vertex-index, *, x/y/z\n vertices_by_face = tf.gather(vertices_by_index, faces) # indexed by face-index, vertex-in-face, *, x/y/z\n normals_by_face = tf.cross(vertices_by_face[:, 1] - vertices_by_face[:, 0], vertices_by_face[:, 2] - vertices_by_face[:, 0]) # indexed by face-index, *, x/y/z\n normals_by_face /= (tf.norm(normals_by_face, axis=-1, keepdims=True) + 1.e-12) # ditto\n return normals_by_face, vertices_by_index\n\n\ndef vertex_normals(vertices, faces, name=None):\n \"\"\"Computes vertex normals for the given meshes.\n\n This function takes a batch of meshes with common topology, and calculates vertex normals for each.\n\n Args:\n vertices: a `Tensor` of shape [*, vertex count, 3] or [*, vertex count, 4], where * represents arbitrarily\n many leading (batch) dimensions.\n faces: an int32 `Tensor` of shape [face count, 3]; each value is an index into the first dimension of `vertices`, and\n each row defines one triangle.\n name: an optional name for the operation\n\n Returns:\n a `Tensor` of shape [*, vertex count, 3], which for each vertex, gives the (normalised) average of the normals of\n all faces that include that vertex\n \"\"\"\n\n # This computes vertex normals, as the average of the normals of the faces each vertex is part of\n # vertices is indexed by *, vertex-index, x/y/z[/w]\n # faces is indexed by face-index, vertex-in-face\n # result is indexed by *, vertex-index, x/y/z\n\n with ops.name_scope(name, 'VertexNormals', [vertices, faces]) as scope:\n\n vertices, faces = _prepare_vertices_and_faces(vertices, faces)\n vertices = vertices[..., :3] # drop the w-coordinate if present\n\n vertices_ndim = vertices.get_shape().ndims\n normals_by_face, vertices_by_index = _get_face_normals(vertices, faces) # normals_by_face is indexed by face-index, *, x/y/z\n\n face_count = tf.shape(faces)[0]\n vbi_shape = tf.shape(vertices_by_index)\n N_extra = tf.reduce_prod(vbi_shape[1:-1]) # this is the number of 'elements' in the * dimensions\n\n assert vertices_ndim in {2, 3} # ** keep it simple for now; in the general case we need a flattened outer product of ranges\n if vertices_ndim == 2:\n extra_indices = []\n else:\n extra_indices = [tf.tile(_repeat_1d(tf.range(N_extra), 3), [face_count * 3])]\n\n sparse_index = tf.cast(\n tf.stack(\n [ # each element of this stack is repeated a number of times matching the things after, then tiled a number of times matching the things before, so that each has the same length\n _repeat_1d(tf.range(face_count, dtype=tf.int32), N_extra * 9),\n _repeat_1d(tf.reshape(faces, [-1]), N_extra * 3)\n ] + extra_indices + [\n tf.tile(tf.constant([0, 1, 2], dtype=tf.int32), tf.convert_to_tensor([face_count * N_extra * 3]))\n ], axis=1\n ),\n tf.int64\n )\n sparse_value = tf.reshape(tf.tile(normals_by_face[:, tf.newaxis, ...], [1, 3] + [1] * (vertices_ndim - 1)), [-1])\n sparse_dense_shape = tf.cast(tf.concat([[face_count], vbi_shape], axis=0), tf.int64)\n normals_by_face_and_vertex = tf.SparseTensor(\n indices=sparse_index,\n values=sparse_value,\n dense_shape=sparse_dense_shape\n ) # indexed by face-index, vertex-index, *, x/y/z\n\n summed_normals_by_vertex = tf.sparse_reduce_sum(normals_by_face_and_vertex, axis=0) # indexed by vertex-index, *, x/y/z\n # summed_normals_by_vertex = tf_render.Print(summed_normals_by_vertex, [summed_normals_by_vertex.shape],\n # message='summed_normals_by_vertex', summarize=16)\n renormalised_normals_by_vertex = summed_normals_by_vertex / (tf.norm(summed_normals_by_vertex, axis=-1, keep_dims=True) + 1.e-12) # ditto\n\n result = tf.transpose(renormalised_normals_by_vertex, range(1, vertices_ndim - 1) + [0, vertices_ndim - 1])\n result.set_shape(vertices.get_shape())\n return result\n\n\ndef _static_map_fn(f, elements):\n assert elements.get_shape()[0].value is not None\n return tf.stack([f(elements[index]) for index in xrange(int(elements.get_shape()[0]))])\n\n\ndef vertex_normals_pre_split_fixtopo(vertices, faces, ver_ref_face, ver_ref_face_index, ver_ref_face_num, name=None):\n \"\"\"\n :param vertices: batch size, vertex-index, x/y/z[/w]\n :param faces: face-index, vertex-in-face, tf_render.int32\n :param ver_ref_face: vertex-index*flat\n :param ver_ref_face_index: vertex-index*flat\n :param ver_ref_face_num: vertex-index\n :param name:\n :return:\n \"\"\"\n \"\"\"Computes vertex normals for the given pre-split meshes.\n\n This function is identical to `vertex_normals`, except that it assumes each vertex is used by just one face, which\n allows a more efficient implementation.\n \"\"\"\n\n # This is identical to vertex_normals, but assumes each vertex appears in exactly one face, e.g. due to having been\n # processed by split_vertices_by_face\n # vertices is indexed by\n # faces is indexed by\n # result is indexed by *\n with ops.name_scope(name, 'VertexNormalsPreSplit', [vertices, faces]) as scope:\n vertices_num = int(vertices.get_shape()[1])\n vertices, faces = _prepare_vertices_and_faces(vertices, faces)\n normals_by_face, _ = _get_face_normals(vertices, faces) # indexed by face-index, batch_size, x/y/z\n normals_by_face = tf.transpose(normals_by_face, perm=[1, 0, 2])\n\n ver_ref_face_num_tile = tf.tile(tf.expand_dims(ver_ref_face_num, -1), multiples=[1, 3])\n\n list_normals_by_ver = []\n for b in range(vertices.shape[0]):\n normals_by_face_b = normals_by_face[b]\n normals_by_vertex_flat_b = tf.gather(normals_by_face_b, ver_ref_face)\n\n nv = tf.scatter_add(\n tf.Variable(tf.zeros(shape=[vertices_num, 3]), trainable=False),\n ver_ref_face_index,\n normals_by_vertex_flat_b\n )\n\n nv = nv / (ver_ref_face_num_tile + 1e-6)\n nv = nv / (tf.norm(nv, axis=-1, keep_dims=True) + 1e-12) # ditto\n\n list_normals_by_ver.append(nv)\n\n normals_by_vertex = tf.stack(list_normals_by_ver)\n return normals_by_vertex\n\n\ndef vertex_normals_pre_split(vertices, faces, name=None, static=False):\n \"\"\"Computes vertex normals for the given pre-split meshes.\n\n This function is identical to `vertex_normals`, except that it assumes each vertex is used by just one face, which\n allows a more efficient implementation.\n \"\"\"\n\n # This is identical to vertex_normals, but assumes each vertex appears in exactly one face, e.g. due to having been\n # processed by split_vertices_by_face\n # vertices is indexed by *, vertex-index, x/y/z[/w]\n # faces is indexed by face-index, vertex-in-face\n # result is indexed by *, vertex-index, x/y/z\n\n with ops.name_scope(name, 'VertexNormalsPreSplit', [vertices, faces]) as scope:\n\n vertices, faces = _prepare_vertices_and_faces(vertices, faces)\n vertices = vertices[..., :3] # drop the w-coordinate if present\n face_count = int(faces.get_shape()[0]) if static else tf.shape(faces)[0]\n\n normals_by_face, _ = _get_face_normals(vertices, faces) # indexed by face-index, *, x/y/z\n normals_by_face_flat = tf.reshape(\n tf.transpose(normals_by_face, range(1, normals_by_face.get_shape().ndims - 1) + [0, normals_by_face.get_shape().ndims - 1]),\n [-1, face_count, 3]\n ) # indexed by prod(*), face-index, x/y/z\n\n normals_by_vertex_flat = (_static_map_fn if static else tf.map_fn)(\n lambda normals_for_iib: tf.scatter_nd(\n indices=tf.reshape(faces, [-1, 1]),\n updates=tf.reshape(tf.tile(normals_for_iib[:, tf.newaxis, :], [1, 3, 1]), [-1, 3]),\n shape=tf.shape(vertices)[-2:]\n ), normals_by_face_flat\n )\n normals_by_vertex = tf.reshape(normals_by_vertex_flat, tf.shape(vertices))\n\n return normals_by_vertex\n\n\ndef split_vertices_by_face(vertices, faces, name=None):\n \"\"\"Returns a new mesh where each vertex is used by exactly one face.\n\n This function takes a batch of meshes with common topology as input, and also returns a batch of meshes\n with common topology. The resulting meshes have the same geometry, but each vertex is used by exactly\n one face.\n\n Args:\n vertices: a `Tensor` of shape [*, vertex count, 3] or [*, vertex count, 4], where * represents arbitrarily\n many leading (batch) dimensions.\n faces: an int32 `Tensor` of shape [face count, 3]; each value is an index into the first dimension of `vertices`, and\n each row defines one triangle.\n\n Returns:\n a tuple of two tensors `new_vertices, new_faces`, where `new_vertices` has shape [*, V, 3] or [*, V, 4], where\n V is the new vertex count after splitting, and `new_faces` has shape [F, 3] where F is the new face count after\n splitting.\n \"\"\"\n\n # This returns an equivalent mesh, with vertices duplicated such that there is exactly one vertex per face it is used in\n # vertices is indexed by *, vertex-index, x/y/z[/w]\n # faces is indexed by face-index, vertex-in-face\n # Ditto for results\n\n with ops.name_scope(name, 'SplitVerticesByFace', [vertices, faces]) as scope:\n\n vertices, faces = _prepare_vertices_and_faces(vertices, faces)\n\n vertices_shape = tf.shape(vertices)\n face_count = tf.shape(faces)[0]\n\n flat_vertices = tf.reshape(vertices, [-1, vertices_shape[-2], vertices_shape[-1]])\n new_flat_vertices = tf.map_fn(lambda vertices_for_iib: tf.gather(vertices_for_iib, faces), flat_vertices)\n new_vertices = tf.reshape(new_flat_vertices, tf.concat([vertices_shape[:-2], [face_count * 3, vertices_shape[-1]]], axis=0))\n\n new_faces = tf.reshape(tf.range(face_count * 3), [-1, 3])\n\n static_face_count = faces.get_shape().dims[0] if faces.get_shape().dims is not None else None\n static_new_vertex_count = static_face_count * 3 if static_face_count is not None else None\n if vertices.get_shape().dims is not None:\n new_vertices.set_shape(vertices.get_shape().dims[:-2] + [static_new_vertex_count] + vertices.get_shape().dims[-1:])\n new_faces.set_shape([static_face_count, 3])\n\n return new_vertices, new_faces"
},
{
"alpha_fraction": 0.7482394576072693,
"alphanum_fraction": 0.7623239159584045,
"avg_line_length": 27.399999618530273,
"blob_id": "c41069fdd73ea9ebbb9fcd1c910226b2b4bde459",
"content_id": "92b482eedc70d9a4b183e4c3d0ee3e447de0d2ac",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 568,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 20,
"path": "/Awesome-face-operations/Glitter Filter/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Applying Glitter filter on an image.\n\nConverting an image into glitter filter image using OpenCv, Matplotlib and Numpy.\n\n## Steps:\n* Firstly imported the required libraries which are Numpy, Matplotlib, Os and Cv2.\n* Read the input image/Real image using cv2\n\n## Methods Used\n* Used Bilateral Filter\n* Followed by Median Blur\n* And at last used Bitwise or\n* Finally converted the image into glitter filtered image\n\n\n## Original Image\n<img src=\"Images/Photo.jpg\" height=\"500px\">\n\n## Glitter Filtered Image\n<img src=\"Images/(Glitter Filtered)Photo.jpg\" height=\"500px\">\n"
},
{
"alpha_fraction": 0.5642670392990112,
"alphanum_fraction": 0.6200997829437256,
"avg_line_length": 31.620155334472656,
"blob_id": "82ea60bdf1e73706b9ff8ee7bfb475edc839cab6",
"content_id": "85f2018bf5a54d7f73d2dd03f9d50afcae4ef557",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4209,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 129,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/geometry/face_align/generate_align_self.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n# system\nfrom __future__ import print_function\n\nimport os\nimport sys\n\n# third party\n\n#\n\n# self\n_curr_path = os.path.abspath(__file__) # /home/..../face\n_cur_dir = os.path.dirname(_curr_path) # ./\n_tf_dir = os.path.dirname(_cur_dir) # ./\n_tool_data_dir = os.path.dirname(_tf_dir) # ../\n_deep_learning_dir = os.path.dirname(_tool_data_dir) # ../\nprint(_deep_learning_dir)\nsys.path.append(_deep_learning_dir) # /home/..../pytorch3d\n\nfrom tools_data.face_common.gafr_std_align import cvrt_300w_to_CelebA\nfrom tools_data.face_common.faceIO import write_self_lm\n\nfrom tfmatchd.face.gpmm.bfm09_tf import *\nfrom tfmatchd.face.geometry.camera.rotation import *\n\ndef set_ext_mesh_nose_centre_radio(h_lrgp, intrinsic_mtx, mesh_tri, image_height, image_radio_face):\n idx_nose = h_lrgp.idx_lm68_np[34-1]\n idx_low = h_lrgp.idx_lm68_np[9-1]\n\n\n mesh_c = mesh_tri.vertices[idx_nose] # mm\n mesh_low = mesh_tri.vertices[idx_low]\n\n # Cam\n max_xyz_model = vertex_y_max(mesh_tri)\n min_xyz_model = vertex_y_min(mesh_tri)\n y_mid = (max_xyz_model[1] + mesh_low[1]) / 2.0\n z_mid = (max_xyz_model[2] + mesh_low[2]) / 2.0\n\n k_eye_dis = intrinsic_mtx[4] * (max_xyz_model[1] - mesh_low[1]) / (image_height * image_radio_face)\n print(k_eye_dis)\n\n cam_front_eye = [mesh_c[0], y_mid, z_mid + k_eye_dis]\n cam_front_center = [mesh_c[0], y_mid, z_mid]\n cam_front_up = [0.0, 1.0, 0.0]\n\n ecu = [cam_front_eye, cam_front_center, cam_front_up]\n ecu = tf.constant(ecu)\n\n mtx_rot, t = ExtMtxBatch.create_location_batch(ecu).rotMtx_location(ecu)\n rot = RotationMtxBatch.create_matrixRot_batch(mtx_rot).eular_rotMtx(mtx_rot)\n rot = tf.expand_dims(rot, 0)\n t = tf.expand_dims(t, 0)\n\n # rx, ry, rz to rz, ry, rx\n rot = tf.reverse(rot, axis=[1])\n\n pose = tf.concat([rot, t], axis=1)\n\n return pose\n\n\nif __name__ == '__main__':\n path_gpmm = '/home/jshang/SHANG_Data/ThirdLib/BFM2009/bfm09_dy_gyd_presplit.h5'\n h_lrgp = BFM_TF(path_gpmm, 80, 2)\n tri = h_lrgp.get_mesh_mean()\n #tri.show()\n tri.export(\"/home/jshang/SHANG_Data/ThirdLib/BFM2009/bfm09_mean.ply\")\n\n \"\"\"\n build graph\n \"\"\"\n ver, ver_color, _, _ = h_lrgp.get_random_vertex_color_batch()\n ver_color = tf.cast(ver_color*255.0, dtype=tf.uint8)\n\n lm3d_mean = h_lrgp.get_lm3d_mean()\n lm3d_mean = tf.expand_dims(lm3d_mean, 0)\n\n # test camera\n from tfmatchd.face.deep_3dmm import build_train_graph_3dmm_frustrum, build_train_graph_3dmm_camera\n\n intrinsics_single_np = [800.000000, 0., 112.000000, 0., 800.000000, 112.000000, 0., 0., 1.]\n intrinsics_single = tf.constant(intrinsics_single_np, shape=[1, 3, 3])\n gpmm_frustrum = build_train_graph_3dmm_frustrum(intrinsics_single)\n\n\n # calculate main pose\n defined_pose_main = set_ext_mesh_nose_centre_radio(h_lrgp, intrinsics_single_np, tri, 224, 0.75)\n\n #defined_pose_main = tf.constant([0.000000, 0.000000, 3.141593, 0.17440447, 9.1053238, 5748.0352], shape=[1, 6]) now\n #defined_pose_main = tf.constant([0.000000, 0.000000, 3.141593, 0.088619, 8.519336, 5644.714844], shape=[1, 6]) old\n\n gpmm_tar_ext, gpmm_tar_proj, gpmm_tar_mv, gpmm_tar_eye = \\\n build_train_graph_3dmm_camera(intrinsics_single, defined_pose_main)\n\n # test lm\n from tfmatchd.face.geometry.camera_distribute.camera_utils import project3d_batch\n\n lm2d = project3d_batch(lm3d_mean, gpmm_tar_proj[0]) # bs, ver_num, xy\n\n \"\"\"\n run\n \"\"\"\n sv = tf.train.Supervisor()\n config = tf.ConfigProto()\n config.gpu_options.allow_growth = True\n with sv.managed_session(config=config) as sess:\n fetches = {\n \"defined_pose_main\": defined_pose_main,\n \"lm2d\":lm2d\n }\n \"\"\"\n ********************************************* Start Trainning *********************************************\n \"\"\"\n results = sess.run(fetches)\n\n defined_pose_main = results[\"defined_pose_main\"]\n lm2d = results[\"lm2d\"]\n\n\n # lm\n lm2d = lm2d[0]\n lm2d_5 = cvrt_300w_to_CelebA(lm2d)\n\n print(defined_pose_main)\n path_std_lm_pose = \"./std_lm_pose.txt\"\n with open(path_std_lm_pose, 'w') as f_std:\n write_self_lm(f_std, lm2d)\n write_self_lm(f_std, lm2d_5)\n"
},
{
"alpha_fraction": 0.6268064975738525,
"alphanum_fraction": 0.6365967392921448,
"avg_line_length": 64.01515197753906,
"blob_id": "da16b6565f3ee8f71e6d0d31dadef7ce44c33654",
"content_id": "88221e4aaa6953dbbf9ed6f02a91adb803d34740",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4290,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 66,
"path": "/Face Reconstruction/Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model/train_options.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import argparse\nimport os\n\nclass TrainOptions():\n def __init__(self):\n self.initialized = False\n\n def initialize(self, parser):\n self.initialized = True\n parser.add_argument('--landmark_num', type=int, default=68, help='landmark number')\n parser.add_argument('--vertex_num', type=int, default=6144, help='vertex number of 3D mesh')\n parser.add_argument('--device_num', type=int, default=0, help='gpu id')\n parser.add_argument('--data_path', type=str, default=\"data/\", help='path of related data')\n if_train_parser = parser.add_mutually_exclusive_group(required=False)\n if_train_parser.add_argument('--train', dest='if_train', action='store_true') # train mode\n if_train_parser.add_argument('--no_train', dest='if_train', action='store_false') # test mode\n parser.set_defaults(if_train=True)\n parser.add_argument('--train_image_path', type=str, default=\"exp/train_images.txt\", help='train images path')\n parser.add_argument('--train_landmark_path', type=str, default=\"exp/train_landmarks.txt\",\n help='train landmarks path')\n parser.add_argument('--train_vertex_path', type=str, default=\"exp/train_vertex.txt\",\n help='train vertex path')\n parser.add_argument('--batch_size', type=int, default=32, help='train batch size')\n parser.add_argument('--num_workers', type=int, default=6, help='threads for loading data')\n parser.add_argument('--test_image_path', type=str, default=\"exp/test_images.txt\", help='test images path')\n parser.add_argument('--test_landmark_path', type=str, default=\"exp/test_landmarks.txt\",\n help='test landmarks path')\n parser.add_argument('--test_lrecord_path', type=str, default=\"exp/test_lrecord.txt\",\n help='path to save estimated landmarks')\n parser.add_argument('--test_vrecord_path', type=str, default=\"exp/test_vrecord.txt\",\n help='path to save estimated coordinates of vertices')\n parser.add_argument('--resnet34_lr', type=float, default=1e-4, help='learning rate of ResNet34')\n parser.add_argument('--mynet1_lr', type=float, default=1e-5,\n help='learning rate of the first and second FC layers of MyNet')\n parser.add_argument('--mynet2_lr', type=float, default=1e-8,\n help='learning rate of the last FC layer of MyNet')\n use_premodel_parser = parser.add_mutually_exclusive_group(required=False)\n use_premodel_parser.add_argument('--premodel', dest='use_premodel', action='store_true') # use pretrained model\n use_premodel_parser.add_argument('--no_premodel', dest='use_premodel', action='store_false') # no pretrained model\n parser.set_defaults(use_premodel=True)\n parser.add_argument('--model1_path', type=str, default=\"model/resnet34_adam.pth\",\n help='the pretrained model of ResNet34 structure')\n parser.add_argument('--model2_path', type=str, default=\"model/mynet_adam.pth\",\n help='the pretrained model of MyNet structure')\n parser.add_argument('--total_epoch', type=int, default=1000, help='number of total training epoch')\n parser.add_argument('--lambda_land', type=float, default=1, help='weight of landmark loss')\n parser.add_argument('--lambda_srt', type=float, default=1e-1, help='weight of srt loss')\n parser.add_argument('--test_frequency', type=int, default=100, help='frequency for testing')\n parser.add_argument('--save_frequency', type=int, default=200, help='frequency for saving models')\n parser.add_argument('--save_model_path', type=str, default=\"record/\", help='path to save models')\n return parser\n\n def gather_options(self):\n # initialize parser with basic options\n if not self.initialized:\n parser = argparse.ArgumentParser(\n formatter_class=argparse.ArgumentDefaultsHelpFormatter)\n parser = self.initialize(parser)\n self.parser = parser\n return parser.parse_args()\n \n def parse(self):\n\n opt = self.gather_options()\n self.opt = opt\n return self.opt"
},
{
"alpha_fraction": 0.6023622155189514,
"alphanum_fraction": 0.625984251499176,
"avg_line_length": 19.594594955444336,
"blob_id": "ff59aa51074135513ae7cb0f1ebc1432d06a9fab",
"content_id": "da6cedaf4c95cb3dc17a960def090a65b13efd39",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 762,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 37,
"path": "/Face Reconstruction/Face Alignment in Full Pose Range/Dockerfile",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "FROM python:3.6-slim-stretch\n\nRUN apt-get -y update\nRUN apt-get install -y --fix-missing \\\n build-essential \\\n cmake \\\n gfortran \\\n git \\\n wget \\\n curl \\\n libjpeg-dev \\\n liblapack-dev \\\n libswscale-dev \\\n pkg-config \\\n python3-numpy \\\n zip \\\n libboost-dev \\\n libboost-all-dev \\\n libsm6 \\\n libxext6 \\\n libfontconfig1 \\\n libxrender1 \\\n && apt-get clean && rm -rf /tmp/* /var/tmp/*\n\nADD requirements.txt /root/requirements.txt\n\nRUN pip3.6 install torch\n\nRUN export CPLUS_INCLUDE_PATH=/usr/local/include/python3.6m && \\\n pip3.6 install --upgrade pip==9.0.3 && \\\n pip3.6 install -r /root/requirements.txt\n\nVOLUME [\"/root\"]\n\nWORKDIR /root\n\nENTRYPOINT [\"python\", \"main.py\", \"-f\", \"samples/emma_input.jpg\"]\n"
},
{
"alpha_fraction": 0.7191752791404724,
"alphanum_fraction": 0.7538144588470459,
"avg_line_length": 47.5,
"blob_id": "e9f449ee6f5a595719b2cb8d3470bf07f10a672b",
"content_id": "276bb341e50b77293aa9b7ef55a57d7bf032386f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2425,
"license_type": "permissive",
"max_line_length": 226,
"num_lines": 50,
"path": "/Face-Emotions-Recognition/Emotion-recognition-with-GUI/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Emotion Detection GUI\nA deep learning project that aims at detecting using Human emotions.\n\n# Dataset Used\nThe data set i used was FER2013 competition data set for emotion detection. The dataset has 35685 images. All of these images are of size 48x48 pixel and are in grayscale. It contains images of 7 categories of emotions. </br>\n\nFER 2013 emotions data - https://www.kaggle.com/ananthu017/emotion-detection-fer\n\n# Approach\n* I started off by using the FER2013 data set and carried out some data preprocessing and data augmentation on it.\n* I experimented with many models - VGG16, ResNet, Xception and so on. None of them seemed to work very well.\n* I then went on to build my own custom model. The model was built using Tensorflow and Keras and had the following layers - \n * Conv2D \n * MaxPooling2D\n * Batch Normalization\n * Dense\n * Flatten\n * Dropout \n* After lot of experiments with custom architectures, i was able to attain a model that gave us decent results.\n\n# Results\nThe model was trained for 60 epochs and had a batch size of 64. We were able to achieve an accuracy of 71% on training set and a validation accuracy of 65%.\n\n# Image gallery\n\n* Main GUI window without result - \n<p align=\"center\">\n<img src=\"https://github.com/AM1CODES/Face-X/blob/master/Face-Emotions-Recognition/Emotion-recognition-with-GUI/images/Capture.PNG\" alt=\"drawing\" width=\"450\"/>\n</p>\n\n* Some Model results - \n<p align=\"center\">\n<img src=\"https://github.com/AM1CODES/Face-X/blob/master/Face-Emotions-Recognition/Emotion-recognition-with-GUI/images/Screenshot%20(154).png\" alt=\"drawing\" width=\"450\"/>\n</p>\n<p align=\"center\">\n<img src=\"https://github.com/AM1CODES/Face-X/blob/master/Face-Emotions-Recognition/Emotion-recognition-with-GUI/images/Screenshot%20(155).png\" alt=\"drawing\" width=\"450\"/>\n</p>\n<p align=\"center\">\n<img src=\"https://github.com/AM1CODES/Face-X/blob/master/Face-Emotions-Recognition/Emotion-recognition-with-GUI/images/Screenshot%20(156).png\" alt=\"drawing\" width=\"450\"/>\n</p>\n\n* Main GUI window with result -\n<p align=\"center\">\n<img src=\"https://github.com/AM1CODES/Face-X/blob/master/Face-Emotions-Recognition/Emotion-recognition-with-GUI/images/Capture%20-%202.PNG\" alt=\"drawing\" width=\"450\"/>\n</p>\n\n# Model\n\nThe model was a bit big so i uploaded it in a drive folder and you can get it via this link - \nhttps://drive.google.com/drive/folders/10pmRx3ZVEt1r2zEWsAtiP8BJGwTgH0OF?usp=sharing\n"
},
{
"alpha_fraction": 0.7187761664390564,
"alphanum_fraction": 0.7305113077163696,
"avg_line_length": 40.120689392089844,
"blob_id": "10b8b010e4bf17cf8327bc0cc546f7caea738948",
"content_id": "86a9a2bb46f1cb93175ed515464b3ed50a81333a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2410,
"license_type": "permissive",
"max_line_length": 219,
"num_lines": 58,
"path": "/Facial Recognition Attendance Management System/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n## About:🤔💭\n- Facial recognition attendance management system. It makes use of openCV and python to recognise face. \n\n- User has to:\n\n - Click on 'Automatic attendance'.\n - Enter the subject name.\n - Click on 'Fill attendance' and wait for camera window to open.\n - It will recognise the face and display enrollment number and name.\n - Click on 'Fill attendence'.\n\n----\n\n### List TO-DO📄:\n\n- [x] Check whether your system has a web cam or not. If not, then get one camera for face recognisation.\n- [x] Install [Python.](https://www.howtogeek.com/197947/how-to-install-python-on-windows/)\n- [x] Install [Dependencies.](https://github.com/smriti1313/Face-X/blob/master/Facial%20Recognition%20Attendance%20Management%20System/README.md#dependencies)\n- [x] [Download](https://www.wikihow.com/Download-a-GitHub-Folder) [Face-X](https://github.com/akshitagupta15june/Face-X) and open `Facial Recognition Attendance Management System folder`.\n- [x] Create a **TrainingImage** folder in this folder.\n- [x] Open a **run.py** and change the all paths with your system path.\n- [x] Run run.py.\n\n----\n\n### Requirements:🧱🧱\n\n|Hardware|Software|\n|----|-----|\n|web cam or camera|python|\n\n----\n\n### Dependencies🔧🛠:\nOpen terminal and write:\n\n* `pip install Pillow`\n* `pip install opencv-python`\n* `pip install pandas`\n* `pip install pymysql`\n* `pip install opencv-contrib-python`\n* Tkinter already comes with python when python is downloaded.\n\n----\n\n## Testing🧰:\n\n- After running, you need to give your face data to system so `enter your ID` and `name` in box. \n- Then click on `Take Images` button.\n- It will collect 200 images of your faces and will save it in `TrainingImage folder`.\n- After that we need to train a model (to train a model click on `Train Image` button.)\n- It will take 5-10 minutes for training(for 10 person data).\n- After training click on `Automatic Attendance` ,it can fill attendace by your face using our trained model (model will save in `TrainingImageLabel`). It will create .csv file of attendance according to time & subject.\n- You can store data in database (install wampserver),change the DB name according to your in `run.py`.\n- `Manually Fill Attendace Button` in UI is for fill a manually attendance (without face recognition),it's also create a .csv and store in a database.\n\n\n>For better understanding watch [this.](https://www.youtube.com/watch?v=dXViSRRydRs)\n"
},
{
"alpha_fraction": 0.7730756402015686,
"alphanum_fraction": 0.7840719819068909,
"avg_line_length": 57.80392074584961,
"blob_id": "4d1997f93ccf4b9d7901647cb6f6d642ac6fbb66",
"content_id": "9f495616351fcf983fbb2d80d0f5a9ae4ed4a4e8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3009,
"license_type": "permissive",
"max_line_length": 334,
"num_lines": 51,
"path": "/Recognition-Algorithms/Recognition_using_mtcnn/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "## Quick Start\n- Clone this repository.\n`git clone https://github.com/akshitagupta15june/Face-X.git`\n- Change Directory.\n`cd Recognition_using_mtcnn`\n- Run File.\n`python mtcnn.py`\n## Dependencies\n- `pip install tensorflow`\n- `pip install mtcnn`\n- `pip install matplotlib`\n# Screenshots\n\n\n\n\n# Face Recognition with MTCNN\n\nDeep learning advancements in recent years have enabled widespread use of face recognition technology. This project tries to explain deep learning models used for face recognition and introduces a simple framework for creating and using a custom face recognition system.\n\nFace recognition can be divided into multiple steps. The image below shows an example of a face recognition pipeline.\n\n\n\n# What is MTCNN:\n\nMulti-Task Cascaded Convolutional Neural Networks(MTCNN) is a neural network which detects faces and facial landmarks on images.\n\n## Features of MTCNN:\n\n1. Consists of 3 neural networks connected in a cascade.\n2. One of the most popular and most accurate face detection tools today.\n\n# How to Implement MTCNN:\n\n1. After cloning the repo from github (link here), open up and run mtcnn.py which produces the image:\n \n\n2. As seen in the image above, the neural network detects individual faces, locates facial landmarks (i.e. two eyes, nose, and endpoints of the mouth), and draws a bounding box around the face. The code from mtcnn.py supports this.\n\n## How does the algorithm works:\n\n1. First, MTCNN. Checking ./mtcnn/mtcnn.py showed the MTCNN class, which performed the facial detection.\n2. Then, a detector of the MTCNN class was created, and the image read in with cv2.imread. The detect_faces function within the MTCNN class is called, to “detect faces” within the image we passed in and output the faces in “result”.\n3.Now we draw the rectangle of the bounding box by passing in the coordinates, the color (RGB), and the thickness of the box outline. Here, bounding_box[0] and bounding_box[1] represent the x and y coordinates of the top left corner, and bounding_box[2] and bounding_box[3] represent the width and the height of the box, respectively.\n4. Similarly, we can draw the points of the facial landmarks by passing in their coordinates, the radius of the circle, and the thickness of the line.\n\n\n# Concluding statements:\n\nRunning this new file, one can see that the MTCNN network can indeed run in real time. boxing his/her face and marking out features. \n\n"
},
{
"alpha_fraction": 0.600126326084137,
"alphanum_fraction": 0.6146557331085205,
"avg_line_length": 51.733333587646484,
"blob_id": "de73a8e886fcc50b70a6b23c3e4c98338413a65f",
"content_id": "079e4e0548febd87751d8f3033ab7916986f83a9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1583,
"license_type": "permissive",
"max_line_length": 137,
"num_lines": 30,
"path": "/Face Reconstruction/RingNet for Face Reconstruction/util/using_flame_parameters.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n# This function Netralize the pose and expression of the predicted mesh and generates a template mesh with only the identity information\nimport numpy as np\nimport chumpy as ch\nfrom smpl_webuser.serialization import load_model\nfrom smpl_webuser.verts import verts_decorated\nfrom psbody.mesh import Mesh\n\n\ndef make_prdicted_mesh_neutral(predicted_params_path, flame_model_path):\n params = np.load(predicted_params_path, allow_pickle=True)\n params = params[()]\n pose = np.zeros(15)\n expression = np.zeros(100)\n shape = np.hstack((params['shape'], np.zeros(300-params['shape'].shape[0])))\n flame_genral_model = load_model(flame_model_path)\n generated_neutral_mesh = verts_decorated(ch.array([0.0,0.0,0.0]),\n ch.array(pose),\n ch.array(flame_genral_model.r),\n flame_genral_model.J_regressor,\n ch.array(flame_genral_model.weights),\n flame_genral_model.kintree_table,\n flame_genral_model.bs_style,\n flame_genral_model.f,\n bs_type=flame_genral_model.bs_type,\n posedirs=ch.array(flame_genral_model.posedirs),\n betas=ch.array(np.hstack((shape,expression))),#betas=ch.array(np.concatenate((theta[0,75:85], np.zeros(390)))), #\n shapedirs=ch.array(flame_genral_model.shapedirs),\n want_Jtr=True)\n neutral_mesh = Mesh(v=generated_neutral_mesh.r, f=generated_neutral_mesh.f)\n return neutral_mesh\n"
},
{
"alpha_fraction": 0.7204724550247192,
"alphanum_fraction": 0.7381889820098877,
"avg_line_length": 23.047618865966797,
"blob_id": "0208687e9e2ae3a7966c0e65e0225631a2b0d28d",
"content_id": "9cdad5568df266892bd98aa8360c1cf18412fca1",
"detected_licenses": [
"BSD-3-Clause",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 508,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 21,
"path": "/Awesome-face-operations/Ghost Image/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Converting an image into ghost image.\n\nUsed OpenCv and Numpy to convert an image into ghost image.\n\n## Steps:\n* Imported the required libraries ( Numpy, Matplotlib, Os, Cv2)\n* Read the input image using cv2\n\n### Methods applied Using Cv2\n* Used Bilateral Filter\n* Used Median Blur\n* Used Adaptive Threshold\n* Used Bitwise Xor\n* Finally converted the image into ghost image\n\n\n## Original Image\n<img src=\"Images/photo.jpg\" height=\"300px\">\n\n## Ghost Image\n<img src=\"Images/Ghost Photo.jpg\" height=\"300px\">\n\n\n\n"
},
{
"alpha_fraction": 0.7523511052131653,
"alphanum_fraction": 0.7596656084060669,
"avg_line_length": 30.933332443237305,
"blob_id": "777cffda6eb9eaf06f2fa634ac2853b2ca288378",
"content_id": "c6989f587acafb561ff05dca505e1e10ad82cd69",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 957,
"license_type": "permissive",
"max_line_length": 219,
"num_lines": 30,
"path": "/Virtual_makeover/makeup/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "## Quick Start\n- Clone this repository-\n`git clone https://github.com/akshitagupta15june/Face-X.git`\n- Change Directory\n\n `cd Virtual_makeover`\n- Run file-\n`python digital_makeup.py`\n\n## Explaination\nThis is simply done by using PIL (Python Image Library) and face_recognition libraries. With just five steps, code works like this:\n\nStep 1: Load the jpg file into a numpy array.\n\nStep 2: Find all facial features in all the faces in the image.\n\nStep 3: Load the image into a Python Image Library object so that we can draw on the top of image.\n\nStep 4: Create a PIL drawing object to be able to draw lines later.\n\nStep 5: The face landmark detection model returns these features: chin, left_eyebrow, right_eyebrow, nose_bridge, nose_tip, left_eye, right_eye. Thus, draw a line over the eyebrows and the lips and show the final image.\n\n## Screenshots\nOriginal Image:\n\n\n\nMakeover Image:\n\n"
},
{
"alpha_fraction": 0.5994898080825806,
"alphanum_fraction": 0.6206632852554321,
"avg_line_length": 36.33333206176758,
"blob_id": "3673a5e5c3975dfa34ed7ff1eaa45b4c72d61729",
"content_id": "8968cffd2f9afb0d5d41a882baf0f80a989ef93a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3920,
"license_type": "permissive",
"max_line_length": 178,
"num_lines": 105,
"path": "/Face Reconstruction/3D Face Reconstruction with Weakly-Supervised Learning/recon_demo.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import os\nimport glob\nimport torch\nimport numpy as np\nfrom models.resnet_50 import resnet50_use\nfrom load_data import transfer_BFM09, BFM, load_img, Preprocess, save_obj\nfrom reconstruction_mesh import reconstruction, render_img, transform_face_shape, estimate_intrinsic\n\n\ndef recon():\n # input and output folder\n image_path = r'dataset'\n save_path = 'output'\n if not os.path.exists(save_path):\n os.makedirs(save_path)\n img_list = glob.glob(image_path + '/**/' + '*.png', recursive=True)\n img_list += glob.glob(image_path + '/**/' + '*.jpg', recursive=True)\n\n # read BFM face model\n # transfer original BFM model to our model\n if not os.path.isfile('BFM/BFM_model_front.mat'):\n transfer_BFM09()\n\n device = 'cuda:0' if torch.cuda.is_available() else 'cpu:0'\n bfm = BFM(r'BFM/BFM_model_front.mat', device)\n\n # read standard landmarks for preprocessing images\n lm3D = bfm.load_lm3d()\n\n model = resnet50_use().to(device)\n model.load_state_dict(torch.load(r'models\\params.pt'))\n model.eval()\n\n for param in model.parameters():\n param.requires_grad = False\n\n for file in img_list:\n # load images and corresponding 5 facial landmarks\n img, lm = load_img(file, file.replace('jpg', 'txt'))\n\n # preprocess input image\n input_img_org, lm_new, transform_params = Preprocess(img, lm, lm3D)\n\n input_img = input_img_org.astype(np.float32)\n input_img = torch.from_numpy(input_img).permute(0, 3, 1, 2)\n # the input_img is BGR\n input_img = input_img.to(device)\n\n arr_coef = model(input_img)\n\n coef = torch.cat(arr_coef, 1)\n\n # reconstruct 3D face with output coefficients and face model\n face_shape, face_texture, face_color, landmarks_2d, z_buffer, angles, translation, gamma = reconstruction(coef, bfm)\n\n fx, px, fy, py = estimate_intrinsic(landmarks_2d, transform_params, z_buffer, face_shape, bfm, angles, translation)\n\n face_shape_t = transform_face_shape(face_shape, angles, translation)\n face_color = face_color / 255.0\n face_shape_t[:, :, 2] = 10.0 - face_shape_t[:, :, 2]\n\n images = render_img(face_shape_t, face_color, bfm, 300, fx, fy, px, py)\n images = images.detach().cpu().numpy()\n images = np.squeeze(images)\n\n path_str = file.replace(image_path, save_path)\n path = os.path.split(path_str)[0]\n if os.path.exists(path) is False:\n os.makedirs(path)\n\n from PIL import Image\n images = np.uint8(images[:, :, :3] * 255.0)\n # init_img = np.array(img)\n # init_img[images != 0] = 0\n # images += init_img\n img = Image.fromarray(images)\n img.save(file.replace(image_path, save_path).replace('jpg', 'png'))\n\n face_shape = face_shape.detach().cpu().numpy()\n face_color = face_color.detach().cpu().numpy()\n\n face_shape = np.squeeze(face_shape)\n face_color = np.squeeze(face_color)\n save_obj(file.replace(image_path, save_path).replace('.jpg', '_mesh.obj'), face_shape, bfm.tri, np.clip(face_color, 0, 1.0)) # 3D reconstruction face (in canonical view)\n\n from load_data import transfer_UV\n from utils import process_uv\n # loading UV coordinates\n uv_pos = transfer_UV()\n tex_coords = process_uv(uv_pos.copy())\n tex_coords = torch.tensor(tex_coords, dtype=torch.float32).unsqueeze(0).to(device)\n\n face_texture = face_texture / 255.0\n images = render_img(tex_coords, face_texture, bfm, 600, 600.0 - 1.0, 600.0 - 1.0, 0.0, 0.0)\n images = images.detach().cpu().numpy()\n images = np.squeeze(images)\n\n # from PIL import Image\n images = np.uint8(images[:, :, :3] * 255.0)\n img = Image.fromarray(images)\n img.save(file.replace(image_path, save_path).replace('.jpg', '_texture.png'))\n\n\nif __name__ == '__main__':\n recon()\n"
},
{
"alpha_fraction": 0.5867944359779358,
"alphanum_fraction": 0.6214057803153992,
"avg_line_length": 24.828571319580078,
"blob_id": "96ba21d58988905f53580c45d2df8b0835456f1e",
"content_id": "ba8e75e3c540a9edef78654e29fabcf8a91bf63a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1878,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 70,
"path": "/Recognition-using-IOT/DETECTION AND RECOGNITION USING RASPBERRY PI/face.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Import OpenCV2 for image processing\r\nimport cv2\r\n\r\n# Import numpy for matrices calculations\r\nimport numpy as np\r\n\r\n# Create Local Binary Patterns Histograms for face recognization\r\nrecognizer = cv2.face.createLBPHFaceRecognizer()\r\n\r\n# Load the trained mode\r\nrecognizer.load('trainer/trainer.yml')\r\n\r\n# Load prebuilt model for Frontal Face\r\ncascadePath = \"haarcascade_frontalface_default.xml\"\r\n\r\n# Create classifier from prebuilt model\r\nfaceCascade = cv2.CascadeClassifier(cascadePath);\r\n\r\n# Set the font style\r\nfont = cv2.FONT_HERSHEY_SIMPLEX\r\n\r\n# Initialize and start the video frame capture\r\ncam = cv2.VideoCapture(0)\r\n\r\n# Loop\r\nwhile True:\r\n # Read the video frame\r\n ret, im =cam.read()\r\n\r\n # Convert the captured frame into grayscale\r\n gray = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)\r\n\r\n # Get all face from the video frame\r\n faces = faceCascade.detectMultiScale(gray, 1.2,5)\r\n\r\n # For each face in faces\r\n for(x,y,w,h) in faces:\r\n\r\n # Create rectangle around the face\r\n cv2.rectangle(im, (x-20,y-20), (x+w+20,y+h+20), (0,255,0), 4)\r\n\r\n # Recognize the face belongs to which ID\r\n Id = recognizer.predict(gray[y:y+h,x:x+w])\r\n\r\n # Check the ID if exist \r\n if(Id == 1):\r\n Id = \"Jacky\"\r\n #If not exist, then it is Unknown\r\n elif(Id == 2):\r\n Id = \"Jenifer\"\r\n else:\r\n print(Id)\r\n\t\t\tId = \"Unknow\"\r\n\r\n # Put text describe who is in the picture\r\n cv2.rectangle(im, (x-22,y-90), (x+w+22, y-22), (0,255,0), -1)\r\n cv2.putText(im, str(Id), (x,y-40), font, 2, (255,255,255), 3)\r\n\r\n # Display the video frame with the bounded rectangle\r\n cv2.imshow('im',im) \r\n\r\n # If 'q' is pressed, close program\r\n if cv2.waitKey(10) & 0xFF == ord('q'):\r\n break\r\n\r\n# Stop the camera\r\ncam.release()\r\n\r\n# Close all windows\r\ncv2.destroyAllWindows()\r\n"
},
{
"alpha_fraction": 0.4821428656578064,
"alphanum_fraction": 0.6964285969734192,
"avg_line_length": 17.66666603088379,
"blob_id": "1c801b67d91c9817e6ce959fc60c2f8185c73247",
"content_id": "364d7a85dc5aab5fd41f35a31e85efd886ecf2e4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 56,
"license_type": "permissive",
"max_line_length": 23,
"num_lines": 3,
"path": "/Face-Emotions-Recognition/face-emotions-recognition-using-deep-learning/requirements.txt",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "numpy==1.17.4\nopencv-python==4.1.2.30\ntensorflow==2.4.0\n"
},
{
"alpha_fraction": 0.7411289215087891,
"alphanum_fraction": 0.7532516717910767,
"avg_line_length": 57.877323150634766,
"blob_id": "4247da744e898ad135c9bebfb7c9b41d7677c854",
"content_id": "6b6c43447b281893a81bcf8ab45185bf766e5ffa",
"detected_licenses": [
"BSD-3-Clause",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 15905,
"license_type": "permissive",
"max_line_length": 886,
"num_lines": 269,
"path": "/Snapchat_Filters/Bunny_Nose/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Bunny Nose Snapchat Filter Using Computer Vision Techniques\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Snapchat_Filters/Bunny_Nose/Images/Bunny-nose4.png\" align=\"left\" height=\"450px\"/>\n\n## 1.Introduction \n\nSocial media platforms such as Instagram and Snapchat are visual-based\nsocial media platforms that are popular among young women. One popular\ncontent many young women use on Snapchat and Instagram are beauty filters. A\nbeauty filter is a photo-editing tool that allows users to smooth out their skin,\nenhance their lips and eyes, contour their nose, alter their jawline and\ncheekbones, etc. Due to these beauty filters, young women are now seeking\nplastic surgeons to alter their appearance to look just like their filtered photos\n(this trend is called `Snapchat dysmorphia`)\n Overall, this study’s findings explain how beauty filters,\nfitspirations, and social media likes affect many young women’s perceptions of\nbeauty and body image. By understanding why many young women use these\nbeauty filters it can help and encourage companies to create reliable resources\nand campaigns that encourage natural beauty and self-love for women all around\nthe world. \n<br><br/>\n## 2.History \n\n`Face filters` are augmented reality effects enabled with face detection technology that overlay virtual objects on the face. Introduced by Snapchat back in 2015 as a fun way to dress-up your selfie, today face filters have become a meaningful tool to improve digital communication and interaction. \n Many people use social media apps such as Instagram or Snapchat, which have face filters for people to take and post pictures of themselves. But many people do not realize how these filters are created and the technology behind how they fit people’s faces almost perfectly. The mechanics behind face filters was originally created by a Ukrainian company called Looksery; they used the technology to photoshop faces during video chats. Snapchat bought their algorithm, called the `Viola-Jones algorithm`, and created the face filters seen in many social media apps today.\n\nCreating face filters is more difficult than you may think, so I’ll break it down into five key steps:\n\n- The first step is face detection. The image is initially viewed in ones and zeros, so the algorithm scans the image, looking specifically for color patterns. This can include finding that the cheek is lighter than the eye or that the nose bridge is lighter than surrounding areas. After detecting these patterns, a face can be distinguished in the camera.\n- The second step is the `landmark extractio`n. Using specific algorithms in a 2D image, facial features such as the chin, nose, forehead, etc are determined.\n- The third step is face alignment. The coordinates of landmarks on people’s faces are taken to properly fit the filter to a particular face.\n- The fourth step is 3D mesh. Using the 2D image, a 3D model of the user’s face is built to fit the filter animation to a specific face.\n- The last step is face tracking, which approximates and locates the 3D mask in real time. This allows the user to move their face without the filter disappearing or moving to an incorrect location.\n\nAnother way to think of these steps is to imagine a human body. The landmarks identified in a 2D image serve as the skeleton for the future mask. Similar to how bodies differ in shape, so do people’s face structures. Using face alignment, the filter matches with the coordinates of landmarks from a certain face. People’s skin makes them look the way they are and 3D mesh step is like aligning the skin to the skeleton. Similar to how bodies move while keeping the skeleton, skin and muscle together, face tracking follows the face to make sure the filter stays on the right coordinates.\n\n\n## 3.How does Snapchat recognize a face?\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Snapchat_Filters/Bunny_Nose/Images/Bunny.png\" width=\"480px\" align=\"right\"/>\n\n- his large `matrix` of numbers are codes, and each combination of the number represents a different color.\n- The face detection algorithm goes through this code and looks for color patterns that would represent a face.\n- Different parts of the face give away various details. For example, the bridge of the nose is lighter than its surroundings. The eye socket is darker than the forehead, and - - the center of the forehead is lighter than its sides.\n- This could take a lot of time, but Snapchat created a statistical model of a face by manually pointing out different borders of the facial features. When you click your face on the screen, these already predefined points align themselves and look for areas of contrast to know precisely where your lips, jawline, eyes, eyebrows, etc. are. This `statistical model` looks something like this.\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Snapchat_Filters/Bunny_Nose/Images/face-landmark.png\" height=\"400px\" align=\"right\"/>\nOnce these points are located, the face is modified in any way that seems suitable.\n\n\n### Step 1: Find Faces in a Picture\nNow that we know the basics of how computer vision works, we can begin to build our filter. First, let’s find faces and eyes in a static picture. Begin by installing on your computer and then importing OpenCV (an open-source python package for image processing) into a py file. All image structures in OpenCV are can be converted to and from NumPy arrays so it may be useful to import NumPy as well. Once you’ve installed OpenCV, you should have access to .xml files that contain facial recognition and other image processing algorithms. For this tutorial, we’ll use an algorithm called the Haar Cascade for faces and eyes. If you are having trouble finding the directory where these .xml files are, I suggest a quick file search for` “haarcascade”`. Once you have found the path to the directory where your Haar Cascades are stored, call CascadeClassifier and pass the path through it:\n\n```\nimport cv2\nimport numpy as np \n\n#path to classifiers\npath = '/Users/mitchellkrieger/opt/anaconda3/envs/learn-env/share/opencv4/haarcascades/'\n\n#get image classifiers\nface_cascade = cv2.CascadeClassifier(path +'haarcascade_frontalface_default.xml')\neye_cascade = cv2.CascadeClassifier(path +'haarcascade_eye.xml')\n```\nGreat, now that we’re set up, we can load in the images and look for faces. Note that Haar Cascades and many facial recognition algorithms require images to be in grayscale. So, after loading in the image, convert it to `grayscale`, and then use the face_cascade to detect faces. After you’ve got the faces, draw a rectangle around it and search within the facial region for eyes. Then draw rectangles around each eye.\n\nThe Tools of Face Detection in Python: \n\n We’ll use two of the biggest, most exciting image processing libraries available for` Python 3`, `Dlib` and `OpenCV`.\n\nInstalling Dlib is easy enough, thanks to wheels being available for most platforms. Just a simple pip install dlib should be enough to get you up and running.\n\nFor OpenCV, however, installation is a bit more complicated. If you’re running on MacOS, you can try this post to get OpenCV setup. Otherwise, you’ll need to figure out installation on your own platform.\n\nwe are going to use dlib and OpenCV to detect facial landmarks in an image.\n\nFacial landmarks are used to localize and represent salient regions of the face, such as:\n\n- `1.Eyes`\n- `2.Eyebrows`\n- `3.Nose`\n- `4.Mouth`\n- `5.Jawline`\n- `6.Facial landmarks have been successfully applied to face alignment, head pose estimation, face swapping, blink detection and much more.`\n\n\n\n\n\n\n### Step 2: Create your image filter\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Snapchat_Filters/Bunny_Nose/Images/eyeflow.png\" height=\"450px\" align=\"right\"/>\n\nWe’ll use OpenCV to get a raw video stream from the webcam. We’ll then resize this raw stream, using the imutils resize function, so we get a decent frame rate for face detection.\n\nOnce we’ve got a decent frame rate, we’ll convert our webcam image frame to black and white, then pass it to Dlib for face detection.\n\nDlib’s get_frontal_face_detector returns a set of bounding rectangles for each detected face an image. With this, we can then use a model (in this case, the` shape_predictor_68_face_landmarks on Github`), and get back a set of 68 points with our face’s orientation.\n\nFrom the points that match the eyes, we can create a polygon matching their shape in a new channel.\n\nWith this, we can do a bitwise_and, and copy just our eyes from the frame.\n\nWe then create an object to track the n positions our eyes have been. OpenCV’s boundingRect function gives us a base x and y coordinate to draw from.\n\nFinally, create a mask to build up all the previous places where our eyes where, and then once more, bitwise_and copy our previous eye image into the frame before showing.\n\n### Step 3: Put the model into action\n\nFinally, we’ll look at some results of applying facial landmark detection to images.\n\nWhat are facial landmarks?\n\nFigure 1: Facial landmarks are used to label and identify key facial attributes in an image (source).\nDetecting facial landmarks is a subset of the shape prediction problem. Given an input image (and normally an ROI that specifies the object of interest), a shape predictor attempts to localize key points of interest along the shape.\n\nIn the context of facial landmarks, our goal is detect important facial structures on the face using shape prediction methods.\n\n`Detecting facial landmark`s is therefore a two step process:\n\n- `Step 1`: Localize the face in the image.\n- `Step 2`: Detect the key facial structures on the face ROI.\n- `Face detection` (Step #1) can be achieved in a number of ways.\n\nWe could use OpenCV’s built-in Haar cascades.\n\nWe might apply a pre-trained HOG + Linear SVM object detector specifically for the task of face detection.\n\nOr we might even use deep learning-based algorithms for face localization.\n\nIn either case, the actual algorithm used to detect the face in the image doesn’t matter. Instead, what’s important is that through some method we obtain the face bounding box (i.e., the `(x, y)-coordinates` of the face in the image).\n\nGiven the face region we can then apply Step #2: detecting key facial structures in the face region.\n\nThere are a variety of facial landmark detectors, but all methods essentially try to localize and label the following facial regions:\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Snapchat_Filters/Bunny_Nose/Images/Bunny-nose3.png\" height=\"400px\" align=\"right\"/>\n\n- `Mouth`\n- `Right eyebrow`\n- `Left eyebrow`\n- `Right eye`\n- `Left eye`\n- `Nose`\n- `Jaw`\n\nWe got our model working, so all we gotta do now is use OpenCV to do the following:\n- Get image frames from the webcam\n- Detect region of the face in each image frame because the other sections of the image are useless to the model (I used the Frontal Face Haar Cascade to crop out the region of the face)\n- Preprocess this cropped region by — converting to grayscale, normalizing, and reshaping\n- Pass the preprocessed image as input to the model\n- Get predictions for the key points and use them to position different filters on the face\n\nThis method starts by using:\n\n- A training set of labeled facial landmarks on an image. These images are manually labeled, specifying specific (x, y)-coordinates of regions surrounding each facial structure.\n- Priors, of more specifically, the `probabilit`y on distance between pairs of input pixels.\n\nGiven this training data, an ensemble of regression trees are trained to estimate the facial landmark positions directly from the pixel intensities themselves (i.e., no “feature extraction” is taking place).\n\nThe end result is a facial landmark detector that can be used to detect facial landmarks in real-time with high quality predictions.\n\n## 4.How to setup on Local Environment :\n\n- Fork and Clone the repository using \n```\ngit clone https://github.com/akshitagupta15june/Face-X.git\n```\n- Create virtual environment \n```\n- python -m venv env\n- source env/bin/activate (Linux)\n- env\\Scripts\\activate (Windows)\n\n```\n- Go to project directory\n```\ncd Sanpchat_Filters/Bunny_Nose \n\n```\n- Run Program\n```\npy Bunny_Nose_Filter.py\n```\n\n## 5.Code Overview \n\n```\nimport cv2\nimport numpy as np\nimport dlib\nfrom math import hypot\n\n# Loading Camera and Nose image and Creating mask\ncap = cv2.VideoCapture(0)\nnose_image = cv2.imread(\"bunny.png\")\n_, frame = cap.read()\nrows, cols, _ = frame.shape\nnose_mask = np.zeros((rows, cols), np.uint8)\n\n# Loading Face detector\ndetector = dlib.get_frontal_face_detector()\npredictor = dlib.shape_predictor(\"shape_predictor_68_face_landmarks.dat\")\n\nwhile True:\n _, frame = cap.read()\n nose_mask.fill(0)\n gray_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)\n\n faces = detector(frame)\n for face in faces:\n landmarks = predictor(gray_frame, face)\n\n # Nose coordinates\n top_nose = (landmarks.part(29).x, landmarks.part(29).y)\n center_nose = (landmarks.part(30).x, landmarks.part(30).y)\n left_nose = (landmarks.part(31).x, landmarks.part(31).y)\n right_nose = (landmarks.part(35).x, landmarks.part(35).y)\n\n nose_width = int(hypot(left_nose[0] - right_nose[0],\n left_nose[1] - right_nose[1]) * 1.7)\n nose_height = int(nose_width * 0.77)\n\n # New nose position\n top_left = (int(center_nose[0] - nose_width / 2),\n int(center_nose[1] - nose_height / 2))\n bottom_right = (int(center_nose[0] + nose_width / 2),\n int(center_nose[1] + nose_height / 2))\n\n\n # Adding the new nose\n nose_bunny = cv2.resize(nose_image, (nose_width, nose_height))\n nose_bunny_gray = cv2.cvtColor(nose_bunny, cv2.COLOR_BGR2GRAY)\n _, nose_mask = cv2.threshold(nose_bunny_gray, 25, 255, cv2.THRESH_BINARY_INV)\n\n nose_area = frame[top_left[1]: top_left[1] + nose_height,\n top_left[0]: top_left[0] + nose_width]\n nose_area_no_nose = cv2.bitwise_and(nose_area, nose_area, mask=nose_mask)\n final_nose = cv2.add(nose_area_no_nose, nose_bunny)\n\n frame[top_left[1]: top_left[1] + nose_height,\n top_left[0]: top_left[0] + nose_width] = final_nose\n\n cv2.imshow(\"Nose area\", nose_area)\n cv2.imshow(\"Nose bunny\", nose_bunny)\n cv2.imshow(\"final nose\", final_nose)\n\n\n\n cv2.imshow(\"Frame\", frame)\n\n\n\n key = cv2.waitKey(1)\n if key == 27:\n break\n```\n\n\n## Result Obtain\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Snapchat_Filters/Bunny_Nose/Images/result.jpg\"/>\n\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Snapchat_Filters/Bunny_Nose/Images/Bunny-nose5.png\" height=\"400px\" align=\"left\"/>\n<p style=\"clear:both;\">\n<h1><a name=\"contributing\"></a><a name=\"community\"></a> <a href=\"https://github.com/akshitagupta15june/Face-X\">Community</a> and <a href=\"https://github.com/akshitagupta15june/Face-X/blob/master/CONTRIBUTING.md\">Contributing</a></h1>\n<p>Please do! Contributions, updates, <a href=\"https://github.com/akshitagupta15june/Face-X/issues\"></a> and <a href=\" \">pull requests</a> are welcome. This project is community-built and welcomes collaboration. Contributors are expected to adhere to the <a href=\"https://gssoc.girlscript.tech/\">GOSSC Code of Conduct</a>.\n</p>\n<p>\nJump into our <a href=\"https://discord.com/invite/Jmc97prqjb\">Discord</a>! Our projects are community-built and welcome collaboration. 👍Be sure to see the <a href=\"https://github.com/akshitagupta15june/Face-X/blob/master/Readme.md\">Face-X Community Welcome Guide</a> for a tour of resources available to you.\n</p>\n<p>\n<i>Not sure where to start?</i> Grab an open issue with the <a href=\"https://github.com/akshitagupta15june/Face-X/issues\">help-wanted label</a>\n</p>\n"
},
{
"alpha_fraction": 0.5867117047309875,
"alphanum_fraction": 0.6067004799842834,
"avg_line_length": 31.587156295776367,
"blob_id": "37d02af97e23274ea6d0be645c6b7ade8cccefa9",
"content_id": "e12cd3af8f0736483f7cbbe1499072e95ce95717",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3552,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 109,
"path": "/Face Reconstruction/Face Alignment in Full Pose Range/video_demo.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# coding: utf-8\nimport torch\nimport torchvision.transforms as transforms\nimport mobilenet_v1\nimport numpy as np\nimport cv2\nimport dlib\nfrom utils.ddfa import ToTensorGjz, NormalizeGjz\nimport scipy.io as sio\nfrom utils.inference import (\n parse_roi_box_from_landmark,\n crop_img,\n predict_68pts,\n predict_dense,\n)\nfrom utils.cv_plot import plot_kpt\nfrom utils.render import get_depths_image, cget_depths_image, cpncc\nfrom utils.paf import gen_img_paf\nimport argparse\nimport torch.backends.cudnn as cudnn\n\nSTD_SIZE = 120\n\n\ndef main(args):\n # 0. open video\n # vc = cv2.VideoCapture(str(args.video) if len(args.video) == 1 else args.video)\n vc = cv2.VideoCapture(args.video if int(args.video) != 0 else 0)\n\n # 1. load pre-tained model\n checkpoint_fp = 'models/phase1_wpdc_vdc.pth.tar'\n arch = 'mobilenet_1'\n\n tri = sio.loadmat('visualize/tri.mat')['tri']\n transform = transforms.Compose([ToTensorGjz(), NormalizeGjz(mean=127.5, std=128)])\n\n checkpoint = torch.load(checkpoint_fp, map_location=lambda storage, loc: storage)[\n 'state_dict'\n ]\n model = getattr(mobilenet_v1, arch)(\n num_classes=62\n ) # 62 = 12(pose) + 40(shape) +10(expression)\n\n model_dict = model.state_dict()\n # because the model is trained by multiple gpus, prefix module should be removed\n for k in checkpoint.keys():\n model_dict[k.replace('module.', '')] = checkpoint[k]\n model.load_state_dict(model_dict)\n if args.mode == 'gpu':\n cudnn.benchmark = True\n model = model.cuda()\n model.eval()\n\n # 2. load dlib model for face detection and landmark used for face cropping\n dlib_landmark_model = 'models/shape_predictor_68_face_landmarks.dat'\n face_regressor = dlib.shape_predictor(dlib_landmark_model)\n face_detector = dlib.get_frontal_face_detector()\n\n # 3. forward\n success, frame = vc.read()\n last_frame_pts = []\n\n while success:\n if len(last_frame_pts) == 0:\n rects = face_detector(frame, 1)\n for rect in rects:\n pts = face_regressor(frame, rect).parts()\n pts = np.array([[pt.x, pt.y] for pt in pts]).T\n last_frame_pts.append(pts)\n\n vertices_lst = []\n for lmk in last_frame_pts:\n roi_box = parse_roi_box_from_landmark(lmk)\n img = crop_img(frame, roi_box)\n img = cv2.resize(\n img, dsize=(STD_SIZE, STD_SIZE), interpolation=cv2.INTER_LINEAR\n )\n input = transform(img).unsqueeze(0)\n with torch.no_grad():\n if args.mode == 'gpu':\n input = input.cuda()\n param = model(input)\n param = param.squeeze().cpu().numpy().flatten().astype(np.float32)\n pts68 = predict_68pts(param, roi_box)\n vertex = predict_dense(param, roi_box)\n lmk[:] = pts68[:2]\n vertices_lst.append(vertex)\n\n pncc = cpncc(frame, vertices_lst, tri - 1) / 255.0\n frame = frame / 255.0 * (1.0 - pncc)\n cv2.imshow('3ddfa', frame)\n cv2.waitKey(1)\n success, frame = vc.read()\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(description='3DDFA inference pipeline')\n parser.add_argument(\n '-v',\n '--video',\n default='0',\n type=str,\n help='video file path or opencv cam index',\n )\n parser.add_argument('-m', '--mode', default='cpu', type=str, help='gpu or cpu mode')\n\n args = parser.parse_args()\n main(args)\n"
},
{
"alpha_fraction": 0.6390243768692017,
"alphanum_fraction": 0.7200750708580017,
"avg_line_length": 44.169490814208984,
"blob_id": "64f51c298754db1e2f9c384715120711f022d96d",
"content_id": "a2b401f25d9536bbcc4e36090114b155d40ee2f8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2665,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 59,
"path": "/CONTRIBUTORS.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "1) [Akshita Gupta] https://github.com/akshitagupta15june\n2) [Kerin Pithawala] https://github.com/Kerveyfelix\n3) [Ashwani Rathee] https://github.com/ashwani-rathee\n4) [Harshit Dhyani] https://github.com/Halix267\n5) [Aayush Garg] https://github.com/Aayush-hub\n6) [Soyabul Islam Lincoln] https://github.com/SoyabulIslamLincoln\n7) [HIMANSHU] https://github.com/himanshu007-creator\n8) [Sagnik Roy] https://github.com/sagnik1511\n9) [Lipika] https://github.com/lipika02\n10) [Sagnik Mazumder] https://github.com/Karnak123\n11) [Meha Bhalodiya] https://github.com/mehabhalodiya\n12) [Aswin Gopinathan] https://github.com/infiniteoverflow\n13) [Smriti Singh] https://github.com/smriti1313\n14) [Salma] https://github.com/IdealisticINTJ\n15) [Harsh Sinha] https://github.com/harshsinha03\n16) [Rajesh Panjiyar] https://github.com/rajeshpanjiyar\n17) [Sudip Ghosh] https://github.com/sudipg4112001\n18) [Rudrani] https://github.com/rudrani05\n19) [Jeelnathani] https://github.com/jeelnathani\n20) [Akriti] https://github.com/A-kriti\n21) [Sherin Shibu] https://github.com/sherin527\n22) [Suneel Kumar Pentela] https://github.com/suneelkumarpentela\n23) [Vinamrata] https://github.com/Vinamrata1086\n24) [Padmanabha Banarjee] https://github.com/BlueBlaze6335\n25) [Animesh Gupta] https://github.com/animesh-007\n26) [Adarsh Narayanan] https://github.com/Adarsh88\n27) [Lee Ren Jie] https://github.com/LeeRenJie\n28) [Kerin Pithawala] https://github.com/KerinPithawala\n29) [Satyam Goyal] https://github.com/SatYu26\n30) [Achyut Kumar Panda] https://github.com/Sloth-Panda\n31) [Ashish Singh] https://github.com/Ashishsingh619\n32) [Sadaf Fateema] https://github.com/sadaffateema\n33) [Arnab] https://github.com/arnab031\n34) [Diksha Verma] https://github.com/zenithexpo\n35) [Hemanth Kollipara] https://github.com/Defcon27\n36) [Vishal Dhanure ] https://github.com/Vi1234sh12\n37) [Utkarsh Chauhan] https://github.com/utkarsh147-del\n38) [Nihar Sanda] https://github.com/koolgax99\n39) [Avishkar] https://github.com/avishkar2001\n40) [Bharath_acchu] https://github.com/bharath-acchu\n41) [Aditya Nikhil] https://github.com/AdityaNikhil\n42) [Yashasvi] https://github.com/kmryashasvi\n43) [Anirudh Sai S B] https://github.com/anirudhsai20\n44) [Anubhav] https://github.com/anubhav201241\n45) [Samir Rajesh Prajapati] https://github.com/samir-0711\n46) [iaditichine] https://github.com/iaditichine\n47) [Amandeep] https://github.com/amandp13\n48) [Musavveer Rehaman] https://github.com/musavveer\n49) [Ashutosh Verma] https://github.com/AshuKV\n50) [Preeti] https://github.com/Preeti2095\n51) [Aditi] https://github.com/aditi-saxena-1206\n52) [Bhagyashri] https://github.com/Bhagyashri2000\n53) [Eddie Jaoude] https://github.com/eddiejaoude\n54) [Aditya Raute] https://github.com/adityaraute\n55) [Saiharsha] https://github.com/saiharsha-22\n56) [Manvi Goel] https://github.com/ManviGoel26\n57) [Raghav Modi] https://github.com/RaghavModi\n58) [Pankaj Sharma] https://github.com/PankajGit2711\n59) [Anand Kumar] https://github.com/anandxkumar\n"
},
{
"alpha_fraction": 0.608906626701355,
"alphanum_fraction": 0.6378443837165833,
"avg_line_length": 28.594871520996094,
"blob_id": "cb4ab0731a5b0f17c829ab6eabb6cafa92b2d4dc",
"content_id": "7a586bd7ab31774603fdb81d3cc03c7e11e898b0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5771,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 195,
"path": "/Face Reconstruction/3D Face Reconstruction using Graph Convolution Network/face_segment.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport torch\nimport torch.nn as nn\n\nimport utils\n\n\nclass Segment():\n\n def __init__(self):\n self.cuda = torch.cuda.is_available()\n model = resnet50(num_classes=19)\n self.model = torch.nn.DataParallel(model)\n if self.cuda:\n self.model.cuda()\n self.model.eval()\n if self.cuda:\n checkpoint = torch.load('data/torch_FaceSegment_300.pkl')\n else:\n checkpoint = torch.load('data/torch_FaceSegment_300.pkl', map_location='cpu')\n self.model.load_state_dict(checkpoint['model_state'])\n\n def inference(self, inputs):\n # inputs should be in [-1, 1]\n image = utils.img_denormalize(inputs).astype(np.float32)\n # image = np.array(inputs, dtype=np.float32)\n image = image - 128\n if len(image.shape) < 4:\n image = np.expand_dims(image, 0)\n image = image.transpose(0, 3, 1, 2)\n image = torch.from_numpy(image).float()\n if self.cuda:\n image = image.cuda()\n result = self.model(image)\n result = torch.argmax(result, dim=1)\n alpha = result.data.cpu().numpy()\n\n alpha = alpha.astype(np.uint8)\n for x in [1, 2, 3, 4, 5, 6, 7, 9]:\n alpha[alpha == x] = 1\n alpha = np.where(alpha == 1, 1, 0).astype(np.float32)\n return alpha\n\n def segment(self, inputs, batch_size=4):\n num_input = inputs.shape[0]\n if num_input < batch_size:\n return self.inference(inputs)\n else:\n alphas = []\n for i in range(0, num_input, batch_size):\n alpha = self.inference(inputs[i:i + batch_size])\n alphas.append(alpha)\n return np.concatenate(alphas, axis=0)\n\n\ndef conv3x3(in_planes, out_planes, stride=1):\n \"\"\"3x3 convolution with padding\"\"\"\n return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False)\n\n\nclass BasicBlock(nn.Module):\n expansion = 1\n\n def __init__(self, inplanes, planes, stride=1, downsample=None):\n super(BasicBlock, self).__init__()\n self.conv1 = conv3x3(inplanes, planes, stride)\n self.bn1 = nn.BatchNorm2d(planes)\n self.relu = nn.ReLU(inplace=True)\n self.conv2 = conv3x3(planes, planes)\n self.bn2 = nn.BatchNorm2d(planes)\n self.downsample = downsample\n self.stride = stride\n\n def forward(self, x):\n residual = x\n\n out = self.conv1(x)\n out = self.bn1(out)\n out = self.relu(out)\n\n out = self.conv2(out)\n out = self.bn2(out)\n\n if self.downsample is not None:\n residual = self.downsample(x)\n\n out += residual\n out = self.relu(out)\n\n return out\n\n\nclass Bottleneck(nn.Module):\n expansion = 4\n\n def __init__(self, inplanes, planes, stride=1, downsample=None):\n super(Bottleneck, self).__init__()\n self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)\n self.bn1 = nn.BatchNorm2d(planes)\n self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)\n self.bn2 = nn.BatchNorm2d(planes)\n self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1, bias=False)\n self.bn3 = nn.BatchNorm2d(planes * self.expansion)\n self.relu = nn.ReLU(inplace=True)\n self.downsample = downsample\n self.stride = stride\n\n def forward(self, x):\n residual = x\n\n out = self.conv1(x)\n out = self.bn1(out)\n out = self.relu(out)\n\n out = self.conv2(out)\n out = self.bn2(out)\n out = self.relu(out)\n\n out = self.conv3(out)\n out = self.bn3(out)\n\n if self.downsample is not None:\n residual = self.downsample(x)\n\n out += residual\n out = self.relu(out)\n\n return out\n\n\nclass ResNet(nn.Module):\n\n def __init__(self, block, layers, num_classes):\n print(\"create resnet for semantic segmantation with %d num_classes\" % (num_classes))\n self.inplanes = 64\n super(ResNet, self).__init__()\n self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)\n self.bn1 = nn.BatchNorm2d(64)\n self.relu = nn.ReLU(inplace=True)\n self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)\n self.layer1 = self._make_layer(block, 64, layers[0], stride=2)\n self.layer2 = self._make_layer(block, 128, layers[1], stride=1)\n self.layer3 = self._make_layer(block, 256, layers[2], stride=1)\n self.layer4 = self._make_layer(block, 512, layers[3], stride=1)\n self.output = nn.Conv2d(512 * block.expansion, num_classes, kernel_size=1)\n self.upsample = nn.UpsamplingBilinear2d(scale_factor=8)\n for m in self.modules():\n if isinstance(m, nn.Conv2d):\n nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')\n elif isinstance(m, nn.BatchNorm2d):\n nn.init.constant_(m.weight, 1)\n nn.init.constant_(m.bias, 0)\n\n def _make_layer(self, block, planes, blocks, stride=1):\n downsample = None\n if stride != 1 or self.inplanes != planes * block.expansion:\n downsample = nn.Sequential(\n nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=1, stride=stride,\n bias=False),\n nn.BatchNorm2d(planes * block.expansion),\n )\n\n layers = []\n layers.append(block(self.inplanes, planes, stride, downsample))\n self.inplanes = planes * block.expansion\n for _ in range(1, blocks):\n layers.append(block(self.inplanes, planes))\n\n return nn.Sequential(*layers)\n\n def forward(self, x):\n x = self.conv1(x)\n x = self.bn1(x)\n x = self.relu(x)\n x = self.maxpool(x)\n\n x = self.layer1(x)\n x = self.layer2(x)\n x = self.layer3(x)\n #x = nn.functional.dropout2d(x)\n x = self.layer4(x)\n #x = nn.functional.dropout2d(x)\n x = self.output(x)\n x = self.upsample(x)\n return x\n\n\ndef resnet50(**kwargs):\n \"\"\"Constructs a ResNet-50 model.\n\n Args:\n pretrained (bool): If True, returns a model pre-trained on ImageNet\n \"\"\"\n model = ResNet(Bottleneck, [3, 4, 6, 3], **kwargs)\n return model\n"
},
{
"alpha_fraction": 0.7114243507385254,
"alphanum_fraction": 0.7396142482757568,
"avg_line_length": 30.34883689880371,
"blob_id": "e7b4e3b8f13db09908ed076501a2c8b7582357ba",
"content_id": "3118065c0c423930108ba19238119ae39d293958",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1348,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 43,
"path": "/Awesome-face-operations/Colorful Sketch Filter/colorful_sketch_filter.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from matplotlib import pyplot as plt\nimport numpy as np\nimport cv2\nimport os.path #imported the required libraries\n\n# take path of the image as input\nimage_path = input(\"Enter the path here:\") #example -> C:\\Users\\xyz\\OneDrive\\Desktop\\project\\image.jpg \nimg = cv2.imread(image_path)\n\n#plt.imshow(img)\n#plt.show()\nimage = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)\n#plt.figure(figsize= (10,10))\n#plt.imshow(image)\n#plt.show()\nimage_small = cv2.pyrDown(image)\nnum_iter = 5\nfor _ in range(num_iter):\n image_small= cv2.bilateralFilter(image_small, d=9, sigmaColor=9, sigmaSpace=7)\nimage_rgb = cv2.pyrUp(image_small)\n#plt.imshow(image_rgb)\n#plt.show()\n\n\nimage_gray = cv2.cvtColor(image_rgb, cv2.COLOR_RGB2GRAY)\nimage_blur = cv2.medianBlur(image_gray, 7)\nimage_edge = cv2.adaptiveThreshold(image_blur, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 7, 0.2)\n\n#plt.imshow(image_edge)\n#plt.show()\nimage_edge = cv2.cvtColor(image_edge, cv2.COLOR_GRAY2RGB)\n#plt.imshow(image_edge)\n#plt.show()\n\nresult = cv2.bitwise_or(image_edge, image) #used bitwise or method between the image_edge and image\n\nplt.figure(figsize= (10,10))\nplt.imshow(result)\nplt.axis('off')\nfilename = os.path.basename(image_path)\nplt.savefig(\"(Colorful Sketch Filtered)\"+filename) #saved file name as (Filtered)image_name.jpg\n\nplt.show() #final colorful sketch filtered photo\n"
},
{
"alpha_fraction": 0.5721649527549744,
"alphanum_fraction": 0.7216494679450989,
"avg_line_length": 26.714284896850586,
"blob_id": "c9c0f788c1b55a1025bb9c9dcf01a5c85400f3bc",
"content_id": "c4577ecd59b7911d873ecc08bb5484967f508c50",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 194,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 7,
"path": "/Face Reconstruction/Face Alignment in Full Pose Range/requirements.txt",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "torch>=0.4.1\ntorchvision>=0.2.1\nnumpy>=1.15.4\nscipy>=1.1.0\nmatplotlib==3.0.2\ndlib==19.5.0 # 19.15+ version may cause conflict with pytorch, this may take several minutes\nopencv-python>=3.4.3.18\n"
},
{
"alpha_fraction": 0.6540049314498901,
"alphanum_fraction": 0.6738232970237732,
"avg_line_length": 38.064517974853516,
"blob_id": "15c5637ebfaf6a285b77f2125b9afd4dfb5eca99",
"content_id": "d2f73f30589304c67a1b1a1ea288f41574ddee85",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1211,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 31,
"path": "/Face Reconstruction/Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model/cal_error/cal_error.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# encoding:utf-8\n\n# This method is for calculating serveral usual errors of landmark detection\n\nnum = 5\nimport numpy as np\nfile = open('testset/test.txt','r')\nimg_list = file.readlines()\nfile.readlines()\n\nerrors_norm = []\nerrors_pupil = []\nerrors_ocular = []\nerrors_diagnal = []\nfor i in range(num):\n img_name = img_list[i].strip('\\n')\n land2d = np.load('testset/landmarks/'+img_name+'_l.npy')\n gt_land = np.load('testset/landmarks_gt/'+img_name+'.jpg.npy')\n error = np.mean(np.sqrt(np.sum((land2d-gt_land)**2, axis=1)))\n pupil_norm = np.linalg.norm(np.mean(gt_land[36:42], axis=0) - np.mean(gt_land[42:48], axis=0))\n ocular_norm = np.linalg.norm(gt_land[36] - gt_land[45])\n height, width = np.max(gt_land, axis=0) - np.min(gt_land, axis=0)\n diagnal_norm = np.sqrt(height**2 + width**2)\n errors_norm.append(error)\n errors_pupil.append(error/pupil_norm)\n errors_ocular.append(error/ocular_norm)\n errors_diagnal.append(error/diagnal_norm)\nprint(\"the mean error: \"+str(np.mean(errors_norm)))\nprint(\"the mean error(pupil): \"+str(np.mean(errors_pupil)))\nprint(\"the mean error(ocular): \"+str(np.mean(errors_ocular)))\nprint(\"the mean error(diagnal): \"+str(np.mean(errors_diagnal)))\n"
},
{
"alpha_fraction": 0.7225296497344971,
"alphanum_fraction": 0.7525691986083984,
"avg_line_length": 42.1363639831543,
"blob_id": "2432dabb310f54d33ea75db69159a22658fb953f",
"content_id": "5ff8fd55229cf468f025d2de948130436ac89fd5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3795,
"license_type": "permissive",
"max_line_length": 213,
"num_lines": 88,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency(ECCV 2020)\nThis is an official python implementation of MGCNet. This is the pre-print version https://arxiv.org/abs/2007.12494.\n\n# Result\n1. video\n <p align=\"center\"> \n <img src=\"githubVisual/ECCV2020_Github.gif\">\n </p>\n \n2. image\n \n \n3. Full video can be seen in [YouTube] https://www.youtube.com/watch?v=DXzkO3OwlYQ\n \n# Running code\n## 1. Code + Requirement + thirdlib\nWe run the code with python3.7, tensorflow 1.13\n```bash\ngit clone --recursive https://github.com/jiaxiangshang/MGCNet.git\ncd MGCNet\n(sudo) pip install -r requirement.txt\n```\n(1) For render loss(reconstruction loss), we use the differential renderer named tf_mesh_render(thanks!) https://github.com/google/tf_mesh_renderer. \nI find many issue happens here, so let's make this more clear.\nThe tf_mesh_render does not return triangle id for each pixel after rasterise, we do this by our self and add these changes as submodule to mgcnet. \n\n(2) Then how to compile tf_mesh_render, my setting is bazel==10.1, gcc==5.*, the compile command is \n```bash\nbazel build ...\n```\nThe gcc/g++ version higher than 5.* will bring problems, a good solution is virtual environment with a gcc maybe 5.5.\nIf the The gcc/g++ version is 4.* that you can try to change the compile cmd in BUILD file, about the flag -D_GLIBCXX_USE_CXX11_ABI=0 or -D_GLIBCXX_USE_CXX11_ABI=1 for 4.* or 5.*\n\n## 2.Model\n1. 3dmm model + network weight\n\n We include BFM09/BFM09 expression, BFM09 face region from https://github.com/microsoft/Deep3DFaceReconstruction, BFM09 uv from https://github.com/anilbas/3DMMasSTN into a whole 3dmm model.\n https://drive.google.com/file/d/1RkTgcSGNs2VglHriDnyr6ZS5pbnZrUnV/view?usp=sharing\n Extract this file to /MGCNet/model\n2. pretain\n\n This include the pretrail model for the Resnet50 and vgg pretrain model for Facenet.\n https://drive.google.com/file/d/1jVlf05_Bm_nbIQXZRfmz-dA03xGCawBw/view?usp=sharing\n Extract this file to /MGCNet/pretain\n \n## 3.Data\n1. data demo: https://drive.google.com/file/d/1Du3iRO0GNncZsbK4K5sboSeCUv0-SnRV/view?usp=sharing\n \n Extract this file to /MGCNet/data, we can not provide all datas, as it is too large and the license of MPIE dataset http://www.cs.cmu.edu/afs/cs/project/PIE/MultiPie/Multi-Pie/Home.html not allow me to do this.\n \n2. data: landmark ground truth \n\n The detection method from https://github.com/1adrianb/2D-and-3D-face-alignment, and we use the SFD face detector\n \n3. data: skin probability\n\n I get this part code from Yu DENG([email protected]), maybe you can ask help from him.\n\n## 4.Testing\n1. test_image.py\n This is used to inference a single unprocessed image(cmd in file).\n This file can also render the images(geometry, texture, shading,multi-pose), like above or in our paper(read code), which makes visualization and comparison more convenient.\n \n2. preprocess\n All the preprocess has been included in 'test_image.py', we show the outline here.\n (1) face detection and face alignment are package in ./tools/preprocess/detect_landmark,py.\n (2) face alignment by affine transformation to warp the unprocess image.\n Test all the images in a folder can follow this preprocess.\n \n## 5.Training\n1. train_unsupervise.py\n\n# Useful tools(keep updating)\n1. face alignment tools\n2. 3D face render tools.\n3. Camera augment for rendering.\n\n# Citation\nIf you use this code, please consider citing:\n\n```\n@article{shang2020self,\n title={Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency},\n author={Shang, Jiaxiang and Shen, Tianwei and Li, Shiwei and Zhou, Lei and Zhen, Mingmin and Fang, Tian and Quan, Long},\n journal={arXiv preprint arXiv:2007.12494},\n year={2020}\n}\n```"
},
{
"alpha_fraction": 0.7872849106788635,
"alphanum_fraction": 0.7987571954727173,
"avg_line_length": 82.68000030517578,
"blob_id": "2c92323b31c08611cc94f9f2d7eae1ca1a91fbc5",
"content_id": "f34a591af07c24303dce7d762f52fe159b8f6ada",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2092,
"license_type": "permissive",
"max_line_length": 470,
"num_lines": 25,
"path": "/Recognition-Algorithms/Recognition using SIFT/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Facial-recognition-using-SIFT\nThis is an experimental facial recognition project by matching the features extracted using SIFT. \n\n### Dependencies\n1. numpy\n2. opencv-contrib-python version 3.4.2.16\n3. pnslib\n\n### Brief\nTwo images are taken as input. For now, only images consisting of a single face are considered. The images are passed through a face detection algorithm. For face detection, we use OpenCV's haarcascade classifier. After the faces are detected, we crop out the region of interests from the images and pass it on to the feature extraction algorithm.\n\nFor feature extraction ,we use the SIFT algorithm in OpenCV.SIFT produces a list of good features for each image. Each of this features is a 128 dimensional vector. We use a BruteForce matcher to match the features of the 2 images. For each feature in each image, we consider the 2 most similar features in the other image and filter out the good matches among them. Good matches are those matches which are atmost 0.75 times closer than the second most similar feature.\n\nAfter feature matching using the BruteForce matcher, the decision of Match or No-Match is done based on the number of good matches for the image pair. This is a crude way of deciding, still worth being a starting point. \n\n### Screenshot\n\n\n\n### References\n1. Face detection using Haar Cascades : https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_objdetect/py_face_detection/py_face_detection.html\n2. Introduction to SIFT in OpenCV : https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_feature2d/py_sift_intro/py_sift_intro.html\n3. Feature matching in OpenCV : https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_feature2d/py_matcher/py_matcher.html\n4. BruteForce OpenCV tutorial (future ref) : https://pythonprogramming.net/feature-matching-homography-python-opencv-tutorial/\n5. Feature matching + homography (future ref) : https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_feature2d/py_feature_homography/py_feature_homography.html\n"
},
{
"alpha_fraction": 0.5803195834159851,
"alphanum_fraction": 0.6593776345252991,
"avg_line_length": 31.135135650634766,
"blob_id": "d80c3910545f32754270ee2b9fe512cecf48b20a",
"content_id": "b18ffb5456966a25fa51f3ccdda87c04d9bdd262",
"detected_licenses": [
"BSD-3-Clause",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1189,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 37,
"path": "/Snapchat_Filters/Mask_filter/mask.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import cv2\n\neye_detector=cv2.CascadeClassifier('/home/ebey/OpenCV/data/haarcascades/haarcascade_eye_tree_eyeglasses.xml')\nface_detector = cv2.CascadeClassifier('/home/ebey/OpenCV/data/haarcascades/haarcascade_frontalface_alt.xml')\n\n#feed = cv2.imread('face.jpg')\nmask = cv2.imread('mask.png',cv2.IMREAD_UNCHANGED)\n\ncap=cv2.VideoCapture(0)\n\nwhile(cap.isOpened()):\n\t_,feed=cap.read()\n\tgray = cv2.cvtColor(feed,cv2.COLOR_BGR2GRAY)\n\tfeed = cv2.cvtColor(feed,cv2.COLOR_BGR2BGRA)\n\tfaces=face_detector.detectMultiScale(gray,1.1,2)\n\tfor (x,y,w,h) in faces:\n\t\t#cv2.rectangle(feed,(x,y),(x+w,y+h),(0,0,255),2)\n\t\teyes = eye_detector.detectMultiScale(gray[y:y+h,x:x+w],1.1,2)\n\t\tif len(eyes)<2:\n\t\t\tbreak\n\t\tX1 = eyes[0,0] -50\n\t\tY1 = eyes[0,1] -110\n\t\tX2 = eyes[1,0] + eyes[1,2] + 50\n\t\tY2 = eyes[1,1] + eyes[1,3] + 20\n\t\t#cv2.rectangle(feed,(x+X1,y+Y1),(x+X2,y+Y2),(255,0,0),2)\n\t\ttemp = cv2.resize(mask,(X2-X1+1,Y2-Y1+1))\n\t\tfor i in range(y+Y1,y+Y2+1):\n\t\t\tfor j in range(x+X1,x+X2+1):\n\t\t\t\tif temp[i-y-Y1,j-x-X1,3] != 0:\n\t\t\t\t\tfeed[i,j] = temp[i-y-Y1,j-x-X1]\n\t\t#feed[y+Y1:y+Y2+1,x+X1:x+X2+1] = mask\n\tcv2.imshow(\"FEED\",feed)\n\tk=cv2.waitKey(10)\n\tif k == ord('q'):\n\t\tbreak\ncap.release()\ncv2.destroyAllWindows()\n"
},
{
"alpha_fraction": 0.5487407445907593,
"alphanum_fraction": 0.6083657741546631,
"avg_line_length": 90.5381851196289,
"blob_id": "c5c09dd646e52222f9386bd8870ab35811cfa151",
"content_id": "beae8b5983c501a3aeeae24f9431ce4b756ed8c2",
"detected_licenses": [
"BSD-3-Clause",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 25247,
"license_type": "permissive",
"max_line_length": 468,
"num_lines": 275,
"path": "/Awesome-face-operations/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Awesome-face-operations\n\n\n\n# Face Morphing\nThis is a tool that creates a morphing effect. It takes two facial images as input and returns morphing from the first image to the second.\n### Example:\n\n\n### Steps:\n```diff\n- Find point-to-point correspondences between the two images.\n- Find the Delaunay Triangulation for the average of these points.\n- Using these corresponding triangles in both initial and final images, perform Warping and Alpha Blending and obtain intermediate images. \n```\n\n# Converting an image into a ghost image.\n\nUsed OpenCV and Numpy to convert an image into a ghost image.\n\n### Steps:\n```diff\n- Imported the required libraries ( Numpy, Matplotlib, Cv2)\n- Read the input image using cv2\n```\n### Methods applied Using Cv2\n```diff\n- Used Bilateral Filter\n- Used Median Blur\n- Used Adaptive Threshold\n- Used Bitwise Xor\n- Finally converted the image into a ghost image\n```\n\n### Original Image\n\n\n\n\n### Ghost Image\n\n\n\n\n# Pencil Sketch In Python Using OpenCV\n### OpenCV\n\nOpenCV is an open-source computer vision and machine learning software library. It is a BSD-licence product thus free for both business and academic purposes. OpenCV is written natively in C/C++. It has C++, C, Python, and Java interfaces and supports Windows, Linux, Mac OS, iOS, and Android. OpenCV was designed for computational efficiency and targeted for real-time applications. Written in optimized C/C++, the library can take advantage of multi-core processing.\n\n### Pencil Sketch in OpenCV\n\nOpenCV 3 comes with a pencil sketch effect right out of the box. The cv2.pencilSketch function uses a domain filter introduced in the 2011 paper Domain transform for edge-aware image and video processing, by Eduardo Gastal and Manuel Oliveira. For customizations, other filters can also be developed.\n\n### Libraries Used\n\n#### imread()\ncv2.imread() method loads an image from the specified file. If the image cannot be read (because of missing file, improper permissions, unsupported or invalid format) then this method returns an empty matrix.\n#### cvtColor()\ncv2.cvtColor() method is used to convert an image from one color space to another. There are more than 150 color-space conversion methods available in OpenCV. \n#### bitwise_not()\nTo make brighter regions lighter and lighter regions darker so that we could find edges to create a pencil sketch.\n#### GaussianBlur()\nIn the Gaussian Blur operation, the image is convolved with a Gaussian filter instead of the box filter. The Gaussian filter is a low-pass filter that removes the high-frequency components are reduced. It also smoothens or blurs the image. You can perform this operation on an image using the Gaussianblur() method of the imgproc class.\n#### dodgeV2()\nIt is used to divide the grey-scale value of the image by the inverse of the blurred image which highlights the sharpest edges.\n### Results Obtained\n\n\n\n\n\n\n\n\n<h1> Image Segmentation Using Color space and Opencv</h1>\n<h2>Introduction</h2>\n<p>\nThe process of partitioning a digital image into multiple segments is defined as image segmentation. Segmentation aims to divide an image into regions that can be more representative and easier to analyze.</p>\n\n<h2>What are color spaces?</h2>\n<p>Basically, Color spaces represent color through discrete structures (a fixed number of whole number integer values), which is acceptable since the human eye and perception are also limited. Color spaces are fully able to represent all the colors that humans are able to distinguish between.</p>\n\n \n## Steps followed for implementation\n```diff\n- Converted the image into HSV\n- Choosing swatches of the desired color, In this, shades of light and dark orange have been taken.\n- Applying an orange shade mask to the image\n- Adding the second swatches of color, Here shades of white were chosen i.e light and dark shades\n- Apply the white mask onto the image\n- Now combine the two masks, Adding the two masks together results in 1 value wherever there is an orange shade or white shade.\n- Clean up the segmentation using a blur \n```\n\n \n ### Default image in BGR color space\n \n\n\n ### Image converted to RGB color space\n \n\n\n ### Image converted to GRAY color space\n \n\n\n### Image converted to HSV color space\n \n\n\n\n### Segmented images\n\n\n\n# More Awesome Face Operations That Can Be Added Here \n\n\n\n### Face Detection\n### Face Alignment\n### Face Recognition\n### Face Identification\n### Face Verification\n### Face Representation\n### Face Alignment\n### Face(Facial) Attribute & Face(Facial) Analysis\n### Face Reconstruction\n### Face 3D\n### Face Tracking\n### Face Clustering\n### Face Super-Resolution\n### Face Deblurring\n### Face Hallucination\n### Face Generation\n### Face Synthesis\n### Face Completion\n### Face Restoration\n### Face De-Occlusion\n### Face Transfer\n### Face Editing\n### Face Anti-Spoofing\n### Face Retrieval\n### Face Application\n\n---\n## Piplines\n\n- [seetaface/SeetaFaceEngine](https://github.com/seetaface/SeetaFaceEngine)\n---\n## DataSets\n\n- Andreas Rössler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, Matthias Nießner .[FaceForensics: A Large-scale Video Dataset for Forgery Detection in Human Faces](https://arxiv.org/pdf/1803.09179) .[J] arXiv preprint arXiv:1803.09179.\n- Ziyi Liu, Jie Yang, Mengchen Lin, Kenneth Kam Fai Lai, Svetlana Yanushkevich, Orly Yadid-Pecht .[WDR FACE: The First Database for Studying Face Detection in Wide Dynamic Range](https://arxiv.org/pdf/2101.03826) [J]. arXiv preprint arXiv:2101.03826.\n- Jianglin Fu, Ivan V. Bajic, Rodney G. Vaughan .[Datasets for Face and Object Detection in Fisheye Images](https://arxiv.org/pdf/1906.11942) .[J] arXiv preprint arXiv:1906.11942.\n- Huang G B, Mattar M, Berg T, et al. [Labeled faces in the wild: A database forstudying face recognition in unconstrained environments](http://vis-www.cs.umass.edu/lfw/lfw.pdf)[C]//Workshop on faces in'Real-Life'Images: detection, alignment, and recognition. 2008.\n- Yandong Guo, Lei Zhang, Yuxiao Hu, Xiaodong He, Jianfeng Gao .[MS-Celeb-1M: A Dataset and Benchmark for Large-Scale Face Recognition](https://arxiv.org/pdf/1607.08221) .[J] arXiv preprint arXiv:1607.08221.\n- Ankan Bansal, Anirudh Nanduri, Carlos Castillo, Rajeev Ranjan, Rama Chellappa .[UMDFaces: An Annotated Face Dataset for Training Deep Networks](https://arxiv.org/pdf/1611.01484) .[J] arXiv preprint arXiv:1611.01484.\n- Tianyue Zheng, Weihong Deng, Jiani Hu .[Cross-Age LFW: A Database for Studying Cross-Age Face Recognition in Unconstrained Environments](https://arxiv.org/pdf/1708.08197) .[J] arXiv preprint arXiv:1708.08197.\n- Cao Q, Shen L, Xie W, et al. [Vggface2: A dataset for recognising faces across pose and age](https://arxiv.org/abs/1710.08092)[C]//Automatic Face & Gesture Recognition (FG 2018), 2018 13th IEEE International Conference on. IEEE, 2018: 67-74.\n- Mei Wang, Weihong Deng, Jiani Hu, Jianteng Peng, Xunqiang Tao, Yaohai Huang .[Racial Faces in-the-Wild: Reducing Racial Bias by Deep Unsupervised Domain Adaptation](https://arxiv.org/pdf/1812.00194) .[J] arXiv preprint arXiv:1812.00194.\n- Michele Merler, Nalini Ratha, Rogerio S. Feris, John R. Smith .[Diversity in Faces](https://arxiv.org/pdf/1901.10436) .[J] arXiv preprint arXiv:1901.10436.\n- Shan Jia, Chuanbo Hu, Guodong Guo, Zhengquan Xu .[A database for face presentation attack using wax figure faces](https://arxiv.org/pdf/1906.11900) .[J] arXiv preprint arXiv:1906.11900.\n- Muhammad Haris Khan, John McDonagh, Salman Khan, Muhammad Shahabuddin, Aditya Arora, Fahad Shahbaz Khan, Ling Shao, Georgios Tzimiropoulos .[AnimalWeb: A Large-Scale Hierarchical Dataset of Annotated Animal Faces](https://arxiv.org/pdf/1909.04951) .[J] arXiv preprint arXiv:1909.04951.\n- Zhongyuan Wang, Guangcheng Wang, Baojin Huang, Zhangyang Xiong, Qi Hong, Hao Wu, Peng Yi, Kui Jiang, Nanxi Wang, Yingjiao Pei, Heling Chen, Yu Miao, Zhibing Huang, Jinbi Liang .[Masked Face Recognition Dataset and Application](https://arxiv.org/pdf/2003.09093) .[J] arXiv preprint arXiv:2003.09093\n- Viktor Varkarakis, Peter Corcoran .[Dataset Cleaning -- A Cross Validation Methodology for Large Facial Datasets using Face Recognition](https://arxiv.org/pdf/2003.10815) .[J] arXiv preprint arXiv:2003.10815.\n- Raj Kuwar Gupta, Shresth Verma, KV Arya, Soumya Agarwal, Prince Gupta .IIITM Face: A Database for Facial Attribute Detection in Constrained and Simulated Unconstrained Environments .[J] arXiv preprint arXiv:1910.01219.\n- Shifeng Zhang, Xiaobo Wang, Ajian Liu, Chenxu Zhao, Jun Wan, Sergio Escalera, Hailin Shi, Zezheng Wang, Stan Z. Li .CASIA-SURF: A Dataset and Benchmark for Large-scale Multi-modal Face Anti-spoofing .[J] arXiv preprint arXiv:1812.00408.\n- Liming Jiang, Wayne Wu, Ren Li, Chen Qian, Chen Change Loy .[DeeperForensics-1.0: A Large-Scale Dataset for Real-World Face Forgery Detection](https://arxiv.org/pdf/2001.03024) .[J] arXiv preprint arXiv:2001.03024\n- Jian Han, Sezer Karaoglu, Hoang-An Le, Theo Gevers .[Improving Face Detection Performance with 3D-Rendered Synthetic Data](https://arxiv.org/pdf/1812.07363) .[J] arXiv preprint arXiv:1812.07363.\n- Andreas Rössler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, Matthias Nießner .[FaceForensics++: Learning to Detect Manipulated Facial Images](https://arxiv.org/pdf/1901.08971) .[J] arXiv preprint arXiv:1901.08971.<br>[data:[ondyari/FaceForensics](https://github.com/ondyari/FaceForensics)]\n- Ziyi Liu, Jie Yang, Mengchen Lin, Kenneth Kam Fai Lai, Svetlana Yanushkevich, Orly Yadid-Pecht .[WDR FACE: The First Database for Studying Face Detection in Wide Dynamic Range](https://arxiv.org/pdf/2101.03826) [J]. arXiv preprint arXiv:2101.03826.\n- Kai Zhang, Vítor Albiero, Kevin W. Bowyer .[A Method for Curation of Web-Scraped Face Image Datasets](https://arxiv.org/pdf/2004.03074) [J]. arXiv preprint arXiv:2004.03074.\n- 【Datasets】Philipp Terhörst, Daniel Fährmann, Jan Niklas Kolf, Naser Damer, Florian Kirchbuchner, Arjan Kuijper .[MAAD-Face: A Massively Annotated Attribute Dataset for Face Images](https://arxiv.org/pdf/2012.01030) [J]. arXiv preprint arXiv:2012.01030.\n- Domenick Poster, Matthew Thielke, Robert Nguyen, Srinivasan Rajaraman, Xing Di, Cedric Nimpa Fondje, Vishal M. Patel, Nathaniel J. Short, Benjamin S. Riggan, Nasser M. Nasrabadi, Shuowen Hu .[A Large-Scale, Time-Synchronized Visible and Thermal Face Dataset](https://arxiv.org/pdf/2101.02637) [J]. arXiv preprint arXiv:2101.02637.\n- Anselmo Ferreira, Ehsan Nowroozi, Mauro Barni .[VIPPrint: A Large Scale Dataset of Printed and Scanned Images for Synthetic Face Images Detection and Source Linking](https://arxiv.org/pdf/2102.06792) [J]. arXiv preprint arXiv:2102.06792.\n\n\n> * **2D face recognition** \n> * **Video face recognition** \n> * **3D face recognition** \n> * **Anti-spoofing** \n> * **cross age and cross pose** \n> * **Face Detection** \n> * **Face Attributes** \n> * **Others** \n\n### 📌 2D Face Recognition\n\n| Datasets | Description | Links | Publish Time |\n| -------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------ |\n| **CASIA-WebFace** | **10,575** subjects and **494,414** images | [Download](http://www.cbsr.ia.ac.cn/english/CASIA-WebFace-Database.html) | 2014 |\n| **MegaFace**🏅 | **1 million** faces, **690K** identities | [Download](http://megaface.cs.washington.edu/) | 2016 |\n| **MS-Celeb-1M**🏅 | about **10M** images for **100K** celebrities Concrete measurement to evaluate the performance of recognizing one million celebrities | [Download](http://www.msceleb.org) | 2016 |\n| **LFW**🏅 | **13,000** images of faces collected from the web. Each face has been labeled with the name of the person pictured. **1680** of the people pictured have two or more distinct photos in the data set. | [Download](http://vis-www.cs.umass.edu/lfw/) | 2007 |\n| **VGG Face2**🏅 | The dataset contains **3.31 million** images of **9131** subjects (identities), with an average of 362.6 images for each subject. | [Download](http://www.robots.ox.ac.uk/~vgg/data/vgg_face2/) | 2017 |\n| **UMDFaces Dataset-image** | **367,888 face annotations** for **8,277 subjects.** | [Download](http://www.umdfaces.io) | 2016 |\n| **Trillion Pairs**🏅 | Train: **MS-Celeb-1M-v1c** & **Asian-Celeb** Test: **ELFW&DELFW** | [Download](http://trillionpairs.deepglint.com/overview) | 2018 |\n| **FaceScrub** | It comprises a total of **106,863** face images of male and female **530** celebrities, with about **200 images per person**. | [Download](http://vintage.winklerbros.net/facescrub.html) | 2014 |\n| **Mut1ny**🏅 | head/face segmentation dataset contains over 17.3k labeled images | [Download](http://www.mut1ny.com/face-headsegmentation-dataset) | 2018 |\n| **IMDB-Face** | The dataset contains about 1.7 million faces, 59k identities, which is manually cleaned from 2.0 million raw images. | [Download](https://github.com/fwang91/IMDb-Face) | 2018 |\n\n### 📌 Video Face Recognition \n\n| Datasets | Description | Links | Publish Time |\n| --------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------ |\n| **YouTube Face**🏅 | The data set contains **3,425** videos of **1,595** different people. | [Download](http://www.cs.tau.ac.il/%7Ewolf/ytfaces/) | 2011 |\n| **UMDFaces Dataset-video**🏅 | Over **3.7 million** annotated video frames from over **22,000** videos of **3100 subjects.** | [Download](http://www.umdfaces.io) | 2017 |\n| **PaSC** | The challenge includes 9,376 still images and 2,802 videos of 293 people. | [Download](https://www.nist.gov/programs-projects/point-and-shoot-face-recognition-challenge-pasc) | 2013 |\n| **YTC** | The data consists of two parts: video clips (1910 sequences of 47 subjects) and initialization data(initial frame face bounding boxes, manually marked). | [Download](http://seqamlab.com/youtube-celebrities-face-tracking-and-recognition-dataset/) | 2008 |\n| **iQIYI-VID**🏅 | The iQIYI-VID dataset **contains 500,000 videos clips of 5,000 celebrities, adding up to 1000 hours**. This dataset supplies multi-modal cues, including face, cloth, voice, gait, and subtitles, for character identification. | [Download](http://challenge.ai.iqiyi.com/detail?raceId=5b1129e42a360316a898ff4f) | 2018 |\n\n### 📌3D Face Recognition \n\n| Datasets | Description | Links | Publish Time |\n| -------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------ |\n| **Bosphorus**🏅 | 105 subjects and 4666 faces 2D & 3D face data | [Download](http://bosphorus.ee.boun.edu.tr/default.aspx) | 2008 |\n| **BD-3DFE** | Analyzing **Facial Expressions** in **3D** Space | [Download](http://www.cs.binghamton.edu/~lijun/Research/3DFE/3DFE_Analysis.html) | 2006 |\n| **ND-2006** | 422 subjects and 9443 faces 3D Face Recognition | [Download](https://sites.google.com/a/nd.edu/public-cvrl/data-sets) | 2006 |\n| **FRGC V2.0** | 466 subjects and 4007 of 3D Face, Visible Face Images | [Download](https://sites.google.com/a/nd.edu/public-cvrl/data-sets) | 2005 |\n| **B3D(AC)^2** | **1000** high quality, dynamic **3D scans** of faces, recorded while pronouncing a set of English sentences. | [Download](http://www.vision.ee.ethz.ch/datasets/b3dac2.en.html) | 2010 |\n\n### 📌 Anti-Spoofing \n\n| Datasets | \\# of subj. / \\# of sess. | Links | Year | Spoof attacks attacks | Publish Time |\n| ----------------- | :-----------------------: | ------------------------------------------------------------ | ---- | --------------------- | ------------ |\n| **NUAA** | 15/3 | [Download](http://parnec.nuaa.edu.cn/xtan/data/nuaaimposterdb.html) | 2010 | **Print** | 2010 |\n| **CASIA-MFSD** | 50/3 | Download(link failed) | 2012 | **Print, Replay** | 2012 |\n| **Replay-Attack** | 50/1 | [Download](https://www.idiap.ch/dataset/replayattack) | 2012 | **Print, 2 Replay** | 2012 |\n| **MSU-MFSD** | 35/1 | [Download](https://www.cse.msu.edu/rgroups/biometrics/Publications/Databases/MSUMobileFaceSpoofing/index.htm) | 2015 | **Print, 2 Replay** | 2015 |\n| **MSU-USSA** | 1140/1 | [Download](http://biometrics.cse.msu.edu/Publications/Databases/MSU_USSA/) | 2016 | **2 Print, 6 Replay** | 2016 |\n| **Oulu-NPU** | 55/3 | [Download](https://sites.google.com/site/oulunpudatabase/) | 2017 | **2 Print, 6 Replay** | 2017 |\n| **Siw** | 165/4 | [Download](http://cvlab.cse.msu.edu/spoof-in-the-wild-siw-face-anti-spoofing-database.html) | 2018 | **2 Print, 4 Replay** | 2018 |\n\n### 📌 Cross-Age and Cross-Pose\n\n| Datasets | Description | Links | Publish Time |\n| ------------ | :----------------------------------------------------------- | ------------------------------------------------------------ | ------------ |\n| **CACD2000** | The dataset contains more than 160,000 images of 2,000 celebrities with **age ranging from 16 to 62**. | [Download](http://bcsiriuschen.github.io/CARC/) | 2014 |\n| **FGNet** | The dataset contains more than 1002 images of 82 people with **age ranging from 0 to 69**. | [Download](http://www-prima.inrialpes.fr/FGnet/html/benchmarks.html) | 2000 |\n| **MPRPH** | The MORPH database contains **55,000** images of more than **13,000** people within the age ranges of **16** to **77** | [Download](http://www.faceaginggroup.com/morph/) | 2016 |\n| **CPLFW** | we construct a Cross-Pose LFW (CPLFW) which deliberately searches and selects **3,000 positive face pairs** with **pose difference** to add pose variation to intra-class variance. | [Download](http://www.whdeng.cn/cplfw/index.html) | 2017 |\n| **CALFW** | Thereby we construct a Cross-Age LFW (CALFW) which deliberately searches and selects **3,000 positive face pairs** with **age gaps** to add aging process intra-class variance. | [Download](http://www.whdeng.cn/calfw/index.html) | 2017 |\n\n### 📌Face Detection\n\n| Datasets | Description | Links | Publish Time |\n| -------------- | ------------------------------------------------------------ | ----------------------------------------------------------- | ------------ |\n| **FDDB**🏅 | **5171** faces in a set of **2845** images | [Download](http://vis-www.cs.umass.edu/fddb/index.html) | 2010 |\n| **Wider-face** | **32,203** images and label **393,703** faces with a high degree of variability in scale, pose and occlusion, organized based on **61** event classes | [Download](http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/) | 2015 |\n| **AFW** | AFW dataset is built using Flickr images. It has **205** images with **473** labeled faces. For each face, annotations include a rectangular **bounding box**, **6 landmarks** and the **pose angles**. | [Download](http://www.ics.uci.edu/~xzhu/face/) | 2013 |\n| **MALF** | MALF is the first face detection dataset that supports fine-gained evaluation. MALF consists of **5,250** images and **11,931** faces. | [Download](http://www.cbsr.ia.ac.cn/faceevaluation/) | 2015 |\n\n### 📌 Face Attributes \n\n| Datasets | Description | Links | Key features | Publish Time |\n| ------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | -------------------------------------------- | ------------ |\n| **CelebA** | **10,177** number of **identities**, **202,599** number of **face images**, and **5 landmark locations**, **40 binary attributes** annotations per image. | [Download](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html) | **attribute & landmark** | 2015 |\n| **IMDB-WIKI** | 500k+ face images with **age** and **gender** labels | [Download](https://data.vision.ee.ethz.ch/cvl/rrothe/imdb-wiki/) | **age & gender** | 2015 |\n| **Adience** | Unfiltered faces for **gender** and **age** classification | [Download](http://www.openu.ac.il/home/hassner/Adience/data.html) | **age & gender** | 2014 |\n| **WFLW**🏅 | WFLW contains **10000 faces** (7500 for training and 2500 for testing) with **98 fully manual annotated landmarks**. | [Download](https://wywu.github.io/projects/LAB/WFLW.html) | **landmarks** | 2018 |\n| **Caltech10k Web Faces** | The dataset has 10,524 human faces of various resolutions and in **different settings** | [Download](http://www.vision.caltech.edu/Image_Datasets/Caltech_10K_WebFaces/#Description) | **landmarks** | 2005 |\n| **EmotioNet** | The EmotioNet database includes**950,000 images** with **annotated AUs**. A **subset** of the images in the EmotioNet database correspond to **basic and compound emotions.** | [Download](http://cbcsl.ece.ohio-state.edu/EmotionNetChallenge/index.html#overview) | **AU and Emotion** | 2017 |\n| **RAF( Real-world Affective Faces)** | **29672** number of **real-world images**, including **7** classes of basic emotions and **12** classes of compound emotions, **5 accurate landmark locations**, **37 automatic landmark locations**, **race, age range** and **gender** **attributes** annotations per image | [Download]( <http://www.whdeng.cn/RAF/model1.html>) | **Emotions、landmark、race、age and gender** | 2017 |\n\n### 📌 Others\n\n| Datasets | Description | Links | Publish Time |\n| ------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------ |\n| **IJB C/B/A**🏅 | IJB C/B/A is currently running **three challenges** related to **face detection, verification, identification, and identity clustering.** | [Download](https://www.nist.gov/programs-projects/face-challenges) | 2015 |\n| **MOBIO** | **bi-modal** (**audio** and **video**) data taken from 152 people. | [Download](https://www.idiap.ch/dataset/mobio) | 2012 |\n| **BANCA** | The BANCA database was captured in four European languages in **two modalities** (**face** and **voice**). | [Download](http://www.ee.surrey.ac.uk/CVSSP/banca/) | 2014 |\n| **3D Mask Attack** | **76500** frames of **17** persons using Kinect RGBD with eye positions (Sebastien Marcel). | [Download](https://www.idiap.ch/dataset/3dmad) | 2013 |\n| **WebCaricature** | **6042** **caricatures** and **5974 photographs** from **252 persons** collected from the web | [Download](https://cs.nju.edu.cn/rl/WebCaricature.htm) | 2018 |\n\n"
},
{
"alpha_fraction": 0.7229917049407959,
"alphanum_fraction": 0.7626962065696716,
"avg_line_length": 35.099998474121094,
"blob_id": "06bd2fcb212514881e3e7b8195321fd5192226d3",
"content_id": "6e3bd39b7f0149234d851eb549ecd372ce630901",
"detected_licenses": [
"BSD-3-Clause",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1083,
"license_type": "permissive",
"max_line_length": 224,
"num_lines": 30,
"path": "/Snapchat_Filters/Dog_filter/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "## Build a Dog Filter with Computer Vision\n\n- A real-time filter that adds dog masks to faces on a live feed.\n- A dog filter that responds to your emotions. (Couldn't find a pug mask, so I used a cat.) A generic dog for smiling \"happy\", a dalmation for frowning \"sad\", and a cat for dropped jaws \"surprise\".\n- Utilities used for portions of the understanding, such as plotting and advesarial example generation.\n- Ordinary least squares and ridge regression models using randomized features.\n\n\n\n# Getting Started\n\n> (Optional) [Setup a Python virtual environment](https://www.digitalocean.com/community/tutorials/common-python-tools-using-virtualenv-installing-with-pip-and-managing-packages#a-thorough-virtualenv-how-to) with Python 3.6.\n\n1. Install all Python dependencies.\n\n```\npip install -r requirements.txt\n```\n\n2. Navigate into `src`.\n\n```\ncd src\n```\n\n3. Launch the script for an emotion-based dog filter:\n\n```\npython step_8_dog_emotion_mask.py\n```\n"
},
{
"alpha_fraction": 0.7390272617340088,
"alphanum_fraction": 0.791814923286438,
"avg_line_length": 61.44444274902344,
"blob_id": "ec5b5200de5da2c6c00747601ecd975af064a108",
"content_id": "03e556903a0da57c6d7c9989a8d65537359f8f8c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3401,
"license_type": "permissive",
"max_line_length": 541,
"num_lines": 54,
"path": "/Recognition-Algorithms/Recognition using LDA/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Face Recognition Using Linear Discriminant Analysis👨💻👨💻\nLinear Discriminant Analysis (LDA) has been successfully applied to face recognition which is based on a linear projection from the image space to a low dimensional space by maximizing the between-class scatter and minimizing within-class scatter.LDA method overcomes the limitation of the Principle Component Analysis method by applying the linear discriminant criterion. Analysis (LDA) which is also called fisher face is an appearance-based technique used for dimensionality reduction and recorded a great performance in face recognition.\n\n## Applications:\n\n#### Face Recognition:\n In the field of Computer Vision, face recognition is a very popular application in which each face is represented by a very large number of pixel values. Linear discriminant analysis (LDA) is used here to reduce the number of features to a more manageable number before the process of classification. Each of the new dimensions generated is a linear combination of pixel values, which form a template. The linear combinations obtained using Fisher’s linear discriminant are called Fisher's faces.\n#### Medical: \nIn this field, Linear discriminant analysis (LDA) is used to classify the patient's disease state as mild, moderate, or severe based upon the patient various parameters and the medical treatment he is going through. This helps the doctors to intensify or reduce the pace of their treatment.\n#### Customer Identification: \nSuppose we want to identify the type of customers who are most likely to buy a particular product in a shopping mall. By doing a simple question and answers survey, we can gather all the features of the customers. Here, the Linear discriminant analysis will help us to identify and select the features which can describe the characteristics of the group of customers that are most likely to buy that particular product in the shopping mall.\n\n**The following is a demonstration of Linear Discriminant Analysis. The following has been developed in python 3.8.**\n\n**Dataset courtesy**\n- http://vis-www.cs.umass.edu/lfw/\n## Proposed method\n<img width=\"283\" alt=\"Screenshot 2021-03-20 at 2 55 20 AM\" src=\"https://user-images.githubusercontent.com/78999467/111843334-155ccd80-8929-11eb-8552-d935aad99e2c.png\">\n\n## Dependencies📝:\n- ```pip install sklearn```\n- ```pip install matplotlib```\n\n## QuickStart✨:\n- Clone this repository\n` git clone https://github.com/akshitagupta15june/Face-X.git`\n- Change Directory\n` cd Recognition-Algorithms/Recognition Using LDA`\n- Run the program with the set dataset:\n``` py main.py```\n- Make a folder and add your code file and a readme file with screenshots.\n- Commit message\n` git commit -m \"Enter message\"`\n- Push your code\n` git push`\n- Make a Pull request\n- Wait for reviewers to review your PR\n\n## Result📉:\nThe dataset details along with the classification report and confusion matrix are printed.\nThe time taken by each step is also included.\n\n\n\n\n## Screenshot📸:\nFaces with the names predicted\n\n\n\n\nThe fisher faces \n\n\n"
},
{
"alpha_fraction": 0.7058365941047668,
"alphanum_fraction": 0.7424124479293823,
"avg_line_length": 31.94871711730957,
"blob_id": "2aeee554992ef436f50d68bae0ce85da6c9faab4",
"content_id": "70fc4d36468be0a8ece14fd38b16c9c29ca4d7a1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1285,
"license_type": "permissive",
"max_line_length": 250,
"num_lines": 39,
"path": "/Face Reconstruction/Face Alignment in Full Pose Range/demo@obama/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "### How to build\n\n1. Prepaing reconstructed 3D dense alignment result\n\nYou can download the reconstructed results from [BaiduYun](https://pan.baidu.com/s/1R5Tf1X0b0gLff97G2dKS6w) / [Google Drive](https://drive.google.com/drive/folders/12kNVAxdgomKXfqiJPRmZMA6wexVPaNIh?usp=sharing) or run `main.py` in the root directory.\n\n2. Run `rendering.m` to rendering 3D face meshes. The rendered images will be in `obama_res@dense` directory.\n\n3. Run `python3 convert_imgs_to_video.py obama_res@dense` to convert images to one video.\n\nA frame of the video:\n<p align=\"center\">\n <img src=\"0013.jpg\" alt=\"Vertex 3D\" width=\"750px\">\n</p>\n\nThe output video named `[email protected]` lies in this directory.\n\n\n### A simple Python render\n\n_Thanks for [liguohao96](https://github.com/liguohao96) for contributions of the original version of this simple Python render._\n\n**Speed**: ~25ms for one frame (720p), CPU.\n\n\nAfter preparing the vertices, just run\n```\npython3 rendering.py && python3 convert_imgs_to_video.py obama_res@dense_py\n```\n\nA frame of the outputed video:\n<p align=\"center\">\n <img src=\"0013_py.jpg\" alt=\"Vertex 3D\" width=\"750px\">\n</p>\n\nThe output video named `obama_res@dense_py.mp4` lies in this directory.\n\n### Future\n**Welcome for contributions of a FASTer Python/PyTorch render.**\n"
},
{
"alpha_fraction": 0.745192289352417,
"alphanum_fraction": 0.7564102411270142,
"avg_line_length": 30.200000762939453,
"blob_id": "ff6e9a7d3a9b7cae1db1f30165769a40327773b4",
"content_id": "c5ebc6ebd3d8d60328767945b2441a4b6a59d2d4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 624,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 20,
"path": "/Recognition-Algorithms/Recognition using FisherFaceRecogniser/facial_recognition_part2.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import cv2\nimport numpy as np\nfrom os import listdir\nfrom os.path import isfile, join\ndata_path='/home/akshita/Desktop/Face_reco/'\nonlyfiles=[f for f in listdir(data_path) if isfile(join(data_path,f))]\n\nTraining_data,Labels=[],[]\n\nfor i, files in enumerate(onlyfiles):\n image_path=data_path + onlyfiles[i]\n images=cv2.imread(image_path,cv2.IMREAD_GRAYSCALE)\n Training_data.append(np.asarray(images,dtype=np.uint8))\n Labels.append(i)\nLabels=np.asarray(Labels,dtype=np.int32)\n\nmodel=cv2.face.FisherFaceRecognizer_create()\n\nmodel.train(np.asarray(Training_data),np.asarray(Labels))\nprint(\"Model Training Complete\")\n"
},
{
"alpha_fraction": 0.6412371397018433,
"alphanum_fraction": 0.6649484634399414,
"avg_line_length": 18.125,
"blob_id": "4cd8320efaa912cdf990529901e455d955c5e5d2",
"content_id": "fe270437a9c15617426ec989928d6e72c2b6370f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 970,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 48,
"path": "/Cartoonify Image/Cartoonify-GUI/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "## Cartoonify Image and save it\r\n### This is a very baisc GUI for cartoonifying iage and save it\r\n## How to start\r\n\r\n\r\n- Fork the repository\r\n\r\n- Git clone your forked repository\r\n- Create virtual environment-\r\n```\r\n- python -m venv env\r\n- source env/bin/activate (Linux)\r\n- env\\Scripts\\activate (Windows)\r\n```\r\n- Install dependencies\r\n- Go to project directory\r\n```\r\n- cd Cartoonify Image\r\n```\r\n- install these requirements\r\n\r\n```\r\n- pip install opencv-python\r\n- pip install tkinter\r\n- pip install easygui\r\n- pip install pillow\r\n``` \r\n- Open Terminal\r\n```\r\npython cartoonify_GUI.py\r\n```\r\n\r\n### Video recording of the process\r\n\r\n[](https://youtu.be/VDqEv6_FDt4 \"Cartoonify GUI\")\r\n\r\n\r\n### Screenshots: \r\n<img src=\"mq2.jpg\" height=\"300px\">\r\n\r\n### GUI Interface\r\n<img src=\"Updated GUI.png\" height=\"600px\">\r\n\r\n### Cartoonified Image \r\n<img src=\"cartoonified.jpg\" height=\"600px\">\r\n\r\n### Original Image\r\n<img src=\"wp2030093.jpg\" height=\"600px\">\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.7208211421966553,
"alphanum_fraction": 0.8070381283760071,
"avg_line_length": 80.0952377319336,
"blob_id": "86ba5e2fecc4882d8560c4eb76cdeb0b28d5f73d",
"content_id": "88e822fb7b880bcb00d598b612a96d6557c80fa0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1713,
"license_type": "permissive",
"max_line_length": 632,
"num_lines": 21,
"path": "/Recognition-using-IOT/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Recognition-using-IOT\n## What is IOT?\n**The Internet of Things (IoT) refers to a system of interrelated, internet-connected objects that are able to collect and transfer data over a wireless network without human intervention.** The Internet of things describes the network of physical objects—“things”—that are embedded with sensors, software, and other technologies for the purpose of connecting and exchanging data with other devices and systems over the Internet.\n## How it works?\n\n\n\nThe face detection part is deployed in the IoT devices and the computation-intensive task, i.e., face recognition is carried out in backend Cloud servers. The system uses Local Binary Pattern Histograms to recognize the person from the local database created for the family members of the house. Security, monitoring, and control to automation in real-time are the key components of this system. Total processing time can be further reduced by deploying a face recognition application from Core Cloud to Edge Cloud. Furthermore, the k-nearest neighbor algorithm shows promising results compared to other face recognition algorithms.\n\n### The hardware required to implement this system:\n- Raspberry Pi 3 microprocessor\n \n\n\n- external web camera\n \n\n\n- stepper motor\n \n\n\n "
},
{
"alpha_fraction": 0.6735484004020691,
"alphanum_fraction": 0.7746236324310303,
"avg_line_length": 51.8636360168457,
"blob_id": "ee7d81861fdc66d748a9e904afb60f03f2344e5c",
"content_id": "0c5478de506b49bce573c2b019fbbac2b15d3a5e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2343,
"license_type": "permissive",
"max_line_length": 315,
"num_lines": 44,
"path": "/Virtual_makeover/Virtual-Makeup/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Virtual-Makeup🧚♀️💅💄 👓\n**Virtual Makeup** is a smart beauty camera app feature that allows users to try on **makeup, hair colors, and accessories** via augmented reality. It works with neural networks trained to detect and modify the right part of the face e.g. lips or hair and face tracking technology to provide real-time experience. \n## Main features of virtual makeovers\nYou need to determine what features it should include and how you can scale them in future. Here is a shortlist of the most significant functionality considered while building a beauty AR app:\n- Real-time makeover\n- Face beautification\n- Virtual hair color try on\n- Facial feature modification e.g. slim down cheeks\n- Photo / video editing \n- Face filters and AR effects\n- Beauty community\n- Social network integration\n\n## Quick Start\n- Clone this repository\n` git clone https://github.com/akshitagupta15june/Face-X.git`\n- Change Directory\n` cd Virtual_makeover`\n- Make a folder and add your code file and a readme file with screenshots.\n- Commit message\n` git commit -m \"Enter message\"`\n- Push your code\n` git push`\n- Make Pull request\n- Wait for reviewers to review your PR\n\n### If you want to run script for your images or want to run real-time frame.\n- Save Image in folder.\n- Change script and enter your image path in VideoCapture(\"Enter your path here\").\n- Run camera.py `python camera.py` for real-time frame.\n- If you want to click real-time picture and run that, then run picsaver.py ` python Picsaver.py`\n\n## Screenshots of result\n**Original Image:**\n\n\n**Makeover Image:**\n\n\n\n**Comparing face and hair before and after:**\n\n<img width=\"295\" alt=\"haircolor\" src=\"https://user-images.githubusercontent.com/78999467/111756825-c1b79900-88c2-11eb-96ee-301aec755b9b.png\">\n<img width=\"147\" alt=\"blush\" src=\"https://user-images.githubusercontent.com/78999467/111756854-c9773d80-88c2-11eb-8f48-d5a4621a8718.png\">"
},
{
"alpha_fraction": 0.5240715146064758,
"alphanum_fraction": 0.54676753282547,
"avg_line_length": 28.67346954345703,
"blob_id": "9de74920ec2998ee85e84b8992465fbe291f1b6b",
"content_id": "aa4b7f935f651c619df22c70877b248dd1b51ef3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4362,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 147,
"path": "/Recognition-Algorithms/Recognition_using_NasNet/main.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nimport torch.optim as optim\nfrom torch.optim import lr_scheduler\nimport torchvision\nfrom torchvision import datasets, models, transforms\nimport time\nimport os\nimport copy\nfrom tqdm import tqdm\nfrom models import *\n\n# change device to GPU if available\ndevice = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\n\n# preprocess the input image\npreprocess = {\n \"train\": transforms.Compose(\n [\n transforms.Resize(224),\n transforms.RandomRotation(30),\n transforms.RandomHorizontalFlip(),\n transforms.ToTensor(),\n transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),\n ]\n ),\n \"val\": transforms.Compose(\n [\n transforms.Resize(224),\n transforms.ToTensor(),\n transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),\n ]\n ),\n}\n\n# load datasets\ndata_dir = \"Datasets\"\ndatasets = {\n x: datasets.ImageFolder(os.path.join(data_dir, x), preprocess[x])\n for x in [\"train\", \"val\"]\n}\ndataloader = {\n x: torch.utils.data.DataLoader(\n datasets[x], batch_size=16, shuffle=True, num_workers=0\n )\n for x in [\"train\", \"val\"]\n}\ndatasets_size = {x: len(datasets[x]) for x in [\"train\", \"val\"]}\nclass_names = datasets[\"train\"].classes\n\n# initialize model\nmodel = NASNetAMobile(len(class_names)).to(device)\n\n# initialize model parameters\ncriterion = nn.CrossEntropyLoss()\noptimizer = optim.Adam(model.parameters())\nexp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)\n\n\ndef train(model, criterion, optimizer, scheduler, num_epochs=25):\n # helper function to train model\n since = time.time()\n\n best_model_wts = copy.deepcopy(model.state_dict())\n best_acc = 0.0\n best_loss = 0.0\n\n for epoch in range(num_epochs):\n print(\"Epoch {}/{}\".format(epoch + 1, num_epochs))\n\n metrics = {\n \"loss\": {\"train\": 0.0, \"val\": 0.0},\n \"acc\": {\"train\": 0.0, \"val\": 0.0},\n }\n\n for phase in [\"train\", \"val\"]:\n running_loss = 0.0\n running_corrects = 0.0\n\n if phase == \"train\":\n model.train()\n else:\n model.eval()\n\n for inputs, labels in tqdm(dataloader[phase], ncols=100):\n # iterate through the datasets\n inputs = inputs.to(device)\n labels = labels.to(device)\n\n optimizer.zero_grad()\n\n with torch.set_grad_enabled(phase == \"train\"):\n outputs = model(inputs)\n _, preds = outputs.max(dim=1)\n loss = criterion(outputs, labels)\n if phase == \"train\":\n loss.backward()\n optimizer.step()\n scheduler.step()\n\n running_loss += loss.item() * inputs.size(0)\n running_corrects += torch.sum(preds == labels.data)\n\n metrics[\"loss\"][phase] = running_loss / datasets_size[phase]\n metrics[\"acc\"][phase] = running_corrects.double() / datasets_size[phase]\n\n print(\n \"Loss: {:.4f} Acc: {:.4f} Val Loss: {:.4f} Val Acc: {:.4f}\".format(\n metrics[\"loss\"][\"train\"],\n metrics[\"loss\"][\"val\"],\n metrics[\"acc\"][\"train\"],\n metrics[\"acc\"][\"val\"],\n )\n )\n\n # update best model weights\n if (\n metrics[\"acc\"][\"val\"]\n + metrics[\"acc\"][\"train\"]\n - metrics[\"loss\"][\"val\"]\n - metrics[\"loss\"][\"train\"]\n > best_acc - best_loss\n ):\n best_acc = metrics[\"acc\"][\"val\"]\n best_loss = metrics[\"loss\"][\"val\"]\n best_model_wts = copy.deepcopy(model.state_dict())\n print(\"Best weights updated\")\n\n print()\n time_elapsed = time.time() - since\n print(\n \"Training complete in {:.0f}m {:.0f}s\".format(\n time_elapsed // 60, time_elapsed % 60\n )\n )\n print(\"Best val Acc: {:4f}\".format(best_acc))\n\n # load best model weights\n model.load_state_dict(best_model_wts)\n return model\n\n\n# train model\nmodel = train(model, criterion, optimizer, exp_lr_scheduler, num_epochs=5)\n\n# save model weights\ntorch.save(model.state_dict(), \"saved_model.pt\")\n"
},
{
"alpha_fraction": 0.6308119297027588,
"alphanum_fraction": 0.657182514667511,
"avg_line_length": 25.200000762939453,
"blob_id": "9c744b97aa6ebddc4ce052b541f4afa122852972",
"content_id": "5ebbd76bf5f682b4827ea37f042c8dd13c73c6cf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1441,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 55,
"path": "/Recognition-using-IOT/DETECTION AND RECOGNITION USING RASPBERRY PI/face_to_system.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Import OpenCV2 for image processing\nimport cv2\n\n# Start capturing video \nvid_cam = cv2.VideoCapture(0)\n\n# Detect object in video stream using Haarcascade Frontal Face\nface_detector = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')\n\n# For each person, one face id\nface_id = 5\n\n# Initialize sample face image\ncount = 0\n\n# Start looping\nwhile(True):\n\n # Capture video frame\n _, image_frame = vid_cam.read()\n\n # Convert frame to grayscale\n gray = cv2.cvtColor(image_frame, cv2.COLOR_BGR2GRAY)\n\n # Detect frames of different sizes, list of faces rectangles\n faces = face_detector.detectMultiScale(gray, 1.3, 5)\n\n # Loops for each faces\n for (x,y,w,h) in faces:\n\n # Crop the image frame into rectangle\n cv2.rectangle(image_frame, (x,y), (x+w,y+h), (255,0,0), 2)\n \n # Increment sample face image\n count += 1\n\n # Save the captured image into the datasets folder\n cv2.imwrite(\"dataset/User.\" + str(face_id) + '.' + str(count) + \".jpg\", gray[y:y+h,x:x+w])\n\n # Display the video frame, with bounded rectangle on the person's face\n cv2.imshow('frame', image_frame)\n\n # To stop taking video, press 'q' for at least 100ms\n if cv2.waitKey(100) & 0xFF == ord('q'):\n break\n\n # If image taken reach 100, stop taking video\n elif count>100:\n break\n\n# Stop video\nvid_cam.release()\n\n# Close all started windows\ncv2.destroyAllWindows()\n"
},
{
"alpha_fraction": 0.584613561630249,
"alphanum_fraction": 0.6083124876022339,
"avg_line_length": 36.875,
"blob_id": "f2755b02d36d5911d374ac948c6f31ac5ffe93bf",
"content_id": "02d042243f1062e84331442a5bd2d8e1cdaaa413",
"detected_licenses": [
"BSD-3-Clause",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8397,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 216,
"path": "/Snapchat_Filters/Goggles_Changing_Filter/Goggle_filter.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import dlib\r\nimport cv2\r\nfrom scipy.spatial import distance as dist\r\nimport numpy as np\r\n\r\n\r\ndef eye_aspect_ratio(eye):\r\n \"\"\"\r\n It is used to determine EAR value based on the list we passed\r\n which consists of 6 points.\r\n :param eye: list of 6 points that we get from landmark\r\n :return: calculated ear value\r\n \"\"\"\r\n # A & B for Vertical distance\r\n A = dist.euclidean(eye[1], eye[5])\r\n B = dist.euclidean(eye[2], eye[4])\r\n # C for Horizontal distance\r\n C = dist.euclidean(eye[0], eye[3])\r\n\r\n # Formula for calculating EAR\r\n ear = (A + B) / (2.0 * C)\r\n\r\n return ear\r\n\r\n\r\ndef filter_1(frame, landmarks):\r\n \"\"\"\r\n Generating 1 filter according to the face landmarks produced\r\n from the frame and displaying accordingly.\r\n :param : the current frame captured, landmarks generated from it\r\n :return: frame with the filter on it\r\n \"\"\"\r\n # Storing image with the desired filter\r\n imgGlass = cv2.imread(\"assets/sun_1.png\", -1)\r\n\r\n # selecting all 3 color channels for the image\r\n orig_mask_g = imgGlass[:, :, 3]\r\n # Colorwise inverted mask of the image\r\n orig_mask_inv_g = cv2.bitwise_not(orig_mask_g)\r\n imgGlass = imgGlass[:, :, 0:3]\r\n\r\n # Generating dimensions of goggles from original image\r\n origGlassHeight, origGlassWidth = imgGlass.shape[:2]\r\n\r\n # Generating required width and height according to the landmarks\r\n glassWidth = abs(landmarks.part(16).x - landmarks.part(1).x)\r\n glassHeight = int(glassWidth * origGlassHeight / origGlassWidth)\r\n\r\n # Resizing the image according to the dimensions generated from the frame\r\n glass = cv2.resize(imgGlass, (glassWidth, glassHeight), interpolation=cv2.INTER_AREA)\r\n mask = cv2.resize(orig_mask_g, (glassWidth, glassHeight), interpolation=cv2.INTER_AREA)\r\n mask_inv = cv2.resize(orig_mask_inv_g, (glassWidth, glassHeight), interpolation=cv2.INTER_AREA)\r\n\r\n # For obtaining the Region-of-interest (ROI)\r\n y1 = int(landmarks.part(24).y)\r\n y2 = int(y1 + glassHeight)\r\n x1 = int(landmarks.part(27).x - (glassWidth / 2))\r\n x2 = int(x1 + glassWidth)\r\n roi1 = frame[y1:y2, x1:x2]\r\n\r\n # Obtaining the background and foreground of the ROI\r\n roi_bg = cv2.bitwise_and(roi1, roi1, mask=mask_inv)\r\n roi_fg = cv2.bitwise_and(glass, glass, mask=mask)\r\n\r\n # Adding the filter to the frame\r\n frame[y1:y2, x1:x2] = cv2.add(roi_bg, roi_fg)\r\n\r\n return frame\r\n\r\n\r\ndef filter_2(frame, landmarks):\r\n \"\"\"\r\n Generating 2 filter according to the face landmarks produced\r\n from the frame and displaying accordingly.\r\n :param : the current frame captured, landmarks generated from it\r\n :return: frame with the filter on it\r\n \"\"\"\r\n imgMustache = cv2.imread(\"assets/moustache.png\", -1)\r\n\r\n orig_mask = imgMustache[:, :, 3]\r\n orig_mask_inv = cv2.bitwise_not(orig_mask)\r\n\r\n imgMustache = imgMustache[:, :, 0:3]\r\n origMustacheHeight, origMustacheWidth = imgMustache.shape[:2]\r\n\r\n imgGlass = cv2.imread(\"assets/glasses.png\", -1)\r\n orig_mask_g = imgGlass[:, :, 3]\r\n orig_mask_inv_g = cv2.bitwise_not(orig_mask_g)\r\n imgGlass = imgGlass[:, :, 0:3]\r\n origGlassHeight, origGlassWidth = imgGlass.shape[:2]\r\n\r\n mustacheWidth = abs(3 * (landmarks.part(31).x - landmarks.part(35).x))\r\n mustacheHeight = int(mustacheWidth * origMustacheHeight / origMustacheWidth) - 10\r\n mustache = cv2.resize(imgMustache, (mustacheWidth, mustacheHeight), interpolation=cv2.INTER_AREA)\r\n mask = cv2.resize(orig_mask, (mustacheWidth, mustacheHeight), interpolation=cv2.INTER_AREA)\r\n mask_inv = cv2.resize(orig_mask_inv, (mustacheWidth, mustacheHeight), interpolation=cv2.INTER_AREA)\r\n y1 = int(landmarks.part(33).y - (mustacheHeight / 2)) + 10\r\n y2 = int(y1 + mustacheHeight)\r\n x1 = int(landmarks.part(51).x - (mustacheWidth / 2))\r\n x2 = int(x1 + mustacheWidth)\r\n roi = frame[y1:y2, x1:x2]\r\n roi_bg = cv2.bitwise_and(roi, roi, mask=mask_inv)\r\n roi_fg = cv2.bitwise_and(mustache, mustache, mask=mask)\r\n frame[y1:y2, x1:x2] = cv2.add(roi_bg, roi_fg)\r\n\r\n glassWidth = abs(landmarks.part(16).x - landmarks.part(1).x)\r\n glassHeight = int(glassWidth * origGlassHeight / origGlassWidth)\r\n glass = cv2.resize(imgGlass, (glassWidth, glassHeight), interpolation=cv2.INTER_AREA)\r\n mask = cv2.resize(orig_mask_g, (glassWidth, glassHeight), interpolation=cv2.INTER_AREA)\r\n mask_inv = cv2.resize(orig_mask_inv_g, (glassWidth, glassHeight), interpolation=cv2.INTER_AREA)\r\n y1 = int(landmarks.part(24).y)\r\n y2 = int(y1 + glassHeight)\r\n x1 = int(landmarks.part(27).x - (glassWidth / 2))\r\n x2 = int(x1 + glassWidth)\r\n roi1 = frame[y1:y2, x1:x2]\r\n roi_bg = cv2.bitwise_and(roi1, roi1, mask=mask_inv)\r\n roi_fg = cv2.bitwise_and(glass, glass, mask=mask)\r\n frame[y1:y2, x1:x2] = cv2.add(roi_bg, roi_fg)\r\n\r\n return frame\r\n\r\n\r\ndef snapchat_filter():\r\n \"\"\"\r\n This function consists main logic of the program in which\r\n 1. detect faces\r\n 2. from 68 landmark points we detect eyes\r\n 3. from that points, calculation eye aspect ratio (EAR), then taking\r\n median of both eye EAR ratios.\r\n 4. Checking for how many frames EAR is below our Threshold limit indicating,\r\n closed eyes.\r\n 5. if eyes closed for more than the threshold we set for frames means person\r\n is feeling drowsy.\r\n :return: None\r\n \"\"\"\r\n\r\n # detector for detecting the face in the image\r\n detector = dlib.get_frontal_face_detector()\r\n # predictor of locating 68 landmark points from the face by using a pretrained model\r\n predictor = dlib.shape_predictor('shape_predictor_68_face_landmarks.dat')\r\n\r\n EYE_AR_THRESH = 0.27\r\n # if eye is closed (ear < threshold) for a minimum consecutive frames ie person\r\n # feeling drowsy.\r\n EYE_AR_CONSEC_FRAMES = 5\r\n # for keeping count of frames below ear\r\n COUNTER = 0\r\n Blink = True\r\n\r\n cap = cv2.VideoCapture(0)\r\n while True:\r\n ret, frame = cap.read()\r\n if ret:\r\n frameGray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)\r\n # detecting faces in the frame\r\n faces = detector(frameGray)\r\n\r\n # if faces are present then locating the landmark points\r\n for face in faces:\r\n landmarks = predictor(frameGray, face)\r\n # list for storing points location in pixel.\r\n landmark_points_location = []\r\n\r\n for i in range(36, 48):\r\n x = landmarks.part(i).x\r\n y = landmarks.part(i).y\r\n # calculating x and y and appending it into a list\r\n landmark_points_location.append([x, y])\r\n\r\n # changing the list into numpy array to perform computations.\r\n landmark_points_location = np.array(landmark_points_location)\r\n\r\n leftEye = landmark_points_location[:6]\r\n rightEye = landmark_points_location[6:]\r\n\r\n # calculating left and right eye EAR\r\n leftEye_ear = eye_aspect_ratio(leftEye)\r\n rightEye_ear = eye_aspect_ratio(rightEye)\r\n\r\n # calculating mean EAR\r\n ear = (leftEye_ear + rightEye_ear) / 2\r\n\r\n # cv2.putText(frame, \"EAR: {:.2f}\".format(ear), (int(cap.get(3)) - 125, 30),\r\n # cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)\r\n\r\n if ear < EYE_AR_THRESH:\r\n COUNTER += 1\r\n # If counter is greater than threshold then DROWSINESS\r\n if COUNTER >= EYE_AR_CONSEC_FRAMES:\r\n if Blink:\r\n Blink = False\r\n else:\r\n Blink = True\r\n else:\r\n if Blink:\r\n frame = filter_2(frame, landmarks)\r\n else:\r\n frame = filter_1(frame, landmarks)\r\n\r\n # for showing frames on the window named Detector\r\n cv2.imshow('Detector', frame)\r\n\r\n # for quiting the program press 'ESC'\r\n if cv2.waitKey(1) & 0xFF == 27:\r\n break\r\n\r\n else:\r\n break\r\n\r\n # releasing all the frames we captured and destroying the windows\r\n cap.release()\r\n cv2.destroyAllWindows()\r\n\r\n\r\nif __name__ == '__main__':\r\n snapchat_filter()\r\n"
},
{
"alpha_fraction": 0.6345422863960266,
"alphanum_fraction": 0.6721934080123901,
"avg_line_length": 34.30487823486328,
"blob_id": "47f87193714eeb8d382bd0c894a4b2fb328eaee7",
"content_id": "71c800873607148bdeece508a760ca2fe378a870",
"detected_licenses": [
"BSD-3-Clause",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2895,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 82,
"path": "/Snapchat_Filters/Detective Filter/detective_filter.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from imutils import face_utils\nimport numpy as np\nimport imutils\nimport dlib\nimport cv2\nimport math\n\nhat = cv2.imread(\"assets/det_hat.png\")\ncigar = cv2.imread(\"assets/detective_cigar.png\")\ncap = cv2.VideoCapture(0)\n\n\ndetector = dlib.get_frontal_face_detector()\npredictor = dlib.shape_predictor(\"shape_predictor_68_face_landmarks.dat\")\n\n\nwhile (True):\n\tret, frame = cap.read()\n\tgray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)\n\tfaces = detector(gray)\n\t\n\tfor face in faces:\n\t\ttry:\n\t\t\n\t\t\tlandmarks = predictor(gray, face)\n\t\t\tlandmarks_np = face_utils.shape_to_np(landmarks)\n\n\n\t\t\t# Detective Hat\t\t\n\t\t\tbottom_left = (landmarks.part(0).x, landmarks.part(0).y)\n\t\t\tbottom_right = (landmarks.part(16).x, landmarks.part(16).y)\n\t\t\tfore_wd = int(math.hypot(bottom_left[0] - bottom_right[0], bottom_left[1] - bottom_right[1]))\n\t\t\tfore_adj = imutils.resize(hat, width=fore_wd)\n\t\t\tfore_ht = fore_adj.shape[0]\n\n\t\t\tbottom_left = (int(bottom_left[0]-fore_wd//4), int(bottom_left[1]-fore_ht*1.7))\n\t\t\tbottom_right = (int(bottom_right[0]+fore_wd//4), int(bottom_right[1]-fore_ht*1.7))\n\t\t\ttop_left = (bottom_left[0], bottom_left[1]-fore_ht)\n\t\t\ttop_right = (bottom_right[0], bottom_right[1]-fore_ht)\n\n\t\t\that_wd = int(math.hypot(bottom_left[0] - bottom_right[0], bottom_left[1] - bottom_right[1]))\n\t\t\that_adj = imutils.resize(hat, width=hat_wd)\n\t\t\that_ht = hat_adj.shape[0]\n\t\t\that_gray = cv2.cvtColor(hat_adj, cv2.COLOR_BGR2GRAY)\n\t\t\t_, hat_mask = cv2.threshold(hat_gray, 22, 255, cv2.THRESH_BINARY)\n\n\t\t\that_area = frame[top_left[1]: top_left[1] + hat_ht, top_left[0]: top_left[0] + hat_wd]\n\t\t\that_area_no_hat = cv2.subtract(hat_area, cv2.cvtColor(hat_mask, cv2.COLOR_GRAY2BGR))\n\t\t\that_final = cv2.add(hat_area_no_hat, hat_adj)\n\t\t\tframe[top_left[1]: top_left[1] + hat_ht, top_left[0]: top_left[0] + hat_wd] = hat_final\n\n\n\n\n\t\t\t# Detective Cigar\n\t\t\ttop_left = (landmarks.part(52).x, landmarks.part(52).y)\n\t\t\ttop_right = (landmarks.part(13).x, landmarks.part(13).y)\n\n\t\t\tcigar_wd = int(math.hypot(top_left[0] - top_right[0], top_left[1] - top_right[1])*0.85)\n\t\t\tcigar_adj = imutils.resize(cigar, width=cigar_wd)\n\t\t\tcigar_ht = cigar_adj.shape[0]\n\n\t\t\tbottom_left = (landmarks.part(3).x, landmarks.part(3).y+cigar_ht)\n\t\t\tbottom_right = (landmarks.part(13).x, landmarks.part(13).y+cigar_ht)\n\n\t\t\tcigar_gray = cv2.cvtColor(cigar_adj, cv2.COLOR_BGR2GRAY)\n\t\t\t_, cigar_mask = cv2.threshold(cigar_gray, 25, 255, cv2.THRESH_BINARY_INV)\n\t\t\tcigar_area = frame[top_left[1]: top_left[1] + cigar_ht, top_left[0]: top_left[0] + cigar_wd]\n\t\t\tcigar_area_no_cigar = cv2.bitwise_and(cigar_area, cigar_area, mask=cigar_mask)\n\t\t\tcigar_final = cv2.add(cigar_area_no_cigar, cigar_adj)\n\t\t\tframe[top_left[1]: top_left[1] + cigar_ht, top_left[0]: top_left[0] + cigar_wd] = cigar_final\n\t\t\n\t\texcept Exception as err:\n\t\t\tprint(err)\n\t\t\tcontinue\n\t\t\n\tcv2.imshow(\"Detective Filter\",frame)\t\n\tq = cv2.waitKey(1)\n\tif q==ord(\"q\"):\n\t\tbreak\n\ncv2.destroyAllWindows()\n"
},
{
"alpha_fraction": 0.6431818008422852,
"alphanum_fraction": 0.6522727012634277,
"avg_line_length": 17.913043975830078,
"blob_id": "1684f2195182d440926cda39c1bf0b9265fde5cc",
"content_id": "29b602059a9023999ddc460ee166ecad7b2e03ad",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 440,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 23,
"path": "/Face Reconstruction/Facial Reconstruction and Dense Alignment/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Face Reconstruction and Dense Alignment\n \n## Introduction\n \n This project implements some features related to face reconstruction and dense alignment. \n\n## Features\n\n### Face Dense Alignment\n \n   \n\n \n### Face 3D landmarks\n  \n\n\n### 3D Pose Estimation\n  \n\n \n### Face Reconstruction\n  \n\n\n"
},
{
"alpha_fraction": 0.5421203374862671,
"alphanum_fraction": 0.5722063183784485,
"avg_line_length": 31.60747718811035,
"blob_id": "9147d1ddff92a762f0cc4a3677c7fc56488e4d2b",
"content_id": "a4f6e8bc6ffe3e11d4c2aef57e52cf8e2fbbaecd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3490,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 107,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/geometry/camera/camera_render.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n# system\nfrom __future__ import print_function\n\n# python lib\nimport math\nfrom copy import deepcopy\nimport numpy as np\n\n# tf_render\nimport tensorflow as tf\n\n# self\nfrom rotation import RotationMtxBatch\nfrom camera import IntrinsicMtxBatch, CameraMtxBatch\n\n\"\"\"\nparam numpy\ninherit tensor\n\"\"\"\n\nclass CameraRender(CameraMtxBatch):\n\n def __init__(self, h_intrinsic, h_extenal, near=0.1, far=2000.0):\n super(CameraRender, self).__init__(h_intrinsic, h_extenal)\n\n self.h_intrinsic = h_intrinsic\n self.h_extenal = h_extenal\n\n self.focal_len_x = h_intrinsic.focal_len_x\n self.focal_len_y = h_intrinsic.focal_len_y\n\n self.u = h_intrinsic.u\n self.v = h_intrinsic.v\n\n self.image_width_batch = h_intrinsic.Get_image_width()\n self.image_height_batch = h_intrinsic.Get_image_height()\n\n #super(CameraRender, self)._Cal_mtxProj()\n self.near = tf.reshape(tf.constant(near), shape=[1, 1])\n self.far = tf.reshape(tf.constant(far), shape=[1, 1])\n self.near = tf.tile(self.near, [self.batch_size, 1])\n self.far = tf.tile(self.far, [self.batch_size, 1])\n #\n def Get_modelViewMatrix_batch(self, re_grad=False):\n mtx_inv = tf.constant(\n [\n [1., 0., 0.],\n [0., -1., 0.],\n [0., 0., -1.]\n ], shape=[1, 3, 3]\n )\n mtx_inv = tf.tile(mtx_inv, [self.batch_size, 1, 1])\n\n # Inv rotate\n rot_inv = tf.matmul(mtx_inv, self.mtx_rot)\n c4 = tf.constant([0., 0., 0.], shape=[1, 3, 1])\n c4 = tf.tile(c4, [self.batch_size, 1, 1])\n rot_inv = tf.concat([rot_inv, c4], axis=2)\n\n r4 = tf.constant([0., 0., 0., 1.], shape=[1, 1, 4])\n r4 = tf.tile(r4, [self.batch_size, 1, 1])\n rot_inv = tf.concat([rot_inv, r4], axis=1)\n\n eye_inv = -self.Get_eye_batch()\n eye_inv_trans = tf.expand_dims(eye_inv, axis=-1)\n trans_id_inv = tf.eye(3, batch_shape=[self.batch_size])\n trans_inv = tf.concat([trans_id_inv, eye_inv_trans], axis=2)\n trans_inv = tf.concat([trans_inv, r4], axis=1)\n\n mv = tf.matmul(rot_inv, trans_inv)\n\n return mv\n\n def Get_projectionFrustrumMatrix_batch(self, re_grad=False):\n # From triangle similarity\n width = self.image_width_batch * self.near / self.focal_len_x\n height = self.image_height_batch * self.near / self.focal_len_y\n\n right = width - (self.u * self.near / self.focal_len_x)\n left = right - width\n\n top = self.v * self.near / self.focal_len_y\n bottom = top - height\n\n vertical_range = right - left\n p00 = 2 * self.near / vertical_range\n p02 = (right + left) / vertical_range\n\n horizon_range = top-bottom\n p11 = 2 * self.near / horizon_range\n p12 = (top + bottom) / horizon_range\n\n depth_range = self.far - self.near\n p_22 = -(self.far + self.near) / depth_range\n p_23 = -2.0 * (self.far * self.near / depth_range)\n\n zero_fill = tf.zeros_like(p00)\n minus_one_fill = tf.ones_like(p00)\n\n r1 = tf.stack([p00, zero_fill, p02, zero_fill], axis=2)\n r2 = tf.stack([zero_fill, p11, p12, zero_fill], axis=2)\n r3 = tf.stack([zero_fill, zero_fill, p_22, p_23], axis=2, name='mtx_fustrum_r3_batch')\n r4 = tf.stack([zero_fill, zero_fill, -minus_one_fill, zero_fill], axis=2)\n\n P = tf.concat([r1, r2, r3, r4], axis=1, name='mtx_fustrum_batch')\n\n return P\n"
},
{
"alpha_fraction": 0.6842822432518005,
"alphanum_fraction": 0.7108105421066284,
"avg_line_length": 38.92274856567383,
"blob_id": "76e6b052c0ffbda22f1b427396d92f5c3767140f",
"content_id": "ced7245c23a9c614c372e4b14a04ea93270705ca",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 9547,
"license_type": "permissive",
"max_line_length": 421,
"num_lines": 233,
"path": "/Face-Detection/face detection using caffe/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\r\n# Face Detection Using Caffe\r\n\r\n## About\r\n\r\nTo perform fast, accurate face detection with OpenCV using a pre-trained deep learning face detector model shipped with the library.\r\n\r\nCaffe is a deep learning framework made with expression, speed, and modularity in mind. It has a huge applications \r\n\r\n## Files included\r\n\r\n- The `source code`\r\n- The `Caffe prototxt` files for deep learning face detection (defines model architecture)\r\n- The `Caffe weight` files used for deep learning face detection (contains the weights of actual layers)\r\n- The `example images` \r\n\r\n## Face Detection in Images using OpenCV and Deep Learning\r\n\r\n**Code for Face Detection**\r\n\r\nThese are following lines of code from the file `detect_face.py` :\r\n\r\n```\r\n# import the necessary packages\r\nimport numpy as np\r\nimport argparse\r\nimport cv2\r\n\r\n# construct the argument parse and parse the arguments\r\nap = argparse.ArgumentParser()\r\nap.add_argument(\"-i\", \"--image\", required=True,help=\"path to input image\")\r\nap.add_argument(\"-p\", \"--prototxt\", required=True,help=\"path to Caffe 'deploy' prototxt file\")\r\nap.add_argument(\"-m\", \"--model\", required=True,help=\"path to Caffe pre-trained model\")\r\nap.add_argument(\"-c\", \"--confidence\", type=float, default=0.5,help=\"minimum probability to filter weak detections\")\r\nargs = vars(ap.parse_args())\r\n```\r\nWe have three required arguments:\r\n- `--image` : The path to the input image.\r\n- `--prototxt` : The path to the Caffe prototxt file.\r\n- `--model` : The path to the pretrained Caffe model.\r\n\r\nAn optional argument, `--confidence` , can overwrite the default threshold of 0.5.\r\n\r\nLoad the model and create a blob from the image:\r\n\r\n```\r\n# load our serialized model from disk\r\nprint(\"[INFO] loading model...\")\r\nnet = cv2.dnn.readNetFromCaffe(args[\"prototxt\"], args[\"model\"])\r\n# load the input image and construct an input blob for the image\r\n# by resizing to a fixed 300x300 pixels and then normalizing it\r\nimage = cv2.imread(args[\"image\"])\r\n(h, w) = image.shape[:2]\r\nblob = cv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 1.0,(300, 300), (104.0, 177.0, 123.0))\r\n```\r\n- Load the model using `--prototxt` and `--model` file paths and store the model as net.\r\n- Then load the image extract the dimensions and create a blob.\r\n- The `dnn.blobFromImage` takes care of pre-processing which includes setting the blob dimensions and normalization.\r\n\r\nNext, apply face detection:\r\n\r\n```\r\n# pass the blob through the network and obtain the detections and\r\n# predictions\r\nprint(\"[INFO] computing object detections...\")\r\nnet.setInput(blob)\r\ndetections = net.forward()\r\n```\r\nTo detect faces, pass the blob through the net and from there loop over the detections and draw boxes around the detected faces:\r\n\r\n```\r\n# loop over the detections\r\nfor i in range(0, detections.shape[2]):\r\n\t# extract the confidence (i.e., probability) associated with the\r\n\t# prediction\r\n\tconfidence = detections[0, 0, i, 2]\r\n\t# filter out weak detections by ensuring the `confidence` is\r\n\t# greater than the minimum confidence\r\n\tif confidence > args[\"confidence\"]:\r\n\t\t# compute the (x, y)-coordinates of the bounding box for the\r\n\t\t# object\r\n\t\tbox = detections[0, 0, i, 3:7] * np.array([w, h, w, h])\r\n\t\t(startX, startY, endX, endY) = box.astype(\"int\")\r\n \r\n\t\t# draw the bounding box of the face along with the associated\r\n\t\t# probability\r\n\t\ttext = \"{:.2f}%\".format(confidence * 100)\r\n\t\ty = startY - 10 if startY - 10 > 10 else startY + 10\r\n\t\tcv2.rectangle(image, (startX, startY), (endX, endY),(0, 0, 255), 2)\r\n\t\tcv2.putText(image, text, (startX, y),cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)\r\n# show the output image\r\ncv2.imshow(\"Output\", image)\r\ncv2.waitKey(0)\r\n```\r\nWe extract the confidence and compare it to the confidence threshold . We perform this check to filter out weak detections.If the confidence meets the minimum threshold, we proceed to draw a rectangle and along with the probability of the detection.To accomplish this, we first calculate the (x, y)-coordinates of the bounding box ,then build our confidence text string which contains the probability of the detection.\r\nIn case the our text would go off-image (such as when the face detection occurs at the very top of an image), we shift it down by 10 pixels.\r\nFrom there we loop back for additional detections following the process again. If no detections remain, we’re ready to show our output image on the screen.\r\n\r\n## Face detection in images with OpenCV result\r\n\r\nDownload `detect_faces.py` , `deploy.prototxt.txt` , `res10_300x300_ssd_iter_140000.caffemodel` and the input image .\r\n\r\n### Image 1\r\n\r\n**Command used:**\r\n\r\n > *$ python detect_faces.py --image rooster.jpg --prototxt deploy.prototxt.txt --model res10_300x300_ssd_iter_140000.caffemodel*\r\n\r\nIn this given image , face is detected with 74% confidence using OpenCV deep learning face detection. \r\n\r\n\r\n\r\n### Image 2\r\n\r\n**Command used:**\r\n\r\n > *$ python detect_faces.py --image iron_chic.jpg --prototxt deploy.prototxt.txt --model res10_300x300_ssd_iter_140000.caffemodel*\r\n \r\nIn this another example , the OpenCV DNN Face detector successfully finds all the three faces.\r\n\r\n\r\n\r\n## Face detection in video and webcam with openCV and Deep Learning\r\n\r\nMost of code from `detect_faces.py` can be reused here in `detect_faces_video.py` \r\n\r\n```\r\n# import the necessary packages\r\nfrom imutils.video import VideoStream\r\nimport numpy as np\r\nimport argparse\r\nimport imutils\r\nimport time\r\nimport cv2\r\n# construct the argument parse and parse the arguments\r\nap = argparse.ArgumentParser()\r\nap.add_argument(\"-p\", \"--prototxt\", required=True,help=\"path to Caffe 'deploy' prototxt file\")\r\nap.add_argument(\"-m\", \"--model\", required=True,help=\"path to Caffe pre-trained model\")\r\nap.add_argument(\"-c\", \"--confidence\", type=float, default=0.5,help=\"minimum probability to filter weak detections\")\r\nargs = vars(ap.parse_args())\r\n```\r\nImported three additional packages: `VideoStream` ,` imutils` , and `time`.\r\n\r\nLoad the model and initialize the video stream:\r\n\r\n```\r\n# load our serialized model from disk\r\nprint(\"[INFO] loading model...\")\r\nnet = cv2.dnn.readNetFromCaffe(args[\"prototxt\"], args[\"model\"])\r\n# initialize the video stream and allow the camera sensor to warm up\r\n\r\nprint(\"[INFO] starting video stream...\")\r\nvs = VideoStream(src=0).start()\r\ntime.sleep(2.0)\r\n```\r\nInitialize a VideoStream object specifying camera with index zero as the source \r\n\r\n`Raspberry Pi + picamera` users can replace with `vs = VideoStream(usePiCamera=True).start()` \r\nIf you to parse a video file (rather than a video stream) swap out the VideoStream class for FileVideoStream .\r\n\r\nThen allow the camera sensor to warm up for 2 seconds.\r\n\r\nFrom there we loop over the frames and compute face detections with OpenCV:\r\n\r\n```\r\n# loop over the frames from the video stream\r\nwhile True:\r\n\t# grab the frame from the threaded video stream and resize it\r\n\t# to have a maximum width of 400 pixels\r\n\tframe = vs.read()\r\n\tframe = imutils.resize(frame, width=400)\r\n \r\n\t# grab the frame dimensions and convert it to a blob\r\n\t(h, w) = frame.shape[:2]\r\n\tblob = cv2.dnn.blobFromImage(cv2.resize(frame, (300, 300)), 1.0,(300, 300), (104.0, 177.0, 123.0))\r\n \r\n\t# pass the blob through the network and obtain the detections and\r\n\t# predictions\r\n\tnet.setInput(blob)\r\n\tdetections = net.forward()\r\n```\r\nIn this block, we’re reading a frame from the video stream , creating a blob , and passing the blob through the deep neural net to obtain face detections .\r\n\r\nWe can now loop over the detections, compare to the confidence threshold, and draw face boxes + confidence values on the screen:\t\r\n\r\n```\r\n# loop over the detections\r\n\tfor i in range(0, detections.shape[2]):\r\n\t\t# extract the confidence (i.e., probability) associated with the\r\n\t\t# prediction\r\n\t\tconfidence = detections[0, 0, i, 2]\r\n\t\t# filter out weak detections by ensuring the `confidence` is\r\n\t\t# greater than the minimum confidence\r\n\t\tif confidence < args[\"confidence\"]:\r\n\t\t\tcontinue\r\n\t\t# compute the (x, y)-coordinates of the bounding box for the\r\n\t\t# object\r\n\t\tbox = detections[0, 0, i, 3:7] * np.array([w, h, w, h])\r\n\t\t(startX, startY, endX, endY) = box.astype(\"int\")\r\n \r\n\t\t# draw the bounding box of the face along with the associated\r\n\t\t# probability\r\n\t\ttext = \"{:.2f}%\".format(confidence * 100)\r\n\t\ty = startY - 10 if startY - 10 > 10 else startY + 10\r\n\t\tcv2.rectangle(frame, (startX, startY), (endX, endY),\r\n\t\t\t(0, 0, 255), 2)\r\n\t\tcv2.putText(frame, text, (startX, y),\r\n\t\t\tcv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)\r\n```\r\nNow OpenCV face detections have been drawn, let’s display the frame on the screen and wait for a keypress:\r\n\r\n```\r\n# show the output frame\r\n\tcv2.imshow(\"Frame\", frame)\r\n\tkey = cv2.waitKey(1) & 0xFF\r\n \r\n\t# if the `q` key was pressed, break from the loop\r\n\tif key == ord(\"q\"):\r\n\t\tbreak\r\n# do a bit of cleanup\r\ncv2.destroyAllWindows()\r\nvs.stop()\r\n```\r\nDisplay the frame on the screen until the “q” key is pressed at which point we break out of the loop and perform cleanup.\r\n\r\n## Face detection in video and webcam with OpenCV result\r\n\r\nDownload `detect_faces_video.py` , `deploy.prototxt.txt` , `res10_300x300_ssd_iter_140000.caffemodel` and run the deep learning OpenCV face detector with a webcam feed.\r\n\r\n**Command used:**\r\n\r\n > *$ python detect_faces_video.py --prototxt deploy.prototxt.txt --model res10_300x300_ssd_iter_140000.caffemodel*\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5509355664253235,
"alphanum_fraction": 0.6164241433143616,
"avg_line_length": 32.2068977355957,
"blob_id": "d8d63c71e98f1fc1344cf7ddc0b7d9b2ed066e6d",
"content_id": "678774879583012b5e07a39d74f54792da448c94",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 962,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 29,
"path": "/Facial Recognition Attendance Management System/test.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from cv2 import cv2\nimport numpy as np\n\nrecognizer = cv2.face.LBPHFaceRecognizer_create()\nrecognizer.read('TrainingImageLabel/trainner.yml')\ncascadePath = \"haarcascade_frontalface_default.xml\"\nfaceCascade = cv2.CascadeClassifier(cascadePath)\nfont = cv2.FONT_HERSHEY_SIMPLEX\n\ncam = cv2.VideoCapture(0)\nwhile True:\n ret, im =cam.read()\n gray=cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)\n faces=faceCascade.detectMultiScale(gray, 1.2,5)\n for(x,y,w,h) in faces:\n Id, conf = recognizer.predict(gray[y:y+h,x:x+w])\n\n # # else:\n # # Id=\"Unknown\"\n # cv2.rectangle(im, (x-22,y-90), (x+w+22, y-22), (0,255,0), -1)\n cv2.rectangle(im, (x, y), (x + w, y + h), (0, 260, 0), 7)\n cv2.putText(im, str(Id), (x,y-40),font, 2, (255,255,255), 3)\n\n # cv2.putText(im, str(Id), (x + h, y), font, 1, (0, 260, 0), 2)\n cv2.imshow('im',im)\n if cv2.waitKey(10) & 0xFF==ord('q'):\n break\ncam.release()\ncv2.destroyAllWindows()"
},
{
"alpha_fraction": 0.6247544288635254,
"alphanum_fraction": 0.667976438999176,
"avg_line_length": 24.450000762939453,
"blob_id": "df4f9aca6b8aa7fe6e6a1b65859e640a9dda5175",
"content_id": "2f3077c63146ba65fa9e5399db407ab46c68c34b",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 509,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 20,
"path": "/Awesome-face-operations/Blurring image across face/main.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import cv2\n\ncamera = cv2.VideoCapture(0)\ndetector = cv2.CascadeClassifier(\"haarcascade_frontalface_default.xml\")\nwhile True:\n\tret, frame = camera.read()\n\tgray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)\n\tfaces = detector.detectMultiScale(gray, 1.3, 5)\n\n\tfor (x, y, w, h) in faces:\n\t\tface = frame[y:y + h, x:x + w]\n\t\tframe = cv2.blur(frame, ksize = (10, 10))\n\t\tframe[y:y + h, x:x + w] = face\n\n\tcv2.imshow(\"frame\", frame)\n\tif cv2.waitKey(100) & 0xFF == ord('q'):\n\t\tbreak\n\ncamera.release()\ncv2.destroyAllWindows()\n"
},
{
"alpha_fraction": 0.6389961242675781,
"alphanum_fraction": 0.6629343628883362,
"avg_line_length": 34,
"blob_id": "0370d52c10ca3153aa5b6ba30b51336f90679713",
"content_id": "b8b0583aca53f29b4cd97e9c25588139931286d1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2590,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 72,
"path": "/Face-Swapping/Face_Swapping.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import sys\r\nimport getopt\r\nimport cv2\r\nfrom components.landmark_detection import detect_landmarks\r\nfrom components.convex_hull import find_convex_hull\r\nfrom components.delaunay_triangulation import find_delauney_triangulation\r\nfrom components.affine_transformation import apply_affine_transformation\r\nfrom components.clone_mask import merge_mask_with_image\r\n\r\nEXPECTED_NUM_IN = 2\r\n\r\n\r\ndef exit_error():\r\n print('Error: unexpected arguments')\r\n print('face_swap.py -i <path/to/inputFile1> -i <path/to/inputFile2>')\r\n sys.exit()\r\n\r\n\r\ndef main(argv):\r\n in_imgs = []\r\n try:\r\n opts, args = getopt.getopt(argv, \"hi:\", [\"ifile=\"])\r\n except getopt.GetoptError:\r\n exit_error()\r\n\r\n for opt, arg in opts:\r\n if opt in (\"-i\", \"--ifile\"):\r\n in_imgs.append(arg)\r\n else:\r\n exit_error()\r\n\r\n # need specific number of ins\r\n if len(in_imgs) != EXPECTED_NUM_IN:\r\n exit_error()\r\n\r\n print('Input files', in_imgs)\r\n\r\n img_1 = cv2.imread(in_imgs[0])\r\n img_2 = cv2.imread(in_imgs[1])\r\n\r\n # find the facial landmarks which return the key points of the face\r\n # localizes and labels areas such as eyebrows and nose\r\n # we are using the first face found no matter what in this case, could be expanded for multiple faces here\r\n landmarks_1 = detect_landmarks(img_1)[0]\r\n landmarks_2 = detect_landmarks(img_2)[0]\r\n\r\n # create a convex hull around the points, this will be like a mask for transferring the points\r\n # essentially this circles the face, swapping a convex hull looks more natural than a bounding box\r\n # we need to pass both sets of landmarks here because we map the convex hull from one face to another\r\n hull_1, hull_2 = find_convex_hull(landmarks_1, landmarks_2, img_1, img_2)\r\n\r\n # divide the boundary of the face into triangular sections to morph\r\n delauney_1 = find_delauney_triangulation(img_1, hull_1)\r\n delauney_2 = find_delauney_triangulation(img_2, hull_2)\r\n\r\n # warp the source triangles onto the target face\r\n img_1_face_to_img_2 = apply_affine_transformation(delauney_1, hull_1, hull_2, img_1, img_2)\r\n img_2_face_to_img_1 = apply_affine_transformation(delauney_2, hull_2, hull_1, img_2, img_1)\r\n\r\n swap_1 = merge_mask_with_image(hull_2, img_1_face_to_img_2, img_2)\r\n swap_2 = merge_mask_with_image(hull_1, img_2_face_to_img_1, img_1)\r\n\r\n # show the results\r\n cv2.imshow(\"Face Swap 1: \", swap_1)\r\n cv2.imshow(\"Face Swap 2: \", swap_2)\r\n cv2.waitKey(0)\r\n\r\n cv2.destroyAllWindows()\r\n\r\n\r\nif __name__ == \"__main__\":\r\n main(sys.argv[1:])"
},
{
"alpha_fraction": 0.6145313382148743,
"alphanum_fraction": 0.6550194025039673,
"avg_line_length": 27.171875,
"blob_id": "f217c4c8d992bfdbc676a021602fdef58d54d63e",
"content_id": "d3ecdb8ad53f5499eeaecb912f6ff8b25372d771",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1803,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 64,
"path": "/Recognition-Algorithms/Recognition using vgg-19/display_output.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from PIL import Image\nfrom keras.applications.vgg16 import preprocess_input\nimport base64\nfrom io import BytesIO\nimport json\nimport random\nimport cv2\nfrom keras.models import load_model\nimport numpy as np\n\nfrom keras.preprocessing import image\nmodel = load_model('final_file.h5')\n\n# Loading the cascades\nface_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')\n\ndef face_extractor(img):\n # Function detects faces and returns the cropped face\n # If no face detected, it returns the input image\n\n #gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)\n faces = face_cascade.detectMultiScale(img, 1.3, 5)\n\n if faces is ():\n return None\n\n # Crop all faces found\n for (x,y,w,h) in faces:\n cv2.rectangle(img,(x,y),(x+w,y+h),(0,255,255),2)\n cropped_face = img[y:y+h, x:x+w]\n\n return cropped_face\n\n# Doing some Face Recognition with the webcam\nvideo_capture = cv2.VideoCapture(0)\nwhile True:\n _, frame = video_capture.read()\n\n\n\n face=face_extractor(frame)\n if type(face) is np.ndarray:\n face = cv2.resize(face, (224, 224))\n im = Image.fromarray(face, 'RGB')\n\n #Resizing into 128x128 because we trained the model with this image size.\n img_array = np.array(im)\n\n img_array = np.expand_dims(img_array, axis=0)\n pred = model.predict(img_array)\n print(pred)\n\n name=\"None matching\"\n\n if(pred[0][1]>0.5):\n name='User' # Insert your name here \n cv2.putText(frame,name, (50, 50), cv2.FONT_HERSHEY_COMPLEX, 1, (0,255,0), 2)\n else:\n cv2.putText(frame,\" Sorry No face found\", (50, 50), cv2.FONT_HERSHEY_COMPLEX, 1, (0,255,0), 2)\n cv2.imshow('Video', frame)\n if cv2.waitKey(1) & 0xFF == ord('q'):\n break\nvideo_capture.release()\ncv2.destroyAllWindows()\n"
},
{
"alpha_fraction": 0.6976743936538696,
"alphanum_fraction": 0.708690345287323,
"avg_line_length": 35.727272033691406,
"blob_id": "4445def9340297ff6fbd25276647312805255a94",
"content_id": "13ee56f449a205b7a00eb5ed13f0e71c410bac03",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 817,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 22,
"path": "/Recognition-Algorithms/Recognition Using LBP_SVM/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "## Overview\n Face detection and recognition using LBP features and Support Vector Machine.\n This model first creates the rectangle and crop the facial area from image then extracts LBP features from image and pass it through SVM.\n\n## Dependencies\n pip install numpy\n pip install opencv-python\n pip install sklearn\n pip install skimage\n \n \n## Quick Start\n 1] git clone https://github.com/akshitagupta15june/Face-X.git\n 2] cd Recognition using LBP_SVM\n \n \n -->To collect live data run below command\n 3] python create_dataset.py\n (First it will ask your name and then after it will take your 100 snapshots. You can press 'Esc' to exit)\n \n -->After data collection, run below command to train model and recognising images using webcam.\n 4] python model.py\n \n \n"
},
{
"alpha_fraction": 0.7004087567329407,
"alphanum_fraction": 0.7266169786453247,
"avg_line_length": 73.28571319580078,
"blob_id": "7be80e3ebe882e2047d116dd8b68a4e4cbd4e8f9",
"content_id": "95f2552005d3c60711280c0fae15164c5db3cd38",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4159,
"license_type": "permissive",
"max_line_length": 343,
"num_lines": 56,
"path": "/Face-Emotions-Recognition/Emotion-recognition-with-GUI/app.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#importing our libraries that we will be using for emotion detection\nfrom operator import index\nfrom textwrap import fill\nfrom tkinter import Label, Tk\nimport numpy as np\nimport cv2\nimport keras\nfrom tkinter import *\nimport pandas as pd\nimport webbrowser\n\nwin = Tk() #main application window\nwin.geometry('600x500')\nwin.title(\"Emotional Recommender\")\nlabel = Label(win,text=\"Welcome To Emotional Recommender\",font=50,relief = RAISED,bg = 'red').pack(fill=X,padx=15,pady=30)\nuser_label = Label(win,text=\"Here's How this application works: \\n 1) Click on Capture button to Open up your camera. \\n 2) The Model will detect your emotions, \\n you can exit the camera window by clicking 'q' on your keyboard. \\n 3) The Result will be displayed in the window\",font=50,relief = RAISED,bg = 'red').pack(fill=X,padx=15,pady=30)\nwin.iconbitmap(r'Face-Emotions-Recognition\\Emotion-recognition-with-GUI\\\\images\\\\Icons8-Ios7-Logos-Google-Drive-Copyrighted.ico') #giving the window an icon\nnew = 1\n\ncap = cv2.VideoCapture(0) #used for capturing the video using the webcam\nmodel_path = 'Face-Emotions-Recognition\\Emotion-recognition-with-GUI\\model_optimal.h5' #path of our model\nmodel = keras.models.load_model(model_path) #loading our model that we will use to make predictions of emotions\n\n\nemotion_dict = {0:'Angry',1:'Disgust',2:'Fear',3:'Happy',4:'Neutral',5:'Sad',6:'Surprise'} #dictionary containing different values\ndef videocapture():\n while True: #continuous loop to keep the window running\n isTrue,frame = cap.read() #reading our frames from the capture\n facecascade = cv2.CascadeClassifier('Face-Emotions-Recognition\\Emotion-recognition-with-GUI\\haarcascade_frontalface_default.xml') #using the cascade classifier for face detection\n gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) #converting whatever we are reading into gray\n faces = facecascade.detectMultiScale(gray,scaleFactor=1.3, minNeighbors=5) #this helps in finding features and location in our images - we are passing in our grayscale input, we are scaling down the image which is done with scaleFactor \n # min neighbors helps in determining the quality of detection \n\n for (x, y, w, h) in faces: #drawing rectangles on the faces detected and also adding text\n cv2.rectangle(frame, (x, y-50), (x+w, y+h+10), (255, 0, 0), 2) #used to draw our rectangle, we are specifying the start and end point and also color and width of our rectangle\n roi_gray = gray[y:y + h, x:x + w] #ROI - Region of interest, in this we are trying to select the rows starting from y to y+h and then columns from x to x+h - this works like NumPy slicing\n cropped_img = np.expand_dims(np.expand_dims(cv2.resize(roi_gray, (48, 48)), -1), 0) #resizing the inputs in order to get them in the same shape as the images on which our images were trained\n prediction = model.predict(cropped_img) #making predictions on the face detected\n maxindex = int(np.argmax(prediction)) #getting the maximum index out of all the predicted indices\n cv2.putText(frame, emotion_dict[maxindex], (x+20, y-60), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2, cv2.LINE_AA) #printing the emotion label corresponding to the output index from our emotio dictionary\n \n \n cv2.imshow('Video', cv2.resize(frame,(700,500),interpolation = cv2.INTER_CUBIC)) #creating our video window in which we will be detecting emotions\n if cv2.waitKey(1) & 0xFF == ord('q'): #we will have to press q if we wish to exit our window\n break\n \n var = emotion_dict[maxindex]\n label1 = Label(win,text=\"Emotion Detected \" + \" ==> \"+ var,font=50,relief=RAISED,bg = 'red').pack(fill=X,padx=15,pady=30)\n\n cap.release() #this will release the hardware and software resources that are being used\n cv2.destroyAllWindows() #destroys the window that we created for emotion detection\n\n\nButton(win,text=\"Capture\",command = videocapture,relief=RAISED,width=15,font=10,bg = 'black',fg = 'green').pack(pady=20)\nButton(win,text=\"Exit Application\",command = win.destroy,relief=RAISED,width=15,font=10).pack(pady=5)\nwin.mainloop()"
},
{
"alpha_fraction": 0.7492466568946838,
"alphanum_fraction": 0.7836849093437195,
"avg_line_length": 60.93333435058594,
"blob_id": "a11afa2003ee57e9896bf3d545e4284e44635520",
"content_id": "82c318de9213baacec77027b305a4aff6e610df0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4648,
"license_type": "permissive",
"max_line_length": 432,
"num_lines": 75,
"path": "/Face-Mask-Detection/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Face Mask detection\n### Introduction:\n- Face mask detection had seen significant progress in the domains of Image processing and Computer vision, since the rise of the Covid-19 pandemic. Many face detection models have been created using several algorithms and techniques. The approach in this project uses deep learning, pytorch, numPy, and matplotlib to detect face masks and calculate the accuracy of this model.\n- Convolutional Neural Network, Data augmentation are the key to this project.\n\n# Face-mask-detection-pytorch\nPyTorch is an excellent deep learning framework with thousands of inbuilt functionalities that makes it a child’s play to create / train/test various models.\n\n### Flowchart\n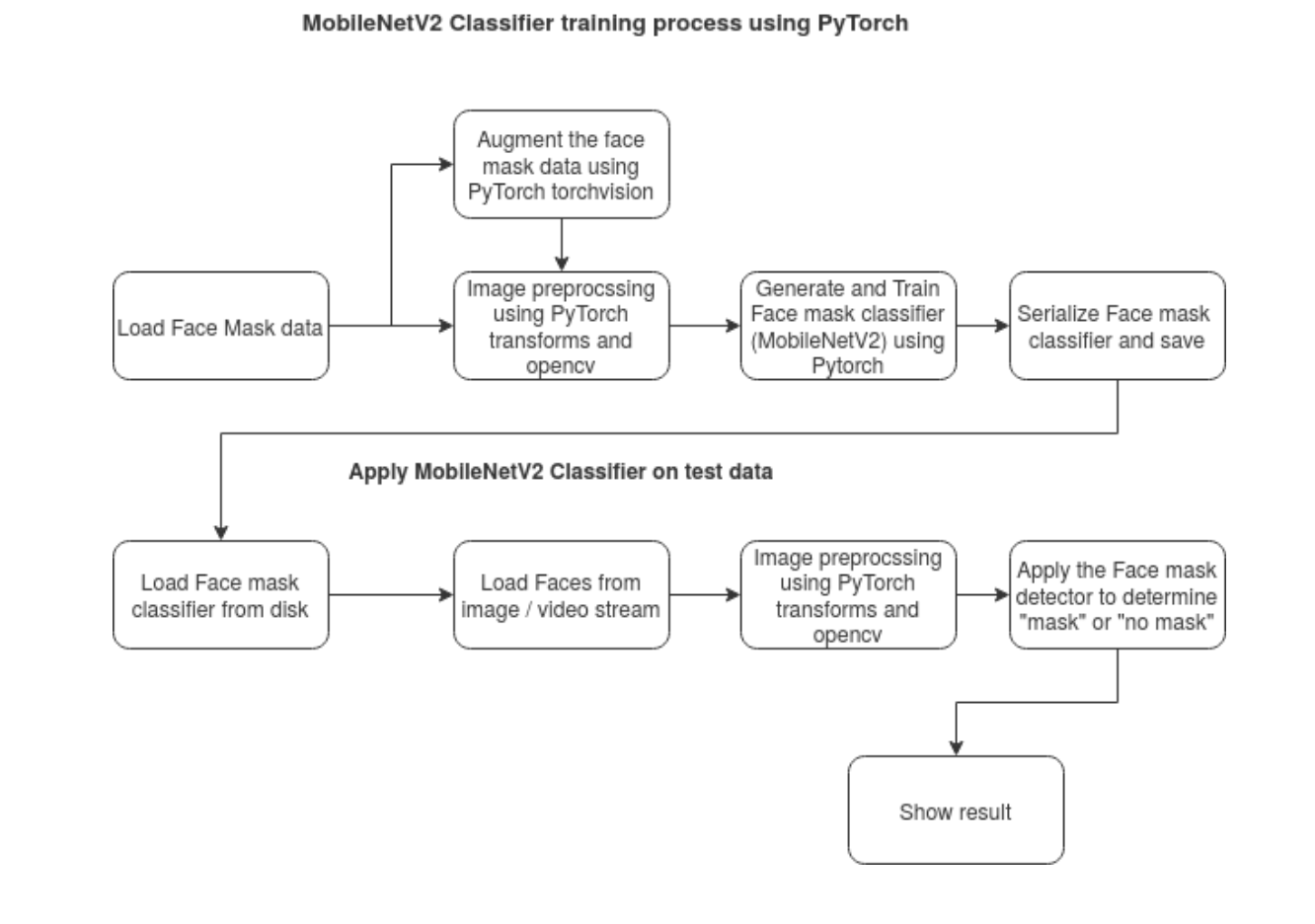\n\n### Dependencies:\n- opendatasets\n- os\n- torch\n- torchvision\n- numPy\n- matplotlib\n\n### Dataset Used:\nWe'll use the COVID Face Mask Detection Dataset dataset from [Kaggle](https://www.kaggle.com/prithwirajmitra/covid-face-mask-detection-dataset). This dataset contains about 1006 equally distributed images of 2 distinct types, namely `Mask` and `Non-Mask`.\n\n# Face-mask-detection-using-cnn\nConvolutional Neural Networks (CNNs) have been demonstrated as an effective class of models for understanding image content, giving state-of-the-art results on image and video recognition, segmentation, detection, and retrieval. \n\nIn our problem statement, we are dealing with images. We need to use the [**Convolutional Neural Network (CNN)**](https://en.wikipedia.org/wiki/Convolutional_neural_network) to train the image classification model. CNN contains many convolutional layers and many kernels for each layer. Values of these kernels changes to get the best possible prediction.\n\n### Methodology used:\n\n#### This is the step-by-step methodology of how this project is created..!!!\n### Example:\n\n\n\n# Face Mask Detection Using VGG16 Architecture\n## Introduction\n[VGG16 Architecture](https://neurohive.io/en/popular-networks/vgg16/) is a winner of the 2014 Imagenet competition which means it is already trained on thousands of images and it has a good set of kernels. So, that's why we are going to use the VGG16 architecture to train our model with a good set kernel. Using weights of other pre-trained models for training new models on the new dataset is the concept of **Transfer Learning**.\n\nThe VGG16 Architecture model achieves 92.7% top-5 test accuracy in ImageNet, which is a dataset of over 14 million images belonging to 1000 classes. ## VGG16 architecture\n\n\nDue to this Covid-19 pandemic, the masks became lifesavers. Nowadays, in most places, masks are compulsory. So, we can take the compulsion as a problem statement for our **computer vision** project.\n\nIn this problem statement, we are trying to classify the images of the person in two classes **with a mask** and **without a mask**. So, to solve this classification problem we will use **Supervised Machine Learning** techniques.\n## Dataset\nFor the supervised machine learning problem, we will require labeled good quality data and here kaggle comes into the picture. [Kaggle](https://kaggle.com) is a platform where Data Scientists play with the various datasets and provide some good quality datasets.\n\n# Face Mask Detection Using `facex-library`\nThe `FaceX` finally has it's own `face mask detection` algorithm which anybody can use by writing only one line of code. It can support both images and videos at the same time.\n\nFor more information about the all new `facex-library`, checkout readme at this [link](https://github.com/akshitagupta15june/Face-X/tree/master/facex-library).\n\nJoin this [discussion](https://github.com/akshitagupta15june/Face-X/discussions/323) for any queries or changes.\n\nOriginal issue [here](https://github.com/akshitagupta15june/Face-X/issues/312).\n\n### Inference on image\n\n```\nimport facex\n\nimage = facex.face_mask('your-image.jpg')\ncv2.imshow(\"face_mask\", cv2.resize(image, (600,600)))\ncv2.waitKey()\n```\n\n\n\n\n\n### Inference on video\n\n```\nfacex.face_mask('your-video.mp4')\n```\n\n"
},
{
"alpha_fraction": 0.5614258050918579,
"alphanum_fraction": 0.5807287693023682,
"avg_line_length": 36.515872955322266,
"blob_id": "113a9f690bf195e189c59fb886485574d5eec5ac",
"content_id": "376bf1eff9632290eb6f9fbdb65d7ca47eafdc5f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18909,
"license_type": "permissive",
"max_line_length": 128,
"num_lines": 504,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/geometry/gpmm/bfm09_tf_uv.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n# system\nfrom __future__ import print_function\n\nimport os\nimport sys\n\n#\nimport tensorflow as tf\n# third party\nimport trimesh\n\n# self\n_curr_path = os.path.abspath(__file__) # /home/..../face\n_cur_dir = os.path.dirname(_curr_path) # ./\n_tf_dir = os.path.dirname(_cur_dir) # ./\n_tool_data_dir = os.path.dirname(_tf_dir) # ../\n_deep_learning_dir = os.path.dirname(_tool_data_dir) # ../\nprint(_deep_learning_dir)\nsys.path.append(_deep_learning_dir) # /home/..../pytorch3d\n\nfrom .HDF5IO import *\nfrom .trimesh_util import *\n\n\nclass BFM_singleTopo():\n #\n def __init__(self, path_gpmm, name, batch_size, rank=80, gpmm_exp_rank=64, mode_light=False, CVRT_MICRON_MM = 1000.0):\n self.path_gpmm = path_gpmm\n self.name = name\n self.hdf5io = HDF5IO(path_gpmm, mode='r')\n\n self.batch_size = batch_size\n self.rank = rank\n self.gpmm_exp_rank = gpmm_exp_rank\n self.CVRT_MICRON_MM = CVRT_MICRON_MM\n\n self._read_hdf5()\n self._generate_tensor(mode_light)\n\n def _read_hdf5(self):\n CVRT_MICRON_MM = self.CVRT_MICRON_MM\n name = self.name\n \"\"\"\n Shape\n Origin Unit of measurement is micron\n We convert to mm\n pcaVar is eignvalue rather Var\n \"\"\"\n hdf5io_shape = HDF5IO(self.path_gpmm, self.hdf5io.handler_file['shape' + name])\n self.hdf5io_pt_model = HDF5IO(self.path_gpmm, hdf5io_shape.handler_file['model'])\n self.hdf5io_pt_representer = HDF5IO(self.path_gpmm, hdf5io_shape.handler_file['representer'])\n\n pt_mean = self.hdf5io_pt_model.GetValue('mean').value\n pt_mean = np.reshape(pt_mean, [-1])\n self.pt_mean_np = pt_mean / CVRT_MICRON_MM\n\n pt_pcaBasis = self.hdf5io_pt_model.GetValue('pcaBasis').value\n self.pt_pcaBasis_np = pt_pcaBasis / CVRT_MICRON_MM\n\n pt_pcaVariance = self.hdf5io_pt_model.GetValue('pcaVariance').value\n pt_pcaVariance = np.reshape(pt_pcaVariance, [-1])\n self.pt_pcaVariance_np = np.square(pt_pcaVariance)\n\n self.point3d_mean_np = np.reshape(self.pt_mean_np, [-1, 3])\n\n \"\"\"\n Vertex color\n Origin Unit of measurement is uint\n We convert to float\n pcaVar is eignvalue rather Var\n \"\"\"\n hdf5io_color = HDF5IO(self.path_gpmm, self.hdf5io.handler_file['color' + name])\n self.hdf5io_rgb_model = HDF5IO(self.path_gpmm, hdf5io_color.handler_file['model'])\n\n rgb_mean = self.hdf5io_rgb_model.GetValue('mean').value\n rgb_mean = np.reshape(rgb_mean, [-1])\n self.rgb_mean_np = rgb_mean / 255.0\n\n rgb_pcaBasis = self.hdf5io_rgb_model.GetValue('pcaBasis').value\n self.rgb_pcaBasis_np = rgb_pcaBasis / 255.0\n\n rgb_pcaVariance = self.hdf5io_rgb_model.GetValue('pcaVariance').value\n rgb_pcaVariance = np.reshape(rgb_pcaVariance, [-1])\n self.rgb_pcaVariance_np = np.square(rgb_pcaVariance)\n\n self.rgb3d_mean_np = np.reshape(self.rgb_mean_np, [-1, 3])\n\n uv = self.hdf5io_rgb_model.GetValue('uv').value\n self.uv_np = np.reshape(uv, [-1, 2])\n\n if 0:\n import cv2\n texMU_fore_point = self.rgb3d_mean_np\n image = np.zeros(shape=[224, 224, 3])\n for i in range(len(texMU_fore_point)):\n color = texMU_fore_point[i] * 255.0\n uv = self.uv_np[i]\n u = int(uv[0] * 223)\n v = int((1 - uv[1]) * 223)\n image[v, u, :] = color\n image = np.asarray(image, dtype=np.uint8)\n image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)\n cv2.imshow(\"Image Debug\", image)\n k = cv2.waitKey(0) & 0xFF\n if k == 27:\n cv2.destroyAllWindows()\n\n list_uvImageIndex = []\n for i in range(len(self.rgb3d_mean_np)):\n uv = self.uv_np[i]\n u = int(uv[0] * 224)-1\n v = int((1 - uv[1]) * 224)-1\n if u < 0:\n u = 0\n if v < 0:\n v = 0\n\n idx = v * 224 + u\n list_uvImageIndex.append(idx)\n self.uvIdx_np = np.array(list_uvImageIndex)\n\n \"\"\"\n Expression\n Origin Unit of measurement is micron\n We convert to mm\n pcaVar is eignvalue rather Var\n \"\"\"\n hdf5io_exp = HDF5IO(self.path_gpmm, self.hdf5io.handler_file['expression' + name])\n self.hdf5io_exp_model = HDF5IO(self.path_gpmm, hdf5io_exp.handler_file['model'])\n\n # self.exp_mean = self.hdf5io_exp_model.GetValue('mean').value\n exp_pcaBasis = self.hdf5io_exp_model.GetValue('pcaBasis').value\n self.exp_pcaBasis_np = exp_pcaBasis / CVRT_MICRON_MM\n\n exp_pcaVariance = self.hdf5io_exp_model.GetValue('pcaVariance').value\n exp_pcaVariance = np.reshape(exp_pcaVariance, [-1])\n self.exp_pcaVariance_np = np.square(exp_pcaVariance)\n # self.exp3d_mean_np = np.reshape(self.exp_mean, [-1, 3])\n\n \"\"\"\n Tri\n Index from 1\n \"\"\"\n mesh_tri_reference = self.hdf5io_pt_representer.GetValue('tri').value\n mesh_tri_reference = mesh_tri_reference - 1\n self.mesh_tri_np = np.reshape(mesh_tri_reference.astype(np.int32), [-1, 3])\n\n # Here depend on how to generate\n # Here depend on how to generate\n # Here depend on how to generate\n if 'idx_sub' in self.hdf5io_pt_representer.GetMainKeys():\n idx_subTopo = self.hdf5io_pt_representer.GetValue('idx_sub').value\n idx_subTopo = idx_subTopo # Here depend on how to generate\n self.idx_subTopo_np = np.reshape(idx_subTopo.astype(np.int32), [-1])\n self.idx_subTopo = tf.constant(self.idx_subTopo_np, dtype=tf.int32)\n\n self.nplist_v_ring_f_flat_np = self.hdf5io_pt_representer.GetValue('vertex_ring_face_flat').value\n # used in tensor\n self.nplist_ver_ref_face_num = self.hdf5io_pt_representer.GetValue('vertex_ring_face_num').value\n self.nplist_v_ring_f, self.nplist_v_ring_f_index = \\\n self._get_v_ring_f(self.nplist_v_ring_f_flat_np, self.nplist_ver_ref_face_num)\n \"\"\"\n lm idx\n \"\"\"\n if 'idx_lm68' in self.hdf5io_pt_representer.GetMainKeys():\n idx_lm68_np = self.hdf5io_pt_representer.GetValue('idx_lm68').value\n idx_lm68_np = np.reshape(idx_lm68_np, [-1])\n self.idx_lm68_np = idx_lm68_np.astype(dtype=np.int32)\n\n def _generate_tensor(self, mode_light=False):\n rank = self.rank\n gpmm_exp_rank = self.gpmm_exp_rank\n if mode_light:\n pass\n else:\n \"\"\"\n Vertex\n \"\"\"\n self.pt_mean = tf.constant(self.pt_mean_np, dtype=tf.float32)\n self.pt_pcaBasis = tf.constant(self.pt_pcaBasis_np[:, :rank], dtype=tf.float32)\n self.pt_pcaVariance = tf.constant(self.pt_pcaVariance_np[:rank], dtype=tf.float32)\n\n \"\"\"\n Vertex color\n \"\"\"\n self.rgb_mean = tf.constant(self.rgb_mean_np, dtype=tf.float32)\n self.rgb_pcaBasis = tf.constant(self.rgb_pcaBasis_np[:, :rank], dtype=tf.float32)\n self.rgb_pcaVariance = tf.constant(self.rgb_pcaVariance_np[:rank], dtype=tf.float32)\n self.uv = tf.constant(self.uv_np[:rank], dtype=tf.float32)\n\n \"\"\"\n Expression\n \"\"\"\n self.exp_pcaBasis = tf.constant(self.exp_pcaBasis_np[:, :gpmm_exp_rank], dtype=tf.float32)\n self.exp_pcaVariance = tf.constant(self.exp_pcaVariance_np[:gpmm_exp_rank], dtype=tf.float32)\n\n \"\"\"\n Generate normal presplit\n \"\"\"\n self.nplist_v_ring_f_flat = [item for sublist in self.nplist_v_ring_f for item in sublist]\n\n max_padding = max(self.nplist_v_ring_f, key=len)\n max_padding = len(max_padding)\n self.nplist_v_ring_f_index_pad = []\n for sublist in self.nplist_v_ring_f:\n def trp(l, n):\n return np.concatenate([l[:n], [l[-1]] * (n - len(l))])\n sublist_pad = trp(sublist, max_padding)\n self.nplist_v_ring_f_index_pad.append(sublist_pad)\n self.nplist_v_ring_f_index_pad = np.array(self.nplist_v_ring_f_index_pad, dtype=np.int32)\n self.nplist_v_ring_f_index_flat = [item for sublist in self.nplist_v_ring_f_index for item in sublist]\n\n self.mesh_vertex_refer_face = tf.constant(self.nplist_v_ring_f_flat, dtype=tf.int32) # vertex_num*[2/3...8]\n self.mesh_vertex_refer_face_pad = tf.constant(self.nplist_v_ring_f_index_pad, dtype=tf.int32) # vertex_num, max_padding\n self.mesh_vertex_refer_face_index = tf.constant(self.nplist_v_ring_f_index_flat, dtype=tf.int32) # vertex_num*[2/3...8]\n self.mesh_vertex_refer_face_num = tf.constant(self.nplist_ver_ref_face_num, dtype=tf.float32) # vertex_num\n\n # tri\n self.mesh_tri = tf.constant(self.mesh_tri_np, dtype=tf.int32)\n\n # uv\n self.uvIdx = tf.constant(self.uvIdx_np, dtype=tf.int32)\n\n def _get_v_ring_f(self, v_ring_f_flat, v_ring_f_num):\n list_v_ring_f = []\n list_v_ring_f_index = []\n idx_start = 0\n for i in range(len(v_ring_f_num)):\n vf_num = v_ring_f_num[i]\n v_ring_f = v_ring_f_flat[idx_start:idx_start+vf_num]\n list_v_ring_f.append(v_ring_f)\n v_ring_f_index = np.zeros([len(v_ring_f)], dtype=np.int32) + i\n list_v_ring_f_index.append(v_ring_f_index)\n idx_start = idx_start+vf_num\n return np.array(list_v_ring_f), np.array(list_v_ring_f_index)\n\n def instance(self, coeff_batch, coeff_exp_batch=None):\n \"\"\"\n :param coeff_batch: shape=[bs, 80]\n :param coeff_exp_batch: shape=[bs, 64]\n :return:\n \"\"\"\n\n \"\"\"\n Vertex\n \"\"\"\n coeff_var_batch = coeff_batch * tf.sqrt(self.pt_pcaVariance)\n coeff_var_batch = tf.transpose(coeff_var_batch)\n #coeff_var_batch = tf.expand_dims(coeff_var_batch, -1)\n\n mesh_diff = tf.matmul(self.pt_pcaBasis, coeff_var_batch)\n #mesh_diff = tf.squeeze(mesh_diff, axis=-1)\n mesh_diff = tf.transpose(mesh_diff) # shape=[bs, 80]\n\n \"\"\"\n Exp\n \"\"\"\n if coeff_exp_batch is not None:\n coeff_var_batch = coeff_exp_batch * tf.sqrt(self.exp_pcaVariance)\n coeff_var_batch = tf.transpose(coeff_var_batch)\n #coeff_var_batch = tf.expand_dims(coeff_var_batch, -1)\n\n exp_diff = tf.matmul(self.exp_pcaBasis, coeff_var_batch)\n #exp_diff = tf.squeeze(exp_diff, axis=-1)\n exp_diff = tf.transpose(exp_diff)\n\n mesh = self.pt_mean + mesh_diff + exp_diff\n else:\n mesh = self.pt_mean + mesh_diff\n\n mesh = tf.reshape(mesh, [self.batch_size, -1, 3])\n return mesh\n\n def instance_color(self, coeff_batch):\n\n coeff_var_batch = coeff_batch * tf.sqrt(self.rgb_pcaVariance)\n coeff_var_batch = tf.transpose(coeff_var_batch)\n\n #coeff_var_batch = tf.Print(coeff_var_batch, [coeff_batch, coeff_var_batch], summarize=256, message='instance_color')\n #coeff_var_batch = tf.expand_dims(coeff_var_batch, -1)\n\n mesh_diff = tf.matmul(self.rgb_pcaBasis, coeff_var_batch)\n mesh_diff = tf.transpose(mesh_diff) # shape=[bs, 80]\n #mesh_diff = tf.squeeze(mesh_diff, axis=-1)\n\n mesh = self.rgb_mean + mesh_diff\n #mesh = tf.Print(mesh, [self.rgb_mean[:10], mesh_diff[:10]], summarize=256, message='mesh_color')\n\n mesh = tf.clip_by_value(mesh, 0.0, 1.0)\n\n mesh = tf.reshape(mesh, [self.batch_size, -1, 3])\n return mesh\n\n # np only\n def get_mesh_mean(self):\n pt_mean_3d = self.pt_mean_np.reshape(-1, 3)\n rgb_mean_3d = self.rgb_mean_np.reshape(-1, 3)\n\n mesh_mean = trimesh.Trimesh(\n pt_mean_3d,\n self.mesh_tri_np,\n vertex_colors=rgb_mean_3d,\n process = False\n )\n return mesh_mean\n\n\nclass BFM_TF():\n #\n def __init__(self, path_gpmm, rank=80, gpmm_exp_rank=64, batch_size=1, full=False):\n\n # 0. Read HDF5 IO\n self.path_gpmm = path_gpmm\n self.rank = rank\n self.gpmm_exp_rank = gpmm_exp_rank\n self.batch_size = batch_size\n\n \"\"\"\n Read origin model, np only\n \"\"\"\n self.h_curr = self._get_origin_model()\n if full:\n self.h_full = self._get_full_model()\n self.h_fore = self._get_fore_model()\n\n \"\"\"\n Tri\n \"\"\"\n # self.mesh_idx_fore = tf.constant(self.mesh_idx_fore_np, dtype=tf.int32) # 27660\n # self.mesh_tri_reference_fore = tf.constant(self.mesh_tri_reference_fore_np, dtype=tf.int32) # 54681, 3\n\n \"\"\"\n LM\n \"\"\"\n self.idx_lm68 = tf.constant(self.h_curr.idx_lm68_np, dtype=tf.int32)\n\n def _get_origin_model(self):\n return BFM_singleTopo(self.path_gpmm, name='', batch_size=self.batch_size)\n\n def _get_full_model(self):\n return BFM_singleTopo(self.path_gpmm, name='_full', batch_size=self.batch_size, mode_light=False)\n\n def _get_fore_model(self):\n return BFM_singleTopo(self.path_gpmm, name='_fore', batch_size=self.batch_size, mode_light=True)\n\n def instance(self, coeff_batch, coeff_exp_batch=None):\n return self.h_curr.instance(coeff_batch, coeff_exp_batch)\n\n def instance_color(self, coeff_batch):\n return self.h_curr.instance_color(coeff_batch)\n\n def instance_full(self, coeff_batch, coeff_exp_batch=None):\n return self.h_full.instance(coeff_batch, coeff_exp_batch)\n\n def instance_color_full(self, coeff_batch):\n return self.h_full.instance_color(coeff_batch)\n\n def get_lm3d_instance_vertex(self, lm_idx, points_tensor_batch):\n lm3d_batch = tf.gather(points_tensor_batch, lm_idx, axis=1)\n return lm3d_batch\n\n def get_lm3d_mean(self):\n pt_mean = tf.reshape(self.pt_mean, [-1, 3])\n lm3d_mean = tf.gather(pt_mean, self.idx_lm68)\n return lm3d_mean\n\n # np only\n def get_mesh_mean(self, mode_str):\n if mode_str == 'curr':\n return self.h_curr.get_mesh_mean()\n elif mode_str == 'fore':\n return self.h_fore.get_mesh_mean()\n elif mode_str == 'full':\n return self.h_full.get_mesh_mean()\n else:\n return None\n\n def get_mesh_fore_mean(self):\n pt_mean_3d = self.pt_mean_np.reshape(-1, 3)\n rgb_mean_3d = self.rgb_mean_np.reshape(-1, 3)\n\n mesh_mean = trimesh.Trimesh(\n pt_mean_3d[self.mesh_idx_fore_np],\n self.mesh_tri_reference_fore_np,\n vertex_colors=rgb_mean_3d[self.mesh_idx_fore_np],\n process=False\n )\n return mesh_mean\n\n def get_lm3d(self, vertices, idx_lm68_np=None):\n if idx_lm68_np is None:\n idx_lm = self.idx_lm68_np\n else:\n idx_lm = idx_lm68_np\n return vertices[idx_lm]\n\n def get_random_vertex_color_batch(self):\n coeff_shape_batch = []\n coeff_exp_batch = []\n for i in range(self.batch_size):\n coeff_shape = tf.random.normal(shape=[self.rank], mean=0, stddev=tf.sqrt(3.0))\n coeff_shape_batch.append(coeff_shape)\n exp_shape = tf.random.normal(shape=[self.gpmm_exp_rank], mean=0, stddev=tf.sqrt(3.0))\n coeff_exp_batch.append(exp_shape)\n coeff_shape_batch = tf.stack(coeff_shape_batch)\n coeff_exp_batch = tf.stack(coeff_exp_batch)\n points_tensor_batch = self.instance(coeff_shape_batch, coeff_exp_batch)\n\n coeff_color_batch = []\n for i in range(self.batch_size):\n coeff_color = tf.random.normal(shape=[self.rank], mean=0, stddev=tf.sqrt(3.0))\n coeff_color_batch.append(coeff_color)\n coeff_color_batch = tf.stack(coeff_color_batch)\n points_color_tensor_batch = self.instance_color(coeff_color_batch)\n\n # mesh_tri_shape_list = []\n # for i in range(batch):\n # points_np = points_tensor_batch[i]\n # tri_np = tf.transpose(self.mesh_tri_reference)\n # points_color_np = tf.uint8(points_color_tensor_batch[i]*255)\n #\n #\n # mesh_tri_shape = trimesh.Trimesh(\n # points_np,\n # tri_np,\n # vertex_colors=points_color_np,\n # process=False\n # )\n # #mesh_tri_shape.show()\n # #mesh_tri_shape.export(\"/home/jx.ply\")\n # mesh_tri_shape_list.append(mesh_tri_shape)\n\n return points_tensor_batch, points_color_tensor_batch, coeff_shape_batch, coeff_color_batch\n\n\nif __name__ == '__main__':\n path_gpmm = '/home/jshang/SHANG_Data/ThirdLib/BFM2009/bfm09_trim_exp_uv_presplit.h5'\n h_lrgp = BFM_TF(path_gpmm, 80, 2, full=True)\n tri = h_lrgp.get_mesh_mean('curr')\n #tri.show()\n tri.export(\"/home/jshang/SHANG_Data/ThirdLib/BFM2009/bfm09_mean.ply\")\n tri = h_lrgp.get_mesh_mean('fore')\n tri.export(\"/home/jshang/SHANG_Data/ThirdLib/BFM2009/bfm09_mean_fore.ply\")\n tri = h_lrgp.get_mesh_mean('full')\n tri.export(\"/home/jshang/SHANG_Data/ThirdLib/BFM2009/bfm09_mean_full.ply\")\n\n \"\"\"\n build graph\n \"\"\"\n ver, ver_color, _, _ = h_lrgp.get_random_vertex_color_batch()\n ver_color = tf.cast(ver_color*255.0, dtype=tf.uint8)\n\n lm3d_mean = h_lrgp.get_lm3d_mean()\n lm3d_mean = tf.expand_dims(lm3d_mean, 0)\n print(lm3d_mean)\n\n\n # test normal\n from tfmatchd.face.geometry.lighting import vertex_normals_pre_split_fixtopo\n vertexNormal = vertex_normals_pre_split_fixtopo(\n ver, h_lrgp.mesh_tri_reference, h_lrgp.mesh_vertex_refer_face,\n h_lrgp.mesh_vertex_refer_face_index, h_lrgp.mesh_vertex_refer_face_num\n )\n\n \"\"\"\n run\n \"\"\"\n sv = tf.train.Supervisor()\n config = tf.ConfigProto()\n config.gpu_options.allow_growth = True\n with sv.managed_session(config=config) as sess:\n fetches = {\n \"ver\": ver,\n \"ver_color\": ver_color,\n \"vertexNormal\": vertexNormal,\n \"lm3d_mean\":lm3d_mean\n }\n \"\"\"\n ********************************************* Start Trainning *********************************************\n \"\"\"\n results = sess.run(fetches)\n\n ver = results[\"ver\"]\n ver_color = results[\"ver_color\"]\n vertexNormal_np = results[\"vertexNormal\"]\n lm3d_mean_np = results[\"lm3d_mean\"]\n print(lm3d_mean_np)\n\n # # normal test\n # for i in range(len(vertexNormal_np)):\n # ver_trimesh = trimesh.Trimesh(\n # ver[i],\n # h_lrgp.mesh_tri_reference_np,\n # vertex_colors=ver_color[i],\n # process=False\n # )\n # vn_trimesh = ver_trimesh.vertex_normals\n # vn_tf = vertexNormal_np[i]\n # print(vn_trimesh[180:190])\n # print(vn_tf[180:190])\n #\n # error = abs(vn_trimesh - vn_tf)\n # error = np.sum(error)\n # print(error)\n"
},
{
"alpha_fraction": 0.700045108795166,
"alphanum_fraction": 0.7113215923309326,
"avg_line_length": 31.130434036254883,
"blob_id": "828ea538ab0e41d71b4f90a7c61cf138c1df11e2",
"content_id": "c769b330b85be11321711be0b4516b1ddfa608b1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2217,
"license_type": "permissive",
"max_line_length": 262,
"num_lines": 69,
"path": "/Face-Emotions-Recognition/face-emotions-recognition-using-deep-learning/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Emotion detection using deep learning\n\n## Introduction\n\nThis project aims to classify the emotion on a person's face into one of **seven categories**, using deep convolutional neural networks. The model is trained on the **FER-2013** dataset which was published on International Conference on Machine Learning (ICML). \n\n## Dependencies\n\n* Python 3, [OpenCV](https://opencv.org/), [Tensorflow](https://www.tensorflow.org/)\n* To install the required packages, run `pip install -r requirements.txt`.\n\n## Basic Usage\n\nThe repository is currently compatible with `tensorflow-2.0` and makes use of the Keras API using the `tensorflow.keras` library.\n\n* First, clone the repository and enter the folder\n\n```bash\ngit clone https://github.com/akshitagupta15june/Face-X.git\ncd Face-X\n```\n\n* FER-2013 dataset is present in `src` folder and is named as `data`. \n\n* If you want to train this model, use: \n\n```bash\ncd src\npython emotions.py --mode train\n```\n\n* If you want to view the predictions without training again,`model.h5` is present in `src` folder. Run:\n\n```bash\ncd src\npython emotions.py --mode display\n```\n\n* The folder structure is of the form: \n src:\n * data (folder)\n * `emotions.py` (file)\n * `haarcascade_frontalface_default.xml` (file)\n * `model.h5` (file)\n\n* This implementation by default detects emotions on all faces in the webcam feed. With a simple 4-layer CNN, the test accuracy reached 63.2% in 50 epochs.\n\n\n\n## Algorithm\n\n* First, the **haar cascade** method is used to detect faces in each frame of the webcam feed.\n\n* The region of image containing the face is resized and is passed as input to the CNN.\n\n* The network outputs a list of **softmax scores** for the seven classes of emotions.\n\n* The emotion with maximum score is displayed on the screen.\n\n## Example Output\n\n\n\n## References\n\n* \"Challenges in Representation Learning: A report on three machine learning contests.\" I Goodfellow, D Erhan, PL Carrier, A Courville, M Mirza, B\n Hamner, W Cukierski, Y Tang, DH Lee, Y Zhou, C Ramaiah, F Feng, R Li, \n X Wang, D Athanasakis, J Shawe-Taylor, M Milakov, J Park, R Ionescu,\n M Popescu, C Grozea, J Bergstra, J Xie, L Romaszko, B Xu, Z Chuang, and\n Y. Bengio. arXiv 2013.\n"
},
{
"alpha_fraction": 0.5763059258460999,
"alphanum_fraction": 0.6080573797225952,
"avg_line_length": 49.49137878417969,
"blob_id": "864783054d0869f06562699fc3ce7069136d383d",
"content_id": "9154de775ca8fb12cc0f7230bb43b64c86cec487",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5858,
"license_type": "permissive",
"max_line_length": 151,
"num_lines": 116,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/geometry/render/tensor_render.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n#\nimport tensorflow as tf\n\n#\nfrom .api_tf_mesh_render import mesh_depthmap_camera, mesh_renderer_camera, mesh_renderer_camera_light\n\ndef gpmm_render_image(opt, vertex, tri, vertex_normal, vertex_color, mtx_perspect_frustrum, mtx_model_view, cam_position):\n \"\"\"\n :param vertex: [bs, num_ver, 3]\n :param tri: [bs, num_tri, 3] or [num_tri, 3]\n :param vertex_normal: [bs, num_ver, 3]\n :param vertex_color: [bs, num_ver, 3]\n :param mtx_perspect_frustrum: [bs, 4, 4]\n :param mtx_model_view: [bs, 4, 4]\n :param cam_position: [bs, 3]\n :return:\n render_image, shape=[batch_size, h, w, 3], dtype=tf_render.float32\n render_image_mask, shape=[batch_size, h, w, 1], dtype=tf_render.float32\n render_tri_ids, shape=[batch_size, h, w, 1], dtype=tf_render.int32\n \"\"\"\n # manual light\n # light_positions = tf.constant([[0.0, 0.0, 1000.0]], shape=[1, 1, 3])\n # light_intensities = tf.constant([[1.0, 0.0, 0.0]], shape=[1, 1, 3])\n # ambient_color = tf.constant([[1.0, 1.0, 1.0]], shape=[1, 3])\n # ambient_color = tf.tile(ambient_color, [opt.batch_size, 1])\n\n if len(tri.shape) == 2: # common render for bfm09\n render_image, render_image_mask, render_tri_ids = \\\n mesh_renderer_camera_light(vertex, tri, vertex_normal, vertex_color, mtx_model_view,\n mtx_perspect_frustrum, cam_position, opt.img_width, opt.img_height)\n tonemapped_renders = tf.clip_by_value(render_image, 0.0, 100000.0)\n else: # convisiable mask render have diff tri for sample in batch\n list_tonemapped_renders = []\n list_render_image_mask = []\n list_render_tri_ids = []\n for i in range(tri.shape[0]): # bs\n render_image, render_image_mask, render_tri_ids = \\\n mesh_renderer_camera_light(\n vertex[i:i + 1, :, :], tri[i], vertex_normal[i:i + 1, :, :], vertex_color[i:i + 1, :, :],\n mtx_model_view[i:i + 1, :, :], mtx_perspect_frustrum[i:i + 1, :, :], cam_position[i:i + 1, :],\n opt.img_width, opt.img_height)\n tonemapped_renders = tf.clip_by_value(render_image, 0.0, 100000.0)\n\n list_tonemapped_renders.append(tonemapped_renders)\n list_render_image_mask.append(render_image_mask)\n list_render_tri_ids.append(render_tri_ids)\n\n tonemapped_renders = tf.concat(list_tonemapped_renders, axis=0)\n render_image_mask = tf.concat(list_render_image_mask, axis=0)\n render_tri_ids = tf.concat(list_render_tri_ids, axis=0)\n\n return tonemapped_renders[:, :, :, 0:3], render_image_mask, render_tri_ids\n\n\ndef gpmm_render_image_garyLight(opt, vertex, tri, vertex_normal, vertex_color, mtx_perspect_frustrum, mtx_model_view, cam_position, background=10.999):\n \"\"\"\n :param vertex: [bs, num_ver, 3]\n :param tri: [bs, num_tri, 3] or [num_tri, 3]\n :param vertex_normal: [bs, num_ver, 3]\n :param vertex_color: [bs, num_ver, 3]\n :param mtx_perspect_frustrum: [bs, 4, 4]\n :param mtx_model_view: [bs, 4, 4]\n :param cam_position: [bs, 3]\n :return:\n render_image, shape=[batch_size, h, w, 3], dtype=tf_render.float32\n render_image_mask, shape=[batch_size, h, w, 1], dtype=tf_render.float32\n render_tri_ids, shape=[batch_size, h, w, 1], dtype=tf_render.int32\n \"\"\"\n\n # manual light\n light_positions = tf.constant([[0.0, 0.0, 1000.0]], shape=[1, 1, 3])\n light_positions = tf.tile(light_positions, [opt.batch_size, 1, 1])\n light_intensities = tf.constant([[1.0, 1.0, 1.0]], shape=[1, 1, 3])\n light_intensities = tf.tile(light_intensities, [opt.batch_size, 1, 1])\n # ambient_color = tf.constant([[1.0, 1.0, 1.0]], shape=[1, 3])\n # ambient_color = tf.tile(ambient_color, [opt.batch_size, 1])\n\n if len(tri.shape) == 2:\n render_image, render_image_mask = \\\n mesh_renderer_camera(vertex, tri, vertex_normal, vertex_color, mtx_model_view,\n mtx_perspect_frustrum, cam_position, light_positions, light_intensities,\n opt.img_width, opt.img_height, background=background)\n\n tonemapped_renders = tf.clip_by_value(render_image, 0.0, 100000.0)\n\n else:\n list_tonemapped_renders = []\n list_render_image_mask = []\n list_render_tri_ids = []\n for i in range(tri.shape[0]): # bs\n render_image, render_image_mask = \\\n mesh_renderer_camera(\n vertex[i:i + 1, :, :], tri[i], vertex_normal[i:i + 1, :, :], vertex_color[i:i + 1, :, :],\n mtx_model_view[i:i + 1, :, :], mtx_perspect_frustrum[i:i + 1, :, :], cam_position[i:i + 1, :],\n light_positions, light_intensities, opt.img_width, opt.img_height, background=10.999)\n\n tonemapped_renders = tf.clip_by_value(render_image, 0.0, 100000.0)\n\n list_tonemapped_renders.append(tonemapped_renders)\n list_render_image_mask.append(render_image_mask)\n list_render_tri_ids.append(1)\n\n tonemapped_renders = tf.concat(list_tonemapped_renders, axis=0)\n render_image_mask = tf.concat(list_render_image_mask, axis=0)\n return tonemapped_renders[:, :, :, 0:3], render_image_mask, render_image_mask\n\n\ndef gpmm_generate_depthmap(opt, mesh, tri, mtx_perspect_frustrum, mtx_ext, mtx_model_view, cam_position, background=99999999):\n depthmap, depthmap_mask, depth_min, depth_max = mesh_depthmap_camera(mesh, tri, mtx_ext, mtx_model_view, mtx_perspect_frustrum,\n opt.img_width, opt.img_height, background=background)\n\n #depthmap = depthmap * tf.squeeze(depthmap_mask, axis=-1)\n #depthmap = tf.clip_by_value(depthmap, opt.depth_min, opt.depth_max)\n depthmap = tf.expand_dims(depthmap, axis=-1)\n\n return depthmap, depthmap_mask, depth_min, depth_max\n"
},
{
"alpha_fraction": 0.7594823837280273,
"alphanum_fraction": 0.7715305685997009,
"avg_line_length": 52.56097412109375,
"blob_id": "a23b614ffd15b954c1e6f85d28e2d5ba3ec484fd",
"content_id": "ed8e210e5c3dd7526535be703da5753355118b73",
"detected_licenses": [
"BSD-3-Clause",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2241,
"license_type": "permissive",
"max_line_length": 332,
"num_lines": 41,
"path": "/Awesome-face-operations/GAN_Face_Generation/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Generating Faces using GANs\r\n\r\nDataSet: [CelebFaces Attributes Dataset (CelebA)](http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html) to train the adversarial networks.\r\n\r\n### Some samples of generated faces:\r\n\r\n<img src=\"assets/generated_faces.png\" width=640 height=160> \r\n\r\n\r\n## Face Generation\r\nIn this project, you'll define and train a DCGAN on a dataset of faces. Your goal is to get a generator network to generate new images of faces that look as realistic as possible!\r\n\r\nThe project will be broken down into a series of tasks from loading in data to defining and training adversarial networks. At the end of the notebook, you'll be able to visualize the results of your trained Generator to see how it performs; your generated samples should look like fairly realistic faces with small amounts of noise.\r\n\r\n\r\n## To Generate Faces:\r\n1. Just run the script ```dlnd_face_generation.ipynb```\r\n\r\n## Project Steps:\r\n1.Get the Data\r\nYou'll be using the CelebFaces Attributes Dataset (CelebA) to train your adversarial networks.\r\nThis dataset is more complex than the number datasets (like MNIST or SVHN) you've been working with, and so, you should prepare to define deeper networks and train them for a longer time to get good results. It is suggested that you utilize a GPU for training.\r\n\r\n2.Pre-processe the Data\r\nSince the project's main focus is on building the GANs, we've done some of the pre-processing for you. Each of the CelebA images has been cropped to remove parts of the image that don't include a face, then resized down to 64x64x3 NumPy images. Some sample data is show below.\r\n\r\n3.Pre-process and Load the Data\r\nSince the project's main focus is on building the GANs, we've done some of the pre-processing for you. Each of the CelebA images has been cropped to remove parts of the image that don't include a face, then resized down to 64x64x3 NumPy images. This pre-processed dataset is a smaller subset of the very large CelebA data.\r\n\r\n4.Create a DataLoader\r\n\r\n6.Define the Model\r\nA GAN is comprised of two adversarial networks, a discriminator and a generator.\r\n\r\n7.Initialize the weights of your networks\r\n\r\n8.Build complete network\r\n\r\n9.Discriminator and Generator Losses\r\n\r\n10.Generator samples from training\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.7188172340393066,
"alphanum_fraction": 0.7462365627288818,
"avg_line_length": 28.507936477661133,
"blob_id": "b47b33e8ce8e9ba6c6ea93339d2b8e9ad60e5e3f",
"content_id": "41092c0b83663d6373ff82ec4f93d67f6b473713",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1860,
"license_type": "permissive",
"max_line_length": 251,
"num_lines": 63,
"path": "/Recognition-Algorithms/Recognition Using Cnn/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Overview\n\n## *CNN -> Convolutional Neural Network*\n\nIt is a Deep Learning algorithm which can take in an input image, assign importance (learnable weights and biases) to various aspects/objects in the image and be able to differentiate one from the other. \n\n**The role of the CNN is to reduce the images into a form which is easier to process, without losing features which are critical for getting a good prediction.**\n\nCNN models to train and test, each input image will pass it through a series of convolution layers with filters (Kernals), Pooling, fully connected layers (FC) and apply Softmax function to classify an object with probabilistic values between 0 and 1.\n\n# Requirments\n\n* Python-3\n* Keras\n* Numpy\n* OpenCv\n\n# Images\n\n<p align=\"center\"><img src=\"Images/Screenshot from 2020-12-11 21-34-18.png\" height=\"250px\">\n<img src=\"Images/Screenshot from 2020-12-11 17-59-00.png\" height=\"250px\">\n</p>\n\n# Quick-Start\n\n- Fork the repository\n>click on the uppermost button <img src=\"https://github.com/Vinamrata1086/Face-X/blob/master/Recognition-Algorithms/Facial%20Recognition%20using%20LBPH/images/fork.png\" width=50>\n\n- Clone the repository using-\n```\ngit clone https://github.com/akshitagupta15june/Face-X.git\n```\n- Create virtual environment-\n```\n- `python -m venv env`\n- `source env/bin/activate` (Linux)\n- `env\\Scripts\\activate` (Windows)\n```\n- Install dependencies-\n\n- Headover to Project Directory- \n```\ncd Recognition using Cnn\n\n```\n- Create dataset using -\n```\n- Run Creating dataset.py on respective idle(VS Code, PyCharm, Jupiter Notebook, Colab)\n```\nNote: Do split the dataset into Train and Test folders.\n\n- Train the model -\n```\n- Run Training_model.py\n```\nNote: Make sure all dependencies are installed properly.\n\n- Final-output -\n```\n- Run Displaying_results.py\n```\n\nNote: Make sure you have haarcascade_frontalface_default.xml file \n"
},
{
"alpha_fraction": 0.5203515887260437,
"alphanum_fraction": 0.5453850626945496,
"avg_line_length": 28.234636306762695,
"blob_id": "c0f4c7e465b9c1c56c244188bdd7ba9238ea1f4a",
"content_id": "a824bb388b8676bf26f126ee3a2efc9dba70fd8c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5233,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 179,
"path": "/Recognition-Algorithms/Recognition using GhostNet/train-model.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nimport torch.optim as optim\nfrom torch.optim import lr_scheduler\nimport torchvision\nfrom torchvision import datasets, models, transforms\nimport time\nimport os\nimport copy\nfrom tqdm import tqdm\n\n# change device to GPU if available\ndevice = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\n\n# preprocess the input image\npreprocess = {\n \"train\": transforms.Compose(\n [\n transforms.Resize(224),\n transforms.RandomRotation(30),\n transforms.RandomHorizontalFlip(),\n transforms.ToTensor(),\n transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),\n ]\n ),\n \"val\": transforms.Compose(\n [\n transforms.Resize(224),\n transforms.ToTensor(),\n transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),\n ]\n ),\n}\n\n# load datasets\ndata_dir = \"Datasets\"\ndatasets = {\n x: datasets.ImageFolder(os.path.join(data_dir, x), preprocess[x])\n for x in [\"train\", \"val\"]\n}\ndataloader = {\n x: torch.utils.data.DataLoader(\n datasets[x], batch_size=16, shuffle=True, num_workers=0\n )\n for x in [\"train\", \"val\"]\n}\ndatasets_size = {x: len(datasets[x]) for x in [\"train\", \"val\"]}\nclass_names = datasets[\"train\"].classes\n\n\n# Create a facial recognition model using GhostNet as base model\nclass Net(nn.Module):\n def __init__(self):\n super(Net, self).__init__()\n\n self.ghostnet = torch.hub.load(\n \"huawei-noah/ghostnet\", \"ghostnet_1x\", pretrained=True\n )\n self.ghostnet.to(device)\n for param in self.ghostnet.parameters():\n param.requires_grad = False\n\n self.fc1 = nn.Linear(1000, 512)\n self.fc2 = nn.Linear(512, 256)\n self.fc3 = nn.Linear(256, len(class_names))\n\n self.dropout1 = nn.Dropout(0.3)\n self.dropout2 = nn.Dropout(0.3)\n\n def forward(self, x):\n x = self.ghostnet(x)\n x = self.dropout1(x)\n x = self.fc1(x)\n x = nn.functional.relu(x)\n x = self.dropout2(x)\n x = self.fc2(x)\n x = nn.functional.relu(x)\n x = self.fc3(x)\n x = nn.functional.softmax(x, dim=0)\n return x\n\n\n# initialize model\nmodel = Net().to(device)\n\n# initialize model parameters\ncriterion = nn.CrossEntropyLoss()\noptimizer = optim.Adam(model.parameters())\nexp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)\n\n\ndef train(model, criterion, optimizer, scheduler, num_epochs=25):\n # helper function to train model\n since = time.time()\n\n best_model_wts = copy.deepcopy(model.state_dict())\n best_acc = 0.0\n best_loss = 0.0\n\n for epoch in range(num_epochs):\n print(\"Epoch {}/{}\".format(epoch + 1, num_epochs))\n\n metrics = {\n \"loss\": {\"train\": 0.0, \"val\": 0.0},\n \"acc\": {\"train\": 0.0, \"val\": 0.0},\n }\n\n for phase in [\"train\", \"val\"]:\n running_loss = 0.0\n running_corrects = 0.0\n\n if phase == \"train\":\n model.train()\n else:\n model.eval()\n\n for inputs, labels in tqdm(dataloader[phase], ncols=100):\n # iterate through the datasets\n inputs = inputs.to(device)\n labels = labels.to(device)\n\n optimizer.zero_grad()\n\n with torch.set_grad_enabled(phase == \"train\"):\n outputs = model(inputs)\n _, preds = outputs.max(dim=1)\n loss = criterion(outputs, labels)\n if phase == \"train\":\n loss.backward()\n optimizer.step()\n scheduler.step()\n\n running_loss += loss.item() * inputs.size(0)\n running_corrects += torch.sum(preds == labels.data)\n\n metrics[\"loss\"][phase] = running_loss / datasets_size[phase]\n metrics[\"acc\"][phase] = running_corrects.double() / datasets_size[phase]\n\n print(\n \"Loss: {:.4f} Acc: {:.4f} Val Loss: {:.4f} Val Acc: {:.4f}\".format(\n metrics[\"loss\"][\"train\"],\n metrics[\"loss\"][\"val\"],\n metrics[\"acc\"][\"train\"],\n metrics[\"acc\"][\"val\"],\n )\n )\n\n # update best model weights\n if (\n metrics[\"acc\"][\"val\"]\n + metrics[\"acc\"][\"train\"]\n - metrics[\"loss\"][\"val\"]\n - metrics[\"loss\"][\"train\"]\n > best_acc - best_loss\n ):\n best_acc = metrics[\"acc\"][\"val\"]\n best_loss = metrics[\"loss\"][\"val\"]\n best_model_wts = copy.deepcopy(model.state_dict())\n print(\"Best weights updated\")\n\n print()\n time_elapsed = time.time() - since\n print(\n \"Training complete in {:.0f}m {:.0f}s\".format(\n time_elapsed // 60, time_elapsed % 60\n )\n )\n print(\"Best val Acc: {:4f}\".format(best_acc))\n\n # load best model weights\n model.load_state_dict(best_model_wts)\n return model\n\n\n# train model\nmodel = train(model, criterion, optimizer, exp_lr_scheduler, num_epochs=5)\n\n# save model weights\ntorch.save(model.state_dict(), \"saved_model.pt\")\n"
},
{
"alpha_fraction": 0.5093912482261658,
"alphanum_fraction": 0.5362496376037598,
"avg_line_length": 32.49180221557617,
"blob_id": "8b79c501d22c2eddcd13abe6288d40bbf7c12eea",
"content_id": "3cfaa12a68e274f36ab41c1448981316054dccb4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16345,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 488,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/common/visual_helper.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n# system\nfrom __future__ import print_function\n\n# python lib\nimport numpy as np\n\n# tf_render\nimport tensorflow as tf\n\n# visual lm2d\ndef draw_landmark_image(list_img, list_lm, img_height, img_width, color):\n \"\"\"\n :param list_img:\n :param list_lm:\n :param img_height:\n :param img_width:\n :param color: 1:r 2:g 3:b\n :return:\n \"\"\"\n list_img_lm = []\n for i in range(len(list_img)):\n img = list_img[i]\n\n if len(list_img) == len(list_lm):\n lm = list_lm[i]\n else:\n lm = list_lm[0]\n img_draw_lm = img\n\n img_draw_lm = tf.image.convert_image_dtype(img_draw_lm, dtype=tf.float32)\n img_draw_lm = render_lm2d_circle_image(img_draw_lm, lm, img_height, img_width, color=color)\n img_draw_lm = tf.image.convert_image_dtype(img_draw_lm, dtype=tf.uint8)\n list_img_lm.append(img_draw_lm)\n return list_img_lm\n\ndef render_lm2d(lm2d_batch_xy, h, w):\n \"\"\"\n :param lm2d_batch:\n :param h:\n :param w:\n :return:\n \"\"\"\n # preprocess\n \"\"\"\n row correspond to y\n column correspond to x\n (row, column) = (y, x)\n \"\"\"\n x = lm2d_batch_xy[:, :, 0]\n y = lm2d_batch_xy[:, :, 1]\n x = tf.clip_by_value(x, 0, w-1)\n y = tf.clip_by_value(y, 0, h-1)\n lm2d_batch = tf.stack([y, x], axis=-1)\n\n #\n visual_lm2d = []\n for b_it in range(lm2d_batch.shape[0]):\n lm2d = lm2d_batch[b_it]\n lm2d = tf.cast(lm2d, dtype=tf.int64)\n r = tf.sparse_tensor_to_dense(\n tf.SparseTensor(indices=lm2d, values=tf.linspace(0.0, 1.0, lm2d.shape[0]),\n dense_shape=[h, w]),\n validate_indices=False\n )\n g = tf.sparse_tensor_to_dense(\n tf.SparseTensor(indices=lm2d, values=tf.zeros(shape=[lm2d.shape[0]], dtype=tf.float32),\n dense_shape=[h, w]),\n validate_indices=False\n )\n b = tf.sparse_tensor_to_dense(\n tf.SparseTensor(indices=lm2d, values=tf.zeros(shape=[lm2d.shape[0]], dtype=tf.float32),\n dense_shape=[h, w]),\n validate_indices=False\n )\n rgb = tf.stack([r, g, b], axis=-1)\n visual_lm2d.append(rgb)\n\n visual_lm2d = tf.stack(visual_lm2d)\n return visual_lm2d\n\ndef render_lm2d_image(image, lm2d_batch_xy, h, w, color=2, radius=1, light=1.0):\n \"\"\"\n :param image: (0, 1)\n :param lm2d_batch_xy:\n :param h:\n :param w:\n :param color:\n :param radius:\n :param light:\n :return:\n \"\"\"\n # preprocess\n \"\"\"\n row correspond to y\n column correspond to x\n (row, column) = (y, x)\n \"\"\"\n x = lm2d_batch_xy[:, :, 0]\n y = lm2d_batch_xy[:, :, 1]\n x = tf.clip_by_value(x, 0, w-1)\n y = tf.clip_by_value(y, 0, h-1)\n lm2d_batch = tf.stack([y, x], axis=-1)\n\n \"\"\"\n circle lm \n \"\"\"\n #\n visual_lm2d = []\n for b_it in range(lm2d_batch.shape[0]):\n lm2d = lm2d_batch[b_it]\n lm2d = tf.cast(lm2d, dtype=tf.int64)\n if color == 1:\n r = tf.sparse_tensor_to_dense(\n tf.SparseTensor(indices=lm2d, values=tf.linspace(light, 1.0, tf.shape(lm2d)[0]),\n dense_shape=[h, w]),\n validate_indices=False\n )\n else:\n r = tf.sparse_tensor_to_dense(\n tf.SparseTensor(indices=lm2d, values=tf.zeros(shape=[tf.shape(lm2d)[0]], dtype=tf.float32),\n dense_shape=[h, w]),\n validate_indices=False\n )\n if color == 2:\n g = tf.sparse_tensor_to_dense(\n tf.SparseTensor(indices=lm2d, values=tf.linspace(light, 1.0, tf.shape(lm2d)[0]),\n dense_shape=[h, w]),\n validate_indices=False\n )\n else:\n g = tf.sparse_tensor_to_dense(\n tf.SparseTensor(indices=lm2d, values=tf.zeros(shape=[tf.shape(lm2d)[0]], dtype=tf.float32),\n dense_shape=[h, w]),\n validate_indices=False\n )\n if color == 3:\n b = tf.sparse_tensor_to_dense(\n tf.SparseTensor(indices=lm2d, values=tf.linspace(light, 1.0, tf.shape(lm2d)[0]),\n dense_shape=[h, w]),\n validate_indices=False\n )\n else:\n b = tf.sparse_tensor_to_dense(\n tf.SparseTensor(indices=lm2d, values=tf.zeros(shape=[tf.shape(lm2d)[0]], dtype=tf.float32),\n dense_shape=[h, w]),\n validate_indices=False\n )\n rgb = tf.stack([r, g, b], axis=-1)\n visual_lm2d.append(rgb)\n visual_lm2d = tf.stack(visual_lm2d)\n\n \"\"\"\n assign image\n \"\"\"\n # Mask\n mask_lm2d = []\n for b_it in range(lm2d_batch.shape[0]):\n lm2d = lm2d_batch[b_it]\n lm2d = tf.cast(lm2d, dtype=tf.int64)\n r = tf.sparse_tensor_to_dense(\n tf.SparseTensor(indices=lm2d, values=tf.ones(shape=[tf.shape(lm2d)[0]], dtype=tf.float32),\n dense_shape=[h, w]),\n validate_indices=False\n )\n g = tf.sparse_tensor_to_dense(\n tf.SparseTensor(indices=lm2d, values=tf.ones(shape=[tf.shape(lm2d)[0]], dtype=tf.float32),\n dense_shape=[h, w]),\n validate_indices=False\n )\n b = tf.sparse_tensor_to_dense(\n tf.SparseTensor(indices=lm2d, values=tf.ones(shape=[tf.shape(lm2d)[0]], dtype=tf.float32),\n dense_shape=[h, w]),\n validate_indices=False\n )\n rgb = tf.stack([r, g, b], axis=-1)\n mask_lm2d.append(rgb)\n mask_lm2d = tf.stack(mask_lm2d)\n mask_lm2d = 1.0-mask_lm2d\n\n visual_image = image\n visual_image = visual_image * mask_lm2d\n\n visual_image = visual_image + visual_lm2d\n return visual_image\n\ndef lm_expand_circle(lm2d_batch, h, w):\n batch_size = lm2d_batch.shape[0]\n num_lm = tf.shape(lm2d_batch)[1]\n\n neighboor = tf.constant(\n [[-1., -1.], [-1., 0.], [-1., 1.],\n [0., -1.], [0., 0.], [0., 1.],\n [1., -1.], [1., 0.], [1., 1.],\n ]\n )\n # neighboor = tf.expand_dims(neighboor, 0)\n # neighboor = tf.tile(neighboor, [batch_size, num_lm, 1])\n #\n # lm2d_batch = tf.tile(lm2d_batch, [1, 9, 1])\n # lm_neightboor = tf.add(neighboor, lm2d_batch)\n # y = lm_neightboor[:, :, 0]\n # y = tf.clip_by_value(y, 0, h-1)\n # x = lm_neightboor[:, :, 1]\n # x = tf.clip_by_value(x, 0, w-1)\n # lm2d_point_batch = tf.stack([y, x], axis=-1)\n\n neighboor = tf.expand_dims(neighboor, 0)\n neighboor = tf.tile(neighboor, [batch_size, 1, 1])\n neighboor = tf.transpose(neighboor, perm=[1, 0, 2])\n\n lm2d_circle_batch = []\n for i in range(lm2d_batch.shape[1]):\n lm_neightboor = tf.add(neighboor, lm2d_batch[:, i, :])\n lm_neightboor = tf.transpose(lm_neightboor, perm=[1, 0, 2])\n y = lm_neightboor[:, :, 0]\n y = tf.clip_by_value(y, 0, h-1)\n x = lm_neightboor[:, :, 1]\n x = tf.clip_by_value(x, 0, w-1)\n lm2d_point_batch = tf.stack([y, x], axis=-1)\n if i == 0:\n lm2d_circle_batch = lm2d_point_batch\n else:\n lm2d_circle_batch = tf.concat([lm2d_circle_batch, lm2d_point_batch], axis=1)\n return lm2d_circle_batch\n\ndef render_lm2d_circle_image(image, lm2d_batch_xy, h, w, color=2, radius=1, light=1.0):\n \"\"\"\n :param image: (0, 1)\n :param lm2d_batch_xy:\n :param h:\n :param w:\n :param color:\n :param radius:\n :param light:\n :return:\n \"\"\"\n # preprocess\n \"\"\"\n row correspond to y\n column correspond to x\n (row, column) = (y, x)\n \"\"\"\n x = lm2d_batch_xy[:, :, 0]\n y = lm2d_batch_xy[:, :, 1]\n x = tf.clip_by_value(x, 0, w-1)\n y = tf.clip_by_value(y, 0, h-1)\n lm2d_batch = tf.stack([y, x], axis=-1)\n\n \"\"\"\n circle lm \n \"\"\"\n lm2d_batch = lm_expand_circle(lm2d_batch, h, w)\n\n #\n visual_lm2d = []\n for b_it in range(lm2d_batch.shape[0]):\n lm2d = lm2d_batch[b_it]\n lm2d = tf.cast(lm2d, dtype=tf.int64)\n if color == 1:\n r = tf.sparse_tensor_to_dense(\n tf.SparseTensor(indices=lm2d, values=tf.linspace(light, 1.0, lm2d.shape[0]),\n dense_shape=[h, w]),\n validate_indices=False\n )\n else:\n r = tf.sparse_tensor_to_dense(\n tf.SparseTensor(indices=lm2d, values=tf.zeros(shape=[lm2d.shape[0]], dtype=tf.float32),\n dense_shape=[h, w]),\n validate_indices=False\n )\n if color == 2:\n g = tf.sparse_tensor_to_dense(\n tf.SparseTensor(indices=lm2d, values=tf.linspace(light, 1.0, lm2d.shape[0]),\n dense_shape=[h, w]),\n validate_indices=False\n )\n else:\n g = tf.sparse_tensor_to_dense(\n tf.SparseTensor(indices=lm2d, values=tf.zeros(shape=[lm2d.shape[0]], dtype=tf.float32),\n dense_shape=[h, w]),\n validate_indices=False\n )\n if color == 3:\n b = tf.sparse_tensor_to_dense(\n tf.SparseTensor(indices=lm2d, values=tf.linspace(light, 1.0, lm2d.shape[0]),\n dense_shape=[h, w]),\n validate_indices=False\n )\n else:\n b = tf.sparse_tensor_to_dense(\n tf.SparseTensor(indices=lm2d, values=tf.zeros(shape=[lm2d.shape[0]], dtype=tf.float32),\n dense_shape=[h, w]),\n validate_indices=False\n )\n rgb = tf.stack([r, g, b], axis=-1)\n visual_lm2d.append(rgb)\n visual_lm2d = tf.stack(visual_lm2d)\n\n \"\"\"\n assign image\n \"\"\"\n # Mask\n mask_lm2d = []\n for b_it in range(lm2d_batch.shape[0]):\n lm2d = lm2d_batch[b_it]\n lm2d = tf.cast(lm2d, dtype=tf.int64)\n r = tf.sparse_tensor_to_dense(\n tf.SparseTensor(indices=lm2d, values=tf.ones(shape=[lm2d.shape[0]], dtype=tf.float32),\n dense_shape=[h, w]),\n validate_indices=False\n )\n g = tf.sparse_tensor_to_dense(\n tf.SparseTensor(indices=lm2d, values=tf.ones(shape=[lm2d.shape[0]], dtype=tf.float32),\n dense_shape=[h, w]),\n validate_indices=False\n )\n b = tf.sparse_tensor_to_dense(\n tf.SparseTensor(indices=lm2d, values=tf.ones(shape=[lm2d.shape[0]], dtype=tf.float32),\n dense_shape=[h, w]),\n validate_indices=False\n )\n rgb = tf.stack([r, g, b], axis=-1)\n mask_lm2d.append(rgb)\n mask_lm2d = tf.stack(mask_lm2d)\n mask_lm2d = 1.0-mask_lm2d\n\n visual_image = image\n visual_image = visual_image * mask_lm2d\n\n visual_image = visual_image + visual_lm2d\n return visual_image\n\n# visual heatmap\ndef gauss(x, a, b, c, d=0):\n return a * tf.exp(-(x - b)**2 / (2 * c**2)) + d\n\ndef pixel_error_heatmap(image_error):\n \"\"\"\n :param image_error: shape=[bs, h, w, 1], [0, 1]\n :return:\n \"\"\"\n x = image_error\n # x = tf.reduce_max(tf.reshape(x, [x.shape[0], -1]), axis=1)\n # x = tf.divide(x, tf.reshape(v_error_max, [x.shape[0], 1, 1, 1]) + 1e-6)\n\n if len(image_error.shape) == 3:\n x = tf.expand_dims(image_error, -1)\n\n\n color_0 = gauss(x, .5, .6, .2) + gauss(x, 1, .8, .3)\n color_1 = gauss(x, 1, .5, .3)\n color_2 = gauss(x, 1, .2, .3)\n color = tf.concat([color_0, color_1, color_2], axis=3)\n\n color = tf.clip_by_value(color, 0.0, 1.0)\n\n return color\n\n# net image / visual image\ndef preprocess_image(image):\n # Assuming input image is uint8\n image = tf.image.convert_image_dtype(image, dtype=tf.float32)\n return image #* 2. - 1.\n\ndef deprocess_image_series(list_image):\n list_image_depro = []\n for i in range(len(list_image)):\n image = list_image[i]\n image_depro = deprocess_image(image)\n list_image_depro.append(image_depro)\n return list_image_depro\n\ndef deprocess_normal_series(list_image):\n list_image_depro = []\n for i in range(len(list_image)):\n image = list_image[i]\n image = image / 2.0 + 0.5\n image_depro = deprocess_image(image)\n list_image_depro.append(image_depro)\n return list_image_depro\n\ndef deprocess_image(image):\n # Assuming input image is float32\n batch_size = image.shape[0]\n # norm\n\n # image_max = tf.reduce_max(\n # tf.reshape(image, [batch_size, -1]), axis=1)\n # image_norm = tf.divide(image,\n # tf.reshape(image_max, [batch_size, 1, 1, 1]) + 1e-6)\n image = tf.clip_by_value(image, 0.0, 1.0)\n #image = (image + 1.) / 2.\n return tf.image.convert_image_dtype(image, dtype=tf.uint8)\n\ndef deprocess_gary_image_series(list_image, convert=True):\n if isinstance(list_image, list) == False:\n list_image = [list_image]\n\n list_image_depro = []\n for i in range(len(list_image)):\n image = list_image[i]\n image_depro = deprocess_gary_image(image, convert)\n list_image_depro.append(image_depro)\n return list_image_depro\n\ndef deprocess_gary_image(image, convert=True):\n # Assuming input image is float32\n image = tf.image.grayscale_to_rgb(image)\n if convert:\n image = tf.image.convert_image_dtype(image, dtype=tf.uint8)\n\n return image\n\n# multi-view image concat/insert\ndef concate_image_series(list_image_l, list_image_r, axis):\n list_cat = []\n for i in range(len(list_image_l)):\n image_l = list_image_l[i]\n image_r = list_image_r[i]\n image_cat = tf.concat([image_l, image_r], axis=axis)\n list_cat.append(image_cat)\n return list_cat\n\ndef insert_semi_image_series(list_tar, list_src):\n list_cat = []\n for i in range(len(list_src)):\n if i == len(list_src)/2:\n list_cat.append(list_tar[0])\n list_cat.append(list_src[i])\n list_cat = tf.concat(list_cat, axis=2) # bs, h, w\n return list_cat\n\ndef concate_semi_image_series(list, list_src=None):\n if list_src is None:\n list_tar = [list[0]]\n list_src = list[1:]\n else:\n list_tar = list\n list_src = list_src\n list_cat = []\n for i in range(len(list_src)):\n if i == len(list_src)/2:\n list_cat.append(list_tar[0])\n list_cat.append(list_src[i])\n if isinstance(list_cat[0], np.ndarray):\n list_cat = np.concatenate(list_cat, axis=2) # bs, h, w\n else:\n list_cat = tf.concat(list_cat, axis=2) # bs, h, w\n return list_cat\n\n# visual depthmap\ndef normal_max_for_show(disp):\n disp_max = tf.reduce_max(disp)\n disp_new = disp/disp_max\n disp_new = disp_new*255\n disp_new_uint8 = tf.cast(disp_new, dtype=tf.uint8)\n return disp_new_uint8\n\ndef normal_depthmap_for_show_bgMax(disp):\n #disp_min = tf.contrib.distributions.percentile(disp, q=0, axis=[1, 2], interpolation='lower')\n disp_min = tf.reduce_min(disp)\n #disp_max = disp_min+255\n #disp = tf.clip_by_value(disp, disp_min, disp_max)\n #disp_max = tf.expand_dims(tf.expand_dims(disp_max, 1), 1)\n disp_min = tf.reshape(disp_min, [1, 1, 1, 1])\n disp_new = disp-disp_min\n disp_new_uint8 = tf.cast(disp_new, dtype=tf.uint8)\n return disp_new_uint8\n\ndef normal_depthmap_for_show(disp):\n disp_max = tf.contrib.distributions.percentile(disp, q=100, axis=[1, 2], interpolation='lower')\n disp_max = tf.reduce_max(disp_max)\n disp_min = disp_max-255*2\n disp = tf.clip_by_value(disp, disp_min, disp_max)\n #disp_max = tf.expand_dims(tf.expand_dims(disp_max, 1), 1)\n disp_min = tf.reshape(disp_min, [1, 1, 1, 1])\n\n disp_new = disp-disp_min\n #disp_new = (disp_new - disp_min) / (disp_max - disp_min)\n\n # disp_new = []\n # for i in range(disp.shape[0]):\n # #disp_i = tf_render.clip_by_value(disp[i], disp_min[i], disp_max[i])\n # dn = (disp[i] - disp_min[i]) / (disp_max[i] - disp_min[i])\n # disp_new.append(dn)\n # disp_new = tf_render.stack(disp_new)\n disp_new = tf.cast(disp_new, dtype=tf.uint8)\n return disp_new\n"
},
{
"alpha_fraction": 0.559921145439148,
"alphanum_fraction": 0.5994086861610413,
"avg_line_length": 33.90825653076172,
"blob_id": "8666d018b52c74cca6346f86c98709f53f5a46d2",
"content_id": "544fb42c72845a09b1ee92d63a5437a09bcacf7e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15220,
"license_type": "permissive",
"max_line_length": 142,
"num_lines": 436,
"path": "/Face Reconstruction/3D Face Reconstruction with Weakly-Supervised Learning/reconstruction_mesh.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import torch\nimport math\nimport numpy as np\nfrom utils import LeastSquares\n\n\ndef split_coeff(coeff):\n # input: coeff with shape [1,257]\n id_coeff = coeff[:, :80] # identity(shape) coeff of dim 80\n ex_coeff = coeff[:, 80:144] # expression coeff of dim 64\n tex_coeff = coeff[:, 144:224] # texture(albedo) coeff of dim 80\n angles = coeff[:, 224:227] # ruler angles(x,y,z) for rotation of dim 3\n # lighting coeff for 3 channel SH function of dim 27\n gamma = coeff[:, 227:254]\n translation = coeff[:, 254:] # translation coeff of dim 3\n\n return id_coeff, ex_coeff, tex_coeff, angles, gamma, translation\n\n\nclass _need_const:\n a0 = np.pi\n a1 = 2 * np.pi / np.sqrt(3.0)\n a2 = 2 * np.pi / np.sqrt(8.0)\n c0 = 1 / np.sqrt(4 * np.pi)\n c1 = np.sqrt(3.0) / np.sqrt(4 * np.pi)\n c2 = 3 * np.sqrt(5.0) / np.sqrt(12 * np.pi)\n d0 = 0.5 / np.sqrt(3.0)\n\n illu_consts = [a0, a1, a2, c0, c1, c2, d0]\n\n origin_size = 300\n target_size = 224\n camera_pos = 10.0\n\n\ndef shape_formation(id_coeff, ex_coeff, facemodel):\n # compute face shape with identity and expression coeff, based on BFM model\n # input: id_coeff with shape [1,80]\n # ex_coeff with shape [1,64]\n # output: face_shape with shape [1,N,3], N is number of vertices\n\n '''\n S = mean_shape + \\alpha * B_id + \\beta * B_exp\n '''\n n_b = id_coeff.size(0)\n face_shape = torch.einsum('ij,aj->ai', facemodel.idBase, id_coeff) + \\\n torch.einsum('ij,aj->ai', facemodel.exBase, ex_coeff) + \\\n facemodel.meanshape\n\n face_shape = face_shape.view(n_b, -1, 3)\n # re-center face shape\n face_shape = face_shape - \\\n facemodel.meanshape.view(1, -1, 3).mean(dim=1, keepdim=True)\n\n return face_shape\n\n\ndef texture_formation(tex_coeff, facemodel):\n # compute vertex texture(albedo) with tex_coeff\n # input: tex_coeff with shape [1,N,3]\n # output: face_texture with shape [1,N,3], RGB order, range from 0-255\n\n '''\n T = mean_texture + \\gamma * B_texture\n '''\n\n n_b = tex_coeff.size(0)\n face_texture = torch.einsum(\n 'ij,aj->ai', facemodel.texBase, tex_coeff) + facemodel.meantex\n\n face_texture = face_texture.view(n_b, -1, 3)\n return face_texture\n\n\ndef compute_norm(face_shape, facemodel):\n # compute vertex normal using one-ring neighborhood (8 points)\n # input: face_shape with shape [1,N,3]\n # output: v_norm with shape [1,N,3]\n # https://fredriksalomonsson.files.wordpress.com/2010/10/mesh-data-structuresv2.pdf\n\n # vertex index for each triangle face, with shape [F,3], F is number of faces\n face_id = facemodel.tri - 1\n # adjacent face index for each vertex, with shape [N,8], N is number of vertex\n point_id = facemodel.point_buf - 1\n shape = face_shape\n v1 = shape[:, face_id[:, 0], :]\n v2 = shape[:, face_id[:, 1], :]\n v3 = shape[:, face_id[:, 2], :]\n e1 = v1 - v2\n e2 = v2 - v3\n face_norm = e1.cross(e2) # compute normal for each face\n\n # normalized face_norm first\n face_norm = torch.nn.functional.normalize(face_norm, p=2, dim=2)\n empty = torch.zeros((face_norm.size(0), 1, 3),\n dtype=face_norm.dtype, device=face_norm.device)\n\n # concat face_normal with a zero vector at the end\n face_norm = torch.cat((face_norm, empty), 1)\n\n # compute vertex normal using one-ring neighborhood\n v_norm = face_norm[:, point_id, :].sum(dim=2)\n v_norm = torch.nn.functional.normalize(v_norm, p=2, dim=2) # normalize normal vectors\n return v_norm\n\n\ndef compute_rotation_matrix(angles):\n # compute rotation matrix based on 3 ruler angles\n # input: angles with shape [1,3]\n # output: rotation matrix with shape [1,3,3]\n n_b = angles.size(0)\n\n # https://www.cnblogs.com/larry-xia/p/11926121.html\n device = angles.device\n # compute rotation matrix for X-axis, Y-axis, Z-axis respectively\n rotation_X = torch.cat(\n [\n torch.ones([n_b, 1]).to(device),\n torch.zeros([n_b, 3]).to(device),\n torch.reshape(torch.cos(angles[:, 0]), [n_b, 1]),\n - torch.reshape(torch.sin(angles[:, 0]), [n_b, 1]),\n torch.zeros([n_b, 1]).to(device),\n torch.reshape(torch.sin(angles[:, 0]), [n_b, 1]),\n torch.reshape(torch.cos(angles[:, 0]), [n_b, 1])\n ],\n axis=1\n )\n rotation_Y = torch.cat(\n [\n torch.reshape(torch.cos(angles[:, 1]), [n_b, 1]),\n torch.zeros([n_b, 1]).to(device),\n torch.reshape(torch.sin(angles[:, 1]), [n_b, 1]),\n torch.zeros([n_b, 1]).to(device),\n torch.ones([n_b, 1]).to(device),\n torch.zeros([n_b, 1]).to(device),\n - torch.reshape(torch.sin(angles[:, 1]), [n_b, 1]),\n torch.zeros([n_b, 1]).to(device),\n torch.reshape(torch.cos(angles[:, 1]), [n_b, 1]),\n ],\n axis=1\n )\n rotation_Z = torch.cat(\n [\n torch.reshape(torch.cos(angles[:, 2]), [n_b, 1]),\n - torch.reshape(torch.sin(angles[:, 2]), [n_b, 1]),\n torch.zeros([n_b, 1]).to(device),\n torch.reshape(torch.sin(angles[:, 2]), [n_b, 1]),\n torch.reshape(torch.cos(angles[:, 2]), [n_b, 1]),\n torch.zeros([n_b, 3]).to(device),\n torch.ones([n_b, 1]).to(device),\n ],\n axis=1\n )\n\n rotation_X = rotation_X.reshape([n_b, 3, 3])\n rotation_Y = rotation_Y.reshape([n_b, 3, 3])\n rotation_Z = rotation_Z.reshape([n_b, 3, 3])\n\n # R = Rz*Ry*Rx\n rotation = rotation_Z.bmm(rotation_Y).bmm(rotation_X)\n\n # because our face shape is N*3, so compute the transpose of R, so that rotation shapes can be calculated as face_shape*R\n rotation = rotation.permute(0, 2, 1)\n\n return rotation\n\n\ndef projection_layer(face_shape, fx=1015.0, fy=1015.0, px=112.0, py=112.0):\n # we choose the focal length and camera position empirically\n # project 3D face onto image plane\n # input: face_shape with shape [1,N,3]\n # rotation with shape [1,3,3]\n # translation with shape [1,3]\n # output: face_projection with shape [1,N,2]\n # z_buffer with shape [1,N,1]\n\n cam_pos = 10\n p_matrix = np.concatenate([[fx], [0.0], [px], [0.0], [fy], [py], [0.0], [0.0], [1.0]],\n axis=0).astype(np.float32) # projection matrix\n p_matrix = np.reshape(p_matrix, [1, 3, 3])\n p_matrix = torch.from_numpy(p_matrix)\n gpu_p_matrix = None\n\n n_b, nV, _ = face_shape.size()\n if face_shape.is_cuda:\n gpu_p_matrix = p_matrix.cuda()\n p_matrix = gpu_p_matrix.expand(n_b, 3, 3)\n else:\n p_matrix = p_matrix.expand(n_b, 3, 3)\n\n face_shape[:, :, 2] = cam_pos - face_shape[:, :, 2]\n aug_projection = face_shape.bmm(p_matrix.permute(0, 2, 1))\n face_projection = aug_projection[:, :, 0:2] / aug_projection[:, :, 2:]\n\n z_buffer = cam_pos - aug_projection[:, :, 2:]\n\n return face_projection, z_buffer\n\n\ndef illumination_layer(face_texture, norm, gamma):\n # CHJ: It's different from what I knew.\n # compute vertex color using face_texture and SH function lighting approximation\n # input: face_texture with shape [1,N,3]\n # norm with shape [1,N,3]\n # gamma with shape [1,27]\n # output: face_color with shape [1,N,3], RGB order, range from 0-255\n # lighting with shape [1,N,3], color under uniform texture\n\n n_b, num_vertex, _ = face_texture.size()\n n_v_full = n_b * num_vertex\n gamma = gamma.view(-1, 3, 9).clone()\n gamma[:, :, 0] += 0.8\n\n gamma = gamma.permute(0, 2, 1)\n\n a0, a1, a2, c0, c1, c2, d0 = _need_const.illu_consts\n\n Y0 = torch.ones(n_v_full).float() * a0*c0\n if gamma.is_cuda:\n Y0 = Y0.cuda()\n norm = norm.view(-1, 3)\n nx, ny, nz = norm[:, 0], norm[:, 1], norm[:, 2]\n arrH = []\n\n arrH.append(Y0)\n arrH.append(-a1*c1*ny)\n arrH.append(a1*c1*nz)\n arrH.append(-a1*c1*nx)\n arrH.append(a2*c2*nx*ny)\n arrH.append(-a2*c2*ny*nz)\n arrH.append(a2*c2*d0*(3*nz.pow(2)-1))\n arrH.append(-a2*c2*nx*nz)\n arrH.append(a2*c2*0.5*(nx.pow(2)-ny.pow(2)))\n\n H = torch.stack(arrH, 1)\n Y = H.view(n_b, num_vertex, 9)\n\n # Y shape:[batch,N,9].\n\n # shape:[batch,N,3]\n lighting = Y.bmm(gamma)\n\n face_color = face_texture * lighting\n\n return face_color, lighting\n\n\ndef rigid_transform(face_shape, rotation, translation):\n n_b = face_shape.shape[0]\n face_shape_r = face_shape.bmm(rotation) # R has been transposed\n face_shape_t = face_shape_r + translation.view(n_b, 1, 3)\n return face_shape_t\n\n\ndef compute_landmarks(face_shape, facemodel):\n # compute 3D landmark postitions with pre-computed 3D face shape\n keypoints_idx = facemodel.keypoints - 1\n face_landmarks = face_shape[:, keypoints_idx, :]\n return face_landmarks\n\n\ndef compute_3d_landmarks(face_shape, facemodel, angles, translation):\n rotation = compute_rotation_matrix(angles)\n face_shape_t = rigid_transform(face_shape, rotation, translation)\n landmarks_3d = compute_landmarks(face_shape_t, facemodel)\n return landmarks_3d\n\n\ndef transform_face_shape(face_shape, angles, translation):\n rotation = compute_rotation_matrix(angles)\n face_shape_t = rigid_transform(face_shape, rotation, translation)\n return face_shape_t\n\n\ndef render_img(face_shape, face_color, facemodel, image_size=224, fx=1015.0, fy=1015.0, px=112.0, py=112.0, device='cuda:0'):\n '''\n ref: https://github.com/facebookresearch/pytorch3d/issues/184\n The rendering function (just for test)\n Input:\n face_shape: Tensor[1, 35709, 3]\n face_color: Tensor[1, 35709, 3] in [0, 1]\n facemodel: contains `tri` (triangles[70789, 3], index start from 1)\n '''\n from pytorch3d.structures import Meshes\n from pytorch3d.renderer.mesh.textures import TexturesVertex\n from pytorch3d.renderer import (\n PerspectiveCameras,\n PointLights,\n RasterizationSettings,\n MeshRenderer,\n MeshRasterizer,\n SoftPhongShader,\n BlendParams\n )\n\n face_color = TexturesVertex(verts_features=face_color.to(device))\n face_buf = torch.from_numpy(facemodel.tri - 1) # index start from 1\n face_idx = face_buf.unsqueeze(0)\n\n mesh = Meshes(face_shape.to(device), face_idx.to(device), face_color)\n\n R = torch.eye(3).view(1, 3, 3).to(device)\n R[0, 0, 0] *= -1.0\n T = torch.zeros([1, 3]).to(device)\n\n half_size = (image_size - 1.0) / 2\n focal_length = torch.tensor([fx / half_size, fy / half_size], dtype=torch.float32).reshape(1, 2).to(device)\n principal_point = torch.tensor([(half_size - px) / half_size, (py - half_size) / half_size], dtype=torch.float32).reshape(1, 2).to(device)\n\n cameras = PerspectiveCameras(\n device=device,\n R=R,\n T=T,\n focal_length=focal_length,\n principal_point=principal_point\n )\n\n raster_settings = RasterizationSettings(\n image_size=image_size,\n blur_radius=0.0,\n faces_per_pixel=1\n )\n\n lights = PointLights(\n device=device,\n ambient_color=((1.0, 1.0, 1.0),),\n diffuse_color=((0.0, 0.0, 0.0),),\n specular_color=((0.0, 0.0, 0.0),),\n location=((0.0, 0.0, 1e5),)\n )\n\n blend_params = BlendParams(background_color=(0.0, 0.0, 0.0))\n\n renderer = MeshRenderer(\n rasterizer=MeshRasterizer(\n cameras=cameras,\n raster_settings=raster_settings\n ),\n shader=SoftPhongShader(\n device=device,\n cameras=cameras,\n lights=lights,\n blend_params=blend_params\n )\n )\n images = renderer(mesh)\n images = torch.clamp(images, 0.0, 1.0)\n return images\n\n\ndef estimate_intrinsic(landmarks_2d, transform_params, z_buffer, face_shape, facemodel, angles, translation):\n # estimate intrinsic parameters\n\n def re_convert(landmarks_2d, trans_params, origin_size=_need_const.origin_size, target_size=_need_const.target_size):\n # convert landmarks to un_cropped images\n w = (origin_size * trans_params[2]).astype(np.int32)\n h = (origin_size * trans_params[2]).astype(np.int32)\n landmarks_2d[:, :, 1] = target_size - 1 - landmarks_2d[:, :, 1]\n\n landmarks_2d[:, :, 0] = landmarks_2d[:, :, 0] + w / 2 - target_size / 2\n landmarks_2d[:, :, 1] = landmarks_2d[:, :, 1] + h / 2 - target_size / 2\n\n landmarks_2d = landmarks_2d / trans_params[2]\n\n landmarks_2d[:, :, 0] = landmarks_2d[:, :, 0] + trans_params[3] - origin_size / 2\n landmarks_2d[:, :, 1] = landmarks_2d[:, :, 1] + trans_params[4] - origin_size / 2\n\n landmarks_2d[:, :, 1] = origin_size - 1 - landmarks_2d[:, :, 1]\n return landmarks_2d\n\n def POS(xp, x):\n # calculating least sqaures problem\n # ref https://github.com/pytorch/pytorch/issues/27036\n ls = LeastSquares()\n npts = xp.shape[1]\n\n A = torch.zeros([2*npts, 4]).to(x.device)\n A[0:2*npts-1:2, 0:2] = x[0, :, [0, 2]]\n A[1:2*npts:2, 2:4] = x[0, :, [1, 2]]\n\n b = torch.reshape(xp[0], [2*npts, 1])\n\n k = ls.lstq(A, b, 0.010)\n\n fx = k[0, 0]\n px = k[1, 0]\n fy = k[2, 0]\n py = k[3, 0]\n return fx, px, fy, py\n\n # convert landmarks to un_cropped images\n landmarks_2d = re_convert(landmarks_2d, transform_params)\n landmarks_2d[:, :, 1] = _need_const.origin_size - 1.0 - landmarks_2d[:, :, 1]\n landmarks_2d[:, :, :2] = landmarks_2d[:, :, :2] * (_need_const.camera_pos - z_buffer[:, :, :])\n\n # compute 3d landmarks\n landmarks_3d = compute_3d_landmarks(face_shape, facemodel, angles, translation)\n\n # compute fx, fy, px, py\n landmarks_3d_ = landmarks_3d.clone()\n landmarks_3d_[:, :, 2] = _need_const.camera_pos - landmarks_3d_[:, :, 2]\n fx, px, fy, py = POS(landmarks_2d, landmarks_3d_)\n return fx, px, fy, py\n\n\ndef reconstruction(coeff, facemodel):\n # The image size is 224 * 224\n # face reconstruction with coeff and BFM model\n id_coeff, ex_coeff, tex_coeff, angles, gamma, translation = split_coeff(coeff)\n\n # compute face shape\n face_shape = shape_formation(id_coeff, ex_coeff, facemodel)\n # compute vertex texture(albedo)\n face_texture = texture_formation(tex_coeff, facemodel)\n\n # vertex normal\n face_norm = compute_norm(face_shape, facemodel)\n # rotation matrix\n rotation = compute_rotation_matrix(angles)\n face_norm_r = face_norm.bmm(rotation)\n # print(face_norm_r[:, :3, :])\n\n # do rigid transformation for face shape using predicted rotation and translation\n face_shape_t = rigid_transform(face_shape, rotation, translation)\n\n # compute 2d landmark projection\n face_landmark_t = compute_landmarks(face_shape_t, facemodel)\n\n # compute 68 landmark on image plane (with image sized 224*224)\n landmarks_2d, z_buffer = projection_layer(face_landmark_t)\n landmarks_2d[:, :, 1] = _need_const.target_size - 1.0 - landmarks_2d[:, :, 1]\n\n # compute vertex color using SH function lighting approximation\n face_color, lighting = illumination_layer(face_texture, face_norm_r, gamma)\n\n return face_shape, face_texture, face_color, landmarks_2d, z_buffer, angles, translation, gamma\n"
},
{
"alpha_fraction": 0.5437099933624268,
"alphanum_fraction": 0.5872068405151367,
"avg_line_length": 23.946807861328125,
"blob_id": "2edac4775a78015a8d58abd6c2a12d1b4db04098",
"content_id": "5a9505cf6e328a24e56c3142879cfb0c1dc6ba86",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2345,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 94,
"path": "/Recognition-Algorithms/Recognition_using_NasNet/output.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from PIL import Image\nimport cv2\nimport numpy as np\nimport torch\nimport torch.nn as nn\nfrom torchvision import transforms\nfrom glob import glob\nimport os\nfrom models import *\n\n# change device to GPU if available\ndevice = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\n\n# Loading the cascades\nface_classifier = cv2.CascadeClassifier(\n cv2.data.haarcascades + \"haarcascade_frontalface_default.xml\"\n)\n\n# number of unique faces + 1\nclasses = list(\n map(\n lambda x: x.split(\"\\\\\")[-1],\n glob(os.path.join(os.getcwd(), \"Datasets\", \"train\", \"*\")),\n )\n)\n\n\ndef face_extractor(img):\n # Function detects faces and returns the cropped face\n # If no face detected, it returns None\n faces = face_classifier.detectMultiScale(img, 1.3, 5)\n if faces is ():\n return None\n # Crop all faces found\n cropped_face = 0\n for (x, y, w, h) in faces:\n x = x - 10\n y = y - 10\n cropped_face = img[y : y + h + 50, x : x + w + 50]\n cv2.rectangle(img, (x, y), (x + w + 30, y + h + 40), (0, 255, 255), 2)\n return cropped_face\n\n\n# preprocess frame\npreprocess = transforms.Compose(\n [\n transforms.Resize(224),\n transforms.ToTensor(),\n transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),\n ]\n)\n\n\n\n# Initialize webcam\nvideo_capture = cv2.VideoCapture(0)\n\n# load model\nmodel = NASNetAMobile(2).to(device)\nmodel.load_state_dict(torch.load(\"saved_model.pt\"))\nmodel.eval()\n\n# Recognize faces\nwhile True:\n _, frame = video_capture.read()\n face = face_extractor(frame)\n if face is not None:\n face = cv2.resize(face, (224, 224))\n im = Image.fromarray(face, \"RGB\")\n img = preprocess(im)\n img = torch.unsqueeze(img, 0)\n preds = model(img)\n\n name = \"None matching\"\n\n _, pred = preds.max(dim=1)\n if pred != 0:\n name = \"Face found:{}\".format(classes[pred])\n cv2.putText(frame, name, (50, 50), cv2.FONT_HERSHEY_COMPLEX, 1, (0, 255, 0), 2)\n else:\n cv2.putText(\n frame,\n \"No face found\",\n (50, 50),\n cv2.FONT_HERSHEY_COMPLEX,\n 1,\n (0, 255, 0),\n 2,\n )\n cv2.imshow(\"Video\", frame)\n if cv2.waitKey(1) & 0xFF == ord(\"q\"):\n break\nvideo_capture.release()\ncv2.destroyAllWindows()\n"
},
{
"alpha_fraction": 0.7255343198776245,
"alphanum_fraction": 0.7727783918380737,
"avg_line_length": 87.9000015258789,
"blob_id": "ed1474197b06b71230f073e8703e133195d073fa",
"content_id": "8498ccb603cca415eb473c7dfbd2a42ee53ccddb",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 891,
"license_type": "permissive",
"max_line_length": 318,
"num_lines": 10,
"path": "/Awesome-face-operations/Multiple-Template-Matching/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "### Intro:\nTemplate Matching is a method for searching and finding the location of a template image in a larger image. It simply slides the template image over the input image (as in 2D convolution) and compares the template and patch of input image under the template image. Several comparison methods are implemented in OpenCV.\n\n- If input image is of size (WxH) and template image is of size (wxh), output image will have a size of (W-w+1, H-h+1). \n- Take it as the top-left corner of rectangle and take (w,h) as width and height of the rectangle. That rectangle is your region of template.\n\nSuppose you are searching for an object which has multiple occurances, `cv2.minMaxLoc()` won’t give you all the locations. In that case, we will use thresholding. \n\n### Example:\n\n"
},
{
"alpha_fraction": 0.6405156254768372,
"alphanum_fraction": 0.6744014620780945,
"avg_line_length": 33.80769348144531,
"blob_id": "17dbdfc53d62547c445f19b8b9c3755f7d04e66c",
"content_id": "ccfacfd342ec36a69070b60f13dc11ef0cd9d01c",
"detected_licenses": [
"BSD-3-Clause",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2715,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 78,
"path": "/Snapchat_Filters/SantaClaus Filter/santa_filter.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from imutils import face_utils\nimport numpy as np\nimport cv2\nimport imutils\nimport dlib\nimport math\n\n# loading img assets\nsanta_beard = cv2.imread(\"assets/santa_beard.png\")\nsanta_hat = cv2.imread(\"assets/santa_hat.png\")\n# loading face recognition models\ndetector = dlib.get_frontal_face_detector()\npredictor = dlib.shape_predictor(\"shape_predictor_68_face_landmarks.dat\")\n\ncap = cv2.VideoCapture(0)\n\nwhile (True):\n\tret, frame = cap.read()\t\n\tgray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)\n\tfaces = detector(gray)\n\t\n\tfor face in faces:\n\t\ttry:\n\t\t\n\t\t\tlandmarks = predictor(gray, face)\n\t\t\tlandmarks_np = face_utils.shape_to_np(landmarks)\n\n\n\t\t\t# Santa Beard\n\t\t\ttop_left = (landmarks.part(3).x, landmarks.part(3).y)\n\t\t\ttop_right = (landmarks.part(13).x, landmarks.part(13).y)\n\t\t\t\n\t\t\tbeard_wd = int(math.hypot(top_left[0] - top_right[0], top_left[1] - top_right[1]))\n\t\t\tbeard_adj = imutils.resize(santa_beard, width=beard_wd)\n\t\t\tbeard_ht = beard_adj.shape[0]\n\n\t\t\tbottom_left = (landmarks.part(3).x, landmarks.part(3).y+beard_ht)\n\t\t\tbottom_right = (landmarks.part(13).x, landmarks.part(13).y+beard_ht)\n\n\t\t\tbeard_gray = cv2.cvtColor(beard_adj, cv2.COLOR_BGR2GRAY)\n\t\t\t_, beard_mask = cv2.threshold(beard_gray, 25, 255, cv2.THRESH_BINARY_INV)\n\t\t\tbeard_area = frame[top_left[1]: top_left[1] + beard_ht, top_left[0]: top_left[0] + beard_wd]\n\t\t\tbeard_area_no_beard = cv2.bitwise_and(beard_area, beard_area, mask=beard_mask)\n\t\t\tbeard_final = cv2.add(beard_area_no_beard, beard_adj)\n\t\t\tframe[top_left[1]: top_left[1] + beard_ht, top_left[0]: top_left[0] + beard_wd] = beard_final\n\n\n\t\t\t# Santa Cap\n\t\t\tbottom_left = (landmarks.part(0).x, landmarks.part(0).y)\n\t\t\tbottom_right = (landmarks.part(16).x, landmarks.part(16).y)\n\n\t\t\that_wd = int(math.hypot(bottom_left[0] - bottom_right[0], bottom_left[1] - bottom_right[1]))\n\t\t\that_adj = imutils.resize(santa_hat, width=hat_wd)\n\t\t\that_ht = hat_adj.shape[0]\n\n\t\t\tbottom_left = (bottom_left[0], bottom_left[1]-hat_ht//2)\n\t\t\tbottom_right = (bottom_right[0], bottom_right[1]-hat_ht//2)\n\t\t\ttop_left = (bottom_left[0], bottom_left[1]-hat_ht)\n\t\t\ttop_right = (bottom_right[0], bottom_right[1]-hat_ht)\n\n\t\t\that_gray = cv2.cvtColor(hat_adj, cv2.COLOR_BGR2GRAY)\n\t\t\t_, hat_mask = cv2.threshold(hat_gray, 30, 255, cv2.THRESH_BINARY_INV)\n\t\t\that_area = frame[top_left[1]: top_left[1] + hat_ht, top_left[0]: top_left[0] + hat_wd]\n\t\t\that_area_no_hat = cv2.bitwise_and(hat_area, hat_area, mask=hat_mask)\n\t\t\that_final = cv2.add(hat_area_no_hat, hat_adj)\n\t\t\tframe[top_left[1]: top_left[1] + hat_ht, top_left[0]: top_left[0] + hat_wd] = hat_final\n\n\t\t\n\t\texcept Exception as err:\n\t\t\tprint(err)\n\t\t\tcontinue\n\t\t\n\tcv2.imshow(\"Santa Filter\",frame)\t\n\tq = cv2.waitKey(1)\n\tif q==ord(\"q\"):\n\t\tbreak\n\ncv2.destroyAllWindows()\n"
},
{
"alpha_fraction": 0.7488839030265808,
"alphanum_fraction": 0.7672991156578064,
"avg_line_length": 98.5,
"blob_id": "9e630462904a3119870c80eeb5a2cdf9ac8c804b",
"content_id": "5c4c0806ee4383fe6360bb9ba76a9ce89ecb69a3",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1792,
"license_type": "permissive",
"max_line_length": 434,
"num_lines": 18,
"path": "/Awesome-face-operations/Style-Transfer/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Style-Transfer\nIn this project, I have created a style transfer method that is outlined in the paper, [Image Style Transfer Using Convolutional Neural Networks](https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Gatys_Image_Style_Transfer_CVPR_2016_paper.pdf), by Gatys in PyTorch.\n\nIn this paper, style transfer uses the features found in the 19-layer VGG Network, which is comprised of a series of convolutional and pooling layers, and a few fully-connected layers.\n\n## Separating Style and Content\nStyle transfer relies on separating the content and style of an image. Given one content image and one style image, the aim is to create a new, target image which should contain the desired content and style components:\n\n* objects and their arrangement are similar to that of the **content image**\n* style, colors, and textures are similar to that of the **style image**\n\nIn this notebook, I have used a pre-trained VGG19 Net to extract content or style features from a passed in image. I've then formalize the idea of content and style losses and use those to iteratively update the target image until I get a result that I want.\n\n## Example\n\n<img src=\"https://github.com/KKhushhalR2405/Style-Transfer/blob/master/exp1/blonde.jpg\" width=\"50px\"> <img src=\"https://github.com/KKhushhalR2405/Style-Transfer/blob/master/exp1/delaunay.jpg\" width=\"65px\"> <img src=\"https://github.com/KKhushhalR2405/Style-Transfer/blob/master/exp1/final_image.png\" width=\"50px\">\n\ncontent style output\n\n"
},
{
"alpha_fraction": 0.7481849193572998,
"alphanum_fraction": 0.7581200003623962,
"avg_line_length": 52.367347717285156,
"blob_id": "35b88be34132c390dd102ce07ce0fac50af43758",
"content_id": "64d703907b16158fa0edafb32cd1c7b3aca9a384",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2617,
"license_type": "permissive",
"max_line_length": 577,
"num_lines": 49,
"path": "/Awesome-face-operations/image-segmentation/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "<h1> Image Segmentation Using Color space and Opencv</h1>\n<h2>Introduction</h2>\n<p>\nThe process of partitioning a digital image into multiple segments is defined as image segmentation. Segmentation aims to divide an image into regions that can be more representative and easier to analyze. Such regions may correspond to individual surfaces, objects, or natural parts of objects. Typically image segmentation is the process used to locate objects and boundaries (e.g., lines or curves) in images . Furthermore, it can be defined as the process of labeling every pixel in an image, where all pixels having the same label share certain visual characteristics </p>\n\n<h2>What are color spaces?</h2>\n<p>Basically, Color spaces represent color through discrete structures (a fixed number of whole number integer values), which is acceptable since the human eye and perception are also limited. Color spaces are fully able to represent all the colors that humans are able to distinguish between.\nRGB is one of the five major color space models, each of which has many offshoots. There are so many color spaces because different color spaces are useful for different purposes.\nHSV and HSL are descriptions of hue, saturation, and brightness/luminance, which are particularly useful for identifying contrast in images.\n \n <h2>Steps followed for implementation</h2>\n <ul type=\"one\">\n <li>Converted the image into HSV</li>\n<li>Choosing swatches of desired color , In this, shades of light and dark orange has been taken.</li>\n<li> Applying orange shade mask on to the image</li>\n<li>Adding the second swatches of color, Here shades of white was chosen i.e light and dark shades</li>\n<li>Apply the whte mask onto the image</li>\n<li>Now combine the two masks ,Adding the two masks together results in 1 values wherever there is orange shade or white shade.</li>\n <li>Clean up the segmentation using a blur </li>\n </ul>\n\n \n <p>\n <h2>Default image in BGR color space</h2>\n <img src=\"images\\BGR_IMAGE.PNG\">\n \n <h2>Image converted to RGB color space</h2>\n <img src=\"images\\RBG_IMAGE.PNG\">\n \n <h2>Image converted to GRAY color space</h2>\n <img src=\"images\\GRAY_IMAGE.PNG\">\n \n <h2>Image converted to HSV color space</h2>\n <img src=\"images\\HSV_IMAGE.PNG\">\n </p>\n \n <p>\n <h2>Segmented images</h2>\n <img src=\"images\\demo1.PNG\">\n <img src=\"images\\demo2.PNG\">\n </p>\n \n <h2>Instructions to Run</h2>\n <ul>\n <li>Colne this repo https://github.com/akshitagupta15june/Face-X.git</li>\n <li>Change Directory cd Awesome-face-operations</li>\n <li>Then go to cd image_segmentation</li>\n <li>Run code file. python image_segmentation1.py</li>\n </ul>\n \n"
},
{
"alpha_fraction": 0.7016786336898804,
"alphanum_fraction": 0.7402877807617188,
"avg_line_length": 43.82795715332031,
"blob_id": "4f35e3ee27a534b504f686d843946e9b553cd86f",
"content_id": "deba9def68abd2e44c93d217f808ca8e857e8a51",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4170,
"license_type": "permissive",
"max_line_length": 388,
"num_lines": 93,
"path": "/Face Reconstruction/Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# CaricatureFace\nThis repository includes source code, pretrained model and a 3D dataset of paper \"Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model\", [http://arxiv.org/abs/2004.09190](http://arxiv.org/abs/2004.09190).\n\nAuthors: [Juyong Zhang](http://staff.ustc.edu.cn/~juyong/), Hongrui Cai, Yudong Guo and Zhuang Peng.\n\nNote that all of the code is protected under patent. It can be only used for research purposes. If you are interested in business purposes/for-profit use, please contact Juyong Zhang (the corresponding author, email: [email protected]).\n\n\n\n## Update Logs:\n### January 3, 2021\n* Make the entire 3D caricature dataset public! And attach the scripts for visualization!\n### December 5, 2020\n* Update the examples and add a figure for exhibition.\n### August 26, 2020\n* Add a method for computing the dynamical contour indices.\n### July 20, 2020\n* Add a method for calculating errors.\n### May 9, 2020\n* Add a toy example for conversion between 3D face and vertices.\n### April 22, 2020\n* The testset is enlarged.\n### April 8, 2020\n* The source code, pretrained model and some data from testset are released.\n\n## 3D Caricature Dataset\nYou can download the 3D caricature dataset we constructed via [Google Drive](https://drive.google.com/file/d/1M9NVRWpd_L_Cz2yrgEggkpQJ1YV_wBh6/view?usp=sharing), or [Baidu Drive](https://pan.baidu.com/s/14XAd7c5W-sCxnQr5QyMKZw) with password: 0nk6. The 3D caricature dataset contains 7,800 2D caricatures, 2D landmarks and 3D meshes. We also attach the scipts for visualization.\n\n## Comparison with us\nIf you want to do some comparison with our method, you can download a testset here [Google Drive](https://drive.google.com/open?id=1fGHlV8ISUkgCK8OSTQxvEJxtxXXrwjDI), or [Baidu Drive](https://pan.baidu.com/s/1YhniT8yb6C5yvO9gq_YYoA) with password: 4nvs. It includes 2D caricatures, groundtruth 68 landmarks, 68 landmarks detected by our method and 3D meshes recovered by our method.\n\n## Prerequisites and Installation\n- Python 3.7\n- Pytorch 1.4.0\n- opencv-python 3.4.2\n\n### Getting Started\n**Clone this repository:**\n```bash\ngit clone [email protected]:Juyong/CaricatureFace.git\ncd CaricatureFace\n```\n**Install dependencies using Anaconda:**\n ```bash\nconda create -n cariface python=3.7\nsource activate cariface\npip install -r requirements.txt\n```\n\n## Advanced Work\n**Prepare related data:**\n- You can download related data for alogorithm here [Google Drive](https://drive.google.com/open?id=11m9dC6j-SUyjhtSiXsUqiBdZOQ3S8phD), or [Baidu Drive](https://pan.baidu.com/s/1v4V-7rYszDhyhzhCH2aYeA) with password: tjps.\n- Unzip downloaded files and move files into ```./data``` directory.\n\n**Prepare pretrained model:**\n- You can download pretrained model here [Google Drive](https://drive.google.com/open?id=1If_rjQp5mDZMbK1-STGYOPyw_cTG66jO), or [Baidu Drive](https://pan.baidu.com/s/113QFM-zhSUIZfzjFhQfTTA) with password: fukf.\n- Unzip downloaded files and move files into ```./model``` directory.\n\n**Prepare some examples:**\n- You can download some examples here [Google Drive](https://drive.google.com/open?id=1X8TpVpGzRrQuSS93_Hb32ERU-P4q6SSG), or [Baidu Drive](https://pan.baidu.com/s/1fn6Ll3ogF5LrYByBe-T5Ew) with password: sq06.\n- Unzip downloaded files and move files into ```./exp``` directory.\n\n## Test with Pretrained Model\nWithin ```./CaricatureFace``` directory, run following command:\n ```bash\n bash test.sh\n```\n\nNote: Input images must be preprocessed - crop the whole face roughly and resize to size (224, 224).\n\n## Recover 3D faces\nPlease follow README.txt in ```./toy_example``` directory.\n\n## Compute the dynamical contour indices\nPlease follow README.txt in ```./update_contour``` directory.\n\n## Gallery\n\n\n## Citation\nIf you find this useful for your research, please cite the paper:\n```\n@article{Zhang2020Caricature,\n author = {Juyong Zhang and\n Hongrui Cai and\n Yudong Guo and\n Zhuang Peng},\n title = {Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model},\n journal = {CoRR},\n volume = {abs/2004.09190},\n year = {2020}\n}\n``` \n"
},
{
"alpha_fraction": 0.658730149269104,
"alphanum_fraction": 0.7275132536888123,
"avg_line_length": 33.3636360168457,
"blob_id": "6fc8eb0c63c23a76904697bbbc2554ba17f64385",
"content_id": "4741dda7243cdfbb9e8491fac630a7d97b2809e8",
"detected_licenses": [
"BSD-3-Clause",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 378,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 11,
"path": "/Awesome-face-operations/Pencil Sketch/pencil_sketch_code.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import cv2\nimg=cv2.imread(\"img.png\")\nimg_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)\nimg_invert = cv2.bitwise_not(img_gray)\nimg_smoothing = cv2.GaussianBlur(img_invert, (21, 21),sigmaX=0, sigmaY=0)\ndef dodgeV2(x, y):\n return cv2.divide(x, 255 - y, scale=256)\nfinal_img = dodgeV2(img_gray, img_smoothing)\ncv2.imshow('result',final_img)\ncv2.waitKey(0)\ncv2.destroyAllWindows()\n"
},
{
"alpha_fraction": 0.5849952101707458,
"alphanum_fraction": 0.6148445010185242,
"avg_line_length": 36.30861282348633,
"blob_id": "82c4a1a139ec32a6811193aacf9782bf4131abbd",
"content_id": "e17bd52786477c3dbb10fb6da4f6afd1d66918ae",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 31190,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 836,
"path": "/Face Reconstruction/3D Face Reconstruction using Graph Convolution Network/utils.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import logging\nimport os\nimport random\nfrom glob import glob\n\nimport cv2\nimport h5py\nimport imageio\nimport numpy as np\nimport scipy.io as sio\nimport scipy.sparse as sp\nimport tensorflow as tf\nfrom PIL import Image\n\nfrom lib import graph, mesh_sampling, spatialsearch\nfrom lib.mesh_io import read_obj\n\n\ndef make_paths(filenames, prefix, root_dir):\n train_txt = '{}_train.txt'.format(prefix)\n val_txt = '{}_val.txt'.format(prefix)\n test_txt = '{}_test.txt'.format(prefix)\n if os.path.isfile(test_txt):\n with open(train_txt, 'r') as f:\n train_paths = [os.path.join(root_dir, p.strip()) for p in f.readlines()]\n with open(val_txt, 'r') as f:\n val_paths = [os.path.join(root_dir, p.strip()) for p in f.readlines()]\n with open(test_txt, 'r') as f:\n test_paths = [os.path.join(root_dir, p.strip()) for p in f.readlines()]\n else:\n if not os.path.isdir(os.path.split(prefix)[0]):\n os.makedirs(os.path.split(prefix)[0])\n if 'image' in prefix:\n\n if not 'mv' in prefix:\n\n def check_lm(im_f):\n lm_f = im_f.replace('_Segment', '_Landmarks')\n lm_f = lm_f.replace('jpg', 'npy')\n lm_f = lm_f.replace('png', 'npy')\n return os.path.isfile(lm_f)\n\n filenames = [f for f in filenames if check_lm(f)]\n\n train_num = len(filenames) - 8192\n random.shuffle(filenames)\n train_paths = filenames[:train_num]\n val_paths = filenames[train_num:-4096]\n test_paths = filenames[-4096:]\n with open(train_txt, 'w') as f:\n f.writelines(p.split(root_dir, 1)[1][1:] + '\\n' for p in train_paths)\n with open(val_txt, 'w') as f:\n f.writelines(p.split(root_dir, 1)[1][1:] + '\\n' for p in val_paths)\n with open(test_txt, 'w') as f:\n f.writelines(p.split(root_dir, 1)[1][1:] + '\\n' for p in test_paths)\n return train_paths, val_paths, test_paths\n\n\ndef load_image_bin(start_idx, img_file, image_len, img_size):\n img_start = start_idx * image_len\n # lm_start = start_idx * landmark_len\n\n img_file.seek(img_start)\n im_str = img_file.read(image_len)\n # lm_file.seek(lm_start)\n # lm_str = lm_file.read(landmark_len)\n\n images = np.fromstring(im_str, dtype=np.float32).reshape((img_size, img_size, 4))\n # landmarks = np.fromstring(lm_str, dtype=np.float32).reshape((51, 2))\n # return images, landmarks\n return images\n\n\nclass ImageCropper():\n\n def __init__(self, predictor_path, img_size):\n import dlib\n self.detector = dlib.get_frontal_face_detector()\n self.predictor = dlib.shape_predictor(predictor_path)\n self.load_lm3d()\n self.img_size = img_size\n\n def load_lm3d(self):\n Lm3D = sio.loadmat('data/similarity_Lm3D_all.mat')\n Lm3D = Lm3D['lm']\n\n # calculate 5 facial landmarks using 68 landmarks\n lm_idx = np.array([31, 37, 40, 43, 46, 49, 55]) - 1\n Lm3D = np.stack([\n Lm3D[lm_idx[0], :],\n np.mean(Lm3D[lm_idx[[1, 2]], :], 0),\n np.mean(Lm3D[lm_idx[[3, 4]], :], 0), Lm3D[lm_idx[5], :], Lm3D[lm_idx[6], :]\n ], axis=0)\n self.lm3D = Lm3D[[1, 2, 0, 3, 4], :]\n\n def compute_lm_trans(self, lm):\n npts = lm.shape[1]\n A = np.zeros([2 * npts, 8])\n\n A[0:2 * npts - 1:2, 0:3] = self.lm3D\n A[0:2 * npts - 1:2, 3] = 1\n\n A[1:2 * npts:2, 4:7] = self.lm3D\n A[1:2 * npts:2, 7] = 1\n\n b = np.reshape(lm.transpose(), [2 * npts, 1])\n k, _, _, _ = np.linalg.lstsq(A, b, -1)\n\n R1 = k[0:3]\n R2 = k[4:7]\n sTx = k[3]\n sTy = k[7]\n s = (np.linalg.norm(R1) + np.linalg.norm(R2)) / 2\n t = np.stack([sTx, sTy], axis=0)\n\n return t, s\n\n def process_image(self, img, lm, t, s):\n w0, h0 = img.size\n img = img.transform(img.size, Image.AFFINE, (1, 0, t[0] - w0 / 2, 0, 1, h0 / 2 - t[1]))\n\n half_size = self.img_size // 2\n # scale = half_size - 10 * (self.img_size / 224)\n scale = (102 / 224) * self.img_size\n\n # w = (w0 / s * 102).astype(np.int32)\n # h = (h0 / s * 102).astype(np.int32)\n w = (w0 / s * scale).astype(np.int32)\n h = (h0 / s * scale).astype(np.int32)\n img = img.resize((w, h), resample=Image.BILINEAR)\n # lm = np.stack([lm[:, 0] - t[0] + w0 / 2, lm[:, 1] - t[1] + h0 / 2],\n # axis=1) / s * 102\n\n # crop the image to 224*224 from image center\n left = (w / 2 - half_size).astype(np.int32)\n right = left + self.img_size\n up = (h / 2 - half_size).astype(np.int32)\n below = up + self.img_size\n\n img = img.crop((left, up, right, below))\n img = np.array(img)\n # img = img[:, :, ::-1]\n # img = np.expand_dims(img, 0)\n # lm = lm - np.reshape(np.array([(w / 2 - half_size),\n # (h / 2 - half_size)]), [1, 2])\n\n return img\n\n def extend_img(self, inputs):\n width, height, _ = inputs.shape\n top = int(height * 0.3)\n left = int(width * 0.3)\n\n outputs = cv2.copyMakeBorder(inputs, top, top, left, left, cv2.BORDER_REPLICATE)\n return outputs\n\n def get_landmarks(self, image):\n faces = self.detector(np.array(image[..., :3]), 1)\n landmarks = self.predictor(np.array(image[..., :3]), faces[0])\n return landmarks\n\n def crop_image(self, image):\n image = self.extend_img(image)\n\n landmarks = self.get_landmarks(image)\n idxs = [[36, 37, 38, 39, 40, 41], [42, 43, 44, 45, 46, 47], [30], [48], [54]]\n lm = np.zeros([5, 2])\n for i in range(5):\n for j in idxs[i]:\n lm[i] += np.array([landmarks.part(j).x, landmarks.part(j).y])\n lm[i] = lm[i] // len(idxs[i])\n\n new_image = Image.fromarray(image)\n w0, h0 = new_image.size\n\n lm = np.stack([lm[:, 0], h0 - 1 - lm[:, 1]], axis=1)\n t, s = self.compute_lm_trans(lm.transpose())\n\n return self.process_image(new_image, lm, t, s)\n\n\ndef load_image(filename, img_size, alpha, landmark, cropper=None, gray=False):\n if isinstance(filename, str):\n im_f = filename\n else:\n im_f = filename.decode()\n\n image = cv2.imread(im_f, cv2.IMREAD_UNCHANGED)\n image = cv2.resize(image, (img_size, img_size))\n if alpha:\n image = cv2.cvtColor(image, cv2.COLOR_BGRA2RGBA)\n if cropper is not None:\n image = cropper.crop_image(image)\n image = image / [[[127.5, 127.5, 127.5, 255.0]]] - [[[1.0, 1.0, 1.0, 0.0]]]\n else:\n image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)\n if cropper is not None:\n image = cropper.crop_image(image)\n if gray:\n image = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)\n image = image / 127.5 - 1.0\n\n if not landmark:\n return image.astype(np.float32)\n else:\n lm_f = im_f.replace('_Segment', '_Landmarks')\n lm_f = lm_f.replace('jpg', 'npy')\n lm_f = lm_f.replace('png', 'npy')\n landmarks = np.fromfile(lm_f, dtype=np.int32)\n landmarks = np.reshape(landmarks, [68, 2]).astype(np.float32)\n landmarks = landmarks[17:]\n half_size = img_size / 2\n landmarks = landmarks / half_size - 1.0\n return image.astype(np.float32), landmarks.astype(np.float32)\n\n\ndef load_images(filenames, img_size, alpha, landmark, cropper=None, gray=False):\n images = []\n if not landmark:\n for f in filenames:\n image = load_image(f, img_size, alpha, landmark, cropper, gray)\n images.append(image)\n return np.array(images)\n else:\n landmarks = []\n for f in filenames:\n image, lm = load_image(f, img_size, alpha, landmark, cropper, gray)\n images.append(image)\n landmarks.append(lm)\n return np.array(images), np.array(landmarks)\n\n\ndef load_mv_image(filedir, img_size, alpha, landmark):\n if isinstance(filedir, str):\n im_f = filedir\n else:\n im_f = filedir.decode()\n\n im_f0 = os.path.join(im_f, '0.png')\n im_f1s = glob('{}/[1-4].png'.format(im_f))\n # print(filedir, im_f0, im_f1s)\n im_f1 = random.choice(im_f1s)\n im_f2s = glob('{}/[5-8].png'.format(im_f))\n im_f2 = random.choice(im_f2s)\n\n loaded_data = load_images([im_f0, im_f1, im_f2], img_size, alpha, landmark)\n return loaded_data\n\n\ndef load_mv_images(filedirs, img_size, alpha, landmark):\n images = []\n if not landmark:\n for d in filedirs:\n image = load_mv_image(d, img_size, alpha, landmark)\n images.append(image)\n return np.array(images)\n else:\n landmarks = []\n for d in filedirs:\n image, lm = load_mv_image(d, img_size, alpha, landmark)\n images.append(image)\n landmarks.append(lm)\n return np.array(image), np.array(landmarks)\n\n\ndef init_sampling(refer_mesh, data_dir, dataname, ds_factors=(4, 4, 4, 4)):\n # Sampling factor of the mesh at each stage of sampling\n\n # Generates adjecency matrices A, downsampling matrices D, and upsamling matrices U by sampling\n # the mesh 4 times. Each time the mesh is sampled by a factor of 4\n adj_path = os.path.join(data_dir, 'adjacency')\n ds_path = os.path.join(data_dir, 'downsamp_trans')\n us_path = os.path.join(data_dir, 'upsamp_trans')\n lap_path = os.path.join(data_dir, 'laplacians')\n\n if not os.path.isfile(lap_path + '0.npz'):\n logger = logging.getLogger('x')\n logger.info('Computing Sampling Parameters')\n adjacencies, downsamp_trans, upsamp_trans = mesh_sampling.generate_transform_matrices(\n dataname, refer_mesh['vertices'], refer_mesh['faces'], ds_factors)\n adjacencies = [x.astype('float32') for x in adjacencies]\n downsamp_trans = [x.astype('float32') for x in downsamp_trans]\n upsamp_trans = [x.astype('float32') for x in upsamp_trans]\n laplacians = [graph.laplacian(a, normalized=True) for a in adjacencies]\n\n if not os.path.exists(data_dir):\n os.makedirs(data_dir)\n for i, a in enumerate(adjacencies):\n sp.save_npz(adj_path + '{}.npz'.format(i), a)\n for i, d in enumerate(downsamp_trans):\n sp.save_npz(ds_path + '{}.npz'.format(i), d)\n for i, u in enumerate(upsamp_trans):\n sp.save_npz(us_path + '{}.npz'.format(i), u)\n for i, l in enumerate(laplacians):\n sp.save_npz(lap_path + '{}.npz'.format(i), l)\n else:\n adjacencies = []\n downsamp_trans = []\n upsamp_trans = []\n laplacians = []\n for a in sorted(glob('{}*.npz'.format(adj_path))):\n adjacencies.append(sp.load_npz(a))\n for d in sorted(glob('{}*.npz'.format(ds_path))):\n downsamp_trans.append(sp.load_npz(d))\n for u in sorted(glob('{}*.npz'.format(us_path))):\n upsamp_trans.append(sp.load_npz(u))\n for l in sorted(glob('{}*.npz'.format(lap_path))):\n laplacians.append(sp.load_npz(l))\n\n pool_size = [x.shape[0] for x in adjacencies]\n return laplacians, downsamp_trans, upsamp_trans, pool_size\n\n\ndef split_bfm09_coeff(coeff):\n shape_coef = coeff[:, :80] # identity(shape) coeff of dim 80\n exp_coef = coeff[:, 80:144] # expression coeff of dim 64\n color_coef = coeff[:, 144:224] # texture(albedo) coeff of dim 80\n angles = coeff[:, 224:227] # ruler angles(x,y,z) for rotation of dim 3\n gamma = coeff[:, 227:254] # lighting coeff for 3 channel SH function of dim 27\n translation = coeff[:, 254:] # translation coeff of dim 3\n\n return shape_coef, exp_coef, color_coef, angles, gamma, translation\n\n\ndef get_mesh_list(name='bfm_face',):\n mesh_list = []\n for i in range(5):\n path = os.path.join('data', 'reference', name, 'reference{}.obj'.format(i))\n mesh_list.append(read_obj(path))\n\n return mesh_list\n\n\ndef image_augment(image, augment_size):\n seed = random.randint(0, 2**31 - 1)\n ori_image_shape = tf.shape(image)\n image = tf.image.random_flip_left_right(image, seed=seed)\n image = tf.image.resize_images(image, [augment_size, augment_size])\n image = tf.random_crop(image, ori_image_shape, seed=seed)\n return image\n\n\ndef img_normalize(images):\n return images / 127.5 - 1.0\n\n\ndef img_denormalize(image):\n images = np.clip(image, -1, 1)\n if np.shape(images)[-1] == 4:\n shape = [1] * (len(np.shape(images)) - 1) + [4]\n plus = np.reshape([1, 1, 1, 0], shape).astype(np.float32)\n mult = np.reshape([127.5, 127.5, 127.5, 255], shape).astype(np.float32)\n output = (images + plus) * mult\n # output = np.concatenate(\n # [(images[..., :3] + 1) * 127.5, images[..., 3:] * 255.0], axis=-1)\n else:\n output = (images + 1) * 127.5\n return np.clip(output, 0, 255).astype(np.uint8)\n\n\ndef cosine(x, y):\n x_len = tf.sqrt(tf.reduce_sum(x * x, 1))\n y_len = tf.sqrt(tf.reduce_sum(y * y, 1))\n inner_product = tf.reduce_sum(x * y, 1)\n result = tf.div(inner_product, x_len * y_len + 1e-8, name='cosine_dist')\n return result\n\n\ndef cosine_np(x, y):\n x_len = np.sqrt(np.sum(x * x, 1))\n y_len = np.sqrt(np.sum(y * y, 1))\n inner_product = np.sum(x * y, 1)\n result = inner_product / (x_len * y_len + 1e-8)\n return result\n\n\ndef rotation_matrix_np(angles):\n angle_x = angles[:, 0]\n angle_y = angles[:, 1]\n angle_z = angles[:, 2]\n\n ones = np.ones_like(angle_x)\n zeros = np.zeros_like(angle_x)\n\n # yapf: disable\n rotation_X = np.array([[ones, zeros, zeros],\n [zeros, np.cos(angle_x), -np.sin(angle_x)],\n [zeros, np.sin(angle_x), np.cos(angle_x)]],\n dtype=np.float32)\n rotation_Y = np.array([[np.cos(angle_y), zeros, np.sin(angle_y)],\n [zeros, ones, zeros],\n [-np.sin(angle_y), zeros, np.cos(angle_y)]],\n dtype=np.float32)\n rotation_Z = np.array([[np.cos(angle_z), -np.sin(angle_z), zeros],\n [np.sin(angle_z), np.cos(angle_z), zeros],\n [zeros, zeros, ones]],\n dtype=np.float32)\n # yapf: enable\n\n rotation_X = np.transpose(rotation_X, (2, 0, 1))\n rotation_Y = np.transpose(rotation_Y, (2, 0, 1))\n rotation_Z = np.transpose(rotation_Z, (2, 0, 1))\n rotation = np.matmul(np.matmul(rotation_Z, rotation_Y), rotation_X)\n # transpose row and column (dimension 1 and 2)\n rotation = np.transpose(rotation, axis=[0, 2, 1])\n\n return rotation\n\n\ndef rotation_matrix_tf(angles):\n angle_x = angles[:, 0]\n angle_y = angles[:, 1]\n angle_z = angles[:, 2]\n\n ones = tf.ones_like(angle_x)\n zeros = tf.zeros_like(angle_x)\n\n # yapf: disable\n rotation_X = tf.convert_to_tensor(\n [[ones, zeros, zeros],\n [zeros, tf.cos(angle_x), -tf.sin(angle_x)],\n [zeros, tf.sin(angle_x), tf.cos(angle_x)]],\n dtype=np.float32)\n rotation_Y = tf.convert_to_tensor(\n [[tf.cos(angle_y), zeros, tf.sin(angle_y)],\n [zeros, ones, zeros],\n [-tf.sin(angle_y), zeros, tf.cos(angle_y)]],\n dtype=tf.float32)\n rotation_Z = tf.convert_to_tensor(\n [[tf.cos(angle_z), -tf.sin(angle_z), zeros],\n [tf.sin(angle_z), tf.cos(angle_z), zeros],\n [zeros, zeros, ones]],\n dtype=tf.float32)\n # yapf: enable\n\n rotation_X = tf.transpose(rotation_X, (2, 0, 1))\n rotation_Y = tf.transpose(rotation_Y, (2, 0, 1))\n rotation_Z = tf.transpose(rotation_Z, (2, 0, 1))\n rotation = tf.matmul(tf.matmul(rotation_Z, rotation_Y), rotation_X)\n # transpose row and column (dimension 1 and 2)\n rotation = tf.transpose(rotation, perm=[0, 2, 1])\n\n return rotation\n\n\ndef illumination_np(face_texture, norm, gamma):\n\n num_vertex = np.shape(face_texture)[1]\n\n init_lit = np.array([0.8, 0, 0, 0, 0, 0, 0, 0, 0])\n gamma = np.reshape(gamma, [-1, 3, 9])\n gamma = gamma + np.reshape(init_lit, [1, 1, 9])\n\n # parameter of 9 SH function\n a0 = np.pi\n a1 = 2 * np.pi / np.sqrt(3.0)\n a2 = 2 * np.pi / np.sqrt(8.0)\n c0 = 1 / np.sqrt(4 * np.pi)\n c1 = np.sqrt(3.0) / np.sqrt(4 * np.pi)\n c2 = 3 * np.sqrt(5.0) / np.sqrt(12 * np.pi)\n\n Y0 = np.tile(np.reshape(a0 * c0, [1, 1, 1]), [1, num_vertex, 1])\n Y1 = np.reshape(-a1 * c1 * norm[:, :, 1], [1, num_vertex, 1])\n Y2 = np.reshape(a1 * c1 * norm[:, :, 2], [1, num_vertex, 1])\n Y3 = np.reshape(-a1 * c1 * norm[:, :, 0], [1, num_vertex, 1])\n Y4 = np.reshape(a2 * c2 * norm[:, :, 0] * norm[:, :, 1], [1, num_vertex, 1])\n Y5 = np.reshape(-a2 * c2 * norm[:, :, 1] * norm[:, :, 2], [1, num_vertex, 1])\n Y6 = np.reshape(a2 * c2 * 0.5 / np.sqrt(3.0) * (3 * np.square(norm[:, :, 2]) - 1),\n [1, num_vertex, 1])\n Y7 = np.reshape(-a2 * c2 * norm[:, :, 0] * norm[:, :, 2], [1, num_vertex, 1])\n Y8 = np.reshape(a2 * c2 * 0.5 * (np.square(norm[:, :, 0]) - np.square(norm[:, :, 1])),\n [1, num_vertex, 1])\n Y = np.concatenate([Y0, Y1, Y2, Y3, Y4, Y5, Y6, Y7, Y8], axis=2)\n\n # Y shape:[batch,N,9].\n lit_r = np.squeeze(np.matmul(Y, np.expand_dims(gamma[:, 0, :], 2)),\n 2) # [batch,N,9] * [batch,9,1] = [batch,N]\n lit_g = np.squeeze(np.matmul(Y, np.expand_dims(gamma[:, 1, :], 2)), 2)\n lit_b = np.squeeze(np.matmul(Y, np.expand_dims(gamma[:, 2, :], 2)), 2)\n\n # shape:[batch,N,3]\n face_color = np.stack(\n [lit_r * face_texture[:, :, 0], lit_g * face_texture[:, :, 1], lit_b * face_texture[:, :, 2]],\n axis=2)\n # lighting = np.stack([lit_r, lit_g, lit_b], axis=2) * 128\n\n return face_color\n\n\nclass LSFM_model(object):\n\n def __init__(self, root_dir, path='data/LSFM_boxer.mat'):\n super(LSFM_model, self).__init__()\n\n self.root_dir = root_dir\n self.path = os.path.join(root_dir, path)\n self.load_LSFM_boxer()\n self.compute_offset()\n\n self.n_shape_coef = self.shapePC.shape[1]\n self.n_exp_coef = self.expPC.shape[1]\n self.n_tex_coef = self.texPC.shape[1]\n self.n_all_coef = self.n_shape_coef + self.n_exp_coef + self.n_tex_coef\n\n def load_LSFM_boxer(self):\n C = sio.loadmat(self.path)\n model = C['model']\n model = model[0, 0]\n\n # change dtype from double(np.float64) to np.float32,\n # since big matrix process(espetially matrix dot) is too slow in python.\n self.shapeMU = model['shapeMU'].astype(np.float32)\n self.shapePC = model['shapePC'].astype(np.float32)\n self.expMU = model['expMU'].astype(np.float32)\n self.expPC = model['expPC'].astype(np.float32)\n self.texMU = model['texMU'].astype(np.float32)\n self.texPC = model['texPC'].astype(np.float32)\n\n def compute_offset(self):\n mean = read_obj(os.path.join('data/3dmd_mean.obj'))['vertices']\n lsfm = read_obj(os.path.join('data/lsfm_template.obj'))['vertices']\n idxs = [40502, 47965, 18958, 35610]\n scale = [(mean[idxs[0]] - mean[idxs[1]]) / (lsfm[idxs[0]] - lsfm[idxs[1]]),\n (mean[idxs[3]] - mean[idxs[2]]) / (lsfm[idxs[3]] - lsfm[idxs[2]])]\n\n self.scale = np.mean([scale[0][1], scale[1][0]])\n # scale = 1.17\n lsfm_scale = lsfm * self.scale\n self.offset = np.mean(mean, axis=0) - np.mean(lsfm_scale, axis=0)\n\n\nclass BFM_model(object):\n\n def __init__(self, root_dir, path):\n super(BFM_model, self).__init__()\n\n self.root_dir = root_dir\n self.path = os.path.join(root_dir, path)\n if '09' in path:\n self.load_BFM09()\n elif '17' in path:\n self.load_BFM17()\n\n self.n_shape_coef = self.shapePC.shape[1]\n self.n_exp_coef = self.expressionPC.shape[1]\n self.n_color_coef = self.colorPC.shape[1]\n self.n_all_coef = self.n_shape_coef + self.n_exp_coef + self.n_color_coef\n\n def load_BFM09(self):\n model = sio.loadmat(self.path)\n self.shapeMU = model['meanshape'].astype(np.float32) # mean face shape\n self.shapePC = model['idBase'].astype(np.float32) # identity basis\n self.expressionPC = model['exBase'].astype(np.float32) # expression basis\n self.colorMU = model['meantex'].astype(np.float32) # mean face texture\n self.colorPC = model['texBase'].astype(np.float32) # texture basis\n self.point_buf = model['point_buf'].astype(np.int32)\n # adjacent face index for each vertex, starts from 1 (only used for calculating face normal)\n self.triangles = model['tri'].astype(np.int32)\n # vertex index for each triangle face, starts from 1\n self.landmark = np.squeeze(model['keypoints']).astype(\n np.int32) - 1 # 68 face landmark index, starts from 0\n skin_mask = sio.loadmat(os.path.join(self.root_dir,\n 'data/bfm2009_4seg.mat'))['face05_4seg'][:, 0]\n face_id = sio.loadmat(os.path.join(self.root_dir,\n 'data/bfm2009_face_idx.mat'))['select_id'][:, 0] - 1\n skin_mask = skin_mask[face_id]\n self.skin_index = np.where(skin_mask == 3)[0]\n\n sym_index = [\n x.split() for x in open('data/bfm2009_symlist.txt', 'r').readlines() if len(x.strip()) > 1\n ]\n sym_index = np.array([[int(x) for x in y] for y in sym_index])\n self.left_index = sym_index[:, 0]\n self.right_index = sym_index[:, 1]\n # crop_sym_idx = []\n # for x, y in sym_index:\n # if x in face_id and y in face_id:\n # crop_sym_idx.append([\n # np.squeeze(np.where(face_id == x)),\n # np.squeeze(np.where(face_id == y))\n # ])\n\n # with open('data/bfm2009_face_symlist.txt', 'w') as f:\n # for x, y in crop_sym_idx:\n # f.write('{} {}\\n'.format(x, y))\n\n # self.skin_mask = np.reshape(skin_mask == 3, [-1, 1]).astype(np.float32)\n # self.skin_mask = np.reshape(model['skinmask'].astype(np.int32), [-1, 1])\n # self.front_mask = np.zeros_like(self.skin_mask)\n # self.front_mask[np.reshape(model['frontmask2_idx'].astype(np.int32) - 1,\n # [-1, 1])] = 1\n\n def load_BFM17(self):\n with h5py.File(self.path, 'r') as hf:\n self.triangles = np.transpose(np.array(hf['shape/representer/cells']), [1, 0])\n\n self.shapeMU = np.array(hf['shape/model/mean']) / 1e2\n shape_orthogonal_pca_basis = np.array(hf['shape/model/pcaBasis'])\n shape_pca_variance = np.array(hf['shape/model/pcaVariance']) / 1e4\n\n self.colorMU = np.array(hf['color/model/mean'])\n color_orthogonal_pca_basis = np.array(hf['color/model/pcaBasis'])\n color_pca_variance = np.array(hf['color/model/pcaVariance'])\n\n self.expressionMU = np.array(hf['expression/model/mean']) / 1e2\n expression_pca_basis = np.array(hf['expression/model/pcaBasis'])\n expression_pca_variance = np.array(hf['expression/model/pcaVariance']) / 1e4\n\n self.shapePC = shape_orthogonal_pca_basis * np.expand_dims(np.sqrt(shape_pca_variance), 0)\n self.colorPC = color_orthogonal_pca_basis * np.expand_dims(np.sqrt(color_pca_variance), 0)\n self.expressionPC = expression_pca_basis * np.expand_dims(np.sqrt(expression_pca_variance), 0)\n\n\ndef get_vert_connectivity(mesh_v, mesh_f):\n \"\"\"Returns a sparse matrix (of size #verts x #verts) where each nonzero\n element indicates a neighborhood relation. For example, if there is a\n nonzero element in position (15,12), that means vertex 15 is connected\n by an edge to vertex 12.\"\"\"\n\n vpv = sp.csc_matrix((len(mesh_v), len(mesh_v)))\n\n # for each column in the faces...\n for i in range(3):\n IS = mesh_f[:, i]\n JS = mesh_f[:, (i + 1) % 3]\n data = np.ones(len(IS))\n # ij = np.vstack((row(IS.flatten()), row(JS.flatten())))\n ij = np.vstack((IS.reshape((1, -1)), JS.reshape(1, -1)))\n mtx = sp.csc_matrix((data, ij), shape=vpv.shape)\n vpv = vpv + mtx + mtx.T\n\n return vpv\n\n\ndef get_vertices_per_edge(mesh_v, mesh_f):\n \"\"\"Returns an Ex2 array of adjacencies between vertices, where\n each element in the array is a vertex index. Each edge is included\n only once. If output of get_faces_per_edge is provided, this is used to\n avoid call to get_vert_connectivity()\"\"\"\n\n vc = sp.coo_matrix(get_vert_connectivity(mesh_v, mesh_f))\n # result = np.hstack((col(vc.row), col(vc.col)))\n result = np.hstack((vc.row.reshape(-1, 1), vc.col.reshape(-1, 1)))\n result = result[result[:, 0] < result[:, 1]] # for uniqueness\n\n return result\n\n\ndef aabbtree_compute_nearest(src_vert, src_tri, tgt_vert, nearest_part=False):\n cpp_handle = spatialsearch.aabbtree_compute(\n np.array(src_vert).astype(np.float64).copy(order='C'),\n np.array(src_tri).astype(np.uint32).copy(order='C'))\n f_idxs, f_part, v = spatialsearch.aabbtree_nearest(\n cpp_handle, np.array(tgt_vert, dtype=np.float64, order='C'))\n return (f_idxs, f_part, v) if nearest_part else (f_idxs, v)\n\n\ndef init_logger(name='x', filename='log.txt'):\n logger = logging.getLogger(name)\n logger.setLevel(logging.DEBUG)\n formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s: - %(message)s',\n datefmt='%m-%d %H:%M:%S')\n\n fh = logging.FileHandler(filename, encoding='utf-8')\n fh.setLevel(logging.INFO)\n fh.setFormatter(formatter)\n\n ch = logging.StreamHandler()\n ch.setLevel(logging.INFO)\n ch.setFormatter(formatter)\n\n logger.addHandler(ch)\n logger.addHandler(fh)\n\n return logger\n\n\ndef draw_image_with_lm(filename, inputs, landmarks, img_size, color=(0, 255, 0)):\n # image = image[:, :, :3]\n # image = image * 127.5 + 127.5\n # image = image.astype(np.uint8)\n # image = img_denormalize(image)\n image = inputs.copy()\n if np.max(landmarks) <= 1:\n half_size = img_size // 2\n landmarks = np.round(landmarks * half_size + half_size).astype(np.int32)\n # lm_2d[:, 1] = 224 - lm_2d[:, 1]\n for _, (x, y) in enumerate(landmarks):\n # try:\n # print(np.shape(image))\n # print(np.max(image))\n if np.shape(image)[-1] == 3:\n cv2.circle(image, (x, y), 1, color, -1, 8)\n # cv2.putText(image, str(i), (x, y), cv2.FONT_HERSHEY_SIMPLEX, 0.5,\n # (255, 255, 255))\n else:\n cv2.circle(image, (x, y), 1, color + (255,), -1, 8)\n # cv2.putText(image, str(i), (x, y), cv2.FONT_HERSHEY_SIMPLEX, 0.5,\n # (255, 255, 255, 255))\n # except IndexError as e:\n # print(e)\n if filename is not None:\n imageio.imsave(filename, image)\n else:\n return image\n\n\ndef batch_gather(params, indices, name=None):\n \"\"\"Gather slices from params according to indices with leading batch dims.\"\"\"\n with tf.name_scope(name, \"BatchGather\", [params, indices]):\n indices = tf.convert_to_tensor(indices, name=\"indices\")\n params = tf.convert_to_tensor(params, name=\"params\")\n if indices.shape.ndims is None:\n raise ValueError(\"batch_gather does not allow indices with unknown shape.\")\n return _batch_gather(params, indices, batch_dims=indices.shape.ndims - 1)\n\n\ndef _batch_gather(params, indices, batch_dims, axis=None):\n r\"\"\"Gather slices from params according to indices with leading batch dims.\n\n This operation assumes that the leading `batch_dims` dimensions of `indices`\n and `params` are batch dimensions; and performs a `tf.gather` operation within\n each batch. (If `batch_dims` is not specified, then it defaults to\n `rank(indices)-1`.) In the case in which `batch_dims==0`, this operation\n is equivalent to `tf.gather`.\n\n Args:\n params: A Tensor. The tensor from which to gather values.\n indices: A Tensor. Must be one of the following types: int32, int64. Index\n tensor. Must be in range `[0, params.shape[batch_dims]]`.\n batch_dims: An integer or none. The number of batch dimensions. Must be\n less than `rank(indices)`. Defaults to `rank(indices) - 1` if None.\n axis: A `Tensor`. Must be one of the following types: `int32`, `int64`. The\n `axis` in `params` to gather `indices` from. Must be greater than or equal\n to `batch_dims`. Defaults to the first non-batch dimension. Supports\n negative indexes.\n\n Returns:\n A Tensor. Has the same type as `params`.\n\n Raises:\n ValueError: if `indices` has an unknown shape.\n \"\"\"\n if batch_dims is not None and not isinstance(batch_dims, int):\n raise TypeError(\"batch_dims must be an int; got %r\" % (batch_dims,))\n indices = tf.convert_to_tensor(indices, name=\"indices\")\n params = tf.convert_to_tensor(params, name=\"params\")\n\n indices_ndims = indices.shape.ndims\n if indices_ndims is None:\n raise ValueError(\"tf.gather does not allow indices with unknown \"\n \"rank when batch_dims is specified.\")\n if batch_dims is None:\n batch_dims = indices_ndims - 1\n if batch_dims < 0:\n batch_dims += indices_ndims\n if batch_dims < 0 or batch_dims >= indices_ndims:\n raise ValueError(\"batch_dims = %d must be less than rank(indices) = %d\" %\n (batch_dims, indices_ndims))\n if params.shape.ndims is not None and batch_dims >= params.shape.ndims:\n raise ValueError(\"batch_dims = %d must be less than rank(params) = %d\" %\n (batch_dims, params.shape.ndims))\n\n # Handle axis by transposing the axis dimension to be the first non-batch\n # dimension, recursively calling batch_gather with axis=0, and then\n # transposing the result to put the pre-axis dimensions before the indices\n # dimensions.\n if axis is not None and axis != batch_dims:\n # Adjust axis to be positive.\n if not isinstance(axis, int):\n # axis = tf.where(axis < 0, axis + array_ops.rank(params), axis)\n axis = tf.where(axis < 0, axis + tf.rank(params), axis)\n elif axis < 0 and params.shape.ndims is None:\n # axis = axis + array_ops.rank(params)\n axis = axis + tf.rank(params)\n else:\n if (axis < -params.shape.ndims) or (axis >= params.shape.ndims):\n raise ValueError(\"axis (%d) out of range [%d, %d)\" %\n (axis, -params.shape.ndims, params.shape.ndims))\n if axis < 0:\n axis += params.shape.ndims\n if axis < batch_dims:\n raise ValueError(\"batch_dims = %d must be less than or equal to \"\n \"axis = %d\" % (batch_dims, axis))\n\n # Move params[axis] up to params[batch_dims].\n perm = [\n list(range(batch_dims)), [axis],\n tf.range(batch_dims, axis, 1),\n tf.range(axis + 1, tf.rank(params), 1)\n ]\n params = tf.transpose(params, tf.concat(perm, axis=0))\n\n result = _batch_gather(params, indices, batch_dims=batch_dims)\n\n # Move the result dimensions corresponding to params[batch_dims:axis]\n # to just before the dimensions corresponding to indices[batch_dims:].\n params_start = indices_ndims + axis - batch_dims\n perm = [\n list(range(batch_dims)),\n tf.range(indices_ndims, params_start, 1),\n list(range(batch_dims, indices_ndims)),\n tf.range(params_start, tf.rank(result), 1)\n ]\n return tf.transpose(result, perm=tf.concat(perm, axis=0))\n\n indices_shape = tf.shape(indices)\n params_shape = tf.shape(params)\n batch_indices = indices\n indices_dtype = indices.dtype.base_dtype\n accum_dim_value = tf.ones((), dtype=indices_dtype)\n # Use correct type for offset index computation\n casted_params_shape = tf.cast(params_shape, indices_dtype)\n for dim in range(batch_dims, 0, -1):\n dim_value = casted_params_shape[dim - 1]\n accum_dim_value *= casted_params_shape[dim]\n start = tf.zeros((), dtype=indices_dtype)\n step = tf.ones((), dtype=indices_dtype)\n dim_indices = tf.range(start, dim_value, step)\n dim_indices *= accum_dim_value\n dim_shape = tf.stack([1] * (dim - 1) + [dim_value] + [1] * (indices_ndims - dim), axis=0)\n batch_indices += tf.reshape(dim_indices, dim_shape)\n\n flat_indices = tf.reshape(batch_indices, [-1])\n outer_shape = params_shape[batch_dims + 1:]\n flat_inner_shape = tf.reduce_prod(params_shape[:batch_dims + 1], [0], False)\n # flat_inner_shape = gen_math_ops.prod(params_shape[:batch_dims + 1], [0], False)\n\n flat_params = tf.reshape(params, tf.concat([[flat_inner_shape], outer_shape], axis=0))\n flat_result = tf.gather(flat_params, flat_indices)\n result = tf.reshape(flat_result, tf.concat([indices_shape, outer_shape], axis=0))\n final_shape = indices.get_shape()[:batch_dims].merge_with(params.get_shape()[:batch_dims])\n final_shape = final_shape.concatenate(indices.get_shape().dims[batch_dims:])\n final_shape = final_shape.concatenate(params.get_shape()[batch_dims + 1:])\n result.set_shape(final_shape)\n return result\n"
},
{
"alpha_fraction": 0.7437325716018677,
"alphanum_fraction": 0.7548746466636658,
"avg_line_length": 28.91666603088379,
"blob_id": "d15fb9a3b3b762f268a0045ab2ea6c3a24b78648",
"content_id": "cc33f228191fd8fe0b416dee084b983097380c5a",
"detected_licenses": [
"BSD-3-Clause",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 359,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 12,
"path": "/Snapchat_Filters/Joker with Cartoon Effect/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Cool Glass Filter\n## Quick Start\n- Clone this repository\n` git clone https://github.com/akshitagupta15june/Face-X.git`\n- Change Directory\n` cd Snapchat_Filters` ,then, `Joker with Cartoon Effect`\n- Download shape_predictor_68_face_landmarks.dat file in Glasses on face folder.\n- Run code file.\n` python Joker.py`\n\n# Screenshots\n\n"
},
{
"alpha_fraction": 0.48415300250053406,
"alphanum_fraction": 0.5081967115402222,
"avg_line_length": 26.727272033691406,
"blob_id": "4cab177d1862f11c9739cf70cd19df6506910260",
"content_id": "1293a527eec07ed0ea379fb1decf84154793afbd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 915,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 33,
"path": "/Face Reconstruction/3D Face Reconstruction with Weakly-Supervised Learning/utils.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import torch\nimport numpy as np\n\n\nclass LeastSquares:\n # https://github.com/pytorch/pytorch/issues/27036\n def __init__(self):\n pass\n\n def lstq(self, A, Y, lamb=0.0):\n \"\"\"\n Differentiable least square\n :param A: m x n\n :param Y: n x 1\n \"\"\"\n # Assuming A to be full column rank\n cols = A.shape[1]\n if cols == torch.matrix_rank(A):\n q, r = torch.qr(A)\n x = torch.inverse(r) @ q.T @ Y\n else:\n A_dash = A.permute(1, 0) @ A + lamb * torch.eye(cols)\n Y_dash = A.permute(1, 0) @ Y\n x = self.lstq(A_dash, Y_dash)\n return x\n\n\ndef process_uv(uv_coords):\n uv_coords[:, 0] = uv_coords[:, 0]\n uv_coords[:, 1] = uv_coords[:, 1]\n # uv_coords[:, 1] = uv_h - uv_coords[:, 1] - 1\n uv_coords = np.hstack((uv_coords, np.ones((uv_coords.shape[0], 1)))) # add z\n return uv_coords\n"
},
{
"alpha_fraction": 0.5871211886405945,
"alphanum_fraction": 0.6109307408332825,
"avg_line_length": 40.088890075683594,
"blob_id": "96fe6cb07696630f7c59eeba79670e7a7bcbdc0a",
"content_id": "b77ecbf269ee47f42402ee5dd255b0809fcd3b4e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1848,
"license_type": "permissive",
"max_line_length": 131,
"num_lines": 45,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/common/parse_encoder.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# encoding: utf-8\n'''\n@author: Jiaxiang Shang\n@license: (C) Copyright 2013-2017, Node Supply Chain Manager Corporation Limited.\n@contact: [email protected]\n@time: 3/27/20 3:19 PM\n@desc:\n'''\nimport tensorflow as tf\n\ndef parse_coeff_list(opt, coeff_all_list, defined_pose_main):\n list_coeff_shape = []\n list_coeff_color = []\n list_coeff_exp = []\n list_coeff_pose = []\n list_coeff_sh = []\n\n for i in range(len(coeff_all_list)):\n coeff_all = coeff_all_list[i]\n pred_3dmm_shape, pred_3dmm_color, pred_3dmm_exp, pred_pose_render, pred_sh = parse_coeff(opt, coeff_all, defined_pose_main)\n list_coeff_shape.append(pred_3dmm_shape)\n list_coeff_color.append(pred_3dmm_color)\n list_coeff_exp.append(pred_3dmm_exp)\n\n #pred_pose_render = tf.Print(pred_pose_render, [pred_pose_render], summarize=16, message='pred_pose_render')\n list_coeff_pose.append(pred_pose_render)\n list_coeff_sh.append(pred_sh)\n\n return list_coeff_shape, list_coeff_color, list_coeff_exp, list_coeff_pose, list_coeff_sh\n\ndef parse_coeff(opt, coeff_all, defined_pose_main):\n #\n pred_3dmm_shape = coeff_all[:, 0 : opt.gpmm_rank]\n pred_3dmm_color = coeff_all[:, opt.gpmm_rank : 2 * opt.gpmm_rank]\n pred_3dmm_exp = coeff_all[:, 2 * opt.gpmm_rank : 2 * opt.gpmm_rank + opt.gpmm_exp_rank]\n\n #\n pred_pose_render = coeff_all[:, 2 * opt.gpmm_rank + opt.gpmm_exp_rank : 2 * opt.gpmm_rank + opt.gpmm_exp_rank + 6]\n pred_pose_render = pred_pose_render + defined_pose_main\n\n #\n pred_sh = coeff_all[:, 2 * opt.gpmm_rank + opt.gpmm_exp_rank + 6 : 2 * opt.gpmm_rank + opt.gpmm_exp_rank + 6 + 27]\n\n return pred_3dmm_shape, pred_3dmm_color, pred_3dmm_exp, pred_pose_render, pred_sh"
},
{
"alpha_fraction": 0.4375,
"alphanum_fraction": 0.4749999940395355,
"avg_line_length": 9,
"blob_id": "9da580ee9b9ec88b69b79902498e38e23d7ec7e7",
"content_id": "a7c0d9e5e8c6a7cfe82febbf4e71512d3cb50c95",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "YAML",
"length_bytes": 80,
"license_type": "permissive",
"max_line_length": 17,
"num_lines": 8,
"path": "/Face Reconstruction/Face Alignment in Full Pose Range/docker-compose.yml",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "version: '2.3'\n\nservices:\n\n 3ddfa:\n build: .\n volumes:\n - ./:/root/\n"
},
{
"alpha_fraction": 0.5092592835426331,
"alphanum_fraction": 0.7129629850387573,
"avg_line_length": 20.600000381469727,
"blob_id": "9274cdc7aae157038172a25b802a9334116e43d7",
"content_id": "826029cbff320e9026d5b61f5346fb5166ae56f2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 108,
"license_type": "permissive",
"max_line_length": 31,
"num_lines": 5,
"path": "/requirements.txt",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "numpy==1.19.2\nopencv-contrib-python==4.4.0.44\nopencv-python==4.4.0.44\npython-dotenv==0.14.0\nsklearn==0.23.2\n"
},
{
"alpha_fraction": 0.7444444298744202,
"alphanum_fraction": 0.7444444298744202,
"avg_line_length": 90,
"blob_id": "c8dabc2850f961fcde73d890a83fab8118971000",
"content_id": "0ccc9a263dfa6c9a44cf84f64232695f65b0a0c0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 90,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 1,
"path": "/Face Reconstruction/Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model/test.sh",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "mkdir record && mkdir record/lrecord && mkdir record/vrecord && python train.py --no_train"
},
{
"alpha_fraction": 0.6088992953300476,
"alphanum_fraction": 0.6159250736236572,
"avg_line_length": 27.53333282470703,
"blob_id": "eb6cc7f2953689ec28ecfdce2d541be1230e0312",
"content_id": "f6860ffba64048c3722b0b34da73a9cf8bd5c5ef",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 427,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 15,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/geometry/gpmm/HDF5IO.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport h5py\nimport numpy as np\n\nclass HDF5IO:\n def __init__(self, path_file, handler_file = None, mode='a'):\n if(handler_file == None):\n self.handler_file = h5py.File(path_file, mode=mode)\n else:\n self.handler_file = handler_file\n def GetMainKeys(self):\n return self.handler_file.keys()\n def GetValue(self, name):\n return self.handler_file[name]"
},
{
"alpha_fraction": 0.5468000173568726,
"alphanum_fraction": 0.5956000089645386,
"avg_line_length": 35.878787994384766,
"blob_id": "b3d39759ff1518135fb778499386e1d0171517c9",
"content_id": "f8c373923033bfa7ac8c78df11a55e71680cb186",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2500,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 66,
"path": "/Virtual_makeover/Virtual-Makeup/idea.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import cv2\r\nimport dlib\r\nimport numpy as np\r\n\r\n\r\ndef empty(a):\r\n pass\r\ncv2.namedWindow(\"BGR\")\r\ncv2.resizeWindow(\"BGR\",400,240)\r\ncv2.createTrackbar(\"Blue\",\"BGR\",0,255,empty)\r\ncv2.createTrackbar(\"Green\",\"BGR\",0,255,empty)\r\ncv2.createTrackbar(\"Red\",\"BGR\",0,255,empty)\r\ndef create(img, points,masked = False, cropped = True):\r\n if masked:\r\n mask = np.zeros_like(img)\r\n mask = cv2.fillPoly(mask,[points],(255,255,255))\r\n # cv2.imshow(\"mask\",mask)\r\n img = cv2.bitwise_and(img,mask)\r\n if cropped:\r\n b = cv2.boundingRect(points)\r\n x,y,w,h = b\r\n imgCrop = img[y:y+h,x:x+w]\r\n imgCrop = cv2.resize(imgCrop,(0,0),None,5,5)\r\n return imgCrop\r\n else:\r\n return mask\r\ndetector = dlib.get_frontal_face_detector()\r\npredictor = dlib.shape_predictor(\"shape_predictor_68_face_landmarks.dat\")\r\nwhile True:\r\n img = cv2.imread(\"./img.png\")\r\n img = cv2.resize(img,(0,0), None,2,2)\r\n imgOriginal = img.copy()\r\n imgGray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)\r\n faces = detector(imgGray)\r\n for face in faces:\r\n x1,y1 = face.left(),face.top()\r\n x2,y2 = face.right(),face.bottom()\r\n # imgOri = cv2.rectangle(imgOriginal,(x1,y1),(x2,y2),(0,255,0),1)\r\n landmarks = predictor(imgGray,face)\r\n mypoints = []\r\n for n in range(0,68):\r\n x = landmarks.part(n).x\r\n y = landmarks.part(n).y\r\n mypoints.append([x,y])\r\n # cv2.circle(imgOriginal,(x,y),2,(0,0,255),3)\r\n # cv2.putText(imgOriginal,str(n),(x,y-10),cv2.FONT_HERSHEY_COMPLEX,0.5,(0,255,0),1)\r\n mypoints = np.array(mypoints)\r\n lips = create(img,mypoints[48:61],masked=True,cropped=False)\r\n # cv2.imshow(\"Lip\",lips)\r\n imgColor = np.zeros_like(lips)\r\n a = cv2.getTrackbarPos(\"Blue\",\"BGR\")\r\n q = cv2.getTrackbarPos(\"Green\",\"BGR\")\r\n w = cv2.getTrackbarPos(\"Red\",\"BGR\")\r\n imgColor[:] = a,q,w\r\n # cv2.imshow(\"Color\",imgColor)\r\n imgColor = cv2.bitwise_and(lips,imgColor)\r\n imgColor = cv2.GaussianBlur(imgColor,(9,9),20)\r\n imgOriginal_Image = cv2.cvtColor(imgOriginal,cv2.COLOR_BGR2GRAY)\r\n imgOriginal_Image = cv2.cvtColor(imgOriginal_Image,cv2.COLOR_GRAY2BGR)\r\n imgColor =cv2.addWeighted(imgOriginal_Image,1,imgColor,0.8,0)\r\n cv2.imshow(\"BGR\",imgColor)\r\n cv2.imshow(\"Original_Image\",imgOriginal)\r\n key = cv2.waitKey(1)\r\n if key == ord(\"q\"):\r\n break\r\ncv2.destroyAllWindows()\r\n"
},
{
"alpha_fraction": 0.5946765542030334,
"alphanum_fraction": 0.6229784488677979,
"avg_line_length": 31.2608699798584,
"blob_id": "da292f9f90e3a79df8cf1506a6e2cc96bae37c4e",
"content_id": "7b70c1a9291e7bd145f64bbf1511c581b8f42dc2",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2968,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 92,
"path": "/Snapchat_Filters/flower&witch_hat_filter/filter1.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import cv2\nimport numpy as np \nface_cascade = cv2.CascadeClassifier(\"haarcascade_frontalface_default.xml\")\neye_cascade = cv2.CascadeClassifier(\"haarcascade_eye.xml\")\n\nwitch = cv2.imread(\"witch2.png\")\n\noriginal_witch_h,original_witch_w,witch_channels = witch.shape #getting shape of witch\n\n#convert to gray\nwitch_gray = cv2.cvtColor(witch, cv2.COLOR_BGR2GRAY)\n\n#create mask and inverse mask of witch\nret, original_mask = cv2.threshold(witch_gray, 100, 255, cv2.THRESH_BINARY)\noriginal_mask_inv = cv2.bitwise_not(original_mask)\n\ncap = cv2.VideoCapture(0)\nret, img = cap.read()\nimg_h, img_w = img.shape[:2]\n\nwhile True: #continue to run until user breaks loop\n \n #read each frame of video and convert to gray\n ret, img = cap.read()\n gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)\n\n #find faces in image using classifier\n faces = face_cascade.detectMultiScale(gray, 1.3, 5)\n\n #for every face found:\n for (x,y,w,h) in faces:\n \n\n #adjusting the coordinates of face region\n face_w = w\n face_h = h\n face_x1 = x\n face_x2 = face_x1 + face_w\n face_y1 = y\n face_y2 = face_y1 + face_h\n\n #scaling the witch hat image size w.r.t face\n witch_width = int(1.5 * face_w)\n witch_height = int(witch_width * original_witch_h / original_witch_w)\n \n #setting location of coordinates of witch\n witch_x1 = face_x2 - int(face_w/2) - int(witch_width/2)\n witch_x2 = witch_x1 + witch_width\n witch_y1 = face_y1 - int(face_h*1.25)\n witch_y2 = witch_y1 + witch_height \n\n #Conditions to check if any out of frame\n if witch_x1 < 0:\n witch_x1 = 0\n if witch_y1 < 0:\n witch_y1 = 0\n if witch_x2 > img_w:\n witch_x2 = img_w\n if witch_y2 > img_h:\n witch_y2 = img_h\n\n \n witch_width = witch_x2 - witch_x1\n witch_height = witch_y2 - witch_y1\n\n #resizing witch hat image to fit on face\n witch = cv2.resize(witch, (witch_width,witch_height), interpolation = cv2.INTER_AREA)\n mask = cv2.resize(original_mask, (witch_width,witch_height), interpolation = cv2.INTER_AREA)\n mask_inv = cv2.resize(original_mask_inv, (witch_width,witch_height), interpolation = cv2.INTER_AREA)\n\n #take ROI for witch from background that is equal to size of witch image\n roi = img[witch_y1:witch_y2, witch_x1:witch_x2]\n\n #original image in background (bg) where witch is not\n roi_bg = cv2.bitwise_and(roi,roi,mask = mask)\n roi_fg = cv2.bitwise_and(witch,witch,mask=mask_inv)\n dst = cv2.add(roi_bg,roi_fg)\n\n #put back in original image\n img[witch_y1:witch_y2, witch_x1:witch_x2] = dst\n\n break\n \n #display image\n cv2.imshow(\"img\",img) \n\n #if user pressed 'q' break\n if cv2.waitKey(1) == ord(\"q\"): \n break;\n\ncap.release() #turn off camera \ncv2.destroyAllWindows() #close all windows\n"
},
{
"alpha_fraction": 0.5311427116394043,
"alphanum_fraction": 0.5850907564163208,
"avg_line_length": 35.109092712402344,
"blob_id": "6eabbdcae4de754a90629a8f9be395dc55b6c203",
"content_id": "9b08db21cdf559ac1db9aa6ac3e59512ae807d06",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2039,
"license_type": "permissive",
"max_line_length": 145,
"num_lines": 55,
"path": "/Snapchat_Filters/Surgical_Mask_Filter/mask_dlib.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import cv2\r\nimport dlib \r\nimport numpy as np\r\nfrom math import hypot\r\ncap = cv2.VideoCapture(0)\r\nmask = cv2.imread(\"mask/mask.png\")\r\n\r\ndetector = dlib.get_frontal_face_detector()\r\npredictor = dlib.shape_predictor(\"resources/shape_predictor_68_face_landmarks.dat\")\r\n\r\nwhile True:\r\n _,frame = cap.read()\r\n # frame = cv2.imread(\"test1.jpg\")\r\n gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)\r\n\r\n faces = detector(gray)\r\n # print(faces)\r\n\r\n for face in faces:\r\n x1 = face.left()\r\n y1 = face.top()\r\n x2 = face.right()\r\n y2 = face.bottom()\r\n\r\n # cv2.rectangle(frame, (x1,y1), (x2,y2),(0,255,255),3)\r\n landmarks = predictor(gray, face)\r\n l = (landmarks.part(2).x, landmarks.part(2).y)\r\n r = (landmarks.part(15).x, landmarks.part(15).y)\r\n m = (landmarks.part(51).x, landmarks.part(51).y)\r\n face_width = int(hypot(l[0]-r[0],l[1]-r[1]))\r\n face_height = int(face_width*0.9)\r\n\r\n top_left= (int(m[0] - face_width/2), int(m[1]- face_height/2))\r\n bottom_right = (int(m[0]+face_width/2),int(m[1]+face_height/2))\r\n # cv2.rectangle(frame, (int(m[0] - face_width/2), int(m[1]- face_height/2)),(int(m[0]+face_width/2),int(m[1]+face_height/2)),(0,255,0),2)\r\n # cv2.line(frame, l,m, (0,255,0),3)\r\n # cv2.line(frame, m,r, (0,255,0),3)\r\n \r\n face_mask = cv2.resize(mask, (face_width, face_height))\r\n face_area = frame[top_left[1]: top_left[1]+ face_height,top_left[0]:top_left[0]+face_width]\r\n mask_gray=cv2.cvtColor(face_mask,cv2.COLOR_BGR2GRAY)\r\n _,face_mask2 = cv2.threshold(mask_gray, 25,255,cv2.THRESH_BINARY_INV)\r\n\r\n face_area_no_face = cv2.bitwise_and(face_area,face_area, mask = face_mask2)\r\n final_mask = cv2.add(face_area_no_face, face_mask)\r\n\r\n frame[top_left[1]: top_left[1]+ face_height,top_left[0]:top_left[0]+face_width]= final_mask\r\n\r\n cv2.imshow(\"FRame\",frame)\r\n # cv2.imshow(\"Mask\",face_mask)\r\n\r\n key = cv2.waitKey(1)\r\n\r\n if key == 27:\r\n break"
},
{
"alpha_fraction": 0.6390101909637451,
"alphanum_fraction": 0.6754003167152405,
"avg_line_length": 36.72222137451172,
"blob_id": "823e70d0bf631c5083d31591bc5227f6e6dfccfc",
"content_id": "117a84aa49fdf24f4bdd6fa7c3f334f8f44b89bd",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 687,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 18,
"path": "/Snapchat_Filters/flower&witch_hat_filter/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "<h1>Make your pictures lively with these Flower crown and Witch hat filter</h1>\n<p align=\"center\">\n <img src=\"demo3.PNG\" width=\"400\" height=\"350\" title=\"hover text\">\n <img src=\"demo4.PNG\" width=\"400\" height=\"350\" title=\"hover text\">\n </p>\n <h2> Requirements</h2>\n <ul>\n <li>OpenCV</li>\n <li>Python 3.7.x</li>\n <li>Numpy</li>\n <li>Haarcascade classifiers</li>\n </ul>\n <h2> Instructions to run the filter on live video stream</h2>\n <ul>\n <li>Clone this repository git clone https://github.com/akshitagupta15june/Face-X.git </li>\n <li>Change Directory cd Snapchat_Filters</li>\n <li>Then go to cd flower&witch_hat_filter</li>\n <li>Run code file. python filter1.py</li>\n \n \n"
},
{
"alpha_fraction": 0.7387697100639343,
"alphanum_fraction": 0.759510338306427,
"avg_line_length": 58.87272644042969,
"blob_id": "3ab6724eb847750462a48716ef266c3a21fe049e",
"content_id": "320aee589508170499be8c98a9f5eb77f1b9597c",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 9902,
"license_type": "permissive",
"max_line_length": 562,
"num_lines": 165,
"path": "/Awesome-face-operations/Pencil Sketch/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Pencil Sketch In Python Using OpenCV\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Awesome-face-operations/Pencil%20Sketch/Pencil_Image/book-pencil.png\" weight=\"400px\" height=\"400px\"/><img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Awesome-face-operations/Pencil%20Sketch/Pencil_Image/girl_pencil.jpg\" width=\"370px\" height=\"400px\" align=\"right\"/>\n## OpenCV\n\nOpenCV is an open source computer vision and machine learning software library. It is a BSD-licence product thus free for both business and academic purposes.The Library provides more than 2500 algorithms that include machine learning tools for classification and clustering, image processing and vision algorithm, basic algorithms and drawing functions, GUI and I/O functions for images and videos. Some applications of these algorithms include face detection, object recognition, extracting 3D models, image processing, camera calibration, motion analysis etc.\n\nOpenCV is written natively in C/C++. It has C++, C, Python and Java interfaces and supports Windows, Linux, Mac OS, iOS, and Android. OpenCV was designed for computational efficiency and targeted for real-time applications. Written in optimized C/C++, the library can take advantage of multi-core processing.\n\n</p>\n\n<p style=\"clear:both;\">\n<img alt=\"Pencil Sketch in OpenCv\" src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Awesome-face-operations/Pencil%20Sketch/Pencil_Image/pencil2.png\" style=\"margin-right;margin-bottom;\" width=\"45%\" align=\"right\"/></a>\n<h2> Pencil Sketch in OpenCV</h2>\nOpenCV 3 comes with a pencil sketch effect right out of the box. The `cv2.pencilSketch` function uses a domain filter introduced in the 2011 paper Domain transform for edge-aware image and video processing, by Eduardo Gastal and Manuel Oliveira. For customizations, other filters can also be developed.\n<br /><br /><br />\n</p>\n\n## Libraries Used\n\n ### 1] imread()\n\n`cv2.imread()` method loads an image from the specified file. If the image cannot be read (because of missing file, improper permissions, unsupported or invalid format) then this method returns an empty matrix.\nNote: The image should be in the working directory or a full path of image should be given.\n\nAll three types of flags are described below:\n\n- `cv2.IMREAD_COLOR:` It specifies to load a color image. Any transparency of image will be neglected. It is the default flag. Alternatively, we can pass integer value 1 for this flag.\n\n- `cv2.IMREAD_GRAYSCALE:` It specifies to load an image in grayscale mode. Alternatively, we can pass integer value 0 for this flag.\n\n- `cv2.IMREAD_UNCHANGED:` It specifies to load an image as such including alpha channel. Alternatively, we can pass integer value -1 for this flag.\n\n### 2] cvtColor()\n\n`cv2.cvtColor()` method is used to convert an image from one color space to another. There are more than 150 color-space conversion methods available in OpenCV.\n\n```\n cv2.cvtColor(src, code[, dst[, dstCn]])\n```\nParameters:\n\n- `src:` It is the image whose color space is to be changed.\n\n- `code:` It is the color space conversion code.\n\n- `dst:` It is the output image of the same size and depth as src image. It is an optional parameter.\n\n- `dstCn:` It is the number of channels in the destination image. If the parameter is 0 then the number of the channels is derived automatically from src and code. It is an optional parameter.\n\nReturn Value: It returns an image.\n\n ### 3] bitwise_not()\n\nTo make brighter regions lighter and lighter regions darker so that we could find edges to create a pencil sketch.\n\n ### 4] GaussianBlur()\n\nIn Gaussian Blur operation, the image is convolved with a Gaussian filter instead of the box filter. The Gaussian filter is a low-pass filter that removes the high-frequency components are reduced. It also smoothens or blurs the image.\n\nYou can perform this operation on an image using the `Gaussianblur()` method of the `imgproc` class. Following is the syntax of this method −\n\n`GaussianBlur(src, dst, ksize, sigmaX)`\n\nThis method accepts the following parameters −\n\n- `src` − A Mat object representing the source (input image) for this operation.\n\n- `dst` − A Mat object representing the destination (output image) for this operation.\n\n- `ksize` − A Size object representing the size of the kernel.\n\n- `sigmaX` − A variable of the type double representing the Gaussian kernel standard deviation in X direction.\n\n ### 5] dodgeV2()\n\nIt is used to divide the grey-scale value of image by the inverse of blurred image which highlights the sharpest edges.\n\n## Using OpenCV and Python, an RGB color image can be converted into a pencil sketch in four simple steps:\n- Convert the RGB color image to grayscale.\n- Invert the grayscale image to get a negative.\n- Apply a Gaussian blur to the negative from step 2.\n- Blend the grayscale image from step 1 with the blurred negative from step 3 using a color dodge.\n\n### Step 1: Convert the color image to grayscale\n\nThis should be really easy to do even for an OpenCV novice. Images can be opened with `cv2.imread` and can be converted between color spaces with `cv2.cvtColor`. Alternatively, you can pass an additional argument to `cv2.imread` that specifies the color mode in which to open the image.\n\n```\nimport cv2\n\nimg_rgb = cv2.imread(\"img_example.jpg\")\nimg_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)\n```\n### Step 2: Obtain a negative\n\nA negative of the image can be obtained by \"inverting\" the grayscale value of every pixel. Since by default grayscale values are represented as integers in the range [0,255] (i.e., precision CV_8U), the \"inverse\" of a grayscale value x is simply 255-x:\n\n```\nimg_gray_inv = 255 - img_gray\n```\n### Step 3: Apply a Gaussian blur\n\nA Gaussian blur is an effective way to both reduce noise and reduce the amount of detail in an image (also called smoothing an image). Mathematically it is equivalent to convolving an image with a Gaussian kernel. The size of the Gaussian kernel can be passed to cv2.GaussianBlur as an optional argument ksize. If both sigmaX and sigmaY are set to zero, the width of the Gaussian kernel will be derived from ksize:\n\n```\nimg_blur = cv2.GaussianBlur(img_gray_inv, ksize=(21, 21),sigmaX=0, sigmaY=0)\n```\n### Step 4: Blend the grayscale image with the blurred negative\nThis is where things can get a little tricky. Dodging and burning refer to techniques employed during the printing process in traditional photography. In the good old days of traditional photography, people would try to lighten or darken a certain area of a darkroom print by manipulating its exposure time. Dodging lightened an image, whereas burning darkened it.\n\nModern image editing tools such as Photoshop offer ways to mimic these traditional techniques. For example, color dodging of an image A with a mask B is implemented as follows:\n\n```\n((B[idx] == 255) ? B[idx] : min(255, ((A[idx] << 8) / (255-B[idx]))))\n```\nThis is essentially dividing the grayscale (or channel) value of an image pixel A[idx] by the inverse of the mask pixel value B[idx], while making sure that the resulting pixel value will be in the range [0,255] and that we do not divide by zero. We could translate this into a naïve Python function that accepts two OpenCV matrices (an image and a mask) and returns the blended mage:\n\n```\nimport cv2\nimg=cv2.imread(\"img.png\")\nimg_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)\nimg_invert = cv2.bitwise_not(img_gray)\nimg_smoothing = cv2.GaussianBlur(img_invert, (21, 21),sigmaX=0, sigmaY=0)\ndef dodgeV2(x, y):\n return cv2.divide(x, 255 - y, scale=256)\nfinal_img = dodgeV2(img_gray, img_smoothing)\ncv2.imshow('result',final_img)\ncv2.waitKey(0)\ncv2.destroyAllWindows()\n```\nInstead, we should realize that the operation <<8 is the same as multiplying the pixel value with the number 2^8=256, and that pixel-wise division can be achieved with `cv2.divide`. An improved version of the dodging function could thus look like this:\n\n```\ndef dodgeV2(image, mask):\n return cv2.divide(image, 255-mask, scale=256)\n```\nThe function `dodgeV2` produces the same result as dodgeNaive but is orders of magnitude faster. In addition, `cv2.divide` automatically takes care of the division by zero, making the result 0 where 255-mask is zero. A burning function can be implemented analogously:\n\n```\ndef burnV2(image, mask):\n return 255 – cv2.divide(255-image, 255-mask, scale=256)\n```\n#### now complete the pencil sketch transformation:\n```\nimg_blend = dodgeV2(img_gray, img_blur)\ncv2.imshow(\"pencil sketch\", img_blend)\n```\n#### Results Obtained\n\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Awesome-face-operations/Pencil%20Sketch/Pencil_Image/pencil4.png\"/>\n\n<p style=\"clear:both;\">\n<h1><a name=\"contributing\"></a><a name=\"community\"></a> <a href=\"https://github.com/akshitagupta15june/Face-X\">Community</a> and <a href=\"https://github.com/akshitagupta15june/Face-X/blob/master/CONTRIBUTING.md\">Contributing</a></h1>\n<p>Please do! Contributions, updates, <a href=\"https://github.com/akshitagupta15june/Face-X/issues\"></a> and <a href=\" \">pull requests</a> are welcome. This project is community-built and welcomes collaboration. Contributors are expected to adhere to the <a href=\"https://gssoc.girlscript.tech/\">GOSSC Code of Conduct</a>.\n</p>\n<p>\nJump into our <a href=\"https://discord.com/invite/Jmc97prqjb\">Discord</a>! Our projects are community-built and welcome collaboration. 👍Be sure to see the <a href=\"https://github.com/akshitagupta15june/Face-X/blob/master/Readme.md\">Face-X Community Welcome Guide</a> for a tour of resources available to you.\n</p>\n<p>\n<i>Not sure where to start?</i> Grab an open issue with the <a href=\"https://github.com/akshitagupta15june/Face-X/issues\">help-wanted label</a>\n</p>\n\n**Open Source First**\n\n best practices for managing all aspects of distributed services. Our shared commitment to the open-source spirit push the Face-X community and its projects forward.</p>\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.8070175647735596,
"alphanum_fraction": 0.8070175647735596,
"avg_line_length": 56,
"blob_id": "ff49c4eea1b83b58cfd4e2879450362838a391a7",
"content_id": "e5c99b31aaf53aea77f6f2047b7bda02304e33f1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 57,
"license_type": "permissive",
"max_line_length": 56,
"num_lines": 1,
"path": "/Face Reconstruction/Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model/exp/README.txt",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "This folder is used to contain testset and training set.\n"
},
{
"alpha_fraction": 0.49259153008461,
"alphanum_fraction": 0.5337013602256775,
"avg_line_length": 37.24444580078125,
"blob_id": "8f356519d6ff18487a47c682c17a5b9d6c0e1d98",
"content_id": "42d7c402ede1681d996a9ba4162ade1627dcd99c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6884,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 180,
"path": "/Face Reconstruction/3D Face Reconstruction using Graph Convolution Network/model_normal.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import logging\n\nimport tensorflow as tf\n\nfrom base_model import BaseModel\n\nlogger = logging.getLogger('x')\n\n\nclass Model(BaseModel):\n \"\"\"\n Mesh Convolutional Autoencoder which uses the Chebyshev approximation.\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n super(Model, self).__init__(*args, **kwargs)\n logger.info('Using Normal Model...')\n\n def mesh_generator(self, image_emb, pca_color, reuse=False):\n with tf.variable_scope('mesh_generator', reuse=reuse):\n decode_color = self.mesh_decoder(image_emb, reuse=reuse)\n refine_color = self.mesh_refiner(pca_color, reuse=reuse)\n with tf.variable_scope('mesh_concat'):\n concat = tf.concat([decode_color, refine_color], axis=-1)\n outputs = self.chebyshev5(concat, self.laplacians[0], 3, 6)\n outputs = tf.nn.tanh(outputs)\n return outputs\n\n def mesh_decoder(self, image_emb, reuse=False):\n if self.wide:\n F = [32, 32, 64, 128, 256]\n else:\n F = [32, 16, 16, 16, 16]\n with tf.variable_scope('mesh_decoder', reuse=reuse):\n with tf.variable_scope('fc'):\n x = self.fc(image_emb, self.pool_size[-1] * F[0]) # N x MF\n x = tf.reshape(x,\n [self.batch_size, self.pool_size[-1], F[0]]) # N x M x F\n\n for i in range(4):\n with tf.variable_scope('upconv{}'.format(i + 1)):\n with tf.name_scope('unpooling'):\n x = self.unpool(x, self.upsamp_trans[-i - 1])\n with tf.name_scope('filter'):\n x = self.chebyshev5(x, self.laplacians[-i - 2], F[i + 1], 6)\n with tf.name_scope('bias_relu'):\n x = self.brelu(x)\n\n with tf.name_scope('outputs'):\n x = self.chebyshev5(x, self.laplacians[0], 3, 6)\n x = self.brelu(x)\n # outputs = tf.nn.tanh(x)\n\n return x\n\n # def mesh_refiner(self, pca_color, reuse=False):\n # if self.wide:\n # F = [16, 32, 64, 128]\n # else:\n # F = [16, 32, 32, 16]\n # with tf.variable_scope('mesh_refiner', reuse=reuse):\n # x = pca_color\n # for i in range(4):\n # with tf.variable_scope('graph_conv{}'.format(i + 1)):\n # with tf.name_scope('filter'):\n # x = self.chebyshev5(x, self.laplacians[0], F[i], 6)\n # with tf.name_scope('bias_relu'):\n # x = self.brelu(x)\n\n # with tf.name_scope('outputs'):\n # x = self.chebyshev5(x, self.laplacians[0], 3, 6)\n # x = self.brelu(x)\n # # outputs = tf.nn.tanh(x)\n\n # return x\n\n # def mesh_refiner(self, pca_color, reuse=False):\n # if self.wide:\n # F = [16, 32, 64, 128]\n # else:\n # F = [16, 32, 64]\n # with tf.variable_scope('mesh_refiner', reuse=reuse):\n # x = pca_color\n # with tf.variable_scope('graph_conv0'):\n # with tf.name_scope('filter'):\n # x = self.chebyshev5(x, self.laplacians[0], F[0], 6)\n # for i in range(3):\n # with tf.variable_scope('graph_conv{}'.format(i + 1)):\n # with tf.name_scope('pooling'):\n # x = self.unpool(x, self.downsamp_trans[i])\n # with tf.name_scope('filter'):\n # x = self.chebyshev5(x, self.laplacians[i + 1], F[i], 6)\n # with tf.name_scope('bias_relu'):\n # x = self.brelu(x)\n # for i in range(3):\n # with tf.variable_scope('graph_conv{}'.format(i + 4)):\n # with tf.name_scope('unpooling'):\n # x = self.unpool(x, self.upsamp_trans[-i - 2])\n # with tf.name_scope('filter'):\n # x = self.chebyshev5(x, self.laplacians[-i - 3], F[-i - 1], 6)\n # with tf.name_scope('bias_relu'):\n # x = self.brelu(x)\n\n # with tf.name_scope('outputs'):\n # x = self.chebyshev5(x, self.laplacians[0], 3, 6)\n # x = self.brelu(x)\n # # outputs = tf.nn.tanh(x)\n\n # return x\n\n def mesh_refiner(self, pca_color, reuse=False):\n if self.wide:\n F = [16, 32, 64, 128]\n else:\n F = [16, 32, 64, 128]\n with tf.variable_scope('mesh_refiner', reuse=reuse):\n x = pca_color\n with tf.variable_scope('graph_conv0'):\n with tf.name_scope('filter'):\n x = self.chebyshev5(x, self.laplacians[0], F[0], 6)\n layer_enc = []\n for i in range(4):\n with tf.variable_scope('graph_conv{}'.format(i + 1)):\n with tf.name_scope('pooling'):\n x = self.unpool(x, self.downsamp_trans[i])\n with tf.name_scope('filter'):\n x = self.chebyshev5(x, self.laplacians[i + 1], F[i], 6)\n with tf.name_scope('bias_relu'):\n x = self.brelu(x)\n layer_enc.append(x)\n\n x = tf.reshape(x, [self.batch_size, self.pool_size[-1] * F[-1]]) # N x MF\n with tf.variable_scope('fc'):\n x = self.fc(x, int(self.z_dim)) # N x M0\n with tf.variable_scope('fc2'):\n x = self.fc(x, self.pool_size[-1] * F[-1]) # N x MF\n x = tf.reshape(x,\n [self.batch_size, self.pool_size[-1], F[-1]]) # N x M x F\n\n for i in range(4):\n with tf.variable_scope('graph_conv{}'.format(i + 5)):\n with tf.name_scope('unpooling'):\n x = self.unpool(x, self.upsamp_trans[-i - 1])\n #TODO: with skip or not\n if i < 2:\n x = tf.concat([x, layer_enc[-i - 2]], axis=-1)\n with tf.name_scope('filter'):\n x = self.chebyshev5(x, self.laplacians[-i - 2], F[-i - 1], 6)\n with tf.name_scope('bias_relu'):\n x = self.brelu(x)\n\n with tf.name_scope('outputs'):\n x = self.chebyshev5(x, self.laplacians[0], 3, 6)\n x = self.brelu(x)\n # outputs = tf.nn.tanh(x)\n\n return x\n\n def image_disc(self, inputs, t=True, reuse=False):\n with tf.variable_scope('image_disc', reuse=reuse):\n x = inputs\n x = self.conv2d(x, 16, 1, 1, is_training=t, name='conv1_1')\n # x = self.conv2d(x, 32, 3, 1, is_training=t, name='conv1_2')\n x = tf.nn.max_pool(x, [1, 2, 2, 1], [1, 2, 2, 1], 'SAME')\n x = self.conv2d(x, 32, 3, 1, is_training=t, name='conv2_1')\n # x = self.conv2d(x, 64, 3, 1, is_training=t, name='conv2_2')\n x = tf.nn.max_pool(x, [1, 2, 2, 1], [1, 2, 2, 1], 'SAME')\n x = self.conv2d(x, 64, 3, 1, is_training=t, name='conv3_1')\n # x = self.conv2d(x, 128, 3, 1, is_training=t, name='conv3_2')\n x = tf.nn.max_pool(x, [1, 2, 2, 1], [1, 2, 2, 1], 'SAME')\n x = self.conv2d(x, 128, 3, 1, is_training=t, name='conv4_1')\n # x = self.conv2d(x, 256, 3, 1, is_training=t, name='conv4_2')\n x = tf.nn.max_pool(x, [1, 2, 2, 1], [1, 2, 2, 1], 'SAME')\n x = self.conv2d(x, 256, 3, 1, is_training=t, name='conv5_1')\n # x = self.conv2d(x, 512, 3, 1, is_training=t, name='conv5_2')\n x = tf.nn.max_pool(x, [1, 2, 2, 1], [1, 2, 2, 1], 'SAME')\n x = self.conv2d(x, 512, 3, 1, is_training=t, name='conv6_1')\n x = self.conv2d(x, 1, 7, 1, 'VALID', False, False, t, 'outputs')\n\n return tf.squeeze(x, axis=[1, 2])\n"
},
{
"alpha_fraction": 0.7038969993591309,
"alphanum_fraction": 0.7386917471885681,
"avg_line_length": 39.76595687866211,
"blob_id": "b0f954128f58d2669bad78e0da2a5ecb223953fd",
"content_id": "f22e547817b0c090a77e4d79cc1720f485297042",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5780,
"license_type": "permissive",
"max_line_length": 364,
"num_lines": 141,
"path": "/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "<div align=\"center\">\n\n\n\n\n\n\n\n\n[](https://github.com/akshitagupta15june/lane_detection_opencv/blob/master/LICENSE)\n\n<img src=\"https://github.com/akshitagupta15june/Face-X/blob/master/Cartoonify%20Image/logo/Face-X.png\" width=250 height=250>\n\n<h3>Join official <a href=\"https://discord.com/invite/Jmc97prqjb\">Discord Channel</a> for discussion.</h3>\n\n[](https://forthebadge.com) [](https://forthebadge.com) [](https://forthebadge.com)\n</div>\n\n\n<div align=\"center\">\n<img src=\"https://github.com/akshitagupta15june/Face-X/blob/master/Cartoonify%20Image/Cartoonify_face_image/Images/recof.gif\" width=\"390px\" height=\"350px\" align='center'>\n</div>\n\n### Demonstration of different algorithms and operations on faces \n\n#### [Recognition-Algorithms](https://github.com/akshitagupta15june/Face-X/tree/master/Recognition-Algorithms)\n \n\nDespite the availability of a variety of open source face recognition algorithms, there are no ready-made solutions which can be implemented directly. This project demonstrates all kinds of algorithms and various operations that can be implemented on a frontal face. The available algorithms process only high-resolution static shots and perform sufficiently well.\n\n\n<div align=\"center\">\n<img src=\"https://media.giphy.com/media/AXorq76Tg3Vte/giphy.gif\" width=\"20%\"><br>\n</div>\nThere are several approaches for an algorithm to recognize a face. An algorithm can make use of statistics, try to find a pattern which represents a specific person or use a Convolutional Neural Network (CNN).\n\n\n\n## ⭐ How to get started with open source?\n\nYou can refer to the following articles on the basics of Git and Github.\n\n- [Watch this video to get started, if you have no clue about open source](https://youtu.be/SYtPC9tHYyQ)\n- [Forking a Repo](https://help.github.com/en/github/getting-started-with-github/fork-a-repo)\n- [Cloning a Repo](https://help.github.com/en/desktop/contributing-to-projects/creating-a-pull-request)\n- [How to create a Pull Request](https://opensource.com/article/19/7/create-pull-request-github)\n- [Getting started with Git and GitHub](https://towardsdatascience.com/getting-started-with-git-and-github-6fcd0f2d4ac6)\n\n</br>\n\n## 💥 How to Contribute to Face-X?\n\n- Take a look at the Existing [Issues](https://github.com/akshitagupta15june/Face-X/issues) or create your own Issues!\n- Wait for the Issue to be assigned to you.\n- Fork the repository\n>click on the uppermost button <img src=\"https://github.com/Vinamrata1086/Face-X/blob/master/Recognition-Algorithms/Facial%20Recognition%20using%20LBPH/images/fork.png\" width=50>\n\n- Clone the repository using-\n```\ngit clone https://github.com/akshitagupta15june/Face-X.git\n```\n### Installation 👇\n\n1. **Create virtual environment**\n\n```bash\npython -m venv env\n``` \n\n2. **Linux**\n```\nsource env/bin/activate\n```\n\n### OR\n\n2. **Windows**\n```bash\nenv\\Scripts\\activate\n```\n\n3. **Install**\n\n```bash\npip install -r requirements.txt\n```\n- Have a look at [Contibuting Guidelines](https://github.com/akshitagupta15june/Face-X/blob/master/CONTRIBUTING.md)\n- Read the [Code of Conduct](https://github.com/akshitagupta15june/Face-X/blob/master/CODE_OF_CONDUCT.md)\n\n</br>\n\n## Face-X is a part of these open source programs❄\n\n<p align=\"center\">\n \n [<img width=\"420\" height=\"120\" src=\"https://github.com/akshitagupta15june/Face-X/blob/master/Cartoonify%20Image/Cartoonification/Assets/gssoc.png\">](https://gssoc.girlscript.tech/)\n [<img width=\"160\" height=\"160\" src=\"https://njackwinterofcode.github.io/images/nwoc-logo.png\">](https://njackwinterofcode.github.io/)\n [<img src=\"https://devscript.tech/woc/img/WOC-logo.png\" width=\"160\" height=\"160\"/>](https://devscript.tech/woc/) <br>\n [<img width=\"160\" height=\"160\" src=\"https://github.com/akshitagupta15june/Face-X/blob/master/Cartoonify%20Image/Cartoonification/Assets/uaceit.jpeg\">](https://uaceit.com/)\n [<img width=\"160\" height=\"160\" src=\"https://github.com/akshitagupta15june/Face-X/blob/master/Cartoonify%20Image/Cartoonification/Assets/cwoc.jpeg\">](https://crosswoc.ieeedtu.in/)\n [<img width=\"180\" height=\"180\" src=\"https://media-exp1.licdn.com/dms/image/C560BAQGh8hr-FgbrHw/company-logo_200_200/0/1602422883512?e=2159024400&v=beta&t=s8IX2pN1J2v5SRRbgzVNzxnQ2rWeeMq2Xb__BYW60qE\">](https://swoc.tech/)\n \n</p>\n\t\n</br>\n\t\n## Get Started with Open Source programs 👨💻\n\n[Start Open Source](https://anush-venkatakrishna.medium.com/part-1-winter-or-summer-take-your-baby-steps-into-opensource-now-7d661235d7ff) an article by [Anush Krishna](https://github.com/anushkrishnav)\n</br>\n\n\n## ❤️ Project Admin\n\n<table>\n\t<tr>\n\t\t<td align=\"center\">\n\t\t\t<a href=\"https://github.com/akshitagupta15june\">\n\t\t\t\t<img src=\"https://avatars0.githubusercontent.com/u/57909583?v=4\" width=\"100px\" alt=\"\" />\n\t\t\t\t<br /> <sub><b>akshitagupta15june</b></sub>\n\t\t\t</a>\n\t\t\t<br /> <a href=\"https://github.com/akshitagupta15june\"> \n\t\t👑 Admin\n\t </a>\n\t\t</td>\n\t</tr>\n</table>\n\n## 🌟 Contributors \n\nThanks goes to these wonderful people ✨✨:\n\n<table>\n\t<tr>\n\t\t<td>\n\t\t\t<a href=\"https://github.com/akshitagupta15june/Face-X/graphs/contributors\">\n \t\t\t\t<img src=\"https://contrib.rocks/image?repo=akshitagupta15june/Face-X\" />\n\t\t\t</a>\n\t\t</td>\n\t</tr>\n</table>\n"
},
{
"alpha_fraction": 0.6422222256660461,
"alphanum_fraction": 0.6911110877990723,
"avg_line_length": 17.955554962158203,
"blob_id": "6e1f9015306db9a1394e0ed4324ca261b2ee3ee1",
"content_id": "74c44c2471af924d3b4c5984e67dbf69739c74e2",
"detected_licenses": [
"BSD-3-Clause",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 900,
"license_type": "permissive",
"max_line_length": 131,
"num_lines": 45,
"path": "/Snapchat_Filters/Surgical_Mask_Filter/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Snapchat Filter using OpenCV\r\n\r\n\r\n## Description\r\n\r\nThis repository contains python implmentation of snapchat filters like surgical mask. \r\n\r\n## Getting Started\r\n\r\n### Dependencies\r\n\r\n* Python\r\n* The program makes use of Dlib-facial feature points\r\n* OpenCV\r\n* Tkinter\r\n* Shape predictor 68 face landmark points Model\r\n\r\n\r\n### Installing\r\n\r\n* Git clone repository: \r\n```\r\ngit clone \r\n```\r\n* Make sure to install the dependencies:\r\n```\r\npip install dlib\r\n```\r\n* Any modifications needed to be made to files/folders\r\n```\r\npip install opencv-python\r\n```\r\n\r\n\r\n* Run using: \r\n* \r\n * For surgical mask filter\r\n \r\n \r\n```\r\npython mask_dlib.py\r\n```\r\n\r\n## Acknowledgments\r\n* [Sergio's Youtube tutorial on simple dlib](https://www.youtube.com/watch?v=IJpTe-1cimE&t=1425s)\r\n\r\n"
},
{
"alpha_fraction": 0.5555995106697083,
"alphanum_fraction": 0.5632502436637878,
"avg_line_length": 38.27461242675781,
"blob_id": "f4a1d61566a73700eb476d17c5ca04f1b010ef2b",
"content_id": "3aee8421414f347b38d5a889f8f83284dd27660a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7581,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 193,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/geometry/camera/camera_augment.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n# system\nfrom __future__ import print_function\n\n# python lib\nimport math\nfrom copy import deepcopy\nimport numpy as np\n\n# tf_render\nimport tensorflow as tf\n\n# self\nfrom rotation import RotationMtxBatch, ExtMtxBatch\nfrom camera import IntrinsicMtxBatch, CameraMtxBatch\nfrom camera_render import CameraRender\n\"\"\"\nparam numpy\ninherit tensor\nno weight update\n\"\"\"\n\nclass CameraAugment(CameraRender):\n\n def __init__(self, h_intrinsic, h_extenal,\n centre_camera_rot,\n roll_num=0, roll_max_angle=0, #\n pitch_num=0, pitch_max_angle=0, #\n yaw_num=0, yaw_max_angle=0, #\n near = 0.1, far = 2000.0\n ):\n super(CameraAugment, self).__init__(h_intrinsic, h_extenal, near, far)\n\n self.image_width_batch = h_intrinsic.Get_image_width()\n self.image_height_batch = h_intrinsic.Get_image_height()\n\n #super(CameraRender, self)._Cal_mtxProj()\n\n self.centre_camera_rot = centre_camera_rot\n\n self.roll_num = roll_num\n self.roll_max_angle = roll_max_angle\n\n self.pitch_num = pitch_num\n self.pitch_max_angle = pitch_max_angle\n\n self.yaw_num = yaw_num\n self.yaw_max_angle = yaw_max_angle\n\n def Augment_Single_Random(self):\n cam = CameraRender(self.h_intrinsic, self.h_extenal)\n\n z_axis = self.h_extenal.Get_viewDirect_batch()\n y_axis = self.h_extenal.Get_upDirect_batch()\n x_axis= self.h_extenal.Get_rightDirect_batch()\n\n #\n psi_angle = tf.random_uniform(shape=[int(self.batch_size)])\n psi_angle = psi_angle * (2 * self.roll_max_angle) - self.roll_max_angle\n psi = psi_angle * math.pi / (180.)\n\n mtx_rel_rot = self.h_extenal.rotMtx_axisAngle_batch(z_axis, psi)\n mtx_rot_batch, mtx_t_batch = cam.h_extenal.rotate_batch(mtx_rel_rot, self.centre_camera_rot)\n # New\n h_ext_tmp = ExtMtxBatch.create_matrixExt_batch(mtx_rot_batch, mtx_t_batch)\n cam_psi = CameraRender(self.h_intrinsic, h_ext_tmp)\n\n #\n phi_angle = tf.random_uniform(shape=[1]) * (2 * self.pitch_max_angle) - self.pitch_max_angle\n phi = phi_angle * math.pi / (180.)\n\n mtx_rel_rot = self.h_extenal.rotMtx_axisAngle_batch(x_axis, phi)\n mtx_rot_batch, mtx_t_batch = cam_psi.h_extenal.rotate_batch(mtx_rel_rot, self.centre_camera_rot)\n # New\n h_ext_tmp = ExtMtxBatch.create_matrixExt_batch(mtx_rot_batch, mtx_t_batch)\n cam_phi = CameraRender(self.h_intrinsic, h_ext_tmp)\n\n #\n theta_angle = tf.random_uniform(shape=[1]) * (2 * self.yaw_max_angle) - self.yaw_max_angle\n theta = theta_angle * math.pi / (180.)\n\n mtx_rel_rot = self.h_extenal.rotMtx_axisAngle_batch(y_axis, theta)\n mtx_rot_batch, mtx_t_batch = cam_phi.h_extenal.rotate_batch(mtx_rel_rot, self.centre_camera_rot)\n # New\n h_ext_tmp = ExtMtxBatch.create_matrixExt_batch(mtx_rot_batch, mtx_t_batch)\n cam_th = CameraRender(self.h_intrinsic, h_ext_tmp)\n\n #\n rot, t = cam_th.Get_eularAngle_rot_t_batch()\n rot = tf.reverse(rot, axis=[1]) # rx, ry, rz, to, rz, ry, rx\n\n return tf.concat([rot, t], axis=1)\n\n def Augment_Average_Interval(self):\n self.list_cam = list()\n self.list_cam.append(CameraRender(self.h_intrinsic, self.h_extenal))\n\n z_axis = self.h_extenal.Get_viewDirect_batch()\n y_axis = self.h_extenal.Get_upDirect_batch()\n x_axis= self.h_extenal.Get_rightDirect_batch()\n\n list_cam_prev = []\n if self.roll_num != 0:\n for r in range(-self.roll_num, self.roll_num+1):\n if r == 0:\n continue\n psi_angle = r * (self.roll_max_angle / (self.roll_num+1.))\n psi = psi_angle * math.pi / (180.)\n psi = tf.Variable([psi])\n\n for cam in self.list_cam:\n # Rotate\n mtx_rel_rot = self.h_extenal.rotMtx_axisAngle(z_axis, psi)\n mtx_rot_batch, mtx_t_batch = cam.h_extenal.rotate_batch(mtx_rel_rot, self.centre_camera_rot)\n # New\n h_ext_tmp = ExtMtxBatch.create_matrixExt_batch(mtx_rot_batch, mtx_t_batch)\n cam_aug = CameraRender(self.h_intrinsic, h_ext_tmp)\n list_cam_prev.append(cam_aug)\n self.list_cam = self.list_cam + list_cam_prev\n\n list_cam_prev = []\n if self.pitch_num != 0:\n for p in range(-self.pitch_num, self.pitch_num+1):\n phi_angle = p * (self.pitch_max_angle / (self.pitch_num+1.))\n phi = phi_angle * math.pi / (180.)\n phi = tf.Variable([phi])\n\n for cam in self.list_cam:\n # Rotate\n mtx_rel_rot = self.h_extenal.rotMtx_axisAngle(x_axis, phi)\n mtx_rot_batch, mtx_t_batch = cam.h_extenal.rotate_batch(mtx_rel_rot, self.centre_camera_rot)\n # New\n h_ext_tmp = ExtMtxBatch.create_matrixExt_batch(mtx_rot_batch, mtx_t_batch)\n cam_aug = CameraRender(self.h_intrinsic, h_ext_tmp)\n list_cam_prev.append(cam_aug)\n self.list_cam = self.list_cam + list_cam_prev\n\n list_cam_prev = []\n if self.yaw_num != 0:\n for y in range(-self.yaw_num, self.yaw_num+1):\n theta_angle = y * (self.yaw_max_angle / (self.yaw_num+1.))\n theta = theta_angle * math.pi / (180.)\n theta = tf.Variable([theta])\n\n for cam in self.list_cam:\n # Rotate\n mtx_rel_rot = self.h_extenal.rotMtx_axisAngle(y_axis, theta)\n mtx_rot_batch, mtx_t_batch = cam.h_extenal.rotate_batch(mtx_rel_rot, self.centre_camera_rot)\n # New\n h_ext_tmp = ExtMtxBatch.create_matrixExt_batch(mtx_rot_batch, mtx_t_batch)\n cam_aug = CameraRender(self.h_intrinsic, h_ext_tmp)\n list_cam_prev.append(cam_aug)\n self.list_cam = self.list_cam + list_cam_prev\n if len(self.list_cam) > 1:\n self.list_cam = self.list_cam[1:]\n\n def Get_aug_mtxMV_batch(self): # Model View matrix\n list_mv = []\n for i in range(len(self.list_cam)):\n cam = self.list_cam[i]\n mv = cam.Get_modelViewMatrix_batch()\n list_mv.append(mv)\n mv_batch = tf.concat(list_mv, axis=0)\n return mv_batch\n\n def Get_aug_eye_batch(self):\n list_eye = []\n for i in range(len(self.list_cam)):\n cam = self.list_cam[i]\n eye = cam.Get_eye_batch()\n list_eye.append(eye)\n eye_batch = tf.concat(list_eye, axis=0)\n return eye_batch\n\n def Get_aug_eularAngle_rot_t_batch(self):\n list_rot = []\n list_t = []\n for i in range(len(self.list_cam)):\n cam = self.list_cam[i]\n mtx_param_rot, mtx_t = cam.Get_eularAngle_rot_t_batch()\n list_rot.append(mtx_param_rot)\n list_t.append(mtx_t)\n param_rot_batch = tf.concat(list_rot, axis=0)\n t_batch = tf.concat(list_t, axis=0)\n return param_rot_batch, t_batch\n\n def Get_aug_proj_pt2d_batch(self, lm3d_batch):\n list_proj = []\n for i in range(len(self.list_cam)):\n cam = self.list_cam[i]\n proj = super(CameraRender, cam).Project(lm3d_batch)\n list_proj.append(proj)\n proj_batch = tf.concat(list_proj, axis=0)\n return proj_batch\n"
},
{
"alpha_fraction": 0.6341463327407837,
"alphanum_fraction": 0.6439024209976196,
"avg_line_length": 16.727272033691406,
"blob_id": "d22bc52eb23040cf3d21d07628fbc7d4dca9a20d",
"content_id": "b96b501851e74105c9b3ac6a07c5121cf3e22e5c",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 425,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 22,
"path": "/Snapchat_Filters/Goggles_Changing_Filter/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# 👓Goggles changing filters on a Blink of an Eye 👀😎.\r\n## Setting up:\r\n\r\n- Create a virtual environment and activate it.\r\n\r\n- Install the requirements\r\n\r\n```sh\r\n $ pip install -r requirements.txt\r\n```\r\n\r\n## Running the script:\r\n\r\n```sh\r\n $ python Goggle_filter.py\r\n```\r\n\r\n## Output:\r\n\r\n\r\n## Author\r\n[🛡 Akhil Bhalerao 🛡 ](https://github.com/iamakkkhil)"
},
{
"alpha_fraction": 0.6791236996650696,
"alphanum_fraction": 0.7474226951599121,
"avg_line_length": 24.850000381469727,
"blob_id": "96d077998eeb1f612f465c185bea695811f5cada",
"content_id": "9b9c5dcbe5fb10af2b2bdd79f92caa8137036363",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1552,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 60,
"path": "/Recognition-Algorithms/Recognition_using_Xception/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "## Overview\nFace Recognition Using OpenCV and PyTorch.\n\nThis model uses Xception model for the recognition of the User face.\n\nProgram is trained for 5 epochs, You can increase the number of epochs and the number of layers accordingly.\n\n\n### Dependencies:\n* pytorch version **1.2.0** (get from https://pytorch.org/)\n\n\nDownload haarcascades file from here=> https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml\n\n## ScreenShots\n\n\n\n\n\n\n\n## Quick Start\n\n- Fork and Clone the repository using-\n```\ngit clone https://github.com/akshitagupta15june/Face-X.git\n```\n- Create virtual environment-\n```\n- `python -m venv env`\n- `source env/bin/activate` (Linux)\n- `env\\Scripts\\activate` (Windows)\n```\n- Install dependencies-\n```\n pip install -r requirements.txt\n```\n\n- Headover to Project Directory- \n```\ncd \"Recognition using NasNet\"\n```\n- Create dataset using -\n```\n python create_dataset.py on respective idle(VS Code, PyCharm, Jupiter Notebook, Colab)\n```\nNote: Dataset is automatically split into train and val folders.\n\n- Train the model -\n```\n python main.py\n```\nNote: Make sure all dependencies are installed properly.\n\n- Final-output -\n```\n python output.py\n```\nNote: Make sure you have haarcascade_frontalface_default.xml file \n"
},
{
"alpha_fraction": 0.7597911357879639,
"alphanum_fraction": 0.7963446378707886,
"avg_line_length": 44.05882263183594,
"blob_id": "b5b1671736ba719b8539779c11f9f4c93b13d3c2",
"content_id": "a27e4df6af4dc3d22d93d28cc2b759ac2f2b765b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 766,
"license_type": "permissive",
"max_line_length": 154,
"num_lines": 17,
"path": "/Recognition-Algorithms/Recognition using Efficient Net B1/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "## EfficientNet B1\n\nI have implemented EfficientNetB1 architecture on Karolinska Directed Emotional Faces (KDEF) dataset. The dataset can be found here : https://www.kdef.se/\nThe model has been trained for 50 Epochs with a learning rate of 0.001. And the following Accuracy and Heatmap is obtained post training.\n\n### Accuracy\n\n\n### Heatmap\n\n\n### Dependencies:\n* pip install numpy\n* pip install pandas\n* pip install tensorflow\n* pip install keras\n* pip install opencv-python\n"
},
{
"alpha_fraction": 0.7385188341140747,
"alphanum_fraction": 0.7612742781639099,
"avg_line_length": 31.213333129882812,
"blob_id": "38f1c01f6041de4c524dd289f59df91b02d1d2a7",
"content_id": "de8fa474b460e6b9fe3f29e9f3c8707e84bb6918",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2417,
"license_type": "permissive",
"max_line_length": 277,
"num_lines": 75,
"path": "/Recognition-Algorithms/Facial Recognition using LBPH/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Overview\n\n## *LBPH -> Local Binary Patterns Histogram*\n\nIt is based on local binary operator. It is widely used in facial recognition due to its computational simplicity and discriminative power. \n\n**It is very efficient texture operator which labels the pixels of an image by thresholding the neighborhood of each pixel and considers the result as a binary number.**\nThe steps involved to achieve this are:\n\n* creating dataset\n* face acquisition\n* feature extraction\n* classification\n\nThe LBPH algorithm is a part of opencv.\n\n\n# Dependencies\n\n pip install numpy\n pip install opencv-python\n pip install opencv-contrib-python\n pip install skimage or pip install scikit-image\n# Images\n\n<p align=\"center\"><img src=\"https://github.com/Vinamrata1086/Face-X/blob/master/Recognition-Algorithms/Facial%20Recognition%20using%20LBPH/images/pic1.png\"><br>\nDivide face images into R( for example R = 3 x 3 = 9 Regions) local regions to extract LBP histograms.</p>\n\n\n<p align=\"center\"><img src=\"https://github.com/Vinamrata1086/Face-X/blob/master/Recognition-Algorithms/Facial%20Recognition%20using%20LBPH/images/pic2.png\" ><br>\nThree neighborhood examples used to define a texture and calculate a local binary pattern (LBP).</p>\n\n<p align=\"center\">\n <img src=\"https://github.com/Vinamrata1086/Face-X/blob/master/Recognition-Algorithms/Facial%20Recognition%20using%20LBPH/images/pic3.png\"><br>\n After applying the LBP operation we extract the histograms of each image based on the number of grids (X and Y) passed by parameter. After extracting the histogram of each region, we concatenate all histograms and create a new one which will be used to represent the image.\n</p>\n \n# Quick-Start\n\n- Fork the repository\n>click on the uppermost button <img src=\"https://github.com/Vinamrata1086/Face-X/blob/master/Recognition-Algorithms/Facial%20Recognition%20using%20LBPH/images/fork.png\" width=50>\n\n- Clone the repository using-\n```\ngit clone https://github.com/akshitagupta15june/Face-X.git\n```\n\n1. **Create virtual environment**\n\n```bash\npython -m venv env\n``` \n\n2. **Linux**\n```\nsource env/bin/activate\n```\n\n### OR\n\n2. **Windows**\n```bash\nenv\\Scripts\\activate\n```\n\n- Install dependencies\n\n\n- Execute -\n```\npython facial_recognition_part1.py (face images collection)\npython facial_recognition_part2.py (model training + final recognition)\n```\n\nNote: Make sure you have haarcascade_frontalface_default.xml file \n"
},
{
"alpha_fraction": 0.7840290665626526,
"alphanum_fraction": 0.7858439087867737,
"avg_line_length": 109.19999694824219,
"blob_id": "361aaad9428698049e01dd009ae20c03de6d87ef",
"content_id": "188ed4b188d4ce1f15f3d6609ff7aeb7441c5329",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 551,
"license_type": "permissive",
"max_line_length": 240,
"num_lines": 5,
"path": "/Face Reconstruction/Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model/update_contour/README.txt",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "This folder contains a function for computing the dynamical contour indices of facial landmarks based on horizontal lines, which named 'FittingIndicesPlus' in './fit_indices.py' file. We also attach the corresponding data('./parallel.txt').\n\nAccording to the practical situation, you can use this function to replace the function 'CalculateLandmark2D' in the '../cariface.py' file.\n\nFor reference, you can also visualize './parallel.txt' on the template face('../toy_example/mean_face.obj') and adjust them by Blender, OpenFlipper or other softwares.\n"
},
{
"alpha_fraction": 0.5307125449180603,
"alphanum_fraction": 0.5511875748634338,
"avg_line_length": 19.421052932739258,
"blob_id": "c0049c7c300407417a8e7114ca35da733a97366b",
"content_id": "8e8d36f68a5854e91dff9f85fdb7f6480f2bfd5c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1221,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 57,
"path": "/Recognition-Algorithms/Recognition using KNearestNeighbors/live_data_collection.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#Live Data Collection\r\nimport cv2\r\nimport numpy as np\r\nimport os\r\n\r\ncap = cv2.VideoCapture(0)\r\n\r\ndetector = cv2.CascadeClassifier(\"./haarcascade_frontalface_default.xml\")\r\n\r\nname = input(\"Enter your name : \")\r\n\r\nframes = [] #should be greter than 5\r\noutputs = [] #should be greter than 5\r\n\r\nwhile True:\r\n\r\n ret, frame = cap.read()\r\n\r\n if ret:\r\n faces = detector.detectMultiScale(frame,1.1,4)\r\n\r\n for face in faces:\r\n x, y, w, h = face\r\n\r\n cut = frame[y:y+h, x:x+w]\r\n\r\n fix = cv2.resize(cut, (100, 100))\r\n gray = cv2.cvtColor(fix, cv2.COLOR_BGR2GRAY)\r\n cv2.imshow(\"My Face\", gray)\r\n cv2.imshow(\"My Screen\", frame)\r\n \r\n\r\n key = cv2.waitKey(1)\r\n\r\n if key == ord(\"q\"):\r\n print(\"Data Collected\")\r\n break\r\n if key == ord(\"c\"):\r\n # cv2.imwrite(name + \".jpg\", frame)\r\n frames.append(gray.flatten())\r\n outputs.append([name])\r\n\r\nX = np.array(frames)\r\ny = np.array(outputs)\r\n\r\ndata = np.hstack([y, X])\r\n\r\nf_name = \"face_data.npy\"\r\n\r\nif os.path.exists(f_name):\r\n old = np.load(f_name)\r\n data = np.vstack([old, data])\r\n\r\nnp.save(f_name, data)\r\n\r\ncap.release()\r\ncv2.destroyAllWindows()\r\n"
},
{
"alpha_fraction": 0.6929824352264404,
"alphanum_fraction": 0.719298243522644,
"avg_line_length": 27.5,
"blob_id": "135b62c17b79a6a3667f5fbb824cb4a95efc1f78",
"content_id": "c3c777d37e1df536e94480d9a0e25b6b2068efcb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1026,
"license_type": "permissive",
"max_line_length": 123,
"num_lines": 36,
"path": "/Recognition-Algorithms/Recognition using EigenFaceRecogniser/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "Face Recognition using EigenFaceRecognizer\n\n## Requirements\n\n Python3.6+\n virtualenv (pip install virtualenv)\n\n## ScreenShots\n\n\n\n\n## Installation\n\n virtualenvv env\n source venv/bin/activate (Linux)\n venv\\Scripts\\activate (Windows)\n pip install numpy==1.19.2\n pip install opencv-contrib-python==4.4.0.44\n pip install opencv-python==4.4.0.44\n pip install python-dotenv==0.14.0\n \n## Execution\n\nUpdate the datapath accordingly as in the files used in this repository ,follow the data path for akshita as the main user.\n\nIn Ubuntu,\nMeaning if there are data paths like:\n file_name_path='/home/akshita/Desktop/Face_reco/user'+str(count)+'.jpg'\n\nThen Update it to:\n file_name_path='/home/yourusername/Desktop/Face_reco/user'+str(count)+'.jpg'\n\n python facial_recognition_part1.py (face images collection)\n python facial_recognition_part2.py (training)\n python facial_recognition_part3.py (final recognition)\n"
},
{
"alpha_fraction": 0.5694316625595093,
"alphanum_fraction": 0.58556067943573,
"avg_line_length": 28.635812759399414,
"blob_id": "c861bd6a6fc149f52336907d09f5f8bc64a22191",
"content_id": "c9245e6cff4668992471d1abeb3a19a1e7220483",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 19530,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 659,
"path": "/Face Reconstruction/3D Face Reconstruction using Graph Convolution Network/lib/mesh_io.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import collections\nimport os\n\nimport numpy as np\nfrom PIL import Image\n\n\ndef read_obj_with_group(filename, swapyz=False):\n vertices = []\n colors = []\n normals = []\n texcoords = []\n faces = []\n normal_idxs = []\n texcoord_idxs = []\n materials = []\n mtl = None\n group = [[], [], []]\n\n material = None\n for line in open(filename, \"r\"):\n if line.startswith('#'):\n continue\n values = line.split()\n if not values:\n continue\n if values[0] == 'g':\n group[0].append(len(vertices))\n group[1].append(len(faces))\n g_name = ''\n for n in values[1:]:\n g_name += n + ' '\n group[2].append(g_name[:-1])\n elif values[0] == 'v':\n v = [float(x) for x in values[1:4]]\n if swapyz:\n v = v[0], v[2], v[1]\n vertices.append(v)\n if len(values) > 4:\n c = [float(x) for x in values[4:7]]\n colors.append(c)\n elif values[0] == 'vn':\n v = [float(x) for x in values[1:4]]\n if swapyz:\n v = v[0], v[2], v[1]\n normals.append(v)\n elif values[0] == 'vt':\n v = [float(x) for x in values[1:3]]\n texcoords.append(v)\n elif values[0] in ('usemtl', 'usemat'):\n material = values[1]\n elif values[0] == 'mtllib':\n mtl = [os.path.split(filename)[0], values[1]]\n elif values[0] == 'f':\n face = []\n texcoord = []\n normal = []\n for v in values[1:]:\n w = v.split('/')\n face.append(int(w[0]))\n # if len(w) >= 2 and len(w[1]) > 0:\n if len(w) >= 2 and w[1]:\n texcoord.append(int(w[1]))\n else:\n texcoord.append(0)\n # if len(w) >= 3 and len(w[2]) > 0:\n if len(w) >= 3 and w[2]:\n normal.append(int(w[2]))\n else:\n normal.append(0)\n # faces.append((face, normal, texcoord, material))\n faces.append(face)\n normal_idxs.append(normal)\n texcoord_idxs.append(texcoord)\n materials.append(material)\n\n dicts = {\n 'groups': group,\n 'vertices': vertices,\n 'colors': colors,\n 'faces': faces,\n 'normals': normals,\n 'normal_idxs': normal_idxs,\n 'texcoords': texcoords,\n 'texcoord_idxs': texcoord_idxs,\n 'materials': materials,\n 'mtl': mtl\n }\n return dicts\n\n\ndef read_obj(filename, uv_filename=None):\n \"\"\"\n Parse raw OBJ text into vertices, vertex normals,\n vertex colors, and vertex textures.\n \"\"\"\n\n # get text as bytes or string blob\n with open(filename, 'r') as f:\n text = f.read()\n\n try:\n text = text.decode('utf-8')\n except:\n pass\n\n text = '\\n{}\\n'.format(text.strip().replace('\\r\\n', '\\n'))\n # extract vertices from raw text\n v, vn, vt, vc = _parse_vertices(text=text)\n\n face_tuples = _preprocess_faces(text=text)\n\n # geometry = {}\n while face_tuples:\n # consume the next chunk of text\n _, _, chunk = face_tuples.pop()\n face_lines = [i.split('\\n', 1)[0] for i in chunk.split('\\nf ')[1:]]\n joined = ' '.join(face_lines).replace('/', ' ')\n\n array = np.fromstring(joined, sep=' ', dtype=np.int64) - 1\n\n columns = len(face_lines[0].strip().replace('/', ' ').split())\n\n if len(array) == (columns * len(face_lines)):\n faces, faces_tex, faces_norm = _parse_faces_vectorized(\n array=array, columns=columns, sample_line=face_lines[0])\n else:\n faces, faces_tex, faces_norm = _parse_faces_fallback(face_lines)\n\n if uv_filename is not None:\n uv_image = Image.open(uv_filename)\n vc = uv_to_color(vt, uv_image)\n vc = vc[:, :3]\n\n dicts = {\n 'vertices': v,\n 'colors': vc,\n 'faces': faces,\n 'normals': vn,\n 'normal_idxs': faces_norm,\n 'texcoords': vt,\n 'texcoord_idxs': faces_tex,\n }\n return dicts\n\n\ndef _parse_vertices(text):\n starts = {k: text.find('\\n{} '.format(k)) for k in ['v', 'vt', 'vn']}\n\n # no valid values so exit early\n if not any(v >= 0 for v in starts.values()):\n return None, None, None, None\n\n # find the last position of each valid value\n ends = {\n k: text.find('\\n',\n text.rfind('\\n{} '.format(k)) + 2 + len(k))\n for k, v in starts.items()\n if v >= 0\n }\n\n # take the first and last position of any vertex property\n start = min(s for s in starts.values() if s >= 0)\n end = max(e for e in ends.values() if e >= 0)\n # get the chunk of test that contains vertex data\n chunk = text[start:end].replace('+e', 'e').replace('-e', 'e')\n\n # get the clean-ish data from the file as python lists\n data = {\n k: [i.split('\\n', 1)[0] for i in chunk.split('\\n{} '.format(k))[1:]\n ] for k, v in starts.items() if v >= 0\n }\n\n # count the number of data values per row on a sample row\n per_row = {k: len(v[1].split()) for k, v in data.items()}\n\n # convert data values into numpy arrays\n result = collections.defaultdict(lambda: None)\n for k, value in data.items():\n # use joining and fromstring to get as numpy array\n array = np.fromstring(' '.join(value), sep=' ', dtype=np.float64)\n # what should our shape be\n shape = (len(value), per_row[k])\n # check shape of flat data\n if len(array) == np.product(shape):\n # we have a nice 2D array\n result[k] = array.reshape(shape)\n else:\n # try to recover with a slightly more expensive loop\n count = per_row[k]\n try:\n # try to get result through reshaping\n result[k] = np.fromstring(' '.join(i.split()[:count] for i in value),\n sep=' ',\n dtype=np.float64).reshape(shape)\n except BaseException:\n pass\n\n # vertices\n v = result['v']\n # vertex colors are stored next to vertices\n vc = None\n if v is not None and v.shape[1] >= 6:\n # vertex colors are stored after vertices\n v, vc = v[:, :3], v[:, 3:6]\n elif v is not None and v.shape[1] > 3:\n # we got a lot of something unknowable\n v = v[:, :3]\n\n # vertex texture or None\n vt = result['vt']\n if vt is not None:\n # sometimes UV coordinates come in as UVW\n vt = vt[:, :2]\n # vertex normals or None\n vn = result['vn']\n\n return v, vn, vt, vc\n\n\ndef _preprocess_faces(text, split_object=False):\n # Pre-Process Face Text\n # Rather than looking at each line in a loop we're\n # going to split lines by directives which indicate\n # a new mesh, specifically 'usemtl' and 'o' keys\n # search for materials, objects, faces, or groups\n starters = ['\\nusemtl ', '\\no ', '\\nf ', '\\ng ', '\\ns ']\n f_start = len(text)\n # first index of material, object, face, group, or smoother\n for st in starters:\n search = text.find(st, 0, f_start)\n # if not contained find will return -1\n if search < 0:\n continue\n # subtract the length of the key from the position\n # to make sure it's included in the slice of text\n if search < f_start:\n f_start = search\n # index in blob of the newline after the last face\n f_end = text.find('\\n', text.rfind('\\nf ') + 3)\n # get the chunk of the file that has face information\n if f_end >= 0:\n # clip to the newline after the last face\n f_chunk = text[f_start:f_end]\n else:\n # no newline after last face\n f_chunk = text[f_start:]\n\n # start with undefined objects and material\n current_object = None\n current_material = None\n # where we're going to store result tuples\n # containing (material, object, face lines)\n face_tuples = []\n\n # two things cause new meshes to be created: objects and materials\n # first divide faces into groups split by material and objects\n # face chunks using different materials will be treated\n # as different meshes\n for m_chunk in f_chunk.split('\\nusemtl '):\n # if empty continue\n # if len(m_chunk) == 0:\n # continue\n if not m_chunk:\n continue\n\n # find the first newline in the chunk\n # everything before it will be the usemtl direction\n new_line = m_chunk.find('\\n')\n # if the file contained no materials it will start with a newline\n if new_line == 0:\n current_material = None\n else:\n # remove internal double spaces because why wouldn't that be OK\n current_material = ' '.join(m_chunk[:new_line].strip().split())\n\n # material chunk contains multiple objects\n if split_object:\n o_split = m_chunk.split('\\no ')\n else:\n o_split = [m_chunk]\n if len(o_split) > 1:\n for o_chunk in o_split:\n # set the object label\n current_object = o_chunk[:o_chunk.find('\\n')].strip()\n # find the first face in the chunk\n f_idx = o_chunk.find('\\nf ')\n # if we have any faces append it to our search tuple\n if f_idx >= 0:\n face_tuples.append(\n (current_material, current_object, o_chunk[f_idx:]))\n else:\n # if there are any faces in this chunk add them\n f_idx = m_chunk.find('\\nf ')\n if f_idx >= 0:\n face_tuples.append((current_material, current_object, m_chunk[f_idx:]))\n return face_tuples\n\n\ndef _parse_faces_vectorized(array, columns, sample_line):\n \"\"\"\n Parse loaded homogeneous (tri/quad) face data in a\n vectorized manner.\n \"\"\"\n # reshape to columns\n array = array.reshape((-1, columns))\n # how many elements are in the first line of faces\n # i.e '13/1/13 14/1/14 2/1/2 1/2/1' is 4\n group_count = len(sample_line.strip().split())\n # how many elements are there for each vertex reference\n # i.e. '12/1/13' is 3\n per_ref = int(columns / group_count)\n # create an index mask we can use to slice vertex references\n index = np.arange(group_count) * per_ref\n # slice the faces out of the blob array\n faces = array[:, index]\n\n # or do something more general\n faces_tex, faces_norm = None, None\n if columns == 6:\n # if we have two values per vertex the second\n # one is index of texture coordinate (`vt`)\n # count how many delimiters are in the first face line\n # to see if our second value is texture or normals\n count = sample_line.count('/')\n if count == columns:\n # case where each face line looks like:\n # ' 75//139 76//141 77//141'\n # which is vertex/nothing/normal\n faces_norm = array[:, index + 1]\n elif count == int(columns / 2):\n # case where each face line looks like:\n # '75/139 76/141 77/141'\n # which is vertex/texture\n faces_tex = array[:, index + 1]\n # else:\n # log.warning('face lines are weird: {}'.format(sample_line))\n elif columns == 9:\n # if we have three values per vertex\n # second value is always texture\n faces_tex = array[:, index + 1]\n # third value is reference to vertex normal (`vn`)\n faces_norm = array[:, index + 2]\n return faces, faces_tex, faces_norm\n\n\ndef _parse_faces_fallback(lines):\n \"\"\"\n Use a slow but more flexible looping method to process\n face lines as a fallback option to faster vectorized methods.\n \"\"\"\n\n # collect vertex, texture, and vertex normal indexes\n v, vt, vn = [], [], []\n\n # loop through every line starting with a face\n for line in lines:\n # remove leading newlines then\n # take first bit before newline then split by whitespace\n split = line.strip().split('\\n')[0].split()\n # split into: ['76/558/76', '498/265/498', '456/267/456']\n if len(split) == 4:\n # triangulate quad face\n split = [split[0], split[1], split[2], split[2], split[3], split[0]]\n elif len(split) != 3:\n # log.warning('face has {} elements! skipping!'.format(len(split)))\n continue\n\n # f is like: '76/558/76'\n for f in split:\n # vertex, vertex texture, vertex normal\n split = f.split('/')\n # we always have a vertex reference\n v.append(int(split[0]))\n\n # faster to try/except than check in loop\n try:\n vt.append(int(split[1]))\n except BaseException:\n pass\n try:\n # vertex normal is the third index\n vn.append(int(split[2]))\n except BaseException:\n pass\n\n # shape into triangles and switch to 0-indexed\n faces = np.array(v, dtype=np.int64).reshape((-1, 3)) - 1\n faces_tex, normals = None, None\n if len(vt) == len(v):\n faces_tex = np.array(vt, dtype=np.int64).reshape((-1, 3)) - 1\n if len(vn) == len(v):\n normals = np.array(vn, dtype=np.int64).reshape((-1, 3)) - 1\n\n return faces, faces_tex, normals\n\n\ndef uv_to_color(uv, image):\n \"\"\"\n Get the color in a texture image.\n\n Parameters\n -------------\n uv : (n, 2) float\n UV coordinates on texture image\n image : PIL.Image\n Texture image\n\n Returns\n ----------\n colors : (n, 4) float\n RGBA color at each of the UV coordinates\n \"\"\"\n if image is None or uv is None:\n return None\n\n # UV coordinates should be (n, 2) float\n uv = np.asanyarray(uv, dtype=np.float64)\n\n # get texture image pixel positions of UV coordinates\n x = (uv[:, 0] * (image.width - 1))\n y = ((1 - uv[:, 1]) * (image.height - 1))\n\n # convert to int and wrap to image\n # size in the manner of GL_REPEAT\n x = x.round().astype(np.int64) % image.width\n y = y.round().astype(np.int64) % image.height\n\n # access colors from pixel locations\n # make sure image is RGBA before getting values\n colors = np.asanyarray(image.convert('RGBA'))[y, x]\n\n # conversion to RGBA should have corrected shape\n assert colors.ndim == 2 and colors.shape[1] == 4\n\n return colors\n\n\ndef to_float(colors):\n \"\"\"\n Convert integer colors to 0.0 - 1.0 floating point colors\n\n Parameters\n -------------\n colors : (n, d) int\n Integer colors\n\n Returns\n -------------\n as_float : (n, d) float\n Float colors 0.0 - 1.0\n \"\"\"\n\n # colors as numpy array\n colors = np.asanyarray(colors)\n if colors.dtype.kind == 'f':\n return colors\n elif colors.dtype.kind in 'iu':\n # integer value for opaque alpha given our datatype\n opaque = np.iinfo(colors.dtype).max\n return colors.astype(np.float64) / opaque\n else:\n raise ValueError('only works on int or float colors!')\n\n\ndef array_to_string(array,\n col_delim=' ',\n row_delim='\\n',\n digits=8,\n value_format='{}'):\n \"\"\"\n Convert a 1 or 2D array into a string with a specified number\n of digits and delimiter. The reason this exists is that the\n basic numpy array to string conversions are surprisingly bad.\n\n Parameters\n ------------\n array : (n,) or (n, d) float or int\n Data to be converted\n If shape is (n,) only column delimiter will be used\n col_delim : str\n What string should separate values in a column\n row_delim : str\n What string should separate values in a row\n digits : int\n How many digits should floating point numbers include\n value_format : str\n Format string for each value or sequence of values\n If multiple values per value_format it must divide\n into array evenly.\n\n Returns\n ----------\n formatted : str\n String representation of original array\n \"\"\"\n # convert inputs to correct types\n array = np.asanyarray(array)\n digits = int(digits)\n row_delim = str(row_delim)\n col_delim = str(col_delim)\n value_format = str(value_format)\n\n # abort for non- flat arrays\n # if len(array.shape) > 2:\n # raise ValueError('conversion only works on 1D/2D arrays not %s!',\n # str(array.shape))\n\n # allow a value to be repeated in a value format\n repeats = value_format.count('{}')\n\n if array.dtype.kind == 'i':\n # integer types don't need a specified precision\n format_str = value_format + col_delim\n elif array.dtype.kind == 'f':\n # add the digits formatting to floats\n format_str = value_format.replace('{}',\n '{:.' + str(digits) + 'f}') + col_delim\n # else:\n # raise (ValueError('dtype %s not convertible!', array.dtype.name))\n\n # length of extra delimiters at the end\n end_junk = len(col_delim)\n # if we have a 2D array add a row delimiter\n if len(array.shape) == 2:\n format_str *= array.shape[1]\n # cut off the last column delimiter and add a row delimiter\n format_str = format_str[:-len(col_delim)] + row_delim\n end_junk = len(row_delim)\n\n # expand format string to whole array\n format_str *= len(array)\n\n # if an array is repeated in the value format\n # do the shaping here so we don't need to specify indexes\n shaped = np.tile(array.reshape((-1, 1)), (1, repeats)).reshape(-1)\n\n # run the format operation and remove the extra delimiters\n formatted = format_str.format(*shaped)[:-end_junk]\n\n return formatted\n\n\ndef read_obj_bak(filename, swapyz=False):\n vertices = []\n colors = []\n normals = []\n texcoords = []\n faces = []\n normal_idxs = []\n texcoord_idxs = []\n materials = []\n mtl = None\n\n material = None\n for line in open(filename, \"r\"):\n if line.startswith('#'):\n continue\n values = line.split()\n if not values:\n continue\n if values[0] == 'v':\n v = [float(x) for x in values[1:4]]\n if swapyz:\n v = v[0], v[2], v[1]\n vertices.append(v)\n if len(values) > 4:\n c = [float(x) for x in values[4:7]]\n colors.append(c)\n elif values[0] == 'vn':\n v = [float(x) for x in values[1:4]]\n if swapyz:\n v = v[0], v[2], v[1]\n normals.append(v)\n elif values[0] == 'vt':\n v = [float(x) for x in values[1:3]]\n texcoords.append(v)\n elif values[0] in ('usemtl', 'usemat'):\n material = values[1]\n elif values[0] == 'mtllib':\n mtl = [os.path.split(filename)[0], values[1]]\n elif values[0] == 'f':\n face = []\n texcoord = []\n normal = []\n for v in values[1:]:\n w = v.split('/')\n face.append(int(w[0]))\n # if len(w) >= 2 and len(w[1]) > 0:\n if len(w) >= 2 and w[1]:\n texcoord.append(int(w[1]))\n else:\n texcoord.append(0)\n # if len(w) >= 3 and len(w[2]) > 0:\n if len(w) >= 3 and w[2]:\n normal.append(int(w[2]))\n else:\n normal.append(0)\n # faces.append((face, normal, texcoord, material))\n faces.append(face)\n normal_idxs.append(normal)\n texcoord_idxs.append(texcoord)\n materials.append(material)\n\n dicts = {\n 'vertices': vertices,\n 'colors': colors,\n 'faces': faces,\n 'normals': normals,\n 'normal_idxs': normal_idxs,\n 'texcoords': texcoords,\n 'texcoord_idxs': texcoord_idxs,\n 'materials': materials,\n 'mtl': mtl\n }\n return dicts\n\n\ndef write_obj(obj_name, vertices, triangles=None, colors=None, normals=None):\n ''' Save 3D face model with texture represented by colors.\n Args:\n obj_name: str\n vertices: shape = (nver, 3)\n triangles: shape = (ntri, 3)\n colors: shape = (nver, 3)\n '''\n try:\n if not os.path.isdir(os.path.split(obj_name)[0]):\n os.makedirs(os.path.split(obj_name)[0])\n except FileNotFoundError:\n pass\n\n if triangles is not None:\n triangles = triangles.copy()\n triangles += 1 # meshlab start with 1\n\n if obj_name.split('.')[-1] != 'obj':\n obj_name = obj_name + '.obj'\n\n with open(obj_name, 'w') as f:\n if colors is None:\n for v in vertices:\n s = 'v {} {} {}\\n'.format(v[0], v[1], v[2])\n f.write(s)\n else:\n for v, c in zip(vertices, colors):\n s = 'v {} {} {} {} {} {}\\n'.format(v[0], v[1], v[2], int(c[0]),\n int(c[1]), int(c[2]))\n f.write(s)\n\n if normals is not None:\n for vn in normals:\n s = 'vn {} {} {}\\n'.format(vn[0], vn[1], vn[2])\n f.write(s)\n\n if triangles is not None:\n for t in triangles:\n s = 'f {} {} {}\\n'.format(t[0], t[1], t[2])\n f.write(s)\n"
},
{
"alpha_fraction": 0.7664704918861389,
"alphanum_fraction": 0.789633572101593,
"avg_line_length": 50.63725662231445,
"blob_id": "6c30428648eb854021466283a5842dd05d52243a",
"content_id": "da788a881f9249870f76f752dbab520ffc9f571b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5315,
"license_type": "permissive",
"max_line_length": 387,
"num_lines": 102,
"path": "/Face Reconstruction/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "## Facial reconstruction 🎭🎭\n\n<p align=\"center\"> \n<img src=\"https://github.com/smriti1313/Face-X/blob/master/Face%20Reconstruction/Joint%203D%20Face%20Reconstruction/Docs/images/prnet.gif\">\n</p>\n\n## Abstract📃:\n- Face as a biometric identification in computer vision is an important medium, in areas such as \n - video surveillance\n - animation games\n - security \n - anti-terrorist \nhas a very wide range of applications, creating vivid, strong visibility of 3d face model, now has become a challenging in the field of computer vision is one of the important topics.\n\n- Using camera calibration, three-dimensional data of facial images were extracted using the functions of OpenCV computer vision library, and then 3d face model were reconstructed.\n\n## Introduction📝:\n\n- As a branch of stereo vision, 3D facial reconstruction is getting more and more importance in the field of animation, medical cosmetology and privacy protection.\n- Traditional 3D facial reconstruction approach is mainly based on prior information and model, in which 3D facial information is collected by modifying the standard model according to individual difference. \n- Such approach suffers from huge complexity and unobvious detailed information. The introduction of theory of computer vision further pushed forward the development of 3D reconstruction, in that 3D information could be retrieved by multiple 2D images through simulated bionics computation. \n- 3D facial reconstruction has been an important and popular topic in the cross section of computer vision and graphics. \n- As a traditional mark for identification, human face could be used for identity recognition, security monitoring, and video games. \n- The requirement and expectation for 3D facial reconstruction are expanding, along with the wider application of 3D facial model\n\n\n\n## What is facial reconstruction❓❓\n\n- Facial reconstruction means to develop a three dimensional structure of face using a two dimensional input and different restructuring techniques.\n\n- Face reconstruction creates a 3D face model from a set of input such as image(s), video, or depth data.\n\n## Applications✨:\nThese technologies are higly used in:\n\n- Forensic science \n- anthropology\n\nTo recreate the appearance that best resembles the original face of the deceased, in an effort to stimulate public recognition that will eventually contribute to personal identification\n\n## Why computerized facial reconstruction is better than manual facial reconstruction?👨💻👩💻\n\n- The computer-based reconstructions were found to be more rapid and objective in nature. \n- Unlike the manual techniques, when the same input was given, it would always result in producing the same output.\n- Furthermore, it was possible to generate many faces with little variations from the same skull. \n- An advantage of this system, thus, was that the reconstruction work could be carried out on the image of the actual skull, rather than a replica as in manual reconstructions \n\n## How does 3D data extraction work?!:\n\n- OpenCV, short for Open Source Computer Vision Library, is an open source library containing C functions and C++ classes which are developed by R&D lab of Intel in Russia. Through OpenCV, common image processing and computer vision algorithms could be implemented, such as feature detection and tracking, motion analysis, object segmentation and recognition, and 3D reconstruction, etc.\n\n- Due to the efficient and elegant source code in\nOpenCV, in which most functions have been optimized\nfor excellent performance based on the design architecture\nof Intel processing chips such as Pentium MMX, MMX,\nPentium, Pentium III and Pentium IV, it has been widely\nused in image processing all over the world, and OpenCV\nhas become a popular image processing software\n\n## Workflow🔗:\n\n<div align=\"center\">\n<img src=\"https://github.com/smriti1313/Face-X/blob/master/Face%20Reconstruction/workflow.png\" width=\"395px\" height=\"390px\" align='center'>\n</div>\n\n## Different techniques in facial reconstruction💥💥:\n\n[3D Face Reconstruction using Graph Convolution Network](https://github.com/smriti1313/Face-X/tree/master/Face%20Reconstruction/3D%20Face%20Reconstruction%20using%20Graph%20Convolution%20Network)\n\n[Joint 3D Face Reconstruction](https://github.com/akshitagupta15june/Face-X/tree/master/Face%20Reconstruction/Joint%203D%20Face%20Reconstruction)\n\n[RingNet for Face Reconstruction](https://github.com/akshitagupta15june/Face-X/tree/master/Face%20Reconstruction/RingNet%20for%20Face%20Reconstruction)\n\n## Have an idea?? Wanna contribute ⁉\n\n- Clone this repository\n` git clone https://github.com/akshitagupta15june/Face-X.git`\n- Change Directory\n` cd Face Reconstruction`\n- Make a folder and add your code file and a readme file with screenshots.\n- Commit message\n` git commit -m \"Enter message\"`\n- Push your code\n` git push`\n- Make Pull request\n- Wait for reviewers to review your PR\n\n## Citation📄:\n\nA part of this readme is from:\n\n```@INPROCEEDINGS{7846562,\n author={J. {Yin} and X. {Yang}},\n booktitle={2016 International Conference on Audio, Language and Image Processing (ICALIP)}, \n title={3D facial reconstruction of based on OpenCV and DirectX}, \n year={2016},\n volume={},\n number={},\n pages={341-344},\n doi={10.1109/ICALIP.2016.7846562}}\n```\n"
},
{
"alpha_fraction": 0.7646334171295166,
"alphanum_fraction": 0.7701786756515503,
"avg_line_length": 37.64285659790039,
"blob_id": "0f5dd336ad972d97e372420c24d968f98d063e6e",
"content_id": "bd6e0f1b5141246f069a41a7b79e1ece8414bb90",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1646,
"license_type": "permissive",
"max_line_length": 210,
"num_lines": 42,
"path": "/Virtual_makeover/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "## Virtual Makeover 🎭🎭\n<p align = \"center\"> \n<img src = \"https://github.com/akshitagupta15june/Face-X/blob/master/Virtual_makeover/images/1.jpg?raw=true\">\n</p>\n\n\n## Introduction📝:\n- Using the illusion of AR with technologies like facial feature and finger tracking. The program does meticulous work to match real-life colors and textures of beauty products with what pops up on the screen. \n\n- It is gaining popularity with consumers as the industry expands from pictures to live video feed as it now moves to trying on three-dimensional products like shoes\n\n\n## What is Virtual Makeover❓❓\n- Virtual Makeover means virtually applying a product onto one's face as if they are actually wearing it. \n\n\n## Applications✨:\n- These technologies are highly used in \n\t-Cosmetics industry \n\t-Hair care industry\n\n To accelerate product sale by remote access, more choices and saving the time spent on trying the products.\n\n\n## Different techniques in Virtual Makeover💥💥:\n -[Using Face Landmark detection via DLIB](https://github.com/akshitagupta15june/Face-X/tree/master/Virtual_makeover/Virtual-Makeup)\n \n -[Using Face Landmark detection via PIL](https://github.com/akshitagupta15june/Face-X/tree/master/Virtual_makeover/makeup)\n\n\n## Have an Idea? Wanna contribute your own Virtual Makeover⁉\n- Clone this repository\n` git clone https://github.com/akshitagupta15june/Face-X.git`\n- Change Directory\n` cd Virtual_makeover`\n- Make a folder and add your code file and a readme file with screenshots.\n- Commit message\n` git commit -m \"Enter message\"`\n- Push your code\n` git push`\n- Make Pull request\n- Wait for reviewers to review your PR\n"
},
{
"alpha_fraction": 0.6440340876579285,
"alphanum_fraction": 0.6735795736312866,
"avg_line_length": 41.409637451171875,
"blob_id": "60fbe44b126f5a53c626c633d80b21aa6616b6f7",
"content_id": "332bacd0f9082616e13dd9c733215072f2e8b9f1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3520,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 83,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/net/resnet_v1_3dmm.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Copyright 2016 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Contains definitions for the original form of Residual Networks.\nThe 'v1' residual networks (ResNets) implemented in this module were proposed\nby:\n[1] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun\n Deep Residual Learning for Image Recognition. arXiv:1512.03385\nOther variants were introduced in:\n[2] Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun\n Identity Mappings in Deep Residual Networks. arXiv: 1603.05027\nThe networks defined in this module utilize the bottleneck building block of\n[1] with projection shortcuts only for increasing depths. They employ batch\nnormalization *after* every weight layer. This is the architecture used by\nMSRA in the Imagenet and MSCOCO 2016 competition models ResNet-101 and\nResNet-152. See [2; Fig. 1a] for a comparison between the current 'v1'\narchitecture and the alternative 'v2' architecture of [2] which uses batch\nnormalization *before* every weight layer in the so-called full pre-activation\nunits.\nTypical use:\n from tensorflow.contrib.slim.nets import resnet_v1\nResNet-101 for image classification into 1000 classes:\n # inputs has shape [batch, 224, 224, 3]\n with slim.arg_scope(resnet_v1.resnet_arg_scope()):\n net, end_points = resnet_v1.resnet_v1_101(inputs, 1000, is_training=False)\nResNet-101 for semantic segmentation into 21 classes:\n # inputs has shape [batch, 513, 513, 3]\n with slim.arg_scope(resnet_v1.resnet_arg_scope()):\n net, end_points = resnet_v1.resnet_v1_101(inputs,\n 21,\n is_training=False,\n global_pool=False,\n output_stride=16)\n\"\"\"\n\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\n# import os, sys\n# #self\n# _curr_path = os.path.abspath(__file__) # /home/..../face\n# _cur_dir = os.path.dirname(_curr_path) # ./\n# print(_cur_dir)\n# sys.path.append(_cur_dir) # /home/..../pytorch3d\n\n#\nimport tensorflow as tf\nfrom tensorflow.contrib import layers\nfrom tensorflow.contrib.slim.nets import resnet_v1\n\ndef encoder_resnet50(images, num_classes, is_training=True, reuse=None):\n\n \"\"\"Predict prediction tensors from inputs tensor.\n\n Outputs of this function can be passed to loss or postprocess functions.\n\n Args:\n preprocessed_inputs: A float32 tensor with shape [batch_size,\n height, width, num_channels] representing a batch of images.\n\n Returns:\n prediction_dict: A dictionary holding prediction tensors to be\n passed to the Loss or Postprocess functions.\n \"\"\"\n net, endpoints = resnet_v1.resnet_v1_50(\n images,\n num_classes=num_classes,\n is_training=is_training,\n reuse = reuse)\n net = tf.squeeze(net, axis=[1, 2])\n return net, endpoints\n"
},
{
"alpha_fraction": 0.6846733689308167,
"alphanum_fraction": 0.7223618030548096,
"avg_line_length": 55.92856979370117,
"blob_id": "857577e1a706011838404df3b84c8ccefccfd0ee",
"content_id": "08c1f1097f6009055f1686ce9f15ccc11647bd6c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 796,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 14,
"path": "/Cartoonify Image/Cartoonify_face_image/Cartoonify-face_image.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import cv2\nframe_cap = cv2.VideoCapture(0) #Capturing each Frames from the Camera\nwhile(True):\n ret, frame = frame_cap.read() #Reading the Captured Frames\n gray_img = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) #Applying gray filter\n blur_img = cv2.medianBlur(gray_img, 5) #Applying Median Blur\n edges = cv2.adaptiveThreshold(blur_img, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 9, 9)\n color = cv2.bilateralFilter(frame, 9, 250, 250) #Applying Bilateral Filter\n cartoon_img = cv2.bitwise_and(color, color, mask=edges) # Bit wise And operation on color and edges images\n cv2.imshow(\"Cartoon Image\", cartoon_img) #Displaying the cartoonified Image\n if cv2.waitKey(1) & 0xFF == ord(' '): #Press space bar to exit\n break\nframe_cap.release()\ncv2.destroyAllWindows()"
},
{
"alpha_fraction": 0.7331022620201111,
"alphanum_fraction": 0.7521663904190063,
"avg_line_length": 31.11111068725586,
"blob_id": "03f8ee5cd7485da59ffacfcaf6a38e256258296d",
"content_id": "1b1dd663664b624c1b94f2288fb4487f74372f48",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 577,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 18,
"path": "/Snapchat_Filters/SantaClaus Filter/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Santa Claus Filter\n\n\n#### Requirements\n- Python 3.7.x\n- OpenCV\n- Imutils\n- Dlib library\n- Download Face Landmark Detection Model (shape_predictor_68_face_landmarks.dat file) \nfrom [here](https://github.com/italojs/facial-landmarks-recognition/blob/master/shape_predictor_68_face_landmarks.dat).\n\n#### Instruction\n- Clone this repository ` git clone https://github.com/akshitagupta15june/Face-X.git`\n- Change Directory to ` Snapchat_Filters` then to `SantaClaus Filter`\n- Run code using the cmd ` python santa_filter.py`\n\n### Screenshot\n<img height=\"380\" src=\"assets/out.png\">"
},
{
"alpha_fraction": 0.7338069081306458,
"alphanum_fraction": 0.7509402632713318,
"avg_line_length": 45,
"blob_id": "090eb46201bde2e25e2714d52e8d3a9ae3d1e04a",
"content_id": "834025cff5cf9202e26185d9690cdf737c0a7dc3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2393,
"license_type": "permissive",
"max_line_length": 547,
"num_lines": 52,
"path": "/Face Reconstruction/3D Face Reconstruction using Graph Convolution Network/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n# 3D Face Reconstuction using Graph Convolutional Networks\n\nResearch paper : https://arxiv.org/abs/2003.05653\n\nIn this paper, they seek to reconstruct the 3D facial shape with high fidelity texture from a single image, without the need to capture a large-scale face texture database.\n\n**An overview of the method.** \n\n\n\nSource : Internet\n\n\n#### 1. Package Requirements\n> tensorflow \n> tqdm \n> scikit-learn \n> scipy \n> mesh-renderer\n\n#### 2. References\n\n- The shapes and coarse textures : https://github.com/microsoft/Deep3DFaceReconstruction\n- GCNs code : https://github.com/anuragranj/coma\n- mesh processing libraries : https://github.com/MPI-IS/mesh\n\n\n#### 3. Preparing dataset\nAs its mentioned in the paper, they use a face segmentation network to segment out the non-face areas. Here, they treat the segmentation result as alpha channel and store it in a `.png` file along with the face image. More specifically, we acquire the face segmentation result by a face segmentation network, then store the image and segmentation results as a `.png` file, where the RGB channels store the image, and alpha channel stores the segmentation results. In the alpha channel, 0 means `non-skin region` and 255 represents `skin region`. \nFor efficiency, we then write all `.png` images into a binary file in advance. Please change the data folder in `create_bin.py` to yours.\n> python create_bin.py\n\n#### 4. Training\nIt is worth mentioning that, our network involves the mesh sampling algorithm. We save the sampling-related parameters into `.npz` files in advance and load them before training to avoid meaningless repeat calculation. \nMore details could be found in utils.py#L266 init_sampling().\n\nAfter the dataset files are ready, the training can be started.\n> python main.py --mode train\n\n#### 5. Output\nThe following gives the comparison for various face constraints retrieved using this model and using the ones mentioned in the paper: \n\n\n\n#### Citation\n @inproceedings{lin2020towards, \n title={Towards high-fidelity 3D face reconstruction from in-the-wild images using graph convolutional networks}, \n author={Lin, Jiangke and Yuan, Yi and Shao, Tianjia and Zhou, Kun}, \n booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition}, \n pages={5891--5900}, \n year={2020} \n }\n"
},
{
"alpha_fraction": 0.7558320164680481,
"alphanum_fraction": 0.7807154059410095,
"avg_line_length": 48.46154022216797,
"blob_id": "c791253ee6b0f94f67291012ba5b12ef6f54595c",
"content_id": "be8ba0e2a5f206ffaa19f1ed6483bbfe0af1bd53",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1290,
"license_type": "permissive",
"max_line_length": 250,
"num_lines": 26,
"path": "/Face-Mask-Detection/Recognition using EfficientNetB3/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# FACE MASK DETECTION FROM LIVE WEBCAM\n\nThis is a project to detect face mask using MTCNN + OPENCV + EFFICIENTNETB3 from LIVE WEBCAM.\n\n### PROJECT WORKFLOW:\n\n\n\n\n## About :\n\nData is available at: [Link](https://www.kaggle.com/ashishjangra27/face-mask-12k-images-dataset)\n### NOTE: I have created a folder 'Test' and put a mixure of with mask and without mask images. In original dataset these images are placed under separate folders.\n\n### Data augmentation:\n1. Data augmentation encompasses a wide range of techniques used to generate “new” training samples from the original ones by applying random jitters and perturbations (but at the same time ensuring that the class labels of the data are not changed).\n2.The basic idea behind the augmentation is to train the model on all kind of possible transformations of an image\n3. Here we are using flow_from_directory. This is because we have limited ram and we need to get images in batches\n\n### Callbacks\n### Building Model\n### Model Training\n\n## Output :\n\n\n"
},
{
"alpha_fraction": 0.517179012298584,
"alphanum_fraction": 0.5370705127716064,
"avg_line_length": 20.1200008392334,
"blob_id": "17410584a13d63d1067753caec3b84588c05b0b6",
"content_id": "45d41590ab94f62fb903c65c9ef779054cf5fe5f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 553,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 25,
"path": "/Virtual_makeover/Virtual-Makeup/Picsaver.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import cv2\r\ncap = cv2.VideoCapture(0)\r\ncv2.namedWindow(\"Picture Saver\")\r\nimg_counter = 0\r\nwhile True:\r\n ret, frame = cap.read()\r\n if not ret:\r\n print(\"failed to grab frame\")\r\n break\r\n cv2.imshow(\"test\", frame)\r\n\r\n k = cv2.waitKey(1)\r\n if k == ord(\"q\"):\r\n # q pressed\r\n break\r\n elif k == ord(\"c\"):\r\n # c pressed\r\n img_name = \"image{}.png\".format(img_counter)\r\n cv2.imwrite(img_name, frame)\r\n print(\"Success\")\r\n img_counter += 1\r\n\r\ncam.release()\r\n\r\ncv2.destroyAllWindows()\r\n"
},
{
"alpha_fraction": 0.5964444279670715,
"alphanum_fraction": 0.6382222175598145,
"avg_line_length": 37.68965530395508,
"blob_id": "ea3078f671cfbcb342f4d1e496af19c421013f7f",
"content_id": "8c3b8596c55452ea012c04b6c856d5bdde993d12",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1125,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 29,
"path": "/Face-Detection/Face-Detection-using-OpenCV/FACE_DETECTION.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#FACE DETECTION CV\nimport cv2\nCLASSIFIER_PATH = \"Facedetection/haarcascade_frontalface_default.xml\" #Path of the file \ncam = cv2.VideoCapture(0)\nface_classifier = cv2.CascadeClassifier(CLASSIFIER_PATH)\nwhile(True):\n _, frame = cam.read()\n #Converting to Grayscale img\n gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)\n #Returns coordinates of all faces in the frame \n faces = face_classifier.detectMultiScale(gray, 1.3, 5)\n #cyclye through each coordinate list \n for face_dims in faces:\n #Desctructing data and extracted bounding box coordinates\n (x,y,w,h) = face_dims\n mid_x = int(x + h/2)\n mid_y = int(y+ h/2)\n #Drawing -\"Bounding Box\"\n frame = cv2.rectangle(frame, (x,y), (x+h, y+h), (0,255,255), 2)\n frame = cv2.putText(frame, str(x), (x,y), cv2.FONT_HERSHEY_DUPLEX, 0.7,(0,0,255), 2) \n frame = cv2.putText(frame,\"Mid\", (mid_x, mid_y), cv2.FONT_HERSHEY_DUPLEX, 0.7, (0,0,255),2) \n #Displaying -\"Bounding Box\"\n cv2.imshow('Frame', frame)\n key = cv2.waitKey(1)\n if(key == 27):\n break\n\ncam.release()\ncv2.destroyAllWindows() \n"
},
{
"alpha_fraction": 0.5427544713020325,
"alphanum_fraction": 0.5525917410850525,
"avg_line_length": 27.267379760742188,
"blob_id": "802db79b0a6c6c6b99741a18c6bd08eede6e8923",
"content_id": "6726375e69f9257e3c37fa23b4350a0c98cfcbd0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5286,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 187,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/common/face_io.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport os\nimport numpy as np\nfrom collections import defaultdict\n\ndef write_self_lm(path_info_save, lm_all, inter=\",\"):\n if isinstance(path_info_save, str):\n f_info = open(path_info_save, 'w')\n else:\n f_info = path_info_save\n\n if isinstance(lm_all, list):\n lm_all = np.array(lm_all)\n\n f_info.write(str(lm_all.shape[0]))\n f_info.write(\"\\n\")\n for i in range(lm_all.shape[0]):\n lm = lm_all[i]\n for j in range(len(lm)):\n lm_xyz = lm[j]\n if j != len(lm)-1:\n f_info.write((\"%f\"+inter) % (lm_xyz))\n else:\n f_info.write(\"%f\" % (lm_xyz))\n f_info.write('\\n')\n\ndef parse_self_lm(path_info_save):\n with open(path_info_save) as f_info:\n lines = f_info.readlines()\n lines_lm = lines[1:]\n list_lm = []\n for lm2d in lines_lm:\n xyz = lm2d[:-1].split(',')\n xyz = [float(ele) for ele in xyz]\n list_lm.append(xyz)\n return list_lm\n\ndef format_file_list(data_root, split, fmt=None, sort=False):\n with open(data_root + '/%s.txt' % split, 'r') as f:\n frames = f.readlines()\n\n if sort:\n import re\n def atoi(text):\n return int(text) if text.isdigit() else text\n\n def natural_keys(text):\n '''\n alist.sort(key=natural_keys) sorts in human order\n http://nedbatchelder.com/blog/200712/human_sorting.html\n (See Toothy's implementation in the comments)\n '''\n return [atoi(c) for c in re.split(r'(\\d+)', text)]\n\n frames = sorted(frames, key=natural_keys)\n\n\n subfolders = [x.split(' ')[0] for x in frames]\n frame_ids = [x.split(' ')[1][:-1] for x in frames]\n\n if fmt is None:\n image_file_list = [os.path.join(data_root, subfolders[i], frame_ids[i] + '.jpg') for i in range(len(frames))]\n else:\n image_file_list = [os.path.join(data_root, subfolders[i], frame_ids[i] + fmt) for i in range(len(frames))]\n cam_file_list = [os.path.join(data_root, subfolders[i], frame_ids[i] + '_info.txt') for i in range(len(frames))]\n\n return image_file_list, cam_file_list, subfolders, frame_ids\n\n# MFS\ndef write_self_6DoF(path_info_save, dof, inter=\",\"):\n if isinstance(path_info_save, str):\n f_info = open(path_info_save, 'w')\n else:\n f_info = path_info_save\n\n # intrinsic\n f_info.write('%f,%f,%f,%f,%f,%f\\n' %\n (\n dof[0],dof[1],dof[2],dof[3],dof[4],dof[5]\n )\n )\n\ndef parse_self_6DoF(path_info_save, inter=\",\"):\n if isinstance(path_info_save, str):\n f_info = open(path_info_save, 'r')\n else:\n f_info = path_info_save\n\n dof = f_info.readline()[:-1]\n dof = dof.split(inter)\n dof = [float(p) for p in dof]\n return dof\n\n\ndef write_self_intrinsicMtx(path_info_save, intrinsic, inter=\",\"):\n \"\"\"\n :param path_info_save:\n :param intrinsic: [focalx focaly u v]\n :param inter:\n :return:\n \"\"\"\n if isinstance(path_info_save, str):\n f_info = open(path_info_save, 'w')\n else:\n f_info = path_info_save\n\n # intrinsic\n f_info.write('%f,0.,%f,0.,%f,%f,0.,0.,1.\\n' %\n (\n intrinsic[0], intrinsic[1], intrinsic[2], intrinsic[3]\n )\n )\n\ndef parse_self_intrinsicMtx(path_info_save, inter=\",\"):\n if isinstance(path_info_save, str):\n f_info = open(path_info_save, 'w')\n else:\n f_info = path_info_save\n\n intrin_mtx = f_info.readline()[:-1]\n intrin_mtx = intrin_mtx.split(inter)\n intrin_mtx = [float(p) for p in intrin_mtx]\n intrin_mtx = np.array(intrin_mtx)\n intrin_mtx = np.reshape(intrin_mtx, [3,3])\n return intrin_mtx\n\n#\ndef write_self_camera(path_info_save, img_width, img_height, intrinsic, pose):\n \"\"\"\n :param path_info_save: str\n :param intrinsic: shape=[3, 3]\n :param pose: shape=[6], rx, ry, rz, tx, ty, tz\n :return:\n \"\"\"\n if isinstance(path_info_save, str):\n f_info = open(path_info_save, 'w')\n else:\n f_info = path_info_save\n\n if len(intrinsic.shape) == 2:\n intrinsic = np.reshape(intrinsic, [-1])\n\n f_info.write(str(img_width))\n f_info.write(\" \")\n f_info.write(str(img_height))\n f_info.write(\"\\n\")\n\n f_info.write(\"intrinsic\")\n f_info.write(\"\\n\")\n for i in range(intrinsic.shape[0]):\n row = intrinsic[i]\n if i != len(intrinsic) - 1:\n f_info.write(\"%f,\" % (row))\n else:\n f_info.write(\"%f\" % (row))\n f_info.write('\\n')\n\n f_info.write(\"external\")\n f_info.write(\"\\n\")\n for i in range(pose.shape[0]):\n row = pose[i]\n if i != len(pose) - 1:\n f_info.write(\"%f,\" % (row))\n else:\n f_info.write(\"%f\" % (row))\n f_info.write('\\n')\n\ndef parser_self_camera(path_info_save):\n \"\"\"\n :param path_info_save: str\n :param intrinsic: shape=[3, 3]\n :param pose: shape=[6], rx, ry, rz, tx, ty, tz\n :return:\n \"\"\"\n f_info = open(path_info_save, 'r')\n\n frs = f_info.readline()\n img_width = int(frs[0])\n img_height = int(frs[1])\n\n f_info.readline()\n intrin_mtx = parse_self_intrinsicMtx(f_info)\n\n f_info.readline()\n pose = parse_self_6DoF(f_info)\n\n return img_width, img_height, intrin_mtx, pose\n"
},
{
"alpha_fraction": 0.4399999976158142,
"alphanum_fraction": 0.6600000262260437,
"avg_line_length": 15.666666984558105,
"blob_id": "dafdd55fc776c433d0142aa278a4db9b8870d98a",
"content_id": "ea7d05da8be8a4bd18c0857f7ad4d0a4f2341568",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 50,
"license_type": "permissive",
"max_line_length": 22,
"num_lines": 3,
"path": "/Snapchat_Filters/Dog_filter/requirements.txt",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "opencv-python==3.3.0.9\nnumpy==1.13.3\ntorch==1.0.0\n"
},
{
"alpha_fraction": 0.8115941882133484,
"alphanum_fraction": 0.8115941882133484,
"avg_line_length": 68,
"blob_id": "bd631808e9d80735d078f19865c75a78a1eeae96",
"content_id": "a94c8ccb444fd54623faf7b0c9859b22b37cc22c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 69,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 1,
"path": "/Face Reconstruction/Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model/model/README.txt",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "This folder is used to contain two pretrained models for our method.\n"
},
{
"alpha_fraction": 0.7568345069885254,
"alphanum_fraction": 0.768345296382904,
"avg_line_length": 30.545454025268555,
"blob_id": "206aaa5282568419e0ac858446640dd85c86f8df",
"content_id": "be860b56a6ec2f583274d1a41b08cfe9506e2bdf",
"detected_licenses": [
"BSD-3-Clause",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 695,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 22,
"path": "/Awesome-face-operations/Colorful Sketch Filter/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Applying \"Colorful Sketch Filter\" on an image.\n\nConverting an image into a colorful sketch filtered image using OpenCv, Os, Matplotlib and Numpy.\n\n## Steps:\n* Firstly imported the required libraries which are Numpy, Os, Matplotlib and Cv2.\n* Taking path of the image/Real image as input using os and finally reading it using cv2\n\n## Methods Used\n* Used Bilateral Filter\n* Followed by Median Blur\n* Followed by Adaptive Threshold\n* And at last used Bitwise or\n* Finally converted the image into colorful sketch filter image\n\n\n\n## Original Image\n<img src=\"Images/Photo.jpg\" height=\"300px\">\n\n## Colorful Sketch Filtered Image\n<img src=\"Images/Colorful Sketch Filtered Photo.jpg\" height=\"300px\">\n\n"
},
{
"alpha_fraction": 0.6920031905174255,
"alphanum_fraction": 0.7236738204956055,
"avg_line_length": 29.80487823486328,
"blob_id": "60d3cdbc78c35f8c8f0bfdc3fd25b6502a51399e",
"content_id": "1dc6b1b92eadc4f690127bbe1cd4e9a98065e826",
"detected_licenses": [
"BSD-3-Clause",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1263,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 41,
"path": "/Awesome-face-operations/Ghost Image/ghost_image.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from matplotlib import pyplot as plt\nimport numpy as np\nimport cv2\nimport os.path\n\n# take path of the image as input\nimg_path = input(\"Enter the path here:\") #example -> C:\\Users\\xyz\\OneDrive\\Desktop\\project\\image.jpg \nimg = cv2.imread(img_path)\n\n\n\n#plt.imshow(img)\n#plt.show()\nimage = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)\n#plt.figure(figsize= (10,10))\n#plt.imshow(image)\n#plt.show()\nimg_small = cv2.pyrDown(image)\nnum_iter = 5\nfor _ in range(num_iter):\n img_small= cv2.bilateralFilter(img_small, d=9, sigmaColor=9, sigmaSpace=7)\nimg_rgb = cv2.pyrUp(img_small)\n#plt.imshow(img_rgb)\n#plt.show()\nimg_gray = cv2.cvtColor(img_rgb, cv2.COLOR_RGB2GRAY)\nimg_blur = cv2.medianBlur(img_gray, 7)\nimg_edge = cv2.adaptiveThreshold(img_blur, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 7, 2)\n#plt.imshow(img_edge)\n#plt.show()\nimg_edge = cv2.cvtColor(img_edge, cv2.COLOR_GRAY2RGB)\n#plt.imshow(img_edge)\n#plt.show()\n# img_edge = cv2.cvtColor(img_edge, cv2.COLOR_GRAY2RGB)\narray = cv2.bitwise_xor(image, img_edge) #used bitwise xor method \nplt.figure(figsize= (10,10))\nplt.imshow(array)\nplt.axis('off')\nfilename = os.path.basename(img_path)\nplt.savefig(\"(Filtered)\"+filename) #saved file name as (Filtered)image_name.jpg\n\nplt.show() #final filtered photo\n"
},
{
"alpha_fraction": 0.5866666436195374,
"alphanum_fraction": 0.5933333039283752,
"avg_line_length": 59,
"blob_id": "519abdaffffff88e14c436e4a6824687972252f9",
"content_id": "fa78c4b6b00d4ba5bbc5f912bb5c87968ffb1bfb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 300,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 5,
"path": "/Face Reconstruction/Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model/toy_example/README.txt",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "Based on OpenMesh and Numpy, this folder contains a toy example for:\nrecovering 3D face from vertices (vertex_to_mesh.py),\nobtaining vertices of the 3D face (mesh_to_vertex.py).\n--------------------------------------------------------------------\n'mean_face.obj' is the mean face used by our method.\n"
},
{
"alpha_fraction": 0.3333333432674408,
"alphanum_fraction": 0.4861111044883728,
"avg_line_length": 13.399999618530273,
"blob_id": "5433cbe13e46c28cf409738e0b4afc4bf65cdd7b",
"content_id": "99fa402eedb17afc733b2c719a6185a7608eba79",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 72,
"license_type": "permissive",
"max_line_length": 26,
"num_lines": 5,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/geometry/face_align/__init__.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\"\"\"\n@Author : Jiaxiang Shang\n@Email : [email protected]\n@Time : 2020/7/25 14:16\n\"\"\"\n"
},
{
"alpha_fraction": 0.5506336688995361,
"alphanum_fraction": 0.5927987694740295,
"avg_line_length": 33.60245895385742,
"blob_id": "0c218a66eae5fb96f688d2b22424f080e8f90ddd",
"content_id": "fc386ed3b9f93682353cd7f807ebd75de5b20164",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8443,
"license_type": "permissive",
"max_line_length": 180,
"num_lines": 244,
"path": "/Face Reconstruction/3D Face Reconstruction with Weakly-Supervised Learning/load_data.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import torch\nfrom scipy.io import loadmat, savemat\nfrom array import array\nimport numpy as np\nfrom PIL import Image\n\n\nclass BFM(object):\n # BFM 3D face model\n def __init__(self, model_path='BFM/BFM_model_front.mat', device='cpu'):\n model = loadmat(model_path)\n # mean face shape. [3*N,1]\n self.meanshape = torch.from_numpy(model['meanshape'])\n # identity basis. [3*N,80]\n self.idBase = torch.from_numpy(model['idBase'])\n self.exBase = torch.from_numpy(model['exBase'].astype(\n np.float32)) # expression basis. [3*N,64]\n # mean face texture. [3*N,1] (0-255)\n self.meantex = torch.from_numpy(model['meantex'])\n # texture basis. [3*N,80]\n self.texBase = torch.from_numpy(model['texBase'])\n # triangle indices for each vertex that lies in. starts from 1. [N,8]\n self.point_buf = model['point_buf'].astype(np.int32)\n # vertex indices in each triangle. starts from 1. [F,3]\n self.tri = model['tri'].astype(np.int32)\n # vertex indices of 68 facial landmarks. starts from 1. [68,1]\n self.keypoints = model['keypoints'].astype(np.int32)[0]\n self.to_device(device)\n\n def to_device(self, device):\n self.meanshape = self.meanshape.to(device)\n self.idBase = self.idBase.to(device)\n self.exBase = self.exBase.to(device)\n self.meantex = self.meantex.to(device)\n self.texBase = self.texBase.to(device)\n\n def load_lm3d(self, fsimilarity_Lm3D_all_mat='BFM/similarity_Lm3D_all.mat'):\n # load landmarks for standard face, which is used for image preprocessing\n Lm3D = loadmat(fsimilarity_Lm3D_all_mat)\n Lm3D = Lm3D['lm']\n\n # calculate 5 facial landmarks using 68 landmarks\n lm_idx = np.array([31, 37, 40, 43, 46, 49, 55]) - 1\n Lm3D = np.stack([Lm3D[lm_idx[0], :], np.mean(Lm3D[lm_idx[[1, 2]], :], 0), np.mean(\n Lm3D[lm_idx[[3, 4]], :], 0), Lm3D[lm_idx[5], :], Lm3D[lm_idx[6], :]], axis=0)\n Lm3D = Lm3D[[1, 2, 0, 3, 4], :]\n self.Lm3D = Lm3D\n return Lm3D\n\n\ndef load_expbasis():\n # load expression basis\n n_vertex = 53215\n exp_bin = open(r'BFM\\Exp_Pca.bin', 'rb')\n exp_dim = array('i')\n exp_dim.fromfile(exp_bin, 1)\n expMU = array('f')\n expPC = array('f')\n expMU.fromfile(exp_bin, 3*n_vertex)\n expPC.fromfile(exp_bin, 3*exp_dim[0]*n_vertex)\n\n expPC = np.array(expPC)\n expPC = np.reshape(expPC, [exp_dim[0], -1])\n expPC = np.transpose(expPC)\n\n expEV = np.loadtxt(r'BFM\\std_exp.txt')\n\n return expPC, expEV\n\n\ndef transfer_BFM09():\n # tranfer original BFM2009 to target face model\n original_BFM = loadmat(r'BFM\\01_MorphableModel.mat')\n shapePC = original_BFM['shapePC'] # shape basis\n shapeEV = original_BFM['shapeEV'] # corresponding eigen values\n shapeMU = original_BFM['shapeMU'] # mean face\n texPC = original_BFM['texPC'] # texture basis\n texEV = original_BFM['texEV'] # corresponding eigen values\n texMU = original_BFM['texMU'] # mean texture\n\n expPC, expEV = load_expbasis()\n\n idBase = shapePC * np.reshape(shapeEV, [-1, 199])\n idBase = idBase / 1e5\t\t# unify the scale to decimeter\n idBase = idBase[:, :80]\t\t# use only first 80 basis\n\n exBase = expPC * np.reshape(expEV, [-1, 79])\n exBase = exBase / 1e5\t\t# unify the scale to decimeter\n exBase = exBase[:, :64]\t\t# use only first 64 basis\n\n texBase = texPC*np.reshape(texEV, [-1, 199])\n texBase = texBase[:, :80] # use only first 80 basis\n\n # our face model is cropped align face landmarks which contains only 35709 vertex.\n # original BFM09 contains 53490 vertex, and expression basis provided by JuYong contains 53215 vertex.\n # thus we select corresponding vertex to get our face model.\n index_exp = loadmat('BFM/BFM_front_idx.mat')\n index_exp = index_exp['idx'].astype(\n np.int32) - 1 # starts from 0 (to 53215)\n\n index_shape = loadmat('BFM/BFM_exp_idx.mat')\n index_shape = index_shape['trimIndex'].astype(\n np.int32) - 1 # starts from 0 (to 53490)\n index_shape = index_shape[index_exp]\n\n idBase = np.reshape(idBase, [-1, 3, 80])\n idBase = idBase[index_shape, :, :]\n idBase = np.reshape(idBase, [-1, 80])\n\n texBase = np.reshape(texBase, [-1, 3, 80])\n texBase = texBase[index_shape, :, :]\n texBase = np.reshape(texBase, [-1, 80])\n\n exBase = np.reshape(exBase, [-1, 3, 64])\n exBase = exBase[index_exp, :, :]\n exBase = np.reshape(exBase, [-1, 64])\n\n meanshape = np.reshape(shapeMU, [-1, 3]) / 1e5\n meanshape = meanshape[index_shape, :]\n meanshape = np.reshape(meanshape, [1, -1])\n\n meantex = np.reshape(texMU, [-1, 3])\n meantex = meantex[index_shape, :]\n meantex = np.reshape(meantex, [1, -1])\n\n # other info contains triangles, region used for computing photometric loss,\n # region used for skin texture regularization, and 68 landmarks index etc.\n other_info = loadmat('BFM/facemodel_info.mat')\n frontmask2_idx = other_info['frontmask2_idx']\n skinmask = other_info['skinmask']\n keypoints = other_info['keypoints']\n point_buf = other_info['point_buf']\n tri = other_info['tri']\n tri_mask2 = other_info['tri_mask2']\n\n # save our face model\n savemat('BFM/BFM_model_front.mat', {'meanshape': meanshape, 'meantex': meantex, 'idBase': idBase, 'exBase': exBase, 'texBase': texBase,\n 'tri': tri, 'point_buf': point_buf, 'tri_mask2': tri_mask2, 'keypoints': keypoints, 'frontmask2_idx': frontmask2_idx, 'skinmask': skinmask})\n\n\n# calculating least sqaures problem\ndef POS(xp, x):\n npts = xp.shape[1]\n\n A = np.zeros([2*npts, 8])\n\n A[0:2*npts-1:2, 0:3] = x.transpose()\n A[0:2*npts-1:2, 3] = 1\n\n A[1:2*npts:2, 4:7] = x.transpose()\n A[1:2*npts:2, 7] = 1\n\n b = np.reshape(xp.transpose(), [2*npts, 1])\n\n k, _, _, _ = np.linalg.lstsq(A, b, rcond=None)\n\n R1 = k[0:3]\n R2 = k[4:7]\n sTx = k[3]\n sTy = k[7]\n s = (np.linalg.norm(R1) + np.linalg.norm(R2))/2\n t = np.stack([sTx, sTy], axis=0)\n\n return t, s\n\n\ndef process_img(img, lm, t, s, target_size=224.):\n w0, h0 = img.size\n w = (w0/s*102).astype(np.int32)\n h = (h0/s*102).astype(np.int32)\n img = img.resize((w, h), resample=Image.BICUBIC)\n\n left = (w/2 - target_size/2 + float((t[0] - w0/2)*102/s)).astype(np.int32)\n right = left + target_size\n up = (h/2 - target_size/2 + float((h0/2 - t[1])*102/s)).astype(np.int32)\n below = up + target_size\n\n img = img.crop((left, up, right, below))\n img = np.array(img)\n img = img[:, :, ::-1] # RGBtoBGR\n img = np.expand_dims(img, 0)\n lm = np.stack([lm[:, 0] - t[0] + w0/2, lm[:, 1] -\n t[1] + h0/2], axis=1)/s*102\n lm = lm - \\\n np.reshape(\n np.array([(w/2 - target_size/2), (h/2-target_size/2)]), [1, 2])\n\n return img, lm\n\n\ndef Preprocess(img, lm, lm3D):\n # resize and crop input images before sending to the R-Net\n w0, h0 = img.size\n\n # change from image plane coordinates to 3D sapce coordinates(X-Y plane)\n lm = np.stack([lm[:, 0], h0 - 1 - lm[:, 1]], axis=1)\n\n # calculate translation and scale factors using 5 facial landmarks and standard landmarks\n # lm3D -> lm\n t, s = POS(lm.transpose(), lm3D.transpose())\n\n # processing the image\n img_new, lm_new = process_img(img, lm, t, s)\n\n lm_new = np.stack([lm_new[:, 0], 223 - lm_new[:, 1]], axis=1)\n trans_params = np.array([w0, h0, 102.0/s, t[0, 0], t[1, 0]])\n\n return img_new, lm_new, trans_params\n\n\ndef load_img(img_path, lm_path):\n # load input images and corresponding 5 landmarks\n image = Image.open(img_path)\n lm = np.loadtxt(lm_path)\n return image, lm\n\n\ndef save_obj(path, v, f, c):\n # save 3D face to obj file\n with open(path, 'w') as file:\n for i in range(len(v)):\n file.write('v %f %f %f %f %f %f\\n' %\n (v[i, 0], v[i, 1], v[i, 2], c[i, 0], c[i, 1], c[i, 2]))\n\n file.write('\\n')\n\n for i in range(len(f)):\n file.write('f %d %d %d\\n' % (f[i, 0], f[i, 1], f[i, 2]))\n\n file.close()\n\n\ndef transfer_UV():\n uv_model = loadmat('BFM/BFM_UV.mat')\n\n index_exp = loadmat('BFM/BFM_front_idx.mat')\n index_exp = index_exp['idx'].astype(\n np.int32) - 1 # starts from 0 (to 53215)\n\n uv_pos = uv_model['UV']\n uv_pos = uv_pos[index_exp, :]\n uv_pos = np.reshape(uv_pos, (-1, 2))\n\n return uv_pos\n"
},
{
"alpha_fraction": 0.8059701323509216,
"alphanum_fraction": 0.8059701323509216,
"avg_line_length": 66,
"blob_id": "086bc13fae2bbf2ffff228f925ca8c0520892c59",
"content_id": "382325aede01583ca254a7df65eba57e62d0106f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 67,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 1,
"path": "/Face Reconstruction/Landmark Detection and 3D Face Reconstruction for Caricature using a Nonlinear Parametric Model/data/README.txt",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "This folder is used to contain some necessary data for our method.\n"
},
{
"alpha_fraction": 0.6391912698745728,
"alphanum_fraction": 0.7091757655143738,
"avg_line_length": 25.75,
"blob_id": "05db9cf5393464c81482df7444640a9b3233cabc",
"content_id": "6fce8dff75cc11a40da0291d2aa8cfa58d3439eb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 643,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 24,
"path": "/facex-library/demo.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from facex import cartoonify, face_detection, blur_bg, ghost_img, mosaic, sketch\nfrom facex import face_mask\nimport cv2\n\n## Cartoonify effect(Command similar to face_det, blur_bg, ghost_img)\nimage = cartoonify(img_path='face.jpg')\ncv2.imshow(\"cartoon\", cv2.resize(image, (600,600)))\ncv2.waitKey()\n\n\n## Mosaic Effect\nimage = mosaic(img_path='face.jpg', x=219, y=61, w=460-219, h=412-61)\ncv2.imshow(\"ghost\", cv2.resize(image, (600,600)))\ncv2.waitKey()\n\n\n## Face mask detection(Image)\nimage = face_mask('face.jpg')\ncv2.imshow(\"face_mask\", cv2.resize(image, (600,600)))\ncv2.waitKey()\n\n\n## Face mask detection(Video)\n# face_mask('your-video.mp4') \n"
},
{
"alpha_fraction": 0.5227803587913513,
"alphanum_fraction": 0.5630841255187988,
"avg_line_length": 25.516128540039062,
"blob_id": "5db095330a9def3e96239124a0748e4f4111cb46",
"content_id": "678618ca1aca5c939e653f2948e49a275e727401",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1712,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 62,
"path": "/Recognition-Algorithms/Recognition using KNearestNeighbors/GUI.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import cv2\r\nimport numpy as np\r\nfrom sklearn.neighbors import KNeighborsClassifier\r\nfrom tkinter import Tk , Label , Frame \r\n\r\n\r\n\r\ndata = np.load(\"face_data.npy\")\r\n# Name = input(\"Whom you want to search: \\n\")\r\n\r\n# print(data.shape, data.dtype)\r\n\r\nX = data[:, 1:].astype(int)\r\ny = data[:, 0]\r\nmodel = KNeighborsClassifier()\r\nmodel.fit(X, y)\r\ncap = cv2.VideoCapture(0)\r\ndetector = cv2.CascadeClassifier(\"./haarcascade_frontalface_default.xml\")\r\nwhile True:\r\n\r\n ret, frame = cap.read()\r\n\r\n if ret:\r\n faces = detector.detectMultiScale(frame,1.1,4)\r\n\r\n for face in faces:\r\n x, y, w, h = face\r\n\r\n\r\n cut = frame[y:y+h, x:x+w]\r\n\r\n fix = cv2.resize(cut, (100, 100))\r\n gray = cv2.cvtColor(fix, cv2.COLOR_BGR2GRAY)\r\n\r\n out = model.predict([gray.flatten()])\r\n \r\n \r\n cv2.rectangle(frame, (x, y), (x+w, y+h), (255, 0, 0), 2)\r\n cv2.putText(frame, str(f\"User Identified:{out[0]}\"), (x, y - 10), cv2.FONT_HERSHEY_COMPLEX, 2, (255, 0, 0), 2)\r\n \r\n cv2.imshow(\"My Face\", gray)\r\n \r\n cv2.imshow(\"My Screen\", frame)\r\n key = cv2.waitKey(1)\r\n if key == ord(\"q\"):\r\n break\r\ncap.release()\r\ncv2.destroyAllWindows()\r\n\r\nroot = Tk()\r\n\r\nroot.geometry(\"400x200\")\r\nroot.maxsize(400, 200)\r\nroot.minsize(350,180)\r\nroot.configure(background='Azure')\r\nroot.title(\"Recogniser\")\r\nmy = Label(text=\"Image Recogniser Result\",bg = \"Azure\",\r\n fg='Black', font=('comicsansms', 19, 'bold'))\r\nmy.pack()\r\nmy3 = Label(text=f'User Identified: {out}',bg = \"Beige\", fg='Black',font=('comicsansms', 15),relief=\"sunken\")\r\nmy3.pack(pady=50)\r\nroot.mainloop()\r\n \r\n"
},
{
"alpha_fraction": 0.6203975677490234,
"alphanum_fraction": 0.6459227204322815,
"avg_line_length": 41.3636360168457,
"blob_id": "ff46a031e151d8961b28913504aa01897973f29e",
"content_id": "2539b011dabe39463f8245feb3a1fe263be5ecb3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8854,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 209,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/geometry/render/trimesh_render.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n# system\nfrom __future__ import print_function\n\n# python lib\nimport trimesh\nfrom copy import deepcopy\nimport numpy as np\n\n# tf_render\nimport tensorflow as tf\n\n# self\nfrom tfmatchd.face.common.format_helper import batch_size_extract\n\nfrom tfmatchd.face.geometry.camera.rotation import RotationMtxBatch, ExtMtxBatch\n\n#\nfrom tf_mesh_renderer.mesh_renderer.mesh_renderer import tone_mapper\nfrom tfmatchd.face.geometry.render.api_tf_mesh_render import mesh_renderer_camera, mesh_depthmap_camera\n\ndef Render_Trimesh_feed(vertices, triangles, normals, diffuse_colors,\n mtx_cam, mtx_perspect_frustrum, cam_position, image_width, image_height):\n \"\"\"\n :param trimesh:\n :param mtx_cam:\n :param mtx_perspect_frustrum:\n :param cam_position:\n :param image_width:\n :param image_height:\n :return:\n A 4-D float32 tensor of shape [batch_size, image_height, image_width, 4]\n containing the lit RGBA color values for each image at each pixel. RGB\n colors are the intensity values before tonemapping and can be in the range\n [0, infinity]. Clipping to the range [0,1] with tf_render.clip_by_value is likely\n reasonable for both viewing and training most scenes. More complex scenes\n with multiple lights should tone map color values for display only. One\n simple tonemapping approach is to rescale color values as x/(1+x); gamma\n compression is another common techinque. Alpha values are zero for\n background pixels and near one for mesh pixels.\n \"\"\"\n batch_size = batch_size_extract(vertices, normals, diffuse_colors,\n mtx_cam, mtx_perspect_frustrum, cam_position)\n\n light_positions = tf.constant([[0.0, 0.0, 1000.0, -1000.0, 0.0, 1000.0, 1000.0, 0.0, 1000.0]], shape=[1, 3, 3])\n light_positions = tf.tile(light_positions, [batch_size, 1, 1])\n light_intensities = tf.constant([[0.50, 0.50, 0.50]], shape=[1, 3, 3])\n light_intensities = tf.tile(light_intensities, [batch_size, 1, 1])\n\n # light_positions = tf.constant([[0.0, 0.0, 2000.0]], shape=[1, 1, 3])\n # light_intensities = tf.constant([[0.5, 0.5, 0.5]], shape=[1, 1, 3])\n #light_intensities = tf.constant([[1.0, 1.0, 1.0]], shape=[1, 1, 3])\n #ambient_color = tf.constant([[1.0, 1.0, 1.0]])\n # Batch\n\n #print(batch_size, image_width, image_height)\n\n if vertices.shape[0] != batch_size:\n vertices = tf.tile(vertices, [batch_size, 1, 1])\n normals = tf.tile(normals, [batch_size, 1, 1])\n diffuse_colors = tf.tile(diffuse_colors, [batch_size, 1, 1])\n\n if mtx_perspect_frustrum.shape[0] != batch_size:\n mtx_perspect_frustrum = tf.tile(mtx_perspect_frustrum, [batch_size, 1, 1])\n\n # if ambient_color.shape[0] != batch_size:\n # ambient_color = tf.tile(ambient_color, [batch_size, 1])\n\n renders, pixel_mask = mesh_renderer_camera(\n vertices, triangles, normals, diffuse_colors,\n mtx_cam, mtx_perspect_frustrum, cam_position,\n light_positions, light_intensities, image_width, image_height#, ambient_color=ambient_color\n )\n renders = tf.clip_by_value(renders, 0.0, 1.0)\n # tonemapped_renders = tf.concat(\n # [\n # tone_mapper(renders[:, :, :, 0:3], 0.7),\n # renders[:, :, :, 3:4]\n # ],\n # axis=3)\n # return tonemapped_renders\n return renders\n\ndef RenderDepthmap_Trimesh_feed(vertices, triangles, mtx_ext, mtx_cam, mtx_perspect_frustrum,\n image_width, image_height):\n \"\"\"\n :param trimesh:\n :param mtx_cam:\n :param mtx_perspect_frustrum:\n :param cam_position:\n :param image_width:\n :param image_height:\n :return:\n A 4-D float32 tensor of shape [batch_size, image_height, image_width, 4]\n containing the lit RGBA color values for each image at each pixel. RGB\n colors are the intensity values before tonemapping and can be in the range\n [0, infinity]. Clipping to the range [0,1] with tf_render.clip_by_value is likely\n reasonable for both viewing and training most scenes. More complex scenes\n with multiple lights should tone map color values for display only. One\n simple tonemapping approach is to rescale color values as x/(1+x); gamma\n compression is another common techinque. Alpha values are zero for\n background pixels and near one for mesh pixels.\n \"\"\"\n # Batch\n batch_size = batch_size_extract(vertices, mtx_cam, mtx_perspect_frustrum)\n #print(batch_size, image_width, image_height)\n\n if vertices.shape[0] != batch_size:\n vertices = tf.tile(vertices, [batch_size, 1, 1])\n\n if mtx_perspect_frustrum.shape[0] != batch_size:\n mtx_perspect_frustrum = tf.tile(mtx_perspect_frustrum, [batch_size, 1, 1])\n\n renders, pixel_mask = mesh_depthmap_camera(\n vertices, triangles, mtx_ext, mtx_cam, mtx_perspect_frustrum, image_width, image_height\n )\n renders = tf.expand_dims(renders, -1) # * pixel_mask\n #renders = tf.clip_by_value(renders, 0.0, 100000.0)\n # tonemapped_renders = tf.concat(\n # [\n # tone_mapper(renders[:, :, :, 0:3], 0.7),\n # renders[:, :, :, 3:4]\n # ],\n # axis=3)\n # return tonemapped_renders\n return renders, pixel_mask\n\n\ndef Render_Trimesh(trimesh, mtx_cam, mtx_perspect_frustrum, cam_position,\n light_positions, light_intensities, image_width, image_height, ambient_color=None):\n \"\"\"\n\n :param trimesh:\n :param mtx_cam:\n :param mtx_perspect_frustrum:\n :param cam_position:\n :param light_positions:\n :param light_intensities:\n :param image_width:\n :param image_height:\n :param ambient_color:\n :return:\n A 4-D float32 tensor of shape [batch_size, image_height, image_width, 4]\n containing the lit RGBA color values for each image at each pixel. RGB\n colors are the intensity values before tonemapping and can be in the range\n [0, infinity]. Clipping to the range [0,1] with tf_render.clip_by_value is likely\n reasonable for both viewing and training most scenes. More complex scenes\n with multiple lights should tone map color values for display only. One\n simple tonemapping approach is to rescale color values as x/(1+x); gamma\n compression is another common techinque. Alpha values are zero for\n background pixels and near one for mesh pixels.\n \"\"\"\n vertices = tf.constant(np.array(trimesh.vertices), dtype=tf.float32)\n vertices = tf.reshape(vertices, [1, -1, 3])\n triangles = tf.constant(np.array(trimesh.faces), dtype=tf.int32)\n triangles = tf.reshape(triangles, [-1, 3])\n #normals = tf_render.nn.l2_normalize(vertices, dim=2)\n normals = tf.constant(np.array(trimesh.vertex_normals), dtype=tf.float32)\n normals = tf.reshape(normals, [1, -1, 3])\n diffuse_colors = tf.constant(np.array(trimesh.visual.vertex_colors[:, 0:3])/255.0, dtype=tf.float32)\n diffuse_colors = tf.reshape(diffuse_colors, [1, -1, 3])\n\n # Batch\n batch_size = batch_size_extract(vertices, normals, diffuse_colors,\n mtx_cam, mtx_perspect_frustrum, cam_position,\n light_positions, light_intensities)\n\n if vertices.shape[0] != batch_size:\n vertices = tf.tile(vertices, [batch_size, 1, 1])\n normals = tf.tile(normals, [batch_size, 1, 1])\n diffuse_colors = tf.tile(diffuse_colors, [batch_size, 1, 1])\n\n if mtx_perspect_frustrum.shape[0] != batch_size:\n mtx_perspect_frustrum = tf.tile(mtx_perspect_frustrum, [batch_size, 1, 1])\n\n if ambient_color.shape[0] != batch_size:\n ambient_color = tf.tile(ambient_color, [batch_size, 1])\n\n renders, pixel_mask = mesh_renderer_camera(\n vertices, triangles, normals, diffuse_colors,\n mtx_cam, mtx_perspect_frustrum, cam_position,\n light_positions, light_intensities, image_width, image_height, ambient_color=ambient_color\n )\n tonemapped_renders = tf.concat(\n [\n tone_mapper(renders[:, :, :, 0:3], 0.7),\n renders[:, :, :, 3:4]\n ],\n axis=3)\n return tonemapped_renders\n\n\ndef RotationMtx_Trimesh(mesh_tri, idx_nose, camera_centre_distance):\n mesh_c = tf.constant(mesh_tri.vertices[idx_nose], dtype=tf.float32) # mm\n\n cam_front_eye = tf.Variable(\n [[mesh_c[0], mesh_c[1], mesh_c[2] + camera_centre_distance]], dtype=tf.float32\n )\n cam_front_center = tf.Variable(\n [[mesh_c[0], mesh_c[1], mesh_c[2]]], dtype=tf.float32\n )\n cam_front_up = tf.Variable(\n [[0.0, 1.0, 0.0]], dtype=tf.float32\n )\n location = tf.stack([cam_front_eye, cam_front_center, cam_front_up], axis=1)\n\n h_ext = ExtMtxBatch.create_location_batch(location)\n\n mesh_c_batch = tf.expand_dims(mesh_c, 0)\n return h_ext, mesh_c_batch"
},
{
"alpha_fraction": 0.6831735968589783,
"alphanum_fraction": 0.7000355124473572,
"avg_line_length": 26.32524299621582,
"blob_id": "1bc1d0a7213b29ee56201350e46143e43af448fa",
"content_id": "b48b5665a85d2e682edd2c5913dc6187f020d4ad",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5634,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 206,
"path": "/Recognition-Algorithms/Recognition using LDA/FaceRecognitionUsingLDA.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Importing libraries\nfrom time import time\nfrom sklearn.datasets import fetch_lfw_people\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.decomposition import PCA\nfrom sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA\nfrom sklearn.model_selection import GridSearchCV\nfrom sklearn.svm import SVC\nfrom sklearn.metrics import classification_report \nfrom sklearn.metrics import confusion_matrix\nimport matplotlib\nimport matplotlib.pyplot as plt\nimport warnings\n\n# Fetching the dataset\n# To change the dataset, alter the dataset geting return\ndef fetch_dataset():\n\tdataset = fetch_lfw_people(min_faces_per_person = 100)\n\n\treturn dataset\n\n\ndef get_dataset_details(dataset):\n\tn_samples, height, width = dataset.images.shape\n\n\tX = dataset.data\n\tn_features = X.shape[1]\n\n\t# The identification label\n\ty = dataset.target\n\tt_names = dataset.target_names\n\tn_classes = t_names.shape[0]\n\n\tprint(\"Dataset Size: \")\n\tprint(\"n_samples: %d\" %n_samples)\n\tprint(\"n_features: %d\" %n_features)\n\tprint(\"n_classes: %d\" %n_classes)\n\tprint()\n\n\treturn n_samples, height, width, X, n_features, y, t_names, n_classes\n\n\n# Splitting the dataset in train and test data sets\n# Change the test size here\ndef split_data(X, y):\n\tX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 42)\n\n\treturn X_train, X_test, y_train, y_test \n\n\n# reducing the dimenionality of the dataset using PCA\ndef dimensionality_reduction(n_components, X_train, y_train):\n\tprint(\"Selecting top %d fisher faces from %d faces\" %(n_components, X_train.shape[0]))\n\n\tt_begin = time()\n\t\n\tpca = PCA(n_components = n_components).fit(X_train)\n\tlda = LDA().fit(pca.transform(X_train), y_train)\n\n\tprint(\"Time taken: %0.3fs\\n\" %(time() - t_begin))\n\n\treturn lda, pca\n\n\n# Projecting the dataset on the eigenfaces orthonormal basis\ndef train_text_transform(lda, pca, X_train, X_test):\n\tprint(\"Projecting the dataset on the eigenfaces orthonormal basis\")\n\n\tt_begin = time() \n\tX_train = lda.transform(pca.transform(X_train))\n\tX_test = lda.transform(pca.transform(X_test))\n\n\ttime_taken = time() - t_begin\n\tprint(\"Time taken: %0.3fs\\n\" %time_taken)\n\n\treturn X_train, X_test\n\n# Fitting classifier\ndef classification(X_train_model, y_train):\n\tprint(\"Fitting classifier to the training set\")\n\n\tt_begin = time()\n\tparam_grid = {'C': [1e3, 5e3, 1e4, 5e4, 1e5], 'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1],}\n\t\n\tclf = GridSearchCV(SVC(kernel = 'rbf', class_weight = 'balanced'), param_grid)\n\tclf = clf.fit(X_train_model, y_train)\n\n\ttime_taken = time() - t_begin\n\n\tprint(\"Time taken: %0.3fs\" %time_taken)\n\tprint(\"Best estimator selected by grid search: \")\n\tprint(clf.best_estimator_)\n\tprint()\n\n\treturn clf\n\n\n# finding y_prediction\ndef prediction(model, data):\n\tprint(\"Printing names of faces on test set\")\n\n\tt_begin = time()\n\ty_pred = model.predict(data)\n\ttime_taken = time() - t_begin\n\n\tprint(\"Time taken: %0.3fs\\n\" %time_taken)\n\n\treturn y_pred\n\n\n# print classification report and confusion matrix\ndef report(y_test, y_pred, t_names, n_classes):\n\tprint(\"Classification Report: \")\n\tprint(classification_report(y_test, y_pred, target_names = t_names))\n\tprint()\n\tprint(\"Confusion Matrix: \")\n\tprint(confusion_matrix(y_test, y_pred, labels = range(n_classes)))\n\tprint()\n\n\n# Plotting the data\n\nmatplotlib.rcParams.update(\n\t{\n\t\t'text.usetex': False,\n\t\t# Use the Computer modern font\n\t\t'font.family': 'stixgeneral',\n\t\t'font.serif': 'cmr10',\n\t\t'mathtext.fontset': 'cm',\n\t\t# Use ASCII minus\n\t\t'axes.unicode_minus': False,\n\t}\n)\n\ndef plot_images(images, titles, height, width, n_row = 1, n_col = 4):\n\tplt.figure(figsize=(1.8*n_col, 2.6*n_row))\n\tplt.subplots_adjust(bottom = 0, left = 0.01, right = 0.99, top = 0.90, hspace = 0.35)\n\n\tfor i in range(n_row*n_col):\n\t\tplt.subplot(n_row, n_col, i + 1)\n\t\tplt.imshow(images[i].reshape((height, width)), cmap = plt.cm.gray)\n\t\tplt.title(titles[i], size = 12)\n\t\tplt.xticks(())\n\t\tplt.yticks(())\n\n\twarnings.filterwarnings(\"ignore\", message=\"Glyph 9 missing from current font.\")\n\tplt.show()\n\n\n\ndef plot_with_pca(pca, lda, titles, height, width, n_row = 1, n_col = 4):\n\tplt.figure(figsize = (1.8*n_col, 2.4*n_row))\n\tfor i in range(n_row * n_col):\n\t\tplt.subplot(n_row, n_col, i + 1)\n\t\tplt.imshow(pca.inverse_transform(lda.scalings_[:, i]).reshape((height, width)), cmap = plt.cm.gray)\n\t\tplt.title(titles[i], size = 12)\n\t\tplt.xticks(())\n\t\tplt.yticks(())\n\n\tplt.show()\n\n\n# The predicted titles\ndef titles(y_pred, y_test, t_names, i):\n\tpred_name = t_names[y_pred[i]].rsplit(' ', 1)[-1]\n\treal_name = t_names[y_test[i]].rsplit(' ', 1)[-1]\n\t\n\treturn 'predicted: %s\\n true: \t%s' %(pred_name, real_name)\n\n\n\n\n\n# Main\n# Loading dataset\ndataset = fetch_dataset()\n\n# get dataset details and target names\nn_samples, height, width, X, n_features, y, t_names, n_classes = get_dataset_details(dataset)\n\n# splitting dataset\nX_train, X_test, y_train, y_test = train_test_split(X, y)\n\n# Computing Linear Discriminant Analysis\nn_components = 150 \nlda, pca = dimensionality_reduction(n_components, X_train, y_train)\nX_train_lda, X_test_lda = train_text_transform(lda, pca, X_train, X_test)\n\n\n# training a SVM classification model\nclf = classification(X_train_lda, y_train)\n\n# Quantitative evaluation of the model quality on the test set\ny_pred = prediction(clf, X_test_lda)\n\n# printing report\nreport(y_test, y_pred, t_names, n_classes)\n\n# print images\nprediction_titles = [titles(y_pred, y_test, t_names, i) for i in range(y_pred.shape[0])]\n\nplot_images(X_test, prediction_titles, height, width)\n\n# plot fisherfaces\nfisherfaces_names = [\"fisherface %d\" % i for i in range(4)]\nplot_with_pca(pca, lda, fisherfaces_names, height, width)\n\n\n\n\n "
},
{
"alpha_fraction": 0.592783510684967,
"alphanum_fraction": 0.6855670213699341,
"avg_line_length": 20.66666603088379,
"blob_id": "ede853c12bbd1054f56393952207711e7140500c",
"content_id": "f8b9f3123590a396763d3065f88acfe2d4274224",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 194,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 9,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_tfGraph/__init__.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# encoding: utf-8\n'''\n@author: Jiaxiang Shang\n@license: (C) Copyright 2013-2017, Node Supply Chain Manager Corporation Limited.\n@contact: [email protected]\n@time: 7/12/20 11:05 AM\n@desc:\n'''"
},
{
"alpha_fraction": 0.45296522974967957,
"alphanum_fraction": 0.48364007472991943,
"avg_line_length": 19.808509826660156,
"blob_id": "5048d190a2e44515ee939a67189ddf25c5f32d80",
"content_id": "068a0146cffc2c5444b791aa57eb1651133b580c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 978,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 47,
"path": "/Face Reconstruction/Facial Reconstruction and Dense Alignment/python/utils.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport cv2\n\n\ndef plot_vertices(image, vertices):\n image = image.copy()\n vertices = np.round(vertices).astype(np.int32)\n for i in range(0, vertices.shape[1], 2):\n st = vertices[:2, i]\n\n image = cv2.circle(image, (st[0], st[1]), 0, (128, 128, 0), 1)\n\n return image\n\n\ndef crop_img(img, roi_box):\n h, w = img.shape[:2]\n\n sx, sy, ex, ey = [int(round(_)) for _ in roi_box]\n dh, dw = ey - sy, ex - sx\n if len(img.shape) == 3:\n res = np.zeros((dh, dw, 3), dtype=np.uint8)\n else:\n res = np.zeros((dh, dw), dtype=np.uint8)\n if sx < 0:\n sx, dsx = 0, -sx\n else:\n dsx = 0\n\n if ex > w:\n ex, dex = w, dw - (ex - w)\n else:\n dex = dw\n\n if sy < 0:\n sy, dsy = 0, -sy\n else:\n dsy = 0\n\n if ey > h:\n ey, dey = h, dh - (ey - h)\n else:\n dey = dh\n\n res[dsy:dey, dsx:dex] = img[sy:ey, sx:ex]\n ret_roi = [sx, sy, ex, ey]\n return res, ret_roi\n"
},
{
"alpha_fraction": 0.7233502268791199,
"alphanum_fraction": 0.7512690424919128,
"avg_line_length": 27.14285659790039,
"blob_id": "158b93ea766dda2f940f3e149cd7bc16e01bcd06",
"content_id": "d5fea86d2e6c03f68cde1d40e8f8e92bdec9d2be",
"detected_licenses": [
"BSD-3-Clause",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 394,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 14,
"path": "/Snapchat_Filters/Glasses on face/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Cool Glass Filter\n## Quick Start\n- Clone this repository\n` git clone https://github.com/akshitagupta15june/Face-X.git`\n- Change Directory\n` cd Snapchat_Filters` ,then, `cd Glasses on face`\n- Download shape_predictor_68_face_landmarks.dat file in Glasses on face folder.\n- Run code file.\n` python Face_glasses.py`\n\n# Screenshots\n\n\n\n"
},
{
"alpha_fraction": 0.7648000121116638,
"alphanum_fraction": 0.774399995803833,
"avg_line_length": 58.47618865966797,
"blob_id": "3e8111382467ae628f458cc093f20730665786ff",
"content_id": "51b7775aec462f57784421ff21c00c7a2e0888e7",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1252,
"license_type": "permissive",
"max_line_length": 449,
"num_lines": 21,
"path": "/Awesome-face-operations/Image-Stiching/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n### What is image stitching?\nAt the beginning of the stitching process, as input, we have several images with overlapping areas. The output is a unification of these images. It is important to note that a full scene from the input image must be preserved in the process. To construct our image stiching, we’ll utilize computer vision and image processing techniques such as: keypoint detection and local invariant descriptors; keypoint matching; RANSAC; and perspective warping.\n\n### Dependencies used:\n- openCV\n- numpy\n\n### Steps to run:\n- Download the directory.\n- You can use any Editor, Notebook Or IDE's to open the image-stiching.py file.\n- Run the code\n\n### Example:\n\n\n### Our panorama stitching algorithm consists of four steps:\n\n- Step #1: Detect keypoints (DoG, Harris, etc.) and extract local invariant descriptors (SIFT, SURF, etc.) from the two input images.\n- Step #2: Match the descriptors between the two images.\n- Step #3: Use the RANSAC algorithm to estimate a homography matrix using our matched feature vectors.\n- Step #4: Apply a warping transformation using the homography matrix obtained from Step #3.\n"
},
{
"alpha_fraction": 0.6333652138710022,
"alphanum_fraction": 0.6429254412651062,
"avg_line_length": 43.51063919067383,
"blob_id": "4ad370eb8ab2e4eefd2e88774c2f2efee40e7735",
"content_id": "bac229e64a5b7e8e0e3755a1fac4b210020c2c0d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4184,
"license_type": "permissive",
"max_line_length": 157,
"num_lines": 94,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_tfGraph/decoder_multiView.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n# system\nfrom __future__ import print_function\n\n# tf_render\nimport tensorflow as tf\n\n# tianwei\nfrom src_common.geometry.geo_utils import get_relative_pose, mat2pose_vec\n\n# self\n# jiaxiang\nfrom src_common.geometry.render.tensor_render import *\nfrom src_common.geometry.covisible import mm_covisible_tri\n# python lib\n#\n\n\"\"\"\nMulti-view decoder\n\"\"\"\ndef decoder_warppose(opt, list_pred_pose):\n pred_pose_render = list_pred_pose[0]\n rel_pose_list = []\n for i in range(opt.num_source):\n rel_pose_l = get_relative_pose(pred_pose_render, list_pred_pose[1+i]) # careful of [tar, src]\n rel_pose_l = mat2pose_vec(rel_pose_l)\n #rel_pose_l = tf.Print(rel_pose_l, [rel_pose_l], message='rel_pose_l')\n rel_pose_list.append(rel_pose_l)\n #image_pred_poses = tf.stack(rel_pose_list, axis=1)\n return rel_pose_list\n\ndef decoder_covisible_map(opt, h_lrgp, gpmm_frustrum, dict_inter_common):\n # input\n list_tri_buffer = dict_inter_common['3dmm_render_tri_id']\n\n # return\n list_gpmm_covisibleMap = []\n\n \"\"\"\n Here calculate consistence triangle\n \"\"\"\n tri_ids_tar = list_tri_buffer[0] # triangle id on image for per pixel\n for i in range(opt.num_source):\n # careful of [tar, src]\n tri_ids_src = list_tri_buffer[1+i] # triangle id on image for per pixel\n\n tri_consistency = mm_covisible_tri(h_lrgp, tri_ids_tar, tri_ids_src)\n\n # fore render\n zbf_vertex_fore_tar = tf.gather(dict_inter_common['gpmm_vertex'][0], h_lrgp.h_curr.idx_subTopo, axis=1)\n zbf_vertex_normal_fore = tf.gather(dict_inter_common['gpmm_vertexNormal'][0], h_lrgp.h_curr.idx_subTopo, axis=1)\n zbf_vertex_color_fore = tf.gather(dict_inter_common['gpmm_vertexColor'][0], h_lrgp.h_curr.idx_subTopo, axis=1)\n\n _, zbuffer_mask, _ = gpmm_render_image(\n opt, zbf_vertex_fore_tar, tri_consistency, zbf_vertex_normal_fore, zbf_vertex_color_fore,\n gpmm_frustrum, dict_inter_common['pred_cam_mv'][0], dict_inter_common['pred_cam_eye'][0]\n )\n list_gpmm_covisibleMap.append(zbuffer_mask)\n # mid\n # _, zbuffer_mask, _ = gpmm_render_image(\n # opt, dict_inter_common['gpmm_vertex'][0], tri_consistency, dict_inter_common['gpmm_vertexNormal'][0], dict_inter_common['gpmm_vertexColor'][0],\n # gpmm_frustrum, dict_inter_common['pose_mv'][0], dict_inter_common['pose_eye'][0]\n # )\n # list_gpmm_covisibleMap.append(zbuffer_mask)\n return list_gpmm_covisibleMap\n\ndef decoder_align_depthMap(opt, list_depthMap, list_syn_depthMap, list_syn_mask):\n list_depth_align = []\n for i in range(len(list_depthMap)):\n visible_target_depth = list_depthMap[i]\n visible_source_depth = list_syn_depthMap[i]\n proj_mask = list_syn_mask[i]\n\n # radio\n visible_target_depth_mask = tf.multiply(visible_target_depth, proj_mask)\n visible_source_depth_mask = tf.multiply(visible_source_depth, proj_mask)\n\n # visible_tar_depth_value = tf.boolean_mask(visible_source_depth_mask, proj_mask)\n # visible_src_depth_value = tf.boolean_mask(visible_source_depth_mask, proj_mask)\n mean_target_depth = tf.reduce_sum(visible_target_depth_mask, axis=[1, 2]) / \\\n (tf.reduce_sum(proj_mask, axis=[1, 2]) + 1.0)\n mean_source_depth = tf.reduce_sum(visible_source_depth_mask, axis=[1, 2]) / \\\n (tf.reduce_sum(proj_mask, axis=[1, 2]) + 1.0)\n\n depth_ratio = mean_target_depth / (mean_source_depth + 1e-6)\n #depth_ratio = tf.Print(depth_ratio ,[depth_ratio], message='depth_ratio ')\n visible_source_depth_radio = list_syn_depthMap[i] * \\\n tf.tile(tf.reshape(depth_ratio, [opt.batch_size, 1, 1, 1]), [1, opt.img_height, opt.img_width, 1])\n\n #pred_render_max = tf.reduce_max(visible_source_depth_radio)\n #pred_render_min = tf.reduce_min(visible_source_depth_radio)\n #visible_source_depth_radio = tf.Print(visible_source_depth_radio, [pred_render_max, pred_render_min], message='src align depthmap')\n list_depth_align.append(visible_source_depth_radio)\n\n return list_depth_align"
},
{
"alpha_fraction": 0.7363796234130859,
"alphanum_fraction": 0.7785588502883911,
"avg_line_length": 102.36363983154297,
"blob_id": "9c6a45dce3bb22af1e7b28a8a84a3aa6f85ba136",
"content_id": "875da096337eb337da373d89a0d31a3fd5f29eb6",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1138,
"license_type": "permissive",
"max_line_length": 548,
"num_lines": 11,
"path": "/Awesome-face-operations/Template-Detection/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "### Introduction:\nTemplate Matching is a method for searching and finding the location of a template image in a larger image. OpenCV comes with a function `cv2.matchTemplate()` for this purpose. It simply slides the template image over the input image (as in 2D convolution) and compares the template and patch of input image under the template image. Several comparison methods are implemented in OpenCV. (You can check docs for more details). It returns a grayscale image, where each pixel denotes how much does the neighbourhood of that pixel match with template.\n\nIf input image is of size (WxH) and template image is of size (wxh), output image will have a size of (W-w+1, H-h+1). Once you got the result, you can use `cv2.minMaxLoc()` function to find where is the maximum/minimum value. Take it as the top-left corner of rectangle and take (w,h) as width and height of the rectangle. That rectangle is your region of template.\n\n### Basically, it's like object detection using templates for matching. \n\n### Example:\n\n\n\n\n"
},
{
"alpha_fraction": 0.5093666315078735,
"alphanum_fraction": 0.547725260257721,
"avg_line_length": 22.91111183166504,
"blob_id": "56e72af4ac1f8f43b76fdc895e3191672df61d05",
"content_id": "d4055c805166a489d01fd176e066c3dd5a391f5e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1121,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 45,
"path": "/Recognition-Algorithms/Recognition using KNearestNeighbors/image_recogniser.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import cv2\r\nimport numpy as np\r\nfrom sklearn.neighbors import KNeighborsClassifier\r\n\r\ndata = np.load(\"face_data.npy\")\r\n\r\n# print(data.shape, data.dtype)\r\nX = data[:, 1:].astype(int)\r\ny = data[:, 0]\r\nmodel = KNeighborsClassifier()\r\nmodel.fit(X, y)\r\ncap = cv2.VideoCapture(0)\r\ndetector = cv2.CascadeClassifier(\"./haarcascade_frontalface_default.xml\")\r\nwhile True:\r\n\r\n ret, frame = cap.read()\r\n\r\n if ret:\r\n faces = detector.detectMultiScale(frame,1.1,4)\r\n\r\n for face in faces:\r\n x, y, w, h = face\r\n\r\n cut = frame[y:y+h, x:x+w]\r\n\r\n fix = cv2.resize(cut, (100, 100))\r\n gray = cv2.cvtColor(fix, cv2.COLOR_BGR2GRAY)\r\n\r\n out = model.predict([gray.flatten()])\r\n \r\n cv2.rectangle(frame, (x, y), (x+w, y+h), (255, 0, 0), 2)\r\n cv2.putText(frame, str(out[0]), (x, y - 10), cv2.FONT_HERSHEY_COMPLEX, 2, (255, 0, 0), 2)\r\n \r\n cv2.imshow(\"My Face\", gray)\r\n\r\n cv2.imshow(\"My Screen\", frame)\r\n\r\n\r\n key = cv2.waitKey(1)\r\n\r\n if key == ord(\"q\"):\r\n break\r\n\r\ncap.release()\r\ncv2.destroyAllWindows()\r\n"
},
{
"alpha_fraction": 0.7470167279243469,
"alphanum_fraction": 0.807478129863739,
"avg_line_length": 95.69230651855469,
"blob_id": "b79dd1aae7f8ec2a5ebe1fbc369a03891d844873",
"content_id": "c46ce00c8a9dae76c466c4760e31e16d4ca06870",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1257,
"license_type": "permissive",
"max_line_length": 444,
"num_lines": 13,
"path": "/Awesome-face-operations/Video-BG-Substraction/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "Background subtraction is a major preprocessing steps in many vision based applications. For example, consider the cases like visitor counter where a static camera takes the number of visitors entering or leaving the room, or a traffic camera extracting information about the vehicles etc. In all these cases, first you need to extract the person or vehicles alone. Technically, you need to extract the moving foreground from static background.\n\n### Algorithm used: BackgroundSubtractorMOG2\n\nOne important feature of this algorithm is that it selects the appropriate number of gaussian distribution for each pixel. (Remember, in last case, we took a K gaussian distributions throughout the algorithm). It provides better adaptibility to varying scenes due illumination changes etc.\n\nHere, you have an option of selecting whether shadow to be detected or not. If `detectShadows = True` (which is so by default), it detects and marks shadows, but decreases the speed. Shadows will be marked in gray color.\n\n### Input:\n\n\n### Output:\n\n"
},
{
"alpha_fraction": 0.5325849652290344,
"alphanum_fraction": 0.5740567445755005,
"avg_line_length": 25.073171615600586,
"blob_id": "38507959d1da798ef978505f322386c81fdbc023",
"content_id": "be5361ac5aacc306e6dcfc4f2fa526bdaabb9534",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3207,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 123,
"path": "/Recognition-Algorithms/Recognition using GhostNet/output.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from PIL import Image\nimport cv2\nimport numpy as np\nimport torch\nimport torch.nn as nn\nfrom torchvision import transforms\nfrom glob import glob\nimport os\n\n# change device to GPU if available\ndevice = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\n\n# Loading the cascades\nface_classifier = cv2.CascadeClassifier(\n cv2.data.haarcascades + \"haarcascade_frontalface_default.xml\"\n)\n\n# number of unique faces + 1\nclasses = list(\n map(\n lambda x: x.split(\"\\\\\")[-1],\n glob(os.path.join(os.getcwd(), \"Datasets\", \"train\", \"*\")),\n )\n)\n\n\ndef face_extractor(img):\n # Function detects faces and returns the cropped face\n # If no face detected, it returns None\n faces = face_classifier.detectMultiScale(img, 1.3, 5)\n if faces is ():\n return None\n # Crop all faces found\n cropped_face = 0\n for (x, y, w, h) in faces:\n x = x - 10\n y = y - 10\n cropped_face = img[y : y + h + 50, x : x + w + 50]\n cv2.rectangle(img, (x, y), (x + w + 30, y + h + 40), (0, 255, 255), 2)\n return cropped_face\n\n\n# preprocess frame\npreprocess = transforms.Compose(\n [\n transforms.Resize(224),\n transforms.ToTensor(),\n transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),\n ]\n)\n\n# create model to load pretrained weights into\nclass Net(nn.Module):\n def __init__(self):\n super(Net, self).__init__()\n\n self.ghostnet = torch.hub.load(\n \"huawei-noah/ghostnet\", \"ghostnet_1x\", pretrained=False\n )\n self.ghostnet.to(device)\n for param in self.ghostnet.parameters():\n param.requires_grad = False\n\n self.fc1 = nn.Linear(1000, 512)\n self.fc2 = nn.Linear(512, 256)\n self.fc3 = nn.Linear(256, len(classes))\n\n self.dropout1 = nn.Dropout(0.3)\n self.dropout2 = nn.Dropout(0.3)\n\n def forward(self, x):\n x = self.ghostnet(x)\n x = self.dropout1(x)\n x = self.fc1(x)\n x = nn.functional.relu(x)\n x = self.dropout2(x)\n x = self.fc2(x)\n x = nn.functional.relu(x)\n x = self.fc3(x)\n x = nn.functional.softmax(x, dim=0)\n return x\n\n\n# Initialize webcam\nvideo_capture = cv2.VideoCapture(0)\n\n# load model\nmodel = Net().to(device)\nmodel.load_state_dict(torch.load(\"saved_model.pt\"))\nmodel.eval()\n\n# Recognize faces\nwhile True:\n _, frame = video_capture.read()\n face = face_extractor(frame)\n if face is not None:\n face = cv2.resize(face, (224, 224))\n im = Image.fromarray(face, \"RGB\")\n img = preprocess(im)\n img = torch.unsqueeze(img, 0)\n preds = model(img)\n\n name = \"None matching\"\n\n _, pred = preds.max(dim=1)\n if pred != 0:\n name = \"Face found:{}\".format(classes[pred])\n cv2.putText(frame, name, (50, 50), cv2.FONT_HERSHEY_COMPLEX, 1, (0, 255, 0), 2)\n else:\n cv2.putText(\n frame,\n \"No face found\",\n (50, 50),\n cv2.FONT_HERSHEY_COMPLEX,\n 1,\n (0, 255, 0),\n 2,\n )\n cv2.imshow(\"Video\", frame)\n if cv2.waitKey(1) & 0xFF == ord(\"q\"):\n break\nvideo_capture.release()\ncv2.destroyAllWindows()\n"
},
{
"alpha_fraction": 0.660592257976532,
"alphanum_fraction": 0.6651480793952942,
"avg_line_length": 22.105262756347656,
"blob_id": "2038150b86abd83e25a906d76b03e6fddfddfe49",
"content_id": "38c1a9100f2f9d8b3fa42a25e0474ee7ca880e8a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 439,
"license_type": "permissive",
"max_line_length": 41,
"num_lines": 19,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/geometry/gpmm/trimesh_util.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# system\nfrom __future__ import print_function\nimport os\nimport sys\n\n# python lib\nimport numpy as np\n\ndef vertex_y_max(trimesh):\n vertex = np.array(trimesh.vertices)\n vertex_y = list(vertex[:, 1])\n y_idx = vertex_y.index(max(vertex_y))\n return vertex[y_idx]\n\ndef vertex_y_min(trimesh):\n vertex = np.array(trimesh.vertices)\n vertex_y = list(vertex[:, 1])\n y_idx = vertex_y.index(min(vertex_y))\n return vertex[y_idx]\n"
},
{
"alpha_fraction": 0.7663969397544861,
"alphanum_fraction": 0.7818182110786438,
"avg_line_length": 52.59693908691406,
"blob_id": "2d208ea788d022d6a4070c7d6c042922c863bd37",
"content_id": "74633664be041cb348c2f3bc76f681ef9e65ba7f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 10513,
"license_type": "permissive",
"max_line_length": 723,
"num_lines": 196,
"path": "/Recognition-Algorithms/Recognition using DWT algorithm/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Recognition using DWT Alogrithm\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Recognition-Algorithms/Recognition%20using%20DWT%20algorithm/Images/C.png\" height=\"440px\" align=\"left\"/>\n\n## Introduction\nImage compression is important for many applications that\ninvolve huge data storage, transmission and retrieval such\nas for multimedia, documents, videoconferencing, and medical\nimaging. Uncompressed images require\nconsiderable storage capacity and transmission bandwidth.\nThe objective of image compression technique is to reduce\nredundancy of the image data in order to be able to store\nor transmit data in an efficient form. This results in the\nreduction of file size and allows more images to be stored\nin a given amount of disk or memory space [1-3]. In a\nlossless compression algorithm, compressed data can be\nused to recreate an exact replica of the original; no\ninformation is lost to the compression process. This type\nof compression is also known as entropy coding. This\nname comes from the fact that a compressed signal is\ngenerally more random than the original; patterns are\nremoved when a signal is compressed. While lossless\ncompression is useful for exact reconstruction, it generally\ndoes not provide sufficiently high compression ratios to be\ntruly useful in image compression.\n\nIn numerical analysis and functional analysis, a discrete wavelet transform (DWT) is any wavelet transform for which the wavelets are discretely sampled. As with other wavelet transforms, a key advantage it has over Fourier transforms is temporal resolution: it captures both frequency and location information (location in time).\n\n## Image Compression and Reconstruction\n The image compression system is composed of\ntwo distinct structural blocks: an encoder and a decoder.\nImage f(x,y) is fed into the encoder, which creates a set of\nsymbols from the input data and uses them to represent\nthe image. Image f\nˆ (x,y) denotes an approximation of the\ninput image that results from compressing and\nsubsequently decompressing the input image. \n\n### 1.PROPOSED SYSTEM\n<img src =\"https://github.com/Vi1234sh12/Face-X/blob/master/Recognition-Algorithms/Recognition%20using%20DWT%20algorithm/Images/1-Figure.png\" align=\"right\"/>\nconcerns face recognition using multi\nresolution analysis, namely wavelet decomposition. The wavelet transform provides a powerful\nmathematical tool for analysing non-stationary signals. The images used in this paper have been\ntaken from the ORL database.\n A. Wavelet Transform\nWavelet Transform is a popular tool in image processing and computer vision. Many applications, such as compression, detection, recognition, image retrieval et al. have been investigated. WT has the nice features of space frequency localization and multi-resolutions.\n1-D continuous WT of function f(t) defined as\n\nis wavelet basis function\n\nis called mother wavelet which has at least one vanishing moment. The arguments and denote the scale and location parameters, respectively. The oscillation in the basis functions increases with a decrease in a. The transform can be discretized by restraining and to a discrete lattice. 2-D DWT is generally carried out using a separable approach, by first calculating the 1-D DWT on the rows, and then\nthe `1-D DWT` on the columns :\n`DWTn[DWTm[x[m,n]]`. \nTwo-dimensional WT decomposes an image into 4 “subbands” that are localized in frequency and orientation, by LL, HL, LH, HH.\nEach of these sub bands can be thought of as a smaller version of the image representing different image properties. The band LL is a coarser approximation to the original image. The bands LH and HL record the changes of the image along horizontal and vertical directions, respectively. The HH band shows the high frequency component of the\nimage. Second level decomposition can then be conducted on the LL sub band. Fig.2 shows a two-level wavelet decomposition of two images of size 112X92 pixels.\nThey found that facial expressions and small occlusions affect the intensity manifold locally. Under frequency-based representation, only high-frequency spectrum is\naffected, called high-frequency phenomenon.\n\n### B. Haar Wavelet Transform (HWT)\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Recognition-Algorithms/Recognition%20using%20DWT%20algorithm/Images/hqdefault%20.jpg\" align=\"right\"/>\n\nHWT decomposition works on an averaging and differencing process as follows: \n \n It can be seen that the number of decomposition steps is `22 = 4`.\nGiven an original image, the Harr wavelet transform method separates high frequency and low frequency bands of the image by high-pass and low-pass filters from the horizontal direction and so does the vertical direction of the image.\n - Two-dimensional Haar wavelet transforms: \n There are two ways we can use wavelets to transform the pixel values within an image. Each is a generalization to two dimensions of the one-dimensional wavelet transform .To obtain the standard decomposition of an image; we first apply the one-dimensional wavelet transform to each row of pixel values. This operation gives us an average value along with detail coefficients for each row. Next, we treat these transformed rows as if they were themselves an image and apply the one-dimensional transform to each column. The resulting values are all detail coefficients except for a single overall average coefficient. The algorithm below computes the standard decomposition. Figure 3 illustrates each step of its operation.\n \n```\nprocedure StandardDecomposition (C: array [1. . h,\n1. . w] of reals)\nfor row 1 to h do\nDecomposition (C[row, 1. . w])\nend for\nfor col 1 to w do\nDecomposition (C[1. . h, col])\nend for\nend procedure\n```\nThe second type of two-dimensional wavelet transform, called the nonstandard decomposition, alternates between operations on rowsand columns. First, we perform one step of horizontal pairwise averaging and differencing on the pixel values in averaging and differencing to each column of the result. To complete the transformation, we repeat this\nprocess recursively only on the quadrant containing averages in both directions.\n```\nthe steps involved in the nonstandard decomposition.\nprocedure NonstandardDecomposition(C: array [1. .\nh, 1. . h] of reals)\nC C=h (normalize input coefficients)\nwhile h > 1 do\nfor row 1 to h do\nDecompositionStep (C[row, 1. . h])\nend for\nfor col 1 to h do\nDecompositionStep (C[1. . h, col])\nend for\nh h=2\nend while\nend procedure \n\n```\nB. Biorthogonal 9/7\nThe family of biorthogonal filters considered here are of lengths 9 and 7 and represent a super-set of the 9/7 pair that is used for face recognition. A biorthogonal\nwavelet is a wavelet where the associated wavelet transform is invertible but not necessarily orthogonal. Designing biorthogonal wavelets allows more degrees of freedom than orthogonal wavelets. One additional degree of freedom is the possibility to construct symmetric wavelet functions biorthogonal filters are the shortest odd length filter pair with the following properties:\n - minimum number of vanishing moments\n (which is 2 for any linear phase odd length filter);\n - two degrees of freedom;\n the structure of one stage of a twochannel biorthogonal filter bank. For the 9/7 DWT, filters H(z) and G(z) are symmetric FIR filters with nine and seven taps, respectively. Traditionally, the filters are implemented using convolution. This implementation is non-polyphase, and suffers from inefficient hardware utility and low throughput.\n <img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Recognition-Algorithms/Recognition%20using%20DWT%20algorithm/Images/oj.png\" hight=\"400px\"/>\n \n The steps of the proposed compression algorithm based on\nDWT are described below:\n - Decompose : \n Choose a wavelet; choose a level N. Compute the wavelet. Decompose the signals at level N.\n - Threshold detail coefficients : \n For each level from 1 to N, a threshold is selected and hard thresholding is applied to the detail coefficients.\n - Reconstruct : \n Compute wavelet reconstruction using the original approximation coefficients of level N and the modified detail coefficients of levels from 1 to N.\n \n## Code Overview: \n\n```\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nimport pywt\nimport pywt.data\n\n\n# Load image\noriginal = pywt.data.camera()\n\n# Wavelet transform of image, and plot approximation and details\ntitles = ['Approximation', ' Horizontal detail',\n 'Vertical detail', 'Diagonal detail']\ncoeffs2 = pywt.dwt2(original, 'bior1.3')\nLL, (LH, HL, HH) = coeffs2\nfig = plt.figure(figsize=(12, 3))\nfor i, a in enumerate([LL, LH, HL, HH]):\n ax = fig.add_subplot(1, 4, i + 1)\n ax.imshow(a, interpolation=\"nearest\", cmap=plt.cm.gray)\n ax.set_title(titles[i], fontsize=10)\n ax.set_xticks([])\n ax.set_yticks([])\n\nfig.tight_layout()\nplt.show()\n\n```\n\n## Result Obtains: \n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Recognition-Algorithms/Recognition%20using%20DWT%20algorithm/Images/lena2.png\" height=\"400px\" width=\"600px\" />\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Recognition-Algorithms/Recognition%20using%20DWT%20algorithm/Images/Gorup1.png\" height=\"470px\" align=\"left\"/>\n<p style=\"clear:both;\">\n<h1><a name=\"contributing\"></a><a name=\"community\"></a> <a href=\"https://github.com/akshitagupta15june/Face-X\">Community</a> and <a href=\"https://github.com/akshitagupta15june/Face-X/blob/master/CONTRIBUTING.md\">Contributing</a></h1>\n<p>Please do! Contributions, updates, <a href=\"https://github.com/akshitagupta15june/Face-X/issues\"></a> and <a href=\" \">pull requests</a> are welcome. This project is community-built and welcomes collaboration. Contributors are expected to adhere to the <a href=\"https://gssoc.girlscript.tech/\">GOSSC Code of Conduct</a>.\n</p>\n<p>\nJump into our <a href=\"https://discord.com/invite/Jmc97prqjb\">Discord</a>! Our projects are community-built and welcome collaboration. 👍Be sure to see the <a href=\"https://github.com/akshitagupta15june/Face-X/blob/master/Readme.md\">Face-X Community Welcome Guide</a> for a tour of resources available to you.\n</p>\n<p>\n<i>Not sure where to start?</i> Grab an open issue with the <a href=\"https://github.com/akshitagupta15june/Face-X/issues\">help-wanted label</a>\n</p>\n\n**Open Source First**\n\n best practices for managing all aspects of distributed services. Our shared commitment to the open-source spirit push the Face-X community and its projects forward.</p>\n"
},
{
"alpha_fraction": 0.6413214206695557,
"alphanum_fraction": 0.6469148993492126,
"avg_line_length": 42.015037536621094,
"blob_id": "0a287fe9167102c1b8c3d4e2fbbf1082450eaec8",
"content_id": "1b510c2e29fe9fc9acf26abf8b53817243d30f19",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5721,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 133,
"path": "/Face Reconstruction/3D Face Reconstruction using Graph Convolution Network/main.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import argparse\nimport os\nimport time\nfrom glob import glob\n\nimport numpy as np\nimport tensorflow as tf\n\nimport utils\nfrom lib.mesh_io import read_obj\nfrom model_normal import Model as NormalModel\nfrom model_resnet import Model as ResnetModel\n\n\ndef get_args():\n parser = argparse.ArgumentParser()\n parser.add_argument('--name', default='bfm09_face', help='dataset name')\n parser.add_argument('--suffix', default=None, help='suffix for training name')\n parser.add_argument('--mode', default='train', type=str, choices=['train', 'test'],\n help='train or test')\n parser.add_argument('--stage', default='all', choices=['all', 'rec', 'render'],\n help='training stage, only rec_loss, only render_loss or all_loss')\n parser.add_argument('--restore', default=False, action='store_true',\n help='restore checkpoint for training')\n parser.add_argument('--gan', default=False, action='store_true', help='using gan or not')\n parser.add_argument('--wide', default=False, action='store_true', help='using gan or not')\n parser.add_argument('--model', default='normal',\n help='using model, chose from normal, resnet, adv')\n parser.add_argument('--root_dir', default='/data/gcn_face', help='data root directory')\n parser.add_argument('--batch_size', type=int, default=4,\n help='input batch size for training (default: 64)')\n parser.add_argument('--epoch', type=int, default=50,\n help='number of epochs to train (default: 2)')\n parser.add_argument('--eval', type=float, default=0, help='eval frequency')\n parser.add_argument('--img_size', type=int, default=224, help='Size of input image')\n parser.add_argument('--nz', type=int, default=512, help='Size of latent variable')\n parser.add_argument('--lr', type=float, default=1e-4, help='Learning Rate')\n parser.add_argument('--buffer_size', type=int, default=10,\n help='buffer size for training data loading')\n parser.add_argument('--workers', type=int, default=4, help='number of data loading threads')\n parser.add_argument('--drop_rate', type=float, default=0.2, help='dropout rate')\n parser.add_argument('--adv_lambda', type=float, default=1e-3, help='lambda for adversarial loss')\n parser.add_argument('--seed', type=int, default=2, help='random seed (default: 1)')\n parser.add_argument('--input', default='data/test/raw', type=str,\n help='test input data path or directory')\n parser.add_argument('--output', default='results/raw', type=str,\n help='test output path or directory')\n\n return parser.parse_args()\n\n\ndef main():\n args = get_args()\n logger = utils.init_logger()\n logger.info(args)\n\n np.random.seed(args.seed)\n if not os.path.isdir(args.root_dir):\n # args.root_dir = '.'\n args.root_dir = '/mnt/d/Codes/gcn_face'\n logger.info(\"Loading data from %s\", args.root_dir)\n\n if args.suffix is None:\n args.suffix = args.model\n if args.gan:\n args.suffix = args.suffix + '_gan'\n\n refer_mesh = read_obj(os.path.join(args.root_dir, 'data', 'bfm09_face_template.obj'))\n # refer_meshes = utils.get_mesh_list(args.name)\n\n image_paths = glob('{}/data/CelebA_Segment/*.*'.format(args.root_dir))\n _, val_image_paths, test_image_paths = utils.make_paths(\n image_paths, os.path.join(args.root_dir, 'data', 'params', args.name, 'image'), args.root_dir)\n\n if args.mode == 'train':\n img_file = open(os.path.join(args.root_dir, 'data', 'CelebA_RGBA.bin'), 'rb')\n # lm_file = open(os.path.join(args.root_dir, 'data', 'CelebA_Landmark.bin'), 'rb')\n else:\n img_file = None\n\n gpu_config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)\n # pylint: disable=no-member\n gpu_config.gpu_options.allow_growth = True\n with tf.Graph().as_default() as graph, tf.device('/gpu:0'), tf.Session(config=gpu_config) as sess:\n if args.model == 'normal':\n model = NormalModel(args, sess, graph, refer_mesh, image_paths, img_file)\n elif args.model == 'resnet':\n model = ResnetModel(args, sess, graph, refer_mesh, image_paths, img_file)\n\n if args.mode in ['train']:\n # if not os.path.exists(os.path.join('checkpoints', args.name)):\n # os.makedirs(os.path.join('checkpoints', args.name))\n model.fit()\n img_file.close()\n # lm_file.close()\n else:\n if args.input and not os.path.isdir(args.input):\n args.input = None\n if args.input is not None:\n # input_dir = os.path.join('data', 'test', args.input)\n input_dir = args.input\n test_image_paths = [os.path.join(input_dir, x) for x in sorted(os.listdir(input_dir))]\n if args.output is None:\n test_dir = os.path.join('results', args.input)\n else:\n if args.output is None:\n test_dir = model.samp_dir + '_test'\n if args.output is not None:\n test_dir = args.output\n if not os.path.isdir(test_dir):\n os.makedirs(test_dir)\n\n predictor_path = os.path.join('data', 'shape_predictor_68_face_landmarks.dat')\n cropper = utils.ImageCropper(predictor_path, model.img_size)\n\n test_image = utils.load_images(test_image_paths, model.img_size, False, False, cropper)\n\n from face_segment import Segment\n segmenter = Segment()\n alphas = segmenter.segment(test_image)\n\n test_rgba = np.concatenate([test_image, alphas[..., np.newaxis]], axis=-1)\n\n string, results = model.evaluate(test_rgba)\n logger.info(string)\n\n for i, path in enumerate(test_image_paths):\n model.save_sample(results, i, test_rgba, None, test_dir, i, False)\n logger.info('Saving results from %s', path)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.4916343092918396,
"alphanum_fraction": 0.5154616236686707,
"avg_line_length": 33.95561218261719,
"blob_id": "749cde3c80bd9229cf6472c4d9cb2a2dee56e47b",
"content_id": "2ce8b71150c3ffe6745feb6ed98be30f0237fea1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13388,
"license_type": "permissive",
"max_line_length": 134,
"num_lines": 383,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/geometry/camera/rotation.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n# system\nfrom __future__ import print_function\n\n# python lib\nfrom copy import deepcopy\n\n# tf_render\nimport tensorflow as tf\n\n# self\n\n\"\"\"\nnumpy or tensor\n\"\"\"\nclass RotationMtxBatch(object):\n \"\"\"\n 0. batch\n 1. broadcast support\n \"\"\"\n def __init__(self, **rotation_param):\n # Normalize [batch_size, data]\n #\n if rotation_param['type_rot'] == 'matrix':\n self.rot_batch = tf.reshape(rotation_param['data'], [-1, 3, 3])\n elif rotation_param['type_rot'] == 'quaternion':\n self.data = tf.reshape(rotation_param['data'], [-1, 4])\n self.rotMtx_quat_batch(self.data)\n elif rotation_param['type_rot'] == 'eularangle':\n pass\n # self.data = tf_render.reshape(rotation_param['data'], [-1, 3, 3])\n # self.rotMtx_quat_batch(self.data)\n self.batch_size = self.rot_batch.shape[0]\n\n @classmethod\n def create_matrixRot_batch(class_self, data_batch):\n return class_self(type_rot='matrix', data=data_batch)\n\n @classmethod\n def create_quaternion_batch(class_self, data_batch):\n return class_self(type_rot='quaternion', data=data_batch)\n\n def rotMtx_quat_batch(self, quat_tensor_batch, re_grad=False):\n rot_batch_list = []\n for i in range(quat_tensor_batch.shape[0]):\n quat = quat_tensor_batch[i, :]\n rot = self.rotMtx_quat(quat, re_grad)\n rot_batch_list.append(rot)\n self.rot_batch = tf.stack(rot_batch_list)\n\n def rotMtx_quat(self, quat_tensor, re_grad=False):\n # (*this)(0) = DT(1) - yy - zz;\n # (*this)(1) = xy - zw;\n # (*this)(2) = xz + yw;\n # (*this)(3) = xy + zw;\n # (*this)(4) = DT(1) - xx - zz;\n # (*this)(5) = yz - xw;\n # (*this)(6) = xz - yw;\n # (*this)(7) = yz + xw;\n # (*this)(8) = DT(1) - xx - yy;\n\n X = quat_tensor[0]\n Y = quat_tensor[1]\n Z = quat_tensor[2]\n W = quat_tensor[3]\n\n sqX = X * X\n sqY = Y * Y\n sqZ = Z * Z\n sqW = W * W\n\n invs = 1.0 / (sqX + sqY + sqZ + sqW)\n\n xy = X * Y\n zw = Z * W\n\n xz = X * Z\n yw = Y * W\n\n yz = Y * Z\n xw = X * W\n\n rot_r0 = tf.stack([1 - 2.0 * (sqY + sqZ), 2 * (xy - zw), 2 * (xz + yw)])\n rot_r1 = tf.stack([ 2 * (xy + zw), 1 - 2.0 * (sqX + sqZ), 2 * (yz - xw)])\n rot_r2 = tf.stack([ 2 * (xz - yw), 2 * (yz + xw), 1 - 2.0 * (sqX + sqY) ])\n\n rot_r0 = rot_r0.unsqueeze(0)\n rot_r1 = rot_r1.unsqueeze(0)\n rot_r2 = rot_r2.unsqueeze(0)\n\n rot = tf.stack([rot_r0, rot_r1, rot_r2], dim=1)\n\n tf.mul(rot, invs)\n\n return rot\n\n #\n def Get_viewDirect_batch(self):\n return self.rot_batch[:, 2, :]\n\n def Get_upDirect_batch(self):\n return self.rot_batch[:, 1, :]\n\n def Get_rightDirect_batch(self):\n return self.rot_batch[:, 0, :]\n\n #\n def rotMtx_eular_batch(self, eular_batch):\n rot_batch_list = []\n for i in range(eular_batch.shape[0]):\n eular = eular_batch[i, :]\n rot = self.rotMtx_eular(eular)\n rot_batch_list.append(rot)\n self.rot_batch = tf.stack(rot_batch_list)\n\n \"\"\"\n /// \\brief Mat2Euler\n /// \\param R = Rx * Ry * Rz =\n ///\t[ cos(y)*cos(z), -cos(y)*sin(z), sin(y)],\n ///\t[cos(x)*sin(z) + cos(z)*sin(x)*sin(y), cos(x)*cos(z) - sin(x)*sin(y)*sin(z), -cos(y)*sin(x)],\n ///\t[sin(x)*sin(z) - cos(x)*cos(z)*sin(y), cos(z)*sin(x) + cos(x)*sin(y)*sin(z), cos(x)*cos(y)]\n ///\n /// Derivation:\n /// z = atan2(-r12, r11)\n /// y = asin(r13)\n /// x = atan2(-r23, r33)\n /// We only keep the zyx order. Problems arise when cos(y) is close to zero, because both of::\n /// z = atan2(cos(y)*sin(z), cos(y)*cos(z))\n /// x = atan2(cos(y)*sin(x), cos(x)*cos(y))\n /// will be close to atan2(0, 0), and highly unstable.\n ///\n /// We use the ``cy`` fix for numerical instability below is from: *Graphics\n /// Gems IV*, Paul Heckbert (editor), Academic Press, 1994, ISBN:\n /// 0123361559. Specifically it comes from EulerAngles.c by Ken\n /// Shoemake, and deals with the case where cos(y) is close to zero:\n \"\"\"\n def rotMtx_eular(self, euler_tensor):\n phi = euler_tensor[0] # x\n theta = euler_tensor[1] # y\n psi = euler_tensor[2] # z\n\n s_ph = tf.sin(phi) # x\n c_ph = tf.cos(phi)\n\n s_t = tf.sin(theta) # y\n c_t = tf.cos(theta)\n\n s_ps = tf.sin(psi) # z\n c_ps = tf.cos(psi)\n\n r1 = tf.concat([c_t * c_ps, -c_t * s_ps, s_t])\n r2 = tf.concat([c_ph * s_ps + c_ps * s_ph * s_t, c_ph * c_ps - s_ph * s_t * s_ps, -c_t * s_ph])\n r3 = tf.concat([s_ps * s_ph - c_ph * c_ps * s_t, c_ps * s_ph + c_ph * s_t * s_ps, c_t * c_ph])\n\n rot = tf.concat([r1, r2, r3])\n\n return rot\n\n def eular_rotMtx_batch(self, rot_batch):\n eular_batch_list = []\n for i in range(rot_batch.shape[0]):\n rot = rot_batch[i, :]\n eular = self.eular_rotMtx(rot)\n eular_batch_list.append(eular)\n eular_batch = tf.stack(eular_batch_list)\n return eular_batch\n\n def eular_rotMtx(self, rot):\n c_t_y = tf.sqrt(\n rot[2][2] * rot[2][2] + rot[1][2] * rot[1][2]\n )\n\n psi_z = tf.cond(tf.less(c_t_y, 1e-6), lambda : tf.atan2(rot[1][0], rot[1][1]), lambda : tf.atan2(rot[0][1], rot[0][0]))\n theta_y = tf.cond(tf.less(c_t_y, 1e-6), lambda : tf.atan2(rot[0][2], c_t_y), lambda : tf.atan2(rot[0][2], c_t_y))\n phi_x = tf.cond(tf.less(c_t_y, 1e-6), lambda : tf.zeros_like(theta_y), lambda : tf.atan2(rot[1][2], rot[2][2]))\n\n euler_tensor = tf.stack([phi_x, theta_y, psi_z])\n\n return euler_tensor\n\n #\n def rotMtx_axisAngle(self, axis_tensor, rad_tensor):\n if len(axis_tensor.shape) > 1:\n axis_tensor = tf.squeeze(axis_tensor)\n if len(rad_tensor.shape) > 1:\n rad_tensor = tf.squeeze(rad_tensor)\n\n c = tf.cos(rad_tensor)\n s = tf.sin(rad_tensor)\n\n x = axis_tensor[0]\n y = axis_tensor[1]\n z = axis_tensor[2]\n\n rot_r0 = tf.stack([ c + (1.0-c) * x * x, (1.0-c) * x * y - s * z, (1.0-c) * x * z + s * y ], axis=1)\n rot_r1 = tf.stack([ (1.0 - c) * x * y + s * z, c + (1.0 - c) * y * y, (1.0 - c) * y * z - s * x ], axis=1)\n rot_r2 = tf.stack([ (1.0 - c) * x * z - s * y, (1.0 - c) * y * z + s * x, c + (1.0 - c) * z * z ], axis=1)\n\n # rot_r0 = rot_r0.unsqueeze(0)\n # rot_r1 = rot_r1.unsqueeze(0)\n # rot_r2 = rot_r2.unsqueeze(0)\n\n rot = tf.stack([rot_r0, rot_r1, rot_r2], axis=1) # [batch, row, col] so axis=1\n\n return rot\n\n def rotMtx_axisAngle_batch(self, axis_tensor, rad_tensor):\n c = tf.cos(rad_tensor)\n s = tf.sin(rad_tensor)\n\n x = axis_tensor[:, 0]\n y = axis_tensor[:, 1]\n z = axis_tensor[:, 2]\n\n rot_r0 = tf.stack([ c + (1.0-c) * x * x, (1.0-c) * x * y - s * z, (1.0-c) * x * z + s * y ], axis=-1)\n rot_r1 = tf.stack([ (1.0 - c) * x * y + s * z, c + (1.0 - c) * y * y, (1.0 - c) * y * z - s * x ], axis=-1)\n rot_r2 = tf.stack([ (1.0 - c) * x * z - s * y, (1.0 - c) * y * z + s * x, c + (1.0 - c) * z * z ], axis=-1)\n\n # rot_r0 = rot_r0.unsqueeze(0)\n # rot_r1 = rot_r1.unsqueeze(0)\n # rot_r2 = rot_r2.unsqueeze(0)\n\n rot = tf.stack([rot_r0, rot_r1, rot_r2], axis=1) # [batch, row, col] so axis=1\n\n return rot\n\n\n\n\nclass ExtMtxBatch(RotationMtxBatch):\n def __init__(self, **ext_param):\n # Normalize [batch_size, data]\n #\n if ext_param['type_ext'] == 'matrix':\n self.data_rot = tf.reshape(ext_param['data_rot'], [-1, 3, 3])\n self.data_t = tf.reshape(ext_param['data_t'], [-1, 3])\n super(ExtMtxBatch, self).__init__(type_rot='matrix', data=self.data_rot)\n self.t_batch = self.data_t\n elif ext_param['type_ext'] == 'location':\n self.data = tf.reshape(ext_param['data'], [-1, 3, 3])\n # super(ExtMtxBatch, self).__init__(type_rot='data', data=self.data)\n self.rotMtx_location_batch(self.data)\n elif ext_param['type_ext'] == 'locationOpengl':\n self.data = tf.reshape(ext_param['data'], [-1, 3, 3])\n # super(ExtMtxBatch, self).__init__(type_rot='data', data=self.data)\n self.rotMtx_locationOpengl_batch(self.data)\n\n @classmethod\n def create_matrixExt_batch(class_self, rot_data_batch, t_data_batch):\n return class_self(type_ext='matrix', data_rot=rot_data_batch, data_t=t_data_batch)\n\n\n @classmethod\n def create_location_batch(class_self, data_batch):\n return class_self(type_ext='location', data=data_batch)\n @classmethod\n def create_locationOpengl_batch(class_self, data_batch):\n return class_self(type_ext='locationOpengl', data=data_batch)\n #\n def rotMtx_location_batch(self, eye_center_up_batch, re_grad=False):\n rot_batch_list = []\n t_batch_list = []\n for i in range(eye_center_up_batch.shape[0]):\n eye_center_up = eye_center_up_batch[i, :, :]\n rot, t = self.rotMtx_location(eye_center_up, re_grad)\n rot_batch_list.append(rot)\n t_batch_list.append(t)\n self.rot_batch = tf.stack(rot_batch_list)\n self.t_batch = tf.stack(t_batch_list)\n\n def rotMtx_location(self, eye_center_up, re_grad=False):\n eye = eye_center_up[0]\n center = eye_center_up[1]\n up = eye_center_up[2]\n\n view_dir = center - eye\n view_dir = tf.nn.l2_normalize(view_dir)\n\n down_dir = -up\n\n right_dir = tf.cross(down_dir, view_dir)\n right_dir = tf.nn.l2_normalize(right_dir)\n\n down_dir = tf.cross(view_dir, right_dir)\n\n rot = tf.stack([right_dir, down_dir, view_dir])\n eye_trans = tf.expand_dims(eye, -1)\n t_trans = -tf.matmul(rot, eye_trans)\n t = tf.transpose(tf.squeeze(t_trans))\n\n return rot, t\n\n #\n def rotMtx_locationOpengl_batch(self, eye_center_up_batch, re_grad=False):\n rot_batch_list = []\n t_batch_list = []\n for i in range(eye_center_up_batch.shape[0]):\n eye_center_up = eye_center_up_batch[i, :, :]\n rot, t = self.rotMtx_locationOpengl(eye_center_up, re_grad)\n rot_batch_list.append(rot)\n t_batch_list.append(t)\n self.rot_batch = tf.stack(rot_batch_list)\n self.t_batch = tf.stack(t_batch_list)\n\n def rotMtx_locationOpengl(self, eye_center_up, re_grad=False):\n eye = eye_center_up[0]\n center = eye_center_up[1]\n up = eye_center_up[2]\n\n view_dir = -(center - eye)\n view_dir = tf.nn.l2_normalize(view_dir)\n\n\n right_dir = tf.cross(up, view_dir)\n right_dir = tf.nn.l2_normalize(right_dir)\n\n up_dir = tf.cross(view_dir, right_dir)\n\n rot = tf.stack([right_dir, up_dir, view_dir])\n eye_trans = tf.expand_dims(eye, -1)\n t_trans = -tf.matmul(rot, eye_trans)\n t = tf.transpose(tf.squeeze(t_trans))\n\n return rot, t\n\n #\n def Apply_batch(self, v3d):\n if len(v3d.shape) < 3:\n v3d = tf.expand_dims(v3d, -1)\n v3d_rot = tf.matmul(self.rot_batch, v3d)\n v3d_rot = tf.squeeze(v3d_rot, -1)\n\n v3d_transform = v3d_rot + self.t_batch\n\n return v3d_transform\n\n def Get_ext_batch(self):\n t_batch_trans = tf.expand_dims(self.t_batch, axis=-1)\n ext_batch = tf.concat([self.rot_batch, t_batch_trans], axis=2)\n\n r4 = tf.constant([0., 0., 0., 1.], shape=[1, 1, 4])\n r4 = tf.tile(r4, [self.batch_size, 1, 1])\n ext_batch = tf.concat([ext_batch, r4], axis=1)\n\n return ext_batch\n #\n def Get_eye_batch(self):\n mtx_t_trans = tf.expand_dims(self.t_batch, 1)\n eye_trans = - tf.matmul(mtx_t_trans, self.rot_batch)\n eye = tf.squeeze(eye_trans, squeeze_dims=1)\n return eye\n\n # Same from pipline\n \"\"\"\n Concatenate a rotation R1 around center c1(both in camera coordinate frame) before current camera external transformation [R, -Rc]\n\n |R1 -R1c1+c1| * |R -Rc| = |R1R -R1Rc-R1c1+c1|\n | 0 1 | | 0 1| | 0 1 |\t|\n \"\"\"\n def rotate_batch(self, rel_rot_batch, centre_mesh_batch):\n \"\"\"\n :param rel_rot_batch:\n :param centre_mesh_batch: world xyz\n :return:\n \"\"\"\n # Camera centre\n centre_mesh_cameraAxis_batch = self.Apply_batch(centre_mesh_batch)\n\n # Rotation\n r1_r = tf.matmul(rel_rot_batch, self.rot_batch)\n\n # Translation\n eye_trans = tf.expand_dims(self.Get_eye_batch(), -1)\n r1_r_c = tf.matmul(r1_r, eye_trans)\n r1_r_c = tf.squeeze(r1_r_c, squeeze_dims=-1)\n\n centre_mesh_cameraAxis_batch_trans = tf.expand_dims(centre_mesh_cameraAxis_batch, -1)\n r1_c1 = tf.matmul(rel_rot_batch, centre_mesh_cameraAxis_batch_trans)\n r1_c1 = tf.squeeze(r1_c1, squeeze_dims=-1)\n\n t = centre_mesh_cameraAxis_batch - r1_r_c - r1_c1\n\n\n return r1_r, t"
},
{
"alpha_fraction": 0.7030725479125977,
"alphanum_fraction": 0.7490317821502686,
"avg_line_length": 52.05479431152344,
"blob_id": "f482f516b3fb927e992f14853a6ef5cb032eab12",
"content_id": "ffb15d0f25d1b60683b9d468739763dd4dcb2a0b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3903,
"license_type": "permissive",
"max_line_length": 507,
"num_lines": 73,
"path": "/Recognition-using-IOT/DETECTION AND RECOGNITION USING RASPBERRY PI/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Face Detect-Recog using Raspberry Pi and OpenCV🎭\n\n## About:🤔💭\n\nThis project uses python and OpenCV to recognize multiple faces and show the name #Sample to get video from PiCam.\n\n## List TO-DO📄:\n\n- [x] Get the [hardware.](https://github.com/smriti1313/Face-X/tree/master/DETECTION%20AND%20RECOGNITION%20USING%20RASPBERRY%20PI#requirements)\n- [x] Install [Python](https://www.howtogeek.com/197947/how-to-install-python-on-windows/)\n- [x] Install [Dependencies.](https://github.com/smriti1313/Face-X/tree/master/DETECTION%20AND%20RECOGNITION%20USING%20RASPBERRY%20PI#dependencies)\n- [x] Make a folder and name it anything(or you can see [quick start](https://github.com/smriti1313/Face-X/tree/master/DETECTION%20AND%20RECOGNITION%20USING%20RASPBERRY%20PI#quick-start))\n - [x] Download [Haarcascade](https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml) and paste it here\n - [x] Open notepad,write [this](https://github.com/smriti1313/Face-X/blob/master/DETECTION%20AND%20RECOGNITION%20USING%20RASPBERRY%20PI/face.py) script and save it as 'face.py'.\n - [x] Paste [this](https://github.com/smriti1313/Face-X/blob/master/DETECTION%20AND%20RECOGNITION%20USING%20RASPBERRY%20PI/train.py) in notepad and save it as 'train.py'.\n - [x] Copy and paste [this](https://github.com/smriti1313/Face-X/blob/master/DETECTION%20AND%20RECOGNITION%20USING%20RASPBERRY%20PI/face_to_system.py) in notepad and save it as 'face_to_system.py'.\n - [x] Create a [sample file](https://github.com/smriti1313/Face-X/blob/master/DETECTION%20AND%20RECOGNITION%20USING%20RASPBERRY%20PI/samplePiCamOpenCV.py) and save it as '\nsamplePiCamOpenCV.py '.\n- [x] [Initialize](https://github.com/smriti1313/Face-X/tree/master/DETECTION%20AND%20RECOGNITION%20USING%20RASPBERRY%20PI#initialize-the-camera-and-grab-a-reference-to-the-raw-camera-capture),[warmup](https://github.com/smriti1313/Face-X/tree/master/DETECTION%20AND%20RECOGNITION%20USING%20RASPBERRY%20PI#allow-the-camera-to-warmup) and [capture](https://github.com/smriti1313/Face-X/tree/master/DETECTION%20AND%20RECOGNITION%20USING%20RASPBERRY%20PI#capture-frames-from-the-camera) frames from the camera.\n- [x] Test the code.\n- [x] Run the final project.\n\n### Requirements:🧱🧱\n\n|Hardware|Software|\n|----|-----|\n|[Raspberry PiCam](https://www.raspberrypi.org/products/camera-module-v2/) or Web cam|[Python 2.7 or newer](https://www.howtogeek.com/197947/how-to-install-python-on-windows/)|\n||[Haarcascade](https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml)|\n\n\n### Dependencies🔧🛠:\nOpen terminal and write:\n* `sudo pip install picamera`\n* `sudo pip install \"picamera[array]\"`\n* `pip install opencv-python`\n\n\n## Quick Start📘\nYou can directly [download](https://www.wikihow.com/Download-a-GitHub-Folder) the entire [Face-X](https://github.com/akshitagupta15june/Face-X) and select the folder you want. \n\n## Initialize the camera and grab a reference to the raw camera capture\n```py\ncamera = PiCamera() camera.resolution = (640, 480) \ncamera.framerate = 32 \nrawCapture = PiRGBArray(camera, size=(640, 480))\n```\n\n## Allow the camera to warmup\n```py\ntime.sleep(0.1)\n```\n\n## Capture frames from the camera\n```py\nfor frame in camera.capture_continuous(rawCapture, format=\"bgr\", use_video_port=True): \n # grab the raw NumPy array representing the image, then initialize the timestamp and occupied/unoccupied text image = frame.array\n\n # show the frame\n cv2.imshow(\"Frame\", image)\n key = cv2.waitKey(1) & 0xFF\n\n #clear the stream in preparation for the next frame\n rawCapture.truncate(0)\n\n # if the `q` key was pressed, break from the loop\n if key == ord(\"q\"):\n break\n```\n## Testing🧰:\n\n- Run the code and observe if it working fine or not.\n\n>For better understanding watch [this](https://www.youtube.com/watch?v=Fggavxx-Kds)\n"
},
{
"alpha_fraction": 0.7162868976593018,
"alphanum_fraction": 0.7384827733039856,
"avg_line_length": 58.700599670410156,
"blob_id": "571865233f7ab573ad6aefe743ccaee1d1fef4ef",
"content_id": "77f746b112e2a73694351d3909c0da23b1c3a3bb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 10156,
"license_type": "permissive",
"max_line_length": 569,
"num_lines": 167,
"path": "/Cartoonify Image/Cartoonification/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Cartoonify an Image with OpenCV in Python\r\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Cartoonify%20Image/Cartoonification/Assets/preview-removebg.png\" height=\"400px\" align=\"left\"/><img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Cartoonify%20Image/Cartoonification/Assets/abe_toon.png\" height=\"400px\" width=\"600px\" align=\"top\"/>\r\n\r\n## Process of converting an image to a cartoon\r\n\r\n- To convert an image to a cartoon, multiple transformations are done.\r\n- Convert the image to a Grayscale image. Yes, similar to the old day’s pictures.!\r\n- The Grayscale image is smoothened\r\n- Extract the edges in the image\r\n- Form a colour image and mask it with edges.\r\n- This creates a beautiful cartoon image with edges and lightened colour of the original image.\r\n\r\n## How to start\r\n\r\n- Fork and Clone the repository using-\r\n```\r\ngit clone https://github.com/akshitagupta15june/Face-X.git\r\n```\r\n- Create virtual environment-\r\n```\r\n- python -m venv env\r\n- source env/bin/activate (Linux)\r\n- env\\Scripts\\activate (Windows)\r\n```\r\n- Install dependencies\r\n- Go to project directory\r\n```\r\n- cd Cartoonify Image\r\n```\r\n- Open Terminal\r\n```\r\npython cartoonify_without_GUI.py --image IMAGE_PATH\r\n```\r\n### 1. Detecting and emphasizing edges\r\n- Convert the original color image into grayscale\r\n- Using adaptive`thresholding` to detect and `emphasize` the edges in an edge mask. \r\n- Apply a median blur to reduce image noise.\r\n - `-->` To produce accurate carton effects, as the first step, we need to understand the difference between a common digital image and a cartoon image.At the first glance we can clearly see two major differences.\r\n - The first difference is that the colors in the cartoon image are more homogeneous as compared to the normal image.\r\n - The second difference is noticeable within the edges that are much sharper and more pronounced in the cartoon.\r\n - Let’s begin by importing the necessary libraries and loading the input image.\r\n```\r\n import cv2\r\n import numpy as np\r\n```\r\n - Now, we are going to load the image.\r\n```\r\nimg = cv2.imread(\"Superman.jpeg\")\r\ncv2_imshow(img)\r\n```\r\n - The next step is to detect the edges. For that task, we need to choose the most suitable method. Remember, our goal is to detect clear edges. There are several edge detectors that we can pick. Our first choice will be one of the most common detectors, and that is the `Canny edge detector`. But unfortunately, if we apply this detector we will not be able to achieve desirable results. We can proceed with Canny, and yet you can see that there are too many details captured. This can be changed if we play around with Canny’s input parameters (numbers 100 and 200).\r\n - Although Canny is an excellent edge detector that we can use in many cases in our code we will use a threshold method that gives us more satisfying results. It uses a threshold pixel value to convert a grayscale image into a binary image. For instance, if a pixel value in the original image is above the threshold, it will be assigned to 255. Otherwise, it will be assigned to 0 as we can see in the following image.\r\n - <img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Cartoonify%20Image/Cartoonification/Assets/Threshold.jpg\" height=\"300px\" align=\"right\"/>\r\n \r\n #### The next step is to apply `cv2.adaptiveThreshold()function`. As the parameters for this function we need to define:\r\n\r\n - max value which will be set to 255\r\n - `cv2.ADAPTIVE_THRESH_MEAN_C `: a threshold value is the mean of the neighbourhood area.\r\n - `cv2.ADAPTIVE_THRESH_GAUSSIAN_C` : a threshold value is the weighted sum of neighbourhood values where weights are a gaussian window.\r\n - `Block Size` – It determents the size of the neighbourhood area.\r\n - `C `– It is just a constant which is subtracted from the calculated mean (or the weighted mean).\r\n```\r\ngray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)\r\nedges = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 9, 5)\r\n```\r\n```\r\ngray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)\r\ngray_1 = cv2.medianBlur(gray, 5)\r\nedges = cv2.adaptiveThreshold(gray_1, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 9, 5)\r\n```\r\n - <img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Cartoonify%20Image/Cartoonification/Assets/filters_tutorial_02.png\" align =\"right\" height=\"400px\"/>\r\n### 2. Image filtering\r\n- Apply a bilateral filter to create homogeneous colors on the image. \r\n### 3. Creating a cartoon effect\r\n- Use a bitwise operation to combine the processed color image with the edge mask image.\r\n- Our final step is to combine the previous two: We will use `cv2.bitwise_and()` the function to mix edges and the color image into a single one\r\n```\r\n cartoon = cv2.bitwise_and(color, color, mask=edges)\r\n cv2_imshow(cartoon)\r\n```\r\n### 4. Creating a cartoon effect using color quantization\r\n - Another interesting way to create a cartoon effect is by using the color quantization method. This method will reduce the number of colors in the image and that will create a cartoon-like effect. We will perform color quantization by using the K-means clustering algorithm for displaying output with a limited number of colors. First, we need to define `color_quantization()` function.\r\n ```\r\n def color_quantization(img, k):\r\n# Defining input data for clustering\r\n data = np.float32(img).reshape((-1, 3))\r\n# Defining criteria\r\n criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 20, 1.0)\r\n# Applying cv2.kmeans function\r\n ret, label, center = cv2.kmeans(data, k, None, criteria, 10, cv2.KMEANS_RANDOM_CENTERS)\r\n center = np.uint8(center)\r\n result = center[label.flatten()]\r\n result = result.reshape(img.shape)\r\n return result\r\n ```\r\n - Different values for K will determine the number of colors in the output picture. So, for our goal, we will reduce the number of colors to 7. Let’s look at our results.\r\n ```\r\nimg_1 = color_quantization(img, 7)\r\ncv2_imshow(img_1)\r\n```\r\n\r\n## Steps to develop Image Cartoonifier\r\n\r\n- Step 1: Importing the required modules\r\n```\r\nimport cv2\r\nimport argparse\r\n```\r\n- Step 2: Transforming an image to grayscale\r\n```\r\n#converting an image to grayscale\r\ngrayScaleImage = cv2.cvtColor(originalmage, cv2.COLOR_BGR2GRAY)\r\nReSized2 = cv2.resize(grayScaleImage, (960, 540))\r\n#plt.imshow(ReSized2, cmap='gray')\r\n```\r\n - Transforming an image to grayscale\r\n - `cvtColor(image, flag)` is a method in cv2 which is used to transform an image into the colour-space mentioned as ‘flag’. Here, our first step is to convert the image into grayscale. Thus, we use the `BGR2GRAY` flag. This returns the image in grayscale. A grayscale image is stored as `grayScaleImage`.\r\n - After each transformation, we resize the resultant image using the resize() method in cv2 and display it using imshow() method. This is done to get more clear insights into every single transformation step.\r\n- Step 3: Smoothening a grayscale image\r\n```\r\n#applying median blur to smoothen an image\r\nsmoothGrayScale = cv2.medianBlur(grayScaleImage, 5)\r\nReSized3 = cv2.resize(smoothGrayScale, (960, 540))\r\n#plt.imshow(ReSized3, cmap='gray')\r\n```\r\n - Smoothening a grayscale image\r\n - To smoothen an image, we simply apply a blur effect. This is done using medianBlur() function. Here, the center pixel is assigned a mean value of all the pixels which fall under the kernel. In turn, creating a blur effect.\r\n- Step 4: Retrieving the edges of an image\r\n```\r\n#retrieving the edges for cartoon effect\r\n#by using thresholding technique\r\ngetEdge = cv2.adaptiveThreshold(smoothGrayScale, 255, \r\n cv2.ADAPTIVE_THRESH_MEAN_C, \r\n cv2.THRESH_BINARY, 9, 9)\r\nReSized4 = cv2.resize(getEdge, (960, 540))\r\n#plt.imshow(ReSized4, cmap='gray')\r\n```\r\n - Cartoon effect has two specialties:\r\n - Highlighted Edges\r\n - Smooth color\r\n - In this step, we will work on the first specialty. Here, we will try to retrieve the edges and highlight them. This is attained by the adaptive thresholding technique. The threshold value is the mean of the neighborhood pixel values area minus the constant C. C is a constant that is subtracted from the mean or weighted sum of the neighborhood pixels. Thresh_binary is the type of threshold applied, and the remaining parameters determine the block size.\r\n- Step 5: Giving a Cartoon Effect\r\n``` \r\n#masking edged image with our \"BEAUTIFY\" image\r\ncartoonImage = cv2.bitwise_and(colorImage, colorImage, mask=getEdge)\r\nReSized6 = cv2.resize(cartoonImage, (960, 540))\r\n#plt.imshow(ReSized6, cmap='gray')\r\n\r\n```\r\n### Results Obtained\r\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Cartoonify%20Image/Cartoonification/Assets/result%20(2).jpg\" hight=\"300px\" width=\"700px\"/>\r\n\r\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Cartoonify%20Image/Cartoonification/Assets/boy.png\" height=\"400px\" align=\"left\"/>\r\n<p style=\"clear:both;\">\r\n<h1><a name=\"contributing\"></a><a name=\"community\"></a> <a href=\"https://github.com/akshitagupta15june/Face-X\">Community</a> and <a href=\"https://github.com/akshitagupta15june/Face-X/blob/master/CONTRIBUTING.md\">Contributing</a></h1>\r\n<p>Please do! Contributions, updates, <a href=\"https://github.com/akshitagupta15june/Face-X/issues\"></a> and <a href=\" \">pull requests</a> are welcome. This project is community-built and welcomes collaboration. Contributors are expected to adhere to the <a href=\"https://gssoc.girlscript.tech/\">GOSSC Code of Conduct</a>.\r\n</p>\r\n<p>\r\nJump into our <a href=\"https://discord.com/invite/Jmc97prqjb\">Discord</a>! Our projects are community-built and welcome collaboration. 👍Be sure to see the <a href=\"https://github.com/akshitagupta15june/Face-X/blob/master/Readme.md\">Face-X Community Welcome Guide</a> for a tour of resources available to you.\r\n</p>\r\n<p>\r\n<i>Not sure where to start?</i> Grab an open issue with the <a href=\"https://github.com/akshitagupta15june/Face-X/issues\">help-wanted label</a>\r\n</p>\r\n\r\n**Open Source First**\r\n\r\n best practices for managing all aspects of distributed services. Our shared commitment to the open-source spirit push the Face-X community and its projects forward.</p>\r\n"
},
{
"alpha_fraction": 0.6741595268249512,
"alphanum_fraction": 0.6910019516944885,
"avg_line_length": 48.25324630737305,
"blob_id": "e8f56511e4674c7ae6a01d4af7e5f38268f2621a",
"content_id": "ff95fd3a0b7b4a397fe2aa271b7a4e73e5fb94cf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 30340,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 616,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/geometry/render/api_tf_mesh_render.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n# system\nfrom __future__ import print_function\n\n# python lib\nimport math\nfrom copy import deepcopy\nimport numpy as np\n\n# tf_render\nimport tensorflow as tf\n\n# self\nfrom thirdParty.tf_mesh_renderer.mesh_renderer.mesh_renderer import phong_shader, tone_mapper\nfrom thirdParty.tf_mesh_renderer.mesh_renderer.rasterize_triangles import rasterize_triangles\n\n# perspective\ndef mesh_renderer_camera_light(vertices, triangles, normals, diffuse_colors,\n mtx_camera, mtx_perspective_frustrum, camera_position,\n image_width, image_height):\n \"\"\"Renders an input scene using phong shading, and returns an output image.\n\n Args:\n vertices: 3-D float32 tensor with shape [batch_size, vertex_count, 3]. Each\n triplet is an xyz position in world space.\n triangles: 2-D int32 tensor with shape [triangle_count, 3]. Each triplet\n should contain vertex indices describing a triangle such that the\n triangle's normal points toward the viewer if the forward order of the\n triplet defines a clockwise winding of the vertices. Gradients with\n respect to this tensor are not available.\n normals: 3-D float32 tensor with shape [batch_size, vertex_count, 3]. Each\n triplet is the xyz vertex normal for its corresponding vertex. Each\n vector is assumed to be already normalized.\n diffuse_colors: 3-D float32 tensor with shape [batch_size,\n vertex_count, 3]. The RGB diffuse reflection in the range [0,1] for\n each vertex.\n\n mtx_camera: 3-D tensor with shape [batch_size, 4, 4] or 2-D tensor with\n shape [4, 4] specifying the camera model view matrix\n mtx_perspective_frustrum: 3-D tensor with shape [batch_size, 4, 4] or 2-D tensor with\n shape [4, 4] specifying the perspective and frustrum matrix\n camera_position: 2-D tensor with shape [batch_size, 3] or 1-D tensor with\n shape [3] specifying the XYZ world space camera position.\n\n light_intensities: a 3-D tensor with shape [batch_size, light_count, 3]. The\n RGB intensity values for each light. Intensities may be above one.\n image_width: int specifying desired output image width in pixels.\n image_height: int specifying desired output image height in pixels.\n\n Returns:\n A 4-D float32 tensor of shape [batch_size, image_height, image_width, 4]\n containing the lit RGBA color values for each image at each pixel. RGB\n colors are the intensity values before tonemapping and can be in the range\n [0, infinity]. Clipping to the range [0,1] with tf_render.clip_by_value is likely\n reasonable for both viewing and training most scenes. More complex scenes\n with multiple lights should tone map color values for display only. One\n simple tonemapping approach is to rescale color values as x/(1+x); gamma\n compression is another common techinque. Alpha values are zero for\n background pixels and near one for mesh pixels.\n Raises:\n ValueError: An invalid argument to the method is detected.\n \"\"\"\n if len(vertices.shape) != 3:\n raise ValueError('Vertices must have shape [batch_size, vertex_count, 3].')\n batch_size = vertices.shape[0].value\n if len(normals.shape) != 3:\n raise ValueError('Normals must have shape [batch_size, vertex_count, 3].')\n\n if len(diffuse_colors.shape) != 3:\n raise ValueError(\n 'vertex_diffuse_colors must have shape [batch_size, vertex_count, 3].')\n\n if camera_position.get_shape().as_list() == [3]:\n camera_position = tf.tile(\n tf.expand_dims(camera_position, axis=0), [batch_size, 1])\n elif camera_position.get_shape().as_list() != [batch_size, 3]:\n raise ValueError('Camera_position must have shape [batch_size, 3]')\n\n # TODO: Debug Shape\n if mtx_camera.get_shape().as_list() == [4, 4]:\n mtx_camera = tf.tile(\n tf.expand_dims(mtx_camera, axis=0), [batch_size, 1, 1])\n elif mtx_camera.get_shape().as_list() != [batch_size, 4, 4]:\n raise ValueError('Camera_lookat must have shape [batch_size, 4, 4]')\n\n if mtx_perspective_frustrum.get_shape().as_list() == [4, 4]:\n mtx_camera = tf.tile(\n tf.expand_dims(mtx_perspective_frustrum, axis=0), [batch_size, 1])\n elif mtx_camera.get_shape().as_list() != [batch_size, 4, 4]:\n raise ValueError('Camera_lookat must have shape [batch_size, 4, 4]')\n\n\n vertex_attributes = tf.concat([normals, vertices, diffuse_colors], axis=2)\n\n clip_space_transforms = tf.matmul(mtx_perspective_frustrum, mtx_camera, name=\"mtx_clip_space_transforms_batch\")\n\n pixel_attributes, alpha, tri_ids = rasterize_triangles(\n vertices, vertex_attributes, triangles, clip_space_transforms,\n image_width, image_height, [-1] * vertex_attributes.shape[2].value)\n\n # Extract the interpolated vertex attributes from the pixel buffer and\n # supply them to the shader:\n #pixel_normals = tf.nn.l2_normalize(pixel_attributes[:, :, :, 0:3], dim=3)\n #pixel_positions = pixel_attributes[:, :, :, 3:6]\n diffuse_colors = pixel_attributes[:, :, :, 6:9]\n diffuse_colors = tf.reverse(diffuse_colors, axis=[1])\n\n #return renders, pixel_mask\n pixel_mask = alpha > 0.5\n pixel_mask = tf.cast(pixel_mask, dtype=tf.float32)\n pixel_mask = tf.reverse(pixel_mask, axis=[1])\n\n #\n tri_ids = tf.expand_dims(tri_ids, -1)\n\n return diffuse_colors, pixel_mask, tri_ids\n\n\ndef mesh_renderer_camera(vertices, triangles, normals, diffuse_colors,\n mtx_camera, mtx_perspective_frustrum, camera_position,\n light_positions, light_intensities, image_width, image_height,\n specular_colors=None, shininess_coefficients=None, ambient_color=None, background=-1\n ):\n \"\"\"Renders an input scene using phong shading, and returns an output image.\n\n Args:\n vertices: 3-D float32 tensor with shape [batch_size, vertex_count, 3]. Each\n triplet is an xyz position in world space.\n triangles: 2-D int32 tensor with shape [triangle_count, 3]. Each triplet\n should contain vertex indices describing a triangle such that the\n triangle's normal points toward the viewer if the forward order of the\n triplet defines a clockwise winding of the vertices. Gradients with\n respect to this tensor are not available.\n normals: 3-D float32 tensor with shape [batch_size, vertex_count, 3]. Each\n triplet is the xyz vertex normal for its corresponding vertex. Each\n vector is assumed to be already normalized.\n diffuse_colors: 3-D float32 tensor with shape [batch_size,\n vertex_count, 3]. The RGB diffuse reflection in the range [0,1] for\n each vertex.\n\n mtx_camera: 3-D tensor with shape [batch_size, 4, 4] or 2-D tensor with\n shape [4, 4] specifying the camera model view matrix\n mtx_perspective_frustrum: 3-D tensor with shape [batch_size, 4, 4] or 2-D tensor with\n shape [4, 4] specifying the perspective and frustrum matrix\n camera_position: 2-D tensor with shape [batch_size, 3] or 1-D tensor with\n shape [3] specifying the XYZ world space camera position.\n\n light_positions: a 3-D tensor with shape [batch_size, light_count, 3]. The\n XYZ position of each light in the scene. In the same coordinate space as\n pixel_positions.\n light_intensities: a 3-D tensor with shape [batch_size, light_count, 3]. The\n RGB intensity values for each light. Intensities may be above one.\n image_width: int specifying desired output image width in pixels.\n image_height: int specifying desired output image height in pixels.\n\n specular_colors: 3-D float32 tensor with shape [batch_size,\n vertex_count, 3]. The RGB specular reflection in the range [0, 1] for\n each vertex. If supplied, specular reflections will be computed, and\n both specular_colors and shininess_coefficients are expected.\n shininess_coefficients: a 0D-2D float32 tensor with maximum shape\n [batch_size, vertex_count]. The phong shininess coefficient of each\n vertex. A 0D tensor or float gives a constant shininess coefficient\n across all batches and images. A 1D tensor must have shape [batch_size],\n and a single shininess coefficient per image is used.\n ambient_color: a 2D tensor with shape [batch_size, 3]. The RGB ambient\n color, which is added to each pixel in the scene. If None, it is\n assumed to be black.\n\n\n Returns:\n A 4-D float32 tensor of shape [batch_size, image_height, image_width, 4]\n containing the lit RGBA color values for each image at each pixel. RGB\n colors are the intensity values before tonemapping and can be in the range\n [0, infinity]. Clipping to the range [0,1] with tf_render.clip_by_value is likely\n reasonable for both viewing and training most scenes. More complex scenes\n with multiple lights should tone map color values for display only. One\n simple tonemapping approach is to rescale color values as x/(1+x); gamma\n compression is another common techinque. Alpha values are zero for\n background pixels and near one for mesh pixels.\n Raises:\n ValueError: An invalid argument to the method is detected.\n \"\"\"\n if len(vertices.shape) != 3:\n raise ValueError('Vertices must have shape [batch_size, vertex_count, 3].')\n batch_size = vertices.shape[0].value\n if len(normals.shape) != 3:\n raise ValueError('Normals must have shape [batch_size, vertex_count, 3].')\n if len(light_positions.shape) != 3:\n raise ValueError(\n 'Light_positions must have shape [batch_size, light_count, 3].')\n if len(light_intensities.shape) != 3:\n raise ValueError(\n 'Light_intensities must have shape [batch_size, light_count, 3].')\n if len(diffuse_colors.shape) != 3:\n raise ValueError(\n 'vertex_diffuse_colors must have shape [batch_size, vertex_count, 3].')\n if (ambient_color is not None and\n ambient_color.get_shape().as_list() != [batch_size, 3]):\n raise ValueError('Ambient_color must have shape [batch_size, 3].')\n if camera_position.get_shape().as_list() == [3]:\n camera_position = tf.tile(\n tf.expand_dims(camera_position, axis=0), [batch_size, 1])\n elif camera_position.get_shape().as_list() != [batch_size, 3]:\n raise ValueError('Camera_position must have shape [batch_size, 3]')\n\n # TODO: Debug Shape\n if mtx_camera.get_shape().as_list() == [4, 4]:\n mtx_camera = tf.tile(\n tf.expand_dims(mtx_camera, axis=0), [batch_size, 1, 1])\n elif mtx_camera.get_shape().as_list() != [batch_size, 4, 4]:\n raise ValueError('Camera_lookat must have shape [batch_size, 4, 4]')\n\n if mtx_perspective_frustrum.get_shape().as_list() == [4, 4]:\n mtx_camera = tf.tile(\n tf.expand_dims(mtx_perspective_frustrum, axis=0), [batch_size, 1])\n elif mtx_camera.get_shape().as_list() != [batch_size, 4, 4]:\n raise ValueError('Camera_lookat must have shape [batch_size, 4, 4]')\n\n if specular_colors is not None and shininess_coefficients is None:\n raise ValueError(\n 'Specular colors were supplied without shininess coefficients.')\n if shininess_coefficients is not None and specular_colors is None:\n raise ValueError(\n 'Shininess coefficients were supplied without specular colors.')\n if specular_colors is not None:\n # Since a 0-D float32 tensor is accepted, also accept a float.\n if isinstance(shininess_coefficients, float):\n shininess_coefficients = tf.constant(\n shininess_coefficients, dtype=tf.float32)\n if len(specular_colors.shape) != 3:\n raise ValueError('The specular colors must have shape [batch_size, '\n 'vertex_count, 3].')\n if len(shininess_coefficients.shape) > 2:\n raise ValueError('The shininess coefficients must have shape at most'\n '[batch_size, vertex_count].')\n # If we don't have per-vertex coefficients, we can just reshape the\n # input shininess to broadcast later, rather than interpolating an\n # additional vertex attribute:\n if len(shininess_coefficients.shape) < 2:\n vertex_attributes = tf.concat(\n [normals, vertices, diffuse_colors, specular_colors], axis=2)\n else:\n vertex_attributes = tf.concat(\n [\n normals, vertices, diffuse_colors, specular_colors,\n tf.expand_dims(shininess_coefficients, axis=2)\n ],\n axis=2)\n else:\n vertex_attributes = tf.concat([normals, vertices, diffuse_colors], axis=2)\n\n # camera_matrices = camera_utils.look_at(camera_position, camera_lookat,\n # camera_up)\n #\n # perspective_transforms = camera_utils.perspective(image_width / image_height,\n # fov_y, near_clip, far_clip)\n\n clip_space_transforms = tf.matmul(mtx_perspective_frustrum, mtx_camera, name=\"mtx_clip_space_transforms_batch\")\n\n pixel_attributes, alpha, tri_ids = rasterize_triangles(\n vertices, vertex_attributes, triangles, clip_space_transforms,\n image_width, image_height, [background] * vertex_attributes.shape[2].value)\n\n # Extract the interpolated vertex attributes from the pixel buffer and\n # supply them to the shader:\n pixel_normals = tf.nn.l2_normalize(pixel_attributes[:, :, :, 0:3], dim=3)\n pixel_positions = pixel_attributes[:, :, :, 3:6]\n diffuse_colors = pixel_attributes[:, :, :, 6:9]\n if specular_colors is not None:\n specular_colors = pixel_attributes[:, :, :, 9:12]\n # Retrieve the interpolated shininess coefficients if necessary, or just\n # reshape our input for broadcasting:\n if len(shininess_coefficients.shape) == 2:\n shininess_coefficients = pixel_attributes[:, :, :, 12]\n else:\n shininess_coefficients = tf.reshape(shininess_coefficients, [-1, 1, 1])\n\n pixel_mask = tf.cast(tf.reduce_any(diffuse_colors >= 0, axis=3), tf.float32)\n\n renders = phong_shader(\n normals=pixel_normals,\n alphas=pixel_mask,\n pixel_positions=pixel_positions,\n light_positions=light_positions,\n light_intensities=light_intensities,\n diffuse_colors=diffuse_colors,\n camera_position=camera_position if specular_colors is not None else None,\n specular_colors=specular_colors,\n shininess_coefficients=shininess_coefficients,\n ambient_color=ambient_color)\n\n #return renders, pixel_mask\n pixel_mask = alpha > 0.5\n pixel_mask = tf.cast(pixel_mask, dtype=tf.float32)\n pixel_mask = tf.reverse(pixel_mask, axis=[1])\n\n return renders, pixel_mask\n\n\ndef mesh_depthmap_camera(vertices, triangles, mtx_ext,\n mtx_camera, mtx_perspective_frustrum,\n image_width, image_height\n ):\n \"\"\"Renders an input scene using phong shading, and returns an output image.\n\n Args:\n vertices: 3-D float32 tensor with shape [batch_size, vertex_count, 3]. Each\n triplet is an xyz position in world space.\n triangles: 2-D int32 tensor with shape [triangle_count, 3]. Each triplet\n should contain vertex indices describing a triangle such that the\n triangle's normal points toward the viewer if the forward order of the\n triplet defines a clockwise winding of the vertices. Gradients with\n respect to this tensor are not available.\n normals: 3-D float32 tensor with shape [batch_size, vertex_count, 3]. Each\n triplet is the xyz vertex normal for its corresponding vertex. Each\n vector is assumed to be already normalized.\n\n mtx_camera: 3-D tensor with shape [batch_size, 4, 4] or 2-D tensor with\n shape [4, 4] specifying the camera model view matrix\n mtx_perspective_frustrum: 3-D tensor with shape [batch_size, 4, 4] or 2-D tensor with\n shape [4, 4] specifying the perspective and frustrum matrix\n camera_position: 2-D tensor with shape [batch_size, 3] or 1-D tensor with\n shape [3] specifying the XYZ world space camera position.\n\n image_width: int specifying desired output image width in pixels.\n image_height: int specifying desired output image height in pixels.\n\n Returns:\n A 4-D float32 tensor of shape [batch_size, image_height, image_width, 4]\n containing the lit RGBA color values for each image at each pixel. RGB\n colors are the intensity values before tonemapping and can be in the range\n [0, infinity]. Clipping to the range [0,1] with tf_render.clip_by_value is likely\n reasonable for both viewing and training most scenes. More complex scenes\n with multiple lights should tone map color values for display only. One\n simple tonemapping approach is to rescale color values as x/(1+x); gamma\n compression is another common techinque. Alpha values are zero for\n background pixels and near one for mesh pixels.\n Raises:\n ValueError: An invalid argument to the method is detected.\n \"\"\"\n if len(vertices.shape) != 3:\n raise ValueError('Vertices must have shape [batch_size, vertex_count, 3].')\n batch_size = vertices.shape[0].value\n\n # TODO: Debug Shape\n if mtx_camera.get_shape().as_list() == [4, 4]:\n mtx_camera = tf.tile(\n tf.expand_dims(mtx_camera, axis=0), [batch_size, 1, 1])\n elif mtx_camera.get_shape().as_list() != [batch_size, 4, 4]:\n raise ValueError('Camera_lookat must have shape [batch_size, 4, 4]')\n\n if mtx_perspective_frustrum.get_shape().as_list() == [4, 4]:\n mtx_camera = tf.tile(\n tf.expand_dims(mtx_perspective_frustrum, axis=0), [batch_size, 1])\n elif mtx_camera.get_shape().as_list() != [batch_size, 4, 4]:\n raise ValueError('Camera_lookat must have shape [batch_size, 4, 4]')\n\n\n # vertex attribute of depthmap is only z\n vertex_attributes = vertices\n #vertex_attributes = tf_render.expand_dims(vertex_attributes, -1)\n # camera_matrices = camera_utils.look_at(camera_position, camera_lookat,\n # camera_up)\n #\n # perspective_transforms = camera_utils.perspective(image_width / image_height,\n # fov_y, near_clip, far_clip)\n\n clip_space_transforms = tf.matmul(mtx_perspective_frustrum, mtx_camera, name=\"mtx_clip_space_transforms_batch\")\n\n pixel_attributes, alpha, _ = rasterize_triangles(\n vertices, vertex_attributes, triangles, clip_space_transforms,\n image_width, image_height, [99999999] * vertex_attributes.shape[2].value)\n\n # Extract the interpolated vertex attributes from the pixel buffer and\n # supply them to the shader:\n filler_homo = tf.ones(shape=[pixel_attributes.shape[0], pixel_attributes.shape[1], pixel_attributes.shape[2], 1])\n pixel_attributes = tf.concat([pixel_attributes, filler_homo], axis=3)\n pixel_attributes = tf.reshape(pixel_attributes, shape=[batch_size, -1, 4])\n pixel_attributes = tf.transpose(pixel_attributes, perm=[0, 2, 1])\n\n pixel_attributes = tf.matmul(mtx_ext, pixel_attributes)\n pixel_attributes = tf.transpose(pixel_attributes, perm=[0, 2, 1])\n pixel_attributes = tf.reshape(pixel_attributes, shape=[batch_size, image_height, image_width, 4])\n depth_map = pixel_attributes[:, :, :, 2]\n\n pixel_mask = alpha > 0.5\n pixel_mask = tf.cast(pixel_mask, dtype=tf.float32)\n\n depth_map = tf.reverse(depth_map, axis=[1])\n pixel_mask = tf.reverse(pixel_mask, axis=[1])\n\n return depth_map, pixel_mask\n\n# ortho\ndef mesh_rendererOrtho_camera(vertices, triangles, normals, diffuse_colors,\n mtx_camera, mtx_perspective_frustrum, light_positions, light_intensities,\n image_width, image_height, ambient_color=None, background=-1\n ):\n \"\"\"Renders an input scene using phong shading, and returns an output image.\n\n Args:\n vertices: 3-D float32 tensor with shape [batch_size, vertex_count, 3]. Each\n triplet is an xyz position in world space.\n triangles: 2-D int32 tensor with shape [triangle_count, 3]. Each triplet\n should contain vertex indices describing a triangle such that the\n triangle's normal points toward the viewer if the forward order of the\n triplet defines a clockwise winding of the vertices. Gradients with\n respect to this tensor are not available.\n normals: 3-D float32 tensor with shape [batch_size, vertex_count, 3]. Each\n triplet is the xyz vertex normal for its corresponding vertex. Each\n vector is assumed to be already normalized.\n diffuse_colors: 3-D float32 tensor with shape [batch_size,\n vertex_count, 3]. The RGB diffuse reflection in the range [0,1] for\n each vertex.\n\n mtx_camera: 3-D tensor with shape [batch_size, 4, 4] or 2-D tensor with\n shape [4, 4] specifying the camera model view matrix\n mtx_perspective_frustrum: 3-D tensor with shape [batch_size, 4, 4] or 2-D tensor with\n shape [4, 4] specifying the perspective and frustrum matrix\n camera_position: 2-D tensor with shape [batch_size, 3] or 1-D tensor with\n shape [3] specifying the XYZ world space camera position.\n\n light_positions: a 3-D tensor with shape [batch_size, light_count, 3]. The\n XYZ position of each light in the scene. In the same coordinate space as\n pixel_positions.\n light_intensities: a 3-D tensor with shape [batch_size, light_count, 3]. The\n RGB intensity values for each light. Intensities may be above one.\n image_width: int specifying desired output image width in pixels.\n image_height: int specifying desired output image height in pixels.\n\n specular_colors: 3-D float32 tensor with shape [batch_size,\n vertex_count, 3]. The RGB specular reflection in the range [0, 1] for\n each vertex. If supplied, specular reflections will be computed, and\n both specular_colors and shininess_coefficients are expected.\n shininess_coefficients: a 0D-2D float32 tensor with maximum shape\n [batch_size, vertex_count]. The phong shininess coefficient of each\n vertex. A 0D tensor or float gives a constant shininess coefficient\n across all batches and images. A 1D tensor must have shape [batch_size],\n and a single shininess coefficient per image is used.\n ambient_color: a 2D tensor with shape [batch_size, 3]. The RGB ambient\n color, which is added to each pixel in the scene. If None, it is\n assumed to be black.\n\n\n Returns:\n A 4-D float32 tensor of shape [batch_size, image_height, image_width, 4]\n containing the lit RGBA color values for each image at each pixel. RGB\n colors are the intensity values before tonemapping and can be in the range\n [0, infinity]. Clipping to the range [0,1] with tf_render.clip_by_value is likely\n reasonable for both viewing and training most scenes. More complex scenes\n with multiple lights should tone map color values for display only. One\n simple tonemapping approach is to rescale color values as x/(1+x); gamma\n compression is another common techinque. Alpha values are zero for\n background pixels and near one for mesh pixels.\n Raises:\n ValueError: An invalid argument to the method is detected.\n \"\"\"\n if len(vertices.shape) != 3:\n raise ValueError('Vertices must have shape [batch_size, vertex_count, 3].')\n batch_size = vertices.shape[0].value\n if len(normals.shape) != 3:\n raise ValueError('Normals must have shape [batch_size, vertex_count, 3].')\n if len(light_positions.shape) != 3:\n raise ValueError(\n 'Light_positions must have shape [batch_size, light_count, 3].')\n if len(light_intensities.shape) != 3:\n raise ValueError(\n 'Light_intensities must have shape [batch_size, light_count, 3].')\n if len(diffuse_colors.shape) != 3:\n raise ValueError(\n 'vertex_diffuse_colors must have shape [batch_size, vertex_count, 3].')\n if (ambient_color is not None and\n ambient_color.get_shape().as_list() != [batch_size, 3]):\n raise ValueError('Ambient_color must have shape [batch_size, 3].')\n\n # TODO: Debug Shape\n if mtx_camera.get_shape().as_list() == [4, 4]:\n mtx_camera = tf.tile(\n tf.expand_dims(mtx_camera, axis=0), [batch_size, 1, 1])\n elif mtx_camera.get_shape().as_list() != [batch_size, 4, 4]:\n raise ValueError('Camera_lookat must have shape [batch_size, 4, 4]')\n\n if mtx_perspective_frustrum.get_shape().as_list() == [4, 4]:\n mtx_camera = tf.tile(\n tf.expand_dims(mtx_perspective_frustrum, axis=0), [batch_size, 1])\n elif mtx_camera.get_shape().as_list() != [batch_size, 4, 4]:\n raise ValueError('Camera_lookat must have shape [batch_size, 4, 4]')\n\n\n vertex_attributes = tf.concat([normals, vertices, diffuse_colors], axis=2)\n\n clip_space_transforms = tf.matmul(mtx_perspective_frustrum, mtx_camera, name=\"mtx_clip_space_transforms_batch\")\n\n pixel_attributes, alpha, tri_ids = rasterize_triangles(\n vertices, vertex_attributes, triangles, clip_space_transforms,\n image_width, image_height, [background] * vertex_attributes.shape[2].value)\n\n # Extract the interpolated vertex attributes from the pixel buffer and\n # supply them to the shader:\n pixel_normals = tf.nn.l2_normalize(pixel_attributes[:, :, :, 0:3], dim=3)\n pixel_positions = pixel_attributes[:, :, :, 3:6]\n diffuse_colors = pixel_attributes[:, :, :, 6:9]\n\n pixel_mask = tf.cast(tf.reduce_any(diffuse_colors >= 0, axis=3), tf.float32)\n\n renders = phong_shader(\n normals=pixel_normals,\n alphas=pixel_mask,\n pixel_positions=pixel_positions,\n light_positions=light_positions,\n light_intensities=light_intensities,\n diffuse_colors=diffuse_colors,\n camera_position=None,\n specular_colors=None,\n shininess_coefficients=None,\n ambient_color=ambient_color)\n\n #return renders, pixel_mask\n pixel_mask = alpha > 0.5\n pixel_mask = tf.cast(pixel_mask, dtype=tf.float32)\n pixel_mask = tf.reverse(pixel_mask, axis=[1])\n\n return renders, pixel_mask\n\n\ndef mesh_depthmapOrtho_camera(vertices, triangles,\n mtx_ext, mtx_perspective_frustrum, image_width, image_height\n ):\n \"\"\"Renders an input scene using phong shading, and returns an output image.\n\n Args:\n vertices: 3-D float32 tensor with shape [batch_size, vertex_count, 3]. Each\n triplet is an xyz position in world space.\n triangles: 2-D int32 tensor with shape [triangle_count, 3]. Each triplet\n should contain vertex indices describing a triangle such that the\n triangle's normal points toward the viewer if the forward order of the\n triplet defines a clockwise winding of the vertices. Gradients with\n respect to this tensor are not available.\n normals: 3-D float32 tensor with shape [batch_size, vertex_count, 3]. Each\n triplet is the xyz vertex normal for its corresponding vertex. Each\n vector is assumed to be already normalized.\n\n mtx_camera: 3-D tensor with shape [batch_size, 4, 4] or 2-D tensor with\n shape [4, 4] specifying the camera model view matrix\n mtx_perspective_frustrum: 3-D tensor with shape [batch_size, 4, 4] or 2-D tensor with\n shape [4, 4] specifying the perspective and frustrum matrix\n camera_position: 2-D tensor with shape [batch_size, 3] or 1-D tensor with\n shape [3] specifying the XYZ world space camera position.\n\n image_width: int specifying desired output image width in pixels.\n image_height: int specifying desired output image height in pixels.\n\n Returns:\n A 4-D float32 tensor of shape [batch_size, image_height, image_width, 4]\n containing the lit RGBA color values for each image at each pixel. RGB\n colors are the intensity values before tonemapping and can be in the range\n [0, infinity]. Clipping to the range [0,1] with tf_render.clip_by_value is likely\n reasonable for both viewing and training most scenes. More complex scenes\n with multiple lights should tone map color values for display only. One\n simple tonemapping approach is to rescale color values as x/(1+x); gamma\n compression is another common techinque. Alpha values are zero for\n background pixels and near one for mesh pixels.\n Raises:\n ValueError: An invalid argument to the method is detected.\n \"\"\"\n if len(vertices.shape) != 3:\n raise ValueError('Vertices must have shape [batch_size, vertex_count, 3].')\n batch_size = vertices.shape[0].value\n\n # TODO: Debug Shape\n if mtx_ext.get_shape().as_list() == [4, 4]:\n mtx_ext = tf.tile(\n tf.expand_dims(mtx_ext, axis=0), [batch_size, 1, 1])\n elif mtx_ext.get_shape().as_list() != [batch_size, 4, 4]:\n raise ValueError('Camera_lookat must have shape [batch_size, 4, 4]')\n\n if mtx_perspective_frustrum.get_shape().as_list() == [4, 4]:\n mtx_perspective_frustrum = tf.tile(\n tf.expand_dims(mtx_perspective_frustrum, axis=0), [batch_size, 1])\n elif mtx_perspective_frustrum.get_shape().as_list() != [batch_size, 4, 4]:\n raise ValueError('Camera_lookat must have shape [batch_size, 4, 4]')\n\n\n # vertex attribute of depthmap is only z\n vertex_attributes = vertices\n #vertex_attributes = tf_render.expand_dims(vertex_attributes, -1)\n # camera_matrices = camera_utils.look_at(camera_position, camera_lookat,\n # camera_up)\n #\n # perspective_transforms = camera_utils.perspective(image_width / image_height,\n # fov_y, near_clip, far_clip)\n\n clip_space_transforms = tf.matmul(mtx_perspective_frustrum, mtx_ext, name=\"mtx_clip_space_transforms_batch\")\n\n pixel_attributes, alpha, _ = rasterize_triangles(\n vertices, vertex_attributes, triangles, clip_space_transforms,\n image_width, image_height, [99999999] * vertex_attributes.shape[2].value)\n\n # Extract the interpolated vertex attributes from the pixel buffer and\n # supply them to the shader:\n filler_homo = tf.ones(shape=[pixel_attributes.shape[0], pixel_attributes.shape[1], pixel_attributes.shape[2], 1])\n pixel_attributes = tf.concat([pixel_attributes, filler_homo], axis=3)\n pixel_attributes = tf.reshape(pixel_attributes, shape=[batch_size, -1, 4])\n pixel_attributes = tf.transpose(pixel_attributes, perm=[0, 2, 1])\n\n pixel_attributes = tf.matmul(mtx_ext, pixel_attributes)\n pixel_attributes = tf.transpose(pixel_attributes, perm=[0, 2, 1])\n pixel_attributes = tf.reshape(pixel_attributes, shape=[batch_size, image_height, image_width, 4])\n depth_map = pixel_attributes[:, :, :, 2]\n\n pixel_mask = alpha > 0.5\n pixel_mask = tf.cast(pixel_mask, dtype=tf.float32)\n\n depth_map = tf.reverse(depth_map, axis=[1])\n pixel_mask = tf.reverse(pixel_mask, axis=[1])\n\n return depth_map, pixel_mask"
},
{
"alpha_fraction": 0.758884072303772,
"alphanum_fraction": 0.7638658285140991,
"avg_line_length": 40.26027297973633,
"blob_id": "86db4d509c14bb3a57a98b3a0d52ea4eed650814",
"content_id": "8fc30e7134b418547106ceb9ccef3de0936a22cf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3011,
"license_type": "permissive",
"max_line_length": 360,
"num_lines": 73,
"path": "/Cartoonify Image/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Cartoonify Image \nCurrently many of us wants to have our photo to be cartoonify, and we try to use the professional cartoonizer application available in market and most of them are not freeware. In order to have basic cartoonifying effects, we just need the bilateral filter, some edge detection mechanism and some filters. \n\nThe bilateral filter is use to reduce the color palettle, which is the most important task for cartoonifying the image and have a look like cartoon.And then comes the edge detection to produce the bold silhouettes.\n\n<p align=\"center\">\n <img src=\"logo\\original.jpeg\" width=\"250\" title=\"hover text\">\n <img src=\"logo\\cartoonified.png\" width=\"250\" alt=\"accessibility text\">\n</p>\n\n## Dependencies:\n\nThe Dependencies used are:\n\n- Opencv :It provides the tool for applying computer vison techniques on the image.\n- Numpy :Images are stored and processed as numbers, These are taken as arrays.\n\n## How to create a Cortoonify Image?\n- Cartoonify Images can be created using the opencv library.\n- OpenCV (Open Source Computer Vision Library) is an open source computer vision and machine learning software library. It is mainly aimed at real-time computer vision and image processing. It is used to perform different operations on images which transform them using different techniques. Majorly supports all lannguages like Python, C++,Android, Java, etc.\n- In Opencv there are various functions like bilateral filters, median blur, adaptive thresholding which help in cartoonify the image.\n\n## Algorithm\n- Firstly importing the cv2 and numpy library.\n- Now applying the bilateral filter to reduce the color palette of the image.\n- Covert the actual image to grayscale.\n- Apply the median blur to reduce the image noise in the grayscale image.\n- reate an edge mask from the grayscale image using adaptive thresholding.\n- Finally combine the color image produced from step 1 with edge mask produced from step 4.\n\n\n## Want to contribute in Cartoonify Images?\n You can refer to CONTRIBUTING.md (`https://github.com/akshitagupta15june/Face-X/blob/master/CONTRIBUTING.md`)\n#### Or follow the below steps - \n- Fork this repository `https://github.com/akshitagupta15june/Face-X`. \n- Clone the forked repository\n``` \ngit clone https://github.com/<your-username>/<repo-name> \n```\n- Create a Virtual Environment(that can fulfill the required dependencies)\n```\n- python -m venv env\n- source env/bin/activate (Linux)\n- env\\Scripts\\activate (Windows)\n```\n- Install dependencies\n- Go to project directory\n``` \ncd Cartoonify Image\n```\n- Make a new branch\n```\ngit branch < YOUR_USERNAME >\n```\n- Switch to Development Branch\n```\ngit checkout < YOURUSERNAME >\n```\n- Make a folder and add your code file and a readme file with screenshots.\n- Add your files or changes to staging area\n```\ngit add .\n```\n- Commit message\n```\ngit commit -m \"Enter message\"\n```\n- Push your code\n``` \ngit push\n```\n- Make Pull request with the Master branch of `akshitagupta15june/Face-X` repo.\n- Wait for reviewers to review your PR"
},
{
"alpha_fraction": 0.6459606885910034,
"alphanum_fraction": 0.6851528286933899,
"avg_line_length": 45.46113967895508,
"blob_id": "144cef5ba60eba4116b34cffc95d9d3c70baff32",
"content_id": "97efb53a492ff23b999e03365aad79c137583456",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 9168,
"license_type": "permissive",
"max_line_length": 607,
"num_lines": 193,
"path": "/Face Reconstruction/Face Alignment in Full Pose Range/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Face Alignment in Full Pose Range\r\n<p align=\"center\">\r\n <img src=\"samples/obama_three_styles.gif\" alt=\"obama\">\r\n</p>\r\n\r\n## Introduction\r\nThis repo holds the pytorch improved version of the paper: [Face Alignment in Full Pose Range: A 3D Total Solution](https://arxiv.org/abs/1804.01005). Several works beyond the original paper are added, including the real-time training, training strategies. Therefore, this repo is an improved version of the original work. As far, this repo releases the pre-trained first-stage pytorch models of MobileNet-V1 structure, the pre-processed training&testing dataset and codebase. Note that the inference time is about **0.27ms per image** (input batch with 128 images as an input batch) on GeForce GTX TITAN X.\r\n<!-- Note that if your academic work use the code of this repo, you should cite this repo not the original paper.-->\r\n<!-- One related blog will be published for some important technique details in future. -->\r\n<!-- Why not evaluate it on single image? Because most time for single image is spent on function call. The inference speed is equal to MobileNet-V1 with 120x120x3 tensor as input, therefore it is possible to convert to mobile devices. -->\r\n\r\nSeveral results on ALFW-2000 dataset (inferenced from model *phase1_wpdc_vdc.pth.tar*) are shown below.\r\n<p align=\"center\">\r\n <img src=\"imgs/landmark_3d.jpg\" alt=\"Landmark 3D\" width=\"1000px\">\r\n</p>\r\n\r\n\r\n## Applications & Features\r\n#### 1. Face Alignment\r\n<p align=\"center\">\r\n <img src=\"samples/dapeng_3DDFA_trim.gif\" alt=\"dapeng\">\r\n</p>\r\n\r\n#### 2. Face Reconstruction\r\n<p align=\"center\">\r\n <img src=\"samples/5.png\" alt=\"demo\" width=\"750px\">\r\n</p>\r\n\r\n#### 3. 3D Pose Estimation\r\n<p align=\"center\">\r\n <img src=\"samples/pose.png\" alt=\"tongliya\" width=\"750px\">\r\n</p>\r\n\r\n#### 4. Depth Image Estimation\r\n<p align=\"center\">\r\n <img src=\"samples/demo_depth.jpg\" alt=\"demo_depth\" width=\"750px\">\r\n</p>\r\n\r\n### Usage\r\n\r\n1. Clone this repo (this may take some time as it is a little big)\r\n ```\r\n git clone https://github.com/cleardusk/3DDFA.git # or [email protected]:cleardusk/3DDFA.git\r\n cd 3DDFA\r\n ```\r\n\r\n Then, download dlib landmark pre-trained model in [Google Drive](https://drive.google.com/open?id=1kxgOZSds1HuUIlvo5sRH3PJv377qZAkE) or [Baidu Yun](https://pan.baidu.com/s/1bx-GxGf50-KDk4xz3bCYcw), and put it into `models` directory. (To reduce this repo's size, I remove some large size binary files including this model, so you should download it : ) )\r\n\r\n\r\n2. Build cython module (just one line for building)\r\n ```\r\n cd utils/cython\r\n python3 setup.py build_ext -i\r\n ```\r\n This is for accelerating depth estimation and PNCC render since Python is too slow in for loop.\r\n \r\n \r\n3. Run the `main.py` with arbitrary image as input\r\n ```\r\n python3 main.py -f samples/test1.jpg\r\n ```\r\n If you can see these output log in terminal, you run it successfully.\r\n ```\r\n Dump tp samples/test1_0.ply\r\n Save 68 3d landmarks to samples/test1_0.txt\r\n Dump obj with sampled texture to samples/test1_0.obj\r\n Dump tp samples/test1_1.ply\r\n Save 68 3d landmarks to samples/test1_1.txt\r\n Dump obj with sampled texture to samples/test1_1.obj\r\n Dump to samples/test1_pose.jpg\r\n Dump to samples/test1_depth.png\r\n Dump to samples/test1_pncc.png\r\n Save visualization result to samples/test1_3DDFA.jpg\r\n ```\r\n\r\n Because `test1.jpg` has two faces, there are two `.ply` and `.obj` files (can be rendered by Meshlab or Microsoft 3D Builder) predicted. Depth, PNCC, PAF and pose estimation are all set true by default. Please run `python3 main.py -h` or review the code for more details.\r\n\r\n The 68 landmarks visualization result `samples/test1_3DDFA.jpg` and pose estimation result `samples/test1_pose.jpg` are shown below:\r\n\r\n<p align=\"center\">\r\n <img src=\"samples/test1_3DDFA.jpg\" alt=\"samples\" width=\"650px\">\r\n</p>\r\n\r\n<p align=\"center\">\r\n <img src=\"samples/test1_pose.jpg\" alt=\"samples\" width=\"650px\">\r\n</p>\r\n\r\n4. Additional example\r\n\r\n ```\r\n python3 ./main.py -f samples/emma_input.jpg --bbox_init=two --dlib_bbox=false\r\n ```\r\n\r\n<p align=\"center\">\r\n <img src=\"samples/emma_input_3DDFA.jpg\" alt=\"samples\" width=\"750px\">\r\n</p>\r\n\r\n<p align=\"center\">\r\n <img src=\"samples/emma_input_pose.jpg\" alt=\"samples\" width=\"750px\">\r\n</p>\r\n\r\n\r\n<p align=\"center\">\r\n <img src=\"imgs/inference_speed.png\" alt=\"Inference speed\" width=\"600px\">\r\n</p>\r\n\r\n## Training details\r\nThe training scripts lie in `training` directory. The related resources are in below table.\r\n\r\n| Data | Download Link | Description |\r\n|:-:|:-:|:-:|\r\n| train.configs | [BaiduYun](https://pan.baidu.com/s/1ozZVs26-xE49sF7nystrKQ) or [Google Drive](https://drive.google.com/open?id=1dzwQNZNMppFVShLYoLEfU3EOj3tCeXOD), 217M | The directory contraining 3DMM params and filelists of training dataset |\r\n| train_aug_120x120.zip | [BaiduYun](https://pan.baidu.com/s/19QNGst2E1pRKL7Dtx_L1MA) or [Google Drive](https://drive.google.com/open?id=17LfvBZFAeXt0ACPnVckfdrLTMHUpIQqE), 2.15G | The cropped images of augmentation training dataset |\r\n| test.data.zip | [BaiduYun](https://pan.baidu.com/s/1DTVGCG5k0jjjhOc8GcSLOw) or [Google Drive](https://drive.google.com/file/d/1r_ciJ1M0BSRTwndIBt42GlPFRv6CvvEP/view?usp=sharing), 151M | The cropped images of AFLW and ALFW-2000-3D testset |\r\n\r\nAfter preparing the training dataset and configuration files, go into `training` directory and run the bash scripts to train. `train_wpdc.sh`, `train_vdc.sh` and `train_pdc.sh` are examples of training scripts. After configuring the training and testing sets, just run them for training. Take `train_wpdc.sh` for example as below:\r\n\r\n```\r\n#!/usr/bin/env bash\r\n\r\nLOG_ALIAS=$1\r\nLOG_DIR=\"logs\"\r\nmkdir -p ${LOG_DIR}\r\n\r\nLOG_FILE=\"${LOG_DIR}/${LOG_ALIAS}_`date +'%Y-%m-%d_%H:%M.%S'`.log\"\r\n#echo $LOG_FILE\r\n\r\n./train.py --arch=\"mobilenet_1\" \\\r\n --start-epoch=1 \\\r\n --loss=wpdc \\\r\n --snapshot=\"snapshot/phase1_wpdc\" \\\r\n --param-fp-train='../train.configs/param_all_norm.pkl' \\\r\n --param-fp-val='../train.configs/param_all_norm_val.pkl' \\\r\n --warmup=5 \\\r\n --opt-style=resample \\\r\n --resample-num=132 \\\r\n --batch-size=512 \\\r\n --base-lr=0.02 \\\r\n --epochs=50 \\\r\n --milestones=30,40 \\\r\n --print-freq=50 \\\r\n --devices-id=0,1 \\\r\n --workers=8 \\\r\n --filelists-train=\"../train.configs/train_aug_120x120.list.train\" \\\r\n --filelists-val=\"../train.configs/train_aug_120x120.list.val\" \\\r\n --root=\"/path/to//train_aug_120x120\" \\\r\n --log-file=\"${LOG_FILE}\"\r\n```\r\n\r\nThe specific training parameters are all presented in bash scripts, including learning rate, mini-batch size, epochs and so on.\r\n\r\n## Evaluation\r\nFirst, you should download the cropped testset ALFW and ALFW-2000-3D in [test.data.zip](https://pan.baidu.com/s/1DTVGCG5k0jjjhOc8GcSLOw), then unzip it and put it in the root directory.\r\nNext, run the benchmark code by providing trained model path.\r\nI have already provided five pre-trained models in `models` directory (seen in below table). These models are trained using different loss in the first stage. The model size is about 13M due to the high efficiency of MobileNet-V1 structure.\r\n```\r\npython3 ./benchmark.py -c models/phase1_wpdc_vdc.pth.tar\r\n```\r\n\r\nThe performances of pre-trained models are shown below. In the first stage, the effectiveness of different loss is in order: WPDC > VDC > PDC. While the strategy using VDC to finetune WPDC achieves the best result.\r\n\r\n| Model | AFLW (21 pts) | AFLW 2000-3D (68 pts) | Download Link |\r\n|:-:|:-:|:-:| :-: |\r\n| *phase1_pdc.pth.tar* | 6.956±0.981 | 5.644±1.323 | [Baidu Yun](https://pan.baidu.com/s/1xeyZa4rxVazd_QGWx6QXFw) or [Google Drive](https://drive.google.com/open?id=18UQfDkGNzotKoFV0Lh_O-HnXsp1ABdjl) |\r\n| *phase1_vdc.pth.tar* | 6.717±0.924 | 5.030±1.044 | [Baidu Yun](https://pan.baidu.com/s/10-0YpYKj1_efJYqC1q-aNQ) or [Google Drive](https://drive.google.com/open?id=1iHADYNIQR2Jqvt4nwmnh5n3Axe-HXMRR) |\r\n| *phase1_wpdc.pth.tar* | 6.348±0.929 | 4.759±0.996 | [Baidu Yun](https://pan.baidu.com/s/1yqaJ3S3MNpYBgyA5BYtHuw) or [Google Drive](https://drive.google.com/open?id=1ebwkOWjaQ7U4mpA89ldfmjeQdfDDdFS-) |\r\n| *phase1_wpdc_vdc.pth.tar* | **5.401±0.754** | **4.252±0.976** | In this repo. |\r\n\r\n\r\n## Citation\r\n**If your work benefits from this repo, please cite three bibs below.**\r\n\r\n @misc{3ddfa_cleardusk,\r\n author = {Guo, Jianzhu and Zhu, Xiangyu and Lei, Zhen},\r\n title = {3DDFA},\r\n howpublished = {\\url{https://github.com/cleardusk/3DDFA}},\r\n year = {2018}\r\n }\r\n \r\n @inproceedings{guo2020towards,\r\n title= {Towards Fast, Accurate and Stable 3D Dense Face Alignment},\r\n author= {Guo, Jianzhu and Zhu, Xiangyu and Yang, Yang and Yang, Fan and Lei, Zhen and Li, Stan Z},\r\n booktitle= {Proceedings of the European Conference on Computer Vision (ECCV)},\r\n year= {2020}\r\n }\r\n\r\n @article{zhu2017face,\r\n title= {Face alignment in full pose range: A 3d total solution},\r\n author= {Zhu, Xiangyu and Liu, Xiaoming and Lei, Zhen and Li, Stan Z},\r\n journal= {IEEE transactions on pattern analysis and machine intelligence},\r\n year= {2017},\r\n publisher= {IEEE}\r\n }\r\n"
},
{
"alpha_fraction": 0.7496616840362549,
"alphanum_fraction": 0.7780784964561462,
"avg_line_length": 37.894737243652344,
"blob_id": "ab36b3dbfa7b6bc8d6766a7d5fca744c355bbc73",
"content_id": "1041b80a61326c20cd0310b68358300ead39aea0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1478,
"license_type": "permissive",
"max_line_length": 368,
"num_lines": 38,
"path": "/Face-Mask-Detection/face-mask-detection-pytorch/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "## Transfer Learning for Image Classification in PyTorch\n\n### Introduction:\n- Face mask detection is a significant progress in the domains of Image processing and Computer vision, since the rise of the Covid-19 pandemic. Many face detection models have been created using several algorithms and techniques. The approach in this project uses deep learning, pytorch, numpy and matplotlib to detect face masks and calculate accuracy of this model.\n- Transfer Learning, Data augmentation are the key to this project.\n\n### Major features:\n\n- How a CNN works\n- Layer and classifier visualization\n- Data preparation\n- Modifying a Pretrained Model (ResNet34), using transfer learning\n\n### Methodology used:\n\n\n### Dependencies:\n- opendatasets\n- os\n- torch\n- torchvision\n- numpy\n- matplotlib\n\n### Dataset Used:\nWe'll use the COVID Face Mask Detection Dataset dataset from [Kaggle](https://www.kaggle.com/prithwirajmitra/covid-face-mask-detection-dataset). This dataset contains about 1006 equally distributed images of 2 distinct types, namely `Mask` and `Non Mask`.\n\n### Demo\n\nJust head over to [face-mask-detection-pytorch.ipynb](Face-X/Face-Mask-Detection/face-mask-detection-pytorch/face-mask-detection-pytorch.ipynb), and run the python notebook on your local computer.\n\n\n### Example:\n \n\n### Results:\n- Validation loss: 0.943358838558197\n- Validation accuracy: 0.8799999952316284\n"
},
{
"alpha_fraction": 0.7134791612625122,
"alphanum_fraction": 0.7395907044410706,
"avg_line_length": 23.413793563842773,
"blob_id": "2f21138afea1dc491f2d52de4ce840b9145995f0",
"content_id": "3c000c61a368b35662ae122c63a5944d8b194986",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1417,
"license_type": "permissive",
"max_line_length": 137,
"num_lines": 58,
"path": "/Recognition-Algorithms/Recognition using GhostNet/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "## Overview\nFace Recognition Using OpenCV and PyTorch.\n\nThis model uses GhostNet model for the recognition of the User face.\n\nProgram is trained for 5 epochs, You can increase the number of epochs and the number of layers accordingly.\n\n\n### Dependencies:\n* pip install numpy\n* pip install Pillow\n* pip install tqdm\n* pytorch (get from https://pytorch.org/)\n* pip install opencv-python\n\nDownload haarcascades file from here=> https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml\n\n## ScreenShots\n\n<img src=\"Screenshot 2021-01-15 115306.png\" height=\"250px\">\n<img src=\"Screenshot 2021-01-15 115354.png\" height=\"250px\">\n\n\n## Quick Start\n\n- Fork and Clone the repository using-\n```\ngit clone https://github.com/akshitagupta15june/Face-X.git\n```\n- Create virtual environment-\n```\n- `python -m venv env`\n- `source env/bin/activate` (Linux)\n- `env\\Scripts\\activate` (Windows)\n```\n- Install dependencies-\n\n- Headover to Project Directory- \n```\ncd \"Recognition using GhostNet\"\n```\n- Create dataset using -\n```\n- Run create_dataset.py on respective idle(VS Code, PyCharm, Jupiter Notebook, Colab)\n```\nNote: Dataset is automatically split into train and val folders.\n\n- Train the model -\n```\n- Run train-model.py\n```\nNote: Make sure all dependencies are installed properly.\n\n- Final-output -\n```\n- Run output.py\n```\nNote: Make sure you have haarcascade_frontalface_default.xml file \n"
},
{
"alpha_fraction": 0.5276371836662292,
"alphanum_fraction": 0.57707279920578,
"avg_line_length": 43.678260803222656,
"blob_id": "f644e73631853ef2ada7dd5b719e05fa626bb922",
"content_id": "31983f03df9a7e35c13c23243bbb757fd62a5e25",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5138,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 115,
"path": "/Face Reconstruction/3D Face Reconstruction using Graph Convolution Network/model_resnet.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import logging\n\nimport tensorflow as tf\n\nfrom base_model import BaseModel\n\nlogger = logging.getLogger('x')\n\n\nclass Model(BaseModel):\n \"\"\"\n Mesh Convolutional Autoencoder which uses the Chebyshev approximation.\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n super(Model, self).__init__(*args, **kwargs)\n logger.info('Using ResNet Model...')\n\n def mesh_generator(self, image_emb, pca_color, reuse=False):\n with tf.variable_scope('mesh_generator', reuse=reuse):\n decode_color = self.mesh_decoder(image_emb, reuse=reuse)\n refine_color = self.mesh_refiner(pca_color, reuse=reuse)\n with tf.variable_scope('mesh_concat'):\n concat = tf.concat([decode_color, refine_color], axis=-1)\n outputs = self.chebyshev5(concat, self.laplacians[0], 3, 6)\n outputs = tf.nn.tanh(outputs)\n return outputs\n\n def mesh_decoder(self, image_emb, reuse=False):\n if self.wide:\n F = [32, 64, 128, 256]\n else:\n F = [32, 16, 16, 16]\n with tf.variable_scope('mesh_decoder', reuse=reuse):\n with tf.variable_scope('fc'):\n layer1 = self.fc(image_emb, self.pool_size[-1] * F[0]) # N x MF\n layer1 = tf.reshape(\n layer1, [self.batch_size, self.pool_size[-1], F[0]]) # N x M x F\n\n with tf.variable_scope('resblock1'):\n with tf.name_scope('unpooling'):\n layer2 = self.unpool(layer1, self.upsamp_trans[-1])\n layer2 = self.cheb_res_block(layer2, self.laplacians[-2], F[1],\n self.c_k)\n with tf.variable_scope('resblock2'):\n # layer3 = tf.nn.dropout(layer2, 1 - self.drop_rate)\n with tf.name_scope('unpooling'):\n layer3 = self.unpool(layer2, self.upsamp_trans[-2])\n layer3 = self.cheb_res_block(layer3, self.laplacians[-3], F[2],\n self.c_k)\n with tf.variable_scope('resblock3'):\n # layer4 = tf.nn.dropout(layer3, 1 - self.drop_rate)\n with tf.name_scope('unpooling'):\n layer4 = self.unpool(layer3, self.upsamp_trans[-3])\n layer4 = self.cheb_res_block(layer4, self.laplacians[-4], F[3],\n self.c_k)\n with tf.variable_scope('resblock4'):\n # layer5 = tf.nn.dropout(layer4, 1 - self.drop_rate)\n with tf.name_scope('unpooling'):\n layer5 = self.unpool(layer4, self.upsamp_trans[-4])\n outputs = self.cheb_res_block(layer5, self.laplacians[-5], 3, self.c_k)\n # relu=False)\n # outputs = tf.nn.tanh(outputs)\n return outputs\n\n def mesh_refiner(self, pca_color, reuse=False):\n if self.wide:\n F = [16, 32, 64, 128]\n else:\n F = [16, 32, 32, 16]\n with tf.variable_scope('mesh_refiner', reuse=reuse):\n with tf.variable_scope('resblock1'):\n layer1 = self.cheb_res_block(pca_color, self.laplacians[0], F[0],\n self.c_k)\n with tf.variable_scope('resblock2'):\n with tf.name_scope('pooling'):\n layer2 = self.pool(layer1, self.downsamp_trans[0])\n layer2 = self.cheb_res_block(layer2, self.laplacians[1], F[1], self.c_k)\n with tf.variable_scope('resblock3'):\n # layer3 = tf.nn.dropout(layer2, 1 - self.drop_rate)\n layer3 = self.cheb_res_block(layer2, self.laplacians[1], F[2], self.c_k)\n with tf.variable_scope('resblock4'):\n # layer4 = tf.nn.dropout(layer3, 1 - self.drop_rate)\n with tf.name_scope('unpooling'):\n layer4 = self.unpool(layer3, self.upsamp_trans[0])\n layer4 = self.cheb_res_block(layer4, self.laplacians[0], F[3], self.c_k)\n with tf.variable_scope('resblock5'):\n # layer5 = tf.nn.dropout(layer4, 1 - self.drop_rate)\n outputs = self.cheb_res_block(layer4, self.laplacians[0], 3, self.c_k)\n # relu=False)\n # outputs = tf.nn.tanh(outputs)\n return outputs\n\n def image_disc(self, inputs, t=True, reuse=False):\n with tf.variable_scope('image_disc', reuse=reuse):\n x = inputs\n x = self.conv2d(x, 16, 1, 1, is_training=t, name='conv1_1')\n # x = self.conv2d(x, 32, 3, 1, is_training=t, name='conv1_2')\n x = tf.nn.max_pool(x, [1, 2, 2, 1], [1, 2, 2, 1], 'SAME')\n x = self.conv2d(x, 32, 3, 1, is_training=t, name='conv2_1')\n # x = self.conv2d(x, 64, 3, 1, is_training=t, name='conv2_2')\n x = tf.nn.max_pool(x, [1, 2, 2, 1], [1, 2, 2, 1], 'SAME')\n x = self.conv2d(x, 64, 3, 1, is_training=t, name='conv3_1')\n # x = self.conv2d(x, 128, 3, 1, is_training=t, name='conv3_2')\n x = tf.nn.max_pool(x, [1, 2, 2, 1], [1, 2, 2, 1], 'SAME')\n x = self.conv2d(x, 128, 3, 1, is_training=t, name='conv4_1')\n # x = self.conv2d(x, 256, 3, 1, is_training=t, name='conv4_2')\n x = tf.nn.max_pool(x, [1, 2, 2, 1], [1, 2, 2, 1], 'SAME')\n x = self.conv2d(x, 256, 3, 1, is_training=t, name='conv5_1')\n # x = self.conv2d(x, 512, 3, 1, is_training=t, name='conv5_2')\n x = tf.nn.max_pool(x, [1, 2, 2, 1], [1, 2, 2, 1], 'SAME')\n x = self.conv2d(x, 512, 3, 1, is_training=t, name='conv6_1')\n x = self.conv2d(x, 1, 7, 1, 'VALID', False, False, t, 'outputs')\n\n return tf.squeeze(x, axis=[1, 2])\n"
},
{
"alpha_fraction": 0.6323492527008057,
"alphanum_fraction": 0.68155437707901,
"avg_line_length": 22.299999237060547,
"blob_id": "7efe9864125f2959ea7667ae9461f32c7075cf83",
"content_id": "b07b4ca48ca8a226edb525336e2cabed046f0a6b",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3963,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 170,
"path": "/Awesome-face-operations/image-segmentation/image_segmenation1.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import numpy as np \nimport pandas as pd \nimport matplotlib.pyplot as plt\nfrom mpl_toolkits.mplot3d import Axes3D\nfrom matplotlib import cm\nfrom matplotlib import colors\nfrom matplotlib.colors import hsv_to_rgb\nimport cv2\nimport os\n\nimg_path='train'\nimage_list=os.listdir(img_path)\nprint(image_list[0:5])\n\n#Looking at all the color space conversions OpenCV provides\nflags = [i for i in dir(cv2) if i.startswith('COLOR_')]\nprint(len(flags))\nprint(flags[30:40])\n\n\n#Loading an image\nimg_emma = cv2.imread(img_path+'/'+image_list[0])\nplt.imshow(img_emma)\nplt.show()\n\n#By default opencv reads any images in BGR format,\n#converting from BGR to RGB color space\n\nimg_rgb = cv2.cvtColor(img_emma, cv2.COLOR_BGR2RGB)\nplt.imshow(img_rgb)\nplt.show()\n\n#convering from BGR to GRAY color space\nimg_gray = cv2.cvtColor(img_emma, cv2.COLOR_BGR2GRAY)\nplt.imshow(img_gray)\nplt.show()\n\n#converting from BGR to HSV color space\nimg_hsv = cv2.cvtColor(img_emma, cv2.COLOR_BGR2HSV)\nplt.imshow(img_hsv)\nplt.show()\n\n#separting the channels of RBG imgae\n\n#R channel\nred = img_rgb.copy()\n# set blue and green channels to 0\nred[:, :, 1] = 0\nred[:, :, 2] = 0\nplt.imshow(red)\nplt.show()\n\n\n#G channel\ngreen = img_rgb.copy()\ngreen[:, :, 0] = 0\ngreen[:, :, 2] = 0\nplt.imshow(green)\nplt.show()\n\n#B channel\nblue = img_rgb.copy()\nblue[:, :, 0] = 0\nblue[:, :, 1] = 0\nplt.imshow(blue)\nplt.show()\n\n\n\nlight_orange = (1, 190, 200)\ndark_orange = (18, 255, 255)\n\nlo_square = np.full((10, 10, 3), light_orange, dtype=np.uint8) / 255.0\ndo_square = np.full((10, 10, 3), dark_orange, dtype=np.uint8) / 255.0\n\nplt.subplot(1, 2, 1)\nplt.imshow(hsv_to_rgb(do_square))\nplt.subplot(1, 2, 2)\nplt.imshow(hsv_to_rgb(lo_square))\nplt.show()\n\nmask = cv2.inRange(img_hsv, light_orange, dark_orange)\nresult = cv2.bitwise_and(img_rgb, img_rgb, mask=mask)\n\nplt.subplot(1, 2, 1)\nplt.imshow(mask, cmap=\"gray\")\nplt.subplot(1, 2, 2)\nplt.imshow(result)\nplt.show()\n\n#adding a second mask that looks for whites\nlight_white = (0, 0, 200)\ndark_white = (145, 60, 255)\n\nlw_square = np.full((10, 10, 3), light_white, dtype=np.uint8) / 255.0\ndw_square = np.full((10, 10, 3), dark_white, dtype=np.uint8) / 255.0\n\nplt.subplot(1, 2, 1)\nplt.imshow(hsv_to_rgb(lw_square))\nplt.subplot(1, 2, 2)\nplt.imshow(hsv_to_rgb(dw_square))\nplt.show()\n\nmask_white = cv2.inRange(img_hsv, light_white, dark_white)\nresult_white = cv2.bitwise_and(img_hsv, img_hsv, mask=mask_white)\n\nplt.subplot(1, 2, 1)\nplt.imshow(mask_white, cmap=\"gray\")\nplt.subplot(1, 2, 2)\nplt.imshow(result_white)\nplt.show()\n\n#Adding mask together and plotting the result\nfinal_mask = mask + mask_white\n\nfinal_result = cv2.bitwise_and(img_rgb, img_rgb, mask=final_mask)\nplt.subplot(1, 2, 1)\nplt.imshow(final_mask, cmap=\"gray\")\nplt.subplot(1, 2, 2)\nplt.imshow(final_result)\nplt.show()\n\nblur = cv2.GaussianBlur(final_result, (7, 7), 0)\nplt.imshow(blur)\nplt.show()\n\n#Applying segmenattion on list of images\nemma_images = []\nfor images in image_list[:5]:\n friend = cv2.cvtColor(cv2.imread(img_path +'/'+ images), cv2.COLOR_BGR2RGB)\n emma_images.append(friend)\n\n\ndef segment_image(image):\n \n\n # Convert the image into HSV\n hsv_image = cv2.cvtColor(image, cv2.COLOR_RGB2HSV)\n\n \n light_orange = (1, 190, 200)\n dark_orange = (18, 255, 255)\n\n # Apply the orange shade mask \n mask = cv2.inRange(hsv_image, light_orange, dark_orange)\n\n # Set a white range\n light_white = (0, 0, 200)\n dark_white = (145, 60, 255)\n\n # Apply the white mask\n mask_white = cv2.inRange(hsv_image, light_white, dark_white)\n\n # Combine the two masks\n final_mask = mask + mask_white\n result = cv2.bitwise_and(image, image, mask=final_mask)\n\n # Clean up the segmentation using a blur\n blur = cv2.GaussianBlur(result, (7, 7), 0)\n return blur\n\nresults = [segment_image(i) for i in emma_images]\n\nfor i in range(5):\n plt.figure(figsize=(15,20))\n plt.subplot(1, 2, 1)\n plt.imshow(emma_images[i])\n plt.subplot(1, 2, 2)\n plt.imshow(results[i])\n plt.show()\n\n\n"
},
{
"alpha_fraction": 0.489308625459671,
"alphanum_fraction": 0.536350667476654,
"avg_line_length": 36.400001525878906,
"blob_id": "5daec3a0e0a406fe036d3619c4f9cc91ffebf381",
"content_id": "ee5d5aaca89e74dd72994ef5a54591dc942675c6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2806,
"license_type": "permissive",
"max_line_length": 151,
"num_lines": 75,
"path": "/Face-Emotions-Recognition/Facial-Expression-Recognition-using-custom-CNN/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n# Facial-Expression-Recognition-using-custom-CNN\nRecognizing facial expression with CNN\n\n\n[](https://www.python.org/)\n[](https://jupyter.org/try)\n\n[](https://GitHub.com/Naereen/ama)\n[](https://github.com/Naereen/StrapDown.js/blob/master/LICENSE)\n ## Project Environment : \n\n 1. Python\n 2. Google Collab\n 3. API Docker\n ## Data Description :\n\n * **Link of the Dataset** : https://www.kaggle.com/ashishpatel26/facial-expression-recognitionferchallenge\n * **Usage** : \n \n 1. Train Data : (28709,3)\n \n 2. Public Test Data : (3589,3)\n \n 3. Private Test Data : (3589,3)\n * **Columns** : \n \n emotion\n pixels\n emotion\n * **Type** : \n \n Image Data\n 2D Images\n Data stored in tabular format into a comma seperated file. (fer2013.csv)\n \n * **Iamge Shape** :\n \n On the dataset : ( 48,48,1 ) (Unilayered Images)\n \n\n \n * **Expressions** :\n The expressions are encoded into numerical values. They represent :\n \n 1: ANGER \n 2: DISGUST\n 3: FEAR \n 4: HAPPINESS \n 5: NEUTRAL\n 6: SADNESS\n 7: SURPRISE\n ## Model : \n Sequential model having \n 1. Conv2D\n 2. MaxPool2D\n 3. Dropout\n 4. Dense\n 5. Flatten\n ## Model evaluation Metric :\n **Accuracy** :\n \n Train Data --> 0.6605\n Validation(Private Test) --> 0.5804\n Test(Private Test) --> 0.5887\n \n **Sparse categorical Crossentropy** :\n \n Train Data --> 0.8757\n Validation(Private Test) --> 1.1807\n## Some screenshots of Classification\n---\n\n\n\n## Do ***STAR*** if you find it useful :)\n"
},
{
"alpha_fraction": 0.7165108919143677,
"alphanum_fraction": 0.7422118186950684,
"avg_line_length": 26.913043975830078,
"blob_id": "565be938ca3fc5a3fc9e76846595ab188a83a127",
"content_id": "23f8952f7624f3a7decc0b3f325c2f59ee1a6352",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1284,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 46,
"path": "/Cartoonify Image/Cartoonifying using OpenCV/Cartoonify.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#step 1\n#Use bilateral filter for edge-aware smoothing.\nimport cv2\n\nnum_down = 2 # number of downsampling steps\nnum_bilateral = 7 # number of bilateral filtering steps\n\nimg_rgb = cv2.imread(\"myCat.jpg\")\n\n# downsample image using Gaussian pyramid\nimg_color = img_rgb\nfor _ in range(num_down):\n img_color = cv2.pyrDown(img_color)\n\n# repeatedly apply small bilateral filter instead of\n# applying one large filter\nfor _ in range(num_bilateral):\nimg_color = cv2.bilateralFilter(img_color, d=9, sigmaColor=9, sigmaSpace=7)\n\n# upsample image to original size\nfor _ in range(num_down):\n img_color = cv2.pyrUp(img_color)\n\n#STEP 2 & 3\n#Use median filter to reduce noise\n# convert to grayscale and apply median blur\nimg_gray = cv2.cvtColor(img_rgb, cv2.COLOR_RGB2GRAY)\nimg_blur = cv2.medianBlur(img_gray, 7)\n\n#STEP 4\n#Use adaptive thresholding to create an edge mask\n# detect and enhance edges\nimg_edge = cv2.adaptiveThreshold(img_blur, 255,\n cv2.ADAPTIVE_THRESH_MEAN_C,\n cv2.THRESH_BINARY,\n blockSize=9,\n C=2)\n\n# Step 5\n# Combine color image with edge mask & display picture\n# convert back to color, bit-AND with color image\nimg_edge = cv2.cvtColor(img_edge, cv2.COLOR_GRAY2RGB)\nimg_cartoon = cv2.bitwise_and(img_color, img_edge)\n\n# display\ncv2.imshow(\"myCat_cartoon\", img_cartoon)\n"
},
{
"alpha_fraction": 0.6598048210144043,
"alphanum_fraction": 0.6977817416191101,
"avg_line_length": 39.53956985473633,
"blob_id": "a5537b8d6f958d5497141f7151ef15796cbfe4bc",
"content_id": "970248687478a20e9ad983fd4ccda81044e9a25a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5635,
"license_type": "permissive",
"max_line_length": 127,
"num_lines": 139,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/train_unsupervise.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from __future__ import division\n\nimport os\n# python lib\nimport random\nimport sys\n\nimport numpy as np\n# tf_render\nimport tensorflow as tf\n\n#self\n_curr_path = os.path.abspath(__file__) # /home/..../face\n_cur_dir = os.path.dirname(_curr_path) # ./\n_tf_dir = os.path.dirname(_cur_dir) # ./\n_deep_learning_dir = os.path.dirname(_tf_dir) # ../\nprint(_deep_learning_dir)\nsys.path.append(_deep_learning_dir) # /home/..../pytorch3d\n\nfrom src_tfGraph.build_graph import MGC_TRAIN\n\n#\nflags = tf.app.flags\n\n# data\nflags.DEFINE_string(\"dataset_dir\", \"\", \"Dataset directory\")\nflags.DEFINE_string(\"dataset_loader\", \"\", \"data_loader_semi_unsupervised_skin\")\nflags.DEFINE_string(\"dataset_name_list\", \"train\", \"train train_debug\")\nflags.DEFINE_boolean(\"flag_shuffle\", True, \"source images (seq_length-1)\")\nflags.DEFINE_string(\"checkpoint_dir\", \"../default_checkpoints/\", \"Directory name to save the checkpoints\")\n\n# continue training\nflags.DEFINE_boolean(\"continue_train\", False, \"Continue training from previous checkpoint\")\nflags.DEFINE_string(\"init_ckpt_file\", None, \"Specific checkpoint file to initialize from\")\n\nflags.DEFINE_boolean(\"flag_data_aug\", False, \"The size of of a sample batch\")\nflags.DEFINE_integer(\"batch_size\", 1, \"The size of of a sample batch\")\nflags.DEFINE_integer(\"img_height\", 224, \"Image height\")\nflags.DEFINE_integer(\"img_width\", 224, \"Image width\")\nflags.DEFINE_integer(\"seq_length\", 3, \"Sequence length for each example\")\nflags.DEFINE_integer(\"num_source\", 2, \"source images (seq_length-1)\")\n\n# save\nflags.DEFINE_integer(\"min_steps\", 200000, \"Maximum number of training iterations\")\nflags.DEFINE_integer(\"max_steps\", 200000, \"Maximum number of training iterations\")\nflags.DEFINE_integer(\"max_d\", 64, \"Maximum depth step when training.\")\nflags.DEFINE_integer(\"summary_freq\", 1, \"Logging every log_freq iterations\")\nflags.DEFINE_integer(\"save_freq\", 50000, \"Save the model every save_freq iterations (overwrites the previous latest model)\")\n\n# opt\nflags.DEFINE_float(\"learning_rate\", 0.0001, \"Learning rate of for adam\")\nflags.DEFINE_float(\"beta1\", 0.9, \"Momentum term of adam or decay rate for RMSProp\")\n\n# loss\nflags.DEFINE_float(\"MULTIVIEW_weight\", 0.1, \"Weight for smoothness\")\n\nflags.DEFINE_float(\"photom_weight\", 0.15, \"Weight for SSIM loss\")\nflags.DEFINE_float(\"ssim_weight\", 0.85, \"Weight for SSIM loss\")\nflags.DEFINE_float(\"depth_weight\", 0.1, \"Weight for depth loss\")\nflags.DEFINE_float(\"epipolar_weight\", 0.0, \"Weight for epipolar_weight loss\")\n\nflags.DEFINE_float(\"gpmm_lm_loss_weight\", 0.0, \"\")\nflags.DEFINE_float(\"lm_detail_weight\", 1.0, \"Depth minimum\")\n\nflags.DEFINE_float(\"gpmm_pixel_loss_weight\", 0.0, \"\")\nflags.DEFINE_float(\"gpmm_id_loss_weight\", 0.0, \"\")\nflags.DEFINE_float(\"gpmm_regular_shape_loss_weight\", 1.0, \"3DMM coeffient rank\")\nflags.DEFINE_float(\"gpmm_regular_color_loss_weight\", 1.0, \"3DMM coeffient rank\")\n\n# aug\nflags.DEFINE_integer(\"match_num\", 0, \"Train with epipolar matches\")\n\nflags.DEFINE_boolean(\"is_read_pose\", False, \"Train with pre-computed pose\")\nflags.DEFINE_boolean(\"is_read_gpmm\", False, \"Train with pre-computed pose\")\nflags.DEFINE_boolean(\"disable_log\", False, \"Disable image log in tensorboard to accelerate training\")\n\n# gpmm\nflags.DEFINE_string(\"ckpt_face_pretrain\", None, \"Dataset directory\")\nflags.DEFINE_string(\"ckpt_face_id_pretrain\", None, \"Dataset directory\")\nflags.DEFINE_string(\"path_gpmm\", \"/home/jshang/SHANG_Data/ThirdLib/BFM2009/bfm09_trim_exp_uv_presplit.h5\", \"Dataset directory\")\n\nflags.DEFINE_integer(\"flag_fore\", 1, \"\")\nflags.DEFINE_integer(\"gpmm_rank\", 80, \"3DMM coeffient rank\")\nflags.DEFINE_integer(\"gpmm_exp_rank\", 64, \"3DMM coeffient rank\")\n\n#\nflags.DEFINE_float(\"depth_min\", 0.0, \"Depth minimum\")\nflags.DEFINE_float(\"depth_max\", 7500.0, \"Depth minimum\")\n\nFLAGS = flags.FLAGS\n\n\"\"\"\nCUDA_VISIBLE_DEVICES=${gpu} python train_unsupervise.py --dataset_name_list train \\\n--dataset_loader data_loader_semi_unsupervised_skin \\\n--dataset_dir ./data/eccv2020_MGCNet_data \\\n--checkpoint_dir ./logs_release_2020.07.23/0_local \\\n--learning_rate 0.0001 --MULTIVIEW_weight 1.0 \\\n--photom_weight 0.15 --ssim_weight 0.0 --epipolar_weight 0.00 --depth_weight 0.0001 \\\n--gpmm_lm_loss_weight 0.001 --gpmm_pixel_loss_weight 1.9 --gpmm_id_loss_weight 0.2 \\\n--gpmm_regular_shape_loss_weight 0.0001 --gpmm_regular_color_loss_weight 0.0003 \\\n--flag_fore 1 \\\n--batch_size 2 --img_height 224 --img_width 224 --num_scales 1 \\\n--min_steps 2000 --max_steps 20001 --save_freq 20000 --summary_freq 100 \\\n--seq_length 3 --num_source 2 --match_num 68 \\\n--net resnet --net_id facenet \\\n--ckpt_face_pretrain ./pretrain/resnet_v1_50_2016_08_28/resnet_v1_50.ckpt \\\n--ckpt_face_id_pretrain ./pretrain/facenet_vgg2/model-20180402-114759.ckpt-275 \\\n--path_gpmm /home/jshang/SHANG_Data/ThirdLib/BFM2009/bfm09_trim_exp_uv_presplit.h5 \\\n--lm_detail_weight 5.0\n\"\"\"\n\ndef main(_):\n # static random and shuffle\n seed = 8964\n tf.set_random_seed(seed)\n np.random.seed(seed)\n random.seed(seed)\n\n # print and store all flags\n print('**************** Arguments ******************')\n for key in FLAGS.__flags.keys():\n print('{}: {}'.format(key, getattr(FLAGS, key)))\n print('**************** Arguments ******************')\n\n if not os.path.exists(FLAGS.checkpoint_dir):\n os.makedirs(FLAGS.checkpoint_dir)\n path_arg_log = os.path.join(FLAGS.checkpoint_dir, \"flag.txt\")\n with open(path_arg_log, 'w') as f:\n for key in FLAGS.__flags.keys():\n v = '{} : {}'.format(key, getattr(FLAGS, key))\n f.write(v)\n f.write('\\n')\n\n #\n system = MGC_TRAIN(FLAGS)\n system.train(FLAGS)\n\nif __name__ == '__main__':\n tf.app.run()\n"
},
{
"alpha_fraction": 0.5278310775756836,
"alphanum_fraction": 0.5535508394241333,
"avg_line_length": 27.315217971801758,
"blob_id": "c4e2ed3d8a2661fd5fa512cd9a9ec56372e2de27",
"content_id": "2e8fddc99dfa226695ddc37ee94317b4ea64eb14",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2605,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 92,
"path": "/Recognition-Algorithms/Recognition using GhostNet/create_dataset.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import cv2\nimport os\nimport numpy as np\n\n# Load HAAR face classifier\nface_classifier = cv2.CascadeClassifier(\n cv2.data.haarcascades + \"haarcascade_frontalface_default.xml\"\n)\n\n# Load functions\ndef face_extractor(img):\n # Function detects faces and returns the cropped face\n # If no face detected, it returns None\n faces = face_classifier.detectMultiScale(img, 1.3, 5)\n if faces is ():\n return None\n # Crop all faces found\n cropped_face = 0\n for (x, y, w, h) in faces:\n x = x - 10\n y = y - 10\n cropped_face = img[y : y + h + 50, x : x + w + 50]\n return cropped_face\n\n\ndef check_make_dir(name, parent=\"train\"):\n # Function checks if required directory exists\n # If not, make directory\n if not os.path.exists(\"Datasets/{}/{}\".format(parent, name)):\n path = os.path.join(os.getcwd(), \"Datasets\", parent, name)\n os.makedirs(path)\n\n\ndef write_show_img(name, count, img):\n # Function puts image in train or val directories\n # And displays image with image count\n if count <= 400:\n file_name_path = \"Datasets/train/{}/\".format(name) + str(count) + \".jpg\"\n else:\n file_name_path = \"Datasets/val/{}/\".format(name) + str(count) + \".jpg\"\n cv2.imwrite(file_name_path, img)\n cv2.putText(\n img,\n str(count),\n (50, 50),\n cv2.FONT_HERSHEY_COMPLEX,\n 1,\n (0, 255, 0),\n 2,\n )\n cv2.imshow(\"Face Cropper\", img)\n\n\n# Initialize Webcam\ncap = cv2.VideoCapture(0)\n\nwhile True:\n name = input(\"Enter candidate name:\")\n check_make_dir(name)\n check_make_dir(name, \"val\")\n count = 0\n if name != \"Blank\":\n # Create dataset for unique faces\n while True:\n ret, frame = cap.read()\n if face_extractor(frame) is not None:\n count += 1\n face = cv2.resize(face_extractor(frame), (400, 400))\n write_show_img(name, count, face)\n else:\n print(\"Face not found\")\n pass\n if cv2.waitKey(1) == 13 or count == 450:\n break\n else:\n # For ground truth\n while True:\n ret, frame = cap.read()\n if face_extractor(frame) is None:\n count += 1\n bg = cv2.resize(frame, (400, 400))\n write_show_img(name, count, bg)\n else:\n print(\"Face found\")\n pass\n if cv2.waitKey(1) == 13 or count == 450:\n break\n break\n\ncap.release()\ncv2.destroyAllWindows()\nprint(\"Collecting Samples Complete\")\n"
},
{
"alpha_fraction": 0.3498603403568268,
"alphanum_fraction": 0.6164804697036743,
"avg_line_length": 26.751937866210938,
"blob_id": "0ae92e47c48a97c00051a7035c80e78271b2a426",
"content_id": "0acc97890296058dec4d3121637ea425168dfa6e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7160,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 258,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/geometry/face_align/gafr_std_align.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n# system\nfrom __future__ import print_function\n\nimport os\nimport sys\n\n# third party\nimport math\nimport numpy as np\nimport cv2\nfrom skimage import transform as trans\n\n# 0.75, 4700 intrinsic\n# main pose [0.000000, 0.000000, 3.141593, 0.17440447, 9.1053238, 4994.3359]\n\nstd_224_bfm09 = [\n 81.672401, 88.470589,\n 141.862671, 88.462921,\n 112.000000, 132.863434,\n 87.397392, 153.562943,\n 136.007263, 153.552078\n]\nstd_224_bfm09 = np.array(std_224_bfm09)\nstd_224_bfm09 = np.reshape(std_224_bfm09, [-1, 2])\n\nstd_224_bfm09_lmFull = [\n 42.820927, 96.560013,\n 44.740612, 115.502319,\n 48.336060, 131.956711,\n 51.973404, 147.542618,\n 56.942982, 163.242767,\n 66.128014, 176.873581,\n 77.121262, 185.345123,\n 91.350266, 192.333847,\n 112.111984, 195.973877,\n 132.907944, 192.150299,\n 147.110550, 185.404709,\n 158.049088, 177.110962,\n 167.180313, 163.636917,\n 172.164627, 148.013474,\n 175.628494, 132.314041,\n 178.904556, 115.763123,\n 180.747192, 96.624603,\n 57.339161, 75.401939,\n 65.075607, 69.420296,\n 75.346153, 67.477211,\n 84.851959, 68.512169,\n 93.684509, 70.445839,\n 129.837448, 70.238472,\n 138.728607, 68.199989,\n 148.288986, 67.130638,\n 158.729416, 69.066544,\n 166.466049, 75.241402,\n 112.025818, 88.439606,\n 112.079277, 100.463402,\n 112.175385, 112.699623,\n 112.155502, 123.107132,\n 100.997696, 130.704987,\n 105.334106, 131.744461,\n 112.000000, 132.863434,\n 118.604187, 131.729279,\n 122.843803, 130.633392,\n 70.887840, 88.658264,\n 76.957016, 84.771416,\n 85.494408, 84.991066,\n 93.396942, 89.300255,\n 86.316574, 91.344498,\n 76.981613, 91.758080,\n 129.938248, 89.322220,\n 137.879929, 84.897110,\n 146.571060, 84.798187,\n 152.894745, 88.773125,\n 146.685852, 91.653938,\n 137.206253, 91.332932,\n 87.397392, 153.562943,\n 95.851616, 147.984695,\n 106.369308, 144.729660,\n 111.973000, 145.595917,\n 117.534439, 144.735779,\n 128.142181, 147.902420,\n 136.007263, 153.552078,\n 127.221329, 157.526154,\n 119.790115, 160.680283,\n 112.020966, 160.912857,\n 104.267090, 160.673126,\n 96.875687, 157.533768,\n 89.817505, 152.756683,\n 104.776360, 150.597717,\n 111.898491, 150.485580,\n 119.044411, 150.646561,\n 134.418503, 152.868683,\n 119.012489, 152.582932,\n 111.951797, 152.893265,\n 104.901955, 152.522141\n]\nstd_224_bfm09_lmFull = np.array(std_224_bfm09_lmFull)\nstd_224_bfm09_lmFull = np.reshape(std_224_bfm09_lmFull, [-1, 2])\n\n# 0.75, 800 intrinsic\n# main pose [0.000000, 0.000000, -3.141593 0.1744 9.1053 929.1698]\nstd_224_bfm09_800 = [\n 81.774864, 88.538139,\n 141.755737, 88.535439,\n 112.000000, 133.284698,\n 87.324623, 153.685867,\n 136.077255, 153.673218\n]\n\n\nDLIB_TO_CELEA_INDEX = [36, 42, 33, 48, 54]\n\ndef cvrt_PRN_to_DY(lm68):\n if isinstance(lm68, np.ndarray) == True:\n lm68 = lm68.tolist()\n\n l_1_17_syn = lm68[1-1:17][::-1]\n\n l_18_27_syn = lm68[18-1:27][::-1]\n\n l_28_31 = lm68[28-1:31]\n\n l_32_36_syn = lm68[32-1:36][::-1]\n\n l_37_40_syn = lm68[43-1:46][::-1]\n\n l_41_42_syn = lm68[47-1:48][::-1]\n\n l_43_46_syn = lm68[37-1:40][::-1]\n\n l_47_48_syn = lm68[41-1:42][::-1]\n\n l_49_55_syn = lm68[49-1:55][::-1]\n\n l_56_60_syn = lm68[56-1:60][::-1]\n\n l_61_65_syn = lm68[61-1:65][::-1]\n\n l_66_68_syn = lm68[66-1:68][::-1]\n\n lm = l_1_17_syn + l_18_27_syn + l_28_31 + \\\n l_32_36_syn + l_37_40_syn + l_41_42_syn + l_43_46_syn + l_47_48_syn + \\\n l_49_55_syn + l_56_60_syn + l_61_65_syn + l_66_68_syn\n\n return lm\n\ndef cvrt_300w_to_CelebA(lm68):\n l_eye = np.mean(lm68[37 - 1:43 - 1], axis=0)\n\n r_eye = np.mean(lm68[43 - 1:49 - 1], axis=0)\n\n nose = lm68[34 - 1]\n l_m = lm68[49 - 1]\n r_m = lm68[55 - 1]\n\n return [l_eye, r_eye, nose, l_m, r_m]\n\ndef cvrt_Now_to_CelebA(lm7):\n l_eye = (lm7[0]+lm7[1])/2.0\n\n r_eye = (lm7[2]+lm7[3])/2.0\n\n return np.concatenate([np.array([l_eye, r_eye]), lm7[4:]])\n\n\ndef cvrt_300w_to_Now(lm68):\n l_eye_out = lm68[37 - 1]\n l_eye_in = lm68[40 - 1]\n\n r_eye_in = lm68[43 - 1]\n r_eye_out = lm68[46 - 1]\n\n nose = lm68[34 - 1]\n l_m = lm68[49 - 1]\n r_m = lm68[55 - 1]\n\n return [l_eye_out, l_eye_in, r_eye_in, r_eye_out, nose, l_m, r_m]\n\ndef crop_align_affine_transform(h_lm2d, image, crop_size, std_landmark):\n lm_celebA = np.array(h_lm2d.get_lm())\n if lm_celebA.shape[0] != 5:\n lm_celebA = cvrt_300w_to_CelebA(lm_celebA)\n # Transform\n std_points = np.array(std_landmark) * (crop_size / 224.0)\n\n tform = trans.SimilarityTransform()\n tform.estimate(np.array(lm_celebA), std_points)\n M = tform.params[0:2, :]\n\n rot_angle = tform.rotation * 180.0 / (math.pi)\n #print(rot_angle, tform.translation)\n\n img_warped = cv2.warpAffine(image, M, (crop_size, crop_size), flags=cv2.INTER_LINEAR, borderMode=cv2.BORDER_REPLICATE)\n\n lm_trans = np.matmul(M, np.array(np.transpose(h_lm2d.get_lm_homo())))\n lm_trans = np.transpose(lm_trans)\n\n return lm_trans, img_warped, tform\n\ndef crop_align_affine_transform_5(h_lm2d, image, crop_size, std_224_bfm09):\n lm_celebA = np.array(h_lm2d.get_lm())\n if lm_celebA.shape[0] != 5:\n lm_celebA = cvrt_300w_to_CelebA(lm_celebA)\n # Transform\n std_points = np.array(std_224_bfm09) * (crop_size / 224.0)\n\n tform = trans.SimilarityTransform()\n tform.estimate(np.array(lm_celebA), std_points)\n M = tform.params[0:2, :]\n\n rot_angle = tform.rotation * 180.0 / (math.pi)\n #print(tform.scale)\n\n img_warped = cv2.warpAffine(image, M, (crop_size, crop_size), flags=cv2.INTER_LINEAR, borderMode=cv2.BORDER_REPLICATE)\n\n lm_trans = np.matmul(M, np.array(np.transpose(h_lm2d.get_lm_homo())))\n lm_trans = np.transpose(lm_trans)\n\n return lm_trans, img_warped, rot_angle\n\n# need more robust to detect very bad lm detection sequence\ndef crop_align_affine_transform_68(h_lm2d, image, crop_size, std_224_bfm09_lmFull):\n lm_celebA = h_lm2d.get_lm()\n # Transform\n std_points = np.array(std_224_bfm09_lmFull) * (crop_size / 224.0)\n\n tform = trans.SimilarityTransform()\n tform.estimate(np.array(lm_celebA), std_points)\n M = tform.params[0:2, :]\n\n rot_angle = tform.rotation * 180.0 / (math.pi)\n #print(rot_angle, tform.translation)\n\n img_warped = cv2.warpAffine(image, M, (crop_size, crop_size), flags=cv2.INTER_LINEAR, borderMode=cv2.BORDER_REPLICATE)\n\n lm_trans = np.matmul(M, np.array(np.transpose(h_lm2d.get_lm_homo())))\n lm_trans = np.transpose(lm_trans)\n\n return lm_trans, img_warped, rot_angle\n\ndef crop_bbox_affine_transform(bbox, image, crop_size):\n contour = np.array(\n [[bbox[0], bbox[1]],\n [bbox[2], bbox[1]],\n [bbox[2], bbox[3]],\n [bbox[0], bbox[3]]]\n )\n contour_image = np.array(\n [[0.0, 0.0],\n [crop_size, 0.0],\n [crop_size, crop_size],\n [0.0, crop_size]]\n )\n tform = trans.SimilarityTransform()\n tform.estimate(contour, contour_image)\n M = tform.params[0:2, :]\n img_warped = cv2.warpAffine(image, M, (crop_size, crop_size), flags=cv2.INTER_LINEAR, borderMode=cv2.BORDER_REPLICATE)\n\n return img_warped"
},
{
"alpha_fraction": 0.4553706645965576,
"alphanum_fraction": 0.4992435574531555,
"avg_line_length": 33.78947448730469,
"blob_id": "7c600e1c45700bd7900e6ee1fcc6a7d7ddd9cb28",
"content_id": "06b0226411ade660882b2fc60297ee66c7d83773",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1983,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 57,
"path": "/Face Reconstruction/Facial Reconstruction and Dense Alignment/python/facerda.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import onnxruntime as ort\nimport numpy as np\nimport cv2\nimport datetime\n\n\nclass FaceRDA(object):\n def __init__(self, model_path, bfm=False):\n self.ort_session = ort.InferenceSession(model_path)\n self.input_name = self.ort_session.get_inputs()[0].name\n self.bfm = bfm\n\n def __call__(self, img, roi_box):\n h, w = img.shape[:2]\n if self.bfm:\n image = cv2.resize(img, (120, 120))\n else:\n image = cv2.resize(img, (112, 112))\n input_data = ((image - 127.5) / 128).transpose((2, 0, 1))\n tensor = input_data[np.newaxis, :, :, :].astype(\"float32\")\n begin = datetime.datetime.now()\n output = self.ort_session.run(None, {self.input_name: tensor})[0][0]\n end = datetime.datetime.now()\n print(\"facerda cpu times = \", end - begin)\n if self.bfm:\n vertices = self.decode_bfm(output, w, h, roi_box)\n else:\n vertices = self.decode(output, w, h, roi_box)\n return vertices\n\n def decode(self, output, w, h, roi_box):\n x1, x2, y1, y2 = w / 2, w / 2, -h / 2, h / 2\n v = np.array([[x1, 0, 0, x2],\n [0, y1, 0, y2],\n [0, 0, 1, 0],\n [0, 0, 0, 1]])\n vertices = v @ output\n sx, sy, ex, ey = roi_box\n vertices[0, :] = vertices[0, :] + sx\n vertices[1, :] = vertices[1, :] + sy\n return vertices\n\n def decode_bfm(self, output, w, h, roi_box):\n print(output.shape)\n # move to center of image\n output[0, :] = output[0, :] + 120 / 2\n output[1, :] = output[1, :] + 120 / 2\n # flip vertices along y-axis.\n output[1, :] = 120 - output[1, :] - 1\n vertices = output\n sx, sy, ex, ey = roi_box\n scale_x = (ex - sx) / 120\n scale_y = (ey - sy) / 120\n vertices[0, :] = vertices[0, :] * scale_x + sx\n vertices[1, :] = vertices[1, :] * scale_y + sy\n\n return vertices\n"
},
{
"alpha_fraction": 0.7705479264259338,
"alphanum_fraction": 0.7825342416763306,
"avg_line_length": 45.7599983215332,
"blob_id": "7bbd11d47a090a20065ce93d0d1ee118e394e8d1",
"content_id": "6c9a57590e1ed833fd12333ebbc1c192ad727fa7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1168,
"license_type": "permissive",
"max_line_length": 268,
"num_lines": 25,
"path": "/Recognition-Algorithms/Recognition using SURF/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Facial Rcognition using SURF \n\nIntoduction about SURF:-\nSURF stands for Speeded-Up Robust Features.Basically SURF is an algorithm used in computer vision. It is a patented local feature detector and descriptor. We use SURF for various tasks like object recognition, image registration, classification or 3D reconstruction .\n\nAnd here we are experimenting with SURF in context of facial recognition.\n\n### Library Requirements\n1. opencv-contrib-python\n2. numpy\n3. matplotlib\n\n### So what been done?\n1. First required libraries have been imported.\n2. Then two images have been imported to work on.\n3. Converted both the images in grayscale.\n4. Take out the features i.e. keypoints and descriptors of both the images\n5. Then we proceed to feature matching.\n6. For feature matching two algorithms are used:- i. BruteForceMatch\n ii. FLANN(Fast Approximate Nearest Neighbour Search Algorithm)\n\n### References\n1. SURF implementation: https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_feature2d/py_surf_intro/py_surf_intro.html\n\n2. Feature Matching(BruteForce and FLANN): https://docs.opencv.org/master/dc/dc3/tutorial_py_matcher.html"
},
{
"alpha_fraction": 0.7283172607421875,
"alphanum_fraction": 0.745984673500061,
"avg_line_length": 83.3125,
"blob_id": "a482cdd606ba09efb128e9475e2813ead8372e2e",
"content_id": "825b41e321c6d6652d77cf69af6d5a842a959d88",
"detected_licenses": [
"BSD-3-Clause",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 8113,
"license_type": "permissive",
"max_line_length": 916,
"num_lines": 96,
"path": "/Awesome-face-operations/Mosaic-Effect/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# [Mosaic Effect In Python Using OpenCV](https://github.com/Vi1234sh12/Face-X/edit/master/Awesome-face-operations/Mosaic-Effect/readme.md)\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Awesome-face-operations/Mosaic-Effect/Mosaic-Images/mosaic.png\" height=\"100%\" align=\"right\"/>\n\n## Introduction:\nA photomosaic is an image split into a grid of rectangles, with each replaced by another image that matches the target (the image you ultimately want to appear in the photomosaic). In other words, if you look at a photomosaic from a distance, you see the target image; but if you come closer, you will see that the image actually consists of many smaller images. This works because of how the human eye works.\n\n## History of Photomosaic: \n Registration and mosaicing of images have been in practice since long before the age of digital computers. Shortly after the photographic process was developed in 1839, the use of photographs was demonstrated on topographical mapping . Images acquired from hill-tops or balloons were manually pieced together. After the development of airplane technology 1903 aerophotography became an exciting new field. The limited flying heights of the early airplanes and the need for large photo-maps, forced imaging experts to construct mosaic images from overlapping photographs. This was initially done by manually mosaicing images which were acquired by calibrated equipment. The need for mosaicing continued to increase later in history as satellites started sending pictures back to earth. Improvements in computer technology became a natural motivation to develop computational techniques and to solve related problems.\n \n## The problem of image mosaicing is a combination of three problems:\n- Correcting geometric deformations using image data and/or camera models.\n- Image registration using image data and/or camera models.\n- Eliminating seams from image mosaics.\n\n## Mosaic Image Generator I/O.\n a `photographic mosaic`, also known under the term Photomosaic (a `portmanteau` of photo and `mosaic`), is a picture (usually a photograph) that has been divided into `usually equal sized` tiled sections, each of which is replaced with another photograph that matches the target photo. When viewed at low magnifications, the individual pixels appear as the primary image, while close examination reveals that the image is in fact made up of many hundreds or thousands of smaller images. Most of the time they are a computer-created type of montage.\n <br></br>\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Awesome-face-operations/Mosaic-Effect/Mosaic-Images/Mosaic3.png\" align=\"right\" width=\"650\" height=\"360px\"/>\nThere are two kinds of mosaic, depending on how the matching is done. In the simpler kind, each part of the target image is averaged down to a single color. Each of the library images is also reduced to a single color. Each part of the target image is then replaced with one from the library where these colors are as similar as possible. In effect, the target image is reduced in resolution , and then each of the resulting pixels is replaced with an image whose average color matches that pixel.\n\n## Generating the Mosaic Image\nGiven the average RGB dataset and the target image, the first thing we have to do is generating a list of relevant source image filenames for each of the target image’s pixels.\n We can simply measure the RMSE `Root Mean Squared Error` between the RGB vector of each target image’s pixel with the RGB vector from our database. Then, choose the one with the lowest `RMSE` value. \n There’s also a way to optimize our method when measuring the relevancy of source images and the pixel ‘batch’. We can filter out data points in our average RGB database which has a ‘too different’ RGB value with the pixel `batch` average RGB value.\n \n## Splitting the images into tiles\n\nNow let’s look at how to calculate the coordinates for a single tile from this grid. The tile with index (i, j) has a top-left corner coordinate of (i*w, i*j) and a bottom-right corner coordinate of `((i+1)*w, (j+1)*h)`, where w and h stand for the width and height of a tile, respectively. These can be used with the PIL to crop and create a tile from this image.\n\n### 1.Averaging Color Values\n\nEvery pixel in an image has a color that can be represented by its red, green, and blue values. In this case, you are using 8-bit images, so each of these components has an 8-bit value in the range [0, 255]. Given an image with a total of N pixels, the average RGB is calculated as follows:\n\n`\\left ( r,g,b \\right )_{avg}=\\left ( \\frac{\\left ( r_{1} + r_{2} +....+ r_{N} \\right )}{N}, \\frac{\\left ( g_{1} + g_{2} +....+ g_{N} \\right )}{N}, \\frac{\\left ( b_{1} + b_{2} +....+ b_{N} \\right )}{N} \\right )`\n\n`D_{1, 2}=\\sqrt{\\left ( r_{1} - r_{2} \\right )^{2} + \\left ( g_{1} - g_{2} \\right )^{2} + \\left ( b_{1} - b_{2} \\right )^{2}}`\n\n\n### 2.Matching Images\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Awesome-face-operations/Mosaic-Effect/Mosaic-Images/pyramid.png\" align=\"right\"/>\nFor each tile in the target image, you need to find a matching image from the images in the input folder specified by the user. To determine whether two images match, use the average RGB values. The closest match is the image with the closest average RGB value.\n\n### The process of creating a panoramic image consists of the following steps. \n - Detect keypoints and descriptors\n - Detect a set of matching points that is present in both images (overlapping area)\n - Apply the RANSAC method to improve the matching process detection\n - Apply perspective transformation on one image using the other image as a reference frame\n - Stitch images togethe\n\n\n### Code Overview : \n\n```\nimport cv2\ndef do_mosaic (frame, x, y, w, h, neighbor=9):\n fh, fw=frame.shape [0], frame.shape [1]\n if (y + h>fh) or (x + w>fw):\n return\n for i in range (0, h-neighbor, neighbor):#keypoint 0 minus neightbour to prevent overflow\n for j in range (0, w-neighbor, neighbor):\n rect=[j + x, i + y, neighbor, neighbor]\n color=frame [i + y] [j + x] .tolist () #key point 1 tolist\n left_up=(rect [0], rect [1])\n right_down=(rect [0] + neighbor-1, rect [1] + neighbor-1) #keypoint 2 minus one pixel\n cv2.rectangle (frame, left_up, right_down, color, -1)\nim=cv2.imread (\"test.jpg\", 1)\ndo_mosaic (im, 219, 61, 460-219, 412-61)\nwhile 1:\n k=cv2.waitkey (10)\n if k == 27:\n break\n cv2.imshow (\"mosaic\", im)\n \n```\n\n\n## Results Obtained :\n### Mark Zuckerberg \n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Awesome-face-operations/Mosaic-Effect/Mosaic-Images/mark-zuckerberg.jpg\" hight=\"65%\" alt=\"Mark-Zuckerberg\"/>\n\n\n<img src=\"https://github.com/Vi1234sh12/Face-X/blob/master/Awesome-face-operations/Mosaic-Effect/Mosaic-Images/images1.png\" height=\"450px\" align=\"left\"/>\n<p style=\"clear:both;\">\n<h1><a name=\"contributing\"></a><a name=\"community\"></a> <a href=\"https://github.com/akshitagupta15june/Face-X\">Community</a> and <a href=\"https://github.com/akshitagupta15june/Face-X/blob/master/CONTRIBUTING.md\">Contributing</a></h1>\n<p>Please do! Contributions, updates, <a href=\"https://github.com/akshitagupta15june/Face-X/issues\"></a> and <a href=\" \">pull requests</a> are welcome. This project is community-built and welcomes collaboration. Contributors are expected to adhere to the <a href=\"https://gssoc.girlscript.tech/\">GOSSC Code of Conduct</a>.\n</p>\n<p>\nJump into our <a href=\"https://discord.com/invite/Jmc97prqjb\">Discord</a>! Our projects are community-built and welcome collaboration. 👍Be sure to see the <a href=\"https://github.com/akshitagupta15june/Face-X/blob/master/Readme.md\">Face-X Community Welcome Guide</a> for a tour of resources available to you.\n</p>\n<p>\n<i>Not sure where to start?</i> Grab an open issue with the <a href=\"https://github.com/akshitagupta15june/Face-X/issues\">help-wanted label</a>\n</p>\n\n**Open Source First**\n\n best practices for managing all aspects of distributed services. Our shared commitment to the open-source spirit push the Face-X community and its projects forward.</p>\n"
},
{
"alpha_fraction": 0.6020362973213196,
"alphanum_fraction": 0.6210712790489197,
"avg_line_length": 26.88888931274414,
"blob_id": "ce48c127ccc5d7800c07ebd67219481c61f187e1",
"content_id": "3d49adde103804788944f4d5ebe29ee0261e3457",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2259,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 81,
"path": "/Recognition-Algorithms/Recognition using ResNet50/Training the model.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from keras.layers import Input, Lambda, Dense, Flatten\nfrom keras.models import Model\nfrom keras.applications.resnet50 import ResNet50\nfrom keras.preprocessing import image\nfrom keras.preprocessing.image import ImageDataGenerator\nfrom keras.models import Sequential\nimport numpy as np\nfrom glob import glob\nimport matplotlib.pyplot as plt\n\n# re-size all the images to this\nIMAGE_SIZE = [224, 224]\n\ntrain_path = 'Datasets/Train'\nvalid_path = 'Datasets/Test'\n\n# add preprocessing layer to the front of resNet\nres = ResNet50(input_shape=IMAGE_SIZE + [3], weights='imagenet', include_top=False)\n\nfor layer in res.layers:\n layer.trainable = False\n\n\n\n# useful for getting number of classes\nfolders = glob('Datasets/Train/*')\n\n\n# Number of layers - Add more if u want \nx = Flatten()(res.output)\n\nprediction = Dense(len(folders), activation='softmax')(x)\n\n# create a model object\nmodel = Model(inputs=res.input, outputs=prediction)\n\n# view the structure of the model\nmodel.summary()\n\n# Compiling the model\nmodel.compile(\n loss='categorical_crossentropy',\n optimizer='adam',\n metrics=['accuracy']\n)\n\nfrom keras.preprocessing.image import ImageDataGenerator\n\ntrain_datagen = ImageDataGenerator(rescale = 1./255,\n shear_range = 0.2,\n zoom_range = 0.2,\n horizontal_flip = True)\n\ntest_datagen = ImageDataGenerator(rescale = 1./255)\n\ntraining_set = train_datagen.flow_from_directory('Datasets/Train',\n target_size = (224, 224),\n batch_size = 32,\n class_mode = 'categorical')\n\ntest_set = test_datagen.flow_from_directory('Datasets/Test',\n target_size = (224, 224),\n batch_size = 32,\n class_mode = 'categorical')\n\n\n\n# fit the model\nr = model.fit_generator(\n training_set,\n validation_data=test_set,\n epochs=5,\n steps_per_epoch=len(training_set),\n validation_steps=len(test_set)\n)\n\n\nimport tensorflow as tf\n\nfrom keras.models import load_model\nmodel.save('final_file.h5') # saving the model\n"
},
{
"alpha_fraction": 0.6935185194015503,
"alphanum_fraction": 0.7490741014480591,
"avg_line_length": 28.189189910888672,
"blob_id": "ede4ad25a2b1bf2a787e5e550fd0e4781b1489fb",
"content_id": "a7df061db197cb7eca6702034397c5b4a74d22e4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1080,
"license_type": "permissive",
"max_line_length": 203,
"num_lines": 37,
"path": "/Face-Emotions-Recognition/Face-Exp-Recognition-main/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Facial Expression Recognition\nA CNN model to recognize facial expressions from 2D images.\n\n### Dataset\nFER2013 - https://www.kaggle.com/ashishpatel26/facial-expression-recognitionferchallenge \nThe data consists of 48x48 pixel grayscale images of faces. The emotion shown in the facial expression is of one of seven categories (0=Angry, 1=Disgust, 2=Fear, 3=Happy, 4=Sad, 5=Surprise, 6=Neutral). \n\n\nThe images are divided in the following categories- \n1. Training - 28709\n2. Private Test - 3589\n3. Public Test - 3589\n\n### Requirements \n1. Python 3.x\n2. Google Colab\n\n### Model Layers\n- Conv2D\n- MaxPooling2D\n- Batch Normalization\n- Dense\n- Flatten\n- Dropout \nin different numbers and order\n\n### Accuracy and loss\n- loss: 0.8406 \n- accuracy: 0.6644 \n- val_loss: 1.5589 \n- val_accuracy: 0.6403\n\n### Files usage\n- face-exp.ipynb : Data preprocessing, the CNN model and different approaches to it.\n- weights.h5 : saved weights after training with maximum accuracy\n- model.json : saved model configuration\n- predict.py : script to predict emotions in real time from camera feed.\n"
},
{
"alpha_fraction": 0.6102253794670105,
"alphanum_fraction": 0.8301264643669128,
"avg_line_length": 61.72413635253906,
"blob_id": "7b1c7bc3344bd9e51d8da38a5bac5ed2a82f7664",
"content_id": "521fade459c4e326a7de8c6e42220132c4f14fd9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1819,
"license_type": "permissive",
"max_line_length": 854,
"num_lines": 29,
"path": "/Recognition-Algorithms/Recognition using EfficientNetB2/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Recognition using EfficientNetB2 :\n\n\n\n\nEfficientNetB2 is an earlier variety of Eff-nets.\nThough it has upgraded version it is very good and optimized model to train images.\n\n## Summary :\n### Dataset : \n#### Link of the dataset : https://www.kaggle.com/jonathanoheix/face-expression-recognition-dataset\n#### Data Type : Image Data\n\n#### Sample Image :\n\n\n\n ## PS : \n In this project you have to connect the system to GPU . \n **Nevertheless if you connect it to your local gpu or cloud gpu it would \n still take minimum of 2.5 hours to complete just 3 epochs. So running this notebook \n may take a large time to fit on 10 epochs which can produce a promisable accuracy over the dataset**.\n \n \n ## Goal of the project :\n Goal of this project is to learn to use efficientnet.\n We can tune downgraded versions or upgraded versions of Eff-Net similarly.\n \n # THANK YOU :)\n"
},
{
"alpha_fraction": 0.7330960631370544,
"alphanum_fraction": 0.7437722682952881,
"avg_line_length": 36.5,
"blob_id": "db4df1f14fbc59c76dbd9db29b6839278c8c7f49",
"content_id": "8e88f717277c9f331f53892481ff675483f2d855",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1124,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 30,
"path": "/Recognition-Algorithms/Recognition Using Dlib/face.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#Import face_recognition package\nimport face_recognition\n\n#Loading images from dataset and getting the face encoding array\nimage1 = face_recognition.load_image_file(\"images/Bill_Gates.jpg\")\nimage2 = face_recognition.load_image_file(\"images/Mark_Zuckerberg.jpg\")\nimg1_encoding = face_recognition.face_encodings(image1)[0]\nimg2_encoding = face_recognition.face_encodings(image2)[0]\n\n#Storing details of person along with face encodings in a database/data structure\ndic = {\"Bill Gates\" : img1_encoding, \"Mark Zuckerberg\": img2_encoding}\n\n#Taking new sample image and finding it's face encoding array\nunknown_image = face_recognition.load_image_file(\"Unknown.jpg\")\nunknown_img_encoding = face_recognition.face_encodings(unknown_image)[0]\n\n#Comparing face encoding of unknown image with all the images in dataset\nfor i in dic:\n result = face_recognition.compare_faces([dic[i]], unknown_img_encoding)\n #If face encoding matches then result is true and we can fetch name of Person\n if(result[0]==True):\n print(\"Hey! this is\",i)\n break\nelse:\n print(\"Oops...Don't Know who is this.\")\n\n'''\nOutput:\nHey! This is Bill Gates\n'''"
},
{
"alpha_fraction": 0.6151411533355713,
"alphanum_fraction": 0.6367713212966919,
"avg_line_length": 34.10185241699219,
"blob_id": "5cfb0099fac5009f06038c41406eb2096a281cab",
"content_id": "bcf1cc6c3c737d95a2e99663fe9a25696736de45",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3791,
"license_type": "permissive",
"max_line_length": 149,
"num_lines": 108,
"path": "/Face Reconstruction/3D Face Reconstruction using Graph Convolution Network/lib/search.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# encoding: utf-8\n\n# Created by Matthew Loper on 2013-02-20.\n# Copyright (c) 2018 Max Planck Society for non-commercial scientific research\n# This file is part of psbody.mesh project which is released under MPI License.\n# See file LICENSE.txt for full license details.\n\"\"\"\nSearching and lookup of geometric entities\n==========================================\n\n\"\"\"\n\nimport numpy as np\n\nfrom lib import aabb_normals, spatialsearch\n\n__all__ = [\n 'AabbTree', 'AabbNormalsTree', 'ClosestPointTree', 'CGALClosestPointTree'\n]\n\n\nclass AabbTree():\n \"\"\"Encapsulates an AABB (Axis Aligned Bounding Box) Tree\"\"\"\n\n def __init__(self, m):\n self.cpp_handle = spatialsearch.aabbtree_compute(\n m.v.astype(np.float64).copy(order='C'),\n m.f.astype(np.uint32).copy(order='C'))\n\n def nearest(self, v_samples, nearest_part=False):\n \"nearest_part tells you whether the closest point in triangle abc is in the interior (0), on an edge (ab:1,bc:2,ca:3), or a vertex (a:4,b:5,c:6)\"\n f_idxs, f_part, v = spatialsearch.aabbtree_nearest(\n self.cpp_handle, np.array(v_samples, dtype=np.float64, order='C'))\n return (f_idxs, f_part, v) if nearest_part else (f_idxs, v)\n\n def nearest_alongnormal(self, points, normals):\n distances, f_idxs, v = spatialsearch.aabbtree_nearest_alongnormal(\n self.cpp_handle, points.astype(np.float64), normals.astype(np.float64))\n return (distances, f_idxs, v)\n\n\nclass ClosestPointTree():\n \"\"\"Provides nearest neighbor search for a cloud of vertices (i.e. triangles are not used)\"\"\"\n\n def __init__(self, m):\n from scipy.spatial import KDTree\n self.v = m.v\n self.kdtree = KDTree(self.v)\n\n def nearest(self, v_samples):\n (distances, indices) = zip(*[self.kdtree.query(v) for v in v_samples])\n return (indices, distances)\n\n def nearest_vertices(self, v_samples):\n # (distances, indices) = zip(*[self.kdtree.query(v) for v in v_samples])\n (_, indices) = zip(*[self.kdtree.query(v) for v in v_samples])\n return self.v[indices]\n\n\nclass CGALClosestPointTree():\n \"\"\"Encapsulates an AABB (Axis Aligned Bounding Box) Tree \"\"\"\n\n def __init__(self, m):\n self.v = m.v\n n = m.v.shape[0]\n faces = np.vstack([\n np.array(range(n)),\n np.array(range(n)) + n,\n np.array(range(n)) + 2 * n\n ]).T\n eps = 0.000000000001\n self.cpp_handle = spatialsearch.aabbtree_compute(\n np.vstack([\n m.v + eps * np.array([1.0, 0.0, 0.0]),\n m.v + eps * np.array([0.0, 1.0, 0.0]),\n m.v - eps * np.array([1.0, 1.0, 0.0])\n ]).astype(np.float64).copy(order='C'),\n faces.astype(np.uint32).copy(order='C'))\n\n def nearest(self, v_samples):\n # f_idxs, f_part, v = spatialsearch.aabbtree_nearest(\n f_idxs, _, _ = spatialsearch.aabbtree_nearest(\n self.cpp_handle, np.array(v_samples, dtype=np.float64, order='C'))\n return (f_idxs.flatten(), (np.sum(\n ((self.v[f_idxs.flatten()] - v_samples)**2.0), axis=1)**0.5).flatten())\n\n def nearest_vertices(self, v_samples):\n # f_idxs, f_part, v = spatialsearch.aabbtree_nearest(\n f_idxs, _, _ = spatialsearch.aabbtree_nearest(\n self.cpp_handle, np.array(v_samples, dtype=np.float64, order='C'))\n return self.v[f_idxs.flatten()]\n\n\nclass AabbNormalsTree():\n\n def __init__(self, m):\n # the weight of the normals cosine is proportional to the std of the vertices\n # the best point can be translated up to 2*eps because of the normals\n eps = 0.1 # np.std(m.v)#0\n self.tree_handle = aabb_normals.aabbtree_n_compute(\n m.v,\n m.f.astype(np.uint32).copy(), eps)\n\n def nearest(self, v_samples, n_samples):\n closest_tri, closest_p = aabb_normals.aabbtree_n_nearest(\n self.tree_handle, v_samples, n_samples)\n return (closest_tri, closest_p)\n"
},
{
"alpha_fraction": 0.5291828513145447,
"alphanum_fraction": 0.5603112578392029,
"avg_line_length": 29.85950469970703,
"blob_id": "a9cfc3808dfdf30099c12fec8e0d7a17ba308255",
"content_id": "0c0a9efa44c86b50f3016ead1927dd2ac046d695",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3855,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 121,
"path": "/Snapchat_Filters/Glasses on face/Face_glasses.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import dlib\r\nimport cv2\r\nimport numpy as np\r\nfrom scipy import ndimage\r\n\r\nvideo_capture = cv2.VideoCapture(0)\r\nglasses = cv2.imread(\"specs.png\", -1)\r\ndetector = dlib.get_frontal_face_detector()\r\npredictor = dlib.shape_predictor(\"shape_predictor_68_face_landmarks.dat\")\r\n\r\n#Resize an image to a certain width\r\ndef resize(img, width):\r\n r = float(width) / img.shape[1]\r\n dim = (width, int(img.shape[0] * r))\r\n img = cv2.resize(img, dim, interpolation=cv2.INTER_AREA)\r\n return img\r\n\r\n#Combine an image that has a transparency alpha channel\r\ndef blend_transparent(face_img, sunglasses_img):\r\n\r\n overlay_img = sunglasses_img[:,:,:3]\r\n overlay_mask = sunglasses_img[:,:,3:]\r\n \r\n background_mask = 255 - overlay_mask\r\n\r\n overlay_mask = cv2.cvtColor(overlay_mask, cv2.COLOR_GRAY2BGR)\r\n background_mask = cv2.cvtColor(background_mask, cv2.COLOR_GRAY2BGR)\r\n\r\n face_part = (face_img * (1 / 255.0)) * (background_mask * (1 / 255.0))\r\n overlay_part = (overlay_img * (1 / 255.0)) * (overlay_mask * (1 / 255.0))\r\n\r\n return np.uint8(cv2.addWeighted(face_part, 255.0, overlay_part, 255.0, 0.0))\r\n\r\n#Find the angle between two points\r\ndef angle_between(point_1, point_2):\r\n angle_1 = np.arctan2(*point_1[::-1])\r\n angle_2 = np.arctan2(*point_2[::-1])\r\n return np.rad2deg((angle_1 - angle_2) % (2 * np.pi))\r\n\r\n\r\n#Start main program\r\nwhile True:\r\n\r\n ret, img = video_capture.read()\r\n img = resize(img, 700)\r\n img_copy = img.copy()\r\n gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)\r\n\r\n try:\r\n # detect faces\r\n dets = detector(gray, 1)\r\n\r\n #find face box bounding points\r\n for d in dets:\r\n\r\n x = d.left()\r\n y = d.top()\r\n w = d.right()\r\n h = d.bottom()\r\n\r\n dlib_rect = dlib.rectangle(x, y, w, h)\r\n\r\n ############## Find facial landmarks ##############\r\n detected_landmarks = predictor(gray, dlib_rect).parts()\r\n\r\n landmarks = np.matrix([[p.x, p.y] for p in detected_landmarks])\r\n\r\n for idx, point in enumerate(landmarks):\r\n pos = (point[0, 0], point[0, 1])\r\n if idx == 0:\r\n eye_left = pos\r\n elif idx == 16:\r\n eye_right = pos\r\n\r\n try:\r\n # cv2.line(img_copy, eye_left, eye_right, color=(0, 255, 255))\r\n degree = np.rad2deg(np.arctan2(eye_left[0] - eye_right[0], eye_left[1] - eye_right[1]))\r\n\r\n except:\r\n pass\r\n\r\n ############## Resize and rotate glasses ##############\r\n\r\n #Translate facial object based on input object.\r\n\r\n eye_center = (eye_left[1] + eye_right[1]) / 2\r\n\r\n #Sunglasses translation\r\n glass_trans = int(.2 * (eye_center - y))\r\n\r\n #Funny tanslation\r\n # glass_trans = int(-.3 * (eye_center - y ))\r\n\r\n # Mask translation\r\n #glass_trans = int(-.8 * (eye_center - y))\r\n\r\n\r\n # resize glasses to width of face and blend images\r\n face_width = w - x\r\n\r\n # resize_glasses\r\n glasses_resize = resize(glasses, face_width)\r\n\r\n # Rotate glasses based on angle between eyes\r\n yG, xG, cG = glasses_resize.shape\r\n glasses_resize_rotated = ndimage.rotate(glasses_resize, (degree+90))\r\n glass_rec_rotated = ndimage.rotate(img[y + glass_trans:y + yG + glass_trans, x:w], (degree+90))\r\n\r\n\r\n #blending with rotation\r\n h5, w5, s5 = glass_rec_rotated.shape\r\n rec_resize = img_copy[y + glass_trans:y + h5 + glass_trans, x:x + w5]\r\n blend_glass3 = blend_transparent(rec_resize , glasses_resize_rotated)\r\n img_copy[y + glass_trans:y + h5 + glass_trans, x:x+w5 ] = blend_glass3\r\n cv2.imshow('Output', img_copy)\r\n\r\n except:\r\n cv2.imshow('Output', img_copy)\r\n\r\n if cv2.waitKey(1) & 0xFF == ord('q'):\r\n break\r\n"
},
{
"alpha_fraction": 0.38805970549583435,
"alphanum_fraction": 0.641791045665741,
"avg_line_length": 15.25,
"blob_id": "02e10a88bb480139767b164b9aa651fb0991bc10",
"content_id": "c6077b55431afafce230570ac0efa60d03bdc44e",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 67,
"license_type": "permissive",
"max_line_length": 23,
"num_lines": 4,
"path": "/Snapchat_Filters/Goggles_Changing_Filter/requirements.txt",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "dlib==19.21.1\r\nnumpy==1.20.1\r\nopencv-python==4.5.1.48\r\nscipy==1.6.1"
},
{
"alpha_fraction": 0.5324051380157471,
"alphanum_fraction": 0.5635388493537903,
"avg_line_length": 42.40376663208008,
"blob_id": "b66b3a3098789d78d175d98f693a3c80d5eb8f54",
"content_id": "717c443355c77d46d3375756756aa5d450a837f7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 32248,
"license_type": "permissive",
"max_line_length": 171,
"num_lines": 743,
"path": "/Recognition-Algorithms/Recognition_using_NasNet/models/nasnet.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torch.utils.model_zoo as model_zoo\nfrom torch.autograd import Variable\n\npretrained_settings = {\n 'nasnetalarge': {\n 'imagenet': {\n 'url': 'http://data.lip6.fr/cadene/pretrainedmodels/nasnetalarge-a1897284.pth',\n 'input_space': 'RGB',\n 'input_size': [3, 331, 331], # resize 354\n 'input_range': [0, 1],\n 'mean': [0.5, 0.5, 0.5],\n 'std': [0.5, 0.5, 0.5],\n 'num_classes': 1000\n },\n 'imagenet+background': {\n 'url': 'http://data.lip6.fr/cadene/pretrainedmodels/nasnetalarge-a1897284.pth',\n 'input_space': 'RGB',\n 'input_size': [3, 331, 331], # resize 354\n 'input_range': [0, 1],\n 'mean': [0.5, 0.5, 0.5],\n 'std': [0.5, 0.5, 0.5],\n 'num_classes': 1001\n }\n }\n}\n\nclass MaxPool(nn.Module):\n\n def __init__(self, pad=False):\n super(MaxPool, self).__init__()\n self.pad = pad\n self.pad = nn.ZeroPad2d((1, 0, 1, 0)) if pad else None\n self.pool = nn.MaxPool2d(3, stride=2, padding=1)\n\n def forward(self, x):\n if self.pad:\n x = self.pad(x)\n x = self.pool(x)\n if self.pad:\n x = x[:, :, 1:, 1:]\n return x\n\n\nclass AvgPool(nn.Module):\n\n def __init__(self, pad=False, stride=2, padding=1):\n super(AvgPool, self).__init__()\n self.pad = pad\n self.pad = nn.ZeroPad2d((1, 0, 1, 0)) if pad else None\n self.pool = nn.AvgPool2d(3, stride=stride, padding=padding)\n\n def forward(self, x):\n if self.pad:\n x = self.pad(x)\n x = self.pool(x)\n if self.pad:\n x = x[:, :, 1:, 1:]\n return x\n\n\nclass SeparableConv2d(nn.Module):\n\n def __init__(self, in_channels, out_channels, dw_kernel, dw_stride, dw_padding, bias=False):\n super(SeparableConv2d, self).__init__()\n self.depthwise_conv2d = nn.Conv2d(in_channels, in_channels, dw_kernel,\n stride=dw_stride,\n padding=dw_padding,\n bias=bias,\n groups=in_channels)\n self.pointwise_conv2d = nn.Conv2d(in_channels, out_channels, 1, stride=1, bias=bias)\n\n def forward(self, x):\n x = self.depthwise_conv2d(x)\n x = self.pointwise_conv2d(x)\n return x\n\n\nclass BranchSeparables(nn.Module):\n\n def __init__(self, in_channels, out_channels, kernel_size, stride, padding,\n bias=False, reduction=False, z_padding=1, stem=False):\n super(BranchSeparables, self).__init__()\n self.relu = nn.ReLU()\n self.separable_1 = SeparableConv2d(in_channels,\n out_channels if stem else in_channels,\n kernel_size, stride, padding, bias=bias)\n self.bn_sep_1 = nn.BatchNorm2d(\n out_channels if stem else in_channels,\n eps=0.001, momentum=0.1, affine=True)\n self.relu1 = nn.ReLU()\n self.separable_2 = SeparableConv2d(\n out_channels if stem else in_channels,\n out_channels, kernel_size, 1, padding, bias=bias)\n self.bn_sep_2 = nn.BatchNorm2d(out_channels, eps=0.001, momentum=0.1,\n affine=True)\n if reduction:\n self.padding = nn.ZeroPad2d((z_padding, 0, z_padding, 0))\n\n def forward(self, x):\n x = self.relu(x)\n x = self.padding(x) if hasattr(self, 'padding') else x\n x = self.separable_1(x)\n x = x[:, :, 1:, 1:].contiguous() if hasattr(self, 'padding') else x\n x = self.bn_sep_1(x)\n x = self.relu1(x)\n x = self.separable_2(x)\n x = self.bn_sep_2(x)\n return x\n\n\nclass AuxHead(nn.Module):\n def __init__(self, in_planes, num_classes=10):\n super(AuxHead, self).__init__()\n # aux output to improve convergence (classification shortcut)\n self.pool = nn.AvgPool2d(5, stride=3)\n # local shape inference\n self.pointwise = nn.Conv2d(in_planes, 128, 1)\n self.pointwise_bn = nn.BatchNorm2d(128)\n # NASNet's way of implementing a fc layer is wild\n self.conv2d_fc = nn.Conv2d(128, 728, 1)\n self.conv2d_fc_bn = nn.BatchNorm2d(728)\n self.linear = nn.Linear(728, num_classes)\n\n def forward(self, x):\n out = self.pool(x)\n out = self.pointwise(out)\n out = self.pointwise_bn(out)\n out = F.relu(out)\n out = self.conv2d_fc(out)\n out = self.conv2d_fc_bn(out)\n out = F.relu(out)\n n, c, w, h = out.size() \n out = out.view(n, c, w*h).mean(2) # this is not true in tf\n return self.linear(out)\n\n\nclass DropPath(nn.Module):\n \"\"\"\n Zeros input x with probability 1-p independently over examples.\n p is the probability of keeping the input, the opposite of the normal\n operation of the Dropout module.\n \"\"\"\n\n def __init__(self, p=0.5, inplace=False):\n super(DropPath, self).__init__()\n if p < 0 or p > 1:\n raise ValueError(\"dropout probability has to be between 0 and 1, \"\n \"but got {}\".format(p))\n self.keep_prob, self.p = p, 1.-p\n self.inplace = inplace\n\n def forward(self, input):\n if not self.training or self.keep_prob > 0.99:\n return input\n batch_size = input.size(0)\n mask = torch.ones(batch_size, 1, 1, 1)\n if input.is_cuda:\n mask = mask.cuda()\n mask = F.dropout(mask, self.p, self.training, self.inplace)\n return mask*input\n\n def __repr__(self):\n inplace_str = ', inplace' if self.inplace else ''\n return self.__class__.__name__ + '(' \\\n + 'p=' + str(self.p) \\\n + inplace_str + ')'\n\n\nclass CellStem0(nn.Module):\n\n def __init__(self, num_conv_filters, stem_multiplier, celltype='A'):\n super(CellStem0, self).__init__()\n nf1, nf2 = 32*stem_multiplier, num_conv_filters//4\n self.conv_1x1 = nn.Sequential()\n self.conv_1x1.add_module('relu', nn.ReLU())\n self.conv_1x1.add_module('conv', nn.Conv2d(nf1, nf2, 1, stride=1, bias=False))\n self.conv_1x1.add_module('bn', nn.BatchNorm2d(nf2, eps=0.001, momentum=0.1, affine=True))\n\n self.comb_iter_0_left = BranchSeparables(nf2, nf2, 5, 2, 2)\n self.comb_iter_0_right = BranchSeparables(nf1, nf2, 7, 2, 3, bias=False, stem=True)\n\n self.comb_iter_1_left = nn.MaxPool2d(3, stride=2, padding=1)\n self.comb_iter_1_right = BranchSeparables(nf1, nf2, 7, 2, 3, bias=False, stem=True)\n\n self.comb_iter_2_left = nn.AvgPool2d(3, stride=2, padding=1, count_include_pad=False)\n self.comb_iter_2_right = BranchSeparables(nf1, nf2, 5, 2, 2, bias=False, stem=True)\n\n self.comb_iter_3_right = nn.AvgPool2d(3, stride=1, padding=1, count_include_pad=False)\n\n self.comb_iter_4_left = BranchSeparables(nf2, nf2, 3, 1, 1, bias=False)\n self.comb_iter_4_right = nn.MaxPool2d(3, stride=2, padding=1)\n\n def forward(self, x):\n x1 = self.conv_1x1(x)\n\n x_comb_iter_0_left = self.comb_iter_0_left(x1)\n x_comb_iter_0_right = self.comb_iter_0_right(x)\n x_comb_iter_0 = x_comb_iter_0_left + x_comb_iter_0_right\n\n x_comb_iter_1_left = self.comb_iter_1_left(x1)\n x_comb_iter_1_right = self.comb_iter_1_right(x)\n x_comb_iter_1 = x_comb_iter_1_left + x_comb_iter_1_right\n\n x_comb_iter_2_left = self.comb_iter_2_left(x1)\n x_comb_iter_2_right = self.comb_iter_2_right(x)\n x_comb_iter_2 = x_comb_iter_2_left + x_comb_iter_2_right\n\n x_comb_iter_3_right = self.comb_iter_3_right(x_comb_iter_0)\n x_comb_iter_3 = x_comb_iter_3_right + x_comb_iter_1\n\n x_comb_iter_4_left = self.comb_iter_4_left(x_comb_iter_0)\n x_comb_iter_4_right = self.comb_iter_4_right(x1)\n x_comb_iter_4 = x_comb_iter_4_left + x_comb_iter_4_right\n\n x_out = torch.cat([x_comb_iter_1, x_comb_iter_2, x_comb_iter_3, x_comb_iter_4], 1)\n return x_out\n\n\nclass CellStem1(nn.Module):\n\n def __init__(self, num_conv_filters, stem_multiplier, celltype='A'):\n super(CellStem1, self).__init__()\n self.conv_1x1 = nn.Sequential()\n self.conv_1x1.add_module('relu', nn.ReLU())\n self.conv_1x1.add_module('conv', nn.Conv2d(num_conv_filters, num_conv_filters//2, 1, stride=1, bias=False))\n self.conv_1x1.add_module('bn', nn.BatchNorm2d(num_conv_filters//2, eps=0.001, momentum=0.1, affine=True))\n\n self.relu = nn.ReLU()\n self.path_1 = nn.Sequential()\n self.path_1.add_module('avgpool', nn.AvgPool2d(1, stride=2, count_include_pad=False))\n self.path_1.add_module('conv', nn.Conv2d(32*stem_multiplier, num_conv_filters//4, 1, stride=1, bias=False))\n self.path_2 = nn.ModuleList()\n self.path_2.add_module('pad', nn.ZeroPad2d((0, 1, 0, 1)))\n self.path_2.add_module('avgpool', nn.AvgPool2d(1, stride=2, count_include_pad=False))\n self.path_2.add_module('conv', nn.Conv2d(32*stem_multiplier, num_conv_filters//4, 1, stride=1, bias=False))\n\n nf = num_conv_filters//2\n self.final_path_bn = nn.BatchNorm2d(nf, eps=0.001, momentum=0.1, affine=True)\n\n self.comb_iter_0_left = BranchSeparables(nf, nf, 5, 2, 2, bias=False)\n self.comb_iter_0_right = BranchSeparables(nf, nf, 7, 2, 3, bias=False)\n\n self.comb_iter_1_left = nn.MaxPool2d(3, stride=2, padding=1)\n self.comb_iter_1_right = BranchSeparables(nf, nf, 7, 2, 3, bias=False)\n\n self.comb_iter_2_left = nn.AvgPool2d(3, stride=2, padding=1, count_include_pad=False)\n self.comb_iter_2_right = BranchSeparables(nf, nf, 5, 2, 2, bias=False)\n\n self.comb_iter_3_right = nn.AvgPool2d(3, stride=1, padding=1, count_include_pad=False)\n\n self.comb_iter_4_left = BranchSeparables(nf, nf, 3, 1, 1, bias=False)\n self.comb_iter_4_right = nn.MaxPool2d(3, stride=2, padding=1)\n\n def forward(self, x_conv0, x_stem_0):\n x_left = self.conv_1x1(x_stem_0)\n\n x_relu = self.relu(x_conv0)\n # path 1\n x_path1 = self.path_1(x_relu)\n # path 2\n x_path2 = self.path_2.pad(x_relu)\n x_path2 = x_path2[:, :, 1:, 1:]\n x_path2 = self.path_2.avgpool(x_path2)\n x_path2 = self.path_2.conv(x_path2)\n # final path\n x_right = self.final_path_bn(torch.cat([x_path1, x_path2], 1))\n\n x_comb_iter_0_left = self.comb_iter_0_left(x_left)\n x_comb_iter_0_right = self.comb_iter_0_right(x_right)\n x_comb_iter_0 = x_comb_iter_0_left + x_comb_iter_0_right\n\n x_comb_iter_1_left = self.comb_iter_1_left(x_left)\n x_comb_iter_1_right = self.comb_iter_1_right(x_right)\n x_comb_iter_1 = x_comb_iter_1_left + x_comb_iter_1_right\n\n x_comb_iter_2_left = self.comb_iter_2_left(x_left)\n x_comb_iter_2_right = self.comb_iter_2_right(x_right)\n x_comb_iter_2 = x_comb_iter_2_left + x_comb_iter_2_right\n\n x_comb_iter_3_right = self.comb_iter_3_right(x_comb_iter_0)\n x_comb_iter_3 = x_comb_iter_3_right + x_comb_iter_1\n\n x_comb_iter_4_left = self.comb_iter_4_left(x_comb_iter_0)\n x_comb_iter_4_right = self.comb_iter_4_right(x_left)\n x_comb_iter_4 = x_comb_iter_4_left + x_comb_iter_4_right\n\n x_out = torch.cat([x_comb_iter_1, x_comb_iter_2, x_comb_iter_3, x_comb_iter_4], 1)\n return x_out\n\ndef guess_output_channels(module, in_channels):\n if isinstance(module, BranchSeparables):\n n_out = module.bn_sep_2.num_features\n elif isinstance(module, MaxPool) or isinstance(module, AvgPool) or \\\n isinstance(module, nn.MaxPool2d) or isinstance(module, nn.AvgPool2d):\n n_out = in_channels\n else:\n raise ValueError(\"Don't know how many output channels this module has\"\n \": %s\"%module)\n return n_out\n\nclass BaseCell(nn.Module):\n def __init__(self, in_channels_left, out_channels_left, in_channels_right,\n out_channels_right, factorized_reduction, keep_prob):\n super(BaseCell, self).__init__()\n self.in_channels_left, self.out_channels_left = in_channels_left, out_channels_left\n self.in_channels_right, self.out_channels_right = in_channels_right, out_channels_right\n self.factorized_reduction = factorized_reduction\n\n self.conv_1x1 = nn.Sequential()\n self.conv_1x1.add_module('relu', nn.ReLU())\n self.conv_1x1.add_module('conv', nn.Conv2d(in_channels_right, out_channels_right, 1, stride=1, bias=False))\n self.conv_1x1.add_module('bn', nn.BatchNorm2d(out_channels_right, eps=0.001, momentum=0.1, affine=True))\n\n if self.factorized_reduction:\n self.relu = nn.ReLU()\n self.path_1 = nn.Sequential()\n self.path_1.add_module('avgpool', nn.AvgPool2d(1, stride=2, count_include_pad=False))\n self.path_1.add_module('conv', nn.Conv2d(in_channels_left, out_channels_left, 1, stride=1, bias=False))\n self.path_2 = nn.ModuleList()\n self.path_2.add_module('pad', nn.ZeroPad2d((0, 1, 0, 1)))\n self.path_2.add_module('avgpool', nn.AvgPool2d(1, stride=2, count_include_pad=False))\n self.path_2.add_module('conv', nn.Conv2d(in_channels_left, out_channels_left, 1, stride=1, bias=False))\n self.final_path_bn = nn.BatchNorm2d(out_channels_left * 2, eps=0.001, momentum=0.1, affine=True)\n else:\n self.conv_prev_1x1 = nn.Sequential()\n self.conv_prev_1x1.add_module('relu', nn.ReLU())\n self.conv_prev_1x1.add_module('conv', nn.Conv2d(in_channels_left, out_channels_left, 1, stride=1, bias=False))\n self.conv_prev_1x1.add_module('bn', nn.BatchNorm2d(out_channels_left, eps=0.001, momentum=0.1, affine=True))\n\n self.drop_path = DropPath(p=keep_prob)\n\n def output_channels(self):\n n_out = {}\n for i in range(self._count_branches()):\n try:\n left = getattr(self, 'comb_iter_%i_left'%i)\n if self.factorized_reduction:\n ch = self.out_channels_left*2\n else:\n ch = self.out_channels_left\n n_out['comb_iter_%i'%i] = \\\n guess_output_channels(left, ch)\n except AttributeError:\n pass\n try:\n right = getattr(self, 'comb_iter_%i_right'%i)\n if 'comb_iter_%i' not in n_out:\n n_out['comb_iter_%i'%i] = \\\n guess_output_channels(right, self.out_channels_right)\n except AttributeError:\n pass\n n_out['left'] = self.out_channels_left*2 if self.factorized_reduction \\\n else self.out_channels_left\n n_out['right'] = self.out_channels_right\n return sum([n_out[k] for k in self.to_cat])\n\n def _count_branches(self):\n branch_idx = 0\n while hasattr(self, 'comb_iter_%i_left'%branch_idx) or\\\n hasattr(self, 'comb_iter_%i_right'%branch_idx):\n branch_idx += 1\n return branch_idx\n\n def register_branch(self, left, right, left_input_key, right_input_key):\n # how many do we have already?\n n_branches = self._count_branches()\n self.__dict__['comb_iter_%i_left_input'%n_branches] = left_input_key\n self.__dict__['comb_iter_%i_right_input'%n_branches] = right_input_key\n if left is not None:\n setattr(self, 'comb_iter_%i_left'%n_branches, left)\n if right is not None:\n setattr(self, 'comb_iter_%i_right'%n_branches, right)\n\n def forward(self, x, x_prev):\n if self.factorized_reduction:\n x_relu = self.relu(x_prev)\n # path 1\n x_path1 = self.path_1(x_relu)\n\n # path 2\n x_path2 = self.path_2.pad(x_relu)\n x_path2 = x_path2[:, :, 1:, 1:]\n x_path2 = self.path_2.avgpool(x_path2)\n x_path2 = self.path_2.conv(x_path2)\n # final path\n x_left = self.final_path_bn(torch.cat([x_path1, x_path2], 1))\n else:\n x_left = self.conv_prev_1x1(x_prev)\n\n x_right = self.conv_1x1(x)\n # branch_inputs is a bad name, considering these are combined to create the output\n branch_inputs = {'left':x_left, 'right':x_right}\n\n for i in range(self._count_branches()):\n left_input = branch_inputs[getattr(self, 'comb_iter_%i_left_input'%i)]\n right_input = branch_inputs[getattr(self, 'comb_iter_%i_right_input'%i)]\n if hasattr(self, 'comb_iter_%i_left'%i):\n left_out = getattr(self, 'comb_iter_%i_left'%i)(left_input)\n else:\n left_out = left_input\n if hasattr(self, 'comb_iter_%i_right'%i):\n right_out = getattr(self, 'comb_iter_%i_right'%i)(right_input)\n else:\n right_out = right_input\n out = right_out + left_out\n out = self.drop_path(out) # randomly drop branches during training\n branch_inputs['comb_iter_%i'%i] = out\n\n return torch.cat([branch_inputs[k] for k in self.to_cat], 1)\n\n\nclass NormalCell(BaseCell):\n\n def __init__(self, in_channels_left, out_channels_left, in_channels_right,\n out_channels_right, keep_prob, factorized_reduction=False):\n super(NormalCell, self).__init__(in_channels_left, out_channels_left,\n in_channels_right, out_channels_right, factorized_reduction,\n keep_prob)\n\n self.register_branch(BranchSeparables(out_channels_right, out_channels_right, 5, 1, 2, bias=False),\n BranchSeparables(out_channels_right, out_channels_right, 3, 1, 1, bias=False),\n 'right', 'left')\n\n self.register_branch(BranchSeparables(out_channels_right, out_channels_right, 5, 1, 2, bias=False),\n BranchSeparables(out_channels_right, out_channels_right, 3, 1, 1, bias=False),\n 'left', 'left')\n\n self.register_branch(nn.AvgPool2d(3, stride=1, padding=1, count_include_pad=False), None,\n 'right', 'left')\n\n self.register_branch(nn.AvgPool2d(3, stride=1, padding=1, count_include_pad=False),\n nn.AvgPool2d(3, stride=1, padding=1, count_include_pad=False),\n 'left', 'left')\n\n self.register_branch(BranchSeparables(out_channels_right, out_channels_right, 3, 1, 1, bias=False), None,\n 'right', 'right')\n \n self.to_cat = ['left'] + ['comb_iter_%i'%i for i in range(5)]\n\n\nclass ReductionCell(BaseCell):\n\n def __init__(self, in_channels_left, out_channels_left, in_channels_right, out_channels_right, keep_prob, pad=False):\n super(ReductionCell, self).__init__(in_channels_left, out_channels_left, in_channels_right, out_channels_right, False, keep_prob) \n \n self.register_branch(BranchSeparables(out_channels_right, out_channels_right, 5, 2, 2, bias=False, reduction=pad),\n BranchSeparables(out_channels_right, out_channels_right, 7, 2, 3, bias=False, reduction=pad),\n 'right', 'left')\n \n self.register_branch(MaxPool(pad=pad),\n BranchSeparables(out_channels_right, out_channels_right, 7, 2, 3, bias=False, reduction=pad),\n 'right', 'left')\n\n self.register_branch(AvgPool(pad=pad),\n BranchSeparables(out_channels_right, out_channels_right, 5, 2, 2, bias=False, reduction=pad),\n 'right', 'left')\n\n self.register_branch(None, nn.AvgPool2d(3, stride=1, padding=1, count_include_pad=False),\n 'comb_iter_1', 'comb_iter_0')\n\n self.register_branch(BranchSeparables(out_channels_right, out_channels_right, 3, 1, 1, bias=False, reduction=pad),\n MaxPool(pad=pad), 'comb_iter_0', 'right')\n\n self.to_cat = ['comb_iter_%i'%i for i in range(1,5)]\n\n\nclass NASNet(nn.Module):\n\n def __init__(self, num_conv_filters, filter_scaling_rate, num_classes,\n num_cells, stem_multiplier, stem, drop_path_keep_prob):\n super(NASNet, self).__init__()\n self.num_classes = num_classes\n self.num_cells = num_cells\n self.stem = stem\n\n stem_filters = 32*stem_multiplier\n if self.stem == 'imagenet':\n self.conv0 = nn.Sequential()\n self.conv0.add_module('conv', nn.Conv2d(in_channels=3,\n out_channels=stem_filters, kernel_size=3, padding=0, stride=2,\n bias=False))\n self.conv0.add_module('bn', nn.BatchNorm2d(stem_filters, eps=0.001,\n momentum=0.1, affine=True))\n\n self.cell_stem_0 = CellStem0(num_conv_filters, stem_multiplier)\n self.cell_stem_1 = CellStem1(num_conv_filters, stem_multiplier)\n elif self.stem == 'cifar':\n self.conv0 = nn.Sequential()\n self.conv0.add_module('conv', nn.Conv2d(in_channels=3,\n out_channels=stem_filters, kernel_size=3, padding=1, stride=2,\n bias=False))\n self.conv0.add_module('bn', nn.BatchNorm2d(stem_filters, eps=0.001,\n momentum=0.1, affine=True)) \n else:\n raise ValueError(\"Don't know what type of stem %s is.\"%stem)\n\n self.block1 = []\n nf, fs = num_conv_filters, filter_scaling_rate\n cell_idx = 0\n self.cell_0 = NormalCell(\n in_channels_left=nf if self.stem == 'imagenet' else 3,\n out_channels_left=nf//fs,\n in_channels_right=nf*fs if self.stem == 'imagenet' else nf*stem_multiplier,\n out_channels_right=nf,\n keep_prob=drop_path_keep_prob,\n factorized_reduction=True)\n self.block1.append(self.cell_0)\n in_ch, out_ch = nf*(fs*3), nf\n cells_per_block = num_cells//3\n for i in range(cells_per_block-1):\n cell_idx += 1\n if i==0 and self.stem=='imagenet':\n ch_left = nf*fs if i == 0 else in_ch\n elif i==0 and self.stem=='cifar':\n ch_left = nf*stem_multiplier\n else:\n ch_left = in_ch\n next_cell = NormalCell(in_channels_left=ch_left,\n out_channels_left=nf,\n in_channels_right=in_ch,\n out_channels_right=out_ch,\n keep_prob=drop_path_keep_prob)\n # hack to not break sanity check\n setattr(self, \"cell_%i\"%cell_idx, next_cell)\n self.block1.append(next_cell)\n\n out_ch = nf*fs\n self.reduction_cell_0 = ReductionCell(in_channels_left=in_ch, out_channels_left=out_ch,\n in_channels_right=in_ch, out_channels_right=out_ch,\n keep_prob=drop_path_keep_prob,\n pad=True)\n\n cell_idx += 1\n next_cell = NormalCell(in_channels_left=in_ch, out_channels_left=out_ch//fs,\n in_channels_right=in_ch+nf*fs, out_channels_right=out_ch,\n keep_prob=drop_path_keep_prob,\n factorized_reduction=True)\n setattr(self, \"cell_%i\"%cell_idx, next_cell)\n in_ch = nf*(fs*6)\n for i in range(cells_per_block-1):\n cell_idx += 1\n next_cell = NormalCell(in_channels_left=nf*fs*4 if i == 0 else in_ch, out_channels_left=out_ch,\n in_channels_right=in_ch, out_channels_right=out_ch,\n keep_prob=drop_path_keep_prob)\n setattr(self, \"cell_%i\"%cell_idx, next_cell)\n self.block1.append(next_cell)\n\n\n in_planes = next_cell.output_channels()\n self.aux_head = AuxHead(in_planes, num_classes=num_classes)\n\n out_ch = nf*fs*2\n self.reduction_cell_1 = ReductionCell(in_channels_left=in_ch, out_channels_left=out_ch,\n in_channels_right=in_ch, out_channels_right=out_ch,\n keep_prob=drop_path_keep_prob)\n\n cell_idx += 1\n next_cell = NormalCell(in_channels_left=in_ch, out_channels_left=out_ch//fs,\n in_channels_right=in_ch+nf*fs*2, out_channels_right=out_ch, \n keep_prob=drop_path_keep_prob,\n factorized_reduction=True)\n setattr(self, \"cell_%i\"%cell_idx, next_cell)\n\n in_ch = nf*(fs*12)\n for i in range(cells_per_block-1):\n cell_idx += 1\n next_cell = NormalCell(in_channels_left=nf*fs*8 if i == 0 else in_ch, out_channels_left=out_ch,\n in_channels_right=in_ch, out_channels_right=out_ch,\n keep_prob=drop_path_keep_prob)\n setattr(self, \"cell_%i\"%cell_idx, next_cell)\n self.block1.append(next_cell)\n\n self.relu = nn.ReLU()\n self.dropout = nn.Dropout()\n self.last_linear = nn.Linear(in_ch, self.num_classes)\n\n def features(self, input):\n x_conv0 = self.conv0(input)\n if self.stem == 'imagenet':\n x_stem_0 = self.cell_stem_0(x_conv0)\n x_stem_1 = self.cell_stem_1(x_conv0, x_stem_0)\n cell_stack = [x_stem_1, x_stem_0]\n else:\n cell_stack = [x_conv0, input]\n\n cell_idx = 0\n for i in range(self.num_cells//3):\n next_cell = getattr(self, \"cell_%i\"%cell_idx)\n next_out = next_cell(*cell_stack[:2])\n cell_stack = [next_out] + cell_stack\n cell_idx += 1\n\n x_reduction_cell_0 = self.reduction_cell_0(*cell_stack[:2])\n cell_stack = [x_reduction_cell_0] + cell_stack\n\n for i in range(self.num_cells//3):\n next_cell = getattr(self, \"cell_%i\"%cell_idx)\n next_out = next_cell(*cell_stack[:2])\n cell_stack = [next_out] + cell_stack\n cell_idx += 1\n\n # stores most recent aux out in model\n self.aux_out = self.aux_head(cell_stack[0])\n\n x_reduction_cell_1 = self.reduction_cell_1(*cell_stack[:2])\n cell_stack = [x_reduction_cell_1] + cell_stack\n\n for i in range(self.num_cells//3):\n next_cell = getattr(self, \"cell_%i\"%cell_idx)\n next_out = next_cell(*cell_stack[:2])\n cell_stack = [next_out] + cell_stack\n cell_idx += 1\n\n return cell_stack[0]\n\n def logits(self, features):\n x = self.relu(features)\n x = F.avg_pool2d(x, x.size(2))\n x = x.view(x.size(0), -1)\n x = self.dropout(x)\n x = self.last_linear(x)\n return x\n\n def forward(self, input):\n x = self.features(input)\n x = self.logits(x)\n return x\n\n\nclass NASNetALarge(NASNet):\n def __init__(self, num_classes=1001):\n super(NASNetALarge, self).__init__(num_conv_filters=168,\n filter_scaling_rate=2, num_classes=num_classes, num_cells=18,\n stem_multiplier=3, stem='imagenet', drop_path_keep_prob=0.7)\n\n\nclass NASNetAMobile(NASNet):\n def __init__(self, num_classes=1001):\n super(NASNetAMobile, self).__init__(num_conv_filters=44,\n filter_scaling_rate=2, num_classes=num_classes, num_cells=12,\n stem_multiplier=1, stem='imagenet', drop_path_keep_prob=1.0)\n\n\nclass NASNetAcifar(NASNet):\n def __init__(self, num_classes=10):\n super(NASNetAcifar, self).__init__(num_conv_filters=32,\n filter_scaling_rate=2, num_classes=num_classes, num_cells=18,\n stem_multiplier=3, stem='cifar', drop_path_keep_prob=0.6)\n\n\ndef nasnetalarge(num_classes=1001, pretrained='imagenet'):\n r\"\"\"NASNetALarge model architecture from the\n `\"NASNet\" <https://arxiv.org/abs/1707.07012>`_ paper.\n \"\"\"\n if pretrained:\n settings = pretrained_settings['nasnetalarge'][pretrained]\n assert num_classes == settings['num_classes'], \\\n \"num_classes should be {}, but is {}\".format(settings['num_classes'], num_classes)\n\n # both 'imagenet'&'imagenet+background' are loaded from same parameters\n model = NASNetALarge(num_classes=1001)\n model.load_state_dict(model_zoo.load_url(settings['url']))\n\n if pretrained == 'imagenet':\n new_last_linear = nn.Linear(model.last_linear.in_features, 1000)\n new_last_linear.weight.data = model.last_linear.weight.data[1:]\n new_last_linear.bias.data = model.last_linear.bias.data[1:]\n model.last_linear = new_last_linear\n\n model.input_space = settings['input_space']\n model.input_size = settings['input_size']\n model.input_range = settings['input_range']\n\n model.mean = settings['mean']\n model.std = settings['std']\n else:\n model = NASNetALarge(num_classes=num_classes)\n return model\n\n\ndef nasnetamobile(num_classes=1001, pretrained='imagenet'):\n r\"\"\"NASNetAMobile model architecture from the\n `\"NASNet\" <https://arxiv.org/abs/1707.07012>`_ paper.\n \"\"\"\n raise NotImplementedError(\"Not yet trained a mobile ImageNet model.\")\n if pretrained:\n settings = pretrained_settings['nasnetalarge'][pretrained]\n assert num_classes == settings['num_classes'], \\\n \"num_classes should be {}, but is {}\".format(settings['num_classes'], num_classes)\n\n # both 'imagenet'&'imagenet+background' are loaded from same parameters\n model = NASNetALarge(num_classes=1001)\n model.load_state_dict(model_zoo.load_url(settings['url']))\n\n if pretrained == 'imagenet':\n new_last_linear = nn.Linear(model.last_linear.in_features, 1000)\n new_last_linear.weight.data = model.last_linear.weight.data[1:]\n new_last_linear.bias.data = model.last_linear.bias.data[1:]\n model.last_linear = new_last_linear\n\n model.input_space = settings['input_space']\n model.input_size = settings['input_size']\n model.input_range = settings['input_range']\n\n model.mean = settings['mean']\n model.std = settings['std']\n else:\n model = NASNetALarge(num_classes=num_classes)\n return model\n\ndef channel_inference_test(model, batch_size=2):\n assert isinstance(model, NASNetALarge)\n endpoints_shapes = {'cell_0': [batch_size, 42, 42, 1008],\n 'cell_1': [batch_size, 42, 42, 1008],\n 'cell_2': [batch_size, 42, 42, 1008],\n 'cell_3': [batch_size, 42, 42, 1008],\n 'cell_4': [batch_size, 42, 42, 1008],\n 'cell_5': [batch_size, 42, 42, 1008],\n 'cell_6': [batch_size, 21, 21, 2016],\n 'cell_7': [batch_size, 21, 21, 2016],\n 'cell_8': [batch_size, 21, 21, 2016],\n 'cell_9': [batch_size, 21, 21, 2016],\n 'cell_10': [batch_size, 21, 21, 2016],\n 'cell_11': [batch_size, 21, 21, 2016],\n 'cell_12': [batch_size, 11, 11, 4032],\n 'cell_13': [batch_size, 11, 11, 4032],\n 'cell_14': [batch_size, 11, 11, 4032],\n 'cell_15': [batch_size, 11, 11, 4032],\n 'cell_16': [batch_size, 11, 11, 4032],\n 'cell_17': [batch_size, 11, 11, 4032],\n 'reduction_cell_0': [batch_size, 21, 21, 1344],\n 'reduction_cell_1': [batch_size, 11, 11, 2688]}\n for k in sorted(endpoints_shapes.keys()):\n cell = getattr(model, k)\n if not cell.output_channels() == endpoints_shapes[k][3]:\n raise ValueError(\"Cell %s: inferred channels %i does not match expected output channels for this model %i\"%(k, cell.output_channels(), endpoints_shapes[k][3]))\n\nif __name__ == \"__main__\":\n model = NASNetALarge()\n model.eval()"
},
{
"alpha_fraction": 0.6819819808006287,
"alphanum_fraction": 0.7198198437690735,
"avg_line_length": 37.24137878417969,
"blob_id": "246735807ad8e1bcc2830dd290eb84cdb5d5ec2f",
"content_id": "1ab4e673b3538e0ac3eb9e3f4588c0212885e853",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1110,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 29,
"path": "/Virtual_makeover/makeup/digital_makeup.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from PIL import Image,ImageDraw\nimport face_recognition\n\n# load the jpg file into a numpy array\nimage = face_recognition.load_image_file(\"Emma-watson_main_character_pic.jpg\")\n\n# find all facial features in all the faces in the image\nface_landmarks_list = face_recognition.face_landmarks(image)\n\n# Load the image into a Python Image Library object so that we can draw on the top of image\npil_image = Image.fromarray(image)\n\n# Create a PIL drawing object to be able to draw lines later\nd = ImageDraw.Draw(pil_image, 'RGBA')\n\nfor face_landmarks in face_landmarks_list:\n # The face landmark detection model returns these features:\n # - chin, left_eyebrow, right_eyebrow, nose_bridge, nose_tip, left_eye, right_eye\n\n # Draw a line over the eyebrows\n d.line(face_landmarks[\"left_eyebrow\"], fill=(128, 0, 128, 100), width=3)\n d.line(face_landmarks[\"right_eyebrow\"], fill=(128, 0, 128, 100), width=3)\n\n # Draw over the lips\n d.polygon(face_landmarks[\"top_lip\"], fill=(128, 0, 128,100))\n d.polygon(face_landmarks[\"bottom_lip\"], fill=(128, 0, 128, 100))\n\n# Show the final image\npil_image.show()\n\n"
},
{
"alpha_fraction": 0.669829249382019,
"alphanum_fraction": 0.6812143921852112,
"avg_line_length": 30,
"blob_id": "9ad5db47fc949581ce17fa7a7b955a8c5ece7ab2",
"content_id": "3d16360bc97d9215d6c5cc1ec7eb121ba5ece397",
"detected_licenses": [
"BSD-3-Clause",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 527,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 17,
"path": "/Snapchat_Filters/Filters with GUI/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Cool Snapchat Filters with GUI.\n#### Quick Start\n- Clone this repository\n` git clone https://github.com/akshitagupta15june/Face-X.git`\n- Change Directory\n` cd Snapchat_Filters` ,then, `cd Filters with GUI`\n- Download shape_predictor_68_face_landmarks.dat file in Filters with GUI folder.\n- Run code file.\n` python main.py`\n\n# Screenshots\n| Original Image | Updated Image |\n| ------------- | ------------- |\n|  |  |\n\n# Gui\n\n"
},
{
"alpha_fraction": 0.5151515007019043,
"alphanum_fraction": 0.5569985508918762,
"avg_line_length": 18.799999237060547,
"blob_id": "de3d022c2b068130ae3b6cd2ffeb0c646f776770",
"content_id": "3949d2bec641a518c4287ecdae26f68e82ab19b1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 694,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 35,
"path": "/Face Reconstruction/Face Alignment in Full Pose Range/speed_cpu.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# coding: utf-8\n\nimport timeit\nimport numpy as np\n\nSETUP_CODE = '''\nimport mobilenet_v1\nimport torch\n\nmodel = mobilenet_v1.mobilenet_1()\nmodel.eval()\ndata = torch.rand(1, 3, 120, 120)\n'''\n\nTEST_CODE = '''\nwith torch.no_grad():\n model(data)\n'''\n\n\ndef main():\n repeat, number = 5, 100\n res = timeit.repeat(setup=SETUP_CODE,\n stmt=TEST_CODE,\n repeat=repeat,\n number=number)\n res = np.array(res, dtype=np.float32)\n res /= number\n mean, var = np.mean(res), np.std(res)\n print('Inference speed: {:.2f}±{:.2f} ms'.format(mean * 1000, var * 1000))\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.7441797256469727,
"alphanum_fraction": 0.7691819667816162,
"avg_line_length": 47.41666793823242,
"blob_id": "90e2f9451ab200474c799eba97ab2a8d1f27e929",
"content_id": "440144ec2ae3706af4289ab9f015e4c6a4765ea6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 11069,
"license_type": "permissive",
"max_line_length": 455,
"num_lines": 228,
"path": "/Cartoonify Image/Cartoonifying using OpenCV/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "Currently there are lots of professional cartoonizer applications available in the market but most of the them are not freeware. In order to get the basic cartoon effect, we just need the bilateral filter and some edge dectection mechanism. The bilateral filter will reduce the color palette, which is essential for the cartoon look and edge detection is to produce bold silhouettes.\n\nWe are going to use openCV python library to convert an RGB color image to a cartoon image.\n\nSteps to develop Image Cartoonifier\nDownload Image Cartoonifies Code\nPlease download source code of Image Cartoonfier Project: Cartoonify an Image in Python\n\nStep 1: Importing the required modules\nWe will import the following modules:\n\nCV2: Imported to use OpenCV for image processing\neasygui: Imported to open a file box. It allows us to select any file from our system.\nNumpy: Images are stored and processed as numbers. These are taken as arrays. We use NumPy to deal with arrays.\nImageio: Used to read the file which is chosen by file box using a path.\nMatplotlib: This library is used for visualization and plotting. Thus, it is imported to form the plot of images.\nOS: For OS interaction. Here, to read the path and save images to that path.\n\nStep 2: Building a File Box to choose a particular file\nIn this step, we will build the main window of our application, where the buttons, labels, and images will reside. We also give it a title by title() function.\n\n\nCode:\n\n\"\"\" fileopenbox opens the box to choose file\nand help us store file path as string \"\"\"\ndef upload():\n ImagePath=easygui.fileopenbox()\n cartoonify(ImagePath)\n \n \nExplanation:\nThe above code opens the file box, i.e the pop-up box to choose the file from the device, which opens every time you run the code. fileopenbox() is the method in easyGUI module which returns the path of the chosen file as a string.\n\nStep 3: How is an image stored?\nNow, just think, how will a program read an image? For a computer, everything is just numbers. Thus, in the below code, we will convert our image into a numpy array.\n\nBeginning with image transformations:\n\nTo convert an image to a cartoon, multiple transformations are done. Firstly, an image is converted to a Grayscale image. Yes, similar to the old day’s pictures.! Then, the Grayscale image is smoothened, and we try to extract the edges in the image. Finally, we form a color image and mask it with edges. This creates a beautiful cartoon image with edges and lightened color of the original image.\n\nLet’s start with these transformations to convert an image to its cartoon image.\n\nStep 4: Transforming an image to grayscale\nCode:\n\n#converting an image to grayscale\ngrayScaleImage = cv2.cvtColor(originalmage, cv2.COLOR_BGR2GRAY)\nReSized2 = cv2.resize(grayScaleImage, (960, 540))\n#plt.imshow(ReSized2, cmap='gray')\nExplanation:\n\ncvtColor(image, flag) is a method in cv2 which is used to transform an image into the colour-space mentioned as ‘flag’. Here, our first step is to convert the image into grayscale. Thus, we use the BGR2GRAY flag. This returns the image in grayscale. A grayscale image is stored as grayScaleImage.\n\nAfter each transformation, we resize the resultant image using the resize() method in cv2 and display it using imshow() method. This is done to get more clear insights into every single transformation step.\n\nThe above code will generate the following output:\n\n<p align=\"center\">\n <img src=\"https://analyticsindiamag.com/wp-content/uploads/2020/08/432a6b258bfa7df163a88bed81255db6.jpg\" width=\"350\" title=\"hover text\">\n</p>\n\n\nStep 5: Smoothening a grayscale image\nCode:\n\n#applying median blur to smoothen an image\nsmoothGrayScale = cv2.medianBlur(grayScaleImage, 5)\nReSized3 = cv2.resize(smoothGrayScale, (960, 540))\n#plt.imshow(ReSized3, cmap='gray')\nExplanation:\n\n\nTo smoothen an image, we simply apply a blur effect. This is done using medianBlur() function. Here, the center pixel is assigned a mean value of all the pixels which fall under the kernel. In turn, creating a blur effect.\n\nThe above code generates the following output:\n<p align=\"center\">\n <img src=\"https://d2h0cx97tjks2p.cloudfront.net/blogs/wp-content/uploads/sites/2/2020/09/smooth-gray.png\" width=\"350\" title=\"hover text\">\n</p>\n\nStep 6: Retrieving the edges of an image\nCode:\n\n#retrieving the edges for cartoon effect\n#by using thresholding technique\ngetEdge = cv2.adaptiveThreshold(smoothGrayScale, 255, \n cv2.ADAPTIVE_THRESH_MEAN_C, \n cv2.THRESH_BINARY, 9, 9)\nReSized4 = cv2.resize(getEdge, (960, 540))\n#plt.imshow(ReSized4, cmap='gray')\nExplanation:\n\nCartoon effect has two specialties:\n\nHighlighted Edges\nSmooth colors\nIn this step, we will work on the first specialty. Here, we will try to retrieve the edges and highlight them. This is attained by the adaptive thresholding technique. The threshold value is the mean of the neighborhood pixel values area minus the constant C. C is a constant that is subtracted from the mean or weighted sum of the neighborhood pixels. Thresh_binary is the type of threshold applied, and the remaining parameters determine the block size.\n\nThe above code will generate output like below:\n\n<p align=\"center\">\n <img src=\"https://d2h0cx97tjks2p.cloudfront.net/blogs/wp-content/uploads/sites/2/2020/09/edge-image.png\" width=\"350\" title=\"hover text\">\n</p>\n\n\nStep 7: Preparing a Mask Image\nCode:\n\n#applying bilateral filter to remove noise \n#and keep edge sharp as required\ncolorImage = cv2.bilateralFilter(originalmage, 9, 300, 300)\nReSized5 = cv2.resize(colorImage, (960, 540))\n#plt.imshow(ReSized5, cmap='gray')\nExplanation:\n\nIn the above code, we finally work on the second specialty. We prepare a lightened color image that we mask with edges at the end to produce a cartoon image. We use bilateralFilter which removes the noise. It can be taken as smoothening of an image to an extent.\n\nThe third parameter is the diameter of the pixel neighborhood, i.e, the number of pixels around a certain pixel which will determine its value. The fourth and Fifth parameter defines signmaColor and sigmaSpace. These parameters are used to give a sigma effect, i.e make an image look vicious and like water paint, removing the roughness in colors.\n\nYes, it’s similar to BEAUTIFY or AI effect in cameras of modern mobile phones.\n\nThe above code generates the following output:\n\n\n<p align=\"center\">\n <img src=\"https://d2h0cx97tjks2p.cloudfront.net/blogs/wp-content/uploads/sites/2/2020/09/color-mask.png\" width=\"350\" title=\"hover text\">\n</p>\n\nStep 8: Giving a Cartoon Effect\nCode:\n\n\n#masking edged image with our \"BEAUTIFY\" image\ncartoonImage = cv2.bitwise_and(colorImage, colorImage, mask=getEdge)\nReSized6 = cv2.resize(cartoonImage, (960, 540))\n#plt.imshow(ReSized6, cmap='gray')\nExplanation:\n\nSo, let’s combine the two specialties. This will be done using MASKING. We perform bitwise and on two images to mask them. Remember, images are just numbers?\n\nYes, so that’s how we mask edged image on our “BEAUTIFY” image.\n\nThis finally CARTOONIFY our image!\n\nThe above code will generate output like below:\n\n\n<p align=\"center\">\n <img src=\"https://d2h0cx97tjks2p.cloudfront.net/blogs/wp-content/uploads/sites/2/2020/09/cartoon-effect.png\" width=\"350\" title=\"hover text\">\n</p>\n\nStep 9: Plotting all the transitions together\nCode:\n\n# Plotting the whole transition\nimages=[ReSized1, ReSized2, ReSized3, ReSized4, ReSized5, ReSized6]\nfig, axes = plt.subplots(3,2, figsize=(8,8), subplot_kw={'xticks':[], 'yticks':[]}, gridspec_kw=dict(hspace=0.1, wspace=0.1))\nfor i, ax in enumerate(axes.flat):\n ax.imshow(images[i], cmap='gray')\n//save button code\nplt.show()\nExplanation:\n\nTo plot all the images, we first make a list of all the images. The list here is named “images” and contains all the resized images. Now, we create axes like subl=plots in a plot and display one-one images in each block on the axis using imshow() method.\n\nplt.show() plots the whole plot at once after we plot on each subplot.\n\nThe above code will generate output like below:\n\n<p align=\"center\">\n <img src=\"https://d2h0cx97tjks2p.cloudfront.net/blogs/wp-content/uploads/sites/2/2020/09/cartoonifier-output.png\" width=\"350\" title=\"hover text\">\n</p>\n \n\nStep 10: Functionally of save button\ndef save(ReSized6, ImagePath):\n #saving an image using imwrite()\n newName=\"cartoonified_Image\"\n path1 = os.path.dirname(ImagePath)\n extension=os.path.splitext(ImagePath)[1]\n path = os.path.join(path1, newName+extension)\n cv2.imwrite(path, cv2.cvtColor(ReSized6, cv2.COLOR_RGB2BGR))\n I = \"Image saved by name \" + newName +\" at \"+ path\n tk.messagebox.showinfo(title=None, message=I)\nExplanation:\n\nHere, the idea is to save the resultant image. For this, we take the old path, and just change the tail (name of the old file) to a new name and store the cartoonified image with a new name in the same folder by appending the new name to the head part of the file.\n\n\nFor this, we extract the head part of the file path by os.path.dirname() method. Similarly, os.path.splitext(ImagePath)[1] is used to extract the extension of the file from the path.\n\nHere, newName stores “Cartoonified_Image” as the name of a new file. os.path.join(path1, newName + extension) joins the head of path to the newname and extension. This forms the complete path for the new file.\n\nimwrite() method of cv2 is used to save the file at the path mentioned. cv2.cvtColor(ReSized6, cv2.COLOR_RGB2BGR) is used to assure that no color get extracted or highlighted while we save our image. Thus, at last, the user is given confirmation that the image is saved with the name and path of the file.\n\n\nStep 11: Making the main window\ntop=tk.Tk()\ntop.geometry('400x400')\ntop.title('Cartoonify Your Image !')\ntop.configure(background='white')\nlabel=Label(top,background='#CDCDCD', font=('calibri',20,'bold'))\nStep 12: Making the Cartoonify button in the main window\nupload=Button(top,text=\"Cartoonify an Image\",command=upload,padx=10,pady=5)\nupload.configure(background='#364156', foreground='white',font=('calibri',10,'bold'))\nupload.pack(side=TOP,pady=50)\nbox\n\nStep 13: Making a Save button in the main window\nsave1=Button(top,text=\"Save cartoon image\",command=lambda: save(ImagePath, ReSized6),padx=30,pady=5)\nsave1.configure(background='#364156', foreground='white',font=('calibri',10,'bold'))\nsave1.pack(side=TOP,pady=50)\nThe above code makes a button as soon as the image transformation is done. It gives an option to the user to save cartoonified image.\n\nsave\n\nStep 14: Main function to build the tkinter window\ntop.mainloop()\nThe Final Result:\n<p align=\"center\">\n <img src=\"https://d2h0cx97tjks2p.cloudfront.net/blogs/wp-content/uploads/sites/2/2020/09/image-Save.png\" width=\"350\" title=\"hover text\">\n</p>\n\n\nSummary\nYes, now you have a reason to tease your sibling by saying “You look like a cartoon”. Just cartoonify his/ her image, and show it!\n\nWe have successfully developed Image Cartoonifier with OpenCV in Python. This is the magic of openCV which let us do miracles. We suggest you make a photo editor of your own and try different effects.\n"
},
{
"alpha_fraction": 0.4874759018421173,
"alphanum_fraction": 0.52671217918396,
"avg_line_length": 33.367469787597656,
"blob_id": "8fcaaf1c4629965e0cddc8399058bb8e2a8eaf41",
"content_id": "8a870e8717186026cf053a5057f46e46b603ba76",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5709,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 166,
"path": "/Snapchat_Filters/Joker with Cartoon Effect/Joker.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat Jan 2 17:18:34 2021\n\n@author: dell\n\"\"\"\n\n\nimport cv2\nimport numpy as np\nimport dlib\nimport math\n\ncap = cv2.VideoCapture(0)\n\nhat_image = cv2.imread(\"Hat.jpg\")\nlip_image = cv2.imread(\"Lips.jpg\")\nnose_image = cv2.imread(\"Nose.jpg\")\n\ndetector = dlib.get_frontal_face_detector()\npredictor = dlib.shape_predictor(\"shape_predictor_68_face_landmarks.dat\")\n\nlast_foreground = np.zeros((480, 640), dtype='uint8')\n\n\nwhile (cap.isOpened()):\n _, frame = cap.read()\n \n gray_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)\n \n faces = detector(frame)\n \n for face in faces:\n \n #Hat\n landmarks = predictor(gray_frame, face)\n \n \n left_hat = (landmarks.part(17).x, landmarks.part(17).y)\n center_hat = (landmarks.part(21).x, landmarks.part(21).y)\n right_hat = (landmarks.part(26).x, landmarks.part(26).y)\n nose_top = (landmarks.part(27).x, landmarks.part(27).y)\n nose_bottom = (landmarks.part(30).x, landmarks.part(30).y)\n nose_height = math.sqrt((nose_top[0] - nose_bottom[0])**2 + \n (nose_top[1] - nose_bottom[1])**2)\n hat_width = int(math.hypot(left_hat[0] - right_hat[0], \n left_hat[1] - right_hat[1])*2)\n \n \n hat_height = int(hat_width*0.5)\n hat = cv2.resize(hat_image, (hat_width, hat_height))\n \n hat_gray = cv2.cvtColor(hat, cv2.COLOR_BGR2GRAY)\n \n _, hat_mask = cv2.threshold(hat_gray, 25,255, cv2.THRESH_BINARY_INV)\n\n top_left = (int(center_hat[0]-hat_width/2),\n int(center_hat[1] - hat_height/2 - nose_height*2))\n bottom_right = (int(center_hat[0] + hat_width/2),\n int(center_hat[1] + hat_height*2 + nose_height))\n \n hat_area = frame[top_left[1]: top_left[1] + hat_height,\n top_left[0]: top_left[0] + hat_width]\n \n hat_area_no_head = cv2.bitwise_and(hat_area, hat_area, mask =hat_mask)\n final_hat = cv2.add(hat_area_no_head, hat)\n \n frame[top_left[1]: top_left[1] + hat_height,\n top_left[0]: top_left[0] + hat_width] = final_hat\n \n #Nose\n \n top_nose = (landmarks.part(29).x, landmarks.part(29).y)\n left_nose = (landmarks.part(31).x, landmarks.part(31).y)\n center_nose = (landmarks.part(30).x, landmarks.part(30).y)\n right_nose = (landmarks.part(35).x, landmarks.part(35).y)\n \n \n nose_width = int(math.hypot(left_nose[0] - right_nose[0], \n left_nose[1] - right_nose[1]))\n \n \n nose_height = nose_width\n nose_pig = cv2.resize(nose_image, (nose_width, nose_height))\n \n nose_pig_gray = cv2.cvtColor(nose_pig, cv2.COLOR_BGR2GRAY)\n \n _, nose_mask = cv2.threshold(nose_pig_gray, 25,255, cv2.THRESH_BINARY_INV)\n\n top_left = (int(center_nose[0]-nose_width/2),\n int(center_nose[1] - nose_height/2))\n bottom_right = (int(center_nose[0] + nose_width/2),\n int(center_nose[1] + nose_width/2))\n \n nose_area = frame[top_left[1]: top_left[1] + nose_height,\n top_left[0]: top_left[0] + nose_width]\n \n nose_area_no_nose = cv2.bitwise_and(nose_area, nose_area, mask =nose_mask)\n final_nose = cv2.add(nose_area_no_nose, nose_pig)\n \n frame[top_left[1]: top_left[1] + nose_height,\n top_left[0]: top_left[0] + nose_width] = final_nose\n \n \n #Lip\n \n \n left_lip = (landmarks.part(48).x, landmarks.part(48).y)\n center_lip = (landmarks.part(62).x, landmarks.part(62).y)\n right_lip = (landmarks.part(54).x, landmarks.part(54).y)\n \n \n lip_width = int(math.hypot(left_lip[0] - right_lip[0], \n left_lip[1] - right_lip[1])*1.5)\n \n \n lip_height = lip_width\n lip = cv2.resize(lip_image, (lip_width, lip_height))\n \n lip_gray = cv2.cvtColor(lip, cv2.COLOR_BGR2GRAY)\n \n _, lip_mask = cv2.threshold(lip_gray, 25,255, cv2.THRESH_BINARY_INV)\n\n top_left = (int(center_lip[0]-lip_width/2),\n int(center_lip[1] - lip_height/2))\n bottom_right = (int(center_lip[0] + lip_width/2),\n int(center_lip[1] + lip_width/2))\n \n lip_area = frame[top_left[1]: top_left[1] + lip_height,\n top_left[0]: top_left[0] + lip_width]\n \n lip_area_no_lip = cv2.bitwise_and(lip_area, lip_area, mask =lip_mask)\n final_lip = cv2.add(lip_area_no_lip, lip)\n \n frame[top_left[1]: top_left[1] + lip_height,\n top_left[0]: top_left[0] + lip_width] = final_lip\n \n \n \n gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)\n\n foreground = gray\n \n abs_diff = cv2.absdiff(foreground, last_foreground)\n \n last_foreground = foreground\n\n _, mask = cv2.threshold(abs_diff, 20, 255, cv2.THRESH_BINARY)\n mask = cv2.dilate(mask, None, iterations=3)\n se = np.ones((85, 85), dtype='uint8')\n mask = cv2.morphologyEx(mask, cv2.MORPH_CLOSE, se)\n\n frame_effect = cv2.stylization(frame, sigma_s=150, sigma_r=0.25)\n idx = (mask > 1)\n frame[idx] = frame_effect[idx]\n\n # cv2.imshow('WebCam (Mask)', mask)\n \n \n \n \n cv2.imshow(\"Frame\", frame)\n #cv2.imshow(\"Pig Nose\", nose_pig)\n key = cv2.waitKey(1);\n if key == 27:\n break\n "
},
{
"alpha_fraction": 0.5501239895820618,
"alphanum_fraction": 0.6326602697372437,
"avg_line_length": 31.43678092956543,
"blob_id": "4cb8b89fbc01fa90c1aeeb4e823ace99bd6c603d",
"content_id": "9417945d8f7e2a4e22aa03a8d290d689bce182ed",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2823,
"license_type": "permissive",
"max_line_length": 128,
"num_lines": 87,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/tools/preprocess/crop_image_affine.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# @Author : Jiaxiang Shang\n# @Email : [email protected]\n# @Time : 8/11/20 8:46 PM\n\nimport numpy as np\nimport cv2\nimport math\nfrom skimage import transform as trans\n\nstd_224_bfm09 = [\n 81.672401, 88.470589,\n 141.862671, 88.462921,\n 112.000000, 132.863434,\n 87.397392, 153.562943,\n 136.007263, 153.552078\n]\nstd_224_bfm09 = np.array(std_224_bfm09)\nstd_224_bfm09 = np.reshape(std_224_bfm09, [-1, 2])\n\ndef cvrt_300w_to_CelebA(lm68):\n l_eye = np.mean(lm68[37 - 1:43 - 1], axis=0)\n\n r_eye = np.mean(lm68[43 - 1:49 - 1], axis=0)\n\n nose = lm68[34 - 1]\n l_m = lm68[49 - 1]\n r_m = lm68[55 - 1]\n\n return [l_eye, r_eye, nose, l_m, r_m]\n\ndef inverse_affine_warp_overlay(m_inv, image_ori, image_now, image_mask_now):\n from skimage import transform as trans\n tform = trans.SimilarityTransform(m_inv)\n M = tform.params[0:2, :]\n\n image_now_cv = cv2.cvtColor(image_now, cv2.COLOR_RGB2BGR)\n image_mask_now_cv = cv2.cvtColor(image_mask_now, cv2.COLOR_RGB2BGR)\n\n\n\n img_now_warp = cv2.warpAffine(image_now_cv, M, (image_ori.shape[1], image_ori.shape[0]), flags=cv2.INTER_LINEAR,\n borderMode=cv2.BORDER_REPLICATE)\n image_mask_now_warp = cv2.warpAffine(image_mask_now_cv, M, (image_ori.shape[1], image_ori.shape[0]), flags=cv2.INTER_LINEAR,\n borderMode=cv2.BORDER_REPLICATE)\n\n image_ori_back = (1.0 - image_mask_now_warp) * image_ori\n image_ori_back = image_ori_back.astype(np.uint8)\n image_ori_back = np.clip(image_ori_back, 0, 255)\n # if 1:\n # cv2.imshow(\"Image Debug\", image_ori_back)\n # k = cv2.waitKey(0) & 0xFF\n # if k == 27:\n # cv2.destroyAllWindows()\n\n img_now_warp = img_now_warp * image_mask_now_warp\n img_now_warp = img_now_warp.astype(np.uint8)\n img_now_warp = np.clip(img_now_warp, 0, 255)\n\n img_replace = img_now_warp + image_ori_back\n img_replace = np.clip(img_replace, 0, 255)\n\n\n img_replace = img_replace.astype(np.uint8)\n img_replace = np.clip(img_replace, 0, 255)\n\n return img_replace\n\ndef crop_align_affine_transform(lm2d, image, crop_size, std_landmark):\n lm_celebA = cvrt_300w_to_CelebA(lm2d)\n # Transform\n std_points = np.array(std_landmark) * (crop_size / 224.0)\n\n tform = trans.SimilarityTransform()\n tform.estimate(np.array(lm_celebA), std_points)\n M = tform.params[0:2, :]\n\n rot_angle = tform.rotation * 180.0 / (math.pi)\n #print(rot_angle, tform.translation)\n\n img_warped = cv2.warpAffine(image, M, (crop_size, crop_size), flags=cv2.INTER_LINEAR, borderMode=cv2.BORDER_REPLICATE)\n\n h_lm2d_home = np.concatenate([lm2d, np.ones([lm2d.shape[0], 1])], axis=1)\n lm_trans = np.matmul(M, np.array(np.transpose(h_lm2d_home)))\n lm_trans = np.transpose(lm_trans)\n\n return lm_trans, img_warped, tform\n\n"
},
{
"alpha_fraction": 0.6982892751693726,
"alphanum_fraction": 0.7573872208595276,
"avg_line_length": 23.653846740722656,
"blob_id": "7441cb9bfac642c27c392c9b57c3c4796c4d74f4",
"content_id": "bcb05718d45c62de2bca3bd9aac9da42602b5942",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 643,
"license_type": "permissive",
"max_line_length": 224,
"num_lines": 26,
"path": "/Snapchat_Filters/Mask_filter/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Face-Filters\nSnapchat like filters using OpenCV (Hobby Project)\n\n\n\n# Getting Started\n\n> (Optional) [Setup a Python virtual environment](https://www.digitalocean.com/community/tutorials/common-python-tools-using-virtualenv-installing-with-pip-and-managing-packages#a-thorough-virtualenv-how-to) with Python 3.6.\n\n1. Install all Python dependencies.\n\n```\npip install -r requirements.txt\n```\n\n2. Navigate into `src`.\n\n```\ncd src\n```\n\n3. Launch the script for an emotion-based dog filter:\n\n```\npython step_8_dog_emotion_mask.py\n```\n\n\n"
},
{
"alpha_fraction": 0.7607618570327759,
"alphanum_fraction": 0.8021059036254883,
"avg_line_length": 139.36956787109375,
"blob_id": "058eea0cb5bf85cf14eb40e84a532a7b0832ded1",
"content_id": "f2bb79ecf586888d86995327253011c3ef87d4af",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6492,
"license_type": "permissive",
"max_line_length": 1956,
"num_lines": 46,
"path": "/Face-Emotions-Recognition/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Facial-Emotion-Recognition\n\nFacial emotion recognition is the process of detecting human emotions from facial expressions. The human brain recognizes emotions automatically, and software has now been developed that can recognize emotions as well. This technology is becoming more accurate all the time, and will eventually be able to read emotions as well as our brains do. \n\nAI can detect emotions by learning what each facial expression means and applying that knowledge to the new information presented to it. Emotional artificial intelligence, or emotion AI, is a technology that is capable of reading, imitating, interpreting, and responding to human facial expressions and emotions. \n\n## About\n## Eye 👁️ Blinker-Counter\n\n\n\n##### In terms of blink detection, we are only interested in two sets of facial structures — the eyes.\nThe first step in building a blink detector is to perform facial landmark detection to localize the eyes in a given frame from a video stream.\nEach eye is represented by coordinates, starting at the left corner of the eye (as if you were looking at the person), and then working clockwise around the remainder of the region.\nOnce we have the eye aspect ratio, we can threshold it to determine if a person is blinking — the eye aspect ratio will remain approximately constant when the eyes are open and then will rapidly approach zero during a blink, then increase again as the eye opens.\n\n## Facial-Expression-Recognition-using-custom-CNN 😄 :angry: 😢 😭 😆 \n\n\n\nA convolutional neural network (CNN) is the most popular way of analyzing images. The proposed method is based on a two-level CNN framework. The first level recommended is background removal [29], used to extract emotions from an image, as shown in Fig. 1. Here, the conventional CNN network module is used to extract the primary expressional vector (EV). The expressional vector (EV) is generated by tracking down relevant facial points of importance. EV is directly related to changes in expression. The EV is obtained using a basic perceptron unit applied to a background-removed face image. In the proposed FERC model, we also have a non-convolutional perceptron layer as the last stage. Each of the convolutional layers receives the input data (or image), transforms it, and then outputs it to the next level. This transformation is a convolution operation. All the convolutional layers used are capable of pattern detection. Within each convolutional layer, four filters were used. The input image fed to the first-part CNN (used for background removal) generally consists of shapes, edges, textures, and objects along with the face. The **edge detector, circle detector, and corner detector filters** are used at the start of the convolutional layer 1. Once the face has been detected, the second-part CNN filter catches facial features, such as eyes, ears, lips, nose, and cheeks. The edge detection filters used in this layer. The second-part CNN consists of layers with 3×3 kernel matrix, e.g., [0.25, 0.17, 0.9; 0.89, 0.36, 0.63; 0.7, 0.24, 0.82]. These numbers are selected between 0 and 1 initially. These numbers are optimized for EV detection, based on the ground truth we had, in the supervisory training dataset. Once the filter is tuned by supervisory learning, it is then applied to the background-removed face (i.e., on the output image of the first-part CNN), for detection of different facial parts (e.g., eye, lips. nose, ears, etc.)\n\n## Smile 😄 Percentage Detection\n\n\n\n*We propose a method to automatically refine for real-time usage.*\nThe smile detect algorithm is as follows:\n1. Detect the first human face in the first image frame\nand locate the twenty standard facial features\nposition.\n2. In every image frame, use optical flow to track the\nposition of left mouth corner and right mouth\ncorner with an accuracy of 0.01 pixels and update the\nstandard facial feature position by face tracking\nand detection.\n3. If x-direction distance between the tracked left\nmouth corner and right mouth corner is larger than\nthe standard distance plus a threshold Tsmile, then\nwe claim a smile detected.\n4. Repeat from Step 2 to Step 3\n## face-emotions-recognition-using-deep-learning\n\n\nAn emotion recognition system can be built by utilizing the benefits of deep learning and different applications such as feedback analysis, face unlocking, etc. can be implemented with good accuracy. The main focus of this work is to create a Deep Convolutional Neural Network (DCNN) model that classifies 5 different human facial emotions. The model is trained, tested, and validated using the manually collected image dataset. We aim to construct a system that captures real-world facial images through the front camera on a laptop. The system is capable of processing/recognizing the captured image and predict a result in real-time. In this system, we exploit the power of the **deep learning technique** to learn a facial emotion recognition (FER) model based on a set of labeled facial images. Finally, experiments are conducted to evaluate our model using a largely used public database. A 3D facial emotion recognition model using a deep learning technique is proposed. In the deep learning architecture, two convolution layers and a pooling layer are used. Pooling is performed after convolution operation. The sigmoid activation function is used to obtain the probabilities for different classes of human faces. In order to validate the performance of the deep learning-based face recognition model, the Kaggle dataset is used. The accuracy of the model is approximately 65% which is less than the other techniques used for facial emotion recognition. Despite dramatic improvements in representation precision attributable to the non-linearity of profound image representations. \n💫 💫 💫 \n"
},
{
"alpha_fraction": 0.7140845060348511,
"alphanum_fraction": 0.7415493130683899,
"avg_line_length": 23.465517044067383,
"blob_id": "c53fdcdac812a5848d2c598c3040615af60e7ef9",
"content_id": "97e78c99043fed8175ee2140e7dece57cdbc09fe",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1420,
"license_type": "permissive",
"max_line_length": 137,
"num_lines": 58,
"path": "/Recognition-Algorithms/Recognition Using MobileNetV2/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "## Overview\nFace Recognition Using opencv, keras and tensorflow.\n\nThis model uses MobileNetV2 model for the recognition of the User face.\n\nProgram is trained for 5 epochs, You can increase the number of epochs and the number of layers accordingly.\n\n\n### Dependencies:\n* pip install numpy\n* pip install pandas\n* pip install tensorflow\n* pip install keras\n* pip install opencv-python\n\nDownload haarcascades file from here=> https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml\n\n## ScreenShots\n\n<img src=\"Screenshot from 2020-12-15 21-17-56.png\" height=\"250px\">\n<img src=\"Screenshot from 2020-12-15 21-18-31.png\" height=\"250px\">\n\n\n## Quick Start\n\n- Fork and Clone the repository using-\n```\ngit clone https://github.com/akshitagupta15june/Face-X.git\n```\n- Create virtual environment-\n```\n- `python -m venv env`\n- `source env/bin/activate` (Linux)\n- `env\\Scripts\\activate` (Windows)\n```\n- Install dependencies-\n\n- Headover to Project Directory- \n```\ncd Recognition using MobileNetV2\n```\n- Create dataset using -\n```\n- Run create_dataset.py on respective idle(VS Code, PyCharm, Jupiter Notebook, Colab)\n```\nNote: Do split the dataset into Train and Test folders.\n\n- Train the model -\n```\n- Run train-model.py\n```\nNote: Make sure all dependencies are installed properly.\n\n- Final-output -\n```\n- Run output.py\n```\nNote: Make sure you have haarcascade_frontalface_default.xml file \n"
},
{
"alpha_fraction": 0.5410798192024231,
"alphanum_fraction": 0.5625419020652771,
"avg_line_length": 40.713287353515625,
"blob_id": "facaf735d986d72535d0f882ff3a8b832c2495fe",
"content_id": "650304bdb144816f178c798db6b68930a3879b87",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5964,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 143,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/src_common/common/tf_io.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# encoding: utf-8\n'''\n@author: Jiaxiang Shang\n@license: (C) Copyright 2013-2017, Node Supply Chain Manager Corporation Limited.\n@contact: [email protected]\n@time: 3/25/20 12:47 PM\n@desc:\n'''\nimport tensorflow as tf\n\n#\ndef unpack_image_sequence(image_seq, img_height, img_width, num_source):\n if len(image_seq.shape) == 2:\n image_seq = tf.expand_dims(image_seq, -1)\n channel = image_seq.shape[2]\n\n # Assuming the center image is the target frame\n tgt_start_idx = int(img_width * (num_source // 2))\n tgt_image = tf.slice(image_seq,\n [0, tgt_start_idx, 0],\n [-1, img_width, -1])\n # Source frames before the target frame\n src_image_1 = tf.slice(image_seq,\n [0, 0, 0],\n [-1, int(img_width * (num_source // 2)), -1])\n # Source frames after the target frame\n src_image_2 = tf.slice(image_seq,\n [0, int(tgt_start_idx + img_width), 0],\n [-1, int(img_width * (num_source // 2)), -1])\n src_image_seq = tf.concat([src_image_1, src_image_2], axis=1)\n # Stack source frames along the color channels (i.e. [H, W, N*3])\n src_image_stack = tf.concat([tf.slice(src_image_seq,\n [0, i * img_width, 0],\n [-1, img_width, -1])\n for i in range(num_source)], axis=2)\n src_image_stack.set_shape([img_height, img_width, num_source * channel])\n tgt_image.set_shape([img_height, img_width, channel])\n return tgt_image, src_image_stack\n\ndef data_augmentation_mul(im, intrinsics, out_h, out_w, matches=None):\n out_h = tf.cast(out_h, dtype=tf.int32)\n out_w = tf.cast(out_w, dtype=tf.int32)\n\n # Random scaling\n def random_scaling(im, intrinsics, matches):\n # print(tf_render.unstack(tf_render.shape(im)))\n # print(im.get_shape().as_list())\n _, in_h, in_w, _ = tf.unstack(tf.shape(im))\n in_h = tf.cast(in_h, dtype=tf.float32)\n in_w = tf.cast(in_w, dtype=tf.float32)\n scaling = tf.random_uniform([2], 1.0, 1.2)\n x_scaling = scaling[0]\n y_scaling = scaling[0]\n\n out_h = tf.cast(in_h * y_scaling, dtype=tf.int32)\n out_w = tf.cast(in_w * x_scaling, dtype=tf.int32)\n\n im = tf.image.resize_area(im, [out_h, out_w])\n\n list_intrinsics = []\n for i in range(intrinsics.shape[1]): # bs, num_src+1, 3, 3\n fx = intrinsics[:, i, 0, 0] * x_scaling\n fy = intrinsics[:, i, 1, 1] * y_scaling\n cx = intrinsics[:, i, 0, 2] * x_scaling\n cy = intrinsics[:, i, 1, 2] * y_scaling\n intrinsics_new = make_intrinsics_matrix(fx, fy, cx, cy)\n list_intrinsics.append(intrinsics_new)\n intrinsics = tf.stack(list_intrinsics, axis=1)\n\n if matches is None:\n return im, intrinsics, None\n else:\n x = matches[:, :, :, 0] * x_scaling\n y = matches[:, :, :, 1] * y_scaling\n matches = tf.stack([x, y], axis=3) # bs, tar, num, axis\n return im, intrinsics, matches\n\n # Random cropping\n def random_cropping(im, intrinsics, out_h, out_w, matches):\n # batch_size, in_h, in_w, _ = im.get_shape().as_list()\n batch_size, in_h, in_w, _ = tf.unstack(tf.shape(im))\n offset_y = tf.random_uniform([1], 0, in_h - out_h + 1, dtype=tf.int32)[0]\n offset_x = offset_y\n im = tf.image.crop_to_bounding_box(\n im, offset_y, offset_x, out_h, out_w)\n\n list_intrinsics = []\n for i in range(intrinsics.shape[1]): # bs, num_src+1, 3, 3\n fx = intrinsics[:, i, 0, 0]\n fy = intrinsics[:, i, 1, 1]\n cx = intrinsics[:, i, 0, 2] - tf.cast(offset_x, dtype=tf.float32)\n cy = intrinsics[:, i, 1, 2] - tf.cast(offset_y, dtype=tf.float32)\n intrinsics_new = make_intrinsics_matrix(fx, fy, cx, cy)\n list_intrinsics.append(intrinsics_new)\n intrinsics = tf.stack(list_intrinsics, axis=1)\n\n if matches is None:\n return im, intrinsics, None\n else:\n x = matches[:, :, :, 0] - tf.cast(offset_x, dtype=tf.float32)\n y = matches[:, :, :, 1] - tf.cast(offset_y, dtype=tf.float32)\n matches = tf.stack([x, y], axis=3) # bs, tar, num, axis\n return im, intrinsics, matches\n\n batch_size, in_h, in_w, _ = tf.unstack(tf.shape(im))\n im, intrinsics, matches = random_scaling(im, intrinsics, matches)\n im, intrinsics, matches = random_cropping(im, intrinsics, out_h, out_w, matches)\n # im, intrinsics, matches = random_scaling(im, intrinsics, matches, in_h, in_w)\n im = tf.cast(im, dtype=tf.uint8)\n\n if matches is None:\n return im, intrinsics, None\n else:\n return im, intrinsics, matches\n\n#\ndef unpack_image_batch_list(image_seq, img_height, img_width, num_source):\n tar_list = []\n src_list = []\n for i in range(image_seq.shape[0]):\n tgt_image, src_image_stack = unpack_image_sequence(image_seq[i], img_height, img_width, num_source)\n tar_list.append(tgt_image)\n src_list.append(src_image_stack)\n tgt_image_b = tf.stack(tar_list)\n src_image_stack_b = tf.stack(src_list)\n\n list_tar_image = [tgt_image_b]\n list_src_image = [src_image_stack_b[:, :, :, i * 3:(i + 1) * 3] for i in range(num_source)]\n list_image = list_tar_image + list_src_image\n\n return list_image\n\n# np\ndef unpack_image_np(image_seq, img_height, img_width, num_source):\n\n tgt_start_idx = int(img_width * (num_source // 2))\n\n tgt_image = image_seq[:, tgt_start_idx:tgt_start_idx+img_width, :]\n src_image_1 = image_seq[:, 0:int(img_width * (num_source // 2)), :]\n src_image_2 = image_seq[:, tgt_start_idx+img_width:tgt_start_idx+img_width+int(img_width * (num_source // 2)), :]\n\n return src_image_1, tgt_image, src_image_2, [tgt_image, src_image_1, src_image_2]"
},
{
"alpha_fraction": 0.6490648984909058,
"alphanum_fraction": 0.6798679828643799,
"avg_line_length": 36.91666793823242,
"blob_id": "463964be8118ff8604312f8eaef191b2dace4cdb",
"content_id": "2e9128cb3ad6addf6a0585a3aa61ac34f39e5a7c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 909,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 24,
"path": "/Face-Detection/face and eye detection/code.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#import all the necessary libraries\nimport cv2\n#Add the path of .xml for face recognition\nface_cascade=cv2.CascadeClassifier(\"haarcascade_frontalface_default.xml\")\n#Add the path of .xml file for eye recognition\neye_cascade=cv2.CascadeClassifier(\"haarcascade_eye_tree_eyeglasses.xml\")\n#function to capture our live video using webcam\nv=cv2.VideoCapture(0)\nwhile True:\n check,frame=v.read()\n g=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)\n faces=face_cascade.detectMultiScale(g,1.3,5)\n for (x,y,w,h) in faces:\n cv2.rectangle(frame,(x,y),(x+w,y+h),(255,0,0),2)\n roi_gray=g[y:y+h,x:x+w]\n roi_color=frame[y:y+h,x:x+w]\n eyes=eye_cascade.detectMultiScale(roi_gray)\n for (ex,ey,ew,eh) in eyes:\n cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,255,0),2)\n cv2.imshow('IMAGE',frame)\n if cv2.waitKey()==ord('q'):\n break\nv.release()\ncv2.destroyAllWindows()"
},
{
"alpha_fraction": 0.4860398769378662,
"alphanum_fraction": 0.5532763600349426,
"avg_line_length": 27.770492553710938,
"blob_id": "851b4aa59802f75a20c64cef906756195d17337c",
"content_id": "dc830b76352f8cf7d4ad86b897b9636a49587234",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3510,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 122,
"path": "/Face Reconstruction/Face Alignment in Full Pose Range/visualize.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# coding: utf-8\n\nfrom benchmark import extract_param\nfrom utils.ddfa import reconstruct_vertex\nfrom utils.io import _dump, _load\nimport os.path as osp\nfrom skimage import io\nimport matplotlib.pyplot as plt\nfrom benchmark_aflw2000 import convert_to_ori\nimport scipy.io as sio\n\n\ndef aflw2000():\n arch = 'mobilenet_1'\n device_ids = [0]\n checkpoint_fp = 'models/phase1_wpdc_vdc.pth.tar'\n\n params = extract_param(\n checkpoint_fp=checkpoint_fp,\n root='test.data/AFLW2000-3D_crop',\n filelists='test.data/AFLW2000-3D_crop.list',\n arch=arch,\n device_ids=device_ids,\n batch_size=128)\n _dump('res/params_aflw2000.npy', params)\n\n\ndef draw_landmarks():\n filelists = 'test.data/AFLW2000-3D_crop.list'\n root = 'AFLW-2000-3D/'\n fns = open(filelists).read().strip().split('\\n')\n params = _load('res/params_aflw2000.npy')\n\n for i in range(2000):\n plt.close()\n img_fp = osp.join(root, fns[i])\n img = io.imread(img_fp)\n lms = reconstruct_vertex(params[i], dense=False)\n lms = convert_to_ori(lms, i)\n\n # print(lms.shape)\n fig = plt.figure(figsize=plt.figaspect(.5))\n # fig = plt.figure(figsize=(8, 4))\n ax = fig.add_subplot(1, 2, 1)\n ax.imshow(img)\n\n alpha = 0.8\n markersize = 4\n lw = 1.5\n color = 'w'\n markeredgecolor = 'black'\n\n nums = [0, 17, 22, 27, 31, 36, 42, 48, 60, 68]\n for ind in range(len(nums) - 1):\n l, r = nums[ind], nums[ind + 1]\n ax.plot(lms[0, l:r], lms[1, l:r], color=color, lw=lw, alpha=alpha - 0.1)\n\n ax.plot(lms[0, l:r], lms[1, l:r], marker='o', linestyle='None', markersize=markersize, color=color,\n markeredgecolor=markeredgecolor, alpha=alpha)\n\n ax.axis('off')\n\n # 3D\n ax = fig.add_subplot(1, 2, 2, projection='3d')\n lms[1] = img.shape[1] - lms[1]\n lms[2] = -lms[2]\n\n # print(lms)\n ax.scatter(lms[0], lms[2], lms[1], c=\"cyan\", alpha=1.0, edgecolor='b')\n\n for ind in range(len(nums) - 1):\n l, r = nums[ind], nums[ind + 1]\n ax.plot3D(lms[0, l:r], lms[2, l:r], lms[1, l:r], color='blue')\n\n ax.view_init(elev=5., azim=-95)\n # ax.set_xlabel('x')\n # ax.set_ylabel('y')\n # ax.set_zlabel('z')\n\n ax.set_xticklabels([])\n ax.set_yticklabels([])\n ax.set_zticklabels([])\n\n plt.tight_layout()\n # plt.show()\n\n wfp = f'res/AFLW-2000-3D/{osp.basename(img_fp)}'\n plt.savefig(wfp, dpi=200)\n\n\ndef gen_3d_vertex():\n filelists = 'test.data/AFLW2000-3D_crop.list'\n root = 'AFLW-2000-3D/'\n fns = open(filelists).read().strip().split('\\n')\n params = _load('res/params_aflw2000.npy')\n\n sel = ['00427', '00439', '00475', '00477', '00497', '00514', '00562', '00623', '01045', '01095', '01104', '01506',\n '01621', '02214', '02244', '03906', '04157']\n sel = list(map(lambda x: f'image{x}.jpg', sel))\n for i in range(2000):\n fn = fns[i]\n if fn in sel:\n vertex = reconstruct_vertex(params[i], dense=True)\n wfp = osp.join('res/AFLW-2000-3D_vertex/', fn.replace('.jpg', '.mat'))\n print(wfp)\n sio.savemat(wfp, {'vertex': vertex})\n\n\ndef main():\n # step1: extract params\n # aflw2000()\n\n # step2: draw landmarks\n # draw_landmarks()\n\n # step3: visual 3d vertex\n gen_3d_vertex()\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5484189987182617,
"alphanum_fraction": 0.5632411241531372,
"avg_line_length": 32.196720123291016,
"blob_id": "cdc4dc65de02fbf7b2a2e9e00305aa0f2fb337a7",
"content_id": "ff4b6b3077810090fccafd1e39b94fd43480d561",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2024,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 61,
"path": "/Face Reconstruction/Self-Supervised Monocular 3D Face Reconstruction by Occlusion-Aware Multi-view Geometry Consistency/tools/preprocess/detect_landmark.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# @Author : Jiaxiang Shang\n# @Email : [email protected]\n# @Time : 8/11/20 8:30 PM\n\n\n# system\nfrom __future__ import print_function\n\nimport os\nimport sys\n\n# python lib\nimport face_alignment\nimport numpy as np\nimport cv2\n\nclass LM_detector_howfar():\n def __init__(self, use_cnn_face_detector=True ,lm_type=2, device='cpu', face_detector='sfd'):\n if lm_type == 2:\n self.fa = face_alignment.FaceAlignment(\n face_alignment.LandmarksType._2D, device=device, flip_input=False, face_detector=face_detector)\n else:\n self.fa = face_alignment.FaceAlignment(\n face_alignment.LandmarksType._3D, device=device, flip_input=False, face_detector=face_detector)\n\n def lm_detection_howfar(self, image):\n \"\"\"\n :param image: ndarray\n :return:\n lm: ndarray or None\n \"\"\"\n # filter very large image\n scale = 1.0\n h, w, c = image.shape\n if max(h, w) > 900:\n scale = max(h, w) / (900.0)\n #image = sktrans.resize(image, [int(h/scale), int(w/scale), 3], anti_aliasing=True)\n image = cv2.resize(image, (int(w / scale), int(h / scale)))\n\n # torch\n detected_faces = self.fa.face_detector.detect_from_image(image[..., ::-1].copy())\n lm_howfar = self.fa.get_landmarks(image, detected_faces=detected_faces)\n\n # check the face detection bbox, that choose the largest one\n if lm_howfar is not None:\n list_hf = []\n list_size_detected_face = []\n for i in range(len(lm_howfar)):\n l_hf = lm_howfar[i]\n l_hf = l_hf * scale\n list_hf.append(l_hf)\n\n bbox = detected_faces[i]\n list_size_detected_face.append(bbox[2]-bbox[0] + bbox[3]-bbox[1])\n\n list_size_detected_face = np.array(list_size_detected_face)\n idx_max = np.argmax(list_size_detected_face)\n return list_hf[idx_max]\n else:\n return None"
},
{
"alpha_fraction": 0.5297743082046509,
"alphanum_fraction": 0.5510740280151367,
"avg_line_length": 31.433332443237305,
"blob_id": "73744d122d9ce35bfb1acd2753d4ce9a369c36df",
"content_id": "30f87e6760bfdb23c646bdba69d6b28359914f80",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11033,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 330,
"path": "/Snapchat_Filters/Filters with GUI/main.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from __future__ import absolute_import, print_function\r\n\r\nimport argparse\r\nimport math\r\nimport os\r\nimport sys\r\nimport threading\r\nimport time\r\nfrom os import listdir\r\nfrom os.path import isfile, join\r\nfrom sys import platform as _platform\r\nfrom threading import Thread\r\nimport cv2\r\nfrom PIL import Image, ImageTk\r\nimport dlib\r\nfrom imutils import face_utils, rotate_bound\r\n\r\nif sys.version_info.major >= 3:\r\n from tkinter import SUNKEN, RAISED, Tk, PhotoImage, Button, Label\r\nelse:\r\n from Tkinter import SUNKEN, RAISED, Tk, PhotoImage, Button, Label\r\n\r\n\r\n_streaming = False\r\n\r\n\r\ndef put_sprite(num):\r\n global SPRITES, BTNS\r\n SPRITES[num] = 1 - SPRITES[num] \r\n if SPRITES[num]:\r\n BTNS[num].config(relief=SUNKEN)\r\n else:\r\n BTNS[num].config(relief=RAISED)\r\n\r\n\r\ndef draw_sprite(frame, sprite, x_offset, y_offset):\r\n (h, w) = (sprite.shape[0], sprite.shape[1])\r\n (imgH, imgW) = (frame.shape[0], frame.shape[1])\r\n\r\n if y_offset + h >= imgH: \r\n sprite = sprite[0 : imgH - y_offset, :, :]\r\n\r\n if x_offset + w >= imgW: \r\n sprite = sprite[:, 0 : imgW - x_offset, :]\r\n\r\n if x_offset < 0: \r\n sprite = sprite[:, abs(x_offset) : :, :]\r\n w = sprite.shape[1]\r\n x_offset = 0\r\n\r\n \r\n for c in range(3):\r\n \r\n frame[y_offset : y_offset + h, x_offset : x_offset + w, c] = sprite[:, :, c] * (\r\n sprite[:, :, 3] / 255.0\r\n ) + frame[y_offset : y_offset + h, x_offset : x_offset + w, c] * (\r\n 1.0 - sprite[:, :, 3] / 255.0\r\n )\r\n return frame\r\n\r\n\r\ndef adjust_sprite2head(sprite, head_width, head_ypos, ontop=True):\r\n (h_sprite, w_sprite) = (sprite.shape[0], sprite.shape[1])\r\n factor = 1.0 * head_width / w_sprite\r\n sprite = cv2.resize(\r\n sprite, (0, 0), fx=factor, fy=factor\r\n ) \r\n (h_sprite, w_sprite) = (sprite.shape[0], sprite.shape[1])\r\n\r\n y_orig = (\r\n head_ypos - h_sprite if ontop else head_ypos\r\n ) \r\n if(\r\n y_orig < 0\r\n ): \r\n sprite = sprite[abs(y_orig) : :, :, :] \r\n y_orig = 0 \r\n return (sprite, y_orig)\r\n\r\n\r\n\r\ndef apply_sprite(image, path2sprite, w, x, y, angle, ontop=True):\r\n sprite = cv2.imread(path2sprite, -1)\r\n \r\n sprite = rotate_bound(sprite, angle)\r\n (sprite, y_final) = adjust_sprite2head(sprite, w, y, ontop)\r\n image = draw_sprite(image, sprite, x, y_final)\r\n\r\n\r\n\r\ndef calculate_inclination(point1, point2):\r\n x1, x2, y1, y2 = point1[0], point2[0], point1[1], point2[1]\r\n incl = 180 / math.pi * math.atan((float(y2 - y1)) / (x2 - x1))\r\n return incl\r\n\r\n\r\ndef calculate_boundbox(list_coordinates):\r\n x = min(list_coordinates[:, 0])\r\n y = min(list_coordinates[:, 1])\r\n w = max(list_coordinates[:, 0]) - x\r\n h = max(list_coordinates[:, 1]) - y\r\n return (x, y, w, h)\r\n\r\n\r\ndef get_face_boundbox(points, face_part):\r\n if face_part == 1:\r\n (x, y, w, h) = calculate_boundbox(points[17:22]) # left eyebrow\r\n elif face_part == 2:\r\n (x, y, w, h) = calculate_boundbox(points[22:27]) # right eyebrow\r\n elif face_part == 3:\r\n (x, y, w, h) = calculate_boundbox(points[36:42]) # left eye\r\n elif face_part == 4:\r\n (x, y, w, h) = calculate_boundbox(points[42:48]) # right eye\r\n elif face_part == 5:\r\n (x, y, w, h) = calculate_boundbox(points[29:36]) # nose\r\n elif face_part == 6:\r\n (x, y, w, h) = calculate_boundbox(points[48:68]) # mouth\r\n return (x, y, w, h)\r\n\r\n\r\ndef cvloop(run_event, read_camera=0, virtual_camera=0):\r\n global panelA\r\n global SPRITES\r\n\r\n dir_ = \"./sprites/flyes/\"\r\n flies = [\r\n f for f in listdir(dir_) if isfile(join(dir_, f))\r\n ] # image of flies to make the \"animation\"\r\n i = 0\r\n video_capture = cv2.VideoCapture(read_camera) # read from webcam\r\n (x, y, w, h) = (0, 0, 10, 10) # whatever initial values\r\n\r\n # Filters path\r\n detector = dlib.get_frontal_face_detector()\r\n\r\n # Facial landmarks\r\n # print(\"[INFO] loading facial landmark predictor...\")\r\n model = \"shape_predictor_68_face_landmarks.dat\"\r\n predictor = dlib.shape_predictor(\r\n model\r\n ) \r\n stream_camera = None\r\n img_counter = 0\r\n while run_event.is_set(): \r\n ret, image = video_capture.read()\r\n\r\n if not ret:\r\n print(\"Error reading camera, exiting\")\r\n break\r\n\r\n if _streaming:\r\n if stream_camera is None:\r\n if virtual_camera:\r\n h, w = image.shape[:2]\r\n stream_camera = pyfakewebcam.FakeWebcam(\r\n \"/dev/video{}\".format(virtual_camera), w, h\r\n )\r\n gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)\r\n faces = detector(gray, 0)\r\n \r\n for face in faces: # if there are faces\r\n (x, y, w, h) = (face.left(), face.top(), face.width(), face.height())\r\n # *** Facial Landmarks detection\r\n shape = predictor(gray, face)\r\n shape = face_utils.shape_to_np(shape)\r\n incl = calculate_inclination(\r\n shape[17], shape[26]\r\n ) # inclination based on eyebrows\r\n\r\n # condition to see if mouth is open\r\n is_mouth_open = (\r\n shape[66][1] - shape[62][1]\r\n ) >= 10 # y coordiantes of landmark points of lips\r\n\r\n # hat condition\r\n if SPRITES[0]:\r\n apply_sprite(image, \"./sprites/hat.png\", w, x, y, incl)\r\n\r\n # mustache condition\r\n if SPRITES[1]:\r\n (x1, y1, w1, h1) = get_face_boundbox(shape, 6)\r\n apply_sprite(image, \"./sprites/mustache.png\", w1, x1, y1, incl)\r\n\r\n # glasses condition\r\n if SPRITES[3]:\r\n (x3, y3, _, h3) = get_face_boundbox(shape, 1)\r\n apply_sprite(\r\n image, \"./sprites/glasses.png\", w, x, y3, incl, ontop=False\r\n )\r\n # spring eyes condition\r\n if SPRITES[5]:\r\n (x3, y3, _, h3) = get_face_boundbox(shape, 1)\r\n apply_sprite(\r\n image, \"./sprites/spring_eye.png\", w, x, y3, incl, ontop=False\r\n )\r\n # flies condition\r\n if SPRITES[2]:\r\n # to make the \"animation\" we read each time a different image of that folder\r\n # the images are placed in the correct order to give the animation impresion\r\n apply_sprite(image, dir_ + flies[i], w, x, y, incl)\r\n i += 1\r\n i = (\r\n 0 if i >= len(flies) else i\r\n ) # when done with all images of that folder, begin again\r\n\r\n # doggy condition\r\n (x0, y0, w0, h0) = get_face_boundbox(shape, 6) # bound box of mouth\r\n if SPRITES[4]:\r\n (x3, y3, w3, h3) = get_face_boundbox(shape, 5) # nose\r\n apply_sprite(\r\n image, \"./sprites/doggy_nose.png\", w3, x3, y3, incl, ontop=False\r\n )\r\n\r\n apply_sprite(image, \"./sprites/doggy_ears.png\", w, x, y, incl)\r\n\r\n if is_mouth_open:\r\n apply_sprite(\r\n image,\r\n \"./sprites/doggy_tongue.png\",\r\n w0,\r\n x0,\r\n y0,\r\n incl,\r\n ontop=False,\r\n )\r\n if SPRITES[6]:\r\n img_name = \"image{}.png\".format(img_counter)\r\n cv2.imwrite(img_name, image)\r\n # print(\"Success\")\r\n \r\n break\r\n img_counter += 1\r\n # OpenCV represents image as BGR; PIL but RGB, we need to change the chanel order\r\n image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)\r\n\r\n if _streaming:\r\n if virtual_camera:\r\n stream_camera.schedule_frame(image)\r\n\r\n # conerts to PIL format\r\n image = Image.fromarray(image)\r\n # Converts to a TK format to visualize it in the GUI\r\n image = ImageTk.PhotoImage(image)\r\n # Actualize the image in the panel to show it\r\n panelA.configure(image=image)\r\n panelA.image = image\r\n\r\n video_capture.release()\r\n\r\n\r\n# Parser\r\nparser = argparse.ArgumentParser()\r\nparser.add_argument(\"--read_camera\", type=int, default=0, help=\"Id to read camera from\")\r\nparser.add_argument(\r\n \"--virtual_camera\",\r\n type=int,\r\n default=0,\r\n help=\"If different from 0, creates a virtual camera with results on that id (linux only)\",\r\n)\r\nargs = parser.parse_args()\r\n\r\n# Initialize GUI object\r\nroot = Tk()\r\nroot.title(\"Snap chat filters\")\r\nthis_dir = os.path.dirname(os.path.realpath(__file__))\r\n# Adds a custom logo\r\nimgicon = PhotoImage(file=os.path.join(this_dir, \"imgs\", \"icon.gif\"))\r\nroot.tk.call(\"wm\", \"iconphoto\", root._w, imgicon)\r\n\r\n##Create 5 buttons and assign their corresponding function to active sprites\r\nbtn1 = Button(root, text=\"Hat\", command=lambda: put_sprite(0))\r\nbtn1.pack(side=\"top\", fill=\"both\", expand=\"no\", padx=\"5\", pady=\"5\")\r\n\r\nbtn2 = Button(root, text=\"Mustache\", command=lambda: put_sprite(1))\r\nbtn2.pack(side=\"top\", fill=\"both\", expand=\"no\", padx=\"5\", pady=\"5\")\r\n\r\nbtn3 = Button(root, text=\"Flies\", command=lambda: put_sprite(2))\r\nbtn3.pack(side=\"top\", fill=\"both\", expand=\"no\", padx=\"5\", pady=\"5\")\r\n\r\nbtn4 = Button(root, text=\"Glasses\", command=lambda: put_sprite(3))\r\nbtn4.pack(side=\"top\", fill=\"both\", expand=\"no\", padx=\"5\", pady=\"5\")\r\n\r\nbtn5 = Button(root, text=\"Doggy\", command=lambda: put_sprite(4))\r\nbtn5.pack(side=\"top\", fill=\"both\", expand=\"no\", padx=\"5\", pady=\"5\")\r\n\r\nbtn6 = Button(root, text=\"Spring Eye\", command=lambda: put_sprite(5))\r\nbtn6.pack(side=\"top\", fill=\"both\", expand=\"no\", padx=\"5\", pady=\"5\")\r\n\r\nbtn7 = Button(root, text=\"Capture\", command=lambda: put_sprite(6))\r\nbtn7.pack(side=\"top\", fill=\"both\", expand=\"no\", padx=\"5\", pady=\"5\")\r\n\r\n# Create the panel where webcam image will be shown\r\npanelA = Label(root)\r\npanelA.pack(padx=10, pady=10)\r\n\r\n# Variable to control which sprite you want to visualize\r\nSPRITES = [\r\n 0,\r\n 0,\r\n 0,\r\n 0,\r\n 0,\r\n 0,\r\n 0,\r\n] # hat, mustache, flies, glasses, doggy -> 1 is visible, 0 is not visible\r\nBTNS = [btn1, btn2, btn3, btn4, btn5,btn6,btn7]\r\n\r\n\r\n# Creates a thread where the magic ocurs\r\nrun_event = threading.Event()\r\nrun_event.set()\r\naction = Thread(target=cvloop, args=(run_event, args.read_camera, args.virtual_camera))\r\naction.setDaemon(True)\r\naction.start()\r\n\r\n\r\n# Function to close all properly, aka threads and GUI\r\ndef terminate():\r\n global root, run_event, action\r\n print(\"Closing ...\")\r\n run_event.clear()\r\n time.sleep(1)\r\n # action.join() #strangely in Linux this thread does not terminate properly, so .join never finishes\r\n root.destroy()\r\n print(\"Hope You Enjoyed\")\r\n\r\n\r\n# When the GUI is closed it actives the terminate function\r\nroot.protocol(\"WM_DELETE_WINDOW\", terminate)\r\nroot.mainloop() # creates loop of GUI\r\n"
},
{
"alpha_fraction": 0.7045454382896423,
"alphanum_fraction": 0.7954545617103577,
"avg_line_length": 10,
"blob_id": "f04f4bc145f54f0dfe171dea144e7746d0546bab",
"content_id": "5ba7442fdd29ff577b2dcdd22ba6dc306f6ce5db",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 44,
"license_type": "permissive",
"max_line_length": 13,
"num_lines": 4,
"path": "/Face Reconstruction/Joint 3D Face Reconstruction/requirements.txt",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "numpy>=1.14.3\nscikit-image\nscipy\ntensorflow\n"
},
{
"alpha_fraction": 0.7723880410194397,
"alphanum_fraction": 0.7880597114562988,
"avg_line_length": 36.22222137451172,
"blob_id": "5daaf9cde32f8f7c10e7cfebc0cfc24ba6a7812b",
"content_id": "3fdfe2a9670b72b37cd9f2f9b71be67c46ad2314",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1340,
"license_type": "permissive",
"max_line_length": 140,
"num_lines": 36,
"path": "/Awesome-face-operations/Face-Morphing/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Face Morphing\nThis is a tool which creates a morphing effect. It takes two facial images as input and returns morphing from the first image to the second.\n\n## Problem Statement:\nInput: Tow images containing human faces(Image I1 and Image I2)\n\nOutput: A fluid transformation video transitioning from I1 to I2\n\nGoal: The transition should be smooth and the intermediate frames should be as realistic as possible.\n\n## Requirements\n```\nnumpy\nscikit_image\nopencv_python\nPillow\nskimage\ndlib\n```\n\n# Example:\n\n\n## Steps:\n- Provide two images in Images folder\n- Generating a morphing animation video sequence\n```\npython3 code/__init__.py --img1 images/aligned_images/jennie.png --img2 images/aligned_images/rih.png --output output.mp4\n```\n- Run Face_Morpher.py above on your aligned face images with arg --img1 and --img2\n\n## Features:\n1. Detect and auto align faces in images (Optional for face morphing)\n2. Generate corresponding features points between the two images using Dlib's Facial Landmark Detection\n3. Calculate the triangular mesh with Delaunay Triangulation for each intermediate shape\n4. Warp the two input images towards the intermediate shape, perform cross-dissolve and obtain intermediate images each frame\n"
},
{
"alpha_fraction": 0.7275383472442627,
"alphanum_fraction": 0.7710007429122925,
"avg_line_length": 30.837209701538086,
"blob_id": "a13c8104c5909a99b0b9ce29600de9627927e3fb",
"content_id": "ac642f09900dd6086aae3f0600778e85f28b879d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2738,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 86,
"path": "/Recognition-Algorithms/Recognition_using_NasNet/FR_README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Face Recognition\n\nSteps to face recognition-\n\ni. Training Data Gathering: Gather face data. \n\nii. Training of Recognizer: Feed that face data to the face recognizer so that it can learn.\n\niii. Recognition: Feed new faces of the persons and see if the face recognizer you just trained recognizes them.\n\n## Overview of this project\nFace Recognition Using OpenCV and PyTorch.\n\nThis model uses NasNet model for the recognition of the User face.\n\nProgram is trained for 5 epochs, You can increase the number of epochs and the number of layers accordingly.\n\n## Neural Architecture Search Network (NASNet)\nNasnet is the state-of-the-art image classification architecture on ImageNet dataset (ArXiv release date is 21 Jul. 2017).\nFor details of nasnet, please refer to paper Learning Transferable Architectures for Scalable Image Recognition by Barret Zoph, etc.\n\n### Example of a NASNet Model\n\n\n## OpenCV Face Recognizers\nOpenCV has three built in face recognizers. The names of those face recognizers and their function calls have been given below-\n\ni. EigenFaces Face Recognizer Recognizer - cv2.face.createEigenFaceRecognizer()\n\nii. FisherFaces Face Recognizer Recognizer - cv2.face.createFisherFaceRecognizer()\n\niii. Local Binary Patterns Histograms (LBPH) Face Recognizer - cv2.face.createLBPHFaceRecognizer()\n\n\n### Dependencies:\n* pytorch version **1.2.0** (get from https://pytorch.org/)\n\n\nDownload haarcascades file from here=> https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml\n\n## ScreenShots\n\n\n\n\n\n\n\n## Quick Start\n\n- Fork and Clone the repository using-\n```\ngit clone https://github.com/akshitagupta15june/Face-X.git\n```\n- Create virtual environment-\n```\n- `python -m venv env`\n- `source env/bin/activate` (Linux)\n- `env\\Scripts\\activate` (Windows)\n```\n- Install dependencies-\n```\n pip install -r requirements.txt\n```\n\n- Headover to Project Directory- \n```\ncd \"Recognition using NasNet\"\n```\n- Create dataset using -\n```\n python create_dataset.py on respective idle(VS Code, PyCharm, Jupiter Notebook, Colab)\n```\nNote: Dataset is automatically split into train and val folders.\n\n- Train the model -\n```\n python main.py\n```\nNote: Make sure all dependencies are installed properly.\n\n- Final-output -\n```\n python output.py\n```\nNote: Make sure you have haarcascade_frontalface_default.xml file "
},
{
"alpha_fraction": 0.7695772647857666,
"alphanum_fraction": 0.7778933048248291,
"avg_line_length": 60.40425491333008,
"blob_id": "f8c45ad70f8e7a7720a7e9c14aa5e902a0b5f20b",
"content_id": "9902980f9f58fb16063d03f1494718f65990ee63",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2886,
"license_type": "permissive",
"max_line_length": 466,
"num_lines": 47,
"path": "/Recognition-Algorithms/Ensemble_facial_recognition/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Facial Recongtion using Ensemble Learning.\n\n## What is deepface?\nDeepface is a lightweight face recognition and facial attribute analysis (age, gender, emotion and race) framework for python. It is a hybrid face recognition framework wrapping state-of-the-art models: VGG-Face, Google FaceNet, OpenFace, Facebook DeepFace, DeepID, ArcFace and Dlib. The library is mainly based on Keras and TensorFlow.\n\nDeepface also offers facial attribute analysis including age, gender, facial expression (including angry, fear, neutral, sad, disgust, happy and surprise) and race (including asian, white, middle eastern, indian, latino and black) predictions. Analysis function under the DeepFace interface is used to find demography of a face.\n\n## First we have to install the deepface library.\nThe easiest way to install deepface is to download it from [`PyPI`].\n```\npip install deepface\n```\n## Secondly we should install the dependencies.\n```\npip install tensorflow==2.4.1\npip install keras==2.4.3\n```\n## Face Recognition\n\nA modern face recognition pipeline consists of 4 common stages: detect, align, represent and verify. Deepface handles all these common stages in the background. You can just call its verification, find or analysis function in its interface with a single line of code.\n\nFace Verification - [`Demo`]\n\nVerification function under the deepface interface offers to verify face pairs as same person or different persons. You should pass face pairs as array instead of calling verify function in a for loop for the best practice. This will speed the function up dramatically and reduce the allocated memory.\n\nthis is the sample code we can use to verify diiferent faces\n```\nfrom deepface import DeepFace\nresult = DeepFace.verify(\"img1.jpg\", \"img2.jpg\")\n#results = DeepFace.verify([['img1.jpg', 'img2.jpg'], ['img1.jpg', 'img3.jpg']])\nprint(\"Is verified: \", result[\"verified\"])\n```\n## Ensemble learning for face recognition \n\nA face recognition task can be handled by several models and similarity metrics. Herein, deepface offers a special boosting and combination solution to improve the accuracy of a face recognition task. This provides a huge improvement on accuracy metrics. Human beings could have 97.53% score for face recognition tasks whereas this ensemble method passes the human level accuracy and gets 98.57% accuracy. On the other hand, this runs much slower than single models.\n\nFor comparing two photos we can also use this code.\n```\nobj=DeepFace.verify(\"Dataset\\steve1.jpg\",\"Dataset\\steve2.jfif\" , model_name=\"Ensemble\") \n```\nHere we insert two photos and use the ensemble model.\n\n## For checking whether a given face is in a database.\n```\ndf= DeepFace.find(img_path=\"Database\\mark1.jpg\",db_path=\"Database\",model_name=\"Ensemble\")\n```\nwhere img_path is the image you want to find resemblance, db_path is the database folder and model_name is the ensemble model.\n"
},
{
"alpha_fraction": 0.734277606010437,
"alphanum_fraction": 0.7439093589782715,
"avg_line_length": 37.369564056396484,
"blob_id": "72c4b27f333024366fa523155b9078ea5bcf1d47",
"content_id": "cfbeca3d856b0a80723790c54e7755f9d5048812",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1773,
"license_type": "permissive",
"max_line_length": 189,
"num_lines": 46,
"path": "/Realtime-liveness-recognition-system/README.MD",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Real time liveness based face recognition system:\n\n## About:\nCreate a liveness detector capable of spotting fake faces and performing anti-face spoofing in face recognition systems.\n\n## Workflow:\n\n1. Build the image dataset itself.\n2. Implement a CNN capable of performing liveness detector (we’ll call this network “LivenessNet”).\n3. Train the liveness detector network.\n4. Create a Python + OpenCV script capable of taking our trained livenes detector model and apply it to real-time video.\n\n\n## What does each script do?!:\n\n1. `gather_examples.py` : This script grabs face ROIs from input video files and helps us to create a deep learning face liveness dataset.\n \n2. `train.py` : As the filename indicates, this script will train our LivenessNet classifier. We’ll use Keras and TensorFlow to train the model. The training process results in a few files:\n\n i. `le.pickle`: Our class label encoder.\n \n ii. `liveness.model`: Our serialized Keras model which detects face liveness.\n \n iii. `plot.png`: The training history plot shows accuracy and loss curves so we can assess our model (i.e. over/underfitting).\n\n3. `liveness_demo.py`: Our demonstration script will fire up your webcam to grab frames to conduct face liveness detection in real-time.\n\n## Dependencies:\n\n* Python 3, [OpenCV](https://opencv.org/), [Tensorflow](https://www.tensorflow.org/)\n\n\n## Graph:\n\n\n#### A plot of training a face liveness model using OpenCV, Keras and deep learning\n\n## Output:\n\n\n\n\n\n## Credits:\n\nTo read a more detailed version of this for better understanding, read[PyImageSearch](https://www.pyimagesearch.com/2019/03/11/liveness-detection-with-opencv/)\n"
},
{
"alpha_fraction": 0.6389432549476624,
"alphanum_fraction": 0.6682974696159363,
"avg_line_length": 23.33333396911621,
"blob_id": "e540519baf31306d21edcdf3f211a534a923cf87",
"content_id": "e5273a44a3a9a3aac98c6ce3319e040b49772aca",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1022,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 42,
"path": "/Face Reconstruction/3D Face Reconstruction with Weakly-Supervised Learning/detect_landmarks_in_image.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "from preprocess.mtcnn import MTCNN\nfrom torch.utils.data import DataLoader\nfrom torchvision import datasets, transforms\nimport torch\nimport os\n\n\ndef collate_pil(x):\n out_x, out_y = [], []\n for xx, yy in x:\n out_x.append(xx)\n out_y.append(yy)\n return out_x, out_y\n\n\nbatch_size = 1\nworkers = 0 if os.name == 'nt' else 8\ndataset_dir = r'facebank'\ncropped_dataset = r'dataset'\ndevice = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')\n\nmtcnn = MTCNN(\n image_size=(300, 300), margin=20, min_face_size=20,\n thresholds=[0.6, 0.7, 0.7], factor=0.709, post_process=True,\n device=device\n)\n\ndataset = datasets.ImageFolder(\n dataset_dir, transform=transforms.Resize((512, 512)))\ndataset.samples = [\n (p, p.replace(dataset_dir, cropped_dataset))\n for p, _ in dataset.samples\n]\nloader = DataLoader(\n dataset,\n num_workers=workers,\n batch_size=batch_size,\n collate_fn=collate_pil\n)\n\nfor i, (x, y) in enumerate(loader):\n x = mtcnn(x, save_path=y, save_landmarks=True)\n"
},
{
"alpha_fraction": 0.746846079826355,
"alphanum_fraction": 0.7510513067245483,
"avg_line_length": 36.15625,
"blob_id": "910739ea951b4c2e73d0dac67a6f10aa4d6d0975",
"content_id": "f947a108a77c427d0fe34a7541aef24b0f10138d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1189,
"license_type": "permissive",
"max_line_length": 305,
"num_lines": 32,
"path": "/Face-Detection/Face detection using dlib hog/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "## FACE DETECTION USING DLIB HOG\nDlib is a toolkit for making real world machine learning and data analysis applications in C++. It is widely used for image processing, computer vision etc. Though it is originally written in C++ it can be easily used in python.\nHOG is short for Histogram of oriented gradients. The detector is based on HOG and Linear SVM.\nHOG is a simple and powerful feature descriptor. It is not only used for face detection but also it is widely used for object detection like cars, pets, and fruits. HOG is robust for object detection because object shape is characterized using the local intensity gradient distribution and edge direction.\n\n\n### Step1: The basic idea of HOG is dividing the image into small connected cells\n\n### Step2: Computes histogram for each cell. \n\n### Step3: Bring all histograms together to form feature vector i.e., it forms one histogram from all small histograms which is unique for each face\n\nMake sure to install necessary libraries \n```\n pip3 install opencv-python\n```\n```\n pip install dlib\n```\n\n### Run the program\n```\n python face_det.py\n```\n\n## The input image is :\n\n\n\n## The output\n\n\n"
},
{
"alpha_fraction": 0.7488158345222473,
"alphanum_fraction": 0.7582893371582031,
"avg_line_length": 33.69013977050781,
"blob_id": "f897a84f7b4e869a1d1297626e5fb715e8f92f70",
"content_id": "6a54cea0e066b8c7381bb58fbfc3b82ad0c16eba",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 7389,
"license_type": "permissive",
"max_line_length": 464,
"num_lines": 213,
"path": "/Recognition-Algorithms/Recognition using PCA/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Eigen Faces\nThe following is a Demonstration of Principal Component Analysis, dimensional reduction. The following has been developed in python2.7 however can be run on machines which use Python3, by using a python virtual environment\n\nThis project is based on the following paper:- \n[Face recognition using eigenfaces by Matthew A. Turk and Alex P. Pentland](https://ieeexplore.ieee.org/document/139758)\n\nDataset courtesy - http://vis-www.cs.umass.edu/lfw/\n\n### Development\nThe following can be best developed using `pipenv`. If you do not have `pipen`, simply run the following command (using pip3 or pip based on your version of Python)\n```\npip install pipenv\n```\n\nThen clone the following repository\n```\ngit clone https://github.com/sahitpj/EigenFaces\n```\n\nThen change the following working directory and then run the following commands\n\n```\npipenv install --dev\n```\n\nThis should have installed all the necessary dependencies for the project. If the pipenv shell doesn't start running after this, simply run the following command\n\n```\npipenv shell\n```\n\nNow in order to run the main program run the following command\n\n```\npipenv run python main.py\n```\n\nMake sure to use python and not python3 because the following pip environment is of Python2.7. Any changes which are to be made, are to documented and make sure to lock dependencies if dependencies have been changed during the process.\n\n```\npipenv lock\n```\n\nThe detailed report about this, can be viewd [here](REPORT.md)\nor can be found at https://sahitpj.github.io/EigenFaces\n\nIf you like this repository and find it useful, please consider ★ starring it :)\n\nproject repo link - https://github.com/sahitpj/EigenFaces\n\n\n# Principal Component Analysis \n\nFace Recognition using Eigen Faces - Matthew A. Turk and Alex P. Pentland \n\n## Abstract \n\nIn this project I would like to demonstarte the use of Principal Component Analysis, a method of dimensional reduction in order to help us create a model for Facial Recognition. The idea is to project faces onto a feature space which best encodes them, these features spaces mathematically correspond to the eigen vector space of these vectors.\n\nWe then use the following projections along with Machine Learning techniques to build a Facial Recognizer.\n\nWe will be using Python to help us develop this model.\n\n## Introduction \n\nFace Structures are 2D images, which can be represented as a 3D matrix, and can be reduced to a 2D space, by converting it to a greyscale image. Since human faces have a huge amount of variations in extremely small detail shifts, it can be tough to identify to minute differences in order to distinguish people two people's faces. Thus in order to be sure that a machine learning can acquire the best accuracy, the whole of the face must be used as a feature set. \n\nThus in order to develop a Facial Recognition model which is fast, reasonably simple and is quite accurate, a method of pattern Recognition is necessary.\n\nThus the main idea is to transform these images, into features images, which we shall call as **Eigen Faces** upon which we apply our learning techniques.\n\n## Eigen Faces\n\nIn order to find the necessary **Eigen Faces** it would be necessary to capture the vriation of the features in the face without and using this to encode our faces.\n\nThus mathematically we wish to find the principal components of the distribution. However rather than taking all of the possible Eigen Faces, we choose the best faces. why? computationally better.\n\nThus our images, can be represented as a linear combination of our selected eigen faces. \n\n## Developing the Model \n\n### Initialization\n\nFor the followoing we first need a dataset. We use `sklearn` for this, and use the following `lfw_people` dataset. Firstly we import the `sklearn` library\n\n\n```\nfrom sklearn.datasets import fetch_lfw_people\n```\n\nThe following datset contains images of people\n\n```\nno_of_sample, height, width = lfw_people.images.shape\ndata = lfw_people.data\nlabels = lfw_people.target\n```\n\nWe then import the plt function in matplotlib to plot our images\n\n```\nimport matplotlib.pyplot as plt\n\nplt.imshow(image_data[30, :, :]) #30 is the image number\nplt.show()\n```\n\n\n\n```\nplt.imshow(image_data[2, :, :]) \nplt.show()\n```\n\n\n\nWe now understand see our labels, which come out of the form as number, each number referring to a specific person.\n\n```\njayakrishnasahit@Jayakrishna-Sahit in ~/Documents/Github/Eigenfaces on master [!?]$ python main.py\nthese are the label [5 6 3 ..., 5 3 5]\ntarget labels ['Ariel Sharon' 'Colin Powell' 'Donald Rumsfeld' 'George W Bush'\n 'Gerhard Schroeder' 'Hugo Chavez' 'Tony Blair']\n```\n\nWe now find the number of samples and the image dimensions\n\n```\noem@Meha in ~/Documents/Github/Eigenfaces on master [!?]$ python main.py\nnumber of images 1288\nimage height and width 50 37\n```\n\n### Applying Principal Component Analysis\n\nNow that we have our data matrix, we now apply the Principal Component Analysis method to obtain our Eigen Face vectors. In order to do so we first need to find our eigen vectors. \n\n1. First we normalize our matrix, with respect to each feature. For this we use the sklearn normalize function. This subtracts the meam from the data and divides it by the variance\n\n```\nfrom sklearn.preprocessing import normalize\n\nsk_norm = normalize(data, axis=0)\n```\n\n\n2. Now that we have our data normalized we can now apply PCA. Firstly we compute the covariance matrix, which is given by \n\n```\nCov = 1/m(X'X)\n```\n\nwhere m is the number of samples, X is the feature matrix and X' is the transpose of the feature matrix. We now perform this with the help of the numpy module.\n\n```\nimport numpy as np \n\ncov_matrix = matrix.T.dot(matrix)/(matrix.shape[0])\n```\nthe covariance matirx has dimensions of nxn, where n is the number of features of the original feature matrix.\n\n3. Now we simply have to find the eigen vectors of this matrix. This can be done using the followoing\n\n```\nvalues, vectors = np.linalg.eig(cov_matrix)\n```\n\nThe Eigen vectors form the Eigen Face Space and when visualised look something like this.\n\n\n\n\n\nNow that we have our Eigen vector space, we choose the top k number of eigen vectors. which will form our projection space. \n\n```\npca_vectors = vectors[:, :red_dim]\n```\n\nNow in order to get our new features which have been projected on our new eigen space, we do the following\n\n```\npca_vectors = matrix.dot(eigen_faces) \n```\n\nWe now have our PCA space ready to be used for Face Recognition\n\n### Applying Facial Recognition\n\nOnce we have our feature set, we now have a classification problem at our hands. In this model I will be developing a K Nearest Neighbour model (Disclaimer! - This may not be the best model to use for this dataset, the idea is to understand how to implement it)\n\nUsing out sklearn library we split our data into train and test and then apply our training data for the Classifier. \n\n```\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.neighbors import KNeighborsClassifier\n\nX_train, X_test, y_train, y_test = train_test_split(pca_vectors, labels, random_state=42)\n\nknn = KNeighborsClassifier(n_neighbors=10)\nknn.fit(X_train, y_train)\n```\n\nAnd we then use the trained model on the test data\n\n```\nprint 'accuracy', knn.score(X_test, y_test)\n```\n\n```\noem@Meha in ~/Documents/Github/Eigenfaces on master [!?]$ python main.py\naccuracy 0.636645962733\n```\n"
},
{
"alpha_fraction": 0.7284482717514038,
"alphanum_fraction": 0.7586206793785095,
"avg_line_length": 32.28571319580078,
"blob_id": "a0d11b77c506bc3bfd84f28705be521050cdbd72",
"content_id": "3363c4282b36d50b012f69bd58f79d0892dbd137",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 232,
"license_type": "permissive",
"max_line_length": 130,
"num_lines": 7,
"path": "/Face Reconstruction/Face Alignment in Full Pose Range/visualize/readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "`image00427.mat` is generated by `visualize.py` in root directory. `render_demo.m` is a simple matlab demo to render 3D face mesh.\n\n`tri.mat` provides the 3D mesh triangle indices.\n\nThe rendered result:\n\n"
},
{
"alpha_fraction": 0.664237380027771,
"alphanum_fraction": 0.7704320549964905,
"avg_line_length": 28.953125,
"blob_id": "1ec38065d168e652c72555d1ad50e73d6a0ff634",
"content_id": "8b4bd6a174b5f6d1a7f39082c944612e25a34e70",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1923,
"license_type": "permissive",
"max_line_length": 439,
"num_lines": 64,
"path": "/Awesome-face-operations/Real_Time_Age_prediction/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Real-Time-Age Predictor\n## Table of content\n\n- Introduction\n- Model Architecture\n- Dataset\n- Outputs\n- Dependencies\n- Running Procedure\n# Introduction\n\n\n\nAge detection is the process of automatically discerning the age of a person solely from a photo of their face.\nTypically, you’ll see age detection implemented as a two-stage process:\n\n\n\n__Stage #1__ Detect faces in the input image/video stream\n\n\n__Stage #2__ Extract the face Region of Interest (ROI), and apply the age detector algorithm to predict the age of the person\n\n## Model Architecture\n\n\n\n## Dataset\n\n\nUTKFace dataset is a large-scale face dataset with long age span (range from 0 to 116 years old). The dataset consists of over 20,000 face images with annotations of age, gender, and ethnicity. The images cover large variation in pose, facial expression, illumination, occlusion, resolution, etc. This dataset could be used on a variety of tasks, e.g., face detection, age estimation, age progression/regression, landmark localization, etc\n\n\n__Link to dataset :__ https://susanqq.github.io/UTKFace/\n\n\n\n## Outputs\nReal Age = 35\n\n\n\n\n\n\nReal Age = 85 \n\n\n\n\n\n## Dependencies\n- tensorflow 2.4.1\n- openCV\n- Numpy\n- OS\n- Matplotlib\n\n\n## Running Procedure\n- Clone the Repository \n- Open your notebook\n- check paths for the test data\n- Enjoy the experience \n\n\n\n"
},
{
"alpha_fraction": 0.6508108377456665,
"alphanum_fraction": 0.685405433177948,
"avg_line_length": 21.439023971557617,
"blob_id": "9b5587ee0c8eea8de378a3116978dfccb0161e5f",
"content_id": "ad284229f60de3b99464549917565a4dcd0ddbc5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 925,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 41,
"path": "/Face-Detection/Face detection using dlib hog/face_det.py",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\nimport dlib\nimport cv2\n\n#step1: read the image\nimage = cv2.imread(\"grp_1.jpg\")\nimage = cv2.resize(image, (600, 600)) \n\n\n#step2: converts to gray image\ngray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)\n\n#step3: get HOG face detector and faces\nhogFaceDetector = dlib.get_frontal_face_detector()\nfaces = hogFaceDetector(gray, 1)\n\n#step4: loop through each face and draw a rect around it\nfor (i, rect) in enumerate(faces):\n x = rect.left()\n y = rect.top()\n w = rect.right() - x\n h = rect.bottom() - y\n #draw a rectangle\n cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 4)\n \n#step5: display the resulted image\ncv2.imshow(\"Image\", image)\ncv2.waitKey(0)\n\n\n\n\n'''\n%matplotlib inline\n#The line above is necesary to show Matplotlib's plots inside a Jupyter Notebook\nfrom matplotlib import pyplot as plt\n\n\n#Show the image with matplotlib\nplt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))\nplt.show()\n'''\n\n\n\n\n"
},
{
"alpha_fraction": 0.7074546217918396,
"alphanum_fraction": 0.7670426964759827,
"avg_line_length": 75.92453002929688,
"blob_id": "650ac98d5a53378287f8a571f8d7fc5020179d53",
"content_id": "9ff2af7afc6eb28aa4e0b272970b50c96edddab3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4108,
"license_type": "permissive",
"max_line_length": 342,
"num_lines": 53,
"path": "/Recognition-using-IOT/Tracking using python and arduino/README.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "\n## About:🤔💭\nFace tracking using python and arduino. An Arduino UNO is programmed using python language which makes the camera moves in the direction of face present.\n\n### List TO-DO📄:\n\n- [x] Get the [hardware.](https://github.com/smriti1313/Face-X/blob/master/Tracking%20using%20python%20and%20arduino/README.md#requirements)\n- [x] Install [Python](https://www.howtogeek.com/197947/how-to-install-python-on-windows/)\n- [x] Install [Dependencies.](https://github.com/smriti1313/Face-X/blob/master/Tracking%20using%20python%20and%20arduino/README.md#dependencies)\n- [x] Make a folder and name it anything(or you can see [quick start](https://github.com/smriti1313/Face-X/blob/master/Tracking%20using%20python%20and%20arduino/README.md#quick-start))\n - [x] Download [Haarcascade](https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml) and paste it here\n - [x] Open notepad,write [this](https://github.com/smriti1313/Face-X/blob/master/Tracking%20using%20python%20and%20arduino/face.py) script and save it as 'face.py'.\n - [x] Paste [arduino code](https://github.com/smriti1313/Face-X/blob/master/Tracking%20using%20python%20and%20arduino/servo.ino) in [Arduino IDE](https://www.arduino.cc/en/guide/windows) and save it as 'servo.ino'.\n- [x] Assemble [rotation platform](https://www.learnrobotics.org/blog/how-to-assemble-pan-tilt-for-arduino-servos/)\n- [x] Make [connections.](https://github.com/smriti1313/Face-X/blob/master/Tracking%20using%20python%20and%20arduino/README.md#connections)\n- [x] [Test](https://github.com/smriti1313/Face-X/blob/master/Tracking%20using%20python%20and%20arduino/README.md#testing) the code.\n- [x] Fit the camera on rotation platform.\n- [x] Run the final project.\n\n### Requirements:🧱🧱\n\n|Hardware|Software|\n|----|-----|\n|[Arduino UNO](https://www.banggood.in/Wholesale-Geekcreit-UNO-R3-ATmega16U2-AVR-USB-Development-Main-Board-Geekcreit-for-Arduino-products-that-work-with-official-Arduino-boards-p-68537.html?akmClientCountry=IN&p=1L111111347088201706&cur_warehouse=CN)|[Python 2.7 or newer](https://www.howtogeek.com/197947/how-to-install-python-on-windows/)|\n|Web Cam or phone camera|[Haarcascade](https://github.com/opencv/opencv/blob/master/data/haarcascades/haarcascade_frontalface_default.xml)|\n|[2 x 9g servos](https://www.banggood.in/6PCS-SG92R-Micro-Digital-Servo-9g-2_5kg-For-RC-Airplane-p-1164389.html?p=1L111111347088201706&custlinkid=796242&cur_warehouse=CN)||\n|[Breadboard](https://www.banggood.in/Geekcreit-MB-102-MB102-Solderless-Breadboard-+-Power-Supply-+-Jumper-Cable-Kits-p-933600.html?cur_warehouse=CN&rmmds=search)||\n|[Servo Pan Tilt Kit](https://www.banggood.in/Two-DOF-Robot-PTZ-FPV-Dedicated-Nylon-PTZ-Kit-With-Two-9G-Precision-160-Degree-Servo-p-1063479.html?p=1L111111347088201706&cur_warehouse=CN)||\n\n\n### Dependencies🔧🛠:\nOpen terminal and write:\n* `pip install numpy`\n* `pip install serial`\n* `pip install opencv-python`\n\n\n## Quick Start📘\nYou can directly [download](https://www.wikihow.com/Download-a-GitHub-Folder) the entire [Face-X](https://github.com/akshitagupta15june/Face-X) and select the folder you want. All you have to do is now assemble hardware part.\n\n\n## Connections🔗:\n\n\n\n\n## Testing🧰:\n\n- After everything is done last thing to do is test if it works. \n- To test first make sure that servos are properly connected to arduino and sketch is uploaded.\n- After sketch is uploaded make sure to close the IDE so the port is free to connect to python.\n- Now open 'face.py' with Python IDLE and press 'F5' to run the code. It will take a few seconds to connect to arduino and then you should be able to see it working.\n- The camera will move in the same direction as of the face since the code is trying to detect a face in the environment.\n>For better understanding watch [this](https://www.youtube.com/watch?v=O3_C-R7Jrvo)\n"
},
{
"alpha_fraction": 0.7672551870346069,
"alphanum_fraction": 0.7800962924957275,
"avg_line_length": 73.76000213623047,
"blob_id": "a52bdcf82dcc9a82b015aff1b5709c54162867a5",
"content_id": "f0ac3ee18df4570f8b70468f943cac1cca249bd7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1869,
"license_type": "permissive",
"max_line_length": 432,
"num_lines": 25,
"path": "/Face-Mask-Detection/face-mask-detection-vgg16/Readme.md",
"repo_name": "KKhushhalR2405/Face-X",
"src_encoding": "UTF-8",
"text": "# Face Mask Detection Using VGG16 Architecture\n\n## Introduction\n\n\n\nDue to this Covid-19 pandemic, the masks became lifesavers. Nowadays, in most places, masks are compulsory. So, we can take the compulsion as a problem statement for our **computer vision** project.\n\nIn this problem statement, we are trying to classify the images of the person in two classes **with a mask** and **without a mask**. So, to solve this classification problem we will use **Supervised Machine Learning** techniques.\n\n## Dataset\n\n\n\nFor the supervised machine learning problem, we will require labeled good quality data and here kaggle comes into the picture. [Kaggle](https://kaggle.com) is a platform where Data Scientists play with the various datasets and provide some good quality datasets.\n\nThe dataset that we are going to use in this project is also from kaggle named [Face Mask ~12K Images Dataset](https://www.kaggle.com/ashishjangra27/face-mask-12k-images-dataset).\n\n## VGG16 architecture\n\n\n\nIn our problem statement, we are dealing with images. We need to use the [**Convolutional Neural Network (CNN)**](https://en.wikipedia.org/wiki/Convolutional_neural_network) to train the image classification model. CNN contains many convolutional layers and many kernels for each layer. Values of these kernels changes to get the best possible prediction.\n\n[VGG16 Architecture](https://neurohive.io/en/popular-networks/vgg16/) is a winner of the 2014 Imagenet competition which means it is already trained on thousands of images and it has a good set of kernels. So, that's why we are going to use the VGG16 architecture to train our model with a good set kernel. Using weights of other pre-trained models for training new models on the new dataset is the concept of **Transfer Learning**.\n"
}
] | 251 |
gracez72/sleepAppBackend
|
https://github.com/gracez72/sleepAppBackend
|
ee3ea224fcdbbf5755a8a0a0cfb1fb86f601d9f8
|
bf0cffd77e0b745a625033134267b56e40595875
|
301db09786cd88e42b0b45a1f16d7d609f9695d0
|
refs/heads/master
| 2022-12-11T18:58:56.839041 | 2019-04-24T22:53:20 | 2019-04-24T22:53:20 | 177,882,214 | 0 | 0 | null | 2019-03-26T23:10:18 | 2019-04-24T22:53:22 | 2022-12-08T01:43:02 |
JavaScript
|
[
{
"alpha_fraction": 0.7904483675956726,
"alphanum_fraction": 0.7904483675956726,
"avg_line_length": 41.79166793823242,
"blob_id": "9db23ce315cb324dfef8b5a892ec462191de2e34",
"content_id": "4fa993a739319a418024efc9ebed41f5d9b17f8a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1026,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 24,
"path": "/sleepsite/urls.py",
"repo_name": "gracez72/sleepAppBackend",
"src_encoding": "UTF-8",
"text": "from django.urls import path, include\nfrom rest_framework.routers import DefaultRouter\nfrom rest_framework.urlpatterns import format_suffix_patterns\nfrom sleepsite import views\nfrom django.conf.urls import url\nfrom django.conf.urls.static import static\nfrom django.conf import settings\n\nrouter = DefaultRouter()\nrouter.register(r'alarms', views.AlarmViewSet)\nrouter.register(r'sleepdata', views.SleepDataViewSet)\nrouter.register(r'events', views.EventViewSet)\nrouter.register(r'songs', views.SongViewSet)\nrouter.register(r'query-summary', views.SummaryViewSet, base_name='summary')\nrouter.register(r'compute', views.ComputationViewSet, base_name='compute')\nrouter.register(r\"song-summary\", views.SongSummaryViewSet, base_name='song-summary')\nrouter.register(r\"profile\", views.ProfileViewSet)\nrouter.register(r\"users\", views.UserViewSet)\n\nurlpatterns = [\n path('', include(router.urls)),\n path('', views.api_root),\n path('summary/', views.summary_view)\n] + static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)"
},
{
"alpha_fraction": 0.5027777552604675,
"alphanum_fraction": 0.5291666388511658,
"avg_line_length": 27.799999237060547,
"blob_id": "3efdd0408ca15aba1f7c1b298f58a88bf3cae03a",
"content_id": "e13933b9976577cf46d1c3c1548f41a77cdf63ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 720,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 25,
"path": "/sleepsite/migrations/0009_event.py",
"repo_name": "gracez72/sleepAppBackend",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.1 on 2019-02-27 00:48\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('sleepsite', '0008_alarm_active'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Event',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('event_name', models.TextField(blank=True)),\n ('start_time', models.DateTimeField(auto_now_add=True)),\n ('end_time', models.DateTimeField()),\n ],\n options={\n 'ordering': ('start_time',),\n },\n ),\n ]\n"
},
{
"alpha_fraction": 0.5649635195732117,
"alphanum_fraction": 0.6131386756896973,
"avg_line_length": 27.54166603088379,
"blob_id": "0a6c5bbd2138cf8dfb8292ec7296efece48b803c",
"content_id": "ffdd5ea7dd87648d80154f9d7f905e4ae1ee2e41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 685,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 24,
"path": "/sleepsite/migrations/0006_auto_20190215_1316.py",
"repo_name": "gracez72/sleepAppBackend",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.1 on 2019-02-15 21:16\n\nfrom django.db import migrations, models\nimport uuid\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('sleepsite', '0005_auto_20190215_1312'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='alarm',\n name='id',\n field=models.UUIDField(default=uuid.uuid4, editable=False, primary_key=True, serialize=False, unique=True),\n ),\n migrations.AlterField(\n model_name='sleepdata',\n name='id',\n field=models.UUIDField(default=uuid.uuid4, editable=False, primary_key=True, serialize=False, unique=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6089030504226685,
"alphanum_fraction": 0.6271860003471375,
"avg_line_length": 33.94444274902344,
"blob_id": "a1886450fcecc53f8fe5eff480690fc4269af20c",
"content_id": "0c773823a32cc8228ebee05168e9f236681432cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1258,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 36,
"path": "/sleepsite/migrations/0016_auto_20190328_1551.py",
"repo_name": "gracez72/sleepAppBackend",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.1 on 2019-03-28 22:51\n\nfrom django.conf import settings\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n migrations.swappable_dependency(settings.AUTH_USER_MODEL),\n ('sleepsite', '0015_profile_image'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='alarm',\n name='username',\n field=models.ForeignKey(default=1, on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL),\n ),\n migrations.AddField(\n model_name='event',\n name='username',\n field=models.ForeignKey(default=1, on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL),\n ),\n migrations.AddField(\n model_name='sleepdata',\n name='username',\n field=models.ForeignKey(default=1, on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL),\n ),\n migrations.AddField(\n model_name='song',\n name='username',\n field=models.ForeignKey(default=1, on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL),\n ),\n ]\n"
},
{
"alpha_fraction": 0.4952561557292938,
"alphanum_fraction": 0.5540797114372253,
"avg_line_length": 21.913043975830078,
"blob_id": "3e4f1721560b1ede9e26e8cb3beb705f7aa93bd0",
"content_id": "e6752b1fa70a4203b3c4b8bff0c942c6642cb7f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 527,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 23,
"path": "/sleepsite/migrations/0011_auto_20190226_1654.py",
"repo_name": "gracez72/sleepAppBackend",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.1 on 2019-02-27 00:54\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('sleepsite', '0010_auto_20190226_1653'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='event',\n name='end_time',\n field=models.DateTimeField(),\n ),\n migrations.AlterField(\n model_name='event',\n name='start_time',\n field=models.DateTimeField(),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5913263559341431,
"alphanum_fraction": 0.6031972169876099,
"avg_line_length": 33.91160202026367,
"blob_id": "9f3e1530f8b4ce5d356892265600b1e430a5b0de",
"content_id": "9c673353b9b2dda5b5b41b1b8cf10d17815c3d1b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6318,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 181,
"path": "/sleepsite/computation.py",
"repo_name": "gracez72/sleepAppBackend",
"src_encoding": "UTF-8",
"text": "from scipy.signal import find_peaks\nimport numpy as np\nfrom django.db.models import Count, Min, Max, Avg, Sum\n\n\ndef get_peaks(data, threshold):\n \"\"\" \n Given array of sleep data return number of local maxima over given height \n \"\"\"\n peaks, _ = find_peaks(data, height=threshold)\n return peaks\n\ndef get_polyfit(data):\n \"\"\" \n Given array of sleep data perform linear degression for 1, 2, 3, 4, 5 degree function and \n return coefficients and degree of least error\n \"\"\"\n fit_error = list()\n result_coeff = list()\n\n if (len(data) < 3):\n return result_coeff, 0\n \n x_val = list(range(len(data)))\n\n ## Compute errors and grab coefficients for functions up to degree 5\n for i in range(3):\n result = np.polyfit(x_val, data, i+1, full=True)\n result_coeff.append(result[0]) # resulting coefficients\n if len(result[1]) > 0: # check error calculated\n fit_error.append(abs(result[1][0]))\n\n if (abs(result[1][0]) < 5): # prevent overfitting\n break \n else:\n fit_error.append(np.finfo(np.float64).max)\n\n # Find index of min element\n min_index = np.argmin(fit_error)\n ret_coeff = result_coeff[min_index]\n\n # convert back to native python type\n ret_coeff = list(map(lambda x : x.item(), ret_coeff))\n degree = len(ret_coeff) - 1\n\n return ret_coeff, degree\n\n\ndef bin(data, bin_list):\n \"\"\" \n Performs binning using given bin range.\n \"\"\"\n bin_counts = np.histogram(data, bins=bin_list)\n result = list(map(lambda x : x.item() , bin_counts[0]))\n\n return result\n\n\ndef getSummary(queryset):\n \"\"\"\n Computes averages, max, min for given queryset\n \"\"\"\n average_hr = queryset.aggregate(Avg('heart_rate'))\n max_hr = queryset.aggregate(Max('heart_rate'))\n min_hr = queryset.aggregate(Min('heart_rate'))\n\n average_ol = queryset.aggregate(Avg('oxygen_level'))\n max_ol = queryset.aggregate(Max('oxygen_level'))\n min_ol = queryset.aggregate(Min('oxygen_level'))\n\n return average_hr, max_hr, min_hr, average_ol, max_ol, min_ol\n\ndef getStats(queryset): \n \"\"\"\n Computes amount of hours for given queryset and returns percentages below threshold of 60\n \"\"\"\n if queryset is not None: \n max_date = queryset.aggregate(Max('date'))[\"date__max\"]\n min_date = queryset.aggregate(Min('date'))[\"date__min\"]\n delta = 0\n total_time = 0\n if None not in (max_date, min_date):\n delta = max_date - min_date\n total_time = delta.total_seconds() / 3600\n\n total_count = queryset.aggregate(Count('id'))['id__count']\n if (total_count <= 0):\n awake_percentage = 0\n below_threshold = 0\n above_threshold = 0\n between_threshold = 0\n else:\n awake_percentage = queryset.filter(heart_rate__gte = 60).aggregate(Count('id'))['id__count'] / total_count * 100\n below_threshold = queryset.filter(heart_rate__lt = 40).aggregate(Count('id'))['id__count'] / total_count \n above_threshold = queryset.filter(heart_rate__gt = 60).aggregate(Count('id'))['id__count'] / total_count\n between_threshold = queryset.filter(heart_rate__gte = 40, heart_rate__lte = 60).aggregate(Count('id'))['id__count'] / total_count\n\n return max_date, min_date, total_time, total_count, awake_percentage, below_threshold, above_threshold, between_threshold\n\n return None\n\n\ndef getBins(queryset):\n \"\"\"\n Produces bin counts for given queryset for display as bar graph\n \"\"\"\n data = list(queryset.values_list('heart_rate', flat=True))\n ol_data = list(queryset.values_list('oxygen_level', flat=True))\n\n # Heart rate binning: \n hr_bins_list = list(range(20, 95, 5))\n ol_bins_list = list(range(50, 105, 5))\n\n hr_bin_count = bin(data, hr_bins_list)\n ol_bin_count = bin(ol_data, ol_bins_list)\n\n return hr_bins_list, ol_bins_list, hr_bin_count, ol_bin_count\n\n\ndef getPeaks(queryset):\n \"\"\"\n Computes the number of local maxima and the ids of the sleepdata objects given queryset data\n \"\"\"\n data = list(queryset.values_list('heart_rate', flat=True))\n id_index = list(queryset.values_list('id', flat=True))\n \n peaks = list(map(lambda x : x.item() , get_peaks(data, 50)))\n num_peaks = len(peaks)\n sleepdata_index = list(map(lambda x : id_index[x], peaks))\n sleepdata_peaks = list(map(lambda x: x.strftime(\"%Y-%m-%d %H:%M:%S\"), list(queryset.filter(pk__in=sleepdata_index).values_list('date', flat=True))))\n\n # Compute polynomial func with regression\n coefficients, degree = get_polyfit(data)\n\n return id_index, peaks, num_peaks, sleepdata_index, sleepdata_peaks, degree, coefficients\n\n\ndef getFormattedBins(hr_bins_list, ol_bins_list, hr_bin_count, ol_bin_count):\n \"\"\"\n Returns formatted JSON bins list for recharts\n \"\"\"\n ol_bin = list()\n ol_bin = list(map(lambda x: {\"oxygen_bin\": x}, ol_bins_list))\n \n for i in range(len(ol_bin_count)):\n ol_bin[i]['oxygen_level'] = ol_bin_count[i]\n\n hr_bin = list()\n hr_bin = list(map(lambda x: {\"heart_rate_bin\": x}, hr_bins_list))\n \n for i in range(len(hr_bin_count)):\n hr_bin[i]['heart_rate'] = hr_bin_count[i]\n\n return ol_bin, hr_bin\n\ndef getFunctionPoints(coefficients, degree, length):\n \"\"\"\n Computes function points for display in graph given function\n Returns empty list if no function given\n \"\"\"\n \n results = list()\n if (len(coefficients) == 0 or length < 1):\n return results\n \n else: \n x = list(range(length))\n results = list(map(lambda x: {\"x\": x}, x))\n\n if (degree == 1):\n for i in range(len(results)):\n results[i]['y'] = coefficients[1] + coefficients[0] * x[i]\n elif (degree == 2):\n for i in range(len(results)):\n results[i]['y'] = coefficients[2] + (x[i] * coefficients[1]) + (x[i] * x[i] * coefficients[0])\n elif (degree == 3):\n for i in range(len(results)):\n results[i]['y'] = coefficients[3] + (coefficients[2] * x[i]) + (x[i] * x[i] * coefficients[1]) + (x[i] * x[i] * x[i] * coefficients[0]) \n else: \n return list()\n return results"
},
{
"alpha_fraction": 0.49103662371635437,
"alphanum_fraction": 0.5050662755966187,
"avg_line_length": 31.075000762939453,
"blob_id": "d1a964164a537fa1074c8c461e65b10e7c0a14d2",
"content_id": "3b893a72aef998fb0de7d59e56c45edb89a1ec10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1283,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 40,
"path": "/sleepsite/migrations/0001_initial.py",
"repo_name": "gracez72/sleepAppBackend",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.2 on 2019-02-08 23:36\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='Alarm',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('description', models.TextField()),\n ('created_on', models.DateTimeField(auto_now_add=True)),\n ('alarm_time', models.DateTimeField(unique=True)),\n ('spotify_id', models.CharField(max_length=255)),\n ('volume', models.IntegerField()),\n ],\n options={\n 'ordering': ('created_on',),\n },\n ),\n migrations.CreateModel(\n name='SleepData',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('oxygen_level', models.IntegerField()),\n ('date', models.DateTimeField()),\n ('blood_pressure', models.IntegerField()),\n ],\n options={\n 'ordering': ('date',),\n },\n ),\n ]\n"
},
{
"alpha_fraction": 0.6677067279815674,
"alphanum_fraction": 0.7176287174224854,
"avg_line_length": 32.73684310913086,
"blob_id": "834db034452edbf08af86fca7e1555ee0f448235",
"content_id": "2d3d58e3773aea35f3aed885fed504621e55d733",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 641,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 19,
"path": "/README.md",
"repo_name": "gracez72/sleepAppBackend",
"src_encoding": "UTF-8",
"text": "# **DEMO**\n\n[Android App Repo](https://github.com/ameliacasciola/sleepApp)\n\n##### HOME PAGE\n\n<img src=\"https://github.com/gracez72/sleepAppBackend/blob/master/demo/homepage_demo.gif\" width=\"200\" height=\"356\" />\n\n##### ALARMS LIST PAGE\n\n<img src=\"https://github.com/gracez72/sleepAppBackend/blob/master/demo/alarms_demo.gif\" width=\"200\" height=\"356\" />\n\n##### SAMPLE ALARM GAME\n\n<img src=\"https://github.com/gracez72/sleepAppBackend/blob/master/demo/sample_game.gif\" width=\"200\" height=\"356\" />\n\n##### SLEEP DATA TRENDS PAGE\n\n<img src=\"https://github.com/gracez72/sleepAppBackend/blob/master/demo/trends_demo.gif\" width=\"200\" height=\"356\" />\n"
},
{
"alpha_fraction": 0.48379629850387573,
"alphanum_fraction": 0.6990740895271301,
"avg_line_length": 15.615385055541992,
"blob_id": "30a0ab67ce03e7c5c05a91d2d6cf201dd831de2a",
"content_id": "7768f567f712b7bc6abe4ce15b21e07f3f834cbc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 432,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 26,
"path": "/requirements.txt",
"repo_name": "gracez72/sleepAppBackend",
"src_encoding": "UTF-8",
"text": "awsebcli==3.14.11\nbotocore==1.12.91\ncement==2.8.2\ncertifi==2018.11.29\nchardet==3.0.4\ncolorama==0.3.9\nDjango==2.1.1\ndjango-cors-headers==2.4.0\ndjangorestframework==3.9.1\ndocutils==0.14\nhttpie==1.0.2\nidna==2.7\njmespath==0.9.3\nnumpy==1.16.1\npathspec==0.5.5\nPillow==5.4.1\nPygments==2.3.1\npython-dateutil==2.8.0\npytz==2018.9\nPyYAML==3.13\nrequests==2.20.1\nscipy==1.2.1\nsemantic-version==2.5.0\nsix==1.11.0\ntermcolor==1.1.0\nurllib3==1.24.1\n"
},
{
"alpha_fraction": 0.5143266320228577,
"alphanum_fraction": 0.5472779273986816,
"avg_line_length": 23.928571701049805,
"blob_id": "8e708d257c87bfdc43d030484e836485a247e4ff",
"content_id": "504c5731831acff7f690a18af5ca02b05fc3d8de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 698,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 28,
"path": "/sleepsite/migrations/0002_auto_20190208_1544.py",
"repo_name": "gracez72/sleepAppBackend",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.2 on 2019-02-08 23:44\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('sleepsite', '0001_initial'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='alarm',\n name='description',\n field=models.TextField(blank=True),\n ),\n migrations.AlterField(\n model_name='alarm',\n name='spotify_id',\n field=models.CharField(default='', max_length=255),\n ),\n migrations.AlterField(\n model_name='alarm',\n name='volume',\n field=models.IntegerField(default=5),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5130260586738586,
"alphanum_fraction": 0.5571142435073853,
"avg_line_length": 21.68181800842285,
"blob_id": "945a3dd7e56ee8814b4dabd1c98d5c1b62eb9f35",
"content_id": "47873555d70f5a3f5faae2916a7eb67576ace5d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 499,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 22,
"path": "/sleepsite/migrations/0014_auto_20190328_1356.py",
"repo_name": "gracez72/sleepAppBackend",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.1 on 2019-03-28 20:56\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('sleepsite', '0013_profile'),\n ]\n\n operations = [\n migrations.RemoveField(\n model_name='profile',\n name='birth_date',\n ),\n migrations.AddField(\n model_name='profile',\n name='name',\n field=models.CharField(default='name', max_length=100),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7634408473968506,
"alphanum_fraction": 0.7634408473968506,
"avg_line_length": 17.600000381469727,
"blob_id": "c56b3b47e553e1a737e2e4dac9b36928554739f4",
"content_id": "4a1354752c2f5b25b34ac9c1ae9526036c1a79c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 93,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 5,
"path": "/sleepsite/apps.py",
"repo_name": "gracez72/sleepAppBackend",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass SleepsiteConfig(AppConfig):\n name = 'sleepsite'\n"
},
{
"alpha_fraction": 0.49197861552238464,
"alphanum_fraction": 0.5748662948608398,
"avg_line_length": 19.77777862548828,
"blob_id": "fd8464596f38640f8542e0dd7b8485aff2fccf87",
"content_id": "ee6129d61670a7b831c319775afe2b9481e085f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 374,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 18,
"path": "/sleepsite/migrations/0004_auto_20190214_1501.py",
"repo_name": "gracez72/sleepAppBackend",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.1 on 2019-02-14 23:01\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('sleepsite', '0003_auto_20190214_1308'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='alarm',\n old_name='spotify_id',\n new_name='youtube_link',\n ),\n ]\n"
},
{
"alpha_fraction": 0.4746621549129486,
"alphanum_fraction": 0.5270270109176636,
"avg_line_length": 24.7391300201416,
"blob_id": "c84b1269e8885375593b09ce1db137d19cd79928",
"content_id": "d874608db331e845b4ef5cc22d5f9bcabdf85ccd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 592,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 23,
"path": "/sleepsite/migrations/0012_song.py",
"repo_name": "gracez72/sleepAppBackend",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.1 on 2019-02-28 02:57\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('sleepsite', '0011_auto_20190226_1654'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Song',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('youtube_link', models.TextField()),\n ],\n options={\n 'ordering': ('youtube_link',),\n },\n ),\n ]\n"
},
{
"alpha_fraction": 0.7799479365348816,
"alphanum_fraction": 0.7799479365348816,
"avg_line_length": 27.44444465637207,
"blob_id": "4d2cedb29ae40e5d99c2d4f2c36bbf51155293ed",
"content_id": "87ead4c463ef57750a27b3769f5024b2890dbf20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 768,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 27,
"path": "/sleepsite/admin.py",
"repo_name": "gracez72/sleepAppBackend",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom django.contrib.auth.admin import UserAdmin as BaseUserAdmin\nfrom django.contrib.auth.models import User\n\n\nfrom .models import Alarm, SleepData, Event, Song, Profile\n# Define an inline admin descriptor for Profile model\n# which acts a bit like a singleton\nclass ProfileInline(admin.StackedInline):\n model = Profile\n can_delete = False\n verbose_name_plural = 'Profile'\n\n# Define a new User admin\nclass UserAdmin(BaseUserAdmin):\n inlines = (ProfileInline,)\n\n# Re-register UserAdmin\nadmin.site.unregister(User)\nadmin.site.register(User, UserAdmin)\n \n# Register your models here.\nadmin.site.register(Alarm)\nadmin.site.register(SleepData)\nadmin.site.register(Event)\nadmin.site.register(Song)\nadmin.site.register(Profile)\n"
},
{
"alpha_fraction": 0.6904761791229248,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 35.07143020629883,
"blob_id": "1b0edb40bf71f1b4100037d6c2eeb060fd4becfa",
"content_id": "0a3b504c4bc350afa67f4e845e9b9854087a3e78",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 504,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 14,
"path": "/sleepsite/tests.py",
"repo_name": "gracez72/sleepAppBackend",
"src_encoding": "UTF-8",
"text": "from django.test import TestCase\nfrom sleepsite.models import SleepData\nimport datetime\n\nclass SleepDataTestCase(TestCase):\n def setUp(self):\n SleepData.objects.create(oxygen_level=98, date=datetime.date.today(), heart_rate=67)\n SleepData.objects.create(oxygen_level=97, date=datetime.date.today(), heart_rate=78)\n\n def sleepdata_date(self):\n \"\"\"SleepData with specific date are identified\"\"\"\n\n sd1 = SleepData.objects.get(id=1)\n sd2 = SleepData.objects.get(id=2)"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5815789699554443,
"avg_line_length": 20.11111068725586,
"blob_id": "6ac7e00e34826d967ae183e152f982910f8da20d",
"content_id": "138f8a3bc497b62c8a7f3f325cdc08dde5fb0760",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 380,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 18,
"path": "/sleepsite/migrations/0003_auto_20190214_1308.py",
"repo_name": "gracez72/sleepAppBackend",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.1 on 2019-02-14 21:08\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('sleepsite', '0002_auto_20190208_1544'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='sleepdata',\n old_name='blood_pressure',\n new_name='heart_rate',\n ),\n ]\n"
},
{
"alpha_fraction": 0.5530399680137634,
"alphanum_fraction": 0.553241491317749,
"avg_line_length": 39.44565200805664,
"blob_id": "da363f0d53d4c8a2cbcf70b3d3f4aaa6253fcce3",
"content_id": "6c4b0d5451a0a4b24e38724e908d616c3ac32951",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14885,
"license_type": "no_license",
"max_line_length": 159,
"num_lines": 368,
"path": "/sleepsite/views.py",
"repo_name": "gracez72/sleepAppBackend",
"src_encoding": "UTF-8",
"text": "from rest_framework import viewsets\nfrom rest_framework.decorators import action\nfrom .models import Alarm, SleepData, Event, Song, Profile\nfrom .serializers import AlarmSerializer, SleepDataSerializer, EventSerializer, SongSerializer, ProfileSerializer, UserSerializer\nfrom django.db.models import Count, Min, Max, Avg, Sum\nfrom rest_framework.views import APIView\nfrom rest_framework.renderers import JSONRenderer\nfrom django.http import JsonResponse\nfrom django.contrib.auth.models import User\n\nimport datetime\nfrom numpy import polyfit \n\nfrom rest_framework.decorators import api_view, renderer_classes \nfrom rest_framework.response import Response \nfrom rest_framework import permissions\n\nimport json\nfrom django.core.serializers.json import DjangoJSONEncoder\n\nfrom sleepsite import computation\n\nclass UserViewSet(viewsets.ModelViewSet):\n queryset = User.objects.all()\n serializer_class = UserSerializer\n permission_classes = (permissions.AllowAny,) \n\nclass AlarmViewSet(viewsets.ModelViewSet):\n queryset = Alarm.objects.all()\n serializer_class = AlarmSerializer\n permission_classes = (permissions.AllowAny,) \n\n @action(detail=True)\n def js_time(self, request, pk=None):\n \"\"\"\n Returns datetimefield as js accepted time\n \"\"\"\n alarm = self.get_object()\n date = alarm.alarm_time.strftime(\"%Y-%m-%d %H:%M:%S\")\n return Response({\"time\": date})\n\n def get_queryset(self):\n \"\"\"\n Allows queryset to be filtered by alarms for given date\n \"\"\"\n queryset = Alarm.objects.all()\n query_date = self.request.query_params.get('date', None)\n query_user = self.request.query_params.get('username', None)\n\n if query_date is not None: \n date = datetime.datetime.strptime(query_date, '%Y-%m-%d').date()\n queryset = queryset.filter(alarm_time__year=date.year,\n alarm_time__month=date.month, \n alarm_time__day=date.day)\n return queryset \n elif query_user is not None:\n queryset = queryset.filter(username__username=query_user)\n return queryset \n\nclass EventViewSet(viewsets.ModelViewSet):\n queryset = Event.objects.all()\n serializer_class = EventSerializer\n permission_classes = (permissions.AllowAny,) \n\n def get_queryset(self):\n queryset = Event.objects.all()\n query_date = self.request.query_params.get('start_time', None)\n \n if query_date is not None: \n date = datetime.datetime.strptime(query_date, '%Y-%m-%d').date()\n queryset = queryset.filter(start_time__year=date.year,\n start_time__month=date.month, \n start_time__day=date.day)\n for obj in queryset:\n obj.date = obj.date.strftime(\"%Y-%m-%d %H:%M:%S\")\n\n return queryset\n\nclass SongViewSet(viewsets.ModelViewSet):\n queryset = Song.objects.all()\n serializer_class = SongSerializer\n permission_classes =(permissions.AllowAny,) \n\nclass ProfileViewSet(viewsets.ModelViewSet):\n queryset = Profile.objects.all()\n serializer_class = ProfileSerializer\n permission_classes = (permissions.AllowAny,) \n\n\nclass SleepDataViewSet(viewsets.ModelViewSet):\n permission_classes = (permissions.AllowAny,) \n queryset = SleepData.objects.all()\n serializer_class = SleepDataSerializer\n\n def get_queryset(self):\n \"\"\"\n Allows sleepdata to be filtered by given date or date range\n \"\"\"\n queryset = SleepData.objects.all()\n query_date = self.request.query_params.get('date', None)\n query_start_date = self.request.query_params.get('start_date', None)\n query_end_date = self.request.query_params.get('end_date', None)\n \n if query_date is not None: \n date = datetime.datetime.strptime(query_date, '%Y-%m-%d').date()\n queryset = queryset.filter(date__year=date.year,\n date__month=date.month, \n date__day=date.day)\n for obj in queryset:\n obj.date = obj.date.strftime(\"%Y-%m-%d %H:%M:%S\")\n\n return queryset\n\n if None not in (query_start_date, query_end_date):\n start_date = datetime.datetime.strptime(query_start_date, '%Y-%m-%d').date()\n end_date = datetime.datetime.strptime(query_end_date, '%Y-%m-%d').date()\n\n if start_date.year == end_date.year:\n queryset = queryset.filter(date__range=[start_date, end_date])\n\n for obj in queryset:\n obj.date = obj.date.strftime(\"%Y-%m-%d %H:%M:%S\") \n\n return queryset\n \n return queryset \n\nclass ComputationViewSet(viewsets.ViewSet):\n \"\"\"\n A view that returns computation results eg. approximate function, peaks, etc.\n \"\"\"\n\n def list(self, request, format=None):\n \"\"\"\n Given date or date range, returns: \n number of local maxima given data\n id of peak sleepdata objects\n list of sleepdata peak times\n degree of polynomial fit for data\n list of coefficients of polynomial fit function\n bin data for heartrate and oxygen level\n \"\"\"\n queryset = SleepData.objects.all()\n\n query_date = self.request.query_params.get('date', None) \n query_start_date = self.request.query_params.get('start_date', None)\n query_end_date = self.request.query_params.get('end_date', None)\n\n if query_date is not None: \n date = datetime.datetime.strptime(query_date, '%Y-%m-%d').date()\n queryset = queryset.filter(date__year=date.year,\n date__month=date.month, \n date__day=date.day)\n\n data = list(queryset.values_list('heart_rate', flat=True))\n ol_data = list(queryset.values_list('oxygen_level', flat=True))\n\n if len(data) > 0: \n\n # Heart rate binning: \n hr_bins_list, ol_bins_list, hr_bin_count, ol_bin_count = computation.getBins(queryset)\n id_index, peaks, num_peaks, sleepdata_index, sleepdata_peaks, degree, coefficients = computation.getPeaks(queryset)\n \n ol_bin, hr_bin = computation.getFormattedBins(hr_bins_list, ol_bins_list, hr_bin_count, ol_bin_count)\n results = computation.getFunctionPoints(coefficients, degree, len(data))\n\n if None not in (data):\n return JsonResponse({\n \"id_index\": id_index,\n \"peaks\": peaks,\n \"num_peaks\": num_peaks,\n \"sleepdata_id_index\": sleepdata_index,\n \"sleepdata_time\": sleepdata_peaks,\n \"degree\": degree,\n \"coefficients\" : coefficients,\n \"hr_bin_list\": hr_bins_list,\n \"ol_bin_list\": ol_bins_list,\n \"hr_bin_count\": hr_bin_count,\n \"ol_bin_count\": ol_bin_count,\n \"ol_bins\": ol_bin,\n \"hr_bins\": hr_bin,\n \"function\": results,\n })\n else: \n return JsonResponse({\n \"error\": \"no data available for given date\"\n })\n\n elif None not in (query_start_date, query_end_date): \n \n start_date = datetime.datetime.strptime(query_start_date, '%Y-%m-%d').date()\n end_date = datetime.datetime.strptime(query_end_date, '%Y-%m-%d').date()\n\n if start_date.year == end_date.year:\n queryset = queryset.filter(date__range=[start_date, end_date])\n\n \n data = list(queryset.values_list('heart_rate', flat=True))\n ol_data = list(queryset.values_list('oxygen_level', flat=True))\n\n\n if len(data) > 0 and len(ol_data) > 0: \n hr_bins_list, ol_bins_list, hr_bin_count, ol_bin_count = computation.getBins(queryset)\n id_index, peaks, num_peaks, sleepdata_index, sleepdata_peaks, degree, coefficients = computation.getPeaks(queryset)\n\n ol_bin, hr_bin = computation.getFormattedBins(hr_bins_list, ol_bins_list, hr_bin_count, ol_bin_count)\n results = computation.getFunctionPoints(coefficients, degree, len(data))\n\n return JsonResponse({\n \"id_index\": id_index,\n \"peaks\": peaks,\n \"num_peaks\": num_peaks,\n \"sleepdata_id_index\": sleepdata_index,\n \"sleepdata_time\": sleepdata_peaks,\n \"degree\": degree,\n \"coefficients\" : coefficients,\n \"hr_bin_list\": hr_bins_list,\n \"ol_bin_list\": ol_bins_list,\n \"hr_bin_count\": hr_bin_count,\n \"ol_bin_count\": ol_bin_count,\n \"ol_bins\": ol_bin,\n \"hr_bins\": hr_bin,\n \"function\": results,\n })\n else: \n return JsonResponse({\n \"error\": \"date range accepted but no data found\"\n })\n\n else:\n return JsonResponse({\n \"error\": 'no data found'\n })\n\n return JsonResponse({\n \"error\": 'no date range given'\n })\n\nclass SongSummaryViewSet(viewsets.ViewSet):\n \"\"\"\n A view that returns song summary stats\n \"\"\"\n def list(self, request, format=None):\n queryset = Song.objects.all()\n song_count = queryset.aggregate(Count('id'))['id__count']\n\n return JsonResponse({\n \"song_count\": song_count\n })\n\nclass SummaryViewSet(viewsets.ViewSet):\n\n \"\"\"\n A view that returns filtered summary stats for all data\n \"\"\"\n def list(self, request, format=None):\n \"\"\"\n Returns aggregate data for given date or date range\n \"\"\"\n queryset = SleepData.objects.all()\n\n query_date = self.request.query_params.get('date', None)\n query_start_date = self.request.query_params.get('start_date', None)\n query_end_date = self.request.query_params.get('end_date', None)\n \n if query_date is not None: \n date = datetime.datetime.strptime(query_date, '%Y-%m-%d').date()\n queryset = queryset.filter(date__year=date.year,\n date__month=date.month, \n date__day=date.day)\n for obj in queryset:\n obj.date = obj.date.strftime(\"%Y-%m-%d %H:%M:%S\")\n\n average_hr, max_hr, min_hr, average_ol, max_ol, min_ol = computation.getSummary(queryset)\n\n max_date, min_date, total_time, total_count, awake_percentage, below_threshold, above_threshold, between_threshold = computation.getStats(queryset)\n\n if None not in (max_date, min_date, total_time, total_count, awake_percentage, below_threshold, above_threshold, between_threshold):\n return JsonResponse({\n \"average_hr\": average_hr,\n \"average_ol\": average_ol,\n \"max_hr\": max_hr,\n \"max_ol\": max_ol,\n \"min_hr\": min_hr,\n \"min_ol\": min_ol,\n \"total_time\": total_time,\n \"max_date\": max_date,\n \"min_date\": min_date,\n \"total_count\": total_count,\n \"awake_percentage\": awake_percentage,\n \"below_threshold\": below_threshold,\n \"above_threshold\": above_threshold,\n \"between_threshold\": between_threshold\n })\n else:\n return JsonResponse({\n \"error\": \"No entries match filters\"\n })\n\n if None not in (query_start_date, query_end_date):\n start_date = datetime.datetime.strptime(query_start_date, '%Y-%m-%d').date()\n end_date = datetime.datetime.strptime(query_end_date, '%Y-%m-%d').date()\n\n if start_date.year == end_date.year:\n queryset = queryset.filter(date__range=[start_date, end_date])\n\n for obj in queryset:\n obj.date = obj.date.strftime(\"%Y-%m-%d %H:%M:%S\") \n\n average_hr, max_hr, min_hr, average_ol, max_ol, min_ol = computation.getSummary(queryset)\n max_date, min_date, total_time, total_count, awake_percentage, below_threshold, above_threshold, between_threshold = computation.getStats(queryset)\n\n if None not in (max_date, min_date, total_time, total_count, awake_percentage, below_threshold, above_threshold, between_threshold):\n return JsonResponse({\n \"average_hr\": average_hr,\n \"average_ol\": average_ol,\n \"max_hr\": max_hr,\n \"max_ol\": max_ol,\n \"min_hr\": min_hr,\n \"min_ol\": min_ol,\n \"total_time\": total_time,\n \"max_date\": max_date,\n \"min_date\": min_date,\n \"total_count\": total_count,\n \"awake_percentage\": awake_percentage,\n \"below_threshold\": below_threshold,\n \"above_threshold\": above_threshold,\n \"between_threshold\": between_threshold\n })\n else:\n return JsonResponse({\n \"error\": \"No entries match filters\"\n })\n\n return JsonResponse({\n \"data\": list(queryset.values())\n })\n\n\n@api_view(['GET'])\n@renderer_classes((JSONRenderer,))\ndef summary_view(request, format=None):\n \"\"\"\n A view that returns summary stats in JSON FOR ALL OBJECTS.\n \"\"\"\n\n queryset = SleepData.objects.all()\n\n average_hr, max_hr, min_hr, average_ol, max_ol, min_ol = computation.getSummary(queryset)\n content = {\n 'average_hr': average_hr, \n 'average_ol': average_ol,\n 'max_hr': max_hr,\n 'min_hr': min_hr,\n 'average_ol': average_ol,\n 'max_ol': max_ol,\n 'min_ol': min_ol\n }\n return Response(content)\n\n@api_view(['GET'])\ndef api_root(request, format=None):\n return Response({\n 'alarms': reverse('alarm-list', request=request, format=format), \n 'sleepdata': reverse('sleepdata-list', request=request, format=format),\n 'events': reverse('event-list', request=request, format=format),\n 'songs': reverse('song-list', request=request, format=format)\n })\n\n"
},
{
"alpha_fraction": 0.6544368863105774,
"alphanum_fraction": 0.6544368863105774,
"avg_line_length": 27.560976028442383,
"blob_id": "0d8b76ae5961b4281d4f9a0cfa2f1149f0252c5d",
"content_id": "25b67b274fe93fc2a7ebd7cf384f82f6e51caf9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1172,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 41,
"path": "/sleepsite/serializers.py",
"repo_name": "gracez72/sleepAppBackend",
"src_encoding": "UTF-8",
"text": "from rest_framework import serializers\nfrom .models import Alarm, SleepData, Event, Song, Profile\nfrom django.contrib.auth.models import User\n\nclass AlarmSerializer(serializers.ModelSerializer):\n\n class Meta:\n model = Alarm\n fields = ('id', 'description', 'created_on', 'alarm_time', 'youtube_link', 'volume', 'active', 'username')\n\n\nclass SleepDataSerializer(serializers.ModelSerializer):\n\n class Meta:\n model = SleepData\n fields = ('id', 'oxygen_level', 'date', 'heart_rate', 'username')\n\n\nclass EventSerializer(serializers.ModelSerializer):\n\n class Meta: \n model = Event\n fields = ('id', 'event_name', 'start_time', 'end_time', 'username')\n\nclass SongSerializer(serializers.ModelSerializer):\n\n class Meta: \n model = Song\n fields = ('id', 'youtube_link', 'username')\n\nclass ProfileSerializer(serializers.ModelSerializer):\n\n class Meta: \n model = Profile\n fields = ('user', 'bio', 'name', 'location', 'image')\n\nclass UserSerializer(serializers.ModelSerializer):\n\n class Meta: \n model = User\n fields = ('username', 'email', 'password', 'first_name', 'last_name', 'id') \n"
},
{
"alpha_fraction": 0.6830188632011414,
"alphanum_fraction": 0.6891509294509888,
"avg_line_length": 29.27142906188965,
"blob_id": "a12c13ff13c08495d359f402e0ebf8e159d30419",
"content_id": "d7d6929863ce59d65eec5c83c120e285d12f7105",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2120,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 70,
"path": "/sleepsite/models.py",
"repo_name": "gracez72/sleepAppBackend",
"src_encoding": "UTF-8",
"text": "from django.db import models \nfrom django.contrib.auth.models import User\nfrom django.db.models.signals import post_save\nfrom django.dispatch import receiver\nimport uuid\nimport time\nimport datetime\n\nclass Profile(models.Model):\n user = models.OneToOneField(User, on_delete=models.CASCADE, primary_key=True)\n bio = models.TextField(max_length=500, blank=True)\n location = models.CharField(max_length=30, blank=True)\n name = models.CharField(max_length=100, default=\"name\")\n image = models.ImageField(blank=True, upload_to=\"images/\", default='images/moon.jpg')\n\nDEFAULT_USER_ID = 1\nclass Alarm(models.Model):\n description = models.TextField(blank=True)\n created_on = models.DateTimeField(auto_now_add=True)\n alarm_time = models.DateTimeField(unique=True)\n youtube_link = models.CharField(max_length=255, default='')\n volume = models.IntegerField(default=5)\n active = models.BooleanField(default=True)\n username = models.ForeignKey(User, on_delete=models.CASCADE, default=DEFAULT_USER_ID)\n\n class Meta:\n ordering = ('created_on',)\n\n def __str__(self):\n return str(self.alarm_time) \n\nclass Event(models.Model):\n event_name = models.TextField(blank=True)\n start_time = models.DateTimeField()\n end_time = models.DateTimeField()\n username = models.ForeignKey(User, on_delete=models.CASCADE,default=DEFAULT_USER_ID)\n\n\n class Meta:\n ordering = ('start_time',)\n\n def __str__(self):\n return str(self.event_name) \n\n\nclass Song(models.Model):\n youtube_link = models.TextField()\n username = models.ForeignKey(User, on_delete=models.CASCADE, default=DEFAULT_USER_ID)\n\n\n class Meta:\n ordering = ('youtube_link',)\n\n def __str__(self):\n return str(self.youtube_link) \n\n \nclass SleepData(models.Model):\n oxygen_level = models.IntegerField()\n date = models.DateTimeField()\n heart_rate = models.IntegerField()\n username = models.ForeignKey(User, on_delete=models.CASCADE, default=DEFAULT_USER_ID)\n\n\n class Meta:\n ordering = ('date',)\n\n \n def __str__(self):\n return str(self.date)\n\n"
}
] | 20 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.