
repo_name
stringlengths 5
114
| repo_url
stringlengths 24
133
| snapshot_id
stringlengths 40
40
| revision_id
stringlengths 40
40
| directory_id
stringlengths 40
40
| branch_name
stringclasses 209
values | visit_date
timestamp[ns] | revision_date
timestamp[ns] | committer_date
timestamp[ns] | github_id
int64 9.83k
683M
⌀ | star_events_count
int64 0
22.6k
| fork_events_count
int64 0
4.15k
| gha_license_id
stringclasses 17
values | gha_created_at
timestamp[ns] | gha_updated_at
timestamp[ns] | gha_pushed_at
timestamp[ns] | gha_language
stringclasses 115
values | files
listlengths 1
13.2k
| num_files
int64 1
13.2k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
jpurma/PixelAnts
|
https://github.com/jpurma/PixelAnts
|
fffa75cf3b95d86ab7d182f4eef17de2deefb0c9
|
83cc69bb454a4c3198018181762880f439286774
|
35c4cd80a1f3445e7a78f5e98e132e13912c6f8d
|
refs/heads/main
| 2023-04-06T14:36:02.728899 | 2021-04-11T12:53:42 | 2021-04-11T12:53:42 | 356,030,277 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5256090760231018,
"alphanum_fraction": 0.5503979325294495,
"avg_line_length": 34.78260803222656,
"blob_id": "4f5b1c3af053d6aaae4520e38b40074352342d20",
"content_id": "bd675236dfee18ef3dbdd67c04da2fc01bb4f07d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16459,
"license_type": "permissive",
"max_line_length": 131,
"num_lines": 460,
"path": "/pixelants.py",
"repo_name": "jpurma/PixelAnts",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom random import random, randint, choice\nimport math\n\nfrom kivy.app import App\nfrom kivy.graphics.context_instructions import Color\nfrom kivy.graphics.fbo import Fbo\nfrom kivy.graphics.texture import Texture\nfrom kivy.graphics.vertex_instructions import Line, Rectangle\nfrom kivy.clock import Clock\nfrom kivy.uix.widget import Widget\nfrom kivy.core.window import Window\n\nSIZE = W, H = [800, 800]\nHIVE_CENTER = W / 2, H / 2\nWindow.size = SIZE\n\nSPEED = 1.5\nANTS = 400\nRETURN_AT = 2000\nGOALS = 30\nROCKS = 30\nDECAY_FREQ = 100\nNEW_FOOD_FREQ = 200\nGOAL_SIZE = (20, 150)\nIN_SCENT_STRENGTH = 20\nPATH_INTEGRATION = False\n\nSTONE_COLOR = [80, 80, 80, 255]\nSTONE_COLOR_FLOAT = list(np.array(STONE_COLOR) / 255)\n\nant_list = []\n\nant_world_array = np.zeros(SIZE + [4], dtype=np.uint8)\nworld_array = np.zeros(SIZE + [4], dtype=np.uint8)\nfood_array = np.zeros(SIZE, dtype=np.uint32)\nforaging_scent_distance_array = np.zeros(SIZE, dtype=np.uint32)\nforaging_scent_direction_array = np.zeros(SIZE, dtype=np.float32)\nreturning_scent_decay_array = np.zeros(SIZE + [10], dtype=np.int32)\nreturning_scent_direction_array = np.zeros(SIZE + [10], dtype=np.float32)\nreturning_scent_decay_element_count_array = np.zeros(SIZE, dtype=np.uint32)\nreturning_scent_rgba_array = np.zeros(SIZE + [4], dtype=np.uint8)\nreturning_scent_rgba_base_array = np.full(SIZE + [4], [128, 128, 240, 0], dtype=np.uint8)\nreturning_scent_alpha_base_array = np.full(SIZE + [4], [5, 7, 1, 20], dtype=np.uint8)\n\nPI2 = math.pi * 2\nMAX_X = W - 1\nMAX_Y = H - 1\n\n\ndef limit_radian(r):\n if r < 0:\n return r + PI2\n elif r >= PI2:\n return r - PI2\n return r\n\n\ndef limit(min_v, value, max_v):\n return min((max_v, max((min_v, value))))\n\n\ndef rad_dist(r1, r2):\n if r1 > r2:\n if abs(r1 - r2) < abs(r1 - (r2 + PI2)):\n return r1 - r2\n else:\n return r1 - (r2 + PI2)\n if abs(r1 - r2) < abs(r1 + PI2 - r2):\n return r1 - r2\n return r1 + PI2 - r2\n\n\ndef randn_bm():\n u = 0\n v = 0\n while u == 0:\n u = random()\n while v == 0:\n v = random()\n num = math.sqrt(-2 * math.log(u)) * math.cos(PI2 * v)\n num = num / 10.0 + 0.5 # Translate to 0 -> 1\n if num > 1 or num < 0:\n num = randn_bm() # resample between 0 and 1 if out of range\n return num\n\n\ndef d_change():\n return randn_bm() * PI2 - math.pi\n\n\ndef opposite(d):\n nd = d + math.pi\n return nd - PI2 if nd > PI2 else nd\n\n\ndef is_occupied(x, y):\n if y < 0 or y > MAX_Y or x < 0 or x > MAX_X:\n return True\n rgba = world_array[y][x]\n return all(rgba == STONE_COLOR)\n\n\nclass Ant:\n FORAGING = 0\n FORAGING_RGBA = [255, 225, 50, 255]\n RETURNING = 1\n RETURNING_RGBA = [230, 230, 255, 255]\n RETURNING_EMPTY = 2\n RETURNING_EMPTY_RGBA = [255, 0, 50, 255]\n\n def __init__(self, x, y):\n self.mode = Ant.FORAGING\n self.has_last_route = False\n self.last_route_dist = 0\n self.last_route_d = 0.0\n self.travel_time = 0\n self.turn_direction = -1 if random() > 0.5 else 1\n self.x = int(x)\n self.fx = float(x)\n self.y = int(y)\n self.fy = float(y)\n self.d = random() * PI2\n self.home_d = 0.0\n self.dist = 0.0\n\n def limit_to_area(self):\n # remain inside world limits\n hit = False\n if self.x < 0:\n self.fx = 0.0\n hit = True\n elif self.x > MAX_X:\n self.fx = float(MAX_X)\n hit = True\n if self.y < 0:\n self.fy = 0.0\n hit = True\n elif self.y > MAX_Y:\n self.fy = float(MAX_Y)\n hit = True\n if hit:\n self.x = int(self.fx)\n self.y = int(self.fy)\n self.d = opposite(self.d)\n\n def at_food(self):\n if food_array[self.y][self.x]:\n return True\n\n def at_home(self):\n if self.dist < 9:\n return True\n\n def leave_foraging_scent(self, as_opposite=False):\n scent_closeness = foraging_scent_distance_array[self.y][self.x]\n if not scent_closeness or scent_closeness > self.travel_time:\n foraging_scent_distance_array[self.y][self.x] = self.travel_time\n foraging_scent_direction_array[self.y][self.x] = self.d if not as_opposite else opposite(self.d)\n closeness_log = math.log2(max((1, 5000 - self.travel_time))) / 13\n r, g, b = Color(self.d / PI2, 0.9, closeness_log, mode='hsv').rgb\n world_array[self.y][self.x] = [r * 255, g * 255, b * 255, 80]\n\n def leave_returning_scent(self):\n decays = [decay for decay in returning_scent_decay_array[self.y][self.x] if decay > 0]\n directions = list(returning_scent_direction_array[self.y][self.x])\n directions = directions[:len(decays)]\n decays.append(IN_SCENT_STRENGTH)\n directions.append(self.d)\n scents_size = len(decays)\n if len(decays) > 10:\n decays = decays[1:]\n directions = directions[1:]\n elif len(decays) < 10:\n decays += [0] * (10 - len(decays))\n directions += [0] * (10 - len(directions))\n returning_scent_decay_array[self.y][self.x] = decays\n returning_scent_direction_array[self.y][self.x] = directions\n returning_scent_decay_element_count_array[self.y][self.x] = scents_size\n returning_scent_rgba_array[self.y][self.x] = [128 + 5 * scents_size,\n 128 + 7 * scents_size,\n 240 + scents_size,\n 20 + 20 * scents_size]\n\n def pick_foraging_scent(self, chance=.3, rebel=.1):\n if random() < rebel or random() > chance:\n return\n if foraging_scent_distance_array[self.y][self.x]:\n return foraging_scent_direction_array[self.y][self.x]\n\n def pick_returning_scent(self, chance=.3, rebel=.1):\n if random() < rebel:\n return\n scents = [i for i, decay in enumerate(returning_scent_decay_array[self.y][self.x]) if decay > 0]\n for s in scents:\n if random() < chance:\n scent_direction = returning_scent_direction_array[(self.y, self.x, choice(scents))]\n self.has_last_route = True\n self.last_route_dist = 0\n return scent_direction\n\n def compute_home(self, speed, target_rad, current_rad, current_dist):\n \"\"\" compute the angle and distance to home based on the previous angle to target and dist, and the angle and speed\n of current movement. This is optional, if we want to try what happens with path integration capability.\"\"\"\n\n c = math.pi - (target_rad - current_rad)\n speed2 = speed * speed\n dist2 = current_dist * current_dist\n new_dist2 = speed2 + dist2 - 2 * speed * current_dist * math.cos(c)\n if current_dist <= 0 or new_dist2 <= 0:\n return current_rad, speed\n new_dist = math.sqrt(new_dist2)\n cos_rule = (dist2 + new_dist2 - speed2) / (2 * current_dist * new_dist)\n cos_rule = limit(-1, cos_rule, 1) # floating point inaccuracies may lead to 1.0000000002\n diff = math.acos(cos_rule)\n if rad_dist(current_rad, target_rad) < 0:\n diff = -diff\n return limit_radian(target_rad + diff), new_dist\n\n def move_step(self, speed):\n attempts = 0\n while True:\n attempts += 1\n fx = self.fx + speed * math.cos(self.d)\n fy = self.fy + speed * math.sin(self.d)\n x = int(fx)\n y = int(fy)\n if not is_occupied(x, y):\n break\n if random() < 0.0001:\n self.turn_direction *= -1\n attempts = -attempts\n change = math.pi / 32 * self.turn_direction\n #change = abs(d_change() / 8) * self.turn_direction\n self.d = limit_radian(self.d + change)\n if attempts == 64:\n fx, fy = HIVE_CENTER\n x = int(fx)\n y = int(fy)\n print('dead end')\n break\n self.fx = fx\n self.fy = fy\n self.x = x\n self.y = y\n self.limit_to_area()\n if PATH_INTEGRATION:\n self.home_d, self.dist = self.compute_home(speed, self.home_d, self.d, self.dist)\n else:\n self.dist = math.dist(HIVE_CENTER, (self.x, self.y))\n if self.has_last_route:\n self.last_route_d, self.last_route_dist = self.compute_home(speed, self.last_route_d, self.d, self.last_route_dist)\n self.draw()\n\n def draw(self):\n if self.mode == Ant.RETURNING:\n color = Ant.RETURNING_RGBA\n elif self.mode == Ant.RETURNING_EMPTY:\n color = Ant.RETURNING_EMPTY_RGBA\n else:\n color = Ant.FORAGING_RGBA\n ant_world_array[self.y][self.x] = color\n\n def travel(self, speed):\n self.travel_time += 1\n if self.mode == Ant.FORAGING or Ant.RETURNING_EMPTY:\n if self.at_food():\n food_array[self.y][self.x] -= 1\n self.mode = Ant.RETURNING\n food_left = food_array[self.y][self.x]\n world_array[self.y][self.x] = [255, 160, 160, min((255, 200 + food_left * 2)) if food_left else 0]\n self.d = opposite(self.d)\n\n if self.mode == Ant.RETURNING:\n if (foraging_scent_direction := self.pick_foraging_scent(.7)) is not None:\n self.d = opposite(foraging_scent_direction)\n # elif (returning_scent_direction := self.pick_returning_scent(.7)) is not None:\n # self.d = returning_scent_direction\n # self.has_last_route = True\n # elif PATH_INTEGRATION and self.has_last_route:\n # self.d = opposite(self.last_route_d)\n # if self.last_route_dist <= speed:\n # self.has_last_route = False\n elif PATH_INTEGRATION and self.travel_time < 1000:\n # Go home\n self.d = opposite(self.home_d)\n else:\n # Random walk\n self.d = limit_radian(self.d + d_change() / 4)\n self.move_step(speed)\n if self.at_home():\n self.mode = Ant.FORAGING\n self.travel_time = 0\n else:\n self.leave_returning_scent()\n\n elif self.mode == Ant.RETURNING_EMPTY:\n if (foraging_scent_direction := self.pick_foraging_scent(.7)) is not None:\n self.d = opposite(foraging_scent_direction)\n else:\n # Random walk\n self.d = limit_radian(self.d + d_change() / 4)\n self.move_step(speed)\n if self.at_home():\n self.mode = Ant.FORAGING\n self.travel_time = 0\n\n else:\n if (returning_scent_direction := self.pick_returning_scent(.7)) is not None:\n self.d = opposite(returning_scent_direction)\n self.has_last_route = True\n else:\n # Random walk\n self.d = limit_radian(self.d + d_change() / 4)\n self.move_step(speed)\n self.leave_foraging_scent()\n if self.travel_time > RETURN_AT:\n self.mode = Ant.RETURNING_EMPTY\n\n\nclass Hive:\n def __init__(self, x, y):\n self.x = x\n self.y = y\n self.load = 0\n\n\nclass Rock:\n def __init__(self):\n point_n = randint(6, 12)\n radius = randint(20, 100)\n screen_cx = MAX_X / 2\n screen_cy = MAX_Y / 2\n center_x = screen_cx\n center_y = screen_cy\n while abs(screen_cx - center_x) < radius and abs(screen_cy - center_y) < radius:\n center_x = randint(0, MAX_X)\n center_y = randint(0, MAX_Y)\n self.points = []\n rotation = randint(0, 12)\n for n in range(rotation, point_n + rotation):\n x_adj = int(random() * (radius / 2) - radius / 4)\n y_adj = int(random() * (radius / 2) - radius / 4)\n rad = n * (PI2 / (point_n + 6))\n x = center_x + math.cos(rad) * radius + x_adj\n y = center_y + math.sin(rad) * radius + y_adj\n self.points.append(x)\n self.points.append(y)\n\n\ndef turn_to_world_array(pixels):\n global world_array\n buffer = np.frombuffer(pixels, dtype=np.uint8)\n world_array = np.reshape(buffer, (W, H, 4)).copy()\n\n\nclass World(Widget):\n def __init__(self, app):\n super(World, self).__init__()\n self.size_hint = None, None\n self.size = SIZE\n self.pos_hint = {'center': (.5, 5)}\n self.hive = None\n self.rocks = []\n self.add_ground()\n w, h = SIZE\n with self.canvas:\n ground_fbo = Fbo(size=self.size)\n Rectangle(pos=(0, 0), size=(w * 2, h * 2), texture=ground_fbo.texture)\n Rectangle(pos=(0, 0), size=(w * 2, h * 2), texture=app.texture)\n Rectangle(pos=(0, 0), size=(w * 2, h * 2), texture=app.returning_paths_texture)\n with ground_fbo:\n Color(*STONE_COLOR_FLOAT)\n Line(rectangle=[0, 0, w, h], width=4)\n for rock in self.rocks:\n Line(points=rock.points, close=False, width=4)\n ground_fbo.draw()\n turn_to_world_array(ground_fbo.texture.pixels)\n self.populate()\n\n def add_food(self):\n c_x = randint(0, MAX_X)\n c_y = randint(0, MAX_Y)\n load = randint(*GOAL_SIZE)\n size = load / 3\n for i in range(0, load):\n x = int(round(limit(0, c_x + (random() * load / 2.5) - size, MAX_X)))\n y = int(round(limit(0, c_y + (random() * load / 2.5) - size, MAX_Y)))\n food_array[y][x] += 1\n world_array[y][x] = [255, 160, 160, min((255, 200 + food_array[y][x] * 2))]\n\n def global_decay(self):\n global returning_scent_decay_element_count_array, returning_scent_rgba_array\n np.putmask(returning_scent_decay_array, returning_scent_decay_array >= 1, returning_scent_decay_array - 1)\n returning_scent_decay_element_count_array = np.array(np.ma.count_masked(\n np.ma.array(\n returning_scent_decay_array,\n mask=np.ma.make_mask(returning_scent_decay_array),\n dtype=np.uint8\n ), 2),\n dtype=np.uint8)\n returning_scent_alpha_array = returning_scent_alpha_base_array * returning_scent_decay_element_count_array.reshape(W, H, 1)\n returning_scent_rgba_array = returning_scent_rgba_base_array + returning_scent_alpha_array\n\n def add_ground(self):\n for rock_id in range(0, ROCKS):\n rock = Rock()\n self.rocks.append(rock)\n\n x, y = HIVE_CENTER\n hive = Hive(x=x, y=y)\n self.hive = hive\n\n def populate(self):\n x = self.hive.x\n y = self.hive.y\n for ant_id in range(0, ANTS):\n ant = Ant(x, y)\n ant_list.append(ant)\n\n for goal_id in range(0, GOALS):\n self.add_food()\n\n\nclass PixelAnts(App):\n\n def __init__(self, **kwargs):\n super(PixelAnts, self).__init__(**kwargs)\n self.main = None\n self.tick = 0\n self.returning_paths_texture = None\n\n def build(self):\n Clock.schedule_interval(self.refresh, 0)\n self.texture = Texture.create(size=SIZE, colorfmt='rgba', bufferfmt='ubyte')\n self.texture.min_filter = 'nearest'\n self.texture.mag_filter = 'nearest'\n self.returning_paths_texture = Texture.create(size=SIZE, colorfmt='rgba', bufferfmt='ubyte')\n self.returning_paths_texture.min_filter = 'nearest'\n self.returning_paths_texture.mag_filter = 'nearest'\n self.main = World(self)\n return self.main\n\n def refresh(self, dt):\n global ant_world_array\n ant_world_array = world_array.copy()\n self.tick += 1\n if self.tick % DECAY_FREQ == 0:\n self.main.global_decay()\n if self.tick % NEW_FOOD_FREQ == 0:\n self.main.add_food()\n for ant in ant_list:\n ant.travel(SPEED)\n self.texture.blit_buffer(ant_world_array.tobytes(), colorfmt='rgba', bufferfmt='ubyte')\n self.returning_paths_texture.blit_buffer(returning_scent_rgba_array.tobytes(), colorfmt='rgba', bufferfmt='ubyte')\n self.main.canvas.flag_update()\n\n\nif __name__ == '__main__':\n PixelAnts().run()"
},
{
"alpha_fraction": 0.7808219194412231,
"alphanum_fraction": 0.7976817488670349,
"avg_line_length": 128.36363220214844,
"blob_id": "b87435ee26ed2b0c6ab19487bb05c21c6cd10ebf",
"content_id": "da09b39d39a746adbb3cdb1c4ded3c5029505516",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2847,
"license_type": "permissive",
"max_line_length": 796,
"num_lines": 22,
"path": "/README.md",
"repo_name": "jpurma/PixelAnts",
"src_encoding": "UTF-8",
"text": "# PixelAnts\nAnt colony algorithm with [Numpy](https://numpy.org) and [Kivy](https://kivy.org).\n\nThis is a toy simulation for testing if the fast array handling from Numpy and the easy access to OpenGL bitmaps from Kivy are enough when drawing hundreds of ants with their pheromone paths. Seems to be so.\n\n<img width=\"477\" alt=\"screenshot\" src=\"https://user-images.githubusercontent.com/5269272/114096061-e520a300-98c6-11eb-8307-4a6864321c01.png\">\n\nAnt colony algorithm here is a bit unrealistic, but interesting variation: foraging aka. outgoing ants leave one kind of a scent signal and returning ants leave another kind of a scent signal, and they always use the other kind of signal to help themselves navigate either towards food or towards home.\n\nOutgoing signals are tuples of (travel time, direction), where if an ant encounters a signal where travel time (time since last visit to the hive) is longer than its current travel time, it leaves a new signal with its current direction replacing the old one. Outgoing signal are visualised with hue corresponding to direction. Because the signals get replaced with ones suggesting a faster route to that point, they have an effect of slowly painting the world with fast routes from hive to each point.\n\nReturning or incoming signals are tuples of (decay, direction). These are drawn when an ant has found food and is returning to the hive by following outgoing signals to their reverse direction, or when there is no outgoing signal present and it is traversing randomly. There can be up to 10 returning signals on each point. Returning signals are used by outgoing/foraging ants, for each signal there is a chance for it to be chosen and followed into reverse direction and towards food. These signals decay over time, and when there are new signals, they pop out the older signals so that there are maximum ten signals at each point. These are visualised with transparent white pixels.\n\nThere is also an option for ants to use path integration to keep track on how far they are from the hive and in which direction, and how far they are from their last known path point. This path integration uses the cosine rule to calculate how the current step has modified an ant's position relative to the previous step's calculation of hive position. It is known that at least some real ant species use path integration to return directly to hive, but in this simulation it often leads to 'tar pits', where ants get stuck in U-shapes and keep drawing routes, attracting more ants into the same trap. Adjusting values and adding heuristics for when to attempt a direct path and when to give up and rely on scent routes would improve it, but I'm currently more fascinated with pure scent routes.\n\nRequires Python 3.8, Numpy and Kivy,\n\n pip install -r requirements.txt\n\nthen:\n\n python pixelants.py\n\n"
}
] | 2 |
MonteroAllen/UltimateAPI
|
https://github.com/MonteroAllen/UltimateAPI
|
1e03c2f7fe4d4f28ad792e72a747faef96deb45c
|
d06cb553a1d63270ea9d5dea14ec42ee140b9804
|
bff6a1e6c6335967208f2315f3bc69babcaef1f5
|
refs/heads/master
| 2020-05-17T01:53:11.772860 | 2019-05-19T08:54:57 | 2019-05-19T08:54:57 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6516219973564148,
"alphanum_fraction": 0.6713681221008301,
"avg_line_length": 26.30769157409668,
"blob_id": "921bfa84072a3b53c2792439949d2de918c68cdf",
"content_id": "f5fab2f2b09f82e30decc6eddba268d2e16d6bb6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 709,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 26,
"path": "/ExcelParser/excelParser.py",
"repo_name": "MonteroAllen/UltimateAPI",
"src_encoding": "UTF-8",
"text": "#!python\n# Uses Python 3\n# needs to install openpyxl\n\nfrom openpyxl import load_workbook\nimport re\n\nwb = load_workbook(\"./parse.xlsx\")\n\nprint(wb.sheetnames)\n\nfor sheet in wb:\n if sheet.title == \"GlossaryNotes\":\n continue\n # Take sheet name, trim the 'n - ' (Where n is a number) and set it as character name\n print(\"Splitting: \" + sheet.title)\n charName = re.split(r\"[a-zA-Z]+\", sheet.title)[0]\n # From each line I have: \n # Column | Desc\n # 0 move name\n # 1 Startup, 2 Total Frames, Landing lag\n # 5 Base dmg, 6 shieldlag, 7 shieldstun, 8 which hitbox, 9 Advantage\n # number of hitboxes from 5 | number of hits from 1\n for line in sheet:\n if line[0].value != None:\n print(line[0].value)"
},
{
"alpha_fraction": 0.8372092843055725,
"alphanum_fraction": 0.8372092843055725,
"avg_line_length": 20.5,
"blob_id": "8e9d6c0771494a81a78a74c47275f132cf0aa6c8",
"content_id": "8779722076fe4b2d63ce74f8ecb95609bd1fc3b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 43,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 2,
"path": "/README.md",
"repo_name": "MonteroAllen/UltimateAPI",
"src_encoding": "UTF-8",
"text": "# UltimateAPI\nSmash Ultimate Framedata API\n"
},
{
"alpha_fraction": 0.7545787692070007,
"alphanum_fraction": 0.7545787692070007,
"avg_line_length": 38.14285659790039,
"blob_id": "8f03d240b00669acea11fac5dd6daa575fbb3948",
"content_id": "713c78fe7fede6685a3687103445096988ca5d76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 273,
"license_type": "no_license",
"max_line_length": 176,
"num_lines": 7,
"path": "/ParamsParser/README.md",
"repo_name": "MonteroAllen/UltimateAPI",
"src_encoding": "UTF-8",
"text": "# How to use this parser\n\nThis parser takes the pages from the [kuroganehammer](http://kuroganehammer.com/) website reguarding the characters attributes and prints it to the terminal in a json format. \nTo get a file on Linux, use:\n```bash\n./parser.py > characters.json\n```"
},
{
"alpha_fraction": 0.6172531247138977,
"alphanum_fraction": 0.6263337135314941,
"avg_line_length": 42.186275482177734,
"blob_id": "b1275d15318bc6b4a75e995200cf2fbaaff712cb",
"content_id": "92b8081912d742d46c270b945c539269fe1e3cd6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4405,
"license_type": "no_license",
"max_line_length": 202,
"num_lines": 102,
"path": "/ParamsParser/parser.py",
"repo_name": "MonteroAllen/UltimateAPI",
"src_encoding": "UTF-8",
"text": "#!python\n\nimport requests\nimport re\n\nweigthUrl = \"http://kuroganehammer.com/Ultimate/Weight\"\nrunSpeedUrl = \"http://kuroganehammer.com/Ultimate/RunSpeed\"\nwalkSpeedUrl = \"http://kuroganehammer.com/Ultimate/WalkSpeed\"\nairSpeedUrl = \"http://kuroganehammer.com/Ultimate/AirSpeed\"\nairAccelUrl = \"http://kuroganehammer.com/Ultimate/AirAcceleration\"\nfallSpeedUrl = \"http://kuroganehammer.com/Ultimate/FallSpeed\"\ninitDashUrl = \"http://kuroganehammer.com/Ultimate/DashSpeed\"\n\njsonTemplate = \"\"\"\n\\t\\t\\\"Character Name\\\": \\\"{0}\\\",\n\\t\\t\\\"Weight\\\": {1},\n\\t\\t\\\"Run Speed\\\": {2},\n\\t\\t\\\"Walk Speed\\\": {3},\n\\t\\t\\\"Air Speed\\\": {4},\n\\t\\t\\\"Air Acceleration Speed\\\": {5},\n\\t\\t\\\"Fall Speed\\\": {6},\n\\t\\t\\\"Initial Dash Speed\\\": {7}\n\"\"\"\n\ndef createDict(cleanList, valueCol=3):\n weightDict = {}\n for clean in cleanList:\n singleColumn = clean.replace(';;', ';')\n for ch in clean:\n singleColumn = singleColumn.replace(';;', ';')\n charEntry = singleColumn.split(';')\n if (len(charEntry) > 3):\n if charEntry[2] == \"Dedede\":\n charEntry[2] = \"King Dedede\"\n if charEntry[2] == \"Dank Samus\":\n charEntry[2] = \"Dark Samus\"\n if charEntry[2] == \"Mii Swordspider\":\n charEntry[2] = \"Mii Swordfighter\"\n if charEntry[2] == \"Educated Mario\" or charEntry[2] == \"Dr Mario\":\n charEntry[2] = \"Dr. Mario\"\n if charEntry[2] == \"Pit, but edgy\":\n charEntry[2] = \"Dark Pit\"\n if charEntry[2] == \"Popo\":\n charEntry[2] = \"Ice Climbers\"\n if charEntry[2] == \"M. Game & Watch\":\n charEntry[2] = \"Mr. Game & Watch\"\n weightDict[charEntry[2]] = charEntry[valueCol]\n return weightDict\n\ndef parseResponse(responseText):\n tbody = re.findall(r\"<tbody>(.*?)<\\/tbody>\", responseText, re.MULTILINE | re.DOTALL)\n entries = re.findall(r\"<tr>(.*?)<\\/tr>\", tbody[0], re.MULTILINE | re.DOTALL)\n cleaned = []\n for entry in entries:\n cleaned.append(re.sub(r'<(.*?)>', ';', entry.replace('\\t', '').replace('\\n', ''), count=15, flags=(re.MULTILINE | re.DOTALL)))\n return cleaned\n\nif __name__ == \"__main__\":\n ########################## Weight #################################\n weightresponse = requests.get(weigthUrl)\n weightcleaned = parseResponse(weightresponse.text)\n weightDict = createDict(weightcleaned)\n ######################### RunSpeed ################################\n runSpeedResponse = requests.get(runSpeedUrl)\n runSpeedCleaned = parseResponse(runSpeedResponse.text)\n runSpeedDict = createDict(runSpeedCleaned)\n ######################## WalkSpeed ###############################\n walkSpeedResponse = requests.get(walkSpeedUrl)\n walkSpeedCleaned = parseResponse(walkSpeedResponse.text)\n walkSpeedDict = createDict(walkSpeedCleaned)\n ######################## AirSpeed ###############################\n airSpeedResponse = requests.get(airSpeedUrl)\n airSpeedCleaned = parseResponse(airSpeedResponse.text)\n airSpeedDict = createDict(airSpeedCleaned)\n #################### Air Accceleration ###########################\n airAccelResponse = requests.get(airAccelUrl)\n airAccelCleaned = parseResponse(airAccelResponse.text)\n airAccelDict = createDict(airAccelCleaned, 5)\n ####################### Fall Speed ##############################\n fallSpeedResponse = requests.get(fallSpeedUrl)\n fallSpeedCleaned = parseResponse(fallSpeedResponse.text)\n fallSpeedDict = createDict(fallSpeedCleaned)\n ################### Initial Dash Speed ##########################\n initDashResponse = requests.get(initDashUrl)\n initDashCleaned = parseResponse(initDashResponse.text)\n initDashDict = createDict(initDashCleaned)\n #################### Rest of the code ###########################\n finalDict = {}\n for character in weightDict.keys():\n finalDict[character] = [weightDict[character], runSpeedDict[character], walkSpeedDict[character], airSpeedDict[character], airAccelDict[character], fallSpeedDict[character], initDashDict[character]]\n # CharName: [weight, runSpeed, walkSpeed, airSpeed, airAccelSpeed, fallSpeed, InitDashSpeed]\n jsonString = \"{\"\n iterator = 0\n for charName in finalDict:\n currEntry = finalDict[charName]\n jsonString += \"\\n\\t\\\"{}\\\"\".format(iterator) + \": {\"\n jsonString += jsonTemplate.format(charName, currEntry[0], currEntry[1], currEntry[2], currEntry[3], currEntry[4], currEntry[5], currEntry[6])\n jsonString += \"\\t},\"\n iterator += 1\n jsonString = jsonString[:-1]\n jsonString += \"\\n}\"\n print(jsonString)\n"
}
] | 4 |
bocyn/url-clicker
|
https://github.com/bocyn/url-clicker
|
7b57bc1f7564cda03028cad5c9bc37eaed4a17f3
|
66fdf59cbafe0cecd74820714e7b3a3d4318e6ca
|
65f13f0c4f002dcb612757a69606e425dc269a04
|
refs/heads/master
| 2018-10-07T13:54:28.720093 | 2018-06-22T15:17:32 | 2018-06-22T15:17:32 | 138,300,710 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.42241379618644714,
"alphanum_fraction": 0.6724137663841248,
"avg_line_length": 13.5,
"blob_id": "cea83ffafa5d8535b9ea2dc27e02cb1914c450e5",
"content_id": "83f0f99c16f0281bcba59ab600fc2645078edb8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 116,
"license_type": "no_license",
"max_line_length": 18,
"num_lines": 8,
"path": "/requirements.txt",
"repo_name": "bocyn/url-clicker",
"src_encoding": "UTF-8",
"text": "certifi==2018.4.16\nchardet==3.0.4\nidna==2.7\nPySocks==1.6.8\nrequests==2.19.1\nstem==1.6.0\ntailer==0.4.1\nurllib3==1.23\n"
},
{
"alpha_fraction": 0.6140404939651489,
"alphanum_fraction": 0.6305947303771973,
"avg_line_length": 30.365385055541992,
"blob_id": "3c1fd3e0f642a9d47d46f65378178726259f577d",
"content_id": "78094581ad8f1e807ccd996da8903257eaefefd7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3262,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 104,
"path": "/url-clicker.py",
"repo_name": "bocyn/url-clicker",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# this script is made for fetching of url's from source file\n# and clicking of them through proxy external ip with changeable User-Agent field\n# /home/roman/url-clicker/log/url-clicker.log - default log file\n# /var/log/jasmin/sms.log - default source file\n\nimport logging\nimport re\nimport random\nfrom time import sleep\nfrom argparse import ArgumentParser\n\nimport tailer\nimport requests\nfrom requests.exceptions import MissingSchema\nimport socks\nimport socket\nfrom stem import Signal\nfrom stem.control import Controller\n\n\nparser = ArgumentParser()\nparser.add_argument('-f', '--file', dest='source_file', help='takes source file')\nparser.add_argument('-l', '--log', dest='log_file', help='writes to log file')\nargs = parser.parse_args()\n\nLOG_FILE = args.log_file\nSOURCE_FILE = args.source_file\nGET_EXT_IP = ['http://ipinfo.io/ip', 'http://icanhazip.com']\n\nif not LOG_FILE:\n LOG_FILE = '/home/roman/url-clicker/log/url-clicker.log'\nif not SOURCE_FILE:\n SOURCE_FILE = '/var/log/jasmin/sms.log'\n\nlogging.basicConfig(\n level=logging.DEBUG,\n format='%(asctime)s : %(levelname)s : %(message)s',\n filename=LOG_FILE,\n filemode='a',\n)\n\n\nregex = r'https?://(?:[-\\w.]|(?:%[\\da-fA-F]{2}))+\\S+|www\\.(?:[-\\w.]|(?:%[\\da-fA-F]{2}))+\\S+'\nFIND_URLS_IN_STRING = re.compile(regex, re.IGNORECASE)\nMSG_ID = re.compile(r'queue-msgid:.{0,36}')\n\n\ncontroller = Controller.from_port(port=9061)\ncontroller.authenticate(password='377sdd350')\nsocks.setdefaultproxy(socks.PROXY_TYPE_SOCKS5, \"127.0.0.1\", 9060)\nsocket.socket = socks.socksocket\n\n\ndef renew_ip():\n controller.signal(Signal.NEWNYM)\n sleep(10)\n\n\ndef get_ip():\n ip = requests.get(GET_EXT_IP[0], verify=False, timeout=5)\n if ip.status_code != 200:\n logging.warning('got NOT 200 code from:{0}, will try through:{1}'.format(GET_EXT_IP[0], GET_EXT_IP[1]))\n ip = r_session.get(GET_EXT_IP[1], verify=False, timeout=5)\n return ip.text.rstrip()\n\nagents = open('agents.txt', 'r').read().splitlines()\n\nfor line in tailer.follow(open(SOURCE_FILE), delay=0.1):\n url = FIND_URLS_IN_STRING.search(line)\n\n if url:\n url_str = url.group()\n msg_id = MSG_ID.search(line).group()\n agent = random.choice(agents)\n\n try:\n r_session = requests.Session()\n r_session.headers['User-Agent'] = agent\n ext_ip = get_ip()\n resp_code = r_session.get(url_str, verify=False, timeout=5).status_code\n\n except MissingSchema as err:\n logging.warning('adding prefix http:// to URL:{0}'.format(url_str))\n try:\n resp_code = r_session.get('http://'+url_str, verify=False, timeout=5).status_code\n except BaseException as err:\n logging.error(err)\n resp_code = 'NOT_200_OK error upper ^'\n\n except BaseException as err:\n logging.error(err)\n resp_code = 'NOT_200_OK error upper ^'\n\n finally:\n logging.info('[{0}] [url:{1}] [http_response:{2}] [ext_ip:{3}] [agent:{4}]'\n .format(msg_id, url_str, resp_code, ext_ip, agent))\n r_session.close()\n renew_ip()\n\n if not url:\n pass\n # logging.warning('URL_not_found in string: {0}'.format(line))\n"
}
] | 2 |
AlbertoAmbriz/bar-charts-matplotlib
|
https://github.com/AlbertoAmbriz/bar-charts-matplotlib
|
a628dfbd33e6fdb62fb2d5e562260e5747db385d
|
aa15ada0ea5fd8069c0a36cd75ec834b311f96ce
|
69a9f6c7e88ad33816338818c3b51cf405b51d24
|
refs/heads/master
| 2023-08-27T21:43:20.451405 | 2021-09-14T04:31:25 | 2021-09-14T04:31:25 | 406,200,193 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5520262718200684,
"alphanum_fraction": 0.7940854430198669,
"avg_line_length": 34.07692337036133,
"blob_id": "2af859b4d3a07d2d93c6b84c49f0ea3c907f5641",
"content_id": "eb7fc1432c429a66ee91a63faaa4140b76a29368",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 913,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 26,
"path": "/README.md",
"repo_name": "AlbertoAmbriz/bar-charts-matplotlib",
"src_encoding": "UTF-8",
"text": "# bar-charts-matplotlib\n\nSome examples of bar charts using matplotlib\n\n**Oil Production**\n\n\n\n**Gas Production**\n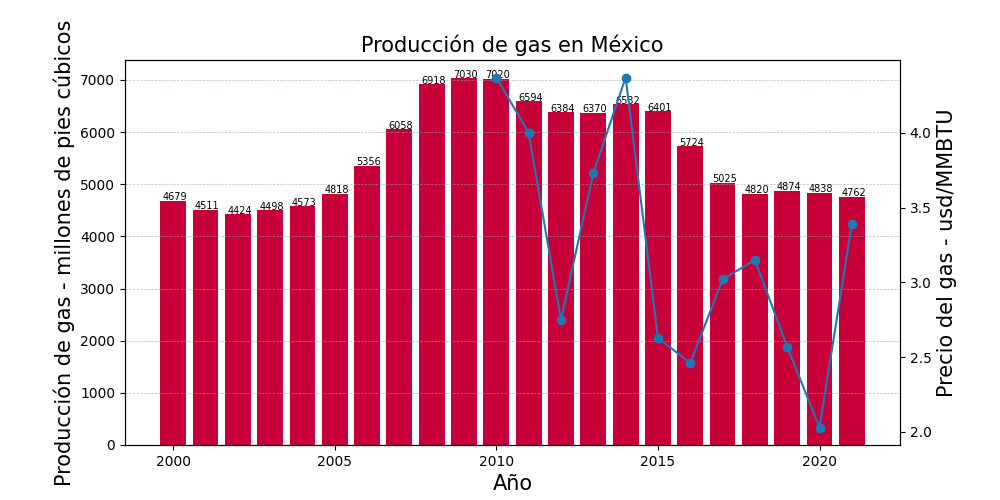\n\n\n**Gas Production**\n\n\n\n**Oil Reserves**\n\n\n\n**Gas reserves**\n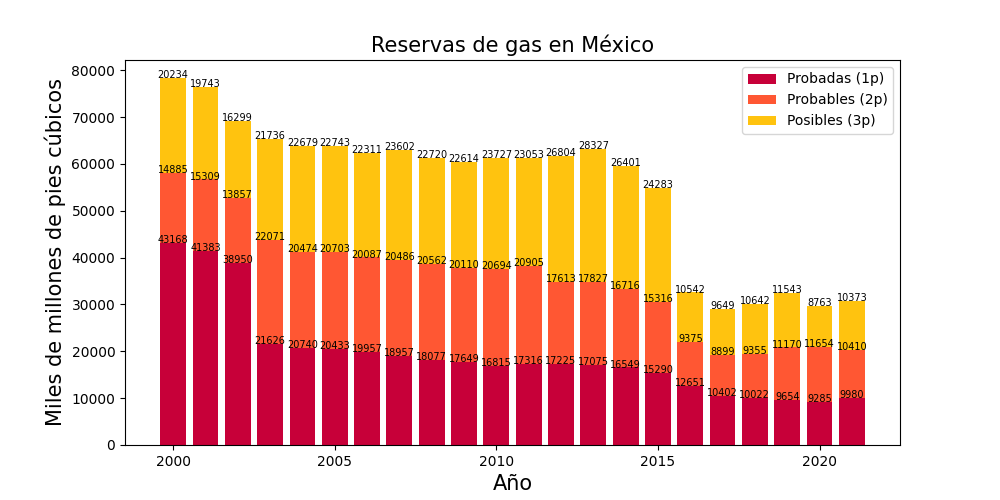\n\n\n**Well drilled**\n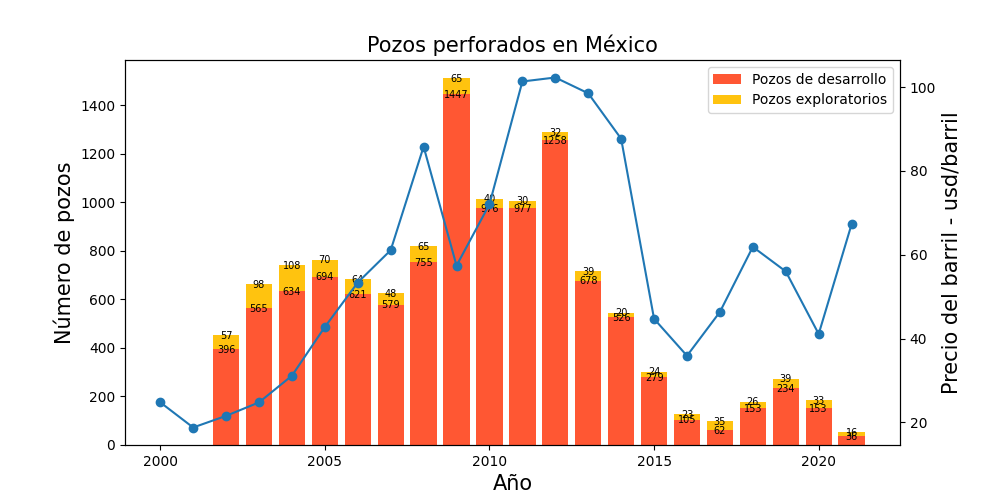\n\n"
},
{
"alpha_fraction": 0.41604897379875183,
"alphanum_fraction": 0.6123106479644775,
"avg_line_length": 45.54999923706055,
"blob_id": "d9408de2a0af19ac133acd8943169dd7dfbd00be",
"content_id": "6ee3071e97902a6532803fc5d17597801497ad53",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9332,
"license_type": "no_license",
"max_line_length": 186,
"num_lines": 200,
"path": "/Bar chart.py",
"repo_name": "AlbertoAmbriz/bar-charts-matplotlib",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\n\noil_prod = [3012, 3127, 3177, 3371, 3383, 3333, 3256, 3076, 2792, 2601, 2577, 2553, 2548, 2522, 2429, 2267, 2147, 1944, 1809, 1678, 1663, 1677]\ngas_prod = [4679, 4511, 4424, 4498, 4573, 4818, 5356, 6058, 6918, 7030, 7020, 6594, 6384, 6370, 6532, 6401, 5724, 5025, 4820, 4874, 4838, 4762]\nagno_prod = [2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021]\noil_price = [24.78, 18.77, 21.55, 24.76, 31.13, 42.75, 53.36, 61.07, 85.78, 57.39, 72.02, 101.32, 102.27, 98.50, 87.66, 44.70, 35.88, 46.34, 61.86, 56.01, 41.08, 67.27]\ngas_asociado =[3380, 3239, 3118, 3119.2, 3009.6, 2954.1, 3090, 3445.4, 4319.8, 4480.3, 4561.9, 4423.1, 4474.9, 4607.7, 4819.9, 4825.7, 4476.7, 4003.3, 3752.5, 3840.2, 3734.1, 3567.6]\ngas_no_asociado = [1299.2, 1271.7, 1305.4, 1379.2, 1563.3, 1863.9, 2266.1, 2613, 2598.4, 2549.9, 2458.1, 2171, 1909.8, 1762.6, 1712, 1575.3, 1247.3, 1022.5, 1068, 1033.8, 1103.8, 1194.3]\n\n\nagno_prod2 = [2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021]\ngas_price = [4.37, 4, 2.75, 3.73, 4.37, 2.63, 2.46, 3.02, 3.15, 2.57, 2.03, 3.39]\n\n\ndfoil = pd.DataFrame({'Oil_prod': oil_prod, 'Agno_prod': agno_prod})\n\nwidth = 0.8\nplt.figure(figsize=[10, 5])\n\npl = plt.bar(dfoil.Agno_prod, dfoil.Oil_prod, width, color = '#C70039')\nplt.grid(color='#95a5a6', linestyle='--', linewidth=0.5, axis='y', alpha=0.7)\nplt.title('Producción de aceite en México', fontsize=15)\nplt.xlabel('Año', fontsize=15)\nplt.ylabel('Producción de aceite - miles de barriles diarios', fontsize=15)\n\nfor bar in pl:\n plt.annotate(bar.get_height(),\n xy=(bar.get_x()+0.07, bar.get_height()+10),\n fontsize=7)\n\nax2 = plt.twinx()\nax2.set_ylabel(\"Precio del barril - usd/barril\", fontsize=15)\nplt.plot(agno_prod, oil_price, marker = 'o')\n#-------------------------------------------------------------------------------------------------\ndfgas = pd.DataFrame({'Gas_prod': gas_prod, 'Agno_prod': agno_prod})\n\nwidth = 0.8 \nplt.figure(figsize=[10, 5])\n\npl = plt.bar(dfgas.Agno_prod, dfgas.Gas_prod, width, color = '#C70039')\nplt.grid(color='#95a5a6', linestyle='--', linewidth=0.5, axis='y', alpha=0.7)\nplt.title('Producción de gas en México', fontsize=15)\nplt.xlabel('Año', fontsize=15)\nplt.ylabel('Producción de gas - millones de pies cúbicos', fontsize=15)\n\nfor bar in pl:\n plt.annotate(bar.get_height(),\n xy=(bar.get_x()+0.07, bar.get_height()+10),\n fontsize=7)\n\nax2 = plt.twinx()\nax2.set_ylabel(\"Precio del gas - usd/MMBTU\", fontsize=15)\nplt.plot(agno_prod2, gas_price, marker = 'o')\n#-------------------------------------------------------------------------------------------------\nfig, ax = plt.subplots(1, figsize=(10, 5))\n\nax.bar(agno_prod, gas_asociado, label = 'Gas asociado', color = '#ff5733', width = 0.8)\nax.bar(agno_prod, gas_no_asociado, bottom = gas_asociado, label = 'Gas no asociado', color = '#ffc30f', width = 0.8)\nax.set_ylabel('Producción de gas - millones de pies cúbicos', fontsize=15)\nax.set_xlabel('Año', fontsize=15)\nax.set_title('Producción de gas en México', fontsize=15)\n\ny_offset = -15\n\nfor bar in ax.patches:\n ax.text(\n # Put the text in the middle of each bar. get_x returns the start\n # so we add half the width to get to the middle.\n bar.get_x() + bar.get_width() / 2,\n # Vertically, add the height of the bar to the start of the bar,\n # along with the offset.\n bar.get_height() + bar.get_y() + y_offset,\n # This is actual value we'll show.\n round(bar.get_height()),\n # Center the labels and style them a bit.\n ha='center',\n color='black',\n # weight='bold',\n size=7\n )\n\nax.legend()\n# plt.show()\n#-------------------------------------------------------------------------------------------------\n\nagno_reservas = [2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021]\nreservas_petroleo_1p = np.array([24631, 23660, 22419, 15124, 14120, 12882, 11814, 11048, 10501, 10404, 10420, 10161, 10025, 10073, 9812, 9711, 7641, 7037, 6464, 6065, 6346, 6119])\nreservas_petroleo_2p = np.array([9035, 8982, 8930, 12531, 11814, 11621, 11644, 11034, 10819, 10376, 10021, 10736, 8548, 8457, 7800, 6764, 5632, 5813, 5817, 5879, 5755, 5350])\nreservas_petroleo_3p = np.array([7829, 7275, 6937, 8611, 8455, 8809, 9635, 9827, 9891, 10150, 10057, 9662, 12039, 12286, 11715, 9350, 6182, 7121, 7139, 7101, 5624, 5649])\n\nfig, ax = plt.subplots(1, figsize=(10, 5))\n\nax.bar(agno_reservas, reservas_petroleo_1p, label = 'Probadas (1p)', color = '#c70039', width = 0.8)\nax.bar(agno_reservas, reservas_petroleo_2p, bottom = reservas_petroleo_1p, label = 'Probables (2p)', color = '#ff5733', width = 0.8)\nax.bar(agno_reservas, reservas_petroleo_3p, bottom = reservas_petroleo_1p + reservas_petroleo_2p, label = 'Posibles (3p)', color = '#ffc30f', width = 0.8)\n\nax.set_ylabel('Millones de barriles', fontsize=15)\nax.set_xlabel('Año', fontsize=15)\nax.set_title('Reservas de petróleo en México', fontsize=15)\n\ny_offset = -15\n\nfor bar in ax.patches:\n ax.text(\n # Put the text in the middle of each bar. get_x returns the start\n # so we add half the width to get to the middle.\n bar.get_x() + bar.get_width() / 2,\n # Vertically, add the height of the bar to the start of the bar,\n # along with the offset.\n bar.get_height() + bar.get_y() + y_offset,\n # This is actual value we'll show.\n round(bar.get_height()),\n # Center the labels and style them a bit.\n ha='center',\n color='black',\n # weight='bold',\n size=7\n )\n\nax.legend()\n#-------------------------------------------------------------------------------------------------\n\nagno_reservas = [2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021]\nreservas_gas_1p = np.array([43168, 41383, 38950, 21626, 20740, 20433, 19957, 18957, 18077, 17649, 16815, 17316, 17225, 17075, 16549, 15290, 12651, 10402, 10022, 9654, 9285, 9980])\nreservas_gas_2p = np.array([14885, 15309, 13857, 22071, 20474, 20703, 20087, 20486, 20562, 20110, 20694, 20905, 17613, 17827, 16716, 15316, 9375, 8899, 9355, 11170, 11654, 10410])\nreservas_gas_3p = np.array([20234, 19743, 16299, 21736, 22679, 22743, 22311, 23602, 22720, 22614, 23727, 23053, 26804, 28327, 26401, 24283, 10542, 9649, 10642, 11543, 8763, 10373])\n\nfig, ax = plt.subplots(1, figsize=(10, 5))\n\nax.bar(agno_reservas, reservas_gas_1p, label = 'Probadas (1p)', color = '#c70039', width = 0.8)\nax.bar(agno_reservas, reservas_gas_2p, bottom = reservas_gas_1p, label = 'Probables (2p)', color = '#ff5733', width = 0.8)\nax.bar(agno_reservas, reservas_gas_3p, bottom = reservas_gas_1p + reservas_gas_2p, label = 'Posibles (3p)', color = '#ffc30f', width = 0.8)\n\nax.set_ylabel('Miles de millones de pies cúbicos', fontsize=15)\nax.set_xlabel('Año', fontsize=15)\nax.set_title('Reservas de gas en México', fontsize=15)\n\ny_offset = -15\n\nfor bar in ax.patches:\n ax.text(\n # Put the text in the middle of each bar. get_x returns the start\n # so we add half the width to get to the middle.\n bar.get_x() + bar.get_width() / 2,\n # Vertically, add the height of the bar to the start of the bar,\n # along with the offset.\n bar.get_height() + bar.get_y() + y_offset,\n # This is actual value we'll show.\n round(bar.get_height()),\n # Center the labels and style them a bit.\n ha='center',\n color='black',\n # weight='bold',\n size=7\n )\n\nax.legend()\n#-------------------------------------------------------------------------------------------------\n\nagno_perf = [2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021]\nnum_pozos_desarrollo = np.array([396, 565, 634, 694, 621, 579, 755, 1447, 976, 977, 1258, 678, 526, 279, 105, 62, 153, 234, 153, 36])\nnum_pozos_exploratorios = np.array([57, 98, 108, 70, 64, 48, 65, 65, 40, 30, 32, 39, 20, 24, 23, 35, 26, 39, 33, 16])\n\nfig, ax = plt.subplots(1, figsize=(10, 5))\n\nax.bar(agno_perf, num_pozos_desarrollo, label = 'Pozos de desarrollo', color = '#ff5733', width = 0.8)\nax.bar(agno_perf, num_pozos_exploratorios, bottom = num_pozos_desarrollo, label = 'Pozos exploratorios', color = '#ffc30f', width = 0.8)\n\nax.set_ylabel('Número de pozos', fontsize=15)\nax.set_xlabel('Año', fontsize=15)\nax.set_title('Pozos perforados en México', fontsize=15)\n\nax2 = plt.twinx()\nax2.set_ylabel(\"Precio del barril - usd/barril\", fontsize=15)\nplt.plot(agno_prod, oil_price, marker = 'o')\n\ny_offset = -15\n\nfor bar in ax.patches:\n ax.text(\n # Put the text in the middle of each bar. get_x returns the start\n # so we add half the width to get to the middle.\n bar.get_x() + bar.get_width() / 2,\n # Vertically, add the height of the bar to the start of the bar,\n # along with the offset.\n bar.get_height() + bar.get_y() + y_offset,\n # This is actual value we'll show.\n round(bar.get_height()),\n # Center the labels and style them a bit.\n ha='center',\n color='black',\n # weight='bold',\n size=7\n )\n\nax.legend()\n\nplt.show()"
}
] | 2 |
sagniksom/Natural-Language-Processing
|
https://github.com/sagniksom/Natural-Language-Processing
|
5b62520ec15356de2c8b2a370e0256b4295b53e6
|
45aad40a4600b24c1447b95492d4b94bec8756d2
|
e89f33ebfb895fb76877d325494ca700ddc22493
|
refs/heads/main
| 2023-04-29T09:01:07.223068 | 2021-05-14T15:16:55 | 2021-05-14T15:16:55 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.61272132396698,
"alphanum_fraction": 0.6183606386184692,
"avg_line_length": 33.97706604003906,
"blob_id": "c4c2b46054a0f7eca3aef3f5078c64b3d3a36292",
"content_id": "f7eaea31fa6e7f78f533ec652282251fa083d1c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7625,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 218,
"path": "/Assignment2/a2_training_and_testing.py",
"repo_name": "sagniksom/Natural-Language-Processing",
"src_encoding": "UTF-8",
"text": "import torch\nimport a2_bleu_score\n\nfrom tqdm import tqdm\n\n\ndef train_for_epoch(model, dataloader, optimizer, device):\n '''Train an EncoderDecoder for an epoch\n\n An epoch is one full loop through the training data. This function:\n\n 1. Defines a loss function using :class:`torch.nn.CrossEntropyLoss`,\n keeping track of what id the loss considers \"padding\"\n 2. For every iteration of the `dataloader` (which yields triples\n ``F, F_lens, E``)\n 1. Sends ``F`` to the appropriate device using ``F = F.to(device)``. Same\n for ``F_lens`` and ``E``.\n 2. Zeros out the model's previous gradient with ``optimizer.zero_grad()``\n 3. Calls ``logits = model(F, F_lens, E)`` to determine next-token\n probabilities.\n 4. Modifies ``E`` for the loss function, getting rid of a token and\n replacing excess end-of-sequence tokens with padding using\n ``model.get_target_padding_mask()`` and ``torch.masked_fill``\n 5. Flattens out the sequence dimension into the batch dimension of both\n ``logits`` and ``E``\n 6. Calls ``loss = loss_fn(logits, E)`` to calculate the batch loss\n 7. Calls ``loss.backward()`` to backpropagate gradients through\n ``model``\n 8. Calls ``optim.step()`` to update model parameters\n 3. Returns the average loss over sequences\n\n Parameters\n ----------\n model : EncoderDecoder\n The model we're training.\n dataloader : HansardDataLoader\n Serves up batches of data.\n device : torch.device\n A torch device, like 'cpu' or 'cuda'. Where to perform computations.\n optimizer : torch.optim.Optimizer\n Implements some algorithm for updating parameters using gradient\n calculations.\n\n Returns\n -------\n avg_loss : float\n The total loss divided by the total numer of sequence\n '''\n # If you want, instead of looping through your dataloader as\n # for ... in dataloader: ...\n # you can wrap dataloader with \"tqdm\":\n # for ... in tqdm(dataloader): ...\n # This will update a progress bar on every iteration that it prints\n # to stdout. It's a good gauge for how long the rest of the epoch\n # will take. This is entirely optional - we won't grade you differently\n # either way.\n # If you are running into CUDA memory errors part way through training,\n # try \"del F, F_lens, E, logits, loss\" at the end of each iteration of\n # the loop.\n\n # initialize a timer, loss function, and total loss and batches accumulators\n func = torch.nn.CrossEntropyLoss(ignore_index = model.source_pad_id)\n loss_tot = 0\n batches = 0\n\n print(\"__________________________________________________\")\n print(\"starting train\")\n\n # iterate through each F, F_lens, E in dataloader to train\n for F, F_lens, E in dataloader:\n F = F.to(device)\n F_lens = F_lens.to(device)\n E = E.to(device)\n\n optimizer.zero_grad()\n\n # call the model for logits\n logits = model(F, F_lens, E)\n\n E = E[1:, :]\n\n # mask E\n model_mask = model.get_target_padding_mask(E)\n E = E.masked_fill(model_mask, model.source_pad_id)\n\n logits = logits.flatten(0, 1)\n\n # modify E for loss function\n E = torch.flatten(E, start_dim =0)\n\n loss_curr = func(logits, E)\n\n loss_curr.backward()\n\n optimizer.step()\n\n # add to total loss, and total batches, and remove temporary variables for memory space\n loss_tot = loss_tot + loss_curr.item()\n batches = batches + 1\n del F, F_lens, E, logits, loss_curr\n\n # compute average loss and total time taken.\n # return average loss\n avg_loss = loss_tot/batches\n\n print(\"ended train\")\n\n return avg_loss\n\n\ndef compute_batch_total_bleu(E_ref, E_cand, target_sos, target_eos):\n '''Compute the total BLEU score over elements in a batch\n\n Parameters\n ----------\n E_ref : torch.LongTensor\n A batch of reference transcripts of shape ``(T, M)``, including\n start-of-sequence tags and right-padded with end-of-sequence tags.\n E_cand : torch.LongTensor\n A batch of candidate transcripts of shape ``(T', M)``, also including\n start-of-sequence and end-of-sequence tags.\n target_sos : int\n The ID of the start-of-sequence tag in the target vocabulary.\n target_eos : int\n The ID of the end-of-sequence tag in the target vocabulary.\n\n Returns\n -------\n total_bleu : float\n The sum total BLEU score for across all elements in the batch. Use\n n-gram precision 4.\n '''\n # you can use E_ref.tolist() to convert the LongTensor to a python list\n # of numbers\n\n # initialize total bleu score\n # create strings to check for EOS and SOS\n total_bleu = 0\n eos = str(target_eos)\n sos = str(target_sos)\n\n # create lists for reference and candidates\n E_ref = E_ref.permute(1, 0).tolist()\n E_cand = E_cand.permute(1, 0).tolist()\n\n # iterate through each reference and candidate in the list of references and candidates\n # add the string if it is not a target_EOS or target_SOS to reference and candidate\n # add to the total bleu score\n for reference, candidate in zip(E_ref, E_cand):\n reference = [str(i) for i in reference if ((str(i) != eos) and (str(i) != sos))]\n candidate = [str(j) for j in candidate if ((str(j) != eos) and (str(j) != sos))]\n total_bleu = total_bleu + a2_bleu_score.BLEU_score(reference, candidate, 4)\n\n return total_bleu\n\n\ndef compute_average_bleu_over_dataset(\n model, dataloader, target_sos, target_eos, device):\n '''Determine the average BLEU score across sequences\n\n This function computes the average BLEU score across all sequences in\n a single loop through the `dataloader`.\n\n 1. For every iteration of the `dataloader` (which yields triples\n ``F, F_lens, E_ref``):\n 1. Sends ``F`` to the appropriate device using ``F = F.to(device)``. Same\n for ``F_lens``. No need for ``E_cand``, since it will always be\n compared on the CPU.\n 2. Performs a beam search by calling ``b_1 = model(F, F_lens)``\n 3. Extracts the top path per beam as ``E_cand = b_1[..., 0]``\n 4. Computes the total BLEU score of the batch using\n :func:`compute_batch_total_bleu`\n 2. Returns the average per-sequence BLEU score\n\n Parameters\n ----------\n model : EncoderDecoder\n The model we're testing.\n dataloader : HansardDataLoader\n Serves up batches of data.\n target_sos : int\n The ID of the start-of-sequence tag in the target vocabulary.\n target_eos : int\n The ID of the end-of-sequence tag in the target vocabulary.\n\n Returns\n -------\n avg_bleu : float\n The total BLEU score summed over all sequences divided by the number of\n sequences\n '''\n\n print(\"starting average bleu\")\n\n points = 0\n tot = 0\n\n # iterate through each F, F_lens, E in the data\n for F, F_lens, E in dataloader:\n F = F.to(device)\n F_lens = F_lens.to(device)\n \n # retrieve b_1 and retrieve E_cand from that\n b_1 = model(F, F_lens)\n E_cand = b_1[:,:,0]\n \n # add to the total bleu score\n # add to the total # of points\n tot = tot + compute_batch_total_bleu(E, E_cand, target_sos, target_eos)\n points = points + F_lens.shape[0]\n\n # compute the average bleu score\n avg_bleu = tot/points\n\n print(\"ended average bleu\")\n\n print(\"- - - - - - - - - - - - - - - - - - -\")\n return avg_bleu\n"
},
{
"alpha_fraction": 0.6066371202468872,
"alphanum_fraction": 0.6229312419891357,
"avg_line_length": 38.04999923706055,
"blob_id": "a03ea4538616ce64a3552db8b367653a596970d3",
"content_id": "eb78799611b606e263e5a280456880de45f052d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11722,
"license_type": "no_license",
"max_line_length": 164,
"num_lines": 300,
"path": "/Assignment 1/a1_classify.py",
"repo_name": "sagniksom/Natural-Language-Processing",
"src_encoding": "UTF-8",
"text": "import argparse\nimport os\nimport sklearn\nfrom scipy.stats import ttest_rel\nfrom sklearn.ensemble import AdaBoostClassifier\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.feature_selection import f_classif\nfrom sklearn.feature_selection import SelectKBest\nfrom sklearn.metrics import confusion_matrix\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.model_selection import KFold\nfrom sklearn.neural_network import MLPClassifier\nfrom sklearn.naive_bayes import GaussianNB\nfrom sklearn.linear_model import SGDClassifier \nimport numpy as np\nimport csv\nimport argparse\nimport time\nfrom scipy import stats \n\n# set the random state for reproducibility \nimport numpy as np\nnp.random.seed(401)\n\nclassifiers = [SGDClassifier(max_iter = 10000), GaussianNB(), RandomForestClassifier(max_depth=5, n_estimators=10), MLPClassifier(alpha=0.05), AdaBoostClassifier()]\nclassifier_names = [\"SDGClassifier\", \"GaussianNB\", \"RandomForestClassifier\", \"MLPCLassifier\", \"AdaBoostClassifier\"]\n\ndef accuracy(C):\n ''' Compute accuracy given Numpy array confusion matrix C. Returns a floating point value '''\n numer = np.diag(C).sum()\n denom = C.sum()\n return numer/denom\n\n\ndef recall(C):\n ''' Compute recall given Numpy array confusion matrix C. Returns a list of floating point values '''\n numers = np.diag(C).sum()\n denoms = C.sum(axis = 1) #axis 1 is columns\n return numers/denoms\n\ndef precision(C):\n ''' Compute precision given Numpy array confusion matrix C. Returns a list of floating point values '''\n numers = np.diag(C).sum()\n denoms = C.sum(axis = 0) #axis 0 is rows\n return numers/denoms\n\ndef class31(output_dir, X_train, X_test, y_train, y_test):\n ''' This function performs experiment 3.1\n \n Parameters\n output_dir: path of directory to write output to\n X_train: NumPy array, with the selected training features\n X_test: NumPy array, with the selected testing features\n y_train: NumPy array, with the selected training classes\n y_test: NumPy array, with the selected testing classes\n\n Returns: \n i: int, the index of the supposed best classifier\n '''\n print(\"This is part 3.1: \")\n \n with open(f\"{output_dir}/a1_3.1.txt\", \"w\") as outf:\n # For each classifier, compute results and write the following output:\n # start an accuracy list and accuracy dictionary to later find the best index\n accuracy_list = [0]*5\n acc_dict = {}\n\n # iterate through all the classifiers\n for (i,c) in enumerate(classifiers):\n\n # use each classifier to train\n c.fit(X_train, y_train)\n classifier_name = classifier_names[i]\n\n # obtain accuracy from the confusion matrix\n # add accuracy to accuracy list and save index to dictionary under the accuracy\n conf_matrix = confusion_matrix(y_test, c.predict(X_test))\n accuracy_curr = accuracy(conf_matrix)\n accuracy_list[i] = accuracy_curr\n acc_dict[accuracy_curr] = i\n\n # Computer recall and precision\n recall_curr = recall(conf_matrix)\n precision_curr = precision(conf_matrix)\n\n print(\"For classifier: \", classifier_name, \" Accuracy: \", accuracy_curr)\n\n outf.write(f'Results for {classifier_name}:\\n') # Classifier name\n outf.write(f'\\tAccuracy: {accuracy_curr:.4f}\\n')\n outf.write(f'\\tRecall: {[round(item, 4) for item in recall_curr]}\\n')\n outf.write(f'\\tPrecision: {[round(item, 4) for item in precision_curr]}\\n')\n outf.write(f'\\tConfusion Matrix: \\n{conf_matrix}\\n\\n')\n pass\n\n # find best accuracy index and return\n best_acc = max(accuracy_list)\n iBest = acc_dict[best_acc]\n print(iBest)\n return iBest\n\n\ndef class32(output_dir, X_train, X_test, y_train, y_test, iBest):\n ''' This function performs experiment 3.2\n \n Parameters:\n output_dir: path of directory to write output to\n X_train: NumPy array, with the selected training features\n X_test: NumPy array, with the selected testing features\n y_train: NumPy array, with the selected training classes\n y_test: NumPy array, with the selected testing classes\n iBest: int, the index of the supposed best classifier (from task 3.1) \n\n Returns:\n X_1k: numPy array, just 1K rows of X_train\n y_1k: numPy array, just 1K rows of y_train\n '''\n print(\"This is experiment 3.2: \")\n \n with open(f\"{output_dir}/a1_3.2.txt\", \"w\") as outf:\n classifier = classifiers[iBest]\n # For each number of training examples, compute results and write\n # the following output:\n # outf.write(f'{num_train}: {accuracy:.4f}\\n'))\n\n # iterate through all specified subsets\n for num_train in [1000, 5000, 10000, 15000, 20000]:\n print(\"num_train: \", num_train)\n\n #create subsets for training data\n X_train_sub = X_train[:num_train]\n y_train_sub = y_train[:num_train]\n\n # call best classifier and find best accuracy \n classifier.fit(X_train_sub, y_train_sub)\n conf_matrix = confusion_matrix(y_test, classifier.predict(X_test))\n accuracy_curr = accuracy(conf_matrix)\n\n print(num_train,\": \", accuracy_curr)\n outf.write(f'{num_train}: {accuracy_curr:.4f}\\n')\n pass\n\n X_1k, y_1k = X_train[:1000], y_train[:1000]\n\n return (X_1k, y_1k)\n\n\ndef class33(output_dir, X_train, X_test, y_train, y_test, i, X_1k, y_1k):\n ''' This function performs experiment 3.3\n \n Parameters:\n output_dir: path of directory to write output to\n X_train: NumPy array, with the selected training features\n X_test: NumPy array, with the selected testing features\n y_train: NumPy array, with the selected training classes\n y_test: NumPy array, with the selected testing classes\n i: int, the index of the supposed best classifier (from task 3.1) \n X_1k: numPy array, just 1K rows of X_train (from task 3.2)\n y_1k: numPy array, just 1K rows of y_train (from task 3.2)\n '''\n print(\"We are doing part 3.3 now\")\n\n with open(f\"{output_dir}/a1_3.3.txt\", \"w\") as outf:\n # Prepare the variables with corresponding names, then uncomment\n # this, so it writes them to outf.\n \n # for each number of features k_feat, write the p-values for\n # that number of features:\n classifier = classifiers[i]\n acc_list = []\n\n for k_feat in [5, 50]:\n selector = SelectKBest(score_func=f_classif, k=k_feat)\n X_new = selector.fit_transform(X_train, y_train)\n p_values = selector.pvalues_\n \n outf.write(f'{k_feat} p-values: {[format(pval) for pval in p_values]}\\n')\n\n for (train_x, train_y) in [(X_1k, y_1k), (X_train, y_train)]:\n selector = SelectKBest(score_func = f_classif, k = 5) # k = 5\n\n x_trans_train = selector.fit_transform(train_x, train_y) # reduced x train data\n x_trans_test = selector.transform(X_test)\n\n classifier.fit(x_trans_train, train_y)\n conf_matrix = confusion_matrix(y_test, classifier.predict(x_trans_test))\n\n acc = accuracy(conf_matrix)\n acc_list.append(acc)\n\n\n accuracy_1k = acc_list[0]\n accuracy_full = acc_list[1]\n\n ind_1k = set(SelectKBest(score_func=f_classif, k=5).fit(X_1k, y_1k).get_support(indices=True))\n ind_full = set(SelectKBest(score_func=f_classif, k=5).fit(X_train, y_train).get_support(indices=True))\n\n print(\"ind_1k: \",ind_1k)\n print(\"ind_full: \",ind_full)\n\n feature_intersection = ind_1k.intersection(ind_full)\n\n outf.write(f'Accuracy for 1k: {accuracy_1k:.4f}\\n')\n outf.write(f'Accuracy for full dataset: {accuracy_full:.4f}\\n')\n outf.write(f'Chosen feature intersection: {feature_intersection}\\n')\n outf.write(f'Top-5 at higher: {ind_full}\\n')\n pass\n\n\ndef class34(output_dir, X_train, X_test, y_train, y_test, X_data, y_data, i):\n ''' This function performs experiment 3.4\n \n Parameters\n output_dir: path of directory to write output to\n X_train: NumPy array, with the selected training features\n X_test: NumPy array, with the selected testing features\n y_train: NumPy array, with the selected training classes\n y_test: NumPy array, with the selected testing classes\n i: int, the index of the supposed best classifier (from task 3.1) \n '''\n print('We are doing 3.4 now')\n \n with open(f\"{output_dir}/a1_3.4.txt\", \"w\") as outf:\n\n kfold = KFold(n_splits = 5, shuffle = True, random_state = 401)\n kfold_accuracies = np.zeros((5,5))\n # Prepare kfold_accuracies, then uncomment this, so it writes them to outf.\n # for each fold:\n z = 0\n for (train_ind, test_ind) in kfold.split(X_data):\n x_train, y_train = X_data[train_ind], y_data[train_ind]\n x_test, y_test = X_data[test_ind], y_data[test_ind]\n j = 0\n for c in classifiers:\n c.fit(x_train, y_train)\n class_name = classifier_names[j]\n conf_matrix = confusion_matrix(y_test, c.predict(x_test))\n accuracy_curr = accuracy(conf_matrix)\n kfold_accuracies[z][j] = round(accuracy_curr,4)\n print(\"for class: \", class_name, \" K fold #: \",z, \" Accuracy: \", accuracy_curr) \n j = j+1\n print(\"acc row: \", kfold_accuracies[z])\n\n outf.write(f'Kfold Accuracies: {kfold_accuracies[z]}\\n')\n z = z + 1\n \n class_accs = np.array(kfold_accuracies).transpose()\n\n p_values = []\n for h in range(0,5):\n if h != i:\n p_values.append(stats.ttest_rel(class_accs[h], class_accs[i]).pvalue)\n\n p_values = np.array(p_values)\n print(\"p_vals: \", p_values)\n\n outf.write(f'p-values: {[round(pval, 4) for pval in p_values]}\\n')\n \n pass\n\n\n \nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser()\n parser.add_argument(\"-i\", \"--input\", help=\"the input npz file from Task 2\", required=True)\n parser.add_argument(\n \"-o\", \"--output_dir\",\n help=\"The directory to write a1_3.X.txt files to.\",\n default=os.path.dirname(os.path.dirname(__file__)))\n args = parser.parse_args()\n \n # TODO: load data and split into train and test.\n # TODO : complete each classification experiment, in sequence.\n\n feats = np.load(args.input)\n data = feats[feats.files[0]]\n\n # set the output directory\n output_dir = \"part3\"\n\n X_data = data[:, 0:173]\n y_data = data[:, -1]\n\n X_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size = 0.2, random_state = 123, shuffle = True)\n\n print(\"X_train length and shape: \", len(X_train), X_train.shape)\n print(\"y_train length and shape: \", len(y_train), y_train.shape)\n print(\"x_test length and shape: \", len(X_test), X_test.shape)\n print(\"y_test length and shape: \", len(y_test), y_test.shape)\n\n x_1k, y_1k = X_train[:1000], y_train[:1000]\n #RUN EACH OF THESE STEP BY STEP OTHERWISE ITS GONNA TAKE FOREVER MAN\n\n #i_best = class31(output_dir, X_train, X_test, y_train, y_test)\n \n # we know i_best is ada_boost. thus \n i_best = 4\n #x_1k, y_1k = class32(output_dir, X_train, X_test, y_train, y_test, i_best)\n\n #class33(output_dir, X_train, X_test, y_train, y_test, i_best, x_1k, y_1k)\n class34(output_dir, X_train, X_test, y_train, y_test, X_data, y_data, i_best)\n\n\n \n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.8226414918899536,
"avg_line_length": 32.125,
"blob_id": "f39df998f450ee193e188e6eb758ff96a77bb133",
"content_id": "29ef7602e101ad798b121e4d8cac49bf21d877de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 265,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 8,
"path": "/README.md",
"repo_name": "sagniksom/Natural-Language-Processing",
"src_encoding": "UTF-8",
"text": "# Natural-Language-Processing\ncsc401 natural language processing course assignments\n\nAssignment 1: Determining political bias based off of reddit comments. \n\nAssignment 2: Translating speech (English and French).\n\nAssignment 3: Detecting lies in audio information.\n"
},
{
"alpha_fraction": 0.5330585837364197,
"alphanum_fraction": 0.5430190563201904,
"avg_line_length": 33.2529411315918,
"blob_id": "81bc1dcfa886eb79866a6f5cd1118452dfe7bb45",
"content_id": "a861fcf0789fed41a2237a1471d82915d4991b7d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5823,
"license_type": "no_license",
"max_line_length": 157,
"num_lines": 170,
"path": "/Assignment 1/a1_preproc.py",
"repo_name": "sagniksom/Natural-Language-Processing",
"src_encoding": "UTF-8",
"text": "import sys\nimport argparse\nimport os\nimport json\nimport re\nimport spacy\nimport unicodedata\nimport html\nfrom spacy.tokens import Doc \nimport string\n\nnlp = spacy.load('en_core_web_sm', disable=['parser', 'ner'])\nsentencizer = nlp.create_pipe(\"sentencizer\")\nnlp.add_pipe(sentencizer)\n\n#def punctuations(comm)\n\n \ndef preproc(data, category):\n for i in range(0, len(data)):\n line = json.loads(data[i])\n\n print(\"~~~Original: \")\n print(line['body'])\n\n preproc_bod = preproc1(line['body'])\n\n print(\"!!!parsed: \")\n print(preproc_bod.encode('unicode_escape').decode('utf-8'))\n\n line['body'] = preproc_bod\n line['cat'] = category\n\n data[i] = json.JSONEncoder().encode(line)\n\n return data\n\ndef preproc1(comment , steps=range(1, 6)):\n ''' This function pre-processes a single comment\n\n Parameters: \n comment : string, the body of a comment\n steps : list of ints, each entry in this list corresponds to a preprocessing step \n\n Returns:\n modComm : string, the modified comment \n '''\n modComm = comment\n if 1 in steps: \n #modify this to handle other whitespace chars.\n #replace newlines with spaces\n modComm = re.sub(r\"\\n{1,}\", \" \", modComm)\n modComm = re.sub(r'\\s+', \" \", modComm)\n modComm = modComm.replace('\\\\s+', \" \")\n modComm = modComm.strip()\n print (\"after step 1: \", modComm)\n\n if 2 in steps: # unescape html\n modComm = modComm.strip()\n temp = html.unescape(modComm)\n modComm = unicodedata.normalize(\"NFD\", temp).encode(\"ascii\", \"ignore\").decode(\"utf-8\").encode(\"ascii\", \"ignore\").decode()\n \n print(\"after step 2: \", modComm)\n if (modComm == \"\"):\n return \"\"\n\n if 3 in steps: # remove URLs\n modComm = modComm.strip()\n modComm = re.sub(r\"(http|www)\\S+\", \"\", modComm)\n print(\"after step 3: \", modComm)\n\n if (modComm == \"\"):\n return \"\"\n \n if 4 in steps: #remove duplicate spaces.\n\n modComm = modComm.strip()\n modComm = re.sub(r\"\\s+\", \" \", modComm) \n print(\"after step 4: \", modComm)\n\n if (modComm == \"\"):\n return \"\"\n\n if 5 in steps:\n # TODO: get Spacy document for modComm\n \n # TODO: use Spacy document for modComm to create a string.\n # Make sure to:\n # * Insert \"\\n\" between sentences.\n # * Split tokens with spaces.\n # * Write \"/POS\" after each token.\n tag_line = \"\"\n \n doc = nlp(modComm)\n\n upper = False\n for i, token in enumerate(doc):\n upper = token.text.isupper()\n if ((str(token.lemma_)[0] != '-') or (str(token.lemma_)[0] == '-' and token.text[0] =='-')):\n if (upper == True):\n tag_line = tag_line + token.lemma_.upper() + '/' + token.tag_\n else:\n tag_line = tag_line + token.lemma_.lower() + '/' + token.tag_\n else: \n if (upper == True):\n tag_line = tag_line + token.text.upper() + '/' + token.tag_\n else:\n tag_line = tag_line + token.text.lower() + '/' + token.tag_\n if ((token.text == '.') or (token.text == '!') or (token.text == '?') or (i == len(doc) - 1)):\n tag_line = tag_line + '\\n '\n else: \n tag_line = tag_line + \" \"\n\n modComm = tag_line\n print(\"after step 5.1, 5.2 and 5.3: \", modComm)\n\n return modComm\n\n\ndef main(args):\n allOutput = []\n for subdir, dirs, files in os.walk(indir):\n for file in files:\n fullFile = os.path.join(subdir, file)\n #fullFile = \"sample_in.json\"\n print( \"Processing \" + fullFile)\n\n data = json.load(open(fullFile))\n\n start = student_id % len(data)\n\n if (len(data)- (start + 1)<args.max):\n data = data[start : ] + data[0: args.max - len(data) + start]\n else:\n data = data[start : start + args.max]\n\n preprocData = preproc(data, file)\n allOutput = allOutput + preprocData\n\n # TODO: select appropriate args.max lines\n # TODO: read those lines with something like `j = json.loads(line)`\n # TODO: choose to retain fields from those lines that are relevant to you\n # TODO: add a field to each selected line called 'cat' with the value of 'file' (e.g., 'Alt', 'Right', ...) \n # TODO: process the body field (j['body']) with preproc1(...) using default for `steps` argument\n # TODO: replace the 'body' field with the processed text\n # TODO: append the result to 'allOutput'\n \n fout = open(args.output, 'w')\n fout.write(json.dumps(allOutput))\n fout.close()\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser(description='Process each .')\n parser.add_argument('ID', metavar='N', type=int, nargs=1,\n help='your student ID')\n parser.add_argument(\"-o\", \"--output\", help=\"Directs the output to a filename of your choice\", required=True)\n parser.add_argument(\"--max\", type=int, help=\"The maximum number of comments to read from each file\", default=10000)\n parser.add_argument(\"--a1_dir\", help=\"The directory for A1. Should contain subdir data. Defaults to the directory for A1 on cdf.\", default='/u/cs401/A1')\n \n args = parser.parse_args()\n\n student_id = args.ID[0]\n\n if (args.max > 200272):\n print( \"Error: If you want to read more than 200,272 comments per file, you have to read them all.\" )\n sys.exit(1)\n \n indir = os.path.join(args.a1_dir, 'data')\n main(args)\n"
},
{
"alpha_fraction": 0.5468799471855164,
"alphanum_fraction": 0.555794358253479,
"avg_line_length": 40.12602233886719,
"blob_id": "6f914d3e319a7cdf0f5e2e25c931a32ec049ef8a",
"content_id": "0de6609a92b803521120a982818cc2f7870f4524",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 25128,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 611,
"path": "/Assignment2/a2_encoder_decoder.py",
"repo_name": "sagniksom/Natural-Language-Processing",
"src_encoding": "UTF-8",
"text": "import torch\n\nfrom a2_abcs import EncoderBase, DecoderBase, EncoderDecoderBase\n\n# All docstrings are omitted in this file for simplicity. So please read\n# a2_abcs.py carefully so that you can have a solid understanding of the\n# structure of the assignment.\n\nclass Encoder(EncoderBase):\n\n\n def init_submodules(self):\n # Hints:\n # 1. You must initialize the following submodules:\n # self.rnn, self.embedding\n # 2. You will need the following object attributes:\n # self.source_vocab_size, self.word_embedding_size,\n # self.pad_id, self.dropout, self.cell_type, self.heads\n # self.hidden_state_size, self.num_hidden_layers.\n # 3. cell_type will be one of: ['lstm', 'gru', 'rnn']\n # 4. Relevant pytorch modules: torch.nn.{LSTM, GRU, RNN, Embedding}\n #super(Encoder, self).__init__()\n\n #YOU CAN CHANGE THE ORDER OF THE PARAMETERS BC YOU SAY param = ____\n\n self.embedding = torch.nn.Embedding(num_embeddings = self.source_vocab_size, \n embedding_dim = self.word_embedding_size, \n padding_idx = self.pad_id)\n\n if self.cell_type == 'lstm':\n self.rnn = torch.nn.LSTM(input_size = self.word_embedding_size, \n hidden_size = self.hidden_state_size, \n num_layers = self.num_hidden_layers, \n dropout = self.dropout, \n bidirectional=True)\n \n elif self.cell_type == 'gru':\n self.rnn = torch.nn.GRU(input_size = self.word_embedding_size, \n hidden_size = self.hidden_state_size, \n num_layers = self.num_hidden_layers, \n dropout = self.dropout, \n bidirectional=True)\n \n elif self.cell_type == 'rnn':\n self.rnn = torch.nn.RNN(input_size = self.word_embedding_size, \n hidden_size = self.hidden_state_size, \n num_layers = self.num_hidden_layers, \n dropout = self.dropout, \n bidirectional = True)\n\n # guard against invalid input\n else:\n print(\"WRONG CELL TYPE INPUT\")\n\n\n def forward_pass(self, F, F_lens, h_pad=0.):\n # Recall:\n # F is size (S, M)\n # F_lens is of size (M,)\n # h_pad is a float\n #\n # Hints:\n # 1. The structure of the encoder should be:\n # input seq -> |embedding| -> embedded seq -> |rnn| -> seq hidden\n # 2. You will need to use the following methods:\n # self.get_all_rnn_inputs, self.get_all_hidden_states\n\n # rnn_input shape (S,M,I) --> I=size of word\n # hidden_states shape = (S, M, 2*hidden_state_size)\n\n rnn_input = self.get_all_rnn_inputs(F)\n\n hidden_states = self.get_all_hidden_states(rnn_input, F_lens, h_pad)\n\n return hidden_states\n\n def get_all_rnn_inputs(self, F):\n # Recall:\n # F is size (S, M)\n # x (output) is size (S, M, I)\n result = self.embedding(F)\n\n return result\n\n def get_all_hidden_states(self, x, F_lens, h_pad):\n # Recall:\n # x is of size (S, M, I)\n # F_lens is of size (M,)\n # h_pad is a float\n # h (output) is of size (S, M, 2 * H)\n #\n # Hint:\n # relevant pytorch modules:\n # torch.nn.utils.rnn.{pad_packed,pack_padded}_sequence\n\n # using pad_padded_sequence and the rnn function defined to get the input to pad_packed_sequence\n # unpacked is all the hidden states\n pack = torch.nn.utils.rnn.pack_padded_sequence(input = x, lengths = F_lens, enforce_sorted = False)\n out, _ = self.rnn.forward(pack)\n unpacked, _ = torch.nn.utils.rnn.pad_packed_sequence(sequence = out, padding_value = h_pad)\n \n return unpacked\n\n\nclass DecoderWithoutAttention(DecoderBase):\n '''A recurrent decoder without attention'''\n\n def init_submodules(self):\n # Hints:\n # 1. You must initialize the following submodules:\n # self.embedding, self.cell, self.ff\n # 2. You will need the following object attributes:\n # self.target_vocab_size, self.word_embedding_size, self.pad_id\n # self.hidden_state_size, self.cell_type.\n # 3. cell_type will be one of: ['lstm', 'gru', 'rnn']\n # 4. Relevant pytorch modules:\n # torch.nn.{Embedding, Linear, LSTMCell, RNNCell, GRUCell}\n self.embedding = torch.nn.Embedding(num_embeddings = self.target_vocab_size, \n embedding_dim = self.word_embedding_size, \n padding_idx = self.pad_id)\n \n self.ff = torch.nn.Linear(in_features = self.hidden_state_size, out_features = self.target_vocab_size)\n \n if self.cell_type == 'lstm':\n self.cell = torch.nn.LSTMCell(input_size = self.word_embedding_size, hidden_size = self.hidden_state_size)\n \n elif self.cell_type == 'gru':\n self.cell = torch.nn.GRUCell(input_size = self.word_embedding_size, hidden_size = self.hidden_state_size)\n \n elif self.cell_type == 'rnn':\n self.cell = torch.nn.RNNCell(input_size = self.word_embedding_size, hidden_size = self.hidden_state_size)\n \n # guard against invalid cell type\n else:\n print(\"WRONG INPUT FOR CELL TYPE\")\n\n def forward_pass(self, E_tm1, htilde_tm1, h, F_lens):\n # Recall:\n # E_tm1 is of size (M,)\n # htilde_tm1 is of size (M, 2 * H)\n # h is of size (S, M, 2 * H)\n # F_lens is of size (M,)\n # logits_t (output) is of size (M, V)\n # htilde_t (output) is of same size as htilde_tm1\n #\n # Hints:\n # 1. The structure of the encoder should be:\n # encoded hidden -> |embedding| -> embedded hidden -> |rnn| ->\n # decoded hidden -> |output layer| -> output logits\n # 2. You will need to use the following methods:\n # self.get_current_rnn_input, self.get_current_hidden_state,\n # self.get_current_logits\n # 3. You can assume that htilde_tm1 is not empty. I.e., the hidden state\n # is either initialized, or t > 1.\n # 4. The output of an LSTM cell is a tuple (h, c), but a GRU cell or an\n # RNN cell will only output h.\n \n ####################\n # first encode target sequence E_tm1 --> x_tilde\n # pass in last hidden state of last time stamp and x_tilde into rnn cell --> h_tilde\n # pass h_tilde into fully connected layer to convert to logits\n ####################\n\n # lstm is special as stated in a2_abcs.py\n if htilde_tm1 is None:\n htilde_tm1 = self.get_first_hidden_state(h, F_lens)\n if self.cell_type == 'lstm':\n htilde_tm1 = (htilde_tm1, torch.zeros_like(htilde_tm1))\n\n xtilde_t = self.get_current_rnn_input(E_tm1, htilde_tm1, h, F_lens)\n\n htilde_t = self.get_current_hidden_state(xtilde_t, htilde_tm1)\n\n # check for lstm and input the first dim of htilde_t if lstm\n # input normally otherwise\n if self.cell_type == \"lstm\":\n logits_t = self.get_current_logits(htilde_t[0])\n else:\n logits_t = self.get_current_logits(htilde_t)\n\n return logits_t, htilde_t\n\n\n def get_first_hidden_state(self, h, F_lens):\n # Recall:\n # h is of size (S, M, 2 * H)\n # F_lens is of size (M,)\n # htilde_tm1 (output) is of size (M, 2 * H)\n #\n # Hint:\n # 1. Ensure it is derived from encoder hidden state that has processed\n # the entire sequence in each direction. You will need to:\n # - Populate indices [0: self.hidden_state_size // 2] with the hidden\n # states of the encoder's forward direction at the highest index in\n # time *before padding*\n # - Populate indices [self.hidden_state_size//2:self.hidden_state_size]\n # with the hidden states of the encoder's backward direction at time\n # t=0\n # 2. Relevant pytorch function: torch.cat\n\n # populating indices as described in abcs.py\n\n bwd_states = h[0,:, self.hidden_state_size // 2:]\n fwd_states = h[F_lens - 1, torch.arange(F_lens.shape[0]), :self.hidden_state_size // 2]\n\n htilde_0 = torch.cat([fwd_states, bwd_states], dim = 1)\n\n return htilde_0\n\n def get_current_rnn_input(self, E_tm1, htilde_tm1, h, F_lens):\n # Recall:\n # E_tm1 is of size (M,)\n # htilde_tm1 is of size (M, 2 * H) or a tuple of two of those (LSTM)\n # h is of size (S, M, 2 * H)\n # F_lens is of size (M,)\n # xtilde_t (output) is of size (M, Itilde)\n\n xtilde_t = self.embedding(E_tm1)\n\n # mask xtilde_t as specified\n mask = (E_tm1 != self.pad_id).float().unsqueeze(-1)\n\n xtilde_t = xtilde_t * mask\n\n return xtilde_t\n\n def get_current_hidden_state(self, xtilde_t, htilde_tm1):\n # Recall:\n # xtilde_t is of size (M, Itilde)\n # htilde_tm1 is of size (M, 2 * H) or a tuple of two of those (LSTM)\n # htilde_t (output) is of same size as htilde_tm1\n \n # check for lstm for special case\n # compute normally for other cell types\n if self.cell_type == 'lstm':\n htilde_tm1 = (htilde_tm1[0][:, :self.hidden_state_size], htilde_tm1[1][:, :self.hidden_state_size])\n else:\n htilde_tm1 = htilde_tm1[:, :self.hidden_state_size]\n \n htilde_t = self.cell(xtilde_t, htilde_tm1)\n\n return htilde_t\n\n def get_current_logits(self, htilde_t):\n # Recall:\n # htilde_t is of size (M, 2 * H), even for LSTM (cell state discarded)\n # logits_t (output) is of size (M, V)\n #assert False, \"Fill me\"\n\n # not sure why we cant just do logits = self.ff(htilde_t)\n logits_unnorm = self.ff.forward(htilde_t)\n\n return logits_unnorm\n\n\nclass DecoderWithAttention(DecoderWithoutAttention):\n '''A decoder, this time with attention\n\n Inherits from DecoderWithoutAttention to avoid repeated code.\n '''\n\n def init_submodules(self):\n # Hints:\n # 1. Same as the case without attention, you must initialize the\n # following submodules: self.embedding, self.cell, self.ff\n # 2. You will need the following object attributes:\n # self.target_vocab_size, self.word_embedding_size, self.pad_id\n # self.hidden_state_size, self.cell_type.\n # 3. cell_type will be one of: ['lstm', 'gru', 'rnn']\n # 4. Relevant pytorch modules:\n # torch.nn.{Embedding, Linear, LSTMCell, RNNCell, GRUCell}\n # 5. The implementation of this function should be different from\n # DecoderWithoutAttention.init_submodules.\n self.embedding = torch.nn.Embedding(num_embeddings = self.target_vocab_size, \n embedding_dim = self.word_embedding_size, \n padding_idx = self.pad_id)\n \n self.ff = torch.nn.Linear(in_features = self.hidden_state_size, \n out_features = self.target_vocab_size)\n \n input_size = self.word_embedding_size + self.hidden_state_size\n\n if self.cell_type == 'lstm':\n self.cell = torch.nn.LSTMCell(input_size = input_size, hidden_size = self.hidden_state_size)\n \n elif self.cell_type == 'gru':\n self.cell = torch.nn.GRUCell(input_size = input_size, hidden_size = self.hidden_state_size)\n \n elif self.cell_type == 'rnn':\n self.cell = torch.nn.RNNCell(input_size = input_size, hidden_size = self.hidden_state_size)\n \n # guard against wrong input type\n else:\n print(\"WRONG INPUT FOR CELL TYPE\")\n\n def get_first_hidden_state(self, h, F_lens):\n # Hint: For this time, the hidden states should be initialized to zeros.\n\n htilde_0 = torch.zeros_like(h[0])\n\n return htilde_0\n\n def get_current_rnn_input(self, E_tm1, htilde_tm1, h, F_lens):\n \n # check for lstm special case\n if self.cell_type == 'lstm':\n htilde_tm1 = htilde_tm1[0]\n \n # obtain T_e and c_t from embedding and attend\n T_e = self.embedding(E_tm1)\n c_t = self.attend(htilde_tm1, h, F_lens)\n\n # mask T_e for pad_id\n mask = (E_tm1 != self.pad_id).float().unsqueeze(-1)\n\n T_e = T_e * mask\n\n xtilde_t = torch.cat([T_e, c_t], dim = 1)\n\n return xtilde_t\n\n def attend(self, htilde_t, h, F_lens):\n '''The attention mechanism. Calculate the context vector c_t.\n\n Parameters\n ----------\n htilde_t : torch.FloatTensor or tuple\n Like `htilde_tm1` (either a float tensor or a pair of float\n tensors), but matching the current hidden state.\n h : torch.FloatTensor\n A float tensor of size ``(S, M, self.hidden_state_size)`` of\n hidden states of the encoder. ``h[s, m, i]`` is the\n ``i``-th index of the encoder RNN's last hidden state at time ``s``\n of the ``m``-th sequence in the batch. The states of the\n encoder have been right-padded such that ``h[F_lens[m]:, m]``\n should all be ignored.\n F_lens : torch.LongTensor\n An integer tensor of size ``(M,)`` corresponding to the lengths\n of the encoded source sentences.\n\n Returns\n -------\n c_t : torch.FloatTensor\n A float tensor of size ``(M, self.hidden_state_size)``. The\n context vectorc_t is the product of weights alpha_t and h.\n\n Hint: Use get_attention_weights() to calculate alpha_t.\n '''\n ####################\n # get attention to alculate attention over last hidden layer\n # get attention weights\n # calculate sums of attention weights*hidden states?\n # get attention weights from the softmax of the attention score (already provided func)\n # attention scores are calculated from cosine similarity \n ####################\n\n # attention_weights shape (S, M)\n attention_weights = self.get_attention_weights(htilde_t, h, F_lens)\n \n # h (S, M, self.hidden_state_size)\n\n #c_t (M, self.hidden_state_size) \n \n #trying matmul --> should give (S, M, self.hiddenstatesize)\n\n attention_weights = attention_weights.transpose(0,1).unsqueeze(2)\n\n h = h.permute(1, 2, 0)\n\n c_t = torch.matmul(h, attention_weights).squeeze()\n\n return c_t\n\n def get_attention_weights(self, htilde_t, h, F_lens):\n # DO NOT MODIFY! Calculates attention weights, ensuring padded terms\n # in h have weight 0 and no gradient. You have to implement\n # get_energy_scores()\n # alpha_t (output) is of size (S, M)\n e_t = self.get_energy_scores(htilde_t, h)\n pad_mask = torch.arange(h.shape[0], device=h.device)\n pad_mask = pad_mask.unsqueeze(-1) >= F_lens # (S, M)\n e_t = e_t.masked_fill(pad_mask, -float('inf'))\n return torch.nn.functional.softmax(e_t, 0)\n\n def get_energy_scores(self, htilde_t, h):\n # Recall:\n # htilde_t is of size (M, 2 * H)\n # h is of size (S, M, 2 * H)\n # e_t (output) is of size (S, M)\n #\n # Hint:\n # Relevant pytorch function: torch.nn.functional.cosine_similarity\n\n # using cosine_cosine similarity to obtain energy scores\n htilde_t = htilde_t.unsqueeze(0)\n e_t = torch.nn.functional.cosine_similarity(htilde_t, h, dim = 2)\n\n return e_t\n\nclass DecoderWithMultiHeadAttention(DecoderWithAttention):\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n assert self.W is not None, 'initialize W!'\n assert self.Wtilde is not None, 'initialize Wtilde!'\n assert self.Q is not None, 'initialize Q!'\n\n def init_submodules(self):\n super().init_submodules() # Do not change this line\n\n # Hints:\n # 1. The above line should ensure self.ff, self.embedding, self.cell are\n # initialized\n # 2. You need to initialize the following submodules:\n # self.W, self.Wtilde, self.Q\n # 3. You will need the following object attributes:\n # self.hidden_state_size\n # 4. self.W, self.Wtilde, and self.Q should process all heads at once. They\n # should not be lists!\n # 5. Relevant pytorch module: torch.nn.Linear (note: set bias=False!)\n # 6. You do *NOT* need self.heads at this point\n #assert False, \"Fill me\"\n\n ###############\n # don't use for loops\n # just reshape the hidden weights\n # calculate the weight first\n # then slice it when you're finding htilde_t_1\n # initialize W as random stuff?\n # Wtilde and W and Q are learned weights\n # different weight matrix for each of the attention heads\n ###############\n\n self.W = torch.nn.Linear(in_features = self.hidden_state_size,\n out_features = self.hidden_state_size,\n bias = False)\n self.Wtilde = torch.nn.Linear(in_features = self.hidden_state_size,\n out_features = self.hidden_state_size,\n bias = False)\n self.Q = torch.nn.Linear(in_features = self.hidden_state_size,\n out_features = self.hidden_state_size,\n bias = False)\n\n def attend(self, htilde_t, h, F_lens):\n # Hints:\n # 1. You can use super().attend to call for the regular attention\n # function.\n # 2. Relevant pytorch function:\n # tensor().view, tensor().repeat_interleave\n # 3. You *WILL* need self.heads at this point\n # 4. Fun fact:\n # tensor([1,2,3,4]).repeat(2) will output tensor([1,2,3,4,1,2,3,4]).\n # tensor([1,2,3,4]).repeat_interleave(2) will output\n # tensor([1,1,2,2,3,3,4,4]), just like numpy.repeat.\n #assert False, \"Fill me\"\n\n ###############\n # attention vect is concatenated attent vect of smaller chuncks\n # slicing/ reshapping happens here using self.heads\n # you get full hidden state as input\n # concatenate all together and then mutiply with Q to get xtilde_t\n # xtilde_t = [Tf(E_t_1), Qc(t_1)] --> c concatenated here\n ###############\n # htilde_tn = Wtilde_n*htilde_tn\n # hs_n = W_n*hs\n # c_tn = attend(htilde_tn, hs_n)\n # xtilde_t = [Tf(Et_1), Q*c_t]\n # return Q*c_t to be used in decoderWithAttention get_current_rnn_input\n\n heads = self.heads\n partition = self.hidden_state_size//heads\n\n htilde_t_n = self.Wtilde(htilde_t)\n\n htilde_t_n = htilde_t_n.view(htilde_t_n.shape[0]*heads, partition)\n\n hs_n = self.W(h)\n hs_n = hs_n.view(hs_n.shape[0], hs_n.shape[1]*heads, partition)\n\n new_flens = F_lens.repeat_interleave(repeats = heads)\n\n c_t_concat = super().attend(htilde_t_n, hs_n, new_flens)\n c_t_concat = c_t_concat.view(htilde_t.shape[0], htilde_t.shape[1])\n\n c_t = self.Q(c_t_concat)\n\n return c_t\n\nclass EncoderDecoder(EncoderDecoderBase):\n\n def init_submodules(self, encoder_class, decoder_class):\n # Hints:\n # 1. You must initialize the following submodules:\n # self.encoder, self.decoder\n # 2. encoder_class and decoder_class inherit from EncoderBase and\n # DecoderBase, respectively.\n # 3. You will need the following object attributes:\n # self.source_vocab_size, self.source_pad_id,\n # self.word_embedding_size, self.encoder_num_hidden_layers,\n # self.encoder_hidden_size, self.encoder_dropout, self.cell_type,\n # self.target_vocab_size, self.target_eos,self.heads\n # 4. Recall that self.target_eos doubles as the decoder pad id since we\n # never need an embedding for it\n #assert False, \"Fill me\"\n\n self.encoder = encoder_class(source_vocab_size = self.source_vocab_size, \n pad_id = self.source_pad_id, \n word_embedding_size = self.word_embedding_size,\n num_hidden_layers = self.encoder_num_hidden_layers,\n hidden_state_size = self.encoder_hidden_size,\n dropout = self.encoder_dropout,\n cell_type = self.cell_type)\n self.encoder.init_submodules()\n \n self.decoder = decoder_class(target_vocab_size = self.target_vocab_size,\n pad_id = self.target_eos,\n word_embedding_size = self.word_embedding_size,\n hidden_state_size = self.encoder_hidden_size * 2,\n cell_type = self.cell_type,\n heads = self.heads)\n self.decoder.init_submodules()\n\n def get_logits_for_teacher_forcing(self, h, F_lens, E):\n # Recall:\n # h is of size (S, M, 2 * H)\n # F_lens is of size (M,)\n # E is of size (T, M)\n # logits (output) is of size (T - 1, M, Vo)\n #\n # Hints:\n # 1. Relevant pytorch modules: torch.{zero_like, stack}\n # 2. Recall an LSTM's cell state is always initialized to zero.\n # 3. Note logits sequence dimension is one shorter than E (why?)\n #assert False, \"Fill me\"\n htilde_tm1 = None\n logits = []\n\n # iterate through each time step and add the logits at the step to total logits list\n for time in range(E.shape[0]-1):\n curr_logits, htilde_tm1 = self.decoder.forward_pass(E[time], htilde_tm1, h, F_lens)\n logits = logits + [curr_logits]\n \n # no sos\n logits_t = torch.stack(logits[:], 0)\n\n return logits_t\n\n def update_beam(self, htilde_t, b_tm1_1, logpb_tm1, logpy_t):\n # perform the operations within the psuedo-code's loop in the\n # assignment.\n # You do not need to worry about which paths have finished, but DO NOT\n # re-normalize logpy_t.\n #\n # Recall\n # htilde_t is of size (M, K, 2 * H) or a tuple of two of those (LSTM)\n # logpb_tm1 is of size (M, K)\n # b_tm1_1 is of size (t, M, K)\n # b_t_0 (first output) is of size (M, K, 2 * H) or a tuple of two of\n # those (LSTM)\n # b_t_1 (second output) is of size (t + 1, M, K)\n # logpb_t (third output) is of size (M, K)\n #\n # Hints:\n # 1. Relevant pytorch modules:\n # torch.{flatten, topk (returns k largest/smallest dimensions), unsqueeze, expand_as, gather, cat}\n # 2. If you flatten a two-dimensional array of size z of (A, B),\n # then the element z[a, b] maps to z'[a*B + b]\n #assert False, \"Fill me\"\n \n ##############\n # b_t_0 size --->(M, self.beam_width, 2 * self.encoder_hidden_size) float tensor\n # hidden states of the remaining paths after the update\n # b_t_1 size --->(t + 1, M, self.beam_width) long tensor\n # the token sequences of the remaining paths after the update\n # logpb_t ---> (M, self.beam_width) float tensor\n # log-probabilities of the remaining paths in the beam after the update.\n ##############\n V = logpy_t.shape[-1]\n #V = logpy_t.size()[-1]\n\n # (M, K, V)\n log_probs = logpb_tm1.unsqueeze(-1) + logpy_t\n\n # (M, K*V)\n paths = log_probs.view((log_probs.shape[0], -1))\n\n # best indecies\n # (N, K) --> logpbt\n # (N, K) --> indecies\n logpb_t, indecies = paths.topk(self.beam_width, -1, largest = True, sorted = True)\n #logpb_t = logpb_t\n\n kept_paths = torch.div(indecies, V)\n indecies = torch.remainder(indecies, V)\n\n path_b_tm1_1 = b_tm1_1.gather(2, kept_paths.unsqueeze(0).expand_as(b_tm1_1))\n\n if self.cell_type == 'lstm':\n first = htilde_t[0].gather(1, kept_paths.unsqueeze(-1).expand_as(htilde_t[0]))\n second = htilde_t[1].gather(1, kept_paths.unsqueeze(-1).expand_as(htilde_t[1]))\n b_t_0 = (first, second)\n else: \n b_t_0 = htilde_t.gather(1, kept_paths.unsqueeze(-1).expand_as(htilde_t))\n \n \n # (1, N, K)\n indecies = indecies.unsqueeze(0) \n\n b_t_1 = torch.cat([path_b_tm1_1, indecies], dim = 0)\n\n return b_t_0, b_t_1, logpb_t\n"
},
{
"alpha_fraction": 0.5238251090049744,
"alphanum_fraction": 0.5450273156166077,
"avg_line_length": 29.194719314575195,
"blob_id": "0f48297d96427200ba7ce188625940393497716d",
"content_id": "68a36f077f97fc3bb62b623181f46006baac32aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9150,
"license_type": "no_license",
"max_line_length": 164,
"num_lines": 303,
"path": "/Assignment 1/a1_extractFeatures.py",
"repo_name": "sagniksom/Natural-Language-Processing",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport argparse\nimport json\nimport string \nimport sys\nimport re\nimport csv\nimport os\n\nfeatdir = '/u/cs401/A1/feats/'\nwordlistdir = '/u/cs401/Wordlists'\n\n# Provided wordlists.\nFIRST_PERSON_PRONOUNS = {\n 'i', 'me', 'my', 'mine', 'we', 'us', 'our', 'ours'}\nSECOND_PERSON_PRONOUNS = {\n 'you', 'your', 'yours', 'u', 'ur', 'urs'}\nTHIRD_PERSON_PRONOUNS = {\n 'he', 'him', 'his', 'she', 'her', 'hers', 'it', 'its', 'they', 'them',\n 'their', 'theirs', 'they\\'re', 'he\\'s', 'she\\'s'}\nSLANG = {\n 'smh', 'fwb', 'lmfao', 'lmao', 'lms', 'tbh', 'rofl', 'wtf', 'bff',\n 'wyd', 'lylc', 'brb', 'atm', 'imao', 'sml', 'btw', 'bw', 'imho', 'fyi',\n 'ppl', 'sob', 'ttyl', 'imo', 'ltr', 'thx', 'kk', 'omg', 'omfg', 'ttys',\n 'afn', 'bbs', 'cya', 'ez', 'f2f', 'gtr', 'ic', 'jk', 'k', 'ly', 'ya',\n 'nm', 'np', 'plz', 'ru', 'so', 'tc', 'tmi', 'ym', 'ur', 'u', 'sol', 'fml'}\n\nCLASS = {\"Left\": 0, \"Center\": 1, \"Right\": 2, \"Alt\": 3}\n\n\ndef getWordList(comm):\n toks = re.sub(r\"(\\S+)\\/(\\S+)\", r\"\\1\", comm).split(\" \")\n return toks\n \ndef upperCase(comm):\n tok_list = getWordList(comm)\n cnt = 0\n for i in tok_list:\n if i.isupper() and len(i)>3:\n cnt = cnt + 1\n return cnt\n\n# function to turn all text to lowercase but keeping PoS tags uppercase\ndef turnLower(comm):\n temp = \"\"\n copy = \" \" + comm\n for i in range(1, len(copy)):\n if copy[i].isupper() and copy[i-1] == \" \":\n temp = temp + copy[i].lower() \n else: \n temp = temp + copy[i]\n temp = temp.strip()\n return temp\n\ndef firstSecondThirdSlangTok(comm):\n result = [0, 0, 0, 0, 0]\n\n token_list = getWordList(comm)\n sum_tok_len = 0\n\n for i in token_list:\n if i in FIRST_PERSON_PRONOUNS:\n result[0] = result[0] + 1\n if i in SECOND_PERSON_PRONOUNS:\n result[1] = result[1] + 1\n if i in THIRD_PERSON_PRONOUNS:\n result[2] = result[2] + 1\n if i in SLANG:\n result[3] = result[3] + 1\n sum_tok_len = sum_tok_len + len(i)\n\n result[4] = sum_tok_len/len(token_list)\n\n return result\n\n#function to extract features of \ndef PoSFeatures(comm):\n # index 0-8 of result will contain the count of steps 5-13\n result = [0]*9\n copy = comm\n\n #coordinating conjunctions\n result[0] = copy.count(\"/CC\")\n \n #past tense verbs\n result[1] = copy.count(\"/VBD\")\n\n # commas\n result[3] = copy.count(\",/\")\n\n # future tense verbs\n temp = copy.split(\" \")\n first = [\"'ll\", \"will\", \"gonna\", \"going/VBG to/TO\"]\n for i in range(0, len(temp)-2):\n if any(temp[i] in s for s in first):\n if \"VB\" in temp[i+1]:\n result[2] = result[2] + 1\n\n # multichar punctuations\n for word in temp:\n if \"/:\" in word:\n if len(word)>3:\n result[4] = result[4] + 1\n\n # common nouns\n result[5] = copy.count(\"/NN\") + copy.count(\"/NNS\")\n\n # propernouns\n result[6] = copy.count(\"/NNP\") + copy.count(\"/NNPS\")\n\n # adverbs\n result[7] = copy.count(\"/RB\") + copy.count(\"/RBR\") + copy.count(\"/RBS\")\n\n # wh- words\n result[8] = copy.count(\"/WDT\") + copy.count(\"/WP\") + copy.count(\"/WP$\") + copy.count(\"/WRB\")\n\n return result\n\ndef exBLGFeats(comm):\n aoa = []\n img = []\n fam = []\n toks = getWordList(comm)\n zeros = True\n\n for token in toks:\n if token in BGLFeats.keys():\n zeros = False\n aoa = aoa + [BGLFeats[token][\"AoA\"]]\n img = img + [BGLFeats[token][\"IMG\"]]\n fam = fam + [BGLFeats[token][\"FAM\"]]\n \n if zeros:\n return np.zeros((6,))\n \n aoa = np.array(aoa)\n img = np.array(img)\n fam = np.array(fam)\n\n return [aoa.mean(), img.mean(), fam.mean(), aoa.std(), img.std(), fam.std()]\n\ndef exWarrFeats(comm):\n v = []\n a = []\n d = []\n toks = getWordList(comm)\n zeros = True\n\n for tok in toks:\n if tok in WarrFeats.keys():\n zeros = False\n v = v + [WarrFeats[tok][\"V.Mean.Sum\"]]\n a = a + [WarrFeats[tok][\"A.Mean.Sum\"]]\n d = d + [WarrFeats[tok][\"D.Mean.Sum\"]]\n \n if zeros:\n return np.zeros((6,))\n\n v = np.array(v)\n a = np.array(a)\n d = np.array(d)\n\n return [v.mean(), a.mean(), d.mean(), v.std(), a.std(), d.std()]\n\ndef extract1(comment):\n ''' This function extracts features from a single comment\n\n Parameters:\n comment : string, the body of a comment (after preprocessing)\n\n Returns:\n feats : numpy Array, a 173-length vector of floating point features (only the first 29 are expected to be filled, here)\n ''' \n # TODO: Extract features that rely on capitalization.\n # TODO: Lowercase the text in comment. Be careful not to lowercase the tags. (e.g. \"Dog/NN\" -> \"dog/NN\").\n # TODO: Extract features that do not rely on capitalization.\n feats = np.zeros((174))\n\n feats[0] = upperCase(comment)\n comment = turnLower(comment)\n\n feat_2to4_1415 = firstSecondThirdSlangTok(comment)\n feats[1] = feat_2to4_1415[0] \n feats[2] = feat_2to4_1415[1]\n feats[3] = feat_2to4_1415[2]\n feats[13] = feat_2to4_1415[3]\n feats[15] = feat_2to4_1415[4]\n \n #feat[4] to feat[12]\n posfeat = PoSFeatures(comment)\n cnt = 4\n for i in posfeat:\n feats[cnt] = i\n cnt = cnt + 1\n\n #finding number of sentences\n temp = comment\n temp = temp.split(\"/.\")\n feats[16] = len(temp)\n\n # ave length of sentences\n word_sum = 0\n for sent in temp:\n toks_split = sent.split(\" \")\n word_sum = word_sum + len(toks_split)\n feats[14] = word_sum/len(temp)\n \n blgfeats = list(exBLGFeats(comment))\n warfeats = list(exWarrFeats(comment))\n cnt = 17\n for j in blgfeats:\n feats[cnt] = j\n cnt = cnt + 1\n \n cnt_2 = 23\n for h in warfeats:\n feats[cnt_2] = h\n cnt_2 = cnt_2 +1 \n return feats\n \ndef extract2(feat, comment_class, comment_id):\n ''' This function adds features 30-173 for a single comment.\n\n Parameters:\n feat: np.array of length 173\n comment_class: str in {\"Alt\", \"Center\", \"Left\", \"Right\"}\n comment_id: int indicating the id of a comment\n\n Returns:\n feat : numpy Array, a 173-length vector of floating point features (this \n function adds feature 30-173). This should be a modified version of \n the parameter feats.\n ''' \n \n feat[29:-1] = idtoFeats[comment_id]\n feat[-1] = CLASS[comment_class]\n return feat\n\ndef buildLIWCFeats():\n res = {}\n for cat in [\"Left\", \"Center\", \"Right\", \"Alt\"]:\n idspath = os.path.join(featdir, f\"{cat}_IDs.txt\")\n with open(idspath, \"r\") as id_file:\n pathLIWC = os.path.join(featdir, f\"{cat}_feats.dat.npy\")\n featLIWC = np.load(pathLIWC)\n\n #match comment ids with LIWC rows\n for (row_num, id_line) in enumerate(id_file.readlines()):\n res[id_line.strip()] = featLIWC[row_num]\n return res\n\nidtoFeats = buildLIWCFeats()\n\ndef main(args):\n #Declare necessary global variables here. \n global BGLFeats, WarrFeats, idtoFeats\n\n #Load data\n data = json.load(open(args.input))\n feats = np.zeros((len(data), 173+1))\n\n BGLFeats = {row[\"WORD\"]: {\n \"AoA\": float(row[\"AoA (100-700)\"]),\n \"IMG\": float(row[\"IMG\"]),\n \"FAM\": float(row[\"FAM\"])\n }\n for row in csv.DictReader(open(os.path.join(wordlistdir, \"BristolNorms+GilhoolyLogie.csv\")))\n if ((row[\"AoA (100-700)\"] != \"\") or (row[\"IMG\"] != \"\") or (row[\"FAM\"] != \"\"))\n }\n\n WarrFeats = {row[\"Word\"]: {\n \"V.Mean.Sum\": float(row[\"V.Mean.Sum\"]),\n \"A.Mean.Sum\": float(row[\"A.Mean.Sum\"]),\n \"D.Mean.Sum\": float(row[\"D.Mean.Sum\"])\n }\n for row in csv.DictReader(open(os.path.join(wordlistdir, \"Ratings_Warriner_et_al.csv\")))\n if ((row[\"V.Mean.Sum\"] != \"\") or (row[\"A.Mean.Sum\"] != \"\") or (row[\"D.Mean.Sum\"] != \"\"))\n }\n\n for (row_num, comment) in enumerate(data):\n comment = json.loads(comment)\n\n feats[row_num] = extract1(comment[\"body\"])\n feats[row_num] = extract2(feats[row_num], comment[\"cat\"], comment[\"id\"])\n\n print(CLASS[comment[\"cat\"]])\n\n print(\"Type feats: \", type(feats))\n print(\"Type rows: \", type(feats[1]))\n print(\"Type rows at 1\", type(feats[1][1]))\n print(\"shape of feats: \", feats.shape)\n np.savez_compressed(args.output, feats)\n\n \nif __name__ == \"__main__\": \n\n parser = argparse.ArgumentParser(description='Process each .')\n parser.add_argument(\"-o\", \"--output\", help=\"Directs the output to a filename of your choice\", required=True)\n parser.add_argument(\"-i\", \"--input\", help=\"The input JSON file, preprocessed as in Task 1\", required=True)\n parser.add_argument(\"-p\", \"--a1_dir\", help=\"Path to csc401 A1 directory. By default it is set to the cdf directory for the assignment.\", default=\"/u/cs401/A1/\")\n args = parser.parse_args() \n\n main(args)\n\n"
},
{
"alpha_fraction": 0.5976300835609436,
"alphanum_fraction": 0.6038124561309814,
"avg_line_length": 24.045162200927734,
"blob_id": "0773dd6f617cca62e0b1b400cf9e8b15e3a7d5f9",
"content_id": "dcc63451ae975d6974fb9ef0cdcae025d548d94d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3882,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 155,
"path": "/Assignment2/a2_bleu_score.py",
"repo_name": "sagniksom/Natural-Language-Processing",
"src_encoding": "UTF-8",
"text": "'''Compute BLEU score for one reference and one hypothesis\n\nYou do not need to import anything more than what is here\n'''\n\nfrom math import exp # exp(x) gives e^x\n\n\ndef grouper(seq, n):\n '''Get all n-grams from a sequence\n\n An n-gram is a contiguous sub-sequence within `seq` of length `n`. This\n function extracts them (in order) from `seq`.\n\n Parameters\n ----------\n seq : sequence\n A sequence of words or token ids representing a transcription.\n n : int\n The size of sub-sequence to extract.\n\n Returns\n -------\n ngrams : list\n '''\n # create the return list of ngrams, a copy of the sequence, and a temporary string for the current n_gram\n ngrams = []\n temp_seq = seq\n n_gram = \"\"\n\n # iterate through each beginning of each n-gram\n for i in range(0, len(temp_seq)-n+1):\n\n # add the next words to each n_gram\n for j in range(0, n):\n n_gram = n_gram + \" \" + str(temp_seq[i+j])\n\n # add each n_gram to the list of n_grams\n n_gram = n_gram.strip()\n ngrams.append(n_gram)\n n_gram = \"\"\n\n return ngrams\n\n\ndef n_gram_precision(reference, candidate, n):\n '''Compute the precision for a given order of n-gram\n\n Parameters\n ----------\n reference : sequence\n The reference transcription. A sequence of words or token ids.\n candidate : sequence\n The candidate transcription. A sequence of words or token ids\n (whichever is used by `reference`)\n n : int\n The order of n-gram precision to compute\n\n Returns\n -------\n p_n : float\n The n-gram precision. In the case that the candidate has length 0,\n `p_n` is 0.\n '''\n\n p_n = 0\n\n # check for an empty candidate list\n if len(candidate)==0:\n return p_n\n\n can_ngrams = grouper(candidate, n)\n ref_ngrams = grouper(reference, n)\n\n # accumulate the number of matching n grams in candidate and reference\n C = 0\n for word in can_ngrams:\n if word in ref_ngrams:\n C = C + 1\n\n # check if the candidate n_grams list is 0.\n # if so, return 0\n N = len(can_ngrams)\n if N == 0:\n return 0\n\n # compute p_n\n p_n = C/N\n\n return p_n\n\n\ndef brevity_penalty(reference, candidate):\n '''Compute the brevity penalty between a reference and candidate\n\n Parameters\n ----------\n reference : sequence\n The reference transcription. A sequence of words or token ids.\n candidate : sequence\n The candidate transcription. A sequence of words or token ids\n (whichever is used by `reference`)\n\n Returns\n -------\n BP : float\n The brevity penalty. In the case that the candidate transcription is\n of 0 length, `BP` is 0.\n '''\n BP = 0\n\n # compute r\n r = len(reference)/len(candidate)\n\n # compute BP\n if r < 1:\n return 1\n else:\n BP = exp(1-r)\n return BP\n\n\ndef BLEU_score(reference, candidate, n):\n '''Compute the BLEU score\n\n Parameters\n ----------\n reference : sequence\n The reference transcription. A sequence of words or token ids.\n candidate : sequence\n The candidate transcription. A sequence of words or token ids\n (whichever is used by `reference`)\n n : int\n The maximum order of n-gram precision to use in the calculations,\n inclusive. For example, ``n = 2`` implies both unigram and bigram\n precision will be accounted for, but not trigram.\n\n Returns\n -------\n bleu : float\n The BLEU score\n '''\n\n # compute the p_scores using n_gram_precision for each n\n p_scores = 1\n for i in range (1, n+1):\n ngramPrec = n_gram_precision(reference, candidate, i)\n p_scores = p_scores * ngramPrec \n\n bp = brevity_penalty(reference, candidate)\n\n # compute the BLEU score\n res = bp * (p_scores ** (1/n))\n\n return res\n"
},
{
"alpha_fraction": 0.5863935947418213,
"alphanum_fraction": 0.5982081294059753,
"avg_line_length": 30.064220428466797,
"blob_id": "c414132725d55b612e505200ffdf3ca29a1c2226",
"content_id": "26147abaf460f8d9100cd7b40ce40c2743d5b87e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10157,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 327,
"path": "/Assignment3/a3_gmm_structured.py",
"repo_name": "sagniksom/Natural-Language-Processing",
"src_encoding": "UTF-8",
"text": "from sklearn.model_selection import train_test_split\nimport numpy as np\nimport os, fnmatch\nimport random\nfrom scipy.special import logsumexp\nimport sys\n\ndataDir = \"/u/cs401/A3/data/\"\nrandom.seed(3)\nnp.random.seed(3)\n\nclass theta:\n def __init__(self, name, M=8, d=13):\n \"\"\"Class holding model parameters.\n Use the `reset_parameter` functions below to\n initialize and update model parameters during training.\n \"\"\"\n self.name = name\n self._M = M\n self._d = d\n self.omega = np.zeros((M, 1))\n self.mu = np.zeros((M, d))\n self.Sigma = np.zeros((M, d))\n self.precompute = None\n\n def reset_preCompute(self):\n\n const = self._d/2 * np.log(2 * np.pi)\n\n precomputed = const + np.sum(np.power(self.mu, 2)/(2* self.Sigma)) + np.sum(np.log(self.Sigma))/2\n self.precompute = precomputed\n\n def precomputedForM(self, m):\n \"\"\"Put the precomputedforM for given `m` computation here\n This is a function of `self.mu` and `self.Sigma` (see slide 32)\n This should output a float or equivalent (array of size [1] etc.)\n NOTE: use this in `log_b_m_x` below\n \"\"\"\n\n const = self.mu.shape[1]/2 * np.log(2 * np.pi)\n\n self.precompute = const + np.sum(np.power(self.mu[m], 2)/(2* self.Sigma[m])) + np.sum(np.log(self.Sigma[m]))/2\n \n return self.precompute\n\n\n def reset_omega(self, omega):\n \"\"\"Pass in `omega` of shape [M, 1] or [M]\n \"\"\"\n omega = np.asarray(omega)\n assert omega.size == self._M, \"`omega` must contain M elements\"\n self.omega = omega.reshape(self._M, 1)\n\n def reset_mu(self, mu):\n \"\"\"Pass in `mu` of shape [M, d]\n \"\"\"\n mu = np.asarray(mu)\n shape = mu.shape\n assert shape == (self._M, self._d), \"`mu` must be of size (M,d)\"\n self.mu = mu\n\n def reset_Sigma(self, Sigma):\n \"\"\"Pass in `sigma` of shape [M, d]\n \"\"\"\n Sigma = np.asarray(Sigma)\n shape = Sigma.shape\n assert shape == (self._M, self._d), \"`Sigma` must be of size (M,d)\"\n self.Sigma = Sigma\n\n\ndef log_b_m_x(m, x, myTheta):\n \"\"\" Returns the log probability of d-dimensional vector x using only\n component m of model myTheta (See equation 1 of the handout)\n\n As you'll see in tutorial, for efficiency, you can precompute\n something for 'm' that applies to all x outside of this function.\n Use `myTheta.preComputedForM(m)` for this.\n\n Return shape:\n (single row) if x.shape == [d], then return value is float (or equivalent)\n (vectorized) if x.shape == [T, d], then return shape is [T]\n\n You should write your code such that it works for both types of inputs.\n But we encourage you to use the vectorized version in your `train`\n function for faster/efficient computation.\n \"\"\"\n mu = myTheta.mu[m]\n sigma = myTheta.Sigma[m]\n\n if len(x.shape)==1:\n axis = 0\n else:\n axis = 1\n\n temp = 0.5*np.square(x) - (mu * x)\n return -np.sum(temp/sigma, axis = axis) - myTheta.precomputedForM(m)\n\n\n\ndef log_p_m_x(log_Bs, myTheta):\n \"\"\" Returns the matrix of log probabilities i.e. log of p(m|X;theta)\n\n Specifically, each entry (m, t) in the output is the\n log probability of p(m|x_t; theta)\n\n For further information, See equation 2 of handout\n\n Return shape:\n same as log_Bs, np.ndarray of shape [M, T]\n\n NOTE: For a description of `log_Bs`, refer to the docstring of `logLik` below\n \"\"\"\n omegas = myTheta.omega\n log_omeg = np.log(omegas)\n\n all_logs = log_Bs + log_omeg\n\n log_pmx = np.zeros(log_Bs.shape)\n\n lse = logsumexp(all_logs, axis = 0, keepdims = True)\n\n # probably can just do all_logs - lse for log_pmx \n for m in range(0, log_Bs.shape[0]):\n omega_m = myTheta.omega[m]\n log_p_num = np.log(omega_m) + log_Bs[m,:]\n log_pmx[m,:] = log_p_num - lse\n\n return log_pmx\n\n\ndef logLik(log_Bs, myTheta):\n \"\"\" Return the log likelihood of 'X' using model 'myTheta' and precomputed MxT matrix, 'log_Bs', of log_b_m_x\n\n X can be training data, when used in train( ... ), and\n X can be testing data, when used in test( ... ).\n\n We don't actually pass X directly to the function because we instead pass:\n\n log_Bs(m,t) is the log probability of vector x_t in component m, which is computed and stored outside of this function for efficiency.\n\n See equation 3 of the handout\n \"\"\"\n omegas = myTheta.omega\n log_omeg = np.log(omegas)\n\n all_logs = log_Bs + log_omeg\n\n lse = logsumexp(all_logs, axis = 0, keepdims = True)\n\n log_lik = lse.sum()\n\n return log_lik\n\ndef updateTheta(myTheta, X, log_probs):\n #update omega, mu, and sigma in myTheta\n\n # print(\"shape of log_probs, \", log_probs.shape)\n #update omega\n probs = np.exp(log_probs)\n M = log_probs.shape[0]\n T = len(X)\n\n mu_reset = probs.dot(X) / (probs.sum(axis = 1, keepdims = True))\n myTheta.reset_mu(mu_reset)\n\n # instead of log_probs.shape[1] can just write T\n omeg_reset = (np.sum(probs, axis = 1)/log_probs.shape[1]).reshape((M, 1))\n myTheta.reset_omega(omeg_reset)\n\n sig_reset = (probs.dot(np.power(X, 2)) / (probs.sum(axis = 1, keepdims = True)))\n sig_reset = sig_reset - np.power(myTheta.mu, 2)\n myTheta.reset_Sigma(sig_reset)\n\n return myTheta\n\n\ndef train(speaker, X, M=8, epsilon=0.0, maxIter=20):\n \"\"\" Train a model for the given speaker. Returns the theta (omega, mu, sigma)\"\"\"\n # experiments\n # maxIter = 20\n # M = 5\n\n myTheta = theta(speaker, M, X.shape[1])\n # perform initialization (Slide 32)\n # print(\"TODO : Initialization\")\n # for ex.,\n # myTheta.reset_omega(omegas_with_constraints)\n # myTheta.reset_mu(mu_computed_using_data)\n # myTheta.reset_Sigma(some_appropriate_sigma)\n\n omeg_const = np.ones(myTheta.omega.shape)/M\n myTheta.reset_omega(omeg_const)\n\n myTheta.reset_mu(X[np.array(random.sample(range(X.shape[0]), M))])\n\n sig = np.ones((M, X.shape[1]))\n myTheta.reset_Sigma(sig)\n\n # print(\"TODO: Rest of training\")\n iteration = 0\n lik_prev = - float(\"inf\")\n dif = float(\"inf\")\n\n while (iteration < maxIter) and (dif >= epsilon):\n myTheta.precompute = None\n # compute logbs and logprobs\n log_bs = np.array([log_b_m_x(m, X, myTheta) for m in range(0, M, 1)])\n log_probs = np.array(log_p_m_x(log_bs, myTheta))\n\n # compute likelihood\n lik_curr = logLik(log_bs, myTheta)\n\n # update parameters\n myTheta = updateTheta(myTheta, X, log_probs)\n\n dif = lik_curr - lik_prev\n lik_prev = lik_curr\n iteration = iteration + 1\n\n print(f\"Iteration {iteration} likelihood of {round(lik_curr, 4)} and dif of {round(dif, 4)}\")\n myTheta.precompute = None\n return myTheta\n\n\ndef test(mfcc, correctID, models, k=5):\n \"\"\" Computes the likelihood of 'mfcc' in each model in 'models', where the correct model is 'correctID'\n If k>0, print to stdout the actual speaker and the k best likelihoods in this format:\n [ACTUAL_ID]\n [SNAME1] [LOGLIK1]\n [SNAME2] [LOGLIK2]\n ...\n [SNAMEK] [LOGLIKK]\n\n e.g.,\n S-5A -9.21034037197\n the format of the log likelihood (number of decimal places, or exponent) does not matter\n \"\"\"\n bestModel = -1\n # print(\"TODO\")\n\n # store log likelihoods in dict\n # dict key will be likelihood and value will be the model to find best model later\n logLiks = {}\n\n # list to store the logLikelihoods\n logLiks_list = []\n\n M = len(models[0].omega)\n\n i = 0\n for model in models:\n log_bs = np.array([log_b_m_x(m, mfcc, model) for m in range(0, M, 1)])\n \n # find the log likelihood of this model\n logLik_curr = logLik(log_bs, model)\n #print(\"testing model: \", model.name, \" loglik: \", logLik_curr)\n\n # add loglik to the list and the dictionary\n if not (isinstance(logLik_curr, float) and np.isnan(logLik_curr)):\n logLiks_list.append(logLik_curr)\n logLiks[logLik_curr] = (model, i)\n\n i += 1\n \n # sort the list of logLiks\n sorted_logLiks = sorted(logLiks_list, key = lambda x: x, reverse = True)\n\n # find best model\n _, best_ind = logLiks[sorted_logLiks[0]]\n bestModel = best_ind\n\n # write to file\n if k > 0:\n k = min(k, len(models))\n print(models[correctID].name)\n for i in range(0, k, 1):\n print(logLiks[sorted_logLiks[i]][0].name, \" \", sorted_logLiks[i], \"\\n\")\n\n return 1 if (bestModel == correctID) else 0\n\n\nif __name__ == \"__main__\":\n random.seed(3)\n trainThetas = []\n testMFCCs = []\n # print(\"TODO: you will need to modify this main block for Sec 2.3\")\n d = 13\n k = 5 # number of top speakers to display, <= 0 if none\n M = 8\n epsilon = 0.0\n maxIter = 20\n # train a model for each speaker, and reserve data for testing\n\n for subdir, dirs, files in os.walk(dataDir):\n for speaker in dirs:\n print(speaker)\n\n files = fnmatch.filter(os.listdir(os.path.join(dataDir, speaker)), \"*npy\")\n random.shuffle(files)\n\n testMFCC = np.load(os.path.join(dataDir, speaker, files.pop()))\n testMFCCs.append(testMFCC)\n\n X = np.empty((0, d))\n\n for file in files:\n myMFCC = np.load(os.path.join(dataDir, speaker, file))\n X = np.append(X, myMFCC, axis=0)\n\n trainThetas.append(train(speaker, X, M, epsilon, maxIter))\n\n # evaluate\n numCorrect = 0\n\n for i in range(0, len(testMFCCs)):\n numCorrect += test(testMFCCs[i], i, trainThetas, k)\n accuracy = 1.0 * numCorrect / len(testMFCCs)\n \n stdout = sys.stdout # steal stdout so that we can redirect to file.\n print(f\"accuracy: {accuracy}\")\n sys.stdout = open('gmmLiks.txt', 'w')\n # evaluate\n numCorrect = 0\n for i in range(0, len(testMFCCs)):\n numCorrect += test(testMFCCs[i], i, trainThetas, k)\n accuracy = 1.0*numCorrect/len(testMFCCs)\n sys.stdout = stdout"
},
{
"alpha_fraction": 0.37155359983444214,
"alphanum_fraction": 0.3804522156715393,
"avg_line_length": 37.72881317138672,
"blob_id": "2f4a4e2ae60859bbc161350566e96ed9f8da62ab",
"content_id": "6812424cb318264252d41e81806a417c071334f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6855,
"license_type": "no_license",
"max_line_length": 168,
"num_lines": 177,
"path": "/Assignment3/a3_levenshtein.py",
"repo_name": "sagniksom/Natural-Language-Processing",
"src_encoding": "UTF-8",
"text": "import os\nimport numpy as np\nimport re\nimport sys\nimport string\n\ndataDir = '/u/cs401/A3/data/'\n\ndef Levenshtein(r, h):\n \"\"\" \n Calculation of WER with Levenshtein distance. \n \n Works only for iterables up to 254 elements (uint8). \n O(nm) time ans space complexity. \n \n Parameters \n ---------- \n r : list of strings \n h : list of strings \n \n Returns \n ------- \n (WER, nS, nI, nD): (float, int, int, int) WER, number of substitutions, insertions, and deletions respectively\n \n Examples \n -------- \n >>> wer(\"who is there\".split(), \"is there\".split()) \n 0.333 0 0 1 \n >>> wer(\"who is there\".split(), \"\".split()) \n 1.0 0 0 3 \n >>> wer(\"\".split(), \"who is there\".split()) \n Inf 0 3 0 \n \"\"\"\n # WER = (numsubs + numinserts + numdeletes) / numrefwords\n # make matrix\n # add s at beginning and /s to end\n # fill [0:end] along first row and col\n # for each ref word, for each hypothesis word, ... O(nm)\n\n cache = {}\n n = len(r)\n m = len(h)\n\n for i in range(0, n + 1, 1):\n for j in range(0, m + 1, 1):\n\n # target empty. delete everything in reference\n if j == 0:\n num_del = i\n num_ins = 0\n num_sub = 0\n\n # ref empty. make into target by inserting\n elif i == 0:\n num_del = 0\n num_ins = j\n num_sub = 0\n\n else:\n # r_head = r[:-1] (Deletion)\n sub_r, ins_r, del_r = cache[(i - 1, j)]\n r_dist = sum([sub_r, ins_r, del_r]) # Lev[i-1][j]\n\n # h_head = h[:-1] (Insertion)\n sub_h, ins_h, del_h = cache[(i, j - 1)]\n h_dist = sum([sub_h, ins_h, del_h]) # Lev[i][j-1]\n\n # r_head and h_head\n sub_hr, ins_hr, del_hr = cache[(i - 1, j - 1)]\n hr_dist = sum([sub_hr, ins_hr, del_hr]) # Lev[i-1][j-1]\n\n if r[i -1] == h[j - 1]:\n const = 0\n else:\n const = 1\n\n # find min for dist source\n delete = r_dist + 1\n insert = h_dist + 1\n subs = hr_dist + const\n lev_dist = min(delete, insert, subs)\n\n # deletion\n if lev_dist == delete:\n num_del = del_r + 1\n num_ins = ins_r\n num_sub = sub_r\n\n # insertion\n elif lev_dist == insert:\n num_del = del_h\n num_ins = ins_h + 1\n num_sub = sub_h\n\n elif lev_dist == subs:\n # Carry forward deletion and insertion from r[i-1], h[j-1]\n num_del = del_hr\n num_ins = ins_hr\n num_sub = (sub_hr) + const\n else:\n print(\"something is wrong at [{}, {}]\".format(i, j))\n\n # update dict\n cache[(i, j)] = (num_sub, num_ins, num_del)\n\n nS, nI, nD = cache[(n, m)]\n\n if n == 0:\n WER = float('inf')\n else:\n WER = (nS + nI + nD) / n\n\n return (WER, nS, nI, nD)\n\n\ndef preprocess(line):\n # remove all punctuation other than [and]\n # put all text to lowercase\n preproc = re.sub(r\"[^a-zA-Z0-9\\s\\[\\]]\", r\"\", line)\n preproc = preproc.lower().strip().split()\n\n return preproc\n\n\nif __name__ == \"__main__\":\n sys.stdout = open(\"asrDiscussion.txt\", \"w\")\n\n googErr = []\n kaldiErr = []\n\n for root, dirs, files in os.walk(dataDir):\n for speaker in dirs:\n rootPath = os.path.join(dataDir, speaker)\n refPath = os.path.join(rootPath, 'transcripts.txt')\n googPath = os.path.join(rootPath, 'transcripts.Google.txt')\n kaldiPath = os.path.join(rootPath, 'transcripts.Kaldi.txt')\n\n # open the files\n googFile = open(googPath, 'r')\n kaldiFile = open(kaldiPath, 'r')\n refFile = open(refPath, 'r')\n\n cnt = 0\n for goog_h, kaldi_h, ref in zip(googFile, kaldiFile, refFile):\n # preprocess the lines\n goog_h = preprocess(goog_h)\n kaldi_h = preprocess(kaldi_h)\n ref = preprocess(ref)\n\n # find errors of kaldi and google\n # add to the respective errors list\n # print result so we can write to file\n WER, nS, nI, nD = Levenshtein(ref, kaldi_h)\n kaldiErr.append(WER)\n print('{speaker} {system} {i} {wer} S:{nS}, I:{nI}, D:{nD}'.format(speaker = speaker, system = \"Kaldi\", i = cnt, wer = WER, nS = nS, nI = nI, nD = nD))\n \n WER, nS, nI, nD = Levenshtein(ref, goog_h)\n googErr.append(WER)\n print('{speaker} {system} {i} {wer} S:{nS}, I:{nI}, D:{nD}'.format(speaker = speaker, system = \"Google\", i = cnt, wer = WER, nS = nS, nI = nI, nD = nD))\n\n cnt += 1\n\n print(\"\")\n\n googErr = np.array(googErr)\n kaldiErr = np.array(kaldiErr)\n\n g_mean = np.mean(googErr)\n k_mean = np.mean(kaldiErr)\n\n # this below also works for the record\n # g_std = np.sqrt(np.var(googErr))\n # k_std = np.sqrt(np.var(kaldiErr))\n g_std = np.std(googErr)\n k_std = np.std(kaldiErr)\n\n print(\"Google has a mean of: \", g_mean, \" and a standard deviation of: \", g_std, \" . Kaldi has a mean of :\", k_mean, \" and a standard deviation of: \", k_std)\n"
}
] | 9 |
Liuheng268/online
|
https://github.com/Liuheng268/online
|
a1382baccad61f896c333a5d7c362c4d5cc02ea3
|
0d4864776e1d97ed95b25c1d5c1a3b6712d0f0c6
|
bcdca9045e6d6605eb244f1723534e3985736a6c
|
refs/heads/master
| 2021-01-16T18:38:08.969097 | 2017-08-19T01:47:39 | 2017-08-19T01:47:39 | 100,104,250 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5263158082962036,
"alphanum_fraction": 0.5438596606254578,
"avg_line_length": 29.09433937072754,
"blob_id": "9c9489495d8876ddec1a8df898c6bbe891634809",
"content_id": "133f22455b95db573ec6a0afc6b03dfcbaf282d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1644,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 53,
"path": "/info_search/info_search.py",
"repo_name": "Liuheng268/online",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport data_base\nimport numpy as np\n#***************************************************************************\n\ndef user_info():\n user_info = data_base.get_user_info()\n train = data_base.create_re_train()\n new_lst = []\n for row in user_info:\n try:\n rating_std = np.std(train[row[0]].values())\n new_lst.append([row[1],row[2],row[3],row[4],row[5],row[6],rating_std])\n except:\n new_lst.append([row[1],row[2],row[3],row[4],row[5],row[6],'未填写评分'])\n dic = {}\n dic['user_info'] = new_lst\n dic1 = extra_info(new_lst)\n dic.update(dic1)\n return dic\n\ndef extra_info(new_lst):\n #计算用户评分标准差,用于判断评分有效性\n dic = {}\n user_num = len(new_lst)\n dic['user_num'] = user_num\n rating_num = 0\n useful_rating_num = 0\n for row in new_lst:\n if row[6]>0.5:\n useful_rating_num+=1\n if row[1] ==1:\n rating_num +=1\n dic['useful_rating_num'] = useful_rating_num\n dic['rating_num'] = rating_num\n return dic\n\ndef get_maj_avr(user_id, threshold=5):\n maj = data_base.get_maj(user_id)\n maj_name = data_base.get_maj_name(maj)\n user_tuple_str = data_base.get_maj_user_tuple(maj)\n #print user_tuple_str\n item_avr = data_base.get_maj_avr_rating(user_tuple_str,threshold)\n lst = []\n for item in item_avr.keys():\n lst.append([item,item_avr[item]['rating'],item_avr[item]['count']])\n rank = data_base.transfer_lst(0,0,lst)\n #for row in rank:\n #print row\n dic = {}\n dic['rank'] = rank\n dic['maj_name'] = maj_name\n return dic\n\n"
},
{
"alpha_fraction": 0.3459959030151367,
"alphanum_fraction": 0.3969883620738983,
"avg_line_length": 25.563636779785156,
"blob_id": "8e6a8d828fd85ff6f7adeb5ef87f99fd496bd438",
"content_id": "42259c2254ea926e2c5b35fa740b80b12aa52ad2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3364,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 110,
"path": "/recommend/SKSJ_compare.py",
"repo_name": "Liuheng268/online",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# 此代码目的:课程时间转换\n# 此代码需要调用的变量形式或文件类型如下:\n# \n# \n# 此代码归属模块:推荐模块\n\n\n\ndef time_convert(time):\n # 将数据库中上课时间转换成可以计算比较的结构\n # XQ:星期\n # SJBH:课程时间编号,例如,1,2(节)\n # WEEK:上课周数,例如,1-16(周)\n lst = []\n s = time.split(';')\n for row in s:\n if not row:\n continue\n spt = row.split(u'第')\n spt2 = spt[2].split(u'周')\n WEEK = spt2[0]\n XQ = spt[0]\n spt = spt[1].split(u'节')\n SJBH = spt[0]\n lst.append([XQ,SJBH,WEEK])\n return lst\n \ndef whether_conflict(t1,t2):\n # 判断两个上课时间t1,t2是否覆盖重复时段\n # flag 返回值为 0:不重复 或 1:重复\n flag = 0\n for time in t1:\n for time2 in t2:\n if time[0] == time2[0]:\n if time[1] == time2[1]:\n spt = time[2].split('-')\n l1 = int(spt[0])\n h1 = int(spt[1])\n spt2 = time2[2].split('-')\n l2 = int(spt2[0])\n h2 = int(spt2[1])\n if h1>h2:\n if h2>=l1:\n flag = 1\n else:\n pass\n else:\n if h1>=l2:\n flag = 1\n else:\n pass \n else:\n pass\n else:\n pass\n \n \n return flag\n\ndef whether_contain(t1,t2):\n # 判断两个上课时间t1,t2是否存在t1包含t2的情况\n # flag 返回值为 0:不包含 或 1:包含\n flag = 0\n for time in t1:\n for time2 in t2:\n if time[0] == time2[0]:\n if time[1] == time2[1]:\n spt = time[2].split('-')\n l1 = int(spt[0])\n h1 = int(spt[1])\n spt2 = time2[2].split('-')\n l2 = int(spt2[0])\n h2 = int(spt2[1])\n if h1>=h2:\n if l2>=l1:\n flag = 1\n else:\n pass\n else:\n pass \n else:\n pass\n else:\n pass\n return flag\n\ndef judge_conflicit(time1,time2):\n #flag是判断标志,0表示没有冲突,1表示有冲突\n t1 = time_convert(time1)\n t2 = time_convert(time2)\n flag = whether_conflict(t1,t2)\n return flag\n\ndef judge_contain(time1,time2):\n #flag是判断标志,0表示time1包含time2,1表示time1不包含time2\n t1 = time_convert(time1)\n t2 = time_convert(time2)\n flag = whether_contain(t1,t2)\n return flag\n\nif __name__ == '__main__':\n #time1 = u'周一第1,2节{第1-16周};周四第1,2节{第3-5周}'\n #time2 = u'周一第1,2节{第7-10周};周三第1,2节{第6-10周}'\n #flag = judge_conflicit(time1,time2)\n time1 = u'周一第1,2节{第1-16周}'\n time2 = u'周一第1,2节{第1-15周}'\n flag = judge_contain(time1,time2)\n \n print flag\n"
},
{
"alpha_fraction": 0.5761755704879761,
"alphanum_fraction": 0.5967084765434265,
"avg_line_length": 34.79213333129883,
"blob_id": "616472ccc8ebca7e467dd6a10c3d0b802121ee0d",
"content_id": "e8e29776b1efb5c022d6389ff54a8eba6234ec60",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6814,
"license_type": "no_license",
"max_line_length": 171,
"num_lines": 178,
"path": "/recommend/data_base.py",
"repo_name": "Liuheng268/online",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport pymssql\nimport numpy as np\nfrom online.timeout_deco import timeout\nfrom online import user_password\ndbo_user,dbo_password = user_password.get_user_password()\nclass MSSQL:\n \n\n def __init__(self,host,user,pwd,db):\n self.host = host\n self.user = user\n self.pwd = pwd\n self.db = db\n @timeout(0.5)\n def __GetConnect(self):\n \n if not self.db:\n raise(NameError,\"没有设置数据库信息\")\n self.conn = pymssql.connect(host=self.host,user=self.user,password=self.pwd,database=self.db,charset=\"utf8\")\n cur = self.conn.cursor()\n if not cur:\n raise(NameError,\"连接数据库失败\")\n else:\n return cur\n @timeout(3)\n def ExecQuery(self,sql):\n cur = self.__GetConnect()\n cur.execute(sql)\n resList = cur.fetchall()\n self.conn.close()\n return resList\n @timeout(0.5)\n def ExecNonQuery(self,sql):\n \n cur = self.__GetConnect()\n cur.execute(sql)\n self.conn.commit()\n self.conn.close()\n\n#*************************************************************************\ndef create_train():\n # 从电影评分数据集中获取训练集\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\") \n m = ms.ExecQuery(\"select [user],item,rating from train\")\n #print m[:5]\n train = {}\n for user,item,rating in m:\n user, item, rating = int(user), int(item), int(rating)\n train.setdefault(user, {})\n train[user][item] = rating\n #print train.keys()\n return train\n\ndef re_get_train():\n # 从真实课程评分数据中获取训练集\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n temp = ms.ExecQuery(\"SELECT user_id,BH,rating FROM user_cour_rating \")\n train={}\n for user, item, rating in temp:\n train.setdefault(user, {})\n train[user][item] = rating\n return train\n\ndef search_teacher(BH,KCXZ_flag=0):\n # 已知课程编号,课程性质\n # 获取课程代码,课程名称,教师姓名\n #KCXZ_flag 0:全部课程;1:校选修课;2:必修课\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n if KCXZ_flag ==1:\n KCXZ = u'校选修课'.encode('utf-8')\n m = ms.ExecQuery(\"select KCDM,KCMC,JSXM from jxrwb2 where BH = %d and KCXZ ='%s'\"%(BH,KCXZ))\n elif KCXZ_flag ==2:\n KCXZ = u'必修课'.encode('utf-8')\n m = ms.ExecQuery(\"select KCDM,KCMC,JSXM from jxrwb2 where BH = %d and KCXZ ='%s'\"%(BH,KCXZ))\n else :\n m = ms.ExecQuery(\"select KCDM,KCMC,JSXM from jxrwb2 where BH = %d\"%BH)\n return m\n\ndef course_filtering(user_id):\n # 获取用户已选课程中课程代码相同(相同课程,不同老师或不同时间)的课程的课程编号\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n user_KCDM_list=ms.ExecQuery(\"select t2.KCDM from user_cour_rating as t1 join [XKXX].[dbo].[jxrwb2] as t2 on t1.BH=t2.BH where user_id=%d group by t2.KCDM\"%user_id)\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n all_BH_list = []\n for KCDM in user_KCDM_list:\n BH_list = ms.ExecQuery(\"select BH from jxrwb2 where KCDM='%s' group by BH\"%KCDM)\n for row in BH_list:\n all_BH_list.append(row[0])\n return all_BH_list\n\ndef get_cou_lst(user_id,XN,XQ):\n # 已知学年,学期,用户编号\n # 获取用户对应年度、学期已选课程列表\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n XH = get_XH(user_id)\n m=ms.ExecQuery(\"select KCDM,KCMC,t2.BH,JSXM from ZFXFZB_XKXXB_LH as t1 join jxrwb2 as t2 on t1.XKKH = t2.XKKH where XH ='%s' and t2.XN ='%s' and t2.XQ =%d\"%(XH,XN,XQ))\n cou_lst = []\n for line in m:\n cou_lst.append([line[0].rstrip(),line[1],line[2],line[3]])\n return cou_lst\n\ndef get_spare_time(user_id):\n # 获取用户空闲时间列表\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n lst = ms.ExecQuery(\"select spare_time from spare_time where user_id = %d order by spare_time desc\"%user_id)\n time_lst = []\n for row in lst:\n time_lst.append(row[0])\n return time_lst\ndef get_SKSJ(BH):\n # 获取已知课程编号的课程的上课时间,返回列表\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n m=ms.ExecQuery(\"select SKSJ,XN,XQ from jxrwb2 where BH =%d and XN ='2016-2017' and XQ =2\"%BH)\n lst = []\n for a,b,c in m:\n lst.append(a)\n return lst\ndef get_2016_2017_2XXK():\n # 获取2016-2017年第二学期选修课列表\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n KCXZ = u'校选修课'\n KCXZ = KCXZ.encode('utf-8')\n lst=ms.ExecQuery(\"select KCDM,KCMC,JSXM,SKSJ,BH from jxrwb2 where XN ='2016-2017' and XQ =2 and KCXZ = '%s'\"%KCXZ)\n cou_lst = []\n for line in lst:\n cou_lst.append([line[0],line[1],line[2],line[3],line[4]])\n return cou_lst\n\ndef get_user_rating(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n temp = ms.ExecQuery(\"SELECT user_id,BH,rating FROM user_cour_rating where user_id = %d\"%user_id)\n train={}\n for user, item, rating in temp:\n train[item] = rating\n return train\n\ndef get_all_xuanxiu_BH():\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n KCXZ = u'校选修课'.encode('utf-8')\n temp = ms.ExecQuery(\"SELECT BH FROM jxrwb2 where KCXZ='%s' and XN='2016-2017'\"%KCXZ)\n BH_lst = []\n for row in temp:\n BH_lst.append(row[0])\n #print 12 in BH_lst\n return BH_lst\ndef get_avr():\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n temp = ms.ExecQuery(\"SELECT [BH],count(BH),round(avg(cast(rating as float)),2) FROM [xuanke].[dbo].[user_cour_rating] group by BH\")\n BH_lst = []\n for row in temp:\n BH_lst.append([row[0],row[1],row[2]])\n #print 12 in BH_lst\n return BH_lst\ndef get_cou_name(BH):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n m = ms.ExecQuery(\"select KCMC from jxrwb2 where BH =%d\"%BH)\n try:\n KCMC = m[0][0]\n except:\n KCMC = u'查询错误'\n return KCMC\n \n\nif __name__ == '__main__':\n #write_user_info('liuheng123')\n #maj_dic,sort = search_maj('001')\n #print sort[0][1]\n #gra,fac,maj = get_gra_fac_maj(1)\n #print search_fac()\n #print len(search_cou_dic(gra,maj))\n #get_item_sim(9)\n #get_bind_id(9)\n #get_SKSJ(2203)\n #get_2016_2017_2XXK()\n #re_get_train()\n #get_user_rating(9)\n get_all_xuanxiu_BH()\n \n"
},
{
"alpha_fraction": 0.5858376622200012,
"alphanum_fraction": 0.602072536945343,
"avg_line_length": 26.571428298950195,
"blob_id": "007b258548ccd8aa5cce266d8035116998088c59",
"content_id": "da9955c11e730af73a2d56a41bf00ce6955cdfd2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2895,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 105,
"path": "/recommend/main.py",
"repo_name": "Liuheng268/online",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nfrom __future__ import absolute_import\nfrom __future__ import division\n\nimport method\n\n\ndef test100k_explicit():\n test_count = 5\n evaluation_base = 2\n ans = [0] * evaluation_base\n for k in xrange(1, test_count + 1):\n method.generate_data_100k_explicit(k)\n method.generate_matrix(implicit=False)\n b = method.evaluate_explicit()\n for x in xrange(evaluation_base):\n ans[x] += b[x]\n for x in xrange(evaluation_base):\n ans[x] /= test_count\n print ans\n\n\ndef test100k_implicit():\n test_count = 5\n evaluation_base = 4\n ans = [0] * evaluation_base\n for k in xrange(1, test_count + 1):\n method.generate_data_100k_implicit(k)\n method.generate_matrix(implicit=True)\n b = method.evaluate_implicit()\n for x in xrange(evaluation_base):\n ans[x] += b[x]\n for x in xrange(evaluation_base):\n ans[x] /= test_count\n print ans\n\n\ndef test1m_explicit():\n test_count = 8\n evaluation_base = 2\n ans = [0] * evaluation_base\n for k in xrange(test_count):\n method.generate_data_1m_explicit(test_count, k)\n method.generate_matrix(implicit=False)\n b = method.evaluate_explicit()\n for x in xrange(evaluation_base):\n ans[x] += b[x]\n for x in xrange(evaluation_base):\n ans[x] /= test_count\n print ans\n\n\ndef test1m_implicit():\n test_count = 8\n evaluation_base = 4\n ans = [0] * evaluation_base\n for k in xrange(test_count):\n method.generate_data_1m_implicit(test_count, k)\n method.generate_matrix(implicit=True)\n b = method.evaluate_implicit()\n for x in xrange(evaluation_base):\n ans[x] += b[x]\n for x in xrange(evaluation_base):\n ans[x] /= test_count\n print ans\n\n\ndef test_latest_small_explicit():\n test_count = 8\n evaluation_base = 2\n ans = [0] * evaluation_base\n for k in xrange(test_count):\n method.generate_data_latest_small_explicit(test_count, k)\n method.generate_matrix(implicit=False)\n b = method.evaluate_explicit()\n for x in xrange(evaluation_base):\n ans[x] += b[x]\n for x in xrange(evaluation_base):\n ans[x] /= test_count\n print ans\n\n\ndef test_latest_small_implicit():\n test_count = 8\n evaluation_base = 4\n ans = [0] * evaluation_base\n for k in xrange(test_count):\n method.generate_data_latest_small_implicit(test_count, k)\n method.generate_matrix(implicit=True)\n b = method.evaluate_implicit()\n for x in xrange(evaluation_base):\n ans[x] += b[x]\n for x in xrange(evaluation_base):\n ans[x] /= test_count\n print ans\n\n\nif __name__ == '__main__':\n test100k_explicit()\n # test100k_implicit()\n # test1m_explicit()\n # test1m_implicit()\n # test_latest_small_explicit()\n # test_latest_small_implicit()\n"
},
{
"alpha_fraction": 0.4902084767818451,
"alphanum_fraction": 0.49526214599609375,
"avg_line_length": 19.842105865478516,
"blob_id": "d7ec3a9d5751d41da5a72827f5810e36cbed54fe",
"content_id": "7ba5fd0b0d68cb0ba8f2946ff0660358df4ddc4d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 1793,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 76,
"path": "/templates/info_search/no_time_conflicit.html",
"repo_name": "Liuheng268/online",
"src_encoding": "UTF-8",
"text": "{% extends \"info_search/base.html\" %}\n\n{% block mainbody %}\n<div class ='container'>\n<div class='row clearfix'>\n<div class = \"col-md-9 column\">\n{% ifequal no_spare_time 1 %}\n <div class=\"panel panel-danger\">\n\t\t\t<div class=\"panel-heading\">\n\t\t\t\t<h3 class=\"panel-title\">系统提示</h3>\n\t\t\t</div>\n\t\t\t<div class=\"panel-body\">\n\t\t\t\t<p>您未添加无课时间,请添加后再查看无时间冲突的所有选修课。<br></p>\n <p><a class=\"btn btn-success\" href=\"/online/spare_time\">添加无课时间</a></p>\n\t\t\t</div>\n\t\t</div>\n{% endifequal %}\n{% ifequal no_spare_time 2 %}\n <div class=\"panel panel-danger\">\n\t\t\t<div class=\"panel-heading\">\n\t\t\t\t<h3 class=\"panel-title\">系统提示</h3>\n\t\t\t</div>\n\t\t\t<div class=\"panel-body\">\n\t\t\t\t<p>经筛选,您添加的空闲时间内没有选修课。请重新填写空课信息。<br></p>\n <p><a class=\"btn btn-success\" href=\"/online/spare_time\">修改无课时间</a></p>\n\t\t\t</div>\n\t\t</div>\n{% endifequal %}\n\n{% ifequal spare_time 1 %}\n\t\t<div id=\"legend\">\n\t\t\t<legend>无时间冲突选修课列表</legend>\n\t\t</div>\n <div class=\"table-responsive\">\n\t\t\t<table class=\"table table-striped\">\n\t\t\t\t<thead>\n\t\t\t\t\t<tr>\n\t\t\t\t\t\t<th>\n\t\t\t\t\t\t\t课程名称\n\t\t\t\t\t\t</th>\n\t\t\t\t\t\t<th>\n\t\t\t\t\t\t\t授课教师\n\t\t\t\t\t\t</th>\n\t\t\t\t\t\t<th>\n\t\t\t\t\t\t\t上课时间\n\t\t\t\t\t\t</th>\n\t\t\t\t\t\t<th>\n\t\t\t\t\t\t\t详情信息\n\t\t\t\t\t\t</th>\n\t\t\t\t\t</tr>\n\t\t\t\t</thead>\n\t\t\t\t<tbody>\n\t\t\t\t{% for xkkh,cou_name,jsxm,rating,BH in rank %}\n\t\t\t\t\t<tr>\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t{{cou_name}}\n\t\t\t\t\t\t</td>\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t{{jsxm}}\n\t\t\t\t\t\t</td>\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t{{rating}}\n\t\t\t\t\t\t</td>\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t\t<a href=\"?BH={{BH}}\" target='_blank'>详情</a>\n\t\t\t\t\t\t</td>\n\t\t\t\t\t</tr>\n\t\t\t\t\t{% endfor %}\n\t\t\t\t</tbody>\n\t\t\t</table>\n </div>\n {% endifequal %}\n</div>\n</div>\n</div>\t\t\t\n{% endblock %}"
},
{
"alpha_fraction": 0.644859790802002,
"alphanum_fraction": 0.649844229221344,
"avg_line_length": 40.153846740722656,
"blob_id": "a90681a2c54e90ea013e3bdf3d1f7d943b3cee29",
"content_id": "1668ada0a766352529cdee8bf3df0e46ffad504b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1605,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 39,
"path": "/urls.py",
"repo_name": "Liuheng268/online",
"src_encoding": "UTF-8",
"text": "\"\"\"mysite5 URL Configuration\n\nThe `urlpatterns` list routes URLs to views. For more information please see:\n https://docs.djangoproject.com/en/1.8/topics/http/urls/\nExamples:\nFunction views\n 1. Add an import: from my_app import views\n 2. Add a URL to urlpatterns: url(r'^$', views.home, name='home')\nClass-based views\n 1. Add an import: from other_app.views import Home\n 2. Add a URL to urlpatterns: url(r'^$', Home.as_view(), name='home')\nIncluding another URLconf\n 1. Add a URL to urlpatterns: url(r'^blog/', include('blog.urls'))\n\"\"\"\nfrom django.conf.urls import url\nfrom online import views\nfrom django.conf import settings\nfrom django.conf.urls.static import static\n\n \nurlpatterns = [\n #url(r'^pachong/$',views.pachong,name = 'pachong'),\n url(r'^$',views.bind_id,name = 'bind_id'),\n url(r'^col_rat/$',views.col_rating_new,name = 'col_rat'),\n url(r'^user_cf/$',views.user_cf,name = 'user_cf'),\n url(r'^item_cf/$',views.item_cf,name = 'item_cf'),\n url(r'^lfm/$',views.lfm,name = 'lfm'),\n url(r'^base_info/$',views.base_info,name = 'base'),\n url(r'^avr_rating/$',views.avr_rating,name = 'avr_rating'),\n url(r'^cou_info/$',views.cou_info,name = 'cou_info'),\n url(r'^spare_time/$',views.spare_time,name = 'spare'),\n url(r'^bind_id/$',views.bind_id,name = 'bind_id'),\n url(r'^detail.*/$',views.course_detail,name = 'detail'),\n url(r'^user_center/$',views.user_center,name = 'user_center'),\n url(r'^online_admin/$',views.online_admin,name = 'online_admin'),\n \n \n \n]+ static(settings.STATIC_URL, document_root = settings.STATIC_ROOT)\n"
},
{
"alpha_fraction": 0.6402438879013062,
"alphanum_fraction": 0.7378048896789551,
"avg_line_length": 26.33333396911621,
"blob_id": "f24c0fdf6fdcf7456cb92bb0a3cb9b1af4156b9f",
"content_id": "c13375cb6dcadd07066457ac35d2affda3f77bd1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 164,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 6,
"path": "/recommend/cosine.py",
"repo_name": "Liuheng268/online",
"src_encoding": "UTF-8",
"text": "from numpy import *\nvector1 = ones(4)\nvector2 = [3,3,6,8]\nprint max(vector1)\ncosV12 = dot(vector1,vector2)/(linalg.norm(vector1)*linalg.norm(vector2))\nprint cosV12\n"
},
{
"alpha_fraction": 0.46112075448036194,
"alphanum_fraction": 0.4771937429904938,
"avg_line_length": 24.414363861083984,
"blob_id": "486b15c3fab121221d50ea5b4f897f866b0e18cd",
"content_id": "aa695110512835e983edaf24c28e510bf1487500",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 5142,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 181,
"path": "/templates/info_collect/spare_time_new.html",
"repo_name": "Liuheng268/online",
"src_encoding": "UTF-8",
"text": "{% extends \"site_base.html\" %}\n\n{% load i18n %}\n\n{% block head_title %}填写空闲时间{% endblock %}\n\n{% block body_class %}home{% endblock %}\n\n{% block body_base %}\n<div class=\"container\">\n {% include \"_messages.html\" %}\n <div class=\"row clearfix\">\n <div class=\"col-md-9 column\">\n <div class=\"jumbotron\">\n\t\t\t\t<h1>\n\t\t\t\tSTEP 4:空闲时间填写\n\t\t\t\t</h1>\n\t\t\t\t<p>\n\t\t\t\t请填写您希望的上课时间与周数,我们将帮您在个性化推荐结果中过滤有<strong>时间冲突</strong>的选修课,节省您的时间,提升您的选课体验。\n\t\t\t\t\n\t\t\t\t</p>\n <p>填写完成后,请单击\"查看推荐\"按钮,获取推荐课程信息</p>\n </div>\n </div>\n <div class=\"col-md-3 column\">\n <div id=\"legend\">\n <br>\n \n <legend>用户信息</legend>\n </div>\n <div>\n <a class=\"btn btn-default\" href=\"/online/user_center\">个人主页</a>\n <h4>用户名:{{user}}</h4>\n {% if grade %}\n <h4>年级:{{grade}}级</h4>\n {% endif %}\n {% if major %}\n <h4>专业:{{major}}</h4>\n {% endif %}\n {% if bind_id %}\n <h4>绑定学号:{{bind_id}}</h4>\n {% endif %}\n \n </div>\n </div>\n </div>\n\n \n</div>\t\n\t\t\t\t\n\n\n<div class=\"container\">\t\n<form name='col_spare_time' method=\"POST\" enctype=\"multipart/form-data\">\n{% csrf_token %}\t\n {% ifequal first_log_in 1 %}\n <div class=\"panel panel-success\">\n\t\t\t<div class=\"panel-heading\">\n\t\t\t\t<h3 class=\"panel-title\">系统提示</h3>\n\t\t\t</div>\n\t\t\t<div class=\"panel-body\">\n\t\t\t\t检测到您初次登录此系统,帮助信息在页面最下方。\n\t\t\t</div>\n\t\t</div>\n {% endifequal %}\t\t\n\t<div class=\"row clearfix\">\n\t\t<div class=\"col-md-8 column\">\n\t\t\t<div id=\"legend\">\n\t\t\t\t<legend>填写空闲时间</legend>\n\t\t\t</div>\n\t\t</div>\n\t\t<div class=\"col-md-4 column\">\n\t\t\t<div id=\"legend\">\n\t\t\t\t<legend>填写示例</legend>\n\t\t\t</div>\n\t\t</div>\n\t</div>\n\t\n\t<div class=\"row clearfix\">\t\t\n\t\n\t\t\t<div class=\"col-md-2 column\">\n\t\t\t\t<div class=\"form-group\">\n\t\t\t\t\t<label for=\"name\">起始周</label>\n\t\t\t\t\t<input type=\"text\" class=\"form-control\" placeholder=\"1-18\" name='start_week' value='1'>\n\t\t\t\t</div>\n\t\t\t</div>\n\t\t\t<div class=\"col-md-2 column\">\n\t\t\t\t<div class=\"form-group\">\n\t\t\t\t\t<label for=\"name\">结束周</label>\n\t\t\t\t\t<input type=\"text\" class=\"form-control\" placeholder=\"1-18\" name='end_week' value='18'>\n\t\t\t\t</div>\n\t\t\t</div>\n\t\t\t<div class=\"col-md-2 column\">\n\t\t\t\t<div class=\"form-group\">\n\t\t\t\t<label for=\"name\">星期</label>\n\t\t\t\t<select class=\"form-control\" name='XQ'>\n\t\t\t\t<option value='周一'>星期一</option>\n\t\t\t\t<option value='周二'>星期二</option>\n\t\t\t\t<option value='周三'>星期三</option>\n\t\t\t\t<option value='周四'>星期四</option>\n\t\t\t\t<option value='周五'>星期五</option>\n\t\t\t\t</select>\n\t\t\t\t</div>\n\t\t\t</div>\n\t\t\t<div class=\"col-md-2 column\">\n\t\t\t\t<div class=\"form-group\">\n\t\t\t\t<label for=\"name\">上课时间</label>\n\t\t\t\t<select class=\"form-control\" name='SKSJ'>\n\t\t\t\t<option value='1,2'>1,2节</option>\n\t\t\t\t<option value='3,4'>3,4节</option>\n\t\t\t\t<option value='5,6'>5,6节</option>\n\t\t\t\t<option value='7,8'>7,8节</option>\n\t\t\t\t<option value='9,10'>9,10节</option>\n\t\t\t\t</select>\n\n\t\t\t\t</div>\n\t\t\t</div>\n\t\t\t\n\t\t\t\n\t\t\t<div class=\"col-md-4 column\">\n\t\t\t\t<p>目标时间:周二第1,2节{第3-6周}</p>\n\t\t\t\t<p>填写项目:起始周:3//结束周:6(全部填写数字)</p>\n\t\t\t\t<p>//周二//1,2节</p>\n\t\t\t\t\n\t\t\t</div>\n\t\t\t\n\t\t\t\n\t\t\t\n\n\t</div>\n\t\t\n\t<div class=\"row clearfix\">\n\t\n\t\t<div class=\"col-md-6 column\">\n\t\t\n\t\t</div>\n\t\t<div class=\"col-md-1 column\">\n\t\t\t<input type=\"submit\" class=\"btn btn-primary\" value = \"添加\" /><p></p>\n \n\t\t</div>\t\n\t\t<div class=\"col-md-1 column\">\n\t\t\t<a href=\"?WC=1\" class=\"btn btn-success\" title=\"计算过程可能需要15s,请耐心等待……\">查看推荐</a><p></p>\n </div>\n\t\t\n\t<div id=\"legend\">\n\t\t<br><br>\n\t\t<legend></legend>\n\t</div>\t\t\n\t</div>\n</form>\n\t<div class=\"row clearfix\">\n\t\t<div class=\"col-md-4 column\">\n\t\t<div id=\"legend\">\n\t\t\t\t<legend>已选择时间</legend>\n\t\t</div>\n\t\t<table class=\"table table-striped\">\n\t\t\t<tbody>\n\t\t\t{% for time in time_lst %}\n\t\t\t\t<tr>\n\t\t\t\t\t<td><p>{{time}}</p></td>\n\t\t\t\t</tr>\n\t\t\t{% endfor %}\n\t\t\t</tbody>\n\t\t</table>\n\t\t<a href=\"?QK=1\" class=\"btn btn-danger\">清空</a>\n <br>\n <br>\n\t\t</div>\n\t\t\n\t</div>\n {% ifequal first_log_in 1 %}\n <div id=\"legend\">\n <legend>帮助信息</legend>\n </div>\n <p>\n <a class=\"btn btn-warning\" href=\"?close_help=1\">关闭帮助信息</a><br><br>\n </p>\n <img class=\"img-responsive\" src=\"/site_media/static/img/spare_time.png\" alt=\"spare_time_help.png\">\n {% endifequal %}\n</div>\n{% endblock %}\t\n\t\n\t"
},
{
"alpha_fraction": 0.49375438690185547,
"alphanum_fraction": 0.5155260562896729,
"avg_line_length": 35.13831329345703,
"blob_id": "d1805cbf94435ec391f283845ba24ab6a0d092f4",
"content_id": "ef19258525a7642faf2754b1cf31bc4aba650209",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 23164,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 629,
"path": "/views.py",
"repo_name": "Liuheng268/online",
"src_encoding": "UTF-8",
"text": "#-*-coding: utf-8 -*-\n# default\nfrom django.shortcuts import render,render_to_response\nfrom django.http import HttpResponse,HttpResponseRedirect\nfrom django.template import RequestContext\nfrom account.decorators import login_required\nfrom django import forms\nfrom django.forms import fields\nfrom django.forms import widgets\n\n# added myself\nimport data_base\nfrom info_search import search\nfrom recommend import recommend\nfrom XH_confirm import XH_confirm\nfrom collect_info import col_rat\nfrom collect_info import col_spare_time\nfrom info_search import info_search\n\n@login_required\ndef col_rating_new(req):\n username = str(req.user)\n user_id = data_base.get_user_id(username)\n if 'close_help' in req.GET:\n data_base.close_help(user_id)\n # 绑定学号成功后提示成功success\n success = int(req.session.get('success',0))\n # 获得个人信息并创建网页信息字典\n dic = search.search_user_info(user_id)\n first_log_in = data_base.get_first_log_in_flag(user_id)\n print 'location_:col_rating_new__id_:01-01'\n if req.method == 'GET':\n dic1 = col_rat.get_cou_lst(user_id)\n dic = dict(dic,**dic1)\n print 'location_:col_rating_new__id_:01-02'\n if dic['lst']:\n if success:\n # 绑定学号成功后跳转到收集评分页面,同时记录收集评分开始的时间\n col_rat.set_col_time(user_id,'start')\n print 'location_:col_rating_new__id_:01-03'\n dic['success'] = '1'\n req.session['success'] = 0\n print 'location_:col_rating_new__id_:01-03-01'\n if first_log_in ==0:\n dic['first_log_in'] = 1\n return render(req,'info_collect/col_rat.html',dic,)\n else:\n # 记录收集评分结束的时间\n # 同时设置user_info中COL_RATING =1\n col_rat.set_col_time(user_id,'end')\n print 'location_:col_rating_new__id_:01-04'\n return HttpResponseRedirect('/online/spare_time')\n if req.method == 'POST':\n print 'location_:col_rating_new__id_:01-05'\n dic = col_rat.get_cou_lst(user_id)\n cou_lst = dic['lst']\n try:\n XN = dic['XN']\n XQ = dic['XQ']\n rat_lst = []\n d = dict(req.POST)\n print 'location_:col_rating_new__id_:01-06'\n for num,name,BH,jsxm in cou_lst:\n if str(BH) in d.keys():\n rating = d[str(BH)]\n rat_lst.append([BH,rating[0]])\n col_rat.write_into_data_base(user_id,rat_lst,XN,XQ)\n print 'location_:col_rating_new__id_:01-07'\n return HttpResponseRedirect('/online/col_rat')\n except:\n return HttpResponseRedirect('/online/col_rat')\n\n@login_required\ndef user_cf(req):\n print 'location_:user_cf__id_:02'\n username = str(req.user)\n user_id = data_base.get_user_id(username)\n if 'update_rating' in req.GET:\n col_rat.update_COL_RATING_delete(user_id)\n return HttpResponseRedirect('/online/col_rat')\n if 'close_help' in req.GET:\n data_base.close_help(user_id)\n first_log_in = data_base.get_first_log_in_flag(user_id)\n if req.method == 'GET':\n # 获取翻页信息\n if 'a' in req.GET:\n opt = req.GET.get('a')\n else:\n opt = 0\n # 获取详细课程信息\n if 'BH' in req.GET:\n BH = req.GET.get('BH')\n else:\n BH = 0\n # 获得个人信息并创建网页信息字典\n dic = search.search_user_info(user_id)\n print 'location_:user_cf__id_:02-01'\n if 'no_time_conflicit' in req.GET:\n flag = data_base.get_spare_time_flag(user_id)\n print 'location_:user_cf__id_:02-02'\n if flag ==0:\n dic['no_spare_time'] = 1\n else:\n rec = recommend.get_2016_2017_2_XXK(user_id)\n if rec:\n dic['spare_time'] = 1\n dic['rank'] = rec\n else:\n dic['no_spare_time'] = 2\n return render(req,'info_search/no_time_conflicit.html',dic,)\n if BH:\n response = HttpResponseRedirect('/online/detail_BH=%s/'%BH)\n response.set_cookie('BH',BH)\n print 'location_:user_cf__id_:02-03'\n return response\n start = 0\n if opt:\n start = int(opt)\n rec = recommend.re_user_cf(start,user_id,10)\n print 'location_:user_cf__id_:02-04'\n if 'invalid_rating' in rec:\n dic['invalid_rating'] = 1\n if first_log_in==0:\n dic['first_log_in'] = 1\n return render(req,'recommend/tuijian.html',dic,)\n if 'less_than_standard' in rec :\n dic['error'] = 1\n dic['notworked'] = 1\n s = search.SEARCH()\n rec = s.avr_rating(start,10)\n dic['rank'] = rec\n print 'location_:user_cf__id_:02-05'\n elif rec:\n dic['rank'] = rec\n dic['worked'] = 1\n else:\n dic['error'] = 2\n dic['notworked'] =1\n s = search.SEARCH()\n rec = s.avr_rating(start,10)\n dic['rank'] = rec\n print 'location_:user_cf__id_:02-06'\n if first_log_in==0:\n dic['first_log_in'] = 1\n return render(req,'recommend/tuijian.html',dic,)\n else:\n return HttpResponseRedirect('/online/user_cf')\n\n@login_required\ndef item_cf(req):\n print 'location_:item_cf__id_:03'\n username = str(req.user)\n user_id = data_base.get_user_id(username)\n if 'close_help' in req.GET:\n data_base.close_help(user_id)\n first_log_in = data_base.get_first_log_in_flag(user_id)\n dic = search.search_user_info(user_id)\n if req.method == 'GET':\n if 'a' in req.GET:\n opt = req.GET.get('a')\n else:\n opt = 0\n if 'BH' in req.GET:\n BH = req.GET.get('BH')\n else:\n BH = 0\n # 获得个人信息并创建网页信息字典\n print 'location_:item_cf__id_:03-01'\n if 'no_time_conflicit' in req.GET:\n flag = data_base.get_spare_time_flag(user_id)\n print 'location_:user_cf__id_:02-02'\n if flag ==0:\n dic['no_spare_time'] = 1\n else:\n rec = recommend.get_2016_2017_2_XXK(user_id)\n if rec:\n dic['spare_time'] = 1\n dic['rank'] = rec\n else:\n dic['no_spare_time'] = 2\n return render(req,'info_search/no_time_conflicit.html',dic,)\n if BH:\n response = HttpResponseRedirect('/online/detail_BH=%s/'%BH)\n response.set_cookie('BH',BH)\n print 'location_:item_cf__id_:03-03'\n return response\n start = 0\n if opt:\n start = int(opt)\n rec = recommend.re_item_cf(start,user_id,10)\n print 'location_:item_cf__id_:03-04'\n if 'invalid_rating' in rec:\n dic['invalid_rating'] = 1\n if first_log_in==0:\n dic['first_log_in'] = 1\n return render(req,'recommend/item_cf.html',dic,)\n if 'less_than_standard' in rec:\n dic['error'] = 1\n dic['notworked'] = 1\n s = search.SEARCH()\n rec = s.avr_rating(start,10)\n dic['rank'] = rec\n print 'location_:item_cf__id_:03-05'\n elif rec:\n dic['rank'] = rec\n dic['worked'] = 1\n else:\n dic['error'] = 2\n dic['notworked'] = 1\n s = search.SEARCH()\n rec = s.avr_rating(start,10)\n dic['rank'] = rec\n print 'location_:item_cf__id_:03-06'\n if first_log_in==0:\n dic['first_log_in'] = 1\n return render(req,'recommend/item_cf.html',dic,)\n else:\n return HttpResponseRedirect('/online/item_cf') \n\n@login_required\ndef lfm(req):\n print 'location_:lfm__id_:02'\n username = str(req.user)\n user_id = data_base.get_user_id(username)\n if 'close_help' in req.GET:\n data_base.close_help(user_id)\n first_log_in = data_base.get_first_log_in_flag(user_id)\n if req.method == 'GET':\n # 获取翻页信息\n if 'a' in req.GET:\n opt = req.GET.get('a')\n else:\n opt = 0\n # 获取详细课程信息\n if 'BH' in req.GET:\n BH = req.GET.get('BH')\n else:\n BH = 0\n # 获得个人信息并创建网页信息字典\n dic = search.search_user_info(user_id)\n print 'location_:lfm__id_:02-01'\n if 'no_time_conflicit' in req.GET:\n flag = data_base.get_spare_time_flag(user_id)\n print 'location_:user_cf__id_:02-02'\n if flag ==0:\n dic['no_spare_time'] = 1\n else:\n rec = recommend.get_2016_2017_2_XXK(user_id)\n if rec:\n dic['spare_time'] = 1\n dic['rank'] = rec\n else:\n dic['no_spare_time'] = 2\n return render(req,'info_search/no_time_conflicit.html',dic,)\n if BH:\n response = HttpResponseRedirect('/online/detail_BH=%s/'%BH)\n response.set_cookie('BH',BH)\n print 'location_:lfm__id_:02-03'\n return response\n start = 0\n if opt:\n start = int(opt)\n rec = recommend.re_lfm(start,user_id,10)\n print 'location_:lfm__id_:02-04'\n if 'invalid_rating' in rec:\n dic['invalid_rating'] = 1\n if first_log_in==0:\n dic['first_log_in'] = 1\n return render(req,'recommend/tuijian.html',dic,)\n if 'less_than_standard' in rec:\n dic['error'] = 1\n dic['notworked'] = 1\n s = search.SEARCH()\n rec = s.avr_rating(start,10)\n dic['rank'] = rec\n print 'location_:lfm__id_:02-05'\n elif rec:\n dic['rank'] = rec\n dic['worked'] = 1\n else:\n dic['error'] = 2\n dic['notworked'] =1\n s = search.SEARCH()\n rec = s.avr_rating(start,10)\n dic['rank'] = rec\n print 'location_:lfm__id_:02-06'\n if first_log_in==0:\n dic['first_log_in'] = 1\n return render(req,'recommend/tuijian.html',dic,)\n else:\n return HttpResponseRedirect('/online/lfm')\n \n#********************************************************************\n@login_required \ndef base_info(req):\n print 'location_:base_info__id_:04'\n if req.method == 'GET':\n if 'a' in req.GET:\n opt = req.GET.get('a')\n else:\n opt = 0\n if 'BH' in req.GET:\n BH = req.GET.get('BH')\n else:\n BH = 0\n if BH:\n response = HttpResponseRedirect('/online/detail_BH=%s/'%BH)\n response.set_cookie('BH',BH)\n return response\n if opt:\n start = int(opt)\n s = search.SEARCH()\n rec = s.avr_rating(start,10)\n dic = {}\n dic['rank'] = rec\n print 'location_:base_info__id_:04-01'\n return render(req,'info_search/avr_rating.html',dic,)\n else:\n s = search.SEARCH()\n rec = s.avr_rating(0,10)\n dic = {}\n dic['rank'] = rec\n print 'location_:base_info__id_:04-02'\n return render(req,'info_search/avr_rating.html',dic,)\n else:\n print 'location_:base_info__id_:04-03'\n s = search.SEARCH()\n rec = s.avr_rating(0,10)\n dic = {}\n dic['rank'] = rec\n print 'location_:base_info__id_:04-04'\n return render(req,'info_search/avr_rating.html',dic,)\n@login_required \ndef avr_rating(req):\n print 'location_:avr_rating__id_:05'\n username = str(req.user)\n user_id = data_base.get_user_id(username)\n dic = search.search_user_info(user_id)\n if req.method == 'GET':\n print 'location_:avr_rating__id_:05-01'\n if 'maj_avr' in req.GET:\n result_dic = info_search.get_maj_avr(user_id, threshold=5)\n if result_dic['rank']==[]:\n dic['error']=1\n else:\n dic['maj_avr']=1\n dic['rank'] = result_dic['rank']\n dic['maj_name'] = result_dic['maj_name']\n return render(req,'info_search/avr_rating.html',dic,)\n if 'a' in req.GET:\n opt = req.GET.get('a')\n else:\n opt = 0\n if opt:\n start = int(opt)\n s = search.SEARCH()\n rec = s.avr_rating(start,50)\n if rec==[]:\n dic['error']=1\n else:\n dic['worked']=1\n dic['rank'] = rec\n print 'location_:avr_rating__id_:05-02'\n return render(req,'info_search/avr_rating.html',dic,)\n else:\n s = search.SEARCH()\n rec = s.avr_rating(0,50)\n if rec==[]:\n dic['error']=1\n else:\n dic['worked']=1\n dic['rank'] = rec\n print 'location_:avr_rating__id_:05-03'\n return render(req,'info_search/avr_rating.html',dic,)\n else:\n print 'location_:avr_rating__id_:05-04'\n s = search.SEARCH()\n rec = s.avr_rating(0,50)\n dic['rank'] = rec\n print 'location_:avr_rating__id_:05-05'\n return render(req,'info_search/avr_rating.html',dic,)\n@login_required \ndef cou_info(req):\n print 'location_:cou_info__id_:06'\n username = str(req.user)\n user_id = data_base.get_user_id(username)\n dic = search.search_user_info(user_id)\n if req.method == 'GET':\n print 'location_:cou_info__id_:06-01'\n if 'a' in req.GET:\n opt = req.GET.get('a')\n else:\n opt = 0\n if opt:\n XN = str(req.COOKIES['XN'])\n XQ = int(str(req.COOKIES['XQ']))\n start = int(opt)*30\n s = search.SEARCH()\n rec = s.search_cou_info(start,30,XN,XQ)\n dic['lst'] = rec\n print 'location_:cou_info__id_:06-02'\n return render(req,'info_search/cou_info.html',dic,)\n else:\n if 'XN' in req.GET:\n XN = req.GET.get('XN').encode('utf-8')\n else:\n XN = '2016-2017'\n if 'XQ' in req.GET:\n XQ = int(req.GET.get('XQ'))\n else:\n XQ = 2\n s = search.SEARCH()\n rec = s.search_cou_info(0,30,XN,XQ)\n print 'location_:cou_info__id_:06-03'\n dic['lst'] = rec\n response = render(req,'info_search/cou_info.html',dic,)\n response.set_cookie('XN',XN)\n response.set_cookie('XQ',XQ)\n print 'location_:cou_info__id_:06-04'\n return response\n else:\n \n if 'XN' in req.GET:\n XN = req.GET.get('XN').encode('utf-8')\n else:\n XN = '2016-2017'\n if 'XQ' in req.GET:\n XQ = int(req.GET.get('XQ'))\n else:\n XQ = 2\n s = search.SEARCH()\n rec = s.search_cou_info(0,30,XN,XQ)\n print 'location_:cou_info__id_:06-05'\n dic['lst'] = rec\n response = render(req,'info_search/cou_info.html',dic,)\n response.set_cookie('XN',XN)\n response.set_cookie('XQ',XQ)\n print 'location_:cou_info__id_:06-06'\n return response\n \n@login_required\ndef spare_time(req):\n print 'location_:spare_time__id_:07'\n if req.method == 'GET':\n username = str(req.user)\n user_id = data_base.get_user_id(username)\n if 'close_help' in req.GET:\n data_base.close_help(user_id)\n flag_dic = data_base.get_user_info_flag(user_id)\n first_log_in = data_base.get_first_log_in_flag(user_id)\n dic = search.search_user_info(user_id)\n print 'location_:spare_time__id_:07-01'\n #if flag_dic['spare_time']:\n #return HttpResponseRedirect('/online/user_cf')\n if 'QK' in req.GET:\n print 'location_:spare_time__id_:07-02-01'\n QK = str(req.GET.get('QK'))\n if QK=='1':\n print 'location_:spare_time__id_:07-02-02'\n col_spare_time.delete_spare_time(user_id)\n time_lst = col_spare_time.get_spare_time(user_id)\n dic['error'] = 1\n dic['time_lst'] = time_lst\n print 'location_:spare_time__id_:07-03'\n if 'WC' in req.GET:\n print 'location_:spare_time__id_:07-04-01'\n return HttpResponseRedirect('/online/user_cf')\n print 'location_:spare_time__id_:07-05'\n if first_log_in==0:\n dic['first_log_in'] = 1 \n return render(req,'info_collect/spare_time_new.html',dic,)\n if req.method == 'POST':\n username = str(req.user)\n user_id = data_base.get_user_id(username)\n dic = req.POST\n col_spare_time.col_spare_time(user_id,dic)\n col_spare_time.write_user_info_flag(user_id)\n print 'location_:spare_time__id_:07-06'\n return HttpResponseRedirect('/online/spare_time')\n\n@login_required\ndef bind_id(req):\n print 'location_:bind_id__id_:08'\n username = str(req.user)\n user_id = data_base.get_user_id(username)\n if 'close_help' in req.GET:\n data_base.close_help(user_id)\n dic = {}\n if req.method == 'GET':\n print 'get in GET path'\n first_log_in = data_base.get_first_log_in_flag(user_id)\n print 'location_:bind_id__id_:08-00'\n flag_dic = data_base.get_user_info_flag(user_id)\n print 'location_:bind_id__id_:08-01'\n if flag_dic['bind_id']:\n print 'location_:bind_id__id_:08-02'\n return HttpResponseRedirect('/online/col_rat')\n if 'input' in req.GET:\n print 'location_:bind_id__id_:08-03'\n XH = str(req.GET.get('input'))\n if len(XH)!=10:\n print 'error_len(XH)!=10'\n dic['wrong_XH']=1\n return render(req,'bind_id.html',dic)\n result_dic= XH_confirm.get_cou_list(XH)\n lst = result_dic['result']\n confirm = result_dic['confirm']\n dic['cou_lst']=lst\n if first_log_in ==0:\n dic['first_log_in'] = 1\n response = render(req,'bind_id.html',dic)\n response.set_cookie('confirm',confirm)\n print 'location_:bind_id__id_:08-04'\n return response\n else:\n print 'location_:bind_id__id_:08-05'\n if first_log_in ==0:\n dic['first_log_in'] = 1\n return render(req,'bind_id.html',dic)\n else:\n print 'get_in_POST_path'\n post_dic = dict(req.POST)\n confirm = req.COOKIES['confirm']\n if 'select' in post_dic.keys():\n print 'location_:bind_id__id_:08-06'\n flag = XH_confirm.confirm(post_dic['select'],confirm)\n else:\n return HttpResponseRedirect('/online/bind_id') \n print 'location_:bind_id__id_:08-07'\n if flag ==1:\n print 'location_:bind_id__id_:08-08'\n if 'input' in req.GET:\n print 'location_:bind_id__id_:08-09'\n bind_id = str(req.GET.get('input'))\n else:\n return HttpResponseRedirect('/online/bind_id')\n # 更新user_info表中绑定的学号\n data_base.update_bind_id(user_id,bind_id)\n print 'location_:bind_id__id_:08-09'\n # 初始化用户选课时间\n data_base.insert_xksj(user_id)\n print 'location_:bind_id__id_:08-10'\n req.session['success'] = 1\n # 初始化用户评分\n data_base.delete_rating(user_id)\n print 'location_:bind_id__id_:08-11'\n return HttpResponseRedirect('/online/col_rat')\n else:\n dic = {'error':'1'}\n print 'location_:bind_id__id_:08-12'\n return render(req,'bind_id.html',dic)\n@login_required\ndef course_detail(req):\n username = str(req.user)\n user_id = data_base.get_user_id(username)\n if req.method == 'GET':\n # 获得个人信息并创建网页信息字典\n dic = search.search_user_info(user_id)\n BH = int(req.COOKIES['BH'])\n lst = data_base.search_detail(BH)\n lst = sorted(lst,key=lambda t:t[4],reverse=True)\n dic['detail'] = lst\n return render(req,'detail.html',dic)\n else:\n dic = search.search_user_info(user_id)\n BH = int(req.COOKIES['BH'])\n lst = data_base.search_detail(BH)\n lst = sorted(lst,key=lambda t:t[4],reverse=True)\n dic['detail'] = lst\n return render(req,'detail.html',dic)\n \n@login_required\ndef user_center(req):\n username = str(req.user)\n user_id = data_base.get_user_id(username)\n print 'location_:user_center__id_:09'\n if req.method == 'GET':\n print 'location_:user_center__id_:09-01-00'\n #update_bind_id = str(req.GET.get('update_bind_id'))\n #锁定绑定id,不可以更改绑定的学号\n update_bind_id = 0\n if 'update_rating' in req.GET:\n update_rating = str(req.GET.get('update_rating'))\n else:\n update_rating = 0\n if 'update_spare_time' in req.GET:\n update_spare_time = str(req.GET.get('update_spare_time'))\n else:\n update_spare_time = 0\n print 'location_:user_center__id_:09-01'\n if update_bind_id =='1':\n XH_confirm.delete_bind_id(user_id)\n print 'location_:user_center__id_:09-02'\n return HttpResponseRedirect('/online/bind_id')\n if update_rating =='1':\n col_rat.update_COL_RATING_delete(user_id)\n print 'location_:user_center__id_:09-03'\n return HttpResponseRedirect('/online/col_rat')\n if update_spare_time =='1':\n print 'location_:user_center__id_:09-04'\n return HttpResponseRedirect('/online/spare_time')\n flag_dic = data_base.get_user_info_flag(user_id)\n # 获得个人信息并创建网页信息字典\n dic = search.search_user_info(user_id)\n print 'location_:user_center__id_:09-05'\n return render(req,'user_center.html',dic)\n else:\n flag_dic = data_base.get_user_info_flag(user_id)\n dic = search.search_user_info(user_id)\n print 'location_:user_center__id_:09-06'\n return render(req,'user_center.html',dic)\n\n@login_required\ndef online_admin(req):\n print 'location_:online_admin_id_:10'\n if req.method =='GET':\n username = str(req.user)\n user_id = data_base.get_user_id(username)\n if username=='admin':\n dic = info_search.user_info()\n dic['worked'] = 1\n return render(req,'online_admin.html',dic,)\n else:\n dic ={}\n dic['error'] = 1\n return render(req,'online_admin.html',dic,)\n \n else:\n return HttpResponseRedirect('/online/admin')\n \n"
},
{
"alpha_fraction": 0.5796020030975342,
"alphanum_fraction": 0.5827114582061768,
"avg_line_length": 25.799999237060547,
"blob_id": "797756265bc8346d9bab6424e5a75d883758fa44",
"content_id": "18538ddbaa7a73c62d01a71d71429b1e387ab531",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1888,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 60,
"path": "/collect_info/col_rat.py",
"repo_name": "Liuheng268/online",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# 此代码目的:评分收集程序\n# 此代码需要调用的变量形式或文件类型如下:\n# \n# \n# 此代码归属模块:评分收集模块\n\nimport data_base\nimport time\nfrom datetime import datetime\n\ndef get_cou_lst(user_id):\n # 获取用户已选课程列表\n flag = data_base.get_user_XKSJ_flag(user_id)\n count = data_base.count_flag(user_id)\n if flag:\n for XN,XQ,f in flag[:1]:\n cou_lst = data_base.get_cou_lst(user_id,XN,XQ)\n dic = {}\n dic['lst'] =cou_lst\n dic['XN'] =XN\n dic['XQ'] =XQ\n if count>=4:\n dic['count']=1\n return dic\n else:\n dic ={}\n dic['lst'] =''\n return dic\ndef write_into_data_base(user_id,rat_lst,XN,XQ):\n # 将用户评分存入数据库\n data_base.update_rating(user_id,rat_lst,XN,XQ)\n\ndef set_col_time(user_id,flag):\n # 记录评分开始与结束时间,为提升系统健壮性做准备\n if flag =='start':\n start_time = time.strftime(\"%Y-%m-%d %H:%M:%S\", time.localtime())\n # 先删除已有的时间数据,避免重复,重新设置时间数据\n data_base.delete_time(user_id)\n write_time(user_id,start_time,flag)\n elif flag =='end':\n end_time = time.strftime(\"%Y-%m-%d %H:%M:%S\", time.localtime())\n write_time(user_id,end_time,flag)\n update_COL_RATING(user_id)\n else:\n pass\n\ndef write_time(user_id,time,flag):\n # 将评分开始和结束时间存入数据库\n data_base.write_time(user_id,time,flag)\n\ndef update_COL_RATING(user_id):\n # 更新user_info 中评分收集完成的标志\n data_base.update_COL_RATING(user_id)\n\ndef update_COL_RATING_delete(user_id):\n data_base.update_COL_RATING_delete(user_id)\n data_base.update_XKSJ_flag(user_id)\nif __name__ == '__main__':\n get_cou_lst(9)\n"
},
{
"alpha_fraction": 0.5582272410392761,
"alphanum_fraction": 0.5731573104858398,
"avg_line_length": 36.54438018798828,
"blob_id": "0edebc0bbe9d610462396440e427ce97cc7badc8",
"content_id": "77982dd30c867aaa797bf50891616044d16e14f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6611,
"license_type": "no_license",
"max_line_length": 246,
"num_lines": 169,
"path": "/info_search/data_base.py",
"repo_name": "Liuheng268/online",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport pymssql\nfrom online.timeout_deco import timeout\nfrom online import user_password\ndbo_user,dbo_password = user_password.get_user_password()\nclass MSSQL:\n \n\n def __init__(self,host,user,pwd,db):\n self.host = host\n self.user = user\n self.pwd = pwd\n self.db = db\n @timeout(0.5)\n def __GetConnect(self):\n \n if not self.db:\n raise(NameError,\"没有设置数据库信息\")\n self.conn = pymssql.connect(host=self.host,user=self.user,password=self.pwd,database=self.db,charset=\"utf8\")\n cur = self.conn.cursor()\n if not cur:\n raise(NameError,\"连接数据库失败\")\n else:\n return cur\n @timeout(0.5)\n def ExecQuery(self,sql):\n \n cur = self.__GetConnect()\n cur.execute(sql)\n resList = cur.fetchall()\n self.conn.close()\n return resList\n @timeout(0.5)\n def ExecNonQuery(self,sql):\n \n cur = self.__GetConnect()\n cur.execute(sql)\n self.conn.commit()\n self.conn.close()\n\n#*************************************************************************\ndef get_user_info():\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n user_info = ms.ExecQuery(\"select user_id,user_name,COL_RATING,gra,ZYMC,spare_time,bind_id from user_info as t1 join [XKXX].[dbo].[maj_info] as t2 on convert(int,t2.ZYBH)=convert(int,t1.maj)\")\n return user_info\n\ndef create_re_train():\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\") \n m = ms.ExecQuery(\"select user_id,BH,rating from user_cour_rating\")\n train = {}\n for user,item,rating in m:\n user, item, rating = int(user), int(item), int(rating)\n train.setdefault(user, {})\n train[user][item] = rating\n return train\ndef get_all_xuanxiu_BH():\n ms = MSSQL(host=\"localhost\",user=\"xuankeadmin\",pwd=\"xuanketuijian1996LH\",db=\"XKXX\")\n KCXZ = u'校选修课'.encode('utf-8')\n temp = ms.ExecQuery(\"SELECT BH FROM jxrwb2 where KCXZ='%s' and XN='2016-2017'\"%KCXZ)\n BH_lst = []\n for row in temp:\n BH_lst.append(row[0])\n #print 12 in BH_lst\n return BH_list\n\ndef get_avr(threshold=0):\n #根据数据集计算平均评分\n #threshold:评分人数阈值,小于阈值则过滤数据\n KCXZ = u'校选修课'.encode('utf-8')\n ms = MSSQL(host=\"localhost\",user=\"xuankeadmin\",pwd=\"xuanketuijian1996LH\",db=\"xuanke\") \n m = ms.ExecQuery(\"select user_id,t1.BH,rating from [xuanke].[dbo].[user_cour_rating] as t1 left join [XKXX].[dbo].[jxrwb2] as t2 on t1.BH=t2.BH where KCXZ='%s' group by user_id,t1.BH,rating\"%KCXZ)\n _item_users = {}\n for user,item,rating in m:\n user, item, rating = int(user), int(item), int(rating)\n _item_users.setdefault(item, {})\n _item_users[item][user] = rating\n _avr = {}\n for item, users in _item_users.iteritems():\n if len(users)>threshold:\n _avr[item]={}\n _avr[item]['rating'] = sum(users.itervalues())*1.0 / len(users)\n _avr[item]['count'] = len(users)\n print _avr\n return _avr\ndef get_maj(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\") \n m = ms.ExecQuery(\"select maj from user_info where user_id =%d\"%user_id)\n try:\n maj = int(m[0][0])\n except:\n maj = 5\n return maj\ndef get_maj_user_tuple(maj):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\") \n m = ms.ExecQuery(\"select user_id from user_info where maj =%d\"%maj)\n user_lst = []\n for row in m:\n user_lst.append(row[0])\n if len(user_lst) ==1:\n user_tuple_str = '(%d)'%user_lst[0]\n else:\n user_tuple_str = str(tuple(user_lst))\n return user_tuple_str\n\ndef get_all_xuanxiu_BH():\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n KCXZ = u'校选修课'.encode('utf-8')\n temp = ms.ExecQuery(\"SELECT BH FROM jxrwb2 where KCXZ='%s' and XN='2016-2017'\"%KCXZ)\n BH_lst = []\n for row in temp:\n BH_lst.append(row[0])\n #print 12 in BH_lst\n return BH_lst\n\ndef get_maj_avr_rating(user_tuple_str, threshold=5):\n #只保留与用户同专业的选修课平均分\n BH_list = get_all_xuanxiu_BH() #选修课列表\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n sql = \"select a.BH,count(BH),round(avg(cast(a.rating as float)),2) as avr from (select user_id,BH,rating from [xuanke].[dbo].[user_cour_rating] where user_id in %s group by user_id,BH,rating) a group by a.BH order by avr desc\"%user_tuple_str\n m = ms.ExecQuery(sql)\n _avr = {} #平均评分字典\n for item,count,avr in m:\n if item not in BH_list:\n continue\n if count>=threshold: #评分人数阈值\n _avr[item]={}\n _avr[item]['rating'] = avr\n _avr[item]['count'] = count\n return _avr\ndef transfer_lst(start,n,rank):\n #如果n=0,返回全部平均评分 \n lst = list(rank)\n lst = sorted(lst,key=lambda t:t[1],reverse=True)\n rec = []\n if n==0:\n for line in lst:\n temp = search_teacher(line[0],KCXZ_flag=0)\n if temp:\n rec.append([temp[0][0],temp[0][1],temp[0][2],line[1],line[0],line[2]])\n else:\n for line in lst[start:start+n]:\n temp = search_teacher(line[0],KCXZ_flag=0)\n if temp:\n rec.append([temp[0][0],temp[0][1],temp[0][2],line[1],line[0],line[2]])\n return rec\n\ndef search_teacher(BH,KCXZ_flag=0):\n #KCXZ_flag 0:全部课程;1:校选修课;2:必修课\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n if KCXZ_flag ==1:\n KCXZ = u'校选修课'.encode('utf-8')\n m = ms.ExecQuery(\"select KCDM,KCMC,JSXM from jxrwb2 where BH = %d and KCXZ ='%s'\"%(BH,KCXZ))\n elif KCXZ_flag ==2:\n KCXZ = u'必修课'.encode('utf-8')\n m = ms.ExecQuery(\"select KCDM,KCMC,JSXM from jxrwb2 where BH = %d and KCXZ ='%s'\"%(BH,KCXZ))\n else :\n m = ms.ExecQuery(\"select KCDM,KCMC,JSXM from jxrwb2 where BH = %d\"%BH)\n return m\ndef get_maj_name(maj):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n m = ms.ExecQuery(\"select ZYMC from maj_info where ZYBH=%d\"%maj)\n try:\n maj_name = m[0][0]\n except:\n maj_name = u'查询错误'\n return maj_name\nif __name__ == '__main__':\n \n get_user_info()\n \n \n"
},
{
"alpha_fraction": 0.5201385021209717,
"alphanum_fraction": 0.5357183814048767,
"avg_line_length": 36.245689392089844,
"blob_id": "038f56f9589ce816a51f664aea6ab9cdbf61b5aa",
"content_id": "ec21d07f8ab9d7fcdfd5378e0b9e6b0e23d5416f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8991,
"license_type": "no_license",
"max_line_length": 226,
"num_lines": 232,
"path": "/info_search/search.py",
"repo_name": "Liuheng268/online",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport pymssql\nfrom online import data_base\nfrom online.collect_info import col_spare_time\nfrom online.timeout_deco import timeout\nfrom online import user_password\ndbo_user,dbo_password = user_password.get_user_password()\nclass MSSQL:\n \n\n def __init__(self,host,user,pwd,db):\n self.host = host\n self.user = user\n self.pwd = pwd\n self.db = db\n @timeout(0.5)\n def __GetConnect(self):\n \n if not self.db:\n raise(NameError,\"没有设置数据库信息\")\n self.conn = pymssql.connect(host=self.host,user=self.user,password=self.pwd,database=self.db,charset=\"utf8\")\n cur = self.conn.cursor()\n if not cur:\n raise(NameError,\"连接数据库失败\")\n else:\n return cur\n @timeout(3)\n def ExecQuery(self,sql):\n \n cur = self.__GetConnect()\n cur.execute(sql)\n resList = cur.fetchall()\n self.conn.close()\n return resList\n @timeout(0.5)\n def ExecNonQuery(self,sql):\n \n cur = self.__GetConnect()\n cur.execute(sql)\n self.conn.commit()\n self.conn.close()\n\n#*************************************************************************\n\n#***************************************************************************\n #s = data_base.SEARCH()\n \n #lst = s.search_detail(3)#课程基础信息\n #lst = s.count(5,233)#各专业历年选特定课程人数(专业编号,课程编号)\n #lst = s.avr_rating()#课程平均评分降序排列\n\nclass SEARCH:\n def __init__(self):\n pass\n def search_detail(self,BH):\n #课程基本信息\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\") \n m = ms.ExecQuery(\"select KCDM,KCMC,JSXM,SKSJ,XF,XN from jxrwb2 where BH = %d\"%BH)\n return m\n def count(self,ZYBH,BH):\n #各专业历年选特定课程人数\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\") \n m = ms.ExecQuery(\"select * from Count1 where BH = %d and ZYBH =%d\"%(BH,ZYBH))\n return m\n def create_re_train(self):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\") \n m = ms.ExecQuery(\"select user_id,BH,rating from user_cour_rating\")\n train = {}\n for user,item,rating in m:\n user, item, rating = int(user), int(item), int(rating)\n train.setdefault(user, {})\n train[user][item] = rating\n #print train.keys()\n return train\n def maj_re_train(self,maj):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n m = ms.ExecQuery(\"select t1.user_id,XKKH,rating from user_cour_rating as t1 join user_info as t2 on t1.user_id =t2.user_id where t2.maj=%d \"%maj)\n train = {}\n for user,item,rating in m:\n user, item, rating = int(user), int(item), int(rating)\n train.setdefault(user, {})\n train[user][item] = rating\n return train\n def get_maj(self):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n m = ms.ExecQuery(\"select ZYBH from maj_info\")\n return m\n def avr_rating(self,start,n,threshold = 5):\n #生成各课程平均评分降序列表\n s=SEARCH()\n item_avr = s.get_avr(threshold)\n lst = []\n for item in item_avr.keys():\n lst.append([item,item_avr[item]['rating'],item_avr[item]['count']])\n rank = s.transfer_lst(start,n,lst)\n return rank\n def transfer_lst(self,start,n,rank):\n #如果n=0,返回全部平均评分 \n lst = list(rank)\n lst = sorted(lst,key=lambda t:t[1],reverse=True)\n rec = []\n if n==0:\n for line in lst:\n temp = data_base.search_teacher(line[0],KCXZ_flag=0)\n if temp:\n rec.append([temp[0][0],temp[0][1],temp[0][2],line[1],line[0],line[2]])\n else:\n for line in lst[start:start+n]:\n temp = data_base.search_teacher(line[0],KCXZ_flag=0)\n if temp:\n rec.append([temp[0][0],temp[0][1],temp[0][2],line[1],line[0],line[2]])\n return rec\n def maj_avr_rating(self):\n #各专业各课程平均评分降序列表\n s=SEARCH()\n maj_lst = s.get_maj()\n final = {}\n for maj in maj_lst:\n train = s.maj_re_train(int(maj[0]))\n item_avr = s.get_avr(train)\n if item_avr:\n lst = []\n for item in item_avr.keys():\n lst.append([item,item_avr[item]])\n lst = sorted(lst,key=lambda t:t[1],reverse=True)\n final[maj] = lst\n return final\n def get_avr(self, threshold=5):\n #根据数据集计算平均评分\n #threshold:评分人数阈值,小于阈值则过滤数据\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\") \n m = ms.ExecQuery(\"select a.BH,count(BH),round(avg(cast(a.rating as float)),2) as avr from (select user_id,BH,rating from [xuanke].[dbo].[user_cour_rating] group by user_id,BH,rating) a group by a.BH order by avr desc\")\n _avr = {}\n s = SEARCH()\n BH_list = s.get_all_xuanxiu_BH()\n for item,count,avr in m:\n if item not in BH_list:\n continue\n if count>=threshold:\n _avr[item]={}\n _avr[item]['rating'] = avr\n _avr[item]['count'] = count\n return _avr\n \n def get_all_xuanxiu_BH(self):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n KCXZ = u'校选修课'.encode('utf-8')\n temp = ms.ExecQuery(\"SELECT BH FROM jxrwb2 where KCXZ='%s' and XN='2016-2017'\"%KCXZ)\n BH_lst = []\n for row in temp:\n BH_lst.append(row[0])\n #print 12 in BH_lst\n return BH_lst\n\n def search_cou_info(self,start,n,XN,XQ):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n if XN=='2017-2018':\n cou_list=ms.ExecQuery(\"select KCMC,JSXM,SKSJ,SKDD,XF from dbo.[2017-2018-1-1] order by KCMC,SKSJ,JSXM,SKDD,XF\")\n else:\n KCXZ = u'校选修课'.encode('utf-8')\n cou_list=ms.ExecQuery(\"select KCMC,JSXM,SKSJ,SKDD,XF from jxrwb where XQ =%d and XN='%s' and KCXZ='%s' order by KCMC,SKSJ,JSXM,SKDD,XF\"%(XQ,XN,KCXZ))\n rec = []\n for line in cou_list[start:start+n]:\n if line:\n rec.append([line[0],line[1],line[2],line[3],line[4]])\n return rec\n\ndef search_user_info(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n m = ms.ExecQuery(\"select gra,maj,bind_id,COL_RATING from user_info where user_id =%d\"%user_id)\n if m:\n if m[0][0]==None:\n gra = 0\n else:\n gra = m[0][0]\n if m[0][1]==None:\n maj = 0\n else:\n maj= ms.ExecQuery(\"SELECT ZYMC from [XKXX].[dbo].[maj_info] where ZYBH =%s\"%m[0][1])\n maj = maj[0][0]\n if m[0][2]==None:\n bind_id =0\n else:\n bind_id = m[0][2]\n if m[0][3]==None:\n col_rating ='未填写'\n else:\n col_rating ='已填写'\n info_dic = {'grade':gra,'major':maj,'bind_id':bind_id,'col_rating':col_rating}\n else:\n info_dic = {}\n spare_time = col_spare_time.get_spare_time(user_id)\n info_dic['spare_time'] = spare_time\n dic = search_xuanxiu_num_XF(user_id)\n info_dic = dict(info_dic,**dic)\n return info_dic\n\ndef search_xuanxiu_num_XF(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n KCXZ =u'校选修课'\n KCXZ = KCXZ.encode('utf-8')\n XH = str(get_XH(user_id))\n m = ms.ExecQuery(\"SELECT count(KCMC),sum(XF) FROM [XKXX].[dbo].[jxrwb2] as t1 join [XKXX].[dbo].[ZFXFZB_XKXXB_LH] as t2 on t1.XKKH=t2.XKKH where t2.XH='%s' and t1.KCXZ='%s'\"%(XH,KCXZ))\n if m[0][0]:\n xuanxiu_num=m[0][0]\n else:\n xuanxiu_num='未找到数据'\n if m[0][1]!=None:\n xuanxiu_XF=m[0][1]\n else:\n xuanxiu_XF='未找到数据'\n dic = {'xuanxiu_num':xuanxiu_num,'xuanxiu_XF':xuanxiu_XF}\n return dic\ndef get_XH(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\") \n m = ms.ExecQuery(\"select bind_id from user_info where user_id = %d\"%user_id)\n try:\n XH = m[0][0]\n except:\n XH = ''\n return XH\nif __name__ == '__main__':\n #write_user_info('liuheng123')\n #maj_dic,sort = search_maj('001')\n #print sort[0][1]\n #gra,fac,maj = get_gra_fac_maj(1)\n #print search_fac()\n #print len(search_cou_dic(gra,maj))\n #get_item_sim(9)\n #get_bind_id(9)\n s = SEARCH()\n final_dic = s.maj_avr_rating()\n\n \n \n \n"
},
{
"alpha_fraction": 0.5761298537254333,
"alphanum_fraction": 0.5866608023643494,
"avg_line_length": 34.328125,
"blob_id": "a8bdbc7fe04f745786f2a70c4793c570270774a5",
"content_id": "38b77b2271c28e9d25cdabb8a118d238da1cf00a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2327,
"license_type": "no_license",
"max_line_length": 162,
"num_lines": 64,
"path": "/XH_confirm/data_base.py",
"repo_name": "Liuheng268/online",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport pymssql\nfrom online.timeout_deco import timeout\nfrom online import user_password\ndbo_user,dbo_password = user_password.get_user_password()\nclass MSSQL:\n \n\n def __init__(self,host,user,pwd,db):\n self.host = host\n self.user = user\n self.pwd = pwd\n self.db = db\n @timeout(0.5)\n def __GetConnect(self):\n \n if not self.db:\n raise(NameError,\"没有设置数据库信息\")\n self.conn = pymssql.connect(host=self.host,user=self.user,password=self.pwd,database=self.db,charset=\"utf8\")\n cur = self.conn.cursor()\n if not cur:\n raise(NameError,\"连接数据库失败\")\n else:\n return cur\n @timeout(3)\n def ExecQuery(self,sql):\n \n cur = self.__GetConnect()\n cur.execute(sql)\n resList = cur.fetchall()\n self.conn.close()\n return resList\n @timeout(0.5)\n def ExecNonQuery(self,sql):\n \n cur = self.__GetConnect()\n cur.execute(sql)\n self.conn.commit()\n self.conn.close()\n\n#*************************************************************************\n\ndef get_selected_cou(XH):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n KCXZ = u'校选修课'\n KCXZ = KCXZ.encode('utf-8')\n m=ms.ExecQuery(\"select jxrwb2.KCDM,jxrwb2.KCMC from ZFXFZB_XKXXB_LH as XKXXB join jxrwb2 on XKXXB.XKKH = jxrwb2.XKKH where XH ='%s' and KCXZ ='%s'\"%(XH,KCXZ))\n return m\ndef get_full_cou():\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n KCXZ = u'校选修课'\n KCXZ = KCXZ.encode('utf-8')\n m=ms.ExecQuery(\"select top 50 KCDM,KCMC from jxrwb2 where KCXZ='%s' and XN='2015-2016' group by KCDM,KCMC\"%KCXZ)\n return m\ndef delete_bind_id(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n ms.ExecNonQuery(\"update user_info set bind_id =null,gra=null,maj=null,COL_RATING=null,spare_time=null where user_id = %d\"%user_id)\n delete_spare_time(user_id)\n \ndef delete_spare_time(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n ms.ExecNonQuery(\"delete from spare_time where user_id = %d \"%user_id)\nif __name__ == '__main__':\n pass\n \n \n"
},
{
"alpha_fraction": 0.617829442024231,
"alphanum_fraction": 0.630232572555542,
"avg_line_length": 27.66666603088379,
"blob_id": "f3023895e9a307df858e50e33c1c843b05dfb84b",
"content_id": "e46384c0687d89b48e9b11f259a28b31245964b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1490,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 45,
"path": "/collect_info/col_spare_time.py",
"repo_name": "Liuheng268/online",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# 此代码目的:空闲时间收集程序\n# 此代码需要调用的变量形式或文件类型如下:\n# \n# \n# 此代码归属模块:推荐系统模块\nimport time\nimport data_base\n\ndef col_spare_time(user_id,dic):\n spare_time = transfer_to_str(dic)\n spare_time = spare_time.encode('utf-8')\n time_flag = time.strftime(\"%Y-%m-%d %H:%M:%S\", time.localtime())\n write_into_data_base(user_id,spare_time,time_flag)\n \ndef transfer_to_str(dic):\n # 将网页收集的空闲时间数据转换成固定格式\n # 例如:'周二第1,2节{第3-6周};周四第1,2节{第3-5周}'\n XQ = dic['XQ']\n start_week = dic['start_week']\n end_week = dic['end_week']\n SKSJ = dic['SKSJ']\n result = XQ+u'第'+SKSJ+u'节'+u'{第'+start_week+'-'+end_week+u'周}'\n return result\n\ndef write_into_data_base(user_id,time,time_flag):\n #将用户空闲时间存入数据库\n data_base.write_spare_time(user_id,time,time_flag)\n\ndef delete_spare_time(user_id):\n data_base.delete_spare_time(user_id)\n data_base.update_spare_time_flag(user_id)\n\ndef get_spare_time(user_id):\n time_lst = data_base.get_spare_time(user_id)\n return time_lst\ndef write_user_info_flag(user_id):\n data_base.write_user_info_flag(user_id)\n\nif __name__ == '__main__':\n dic = {'XQ':u'周一','start_week':'2','end_week':'8','SKSJ':'1,2'}\n user_id = 9\n time = transfer_to_str(dic)\n time = time.encode('utf-8')\n write_into_data_base(user_id,time)\n"
},
{
"alpha_fraction": 0.5905973315238953,
"alphanum_fraction": 0.6047812700271606,
"avg_line_length": 41.49008560180664,
"blob_id": "fee76fbd88908a158f1fb411260a091aab314f06",
"content_id": "a205f3192a79289785ce151f1d596f10e29e6fee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15205,
"license_type": "no_license",
"max_line_length": 187,
"num_lines": 353,
"path": "/data_base.py",
"repo_name": "Liuheng268/online",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport pymssql\n\nfrom timeout_deco import timeout\nimport user_password\ndbo_user,dbo_password = user_password.get_user_password()\nclass MSSQL:\n \n\n def __init__(self,host,user,pwd,db):\n self.host = host\n self.user = user\n self.pwd = pwd\n self.db = db\n @timeout(0.5)\n def __GetConnect(self):\n \n if not self.db:\n raise(NameError,\"没有设置数据库信息\")\n self.conn = pymssql.connect(host=self.host,user=self.user,password=self.pwd,database=self.db,charset=\"utf8\")\n cur = self.conn.cursor()\n if not cur:\n raise(NameError,\"连接数据库失败\")\n else:\n return cur\n @timeout(0.5)\n def ExecQuery(self,sql):\n \n cur = self.__GetConnect()\n cur.execute(sql)\n resList = cur.fetchall()\n self.conn.close()\n return resList\n @timeout(0.5)\n def ExecNonQuery(self,sql):\n \n cur = self.__GetConnect()\n cur.execute(sql)\n self.conn.commit()\n self.conn.close()\n\n#*************************************************************************\ndef search_fac():\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n temp = ms.ExecQuery(\"SELECT fac_num,fac_name FROM fac_info\")\n fac_lst = []\n for line in temp:\n fac_lst.append([line[0],line[1]])\n return fac_lst\ndef search_maj(f):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n temp = ms.ExecQuery(\"SELECT ZYBH,ZYMC FROM maj_info where YXBH = %s\"%f)\n maj_lst = []\n for line in temp:\n maj_lst.append([line[0].rstrip(),line[1]])\n return maj_lst\ndef get_gra_fac_maj(user_id_):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n m=ms.ExecQuery(\"select gra,fac,maj from user_info where user_id =%d \"%user_id_)\n for a,b,c in m:\n a = str(a).rstrip()\n b = str(b).rstrip()\n c = str(c).rstrip()\n return a,b,c\ndef user_info_update_gra_fac(user_id,g,f):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n ms.ExecNonQuery(\"update user_info set gra = %s,fac = %s where user_id = %d\"%(g,f,user_id))\ndef user_info_update_maj(user_id,maj):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n ms.ExecNonQuery(\"update user_info set maj = %s,COL_GRA_MAJ = 1 where user_id = %d\"%(maj,user_id))\ndef search_cou_dic(gra,maj):\n #gra未使用,待完善\n #\n #!!!!!!!!!!!!!!\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n ZYMC=ms.ExecQuery(\"select ZYMC from maj_info where ZYBH = %s\"%maj)\n try:\n ZYMC = ZYMC[0][0]\n except:\n ZYMC = u'电气工程及其自动化'\n ZYMC = ZYMC.encode('utf-8')\n m=ms.ExecQuery(\"select KCDM,KCMC from KCXX where NJ=%s and ZYMC = '%s' group by KCDM,KCMC\"%(gra,ZYMC))\n cou_lst = []\n i = 0\n for line in m:\n jsxm=ms.ExecQuery(\"select XKKH,JSXM from KCXX where KCMC ='%s' and NJ=%s and ZYMC = '%s' group by XKKH,JSXM\"%(line[1].encode('utf-8'),gra,ZYMC))\n jsxm_list = [[]]\n for i in jsxm:\n jsxm_list[0].append([i[0],i[1]])\n cou_lst.append([line[0].rstrip(),line[1],jsxm_list[0]])\n #print cou_lst\n #sort = sorted(cou_dic.iteritems(), key = lambda asd:asd[0], reverse=False)\n return cou_lst\ndef search_cou_bind_id(bind_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n m=ms.ExecQuery(\"select KCDM,KCMC,jxrwb2.BH,JSXM from ZFXFZB_XKXXB_LH join jxrwb2 on ZFXFZB_XKXXB_LH.XKKH = jxrwb2.XKKH where XH =%s\"%bind_id)\n cou_lst = []\n for line in m:\n jsxm_list = []\n jsxm_list.append([line[2],line[3]])\n cou_lst.append([line[0].rstrip(),line[1],jsxm_list])\n #print cou_lst\n #sort = sorted(cou_dic.iteritems(), key = lambda asd:asd[0], reverse=False)\n return cou_lst\ndef update_rating(user_id,rat_lst):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n for i,j in rat_lst:\n ms.ExecNonQuery(u\"insert into user_cour_rating values (%d,%d,%d)\"%(user_id,int(i),int(j)))\ndef delete_rating(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n ms.ExecNonQuery(\"delete from user_cour_rating where user_id = %d \"%user_id)\n \ndef get_COL_RATING(user_id_):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n m=ms.ExecQuery(\"select COL_RATING from user_info where user_id =%d \"%user_id_)\n try:\n COL = m[0][0]\n except:\n COL = 0\n return COL\n\ndef user_info_update_COL_RATING(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n ms.ExecNonQuery(\"update user_info set COL_RATING = 1 where user_id = %d\"%user_id)\n \ndef get_user_id(user):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n m=ms.ExecQuery(\"select user_id from user_info where user_name=%r\"%user)\n try:\n user_id = m[0][0]\n except:\n #admin_id = 9\n user_id = 9\n return user_id\ndef write_user_info(user):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n ms.ExecNonQuery(\"insert into user_info (user_name,first_log_in,COl_RATING,gra,fac,maj,spare_time,bind_id) values (%r,%d,%d,NULL,NULL,NULL,NULL,NULL)\"%(user,0,0))\n print 'location_:sign_up_online_data_base_write_user_info__id_:00'\ndef delete_user_info(user_name):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n user_id = get_user_id(user_name)\n ms.ExecNonQuery(\"delete from spare_time where user_id = '%s' \"%user_id)\n ms.ExecNonQuery(\"delete from user_xksj where user_id = '%s' \"%user_id)\n ms.ExecNonQuery(\"delete from col_rat_time where user_id = '%s' \"%user_id)\n ms.ExecNonQuery(\"delete from user_info where user_name = '%s' \"%user_name)\n print 'location_:delete_account_online_data_base_delete_user_info__id_:00' \ndef create_train():\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\") \n m = ms.ExecQuery(\"select [user],item,rating from train\")\n #print m[:5]\n train = {}\n for user,item,rating in m:\n user, item, rating = int(user), int(item), int(rating)\n train.setdefault(user, {})\n train[user][item] = rating\n #print train.keys()\n return train\n\ndef get_user_sim(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\") \n m = ms.ExecQuery(\"select other_user_id,sim from user_sim where user_id = %d\"%user_id)\n #print m[:10]\n _w = []\n n = len(m)\n for other,sim in m:\n if other==None or sim == None:\n continue\n else:\n _w.append([other,sim]) \n return _w\ndef get_item_sim(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\") \n item_lst = ms.ExecQuery(\"select item from train where [user] = %d\"%int(user_id))\n _w = {}\n #print item_lst\n for item in item_lst:\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\") \n m = ms.ExecQuery(\"select other_item,sim from item_sim where item = %d\"%item[0])\n #print m[:10]\n _w.setdefault(item[0],[])\n for lst in m:\n if lst[0]==None or lst[1] == None:\n continue\n else:\n _w[item[0]].append((lst[0],lst[1]))\n #print _w.keys()\n #print _w[385]\n return _w\ndef write_spare_time(lst):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n for user_id,time in lst:\n ms.ExecNonQuery(\"insert into spare_time values ('%d','%d')\"%(int(user_id),int(time)))\n #print m[:10]\n user_id = lst[0][0]\n ms.ExecNonQuery(\"update user_info set spare_time = 1 where user_id = %d\"%(user_id))\ndef delete_spare_time(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n ms.ExecNonQuery(\"delete from spare_time where user_id = %d \"%user_id)\n \ndef get_spare_time_flag(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\") \n m = ms.ExecQuery(\"select spare_time from user_info where user_id = %d\"%user_id)\n try:\n flag = m[0][0]\n except:\n flag = 0\n return flag\n\ndef get_bind_id(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\") \n m = ms.ExecQuery(\"select bind_id from user_info where user_id = %d\"%user_id)\n try:\n XH = m[0][0]\n except:\n XH = '1151180812'\n return XH\ndef update_bind_id(user_id,bind_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n NJ_ZYMC = ms.ExecQuery(\"select NJ,ZYMC from ZFXFZB_XKXXB_LH where XH = '%s' and NJ>2000\"%bind_id)\n print 'location_:online_data_base_update_bind_id__id_:11-01'\n try:\n ZYMC = NJ_ZYMC[0][1].encode('utf-8')\n NJ = NJ_ZYMC[0][0]\n except:\n ZYMC = u'读取专业出错'.encode('utf-8')\n NJ = 0\n print 'location_:online_data_base_update_bind_id__id_:11-02'\n fac_maj = ms.ExecQuery(\"select YXBH,ZYBH from maj_info where ZYMC ='%s'\"%ZYMC)\n try:\n fac = fac_maj[0][0]\n maj = fac_maj[0][1]\n except:\n fac = 001\n maj = 001\n print 'location_:online_data_base_update_bind_id__id_:11-03'\n ms1 = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\") \n ms1.ExecNonQuery(\"update user_info set gra = %s,fac = %s,maj = %s,bind_id = %s where user_id = %d\"%(NJ,fac,maj,bind_id,user_id))\n print 'location_:online_data_base_update_bind_id__id_:11-04'\n\ndef re_get_train():\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n temp = ms.ExecQuery(\"SELECT user_id,BH,rating FROM user_cour_rating \")\n train={}\n for user, item, rating in temp:\n train.setdefault(user, {})\n train[user][item] = rating\n return train\ndef search_teacher(BH,KCXZ_flag=0):\n #KCXZ_flag 0:全部课程;1:校选修课;2:必修课\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n if KCXZ_flag ==1:\n KCXZ = u'校选修课'.encode('utf-8')\n m = ms.ExecQuery(\"select KCDM,KCMC,JSXM from jxrwb2 where BH = %d and KCXZ ='%s'\"%(BH,KCXZ))\n elif KCXZ_flag ==2:\n KCXZ = u'必修课'.encode('utf-8')\n m = ms.ExecQuery(\"select KCDM,KCMC,JSXM from jxrwb2 where BH = %d and KCXZ ='%s'\"%(BH,KCXZ))\n else :\n m = ms.ExecQuery(\"select KCDM,KCMC,JSXM from jxrwb2 where BH = %d\"%BH)\n return m\ndef search_detail(BH):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\") \n m = ms.ExecQuery(\"select KCMC,JSXM,SKSJ,XF,XN from jxrwb2 where BH = %d group by KCMC,JSXM,SKSJ,XF,XN\"%BH)\n return m\ndef get_selected_cou(XH):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n KCXZ = u'校选修课'\n KCXZ = KCXZ.encode('utf-8')\n m=ms.ExecQuery(\"select jxrwb2.KCDM,jxrwb2.KCMC from ZFXFZB_XKXXB_LH as XKXXB join jxrwb2 on XKXXB.XKKH = jxrwb2.XKKH where XH ='%s' and KCXZ ='%s'\"%(XH,KCXZ))\n return m\ndef get_full_cou():\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n KCXZ = u'校选修课'\n KCXZ = KCXZ.encode('utf-8')\n m=ms.ExecQuery(\"select top 50 KCDM,KCMC from jxrwb2 where KCXZ='%s' and XN='2015-2016' group by KCDM,KCMC\"%KCXZ)\n return m\ndef course_filtering(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n user_KCDM_list=ms.ExecQuery(\"select t2.KCDM from user_cour_rating as t1 join [XKXX].[dbo].[jxrwb2] as t2 on t1.BH=t2.BH where user_id=%d group by t2.KCDM\"%user_id)\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n all_BH_list = []\n for KCDM in user_KCDM_list:\n BH_list = ms.ExecQuery(\"select BH from jxrwb2 where KCDM='%s' group by BH\"%KCDM)\n for row in BH_list:\n all_BH_list.append(row[0])\n return all_BH_list\ndef insert_xksj(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n ms.ExecNonQuery(\"delete from [xuanke].[dbo].[user_XKSJ] where user_id = %d \"%user_id)\n XH = get_bind_id(user_id)\n XN_list = ms.ExecQuery(\"select t2.XN,t2.XQ from ZFXFZB_XKXXB_LH as t1 join jxrwb2 as t2 on t1.XKKH = t2.XKKH where t1.XH ='%s' group by t2.XN,t2.XQ\"%XH)\n for XN,XQ in XN_list:\n ms.ExecNonQuery(u\"insert into [xuanke].[dbo].[user_XKSJ] (user_id,XN,XQ,flag,ulike,dislike) values(%d,%r,%d,0,0,0)\"%(user_id,str(XN),XQ))\ndef get_user_XKSJ_flag(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n flag = ms.ExecQuery(\"select flag from user_XKSJ where user_id = %d\"%user_id)\n return flag\ndef get_user_info_flag(user_id):\n # 查询用户是否完成规定流程\n # 返回标志字典,没有完成标志为0\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n flag = ms.ExecQuery(\"select user_id,bind_id,COL_RATING,spare_time from user_info where user_id = %d\"%user_id)\n try:\n user_id = flag[0][0]\n except:\n user_id = 9\n flag = ms.ExecQuery(\"select user_id,bind_id,COL_RATING,spare_time from user_info where user_id = %d\"%user_id)\n if flag[0][1]==None:\n bind_id = 0\n else:\n bind_id = flag[0][1]\n if flag[0][2]==None:\n COL_RATING = 0\n else:\n COL_RATING = flag[0][2]\n if flag[0][3]==None:\n spare_time = 0\n else:\n spare_time = flag[0][3]\n flag_dic = {'user_id':user_id,'bind_id':bind_id ,'COL_RATING':COL_RATING,'spare_time':spare_time} \n return flag_dic\ndef online_admin():\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n user_info = ms.ExecQuery(\"select user_name,COL_RATING,gra,ZYMC,spare_time,bind_id from user_info as t1 join [XKXX].[dbo].[maj_info] as t2 on convert(int,t2.ZYBH)=convert(int,t1.maj)\")\n #user_rating= ms.ExecQuery(\"select * from user_cour_rating\")\n #print user_rating[:10]\n print user_info\n dic ={}\n dic['user_info'] = user_info\n return dic\n\ndef get_first_log_in_flag(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n m = ms.ExecQuery(\"select first_log_in from user_info where user_id =%d\"%user_id)\n if m:\n first_log_in = m[0][0]\n else:\n first_log_in = 'not found'\n return first_log_in\ndef close_help(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n m = ms.ExecNonQuery(\"update user_info set first_log_in=1 where user_id =%d\"%user_id)\n \nif __name__ == '__main__':\n #write_user_info('liuheng123')\n #maj_dic,sort = search_maj('001')\n #print sort[0][1]\n #gra,fac,maj = get_gra_fac_maj(1)\n #print search_fac()\n #print len(search_cou_dic(gra,maj))\n #get_item_sim(9)\n #get_bind_id(9)\n #get_user_info_flag(3)\n online_admin()\n \n \n"
},
{
"alpha_fraction": 0.585552453994751,
"alphanum_fraction": 0.6032072901725769,
"avg_line_length": 29.594594955444336,
"blob_id": "12c1e097d18e9a12ef496fc8a76e839d92f795c4",
"content_id": "de4fd073fbde238a273213976520748a13aca734",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7599,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 222,
"path": "/recommend/recommend.py",
"repo_name": "Liuheng268/online",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# 此代码目的:推荐程序调用\n# 此代码需要调用的变量形式或文件类型如下:\n# \n# \n# 此代码归属模块:推荐模块\nimport numpy as np\nimport lfm\nimport user_cf\nimport item_cf\nimport data_base\nimport SKSJ_compare\nfrom online.info_search import search\n\ndef re_user_cf(start,user,n):\n #根据真实评分数据产生推荐列表\n #获取原始训练集\n train = data_base.re_get_train()\n #过滤无效信息的有效训练集\n train = screening_training_set(train,threshold = 0.4)\n #如果有效训练集中不含当前用户,则添加当前用户评分到训练集中备用\n '''\n if user not in train.keys():\n print 'user not in screening_training_set'\n user_rating = data_base.get_user_rating(user)\n train[user] = user_rating\n print 'adding user rating successfully'\n '''\n if user not in train.keys():\n rank = {}\n rank['invalid_rating'] = 1\n return rank\n user_cf.pre_treat(train, False)\n user_cf.user_similarity_cosine(train, iif=True, implicit=False)\n result = user_cf.recommend_explicit(user)\n if result =='less_than_standard':\n rank = {}\n rank['less_than_standard'] = 1\n return rank\n else:\n new_rank = Course_filtering(user,result)\n \n rank_lst = transfer_lst(start,n,new_rank)\n #rank = course_filtering_SKSJ(rank_lst,user)\n rec = add_pre_avr_min(rank_lst)\n return rec\n\ndef re_lfm(start,user,n):\n #根据真实评分数据产生推荐列表\n #获取原始训练集\n train = data_base.re_get_train()\n #过滤无效信息的有效训练集\n train = screening_training_set(train,threshold = 0.4)\n #如果有效训练集中不含当前用户,则添加当前用户评分到训练集中备用\n '''\n if user not in train.keys():\n print 'user not in screening_training_set'\n user_rating = data_base.get_user_rating(user)\n train[user] = user_rating\n print 'adding user rating successfully'\n '''\n if user not in train.keys():\n rank = {}\n rank['invalid_rating'] = 1\n return rank\n lfm.factorization(train, bias=True, svd=True, svd_pp=True, steps=5, gamma=0.03, slow_rate=0.94, Lambda=0.1)\n result = lfm.recommend_explicit(user)\n if result =='less_than_standard':\n rank = {}\n rank['less_than_standard'] = 1\n return rank\n else:\n new_rank = Course_filtering(user,result)\n rank_lst = transfer_lst(start,n,new_rank)\n #rank = course_filtering_SKSJ(rank_lst,user)\n rec = add_pre_avr_min(rank_lst)\n return rec\n\ndef re_item_cf(start,user,n):\n train = data_base.re_get_train()\n #train = get_train()\n #过滤无效信息的有效训练集\n train = screening_training_set(train,threshold = 0.4)\n #如果有效训练集中不含当前用户,则添加当前用户评分到训练集中备用\n '''\n if user not in train.keys():\n print 'user not in screening_training_set'\n user_rating = data_base.get_user_rating(user)\n train[user] = user_rating\n print 'adding user rating successfully'\n '''\n if user not in train.keys():\n rank = {}\n rank['invalid_rating'] = 1\n return rank\n item_cf.__pre_treat(train, False)\n item_cf.item_similarity_cosine(train, iuf=True, implicit=False)\n #item_cf.item_similarity_cosine_single(train, user, iuf=False, implicit=False)\n result = item_cf.recommend_explicit(user)\n #print list(result['rank'])\n rank1 = result['rank']\n explain = result['explain']\n if rank1 ==[]:\n rank = {}\n rank['less_than_standard'] = 1\n return rank\n else:\n rank2 = Course_filtering(user,rank1)\n rank3 = transfer_lst(start,n,rank2)\n #print rank_lst\n #rank = course_filtering_SKSJ(rank_lst,user)\n rank4 = add_pre_avr_min(rank3)\n rank5 = add_explain(explain,rank4)\n return rank5\ndef add_explain(explain, rank):\n explain_lst = list(explain)\n new_rank = []\n for item,item1 in explain_lst:\n KCMC = data_base.get_cou_name(item1)\n for row in rank:\n if item == row[4]:\n new_rank.append([row[0],row[1],row[2],row[3],row[4],row[5],KCMC])\n #print new_rank\n new_rank.sort(key=lambda x:x[3] ,reverse=True)\n return new_rank\ndef get_train():\n # 从数据库获取用户评分数据\n train = data_base.create_train()\n return train\ndef Course_filtering(user,rank):\n # 过滤用户已选课程及相似课程(不同教师)\n all_BH_list = data_base.course_filtering(user)\n rank2 = list(rank)\n rank2.sort(key=lambda x:x[1] ,reverse=True)\n new_rank = []\n for BH,rating in rank2 :\n if BH in all_BH_list:\n continue\n else:\n new_rank.append([BH,rating])\n return new_rank\n\ndef course_filtering_SKSJ(rank,user_id):\n # 将已经获得的课程列表中与用户空闲时间列表有冲突的课程过滤\n user_spare_time = data_base.get_spare_time(user_id)\n time1 = transfer_lst_to_string(user_spare_time)\n new_rank = []\n for row in rank:\n if not row:\n continue\n time2_lst = data_base.get_SKSJ(row[4])\n time2 = transfer_lst_to_string(time2_lst)\n if not time2:\n continue\n flag = SKSJ_compare.judge_contain(time1,time2)\n if flag ==1:\n new_rank.append(row)\n return new_rank\n\ndef transfer_lst_to_string(time_lst):\n # 将从数据库获得的SKSJ列表转化成字符串str,与上课时间比较程序算法衔接\n string = ''\n for row in time_lst:\n string +=row+';'\n return string\n \n \ndef transfer_lst(start,n,rank):\n # 将协同过滤算法获得的推荐列表变换成向用户展示的形式\n lst = list(rank)\n #lst = sorted(lst,key=lambda t:t[1],reverse=True)\n rec = []\n for line in lst[start:start+n]:\n temp = data_base.search_teacher(line[0])\n if temp:\n rec.append([temp[0][0],temp[0][1],temp[0][2],line[1],line[0]])\n return rec\n\ndef get_2016_2017_2_XXK(user_id):\n # 在用户已经填写空闲课程时间后!!\n # 获取与该用户没有时间冲突的所有选修课列表\n rank = data_base.get_2016_2017_2XXK()\n new_rank = course_filtering_SKSJ(rank,user_id)\n return new_rank\n\ndef add_pre_avr_min(rank):\n #增加预测-平均分差\n s = search.SEARCH()\n #time_start = time.time()\n avr_rank = data_base.get_avr()\n #time_stop = time.time()\n #print 'calculate recommend rank cost %.05f seconds'%(time_stop-time_start) \n new_rank = []\n for row in rank:\n for avr_row in avr_rank:\n if row[4]==avr_row[0]:\n new_rank.append([row[0],row[1],row[2],row[3],row[4],row[3]-avr_row[2]])\n new_rank.sort(key=lambda x:x[3] ,reverse=True)\n return new_rank\n\ndef screening_training_set(train,threshold=0.1):\n #筛选训练集,删除无效数据,提高算法精度\n #返回有效训练集\n #threshold:阈值\n s_train = {}\n for user in train.keys():\n rating_std = np.std(train[user].values())\n #print 'user:',user,' *** std:',rating_std\n if rating_std > threshold:\n s_train[user] = train[user]\n #print len(s_train.keys())\n #print s_train\n return s_train\nif __name__ == '__main__':\n\n #rank = re_user_cf(0,9,10)\n rank = get_2016_2017_2_XXK(9)\n print len(rank)\n for a,b,c,d,e in rank:\n print a,b,c,d,e\n #print re_item_cf(0,1,10)\n #print re_lfm(0,1,10)\n \n"
},
{
"alpha_fraction": 0.33436745405197144,
"alphanum_fraction": 0.348500519990921,
"avg_line_length": 17.602563858032227,
"blob_id": "ac3da7ebdc535a7225a7cb6f0e7d4b34f559b02d",
"content_id": "8de55d18d8481a9d2a9586ac3cd2a697eb063f59",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 3133,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 156,
"path": "/templates/user_center.html",
"repo_name": "Liuheng268/online",
"src_encoding": "UTF-8",
"text": "{% extends \"site_base.html\" %}\n{% load i18n %}\n\n{% block head_title %}用户中心{% endblock %}\n\n{% block body_class %}home{% endblock %}\n\n{% block body_base %}\n\n<div class=\"container\">\n {% include \"_messages.html\" %}\n <div class=\"row clearfix\">\n <div class=\"col-md-9 column\">\n <div class=\"jumbotron\">\n \n\t\t\t\t<h1>\n\t\t\t\t用户中心\n\t\t\t\t</h1>\n\t\t\t\t<p>\n\t\t\t\t以下是您的个人信息,您可以根据提示对其进行更改。\n\t\t\t\t</p>\n\n </div>\n </div>\n </div>\n \n <div class=\"row clearfix\">\n <div class=\"col-md-9 column\">\n <div id=\"legend\">\n <legend>个人信息</legend>\n </div>\n <div class=\"table-responsive\">\n\t<table class=\"table table-striped\">\n\t\t\t\t<tbody>\n\t\t\t\t\t<tr>\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t<h4>用户名</h4>\n\t\t\t\t\t\t</td>\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t<h4>{{user}}</h4>\n\t\t\t\t\t\t</td>\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t\n\t\t\t\t\t\t</td>\n\t\t\t\t\t\t\n\t\t\t\t\t</tr>\n\t\t\t\t\t<tr>\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t<h4>年级</h4>\n\t\t\t\t\t\t</td>\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t<h4>{{grade}}级</h4>\n\t\t\t\t\t\t</td>\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t<!--\n <a href=\"?update_bind_id=1\" class=\"btn btn-default\" >更改</a>\n -->\n\t\t\t\t\t\t</td>\n\t\t\t\t\t</tr>\n\t\t\t\t\t<tr>\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t<h4>专业</h4>\n\t\t\t\t\t\t</td>\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t<h4>{{major}}</h4>\n\t\t\t\t\t\t</td>\n\t\t\t\t\t\t<td>\n <!--\n\t\t\t\t\t\t<a href=\"?update_bind_id=1\" class=\"btn btn-default\" >更改</a>\n -->\n\t\t\t\t\t\t</td>\n\t\t\t\t\t</tr>\n\t\t\t\t\t<tr>\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t<h4>绑定学号</h4>\n\t\t\t\t\t\t</td>\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t<h4>{{bind_id}}</h4>\n\t\t\t\t\t\t</td>\n\t\t\t\t\t\t<td>\n <!--\n\t\t\t\t\t\t<a href=\"?update_bind_id=1\" class=\"btn btn-default\" >更改</a>\n -->\n\t\t\t\t\t\t</td>\n\t\t\t\t\t</tr>\n\t\t\t\t\t<tr>\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t<h4>评分填写状态</h4>\n\t\t\t\t\t\t</td>\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t<h4>{{col_rating}}</h4>\n\t\t\t\t\t\t</td>\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t<a href=\"?update_rating=1\" class=\"btn btn-success\" >重新填写评分</a>\n\t\t\t\t\t\t</td>\n\t\t\t\t\t</tr>\n\t\t\t\t\t<tr>\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t<h4>已选\"校选修课\"课程数</h4>\n\t\t\t\t\t\t</td>\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t<h4>{{xuanxiu_num}}</h4>\n\t\t\t\t\t\t</td>\n\t\t\t\t\t\t<td>\n (包括选修但未通过的课程)\n\t\t\t\t\t\t</td>\n\t\t\t\t\t</tr>\n\t\t\t\t\t<tr>\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t<h4>已选修学分</h4>\n\t\t\t\t\t\t</td>\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t<h4>{{xuanxiu_XF}}</h4>\n\t\t\t\t\t\t</td>\n\t\t\t\t\t\t<td>\n (包括选修但未通过的课程)\n\t\t\t\t\t\t</td>\n\t\t\t\t\t</tr>\n\t\t\t\t</tbody>\n\t</table>\n </div>\n <div id=\"legend\">\n <legend>空闲时间列表</legend>\n </div>\n <div class=\"table-responsive\">\n <table class=\"table table-striped\">\n\n\t\t\t\t<tbody>\n\n {% for time in spare_time %}\n\t\t\t\t\t<tr>\n\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t<h4>{{time}}</h4>\n\t\t\t\t\t\t</td>\n <td>\n\t\t\t\t\t\t\n\t\t\t\t\t\t</td>\t\t\t\t\t\t\n\t\t\t\t\t</tr>\n\t\t\t\t{% endfor %}\n <tr>\n\n\t\t\t\t\t\t<td>\n\t\t\t\t\t\t\n\t\t\t\t\t\t</td>\n <td>\n\t\t\t\t\t\t<a href=\"?update_spare_time=1\" class=\"btn btn-success\" >更改空闲时间</a>\n\t\t\t\t\t\t</td>\t\t\t\t\t\t\n\t\t\t\t\t</tr>\n\t\t\t\t</tbody>\n\t</table>\n </div>\n </div>\n </div>\n</div>\n{% endblock %}"
},
{
"alpha_fraction": 0.554280698299408,
"alphanum_fraction": 0.5719329118728638,
"avg_line_length": 25.325580596923828,
"blob_id": "d1a4775ae9c63b2a955afb81559410f29b87ad67",
"content_id": "dfc63fad4aa7488632d61bc9a2d822a52670c2d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1229,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 43,
"path": "/XH_confirm/XH_confirm.py",
"repo_name": "Liuheng268/online",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# 此代码目的:学号绑定认证程序\n# 此代码需要调用的变量形式或文件类型如下:\n# \n# \n# 此代码归属模块:学号绑定模块\nimport random\nimport data_base\n\ndef get_cou_list(XH):\n selected_lst = data_base.get_selected_cou(XH)\n full_lst = data_base.get_full_cou()\n flag = 0\n while flag ==0:\n n = 0\n random_selected_lst = random.sample(selected_lst,2)\n random_full_lst = random.sample(full_lst, 3)\n selected_dic = dict(selected_lst)\n full_dic = dict(random_full_lst)\n for value in selected_dic.values():\n if value in full_dic.values():\n continue\n else:\n n += 1\n if n == len(selected_dic):\n flag = 1\n result= random_selected_lst+random_full_lst\n random.shuffle(result)\n dic = {}\n dic['result'] = result\n dic['confirm'] = list(dict(random_selected_lst).keys())\n return dic\ndef confirm(select,result):\n flag = 1\n for i in select:\n if i not in result:\n flag = 0\n return flag\ndef delete_bind_id(user_id):\n data_base.delete_bind_id(user_id)\n\nif __name__ == '__main__':\n get_cou_list('1151180812')\n\n"
},
{
"alpha_fraction": 0.6156402826309204,
"alphanum_fraction": 0.6236879229545593,
"avg_line_length": 45.32520294189453,
"blob_id": "9debe14df868534fa3f6109a4238e50d59f47b04",
"content_id": "034e0c327e0a64b224943d78b26ddb28e7679283",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5748,
"license_type": "no_license",
"max_line_length": 171,
"num_lines": 123,
"path": "/collect_info/data_base.py",
"repo_name": "Liuheng268/online",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport pymssql\nfrom online.timeout_deco import timeout\nfrom online import user_password\ndbo_user,dbo_password = user_password.get_user_password()\nclass MSSQL:\n \n\n def __init__(self,host,user,pwd,db):\n self.host = host\n self.user = user\n self.pwd = pwd\n self.db = db\n @timeout(0.5)\n def __GetConnect(self):\n \n if not self.db:\n raise(NameError,\"没有设置数据库信息\")\n self.conn = pymssql.connect(host=self.host,user=self.user,password=self.pwd,database=self.db,charset=\"utf8\")\n cur = self.conn.cursor()\n if not cur:\n raise(NameError,\"连接数据库失败\")\n else:\n return cur\n @timeout(3)\n def ExecQuery(self,sql):\n \n cur = self.__GetConnect()\n cur.execute(sql)\n resList = cur.fetchall()\n self.conn.close()\n return resList\n @timeout(0.5)\n def ExecNonQuery(self,sql):\n cur = self.__GetConnect()\n cur.execute(sql)\n self.conn.commit()\n self.conn.close()\n\n#*************************************************************************\n\ndef get_user_XKSJ_flag(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n flag = ms.ExecQuery(\"select XN,XQ,flag from user_XKSJ where user_id = %d and flag = 0 order by XN,XQ \"%user_id)\n return flag\ndef count_flag(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n lst = ms.ExecQuery(\"select count(flag) from user_XKSJ where user_id = %d and flag = 1\"%user_id)\n if lst:\n count = lst[0][0]\n else:count =0\n return count\ndef get_user_xksj(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n user_xksj = ms.ExecQuery(\"select XN,XQ from user_XKSJ where user_id = %d\"%user_id)\n return user_xksj\ndef get_XH(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\") \n m = ms.ExecQuery(\"select bind_id from user_info where user_id = %d\"%user_id)\n return m[0][0]\ndef get_cou_lst(user_id,XN,XQ):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"XKXX\")\n XH = get_XH(user_id)\n m=ms.ExecQuery(\"select KCDM,KCMC,t2.BH,JSXM from ZFXFZB_XKXXB_LH as t1 join jxrwb2 as t2 on t1.XKKH = t2.XKKH where XH ='%s' and t2.XN ='%s' and t2.XQ =%d\"%(XH,XN,XQ))\n cou_lst = []\n for line in m:\n cou_lst.append([line[0].rstrip(),line[1],line[2],line[3]])\n return cou_lst\ndef delete_rating(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n ms.ExecNonQuery(\"delete from user_cour_rating where user_id = %d \"%user_id)\ndef update_rating(user_id,rat_lst,XN,XQ):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n for i,j in rat_lst:\n ms.ExecNonQuery(u\"insert into user_cour_rating values (%d,%d,%d)\"%(user_id,int(i),int(j)))\n ms.ExecNonQuery(u\"update user_XKSJ set flag =1 where user_id = '%s' and XN ='%s' and XQ =%d\"%(user_id,XN,XQ))\ndef update_XKSJ_flag(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n ms.ExecNonQuery(u\"update user_XKSJ set flag =0 where user_id = '%s'\" %user_id)\n print 'set XKSJ_flag = 0 successfully'\ndef write_time(user_id,time,flag):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n if flag =='start':\n ms.ExecNonQuery(\"insert into col_rat_time (user_id,start_time,end_time) values(%d,%r,0)\"%(user_id,time))\n elif flag =='end':\n ms.ExecNonQuery(\"update col_rat_time set end_time = %r where user_id =%d\"%(time,user_id))\ndef delete_time(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n ms.ExecNonQuery(\"delete from col_rat_time where user_id = %d \"%user_id)\ndef write_spare_time(user_id,time,time_flag):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n ms.ExecNonQuery(\"insert into spare_time (user_id,spare_time,time_flag) values(%d,'%s','%s')\"%(user_id,time,time_flag))\ndef delete_spare_time(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n ms.ExecNonQuery(\"delete from spare_time where user_id = %d \"%user_id)\ndef get_spare_time(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n lst = ms.ExecQuery(\"select spare_time from spare_time where user_id = %d order by spare_time desc\"%user_id)\n time_lst = []\n for row in lst:\n time_lst.append(row[0])\n return time_lst\ndef update_COL_RATING(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n ms.ExecNonQuery(u\"update user_info set COL_RATING =1 where user_id = %d\"%user_id)\n print 'set COL_RATING = 1 successfully'\ndef update_COL_RATING_delete(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n ms.ExecNonQuery(u\"update user_info set COL_RATING=null where user_id = %d \"%user_id)\n delete_rating(user_id)\n print 'delete rating successfully'\n \ndef write_user_info_flag(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n ms.ExecNonQuery(\"update user_info set spare_time =1 where user_id=%d\"%user_id)\n\ndef update_spare_time_flag(user_id):\n ms = MSSQL(host=\"localhost\",user=\"%s\"%dbo_user,pwd=\"%s\"%dbo_password,db=\"xuanke\")\n ms.ExecNonQuery(\"update user_info set spare_time=0 where user_id = %d\"%user_id)\n\nif __name__ == '__main__':\n #get_cou_lst(9,'2015-2016',1)\n get_spare_time(9)\n \n \n"
},
{
"alpha_fraction": 0.7164179086685181,
"alphanum_fraction": 0.7256027460098267,
"avg_line_length": 42.54999923706055,
"blob_id": "7666225a0c5d0b02cb32f11649ff7cdf8ffdbe9f",
"content_id": "f9f260d1a09b080dd51e556d06a98c17685eb977",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 871,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 20,
"path": "/ICON/urls.py",
"repo_name": "Liuheng268/online",
"src_encoding": "UTF-8",
"text": "from django.conf import settings\nfrom django.conf.urls import include, url\nfrom django.conf.urls.static import static\nfrom django.views.generic import TemplateView\nfrom django.views.generic.base import RedirectView\nfrom django.contrib import admin\n\n#favicon_view = RedirectView.as_view(url='/static/favicon.ico', permanent=True)\n\nurlpatterns = [\n url(r\"^$\", TemplateView.as_view(template_name=\"homepage_new.html\"), name=\"home\"),\n url(r\"^admin/\", include(admin.site.urls)),\n url(r\"^account/\", include(\"account.urls\")),\n url(r\"^online/\", include(\"online.urls\")),\n url(r'^i18n/', include('django.conf.urls.i18n')),\n url(r'^i18n/', include('django.conf.urls.i18n')),\n url(r'^favicon\\.ico$',RedirectView.as_view(url='/site_media/static/favicon/favicon.ico', permanent=True))\n]\n\nurlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)\n"
}
] | 20 |
yonchu/twitter-working-bgm-bot
|
https://github.com/yonchu/twitter-working-bgm-bot
|
8d6bb3b80507d607e5616915471688fcd84eaf29
|
cdd92c07cfcc1208528224de176107b860380d70
|
ba1212c0d5272bbd6216a6966eae146f01118691
|
refs/heads/master
| 2016-09-08T00:32:18.240028 | 2013-03-03T06:10:19 | 2013-03-03T06:10:19 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6468200087547302,
"alphanum_fraction": 0.6468200087547302,
"avg_line_length": 17.475000381469727,
"blob_id": "d0ed8a840f0f58218248e14c61f7705f3e5e4a6a",
"content_id": "e66887a16d271ea3d8cc3be5f64b247464f12cbf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 739,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 40,
"path": "/README.md",
"repo_name": "yonchu/twitter-working-bgm-bot",
"src_encoding": "UTF-8",
"text": "Python twitter bot for @working\\_bgm\\_bot\n====================\n\nBot account: [@working_bgm_bot](https://twitter.com/working_bgm_bot)\n\nInstallation\n---------------------\n\nClone from http://github.com/yonchu/twitter-working-bgm-bot\nand install it with::\n\n```console\n$ git clone git://github.com/yonchu/twitter-working-bgm-bot.git\n$ git submodule update --init\n$ git submodule foreach \"git checkout master\"\n```\n\nUsage\n---------------------\n\nCreate your ``bot.cfg`` file.\n\n```console\n$ cd config\n$ cp bot.cfg.sample bot.cfg\n```\n\nEdit ``bot.cfg`` to suite your environments.\n\nInitialize.\n\n```console\n$ ./working_bgm_bot.py init\n```\n\nRun ``working_bgm_bot.py`` using run-script in cron.\n\n```\nrun-script/run-script start ./working_bgm_bot.py\n```\n"
},
{
"alpha_fraction": 0.5825366377830505,
"alphanum_fraction": 0.5914595127105713,
"avg_line_length": 27.01785659790039,
"blob_id": "4b49734c645635221092071e6b39d02eacfd50be",
"content_id": "dd80181b56a959d72a5422fbc0dc1a0845f0a5bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3138,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 112,
"path": "/working_bgm_bot.py",
"repo_name": "yonchu/twitter-working-bgm-bot",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom __future__ import print_function\nimport logging\nimport logging.config\nimport os\nimport sys\n\nfrom twitter_bot import TwitterBot, TwitterVideoBot, JobManager\n\n# Set default encording.\ntry:\n if sys.version_info[0] >= 3:\n from imp import reload\n reload(sys)\n sys.setdefaultencoding('utf-8')\nexcept ImportError:\n pass\n\nSEARCH_WORD = '作業用BGM'\n\n# Config.\nLOG_CONFIG = 'config/log.cfg'\nBOT_CONFIG = 'config/bot.cfg'\n\n# Initialize logger.\nlogger = logging.getLogger('app')\n\n\n## Main\ndef main(argv):\n \"\"\"main function\"\"\"\n with TwitterBot(BOT_CONFIG) as tw_bot:\n is_test = False\n if len(argv) >= 1:\n if argv[0] == 'test':\n is_test = True\n tw_bot.is_test = is_test\n elif argv[0] == 'init':\n # Initialize database.\n tw_bot.create_database()\n return\n elif argv[0] == 'follow':\n tw_bot.make_follow_list_from_followers()\n return\n else:\n raise Exception('Unknow argument: argv={}'.format(argv))\n\n with JobManager() as job_manager:\n #register_twitter_bot_jobs(job_manager, tw_bot)\n\n video_bot = TwitterVideoBot(BOT_CONFIG)\n video_bot.is_test = is_test\n register_twitter_video_bot_jobs(job_manager, video_bot)\n\n # Run jobs.\n job_manager.run()\n\n\ndef register_twitter_bot_jobs(job_manager, bot):\n # Make func_and_intervals.\n func_and_intervals = []\n\n func_tuple = (TwitterBot.update_database, None, None, 12 * 60)\n func_and_intervals.append(func_tuple)\n\n func_tuple = (TwitterBot.retweet_mentions, None, None, 11)\n func_and_intervals.append(func_tuple)\n\n func_tuple = (TwitterBot.retweet_retweeted_of_me, None, None, 23)\n func_and_intervals.append(func_tuple)\n\n func_tuple = (TwitterBot.follow_not_following_users, None, None, 7 * 60)\n func_and_intervals.append(func_tuple)\n\n # Register.\n job_manager.register_jobs(bot, func_and_intervals)\n\n\ndef register_twitter_video_bot_jobs(job_manager, bot):\n # Make func_and_intervals.\n func_and_intervals = []\n\n prev_datetime = job_manager \\\n .get_job_called_datetime(TwitterVideoBot.__name__,\n TwitterVideoBot\n .nico_latest_commenting_video_post.__name__)\n func_tuple = (TwitterVideoBot.nico_latest_commenting_video_post,\n [SEARCH_WORD, prev_datetime],\n None, 1.1 * 60)\n func_and_intervals.append(func_tuple)\n\n # Register.\n job_manager.register_jobs(bot, func_and_intervals)\n\n\nif __name__ == \"__main__\":\n try:\n os.chdir(os.path.dirname(sys.argv[0]) or '.')\n logging.config.fileConfig(LOG_CONFIG)\n\n logger.info('Start working_bgm_bot.py argv={}, cwd={}'\n .format(sys.argv[1:], os.getcwd()))\n\n main(sys.argv[1:])\n except:\n logger.exception('Unhandled exception')\n raise\n finally:\n logger.info('End working_bgm_bot.py')\n logger.info('-' * 80)\n"
}
] | 2 |
griggz/democratizer
|
https://github.com/griggz/democratizer
|
eaa5d44889127c75e50118c54597114e13efb993
|
0633282933ea1a67c1ac0e685714b6b0435b8ad2
|
b8b3dcf89ac1df5ab348a85d9bd360b68ca3389e
|
refs/heads/master
| 2022-02-28T22:45:38.220324 | 2019-09-23T23:51:57 | 2019-10-10T00:36:53 | 208,864,119 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6096199154853821,
"alphanum_fraction": 0.6124114394187927,
"avg_line_length": 35.3046875,
"blob_id": "2bc3dbc21f5e6cb17f0ae5d4224bba6e431a676d",
"content_id": "24ef34d2c2153dcd9e872234efe9faf478b477a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4657,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 128,
"path": "/scrape/scripts/text_analysis/analyze_text.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "\nimport argparse\nfrom django.conf import settings\nimport nltk\nfrom nltk.corpus import stopwords\nfrom nltk.tokenize import RegexpTokenizer\nimport pandas as pd\nfrom scrape.models import Collect, YelpResults, Analytics\nfrom spacy.lang.en import English\n\nstop_words = set(stopwords.words('english'))\nparser = English()\n\n\nclass AnalyzeText:\n def __init__(self, instance, instance_id):\n self.biz_slug = instance.slug\n self.words_ignore = self.gen_ignore_words()\n self.originData = self.gather_data()\n # self.words = self.clean_data()\n\n def clean_data(self):\n \"\"\"This merges all reviews into a single string and removes all stop\n and non essential words from the ignore_json_file.\"\"\"\n sentence = self.originData\n tokenizer = RegexpTokenizer(r'\\w+')\n tokens = tokenizer.tokenize(sentence)\n filtered_words = [w for w in tokens if w not in stop_words and w not in self.words_ignore]\n data = \" \".join(filtered_words)\n return self.tokenize(data)\n\n def gather_data(self):\n \"\"\"This gathers data from the database based on the object's slug\"\"\"\n yelp_id = [x for x in Collect.objects.filter(slug=self.biz_slug).values_list('id', flat=True)].pop()\n\n results = [x.lower() for x in YelpResults.objects.filter(business=yelp_id).values_list('review', flat=True)]\n\n return ' '.join(results)\n\n def gen_ignore_words(self):\n \"\"\"This compiles words I have tagged as 'non essential'. They are\n currently being stored in a json file I am manually updating\"\"\"\n df = pd.read_json(settings.IGNORE_WORDS_JSON)\n\n return [x for x in df['ignore']]\n\n @staticmethod\n def tokenize(text):\n \"\"\"turns a single string of multiple words into list of words\"\"\"\n lda_tokens = []\n tokens = parser(text)\n for token in tokens:\n if token.orth_.isspace():\n continue\n elif token.like_url:\n lda_tokens.append('URL')\n elif token.orth_.startswith('@'):\n lda_tokens.append('SCREEN_NAME')\n else:\n lda_tokens.append(token.lower_)\n return lda_tokens\n\n\nclass ProcessCommon(AnalyzeText):\n def __init__(self, instance, instance_id, *args):\n super().__init__(instance, instance_id,)\n self.words = self.clean_data()\n self.results = None\n self.instance_id = instance_id\n\n def analyze_data(self):\n \"\"\"word frequencies are generated and are compared against word lengths\"\"\"\n words = nltk.FreqDist(self.words)\n most_common = words.most_common(50)\n\n # sort words by the length of word and then by the number of occurrences in the doc\n # most_common_alt = list(w for w in set(self.words) if len(w) >= 5 and words[w] >= 5)\n # most_common_alt = list(w for w in set(self.words) if len(w) >= 5 and w in most_common)\n self.results = most_common\n # print(len(most_common), most_common)\n # print(len(most_common_alt), most_common_alt)\n\n def upload_results(self):\n for result in self.results:\n # add some custom validation\\parsing for some of the fields\n yelp_obj = Collect.objects.get(id=self.instance_id)\n instance = Analytics(business=yelp_obj, word=result[0], value=result[1])\n try:\n instance.save()\n except:\n pass\n\n def run(self):\n self.analyze_data()\n self.upload_results()\n\n\n# class ProcessSentiment(AnalyzeText):\n# def __init__(self, biz_slug, *args):\n# super().__init__(biz_slug)\n# self.words = self.clean_data()\n#\n# def analyze_data(self):\n# \"\"\"word frequencies are generated and are compared against word lengths\"\"\"\n# words = nltk.FreqDist(self.words)\n# most_common = [x[0] for x in words.most_common(50)]\n#\n# # sort words by the length of word and then by the number of occurrences in the doc\n# # most_common_alt = list(w for w in set(self.words) if len(w) >= 5 and words[w] >= 5)\n# most_common_alt = list(w for w in set(self.words) if len(w) >= 5 and w in most_common)\n# print(len(most_common), most_common)\n# print(len(most_common_alt), most_common_alt)\n#\n# def run(self):\n# self.analyze_data()\n\ndef main():\n parser = argparse.ArgumentParser(description='business slug')\n\n parser.add_argument('-s', '--slug', required=True,\n help='Dont forget the biz slug!'),\n\n args = vars(parser.parse_args())\n\n ProcessCommon(args['slug']).run()\n\n\nif __name__ == '__main__':\n main()\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6493955254554749,
"alphanum_fraction": 0.6502590775489807,
"avg_line_length": 88.07691955566406,
"blob_id": "a0b1fcb747ca0d24ca2e9c8698759d1da0e60984",
"content_id": "1c65f4fd6892eb68a0c4e736d682b26f899a560f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1158,
"license_type": "no_license",
"max_line_length": 343,
"num_lines": 13,
"path": "/comm/forms.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from .models import Comms\nfrom django.forms import ModelForm, HiddenInput\n\n\nclass CommsForm(ModelForm):\n class Meta:\n model = Comms\n # widgets = {'unsplash_url': HiddenInput()}\n fields = ['site_location', 'author', 'title', 'content']\n # labels = {'author': 'Author', 'title': 'Title', 'slug': 'Slug', 'content': 'Content', 'post_image': 'Post Image', 'height_field': 'Image Height', 'width_field': 'Image Width', 'draft': \"Draft\", 'publish': 'Publish Date'}\n # help_texts = {'post_image': 'Get your photo ID from <a href=\"https://unsplash.com\" target=\"_blank\">Unsplash.com</a>. Use this <a href=\"http://quick.as/x3vycpgog\" target=\"_blank\">guide</a> if you need help. Or, if you want a random image, copy/paste this url \"https://source.unsplash.com/random\" to pull random images from unsplash.',\n # 'draft': 'Is this post a draft? (Any post marked as \"draft\" will not be displayed to unauthorized users)', 'publish': 'When would you like this post published? (Any post marked with a date in the future will not be displayed to public users until the future date arrives.)'\n # }\n"
},
{
"alpha_fraction": 0.6505171656608582,
"alphanum_fraction": 0.6521502733230591,
"avg_line_length": 32.38181686401367,
"blob_id": "67d0f690387f13fff54bc4c000d71a0f8321149c",
"content_id": "a61d744c730f3a10b3117b788615c52b1d453813",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1837,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 55,
"path": "/landing/views.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from .models import Feedback\nfrom rest_framework import generics, permissions, pagination\nfrom rest_framework.response import Response\nfrom .permissions import IsOwnerOrReadOnly\nfrom django.contrib.auth.models import User\nfrom .serializers import FeedbackSerializer\n\n\nclass FeedbackPageNumberPagination(pagination.PageNumberPagination):\n page_size = 5\n page_size_query_param = 'size'\n max_page_size = 20\n\n def get_paginated_response(self, data):\n user = False\n user = self.request.user\n if user.is_authenticated:\n user = True\n context = {\n 'next': self.get_next_link(),\n 'previous': self.get_previous_link(),\n 'count': self.page.paginator.count,\n 'user': user,\n 'results': data,\n }\n return Response(context)\n\n\nclass FeedbackDetailAPIView(generics.RetrieveUpdateDestroyAPIView):\n queryset = Feedback.objects.all()\n serializer_class = FeedbackSerializer\n lookup_field = 'id'\n permission_classes = [IsOwnerOrReadOnly]\n\n def get_serializer_context(self):\n context = super().get_serializer_context()\n context['request'] = self.request\n return context\n\n\nclass FeedbackListCreateAPIView(generics.ListCreateAPIView):\n queryset = Feedback.objects.all()\n serializer_class = FeedbackSerializer\n permission_classes = [permissions.AllowAny]\n pagination_class = FeedbackPageNumberPagination\n\n def perform_create(self, serializer):\n anon = User.objects.get(username='anon')\n if self.request.user.is_anonymous is True:\n try:\n serializer.save(user=anon)\n except:\n print('anon user doesnt exist, create them.')\n else:\n serializer.save(user=self.request.user)\n\n"
},
{
"alpha_fraction": 0.5031847357749939,
"alphanum_fraction": 0.5636942386627197,
"avg_line_length": 17.47058868408203,
"blob_id": "1ec3540e8e5bf7cc9efbcfbb5c911f43653204ea",
"content_id": "b15d4af80708656045cebf643f8cf57986c7414e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 314,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 17,
"path": "/comm/migrations/0005_remove_comms_meta.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.5 on 2019-09-12 15:01\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('comm', '0004_comms_meta'),\n ]\n\n operations = [\n migrations.RemoveField(\n model_name='comms',\n name='meta',\n ),\n ]\n"
},
{
"alpha_fraction": 0.5735294222831726,
"alphanum_fraction": 0.608660101890564,
"avg_line_length": 39.79999923706055,
"blob_id": "39474a5a5bfbbf6a4b9a98d42dd66f4a6a89bf9e",
"content_id": "78c343a8ccc08e571546e5dbe5ddfa5e94de5af7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1224,
"license_type": "no_license",
"max_line_length": 159,
"num_lines": 30,
"path": "/scrape/migrations/0007_auto_20190924_1008.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.5 on 2019-09-24 14:08\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('scrape', '0006_auto_20190924_1006'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='yelpresults',\n name='business',\n field=models.ForeignKey(null=True, on_delete=django.db.models.deletion.CASCADE, related_name='yelp_reviews', to='scrape.Collect'),\n ),\n migrations.CreateModel(\n name='GlassdoorResults',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('author', models.CharField(blank=True, max_length=120, null=True)),\n ('date', models.CharField(blank=True, max_length=120)),\n ('rating', models.CharField(blank=True, max_length=120, null=True)),\n ('review', models.TextField(blank=True, max_length=500)),\n ('business', models.ForeignKey(null=True, on_delete=django.db.models.deletion.CASCADE, related_name='glassdoor_reviews', to='scrape.Collect')),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.7022058963775635,
"alphanum_fraction": 0.7022058963775635,
"avg_line_length": 24.904762268066406,
"blob_id": "9dba4ec41a8661c49e112cc9d19a5fbcddc55b5b",
"content_id": "a2eeea063a49210297a4e7cbe18a4d489b1280c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 544,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 21,
"path": "/comm/admin.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom django.db import models\nfrom .models import Comms\nfrom .forms import CommsForm\nfrom pagedown.widgets import AdminPagedownWidget\n\n\nclass CommsAdmin(admin.ModelAdmin):\n formfield_overrides = {\n models.TextField: {'widget': AdminPagedownWidget},\n }\n list_display = [\"site_location\", \"title\", \"updated\"]\n list_filter = [\"site_location\"]\n search_fields = [\"title\", \"content\", \"location\"]\n form = CommsForm\n\n class Meta:\n model = Comms\n\n\nadmin.site.register(Comms, CommsAdmin)\n"
},
{
"alpha_fraction": 0.5570565462112427,
"alphanum_fraction": 0.5630999207496643,
"avg_line_length": 30.965909957885742,
"blob_id": "5efb4f6f4eb85e92b327b5965b62f662f26cda22",
"content_id": "1d0ae0a3a8b8c36c9304f0c27fec3f8106a83e50",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5626,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 176,
"path": "/scrape/scripts/glassdoor/glassdoor.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "import os\nimport math\nimport numpy as np\nimport pandas as pd\nfrom bs4 import BeautifulSoup\nimport requests\nimport time\nimport re\n\nfrom scrape.scripts.glassdoor.attempt import trial\n\nMAX_ATTEMPTS = 20\n\n\n@trial(max_trial=MAX_ATTEMPTS)\ndef _get_number_of_pages(url, hdr):\n \"\"\"fetch total number of review pages from glassdoor\"\"\"\n # fetch the content using url provided\n html_page = requests.get(url, headers=hdr)\n\n # Parse html content\n page_content = BeautifulSoup(html_page.content, 'html.parser')\n\n # ID Max Number of Pages\n # Gather number of reviews meta data from page link\n num_of_reviews_tag = page_content.find(\n attrs={'class': 'padTopSm margRtSm margBot minor'})\n num_of_reviews = float(\n num_of_reviews_tag.text.split(' ')[0].replace(\",\", ''))\n\n # Glassdoor lists 10 reviews /page\n num_of_pages = math.ceil(num_of_reviews / 10)\n html_loaded = True\n\n return num_of_pages\n\n\ndef _get_page_content(url, page_, hdr):\n \"\"\"gather_page_content\"\"\"\n\n # Get URL\n page_url = re.sub(r'\\.htm$', '', url) + '_P' + str(page_) + \\\n '.htm?sort.sortType=RD&sort.ascending=false'\n session = requests.Session()\n html_page = session.get(page_url, headers=hdr)\n session.close()\n\n # Parse HTML with BeautifulSoup\n page_content = BeautifulSoup(html_page.text, 'html.parser')\n\n return page_content\n\n\n@trial(max_trial=MAX_ATTEMPTS)\ndef _get_reviews(url, page_, hdr):\n \"\"\"getting reviews\"\"\"\n\n print('Loading page: ' + str(page_) + ' ... ',\n end='',\n flush=True)\n\n page_content = _get_page_content(url, page_, hdr)\n\n # Gather all Data: reviews, date, rating, location, title\n overall_rating = page_content.findAll(\n attrs={'class': 'value-title'})\n pros = page_content.findAll(\n attrs={'class':\n ' pros mainText truncateThis wrapToggleStr'})\n cons = page_content.findAll(\n attrs={'class':\n ' cons mainText truncateThis wrapToggleStr'})\n date = page_content.findAll(\n attrs={'class': 'date subtle small'})\n job_title = page_content.findAll(\n attrs={'class': 'authorJobTitle reviewer'})\n\n # Create Dictionary From Scraped Info\n # first page structured differently\n if page_ == 1:\n # this happens randomly\n if len(pros) == len(date):\n data_ = {\n 'Overall_Rating': [float(x['title'])\n for x in overall_rating[1:]],\n 'Pros': [x.text for x in pros],\n 'Cons': [x.text for x in cons],\n 'Date': [x['datetime'] for x in date],\n 'Current_Employee': [x.text.split('-')[0] for x in job_title],\n 'Job_Title': [x.text.split('-')[1] for x in job_title]}\n else:\n data_ = {\n 'Overall_Rating': [float(x['title'])\n for x in overall_rating[2:]],\n 'Pros': [x.text for x in pros[1:]],\n 'Cons': [x.text for x in cons[1:]],\n 'Date': [x['datetime'] for x in date],\n 'Current_Employee': [x.text.split('-')[0]\n for x in job_title[1:]],\n 'Job_Title': [x.text.split('-')[1] for x in job_title[1:]]}\n else:\n data_ = {\n 'Overall_Rating': [float(x['title']) for x in overall_rating],\n 'Pros': [x.text for x in pros],\n 'Cons': [x.text for x in cons],\n 'Date': [x['datetime'] for x in date],\n 'Current_Employee': [x.text.split('-')[0] for x in job_title],\n 'Job_Title': [x.text.split('-')[1] for x in job_title]}\n\n # check if loaded properly\n if len(data_['Overall_Rating']) != len(data_['Pros']):\n raise Exception('length error')\n\n print('Page loaded successfully! Data length:',\n len(data_['Overall_Rating']))\n return pd.DataFrame(data_)\n\n\ndef glassdoor_reviews_for_business(url, pages=\"all\"):\n \"\"\"\n This module scrapes reviews from the Glassdoor website.\n\n Parameters\n ----------\n url : str\n Glassdoor's main review page url\n pages : int or 'all', optional (default = 'all')\n number of review pages that needs to be scraped. Each page has\n 10 reviews in it\n If 'all', all pages will be reviewed.\n\n Returns\n -------\n df_reviews_final : DataFrame\n DataFrame of all the reviews\n\n Notes\n -----\n If after 5 tries, it cannot load a review page, it\n will skip the page and continues. If 'pages' is set to all and it cannot\n load the number of pages it will return -1.\n \"\"\"\n\n # header\n hdr = {'User-Agent': 'Mozilla/5.0',\n 'Cache-Control': 'no-cache'}\n\n if pages == 'all':\n num_of_pages = _get_number_of_pages(url, hdr)\n if num_of_pages == -1:\n print('Error: Cannot load the page properly!')\n return -1\n else:\n try:\n num_of_pages = int(pages)\n except BaseException:\n print('Error: \"pages\" must be an integer or \"all\"')\n return -1\n\n if num_of_pages == 1:\n print('1 page will be loaded!')\n else:\n print(num_of_pages, 'pages will be loaded!')\n\n # Initialize Final DataFrames\n df_reviews_final = pd.DataFrame()\n\n for page_ in range(1, num_of_pages + 1):\n df_reviews_final = df_reviews_final.append(_get_reviews(url, page_,\n hdr))\n\n df_reviews_final.reset_index(drop=True, inplace=True)\n\n print(len(df_reviews_final), 'reviews loaded!')\n\n return df_reviews_final\n"
},
{
"alpha_fraction": 0.7421203255653381,
"alphanum_fraction": 0.7421203255653381,
"avg_line_length": 23.928571701049805,
"blob_id": "28c46e8f327335c2b195562acb451059091c8cf2",
"content_id": "32c577357ecfd746df041f3eb2bc2252978c76ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 349,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 14,
"path": "/harvstr/wsgi.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "import os\nfrom django.conf import settings\nfrom django.core.wsgi import get_wsgi_application\n\nos.environ.setdefault(\"DJANGO_SETTINGS_MODULE\", \"harvstr.settings\")\n\napplication = get_wsgi_application()\n# application = DjangoWhiteNoise(application)\n\nif not settings.DEBUG:\n try:\n application = get_wsgi_application()\n except:\n pass\n"
},
{
"alpha_fraction": 0.5668317079544067,
"alphanum_fraction": 0.5668317079544067,
"avg_line_length": 24.25,
"blob_id": "6828bf361110b5329e993718a7e34d5b4981efec",
"content_id": "598c5862d3ced159beb3f8ae05d56f0ed75a8dea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1212,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 48,
"path": "/landing/serializers.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from django.contrib.auth import get_user_model\nfrom rest_framework import serializers\nfrom .models import Feedback\n\nUser = get_user_model()\n\n\nclass UserPublicSerializer(serializers.ModelSerializer):\n username = serializers.CharField(required=False, allow_blank=True,\n read_only=True)\n\n class Meta:\n model = User\n fields = [\n 'username'\n ]\n\n\nclass FeedbackSerializer(serializers.ModelSerializer):\n url = serializers.HyperlinkedIdentityField(\n view_name='landing-api:detail',\n lookup_field='id'\n )\n user = UserPublicSerializer(read_only=True)\n\n class Meta:\n model = Feedback\n fields = (\n 'url',\n 'id',\n 'user',\n 'name',\n 'email',\n 'phone_number',\n 'comments',\n 'timestamp'\n )\n\n @staticmethod\n def create(validated_data):\n return Feedback.objects.create(**validated_data)\n\n def get_owner(self, obj):\n request = self.context['request']\n if request.user.is_authenticated:\n if request.user == request.user:\n return True\n return False\n"
},
{
"alpha_fraction": 0.6521739363670349,
"alphanum_fraction": 0.6545893549919128,
"avg_line_length": 31.657894134521484,
"blob_id": "6f032e19b4996863f2be07662438ebd7a2364fa0",
"content_id": "214416dca5b3512387d930bf9835fa54ceed4653",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2484,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 76,
"path": "/scrape/views.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from rest_framework import generics, permissions, pagination\nfrom rest_framework.response import Response\nfrom .permissions import IsOwnerOrReadOnly\nfrom django.contrib.auth.models import User\nfrom .serializers import ScrapeSerializer, IndeedScrapeSerializer\n# from .scripts.text_analysis.analyze_text import ProcessCommon\nfrom .pipeline import *\n\n\nclass ScrapePageNumberPagination(pagination.PageNumberPagination):\n page_size = 5\n page_size_query_param = 'size'\n max_page_size = 20\n\n def get_paginated_response(self, data):\n user = False\n user = self.request.user\n if user.is_authenticated:\n user = True\n context = {\n 'next': self.get_next_link(),\n 'previous': self.get_previous_link(),\n 'count': self.page.paginator.count,\n 'user': user,\n 'results': data,\n }\n return Response(context)\n\n\nclass ScrapeDetailAPIView(generics.RetrieveUpdateDestroyAPIView):\n queryset = Collect.objects.all()\n # serializer_class = ScrapeSerializer\n lookup_field = 'slug'\n permission_classes = [IsOwnerOrReadOnly]\n\n def get_serializer_class(self):\n if 'yelp' in self.request.path:\n return ScrapeSerializer\n elif 'indeed' in self.request.path:\n return IndeedScrapeSerializer\n return -1 #\n\n def get_serializer_context(self):\n context = super().get_serializer_context()\n context['request'] = self.request\n return context\n\n\nclass ScrapeListCreateAPIView(generics.ListCreateAPIView):\n permission_classes = [permissions.AllowAny]\n pagination_class = ScrapePageNumberPagination\n\n def get_queryset(self):\n if 'yelp' in self.request.path:\n queryset = Collect.objects.filter(site='yelp')\n return queryset\n elif 'indeed' in self.request.path:\n queryset = Collect.objects.filter(site='indeed')\n return queryset\n return -1 #\n\n def get_serializer_class(self):\n if 'yelp' in self.request.path:\n return ScrapeSerializer\n elif 'indeed' in self.request.path:\n return IndeedScrapeSerializer\n return -1 #\n\n def perform_create(self, serializer):\n anon = User.objects.get(username='scrapeAnon')\n if self.request.user.is_anonymous is True:\n serializer.save(user=anon)\n else:\n serializer.save(user=self.request.user)\n\n run_flow(serializer.instance)\n\n\n"
},
{
"alpha_fraction": 0.5608000159263611,
"alphanum_fraction": 0.5608000159263611,
"avg_line_length": 25.04166603088379,
"blob_id": "c588bee19f89b390eb770390b24c55c68bf1815a",
"content_id": "ba457cbee7156d47905d5f4eb8d14b8e91b1d121",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1250,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 48,
"path": "/comm/serializers.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from django.contrib.auth import get_user_model, authenticate, login, logout\nfrom rest_framework import serializers\nfrom .models import Comms\n\nUser = get_user_model()\n\n\nclass UserPublicSerializer(serializers.ModelSerializer):\n username = serializers.CharField(required=False, allow_blank=True,\n read_only=True)\n\n class Meta:\n model = User\n fields = [\n 'username',\n 'first_name',\n 'last_name',\n ]\n\n\nclass CommsSerializer(serializers.ModelSerializer):\n url = serializers.HyperlinkedIdentityField(\n view_name='comms-api:detail',\n lookup_field='slug'\n )\n author = UserPublicSerializer(read_only=True)\n owner = serializers.SerializerMethodField(read_only=True)\n\n class Meta:\n model = Comms\n fields = [\n 'url',\n 'site_location',\n 'title',\n 'slug',\n 'author',\n 'owner',\n 'content',\n 'updated',\n 'draft'\n ]\n\n def get_owner(self, obj):\n request = self.context['request']\n if request.user.is_authenticated:\n if obj.author == request.user:\n return True\n return False\n"
},
{
"alpha_fraction": 0.6579304337501526,
"alphanum_fraction": 0.6624491810798645,
"avg_line_length": 29.3150691986084,
"blob_id": "15a35728c8b8bc1b3e294e098acf5ef9849fdae5",
"content_id": "d61611725d0bad381096ba9ef19c406baa66cf85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2213,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 73,
"path": "/comm/models.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.urls import reverse\nfrom django.db.models.signals import pre_save\nfrom .utils import unique_slug_generator\nfrom django.conf import settings\nfrom django.utils import timezone\nfrom markdown_deux import markdown\nfrom django.utils.safestring import mark_safe\nfrom django.contrib.contenttypes.models import ContentType\n\n\nclass CommsManager(models.Manager):\n def active(self, *args, **kwargs):\n return super(CommsManager, self).filter(draft=False).filter(\n updated__lte=timezone.now())\n\n\nclass Comms(models.Model):\n comms = 'comms'\n scrape = 'scrape'\n landing = 'landing'\n APP_CHOICES = [\n (comms, 'comms'),\n (scrape, 'scrape'),\n (landing, 'landing'),\n ]\n site_location = models.CharField(\n max_length=120,\n choices=APP_CHOICES\n )\n author = models.ForeignKey(settings.AUTH_USER_MODEL, default=1,\n on_delete=models.CASCADE)\n title = models.CharField(max_length=120)\n slug = models.SlugField(unique=True, blank=True, null=True)\n content = models.TextField()\n draft = models.BooleanField(default=False)\n updated = models.DateTimeField(auto_now=True, auto_now_add=False)\n # meta = models.CharField(max_length=120, blank=True, null=True)\n\n objects = CommsManager()\n\n def __str__(self):\n return self.title\n\n def get_absolute_url(self):\n return reverse('comms:detail', kwargs={'slug': self.slug})\n\n class Meta:\n ordering = [\"-updated\"]\n\n def get_markdown(self):\n content = self.content\n markdown_text = markdown(content)\n return mark_safe(markdown_text)\n\n @property\n def get_content_type(self):\n instance = self\n content_type = ContentType.objects.get_for_model(instance.__class__)\n return content_type\n\n\ndef pre_save_post_receiver(sender, instance, *args, **kwargs):\n if not instance.slug:\n instance.slug = unique_slug_generator(instance)\n\n # if instance.content:\n # html_string = instance.get_markdown()\n # read_time = get_read_time(html_string)\n # instance.read_time = read_time\n\n\npre_save.connect(pre_save_post_receiver, sender=Comms)\n"
},
{
"alpha_fraction": 0.6258992552757263,
"alphanum_fraction": 0.6258992552757263,
"avg_line_length": 26.5,
"blob_id": "2762e0d784b4f1c5e40964feaf6243abd118cba6",
"content_id": "45f4f568258dd6cf73807351870eae399d84b519",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 278,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 10,
"path": "/comm/urls.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from django.urls import re_path, path\nfrom . import views\n\napp_name = 'comms-api'\n\nurlpatterns = [\n path('', views.CommsListCreateAPIView.as_view(), name='list-create'),\n re_path(r'^(?P<slug>[\\w-]+)/$', views.CommsDetailAPIView.as_view(),\n name='detail'),\n]\n\n\n\n"
},
{
"alpha_fraction": 0.5967982411384583,
"alphanum_fraction": 0.6021965742111206,
"avg_line_length": 35.53741455078125,
"blob_id": "ea081668b4a24ce3e85fd6a1991ce2dbb9a856ff",
"content_id": "1902d18b14b6ec29d9dfd7b38f849fac75ba452d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5372,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 147,
"path": "/scrape/scripts/indeed/indeed.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "import requests\nimport math\nimport pandas as pd\nfrom bs4 import BeautifulSoup\n\n\ndef number_of_pages(url_path, hdr):\n \"\"\"returns number of Indeed review pages\"\"\"\n # Need to get first page to find max number of pages\n # Sort Indeed Pages by Date\n # Request URL\n url = url_path + \"?start=0&sort=helpfulness\"\n payload = requests.get(url, headers=hdr, timeout=5)\n\n # Organize HTML Code with BeautifulSoup\n page_content = BeautifulSoup(payload.content, \"html.parser\")\n\n # Find Maximum Number of Pages\n # Get the number of reviews from a HTML link on the top of the page\n click_num_of_reviews = page_content.find(\n \"a\", {\"data-tn-element\": \"reviews-viewAllLink\"})\n\n if click_num_of_reviews is None:\n click_num_of_reviews = page_content.find(\n attrs={'class': 'cmp-filter-result'})\n split_text = click_num_of_reviews.text.split(' ')\n num_of_reviews = [int(i) for i in split_text if i.isdigit()][0]\n else:\n split_text = click_num_of_reviews.text.split()\n num_of_reviews = int(split_text[2].replace(',', ''))\n\n # The pages have 20 reviews each, and this is reflected in the URL\n # link; use this to find num of pages\n num_of_pages = math.ceil(num_of_reviews / 20)\n\n return num_of_pages\n\n\ndef get_reviews(url_path, hdr, page_):\n # Get URL of this page\n url = url_path + \"?start=\" + str(page_ * 20) + \"&sort=helpfulness\"\n payload = requests.get(url, headers=hdr, timeout=5)\n # Organize HTML Code with BeautifulSoup\n page_content = BeautifulSoup(payload.content, \"html.parser\")\n # Get all Relevant Info: reviews, date, rating, location, job_title,\n # current_employee?\n review = page_content.findAll(itemprop=\"reviewBody\")\n pros = page_content.findAll(attrs={'class': 'cmp-review-pros'})\n cons = page_content.findAll(attrs={'class': 'cmp-review-cons'})\n date = page_content.findAll(attrs={\"class\": \"cmp-review-date-created\"})\n rating = page_content.findAll(attrs={\"class\": \"cmp-ratingNumber\"})\n location = page_content.findAll(\n attrs={\"class\": \"cmp-reviewer-job-location\"})\n job_title = page_content.findAll(attrs={\"class\": \"cmp-reviewer\"})\n current_employee = page_content.findAll(\n attrs={\"class\": \"cmp-reviewer-job-title\"})\n # Create Dictionary From Scraped Info\n d = {'Review': [x.text for x in review],\n 'Rating': [int(float(x.text)) for x in rating],\n 'Date': [x.text for x in date],\n 'Location_City': [x.text.split(\",\")[0] for x in location],\n 'Location_State': [x.text.split(\",\")[1]\n if len(x.text.split(\",\")) > 1 else float('NaN')\n for x in location],\n 'Job_Title': [x.text for x in job_title],\n 'Current_Employee': [x.text.split(\"(\")[1].split(\")\")[0]\n for x in current_employee]}\n\n d_pros = {'Pros': [x.text.split('Pros')[1]\n for x in pros if len(x.text.split('Pros')) > 1]}\n d_cons = {'Cons': [x.text.split('Cons')[1]\n for x in cons if len(x.text.split('Cons')) > 1]}\n\n return pd.DataFrame(d), pd.DataFrame(d_pros), pd.DataFrame(d_cons)\n\n\ndef scrape_indeed(url, pages):\n \"\"\"\n This module scrapes reviews from the Indeed website.\n\n Parameters\n ----------\n url : str\n Indeed's main review page url\n pages : int or 'all', optional (default = 'all')\n number of review pages that needs to be scraped. Each page has\n 20 reviews in it\n If 'all', all pages will be reviewed.\n\n Returns\n -------\n df_reviews_final : DataFrame\n DataFrame of the reviews\n df_pros_final : DataFrame\n DataFrame of pros in the reviews\n df_cons_final : DataFrame\n DataFrame of cons in the reviews\n \"\"\"\n\n # header\n hdr = {'User-Agent': 'Mozilla/5.0',\n 'Cache-Control': 'no-cache'}\n\n # If the user wants all pages follow this condition\n if pages is None:\n num_of_pages = number_of_pages(url, hdr)\n else:\n try:\n num_of_pages = int(pages)\n except Exception as exc:\n formatted = 'must enter integer or \"all\": {}\"'.format(\n repr(exc))\n raise Exception(formatted)\n\n # Initialize Final DataFrames\n df_reviews_final = pd.DataFrame()\n df_pros_final = pd.DataFrame()\n df_cons_final = pd.DataFrame()\n # Loop through all selected pages\n\n if num_of_pages == 1:\n print('1 page will be loaded!')\n else:\n print(num_of_pages, 'pages will be loaded!')\n\n for page_ in range(1, num_of_pages + 1):\n\n print('Loadin page: ' + str(page_) + ' ... ',\n end='',\n flush=True)\n\n df_reviews_temp, df_pros_temp, df_cons_temp = get_reviews(\n url, hdr, page_)\n\n # Vertically Concatenate DataFrames\n df_reviews_final = df_reviews_final.append(\n df_reviews_temp, ignore_index=True)\n df_pros_final = df_pros_final.append(df_pros_temp, ignore_index=True)\n df_cons_final = df_cons_final.append(df_cons_temp, ignore_index=True)\n\n print('Page loaded successfully!')\n\n print(len(df_pros_final), 'pros,', len(df_cons_final), 'cons, and',\n len(df_reviews_final), 'reviews loaded!')\n\n # return df_reviews_final, df_pros_final, df_cons_final\n return df_reviews_final\n\n"
},
{
"alpha_fraction": 0.4246031641960144,
"alphanum_fraction": 0.43518519401550293,
"avg_line_length": 18.41025733947754,
"blob_id": "64abf1748bec0de40bb191084453a994279b28f5",
"content_id": "39255171c78dba9dbb726b31fd607864b6816b0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 756,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 39,
"path": "/frontend/src/myblock/MyBlock.js",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "import React, {Component} from 'react'\nimport 'whatwg-fetch'\n\nclass MyBlock extends Component {\n constructor(props) {\n super(props);\n this.state = {\n slug: null,\n };\n }\n\n loadCommsView() {\n this.setState({\n CommsView: true\n });\n }\n\n render() {\n const {blocks} = this.state;\n // console.log(scrape);\n const hrStyle = {\n display: 'block',\n height: '1px',\n border: 0,\n borderTop: '1px solid #ccc',\n margin: '1em 0',\n padding: '0',\n color: 'white'\n };\n\n return (\n <div>\n <h2>Main Page</h2>\n </div>\n )\n }\n}\n\nexport default MyBlock"
},
{
"alpha_fraction": 0.44526776671409607,
"alphanum_fraction": 0.44964635372161865,
"avg_line_length": 29,
"blob_id": "5886d75b79929adc3959dded6a9b186eb95388af",
"content_id": "388586255e48f8af456a8b142c9c30fa661cc068",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2969,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 99,
"path": "/frontend/src/scrape/ScrapeCreate.js",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "import React, {Component} from 'react'\nimport ScrapeForm from './ScrapeForm'\nimport cookie from \"react-cookies\";\nimport ReactMarkdown from \"react-markdown\";\n\nclass ScrapeCreate extends Component {\n constructor(props) {\n super(props);\n this.state = {\n slug: null,\n comms: [],\n commsListClass: \"card\",\n previous: null,\n author: false,\n draft: null,\n count: 0\n };\n }\n\n loadComms(nextEndpoint) {\n let endpoint = '/api/comms/';\n if (nextEndpoint !== undefined) {\n endpoint = nextEndpoint\n }\n let thisComp = this;\n let lookupOptions = {\n method: \"GET\",\n headers: {\n 'Content-Type': 'application/json'\n }\n };\n const csrfToken = cookie.load('csrftoken');\n if (csrfToken !== undefined) {\n lookupOptions['credentials'] = 'include';\n lookupOptions['headers']['X-CSRFToken'] = csrfToken\n }\n\n fetch(endpoint, lookupOptions)\n .then(function (response) {\n return response.json()\n }).then(function (responseData) {\n thisComp.setState({\n comms: thisComp.state.comms.concat(responseData.results.filter(post => post.site_location === 'scrape' && post.draft === false)),\n next: responseData.next,\n previous: responseData.previous,\n staff: responseData.staff,\n draft: responseData.draft,\n count: responseData.count\n })\n }\n ).catch(function (error) {\n console.log(\"error\", error)\n })\n }\n\n componentDidMount() {\n this.setState({\n comms: [],\n next: null,\n previous: null,\n count: 0\n });\n this.loadComms()\n }\n\n render() {\n const {comms} = this.state;\n const hrStyle = {\n display: 'block',\n height: '1px',\n border: 0,\n borderTop: '1px solid #ccc',\n margin: '1em 0',\n padding: '0',\n color: 'white'\n };\n return (\n <div class=\"container col-sm-10\">\n <div className=\"scrape_form\">\n <ScrapeForm/>\n </div>\n {comms.length > 0 ? comms.map((commItem, index) => {\n return (\n <div className=\"comms\">\n <h1 class=\"side-lines--double\">Instructions</h1>\n {commItem !== undefined ?\n <ReactMarkdown source={commItem.content}/>\n : \"\"}\n </div>\n )\n }) : <p>No Messages To Display</p>\n }\n </div>\n )\n }\n\n}\n\nexport default ScrapeCreate"
},
{
"alpha_fraction": 0.676577091217041,
"alphanum_fraction": 0.6821040511131287,
"avg_line_length": 26.1865291595459,
"blob_id": "390885374781f3902072f7fea977bc8071235a18",
"content_id": "931d8ad8f5dca1a998538fe67f274d2de00a6f29",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5247,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 193,
"path": "/harvstr/settings/production.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "import os\nimport dj_database_url\n\n# import environ\n\n# env = environ.Env(\n# # set casting, default value\n# DEBUG=(bool, False)\n# )\n# # reading .env file\n# environ.Env.read_env()\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))\nPROJECT_ROOT = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/1.10/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = 'check host location'\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = False\n\nALLOWED_HOSTS = ['www.democratizer.io', 'democratizer.io',\n 'democratizer-staging.herokuapp.com']\n\n# EMAIL_HOST = 'mail.name.com'\n# EMAIL_HOST_USER = '[email protected]'\n# DEFAULT_FROM_EMAIL = '[email protected]'\n# EMAIL_HOST_PASSWORD = 'LBbjH8Z7!7!'\n# EMAIL_PORT = 587\n# EMAIL_USE_TLS = True\n\n# Application definition\n\nINSTALLED_APPS = [\n # Django Apps\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n # Third Party Apps\n 'crispy_forms',\n 'django.contrib.humanize',\n 'django_hosts',\n 'rest_framework',\n 'pagedown',\n 'markdown_deux',\n 'corsheaders',\n 'django_celery_beat',\n 'django_celery_results',\n # My Apps\n 'accounts',\n 'scrape',\n 'comm',\n 'landing',\n 'myblock'\n\n]\n\nMIDDLEWARE = [\n 'django_hosts.middleware.HostsRequestMiddleware',\n 'django.middleware.security.SecurityMiddleware',\n 'whitenoise.middleware.WhiteNoiseMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n 'harvstr.middleware.LoginRequiredMiddleware',\n 'django_hosts.middleware.HostsResponseMiddleware',\n]\n\nLOGIN_URL = '/account/login'\n\nLOGIN_EXEMPT_URLS = [\n '/account/logout',\n '/account/register',\n '/account/reset-password/',\n '/account/reset-password/done/',\n '/account/reset-password/confirm/',\n '/account/reset-password/complete/',\n '/'\n]\n\nROOT_URLCONF = 'harvstr.urls'\nROOT_HOSTCONF = 'harvstr.hosts'\nDEFAULT_HOST = 'www'\n# DEFAULT_REDIRECT_URL = 'http://www.harvstr.io'\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [os.path.join(BASE_DIR, 'templates')],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n },\n },\n]\n\nWSGI_APPLICATION = 'harvstr.wsgi.application'\n\n# Database\n# https://docs.djangoproject.com/en/1.10/ref/settings/#databases\n\nDATABASES = {\n 'default': {\n 'ENGINE': 'django.db.backends.sqlite3',\n 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),\n }\n}\n\n# Update database configuration with $DATABASE_URL.\ndb_from_env = dj_database_url.config(conn_max_age=500)\nDATABASES['default'].update(db_from_env)\n\n# Password validation\n# https://docs.djangoproject.com/en/1.10/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',\n },\n]\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.10/topics/i18n/\n\nLANGUAGE_CODE = 'en-us'\n\nTIME_ZONE = 'America/New_York'\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\nCRISPY_TEMPLATE_PACK = 'bootstrap4'\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.9/howto/static-files/\n\nSTATIC_URL = '/static/'\n\nSTATICFILES_DIRS = (\n os.path.join(BASE_DIR, \"static\"),\n)\n\nSTATIC_ROOT = os.path.join(BASE_DIR, \"live-static\", \"static-root\")\n\nMEDIA_URL = \"/media/\"\n\nMEDIA_ROOT = os.path.join(BASE_DIR, \"live-static\", \"media-root\")\n\nREST_FRAMEWORK = {\n 'DEFAULT_PERMISSION_CLASSES': (\n 'rest_framework.permissions.IsAuthenticatedOrReadOnly',\n )\n}\n\nCELERY_BROKER_URL = os.environ['REDIS_URL']\nCELERY_RESULT_BACKEND = 'django-db'\nCELERY_ACCEPT_CONTENT = ['application/json']\nCELERY_TASK_SERIALIZER = 'json'\nCELERY_RESULT_SERIALIZER = 'json'\nCELERY_TIMEZONE = TIME_ZONE\n\n# REACT VARIABLES\nBUILD_JSON = os.path.join(BASE_DIR, \"frontend/utils/build.json\")\n\n# SCRAPE\nIGNORE_WORDS_JSON = 'src/scrape/scripts/text_analysis/constants/words_ignore.json'\nACTIVESITES_JSON = os.path.join(BASE_DIR, \"scrape/constants/activeSites.json\")\n"
},
{
"alpha_fraction": 0.7086383700370789,
"alphanum_fraction": 0.7086383700370789,
"avg_line_length": 21.064516067504883,
"blob_id": "09ca98de0fbbb2671cd7f3be5731c2e4f1f6210e",
"content_id": "7b3841676b9fadc642c8069b4d18f81fe457bf38",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 683,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 31,
"path": "/landing/admin.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import Feedback, About\nfrom pagedown.widgets import AdminPagedownWidget\nfrom django.db import models\nfrom .forms import AboutMeForm\n\n\nclass FeedbackAdmin(admin.ModelAdmin):\n list_display = [\"timestamp\"]\n list_filter = [\"timestamp\"]\n search_fields = [\"comments\"]\n\n class Meta:\n model = Feedback\n\n\nadmin.site.register(Feedback, FeedbackAdmin)\n\n\nclass AboutMeAdmin(admin.ModelAdmin):\n formfield_overrides = {\n models.TextField: {'widget': AdminPagedownWidget},\n }\n list_display = [\"title\", \"updated\"]\n form = AboutMeForm\n\n class Meta:\n model = About\n\n\nadmin.site.register(About, AboutMeAdmin)"
},
{
"alpha_fraction": 0.7044917345046997,
"alphanum_fraction": 0.7044917345046997,
"avg_line_length": 31.538461685180664,
"blob_id": "c9fba45053af9aceeee0da524b634fca7704d150",
"content_id": "4b7d76cec7579e6ad5fa9fdcc0f0094541367ccd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 423,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 13,
"path": "/landing/urls.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from django.urls import path, re_path, include\nfrom django.views.generic import TemplateView\nfrom . import views\n# from django.contrib import admin\n# from django.contrib.auth import views as auth_views\n\napp_name = 'landing-api'\n\nurlpatterns = [\n path('', views.FeedbackListCreateAPIView.as_view(), name='list-create'),\n re_path(r'^(?P<id>[\\d]+)/$', views.FeedbackDetailAPIView.as_view(),\n name='detail')\n]\n"
},
{
"alpha_fraction": 0.5577617287635803,
"alphanum_fraction": 0.5577617287635803,
"avg_line_length": 24.374046325683594,
"blob_id": "9a48ec4b21d6a523fd3f8d4af93e4b3f7016a997",
"content_id": "5d54c2401bd52bc6b54496165c59e961479ca2f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3324,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 131,
"path": "/scrape/serializers.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from django.contrib.auth import get_user_model\n\nfrom rest_framework import serializers\n\nfrom .models import Collect, Results, Analytics, IndeedResults\n\nUser = get_user_model()\n\n\nclass UserPublicSerializer(serializers.ModelSerializer):\n username = serializers.CharField(required=False, allow_blank=True,\n read_only=True)\n\n class Meta:\n model = User\n fields = [\n 'username'\n ]\n\n\nclass AnalyticsSerializer(serializers.ModelSerializer):\n class Meta:\n model = Analytics\n fields = (\n 'word',\n 'value',\n )\n\n\nclass ResultsSerializer(serializers.ModelSerializer):\n class Meta:\n model = Results\n fields = (\n 'author',\n 'date',\n 'rating',\n 'review'\n )\n\n\nclass ScrapeSerializer(serializers.ModelSerializer):\n url = serializers.HyperlinkedIdentityField(\n view_name='scrape-api:yelp_detail',\n lookup_field='slug'\n )\n reviews = ResultsSerializer(many=True, read_only=True)\n user = UserPublicSerializer(read_only=True)\n analytics = AnalyticsSerializer(many=True, read_only=True)\n owner = serializers.SerializerMethodField(read_only=True)\n\n class Meta:\n model = Collect\n fields = (\n 'user',\n 'owner',\n 'url',\n 'business_name',\n 'link',\n 'page_amount',\n 'scrape_date',\n 'slug',\n 'site',\n 'analytics',\n 'reviews',\n )\n\n @staticmethod\n def create(validated_data):\n return Collect.objects.create(**validated_data)\n\n def get_owner(self, obj):\n request = self.context['request']\n if request.user.is_authenticated:\n if request.user == request.user:\n return True\n return False\n\n\n\"\"\"Indeed Serializers\"\"\"\n\n\nclass IndeedResultsSerializer(serializers.ModelSerializer):\n class Meta:\n model = IndeedResults\n fields = (\n 'date',\n 'rating',\n 'review',\n 'location_city',\n 'location_state',\n 'job_title',\n 'current_employee'\n )\n\n\nclass IndeedScrapeSerializer(serializers.ModelSerializer):\n url = serializers.HyperlinkedIdentityField(\n view_name='scrape-api:indeed_detail',\n lookup_field='slug'\n )\n indeed_reviews = IndeedResultsSerializer(many=True, read_only=True)\n user = UserPublicSerializer(read_only=True)\n analytics = AnalyticsSerializer(many=True, read_only=True)\n owner = serializers.SerializerMethodField(read_only=True)\n\n class Meta:\n model = Collect\n fields = (\n 'user',\n 'owner',\n 'url',\n 'business_name',\n 'link',\n 'page_amount',\n 'scrape_date',\n 'slug',\n 'site',\n 'analytics',\n 'indeed_reviews',\n )\n\n @staticmethod\n def create(validated_data):\n return Collect.objects.create(**validated_data)\n\n def get_owner(self, obj):\n request = self.context['request']\n if request.user.is_authenticated:\n if request.user == request.user:\n return True\n return False\n"
},
{
"alpha_fraction": 0.5354838967323303,
"alphanum_fraction": 0.5827956795692444,
"avg_line_length": 24.83333396911621,
"blob_id": "2ec4ae0bd4ee416514c24acf545b93c64ae74047",
"content_id": "6388ff6cfbdd85d450bd022316172ea6737a46d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 465,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 18,
"path": "/comm/migrations/0006_auto_20190917_1309.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.5 on 2019-09-17 17:09\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('comm', '0005_remove_comms_meta'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='comms',\n name='site_location',\n field=models.CharField(choices=[('comms', 'comms'), ('scrape', 'scrape'), ('landing', 'landing')], max_length=120),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5164835453033447,
"alphanum_fraction": 0.5686812996864319,
"avg_line_length": 19.22222137451172,
"blob_id": "f6c37e91de43eda4326bbb76927696ccba3b80a5",
"content_id": "88f9fedb851d02d89e2d6f0842abd247a0ff0459",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 364,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 18,
"path": "/comm/migrations/0003_auto_20190906_1521.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.5 on 2019-09-06 19:21\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('comm', '0002_comms_location'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='comms',\n old_name='location',\n new_name='site_location',\n ),\n ]\n"
},
{
"alpha_fraction": 0.4658125638961792,
"alphanum_fraction": 0.4715220630168915,
"avg_line_length": 29.050209045410156,
"blob_id": "5a14bec7d66d775927692abd1167c88d936dc8b0",
"content_id": "4a7d49fc7649b8416f3e2fcd909d54cf9b59d86d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 7181,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 239,
"path": "/frontend/src/landing/Landing.js",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "import React, {Component} from 'react'\nimport 'whatwg-fetch'\nimport cookie from 'react-cookies'\nimport {Link} from 'react-router-dom'\nimport ReactMarkdown from \"react-markdown\";\nimport FeedbackForm from \"../landing/FeedbackForm\";\nimport ReactLoading from \"react-loading\";\n\n\nclass Landing extends Component {\n constructor(props) {\n super(props);\n this.state = {\n slug: null,\n words: null,\n comms: [],\n about: [],\n aboutCardClass: \"shadow card rounded-0 invisible\",\n aboutCardAnimate: \"\",\n animate: false,\n mobile: false,\n previous: null,\n author: false,\n draft: null,\n count: 0,\n pagePosition: null,\n doneLoading: undefined\n };\n }\n\n checkMobileState = () => {\n const width = document.documentElement.clientWidth;\n if (width <= 768) {\n this.setState({\n mobile: true\n })\n }\n return this.state.mobile\n };\n\n listenToScroll = () => {\n const winScroll = document.body.scrollTop || document.documentElement.scrollTop;\n const height = document.documentElement.scrollHeight - document.documentElement.clientHeight;\n const scrolled = winScroll / height;\n //\n // console.log('mobile in scroll', this.state.mobile);\n // console.log('animate', this.state.animate);\n\n this.setState({\n pagePosition: scrolled\n });\n\n if (scrolled >= .40 && this.state.mobile === false) {\n this.setState({\n animate: true\n });\n }\n\n if (this.state.animate === true) {\n this.setState({\n aboutCardClass: \"shadow card rounded-0\",\n aboutCardAnimate: \"card-animate\"\n })\n }\n\n if (this.state.mobile === true) {\n this.setState({\n aboutCardClass: \"shadow card rounded-0\"\n })\n }\n };\n\n loadComms(nextEndpoint) {\n let endpoint = '/api/comms/';\n if (nextEndpoint !== undefined) {\n endpoint = nextEndpoint\n }\n let thisComp = this;\n let lookupOptions = {\n method: \"GET\",\n headers: {\n 'Content-Type': 'application/json'\n }\n };\n const csrfToken = cookie.load('csrftoken');\n if (csrfToken !== undefined) {\n lookupOptions['credentials'] = 'include';\n lookupOptions['headers']['X-CSRFToken'] = csrfToken\n }\n\n fetch(endpoint, lookupOptions)\n .then(function (response) {\n return response.json()\n }).then(function (responseData) {\n\n thisComp.setState({\n comms: thisComp.state.comms.concat(responseData.results.filter(post => post.slug === 'landing-tag' && post.draft === false)),\n about: thisComp.state.about.concat(responseData.results.filter(post => post.slug === 'about' && post.draft === false)),\n next: responseData.next,\n previous: responseData.previous,\n staff: responseData.staff,\n draft: responseData.draft,\n count: responseData.count,\n doneLoading: true,\n })\n }\n ).catch(function (error) {\n console.log(\"error\", error)\n })\n }\n\n componentDidMount() {\n this.checkMobileState();\n if (this.state.mobile === false) {\n window.addEventListener('scroll', this.listenToScroll);\n }\n this.setState({\n comms: [],\n about: [],\n next: null,\n previous: null,\n count: 0,\n });\n\n setTimeout(() => {\n this.loadComms()\n }, 1200);\n console.log(this.state.doneLoading)\n }\n\n\n render() {\n const {comms} = this.state;\n const {about} = this.state;\n const {aboutCardClass} = this.state;\n const {aboutCardAnimate} = this.state;\n const {mobile} = this.state;\n const hrStyle = {\n display: 'block',\n height: '1px',\n border: 0,\n borderTop: '1px solid #ccc',\n margin: '0 1em',\n padding: '0',\n color: '#18181E'\n };\n\n return (\n <div>\n {!this.state.doneLoading ? (\n <div className=\"loading\">\n <ReactLoading type={\"bars\"} color={\"white\"} height={'15%'}\n width={'15%'} id='spinner'/>\n </div>\n ) : (\n <div>\n <section className=\"fork\">\n <div className=\"container\" id=\"top\">\n {comms.length > 0 ? comms.map((commItem, index) => {\n return (\n <div className=\"tag\">\n {commItem !== undefined ?\n <ReactMarkdown source={commItem.content}/>\n : \"\"}\n </div>\n )\n }) : \"\"}\n <div class=\"vl\"></div>\n <div className=\"btn-group-vertical\">\n <div class=\"container-fluid\">\n <h3>DataSet Builders: </h3>\n <h5>Select your data source below.</h5>\n <a id=\"landing-btn\" href=\"/scrape/\">\n <button class=\"btn-fill\">\n Yelp\n </button>\n </a>\n <a id=\"landing-btn\" href=\"/scrape/\">\n <button className=\"btn-fill\">\n Indeed\n </button>\n </a>\n <Link id=\"landing-btn\" maintainScrollPosition={false} to={{\n pathname: `/`,\n state: {fromDashboard: false}\n }}>\n <button class=\"btn-flip\">\n GlassDoor\n </button>\n </Link>\n <Link id=\"landing-btn\" maintainScrollPosition={false} to={{\n pathname: `/`,\n state: {fromDashboard: false}\n }}>\n <button class=\"btn-flip\">\n Twitter\n </button>\n </Link>\n </div>\n <hr style={hrStyle}/>\n </div>\n </div>\n </section>\n\n <section class=\"about\" id=\"about\">\n <div className=\"container-fluid\">\n <div className=\"row\">\n <div className=\"col-sm-6 py-2\">\n {about.length > 0 ? about.map((aboutItem, index) => {\n return (\n <div className={aboutCardClass} id={aboutCardAnimate}>\n <h1 class=\"hook\">{aboutItem.title}</h1>\n <hr style={hrStyle}/>\n <div className=\"card-body d-flex flex-column\">\n <h5 className=\"card-title\">Democratizing the Worlds\n Data</h5>\n <p className=\"card-text\">\n {aboutItem !== undefined ?\n <ReactMarkdown source={aboutItem.content}/>\n : \"\"}\n </p>\n </div>\n </div>\n )\n }) : \"\"\n }\n </div>\n <FeedbackForm/>\n </div>\n </div>\n </section>\n </div>\n )}\n </div>\n )\n }\n}\n\nexport default Landing"
},
{
"alpha_fraction": 0.5655789971351624,
"alphanum_fraction": 0.5655789971351624,
"avg_line_length": 30.260000228881836,
"blob_id": "bd5fa86763f3d019d4c91735d5755341991dcaa9",
"content_id": "2c1c04ec8aee2437a1173e10d891e695d6e6f712",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1563,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 50,
"path": "/landing/forms.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from django import forms\nfrom django.forms import ModelForm, HiddenInput\nfrom .models import Feedback, About\nfrom django.forms import TextInput, Textarea\nfrom django.core.validators import ValidationError\n\n\nclass FeedbackForm(forms.ModelForm):\n class Meta:\n model = Feedback\n widgets = {'comments': Textarea(attrs={'placeholder': 'Hi!'})}\n labels = {'comments': 'Message', 'name': 'Name', 'email': 'Email', 'phone_number': 'Phone Number'}\n fields = [\n 'name',\n 'email',\n 'phone_number',\n \"comments\"\n ]\n\n\nclass AboutMeForm(ModelForm):\n class Meta:\n model = About\n widgets = {'unsplash_url': HiddenInput()}\n fields = [\n \"user\",\n \"title\",\n \"post_image\",\n \"unsplash_url\",\n 'width_field',\n 'height_field',\n \"content\"\n ]\n\n def clean_unsplash_url(self):\n post_image = self.cleaned_data.get(\"post_image\")\n image_height = self.cleaned_data.get(\"height_field\")\n image_width = self.cleaned_data.get('width_field')\n\n if not post_image:\n raise ValidationError('Error')\n else:\n unsplash_api = str(\"https://source.unsplash.com\")\n unsplash_image_id = str(post_image)\n image_size = str(image_width), str(image_height)\n join_size = 'x'.join(image_size)\n join_fields = unsplash_api, unsplash_image_id, join_size\n compile_url = '/'.join(join_fields)\n\n return compile_url\n"
},
{
"alpha_fraction": 0.5145630836486816,
"alphanum_fraction": 0.5970873832702637,
"avg_line_length": 21.88888931274414,
"blob_id": "68752754633a9ec9791110596dae6a6602557bf6",
"content_id": "e289246b054a9834149aad102e45edb82863bc10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 412,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 18,
"path": "/scrape/migrations/0010_workflow_timestamp.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.5 on 2019-10-04 14:40\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('scrape', '0009_auto_20191004_0954'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='workflow',\n name='timestamp',\n field=models.CharField(blank=True, max_length=120, null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5284472107887268,
"alphanum_fraction": 0.5354037284851074,
"avg_line_length": 28.59558868408203,
"blob_id": "2ce1ea13e54f7cfeb0e1ee2081b8b642370ef25e",
"content_id": "f24ef845ec430d6535ffebb1ca8589a35b549675",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4025,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 136,
"path": "/scrape/scripts/yelp/scrape_yelp.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "\"\"\"\nThis code scrapes the yelp link you provide for reviews and outputes them into csv file.\n\nsample 1: 'python reviews.py -l https://www.yelp.com/biz/schoolsfirst-federal-credit-union-santa-ana-5`\n\n\"\"\"\nfrom lxml import html\nimport requests\nimport argparse\nimport os\nimport pandas as pd\n\n\ndef data_set(data, biz):\n \"\"\"Collects review, formats, and exports to csv.\"\"\"\n df = pd.DataFrame(data)\n\n cnt_records = len(df)\n\n biz = str(biz)\n\n if not os.path.isfile('{}_reviews.csv'.format(biz)):\n df.to_csv('data/{}_reviews.csv'.format(biz), index=False,\n header='column_names')\n else: # else it exists, overwrite\n df.to_csv('data/{}_reviews.csv'.format(biz), index=False,\n header='column_names')\n\n print(cnt_records, \"reviews scraped and exported to\",\n 'data/{}_reviews.csv'.format(biz))\n\n\ndef _fetch_reviews(link, num_pages):\n \"\"\"\n gathers the reviews from the link/business provided using\n NUM PAGES as the limit of pages to crawl. NOTE: 1\n page = 20 reviews.\n \"\"\"\n\n biz_url = link.rsplit('biz/', 1)\n if '?' in biz_url[1]:\n business = biz_url[1].split('?')[0]\n else:\n business = biz_url[1]\n start_url = ['http://www.yelp.com/biz/%s' % business]\n biz_reviews = []\n cnt = 0\n offset = 0\n\n for url in start_url:\n page_ = 0\n while True:\n # if num_pages == None it will scrape all reviews\n if num_pages is not 0:\n page_ += 1\n if page_ > num_pages:\n break\n\n page = requests.get(url + \"?start=%s\" % offset)\n parser = html.fromstring(page.text)\n reviews = parser.xpath('//div[@itemprop=\"review\"]')\n offset += 20\n cnt += 1\n if reviews:\n for rev in reviews:\n author = rev.xpath('.//meta[@itemprop=\"author\"]/@content')\n date = rev.xpath(\n './/meta[@itemprop=\"datePublished\"]/@content')\n rating = rev.xpath(\n './/meta[@itemprop=\"ratingValue\"]/@content')\n reviews = rev.xpath('.//p[@itemprop=\"description\"]/text()')\n for data in zip(author, date, rating, reviews):\n resp = {'author': data[0], 'date': data[1],\n 'rating': data[2], 'reviews': data[3]}\n biz_reviews.append(resp)\n else:\n print('page', cnt, 'had no reviews...ending.')\n break\n print('page {}'.format(cnt), 'scraped...')\n return biz_reviews, str(business)\n\n\ndef scrape(link, num_pages):\n \"\"\"\n Scrapes review from the Yelp page\n\n Parameters\n ----------\n link : str\n link to the yelp page\n e.g. https://www.yelp.com/biz/the-gallup-organization-washington\n num_pages : int, optional (default = 0)\n number of pages to be scraped\n If 0, scrapes all of pages\n\n Returns\n -------\n reviews : DataFrame\n reviews\n \"\"\"\n\n # Assign returned tuple\n if num_pages is None:\n reviews, biz_title = _fetch_reviews(link, num_pages=0)\n else:\n reviews, biz_title = _fetch_reviews(link, num_pages)\n\n # return data_set(reviews, biz_title)\n\n return reviews\n\n# def meta_scrape(link):\n\n\ndef main():\n parser = argparse.ArgumentParser()\n\n parser.add_argument('-p', '--num_pages',\n default=0, type=int, required=False,\n help='enter the number of pages you would like reviews'\n 'to be pulled from. NOTE: 20 reviews per page.')\n\n parser.add_argument('-l', '--link',\n default=False, type=str, required=True,\n help='enter link to business...')\n\n args_dict = vars(parser.parse_args())\n\n num_pages = args_dict['num_pages']\n link = args_dict['link']\n\n scrape(link, num_pages)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5356283783912659,
"alphanum_fraction": 0.5365143418312073,
"avg_line_length": 27.73454475402832,
"blob_id": "466c34e3bd212761fa5bc496d9f7c941a6328bb5",
"content_id": "5c1f9f8c8238a7d8175535fdde7e0c9896034fa2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 7901,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 275,
"path": "/frontend/src/comm/CommForm.js",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "import React, {Component} from 'react'\nimport 'whatwg-fetch'\nimport cookie from 'react-cookies'\nimport moment from 'moment'\nimport ReactMarkdown from \"react-markdown\";\nimport {Redirect} from \"react-router-dom\";\nimport Button from \"react-bootstrap/Button\";\n\nclass CommForm extends Component {\n constructor(props) {\n super(props);\n this.handleSubmit = this.handleSubmit.bind(this);\n this.handleInputChange = this.handleInputChange.bind(this);\n this.handleDraftChange = this.handleDraftChange.bind(this);\n this.clearForm = this.clearForm.bind(this);\n this.commTitleRef = React.createRef();\n this.commContentRef = React.createRef();\n this.commSiteLocationRef = React.createRef();\n this.commSlugRef = React.createRef();\n this.state = {\n draft: false,\n title: null,\n content: null,\n site_location: '',\n redirect: false,\n redirectLink: null,\n errors: {},\n }\n }\n\n createComm(data) {\n const endpoint = '/api/comms/';\n const csrfToken = cookie.load('csrftoken');\n let thisComp = this;\n if (csrfToken !== undefined) {\n let lookupOptions = {\n method: \"POST\",\n headers: {\n 'Content-Type': 'application/json',\n 'X-CSRFToken': csrfToken\n },\n body: JSON.stringify(data),\n credentials: 'include'\n };\n\n fetch(endpoint, lookupOptions)\n .then(function (response) {\n return response.json()\n }).then(function (responseData) {\n thisComp.setState({redirectLink: `/site-management/comms/${responseData.slug}/`});\n if (thisComp.props.newCommItemCreated) {\n thisComp.props.newCommItemCreated(responseData)\n }\n thisComp.clearForm();\n }).catch(function (error) {\n console.log(\"error\", error);\n alert(\"An error occurred, please try again later.\")\n }).then(() => this.setState({redirect: true}));\n }\n }\n\n updateComm(data) {\n const {post} = this.props;\n const endpoint = `/api/comms/${post.slug}/`;\n const csrfToken = cookie.load('csrftoken');\n let thisComp = this;\n if (csrfToken !== undefined) {\n let lookupOptions = {\n method: \"PUT\",\n headers: {\n 'Content-Type': 'application/json',\n 'X-CSRFToken': csrfToken\n },\n body: JSON.stringify(data),\n credentials: 'include'\n };\n\n fetch(endpoint, lookupOptions)\n .then(function (response) {\n return response.json()\n }).then(function (responseData) {\n thisComp.setState({redirectLink: `/site-management/comms/${responseData.slug}`});\n // console.log(responseData)\n if (thisComp.props.commItemUpdated) {\n thisComp.props.commItemUpdated(responseData)\n }\n\n }).catch(function (error) {\n console.log(\"error\", error);\n alert(\"An error occurred, please try again later.\")\n }).then(() => this.setState({redirect: true}));\n }\n\n }\n\n handleSubmit(event) {\n event.preventDefault();\n let data = this.state;\n\n const {post} = this.props;\n if (post !== undefined) {\n this.updateComm(data)\n } else {\n this.createComm(data)\n }\n\n }\n\n handleInputChange(event) {\n event.preventDefault();\n let key = event.target.name;\n let value = event.target.value;\n if (key === 'title') {\n if (value.length > 120) {\n alert(\"This title is too long\")\n }\n }\n this.setState({\n [key]: value\n })\n }\n\n handleDraftChange(event) {\n this.setState({\n draft: !this.state.draft\n })\n }\n\n clearForm(event) {\n if (event) {\n event.preventDefault()\n }\n this.commCreateForm.reset();\n this.defaultState()\n }\n\n\n clearFormRefs() {\n this.commTitleRef.current = '';\n this.commContentRef.current = '';\n this.commSiteLocationRef.current = '';\n this.commSlugRef.current = ''\n }\n\n\n defaultState() {\n this.setState({\n draft: false,\n title: null,\n content: null,\n site_location: null,\n slug: null\n });\n }\n\n componentDidMount() {\n const {post} = this.props;\n if (post !== undefined) {\n this.setState({\n draft: post.draft,\n title: post.title,\n content: post.content,\n site_location: post.site_location,\n slug: post.slug\n })\n } else {\n this.defaultState()\n }\n // this.commTitleRef.current.focus()\n }\n\n render() {\n const {title} = this.state;\n const {content} = this.state;\n const {site_location} = this.state;\n const {redirect} = this.state;\n const {redirectLink} = this.state;\n const {slug} = this.state;\n if (redirect) {\n return <Redirect to={redirectLink}/>;\n }\n return (\n <div>\n <h1 id='alt'>Create Comm</h1>\n <form onSubmit={this.handleSubmit}\n ref={(el) => this.commCreateForm = el}>\n <div className='form-group' id='top-row-form'>\n <label htmlFor='draft'>\n <input type='checkbox'\n checked={this.state.draft}\n id='draft'\n name='draft'\n className='mr-2'\n onChange={this.handleDraftChange}/>\n </label>\n <Button variant=\"outline-dark\"\n onClick={(event) => {\n event.preventDefault();\n this.handleDraftChange()\n }}>Draft\n </Button>\n <label htmlFor='site_location'>Site Location:<span> </span>\n <select value={site_location}\n id='site_location'\n name='site_location'\n ref={this.commSiteLocationRef}\n className='mr-2'\n onChange={this.handleInputChange}>\n <option value=\"select\">Select</option>\n <option value=\"comms\">comms</option>\n <option value=\"scrape\">scrape</option>\n <option value=\"landing\">landing</option>\n </select>\n </label>\n <button type='submit' className='btn btn-primary'\n id='create-submit'>Save\n </button>\n </div>\n <div className='form-group'>\n <input\n type='text'\n id='title'\n name='title'\n value={title}\n className='form-control'\n placeholder='Comms Title'\n ref={this.commTitleRef}\n onChange={this.handleInputChange}\n required='required'/>\n </div>\n <div className='form-group'>\n <input\n type='text'\n id='slug'\n name='slug'\n readOnly value={slug}\n className='form-control'\n // placeholder='Comms Title'\n ref={this.commSlugRef}\n // onChange={this.handleInputChange}\n // required='required'\n />\n </div>\n <div className='form-group'>\n <label for='content'>\n <small>Markdown <a\n href=\"https://www.markdownguide.org/basic-syntax/\"\n target=\"_blank\" rel=\"noopener noreferrer\">guide</a> For local\n images use this ex. \"/static/images/deploy_process.svg\"\n </small>\n </label>\n <textarea\n id='content'\n ref={this.commContentRef}\n name='content'\n value={content}\n className='form-control'\n placeholder='Tell me something!'\n onChange={this.handleInputChange}\n required='required'/>\n\n </div>\n <div className=\"preview\">\n <div className=\"preview-text\">\n <ReactMarkdown source={content}/>\n </div>\n </div>\n </form>\n </div>\n )\n }\n\n}\n\nexport default CommForm"
},
{
"alpha_fraction": 0.4457534849643707,
"alphanum_fraction": 0.44698435068130493,
"avg_line_length": 32.069766998291016,
"blob_id": "a7bac6695d8ef0cc2be36f7c07669d30bda7b551",
"content_id": "27dc78511085bac7404cce756813b345ae254d30",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 5687,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 172,
"path": "/frontend/src/comm/Comms.js",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "import React, {Component} from 'react';\nimport 'whatwg-fetch'\nimport cookie from 'react-cookies'\nimport CommInline from './CommInline'\nimport Button from 'react-bootstrap/Button';\nimport {Link} from 'react-router-dom'\nimport Moment from \"react-moment\";\n\nclass Comms extends Component {\n\n constructor(props) {\n super(props);\n this.toggleCommListClass = this.toggleCommListClass.bind(this);\n this.handleNewComm = this.handleNewComm.bind(this);\n this.loadMoreComms = this.loadMoreComms.bind(this);\n this.state = {\n comms: [],\n commsPublic: [],\n commsListClass: \"card\",\n previous: null,\n author: false,\n draft: null,\n count: 0\n }\n }\n\n loadMoreComms() {\n const {next} = this.state;\n if (next !== null || next !== undefined) {\n this.loadComms(next)\n }\n\n }\n\n loadComms(nextEndpoint) {\n let endpoint = '/api/comms/';\n if (nextEndpoint !== undefined) {\n endpoint = nextEndpoint\n }\n let thisComp = this;\n let lookupOptions = {\n method: \"GET\",\n headers: {\n 'Content-Type': 'application/json'\n }\n };\n const csrfToken = cookie.load('csrftoken');\n if (csrfToken !== undefined) {\n lookupOptions['credentials'] = 'include';\n lookupOptions['headers']['X-CSRFToken'] = csrfToken\n }\n\n fetch(endpoint, lookupOptions)\n .then(function (response) {\n return response.json()\n }).then(function (responseData) {\n // let currentcomms = thisComp.state.comms;\n // let allcomms = currentcomms.concat(responseData.results);\n let commsPublicList = responseData.results.filter(comm => comm.draft === false);\n\n thisComp.setState({\n comms: thisComp.state.comms.concat(responseData.results),\n commsPublic: thisComp.state.commsPublic.concat(commsPublicList),\n next: responseData.next,\n previous: responseData.previous,\n staff: responseData.staff,\n draft: responseData.draft,\n count: responseData.count\n })\n }\n ).catch(function (error) {\n console.log(\"error\", error)\n })\n }\n\n handleComms(responseData) {\n let comms = responseData.filter(comm => comm.draft === false);\n this.setState({\n commsPublic: comms\n })\n }\n\n handleNewComm(commItemData) {\n // console.log(commItemData)\n let currentcomms = this.state.comms;\n currentcomms.unshift(commItemData); // unshift\n this.setState({\n comms: currentcomms\n })\n }\n\n\n toggleCommListClass(event) {\n event.preventDefault();\n let currentListClass = this.state.commsListClass;\n if (currentListClass === \"\") {\n this.setState({\n commsListClass: \"card\",\n })\n } else {\n this.setState({\n commsListClass: \"\",\n })\n }\n\n }\n\n componentDidMount() {\n this.setState({\n comms: [],\n commsListClass: \"card\",\n next: null,\n previous: null,\n // author: true,\n count: 0\n });\n this.loadComms()\n }\n\n render() {\n const {comms} = this.state;\n const {commsPublic} = this.state;\n const {commsListClass} = this.state;\n const {staff} = this.state;\n const {next} = this.state;\n return (\n <div className=\"container-fluid\">\n <h1>\n {staff === true ? <Link className='mr-2'\n maintainScrollPosition={false}\n to={{\n pathname: `/site-management/comms/create/`,\n state: {fromDashboard: false}\n }}><Button variant=\"outline-dark\"\n type=\"button\">Create New Comm</Button>\n </Link> : \"\"}\n <Button onClick={this.toggleCommListClass}>List View</Button>\n </h1>\n <br/>\n {staff === true ?\n <div>\n {comms.length > 0 ? comms.map((commItem, index) => {\n return (\n <CommInline comm={commItem}\n elClass={commsListClass}/>\n )\n }) : <p>No comms Found</p>\n }\n </div>\n :\n <div>\n {comms.length > 0 ? commsPublic.map((commItem, index) => {\n return (\n <CommInline comm={commItem}\n elClass={commsListClass}/>\n )\n }) : <p>No Comms Found</p>\n }\n </div>}\n <div className=\"d-flex flex-column text-center\">\n {next !== null ? <Button\n variant=\"outline-dark\"\n onClick={this.loadMoreComms}>Load\n more</Button> : ''}\n </div>\n <br/>\n </div>\n );\n }\n}\n\nexport default Comms;"
},
{
"alpha_fraction": 0.49253731966018677,
"alphanum_fraction": 0.5850746035575867,
"avg_line_length": 18.705883026123047,
"blob_id": "73b77cc3f21166da80d3cf759f35b3ce40979d56",
"content_id": "964e00ca93174d6cb53e6dcb2ea75be5a50a9b32",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 335,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 17,
"path": "/scrape/migrations/0006_auto_20190924_1006.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.5 on 2019-09-24 14:06\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('scrape', '0005_auto_20190924_0958'),\n ]\n\n operations = [\n migrations.RenameModel(\n old_name='Results',\n new_name='YelpResults',\n ),\n ]\n"
},
{
"alpha_fraction": 0.5155482888221741,
"alphanum_fraction": 0.5294598937034607,
"avg_line_length": 30.35897445678711,
"blob_id": "2510177584683ad78d8006ea12ca75c7e3af8798",
"content_id": "d9bd9477d31df9fcab4d6da460afe5d7af2e3d3b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1222,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 39,
"path": "/frontend/src/scrape/ScrapeInline.js",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "import React, {Component} from 'react';\n\nclass ScrapeInline extends Component {\n\n render() {\n const {reviews} = this.props;\n const {site} = this.props\n const hrStyle = {\n display: 'block',\n height: '1px',\n border: 0,\n borderTop: '1px solid #ccc',\n margin: '1em 0',\n padding: '0',\n color: 'white'\n };\n return (\n <div>\n {site === 'yelp' ? <div className=\"col-lg-12\">\n <td className=\"dash h5\"><b>{reviews.author}</b> |</td>\n <td className=\"dash h5\"><b>{reviews.date}</b> |</td>\n <td className=\"dash h5\"><b>{reviews.rating}</b></td>\n <p className=\"dash\">{reviews.review}</p>\n <hr style={hrStyle}/>\n </div> : <div className=\"col-lg-12\">\n <td className=\"dash h5\"><b>{reviews.current_employee}</b> |</td>\n <td className=\"dash h5\"><b>{reviews.job_title}</b> |</td>\n <td className=\"dash h5\"><b>{reviews.location_city}, {reviews.location_state}</b> |</td>\n <td className=\"dash h5\"><b>(Rating: {reviews.rating})</b></td>\n <p className=\"dash\">{reviews.review}</p>\n <hr style={hrStyle}/>\n </div>\n }\n </div>\n )\n }\n}\n\nexport default ScrapeInline"
},
{
"alpha_fraction": 0.554233729839325,
"alphanum_fraction": 0.554233729839325,
"avg_line_length": 33.43373489379883,
"blob_id": "9a62888748debd9fe115b2a12c86b1ab27982ca7",
"content_id": "725aba8ddd69c9745e1605cfeed99a89f8b1fe7a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2858,
"license_type": "no_license",
"max_line_length": 197,
"num_lines": 83,
"path": "/accounts/views.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from django.contrib.auth import (authenticate, get_user_model, login, logout)\nfrom django.contrib import messages\nfrom django.shortcuts import render, redirect\nfrom .forms import UserLoginForm, UserRegisterForm\nfrom django.core.mail import send_mail\n# from harvstr.settings import BASE_DIR\n#\n# test = BASE_DIR\n\n\ndef login_view(request):\n next = request.GET.get('next')\n title = \"Login\"\n form = UserLoginForm(request.POST or None)\n if form.is_valid():\n username = form.cleaned_data.get(\"username\").lower()\n password = form.cleaned_data.get(\"password\")\n user = authenticate(username=username, password=password)\n login(request, user)\n if next:\n return redirect(next)\n return redirect(\"/\")\n\n return render(request, \"accounts/login_form.html\", {\"form\": form, \"title\": title})\n\n\ndef register_view(request):\n next = request.GET.get('next')\n title = \"Register\"\n form = UserRegisterForm(request.POST or None)\n if form.is_valid():\n user = form.save(commit=False)\n password = form.cleaned_data.get(\"password\")\n # username = form.cleaned_data.get(\"username\")\n # user_email = form.cleaned_data.get(\"email\")\n user.set_password(password)\n # user.is_active = False\n user.save()\n\n # # Email User\n # subject = 'vvayne.io Registration'\n # from_email = settings.EMAIL_HOST_USER\n # to_email = user_email\n # message = 'Thank You For Registering!'\n # send_mail(\n # subject,\n # message,\n # from_email,\n # [to_email],\n # fail_silently=False,\n # html_message='<p>Thank you for registering with <a href=\"https://www.vvayne.io\">vvayne.io</a>! If you have any questions, wish to know more about my background, or find a bug, <br />'\n # 'contact me anytime at [email protected]. <br/>'\n # '<br/ >'\n # 'Regards,<br />'\n # '<br />'\n # 'Wayne Grigsby <br />'\n # '[email protected] <br />'\n # '<a href=\"https://www.vvayne.io\">vvayne.io</a></p>'\n # )\n # send_mail(\n # 'New Registration',\n # 'New user created!',\n # from_email,\n # ['[email protected]'],\n # fail_silently=False,\n # )\n messages.success(request, \"Thank you for registering!\")\n new_user = authenticate(username=user.username, password=password)\n login(request, new_user)\n if next:\n return redirect(next)\n return redirect('/')\n\n context = {\n \"form\": form,\n \"title\": title\n }\n return render(request, \"accounts/register_form.html\", context)\n\n\ndef logout_view(request):\n logout(request)\n return redirect(\"/\")\n"
},
{
"alpha_fraction": 0.7058823704719543,
"alphanum_fraction": 0.7058823704719543,
"avg_line_length": 30,
"blob_id": "c4d2d0908c448cd40af451891e24221d2979e6d4",
"content_id": "b293ea31770113e2bb506122c77ca9574d1725bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 340,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 11,
"path": "/myblock/urls.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from django.urls import path, re_path, include\nfrom django.views.generic import TemplateView\nfrom . import views\n\napp_name = 'myblock'\n\nurlpatterns = [\n path('walking', TemplateView.as_view(template_name='myblock/walking.html')),\n re_path(r'^$', TemplateView.as_view(template_name='myblock/react.html'),\n name='myblock'),\n]"
},
{
"alpha_fraction": 0.6411504149436951,
"alphanum_fraction": 0.6542035341262817,
"avg_line_length": 36.983192443847656,
"blob_id": "b7aa884dd6abb1fdc78d944605af544506e8d33a",
"content_id": "ed9d6bd96fc9d2bb85f2a149ea0459ce8c79a0ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4520,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 119,
"path": "/scrape/models.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.urls import reverse\nfrom django.db.models.signals import pre_save\nfrom django.conf import settings\nfrom .utils import unique_slug_generator as slugger\nimport pandas as pd\nimport datetime\nfrom django.core.exceptions import ValidationError\nfrom django.utils.translation import gettext_lazy as _\nfrom .utils import getBusinessName\nfrom scrape.utils import websiteIdentifier\n\ntime = datetime.datetime.now()\n\n\n# class ScrapeManager(models.Manager):\n# def active(self, *args, **kwargs):\n# return super(ScrapeManager, self).filter(draft=False).filter(\n# scrape_date__lte=timezone.now())\n\n\nclass Collect(models.Model):\n user = models.ForeignKey(settings.AUTH_USER_MODEL, default=1,\n on_delete=models.CASCADE)\n site = models.CharField(max_length=120, blank=True, null=True)\n business_name = models.CharField(max_length=120, blank=True, null=True)\n link = models.CharField(max_length=120)\n page_amount = models.IntegerField(default=None, blank=True, null=True)\n scrape_date = models.DateTimeField(blank=True, null=True)\n slug = models.SlugField(unique=True, blank=True, null=True)\n\n def get_business_name(self):\n self.business_name = getBusinessName(self.link)\n\n def clean_scrape_date(self):\n self.scrape_date = pd.to_datetime(time)\n\n def clean_site(self):\n self.site = websiteIdentifier(self)[0]\n\n def clean_page_amount(self):\n if self.page_amount is not None:\n if not isinstance(self.page_amount, int):\n raise ValidationError(\n _('(value) is not even a number!'),\n params={'value': self.page_amount},\n )\n if self.page_amount >= 100:\n raise ValidationError(\n _('(value) is too high!'),\n params={'value': self.page_amount},\n )\n\n def get_slug(self):\n self.slug = slugger(self)\n\n def save(self, **kwargs):\n self.clean()\n return super(Collect, self).save(**kwargs)\n\n def clean(self):\n self.get_business_name()\n self.get_slug()\n self.clean_site()\n self.clean_scrape_date()\n self.clean_page_amount()\n\n def get_absolute_url(self):\n return reverse('scrape-api:detail', kwargs={'slug': self.slug})\n\n\nclass Results(models.Model):\n collection_id = models.ForeignKey(Collect, related_name='reviews',\n on_delete=models.CASCADE, null=True)\n author = models.CharField(max_length=120, blank=True, null=True)\n date = models.CharField(max_length=120, blank=True)\n rating = models.CharField(max_length=120, blank=True, null=True)\n review = models.TextField(max_length=500, blank=True)\n\n def get_absolute_url(self):\n return reverse('scrape-api:detail', kwargs={'pk': self.pk})\n\n\nclass IndeedResults(models.Model):\n collection_id = models.ForeignKey(Collect, related_name='indeed_reviews',\n on_delete=models.CASCADE, null=True)\n date = models.CharField(max_length=120, blank=True)\n rating = models.CharField(max_length=120, blank=True, null=True)\n review = models.TextField(max_length=500, blank=True)\n location_city = models.CharField(max_length=120, blank=True, null=True)\n location_state = models.CharField(max_length=120, blank=True, null=True)\n job_title = models.CharField(max_length=120, blank=True, null=True)\n current_employee = models.CharField(max_length=120, blank=True, null=True)\n\n\nclass Analytics(models.Model):\n collection_id = models.ForeignKey(Collect, related_name='analytics',\n on_delete=models.CASCADE, null=True)\n word = models.CharField(max_length=120, blank=True, null=True)\n value = models.IntegerField(blank=True, null=True)\n\n def get_absolute_url(self):\n return reverse('scrape-api:detail', kwargs={'pk': self.pk})\n\n\nclass WorkFlow(models.Model):\n collection_id = models.ForeignKey(Collect, related_name='flow',\n on_delete=models.CASCADE, null=True)\n status = models.CharField(max_length=120, blank=True, null=True)\n timestamp = models.CharField(max_length=120, blank=True, null=True)\n details = models.TextField(max_length=500, blank=True)\n\n\ndef pre_save_scrape_receiver(sender, instance, *args, **kwargs):\n if not instance.slug:\n pass\n\n\npre_save.connect(pre_save_scrape_receiver, sender=Collect)\n"
},
{
"alpha_fraction": 0.5492196679115295,
"alphanum_fraction": 0.5732293128967285,
"avg_line_length": 36.022220611572266,
"blob_id": "a27deed3cf54cf22a1e727b3c853deffb9f77ca9",
"content_id": "e11fdb041e9f87a8ab4e33d639af4ef3e19e5b1d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1666,
"license_type": "no_license",
"max_line_length": 161,
"num_lines": 45,
"path": "/scrape/migrations/0011_auto_20191007_0937.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.5 on 2019-10-07 13:37\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('scrape', '0010_workflow_timestamp'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='results',\n old_name='author',\n new_name='current_employee',\n ),\n migrations.AddField(\n model_name='results',\n name='job_title',\n field=models.CharField(blank=True, max_length=120, null=True),\n ),\n migrations.AddField(\n model_name='results',\n name='location_city',\n field=models.CharField(blank=True, max_length=120, null=True),\n ),\n migrations.AddField(\n model_name='results',\n name='location_state',\n field=models.CharField(blank=True, max_length=120, null=True),\n ),\n migrations.CreateModel(\n name='indeedResults',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('author', models.CharField(blank=True, max_length=120, null=True)),\n ('date', models.CharField(blank=True, max_length=120)),\n ('rating', models.CharField(blank=True, max_length=120, null=True)),\n ('review', models.TextField(blank=True, max_length=500)),\n ('collection_id', models.ForeignKey(null=True, on_delete=django.db.models.deletion.CASCADE, related_name='indeed_reviews', to='scrape.Collect')),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.5573956370353699,
"alphanum_fraction": 0.5578493475914001,
"avg_line_length": 33.1705436706543,
"blob_id": "080fa5f8fef99a1fa9f68885d3cd9c778689694e",
"content_id": "2df5e8e942f1782a907a13772bd4766454962be3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4408,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 129,
"path": "/frontend/utils/update_react_files.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "\"\"\"\nI developed this script to build more accurate references within each Reactjs Build\nfiles. Currently, all name changes and updates made to my react files within my Build directory\nare not updated within the files itself. This script updates the file content\nto reflect the django name.\n \"\"\"\nimport json\nfrom pathlib import Path\nimport re\nimport sys\n\nsys.path.append(\"..\")\ntry:\n from harvstr.settings.local import *\nexcept:\n from harvstr.settings.production import *\n\n\nclass Cleaner:\n def __init__(self):\n self.dirs = []\n self.react_paths = []\n self.manifest = self.build_manifest()\n self.files_cleaned = 0\n\n @staticmethod\n def build_manifest():\n \"\"\"captures the json built to illustrate the baseline names of all\n reactjs files, including patter, and substitute name\"\"\"\n if BUILD_JSON:\n with open(Path(BUILD_JSON), 'r') as f:\n return json.load(f)\n\n @staticmethod\n def clean(file, pattern, subst):\n \"\"\"\n Process all build files, replacing hashed names with accurate django\n relevant names.\n :param file: react build file\n :param pattern: the regex used to id the hashed name within the file.\n :param subst: the name to replace the original hashed name.\n :return: returns updated file with accurate file and image references.\n \"\"\"\n with open(Path(file)) as f:\n if not any(re.search(pattern, line) for line in f):\n print('no matches in ' + str(Path(file).name))\n\n with open(Path(file)) as f:\n out_fname = Path(file).name\n out = open(out_fname, \"w\")\n for line in f:\n out.write(re.sub(pattern, subst, line))\n out.close()\n os.rename(out_fname, Path(file))\n\n @staticmethod\n def check_name(pattern, file):\n \"\"\"\n Checks if the pattern exists within the file in question.\n :param pattern: regex used to id the hashed name within the file.\n :param file: react build file\n :return: True/False\n \"\"\"\n with open(Path(file)) as f:\n if any(re.search(pattern, line) for line in f):\n return True\n\n def get_dirs(self):\n \"\"\"\n Gathers all relevant directories.\n :return: list of relevant paths\n \"\"\"\n dirs = ['/frontend/build']\n for dirName, subdirList, fileList in os.walk(BASE_DIR):\n for name in dirs:\n if dirName.endswith(name):\n self.dirs.append(Path(dirName).resolve())\n\n def get_files(self):\n \"\"\"\n Gathers all relevant file paths.\n :return: list of relevant file paths\n \"\"\"\n for path in self.dirs:\n if Path(path).is_dir() is True:\n file_paths = [Path(f) for f in Path(path).glob('**/*') if\n '/frontend/build/static/' in str(\n Path(f)) and '.DS_Store' not in str(\n Path(f)) and f.is_file()]\n for js_path in file_paths:\n self.react_paths.append(str(Path(js_path).resolve()))\n else:\n raise ValueError\n\n def process_files(self):\n \"\"\"\n Uses buildNames to id the files in need of being checked. It then\n checks if any of the file patters exist within the file in question. It\n repeats this process for each file, updating files where it finds a match.\n :return: Updating files\n \"\"\"\n buildNames = [x for x in self.manifest['files']]\n for file in self.react_paths:\n for name in buildNames:\n check = self.check_name(\n self.manifest['files'][name]['pattern'], file)\n if check is True:\n self.clean(file, self.manifest['files'][name]['pattern'],\n self.manifest['files'][name]['subst'])\n print(Path(file).name + ' updated!')\n self.files_cleaned += 1\n else:\n pass\n\n def run(self):\n self.get_dirs()\n self.get_files()\n self.process_files()\n\n print(str(\n self.files_cleaned) + ' react build files have been successfully updated')\n\n\ndef main():\n Cleaner().run()\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.540145993232727,
"alphanum_fraction": 0.5912408828735352,
"avg_line_length": 21.83333396911621,
"blob_id": "056e7037e948e1b9c8e06161599908a3074d1e09",
"content_id": "1fadc5008784700ef4fe05bb4c70dbe08b9644c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 411,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 18,
"path": "/scrape/migrations/0002_yelp_page_amount.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.5 on 2019-09-18 17:28\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('scrape', '0001_initial'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='yelp',\n name='page_amount',\n field=models.IntegerField(blank=True, default=1, max_length=2, null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5391620993614197,
"alphanum_fraction": 0.5728597640991211,
"avg_line_length": 32.272727966308594,
"blob_id": "8550f659fbad08d12df51efadde77941ab786a96",
"content_id": "e84710bb29a2b5f5e66fe317880292cf60d40dd7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1098,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 33,
"path": "/scrape/migrations/0009_auto_20191004_0954.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.5 on 2019-10-04 13:54\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('scrape', '0008_auto_20191003_2305'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='analytics',\n old_name='business',\n new_name='collection_id',\n ),\n migrations.RenameField(\n model_name='results',\n old_name='business',\n new_name='collection_id',\n ),\n migrations.CreateModel(\n name='WorkFlow',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('status', models.CharField(blank=True, max_length=120, null=True)),\n ('details', models.TextField(blank=True, max_length=500)),\n ('collection_id', models.ForeignKey(null=True, on_delete=django.db.models.deletion.CASCADE, related_name='flow', to='scrape.Collect')),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.738095223903656,
"alphanum_fraction": 0.738095223903656,
"avg_line_length": 15.800000190734863,
"blob_id": "e3343ed6b5c2f5cdea42b709c86afa4900d53f88",
"content_id": "0f661e9e079b2b125943557cb0104eb4d1c8ec58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 84,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 5,
"path": "/comm/apps.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass CommsConfig(AppConfig):\n name = 'comm'\n"
},
{
"alpha_fraction": 0.541050910949707,
"alphanum_fraction": 0.5763546824455261,
"avg_line_length": 33.79999923706055,
"blob_id": "083169fd35e43f6ad887171e2b71446d9987075b",
"content_id": "8969918aea0347431176dc1dce9b73d3a08dc613",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1218,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 35,
"path": "/scrape/migrations/0008_auto_20191003_2305.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.5 on 2019-10-04 03:05\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('scrape', '0007_auto_20190924_1008'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Results',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('author', models.CharField(blank=True, max_length=120, null=True)),\n ('date', models.CharField(blank=True, max_length=120)),\n ('rating', models.CharField(blank=True, max_length=120, null=True)),\n ('review', models.TextField(blank=True, max_length=500)),\n ('business', models.ForeignKey(null=True, on_delete=django.db.models.deletion.CASCADE, related_name='reviews', to='scrape.Collect')),\n ],\n ),\n migrations.RemoveField(\n model_name='yelpresults',\n name='business',\n ),\n migrations.DeleteModel(\n name='GlassdoorResults',\n ),\n migrations.DeleteModel(\n name='YelpResults',\n ),\n ]\n"
},
{
"alpha_fraction": 0.6575984954833984,
"alphanum_fraction": 0.6622889041900635,
"avg_line_length": 32.3125,
"blob_id": "6e989d3a03717e931050ba9ad9e71e4cac627aa8",
"content_id": "364df388a464fc5352741c8538cca673be7b5d62",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1066,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 32,
"path": "/scrape/tasks.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from __future__ import absolute_import, unicode_literals\nfrom celery.task import task\nfrom django.db import Error\nfrom .models import Collect\nimport datetime\nfrom datetime import timedelta\n\n\nclass ObjectsMissingError(Error):\n \"\"\"Raised when the input value is too large\"\"\"\n pass\n\n\n@task(name='clean_reviews')\ndef clean_db():\n \"\"\"This task deletes all records older than 24 hours.\n These records include yelp parent and review child records.\"\"\"\n # logger = logging.getLogger(__name__)\n time_threshold = datetime.datetime.now() - timedelta(hours=2)\n objects = Collect.objects.filter(scrape_date__lt=time_threshold)\n # objects = Yelp.objects.all()\n\n if objects:\n records_removed = objects.delete()\n results = str(records_removed[1]['scrape.Yelp']) + \\\n ' Yelp record(s) and ' + str(\n records_removed[1]['scrape.Results']) + \\\n ' associated reviews have been successfully deleted.'\n return results\n else:\n results = str('No records to delete')\n return results\n"
},
{
"alpha_fraction": 0.5150798559188843,
"alphanum_fraction": 0.6989946961402893,
"avg_line_length": 16.61458396911621,
"blob_id": "eafbb18e8ab16865fa1e2eba662ae25d74740dd6",
"content_id": "bf5ca4f9bcffcd53519b7732475e39097ed5c951",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 1691,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 96,
"path": "/requirements.txt",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "amqp==2.5.1\nbeautifulsoup4==4.8.0\nbilliard==3.6.1.0\nblis==0.2.4\nbs4==0.0.1\ncelery==4.3.0\ncertifi==2019.6.16\nchardet==3.0.4\nClick==7.0\ncloudpickle==1.2.2\ncroniter==0.3.30\ncymem==2.0.2\ndask==2.5.0\ndistributed==2.5.1\ndj-config-url==0.1.1\ndj-database-url==0.5.0\nDjango==2.2.5\ndjango-celery-beat==1.5.0\ndjango-celery-results==1.1.2\ndjango-compat==1.0.15\ndjango-cors-headers==3.0.2\ndjango-crispy-forms==1.7.2\ndjango-environ==0.4.5\ndjango-filter==2.1.0\ndjango-hosts==3.0\ndjango-luigi==0.2.5\ndjango-markdown-deux==1.0.5\ndjango-pagedown==1.0.6\ndjango-storages-redux==1.3.3\ndjango-timezone-field==3.0\ndjangorestframework==3.9.2\ndjangorestframework-stubs==0.3.0\ndocker==4.1.0\ndocutils==0.15.2\nenviron==1.0\nfsspec==0.5.1\ngunicorn==19.7.1\nHeapDict==1.0.1\nidna==2.6\nimportlib-metadata==0.20\nkombu==4.6.4\nlocket==0.2.0\nlockfile==0.12.2\nluigi==2.8.9\nlxml==4.3.4\nmarkdown2==2.3.8\nmarshmallow==3.0.5\nmarshmallow-oneofschema==2.0.1\nmore-itertools==7.2.0\nmsgpack==0.6.2\nmurmurhash==1.0.2\nmypy==0.720\nmypy-extensions==0.4.1\nnltk==3.4.4\nnumpy==1.17.1\npandas==0.25.1\npartd==1.0.0\npendulum==2.0.5\nplac==0.9.6\nprefect==0.6.5\npreshed==2.0.1\npsutil==5.6.3\npsycopg2-binary==2.8.3\npython-crontab==2.3.8\npython-daemon==2.1.2\npython-dateutil==2.8.0\npython-slugify==3.0.4\npytz==2019.2\npytzdata==2019.3\nPyYAML==5.1.2\nredis==3.3.6\nrequests==2.22.0\nsix==1.12.0\nsortedcontainers==2.1.0\nsoupsieve==1.9.3\nspacy==2.1.8\nsqlparse==0.3.0\nsrsly==0.1.0\ntabulate==0.8.5\ntblib==1.4.0\ntext-unidecode==1.3\nthinc==7.0.8\ntoml==0.10.0\ntoolz==0.10.0\ntornado==5.1.1\ntqdm==4.35.0\ntyped-ast==1.4.0\ntyping==3.7.4.1\ntyping-extensions==3.7.4\nurllib3==1.22\nvine==1.3.0\nwasabi==0.2.2\nwebsocket-client==0.56.0\nwhitenoise==4.1.2\nzict==1.0.0\nzipp==0.6.0\n"
},
{
"alpha_fraction": 0.5525727272033691,
"alphanum_fraction": 0.6219239234924316,
"avg_line_length": 21.350000381469727,
"blob_id": "983226a2eeb7f20b08044806fe54a251a2f36f80",
"content_id": "9cdda2f9be0104f8e8986742dffb4d1832fa1489",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 447,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 20,
"path": "/scrape/migrations/0005_auto_20190924_0958.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.5 on 2019-09-24 13:58\n\nfrom django.conf import settings\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n atomic = False\n\n dependencies = [\n migrations.swappable_dependency(settings.AUTH_USER_MODEL),\n ('scrape', '0004_auto_20190918_1359'),\n ]\n\n operations = [\n migrations.RenameModel(\n old_name='Yelp',\n new_name='Collect',\n ),\n ]\n"
},
{
"alpha_fraction": 0.6331784129142761,
"alphanum_fraction": 0.6367536783218384,
"avg_line_length": 42.03076934814453,
"blob_id": "7b6d665fd7acf2490e58f99894d6db88cdb8c137",
"content_id": "10af3eb6456b76abfcf015bda072150a6eda17d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2797,
"license_type": "no_license",
"max_line_length": 177,
"num_lines": 65,
"path": "/accounts/forms.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from django import forms\nfrom django.contrib.auth import (authenticate, get_user_model)\nfrom django.forms import TextInput\n\nUser = get_user_model()\n\n\nclass UserLoginForm(forms.Form):\n # class Meta:\n # model = get_user_model()\n # widgets = {'username': TextInput(attrs={'placeholder': 'Username'}), 'password': TextInput(attrs={'placeholder': 'Password'}), }\n username = forms.CharField(widget=TextInput(attrs={'placeholder': 'Username'}), label='')\n password = forms.CharField(widget=forms.PasswordInput(attrs={'placeholder': 'Password'}), label='',)\n\n def clean(self, *args, **kwargs):\n username = self.cleaned_data.get(\"username\").lower()\n password = self.cleaned_data.get(\"password\")\n user_qs = User.objects.filter(username=username)\n if user_qs.count() == 0:\n raise forms.ValidationError(\"This user does not exist\")\n\n else:\n user_status = User.objects.get(username=username)\n if user_status.is_active == False:\n raise forms.ValidationError(\"This user is either pending approval or no longer active.\")\n\n user = authenticate(username=username, password=password)\n if not user:\n raise forms.ValidationError(\"Incorrect Password\")\n\n return super(UserLoginForm, self).clean(*args, **kwargs)\n\n\nclass UserRegisterForm(forms.ModelForm):\n username = forms.CharField(widget=TextInput(attrs={'placeholder': 'Username'}), label='', help_text='Required. 150 characters or fewer. Letters, digits and @/./+/-/_ only.')\n first_name = forms.CharField(widget=forms.TextInput(attrs={'placeholder': 'First Name'}), label='')\n last_name = forms.CharField(widget=forms.TextInput(attrs={'placeholder': 'Last Name'}), label='')\n email = forms.EmailField(widget=forms.TextInput(attrs={'placeholder': 'Email'}), label='')\n email2 = forms.EmailField(widget=forms.TextInput(attrs={'placeholder': 'Confirm Email'}), label='')\n password = forms.CharField(widget=forms.PasswordInput(attrs={'placeholder': 'Password'}), label='')\n\n class Meta:\n model = User\n fields = [\n 'username',\n 'first_name',\n 'last_name',\n 'email',\n 'email2',\n 'password'\n ]\n\n def clean_email2(self):\n email = self.cleaned_data.get('email')\n email2 = self.cleaned_data.get('email2')\n if email != email2:\n raise forms.ValidationError(\"Emails must match\")\n email_qs = User.objects.filter(email=email)\n if email_qs.exists():\n raise forms.ValidationError(\"This email has already been registered\")\n return email\n\n def clean_username(self):\n username = self.cleaned_data.get('username')\n return username.lower()\n"
},
{
"alpha_fraction": 0.6720430254936218,
"alphanum_fraction": 0.6720430254936218,
"avg_line_length": 24.271604537963867,
"blob_id": "fb5daf0c949359d3917c2bef611d096a584c0852",
"content_id": "9d75df2fd6709c09ffa10dda269849733d461705",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2046,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 81,
"path": "/scrape/admin.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom django.db import models\nfrom .models import Collect, Results, Analytics, WorkFlow, IndeedResults\nfrom .forms import YelpForm\nfrom pagedown.widgets import AdminPagedownWidget\n\n\nclass ScrapeAdmin(admin.ModelAdmin):\n formfield_overrides = {\n models.TextField: {'widget': AdminPagedownWidget},\n }\n list_display = ['id', 'site', 'business_name', \"scrape_date\", \"id\", 'slug']\n list_filter = [\"scrape_date\"]\n search_fields = [\"business_name\"]\n form = YelpForm\n\n class Meta:\n model = Collect\n\n\nadmin.site.register(Collect, ScrapeAdmin)\n\n\nclass ResultsAdmin(admin.ModelAdmin):\n formfield_overrides = {\n models.TextField: {'widget': AdminPagedownWidget},\n }\n list_display = ['collection_id', \"date\", 'rating', 'review']\n list_filter = [\"collection_id\"]\n search_fields = [\"collection_id\"]\n\n class Meta:\n model = Results\n\n\nadmin.site.register(Results, ResultsAdmin)\n\n\nclass IndeedResultsAdmin(admin.ModelAdmin):\n formfield_overrides = {\n models.TextField: {'widget': AdminPagedownWidget},\n }\n list_display = ['collection_id', \"date\", 'rating', 'review']\n list_filter = [\"collection_id\"]\n search_fields = [\"collection_id\"]\n\n class Meta:\n model = Results\n\n\nadmin.site.register(IndeedResults, IndeedResultsAdmin)\n\n\nclass AnalyticsAdmin(admin.ModelAdmin):\n formfield_overrides = {\n models.TextField: {'widget': AdminPagedownWidget},\n }\n list_display = ['collection_id', \"word\", \"value\"]\n list_filter = [\"collection_id\"]\n search_fields = [\"collection_id\"]\n\n class Meta:\n model = Analytics\n\n\nadmin.site.register(Analytics, AnalyticsAdmin)\n\n\nclass WorkflowAdmin(admin.ModelAdmin):\n formfield_overrides = {\n models.TextField: {'widget': AdminPagedownWidget},\n }\n list_display = ['collection_id', \"status\", \"timestamp\"]\n list_filter = [\"collection_id\"]\n search_fields = [\"collection_id\"]\n\n class Meta:\n model = WorkFlow\n\n\nadmin.site.register(WorkFlow, WorkflowAdmin)"
},
{
"alpha_fraction": 0.6439999938011169,
"alphanum_fraction": 0.6439999938011169,
"avg_line_length": 37.46154022216797,
"blob_id": "9738125e28cf1c9de83533eb096c8762262e5edb",
"content_id": "70a536405bd40d4a4cfe6babde5245c9f995b6d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 500,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 13,
"path": "/scrape/urls.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from django.urls import re_path, path\nfrom . import views\n\napp_name = 'scrape-api'\n\nurlpatterns = [\n path('yelp', views.ScrapeListCreateAPIView.as_view(), name='yelp-list-create'),\n re_path(r'^yelp/(?P<slug>[\\w-]+)/$', views.ScrapeDetailAPIView.as_view(),\n name='yelp_detail'),\n path('indeed', views.ScrapeListCreateAPIView.as_view(), name='indeed-list-create'),\n re_path(r'^indeed/(?P<slug>[\\w-]+)/$', views.ScrapeDetailAPIView.as_view(),\n name='indeed_detail'),\n]\n"
},
{
"alpha_fraction": 0.5176132321357727,
"alphanum_fraction": 0.5377426147460938,
"avg_line_length": 27.387754440307617,
"blob_id": "a5bc155859cd147eb5d1b08b0084c5e34f156415",
"content_id": "18672155f731bf9788bab70387bca874c4da2618",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1391,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 49,
"path": "/scrape/migrations/0013_auto_20191007_1421.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.5 on 2019-10-07 18:21\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('scrape', '0012_results_author'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='indeedresults',\n old_name='author',\n new_name='current_employee',\n ),\n migrations.RemoveField(\n model_name='results',\n name='current_employee',\n ),\n migrations.RemoveField(\n model_name='results',\n name='job_title',\n ),\n migrations.RemoveField(\n model_name='results',\n name='location_city',\n ),\n migrations.RemoveField(\n model_name='results',\n name='location_state',\n ),\n migrations.AddField(\n model_name='indeedresults',\n name='job_title',\n field=models.CharField(blank=True, max_length=120, null=True),\n ),\n migrations.AddField(\n model_name='indeedresults',\n name='location_city',\n field=models.CharField(blank=True, max_length=120, null=True),\n ),\n migrations.AddField(\n model_name='indeedresults',\n name='location_state',\n field=models.CharField(blank=True, max_length=120, null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.49294301867485046,
"alphanum_fraction": 0.4979090392589569,
"avg_line_length": 25.393102645874023,
"blob_id": "963d4998c4b4d118bf30f802186f4465b2bddf15",
"content_id": "7c4328d6cf439efb69dbe8d03fcbc397e53e5a77",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3826,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 145,
"path": "/frontend/src/comm/CommDetail.js",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "import React, {Component} from 'react'\nimport 'whatwg-fetch'\nimport cookie from 'react-cookies'\nimport Moment from \"react-moment\";\nimport ReactMarkdown from \"react-markdown\";\nimport {Link} from \"react-router-dom\";\nimport Button from \"react-bootstrap/Button\";\nimport ReactLoading from \"react-loading\";\n\nclass CommDetail extends Component {\n constructor(props) {\n super(props);\n this.handleCommItemUpdated = this.handleCommItemUpdated.bind(this);\n this.state = {\n slug: null,\n comm: null,\n doneLoading: false,\n owner: null\n }\n }\n\n handleCommItemUpdated(commItemData) {\n this.setState({\n comm: commItemData\n })\n }\n\n loadComm(slug) {\n const endpoint = `/api/comms/${slug}/`;\n let thisComp = this;\n let lookupOptions = {\n method: \"GET\",\n headers: {\n 'Content-Type': 'application/json'\n }\n };\n\n const csrfToken = cookie.load('csrftoken');\n if (csrfToken !== undefined) {\n lookupOptions['credentials'] = 'include';\n lookupOptions['headers']['X-CSRFToken'] = csrfToken\n }\n\n fetch(endpoint, lookupOptions)\n .then(function (response) {\n if (response.status === 404) {\n console.log('Page not found')\n }\n return response.json()\n }).then(function (responseData) {\n if (responseData.detail) {\n thisComp.setState({\n doneLoading: true,\n comm: null\n })\n } else {\n thisComp.setState({\n doneLoading: true,\n comm: responseData,\n owner: responseData.owner,\n });\n }\n }).catch(function (error) {\n console.log(\"error\", error)\n })\n }\n\n\n componentDidMount() {\n this.setState({\n slug: null,\n comm: null\n });\n if (this.props.match) {\n const {slug} = this.props.match.params;\n this.setState({\n slug: slug,\n doneLoading: false\n });\n this.loadComm(slug)\n }\n }\n\n render() {\n const {doneLoading} = this.state;\n const {comm} = this.state;\n const {owner} = this.state;\n\n const hrStyle = {\n display: 'block',\n height: '1px',\n border: 0,\n borderTop: '1px solid #ccc',\n margin: '1em 0',\n padding: '0',\n color: 'white'\n };\n return (\n <p>{(doneLoading === true) ? <div class=\"Main\">\n {comm === null ? \"Not Found\" :\n <div className='row'>\n <div className='col-md-10'>\n <h1 id='alt'>{comm.title}\n <small class=\"text-muted\">({comm.slug})</small>\n </h1>\n <h4 id='alt'>By {comm.author.username} \n {owner === true ?\n <Link className='mr-2'\n maintainScrollPosition={false}\n to={{\n pathname: `/site-management/comms/${comm.slug}/edit`,\n state: {post: comm}\n }}><Button variant=\"outline-dark\"\n type=\"button\" id=\"edit-button\">Edit</Button>\n </Link> : \"\"} </h4>\n <hr style={hrStyle}/>\n <h4>\n <small\n className=\"publish_date\"\n id='alt'> Updated: <Moment\n fromNow\n ago>{comm.updated}</Moment> ago \n </small>\n </h4>\n <hr style={hrStyle}/>\n <p id=\"alt\">\n <ReactMarkdown\n source={comm.content}/>\n </p>\n </div>\n\n <div className='col-md-2'>\n <br/>\n </div>\n </div>\n }\n </div> : <div className=\"loading\">\n <div className=\"spinner\">\n <ReactLoading type={\"bars\"} color={\"white\"}/></div>\n </div>}</p>\n )\n }\n}\n\nexport default CommDetail"
},
{
"alpha_fraction": 0.588403046131134,
"alphanum_fraction": 0.588403046131134,
"avg_line_length": 34,
"blob_id": "7ed9cd69a084975ef15f6616d05066436bf5e551",
"content_id": "f310f23dd0e923a7ec66ec90c163bfee2e272453",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1052,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 30,
"path": "/scrape/forms.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from .models import Collect\nfrom django.forms import ModelForm, HiddenInput\nfrom django.core.validators import ValidationError\n\n\nclass YelpForm(ModelForm):\n\n class Meta:\n model = Collect\n widgets = {'business_name': HiddenInput(), 'slug': HiddenInput()}\n fields = ['link', 'page_amount', 'business_name', 'slug']\n labels = {'link': 'Yelp Link', 'scrape_date': 'Date Scraped',\n 'slug': 'Slug'}\n\n def __init__(self, *args, **kwargs):\n self.results = None\n super(YelpForm, self).__init__(*args, **kwargs)\n\n def clean_link(self):\n link = self.cleaned_data.get('link')\n link = str(link)\n valid_link = ['https', 'http', 'www.']\n if not link:\n raise ValidationError('Enter a valid yelp link!')\n elif not link.startswith(tuple(valid_link)):\n raise ValidationError('Enter a valid yelp link!')\n elif 'www.yelp.com' not in link:\n raise ValidationError('Enter a valid yelp link!')\n else:\n return link\n\n\n"
},
{
"alpha_fraction": 0.6229357719421387,
"alphanum_fraction": 0.6279816627502441,
"avg_line_length": 31.477611541748047,
"blob_id": "529dcc457582e23ff7a844de0bdb7fdb027f9e6e",
"content_id": "02f425805e4b59269f8d41f44d79e47cc5e14b8c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2180,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 67,
"path": "/scrape/utils.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from django.utils.text import slugify\nimport random\nimport string\nimport json\nfrom pathlib import Path\nimport re\ntry:\n from harvstr.settings.local import *\nexcept:\n from harvstr.settings.production import *\n\n\ndef random_string_generator(size=10,\n chars=string.ascii_lowercase + string.digits):\n return ''.join(random.choice(chars) for _ in range(size))\n\n\ndef unique_slug_generator(instance, new_slug=None):\n \"\"\"\n This is for a Django project and it assumes your instance\n has a model with a slug field and a title character (char) field.\n \"\"\"\n if new_slug is not None:\n slug = new_slug\n else:\n slug = slugify(instance.business_name)\n Klass = instance.__class__\n qs_exists = Klass.objects.filter(slug=slug).exists()\n if qs_exists:\n new_slug = \"{slug}-{randstr}\".format(\n slug=slug,\n randstr=random_string_generator(size=4)\n )\n return unique_slug_generator(instance, new_slug=new_slug)\n return slug\n\n\ndef build_dict_from_json(json_path):\n \"\"\"takes JSON Path and outputes a dictionary\"\"\"\n if json_path:\n with open(Path(json_path), 'r') as f:\n return json.load(f)\n\n\ndef websiteIdentifier(instance):\n site_dir_dict = build_dict_from_json(ACTIVESITES_JSON)\n\n for site in site_dir_dict['sites']:\n try:\n if site_dir_dict['sites'][site]['pattern'] in instance.link:\n return site, instance\n except ValueError:\n return 'A valid site pattern was not found...Please update the source JSON file.'\n\n\ndef getBusinessName(link):\n valid_sites = ['www.yelp.com', 'www.glassdoor.com', 'www.indeed.com']\n site = [x for x in valid_sites if x in str(link)].pop()\n\n biz_switch = {\n 'www.yelp.com': [re.split(r'biz/', link)[1].split('?')[0] if 'yelp' in site else 'not a match'],\n 'www.glassdoor.com': [link.rsplit('Reviews/', 1)[1].rsplit('-Reviews-')[0] if 'glassdoor' in site else 'not a match'],\n 'www.indeed.com': [re.split(r'cmp/', link)[1].split('/')[0] if 'indeed' in site else 'not a match']\n }\n business = biz_switch.get(site)[0]\n\n return business\n\n\n\n\n"
},
{
"alpha_fraction": 0.7528089880943298,
"alphanum_fraction": 0.7528089880943298,
"avg_line_length": 16.799999237060547,
"blob_id": "baa0dfdcdc59e75ff5791d8b64364f0a2bd906b6",
"content_id": "5b45eeff25458684576f510e652a91ef9275e017",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 89,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 5,
"path": "/myblock/apps.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass MyblockConfig(AppConfig):\n name = 'myblock'\n"
},
{
"alpha_fraction": 0.5098039507865906,
"alphanum_fraction": 0.593137264251709,
"avg_line_length": 21.66666603088379,
"blob_id": "dc958345a7a12d2707d21b475e16c27f0f431971",
"content_id": "682bb7f75f6d60199369dda56f00aabea99c93e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 408,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 18,
"path": "/scrape/migrations/0012_results_author.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.5 on 2019-10-07 13:42\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('scrape', '0011_auto_20191007_0937'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='results',\n name='author',\n field=models.CharField(blank=True, max_length=120, null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6066234111785889,
"alphanum_fraction": 0.609532356262207,
"avg_line_length": 34.1889762878418,
"blob_id": "315402918467401316b3bf7d7c796dd1d81eed38",
"content_id": "e0907b05157d97e49fb4fde6db8b13572791d47c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4469,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 127,
"path": "/scrape/pipeline.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from scrape.scripts.indeed.indeed import scrape_indeed\nimport pandas as pd\nfrom scrape.utils import websiteIdentifier\nfrom scrape.models import Collect, Results, WorkFlow, IndeedResults\nfrom scrape.scripts.yelp.scrape_yelp import scrape as scrape_yelp\nfrom prefect import task, Flow, Parameter\nimport pendulum\n\n\n# import datetime\n# from prefect.utilities.logging import get_logger\n# import logging\n# import prefect\n\n\ndef timestamper(task, old_state, new_state):\n \"\"\"\n Task state handler that timestamps new states\n and logs the duration between state changes using\n the task's logger.\n \"\"\"\n new_state.timestamp = pendulum.now(\"utc\")\n if hasattr(old_state, \"timestamp\"):\n duration = (new_state.timestamp - old_state.timestamp).in_seconds()\n task.logger.info(\n \"{} seconds passed in between state transitions\".format(duration)\n )\n return new_state\n\n\n# class LogHandler(logging.StreamHandler):\n# # def __init__(self, instance_id):\n# # super().__init__(instance_id)\n# # self.instance_id = instance_id\n#\n# def emit(self, record):\n# print('THIS IS THE RECORD')\n# # yelp_obj = Collect.objects.get(id=self.instance_id)\n# instance = WorkFlow(collection_id=97, status=record.exc_info,\n# details=record.msg,\n# timestamp=datetime.datetime.now())\n# try:\n# instance.save()\n# except Exception as exc:\n# formatted = \"Unexpected error, cannot save logs!: {}\".format(\n# repr(exc))\n# raise Exception(formatted)\n\n\n@task(name='Analyze Website Url', state_handlers=[timestamper])\ndef get_website(instance):\n \"\"\"Get a list of data\"\"\"\n link_type, instance = websiteIdentifier(instance)\n return link_type, instance\n\n\n@task(name='Scrape Website', state_handlers=[timestamper])\ndef gather_data(head):\n \"\"\"Multiply the input by 10\"\"\"\n # logger = prefect.context.get(\"logger\")\n\n runner_switch = {\n 'yelp': scrape_yelp,\n 'indeed': scrape_indeed\n }\n\n data = runner_switch.get(head[0])(head[1].link, head[1].page_amount)\n\n return pd.DataFrame(data), head[1]\n\n\n@task(name='Upload Results to Database', state_handlers=[timestamper])\ndef upload_yelp_data(data):\n print()\n \"\"\"Print the data to indicate it was received\"\"\"\n # logger = prefect.context.get(\"logger\")\n for row in data[0].itertuples():\n # add some custom validation\\parsing for some of the fields\n yelp_obj = Collect.objects.get(id=data[1].id)\n instance = Results(collection_id=yelp_obj, author=row.author,\n date=row.date, rating=row.rating,\n review=row.reviews)\n try:\n instance.save()\n except Exception as exc:\n formatted = \"Unexpected error, cannot upload data to database!: {}\".format(\n repr(exc))\n raise Exception(formatted)\n\n\n@task(name='Upload Results to Database', state_handlers=[timestamper])\ndef upload_indeed_data(data):\n print()\n \"\"\"Print the data to indicate it was received\"\"\"\n # logger = prefect.context.get(\"logger\")\n for row in data[0].itertuples():\n # add some custom validation\\parsing for some of the fields\n yelp_obj = Collect.objects.get(id=data[1].id)\n instance = IndeedResults(collection_id=yelp_obj,\n date=row.Date, rating=row.Rating,\n review=row.Review,\n location_city=row.Location_City,\n location_state=row.Location_State,\n job_title=row.Job_Title,\n current_employee=row.Current_Employee)\n try:\n instance.save()\n except Exception as exc:\n formatted = \"Unexpected error, cannot upload data to database!: {}\".format(\n repr(exc))\n raise Exception(formatted)\n\n\ndef run_flow(data):\n site = websiteIdentifier(data)[0]\n upload_dispatcher = {\n 'yelp': upload_yelp_data,\n 'indeed': upload_indeed_data\n }\n with Flow('ScrapeData') as flow:\n instance = Parameter(\"instance\")\n get_type = get_website(instance=instance)\n scrape = gather_data(get_type)\n upload_dispatcher.get(site)(scrape)\n\n # now attach our custom handler to Task B's logger\n flow.run(instance=data)\n"
},
{
"alpha_fraction": 0.5230024456977844,
"alphanum_fraction": 0.5980629324913025,
"avg_line_length": 21.94444465637207,
"blob_id": "9bdb83a3303c5d2d35174ec82a9d74ad14d578a3",
"content_id": "92b1f346c0009c473cb2fd3517bf7878d77ebd8f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 413,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 18,
"path": "/scrape/migrations/0004_auto_20190918_1359.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.5 on 2019-09-18 17:59\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('scrape', '0003_auto_20190918_1329'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='yelp',\n name='page_amount',\n field=models.IntegerField(blank=True, default=None, null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5362903475761414,
"alphanum_fraction": 0.5766128897666931,
"avg_line_length": 25.105262756347656,
"blob_id": "b58f16aa0d28746571897ad283da73f2ab64b3bb",
"content_id": "a5e0f7eb56cdab80c8c6b85270bffe8d56251855",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 496,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 19,
"path": "/comm/migrations/0002_comms_location.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.5 on 2019-09-06 19:13\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('comm', '0001_initial'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='comms',\n name='location',\n field=models.CharField(choices=[('comms', 'comms'), ('scrape', 'scrape'), ('landing', 'landing')], default=None, max_length=2),\n preserve_default=False,\n ),\n ]\n"
},
{
"alpha_fraction": 0.5563034415245056,
"alphanum_fraction": 0.5601236820220947,
"avg_line_length": 25.560386657714844,
"blob_id": "14344194dd0b4b46f8954032362f8a63aa689c46",
"content_id": "cd3fbdb97bd0f3aa1cef392432966a52f76dacf2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 5497,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 207,
"path": "/frontend/src/scrape/ScrapeForm.js",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "import React, {Component} from 'react'\nimport 'whatwg-fetch'\nimport cookie from 'react-cookies'\nimport {Redirect} from \"react-router-dom\";\nimport Loader from 'react-loader-spinner';\nimport validate from './ScrapeFormValidationRules'\n\n\nclass ScrapeForm extends Component {\n constructor(props) {\n super(props);\n this.handleSubmit = this.handleSubmit.bind(this);\n this.handleInputChange = this.handleInputChange.bind(this);\n this.clearForm = this.clearForm.bind(this);\n this.scrapeLinkRef = React.createRef();\n this.scrapePagesRef = React.createRef();\n this.state = {\n link: null,\n pages_amount: null,\n redirect: false,\n redirectLink: null,\n slug: null,\n scraping: null,\n errors: null,\n site: null\n }\n }\n\n createScrape(data) {\n const scrape_type = this.identifySite(data);\n const endpoint = `/api/scrape/${scrape_type}`;\n const csrfToken = cookie.load('csrftoken');\n let thisComp = this;\n if (csrfToken !== undefined) {\n let lookupOptions = {\n method: \"POST\",\n headers: {\n 'Content-Type': 'application/json',\n 'X-CSRFToken': csrfToken\n },\n body: JSON.stringify(data),\n credentials: 'include'\n };\n\n fetch(endpoint, lookupOptions)\n .then(function (response) {\n return response.json()\n }).then(function (responseData) {\n thisComp.setState({\n redirectLink: `/scrape/results/${responseData.slug}`,\n scraping: null,\n site: scrape_type\n });\n // console.log(`scrape/results/${responseData.slug}`);\n thisComp.clearForm()\n }).catch(function (error) {\n console.log(\"error\", error);\n alert(\"An error occurred, please try again later.\")\n }).then(() => this.setState({redirect: true}));\n }\n }\n\n identifySite() {\n let data = this.state;\n if (data.link.includes('yelp.com')) {\n return 'yelp';\n } else if (data.link.includes('indeed.com')) {\n return 'indeed';\n }\n }\n\n handleSubmit(event) {\n event.preventDefault();\n let data = this.state;\n const {scrape} = this.props;\n const verify = validate(data);\n\n if (scrape === undefined) {\n if (Object.keys(verify).length > 0) {\n this.setState({errors: verify});\n // console.log('ERRORS', verify)\n } else if (Object.keys(verify).length === 0) {\n this.setState({scraping: true});\n this.createScrape(data)\n } else {\n this.clearFormRefs();\n }\n }\n }\n\n handleInputChange(event) {\n event.preventDefault();\n let key = event.target.name;\n let value = event.target.value;\n if (key === 'link') {\n if (value.length > 120) {\n alert(\"This link is too long\")\n }\n }\n if (key === 'page_amount') {\n if (parseInt(value) > 100) {\n alert(\"This app can't process more than 100 pages.\")\n }\n }\n this.setState({\n [key]: value\n });\n }\n\n clearForm(event) {\n if (event) {\n event.preventDefault()\n }\n this.scrapeCreateForm.reset();\n this.defaultState();\n }\n\n\n clearFormRefs() {\n this.scrapeLinkRef.current = '';\n this.scrapePagesRef.current = '';\n }\n\n\n defaultState() {\n this.setState({\n link: null,\n })\n }\n\n componentDidMount() {\n const {scrape} = this.props;\n if (scrape !== undefined) {\n this.setState({\n link: scrape.link,\n page_number: scrape.page_number,\n })\n } else {\n this.defaultState()\n }\n // this.postTitleRef.current.focus()\n }\n\n render() {\n const {link} = this.state;\n const {page_amount} = this.state;\n const {redirect} = this.state;\n const {redirectLink} = this.state;\n const {scraping} = this.state;\n const {errors} = this.state;\n const {site} = this.state;\n\n if (scraping) {\n return <div id=\"react-loader\">\n <Loader type=\"Puff\" color=\"#00BFFF\"\n height=\"200\"\n width=\"200\"/> ...gathering data </div>\n }\n if (redirect) {\n return <Redirect to={{\n pathname: redirectLink,\n state: {site: site}\n }}/>;\n }\n return (\n <form onSubmit={this.handleSubmit}\n ref={(el) => this.scrapeCreateForm = el}>\n <h3>Web Scraper <small>(This app currently only accepts yelp, and indeed links)</small></h3>\n <div className='form-group'>\n {errors === null ? \"\" :\n <label htmlFor='link'>\n <small className=\"errors\">{errors['link']}</small>\n </label>}\n < input\n type='text'\n id='link'\n name='link'\n value={link}\n className='form-control'\n placeholder='Link'\n ref={this.scrapeLinkRef}\n onChange={this.handleInputChange}\n required='required'/>\n </div>\n <div className='form-group'>\n <input\n type='number'\n id='page_amount'\n name='page_amount'\n value={page_amount || ''}\n className='form-control'\n placeholder='Number of pages | NOTE: leave blank if you want to scrape ALL pages'\n ref={this.scrapePagesRef}\n onChange={this.handleInputChange}/>\n </div>\n <button type='submit' className='btn btn-primary'>Scrape</button>\n \n <button className={`btn btn-secondary`}\n onClick={this.clearForm}>Clear\n </button>\n </form>\n )\n }\n\n}\n\nexport default ScrapeForm"
},
{
"alpha_fraction": 0.6968590021133423,
"alphanum_fraction": 0.6968590021133423,
"avg_line_length": 44.63333511352539,
"blob_id": "ae45fa1173e726028e49be60899d4c03d5c8130d",
"content_id": "226f2dada86e7f9582c2c754576310011ebe1d83",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1369,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 30,
"path": "/harvstr/urls.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from django.urls import re_path, include, path\nfrom django.conf import settings\nfrom django.conf.urls.static import static\nfrom django.contrib import admin\nfrom django.views.generic import TemplateView\n\nurlpatterns = [\n re_path(r'^admin/', admin.site.urls),\n re_path(r'^account/', include('accounts.urls')),\n # Comms Links\n path('walking', TemplateView.as_view(template_name='comm/walking.html')),\n path('api/comms/', include('comm.urls')),\n # Scraper Links\n re_path(r'^scrape/', TemplateView.as_view(template_name='scrape/react.html'),\n name='scrape-list'),\n path('walking', TemplateView.as_view(template_name='scrape/walking.html')),\n path('api/scrape/', include('scrape.urls')),\n # Myblock Link\n re_path(r'^site-management/', include('myblock.urls'), name='myblock'),\n re_path(r'^site-management/comms/', TemplateView.as_view(template_name='comm/react.html'), name='comms-list'),\n # Homepage Link\n path('walking', TemplateView.as_view(template_name='landing/walking.html')),\n path('api/landing/', include('landing.urls')),\n re_path(r'^$', TemplateView.as_view(template_name='landing/react.html'), name='landing'),\n\n]\n\n# if settings.DEBUG:\n# urlpatterns += static(settings.STATIC_URL, document_root=settings.STATIC_ROOT)\n# urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)\n"
},
{
"alpha_fraction": 0.5204461216926575,
"alphanum_fraction": 0.5269516706466675,
"avg_line_length": 27.3157901763916,
"blob_id": "8e90fd4bf262c9cfdaa6183cc44a71d35e5a8a85",
"content_id": "8647f5b7de1a79f26c9df88fd3e3844a431e6e9f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1076,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 38,
"path": "/scrape/scripts/glassdoor/attempt.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "import functools\n\n\ndef trial(max_trial=5):\n \"\"\"\n Decorator\n Tries maximum of max_trial times to succeed. It will stop if it succeeds.\n\n use like:\n > @trial(max_trial=10)\n > def function_name(inputs):\n > # define function normally\n > return outputs\n\n Parameters\n ----------\n max_trial : int, optional(5)\n\n Notes\n -----\n When function fails, it will print error messages.\n If it fails after max_trial number of tries. It will return -1.\n \"\"\"\n def decorator_trial(func):\n @functools.wraps(func)\n def wrapper_trial(*args, **kwargs):\n for counter in range(max_trial):\n try:\n return func(*args, **kwargs)\n except BaseException:\n print('ERROR: cannot load the page!')\n if counter < max_trial - 1:\n print('trying again ...')\n else:\n print('Error: skipping the page!!!')\n return -1\n return wrapper_trial\n return decorator_trial\n"
},
{
"alpha_fraction": 0.7051851749420166,
"alphanum_fraction": 0.7081481218338013,
"avg_line_length": 78.4117660522461,
"blob_id": "ec0daca999b1bd43fe909638f1668d13f88cbcd9",
"content_id": "568c21c4579236679a0da9d583cf489765968574",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1350,
"license_type": "no_license",
"max_line_length": 266,
"num_lines": 17,
"path": "/accounts/urls.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from django.urls import path, re_path, include\nfrom django.contrib.auth.views import (PasswordResetView, PasswordResetDoneView,\n PasswordResetConfirmView, PasswordResetCompleteView)\nfrom accounts.views import (login_view, register_view, logout_view)\n\napp_name = 'accounts'\n\nurlpatterns = [\n re_path(r'^login/$', login_view, name='login'),\n re_path(r'^logout/$', logout_view, name='logout'),\n re_path(r'^register/$', register_view, name='register'),\n re_path(r'^reset-password/$', PasswordResetView.as_view(), {'template_name': 'accounts/reset_password.html', 'post_reset_redirect': 'accounts:password_reset_done', 'email_template_name': 'accounts/reset_password_email.html'}, name='reset_password'),\n re_path(r'^reset-password/done/$', PasswordResetDoneView.as_view(), {'template_name': 'accounts/reset_password_done.html'}, name='password_reset_done'),\n re_path(r'^reset-password/confirm/(?P<uidb64>[0-9A-Za-z]+)-(?P<token>.+)/$', PasswordResetConfirmView.as_view(), {'template_name': 'accounts/reset_password_confirm.html', 'post_reset_redirect': 'accounts:password_reset_complete'}, name='password_reset_confirm'),\n re_path(r'^reset-password/complete/$', PasswordResetCompleteView.as_view(), {'template_name': 'accounts/reset_password_complete.html'}, name='password_reset_complete'),\n\n]\n"
},
{
"alpha_fraction": 0.5567322373390198,
"alphanum_fraction": 0.577407956123352,
"avg_line_length": 42.10869598388672,
"blob_id": "813eb6e309cb3c84327d76a0c5d67220c9a54ee4",
"content_id": "5a683914cf00abdfaa4800d091abce4a9befc9b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1983,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 46,
"path": "/landing/migrations/0001_initial.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.5 on 2019-09-12 14:50\n\nfrom django.conf import settings\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n migrations.swappable_dependency(settings.AUTH_USER_MODEL),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Feedback',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(blank=True, max_length=120, null=True)),\n ('email', models.EmailField(max_length=254, null=True)),\n ('phone_number', models.CharField(blank=True, max_length=120, null=True)),\n ('comments', models.TextField(blank=True, null=True)),\n ('timestamp', models.DateTimeField(auto_now_add=True)),\n ],\n options={\n 'ordering': ['-id'],\n },\n ),\n migrations.CreateModel(\n name='About',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('title', models.CharField(blank=True, max_length=500, null=True)),\n ('post_image', models.CharField(blank=True, max_length=120, null=True)),\n ('unsplash_url', models.CharField(blank=True, max_length=120, null=True)),\n ('height_field', models.IntegerField(default=900)),\n ('width_field', models.IntegerField(default=1440)),\n ('content', models.TextField(blank=True, null=True)),\n ('timestamp', models.DateTimeField(auto_now_add=True)),\n ('updated', models.DateTimeField(auto_now=True)),\n ('user', models.ForeignKey(default=1, on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL)),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.42321643233299255,
"alphanum_fraction": 0.4268440008163452,
"avg_line_length": 39.34146499633789,
"blob_id": "f4aa67208200d685f20b51d4ed92397710e52c04",
"content_id": "60e7edf17dc9d40fbc072d0d7bac256b5a5f941e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1654,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 41,
"path": "/frontend/src/comm/CommInline.js",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "import React, {Component} from 'react';\nimport {Link} from 'react-router-dom'\nimport ReactMarkdown from 'react-markdown'\nimport Moment from 'react-moment';\n\nclass CommInline extends Component {\n\n render() {\n const {comm} = this.props;\n const {elClass} = this.props;\n const showContent = elClass === 'card' ? 'd-block' : 'd-none';\n return (\n <div class=\"comms-list\">\n {comm !== undefined ? <div className={elClass}>\n <h1 class=\"comms-title\"><Link\n maintainScrollPosition={false} to={{\n pathname: `/site-management/comms/${comm.slug}/`,\n state: {fromDashboard: false}\n }}>{comm.title}</Link> \n <small className=\"publish_date text-muted\"\n id='alt'>(Updated: <Moment fromNow ago>{comm.updated}</Moment> ago)\n </small>\n </h1>\n\n <p className={showContent}>\n <ReactMarkdown\n source={comm.content.slice(0, 200).trim().concat('...')}/>\n <Link\n maintainScrollPosition={false} to={{\n pathname: `/site-management/comms/${comm.slug}/`,\n state: {fromDashboard: false}\n }}>Read more\n </Link></p>\n </div>\n : \"\"}\n </div>\n );\n }\n}\n\nexport default CommInline\n"
},
{
"alpha_fraction": 0.7036316394805908,
"alphanum_fraction": 0.7211413979530334,
"avg_line_length": 40.67567443847656,
"blob_id": "0abe94d65e0d97abf31a236537478dcca07a4d26",
"content_id": "9288042389895be659b68d8d88889bc7a8677f1c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1542,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 37,
"path": "/landing/models.py",
"repo_name": "griggz/democratizer",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.conf import settings\nfrom markdown_deux import markdown\nfrom django.utils.safestring import mark_safe\n\n\n# Create your models here.\nclass Feedback(models.Model):\n user = models.ForeignKey(settings.AUTH_USER_MODEL, default=1, on_delete=models.CASCADE)\n name = models.CharField(max_length=120, null=True, blank=True)\n email = models.EmailField(max_length=254, null=True, blank=False)\n phone_number = models.CharField(max_length=120, null=True, blank=True)\n comments = models.TextField(blank=True, null=True)\n timestamp = models.DateTimeField(auto_now=False, auto_now_add=True)\n\n class Meta:\n ordering = [\"-id\"]\n\n def save(self, **kwargs):\n return super(Feedback, self).save(**kwargs)\n\n\nclass About(models.Model):\n user = models.ForeignKey(settings.AUTH_USER_MODEL, default=1, on_delete=models.CASCADE)\n title = models.CharField(max_length=500, blank=True, null=True)\n post_image = models.CharField(max_length=120, null=True, blank=True,)\n unsplash_url = models.CharField(max_length=120, null=True, blank=True, )\n height_field = models.IntegerField(default=900)\n width_field = models.IntegerField(default=1440)\n content = models.TextField(blank=True, null=True)\n timestamp = models.DateTimeField(auto_now=False, auto_now_add=True)\n updated = models.DateTimeField(auto_now=True, auto_now_add=False)\n\n def get_markdown(self):\n content = self.content\n markdown_text = markdown(content)\n return mark_safe(markdown_text)\n"
}
] | 61 |
cnyy7/LeetCode_EY
|
https://github.com/cnyy7/LeetCode_EY
|
4f6af6e7cae61387e984332b5bb9440e8a39974b
|
a7181138f5d6bc7c49c8ded2d302c172d6082682
|
f89582f35c76d2e58b7b2a9cf61736bf4227c020
|
refs/heads/master
| 2023-09-01T06:28:12.379813 | 2022-01-20T03:55:51 | 2022-01-20T03:55:51 | 175,537,246 | 0 | 0 |
MIT
| 2019-03-14T02:53:51 | 2019-04-26T02:24:14 | 2019-04-26T02:24:13 |
C++
|
[
{
"alpha_fraction": 0.37578028440475464,
"alphanum_fraction": 0.4244694113731384,
"avg_line_length": 18.538461685180664,
"blob_id": "7432752b96c875d22468c6aa97b48d33305dbc18",
"content_id": "8554b5fdceef2721b2a858ac9131a00d3f0c6957",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1606,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 78,
"path": "/leetcode-algorithms/977. Squares of a Sorted Array/977.squares-of-a-sorted-array.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=977 lang=cpp\r\n *\r\n * [977] Squares of a Sorted Array\r\n *\r\n * https://leetcode.com/problems/squares-of-a-sorted-array/description/\r\n *\r\n * algorithms\r\n * Easy (72.86%)\r\n * Total Accepted: 56.2K\r\n * Total Submissions: 77.7K\r\n * Testcase Example: '[-4,-1,0,3,10]'\r\n *\r\n * Given an array of integers A sorted in non-decreasing order, return an array\r\n * of the squares of each number, also in sorted non-decreasing order.\r\n * \r\n * \r\n * \r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: [-4,-1,0,3,10]\r\n * Output: [0,1,9,16,100]\r\n * \r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: [-7,-3,2,3,11]\r\n * Output: [4,9,9,49,121]\r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * 1 <= A.length <= 10000\r\n * -10000 <= A[i] <= 10000\r\n * A is sorted in non-decreasing order.\r\n * \r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n vector<int> sortedSquares(vector<int> &A)\r\n {\r\n // for(int i=0;i<A.size()&&A[i]<0;i++)\r\n // {\r\n // A[i]=abs(A[i]);\r\n // }\r\n // sort(A.begin(),A.end());\r\n // vector<int>sol(A.size(),0);\r\n // for(int i=0;i<sol.size();i++)\r\n // {\r\n // sol[i]=pow(A[i],2);\r\n // }\r\n // return sol;\r\n int left = 0, right = A.size() - 1;\r\n vector<int> sol(A.size(), 0);\r\n for (int i = A.size() - 1; i >= 0; i--)\r\n {\r\n if (abs(A[left]) > abs(A[right]))\r\n {\r\n sol[i] = A[left] * A[left++];\r\n }\r\n else\r\n {\r\n sol[i] = A[right] * A[right--];\r\n }\r\n }\r\n return sol;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.4409722089767456,
"alphanum_fraction": 0.4749999940395355,
"avg_line_length": 22.827587127685547,
"blob_id": "25c763b33c896a20d01073bf6d59a087de0c001a",
"content_id": "94cdf33b0fd8e3f23eefa43dd6714bdb66b52e0b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1589,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 58,
"path": "/leetcode-algorithms/118. Pascal's Triangle/118.pascals-triangle.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=118 lang=java\r\n *\r\n * [118] Pascal's Triangle\r\n *\r\n * https://leetcode.com/problems/pascals-triangle/description/\r\n *\r\n * algorithms\r\n * Easy (44.68%)\r\n * Total Accepted: 241.2K\r\n * Total Submissions: 532.3K\r\n * Testcase Example: '5'\r\n *\r\n * Given a non-negative integer numRows, generate the first numRows of Pascal's\r\n * triangle.\r\n * \r\n * \r\n * In Pascal's triangle, each number is the sum of the two numbers directly\r\n * above it.\r\n * \r\n * Example:\r\n * \r\n * \r\n * Input: 5\r\n * Output:\r\n * [\r\n * [1],\r\n * [1,1],\r\n * [1,2,1],\r\n * [1,3,3,1],\r\n * [1,4,6,4,1]\r\n * ]\r\n * \r\n * \r\n */\r\nclass Solution {\r\n public List<List<Integer>> generate(int numRows) {\r\n Integer[][] map = new Integer[numRows][];\r\n ArrayList<List<Integer>> sol = new ArrayList<List<Integer>>(); // 初始化二维数组\r\n for (int i = 0; i < numRows; i++) // 初始化二维数组的每一行\r\n {\r\n map[i] = new Integer[i + 1];\r\n // map[i] = new int[i + 1];\r\n map[i][0] = map[i][i] = 1; // 每一行的开头和末尾置1\r\n }\r\n for (int i = 2; i < numRows; i++) // 从第三行开始\r\n {\r\n for (int j = 1; j < i; j++) // 对于这一行中的第二个到倒数第二个数\r\n {\r\n map[i][j] = (map[i - 1][j] + map[i - 1][j - 1]); // 每一个数位上一行上一列于这一列的和模10\r\n }\r\n }\r\n for (int i = 0; i < numRows; i++) {\r\n sol.add(Arrays.asList(map[i]));\r\n }\r\n return sol;\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.3814935088157654,
"alphanum_fraction": 0.4350649416446686,
"avg_line_length": 13.209877014160156,
"blob_id": "2e6116e414819c906b96eb930b076230792ad455",
"content_id": "9339fe3581763479415e0df6ba453bd54ceb5ceb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1232,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 81,
"path": "/leetcode-algorithms/961. N-Repeated Element in Size 2N Array/961.n-repeated-element-in-size-2-n-array.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=961 lang=cpp\r\n *\r\n * [961] N-Repeated Element in Size 2N Array\r\n *\r\n * https://leetcode.com/problems/n-repeated-element-in-size-2n-array/description/\r\n *\r\n * algorithms\r\n * Easy (73.25%)\r\n * Total Accepted: 37.4K\r\n * Total Submissions: 51.1K\r\n * Testcase Example: '[1,2,3,3]'\r\n *\r\n * In a array A of size 2N, there are N+1 unique elements, and exactly one of\r\n * these elements is repeated N times.\r\n * \r\n * Return the element repeated N times.\r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: [1,2,3,3]\r\n * Output: 3\r\n * \r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: [2,1,2,5,3,2]\r\n * Output: 2\r\n * \r\n * \r\n * \r\n * Example 3:\r\n * \r\n * \r\n * Input: [5,1,5,2,5,3,5,4]\r\n * Output: 5\r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * 4 <= A.length <= 10000\r\n * 0 <= A[i] < 10000\r\n * A.length is even\r\n * \r\n * \r\n * \r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n int repeatedNTimes(vector<int> &A)\r\n {\r\n vector<bool> sol(10000, false);\r\n for (auto &t : A)\r\n {\r\n if (!sol[t])\r\n {\r\n sol[t] = true;\r\n }\r\n else\r\n {\r\n return t;\r\n }\r\n }\r\n return 0;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.4028884470462799,
"alphanum_fraction": 0.42978087067604065,
"avg_line_length": 19.826086044311523,
"blob_id": "d8220c256a4092898ed4de138bd98c5e3d53ad6e",
"content_id": "617abc22fc80a88c585fcf6281e559e4c6d5bf76",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2024,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 92,
"path": "/leetcode-algorithms/102. Binary Tree Level Order Traversal/102.binary-tree-level-order-traversal.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=102 lang=cpp\r\n *\r\n * [102] Binary Tree Level Order Traversal\r\n *\r\n * https://leetcode.com/problems/binary-tree-level-order-traversal/description/\r\n *\r\n * algorithms\r\n * Medium (48.80%)\r\n * Likes: 1532\r\n * Dislikes: 40\r\n * Total Accepted: 389.6K\r\n * Total Submissions: 796.6K\r\n * Testcase Example: '[3,9,20,null,null,15,7]'\r\n *\r\n * Given a binary tree, return the level order traversal of its nodes' values.\r\n * (ie, from left to right, level by level).\r\n * \r\n * \r\n * For example:\r\n * Given binary tree [3,9,20,null,null,15,7],\r\n * \r\n * 3\r\n * / \\\r\n * 9 20\r\n * / \\\r\n * 15 7\r\n * \r\n * \r\n * \r\n * return its level order traversal as:\r\n * \r\n * [\r\n * [3],\r\n * [9,20],\r\n * [15,7]\r\n * ]\r\n * \r\n * \r\n */\r\n/**\r\n * Definition for a binary tree node.\r\n * struct TreeNode {\r\n * int val;\r\n * TreeNode *left;\r\n * TreeNode *right;\r\n * TreeNode(int x) : val(x), left(NULL), right(NULL) {}\r\n * };\r\n */\r\nclass Solution\r\n{\r\npublic:\r\n vector<vector<int>> levelOrder(TreeNode *root)\r\n {\r\n vector<vector<int>> res;\r\n if (!root)\r\n {\r\n return res;\r\n }\r\n queue<TreeNode *> myqueue;\r\n myqueue.push(root);\r\n myqueue.push(NULL);\r\n vector<int> cur_vector;\r\n while (!myqueue.empty())\r\n {\r\n TreeNode *t = myqueue.front();\r\n myqueue.pop();\r\n if (t)\r\n {\r\n cur_vector.push_back(t->val);\r\n if (t->left)\r\n {\r\n myqueue.push(t->left);\r\n }\r\n if (t->right)\r\n {\r\n myqueue.push(t->right);\r\n };\r\n }\r\n else\r\n {\r\n res.push_back(cur_vector);\r\n cur_vector.resize(0);\r\n if (myqueue.size() > 0)\r\n {\r\n myqueue.push(NULL);\r\n }\r\n }\r\n }\r\n return res;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.35561054944992065,
"alphanum_fraction": 0.4467821717262268,
"avg_line_length": 19.83783721923828,
"blob_id": "d212790d614a43eb423d9de74637402f14059de8",
"content_id": "760617999575f097050a96501617cbf33ee4f767",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2430,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 111,
"path": "/leetcode-algorithms/989. Add to Array-Form of Integer/989.add-to-array-form-of-integer.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=989 lang=java\r\n *\r\n * [989] Add to Array-Form of Integer\r\n *\r\n * https://leetcode.com/problems/add-to-array-form-of-integer/description/\r\n *\r\n * algorithms\r\n * Easy (44.85%)\r\n * Total Accepted: 12.6K\r\n * Total Submissions: 28.1K\r\n * Testcase Example: '[1,2,0,0]\\n34'\r\n *\r\n * For a non-negative integer X, the array-form of X is an array of its digits\r\n * in left to right order. For example, if X = 1231, then the array form is\r\n * [1,2,3,1].\r\n * \r\n * Given the array-form A of a non-negative integer X, return the array-form of\r\n * the integer X+K.\r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: A = [1,2,0,0], K = 34\r\n * Output: [1,2,3,4]\r\n * Explanation: 1200 + 34 = 1234\r\n * \r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: A = [2,7,4], K = 181\r\n * Output: [4,5,5]\r\n * Explanation: 274 + 181 = 455\r\n * \r\n * \r\n * \r\n * Example 3:\r\n * \r\n * \r\n * Input: A = [2,1,5], K = 806\r\n * Output: [1,0,2,1]\r\n * Explanation: 215 + 806 = 1021\r\n * \r\n * \r\n * \r\n * Example 4:\r\n * \r\n * \r\n * Input: A = [9,9,9,9,9,9,9,9,9,9], K = 1\r\n * Output: [1,0,0,0,0,0,0,0,0,0,0]\r\n * Explanation: 9999999999 + 1 = 10000000000\r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * 1 <= A.length <= 10000\r\n * 0 <= A[i] <= 9\r\n * 0 <= K <= 10000\r\n * If A.length > 1, then A[0] != 0\r\n * \r\n * \r\n * \r\n * \r\n * \r\n */\r\nclass Solution {\r\n int[] sizeTable = new int[] { 9, 99, 999, 9999, 99999, 999999, 9999999, 99999999, 999999999 };\r\n\r\n int stringSize(int x) {\r\n for (int i = 0;; i++) {\r\n if (x <= sizeTable[i]) {\r\n return i + 1;\r\n }\r\n }\r\n }\r\n\r\n public List<Integer> addToArrayForm(int[] A, int K) {\r\n int len = Math.max(A.length, stringSize(K));\r\n List<Integer> sol = new ArrayList<>(len);\r\n for (int i = 0; i < len; i++) {\r\n sol.add(0);\r\n }\r\n for (int i = 1; i < A.length + 1; i++) {\r\n sol.set(sol.size() - i, A[A.length - i]);\r\n }\r\n int plus = (sol.get(sol.size() - 1) + K) / 10;\r\n sol.set(sol.size() - 1, (sol.get(sol.size() - 1) + K) % 10);\r\n for (int i = sol.size() - 2; i >= 0; i--) {\r\n sol.set(i, sol.get(i) + plus);\r\n plus = sol.get(i) / 10;\r\n if (plus != 0) {\r\n sol.set(i, sol.get(i) % 10);\r\n }\r\n }\r\n if (plus != 0) {\r\n sol.add(0, 1);\r\n }\r\n return sol;\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.5221994519233704,
"alphanum_fraction": 0.5362021923065186,
"avg_line_length": 23.9115047454834,
"blob_id": "81e8f2535978daa42658bfd69f58745c787e3be0",
"content_id": "eb5174db8752d33223cc0af04b7007c4f7cd67fd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2940,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 113,
"path": "/leetcode-algorithms/953. Verifying an Alien Dictionary/953.verifying-an-alien-dictionary.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=953 lang=cpp\r\n *\r\n * [953] Verifying an Alien Dictionary\r\n *\r\n * https://leetcode.com/problems/verifying-an-alien-dictionary/description/\r\n *\r\n * algorithms\r\n * Easy (56.29%)\r\n * Likes: 170\r\n * Dislikes: 62\r\n * Total Accepted: 19.3K\r\n * Total Submissions: 34.8K\r\n * Testcase Example: '[\"hello\",\"leetcode\"]\\n\"hlabcdefgijkmnopqrstuvwxyz\"'\r\n *\r\n * In an alien language, surprisingly they also use english lowercase letters,\r\n * but possibly in a different order. The order of the alphabet is some\r\n * permutation of lowercase letters.\r\n * \r\n * Given a sequence of words written in the alien language, and the order of\r\n * the alphabet, return true if and only if the given words are sorted\r\n * lexicographicaly in this alien language.\r\n * \r\n * \r\n * \r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: words = [\"hello\",\"leetcode\"], order = \"hlabcdefgijkmnopqrstuvwxyz\"\r\n * Output: true\r\n * Explanation: As 'h' comes before 'l' in this language, then the sequence is\r\n * sorted.\r\n * \r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: words = [\"word\",\"world\",\"row\"], order = \"worldabcefghijkmnpqstuvxyz\"\r\n * Output: false\r\n * Explanation: As 'd' comes after 'l' in this language, then words[0] >\r\n * words[1], hence the sequence is unsorted.\r\n * \r\n * \r\n * \r\n * Example 3:\r\n * \r\n * \r\n * Input: words = [\"apple\",\"app\"], order = \"abcdefghijklmnopqrstuvwxyz\"\r\n * Output: false\r\n * Explanation: The first three characters \"app\" match, and the second string\r\n * is shorter (in size.) According to lexicographical rules \"apple\" > \"app\",\r\n * because 'l' > '∅', where '∅' is defined as the blank character which is less\r\n * than any other character (More info).\r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * 1 <= words.length <= 100\r\n * 1 <= words[i].length <= 20\r\n * order.length == 26\r\n * All characters in words[i] and order are english lowercase letters.\r\n * \r\n * \r\n * \r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n bool isAlienSorted(vector<string> &words, string order)\r\n {\r\n map<char, int> ordermap;\r\n int value = 1;\r\n for (int i = 0; i < order.length(); i++)\r\n {\r\n ordermap[order[i]] = value++;\r\n }\r\n for (int i = 0; i < words.size() - 1; i++)\r\n {\r\n if (!compare(words[i], words[i + 1], ordermap))\r\n {\r\n return false;\r\n }\r\n }\r\n return true;\r\n }\r\n bool compare(string &a, string &b, map<char, int> &ordermap)\r\n {\r\n int i = 0;\r\n while (i < a.length() && i < b.length())\r\n {\r\n if (ordermap[a[i]] < ordermap[b[i]])\r\n {\r\n return true;\r\n }\r\n else if (ordermap[a[i]] > ordermap[b[i]])\r\n {\r\n return false;\r\n }\r\n else\r\n {\r\n i++;\r\n }\r\n }\r\n return a.length() == b.length() || a.length() < b.length();\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.5058342814445496,
"alphanum_fraction": 0.5472579002380371,
"avg_line_length": 21.80555534362793,
"blob_id": "a375e8fb24a6381bd5addac1ade4116713d890a8",
"content_id": "dfbc23b0dd86a39baa0682f030f8c3d169b92e0f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1714,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 72,
"path": "/leetcode-algorithms/667. Beautiful Arrangement II/667.beautiful-arrangement-ii.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=667 lang=python3\r\n#\r\n# [667] Beautiful Arrangement II\r\n#\r\n# https://leetcode.com/problems/beautiful-arrangement-ii/description/\r\n#\r\n# algorithms\r\n# Medium (51.49%)\r\n# Total Accepted: 17.5K\r\n# Total Submissions: 33.9K\r\n# Testcase Example: '3\\n2'\r\n#\r\n#\r\n# Given two integers n and k, you need to construct a list which contains n\r\n# different positive integers ranging from 1 to n and obeys the following\r\n# requirement:\r\n#\r\n# Suppose this list is [a1, a2, a3, ... , an], then the list [|a1 - a2|, |a2 -\r\n# a3|, |a3 - a4|, ... , |an-1 - an|] has exactly k distinct integers.\r\n#\r\n#\r\n#\r\n# If there are multiple answers, print any of them.\r\n#\r\n#\r\n# Example 1:\r\n#\r\n# Input: n = 3, k = 1\r\n# Output: [1, 2, 3]\r\n# Explanation: The [1, 2, 3] has three different positive integers ranging from\r\n# 1 to 3, and the [1, 1] has exactly 1 distinct integer: 1.\r\n#\r\n#\r\n#\r\n# Example 2:\r\n#\r\n# Input: n = 3, k = 2\r\n# Output: [1, 3, 2]\r\n# Explanation: The [1, 3, 2] has three different positive integers ranging from\r\n# 1 to 3, and the [2, 1] has exactly 2 distinct integers: 1 and 2.\r\n#\r\n#\r\n#\r\n# Note:\r\n#\r\n# The n and k are in the range 1\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def constructArray(self, n: int, k: int) -> List[int]:\r\n sol = []\r\n first = 1\r\n second = k+1\r\n limit = k//2+1\r\n while limit != 0:\r\n limit -= 1\r\n if first != second:\r\n sol.append(first)\r\n sol.append(second)\r\n else:\r\n sol.append(first)\r\n first += 1\r\n second -= 1\r\n first = first+second\r\n while len(sol) != n:\r\n sol.append(first)\r\n first += 1\r\n return sol\r\n"
},
{
"alpha_fraction": 0.42307692766189575,
"alphanum_fraction": 0.4722222089767456,
"avg_line_length": 21.016393661499023,
"blob_id": "293243044b1ae51819f24c0356a9ce004f594975",
"content_id": "0d0f4d60b8c0233d385e9b888dc41513a1b14036",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1406,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 61,
"path": "/leetcode-algorithms/228. Summary Ranges/228.summary-ranges.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=228 lang=cpp\r\n *\r\n * [228] Summary Ranges\r\n *\r\n * https://leetcode.com/problems/summary-ranges/description/\r\n *\r\n * algorithms\r\n * Medium (35.27%)\r\n * Likes: 360\r\n * Dislikes: 359\r\n * Total Accepted: 130.5K\r\n * Total Submissions: 364K\r\n * Testcase Example: '[0,1,2,4,5,7]'\r\n *\r\n * Given a sorted integer array without duplicates, return the summary of its\r\n * ranges.\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: [0,1,2,4,5,7]\r\n * Output: [\"0->2\",\"4->5\",\"7\"]\r\n * Explanation: 0,1,2 form a continuous range; 4,5 form a continuous range.\r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: [0,2,3,4,6,8,9]\r\n * Output: [\"0\",\"2->4\",\"6\",\"8->9\"]\r\n * Explanation: 2,3,4 form a continuous range; 8,9 form a continuous range.\r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n vector<string> summaryRanges(vector<int> &nums)\r\n {\r\n vector<string> result;\r\n int length = nums.size();\r\n for (int i = 0; i < length; i++)\r\n {\r\n int pre = nums[i];\r\n while (i + 1 < length && nums[i + 1] == nums[i] + 1)\r\n {\r\n i++;\r\n }\r\n if (pre == nums[i])\r\n {\r\n result.push_back(to_string(pre));\r\n }\r\n else\r\n {\r\n result.push_back(to_string(pre) + \"->\" + to_string(nums[i]));\r\n }\r\n }\r\n return result;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.543030321598053,
"alphanum_fraction": 0.5939394235610962,
"avg_line_length": 15.934782981872559,
"blob_id": "8b7a48ec6636a6feafbe6cb9e4581b80121d4a7b",
"content_id": "2716e9e39bdc44781a1d3ec11c5dd9f226b3396b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 826,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 46,
"path": "/leetcode-algorithms/136. Single Number/136.single-number.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=136 lang=python3\r\n#\r\n# [136] Single Number\r\n#\r\n# https://leetcode.com/problems/single-number/description/\r\n#\r\n# algorithms\r\n# Easy (60.39%)\r\n# Likes: 2505\r\n# Dislikes: 93\r\n# Total Accepted: 473.3K\r\n# Total Submissions: 783.8K\r\n# Testcase Example: '[2,2,1]'\r\n#\r\n# Given a non-empty array of integers, every element appears twice except for\r\n# one. Find that single one.\r\n#\r\n# Note:\r\n#\r\n# Your algorithm should have a linear runtime complexity. Could you implement\r\n# it without using extra memory?\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: [2,2,1]\r\n# Output: 1\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: [4,1,2,1,2]\r\n# Output: 4\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def singleNumber(self, nums: List[int]) -> int:\r\n res = nums[0]\r\n for num in nums[1:]:\r\n res ^= num\r\n return res\r\n"
},
{
"alpha_fraction": 0.5113415718078613,
"alphanum_fraction": 0.5489306449890137,
"avg_line_length": 17.817073822021484,
"blob_id": "43d2fa40483642b9c2be819be1b5f6b7cb785006",
"content_id": "d439d613737c327d1c536f1e8b80d113e53036fb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1552,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 82,
"path": "/leetcode-algorithms/124. Binary Tree Maximum Path Sum/124.binary-tree-maximum-path-sum.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\n * @lc app=leetcode id=124 lang=cpp\n *\n * [124] Binary Tree Maximum Path Sum\n *\n * https://leetcode.com/problems/binary-tree-maximum-path-sum/description/\n *\n * algorithms\n * Hard (31.32%)\n * Likes: 2839\n * Dislikes: 240\n * Total Accepted: 294.1K\n * Total Submissions: 900.7K\n * Testcase Example: '[1,2,3]'\n *\n * Given a non-empty binary tree, find the maximum path sum.\n * \n * For this problem, a path is defined as any sequence of nodes from some\n * starting node to any node in the tree along the parent-child connections.\n * The path must contain at least one node and does not need to go through the\n * root.\n * \n * Example 1:\n * \n * \n * Input: [1,2,3]\n * \n * 1\n * / \\\n * 2 3\n * \n * Output: 6\n * \n * \n * Example 2:\n * \n * \n * Input: [-10,9,20,null,null,15,7]\n * \n * -10\n * / \\\n * 9 20\n * / \\\n * 15 7\n * \n * Output: 42\n * \n * \n */\n\n// @lc code=start\n/**\n * Definition for a binary tree node.\n * struct TreeNode {\n * int val;\n * TreeNode *left;\n * TreeNode *right;\n * TreeNode(int x) : val(x), left(NULL), right(NULL) {}\n * };\n */\nclass Solution\n{\npublic:\n int res = INT_MIN;\n int maxPathSum(TreeNode *root)\n {\n pathCalc(root);\n return res;\n }\n int pathCalc(TreeNode *root)\n {\n if (!root)\n {\n return 0;\n }\n int left = max(pathCalc(root->left), 0);\n int right = max(pathCalc(root->right), 0);\n res = max(res, left + right + root->val);\n return max(left, right) + root->val;\n }\n};\n// @lc code=end\n"
},
{
"alpha_fraction": 0.4513692259788513,
"alphanum_fraction": 0.49952784180641174,
"avg_line_length": 27.41666603088379,
"blob_id": "195937695947601ab9d0162cef33b5e3305f19c1",
"content_id": "ffc0722b3163dfc7005db5541d974a76d2d19d92",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2118,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 72,
"path": "/leetcode-algorithms/002. Add Two Numbers/2.add-two-numbers.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=2 lang=java\r\n *\r\n * [2] Add Two Numbers\r\n *\r\n * https://leetcode.com/problems/add-two-numbers/description/\r\n *\r\n * algorithms\r\n * Medium (30.66%)\r\n * Likes: 5024\r\n * Dislikes: 1280\r\n * Total Accepted: 848.6K\r\n * Total Submissions: 2.7M\r\n * Testcase Example: '[2,4,3]\\n[5,6,4]'\r\n *\r\n * You are given two non-empty linked lists representing two non-negative\r\n * integers. The digits are stored in reverse order and each of their nodes\r\n * contain a single digit. Add the two numbers and return it as a linked list.\r\n * \r\n * You may assume the two numbers do not contain any leading zero, except the\r\n * number 0 itself.\r\n * \r\n * Example:\r\n * \r\n * \r\n * Input: (2 . 4 . 3) + (5 . 6 . 4)\r\n * Output: 7 . 0 . 8\r\n * Explanation: 342 + 465 = 807.\r\n * \r\n * \r\n */\r\n/**\r\n * Definition for singly-linked list. public class ListNode { int val; ListNode\r\n * next; ListNode(int x) { val = x; } }\r\n */\r\nclass Solution {\r\n public ListNode addTwoNumbers(ListNode l1, ListNode l2) {\r\n if (l1.next == null && l1.val == 0)\r\n return l2;\r\n if (l2.next == null && l2.val == 0)\r\n return l1;\r\n ListNode p1 = l1, p2 = l2;\r\n ListNode sol = new ListNode(0);\r\n ListNode head = sol;\r\n head.next = null;\r\n int plus = (p1.val + p2.val) / 10;\r\n sol.val = (p1.val + p2.val) % 10;\r\n p1 = p1.next;\r\n p2 = p2.next;\r\n while (p1 != null || p2 != null) {\r\n ListNode temp = new ListNode(0);\r\n int val1, val2;\r\n val1 = p1 == null ? 0 : p1.val;\r\n p1 = p1 == null ? p1 : p1.next;\r\n val2 = p2 == null ? 0 : p2.val;\r\n p2 = p2 == null ? p2 : p2.next;\r\n temp.next = null;\r\n temp.val = val1 + val2 + plus;\r\n plus = temp.val / 10;\r\n temp.val %= 10;\r\n sol.next = temp;\r\n sol = sol.next;\r\n }\r\n if (plus != 0) {\r\n ListNode temp = new ListNode(0);\r\n temp.next = null;\r\n temp.val = 1;\r\n sol.next = temp;\r\n }\r\n return head;\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.5047022104263306,
"alphanum_fraction": 0.5360501408576965,
"avg_line_length": 16.764705657958984,
"blob_id": "dd1d63432b10c4e86685820ad763a7933ef0eeef",
"content_id": "b8b63720766623842849b2803f9cac6793c0c8a4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 961,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 51,
"path": "/leetcode-algorithms/069. Sqrt(x)/69.sqrt-x.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=69 lang=cpp\r\n *\r\n * [69] Sqrt(x)\r\n *\r\n * https://leetcode.com/problems/sqrtx/description/\r\n *\r\n * algorithms\r\n * Easy (30.74%)\r\n * Total Accepted: 339.1K\r\n * Total Submissions: 1.1M\r\n * Testcase Example: '4'\r\n *\r\n * Implement int sqrt(int x).\r\n * \r\n * Compute and return the square root of x, where x is guaranteed to be a\r\n * non-negative integer.\r\n * \r\n * Since the return type is an integer, the decimal digits are truncated and\r\n * only the integer part of the result is returned.\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: 4\r\n * Output: 2\r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: 8\r\n * Output: 2\r\n * Explanation: The square root of 8 is 2.82842..., and since \r\n * the decimal part is truncated, 2 is returned.\r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n int mySqrt(int x)\r\n {\r\n long r = x;\r\n while (r * r > x)\r\n {\r\n r = (r + x / r) / 2;\r\n }\r\n return r;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.5407794117927551,
"alphanum_fraction": 0.573322594165802,
"avg_line_length": 25.351648330688477,
"blob_id": "68598b0c0337bcb1dd1ead28e39f156a479443a0",
"content_id": "3d6bb48e9481c8b234649a3f0afbd00231270ecd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2536,
"license_type": "permissive",
"max_line_length": 134,
"num_lines": 91,
"path": "/leetcode-algorithms/706. Design HashMap/706.design-hash-map.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=706 lang=cpp\r\n *\r\n * [706] Design HashMap\r\n *\r\n * https://leetcode.com/problems/design-hashmap/description/\r\n *\r\n * algorithms\r\n * Easy (56.23%)\r\n * Likes: 341\r\n * Dislikes: 59\r\n * Total Accepted: 38.2K\r\n * Total Submissions: 67.6K\r\n * Testcase Example: '[\"MyHashMap\",\"put\",\"put\",\"get\",\"get\",\"put\",\"get\", \"remove\", \"get\"]\\n[[],[1,1],[2,2],[1],[3],[2,1],[2],[2],[2]]'\r\n *\r\n * Design a HashMap without using any built-in hash table libraries.\r\n * \r\n * To be specific, your design should include these functions:\r\n * \r\n * \r\n * put(key, value) : Insert a (key, value) pair into the HashMap. If the value\r\n * already exists in the HashMap, update the value.\r\n * get(key): Returns the value to which the specified key is mapped, or -1 if\r\n * this map contains no mapping for the key.\r\n * remove(key) : Remove the mapping for the value key if this map contains the\r\n * mapping for the key.\r\n * \r\n * \r\n * \r\n * Example:\r\n * \r\n * \r\n * MyHashMap hashMap = new MyHashMap();\r\n * hashMap.put(1, 1); \r\n * hashMap.put(2, 2); \r\n * hashMap.get(1); // returns 1\r\n * hashMap.get(3); // returns -1 (not found)\r\n * hashMap.put(2, 1); // update the existing value\r\n * hashMap.get(2); // returns 1 \r\n * hashMap.remove(2); // remove the mapping for 2\r\n * hashMap.get(2); // returns -1 (not found) \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * All keys and values will be in the range of [0, 1000000].\r\n * The number of operations will be in the range of [1, 10000].\r\n * Please do not use the built-in HashMap library.\r\n * \r\n * \r\n */\r\nclass MyHashMap\r\n{\r\nprivate:\r\n int data[1000001];\r\n\r\npublic:\r\n /** Initialize your data structure here. */\r\n MyHashMap()\r\n {\r\n memset(data, -1, sizeof(int) * 1000001);\r\n }\r\n\r\n /** value will always be non-negative. */\r\n void put(int key, int value)\r\n {\r\n data[key] = value;\r\n }\r\n\r\n /** Returns the value to which the specified key is mapped, or -1 if this map contains no mapping for the key */\r\n int get(int key)\r\n {\r\n return data[key];\r\n }\r\n\r\n /** Removes the mapping of the specified value key if this map contains a mapping for the key */\r\n void remove(int key)\r\n {\r\n data[key] = -1;\r\n }\r\n};\r\n\r\n/**\r\n * Your MyHashMap object will be instantiated and called as such:\r\n * MyHashMap* obj = new MyHashMap();\r\n * obj->put(key,value);\r\n * int param_2 = obj->get(key);\r\n * obj->remove(key);\r\n */\r\n"
},
{
"alpha_fraction": 0.450647234916687,
"alphanum_fraction": 0.5105177760124207,
"avg_line_length": 20.071428298950195,
"blob_id": "4a9d70d2b93e4a5440844ffb158404b469ae5135",
"content_id": "d1df85903b985f2cdf36758c6e56bcc103c96d83",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1236,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 56,
"path": "/leetcode-algorithms/643. Maximum Average Subarray I/643.maximum-average-subarray-i.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=643 lang=cpp\r\n *\r\n * [643] Maximum Average Subarray I\r\n *\r\n * https://leetcode.com/problems/maximum-average-subarray-i/description/\r\n *\r\n * algorithms\r\n * Easy (39.06%)\r\n * Total Accepted: 49.2K\r\n * Total Submissions: 125.2K\r\n * Testcase Example: '[1,12,-5,-6,50,3]\\n4'\r\n *\r\n * Given an array consisting of n integers, find the contiguous subarray of\r\n * given length k that has the maximum average value. And you need to output\r\n * the maximum average value.\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: [1,12,-5,-6,50,3], k = 4\r\n * Output: 12.75\r\n * Explanation: Maximum average is (12-5-6+50)/4 = 51/4 = 12.75\r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * 1 <= k <= n <= 30,000.\r\n * Elements of the given array will be in the range [-10,000, 10,000].\r\n * \r\n * \r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n double findMaxAverage(vector<int> &nums, int k)\r\n {\r\n int sum = 0, maxsum;\r\n for (int i = 0; i < k; i++)\r\n {\r\n sum += nums[i];\r\n }\r\n maxsum = sum;\r\n for (int i = k; i < nums.size(); i++)\r\n {\r\n sum = sum - nums[i - k] + nums[i];\r\n maxsum = max(maxsum, sum);\r\n }\r\n return maxsum * 1.0 / k;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.4229249060153961,
"alphanum_fraction": 0.4537549316883087,
"avg_line_length": 16.880596160888672,
"blob_id": "efc86728fe01d6810c708a484071f10362af284c",
"content_id": "efef3e63760117e5e4866f753b48020f64e71f41",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1265,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 67,
"path": "/leetcode-algorithms/083. Remove Duplicates from Sorted List/83.remove-duplicates-from-sorted-list.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=83 lang=cpp\r\n *\r\n * [83] Remove Duplicates from Sorted List\r\n *\r\n * https://leetcode.com/problems/remove-duplicates-from-sorted-list/description/\r\n *\r\n * algorithms\r\n * Easy (41.95%)\r\n * Likes: 774\r\n * Dislikes: 82\r\n * Total Accepted: 333.1K\r\n * Total Submissions: 779.9K\r\n * Testcase Example: '[1,1,2]'\r\n *\r\n * Given a sorted linked list, delete all duplicates such that each element\r\n * appear only once.\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: 1->1->2\r\n * Output: 1->2\r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: 1->1->2->3->3\r\n * Output: 1->2->3\r\n * \r\n * \r\n */\r\n/**\r\n * Definition for singly-linked list.\r\n * struct ListNode {\r\n * int val;\r\n * ListNode *next;\r\n * ListNode(int x) : val(x), next(NULL) {}\r\n * };\r\n */\r\nclass Solution\r\n{\r\npublic:\r\n ListNode *deleteDuplicates(ListNode *head)\r\n {\r\n if (!head)\r\n {\r\n return head;\r\n }\r\n ListNode *p = head;\r\n ListNode *q = p->next;\r\n while (q)\r\n {\r\n if (p->val == q->val)\r\n {\r\n p->next = q->next;\r\n q = q->next;\r\n }\r\n else\r\n {\r\n p = p->next;\r\n }\r\n }\r\n return head;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.5094197392463684,
"alphanum_fraction": 0.5599095821380615,
"avg_line_length": 23.037734985351562,
"blob_id": "4f9958116ef5294e3c329d52bce3739d9b2f56e3",
"content_id": "dbae5f2aa571f9f147b4fa943f555992e05d7f0b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1328,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 53,
"path": "/leetcode-algorithms/202. Happy Number/202.happy-number.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=202 lang=python3\r\n#\r\n# [202] Happy Number\r\n#\r\n# https://leetcode.com/problems/happy-number/description/\r\n#\r\n# algorithms\r\n# Easy (44.35%)\r\n# Likes: 825\r\n# Dislikes: 201\r\n# Total Accepted: 228K\r\n# Total Submissions: 507K\r\n# Testcase Example: '19'\r\n#\r\n# Write an algorithm to determine if a number is \"happy\".\r\n#\r\n# A happy number is a number defined by the following process: Starting with\r\n# any positive integer, replace the number by the sum of the squares of its\r\n# digits, and repeat the process until the number equals 1 (where it will\r\n# stay), or it loops endlessly in a cycle which does not include 1. Those\r\n# numbers for which this process ends in 1 are happy numbers.\r\n#\r\n# Example: \r\n#\r\n#\r\n# Input: 19\r\n# Output: true\r\n# Explanation:\r\n# 1^2 + 9^2 = 82\r\n# 8^2 + 2^2 = 68\r\n# 6^2 + 8^2 = 100\r\n# 1^2 + 0^2 + 0^2 = 1\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def isHappy(self, n: int) -> bool:\r\n def getNumSum(n):\r\n ans = 0\r\n while n:\r\n ans += math.pow(n % 10, 2)\r\n n //= 10\r\n return ans\r\n rep = [False for _ in range(1000)]\r\n n = int(getNumSum(n))\r\n while not rep[n]:\r\n rep[n] = True\r\n if n == 1:\r\n return True\r\n n = int(getNumSum(n))\r\n return False\r\n"
},
{
"alpha_fraction": 0.49142858386039734,
"alphanum_fraction": 0.5342857241630554,
"avg_line_length": 20.580644607543945,
"blob_id": "9360f0565a811803ec6f9e196880b9bd32505ddd",
"content_id": "83520c1dd7234820d33334d064d9401f72807ccd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1400,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 62,
"path": "/leetcode-algorithms/674. Longest Continuous Increasing Subsequence/674.longest-continuous-increasing-subsequence.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=674 lang=cpp\r\n *\r\n * [674] Longest Continuous Increasing Subsequence\r\n *\r\n * https://leetcode.com/problems/longest-continuous-increasing-subsequence/description/\r\n *\r\n * algorithms\r\n * Easy (43.82%)\r\n * Total Accepted: 63.6K\r\n * Total Submissions: 144.3K\r\n * Testcase Example: '[1,3,5,4,7]'\r\n *\r\n * \r\n * Given an unsorted array of integers, find the length of longest continuous\r\n * increasing subsequence (subarray).\r\n * \r\n * \r\n * Example 1:\r\n * \r\n * Input: [1,3,5,4,7]\r\n * Output: 3\r\n * Explanation: The longest continuous increasing subsequence is [1,3,5], its\r\n * length is 3. \r\n * Even though [1,3,5,7] is also an increasing subsequence, it's not a\r\n * continuous one where 5 and 7 are separated by 4. \r\n * \r\n * \r\n * \r\n * Example 2:\r\n * \r\n * Input: [2,2,2,2,2]\r\n * Output: 1\r\n * Explanation: The longest continuous increasing subsequence is [2], its\r\n * length is 1. \r\n * \r\n * \r\n * \r\n * Note:\r\n * Length of the array will not exceed 10,000.\r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n int findLengthOfLCIS(vector<int> &nums)\r\n {\r\n int sol = 0, count = 0;\r\n for (int i = 0; i < nums.size(); i++)\r\n {\r\n if (i == 0 || nums[i] > nums[i - 1])\r\n {\r\n sol = max(++count, sol);\r\n }\r\n else\r\n {\r\n count = 1;\r\n }\r\n }\r\n return sol;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.4511008560657501,
"alphanum_fraction": 0.4910394251346588,
"avg_line_length": 23.363636016845703,
"blob_id": "625b061946026c795a4cee04eb1df90d683d7fa5",
"content_id": "9394f009f6500cb9e9b7e89b1f35102ee0b0ffca",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1953,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 77,
"path": "/leetcode-algorithms/697. Degree of an Array/697.degree-of-an-array.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=697 lang=cpp\r\n *\r\n * [697] Degree of an Array\r\n *\r\n * https://leetcode.com/problems/degree-of-an-array/description/\r\n *\r\n * algorithms\r\n * Easy (49.35%)\r\n * Total Accepted: 46.4K\r\n * Total Submissions: 92.9K\r\n * Testcase Example: '[1,2,2,3,1]'\r\n *\r\n * Given a non-empty array of non-negative integers nums , the\r\n * degree of this array is defined as the maximum frequency of any one\r\n * of its elements. \r\n * Your task is to find the smallest possible length of a (contiguous)\r\n * subarray of nums , that has the same degree as\r\n * nums . \r\n * \r\n * Example 1: \r\n * \r\n * Input: [1, 2, 2, 3, 1]\r\n * Output: 2\r\n * Explanation: \r\n * The input array has a degree of 2 because both elements 1 and 2 appear\r\n * twice.\r\n * Of the subarrays that have the same degree:\r\n * [1, 2, 2, 3, 1], [1, 2, 2, 3], [2, 2, 3, 1], [1, 2, 2], [2, 2, 3], [2, 2]\r\n * The shortest length is 2. So return 2.\r\n * \r\n * \r\n * \r\n * \r\n * Example 2: \r\n * \r\n * Input: [1,2,2,3,1,4,2]\r\n * Output: 6\r\n * \r\n * \r\n * \r\n * Note: \r\n * nums.length will be between 1 and 50,000. \r\n * nums[i] will be an integer between 0 and 49,999. \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n int findShortestSubArray(vector<int> &nums)\r\n {\r\n unordered_map<int, int> sol;\r\n unordered_map<int, int> begin;\r\n unordered_map<int, int> end;\r\n int it = 0, max = 0;\r\n for (auto t : nums)\r\n {\r\n sol[t]++;\r\n max = max > sol[t] ? max : sol[t];\r\n if (!begin.count(t))\r\n {\r\n begin[t] = it;\r\n }\r\n end[t] = it++;\r\n }\r\n int soultion = INT_MAX;\r\n for (auto t : sol)\r\n {\r\n if (t.second == max)\r\n {\r\n int dis = end[t.first] - begin[t.first] + 1;\r\n soultion = soultion < dis ? soultion : dis;\r\n }\r\n }\r\n return soultion;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.5153284668922424,
"alphanum_fraction": 0.5795620679855347,
"avg_line_length": 13.568181991577148,
"blob_id": "a6fee94523b006e6e879856b44ba8be4c8e2c102",
"content_id": "2c65b5de92b6e293cd6d02a45339562cc41c28f0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 687,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 44,
"path": "/leetcode-algorithms/231. Power of Two/231.power-of-two.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=231 lang=python3\r\n#\r\n# [231] Power of Two\r\n#\r\n# https://leetcode.com/problems/power-of-two/description/\r\n#\r\n# algorithms\r\n# Easy (42.22%)\r\n# Likes: 496\r\n# Dislikes: 137\r\n# Total Accepted: 245.2K\r\n# Total Submissions: 579.6K\r\n# Testcase Example: '1'\r\n#\r\n# Given an integer, write a function to determine if it is a power of two.\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: 1\r\n# Output: true\r\n# Explanation: 2^0 = 1\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: 16\r\n# Output: true\r\n# Explanation: 2^4 = 16\r\n#\r\n# Example 3:\r\n#\r\n#\r\n# Input: 218\r\n# Output: false\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def isPowerOfTwo(self, n: int) -> bool:\r\n return n > 0 and not(n & (n - 1))\r\n"
},
{
"alpha_fraction": 0.38599106669425964,
"alphanum_fraction": 0.44361647963523865,
"avg_line_length": 21.13793182373047,
"blob_id": "bbca124f508a238de7b53d584d430d0f3175ec08",
"content_id": "f57c7f91ac0be8a7e27c6bd82c9e447d3351f556",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2013,
"license_type": "permissive",
"max_line_length": 131,
"num_lines": 87,
"path": "/leetcode-algorithms/628. Maximum Product of Three Numbers/628.maximum-product-of-three-numbers.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=628 lang=cpp\r\n *\r\n * [628] Maximum Product of Three Numbers\r\n *\r\n * https://leetcode.com/problems/maximum-product-of-three-numbers/description/\r\n *\r\n * algorithms\r\n * Easy (45.61%)\r\n * Total Accepted: 66.3K\r\n * Total Submissions: 144.7K\r\n * Testcase Example: '[1,2,3]'\r\n *\r\n * Given an integer array, find three numbers whose product is maximum and\r\n * output the maximum product.\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: [1,2,3]\r\n * Output: 6\r\n * \r\n * \r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: [1,2,3,4]\r\n * Output: 24\r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * The length of the given array will be in range [3,10^4] and all elements are\r\n * in the range [-1000, 1000].\r\n * Multiplication of any three numbers in the input won't exceed the range of\r\n * 32-bit signed integer.\r\n * \r\n * \r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n int maximumProduct(vector<int> &nums)\r\n {\r\n int min1 = 99999, min2 = 9999999;\r\n int max1 = -99999, max2 = -99999999, max3 = -99999999;\r\n for (int i = 0; i < nums.size(); i++)\r\n {\r\n if (nums[i] <= min1)\r\n {\r\n min2 = min1;\r\n min1 = nums[i];\r\n }\r\n else if (nums[i] <= min2)\r\n {\r\n min2 = nums[i];\r\n }\r\n if (nums[i] >= max1)\r\n {\r\n max3 = max2;\r\n max2 = max1;\r\n max1 = nums[i];\r\n }\r\n else if (nums[i] >= max2)\r\n {\r\n max3 = max2;\r\n max2 = nums[i];\r\n }\r\n else if (nums[i] >= max3)\r\n {\r\n max3 = nums[i];\r\n }\r\n }\r\n // sort(nums.begin(),nums.end());\r\n // int maxs=0;\r\n // maxs=max(nums[nums.size()-1]*nums[nums.size()-2]*nums[nums.size()-3],nums[0]*nums[1]*nums[nums.size()-1]);\r\n int maxs = max(max1 * min1 * min2, max1 * max2 * max3);\r\n return maxs;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.4280094504356384,
"alphanum_fraction": 0.46656176447868347,
"avg_line_length": 20.298246383666992,
"blob_id": "0562c40c702a8737a8fa6b1c2f4754fe94244424",
"content_id": "23112886dbba49bb7c6d2024298321c6094e5f3b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1420,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 57,
"path": "/leetcode-algorithms/118. Pascal's Triangle/118.pascals-triangle.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=118 lang=cpp\r\n *\r\n * [118] Pascal's Triangle\r\n *\r\n * https://leetcode.com/problems/pascals-triangle/description/\r\n *\r\n * algorithms\r\n * Easy (44.68%)\r\n * Total Accepted: 241.2K\r\n * Total Submissions: 532.3K\r\n * Testcase Example: '5'\r\n *\r\n * Given a non-negative integer numRows, generate the first numRows of Pascal's\r\n * triangle.\r\n * \r\n * \r\n * In Pascal's triangle, each number is the sum of the two numbers directly\r\n * above it.\r\n * \r\n * Example:\r\n * \r\n * \r\n * Input: 5\r\n * Output:\r\n * [\r\n * [1],\r\n * [1,1],\r\n * [1,2,1],\r\n * [1,3,3,1],\r\n * [1,4,6,4,1]\r\n * ]\r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n vector<vector<int>> generate(int numRows)\r\n {\r\n vector<vector<int>> map(numRows); //初始化二维数组\r\n for (int i = 0; i < numRows; i++) //初始化二维数组的每一行\r\n {\r\n map[i].resize(i + 1, 1);\r\n //map[i] = new int[i + 1];\r\n //map[i][0] = map[i][i] = 1; //每一行的开头和末尾置1\r\n }\r\n for (int i = 2; i < numRows; i++) //从第三行开始\r\n {\r\n for (int j = 1; j < i; j++) //对于这一行中的第二个到倒数第二个数\r\n {\r\n map[i][j] = (map[i - 1][j] + map[i - 1][j - 1]); //每一个数位上一行上一列于这一列的和模10\r\n }\r\n }\r\n return map;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.5070796608924866,
"alphanum_fraction": 0.5345132946968079,
"avg_line_length": 20.711538314819336,
"blob_id": "00dc2ff38015fe3a93fef3cb5504d49aebe478f4",
"content_id": "ebd7b0aa1420cbc5821e495c10cf941540cc517f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Kotlin",
"length_bytes": 1130,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 52,
"path": "/leetcode-algorithms/344. Reverse String/344.reverse-string.kt",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\n * @lc app=leetcode id=344 lang=kotlin\n *\n * [344] Reverse String\n *\n * https://leetcode.com/problems/reverse-string/description/\n *\n * algorithms\n * Easy (70.65%)\n * Likes: 2351\n * Dislikes: 772\n * Total Accepted: 1M\n * Total Submissions: 1.5M\n * Testcase Example: '[\"h\",\"e\",\"l\",\"l\",\"o\"]'\n *\n * Write a function that reverses a string. The input string is given as an\n * array of characters s.\n * \n * \n * Example 1:\n * Input: s = [\"h\",\"e\",\"l\",\"l\",\"o\"]\n * Output: [\"o\",\"l\",\"l\",\"e\",\"h\"]\n * Example 2:\n * Input: s = [\"H\",\"a\",\"n\",\"n\",\"a\",\"h\"]\n * Output: [\"h\",\"a\",\"n\",\"n\",\"a\",\"H\"]\n * \n * \n * Constraints:\n * \n * \n * 1 <= s.length <= 10^5\n * s[i] is a printable ascii character.\n * \n * \n * \n * Follow up: Do not allocate extra space for another array. You must do this\n * by modifying the input array in-place with O(1) extra memory.\n * \n */\n\n// @lc code=start\nclass Solution {\n fun reverseString(s: CharArray): Unit {\n val length = s.size\n for (i in 0 until (length / 2)) {\n val ch = s[i]\n s[i] = s[length - i - 1]\n s[length - i - 1] = ch\n }\n }\n}\n// @lc code=end\n\n"
},
{
"alpha_fraction": 0.4038997292518616,
"alphanum_fraction": 0.4466109573841095,
"avg_line_length": 20.4375,
"blob_id": "500533ce394659bcd83c1332fa48d1c92ded32e6",
"content_id": "7f0b22825d25aaf7ef465ff0e5aabb0c778ac653",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1077,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 48,
"path": "/leetcode-algorithms/204. Count Primes/204.count-primes.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=204 lang=java\r\n *\r\n * [204] Count Primes\r\n *\r\n * https://leetcode.com/problems/count-primes/description/\r\n *\r\n * algorithms\r\n * Easy (29.13%)\r\n * Likes: 1106\r\n * Dislikes: 419\r\n * Total Accepted: 245.7K\r\n * Total Submissions: 840.2K\r\n * Testcase Example: '10'\r\n *\r\n * Count the number of prime numbers less than a non-negative number, n.\r\n * \r\n * Example:\r\n * \r\n * \r\n * Input: 10\r\n * Output: 4\r\n * Explanation: There are 4 prime numbers less than 10, they are 2, 3, 5, 7.\r\n * \r\n * \r\n */\r\nclass Solution {\r\n public int countPrimes(int n) {\r\n if (n == 0 || n == 1) {\r\n return 0;\r\n }\r\n boolean[] res = new boolean[n];\r\n res[0] = true;\r\n res[1] = true;\r\n for (int i = 0; i * i < n; i++) {\r\n if (!res[i]) {\r\n for (int j = i * i; j < n; j += i) {\r\n res[j] = true;\r\n }\r\n }\r\n }\r\n int count = 0;\r\n for (boolean var : res) {\r\n count += var ? 0 : 1;\r\n }\r\n return count;\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.4629460275173187,
"alphanum_fraction": 0.4949679672718048,
"avg_line_length": 18.240739822387695,
"blob_id": "8cd0a02df31958debae674f9424d62b8f6aaaf70",
"content_id": "cb03bb2bcbe841c3ed0a52ce62538adc331c2fb7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1093,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 54,
"path": "/leetcode-algorithms/387. First Unique Character in a String/387.first-unique-character-in-a-string.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=387 lang=cpp\r\n *\r\n * [387] First Unique Character in a String\r\n *\r\n * https://leetcode.com/problems/first-unique-character-in-a-string/description/\r\n *\r\n * algorithms\r\n * Easy (50.17%)\r\n * Likes: 1055\r\n * Dislikes: 80\r\n * Total Accepted: 283.3K\r\n * Total Submissions: 563.2K\r\n * Testcase Example: '\"leetcode\"'\r\n *\r\n * \r\n * Given a string, find the first non-repeating character in it and return it's\r\n * index. If it doesn't exist, return -1.\r\n * \r\n * Examples:\r\n * \r\n * s = \"leetcode\"\r\n * return 0.\r\n * \r\n * s = \"loveleetcode\",\r\n * return 2.\r\n * \r\n * \r\n * \r\n * \r\n * Note: You may assume the string contain only lowercase letters.\r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n int firstUniqChar(string s)\r\n {\r\n int result[26];\r\n memset(result, 0, sizeof(int) * 26);\r\n for (auto t : s)\r\n {\r\n result[t - 'a']++;\r\n }\r\n for (int i = 0; i < s.length(); i++)\r\n {\r\n if (result[s[i] - 'a'] == 1)\r\n {\r\n return i;\r\n }\r\n }\r\n return -1;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.437724232673645,
"alphanum_fraction": 0.4623270034790039,
"avg_line_length": 20.686046600341797,
"blob_id": "1781c3dbde1fcc63bf0e8b5428eef7ce5962b801",
"content_id": "4ba9085977d69ac8f1477ccc0a8fa6d6bf4e108f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1956,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 86,
"path": "/leetcode-algorithms/1002. Find Common Characters/1002.find-common-characters.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=1002 lang=cpp\r\n *\r\n * [1002] Find Common Characters\r\n *\r\n * https://leetcode.com/problems/find-common-characters/description/\r\n *\r\n * algorithms\r\n * Easy (69.05%)\r\n * Total Accepted: 17.1K\r\n * Total Submissions: 25.9K\r\n * Testcase Example: '[\"bella\",\"label\",\"roller\"]'\r\n *\r\n * Given an array A of strings made only from lowercase letters, return a list\r\n * of all characters that show up in all strings within the list (including\r\n * duplicates). For example, if a character occurs 3 times in all strings but\r\n * not 4 times, you need to include that character three times in the final\r\n * answer.\r\n * \r\n * You may return the answer in any order.\r\n * \r\n * \r\n * \r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: [\"bella\",\"label\",\"roller\"]\r\n * Output: [\"e\",\"l\",\"l\"]\r\n * \r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: [\"cool\",\"lock\",\"cook\"]\r\n * Output: [\"c\",\"o\"]\r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * 1 <= A.length <= 100\r\n * 1 <= A[i].length <= 100\r\n * A[i][j] is a lowercase letter\r\n * \r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n vector<string> commonChars(vector<string> &A)\r\n {\r\n vector<int> charcount(26, 0);\r\n for (auto i = 0; i < A[0].length(); i++)\r\n {\r\n charcount[A[0][i] - 'a']++;\r\n }\r\n for (auto i = 1; i < A.size(); i++)\r\n {\r\n vector<int> tempcount(26, 0);\r\n for (char t : A[i])\r\n {\r\n tempcount[t - 'a']++;\r\n }\r\n for (auto j = 0; j < 26; j++)\r\n {\r\n charcount[j] = min(charcount[j], tempcount[j]);\r\n }\r\n }\r\n vector<string> sol;\r\n for (auto i = 0; i < 26; i++)\r\n {\r\n for (auto j = 0; j < charcount[i]; j++)\r\n {\r\n char temp = 'a' + i;\r\n string tempp = string(1, temp);\r\n sol.push_back(tempp);\r\n }\r\n }\r\n return sol;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.416481077671051,
"alphanum_fraction": 0.46250927448272705,
"avg_line_length": 22.94444465637207,
"blob_id": "806a240420c38e0b1ce23face4c3c9ae982e0d87",
"content_id": "fb800efc710481016edefd5eb5f4511f9ad1afec",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1348,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 54,
"path": "/leetcode-algorithms/067. Add Binary/67.add-binary.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=67 lang=java\r\n *\r\n * [67] Add Binary\r\n *\r\n * https://leetcode.com/problems/add-binary/description/\r\n *\r\n * algorithms\r\n * Easy (39.39%)\r\n * Likes: 987\r\n * Dislikes: 198\r\n * Total Accepted: 309.7K\r\n * Total Submissions: 785.9K\r\n * Testcase Example: '\"11\"\\n\"1\"'\r\n *\r\n * Given two binary strings, return their sum (also a binary string).\r\n * \r\n * The input strings are both non-empty and contains only characters 1 or 0.\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: a = \"11\", b = \"1\"\r\n * Output: \"100\"\r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: a = \"1010\", b = \"1011\"\r\n * Output: \"10101\"\r\n * \r\n */\r\nclass Solution {\r\n public String addBinary(String a, String b) {\r\n StringBuilder res = new StringBuilder();\r\n int plus = 0;\r\n int i = a.length() - 1, j = b.length() - 1;\r\n while (i >= 0 || j >= 0 || plus > 0) {\r\n if (i >= 0) {\r\n plus += a.charAt(i) - '0';\r\n // plus += Character.getNumericValue(a.charAt(i));\r\n i -= 1;\r\n }\r\n if (j >= 0) {\r\n plus += b.charAt(j) - '0';\r\n // plus += Character.getNumericValue(b.charAt(j));\r\n j -= 1;\r\n }\r\n res.append(plus % 2);\r\n plus /= 2;\r\n }\r\n return res.reverse().toString();\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.46517953276634216,
"alphanum_fraction": 0.5195865035057068,
"avg_line_length": 24.257143020629883,
"blob_id": "46b862592e71cfa7d45b92f175bacc4efdf6e497",
"content_id": "56fb8bb498812efe25cbead058e1c050213681e3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1838,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 70,
"path": "/leetcode-algorithms/697. Degree of an Array/697.degree-of-an-array.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=697 lang=python3\r\n#\r\n# [697] Degree of an Array\r\n#\r\n# https://leetcode.com/problems/degree-of-an-array/description/\r\n#\r\n# algorithms\r\n# Easy (49.35%)\r\n# Total Accepted: 46.4K\r\n# Total Submissions: 92.9K\r\n# Testcase Example: '[1,2,2,3,1]'\r\n#\r\n# Given a non-empty array of non-negative integers nums , the\r\n# degree of this array is defined as the maximum frequency of any one of\r\n# its elements.\r\n# Your task is to find the smallest possible length of a (contiguous)\r\n# subarray of nums , that has the same degree as\r\n# nums .\r\n#\r\n# Example 1:\r\n#\r\n# Input: [1, 2, 2, 3, 1]\r\n# Output: 2\r\n# Explanation:\r\n# The input array has a degree of 2 because both elements 1 and 2 appear twice.\r\n# Of the subarrays that have the same degree:\r\n# [1, 2, 2, 3, 1], [1, 2, 2, 3], [2, 2, 3, 1], [1, 2, 2], [2, 2, 3], [2, 2]\r\n# The shortest length is 2. So return 2.\r\n#\r\n#\r\n#\r\n#\r\n# Example 2:\r\n#\r\n# Input: [1,2,2,3,1,4,2]\r\n# Output: 6\r\n#\r\n#\r\n#\r\n# Note:\r\n# nums.length will be between 1 and 50,000.\r\n# nums[i] will be an integer between 0 and 49,999.\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def findShortestSubArray(self, nums: List[int]) -> int:\r\n sol = {}\r\n begin = {}\r\n end = {}\r\n it = 0\r\n max1 = 0\r\n for t in nums:\r\n if t not in sol:\r\n sol[t] = 1\r\n else:\r\n sol[t] += 1\r\n max1 = max1 if max1 > sol[t] else sol[t]\r\n if t not in begin:\r\n begin[t] = it\r\n end[t] = it\r\n it += 1\r\n soultion = 9999999999999\r\n for first, second in sol.items():\r\n if second == max1:\r\n dis = end[first]-begin[first]+1\r\n soultion = soultion if soultion < dis else dis\r\n return soultion\r\n"
},
{
"alpha_fraction": 0.39767441153526306,
"alphanum_fraction": 0.434883713722229,
"avg_line_length": 17.25373077392578,
"blob_id": "2f788deee5aea420a4ae0f1fe4ebeb71038f08e2",
"content_id": "38ad59f9d5e06bc2e029b190558382d3f920b2da",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1291,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 67,
"path": "/leetcode-algorithms/041. First Missing Positive/41.first-missing-positive.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=41 lang=cpp\r\n *\r\n * [41] First Missing Positive\r\n *\r\n * https://leetcode.com/problems/first-missing-positive/description/\r\n *\r\n * algorithms\r\n * Hard (28.27%)\r\n * Total Accepted: 205.6K\r\n * Total Submissions: 717.4K\r\n * Testcase Example: '[1,2,0]'\r\n *\r\n * Given an unsorted integer array, find the smallest missing positive\r\n * integer.\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: [1,2,0]\r\n * Output: 3\r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: [3,4,-1,1]\r\n * Output: 2\r\n * \r\n * \r\n * Example 3:\r\n * \r\n * \r\n * Input: [7,8,9,11,12]\r\n * Output: 1\r\n * \r\n * \r\n * Note:\r\n * \r\n * Your algorithm should run in O(n) time and uses constant extra space.\r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n int firstMissingPositive(vector<int> &nums)\r\n {\r\n int i = 0;\r\n while (i < nums.size())\r\n {\r\n if (nums[i] != (i + 1) && nums[i] >= 1 && nums[i] <= nums.size() && nums[nums[i] - 1] != nums[i])\r\n {\r\n swap(nums[i], nums[nums[i] - 1]);\r\n }\r\n else\r\n {\r\n i++;\r\n }\r\n }\r\n for (i = 0; i < nums.size(); ++i)\r\n if (nums[i] != i + 1)\r\n {\r\n return i + 1;\r\n }\r\n return nums.size() + 1;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.5184029936790466,
"alphanum_fraction": 0.5639426112174988,
"avg_line_length": 21.925373077392578,
"blob_id": "eba37e171a855248882cc53efef0828edbe87d6e",
"content_id": "da44ea75dbabf0024065b47612bf896f711de4e4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1605,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 67,
"path": "/leetcode-algorithms/769. Max Chunks To Make Sorted/769.max-chunks-to-make-sorted.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=769 lang=python3\r\n#\r\n# [769] Max Chunks To Make Sorted\r\n#\r\n# https://leetcode.com/problems/max-chunks-to-make-sorted/description/\r\n#\r\n# algorithms\r\n# Medium (51.06%)\r\n# Total Accepted: 21.9K\r\n# Total Submissions: 42.7K\r\n# Testcase Example: '[4,3,2,1,0]'\r\n#\r\n# Given an array arr that is a permutation of [0, 1, ..., arr.length - 1], we\r\n# split the array into some number of \"chunks\" (partitions), and individually\r\n# sort each chunk. After concatenating them, the result equals the sorted\r\n# array.\r\n#\r\n# What is the most number of chunks we could have made?\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: arr = [4,3,2,1,0]\r\n# Output: 1\r\n# Explanation:\r\n# Splitting into two or more chunks will not return the required result.\r\n# For example, splitting into [4, 3], [2, 1, 0] will result in [3, 4, 0, 1, 2],\r\n# which isn't sorted.\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: arr = [1,0,2,3,4]\r\n# Output: 4\r\n# Explanation:\r\n# We can split into two chunks, such as [1, 0], [2, 3, 4].\r\n# However, splitting into [1, 0], [2], [3], [4] is the highest number of chunks\r\n# possible.\r\n#\r\n#\r\n# Note:\r\n#\r\n#\r\n# arr will have length in range [1, 10].\r\n# arr[i] will be a permutation of [0, 1, ..., arr.length - 1].\r\n#\r\n#\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def maxChunksToSorted(self, arr: List[int]) -> int:\r\n sum = 0\r\n sol = 0\r\n start = 0\r\n for i in range(len(arr)):\r\n sum += arr[i]\r\n expected = (start+i)*(i-start+1)//2\r\n if sum == expected:\r\n sol += 1\r\n start = i+1\r\n sum = 0\r\n return sol\r\n"
},
{
"alpha_fraction": 0.539170503616333,
"alphanum_fraction": 0.5773535370826721,
"avg_line_length": 19.527027130126953,
"blob_id": "3dbc3e1b5551b770c72f44224286078a1636f167",
"content_id": "c3903661c06306cd349b91e864da65842a4d3747",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1528,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 74,
"path": "/leetcode-algorithms/124. Binary Tree Maximum Path Sum/124.binary-tree-maximum-path-sum.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\n * @lc app=leetcode id=124 lang=java\n *\n * [124] Binary Tree Maximum Path Sum\n *\n * https://leetcode.com/problems/binary-tree-maximum-path-sum/description/\n *\n * algorithms\n * Hard (31.32%)\n * Likes: 2839\n * Dislikes: 240\n * Total Accepted: 294.1K\n * Total Submissions: 900.7K\n * Testcase Example: '[1,2,3]'\n *\n * Given a non-empty binary tree, find the maximum path sum.\n * \n * For this problem, a path is defined as any sequence of nodes from some\n * starting node to any node in the tree along the parent-child connections.\n * The path must contain at least one node and does not need to go through the\n * root.\n * \n * Example 1:\n * \n * \n * Input: [1,2,3]\n * \n * 1\n * / \\\n * 2 3\n * \n * Output: 6\n * \n * \n * Example 2:\n * \n * \n * Input: [-10,9,20,null,null,15,7]\n * \n * -10\n * / \\\n * 9 20\n * / \\\n * 15 7\n * \n * Output: 42\n * \n * \n */\n\n// @lc code=start\n/**\n * Definition for a binary tree node. public class TreeNode { int val; TreeNode\n * left; TreeNode right; TreeNode(int x) { val = x; } }\n */\nclass Solution {\n int res = Integer.MIN_VALUE;\n\n public int maxPathSum(TreeNode root) {\n pathCalc(root);\n return res;\n }\n\n int pathCalc(TreeNode root) {\n if (root == null) {\n return 0;\n }\n int left = Integer.max(pathCalc(root.left), 0);\n int right = Integer.max(pathCalc(root.right), 0);\n res = Integer.max(res, left + right + root.val);\n return Integer.max(left, right) + root.val;\n }\n}\n// @lc code=end\n"
},
{
"alpha_fraction": 0.41525423526763916,
"alphanum_fraction": 0.5,
"avg_line_length": 27.095890045166016,
"blob_id": "62451337ff17bbfe18a5b2a1e51a7911ba2ea657",
"content_id": "5622249e509c0827f20cbd1bf931d15bf5710624",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2138,
"license_type": "permissive",
"max_line_length": 129,
"num_lines": 73,
"path": "/leetcode-algorithms/695. Max Area of Island/695.max-area-of-island.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=695 lang=cpp\r\n *\r\n * [695] Max Area of Island\r\n *\r\n * https://leetcode.com/problems/max-area-of-island/description/\r\n *\r\n * algorithms\r\n * Medium (56.07%)\r\n * Total Accepted: 78.7K\r\n * Total Submissions: 138.4K\r\n * Testcase Example: '[[1,1,0,0,0],[1,1,0,0,0],[0,0,0,1,1],[0,0,0,1,1]]'\r\n *\r\n * Given a non-empty 2D array grid of 0's and 1's, an island is a group of 1's\r\n * (representing land) connected 4-directionally (horizontal or vertical.) You\r\n * may assume all four edges of the grid are surrounded by water.\r\n * \r\n * Find the maximum area of an island in the given 2D array. (If there is no\r\n * island, the maximum area is 0.)\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * [[0,0,1,0,0,0,0,1,0,0,0,0,0],\r\n * [0,0,0,0,0,0,0,1,1,1,0,0,0],\r\n * [0,1,1,0,1,0,0,0,0,0,0,0,0],\r\n * [0,1,0,0,1,1,0,0,1,0,1,0,0],\r\n * [0,1,0,0,1,1,0,0,1,1,1,0,0],\r\n * [0,0,0,0,0,0,0,0,0,0,1,0,0],\r\n * [0,0,0,0,0,0,0,1,1,1,0,0,0],\r\n * [0,0,0,0,0,0,0,1,1,0,0,0,0]]\r\n * \r\n * Given the above grid, return 6. Note the answer is not 11, because the\r\n * island must be connected 4-directionally.\r\n * \r\n * Example 2:\r\n * \r\n * \r\n * [[0,0,0,0,0,0,0,0]]\r\n * Given the above grid, return 0.\r\n * \r\n * Note: The length of each dimension in the given grid does not exceed 50.\r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n int depth(vector<vector<int>> &grid, int row, int col)\r\n {\r\n if (row >= grid.size() || col >= grid[0].size() || row < 0 || col < 0 || grid[row][col] == 0)\r\n {\r\n return 0;\r\n }\r\n grid[row][col] = 0;\r\n return 1 + depth(grid, row - 1, col) + depth(grid, row + 1, col) + depth(grid, row, col - 1) + depth(grid, row, col + 1);\r\n }\r\n int maxAreaOfIsland(vector<vector<int>> &grid)\r\n {\r\n int maxarea = 0;\r\n for (int i = 0; i < grid.size(); i++)\r\n {\r\n for (int j = 0; j < grid[0].size(); j++)\r\n {\r\n if (!grid[i][j])\r\n {\r\n continue;\r\n }\r\n maxarea = max(maxarea, depth(grid, i, j));\r\n }\r\n }\r\n return maxarea;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.37860697507858276,
"alphanum_fraction": 0.4880596995353699,
"avg_line_length": 17.900989532470703,
"blob_id": "9591e86f5832bbc84dcf4802f37de66dc3294f96",
"content_id": "6ca5285c7dbaa897829cfaede7e138baba651e5e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2016,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 101,
"path": "/leetcode-algorithms/989. Add to Array-Form of Integer/989.add-to-array-form-of-integer.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=989 lang=python3\r\n#\r\n# [989] Add to Array-Form of Integer\r\n#\r\n# https://leetcode.com/problems/add-to-array-form-of-integer/description/\r\n#\r\n# algorithms\r\n# Easy (44.85%)\r\n# Total Accepted: 12.6K\r\n# Total Submissions: 28.1K\r\n# Testcase Example: '[1,2,0,0]\\n34'\r\n#\r\n# For a non-negative integer X, the array-form of X is an array of its digits\r\n# in left to right order. For example, if X = 1231, then the array form is\r\n# [1,2,3,1].\r\n#\r\n# Given the array-form A of a non-negative integer X, return the array-form of\r\n# the integer X+K.\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: A = [1,2,0,0], K = 34\r\n# Output: [1,2,3,4]\r\n# Explanation: 1200 + 34 = 1234\r\n#\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: A = [2,7,4], K = 181\r\n# Output: [4,5,5]\r\n# Explanation: 274 + 181 = 455\r\n#\r\n#\r\n#\r\n# Example 3:\r\n#\r\n#\r\n# Input: A = [2,1,5], K = 806\r\n# Output: [1,0,2,1]\r\n# Explanation: 215 + 806 = 1021\r\n#\r\n#\r\n#\r\n# Example 4:\r\n#\r\n#\r\n# Input: A = [9,9,9,9,9,9,9,9,9,9], K = 1\r\n# Output: [1,0,0,0,0,0,0,0,0,0,0]\r\n# Explanation: 9999999999 + 1 = 10000000000\r\n#\r\n#\r\n#\r\n#\r\n# Note:\r\n#\r\n#\r\n# 1 <= A.length <= 10000\r\n# 0 <= A[i] <= 9\r\n# 0 <= K <= 10000\r\n# If A.length > 1, then A[0] != 0\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def addToArrayForm(self, A: List[int], K: int) -> List[int]:\r\n sizeTable = [9, 99, 999, 9999, 99999,\r\n 999999, 9999999, 99999999, 999999999]\r\n\r\n def stringSize(x):\r\n for i in range(len(sizeTable)):\r\n if x <= sizeTable[i]:\r\n return i+1\r\n mylen = max(len(A), stringSize(K))\r\n sol = [0 for _ in range(mylen)]\r\n for i in range(1, len(A)+1):\r\n sol[-i] = A[-i]\r\n plus = (sol[-1] + K) // 10\r\n sol[-1] = (sol[-1] + K) % 10\r\n for i in range(len(sol)-2, -1, -1):\r\n sol[i] += plus\r\n plus = sol[i] // 10\r\n if plus != 0:\r\n sol[i] %= 10\r\n if plus:\r\n sol.insert(0, 1)\r\n return sol\r\n"
},
{
"alpha_fraction": 0.4486386179924011,
"alphanum_fraction": 0.49504950642585754,
"avg_line_length": 19.83783721923828,
"blob_id": "9bfe82331a3550afb0c66186dc0c0426ae059e63",
"content_id": "5c748d6f8c1d0a6449de7f267a1035905710895c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1616,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 74,
"path": "/leetcode-algorithms/704. Binary Search/704.binary-search.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=704 lang=cpp\r\n *\r\n * [704] Binary Search\r\n *\r\n * https://leetcode.com/problems/binary-search/description/\r\n *\r\n * algorithms\r\n * Easy (47.96%)\r\n * Likes: 279\r\n * Dislikes: 32\r\n * Total Accepted: 58.7K\r\n * Total Submissions: 121.3K\r\n * Testcase Example: '[-1,0,3,5,9,12]\\n9'\r\n *\r\n * Given a sorted (in ascending order) integer array nums of n elements and a\r\n * target value, write a function to search target in nums. If target exists,\r\n * then return its index, otherwise return -1.\r\n * \r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: nums = [-1,0,3,5,9,12], target = 9\r\n * Output: 4\r\n * Explanation: 9 exists in nums and its index is 4\r\n * \r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: nums = [-1,0,3,5,9,12], target = 2\r\n * Output: -1\r\n * Explanation: 2 does not exist in nums so return -1\r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * You may assume that all elements in nums are unique.\r\n * n will be in the range [1, 10000].\r\n * The value of each element in nums will be in the range [-9999, 9999].\r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n int search(vector<int> &nums, int target)\r\n {\r\n int left = 0, right = nums.size() - 1;\r\n int index;\r\n while (left <= right)\r\n {\r\n index = (right + left) / 2;\r\n if (nums[index] > target)\r\n {\r\n right = index - 1;\r\n }\r\n else if (nums[index] < target)\r\n {\r\n left = index + 1;\r\n }\r\n else\r\n {\r\n return index;\r\n }\r\n }\r\n return -1;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.4188976287841797,
"alphanum_fraction": 0.4669291377067566,
"avg_line_length": 12.767441749572754,
"blob_id": "d44c91494fe0474080f34d0b3e7aec07f533ac1f",
"content_id": "d010078e9d946e733363fdaf8eb332e6ab91ef40",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1274,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 86,
"path": "/leetcode-algorithms/941. Valid Mountain Array/941.valid-mountain-array.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=941 lang=python3\r\n#\r\n# [941] Valid Mountain Array\r\n#\r\n# https://leetcode.com/problems/valid-mountain-array/description/\r\n#\r\n# algorithms\r\n# Easy (34.67%)\r\n# Total Accepted: 17K\r\n# Total Submissions: 48.5K\r\n# Testcase Example: '[2,1]'\r\n#\r\n# Given an array A of integers, return true if and only if it is a valid\r\n# mountain array.\r\n#\r\n# Recall that A is a mountain array if and only if:\r\n#\r\n#\r\n# A.length >= 3\r\n# There exists some i with 0 < i < A.length - 1 such that:\r\n#\r\n# A[0] < A[1] < ... A[i-1] < A[i]\r\n# A[i] > A[i+1] > ... > A[B.length - 1]\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: [2,1]\r\n# Output: false\r\n#\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: [3,5,5]\r\n# Output: false\r\n#\r\n#\r\n#\r\n# Example 3:\r\n#\r\n#\r\n# Input: [0,3,2,1]\r\n# Output: true\r\n#\r\n#\r\n#\r\n#\r\n#\r\n# Note:\r\n#\r\n#\r\n# 0 <= A.length <= 10000\r\n# 0 <= A[i] <= 10000 \r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def validMountainArray(self, A: List[int]) -> bool:\r\n if len(A) <= 2:\r\n return False\r\n N = len(A)\r\n i = 0\r\n while i < N - 1 and A[i] < A[i + 1]:\r\n i += 1\r\n if i == 0 or i == N - 1:\r\n return False\r\n while i < N - 1 and A[i] > A[i + 1]:\r\n i += 1\r\n return i == N - 1\r\n"
},
{
"alpha_fraction": 0.43530499935150146,
"alphanum_fraction": 0.4667282700538635,
"avg_line_length": 17.321428298950195,
"blob_id": "88dec15bd27b8d9ec186363c772cd70c256194b7",
"content_id": "6122c987ee4fe5e61f71b4da54c3c1163dcd85b6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1084,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 56,
"path": "/leetcode-algorithms/078. Subsets/78.subsets.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=78 lang=cpp\r\n *\r\n * [78] Subsets\r\n *\r\n * https://leetcode.com/problems/subsets/description/\r\n *\r\n * algorithms\r\n * Medium (51.15%)\r\n * Total Accepted: 354K\r\n * Total Submissions: 677.8K\r\n * Testcase Example: '[1,2,3]'\r\n *\r\n * Given a set of distinct integers, nums, return all possible subsets (the\r\n * power set).\r\n * \r\n * Note: The solution set must not contain duplicate subsets.\r\n * \r\n * Example:\r\n * \r\n * \r\n * Input: nums = [1,2,3]\r\n * Output:\r\n * [\r\n * [3],\r\n * [1],\r\n * [2],\r\n * [1,2,3],\r\n * [1,3],\r\n * [2,3],\r\n * [1,2],\r\n * []\r\n * ]\r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n vector<vector<int>> subsets(vector<int> &nums)\r\n {\r\n vector<vector<int>> sol;\r\n vector<int> temp;\r\n sol.push_back(temp);\r\n for (auto t : nums)\r\n {\r\n int size = sol.size();\r\n for (int i = 0; i < size; i++)\r\n {\r\n vector<int> subsets(sol[i]);\r\n subsets.push_back(t);\r\n sol.push_back(subsets);\r\n }\r\n }\r\n return sol;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.4850543439388275,
"alphanum_fraction": 0.53125,
"avg_line_length": 15.116278648376465,
"blob_id": "00a7e68e2c7d64a053237f4a314fb01a8cc2bdff",
"content_id": "28a1903b67e72428ad72f5ef015ef2cbccceda27",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 738,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 43,
"path": "/leetcode-algorithms/078. Subsets/78.subsets.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=78 lang=python3\r\n#\r\n# [78] Subsets\r\n#\r\n# https://leetcode.com/problems/subsets/description/\r\n#\r\n# algorithms\r\n# Medium (51.15%)\r\n# Total Accepted: 354K\r\n# Total Submissions: 677.8K\r\n# Testcase Example: '[1,2,3]'\r\n#\r\n# Given a set of distinct integers, nums, return all possible subsets (the\r\n# power set).\r\n#\r\n# Note: The solution set must not contain duplicate subsets.\r\n#\r\n# Example:\r\n#\r\n#\r\n# Input: nums = [1,2,3]\r\n# Output:\r\n# [\r\n# [3],\r\n# [1],\r\n# [2],\r\n# [1,2,3],\r\n# [1,3],\r\n# [2,3],\r\n# [1,2],\r\n# []\r\n# ]\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def subsets(self, nums: List[int]) -> List[List[int]]:\r\n ret = [[]]\r\n for n in nums:\r\n ret += [r + [n] for r in ret]\r\n return ret\r\n"
},
{
"alpha_fraction": 0.5105990767478943,
"alphanum_fraction": 0.5520737171173096,
"avg_line_length": 22.11111068725586,
"blob_id": "c644769a327b07da9f8b8b9d380fee15184011c5",
"content_id": "ac931790497964acc994d0d4a05dde58f02ac444",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1092,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 45,
"path": "/leetcode-algorithms/092. Reverse Linked List II/92.reverse-linked-list-ii.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=92 lang=python3\r\n#\r\n# [92] Reverse Linked List II\r\n#\r\n# https://leetcode.com/problems/reverse-linked-list-ii/description/\r\n#\r\n# algorithms\r\n# Medium (35.73%)\r\n# Likes: 1385\r\n# Dislikes: 97\r\n# Total Accepted: 209.2K\r\n# Total Submissions: 584.7K\r\n# Testcase Example: '[1,2,3,4,5]\\n2\\n4'\r\n#\r\n# Reverse a linked list from position m to n. Do it in one-pass.\r\n#\r\n# Note: 1 ≤ m ≤ n ≤ length of list.\r\n#\r\n# Example:\r\n#\r\n#\r\n# Input: 1->2->3->4->5->NULL, m = 2, n = 4\r\n# Output: 1->4->3->2->5->NULL\r\n#\r\n#\r\n#\r\n# Definition for singly-linked list.\r\n# class ListNode:\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.next = None\r\n\r\n\r\nclass Solution:\r\n def reverseBetween(self, head: ListNode, m: int, n: int) -> ListNode:\r\n newHead = ListNode(-1)\r\n newHead.next, pre = head, newHead\r\n for _ in range(m-1):\r\n pre = pre.next\r\n cur = pre.next\r\n for _ in range(n-m):\r\n pre.next, cur.next, pre.next.next = \\\r\n cur.next, cur.next.next, pre.next\r\n return newHead.next\r\n"
},
{
"alpha_fraction": 0.3371051251888275,
"alphanum_fraction": 0.355021208524704,
"avg_line_length": 15.675000190734863,
"blob_id": "fa982d81aa4e1825ec02df6775183fe778762722",
"content_id": "d7039fb894601e58ae0ff0145f471e955a4d7553",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2123,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 120,
"path": "/leetcode-algorithms/917. Reverse Only Letters/917.reverse-only-letters.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=917 lang=cpp\r\n *\r\n * [917] Reverse Only Letters\r\n *\r\n * https://leetcode.com/problems/reverse-only-letters/description/\r\n *\r\n * algorithms\r\n * Easy (55.96%)\r\n * Likes: 271\r\n * Dislikes: 26\r\n * Total Accepted: 29.7K\r\n * Total Submissions: 53.1K\r\n * Testcase Example: '\"ab-cd\"'\r\n *\r\n * Given a string S, return the \"reversed\" string where all characters that are\r\n * not a letter stay in the same place, and all letters reverse their\r\n * positions.\r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: \"ab-cd\"\r\n * Output: \"dc-ba\"\r\n * \r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: \"a-bC-dEf-ghIj\"\r\n * Output: \"j-Ih-gfE-dCba\"\r\n * \r\n * \r\n * \r\n * Example 3:\r\n * \r\n * \r\n * Input: \"Test1ng-Leet=code-Q!\"\r\n * Output: \"Qedo1ct-eeLg=ntse-T!\"\r\n * \r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * S.length <= 100\r\n * 33 <= S[i].ASCIIcode <= 122 \r\n * S doesn't contain \\ or \"\r\n * \r\n * \r\n * \r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n string reverseOnlyLetters(string S)\r\n {\r\n // string newS = \"\";\r\n // string letters=\"\";\r\n // for(auto ch:S)\r\n // {\r\n // if(isalpha(ch))\r\n // {\r\n // letters += ch;\r\n // newS += \" \";\r\n // }else\r\n // {\r\n // newS += ch;\r\n // }\r\n // }\r\n // reverse(letters.begin(),letters.end());\r\n // for (int i = 0,j=0; i < S.size();i++)\r\n // {\r\n // if(newS[i]!=' ')\r\n // {\r\n // continue;\r\n // }else{\r\n // newS[i] = letters[j++];\r\n // }\r\n // }\r\n // return newS;\r\n int i = 0;\r\n int j = S.size() - 1;\r\n while (i < j)\r\n {\r\n if (!isalpha(S[i]))\r\n {\r\n i++;\r\n }\r\n else if (!isalpha(S[j]))\r\n {\r\n j--;\r\n }\r\n else\r\n {\r\n swap(S[i], S[j]);\r\n i++;\r\n j--;\r\n }\r\n }\r\n return S;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.47779273986816406,
"alphanum_fraction": 0.5020188689231873,
"avg_line_length": 21.967741012573242,
"blob_id": "51a71aad07cfd596f0ec50cc03b259fc2c9442da",
"content_id": "d2fe350d547e70c21388445ef9746d511ba34032",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1487,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 62,
"path": "/leetcode-algorithms/024. Swap Nodes in Pairs/24.swap-nodes-in-pairs.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=24 lang=java\r\n *\r\n * [24] Swap Nodes in Pairs\r\n *\r\n * https://leetcode.com/problems/swap-nodes-in-pairs/description/\r\n *\r\n * algorithms\r\n * Medium (44.99%)\r\n * Likes: 1303\r\n * Dislikes: 115\r\n * Total Accepted: 341.3K\r\n * Total Submissions: 745.3K\r\n * Testcase Example: '[1,2,3,4]'\r\n *\r\n * Given a linked list, swap every two adjacent nodes and return its head.\r\n * \r\n * You may not modify the values in the list's nodes, only nodes itself may be\r\n * changed.\r\n * \r\n * \r\n * \r\n * Example:\r\n * \r\n * \r\n * Given 1.2.3.4, you should return the list as 2.1.4.3.\r\n * \r\n * \r\n */\r\n/**\r\n * Definition for singly-linked list. public class ListNode { int val; ListNode\r\n * next; ListNode(int x) { val = x; } }\r\n */\r\nclass Solution {\r\n public ListNode swapPairs(ListNode head) {\r\n if (head == null) {\r\n return head;\r\n }\r\n ListNode newHead = new ListNode(-1);\r\n newHead.next = head;\r\n ListNode p = newHead, q = head, r = head.next;\r\n while (r != null) {\r\n swapNode(p, q, r);\r\n ListNode temp = q;\r\n q = r;\r\n r = temp;\r\n p = p.next.next;\r\n q = q.next.next;\r\n if (r.next == null) {\r\n break;\r\n }\r\n r = r.next.next;\r\n }\r\n return newHead.next;\r\n }\r\n\r\n void swapNode(ListNode p, ListNode q, ListNode r) {\r\n q.next = r.next;\r\n r.next = q;\r\n p.next = r;\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.48407644033432007,
"alphanum_fraction": 0.5295723676681519,
"avg_line_length": 17.9818172454834,
"blob_id": "53e448b81c75a8fc3b29f402cf860ed6449b3434",
"content_id": "ab695b00d52f47b17f74a435e1d23e3850ecda7a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1100,
"license_type": "permissive",
"max_line_length": 105,
"num_lines": 55,
"path": "/leetcode-algorithms/041. First Missing Positive/41.first-missing-positive.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=41 lang=python3\r\n#\r\n# [41] First Missing Positive\r\n#\r\n# https://leetcode.com/problems/first-missing-positive/description/\r\n#\r\n# algorithms\r\n# Hard (28.27%)\r\n# Total Accepted: 205.6K\r\n# Total Submissions: 717.4K\r\n# Testcase Example: '[1,2,0]'\r\n#\r\n# Given an unsorted integer array, find the smallest missing positive integer.\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: [1,2,0]\r\n# Output: 3\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: [3,4,-1,1]\r\n# Output: 2\r\n#\r\n#\r\n# Example 3:\r\n#\r\n#\r\n# Input: [7,8,9,11,12]\r\n# Output: 1\r\n#\r\n#\r\n# Note:\r\n#\r\n# Your algorithm should run in O(n) time and uses constant extra space.\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def firstMissingPositive(self, nums: List[int]) -> int:\r\n i = 0\r\n while i < len(nums):\r\n if nums[i] != (i+1) and nums[i] >= 1 and nums[i] <= len(nums) and nums[nums[i]-1] != nums[i]:\r\n nums[nums[i]-1], nums[i] = nums[i], nums[nums[i]-1]\r\n else:\r\n i += 1\r\n for i in range(len(nums)):\r\n if nums[i] != i+1:\r\n return i+1\r\n return len(nums)+1\r\n"
},
{
"alpha_fraction": 0.3996194005012512,
"alphanum_fraction": 0.43958136439323425,
"avg_line_length": 18.60784339904785,
"blob_id": "953da0f94aae9a0b3c3f2121b113e5b6d2d8da08",
"content_id": "b3266787db6c39eb759f9df8198dc7e040f55a9f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1051,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 51,
"path": "/leetcode-algorithms/204. Count Primes/204.count-primes.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=204 lang=cpp\r\n *\r\n * [204] Count Primes\r\n *\r\n * https://leetcode.com/problems/count-primes/description/\r\n *\r\n * algorithms\r\n * Easy (29.13%)\r\n * Likes: 1106\r\n * Dislikes: 419\r\n * Total Accepted: 245.7K\r\n * Total Submissions: 840.2K\r\n * Testcase Example: '10'\r\n *\r\n * Count the number of prime numbers less than a non-negative number, n.\r\n * \r\n * Example:\r\n * \r\n * \r\n * Input: 10\r\n * Output: 4\r\n * Explanation: There are 4 prime numbers less than 10, they are 2, 3, 5, 7.\r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n int countPrimes(int n)\r\n {\r\n if (!n || n == 1)\r\n {\r\n return 0;\r\n }\r\n vector<bool> res(n, true);\r\n res[0] = false;\r\n res[1] = false;\r\n for (int i = 0; i * i < n; i++)\r\n {\r\n if (res[i])\r\n {\r\n for (int j = i * i; j < n; j += i)\r\n {\r\n res[j] = false;\r\n }\r\n }\r\n }\r\n return count(res.begin(), res.end(), true);\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.36924076080322266,
"alphanum_fraction": 0.40622973442077637,
"avg_line_length": 14.221052169799805,
"blob_id": "b9029dd486e00324c803cc50082741dd6eeab27c",
"content_id": "6fd00c81f6c2d24f9e9210b84bd7cbed3325e872",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1545,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 95,
"path": "/leetcode-algorithms/941. Valid Mountain Array/941.valid-mountain-array.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=941 lang=cpp\r\n *\r\n * [941] Valid Mountain Array\r\n *\r\n * https://leetcode.com/problems/valid-mountain-array/description/\r\n *\r\n * algorithms\r\n * Easy (34.67%)\r\n * Total Accepted: 17K\r\n * Total Submissions: 48.5K\r\n * Testcase Example: '[2,1]'\r\n *\r\n * Given an array A of integers, return true if and only if it is a valid\r\n * mountain array.\r\n * \r\n * Recall that A is a mountain array if and only if:\r\n * \r\n * \r\n * A.length >= 3\r\n * There exists some i with 0 < i < A.length - 1 such that:\r\n * \r\n * A[0] < A[1] < ... A[i-1] < A[i] \r\n * A[i] > A[i+1] > ... > A[B.length - 1]\r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: [2,1]\r\n * Output: false\r\n * \r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: [3,5,5]\r\n * Output: false\r\n * \r\n * \r\n * \r\n * Example 3:\r\n * \r\n * \r\n * Input: [0,3,2,1]\r\n * Output: true\r\n * \r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * 0 <= A.length <= 10000\r\n * 0 <= A[i] <= 10000 \r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n bool validMountainArray(vector<int> &A)\r\n {\r\n bool des = false;\r\n if (A.size() < 3)\r\n return false;\r\n if (A[0] > A[1])\r\n return false;\r\n for (int i = 0; i < A.size() - 1; i++)\r\n {\r\n if (A[i] == A[i + 1])\r\n return false;\r\n if (des && A[i] < A[i + 1])\r\n return false;\r\n if (A[i] > A[i + 1])\r\n {\r\n des = true;\r\n }\r\n }\r\n return des;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.46006065607070923,
"alphanum_fraction": 0.4868554174900055,
"avg_line_length": 20.5,
"blob_id": "121bc3e9029ddce4353df069881f8eeef8843c6f",
"content_id": "699f810b2d9da7cbfbdbdd26574486193071609a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1994,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 92,
"path": "/leetcode-algorithms/107. Binary Tree Level Order Traversal II/107.binary-tree-level-order-traversal-ii.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\n * @lc app=leetcode id=107 lang=cpp\n *\n * [107] Binary Tree Level Order Traversal II\n *\n * https://leetcode.com/problems/binary-tree-level-order-traversal-ii/description/\n *\n * algorithms\n * Easy (48.66%)\n * Likes: 1105\n * Dislikes: 201\n * Total Accepted: 289.3K\n * Total Submissions: 572.4K\n * Testcase Example: '[3,9,20,null,null,15,7]'\n *\n * Given a binary tree, return the bottom-up level order traversal of its\n * nodes' values. (ie, from left to right, level by level from leaf to root).\n * \n * \n * For example:\n * Given binary tree [3,9,20,null,null,15,7],\n * \n * 3\n * / \\\n * 9 20\n * / \\\n * 15 7\n * \n * \n * \n * return its bottom-up level order traversal as:\n * \n * [\n * [15,7],\n * [9,20],\n * [3]\n * ]\n * \n * \n */\n\n// @lc code=start\n/**\n * Definition for a binary tree node.\n * struct TreeNode {\n * int val;\n * TreeNode *left;\n * TreeNode *right;\n * TreeNode(int x) : val(x), left(NULL), right(NULL) {}\n * };\n */\nclass Solution\n{\npublic:\n vector<vector<int>> levelOrderBottom(TreeNode *root)\n {\n queue<TreeNode *> thisLevel, nextLevel;\n if (root)\n {\n thisLevel.push(root);\n }\n vector<vector<int>> res;\n vector<int> one;\n while (!thisLevel.empty())\n {\n TreeNode *node = thisLevel.front();\n thisLevel.pop();\n one.push_back(node->val);\n if (node->left)\n {\n nextLevel.push(node->left);\n }\n if (node->right)\n {\n nextLevel.push(node->right);\n }\n if (thisLevel.empty())\n {\n thisLevel = nextLevel;\n res.push_back(one);\n one.clear();\n while (!nextLevel.empty())\n {\n nextLevel.pop();\n }\n }\n }\n reverse(res.begin(), res.end());\n return res;\n }\n};\n// @lc code=end\n"
},
{
"alpha_fraction": 0.5111111402511597,
"alphanum_fraction": 0.5363636612892151,
"avg_line_length": 17.799999237060547,
"blob_id": "1ec9f9cc7939ee1428ce8895d9a8e50ddf4a32df",
"content_id": "a416f32db459f8322d06168be1275abb611aa14c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 990,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 50,
"path": "/leetcode-algorithms/389. Find the Difference/389.find-the-difference.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=389 lang=cpp\r\n *\r\n * [389] Find the Difference\r\n *\r\n * https://leetcode.com/problems/find-the-difference/description/\r\n *\r\n * algorithms\r\n * Easy (53.17%)\r\n * Likes: 518\r\n * Dislikes: 232\r\n * Total Accepted: 149.2K\r\n * Total Submissions: 280K\r\n * Testcase Example: '\"abcd\"\\n\"abcde\"'\r\n *\r\n * \r\n * Given two strings s and t which consist of only lowercase letters.\r\n * \r\n * String t is generated by random shuffling string s and then add one more\r\n * letter at a random position.\r\n * \r\n * Find the letter that was added in t.\r\n * \r\n * Example:\r\n * \r\n * Input:\r\n * s = \"abcd\"\r\n * t = \"abcde\"\r\n * \r\n * Output:\r\n * e\r\n * \r\n * Explanation:\r\n * 'e' is the letter that was added.\r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n char findTheDifference(string s, string t)\r\n {\r\n int res = t[t.length() - 1];\r\n for (int i = 0; i < s.length(); ++i)\r\n {\r\n res ^= s[i];\r\n res ^= t[i];\r\n }\r\n return res;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.5905707478523254,
"alphanum_fraction": 0.6253101825714111,
"avg_line_length": 18.66666603088379,
"blob_id": "7401b1b1a433931ffb2eb2ae905feec4cba2bacd",
"content_id": "e77cd0b852fa79e707bc745df7ad66c5fcf2a2ec",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 806,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 39,
"path": "/leetcode-algorithms/058. Length of Last Word/58.length-of-last-word.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=58 lang=python3\r\n#\r\n# [58] Length of Last Word\r\n#\r\n# https://leetcode.com/problems/length-of-last-word/description/\r\n#\r\n# algorithms\r\n# Easy (32.26%)\r\n# Likes: 380\r\n# Dislikes: 1594\r\n# Total Accepted: 273.2K\r\n# Total Submissions: 847K\r\n# Testcase Example: '\"Hello World\"'\r\n#\r\n# Given a string s consists of upper/lower-case alphabets and empty space\r\n# characters ' ', return the length of last word in the string.\r\n#\r\n# If the last word does not exist, return 0.\r\n#\r\n# Note: A word is defined as a character sequence consists of non-space\r\n# characters only.\r\n#\r\n# Example:\r\n#\r\n#\r\n# Input: \"Hello World\"\r\n# Output: 5\r\n#\r\n#\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def lengthOfLastWord(self, s: str) -> int:\r\n word = s.split()\r\n return 0 if len(word) == 0 else len(word[-1])\r\n"
},
{
"alpha_fraction": 0.496889591217041,
"alphanum_fraction": 0.5256609916687012,
"avg_line_length": 20.964284896850586,
"blob_id": "e73058af142ac273498b9cfd78ff326681329cb6",
"content_id": "d56da97e3fb7383a0e4307d3bb190b623a60bd8b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1287,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 56,
"path": "/leetcode-algorithms/024. Swap Nodes in Pairs/24.swap-nodes-in-pairs.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=24 lang=python3\r\n#\r\n# [24] Swap Nodes in Pairs\r\n#\r\n# https://leetcode.com/problems/swap-nodes-in-pairs/description/\r\n#\r\n# algorithms\r\n# Medium (44.99%)\r\n# Likes: 1303\r\n# Dislikes: 115\r\n# Total Accepted: 341.3K\r\n# Total Submissions: 745.3K\r\n# Testcase Example: '[1,2,3,4]'\r\n#\r\n# Given a linked list, swap every two adjacent nodes and return its head.\r\n#\r\n# You may not modify the values in the list's nodes, only nodes itself may be\r\n# changed.\r\n#\r\n#\r\n#\r\n# Example:\r\n#\r\n#\r\n# Given 1.2.3.4, you should return the list as 2.1.4.3.\r\n#\r\n#\r\n#\r\n# Definition for singly-linked list.\r\n# class ListNode:\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.next = None\r\n\r\n\r\nclass Solution:\r\n def swapPairs(self, head: ListNode) -> ListNode:\r\n def swapNode(p, q, r):\r\n q.next = r.next\r\n r.next = q\r\n p.next = r\r\n if not head:\r\n return head\r\n newHead = ListNode(-1)\r\n newHead.next = head\r\n p, q, r = newHead, head, head.next\r\n while r:\r\n swapNode(p, q, r)\r\n r, q = q, r\r\n p = p.next.next\r\n q = q.next.next\r\n if not r.next:\r\n break\r\n r = r.next.next\r\n return newHead.next\r\n"
},
{
"alpha_fraction": 0.42889562249183655,
"alphanum_fraction": 0.48335856199264526,
"avg_line_length": 17.159420013427734,
"blob_id": "8c1aa64998b41229c56c657d0258b79a394433e3",
"content_id": "158b359b59f6f62ce0f5b133ed3d5e1deb3ad719",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1323,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 69,
"path": "/leetcode-algorithms/912. Sort an Array/912.sort-an-array.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=912 lang=python3\r\n#\r\n# [912] Sort an Array\r\n#\r\n# https://leetcode.com/problems/sort-an-array/description/\r\n#\r\n# algorithms\r\n# Medium (63.48%)\r\n# Likes: 58\r\n# Dislikes: 78\r\n# Total Accepted: 10.6K\r\n# Total Submissions: 16.7K\r\n# Testcase Example: '[5,2,3,1]'\r\n#\r\n# Given an array of integers nums, sort the array in ascending order.\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: [5,2,3,1]\r\n# Output: [1,2,3,5]\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: [5,1,1,2,0,0]\r\n# Output: [0,0,1,1,2,5]\r\n#\r\n#\r\n#\r\n#\r\n# Note:\r\n#\r\n#\r\n# 1 <= A.length <= 10000\r\n# -50000 <= A[i] <= 50000\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def sortArray(self, nums: List[int]) -> List[int]:\r\n self.qsort(nums, 0, len(nums)-1)\r\n # nums = sorted(nums)\r\n return nums\r\n\r\n def qsort(self, nums, low, high):\r\n def partition(nums, low, high):\r\n i = low - 1\r\n pivot = nums[high]\r\n for j in range(low, high):\r\n if nums[j] <= pivot:\r\n i = i + 1\r\n nums[i], nums[j] = nums[j], nums[i]\r\n nums[i+1], nums[high] = nums[high], nums[i+1]\r\n return i + 1\r\n\r\n if low < high:\r\n pi = partition(nums, low, high)\r\n self.qsort(nums, low, pi-1)\r\n self.qsort(nums, pi+1, high)\r\n"
},
{
"alpha_fraction": 0.43544137477874756,
"alphanum_fraction": 0.4802371561527252,
"avg_line_length": 24.172412872314453,
"blob_id": "830861db19e0ca9085bc73d91067fefa6ba80f3a",
"content_id": "20b9174f876787aef4aa18849eb8fc196f65633f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1518,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 58,
"path": "/leetcode-algorithms/021. Merge Two Sorted Lists/21.merge-two-sorted-lists.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=21 lang=java\r\n *\r\n * [21] Merge Two Sorted Lists\r\n *\r\n * https://leetcode.com/problems/merge-two-sorted-lists/description/\r\n *\r\n * algorithms\r\n * Easy (47.58%)\r\n * Likes: 2335\r\n * Dislikes: 336\r\n * Total Accepted: 608.6K\r\n * Total Submissions: 1.3M\r\n * Testcase Example: '[1,2,4]\\n[1,3,4]'\r\n *\r\n * Merge two sorted linked lists and return it as a new list. The new list\r\n * should be made by splicing together the nodes of the first two lists.\r\n * \r\n * Example:\r\n * \r\n * Input: 1.2.4, 1.3.4\r\n * Output: 1.1.2.3.4.4\r\n * \r\n * \r\n */\r\n/**\r\n * Definition for singly-linked list. public class ListNode { int val; ListNode\r\n * next; ListNode(int x) { val = x; } }\r\n */\r\nclass Solution {\r\n public ListNode mergeTwoLists(ListNode l1, ListNode l2) {\r\n // iteratively\r\n ListNode newl = new ListNode(0);\r\n ListNode l = newl;\r\n while (l1 != null && l2 != null) {\r\n if (l1.val > l2.val) {\r\n l.next = l2;\r\n l2 = l2.next;\r\n } else {\r\n l.next = l1;\r\n l1 = l1.next;\r\n }\r\n l = l.next;\r\n }\r\n l.next = l1 != null ? l1 : l2;\r\n return newl.next;\r\n // recursively\r\n // if (l1 == null || l2 != null && l1.val > l2.val) {\r\n // ListNode temp = l2;\r\n // l2 = l1;\r\n // l1 = temp;\r\n // }\r\n // if (l1 != null) {\r\n // l1.next = mergeTwoLists(l1.next, l2);\r\n // }\r\n // return l1;\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.44041869044303894,
"alphanum_fraction": 0.47665056586265564,
"avg_line_length": 19.789474487304688,
"blob_id": "04b0ed8dfc617be636584086bf2624a7aa024f44",
"content_id": "26caf2f9990d9eb41186a2125552627ec2ffc920",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1242,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 57,
"path": "/leetcode-algorithms/203. Remove Linked List Elements/203.remove-linked-list-elements.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=203 lang=cpp\r\n *\r\n * [203] Remove Linked List Elements\r\n *\r\n * https://leetcode.com/problems/remove-linked-list-elements/description/\r\n *\r\n * algorithms\r\n * Easy (35.89%)\r\n * Likes: 915\r\n * Dislikes: 57\r\n * Total Accepted: 241.4K\r\n * Total Submissions: 666.6K\r\n * Testcase Example: '[1,2,6,3,4,5,6]\\n6'\r\n *\r\n * Remove all elements from a linked list of integers that have value val.\r\n * \r\n * Example:\r\n * \r\n * \r\n * Input: 1->2->6->3->4->5->6, val = 6\r\n * Output: 1->2->3->4->5\r\n * \r\n * \r\n */\r\n/**\r\n * Definition for singly-linked list.\r\n * struct ListNode {\r\n * int val;\r\n * ListNode *next;\r\n * ListNode(int x) : val(x), next(NULL) {}\r\n * };\r\n */\r\nclass Solution\r\n{\r\npublic:\r\n ListNode *removeElements(ListNode *head, int val)\r\n {\r\n ListNode newHead = ListNode(-1);\r\n newHead.next = head;\r\n ListNode *p = &newHead;\r\n while (p->next)\r\n {\r\n if (p->next->val == val)\r\n {\r\n ListNode *temp = p->next;\r\n p->next = p->next->next;\r\n // delete temp;\r\n }\r\n else\r\n {\r\n p = p->next;\r\n }\r\n }\r\n return newHead.next;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.513131320476532,
"alphanum_fraction": 0.5494949221611023,
"avg_line_length": 21.149253845214844,
"blob_id": "432473256aa124d6a83c28b04223d31ad679846f",
"content_id": "c7fd3ba288c68945f082fd623cdb47c96e4e8977",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1501,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 67,
"path": "/leetcode-algorithms/107. Binary Tree Level Order Traversal II/107.binary-tree-level-order-traversal-ii.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode id=107 lang=python3\n#\n# [107] Binary Tree Level Order Traversal II\n#\n# https://leetcode.com/problems/binary-tree-level-order-traversal-ii/description/\n#\n# algorithms\n# Easy (48.66%)\n# Likes: 1105\n# Dislikes: 201\n# Total Accepted: 289.3K\n# Total Submissions: 572.4K\n# Testcase Example: '[3,9,20,null,null,15,7]'\n#\n# Given a binary tree, return the bottom-up level order traversal of its nodes'\n# values. (ie, from left to right, level by level from leaf to root).\n# \n# \n# For example:\n# Given binary tree [3,9,20,null,null,15,7],\n# \n# 3\n# / \\\n# 9 20\n# / \\\n# 15 7\n# \n# \n# \n# return its bottom-up level order traversal as:\n# \n# [\n# [15,7],\n# [9,20],\n# [3]\n# ]\n# \n# \n#\n\n# @lc code=start\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, x):\n# self.val = x\n# self.left = None\n# self.right = None\n\nclass Solution:\n def levelOrderBottom(self, root: TreeNode) -> List[List[int]]:\n if not root:\n return []\n stack = deque([root])\n ans = collections.deque()\n while stack:\n one,length = [],len(stack)\n for _ in range(length):\n node = stack.popleft()\n one.append(node.val)\n if node.left:\n stack.append(node.left)\n if node.right:\n stack.append(node.right)\n ans.appendleft(one)\n return list(ans)\n# @lc code=end\n\n"
},
{
"alpha_fraction": 0.570103645324707,
"alphanum_fraction": 0.5962902307510376,
"avg_line_length": 22.792207717895508,
"blob_id": "1bc09aa7b503e258be40164afdbaaba070e77ae9",
"content_id": "ce2b641a70fbacd57cb6066c8847527966c9e11d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Kotlin",
"length_bytes": 1835,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 77,
"path": "/leetcode-algorithms/278. First Bad Version/278.first-bad-version.kt",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\n * @lc app=leetcode id=278 lang=kotlin\n *\n * [278] First Bad Version\n *\n * https://leetcode.com/problems/first-bad-version/description/\n *\n * algorithms\n * Easy (37.79%)\n * Likes: 2180\n * Dislikes: 844\n * Total Accepted: 564.9K\n * Total Submissions: 1.5M\n * Testcase Example: '5\\n4'\n *\n * You are a product manager and currently leading a team to develop a new\n * product. Unfortunately, the latest version of your product fails the quality\n * check. Since each version is developed based on the previous version, all\n * the versions after a bad version are also bad.\n * \n * Suppose you have n versions [1, 2, ..., n] and you want to find out the\n * first bad one, which causes all the following ones to be bad.\n * \n * You are given an API bool isBadVersion(version) which returns whether\n * version is bad. Implement a function to find the first bad version. You\n * should minimize the number of calls to the API.\n * \n * \n * Example 1:\n * \n * \n * Input: n = 5, bad = 4\n * Output: 4\n * Explanation:\n * call isBadVersion(3) -> false\n * call isBadVersion(5) -> true\n * call isBadVersion(4) -> true\n * Then 4 is the first bad version.\n * \n * \n * Example 2:\n * \n * \n * Input: n = 1, bad = 1\n * Output: 1\n * \n * \n * \n * Constraints:\n * \n * \n * 1 <= bad <= n <= 2^31 - 1\n * \n * \n */\n\n// @lc code=start\n/* The isBadVersion API is defined in the parent class VersionControl.\n def isBadVersion(version: Int): Boolean = {} */\n\nclass Solution: VersionControl() {\n override fun firstBadVersion(n: Int) : Int {\n var low = 1\n var high = n\n var mid : Int\n while (low <= high) {\n mid = low + (high - low) / 2\n if(isBadVersion(mid)) {\n high = mid - 1\n } else {\n low = mid + 1\n }\n }\n return low\n\t}\n}\n// @lc code=end\n\n"
},
{
"alpha_fraction": 0.4533073902130127,
"alphanum_fraction": 0.4785992205142975,
"avg_line_length": 22.57798194885254,
"blob_id": "889af7f4c225deb9f1623cbf9c09e70176551d6a",
"content_id": "436a66b61dc11ee5d3e3a5895e5b74f22497d596",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2574,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 109,
"path": "/leetcode-algorithms/065. Valid Number/65.valid-number.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\n * @lc app=leetcode id=65 lang=cpp\n *\n * [65] Valid Number\n *\n * https://leetcode.com/problems/valid-number/description/\n *\n * algorithms\n * Hard (14.45%)\n * Likes: 580\n * Dislikes: 4074\n * Total Accepted: 147.8K\n * Total Submissions: 1M\n * Testcase Example: '\"0\"'\n *\n * Validate if a given string can be interpreted as a decimal number.\n * \n * Some examples:\n * \"0\" => true\n * \" 0.1 \" => true\n * \"abc\" => false\n * \"1 a\" => false\n * \"2e10\" => true\n * \" -90e3 \" => true\n * \" 1e\" => false\n * \"e3\" => false\n * \" 6e-1\" => true\n * \" 99e2.5 \" => false\n * \"53.5e93\" => true\n * \" --6 \" => false\n * \"-+3\" => false\n * \"95a54e53\" => false\n * \n * Note: It is intended for the problem statement to be ambiguous. You should\n * gather all requirements up front before implementing one. However, here is a\n * list of characters that can be in a valid decimal number:\n * \n * \n * Numbers 0-9\n * Exponent - \"e\"\n * Positive/negative sign - \"+\"/\"-\"\n * Decimal point - \".\"\n * \n * \n * Of course, the context of these characters also matters in the input.\n * \n * Update (2015-02-10):\n * The signature of the C++ function had been updated. If you still see your\n * function signature accepts a const char * argument, please click the reload\n * button to reset your code definition.\n * \n */\n\n// @lc code=start\nclass Solution\n{\nprivate:\n bool isSgn(char c) { return c == '+' || c == '-'; }\n bool isDot(char c) { return c == '.'; }\n bool isNum(char c) { return c <= '9' && c >= '0'; }\n bool isE(char c) { return c == 'e' || c == 'E'; }\n\npublic:\n bool isNumber(string s)\n {\n int pos = 0;\n bool hasNum = false;\n while (pos < s.size() && s[pos] == ' ')\n {\n pos++;\n }\n if (pos < s.size() && isSgn(s[pos]))\n {\n pos++;\n }\n while (pos < s.size() && isNum(s[pos]))\n {\n hasNum = true;\n pos++;\n }\n if (pos < s.size() && isDot(s[pos]))\n {\n pos++;\n }\n while (pos < s.size() && isNum(s[pos]))\n {\n hasNum = true;\n pos++;\n }\n if (hasNum && pos < s.size() && isE(s[pos]))\n {\n hasNum = false;\n pos++;\n if (pos < s.size() && isSgn(s[pos]))\n pos++;\n }\n while (pos < s.size() && isNum(s[pos]))\n {\n hasNum = true;\n pos++;\n }\n while (pos < s.size() && s[pos] == ' ')\n {\n pos++;\n }\n return (pos == s.size()) && hasNum;\n }\n};\n// @lc code=end\n"
},
{
"alpha_fraction": 0.46661609411239624,
"alphanum_fraction": 0.4977238178253174,
"avg_line_length": 13.505882263183594,
"blob_id": "982d3f2887252f8ee4a8ff44aabf0179571c2471",
"content_id": "3e44116219d351e3c0e29c08932505dc701c853f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1320,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 85,
"path": "/leetcode-algorithms/917. Reverse Only Letters/917.reverse-only-letters.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=917 lang=python3\r\n#\r\n# [917] Reverse Only Letters\r\n#\r\n# https://leetcode.com/problems/reverse-only-letters/description/\r\n#\r\n# algorithms\r\n# Easy (55.96%)\r\n# Likes: 271\r\n# Dislikes: 26\r\n# Total Accepted: 29.7K\r\n# Total Submissions: 53.1K\r\n# Testcase Example: '\"ab-cd\"'\r\n#\r\n# Given a string S, return the \"reversed\" string where all characters that are\r\n# not a letter stay in the same place, and all letters reverse their\r\n# positions.\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: \"ab-cd\"\r\n# Output: \"dc-ba\"\r\n#\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: \"a-bC-dEf-ghIj\"\r\n# Output: \"j-Ih-gfE-dCba\"\r\n#\r\n#\r\n#\r\n# Example 3:\r\n#\r\n#\r\n# Input: \"Test1ng-Leet=code-Q!\"\r\n# Output: \"Qedo1ct-eeLg=ntse-T!\"\r\n#\r\n#\r\n#\r\n#\r\n#\r\n# Note:\r\n#\r\n#\r\n# S.length <= 100\r\n# 33 <= S[i].ASCIIcode <= 122 \r\n# S doesn't contain \\ or \"\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def reverseOnlyLetters(self, S: str) -> str:\r\n i, j = 0, len(S) - 1\r\n strlist = list(S)\r\n while i < j:\r\n if not strlist[i].isalpha():\r\n i += 1\r\n elif not strlist[j].isalpha():\r\n j -= 1\r\n else:\r\n strlist[i], strlist[j] = strlist[j], strlist[i]\r\n i += 1\r\n j -= 1\r\n return ''.join(strlist)\r\n"
},
{
"alpha_fraction": 0.45052769780158997,
"alphanum_fraction": 0.4742743968963623,
"avg_line_length": 19.35211181640625,
"blob_id": "e8aed1706bacc414d5660dc0fed9f0227e06120e",
"content_id": "83a5597e6c495e0553b10b74ae9cdbba07b5bb8b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1517,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 71,
"path": "/leetcode-algorithms/024. Swap Nodes in Pairs/24.swap-nodes-in-pairs.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=24 lang=cpp\r\n *\r\n * [24] Swap Nodes in Pairs\r\n *\r\n * https://leetcode.com/problems/swap-nodes-in-pairs/description/\r\n *\r\n * algorithms\r\n * Medium (44.99%)\r\n * Likes: 1303\r\n * Dislikes: 115\r\n * Total Accepted: 341.3K\r\n * Total Submissions: 745.3K\r\n * Testcase Example: '[1,2,3,4]'\r\n *\r\n * Given a linked list, swap every two adjacent nodes and return its head.\r\n * \r\n * You may not modify the values in the list's nodes, only nodes itself may be\r\n * changed.\r\n * \r\n * \r\n * \r\n * Example:\r\n * \r\n * \r\n * Given 1->2->3->4, you should return the list as 2->1->4->3.\r\n * \r\n * \r\n */\r\n/**\r\n * Definition for singly-linked list.\r\n * struct ListNode {\r\n * int val;\r\n * ListNode *next;\r\n * ListNode(int x) : val(x), next(NULL) {}\r\n * };\r\n */\r\nclass Solution\r\n{\r\npublic:\r\n ListNode *swapPairs(ListNode *head)\r\n {\r\n if (!head)\r\n {\r\n return head;\r\n }\r\n ListNode newHead = ListNode(-1);\r\n newHead.next = head;\r\n ListNode *p = &newHead, *q = head, *r = head->next;\r\n while (r)\r\n {\r\n swapNode(p, q, r);\r\n swap(r, q);\r\n p = p->next->next;\r\n q = q->next->next;\r\n if (!r->next)\r\n {\r\n break;\r\n }\r\n r = r->next->next;\r\n }\r\n return newHead.next;\r\n }\r\n\r\n void swapNode(ListNode *p, ListNode *q, ListNode *r)\r\n {\r\n q->next = r->next;\r\n r->next = q;\r\n p->next = r;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.4628751873970032,
"alphanum_fraction": 0.49815693497657776,
"avg_line_length": 22.986841201782227,
"blob_id": "d8c762db2a0e3083257b3211b5a38fbcf417fb9e",
"content_id": "611e8adf22686935285089edf815614b314df5fa",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1899,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 76,
"path": "/leetcode-algorithms/667. Beautiful Arrangement II/667.beautiful-arrangement-ii.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=667 lang=java\r\n *\r\n * [667] Beautiful Arrangement II\r\n *\r\n * https://leetcode.com/problems/beautiful-arrangement-ii/description/\r\n *\r\n * algorithms\r\n * Medium (51.49%)\r\n * Total Accepted: 17.5K\r\n * Total Submissions: 33.9K\r\n * Testcase Example: '3\\n2'\r\n *\r\n * \r\n * Given two integers n and k, you need to construct a list which contains n\r\n * different positive integers ranging from 1 to n and obeys the following\r\n * requirement: \r\n * \r\n * Suppose this list is [a1, a2, a3, ... , an], then the list [|a1 - a2|, |a2 -\r\n * a3|, |a3 - a4|, ... , |an-1 - an|] has exactly k distinct integers.\r\n * \r\n * \r\n * \r\n * If there are multiple answers, print any of them.\r\n * \r\n * \r\n * Example 1:\r\n * \r\n * Input: n = 3, k = 1\r\n * Output: [1, 2, 3]\r\n * Explanation: The [1, 2, 3] has three different positive integers ranging\r\n * from 1 to 3, and the [1, 1] has exactly 1 distinct integer: 1.\r\n * \r\n * \r\n * \r\n * Example 2:\r\n * \r\n * Input: n = 3, k = 2\r\n * Output: [1, 3, 2]\r\n * Explanation: The [1, 3, 2] has three different positive integers ranging\r\n * from 1 to 3, and the [2, 1] has exactly 2 distinct integers: 1 and 2.\r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * The n and k are in the range 1 \r\n * \r\n * \r\n */\r\nclass Solution {\r\n public int[] constructArray(int n, int k) {\r\n int[] sol = new int[n];\r\n // List<Integer> sol=new ArrayList<>();\r\n int first = 1;\r\n int second = k + 1;\r\n int limit = k / 2 + 1;\r\n int i = 0;\r\n while (limit != 0) {\r\n limit--;\r\n if (first != second) {\r\n sol[i++] = first;\r\n sol[i++] = second;\r\n } else {\r\n sol[i++] = first;\r\n }\r\n first++;\r\n second--;\r\n }\r\n first = first + second;\r\n while (i < n) {\r\n sol[i++] = first++;\r\n }\r\n return sol;\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.46235984563827515,
"alphanum_fraction": 0.558462381362915,
"avg_line_length": 29.21666717529297,
"blob_id": "ae00eeba985f9d208b150efa35a8f83520295df0",
"content_id": "55dcfb9f29bcd292cf95ae65944c7ece441c18cb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1887,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 60,
"path": "/leetcode-algorithms/695. Max Area of Island/695.max-area-of-island.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=695 lang=python3\r\n#\r\n# [695] Max Area of Island\r\n#\r\n# https://leetcode.com/problems/max-area-of-island/description/\r\n#\r\n# algorithms\r\n# Medium (56.07%)\r\n# Total Accepted: 78.7K\r\n# Total Submissions: 138.4K\r\n# Testcase Example: '[[1,1,0,0,0],[1,1,0,0,0],[0,0,0,1,1],[0,0,0,1,1]]'\r\n#\r\n# Given a non-empty 2D array grid of 0's and 1's, an island is a group of 1's\r\n# (representing land) connected 4-directionally (horizontal or vertical.) You\r\n# may assume all four edges of the grid are surrounded by water.\r\n#\r\n# Find the maximum area of an island in the given 2D array. (If there is no\r\n# island, the maximum area is 0.)\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# [[0,0,1,0,0,0,0,1,0,0,0,0,0],\r\n# [0,0,0,0,0,0,0,1,1,1,0,0,0],\r\n# [0,1,1,0,1,0,0,0,0,0,0,0,0],\r\n# [0,1,0,0,1,1,0,0,1,0,1,0,0],\r\n# [0,1,0,0,1,1,0,0,1,1,1,0,0],\r\n# [0,0,0,0,0,0,0,0,0,0,1,0,0],\r\n# [0,0,0,0,0,0,0,1,1,1,0,0,0],\r\n# [0,0,0,0,0,0,0,1,1,0,0,0,0]]\r\n#\r\n# Given the above grid, return 6. Note the answer is not 11, because the island\r\n# must be connected 4-directionally.\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# [[0,0,0,0,0,0,0,0]]\r\n# Given the above grid, return 0.\r\n#\r\n# Note: The length of each dimension in the given grid does not exceed 50.\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def maxAreaOfIsland(self, grid: List[List[int]]) -> int:\r\n def depth(grid, row, col):\r\n if row >= len(grid) or col >= len(grid[0]) or row < 0 or col < 0 or grid[row][col] == 0:\r\n return 0\r\n grid[row][col] = 0\r\n return 1+depth(grid, row-1, col)+depth(grid, row+1, col)+depth(grid, row, col-1)+depth(grid, row, col+1)\r\n maxarea = 0\r\n for i in range(len(grid)):\r\n for j in range(len(grid[0])):\r\n if grid[i][j] == 0:\r\n continue\r\n maxarea = max(maxarea, depth(grid, i, j))\r\n return maxarea\r\n"
},
{
"alpha_fraction": 0.560706377029419,
"alphanum_fraction": 0.5883002281188965,
"avg_line_length": 18.133333206176758,
"blob_id": "4eac32ae67daa30f4aad940c2b574961c54d7ffb",
"content_id": "2f5c9568ff769519622cc505ccf21179fb48061f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 906,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 45,
"path": "/leetcode-algorithms/389. Find the Difference/389.find-the-difference.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=389 lang=python3\r\n#\r\n# [389] Find the Difference\r\n#\r\n# https://leetcode.com/problems/find-the-difference/description/\r\n#\r\n# algorithms\r\n# Easy (53.17%)\r\n# Likes: 518\r\n# Dislikes: 232\r\n# Total Accepted: 149.2K\r\n# Total Submissions: 280K\r\n# Testcase Example: '\"abcd\"\\n\"abcde\"'\r\n#\r\n#\r\n# Given two strings s and t which consist of only lowercase letters.\r\n#\r\n# String t is generated by random shuffling string s and then add one more\r\n# letter at a random position.\r\n#\r\n# Find the letter that was added in t.\r\n#\r\n# Example:\r\n#\r\n# Input:\r\n# s = \"abcd\"\r\n# t = \"abcde\"\r\n#\r\n# Output:\r\n# e\r\n#\r\n# Explanation:\r\n# 'e' is the letter that was added.\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def findTheDifference(self, s: str, t: str) -> str:\r\n res = ord(t[len(t) - 1])\r\n for i in range(len(s)):\r\n res ^= ord(s[i])\r\n res ^= ord(t[i])\r\n return chr(res)\r\n"
},
{
"alpha_fraction": 0.4001706540584564,
"alphanum_fraction": 0.47098976373672485,
"avg_line_length": 24.636363983154297,
"blob_id": "6fdd07635608a186effffed60fee04b98adb441b",
"content_id": "2e46f3ef9d31c8e119328f2bf1f592739a40c935",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2354,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 88,
"path": "/leetcode-algorithms/832. Flipping an Image/832.flipping-an-image.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=832 lang=python3\r\n#\r\n# [832] Flipping an Image\r\n#\r\n# https://leetcode.com/problems/flipping-an-image/description/\r\n#\r\n# algorithms\r\n# Easy (71.59%)\r\n# Total Accepted: 87.7K\r\n# Total Submissions: 121.4K\r\n# Testcase Example: '[[1,1,0],[1,0,1],[0,0,0]]'\r\n#\r\n# Given a binary matrix A, we want to flip the image horizontally, then invert\r\n# it, and return the resulting image.\r\n#\r\n# To flip an image horizontally means that each row of the image is reversed.\r\n# For example, flipping [1, 1, 0] horizontally results in [0, 1, 1].\r\n#\r\n# To invert an image means that each 0 is replaced by 1, and each 1 is replaced\r\n# by 0. For example, inverting [0, 1, 1] results in [1, 0, 0].\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: [[1,1,0],[1,0,1],[0,0,0]]\r\n# Output: [[1,0,0],[0,1,0],[1,1,1]]\r\n# Explanation: First reverse each row: [[0,1,1],[1,0,1],[0,0,0]].\r\n# Then, invert the image: [[1,0,0],[0,1,0],[1,1,1]]\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: [[1,1,0,0],[1,0,0,1],[0,1,1,1],[1,0,1,0]]\r\n# Output: [[1,1,0,0],[0,1,1,0],[0,0,0,1],[1,0,1,0]]\r\n# Explanation: First reverse each row:\r\n# [[0,0,1,1],[1,0,0,1],[1,1,1,0],[0,1,0,1]].\r\n# Then invert the image: [[1,1,0,0],[0,1,1,0],[0,0,0,1],[1,0,1,0]]\r\n#\r\n#\r\n# Notes:\r\n#\r\n#\r\n# 1 <= A.length = A[0].length <= 20\r\n# 0 <= A[i][j] <= 1\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def flipAndInvertImage(self, A: List[List[int]]) -> List[List[int]]:\r\n # for t in A:\r\n # t.reverse()\r\n # for i in range(len(t)):\r\n # if t[i]==0:\r\n # t[i]=1;\r\n # else:\r\n # t[i]=0;\r\n # return A\r\n return [[1-i for i in row[::-1]] for row in A]\r\n '''\r\n return [[1-i for i in row[::-1]] for row in A]\r\n\r\n \r\n for row in A:\r\n for i in xrange((len(row) + 1) / 2):\r\n \"\"\"\r\n In Python, the shortcut row[~i] = row[-i-1] = row[len(row) - 1 - i]\r\n helps us find the i-th value of the row, counting from the right.\r\n \"\"\"\r\n row[i], row[~i] = row[~i] ^ 1, row[i] ^ 1\r\n \r\n b = 0\r\n d = []\r\n for alist in A:\r\n alist.reverse()\r\n c=[]\r\n for a in alist:\r\n\r\n b = 1-a\r\n\r\n c.append(b)\r\n print(c)\r\n d.append(c)\r\n return d\r\n '''\r\n"
},
{
"alpha_fraction": 0.3692910075187683,
"alphanum_fraction": 0.42148759961128235,
"avg_line_length": 25.369047164916992,
"blob_id": "9391deda9b38035f8e3266692484d7074613be6a",
"content_id": "b6090c2e396156d6b873fc0d99e1e3e2cf10403d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2307,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 84,
"path": "/leetcode-algorithms/661. Image Smoother/661.image-smoother.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=661 lang=cpp\r\n *\r\n * [661] Image Smoother\r\n *\r\n * https://leetcode.com/problems/image-smoother/description/\r\n *\r\n * algorithms\r\n * Easy (48.01%)\r\n * Total Accepted: 33.7K\r\n * Total Submissions: 69.5K\r\n * Testcase Example: '[[1,1,1],[1,0,1],[1,1,1]]'\r\n *\r\n * Given a 2D integer matrix M representing the gray scale of an image, you\r\n * need to design a smoother to make the gray scale of each cell becomes the\r\n * average gray scale (rounding down) of all the 8 surrounding cells and\r\n * itself. If a cell has less than 8 surrounding cells, then use as many as\r\n * you can.\r\n * \r\n * Example 1:\r\n * \r\n * Input:\r\n * [[1,1,1],\r\n * [1,0,1],\r\n * [1,1,1]]\r\n * Output:\r\n * [[0, 0, 0],\r\n * [0, 0, 0],\r\n * [0, 0, 0]]\r\n * Explanation:\r\n * For the point (0,0), (0,2), (2,0), (2,2): floor(3/4) = floor(0.75) = 0\r\n * For the point (0,1), (1,0), (1,2), (2,1): floor(5/6) = floor(0.83333333) = 0\r\n * For the point (1,1): floor(8/9) = floor(0.88888889) = 0\r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * The value in the given matrix is in the range of [0, 255].\r\n * The length and width of the given matrix are in the range of [1, 150].\r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n vector<vector<int>> imageSmoother(vector<vector<int>> &M)\r\n {\r\n struct dir\r\n {\r\n int a, b;\r\n };\r\n dir m[9];\r\n for (int i = -1, k = 0; i < 2; i++)\r\n {\r\n for (int j = -1; j < 2; j++, k++)\r\n {\r\n m[k].a = i;\r\n m[k].b = j;\r\n }\r\n }\r\n vector<vector<int>> sol(M.size(), vector<int>(M[0].size()));\r\n for (auto i = 0; i < M.size(); i++)\r\n {\r\n for (auto j = 0; j < M[0].size(); j++)\r\n {\r\n int sum = 0, count = 0;\r\n for (int k = 0; k < 9; k++)\r\n {\r\n int newi = i + m[k].a;\r\n int newj = j + m[k].b;\r\n if (newi >= 0 && newi < M.size() && newj >= 0 && newj < M[0].size())\r\n {\r\n sum += M[newi][newj];\r\n count++;\r\n }\r\n }\r\n if (count)\r\n sol[i][j] = sum / count;\r\n }\r\n }\r\n return sol;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.5370219945907593,
"alphanum_fraction": 0.5646867156028748,
"avg_line_length": 20.759260177612305,
"blob_id": "0ee8b7097034d924847ade10019fc686d6ade4d5",
"content_id": "2e3087e23e964387518015e40935f43c5b2d40dd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1241,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 54,
"path": "/leetcode-algorithms/145. Binary Tree Postorder Traversal/145.binary-tree-postorder-traversal.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "import java.util.ArrayList;\r\n\r\n/*\r\n * @lc app=leetcode id=145 lang=java\r\n *\r\n * [145] Binary Tree Postorder Traversal\r\n *\r\n * https://leetcode.com/problems/binary-tree-postorder-traversal/description/\r\n *\r\n * algorithms\r\n * Hard (48.80%)\r\n * Likes: 977\r\n * Dislikes: 47\r\n * Total Accepted: 273.9K\r\n * Total Submissions: 555K\r\n * Testcase Example: '[1,null,2,3]'\r\n *\r\n * Given a binary tree, return the postorder traversal of its nodes' values.\r\n * \r\n * Example:\r\n * \r\n * \r\n * Input: [1,null,2,3]\r\n * 1\r\n * \\\r\n * 2\r\n * /\r\n * 3\r\n * \r\n * Output: [3,2,1]\r\n * \r\n * \r\n * Follow up: Recursive solution is trivial, could you do it iteratively?\r\n * \r\n */\r\n/**\r\n * Definition for a binary tree node. public class TreeNode { int val; TreeNode\r\n * left; TreeNode right; TreeNode(int x) { val = x; } }\r\n */\r\nclass Solution {\r\n public List<Integer> postorderTraversal(TreeNode root) {\r\n List<Integer> res = new ArrayList<>();\r\n postorder(res, root);\r\n return res;\r\n }\r\n\r\n void postorder(List<Integer> res, TreeNode node) {\r\n if (node != null) {\r\n postorder(res, node.left);\r\n postorder(res, node.right);\r\n res.add(node.val);\r\n }\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.48269039392471313,
"alphanum_fraction": 0.5390702486038208,
"avg_line_length": 15.833333015441895,
"blob_id": "365c189189b1ce38273809d0719d4eaafac6fe35",
"content_id": "31a1dc0aadfec92d937585908d3ad874a38272dc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Kotlin",
"length_bytes": 1011,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 60,
"path": "/leetcode-algorithms/258. Add Digits/258.add-digits.kt",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\n * @lc app=leetcode id=258 lang=kotlin\n *\n * [258] Add Digits\n *\n * https://leetcode.com/problems/add-digits/description/\n *\n * algorithms\n * Easy (58.67%)\n * Likes: 1172\n * Dislikes: 1300\n * Total Accepted: 353.4K\n * Total Submissions: 600.8K\n * Testcase Example: '38'\n *\n * Given an integer num, repeatedly add all its digits until the result has\n * only one digit, and return it.\n * \n * \n * Example 1:\n * \n * \n * Input: num = 38\n * Output: 2\n * Explanation: The process is\n * 38 --> 3 + 8 --> 11\n * 11 --> 1 + 1 --> 2 \n * Since 2 has only one digit, return it.\n * \n * \n * Example 2:\n * \n * \n * Input: num = 0\n * Output: 0\n * \n * \n * \n * Constraints:\n * \n * \n * 0 <= num <= 2^31 - 1\n * \n * \n * \n * Follow up: Could you do it without any loop/recursion in O(1) runtime?\n * \n */\n\n// @lc code=start\nclass Solution {\n fun addDigits(num: Int): Int {\n if (num <= 9) {\n return num\n }\n val res = num % 9 \n return if (res == 0) 9 else res \n }\n}\n// @lc code=end\n\n"
},
{
"alpha_fraction": 0.5505359768867493,
"alphanum_fraction": 0.5880551338195801,
"avg_line_length": 25.787233352661133,
"blob_id": "8e42aec8a0aa3bb3e3c828bbf0184647347b4e1c",
"content_id": "9b2d9b30f545ce5f3dd42ff1098c7b8662a3a159",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1307,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 47,
"path": "/leetcode-algorithms/238. Product of Array Except Self/238.product-of-array-except-self.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=238 lang=python3\r\n#\r\n# [238] Product of Array Except Self\r\n#\r\n# https://leetcode.com/problems/product-of-array-except-self/description/\r\n#\r\n# algorithms\r\n# Medium (53.95%)\r\n# Total Accepted: 246.9K\r\n# Total Submissions: 451.9K\r\n# Testcase Example: '[1,2,3,4]'\r\n#\r\n# Given an array nums of n integers where n > 1, return an array output such\r\n# that output[i] is equal to the product of all the elements of nums except\r\n# nums[i].\r\n#\r\n# Example:\r\n#\r\n#\r\n# Input: [1,2,3,4]\r\n# Output: [24,12,8,6]\r\n#\r\n#\r\n# Note: Please solve it without division and in O(n).\r\n#\r\n# Follow up:\r\n# Could you solve it with constant space complexity? (The output array does not\r\n# count as extra space for the purpose of space complexity analysis.)\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def productExceptSelf(self, nums: List[int]) -> List[int]:\r\n sol = [0 for i in range(len(nums))]\r\n left = [1 for i in range(len(nums))]\r\n right = [1 for i in range(len(nums))]\r\n left[0] = 1\r\n right[len(nums)-1] = 1\r\n for i in range(1, len(nums)):\r\n left[i] = left[i-1]*nums[i-1]\r\n for i in range(len(nums)-2, -1, -1):\r\n right[i] = right[i+1]*nums[i+1]\r\n for i in range(len(nums)):\r\n sol[i] = left[i]*right[i]\r\n return sol\r\n"
},
{
"alpha_fraction": 0.4724409580230713,
"alphanum_fraction": 0.5129358768463135,
"avg_line_length": 22.027027130126953,
"blob_id": "43594e04e1d1335955b71b7db1616e76e44e22d3",
"content_id": "ed620d0e960012a6f1b31edbf41064539200996a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1780,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 74,
"path": "/leetcode-algorithms/769. Max Chunks To Make Sorted/769.max-chunks-to-make-sorted.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=769 lang=cpp\r\n *\r\n * [769] Max Chunks To Make Sorted\r\n *\r\n * https://leetcode.com/problems/max-chunks-to-make-sorted/description/\r\n *\r\n * algorithms\r\n * Medium (51.06%)\r\n * Total Accepted: 21.9K\r\n * Total Submissions: 42.7K\r\n * Testcase Example: '[4,3,2,1,0]'\r\n *\r\n * Given an array arr that is a permutation of [0, 1, ..., arr.length - 1], we\r\n * split the array into some number of \"chunks\" (partitions), and individually\r\n * sort each chunk. After concatenating them, the result equals the sorted\r\n * array.\r\n * \r\n * What is the most number of chunks we could have made?\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: arr = [4,3,2,1,0]\r\n * Output: 1\r\n * Explanation:\r\n * Splitting into two or more chunks will not return the required result.\r\n * For example, splitting into [4, 3], [2, 1, 0] will result in [3, 4, 0, 1,\r\n * 2], which isn't sorted.\r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: arr = [1,0,2,3,4]\r\n * Output: 4\r\n * Explanation:\r\n * We can split into two chunks, such as [1, 0], [2, 3, 4].\r\n * However, splitting into [1, 0], [2], [3], [4] is the highest number of\r\n * chunks possible.\r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * arr will have length in range [1, 10].\r\n * arr[i] will be a permutation of [0, 1, ..., arr.length - 1].\r\n * \r\n * \r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n int maxChunksToSorted(vector<int> &arr)\r\n {\r\n int sum = 0;\r\n int sol = 0;\r\n int start = 0;\r\n for (int i = 0; i < arr.size(); i++)\r\n {\r\n sum += arr[i];\r\n int expected = (start + i) * (i - start + 1) / 2;\r\n if (sum == expected)\r\n {\r\n sol++;\r\n start = i + 1;\r\n sum = 0;\r\n }\r\n }\r\n return sol;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.45120933651924133,
"alphanum_fraction": 0.5145955085754395,
"avg_line_length": 17.655736923217773,
"blob_id": "537dfb77c16ba8c1c8c7ff7598cfe8ab9a785a60",
"content_id": "91b16e048afc0fb169c2bd8ce5c74bbbeb9067eb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1203,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 61,
"path": "/leetcode-algorithms/977. Squares of a Sorted Array/977.squares-of-a-sorted-array.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=977 lang=python3\r\n#\r\n# [977] Squares of a Sorted Array\r\n#\r\n# https://leetcode.com/problems/squares-of-a-sorted-array/description/\r\n#\r\n# algorithms\r\n# Easy (72.86%)\r\n# Total Accepted: 56.2K\r\n# Total Submissions: 77.7K\r\n# Testcase Example: '[-4,-1,0,3,10]'\r\n#\r\n# Given an array of integers A sorted in non-decreasing order, return an array\r\n# of the squares of each number, also in sorted non-decreasing order.\r\n#\r\n#\r\n#\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: [-4,-1,0,3,10]\r\n# Output: [0,1,9,16,100]\r\n#\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: [-7,-3,2,3,11]\r\n# Output: [4,9,9,49,121]\r\n#\r\n#\r\n#\r\n#\r\n# Note:\r\n#\r\n#\r\n# 1 <= A.length <= 10000\r\n# -10000 <= A[i] <= 10000\r\n# A is sorted in non-decreasing order.\r\n#\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def sortedSquares(self, A: List[int]) -> List[int]:\r\n # left,right=0,len(A)-1\r\n # sol=[_ for _ in range(len(A))]\r\n # for i in range(len(A)-1,-1,-1):\r\n # if abs(A[left])>abs(A[right]):\r\n # sol[i]=A[left]*A[left]\r\n # left+=1\r\n # else:\r\n # sol[i]=A[right]*A[right]\r\n # right-=1\r\n # return sol\r\n return sorted(x*x for x in A)\r\n"
},
{
"alpha_fraction": 0.3491773307323456,
"alphanum_fraction": 0.4277879297733307,
"avg_line_length": 14.57575798034668,
"blob_id": "3ba047826a4bdaa03ddfefabd619375253235750",
"content_id": "a588b923762039366eee4c03c10a70868047bb31",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1095,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 66,
"path": "/leetcode-algorithms/912. Sort an Array/912.sort-an-array.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=912 lang=cpp\r\n *\r\n * [912] Sort an Array\r\n *\r\n * https://leetcode.com/problems/sort-an-array/description/\r\n *\r\n * algorithms\r\n * Medium (63.48%)\r\n * Likes: 58\r\n * Dislikes: 78\r\n * Total Accepted: 10.6K\r\n * Total Submissions: 16.7K\r\n * Testcase Example: '[5,2,3,1]'\r\n *\r\n * Given an array of integers nums, sort the array in ascending order.\r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: [5,2,3,1]\r\n * Output: [1,2,3,5]\r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: [5,1,1,2,0,0]\r\n * Output: [0,0,1,1,2,5]\r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * 1 <= A.length <= 10000\r\n * -50000 <= A[i] <= 50000\r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n vector<int> sortArray(vector<int> &nums)\r\n {\r\n vector<int> count(50000 + 50000 + 1, 0);\r\n for (auto t : nums)\r\n {\r\n count[t + 50000]++;\r\n }\r\n for (int i = 0, j = 0; i < count.size(); i++)\r\n {\r\n if (count[i]--)\r\n {\r\n nums[j++] = i - 50000;\r\n }\r\n }\r\n return nums;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.4644913673400879,
"alphanum_fraction": 0.5086372494697571,
"avg_line_length": 19.26530647277832,
"blob_id": "310e4224c43303555ef9182f0ba31b842010ea96",
"content_id": "014ada47f1f0715123641d8c6c6e19c8109da790",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1053,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 49,
"path": "/leetcode-algorithms/118. Pascal's Triangle/118.pascals-triangle.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=118 lang=python3\r\n#\r\n# [118] Pascal's Triangle\r\n#\r\n# https://leetcode.com/problems/pascals-triangle/description/\r\n#\r\n# algorithms\r\n# Easy (44.68%)\r\n# Total Accepted: 241.2K\r\n# Total Submissions: 532.3K\r\n# Testcase Example: '5'\r\n#\r\n# Given a non-negative integer numRows, generate the first numRows of Pascal's\r\n# triangle.\r\n#\r\n#\r\n# In Pascal's triangle, each number is the sum of the two numbers directly\r\n# above it.\r\n#\r\n# Example:\r\n#\r\n#\r\n# Input: 5\r\n# Output:\r\n# [\r\n# [1],\r\n# [1,1],\r\n# [1,2,1],\r\n# [1,3,3,1],\r\n# [1,4,6,4,1]\r\n# ]\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def generate(self, numRows: int) -> List[List[int]]:\r\n map = [[]for _ in range(numRows)]\r\n for i in range(numRows):\r\n tmp = [1 for _ in range(i+1)]\r\n map[i] = tmp\r\n # map[i][0]=map[i][i]=1;\r\n if numRows > 2:\r\n for i in range(2, numRows):\r\n for j in range(1, i):\r\n map[i][j] = (map[i - 1][j] + map[i - 1][j - 1])\r\n return map\r\n"
},
{
"alpha_fraction": 0.47264260053634644,
"alphanum_fraction": 0.5273573994636536,
"avg_line_length": 18.95121955871582,
"blob_id": "f587b0ebb26a21e89c6ea23205aca8ec31e98060",
"content_id": "c7a6595dc7c3cc359a8daf004b7521c3c359f753",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 859,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 41,
"path": "/leetcode-algorithms/204. Count Primes/204.count-primes.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=204 lang=python3\r\n#\r\n# [204] Count Primes\r\n#\r\n# https://leetcode.com/problems/count-primes/description/\r\n#\r\n# algorithms\r\n# Easy (29.13%)\r\n# Likes: 1106\r\n# Dislikes: 419\r\n# Total Accepted: 245.7K\r\n# Total Submissions: 840.2K\r\n# Testcase Example: '10'\r\n#\r\n# Count the number of prime numbers less than a non-negative number, n.\r\n#\r\n# Example:\r\n#\r\n#\r\n# Input: 10\r\n# Output: 4\r\n# Explanation: There are 4 prime numbers less than 10, they are 2, 3, 5, 7.\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def countPrimes(self, n: int) -> int:\r\n if not n or n == 1:\r\n return 0\r\n res = [False]*n\r\n res[0] = True\r\n res[1] = True\r\n i = 0\r\n while i**2 < n:\r\n if not res[i]:\r\n res[i**2:n:i] = [True]*len(res[i**2:n:i])\r\n i += 1\r\n return res.count(False)\r\n"
},
{
"alpha_fraction": 0.5082873106002808,
"alphanum_fraction": 0.5393115282058716,
"avg_line_length": 23.257732391357422,
"blob_id": "28a3dfd0511522f191a87c86fcc578e11d8004ba",
"content_id": "1a2752a14510eb634b25c63b74e6fcb398751941",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2357,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 97,
"path": "/leetcode-algorithms/065. Valid Number/65.valid-number.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode id=65 lang=python3\n#\n# [65] Valid Number\n#\n# https://leetcode.com/problems/valid-number/description/\n#\n# algorithms\n# Hard (14.45%)\n# Likes: 580\n# Dislikes: 4074\n# Total Accepted: 147.8K\n# Total Submissions: 1M\n# Testcase Example: '\"0\"'\n#\n# Validate if a given stringcan be interpreted as a decimal number.\n#\n# Some examples:\n# \"0\" => true\n# \" 0.1 \" => true\n# \"abc\" => false\n# \"1 a\" => false\n# \"2e10\" => true\n# \" -90e3 \" => true\n# \" 1e\" => false\n# \"e3\" => false\n# \" 6e-1\" => true\n# \" 99e2.5 \" => false\n# \"53.5e93\" => true\n# \" --6 \" => false\n# \"-+3\" => false\n# \"95a54e53\" => false\n#\n# Note: It is intended for the problem statement to be ambiguous. You should\n# gather all requirements up front before implementing one. However, here is a\n# list of acters thatcan be in a valid decimal number:\n#\n#\n# Numbers 0-9\n# Exponent - \"e\"\n# Positive/negative sign - \"+\"/\"-\"\n# Decimal point - \".\"\n#\n#\n# Ofcourse, thecontext of these acters also matters in the input.\n#\n# Update (2015-02-10):\n# The signature of thec++ function had been updated. If you still see your\n# function signature accepts aconst * argument, pleaseclick the reload\n# button to reset yourcode definition.\n#\n#\n\n# @lc code=start\n\n\nclass Solution:\n def isNumber(self, s: str) -> bool:\n # version 1\n def isSgn(c):\n return c == '+' or c == '-'\n\n def isDot(c):\n return c == '.'\n\n def isE(c):\n return c == 'e' or c == 'E'\n s = s.strip()\n pos, hasNum, sLength = 0, False, len(s)\n if (pos < sLength and isSgn(s[pos])):\n pos += 1\n while (pos < sLength and s[pos].isdigit()):\n hasNum = True\n pos += 1\n if (pos < sLength and isDot(s[pos])):\n pos += 1\n while (pos < sLength and s[pos].isdigit()):\n hasNum = True\n pos += 1\n if (hasNum and pos < sLength and isE(s[pos])):\n hasNum = False\n pos += 1\n if (pos < sLength and isSgn(s[pos])):\n pos += 1\n while (pos < sLength and s[pos].isdigit()):\n hasNum = True\n pos += 1\n return (pos == sLength) and hasNum\n\n # version 2\n # try:\n # float(s)\n # return True\n # except Exception as e:\n # return False\n\n# @lc code=end\n"
},
{
"alpha_fraction": 0.4373503625392914,
"alphanum_fraction": 0.4740622639656067,
"avg_line_length": 19.237287521362305,
"blob_id": "5b9089359179204e2feb71f73d0dec9bc4dd408d",
"content_id": "a72d2c0e9d5b3211d9cee168819389eb537bb188",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1253,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 59,
"path": "/leetcode-algorithms/268. Missing Number/268.missing-number.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=268 lang=cpp\r\n *\r\n * [268] Missing Number\r\n *\r\n * https://leetcode.com/problems/missing-number/description/\r\n *\r\n * algorithms\r\n * Easy (47.59%)\r\n * Total Accepted: 262.3K\r\n * Total Submissions: 546.8K\r\n * Testcase Example: '[3,0,1]'\r\n *\r\n * Given an array containing n distinct numbers taken from 0, 1, 2, ..., n,\r\n * find the one that is missing from the array.\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: [3,0,1]\r\n * Output: 2\r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: [9,6,4,2,3,5,7,0,1]\r\n * Output: 8\r\n * \r\n * \r\n * Note:\r\n * Your algorithm should run in linear runtime complexity. Could you implement\r\n * it using only constant extra space complexity?\r\n */\r\nclass Solution\r\n{\r\npublic:\r\n int missingNumber(vector<int> &nums)\r\n {\r\n int sol = nums.size();\r\n for (int i = 0; i < nums.size(); i++)\r\n {\r\n sol ^= nums[i];\r\n sol ^= i;\r\n }\r\n return sol;\r\n // unordered_map<int,int>mp;\r\n // for (int i =0;i<nums.size();i++)\r\n // {\r\n // mp[nums[i]]++;\r\n // }\r\n // for(int i=0;i<nums.size()+1;i++)\r\n // {\r\n // if(mp[i]==0)\r\n // return i;\r\n // }\r\n // return 0;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.4644351601600647,
"alphanum_fraction": 0.5246862173080444,
"avg_line_length": 20.980770111083984,
"blob_id": "7f95bc00bbef510feb168e10bbd9566cbf278bf2",
"content_id": "afce4797c032d5505e13cd9cff2f9ecbe64737af",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1197,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 52,
"path": "/leetcode-algorithms/228. Summary Ranges/228.summary-ranges.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=228 lang=python3\r\n#\r\n# [228] Summary Ranges\r\n#\r\n# https://leetcode.com/problems/summary-ranges/description/\r\n#\r\n# algorithms\r\n# Medium (35.27%)\r\n# Likes: 360\r\n# Dislikes: 359\r\n# Total Accepted: 130.5K\r\n# Total Submissions: 364K\r\n# Testcase Example: '[0,1,2,4,5,7]'\r\n#\r\n# Given a sorted integer array without duplicates, return the summary of its\r\n# ranges.\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: [0,1,2,4,5,7]\r\n# Output: [\"0->2\",\"4->5\",\"7\"]\r\n# Explanation: 0,1,2 form a continuous range; 4,5 form a continuous range.\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: [0,2,3,4,6,8,9]\r\n# Output: [\"0\",\"2->4\",\"6\",\"8->9\"]\r\n# Explanation: 2,3,4 form a continuous range; 8,9 form a continuous range.\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def summaryRanges(self, nums: List[int]) -> List[str]:\r\n length = len(nums)\r\n i = 0\r\n result = []\r\n while i < length:\r\n pre = nums[i]\r\n while i+1 < length and nums[i]+1 == nums[i+1]:\r\n i += 1\r\n if pre == nums[i]:\r\n result.append(str(pre))\r\n else:\r\n result.append(str(pre)+'->'+str(nums[i]))\r\n i += 1\r\n return result\r\n"
},
{
"alpha_fraction": 0.38425102829933167,
"alphanum_fraction": 0.42095914483070374,
"avg_line_length": 17.870588302612305,
"blob_id": "7c9b88f237c51c5366c0ba167a3f329ca2bb3f71",
"content_id": "9c95379c9f4f3d0138df41ca4c2de9532757cf62",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1695,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 85,
"path": "/leetcode-algorithms/007. Reverse Integer/7.reverse-integer.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=7 lang=cpp\r\n *\r\n * [7] Reverse Integer\r\n *\r\n * https://leetcode.com/problems/reverse-integer/description/\r\n *\r\n * algorithms\r\n * Easy (25.17%)\r\n * Total Accepted: 651.5K\r\n * Total Submissions: 2.6M\r\n * Testcase Example: '123'\r\n *\r\n * Given a 32-bit signed integer, reverse digits of an integer.\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: 123\r\n * Output: 321\r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: -123\r\n * Output: -321\r\n * \r\n * \r\n * Example 3:\r\n * \r\n * \r\n * Input: 120\r\n * Output: 21\r\n * \r\n * \r\n * Note:\r\n * Assume we are dealing with an environment which could only store integers\r\n * within the 32-bit signed integer range: [−2^31, 2^31 − 1]. For the purpose\r\n * of this problem, assume that your function returns 0 when the reversed\r\n * integer overflows.\r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n int reverse(int x)\r\n {\r\n bool t = true;\r\n long newx = x;\r\n if (newx < 0)\r\n {\r\n newx = -newx;\r\n t = false;\r\n }\r\n long long n = 0;\r\n if (0 <= newx && newx < 10)\r\n {\r\n if (t)\r\n return newx;\r\n else\r\n return -newx;\r\n }\r\n int old = 0;\r\n while (newx > 0)\r\n {\r\n old = n;\r\n n = newx % 10 + (n * 10);\r\n if (n > INT_MAX && t)\r\n {\r\n return 0;\r\n }\r\n if (-n < INT_MIN && !t)\r\n {\r\n return 0;\r\n }\r\n // std::cout<<old<<\"\\t\"<<n<<std::endl;\r\n newx = newx / 10;\r\n }\r\n if (t)\r\n return n;\r\n else\r\n return -n;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.4371257424354553,
"alphanum_fraction": 0.5089820623397827,
"avg_line_length": 20.266666412353516,
"blob_id": "d3485fe7a5f9eb6f0ba9805f6ef31dfddd5785c3",
"content_id": "671067bb7d88181c7576f0b26897701e838f4600",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1670,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 75,
"path": "/leetcode-algorithms/628. Maximum Product of Three Numbers/628.maximum-product-of-three-numbers.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=628 lang=python3\r\n#\r\n# [628] Maximum Product of Three Numbers\r\n#\r\n# https://leetcode.com/problems/maximum-product-of-three-numbers/description/\r\n#\r\n# algorithms\r\n# Easy (45.61%)\r\n# Total Accepted: 66.3K\r\n# Total Submissions: 144.7K\r\n# Testcase Example: '[1,2,3]'\r\n#\r\n# Given an integer array, find three numbers whose product is maximum and\r\n# output the maximum product.\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: [1,2,3]\r\n# Output: 6\r\n#\r\n#\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: [1,2,3,4]\r\n# Output: 24\r\n#\r\n#\r\n#\r\n#\r\n# Note:\r\n#\r\n#\r\n# The length of the given array will be in range [3,10^4] and all elements are\r\n# in the range [-1000, 1000].\r\n# Multiplication of any three numbers in the input won't exceed the range of\r\n# 32-bit signed integer.\r\n#\r\n#\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def maximumProduct(self, nums: List[int]) -> int:\r\n # min1=999999999\r\n # min2=999999999\r\n # max1=-99999999\r\n # max2=-99999999\r\n # max3=-99999999\r\n # for i in range(len(nums)):\r\n # if nums[i]<=min1:\r\n # min2=min1\r\n # min1=nums[i]\r\n # elif nums[i]<=min2:\r\n # min2=nums[i]\r\n # if nums[i]>=max1:\r\n # max3=max2\r\n # max2=max1\r\n # max1=nums[i]\r\n # elif nums[i]>=max2:\r\n # max3=max2\r\n # max2=nums[i]\r\n # elif nums[i]>=max3:\r\n # max3=nums[i]\r\n # maxs=max(max1*min1*min2,max1*max2*max3)\r\n # return maxs\r\n a, b, c = heapq.nlargest(3, nums)\r\n d, e = heapq.nsmallest(2, nums)\r\n return max(a * b * c, d * e * a)\r\n"
},
{
"alpha_fraction": 0.5250481963157654,
"alphanum_fraction": 0.5953757166862488,
"avg_line_length": 20.565217971801758,
"blob_id": "ad31471a683e3b53bda99a73c6d0865abdf16804",
"content_id": "a8d11dc46e8307784b28f1f4c394b0d73c8a8643",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1038,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 46,
"path": "/leetcode-algorithms/643. Maximum Average Subarray I/643.maximum-average-subarray-i.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=643 lang=python3\r\n#\r\n# [643] Maximum Average Subarray I\r\n#\r\n# https://leetcode.com/problems/maximum-average-subarray-i/description/\r\n#\r\n# algorithms\r\n# Easy (39.06%)\r\n# Total Accepted: 49.2K\r\n# Total Submissions: 125.2K\r\n# Testcase Example: '[1,12,-5,-6,50,3]\\n4'\r\n#\r\n# Given an array consisting of n integers, find the contiguous subarray of\r\n# given length k that has the maximum average value. And you need to output the\r\n# maximum average value.\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: [1,12,-5,-6,50,3], k = 4\r\n# Output: 12.75\r\n# Explanation: Maximum average is (12-5-6+50)/4 = 51/4 = 12.75\r\n#\r\n#\r\n#\r\n#\r\n# Note:\r\n#\r\n#\r\n# 1 <= k <= n <= 30,000.\r\n# Elements of the given array will be in the range [-10,000, 10,000].\r\n#\r\n#\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def findMaxAverage(self, nums: List[int], k: int) -> float:\r\n maxsum = mysum = sum(nums[:k])\r\n for i in range(k, len(nums)):\r\n mysum = mysum-nums[i-k]+nums[i]\r\n maxsum = max(maxsum, mysum)\r\n return maxsum*1.0/k\r\n"
},
{
"alpha_fraction": 0.4616657495498657,
"alphanum_fraction": 0.4853833317756653,
"avg_line_length": 22.1733341217041,
"blob_id": "daff10056263f5756cba497c03e4cc6aa7d69564",
"content_id": "17d44ea60b292ef4d206adacb0a7aabfc715c402",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1818,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 75,
"path": "/leetcode-algorithms/1002. Find Common Characters/1002.find-common-characters.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=1002 lang=java\r\n *\r\n * [1002] Find Common Characters\r\n *\r\n * https://leetcode.com/problems/find-common-characters/description/\r\n *\r\n * algorithms\r\n * Easy (69.05%)\r\n * Total Accepted: 17.1K\r\n * Total Submissions: 25.9K\r\n * Testcase Example: '[\"bella\",\"label\",\"roller\"]'\r\n *\r\n * Given an array A of strings made only from lowercase letters, return a list\r\n * of all characters that show up in all strings within the list (including\r\n * duplicates). For example, if a character occurs 3 times in all strings but\r\n * not 4 times, you need to include that character three times in the final\r\n * answer.\r\n * \r\n * You may return the answer in any order.\r\n * \r\n * \r\n * \r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: [\"bella\",\"label\",\"roller\"]\r\n * Output: [\"e\",\"l\",\"l\"]\r\n * \r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: [\"cool\",\"lock\",\"cook\"]\r\n * Output: [\"c\",\"o\"]\r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * 1 <= A.length <= 100\r\n * 1 <= A[i].length <= 100\r\n * A[i][j] is a lowercase letter\r\n * \r\n * \r\n * \r\n */\r\nclass Solution {\r\n public List<String> commonChars(String[] A) {\r\n int[] charcount = new int[26];\r\n for (char t : A[0].toCharArray()) {\r\n charcount[t - 'a']++;\r\n }\r\n for (int i = 1; i < A.length; i++) {\r\n int[] tempcount = new int[26];\r\n for (char t : A[i].toCharArray()) {\r\n tempcount[t - 'a']++;\r\n }\r\n for (int j = 0; j < 26; j++) {\r\n charcount[j] = Math.min(charcount[j], tempcount[j]);\r\n }\r\n }\r\n List<String> sol = new ArrayList<>();\r\n for (int i = 0; i < 26; i++) {\r\n for (int j = 0; j < charcount[i]; j++) {\r\n sol.add((char) ('a' + i) + \"\");\r\n }\r\n }\r\n return sol;\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.40390878915786743,
"alphanum_fraction": 0.45521172881126404,
"avg_line_length": 15.295774459838867,
"blob_id": "843970c4ace1ca39981f861c3b23318a0c0436cf",
"content_id": "f30bdd3cb6c9f9c21eb7b1bf60f8a81cb8a385eb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1238,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 71,
"path": "/leetcode-algorithms/509. Fibonacci Number/509.fibonacci-number.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=509 lang=cpp\r\n *\r\n * [509] Fibonacci Number\r\n *\r\n * https://leetcode.com/problems/fibonacci-number/description/\r\n *\r\n * algorithms\r\n * Easy (66.51%)\r\n * Total Accepted: 41K\r\n * Total Submissions: 61.3K\r\n * Testcase Example: '2'\r\n *\r\n * The Fibonacci numbers, commonly denoted F(n) form a sequence, called the\r\n * Fibonacci sequence, such that each number is the sum of the two preceding\r\n * ones, starting from 0 and 1. That is,\r\n * \r\n * \r\n * F(0) = 0, F(1) = 1\r\n * F(N) = F(N - 1) + F(N - 2), for N > 1.\r\n * \r\n * \r\n * Given N, calculate F(N).\r\n * \r\n * \r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: 2\r\n * Output: 1\r\n * Explanation: F(2) = F(1) + F(0) = 1 + 0 = 1.\r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: 3\r\n * Output: 2\r\n * Explanation: F(3) = F(2) + F(1) = 1 + 1 = 2.\r\n * \r\n * \r\n * Example 3:\r\n * \r\n * \r\n * Input: 4\r\n * Output: 3\r\n * Explanation: F(4) = F(3) + F(2) = 2 + 1 = 3.\r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * 0 ≤ N ≤ 30.\r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n int fib(int N)\r\n {\r\n vector<int> sol(31, 0);\r\n sol[1] = 1;\r\n for (int i = 2; i <= N; i++)\r\n {\r\n sol[i] = sol[i - 1] + sol[i - 2];\r\n }\r\n return sol[N];\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.3627775013446808,
"alphanum_fraction": 0.3897024095058441,
"avg_line_length": 22.905881881713867,
"blob_id": "2e0b35fa61bb5f34c35edc349c60a2c9df6c7def",
"content_id": "8e9486daac1bbf8971eae215a22d412230db6b3a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2117,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 85,
"path": "/leetcode-algorithms/219. Contains Duplicate II/219.contains-duplicate-ii.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=219 lang=cpp\r\n *\r\n * [219] Contains Duplicate II\r\n *\r\n * https://leetcode.com/problems/contains-duplicate-ii/description/\r\n *\r\n * algorithms\r\n * Easy (34.74%)\r\n * Total Accepted: 190.8K\r\n * Total Submissions: 545K\r\n * Testcase Example: '[1,2,3,1]\\n3'\r\n *\r\n * Given an array of integers and an integer k, find out whether there are two\r\n * distinct indices i and j in the array such that nums[i] = nums[j] and the\r\n * absolute difference between i and j is at most k.\r\n * \r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: nums = [1,2,3,1], k = 3\r\n * Output: true\r\n * \r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: nums = [1,0,1,1], k = 1\r\n * Output: true\r\n * \r\n * \r\n * \r\n * Example 3:\r\n * \r\n * \r\n * Input: nums = [1,2,3,1,2,3], k = 2\r\n * Output: false\r\n * \r\n * \r\n * \r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n bool containsNearbyDuplicate(vector<int> &nums, int k)\r\n {\r\n unordered_map<int, int> sol;\r\n for (int i = 0; i < nums.size(); i++)\r\n {\r\n if (sol[nums[i]] && abs(sol[nums[i]] - i - 1) <= k)\r\n return true;\r\n sol[nums[i]] = i + 1;\r\n }\r\n return false;\r\n // unordered_map<int,vector<int>>sol;\r\n // for(int i=0;i<nums.size();i++)\r\n // {\r\n // if(sol[nums[i]].size()<2)\r\n // {\r\n // sol[nums[i]].push_back(i);\r\n // if(sol[nums[i]].size()==2)\r\n // {\r\n // sol[nums[i]].push_back(sol[nums[i]][1]-sol[nums[i]][0]);\r\n // if(sol[nums[i]][2]<=k)\r\n // return true;\r\n // }\r\n // }\r\n // else\r\n // {\r\n // if(i-sol[nums[i]][1]<sol[nums[i]][2])\r\n // {\r\n // sol[nums[i]][2]=i-sol[nums[i]][1];\r\n // }\r\n // sol[nums[i]][1]=i;\r\n // if(sol[nums[i]][2]<=k)\r\n // return true;\r\n // }\r\n // }\r\n // return false;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.4620418846607208,
"alphanum_fraction": 0.47971203923225403,
"avg_line_length": 18.931507110595703,
"blob_id": "ebf89178e7dc940d698373c1e5103f9e3e7d74e8",
"content_id": "48b35b2383de6b049969f0ffa9c0712434804d87",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1528,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 73,
"path": "/leetcode-algorithms/014. Longest Common Prefix/14.longest-common-prefix.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=14 lang=cpp\r\n *\r\n * [14] Longest Common Prefix\r\n *\r\n * https://leetcode.com/problems/longest-common-prefix/description/\r\n *\r\n * algorithms\r\n * Easy (33.98%)\r\n * Likes: 1588\r\n * Dislikes: 1451\r\n * Total Accepted: 534.7K\r\n * Total Submissions: 1.6M\r\n * Testcase Example: '[\"flower\",\"flow\",\"flight\"]'\r\n *\r\n * Write a function to find the longest common prefix string amongst an array\r\n * of strings.\r\n * \r\n * If there is no common prefix, return an empty string \"\".\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: [\"flower\",\"flow\",\"flight\"]\r\n * Output: \"fl\"\r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: [\"dog\",\"racecar\",\"car\"]\r\n * Output: \"\"\r\n * Explanation: There is no common prefix among the input strings.\r\n * \r\n * \r\n * Note:\r\n * \r\n * All given inputs are in lowercase letters a-z.\r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n string longestCommonPrefix(vector<string> &strs)\r\n {\r\n if (strs.empty())\r\n {\r\n return \"\";\r\n }\r\n string res = strs[0];\r\n for (auto str : strs)\r\n {\r\n res = find(res, str);\r\n if (res == \"\")\r\n {\r\n break;\r\n }\r\n }\r\n return res;\r\n }\r\n string find(const string &left, const string &right)\r\n {\r\n int size = min(left.size(), right.size()), i = 0;\r\n for (; i < size; i++)\r\n {\r\n if (left[i] != right[i])\r\n {\r\n break;\r\n }\r\n }\r\n return left.substr(0, i);\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.536796510219574,
"alphanum_fraction": 0.5822510719299316,
"avg_line_length": 19,
"blob_id": "b2ea3bc238ad866826597e640a7b673db2973109",
"content_id": "007faa425e15035a82b1d1672fe972e95b8efe0b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 924,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 44,
"path": "/leetcode-algorithms/268. Missing Number/268.missing-number.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=268 lang=python3\r\n#\r\n# [268] Missing Number\r\n#\r\n# https://leetcode.com/problems/missing-number/description/\r\n#\r\n# algorithms\r\n# Easy (47.59%)\r\n# Total Accepted: 262.3K\r\n# Total Submissions: 546.8K\r\n# Testcase Example: '[3,0,1]'\r\n#\r\n# Given an array containing n distinct numbers taken from 0, 1, 2, ..., n, find\r\n# the one that is missing from the array.\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: [3,0,1]\r\n# Output: 2\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: [9,6,4,2,3,5,7,0,1]\r\n# Output: 8\r\n#\r\n#\r\n# Note:\r\n# Your algorithm should run in linear runtime complexity. Could you implement\r\n# it using only constant extra space complexity?\r\n#\r\n\r\n\r\nclass Solution:\r\n def missingNumber(self, nums: List[int]) -> int:\r\n # sol = len(nums);\r\n # for i in range(len(nums)):\r\n # sol ^= nums[i]\r\n # sol ^= i\r\n # return sol\r\n return sum(range(len(nums)+1)) - sum(nums)\r\n"
},
{
"alpha_fraction": 0.4324786365032196,
"alphanum_fraction": 0.4683760702610016,
"avg_line_length": 22.71830940246582,
"blob_id": "ed73c92716b671db72e1dd94d1580f2f08af786d",
"content_id": "f9572959487dc112185bfd43dbb247a50dfa59ca",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1755,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 71,
"path": "/leetcode-algorithms/034. Find First and Last Position of Element in Sorted Array/34.find-first-and-last-position-of-element-in-sorted-array.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=34 lang=cpp\r\n *\r\n * [34] Find First and Last Position of Element in Sorted Array\r\n *\r\n * https://leetcode.com/problems/find-first-and-last-position-of-element-in-sorted-array/description/\r\n *\r\n * algorithms\r\n * Medium (33.68%)\r\n * Likes: 1771\r\n * Dislikes: 91\r\n * Total Accepted: 323.9K\r\n * Total Submissions: 956.1K\r\n * Testcase Example: '[5,7,7,8,8,10]\\n8'\r\n *\r\n * Given an array of integers nums sorted in ascending order, find the starting\r\n * and ending position of a given target value.\r\n * \r\n * Your algorithm's runtime complexity must be in the order of O(log n).\r\n * \r\n * If the target is not found in the array, return [-1, -1].\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: nums = [5,7,7,8,8,10], target = 8\r\n * Output: [3,4]\r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: nums = [5,7,7,8,8,10], target = 6\r\n * Output: [-1,-1]\r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n vector<int> searchRange(vector<int> &nums, int target)\r\n {\r\n int left = 0, right = nums.size() - 1;\r\n int index;\r\n bool found = false;\r\n while (left <= right)\r\n {\r\n index = (right + left) / 2;\r\n if (nums[index] > target)\r\n {\r\n right = index - 1;\r\n }\r\n else if (nums[index] < target)\r\n {\r\n left = index + 1;\r\n }\r\n else\r\n {\r\n found = true;\r\n break;\r\n }\r\n }\r\n if (found)\r\n {\r\n while (nums[left] != nums[index] && left++ != -1)\r\n ;\r\n while (nums[right] != nums[index] && right-- != -1)\r\n ;\r\n return {left, right};\r\n }\r\n return {-1, -1};\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.5142315030097961,
"alphanum_fraction": 0.5436432361602783,
"avg_line_length": 21.954545974731445,
"blob_id": "8e8c0afe4ff3e636f7783850cb224ac34cc8892b",
"content_id": "8af976a55143ed82c886fdce61863e0b69cbdb80",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1054,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 44,
"path": "/leetcode-algorithms/058. Length of Last Word/58.length-of-last-word.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=58 lang=java\r\n *\r\n * [58] Length of Last Word\r\n *\r\n * https://leetcode.com/problems/length-of-last-word/description/\r\n *\r\n * algorithms\r\n * Easy (32.26%)\r\n * Likes: 380\r\n * Dislikes: 1594\r\n * Total Accepted: 273.2K\r\n * Total Submissions: 847K\r\n * Testcase Example: '\"Hello World\"'\r\n *\r\n * Given a string s consists of upper/lower-case alphabets and empty space\r\n * characters ' ', return the length of last word in the string.\r\n * \r\n * If the last word does not exist, return 0.\r\n * \r\n * Note: A word is defined as a character sequence consists of non-space\r\n * characters only.\r\n * \r\n * Example:\r\n * \r\n * \r\n * Input: \"Hello World\"\r\n * Output: 5\r\n * \r\n * \r\n * \r\n * \r\n */\r\nclass Solution {\r\n public int lengthOfLastWord(String s) {\r\n s = s.trim();\r\n int len = 0, tail = s.length() - 1;\r\n while (tail >= 0 && s.charAt(tail--) != ' ' && ++len != 0)\r\n ;\r\n return len;\r\n // String[] res = s.split(\"\\\\s+\");\r\n // return res.length == 0 ? 0 : res[res.length - 1].size();\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.46192052960395813,
"alphanum_fraction": 0.5231788158416748,
"avg_line_length": 21.6862735748291,
"blob_id": "dd0a3e33837de666d7e9d26f80fc46e9cf29ac08",
"content_id": "4a33bafaa8a2ea1ca007eefa2332d2771b2a0e3f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1208,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 51,
"path": "/leetcode-algorithms/643. Maximum Average Subarray I/643.maximum-average-subarray-i.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=643 lang=java\r\n *\r\n * [643] Maximum Average Subarray I\r\n *\r\n * https://leetcode.com/problems/maximum-average-subarray-i/description/\r\n *\r\n * algorithms\r\n * Easy (39.06%)\r\n * Total Accepted: 49.2K\r\n * Total Submissions: 125.2K\r\n * Testcase Example: '[1,12,-5,-6,50,3]\\n4'\r\n *\r\n * Given an array consisting of n integers, find the contiguous subarray of\r\n * given length k that has the maximum average value. And you need to output\r\n * the maximum average value.\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: [1,12,-5,-6,50,3], k = 4\r\n * Output: 12.75\r\n * Explanation: Maximum average is (12-5-6+50)/4 = 51/4 = 12.75\r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * 1 <= k <= n <= 30,000.\r\n * Elements of the given array will be in the range [-10,000, 10,000].\r\n * \r\n * \r\n * \r\n * \r\n */\r\nclass Solution {\r\n public double findMaxAverage(int[] nums, int k) {\r\n int sum = 0, maxsum;\r\n for (int i = 0; i < k; i++) {\r\n sum += nums[i];\r\n }\r\n maxsum = sum;\r\n for (int i = k; i < nums.length; i++) {\r\n sum = sum - nums[i - k] + nums[i];\r\n maxsum = Math.max(maxsum, sum);\r\n }\r\n return maxsum * 1.0 / k;\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.39231663942337036,
"alphanum_fraction": 0.4534342288970947,
"avg_line_length": 20.605262756347656,
"blob_id": "e7c9e6c690cc6d029ec83f353216d8d5c599ce45",
"content_id": "0800624bdbc0072274490bb11efa5cca2f5f2c9e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1719,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 76,
"path": "/leetcode-algorithms/200. Number of Islands/200.number-of-islands.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=200 lang=cpp\r\n *\r\n * [200] Number of Islands\r\n *\r\n * https://leetcode.com/problems/number-of-islands/description/\r\n *\r\n * algorithms\r\n * Medium (42.46%)\r\n * Likes: 3014\r\n * Dislikes: 109\r\n * Total Accepted: 408K\r\n * Total Submissions: 958.3K\r\n * Testcase Example: '[[\"1\",\"1\",\"1\",\"1\",\"0\"],[\"1\",\"1\",\"0\",\"1\",\"0\"],[\"1\",\"1\",\"0\",\"0\",\"0\"],[\"0\",\"0\",\"0\",\"0\",\"0\"]]'\r\n *\r\n * Given a 2d grid map of '1's (land) and '0's (water), count the number of\r\n * islands. An island is surrounded by water and is formed by connecting\r\n * adjacent lands horizontally or vertically. You may assume all four edges of\r\n * the grid are all surrounded by water.\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input:\r\n * 11110\r\n * 11010\r\n * 11000\r\n * 00000\r\n * \r\n * Output: 1\r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input:\r\n * 11000\r\n * 11000\r\n * 00100\r\n * 00011\r\n * \r\n * Output: 3\r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n void depth(vector<vector<char>> &grid, int row, int col)\r\n {\r\n if (row >= grid.size() || col >= grid[0].size() || row < 0 || col < 0 || grid[row][col] == '0')\r\n {\r\n return;\r\n }\r\n grid[row][col] = '0';\r\n depth(grid, row - 1, col);\r\n depth(grid, row + 1, col);\r\n depth(grid, row, col - 1);\r\n depth(grid, row, col + 1);\r\n }\r\n int numIslands(vector<vector<char>> &grid)\r\n {\r\n int num = 0;\r\n for (int i = 0; i < grid.size(); i++)\r\n {\r\n for (int j = 0; j < grid[0].size(); j++)\r\n {\r\n if (grid[i][j] == '1')\r\n {\r\n num++;\r\n depth(grid, i, j);\r\n }\r\n }\r\n }\r\n return num;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.49887892603874207,
"alphanum_fraction": 0.5493273735046387,
"avg_line_length": 15.84000015258789,
"blob_id": "327027104dbd3c726dee75edaf479dded3fc1bb2",
"content_id": "ea6e94b6e54c45bb830cb42a6ed9d728f37195bd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 892,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 50,
"path": "/leetcode-algorithms/326. Power of Three/326.power-of-three.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=326 lang=java\r\n *\r\n * [326] Power of Three\r\n *\r\n * https://leetcode.com/problems/power-of-three/description/\r\n *\r\n * algorithms\r\n * Easy (41.79%)\r\n * Likes: 324\r\n * Dislikes: 1152\r\n * Total Accepted: 202.2K\r\n * Total Submissions: 483.3K\r\n * Testcase Example: '27'\r\n *\r\n * Given an integer, write a function to determine if it is a power of three.\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: 27\r\n * Output: true\r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: 0\r\n * Output: false\r\n * \r\n * Example 3:\r\n * \r\n * \r\n * Input: 9\r\n * Output: true\r\n * \r\n * Example 4:\r\n * \r\n * \r\n * Input: 45\r\n * Output: false\r\n * \r\n * Follow up:\r\n * Could you do it without using any loop / recursion?\r\n */\r\nclass Solution {\r\n public boolean isPowerOfThree(int n) {\r\n return n > 0 && (int) Math.pow(3, (int) (Math.log10(Integer.MAX_VALUE) / Math.log10(3))) % n == 0;\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.44900423288345337,
"alphanum_fraction": 0.47133374214172363,
"avg_line_length": 18.97468376159668,
"blob_id": "c18d93d8cfff7ddf263b1fed81cde8b80bc0d38a",
"content_id": "419f447b653405815d692cf3b96bd4a2741804dd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1667,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 79,
"path": "/leetcode-algorithms/094. Binary Tree Inorder Traversal/94.binary-tree-inorder-traversal.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=94 lang=cpp\r\n *\r\n * [94] Binary Tree Inorder Traversal\r\n *\r\n * https://leetcode.com/problems/binary-tree-inorder-traversal/description/\r\n *\r\n * algorithms\r\n * Medium (56.97%)\r\n * Likes: 1673\r\n * Dislikes: 72\r\n * Total Accepted: 475.2K\r\n * Total Submissions: 832.7K\r\n * Testcase Example: '[1,null,2,3]'\r\n *\r\n * Given a binary tree, return the inorder traversal of its nodes' values.\r\n * \r\n * Example:\r\n * \r\n * \r\n * Input: [1,null,2,3]\r\n * 1\r\n * \\\r\n * 2\r\n * /\r\n * 3\r\n * \r\n * Output: [1,3,2]\r\n * \r\n * Follow up: Recursive solution is trivial, could you do it iteratively?\r\n * \r\n */\r\n/**\r\n * Definition for a binary tree node.\r\n * struct TreeNode {\r\n * int val;\r\n * TreeNode *left;\r\n * TreeNode *right;\r\n * TreeNode(int x) : val(x), left(NULL), right(NULL) {}\r\n * };\r\n */\r\nclass Solution\r\n{\r\npublic:\r\n vector<int> inorderTraversal(TreeNode *root)\r\n {\r\n stack<TreeNode *> st;\r\n vector<int> res2;\r\n TreeNode *p = root;\r\n while (p || !st.empty())\r\n {\r\n while (p)\r\n {\r\n st.push(p);\r\n p = p->left;\r\n }\r\n p = st.top();\r\n st.pop();\r\n res2.push_back(p->val);\r\n p = p->right;\r\n }\r\n // vector<int> res;\r\n // inorder(root, res);\r\n // return res;\r\n return res2;\r\n }\r\n\r\nprivate:\r\n void inorder(TreeNode *root, vector<int> &res)\r\n {\r\n if (!root)\r\n {\r\n return;\r\n }\r\n inorder(root->left, res);\r\n res.push_back(root->val);\r\n inorder(root->right, res);\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.4663594365119934,
"alphanum_fraction": 0.5244239568710327,
"avg_line_length": 12.090909004211426,
"blob_id": "242bebda18c824d051bd28f08a2650e5e9f5ceff",
"content_id": "f07d31c5008f89752d4215fc9f244ab95c4df067",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1086,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 77,
"path": "/leetcode-algorithms/976. Largest Perimeter Triangle/976.largest-perimeter-triangle.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=976 lang=python3\r\n#\r\n# [976] Largest Perimeter Triangle\r\n#\r\n# https://leetcode.com/problems/largest-perimeter-triangle/description/\r\n#\r\n# algorithms\r\n# Easy (56.89%)\r\n# Total Accepted: 13.6K\r\n# Total Submissions: 23.9K\r\n# Testcase Example: '[2,1,2]'\r\n#\r\n# Given an array A of positive lengths, return the largest perimeter of a\r\n# triangle with non-zero area, formed from 3 of these lengths.\r\n#\r\n# If it is impossible to form any triangle of non-zero area, return 0.\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: [2,1,2]\r\n# Output: 5\r\n#\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: [1,2,1]\r\n# Output: 0\r\n#\r\n#\r\n#\r\n# Example 3:\r\n#\r\n#\r\n# Input: [3,2,3,4]\r\n# Output: 10\r\n#\r\n#\r\n#\r\n# Example 4:\r\n#\r\n#\r\n# Input: [3,6,2,3]\r\n# Output: 8\r\n#\r\n#\r\n#\r\n#\r\n# Note:\r\n#\r\n#\r\n# 3 <= A.length <= 10000\r\n# 1 <= A[i] <= 10^6\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def largestPerimeter(self, A: List[int]) -> int:\r\n A = sorted(A)\r\n for i in range(len(A)-1, 1, -1):\r\n if A[i-2]+A[i-1] > A[i]:\r\n return A[i-2]+A[i-1]+A[i]\r\n return 0\r\n"
},
{
"alpha_fraction": 0.4807581901550293,
"alphanum_fraction": 0.5221137404441833,
"avg_line_length": 23.231884002685547,
"blob_id": "a041c4f7f626fe9b7460510ae524deef69bb497d",
"content_id": "e224d7344c2371e89cec7f4173f37bd0611e704b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1743,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 69,
"path": "/leetcode-algorithms/769. Max Chunks To Make Sorted/769.max-chunks-to-make-sorted.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=769 lang=java\r\n *\r\n * [769] Max Chunks To Make Sorted\r\n *\r\n * https://leetcode.com/problems/max-chunks-to-make-sorted/description/\r\n *\r\n * algorithms\r\n * Medium (51.06%)\r\n * Total Accepted: 21.9K\r\n * Total Submissions: 42.7K\r\n * Testcase Example: '[4,3,2,1,0]'\r\n *\r\n * Given an array arr that is a permutation of [0, 1, ..., arr.length - 1], we\r\n * split the array into some number of \"chunks\" (partitions), and individually\r\n * sort each chunk. After concatenating them, the result equals the sorted\r\n * array.\r\n * \r\n * What is the most number of chunks we could have made?\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: arr = [4,3,2,1,0]\r\n * Output: 1\r\n * Explanation:\r\n * Splitting into two or more chunks will not return the required result.\r\n * For example, splitting into [4, 3], [2, 1, 0] will result in [3, 4, 0, 1,\r\n * 2], which isn't sorted.\r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: arr = [1,0,2,3,4]\r\n * Output: 4\r\n * Explanation:\r\n * We can split into two chunks, such as [1, 0], [2, 3, 4].\r\n * However, splitting into [1, 0], [2], [3], [4] is the highest number of\r\n * chunks possible.\r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * arr will have length in range [1, 10].\r\n * arr[i] will be a permutation of [0, 1, ..., arr.length - 1].\r\n * \r\n * \r\n * \r\n * \r\n */\r\nclass Solution {\r\n public int maxChunksToSorted(int[] arr) {\r\n int sum = 0;\r\n int sol = 0;\r\n int start = 0;\r\n for (int i = 0; i < arr.length; i++) {\r\n sum += arr[i];\r\n int expected = (start + i) * (i - start + 1) / 2;\r\n if (sum == expected) {\r\n sol++;\r\n start = i + 1;\r\n sum = 0;\r\n }\r\n }\r\n return sol;\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.39549338817596436,
"alphanum_fraction": 0.4428904354572296,
"avg_line_length": 13.321428298950195,
"blob_id": "18fe809864733e9b7f4805b9681fd14d38931349",
"content_id": "80df2afbc8a684d32cf6f3743160521383f0f6e3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1288,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 84,
"path": "/leetcode-algorithms/976. Largest Perimeter Triangle/976.largest-perimeter-triangle.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=976 lang=cpp\r\n *\r\n * [976] Largest Perimeter Triangle\r\n *\r\n * https://leetcode.com/problems/largest-perimeter-triangle/description/\r\n *\r\n * algorithms\r\n * Easy (56.89%)\r\n * Total Accepted: 13.6K\r\n * Total Submissions: 23.9K\r\n * Testcase Example: '[2,1,2]'\r\n *\r\n * Given an array A of positive lengths, return the largest perimeter of a\r\n * triangle with non-zero area, formed from 3 of these lengths.\r\n * \r\n * If it is impossible to form any triangle of non-zero area, return 0.\r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: [2,1,2]\r\n * Output: 5\r\n * \r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: [1,2,1]\r\n * Output: 0\r\n * \r\n * \r\n * \r\n * Example 3:\r\n * \r\n * \r\n * Input: [3,2,3,4]\r\n * Output: 10\r\n * \r\n * \r\n * \r\n * Example 4:\r\n * \r\n * \r\n * Input: [3,6,2,3]\r\n * Output: 8\r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * 3 <= A.length <= 10000\r\n * 1 <= A[i] <= 10^6\r\n * \r\n * \r\n * \r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n int largestPerimeter(vector<int> &A)\r\n {\r\n sort(A.begin(), A.end());\r\n for (int i = A.size() - 1; i >= 2; i--)\r\n {\r\n if (A[i - 2] + A[i - 1] > A[i])\r\n {\r\n return A[i - 2] + A[i - 1] + A[i];\r\n }\r\n }\r\n return 0;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.4625954329967499,
"alphanum_fraction": 0.48040711879730225,
"avg_line_length": 25.29166603088379,
"blob_id": "162f0c6f512d00f4e2d17aba6f1871e352635fd5",
"content_id": "2d358098b978b1636be9c824e9ad9fa791cf198f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1971,
"license_type": "permissive",
"max_line_length": 167,
"num_lines": 72,
"path": "/leetcode-algorithms/079. Word Search/79.word-search.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=79 lang=cpp\r\n *\r\n * [79] Word Search\r\n *\r\n * https://leetcode.com/problems/word-search/description/\r\n *\r\n * algorithms\r\n * Medium (30.46%)\r\n * Likes: 1780\r\n * Dislikes: 87\r\n * Total Accepted: 288.6K\r\n * Total Submissions: 918.2K\r\n * Testcase Example: '[[\"A\",\"B\",\"C\",\"E\"],[\"S\",\"F\",\"C\",\"S\"],[\"A\",\"D\",\"E\",\"E\"]]\\n\"ABCCED\"'\r\n *\r\n * Given a 2D board and a word, find if the word exists in the grid.\r\n * \r\n * The word can be constructed from letters of sequentially adjacent cell,\r\n * where \"adjacent\" cells are those horizontally or vertically neighboring. The\r\n * same letter cell may not be used more than once.\r\n * \r\n * Example:\r\n * \r\n * \r\n * board =\r\n * [\r\n * ['A','B','C','E'],\r\n * ['S','F','C','S'],\r\n * ['A','D','E','E']\r\n * ]\r\n * \r\n * Given word = \"ABCCED\", return true.\r\n * Given word = \"SEE\", return true.\r\n * Given word = \"ABCB\", return false.\r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n bool exist(vector<vector<char>> &board, string word)\r\n {\r\n for (auto i = 0; i < board.size(); i++)\r\n {\r\n for (auto j = 0; j < board[0].size(); j++)\r\n {\r\n if (dfs(board, i, j, word))\r\n {\r\n return true;\r\n }\r\n }\r\n }\r\n return false;\r\n }\r\n bool dfs(vector<vector<char>> &board, int row, int col, string &word)\r\n {\r\n if (word.empty())\r\n {\r\n return true;\r\n }\r\n if (row < 0 || col < 0 || row >= board.size() || col >= board[0].size() || word[0] != board[row][col])\r\n {\r\n return false;\r\n }\r\n char ch = board[row][col];\r\n board[row][col] = '.';\r\n string newword = word.substr(1);\r\n bool result = dfs(board, row - 1, col, newword) || dfs(board, row, col - 1, newword) || dfs(board, row + 1, col, newword) || dfs(board, row, col + 1, newword);\r\n board[row][col] = ch;\r\n return result;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.5102880597114563,
"alphanum_fraction": 0.5380658507347107,
"avg_line_length": 19.130434036254883,
"blob_id": "b2e311a44aeb6eecd78410284b660e014bd8353b",
"content_id": "4906456979845e590b70e715cd0e6a9904162beb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 972,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 46,
"path": "/leetcode-algorithms/058. Length of Last Word/58.length-of-last-word.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=58 lang=cpp\r\n *\r\n * [58] Length of Last Word\r\n *\r\n * https://leetcode.com/problems/length-of-last-word/description/\r\n *\r\n * algorithms\r\n * Easy (32.26%)\r\n * Likes: 380\r\n * Dislikes: 1594\r\n * Total Accepted: 273.2K\r\n * Total Submissions: 847K\r\n * Testcase Example: '\"Hello World\"'\r\n *\r\n * Given a string s consists of upper/lower-case alphabets and empty space\r\n * characters ' ', return the length of last word in the string.\r\n * \r\n * If the last word does not exist, return 0.\r\n * \r\n * Note: A word is defined as a character sequence consists of non-space\r\n * characters only.\r\n * \r\n * Example:\r\n * \r\n * \r\n * Input: \"Hello World\"\r\n * Output: 5\r\n * \r\n * \r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n int lengthOfLastWord(string s)\r\n {\r\n int len = 0, tail = s.length();\r\n while (tail >= 0 && s[tail--] == ' ')\r\n ;\r\n while (tail >= 0 && s[tail--] != ' ' && ++len)\r\n ;\r\n return len;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.47236180305480957,
"alphanum_fraction": 0.49497488141059875,
"avg_line_length": 22.268293380737305,
"blob_id": "e8a973d472a8aca16897bf51a54a13e1d58f4a6e",
"content_id": "8622f2e6adf8e7fa29e7ad6579b53c8d71d6a164",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2008,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 82,
"path": "/leetcode-algorithms/028. Implement strStr()/28.implement-str-str.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=28 lang=cpp\r\n *\r\n * [28] Implement strStr()\r\n *\r\n * https://leetcode.com/problems/implement-strstr/description/\r\n *\r\n * algorithms\r\n * Easy (31.30%)\r\n * Likes: 839\r\n * Dislikes: 1261\r\n * Total Accepted: 415.4K\r\n * Total Submissions: 1.3M\r\n * Testcase Example: '\"hello\"\\n\"ll\"'\r\n *\r\n * Implement strStr().\r\n * \r\n * Return the index of the first occurrence of needle in haystack, or -1 if\r\n * needle is not part of haystack.\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: haystack = \"hello\", needle = \"ll\"\r\n * Output: 2\r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: haystack = \"aaaaa\", needle = \"bba\"\r\n * Output: -1\r\n * \r\n * \r\n * Clarification:\r\n * \r\n * What should we return when needle is an empty string? This is a great\r\n * question to ask during an interview.\r\n * \r\n * For the purpose of this problem, we will return 0 when needle is an empty\r\n * string. This is consistent to C's strstr() and Java's indexOf().\r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n int bc[256];\r\n int *getbc(const string &pattern) //求模板串坏字符表\r\n {\r\n int patternLen = pattern.length();\r\n for (int i = 0; i < 256; ++i)\r\n bc[i] = -1;\r\n\r\n for (int i = 0; i < patternLen; ++i)\r\n {\r\n bc[pattern[i]] = i;\r\n }\r\n return bc;\r\n }\r\n\r\n int strStr(string haystack, string needle)\r\n {\r\n if (needle == \"\")\r\n return 0;\r\n int *abc = getbc(needle);\r\n long long i = 0, j, span;\r\n const long long patternlast = needle.length() - 1, patternLen = needle.length(), strLen = haystack.length();\r\n while (i + patternLen <= strLen)\r\n {\r\n for (j = patternlast; j >= 0 && needle[j] == haystack[i + j]; --j)\r\n ;\r\n if (j == -1)\r\n break;\r\n else\r\n {\r\n span = j - abc[haystack[i + j]];\r\n i += (span > 0) ? span : 1;\r\n }\r\n }\r\n return j == -1 ? i : -1;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.48427072167396545,
"alphanum_fraction": 0.5219256281852722,
"avg_line_length": 19.191919326782227,
"blob_id": "dce7ac57edd47a46c8bec298ecb8ecbe6a60cdf9",
"content_id": "e1d9731ade508803aea9295cd509a12ed82455ee",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2103,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 99,
"path": "/leetcode-algorithms/888. Fair Candy Swap/888.fair-candy-swap.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=888 lang=cpp\r\n *\r\n * [888] Fair Candy Swap\r\n *\r\n * https://leetcode.com/problems/fair-candy-swap/description/\r\n *\r\n * algorithms\r\n * Easy (56.18%)\r\n * Total Accepted: 24.7K\r\n * Total Submissions: 43.8K\r\n * Testcase Example: '[1,1]\\n[2,2]'\r\n *\r\n * Alice and Bob have candy bars of different sizes: A[i] is the size of the\r\n * i-th bar of candy that Alice has, and B[j] is the size of the j-th bar of\r\n * candy that Bob has.\r\n * \r\n * Since they are friends, they would like to exchange one candy bar each so\r\n * that after the exchange, they both have the same total amount of candy.\r\n * (The total amount of candy a person has is the sum of the sizes of candy\r\n * bars they have.)\r\n * \r\n * Return an integer array ans where ans[0] is the size of the candy bar that\r\n * Alice must exchange, and ans[1] is the size of the candy bar that Bob must\r\n * exchange.\r\n * \r\n * If there are multiple answers, you may return any one of them. It is\r\n * guaranteed an answer exists.\r\n * \r\n * \r\n * \r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: A = [1,1], B = [2,2]\r\n * Output: [1,2]\r\n * \r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: A = [1,2], B = [2,3]\r\n * Output: [1,2]\r\n * \r\n * \r\n * \r\n * Example 3:\r\n * \r\n * \r\n * Input: A = [2], B = [1,3]\r\n * Output: [2,3]\r\n * \r\n * \r\n * \r\n * Example 4:\r\n * \r\n * \r\n * Input: A = [1,2,5], B = [2,4]\r\n * Output: [5,4]\r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * 1 <= A.length <= 10000\r\n * 1 <= B.length <= 10000\r\n * 1 <= A[i] <= 100000\r\n * 1 <= B[i] <= 100000\r\n * It is guaranteed that Alice and Bob have different total amounts of\r\n * candy.\r\n * It is guaranteed there exists an answer.\r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n vector<int> fairCandySwap(vector<int> &A, vector<int> &B)\r\n {\r\n int dif = (accumulate(A.begin(), A.end(), 0) - accumulate(B.begin(), B.end(), 0)) / 2;\r\n unordered_set<int> S(A.begin(), A.end());\r\n for (auto b : B)\r\n {\r\n if (S.count(b + dif))\r\n {\r\n return {b + dif, b};\r\n }\r\n }\r\n return {};\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.4882226884365082,
"alphanum_fraction": 0.5321199297904968,
"avg_line_length": 16.3137264251709,
"blob_id": "223e720b827da62d1b016ea1f084bcb618727c86",
"content_id": "9e6e1b1c7ff667b2b4a087cdeecba411204e551f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 935,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 51,
"path": "/leetcode-algorithms/136. Single Number/136.single-number.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=136 lang=cpp\r\n *\r\n * [136] Single Number\r\n *\r\n * https://leetcode.com/problems/single-number/description/\r\n *\r\n * algorithms\r\n * Easy (60.39%)\r\n * Likes: 2505\r\n * Dislikes: 93\r\n * Total Accepted: 473.3K\r\n * Total Submissions: 783.8K\r\n * Testcase Example: '[2,2,1]'\r\n *\r\n * Given a non-empty array of integers, every element appears twice except for\r\n * one. Find that single one.\r\n * \r\n * Note:\r\n * \r\n * Your algorithm should have a linear runtime complexity. Could you implement\r\n * it without using extra memory?\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: [2,2,1]\r\n * Output: 1\r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: [4,1,2,1,2]\r\n * Output: 4\r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n int singleNumber(vector<int> &nums)\r\n {\r\n int res = nums[0];\r\n for (int i = 1; i < nums.size(); i++)\r\n {\r\n res ^= nums[i];\r\n }\r\n return res;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.46542346477508545,
"alphanum_fraction": 0.5089355111122131,
"avg_line_length": 16.926469802856445,
"blob_id": "573e70cadb24b6282871f5a94159c10904e5c4cd",
"content_id": "2321be8131375c14a4ab79e155da05990ee4946d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1287,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 68,
"path": "/leetcode-algorithms/035. Search Insert Position/35.search-insert-position.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=35 lang=python3\r\n#\r\n# [35] Search Insert Position\r\n#\r\n# https://leetcode.com/problems/search-insert-position/description/\r\n#\r\n# algorithms\r\n# Easy (40.48%)\r\n# Total Accepted: 381.4K\r\n# Total Submissions: 938.6K\r\n# Testcase Example: '[1,3,5,6]\\n5'\r\n#\r\n# Given a sorted array and a target value, return the index if the target is\r\n# found. If not, return the index where it would be if it were inserted in\r\n# order.\r\n#\r\n# You may assume no duplicates in the array.\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: [1,3,5,6], 5\r\n# Output: 2\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: [1,3,5,6], 2\r\n# Output: 1\r\n#\r\n#\r\n# Example 3:\r\n#\r\n#\r\n# Input: [1,3,5,6], 7\r\n# Output: 4\r\n#\r\n#\r\n# Example 4:\r\n#\r\n#\r\n# Input: [1,3,5,6], 0\r\n# Output: 0\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def searchInsert(self, nums: List[int], target: int) -> int:\r\n # low=0\r\n # high=len(nums)-1\r\n # mid=0\r\n # while low<=high:\r\n # mid=(low+high)//2\r\n # if nums[mid]==target:\r\n # return mid\r\n # elif nums[mid]>target:\r\n # high=mid-1\r\n # else:\r\n # low=mid+1\r\n # return low\r\n for i in range(len(nums)):\r\n if target <= nums[i]:\r\n return i\r\n return len(nums)\r\n"
},
{
"alpha_fraction": 0.5414634346961975,
"alphanum_fraction": 0.5825784206390381,
"avg_line_length": 18.657533645629883,
"blob_id": "ddb4409e04ab717245fc169725ec0d66e10a4a64",
"content_id": "67f82f43b4cd3ecf9686b4b3567bc1431d873c7e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1444,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 73,
"path": "/leetcode-algorithms/124. Binary Tree Maximum Path Sum/124.binary-tree-maximum-path-sum.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode id=124 lang=python3\n#\n# [124] Binary Tree Maximum Path Sum\n#\n# https://leetcode.com/problems/binary-tree-maximum-path-sum/description/\n#\n# algorithms\n# Hard (31.32%)\n# Likes: 2839\n# Dislikes: 240\n# Total Accepted: 294.1K\n# Total Submissions: 900.7K\n# Testcase Example: '[1,2,3]'\n#\n# Given a non-empty binary tree, find the maximum path sum.\n#\n# For this problem, a path is defined as any sequence of nodes from some\n# starting node to any node in the tree along the parent-child connections. The\n# path must contain at least one node and does not need to go through the\n# root.\n#\n# Example 1:\n#\n#\n# Input: [1,2,3]\n#\n# 1\n# / \\\n# 2 3\n#\n# Output: 6\n#\n#\n# Example 2:\n#\n#\n# Input: [-10,9,20,null,null,15,7]\n#\n# -10\n# / \\\n# 9 20\n# / \\\n# 15 7\n#\n# Output: 42\n#\n#\n#\n\n# @lc code=start\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, x):\n# self.val = x\n# self.left = None\n# self.right = None\n\n\nclass Solution:\n def maxPathSum(self, root: TreeNode) -> int:\n self.res = float('-inf')\n\n def pathCalc(root):\n if not root:\n return 0\n left = max(pathCalc(root.left), 0)\n right = max(pathCalc(root.right), 0)\n self.res = max(self.res, left + right + root.val)\n return max(left, right) + root.val\n pathCalc(root)\n return self.res\n# @lc code=end\n"
},
{
"alpha_fraction": 0.3681125342845917,
"alphanum_fraction": 0.38980069756507874,
"avg_line_length": 22.028169631958008,
"blob_id": "e69289a509f179963d4c1c34ed26dd5a8a19499c",
"content_id": "e4f881dbd579e2e89e8f0afa651a44db718b6dc4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1706,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 71,
"path": "/leetcode-algorithms/001. Two Sum/1.two-sum.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=1 lang=cpp\r\n *\r\n * [1] Two Sum\r\n *\r\n * https://leetcode.com/problems/two-sum/description/\r\n *\r\n * algorithms\r\n * Easy (42.22%)\r\n * Total Accepted: 1.6M\r\n * Total Submissions: 3.7M\r\n * Testcase Example: '[2,7,11,15]\\n9'\r\n *\r\n * Given an array of integers, return indices of the two numbers such that they\r\n * add up to a specific target.\r\n *\r\n * You may assume that each input would have exactly one solution, and you may\r\n * not use the same element twice.\r\n *\r\n * Example:\r\n *\r\n *\r\n * Given nums = [2, 7, 11, 15], target = 9,\r\n *\r\n * Because nums[0] + nums[1] = 2 + 7 = 9,\r\n * return [0, 1].\r\n *\r\n *\r\n *\r\n *\r\n */\r\nclass Solution\r\n{\r\npublic:\r\n vector<int> twoSum(vector<int> &nums, int target)\r\n {\r\n // vector<int>temp;\r\n // bool t=false;\r\n // for(int i=0;i<nums.size();i++)\r\n // {\r\n // for(int j=0;j<nums.size();j++)\r\n // {\r\n // if(i!=j)\r\n // {\r\n // if(nums[i]+nums[j]==target)\r\n // {\r\n // temp.push_back(i);\r\n // temp.push_back(j);\r\n // t=true;\r\n // break;\r\n // }\r\n // }\r\n // }\r\n // if(t)\r\n // break;\r\n // }\r\n // return temp;\r\n map<int, int> a;\r\n vector<int> sol(2);\r\n for (int i = 0; i < nums.size(); i++)\r\n {\r\n if (a.find(target - nums[i]) != a.end())\r\n {\r\n sol[0] = a[target - nums[i]];\r\n sol[1] = i;\r\n }\r\n a[nums[i]] = i;\r\n }\r\n return sol;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.48380130529403687,
"alphanum_fraction": 0.5383369326591492,
"avg_line_length": 26.492307662963867,
"blob_id": "fdbcfb560854133f0c2665469b1bb70b4656edd4",
"content_id": "f116672c62338c1f88d565a169ea92bc99e0cf6c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1852,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 65,
"path": "/leetcode-algorithms/002. Add Two Numbers/2.add-two-numbers.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=2 lang=python3\r\n#\r\n# [2] Add Two Numbers\r\n#\r\n# https://leetcode.com/problems/add-two-numbers/description/\r\n#\r\n# algorithms\r\n# Medium (30.66%)\r\n# Likes: 5024\r\n# Dislikes: 1280\r\n# Total Accepted: 848.6K\r\n# Total Submissions: 2.7M\r\n# Testcase Example: '[2,4,3]\\n[5,6,4]'\r\n#\r\n# You are given two non-empty linked lists representing two non-negative\r\n# integers. The digits are stored in reverse order and each of their nodes\r\n# contain a single digit. Add the two numbers and return it as a linked list.\r\n#\r\n# You may assume the two numbers do not contain any leading zero, except the\r\n# number 0 itself.\r\n#\r\n# Example:\r\n#\r\n#\r\n# Input: (2 -> 4 -> 3) + (5 -> 6 -> 4)\r\n# Output: 7 -> 0 -> 8\r\n# Explanation: 342 + 465 = 807.\r\n#\r\n#\r\n#\r\n# Definition for singly-linked list.\r\n# class ListNode:\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.next = None\r\n\r\n\r\nclass Solution:\r\n def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode:\r\n if not l1.next and l1.val == 0:\r\n return l2\r\n if not l2.next and l2.val == 0:\r\n return l1\r\n p1, p2 = l1, l2\r\n sol = ListNode(0)\r\n head = sol\r\n head.next = None\r\n plus, sol.val = (p1.val + p2.val) // 10, (p1.val + p2.val) % 10\r\n p1, p2 = p1.next, p2.next\r\n while p1 or p2:\r\n temp = ListNode(0)\r\n val1 = p1.val if p1 else 0\r\n p1 = p1.next if p1 else p1\r\n val2 = p2.val if p2 else 0\r\n p2 = p2.next if p2 else p2\r\n temp.next, temp.val = None, val1+val2+plus\r\n plus = temp.val // 10\r\n temp.val %= 10\r\n sol.next = temp\r\n sol = sol.next\r\n if plus != 0:\r\n temp = ListNode(0)\r\n temp.next, temp.val, sol.next = None, 1, temp\r\n return head\r\n"
},
{
"alpha_fraction": 0.44170403480529785,
"alphanum_fraction": 0.48206278681755066,
"avg_line_length": 19.934425354003906,
"blob_id": "58de6a843c82f475d4a9035eb4457e753d83c682",
"content_id": "fa3f371ea947cfc3d259a027400820e52e9066cf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1338,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 61,
"path": "/leetcode-algorithms/905. Sort Array By Parity/905.sort-array-by-parity.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=905 lang=java\r\n *\r\n * [905] Sort Array By Parity\r\n *\r\n * https://leetcode.com/problems/sort-array-by-parity/description/\r\n *\r\n * algorithms\r\n * Easy (72.13%)\r\n * Total Accepted: 85.5K\r\n * Total Submissions: 118K\r\n * Testcase Example: '[3,1,2,4]'\r\n *\r\n * Given an array A of non-negative integers, return an array consisting of all\r\n * the even elements of A, followed by all the odd elements of A.\r\n * \r\n * You may return any answer array that satisfies this condition.\r\n * \r\n * \r\n * \r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: [3,1,2,4]\r\n * Output: [2,4,3,1]\r\n * The outputs [4,2,3,1], [2,4,1,3], and [4,2,1,3] would also be accepted.\r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * 1 <= A.length <= 5000\r\n * 0 <= A[i] <= 5000\r\n * \r\n * \r\n * \r\n */\r\nclass Solution {\r\n public int[] sortArrayByParity(int[] A) {\r\n ArrayList<Integer> a = new ArrayList<>();\r\n ArrayList<Integer> b = new ArrayList<>();\r\n for (Integer t : A) {\r\n if (t % 2 == 0) {\r\n a.add(t);\r\n } else {\r\n b.add(t);\r\n }\r\n }\r\n a.addAll(b);\r\n Integer[] c = a.toArray(new Integer[A.length]);\r\n int[] d = new int[c.length];\r\n int i = 0;\r\n for (Integer t : c) {\r\n d[i++] = t;\r\n }\r\n return d;\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.4300411641597748,
"alphanum_fraction": 0.48148149251937866,
"avg_line_length": 22.711864471435547,
"blob_id": "cf805cf236e979b0898f4f1328084704531c0452",
"content_id": "1b496bcea37ff60a3b1c605629316e627f5750b5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1458,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 59,
"path": "/leetcode-algorithms/415. Add Strings/415.add-strings.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=415 lang=cpp\r\n *\r\n * [415] Add Strings\r\n *\r\n * https://leetcode.com/problems/add-strings/description/\r\n *\r\n * algorithms\r\n * Easy (44.31%)\r\n * Likes: 466\r\n * Dislikes: 158\r\n * Total Accepted: 108.3K\r\n * Total Submissions: 244.4K\r\n * Testcase Example: '\"0\"\\n\"0\"'\r\n *\r\n * Given two non-negative integers num1 and num2 represented as string, return\r\n * the sum of num1 and num2.\r\n * \r\n * Note:\r\n * \r\n * The length of both num1 and num2 is < 5100.\r\n * Both num1 and num2 contains only digits 0-9.\r\n * Both num1 and num2 does not contain any leading zero.\r\n * You must not use any built-in BigInteger library or convert the inputs to\r\n * integer directly.\r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n string addStrings(string num1, string num2)\r\n {\r\n if (num1.size() < num2.size())\r\n {\r\n return addStrings(num2, num1);\r\n }\r\n string res = num1;\r\n int plus = 0, i = num1.size() - 1, j = num2.size() - 1;\r\n while (j >= 0)\r\n {\r\n int temp = num1[i] - '0' + num2[j] - '0' + plus;\r\n res[i] = temp % 10 + '0';\r\n plus = temp / 10;\r\n i--, j--;\r\n }\r\n while (i >= 0)\r\n {\r\n res[i] = (num1[i] - '0' + plus) % 10 + '0';\r\n plus = (num1[i] - '0' + plus) / 10;\r\n i--;\r\n }\r\n if (plus)\r\n {\r\n res = \"1\" + res;\r\n }\r\n return res;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.5343074798583984,
"alphanum_fraction": 0.5883100628852844,
"avg_line_length": 17.674999237060547,
"blob_id": "2c413a0bf5354e86dec3af10035758bfccacfede",
"content_id": "dec4b02c3777ae0fb7a3478b1d38e88432302b7f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1574,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 80,
"path": "/leetcode-algorithms/991. Broken Calculator/991.broken-calculator.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=991 lang=python3\r\n#\r\n# [991] Broken Calculator\r\n#\r\n# https://leetcode.com/problems/broken-calculator/description/\r\n#\r\n# algorithms\r\n# Medium (40.35%)\r\n# Likes: 159\r\n# Dislikes: 52\r\n# Total Accepted: 7.2K\r\n# Total Submissions: 17.6K\r\n# Testcase Example: '2\\n3'\r\n#\r\n# On a broken calculator that has a number showing on its display, we can\r\n# perform two operations:\r\n#\r\n#\r\n# Double: Multiply the number on the display by 2, or;\r\n# Decrement: Subtract 1 from the number on the display.\r\n#\r\n#\r\n# Initially, the calculator is displaying the number X.\r\n#\r\n# Return the minimum number of operations needed to display the number Y.\r\n#\r\n#\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: X = 2, Y = 3\r\n# Output: 2\r\n# Explanation: Use double operation and then decrement operation {2 -> 4 ->\r\n# 3}.\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: X = 5, Y = 8\r\n# Output: 2\r\n# Explanation: Use decrement and then double {5 -> 4 -> 8}.\r\n#\r\n#\r\n# Example 3:\r\n#\r\n#\r\n# Input: X = 3, Y = 10\r\n# Output: 3\r\n# Explanation: Use double, decrement and double {3 -> 6 -> 5 -> 10}.\r\n#\r\n#\r\n# Example 4:\r\n#\r\n#\r\n# Input: X = 1024, Y = 1\r\n# Output: 1023\r\n# Explanation: Use decrement operations 1023 times.\r\n#\r\n#\r\n#\r\n#\r\n# Note:\r\n#\r\n#\r\n# 1 <= X <= 10^9\r\n# 1 <= Y <= 10^9\r\n#\r\n# reference: https://leetcode.com/problems/broken-calculator/discuss/234484/JavaC%2B%2BPython-Change-Y-to-X-in-1-Line\r\n\r\n\r\nclass Solution:\r\n def brokenCalc(self, X: int, Y: int) -> int:\r\n res = 0\r\n while Y > X:\r\n Y = Y + 1 if Y % 2 else Y // 2\r\n res += 1\r\n return res + X - Y\r\n"
},
{
"alpha_fraction": 0.3359106481075287,
"alphanum_fraction": 0.4299828112125397,
"avg_line_length": 18.068965911865234,
"blob_id": "a34d5ecc58a11a16496d305ac28e7b4913de0444",
"content_id": "c0a8966fb3eece1bf1e543f391f851ff825aceee",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2334,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 116,
"path": "/leetcode-algorithms/989. Add to Array-Form of Integer/989.add-to-array-form-of-integer.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=989 lang=cpp\r\n *\r\n * [989] Add to Array-Form of Integer\r\n *\r\n * https://leetcode.com/problems/add-to-array-form-of-integer/description/\r\n *\r\n * algorithms\r\n * Easy (44.85%)\r\n * Total Accepted: 12.6K\r\n * Total Submissions: 28.1K\r\n * Testcase Example: '[1,2,0,0]\\n34'\r\n *\r\n * For a non-negative integer X, the array-form of X is an array of its A\r\n * in left to right order. For example, if X = 1231, then the array form is\r\n * [1,2,3,1].\r\n * \r\n * Given the array-form A of a non-negative integer X, return the array-form of\r\n * the integer X+K.\r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: A = [1,2,0,0], K = 34\r\n * Output: [1,2,3,4]\r\n * Explanation: 1200 + 34 = 1234\r\n * \r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: A = [2,7,4], K = 181\r\n * Output: [4,5,5]\r\n * Explanation: 274 + 181 = 455\r\n * \r\n * \r\n * \r\n * Example 3:\r\n * \r\n * \r\n * Input: A = [2,1,5], K = 806\r\n * Output: [1,0,2,1]\r\n * Explanation: 215 + 806 = 1021\r\n * \r\n * \r\n * \r\n * Example 4:\r\n * \r\n * \r\n * Input: A = [9,9,9,9,9,9,9,9,9,9], K = 1\r\n * Output: [1,0,0,0,0,0,0,0,0,0,0]\r\n * Explanation: 9999999999 + 1 = 10000000000\r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * 1 <= A.length <= 10000\r\n * 0 <= A[i] <= 9\r\n * 0 <= K <= 10000\r\n * If A.length > 1, then A[0] != 0\r\n * \r\n * \r\n * \r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n int sizeTable[9] = {9, 99, 999, 9999, 99999, 999999, 9999999, 99999999, 999999999};\r\n\r\n int stringSize(int x)\r\n {\r\n for (int i = 0;; i++)\r\n {\r\n if (x <= sizeTable[i])\r\n {\r\n return i + 1;\r\n }\r\n }\r\n }\r\n vector<int> addToArrayForm(vector<int> &A, int K)\r\n {\r\n vector<int> sol(max((int)A.size(), stringSize(K)), 0);\r\n for (int i = 1; i < A.size() + 1; i++)\r\n {\r\n sol[sol.size() - i] = A[A.size() - i];\r\n }\r\n int plus = (sol[sol.size() - 1] + K) / 10;\r\n sol[sol.size() - 1] = (sol[sol.size() - 1] + K) % 10;\r\n for (int i = sol.size() - 2; i >= 0; i--)\r\n {\r\n sol[i] += plus;\r\n plus = sol[i] / 10;\r\n if (plus != 0)\r\n {\r\n sol[i] %= 10;\r\n }\r\n }\r\n if (plus)\r\n {\r\n sol.insert(sol.begin(), 1);\r\n }\r\n return sol;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.3647440969944,
"alphanum_fraction": 0.41592201590538025,
"avg_line_length": 18.86440658569336,
"blob_id": "dbb205500cf3ae3bd8cf2780bb7cacd25dc2fce7",
"content_id": "8adab7ddde001565f176c7b73fa7b1da57c626e9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1232,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 59,
"path": "/leetcode-algorithms/067. Add Binary/67.add-binary.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=67 lang=cpp\r\n *\r\n * [67] Add Binary\r\n *\r\n * https://leetcode.com/problems/add-binary/description/\r\n *\r\n * algorithms\r\n * Easy (39.39%)\r\n * Likes: 987\r\n * Dislikes: 198\r\n * Total Accepted: 309.7K\r\n * Total Submissions: 785.9K\r\n * Testcase Example: '\"11\"\\n\"1\"'\r\n *\r\n * Given two binary strings, return their res (also a binary string).\r\n * \r\n * The input strings are both non-empty and contains only characters 1 or 0.\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: a = \"11\", b = \"1\"\r\n * Output: \"100\"\r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: a = \"1010\", b = \"1011\"\r\n * Output: \"10101\"\r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n string addBinary(string a, string b)\r\n {\r\n string res;\r\n int plus = 0;\r\n int i = a.size() - 1, j = b.size() - 1;\r\n while (i >= 0 || j >= 0 || plus > 0)\r\n {\r\n if (i >= 0)\r\n {\r\n plus += a[i] - '0';\r\n i -= 1;\r\n }\r\n if (j >= 0)\r\n {\r\n plus += b[j] - '0';\r\n j -= 1;\r\n }\r\n res += (plus % 2) + '0';\r\n plus /= 2;\r\n }\r\n reverse(res.begin(), res.end());\r\n return res;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.4828193783760071,
"alphanum_fraction": 0.5180616974830627,
"avg_line_length": 21.64583396911621,
"blob_id": "c0df98c1b2f9ebdba3519c49ebddb894853a0013",
"content_id": "e0c334d864a564a96a4d40f48d05069e1bb57770",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1139,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 48,
"path": "/leetcode-algorithms/442. Find All Duplicates in an Array/442.find-all-duplicates-in-an-array.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=442 lang=python3\r\n#\r\n# [442] Find All Duplicates in an Array\r\n#\r\n# https://leetcode.com/problems/find-all-duplicates-in-an-array/description/\r\n#\r\n# algorithms\r\n# Medium (60.03%)\r\n# Total Accepted: 94.5K\r\n# Total Submissions: 156K\r\n# Testcase Example: '[4,3,2,7,8,2,3,1]'\r\n#\r\n# Given an array of integers, 1 ≤ a[i] ≤ n (n = size of array), some elements\r\n# appear twice and others appear once.\r\n#\r\n# Find all the elements that appear twice in this array.\r\n#\r\n# Could you do it without extra space and in O(n) runtime?\r\n#\r\n# Example:\r\n#\r\n# Input:\r\n# [4,3,2,7,8,2,3,1]\r\n#\r\n# Output:\r\n# [2,3]\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def findDuplicates(self, nums: List[int]) -> List[int]:\r\n list = []\r\n for i in range(len(nums)):\r\n if nums[abs(nums[i])-1] > 0:\r\n nums[abs(nums[i])-1] *= -1\r\n else:\r\n list.append(abs(nums[i]))\r\n return list\r\n # n = set(nums)\r\n # res = []\r\n # for i in nums:\r\n # if i in n:\r\n # n.remove(i)\r\n # else:\r\n # res.append(i)\r\n # return res\r\n"
},
{
"alpha_fraction": 0.5284715294837952,
"alphanum_fraction": 0.5534465312957764,
"avg_line_length": 19.7608699798584,
"blob_id": "5fc302b44df20f6abc09da075e425be0b1af738b",
"content_id": "2786471104481b9bbe6179b5640dde816acd0b9b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1001,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 46,
"path": "/leetcode-algorithms/389. Find the Difference/389.find-the-difference.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=389 lang=java\r\n *\r\n * [389] Find the Difference\r\n *\r\n * https://leetcode.com/problems/find-the-difference/description/\r\n *\r\n * algorithms\r\n * Easy (53.17%)\r\n * Likes: 518\r\n * Dislikes: 232\r\n * Total Accepted: 149.2K\r\n * Total Submissions: 280K\r\n * Testcase Example: '\"abcd\"\\n\"abcde\"'\r\n *\r\n * \r\n * Given two strings s and t which consist of only lowercase letters.\r\n * \r\n * String t is generated by random shuffling string s and then add one more\r\n * letter at a random position.\r\n * \r\n * Find the letter that was added in t.\r\n * \r\n * Example:\r\n * \r\n * Input:\r\n * s = \"abcd\"\r\n * t = \"abcde\"\r\n * \r\n * Output:\r\n * e\r\n * \r\n * Explanation:\r\n * 'e' is the letter that was added.\r\n * \r\n */\r\nclass Solution {\r\n public char findTheDifference(String s, String t) {\r\n int res = t.charAt(t.length() - 1);\r\n for (int i = 0; i < s.length(); ++i) {\r\n res ^= s.charAt(i);\r\n res ^= t.charAt(i);\r\n }\r\n return (char) res;\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.523483395576477,
"alphanum_fraction": 0.5861057043075562,
"avg_line_length": 22.33333396911621,
"blob_id": "c8c4d884cce2e77ea341363382dae621e9aeb223",
"content_id": "171ae330a6800c6522b32448ca770f3974737bb9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1024,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 42,
"path": "/leetcode-algorithms/053. Maximum Subarray/53.maximum-subarray.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=53 lang=python3\r\n#\r\n# [53] Maximum Subarray\r\n#\r\n# https://leetcode.com/problems/maximum-subarray/description/\r\n#\r\n# algorithms\r\n# Easy (42.87%)\r\n# Total Accepted: 497.9K\r\n# Total Submissions: 1.2M\r\n# Testcase Example: '[-2,1,-3,4,-1,2,1,-5,4]'\r\n#\r\n# Given an integer array nums, find the contiguous subarray (containing at\r\n# least one number) which has the largest sum and return its sum.\r\n#\r\n# Example:\r\n#\r\n#\r\n# Input: [-2,1,-3,4,-1,2,1,-5,4],\r\n# Output: 6\r\n# Explanation: [4,-1,2,1] has the largest sum = 6.\r\n#\r\n#\r\n# Follow up:\r\n#\r\n# If you have figured out the O(n) solution, try coding another solution using\r\n# the divide and conquer approach, which is more subtle.\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def maxSubArray(self, nums: List[int]) -> int:\r\n sum = 0\r\n maxs = -99999999999\r\n for i in range(len(nums)):\r\n if maxs != -99999999999 and sum < 0:\r\n sum = 0\r\n sum += nums[i]\r\n maxs = max(sum, maxs)\r\n return maxs\r\n"
},
{
"alpha_fraction": 0.42274510860443115,
"alphanum_fraction": 0.4690196216106415,
"avg_line_length": 18.564516067504883,
"blob_id": "9183b11bfe2cf693817eda53fd92483fb5dea611",
"content_id": "868c2ae2f85e79ece6ccc87f5946d34a54efbcf3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1276,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 62,
"path": "/leetcode-algorithms/922. Sort Array By Parity II/922.sort-array-by-parity-ii.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=922 lang=java\r\n *\r\n * [922] Sort Array By Parity II\r\n *\r\n * https://leetcode.com/problems/sort-array-by-parity-ii/description/\r\n *\r\n * algorithms\r\n * Easy (66.66%)\r\n * Total Accepted: 37.5K\r\n * Total Submissions: 56K\r\n * Testcase Example: '[4,2,5,7]'\r\n *\r\n * Given an array A of non-negative integers, half of the integers in A are\r\n * odd, and half of the integers are even.\r\n * \r\n * Sort the array so that whenever A[i] is odd, i is odd; and whenever A[i] is\r\n * even, i is even.\r\n * \r\n * You may return any answer array that satisfies this condition.\r\n * \r\n * \r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: [4,2,5,7]\r\n * Output: [4,5,2,7]\r\n * Explanation: [4,7,2,5], [2,5,4,7], [2,7,4,5] would also have been\r\n * accepted.\r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * 2 <= A.length <= 20000\r\n * A.length % 2 == 0\r\n * 0 <= A[i] <= 1000\r\n * \r\n * \r\n * \r\n * \r\n * \r\n */\r\nclass Solution {\r\n public int[] sortArrayByParityII(int[] A) {\r\n int[] out = new int[A.length];\r\n int i = 0, j = 1;\r\n for (int t : A) {\r\n if ((t & 1) == 0) {\r\n out[i] = t;\r\n i += 2;\r\n } else {\r\n out[j] = t;\r\n j += 2;\r\n }\r\n }\r\n return out;\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.7104122638702393,
"alphanum_fraction": 0.7918100357055664,
"avg_line_length": 453.253173828125,
"blob_id": "4eb31d62d9b4f4dc90c9d878e87583fe44fd4723",
"content_id": "d906a1610176fadeb3ac124aadbe66484c571203",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 71771,
"license_type": "permissive",
"max_line_length": 847,
"num_lines": 158,
"path": "/README.md",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "# Keep thinking, keep alive\n<div align=center><img src =\"https://raw.githubusercontent.com/cnyy7/LeetCode_EY/master/resources/LeetCode.png\"/></div>\n<div align=center>\n\n    \n\n</div>\n\nIn this repository, I have solved **135** / **1683** problems while **262** are still locked.\n\nCompletion statistic: \n1. Python: 129\n2. Java: 130\n3. C++: 130\n4. Kotlin: 6\n5. Golang: 0\n----------------\n## LeetCode Solution Table\n<div align=center>\n\n| ID | Title | Difficulty | Python | Java | C++ | Kotlin | Golang |\n|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|\n|001|[Two Sum](https://leetcode.com/problems/two-sum/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/001.%20Two%20Sum/1.two-sum.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/001.%20Two%20Sum/1.two-sum.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/001.%20Two%20Sum/1.two-sum.java)|To Do|To Do|\n|002|[Add Two Numbers](https://leetcode.com/problems/add-two-numbers/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/002.%20Add%20Two%20Numbers/2.add-two-numbers.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/002.%20Add%20Two%20Numbers/2.add-two-numbers.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/002.%20Add%20Two%20Numbers/2.add-two-numbers.java)|To Do|To Do|\n|007|[Reverse Integer](https://leetcode.com/problems/reverse-integer/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/007.%20Reverse%20Integer/7.reverse-integer.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/007.%20Reverse%20Integer/7.reverse-integer.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/007.%20Reverse%20Integer/7.reverse-integer.java)|To Do|To Do|\n|008|[String to Integer (atoi)](https://leetcode.com/problems/string-to-integer-atoi/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/008.%20String%20to%20Integer%20(atoi)/8.string-to-integer-atoi.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/008.%20String%20to%20Integer%20(atoi)/8.string-to-integer-atoi.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/008.%20String%20to%20Integer%20(atoi)/8.string-to-integer-atoi.java)|To Do|To Do|\n|009|[Palindrome Number](https://leetcode.com/problems/palindrome-number/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/009.%20Palindrome%20Number/9.palindrome-number.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/009.%20Palindrome%20Number/9.palindrome-number.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/009.%20Palindrome%20Number/9.palindrome-number.java)|To Do|To Do|\n|011|[Container With Most Water](https://leetcode.com/problems/container-with-most-water/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/011.%20Container%20With%20Most%20Water/11.container-with-most-water.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/011.%20Container%20With%20Most%20Water/11.container-with-most-water.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/011.%20Container%20With%20Most%20Water/11.container-with-most-water.java)|To Do|To Do|\n|012|[Integer to Roman](https://leetcode.com/problems/integer-to-roman/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/012.%20Integer%20to%20Roman/12.integer-to-roman.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/012.%20Integer%20to%20Roman/12.integer-to-roman.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/012.%20Integer%20to%20Roman/12.integer-to-roman.java)|To Do|To Do|\n|013|[Roman to Integer](https://leetcode.com/problems/roman-to-integer/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/013.%20Roman%20to%20Integer/13.roman-to-integer.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/013.%20Roman%20to%20Integer/13.roman-to-integer.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/013.%20Roman%20to%20Integer/13.roman-to-integer.java)|To Do|To Do|\n|014|[Longest Common Prefix](https://leetcode.com/problems/longest-common-prefix/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/014.%20Longest%20Common%20Prefix/14.longest-common-prefix.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/014.%20Longest%20Common%20Prefix/14.longest-common-prefix.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/014.%20Longest%20Common%20Prefix/14.longest-common-prefix.java)|To Do|To Do|\n|016|[3Sum Closest](https://leetcode.com/problems/3sum-closest/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/016.%203Sum%20Closest/16.3-sum-closest.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/016.%203Sum%20Closest/16.3-sum-closest.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/016.%203Sum%20Closest/16.3-sum-closest.java)|To Do|To Do|\n|019|[Remove Nth Node From End of List](https://leetcode.com/problems/remove-nth-node-from-end-of-list/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/019.%20Remove%20Nth%20Node%20From%20End%20of%20List/19.remove-nth-node-from-end-of-list.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/019.%20Remove%20Nth%20Node%20From%20End%20of%20List/19.remove-nth-node-from-end-of-list.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/019.%20Remove%20Nth%20Node%20From%20End%20of%20List/19.remove-nth-node-from-end-of-list.java)|To Do|To Do|\n|020|[Valid Parentheses](https://leetcode.com/problems/valid-parentheses/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/020.%20Valid%20Parentheses/20.valid-parentheses.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/020.%20Valid%20Parentheses/20.valid-parentheses.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/020.%20Valid%20Parentheses/20.valid-parentheses.java)|To Do|To Do|\n|021|[Merge Two Sorted Lists](https://leetcode.com/problems/merge-two-sorted-lists/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/021.%20Merge%20Two%20Sorted%20Lists/21.merge-two-sorted-lists.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/021.%20Merge%20Two%20Sorted%20Lists/21.merge-two-sorted-lists.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/021.%20Merge%20Two%20Sorted%20Lists/21.merge-two-sorted-lists.java)|To Do|To Do|\n|024|[Swap Nodes in Pairs](https://leetcode.com/problems/swap-nodes-in-pairs/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/024.%20Swap%20Nodes%20in%20Pairs/24.swap-nodes-in-pairs.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/024.%20Swap%20Nodes%20in%20Pairs/24.swap-nodes-in-pairs.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/024.%20Swap%20Nodes%20in%20Pairs/24.swap-nodes-in-pairs.java)|To Do|To Do|\n|026|[Remove Duplicates from Sorted Array](https://leetcode.com/problems/remove-duplicates-from-sorted-array/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/026.%20Remove%20Duplicates%20from%20Sorted%20Array/26.remove-duplicates-from-sorted-array.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/026.%20Remove%20Duplicates%20from%20Sorted%20Array/26.remove-duplicates-from-sorted-array.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/026.%20Remove%20Duplicates%20from%20Sorted%20Array/26.remove-duplicates-from-sorted-array.java)|To Do|To Do|\n|027|[Remove Element](https://leetcode.com/problems/remove-element/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/027.%20Remove%20Element/27.remove-element.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/027.%20Remove%20Element/27.remove-element.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/027.%20Remove%20Element/27.remove-element.java)|To Do|To Do|\n|028|[Implement strStr()](https://leetcode.com/problems/implement-strstr/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/028.%20Implement%20strStr()/28.implement-str-str.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/028.%20Implement%20strStr()/28.implement-str-str.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/028.%20Implement%20strStr()/28.implement-str-str.java)|To Do|To Do|\n|034|[Find First and Last Position of Element in Sorted Array](https://leetcode.com/problems/find-first-and-last-position-of-element-in-sorted-array/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/034.%20Find%20First%20and%20Last%20Position%20of%20Element%20in%20Sorted%20Array/34.find-first-and-last-position-of-element-in-sorted-array.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/034.%20Find%20First%20and%20Last%20Position%20of%20Element%20in%20Sorted%20Array/34.find-first-and-last-position-of-element-in-sorted-array.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/034.%20Find%20First%20and%20Last%20Position%20of%20Element%20in%20Sorted%20Array/34.find-first-and-last-position-of-element-in-sorted-array.java)|To Do|To Do|\n|035|[Search Insert Position](https://leetcode.com/problems/search-insert-position/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/035.%20Search%20Insert%20Position/35.search-insert-position.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/035.%20Search%20Insert%20Position/35.search-insert-position.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/035.%20Search%20Insert%20Position/35.search-insert-position.java)|To Do|To Do|\n|041|[First Missing Positive](https://leetcode.com/problems/first-missing-positive/description/) |Hard|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/041.%20First%20Missing%20Positive/41.first-missing-positive.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/041.%20First%20Missing%20Positive/41.first-missing-positive.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/041.%20First%20Missing%20Positive/41.first-missing-positive.java)|To Do|To Do|\n|048|[Rotate Image](https://leetcode.com/problems/rotate-image/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/048.%20Rotate%20Image/48.rotate-image.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/048.%20Rotate%20Image/48.rotate-image.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/048.%20Rotate%20Image/48.rotate-image.java)|To Do|To Do|\n|053|[Maximum Subarray](https://leetcode.com/problems/maximum-subarray/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/053.%20Maximum%20Subarray/53.maximum-subarray.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/053.%20Maximum%20Subarray/53.maximum-subarray.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/053.%20Maximum%20Subarray/53.maximum-subarray.java)|To Do|To Do|\n|055|[Jump Game](https://leetcode.com/problems/jump-game/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/055.%20Jump%20Game/55.jump-game.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/055.%20Jump%20Game/55.jump-game.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/055.%20Jump%20Game/55.jump-game.java)|To Do|To Do|\n|058|[Length of Last Word](https://leetcode.com/problems/length-of-last-word/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/058.%20Length%20of%20Last%20Word/58.length-of-last-word.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/058.%20Length%20of%20Last%20Word/58.length-of-last-word.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/058.%20Length%20of%20Last%20Word/58.length-of-last-word.java)|To Do|To Do|\n|065|[Valid Number](https://leetcode.com/problems/valid-number/description/) |Hard|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/065.%20Valid%20Number/65.valid-number.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/065.%20Valid%20Number/65.valid-number.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/065.%20Valid%20Number/65.valid-number.java)|To Do|To Do|\n|066|[Plus One](https://leetcode.com/problems/plus-one/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/066.%20Plus%20One/66.plus-one.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/066.%20Plus%20One/66.plus-one.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/066.%20Plus%20One/66.plus-one.java)|To Do|To Do|\n|067|[Add Binary](https://leetcode.com/problems/add-binary/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/067.%20Add%20Binary/67.add-binary.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/067.%20Add%20Binary/67.add-binary.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/067.%20Add%20Binary/67.add-binary.java)|To Do|To Do|\n|069|[Sqrt(x)](https://leetcode.com/problems/sqrtx/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/069.%20Sqrt(x)/69.sqrt-x.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/069.%20Sqrt(x)/69.sqrt-x.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/069.%20Sqrt(x)/69.sqrt-x.java)|To Do|To Do|\n|070|[Climbing Stairs](https://leetcode.com/problems/climbing-stairs/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/070.%20Climbing%20Stairs/70.climbing-stairs.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/070.%20Climbing%20Stairs/70.climbing-stairs.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/070.%20Climbing%20Stairs/70.climbing-stairs.java)|[Kotlin](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/070.%20Climbing%20Stairs/70.climbing-stairs.kt)|To Do|\n|074|[Search a 2D Matrix](https://leetcode.com/problems/search-a-2d-matrix/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/074.%20Search%20a%202D%20Matrix/74.search-a-2-d-matrix.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/074.%20Search%20a%202D%20Matrix/74.search-a-2-d-matrix.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/074.%20Search%20a%202D%20Matrix/74.search-a-2-d-matrix.java)|To Do|To Do|\n|075|[Sort Colors](https://leetcode.com/problems/sort-colors/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/075.%20Sort%20Colors/75.sort-colors.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/075.%20Sort%20Colors/75.sort-colors.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/075.%20Sort%20Colors/75.sort-colors.java)|To Do|To Do|\n|078|[Subsets](https://leetcode.com/problems/subsets/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/078.%20Subsets/78.subsets.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/078.%20Subsets/78.subsets.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/078.%20Subsets/78.subsets.java)|To Do|To Do|\n|079|[Word Search](https://leetcode.com/problems/word-search/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/079.%20Word%20Search/79.word-search.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/079.%20Word%20Search/79.word-search.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/079.%20Word%20Search/79.word-search.java)|To Do|To Do|\n|080|[Remove Duplicates from Sorted Array II](https://leetcode.com/problems/remove-duplicates-from-sorted-array-ii/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/080.%20Remove%20Duplicates%20from%20Sorted%20Array%20II/80.remove-duplicates-from-sorted-array-ii.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/080.%20Remove%20Duplicates%20from%20Sorted%20Array%20II/80.remove-duplicates-from-sorted-array-ii.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/080.%20Remove%20Duplicates%20from%20Sorted%20Array%20II/80.remove-duplicates-from-sorted-array-ii.java)|To Do|To Do|\n|082|[Remove Duplicates from Sorted List II](https://leetcode.com/problems/remove-duplicates-from-sorted-list-ii/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/082.%20Remove%20Duplicates%20from%20Sorted%20List%20II/82.remove-duplicates-from-sorted-list-ii.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/082.%20Remove%20Duplicates%20from%20Sorted%20List%20II/82.remove-duplicates-from-sorted-list-ii.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/082.%20Remove%20Duplicates%20from%20Sorted%20List%20II/82.remove-duplicates-from-sorted-list-ii.java)|To Do|To Do|\n|083|[Remove Duplicates from Sorted List](https://leetcode.com/problems/remove-duplicates-from-sorted-list/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/083.%20Remove%20Duplicates%20from%20Sorted%20List/83.remove-duplicates-from-sorted-list.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/083.%20Remove%20Duplicates%20from%20Sorted%20List/83.remove-duplicates-from-sorted-list.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/083.%20Remove%20Duplicates%20from%20Sorted%20List/83.remove-duplicates-from-sorted-list.java)|To Do|To Do|\n|088|[Merge Sorted Array](https://leetcode.com/problems/merge-sorted-array/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/088.%20Merge%20Sorted%20Array/88.merge-sorted-array.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/088.%20Merge%20Sorted%20Array/88.merge-sorted-array.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/088.%20Merge%20Sorted%20Array/88.merge-sorted-array.java)|To Do|To Do|\n|092|[Reverse Linked List II](https://leetcode.com/problems/reverse-linked-list-ii/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/092.%20Reverse%20Linked%20List%20II/92.reverse-linked-list-ii.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/092.%20Reverse%20Linked%20List%20II/92.reverse-linked-list-ii.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/092.%20Reverse%20Linked%20List%20II/92.reverse-linked-list-ii.java)|To Do|To Do|\n|094|[Binary Tree Inorder Traversal](https://leetcode.com/problems/binary-tree-inorder-traversal/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/094.%20Binary%20Tree%20Inorder%20Traversal/94.binary-tree-inorder-traversal.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/094.%20Binary%20Tree%20Inorder%20Traversal/94.binary-tree-inorder-traversal.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/094.%20Binary%20Tree%20Inorder%20Traversal/94.binary-tree-inorder-traversal.java)|To Do|To Do|\n|098|[Validate Binary Search Tree](https://leetcode.com/problems/validate-binary-search-tree/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/098.%20Validate%20Binary%20Search%20Tree/98.validate-binary-search-tree.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/098.%20Validate%20Binary%20Search%20Tree/98.validate-binary-search-tree.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/098.%20Validate%20Binary%20Search%20Tree/98.validate-binary-search-tree.java)|To Do|To Do|\n|100|[Same Tree](https://leetcode.com/problems/same-tree/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/100.%20Same%20Tree/100.same-tree.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/100.%20Same%20Tree/100.same-tree.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/100.%20Same%20Tree/100.same-tree.java)|To Do|To Do|\n|101|[Symmetric Tree](https://leetcode.com/problems/symmetric-tree/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/101.%20Symmetric%20Tree/101.symmetric-tree.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/101.%20Symmetric%20Tree/101.symmetric-tree.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/101.%20Symmetric%20Tree/101.symmetric-tree.java)|To Do|To Do|\n|102|[Binary Tree Level Order Traversal](https://leetcode.com/problems/binary-tree-level-order-traversal/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/102.%20Binary%20Tree%20Level%20Order%20Traversal/102.binary-tree-level-order-traversal.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/102.%20Binary%20Tree%20Level%20Order%20Traversal/102.binary-tree-level-order-traversal.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/102.%20Binary%20Tree%20Level%20Order%20Traversal/102.binary-tree-level-order-traversal.java)|To Do|To Do|\n|104|[Maximum Depth of Binary Tree](https://leetcode.com/problems/maximum-depth-of-binary-tree/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/104.%20Maximum%20Depth%20of%20Binary%20Tree/104.maximum-depth-of-binary-tree.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/104.%20Maximum%20Depth%20of%20Binary%20Tree/104.maximum-depth-of-binary-tree.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/104.%20Maximum%20Depth%20of%20Binary%20Tree/104.maximum-depth-of-binary-tree.java)|To Do|To Do|\n|107|[Binary Tree Level Order Traversal II](https://leetcode.com/problems/binary-tree-level-order-traversal-ii/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/107.%20Binary%20Tree%20Level%20Order%20Traversal%20II/107.binary-tree-level-order-traversal-ii.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/107.%20Binary%20Tree%20Level%20Order%20Traversal%20II/107.binary-tree-level-order-traversal-ii.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/107.%20Binary%20Tree%20Level%20Order%20Traversal%20II/107.binary-tree-level-order-traversal-ii.java)|To Do|To Do|\n|108|[Convert Sorted Array to Binary Search Tree](https://leetcode.com/problems/convert-sorted-array-to-binary-search-tree/description/) |Easy|To Do|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/108.%20Convert%20Sorted%20Array%20to%20Binary%20Search%20Tree/108.convert-sorted-array-to-binary-search-tree.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/108.%20Convert%20Sorted%20Array%20to%20Binary%20Search%20Tree/108.convert-sorted-array-to-binary-search-tree.java)|To Do|To Do|\n|110|[Balanced Binary Tree](https://leetcode.com/problems/balanced-binary-tree/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/110.%20Balanced%20Binary%20Tree/110.balanced-binary-tree.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/110.%20Balanced%20Binary%20Tree/110.balanced-binary-tree.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/110.%20Balanced%20Binary%20Tree/110.balanced-binary-tree.java)|To Do|To Do|\n|111|[Minimum Depth of Binary Tree](https://leetcode.com/problems/minimum-depth-of-binary-tree/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/111.%20Minimum%20Depth%20of%20Binary%20Tree/111.minimum-depth-of-binary-tree.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/111.%20Minimum%20Depth%20of%20Binary%20Tree/111.minimum-depth-of-binary-tree.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/111.%20Minimum%20Depth%20of%20Binary%20Tree/111.minimum-depth-of-binary-tree.java)|To Do|To Do|\n|112|[Path Sum](https://leetcode.com/problems/path-sum/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/112.%20Path%20Sum/112.path-sum.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/112.%20Path%20Sum/112.path-sum.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/112.%20Path%20Sum/112.path-sum.java)|To Do|To Do|\n|118|[Pascal's Triangle](https://leetcode.com/problems/pascals-triangle/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/118.%20Pascal's%20Triangle/118.pascals-triangle.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/118.%20Pascal's%20Triangle/118.pascals-triangle.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/118.%20Pascal's%20Triangle/118.pascals-triangle.java)|To Do|To Do|\n|119|[Pascal's Triangle II](https://leetcode.com/problems/pascals-triangle-ii/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/119.%20Pascal's%20Triangle%20II/119.pascals-triangle-ii.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/119.%20Pascal's%20Triangle%20II/119.pascals-triangle-ii.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/119.%20Pascal's%20Triangle%20II/119.pascals-triangle-ii.java)|To Do|To Do|\n|121|[Best Time to Buy and Sell Stock](https://leetcode.com/problems/best-time-to-buy-and-sell-stock/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/121.%20Best%20Time%20to%20Buy%20and%20Sell%20Stock/121.best-time-to-buy-and-sell-stock.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/121.%20Best%20Time%20to%20Buy%20and%20Sell%20Stock/121.best-time-to-buy-and-sell-stock.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/121.%20Best%20Time%20to%20Buy%20and%20Sell%20Stock/121.best-time-to-buy-and-sell-stock.java)|To Do|To Do|\n|122|[Best Time to Buy and Sell Stock II](https://leetcode.com/problems/best-time-to-buy-and-sell-stock-ii/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/122.%20Best%20Time%20to%20Buy%20and%20Sell%20Stock%20II/122.best-time-to-buy-and-sell-stock-ii.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/122.%20Best%20Time%20to%20Buy%20and%20Sell%20Stock%20II/122.best-time-to-buy-and-sell-stock-ii.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/122.%20Best%20Time%20to%20Buy%20and%20Sell%20Stock%20II/122.best-time-to-buy-and-sell-stock-ii.java)|To Do|To Do|\n|124|[Binary Tree Maximum Path Sum](https://leetcode.com/problems/binary-tree-maximum-path-sum/description/) |Hard|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/124.%20Binary%20Tree%20Maximum%20Path%20Sum/124.binary-tree-maximum-path-sum.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/124.%20Binary%20Tree%20Maximum%20Path%20Sum/124.binary-tree-maximum-path-sum.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/124.%20Binary%20Tree%20Maximum%20Path%20Sum/124.binary-tree-maximum-path-sum.java)|To Do|To Do|\n|136|[Single Number](https://leetcode.com/problems/single-number/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/136.%20Single%20Number/136.single-number.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/136.%20Single%20Number/136.single-number.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/136.%20Single%20Number/136.single-number.java)|To Do|To Do|\n|144|[Binary Tree Preorder Traversal](https://leetcode.com/problems/binary-tree-preorder-traversal/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/144.%20Binary%20Tree%20Preorder%20Traversal/144.binary-tree-preorder-traversal.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/144.%20Binary%20Tree%20Preorder%20Traversal/144.binary-tree-preorder-traversal.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/144.%20Binary%20Tree%20Preorder%20Traversal/144.binary-tree-preorder-traversal.java)|To Do|To Do|\n|145|[Binary Tree Postorder Traversal](https://leetcode.com/problems/binary-tree-postorder-traversal/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/145.%20Binary%20Tree%20Postorder%20Traversal/145.binary-tree-postorder-traversal.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/145.%20Binary%20Tree%20Postorder%20Traversal/145.binary-tree-postorder-traversal.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/145.%20Binary%20Tree%20Postorder%20Traversal/145.binary-tree-postorder-traversal.java)|To Do|To Do|\n|155|[Min Stack](https://leetcode.com/problems/min-stack/description/) |Easy|To Do|To Do|To Do|[Kotlin](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/155.%20Min%20Stack/155.min-stack.kt)|To Do|\n|162|[Find Peak Element](https://leetcode.com/problems/find-peak-element/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/162.%20Find%20Peak%20Element/162.find-peak-element.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/162.%20Find%20Peak%20Element/162.find-peak-element.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/162.%20Find%20Peak%20Element/162.find-peak-element.java)|To Do|To Do|\n|167|[Two Sum II - Input array is sorted](https://leetcode.com/problems/two-sum-ii-input-array-is-sorted/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/167.%20Two%20Sum%20II%20-%20Input%20array%20is%20sorted/167.two-sum-ii-input-array-is-sorted.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/167.%20Two%20Sum%20II%20-%20Input%20array%20is%20sorted/167.two-sum-ii-input-array-is-sorted.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/167.%20Two%20Sum%20II%20-%20Input%20array%20is%20sorted/167.two-sum-ii-input-array-is-sorted.java)|To Do|To Do|\n|169|[Majority Element](https://leetcode.com/problems/majority-element/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/169.%20Majority%20Element/169.majority-element.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/169.%20Majority%20Element/169.majority-element.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/169.%20Majority%20Element/169.majority-element.java)|To Do|To Do|\n|172|[Factorial Trailing Zeroes](https://leetcode.com/problems/factorial-trailing-zeroes/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/172.%20Factorial%20Trailing%20Zeroes/172.factorial-trailing-zeroes.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/172.%20Factorial%20Trailing%20Zeroes/172.factorial-trailing-zeroes.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/172.%20Factorial%20Trailing%20Zeroes/172.factorial-trailing-zeroes.java)|To Do|To Do|\n|191|[Number of 1 Bits](https://leetcode.com/problems/number-of-1-bits/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/191.%20Number%20of%201%20Bits/191.number-of-1-bits.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/191.%20Number%20of%201%20Bits/191.number-of-1-bits.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/191.%20Number%20of%201%20Bits/191.number-of-1-bits.java)|To Do|To Do|\n|200|[Number of Islands](https://leetcode.com/problems/number-of-islands/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/200.%20Number%20of%20Islands/200.number-of-islands.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/200.%20Number%20of%20Islands/200.number-of-islands.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/200.%20Number%20of%20Islands/200.number-of-islands.java)|To Do|To Do|\n|202|[Happy Number](https://leetcode.com/problems/happy-number/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/202.%20Happy%20Number/202.happy-number.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/202.%20Happy%20Number/202.happy-number.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/202.%20Happy%20Number/202.happy-number.java)|To Do|To Do|\n|203|[Remove Linked List Elements](https://leetcode.com/problems/remove-linked-list-elements/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/203.%20Remove%20Linked%20List%20Elements/203.remove-linked-list-elements.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/203.%20Remove%20Linked%20List%20Elements/203.remove-linked-list-elements.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/203.%20Remove%20Linked%20List%20Elements/203.remove-linked-list-elements.java)|To Do|To Do|\n|204|[Count Primes](https://leetcode.com/problems/count-primes/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/204.%20Count%20Primes/204.count-primes.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/204.%20Count%20Primes/204.count-primes.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/204.%20Count%20Primes/204.count-primes.java)|To Do|To Do|\n|205|[Isomorphic Strings](https://leetcode.com/problems/isomorphic-strings/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/205.%20Isomorphic%20Strings/205.isomorphic-strings.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/205.%20Isomorphic%20Strings/205.isomorphic-strings.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/205.%20Isomorphic%20Strings/205.isomorphic-strings.java)|To Do|To Do|\n|206|[Reverse Linked List](https://leetcode.com/problems/reverse-linked-list/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/206.%20Reverse%20Linked%20List/206.reverse-linked-list.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/206.%20Reverse%20Linked%20List/206.reverse-linked-list.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/206.%20Reverse%20Linked%20List/206.reverse-linked-list.java)|To Do|To Do|\n|217|[Contains Duplicate](https://leetcode.com/problems/contains-duplicate/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/217.%20Contains%20Duplicate/217.contains-duplicate.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/217.%20Contains%20Duplicate/217.contains-duplicate.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/217.%20Contains%20Duplicate/217.contains-duplicate.java)|To Do|To Do|\n|219|[Contains Duplicate II](https://leetcode.com/problems/contains-duplicate-ii/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/219.%20Contains%20Duplicate%20II/219.contains-duplicate-ii.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/219.%20Contains%20Duplicate%20II/219.contains-duplicate-ii.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/219.%20Contains%20Duplicate%20II/219.contains-duplicate-ii.java)|To Do|To Do|\n|226|[Invert Binary Tree](https://leetcode.com/problems/invert-binary-tree/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/226.%20Invert%20Binary%20Tree/226.invert-binary-tree.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/226.%20Invert%20Binary%20Tree/226.invert-binary-tree.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/226.%20Invert%20Binary%20Tree/226.invert-binary-tree.java)|To Do|To Do|\n|228|[Summary Ranges](https://leetcode.com/problems/summary-ranges/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/228.%20Summary%20Ranges/228.summary-ranges.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/228.%20Summary%20Ranges/228.summary-ranges.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/228.%20Summary%20Ranges/228.summary-ranges.java)|To Do|To Do|\n|231|[Power of Two](https://leetcode.com/problems/power-of-two/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/231.%20Power%20of%20Two/231.power-of-two.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/231.%20Power%20of%20Two/231.power-of-two.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/231.%20Power%20of%20Two/231.power-of-two.java)|To Do|To Do|\n|237|[Delete Node in a Linked List](https://leetcode.com/problems/delete-node-in-a-linked-list/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/237.%20Delete%20Node%20in%20a%20Linked%20List/237.delete-node-in-a-linked-list.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/237.%20Delete%20Node%20in%20a%20Linked%20List/237.delete-node-in-a-linked-list.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/237.%20Delete%20Node%20in%20a%20Linked%20List/237.delete-node-in-a-linked-list.java)|To Do|To Do|\n|238|[Product of Array Except Self](https://leetcode.com/problems/product-of-array-except-self/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/238.%20Product%20of%20Array%20Except%20Self/238.product-of-array-except-self.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/238.%20Product%20of%20Array%20Except%20Self/238.product-of-array-except-self.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/238.%20Product%20of%20Array%20Except%20Self/238.product-of-array-except-self.java)|To Do|To Do|\n|242|[Valid Anagram](https://leetcode.com/problems/valid-anagram/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/242.%20Valid%20Anagram/242.valid-anagram.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/242.%20Valid%20Anagram/242.valid-anagram.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/242.%20Valid%20Anagram/242.valid-anagram.java)|To Do|To Do|\n|258|[Add Digits](https://leetcode.com/problems/add-digits/description/) |Easy|To Do|To Do|To Do|[Kotlin](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/258.%20Add%20Digits/258.add-digits.kt)|To Do|\n|263|[Ugly Number](https://leetcode.com/problems/ugly-number/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/263.%20Ugly%20Number/263.ugly-number.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/263.%20Ugly%20Number/263.ugly-number.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/263.%20Ugly%20Number/263.ugly-number.java)|To Do|To Do|\n|268|[Missing Number](https://leetcode.com/problems/missing-number/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/268.%20Missing%20Number/268.missing-number.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/268.%20Missing%20Number/268.missing-number.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/268.%20Missing%20Number/268.missing-number.java)|To Do|To Do|\n|278|[First Bad Version](https://leetcode.com/problems/first-bad-version/description/) |Easy|To Do|To Do|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/278.%20First%20Bad%20Version/278.first-bad-version.java)|[Kotlin](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/278.%20First%20Bad%20Version/278.first-bad-version.kt)|To Do|\n|283|[Move Zeroes](https://leetcode.com/problems/move-zeroes/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/283.%20Move%20Zeroes/283.move-zeroes.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/283.%20Move%20Zeroes/283.move-zeroes.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/283.%20Move%20Zeroes/283.move-zeroes.java)|To Do|To Do|\n|287|[Find the Duplicate Number](https://leetcode.com/problems/find-the-duplicate-number/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/287.%20Find%20the%20Duplicate%20Number/287.find-the-duplicate-number.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/287.%20Find%20the%20Duplicate%20Number/287.find-the-duplicate-number.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/287.%20Find%20the%20Duplicate%20Number/287.find-the-duplicate-number.java)|To Do|To Do|\n|326|[Power of Three](https://leetcode.com/problems/power-of-three/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/326.%20Power%20of%20Three/326.power-of-three.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/326.%20Power%20of%20Three/326.power-of-three.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/326.%20Power%20of%20Three/326.power-of-three.java)|To Do|To Do|\n|328|[Odd Even Linked List](https://leetcode.com/problems/odd-even-linked-list/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/328.%20Odd%20Even%20Linked%20List/328.odd-even-linked-list.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/328.%20Odd%20Even%20Linked%20List/328.odd-even-linked-list.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/328.%20Odd%20Even%20Linked%20List/328.odd-even-linked-list.java)|To Do|To Do|\n|344|[Reverse String](https://leetcode.com/problems/reverse-string/description/) |Easy|To Do|To Do|To Do|[Kotlin](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/344.%20Reverse%20String/344.reverse-string.kt)|To Do|\n|387|[First Unique Character in a String](https://leetcode.com/problems/first-unique-character-in-a-string/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/387.%20First%20Unique%20Character%20in%20a%20String/387.first-unique-character-in-a-string.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/387.%20First%20Unique%20Character%20in%20a%20String/387.first-unique-character-in-a-string.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/387.%20First%20Unique%20Character%20in%20a%20String/387.first-unique-character-in-a-string.java)|To Do|To Do|\n|389|[Find the Difference](https://leetcode.com/problems/find-the-difference/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/389.%20Find%20the%20Difference/389.find-the-difference.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/389.%20Find%20the%20Difference/389.find-the-difference.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/389.%20Find%20the%20Difference/389.find-the-difference.java)|To Do|To Do|\n|415|[Add Strings](https://leetcode.com/problems/add-strings/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/415.%20Add%20Strings/415.add-strings.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/415.%20Add%20Strings/415.add-strings.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/415.%20Add%20Strings/415.add-strings.java)|To Do|To Do|\n|442|[Find All Duplicates in an Array](https://leetcode.com/problems/find-all-duplicates-in-an-array/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/442.%20Find%20All%20Duplicates%20in%20an%20Array/442.find-all-duplicates-in-an-array.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/442.%20Find%20All%20Duplicates%20in%20an%20Array/442.find-all-duplicates-in-an-array.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/442.%20Find%20All%20Duplicates%20in%20an%20Array/442.find-all-duplicates-in-an-array.java)|To Do|To Do|\n|448|[Find All Numbers Disappeared in an Array](https://leetcode.com/problems/find-all-numbers-disappeared-in-an-array/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/448.%20Find%20All%20Numbers%20Disappeared%20in%20an%20Array/448.find-all-numbers-disappeared-in-an-array.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/448.%20Find%20All%20Numbers%20Disappeared%20in%20an%20Array/448.find-all-numbers-disappeared-in-an-array.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/448.%20Find%20All%20Numbers%20Disappeared%20in%20an%20Array/448.find-all-numbers-disappeared-in-an-array.java)|To Do|To Do|\n|461|[Hamming Distance](https://leetcode.com/problems/hamming-distance/description/) |Easy|To Do|To Do|To Do|[Kotlin](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/461.%20Hamming%20Distance/461.hamming-distance.kt)|To Do|\n|485|[Max Consecutive Ones](https://leetcode.com/problems/max-consecutive-ones/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/485.%20Max%20Consecutive%20Ones/485.max-consecutive-ones.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/485.%20Max%20Consecutive%20Ones/485.max-consecutive-ones.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/485.%20Max%20Consecutive%20Ones/485.max-consecutive-ones.java)|To Do|To Do|\n|495|[Teemo Attacking](https://leetcode.com/problems/teemo-attacking/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/495.%20Teemo%20Attacking/495.teemo-attacking.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/495.%20Teemo%20Attacking/495.teemo-attacking.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/495.%20Teemo%20Attacking/495.teemo-attacking.java)|To Do|To Do|\n|509|[Fibonacci Number](https://leetcode.com/problems/fibonacci-number/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/509.%20Fibonacci%20Number/509.fibonacci-number.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/509.%20Fibonacci%20Number/509.fibonacci-number.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/509.%20Fibonacci%20Number/509.fibonacci-number.java)|To Do|To Do|\n|542|[01 Matrix](https://leetcode.com/problems/01-matrix/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/542.%2001%20Matrix/542.01-matrix.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/542.%2001%20Matrix/542.01-matrix.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/542.%2001%20Matrix/542.01-matrix.java)|To Do|To Do|\n|561|[Array Partition I](https://leetcode.com/problems/array-partition-i/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/561.%20Array%20Partition%20I/561.array-partition-i.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/561.%20Array%20Partition%20I/561.array-partition-i.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/561.%20Array%20Partition%20I/561.array-partition-i.java)|To Do|To Do|\n|566|[Reshape the Matrix](https://leetcode.com/problems/reshape-the-matrix/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/566.%20Reshape%20the%20Matrix/566.reshape-the-matrix.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/566.%20Reshape%20the%20Matrix/566.reshape-the-matrix.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/566.%20Reshape%20the%20Matrix/566.reshape-the-matrix.java)|To Do|To Do|\n|628|[Maximum Product of Three Numbers](https://leetcode.com/problems/maximum-product-of-three-numbers/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/628.%20Maximum%20Product%20of%20Three%20Numbers/628.maximum-product-of-three-numbers.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/628.%20Maximum%20Product%20of%20Three%20Numbers/628.maximum-product-of-three-numbers.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/628.%20Maximum%20Product%20of%20Three%20Numbers/628.maximum-product-of-three-numbers.java)|To Do|To Do|\n|643|[Maximum Average Subarray I](https://leetcode.com/problems/maximum-average-subarray-i/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/643.%20Maximum%20Average%20Subarray%20I/643.maximum-average-subarray-i.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/643.%20Maximum%20Average%20Subarray%20I/643.maximum-average-subarray-i.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/643.%20Maximum%20Average%20Subarray%20I/643.maximum-average-subarray-i.java)|To Do|To Do|\n|661|[Image Smoother](https://leetcode.com/problems/image-smoother/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/661.%20Image%20Smoother/661.image-smoother.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/661.%20Image%20Smoother/661.image-smoother.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/661.%20Image%20Smoother/661.image-smoother.java)|To Do|To Do|\n|667|[Beautiful Arrangement II](https://leetcode.com/problems/beautiful-arrangement-ii/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/667.%20Beautiful%20Arrangement%20II/667.beautiful-arrangement-ii.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/667.%20Beautiful%20Arrangement%20II/667.beautiful-arrangement-ii.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/667.%20Beautiful%20Arrangement%20II/667.beautiful-arrangement-ii.java)|To Do|To Do|\n|674|[Longest Continuous Increasing Subsequence](https://leetcode.com/problems/longest-continuous-increasing-subsequence/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/674.%20Longest%20Continuous%20Increasing%20Subsequence/674.longest-continuous-increasing-subsequence.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/674.%20Longest%20Continuous%20Increasing%20Subsequence/674.longest-continuous-increasing-subsequence.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/674.%20Longest%20Continuous%20Increasing%20Subsequence/674.longest-continuous-increasing-subsequence.java)|To Do|To Do|\n|695|[Max Area of Island](https://leetcode.com/problems/max-area-of-island/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/695.%20Max%20Area%20of%20Island/695.max-area-of-island.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/695.%20Max%20Area%20of%20Island/695.max-area-of-island.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/695.%20Max%20Area%20of%20Island/695.max-area-of-island.java)|To Do|To Do|\n|697|[Degree of an Array](https://leetcode.com/problems/degree-of-an-array/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/697.%20Degree%20of%20an%20Array/697.degree-of-an-array.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/697.%20Degree%20of%20an%20Array/697.degree-of-an-array.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/697.%20Degree%20of%20an%20Array/697.degree-of-an-array.java)|To Do|To Do|\n|704|[Binary Search](https://leetcode.com/problems/binary-search/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/704.%20Binary%20Search/704.binary-search.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/704.%20Binary%20Search/704.binary-search.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/704.%20Binary%20Search/704.binary-search.java)|To Do|To Do|\n|705|[Design HashSet](https://leetcode.com/problems/design-hashset/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/705.%20Design%20HashSet/705.design-hash-set.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/705.%20Design%20HashSet/705.design-hash-set.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/705.%20Design%20HashSet/705.design-hash-set.java)|To Do|To Do|\n|706|[Design HashMap](https://leetcode.com/problems/design-hashmap/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/706.%20Design%20HashMap/706.design-hash-map.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/706.%20Design%20HashMap/706.design-hash-map.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/706.%20Design%20HashMap/706.design-hash-map.java)|To Do|To Do|\n|709|[To Lower Case](https://leetcode.com/problems/to-lower-case/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/709.%20To%20Lower%20Case/709.to-lower-case.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/709.%20To%20Lower%20Case/709.to-lower-case.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/709.%20To%20Lower%20Case/709.to-lower-case.java)|To Do|To Do|\n|717|[1-bit and 2-bit Characters](https://leetcode.com/problems/1-bit-and-2-bit-characters/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/717.%201-bit%20and%202-bit%20Characters/717.1-bit-and-2-bit-characters.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/717.%201-bit%20and%202-bit%20Characters/717.1-bit-and-2-bit-characters.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/717.%201-bit%20and%202-bit%20Characters/717.1-bit-and-2-bit-characters.java)|To Do|To Do|\n|724|[Find Pivot Index](https://leetcode.com/problems/find-pivot-index/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/724.%20Find%20Pivot%20Index/724.find-pivot-index.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/724.%20Find%20Pivot%20Index/724.find-pivot-index.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/724.%20Find%20Pivot%20Index/724.find-pivot-index.java)|To Do|To Do|\n|746|[Min Cost Climbing Stairs](https://leetcode.com/problems/min-cost-climbing-stairs/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/746.%20Min%20Cost%20Climbing%20Stairs/746.min-cost-climbing-stairs.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/746.%20Min%20Cost%20Climbing%20Stairs/746.min-cost-climbing-stairs.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/746.%20Min%20Cost%20Climbing%20Stairs/746.min-cost-climbing-stairs.java)|To Do|To Do|\n|747|[Largest Number At Least Twice of Others](https://leetcode.com/problems/largest-number-at-least-twice-of-others/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/747.%20Largest%20Number%20At%20Least%20Twice%20of%20Others/747.largest-number-at-least-twice-of-others.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/747.%20Largest%20Number%20At%20Least%20Twice%20of%20Others/747.largest-number-at-least-twice-of-others.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/747.%20Largest%20Number%20At%20Least%20Twice%20of%20Others/747.largest-number-at-least-twice-of-others.java)|To Do|To Do|\n|766|[Toeplitz Matrix](https://leetcode.com/problems/toeplitz-matrix/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/766.%20Toeplitz%20Matrix/766.toeplitz-matrix.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/766.%20Toeplitz%20Matrix/766.toeplitz-matrix.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/766.%20Toeplitz%20Matrix/766.toeplitz-matrix.java)|To Do|To Do|\n|769|[Max Chunks To Make Sorted](https://leetcode.com/problems/max-chunks-to-make-sorted/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/769.%20Max%20Chunks%20To%20Make%20Sorted/769.max-chunks-to-make-sorted.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/769.%20Max%20Chunks%20To%20Make%20Sorted/769.max-chunks-to-make-sorted.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/769.%20Max%20Chunks%20To%20Make%20Sorted/769.max-chunks-to-make-sorted.java)|To Do|To Do|\n|771|[Jewels and Stones](https://leetcode.com/problems/jewels-and-stones/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/771.%20Jewels%20and%20Stones/771.jewels-and-stones.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/771.%20Jewels%20and%20Stones/771.jewels-and-stones.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/771.%20Jewels%20and%20Stones/771.jewels-and-stones.java)|To Do|To Do|\n|791|[Custom Sort String](https://leetcode.com/problems/custom-sort-string/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/791.%20Custom%20Sort%20String/791.custom-sort-string.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/791.%20Custom%20Sort%20String/791.custom-sort-string.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/791.%20Custom%20Sort%20String/791.custom-sort-string.java)|To Do|To Do|\n|830|[Positions of Large Groups](https://leetcode.com/problems/positions-of-large-groups/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/830.%20Positions%20of%20Large%20Groups/830.positions-of-large-groups.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/830.%20Positions%20of%20Large%20Groups/830.positions-of-large-groups.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/830.%20Positions%20of%20Large%20Groups/830.positions-of-large-groups.java)|To Do|To Do|\n|832|[Flipping an Image](https://leetcode.com/problems/flipping-an-image/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/832.%20Flipping%20an%20Image/832.flipping-an-image.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/832.%20Flipping%20an%20Image/832.flipping-an-image.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/832.%20Flipping%20an%20Image/832.flipping-an-image.java)|To Do|To Do|\n|867|[Transpose Matrix](https://leetcode.com/problems/transpose-matrix/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/867.%20Transpose%20Matrix/867.transpose-matrix.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/867.%20Transpose%20Matrix/867.transpose-matrix.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/867.%20Transpose%20Matrix/867.transpose-matrix.java)|To Do|To Do|\n|888|[Fair Candy Swap](https://leetcode.com/problems/fair-candy-swap/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/888.%20Fair%20Candy%20Swap/888.fair-candy-swap.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/888.%20Fair%20Candy%20Swap/888.fair-candy-swap.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/888.%20Fair%20Candy%20Swap/888.fair-candy-swap.java)|To Do|To Do|\n|896|[Monotonic Array](https://leetcode.com/problems/monotonic-array/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/896.%20Monotonic%20Array/896.monotonic-array.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/896.%20Monotonic%20Array/896.monotonic-array.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/896.%20Monotonic%20Array/896.monotonic-array.java)|To Do|To Do|\n|905|[Sort Array By Parity](https://leetcode.com/problems/sort-array-by-parity/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/905.%20Sort%20Array%20By%20Parity/905.sort-array-by-parity.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/905.%20Sort%20Array%20By%20Parity/905.sort-array-by-parity.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/905.%20Sort%20Array%20By%20Parity/905.sort-array-by-parity.java)|To Do|To Do|\n|912|[Sort an Array](https://leetcode.com/problems/sort-an-array/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/912.%20Sort%20an%20Array/912.sort-an-array.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/912.%20Sort%20an%20Array/912.sort-an-array.cpp)|To Do|To Do|To Do|\n|917|[Reverse Only Letters](https://leetcode.com/problems/reverse-only-letters/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/917.%20Reverse%20Only%20Letters/917.reverse-only-letters.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/917.%20Reverse%20Only%20Letters/917.reverse-only-letters.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/917.%20Reverse%20Only%20Letters/917.reverse-only-letters.java)|To Do|To Do|\n|922|[Sort Array By Parity II](https://leetcode.com/problems/sort-array-by-parity-ii/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/922.%20Sort%20Array%20By%20Parity%20II/922.sort-array-by-parity-ii.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/922.%20Sort%20Array%20By%20Parity%20II/922.sort-array-by-parity-ii.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/922.%20Sort%20Array%20By%20Parity%20II/922.sort-array-by-parity-ii.java)|To Do|To Do|\n|929|[Unique Email Addresses](https://leetcode.com/problems/unique-email-addresses/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/929.%20Unique%20Email%20Addresses/929.unique-email-addresses.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/929.%20Unique%20Email%20Addresses/929.unique-email-addresses.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/929.%20Unique%20Email%20Addresses/929.unique-email-addresses.java)|To Do|To Do|\n|941|[Valid Mountain Array](https://leetcode.com/problems/valid-mountain-array/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/941.%20Valid%20Mountain%20Array/941.valid-mountain-array.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/941.%20Valid%20Mountain%20Array/941.valid-mountain-array.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/941.%20Valid%20Mountain%20Array/941.valid-mountain-array.java)|To Do|To Do|\n|953|[Verifying an Alien Dictionary](https://leetcode.com/problems/verifying-an-alien-dictionary/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/953.%20Verifying%20an%20Alien%20Dictionary/953.verifying-an-alien-dictionary.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/953.%20Verifying%20an%20Alien%20Dictionary/953.verifying-an-alien-dictionary.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/953.%20Verifying%20an%20Alien%20Dictionary/953.verifying-an-alien-dictionary.java)|To Do|To Do|\n|961|[N-Repeated Element in Size 2N Array](https://leetcode.com/problems/n-repeated-element-in-size-2n-array/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/961.%20N-Repeated%20Element%20in%20Size%202N%20Array/961.n-repeated-element-in-size-2-n-array.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/961.%20N-Repeated%20Element%20in%20Size%202N%20Array/961.n-repeated-element-in-size-2-n-array.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/961.%20N-Repeated%20Element%20in%20Size%202N%20Array/961.n-repeated-element-in-size-2-n-array.java)|To Do|To Do|\n|976|[Largest Perimeter Triangle](https://leetcode.com/problems/largest-perimeter-triangle/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/976.%20Largest%20Perimeter%20Triangle/976.largest-perimeter-triangle.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/976.%20Largest%20Perimeter%20Triangle/976.largest-perimeter-triangle.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/976.%20Largest%20Perimeter%20Triangle/976.largest-perimeter-triangle.java)|To Do|To Do|\n|977|[Squares of a Sorted Array](https://leetcode.com/problems/squares-of-a-sorted-array/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/977.%20Squares%20of%20a%20Sorted%20Array/977.squares-of-a-sorted-array.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/977.%20Squares%20of%20a%20Sorted%20Array/977.squares-of-a-sorted-array.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/977.%20Squares%20of%20a%20Sorted%20Array/977.squares-of-a-sorted-array.java)|To Do|To Do|\n|989|[Add to Array-Form of Integer](https://leetcode.com/problems/add-to-array-form-of-integer/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/989.%20Add%20to%20Array-Form%20of%20Integer/989.add-to-array-form-of-integer.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/989.%20Add%20to%20Array-Form%20of%20Integer/989.add-to-array-form-of-integer.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/989.%20Add%20to%20Array-Form%20of%20Integer/989.add-to-array-form-of-integer.java)|To Do|To Do|\n|991|[Broken Calculator](https://leetcode.com/problems/broken-calculator/description/) |Medium|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/991.%20Broken%20Calculator/991.broken-calculator.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/991.%20Broken%20Calculator/991.broken-calculator.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/991.%20Broken%20Calculator/991.broken-calculator.java)|To Do|To Do|\n|1002|[Find Common Characters](https://leetcode.com/problems/find-common-characters/description/) |Easy|[Python](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/1002.%20Find%20Common%20Characters/1002.find-common-characters.py)|[C++](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/1002.%20Find%20Common%20Characters/1002.find-common-characters.cpp)|[Java](https://github.com/cnyy7/LeetCode_EY/blob/master/leetcode-algorithms/1002.%20Find%20Common%20Characters/1002.find-common-characters.java)|To Do|To Do|\n</div>"
},
{
"alpha_fraction": 0.43372365832328796,
"alphanum_fraction": 0.48009368777275085,
"avg_line_length": 24.6875,
"blob_id": "ad47472199c69cea718b59b72288fa31bbf5d75e",
"content_id": "ac6f4e228557aed61e3ad8b57c9a1bc14ba9789f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2135,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 80,
"path": "/leetcode-algorithms/002. Add Two Numbers/2.add-two-numbers.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=2 lang=cpp\r\n *\r\n * [2] Add Two Numbers\r\n *\r\n * https://leetcode.com/problems/add-two-numbers/description/\r\n *\r\n * algorithms\r\n * Medium (30.66%)\r\n * Likes: 5024\r\n * Dislikes: 1280\r\n * Total Accepted: 848.6K\r\n * Total Submissions: 2.7M\r\n * Testcase Example: '[2,4,3]\\n[5,6,4]'\r\n *\r\n * You are given two non-empty linked lists representing two non-negative\r\n * integers. The digits are stored in reverse order and each of their nodes\r\n * contain a single digit. Add the two numbers and return it as a linked list.\r\n * \r\n * You may assume the two numbers do not contain any leading zero, except the\r\n * number 0 itself.\r\n * \r\n * Example:\r\n * \r\n * \r\n * Input: (2 -> 4 -> 3) + (5 -> 6 -> 4)\r\n * Output: 7 -> 0 -> 8\r\n * Explanation: 342 + 465 = 807.\r\n * \r\n * \r\n */\r\n/**\r\n * Definition for singly-linked list.\r\n * struct ListNode {\r\n * int val;\r\n * ListNode *next;\r\n * ListNode(int x) : val(x), next(NULL) {}\r\n * };\r\n */\r\nclass Solution\r\n{\r\npublic:\r\n ListNode *addTwoNumbers(ListNode *l1, ListNode *l2)\r\n {\r\n if (!l1->next && !l1->val)\r\n return l2;\r\n if (!l2->next && !l2->val)\r\n return l1;\r\n ListNode *p1 = l1, *p2 = l2;\r\n ListNode *sol = new ListNode(0);\r\n ListNode *head = sol;\r\n head->next = NULL;\r\n int plus = (p1->val + p2->val) / 10;\r\n sol->val = (p1->val + p2->val) % 10;\r\n p1 = p1->next, p2 = p2->next;\r\n while (p1 || p2)\r\n {\r\n ListNode *temp = new ListNode(0);\r\n int val1, val2;\r\n val1 = p1 ? p1->val : 0;\r\n p1 = p1 ? p1->next : p1;\r\n val2 = p2 ? p2->val : 0;\r\n p2 = p2 ? p2->next : p2;\r\n temp->next = NULL;\r\n temp->val = val1 + val2 + plus;\r\n plus = temp->val / 10;\r\n temp->val %= 10;\r\n sol->next = temp;\r\n sol = sol->next;\r\n }\r\n if (plus)\r\n {\r\n ListNode *temp = new ListNode(0);\r\n temp->next = NULL;\r\n temp->val = 1;\r\n sol->next = temp;\r\n }\r\n return head;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.3818669021129608,
"alphanum_fraction": 0.43590888381004333,
"avg_line_length": 27.077922821044922,
"blob_id": "fcfcb3bb88757d4236a8c43c3b5e5ab28833850e",
"content_id": "a2d008862c1129c559b92d64d15f59bf18b545d9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2247,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 77,
"path": "/leetcode-algorithms/661. Image Smoother/661.image-smoother.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=661 lang=java\r\n *\r\n * [661] Image Smoother\r\n *\r\n * https://leetcode.com/problems/image-smoother/description/\r\n *\r\n * algorithms\r\n * Easy (48.01%)\r\n * Total Accepted: 33.7K\r\n * Total Submissions: 69.5K\r\n * Testcase Example: '[[1,1,1],[1,0,1],[1,1,1]]'\r\n *\r\n * Given a 2D integer matrix M representing the gray scale of an image, you\r\n * need to design a smoother to make the gray scale of each cell becomes the\r\n * average gray scale (rounding down) of all the 8 surrounding cells and\r\n * itself. If a cell has less than 8 surrounding cells, then use as many as\r\n * you can.\r\n * \r\n * Example 1:\r\n * \r\n * Input:\r\n * [[1,1,1],\r\n * [1,0,1],\r\n * [1,1,1]]\r\n * Output:\r\n * [[0, 0, 0],\r\n * [0, 0, 0],\r\n * [0, 0, 0]]\r\n * Explanation:\r\n * For the point (0,0), (0,2), (2,0), (2,2): floor(3/4) = floor(0.75) = 0\r\n * For the point (0,1), (1,0), (1,2), (2,1): floor(5/6) = floor(0.83333333) = 0\r\n * For the point (1,1): floor(8/9) = floor(0.88888889) = 0\r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * The value in the given matrix is in the range of [0, 255].\r\n * The length and width of the given matrix are in the range of [1, 150].\r\n * \r\n * \r\n */\r\nclass Solution {\r\n class dir {\r\n public int a, b;\r\n }\r\n\r\n public int[][] imageSmoother(int[][] M) {\r\n dir m[] = new dir[9];\r\n for (int i = -1, k = 0; i < 2; i++) {\r\n for (int j = -1; j < 2; j++, k++) {\r\n dir temp = new dir();\r\n temp.a = i;\r\n temp.b = j;\r\n m[k] = temp;\r\n }\r\n }\r\n int[][] sol = new int[M.length][M[0].length];\r\n for (int i = 0; i < M.length; i++) {\r\n for (int j = 0; j < M[0].length; j++) {\r\n int sum = 0, count = 0;\r\n for (int k = 0; k < 9; k++) {\r\n int newi = i + m[k].a;\r\n int newj = j + m[k].b;\r\n if (newi >= 0 && newi < M.length && newj >= 0 && newj < M[0].length) {\r\n sum += M[newi][newj];\r\n count++;\r\n }\r\n }\r\n if (count != 0)\r\n sol[i][j] = sum / count;\r\n }\r\n }\r\n return sol;\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.5805555582046509,
"alphanum_fraction": 0.5972222089767456,
"avg_line_length": 25.09677505493164,
"blob_id": "7e399cf78660ac6f17a5fb779313b96da4d70a34",
"content_id": "8b8152463ccc26a7526c6d98c3778092e9682806",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2532,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 93,
"path": "/leetcode-algorithms/953. Verifying an Alien Dictionary/953.verifying-an-alien-dictionary.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=953 lang=python3\r\n#\r\n# [953] Verifying an Alien Dictionary\r\n#\r\n# https://leetcode.com/problems/verifying-an-alien-dictionary/description/\r\n#\r\n# algorithms\r\n# Easy (56.29%)\r\n# Likes: 170\r\n# Dislikes: 62\r\n# Total Accepted: 19.3K\r\n# Total Submissions: 34.8K\r\n# Testcase Example: '[\"hello\",\"leetcode\"]\\n\"hlabcdefgijkmnopqrstuvwxyz\"'\r\n#\r\n# In an alien language, surprisingly they also use english lowercase letters,\r\n# but possibly in a different order. The order of the alphabet is some\r\n# permutation of lowercase letters.\r\n#\r\n# Given a sequence of words written in the alien language, and the order of the\r\n# alphabet, return true if and only if the given words are sorted\r\n# lexicographicaly in this alien language.\r\n#\r\n#\r\n#\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: words = [\"hello\",\"leetcode\"], order = \"hlabcdefgijkmnopqrstuvwxyz\"\r\n# Output: true\r\n# Explanation: As 'h' comes before 'l' in this language, then the sequence is\r\n# sorted.\r\n#\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: words = [\"word\",\"world\",\"row\"], order = \"worldabcefghijkmnpqstuvxyz\"\r\n# Output: false\r\n# Explanation: As 'd' comes after 'l' in this language, then words[0] >\r\n# words[1], hence the sequence is unsorted.\r\n#\r\n#\r\n#\r\n# Example 3:\r\n#\r\n#\r\n# Input: words = [\"apple\",\"app\"], order = \"abcdefghijklmnopqrstuvwxyz\"\r\n# Output: false\r\n# Explanation: The first three characters \"app\" match, and the second string is\r\n# shorter (in size.) According to lexicographical rules \"apple\" > \"app\",\r\n# because 'l' > '∅', where '∅' is defined as the blank character which is less\r\n# than any other character (More info).\r\n#\r\n#\r\n#\r\n#\r\n# Note:\r\n#\r\n#\r\n# 1 <= words.length <= 100\r\n# 1 <= words[i].length <= 20\r\n# order.length == 26\r\n# All characters in words[i] and order are english lowercase letters.\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def isAlienSorted(self, words: List[str], order: str) -> bool:\r\n def compare(a, b, ordermap):\r\n i = 0\r\n while i < len(a) and i < len(b):\r\n if ordermap[a[i]] < ordermap[b[i]]:\r\n return True\r\n elif ordermap[a[i]] > ordermap[b[i]]:\r\n return False\r\n else:\r\n i += 1\r\n return len(a) == len(b) or len(a) < len(b)\r\n ordermap = {key: value for value, key in enumerate(order)}\r\n i = 0\r\n while i < len(words) - 1:\r\n if not compare(words[i], words[i+1], ordermap):\r\n return False\r\n i += 1\r\n return True\r\n"
},
{
"alpha_fraction": 0.5121738910675049,
"alphanum_fraction": 0.5573912858963013,
"avg_line_length": 16.953125,
"blob_id": "44bf397ccfbca04e320d5e1b4f4cc8756970c512",
"content_id": "d8291f9058384b96f02531b7160e0a3b99ddd1c5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Kotlin",
"length_bytes": 1157,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 64,
"path": "/leetcode-algorithms/461. Hamming Distance/461.hamming-distance.kt",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\n * @lc app=leetcode id=461 lang=kotlin\n *\n * [461] Hamming Distance\n *\n * https://leetcode.com/problems/hamming-distance/description/\n *\n * algorithms\n * Easy (73.25%)\n * Likes: 2204\n * Dislikes: 178\n * Total Accepted: 397K\n * Total Submissions: 541.4K\n * Testcase Example: '1\\n4'\n *\n * The Hamming distance between two integers is the number of positions at\n * which the corresponding bits are different.\n * \n * Given two integers x and y, return the Hamming distance between them.\n * \n * \n * Example 1:\n * \n * \n * Input: x = 1, y = 4\n * Output: 2\n * Explanation:\n * 1 (0 0 0 1)\n * 4 (0 1 0 0)\n * ↑ ↑\n * The above arrows point to positions where the corresponding bits are\n * different.\n * \n * \n * Example 2:\n * \n * \n * Input: x = 3, y = 1\n * Output: 1\n * \n * \n * \n * Constraints:\n * \n * \n * 0 <= x, y <= 2^31 - 1\n * \n * \n */\n\n// @lc code=start\nclass Solution {\n fun hammingDistance(x: Int, y: Int): Int {\n var result = x xor y\n var distance = 0\n while(result != 0)\n {\n result = result and (result -1)\n distance++\n }\n return distance\n }\n}\n// @lc code=end\n\n"
},
{
"alpha_fraction": 0.3985048830509186,
"alphanum_fraction": 0.45428407192230225,
"avg_line_length": 19.469135284423828,
"blob_id": "cdb9ba487d4fd81b480aaf5be7140620b5543794",
"content_id": "2245f93d2755e71dbebbe5f7c2f95057d987abd4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1751,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 81,
"path": "/leetcode-algorithms/074. Search a 2D Matrix/74.search-a-2-d-matrix.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=74 lang=cpp\r\n *\r\n * [74] Search a 2D Matrix\r\n *\r\n * https://leetcode.com/problems/search-a-2d-matrix/description/\r\n *\r\n * algorithms\r\n * Medium (35.11%)\r\n * Likes: 964\r\n * Dislikes: 114\r\n * Total Accepted: 242.4K\r\n * Total Submissions: 689.7K\r\n * Testcase Example: '[[1,3,5,7],[10,11,16,20],[23,30,34,50]]\\n3'\r\n *\r\n * Write an efficient algorithm that searches for a value in an m x n matrix.\r\n * This matrix has the following properties:\r\n * \r\n * \r\n * Integers in each row are sorted from left to right.\r\n * The first integer of each row is greater than the last integer of the\r\n * previous row.\r\n * \r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input:\r\n * matrix = [\r\n * [1, 3, 5, 7],\r\n * [10, 11, 16, 20],\r\n * [23, 30, 34, 50]\r\n * ]\r\n * target = 3\r\n * Output: true\r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input:\r\n * matrix = [\r\n * [1, 3, 5, 7],\r\n * [10, 11, 16, 20],\r\n * [23, 30, 34, 50]\r\n * ]\r\n * target = 13\r\n * Output: false\r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n bool searchMatrix(vector<vector<int>> &matrix, int target)\r\n {\r\n if (matrix.empty() || matrix[0].empty())\r\n {\r\n return false;\r\n }\r\n int m = matrix.size(), n = matrix[0].size();\r\n int low = 0, high = m * n - 1;\r\n while (low <= high)\r\n {\r\n int mid = low + (high - low) / 2;\r\n int current = matrix[mid / n][mid % n];\r\n if (target < current)\r\n {\r\n high = mid - 1;\r\n }\r\n else if (target > current)\r\n {\r\n low = mid + 1;\r\n }\r\n else\r\n {\r\n return true;\r\n }\r\n }\r\n return false;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.5451613068580627,
"alphanum_fraction": 0.5696774125099182,
"avg_line_length": 22.21875,
"blob_id": "4dcc3b873c83b941eaa42c2a3c9ded076ed23392",
"content_id": "6d8ad6c25450d8bcf3aef48ee4e95f390b5693fd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1552,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 64,
"path": "/leetcode-algorithms/205. Isomorphic Strings/205.isomorphic-strings.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=205 lang=python3\r\n#\r\n# [205] Isomorphic Strings\r\n#\r\n# https://leetcode.com/problems/isomorphic-strings/description/\r\n#\r\n# algorithms\r\n# Easy (37.49%)\r\n# Likes: 824\r\n# Dislikes: 237\r\n# Total Accepted: 217.5K\r\n# Total Submissions: 574.6K\r\n# Testcase Example: '\"egg\"\\n\"add\"'\r\n#\r\n# Given two strings s and t, determine if they are isomorphic.\r\n#\r\n# Two strings are isomorphic if the characters in s can be replaced to get t.\r\n#\r\n# All occurrences of a character must be replaced with another character while\r\n# preserving the order of characters. No two characters may map to the same\r\n# character but a character may map to itself.\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: s = \"egg\", t = \"add\"\r\n# Output: true\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: s = \"foo\", t = \"bar\"\r\n# Output: false\r\n#\r\n# Example 3:\r\n#\r\n#\r\n# Input: s = \"paper\", t = \"title\"\r\n# Output: true\r\n#\r\n# Note:\r\n# You may assume both s and t have the same length.\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def isIsomorphic(self, s: str, t: str) -> bool:\r\n import collections\r\n maps, mapt = collections.defaultdict(int), collections.defaultdict(int)\r\n for i in range(len(s)):\r\n if maps[s[i]] != mapt[t[i]]:\r\n return False\r\n maps[s[i]] = mapt[t[i]] = i + 1\r\n return True\r\n\r\n # maps, mapt = [0]*128, [0]*128\r\n # for i in range(len(s)):\r\n # if maps[ord(s[i])] != mapt[ord(t[i])]:\r\n # return False\r\n # maps[ord(s[i])] = mapt[ord(t[i])] = i + 1;\r\n # return True\r\n"
},
{
"alpha_fraction": 0.6541450619697571,
"alphanum_fraction": 0.681347131729126,
"avg_line_length": 27.69230842590332,
"blob_id": "3a9ec3ed83740dce9865b994b3d8a5b459db8273",
"content_id": "5eba3d0c6633d0db6c19257fb82c916097291213",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2316,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 78,
"path": "/leetcode-algorithms/495. Teemo Attacking/495.teemo-attacking.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=495 lang=python3\r\n#\r\n# [495] Teemo Attacking\r\n#\r\n# https://leetcode.com/problems/teemo-attacking/description/\r\n#\r\n# algorithms\r\n# Medium (51.93%)\r\n# Total Accepted: 35.5K\r\n# Total Submissions: 68.2K\r\n# Testcase Example: '[1,4]\\n2'\r\n#\r\n# In LOL world, there is a hero called Teemo and his attacking can make his\r\n# enemy Ashe be in poisoned condition. Now, given the Teemo's attacking\r\n# ascending time series towards Ashe and the poisoning time duration per\r\n# Teemo's attacking, you need to output the total time that Ashe is in poisoned\r\n# condition.\r\n#\r\n# You may assume that Teemo attacks at the very beginning of a specific time\r\n# point, and makes Ashe be in poisoned condition immediately.\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: [1,4], 2\r\n# Output: 4\r\n# Explanation: At time point 1, Teemo starts attacking Ashe and makes Ashe be\r\n# poisoned immediately.\r\n# This poisoned status will last 2 seconds until the end of time point 2.\r\n# And at time point 4, Teemo attacks Ashe again, and causes Ashe to be in\r\n# poisoned status for another 2 seconds.\r\n# So you finally need to output 4.\r\n#\r\n#\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: [1,2], 2\r\n# Output: 3\r\n# Explanation: At time point 1, Teemo starts attacking Ashe and makes Ashe be\r\n# poisoned.\r\n# This poisoned status will last 2 seconds until the end of time point 2.\r\n# However, at the beginning of time point 2, Teemo attacks Ashe again who is\r\n# already in poisoned status.\r\n# Since the poisoned status won't add up together, though the second poisoning\r\n# attack will still work at time point 2, it will stop at the end of time point\r\n# 3.\r\n# So you finally need to output 3.\r\n#\r\n#\r\n#\r\n#\r\n# Note:\r\n#\r\n#\r\n# You may assume the length of given time series array won't exceed 10000.\r\n# You may assume the numbers in the Teemo's attacking time series and his\r\n# poisoning time duration per attacking are non-negative integers, which won't\r\n# exceed 10,000,000.\r\n#\r\n#\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def findPoisonedDuration(self, timeSeries: List[int], duration: int) -> int:\r\n if len(timeSeries) == 0:\r\n return 0\r\n sol = 0\r\n for i in range(len(timeSeries)-1, 0, -1):\r\n temp = timeSeries[i]-timeSeries[i-1]\r\n sol += duration if temp > duration else temp\r\n return sol+duration\r\n"
},
{
"alpha_fraction": 0.5917481184005737,
"alphanum_fraction": 0.6362649202346802,
"avg_line_length": 22.891891479492188,
"blob_id": "82cc33147767cf15f8e1810f3e406a3823dcf371",
"content_id": "62e09d93555ca2a5764b6d76a4892e93f0d17885",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 925,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 37,
"path": "/leetcode-algorithms/448. Find All Numbers Disappeared in an Array/448.find-all-numbers-disappeared-in-an-array.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=448 lang=python3\r\n#\r\n# [448] Find All Numbers Disappeared in an Array\r\n#\r\n# https://leetcode.com/problems/find-all-numbers-disappeared-in-an-array/description/\r\n#\r\n# algorithms\r\n# Easy (52.77%)\r\n# Total Accepted: 144.5K\r\n# Total Submissions: 272.6K\r\n# Testcase Example: '[4,3,2,7,8,2,3,1]'\r\n#\r\n# Given an array of integers where 1 ≤ a[i] ≤ n (n = size of array), some\r\n# elements appear twice and others appear once.\r\n#\r\n# Find all the elements of [1, n] inclusive that do not appear in this array.\r\n#\r\n# Could you do it without extra space and in O(n) runtime? You may assume the\r\n# returned list does not count as extra space.\r\n#\r\n# Example:\r\n#\r\n# Input:\r\n# [4,3,2,7,8,2,3,1]\r\n#\r\n# Output:\r\n# [5,6]\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def findDisappearedNumbers(self, nums: List[int]) -> List[int]:\r\n new = [i for i in range(1, len(nums)+1)]\r\n return list(set(new)-set(nums))\r\n"
},
{
"alpha_fraction": 0.46543535590171814,
"alphanum_fraction": 0.49973616003990173,
"avg_line_length": 21.395061492919922,
"blob_id": "ad586479196e450c2df5d41e43b5a90afd88efea",
"content_id": "2333b3846d8233cee019c924e3d1d333b023b69f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1895,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 81,
"path": "/leetcode-algorithms/667. Beautiful Arrangement II/667.beautiful-arrangement-ii.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=667 lang=cpp\r\n *\r\n * [667] Beautiful Arrangement II\r\n *\r\n * https://leetcode.com/problems/beautiful-arrangement-ii/description/\r\n *\r\n * algorithms\r\n * Medium (51.49%)\r\n * Total Accepted: 17.5K\r\n * Total Submissions: 33.9K\r\n * Testcase Example: '3\\n2'\r\n *\r\n * \r\n * Given two integers n and k, you need to construct a list which contains n\r\n * different positive integers ranging from 1 to n and obeys the following\r\n * requirement: \r\n * \r\n * Suppose this list is [a1, a2, a3, ... , an], then the list [|a1 - a2|, |a2 -\r\n * a3|, |a3 - a4|, ... , |an-1 - an|] has exactly k distinct integers.\r\n * \r\n * \r\n * \r\n * If there are multiple answers, print any of them.\r\n * \r\n * \r\n * Example 1:\r\n * \r\n * Input: n = 3, k = 1\r\n * Output: [1, 2, 3]\r\n * Explanation: The [1, 2, 3] has three different positive integers ranging\r\n * from 1 to 3, and the [1, 1] has exactly 1 distinct integer: 1.\r\n * \r\n * \r\n * \r\n * Example 2:\r\n * \r\n * Input: n = 3, k = 2\r\n * Output: [1, 3, 2]\r\n * Explanation: The [1, 3, 2] has three different positive integers ranging\r\n * from 1 to 3, and the [2, 1] has exactly 2 distinct integers: 1 and 2.\r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * The n and k are in the range 1 \r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n vector<int> constructArray(int n, int k)\r\n {\r\n vector<int> sol;\r\n int first = 1;\r\n int second = k + 1;\r\n int limit = k / 2 + 1;\r\n while (limit--)\r\n {\r\n if (first != second)\r\n {\r\n sol.push_back(first);\r\n sol.push_back(second);\r\n }\r\n else\r\n {\r\n sol.push_back(first);\r\n }\r\n first++;\r\n second--;\r\n }\r\n first = first + second;\r\n while (sol.size() != n)\r\n {\r\n sol.push_back(first++);\r\n }\r\n return sol;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.5140591263771057,
"alphanum_fraction": 0.5688536167144775,
"avg_line_length": 20.370967864990234,
"blob_id": "85f26bd2678733c459ba77e036caf5958ce0e3fc",
"content_id": "ee47f813dfe27899b76fda2f3eeb2e4bd918aa70",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1387,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 62,
"path": "/leetcode-algorithms/704. Binary Search/704.binary-search.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=704 lang=python3\r\n#\r\n# [704] Binary Search\r\n#\r\n# https://leetcode.com/problems/binary-search/description/\r\n#\r\n# algorithms\r\n# Easy (47.96%)\r\n# Likes: 279\r\n# Dislikes: 32\r\n# Total Accepted: 58.7K\r\n# Total Submissions: 121.3K\r\n# Testcase Example: '[-1,0,3,5,9,12]\\n9'\r\n#\r\n# Given a sorted (in ascending order) integer array nums of n elements and a\r\n# target value, write a function to search target in nums. If target exists,\r\n# then return its index, otherwise return -1.\r\n#\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: nums = [-1,0,3,5,9,12], target = 9\r\n# Output: 4\r\n# Explanation: 9 exists in nums and its index is 4\r\n#\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: nums = [-1,0,3,5,9,12], target = 2\r\n# Output: -1\r\n# Explanation: 2 does not exist in nums so return -1\r\n#\r\n#\r\n#\r\n#\r\n# Note:\r\n#\r\n#\r\n# You may assume that all elements in nums are unique.\r\n# n will be in the range [1, 10000].\r\n# The value of each element in nums will be in the range [-9999, 9999].\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def search(self, nums: List[int], target: int) -> int:\r\n left, right = 0, len(nums)-1\r\n while left <= right:\r\n index = (right + left) // 2\r\n if nums[index] > target:\r\n right = index-1\r\n elif nums[index] < target:\r\n left = index+1\r\n else:\r\n return index\r\n return -1\r\n"
},
{
"alpha_fraction": 0.4633967876434326,
"alphanum_fraction": 0.48682284355163574,
"avg_line_length": 15.291139602661133,
"blob_id": "c2f7a345f592dd0c42d97ec1df0c101c296b2a15",
"content_id": "0f7128f6f8663eb03f25caa8e2de174892928ce6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1367,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 79,
"path": "/leetcode-algorithms/020. Valid Parentheses/20.valid-parentheses.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=20 lang=python3\r\n#\r\n# [20] Valid Parentheses\r\n#\r\n# https://leetcode.com/problems/valid-parentheses/description/\r\n#\r\n# algorithms\r\n# Easy (35.96%)\r\n# Likes: 2805\r\n# Dislikes: 138\r\n# Total Accepted: 570.4K\r\n# Total Submissions: 1.6M\r\n# Testcase Example: '\"()\"'\r\n#\r\n# Given a string containing just the characters '(', ')', '{', '}', '[' and\r\n# ']', determine if the input string is valid.\r\n#\r\n# An input string is valid if:\r\n#\r\n#\r\n# Open brackets must be closed by the same type of brackets.\r\n# Open brackets must be closed in the correct order.\r\n#\r\n#\r\n# Note that an empty string is also considered valid.\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: \"()\"\r\n# Output: true\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: \"()[]{}\"\r\n# Output: true\r\n#\r\n#\r\n# Example 3:\r\n#\r\n#\r\n# Input: \"(]\"\r\n# Output: false\r\n#\r\n#\r\n# Example 4:\r\n#\r\n#\r\n# Input: \"([)]\"\r\n# Output: false\r\n#\r\n#\r\n# Example 5:\r\n#\r\n#\r\n# Input: \"{[]}\"\r\n# Output: true\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def isValid(self, s: str) -> bool:\r\n if len(s) % 2 != 0:\r\n return False\r\n sol = []\r\n m = {'[': ']', '{': '}', '(': ')'}\r\n for ch in s:\r\n if ch in ['[', '{', '(']:\r\n sol.append(ch)\r\n elif len(sol) == 0:\r\n return False\r\n elif ch == m[sol[-1]]:\r\n sol.pop()\r\n return len(sol) == 0\r\n"
},
{
"alpha_fraction": 0.5498417615890503,
"alphanum_fraction": 0.5981012582778931,
"avg_line_length": 20.9818172454834,
"blob_id": "18affa6c39e67f3410ea8ada6ecc0e3ef6e18d3d",
"content_id": "cddea189164c797f051623c08fb3f5ca7e1f30b3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1264,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 55,
"path": "/leetcode-algorithms/674. Longest Continuous Increasing Subsequence/674.longest-continuous-increasing-subsequence.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=674 lang=python3\r\n#\r\n# [674] Longest Continuous Increasing Subsequence\r\n#\r\n# https://leetcode.com/problems/longest-continuous-increasing-subsequence/description/\r\n#\r\n# algorithms\r\n# Easy (43.82%)\r\n# Total Accepted: 63.6K\r\n# Total Submissions: 144.3K\r\n# Testcase Example: '[1,3,5,4,7]'\r\n#\r\n#\r\n# Given an unsorted array of integers, find the length of longest continuous\r\n# increasing subsequence (subarray).\r\n#\r\n#\r\n# Example 1:\r\n#\r\n# Input: [1,3,5,4,7]\r\n# Output: 3\r\n# Explanation: The longest continuous increasing subsequence is [1,3,5], its\r\n# length is 3.\r\n# Even though [1,3,5,7] is also an increasing subsequence, it's not a\r\n# continuous one where 5 and 7 are separated by 4.\r\n#\r\n#\r\n#\r\n# Example 2:\r\n#\r\n# Input: [2,2,2,2,2]\r\n# Output: 1\r\n# Explanation: The longest continuous increasing subsequence is [2], its length\r\n# is 1.\r\n#\r\n#\r\n#\r\n# Note:\r\n# Length of the array will not exceed 10,000.\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def findLengthOfLCIS(self, nums: List[int]) -> int:\r\n sol = 0\r\n count = 0\r\n for i in range(len(nums)):\r\n if i == 0 or nums[i] > nums[i-1]:\r\n count += 1\r\n sol = max(count, sol)\r\n else:\r\n count = 1\r\n return sol\r\n"
},
{
"alpha_fraction": 0.45476672053337097,
"alphanum_fraction": 0.4778904616832733,
"avg_line_length": 24.79347801208496,
"blob_id": "a368722ad913696db9572c88800f3f63ca74b0a4",
"content_id": "cdf02b6aaeecae204b6c51fd91be7e0a7a3f313c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2481,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 92,
"path": "/leetcode-algorithms/102. Binary Tree Level Order Traversal/102.binary-tree-level-order-traversal.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=102 lang=java\r\n *\r\n * [102] Binary Tree Level Order Traversal\r\n *\r\n * https://leetcode.com/problems/binary-tree-level-order-traversal/description/\r\n *\r\n * algorithms\r\n * Medium (48.80%)\r\n * Likes: 1532\r\n * Dislikes: 40\r\n * Total Accepted: 389.6K\r\n * Total Submissions: 796.6K\r\n * Testcase Example: '[3,9,20,null,null,15,7]'\r\n *\r\n * Given a binary tree, return the level order traversal of its nodes' values.\r\n * (ie, from left to right, level by level).\r\n * \r\n * \r\n * For example:\r\n * Given binary tree [3,9,20,null,null,15,7],\r\n * \r\n * 3\r\n * / \\\r\n * 9 20\r\n * / \\\r\n * 15 7\r\n * \r\n * \r\n * \r\n * return its level order traversal as:\r\n * \r\n * [\r\n * [3],\r\n * [9,20],\r\n * [15,7]\r\n * ]\r\n * \r\n * \r\n */\r\n/**\r\n * Definition for a binary tree node. public class TreeNode { int val; TreeNode\r\n * left; TreeNode right; TreeNode(int x) { val = x; } }\r\n */\r\nclass Solution {\r\n public List<List<Integer>> levelOrder(TreeNode root) {\r\n List<List<Integer>> res = new ArrayList<>();\r\n if (root == null) {\r\n return res;\r\n }\r\n Deque<TreeNode> myqueue = new ArrayDeque<>();\r\n myqueue.offer(root);\r\n TreeNode nullNode = new TreeNode(Integer.MIN_VALUE);\r\n myqueue.offer(nullNode);\r\n List<Integer> cur_vector = new ArrayList<>();\r\n while (!myqueue.isEmpty()) {\r\n TreeNode t = myqueue.peekFirst();\r\n myqueue.pop();\r\n if (t.val != Integer.MIN_VALUE) {\r\n cur_vector.add(t.val);\r\n if (t.left != null) {\r\n myqueue.offer(t.left);\r\n }\r\n if (t.right != null) {\r\n myqueue.offer(t.right);\r\n }\r\n ;\r\n } else {\r\n res.add(cur_vector);\r\n cur_vector = new ArrayList<>();\r\n if (myqueue.size() > 0) {\r\n myqueue.offer(nullNode);\r\n }\r\n }\r\n }\r\n return res;\r\n // dfs(root, res, 0);\r\n // return res;\r\n }\r\n\r\n private void dfs(TreeNode root, List<List<Integer>> result, int level) {\r\n if (root == null) {\r\n return;\r\n }\r\n if (result.size() < level + 1) {\r\n result.add(new ArrayList<>());\r\n }\r\n result.get(level).add(root.val);\r\n dfs(root.left, result, level + 1);\r\n dfs(root.right, result, level + 1);\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.5047720074653625,
"alphanum_fraction": 0.5440084934234619,
"avg_line_length": 19.930233001708984,
"blob_id": "370ec2f2729ce5a604a9e0137c0e4d58a44e7c42",
"content_id": "6bdd320c88b3397169db47efd6140e849f1f324e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 943,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 43,
"path": "/leetcode-algorithms/001. Two Sum/1.two-sum.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=1 lang=python3\r\n#\r\n# [1] Two Sum\r\n#\r\n# https://leetcode.com/problems/two-sum/description/\r\n#\r\n# algorithms\r\n# Easy (42.22%)\r\n# Total Accepted: 1.6M\r\n# Total Submissions: 3.7M\r\n# Testcase Example: '[2,7,11,15]\\n9'\r\n#\r\n# Given an array of integers, return indices of the two numbers such that they\r\n# add up to a specific target.\r\n#\r\n# You may assume that each input would have exactly one solution, and you may\r\n# not use the same element twice.\r\n#\r\n# Example:\r\n#\r\n#\r\n# Given nums = [2, 7, 11, 15], target = 9,\r\n#\r\n# Because nums[0] + nums[1] = 2 + 7 = 9,\r\n# return [0, 1].\r\n#\r\n#\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def twoSum(self, nums: List[int], target: int) -> List[int]:\r\n a = dict()\r\n sol = [0, 0]\r\n for i in range(0, len(nums)):\r\n if target-nums[i] in a:\r\n sol[0] = a[target-nums[i]]\r\n sol[1] = i\r\n a[nums[i]] = i\r\n return sol\r\n"
},
{
"alpha_fraction": 0.4966442883014679,
"alphanum_fraction": 0.5349951982498169,
"avg_line_length": 18.05769157409668,
"blob_id": "a13157ccd5413a107c904eacc2ee4cd72632e137",
"content_id": "aaf6892c7da7c3e20feee56bc920ea8656604bc3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1043,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 52,
"path": "/leetcode-algorithms/083. Remove Duplicates from Sorted List/83.remove-duplicates-from-sorted-list.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=83 lang=python3\r\n#\r\n# [83] Remove Duplicates from Sorted List\r\n#\r\n# https://leetcode.com/problems/remove-duplicates-from-sorted-list/description/\r\n#\r\n# algorithms\r\n# Easy (41.95%)\r\n# Likes: 774\r\n# Dislikes: 82\r\n# Total Accepted: 333.1K\r\n# Total Submissions: 779.9K\r\n# Testcase Example: '[1,1,2]'\r\n#\r\n# Given a sorted linked list, delete all duplicates such that each element\r\n# appear only once.\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: 1->1->2\r\n# Output: 1->2\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: 1->1->2->3->3\r\n# Output: 1->2->3\r\n#\r\n#\r\n#\r\n# Definition for singly-linked list.\r\n# class ListNode:\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.next = None\r\n\r\n\r\nclass Solution:\r\n def deleteDuplicates(self, head: ListNode) -> ListNode:\r\n if not head:\r\n return head\r\n p, q = head, head.next\r\n while q:\r\n if p.val == q.val:\r\n p.next = q.next\r\n q = q.next\r\n else:\r\n p = p.next\r\n return head\r\n"
},
{
"alpha_fraction": 0.5413451194763184,
"alphanum_fraction": 0.5898566842079163,
"avg_line_length": 17.29787254333496,
"blob_id": "920ca598fb5b9332457e8b75e2a10c55baece599",
"content_id": "4ea2f4f753356d735b92c590f60b02ffbd59bff3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 907,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 47,
"path": "/leetcode-algorithms/217. Contains Duplicate/217.contains-duplicate.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=217 lang=python3\r\n#\r\n# [217] Contains Duplicate\r\n#\r\n# https://leetcode.com/problems/contains-duplicate/description/\r\n#\r\n# algorithms\r\n# Easy (50.90%)\r\n# Total Accepted: 320.3K\r\n# Total Submissions: 622.7K\r\n# Testcase Example: '[1,2,3,1]'\r\n#\r\n# Given an array of integers, find if the array contains any duplicates.\r\n#\r\n# Your function should return true if any value appears at least twice in the\r\n# array, and it should return false if every element is distinct.\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: [1,2,3,1]\r\n# Output: true\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: [1,2,3,4]\r\n# Output: false\r\n#\r\n# Example 3:\r\n#\r\n#\r\n# Input: [1,1,1,3,3,4,3,2,4,2]\r\n# Output: true\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def containsDuplicate(self, nums: List[int]) -> bool:\r\n a = len(set(nums))\r\n b = len(nums)\r\n if a == b:\r\n return False\r\n else:\r\n return True\r\n"
},
{
"alpha_fraction": 0.49634066224098206,
"alphanum_fraction": 0.5395874977111816,
"avg_line_length": 24.839284896850586,
"blob_id": "a527994c6cfa0e0d1f17b76c148ccd68221c9829",
"content_id": "6d822e3abce440fcb96324354c20d40e4edd88a6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1503,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 56,
"path": "/leetcode-algorithms/034. Find First and Last Position of Element in Sorted Array/34.find-first-and-last-position-of-element-in-sorted-array.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=34 lang=python3\r\n#\r\n# [34] Find First and Last Position of Element in Sorted Array\r\n#\r\n# https://leetcode.com/problems/find-first-and-last-position-of-element-in-sorted-array/description/\r\n#\r\n# algorithms\r\n# Medium (33.68%)\r\n# Likes: 1771\r\n# Dislikes: 91\r\n# Total Accepted: 323.9K\r\n# Total Submissions: 956.1K\r\n# Testcase Example: '[5,7,7,8,8,10]\\n8'\r\n#\r\n# Given an array of integers nums sorted in ascending order, find the starting\r\n# and ending position of a given target value.\r\n#\r\n# Your algorithm's runtime complexity must be in the order of O(log n).\r\n#\r\n# If the target is not found in the array, return [-1, -1].\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: nums = [5,7,7,8,8,10], target = 8\r\n# Output: [3,4]\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: nums = [5,7,7,8,8,10], target = 6\r\n# Output: [-1,-1]\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def searchRange(self, nums: List[int], target: int) -> List[int]:\r\n left, right, index, found = 0, len(nums) - 1, 0, False\r\n while left <= right:\r\n index = (right + left) // 2\r\n if nums[index] > target:\r\n right = index - 1\r\n elif nums[index] < target:\r\n left = index + 1\r\n else:\r\n found = True\r\n break\r\n if found:\r\n while nums[left] != nums[index]:\r\n left += 1\r\n while nums[right] != nums[index]:\r\n right -= 1\r\n return [left, right]\r\n return [-1, -1]\r\n"
},
{
"alpha_fraction": 0.49640288949012756,
"alphanum_fraction": 0.5355715155601501,
"avg_line_length": 20.339284896850586,
"blob_id": "daf1fb3ebb70dba2abf58effcec2485913f04679",
"content_id": "2fbbbfee807d67bc5e7015765a87227364730345",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1251,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 56,
"path": "/leetcode-algorithms/082. Remove Duplicates from Sorted List II/82.remove-duplicates-from-sorted-list-ii.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=82 lang=python3\r\n#\r\n# [82] Remove Duplicates from Sorted List II\r\n#\r\n# https://leetcode.com/problems/remove-duplicates-from-sorted-list-ii/description/\r\n#\r\n# algorithms\r\n# Medium (32.25%)\r\n# Likes: 843\r\n# Dislikes: 72\r\n# Total Accepted: 184.7K\r\n# Total Submissions: 556.4K\r\n# Testcase Example: '[1,2,3,3,4,4,5]'\r\n#\r\n# Given a sorted linked list, delete all nodes that have duplicate numbers,\r\n# leaving only distinct numbers from the original list.\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: 1->2->3->3->4->4->5\r\n# Output: 1->2->5\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: 1->1->1->2->3\r\n# Output: 2->3\r\n#\r\n#\r\n#\r\n# Definition for singly-linked list.\r\n# class ListNode:\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.next = None\r\n\r\n\r\nclass Solution:\r\n def deleteDuplicates(self, head: ListNode) -> ListNode:\r\n if not head or not head.next:\r\n return head\r\n phead = ListNode(-1)\r\n phead.next = head\r\n p, q = phead, head\r\n while q:\r\n while q.next and q.val == q.next.val:\r\n q = q.next\r\n if p.next == q:\r\n p = q\r\n else:\r\n p.next = q.next\r\n q = q.next\r\n return phead.next\r\n"
},
{
"alpha_fraction": 0.4500475823879242,
"alphanum_fraction": 0.5061845779418945,
"avg_line_length": 17.10909080505371,
"blob_id": "ef40f67117a26e77107e569ce2a51debc7eda2f7",
"content_id": "4f20fad8dc61c4b34eec2d035264c3a4b4c5ce4e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1051,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 55,
"path": "/leetcode-algorithms/905. Sort Array By Parity/905.sort-array-by-parity.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=905 lang=python3\r\n#\r\n# [905] Sort Array By Parity\r\n#\r\n# https://leetcode.com/problems/sort-array-by-parity/description/\r\n#\r\n# algorithms\r\n# Easy (72.13%)\r\n# Total Accepted: 85.5K\r\n# Total Submissions: 118K\r\n# Testcase Example: '[3,1,2,4]'\r\n#\r\n# Given an array A of non-negative integers, return an array consisting of all\r\n# the even elements of A, followed by all the odd elements of A.\r\n#\r\n# You may return any answer array that satisfies this condition.\r\n#\r\n#\r\n#\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: [3,1,2,4]\r\n# Output: [2,4,3,1]\r\n# The outputs [4,2,3,1], [2,4,1,3], and [4,2,1,3] would also be accepted.\r\n#\r\n#\r\n#\r\n#\r\n# Note:\r\n#\r\n#\r\n# 1 <= A.length <= 5000\r\n# 0 <= A[i] <= 5000\r\n#\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def sortArrayByParity(self, A: List[int]) -> List[int]:\r\n a = [0]*len(A)\r\n i = 0\r\n j = len(A)-1\r\n for t in A:\r\n if t % 2 == 0:\r\n a[i] = t\r\n i = i+1\r\n else:\r\n a[j] = t\r\n j = j-1\r\n return a\r\n"
},
{
"alpha_fraction": 0.47527605295181274,
"alphanum_fraction": 0.5012001991271973,
"avg_line_length": 22.797618865966797,
"blob_id": "23f5b78a26fe1eaf38cf1837a0bc79b044978e76",
"content_id": "8c3a007d30d659e9f92078ab8054f89966120bff",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2088,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 84,
"path": "/leetcode-algorithms/1002. Find Common Characters/1002.find-common-characters.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=1002 lang=python3\r\n#\r\n# [1002] Find Common Characters\r\n#\r\n# https://leetcode.com/problems/find-common-characters/description/\r\n#\r\n# algorithms\r\n# Easy (69.05%)\r\n# Total Accepted: 17.1K\r\n# Total Submissions: 25.9K\r\n# Testcase Example: '[\"bella\",\"label\",\"roller\"]'\r\n#\r\n# Given an array A of strings made only from lowercase letters, return a list\r\n# of all characters that show up in all strings within the list (including\r\n# duplicates). For example, if a character occurs 3 times in all strings but\r\n# not 4 times, you need to include that character three times in the final\r\n# answer.\r\n#\r\n# You may return the answer in any order.\r\n#\r\n#\r\n#\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: [\"bella\",\"label\",\"roller\"]\r\n# Output: [\"e\",\"l\",\"l\"]\r\n#\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: [\"cool\",\"lock\",\"cook\"]\r\n# Output: [\"c\",\"o\"]\r\n#\r\n#\r\n#\r\n#\r\n# Note:\r\n#\r\n#\r\n# 1 <= A.length <= 100\r\n# 1 <= A[i].length <= 100\r\n# A[i][j] is a lowercase letter\r\n#\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def commonChars(self, A: List[str]) -> List[str]:\r\n # charcount =[0 for _ in range(26)]\r\n # for t in A[0]:\r\n # charcount[ord(t)-ord('a')]+=1\r\n # for str in A[1:]:\r\n # tempcount =[0 for _ in range(26)]\r\n # for t in str:\r\n # tempcount[ord(t)-ord('a')]+=1\r\n # for j in range(0,26):\r\n # charcount[j]=min(charcount[j],tempcount[j])\r\n # sol=[]\r\n # for i in range(0,26):\r\n # for j in range(charcount[i]):\r\n # sol.append(chr(ord('a')+i))\r\n # return sol\r\n unique_letters = set(A[0])\r\n res = []\r\n for letter in unique_letters:\r\n min_count = -1\r\n for word in A:\r\n count = word.count(letter)\r\n if count == 0:\r\n min_count = -1\r\n break\r\n if count < min_count or min_count == -1:\r\n min_count = count\r\n while min_count > 0:\r\n res.append(letter)\r\n min_count -= 1\r\n return res\r\n"
},
{
"alpha_fraction": 0.5792563557624817,
"alphanum_fraction": 0.6157860159873962,
"avg_line_length": 22.725807189941406,
"blob_id": "838a4b7a9f322e286e6837b755954e63fafb2d46",
"content_id": "745ade42ba6275dccc960da3066a87ff229fed94",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1533,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 62,
"path": "/leetcode-algorithms/328. Odd Even Linked List/328.odd-even-linked-list.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=328 lang=python3\r\n#\r\n# [328] Odd Even Linked List\r\n#\r\n# https://leetcode.com/problems/odd-even-linked-list/description/\r\n#\r\n# algorithms\r\n# Medium (49.39%)\r\n# Likes: 857\r\n# Dislikes: 235\r\n# Total Accepted: 160.7K\r\n# Total Submissions: 321K\r\n# Testcase Example: '[1,2,3,4,5]'\r\n#\r\n# Given a singly linked list, group all odd nodes together followed by the even\r\n# nodes. Please note here we are talking about the node number and not the\r\n# value in the nodes.\r\n#\r\n# You should try to do it in place. The program should run in O(1) space\r\n# complexity and O(nodes) time complexity.\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: 1.2.3.4.5.NULL\r\n# Output: 1.3.5.2.4.NULL\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: 2.1.3.5.6.4.7.NULL\r\n# Output: 2.3.6.7.1.5.4.NULL\r\n#\r\n#\r\n# Note:\r\n#\r\n#\r\n# The relative order inside both the even and odd groups should remain as it\r\n# was in the input.\r\n# The first node is considered odd, the second node even and so on ...\r\n#\r\n#\r\n#\r\n# Definition for singly-linked list.\r\n# class ListNode:\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.next = None\r\n\r\n\r\nclass Solution:\r\n def oddEvenList(self, head: ListNode) -> ListNode:\r\n if not head or not head.next or not head.next.next:\r\n return head\r\n odd, even, evenhead = head, head.next, head.next\r\n while (odd.next and even.next):\r\n odd.next, even.next = odd.next.next, even.next.next\r\n odd, even = odd.next, even.next\r\n odd.next = evenhead\r\n return head\r\n"
},
{
"alpha_fraction": 0.47680267691612244,
"alphanum_fraction": 0.5103409886360168,
"avg_line_length": 20.935897827148438,
"blob_id": "8c2b94feff70b9aefaba2fccf9e3ed422e1979fe",
"content_id": "ca32cde1ef981c4f5783ae45831a75c373a3deb3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1789,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 78,
"path": "/leetcode-algorithms/747. Largest Number At Least Twice of Others/747.largest-number-at-least-twice-of-others.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=747 lang=cpp\r\n *\r\n * [747] Largest Number At Least Twice of Others\r\n *\r\n * https://leetcode.com/problems/largest-number-at-least-twice-of-others/description/\r\n *\r\n * algorithms\r\n * Easy (40.25%)\r\n * Total Accepted: 47.6K\r\n * Total Submissions: 118K\r\n * Testcase Example: '[0,0,0,1]'\r\n *\r\n * In a given integer array nums, there is always exactly one largest element.\r\n * \r\n * Find whether the largest element in the array is at least twice as much as\r\n * every other number in the array.\r\n * \r\n * If it is, return the index of the largest element, otherwise return -1.\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: nums = [3, 6, 1, 0]\r\n * Output: 1\r\n * Explanation: 6 is the largest integer, and for every other number in the\r\n * array x,\r\n * 6 is more than twice as big as x. The index of value 6 is 1, so we return\r\n * 1.\r\n * \r\n * \r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: nums = [1, 2, 3, 4]\r\n * Output: -1\r\n * Explanation: 4 isn't at least as big as twice the value of 3, so we return\r\n * -1.\r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * nums will have a length in the range [1, 50].\r\n * Every nums[i] will be an integer in the range [0, 99].\r\n * \r\n * \r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n int dominantIndex(vector<int> &nums)\r\n {\r\n int indexmax1, max1 = 0, indexmax, max = 0;\r\n for (int i = 0; i < nums.size(); i++)\r\n {\r\n if (nums[i] > max)\r\n {\r\n max1 = max;\r\n indexmax1 = indexmax;\r\n max = nums[i];\r\n indexmax = i;\r\n }\r\n else if (nums[i] > max1)\r\n {\r\n max1 = nums[i];\r\n indexmax1 = i;\r\n }\r\n }\r\n return max >= 2 * max1 ? indexmax : -1;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.45797598361968994,
"alphanum_fraction": 0.510291576385498,
"avg_line_length": 17.11475372314453,
"blob_id": "1080e9e7aafb076d2c63e8844e377ea96d6ea404",
"content_id": "c80a2e142d393156d5b869537ccd335e7dee2a51",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1167,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 61,
"path": "/leetcode-algorithms/922. Sort Array By Parity II/922.sort-array-by-parity-ii.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=922 lang=python3\r\n#\r\n# [922] Sort Array By Parity II\r\n#\r\n# https://leetcode.com/problems/sort-array-by-parity-ii/description/\r\n#\r\n# algorithms\r\n# Easy (66.66%)\r\n# Total Accepted: 37.5K\r\n# Total Submissions: 56K\r\n# Testcase Example: '[4,2,5,7]'\r\n#\r\n# Given an array A of non-negative integers, half of the integers in A are odd,\r\n# and half of the integers are even.\r\n#\r\n# Sort the array so that whenever A[i] is odd, i is odd; and whenever A[i] is\r\n# even, i is even.\r\n#\r\n# You may return any answer array that satisfies this condition.\r\n#\r\n#\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: [4,2,5,7]\r\n# Output: [4,5,2,7]\r\n# Explanation: [4,7,2,5], [2,5,4,7], [2,7,4,5] would also have been\r\n# accepted.\r\n#\r\n#\r\n#\r\n#\r\n# Note:\r\n#\r\n#\r\n# 2 <= A.length <= 20000\r\n# A.length % 2 == 0\r\n# 0 <= A[i] <= 1000\r\n#\r\n#\r\n#\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def sortArrayByParityII(self, A: List[int]) -> List[int]:\r\n out = [0]*len(A)\r\n i = 0\r\n j = 1\r\n for n in A:\r\n if (n % 2) == 0:\r\n out[i] = n\r\n i += 2\r\n else:\r\n out[j] = n\r\n j += 2\r\n return out\r\n"
},
{
"alpha_fraction": 0.45481568574905396,
"alphanum_fraction": 0.4928656220436096,
"avg_line_length": 25.57377052307129,
"blob_id": "f4587fffdda01cc9539690f6d0b041c8ee52a5bb",
"content_id": "234fc212940ce889b40bfbb307b450ea33448671",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1682,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 61,
"path": "/leetcode-algorithms/034. Find First and Last Position of Element in Sorted Array/34.find-first-and-last-position-of-element-in-sorted-array.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=34 lang=java\r\n *\r\n * [34] Find First and Last Position of Element in Sorted Array\r\n *\r\n * https://leetcode.com/problems/find-first-and-last-position-of-element-in-sorted-array/description/\r\n *\r\n * algorithms\r\n * Medium (33.68%)\r\n * Likes: 1771\r\n * Dislikes: 91\r\n * Total Accepted: 323.9K\r\n * Total Submissions: 956.1K\r\n * Testcase Example: '[5,7,7,8,8,10]\\n8'\r\n *\r\n * Given an array of integers nums sorted in ascending order, find the starting\r\n * and ending position of a given target value.\r\n * \r\n * Your algorithm's runtime complexity must be in the order of O(log n).\r\n * \r\n * If the target is not found in the array, return [-1, -1].\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: nums = [5,7,7,8,8,10], target = 8\r\n * Output: [3,4]\r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: nums = [5,7,7,8,8,10], target = 6\r\n * Output: [-1,-1]\r\n * \r\n */\r\nclass Solution {\r\n public int[] searchRange(int[] nums, int target) {\r\n int left = 0, right = nums.length - 1;\r\n int index = 0;\r\n boolean found = false;\r\n while (left <= right) {\r\n index = (right + left) / 2;\r\n if (nums[index] > target) {\r\n right = index - 1;\r\n } else if (nums[index] < target) {\r\n left = index + 1;\r\n } else {\r\n found = true;\r\n break;\r\n }\r\n }\r\n if (found) {\r\n while (nums[left] != nums[index] && left++ != -1)\r\n ;\r\n while (nums[right] != nums[index] && right-- != -1)\r\n ;\r\n return new int[] { left, right };\r\n }\r\n return new int[] { -1, -1 };\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.5149147510528564,
"alphanum_fraction": 0.5639204382896423,
"avg_line_length": 21.86440658569336,
"blob_id": "220c492ac24384f7089263e74cb647be28c96a2a",
"content_id": "b3612da293c711fec51a5ac920e803a3a0614ee6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1408,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 59,
"path": "/leetcode-algorithms/746. Min Cost Climbing Stairs/746.min-cost-climbing-stairs.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=746 lang=cpp\r\n *\r\n * [746] Min Cost Climbing Stairs\r\n *\r\n * https://leetcode.com/problems/min-cost-climbing-stairs/description/\r\n *\r\n * algorithms\r\n * Easy (46.07%)\r\n * Total Accepted: 75.5K\r\n * Total Submissions: 161.4K\r\n * Testcase Example: '[0,0,0,0]'\r\n *\r\n * \r\n * On a staircase, the i-th step has some non-negative cost cost[i] assigned (0\r\n * indexed).\r\n * \r\n * Once you pay the cost, you can either climb one or two steps. You need to\r\n * find minimum cost to reach the top of the floor, and you can either start\r\n * from the step with index 0, or the step with index 1.\r\n * \r\n * \r\n * Example 1:\r\n * \r\n * Input: cost = [10, 15, 20]\r\n * Output: 15\r\n * Explanation: Cheapest is start on cost[1], pay that cost and go to the\r\n * top.\r\n * \r\n * \r\n * \r\n * Example 2:\r\n * \r\n * Input: cost = [1, 100, 1, 1, 1, 100, 1, 1, 100, 1]\r\n * Output: 6\r\n * Explanation: Cheapest is start on cost[0], and only step on 1s, skipping\r\n * cost[3].\r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * cost will have a length in the range [2, 1000].\r\n * Every cost[i] will be an integer in the range [0, 999].\r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n int minCostClimbingStairs(vector<int> &cost)\r\n {\r\n for (int i = 2; i < cost.size(); i++)\r\n {\r\n cost[i] += min(cost[i - 1], cost[i - 2]);\r\n }\r\n return min(cost[cost.size() - 1], cost[cost.size() - 2]);\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.5378690361976624,
"alphanum_fraction": 0.5905006527900696,
"avg_line_length": 13.579999923706055,
"blob_id": "37ef57580da81e4ac098144fb1013cbe441aad87",
"content_id": "0d3ee4c389b39b6e7a597f4c1d0d1712349b02d2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 779,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 50,
"path": "/leetcode-algorithms/326. Power of Three/326.power-of-three.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=326 lang=python3\r\n#\r\n# [326] Power of Three\r\n#\r\n# https://leetcode.com/problems/power-of-three/description/\r\n#\r\n# algorithms\r\n# Easy (41.79%)\r\n# Likes: 324\r\n# Dislikes: 1152\r\n# Total Accepted: 202.2K\r\n# Total Submissions: 483.3K\r\n# Testcase Example: '27'\r\n#\r\n# Given an integer, write a function to determine if it is a power of three.\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: 27\r\n# Output: true\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: 0\r\n# Output: false\r\n#\r\n# Example 3:\r\n#\r\n#\r\n# Input: 9\r\n# Output: true\r\n#\r\n# Example 4:\r\n#\r\n#\r\n# Input: 45\r\n# Output: false\r\n#\r\n# Follow up:\r\n# Could you do it without using any loop / recursion?\r\n#\r\n\r\n\r\nclass Solution:\r\n def isPowerOfThree(self, n: int) -> bool:\r\n return n > 0 and 3**round(math.log(n, 3)) == n\r\n"
},
{
"alpha_fraction": 0.39438575506210327,
"alphanum_fraction": 0.44219011068344116,
"avg_line_length": 25.465648651123047,
"blob_id": "f7a8d00232e7138a5352109823eba270efb0bef8",
"content_id": "0392dbb61551b1a663b5ebf0f869490b0022ed2d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3862,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 131,
"path": "/leetcode-algorithms/661. Image Smoother/661.image-smoother.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=661 lang=python3\r\n#\r\n# [661] Image Smoother\r\n#\r\n# https://leetcode.com/problems/image-smoother/description/\r\n#\r\n# algorithms\r\n# Easy (48.01%)\r\n# Total Accepted: 33.7K\r\n# Total Submissions: 69.5K\r\n# Testcase Example: '[[1,1,1],[1,0,1],[1,1,1]]'\r\n#\r\n# Given a 2D integer matrix M representing the gray scale of an image, you need\r\n# to design a smoother to make the gray scale of each cell becomes the average\r\n# gray scale (rounding down) of all the 8 surrounding cells and itself. If a\r\n# cell has less than 8 surrounding cells, then use as many as you can.\r\n#\r\n# Example 1:\r\n#\r\n# Input:\r\n# [[1,1,1],\r\n# [1,0,1],\r\n# [1,1,1]]\r\n# Output:\r\n# [[0, 0, 0],\r\n# [0, 0, 0],\r\n# [0, 0, 0]]\r\n# Explanation:\r\n# For the point (0,0), (0,2), (2,0), (2,2): floor(3/4) = floor(0.75) = 0\r\n# For the point (0,1), (1,0), (1,2), (2,1): floor(5/6) = floor(0.83333333) = 0\r\n# For the point (1,1): floor(8/9) = floor(0.88888889) = 0\r\n#\r\n#\r\n#\r\n# Note:\r\n#\r\n# The value in the given matrix is in the range of [0, 255].\r\n# The length and width of the given matrix are in the range of [1, 150].\r\n#\r\n#\r\n#\r\nimport math\r\n\r\n\r\nclass Solution:\r\n def imageSmoother(self, M: List[List[int]]) -> List[List[int]]:\r\n m = [{'a': 0, 'b': 0} for _ in range(9)]\r\n k = 0\r\n for i in range(-1, 2):\r\n for j in range(-1, 2):\r\n m[k]['a'] = i\r\n m[k]['b'] = j\r\n k += 1\r\n sol = [[0 for _ in range(len(M[0]))] for _ in range(len(M))]\r\n for i in range(len(M)):\r\n for j in range(len(M[0])):\r\n sum = 0\r\n count = 0\r\n for k in range(9):\r\n newi = i+m[k]['a']\r\n newj = j+m[k]['b']\r\n if newi >= 0 and newi < len(M) and newj >= 0 and newj < len(M[0]):\r\n sum += M[newi][newj]\r\n count += 1\r\n if count != 0:\r\n sol[i][j] = sum//count\r\n return sol\r\n\r\n # python 巧办法 https://leetcode.com/problems/image-smoother/discuss/272696/python\r\n # rows = len(M)\r\n\r\n # cols = len(M[0])\r\n\r\n # #print rows, cols\r\n\r\n # if rows > 150 or cols > 150:\r\n # return None\r\n\r\n # #创造一个空的rows* cols的答案矩阵\r\n # result = [[0]* cols for _ in range(rows)]\r\n\r\n # #print result\r\n\r\n # #在原矩阵上围上一圈-1,这样每个元素都可以被周围9个(含自己)smooth\r\n\r\n # #顶上面铺上-1行\r\n # M.append([-1]*cols)\r\n\r\n # #底下面铺上-1行\r\n # M.insert(0,[-1]*cols)\r\n\r\n # for i in M:\r\n\r\n # # 最右面铺上-1\r\n # i.append(-1)\r\n\r\n # # 最左边铺上-1\r\n # i.insert(0,-1)\r\n\r\n # #创造一个像素容器\r\n # temp = []\r\n\r\n # for i in range(1,rows+1):\r\n\r\n # for j in range(1,cols+1):\r\n\r\n # # 添加8个方向的邻元素和自己\r\n # temp.append(M[i+1][j])\r\n # temp.append(M[i][j+1])\r\n # temp.append(M[i-1][j])\r\n # temp.append(M[i][j-1])\r\n # temp.append(M[i+1][j+1])\r\n # temp.append(M[i][j])\r\n # temp.append(M[i+1][j-1])\r\n # temp.append(M[i-1][j+1])\r\n # temp.append(M[i-1][j-1])\r\n\r\n # # 筛选出非-1的真实数据\r\n # nums = [x for x in temp if x> -1]\r\n\r\n # # 算出smooth值\r\n # smooth = math.floor(sum(nums)/len(nums))\r\n\r\n # # 给result矩阵加载该smooth值,注意一定要行,列都-1,因为M已经大了一圈\r\n # result[i-1][j-1] = int(smooth)\r\n\r\n # # 清空像素容器\r\n # temp = []\r\n\r\n # return result\r\n"
},
{
"alpha_fraction": 0.5072133541107178,
"alphanum_fraction": 0.5337889194488525,
"avg_line_length": 19.590164184570312,
"blob_id": "c5d3b8afbe27965f5d360b7536128d07fb0202d9",
"content_id": "25ca873ddaba004172a2ec8218303947aaf81743",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1318,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 61,
"path": "/leetcode-algorithms/242. Valid Anagram/242.valid-anagram.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=242 lang=python3\r\n#\r\n# [242] Valid Anagram\r\n#\r\n# https://leetcode.com/problems/valid-anagram/description/\r\n#\r\n# algorithms\r\n# Easy (52.42%)\r\n# Likes: 747\r\n# Dislikes: 111\r\n# Total Accepted: 356.2K\r\n# Total Submissions: 676.9K\r\n# Testcase Example: '\"anagram\"\\n\"nagaram\"'\r\n#\r\n# Given two strings s and t , write a function to determine if t is an anagram\r\n# of s.\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: s = \"anagram\", t = \"nagaram\"\r\n# Output: true\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: s = \"rat\", t = \"car\"\r\n# Output: false\r\n#\r\n#\r\n# Note:\r\n# You may assume the string contains only lowercase alphabets.\r\n#\r\n# Follow up:\r\n# What if the inputs contain unicode characters? How would you adapt your\r\n# solution to such case?\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def isAnagram(self, s: str, t: str) -> bool:\r\n # solution 1\r\n # if len(s)!=len(t):\r\n # return False\r\n # map=[0]*26\r\n # for i in range(len(s)):\r\n # map[ord(s[i]) - ord('a')]+=1\r\n # map[ord(t[i]) - ord('a')]-=1\r\n # for c in map:\r\n # if c:\r\n # return False\r\n # return True\r\n #\r\n # solution 2\r\n # return sorted(s)==sorted(t)\r\n #\r\n # solution 3\r\n return collections.Counter(s) == collections.Counter(t)\r\n"
},
{
"alpha_fraction": 0.4513677954673767,
"alphanum_fraction": 0.48632219433784485,
"avg_line_length": 20.689655303955078,
"blob_id": "1140e8683f8a2d8d200e3a03dd162b6ec50b9b2c",
"content_id": "ca440abf888e8428a3562774245870aa04de00ea",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1323,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 58,
"path": "/leetcode-algorithms/092. Reverse Linked List II/92.reverse-linked-list-ii.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=92 lang=cpp\r\n *\r\n * [92] Reverse Linked List II\r\n *\r\n * https://leetcode.com/problems/reverse-linked-list-ii/description/\r\n *\r\n * algorithms\r\n * Medium (35.73%)\r\n * Likes: 1385\r\n * Dislikes: 97\r\n * Total Accepted: 209.2K\r\n * Total Submissions: 584.7K\r\n * Testcase Example: '[1,2,3,4,5]\\n2\\n4'\r\n *\r\n * Reverse a linked list from position m to n. Do it in one-pass.\r\n * \r\n * Note: 1 ≤ m ≤ n ≤ length of list.\r\n * \r\n * Example:\r\n * \r\n * \r\n * Input: 1->2->3->4->5->NULL, m = 2, n = 4\r\n * Output: 1->4->3->2->5->NULL\r\n * \r\n * \r\n */\r\n/**\r\n * Definition for singly-linked list.\r\n * struct ListNode {\r\n * int val;\r\n * ListNode *next;\r\n * ListNode(int x) : val(x), next(NULL) {}\r\n * };\r\n */\r\nclass Solution\r\n{\r\npublic:\r\n ListNode *reverseBetween(ListNode *head, int m, int n)\r\n {\r\n ListNode newHead = ListNode(-1);\r\n newHead.next = head;\r\n ListNode *pre = &newHead, *cur;\r\n for (int i = 0; i < m - 1; i++)\r\n {\r\n pre = pre->next;\r\n }\r\n cur = pre->next;\r\n for (int i = 0; i < n - m; i++)\r\n {\r\n ListNode *temp = pre->next;\r\n pre->next = cur->next;\r\n cur->next = cur->next->next;\r\n pre->next->next = temp;\r\n }\r\n return newHead.next;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.3951701521873474,
"alphanum_fraction": 0.43834614753723145,
"avg_line_length": 22.401784896850586,
"blob_id": "267c3515614303eea48d5ba9064af59230da1b57",
"content_id": "ffe24397ccb013d64252040e414ce5e4f7b41877",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2745,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 112,
"path": "/leetcode-algorithms/542. 01 Matrix/542.01-matrix.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=542 lang=java\r\n *\r\n * [542] 01 Matrix\r\n *\r\n * https://leetcode.com/problems/01-matrix/description/\r\n *\r\n * algorithms\r\n * Medium (36.50%)\r\n * Likes: 811\r\n * Dislikes: 84\r\n * Total Accepted: 53.2K\r\n * Total Submissions: 144.5K\r\n * Testcase Example: '[[0,0,0],[0,1,0],[0,0,0]]'\r\n *\r\n * Given a matrix consists of 0 and 1, find the distance of the nearest 0 for\r\n * each cell.\r\n * \r\n * The distance between two adjacent cells is 1.\r\n * \r\n * \r\n * \r\n * Example 1: \r\n * \r\n * \r\n * Input:\r\n * [[0,0,0],\r\n * [0,1,0],\r\n * [0,0,0]]\r\n * \r\n * Output:\r\n * [[0,0,0],\r\n * [0,1,0],\r\n * [0,0,0]]\r\n * \r\n * \r\n * Example 2: \r\n * \r\n * \r\n * Input:\r\n * [[0,0,0],\r\n * [0,1,0],\r\n * [1,1,1]]\r\n * \r\n * Output:\r\n * [[0,0,0],\r\n * [0,1,0],\r\n * [1,2,1]]\r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * The number of elements of the given matrix will not exceed 10,000.\r\n * There are at least one 0 in the given matrix.\r\n * The cells are adjacent in only four directions: up, down, left and right.\r\n * \r\n * \r\n */\r\nclass Solution {\r\n public int[][] updateMatrix(int[][] matrix) {\r\n if (matrix.length == 0) {\r\n return matrix;\r\n }\r\n for (int i = 0; i < matrix.length; i++) {\r\n for (int j = 0; j < matrix[0].length; j++) {\r\n if (matrix[i][j] == 1 && !hasNeiberZero(i, j, matrix)) {\r\n matrix[i][j] = Integer.MAX_VALUE;\r\n }\r\n }\r\n }\r\n for (int i = 0; i < matrix.length; i++) {\r\n for (int j = 0; j < matrix[0].length; j++) {\r\n if (matrix[i][j] == 1) {\r\n dfs(matrix, i, j, 1);\r\n }\r\n }\r\n }\r\n return matrix;\r\n }\r\n\r\n private void dfs(int[][] matrix, int row, int col, int val) {\r\n if (row < 0 || col < 0 || col >= matrix[0].length || row >= matrix.length\r\n || (matrix[row][col] <= val && val != 1)) {\r\n return;\r\n }\r\n matrix[row][col] = val;\r\n\r\n dfs(matrix, row + 1, col, matrix[row][col] + 1);\r\n dfs(matrix, row - 1, col, matrix[row][col] + 1);\r\n dfs(matrix, row, col + 1, matrix[row][col] + 1);\r\n dfs(matrix, row, col - 1, matrix[row][col] + 1);\r\n }\r\n\r\n private boolean hasNeiberZero(int row, int col, int[][] matrix) {\r\n if (row > 0 && matrix[row - 1][col] == 0) {\r\n return true;\r\n }\r\n if (row < matrix.length - 1 && matrix[row + 1][col] == 0) {\r\n return true;\r\n }\r\n if (col > 0 && matrix[row][col - 1] == 0) {\r\n return true;\r\n }\r\n if (col < matrix[0].length - 1 && matrix[row][col + 1] == 0) {\r\n return true;\r\n }\r\n return false;\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.4531662166118622,
"alphanum_fraction": 0.5191292762756348,
"avg_line_length": 20.294116973876953,
"blob_id": "9317efcbc0220d2d66e20d2398e47c9c9a1c814c",
"content_id": "f9eadd2a331b88eb6046ca1a27b185d3412ae9c0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1528,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 68,
"path": "/leetcode-algorithms/074. Search a 2D Matrix/74.search-a-2-d-matrix.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=74 lang=python3\r\n#\r\n# [74] Search a 2D Matrix\r\n#\r\n# https://leetcode.com/problems/search-a-2d-matrix/description/\r\n#\r\n# algorithms\r\n# Medium (35.11%)\r\n# Likes: 964\r\n# Dislikes: 114\r\n# Total Accepted: 242.4K\r\n# Total Submissions: 689.7K\r\n# Testcase Example: '[[1,3,5,7],[10,11,16,20],[23,30,34,50]]\\n3'\r\n#\r\n# Write an efficient algorithm that searches for a value in an m x n matrix.\r\n# This matrix has the following properties:\r\n#\r\n#\r\n# Integers in each row are sorted from left to right.\r\n# The first integer of each row is greater than the last integer of the\r\n# previous row.\r\n#\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input:\r\n# matrix = [\r\n# [1, 3, 5, 7],\r\n# [10, 11, 16, 20],\r\n# [23, 30, 34, 50]\r\n# ]\r\n# target = 3\r\n# Output: true\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input:\r\n# matrix = [\r\n# [1, 3, 5, 7],\r\n# [10, 11, 16, 20],\r\n# [23, 30, 34, 50]\r\n# ]\r\n# target = 13\r\n# Output: false\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def searchMatrix(self, matrix: List[List[int]], target: int) -> bool:\r\n if len(matrix) == 0 or len(matrix[0]) == 0:\r\n return False\r\n low, row, col = 0, len(matrix), len(matrix[0])\r\n high = row * col - 1\r\n while low <= high:\r\n mid = low + (high - low) // 2\r\n current = matrix[mid // col][mid % col]\r\n if current < target:\r\n low = mid + 1\r\n elif current != target:\r\n high = mid - 1\r\n else:\r\n return True\r\n return False\r\n"
},
{
"alpha_fraction": 0.4888729453086853,
"alphanum_fraction": 0.5376884341239929,
"avg_line_length": 28.282608032226562,
"blob_id": "2c482da6ea026ea22c51a65b551756b10eac9ce7",
"content_id": "41f89ee02d1368d9562f104f6b89d9f530000dfc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1395,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 46,
"path": "/leetcode-algorithms/016. 3Sum Closest/16.3-sum-closest.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=16 lang=python3\r\n#\r\n# [16] 3Sum Closest\r\n#\r\n# https://leetcode.com/problems/3sum-closest/description/\r\n#\r\n# algorithms\r\n# Medium (41.16%)\r\n# Total Accepted: 329.7K\r\n# Total Submissions: 739.4K\r\n# Testcase Example: '[-1,2,1,-4]\\n1'\r\n#\r\n# Given an array nums of n integers and an integer target, find three integers\r\n# in nums such that the sum is closest to target. Return the sum of the three\r\n# integers. You may assume that each input would have exactly one solution.\r\n#\r\n# Example:\r\n#\r\n#\r\n# Given array nums = [-1, 2, 1, -4], and target = 1.\r\n#\r\n# The sum that is closest to the target is 2. (-1 + 2 + 1 = 2).\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def threeSumClosest(self, nums: List[int], target: int) -> int:\r\n closest, this_len, sol, nums = 9999999999999999999999999999, 0, 0, sorted(\r\n nums)\r\n for i in range(len(nums)):\r\n left, right = i + 1, len(nums) - 1\r\n while left < right:\r\n this_sum = nums[i] + nums[left] + nums[right]\r\n this_len = abs(this_sum - target)\r\n if this_sum == target:\r\n return this_sum\r\n if this_len < closest:\r\n closest, sol = this_len, this_sum\r\n if this_sum > target:\r\n right -= 1\r\n else:\r\n left += 1\r\n return sol\r\n"
},
{
"alpha_fraction": 0.5003088116645813,
"alphanum_fraction": 0.5262507796287537,
"avg_line_length": 21.128570556640625,
"blob_id": "82301aad2d0a012a6eb52c45c9b254afae0abee7",
"content_id": "0605102ccab72f78b56f70c17e017b79b6840507",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1619,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 70,
"path": "/leetcode-algorithms/717. 1-bit and 2-bit Characters/717.1-bit-and-2-bit-characters.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=717 lang=cpp\r\n *\r\n * [717] 1-bit and 2-bit Characters\r\n *\r\n * https://leetcode.com/problems/1-bit-and-2-bit-characters/description/\r\n *\r\n * algorithms\r\n * Easy (48.89%)\r\n * Total Accepted: 39K\r\n * Total Submissions: 79.3K\r\n * Testcase Example: '[1,0,0]'\r\n *\r\n * We have two special characters. The first character can be represented by\r\n * one bit 0. The second character can be represented by two bits (10 or\r\n * 11). \r\n * \r\n * Now given a string represented by several bits. Return whether the last\r\n * character must be a one-bit character or not. The given string will always\r\n * end with a zero.\r\n * \r\n * Example 1:\r\n * \r\n * Input: \r\n * bits = [1, 0, 0]\r\n * Output: True\r\n * Explanation: \r\n * The only way to decode it is two-bit character and one-bit character. So the\r\n * last character is one-bit character.\r\n * \r\n * \r\n * \r\n * Example 2:\r\n * \r\n * Input: \r\n * bits = [1, 1, 1, 0]\r\n * Output: False\r\n * Explanation: \r\n * The only way to decode it is two-bit character and two-bit character. So the\r\n * last character is NOT one-bit character.\r\n * \r\n * \r\n * \r\n * Note:\r\n * 1 .\r\n * bits[i] is always 0 or 1.\r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n bool isOneBitCharacter(vector<int> &bits)\r\n {\r\n for (int i = 0; i < bits.size();)\r\n {\r\n if (bits[i] == 1)\r\n {\r\n i += 2;\r\n if (i == bits.size())\r\n return false;\r\n }\r\n else\r\n {\r\n if (++i == bits.size())\r\n return true;\r\n }\r\n }\r\n return false;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.4273020923137665,
"alphanum_fraction": 0.4701130986213684,
"avg_line_length": 17.650793075561523,
"blob_id": "406caf8797e785a60b240f3df065d84d7a8f7daf",
"content_id": "bbc02fb6c2b8604ef15067f078b2b3cf7ef0799b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1238,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 63,
"path": "/leetcode-algorithms/905. Sort Array By Parity/905.sort-array-by-parity.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=905 lang=cpp\r\n *\r\n * [905] Sort Array By Parity\r\n *\r\n * https://leetcode.com/problems/sort-array-by-parity/description/\r\n *\r\n * algorithms\r\n * Easy (72.13%)\r\n * Total Accepted: 85.5K\r\n * Total Submissions: 118K\r\n * Testcase Example: '[3,1,2,4]'\r\n *\r\n * Given an array A of non-negative integers, return an array consisting of all\r\n * the even elements of A, followed by all the odd elements of A.\r\n * \r\n * You may return any answer array that satisfies this condition.\r\n * \r\n * \r\n * \r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: [3,1,2,4]\r\n * Output: [2,4,3,1]\r\n * The outputs [4,2,3,1], [2,4,1,3], and [4,2,1,3] would also be accepted.\r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * 1 <= A.length <= 5000\r\n * 0 <= A[i] <= 5000\r\n * \r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n vector<int> sortArrayByParity(vector<int> &A)\r\n {\r\n int length = A.size();\r\n vector<int> a;\r\n vector<int> b;\r\n for (auto t : A)\r\n {\r\n if (t % 2 == 0)\r\n {\r\n a.push_back(t);\r\n }\r\n else\r\n {\r\n b.push_back(t);\r\n }\r\n }\r\n a.insert(a.end(), b.begin(), b.end());\r\n return a;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.5183387398719788,
"alphanum_fraction": 0.662351667881012,
"avg_line_length": 21.174999237060547,
"blob_id": "29f90faa03db9424c8e5fd6c4c9acf70f80553ba",
"content_id": "0d31fb1f28a5a86f691fcd37a97d2df663358837",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1859,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 80,
"path": "/leetcode-algorithms/191. Number of 1 Bits/191.number-of-1-bits.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=191 lang=python\r\n#\r\n# [191] Number of 1 Bits\r\n#\r\n# https://leetcode.com/problems/number-of-1-bits/description/\r\n#\r\n# algorithms\r\n# Easy (43.48%)\r\n# Likes: 449\r\n# Dislikes: 397\r\n# Total Accepted: 264.8K\r\n# Total Submissions: 606.4K\r\n# Testcase Example: '00000000000000000000000000001011'\r\n#\r\n# Write a function that takes an unsigned integer and return the number of '1'\r\n# bits it has (also known as the Hamming weight).\r\n#\r\n#\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: 00000000000000000000000000001011\r\n# Output: 3\r\n# Explanation: The input binary string 00000000000000000000000000001011 has a\r\n# total of three '1' bits.\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: 00000000000000000000000010000000\r\n# Output: 1\r\n# Explanation: The input binary string 00000000000000000000000010000000 has a\r\n# total of one '1' bit.\r\n#\r\n#\r\n# Example 3:\r\n#\r\n#\r\n# Input: 11111111111111111111111111111101\r\n# Output: 31\r\n# Explanation: The input binary string 11111111111111111111111111111101 has a\r\n# total of thirty one '1' bits.\r\n#\r\n#\r\n#\r\n# Note:\r\n#\r\n#\r\n# Note that in some languages such as Java, there is no unsigned integer type.\r\n# In this case, the input will be given as signed integer type and should not\r\n# affect your implementation, as the internal binary representation of the\r\n# integer is the same whether it is signed or unsigned.\r\n# In Java, the compiler represents the signed integers using 2's complement\r\n# notation. Therefore, in Example 3 above the input represents the signed\r\n# integer -3.\r\n#\r\n#\r\n#\r\n#\r\n# Follow up:\r\n#\r\n# If this function is called many times, how would you optimize it?\r\n#\r\n#\r\n\r\n\r\nclass Solution(object):\r\n def hammingWeight(self, n):\r\n \"\"\"\r\n :type n: int\r\n :rtype: int\r\n \"\"\"\r\n count = 0\r\n while n:\r\n n &= (n - 1)\r\n count += 1\r\n return count\r\n"
},
{
"alpha_fraction": 0.4616040885448456,
"alphanum_fraction": 0.5017064809799194,
"avg_line_length": 19.703702926635742,
"blob_id": "ef286a15cce6984071bf242e774e0c300e9bfce9",
"content_id": "785194351157d648b9ff2f51567b4d5564217478",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1174,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 54,
"path": "/leetcode-algorithms/485. Max Consecutive Ones/485.max-consecutive-ones.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=485 lang=cpp\r\n *\r\n * [485] Max Consecutive Ones\r\n *\r\n * https://leetcode.com/problems/max-consecutive-ones/description/\r\n *\r\n * algorithms\r\n * Easy (54.54%)\r\n * Total Accepted: 130.8K\r\n * Total Submissions: 238.8K\r\n * Testcase Example: '[1,0,1,1,0,1]'\r\n *\r\n * Given a binary array, find the maximum number of consecutive 1s in this\r\n * array.\r\n * \r\n * Example 1:\r\n * \r\n * Input: [1,1,0,1,1,1]\r\n * Output: 3\r\n * Explanation: The first two digits or the last three digits are consecutive\r\n * 1s.\r\n * The maximum number of consecutive 1s is 3.\r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * The input array will only contain 0 and 1.\r\n * The length of input array is a positive integer and will not exceed 10,000\r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n int findMaxConsecutiveOnes(vector<int> &nums)\r\n {\r\n int m = 0, max = 0;\r\n for (auto it = nums.begin(); it != nums.end(); it++)\r\n {\r\n if (*it == 1)\r\n {\r\n m++;\r\n max = max > m ? max : m;\r\n }\r\n else\r\n {\r\n m = 0;\r\n }\r\n }\r\n return max;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.505250871181488,
"alphanum_fraction": 0.5250875353813171,
"avg_line_length": 27.55172348022461,
"blob_id": "6bef3a9ec6b502b25e29583f5574996dbfa95688",
"content_id": "adb6230bb2ffd1b7ef9a8b9836edcdaa68dc78d4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1720,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 58,
"path": "/leetcode-algorithms/079. Word Search/79.word-search.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=79 lang=python3\r\n#\r\n# [79] Word Search\r\n#\r\n# https://leetcode.com/problems/word-search/description/\r\n#\r\n# algorithms\r\n# Medium (30.46%)\r\n# Likes: 1780\r\n# Dislikes: 87\r\n# Total Accepted: 288.6K\r\n# Total Submissions: 918.2K\r\n# Testcase Example: '[[\"A\",\"B\",\"C\",\"E\"],[\"S\",\"F\",\"C\",\"S\"],[\"A\",\"D\",\"E\",\"E\"]]\\n\"ABCCED\"'\r\n#\r\n# Given a 2D board and a word, find if the word exists in the grid.\r\n#\r\n# The word can be constructed from letters of sequentially adjacent cell, where\r\n# \"adjacent\" cells are those horizontally or vertically neighboring. The same\r\n# letter cell may not be used more than once.\r\n#\r\n# Example:\r\n#\r\n#\r\n# board =\r\n# [\r\n# ['A','B','C','E'],\r\n# ['S','F','C','S'],\r\n# ['A','D','E','E']\r\n# ]\r\n#\r\n# Given word = \"ABCCED\", return true.\r\n# Given word = \"SEE\", return true.\r\n# Given word = \"ABCB\", return false.\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def exist(self, board: List[List[str]], word: str) -> bool:\r\n def dfs(board, row, col, word):\r\n if not word:\r\n return True\r\n if row < 0 or col < 0 or row >= len(board) or col >= len(board[0]) or word[0] != board[row][col]:\r\n return False\r\n ch = board[row][col]\r\n board[row][col] = '.'\r\n newword = word[1:]\r\n result = dfs(board, row - 1, col, newword) or dfs(board, row, col - 1, newword) or dfs(\r\n board, row + 1, col, newword) or dfs(board, row, col + 1, newword)\r\n board[row][col] = ch\r\n return result\r\n for i in range(len(board)):\r\n for j in range(len(board[0])):\r\n if dfs(board, i, j, word):\r\n return True\r\n return False\r\n"
},
{
"alpha_fraction": 0.43377482891082764,
"alphanum_fraction": 0.503311276435852,
"avg_line_length": 21.59375,
"blob_id": "0681004e96e5cea74a7c34ee8882933bbcad04a9",
"content_id": "e4d68a4d4be2a5c04066178c4a488f95d8ad9788",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1511,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 64,
"path": "/leetcode-algorithms/200. Number of Islands/200.number-of-islands.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=200 lang=python3\r\n#\r\n# [200] Number of Islands\r\n#\r\n# https://leetcode.com/problems/number-of-islands/description/\r\n#\r\n# algorithms\r\n# Medium (42.46%)\r\n# Likes: 3014\r\n# Dislikes: 109\r\n# Total Accepted: 408K\r\n# Total Submissions: 958.3K\r\n# Testcase Example: '[[\"1\",\"1\",\"1\",\"1\",\"0\"],[\"1\",\"1\",\"0\",\"1\",\"0\"],[\"1\",\"1\",\"0\",\"0\",\"0\"],[\"0\",\"0\",\"0\",\"0\",\"0\"]]'\r\n#\r\n# Given a 2d grid map of '1's (land) and '0's (water), count the number of\r\n# islands. An island is surrounded by water and is formed by connecting\r\n# adjacent lands horizontally or vertically. You may assume all four edges of\r\n# the grid are all surrounded by water.\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input:\r\n# 11110\r\n# 11010\r\n# 11000\r\n# 00000\r\n#\r\n# Output: 1\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input:\r\n# 11000\r\n# 11000\r\n# 00100\r\n# 00011\r\n#\r\n# Output: 3\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def numIslands(self, grid: List[List[str]]) -> int:\r\n def depth(grid, row, col):\r\n if row >= len(grid) or col >= len(grid[0]) or\\\r\n row < 0 or col < 0 or grid[row][col] == '0':\r\n return\r\n grid[row][col] = '0'\r\n depth(grid, row - 1, col)\r\n depth(grid, row + 1, col)\r\n depth(grid, row, col - 1)\r\n depth(grid, row, col + 1)\r\n num = 0\r\n for i in range(len(grid)):\r\n for j in range(len(grid[0])):\r\n if grid[i][j] == '1':\r\n num += 1\r\n depth(grid, i, j)\r\n return num\r\n"
},
{
"alpha_fraction": 0.4217419922351837,
"alphanum_fraction": 0.4531761705875397,
"avg_line_length": 18.917808532714844,
"blob_id": "af46cb7e9e1f2336145e7658b9a8428fbbe71b76",
"content_id": "910e5284d4515fdf0dc3ecdcbc5de4a3efdd3b93",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1527,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 73,
"path": "/leetcode-algorithms/082. Remove Duplicates from Sorted List II/82.remove-duplicates-from-sorted-list-ii.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=82 lang=cpp\r\n *\r\n * [82] Remove Duplicates from Sorted List II\r\n *\r\n * https://leetcode.com/problems/remove-duplicates-from-sorted-list-ii/description/\r\n *\r\n * algorithms\r\n * Medium (32.25%)\r\n * Likes: 843\r\n * Dislikes: 72\r\n * Total Accepted: 184.7K\r\n * Total Submissions: 556.4K\r\n * Testcase Example: '[1,2,3,3,4,4,5]'\r\n *\r\n * Given a sorted linked list, delete all nodes that have duplicate numbers,\r\n * leaving only distinct numbers from the original list.\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: 1->2->3->3->4->4->5\r\n * Output: 1->2->5\r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: 1->1->1->2->3\r\n * Output: 2->3\r\n * \r\n * \r\n */\r\n/**\r\n * Definition for singly-linked list.\r\n * struct ListNode {\r\n * int val;\r\n * ListNode *next;\r\n * ListNode(int x) : val(x), next(NULL) {}\r\n * };\r\n */\r\nclass Solution\r\n{\r\npublic:\r\n ListNode *deleteDuplicates(ListNode *head)\r\n {\r\n if (!head || !(head->next))\r\n {\r\n return head;\r\n }\r\n ListNode *phead = new ListNode(-1);\r\n phead->next = head;\r\n ListNode *p = phead;\r\n ListNode *q = head;\r\n while (q)\r\n {\r\n while (q->next && q->val == q->next->val)\r\n {\r\n q = q->next;\r\n }\r\n if (p->next == q)\r\n {\r\n p = q;\r\n }\r\n else\r\n {\r\n p->next = q->next;\r\n }\r\n q = q->next;\r\n }\r\n return phead->next;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.4837980270385742,
"alphanum_fraction": 0.5395629405975342,
"avg_line_length": 25.64583396911621,
"blob_id": "d59caf5133e33c699262d5efcefa87d120c83b3a",
"content_id": "d8f3bbd2875a9e33adec80a5e2a08306546a5c0b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1327,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 48,
"path": "/leetcode-algorithms/415. Add Strings/415.add-strings.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=415 lang=python3\r\n#\r\n# [415] Add Strings\r\n#\r\n# https://leetcode.com/problems/add-strings/description/\r\n#\r\n# algorithms\r\n# Easy (44.31%)\r\n# Likes: 468\r\n# Dislikes: 158\r\n# Total Accepted: 108.4K\r\n# Total Submissions: 244.7K\r\n# Testcase Example: '\"0\"\\n\"0\"'\r\n#\r\n# Given two non-negative integers num1 and num2 represented as string, return\r\n# the sum of num1 and num2.\r\n#\r\n# Note:\r\n#\r\n# The length of both num1 and num2 is < 5100.\r\n# Both num1 and num2 contains only digits 0-9.\r\n# Both num1 and num2 does not contain any leading zero.\r\n# You must not use any built-in BigInteger library or convert the inputs to\r\n# integer directly.\r\n#\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def addStrings(self, num1: str, num2: str) -> str:\r\n if len(num1) < len(num2):\r\n return self.addStrings(num2, num1)\r\n res, plus, i, j = ['0'] * len(num1), 0, len(num1) - 1, len(num2) - 1\r\n while j >= 0:\r\n temp = int(num1[i]) + int(num2[j]) + plus\r\n res[i] = str(temp % 10)\r\n plus = temp // 10\r\n i -= 1\r\n j -= 1\r\n while i >= 0:\r\n res[i] = str((int(num1[i]) + plus) % 10)\r\n plus = (int(num1[i]) + plus) // 10\r\n i -= 1\r\n if plus:\r\n return '1' + ''.join(res)\r\n return ''.join(res)\r\n"
},
{
"alpha_fraction": 0.488290399312973,
"alphanum_fraction": 0.5368852615356445,
"avg_line_length": 17.632183074951172,
"blob_id": "9f30df9e2010cd86ed9d46ee2d1beb9e04411ab9",
"content_id": "98037a99251c3502235e101f1258c217d51ff7de",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1708,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 87,
"path": "/leetcode-algorithms/991. Broken Calculator/991.broken-calculator.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=991 lang=cpp\r\n *\r\n * [991] Broken Calculator\r\n *\r\n * https://leetcode.com/problems/broken-calculator/description/\r\n *\r\n * algorithms\r\n * Medium (40.35%)\r\n * Likes: 159\r\n * Dislikes: 52\r\n * Total Accepted: 7.2K\r\n * Total Submissions: 17.6K\r\n * Testcase Example: '2\\n3'\r\n *\r\n * On a broken calculator that has a number showing on its display, we can\r\n * perform two operations:\r\n * \r\n * \r\n * Double: Multiply the number on the display by 2, or;\r\n * Decrement: Subtract 1 from the number on the display.\r\n * \r\n * \r\n * Initially, the calculator is displaying the number X.\r\n * \r\n * Return the minimum number of operations needed to display the number Y.\r\n * \r\n * \r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: X = 2, Y = 3\r\n * Output: 2\r\n * Explanation: Use double operation and then decrement operation {2 -> 4 ->\r\n * 3}.\r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: X = 5, Y = 8\r\n * Output: 2\r\n * Explanation: Use decrement and then double {5 -> 4 -> 8}.\r\n * \r\n * \r\n * Example 3:\r\n * \r\n * \r\n * Input: X = 3, Y = 10\r\n * Output: 3\r\n * Explanation: Use double, decrement and double {3 -> 6 -> 5 -> 10}.\r\n * \r\n * \r\n * Example 4:\r\n * \r\n * \r\n * Input: X = 1024, Y = 1\r\n * Output: 1023\r\n * Explanation: Use decrement operations 1023 times.\r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * 1 <= X <= 10^9\r\n * 1 <= Y <= 10^9\r\n * \r\n */\r\n//reference: https://leetcode.com/problems/broken-calculator/discuss/234484/JavaC%2B%2BPython-Change-Y-to-X-in-1-Line\r\n\r\nclass Solution\r\n{\r\npublic:\r\n int brokenCalc(int X, int Y)\r\n {\r\n int res = 0;\r\n while (Y > X)\r\n {\r\n Y = Y % 2 ? Y + 1 : Y / 2;\r\n res++;\r\n }\r\n return res + X - Y;\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.41321802139282227,
"alphanum_fraction": 0.45089560747146606,
"avg_line_length": 19.586666107177734,
"blob_id": "9b039fe727050114e26fdec3f527b18d39dfec67",
"content_id": "9fc6f4279b71ca824cf4aba5b75dc9ea20fb37f2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1625,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 75,
"path": "/leetcode-algorithms/007. Reverse Integer/7.reverse-integer.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=7 lang=java\r\n *\r\n * [7] Reverse Integer\r\n *\r\n * https://leetcode.com/problems/reverse-integer/description/\r\n *\r\n * algorithms\r\n * Easy (25.17%)\r\n * Total Accepted: 651.5K\r\n * Total Submissions: 2.6M\r\n * Testcase Example: '123'\r\n *\r\n * Given a 32-bit signed integer, reverse digits of an integer.\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: 123\r\n * Output: 321\r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: -123\r\n * Output: -321\r\n * \r\n * \r\n * Example 3:\r\n * \r\n * \r\n * Input: 120\r\n * Output: 21\r\n * \r\n * \r\n * Note:\r\n * Assume we are dealing with an environment which could only store integers\r\n * within the 32-bit signed integer range: [−2^31, 2^31 − 1]. For the purpose\r\n * of this problem, assume that your function returns 0 when the reversed\r\n * integer overflows.\r\n * \r\n */\r\nclass Solution {\r\n public int reverse(int x) {\r\n boolean t = true;\r\n long newx = x;\r\n if (newx < 0) {\r\n newx = -newx;\r\n t = false;\r\n }\r\n long n = 0;\r\n if (0 <= newx && newx < 10) {\r\n if (t)\r\n return (int) newx;\r\n else\r\n return (int) -newx;\r\n }\r\n while (newx > 0) {\r\n n = newx % 10 + (n * 10);\r\n if (n > Integer.MAX_VALUE && t) {\r\n return 0;\r\n }\r\n if (-n < Integer.MIN_VALUE && !t) {\r\n return 0;\r\n }\r\n // std::cout<<old<<\"\\t\"<<n<<std::endl;\r\n newx = newx / 10;\r\n }\r\n if (t)\r\n return (int) n;\r\n else\r\n return (int) -n;\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.40325117111206055,
"alphanum_fraction": 0.41950708627700806,
"avg_line_length": 18.287233352661133,
"blob_id": "f3d80952a18f5b2ad68617491ed1ca4e72cd0bd3",
"content_id": "b6131ae692b2269a96143532ef099e6571743164",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1908,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 94,
"path": "/leetcode-algorithms/020. Valid Parentheses/20.valid-parentheses.java",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=20 lang=java\r\n *\r\n * [20] Valid Parentheses\r\n *\r\n * https://leetcode.com/problems/valid-parentheses/description/\r\n *\r\n * algorithms\r\n * Easy (35.96%)\r\n * Likes: 2805\r\n * Dislikes: 138\r\n * Total Accepted: 570.4K\r\n * Total Submissions: 1.6M\r\n * Testcase Example: '\"()\"'\r\n *\r\n * Given a string containing just the characters '(', ')', '{', '}', '[' and\r\n * ']', determine if the input string is valid.\r\n * \r\n * An input string is valid if:\r\n * \r\n * \r\n * Open brackets must be closed by the same type of brackets.\r\n * Open brackets must be closed in the correct order.\r\n * \r\n * \r\n * Note that an empty string is also considered valid.\r\n * \r\n * Example 1:\r\n * \r\n * \r\n * Input: \"()\"\r\n * Output: true\r\n * \r\n * \r\n * Example 2:\r\n * \r\n * \r\n * Input: \"()[]{}\"\r\n * Output: true\r\n * \r\n * \r\n * Example 3:\r\n * \r\n * \r\n * Input: \"(]\"\r\n * Output: false\r\n * \r\n * \r\n * Example 4:\r\n * \r\n * \r\n * Input: \"([)]\"\r\n * Output: false\r\n * \r\n * \r\n * Example 5:\r\n * \r\n * \r\n * Input: \"{[]}\"\r\n * Output: true\r\n * \r\n * \r\n */\r\nclass Solution {\r\n public boolean isValid(String s) {\r\n if (s.length() % 2 != 0)\r\n return false;\r\n Stack<Character> sol = new Stack<>();\r\n Map<Character, Character> m = new HashMap<>();\r\n m.put('[', ']');\r\n m.put('{', '}');\r\n m.put('(', ')');\r\n for (int i = 0; i < s.length(); i++) {\r\n switch (s.charAt(i)) {\r\n case '[':\r\n case '{':\r\n case '(':\r\n sol.push(s.charAt(i));\r\n break;\r\n case ']':\r\n case ')':\r\n case '}':\r\n if (sol.size() == 0) {\r\n return false;\r\n }\r\n if (s.charAt(i) == m.get(sol.peek())) {\r\n sol.pop();\r\n }\r\n break;\r\n }\r\n }\r\n return sol.size() == 0;\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.5126530528068542,
"alphanum_fraction": 0.5534693598747253,
"avg_line_length": 18.428571701049805,
"blob_id": "aeca0b364dc7e0277872acb1c0847cd191bfeb66",
"content_id": "efe0bbb52ed04425421d8f585f9b8bccf3d9f023",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Kotlin",
"length_bytes": 1225,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 63,
"path": "/leetcode-algorithms/070. Climbing Stairs/70.climbing-stairs.kt",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\n * @lc app=leetcode id=70 lang=kotlin\n *\n * [70] Climbing Stairs\n *\n * https://leetcode.com/problems/climbing-stairs/description/\n *\n * algorithms\n * Easy (45.34%)\n * Likes: 3660\n * Dislikes: 120\n * Total Accepted: 609.8K\n * Total Submissions: 1.3M\n * Testcase Example: '2'\n *\n * You are climbing a stair case. It takes n steps to reach to the top.\n * \n * Each time you can either climb 1 or 2 steps. In how many distinct ways can\n * you climb to the top?\n * \n * Note: Given n will be a positive integer.\n * \n * Example 1:\n * \n * \n * Input: 2\n * Output: 2\n * Explanation: There are two ways to climb to the top.\n * 1. 1 step + 1 step\n * 2. 2 steps\n * \n * \n * Example 2:\n * \n * \n * Input: 3\n * Output: 3\n * Explanation: There are three ways to climb to the top.\n * 1. 1 step + 1 step + 1 step\n * 2. 1 step + 2 steps\n * 3. 2 steps + 1 step\n * \n * \n */\n\n// @lc code=start\nclass Solution {\n fun climbStairs(n: Int): Int {\n if (n <= 3) {\n return n\n }\n var result = 2\n var first = 2\n var second = 1\n for (i in 3..n) {\n result = first + second\n second = first\n first = result\n }\n return result\n }\n}\n// @lc code=end\n\n"
},
{
"alpha_fraction": 0.41494593024253845,
"alphanum_fraction": 0.4759095311164856,
"avg_line_length": 19.1875,
"blob_id": "dde1ee992fa9163363893af7962d8661de02d86a",
"content_id": "61d4aa73d6c9314e98bd8515c67e99917743df85",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1018,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 48,
"path": "/leetcode-algorithms/067. Add Binary/67.add-binary.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=67 lang=python3\r\n#\r\n# [67] Add Binary\r\n#\r\n# https://leetcode.com/problems/add-binary/description/\r\n#\r\n# algorithms\r\n# Easy (39.39%)\r\n# Likes: 987\r\n# Dislikes: 198\r\n# Total Accepted: 309.7K\r\n# Total Submissions: 785.9K\r\n# Testcase Example: '\"11\"\\n\"1\"'\r\n#\r\n# Given two binary strings, return their sum (also a binary string).\r\n#\r\n# The input strings are both non-empty and contains only characters 1 or 0.\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: a = \"11\", b = \"1\"\r\n# Output: \"100\"\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: a = \"1010\", b = \"1011\"\r\n# Output: \"10101\"\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def addBinary(self, a: str, b: str) -> str:\r\n res = ''\r\n plus, i, j = 0, len(a) - 1, len(b) - 1\r\n while i >= 0 or j >= 0 or plus > 0:\r\n if i >= 0:\r\n plus += int(a[i])\r\n i -= 1\r\n if j >= 0:\r\n plus += int(b[j])\r\n j -= 1\r\n res += str(plus % 2)\r\n plus //= 2\r\n return res[::-1]\r\n"
},
{
"alpha_fraction": 0.5249146819114685,
"alphanum_fraction": 0.5556313991546631,
"avg_line_length": 19.231884002685547,
"blob_id": "48d84c66beeb514fe1472e173adcef04b478604b",
"content_id": "815afcf7f2ff6559c2365d03a449b7fe56f77155",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1471,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 69,
"path": "/leetcode-algorithms/830. Positions of Large Groups/830.positions-of-large-groups.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=830 lang=python3\r\n#\r\n# [830] Positions of Large Groups\r\n#\r\n# https://leetcode.com/problems/positions-of-large-groups/description/\r\n#\r\n# algorithms\r\n# Easy (47.49%)\r\n# Total Accepted: 24.8K\r\n# Total Submissions: 51.9K\r\n# Testcase Example: '\"abbxxxxzzy\"'\r\n#\r\n# In a string S of lowercase letters, these letters form consecutive groups of\r\n# the same character.\r\n#\r\n# For example, a string like S = \"abbxxxxzyy\" has the groups \"a\", \"bb\", \"xxxx\",\r\n# \"z\" and \"yy\".\r\n#\r\n# Call a group large if it has 3 or more characters. We would like the\r\n# starting and ending positions of every large group.\r\n#\r\n# The final answer should be in lexicographic order.\r\n#\r\n#\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: \"abbxxxxzzy\"\r\n# Output: [[3,6]]\r\n# Explanation: \"xxxx\" is the single large group with starting 3 and ending\r\n# positions 6.\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: \"abc\"\r\n# Output: []\r\n# Explanation: We have \"a\",\"b\" and \"c\" but no large group.\r\n#\r\n#\r\n# Example 3:\r\n#\r\n#\r\n# Input: \"abcdddeeeeaabbbcd\"\r\n# Output: [[3,5],[6,9],[12,14]]\r\n#\r\n#\r\n#\r\n# Note: 1 <= S.length <= 1000\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def largeGroupPositions(self, S: str) -> List[List[int]]:\r\n result = []\r\n i = 1\r\n j = 0\r\n while i < len(S):\r\n while i < len(S) and S[i] == S[j]:\r\n i += 1\r\n if ((i-1) - j) >= 2:\r\n result.append([j, i-1])\r\n j = i\r\n i += 1\r\n return result\r\n"
},
{
"alpha_fraction": 0.5027888417243958,
"alphanum_fraction": 0.5298804640769958,
"avg_line_length": 18.24193572998047,
"blob_id": "db18e56e05be46c6e8a0ec241dfb5007a9f8379b",
"content_id": "920e6c56bb3abab4f8b85b3bb0c7ad72f87941bc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1267,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 62,
"path": "/leetcode-algorithms/145. Binary Tree Postorder Traversal/145.binary-tree-postorder-traversal.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=145 lang=cpp\r\n *\r\n * [145] Binary Tree Postorder Traversal\r\n *\r\n * https://leetcode.com/problems/binary-tree-postorder-traversal/description/\r\n *\r\n * algorithms\r\n * Hard (48.80%)\r\n * Likes: 977\r\n * Dislikes: 47\r\n * Total Accepted: 273.9K\r\n * Total Submissions: 555K\r\n * Testcase Example: '[1,null,2,3]'\r\n *\r\n * Given a binary tree, return the postorder traversal of its nodes' values.\r\n * \r\n * Example:\r\n * \r\n * \r\n * Input: [1,null,2,3]\r\n * 1\r\n * \\\r\n * 2\r\n * /\r\n * 3\r\n * \r\n * Output: [3,2,1]\r\n * \r\n * \r\n * Follow up: Recursive solution is trivial, could you do it iteratively?\r\n * \r\n */\r\n/**\r\n * Definition for a binary tree node.\r\n * struct TreeNode {\r\n * int val;\r\n * TreeNode *left;\r\n * TreeNode *right;\r\n * TreeNode(int x) : val(x), left(NULL), right(NULL) {}\r\n * };\r\n */\r\nclass Solution\r\n{\r\npublic:\r\n vector<int> postorderTraversal(TreeNode *root)\r\n {\r\n vector<int> res;\r\n postorder(res, root);\r\n return res;\r\n }\r\n\r\n void postorder(vector<int> &res, TreeNode *root)\r\n {\r\n if (root)\r\n {\r\n postorder(res, root->left);\r\n postorder(res, root->right);\r\n res.push_back(root->val);\r\n }\r\n }\r\n};\r\n"
},
{
"alpha_fraction": 0.37578070163726807,
"alphanum_fraction": 0.4167245030403137,
"avg_line_length": 20.88888931274414,
"blob_id": "06572a9fb026d82f4be50143f04136bf6880a8b7",
"content_id": "913fd0e36a46b006ca20567f5feaebd423e2998f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2894,
"license_type": "permissive",
"max_line_length": 123,
"num_lines": 126,
"path": "/leetcode-algorithms/542. 01 Matrix/542.01-matrix.cpp",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\r\n * @lc app=leetcode id=542 lang=cpp\r\n *\r\n * [542] 01 Matrix\r\n *\r\n * https://leetcode.com/problems/01-matrix/description/\r\n *\r\n * algorithms\r\n * Medium (36.50%)\r\n * Likes: 811\r\n * Dislikes: 84\r\n * Total Accepted: 53.2K\r\n * Total Submissions: 144.5K\r\n * Testcase Example: '[[0,0,0],[0,1,0],[0,0,0]]'\r\n *\r\n * Given a matrix consists of 0 and 1, find the distance of the nearest 0 for\r\n * each cell.\r\n * \r\n * The distance between two adjacent cells is 1.\r\n * \r\n * \r\n * \r\n * Example 1: \r\n * \r\n * \r\n * Input:\r\n * [[0,0,0],\r\n * [0,1,0],\r\n * [0,0,0]]\r\n * \r\n * Output:\r\n * [[0,0,0],\r\n * [0,1,0],\r\n * [0,0,0]]\r\n * \r\n * \r\n * Example 2: \r\n * \r\n * \r\n * Input:\r\n * [[0,0,0],\r\n * [0,1,0],\r\n * [1,1,1]]\r\n * \r\n * Output:\r\n * [[0,0,0],\r\n * [0,1,0],\r\n * [1,2,1]]\r\n * \r\n * \r\n * \r\n * \r\n * Note:\r\n * \r\n * \r\n * The number of elements of the given matrix will not exceed 10,000.\r\n * There are at least one 0 in the given matrix.\r\n * The cells are adjacent in only four directions: up, down, left and right.\r\n * \r\n * \r\n */\r\nclass Solution\r\n{\r\npublic:\r\n vector<vector<int>> updateMatrix(vector<vector<int>> &matrix)\r\n {\r\n if (matrix.size() == 0)\r\n {\r\n return matrix;\r\n }\r\n for (int i = 0; i < matrix.size(); i++)\r\n {\r\n for (int j = 0; j < matrix[0].size(); j++)\r\n {\r\n if (matrix[i][j] == 1 && !hasNeiberZero(i, j, matrix))\r\n {\r\n matrix[i][j] = INT_MAX;\r\n }\r\n }\r\n }\r\n for (int i = 0; i < matrix.size(); i++)\r\n {\r\n for (int j = 0; j < matrix[0].size(); j++)\r\n {\r\n if (matrix[i][j] == 1)\r\n {\r\n dfs(matrix, i, j, 1);\r\n }\r\n }\r\n }\r\n return matrix;\r\n }\r\n void dfs(vector<vector<int>> &matrix, int row, int col, int val)\r\n {\r\n if (row < 0 || col < 0 || col >= matrix[0].size() || row >= matrix.size() || (matrix[row][col] <= val && val != 1))\r\n {\r\n return;\r\n }\r\n matrix[row][col] = val;\r\n dfs(matrix, row + 1, col, matrix[row][col] + 1);\r\n dfs(matrix, row - 1, col, matrix[row][col] + 1);\r\n dfs(matrix, row, col + 1, matrix[row][col] + 1);\r\n dfs(matrix, row, col - 1, matrix[row][col] + 1);\r\n }\r\n\r\n bool hasNeiberZero(int row, int col, vector<vector<int>> &matrix)\r\n {\r\n if (row > 0 && matrix[row - 1][col] == 0)\r\n {\r\n return true;\r\n }\r\n if (row < matrix.size() - 1 && matrix[row + 1][col] == 0)\r\n {\r\n return true;\r\n }\r\n if (col > 0 && matrix[row][col - 1] == 0)\r\n {\r\n return true;\r\n }\r\n if (col < matrix[0].size() - 1 && matrix[row][col + 1] == 0)\r\n {\r\n return true;\r\n }\r\n return false;\r\n }\r\n};"
},
{
"alpha_fraction": 0.45069241523742676,
"alphanum_fraction": 0.5023080110549927,
"avg_line_length": 23.060606002807617,
"blob_id": "bd462ef8ed6da421f3a5e54229f6b09687aed143",
"content_id": "d73fc4432a302903378345b2146bb26812b27fd3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2395,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 99,
"path": "/leetcode-algorithms/542. 01 Matrix/542.01-matrix.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode id=542 lang=python3\n#\n# [542] 01 Matrix\n#\n# https://leetcode.com/problems/01-matrix/description/\n#\n# algorithms\n# Medium (37.24%)\n# Likes: 894\n# Dislikes: 90\n# Total Accepted: 58.3K\n# Total Submissions: 155.9K\n# Testcase Example: '[[0,0,0],[0,1,0],[0,0,0]]'\n#\n# Given a matrix consists of 0 and 1, find the distance of the nearest 0 for\n# each cell.\n# \n# The distance between two adjacent cells is 1.\n# \n# \n# \n# Example 1: \n# \n# \n# Input:\n# [[0,0,0],\n# [0,1,0],\n# [0,0,0]]\n# \n# Output:\n# [[0,0,0],\n# [0,1,0],\n# [0,0,0]]\n# \n# \n# Example 2: \n# \n# \n# Input:\n# [[0,0,0],\n# [0,1,0],\n# [1,1,1]]\n# \n# Output:\n# [[0,0,0],\n# [0,1,0],\n# [1,2,1]]\n# \n# \n# \n# \n# Note:\n# \n# \n# The number of elements of the given matrix will not exceed 10,000.\n# There are at least one 0 in the given matrix.\n# The cells are adjacent in only four directions: up, down, left and right.\n# \n# \n#\n\n# @lc code=start\nclass Solution:\n def updateMatrix(self, matrix: List[List[int]]) -> List[List[int]]:\n def hasNeiberZero(row, col, matrix):\n if row > 0 and matrix[row - 1][col] == 0:\n return True\n if (row < len(matrix) - 1 and matrix[row + 1][col] == 0):\n return True\n if (col > 0 and matrix[row][col - 1] == 0):\n return True\n if (col < len(matrix[0]) - 1 and matrix[row][col + 1] == 0):\n return True\n return False\n\n def dfs(matrix, row, col, val):\n if (row < 0 or col < 0 or col >= len(matrix[0]) or row >= len(matrix)\n or (matrix[row][col] <= val and val != 1)):\n return\n matrix[row][col] = val\n\n dfs(matrix, row + 1, col, matrix[row][col] + 1)\n dfs(matrix, row - 1, col, matrix[row][col] + 1)\n dfs(matrix, row, col + 1, matrix[row][col] + 1)\n dfs(matrix, row, col - 1, matrix[row][col] + 1)\n\n if (len(matrix) == 0):\n return matrix\n for i in range(len(matrix)):\n for j in range(len(matrix[0])):\n if (matrix[i][j] == 1 and not hasNeiberZero(i, j, matrix)):\n matrix[i][j] = 99999999\n for i in range(len(matrix)):\n for j in range(len(matrix[0])):\n if (matrix[i][j] == 1):\n dfs(matrix, i, j, 1)\n return matrix\n# @lc code=end\n\n"
},
{
"alpha_fraction": 0.49284252524375916,
"alphanum_fraction": 0.5184049010276794,
"avg_line_length": 23.402597427368164,
"blob_id": "99857293684db3ec83a719314a70080c27e850da",
"content_id": "9e2560f9026c390cb8910859ca491494a1b55a9d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1958,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 77,
"path": "/leetcode-algorithms/028. Implement strStr()/28.implement-str-str.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=28 lang=python3\r\n#\r\n# [28] Implement strStr()\r\n#\r\n# https://leetcode.com/problems/implement-strstr/description/\r\n#\r\n# algorithms\r\n# Easy (31.30%)\r\n# Likes: 839\r\n# Dislikes: 1261\r\n# Total Accepted: 415.4K\r\n# Total Submissions: 1.3M\r\n# Testcase Example: '\"hello\"\\n\"ll\"'\r\n#\r\n# Implement strStr().\r\n#\r\n# Return the index of the first occurrence of needle in haystack, or -1 if\r\n# needle is not part of haystack.\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: haystack = \"hello\", needle = \"ll\"\r\n# Output: 2\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: haystack = \"aaaaa\", needle = \"bba\"\r\n# Output: -1\r\n#\r\n#\r\n# Clarification:\r\n#\r\n# What should we return when needle is an empty string? This is a great\r\n# question to ask during an interview.\r\n#\r\n# For the purpose of this problem, we will return 0 when needle is an empty\r\n# string. This is consistent to C's strstr() and Java's indexOf().\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def strStr(self, haystack: str, needle: str) -> int:\r\n if needle == \"\":\r\n return 0\r\n if len(needle) > len(haystack):\r\n return -1\r\n bc = [0 for _ in range(256)]\r\n\r\n def getbc(pattern):\r\n patternLen = len(pattern)\r\n for i in range(256):\r\n bc[i] = -1\r\n i = 0\r\n for i in range(patternLen):\r\n bc[ord(pattern[i])] = i\r\n return bc\r\n abc = getbc(needle)\r\n global i\r\n global j\r\n i, j = 0, 0\r\n patternlast, patternLen, strLen = len(\r\n needle) - 1, len(needle), len(haystack)\r\n while i + patternLen <= strLen:\r\n for j in range(patternlast, -2, -1):\r\n if j != -1 and needle[j] != haystack[i + j]:\r\n break\r\n if j == -1:\r\n break\r\n else:\r\n span = j - abc[ord(haystack[i + j])]\r\n i += span if span > 0 else 1\r\n return i if j == -1 else -1\r\n"
},
{
"alpha_fraction": 0.548285186290741,
"alphanum_fraction": 0.5717508792877197,
"avg_line_length": 20.930692672729492,
"blob_id": "321f00d0facfb8d3c7e53da89346527c90b201e4",
"content_id": "2eb260db10f2ae94c502c960f44c1b399dc9c14a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Kotlin",
"length_bytes": 2216,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 101,
"path": "/leetcode-algorithms/155. Min Stack/155.min-stack.kt",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "/*\n * @lc app=leetcode id=155 lang=kotlin\n *\n * [155] Min Stack\n *\n * https://leetcode.com/problems/min-stack/description/\n *\n * algorithms\n * Easy (46.75%)\n * Likes: 4834\n * Dislikes: 451\n * Total Accepted: 702.8K\n * Total Submissions: 1.5M\n * Testcase Example: '[\"MinStack\",\"push\",\"push\",\"push\",\"getMin\",\"pop\",\"top\",\"getMin\"]\\n' +\n '[[],[-2],[0],[-3],[],[],[],[]]'\n *\n * Design a stack that supports push, pop, top, and retrieving the minimum\n * element in constant time.\n * \n * Implement the MinStack class:\n * \n * \n * MinStack() initializes the stack object.\n * void push(val) pushes the element val onto the stack.\n * void pop() removes the element on the top of the stack.\n * int top() gets the top element of the stack.\n * int getMin() retrieves the minimum element in the stack.\n * \n * \n * \n * Example 1:\n * \n * \n * Input\n * [\"MinStack\",\"push\",\"push\",\"push\",\"getMin\",\"pop\",\"top\",\"getMin\"]\n * [[],[-2],[0],[-3],[],[],[],[]]\n * \n * Output\n * [null,null,null,null,-3,null,0,-2]\n * \n * Explanation\n * MinStack minStack = new MinStack();\n * minStack.push(-2);\n * minStack.push(0);\n * minStack.push(-3);\n * minStack.getMin(); // return -3\n * minStack.pop();\n * minStack.top(); // return 0\n * minStack.getMin(); // return -2\n * \n * \n * \n * Constraints:\n * \n * \n * -2^31 <= val <= 2^31 - 1\n * Methods pop, top and getMin operations will always be called on non-empty\n * stacks.\n * At most 3 * 10^4 calls will be made to push, pop, top, and getMin.\n * \n * \n */\n\n// @lc code=start\nclass MinStack() {\n\n /** initialize your data structure here. */\n data class node(var value:Int,var min:Int,var next:node?)\n\n var head:node? = null\n fun push(value: Int) {\n if(head == null) {\n head = node(value, value, null)\n }else{\n head = node(value, Math.min(head!!.min, value), head)\n }\n }\n \n fun pop() {\n head = head!!.next\n }\n\n fun top(): Int {\n return head!!.value\n }\n\n fun getMin(): Int {\n return head!!.min\n }\n\n}\n\n/**\n * Your MinStack object will be instantiated and called as such:\n * var obj = MinStack()\n * obj.push(`val`)\n * obj.pop()\n * var param_3 = obj.top()\n * var param_4 = obj.getMin()\n */\n// @lc code=end\n\n"
},
{
"alpha_fraction": 0.4311079680919647,
"alphanum_fraction": 0.48366478085517883,
"avg_line_length": 17.55555534362793,
"blob_id": "376a973bd111ebf5952e8f65fdabed87124d1903",
"content_id": "87fe409dd6fba0d5c6a7ebba192c927491cfec29",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1414,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 72,
"path": "/leetcode-algorithms/007. Reverse Integer/7.reverse-integer.py",
"repo_name": "cnyy7/LeetCode_EY",
"src_encoding": "UTF-8",
"text": "#\r\n# @lc app=leetcode id=7 lang=python3\r\n#\r\n# [7] Reverse Integer\r\n#\r\n# https://leetcode.com/problems/reverse-integer/description/\r\n#\r\n# algorithms\r\n# Easy (25.17%)\r\n# Total Accepted: 651.5K\r\n# Total Submissions: 2.6M\r\n# Testcase Example: '123'\r\n#\r\n# Given a 32-bit signed integer, reverse digits of an integer.\r\n#\r\n# Example 1:\r\n#\r\n#\r\n# Input: 123\r\n# Output: 321\r\n#\r\n#\r\n# Example 2:\r\n#\r\n#\r\n# Input: -123\r\n# Output: -321\r\n#\r\n#\r\n# Example 3:\r\n#\r\n#\r\n# Input: 120\r\n# Output: 21\r\n#\r\n#\r\n# Note:\r\n# Assume we are dealing with an environment which could only store integers\r\n# within the 32-bit signed integer range: [−2^31, 2^31 − 1]. For the purpose\r\n# of this problem, assume that your function returns 0 when the reversed\r\n# integer overflows.\r\n#\r\n#\r\n\r\n\r\nclass Solution:\r\n def reverse(self, x: int) -> int:\r\n t = True\r\n INT_MAX = 2147483647\r\n INT_MIN = -INT_MAX - 1\r\n if x < 0:\r\n x = -x\r\n t = False\r\n n = 0\r\n if 0 <= x and x < 10:\r\n if t:\r\n return x\r\n else:\r\n return -x\r\n old = 0\r\n while x > 0:\r\n old = n\r\n n = x % 10+(n*10)\r\n if n > INT_MAX and t:\r\n return 0\r\n if -n < INT_MIN and not t:\r\n return 0\r\n x = x//10\r\n if t:\r\n return n\r\n else:\r\n return -n\r\n"
}
] | 158 |
xiaoshitou921/test
|
https://github.com/xiaoshitou921/test
|
159c6861057999e6bbf3b7a2156b49cbbb11acb5
|
bbc03a26489925c6fcc80f9eac66854d7fe9f5df
|
8874c77d3b365afffcb69dc79b5dcf417688b092
|
refs/heads/main
| 2023-04-03T18:38:58.305059 | 2021-04-12T07:56:31 | 2021-04-12T07:56:31 | 357,050,182 | 1 | 1 | null | 2021-04-12T03:52:49 | 2021-04-12T07:17:34 | 2021-04-12T07:18:14 |
CMake
|
[
{
"alpha_fraction": 0.7810026407241821,
"alphanum_fraction": 0.7810026407241821,
"avg_line_length": 36.900001525878906,
"blob_id": "f674a895f6522020c5e92f6641774fc2f60ea60c",
"content_id": "70dc8aa5f75f3da37e56a09a0fc4a5f85ec3af63",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 379,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 10,
"path": "/build/CTestTestfile.cmake",
"repo_name": "xiaoshitou921/test",
"src_encoding": "UTF-8",
"text": "# CMake generated Testfile for \n# Source directory: /home/tuo/Documents/catkin_ws/src\n# Build directory: /home/tuo/Documents/catkin_ws/build\n# \n# This file includes the relevant testing commands required for \n# testing this directory and lists subdirectories to be tested as well.\nsubdirs(\"gtest\")\nsubdirs(\"kinova_control\")\nsubdirs(\"kinova_gazebo\")\nsubdirs(\"kinova_description\")\n"
},
{
"alpha_fraction": 0.4675324559211731,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 10.142857551574707,
"blob_id": "fd5a2ecaf448f8149534a37ff2c5ad062843286c",
"content_id": "4c4e4e0a1081e96caf1599be1c8a4d85bffa7e3a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 77,
"license_type": "no_license",
"max_line_length": 17,
"num_lines": 7,
"path": "/test2.py",
"repo_name": "xiaoshitou921/test",
"src_encoding": "UTF-8",
"text": "print('test3333')\nprint('test3333')\nprint('test3333')\nprint('test3333')\n1\n2\n3"
}
] | 2 |
python-kurs/exercise-2-Marjo13
|
https://github.com/python-kurs/exercise-2-Marjo13
|
181459d58899794c1b3395e04b16d2f3da699bf4
|
051cdfc3bbbf7f36ce0929c6c351e14aa6ae5fe9
|
0e132459967b70eaf169ba9bcbfb4e38f309896b
|
refs/heads/master
| 2020-05-20T13:28:53.270272 | 2019-05-13T10:43:07 | 2019-05-13T10:43:07 | 185,598,397 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6736990213394165,
"alphanum_fraction": 0.697609007358551,
"avg_line_length": 36.421051025390625,
"blob_id": "78de796bade091ee81c6b8385318d28b85e79e8f",
"content_id": "d5d8ae665cbc382bc14011230413675235e9aa1b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1422,
"license_type": "no_license",
"max_line_length": 166,
"num_lines": 38,
"path": "/second_steps.py",
"repo_name": "python-kurs/exercise-2-Marjo13",
"src_encoding": "UTF-8",
"text": "# Exercise 2\n\n# Satellites:\nsat_database = {\"METEOSAT\" : 3000,\n \"LANDSAT\" : 30,\n \"MODIS\" : 500\n }\n\n\n# The dictionary above contains the names and spatial resolutions of some \n# satellite systems.\n\n# 1) Add the \"GOES\" and \"worldview\" satellites with their 2000/0.31m resolution\n# to the dictionary [2P]\nsat_database[\"GOES\"] = 2000\nsat_database[\"worldview\"] = 0.31\n\nprint(\"I have the following satellites in my database: \")\n\n# 2) print out all satellite names contained in the dictionary [2P]\nprint(sat_database.keys())\n\n# 3) Ask the user to enter the satellite name from which she/he would like to\n# know the resolution [2P]\nanswer = input(\"Please enter the name of the satellite you would like to know the resolution of: \")\n\n# 4) Check, if the satellite is in the database and inform the user, if it is\n# not [2P]\ncheck = answer in sat_database\nif check == False:\n print(\"Unfortunately the satellite name you have entered is either misspelled, fictitious or not availabe in our database. Sorry!\")\n\n# 5) If the satellite name is in the database, print a meaningful message\n# containing the satellite name and it's resolution [2P] \nfor key, val in sat_database.items():\n if answer == key:\n print(\"It is only with the heart that one can see rightly. What is essential is invisible to the satellit {} even with a resolution of {}m.\".format(key, val))\n break "
}
] | 1 |
zl326/FinanceProjection
|
https://github.com/zl326/FinanceProjection
|
53daa044ffa8299a0c70bea6f1e059984bba5912
|
85273dc39e3bd416398218d41e94add23a8a178f
|
1a53ec97b6c2ef9be81557701ba1104ce4059745
|
refs/heads/master
| 2020-06-04T16:59:31.506706 | 2019-06-16T01:36:34 | 2019-06-16T01:36:34 | 192,114,490 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7232558131217957,
"alphanum_fraction": 0.7441860437393188,
"avg_line_length": 29.785715103149414,
"blob_id": "ba48c0761153e5cfed024effa527c6e28be95193",
"content_id": "bfc6a179bd995f6ed98fe7fd865f4e620171cf50",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 430,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 14,
"path": "/Calc.py",
"repo_name": "zl326/FinanceProjection",
"src_encoding": "UTF-8",
"text": "# Contains mathematical functions\n\nimport math\n\n# Monthly payment calculator, similar to PMT function in Excel.\n# Takes annual interest rate as argument, not monthly rate\ndef PMT(presentValue, interestRate, nMonths):\n r = interestRate / 12\n payment = presentValue * r*(1+r)**nMonths / ((1+r)**nMonths - 1)\n return round(payment, 2)\n\n\ndef getMonthlyInterest(balance, interestRate):\n return round(balance * interestRate / 12, 2)"
},
{
"alpha_fraction": 0.5615465641021729,
"alphanum_fraction": 0.5846922397613525,
"avg_line_length": 26.14285659790039,
"blob_id": "f874c5b2a5ddd3cb2cc93d0b6279aff03015ad5a",
"content_id": "114c1c76221316a38b2c919c3ddbe97f44c61a5f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3802,
"license_type": "no_license",
"max_line_length": 158,
"num_lines": 140,
"path": "/main.py",
"repo_name": "zl326/FinanceProjection",
"src_encoding": "UTF-8",
"text": "# Script to simulate financial outgoings\n\n\n##################################################\n# IMPORTS\n##################################################\n\n# Custom modules\nimport Components\nimport Calc\nimport Results\n\n# Common Python modules\nimport pandas as pd\nimport math\n\n\n##################################################\n# USER INPUTS\n##################################################\n\n# Number of months to simulate\nsimulationLength = 100*12\n\n# Initialise settings dict\nsettings = {}\n\n# Income\nsettings['income'] = {\n 'salary': 31500,\n 'salariseRiseRate': 0.03\n}\n\n# Mortgage settings\nsettings['mortgage'] = {\n 'balance': 130195,\n 'interestRateFixed': 0.0212,\n 'termLength': 300,\n 'interestRateVariable': 0.0424,\n 'interestRateVariableIntroduction': 64\n}\n\n# Student Finance\nsettings['slc'] = {\n 'balance': 26104.72,\n 'repaymentThreshold': 25725,\n 'repaymentFraction': 0.09,\n 'interestRateSalaryLowerBound': 25725,\n 'interestRateSalaryUpperBound': 46305,\n 'interestRateAdditionLowerBound': 0,\n 'interestRateAdditionUpperBound': 0.03,\n 'RPI': 0.033\n}\n\n##################################################\n# Initialise\n##################################################\n\n# Mortgage\nmortgage = Components.Loan('Mortgage',\n settings['mortgage']['balance'],\n settings['mortgage']['interestRateFixed'],\n 1,\n settings['mortgage']['termLength'])\n\n# Student Loan\nsettings['slc']['interestRateSalaryRange'] = settings['slc']['interestRateSalaryUpperBound'] - settings['slc']['interestRateSalaryLowerBound']\nsettings['slc']['interestRateAdditionRange'] = settings['slc']['interestRateAdditionUpperBound'] - settings['slc']['interestRateAdditionLowerBound']\nslc = Components.Loan('Student Finance',\n settings['slc']['balance'],\n 0.033,\n 1,\n 30*12\n)\n\n##################################################\n# Main Solve\n##################################################\n\nfor nMonth in range(1, simulationLength+1):\n\n ##################################################\n # Initialise results storage\n result = Results.Result(nMonth)\n\n ##################################################\n # Mortgage\n if mortgage.termCurrent <= settings['mortgage']['termLength']:\n\n # Check if moving from fixed to variable rate\n if nMonth is settings['mortgage']['interestRateVariableIntroduction'] :\n mortgage.setInterestRate(settings['mortgage']['interestRateVariable'])\n\n # Calculate the interest to be added\n mortgage.calculateInterest()\n\n # Calculate the amount to repay this month\n mortgage.calculateRepayment()\n mortgage.capRepayment()\n\n # Perform the transactions\n mortgage.performTransactions()\n\n # Save the results\n result.saveMortgage(mortgage)\n\n # Update the mortgage term remaining\n mortgage.incrementTermCurrent()\n \n ##################################################\n # Student Finance\n if slc.termRemaining >= 0 and slc.balance > 0:\n\n # Calculate new interest rate\n salary = 31500\n salaryScale = (salary-settings['slc']['interestRateSalaryLowerBound']) / settings['slc']['interestRateSalaryRange']\n slc.setInterestRate(settings['slc']['RPI'] + settings['slc']['interestRateAdditionLowerBound'] + salaryScale*settings['slc']['interestRateAdditionRange'])\n\n # Set the repayment amount\n slc.setRepayment(settings['slc']['repaymentFraction'] * (salary-settings['slc']['repaymentThreshold']) / 12)\n slc.capRepayment()\n\n # Perform the transactions\n slc.performTransactions()\n\n # Update the mortgage term remaining\n slc.incrementTermCurrent()\n\n # Save the results\n result.saveSLC(slc)\n\n ##################################################\n # Collate results\n\n\n##################################################\n# Post Solve\n##################################################\n\nprint('Simulation Complete.')\n\n\n"
},
{
"alpha_fraction": 0.5654718279838562,
"alphanum_fraction": 0.5654718279838562,
"avg_line_length": 32.36585235595703,
"blob_id": "45577594a85578eb3028ddf499843c559355048a",
"content_id": "3fc57fdc3f1ade2528f1f3e8cd9922724fb5f185",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1367,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 41,
"path": "/Results.py",
"repo_name": "zl326/FinanceProjection",
"src_encoding": "UTF-8",
"text": "# Code to collate simulation results\n\nimport pandas as pd\nimport math\n\nclass Result:\n def __init__(self, index):\n self.index = index\n\n self.initialiseValues()\n\n def initialiseValues(self):\n nan = math.nan\n\n # Mortgage\n self.mortgage__balance = nan\n self.mortgage__interestRate = nan\n self.mortgage__interest = nan\n self.mortgage__termCurrent = nan\n self.mortgage__repayment = nan\n\n # Student Finance\n self.slc__balance = nan\n self.slc__interestRate = nan\n self.slc__interest = nan\n self.slc__termCurrent = nan\n self.slc__repayment = nan\n\n def saveMortgage(self, mortgage):\n self.mortgage__balance = mortgage.balance\n self.mortgage__interestRate = mortgage.interestRate\n self.mortgage__interest = mortgage.interest\n self.mortgage__termCurrent = mortgage.termCurrent\n self.mortgage__repayment = mortgage.repayment\n\n def saveSLC(self, slc):\n self.slc__balance = slc.balance\n self.slc__interestRate = slc.interestRate\n self.slc__interest = slc.interest\n self.slc__termCurrent = slc.termCurrent\n self.slc__repayment = slc.repayment"
},
{
"alpha_fraction": 0.727384626865387,
"alphanum_fraction": 0.7347692251205444,
"avg_line_length": 28.436363220214844,
"blob_id": "2237306bcec9c69b96ad617f3aa3b85975ee77e3",
"content_id": "06f305b6ec8b6c68a2ac544c7c62dd89b92210a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1625,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 55,
"path": "/Components.py",
"repo_name": "zl326/FinanceProjection",
"src_encoding": "UTF-8",
"text": "# Class definitions\n\nimport Calc\n\n# Any kind of capital repayment loan, \n# e.g. mortgage\n#\n# interest as a decimal\n# termLength in months\nclass Loan:\n def __init__(self, name, balance, interestRate, termCurrent, termRemaining):\n self.name = name\n self.balance = balance\n self.interestRate = interestRate\n self.termCurrent = termCurrent\n self.termRemaining = termRemaining-1\n\n self.repaymentVoluntary = 0\n self.repaymentPenalty = 0\n self.repaymentCumulative = 0\n self.interestCumulative = 0\n\n self.calculateRepayment()\n self.calculateInterest()\n\n def setBalance(self, newBalance):\n self.balance = newBalance\n\n def offsetBalance(self, deltaBalance):\n self.balance = round(self.balance + deltaBalance, 2)\n\n def calculateRepayment(self):\n self.repayment = Calc.PMT(self.balance, self.interestRate, self.termRemaining+1)\n\n def setRepayment(self, newRepayment):\n self.repayment = round(newRepayment, 2)\n\n def capRepayment(self):\n if self.balance + self.interest < self.repayment:\n self.setRepayment(self.balance + self.interest)\n\n def performTransactions(self):\n self.offsetBalance(self.interest - self.repayment)\n self.repaymentCumulative = round(self.repaymentCumulative + self.repayment, 2)\n self.interestCumulative = round(self.interestCumulative + self.interest, 2)\n\n def setInterestRate(self, newInterestRate):\n self.interestRate = newInterestRate\n\n def calculateInterest(self):\n self.interest = Calc.getMonthlyInterest(self.balance, self.interestRate)\n\n def incrementTermCurrent(self):\n self.termCurrent += 1\n self.termRemaining -= 1\n\n\n\n\n\n\n"
}
] | 4 |
pigmonchu/calendarioTkinter
|
https://github.com/pigmonchu/calendarioTkinter
|
d6a9f61ed80dee4be3d743729eb7573fb788d324
|
5e9574a059dc5836178d8bc2c5e9b48cd3c7f0a4
|
26a274f4587333483025a576987bb7041dc08c71
|
refs/heads/master
| 2020-11-26T09:21:50.673543 | 2019-12-19T10:25:41 | 2019-12-19T10:25:41 | 229,027,917 | 0 | 0 | null | 2019-12-19T10:10:39 | 2019-12-17T12:17:15 | 2019-12-17T12:17:13 | null |
[
{
"alpha_fraction": 0.5018970966339111,
"alphanum_fraction": 0.5115010738372803,
"avg_line_length": 32.82157516479492,
"blob_id": "8155f7cc87ee9313ef998788cb15b273f7d8c48b",
"content_id": "6ffce1a3470b43ac9e9827b18e143a94a4e7f5bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8469,
"license_type": "no_license",
"max_line_length": 161,
"num_lines": 241,
"path": "/Calendar.py",
"repo_name": "pigmonchu/calendarioTkinter",
"src_encoding": "UTF-8",
"text": "from tkinter import *\r\nfrom tkinter import ttk\r\nfrom datetime import datetime\r\nfrom datetime import date\r\nimport calendar\r\n\r\ndt = datetime.now()\r\n\r\nHEIGHTBTN = 50\r\nWIDTHBTN = 50\r\n\r\n#FRAMEWORK PARA LOS BOTONES.\r\n\r\nclass CalButton(ttk.Frame):\r\n def __init__(self, parent, text, command, wbtn=1, hbtn=1):\r\n ttk.Frame.__init__(self, parent, width=wbtn*WIDTHBTN, height=hbtn*HEIGHTBTN)\r\n\r\n self.pack_propagate(0)\r\n\r\n s = ttk.Style()\r\n s.theme_use('alt')\r\n s.configure('my.TButton', font=('Helvetica', '14', 'bold'))\r\n \r\n self.__btn = ttk.Button(self, text= text, command=command, style='my.TButton')\r\n self.__btn.pack(side=TOP, expand=True,fill=BOTH)\r\n\r\n# FRAMEWORK PARA LAS ETIQUETAS.\r\n\r\nclass Days(ttk.Frame): \r\n\r\n def __init__(self, parent, text, foreground, wlabel= 1 ,hlabel=1):\r\n ttk.Frame.__init__(self, parent, width=WIDTHBTN*wlabel, height=HEIGHTBTN*hlabel)\r\n\r\n self.pack_propagate(0) \r\n \r\n s = ttk.Style()\r\n s.theme_use('alt')\r\n s.configure('my.TLabel', font='Helvetica 8')\r\n\r\n self.__lbl = ttk.Label(self, text = text, style='my.TLabel', background='white', foreground= foreground, anchor = CENTER, borderwidth=2, relief=\"groove\")\r\n self.__lbl.pack(side=TOP, fill=BOTH, expand=True)\r\n\r\n \r\n# Clase donde creo todos los botones, etiquetas y métodos de funcionabilidad.\r\n \r\nclass Calendar(ttk.Frame):\r\n \r\n mesAnterior = None\r\n indiceMeses = 0\r\n indiceAños = 0\r\n listaMeses =['Enero',' Febrero', 'Marzo','Abril','Mayo','Junio','Julio', 'Agosto','Septiembre','Octubre', 'Noviembre','Diciembre']\r\n diasSemana = ['Lunes','Martes','Miercoles','Jueves', 'Viernes', 'Sabado', 'Domingo']\r\n __dates = []\r\n \r\n\r\n def __init__(self, parent):\r\n ttk.Frame.__init__(self, parent)\r\n \r\n # CREACIÓN DE LA PRIMERA LÍNEA DEL CALENDARIO. BOTONES + ETIQUETA QUE INDICA EL MES & AÑO\r\n\r\n self.btn_inicio = CalButton(self, text = '«', command = lambda: self.backFull('«'), hbtn=0.5)\r\n self.btn_inicio.grid(column = 0, row = 0)\r\n \r\n self.btn_volver = CalButton(self, text = '<', command = lambda: self.back('<'), hbtn=0.5)\r\n self.btn_volver.grid(column=1 ,row=0)\r\n\r\n self.lbl_mes = Days(self, text = str(self.listaMeses[dt.month-1]) + str(' ') + str(dt.year),wlabel= 3, hlabel= 0.5, foreground= 'black')\r\n self.lbl_mes.grid(column = 2 , row = 0, columnspan = 3)\r\n\r\n self.btn_moveOn = CalButton(self, text = '>', command = lambda: self.moveOn('>'), hbtn=0.5)\r\n self.btn_moveOn.grid(column = 5, row = 0)\r\n\r\n self.btn_final = CalButton(self, text = '»', command = lambda: self.moveOnFull('»'), hbtn=0.5)\r\n self.btn_final.grid(column=6, row=0)\r\n\r\n\r\n # Creación de los nombres de cada día. Son etiquetas fijas que no varían su texto. Lunes/Martes/X/Jueves/Viernes ...etc\r\n \r\n column = 0\r\n row = 1\r\n for i in self.diasSemana: \r\n \r\n self.lbl_i = Days(self, text = i, hlabel= 0.5, foreground='black')\r\n self.lbl_i.grid(column = column, row = row)\r\n \r\n column += 1\r\n \r\n #Creación inicial del los días del mes actual. INICIO\r\n\r\n month = dt.month\r\n year = dt.year\r\n self.createDays(month, year) # RMR: Reutilizo el código duplicado.\r\n\r\n def createDays(self,month,year):\r\n '''\r\n Crea instancias de Days para cada dia y las posiciona adecuadamente.\r\n Guarda referencias para destruirlas en el cambio de mes\r\n ''' \r\n self.deleteDays()\r\n column = date(year, month , 1).weekday()\r\n row = 2\r\n dia = calendar.monthrange(year,month)\r\n\r\n\r\n for i in range(1, dia[1]+1):\r\n\r\n if column == 5 or column == 6:\r\n self.lbl_i = Days(self, text = i, foreground = 'red')\r\n else:\r\n self.lbl_i = Days(self, text = i, foreground='black')\r\n self.lbl_i.grid(column = column, row = row)\r\n self.__dates.append(self.lbl_i)\r\n\r\n column += 1\r\n if column == 7:\r\n column = 0\r\n row += 1\r\n\r\n # Método para borrar los días y escribir los del nuevo mes.\r\n \r\n def deleteDays(self):\r\n\r\n for day in self.__dates:\r\n day.grid_forget()\r\n day.update()\r\n day.destroy()\r\n \r\n self.__dates = []\r\n\r\n # Método para ir al primer mes del año, es decir, a Enero.\r\n\r\n def backFull (self, simbolo):\r\n\r\n if simbolo == '«':\r\n \r\n self.indiceMeses = -(dt.month) \r\n month = dt.month + self.indiceMeses\r\n year = dt.year + self.indiceAños\r\n print(month)\r\n print(self.listaMeses[month]) \r\n print(year)\r\n self.muestraMes(str(self.listaMeses[month]) + str(' ') + str(year))\r\n month = month + 1\r\n self.createDays(month, year)\r\n \r\n return month\r\n\r\n # Método para ir al mes anterior.\r\n\r\n def back(self, simbolo):\r\n\r\n if simbolo == '<':\r\n month = dt.month + self.indiceMeses \r\n\r\n if month == 0 :\r\n self.indiceMeses = 12 - dt.month\r\n self.indiceAños -= 1\r\n month = dt.month + self.indiceMeses \r\n year = dt.year + self.indiceAños\r\n print(month)\r\n print(self.listaMeses[month-1]) \r\n print(year)\r\n self.indiceMeses -= 1\r\n self.muestraMes(str(self.listaMeses[month-1]) + str(' ') + str(year))\r\n self.createDays(month, year)\r\n\r\n \r\n else: \r\n\r\n self.indiceMeses -= 1\r\n month = dt.month + self.indiceMeses\r\n year = dt.year + self.indiceAños\r\n print(month)\r\n print(self.listaMeses[month])\r\n print(year)\r\n self.muestraMes(str(self.listaMeses[month]) + str(' ') + str(year))\r\n month = month + 1\r\n self.createDays(month, year)\r\n \r\n return month\r\n\r\n # Método para ir al último mes del año, es decir, Diciembre.\r\n\r\n def moveOnFull(self,simbolo):\r\n\r\n if simbolo == '»':\r\n \r\n self.indiceMeses = 12 - dt.month\r\n month = dt.month + self.indiceMeses\r\n year = dt.year + self.indiceAños\r\n print(month)\r\n print(self.listaMeses[month-1])\r\n print(year)\r\n self.muestraMes(str(self.listaMeses[month-1]) + str(' ') + str(year))\r\n month = month\r\n self.createDays(month, year)\r\n \r\n return month\r\n \r\n # Método para ir al siguiente mes.\r\n\r\n def moveOn(self, simbolo):\r\n \r\n if simbolo == '>': \r\n \r\n month = dt.month + self.indiceMeses - 1\r\n\r\n if month == len(self.listaMeses) - 1 :\r\n self.indiceMeses = -(dt.month) \r\n self.indiceAños += 1\r\n month = dt.month + self.indiceMeses\r\n year = dt.year + self.indiceAños\r\n print(month)\r\n print(self.listaMeses[month]) \r\n print(year)\r\n self.muestraMes(str(self.listaMeses[month]) + str(' ') + str(year))\r\n month = month + 1\r\n self.createDays(month, year)\r\n \r\n \r\n else: \r\n\r\n self.indiceMeses += 1\r\n month = dt.month + self.indiceMeses \r\n year = dt.year + self.indiceAños \r\n print(month)\r\n print(self.listaMeses[month])\r\n print(year)\r\n self.muestraMes(str(self.listaMeses[month]) + str(' ') + str(year))\r\n month = month + 1\r\n self.createDays(month, year)\r\n \r\n return month\r\n\r\n # Método para eliminar el mes anterior y que aparezca en pantalla el nuevo mes seleccionado.\r\n\r\n def muestraMes(self, cadena):\r\n\r\n self.lbl_mes.forget()\r\n self.lbl_mes = Days(self, text = str(cadena),wlabel= 3, hlabel= 0.5, foreground = 'black')\r\n self.lbl_mes.grid(column = 2 , row = 0, columnspan = 3)\r\n\r\n\r\n\r\n \r\n\r\n \r\n\r\n "
}
] | 1 |
isaacmg/dl_java_stream
|
https://github.com/isaacmg/dl_java_stream
|
27b9dcb7997ef09d082fc9e82b23a43fd7f77813
|
aa156f0422643137b5dd56e7b1e2e29e0d7dc623
|
a847152a149d18e84262cf5ced846b92b902fd7a
|
refs/heads/master
| 2020-04-06T20:26:14.467317 | 2019-05-17T23:37:03 | 2019-05-17T23:37:03 | 157,772,339 | 8 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7193548679351807,
"alphanum_fraction": 0.7193548679351807,
"avg_line_length": 24.83333396911621,
"blob_id": "69ff2516dfa0b0d081d56b12605978be7cdfc853",
"content_id": "367f99408e0ccbaa0db4b3eff99b92afc6b54700",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 310,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 12,
"path": "/src/python/flair_ner.py",
"repo_name": "isaacmg/dl_java_stream",
"src_encoding": "UTF-8",
"text": "\"\"\"\nModel class used for inference\n\"\"\"\nfrom flair.data import Sentence\nfrom flair.models import SequenceTagger\n# make a sentence\ndef get_ner(text):\n sentence = Sentence(text)\n # load the NER tagger\n tagger = SequenceTagger.load('ner')\n tagger.predict(sentence)\n return sentence.get_spans('ner')\n"
},
{
"alpha_fraction": 0.6978922486305237,
"alphanum_fraction": 0.7025761008262634,
"avg_line_length": 24.878787994384766,
"blob_id": "b38741227185e3468d6bd49127acf7a91263c2ec",
"content_id": "4766ba9ca11fca5bd8dc77d9afe76157bdf99b49",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 854,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 33,
"path": "/src/main/java/TweetData.java",
"repo_name": "isaacmg/dl_java_stream",
"src_encoding": "UTF-8",
"text": "import org.apache.flink.api.java.tuple.Tuple2;\nimport org.apache.flink.api.java.tuple.Tuple3;\nimport org.apache.flink.api.java.tuple.Tuple4;\nimport java.util.List;\n\nimport java.util.ArrayList;\n\npublic class TweetData {\n public String tweetText;\n public String language;\n public String user;\n public String tweetDateTime;\n public ArrayList<Tuple2<String, String>> entsLabels;\n public ArrayList<String> urls;\n // Tuple in the format T\n public String sentiment;\n public boolean properHashtag;\n\n\n\n TweetData(String tweetText, String lang, String user, boolean tweetGood, int retweetCount, int favoriteCount,\n int replyCount, String dateString){\n this.tweetText = tweetText;\n language = lang;\n this.user = user;\n properHashtag = tweetGood;\n tweetDateTime = dateString;\n\n\n\n\n }\n}\n"
},
{
"alpha_fraction": 0.7708185315132141,
"alphanum_fraction": 0.7943060398101807,
"avg_line_length": 69.25,
"blob_id": "f2cf26f24cec54a5a693c3d25b54ed37bec469e6",
"content_id": "9157b73ebcfeb835ff6220ac1a684a3c3618ff87",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1405,
"license_type": "no_license",
"max_line_length": 381,
"num_lines": 20,
"path": "/readme.md",
"repo_name": "isaacmg/dl_java_stream",
"src_encoding": "UTF-8",
"text": "# Flink Meets ONNX\n\nA practical example of how to use ONNX in a realtime streaming Flink application using Java Embedded Python (JEP) and comparing its performance with AsyncIO calling an external auto-scaling microservice running on Amazon ECS. \n\n[]( https://g.codefresh.io/pipelines/dl_java_stream/builds?repoOwner=isaacmg&repoName=dl_java_stream&serviceName=isaacmg%2Fdl_java_stream&filter=trigger:build~Build;branch:master;pipeline:5bf5d62e072d52e89e661b64~dl_java_stream)\n\n\n## Background \nFlink has historically not worked well with Python. Although plans are in the works for a broader PythonAPI currently there is no way to use ONNX or plain PyTorch models inside Flink. This is a problem as a lot of the state of the art models are increasingly being written in PyTorch. \n\n## Experiments \nWe aim to compare performance of three seperate scenarios. \n\n1. Using an external Flask/Docker based microservice on ECS with AsyncIO.\n2. With Java Embedded Python (JEP) to embed model directly in map.\n3. (If possible) Use Lantern a new Scala library that provides a backend. \n\n## Setup\n\nWeights are the standard ones from AllenNLP. For SRL they can be download from [here](https://s3-us-west-2.amazonaws.com/allennlp/models/srl-model-2018.05.25.tar.gz )\n"
},
{
"alpha_fraction": 0.6980146169662476,
"alphanum_fraction": 0.7115987539291382,
"avg_line_length": 44.57143020629883,
"blob_id": "09c47c0e839825b8b2b27e1720ab6c931162bba3",
"content_id": "fa1fa27d1ec7861e0e8c14e3ddf12c3542453118",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 957,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 21,
"path": "/src/main/java/TwitterTableMap.java",
"repo_name": "isaacmg/dl_java_stream",
"src_encoding": "UTF-8",
"text": "import org.apache.flink.api.common.functions.FlatMapFunction;\nimport org.apache.flink.api.common.functions.RichFlatMapFunction;\nimport org.apache.flink.api.common.functions.RichMapFunction;\nimport org.apache.flink.api.java.tuple.Tuple2;\nimport org.apache.flink.api.java.tuple.Tuple3;\nimport org.apache.flink.util.Collector;\n\npublic class TwitterTableMap implements FlatMapFunction<TweetData, Tuple3<String, String, Integer >> {\n @Override\n public void flatMap(TweetData tweetData, Collector<Tuple3<String, String, Integer>> out) throws Exception {\n System.out.println(tweetData.tweetText);\n Tuple3<String, String, Integer> fullTup = new Tuple3<>(tweetData.tweetText, \"s\", 1);\n\n out.collect(fullTup);\n int i = 0;\n //for (Tuple2<String, String> tup: tweetData.entsLabels){\n //Tuple3<String, String, String> fullTup = new Tuple3<>(tup.f0, tup.f1, tweetData.sentiment);\n //i++;\n //}\n }\n}\n"
},
{
"alpha_fraction": 0.6911764740943909,
"alphanum_fraction": 0.6977124214172363,
"avg_line_length": 28.190475463867188,
"blob_id": "7537efdeca3a376d87b6712e5b21ff6a315828b8",
"content_id": "67e9452f0453e37cb594adb7d88252daa57fb140",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 612,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 21,
"path": "/src/python/new_pred.py",
"repo_name": "isaacmg/dl_java_stream",
"src_encoding": "UTF-8",
"text": "\"\"\"\nModel class used for inference\n\"\"\"\nimport allennlp\nimport os\nfrom allennlp.predictors.predictor import Predictor\nfrom allennlp.models.archival import Archive, load_archive\nimport logging \nclass NewTest():\n def __init__(self):\n archive = load_archive(\"src/python/models/model2.tar.gz\")\n logging.log(30, \"archive loaded\")\n self.predictor = Predictor.from_archive(archive)\n \n def run(self, text):\n return self.predictor.predict(sentence=text)\n#print(os.path.exists(\"__pycache__\"))\n#load_archive(\"models/model2.tar.gz\")\ns = NewTest() \ndef class_test():\n return \"test data\""
},
{
"alpha_fraction": 0.6412325501441956,
"alphanum_fraction": 0.6568843126296997,
"avg_line_length": 34.8684196472168,
"blob_id": "580b0fa56a1cec26a1dd9ad617b599c2933520f1",
"content_id": "aa42287d70030b5a82f84de6e3ea57a03abc4ca2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 4089,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 114,
"path": "/light_weight/Dockerfile",
"repo_name": "isaacmg/dl_java_stream",
"src_encoding": "UTF-8",
"text": "FROM openjdk:11.0.1-jdk\nENV LANG=C.UTF-8 LC_ALL=C.UTF-8\nENV PATH /opt/conda/bin:$PATH\n\nRUN apt-get update --fix-missing && apt-get install -y wget bzip2 ca-certificates \\\n libglib2.0-0 libxext6 libsm6 libxrender1 \\\n git mercurial subversion &&\\\n rm -rf /var/lib/apt/lists/*\n\nRUN apt-get update && \\\n apt-get -y install gcc mono-mcs && \\\n rm -rf /var/lib/apt/lists/*\n\n# Install anaconda \nRUN wget --quiet https://repo.anaconda.com/miniconda/Miniconda2-4.5.11-Linux-x86_64.sh -O ~/miniconda.sh && \\\n /bin/bash ~/miniconda.sh -b -p /opt/conda && \\\n rm ~/miniconda.sh && \\\n ln -s /opt/conda/etc/profile.d/conda.sh /etc/profile.d/conda.sh && \\\n echo \". /opt/conda/etc/profile.d/conda.sh\" >> ~/.bashrc && \\\n echo \"conda activate base\" >> ~/.bashrc\n\nRUN apt-get install -y curl grep sed dpkg && \\\n TINI_VERSION=`curl https://github.com/krallin/tini/releases/latest | grep -o \"/v.*\\\"\" | sed 's:^..\\(.*\\).$:\\1:'` && \\\n curl -L \"https://github.com/krallin/tini/releases/download/v${TINI_VERSION}/tini_${TINI_VERSION}.deb\" > tini.deb && \\\n dpkg -i tini.deb && \\\n rm tini.deb && \\\n apt-get clean\n\n# CMAKE needed for ONNX\nRUN apt-get update -y && \\\n\tapt-get install -y cmake \nRUN apt-get install build-essential libssl-dev libffi-dev python3-dev -y\nRUN conda create -q -n jep_env python=3.7.1\nRUN /bin/bash -c \"source activate jep_env\"\nENV PATH /opt/conda/envs/jep_env/bin:$PATH\nENV PYTHONHOME /opt/conda/envs/jep_env\nRUN pip install --upgrade pip && \\ \n\tpip install --quiet jep && \\\n\tpip install --quiet model_agnostic && \\\n\tpip show jep | grep Location && \\\n\tpip install allennlp\n\n# RUN cp /opt/conda/envs/jep_env/lib/python3.7/site-packages/jep/libjep.so /lib\n# RUN conda install pytorch-nightly-cpu -c pytorch\n# RUN conda install -c conda-forge onnx \n\n\n# Flink setup\nRUN set -ex; \\\n apt-get -y install libsnappy1v5; \\\n rm -rf /var/lib/apt/lists/*\n\nRUN apt-get install -y git\n #Grab gosu for easy step-down from root\nENV GOSU_VERSION 1.7\n\nRUN set -ex; \\\n wget -nv -O /usr/local/bin/gosu \"https://github.com/tianon/gosu/releases/download/$GOSU_VERSION/gosu-$(dpkg --print-architecture)\"; \\\n wget -nv -O /usr/local/bin/gosu.asc \"https://github.com/tianon/gosu/releases/download/$GOSU_VERSION/gosu-$(dpkg --print-architecture).asc\"; \\\n export GNUPGHOME=\"$(mktemp -d)\"; \\\n for server in $(shuf -e ha.pool.sks-keyservers.net \\\n hkp://p80.pool.sks-keyservers.net:80 \\\n keyserver.ubuntu.com \\\n hkp://keyserver.ubuntu.com:80 \\\n pgp.mit.edu) ; do \\\n gpg --keyserver \"$server\" --recv-keys B42F6819007F00F88E364FD4036A9C25BF357DD4 && break || : ; \\\n done && \\\n gpg --batch --verify /usr/local/bin/gosu.asc /usr/local/bin/gosu; \\\n gpgconf --kill all; \\\n rm -rf \"$GNUPGHOME\" /usr/local/bin/gosu.asc; \\\n chmod +x /usr/local/bin/gosu; \\\n gosu nobody true\n\n\n# Configure Flink version\nENV FLINK_VERSION=1.6.2 \\\n HADOOP_SCALA_VARIANT=hadoop28-scala_2.11\n\n# Prepare environment\nENV FLINK_HOME=/opt/flink\nENV PATH=$FLINK_HOME/bin:$PATH\nRUN groupadd --system --gid=9999 flink && \\\n useradd --system --home-dir $FLINK_HOME --uid=9999 --gid=flink flink\nWORKDIR $FLINK_HOME\n\nENV FLINK_URL_FILE_PATH=flink/flink-${FLINK_VERSION}/flink-${FLINK_VERSION}-bin-${HADOOP_SCALA_VARIANT}.tgz\n# Not all mirrors have the .asc files\nENV FLINK_TGZ_URL=https://www.apache.org/dyn/closer.cgi?action=download&filename=${FLINK_URL_FILE_PATH} \\\n FLINK_ASC_URL=https://www.apache.org/dist/${FLINK_URL_FILE_PATH}.asc\n\n# For GPG verification instead of relying on key servers\nCOPY KEYS /KEYS\n\n# Install Flink\nRUN set -ex; \\\n wget -nv -O flink.tgz \"$FLINK_TGZ_URL\"; \\\n wget -nv -O flink.tgz.asc \"$FLINK_ASC_URL\"; \\\n \\\n export GNUPGHOME=\"$(mktemp -d)\"; \\\n gpg --import /KEYS; \\\n gpg --batch --verify flink.tgz.asc flink.tgz; \\\n gpgconf --kill all; \\\n rm -rf \"$GNUPGHOME\" flink.tgz.asc; \\\n \\\n tar -xf flink.tgz --strip-components=1; \\\n rm flink.tgz; \\\n \\\n chown -R flink:flink .;\n\n# Configure container\nCOPY docker-entrypoint.sh /\nENTRYPOINT [\"/docker-entrypoint.sh\"]\nEXPOSE 6123 8081\nCMD [\"help\"]\n"
},
{
"alpha_fraction": 0.8035714030265808,
"alphanum_fraction": 0.8125,
"avg_line_length": 36.33333206176758,
"blob_id": "4e3dbe0ea51738d76f0aa6d99940c72b8e4c703b",
"content_id": "7e95967c07d064bab4c47b7f53a6b0176d2119e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 224,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 6,
"path": "/micro_service/Dockerfile",
"repo_name": "isaacmg/dl_java_stream",
"src_encoding": "UTF-8",
"text": "FROM tiangolo/uwsgi-nginx-flask:python3.7\nRUN pip install allennlp\nRUN git clone http://github.com/isaacmg/ml_serving_flask\nENV UWSGI_INI /ml_serving_flask/uwsgi.ini\nWORKDIR ml_serving_flask\nENV PYTHONPATH=/ml_serving_flask\n"
},
{
"alpha_fraction": 0.6812652349472046,
"alphanum_fraction": 0.7153284549713135,
"avg_line_length": 36.45454406738281,
"blob_id": "2146b824a9bd94d78b3ed123a3bd73b3a6a039ec",
"content_id": "f191ad7558c118188d0b8e719977c488d59cd7be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 411,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 11,
"path": "/src/python/simple_onnx.py",
"repo_name": "isaacmg/dl_java_stream",
"src_encoding": "UTF-8",
"text": "import onnx\nimport caffe2.python.onnx.backend\n# Prepare the inputs, here we use numpy to generate some random inputs for demo purpose\nimport numpy as np\ndef run_shit():\n img = np.random.randn(1, 3, 224, 224).astype(np.float32)\n # Load the ONNX model\n model = onnx.load('squeezenet.onnx')\n # Run the ONNX model with Caffe2\n outputs = caffe2.python.onnx.backend.run_model(model, [img])\n return 1"
},
{
"alpha_fraction": 0.7339003682136536,
"alphanum_fraction": 0.7377885580062866,
"avg_line_length": 50.412498474121094,
"blob_id": "9318798fe3c5711c71c988846dafa447faf13c8b",
"content_id": "1776031ed241391e3775c6f49c11b7c4b835e912",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 4115,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 80,
"path": "/src/main/java/twitterCEP.java",
"repo_name": "isaacmg/dl_java_stream",
"src_encoding": "UTF-8",
"text": "import jep.Jep;\nimport jep.JepConfig;\nimport org.apache.flink.api.common.functions.FilterFunction;\nimport org.apache.flink.api.common.functions.FlatMapFunction;\nimport org.apache.flink.api.common.functions.MapFunction;\nimport org.apache.flink.api.common.typeinfo.TypeInformation;\nimport org.apache.flink.api.common.typeinfo.Types;\nimport org.apache.flink.api.java.tuple.Tuple2;\nimport org.apache.flink.api.java.tuple.Tuple3;\nimport org.apache.flink.api.java.tuple.Tuple4;\nimport org.apache.flink.api.java.utils.ParameterTool;\nimport org.apache.flink.core.fs.FileSystem;\nimport org.apache.flink.streaming.api.datastream.AsyncDataStream;\nimport org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;\nimport org.apache.flink.streaming.api.datastream.DataStream;\nimport org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;\nimport org.apache.flink.streaming.api.windowing.time.Time;\nimport org.apache.flink.streaming.connectors.twitter.TwitterSource;\n\nimport org.apache.flink.table.api.Table;\nimport org.apache.flink.table.api.Tumble;\nimport org.apache.flink.table.api.java.StreamTableEnvironment;\nimport org.apache.flink.table.sinks.CsvTableSink;\nimport org.apache.flink.table.sinks.TableSink;\n\nimport java.io.File;\nimport java.io.IOException;\nimport java.nio.file.Files;\nimport java.nio.file.StandardCopyOption;\nimport java.util.concurrent.TimeUnit;\n\n\npublic class twitterCEP {\n public static void main(String args[]) throws IOException, Exception {\n //ClassLoader classloader = Thread.currentThread().getContextClassLoader();\n //File configOnDisk = new File(\"myFile.properties\");\n //Files.copy(classloader.getResourceAsStream(\"myFile.properties\"), configOnDisk.toPath(), StandardCopyOption.REPLACE_EXISTING);\n\n\n final ParameterTool params = ParameterTool.fromPropertiesFile(\"myFile.properties\");\n TwitterSource twitterConnect = new TwitterSource(params.getProperties());\n StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();\n DataStream<String> twitterStream = env.addSource(twitterConnect);\n DataStream<TweetData> sentimentStream= twitterStream\n .map(new BasicTweet()).filter(new FilterFunction<TweetData>() {\n @Override\n public boolean filter(TweetData tweetData) throws Exception {\n return tweetData.language.equals(\"en\") && tweetData.properHashtag;\n }\n });\n DataStream<TweetData> tweetStream = twitterStream.map(new BasicTweet());\n //tweetStream = AsyncDataStream.unorderedWait( tweetStream, new dockerAsync(), 1000, TimeUnit.MILLISECONDS, 100);\n DataStream<Tuple4<String, String, String, Integer>> secondTweet = sentimentStream.map(new tweetTupleMap());\n sentimentStream.print();\n secondTweet.timeWindowAll(Time.seconds(20)).sum(3);\n StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);\n secondTweet.print();\n Table table = tableEnv.fromDataStream(secondTweet, \"Elements, Sentiment, Time, Number\");\n TableSink sink = new CsvTableSink(\"new\", \"|\");\n String[] fieldNames = {\"a\", \"b\", \"c\", \"d\"};\n TypeInformation[] fieldTypes = {Types.STRING, Types.STRING, Types.STRING, Types.INT};\n tableEnv.registerTableSink(\"CsvSinkTable\", fieldNames, fieldTypes, sink);\n table.insertInto(\"CsvSinkTable\");\n\n // res = Implement mapFunction -> Tuple3<String, List<String>, String> timeStamp as String, entities, sentiment\n // res.keyby(0).window(\n //flatMap tweetStream -> Tuple<String, String, String> timeStamp\n\n //tweetStream.print();\n // sentimentStream.writeAsCsv(\"file.csv\");\n\n //StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);\n //Table table = tableEnv.fromDataStream(sentimentStream, \"rawText, sentiment, timeStamp\");\n\n //tableEnv.sqlQuery(\"SELECT * FROM \");\n //tableEnv.registerDataStream(\"sentimentTable\", sentimentStream, \"rawText, sentiment, timeStamp\");\n //tableEnv.\n env.execute(\"Flair Filter\");\n }\n}\n\n\n"
}
] | 9 |
nikhiljakks/HackerRank
|
https://github.com/nikhiljakks/HackerRank
|
f2a421cddf2d7b565bf431ad6c74619ef1ad125c
|
50127f1499ef4cdf45562a9bdad56955e317d4ba
|
139bcb062151c2d463512c91718f35ba064591af
|
refs/heads/master
| 2021-01-11T18:11:47.085563 | 2017-01-20T01:26:39 | 2017-01-20T01:26:39 | 79,512,166 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4442307651042938,
"alphanum_fraction": 0.4692307710647583,
"avg_line_length": 20.69565200805664,
"blob_id": "4d62dd6e64258f4ad19584919d21adb5ae9d5b91",
"content_id": "4e2a4f553a1c2e9c6e2c77e9efb9745f38c2fe86",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 520,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 23,
"path": "/sorting.py",
"repo_name": "nikhiljakks/HackerRank",
"src_encoding": "UTF-8",
"text": "#!/bin/python\r\n\r\nimport sys\r\n\r\n\r\nn = int(raw_input().strip())\r\na = map(int,raw_input().strip().split(' '))\r\nswapCount = 0\r\nfor i in xrange(0, n-1):\r\n isswap = 0\r\n for j in xrange(1,n-i):\r\n if (a[j] < a[j-1]):\r\n isswap = 1\r\n swapCount += 1\r\n temp = a[j-1]\r\n a[j-1] = a[j]\r\n a[j] = temp\r\n if (isswap == 0):\r\n break\r\n\r\nprint \"Array is sorted in %s swaps.\" %str(swapCount)\r\nprint \"First Element:\", str(a[0])\r\nprint \"Last Element:\", str(a[-1])"
},
{
"alpha_fraction": 0.4215686321258545,
"alphanum_fraction": 0.45588234066963196,
"avg_line_length": 16.363636016845703,
"blob_id": "8b9f16dd5194cc4182085bc71ac95d3c576261db",
"content_id": "0b108815ae2f4255defa1232211f3ab3e21e4826",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 408,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 22,
"path": "/minus.py",
"repo_name": "nikhiljakks/HackerRank",
"src_encoding": "UTF-8",
"text": "#!/bin/python\r\n\r\nimport sys\r\n\r\n\r\nn = int(raw_input().strip())\r\narr = map(int,raw_input().strip().split(' '))\r\npos = 0.0\r\nneg = 0.0\r\nzeros = 0.0 \r\n\r\nfor i in xrange(n):\r\n if (arr[i] > 0):\r\n pos += 1\r\n elif (arr[i] < 0):\r\n neg += 1\r\n else:\r\n zeros += 1\r\n\r\nprint ('%.6f' %(float(pos / len(arr))))\r\nprint ('%.6f' %( neg / len(arr)))\r\nprint ('%.6f' %( float(zeros) / len(arr)))\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5403726696968079,
"alphanum_fraction": 0.54347825050354,
"avg_line_length": 24.83333396911621,
"blob_id": "b29b57c8eb8523e0f2f3682c08915c2b8944cdc3",
"content_id": "86112249a4dbd250bd2ff6e19cddc9015235c534",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 322,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 12,
"path": "/Left Rotation.py",
"repo_name": "nikhiljakks/HackerRank",
"src_encoding": "UTF-8",
"text": "def array_left_rotation(a, n, k):\r\n b= []\r\n for i in xrange(0, n) :\r\n rIndex = (i+k)%(n)\r\n #b[i] = a[rIndex]\r\n b.append(a[rIndex])\r\n return b\r\n\r\nn, k = map(int, raw_input().strip().split(' '))\r\na = map(int, raw_input().strip().split(' '))\r\nanswer = array_left_rotation(a, n, k);\r\nprint ' '.join(map(str,answer))\r\n"
},
{
"alpha_fraction": 0.5699300765991211,
"alphanum_fraction": 0.5891608595848083,
"avg_line_length": 29.66666603088379,
"blob_id": "0ab1dc1e05b1bf49d5aa1ff88678d8b70e57c8b7",
"content_id": "7fab9ea6e4d3adc7121f34934c6b45a3bf708baf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 572,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 18,
"path": "/Find the Running Median.py",
"repo_name": "nikhiljakks/HackerRank",
"src_encoding": "UTF-8",
"text": "# Enter your code here. Read input from STDIN. Print output to STDOUT\r\nimport bisect\r\ncount = int(raw_input())\r\nordLst = []\r\nordLstMed = 0\r\ndef getMedian(ordLst):\r\n if (len(ordLst)%2 == 0 ):\r\n return (ordLst[len(ordLst)/2] + ordLst[(len(ordLst)/2) - 1])/2.0\r\n else:\r\n return ordLst[int(len(ordLst)/2)]\r\nfor i in xrange(count):\r\n if (len(ordLst) == 0 ):\r\n ordLst.append(int(raw_input()))\r\n ordLstMed = ordLst[0]\r\n else:\r\n newVal = int(raw_input())\r\n bisect.insort_right(ordLst, newVal )\r\n print getMedian(ordLst)\r\n\r\n"
},
{
"alpha_fraction": 0.48794490098953247,
"alphanum_fraction": 0.49368542432785034,
"avg_line_length": 29.10714340209961,
"blob_id": "3692c45bc7e74ea610d16e0c16fcfd95366c17ee",
"content_id": "77b702f31e5ec32d3ac538655c2054dc940f3bdc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 871,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 28,
"path": "/Making Anagrams.py",
"repo_name": "nikhiljakks/HackerRank",
"src_encoding": "UTF-8",
"text": "def number_needed(a, b):\r\n totCount = 0\r\n bLoop = \"\".join(set(b))\r\n aLoop = \"\".join(set(a))\r\n for bchar in bLoop:\r\n delCount = 0\r\n if a.count(bchar) == 0:\r\n delCount = b.count(bchar)\r\n totCount += delCount\r\n elif a.count(bchar) != b.count(bchar):\r\n delCount = abs(a.count(bchar) - b.count(bchar))\r\n totCount += delCount\r\n for achar in aLoop:\r\n delCount = 0\r\n if achar not in bLoop:\r\n if b.count(achar) == 0:\r\n delCount = a.count(achar)\r\n totCount += delCount\r\n elif a.count(achar) != b.count(achar):\r\n delCount = abs(a.count(achar) - b.count(achar))\r\n totCount += delCount\r\n return totCount \r\n #pass\r\n\r\na = raw_input().strip()\r\nb = raw_input().strip()\r\n\r\nprint number_needed(a, b)\r\n"
},
{
"alpha_fraction": 0.5820895433425903,
"alphanum_fraction": 0.6328358054161072,
"avg_line_length": 29.285715103149414,
"blob_id": "bdd9745fb6ff3c581d0776a1a09e3d2759e72146",
"content_id": "69f54f35971d58277779b298725c832001daa085",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 670,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 21,
"path": "/Quartiles.py",
"repo_name": "nikhiljakks/HackerRank",
"src_encoding": "UTF-8",
"text": "# Enter your code here. Read input from STDIN. Print output to STDOUT\r\nimport statistics\r\nimport math\r\ncount = input()\r\nlist1 = list( map (int, (input()).split(\" \")))\r\nlist1.sort()\r\nmedian2 = statistics.median(list1)\r\n\r\nif (len(list1)%2 == 0):\r\n list2 = list1[:(int (len(list1)/2))]\r\n list3 = list1[(int (len(list1)/2)) :]\r\n median1 = statistics.median(list2)\r\n median3 = statistics.median(list3)\r\nelse:\r\n list2 = list1[:math.floor(len(list1)/2)]\r\n list3 = list1[math.ceil(len(list1)/2):]\r\n median1 = statistics.median(list2)\r\n median3 = statistics.median(list3)\r\nprint (int (median1))\r\nprint (int (median2))\r\nprint (int (median3)) \r\n"
},
{
"alpha_fraction": 0.5100864768028259,
"alphanum_fraction": 0.5139288902282715,
"avg_line_length": 23.774999618530273,
"blob_id": "b29f4ee0e1387ebb1ed2c1cf58a58c6b226f8787",
"content_id": "7be16d02e8bdac747c2cf90245d8118ede9dda63",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1041,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 40,
"path": "/Detect a Cycle.py",
"repo_name": "nikhiljakks/HackerRank",
"src_encoding": "UTF-8",
"text": "\"\"\"\r\nDetect a cycle in a linked list. Note that the head pointer may be 'None' if the list is empty.\r\n\r\nA Node is defined as: \r\n \r\n class Node(object):\r\n def __init__(self, data = None, next_node = None):\r\n self.data = data\r\n self.next = next_node\r\n\"\"\"\r\npList = []\r\nresult = 1\r\n\r\ndef has_cycle(head):\r\n \r\n #print \"data is \" + str(head.data)\r\n #print \"next is \" + str(head.next)\r\n #print \"head is \" + str(head)\r\n global pList\r\n pList = []\r\n pList.append(head)\r\n global result\r\n result = 0\r\n def check_node(head):\r\n global pList\r\n global result\r\n # print \"head next is\" + str(head.next)\r\n if (head.next is None):\r\n # print \"head next inside is\" + str(head.next)\r\n result = 0\r\n return\r\n elif (head.next in pList):\r\n result = 1\r\n return\r\n else:\r\n pList.append(head.next)\r\n check_node(head.next)\r\n check_node(head)\r\n #print result\r\n return result\r\n\r\n\r\n \r\n"
},
{
"alpha_fraction": 0.3745819330215454,
"alphanum_fraction": 0.38294315338134766,
"avg_line_length": 20.719999313354492,
"blob_id": "98af5eac3b13cd9ac36d554d5e7f8b103d6ea62d",
"content_id": "36632df7a1b5ab2705d79596de38e9c86d321c25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 598,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 25,
"path": "/Balanced Brackets.py",
"repo_name": "nikhiljakks/HackerRank",
"src_encoding": "UTF-8",
"text": "#!/bin/python3\r\n\r\nimport sys\r\n\r\n\r\nt = int(input().strip())\r\nfor a0 in range(t):\r\n s = input().strip()\r\n stack = []\r\n opens = ['[', '{', '(']\r\n closes = [']', '}', ')']\r\n dict1 = {a:b for a,b in zip(opens, closes)}\r\n result = 'YES'\r\n for i in s:\r\n if (i in opens):\r\n stack.append(i)\r\n latest = i\r\n elif (i in closes):\r\n if (not stack or dict1[stack[-1]] != i):\r\n result = 'NO'\r\n else:\r\n stack.pop()\r\n if (stack):\r\n result = 'NO'\r\n print (result)\r\n \r\n "
},
{
"alpha_fraction": 0.401197612285614,
"alphanum_fraction": 0.473053902387619,
"avg_line_length": 16.55555534362793,
"blob_id": "a19f51a8bfe509529164c128fa7220285d2a0812",
"content_id": "8ef711e2e9e55cfa4b53080e4296c10c6591a463",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 334,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 18,
"path": "/compare triplets.py",
"repo_name": "nikhiljakks/HackerRank",
"src_encoding": "UTF-8",
"text": "import sys\r\n\r\n\r\na0,a1,a2 = raw_input().strip().split(' ')\r\nlist1 = [int(a0),int(a1),int(a2)]\r\nb0,b1,b2 = raw_input().strip().split(' ')\r\nlist2 = [int(b0),int(b1),int(b2)]\r\n\r\na= 0\r\nb= 0\r\n\r\nfor i in xrange (0,3):\r\n if (list1[i] > list2[i]):\r\n a += 1\r\n elif (list1[i] < list2[i]):\r\n b += 1\r\n\r\nprint \"%s %s\" % (a, b)\r\n"
},
{
"alpha_fraction": 0.5608974099159241,
"alphanum_fraction": 0.5608974099159241,
"avg_line_length": 37.25,
"blob_id": "e3d551fcfd20d679e5b889c6a283d1856c28aae5",
"content_id": "e3886930c8ebd7b39270c916e91da1eae1384caa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 312,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 8,
"path": "/Is This a Binary Search Tree.py",
"repo_name": "nikhiljakks/HackerRank",
"src_encoding": "UTF-8",
"text": "def check(root, min_, max_):\r\n return (root is None or \r\n (root.data < max_ and root.data > min_ and \r\n check(root.left, min_, root.data) and \r\n check(root.right, root.data, max_)))\r\n\r\ndef check_binary_search_tree_(root):\r\n return check(root, -float('inf'), float('inf'))"
},
{
"alpha_fraction": 0.5921908617019653,
"alphanum_fraction": 0.5986984968185425,
"avg_line_length": 26.4375,
"blob_id": "2096ad7577289d603d9cd4cad9ffa9c3377c8593",
"content_id": "5777c08f89f22a0ca50a602e19f456121cbfda17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 461,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 16,
"path": "/Ransom Note.py",
"repo_name": "nikhiljakks/HackerRank",
"src_encoding": "UTF-8",
"text": "\r\nfrom collections import defaultdict\r\n\r\ndef ransom_note(magazine, ransom):\r\n dicty = defaultdict(int)\r\n for word in magazine:\r\n dicty[word]+=1\r\n for word in ransom: \r\n if dicty[word]==0 : return 'No' \r\n dicty[word]-=1\r\n return 'Yes'\r\n\r\nm, n = map(int, raw_input().strip().split(' '))\r\nmagazine = raw_input().strip().split(' ')\r\nransom = raw_input().strip().split(' ')\r\nanswer = ransom_note(magazine, ransom)\r\nprint answer \r\n"
}
] | 11 |
lucaskruk13/Classroom
|
https://github.com/lucaskruk13/Classroom
|
eeb3c282c778ebae14061d4b25b7753cfe35710f
|
859827cab057c876ed48fd7f5490dcf0b1405177
|
d200396d3ed44227995b56c667cb744051bf29a7
|
refs/heads/master
| 2020-04-22T23:48:27.041521 | 2019-02-25T16:50:01 | 2019-02-25T16:50:01 | 170,754,449 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.561026930809021,
"alphanum_fraction": 0.562079131603241,
"avg_line_length": 29.267515182495117,
"blob_id": "25bd8205497df0435840a0baf9be5a3f8a8d0aa4",
"content_id": "83156cb361a8c04c7c4ada9c457760c54dd9f6de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4752,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 157,
"path": "/venv/lib/python3.7/site-packages/django_admin_relation_links/options.py",
"repo_name": "lucaskruk13/Classroom",
"src_encoding": "UTF-8",
"text": "import re\nfrom django.urls import reverse\nfrom django.utils.html import format_html\n\n\ndef camel_case_to_underscore(string):\n return re.sub(r'(?!^)([A-Z]+)', r'_\\1', string).lower()\n\n\nclass AdminChangeLinksMixin():\n\n change_links = []\n changelist_links = []\n\n def get_readonly_fields(self, request, obj=None):\n readonly_fields = list(super().get_readonly_fields(request, obj=None))\n self.add_change_link_fields(readonly_fields)\n self.add_changelist_link_fields(readonly_fields)\n return readonly_fields\n\n def get_fields(self, request, obj=None):\n\n fields = list(super().get_fields(request, obj=None))\n\n if not fields:\n return fields\n\n for link_name, field_name, options in self.get_change_link_fields():\n if field_name not in fields:\n fields.append(field_name)\n\n for link_name, field_name, options in self.get_changelist_link_fields():\n if field_name not in fields:\n fields.append(field_name)\n\n return fields\n\n def get_change_link_fields(self):\n\n for link in self.change_links:\n\n if type(link) == tuple:\n link_name, options = (link[0], link[1])\n else:\n link_name, options = (link, {})\n field_name = '{}_change_link'.format(link_name)\n\n yield link_name, field_name, options\n\n def add_change_link_fields(self, readonly_fields):\n\n for link_name, field_name, options in self.get_change_link_fields():\n\n self.add_change_link(link_name, field_name, options)\n\n if field_name not in readonly_fields:\n readonly_fields.append(field_name)\n\n def add_change_link(self, field, field_name, options):\n\n if self.field_already_set(field_name):\n return\n\n def make_change_link(field, options):\n\n def func(instance):\n return self.get_change_link(instance, field, **options)\n\n func.short_description = (\n options.get('label')\n or '{}'.format(field.replace('_', ' '))\n )\n\n return func\n\n setattr(self, field_name, make_change_link(field, options))\n\n def add_changelist_link_fields(self, readonly_fields):\n\n for link_name, field_name, options in self.get_changelist_link_fields():\n\n self.add_changelist_link(link_name, field_name, options)\n\n if field_name not in readonly_fields:\n readonly_fields.append(field_name)\n\n def get_changelist_link_fields(self):\n\n for link in self.changelist_links:\n\n if type(link) == tuple:\n link_name, options = (link[0], link[1])\n else:\n link_name, options = (link, {})\n\n field_name = '{}_changelist_link'.format(link_name)\n\n yield link_name, field_name, options\n\n def add_changelist_link(self, field, field_name, options):\n\n if self.field_already_set(field_name):\n return\n\n def make_changelist_link(field, options):\n\n def func(instance):\n return self.get_changelist_link(instance, field, **options)\n\n func.short_description = (\n options.get('label')\n or '{}s'.format(field)\n )\n\n return func\n\n setattr(self, field_name, make_changelist_link(field, options))\n\n def field_already_set(self, field_name):\n return getattr(self, field_name, None)\n\n def get_link_field(self, url, label):\n return format_html('<a href=\"{}\" class=\"changelink\">{}</a>', url, label)\n\n def get_change_link(self, instance, field):\n target_instance = getattr(instance, field)\n return self.get_link_field(\n reverse(\n 'admin:{}_{}_change'.format(\n self.opts.app_label,\n target_instance._meta.model_name\n ),\n args=[target_instance.id]\n ),\n target_instance\n )\n\n def get_changelist_link(self, instance, target_model_name, lookup_filter=None, label=None):\n\n def get_url():\n return reverse(\n 'admin:{}_{}_changelist'.format(\n self.opts.app_label,\n target_model_name.replace('_', '')\n )\n )\n\n def get_lookup_filter():\n return lookup_filter or camel_case_to_underscore(instance._meta.object_name)\n\n def get_label():\n return label or '{}s'.format(target_model_name.replace('_', ' ').capitalize())\n\n return self.get_link_field(\n '{}?{}={}'.format(get_url(), get_lookup_filter(), instance.id),\n get_label()\n )\n"
},
{
"alpha_fraction": 0.6417590379714966,
"alphanum_fraction": 0.6499820947647095,
"avg_line_length": 33.95000076293945,
"blob_id": "f30990b9d19f7cf4e0d8534518d274df920a12c6",
"content_id": "3fa8968c023c174d7ba83a5de67485c8495b0835",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2797,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 80,
"path": "/School/tests/test_class_view.py",
"repo_name": "lucaskruk13/Classroom",
"src_encoding": "UTF-8",
"text": "from django.test import TestCase\nimport random\nfrom django.shortcuts import reverse\nfrom django.contrib.auth.models import User\nfrom School.models import Class, School\nfrom Account.models import Profile\n\n# Create your tests here.\nclass ClassTest(TestCase):\n\n @classmethod\n def setUpClass(cls):\n\n # unauthenticated URL\n cls.class_url = reverse(\"class\", kwargs={\"pk\":1})\n super(ClassTest, cls).setUpClass() # Have the superclass setup\n\n def setUp(self):\n self.unauthenticated_response = self.client.get(self.class_url)\n\n # Authenticate\n self.client.login(username=self.username, password=self.password)\n\n self.authenticated_response = self.client.get(self.class_url)\n\n super().setUp()\n\n @classmethod\n def setUpTestData(cls):\n cls.school = School.objects.create(name='Pisgah', location='Canton, NC', mascot='Bears')\n\n # Create the First Teacher\n cls.username = 'johnappleseed'\n cls.password = 'secret123'\n\n cls.user = User.objects.create(first_name='John', last_name='Appleseed', email='[email protected]',username=cls.username)\n cls.user.set_password(cls.password)\n\n cls.user.profile.status = 'TR' # Set it to a Teacher\n cls.user.save()\n\n # Create A School\n school = School.objects.create(name='Pisgah', location='Canton, NC', mascot='Black Bears')\n\n # Create a Class\n pe = Class.objects.create(name='PE', subject='Physical Education', start_time='12:00:00', school=school)\n\n # Add the Teacher Profile\n pe.profiles.add(cls.user.profile)\n pe.save()\n\n for i in range(20):\n\n # Create a new Students\n student = User.objects.create(username=\"Student{}\".format(str(i+1)), first_name=\"Student\", last_name=\"{}\".format(str(i+1)))\n student.profile.status='SR'\n student.save()\n\n # Save the Class\n pe.profiles.add(student.profile)\n pe.save()\n\n def test_redirects_to_login_when_not_logged_in(self):\n self.assertRedirects(self.unauthenticated_response, '/login/?next=/class/1/')\n\n def test_can_get_class_page_when_logged_in(self):\n self.assertEqual(self.authenticated_response.status_code, 200)\n\n def test_there_are_twenty_students_and_a_teacher_to_each_class(self):\n this_class = Class.objects.get(name='PE')\n self.assertEqual(this_class.profiles.count(), 21)\n\n # Test there are 20 students, who are Seniors\n self.assertEqual(this_class.profiles.filter(status='SR').count(), 20)\n\n # Test There are no Freshman\n self.assertEqual(this_class.profiles.filter(status='FR').count(), 0)\n\n # Test there is one Teacher\n self.assertEqual(this_class.profiles.filter(status='TR').count(), 1)\n\n"
},
{
"alpha_fraction": 0.6631467938423157,
"alphanum_fraction": 0.6642027497291565,
"avg_line_length": 28.625,
"blob_id": "fb6ce937525dcc66c80e291b31b439a7fc0c3085",
"content_id": "102543ace455c6b72149c70ed5bcf4ed4873cad7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 947,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 32,
"path": "/Account/models.py",
"repo_name": "lucaskruk13/Classroom",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.contrib.auth.models import User\nfrom django.db.models.signals import post_save\nfrom django.dispatch import receiver\n\n\n# Create your models here.\nclass Profile(models.Model):\n STATUS = (\n ('FR','Freshman'),\n ('SO', 'Sophamore'),\n ('JR', 'Junior'),\n ('SR', 'Senior'),\n ('TR', 'Teacher'),\n )\n\n user = models.OneToOneField(User, on_delete=models.CASCADE)\n birth_date = models.DateField(null=True, blank=True)\n status = models.CharField(max_length=2, choices=STATUS, null=True, blank=True)\n\n def __str__(self):\n return \"{}, {}\".format(self.user.last_name, self.user.first_name)\n\n\n@receiver(post_save, sender=User)\ndef create_user_profile(sender, instance, created, **kwargs):\n if created:\n Profile.objects.create(user=instance)\n\n@receiver(post_save, sender=User)\ndef save_user_profile(sender, instance, **kwargs):\n instance.profile.save()"
},
{
"alpha_fraction": 0.8262548446655273,
"alphanum_fraction": 0.8262548446655273,
"avg_line_length": 27.77777862548828,
"blob_id": "03a739d8c98037cc32fb85ce2142965dc50ed824",
"content_id": "eb8de6e00b649cee7552fbfbe0e1cd7db1582c85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 259,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 9,
"path": "/School/admin.py",
"repo_name": "lucaskruk13/Classroom",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom School.models import School, Class, Session\nfrom django_admin_relation_links import AdminChangeLinksMixin\n# Register your models here.\n\n\nadmin.site.register(School)\nadmin.site.register(Class)\nadmin.site.register(Session)\n"
},
{
"alpha_fraction": 0.6526668667793274,
"alphanum_fraction": 0.6624581217765808,
"avg_line_length": 30.30645179748535,
"blob_id": "798cffab11691321a2048053dff600ccc72672be",
"content_id": "44ca6727d61c60925e0879f57a3323b3edce568f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3881,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 124,
"path": "/Feed/tests/test_feed_view.py",
"repo_name": "lucaskruk13/Classroom",
"src_encoding": "UTF-8",
"text": "from django.test import TestCase\nfrom django.urls import reverse, resolve\nfrom django.contrib.auth.models import User\nfrom School.models import Class, School\n\n# Create your tests here.\nclass FeedTest(TestCase):\n\n @classmethod\n def setUpClass(cls):\n super(FeedTest, cls).setUpClass() # Have the superclass setup\n\n # Class Level URLs\n cls.feed_url = reverse('feed')\n\n def setUp(self):\n\n self.feedResponse = self.client.get(self.feed_url)\n self.feedView = resolve('/')\n\nclass FeedViewTest(FeedTest):\n\n def test_redirect_to_login(self):\n # Since no user is authenticated, this needs to redriect to the login\n self.assertRedirects(self.feedResponse, '/login/?next=/')\n\n # With No Status, test it redirects\n\nclass AuthenticatedFeedTest(FeedTest):\n\n\n @classmethod\n def setUpClass(cls):\n super(AuthenticatedFeedTest, cls).setUpClass()\n\n # Create the First User\n cls.username = 'johnappleseed'\n cls.password = 'secret123'\n\n cls.user = User.objects.create(first_name='John', last_name='Appleseed', email='[email protected]',\n username=cls.username)\n cls.user.set_password(cls.password)\n\n cls.user.save()\n\n\n\n def setUp(self):\n # Log the User In\n self.client.login(username=self.username, password=self.password)\n\n super().setUp()\n\nclass AuthenticatedStudentTest(AuthenticatedFeedTest):\n def setUp(self):\n self.user.profile.status = 'SR'\n self.user.save()\n super().setUp()\n\n def test_is_student(self):\n self.assertEqual(self.user.profile.status, 'SR')\n\n def test_feed_is_student_view(self):\n\n self.assertContains(self.feedResponse, 'Student')\n\nclass AuthenticatedTeacherTest(AuthenticatedFeedTest):\n\n def setUp(self):\n self.user.profile.status = 'TR'\n self.user.save()\n super().setUp()\n\n def test_is_teacher(self):\n self.assertEqual(self.user.profile.status, 'TR')\n\n def test_feed_is_teacher_view(self):\n self.feedResponse = self.client.get(self.feed_url)\n self.assertContains(self.feedResponse, 'Teacher')\n\nclass TestFeedPageUserLoggedIn(AuthenticatedFeedTest):\n\n def setUp(self):\n super().setUp()\n\n\n def test_user_is_logged_in(self):\n self.assertTrue(self.user.is_authenticated)\n\nclass TestFeedClassesForTeacher(AuthenticatedTeacherTest):\n def setUp(self):\n\n self.school = School.objects.create(name='Pisgah', location='Canton, NC', mascot='Bears')\n self.class1 = Class.objects.create(school=self.school, name='Gym', subject='PE', start_time='06:00:00')\n self.class2 = Class.objects.create(school=self.school, name='Science', subject='Science', start_time='07:00:00')\n\n self.class1.profiles.add(self.user.profile)\n self.class2.profiles.add(self.user.profile)\n\n super().setUp()\n\n def test_feed_has_2_classes(self):\n self.assertContains(self.feedResponse, 'class-card', 2)\n\n def test_link_to_classes(self):\n\n self.assertContains(self.feedResponse, '<a href=\"%s\">' % reverse('class',kwargs={\"pk\": self.class1.id}))\n self.assertContains(self.feedResponse, '<a href=\"%s\">' % reverse('class', kwargs={\"pk\": self.class2.id}))\n\n\nclass TestFeedClassesForStudent(AuthenticatedStudentTest):\n def setUp(self):\n\n school = School.objects.create(name='Pisgah', location='Canton, NC', mascot='Bears')\n class1 = Class.objects.create(school=school, name='Gym', subject='PE', start_time='06:00:00')\n class2 = Class.objects.create(school=school, name='Science', subject='Science', start_time='07:00:00')\n\n class1.profiles.add(self.user.profile)\n class2.profiles.add(self.user.profile)\n\n super().setUp()\n\n def test_feed_has_2_classes(self):\n self.assertContains(self.feedResponse, 'class-card', 2)"
},
{
"alpha_fraction": 0.6304259896278381,
"alphanum_fraction": 0.634482741355896,
"avg_line_length": 27.674419403076172,
"blob_id": "d453a4621365b86fd2edea7656358f33ccf5f0c7",
"content_id": "909334c8fb882cd25b74e1ebad087ae96f7974c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2465,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 86,
"path": "/Account/tests/test_sign_up.py",
"repo_name": "lucaskruk13/Classroom",
"src_encoding": "UTF-8",
"text": "from django.test import TestCase\nfrom django.urls import reverse, resolve\nfrom Account.views import signup\nfrom django.contrib.auth.forms import UserCreationForm\nfrom django.contrib.auth.models import User\nfrom Account.models import Profile\n\n# Create your tests here.\nclass SignUpTest(TestCase):\n\n @classmethod\n def setUpClass(cls):\n super(SignUpTest, cls).setUpClass() # Have the superclass setup\n\n # Class Level URLs\n cls.signup_url = reverse('signup')\n cls.feed_url = reverse('feed')\n\n # Class Level Views\n cls.signupView = resolve('/signup/')\n\n cls.signupData = {\n 'username': 'john',\n 'email': '[email protected]',\n 'first_name': 'john',\n 'last_name': 'appleseed',\n 'password1': 'abcdef123456',\n 'password2': 'abcdef123456',\n\n }\n\n def setUp(self):\n self.signupResponse = self.client.get(self.signup_url)\n self.signupPost = self.client.post(self.signup_url, self.signupData)\n\n self.feedResponse = self.client.get(self.feed_url)\n\nclass SignupPageSuccessfulTests(SignUpTest):\n\n def test_status_code(self):\n self.assertEquals(self.signupResponse.status_code, 200)\n\n def test_signup_resolves_signup_view(self):\n self.assertEquals(self.signupView.func, signup)\n\n def test_csrf(self):\n self.assertContains(self.signupResponse, 'csrfmiddlewaretoken')\n\n def test_contains_form(self):\n form = self.signupResponse.context.get('form')\n self.assertIsInstance(form, UserCreationForm)\n\n def test_user_creation(self):\n self.assertTrue(User.objects.exists())\n\n\n def test_user_authentication(self):\n user = self.feedResponse.context.get('user')\n self.assertTrue(user.is_authenticated)\n\n\nclass SignupPageInvalidSubmission(SignUpTest):\n\n\n @classmethod\n def setUpClass(cls):\n super().setUpClass()\n cls.signupData = {\n 'username': 'john',\n 'email': '[email protected]',\n 'first_name': 'john',\n 'last_name': 'appleseed',\n 'password1': 'abcdef123456',\n 'password2': 'abcdef123456',\n\n }\n\n def test_signup_status_code(self):\n self.assertEquals(self.signupPost.status_code, 200)\n\n def test_form_errors(self):\n form = self.signupPost.context.get('form')\n self.assertTrue(form.errors)\n\n def test_user_not_created(self):\n self.assertFalse(User.objects.exists())"
},
{
"alpha_fraction": 0.44613581895828247,
"alphanum_fraction": 0.4508196711540222,
"avg_line_length": 26.580644607543945,
"blob_id": "1113c6dbb8c6ed1eaa348d5ce8aebb3a43930ebc",
"content_id": "838046aa66c428791793d47b847dfe759b0cea09",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 854,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 31,
"path": "/templates/school/modules/class_table.html",
"repo_name": "lucaskruk13/Classroom",
"src_encoding": "UTF-8",
"text": "<table class=\"table table-bordered table-striped session-table\">\n <thead>\n <tr>\n <td colspan=\"3\" style=\"background-color: yellow; font-weight: bolder;\" class=\"text-center\">CLASSES</td>\n </tr>\n\n <tr>\n <th scope=\"col\">Date</th>\n <th scope=\"col\">Subject</th>\n <th scope=\"col\">Absences</th>\n </tr>\n </thead>\n\n <tbody>\n {% for session in sessions %}\n <tr>\n <td>{{ session.date }}</td>\n <td>{{ session.summary }}</td>\n <td>{{ session.absences.count }}</td>\n </tr>\n {% endfor %}\n </tbody>\n\n {% if sessions.count >= 10 and sessions %}\n <tfoot>\n <tr>\n <td colspan=\"3\" class=\"text-center\">Show More</td>\n </tr>\n </tfoot>\n {% endif %}\n</table>"
},
{
"alpha_fraction": 0.5572333335876465,
"alphanum_fraction": 0.572820246219635,
"avg_line_length": 39.25490188598633,
"blob_id": "76ecec0f7a4a5b68d71ed87f8f067eb1d70135d4",
"content_id": "7aa9b903d9090aeb4e476e6cd37cab6bb4ecdfe3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2053,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 51,
"path": "/School/migrations/0001_initial.py",
"repo_name": "lucaskruk13/Classroom",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.5 on 2019-02-20 03:31\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\nimport django.utils.timezone\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ('Account', '0001_initial'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Class',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=100)),\n ('subject', models.CharField(max_length=20)),\n ('start_time', models.TimeField(default=django.utils.timezone.now)),\n ('profiles', models.ManyToManyField(to='Account.Profile')),\n ],\n ),\n migrations.CreateModel(\n name='School',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=100)),\n ('location', models.CharField(max_length=100)),\n ('mascot', models.CharField(max_length=30)),\n ],\n ),\n migrations.CreateModel(\n name='Session',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('date', models.DateField(default=django.utils.timezone.now)),\n ('summary', models.TextField(blank=True, null=True)),\n ('absences', models.ManyToManyField(blank=True, to='Account.Profile')),\n ('associated_class', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, related_name='class_session', to='School.Class')),\n ],\n ),\n migrations.AddField(\n model_name='class',\n name='school',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, related_name='school_class', to='School.School'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7386363744735718,
"alphanum_fraction": 0.7386363744735718,
"avg_line_length": 34.20000076293945,
"blob_id": "beeae84c87bf1fb31135068e6ed3ee34ba8176cb",
"content_id": "f1cd00d827e63eb681eb8d263c2f9fda91136836",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 176,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 5,
"path": "/venv/bin/django-admin.py",
"repo_name": "lucaskruk13/Classroom",
"src_encoding": "UTF-8",
"text": "#!/Users/skywalker/Desktop/Developer/Django/Classroom/venv/bin/python\nfrom django.core import management\n\nif __name__ == \"__main__\":\n management.execute_from_command_line()\n"
},
{
"alpha_fraction": 0.7007519006729126,
"alphanum_fraction": 0.7105262875556946,
"avg_line_length": 40.5625,
"blob_id": "0da92c0b6f56d78abdecf7057f6e341bc47f4179",
"content_id": "7567dd27a92baa24553b297bc973efd5fa5d372e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1330,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 32,
"path": "/School/models.py",
"repo_name": "lucaskruk13/Classroom",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom Account.models import Profile\nfrom django.utils.timezone import now\nfrom datetime import datetime as dt\n\nclass School(models.Model):\n name = models.CharField(max_length=100, blank=False, null=False)\n location = models.CharField(max_length=100, blank=False, null=False)\n mascot = models.CharField(max_length=30, blank=False, null=False)\n\n def __str__(self):\n return \"{} | {}\".format(self.name, self.location)\n\nclass Class(models.Model):\n\n school = models.ForeignKey(School, related_name='school_class', on_delete=models.CASCADE)\n profiles = models.ManyToManyField(Profile)\n name = models.CharField(max_length=100, blank=False, null=False)\n subject = models.CharField(max_length=20, blank=False, null=False)\n start_time = models.TimeField(auto_now=False, auto_now_add=False, default=now)\n\n def __str__(self):\n return \"{}: {}\".format(self.start_time, self.name)\n\nclass Session(models.Model):\n associated_class = models.ForeignKey(Class, related_name='class_session', on_delete=models.CASCADE)\n date = models.DateField(blank=False, null=False, default=now)\n absences = models.ManyToManyField(Profile, blank=True)\n summary = models.TextField(blank=True, null=True)\n\n def __str__(self):\n return \"{}, {}\".format(self.date, self.summary)\n"
},
{
"alpha_fraction": 0.7086007595062256,
"alphanum_fraction": 0.7124518752098083,
"avg_line_length": 32.69565200805664,
"blob_id": "a6b1bd5da563d2ab04222d765ff13994202681d6",
"content_id": "a31bbb1e38408560d5f9645807068acf900b2567",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 779,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 23,
"path": "/Feed/views.py",
"repo_name": "lucaskruk13/Classroom",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, get_list_or_404, redirect\nfrom django.views.generic import TemplateView\nfrom School.models import Class\nfrom django.contrib.auth.mixins import LoginRequiredMixin\n\n\nclass FeedView(LoginRequiredMixin,TemplateView):\n template_name = 'feed/feed.html'\n\n def render_to_response(self, context, **response_kwargs):\n if not self.request.user.is_authenticated:\n return redirect('login')\n\n return super(FeedView, self).render_to_response(context)\n\n\n def get_context_data(self, **kwargs):\n # Call the base implementation to get a context\n context = super().get_context_data(**kwargs)\n\n context['class_list'] = Class.objects.filter(profiles__user_id=self.request.user.id)\n\n return context\n\n\n\n\n"
},
{
"alpha_fraction": 0.6971649527549744,
"alphanum_fraction": 0.6997422575950623,
"avg_line_length": 32.65217208862305,
"blob_id": "55d90e41de695a0b93d4b1b3c42047c267576122",
"content_id": "b42d53292e2cecc61ed248e6b27349f6ec7dff92",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 776,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 23,
"path": "/School/views.py",
"repo_name": "lucaskruk13/Classroom",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom django.views.generic import TemplateView\nfrom School.models import Class, Session\nfrom django.contrib.auth.mixins import LoginRequiredMixin\n\n\n\nclass ClassView(LoginRequiredMixin,TemplateView):\n template_name = 'school/class.html'\n\n def get_context_data(self, **kwargs):\n # Call the base implementation to get a context\n context = super().get_context_data(**kwargs)\n\n thisclass = Class.objects.get(id=kwargs['pk'])\n students = thisclass.profiles.exclude(status='TR')\n sessions = Session.objects.filter(associated_class=thisclass).order_by('-date')[:10]\n\n context['class'] = thisclass\n context['students'] = students\n context['sessions'] = sessions\n\n return context\n\n\n"
}
] | 12 |
ruybrito106/dc-sample
|
https://github.com/ruybrito106/dc-sample
|
8d12d9f999572a6af69d55e1ee9aaf37296abd55
|
222998cc700bbe8bcfba4636a7a2cea6548fb57d
|
09e7d203205d0a74ddece443c41e1f783f97ee67
|
refs/heads/master
| 2021-07-22T15:30:31.375745 | 2017-11-01T17:33:52 | 2017-11-01T17:33:52 | 108,933,107 | 1 | 1 | null | 2017-10-31T02:16:35 | 2017-10-31T03:31:21 | 2017-10-31T13:07:02 |
JavaScript
|
[
{
"alpha_fraction": 0.3003003001213074,
"alphanum_fraction": 0.44744744896888733,
"avg_line_length": 36,
"blob_id": "b89fff7d8d6661c941e9b43cef7816a8c839489a",
"content_id": "6d8f1bf365a53c7a2a3bfa6bfa56d8c5b87e036d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 666,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 18,
"path": "/generateCSV.py",
"repo_name": "ruybrito106/dc-sample",
"src_encoding": "UTF-8",
"text": "import csv\nimport random\n\nstuds = ['Divino', 'Higor', 'Ruy', 'Leogal', 'Pedro', 'Lucas']\nranges = [[1, 2, 2, 5, 6, 8.5, 8, 8.7, 9, 10, 10, 10],\n [3, 3, 4, 8, 9, 2, 4.5, 4.4, 4.3, 7, 8, 5],\n [10, 10, 9, 6, 3, 4, 5, 8, 9.5, 8, 7, 7.2],\n [7, 7, 7.8, 8, 9, 10, 7, 5, 3, 2, 0, 0],\n [4, 5, 5.5, 7, 7.5, 6, 6.2, 5.2, 4.5, 4, 6, 7],\n [10, 9, 8, 9, 6.5, 5, 5, 4.3, 2, 5, 5.5, 9]];\n\nwith open('data/grades.csv', 'w') as csvfile:\n writer = csv.writer(csvfile);\n\n writer.writerow(['Name', 'Month', 'Grade']);\n for i in range(6):\n for j in range(12):\n writer.writerow([studs[i], str(j), str(ranges[i][j])])\n"
},
{
"alpha_fraction": 0.73617023229599,
"alphanum_fraction": 0.7553191781044006,
"avg_line_length": 19.434782028198242,
"blob_id": "af82173ee62a4cb34e307aacce24bb3592123715",
"content_id": "e8dac47901803ccfe09369ce3e1fcd146333b17b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 470,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 23,
"path": "/README.md",
"repo_name": "ruybrito106/dc-sample",
"src_encoding": "UTF-8",
"text": "# Samples of DC.js\n\nSamples of DC.js charts (series and pie charts) for learning purposes.\n\n## Generating data\n\nTo generate data, update freely the csv files or the python csv generation code\nwith the following:\n\n``` bash\npython3 generateCSV.py\n```\n\n## Visualizing data\n\nIn order to see the data visualizations, just run a local python http server\nwith the following bash command:\n\n``` bash\npython -m SimpleHTTPServer 8080\n```\n\nTo visualize, just open *localhost:8080*.\n"
}
] | 2 |
VieruTudor/Assignment-6-8
|
https://github.com/VieruTudor/Assignment-6-8
|
737c65d13d1ad2b14941b5da99e03d9ea13b825b
|
be0ba5fa8252c74ecc8f3715467356bf80681463
|
f0bb03c7b1a275b970ec1795ef3b6e475d660a2a
|
refs/heads/master
| 2022-04-04T11:44:50.622835 | 2020-01-05T12:13:39 | 2020-01-05T12:13:39 | 224,328,515 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6699594259262085,
"alphanum_fraction": 0.6725396513938904,
"avg_line_length": 50.577945709228516,
"blob_id": "3b844842b2a1c7bccfffdccafae2a7d06c7b1bde",
"content_id": "651c0b08f242a24e60222a835805bffd1a129615",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13565,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 263,
"path": "/service.py",
"repo_name": "VieruTudor/Assignment-6-8",
"src_encoding": "UTF-8",
"text": "from entities import *\nimport random\nfrom undoRepo import *\n\n\nclass serviceStudents(object):\n def __init__(self, undo, repoStudents, validStudent, gradesService):\n self.__repoStudents = repoStudents\n self.__validStudent = validStudent\n self.__gradesService = gradesService\n self.__undo = undo\n\n # Function that randomly generates 10 students from a certain list of names\n def generateStudents(self):\n self.__repoStudents.clearList()\n nameChoiceList = [\"John\",\n \"Alice\",\n \"Richard\",\n \"Max\",\n \"Chris\",\n \"Robert\",\n \"Megan\",\n \"Liz\",\n \"Mary\",\n \"Harry\"]\n for idChoice in range(10):\n student = Student(idChoice + 1, random.choice(nameChoiceList))\n self.__validStudent.validateStudent(student)\n self.__repoStudents.addUniqueObject(student)\n\n # Calls the repo and gets all the students\n def getStudents(self):\n return self.__repoStudents.getAllObjects()\n\n # With the student ID from the UI, calls the repo function that searches for the student with that ID\n def searchStudentByID(self, studentID):\n return self.__repoStudents.searchEntityByID(studentID)\n\n # Using the partial or full name given by the UI, calls the repo function and returns all students containing that\n # name\n def searchStudentsByName(self, searchName):\n return self.__repoStudents.searchEntityByName(searchName)\n\n # Creates a student based on the parameters from the UI, checks for its logical validity and calls the repo for\n # adding it to the list\n def addStudent(self, studentID, studentName, undoRecord=True):\n student = Student(studentID, studentName)\n self.__validStudent.validateStudent(student)\n self.__repoStudents.addUniqueObject(student)\n if undoRecord:\n undo = FunctionCall(self.removeStudent, studentID)\n redo = FunctionCall(self.addStudent, studentID, studentName)\n operation = Operation(undo, redo)\n self.__undo.recordOperation(operation)\n\n # Creates a new student based on the ID and new name given by the UI, checks for its validity and calls the repo\n # for the updating function\n def updateStudent(self, studentID, studentNewName, undoRecord=True):\n oldStudentName = self.__repoStudents.searchEntityByID(studentID).getName()\n newStudent = Student(studentID, studentNewName)\n self.__validStudent.validateStudent(newStudent)\n self.__repoStudents.updateObject(newStudent.getID(), newStudent)\n if undoRecord:\n redo = FunctionCall(self.updateStudent, studentID, studentNewName)\n undo = FunctionCall(self.updateStudent, studentID, oldStudentName)\n operation = Operation(undo, redo)\n self.__undo.recordOperation(operation)\n\n # Calls the repo for the remove function using the given ID, also removing the grades of that student\n def removeStudent(self, studentID, recordUndo=True):\n deletedStudent = self.searchStudentByID(studentID)\n self.__repoStudents.removeObject(studentID)\n gradesOperation = self.__gradesService.removeGradesByStudentID(studentID)\n if recordUndo:\n undo = FunctionCall(self.addStudent, deletedStudent.getID(), deletedStudent.getName())\n redo = FunctionCall(self.removeStudent, studentID)\n operation = Operation(undo, redo)\n self.__undo.recordOperation(MultipleOperation(operation, gradesOperation))\n\n\nclass serviceDisciplines(object):\n def __init__(self, undo, repoDisciplines, validDiscipline, gradesService):\n self.__repoDisciplines = repoDisciplines\n self.__validDiscipline = validDiscipline\n self.__gradesService = gradesService\n self.__undo = undo\n\n # Randomly generates 3 disciplines from a certain list of names\n def generateDisciplines(self):\n randomDisciplines = [\"Computer Science\", \"Algebra\", \"Robotics\"]\n for idChoice in range(3):\n disciplineName = random.choice(randomDisciplines)\n discipline = Discipline(idChoice + 1, disciplineName)\n self.__validDiscipline.validateDiscipline(discipline)\n self.__repoDisciplines.addUniqueObject(discipline)\n randomDisciplines.remove(disciplineName)\n\n # With the discipline ID from the UI, calls the repo function that searches for the discipline with that ID\n def searchDisciplineByID(self, disciplineID):\n return self.__repoDisciplines.searchEntityByID(disciplineID)\n\n # Using the partial or full name given by the UI, calls the repo function and returns all disciplines containing\n # that name\n def searchDisciplinesByName(self, disciplineName):\n return self.__repoDisciplines.searchEntityByName(disciplineName)\n\n # Creates a discipline based on the parameters from the UI, checks for its logical validity and calls the repo for\n # adding it to the list\n def addDiscipline(self, disciplineID, disciplineName, recordUndo=True):\n discipline = Discipline(disciplineID, disciplineName)\n self.__validDiscipline.validateDiscipline(discipline)\n self.__repoDisciplines.addUniqueObject(discipline)\n if recordUndo:\n undo = FunctionCall(self.removeDiscipline, disciplineID)\n redo = FunctionCall(self.addDiscipline, disciplineID, disciplineName)\n operation = Operation(undo, redo)\n self.__undo.recordOperation(operation)\n\n # Creates a new discipline based on the ID and new name given by the UI, checks for its validity and calls the repo\n # for the updating function\n def updateDiscipline(self, disciplineID, disciplineNewName, recordUndo=True):\n oldDisciplineName = self.__repoDisciplines.searchEntityByID(disciplineID).getName()\n newDiscipline = Discipline(disciplineID, disciplineNewName)\n self.__validDiscipline.validateDiscipline(newDiscipline)\n self.__repoDisciplines.updateObject(newDiscipline.getID(), newDiscipline)\n if recordUndo:\n undo = FunctionCall(self.updateDiscipline, disciplineID, oldDisciplineName)\n redo = FunctionCall(self.updateDiscipline, disciplineID, disciplineNewName)\n operation = Operation(undo, redo)\n self.__undo.recordOperation(operation)\n\n # Calls the repo for the remove function using the given ID, also removing the grades of that student\n def removeDiscipline(self, disciplineID, recordUndo=True):\n deletedDiscipline = self.searchDisciplineByID(disciplineID)\n self.__repoDisciplines.removeObject(disciplineID)\n gradesOperation = self.__gradesService.removeGradesByDisciplineID(disciplineID)\n if recordUndo:\n undo = FunctionCall(self.addDiscipline, deletedDiscipline.getID(), deletedDiscipline.getName())\n redo = FunctionCall(self.removeDiscipline, disciplineID)\n operation = Operation(undo, redo)\n self.__undo.recordOperation(MultipleOperation(operation, gradesOperation))\n\n # Calls the repo and gets the list of all disciplines\n def getDisciplines(self):\n return self.__repoDisciplines.getAllObjects()\n\n\nclass serviceGrades(object):\n def __init__(self, undo, repoStudents, repoDisciplines, repoGrades, validGrade):\n self.__repoStudents = repoStudents\n self.__repoDisciplines = repoDisciplines\n self.__repoGrades = repoGrades\n self.__validGrade = validGrade\n self.__undo = undo\n\n def addGrades(self, gradesList):\n for grade in gradesList:\n self.__repoGrades.addObject(grade)\n\n # Randomly generates 10 grades based on the existing students and disciplines, assigning a random grade\n def generateGrades(self):\n students = self.__repoStudents.getAllObjects()\n disciplines = self.__repoDisciplines.getAllObjects()\n for grades in range(10):\n randomStudentID = random.choice(students).getID()\n randomDisciplineID = random.choice(disciplines).getID()\n randomGradeValue = random.randint(1, 10)\n grade = Grade(randomStudentID, randomDisciplineID, randomGradeValue)\n self.__validGrade.validateGrade(grade)\n self.__repoGrades.addObject(grade)\n\n # Creates a grade based on the parameters from the UI, checks for its logical validity and calls the repo for\n # adding it to the list\n def addGrade(self, studentID, disciplineID, gradeValue):\n grade = Grade(studentID, disciplineID, gradeValue)\n self.__validGrade.validateGrade(grade)\n self.__repoGrades.addObject(grade)\n\n # Function that is called in the students service upon the removal of a student. With the removal of a student, his\n # grades must be removed as well. Removes all the grades associated to a student ID\n def removeGradesByStudentID(self, studentID, recordUndo=True):\n print(self.__repoGrades.getDeletedObjects())\n self.__repoGrades.removeGradeByStudentID(studentID)\n if recordUndo:\n undo = FunctionCall(self.addGrades, self.__repoGrades.getDeletedObjects())\n redo = FunctionCall(self.removeGradesByStudentID, studentID)\n operation = Operation(undo, redo)\n return operation\n\n # Function that is called in the disciplines service upon the removal of a discipline. With the removal of a\n # discipline, its grades must be removed as well. Removes all the grades associated to a discipline ID\n def removeGradesByDisciplineID(self, disciplineID, recordUndo=True):\n self.__repoGrades.removeGradeByDisciplineID(disciplineID)\n if recordUndo:\n undo = FunctionCall(self.addGrades, self.__repoGrades.getDeletedObjects())\n redo = FunctionCall(self.removeGradesByDisciplineID, disciplineID)\n operation = Operation(undo, redo)\n return operation\n\n # Calls the repo and gets all grades in the list\n def getGrades(self):\n return self.__repoGrades.getAllObjects()\n\n # Computes for every student enrolled on a discipline the average of its grades at that discipline. If this average\n # is lower than 5, then he is considered to be failing that discipline.\n # Returns the list of all students failing at a discipline and their failing grade in the form :\n # [Student ID, Discipline, Final Grade]\n def studentsFailing(self):\n studentsFailing = []\n for student in self.__repoStudents.getAllObjects():\n for discipline in self.__repoDisciplines.getAllObjects():\n numberOfGrades = 0\n gradesSum = 0\n for grade in self.__repoGrades.getAllObjects():\n if grade.getStudentID() == student.getID() and grade.getDisciplineID() == discipline.getID():\n gradesSum += grade.getGrade()\n numberOfGrades += 1\n if numberOfGrades > 0:\n average = gradesSum / numberOfGrades\n if average < 5:\n studentsFailing.append([student.getID(), discipline.getName(), average])\n return studentsFailing[:]\n\n # Computes for every student the average of all their average grades at all disciplines they are enrolled in and\n # ranks them by their final average.\n def studentsSituation(self):\n studentsRankings = []\n for student in self.__repoStudents.getAllObjects():\n studentAverage = 0\n studentNumberOfDisciplines = 0\n for discipline in self.__repoDisciplines.getAllObjects():\n numberOfGrades = 0\n gradesSum = 0\n for grade in self.__repoGrades.getAllObjects():\n if grade.getStudentID() == student.getID() and grade.getDisciplineID() == discipline.getID():\n gradesSum += grade.getGrade()\n numberOfGrades += 1\n if numberOfGrades > 0:\n studentNumberOfDisciplines += 1\n average = gradesSum / numberOfGrades\n studentAverage += average\n if studentNumberOfDisciplines > 0:\n studentAverage /= studentNumberOfDisciplines\n studentsRankings.append([student.getID(), studentAverage])\n studentsRankings.sort(key=lambda finalGrade: finalGrade[1], reverse=True)\n return studentsRankings[:]\n\n # Computes for every discipline the average grade received by the students enrolled in it and ranks all the\n # disciplines by their final average.\n def disciplinesRankings(self):\n disciplinesRankings = []\n for discipline in self.__repoDisciplines.getAllObjects():\n disciplineGradesSum = 0\n disciplineNumberOfGrades = 0\n for grade in self.__repoGrades.getAllObjects():\n if grade.getDisciplineID() == discipline.getID():\n disciplineGradesSum += grade.getGrade()\n disciplineNumberOfGrades += 1\n if disciplineNumberOfGrades > 0:\n disciplineAverage = disciplineGradesSum / disciplineNumberOfGrades\n disciplinesRankings.append([discipline.getName(), disciplineAverage])\n disciplinesRankings.sort(key=lambda disciplineFinalGrade: disciplineFinalGrade[1], reverse=True)\n return disciplinesRankings[:]\n"
},
{
"alpha_fraction": 0.5740503668785095,
"alphanum_fraction": 0.5770379900932312,
"avg_line_length": 25.636363983154297,
"blob_id": "6bda1bf104f78dd2238ec98bb36b840cecdee712",
"content_id": "f1a9e14a9de340960365052fdc2d2a7e03bc490d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2343,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 88,
"path": "/entities.py",
"repo_name": "VieruTudor/Assignment-6-8",
"src_encoding": "UTF-8",
"text": "class Student(object):\n def __init__(self, studentID, studentName):\n self.__ID = studentID\n self.__name = studentName\n\n def getID(self):\n return self.__ID\n\n def getName(self):\n return self.__name\n\n def setName(self, newName):\n self.__name = newName\n\n def __eq__(self, other):\n return self.getID() == other.getID()\n\n def __str__(self):\n return \"ID : \" + str(self.__ID) + \", \" + str(self.__name)\n\n @staticmethod\n def readFromFile(line):\n attributes = line.split(\",\")\n return Student(attributes[0].strip(), attributes[1].strip())\n\n @staticmethod\n def writeToFile(student):\n return str(student.getID()) + \",\" + str(student.getName())\n\n\nclass Discipline(object):\n def __init__(self, disciplineID, disciplineName):\n self.__ID = disciplineID\n self.__name = disciplineName\n\n def getID(self):\n return self.__ID\n\n def getName(self):\n return self.__name\n\n def setName(self, newName):\n self.__name = newName\n\n def __eq__(self, other):\n return self.getID() == other.getID()\n\n def __str__(self):\n return \"ID : \" + str(self.__ID) + \", \" + str(self.__name)\n\n @staticmethod\n def readFromFile(line):\n attributes = line.split(\",\")\n return Discipline(attributes[0].strip(), attributes[1].strip())\n\n @staticmethod\n def writeToFile(discipline):\n return str(discipline.getID()) + \",\" + str(discipline.getName())\n\n\nclass Grade(object):\n def __init__(self, studentID, disciplineID, gradeValue):\n self.__student = studentID\n self.__discipline = disciplineID\n self.__grade = gradeValue\n\n def getStudentID(self):\n return self.__student\n\n def getDisciplineID(self):\n return self.__discipline\n\n def getGrade(self):\n return self.__grade\n\n def __str__(self):\n return \"ID : \" + str(self.__student) + \", \" + \"Discipline : \" + str(\n self.__discipline) + \", \" + \"Grade : \" + str(\n self.__grade)\n\n @staticmethod\n def readFromFile(line):\n attributes = line.split(\",\")\n return Grade(attributes[0], attributes[1], attributes[2])\n\n @staticmethod\n def writeToFile(grade):\n return str(grade.getStudentID) + \",\" + str(grade.getDisciplineID) + \",\" + str(grade.getGrade)"
},
{
"alpha_fraction": 0.621148943901062,
"alphanum_fraction": 0.6212834715843201,
"avg_line_length": 34.066036224365234,
"blob_id": "224d5221b1ad6217cb81678922a8a195e87963a8",
"content_id": "abaa9e1a41bbc3be424d6bbf366a93cb922f8f11",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7433,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 212,
"path": "/repo.py",
"repo_name": "VieruTudor/Assignment-6-8",
"src_encoding": "UTF-8",
"text": "from exceptions import RepoError\nimport pickle\n\n\nclass Repo(object):\n def __init__(self):\n self.__objects = []\n self.__deletedObjects = []\n\n # Adds a unique entity passed by the service to the list\n # By unique, we mean that the entity has a unique ID that cannot be duplicate in the list\n\n def addUniqueObject(self, entity):\n if entity in self.__objects:\n raise RepoError(\"Entity already in list\")\n self.__objects.append(entity)\n\n # Adds an entity passed by the service to the list\n # NOTE : Object doesn't have an ID and can be duplicated in the list, e.g : grades\n def addObject(self, entity):\n self.__objects.append(entity)\n\n # Updates an existing entity based on a given ID with a new one passed from the service\n def updateObject(self, entityID, newEntity):\n for entity in self.__objects:\n if entity.getID() == entityID:\n entity.setName(newEntity.getName())\n\n # Removes an entity from the list based on a given ID\n def removeObject(self, entityID):\n found = False\n for entity in self.__objects:\n if entity.getID() == entityID:\n found = True\n if not found:\n raise RepoError(\"Entity not in list\")\n self.__objects[:] = [entity for entity in self.__objects if entity.getID() != entityID]\n\n # Removes grades associated to a student ID\n def removeGradeByStudentID(self, entityID):\n found = False\n for entity in self.__objects:\n if entity.getStudentID() == entityID:\n found = True\n if not found:\n raise RepoError(\"Entity not in list\")\n self.__deletedObjects = [entity for entity in self.__objects if entity.getStudentID() == entityID]\n self.__objects = [entity for entity in self.__objects if entity.getStudentID() != entityID]\n # deletedObjects = self.objects - self.objects[:]\n\n # Removes grades associated to a discipline ID\n def removeGradeByDisciplineID(self, entityID):\n found = False\n for entity in self.__objects:\n if entity.getDisciplineID() == entityID:\n found = True\n if not found:\n raise RepoError(\"Entity not in list\")\n self.__deletedObjects = [entity for entity in self.__objects if entity.getDisciplineID() == entityID]\n self.__objects = [entity for entity in self.__objects if entity.getDisciplineID() != entityID]\n\n # Searches an entity based on its ID\n def searchEntityByID(self, entityID):\n for entity in self.__objects:\n if entity.getID() == entityID:\n return entity\n raise RepoError(\"Entity not in list\")\n\n # Searches an entity based on a partial or full name\n def searchEntityByName(self, entityName):\n foundEntities = [entity for entity in self.__objects if entityName.lower() in entity.getName().lower()]\n if len(foundEntities) == 0:\n raise RepoError(\"No matches found\")\n return foundEntities\n\n # Returns a list containing all the objects in the repo\n def getAllObjects(self):\n return self.__objects[:]\n\n def getDeletedObjects(self):\n return self.__deletedObjects[:]\n\n # Wipes the entire list in the current repo\n def clearList(self):\n self.__objects.clear()\n\n\nclass FileRepo(Repo):\n def __init__(self, file, objectReader, objectWriter):\n Repo.__init__(self)\n self.__file = file\n self.__objectReader = objectReader\n self.__objectWriter = objectWriter\n\n def __readFromFile(self):\n self.__entities = []\n with open(self.__file, 'r') as fileReader:\n lines = fileReader.readlines()\n for line in lines:\n line = line.strip()\n if line != \"\":\n entity = self.__objectReader(line)\n self.__entities.append(entity)\n\n def __writeToFile(self):\n with open(self.__file, 'w') as fileWriter:\n for entity in self.__entities:\n fileWriter.write(self.__objectWriter(entity) + \"\\n\")\n\n def file_addObject(self, entity):\n self.__readFromFile()\n Repo.addObject(self, entity)\n self.__writeToFile()\n\n def file_addUniqueObject(self, entity, newEntity):\n self.__readFromFile()\n Repo.updateObject(self, entity, newEntity)\n self.__writeToFile()\n\n def file_removeObject(self, entityID):\n self.__readFromFile()\n Repo.removeObject(self, entityID)\n self.__writeToFile()\n\n def file_removeGradesByStudentID(self, studentID):\n self.__readFromFile()\n Repo.removeGradeByStudentID(self, studentID)\n self.__writeToFile()\n\n def file_removeGradesByDisciplineID(self, disciplineID):\n self.__readFromFile()\n Repo.removeGradeByDisciplineID(self, disciplineID)\n self.__writeToFile()\n\n def file_searchEntityByID(self, entityID):\n self.__readFromFile()\n return Repo.searchEntityByID(self, entityID)\n\n def file_searchEntityByName(self, partialName):\n self.__readFromFile()\n return Repo.searchEntityByName(self, partialName)\n\n def file_getAllObjects(self):\n self.__readFromFile()\n return Repo.getAllObjects(self)\n\n def file_getDeletedObjects(self):\n return Repo.getDeletedObjects(self)\n\n\nclass BinaryRepo(Repo):\n def __init__(self, file, objectReader, objectWriter):\n Repo.__init__(self)\n self.__file = file\n self.__objectReader = objectReader\n self.__objectWriter = objectWriter\n\n def __readFromFile(self):\n self.__entities = []\n with open(self.__file, 'rb') as fileReader:\n while True:\n try:\n line = pickle.load(fileReader)\n entity = self.__objectReader(line)\n self.__entities.append(entity)\n except EOFError:\n break\n\n def __writeToFile(self):\n with open(self.__file, 'wb') as fileWriter:\n for entity in self.__entities:\n pickle.dump(self.__objectWriter(entity), fileWriter)\n\n def binary_addObject(self, entity):\n self.__readFromFile()\n Repo.addObject(self, entity)\n self.__writeToFile()\n\n def binary_addUniqueObject(self, entity, newEntity):\n self.__readFromFile()\n Repo.updateObject(self, entity, newEntity)\n self.__writeToFile()\n\n def binary_removeObject(self, entityID):\n self.__readFromFile()\n Repo.removeObject(self, entityID)\n self.__writeToFile()\n\n def binary_removeGradesByStudentID(self, studentID):\n self.__readFromFile()\n Repo.removeGradeByStudentID(self, studentID)\n self.__writeToFile()\n\n def binary_removeGradesByDisciplineID(self, disciplineID):\n self.__readFromFile()\n Repo.removeGradeByDisciplineID(self, disciplineID)\n self.__writeToFile()\n\n def binary_searchEntityByID(self, entityID):\n self.__readFromFile()\n return Repo.searchEntityByID(self, entityID)\n\n def binary_searchEntityByName(self, partialName):\n self.__readFromFile()\n return Repo.searchEntityByName(self, partialName)\n\n def binary_getAllObjects(self):\n self.__readFromFile()\n return Repo.getAllObjects(self)\n\n def binary_getDeletedObjects(self):\n return Repo.getDeletedObjects(self)"
},
{
"alpha_fraction": 0.5702614188194275,
"alphanum_fraction": 0.5808823704719543,
"avg_line_length": 28.095237731933594,
"blob_id": "be156b0aa7374563a487b1f2fc10f1478543a576",
"content_id": "170a2928647bf6e171861af5a299477aef8cd94d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1224,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 42,
"path": "/validators.py",
"repo_name": "VieruTudor/Assignment-6-8",
"src_encoding": "UTF-8",
"text": "from exceptions import ValidError\n\n\nclass studentValidator(object):\n\n @staticmethod\n def validateStudent(student):\n errors = \"\"\n if student.getID() < 0:\n errors += \"Student ID cannot be negative\\n\"\n if student.getName() == \"\":\n errors += \"Student name cannot be empty\\n\"\n if len(errors) > 0:\n raise ValidError(errors)\n\n\nclass disciplineValidator(object):\n\n @staticmethod\n def validateDiscipline(discipline):\n errors = \"\"\n if discipline.getID() < 0:\n errors += \"Discipline ID cannot be negative\\n\"\n if discipline.getName() == \"\":\n errors += \"Discipline name cannot be empty\"\n if len(errors) > 0:\n raise ValidError(errors)\n\n\nclass gradeValidator(object):\n\n @staticmethod\n def validateGrade(grade):\n errors = \"\"\n if grade.getStudentID() < 0:\n errors += \"Student ID cannot be negative\\n\"\n if grade.getDisciplineID() < 0:\n errors += \"Discipline ID cannot be negative\\n\"\n if grade.getGrade() < 0 or grade.getGrade() > 10:\n errors += \"Grade must be between 1-10\"\n if len(errors) > 0:\n raise ValidError(errors)\n\n\n"
},
{
"alpha_fraction": 0.612453281879425,
"alphanum_fraction": 0.6239103078842163,
"avg_line_length": 33.31623840332031,
"blob_id": "113d1f89c11d0c9b65e6a2b85aa08512d7280a37",
"content_id": "7ba0f0b6d356f09755b915af1656839633136e4c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4015,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 117,
"path": "/tests.py",
"repo_name": "VieruTudor/Assignment-6-8",
"src_encoding": "UTF-8",
"text": "from entities import *\nfrom service import *\nfrom repo import *\nimport unittest\n\n\nclass studentTests(unittest.TestCase):\n\n def test_studentName_expectedName(self):\n student = Student(1, \"Tudor\")\n self.assertTrue(student.getName() == \"Tudor\")\n\n def test_studentID_expectedID(self):\n student = Student(1, \"Tudor\")\n self.assertTrue(student.getID() == 1)\n\n def test_addStudent_correctAdd(self):\n self.__repo = Repo()\n assert len(self.__repo.getAllObjects()) == 0\n student = Student(1, \"Tudor\")\n self.__repo.addUniqueObject(student)\n assert len(self.__repo.getAllObjects()) == 1\n\n def testAddUniqueObject(self):\n self.__repo = Repo()\n assert len(self.__repo.getAllObjects()) == 0\n student = Student(1, \"Tudor\")\n self.__repo.addUniqueObject(student)\n try:\n duplicateStudent = Student(1, \"Stefan\")\n self.__repo.addUniqueObject(duplicateStudent)\n assert False\n except RepoError as error:\n print(str(error))\n assert len(self.__repo.getAllObjects()) == 1\n\n def test_updateStudent_correctUpdate(self):\n self.__repo = Repo()\n student = Student(1, \"Tudor\")\n self.__repo.addUniqueObject(student)\n newStudent = Student(1, \"Tudorr\")\n self.__repo.updateObject(newStudent.getID(), newStudent)\n students = self.__repo.getAllObjects()\n assert students[0].getName() == \"Tudorr\"\n\n def test_removeStudent_correctRemoval(self):\n self.__repo = Repo()\n student = Student(1, \"Tudor\")\n self.__repo.addUniqueObject(student)\n self.__repo.removeObject(student.getID())\n assert len(self.__repo.getAllObjects()) == 0\n\n\nclass disciplineTests(unittest.TestCase):\n\n def test_disciplineID_expectedID(self):\n discipline = Discipline(1, \"Biology\")\n self.assertTrue(discipline.getID() == 1)\n\n def test_disciplineName_expectedName(self):\n discipline = Discipline(1, \"Biology\")\n self.assertTrue(discipline.getName() == \"Biology\")\n\n def test_addDiscipline_duplicateID_RepoError(self):\n self.__repo = Repo()\n assert len(self.__repo.getAllObjects()) == 0\n discipline = Discipline(1, \"Biology\")\n self.__repo.addUniqueObject(discipline)\n try:\n duplicateDiscipline = Student(1, \"History\")\n self.__repo.addUniqueObject(duplicateDiscipline)\n assert False\n except RepoError as error:\n print(str(error))\n assert len(self.__repo.getAllObjects()) == 1\n\n def test_addDiscipline_correctAdd(self):\n self.__repo = Repo()\n assert len(self.__repo.getAllObjects()) == 0\n discipline = Discipline(1, \"Tudor\")\n self.__repo.addUniqueObject(discipline)\n assert len(self.__repo.getAllObjects()) == 1\n\n def test_updateDiscipline_correctUpdate(self):\n self.__repo = Repo()\n discipline = Discipline(1, \"Biology\")\n self.__repo.addUniqueObject(discipline)\n newDiscipline = Discipline(1, \"Biologyy\")\n self.__repo.updateObject(newDiscipline.getID(), newDiscipline)\n students = self.__repo.getAllObjects()\n assert students[0].getName() == \"Biologyy\"\n\n def test_removeDiscipline_correctRemoval(self):\n self.__repo = Repo()\n discipline = Discipline(1, \"Biology\")\n self.__repo.addUniqueObject(discipline)\n self.__repo.removeObject(discipline.getID())\n assert len(self.__repo.getAllObjects()) == 0\n\n\nclass gradeTests(unittest.TestCase):\n\n def test_gradeStudentID_expectedID(self):\n grade = Grade(1, 1, 10)\n self.assertTrue(grade.getStudentID() == 1)\n\n def test_gradeDisciplineID_expectedID(self):\n grade = Grade(1, 2, 10)\n self.assertTrue(grade.getDisciplineID() == 2)\n\n def test_gradeValue_expectedValue(self):\n grade = Grade(1, 1, 10)\n self.assertTrue(grade.getGrade() == 10)\n\n\nif __name__ == \"__main__\":\n unittest.main()\n"
},
{
"alpha_fraction": 0.7763810753822327,
"alphanum_fraction": 0.7786966562271118,
"avg_line_length": 47.75806427001953,
"blob_id": "afb356e863bc8824991e662c2aede0d88079ae96",
"content_id": "e75c13dd194ada60a3e5ae5c13e4f4db76c31b47",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3023,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 62,
"path": "/main.py",
"repo_name": "VieruTudor/Assignment-6-8",
"src_encoding": "UTF-8",
"text": "from UI import Console\nfrom service import serviceStudents, serviceDisciplines, serviceGrades\nfrom validators import studentValidator, disciplineValidator, gradeValidator\nfrom repo import *\nfrom entities import *\nfrom undoRepo import *\n\nwith open(\"settings.txt\", 'r') as readSettings:\n lines = readSettings.readlines()\n settings = []\n for line in lines:\n line = line.split('=')\n line[1] = line[1].replace(\"\\n\", \"\")\n settings.append(line[1])\n\nsetting = settings[0]\nstudentsFile = settings[1]\ndisciplinesFile = settings[2]\ngradesFile = settings[3]\n\nif setting == \"inmemory\":\n undo = Undo()\n serviceStudentValidator = studentValidator()\n serviceDisciplineValidator = disciplineValidator()\n serviceGradeValidator = gradeValidator()\n studentsRepo = Repo()\n disciplinesRepo = Repo()\n gradesRepo = Repo()\n gradesService = serviceGrades(undo, studentsRepo, disciplinesRepo, gradesRepo, gradeValidator)\n studentsService = serviceStudents(undo, studentsRepo, serviceStudentValidator, gradesService)\n disciplinesService = serviceDisciplines(undo, disciplinesRepo, serviceDisciplineValidator, gradesService)\n UIConsole = Console(studentsService, disciplinesService, gradesService, undo)\n UIConsole.initLists()\n UIConsole.run()\n\nif setting == \"textfiles\":\n undo = Undo()\n serviceStudentValidator = studentValidator()\n serviceDisciplineValidator = disciplineValidator()\n serviceGradeValidator = gradeValidator()\n studentsRepo = FileRepo(studentsFile, Student.readFromFile, Student.writeToFile)\n disciplinesRepo = FileRepo(disciplinesFile, Discipline.readFromFile, Discipline.writeToFile)\n gradesRepo = FileRepo(gradesFile, Grade.readFromFile, Grade.writeToFile)\n gradesService = serviceGrades(undo, studentsRepo, disciplinesRepo, gradesRepo, gradeValidator)\n studentsService = serviceStudents(undo, studentsRepo, serviceStudentValidator, gradesService)\n disciplinesService = serviceDisciplines(undo, disciplinesRepo, serviceDisciplineValidator, gradesService)\n UIConsole = Console(studentsService, disciplinesService, gradesService, undo)\n UIConsole.run()\n\nif setting == \"binaryfiles\":\n undo = Undo()\n serviceStudentValidator = studentValidator()\n serviceDisciplineValidator = disciplineValidator()\n serviceGradeValidator = gradeValidator()\n studentsRepo = BinaryRepo(studentsFile, Student.readFromFile, Student.writeToFile)\n disciplinesRepo = BinaryRepo(disciplinesFile, Discipline.readFromFile, Discipline.writeToFile)\n gradesRepo = BinaryRepo(gradesFile, Grade.readFromFile, Discipline.writeToFile)\n gradesService = serviceGrades(undo, studentsRepo, disciplinesRepo, gradesRepo, gradeValidator)\n studentsService = serviceStudents(undo, studentsRepo, serviceStudentValidator, gradesService)\n disciplinesService = serviceDisciplines(undo, disciplinesRepo, serviceDisciplineValidator, gradesService)\n UIConsole = Console(studentsService, disciplinesService, gradesService, undo)\n UIConsole.run()\n"
},
{
"alpha_fraction": 0.5447196364402771,
"alphanum_fraction": 0.5480559468269348,
"avg_line_length": 42.05524826049805,
"blob_id": "0bd21a18b42afb4c400988e1466757efba08ad86",
"content_id": "49e761e37dff049603735a9726710e66c69d7903",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15586,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 362,
"path": "/UI.py",
"repo_name": "VieruTudor/Assignment-6-8",
"src_encoding": "UTF-8",
"text": "from exceptions import *\n\n\n# Checks if the provided input is a number, throws an exception otherwise\ndef numericalTypeCheck(inputNumber):\n try:\n inputNumber = int(inputNumber)\n except ValueError:\n raise UIError(\"Please insert a numerical value\")\n\n\n# Class managing the UI of the program\nclass Console(object):\n def __init__(self, serviceStudents, serviceDisciplines, serviceGrades, serviceUndo):\n self.__serviceStudents = serviceStudents\n self.__serviceDisciplines = serviceDisciplines\n self.__serviceGrades = serviceGrades\n self.__serviceUndo = serviceUndo\n\n # Randomly generates entries for students, disciplines and grades\n def initLists(self):\n self.__serviceStudents.generateStudents()\n self.__serviceDisciplines.generateDisciplines()\n self.__serviceGrades.generateGrades()\n\n # Prints the UI menu\n @staticmethod\n def __printMenu():\n print(\"1. Student commands\\n\"\n \"2. Discipline commands\\n\"\n \"3. Grade commands\\n\"\n \"4. Undo last action\\n\"\n \"5. Redo last action\\n\"\n \"6. Exit program\")\n\n def userInterface_undo(self):\n try:\n self.__serviceUndo.undoFunction()\n except Exception as ex:\n print(ex)\n\n def userInterface_redo(self):\n try:\n self.__serviceUndo.redoFunction()\n except Exception as ex:\n print(ex)\n\n # region STUDENT METHODS\n # Takes the parameters given by the user, checks for empty input and numerical types and passes them to service\n # for the adding function\n def __UIAddStudent(self, studentID, studentName):\n if studentID == \"\" or studentName == \"\":\n raise UIError(\"Please don't leave any fields empty\")\n try:\n numericalTypeCheck(studentID)\n studentID = int(studentID)\n self.__serviceStudents.addStudent(studentID, studentName)\n except UIError as error:\n print(str(error))\n\n # Takes parameters from the user input, checks them and sends them to the service for the update function\n def __UIUpdateStudent(self, studentID, studentNewName):\n if studentID == \"\" or studentNewName == \"\":\n raise UIError(\"Please don't leave any fields empty\")\n try:\n numericalTypeCheck(studentID)\n studentID = int(studentID)\n self.__serviceStudents.updateStudent(studentID, studentNewName)\n except UIError as error:\n print(str(error))\n\n # Takes parameter from user, checks it and sends it to the service for the remove function\n def __UIRemoveStudent(self, studentID):\n if studentID == \"\":\n raise UIError(\"Please don't leave the ID empty\")\n try:\n numericalTypeCheck(studentID)\n studentID = int(studentID)\n self.__serviceStudents.removeStudent(studentID)\n except UIError as error:\n print(str(error))\n\n # Gets the students list from the service and prints them\n def __UIListStudents(self):\n students = self.__serviceStudents.getStudents()\n for student in students:\n print(student)\n\n # Takes a student ID from the user, checks it, sends it to the service and gets the matching student back\n def __UISearchStudentByID(self, searchStudentID):\n if searchStudentID == \"\":\n raise UIError(\"Please don't leave the ID empty\")\n try:\n numericalTypeCheck(searchStudentID)\n searchStudentID = int(searchStudentID)\n print(self.__serviceStudents.searchStudentByID(searchStudentID))\n except UIError as error:\n print(str(error))\n\n # Takes a student partial or full name from the user, checks it and sends it to service, getting back a list\n # containing the results\n def __UISearchStudentsByName(self, searchStudentName):\n if searchStudentName == \"\":\n raise UIError(\"Please don't leave the name empty\")\n searchMatches = self.__serviceStudents.searchStudentsByName(searchStudentName)\n for student in searchMatches:\n print(student)\n\n # endregion\n\n # region DISCIPLINE METHODS\n\n # Takes the parameters given by the user, checks for empty input and numerical types and passes them to service\n # for the adding function\n def __UIAddDiscipline(self, disciplineID, disciplineName):\n if disciplineID == \"\" or disciplineName == \"\":\n raise UIError(\"Please don't leave any fields empty\")\n try:\n numericalTypeCheck(disciplineID)\n disciplineID = int(disciplineID)\n self.__serviceDisciplines.addDiscipline(disciplineID, disciplineName)\n except UIError as error:\n print(str(error))\n\n # Takes parameters from the user input, checks them and sends them to the service for the update function\n def __UIUpdateDiscipline(self, disciplineID, disciplineNewName):\n if disciplineID == \"\" or disciplineNewName == \"\":\n raise UIError(\"Please don't leave any fields empty\")\n try:\n numericalTypeCheck(disciplineID)\n disciplineID = int(disciplineID)\n self.__serviceDisciplines.updateDiscipline(disciplineID, disciplineNewName)\n except UIError as error:\n print(str(error))\n\n # Takes parameter from user, checks it and sends it to the service for the remove function\n def __UIRemoveDiscipline(self, disciplineID):\n if disciplineID == \"\":\n raise UIError(\"Please don't leave the ID empty\")\n try:\n numericalTypeCheck(disciplineID)\n disciplineID = int(disciplineID)\n self.__serviceDisciplines.removeDiscipline(disciplineID)\n except UIError as error:\n print(str(error))\n\n # Gets the disciplines list from the service and prints them\n def __UIListDisciplines(self):\n disciplines = self.__serviceDisciplines.getDisciplines()\n for discipline in disciplines:\n print(discipline)\n\n # Takes a discipline partial or full name from the user, checks it and sends it to service, getting back a list\n # containing the results\n def __UISearchDisciplinesByName(self, searchDisciplineName):\n if searchDisciplineName == \"\":\n raise UIError(\"Please don't leave the name empty\")\n searchMatches = self.__serviceDisciplines.searchDisciplinesByName(searchDisciplineName)\n for discipline in searchMatches:\n print(discipline)\n\n # Takes a discipline ID from the user, checks it, sends it to the service and gets the matching discipline back\n def __UISearchDisciplineByID(self, searchDisciplineID):\n if searchDisciplineID == \"\":\n raise UIError(\"Please don't leave the ID empty\")\n try:\n numericalTypeCheck(searchDisciplineID)\n searchDisciplineID = int(searchDisciplineID)\n print(self.__serviceDisciplines.searchDisciplineByID(searchDisciplineID))\n except UIError as error:\n print(str(error))\n\n # endregion\n\n # region GRADE METHODS\n\n # Takes parameters from the user, checks them and passes them to the service for the adding function\n def __UIAddGrade(self, studentID, disciplineID, gradeValue):\n if studentID == \"\" or disciplineID == \"\" or gradeValue == \"\":\n raise UIError(\"Please don't leave any fields empty\")\n try:\n numericalTypeCheck(studentID)\n studentID = int(studentID)\n numericalTypeCheck(disciplineID)\n disciplineID = int(disciplineID)\n numericalTypeCheck(gradeValue)\n gradeValue = int(gradeValue)\n self.__serviceGrades.addGrade(studentID, disciplineID, gradeValue)\n except UIError as error:\n print(str(error))\n\n # Gets the list of grades from the service and prints them\n def __UIListGrades(self):\n grades = self.__serviceGrades.getGrades()\n for grade in grades:\n print(grade)\n\n # Gets the list of failing students and prints them in the form [Student ID, Discipline, Grade]\n def __UIFailingStudents(self):\n failingStudents = self.__serviceGrades.studentsFailing()\n print(failingStudents)\n\n # Gets the list of students sorted descending by their average grade on all disciplines\n def __UIStudentsRankings(self):\n studentsRankings = self.__serviceGrades.studentsSituation()\n print(studentsRankings)\n\n # Gets the list of disciplines ranked by the average grade received by all students enrolled on that discipline\n def __UIDisciplinesRankings(self):\n disciplinesRankings = self.__serviceGrades.disciplinesRankings()\n print(disciplinesRankings)\n\n # endregion\n\n def run(self):\n while True:\n self.__printMenu()\n command = input(\">>>\")\n command.strip()\n if command == \"1\":\n print(\"1. Add student.\\n\"\n \"2. Update student.\\n\"\n \"3. Remove student.\\n\"\n \"4. List students.\\n\"\n \"5. Search student by ID.\\n\"\n \"6. Search student(s) by name.\\n\"\n \"7. Exit program.\")\n option = input(\">>>\")\n if option == \"1\":\n try:\n studentID = input(\"Insert student's ID (unique) : \")\n studentName = input(\"Insert student's name : \")\n self.__UIAddStudent(studentID, studentName)\n except RepoError as error:\n print(str(error))\n except UIError as error:\n print(str(error))\n except ValidError as error:\n print(str(error))\n if option == \"2\":\n try:\n studentID = input(\"Insert student ID to be updated : \")\n studentNewName = input(\"Insert student's new name : \")\n self.__UIUpdateStudent(studentID, studentNewName)\n except RepoError as error:\n print(str(error))\n except UIError as error:\n print(str(error))\n except ValidError as error:\n print(str(error))\n if option == \"3\":\n try:\n studentID = input(\"Insert student ID to be removed : \")\n self.__UIRemoveStudent(studentID)\n except RepoError as error:\n print(str(error))\n except UIError as error:\n print(str(error))\n if option == \"4\":\n self.__UIListStudents()\n if option == \"5\":\n try:\n studentID = input(\"Search by student ID : \")\n self.__UISearchStudentByID(studentID)\n except RepoError as error:\n print(str(error))\n except UIError as error:\n print(str(error))\n if option == \"6\":\n try:\n studentSearchName = input(\"Search by student name : \")\n self.__UISearchStudentsByName(studentSearchName)\n except RepoError as error:\n print(str(error))\n except UIError as error:\n print(str(error))\n if option == \"7\":\n return\n if command == \"2\":\n print(\"1. Add discipline.\\n\"\n \"2. Update discipline.\\n\"\n \"3. Remove discipline.\\n\"\n \"4. List disciplines.\\n\"\n \"5. Search discipline by ID.\\n\"\n \"6. Search discipline(s) by name.\\n\"\n \"7. Exit program.\")\n option = input(\">>>\")\n if option == \"1\":\n try:\n disciplineID = input(\"Insert discipline ID (unique) : \")\n disciplineName = input(\"Insert discipline name : \")\n self.__UIAddDiscipline(disciplineID, disciplineName)\n except RepoError as error:\n print(str(error))\n except UIError as error:\n print(str(error))\n except ValidError as error:\n print(str(error))\n if option == \"2\":\n try:\n disciplineID = input(\"Insert discipline ID to be updated : \")\n disciplineNewName = input(\"Insert discipline's new name : \")\n self.__UIUpdateDiscipline(disciplineID, disciplineNewName)\n except RepoError as error:\n print(str(error))\n except UIError as error:\n print(str(error))\n except ValidError as error:\n print(str(error))\n if option == \"3\":\n try:\n disciplineID = input(\"Insert discipline ID to be removed : \")\n self.__UIRemoveDiscipline(disciplineID)\n except RepoError as error:\n print(str(error))\n except UIError as error:\n print(str(error))\n if option == \"4\":\n self.__UIListDisciplines()\n if option == \"5\":\n try:\n disciplineID = input(\"Search by discipline ID : \")\n self.__UISearchDisciplineByID(disciplineID)\n except RepoError as error:\n print(str(error))\n if option == \"6\":\n try:\n disciplineName = input(\"Search discipline by name : \")\n self.__UISearchDisciplinesByName(disciplineName)\n except RepoError as error:\n print(str(error))\n if option == \"7\":\n return\n if command == \"3\":\n print(\"1. Grade a student.\\n\"\n \"2. View all grades.\\n\"\n \"3. Failing students.\\n\"\n \"4. Students rankings.\\n\"\n \"5. Disciplines rankings.\\n\"\n \"6. Exit program. \\n\")\n option = input(\">>>\")\n if option == \"1\":\n studentID = input(\"Insert student's ID : \")\n disciplineID = input(\"Insert the discipline's ID : \")\n gradeValue = input(\"Insert grade value : \")\n self.__UIAddGrade(studentID, disciplineID, gradeValue)\n if option == \"2\":\n self.__UIListGrades()\n if option == \"3\":\n self.__UIFailingStudents()\n if option == \"4\":\n self.__UIStudentsRankings()\n if option == \"5\":\n self.__UIDisciplinesRankings()\n if option == \"6\":\n return\n if command == \"4\":\n self.userInterface_undo()\n if command == \"5\":\n self.userInterface_redo()\n if command == \"6\":\n return\n"
},
{
"alpha_fraction": 0.5765143632888794,
"alphanum_fraction": 0.5797024369239807,
"avg_line_length": 26.28985595703125,
"blob_id": "27e8f2c479ddee38319f0f2ee1169647076b5cbe",
"content_id": "b284a864a1c356e253d0bd8effa5d16d9a9848fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1882,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 69,
"path": "/undoRepo.py",
"repo_name": "VieruTudor/Assignment-6-8",
"src_encoding": "UTF-8",
"text": "class Operation(object):\n def __init__(self, undoFunction, redoFunction):\n self._undo = undoFunction\n self._redo = redoFunction\n\n def undo(self):\n self._undo()\n\n def redo(self):\n self._redo()\n\n\nclass FunctionCall(object):\n def __init__(self, functionName, *functionParameters):\n self._function = functionName\n self._parameters = functionParameters\n\n def __call__(self):\n self.call()\n\n def call(self):\n self._function(*self._parameters)\n\nclass Undo(object):\n def __init__(self):\n self._history = []\n self._historyIndex = 0\n self._isUndo = False\n\n def recordOperation(self, operation):\n if self._isUndo:\n return\n if self._historyIndex == len(self._history):\n self._history.append(operation)\n else:\n self._history[self._historyIndex] = operation\n index = self._historyIndex + 1\n while index < len(self._history):\n self._history.pop(index)\n self._historyIndex += 1\n\n def undoFunction(self):\n if self._historyIndex <= 0:\n raise IndexError(\"Cannot undo more\")\n self._isUndo = True\n self._historyIndex -= 1\n self._history[self._historyIndex].undo()\n self._isUndo = False\n\n def redoFunction(self):\n if self._historyIndex == len(self._history):\n raise IndexError(\"No more redos\")\n self._isUndo = True\n self._history[self._historyIndex].redo()\n self._historyIndex += 1\n self._isUndo = False\n\n\nclass MultipleOperation(object):\n def __init__(self, *operations):\n self._operationList = operations\n\n def undo(self):\n for operation in self._operationList:\n operation.undo()\n\n def redo(self):\n for operation in self._operationList:\n operation.redo()"
}
] | 8 |
pythonghana/pyconghana2018
|
https://github.com/pythonghana/pyconghana2018
|
336d99c7463a3e2f489ddb0692e615e218482748
|
e73bb7443cfaaddfa2c1ce133077614abfb92ed5
|
88805a9f5ecd3d02b3ba19f823d35f37b182121a
|
refs/heads/master
| 2022-12-10T00:00:00.278920 | 2021-03-22T17:55:48 | 2021-03-22T17:55:48 | 117,557,092 | 3 | 3 | null | 2018-01-15T14:42:26 | 2022-10-26T10:50:20 | 2022-12-07T23:48:04 |
JavaScript
|
[
{
"alpha_fraction": 0.7481203079223633,
"alphanum_fraction": 0.7481203079223633,
"avg_line_length": 21.25,
"blob_id": "a9e0572c017e9d2741bd2039f61eca85afd7bf93",
"content_id": "64c459d2d2a41c29fbefb900c12ab4644329d917",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 266,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 12,
"path": "/faq/views.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom django.shortcuts import (\nrender_to_response\n)\nfrom django.template import RequestContext\n\n\n# Create your views here.\ndef faqs(request):\n context = {}\n template = 'faq.html'\n return render(request, template, context)"
},
{
"alpha_fraction": 0.4565751850605011,
"alphanum_fraction": 0.4764440655708313,
"avg_line_length": 60.037498474121094,
"blob_id": "3c861d4ecb428e8b55f16946710cfe22787f890d",
"content_id": "2ae9f044852e37573ef77be08d98e81168fd6de0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 4882,
"license_type": "no_license",
"max_line_length": 551,
"num_lines": 80,
"path": "/home/templates/ticket/ticket.html",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "{% extends \"base2.html\" %}\n{% load i18n %}\n{% block meta_title %}{% if page %}{{ page.meta_title }}{% else %}{% trans \"Tickets | Pycon Ghana 2018\" %}{% endif %}{% endblock %}\n.table {\n width: 100%;\n -webkit-overflow-scrolling: touch;\n overflow-x: auto;\n display: block;\n }\n{% block content %}\n\n<header id=\"top\" class=\"sub-header\">\n <div class=\"container\">\n </div>\n <!-- end .container -->\n </header><br><br>\n <!-- end .sub-header -->\n <!--\n Our Schedule\n ====================================== -->\n\n <section class=\"schedule\" id=\"schedule\">\n <div class=\"col-md-12\">\n <div class=\"panel panel-danger wow fadeInLeft\">\n <div class=\"container\">\n <h5 class=\"page-title wow fadeInDown\">Register for PyCon Ghana</h5><br>\n <div>\n <section class=\"section1\"><h5>Ticket Types</h5>\n <table class=\"table\" WIDTH=\"50%\" cellspacing=\"5\" cellpadding=\"2\">\n <tbody>\n <tr>\n <th><span>Conference registration</span></th>\n <th><span>Early Bird<sup>*</sup></span></th>\n <th><span>Regular</span></th>\n <!-- <th><span>On the day</span><br /> (cash only)</th> -->\n </tr>\n <tr>\n <td class=\"title\">Corporate</td><td>Ghs 130 - USD 28</td><td>Ghs 150 - USD 32</td><!-- <td>Ghs 170</td> -->\n </tr>\n <tr>\n <td class=\"title\">Individual</td><td>Ghs 80 - USD 17</td><td>Ghs 100 - USD 21</td><!-- <td>Ghs 120</td> -->\n </tr>\n <tr>\n <td class=\"title\">Student</td><td>Ghs 60 - USD 13</td><td>Ghs 80 - USD 17</td><!-- <td>Ghs 100</td> -->\n </tr>\n </tbody>\n </table>\n <p style=\"margin-top: 0.5em; font-size: small; color:#666;\"><b><sup>*</sup>USD rate used was 4.78 as of 28th June 2018 <br><sup>*</sup> Early Bird tickets are handled on a first come, first serve basis as we have a limit and it closes on the 1st of July 2018.</b></p>\n </section>\n <p>Please those within Ghana who would love to use Mobile Money can send it directly to this number <b>0546998280 (Name: Mannie Young )</b> Please send an sms to the same number using your <b>email address and Transaction Id</b> as your Reference.</p>\n\n\n <div align=\"center\">\n <a class=\"btn btn-default btn-xl wow zoomIn\" href=\"http://bit.ly/egopyconGH18\">RESERVE YOUR SEAT HERE</a>\n </div>\n\n\n\n <br><br>\n <section class=\"section1\"><h5>What does the cost include?</h5>\n <p>Registration costs go towards offsetting costs for catering, audio visual, recording, internet, and other miscellaneous costs. By offsetting those costs, we can offer attendees reasonable registration rates and offer a financial aid program to those that need it. Furthermore, the revenue that PyCon generates is used to run the Python Software Community in Ghana. It also includes a full breakfast, full lunch, and both morning and afternoon break refreshments on the two conference days (Friday and Saturday).</p>\n <br><h5>Corporate Rate</h5>\n <p>If your company is paying for you to attend PyConGH, you should register at the corporate rate. Government employees should also register at the corporate rate.</p>\n <br><h5>Individual Rate</h5>\n <p>If you are paying for yourself to attend PyConGH, feel free to come as an individual. Employees of non-profits may register at the individual rate.</p>\n <br><h5>Student Rate</h5>\n <p>This rate is for full-time students and scholars (please note student cards will be <strong>required</strong> during registration at the event, failure to present one requires payment for the individual ticket).</p>\n </section>\n\n </div>\n </div>\n <!-- end .container -->\n </div>\n </div>\n\n </section>\n <!-- end section.schedule -->\n\n\n{% endblock %}"
},
{
"alpha_fraction": 0.609555184841156,
"alphanum_fraction": 0.6606260538101196,
"avg_line_length": 32.72222137451172,
"blob_id": "3a4d1fec5819a8cf0f9367f4cea5b4f798f1ee4f",
"content_id": "8992540863725849aed09cdc8595b904013dfc4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 607,
"license_type": "no_license",
"max_line_length": 257,
"num_lines": 18,
"path": "/newsletter/migrations/0005_auto_20180421_2114.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-21 09:14\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('newsletter', '0004_auto_20180407_1043'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='submission',\n name='subscriptions',\n field=models.ManyToManyField(blank=True, db_index=True, help_text='If you select none, the system will automatically find the subscribers for you.', limit_choices_to={'subscribed': True}, to='newsletter.Subscription', verbose_name='recipients'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5308964252471924,
"alphanum_fraction": 0.5543951392173767,
"avg_line_length": 30.054054260253906,
"blob_id": "5dc846d68c18147c06fb0988d613eb79e03afb60",
"content_id": "274a2b0f007c8333d9e387c4fba5c2832b0dc416",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1151,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 37,
"path": "/talks/migrations/0004_auto_20180228_1035.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-02-28 10:35\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('talks', '0003_proposal_image'),\n ]\n\n operations = [\n migrations.RemoveField(\n model_name='proposal',\n name='image',\n ),\n migrations.AddField(\n model_name='proposal',\n name='email',\n field=models.EmailField(default='', help_text='We’ll keep it secret, for internal use only.', max_length=1024),\n ),\n migrations.AddField(\n model_name='proposal',\n name='extra_requirement',\n field=models.TextField(blank=True, default='', help_text='Anything else you want to tell us?.', null=True),\n ),\n migrations.AddField(\n model_name='proposal',\n name='name',\n field=models.CharField(default='', help_text='Your name', max_length=1024),\n ),\n migrations.AddField(\n model_name='proposal',\n name='url',\n field=models.URLField(default='', help_text='Got a video?'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6115702390670776,
"alphanum_fraction": 0.6677685976028442,
"avg_line_length": 32.61111068725586,
"blob_id": "70d035b5af5c95e9060fdba9671643b2c466e815",
"content_id": "fca4caf0cd916f26e7e6f6f29ba61284138c66d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 605,
"license_type": "no_license",
"max_line_length": 242,
"num_lines": 18,
"path": "/talks/migrations/0013_auto_20180419_1626.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-19 16:26\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('talks', '0012_auto_20180419_1622'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='proposal',\n name='Tell_the_audience_about_your_talk',\n field=models.TextField(help_text='Describe your Talk to the your targeted audience . Please include the requirements: libraries and Python version to be installed, required experience with topics/libraries, etc.', max_length=255),\n ),\n ]\n"
},
{
"alpha_fraction": 0.4867924451828003,
"alphanum_fraction": 0.6188679337501526,
"avg_line_length": 17.928571701049805,
"blob_id": "2586f785030881f843bc5623e2be1ec80562d5e4",
"content_id": "ab946767a4c5d58a910bd6c3efdbd14e3982a16f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 265,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 14,
"path": "/talks/migrations/0022_merge_20180428_1340.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-28 13:40\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('talks', '0021_proposal_email'),\n ('talks', '0018_auto_20180425_2338'),\n ]\n\n operations = [\n ]\n"
},
{
"alpha_fraction": 0.5004122257232666,
"alphanum_fraction": 0.5358614921569824,
"avg_line_length": 30.921052932739258,
"blob_id": "e6bc7dc551331bcdeb19ccb1b5460c275b1c9663",
"content_id": "26b4c089be66c3483bd04e55798b809878e43a94",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1215,
"license_type": "no_license",
"max_line_length": 197,
"num_lines": 38,
"path": "/sponsors/migrations/0002_auto_20180420_1950.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-20 19:50\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('sponsors', '0001_initial'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='sponsor',\n old_name='name',\n new_name='sponsor_name',\n ),\n migrations.RenameField(\n model_name='sponsor',\n old_name='url',\n new_name='sponsor_url',\n ),\n migrations.AddField(\n model_name='sponsor',\n name='contact_email',\n field=models.EmailField(default='', help_text='We’ll keep it secret, for internal use only.', max_length=1024),\n ),\n migrations.AddField(\n model_name='sponsor',\n name='contact_name',\n field=models.CharField(default='', max_length=200),\n ),\n migrations.AlterField(\n model_name='sponsor',\n name='category',\n field=models.CharField(choices=[('Bronze', 'Bronze - $500'), ('Silver', 'Silver - $1000'), ('Gold', 'Gold - $2500'), ('Diamond', 'Diamond - $3500'), ('Other', 'Other')], max_length=15),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6106489300727844,
"alphanum_fraction": 0.6672213077545166,
"avg_line_length": 32.38888931274414,
"blob_id": "8c2dc50131170d78b38637f3a97fe4d7e57ab39e",
"content_id": "716973e15c1a09809b66eb9f056c36c9e11b975a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 601,
"license_type": "no_license",
"max_line_length": 238,
"num_lines": 18,
"path": "/talks/migrations/0014_auto_20180419_1627.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-19 16:27\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('talks', '0013_auto_20180419_1626'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='proposal',\n name='Tell_the_audience_about_your_talk',\n field=models.TextField(help_text='Describe your Talk to your targeted audience . Please include the requirements: libraries and Python version to be installed, required experience with topics/libraries, etc.', max_length=255),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5137156844139099,
"alphanum_fraction": 0.5910224318504333,
"avg_line_length": 21.27777862548828,
"blob_id": "719d37780392b8d87f242e15c07dd8b7ae28fc77",
"content_id": "cb1dcc632dc0c86478fda93f233613d8a34f393c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 401,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 18,
"path": "/talks/migrations/0005_auto_20180228_1040.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-02-28 10:40\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('talks', '0004_auto_20180228_1035'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='proposal',\n old_name='extra_requirement',\n new_name='Anything_else_you_want_to_tell_us',\n ),\n ]\n"
},
{
"alpha_fraction": 0.708108127117157,
"alphanum_fraction": 0.708108127117157,
"avg_line_length": 19.66666603088379,
"blob_id": "d8c89af1f9a70ed682536cf15c8e1c3b6e4ab380",
"content_id": "5c03452b13c82cbfe9f7019f8f643ad208e832c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 185,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 9,
"path": "/support_us/views.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\n\n# Create your views here.\n\n\ndef support_us(request):\n context = {}\n template = 'support_us.html'\n return render(request, template, context)"
},
{
"alpha_fraction": 0.7884043455123901,
"alphanum_fraction": 0.7976544499397278,
"avg_line_length": 44.518798828125,
"blob_id": "f035fe46816470d3e16687ac4477bbb0f23e53ec",
"content_id": "5c687798ebfe17a0b415adf716650a9176b36ea6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6054,
"license_type": "no_license",
"max_line_length": 327,
"num_lines": 133,
"path": "/CONTRIBUTING.md",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Contributing\n\nWhen contributing to this repository, please first discuss the change you wish to make via issue,\nemail, or any other method with the owners of this repository before making a change.\n\nPlease note we have a code of conduct, please follow it in all your interactions with the project.\n\n## Before creating a Merge Request\n\n1. Make sure you have the most up to date code\n\nIf you haven't done so, please set upstream as described in [Gitlab Documentation](https://docs.gitlab.com/ce/workflow/forking_workflow.html)\n\nMake sure you do not have any uncommitted changes and rebase master with latest changes from upstream:\n\n```\ngit fetch upstream\ngit checkout master\ngit rebase upstream/master\n```\n\nNow you should rebase your branch with master, to receive the upstream changes\n\n```\ngit checkout branch\ngit rebase master\n```\n\n\nIn both cases, you can have conflicts:\n\n```\nerror: could not apply fa39187... something to add to patch A\n\nWhen you have resolved this problem, run \"git rebase --continue\".\nIf you prefer to skip this patch, run \"git rebase --skip\" instead.\nTo check out the original branch and stop rebasing, run \"git rebase --abort\".\nCould not apply fa39187f3c3dfd2ab5faa38ac01cf3de7ce2e841... Change fake file\n```\n\nHere, Git is telling you which commit is causing the conflict (fa39187). You're given three choices:\n\n* You can run `git rebase --abort` to completely undo the rebase. Git will return you to your branch's state as it was before git rebase was called.\n* You can run `git rebase --skip` to completely skip the commit. That means that none of the changes introduced by the problematic commit will be included. It is very rare that you would choose this option.\n* You can fix the conflict.\n\nTo fix the conflict, you can follow [the standard procedures for resolving merge conflicts from the command line](https://help.github.com/articles/resolving-a-merge-conflict-from-the-command-line). When you're finished, you'll need to call `git rebase --continue` in order for Git to continue processing the rest of the rebase.\n## Merge Request Process\n\n1. Ensure any install or build dependencies are removed before the end of the layer when doing a\n build.\n2. Update the [README.md](./README.md) with details of changes to the interface, this includes new environment\n variables, exposed ports, useful file locations and container parameters.\n3. Increase the version numbers in any examples files and the [README.md](./README.md) to the new version that this\n Merge Request would represent.\n4. You may merge the Merge Request in once you have the sign-off of two other developers, or if you\n do not have permission to do that, you may request the second reviewer to merge it for you.\n\n## Code of Conduct\n\n### Our Pledge\n\nIn the interest of fostering an open and welcoming environment, we as\ncontributors and maintainers pledge to making participation in our project and\nour community a harassment-free experience for everyone, regardless of age, body\nsize, disability, ethnicity, gender identity and expression, level of experience,\nnationality, personal appearance, race, religion, or sexual identity and\norientation.\n\n### Our Standards\n\nExamples of behavior that contributes to creating a positive environment\ninclude:\n\n* Using welcoming and inclusive language\n* Being respectful of differing viewpoints and experiences\n* Gracefully accepting constructive criticism\n* Focusing on what is best for the community\n* Showing empathy towards other community members\n\nExamples of unacceptable behavior by participants include:\n\n* The use of sexualized language or imagery and unwelcome sexual attention or\nadvances\n* Trolling, insulting/derogatory comments, and personal or political attacks\n* Public or private harassment\n* Publishing others' private information, such as a physical or electronic\n address, without explicit permission\n* Other conduct which could reasonably be considered inappropriate in a\n professional setting\n\n### Our Responsibilities\n\nProject maintainers are responsible for clarifying the standards of acceptable\nbehavior and are expected to take appropriate and fair corrective action in\nresponse to any instances of unacceptable behavior.\n\nProject maintainers have the right and responsibility to remove, edit, or\nreject comments, commits, code, wiki edits, issues, and other contributions\nthat are not aligned to this Code of Conduct, or to ban temporarily or\npermanently any contributor for other behaviors that they deem inappropriate,\nthreatening, offensive, or harmful.\n\n### Scope\n\nThis Code of Conduct applies both within project spaces and in public spaces\nwhen an individual is representing the project or its community. Examples of\nrepresenting a project or community include using an official project e-mail\naddress, posting via an official social media account, or acting as an appointed\nrepresentative at an online or offline event. Representation of a project may be\nfurther defined and clarified by project maintainers.\n\n### Enforcement\n\nInstances of abusive, harassing, or otherwise unacceptable behavior may be\nreported by contacting the project team at [INSERT EMAIL ADDRESS]. All\ncomplaints will be reviewed and investigated and will result in a response that\nis deemed necessary and appropriate to the circumstances. The project team is\nobligated to maintain confidentiality with regard to the reporter of an incident.\nFurther details of specific enforcement policies may be posted separately.\n\nProject maintainers who do not follow or enforce the Code of Conduct in good\nfaith may face temporary or permanent repercussions as determined by other\nmembers of the project's leadership.\n\n### Attribution\n\n* This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,\navailable at [http://contributor-covenant.org/version/1/4][version]\n* The contribution guide is adapted from [Good-CONTRIBUTING](https://gist.github.com/PurpleBooth/b24679402957c63ec426)\n\n[homepage]: http://contributor-covenant.org\n[version]: http://contributor-covenant.org/version/1/4/\n"
},
{
"alpha_fraction": 0.4940119683742523,
"alphanum_fraction": 0.5868263244628906,
"avg_line_length": 18.647058486938477,
"blob_id": "c4c006fc5b3d68dbd4c76550bba81f61fe8aa9b5",
"content_id": "69713cc9e13bedddeb6c34fa576c70081a49f03e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 334,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 17,
"path": "/registration/migrations/0010_remove_profile_avatar.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-28 18:08\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('registration', '0009_auto_20180428_1713'),\n ]\n\n operations = [\n migrations.RemoveField(\n model_name='profile',\n name='avatar',\n ),\n ]\n"
},
{
"alpha_fraction": 0.7099296450614929,
"alphanum_fraction": 0.7099296450614929,
"avg_line_length": 44.64285659790039,
"blob_id": "148a99d0cc396e08b10fe21a5184502252c9eb5d",
"content_id": "92e17f6841f396c2404eceedc42ab114fcb60bde",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1279,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 28,
"path": "/talks/urls.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "from rest_framework import routers\nfrom django.urls import include, path, re_path\nfrom talks.views import TalkViewsSets\nfrom django.conf.urls import url\nfrom django.contrib.auth.decorators import login_required\nfrom talks import views\n\n\napp_name = 'talks'\nrouter = routers.DefaultRouter()\nrouter.register(r'talks', TalkViewsSets)\n\nurlpatterns = [\n path('accepted_talks', views.AcceptedTalksView.as_view(), name='accepted_talks'),\n path('submit_talk', login_required(views.submit_talk), name='submit_talk'),\n re_path(r'^edit_talk/(?P<pk>\\d+)', login_required(views.TalkView.as_view()), name='edit_talk'),\n path('talk_list', login_required(views.TalkList.as_view()), name='talk_list'),\n re_path(r'^talk_details/(?P<pk>\\d+)', views.TalkDetailView.as_view(), name='talk_details'),\n path('submitted', login_required(views.SuccessView.as_view()), name='submitted'),\n path('uploads', views.home, name='home'),\n path('submit', views.submit, name='submit'),\n path('proposing_a_talk', views.proposing, name='proposing'),\n path('recording', views.recording, name='recording'),\n path('uploads_simple', views.simple_upload, name='simple_upload'),\n path('uploads_form', views.model_form_upload, name='model_form_upload'),\n ]\n\nurlpatterns += router.urls\n\n"
},
{
"alpha_fraction": 0.6260416507720947,
"alphanum_fraction": 0.6333333253860474,
"avg_line_length": 28.090909957885742,
"blob_id": "22d12ea98c16ef1a78d976eff488186e4b55e66b",
"content_id": "bc869f44184e7d697686e707c2bf5a5576dddb58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 962,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 33,
"path": "/newsletter/management/commands/submit_newsletter.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nactual sending of the submissions\n\"\"\"\nimport logging\n\nfrom django.core.management.base import BaseCommand\nfrom django.utils.translation import ugettext as _\n\nfrom newsletter.models import Submission\n\n\nclass Command(BaseCommand):\n help = _(\"Submit pending messages.\")\n\n def handle(self, *args, **options):\n # Setup logging based on verbosity: 1 -> INFO, >1 -> DEBUG\n verbosity = int(options['verbosity'])\n logger = logging.getLogger('newsletter')\n if verbosity == 0:\n logger.setLevel(logging.WARN)\n elif verbosity == 1: # default\n logger.setLevel(logging.INFO)\n elif verbosity > 1:\n logger.setLevel(logging.DEBUG)\n if verbosity > 2:\n logger = logging.getLogger()\n logger.setLevel(logging.DEBUG)\n\n logger.info(_('Submitting queued newsletter mailings'))\n\n # Call submission\n Submission.submit_queue()\n"
},
{
"alpha_fraction": 0.6097205877304077,
"alphanum_fraction": 0.6103026866912842,
"avg_line_length": 39.89285659790039,
"blob_id": "765112d1f4fecc3307ada2b2c0eb4595ee0f4dfc",
"content_id": "b20cc6fcb8b7e0c60105f0338de332666484545b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3436,
"license_type": "permissive",
"max_line_length": 134,
"num_lines": 84,
"path": "/newsletter/static/js/plugins/directions.js",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "\nvar directionsDisplay;\nvar directionsService = new google.maps.DirectionsService();\n\nvar map_id = $(\"#map_canvas\");\n\nvar map_lat = map_id.attr('data-mapLat');\nvar map_lon = map_id.attr('data-mapLon');\nvar map_title = map_id.attr('data-mapTitle');\n\nfunction initialize() {\n\n var latlng = new google.maps.LatLng(map_lat, map_lon);\n // set direction render options\n var rendererOptions = {\n draggable: true\n };\n directionsDisplay = new google.maps.DirectionsRenderer(rendererOptions);\n var myOptions = {\n zoom: 14,\n center: latlng,\n mapTypeId: google.maps.MapTypeId.ROADMAP,\n mapTypeControl: false\n };\n // add the map to the map placeholder\n var map = new google.maps.Map(document.getElementById(\"map_canvas\"), myOptions);\n directionsDisplay.setMap(map);\n directionsDisplay.setPanel(document.getElementById(\"directionsPanel\"));\n // Add a marker to the map for the end-point of the directions.\n var marker = new google.maps.Marker({\n position: latlng,\n map: map,\n title: map_title\n });\n}\n\nfunction calcRoute() {\n initialize();\n // get the travelmode, startpoint and via point from the form \n var travelMode = $('input[name=\"travelMode\"]:checked').val();\n var start = $(\"#routeStart\").val();\n var via = $(\"#routeVia\").val();\n if (travelMode == 'TRANSIT') {\n via = ''; // if the travel mode is transit, don't use the via waypoint because that will not work\n }\n var end = (map_lat + ',' + map_lon); //endpoint is a geolocation\n var waypoints = []; // init an empty waypoints array\n if (via != '') {\n // if waypoints (via) are set, add them to the waypoints array\n waypoints.push({\n location: via,\n stopover: true\n });\n }\n var request = {\n origin: start,\n destination: end,\n waypoints: waypoints,\n unitSystem: google.maps.UnitSystem.IMPERIAL,\n travelMode: google.maps.DirectionsTravelMode[travelMode]\n };\n directionsService.route(request, function(response, status) {\n if (status == google.maps.DirectionsStatus.OK) {\n $('#directionsPanel').empty(); // clear the directions panel before adding new directions\n directionsDisplay.setDirections(response);\n } else {\n // alert an error message when the route could nog be calculated.\n if (status == 'ZERO_RESULTS') {\n alert('No route could be found between the origin and destination.');\n } else if (status == 'UNKNOWN_ERROR') {\n alert('A directions request could not be processed due to a server error. The request may succeed if you try again.');\n } else if (status == 'REQUEST_DENIED') {\n alert('This webpage is not allowed to use the directions service.');\n } else if (status == 'OVER_QUERY_LIMIT') {\n alert('The webpage has gone over the requests limit in too short a period of time.');\n } else if (status == 'NOT_FOUND') {\n alert('At least one of the origin, destination, or waypoints could not be geocoded.');\n } else if (status == 'INVALID_REQUEST') {\n alert('The DirectionsRequest provided was invalid.');\n } else {\n alert(\"There was an unknown error in your request. Requeststatus: nn\" + status);\n }\n }\n });\n}\n"
},
{
"alpha_fraction": 0.6928571462631226,
"alphanum_fraction": 0.6928571462631226,
"avg_line_length": 19.14285659790039,
"blob_id": "863ddeff25b79d8fb3262cddc8b69f9d7f8adde9",
"content_id": "c5e6705bf4c20ff347d4d622650ab5e4729c9e4e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 140,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 7,
"path": "/support_us/urls.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom . import views\n\napp_name = 'support_us'\nurlpatterns = [\n path('', views.support_us,name='support_us')\n]"
},
{
"alpha_fraction": 0.5108038187026978,
"alphanum_fraction": 0.5315471291542053,
"avg_line_length": 38.86206817626953,
"blob_id": "91e1074347bf2a90a304f4c92915678aa70b7c77",
"content_id": "a3a5e2d1a1bf589cd7384d0319f930416fdc1176",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1157,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 29,
"path": "/sponsors/models.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n\nclass Sponsor(models.Model):\n SPONSOR_PACKAGES = (('Bronze', 'Bronze - $500'),\n ('Silver', 'Silver - $1000'),\n ('Gold', 'Gold - $2500'),\n ('Diamond', 'Diamond - $3500'),\n ('Special', 'Special'),\n ('Other', 'Other'),\n )\n\n SPONSOR_TYPE =(('C', 'Corporate Sponsor'),\n ('S', 'Special Sponsor'),\n ('I', 'Individual Sponsor'),)\n\n name = models.CharField(\"sponsor name\", max_length=200)\n category = models.CharField(max_length=15, choices=SPONSOR_PACKAGES)\n logo = models.ImageField(upload_to=\"sponsors/\",max_length=255, blank=True, null=True)\n type = models.CharField(\"sponsor type\", max_length=1, choices=SPONSOR_TYPE)\n url = models.URLField(default='', help_text='Link to Sponsor website', blank=True,)\n description = models.TextField(default='', help_text = \"Description of the Sponsor\", blank=True, null=True\n )\n\n class Meta:\n managed = True\n\n def __str__(self):\n return self.name\n\n"
},
{
"alpha_fraction": 0.6908745169639587,
"alphanum_fraction": 0.6984791159629822,
"avg_line_length": 45.157894134521484,
"blob_id": "45e220c1529d260a69b8607e357914c48926fbb3",
"content_id": "e6c2e9d9556f34f3d467e7ce4f65bb9be0cbf75b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2630,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 57,
"path": "/PyConGhana/urls.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "\"\"\"PyConGhana URL Configuration\n\nThe `urlpatterns` list routes URLs to views. For more information please see:\n https://docs.djangoproject.com/en/2.0/topics/http/urls/\nExamples:\nFunction views\n 1. Add an import: from my_app import views\n 2. Add a URL to urlpatterns: path('', views.home, name='home')\nClass-based views\n 1. Add an import: from other_app.views import Home\n 2. Add a URL to urlpatterns: path('', Home.as_view(), name='home')\nIncluding another URLconf\n 1. Import the include() function: from django.urls import include, path\n 2. Add a URL to urlpatterns: path('blog/', include('blog.urls'))\n\"\"\"\nfrom django.conf import settings\nfrom django.conf.urls.static import static\nfrom django.contrib import admin\nfrom django.urls import include, path\nfrom django.conf.urls import handler404, handler500\nfrom jet.dashboard.dashboard_modules import google_analytics_views\n\nfrom home import views\n\nurlpatterns = [\n path('', include('home.urls', namespace='home')),\n path('about/', include('about.urls', namespace='about')),\n path('accounts/', include('registration.backends.default.urls')),\n #path('accounts/', include('registration.backends.simple.urls')),\n path('profile/', include('registration.urls', namespace='profiles')),\n # path('accounts/', include('accounts.urls', namespace='accounts')),\n path('avatar/', include('avatar.urls')),\n path('coc/', include('coc.urls', namespace='coc')),\n # path('contact/', include('contact.urls', namespace='contact')),\n path('schedule/', include('schedule.urls', namespace='schedule')),\n path('support_us/', include('support_us.urls', namespace='support_us')),\n path('sponsors/', include('sponsors.urls', namespace='sponsors')),\n path('prospectus/', include('sponsors.urls', namespace='Prospectus')),\n path('talks/', include('talks.urls', namespace='talks')),\n path('privacypolicy/', include('privacypolicy.urls', namespace='privacypolicy')),\n path('newsletter/', include('newsletter.urls')),\n path('tinymce/', include('tinymce.urls')),\n path('jet/', include('jet.urls', 'jet')), # Django JET URLS\n path('jet/dashboard/', include('jet.dashboard.urls', 'jet-dashboard')),\n path('faq/', include('faq.urls', namespace='faqs')),\n path('pyconorganizers/', admin.site.urls),\n]\n\nif settings.DEBUG:\n urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)\n urlpatterns += static(settings.STATIC_URL, document_root=settings.STATIC_ROOT)\n\n\n# Adds ``STATIC_URL`` to the context of error pages, so that error\n# pages can use JS, CSS and images.\n\nhandler404 = 'home.views.handler404'"
},
{
"alpha_fraction": 0.5492662191390991,
"alphanum_fraction": 0.6205450892448425,
"avg_line_length": 25.5,
"blob_id": "5707b8f669d3775a8e47e00e2ce5a0a7d5f9b8ed",
"content_id": "347eebbb9787e8ed7a5dd147cc0f6f405585777e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 477,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 18,
"path": "/registration/migrations/0008_auto_20180428_1710.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-28 17:10\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('registration', '0007_auto_20180428_1653'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='profile',\n name='avatar',\n field=models.ImageField(blank=True, default='profile/avatar.jpg', max_length=255, null=True, upload_to='profile/avatars/'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5427394509315491,
"alphanum_fraction": 0.5849639773368835,
"avg_line_length": 33.67856979370117,
"blob_id": "4c511232d50df196139944f9f4b813e6ad0f7e1a",
"content_id": "35131b64a247a05bdaed2e7cb2c70c0a48d07357",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 973,
"license_type": "no_license",
"max_line_length": 169,
"num_lines": 28,
"path": "/talks/migrations/0019_auto_20180426_0941.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-26 09:41\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('talks', '0018_auto_20180426_0030'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='proposal',\n name='email',\n field=models.EmailField(default='', help_text='We’ll keep it secret, for internal use only.', max_length=1024),\n ),\n migrations.AddField(\n model_name='proposal',\n name='url',\n field=models.URLField(default='', help_text='Got a video? If you have a recording of you giving a talk or leading a workshop, you can paste the link here.'),\n ),\n migrations.AlterField(\n model_name='proposal',\n name='talk_type',\n field=models.CharField(choices=[('Short Talk', 'Short Talk - 30 mins'), ('Long Talk', 'Long Talk - 45 mins')], max_length=20),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7403433322906494,
"alphanum_fraction": 0.7403433322906494,
"avg_line_length": 22.350000381469727,
"blob_id": "9058ee32c3f5fc744e2e08841d9e8c557773855c",
"content_id": "cc16e326dcb65a47cca51931e75ad0370b345fd5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 466,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 20,
"path": "/tickets/views.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\n\n# Create your views here.\nfrom django.shortcuts import render\nfrom django.shortcuts import (\nrender_to_response\n)\nfrom django.template import RequestContext\n\n\n# Create your views here.\ndef ticket(request):\n context = {}\n template = 'ticket/ticket.html'\n return render(request, template, context)\n\ndef register(request):\n context = {}\n template = 'ticket/register.html'\n return render(request, template, context)"
},
{
"alpha_fraction": 0.27721866965293884,
"alphanum_fraction": 0.28270813822746277,
"avg_line_length": 51.0476188659668,
"blob_id": "ef4b7a8db6f42e175d982092d1178fc5abd3d82b",
"content_id": "a68e18ae3d82a309413d2dd411f58f6a342c9f38",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 2186,
"license_type": "no_license",
"max_line_length": 165,
"num_lines": 42,
"path": "/templates/registration/password_reset_form.html",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "{% extends \"registration/log_base.html\" %}\n{% load i18n static crispy_forms_tags %}\n\n{% block title %}{% trans \"Reset password\" %}{% endblock %}\n\n{% block content %}\n\n<div class=\"col-md-6 col-md-offset-3\"><h3>Password Reset</h3><p>\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t {% blocktrans %}\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t Forgot your password? Enter your email in the form below and we'll send you instructions for creating a new one.\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t {% endblocktrans %}\n\t\t\t\t\t\t\t\t\t\t\t\t\t\t</p>\n <div class=\"thumbnail wow fadeInUp\">\n <div class=\"caption\">\n <div class=\"row\">\n <div class=\"col-md-3\">\n \t\n </div>\n <div class=\"col-md-6\">\n <br>\n <form class=\"form col-md-12\" margin=\"auto\" method=\"post\" action=\"\">\n {% csrf_token %}\n <div class=\"row\">\n <div class=\"form-group\">\n <div class=\"row\"> {{ form|crispy }}\n </div>\n </div>\n <div class=\"form-group col-md-12\">\n <button type=\"submit\" class=\"btn btn-success btn-lg\" value=\"{% trans 'Log in' %}\">Reset password</button>\n </div>\n </form>\n\n\n </div>\n </div>\n </div>\n </div>\n </div>\n{% endblock %}\n\n\n{# This is used by django.contrib.auth #}\n"
},
{
"alpha_fraction": 0.5899705290794373,
"alphanum_fraction": 0.605088472366333,
"avg_line_length": 46.578948974609375,
"blob_id": "92925c93ecb1ec3055cd7b8317a71465eedb8321",
"content_id": "eb00bbc714a06614f76acc79a55f78e3c369d331",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2712,
"license_type": "no_license",
"max_line_length": 222,
"num_lines": 57,
"path": "/registration/migrations/0001_initial.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-22 10:24\n\nfrom django.conf import settings\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n migrations.swappable_dependency(settings.AUTH_USER_MODEL),\n ('auth', '0009_alter_user_last_name_max_length'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Profile',\n fields=[\n ('name', models.CharField(default='', max_length=30)),\n ('surname', models.CharField(default='', max_length=30)),\n ('user', models.OneToOneField(on_delete=django.db.models.deletion.CASCADE, primary_key=True, serialize=False, to=settings.AUTH_USER_MODEL)),\n ('bio', models.TextField(help_text='Tell us a bit about yourself and your work with Python', max_length=500)),\n ('city', models.CharField(max_length=30)),\n ('country', models.CharField(default='', max_length=30)),\n ('contact_number', models.CharField(help_text='Please include your country code.', max_length=16, null=True)),\n ('website', models.CharField(blank=True, help_text='Your website/blog URL.', max_length=255, null=True)),\n ('twitter_handle', models.CharField(blank=True, max_length=15, null=True)),\n ('github_username', models.CharField(blank=True, max_length=32, null=True)),\n ],\n ),\n migrations.CreateModel(\n name='RegistrationProfile',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('activation_key', models.CharField(max_length=40, verbose_name='activation key')),\n ('activated', models.BooleanField(default=False)),\n ],\n options={\n 'verbose_name': 'registration profile',\n 'verbose_name_plural': 'registration profiles',\n },\n ),\n migrations.CreateModel(\n name='SupervisedRegistrationProfile',\n fields=[\n ('registrationprofile_ptr', models.OneToOneField(auto_created=True, on_delete=django.db.models.deletion.CASCADE, parent_link=True, primary_key=True, serialize=False, to='registration.RegistrationProfile')),\n ],\n bases=('registration.registrationprofile',),\n ),\n migrations.AddField(\n model_name='registrationprofile',\n name='user',\n field=models.OneToOneField(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL, verbose_name='user'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6962962746620178,
"alphanum_fraction": 0.6962962746620178,
"avg_line_length": 18.428571701049805,
"blob_id": "ae478c568f5c30dd9517286f2231de52f151e422",
"content_id": "87adc6140b4e7a076e4edc5971ee2a0c475dedcb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 135,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 7,
"path": "/schedule/urls.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom . import views\n\napp_name = 'schedule'\nurlpatterns = [\n path('', views.schedule, name='schedule')\n]"
},
{
"alpha_fraction": 0.4911080598831177,
"alphanum_fraction": 0.5608755350112915,
"avg_line_length": 30.782608032226562,
"blob_id": "1fbdd7bd6787ddf9cf583474aa9c0b1780ecc292",
"content_id": "e5917057cb3f7cf27a7b634e58915f94ad17c3ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 731,
"license_type": "no_license",
"max_line_length": 221,
"num_lines": 23,
"path": "/sponsors/migrations/0004_auto_20180428_1543.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-28 15:43\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('sponsors', '0003_auto_20180421_1003'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='sponsor',\n name='description',\n field=models.CharField(default='', max_length=200),\n ),\n migrations.AlterField(\n model_name='sponsor',\n name='category',\n field=models.CharField(choices=[('Bronze', 'Bronze - $500'), ('Silver', 'Silver - $1000'), ('Gold', 'Gold - $2500'), ('Diamond', 'Diamond - $3500'), ('Other', 'Other'), ('Special', 'Special')], max_length=15),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5509259104728699,
"alphanum_fraction": 0.6018518805503845,
"avg_line_length": 23,
"blob_id": "ef24dd0f41284071ae593bf1f11ac7bf4cd5fc62",
"content_id": "e8bd536b24b04a6e5a6bcffb533abb12feeb4d6e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 432,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 18,
"path": "/registration/migrations/0004_profile_avatar.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-28 16:07\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('registration', '0003_remove_profile_avatar'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='profile',\n name='avatar',\n field=models.ImageField(blank=True, max_length=255, null=True, upload_to=''),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6606273055076599,
"alphanum_fraction": 0.6696102023124695,
"avg_line_length": 24.75686264038086,
"blob_id": "60eecd79584943ce20c194e4affd6586062947fd",
"content_id": "bf6865787b9d431e1d1ad19db766e4e0b88ec4fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6568,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 255,
"path": "/PyConGhana/settings.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "\"\"\"\nDjango settings for PyConGhana project.\n\nGenerated by 'django-admin startproject' using Django 2.0.1.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/2.0/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/2.0/ref/settings/\n\"\"\"\nimport os\nfrom .secrets import *\n\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n\n\n# Quick-start development settingss - unsuitable for production\n# See https://docs.djangoproject.com/en/2.0/howto/deployment/checklist/\n\n\nDEBUG = False\n\nLOGIN_REDIRECT_URL = '/profile'\nSIGNUP_REDIRECT_URL = '/profile'\nLOGOUT_REDIRECT_URL = '/'\n\nALLOWED_HOSTS = [\"*\"]\n\nSITE_TITLE = 'Pycon Ghana'\nADMIN_TITLE = \"PYCON GHANA\"\n\n# Application definition\n\nINSTALLED_APPS = [\n 'jet.dashboard',\n 'jet',\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'django.contrib.sites',\n\n# Third party apps\n #'cloudinary_storage',\n #'cloudinary',\n 'captcha',\n 'crispy_forms',\n 'rest_framework',\n 'tinymce',\n 'django_extensions',\n 'sorl.thumbnail',\n 'newsletter',\n 'avatar',\n # 'markitup',\n\n\n# my apps\n 'home',\n 'about',\n 'registration',\n 'contact',\n 'coc',\n 'schedule',\n 'sponsors',\n 'support_us',\n 'talks',\n 'faq',\n 'privacypolicy',\n\n]\n\nMIDDLEWARE = [\n 'django.middleware.security.SecurityMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n]\n# Full filesystem path to the project.\nPROJECT_APP_PATH = os.path.dirname(os.path.abspath(__file__))\nPROJECT_APP = os.path.basename(PROJECT_APP_PATH)\nPROJECT_ROOT = BASE_DIR = os.path.dirname(PROJECT_APP_PATH)\n\nROOT_URLCONF = 'PyConGhana.urls'\n\n# URL prefix for static files.\n# Example: \"http://media.lawrence.com/static/\"\nSTATIC_URL = \"/static/\"\n\n# Absolute path to the directory static files should be collected to.\n# Don't put anything in this directory yourself; store your static files\n# in apps' \"static/\" subdirectories and in STATICFILES_DIRS.\n# Example: \"/home/media/media.lawrence.com/static/\"\nSTATIC_ROOT = os.path.join(PROJECT_ROOT, STATIC_URL.strip(\"/\"))\n\n\n# List of finder classes that know how to find static files in\n# various locations.\nSTATICFILES_FINDERS = (\n 'django.contrib.staticfiles.finders.FileSystemFinder',\n 'django.contrib.staticfiles.finders.AppDirectoriesFinder',\n)\n\n\n# URL that handles the media served from MEDIA_ROOT. Make sure to use a\n# trailing slash.\n# Examples: \"http://media.lawrence.com/media/\", \"http://example.com/media/\"\nMEDIA_URL = STATIC_URL + \"media/\"\n\n# Absolute filesystem path to the directory that will hold user-uploaded files.\n# Example: \"/home/media/media.lawrence.com/media/\"\nMEDIA_ROOT = os.path.join(PROJECT_ROOT, *MEDIA_URL.strip(\"/\").split(\"/\"))\n\n#STATICFILES_STORAGE = 'cloudinary_storage.storage.StaticHashedCloudinaryStorage'\n\n\n\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [os.path.join(BASE_DIR, 'templates')],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.media',\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n },\n },\n]\n\nWSGI_APPLICATION = 'PyConGhana.wsgi.application'\n\n\n# Database\n# https://docs.djangoproject.com/en/2.0/ref/settings/#databases\n\nDATABASES = {\n 'default': {\n 'ENGINE': 'django.db.backends.sqlite3',\n 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),\n }\n}\n# Password validation\n# https://docs.djangoproject.com/en/2.0/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/2.0/topics/i18n/\n\nLANGUAGE_CODE = 'en-us'\n\nTIME_ZONE = 'Africa/Accra'\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n# Sets the default template pack for the project\nCRISPY_TEMPLATE_PACK = 'bootstrap4'\n\n# Registration App account settings\nACCOUNT_ACTIVATION_DAYS = 7\nREGISTRATION_EMAIL_SUBJECT_PREFIX = '[PyCon Ghana 2018]'\nSEND_ACTIVATION_EMAIL = True\nREGISTRATION_AUTO_LOGIN = False\n\n\nJET_THEMES = [\n {\n 'theme': 'default', # theme folder name\n 'color': '#47bac1', # color of the theme's button in user menu\n 'title': 'Default' # theme title\n },\n {\n 'theme': 'green',\n 'color': '#44b78b',\n 'title': 'Green'\n },\n {\n 'theme': 'light-green',\n 'color': '#2faa60',\n 'title': 'Light Green'\n },\n {\n 'theme': 'light-violet',\n 'color': '#a464c4',\n 'title': 'Light Violet'\n },\n {\n 'theme': 'light-blue',\n 'color': '#5EADDE',\n 'title': 'Light Blue'\n },\n {\n 'theme': 'light-gray',\n 'color': '#222',\n 'title': 'Light Gray'\n }\n]\n\n# Path to Google Analytics client_secrets.json\nJET_MODULE_GOOGLE_ANALYTICS_CLIENT_SECRETS_FILE = os.path.join(BASE_DIR, 'client_secrets.json')\n\n\n# Using the new No Captcha reCaptcha\nNOCAPTCHA = True\n\n# All requested actions will be performed without email confirmation.\nNEWSLETTER_CONFIRM_EMAIL = False\n\n# Using django-tinymce\nNEWSLETTER_RICHTEXT_WIDGET = \"tinymce.widgets.TinyMCE\"\n\n# Amount of seconds to wait between each email. Here 100ms is used.\nNEWSLETTER_EMAIL_DELAY = 0.1\n\n# Amount of seconds to wait between each batch. Here one minute is used.\nNEWSLETTER_BATCH_DELAY = 60\n\n# Number of emails in one batch\nNEWSLETTER_BATCH_SIZE = 100\n\n# Sets the default site\nSITE_ID = 1\n\nAVATAR_MAX_AVATARS_PER_USER = 5\n"
},
{
"alpha_fraction": 0.4774281680583954,
"alphanum_fraction": 0.5198358297348022,
"avg_line_length": 22.580644607543945,
"blob_id": "fb0892cfb2b07a8a526bd31434d83eb14347291b",
"content_id": "670301d1317aba37251bb15298658d7bf070ff7f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 731,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 31,
"path": "/sponsors/migrations/0003_auto_20180421_1003.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-21 10:03\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('sponsors', '0002_auto_20180420_1950'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='sponsor',\n old_name='sponsor_name',\n new_name='name',\n ),\n migrations.RenameField(\n model_name='sponsor',\n old_name='sponsor_url',\n new_name='url',\n ),\n migrations.RemoveField(\n model_name='sponsor',\n name='contact_email',\n ),\n migrations.RemoveField(\n model_name='sponsor',\n name='contact_name',\n ),\n ]\n"
},
{
"alpha_fraction": 0.5071574449539185,
"alphanum_fraction": 0.5725971460342407,
"avg_line_length": 26.16666603088379,
"blob_id": "0b6a554aa6aa642cbaa26b8294644092e45a7246",
"content_id": "2487d70f7440c81d584dfe7a8a8d8318b13d0cf2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 489,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 18,
"path": "/talks/migrations/0016_auto_20180419_1931.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-19 19:31\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('talks', '0015_auto_20180419_1633'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='proposal',\n name='status',\n field=models.CharField(choices=[('S', 'Submitted'), ('A', 'Accepted'), ('W', 'Waiting List'), ('R', 'Rejected')], default='S', max_length=1),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5352697372436523,
"alphanum_fraction": 0.5545077323913574,
"avg_line_length": 44.7068977355957,
"blob_id": "420b842648860bb525a7d79cb4879837ea51dea9",
"content_id": "2b8256d20139d11fe9be8fcd19d6e7212bec7f60",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2651,
"license_type": "no_license",
"max_line_length": 163,
"num_lines": 58,
"path": "/schedule/migrations/0001_initial.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-03-01 23:47\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\nimport django.utils.timezone\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ('talks', '0007_auto_20180228_1430'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Day',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('conference_day', models.CharField(max_length=30)),\n ],\n options={\n 'managed': True,\n },\n ),\n migrations.CreateModel(\n name='Event',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=50)),\n ('start_time', models.DateTimeField(default=django.utils.timezone.now)),\n ('end_time', models.DateTimeField(default=django.utils.timezone.now)),\n ('day_session', models.CharField(choices=[('Morning', 'Morning'), ('Afternoon', 'Afternoon'), ('Evening', 'Evening')], default='', max_length=10)),\n ('room', models.CharField(choices=[('Room 1', 'Room 1'), ('Room 2', 'Room 2')], default='', max_length=10)),\n ('conference_day', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='schedule.Day')),\n ],\n options={\n 'managed': True,\n },\n ),\n migrations.CreateModel(\n name='TalkSchedule',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('start_time', models.DateTimeField(default=django.utils.timezone.now)),\n ('end_time', models.DateTimeField(default=django.utils.timezone.now)),\n ('day_session', models.CharField(choices=[('Morning', 'Morning'), ('Afternoon', 'Afternoon'), ('Evening', 'Evening')], default='', max_length=10)),\n ('room', models.CharField(choices=[('Room 1', 'Room 1'), ('Room 2', 'Room 2')], default='', max_length=10)),\n ('conference_day', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='schedule.Day')),\n ('talk', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='talks.Proposal')),\n ],\n options={\n 'managed': True,\n 'verbose_name_plural': 'talk Schedule',\n },\n ),\n ]\n"
},
{
"alpha_fraction": 0.5359477400779724,
"alphanum_fraction": 0.6100217700004578,
"avg_line_length": 24.5,
"blob_id": "8746eae5ac1c7426d9207cc1c4fd91af9db2b9f8",
"content_id": "e74158b5ed5aa921697ba8e6f1297d1b26b072bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 459,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 18,
"path": "/registration/migrations/0007_auto_20180428_1653.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-28 16:53\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('registration', '0006_auto_20180428_1623'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='profile',\n name='avatar',\n field=models.ImageField(blank=True, default='', max_length=255, null=True, upload_to='profile/avatars/'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7553191781044006,
"alphanum_fraction": 0.7553191781044006,
"avg_line_length": 17.799999237060547,
"blob_id": "282c45d04d28d26f1e0bb55916e3a22c53ee73a2",
"content_id": "bd2986fdc7459cf9cda942780b9c257509a2f1cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 94,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 5,
"path": "/support_us/apps.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass SupportUsConfig(AppConfig):\n name = 'support_us'\n"
},
{
"alpha_fraction": 0.6503984332084656,
"alphanum_fraction": 0.6503984332084656,
"avg_line_length": 26.135135650634766,
"blob_id": "570839bb47f0cc8e8f2b0c2003b5b759fa3a3ae6",
"content_id": "77a58764df0577f2b3f008baab19477c9bb42d60",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1004,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 37,
"path": "/sponsors/views.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "from __future__ import absolute_import\nfrom django.shortcuts import render, reverse\nfrom .models import Sponsor\nfrom django.http import HttpRequest, HttpResponseRedirect\n\n# Create your views here.\n\n\ndef Prospectus(request):\n context = {}\n template = 'prospectus.html'\n return render(request, template, context)\n\n\n\ndef sponsors(request):\n assert isinstance(request, HttpRequest)\n diamond = Sponsor.objects.filter(category=\"Diamond\")\n gold = Sponsor.objects.filter(category=\"Gold\")\n silver = Sponsor.objects.filter(category=\"Silver\")\n bronze = Sponsor.objects.filter(category=\"Bronze\")\n special = Sponsor.objects.filter(category=\"Special\")\n individuals = Sponsor.objects.filter(type=\"I\")\n\n return render(\n request,\n 'sponsors/sponsors.html',\n {\n\n 'diamond': diamond,\n 'gold': gold,\n 'silver': silver,\n 'bronze': bronze,\n 'special': special,\n 'individuals': individuals,\n }\n )\n"
},
{
"alpha_fraction": 0.5521582961082458,
"alphanum_fraction": 0.5818345546722412,
"avg_line_length": 33.75,
"blob_id": "f386b0d5325818105cb9f0d3b82c95db7417929a",
"content_id": "1518d4305e310119a8813d4e25d99a451bd81b41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1112,
"license_type": "no_license",
"max_line_length": 226,
"num_lines": 32,
"path": "/talks/migrations/0006_auto_20180228_1053.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-02-28 10:53\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('talks', '0005_auto_20180228_1040'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='proposal',\n old_name='proposal',\n new_name='Tell_the_audience_about_your_talk',\n ),\n migrations.RemoveField(\n model_name='proposal',\n name='name',\n ),\n migrations.AlterField(\n model_name='proposal',\n name='Anything_else_you_want_to_tell_us',\n field=models.TextField(blank=True, default='', help_text='Kindly add anything else you want to tell us?.', null=True),\n ),\n migrations.AlterField(\n model_name='proposal',\n name='programming_experience',\n field=models.CharField(choices=[('BP', 'Beginners'), ('IP', 'Intermediate Programmers'), ('SP', 'Senior Programmers'), ('EP', 'Expert Programmers')], default='', help_text='Your targeted audience.', max_length=30),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5188916921615601,
"alphanum_fraction": 0.5969773530960083,
"avg_line_length": 21.05555534362793,
"blob_id": "13e51774ebb2e38c6e73dc8f07e2f4713930ecdb",
"content_id": "15541cda34a9b2405b90b6f4b6dd91bfb9987074",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 397,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 18,
"path": "/talks/migrations/0010_proposal_recording_release.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-19 15:22\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('talks', '0009_auto_20180418_0905'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='proposal',\n name='recording_release',\n field=models.BooleanField(default=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.31794458627700806,
"alphanum_fraction": 0.3283821642398834,
"avg_line_length": 43.48214340209961,
"blob_id": "7e860595ec6fadbecb5bbfb81b0ca4136840ccd7",
"content_id": "e6d8c0865d917f765bb10f9e8d21b647e6eb822f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 2491,
"license_type": "no_license",
"max_line_length": 179,
"num_lines": 56,
"path": "/talks/templates/talks/talk_form.html",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "{% extends \"base2.html\" %}\n{% load crispy_forms_tags i18n static avatar_tags %}\n{% block meta_title %}{% if page %}{{ page.meta_title }}{% else %}{% trans \"Submit your Talk | Pycon Ghana 2018\" %}{% endif %}{% endblock %}\n{% block content %}\n\n <header id=\"top\" class=\"sub-header\">\n <div class=\"container\">\n </div>\n <!-- end .container -->\n </header>\n\n\n<section class=\"speakers\" id=\"speakers\">\n <div class=\"container\">\n <div class=\"row\">\n <div class=\"col-sm-12 col-md-4\">\n <div class=\"section-title wow fadeInUp\">\n <h4> </h4>\n </div>\n <div class=\"panel panel-warning wow fadeInRight\"> \n <div class=\"panel-body\">\n <div class=\"row\">\n <div class=\"col-md-10\">\n <ul>\n <p><a href=\"/profile\" >Back to My Profile</a></p>\n </ul>\n </div>\n </div>\n </div>\n </div>\n </div>\n <div class=\"col-sm-12 col-md-8\">\n <div class=\"section-title wow fadeInUp\">\n <h4> </h4>\n </div>\n <div class=\"panel panel-danger wow fadeInLeft\"> \n <div class=\"row\">\n\n <div class=\"col-md-12\">\n <div class=\"col-md-12\">\n <h5 class=\"page-title wow fadeInDown\">Submit your talk below, {% firstof user.get_short_name user.get_username %}</small></h5><br>\n <form class=\"form col-md-8\" action=\"{% url 'talks:submit_talk' %}\" method=\"post\">\n {% crispy form form.helper %}\n {% csrf_token %}\n </form>\n </div>\n </div>\n </div> \n </div>\n </div>\n\n </div>\n <!-- end .container -->\n </section>\n\n{% endblock %}\n"
},
{
"alpha_fraction": 0.5814931392669678,
"alphanum_fraction": 0.6235541701316833,
"avg_line_length": 40.34782791137695,
"blob_id": "84e25b00642f0af961569bd2a31413892755ae80",
"content_id": "e7bc0bda86568b3b4886f7010b986e79f3fa4edb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 951,
"license_type": "no_license",
"max_line_length": 314,
"num_lines": 23,
"path": "/talks/migrations/0024_auto_20180501_1043.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-05-01 10:43\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('talks', '0023_auto_20180428_1340'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='proposal',\n name='intended_audience',\n field=models.CharField(choices=[('BP', 'Beginners, no prior knowledge of Python required'), ('IP', 'Intermediate Programmers, some prior knowledge of Python required'), ('EP', 'Expert Programmers, Experienced Python programmers level')], default='', help_text='Your targeted audience.', max_length=30),\n ),\n migrations.AlterField(\n model_name='proposal',\n name='talk_type',\n field=models.CharField(choices=[('Short Talk', 'Short Talk - 30 mins'), ('Long Talk', 'Long Talk - 45 mins'), ('Tutorial', 'Tutorial - 2 hours or more')], max_length=20),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5534442067146301,
"alphanum_fraction": 0.5985748171806335,
"avg_line_length": 22.38888931274414,
"blob_id": "f670aec6aa2287c5e59b2ea87f1f74d411cdc66d",
"content_id": "ef1365a3f0f32bc66870f66438425e1b7f7832a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 421,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 18,
"path": "/registration/migrations/0002_profile_avatar.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-26 00:18\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('registration', '0001_initial'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='profile',\n name='avatar',\n field=models.ImageField(default='media/avatar.jpg', upload_to='media/avatars/'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5346303582191467,
"alphanum_fraction": 0.7120622396469116,
"avg_line_length": 18.17910385131836,
"blob_id": "2192625d87c013d1f19e5658d9103e43dde90df6",
"content_id": "3fb5993a780efebae171ff033d830fde6d1290a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 1285,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 67,
"path": "/requirements.txt",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "beautifulsoup4==4.6.0\ncertifi==2017.11.5\nchardet==3.0.4\ncloudinary==1.11.0\ncoverage==4.4.2\ncoveralls==1.2.0\ndefusedxml==0.5.0\nDjango==2.0.1\ndjango-anymail==2.2\ndjango-appconf==1.0.2\ndjango-avatar==4.1.0\ndjango-cloudinary-storage==0.2.3\ndjango-crispy-forms==1.7.0\ndjango-extensions==2.0.6\ndjango-jet==1.0.7\ndjango-markitup==3.0.0\n-e git://github.com/dokterbob/django-newsletter.git@15a9f3b1535aa3bc9e61e44de43043805b62eac8#egg=django_newsletter\ndjango-recaptcha==1.4.0\ndjango-sendgrid-v5==0.6.87\ndjango-tinymce==2.7.0\ndjango-webtest==1.9.2\ndjangorestframework==3.11.2\ndocopt==0.6.2\ndocutils==0.12\nfeedparser==5.2.1\nflake8==3.5.0\ngoogle-api-python-client==1.4.1\nhttplib2==0.19.0\nidna==2.6\ninvoke==0.12.2\nisort==4.2.15\nldif3==3.1.1\nMarkdown==2.6.11\nmccabe==0.6.1\nmock==2.0.0\noauth2client==2.2.0\noauthlib==2.0.6\npbr==4.0.2\nPillow==7.1.0\npluggy==0.6.0\npsycopg2==2.7.3.2\npy==1.5.2\npyasn1==0.4.2\npyasn1-modules==0.2.1\npycodestyle==2.3.1\npyflakes==1.6.0\npython-card-me==0.9.3\npython-dateutil==2.7.2\npython-http-client==3.0.0\npython3-openid==3.1.0\npytz==2017.3\nrequests==2.18.4\nrequests-oauthlib==0.8.0\nrsa==3.4.2\nsendgrid==5.3.0\nsix==1.11.0\nsorl-thumbnail==12.4.1\nsurlex==0.2.0\ntox==2.9.1\ntox-travis==0.10\nunicodecsv==0.14.1\nuritemplate==3.0.0\nurllib3==1.22\nvirtualenv==15.1.0\nwaitress==1.1.0\nWebOb==1.8.1\nWebTest==2.0.29\n"
},
{
"alpha_fraction": 0.57485032081604,
"alphanum_fraction": 0.5978043675422668,
"avg_line_length": 42.565216064453125,
"blob_id": "426de779a34032194092df5a0f092d93c0f645be",
"content_id": "af229ee7acecda20ab470a09a755b456f0dcd4e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1002,
"license_type": "no_license",
"max_line_length": 286,
"num_lines": 23,
"path": "/schedule/migrations/0002_auto_20180703_0229.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-07-03 02:29\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('schedule', '0001_initial'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='event',\n name='room',\n field=models.CharField(choices=[('Prof. Ebenezer Oduro Owusu', 'Prof. Ebenezer Oduro Owusu'), ('H. E. K Amissah Arthur Seminar Room', 'H. E. K Amissah Arthur Seminar Room'), ('The Foyer', 'The Foyer'), ('Dr. Ernest Addison Seminar Room', 'Dr. Ernest Addison Seminar Room')], default='', max_length=10),\n ),\n migrations.AlterField(\n model_name='talkschedule',\n name='room',\n field=models.CharField(choices=[('Prof. Ebenezer Oduro Owusu', 'Prof. Ebenezer Oduro Owusu'), ('H. E. K Amissah Arthur Seminar Room', 'H. E. K Amissah Arthur Seminar Room'), ('The Foyer', 'The Foyer'), ('Dr. Ernest Addison Seminar Room', 'Dr. Ernest Addison Seminar Room')], default='', max_length=10),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7269503474235535,
"alphanum_fraction": 0.7269503474235535,
"avg_line_length": 27.200000762939453,
"blob_id": "b476805d595ed6ea6f7b29c869360b1858eba77c",
"content_id": "01af409d5441eb2fd23985eaac51bd1c36e001d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 282,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 10,
"path": "/tickets/urls.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "from django.conf.urls.static import static\nfrom django.contrib import admin\nfrom django.urls import include, path\nfrom . import views\n\napp_name = 'tickets'\nurlpatterns = [\n path('', view=views.ticket, name='ticket'),\n path('register', view=views.register, name='register'),\n]\n"
},
{
"alpha_fraction": 0.732159435749054,
"alphanum_fraction": 0.732159435749054,
"avg_line_length": 48.04545593261719,
"blob_id": "4d77a4856be10ada0287cd2e1d271bc8a0a82b65",
"content_id": "0085358f6899f2918d51aa3241f8fcef319bd2b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1079,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 22,
"path": "/registration/urls.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\nfrom django.conf import settings\nfrom django.conf.urls.static import static\nfrom django.contrib.auth.decorators import login_required\n\nfrom .views import UpdateProfileView, ProfileView, UpdateLoginView, CreateProfileView, PasswordView, SuccessView\n\n\napp_name = 'profiles'\n\nurlpatterns = [\n url(r'create_profile/$', login_required(CreateProfileView.as_view()), name='create_profile'),\n url(r'update/(?P<pk>\\d+)/$', login_required(UpdateProfileView.as_view()), name='update'),\n url(r'', login_required(ProfileView.as_view()), name='profile_home'),\n url(r'password_change/(?P<pk>\\d+)/$', login_required(PasswordView.as_view()), name='password_change'),\n url(r'login_details/(?P<pk>\\d+)/$', login_required(UpdateLoginView.as_view()), name='login_details'),\n url(r'profile_update/$', login_required(SuccessView.as_view()), name='profile_update'),\n]\n\nif settings.DEBUG:\n urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)\n urlpatterns += static(settings.STATIC_URL, document_root=settings.STATIC_ROOT)\n"
},
{
"alpha_fraction": 0.7289719581604004,
"alphanum_fraction": 0.7289719581604004,
"avg_line_length": 22.77777862548828,
"blob_id": "3fb7ced8ff1264aa40647799b214b1bea8ca0cdf",
"content_id": "e5c87c01ec38b73d6dd981ab14a44ef5f501b2c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 214,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 9,
"path": "/faq/urls.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "from django.conf.urls.static import static\nfrom django.contrib import admin\nfrom django.urls import include, path\nfrom . import views\n\napp_name = 'faq'\nurlpatterns = [\n path('', view=views.faqs, name='faqs'),\n]\n"
},
{
"alpha_fraction": 0.5489749312400818,
"alphanum_fraction": 0.5990888476371765,
"avg_line_length": 23.38888931274414,
"blob_id": "2760f9b410142aeb634143481058da9adc27c665",
"content_id": "15f5c80c65eeab6bb877bbc8449689c5687cbc98",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 439,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 18,
"path": "/registration/migrations/0005_auto_20180428_1611.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-28 16:11\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('registration', '0004_profile_avatar'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='profile',\n name='avatar',\n field=models.ImageField(blank=True, default='', max_length=255, null=True, upload_to=''),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7142857313156128,
"alphanum_fraction": 0.7329192757606506,
"avg_line_length": 23.846153259277344,
"blob_id": "148d854c51eb554380b7dee859ae85a08b53c3b8",
"content_id": "2fa2673ed8bb868d5ef348de3504bfdd57c25ba4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 322,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 13,
"path": "/home/views.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, render_to_response\nfrom django.template import RequestContext\n\n# Create your views here.\n\n\ndef home(request):\n context = {}\n template = 'home.html'\n return render(request, template, context)\n\ndef handler404(request, exception):\n return render(request, '404.html', locals())"
},
{
"alpha_fraction": 0.5565693378448486,
"alphanum_fraction": 0.6167883276939392,
"avg_line_length": 29.44444465637207,
"blob_id": "69c9468486d7eb81c818cd03d389a7c585bc542f",
"content_id": "d0f62681d9bea4d84b13edda7f36a8ce305ca014",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 548,
"license_type": "no_license",
"max_line_length": 196,
"num_lines": 18,
"path": "/talks/migrations/0008_auto_20180417_1127.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-17 11:27\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('talks', '0007_auto_20180228_1430'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='proposal',\n name='programming_experience',\n field=models.CharField(choices=[('BP', 'Beginners'), ('IP', 'Intermediate Programmers'), ('EP', 'Expert Programmers')], default='', help_text='Your targeted audience.', max_length=30),\n ),\n ]\n"
},
{
"alpha_fraction": 0.4731934666633606,
"alphanum_fraction": 0.5454545617103577,
"avg_line_length": 19.428571701049805,
"blob_id": "d13567f075e754a9797c56df8c5144c226daa2e9",
"content_id": "2fa11acb71b032aae76ee4f331b7f77e7646c124",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 429,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 21,
"path": "/talks/migrations/0018_auto_20180426_0030.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-26 00:30\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('talks', '0017_auto_20180426_0011'),\n ]\n\n operations = [\n migrations.RemoveField(\n model_name='proposal',\n name='email',\n ),\n migrations.RemoveField(\n model_name='proposal',\n name='url',\n ),\n ]\n"
},
{
"alpha_fraction": 0.3775915205478668,
"alphanum_fraction": 0.38800176978111267,
"avg_line_length": 25.67058753967285,
"blob_id": "2d85d121ae1cc05af961d21cd3ff4a9bce5d860b",
"content_id": "d594169d407defaf33904259deada8e61f4e74b4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 11336,
"license_type": "permissive",
"max_line_length": 174,
"num_lines": 425,
"path": "/newsletter/static/js/main.js",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "/*\n\nScript : Main JS\nVersion : 1.0\nAuthor : Surjith S M\nURI : http://themeforest.net/user/surjithctly\n\nCopyright © All rights Reserved\nSurjith S M / @surjithctly\n\n*/\n\n$(function() {\n\n \"use strict\";\n\n /* ================================================\n On Scroll Menu\n ================================================ */\n\n $(window).scroll(function() {\n if ($(window).scrollTop() > 600) {\n $('.js-reveal-menu').removeClass('reveal-menu-hidden').addClass('reveal-menu-visible');\n } else {\n $('.js-reveal-menu').removeClass('reveal-menu-visible').addClass('reveal-menu-hidden');\n }\n });\n\n /* ================================================\n Parallax Header\n ================================================ */\n\n if ($('.parallax-bg').length) {\n $('.parallax-bg').parallax({\n speed: 0.20\n });\n }\n\n /* ================================================\n FLEX SLIDER\n ================================================ */\n\n if ($('.flexslider').length) {\n $('.flexslider').flexslider({\n animation: \"slide\",\n useCSS: Modernizr.touch\n });\n }\n\n /* ================================================\n Initialize Countdown\n ================================================ */\n\n /*Fetch Event Date From HTML. For Not tech Savvy Users */\n\n var get_date = $('#countdown').data('event-date');\n\n if (get_date) {\n $(\"#countdown\").countdown({\n date: get_date,\n /*Change date and time in HTML data-event-date attribute */\n format: \"on\"\n });\n }\n\n /* ================================================\n Initialize Tabs\n ================================================ */\n\n $('#schedule-tabs a').on(\"click\",function(e) {\n e.preventDefault()\n $(this).tab('show')\n });\n\n /* ================================================\n Stat Counter\n ================================================ */\n\n $('#stats-counter').appear(function() {\n $('.count').countTo({\n refreshInterval: 50\n });\n });\n\n /* ================================================\n Initialize Slick Slider \n ================================================ */\n\n /* \n SLICK SLIDER\n ------------ */\n\n if ($('.slick-slider').length) {\n $('.slick-slider').slick({\n slidesToShow: 6,\n slidesToScroll: 6,\n infinite: true,\n autoplay: false,\n arrows: true,\n dots: true,\n responsive: [{\n breakpoint: 1200,\n settings: {\n arrows: true,\n slidesToShow: 5,\n slidesToScroll: 5\n }\n }, {\n breakpoint: 992,\n settings: {\n slidesToShow: 3,\n slidesToScroll: 3\n }\n }, {\n breakpoint: 520,\n settings: {\n slidesToShow: 1,\n slidesToScroll: 1\n }\n }]\n });\n }\n\n /* \n SPONSORS\n -------- */\n\n if ($('.sponsor-slider').length) {\n $('.sponsor-slider').slick({\n centerMode: true,\n centerPadding: '30px',\n slidesToShow: 3,\n autoplay: true,\n arrows: false,\n responsive: [{\n breakpoint: 768,\n settings: {\n arrows: false,\n centerMode: true,\n centerPadding: '40px',\n slidesToShow: 3\n }\n }, {\n breakpoint: 480,\n settings: {\n arrows: false,\n centerMode: true,\n centerPadding: '40px',\n slidesToShow: 1\n }\n }]\n });\n }\n\n /* \n SPEAKERS\n -------- */\n\n if ($('.speaker-slider').length) {\n $('.speaker-slider').slick({\n slidesToShow: 6,\n autoplay: false,\n arrows: true,\n responsive: [{\n breakpoint: 1200,\n settings: {\n arrows: true,\n slidesToShow: 5\n }\n }, {\n breakpoint: 992,\n settings: {\n slidesToShow: 3\n }\n }, {\n breakpoint: 520,\n settings: {\n slidesToShow: 1\n }\n }]\n });\n }\n\n /* ================================================\n Scroll Functions\n ================================================ */\n\n $(window).scroll(function() {\n if ($(window).scrollTop() > 1000) {\n $('.back_to_top').fadeIn('slow');\n } else {\n $('.back_to_top').fadeOut('slow');\n }\n });\n\n $('nav a[href^=#]:not([href=#]), .back_to_top').on('click', function(event) {\n var $anchor = $(this);\n $('html, body').stop().animate({\n scrollTop: $($anchor.attr('href')).offset().top - 50\n }, 1500);\n event.preventDefault();\n });\n\n});\n\n/* ================================================\n Video Gallery\n ================================================ */\n\n$(\".play-video\").on(\"click\",function(e) {\n e.preventDefault();\n var videourl = $(this).data(\"video-url\");\n $(this).append('<i class=\"video-loader fa fa-spinner fa-spin\"></i>')\n $('.media-video iframe').attr('src', videourl);\n setTimeout(function() {\n $('.video-loader').remove();\n }, 1000);\n});\n\n/* ================================================\n Magnific Popup\n ================================================ */\nif ($('.popup-gallery').length) {\n $('.popup-gallery').magnificPopup({\n delegate: 'a',\n type: 'image',\n tLoading: 'Loading image #%curr%...',\n mainClass: 'mfp-img-mobile',\n gallery: {\n enabled: true,\n navigateByImgClick: true,\n preload: [0, 1] // Will preload 0 - before current, and 1 after the current image\n },\n image: {\n tError: '<a href=\"%url%\">The image #%curr%</a> could not be loaded.'\n },\n zoom: {\n enabled: true,\n duration: 300, // don't foget to change the duration also in CSS\n opener: function(element) {\n return element.find('img');\n }\n }\n });\n}\n\n/* ================================================\n jQuery Validate - Reset Defaults\n ================================================ */\n\n$.validator.setDefaults({\n highlight: function(element) {\n $(element).closest('.form-group').addClass('has-error');\n },\n unhighlight: function(element) {\n $(element).closest('.form-group').removeClass('has-error');\n },\n errorElement: 'small',\n errorClass: 'help-block',\n errorPlacement: function(error, element) {\n if (element.parent('.input-group').length) {\n error.insertAfter(element.parent());\n }\n if (element.parent('label').length) {\n error.insertAfter(element.parent());\n } else {\n error.insertAfter(element);\n }\n }\n});\n\n/* ================================================\n Add to Calendar\n ================================================ */\n\n(function() {\n if (window.addtocalendar)\n if (typeof window.addtocalendar.start == \"function\") return;\n if (window.ifaddtocalendar == undefined) {\n window.ifaddtocalendar = 1;\n var d = document,\n s = d.createElement('script'),\n g = 'getElementsByTagName';\n s.type = 'text/javascript';\n s.charset = 'UTF-8';\n s.async = true;\n s.src = ('https:' == window.location.protocol ? 'https' : 'http') + '://addtocalendar.com/atc/1.5/atc.min.js';\n var h = d[g]('body')[0];\n h.appendChild(s);\n }\n})();\n\n/* ================================================\n Twitter Widget\n ================================================ */\n\nwindow.twttr = (function(d, s, id) {\n var js, fjs = d.getElementsByTagName(s)[0],\n t = window.twttr || {};\n if (d.getElementById(id)) return t;\n js = d.createElement(s);\n js.id = id;\n js.src = \"https://platform.twitter.com/widgets.js\";\n fjs.parentNode.insertBefore(js, fjs);\n\n t._e = [];\n t.ready = function(f) {\n t._e.push(f);\n };\n\n return t;\n}(document, \"script\", \"twitter-wjs\"));\n\n/* ================================================\n Paypal Form Validation\n ================================================ */\n\n// validate Registration Form\n$(\"#paypal-regn\").validate({\n rules: {\n first_name: \"required\",\n last_name: \"required\",\n email: {\n required: true,\n email: true\n },\n os0: \"required\",\n quantity: \"required\",\n agree: \"required\"\n },\n messages: {\n first_name: \"Your first name\",\n last_name: \"Your last name\",\n email: \"We need your email address\",\n os0: \"Choose your Pass\",\n quantity: \"How many seats\",\n agree: \"Please accept our terms and privacy policy\"\n },\n submitHandler: function(form) {\n $(\"#reserve-btn\").attr(\"disabled\", true);\n form.submit();\n }\n});\n\n/*\n * // End $ Strict Function\n * ------------------------ */\n\n$(function() {\n\n /* ================================================\n Initialize WOW JS\n ================================================ */\n\n if ($('body').hasClass('animate-page')) {\n wow = new WOW({\n animateClass: 'animated',\n offset: 100,\n mobile: false\n });\n wow.init();\n }\n});\n\n\n(function ($) {\n \"use strict\";\n\n\n /*==================================================================\n [ Validate ]*/\n var input = $('.validate-input .input100');\n\n $('.validate-form').on('submit',function(){\n var check = true;\n\n for(var i=0; i<input.length; i++) {\n if(validate(input[i]) == false){\n showValidate(input[i]);\n check=false;\n }\n }\n\n return check;\n });\n\n\n $('.validate-form .input100').each(function(){\n $(this).focus(function(){\n hideValidate(this);\n });\n });\n\n function validate (input) {\n if($(input).attr('type') == 'email' || $(input).attr('name') == 'email') {\n if($(input).val().trim().match(/^([a-zA-Z0-9_\\-\\.]+)@((\\[[0-9]{1,3}\\.[0-9]{1,3}\\.[0-9]{1,3}\\.)|(([a-zA-Z0-9\\-]+\\.)+))([a-zA-Z]{1,5}|[0-9]{1,3})(\\]?)$/) == null) {\n return false;\n }\n }\n else {\n if($(input).val().trim() == ''){\n return false;\n }\n }\n }\n\n function showValidate(input) {\n var thisAlert = $(input).parent();\n\n $(thisAlert).addClass('alert-validate');\n }\n\n function hideValidate(input) {\n var thisAlert = $(input).parent();\n\n $(thisAlert).removeClass('alert-validate');\n }\n \n \n\n})(jQuery);\n\n/*\n * End $ Function\n * -------------- */\n"
},
{
"alpha_fraction": 0.5107913613319397,
"alphanum_fraction": 0.5695443749427795,
"avg_line_length": 35.260868072509766,
"blob_id": "feb8c00c44c8d266a16d7b760803ef8e38918f76",
"content_id": "a54017015c32bb4a9015288c47d77af32407f768",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 834,
"license_type": "no_license",
"max_line_length": 221,
"num_lines": 23,
"path": "/sponsors/migrations/0007_auto_20180428_1941.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-28 19:41\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('sponsors', '0006_auto_20180428_1808'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='sponsor',\n name='category',\n field=models.CharField(choices=[('Bronze', 'Bronze - $500'), ('Silver', 'Silver - $1000'), ('Gold', 'Gold - $2500'), ('Diamond', 'Diamond - $3500'), ('Special', 'Special'), ('Other', 'Other')], max_length=15),\n ),\n migrations.AlterField(\n model_name='sponsor',\n name='type',\n field=models.CharField(choices=[('C', 'Corporate Sponsor'), ('S', 'Special Sponsor'), ('I', 'Individual Sponsor')], max_length=1, verbose_name='sponsor type'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.48351648449897766,
"alphanum_fraction": 0.5686812996864319,
"avg_line_length": 19.22222137451172,
"blob_id": "09af8cda110420b59d8a5a621a8099fa00b7929a",
"content_id": "4189aa0e6a80141a1e4f8d83a24d5a0a5aeba260",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 364,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 18,
"path": "/talks/migrations/0012_auto_20180419_1622.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-19 16:22\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('talks', '0011_auto_20180419_1620'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='proposal',\n old_name='notes',\n new_name='abstract',\n ),\n ]\n"
},
{
"alpha_fraction": 0.5242494344711304,
"alphanum_fraction": 0.5958429574966431,
"avg_line_length": 23.05555534362793,
"blob_id": "9e85ef27707583137ea29f335b4fe09950c8ba21",
"content_id": "4ffda06e8c03c618425faa0fd8cb0f873ea04f85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 433,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 18,
"path": "/talks/migrations/0009_auto_20180418_0905.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-18 09:05\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('talks', '0008_auto_20180417_1127'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='proposal',\n name='notes',\n field=models.TextField(blank=True, default='', help_text='Your Abstract.', null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5329217910766602,
"alphanum_fraction": 0.604938268661499,
"avg_line_length": 24.578947067260742,
"blob_id": "f421dff84a0459435d207ab9f4e70ea7571a6572",
"content_id": "cd15b71d1dd7d2be3e9c9ecc67dcbb6b38568061",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 486,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 19,
"path": "/talks/migrations/0021_proposal_email.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-27 01:12\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('talks', '0020_auto_20180426_0948'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='proposal',\n name='email',\n field=models.EmailField(default=1, help_text='It will be kept secretly from the Public', max_length=254),\n preserve_default=False,\n ),\n ]\n"
},
{
"alpha_fraction": 0.5946196913719177,
"alphanum_fraction": 0.6298701167106628,
"avg_line_length": 37.5,
"blob_id": "83bab3d89b198b28ac792cd9d4f6438e8a924b20",
"content_id": "e233b4e95125d47a6ebd6d7897e549fcf77858ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1078,
"license_type": "no_license",
"max_line_length": 225,
"num_lines": 28,
"path": "/talks/migrations/0007_auto_20180228_1430.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-02-28 14:30\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('talks', '0006_auto_20180228_1053'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='proposal',\n name='Tell_the_audience_about_your_talk',\n field=models.TextField(help_text='Describe your workshop or sprint. Please include the requirements: libraries and Python version to be installed, required experience with topics/libraries, etc.', max_length=255),\n ),\n migrations.AlterField(\n model_name='proposal',\n name='title',\n field=models.CharField(help_text='Public title. What topic/project is it all about?', max_length=1024),\n ),\n migrations.AlterField(\n model_name='proposal',\n name='url',\n field=models.URLField(default='', help_text='Got a video? If you have a recording of you giving a talk or leading a workshop, you can paste the link here.'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5279383659362793,
"alphanum_fraction": 0.5992292761802673,
"avg_line_length": 27.83333396911621,
"blob_id": "066f3924e9b6d1cfa3521931590065148db99a75",
"content_id": "d725c60ccdff25d6099ef297da6372cd9134013b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 519,
"license_type": "no_license",
"max_line_length": 180,
"num_lines": 18,
"path": "/talks/migrations/0018_auto_20180425_2338.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-25 23:38\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('talks', '0017_auto_20180425_2336'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='proposal',\n name='talk_type',\n field=models.CharField(choices=[('Short Talk', 'Short Talk - 30 mins'), ('Long Talk', 'Long Talk - 45 mins'), ('Tutorial Session', 'Tutorial Session')], max_length=20),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7603305578231812,
"alphanum_fraction": 0.7603305578231812,
"avg_line_length": 25.88888931274414,
"blob_id": "26e331a81082051b6caf13c1ab05f99c5c09c590",
"content_id": "36f0c6b9bc52e882b880cc96f6d287696eb66ed8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 242,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 9,
"path": "/privacypolicy/urls.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "from django.conf.urls.static import static\nfrom django.contrib import admin\nfrom django.urls import include, path\nfrom . import views\n\napp_name = 'privacypolicy'\nurlpatterns = [\n path('', view=views.privacypolicy, name='privacypolicy'),\n]\n"
},
{
"alpha_fraction": 0.7828054428100586,
"alphanum_fraction": 0.7873303294181824,
"avg_line_length": 42.599998474121094,
"blob_id": "1c0f9225be331c656a3e658aee8ee7650d037f01",
"content_id": "cdbc9699890a5c9a57f27cc8c7df83aadde344b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 221,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 5,
"path": "/static/video/readme.txt",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "DemoVideo is not included with package (replaced with dummy video)\r\n\r\nYou should add video in this path with MP4 and WEBM Extension with a Poster JPG Image with same name.\r\n\r\nSupport: https://support.surjithctly.in/forums"
},
{
"alpha_fraction": 0.6611253023147583,
"alphanum_fraction": 0.6696504950523376,
"avg_line_length": 50.0217399597168,
"blob_id": "c5c318c73136d1569a95957701531517ee5f1e3d",
"content_id": "2ea471c276a88d5b40906d605c5c3009be947d45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2346,
"license_type": "no_license",
"max_line_length": 274,
"num_lines": 46,
"path": "/talks/models.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.urls import reverse\nfrom django.conf import settings\nfrom django.contrib.auth.models import User\n\n\nclass Proposal(models.Model):\n TALK_TYPES = (\n ('Short Talk', \"Short Talk - 30 mins\"),\n ('Long Talk', \"Long Talk - 45 mins\"),\n ('Tutorial', \"Tutorial - 2 hours or more\"),\n )\n\n STATUS = (('S', 'Submitted'),\n ('A', 'Accepted'),\n ('W', 'Waiting List'),\n ('R', 'Rejected'),)\n\n PROGRAMMING_EXPERIENCE = (('BP','Beginners, no prior knowledge of Python required'),\n ('IP', 'Intermediate Programmers, some prior knowledge of Python required'),\n ('EP', 'Expert Programmers, Experienced Python programmers level'))\n \n\n email = models.EmailField( help_text=\"It will be kept secretly from the Public\")\n title = models.CharField( help_text=\"Public title. What topic/project is it all about?\", max_length=1024)\n talk_type = models.CharField(choices=TALK_TYPES, max_length=20)\n proposal_id = models.AutoField(primary_key=True, default=None)\n Tell_the_audience_about_your_talk = models.TextField(max_length=255, help_text = \"Describe your Talk to your targeted audience . Please include the requirements: libraries and Python version to be installed, required experience with topics/libraries, etc.\", blank=False)\n abstract = models.TextField(default='', help_text = \"Your Abstract.\", blank=True, null=True\n )\n user = models.ForeignKey(User, related_name=\"proposals\", default='', on_delete=models.CASCADE)\n status = models.CharField(choices=STATUS, max_length=1, default='S')\n intended_audience = models.CharField(choices=PROGRAMMING_EXPERIENCE, help_text = \"Your targeted audience.\", max_length=30, default='')\n Anything_else_you_want_to_tell_us = models.TextField(default='', help_text = \"Kindly add anything else you want to tell us?.\", blank=True, null=True)\n recording_release = models.BooleanField(default=True)\n\n def __str__(self):\n return self.title\n\n def get_absolute_url(self):\n return reverse(\"home\")\n\nclass Document(models.Model):\n description = models.CharField(max_length=255, blank=True)\n document = models.FileField(upload_to='documents/')\n uploaded_at = models.DateTimeField(auto_now_add=True)"
},
{
"alpha_fraction": 0.5410199761390686,
"alphanum_fraction": 0.6097561120986938,
"avg_line_length": 24.05555534362793,
"blob_id": "8e00ec6354f3be749574832f624c98a69012986c",
"content_id": "fde4441328b1f82b0538487e94f4ac67b16c7cc1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 451,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 18,
"path": "/sponsors/migrations/0011_sponsor_description.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-05-01 23:23\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('sponsors', '0010_auto_20180428_2017'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='sponsor',\n name='description',\n field=models.TextField(blank=True, default='', help_text='Description of the Sponsor', null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5128205418586731,
"alphanum_fraction": 0.5923076868057251,
"avg_line_length": 20.66666603088379,
"blob_id": "4178fb63a7f62848c44ed931f99b33c8d0e878f8",
"content_id": "36147ef50bcad13ba572d5091a7cee99322dc2e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 390,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 18,
"path": "/talks/migrations/0015_auto_20180419_1633.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-04-19 16:33\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('talks', '0014_auto_20180419_1627'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='proposal',\n old_name='programming_experience',\n new_name='intended_audience',\n ),\n ]\n"
},
{
"alpha_fraction": 0.5573248267173767,
"alphanum_fraction": 0.6114649772644043,
"avg_line_length": 33.88888931274414,
"blob_id": "67c7669065d7cc6c283114d951c7c461271e86e7",
"content_id": "56bdbbe05d7afcf35734d4c04ec1a8f15161dcbe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 628,
"license_type": "no_license",
"max_line_length": 287,
"num_lines": 18,
"path": "/schedule/migrations/0003_auto_20180703_0253.py",
"repo_name": "pythonghana/pyconghana2018",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.1 on 2018-07-03 02:53\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('schedule', '0002_auto_20180703_0229'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='talkschedule',\n name='room',\n field=models.CharField(choices=[('Prof. Ebenezer Oduro Owusu', 'Prof. Ebenezer Oduro Owusu'), ('H. E. K Amissah Arthur Seminar Room', 'H. E. K Amissah Arthur Seminar Room'), ('The Foyer', 'The Foyer'), ('Dr. Ernest Addison Seminar Room', 'Dr. Ernest Addison Seminar Room')], default='', max_length=100),\n ),\n ]\n"
}
] | 60 |
sweetscientist/quantitative_finance
|
https://github.com/sweetscientist/quantitative_finance
|
9336fa187c03a9d58db19527677af858bb90cdd0
|
940601f7a2befd40fd57c5bc786a071c708453b3
|
043e79b0c86763637cd27b8d50986ed078a10181
|
refs/heads/master
| 2023-08-06T17:33:13.555620 | 2023-07-20T21:34:18 | 2023-07-20T21:34:18 | 349,867,613 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6394366025924683,
"alphanum_fraction": 0.6633802652359009,
"avg_line_length": 21.935483932495117,
"blob_id": "753970a316711517307e41a0590eca94a22538d8",
"content_id": "a8441268e28e426ad52d7db7e036ff9f99057bad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 710,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 31,
"path": "/utils.py",
"repo_name": "sweetscientist/quantitative_finance",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sun Nov 22 19:35:59 2020\n\n@author: Benjamin Lee\n\"\"\"\n\nimport math\n\nimport numpy as np\nimport pandas as pd\n\nfrom scipy import stats\n\n\ndef sma(series, periods: int, fillna: bool = False):\n min_periods = 0 if fillna else periods\n return series.rolling(window=periods, min_periods=min_periods).mean()\n\n\ndef ema(series, periods = 3, fillna=False):\n min_periods = 0 if fillna else periods\n return series.ewm(span=periods, min_periods=min_periods, adjust=False).mean() \n\ndef normaltest(x, alpha):\n k3, p = stats.normaltest(x)\n \n if p < alpha: # Null Hypothesis: X comes from a normal distribution\n print(\"Not Normal\")\n else:\n print(\"Normal\")"
},
{
"alpha_fraction": 0.5248171091079712,
"alphanum_fraction": 0.5382637977600098,
"avg_line_length": 28.810976028442383,
"blob_id": "3d14c89cd1cb5c56c492b42865f482c429be63c2",
"content_id": "2f634e4d8944fa5fa3955fee5a8c9887543a2c0a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5057,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 164,
"path": "/volume_indicators.py",
"repo_name": "sweetscientist/quantitative_finance",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Sun Nov 22 18:56:14 2020\r\n\r\n@author: Benjamin Lee\r\n\"\"\"\r\n\r\nimport pandas as pd\r\nimport yfinance as yf\r\nimport datetime\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\n\r\nimport utils\r\n\r\nfrom scipy import stats\r\n\r\n# The following is a class that helps the user create technical indicators for analysis\r\n\r\nclass volume_indicators():\r\n \r\n def __init__(self, data):\r\n \r\n self.data = data\r\n \r\n def force_index(self):\r\n '''\r\n Force Index\r\n \r\n Indicates how strong the actual buying or selling pressure is.\r\n High = Rising Trend\r\n Low = Downward Trend\r\n \r\n ref: https://school.stockcharts.com/doku.php?id=technical_indicators:force_index\r\n \r\n '''\r\n fi = (self.data.Close - self.data.Close.shift(1)) * self.data.Volume\r\n return utils.ema(fi)\r\n \r\n def vwap(self, n):\r\n ''' \r\n Volume Weighted Average Price \r\n \r\n Is the dollar value of all trading periods divided by total volume of current day\r\n The calculation starts/ends with the market\r\n It is usually used for intraday tading\r\n \r\n ref: https://school.stockcharts.com/doku.php?id=technical_indicators:vwap_intraday\r\n '''\r\n # Usual Price\r\n up = (self.data.High + self.data.Low + self.data.Close) / 3\r\n \r\n # Usual Volume Price\r\n vup = (up * self.data.Volume)\r\n \r\n # Total Volume Price\r\n total_vup = vup.rolling(n).sum()\r\n \r\n # Total Voume\r\n tv = self.data.Volume.rolling(n).sum()\r\n \r\n return total_vup / tv\r\n \r\n def obv(self):\r\n '''\r\n On Balance Volume\r\n \r\n Running total of positive and negative volume\r\n \r\n ref: https://school.stockcharts.com/doku.php?id=technical_indicators:on_balance_volume_obv\r\n '''\r\n obv = np.where(self.data.Close < self.data.Close.shift(1), -self.data.Volume, self.data.Volume)\r\n \r\n return pd.Series(obv, index = self.data.index).cumsum()\r\n \r\n def adi(self):\r\n '''\r\n Accumulation Distribution Index\r\n \r\n Originally referred as Cumulative Money Flow Line\r\n \r\n Calculate money flow multiplier\r\n Multiply by volume\r\n Caculate running sum\r\n \r\n ref: https://school.stockcharts.com/doku.php?id=technical_indicators:accumulation_distribution_line\r\n '''\r\n \r\n clv = ((self.data.Close - self.data.Low) - (self.data.High - self.data.Close)) / (self.data.High - self.data.Low)\r\n clv = clv.fillna(0.0)\r\n ad = self.data.Volume * clv\r\n return ad.cumsum()\r\n \r\n def cmf(self, n):\r\n '''\r\n Chaikin Money Flow \r\n\r\n Indicates sum of Money Flow Volume for a specific look-back period\r\n \r\n ref: https://school.stockcharts.com/doku.php?id=technical_indicators:chaikin_money_flow_cmf\r\n '''\r\n mfv = ((self.data.Close - self.data.Low) - (self.data.High - self.data.Close)) / (self.data.High - self.data.Low)\r\n mfv = mfv.fillna(0.0)\r\n mfv = mfv * self.data.Volume\r\n return mfv.rolling(n).sum() / self.data.Volume.rolling(n).sum()\r\n \r\n def eom(self):\r\n '''\r\n Ease of Movement\r\n \r\n Indicates an price change to the volume\r\n Particularly useful for assessing the trend\r\n \r\n ref: https://school.stockcharts.com/doku.php?id=technical_indicators:ease_of_movement_emv\r\n '''\r\n distance = ((self.data.High + self.data.Low) / 2) - (self.data.High.diff(1) + self.data.Low.diff(1) / 2)\r\n boxratio = (self.data.Volume / 100000000) / (self.data.High - self.data.Low)\r\n return distance / boxratio\r\n \r\n \r\n \r\n \r\n \r\nif __name__ == \"__main__\":\r\n # Download Stock Data\r\n spy = yf.download('SPY', '1990-01-01')\r\n \r\n # Initial Indicator object\r\n ta = volume_indicators(spy)\r\n \r\n # Get Force Index\r\n fi = ta.force_index()\r\n # Get Volume Weighted Average Price\r\n vwap = ta.vwap(300) \r\n # Get On Balance Volume\r\n obv = ta.obv()\r\n # Get adi\r\n adi = ta.adi() \r\n # Get Chaikin Money Flow\r\n cmf = ta.cmf(300)\r\n # Get Ease of Movment\r\n eom = ta.eom()\r\n \r\n ind_data = pd.DataFrame({'spy': spy.Close,\r\n 'fi': fi, \r\n 'vwap': vwap,\r\n 'obv': obv,\r\n 'cmf': cmf,\r\n 'eom': eom})\r\n plt.hist(spy.Close)\r\n plt.hist(ind_data.fi)\r\n plt.hist(ind_data.vwap) \r\n plt.hist(obv)\r\n plt.hist(adi)\r\n plt.hist(cmf)\r\n plt.hist(eom)\r\n \r\n utils.normaltest(spy.Close, 0.05)\r\n utils.normaltest(fi, 0.05)\r\n utils.normaltest(vwap, 0.05)\r\n utils.normaltest(obv, 0.05)\r\n utils.normaltest(adi, 0.05)\r\n utils.normaltest(cmf, 0.05)\r\n utils.normaltest(eom, 0.05)\r\n "
},
{
"alpha_fraction": 0.48689955472946167,
"alphanum_fraction": 0.5014556050300598,
"avg_line_length": 18.205883026123047,
"blob_id": "ab3edbf7c46719cb4d8b6644b20a9b483dbf3ef5",
"content_id": "bb317753e582ac4e3701ac2126883f6d3c4ac615",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1374,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 68,
"path": "/volatility_inidicators.py",
"repo_name": "sweetscientist/quantitative_finance",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Sun Dec 6 22:16:48 2020\r\n\r\n@author: Benjamin Lee\r\n\"\"\"\r\n\r\nimport pandas as pd\r\nimport yfinance as yf\r\nimport datetime\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\n\r\nimport utils\r\n\r\nfrom scipy import stats\r\n\r\nclass volatility_indicators:\r\n \r\n def __init__(self, data):\r\n \r\n self.data = data\r\n \r\n # Bollinger Ban\r\n def bb(self):\r\n '''\r\n Bollinger Bands\r\n \r\n Volatility bands placed above and below a moving average based on standard deviations\r\n Volatility UP: Wider\r\n Volatility DOWN: Contract\r\n \r\n ref: https://school.stockcharts.com/doku.php?id=technical_indicators:bollinger_bands \r\n '''\r\n \r\n \r\n \r\n def dc(self):\r\n '''\r\n Donchian Channel\r\n\r\n \r\n '''\r\n\r\n def ui(self):\r\n '''\r\n Ulcer Index\r\n '''\r\n \r\n def kc(self):\r\n '''\r\n Keltner Channel\r\n '''\r\n \r\n def atr(self):\r\n '''\r\n Average True Range\r\n \r\n \r\n \r\n ref: http://stockcharts.com/school/doku.php?id=chart_school:technical_indicators:average_true_range_atr\r\n '''\r\n \r\nif __name__ == \"__main__\":\r\n # Download Stock Data\r\n spy = yf.download('SPY', '1990-01-01')\r\n \r\n vi = volatility_indicators(spy)\r\n"
},
{
"alpha_fraction": 0.8197932243347168,
"alphanum_fraction": 0.8197932243347168,
"avg_line_length": 74.22222137451172,
"blob_id": "099d53dad401d75b85b1b20ea86401158433ec6b",
"content_id": "f58af28c9e5c8b66c70f63897d2b312ae1adb4e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 677,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 9,
"path": "/README.md",
"repo_name": "sweetscientist/quantitative_finance",
"src_encoding": "UTF-8",
"text": "# Quantitative Finance \n\nFinance related developments in python.\n\n- [Data collection](https://github.com/sweetscientist/quantitative_finance/blob/master/stock_data_collection.ipynb)\n- [Backtesting](https://github.com/sweetscientist/quantitative_finance/blob/master/strat_dev_backtesting.ipynb)\n- [Crypto Backtest](https://github.com/sweetscientist/quantitative_finance/blob/master/coin_backtesting.ipynb)\n- [Optimization using Genetic Algorithm](https://github.com/sweetscientist/quantitative_finance/blob/master/improve_logreg_using_GA.ipynb)\n- [Building a model using tensorflow](https://github.com/sweetscientist/quantitative_finance/blob/master/tensorflow_model_dev.ipynb)\n"
}
] | 4 |
dmh43/mimiciii
|
https://github.com/dmh43/mimiciii
|
e6844aaea142986ac733e5aad4263e40bcd97694
|
ffac214e075d914ca0cc47cef015c4f690232331
|
9292ebb901a52399e713c0d8115ae02056a7e25b
|
refs/heads/master
| 2020-05-24T19:24:52.023482 | 2019-06-09T19:18:50 | 2019-06-09T19:18:50 | 187,433,615 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6897546648979187,
"alphanum_fraction": 0.6955267190933228,
"avg_line_length": 32,
"blob_id": "5a6ab78af37f8b13b8df0b4ecd08727e970e807c",
"content_id": "1ac58bf459719ca4c4fd165a4666041e10a5f679",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 693,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 21,
"path": "/diag/icd_encoder.py",
"repo_name": "dmh43/mimiciii",
"src_encoding": "UTF-8",
"text": "from toolz import pipe\n\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\n\nclass ICDEncoder(nn.Module):\n def __init__(self, icd_token_embeds):\n super().__init__()\n self.icd_token_embeds = icd_token_embeds\n self.weights = nn.Embedding(len(icd_token_embeds.weight), 1)\n torch.nn.init.xavier_normal_(self.weights.weight.data)\n\n def forward(self, icd):\n terms, cnts = icd\n token_weights = self.weights(terms).squeeze() + torch.log(cnts.float())\n normalized_weights = F.softmax(token_weights, 1)\n icd_tokens = self.icd_token_embeds(terms)\n doc_vecs = torch.sum(normalized_weights.unsqueeze(2) * icd_tokens, 1)\n encoded = doc_vecs\n return encoded\n"
},
{
"alpha_fraction": 0.5734206438064575,
"alphanum_fraction": 0.5755335092544556,
"avg_line_length": 36.56349182128906,
"blob_id": "8afa140e61c96c4f9bf2faab89244033d322dc88",
"content_id": "b7efa03276396498f73cb5133c61d72fba9dddd7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4733,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 126,
"path": "/diag/preprocessing.py",
"repo_name": "dmh43/mimiciii",
"src_encoding": "UTF-8",
"text": "import torch\nfrom torch.nn.utils.rnn import pad_sequence\nfrom fastai.text import Tokenizer\nimport pydash as _\n\nfrom operator import itemgetter\nfrom itertools import combinations\nfrom collections import Counter\n\npad_token_idx = 0\nunk_token_idx = 1\n\ndef to_pairs_by_hadm_id(diagnoses):\n cnt = 0\n pairs_by_hadm_id = {}\n label_seq_nums_for_hadm_id = []\n current_hadm_id = None\n current_note_id = None\n for hadm_id, note_id, seq_num, label in zip(diagnoses['hadm_id'],\n diagnoses['note_id'],\n diagnoses['seq_num'],\n diagnoses['label']):\n if (current_hadm_id is None) and (current_note_id is None):\n current_hadm_id = hadm_id\n current_note_id = note_id\n if current_hadm_id == hadm_id:\n label_seq_nums_for_hadm_id.append((label, seq_num))\n else:\n in_order = [label\n for label, seq_num in sorted(label_seq_nums_for_hadm_id,\n key=itemgetter(1))]\n for pair in combinations(in_order, 2):\n pairs_by_hadm_id[hadm_id] = (current_note_id, pair)\n cnt += 1\n label_seq_nums_for_hadm_id = []\n label_seq_nums_for_hadm_id.append((label, seq_num))\n current_hadm_id = hadm_id\n current_note_id = note_id\n return pairs_by_hadm_id, cnt\n\ndef pad(batch, device=torch.device('cpu')):\n batch_lengths = torch.tensor(_.map_(batch, len),\n dtype=torch.long,\n device=device)\n return (pad_sequence(batch, batch_first=True, padding_value=1).to(device),\n batch_lengths)\n\ndef pad_to_len(coll, max_len, pad_with=None):\n pad_with = pad_with if pad_with is not None else pad_token_idx\n return coll + [pad_with] * (max_len - len(coll)) if len(coll) < max_len else coll\n\ndef pad_batch_list(pad_elem, batch, min_len=0):\n assert isinstance(batch, list)\n assert isinstance(pad_elem, (int, str))\n result_len = max(min_len, max(_.map_(batch, len)))\n to_stack = []\n for elem in batch:\n dim_len = len(elem)\n if result_len != dim_len:\n pad_seq = [pad_elem for i in range(result_len - dim_len)]\n to_stack.append(elem + pad_seq)\n else:\n to_stack.append(elem)\n return to_stack\n\ndef collate_bow(bow):\n terms = []\n cnts = []\n max_len = 0\n for doc in bow:\n doc_terms = list(doc.keys())\n max_len = max(max_len, len(doc_terms))\n terms.append(doc_terms)\n cnts.append([doc[term] for term in doc_terms])\n terms = torch.tensor([pad_to_len(doc_terms, max_len) for doc_terms in terms])\n cnts = torch.tensor([pad_to_len(doc_term_cnts, max_len, pad_with=0) for doc_term_cnts in cnts])\n return terms, cnts\n\ndef tokens_to_indexes(tokens, lookup=None, num_tokens=None, token_set=None):\n is_test = lookup is not None\n if lookup is None:\n lookup: dict = {'<unk>': unk_token_idx, '<pad>': pad_token_idx}\n result = []\n for tokens_chunk in tokens:\n tokens_to_parse = tokens_chunk if num_tokens is None else tokens_chunk[:num_tokens]\n chunk_result = []\n for token in tokens_to_parse:\n if (token_set is None) or (token in token_set):\n if is_test:\n chunk_result.append(lookup.get(token) or unk_token_idx)\n else:\n lookup[token] = lookup.get(token) or len(lookup)\n chunk_result.append(lookup[token])\n else:\n chunk_result.append(unk_token_idx)\n result.append(chunk_result)\n return result, lookup\n\ndef get_default_tokenizer(): return Tokenizer()\n\ndef preprocess_texts(texts,\n token_lookup=None,\n num_tokens=None,\n token_set=None,\n get_tokenizer=get_default_tokenizer):\n tokenizer = get_tokenizer()\n tokenized = tokenizer.process_all(texts)\n idx_texts, token_lookup = tokens_to_indexes(tokenized,\n token_lookup,\n num_tokens=num_tokens,\n token_set=token_set)\n return idx_texts, token_lookup\n\ndef prepare_bow(lookup,\n token_lookup=None,\n token_set=None,\n num_tokens=None):\n ids = list(lookup.keys())\n contents = [lookup[text_id] for text_id in ids]\n numericalized, token_lookup = preprocess_texts(contents,\n token_lookup=token_lookup,\n token_set=token_set,\n num_tokens=num_tokens)\n numericalized_bow = {text_id: Counter(doc)\n for text_id, doc in zip(ids, numericalized)}\n return numericalized_bow, token_lookup\n"
},
{
"alpha_fraction": 0.6223805546760559,
"alphanum_fraction": 0.6253143548965454,
"avg_line_length": 43.185184478759766,
"blob_id": "73e17614bf19bd870d835e7e2045bd6eca95b00a",
"content_id": "6b199e34c64e394ee1de95e9855eda14f5460a7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2386,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 54,
"path": "/diag/pointwise_scorer.py",
"repo_name": "dmh43/mimiciii",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nfrom toolz import pipe\n\nfrom .note_encoder import NoteEncoder\nfrom .icd_encoder import ICDEncoder\nfrom .utils import Identity\n\ndef _get_layer(from_size, to_size, dropout_keep_prob, activation=None, use_layer_norm=False, use_batch_norm=False):\n return [nn.Linear(from_size, to_size),\n nn.LayerNorm(to_size) if use_layer_norm else Identity(),\n nn.BatchNorm1d(to_size) if use_batch_norm else Identity(),\n nn.ReLU() if activation is None else activation,\n nn.Dropout(1 - dropout_keep_prob)]\n\nclass PointwiseScorer(nn.Module):\n def __init__(self,\n note_token_embeds,\n icd_token_embeds,\n model_params,\n train_params):\n super().__init__()\n self.use_layer_norm = train_params.use_layer_norm\n self.use_batch_norm = train_params.use_batch_norm\n self.icd_encoder = ICDEncoder(icd_token_embeds)\n self.note_encoder = NoteEncoder(note_token_embeds)\n concat_len = model_params.token_embed_len + model_params.token_embed_len\n self.layers = nn.ModuleList()\n from_size = concat_len + sum([model_params.token_embed_len\n for i in [model_params.append_hadamard, model_params.append_difference]\n if i])\n for to_size in model_params.hidden_layer_sizes:\n self.layers.extend(_get_layer(from_size,\n to_size,\n train_params.dropout_keep_prob,\n use_layer_norm=self.use_layer_norm,\n use_batch_norm=self.use_batch_norm))\n from_size = to_size\n self.layers.extend(_get_layer(from_size, 1, train_params.dropout_keep_prob, activation=Identity()))\n if not train_params.use_bce_loss:\n self.layers.append(nn.Tanh())\n self.append_difference = model_params.append_difference\n self.append_hadamard = model_params.append_hadamard\n\n\n def forward(self, note, icd):\n icd_embed = self.icd_encoder(icd)\n note_embed = self.note_encoder(note)\n hidden = torch.cat([icd_embed, note_embed], 1)\n if self.append_difference:\n hidden = torch.cat([hidden, torch.abs(icd_embed - note_embed)], 1)\n if self.append_hadamard:\n hidden = torch.cat([hidden, icd_embed * note_embed], 1)\n return pipe(hidden, *self.layers).reshape(-1)\n"
},
{
"alpha_fraction": 0.6885964870452881,
"alphanum_fraction": 0.6929824352264404,
"avg_line_length": 37,
"blob_id": "3f91f81dd753c1754a50062959a646e2a0cb59dc",
"content_id": "ba43f741c7f78eec7d9b207b0b2b93d8def6e00b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 456,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 12,
"path": "/diag/dataset.py",
"repo_name": "dmh43/mimiciii",
"src_encoding": "UTF-8",
"text": "from torch.utils.data import Dataset\n\nclass MimicDataset(Dataset):\n def __init__(self, notes_bow, icd_desc_bow, training_pairs):\n self.notes_bow, self.icd_desc_bow, self.training_pairs = notes_bow, icd_desc_bow, training_pairs\n\n def __len__(self):\n return len(self.training_pairs)\n\n def __getitem__(self, idx):\n note_id, pair = self.training_pairs[idx]\n return self.notes_bow[note_id], self.icd_desc_bow[pair[0]], self.icd_desc_bow[pair[1]]\n"
},
{
"alpha_fraction": 0.6829268336296082,
"alphanum_fraction": 0.6829268336296082,
"avg_line_length": 40,
"blob_id": "0c6098966f46038ede2b41f8a063a5752c8f3f0e",
"content_id": "3c88bda1603752f1d98b03129dc75f09efdcbe86",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 41,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 1,
"path": "/sql/create_cache_details.sql",
"repo_name": "dmh43/mimiciii",
"src_encoding": "UTF-8",
"text": "insert into cache_details ({}) values {}\n"
},
{
"alpha_fraction": 0.6792114973068237,
"alphanum_fraction": 0.6810035705566406,
"avg_line_length": 20.882352828979492,
"blob_id": "99c04a7c1f21f985fa5fed9b551b850efdd6dbe8",
"content_id": "b2e733fdcdd29db054fd5aa30d69e3f332f3fb91",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1116,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 51,
"path": "/diag/utils.py",
"repo_name": "dmh43/mimiciii",
"src_encoding": "UTF-8",
"text": "from collections import Counter\n\nimport torch\nimport torch.nn as nn\n\ndef get_to_label_mapping(ids):\n mapping = {}\n for an_id in ids:\n mapping[an_id] = len(mapping)\n return mapping\n\nclass Identity(nn.Module):\n def forward(self, x): return x\n\ndef dont_update(module):\n for p in module.parameters():\n p.requires_grad = False\n\ndef do_update(module):\n for p in module.parameters():\n p.requires_grad = True\n\ndef append_at(obj, key, val):\n if key in obj:\n obj[key].append(val)\n else:\n obj[key] = [val]\n\ndef at_least_one_dim(tensor):\n if len(tensor.shape) == 0:\n return tensor.unsqueeze(0)\n else:\n return tensor\n\ndef to_list(coll):\n if isinstance(coll, torch.Tensor):\n return coll.tolist()\n else:\n return list(coll)\n\ndef maybe(val, default): return val if val is not None else default\n\ndef to_lookup(df, key_col_name, val_col_name):\n df_dict = df.to_dict('list')\n return dict(zip(df_dict[key_col_name], df_dict[val_col_name]))\n\ndef get_token_cnts(tokenizer, texts):\n tokenized = tokenizer.process_all(texts)\n cntr = Counter()\n for doc in tokenized: cntr.update(doc)\n return cntr\n"
},
{
"alpha_fraction": 0.6392573118209839,
"alphanum_fraction": 0.6445623636245728,
"avg_line_length": 24.133333206176758,
"blob_id": "398ba53bcbc5fb79ae3b34b7ce98a30707208ad3",
"content_id": "9a20da00854fb15422983327e1e0e2d8baf4c037",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 377,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 15,
"path": "/tests/test_lazy.py",
"repo_name": "dmh43/mimiciii",
"src_encoding": "UTF-8",
"text": "from diag.lazy import Lazy, Cache\n\n\ndef test_cache(tmp_path):\n cache = Cache(tmp_path)\n assert not cache.is_cached('my_fn', {})\n\ndef test_cache_read(tmp_path):\n cache = Cache(tmp_path)\n cache.cache_result('my_fn', {}, 0)\n assert cache.is_cached('my_fn', {})\n assert cache.read_cache('my_fn', {}) == 0\n\n# def test_lazy(tmp_path):\n# deferred = Lazy(int, tmp_path, cache)\n"
},
{
"alpha_fraction": 0.7701149582862854,
"alphanum_fraction": 0.7701149582862854,
"avg_line_length": 28,
"blob_id": "447583d5bdaeb9c237d685cdf9758a02b0af1fcb",
"content_id": "a5db63951a3395959f6a8b7e4b43cb2c2c7cdc65",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 87,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 3,
"path": "/diag/types.py",
"repo_name": "dmh43/mimiciii",
"src_encoding": "UTF-8",
"text": "from typing import Union, Type, Callable\n\nFactory_T = Union[Type[LazyProxy], Callable]\n"
},
{
"alpha_fraction": 0.6797853112220764,
"alphanum_fraction": 0.6806797981262207,
"avg_line_length": 38.92856979370117,
"blob_id": "5d2035bef11015200a5d70c62209dc3f71a8b465",
"content_id": "0c4d83c9a7d1086cc44326c5cd81b1d9ff1ab7f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1118,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 28,
"path": "/diag/fetchers.py",
"repo_name": "dmh43/mimiciii",
"src_encoding": "UTF-8",
"text": "from pathlib import Path\nimport pandas as pd\n\nfrom .utils import to_lookup, get_token_cnts\n\ndef fetch_note_by_id(note_id, path='./data/notes/'):\n with open(Path(path).joinpath(f'note_{note_id}')) as fh:\n return fh.read()\n\ndef fetch_icd_desc_lookup(path='./data/D_ICD_DIAGNOSES.csv'):\n df = pd.read_csv(path)\n return to_lookup(df, 'ICD9_CODE', 'LONG_TITLE')\n\ndef get_token_set(tokenizer, icd_desc_lookup_by_label, opts):\n min_num_occurances = opts['min_num_occurances']\n notes_df = pd.read_csv('data/notes.csv')\n notes_df.set_index('note_id', inplace=True)\n diagnoses_df = pd.read_csv('data/diagnoses.csv')\n notes_df = notes_df.loc[diagnoses_df.note_id]\n notes_df['note_id'] = notes_df.index\n notes_lookup = to_lookup(notes_df, 'note_id', 'text')\n token_cnts = get_token_cnts(tokenizer, list(notes_lookup.values()))\n icd_token_cnts = get_token_cnts(tokenizer, list(icd_desc_lookup_by_label.values()))\n token_set = {token\n for token, cnt in token_cnts.items()\n if cnt + icd_token_cnts[token] >= min_num_occurances}\n token_set.update(icd_token_cnts.keys())\n return token_set\n"
},
{
"alpha_fraction": 0.5071839094161987,
"alphanum_fraction": 0.5186781883239746,
"avg_line_length": 32.14285659790039,
"blob_id": "197932fa6cf8eb9870138b9845aded9885ac509d",
"content_id": "38bf1a7a5228177d000334658e5eea760e0ae9d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 696,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 21,
"path": "/diag/pairwise_scorer.py",
"repo_name": "dmh43/mimiciii",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\n\nfrom .pointwise_scorer import PointwiseScorer\n\nclass PairwiseScorer(nn.Module):\n def __init__(self,\n note_token_embeds,\n icd_token_embeds,\n model_params,\n train_params):\n super().__init__()\n self.pointwise_scorer = PointwiseScorer(note_token_embeds,\n icd_token_embeds,\n model_params,\n train_params)\n\n def forward(self, note, icd_1, icd_2):\n score_1 = self.pointwise_scorer(note, icd_1)\n score_2 = self.pointwise_scorer(note, icd_2)\n return score_1 - score_2\n"
},
{
"alpha_fraction": 0.6282051205635071,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 12,
"blob_id": "2170ccf97c89029707bdcbd8e2ed7260ae0a0cdb",
"content_id": "33ecf17342d50dc726e3c868c77d7a86e5b41b47",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 78,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 6,
"path": "/setup.py",
"repo_name": "dmh43/mimiciii",
"src_encoding": "UTF-8",
"text": "from setuptools import setup\n\nsetup(\n name='mimiciii',\n version='0.0.1'\n)\n"
},
{
"alpha_fraction": 0.6637537479400635,
"alphanum_fraction": 0.670506477355957,
"avg_line_length": 45.19266128540039,
"blob_id": "7b64c20874f3634bae6f8589de14fadad5ae4208",
"content_id": "7613267699237a300da720bc69319b7628585fd9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5035,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 109,
"path": "/main.py",
"repo_name": "dmh43/mimiciii",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport numpy.linalg as la\nimport pandas as pd\nimport numpy.random as rn\nimport matplotlib.pyplot as plt\nimport torch\nfrom torch import nn\nfrom torch.utils.data import DataLoader\nfrom torch.utils.data.sampler import BatchSampler, RandomSampler\nfrom torch.optim import Adam\nfrom pyrsistent import m\nimport pydash as _\n\nfrom itertools import groupby\nfrom functools import reduce\nfrom operator import itemgetter\n\nfrom diag.fetchers import fetch_note_by_id, fetch_icd_desc_lookup, get_token_set\nfrom diag.preprocessing import to_pairs_by_hadm_id, get_default_tokenizer, prepare_bow, pad_batch_list\nfrom diag.utils import to_lookup, get_token_cnts, get_to_label_mapping\nfrom diag.icd_encoder import ICDEncoder\nfrom diag.note_encoder import NoteEncoder\nfrom diag.pointwise_scorer import PointwiseScorer\nfrom diag.pairwise_scorer import PairwiseScorer\nfrom diag.pointwise_ranker import PointwiseRanker\nfrom diag.dataset import MimicDataset\nfrom diag.cv import get_cv_folds, deal_folds\nfrom diag.metrics import metrics_at_k\nfrom diag.ranking import to_rel_sets\nfrom diag.cached_bow import CachedBoW\nfrom diag.lazy import LazyBuilder\n\ndef main():\n device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')\n model_params = m(min_num_occurances=10,\n append_hadamard=False,\n append_difference=False,\n hidden_layer_sizes=[100],\n token_embed_len=100)\n train_params = m(dropout_keep_prob=0.8,\n batch_size=512,\n use_layer_norm=True,\n use_batch_norm=False,\n use_bce_loss=False,\n num_cv_folds=5)\n lazy = LazyBuilder('./cache')\n diagnoses_desc_df = pd.read_csv('data/D_ICD_DIAGNOSES.csv')\n diagnoses_df = pd.read_csv('data/diagnoses.csv')\n label_lookup = get_to_label_mapping(set(diagnoses_desc_df['ICD9_CODE'].tolist() + diagnoses_df.icd9_code.tolist()))\n num_icd9_codes = len(label_lookup)\n diagnoses_df['label'] = diagnoses_df.icd9_code.map(lambda val: label_lookup[val])\n diagnoses_df.sort_values('hadm_id', inplace=True)\n diagnoses = diagnoses_df.to_dict('list')\n pairs_by_hadm_id, num_pairs = to_pairs_by_hadm_id(diagnoses)\n icd_desc_lookup = fetch_icd_desc_lookup()\n icd_desc_lookup_by_label = {label: icd_desc_lookup.get(icd9, '')\n for icd9, label in label_lookup.items()}\n tokenizer = get_default_tokenizer()\n token_set = get_token_set(tokenizer,\n icd_desc_lookup_by_label,\n opts=dict(min_num_occurances=model_params.min_num_occurances))\n token_lookup = dict(zip(token_set, range(len(token_set))))\n notes_bow = CachedBoW(tokenizer=tokenizer, path='data/notes/', token_lookup=token_lookup)\n icd_desc_bow, __ = prepare_bow(icd_desc_lookup_by_label, token_lookup=token_lookup, token_set=token_set)\n num_unique_tokens = len(token_lookup)\n folds = get_cv_folds(train_params.num_cv_folds, pairs_by_hadm_id.keys())\n for test_fold_num in range(train_params.num_cv_folds):\n print('Fold num', test_fold_num)\n test_keys = folds[test_fold_num]\n test, train = deal_folds(pairs_by_hadm_id, test_keys)\n test_rel_sets = to_rel_sets(test)\n test_hadm_ids = [hadm_id for hadm_id, g in groupby(test, itemgetter(0))]\n test_note_id_by_hadm_id = {hadm_id: next(g)[0]\n for hadm_id, g in groupby(test, itemgetter(0))}\n note = [notes_bow[test_note_id_by_hadm_id[hadm_id]] for hadm_id in test_hadm_ids]\n candidates = list(range(num_icd9_codes))\n icd = [icd_desc_bow[label] for label in candidates]\n token_embeds = nn.Embedding(num_unique_tokens, model_params.token_embed_len)\n pointwise_scorer = PointwiseScorer(token_embeds, token_embeds, model_params, train_params)\n pairwise_scorer = PairwiseScorer(token_embeds, token_embeds, model_params, train_params)\n ranker = PointwiseRanker(device, pointwise_scorer)\n criteria = nn.CrossEntropyLoss()\n optimizer = Adam(pairwise_scorer.parameters())\n dataset = MimicDataset(notes_bow, icd_desc_bow, train)\n dataloader = DataLoader(dataset, batch_sampler=BatchSampler(RandomSampler(dataset),\n train_params.batch_size,\n False))\n for batch_num, batch in enumerate(dataloader):\n optimizer.zero_grad()\n out = pairwise_scorer(*(tens.to(device) for tens in batch))\n loss = criteria(torch.zeros_like(out), out)\n if batch_num % 100 == 0: print('batch', batch_num, 'loss', loss)\n if batch_num % 10000 == 0:\n rankings = ranker(note, icd).tolist()\n print('batch', batch_num, metrics_at_k(rankings, test_rel_sets))\n loss.backward()\n optimizer.step()\n\nif __name__ == \"__main__\":\n import ipdb\n import traceback\n import sys\n\n try:\n main()\n except: # pylint: disable=bare-except\n extype, value, tb = sys.exc_info()\n traceback.print_exc()\n ipdb.post_mortem(tb)\n"
},
{
"alpha_fraction": 0.5841121673583984,
"alphanum_fraction": 0.5841121673583984,
"avg_line_length": 25.75,
"blob_id": "402122892b4c4475ea64ad5e2c8e53c5f14973b8",
"content_id": "fa512f54f45ff319d077b03f98933b658bdf7bc5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 214,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 8,
"path": "/sql/table_create.sql",
"repo_name": "dmh43/mimiciii",
"src_encoding": "UTF-8",
"text": "create table if not exists cache_details (\n id integer primary key,\n cache_id integer not null,\n fn_name text not null,\n opt_name text,\n opt_value text,\n opt_type text\n );\n"
},
{
"alpha_fraction": 0.6703020334243774,
"alphanum_fraction": 0.6711409687995911,
"avg_line_length": 33.05714416503906,
"blob_id": "eb53c8667ffb4c59d770869a8049934e139d0211",
"content_id": "ecc1ed35a430a13c4db3506ee28dcfddea850f9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1192,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 35,
"path": "/diag/cached_bow.py",
"repo_name": "dmh43/mimiciii",
"src_encoding": "UTF-8",
"text": "from collections import Counter\nimport pickle\nfrom pathlib import Path\n\nfrom .preprocessing import tokens_to_indexes\n\nclass CachedBoW():\n def __init__(self, tokenizer, path, token_lookup):\n self.tokenizer, self.path, self.token_lookup = tokenizer, Path(path), token_lookup\n self.cache_path = Path('./cache/').joinpath(self.path)\n\n def _get_bow_name(self, key): return f'note_{key}'\n\n def _cached_get(self, key):\n with open(self.cache_path.joinpath(self._get_bow_name(key)), 'rb') as fh:\n return pickle.load(fh)\n\n def _cache_result(self, key, bow):\n with open(self.cache_path.joinpath(self._get_bow_name(key)), 'wb') as fh:\n pickle.dump(bow, fh)\n\n def _get_bow(self, key):\n with open(self.path.joinpath(self._get_bow_name(key))) as fh:\n text = fh.read()\n tokenized = self.tokenizer.process_text(text, self.tokenizer.tok_func(self.tokenizer.lang))\n numericalized, __ = tokens_to_indexes([tokenized], self.token_lookup)\n return dict(Counter(numericalized[0]))\n\n def __getitem__(self, key):\n try:\n bow = self._cached_get(key)\n except FileNotFoundError:\n bow = self._get_bow(key)\n self._cache_result(key, bow)\n return bow\n"
},
{
"alpha_fraction": 0.513221800327301,
"alphanum_fraction": 0.5153804421424866,
"avg_line_length": 35.33333206176758,
"blob_id": "ebeb13eac04ce9ffeae4b2971f8baed87baf51cf",
"content_id": "a4450036883295cc8b63ccdb902b0fc8484eec17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1853,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 51,
"path": "/diag/pointwise_ranker.py",
"repo_name": "dmh43/mimiciii",
"src_encoding": "UTF-8",
"text": "import pydash as _\n\nimport torch\nimport torch.nn as nn\n\nfrom .preprocessing import collate_bow\nfrom .utils import at_least_one_dim\n\nclass PointwiseRanker:\n def __init__(self,\n device,\n pointwise_scorer,\n chunk_size=-1):\n self.device = device\n self.pointwise_scorer = pointwise_scorer\n self.chunk_size = chunk_size\n\n def _scores_for_chunk(self, note, icd):\n padded_icd = [tens.to(self.device) for tens in collate_bow(icd)]\n padded_note = [tens.to(self.device) for tens in collate_bow(note)]\n with torch.no_grad():\n try:\n self.pointwise_scorer.eval()\n scores = self.pointwise_scorer(padded_note,\n padded_icd)\n finally:\n self.pointwise_scorer.train()\n return at_least_one_dim(scores)\n\n def __call__(self, note, icd, k=None):\n with torch.no_grad():\n k = k if k is not None else len(icd)\n ranks = []\n for note, icd in zip(note, icd):\n if self.chunk_size != -1:\n all_scores = []\n for from_idx, to_idx in zip(range(0,\n len(icd),\n self.chunk_size),\n range(self.chunk_size,\n len(icd) + self.chunk_size,\n self.chunk_size)):\n all_scores.append(self._scores_for_chunk(note,\n icd[from_idx : to_idx]))\n scores = torch.cat(all_scores, 0)\n else:\n scores = self._scores_for_chunk(note, icd)\n topk_scores, topk_idxs = torch.topk(scores, k)\n sorted_scores, sort_idx = torch.sort(topk_scores, descending=True)\n ranks.append(topk_idxs[sort_idx])\n return torch.stack(ranks)\n"
},
{
"alpha_fraction": 0.6107431650161743,
"alphanum_fraction": 0.6261957287788391,
"avg_line_length": 35.72972869873047,
"blob_id": "f794c11f7613beabe3828a6c64ec8dd5e09ef4b0",
"content_id": "5b23ff1e093d56953ba061a30facbf5b5dacaeb5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1359,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 37,
"path": "/diag/metrics.py",
"repo_name": "dmh43/mimiciii",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\ndef metrics_at_k(rankings_to_judge, relevant_doc_ids, k=10):\n correct = 0\n num_relevant = 0\n num_rankings_considered = 0\n avg_precision_sum = 0\n ndcgs = []\n for ranking, relevant in zip(rankings_to_judge, relevant_doc_ids):\n if ranking is None: continue\n num_relevant_in_ranking = len(relevant)\n if num_relevant_in_ranking == 0: continue\n avg_correct = 0\n correct_in_ranking = 0\n dcg = 0\n idcg = 0\n for doc_rank, doc_id in enumerate(ranking[:k]):\n rel = doc_id in relevant\n correct += rel\n correct_in_ranking += rel\n precision_so_far = correct_in_ranking / (doc_rank + 1)\n avg_correct += rel * precision_so_far\n dcg += (2 ** rel - 1) / np.log2(doc_rank + 2)\n num_relevant += num_relevant_in_ranking\n avg_precision_sum += avg_correct / min(k, num_relevant_in_ranking)\n idcg += np.array([1.0/np.log2(rank + 2)\n for rank in range(min(k, num_relevant_in_ranking))]).sum()\n ndcgs.append(dcg / idcg)\n num_rankings_considered += 1\n precision_k = correct / (k * num_rankings_considered)\n recall_k = correct / num_relevant\n ndcg = sum(ndcgs) / len(ndcgs)\n mean_avg_precision = avg_precision_sum / num_rankings_considered\n return {'precision': precision_k,\n 'recall': recall_k,\n 'ndcg': ndcg,\n 'map': mean_avg_precision}\n"
},
{
"alpha_fraction": 0.6163058280944824,
"alphanum_fraction": 0.6172270774841309,
"avg_line_length": 36.11111068725586,
"blob_id": "44478a2f4f2ac376caaecaaa2ad82da19b8b1976",
"content_id": "1841dd2130165d8156774808692a6d91ef26c142",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4342,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 117,
"path": "/diag/lazy.py",
"repo_name": "dmh43/mimiciii",
"src_encoding": "UTF-8",
"text": "from collections import defaultdict\nimport uuid\nfrom pathlib import Path\nimport sqlite3\nimport pydash as _\nimport pickle\n\ndef realize(val):\n if isinstance(val, Lazy):\n return val.realize()\n else:\n return val\n\nclass Cache():\n def __init__(self, cache_path):\n self.cache_path = Path(cache_path)\n self.db_path = self.cache_path.joinpath('cache.db')\n self.connection = sqlite3.connect(str(self.db_path))\n self.cursor = self.connection.cursor()\n with open('./sql/table_create.sql') as table_create_query_fh:\n query = table_create_query_fh.read()\n self.cursor.execute(query)\n\n def _get_fn_cache_details(self, fn_name):\n with open('./sql/get_cache_details.sql') as get_cache_details_query_fh:\n query = get_cache_details_query_fh.read().format(fn_name)\n self.cursor.execute(query)\n fn_cache_details = defaultdict(dict)\n for row in self.cursor.fetchall():\n fn_cache_details[row['cache_id']].update(row)\n return fn_cache_details\n\n def is_cached(self, fn_name, opts):\n fn_cache_details = self._get_fn_cache_details(fn_name)\n return _.some(fn_cache_details, lambda val, key: val == opts)\n\n def _path_from_cache_id(self, cache_id):\n return self.cache_path.joinpath(str(cache_id))\n\n def read_cache(self, fn_name, opts):\n fn_cache_details = self._get_fn_cache_details(fn_name)\n cache_details = _.find(fn_cache_details, lambda val, key: val == opts)\n with open(self._path_from_cache_id(cache_details), 'rb') as fh:\n return pickle.load(fh)\n\n def _create_cache_details(self, fn_name, opts):\n def _get_opt_cols(opt_name, opt_value):\n def _get_type(value):\n if isinstance(value, int): return 'int'\n elif isinstance(value, str): return 'str'\n elif isinstance(value, bool): return 'bool'\n else: raise ValueError\n return (opt_name, opt_value, _get_type(opt_value))\n cache_id = str(uuid.uuid1())\n opt_details_fields = ['opt_name', 'opt_value', 'opt_type']\n if len(opts) != 0:\n columns_str = ', '.join(['cache_id', 'fn_name'] + opt_details_fields)\n cache_details = [', '.join(\"'{}'\".format(val)\n for val in [fn_name, cache_id] + [_get_opt_cols(opt_name, opt_value)\n for opt_name, opt_value in opts.items()])\n for opt in opts]\n else:\n columns_str = ', '.join(['cache_id', 'fn_name'])\n cache_details = [', '.join(\"'{}'\".format(val)\n for val in [fn_name, cache_id])]\n cache_details_str = ', '.join(['({})'.format(cache_detail)\n for cache_detail in cache_details])\n with open('./sql/create_cache_details.sql') as create_cache_details_fh:\n query = create_cache_details_fh.read().format(columns_str, cache_details_str)\n self.cursor.execute(query)\n return cache_id\n\n def cache_result(self, fn_name, opts, result):\n cache_id = self._create_cache_details(fn_name, opts)\n with open(self._path_from_cache_id(cache_id), 'wb') as fh:\n return pickle.dump(result, fh)\n\n\nclass LazyBuilder():\n def __init__(self, cache_path):\n self.cache_path = Path(cache_path)\n self.cache = Cache(self.cache_path)\n\n def __call__(self, fn):\n lazy = Lazy(fn, self.cache_path, self.cache)\n return lazy\n\nclass Lazy():\n def __init__(self, fn, cache_path, cache):\n self._fn, self._cache_path, self._cache = fn, Path(cache_path), cache\n self._args, self._kwargs, self._opts = None, None, None\n self._fn_name = self._fn.__name__\n\n def __call__(self, *args, opts=None, **kwargs):\n opts = opts if opts is not None else {}\n self._args, self._kwargs = args, kwargs\n self._opts = opts\n return self\n\n def _is_cached(self):\n return self._cache.is_cached(self._fn_name, self._opts)\n\n def _read_cache(self):\n return self._cache.read_cache(self._fn_name, self._opts)\n\n def _cache_result(self, result):\n return self._cache.cache_result(self._fn_name, self._opts, result)\n\n def realize(self):\n args = (realize(arg) for arg in self._args)\n kwargs = {key: realize(val) for key, val in self._kwargs.items()}\n if self._is_cached():\n return self._read_cache()\n else:\n result = self._fn(*args, opts=self._opts, **kwargs)\n self._cache_result(result)\n return result\n"
},
{
"alpha_fraction": 0.7083333134651184,
"alphanum_fraction": 0.7083333134651184,
"avg_line_length": 31,
"blob_id": "6c56ae669b05ed662e4340bfc76381d69e203d28",
"content_id": "073dcfd173395fc878322aaa73e2b31c413f73fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 96,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 3,
"path": "/sql/get_cache_details.sql",
"repo_name": "dmh43/mimiciii",
"src_encoding": "UTF-8",
"text": "select cache_id, fn_name, opt_name, opt_value, opt_type\nfrom cache_details\nwhere fn_name = '{}'\n"
},
{
"alpha_fraction": 0.6352530717849731,
"alphanum_fraction": 0.6404886841773987,
"avg_line_length": 27.649999618530273,
"blob_id": "9c621da3ef1ce4085cc6522d1e9e8f0e8656e7d7",
"content_id": "f0104bbb569ba08adc6ff8b204ff18feff364f5d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 573,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 20,
"path": "/diag/cv.py",
"repo_name": "dmh43/mimiciii",
"src_encoding": "UTF-8",
"text": "from random import shuffle\n\ndef get_cv_folds(num_folds, keys):\n num_keys = len(keys)\n fold_len = num_keys // num_folds\n permutation = list(keys)\n shuffle(permutation)\n first_folds = [permutation[i * fold_len : (i + 1) * fold_len] for i in range(num_folds - 1)]\n last_fold = permutation[(num_folds - 1) * fold_len:]\n return first_folds + [last_fold]\n\ndef deal_folds(coll, keys):\n test, train = [], []\n test_keys = set(keys)\n for key in coll.keys():\n if key in test_keys:\n test.append(coll[key])\n else:\n train.append(coll[key])\n return test, train\n"
},
{
"alpha_fraction": 0.7364341020584106,
"alphanum_fraction": 0.7441860437393188,
"avg_line_length": 27.66666603088379,
"blob_id": "0b8580275f77ef8bc90b4bc7c650669c1aad6c66",
"content_id": "59ca6c5b86163f0ee3f0b10d7de164d2193a97cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 258,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 9,
"path": "/diag/ranking.py",
"repo_name": "dmh43/mimiciii",
"src_encoding": "UTF-8",
"text": "from collections import defaultdict\nfrom itertools import groupby\nfrom operator import itemgetter\n\ndef to_rel_sets(diags):\n rel = defaultdict(set)\n for hadm_id, diag in groupby(diags, itemgetter(0)):\n rel[hadm_id].add(list(diag)[-1])\n return dict(rel)\n"
},
{
"alpha_fraction": 0.6941678524017334,
"alphanum_fraction": 0.699857771396637,
"avg_line_length": 32.47618865966797,
"blob_id": "c5905b96684c5815a4f3056bae999f928b229bfb",
"content_id": "a56cf430f98b0c40682d6bef280fd93252d63f95",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 703,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 21,
"path": "/diag/note_encoder.py",
"repo_name": "dmh43/mimiciii",
"src_encoding": "UTF-8",
"text": "from toolz import pipe\n\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\n\nclass NoteEncoder(nn.Module):\n def __init__(self, note_token_embeds):\n super().__init__()\n self.note_token_embeds = note_token_embeds\n self.weights = nn.Embedding(len(note_token_embeds.weight), 1)\n torch.nn.init.xavier_normal_(self.weights.weight.data)\n\n def forward(self, note):\n terms, cnts = note\n token_weights = self.weights(terms).squeeze() + torch.log(cnts.float())\n normalized_weights = F.softmax(token_weights, 1)\n note_tokens = self.note_token_embeds(terms)\n doc_vecs = torch.sum(normalized_weights.unsqueeze(2) * note_tokens, 1)\n encoded = doc_vecs\n return encoded\n"
}
] | 21 |
minusworld/fireboat
|
https://github.com/minusworld/fireboat
|
04271f7d1e767ae5a567ef02629af68c9f8909b9
|
11d7cb637556bcb1b27f26e10cc9d27c578a61f1
|
237a039cd2c2a91c4ffff9f43d27076d543c6397
|
refs/heads/master
| 2021-01-10T06:43:19.968147 | 2015-12-11T00:33:50 | 2015-12-11T00:33:50 | 45,089,558 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.560675859451294,
"alphanum_fraction": 0.5683563947677612,
"avg_line_length": 24.038461685180664,
"blob_id": "141348873aa91afcef7698b4958b34defafc4d8f",
"content_id": "c2d93ba1af3e24470409740100aaab607d068605",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 651,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 26,
"path": "/scripts/pump_client.py",
"repo_name": "minusworld/fireboat",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport sys\nfrom fireboat.srv import PumpControl\nimport rospy\n\ndef pump_control_client(on):\n rospy.wait_for_service(\"pump_control\")\n try:\n sp_pump_control = rospy.ServiceProxy(\"pump_control\", PumpControl)\n success = sp_pump_control(on)\n return success\n except rospy.ServiceException, e:\n print \"service call failed: {0}\".format(e)\n\nif __name__=='__main__':\n d = {\n \"on\": True,\n \"true\": True,\n \"1\" : True,\n \"off\": False,\n \"false\":False,\n \"0\" : False\n }\n if len(sys.argv) == 2:\n print pump_control_client(d[sys.argv[1].lower()])\n"
},
{
"alpha_fraction": 0.5039145946502686,
"alphanum_fraction": 0.5117437839508057,
"avg_line_length": 28.29166603088379,
"blob_id": "d51e321014888a39d19a09f30cf5f871f8600aba",
"content_id": "b2d94a34848f3b0d5476d65136c9c4ebc4587b89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1405,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 48,
"path": "/scripts/pantilt_client.py",
"repo_name": "minusworld/fireboat",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport sys\nfrom fireboat.srv import PumpControl\nimport rospy\nMIN = 60\nMAX = 220\nHORZ_PIN=0\nVIRT_PIN=1\ndef pan_tilt_control_client(degree, direct):\n rospy.wait_for_service(\"pan_tilt_control\")\n try:\n sp_pan_tilt_control = rospy.ServiceProxy(\"pan_tilt_control\", PumpControl)\n success = sp_pan_tilt_control(degree, direct)\n return success\n except rospy.ServiceException, e:\n print \"service call failed: {0}\".format(e)\n\nif __name__=='__main__':\n \n if len(sys.argv) == 3:\n degree = int(sys.argv[2])\n direct = sys.argv[1].lower()\n if(MIN <= degree <= MAX){\n if(direct = \"up\"){\n direct = VIRT_PIN\n }\n elif(direct == \"down\"){\n direct = VIRT_PIN\n degree = -degree\n }\n elif(direct == \"left\"){\n direct = HORZ_PIN\n }\n elif(direct == \"right\"){\n direct = HORZ_PIN\n degree = -degree\n }\n if((direct == VIRT_PIN or direct ==HORZ_PIN) and typeof(degree) == int){\n print pan_tilt_control_client(degree, direct)\n }\n }\n else{\n print (\"The servos have a range of %d and %d.\" % (MIN, MAX))\n }\n else{\n print (\"Syntax: pantilt_client.py {up|down|left|right} {degree of rotataion}\")\n }"
},
{
"alpha_fraction": 0.6423926949501038,
"alphanum_fraction": 0.6488946676254272,
"avg_line_length": 25.517240524291992,
"blob_id": "88881abbcf565decbe9f2e92a34d6319f3d8a32f",
"content_id": "fde1512f1b41ce7e73edf6f0092918aa9f986ca6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 769,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 29,
"path": "/scripts/pantilt_server.py",
"repo_name": "minusworld/fireboat",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os\nfrom fireboat.srv import *\nimport rospy\n\nservoblaster = \"/dev/servoblaster\"\n\ndef pan_tilt_control_callback(degree, direction):\n if(direction == 0){\n rospy.set_param(\"pan_tilt_Y_direction\", direction)\n\n }\n elif(direction == 1){\n rospy.set_param(\"pan_tilt_X_direction\", direction)\n }\n os.system(\"echo %d=%d > %s\" % (direction, degree, servoblaster))\n return True\n\ndef init_tilt_control():\n #os.system(\"gpio mode 7 out\")\n rospy.set_param(\"pan_tilt_X_direction\", 0)\n rospy.set_param(\"pan_tilt_Y_direction\", 0)\n rospy.init_node(\"pan_tilt_control\")\n s = rospy.Service(\"pan_tilt_control\", PumpControl, pan_tilt_control_callback)\n rospy.spin()\n\nif __name__=='__main__':\n init_tilt_control()\n"
},
{
"alpha_fraction": 0.5022313594818115,
"alphanum_fraction": 0.5320975184440613,
"avg_line_length": 35.412498474121094,
"blob_id": "1003b3126199ce1d65943fd557b5e670f64b9dc1",
"content_id": "28372c76b4f10b747411ad39b0a2766489c62b66",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2913,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 80,
"path": "/scripts/fire_scan.py",
"repo_name": "minusworld/fireboat",
"src_encoding": "UTF-8",
"text": "import time\nimport targeting\nimport os\n\n\nclass ServoControl:\n\n def __init__(self):\n self.servo0_max = 150\n self.servo0_min = 80\n self.servo1_max = 150\n self.servo1_min = 100\n\n self.servo0_position = self.servo0_min\n self.servo1_position = self.servo1_min\n\n self.motion = 'pan' # values of pan or tilt\n\n self.servo0_direction = 'up' # values of up or down\n self.servo1_direction = 'up' # values of up or down\n\n\t self.fire_inView = False\n\t self.fire_targeted = False\n\n self.servo_out(0, self.servo0_position)\n time.sleep(1)\n self.servo_out(1, self.servo1_position)\n\n def servo_out(self, servoNum, servoValue):\n with open('/dev/servoblaster', 'a') as f:\n f.write('%d=%d\\n' % (servoNum, servoValue))\n\n def step(self):\n if not self.fire_inView:\n if self.motion == 'pan' and self.servo0_direction == 'up':\n self.servo0_position += 10\n self.servo_out(0, self.servo0_position)\n elif self.motion == 'pan' and self.servo0_direction == 'down':\n self.servo0_position -= 10\n self.servo_out(0, self.servo0_position)\n elif self.motion == 'tilt' and self.servo1_direction == 'up':\n self.servo1_position += 10\n motion = 'pan'\n self.servo_out(1, self.servo1_position)\n elif self.motion == 'tilt' and self.servo1_direction == 'down':\n self.servo1_position -= 10\n self.motion = 'pan'\n self.servo_out(1, self.servo1_position)\n\n time.sleep(1)\n\n score = (-1, -1) # needed for scoping. score format: (grid_index, grid_score)\n try:\n score = targeting.target_from_file(\"test0.png\")\n\t\t print(score)\n except FileNotFoundError as e:\n return \n \n if self.servo0_position > self.servo0_max:\n self.servo0_direction = 'down'\n self.servo0_position -= 10\n self.servo_out(0, self.servo0_position)\n self.motion = 'tilt'\n elif self.servo0_position < self.servo0_min:\n self.servo0_direction = 'up'\n self.servo0_position += 10\n self.servo_out(0, self.servo0_position)\n self.motion = 'tilt'\n elif self.servo1_position > self.servo1_max:\n self.servo1_direction = 'down'\n self.servo1_position -= 10\n self.servo_out(1, self.servo1_position)\n self.motion = 'pan'\n elif self.servo1_position < self.servo1_min:\n self.servo1_direction = 'up'\n self.servo1_position += 10\n self.servo_out(1, self.servo1_position)\n self.motion = 'pan'\n\n time.sleep(1)\n"
},
{
"alpha_fraction": 0.7749999761581421,
"alphanum_fraction": 0.7850000262260437,
"avg_line_length": 49,
"blob_id": "8c8f6d7d49053e44e53c1687867db3771d354007",
"content_id": "60851cc9c6882ceb8f0f88f5b4cc4218f4231467",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 200,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 4,
"path": "/setup.sh",
"repo_name": "minusworld/fireboat",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\nsource /opt/ros/indigo/setup.bash\nexport PYTHONPATH=/home/pi/ros_catkin_ws/devel/lib/python2.7/dist-packages:$PYTHONPATH\nexport ROS_PACKAGE_PATH=$ROS_PACKAGE_PATH:/home/pi/ros_catkin_ws/src\n"
},
{
"alpha_fraction": 0.4938271641731262,
"alphanum_fraction": 0.5308641791343689,
"avg_line_length": 11.789473533630371,
"blob_id": "c8192bdec5b28a2f5f34c7072427e818026c09a5",
"content_id": "6fb9977b9a615c36ffc126a082089f08c453d5a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 243,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 19,
"path": "/autoRotate.sh",
"repo_name": "minusworld/fireboat",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nSERV=/dev/servoblaster\nSTART=60\nEND=220\n\nfor (( c=$START; c<=$END; c++ ))\ndo\n\techo 0=$c > $SERV\n\techo 1=$c > $SERV\ndone\n\n# Aaaand back\n\nfor (( i=$END; i <=$START; i-- ))\ndo\n echo 0=$c > $SERV\n echo 1=$c > $SERV\ndone\n"
},
{
"alpha_fraction": 0.5924932956695557,
"alphanum_fraction": 0.6032171845436096,
"avg_line_length": 25.2265625,
"blob_id": "176f2b7023e2de8cfe1c7af59ca2fd48d3c9e189",
"content_id": "1e97377008f1c53bbdab348e333981f6f6271d9c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3357,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 128,
"path": "/scripts/targeting.py",
"repo_name": "minusworld/fireboat",
"src_encoding": "UTF-8",
"text": "from SimpleCV import *\nimport os\nimport datetime\n\n# width and height of images from FLIR\nglobal_w = 80\nglobal_h = 60\n\n# how many segments to divde the image into\n# along each axis. total number of image\n# segments will be this number, squared (x^2):\n# 1 2 3\n# ---------\n# | | | | 1\n# ---------\n# | | | | 2\n# ---------\n# | | | | 3\n# ---------\nsegments = 3\n\nFILTER_THRESHOLD = sum( (Image((global_w/segments, global_h/segments).invert()) / 13).getNumpy().flatten() )\n\n# helper method for showing an image.\ndef show_image(img):\n win=img.show()\n raw_input()\n win.quit()\n\n#### Scoring mechanism:\n# Find the distance between the image and the color Yellow,\n# resulting in black wherever yellow exists in the original\n# image. This means that a segment with the \"lowest\" color\n# value in the yellow distance image (again, yellow becomes\n# black in the distance image) is the segment which has the\n# most yellow.\ndef yellow_score(img):\n yellow_distance = img.colorDistance(Color.YELLOW)\n return sum(yellow_distance.getNumpy().flatten())\n\ndef score(img):\n return yellow_score(img) # just does yellow_score for now, may change\n\ndef score_alt(img):\n score = sum(img.getNumpy().flatten())\n print img.getNumpy()\n return score\n\n# scores each grid\n# returns the grid index of the winning grid\n# and the score.\ndef score_grids(img):\n grids = gridify(img)\n min_score = 0xffffffff\n grid_index = -1\n for i, grid in enumerate(grids):\n this_score = score(grid)\n if this_score < min_score:\n min_score = this_score\n grid_index = i\n return (grid_index, min_score)\n\ndef score_grids_max(img):\n grids = gridify(img)\n max_score = 0\n grid_index = -1\n for i, grid in enumerate(grids):\n this_score = score_alt(grid)\n if this_score > max_score and filter_img(grid, this_score, FILTER_THRESHOLD):\n max_score = this_score\n grid_index = i\n return (grid_index, max_score)\n\ndef filter_img(img, score, score_threshold):\n if score(img) < score_threshold:\n return False\n else:\n return True\n\n# divides an image into equally-sized regions \n# grids returned like so, for s=3:\n# [ [0] [1] [2]\n# [3] [4] [5]\n# [6] [7] [8] ]\ndef gridify(img, s=3):\n grids = []\n w = 0\n h = 0\n w_delta = img.width / s\n h_delta = img.height / s\n w_part = img.width % s\n h_part = img.height % s\n for i in range(s):\n for j in range(s):\n grids.append(img.crop(w, h, w_delta, h_delta))\n w += w_delta\n if w >= img.width-w_part:\n w = 0\n h += h_delta\n if h >= img.height-h_part:\n h = 0\n return grids\n\n# returns a tuple with the grid index and\n# the grid's score: (index, score)\ndef target(img, show=False):\n grids = gridify(img)\n #score = score_grids(img)\n score = score_grids_max(img)\n if show:\n win = grids[score[0]].show()\n return score\n\ndef fire_in_view(score):\n if score[0] == 5:\n return True\n else:\n return False\n\ndef target_from_file(filename):\n if os.path.isfile(filename):\n img = Image(filename)\n score = target(img, True)\n #os.remove(filename)\n\tos.rename(filename, filename + str(datetime.datetime.now()) + \".png\")\n return score\n else:\n raise FileNotFoundError\n"
},
{
"alpha_fraction": 0.615160346031189,
"alphanum_fraction": 0.6268221735954285,
"avg_line_length": 21.129032135009766,
"blob_id": "80d5a8a72c1ae51de2ddb6aee2488853d5d1115c",
"content_id": "6d6f6695fd4447a844f450f256296e27f3797ed2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 686,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 31,
"path": "/scripts/pump_server.py",
"repo_name": "minusworld/fireboat",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os\nfrom fireboat.srv import *\nimport rospy\nimport wiringpi2 as wpi\n\n_OUTPUT=1\n_PIN=7\n\ndef pump_control_callback(req):\n d = {\n True: 1,\n False: 0\n }\n rospy.set_param(\"pump_state\", req.on)\n #os.system(\"gpio write 7 {0}\".format(d[req.on]))\n val = wpi.digitalWrite(_PIN, d[req.on])\n return True\n\ndef init_pump_control():\n #os.system(\"gpio mode 7 out\")\n wpi.wiringPiSetup()\n wpi.pinMode(_PIN, _OUTPUT)\n rospy.set_param(\"pump_state\", False)\n rospy.init_node(\"pump_control\")\n s = rospy.Service(\"pump_control\", PumpControl, pump_control_callback)\n rospy.spin()\n\nif __name__=='__main__':\n init_pump_control()\n"
},
{
"alpha_fraction": 0.563049852848053,
"alphanum_fraction": 0.5835776925086975,
"avg_line_length": 18.823530197143555,
"blob_id": "bc8464b1f188fc3707dafb85c911cda335614369",
"content_id": "8577fd1727bd891c2f9b59ce84eaa78a5657a7a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 341,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 17,
"path": "/scripts/fireboat_go.py",
"repo_name": "minusworld/fireboat",
"src_encoding": "UTF-8",
"text": "import os\nfrom fire_scan import ServoControl\n\ndef pump_on():\n os.system(\"gpio write 7 {0}\".format(1))\n\ndef pump_off():\n os.system(\"gpio write 7 {0}\".format(0))\n\ndef go():\n servo_control = ServoControl()\n while 1:\n os.system(\"../bin/raspberrypi_video\")\n servo_control.step()\n\nif __name__ == \"__main__\":\n go() \n"
}
] | 9 |
guidoenr4/email-sender
|
https://github.com/guidoenr4/email-sender
|
cc1b31d52e248672ed37f373403a7b3226422165
|
55d34cc500e154a4a3cbe0d98571588313e0660d
|
7a0183156884821a2ad8a59af88014aed32a3d5a
|
refs/heads/master
| 2021-01-01T02:25:45.922208 | 2020-02-08T13:51:24 | 2020-02-08T13:51:24 | 239,139,568 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6970213055610657,
"alphanum_fraction": 0.6995744705200195,
"avg_line_length": 39.96428680419922,
"blob_id": "5bd4458769f23383c2c457f89c099e95919d9524",
"content_id": "46940587e4d3c152a1401d0cd76586ec6a4317ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1175,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 28,
"path": "/emailSending.py",
"repo_name": "guidoenr4/email-sender",
"src_encoding": "UTF-8",
"text": "import smtplib\r\nimport os\r\nimport imghdr\r\nfrom email.message import EmailMessage\r\n\r\n#address=os.environ.get('address') # es para que no se vea en el codigo tus datos, las extrae del OS\r\n#password=os.environ.get('password') # igual ni funca\r\n\r\nmsg=EmailMessage() #creando el mensaje de una mejor forma con las clase EmailMessage\r\nmsg['Subject'] = 'Asunto del Mensaje'\r\nmsg['From'] = '[email protected]'\r\nmsg['To'] = '[email protected]'\r\nmsg.set_content('Cuerpo del Mensaje')\r\n #readByte\r\nwith open('unaFotiko.jpg', 'rb') as archivoAttacheado:\r\n file_data = archivoAttacheado.read()\r\n file_type = imghdr.what(archivoAttacheado.name)\r\n file_name = archivoAttacheado.name\r\n\r\nmsg.add_attachment(file_data, maintype='image', subtype=file_type, filename=file_name) # con el add atachment agregas un archivo\r\n#esta configurado para una foto\r\n\r\nwith smtplib.SMTP('smtp.gmail.com',587) as smtp: #este es el servridor y el puerto al que se conecta\r\n smtp.ehlo() #esto nos identifica en la red\r\n smtp.starttls() #encrypta el trafico\r\n smtp.ehlo()\r\n smtp.login('[email protected]','password') #se logea en el servidor con tus credenciales\r\n smtp.send_message(msg)\r\n"
}
] | 1 |
jcspz0/PythonPractice
|
https://github.com/jcspz0/PythonPractice
|
a8755064b8258a4bf1f67936d4d65e3c0fe2a500
|
ac8f9309573250f03d494b25c7f69f64a6290ee8
|
e6724428dcc24a872a0bef99a9e62e6f5bd61fec
|
refs/heads/master
| 2020-12-11T09:15:48.479321 | 2016-09-16T15:39:38 | 2016-09-16T15:39:38 | 68,392,478 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.43437498807907104,
"alphanum_fraction": 0.48750001192092896,
"avg_line_length": 24.83333396911621,
"blob_id": "8b493ca95da2872d2d7d16dc2f1e6782e26623a6",
"content_id": "3d674b3c1bfcb1df5fc3c001e9ae02af4e6d7a75",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 320,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 12,
"path": "/ranking-project/news/urls.py",
"repo_name": "jcspz0/PythonPractice",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url, include\r\nfrom . import views\r\n\r\nurlpatterns = [\r\n url(r'^$', views.landing),\r\n #url(r'^([0-9]{4})/$',\r\n #\tviews.year_archive),\r\n #url(r'^([0-9]{4})/([0-9]{2})/$',\r\n #\tviews.month_archive),\r\n #url(r'^([0-9]{4})/([0-9]{2})/([-a-z0-9]+)/$',\r\n #\tviews.year_archive),\r\n]"
},
{
"alpha_fraction": 0.807692289352417,
"alphanum_fraction": 0.807692289352417,
"avg_line_length": 17,
"blob_id": "74d7be58938f17f21e652d45ac0b7a14a86a9d16",
"content_id": "675c084048f36700d71d584f42405a5e76139f91",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 234,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 13,
"path": "/ranking-project/news/admin.py",
"repo_name": "jcspz0/PythonPractice",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\n\nfrom .models import Article\nfrom .models import Reporter\n\[email protected](Article)\nclass ArticleAdmin(admin.ModelAdmin):\n\tpass\n\n\[email protected](Reporter)\nclass ReporterAdmin(admin.ModelAdmin):\n\tpass\n"
},
{
"alpha_fraction": 0.8421052694320679,
"alphanum_fraction": 0.8421052694320679,
"avg_line_length": 27.5,
"blob_id": "cfab7a71aba2479f8b2ddea84df2da97cbcde810",
"content_id": "1ccebc73cf77973fcbff3ce5c5cb3f1eeb485df6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 57,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 2,
"path": "/README.md",
"repo_name": "jcspz0/PythonPractice",
"src_encoding": "UTF-8",
"text": "# PythonPractice\npractica del proyecto ranking de phyton\n"
},
{
"alpha_fraction": 0.7402985095977783,
"alphanum_fraction": 0.746268630027771,
"avg_line_length": 24.846153259277344,
"blob_id": "6040656bfd91f4539c7be3d1e80f391178aad8df",
"content_id": "96559a5f625b13fc88b4e530286f823d8cb5e18e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 335,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 13,
"path": "/ranking-project/news/views.py",
"repo_name": "jcspz0/PythonPractice",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom .models import Article\n\nfrom .models import Reporter\n\ndef landing(request):\n\tarticles = (Article.objects.all().order_by('pub_date')[:10])\n\n\tcontext = {'recent_articles': articles}\n\treturn render(request, 'landing.html', context)\n\ndef base(request):\n\treturn render(request, 'base.html', context)"
}
] | 4 |
SusanKilian/ScaRC-Archived
|
https://github.com/SusanKilian/ScaRC-Archived
|
d863a46dd40d3880ad6a066b40d3c182c9464a4b
|
d7c5e2c2e375d6afbe3f186906cbb2b7e66cf767
|
2aab52f878f83737a98875d181388391aa0adbab
|
refs/heads/master
| 2023-02-16T22:19:51.268543 | 2021-01-11T12:51:12 | 2021-01-11T12:51:12 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6625310182571411,
"alphanum_fraction": 0.6625310182571411,
"avg_line_length": 16.434782028198242,
"blob_id": "0cff3512694b1ae9c1f1d7c6f9b87957105ba26c",
"content_id": "5963341b7d890766002bdbadc3ee5495fb3376f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 403,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 23,
"path": "/Verification/Move_Lunarc_csv.sh",
"repo_name": "SusanKilian/ScaRC-Archived",
"src_encoding": "UTF-8",
"text": "cd Pressure_Solver\ncp Lunarc_csv/*.csv .\ncp Lunarc_csv/*.txt .\n\ncd ../Pressure_Effects\ncp Lunarc_csv/*.csv .\ncp Lunarc_csv/*.txt .\n\ncd ../Scalar_Analytical_Solution\ncp Lunarc_csv/*.csv .\ncp Lunarc_csv/*.txt .\n\ncd ../NS_Analytical_Solution\ncp Lunarc_csv/*.csv .\ncp Lunarc_csv/*.txt .\n\ncd ../Turbulence\ncp Lunarc_csv/*.csv .\ncp Lunarc_csv/*.txt .\n\ncd ../HVAC\ncp Lunarc_csv/*.csv .\ncp Lunarc_csv/*.txt .\n\n\n"
},
{
"alpha_fraction": 0.6341853141784668,
"alphanum_fraction": 0.7188498377799988,
"avg_line_length": 39.3870964050293,
"blob_id": "9a28280f3946c5b44e01ba8e622cd96a2ff13b47",
"content_id": "5cf94eb2b9d91e1efa1a962ae7864e56546a82b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1252,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 31,
"path": "/Source/cat_scrc.sh",
"repo_name": "SusanKilian/ScaRC-Archived",
"src_encoding": "UTF-8",
"text": "rm scrc.f90\necho \"Building complete scrc source file\"\ncat \"Modules/scarc_headers.f90\" > scrc.f90\ncat \"Modules/scarc_constants.f90\" >> scrc.f90\ncat \"Modules/scarc_types.f90\" >> scrc.f90\ncat \"Modules/scarc_variables.f90\" >> scrc.f90\ncat \"Modules/scarc_pointers.f90\" >> scrc.f90\ncat \"Modules/scarc_messages.f90\" >> scrc.f90\ncat \"Modules/scarc_errors.f90\" >> scrc.f90\ncat \"Modules/scarc_utilities.f90\" >> scrc.f90\ncat \"Modules/scarc_storage.f90\" >> scrc.f90\ncat \"Modules/scarc_convergence.f90\" >> scrc.f90\ncat \"Modules/scarc_timings.f90\" >> scrc.f90\ncat \"Modules/scarc_stack.f90\" >> scrc.f90\ncat \"Modules/scarc_initialization.f90\" >> scrc.f90\ncat \"Modules/scarc_mpi.f90\" >> scrc.f90\necho \"#ifdef WITH_MKL\" >> scrc.f90\ncat \"Modules/scarc_mkl.f90\" >> scrc.f90\necho \"#endif\" >> scrc.f90\ncat \"Modules/scarc_vectors.f90\" >> scrc.f90\ncat \"Modules/scarc_discretization.f90\" >> scrc.f90\ncat \"Modules/scarc_matrices.f90\" >> scrc.f90\ncat \"Modules/scarc_fft.f90\" >> scrc.f90\ncat \"Modules/scarc_gmg.f90\" >> scrc.f90\necho \"#ifdef WITH_SCARC_AMG\" >> scrc.f90\ncat \"Modules/scarc_amg.f90\" >> scrc.f90\necho \"#endif\" >> scrc.f90\ncat \"Modules/scarc_mgm.f90\" >> scrc.f90\ncat \"Modules/scarc_methods.f90\" >> scrc.f90\ncat \"Modules/scarc_solvers.f90\" >> scrc.f90\necho \" ... done\"\n"
},
{
"alpha_fraction": 0.6943045258522034,
"alphanum_fraction": 0.7090275287628174,
"avg_line_length": 32.96052551269531,
"blob_id": "9ca0297e762b93a677b5d7d0260f9130c4b91b86",
"content_id": "2e1abd1501e63aabfdb3a9693815aac57f7d9db7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 2581,
"license_type": "no_license",
"max_line_length": 195,
"num_lines": 76,
"path": "/CMakeBuild/CMakeLists.txt",
"repo_name": "SusanKilian/ScaRC-Archived",
"src_encoding": "UTF-8",
"text": "cmake_minimum_required(VERSION 3.17)\n\nproject(FDS)\nenable_language(Fortran)\n\nfind_package(MPI)\n\nif(NOT MPI_Fortran_FOUND)\n message(FATAL_ERROR \"Could not find Fortran MPI. Please set MPI_Fortran_COMPILER to point to the mpifort wrapper.\")\nendif()\n\ninclude_directories(${MPI_Fortran_INCLUDE_PATH})\n\nadd_compile_options(${MPI_Fortran_COMPILE_FLAGS})\nadd_compile_options(-cpp)\n#add_compile_options(--param=num-threads=24)\n\nadd_compile_definitions(GITHASH_PP=\"scarc\")\nadd_compile_definitions(GITDATE_PP=\"1.1.1970\")\nadd_compile_definitions(BUILDDATE_PP=\"4.1.1970\")\nadd_compile_definitions(COMPVER_PP=\"0.0.0-pre2\")\n\n# requested source files\nfile(GLOB_RECURSE sources CONFIGURE_DEPENDS ../Source/*.f90)\n\n#\n# GNU Fortran compiler \n#\nif(CMAKE_Fortran_COMPILER_ID MATCHES \"GNU\")\n\n set(CMAKE_Fortran_FLAGS_BASIC \"-m64 -std=f2008 -ffpe-summary=none -fall-intrinsics\")\n \n # Debug version\n if (CMAKE_BUILD_TYPE MATCHES \"Debug\") \n set(CMAKE_Fortran_FLAGS_DEBUG \"${CMAKE_Fortran_FLAGS_BASIC} -O0 -ggdb -Wall -Wcharacter-truncation -Wno-target-lifetime -fcheck=all -fbacktrace -ffpe-trap=invalid,zero,overflow -frecursive\")\n set (FDS \"fds_gnu_db\")\n message (\"Compiling GNU debug version ${FDS} with options: ${CMAKE_Fortran_FLAGS_DEBUG}\")\n endif ()\n\n # Release version\n if (CMAKE_BUILD_TYPE MATCHES \"Release\") \n set(CMAKE_Fortran_FLAGS_RELEASE \"${CMAKE_Fortran_FLAGS_BASIC} -O2\")\n set (FDS \"fds_gnu\")\n message (\"Compiling GNU release version ${FDS} with options: ${CMAKE_Fortran_FLAGS_RELEASE}\")\n endif ()\nendif()\n\n#\n# GNU Fortran compiler \n#\nif(CMAKE_Fortran_COMPILER_ID MATCHES \"Intel\")\n\n set(CMAKE_Fortran_FLAGS_BASIC \"-m64 -mt_mpi -traceback -no-wrap-margin\") \n\n # Debug version\n if (CMAKE_BUILD_TYPE MATCHES \"Debug\") \n set(CMAKE_Fortran_FLAGS_DEBUG \"${CMAKE_Fortran_FLAGS_BASIC} -check all -warn all -O0 -auto -WB -g -fpe0 -fltconsistency -stand:f08\")\n set (FDS \"fds_intel_db\")\n message (\"Compiling Intel debug version ${FDS} with options: ${CMAKE_Fortran_FLAGS_DEBUG}\")\n endif ()\n\n # Release version\n if (CMAKE_BUILD_TYPE MATCHES \"Release\") \n set(CMAKE_Fortran_FLAGS_RELEASE \"${CMAKE_Fortran_FLAGS_BASIC} -O2 -ipo\")\n set (FDS \"fds_intel\")\n message (\"Compiling Intel release version ${FDS} with options : ${CMAKE_Fortran_FLAGS_RELEASE}\")\n endif ()\nendif()\n\n\nadd_executable(${FDS} ${sources})\n\ntarget_link_libraries(${FDS} ${MPI_Fortran_LIBRARIES})\nset_property(TARGET ${FDS} APPEND_STRING PROPERTY LINK_FLAGS \"${MPI_Fortran_LINK_FLAGS}\")\n\n#message (\" CMAKE: MPI_Fortran_LIBRARIES : ${MPI_Fortran_LIBRARIES}\")\n"
},
{
"alpha_fraction": 0.738916277885437,
"alphanum_fraction": 0.8054187297821045,
"avg_line_length": 61.38461685180664,
"blob_id": "d55a8e4dab7a83980a151bc74ec74055d17610cd",
"content_id": "0af863c0a9c96f2d8b16796b6d80649c4e014799",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 812,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 13,
"path": "/Verification/Develop/uscarc/run_uscarc.sh",
"repo_name": "SusanKilian/ScaRC-Archived",
"src_encoding": "UTF-8",
"text": "sbatch -J uscarc1_single $SCRIPTS/fds_opt1.sh uscarc1_single.fds\nsbatch -J uscarc2_single $SCRIPTS/fds_opt2.sh uscarc2_single.fds\nsbatch -J uscarc5a_single $SCRIPTS/fds_opt5.sh uscarc5a_single.fds\nsbatch -J uscarc10a_single $SCRIPTS/fds_opt10.sh uscarc10a_single.fds\nsbatch -J uscarc10b_single $SCRIPTS/fds_opt10.sh uscarc10b_single.fds\nsbatch -J uscarc20_single $SCRIPTS/fds_opt20.sh uscarc20_single.fds\n\nsbatch -J uscarc1_double $SCRIPTS/fds_opt1.sh uscarc1_double.fds\nsbatch -J uscarc2_double $SCRIPTS/fds_opt2.sh uscarc2_double.fds\nsbatch -J uscarc5a_double $SCRIPTS/fds_opt5.sh uscarc5a_double.fds\nsbatch -J uscarc10a_double $SCRIPTS/fds_opt10.sh uscarc10a_double.fds\nsbatch -J uscarc10b_double $SCRIPTS/fds_opt10.sh uscarc10b_double.fds\nsbatch -J uscarc20_double $SCRIPTS/fds_opt20.sh uscarc20_double.fds\n\n"
},
{
"alpha_fraction": 0.6072289347648621,
"alphanum_fraction": 0.6698794960975647,
"avg_line_length": 24.9375,
"blob_id": "79c8f3fa282aa621377273e2e2db6d2ab33fe494",
"content_id": "d9f32834e80d7cfb61063f188b0a18592fa209fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 415,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 16,
"path": "/Python/Laplacian/Laplacian.py",
"repo_name": "SusanKilian/ScaRC-Archived",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\nfrom matplotlib import cm\nfrom mpl_toolkits.mplot3d import Axes3D\n\nX = np.arange(-6, 10, 0.25)\nY = np.arange(-8.5, 7.5, 0.25)\nX, Y = np.meshgrid(X, Y)\nZ = np.sin(X/2+2)+np.cos(Y/2+5)+10-X/8+Y/4\n\nfig = plt.figure()\nax = Axes3D(fig)\nax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap=cm.viridis)\ncset = ax.contour(X, Y, Z, cmap=plt.get_cmap('rainbow'))\n\nplt.show()\n"
},
{
"alpha_fraction": 0.7272372245788574,
"alphanum_fraction": 0.7891754508018494,
"avg_line_length": 45.10810852050781,
"blob_id": "85d4ee0d46204d3b266bf3e61eb802835c208de8",
"content_id": "0628b73067fd2130ad5a23553144f0c82a633f62",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 5118,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 111,
"path": "/Verification/FDS_Cases_scarc_lunarc.sh",
"repo_name": "SusanKilian/ScaRC-Archived",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nVERIFICATION=`pwd`\nLUNARC=\"../Lunarc\"\n\n#\n# NS_Analytical_Solution \n#\ncd VERIFICATION/NS_Analytical_Solution\n\nsbatch -J ns2d_4mesh_8_scarc $LUNARC/avx4.sh ns2d_4mesh_8_scarc.fds\nsbatch -J ns2d_4mesh_8_scarc $LUNARC/avx4.sh ns2d_4mesh_8_scarc_nupt1.fds\nsbatch -J ns2d_4mesh_16_scarc $LUNARC/avx4.sh ns2d_4mesh_16_scarc.fds\nsbatch -J ns2d_4mesh_16_scarc $LUNARC/avx4.sh ns2d_4mesh_16_scarc_nupt1.fds\nsbatch -J ns2d_4mesh_32_scarc $LUNARC/avx4.sh ns2d_4mesh_32_scarc.fds\nsbatch -J ns2d_4mesh_32_scarc $LUNARC/avx4.sh ns2d_4mesh_32_scarc_nupt1.fds\nsbatch -J ns2d_4mesh_64_scarc $LUNARC/avx4.sh ns2d_4mesh_64_scarc.fds\nsbatch -J ns2d_4mesh_64_scarc $LUNARC/avx4.sh ns2d_4mesh_64_scarc_nupt1.fds\n\n#\n# Pressure_Effects\n#\ncd VERIFICATION/Pressure_Effects\n\nsbatch -J pressure_boundary $LUNARC/avx1.sh pressure_boundary.fds\nsbatch -J pressure_boundary_scarc $LUNARC/avx10.sh pressure_boundary_scarc.fds\n\nsbatch -J pressure_rise $LUNARC/avx3.sh pressure_rise.fds\nsbatch -J pressure_rise_glmat $LUNARC/avx3.sh pressure_rise_glmat.fds\nsbatch -J pressure_rise_scarc $LUNARC/avx3.sh pressure_rise_scarc.fds\n\nsbatch -J zone_break_fast_scarc $LUNARC/avx4.sh zone_break_fast_scarc.fds\nsbatch -J zone_break_fast $LUNARC/avx1.sh zone_break_fast.fds\nsbatch -J zone_break_slow_scarc $LUNARC/avx4.sh zone_break_slow_scarc.fds\nsbatch -J zone_break_slow $LUNARC/avx1.sh zone_break_slow.fds\n\nsbatch -J zone_shape $LUNARC/avx2.sh zone_shape.fds\nsbatch -J zone_shape_scarc $LUNARC/avx2.sh zone_shape_scarc.fds\n\nsbatch -J zone_shape_2 $LUNARC/avx8.sh zone_shape_2.fds\nsbatch -J zone_shape_2_uscarc $LUNARC/avx8.sh zone_shape_2_uscarc.fds\n\n#\n# Pressure_Solver \n#\ncd VERIFICATION/Pressure_Solver\n\nsbatch -J dancing_eddies_default $LUNARC/avx4.sh dancing_eddies_default.fds\nsbatch -J dancing_eddies_scarc $LUNARC/avx4.sh dancing_eddies_scarc.fds\nsbatch -J dancing_eddies_scarc_tight $LUNARC/avx4.sh dancing_eddies_scarc_tight.fds\nsbatch -J dancing_eddies_tight $LUNARC/avx4.sh dancing_eddies_tight.fds\nsbatch -J dancing_eddies_tight_overlap $LUNARC/avx4.sh dancing_eddies_tight_overlap.fds\nsbatch -J dancing_eddies_uglmat $LUNARC/avx4.sh dancing_eddies_uglmat.fds\nsbatch -J dancing_eddies_uscarc $LUNARC/avx4.sh dancing_eddies_uscarc.fds\nsbatch -J dancing_eddies_1mesh $LUNARC/avx1.sh dancing_eddies_1mesh.fds\n\nsbatch -J duct_flow $LUNARC/avx8.sh duct_flow.fds\nsbatch -J duct_flow_scarc $LUNARC/avx8.sh duct_flow_scarc.fds\nsbatch -J duct_flow_uglmat $LUNARC/avx8.sh duct_flow_uglmat.fds\nsbatch -J duct_flow_uscarc $LUNARC/avx8.sh duct_flow_uscarc.fds\n\nsbatch -J hallways $LUNARC/avx5.sh hallways.fds\nsbatch -J hallways_scarc $LUNARC/avx5.sh hallways_scarc.fds\n\nsbatch -J poisson2d_fft $LUNARC/avx4_short4.sh poisson2d_fft.fds\nsbatch -J poisson2d_scarc $LUNARC/avx4_short4.sh poisson2d_scarc.fds\nsbatch -J poisson2d_uglmat $LUNARC/avx4_short4.sh poisson2d_uglmat.fds\nsbatch -J poisson2d_uscarc $LUNARC/avx4_short4.sh poisson2d_uscarc.fds\nsbatch -J poisson2d_fft_tight $LUNARC/avx4_short4.sh poisson2d_fft_tight.fds\nsbatch -J poisson2d_scarc_tight $LUNARC/avx4_short4.sh poisson2d_scarc_tight.fds\n\nsbatch -J poisson3d_fft $LUNARC/avx4.sh poisson3d_fft.fds\nsbatch -J poisson3d_glmat $LUNARC/avx4.sh poisson3d_glmat.fds\nsbatch -J poisson3d_scarc $LUNARC/avx4.sh poisson3d_scarc.fds\nsbatch -J poisson3d_uglmat $LUNARC/avx4.sh poisson3d_uglmat.fds\nsbatch -J poisson3d_uscarc $LUNARC/avx4.sh poisson3d_uscarc.fds\nsbatch -J tunnel_demo $LUNARC/avx8.sh tunnel_demo.fds\nsbatch -J tunnel_demo_glmat $LUNARC/avx8.sh tunnel_demo_glmat.fds\nsbatch -J tunnel_demo_scarc $LUNARC/avx8.sh tunnel_demo_scarc.fds\n\n#\n# Scalar_Analytical_Solution\n#\ncd VERIFICATION/Scalar_Analytical_Solutiion\n\nsbatch -J shunn3_16mesh_128_scarc $LUNARC/avx16.sh shunn3_16mesh_128_scarc.fds\nsbatch -J shunn3_16mesh_256_scarc $LUNARC/avx16.sh shunn3_16mesh_256_scarc.fds\nsbatch -J shunn3_16mesh_32_scarc $LUNARC/avx16.sh shunn3_16mesh_32_scarc.fds\nsbatch -J shunn3_16mesh_512_scarc $LUNARC/avx16.sh shunn3_16mesh_512_scarc.fds\nsbatch -J shunn3_16mesh_64_scarc $LUNARC/avx16.sh shunn3_16mesh_64_scarc.fds\nsbatch -J shunn3_4mesh_128_scarc $LUNARC/avx4.sh shunn3_4mesh_128_scarc.fds\nsbatch -J shunn3_4mesh_256_scarc $LUNARC/avx4.sh shunn3_4mesh_256_scarc.fds\nsbatch -J shunn3_4mesh_32_scarc $LUNARC/avx4.sh shunn3_4mesh_32_scarc.fds\nsbatch -J shunn3_4mesh_512_scarc $LUNARC/avx4.sh shunn3_4mesh_512_scarc.fds\nsbatch -J shunn3_4mesh_64_scarc $LUNARC/avx4.sh shunn3_4mesh_64_scarc.fds\n\n#\n#Turbulence\n#\ncd VERIFICATION/Turbulence\n\nsbatch -J ribbed_channel_160_4mesh_uscarc $LUNARC/avx4.sh ribbed_channel_160_4mesh_uscarc.fds\nsbatch -J ribbed_channel_20_4mesh_uscarc $LUNARC/avx4.sh ribbed_channel_20_4mesh_uscarc.fds\nsbatch -J ribbed_channel_40_4mesh_uscarc $LUNARC/avx4.sh ribbed_channel_40_4mesh_uscarc.fds\nsbatch -J ribbed_channel_80_4mesh_uscarc $LUNARC/avx4.sh ribbed_channel_80_4mesh_uscarc.fds\nsbatch -J ribbed_channel_20 $LUNARC/avx1.sh ribbed_channel_20.fds\nsbatch -J ribbed_channel_40 $LUNARC/avx1.sh ribbed_channel_40.fds\nsbatch -J ribbed_channel_80 $LUNARC/avx1.sh ribbed_channel_80.fds\nsbatch -J ribbed_channel_160 $LUNARC/avx1.sh ribbed_channel_160.fds\n\ncd VERIFICATION\n"
},
{
"alpha_fraction": 0.7044854760169983,
"alphanum_fraction": 0.7044854760169983,
"avg_line_length": 15.391304016113281,
"blob_id": "ba0f9fb00c62ff460af4485776b7da1ae2df76a2",
"content_id": "c38907a331ac712b02ec97eeb2df87467a7cc7c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 379,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 23,
"path": "/Verification/Copy_Lunarc_csv.sh",
"repo_name": "SusanKilian/ScaRC-Archived",
"src_encoding": "UTF-8",
"text": "cd Pressure_Solver\ncp *.csv Lunarc_csv\ncp *.txt Lunarc_csv\n\ncd ../Pressure_Effects\ncp *.csv Lunarc_csv\ncp *.txt Lunarc_csv\n\ncd ../Scalar_Analytical_Solution\ncp *.csv Lunarc_csv\ncp *.txt Lunarc_csv\n\ncd ../NS_Analytical_Solution\ncp *.csv Lunarc_csv\ncp *.txt Lunarc_csv\n\ncd ../Turbulence\ncp *.csv Lunarc_csv\ncp *.txt Lunarc_csv\n\ncd ../HVAC\ncp *.csv Lunarc_csv\ncp *.txt Lunarc_csv\n\n\n"
},
{
"alpha_fraction": 0.5477997064590454,
"alphanum_fraction": 0.5872533917427063,
"avg_line_length": 22.368793487548828,
"blob_id": "fa137c3ac55cccbd47dff26736fc030f4f69a02b",
"content_id": "6ef840305c1c0ddabe6af6005dffa5366b2d82fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3295,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 141,
"path": "/Python/dump.py",
"repo_name": "SusanKilian/ScaRC-Archived",
"src_encoding": "UTF-8",
"text": "#me -*- coding: utf-8 -*-\n\nimport sys, os\nimport re\nimport math\nimport glob\nfrom pylab import *\nfrom mpl_toolkits.mplot3d import Axes3D\nimport matplotlib.pyplot as plt\nimport matplotlib.font_manager as fnt\nfrom matplotlib import *\nfrom matplotlib.ticker import LinearLocator, FormatStrFormatter\nimport numpy as np\n\n\n\ndef read_quantity(name):\n ''' read indicated quantity from corresponding save-directory'''\n\n quan = []\n found = False\n dump_name = \"dump/%s\" %(name)\n #print (\"reading from %s\" %dump_name)\n\n if os.path.exists(dump_name) :\n\n found = True\n\n f = open(dump_name ,'r')\n input = f.readlines()\n f.close()\n\n for line in input:\n line, null = line.split (\"\\n\")\n value = line.split (\",\")\n quan.append(float(value[0]))\n \n return (found,quan)\n\n\ndef plot_quantity(name, quan, nx, nz, dx, dz):\n ''' 3D-plot of specified quantity '''\n\n\n\n xp = []\n for ix in range(nx):\n x = ix*dx + dx/2\n xp.append(x)\n \n zp = []\n for iz in range(nz):\n z = iz*dz + dz/2\n zp.append(z)\n\n xp, zp = np.meshgrid(xp, zp)\n val = []\n\n max_val = -10000.0\n min_val = 10000.0\n for iz in range(nz):\n line = []\n for ix in range(nx):\n pos = iz * nx + ix\n max_val = max(max_val, quan[pos])\n min_val = min(min_val, quan[pos])\n line.append(quan[pos])\n val.append(line)\n\n\n #---- First subplot\n fig = plt.figure()\n ax = fig.add_subplot(1, 1, 1, projection='3d')\n\n #print 'max, min:', max_val, min_val\n surf = ax.plot_surface(xp, zp, val, rstride=1, cstride=1, cmap=cm.jet, antialiased=False)\n #surf = ax.plot_surface(xp, zp, val, rstride=8, cstride=8, cmap=cm.jet)\n ax.set_zlim(min_val-0.01, max_val+0.01)\n #if \"err\" in name:\n # ax.set_zlim(min_val-0.01, 0.201)\n #else:\n # ax.set_zlim(min_val-0.01, 1.501)\n ax.set_xlabel('x')\n ax.set_ylabel('y')\n ax.set_zlabel('z')\n ax.set_zlim(0.0, 0.025)\n ax.zaxis.set_major_locator(LinearLocator(10))\n ax.zaxis.set_major_formatter(FormatStrFormatter('%.02f'))\n fig.colorbar(surf, shrink=0.5, aspect=5)\n \n picture = \"pictures/error/3d/%s.png\" %(name)\n #print 'plotting picture ', picture\n savefig(picture)\n plt.close(fig)\n #show()\n\n #---- Second subplot\n fig2 = plt.figure()\n ax2 = fig2.add_subplot(1, 1, 1, projection='3d')\n ax2.plot_wireframe(xp, zp, val, rstride=1, cstride=1, cmap=cm.jet)\n ax2.set_zlim(min_val-0.01, max_val+0.01)\n #if \"err\" in name:\n # ax.set_zlim(min_val-0.01, 0.201)\n #else:\n # ax.set_zlim(min_val-0.01, 1.501)\n ax2.set_xlabel('x')\n ax2.set_ylabel('y')\n ax2.set_zlabel('z')\n ax2.set_zlim(0.0, 0.025)\n\n picture = \"pictures/error/3d_wf/%s.png\" %(name)\n #print 'plotting picture ', picture\n savefig(picture)\n plt.close(fig2)\n #show()\n\nnx0 = int(sys.argv[1])\nnz0 = nx0\n\nfor name in glob.glob(\"dump/err*\"): # generator, search immediate subdirectories \n\n nx=nx0\n nz=nz0\n if \"level2\" in name:\n nx=nx0/2\n nz=nz0/2\n elif \"level3\" in name:\n nx=nx0/4\n nz=nz0/4\n elif \"level4\" in name:\n nx=nx0/8\n nz=nz0/8\n\n dx = 0.8/nx\n dz = 0.8/nz\n\n name = name[5:]\n print name, nx, nz, dx, dz\n (found, quan) = read_quantity(name)\n\n plot_quantity(name, quan, nx, nz, dx, dz)\n"
},
{
"alpha_fraction": 0.5885416865348816,
"alphanum_fraction": 0.625,
"avg_line_length": 21.809524536132812,
"blob_id": "618d52d3d975e3eb8d3277bcc23ba0aa218e8fc6",
"content_id": "b67275e802817fb0c0ce876691f3f918b63aeac5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 960,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 42,
"path": "/Lunarc/avx4_short.sh",
"repo_name": "SusanKilian/ScaRC-Archived",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n#\n#SBATCH -N 1\n#SBATCH --tasks-per-node=4\n#SBATCH --cpus-per-task=4\n##SBATCH --exclusive\n#\n#SBATCH -t 00:15:00\n# \n#SBATCH -o output/stdout_%j.out\n#SBATCH -e output/stderr_%j.out\n#\n#SBATCH -A snic2020-5-79\n#\n#SBATCH [email protected]\n#SBATCH --mail-type=ALL\n##SBATCH --qos=test\n\nif [ $# -ne 1 ]; then\n echo --------------------------------------------\n echo Error when executing $0 \n echo misssing name of fds input file\n echo usage: sbatch -J filename.fds run_fds6_mpi.sh filename.fds\n echo example: sbatch -J roomfire.fds run_fds6_mpi.sh roomfire.fds\n echo --------------------------------------------\n exit 1\nfi\nFDS_FILE=$1\ndir_name=$PWD\necho $dir_name\n\nmodule purge\nmodule load intel/2018a\n\n\nexport OMP_NUM_THREADS=$SLURM_CPUS_PER_TASK\n\n\nexport FDS_AVX=\"/lunarc/nobackup/users/skil/GIT/ScaRC/Build/impi_intel_linux_64_avx/fds_impi_intel_linux_64_avx\"\n\n\nsrun $FDS_AVX $FDS_FILE >output/$1_avx1.out 2>output/$1_avx2.out\n\n\n"
},
{
"alpha_fraction": 0.562332272529602,
"alphanum_fraction": 0.5901439189910889,
"avg_line_length": 27.46527862548828,
"blob_id": "6a54e10bd8f9d7b7baf4eab70e26f55d015f630e",
"content_id": "ab592968e39fbcbab3f7bd7887fcaa7d39e4ec6a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4099,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 144,
"path": "/Python/DumpFDS/DumpFDS.py",
"repo_name": "SusanKilian/ScaRC-Archived",
"src_encoding": "UTF-8",
"text": "#me -*- coding: utf-8 -*-\n\nimport sys, os\nimport re\nimport math\nimport glob\nfrom pylab import *\nfrom mpl_toolkits.mplot3d import Axes3D\nimport matplotlib.pyplot as plt\nimport matplotlib.font_manager as fnt\nfrom matplotlib import *\nfrom matplotlib.ticker import LinearLocator, FormatStrFormatter\nimport numpy as np\n\n\n\ndef read_quantity(base, name, plot_type, cpres, ite):\n ''' read indicated quantity from corresponding save-directory'''\n\n quan = []\n found = False\n if plot_type == 'dump':\n dump_name = \"%s/%s/%s_%3.3d\" %(base, plot_type, name, ite)\n else:\n dump_name = \"%s/%s/%s_%s_%3.3d\" %(base, plot_type, name, cpres, ite)\n print (\"trying to read from %s\" %dump_name)\n\n if os.path.exists(dump_name) :\n\n found = True\n\n f = open(dump_name ,'r')\n input = f.readlines()\n f.close()\n\n for line in input:\n line, null = line.split (\"\\n\")\n value = line.split (\",\")\n quan.append(float(value[0]))\n \n return (found,quan)\n\n\ndef plot_quantity(base, name, plot_type, cpres, quan, ite, nx, nz, dx, dz):\n ''' 3D-plot of specified quantity '''\n\n if plot_type == 'dump':\n plot_name = \"%s/%s_%3.3d.png\" %(plot_type, name, ite)\n else:\n plot_name = \"%s/%s_%s_%3.3d.png\" %(plot_type, cpres, name, ite)\n print (\"trying to plot to %s\" %plot_name)\n\n xp = []\n for ix in range(nx):\n x = ix*dx + dx/2\n xp.append(x)\n \n zp = []\n for iz in range(nz):\n z = iz*dz + dz/2\n zp.append(z)\n\n xp, zp = np.meshgrid(xp, zp)\n val = []\n\n max_val = -10000.0\n min_val = 10000.0\n for iz in range(nz):\n line = []\n for ix in range(nx):\n pos = iz * nx + ix\n max_val = max(max_val, quan[pos])\n min_val = min(min_val, quan[pos])\n line.append(quan[pos])\n val.append(line)\n\n val = np.array(val)\n\n #---- First subplot\n fig = plt.figure()\n ax = fig.add_subplot(1, 1, 1, projection='3d')\n #print 'max, min:', max_val, min_val\n surf = ax.plot_surface(xp, zp, val, rstride=1, cstride=1, cmap=cm.jet, antialiased=False)\n #surf = ax.plot_surface(xp, zp, val, rstride=8, cstride=8, cmap=cm.jet)\n #ax.set_zlim(min_val-0.01, max_val+0.01)\n ax.set_zlim(-10.0, 1500.0)\n #ax.set_xlabel('x')\n #ax.set_ylabel('y')\n ax.set_zlabel('z')\n ax.set_xticklabels([])\n ax.set_yticklabels([])\n #ax.set_zticks([0])\n #ax.zaxis.set_major_locator(LinearLocator(10))\n #ax.zaxis.set_major_formatter(FormatStrFormatter('%.02f'))\n #fig.colorbar(surf, shrink=0.5, aspect=5)\n ax.view_init(24, -69)\n plt.show()\n picture = plot_name\n print 'Plotting picture ', plot_name, min_val, max_val\n savefig(picture)\n plt.close(fig)\n\n #---- Second subplot\n plot_wireframe = False\n if (plot_wireframe):\n fig2 = plt.figure()\n ax2 = fig2.add_subplot(1, 1, 1, projection='3d')\n ax2.plot_wireframe(xp, zp, val, rstride=1, cstride=1, cmap=cm.jet)\n #ax2.set_zlim(min_val-0.01, max_val+0.01)\n ax2.set_xlabel('x')\n ax2.set_ylabel('y')\n ax2.set_zlabel('z')\n picture = \"%wf%s\" %(plot_name)\n savefig(picture)\n plt.close(fig2)\n #show()\n\n#base = '../../VisualStudio/Cases'\nbase = '/Users/susannekilian/GIT/github/01_ScaRC/Verification/Develop/MGM'\n\nnx = 32\nnz = 32\n\ndx = 0.8/nx\ndz = 0.8/nz\n\nnit = 1\n\n#names = ['h1', 'h2', 'h']\n#or ite in range(nit):\n# for name in names:\n# (found, quan) = read_quantity(base, name, 'dump', ' ', ite+1)\n# #if found: plot_quantity(base, name, quan, ite+1, nx, nz, dx, dz)\n\n#names = ['mgm1', 'scarc1','uscarc1', 'glmat1','uglmat1']\nnames = ['mgm32']\nfor ite in range(nit):\n for name in names:\n (found, quan) = read_quantity(base, name, 'pressure', 'h1', ite+1)\n if found: plot_quantity(base, name, 'pressure', 'h1', quan, ite+1, nx, nz, dx, dz)\n (found, quan) = read_quantity(base, name, 'pressure', 'h2', ite+1)\n if found: plot_quantity(base, name, 'pressure', 'h2', quan, ite+1, nx, nz, dx, dz)\n (found, quan) = read_quantity(base, name, 'pressure', 'h', ite+1)\n if found: plot_quantity(base, name, 'pressure', 'h', quan, ite+1, nx, nz, dx, dz)\n"
}
] | 10 |
borosilicate/NLP_final_project
|
https://github.com/borosilicate/NLP_final_project
|
6e7733127f7ca9e9b3815e448f4cfa72d2d1fa88
|
0450fdeb80ef8c1be7be4ba6ecdbee0c16e08068
|
722880e1dc54e14dc0d1eabf33366415644b3ce6
|
refs/heads/master
| 2020-09-09T19:28:03.118893 | 2019-12-07T04:21:47 | 2019-12-07T04:21:47 | 221,542,876 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6948356628417969,
"alphanum_fraction": 0.7528809309005737,
"avg_line_length": 32.91304397583008,
"blob_id": "1bd6320b54b255470f1d60d0c94d1131f5e11c8b",
"content_id": "672636e0d8cdd9ddc6025fa020bac1311508aabb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2347,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 69,
"path": "/README.md",
"repo_name": "borosilicate/NLP_final_project",
"src_encoding": "UTF-8",
"text": "# NLP_final_project Texts\nhttps://github.com/DigiUGA/Gutenberg_Text\n\n#Helpful Resources:Coding Systems for Themes of Agency and Communion\nhttps://www.sesp.northwestern.edu/foley/instruments/agency/\n\n#Article about word2vec digital humanities:\nhttps://www.reddit.com/r/MachineLearning/comments/4m7h4f/word_vectors_word2vec_in_eighteenthcentury/\nhttp://bookworm.benschmidt.org/posts/2015-10-25-Word-Embeddings.html\nhttp://ryanheuser.org/word-vectors-1/\nhttp://ryanheuser.org/word-vectors-2/\n\nWord2Vec:\nhttps://colab.research.google.com/drive/1rJJifX_aL63JNqAnTOXPnXm078ejC-1n\n\nList of autobiographies/letters in Project Gutenburg:\nAnderson, Hans Christian - The True Story of my Life (1847)\nAustin, Jane - The Letters of Jane Austen (1884)\nBalzac, Honore - Letters to Madam Hanska (1833)\nConrad, Joseph - Notes on My Life & Letters (1898-1919)\nDumas, Alexandre - My Memoirs Vol 2 - Vol 6 (1844-1846)\nFranklin, Benjamin - Autobiography and Memoirs (1791)\nGibbon, Edward - Private Letters of Edward Gibbon (1753-1794)\nGoethe, Johann Wolgang von - The Autobiography of Goethe (1774) Letters from Switzerland and Travels in Italy\nHugo, Victor - The Memoirs of Victor Hugo (1899)\nJames, Henry - The Letters of Henry James (1892-1911)\nMorley, Henry - Letters to Sir William Windham and Mr. Pope (1717)\nStevenson, Robert Louis - Memories and Portraits (1887)\nThorough, Henry David -- journal entries (1837-1854)\nTrollope, Anthony - An Autobiography of Anthony Trollope (1876)\nTwain, Mark — autobiography and letters (1835-1910)\nVoltaire — autobiography and letters (1745)\n\n#numbers\n cat -n voltaire_letters.txt | grep LETTER \n\n#gets text\ncat voltaire_letters.txt | awk \"129 <= NR && NR <= 3738\" > voltaire_letters_headings.txt\n\n1.) Setup \t\t\t Tool/ENV/Setup\n\nPython 3.7.3\nMacOS High Sierra\nconda install numpy \nconda install spacy\nconda install requests\n#This will be a siginificant amount of memory 0.6 gb\nconda install -c conda -forge spacy-model-en_core_web_lg\n\n3.) #gathering synonyms \n\tpython agency_synonyms.py\n\tpython communion_synonyms.py\n\n\n\n4.)\n\tMichael Joseph Hearn\n\t\n\n5.) The project was done with a combination of scripts working in an ordered fashion.\n Collect documents\n Recieved Words thematicly related to agency and communion\n web scraped synonyms\n Load spacy word embeddings\n Collect words from docs\n Compare similarity between synonyms and words common to docs\n Use matplotlib to plot scores\n\nhttps://colab.research.google.com/drive/1rJJifX_aL63JNqAnTOXPnXm078ejC-1n\n\n\n\n"
},
{
"alpha_fraction": 0.551143229007721,
"alphanum_fraction": 0.5836341977119446,
"avg_line_length": 32.2400016784668,
"blob_id": "d33fa89bd7fbcd1b7b0fa63f5b888a9b8b6e1a90",
"content_id": "6d54aa1564e6a16fb137549a0844b4df2a98ab0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 831,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 25,
"path": "/agency_synonyms.py",
"repo_name": "borosilicate/NLP_final_project",
"src_encoding": "UTF-8",
"text": "import requests\nimport bs4\nimport time\n#open agency.txt\n#load words\nagency_ranking=''\nclasses=['css-gkae64 etbu2a31','css-q7ic04 etbu2a31','css-zu4egz etbu2a31']\nwith open('agency_words.txt','r') as f:\n words=f.readlines()\nfor w in words:\n time.sleep(3)\n o=requests.request('get',url='https://www.thesaurus.com/browse/'+w+'?s=t') \n soup=bs4.BeautifulSoup(o.text,'html.parser') \n for i,c in enumerate(classes): \n for s in soup.find_all('a',class_=c): \n if('%' not in s.get('href') and '-' not in s.get('href')): \n l=s.get('href').split('/') \n l=l[len(l)-1] \n print(l,1-i*0.15) \n agency_ranking+=' '+str(1-i*0.15)+' '+l+'\\n'\n\nprint(agency_ranking)\nwith open('agency_rankings.txt','w+') as fil:\n fil.write(agency_ranking)\n fil.close()\n"
},
{
"alpha_fraction": 0.6015228629112244,
"alphanum_fraction": 0.6114213466644287,
"avg_line_length": 26.552448272705078,
"blob_id": "df99b80ff09bdf4046c7f08f5f56024fc0092dfe",
"content_id": "ea69a86d1ee8ac4606204c23471cc17045ee878e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3940,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 143,
"path": "/nlp.py",
"repo_name": "borosilicate/NLP_final_project",
"src_encoding": "UTF-8",
"text": "import gensim\nimport spacy\nimport matplotlib.pyplot as plt; plt.rcdefaults()\nimport numpy as np\nimport os\n\nnlp = spacy.load(\"en_core_web_lg\")\n#model=gensim.models.Word2Vec('The monkey runs fast. The eagle is a horse.')\n\naar=np.load('data/agency_rank_ar.npy')\ncar=np.load('data/communion_rank_ar.npy')\nscore_dic={}\nwords=''\nfor k in aar[:]:\n words+=str(k[1])+' '\n score_dic[str(k[1])]=k[0]\nfor k in car[:]:\n words+=str(k[1])+' '\n score_dic[str(k[1])]=k[0]\nmodel=nlp(words)\nz=np.zeros([len(model)+1,len(model)+1])\nharvest=z\nfor i,t1 in enumerate(model):\n for j,t2 in enumerate(model):\n z[i,j]+=t1.similarity(t2)\n print('still running',len(model)-i)\n\nfig, ax = plt.subplots()\nim = ax.imshow(harvest)\n\n# We want to show all ticks...\nprint('starting axis')\nax.set_xticks(np.arange(len(model)))\nax.set_yticks(np.arange(len(model)))\n# ... and label them with the respective list entries\nax.set_xticklabels(words.split())\nax.set_yticklabels(words.split())\nprint('done with axis')\n# Rotate the tick labels and set their alignment.\n#plt.setp(ax.get_xticklabels(), rotation=45, ha=\"right\",\n# rotation_mode=\"anchor\")\n\n# Loop over data dimensions and create text annotations.\n#for i in range(len(model)):\n# for j in range(len(model)):\n# text = ax.text(j, i, harvest[i, j],\n# ha=\"center\", va=\"center\", color=\"w\")\n# print('setting text',len(model)-i)\n\nax.set_title(\"Agency vs Communion Similarity\")\nfig.tight_layout()\nprint('plt.show')\nplt.show()\n#plt.matshow(z)\n#plt.show()\n\n'''\nf=open('pulled/Letters_to_Madame_Hanska/Letters_during_1833.txt')\nhaskal=f.readline()\n\ndata_full=''\ndic2=[]\nfor i in os.listdir('pulled'):\n for j in os.listdir('pulled/'+i):\n print(i,j)\n with open('pulled/'+i+'/'+j, 'r') as file:\n s=file.read().replace('\\n', ' ').lower()\n s=s.strip(',').strip('\\'s').strip('\\\\').replace('-',' ').strip(';')\n s=s.replace(';',' ')\n s=s.replace('\\'s',' ')\n s=s.replace('-',' ')\n s=s.replace('.','')\n s=s.replace(',','')\n s=s.replace('?','')\n s=s.replace('!','')\n s=s.replace('\\\\','')\n dic2.append(s)\n\n\n\nfirst=0\ndictionary={}\nfor i in dic:\n for j in i.split():\n j=j.strip('!')\n j=j.strip('.')\n j=j.strip(',')\n j=j.strip('\\'')\n if(first==0):\n if(j in dictionary):\n dictionary[j]+=1\n else:\n dictionary[j]=1\n else:\n if(j in dictionary):\n dictionary[j]+=1\n first+=1\n\nfor i in os.listdir('pulled'):\n for j in os.listdir('pulled/'+i):\n print(i,j)\nf=open('agency_words.txt','r')\nagency=f.readline()\nagency=f.readlines()\nwith open('pulled/Letters_to_Madame_Hanska/Letters_during_1833.txt', 'r') as file:\n data = file.read().replace('\\n', '')\n\ndoc=nlp(data)\ndoc.count_by\ndoc.count_by()\nwords = [token.text for token in doc if token.is_stop != True and token.is_punct != True]\n\n# noun tokens that arent stop words or punctuations\nnouns = [token.text for token in doc if token.is_stop != True and token.is_punct != True and token.pos_ == \"NOUN\"]\n\n# five most common tokens\nword_freq = Counter(words)\ncommon_words = word_freq.most_common(5)\n\n# five most common noun tokens\nnoun_freq = Counter(nouns)\ncommon_nouns = noun_freq.most_common(5)\nfrom collections import Counter\nwords = [token.text for token in doc if token.is_stop != True and token.is_punct != True]\n\n# noun tokens that arent stop words or punctuations\nnouns = [token.text for token in doc if token.is_stop != True and token.is_punct != True and token.pos_ == \"NOUN\"]\n\n# five most common tokens\nword_freq = Counter(words)\ncommon_words = word_freq.most_common(5)\n\n# five most common noun tokens\nnoun_freq = Counter(nouns)\ncommon_nouns = noun_freq.most_common(5)\ncommon_nouns\ncommon_words\nword_freq.most_common(10)\nnoun_freq.most_common(10)\n\n\n\n'''\n"
}
] | 3 |
mateuszlewko/cloud
|
https://github.com/mateuszlewko/cloud
|
a4cd3db8e01add3f718de2bd8a5de20d4aca0348
|
1d0cd7188cb99a63405fa6f3d234dc784c0c0863
|
2897581949ad284b249dc2d56011a301e7f6cc15
|
refs/heads/master
| 2021-05-07T04:04:16.790793 | 2018-01-18T23:06:12 | 2018-01-18T23:06:12 | 111,082,280 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7198581695556641,
"alphanum_fraction": 0.7517730593681335,
"avg_line_length": 39.42856979370117,
"blob_id": "973e2b13c04f4be61150a5966a93aea3ec569112",
"content_id": "63ef5232ab4a5249cb90fc5eee7351ee61617711",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 282,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 7,
"path": "/assignment4/task2.sh",
"repo_name": "mateuszlewko/cloud",
"src_encoding": "UTF-8",
"text": "cd python-app\n\nsudo docker build -t mateuszlewko/ii-uwr-cloud-python-app:latest . \nsudo docker push mateuszlewko/ii-uwr-cloud-python-app:latest\n\n# on server:\nsudo docker run -p 5001:5000 -e APP_MSG=\"I'm a number one.\" --name app1 --rm -d mateuszlewko/ii-uwr-cloud-python-app:latest"
},
{
"alpha_fraction": 0.6532257795333862,
"alphanum_fraction": 0.7016128897666931,
"avg_line_length": 11.399999618530273,
"blob_id": "fbc28a710733e999604c6e79b98b191aa43565ed",
"content_id": "ee21fc59ddc842c56eba3ea08db868d9041ed8ec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 124,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 10,
"path": "/assignment4/python-app/Dockerfile",
"repo_name": "mateuszlewko/cloud",
"src_encoding": "UTF-8",
"text": "FROM python:3-alpine\n\nADD main.py /\n\nRUN pip3 install flask\n\nEXPOSE 5000\n\nENV FLASK_APP 'main.py'\nCMD [\"python\", \"main.py\"]\n"
},
{
"alpha_fraction": 0.7149758338928223,
"alphanum_fraction": 0.750402569770813,
"avg_line_length": 27.272727966308594,
"blob_id": "bf94ba3858b3ba27bd113ced5324efa9ee8a40fa",
"content_id": "09a3ef2d120389f468b4bac3e7dad7ed6ec28be1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 621,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 22,
"path": "/assignment4/task1.sh",
"repo_name": "mateuszlewko/cloud",
"src_encoding": "UTF-8",
"text": "# on server:\nsudo apt install docker.io\n\nsudo docker run -p 80:80 --name the-nginx -d nginx\n\n# locally:\n# haproxy dockerimage which binds port 80 (loadbalancer) to 79 (app)\ncd haproxy\n\nsudo docker login\n\n# sudo docker build -t my-haproxy .\nsudo docker build -t mateuszlewko/ii-uwr-cloud-haproxy:\nsudo docker push docker.io/mateuszlewko/ii-uwr-cloud-haproxy:latest\n\n# on server: \nsudo docker stop the-nginx\nsudo docker rm the-nginx # remove previous\n\nsudo docker run --name the-nginx -d -rm nginx\n\nsudo docker run -p 80:80 --add-host server1:172.17.0.2 --name haproxy-at-80 --rm -d mateuszlewko/ii-uwr-cloud-haproxy:latest"
},
{
"alpha_fraction": 0.6242038011550903,
"alphanum_fraction": 0.6369426846504211,
"avg_line_length": 20,
"blob_id": "1e806c3ac9e62a476818a82fbe81d93f3a03ca52",
"content_id": "f742ce2573d6404c778ba7c76ea774d10b1e18fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 314,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 15,
"path": "/assignment4/python-app/main.py",
"repo_name": "mateuszlewko/cloud",
"src_encoding": "UTF-8",
"text": "from flask import Flask\nimport os, sys\n\napp = Flask(__name__)\nvar = 'APP_MSG'\nmsg = os.environ[var] if var in os.environ else 'APP_MSG environment variable not set!'\n\nprint('going to print:', msg, file=sys.stderr)\n\[email protected](\"/\")\ndef hello():\n return msg\n\nif __name__ == '__main__':\n app.run(host='0.0.0.0')"
},
{
"alpha_fraction": 0.7941114902496338,
"alphanum_fraction": 0.7997494339942932,
"avg_line_length": 102,
"blob_id": "42c89371b8d01d40d306413f89716857b74e5410",
"content_id": "7709aa35b1d5ebbed6d0a1ee29d8fa87e4b1b258",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 9674,
"license_type": "no_license",
"max_line_length": 569,
"num_lines": 93,
"path": "/exercises/jan-19th.md",
"repo_name": "mateuszlewko/cloud",
"src_encoding": "UTF-8",
"text": "## Task 1.\n\n[source: https://www.tutorialspoint.com/hadoop/hadoop_mapreduce.htm](https://www.tutorialspoint.com/hadoop/hadoop_mapreduce.htm)\n\nthe Algorithm\nGenerally MapReduce paradigm is based on sending the computer to where the data resides!\n\nMapReduce program executes in three stages, namely map stage, shuffle stage, and reduce stage.\n\nMap stage : The map or mapper’s job is to process the input data. Generally the input data is in the form of file or directory and is stored in the Hadoop file system (HDFS). The input file is passed to the mapper function line by line. The mapper processes the data and creates several small chunks of data.\n\nReduce stage : This stage is the combination of the Shuffle stage and the Reduce stage. The Reducer’s job is to process the data that comes from the mapper. After processing, it produces a new set of output, which will be stored in the HDFS.\n\nDuring a MapReduce job, Hadoop sends the Map and Reduce tasks to the appropriate servers in the cluster.\n\nThe framework manages all the details of data-passing such as issuing tasks, verifying task completion, and copying data around the cluster between the nodes.\n\nMost of the computing takes place on nodes with data on local disks that reduces the network traffic.\n\nAfter completion of the given tasks, the cluster collects and reduces the data to form an appropriate result, and sends it back to the Hadoop server.\n\n[source: https://github.com/GoogleCloudPlatform/appengine-mapreduce/wiki/1.2-Jobs-and-Stages](https://github.com/GoogleCloudPlatform/appengine-mapreduce/wiki/1.2-Jobs-and-Stages)\n\n\n## Task 3. Spark vs Hadoop\n\n- Apache Spark is setting the world of Big Data on fire. With a promise of speeds up to 100 times faster than Hadoop MapReduce and comfortable APIs\n\n- How can Spark, an open-source data-processing framework, process data so fast? The secret is that it runs in-memory on the cluster, and that it isn’t tied to Hadoop’s MapReduce two-stage paradigm. This makes repeated access to the same data much faster.\n\n If Spark runs on Hadoop YARN with other resource-demanding services, or if the data is too big to fit entirely into the memory, then there could be major performance degradations for Spark.\n\nBottom line: Spark performs better when all the data fits in the memory, especially on dedicated clusters; Hadoop MapReduce is designed for data that doesn’t fit in the memory and it can run well alongside other services.\n\n- Spark has comfortable APIs for Java, Scala and Python, and also includes Spark SQL (formerly known as Shark) for the SQL savvy. Thanks to Spark’s simple building blocks, it’s easy to write user-defined functions. It even includes an interactive mode for running commands with immediate feedback.\n\n- Hadoop MapReduce is written in Java and is infamous for being very difficult to program.\n\nBottom line: Spark is easier to program and includes an interactive mode; Hadoop MapReduce is more difficult to program but many tools are available to make it easier.\n\nApache Spark\n\n| (source) |\tApache Hadoop balanced workload slaves\n| (source)\nCores\t8–16\t4\nMemory\t8 GB to hundreds of gigabytes\t24 GB\nDisks\t4–8\t4–6 one-TB disks\nNetwork\t10 GB or more\t1 GB Ethernet all-to-all\n\nBottom line: Spark is the Swiss army knife of data processing; Hadoop MapReduce is the commando knife of batch processing.\n\nSpark has retries per task and speculative execution—just like MapReduce. Nonetheless, because MapReduce relies on hard drives, if a process crashes in the middle of execution, it could continue where it left off, whereas Spark will have to start processing from the beginning. This can save time.\n\nBottom line: Spark and Hadoop MapReduce both have good failure tolerance, but Hadoop MapReduce is slightly more tolerant.\n\nBottom line: Spark security is still in its infancy; Hadoop MapReduce has more security features and projects.\n\n[source: https://www.xplenty.com/blog/apache-spark-vs-hadoop-mapreduce/](https://www.xplenty.com/blog/apache-spark-vs-hadoop-mapreduce/)\n\n[source: https://www.infoworld.com/article/3014440/big-data/five-things-you-need-to-know-about-hadoop-v-apache-spark.html](https://www.infoworld.com/article/3014440/big-data/five-things-you-need-to-know-about-hadoop-v-apache-spark.html)\n\n# Task 7.\n\nAbout Cadreon\nCadreon is the advertising tech unit of IPG Mediabrands, the media innovation division of Interpublic Group. Cadreon offers a specialized digital performance platform for media brands that integrates technology, data, and inventory to target audiences in real time. The organization’s solutions are used by many of the world’s top brands to manage and increase the effectiveness of advertising campaigns.\n\nThe Challenge\nIn early 2016, Cadreon sought to develop a new audience-targeting platform that would integrate data from multiple data sources, with the goal of helping media companies maximize the effectiveness of digital advertising campaigns. “We wanted to build a solution that could manage very large datasets—up to 20 billion rows and containing close to a petabyte of data—while also supporting an application to enable real-time data analysis,” says Tushar Patel, senior vice president of engineering for Cadreon.\n\nCadreon, however, was concerned that using its existing on-premises environment to support the platform would be too challenging. “We only have a few people here to manage an IT environment, and it was already taking up too much of our time,” Patel says. “We want to focus on creating and running new solutions, not managing the backend of it all.”\n\nThe company also needed to ensure its new platform could scale to support a potentially fast-growing volume of data, such as demographic data and television-viewing trend data. “We projected a lot of growth for the solution, and we had to have the ability to quickly scale up to support that without investing a lot in hardware and personnel to manage it,” says Patel.\n\nWhy Amazon Web Services\nAs Cadreon considered its technology options, it focused its attention on the cloud. “We saw that the cloud would give us the flexibility to procure new compute resources very quickly and bring them down as needed,” says Bhupen Patel, vice president of data engineering at Cadreon. The company’s search led it to Amazon Web Services (AWS). “AWS is the leader in the cloud space, and we also felt the services from AWS were much more comprehensive than what other providers were offering,” Bhupen Patel says.\n\nCadreon created its new audience-insights platform on AWS, using the Amazon EMR managed Hadoop framework to process large amounts of data across scalable Amazon Elastic Compute Cloud (Amazon EC2) instances. The company also runs the Apache Spark framework on Amazon EMR and the Druid open-source analytics data store on Amazon EC2 for indexing data. The platform contains a total of 240 TB of data from 11 different advertising sources.\n\nCadreon runs its audience-insights database on Amazon Relational Database Service (Amazon RDS), and collects television-viewing trends, demographics, and a range of other data in an Amazon Redshift data warehouse. IPG Mediabrands analysts use the solution to conduct advertising-campaign analysis for media customers throughout the world. \n\nThe Benefits\nCadreon was able to easily get its audience-insights platform up and running on the AWS Cloud. “We built and launched this solution very quickly on AWS, and we were able to immediately spin up several hundred instances,” says Tushar Patel. “It would have taken us three months to order the hardware and get it all set up in a data center. Using AWS, we built a sophisticated big-data platform in the cloud that frees us from having to manage the backend environment. We can support 400 instances with only a few people, which we could never do in a traditional environment.”\n\nLeveraging the audience-insights solution, IPG Mediabrands analysts are able to quickly process data for their customers. “Our solution can process big-data queries from thousands of sources in a few seconds, so media companies can better define ad campaigns and audiences. With that data, these companies can target their audience to best achieve the goals of an ad campaign,” says Tushar Patel.\n\nAdditionally, Cadreon has the elasticity to scale the platform up or down when necessary. “We get our third-party data on a monthly basis, so we really only need to access and process that a few days each month,” Tushar Patel says. “Using AWS, we can scale the platform up quickly and bring it back down when that time period is over. That saves us both time and money.”\n\nAs the platform grows, Cadreon will be able to easily meet demand. “We want to make sure that if this solution takes off in a big way, we can support that growth without compromising the user experience,” says Tushar Patel. “We can definitely do that using AWS. And the fact that we can do it without making a large upfront investment in hardware is a huge advantage for us as a company.”\n\nCadreon is planning to explore additional AWS services—including Amazon Kinesis—as it expands the platform. “We are always interested in seeing how we can integrate additional AWS services into our platform,” says Tushar Patel. “We want to always keep our focus on building and enhancing our products, and AWS helps us do that more efficiently and cost effectively.”\n\n[source: https://aws.amazon.com/solutions/case-studies/cadreon/](https://aws.amazon.com/solutions/case-studies/cadreon/)\n[source: https://aws.amazon.com/solutions/case-studies/weatherrisk/](https://aws.amazon.com/solutions/case-studies/weatherrisk/)"
},
{
"alpha_fraction": 0.6365348696708679,
"alphanum_fraction": 0.6986817121505737,
"avg_line_length": 43.33333206176758,
"blob_id": "68cd4dd42d0d51486c8307138f7206c274658956",
"content_id": "348e5ea372611b2acc27b9ee4513b1c12b3e3ba7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 531,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 12,
"path": "/assignment4/task3.sh",
"repo_name": "mateuszlewko/cloud",
"src_encoding": "UTF-8",
"text": "sudo docker run -p 5101:5000 -e APP_MSG=\"I'm a number one.\" --name app-sd-1 --rm -d mateuszlewko/ii-uwr-cloud-python-app:latest\nsudo docker run -p 5102:5000 -e APP_MSG=\"I'm a number two.\" --name app-sd-2 --rm -d mateuszlewko/ii-uwr-cloud-python-app:latest\nsudo docker run -p 5103:5000 -e APP_MSG=\"I'm a number three.\" --name app-sd-3 --rm -d mateuszlewko/ii-uwr-cloud-python-app:latest\n\n# in order to update\n# 1. build\n# 2. push\n# 3. pull\nsudo docker rm -g app-sd-1\nsudo docker rm -g app-sd-2\nsudo docker rm -g app-sd-3\n# run again"
},
{
"alpha_fraction": 0.7514792680740356,
"alphanum_fraction": 0.7751479148864746,
"avg_line_length": 83.5,
"blob_id": "85bdbb000d6eac09f15f8ac713909cfcf9f3e839",
"content_id": "27c545d4370b4458acd0a9a24796ec6ac75f76ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 169,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 2,
"path": "/assignment1/task4/create_and_deploy.sh",
"repo_name": "mateuszlewko/cloud",
"src_encoding": "UTF-8",
"text": "gcloud compute instances create web-app-instance1 --zone us-east1-b --machine-type f1-micro\ngcloud compute config-ssh web-app-instance1 --ssh-key-file ~/.ssh/id_rsa.pub\n"
}
] | 7 |
NathanSmith470/ascii_animator
|
https://github.com/NathanSmith470/ascii_animator
|
08d765167e9023a13b0d0122d944da325fb783b3
|
2b003418f67e014ae127a08ff60b35dc51f9ad97
|
faf3b52eb110d9b20b0c10f43517d11c78438d91
|
refs/heads/main
| 2023-02-27T10:25:29.470515 | 2021-02-03T01:05:23 | 2021-02-03T01:05:23 | 335,466,791 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7154340744018555,
"alphanum_fraction": 0.7556270360946655,
"avg_line_length": 37.875,
"blob_id": "e6d24de99e9fe2adc6c3b4eb4f2a11d1239a1ba4",
"content_id": "5df0ae0168e17ffafbdea95cb2a6c9511059f376",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 622,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 16,
"path": "/README.txt",
"repo_name": "NathanSmith470/ascii_animator",
"src_encoding": "UTF-8",
"text": "# ascii_animator\na super simple ascii animation script for the terminal\n\n# COMMAND LINE FORMAT: python3 ascii_animator.py {file} {frame_delay=0.5(default)} {iterations=10(default)}\n\n# EX: python3 ascii_animator.py anim01.txt 0.1 30\n -> This will run anim01.txt with a 0.1 second delay between frames for 30 cycles(from beginning to end)\n\nThere are three sample animations in the repository\n\n# Creating a animation file is simple.\n1: make a new .txt file\n2: create an animation frame\n3: on the line after the frame write simply \"next\" and NOTHING else.\n4: repeat steps 2-3 until finished\n5: when finished write \"end\"\n"
},
{
"alpha_fraction": 0.4882780909538269,
"alphanum_fraction": 0.5084882974624634,
"avg_line_length": 21.089284896850586,
"blob_id": "7e84a0a22c7a1b30d679f9e5c0d3365dd89ef5ff",
"content_id": "ad4dbf36596ba0f98e5e2516c51d661d8d4a6d19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1237,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 56,
"path": "/ascii_animator.py",
"repo_name": "NathanSmith470/ascii_animator",
"src_encoding": "UTF-8",
"text": "from time import sleep\nimport os, sys\n\n# COMMAND LINE FORMAT: python3 ascii_animator.py {file} {frame_delay=0.5(default)} {iterations=10(default)}\n\n# EX: python3 ascii_animator.py anim01.txt 0.1 30\n\n# VARS\nanim_file = None\ndelay = 0.5\nt_cycles = 10\n\nif __name__ == \"__main__\":\n # GET ARGUMENTS\n try:\n anim_file = sys.argv[1]\n if anim_file == \"--help\" or anim_file == \"-h\":\n print(\"\")\n quit()\n except IndexError:\n print(\"No Animation File!\")\n quit()\n try:\n delay = float(sys.argv[2])\n except IndexError:\n delay = 0.5\n try:\n t_cycles = int(sys.argv[3])\n except IndexError:\n t_cycles = 10\n\n # READ FILE\n afile = open(anim_file,\"r\")\n frames = []\n tfram = \"\"\n\n for l in afile.readlines():\n if l.replace(\"\\n\",\"\") == \"next\":\n frames.append(tfram)\n tfram = \"\"\n elif l.replace(\"\\n\",\"\") == \"end\":\n frames.append(tfram)\n tfram = \"\"\n else:\n tfram += l\n\n # START ANIMATION\n print(\"Starting Animation...\")\n sleep(1)\n\n\n for t in range(0,t_cycles):\n for f in frames:\n os.system(\"clear\")\n print(f)\n sleep(delay)\n"
}
] | 2 |
zamani9519/test
|
https://github.com/zamani9519/test
|
28c154809b30e8724b382a51b1363d9ef76a7d3e
|
43cfc183bd258514864f09d212320fff32f6e795
|
ca988231d1a32d770dc2f318c4d2dfa739e8e28d
|
refs/heads/main
| 2023-08-21T02:34:38.223252 | 2021-11-02T07:47:06 | 2021-11-02T07:47:06 | 423,745,364 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5555555820465088,
"alphanum_fraction": 0.6296296119689941,
"avg_line_length": 4,
"blob_id": "12e1ded999856a07a821861915248f3b8a7f1bd1",
"content_id": "72d0f7503135c8211c6163ca97942f4c2560d83d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 27,
"license_type": "no_license",
"max_line_length": 11,
"num_lines": 5,
"path": "/test.py",
"repo_name": "zamani9519/test",
"src_encoding": "UTF-8",
"text": "\nmfdslkgas\n\n\n\nmammad = 10\n\n"
}
] | 1 |
graphmp/graphmp
|
https://github.com/graphmp/graphmp
|
198f91a0647f1897d7c2b57ba0c1006e028e850d
|
d09d77ae124bc60ab081e2ba2c04633ac99a5e57
|
67dc6806fdfb4bf3afd1e383de236aafc40459c6
|
refs/heads/master
| 2020-04-21T00:24:39.674448 | 2019-02-15T20:02:02 | 2019-02-15T20:02:02 | 169,195,780 | 3 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.49306029081344604,
"alphanum_fraction": 0.5057045221328735,
"avg_line_length": 46.773292541503906,
"blob_id": "7ad818e4247742c7682950771ab731a504bf99bf",
"content_id": "2862289aee41a5d9b71ba5b0f8d70a4e7b7a260b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 30765,
"license_type": "no_license",
"max_line_length": 165,
"num_lines": 644,
"path": "/graphmp.py",
"repo_name": "graphmp/graphmp",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# !/usr/bin/env python\n\n\nimport numpy as np\nimport tensorflow as tf\nimport argparse\nimport math\nimport glob\nimport tensorflow.contrib.layers as layers\nimport os\nimport random\nfrom tensorflow.contrib import rnn\nfrom sklearn import metrics\n\n\ndef pairwise_distance(cate_pattern):\n \"\"\"Compute pairwise distance of a point cloud.\n Args:\n cate_pattern: tensor (batch_size, num_points, num_dims)\n Returns:\n pairwise distance: (batch_size, num_points, num_points)\n \"\"\"\n og_batch_size, num_points, num_dims = cate_pattern.get_shape().as_list()\n cate_pattern = tf.squeeze(cate_pattern)\n if og_batch_size == 1:\n cate_pattern = tf.expand_dims(cate_pattern, 0)\n\n cate_pattern_transpose = tf.transpose(cate_pattern, perm=[0, 2, 1])\n cate_pattern_inner = tf.matmul(cate_pattern, cate_pattern_transpose)\n cate_pattern_inner = -2 * cate_pattern_inner\n cate_pattern_square = tf.reduce_sum(tf.square(cate_pattern), axis=-1, keep_dims=True)\n cate_pattern_square_tranpose = tf.transpose(cate_pattern_square, perm=[0, 2, 1])\n return tf.reshape(cate_pattern_square + cate_pattern_inner + cate_pattern_square_tranpose, [-1, num_points, num_points])\n# def pairwise_distance(cate_pattern):\n# \"\"\"Compute pairwise distance of a point cloud.\n# Args:\n# cate_pattern: tensor (batch_size, num_points, num_dims)\n# Returns:\n# pairwise distance: (batch_size, num_points, num_points)\n# \"\"\"\n# og_batch_size, num_points, num_dims = cate_pattern.get_shape().as_list()\n# cate_pattern = tf.squeeze(cate_pattern)\n# if og_batch_size == 1:\n# cate_pattern = tf.expand_dims(cate_pattern, 0)\n#\n# cate_pattern_transpose = tf.transpose(cate_pattern, perm=[0, 2, 1])\n# cate_pattern_inner = tf.matmul(cate_pattern, cate_pattern_transpose)\n#\n# return tf.reshape(cate_pattern_inner, [-1, num_points, num_points])\n\n\nclass pfn(object):\n\n def __init__(self, n_filters, filter_sizes,\n top_down_channel , num_steps, attention_size, hidden_dim,\n w=1, b=0, category = False):\n self.n_filters = n_filters\n self.filter_sizes = filter_sizes\n self.num_steps = num_steps\n self.hidden_dim = hidden_dim\n self.attention_size = attention_size\n self.top_down_channel = top_down_channel\n self.regularizer = tf.contrib.layers.l2_regularizer(scale=0.1)\n self.w = w\n self.b = b\n self.category = category\n self.neuron_per_layer = [32,32]\n\n\n def temporal_attention(self, inputs, str_name):\n print('inputs', inputs)\n inputs = tf.stack(inputs, axis = 0)\n print('inputs', inputs)\n inputs = tf.transpose(inputs, [1, 0, 2])\n\n with tf.variable_scope('attention' + str_name):\n inputs_shape = inputs.shape\n sequence_length = inputs_shape[1].value # the length of sequences processed in the antecedent RNN layer\n hidden_size = inputs_shape[2].value # hidden size of the RNN layer\n\n # Attention mechanism\n W_omega = tf.Variable(tf.random_normal([hidden_size, self.attention_size], stddev=0.1))\n b_omega = tf.Variable(tf.random_normal([self.attention_size], stddev=0.1))\n u_omega = tf.Variable(tf.random_normal([self.attention_size], stddev=0.1))\n\n v = tf.tanh(tf.matmul(tf.reshape(inputs, [-1, hidden_size]), W_omega) + tf.reshape(b_omega, [1, -1]))\n vu = tf.matmul(v, tf.reshape(u_omega, [-1, 1]))\n exps = tf.reshape(tf.exp(vu), [-1, sequence_length])\n alphas = exps / tf.reshape(tf.reduce_sum(exps, 1), [-1, 1])\n\n output = tf.reduce_sum(inputs * tf.reshape(alphas, [-1, sequence_length, 1]), 1)\n\n return output\n\n def RNN(self, x, num_steps, hidden_dim, scope):\n print(scope)\n # x.shape ->[batch_size, num_steps, n_category, n_channel]\n dim0, dim1, dim2, dim3 = x.get_shape().as_list() # batch_size, input_dim\n x = tf.unstack(x, axis=1)\n x = x[-num_steps:]\n print('x_x', x)\n with tf.variable_scope(scope):\n # 1-layer LSTM with n_hidden units.\n conv_lstm_cell = tf.contrib.rnn.ConvLSTMCell(conv_ndims = 1,\n input_shape= [dim2, dim3],\n output_channels = hidden_dim,\n kernel_shape = [1])\n # generate prediction\n outputs, states = rnn.static_rnn(conv_lstm_cell, x, dtype=tf.float32)\n return outputs[-1]\n\n def squeeze_excite_block(self, input, filters, name, ratio=1):\n ''' Create a squeeze-excite block\n Args:\n input: input tensor\n filters: number of output filters\n k: width factor\n Returns: a keras tensor\n '''\n\n init = input\n\n se = tf.reduce_mean(init, axis = 1)\n se = tf.layers.dense(se, filters // ratio, activation=tf.nn.relu,\n trainable=True,\n kernel_regularizer=self.regularizer,\n use_bias = False,\n name='se1'+name)\n se = tf.layers.dense(se, filters, activation=tf.nn.sigmoid,\n trainable=True,\n kernel_regularizer=self.regularizer,\n use_bias = False,\n name='se2'+name)\n\n x = tf.multiply(init, tf.expand_dims(se, axis = 1))\n return x, se\n\n def resnet_block(self, conv_output, layer_id, n_output):\n shortcut_connect_ = tf.layers.conv2d(conv_output,\n filters=n_output,\n kernel_size=(1,1),\n strides=(2,1),\n padding='same',\n activation=None,\n use_bias=True,\n kernel_initializer=tf.contrib.layers.xavier_initializer(),\n bias_initializer=tf.contrib.layers.xavier_initializer(),\n kernel_regularizer=self.regularizer,\n trainable=True,\n name='shortcut_layer_%s' % layer_id)\n\n conv_output1 = tf.layers.conv2d(conv_output,\n filters=n_output,\n kernel_size=(3, 1),\n strides=(1,1),\n padding='same',\n activation=tf.nn.relu,\n use_bias=True,\n kernel_initializer=tf.contrib.layers.xavier_initializer(),\n bias_initializer=tf.contrib.layers.xavier_initializer(),\n kernel_regularizer=self.regularizer,\n trainable=True,\n name='layer1_%s' % layer_id)\n\n conv_output2 = tf.layers.conv2d(conv_output1,\n filters=n_output,\n kernel_size=(3,1),\n strides=(1,1),\n padding='same',\n activation=None,\n use_bias=True,\n kernel_initializer=tf.contrib.layers.xavier_initializer(),\n bias_initializer=tf.contrib.layers.xavier_initializer(),\n kernel_regularizer=self.regularizer,\n trainable=True,\n name='layer2_%s' % layer_id)\n\n conv_output2 = tf.layers.max_pooling2d(conv_output2,\n pool_size=(3,1),\n strides=(2,1),\n padding='same',\n name='layer_%s_maxpool' % layer_id)\n\n conv_output = tf.nn.relu(shortcut_connect_+conv_output2)\n return conv_output\n\n def squeeze_excite_block(self, input, filters, name, ratio=1):\n ''' Create a squeeze-excite block\n Args:\n input: input tensor\n filters: number of output filters\n k: width factor\n Returns: a keras tensor\n '''\n\n init = input\n\n se = tf.reduce_mean(init, axis = 1)\n se = tf.layers.dense(se, filters // ratio, activation=tf.nn.relu,\n trainable=True,\n kernel_regularizer=self.regularizer,\n use_bias = False,\n name='se1'+name)\n se = tf.layers.dense(se, filters, activation=tf.nn.sigmoid,\n trainable=True,\n kernel_regularizer=self.regularizer,\n use_bias = False,\n name='se2'+name)\n\n x = tf.multiply(init, tf.expand_dims(se, axis = 1))\n return x, se\n\n def bottle_up_path(self, sequence):\n dim0, dim1, dim2 = sequence.get_shape().as_list() #batch_size, input_dim\n tf.logging.info(\"dim0 %s, dim1 %s, dim2 %s\" % (dim0, dim1, dim2))\n conv_output = tf.expand_dims(sequence, axis = 3)\n conv_outputs = {}; rnn_outputs = []\n conv_outputs[0] = conv_output\n\n rnn_output = self.RNN(conv_output, num_steps=self.num_steps, hidden_dim=self.hidden_dim,\n scope='rnn_')\n tf.logging.info('conv_output', rnn_output.get_shape())\n rnn_output = tf.layers.dense(rnn_output,\n self.hidden_dim,\n activation=tf.nn.tanh,\n trainable=True,\n kernel_regularizer=self.regularizer,\n name='rnn_output')\n rnn_outputs.append(rnn_output)\n\n for layer_id, n_output in enumerate(self.n_filters):\n print('layer_%s' % layer_id)\n conv_output = self.resnet_block(conv_output, layer_id, n_output)\n conv_outputs[layer_id+1] = conv_output\n\n rnn_output = self.RNN(conv_output, num_steps = self.num_steps, hidden_dim = self.hidden_dim, scope = 'rnn_%s' % layer_id)\n tf.logging.info('conv_output', rnn_output.get_shape())\n rnn_output = tf.layers.dense(rnn_output,\n self.hidden_dim,\n activation=tf.nn.tanh,\n trainable=True,\n kernel_regularizer=self.regularizer,\n name='rnn_output%s' %layer_id)\n rnn_outputs.append(rnn_output)\n return rnn_output\n\n def conv2d_transpose(self, input, kernel_size, depth_output, stride, name):\n dim0, dim1, dim2, dim3 = input.get_shape().as_list() # batch_size, n_time, n_category, depth\n print('dim0, dim1, dim2, dim3', dim0, dim1, dim2, dim3)\n with tf.variable_scope(name):\n k = tf.get_variable('kernel', shape = [kernel_size, 1, depth_output, dim3],\n dtype = tf.float32, initializer = tf.contrib.layers.xavier_initializer()) # note k.shape = [cols, depth_output, depth_in]\n output_shape = tf.stack([tf.shape(input)[0], dim1*2, dim2, depth_output])\n output = tf.nn.conv2d_transpose(value=input,\n filter=k,\n output_shape=output_shape,\n strides=(1,stride,1,1),\n padding='SAME')\n\n output = tf.nn.relu(output)\n return output\n\n def top_down_path(self, conv_outputs):\n rnn_outputs = []\n print('conv_outputs', conv_outputs)\n\n for reverse_layer_id in range(len(conv_outputs)-1, 0, -1):\n\n 'lateral connection'\n\n lateral_layer = conv_outputs[reverse_layer_id-1]\n lateral_layer_connect = tf.layers.conv2d(lateral_layer,\n filters=self.top_down_channel,\n kernel_size=(1,1),\n strides=(1,1),\n padding='same',\n activation=None,\n use_bias=True,\n kernel_initializer=tf.contrib.layers.xavier_initializer(),\n bias_initializer=tf.contrib.layers.xavier_initializer(),\n kernel_regularizer=self.regularizer,\n trainable=True,\n name='lateral_layer_%s' % reverse_layer_id)\n if reverse_layer_id>0:\n conv_output = self.conv2d_transpose(conv_outputs[reverse_layer_id], kernel_size = self.filter_sizes[reverse_layer_id-1],\n depth_output = self.top_down_channel, stride = 2, name = 'topdown_%s_bn' % reverse_layer_id)\n else:\n conv_output = self.conv2d_transpose(conv_outputs[reverse_layer_id],\n kernel_size=1,\n depth_output=self.top_down_channel, stride=2,\n name='topdown_%s_bn' % reverse_layer_id)\n\n conv_output = lateral_layer_connect + conv_output\n\n # 'mitigate the overlapping effect caused by upsampling conv1d'\n # conv_output = tf.layers.conv1d(conv_output,\n # filters=self.top_down_channel,\n # kernel_size=3,\n # strides=1,\n # padding='same',\n # activation=tf.nn.relu,\n # use_bias=True,\n # kernel_initializer=tf.contrib.layers.xavier_initializer(),\n # bias_initializer=tf.contrib.layers.xavier_initializer(),\n # kernel_regularizer=self.regularizer,\n # trainable=True,\n # name='output_layer%s' % reverse_layer_id)\n\n\n\n 'Encode the temporal pattern from different resolution'\n rnn_output = self.RNN(conv_output, num_steps = self.num_steps, hidden_dim = self.hidden_dim, scope = 'rnn_%s' % reverse_layer_id)\n tf.logging.info('conv_output', rnn_output.get_shape())\n rnn_output = tf.layers.dense(rnn_output,\n self.hidden_dim,\n activation=tf.nn.tanh,\n trainable=True,\n kernel_regularizer=self.regularizer,\n name='rnn_output%s' %reverse_layer_id)\n rnn_outputs.append(rnn_output)\n return rnn_outputs\n\n\n\n def hie_fusion(self, rnn_outputs):\n intermediate_layer = rnn_outputs[0]\n for idx, rnn_output in enumerate(rnn_outputs[1:]):\n intermediate_layer = tf.layers.dense(tf.concat([rnn_output, intermediate_layer], axis = 1),\n self.hidden_dim,\n activation=tf.nn.relu,\n trainable=True,\n kernel_regularizer=self.regularizer,\n name='hie_output%s' %idx)\n return intermediate_layer\n\n def gcn_op(self, train_features):\n l_ = train_features\n for idx, n_neuron in enumerate(self.neuron_per_layer):\n train_adj = -pairwise_distance(l_)\n l_ = tf.layers.dense(tf.matmul(train_adj, l_),\n n_neuron,\n activation=tf.nn.relu,\n trainable=True,\n kernel_regularizer=self.regularizer,\n name='pred_v'+str(idx))\n return l_\n\n\n def pfn_cnn(self, category_dim, sequence):\n mult_reolution_embeds = self.bottle_up_path(sequence)\n\n\n # 'encode mult_reolution_embeds and then output predicted value'\n # 'TODO: multiple temporal pattern fusion --attention, other way?'\n concat_reolution_embeds = tf.concat(mult_reolution_embeds, axis = 2)#output: batch_size, category, channel\n # resign weight\n concat_reolution_embeds, weights = self.squeeze_excite_block(concat_reolution_embeds, concat_reolution_embeds.get_shape().as_list()[2], 'se_%s' % 0,\n ratio=1) # output: batch_size, category, channel\n\n\n 'normalize adj mtx'\n # deg_matrix = tf.matrix_diag(tf.pow(tf.reduce_sum(adj_matrix, axis = -1), -0.5))\n # adj_matrix = tf.matmul(tf.matmul(deg_matrix, adj_matrix), deg_matrix)\n # print('adj', adj_matrix)\n\n propagate_resolution = self.gcn_op(concat_reolution_embeds)\n\n\n pred_v = tf.squeeze(tf.layers.dense(propagate_resolution,\n 1,\n activation=None,\n trainable=True,\n kernel_regularizer=self.regularizer,\n name='pred_v'), axis = -1)\n\n return pred_v, concat_reolution_embeds\n\n def evaluate(self, preds, ys):\n def confusion_mtx(pred, y):\n TP = tf.count_nonzero(pred * y, dtype=tf.float32)\n TN = tf.count_nonzero((pred - 1) * (y - 1), dtype=tf.float32)\n FP = tf.count_nonzero(pred * (y - 1), dtype=tf.float32)\n FN = tf.count_nonzero((pred - 1) * y, dtype=tf.float32)\n return TP, TN, FP, FN\n sep_TP = []\n sep_TN = []\n sep_FP = []\n sep_FN = []\n for pred, y in zip(preds, ys):\n TP, TN, FP, FN = confusion_mtx(pred, y)\n sep_TP.append(TP)\n sep_TN.append(TN)\n sep_FP.append(FP)\n sep_FN.append(FN)\n preds = tf.reshape(tf.stack(preds), [-1])\n ys = tf.reshape(tf.stack(ys), [-1])\n allTP, allTN, allFP, allFN = confusion_mtx(preds, ys)\n return sep_TP, sep_TN, sep_FP, sep_FN, allTP, allTN, allFP, allFN\n\n def model(self, input_dim, category_dim, lr= 1e-3, decay=False):\n def my_tf_round(x, decimals=0):\n multiplier = tf.constant(10 ** decimals, dtype=x.dtype)\n return tf.round(x * multiplier) / multiplier\n\n train_xs = tf.placeholder(tf.float32, shape=[None, input_dim, category_dim], name=\"train_xs\")\n train_ys = tf.placeholder(tf.float32, shape=[None, category_dim], name=\"train_ys\")\n self.train_phase = tf.placeholder(tf.bool, name='train_phase')\n fusion_mtx = 0\n\n global_step = tf.Variable(0, name='global_step', trainable=False)\n\n pred_y, weights = self.pfn_cnn(category_dim, train_xs)\n\n if self.category:\n label = tf.math.greater(train_ys, -0.999)\n loss = tf.losses.sigmoid_cross_entropy(\n label,\n pred_y,\n weights=5.0)\n scale_back_train_ys = tf.unstack(tf.cast(label, tf.int32), axis = 1)\n scale_back_pred_binary_y = tf.unstack(tf.cast(tf.math.greater(tf.sigmoid(pred_y), 0.5), tf.int32), axis=1)\n\n sep_TP, sep_TN, sep_FP, sep_FN, allTP, allTN, allFP, allFN = self.evaluate(scale_back_pred_binary_y,\n scale_back_train_ys)\n\n fusion_mtx = (sep_TP, sep_TN, sep_FP, sep_FN, allTP, allTN, allFP, allFN)\n scale_back_pred_y = tf.unstack(my_tf_round(tf.sigmoid(pred_y), 2), axis=1)\n else:\n loss = tf.reduce_mean(tf.squared_difference(train_ys, pred_y))\n scale_back_train_ys = tf.divide(tf.add(train_ys, -self.b), self.w)\n scale_back_pred_y = tf.divide(tf.add(pred_y, -self.b), self.w)\n l2_loss = tf.losses.get_regularization_loss()\n loss += 0.0*l2_loss\n\n\n\n saver = tf.train.Saver(max_to_keep=1)\n\n #GradientDescentOptimizer, AdamOptimizer\n if decay:\n opt = tf.train.AdamOptimizer(learning_rate=tf.train.exponential_decay(lr, global_step,\n decay_steps=1000, decay_rate=0.99,\n staircase=True))\n else:\n opt = tf.train.AdamOptimizer(learning_rate=lr)\n\n def ClipIfNotNone(grad):\n if grad is None:\n return grad\n return tf.clip_by_value(grad, -1, 1)\n\n # train_op = opt.minimize(loss, global_step=global_step)\n gvs = opt.compute_gradients(loss)\n capped_gvs = [(ClipIfNotNone(grad), var) for grad, var in gvs]\n train_op = opt.apply_gradients(capped_gvs, global_step=global_step)\n\n init = tf.global_variables_initializer()\n return train_xs, train_ys, scale_back_train_ys, scale_back_pred_y, weights, saver, \\\n loss, self.train_phase, train_op, init, global_step, fusion_mtx\n\n\ndef random_sample(batch_size, input_dim, category_dim, n_epoch):\n\n def load():\n for idx, _ in enumerate(range(100)):\n xs = np.random.rand(batch_size, input_dim, category_dim)\n ys = np.random.rand(batch_size, category_dim)\n yield (xs, ys)\n\n for epoch in range(n_epoch):\n yield load()\n\n\nclass pfnIO:\n def __init__(self, n_filters, filter_sizes,top_down_channel,\n num_steps, attention_size, hidden_dim, w = 1, b = 0, input_dim=256, category_dim = 20, batch_size=64,\n keep_rate=0.6,\n learning_rate=1e-3,\n category = False): # n is number of users\n # map_id_idx = map_dict([], args.dict)\n # self.map_idx_id = {v: k for k, v in map_id_idx.items()}\n # num_nodes = max(self.map_idx_id.values())\n # print(num_nodes)\n self.input_dim = input_dim\n self.category_dim = category_dim\n self.batch_size = batch_size\n self.keep_rate = keep_rate\n self.category_flag = category\n\n pfn_ = pfn(n_filters, filter_sizes,top_down_channel,\n num_steps, attention_size, hidden_dim,\n w, b, category)\n self.train_xs, self.train_ys, self.scale_back_train_ys, self.scale_back_pred_y, self.weight, self.saver, \\\n self.loss, self.train_phase, self.train_op, self.init, self.global_step, self.fusion_mtx = pfn_.model(input_dim, category_dim, lr=learning_rate, decay=False)\n\n self.user_batch = []\n self.article_batch = []\n self.click_batch = []\n\n def create(self, pretrain_flag=0, save_file=''):\n config = tf.ConfigProto()\n config.gpu_options.allow_growth = True\n config.gpu_options.per_process_gpu_memory_fraction = 0.8\n config.log_device_placement = True\n config.allow_soft_placement = True\n self.sess = tf.Session(config=config)\n if pretrain_flag == 0:\n self.sess.run(self.init)\n else:\n self.saver.restore(self.sess, save_file + '.ckpt')\n print('create')\n\n def save_weight(self, save_file):\n try:\n self.saver.save(self.sess, save_file+'.ckpt')\n except:\n print('need to makedir')\n os.makedirs(save_file, exist_ok=True)\n self.saver.save(self.sess, save_file+'.ckpt')\n print(\"Save model to file as pretrain.\")\n\n def ExpUpdateParameters(self, n_epoch=1):\n average_loss = 0\n for epoch in random_sample(self.batch_size, self.input_dim, self.category_dim, n_epoch):\n for (xs, ys) in epoch:\n (step, loss) = self.feedbatch(xs, ys)\n average_loss += loss\n if step % 50 == 0:\n average_loss /= 50;\n print('step %s, avg_loss %.3f, curr_loss %.3f' %(step, average_loss, loss))\n average_loss = 0;\n\n\n def run_eval(self, rs, sequence_vs, sequence_open, ys):\n xs_batches = 1 + len(ys) // 10000;\n my_preds = []\n my_trues = []\n for idx in range(xs_batches):\n idx_begin = idx * 10000\n idx_end = min((idx + 1) * 10000, len(ys))\n\n my_true, my_pred = self.get_prediction(sequence_vs[idx_begin:idx_end],ys[idx_begin:idx_end])\n my_preds = my_preds + list(my_pred)\n my_trues = my_trues + list(my_true)\n my_rmse = np.sqrt(metrics.mean_squared_error(np.array(my_trues), np.array(my_preds)))\n rmspe = np.sqrt(np.mean([((p - t) / t) ** 2 for p, t in zip(my_preds, my_trues) if t > 10]))\n my_mae = metrics.mean_absolute_error(np.array(my_trues), np.array(my_preds))\n my_cr = 1 - my_mae / np.mean(my_trues)\n print('fpn-pred', np.round(np.array(my_preds[:10]),0))\n print('fpn-gt', np.round(np.array(my_trues[:10]),0))\n return ([my_rmse, rmspe, my_mae, my_cr])\n\n def eval_rslt(self, TP, TN, FP, FN):\n prec = TP / (TP + FP + 0.1)\n recall = TP / (TP + FN + 0.1)\n f1 = 2 * TP / (2 * TP + FN + FP + 0.1)\n acc = (TP + TN) / (TP + FN + FP + TN + 0.1)\n return (round(float(prec), 4), round(float(recall), 4), round(float(f1), 4), round(float(acc), 4))\n\n def run_binary_eval(self, rs, sequence_vs, ys, category):\n xs_batches = 1 + len(ys) // 5000;\n my_preds = {c:[] for c in category}; my_trues = {c:[] for c in category}; my_fusions = []\n for idx in range(xs_batches):\n idx_begin = idx * 5000\n idx_end = min((idx + 1) * 5000, len(rs))\n my_true, my_pred, my_fusion = self.get_prediction(sequence_vs[idx_begin:idx_end],ys[idx_begin:idx_end], category = self.category_flag)\n for c, t, p in zip(category, my_true, my_pred):\n my_preds[c] = my_preds[c] + list(p)\n my_trues[c] = my_trues[c] + list(t)\n my_fusions.append(my_fusion)\n\n self.sep_TP = [0]*self.category_dim; self.sep_TN = [0]*self.category_dim; self.sep_FP = [0]*self.category_dim; self.sep_FN = [0]*self.category_dim;\n allTP = 0; allTN = 0; allFP = 0; allFN = 0;\n for _ in my_fusions:\n self.sep_TP = [org_c + up_c for org_c, up_c in zip(self.sep_TP, _[0])]\n self.sep_TN = [org_c + up_c for org_c, up_c in zip(self.sep_TN, _[1])]\n self.sep_FP = [org_c + up_c for org_c, up_c in zip(self.sep_FP, _[2])]\n self.sep_FN = [org_c + up_c for org_c, up_c in zip(self.sep_FN, _[3])]\n allTP += _[4]; allTN += _[5]; allFP += _[6]; allFN += _[7];\n\n self.my_trues = my_trues\n self.my_preds = my_preds\n\n my_true = np.reshape(np.array(list(my_trues.values())), [-1])\n my_pred = np.reshape(np.array(list(my_preds.values())), [-1])\n (prec, recall, f1, acc) = self.eval_rslt(allTP, allTN, allFP, allFN)\n\n fpr, tpr, thresholds = metrics.roc_curve(my_true, my_pred, pos_label=1)\n my_auc = metrics.auc(fpr, tpr)\n my_ap = metrics.average_precision_score(my_true, my_pred)\n print('======>', 'prec', prec, 'recall', recall, 'f1', f1, 'acc', round(float(my_auc), 4), 'ap',\n round(float(my_ap), 4))\n return [prec, recall, f1, acc, my_auc, my_ap]\n\n def run_sep_eval(self, category):\n for idx, c in enumerate(category):\n print(self.sep_TP[idx], self.sep_TN[idx], self.sep_FP[idx], self.sep_FN[idx])\n prec, recall, f1, acc= self.eval_rslt(self.sep_TP[idx], self.sep_TN[idx], self.sep_FP[idx], self.sep_FN[idx])\n fpr, tpr, thresholds = metrics.roc_curve(np.array(self.my_trues[c]), np.array(self.my_preds[c]), pos_label=1)\n my_auc = metrics.auc(fpr, tpr)\n my_ap = metrics.average_precision_score(np.array(self.my_trues[c]), np.array(self.my_preds[c]))\n print('%s: my_rmse %.4f , my_recall %.4f , my_f1 %.4f , my_acc %.4f , my_auc %.4f , my_ap %.4f' % (\n c, prec, recall, f1, acc, my_auc, my_ap))\n\n\n def feedbatch(self, xs, ys):\n feed_dict = {self.train_xs: xs,\n self.train_ys: ys,\n self.train_phase: 1}\n _, step, loss = self.sess.run([self.train_op, self.global_step, self.loss], feed_dict)\n return (step, loss)\n\n def get_prediction(self, xs, ys, category = False):\n feed_dict = {self.train_xs: xs,\n self.train_ys: ys,\n self.train_phase: 0}\n if category:\n gt_, pred_, fusion_mtx = self.sess.run([self.scale_back_train_ys, self.scale_back_pred_y, self.fusion_mtx], feed_dict)\n return gt_, pred_, fusion_mtx\n else:\n gt_, pred_ = self.sess.run([self.scale_back_train_ys, self.scale_back_pred_y], feed_dict)\n return np.reshape(gt_, [-1]), np.reshape(pred_, [-1])\n\n def get_weight(self, xs, ys):\n feed_dict = {self.train_xs: xs,\n self.train_ys: ys,\n self.train_phase: 0}\n gt_, pred_, weight_ = self.sess.run([self.scale_back_train_ys, self.scale_back_pred_y, self.weight], feed_dict)\n return np.reshape(gt_, [-1]), np.reshape(pred_, [-1]), weight_\n\n\n\n\nif __name__ == '__main__':\n #input: n_sequence, category\n nn = pfnIO(n_filters = [32, 64, 128, 256], filter_sizes = [3, 8, 5, 1],\n top_down_channel = 64, num_steps = 5, attention_size = 64,\n w=1, b=0,\n hidden_dim = 64,input_dim=256, batch_size=64,\n keep_rate=0.6,\n learning_rate=1e-3)\n nn.create()\n nn.ExpUpdateParameters(n_epoch=10)"
}
] | 1 |
CalebMcIvor/Erik
|
https://github.com/CalebMcIvor/Erik
|
564cadb068fa83a85164b223cce3f7825666519f
|
5e4a918d10f0a398988fd5ae8293431bf5af433a
|
59b315afbcb30eda9746a3fee80b25ba6138d2a2
|
refs/heads/master
| 2022-10-16T14:40:27.167965 | 2016-09-28T06:33:56 | 2016-09-28T06:33:56 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5531611442565918,
"alphanum_fraction": 0.5719643235206604,
"avg_line_length": 31.144311904907227,
"blob_id": "30a084f428e8afbf42ee7aeeeb928f593f7adcaa",
"content_id": "7685a62eb7bb972395f85ac76fc465827939f6cd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18933,
"license_type": "permissive",
"max_line_length": 132,
"num_lines": 589,
"path": "/main.py",
"repo_name": "CalebMcIvor/Erik",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python \n##### Imports #####\nimport RPi.GPIO as GPIO \nfrom time import sleep, strftime\nimport subprocess\nfrom datetime import datetime\nfrom multiprocessing import Process\nimport speech_recognition\nimport sys\nimport os\n\n##### Constants #####\n#pin number of DHT11 temp senser\nDHTPin = 7\n#refresh rate in secounds for main loop\nrefresh_rate = 2\n#time for alarm to sound\nalarm_time = '07:00'\n#command for IP address\ncmd = \"ip addr show eth0 | grep inet | awk '{print $2}' | cut -d/ -f1\"\n#debug mode [Low, Medium, High] default: Low\nDEBUG = 'Low'\n\n#get aguments passed from terminal\ncommands = []\nfor arg in sys.argv[1:]:\n if arg == '-d' or arg == '--debug':\n print('Debug Mode')\n DEBUG = 'Medium'\n commands.append('-d Debug Mode')\n\n if arg == '-a' or arg == '--advance-debug':\n print('Advance Debug Mode')\n DEBUG = 'High'\n commands.append('-a Advance Debug Mode')\n \n if arg == '-h' or arg == '--help':\n print('Help')\n for command in commands:\n print(command)\n\n\n##### Define Classes #####\n#LCD Class\nclass LCD_Driver(object):\n '''Drives the 16x2 LCD. Use .message([message]) to display something to screen using \\n to go to second line.'''\n # commands\n LCD_CLEARDISPLAY = 0x01\n LCD_RETURNHOME = 0x02\n LCD_ENTRYMODESET = 0x04\n LCD_DISPLAYCONTROL = 0x08\n LCD_CURSORSHIFT = 0x10\n LCD_FUNCTIONSET = 0x20\n LCD_SETCGRAMADDR = 0x40\n LCD_SETDDRAMADDR = 0x80\n\n # flags for display entry mode\n LCD_ENTRYRIGHT = 0x00\n LCD_ENTRYLEFT = 0x02\n LCD_ENTRYSHIFTINCREMENT = 0x01\n LCD_ENTRYSHIFTDECREMENT = 0x00\n\n # flags for display on/off control\n LCD_DISPLAYON = 0x04\n LCD_DISPLAYOFF = 0x00\n LCD_CURSORON = 0x02\n LCD_CURSOROFF = 0x00\n LCD_BLINKON = 0x01\n LCD_BLINKOFF = 0x00\n\n # flags for display/cursor shift\n LCD_DISPLAYMOVE = 0x08\n LCD_CURSORMOVE = 0x00\n\n # flags for display/cursor shift\n LCD_DISPLAYMOVE = 0x08\n LCD_CURSORMOVE = 0x00\n LCD_MOVERIGHT = 0x04\n LCD_MOVELEFT = 0x00\n\n # flags for function set\n LCD_8BITMODE = 0x10\n LCD_4BITMODE = 0x00\n LCD_2LINE = 0x08\n LCD_1LINE = 0x00\n LCD_5x10DOTS = 0x04\n LCD_5x8DOTS = 0x00\n\n def __init__(self, pin_rs=9, pin_e=10, pins_db=[15, 14, 3, 2], GPIO=None):\n # Emulate the old behavior of using RPi.GPIO if we haven't been given\n # an explicit GPIO interface to use\n if not GPIO:\n import RPi.GPIO as GPIO\n GPIO.setwarnings(False)\n self.GPIO = GPIO\n self.pin_rs = pin_rs\n self.pin_e = pin_e\n self.pins_db = pins_db\n\n self.GPIO.setmode(GPIO.BCM)\n self.GPIO.setup(self.pin_e, GPIO.OUT)\n self.GPIO.setup(self.pin_rs, GPIO.OUT)\n\n for pin in self.pins_db:\n self.GPIO.setup(pin, GPIO.OUT)\n\n self.write4bits(0x33) # initialization\n self.write4bits(0x32) # initialization\n self.write4bits(0x28) # 2 line 5x7 matrix\n self.write4bits(0x0C) # turn cursor off 0x0E to enable cursor\n self.write4bits(0x06) # shift cursor right\n\n self.displaycontrol = self.LCD_DISPLAYON | self.LCD_CURSOROFF | self.LCD_BLINKOFF\n\n self.displayfunction = self.LCD_4BITMODE | self.LCD_1LINE | self.LCD_5x8DOTS\n self.displayfunction |= self.LCD_2LINE\n\n # Initialize to default text direction (for romance languages)\n self.displaymode = self.LCD_ENTRYLEFT | self.LCD_ENTRYSHIFTDECREMENT\n self.write4bits(self.LCD_ENTRYMODESET | self.displaymode) # set the entry mode\n\n self.clear()\n\n def begin(self, cols, lines):\n if (lines > 1):\n self.numlines = lines\n self.displayfunction |= self.LCD_2LINE\n\n def home(self):\n self.write4bits(self.LCD_RETURNHOME) # set cursor position to zero\n self.delayMicroseconds(3000) # this command takes a long time!\n\n def clear(self):\n self.write4bits(self.LCD_CLEARDISPLAY) # command to clear display\n self.delayMicroseconds(3000) # 3000 microsecond sleep, clearing the display takes a long time\n\n def setCursor(self, col, row):\n self.row_offsets = [0x00, 0x40, 0x14, 0x54]\n if row > self.numlines:\n row = self.numlines - 1 # we count rows starting w/0\n self.write4bits(self.LCD_SETDDRAMADDR | (col + self.row_offsets[row]))\n\n def noDisplay(self):\n \"\"\" Turn the display off (quickly) \"\"\"\n self.displaycontrol &= ~self.LCD_DISPLAYON\n self.write4bits(self.LCD_DISPLAYCONTROL | self.displaycontrol)\n\n def display(self):\n \"\"\" Turn the display on (quickly) \"\"\"\n self.displaycontrol |= self.LCD_DISPLAYON\n self.write4bits(self.LCD_DISPLAYCONTROL | self.displaycontrol)\n\n def noCursor(self):\n \"\"\" Turns the underline cursor off \"\"\"\n self.displaycontrol &= ~self.LCD_CURSORON\n self.write4bits(self.LCD_DISPLAYCONTROL | self.displaycontrol)\n\n def cursor(self):\n \"\"\" Turns the underline cursor on \"\"\"\n self.displaycontrol |= self.LCD_CURSORON\n self.write4bits(self.LCD_DISPLAYCONTROL | self.displaycontrol)\n\n def noBlink(self):\n \"\"\" Turn the blinking cursor off \"\"\"\n self.displaycontrol &= ~self.LCD_BLINKON\n self.write4bits(self.LCD_DISPLAYCONTROL | self.displaycontrol)\n\n def blink(self):\n \"\"\" Turn the blinking cursor on \"\"\"\n self.displaycontrol |= self.LCD_BLINKON\n self.write4bits(self.LCD_DISPLAYCONTROL | self.displaycontrol)\n\n def DisplayLeft(self):\n \"\"\" These commands scroll the display without changing the RAM \"\"\"\n self.write4bits(self.LCD_CURSORSHIFT | self.LCD_DISPLAYMOVE | self.LCD_MOVELEFT)\n\n def scrollDisplayRight(self):\n \"\"\" These commands scroll the display without changing the RAM \"\"\"\n self.write4bits(self.LCD_CURSORSHIFT | self.LCD_DISPLAYMOVE | self.LCD_MOVERIGHT)\n\n def leftToRight(self):\n \"\"\" This is for text that flows Left to Right \"\"\"\n self.displaymode |= self.LCD_ENTRYLEFT\n self.write4bits(self.LCD_ENTRYMODESET | self.displaymode)\n\n def rightToLeft(self):\n \"\"\" This is for text that flows Right to Left \"\"\"\n self.displaymode &= ~self.LCD_ENTRYLEFT\n self.write4bits(self.LCD_ENTRYMODESET | self.displaymode)\n\n def autoscroll(self):\n \"\"\" This will 'right justify' text from the cursor \"\"\"\n self.displaymode |= self.LCD_ENTRYSHIFTINCREMENT\n self.write4bits(self.LCD_ENTRYMODESET | self.displaymode)\n\n def noAutoscroll(self):\n \"\"\" This will 'left justify' text from the cursor \"\"\"\n self.displaymode &= ~self.LCD_ENTRYSHIFTINCREMENT\n self.write4bits(self.LCD_ENTRYMODESET | self.displaymode)\n\n def write4bits(self, bits, char_mode=False):\n \"\"\" Send command to LCD \"\"\"\n self.delayMicroseconds(1000) # 1000 microsecond sleep\n bits = bin(bits)[2:].zfill(8)\n self.GPIO.output(self.pin_rs, char_mode)\n for pin in self.pins_db:\n self.GPIO.output(pin, False)\n for i in range(4):\n if bits[i] == \"1\":\n self.GPIO.output(self.pins_db[::-1][i], True)\n self.pulseEnable()\n for pin in self.pins_db:\n self.GPIO.output(pin, False)\n for i in range(4, 8):\n if bits[i] == \"1\":\n self.GPIO.output(self.pins_db[::-1][i-4], True)\n self.pulseEnable()\n\n def delayMicroseconds(self, microseconds):\n seconds = microseconds / float(1000000) # divide microseconds by 1 million for seconds\n sleep(seconds)\n\n def pulseEnable(self):\n self.GPIO.output(self.pin_e, False)\n self.delayMicroseconds(1) # 1 microsecond pause - enable pulse must be > 450ns\n self.GPIO.output(self.pin_e, True)\n self.delayMicroseconds(1) # 1 microsecond pause - enable pulse must be > 450ns\n self.GPIO.output(self.pin_e, False)\n self.delayMicroseconds(1) # commands need > 37us to settle\n\n def message(self, text):\n \"\"\" Send string to LCD. Newline wraps to second line\"\"\"\n for char in text:\n if char == '\\n':\n self.write4bits(0xC0) # next line\n else:\n self.write4bits(ord(char), True)\n\ndef temp(self):\n humidity, temperature = Adafruit_DHT.read_retry(sensor, dhtpin)\n if humidity is not None and temperature is not None:\n output = ' Temp={0:0.1f}*C/n Humidity={1:0.1f}%'.format(temperature, humidity)\n else:\n output = 'Failed to get reading./n Try again!'\n \"\"\" Send string to LCD. Newline wraps to second line\"\"\"\n for char in output:\n if char == '\\n':\n self.write4bits(0xC0) # next line\n else:\n self.write4bits(ord(char), True) \n\ndef time_in_range(start, end, x):\n \"\"\"Return true if x is in the range [start, end]\"\"\"\n if start <= end:\n return start <= x <= end\n else:\n return start <= x or x <= end\n\n#DHT Class\nclass DHT11Result:\n '''DHT11 sensor result returned by DHT11.read() method. variables are .temperature, .humidity, and .error_code'''\n\n ERR_NO_ERROR = 0\n ERR_MISSING_DATA = 1\n ERR_CRC = 2\n\n error_code = ERR_NO_ERROR\n temperature = -1\n humidity = -1\n\n def __init__(self, error_code, temperature, humidity):\n self.error_code = error_code\n self.temperature = temperature\n self.humidity = humidity\n\n def is_valid(self):\n return self.error_code == DHT11Result.ERR_NO_ERROR\n\n\nclass DHT11:\n '''DHT11 sensor reader class for Raspberry pi call with pin number, pin is setup in class. read the temperature with .read().'''\n\n __pin = 0\n\n def __init__(self, pin):\n self.__pin = pin\n\n def read(self):\n GPIO.setup(self.__pin, GPIO.OUT)\n\n # send initial high\n self.__send_and_sleep(GPIO.HIGH, 0.05)\n\n # pull down to low\n self.__send_and_sleep(GPIO.LOW, 0.02)\n\n # change to input using pull up\n GPIO.setup(self.__pin, GPIO.IN, GPIO.PUD_UP)\n\n # collect data into an array\n data = self.__collect_input()\n\n # parse lengths of all data pull up periods\n pull_up_lengths = self.__parse_data_pull_up_lengths(data)\n\n # if bit count mismatch, return error (4 byte data + 1 byte checksum)\n if len(pull_up_lengths) != 40:\n return DHT11Result(DHT11Result.ERR_MISSING_DATA, 0, 0)\n\n # calculate bits from lengths of the pull up periods\n bits = self.__calculate_bits(pull_up_lengths)\n\n # we have the bits, calculate bytes\n the_bytes = self.__bits_to_bytes(bits)\n\n # calculate checksum and check\n checksum = self.__calculate_checksum(the_bytes)\n if the_bytes[4] != checksum:\n return DHT11Result(DHT11Result.ERR_CRC, 0, 0)\n\n # ok, we have valid data, return it\n return DHT11Result(DHT11Result.ERR_NO_ERROR, the_bytes[2], the_bytes[0])\n\n def __send_and_sleep(self, output, sleeptime):\n GPIO.output(self.__pin, output)\n sleep(sleeptime)\n\n def __collect_input(self):\n # collect the data while unchanged found\n unchanged_count = 0\n\n # this is used to determine where is the end of the data\n max_unchanged_count = 100\n\n last = -1\n data = []\n while True:\n current = GPIO.input(self.__pin)\n data.append(current)\n if last != current:\n unchanged_count = 0\n last = current\n else:\n unchanged_count += 1\n if unchanged_count > max_unchanged_count:\n break\n\n return data\n\n def __parse_data_pull_up_lengths(self, data):\n STATE_INIT_PULL_DOWN = 1\n STATE_INIT_PULL_UP = 2\n STATE_DATA_FIRST_PULL_DOWN = 3\n STATE_DATA_PULL_UP = 4\n STATE_DATA_PULL_DOWN = 5\n\n state = STATE_INIT_PULL_DOWN\n\n lengths = [] # will contain the lengths of data pull up periods\n current_length = 0 # will contain the length of the previous period\n\n for i in range(len(data)):\n\n current = data[i]\n current_length += 1\n\n if state == STATE_INIT_PULL_DOWN:\n if current == GPIO.LOW:\n # ok, we got the initial pull down\n state = STATE_INIT_PULL_UP\n continue\n else:\n continue\n if state == STATE_INIT_PULL_UP:\n if current == GPIO.HIGH:\n # ok, we got the initial pull up\n state = STATE_DATA_FIRST_PULL_DOWN\n continue\n else:\n continue\n if state == STATE_DATA_FIRST_PULL_DOWN:\n if current == GPIO.LOW:\n # we have the initial pull down, the next will be the data pull up\n state = STATE_DATA_PULL_UP\n continue\n else:\n continue\n if state == STATE_DATA_PULL_UP:\n if current == GPIO.HIGH:\n # data pulled up, the length of this pull up will determine whether it is 0 or 1\n current_length = 0\n state = STATE_DATA_PULL_DOWN\n continue\n else:\n continue\n if state == STATE_DATA_PULL_DOWN:\n if current == GPIO.LOW:\n # pulled down, we store the length of the previous pull up period\n lengths.append(current_length)\n state = STATE_DATA_PULL_UP\n continue\n else:\n continue\n\n return lengths\n\n def __calculate_bits(self, pull_up_lengths):\n # find shortest and longest period\n shortest_pull_up = 1000\n longest_pull_up = 0\n\n for i in range(0, len(pull_up_lengths)):\n length = pull_up_lengths[i]\n if length < shortest_pull_up:\n shortest_pull_up = length\n if length > longest_pull_up:\n longest_pull_up = length\n\n # use the halfway to determine whether the period it is long or short\n halfway = shortest_pull_up + (longest_pull_up - shortest_pull_up) / 2\n bits = []\n\n for i in range(0, len(pull_up_lengths)):\n bit = False\n if pull_up_lengths[i] > halfway:\n bit = True\n bits.append(bit)\n\n return bits\n\n def __bits_to_bytes(self, bits):\n the_bytes = []\n byte = 0\n\n for i in range(0, len(bits)):\n byte = byte << 1\n if (bits[i]):\n byte = byte | 1\n else:\n byte = byte | 0\n if ((i + 1) % 8 == 0):\n the_bytes.append(byte)\n byte = 0\n\n return the_bytes\n\n def __calculate_checksum(self, the_bytes):\n return the_bytes[0] + the_bytes[1] + the_bytes[2] + the_bytes[3] & 255\n\nclass relay:\n \"\"\"Control a relay or pin, create an instance with pin number. dont setup pin that is done in initial setup of the class\"\"\"\n def __init__(self, pin):\n self.pin = pin\n GPIO.setup(self.pin, GPIO.OUT)\n\n def on(self):\n #turn on GPIO defined in class\n GPIO.output(self.pin, True)\n\n def off(self):\n #turn off GPIO defined in class\n GPIO.output(self.pin, True)\n\nclass input:\n def __init__(self, pin):\n self.pin = pin\n GPIO.setup(self.pin, GPIO.IN)\n \n def check(self):\n return False\n\n \nclass speech_engine:\n def speak():\n pass\n def listen():\n pass\n \n##### Functions #####\ndef run_cmd(cmd_to_run):\n output = subprocess.check_output(cmd_to_run, shell=True)\n return output\n\ndef Temp():\n Result = temp.read()\n return Result.temperature\n\ndef check_ButtonState():\n return False\n \ndef listen():\n voice = speech_engine()\n voice.listen()\n\n\ndef update_time():\n #create class instances\n lcd = LCD_Driver()\n temp = DHT11(DHTPin)\n light = relay(17)\n heat = relay(27)\n #add pin numbers\n button = input(4)\n motion = input(22)\n \n\n #if in debug mode display IP address\n if DEBUG == 'Medium':\n ipaddr = run_cmd(cmd)\n lcd.message('IP %s'%ipaddr)\n print('IP %s'%ipaddr)\n sleep(5)\n \n #get initial temp\n for i in range(2000):\n result = temp.read()\n if result.is_valid():\n room_temperature = result.temperature\n break\n else:\n #if invalad, print the error to debug screen\n print(\"Error: %d\" % result.error_code)\n \n #Update Loop\n while True:\n #clear any text on the display\n lcd.clear()\n #read the DHT senser\n result = temp.read()\n #print the time and date on first line\n lcd.message(datetime.now().strftime('%b %d %H:%M\\n'))\n\n #note, time is in 24 hour format\n time_now = datetime.now().strftime('%H:%M')\n #check if alarm should go off\n if time_now == alarm_time:\n alarm()\n\n #check results\n if result.is_valid():\n room_temperature = result.temperature\n else:\n if DEBUG == 'Medium' or DEBUG == 'High':\n #if invalad, print the error to debug screen\n print(\"Error: %d\" % result.error_code)\n\n #debug mode\n if DEBUG == 'High':\n print(\"Temperature: %d C\" % result.temperature)\n print(\"Humidity: %d %%\" % result.humidity)\n\n #print temperature on secound line of LCD\n lcd.message('Temp: %s'%room_temperature+'C')\n\n #pause for refresh rate secounds \n sleep(refresh_rate) \n\n \ndef alarm():\n print(\"ALARM!!!\")\n #play a mp3 file while still updating time\n media_player = subprocess.Popen(['omxplayer', '-o', 'local', 'Alarm.mp3'])\n #Turn Light Relay on\n light.on()\n #if button pressed turn alarm off, otherwise loop\n while True:\n lcd.message(datetime.now().strftime('%b %d %H:%M\\n'))\n lcd.message('Temp: %s'%room_temperature+'C')\n if button.check():\n player.stdin.write(\"q\")\n break\n #stop the alarm file from playing\n media_player.kill()\n media_player.terminate()\n #note: the light will stay on untill it is turned off via another method\n \n \ndef listen():\n pass\n \n##### Main #####\n##### Run and Cleanup #####\ntry:\n if __name__ == '__main__':\n UpdateTime = Process(target=update_time)\n UpdateTime.start()\n \nfinally:\n GPIO.cleanup()\n"
},
{
"alpha_fraction": 0.7903226017951965,
"alphanum_fraction": 0.7903226017951965,
"avg_line_length": 30,
"blob_id": "05e9e35b2a7451484f4b74dceb21e0d61ea3f8b8",
"content_id": "0671e8c19888a332e8b2aa35fd0e3c58c96fb87e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 62,
"license_type": "permissive",
"max_line_length": 54,
"num_lines": 2,
"path": "/README.md",
"repo_name": "CalebMcIvor/Erik",
"src_encoding": "UTF-8",
"text": "# Erik\nRaspberry Pi based home automation, written in Python.\n"
},
{
"alpha_fraction": 0.6043360233306885,
"alphanum_fraction": 0.6165311932563782,
"avg_line_length": 21.33333396911621,
"blob_id": "7653dae0ec76615514230c9b2e838cb9b9d90bdb",
"content_id": "4667a046e05868b940f2ce2758e6d45191a8183e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 738,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 33,
"path": "/TestPrograms/main.py",
"repo_name": "CalebMcIvor/Erik",
"src_encoding": "UTF-8",
"text": "\n#!/usr/bin/python3\n# This is client.py file\n\nimport socket\n\n\nclass connection:\n def __init__(self, port, host, size):\n self.port = port\n self.host = host\n self.size = size\n\n # create a socket object\n self.socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n\n # connection to hostname on the port.\n self.socket.connect((self.host, self.port)) \n\n def recive(self):\n msg = self.socket.recv(self.size)\n return msg.decode('ascii')\n\n def send(self, message):\n self.socket.send(message.encode('ascii'))\n\n def close(self):\n self.socket.close()\n\nErik = connection(9999, 'PowerBox', 1024) \n\nprint(Erik.recive())\nErik.send(\"Hello World!\")\nErik.close()\n"
}
] | 3 |
afcarl/pipeline-live
|
https://github.com/afcarl/pipeline-live
|
874f7a8f6c34aaa83ec195e9a97f5fe3ce628796
|
2bbafd0cfc6e988627badb5748fbfd080d1544b3
|
4cf4274b72e7b0c2980f01c57856f15b32103b83
|
refs/heads/master
| 2021-07-05T01:54:48.847360 | 2021-01-17T11:19:48 | 2021-01-17T11:19:48 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.641986072063446,
"alphanum_fraction": 0.6524389982223511,
"avg_line_length": 27.700000762939453,
"blob_id": "0c6470c98eb3b954e9e83b24c4a1de9713fc1233",
"content_id": "2b372a56a704bf2b446ee1455aa714f65dd5e6b8",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1148,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 40,
"path": "/pipeline_live/data/sources/alpaca.py",
"repo_name": "afcarl/pipeline-live",
"src_encoding": "UTF-8",
"text": "import alpaca_trade_api as tradeapi\n\nfrom .util import (\n daily_cache, parallelize\n)\n\n\ndef list_symbols():\n api = tradeapi.REST()\n return [a.symbol for a in api.list_assets(status=\"active\") if a.tradable]\n\ndef get_stockprices(limit=365, timespan='day'):\n all_symbols = list_symbols()\n\n @daily_cache(filename='alpaca_chart_{}'.format(limit))\n def get_stockprices_cached(all_symbols):\n return _get_stockprices(all_symbols, limit, timespan)\n\n return get_stockprices_cached(all_symbols)\n\n\ndef _get_stockprices(symbols, limit=365, timespan='day'):\n '''Get stock data (key stats and previous) from Alpaca.\n Just deal with Alpaca's 200 stocks per request limit.\n '''\n\n api = tradeapi.REST()\n\n def fetch(symbols):\n barset = api.get_barset(symbols, timespan, limit)\n data = {}\n for symbol in barset:\n df = barset[symbol].df\n # Update the index format for comparison with the trading calendar\n df.index = df.index.tz_convert('UTC').normalize()\n data[symbol] = df.asfreq('C')\n\n return data\n\n return parallelize(fetch, splitlen=199)(symbols)\n"
}
] | 1 |
jfeser/TerpreT
|
https://github.com/jfeser/TerpreT
|
def23b6b6eaa2f0f26c24d2e0401df2c8a6a91c8
|
faab8c14508ad63c30700f5a7a74dbecbc2470d4
|
6e02fe4fd72688502aaf0fb90d17ae398c1a65be
|
refs/heads/master
| 2021-01-01T15:25:57.572213 | 2017-07-18T15:04:56 | 2017-07-18T15:04:56 | 97,614,676 | 0 | 0 | null | 2017-07-18T15:24:06 | 2017-06-13T09:21:48 | 2017-07-18T15:05:13 | null |
[
{
"alpha_fraction": 0.5542291402816772,
"alphanum_fraction": 0.5553514957427979,
"avg_line_length": 35.98490524291992,
"blob_id": "0382034f6ea62a8db155a6e0eea94a59d3acb3ee",
"content_id": "2669763f37387a5df060d881f510565f2aa0ef77",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9801,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 265,
"path": "/lib/tptv1.py",
"repo_name": "jfeser/TerpreT",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nimport ast\nimport copy\nimport json\nimport utils as u\nfrom astunparse import unparse\n\n\ndef ast_uses_varset(root, varset):\n class UsesVarsetVisitor(ast.NodeVisitor):\n def __init__(self):\n self.uses_varset = False\n\n def visit_Name(self, node):\n if node.id in varset:\n self.uses_varset = True\n\n vis = UsesVarsetVisitor()\n vis.visit(root)\n return vis.uses_varset\n\n\ndef is_declaration(node, typ):\n if isinstance(node, ast.Subscript):\n return is_declaration(node.value, typ)\n if not isinstance(node, ast.Call): return False\n if not isinstance(node.func, ast.Name): return False\n return node.func.id == typ\n\n\ndef is_input_declaration(node):\n return is_declaration(node, \"Input\")\n\n\ndef is_output_declaration(node):\n return is_declaration(node, \"Output\")\n\n\ndef is_var_declaration(node):\n return is_declaration(node, \"Var\")\n\n\ndef get_var_name(node):\n if isinstance(node, ast.Name):\n return node.id\n elif isinstance(node, ast.Subscript):\n return get_var_name(node.value)\n elif isinstance(node, ast.Call):\n return None # This is the Input()[10] case\n else:\n raise Exception(\"Can't extract var name from '%s'\" % (unparse(node).rstrip()))\n\n\ndef get_set_vars(root):\n class GetSetVarsVisitor(ast.NodeVisitor):\n def __init__(self):\n self.set_vars = set()\n\n def visit_Call(self, node):\n if u.is_set_to_call(node):\n self.set_vars.add(get_var_name(node.func.value))\n\n vis = GetSetVarsVisitor()\n if isinstance(root, list):\n for stmt in root:\n vis.visit(stmt)\n else:\n vis.visit(root)\n return vis.set_vars\n\n\ndef get_input_dependent_vars(root):\n class GetInputsVisitor(ast.NodeVisitor):\n def __init__(self):\n self.input_vars = set()\n\n def visit_Assign(self, node):\n if is_input_declaration(node.value):\n self.input_vars.add(get_var_name(node.targets[0]))\n elif ast_uses_varset(node.value, self.input_vars):\n self.input_vars.add(get_var_name(node.targets[0]))\n\n def visit_With(self, node):\n if ast_uses_varset(node.context_expr, self.input_vars):\n # Track every set variable in the with. This is an over-approximation.\n self.input_vars.update(get_set_vars(node.body))\n if node.optional_vars is not None\\\n and ast_uses_varset(node.context_expr, self.input_vars):\n with_var = get_var_name(node.optional_vars)\n self.input_vars.add(with_var)\n self.generic_visit(node)\n self.input_vars.remove(with_var)\n else:\n self.generic_visit(node)\n\n def visit_If(self, node):\n # Track setting of values conditional on input-dependent values:\n if ast_uses_varset(node.test, self.input_vars):\n self.input_vars.update(get_set_vars(node.body))\n self.input_vars.update(get_set_vars(node.orelse))\n self.generic_visit(node)\n\n def visit_Call(self, node):\n if u.is_set_to_call(node)\\\n and ast_uses_varset(node.args[0], self.input_vars):\n self.input_vars.add(get_var_name(node.func.value))\n\n reached_fixpoint = False\n old_varnum = 0\n vis = GetInputsVisitor()\n while not reached_fixpoint:\n vis.visit(root)\n reached_fixpoint = (old_varnum == len(vis.input_vars))\n old_varnum = len(vis.input_vars)\n\n input_dependents = vis.input_vars\n\n # Add all variables that are being set below input-dependent statements to the input_dependents set.\n # This is a gross over-approximation, but avoids problems in cases like this:\n # for i in range(I):\n # input_indep.set_to(Func(param[1], i))\n # with input_dep as bla:\n # ...\n # The loop would be marked as input-dependent, and unrolled after translation,\n # yielding several input_indep.set_to(...) statements. They would all use the same\n # value, but things like the ILP backend are unhappy.\n set_growing = True\n while set_growing:\n set_growing = False\n for stmt in root.body:\n if ast_uses_varset(stmt, input_dependents):\n set_vars = get_set_vars(stmt)\n if not(set_vars.issubset(input_dependents)):\n set_growing = True\n input_dependents.update(set_vars)\n\n return input_dependents\n\ndef extend_subscript_for_input(node, extension):\n if isinstance(node.slice, ast.Index):\n idx = node.slice.value\n if isinstance(idx, ast.Tuple):\n new_idx = ast.Tuple([extension] + idx.elts, ast.Load())\n else:\n new_idx = ast.Tuple([extension, idx], ast.Load())\n node.slice.value = new_idx\n else:\n raise Exception(\"Unhandled node indexing: '%s'\" % (unparse(node).rstrip()))\n return node\n\n\ndef add_input_indices(root, input_vars, index_var):\n class AddInputIndicesVisitor(ast.NodeTransformer):\n def visit_Subscript(self, node):\n if get_var_name(node) in input_vars:\n return extend_subscript_for_input(node, index_var)\n return node\n\n def visit_Name(self, node):\n if node.id in input_vars:\n return ast.Subscript(node, ast.Index(index_var), node.ctx)\n return node\n\n vis = AddInputIndicesVisitor()\n root = vis.visit(root)\n return ast.fix_missing_locations(root)\n\n\ndef generate_io_stmt(input_idx, var_name, value, func_name):\n if isinstance(value, list):\n return [ast.Expr(\n ast.Call(\n ast.Attribute(\n ast.Subscript(\n ast.Name(var_name, ast.Load()),\n ast.Index(\n ast.Tuple([ast.Num(input_idx),\n ast.Num(val_idx)],\n ast.Load())),\n ast.Load()),\n func_name,\n ast.Load()),\n [ast.Num(val)],\n [], None, None))\n for val_idx, val in enumerate(value)]\n else:\n return [ast.Expr(\n ast.Call(\n ast.Attribute(\n ast.Subscript(\n ast.Name(var_name, ast.Load()),\n ast.Index(ast.Num(input_idx)),\n ast.Load()),\n func_name,\n ast.Load()),\n [ast.Num(value)],\n [], None, None))]\n\n\ndef translate_to_tptv1(parsed_model, data_batch, hypers):\n parsed_model = u.replace_hypers(parsed_model, hypers)\n input_dependents = get_input_dependent_vars(parsed_model)\n\n idx_var_name = \"input_idx\"\n idx_var = ast.Name(idx_var_name, ast.Load())\n input_number = len(data_batch['instances'])\n range_expr = ast.Num(input_number)\n\n input_vars = set()\n output_vars = set()\n var_decls = []\n input_stmts = []\n general_stmts = []\n output_stmts = []\n for stmt in parsed_model.body:\n if isinstance(stmt, ast.Assign) and is_input_declaration(stmt.value):\n input_vars.add(get_var_name(stmt.targets[0]))\n var_decls.append(stmt)\n elif isinstance(stmt, ast.Assign) and is_output_declaration(stmt.value):\n output_vars.add(get_var_name(stmt.targets[0]))\n var_decls.append(stmt)\n elif isinstance(stmt, ast.Assign) and is_var_declaration(stmt.value):\n var_decls.append(stmt)\n elif ast_uses_varset(stmt, input_dependents):\n input_stmts.append(add_input_indices(stmt, input_dependents, idx_var))\n elif ast_uses_varset(stmt, output_vars):\n output_stmts.append(stmt)\n else:\n general_stmts.append(stmt)\n\n input_init = []\n output_observation = []\n for input_idx, instance in enumerate(data_batch['instances']):\n for var_name, val in instance.iteritems():\n if var_name in input_vars:\n input_init.extend(generate_io_stmt(input_idx, var_name, val, \"set_to_constant\"))\n elif var_name in output_vars:\n output_observation.extend(generate_io_stmt(input_idx, var_name, val, \"observe_value\"))\n\n extended_var_decls = []\n for var_decl in var_decls:\n # If input-dependent, extend dimension by one\n if get_var_name(var_decl.targets[0]) in input_dependents:\n new_decl = copy.deepcopy(var_decl)\n if isinstance(new_decl.value, ast.Subscript):\n new_decl.value = extend_subscript_for_input(new_decl.value,\n ast.Num(input_number))\n else:\n new_decl.value = ast.Subscript(new_decl.value,\n ast.Index(ast.Num(input_number)),\n ast.Load())\n extended_var_decls.append(new_decl)\n else:\n extended_var_decls.append(var_decl)\n\n input_loop = ast.For(ast.Name(idx_var_name, ast.Store()),\n ast.Call(ast.Name(\"range\", ast.Load()),\n [range_expr],\n [], None, None),\n input_stmts,\n [])\n parsed_model.body = general_stmts + extended_var_decls + input_init + [input_loop] + output_stmts + output_observation\n ast.fix_missing_locations(parsed_model)\n\n return parsed_model\n"
}
] | 1 |
kktuax/youtupi
|
https://github.com/kktuax/youtupi
|
1e6cf58457187bb73d5b9e8d7e252ca526750453
|
1d9a948e5a1f0624d967371c805be18944b5268a
|
e7d9f9021cb1f8447b04d0a504db7024c8c54f87
|
refs/heads/master
| 2021-12-14T16:43:37.289651 | 2021-12-12T12:21:06 | 2021-12-12T12:21:06 | 7,974,674 | 15 | 7 | null | 2013-02-02T10:47:03 | 2016-11-27T11:05:56 | 2016-11-27T11:10:48 |
Python
|
[
{
"alpha_fraction": 0.6394671201705933,
"alphanum_fraction": 0.6419650316238403,
"avg_line_length": 23.020000457763672,
"blob_id": "ce88a01b7dd759bfc2adbee9ac99d67e7055fd2d",
"content_id": "4805ddc319cb46b65111779008a81c0856475d69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1201,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 50,
"path": "/youtupi/modules/url.py",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\nimport web, json, codecs, magic\nfrom youtupi.util import config, ensure_dir\nimport urlparse\nimport youtube_dl\n\ndef getUrl(data):\n\tif(data['type'] == \"url\"):\n\t\treturn data['id']\n\telse:\n\t\treturn None\n\ndef ydlInfo(video):\n\tvdata = {'id': video['url'], 'title': video['url'], 'description': '', 'type': 'url', 'operations' : []}\n\tif 'title' in video:\n\t\tvdata['title'] = video['title']\n\tif 'description' in video:\n\t\tvdata['description'] = video['description']\n\tif 'thumbnail' in video:\n\t\tvdata['thumbnail'] = video['thumbnail']\n\treturn vdata\n\nclass search:\n\n\tdef GET(self):\n\t\tuser_data = web.input()\n\t\tsearch = user_data.search.strip()\n\t\tcount = int(user_data.count)\n\t\tvideos = list()\n\t\tif search:\n\t\t\tydl = youtube_dl.YoutubeDL({'ignoreerrors': True})\n\t\t\twith ydl:\n\t\t\t\tresult = ydl.extract_info(search, download=False)\n\t\t\t\tif 'entries' in result:\n\t\t\t\t\tfor video in result['entries']:\n\t\t\t\t\t\tif 'url' in video:\n\t\t\t\t\t\t\tvideos.append(ydlInfo(video))\n\t\t\t\telse:\n\t\t\t\t\tvideo = result\n\t\t\t\t\tif 'url' in video:\n\t\t\t\t\t\tvideos.append(ydlInfo(video))\n\t\treturn json.dumps(videos[0:count], indent=4)\n\nurls = (\n\t\"-search\", \"search\",\n)\n\nmodule_url = web.application(urls, locals())\n"
},
{
"alpha_fraction": 0.402921587228775,
"alphanum_fraction": 0.40477070212364197,
"avg_line_length": 53.62626266479492,
"blob_id": "ae0f1d1056dd78a196044bc516d1240b6a969e3b",
"content_id": "9457d05143c49946cfeb18592d5712ddb6a34867",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5408,
"license_type": "no_license",
"max_line_length": 197,
"num_lines": 99,
"path": "/youtupi/modules/youtube.py",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "import subprocess, re, string, sys, web, json, threading\nimport os.path\nfrom StringIO import StringIO\nfrom os.path import expanduser\nfrom pafy import pafy\nfrom youtupi.video import Video\nfrom youtupi.util import config, downloader\nfrom youtupi.util.ensure_dir import ensure_dir\n\ninfoLock = threading.RLock()\n\ndef getUrl(data):\n with infoLock:\n if(data['type'] == \"youtube\"):\n print 'Locating URL for: ' + data['id']\n try:\n video = None\n if data.has_key('url'):\n return data['url']\n else:\n video = pafy.new(data['id'])\n if data['format'] == \"audio\":\n bestaudio = video.getbestaudio(preftype=\"m4a\")\n return bestaudio.url\n best = video.getbest(preftype=\"mp4\")\n print \"\\n\".join([\"Type: %s Resolution: %s Audio: %s Video: %s\" % (x._info['ext'], x.resolution, x._info['acodec'], x._info['vcodec']) for x in video._allstreams])\n print \"Chosen: \", \"Type: %s Resolution: %s Audio: %s Video: %s\" % (best._info['ext'], best.resolution, best._info['acodec'], best._info['vcodec'])\n if data['format'] == \"high\":\n return best.url\n for stream in video.streams:\n if stream is not best:\n if stream.extension == 'mp4':\n return stream.url\n return best.url\n except Exception as e:\n print \"Error fetching video URL \", e\n data['title'] = \"ERROR loading video\"\n data['description'] = e.message.split(':')[-1:]\n return \"error\"\n return None\n\ndef resolveYoutubePlaylist(data):\n with infoLock:\n if data['type'] == \"youtube\":\n print 'Loading playlist data for ' + data['id']\n try:\n playlist = pafy.get_playlist(data['id'])\n for item in playlist['items']:\n data = dict(id=item['pafy'].playlist_meta['encrypted_id'], type='youtube', format='high')\n data.update(item['pafy'].playlist_meta)\n print \"Found video in playlist: \", data['id']\n yield data\n except Exception as e:\n print \"Error fetching youtube playlist \", e\n\n\ndef updateVideoData(data):\n with infoLock:\n if(data['type'] == \"youtube\"):\n print 'Loading data for ' + data['id']\n try:\n video = pafy.new(data['id'])\n data.update(video._ydl_info)\n if data['format'] == \"audio\":\n bestaudio = video.getbestaudio(preftype=\"m4a\")\n return bestaudio.url\n best = video.getbest(preftype=\"mp4\")\n print \"\\n\".join([\"Type: %s Resolution: %s Audio: %s Video: %s\" % (x._info['ext'], x.resolution, x._info['acodec'], x._info['vcodec']) for x in video._allstreams])\n print \"Chosen: \", \"Type: %s Resolution: %s Audio: %s Video: %s\" % (best._info['ext'], best.resolution, best._info['acodec'], best._info['vcodec'])\n if data['format'] == \"high\":\n data['url'] = best.url\n else:\n for stream in video.streams:\n if stream is not best:\n if stream.extension == 'mp4':\n data['url'] = stream.url\n break\n else:\n data['url'] = best.url\n print data\n except Exception as e:\n print \"Error fetching video data \", e\n data['title'] = \"ERROR fetching video data\"\n data['description'] = e.message.split(':')[-1:]\n return data\n\nclass youtube_dl:\n\n def POST(self):\n\t\tdata = json.load(StringIO(web.data()))\n\t\tvideo = pafy.new(data['id'])\n\t\tdfolder = expanduser(config.conf.get('download-folder', \"~/Downloads\"))\n\t\tensure_dir(dfolder)\n\t\tdfile = os.path.join(dfolder, video.title + \".mp4\")\n\t\tbest = video.getbest(preftype=\"mp4\")\n\t\tbest.download(filepath=dfile)\n\nurls = (\"-download\", \"youtube_dl\")\nmodule_youtube = web.application(urls, locals())\n"
},
{
"alpha_fraction": 0.6736139059066772,
"alphanum_fraction": 0.6775596737861633,
"avg_line_length": 30.5750789642334,
"blob_id": "e9053c1ae81211688d9127f67e0ff986c427ea42",
"content_id": "9562df2222b0c7497a66166f3bddcbd11f831157",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 9884,
"license_type": "permissive",
"max_line_length": 152,
"num_lines": 313,
"path": "/static/youtupi.search.js",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "\nvar Search = {\n server: '',\n engine: '',\n query: '',\n format: '',\n results: [],\n count: 50,\n pageNumber: 1,\n previousPageNumber: 1,\n prevPageAvailable: false,\n nextPageAvailable: false,\n search: function(callback){\n this.fetchResults(function(s){\n s.processResults();\n if(callback !== undefined){\n callback(s);\n }\n });\n },\n fetchResults: function(callback){\n callback(this);\n },\n processResults: function(){\n var start = this.count * (this.pageNumber - 1);\n this.nextPageAvailable = this.results.length > (start + this.count);\n this.prevPageAvailable = this.pageNumber > 1;\n this.results = this.results.slice(start, start + this.count);\n },\n incrementPageNumber: function(callback){\n this.previousPageNumber = this.pageNumber;\n this.pageNumber = this.pageNumber + 1;\n this.search(callback);\n },\n decrementPageNumber: function(callback){\n this.previousPageNumber = this.pageNumber;\n this.pageNumber = this.pageNumber - 1;\n this.search(callback);\n },\n saveInHistory: false\n};\n\nvar PresetSearch = Object.create(Search);\nPresetSearch.engine = 'preset';\nPresetSearch.fetchResults = function(callback){\n var search = this;\n search.results = [];\n var url = this.server + \"/preset\";\n if(this.query){\n url = url + \"/\" + this.query;\n }\n $.getJSON(url, { 'search': this.query, 'count': this.count, 'format': this.format, 'pageNumber': this.pageNumber }, function(response){\n search.results = search.results.concat(response);\n callback(search);\n });\n};\n\nvar EngineSearch = Object.create(Search);\nEngineSearch.fetchResults = function(callback){\n var search = this;\n search.results = [];\n var url = this.url();\n if(url === undefined){\n callback(search);\n return;\n }\n $.getJSON(url, { 'search': this.query, 'count': this.count, 'format': this.format, 'pageNumber': this.pageNumber }, function(response){\n search.results = search.results.concat(response);\n callback(search);\n });\n};\nEngineSearch.url = function(){\n return this.server + \"/\" + this.engine + \"-search\";\n};\n\nvar LocalSearch = Object.create(EngineSearch);\nLocalSearch.saveInHistory = true;\nLocalSearch.engine = 'local';\n\nvar LocalDirSearch = Object.create(EngineSearch);\nLocalDirSearch.engine = 'local-dir';\nLocalDirSearch.url = function(){\n return this.server + \"/local-browse\";\n};\n\nvar HomeSearch = Object.create(Search);\nHomeSearch.keyword = 'home';\nHomeSearch.fetchResults = function(callback){\n var search = this;\n search.results = [{\n\t 'id' : 'youtupi:searchHistory',\n\t 'title' : $.i18n.prop(\"search.history.search.title\"),\n\t 'description' : $.i18n.prop(\"search.history.search.description\"),\n\t 'type' : 'search'\n\t},{\n\t 'id' : 'youtupi:history',\n\t 'title' : $.i18n.prop(\"search.history.title\"),\n\t 'description' : $.i18n.prop(\"search.history.description\"),\n\t 'type' : 'search'\n\t}];\n\tcallback(search);\n};\n\nvar HistorySearch = Object.create(Search);\nHistorySearch.keyword = 'history';\nHistorySearch.localStorageName = \"history\";\nHistorySearch.maxHistoryElements = 50;\nHistorySearch.fetchResults = function(callback){\n var search = this;\n search.results = [];\n if(supports_html5_storage()){\n var history = localStorage.getObj(this.localStorageName);\n if(history != undefined){\n search.results = $.map(Object.keys(history), function(value, index) {\n return history[value];\n }).sort(function (a, b) {\n return b.lastPlayed > a.lastPlayed;\n });\n }\n }\n callback(search);\n};\nHistorySearch.clearHistory = function (){\n if(supports_html5_storage()){\n localStorage.setObj(this.localStorageName, {});\n }\n};\nHistorySearch.saveToHistory = function(video){\n if(!supports_html5_storage()){\n return;\n }\n var history = localStorage.getObj(this.localStorageName);\n if(history == undefined){\n history = {};\n }\n var id = this.localStoreageId(video);\n if(id in Object.keys(history)){\n var existingVideo = history[id];\n existingVideo.lastPlayed = new Date();\n }else{\n video.lastPlayed = new Date();\n history[id] = video;\n }\n if(Object.keys(history).length > HistorySearch.maxHistoryElements){\n var lastVideo = $.map(Object.keys(history), function(value, index) {\n return history[value];\n }).sort(function (a, b) {\n return b.lastPlayed < a.lastPlayed;\n })[0];\n delete history[lastVideo.id];\n }\n localStorage.setObj(this.localStorageName, history);\n};\nHistorySearch.localStoreageId = function(video){\n return video.id;\n};\n\nvar SearchHistorySearch = Object.create(HistorySearch);\nSearchHistorySearch.keyword = 'searchHistory';\nSearchHistorySearch.localStorageName = \"searchHstory\";\nSearchHistorySearch.localStoreageId = function(search){\n return search.engine + \".\" + search.id;\n};\n\nvar YoutubeSearch = Object.create(Search);\nYoutubeSearch.saveInHistory = true;\nYoutubeSearch.engine = 'youtube';\nYoutubeSearch.url = function(){\n\tif(this.query == ''){\n\t\treturn undefined;\n\t}\n\tvar url = 'https://www.googleapis.com/youtube/v3/';\n\tvar key = '&key=AIzaSyAdAR3PofKiUSGFsfQ03FBEpVkVa1WA0J4';\n\tvar maxResults = '&maxResults='+this.count;\n\tif(this.pageNumber > this.previousPageNumber){\n\t\tmaxResults += \"&pageToken=\" + this.nextPageToken;\n\t}else if(this.pageNumber < this.previousPageNumber){\n\t\tmaxResults += \"&pageToken=\" + this.prevPageToken;\n\t}\n\tvar listLookup = 'list:';\n\tvar listsLookup = 'lists:';\n var relatedLookup = 'related:';\n if(this.query.indexOf(relatedLookup) > -1){\n var lookup = this.query.split(relatedLookup);\n url += 'search?order=relevance&part=snippet&relatedToVideoId='+lookup[1]+'&type=video' + maxResults + key;\n } else if(this.query.indexOf(listLookup) > -1){\n\t\tvar lid = this.query.split(listLookup);\n\t\turl += 'playlistItems?part=snippet&playlistId='+lid[1]+'&type=video' + maxResults + key;\n\t} else if(this.query.indexOf(listsLookup) > -1){\n\t\tvar lid = this.query.split(listsLookup);\n\t\turl += 'search?order=relevance&part=snippet&q='+lid[1]+'&type=playlist' + maxResults + key;\n\t} else {\n\t\turl += 'search?order=relevance&part=snippet&q='+this.query+'&type=video' + maxResults + key;\n\t}\n\treturn url;\n};\nYoutubeSearch.processResults = function(){};\nYoutubeSearch.fetchResults = function(callback){\n var search = this;\n search.results = [];\n var url = this.url();\n if(url == undefined){\n callback(search);\n return;\n }\n $.getJSON(url, undefined, function(response){\n search.nextPageAvailable = response.nextPageToken != undefined;\n search.nextPageToken = search.nextPageAvailable ? response.nextPageToken : undefined;\n search.prevPageAvailable = response.prevPageToken != undefined;\n search.prevPageToken = search.prevPageAvailable ? response.prevPageToken : undefined;\n var entries = response.items || [];\n for (var i = 0; i < entries.length; i++) {\n var entry = entries[i];\n var video = search.createPlaylist(entry);\n if(video === null){\n video = search.createVideo(entry);\n }\n if(video !== null){\n search.results.push(video);\n }\n }\n callback(search);\n });\n};\nYoutubeSearch.createPlaylist = function(entry){\n\tif(typeof entry.id != 'undefined'){\n\t\tif(entry.id.kind != 'youtube#playlist'){\n\t\t\treturn null;\n\t\t}\n\t}else{\n\t\treturn null;\n\t}\n\tvar video = {};\n\tvideo.id = \"list:\" + entry.id.playlistId;\n\tvideo.title = entry.snippet.title;\n\tvideo.description = entry.snippet.description;\n\tvideo.thumbnail = this.thumbnailFromSnippet(entry.snippet);\n\tvideo.type = \"search\";\n video.engine = \"youtube\";\n\tvideo.operations = [];\n\treturn video;\n};\nYoutubeSearch.thumbnailFromSnippet = function(snippet){\n\tif(typeof snippet.thumbnails != 'undefined'){\n\t\tif(typeof snippet.thumbnails.high != 'undefined'){\n\t\t\treturn snippet.thumbnails.high.url;\n\t\t}else if(typeof snippet.thumbnails.medium != 'undefined'){\n\t\t\treturn snippet.thumbnails.medium.url;\n\t\t}else if(typeof snippet.thumbnails.default != 'undefined'){\n\t\t\treturn snippet.thumbnails.default.url;\n\t\t}\n\t}\n\treturn null;\n};\nYoutubeSearch.createVideo = function(entry){\n\tif(typeof entry.video != 'undefined'){\n\t\tentry = entry.video;\n\t}\n\tif (typeof entry.snippet == 'undefined'){\n\t\treturn null;\n\t}\n\tvar video = {};\n\tif(typeof entry.id.videoId != 'undefined'){\n\t\tvideo.id = entry.id.videoId;\n\t} else {\n\t\ttry {\n\t\t\tvideo.id = entry.snippet.resourceId.videoId;\t\t\t\n\t\t} catch(err) {\n\t\t\treturn null;\n\t\t}\n\t}\n\tvideo.description = entry.snippet.description;\n\tvideo.title = entry.snippet.title;\n\tvideo.duration = entry.duration;\n\tvideo.thumbnail = this.thumbnailFromSnippet(entry.snippet);\n\tvideo.type = \"youtube\";\n\tvideo.format = this.format;\n\tvideo.operations = [ {'name': 'download', 'text': $.i18n.prop(\"btn.download\"), 'successMessage': $.i18n.prop(\"notification.download.ok\")} ];\n\treturn video;\n};\n\nfunction createSearch(query, selectedEngine, count, format){\n var searchPrototype;\n var availableSearchEngines = [HomeSearch, SearchHistorySearch, HistorySearch, PresetSearch, YoutubeSearch, LocalDirSearch, LocalSearch, EngineSearch];\n for (var i = 0; i < availableSearchEngines.length; i++) {\n searchPrototype = availableSearchEngines[i];\n if(query && searchPrototype.keyword){\n if(query.lastIndexOf(\"youtupi:\", 0) === 0){\n var keyword = query.substring(\"youtupi:\".length);\n if(keyword == searchPrototype.keyword){\n break;\n }\n }\n }else if(searchPrototype.engine == selectedEngine){\n if(query && YouTuPi.isHistoryEnabled() && searchPrototype.saveInHistory){\n SearchHistorySearch.saveToHistory({\n 'id' : query,\n 'title' : query,\n 'description' : $.i18n.prop(\"search.history.search.item.description\") + ' ' + selectedEngine,\n 'type' : 'search',\n 'engine': selectedEngine\n });\n }\n break;\n }\n }\n var search = Object.create(searchPrototype);\n search.server = YouTuPi.server;\n search.engine = selectedEngine;\n search.count = count;\n search.format = format;\n search.query = query;\n return search;\n}\n"
},
{
"alpha_fraction": 0.5760430693626404,
"alphanum_fraction": 0.5773889422416687,
"avg_line_length": 36.20000076293945,
"blob_id": "8de842c2fd40ba9278d755505bc13296f3e445da",
"content_id": "b4692d97611c57e9f0106544f75daa8f41e190df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 743,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 20,
"path": "/youtupi/modules/videoUrl.py",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "import threading\nimport os.path\nfrom youtupi.modules import local, youtube, url\n \nvideoUrlLock = threading.RLock()\n\ndef prepareVideo(video):\n with videoUrlLock:\n if not video.subtitles and video.data['type'] == \"local\":\n path = os.path.splitext(video.vid)[0] + \".srt\"\n if os.path.exists(path):\n print \"Found subtitles in {}\".format(path)\n video.subtitles = path\n if not video.url:\n return_url = local.getUrl(video.data)\n if not return_url and video.data['type'] == \"url\":\n return_url = url.getUrl(video.data)\n if not return_url:\n return_url = youtube.getUrl(video.data)\n video.url = return_url"
},
{
"alpha_fraction": 0.6024096608161926,
"alphanum_fraction": 0.6024096608161926,
"avg_line_length": 15.600000381469727,
"blob_id": "49e2c57195da82bed658c5c5c6e97e84d28e2903",
"content_id": "665236d7cdb3404dae0eb8e0ca4406544f32ba02",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 83,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 5,
"path": "/youtupi/util/ensure_dir.py",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "import os\n\ndef ensure_dir(d):\n if not os.path.exists(d):\n os.makedirs(d)\n"
},
{
"alpha_fraction": 0.6030334830284119,
"alphanum_fraction": 0.6066945791244507,
"avg_line_length": 28.41538429260254,
"blob_id": "b3a2bd52e459f5874b4daa31e904943fbd0af8b0",
"content_id": "64a498f0f3e666ac9def884142d5420e2c36b46e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3824,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 130,
"path": "/youtupi/playlist.py",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "import threading\nfrom youtupi.video import Video\nfrom youtupi.modules.videoUrl import prepareVideo\nfrom youtupi.modules.youtube import updateVideoData, resolveYoutubePlaylist\nfrom youtupi.engine.PlaybackEngineFactory import engine\n\nvideos = list()\n\ndef resetPlaylist():\n global videos\n videos = list()\n\ndef currentVideo():\n viewedVideos = filter(lambda video:video.played==True, videos)\n lastPlayedVideo = viewedVideos[-1:]\n if lastPlayedVideo:\n return lastPlayedVideo[0]\n return None\n\ndef removeOldVideosFromPlaylist():\n viewedVideos = filter(lambda video:video.played==True, videos)\n cv = currentVideo()\n for vv in viewedVideos:\n if vv != cv:\n videos.remove(vv)\n\ndef removeVideo(videoId):\n video = findVideoInPlaylist(videoId)\n if video:\n if video == currentVideo():\n playNextVideo()\n try:\n videos.remove(video)\n except ValueError:\n print \"Video already deleted\"\n\ndef playlistPosition(videoId, position):\n video = findVideoInPlaylist(videoId)\n if (len(videos) > 1) and video:\n isPlaying = None\n if video == currentVideo():\n isPlaying = True\n pos = int(position) - 1\n curPos = videos.index(video)\n if pos != curPos:\n print \"Changing video \" + videoId + \" position to: \" + str(pos) + \" (was \" + str(curPos) + \")\"\n videos.remove(video)\n videos.insert(pos, video)\n if isPlaying:\n video.played=False\n playNextVideo()\n\ndef playList():\n return videos\n\ndef findVideoInPlaylist(vid):\n fvideos = filter(lambda video:video.vid==vid, videos)\n if fvideos:\n return fvideos[0]\n else:\n return None\n\ndef playNextVideo():\n viewedVideos = filter(lambda video:video.played==False, videos)\n nextVideo = viewedVideos[:1]\n if nextVideo:\n playVideo(nextVideo[0].vid)\n removeOldVideosFromPlaylist()\n else:\n engine.stop()\n resetPlaylist()\n\ndef updateData(data):\n data.update(updateVideoData(data))\n\ndef addYoutubePlaylist(data):\n for video in resolveYoutubePlaylist(data):\n addVideos(video)\n\ndef addVideos(data):\n if type(data) is list:\n for vData in data:\n addVideos(vData)\n elif data['type'] == \"youtube\" and len(data['id']) > 12:\n threading.Thread(target=addYoutubePlaylist, args=(data,)).start()\n else:\n if data['type'] == 'youtube' and not data.has_key('title'):\n threading.Thread(target=updateData, args=(data,)).start()\n video = Video(data['id'], data)\n videos.append(video)\n\ndef playVideo(videoId):\n svideo = findVideoInPlaylist(videoId)\n if svideo:\n print 'Requested video ' + videoId\n if svideo == currentVideo():\n engine.setPosition(0)\n else:\n svideo.played = True\n removeOldVideosFromPlaylist()\n if svideo != videos[0]:\n videos.remove(svideo)\n videos.insert(0, svideo)\n if not svideo.url:\n prepareVideo(svideo)\n try:\n engine.play(svideo)\n except RuntimeError:\n print 'Error playing video ' + videoId\n removeVideo(svideo.vid)\n\ndef autoPlay():\n removeOldVideosFromPlaylist()\n if videos:\n if not engine.isPlaying():\n playNextVideo()\n else:\n svideo = currentVideo()\n if svideo:\n position = engine.getPosition()\n if position:\n svideo.data[\"position\"] = position\n duration = engine.getDuration()\n if duration:\n svideo.data[\"duration\"] = duration\n for nvideo in videos[:3]:\n prepareVideo(nvideo)\n threading.Timer(1, autoPlay).start()\n\nautoPlay()\n"
},
{
"alpha_fraction": 0.7929841876029968,
"alphanum_fraction": 0.7969367504119873,
"avg_line_length": 33.89655303955078,
"blob_id": "fdd643d73b69d16572b3538bbc65e7f6db5b7559",
"content_id": "3274712891eb5a385ac380f76db2dfe87c452ec5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 2038,
"license_type": "permissive",
"max_line_length": 55,
"num_lines": 58,
"path": "/static/Messages_es.properties",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "playlist.empty = Sin elementos\nplaylist.refreshing = ...recargando lista...\nplaylist.now = Ahora\nplaylist.soon = En breve\nvideo.loading = Cargando datos para\nsearch.empty = No se encontraron resultados\nsearch.home.title = Inicio\nsearch.home.description = Volver al inicio\nsearch.history.search.title = Historial de búsquedas\nsearch.history.search.description = Búsquedas recientes\nsearch.history.search.item.description = Buscado en\nsearch.history.title = Historial\nsearch.history.description = Reproducciones recientes\nbtn.download = Descargar\nbtn.audio.prev = Audio Anterior\nbtn.audio.next = Audio Siguiente\nbtn.sub.prev = Sub Anterior\nbtn.sub.next = Sub Siguiente\nbtn.volume.up = Vol. Arriba\nbtn.volume.down = Vol. Abajo\nbtn.stop = Parar\nbtn.next = Siguiente\ntab.playlist = Lista\ntab.search = Buscar\nbtn.settings = Configuración\nengine.local = Buscar local\nengine.local-dir = Navegar local\nengine.url = Dirección\nengine.presets = Listas predefinidas\nbtn.page.next = Página siguiente\nbtn.page.prev = Página anterior\nbtn.add.all.random = Añadir todo aleatoriamente\nbtn.add.all = Añadir todo\ncfg.title = Configuración\ncfg.history = Guardar en el historial:\ncfg.history.on = Si\ncfg.history.off = No\ncfg.history.clear.btn = Limpiar historial\ncfg.results.number = Elementos a mostrar\ncfg.quality = Calidad del video:\ncfg.quality.audio = Sólo sonido\ncfg.quality.high = Alta calidad\ncfg.quality.low = Baja calidad\ncfg.volume = Volumen inicial (dB):\nbtn.close = Cerrar\nbtn.seek.back.long = Mover atrás 10m\nbtn.seek.back.short = Mover atrás 30s\nbtn.pause = Pausa/Continuar\nbtn.seek.forward.long = Mover adelante 10m\nbtn.seek.forward.short = Mover adelante 30s\nnotification.load.video.queued = Video añadido\nnotification.load.video.error = Error cargando video\nnotification.load.videos.error = Error cargando videos\nnotification.volume.updated = Volumen actualizado\nnotification.download.ok = Descargado correctamente\nnotification.ok = Solicitud recibida\nnotification.seeked = Posición actualizada\nbtn.related = Buscar relacionados\n"
},
{
"alpha_fraction": 0.5990338325500488,
"alphanum_fraction": 0.5990338325500488,
"avg_line_length": 22.884614944458008,
"blob_id": "7a6e13f793e553b537dc585b83514b685380557f",
"content_id": "4ce3e9095070758222a20d76542419c8e74f9995",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 621,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 26,
"path": "/youtupi/util/config.py",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "import os, json\n\ndef initialize():\n\tdname = os.path.abspath('.')\n\tf = dname + '/pafy/__init__.py'\n\tif not os.path.exists(f):\n\t\tprint 'Initializing pafy folder'\n\t\topen(f, 'w').close()\n\tf = dname + '/vlc/__init__.py'\n\tif not os.path.exists(f):\n\t\tprint 'Initializing vlc folder'\n\t\topen(f, 'w').close()\n\t\tf = dname + '/vlc/generated/__init__.py'\n\t\topen(f, 'w').close()\t\t\n\ndef loadConfig():\n dname = os.path.abspath('.')\n print 'Reading config from: ' + dname\n fname = 'youtupi.conf'\n conf = {}\n if os.path.isfile(fname):\n conf = json.load(open(fname))\n return(conf)\n\ninitialize()\nconf = loadConfig()\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6697530746459961,
"avg_line_length": 21.34482765197754,
"blob_id": "7c8d94dafee8f6d41c4a8c895d41a783b51ddb18",
"content_id": "0cf10c214e3446917804c77cfce85b0bb9e123a3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 648,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 29,
"path": "/static/util.storage.js",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "Storage.prototype.setObj = function(key, obj) {\n return this.setItem(key, JSON.stringify(obj))\n}\nStorage.prototype.getObj = function(key) {\n return JSON.parse(this.getItem(key))\n}\n\nfunction supports_html5_storage() {\n\ttry {\n\t\treturn 'localStorage' in window && window['localStorage'] !== null;\n\t} catch (e) {\n\t\treturn false;\n\t}\n}\n\nfunction addLocalStorageFor(select, key){\n\tif(supports_html5_storage()){\n\t\tvar oldValue = localStorage.getItem(key);\n\t\tif(oldValue){\n\t\t\t$(select).val(oldValue);\n\t\t}\n\t\t$(select).bind(\"change\", function(event, ui) {\n\t\t\tlocalStorage.setItem(key, $(select).val());\n\t\t});\n\t\treturn true;\n\t}else{\n\t\treturn false;\n\t}\n}\n"
},
{
"alpha_fraction": 0.7760881185531616,
"alphanum_fraction": 0.7802831530570984,
"avg_line_length": 31.879310607910156,
"blob_id": "730ecc6ccf89816b5535c309814d644914cfbb0b",
"content_id": "d640030240a581b4550a3dcebe8c07c9d3876808",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 1907,
"license_type": "permissive",
"max_line_length": 53,
"num_lines": 58,
"path": "/static/Messages.properties",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "playlist.empty = No entries in the playlist\nplaylist.refreshing = ...refreshing playlist...\nplaylist.now = Now Playing\nplaylist.soon = Coming soon\nvideo.loading = Loading data for\nsearch.empty = No se encontraron resultados\nsearch.home.title = Home\nsearch.home.description = Back to home\nsearch.history.search.title = Search History\nsearch.history.search.description = Recent searches\nsearch.history.search.item.description = Searched in\nsearch.history.title = History\nsearch.history.description = Recently played items\nbtn.download = Download\nbtn.audio.prev = Audio Prev\nbtn.audio.next = Audio Next\nbtn.sub.prev = Sub Prev\nbtn.sub.next = Sub Prev\nbtn.volume.up = Vol. Up\nbtn.volume.down = Vol. Down\nbtn.stop = Stop\nbtn.next = Next\ntab.playlist = Playlist\ntab.search = Search\nbtn.settings = Settings\nengine.local = Search local\nengine.local-dir = Browse local\nengine.url = Paste Video URL\nengine.presets = Presets\nbtn.page.next = Next page\nbtn.page.prev = Prev. page\nbtn.add.all.random = Random add all\nbtn.add.all = Add all\ncfg.title = Settings\ncfg.history = Store loaded items in history:\ncfg.history.on = On\ncfg.history.off = Off\ncfg.history.clear.btn = Clear history\ncfg.results.number = Show # results\ncfg.quality = Video quality:\ncfg.quality.audio = Audio only\ncfg.quality.high = High quality\ncfg.quality.low = Low quality\ncfg.volume = Start Volume (dB):\nbtn.close = Close\nbtn.seek.back.long = seek back 10m\nbtn.seek.back.short = seek back 30s\nbtn.pause = Pause/Resume\nbtn.seek.forward.long = seek forward 10m\nbtn.seek.forward.short = seek forward 30s\nnotification.load.video.queued = Video queued\nnotification.load.video.error = Error loading video\nnotification.load.videos.error = Error loading videos\nnotification.volume.updated = Updated volume\nnotification.download.ok = Video downloaded\nnotification.ok = Operation requested\nnotification.seeked = Changed video time\nbtn.related = Search related\n"
},
{
"alpha_fraction": 0.5545023679733276,
"alphanum_fraction": 0.5545023679733276,
"avg_line_length": 29.285715103149414,
"blob_id": "e580815f19ba2502102d40a0d742aca52864a8d1",
"content_id": "eb450b7f781b94df54e535fff42107a8154e7188",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 211,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 7,
"path": "/youtupi/video.py",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "class Video:\n def __init__(self, vid, data, url = None, subtitles = None):\n self.vid = vid\n self.data = data\n self.url = url\n self.subtitles = subtitles\n self.played = False"
},
{
"alpha_fraction": 0.7118353247642517,
"alphanum_fraction": 0.7186964154243469,
"avg_line_length": 26.761905670166016,
"blob_id": "0de92135fb45fe98e3c9ebaef64731c6b75123f1",
"content_id": "579c4f43e9452e9f45544ee12b30a1a256db0393",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 583,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 21,
"path": "/service/update.sh",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nINSTALL_SCRIPT='https://raw.githubusercontent.com/kktuax/youtupi/master/service/install.sh'\nYOUTUPI_HOME=/home/pi/youtupi\nYOUTUPI_USER=pi\n\nsystemctl stop youtupi\n\napt-get update\ncurl -s $INSTALL_SCRIPT | grep 'apt-get install -y' | awk '{split($0,a,\" -y \"); print a[2]}' | apt-get install -y\n\nDEPS=$(curl -s $INSTALL_SCRIPT | grep 'pip install' | awk '{split($0,a,\" install \"); print a[2]}')\npip install -I $DEPS\npip install --upgrade youtube_dl\n\ncd $YOUTUPI_HOME\ngit pull\ngit submodule update\nchown -R $YOUTUPI_USER:$YOUTUPI_USER $YOUTUPI_HOME\n\nsystemctl start youtupi\n"
},
{
"alpha_fraction": 0.6719639897346497,
"alphanum_fraction": 0.6766117215156555,
"avg_line_length": 38.46745681762695,
"blob_id": "6bdd40149d87f635e19a2501f5d235ab25ef08a6",
"content_id": "045842d7a7165e10376275dd1076908184e30d8b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6670,
"license_type": "no_license",
"max_line_length": 166,
"num_lines": 169,
"path": "/youtupi/modules/local.py",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\nimport os.path\nfrom os.path import expanduser\nfrom StringIO import StringIO\nfrom shutil import copyfile\nimport heapq, datetime, web, json, codecs, magic\nfrom youtupi.util import config, ensure_dir\nfrom periscope.periscope import Periscope\n\ndef getUrl(data):\n\tif(data['type'] == \"local\"):\n\t\treturn data['id']\n\telse:\n\t\treturn None\n\ndef find_files(rootfolder=expanduser(\"~\"), search=\"\", count=20, extension=(\".avi\", \".mp4\", \".mp3\", \".mkv\", \".ogm\", \".mov\", \".MOV\")):\n\tif not search:\n\t\treturn find_newest_files(rootfolder, count=count, extension=extension)\n\tfiles = set()\n\tfor dirname, dirnames, filenames in os.walk(rootfolder, followlinks=True):\n\t\tfor filename in filenames:\n\t\t\tif filename.endswith(extension):\n\t\t\t\tif isFileInKeyWords(filename, search):\n\t\t\t\t\tfiles.add(os.path.join(dirname, filename))\n\treturn sorted(files)[0:count]\n\ndef find_files_and_folders(rootfolder, path, extension=(\".avi\", \".mp4\", \".mp3\", \".mkv\", \".ogm\", \".mov\", \".MOV\")):\n\twhile path.startswith(\"/\"):\n\t\tpath = path[1:]\n\tfolder = os.path.join(rootfolder, path)\n\tdirs = set()\n\tfiles = set()\n\tfor item, f in [ (os.path.join(folder,f),f) for f in os.listdir(folder) ]:\n\t\tif os.path.isdir(item):\n\t\t\tif not f.startswith('.'):\n\t\t\t\tdirs.add(f)\n\t\telif os.path.isfile(item):\n\t\t\tif item.endswith(extension):\n\t\t\t\tfiles.add(os.path.join(item))\n\treturn sorted(dirs), sorted(files)\n\ndef find_newest_files(rootfolder=expanduser(\"~\"), count=20, extension=(\".avi\", \".mp4\", \".mkv\", \".ogm\", \".mov\", \".MOV\")):\n\treturn heapq.nlargest(count,\n\t\t(os.path.join(dirname, filename)\n\t\tfor dirname, dirnames, filenames in os.walk(rootfolder, followlinks=True)\n\t\tfor filename in filenames\n\t\tif filename.endswith(extension)),\n\t\tkey=lambda fn: os.stat(fn).st_mtime)\n\ndef isFileInKeyWords(filename, search):\n\twords = search.split()\n\tfor word in words:\n\t\tif word.lower() not in filename.lower():\n\t\t\treturn False\n\treturn True\n\nclass search:\n\n\tdef GET(self):\n\t\tuser_data = web.input()\n\t\tsearch = user_data.search\n\t\tcount = int(user_data.count)\n\t\tlocal_videos = list()\n\t\tfolders = config.conf.get('local-folders', ['~'])\n\t\textensions = config.conf.get('local-search-extensions', [\".avi\", \".mp4\", \".mp3\", \".ogg\", \".mkv\", \".flv\"])\n\t\tprint 'Searching \"' + search + '\" in folders: ' + ', '.join(folders)\n\t\tfor folder in folders:\n\t\t\tfor local_video_file in find_files(expanduser(folder), search=search, count=count, extension=tuple(extensions)):\n\t\t\t\tdate = datetime.date.fromtimestamp(os.path.getmtime(local_video_file)).isoformat()\n\t\t\t\tname = os.path.basename(local_video_file)\n\t\t\t\tsubtitleOperation = {'name': 'subtitle', 'text': 'Subtitles', 'successMessage': 'Subtitle downloaded'};\n\t\t\t\tdeleteOperation = {'name': 'delete', 'text': 'Delete', 'successMessage': 'File deleted'};\n\t\t\t\tlocal_video = {'id': local_video_file, 'description': date, 'title': name, 'type': 'local', 'operations' : [subtitleOperation, deleteOperation]}\n\t\t\t\tlocal_videos.append(local_video)\n\t\treturn json.dumps(local_videos[0:count], indent=4)\n\nclass browse:\n\n\tdef GET(self):\n\t\tuser_data = web.input()\n\t\tsearch = user_data.search.strip()\n\t\tcount = int(user_data.count)\n\t\textensions = config.conf.get('local-search-extensions', [\".avi\", \".mp4\", \".mp3\", \".ogg\", \".mkv\", \".flv\"])\n\t\tlocal_dirs = list()\n\t\tlocal_videos = list()\n\t\trootfolders = config.conf.get('local-folders', ['~'])\n\t\tprint 'Browsing \"' + search + '\" in folders: ' + ', '.join(rootfolders)\n\t\tfor rootfolder in rootfolders:\n\t\t\trootfoldername = os.path.basename(rootfolder)\n\t\t\tif search == \"\" or search == \"/\":\n\t\t\t\tname = rootfoldername\n\t\t\t\tlocal_browse_folder = {'id': \"/%s\" % rootfoldername, 'description': \"\", 'title': name, 'type': 'search', 'engine' : 'local-dir', 'operations' : []}\n\t\t\t\tlocal_dirs.append(local_browse_folder)\n\t\t\telif search.startswith(\"/%s\" % rootfoldername):\n\t\t\t\tlocal_dirs.append({'id': os.path.dirname(search), 'description': \"Go back\", 'title': \"..\", 'type': 'search', 'engine' : 'local-dir', 'operations' : []})\n\t\t\t\tprefix = search[(len(rootfoldername)+1):]\n\t\t\t\tdirs, files = find_files_and_folders(expanduser(rootfolder), prefix, extension=tuple(extensions))\n\t\t\t\tfor local_dir in dirs:\n\t\t\t\t\tname = os.path.basename(local_dir)\n\t\t\t\t\tlocal_browse_folder = {'id': os.path.join(search,local_dir), 'description': \"Folder\", 'title': name, 'type': 'search', 'engine' : 'local-dir', 'operations' : []}\n\t\t\t\t\tlocal_dirs.append(local_browse_folder)\n\t\t\t\tfor local_video_file in files:\n\t\t\t\t\tdate = datetime.date.fromtimestamp(os.path.getmtime(local_video_file)).isoformat()\n\t\t\t\t\tname = os.path.basename(local_video_file)\n\t\t\t\t\tsubtitleOperation = {'name': 'subtitle', 'text': 'Subtitles', 'successMessage': 'Subtitle downloaded'};\n\t\t\t\t\tdeleteOperation = {'name': 'delete', 'text': 'Delete', 'successMessage': 'File deleted'};\n\t\t\t\t\tlocal_video = {'id': local_video_file, 'description': date, 'title': name, 'type': 'local', 'operations' : [subtitleOperation, deleteOperation]}\n\t\t\t\t\tlocal_videos.append(local_video)\n\t\treturn json.dumps(local_dirs + local_videos, indent=4)\n\ndef downloadSubtitle(video):\n\tdfolder = expanduser(config.conf.get('download-folder', \"~/Downloads\"))\n\tensure_dir.ensure_dir(dfolder)\n\tp = Periscope(dfolder)\n\tp.downloadSubtitle(video.vid, p.get_preferedLanguages())\n\ttoUtf8File(os.path.splitext(video.vid)[0] + \".srt\")\n\ndef toUtf8File(srtFile):\n\tif os.path.isfile(srtFile):\n\t\tbase = os.path.splitext(srtFile)[0]\n\t\textension = os.path.splitext(srtFile)[1]\n\t\tsrtFileTmp = base + \"-tmp.\" + extension\n\t\tcopyAsUtf8File(srtFile, srtFileTmp)\n\t\tos.rename(srtFileTmp, srtFile)\n\t\t\t\ndef copyAsUtf8File(srtFile, dstFile):\n\tif os.path.isfile(srtFile):\n\t\tblob = open(srtFile, \"r\").read()\n\t\tm = magic.open(magic.MAGIC_MIME_ENCODING)\n\t\tm.load()\n\t\tfile_encoding = m.buffer(blob)\n\t\tif file_encoding != 'utf-8':\n\t\t\tprint \"Saving {} as utf8 in {}\".format(srtFile, dstFile)\n\t\t\tfile_stream = codecs.open(srtFile, 'r', file_encoding)\n\t\t\tfile_output = codecs.open(dstFile, 'w', 'utf-8')\n\t\t\tfor l in file_stream:\n\t\t\t\tfile_output.write(l)\n\t\t\tfile_stream.close()\n\t\t\tfile_output.close()\n\t\telse:\n\t\t\tprint \"Copying utf8 file {} in {}\".format(srtFile, dstFile)\n\t\t\tcopyfile(srtFile, dstFile)\n\nclass subtitle_dl:\n\tdef POST(self):\n\t\tdata = json.load(StringIO(web.data()))\n\t\tfrom youtupi.playlist import findVideoInPlaylist\n\t\tvideo = findVideoInPlaylist(data['id'])\n\t\tif video:\n\t\t\tdownloadSubtitle(video)\n\nclass delete:\n\tdef POST(self):\n\t\tdata = json.load(StringIO(web.data()))\n\t\tfrom youtupi.playlist import removeVideo\n\t\tremoveVideo(data['id'])\n\t\tif os.path.isfile(data['id']):\n\t\t\tos.remove(data['id'])\n\nurls = (\n\t\"-search\", \"search\",\n\t\"-browse\", \"browse\",\n\t'-subtitle', \"subtitle_dl\",\n\t'-delete', \"delete\"\n)\n\nmodule_local = web.application(urls, locals())\n"
},
{
"alpha_fraction": 0.6684871912002563,
"alphanum_fraction": 0.6690332889556885,
"avg_line_length": 26.74242401123047,
"blob_id": "3acfb5367cd67f9ae18f55ff30d6734a566b2e48",
"content_id": "56f40b8784ece46173b679e2c490a52d7f2d94fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1831,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 66,
"path": "/youtupi/modules/control.py",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "import web, threading, json\nfrom StringIO import StringIO\nfrom youtupi.engine.PlaybackEngineFactory import engine\nfrom youtupi.playlist import findVideoInPlaylist, playNextVideo, playVideo, playlistPosition, resetPlaylist\n\nengineLock = threading.RLock()\n\nclass control:\n\n\tdef GET(self, action):\n\t\twith engineLock:\n\t\t\tif action == \"play\":\n\t\t\t\tplayNextVideo()\n\t\t\telif action == \"stop\":\n\t\t\t\tengine.stop()\n\t\t\t\tresetPlaylist()\n\t\t\telif action == \"pause\":\n\t\t\t\tengine.togglePause()\n\t\t\telif action == \"volup\":\n\t\t\t\tengine.volumeUp()\n\t\t\telif action == \"voldown\":\n\t\t\t\tengine.volumeDown()\n\t\t\telif action == \"seekbacksmall\":\n\t\t\t\tengine.seekBackSmall()\n\t\t\telif action == \"seekforwardsmall\":\n\t\t\t\tengine.seekForwardSmall()\n\t\t\telif action == \"seekbacklarge\":\n\t\t\t\tengine.seekBackLarge()\n\t\t\telif action == \"seekforwardlarge\":\n\t\t\t\tengine.seekForwardLarge()\n\t\t\telif action == \"prevaudiotrack\":\n\t\t\t\tengine.prevAudioTrack()\n\t\t\telif action == \"nextaudiotrack\":\n\t\t\t\tengine.nextAudioTrack()\n\t\t\telif action == \"nextsubtitle\":\n\t\t\t\tengine.nextSubtitle()\n\t\t\telif action == \"prevsubtitle\":\n\t\t\t\tengine.prevSubtitle()\n\n\tdef POST(self, action):\n\t\twith engineLock:\n\t\t\tdata = json.load(StringIO(web.data()))\n\t\t\tif action == \"volume\":\n\t\t\t\tprint \"setting volume to \" + data['volume']\n\t\t\t\tvolume = int(data['volume'])\n\t\t\t\tengine.setBaseVolume(volume)\n\t\t\tif action == \"play\":\n\t\t\t\tvideo = findVideoInPlaylist(data['id'])\n\t\t\t\tif video:\n\t\t\t\t\tplayVideo(data['id'])\n\t\t\tif action == \"playNext\":\n\t\t\t\tvideo = findVideoInPlaylist(data['id'])\n\t\t\t\tif video:\n\t\t\t\t\tplaylistPosition(data['id'], 2)\n\t\t\tif action == \"order\":\n\t\t\t\tvideo = findVideoInPlaylist(data['id'])\n\t\t\t\tif video:\n\t\t\t\t\tplaylistPosition(data['id'], data['order'])\n\t\t\tif action == \"position\":\n\t\t\t\tengine.setPosition(int(data['seconds']))\n\nurls = (\n\t'/(.*)', 'control',\n)\n\nmodule_control = web.application(urls, locals())\n"
},
{
"alpha_fraction": 0.6469945311546326,
"alphanum_fraction": 0.6495446562767029,
"avg_line_length": 24.89622688293457,
"blob_id": "6e35f9ff9711b5c50d063625716c7c1ca216c65c",
"content_id": "d06e4f372898722cca77897d6c64db0193733580",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2745,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 106,
"path": "/youtupi/modules/preset.py",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\nimport web, json, urllib, hashlib, os\nimport bs4 as bs\nfrom youtupi.util import config\n\ndef presetFactory(data):\n\tif isinstance(data, dict):\n\t\tif data.get('type', '') == \"peerflix-server\":\n\t\t\treturn PeerflixServerPreset(data)\n\t\tif data.get('type', '') == \"TV-Online-TDT-Spain\":\n\t\t\treturn TvOnlineTDTSpainPreset(data)\n\t\tif data.get('type', '') == \"podcast\":\n\t\t\treturn PodcastPreset(data)\n\treturn Preset({'url': data})\n\nclass Preset(object):\n\n\tdata = {}\n\n\tdef __init__(self, data):\n\t\tself.data = data\n\n\tdef url(self):\n\t\treturn self.data.get('url', '')\n\n\tdef id(self):\n\t\tm = hashlib.md5()\n\t\tm.update(self.url())\n\t\treturn m.hexdigest()\n\n\tdef description(self):\n\t\tif self.data.get('description', ''):\n\t\t\treturn self.data.get('description', '')\n\t\treturn self.url()\n\n\tdef title(self):\n\t\tif self.data.get('title', ''):\n\t\t\treturn self.data.get('title', '')\n\t\treturn os.path.basename(self.url())\n\n\tdef fetch(self):\n\t\tresponse = urllib.urlopen(self.url())\n\t\tcontent = json.loads(response.read())\n\t\treturn content\n\nclass PeerflixServerPreset(Preset):\n\t\n\tdef fetch(self):\n\t\tresponse = urllib.urlopen(self.url() + '/torrents')\n\t\tcontent = []\n\t\ttorrents = json.loads(response.read())\n\t\tfor torrent in torrents:\n\t\t\tfor torrentFile in torrent.get('files', []):\n\t\t\t\tcontent.append({'type': 'url', 'id': self.url() + torrentFile.get('link', ''), 'title': torrentFile.get('name', '')})\n\t\treturn content\n\nclass TvOnlineTDTSpainPreset(Preset):\n\t\n\tdef fetch(self):\n\t\tresponse = urllib.urlopen(self.url())\n\t\tcontent = []\n\t\tchannels = json.loads(response.read())\n\t\tfor channel in channels:\n\t\t\tif channel.get('enabled', False):\n\t\t\t\tcontent.append({'type': 'url', 'id': channel.get('link_m3u8', ''), 'title': channel.get('name', '')})\n\t\treturn content\n\nclass PodcastPreset(Preset):\n\t\n\tdef fetch(self):\n\t\tf = urllib.urlopen(self.url())\n\t\tcontent = []\n\t\tsoup = bs.BeautifulSoup(f.read(), 'xml')\n\t\tfor item in soup.find_all('item'):\n\t\t\tcontent.append({'type': 'url', 'id': item.enclosure['url'], 'title': item.title.text})\n\t\treturn content\n\nclass list:\n\n\tdef GET(self):\n\t\tpresets = []\n\t\tfor presetData in config.conf.get('presets', []):\n\t\t\tpreset = presetFactory(presetData)\n\t\t\tpresets.append({'id': preset.id(), 'description': preset.description(), 'title': preset.title(), 'type': 'search', 'operations' : []})\n\t\treturn json.dumps(presets, indent=4)\n\nclass load:\n\n\tdef GET(self, presetId):\n\t\tprint \"searching for preset \" + presetId\n\t\tdata = []\n\t\tfor presetData in config.conf.get('presets', []):\n\t\t\tpreset = presetFactory(presetData)\n\t\t\tif presetId == preset.id():\n\t\t\t\tdata = preset.fetch()\n\t\t\t\tbreak\n\t\treturn json.dumps(data, indent=4)\n\nurls = (\n\t'', 'list',\n\t'/(.*)', 'load',\n)\n\nmodule_preset = web.application(urls, locals())\n"
},
{
"alpha_fraction": 0.6287317872047424,
"alphanum_fraction": 0.6347923874855042,
"avg_line_length": 30.373239517211914,
"blob_id": "d720216d2857a413dcc382f61b5f8c990e79b439",
"content_id": "cb83b41d38adf90bd6000af8ca89bc7c4eafe7c4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 4455,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 142,
"path": "/static/youtupi.js",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "var YouTuPi = {};\nYouTuPi.server = window.location.protocol + \"//\" + window.location.host;\nYouTuPi.conf = {\n 'save-history' : true\n}\nYouTuPi.refreshPlaylist = function(success){\n var url = this.server + \"/playlist\";\n return $.getJSON(url, success);\n};\nYouTuPi.playVideo = function(video, success){\n var url = this.server + \"/control/play\";\n return $.post(url, $.toJSON(video), success, \"json\");\n};\nYouTuPi.playVideoNext = function(video, success){\n var url = this.server + \"/control/playNext\";\n return $.post(url, $.toJSON(video), success, \"json\");\n};\nYouTuPi.deleteVideo = function(video, success){\n var url = this.server + \"/playlist\";\n return $.ajax({url: url, type: 'DELETE', data: $.toJSON(video), dataType: 'json', success: success});\n};\nYouTuPi.jumpToPosition = function(seconds, success){\n var data = $.toJSON({seconds : seconds});\n var url = this.server + \"/control/position\";\n return $.post(url, data, success);\n};\nYouTuPi.changePlaylistPosition = function(videoId, newPosition, success){\n if(newPosition > 0){\n var data = $.toJSON({id : videoId, order: newPosition + 1});\n var url = this.server + \"/control/order\";\n return $.post(url, data, success, \"json\");\n }else if(newPosition == 0){\n var url = this.server + \"/control/play\";\n return $.post(url, $.toJSON({id : videoId}), success, \"json\");\n }else{\n return $.Deferred().resolve().promise();\n }\n};\nYouTuPi.controlServer = function(action, success){\n var url = this.server + \"/control/\" + action;\n return $.get(url, {}, success);\n};\nYouTuPi.setServerParam = function(param, value, success){\n var jsonobj = {};\n jsonobj[param] = value;\n var url = this.server + \"/control/\" + param;\n return $.post(url, $.toJSON(jsonobj), success);\n};\nYouTuPi.addVideo = function(video, success){\n var url = this.server + \"/playlist\";\n if(this.isHistoryEnabled()){\n HistorySearch.saveToHistory(video);\n }\n var data = $.toJSON(video);\n return $.post(url, data, success, \"json\");\n};\nYouTuPi.addVideos = function(ivideos, random, success){\n var url = this.server + \"/playlist\";\n var videos = random ? YouTuPi._shuffle(ivideos) : ivideos;\n videos = $.grep(videos, function(v){\n return v.type != 'search';\n });\n return $.post(url, $.toJSON(videos), success, \"json\");\n};\nYouTuPi._shuffle = function(array) {\n var currentIndex = array.length, temporaryValue, randomIndex;\n while (0 !== currentIndex) {\n randomIndex = Math.floor(Math.random() * currentIndex);\n currentIndex -= 1;\n temporaryValue = array[currentIndex];\n array[currentIndex] = array[randomIndex];\n array[randomIndex] = temporaryValue;\n }\n return array;\n};\nYouTuPi.videoOperation = function(video, operation, success){\n var type = video.type;\n var url = this.server + \"/\" + type + \"-\" + operation.name;\n return $.post(url, $.toJSON(video), success);\n};\nYouTuPi.isHistoryEnabled = function(){\n return this.conf['save-history'] ? true : false;\n}\nYouTuPi.clearHistory = function(){\n HistorySearch.clearHistory();\n SearchHistorySearch.clearHistory();\n}\n\nfunction Video(data){\n\n this.data = data;\n\n this.id = function(){\n return this.data.id;\n };\n\n this.title = function(){\n var title = this.data.title;\n if(title == undefined) {\n title = $.i18n.prop(\"video.loading\") + \" \" + this.data.id;\n }\n var\tduration = this.getDurationString();\n if(duration){\n return title + \" [\" + duration + \"]\";\n }else{\n return title;\n }\n };\n\n this.getDurationString = function(){\n var time = this.data.duration;\n if(time == undefined) return \"\";\n var duration = \"\";\n var hours = Math.floor(time / 3600);\n if(hours > 0) duration = duration + hours + \":\";\n time = time - hours * 3600;\n var minutes = Math.floor(time / 60);\n duration = duration + (((minutes < 10) && (hours > 0)) ? (\"0\" + minutes) : minutes);\n var seconds = time - minutes * 60;\n duration = duration + ((seconds < 10) ? (\":0\" + seconds) : (\":\" + seconds));\n return duration;\n };\n\n this.description = function(){\n return (this.data.description != undefined) ? this.data.description : \"\";\n };\n\n this.thumbnail = function (){\n var thumbnail = \"images/video.png\";\n if(this.data.type == \"search\") {\n thumbnail = \"images/folder_open.png\";\n if(this.data.title == \"..\") {\n thumbnail = \"images/folder.png\";\n }\n }\n if(this.data.thumbnail != undefined){\n thumbnail = this.data.thumbnail;\n }\n return thumbnail;\n };\n\n};\n"
},
{
"alpha_fraction": 0.5888534188270569,
"alphanum_fraction": 0.5975117683410645,
"avg_line_length": 29.818653106689453,
"blob_id": "0f55df26d09736163e1cd4078971692ac7c9c3dd",
"content_id": "3b690a9595773f8dc3deaa21f3fe00bf98c15125",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 11896,
"license_type": "permissive",
"max_line_length": 262,
"num_lines": 386,
"path": "/static/youtupi.ui.js",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "$(document).bind('pageinit', function () {\n $.mobile.defaultPageTransition = 'none';\n});\n\n$(document).delegate(\"#playlist\", \"pageinit\", function() {\n initControls();\n window.setInterval(function(){\n $('#spinner').css('opacity', 1);\n YouTuPi.refreshPlaylist(loadPlayList);\n }, 5000);\n});\n\n$(document).delegate(\"#search\", \"pageinit\", function() {\n initSearchControls();\n $(\"#search-basic\").val(\"youtupi:home\");\n $(\"#search-basic\").trigger(\"change\");\n});\n\n/**\n* Load playlist items with play video on click event\n* */\nfunction loadPlayList(entries){\n $('#spinner').css('opacity', 0);\n updateControls(entries.length);\n var listSelect = \"#playlist-list\";\n $(listSelect).empty();\n for (var i = 0; i < entries.length; i++) {\n var video = new Video(entries[i]);\n if(i == 0){\n adjustCurrentPositionSlider(video.data.duration, video.data.position);\n }else if(i == 1){\n $(listSelect).append($('<li data-role=\"list-divider\">' + $.i18n.prop(\"playlist.soon\") + '</li>'));\n }\n var theme = i == 0 ? 'b' : 'a';\n var icon = i > 0 ? 'false' : 'carat-r';\n var count = i > 0 ? ' <span class=\"ui-li-count\">'+ i +'</span>' : '';\n var itemval = $('<li data-video-id=\"' + video.id() + '\" data-theme=\"' + theme + '\" data-icon=\"' + icon + '\"><a href=\"#\"><img src=\"'+ video.thumbnail() + '\" /><h3>' + video.title() + '</h3>'+count+'<p>' + video.description() + '</p></a></li>');\n itemval.bind('click', {video: video.data}, playlistClickHandler(video, i));\n $(listSelect).append(itemval);\n }\n try {\n $(listSelect).listview(\"refresh\");\n } catch(err) {}\n}\n\nfunction adjustCurrentPositionSlider(duration, position){\n var positionPct = (position != undefined && duration != undefined) ? 100*position/duration : 0;\n $(\"#position\").val(positionPct);\n if(duration != undefined){\n if(duration != $(\"#position\").data(\"duration\")){\n $(\"#position\").data(\"duration\", duration);\n }\n }\n try {\n $(\"#position\").slider(\"refresh\");\n } catch(err) {}\n}\n\nfunction playlistClickHandler(video, position){\n return function(event) {\n var video = event.data.video;\n var buttons = {};\n if(position > 0){\n buttons['Play'] = {\n click: function () {\n YouTuPi.playVideo(video, loadPlayList);\n },\n close: true\n };\n buttons['Play Next'] = {\n click: function () {\n YouTuPi.playVideoNext(video, loadPlayList);\n },\n close: true\n };\n buttons['Skip'] = {\n click: function () {\n YouTuPi.deleteVideo(video, loadPlayList);\n },\n close: true\n };\n }\n if(video.type == \"youtube\"){\n buttons[$.i18n.prop(\"btn.related\")] = {\n click: function () {\n tabSearch();\n $(\"#search-basic\").val(\"related:\" + video.id);\n $(\"#search-basic\").trigger(\"change\");\n },\n close: true\n };\n }\n for(operationKey in event.data.video.operations){\n var operation = event.data.video.operations[operationKey];\n var buttonClick = function(e, video, operation){\n showNotification($.i18n.prop(\"notification.ok\"));\n YouTuPi.videoOperation(video, operation).done(function(){\n showNotification(operation.successMessage);\n });\n }\n buttons[operation.text] = {\n click: buttonClick,\n args: new Array(video, operation),\n close: true\n };\n }\n $(document).simpledialog2({\n mode: 'button',\n headerText: event.data.video.title,\n headerClose: true,\n buttons : buttons\n });\n };\n}\n\nfunction showNotification(message){\n $(\"<div class='ui-loader ui-overlay-shadow ui-body-e ui-corner-all'><h2>\"+message+\"</h2></div>\").css({ \"display\": \"block\", \"opacity\": 0.8, \"top\": 60, \"left\":\"50\\%\", \"transform\":\"translateX(-50\\%)\", \"z-index\":\"499\", \"padding\": \"0.3em 1em\", \"position\":\"fixed\" })\n .appendTo( $.mobile.pageContainer )\n .delay( 1500 )\n .fadeOut( 400, function(){\n $(this).remove();\n });\n}\n\n$(document).ready(function() {\n\tjQuery.i18n.properties({\n\t\tmode: 'map',\n\t\tname: 'Messages', \n\t\tpath: '/static/',\n\t\tcache: true,\n\t\tcallback: function() { \n\t\t\t$(\"[data-i18n]\").each(function(index) {\n\t\t\t\tvar i18n = $.i18n.prop($(this).data(\"i18n\"));\n\t\t\t\tif($(this).data(\"i18n-att\")){\n\t\t\t\t\t$(this).attr($(this).data(\"i18n-att\"), i18n);\n\t\t\t\t}else{\n\t\t\t\t\t$(this).text(i18n);\n\t\t\t\t}\n\t\t\t});\n\t\t}\n\t});\n});\n\nfunction initControls(){\n $(\".active-on-playing\").each(function() {\n var btn = $(this);\n var action = btn.data(\"player-action\");\n $(this).bind(\"click\", function(event, ui) {\n btn.addClass(\"ui-disabled\");\n YouTuPi.controlServer(action).always(function() {\n \t\tbtn.removeClass(\"ui-disabled\");\n \t});\n \t});\n });\n $(\"#playlist-list\").sortable({\n\t\tdelay: 250\n\t});\n initReorderControl();\n $(\"#position\").bind(\"slidestop\", function(event, ui){\n\t\tvar seconds = $(\"#position\").data(\"duration\") * $(\"#position\").val() / 100;\n if(!isNaN(seconds)){\n YouTuPi.jumpToPosition(seconds, function(){\n showNotification($.i18n.prop(\"notification.seeked\"));\n });\n }\n\t});\n}\n\nfunction initReorderControl(){\n $(\"#playlist-list\").sortable();\n $('#playlist-reorder').change(function() {\n if('on' == $(this).val()){\n $(\"#playlist-list\").sortable(\"enable\");\n \t$(\"#playlist-list\").disableSelection();\n }else{\n $(\"#playlist-list\").sortable('disable');\n $(\"#playlist-list\").enableSelection();\n }\n });\n $(\"#playlist-reorder\").trigger(\"change\");\n\t$(\"#playlist-list\").bind(\"sortstop\", function(event, ui) {\n\t\t$('#playlist-list').listview('refresh');\n\t\tif($(\"#playlist-list\").children().length > 1){\n\t\t\tvar draggedVideoId = ui.item.data(\"video-id\");\n\t\t\tvar draggedPosition = $(\"#playlist-list\").children().index(ui.item);\n YouTuPi.changePlaylistPosition(draggedVideoId, draggedPosition, loadPlayList);\n\t\t}\n\t});\n}\n\nfunction updateControls(playListLength){\n\tif(playListLength == 0){\n\t\t$(\"#playlist-empty\").show();\n\t\t$(\"#playlist-playing\").hide();\n $(\".active-on-playing\").addClass(\"ui-disabled\");\n\t}else{\n\t\t$(\"#playlist-empty\").hide();\n\t\t$(\"#playlist-playing\").show();\n $(\".active-on-playing\").removeClass(\"ui-disabled\");\n\t\tif(playListLength <= 1){\n $(\"#reorder-control\").hide();\n\t\t\t$(\"#next-button\").addClass(\"ui-disabled\");\n\t\t}else{\n $(\"#reorder-control\").show();\n }\n\t}\n}\n\nvar search = null;\n\nfunction initSearchControls(){\n if(addLocalStorageFor(\"#engine\", \"engine\")){\n\t\t$(\"#engine\").selectmenu(\"refresh\");\n\t}\n\tif(addLocalStorageFor(\"#quality\", \"quality\")){\n\t\t$(\"#quality\").selectmenu(\"refresh\");\n\t}\n\tif(addLocalStorageFor(\"#slider\", \"slider\")){\n\t\t$(\"#slider\" ).slider(\"refresh\");\n\t}\n\tif(addLocalStorageFor(\"#save-history\", \"save-history\")){\n\t\t$(\"#save-history\" ).slider(\"refresh\");\n\t}\n $(\"#save-history\").bind(\"change\", function(event, ui) {\n YouTuPi.conf['save-history'] = $(\"#save-history\").val() == 'on' ? true : false;\n });\n\t$(\"#clear-history-button\").bind(\"click\", function(event, ui) {\n\t\tYouTuPi.clearHistory();\n\t});\n $(\"#search-basic\").bind(\"change\", function(event, params) {\n $('#results').empty();\n $(\"#results\").listview(\"refresh\");\n var query = $(\"#search-basic\").val().trim();\n var selectedEngine = $(\"#engine\").val();\n var count = $(\"#slider\").val();\n var format = $(\"#quality\").val();\n search = createSearch(query, selectedEngine, count, format);\n $(\"#spinner-search\").show();\n search.search(function(s){\n fillResults(s.results, \"#results\");\n updateSearchControls(s);\n });\n $(\"#spinner-search\").hide();\n });\n initSearchPageControls();\n initAddAllControls();\n $(\"#engine\").bind(\"change\", function(event, ui) {\n $(\"#search-basic\").trigger(\"change\");\n });\n initVolumeControl();\n}\n\nfunction initAddAllControls(){\n $(\"#add-all-button\").bind(\"click\", function(event, ui) {\n loadVideos(search.results, false);\n });\n $(\"#add-all-random-button\").bind(\"click\", function(event, ui) {\n loadVideos(search.results, true);\n });\n}\n\nfunction loadVideos(ivideos, random){\n tabPlaylist();\n $(\"#spinner\").css('opacity', 1);\n YouTuPi.addVideos(ivideos, random, loadPlayList).fail(function() {\n showNotification($.i18n.prop(\"notification.load.videos.error\"));\n }).always(function() {\n $(\"#spinner\").css('opacity', 0);\n });\n}\n\nfunction loadVideo(video){\n $(\"#spinner\").css('opacity', 1);\n YouTuPi.addVideo(video, loadPlayList).done(function(){\n\tshowNotification($.i18n.prop(\"notification.load.video.queued\"));\n }).fail(function() {\n showNotification($.i18n.prop(\"notification.load.video.error\"));\n }).always(function() {\n $(\"#spinner\").css('opacity', 0);\n });\n}\n\nfunction tabPlaylist(){\n $(\".link-playlist\").first().trigger('click');\n}\n\nfunction tabSearch(){\n $(\".link-search\").first().trigger('click');\n}\n\nfunction initSearchPageControls(){\n $(\"#prev-page-button\").bind(\"click\", function(event, ui) {\n $('#results').empty();\n $(\"#results\").listview(\"refresh\");\n search.decrementPageNumber(function(s){\n fillResults(s.results, \"#results\");\n updateSearchControls(s);\n });\n });\n $(\"#next-page-button\").bind(\"click\", function(event, ui) {\n $('#results').empty();\n $(\"#results\").listview(\"refresh\");\n search.incrementPageNumber(function(s){\n fillResults(s.results, \"#results\");\n updateSearchControls(s);\n });\n });\n}\n\nfunction updateSearchControls(search){\n var videos = $.grep(search.results, function(v){\n return v.type != 'search';\n });\n updateButtonState(\"#add-all-button\", videos.length > 0);\n updateButtonState(\"#add-all-random-button\", videos.length > 0);\n updateButtonState(\"#next-page-button\", search.nextPageAvailable);\n updateButtonState(\"#prev-page-button\", search.prevPageAvailable);\n}\n\nfunction updateButtonState(selector, enabled){\n if(enabled){\n\t\t$(selector).removeClass(\"ui-disabled\");\n\t}else{\n\t\t$(selector).addClass(\"ui-disabled\");\n\t}\n}\n\nfunction initVolumeControl(){\n $(\"#volume\").bind(\"change\", function(event, ui) {\n YouTuPi.setServerParam('volume', $(\"#volume\").val(), function(){\n showNotification($.i18n.prop(\"notification.volume.updated\"));\n });\n });\n if(addLocalStorageFor(\"#volume\", \"volume\")){\n $(\"#volume\").slider(\"refresh\");\n }\n}\n\n/**\n* Refresh listview with array of videos\n* @param {entries} array of videos\n* @param {listSelect} selector of listview to update\n* */\nfunction fillResults(entries, listSelect){\n $(listSelect).empty();\n for (var i = 0; i < entries.length; i++) {\n var video = new Video(entries[i]);\n $(listSelect).append(createResultItem(video, 'a', 'carat-r'));\n }\n if(entries.length == 0){\n var itemval = $('<li data-role=\"list-divider\">' + $.i18n.prop(\"search.empty\") + '</li>');\n $(listSelect).append(itemval);\n var otherVideos = [{\n 'id' : 'youtupi:home',\n 'title' : $.i18n.prop(\"search.home.title\"),\n 'description' : $.i18n.prop(\"search.home.description\"),\n 'type' : 'search',\n }];\n for (var i = 0; i < otherVideos.length; i++) {\n var video = new Video(otherVideos[i]);\n $(listSelect).append(createResultItem(video, 'a', 'carat-r'));\n }\n }\n try {\n $(listSelect).listview(\"refresh\");\n } catch(err) {}\n}\n\nfunction createResultItem(video, theme, icon){\n var itemval = $('<li data-video-id=\"' + video.id() + '\" data-theme=\"' + theme + '\" data-icon=\"' + icon + '\"><a href=\"#\"><img src=\"'+ video.thumbnail() + '\" /><h3>' + video.title() + '</h3><p>' + video.description() + '</p></a></li>');\n itemval.bind('click', {video: video.data}, function(event){\n if(event.data.video.type == \"search\") {\n var engine = event.data.video.engine;\n var selectedEngine = $(\"#engine\").val();\n if(engine && (selectedEngine != engine)){\n $(\"#engine\").val(engine);\n $(\"#engine\").selectmenu(\"refresh\");\n }\n $(\"#search-basic\").val(event.data.video.id);\n $(\"#search-basic\").trigger(\"change\");\n }else{\n loadVideo(event.data.video);\n }\n });\n return itemval;\n}\n"
},
{
"alpha_fraction": 0.5524226427078247,
"alphanum_fraction": 0.5636463165283203,
"avg_line_length": 27.5390625,
"blob_id": "dcc8113031fbaba877b360f6f80c7243eac801ad",
"content_id": "399dcdbe79913b922f9ddfc540c7581bb21db685",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3653,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 128,
"path": "/youtupi/engine/VlcEngine.py",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "from youtupi.engine.PlaybackEngine import PlaybackEngine\nfrom vlc.generated import vlc\n\nSECONDS_FACTOR = 1000\n\n'''\n@author: Max\n'''\nclass VlcEngine(PlaybackEngine):\n\n '''\n VLC playback engine\n '''\n\n player = None\n baseVolume = None\n\n def __init__(self):\n pass\n\n def play(self, video):\n if not video.url:\n raise RuntimeError(\"Video URL not found\")\n if self.isPlaying():\n self.stop()\n if not self.player:\n self.player = vlc.MediaPlayer(video.url)\n self.player.set_fullscreen(True)\n else:\n self.player.set_media(vlc.Instance().media_new(video.url))\n if self.baseVolume:\n linear = pow(10.0, self.baseVolume/20.0)\n self.player.audio_set_volume(int(100 * linear))\n self.player.play()\n\n def stop(self):\n if self.isPlaying():\n self.player.stop()\n self.player = None\n\n def togglePause(self):\n if self.player:\n self.player.pause()\n\n def setPosition(self, seconds):\n if self.isPlaying():\n self.player.set_time(SECONDS_FACTOR*seconds)\n\n def getPosition(self):\n if self.player:\n posmillis = self.player.get_time()\n if posmillis > 0:\n return posmillis/SECONDS_FACTOR\n return 0\n return None\n\n def getDuration(self):\n if self.player:\n durmillis = self.player.get_length()\n if durmillis > 0:\n return durmillis/SECONDS_FACTOR\n return None\n\n def setBaseVolume(self, vol):\n self.baseVolume = vol\n\n def getBaseVolume(self):\n return self.baseVolume\n\n def volumeUp(self):\n if self.player:\n curvol = self.player.audio_get_volume()\n self.player.audio_set_volume(min(100, curvol + 10))\n\n def volumeDown(self):\n if self.player:\n curvol = self.player.audio_get_volume()\n self.player.audio_set_volume(max(0, curvol - 10))\n\n def seekBackSmall(self):\n if self.player:\n self.setPosition(max(self.getPosition() - 30, 0))\n\n def seekForwardSmall(self):\n if self.player:\n self.setPosition(min(self.getPosition() + 30, self.getDuration()))\n\n def seekBackLarge(self):\n if self.player:\n self.setPosition(max(self.getPosition() - 600, 0))\n\n def seekForwardLarge(self):\n if self.player:\n self.setPosition(min(self.getPosition() + 600, self.getDuration()))\n\n def prevAudioTrack(self):\n if self.player:\n currentTrack = self.player.audio_get_track()\n self.player.audio_set_track(currentTrack - 1)\n\n def nextAudioTrack(self):\n if self.player:\n currentTrack = self.player.audio_get_track()\n self.player.audio_set_track(currentTrack + 1)\n\n def prevSubtitle(self):\n if self.player:\n current = self.player.video_get_spu()\n self.player.video_set_spu(current - 1)\n\n def nextSubtitle(self):\n if self.player:\n current = self.player.video_get_spu()\n self.player.video_set_spu(current + 1)\n\n def isPlaying(self):\n if self.player:\n pos = self.getPosition()\n dur = self.getDuration()\n if pos and dur:\n if pos < dur:\n print 'Still playing (Position ' + str(pos) + ', duration ' + str(dur) + \")\"\n return self.player.is_playing() or ((dur - pos) > 1)\n else:\n print 'Finished Playing'\n else:\n return True\n return False\n"
},
{
"alpha_fraction": 0.6184757351875305,
"alphanum_fraction": 0.6207852363586426,
"avg_line_length": 23.325841903686523,
"blob_id": "4803c569c32207d122b8fd1c98fe7d096662b80a",
"content_id": "0ab7935ff1658008d0c4c3bd4a7c86881e601031",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2165,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 89,
"path": "/youtupi/engine/MockEngine.py",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "from youtupi.engine.PlaybackEngine import PlaybackEngine\nimport os, signal, subprocess, time\n\nSECONDS_SLEEP = 15\n\n'''\n@author: Max\n'''\nclass MockEngine(PlaybackEngine):\n\n '''\n Mock engine for testing purposes\n '''\n\n player = None\n baseVolume = None\n\n def play(self, video):\n if self.isPlaying():\n self.stop()\n playerArgs = [\"sleep\", str(SECONDS_SLEEP)]\n print \"Running player: \" + \" \".join(playerArgs)\n self.player = subprocess.Popen(playerArgs, stdin = subprocess.PIPE, stdout = subprocess.PIPE, stderr = subprocess.PIPE, preexec_fn=os.setsid)\n cont = 0\n while not self.isPlaying():\n time.sleep(1)\n cont = cont + 1\n\n def stop(self):\n print 'Stop requested'\n if self.isPlaying():\n os.killpg(self.player.pid, signal.SIGTERM)\n self.player = None\n\n def togglePause(self):\n print 'Toggle pause requested'\n\n def setPosition(self, seconds):\n print 'Requested position ' + str(seconds)\n\n def getPosition(self):\n return None\n\n def getDuration(self):\n if self.isPlaying():\n return SECONDS_SLEEP\n return None\n\n def setBaseVolume(self, vol):\n self.baseVolume = vol\n\n def getBaseVolume(self):\n return self.baseVolume\n\n def volumeUp(self):\n print 'Volume up requested'\n\n def volumeDown(self):\n print 'Volume down requested'\n\n def seekBackSmall(self):\n print 'seekBackSmall requested'\n\n def seekForwardSmall(self):\n print 'seekForwardSmall requested'\n\n def seekBackLarge(self):\n print 'seekBackLarge requested'\n\n def seekForwardLarge(self):\n print 'seekForwardLarge requested'\n\n def prevAudioTrack(self):\n print 'Previous Audio Track requested'\n\n def nextAudioTrack(self):\n print 'Next Audio Track requested'\n\n def prevSubtitle(self):\n print 'Previous Subtitle requested'\n\n def nextSubtitle(self):\n print 'Next Subtitle requested'\n\n def isPlaying(self):\n if self.player:\n if self.player.poll() == None:\n return True\n return False\n"
},
{
"alpha_fraction": 0.6785714030265808,
"alphanum_fraction": 0.680059552192688,
"avg_line_length": 21.399999618530273,
"blob_id": "8a819b4e3ceaa7a32a528e0218903720e0a35bc8",
"content_id": "72a28941691a38e3f7d5d2da90674ffad52550f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 672,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 30,
"path": "/youtupi/modules/playlist.py",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "import web, json\nfrom StringIO import StringIO\nfrom youtupi.playlist import removeVideo, addVideos, playList\n\nclass playlist:\n\tdef GET(self):\n\t\tweb.header('Content-Type', 'application/json')\n\t\tplaylistVideos = list()\n\t\tfor video in playList():\n\t\t\tplaylistVideos.append(video.data)\n\t\treturn json.dumps(playlistVideos, indent=4)\n\n\tdef POST(self):\n\t d = web.data()\n\t s = StringIO(d)\n\t print d\n\t\tdata = json.load(s)\n\t\taddVideos(data)\n\t\tweb.seeother('playlist')\n\n\tdef DELETE(self):\n\t\tdata = json.load(StringIO(web.data()))\n\t\tremoveVideo(data['id'])\n\t\tweb.seeother('playlist')\n\nurls = (\n\t'', 'playlist',\n)\n\nmodule_playlist = web.application(urls, locals())\n"
},
{
"alpha_fraction": 0.6441906094551086,
"alphanum_fraction": 0.6990805268287659,
"avg_line_length": 29.939655303955078,
"blob_id": "f0d8067f3b80b0801423559ab2ec2af45610fe8c",
"content_id": "a74a036848f7072793ad887204193324eae67b2c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3589,
"license_type": "no_license",
"max_line_length": 226,
"num_lines": 116,
"path": "/README.md",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "YouTuPi\n=======\n\nYouTuPi lets you play local and [YouTube](http://www.youtube.com/) videos in your\n[Raspberry Pi](http://www.raspberrypi.org/) using a (mobile) web interface. It\nprovides a web UI for [Omxplayer](https://github.com/huceke/omxplayer) (the\n[raspbian](http://www.raspbian.org/) media player). It has three modules:\n\n * Local file search and browse for available media in the filesystem\n * Youtube support thanks to [pafy](https://github.com/np1/pafy)\n * Paste video URL from anywhere\n\nScreenshots\n-----------\n\n\n\n\n\n\n\nManual installation\n-------------------\n\n1. Install dependencies:\n\n ```bash\n sudo apt-get update\n sudo apt-get install -y libpcre3 fonts-freefont-ttf omxplayer python-pip python-magic python-dbus git\n sudo pip install web.py beautifulsoup4 youtube_dl betterprint\n ```\n\n2. Clone repository:\n\n ```bash\n YOUTUPI_HOME=/home/pi/youtupi\n git clone git://github.com/kktuax/youtupi.git $YOUTUPI_HOME\n cd $YOUTUPI_HOME\n cp youtupi.conf.example youtupi.conf\n git submodule init\n git submodule update\n ```\n\n3. Register service:\n\n ```bash\n sudo cp $YOUTUPI_HOME/service/youtupi /etc/init.d/\n sudo update-rc.d youtupi defaults\n ```\n\nNote: If you want to run youtupi under a different user than `pi` or from a different directory, you'll need to modify `/etc/init.d/youtupi` before starting it.\n\n\nScripted installation\n---------------------\n\n cd ~\n curl https://raw.githubusercontent.com/kktuax/youtupi/master/service/install.sh -o youtupi-install.sh\n cat youtupi-install.sh # well, you need to check whether this shell script from the net is clean.\n chmod +x youtupi-install.sh\n sudo ./youtupi-install.sh\n\nNote: If you want to run youtupi under a different user than `pi` or from a different directory than `/home/pi/youtupi/`, you'll need to modify `youtupi-install.sh` after downloading and `/etc/init.d/youtupi` after installing.\n\nUse YouTuPi\n-----------\n\n * Start youtupi\n\n ```\n sudo /etc/init.d/youtupi start\n ```\n\n * Grab your Tablet/Phone/PC and go to: http://192.168.1.2:8080 (replace 192.168.1.2 with your Raspberry Pi address).\n * Enjoy!\n\nDebug YouTuPi\n-------------\n\n * Don't start the service (or stop it), then cd into `/home/pi/youtupi` and run it from the command line:\n\n ```\n sudo /etc/init.d/youtupi stop\n cd /home/pi/youtupi\n python youtupi.py\n ```\n\n * Grab your Tablet/Phone/PC and go to: http://192.168.1.2:8080 (replace 192.168.1.2 with your Raspberry Pi address).\n\nThis'll give you all the debug messages on the command line. Add more by adding print/pprint statements to the code.\n\n\n# Configuration file\n\nYou can customize the download folder and some other parameters in the JSON configuration file\n\n nano ~/youtupi/youtupi.conf\n\n<!-- -->\n\n {\n \"port\": 8888,\n \"local-folders\": [\n \"~/Media\", \"~/Downloads\"\n ],\n \"download-folder\": \"~/Downloads\"\n }\n\n\n## Problems?\n\nTry updating, or installing again a newer version\n\n sudo /etc/init.d/youtupi update\n\nStill no luck? Raise [an issue](https://github.com/kktuax/youtupi/issues/new)\n"
},
{
"alpha_fraction": 0.5429856777191162,
"alphanum_fraction": 0.5603406429290771,
"avg_line_length": 32.1010627746582,
"blob_id": "7ae399d13ead6fabf6e434c15ac1e225d1b6b7e6",
"content_id": "83ff2724593e354daaed5cf7c0d8c9cba9f5130f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6223,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 188,
"path": "/youtupi/engine/OMXPlayerEngine.py",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "from youtupi.engine.PlaybackEngine import PlaybackEngine\nfrom youtupi.modules import local\nimport os, signal, subprocess, dbus, time, textwrap, codecs, getpass\nfrom betterprint import pprint\n\nSECONDS_FACTOR = 1000000\nDBUS_RETRY_LIMIT = 50\nDISPLAY_SRT = \"/run/shm/youtupi.srt\"\n\n'''\n@author: Max\n'''\nclass OMXPlayerEngine(PlaybackEngine):\n\n '''\n OMXPlayer playback engine using DBUS interface\n '''\n\n def __init__(self):\n pass\n\n player = None\n baseVolume = 0\n\n def subtitleBlock(self, id, text):\n id = max(id, 1)\n r = \"\\n%d\\n00:00:%02d,000 --> 00:00:%02d,000\\n%s\\n\" % (id, (id-1)*5, id*5, \"\\n\".join(textwrap.wrap(text, 42)[:3]))\n return r\n\n def prepareSubtitles(self, fname, video):\n try:\n id = 1\n with codecs.open(fname, 'w', 'utf-8') as f:\n if 'title' in video.data:\n f.write(self.subtitleBlock(id, video.data['title']))\n id += 1\n if 'description' in video.data:\n f.write(self.subtitleBlock(id, video.data['description']))\n id += 1\n except Exception as e:\n pprint(e)\n\n def play(self, video):\n if not video.url:\n raise RuntimeError(\"Video URL not found\")\n if self.isPlaying():\n self.stop()\n volume = self.baseVolume * 100 # OMXPlayer requires factor 100 to dB input\n playerArgs = [\"omxplayer\", \"-b\", \"-o\", \"both\", \"--vol\", \"%d\" % volume ]\n if video.subtitles:\n local.copyAsUtf8File(video.subtitles, DISPLAY_SRT)\n playerArgs.extend((\"--subtitles\", DISPLAY_SRT))\n elif video.data:\n self.prepareSubtitles(DISPLAY_SRT, video)\n playerArgs.extend((\"--subtitles\", DISPLAY_SRT))\n playerArgs.append(video.url)\n print \"Running player: \" + \" \".join(playerArgs)\n self.player = subprocess.Popen(playerArgs, stdin = subprocess.PIPE, stdout = subprocess.PIPE, stderr = subprocess.PIPE, preexec_fn=os.setsid)\n\n def stop(self):\n if self.isProcessRunning():\n try:\n self.controller().Action(dbus.Int32(\"15\"))\n except:\n print \"Failed sending stop signal\"\n os.killpg(self.player.pid, signal.SIGTERM)\n self.player = None\n\n def togglePause(self):\n self.tryToSendAction(dbus.Int32(\"16\"))\n\n def setPosition(self, seconds):\n if self.isPlaying():\n try:\n self.controller().SetPosition(dbus.ObjectPath(\"/not/used\"), dbus.Int64(seconds*SECONDS_FACTOR))\n except:\n print 'Unable to set position'\n\n def getPosition(self):\n if self.isProcessRunning():\n try:\n return int(self.props().Position())/SECONDS_FACTOR\n except:\n print 'Unable to determine position'\n return 0\n return None\n\n def getDuration(self):\n if self.isProcessRunning():\n try:\n return int(self.props().Duration())/SECONDS_FACTOR\n except:\n print 'Unable to determine duration'\n return None\n\n def setBaseVolume(self, vol):\n self.baseVolume = vol\n\n def getBaseVolume(self):\n return self.baseVolume\n\n def volumeUp(self):\n self.tryToSendAction(dbus.Int32(\"18\"))\n\n def volumeDown(self):\n self.tryToSendAction(dbus.Int32(\"17\"))\n\n def seekBackSmall(self):\n self.tryToSendAction(dbus.Int32(\"19\"))\n\n def seekForwardSmall(self):\n self.tryToSendAction(dbus.Int32(\"20\"))\n\n def seekBackLarge(self):\n self.tryToSendAction(dbus.Int32(\"21\"))\n\n def seekForwardLarge(self):\n self.tryToSendAction(dbus.Int32(\"22\"))\n\n def prevAudioTrack(self):\n self.tryToSendAction(dbus.Int32(\"6\"))\n\n def nextAudioTrack(self):\n self.tryToSendAction(dbus.Int32(\"7\"))\n\n def prevSubtitle(self):\n self.tryToSendAction(dbus.Int32(\"10\"))\n\n def nextSubtitle(self):\n self.tryToSendAction(dbus.Int32(\"11\"))\n\n def isPlaying(self):\n if self.isProcessRunning():\n pos = self.getPosition()\n dur = self.getDuration()\n if pos and dur:\n if pos < dur:\n print 'Still playing (Position ' + str(pos) + ', duration ' + str(dur) + \")\"\n return True\n else:\n print 'Finished Playing'\n else:\n return True\n return False\n\n def tryToSendAction(self, action):\n if self.isProcessRunning():\n try:\n self.controller().Action(action)\n except:\n print 'Error connecting with player'\n\n def controller(self):\n retry=0\n while True:\n try:\n with open('/tmp/omxplayerdbus.'+getpass.getuser(), 'r+') as f:\n omxplayerdbus = f.read().strip()\n bus = dbus.bus.BusConnection(omxplayerdbus)\n dbobject = bus.get_object('org.mpris.MediaPlayer2.omxplayer','/org/mpris/MediaPlayer2', introspect=False)\n return dbus.Interface(dbobject,'org.mpris.MediaPlayer2.Player')\n except:\n time.sleep(0.1)\n retry+=1\n if retry >= DBUS_RETRY_LIMIT:\n raise RuntimeError('Error loading player dbus interface')\n\n def props(self):\n retry=0\n while True:\n try:\n with open('/tmp/omxplayerdbus.'+getpass.getuser(), 'r+') as f:\n omxplayerdbus = f.read().strip()\n bus = dbus.bus.BusConnection(omxplayerdbus)\n dbobject = bus.get_object('org.mpris.MediaPlayer2.omxplayer','/org/mpris/MediaPlayer2', introspect=False)\n return dbus.Interface(dbobject,'org.freedesktop.DBus.Properties')\n except:\n time.sleep(0.1)\n retry+=1\n if retry >= DBUS_RETRY_LIMIT:\n raise RuntimeError('Error loading player dbus interface')\n\n\n def isProcessRunning(self):\n if self.player:\n if self.player.poll() == None:\n return True\n return False\n"
},
{
"alpha_fraction": 0.6005586385726929,
"alphanum_fraction": 0.6089385747909546,
"avg_line_length": 28.83333396911621,
"blob_id": "daa0c52950b8959fbd8ff510e5e605fdd6e0db1c",
"content_id": "f1ce2df642fbea6b55a1ad1cef96719d072ccd77",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 358,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 12,
"path": "/youtupi/util/downloader.py",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "import urllib2\nimport os\n\ndef download(url, destination):\n tdestination = destination + \".part\"\n with open(tdestination, 'w') as f:\n try:\n f.write(urllib2.urlopen(url).read())\n f.close()\n os.rename(tdestination, destination)\n except urllib2.HTTPError:\n raise RuntimeError('Error getting URL.')\n"
},
{
"alpha_fraction": 0.7885304689407349,
"alphanum_fraction": 0.7945041656494141,
"avg_line_length": 32.47999954223633,
"blob_id": "3dcd52d1ae5a210fd7e7617ed8daab13467f5ba7",
"content_id": "7b3f1a3ab26dd45c2c37af2efffc18d6b64083b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 837,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 25,
"path": "/service/install.sh",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nYOUTUPI_HOME=/home/pi/youtupi\nYOUTUPI_USER=pi\n\nif [ -d \"$YOUTUPI_HOME\" ]; then\n\trm -rf $YOUTUPI_HOME\nfi\n\napt-get update && apt-get install -y libpcre3 fonts-freefont-ttf omxplayer python-pip python-magic python-dbus python-lxml git \npip install web.py==0.39 beautifulsoup4 youtube_dl betterprint\ngit clone git://github.com/kktuax/youtupi.git $YOUTUPI_HOME\ncd $YOUTUPI_HOME\ngit submodule init\ngit submodule update\ncp youtupi.conf.example youtupi.conf\nchown -R $YOUTUPI_USER:$YOUTUPI_USER $YOUTUPI_HOME\n\ncp $YOUTUPI_HOME/service/youtupi.service /etc/systemd/system/\ncp $YOUTUPI_HOME/service/youtupi-update.service /etc/systemd/system/\ncp $YOUTUPI_HOME/service/youtupi-update.timer /etc/systemd/system/\nsystemctl enable youtupi\nsystemctl start youtupi\nsystemctl enable youtupi-update.timer\nsystemctl start youtupi-update.timer\n"
},
{
"alpha_fraction": 0.6785411238670349,
"alphanum_fraction": 0.6938083171844482,
"avg_line_length": 26.418603897094727,
"blob_id": "19c2f560f478416ee3d2fe2244244205e7df9dcd",
"content_id": "69f40fb6ef40cbcd1378b72dd82648027530b8a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1179,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 43,
"path": "/youtupi.py",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env /usr/bin/python\n# -*- coding: utf-8 -*-\n\nimport web\nfrom youtupi.modules.local import module_local\nfrom youtupi.modules.youtube import module_youtube\nfrom youtupi.modules.url import module_url\nfrom youtupi.modules.control import module_control\nfrom youtupi.modules.playlist import module_playlist\nfrom youtupi.modules.preset import module_preset\nfrom youtupi.util import config\nimport sys\nreload(sys)\nsys.setdefaultencoding(\"utf-8\")\n\nclass redirect:\n\tdef GET(self, path):\n\t\tweb.seeother('/' + path)\n\nclass index:\n\tdef GET(self):\n\t\tweb.seeother('/static/index.html')\n\nclass MyApplication(web.application):\n def run(self, host='0.0.0.0', port=8080, *middleware):\n func = self.wsgifunc(*middleware)\n return web.httpserver.runsimple(func, (host, port))\n\nif __name__ == \"__main__\":\n\turls = (\n\t\t'/(.*)/', 'redirect',\n\t\t'/playlist', module_playlist,\n\t\t'/control', module_control,\n\t\t'/url', module_url,\n\t\t'/local', module_local,\n\t\t'/youtube', module_youtube,\n\t\t'/preset', module_preset,\n\t\t'/', 'index'\n\t)\n\tapp = MyApplication(urls, globals())\n\tport = config.conf.get('port', 8080)\n\thost = config.conf.get('host', '0.0.0.0')\n\tapp.run(host=host, port=port)\n"
},
{
"alpha_fraction": 0.601024866104126,
"alphanum_fraction": 0.601024866104126,
"avg_line_length": 14.522727012634277,
"blob_id": "3cbb2882639df36d74ccef8b15cd704100ef3420",
"content_id": "7af3cd638c63cc6c5306e00c1819230999c73049",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1366,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 88,
"path": "/youtupi/engine/PlaybackEngine.py",
"repo_name": "kktuax/youtupi",
"src_encoding": "UTF-8",
"text": "from abc import ABCMeta, abstractmethod\n\n'''\n@author: Max\n'''\nclass PlaybackEngine(object):\n\n __metaclass__ = ABCMeta\n\n '''\n Base class for video playback engines\n '''\n\n @abstractmethod\n def play(self, video):\n pass\n\n @abstractmethod\n def stop(self):\n pass\n\n @abstractmethod\n def togglePause(self):\n pass\n\n @abstractmethod\n def setPosition(self, seconds):\n pass\n\n @abstractmethod\n def getPosition(self):\n pass\n\n @abstractmethod\n def getDuration(self):\n pass\n\n @abstractmethod\n def isPlaying(self):\n pass\n\n @abstractmethod\n def volumeUp(self):\n pass\n\n @abstractmethod\n def volumeDown(self):\n pass\n\n @abstractmethod\n def seekBackSmall(self):\n pass\n\n @abstractmethod\n def seekForwardSmall(self):\n pass\n\n @abstractmethod\n def seekBackLarge(self):\n pass\n\n @abstractmethod\n def seekForwardLarge(self):\n pass\n\n @abstractmethod\n def prevAudioTrack(self):\n pass\n\n @abstractmethod\n def nextAudioTrack(self):\n pass\n\n @abstractmethod\n def prevSubtitle(self):\n pass\n\n @abstractmethod\n def nextSubtitle(self):\n pass\n\n @abstractmethod\n def getBaseVolume(self):\n pass\n\n @abstractmethod\n def setBaseVolume(self, vol):\n pass\n"
}
] | 26 |
jmore2290/supervised-learning-algos
|
https://github.com/jmore2290/supervised-learning-algos
|
fb338c7528aaf45d7d8da2bd6476c82013fdac07
|
955f7a79803071d551b3f1e67a1bb6a4da65c88b
|
46f3d7ece37836b81cc7dad945f712a6644a85aa
|
refs/heads/master
| 2020-04-04T23:11:34.074882 | 2015-04-20T21:16:10 | 2015-04-20T21:16:10 | 32,097,958 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7157001495361328,
"alphanum_fraction": 0.7751060724258423,
"avg_line_length": 31.136363983154297,
"blob_id": "83fee4f8ac3c36f6113fbec4bed2fd15da5b607d",
"content_id": "2be79d8e6a37e259275b5191ed654ca848125d15",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 707,
"license_type": "no_license",
"max_line_length": 198,
"num_lines": 22,
"path": "/supervised-learning-algos/decision-trees/README.md",
"repo_name": "jmore2290/supervised-learning-algos",
"src_encoding": "UTF-8",
"text": "This is the assignment for Lesson 9: Lab 1\nHere I have created a decision tree classifier on a dataset with the goal of predicting what type of iris a plant will be given a set of features. I've used bagging on this (an ensemble technique).\nI've also used KNN, KNN w/bagging and Logistic Regression on the dataset with the following results:\nDecision Tree:\nAverage Accuracy: 0.96\nSTD: 0.02\n\nDecision Tree w/bagging:\nAverage Accuracy: 0.95\nSTD: 0.0339\n\nKNN Classifier w/5 neighbors-- Varying K beyond of below 5 does not seen to benefit the classifier:\nAverage Accuracy: 0.97\nSTD: 0.0249\n\nKNN Classifier w/bagging:\nAverage Accuracy: 0.986\nSTD: 0.0163\n\nLogistic Regression:\nAverage Accuracy: 0.96\nSTD: 0.038\n"
},
{
"alpha_fraction": 0.6616064310073853,
"alphanum_fraction": 0.665194571018219,
"avg_line_length": 26.03731346130371,
"blob_id": "329d37d9ce13f9982bbd415f66c27f0268ab054c",
"content_id": "d1d854385e4adf8b1a47eab83312bfa765bc45ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3623,
"license_type": "no_license",
"max_line_length": 178,
"num_lines": 134,
"path": "/dat-chapter-7/solution.py",
"repo_name": "jmore2290/supervised-learning-algos",
"src_encoding": "UTF-8",
"text": "#Write a function unpunctuate that takes a string and removes all punctuation \n\ndef unpunctuate(sentence):\n count = 0\n newword = \" \"\n while count < len(sentence):\n if \"!\" in sentence[count] or \"'\" in sentence[count] or \"?\" in sentence[count]:\n count = count + 1\n continue\n else:\n newword = newword + sentence[count]\n count = count + 1\n print newword\n\n\nunpunctuate(\"Hey there! How's it going?\")\n\n\n#Write a function get_bag_of_words_for_single_document that, given any string (a#lso called document), e.g. \"John also likes to watch football games.\", returns #its bag of words.\n\nfrom collections import Counter\n\n\ncounts = Counter()\n\ndef get_bag_of_words_for_single_document(sentence):\n counts.update(word.strip('.,?!\"\\'').lower() for word in sentence.split())\n print counts\n \nget_bag_of_words_for_single_document(\"John also likes to watch football games to.\")\n\n\n\n\n\n\n\n\n\n#Write a function 'get_bag_of_words' that uses the above function to achieve the#following: given a list of strings, it returns the total bag of words for all t#he documents#\n\nimport collections\n\ncounts = collections.Counter()\nnewdict = []\n\nsentenceList = [\"John likes to watch movies. Mary likes movies too.\",\n \"John also likes to watch football games.\",] \n\ndef get_bag_of_words(sentences):\n for sentence in sentences:\n counts.update(word.strip('.,?!\"\\'').lower() for word in sentence.split())\n print counts\n\n\ndef removeduplicates(seq): \n checked = []\n for word in seq:\n if word not in checked:\n checked.append(word)\n return checked\n \nget_bag_of_words(sentenceList)\n\n\n\n\n#Given a bag of words for all of the documents in our data set, write a function# `turn_words_into_indices` take the keys in the bag of words and alphabetize th#em\n\nimport collections\n\ncounts = collections.Counter()\nnewdict = []\n\nsentenceList = [\"John likes to watch movies. Mary likes movies too.\",\n \"John also likes to watch football games.\",] \n\ndef get_bag_of_words(sentences):\n for sentence in sentences:\n counts.update(word.strip('.,?!\"\\'').lower() for word in sentence.split())\n print counts\n\n\ndef removeduplicates(seq): \n checked = []\n for word in seq:\n if word not in checked:\n checked.append(word)\n return checked\n\ndef turn_words_into_indices(collectcount):\n print removeduplicates(sort(list(collectcount.elements())))\n\n \nget_bag_of_words(sentenceList)\n\nturn_words_into_indices(counts)\n\n#iven a document, write a function `vectorize` that turns the document into a li#st (also will be called a vector) the same length as the number of keys of bag #of words where\n#for each index of the list will be 1 only if the word at that index in the word #list is contained in the document and 0 otherwise\n\nimport re\n\nwordlist = [\"also\", \"football\", \"games\", \"John\", \"likes\", \"Mary\", \"movies\", \"to\", \"too\", \"watch\"]\n\ndict1 = {}\nmadelist = []\n\nfor i in range(len(wordlist)):\n dict1[wordlist[i].lower()] = 0\n \n\n \n \n \ndef vectorize(document):\n altdocument = prepString(document)\n print altdocument\n for m in wordlist:\n for phrase in re.finditer(\" \"+m+\" \", altdocument):\n dict1[m] = dict1[m] + 1\n for key in sorted(dict1.iterkeys()):\n madelist.append(dict1[key])\n print madelist\n \ndef prepString(samplestr):\n newword = \" \"\n newstring = \" \"\n for word in samplestr:\n newstring = newstring + word.strip('.,?!\"\\'').lower()\n return newstring\n \n \nvectorize(\"The sun also football rises like watch football? Hey Mary! in football movies \")\n"
},
{
"alpha_fraction": 0.8339622616767883,
"alphanum_fraction": 0.8339622616767883,
"avg_line_length": 28.33333396911621,
"blob_id": "648bffd3915ee8f03524df746b2d03cd062f5ce8",
"content_id": "4990528b6439d17d91819cb3ad27f9144b7e8a9d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 265,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 9,
"path": "/supervised-learning-algos/README.md",
"repo_name": "jmore2290/supervised-learning-algos",
"src_encoding": "UTF-8",
"text": "In this repository, I demonstrate mastery of the most common supervised learningalgorithms:\n-Linear Regression\n-Logistic Regression\n-Naive Bayes Classifier\n- K-Nearest Neighbors\n-Support Vector Machines\n-Artificial Neural Networkds\n-Random Forests\n-Decision Trees\n\n"
},
{
"alpha_fraction": 0.736190676689148,
"alphanum_fraction": 0.752234697341919,
"avg_line_length": 32.037879943847656,
"blob_id": "25ba7d9d9d0b2b6c83856449be1d6c6d01f39e56",
"content_id": "74b2d826a59cd6f8fcb9df1e52c05ce753618bfe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4363,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 132,
"path": "/supervised-learning-algos/decision-trees/solution.py",
"repo_name": "jmore2290/supervised-learning-algos",
"src_encoding": "UTF-8",
"text": "### Run this code separately: Decision Tree ###\nimport pandas as pd\nimport numpy as np\nfrom sklearn.ensemble import BaggingClassifier \nfrom sklearn import tree\nfrom sklearn.cross_validation import cross_val_score\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn import linear_model\nfrom sklearn.cross_validation import train_test_split\n\n\ndf = pd.read_csv('https://s3-us-west-2.amazonaws.com/ga-dat-2015-suneel/datasets/iris.csv')\n\ndecision_tree_clf = tree.DecisionTreeClassifier(\n # dont split if the max number of samples on either side of the slice is less than 2\n min_samples_leaf=2)\nfeatures = [\"sepal_length\", \"sepal_width\", \"petal_length\", \"petal_width\"]\n\n# use K-fold cross validation, with k=5 and get a list of accuracies\nscores = cross_val_score(decision_tree_clf, df[features], df[\"target\"], cv=5)\n\nprint \"\\nDECISION TREE:\\n\"\n# print the accuracies\nprint scores\n# print the average accuracy\nprint scores.mean()\n# print the standard deviation of the scores\nprint np.std(scores)\n\n\n# now let's try a bagging example\nbagging_clf = BaggingClassifier(\n decision_tree_clf,\n #you can pass other classifiers here.\n # bag using 20 trees\n n_estimators=20,\n # the max number of samples to draw from the training set for each tree\n # there are 105 training samples, so each tree will have .8 * 105\n # data points each to train on, chosen randomly with replacement\n max_samples=0.8,\n)\n\n\n# use K-fold cross validation, with k=5 and get a list of accuracies\n# this separates the data into training and test set 5 different times for us\n# and finds out the accuracy in each case to get a sense of the average accuracy\nscores = cross_val_score(bagging_clf, df[features], df[\"target\"], cv=5)\n\nprint \"\\nDECISION TREE WITH BAGGING:\\n\"\n# print the accuracies\nprint scores\n# print the average accuracy\nprint scores.mean()\n# print the standard deviation of the scores\nprint np.std(scores)\n\n### Run this code separately: KNN###\nimport pandas as pd\nimport numpy as np\nfrom sklearn.ensemble import BaggingClassifier \nfrom sklearn import tree\nfrom sklearn.cross_validation import cross_val_score\nfrom sklearn.neighbors import KNeighborsClassifier\n\ndf = pd.read_csv('https://s3-us-west-2.amazonaws.com/ga-dat-2015-suneel/datasets/iris.csv')\n\nfeatures = [\"sepal_length\", \"sepal_width\", \"petal_length\", \"petal_width\"]\n\nclf = KNeighborsClassifier(n_neighbors=5)\nscore2 = cross_val_score(clf, df[features], df[\"target\"], cv=5)\n\nprint score2\n# print the average accuracy\nprint score2.mean()\n# print the standard deviation of the scores\nprint np.std(score2)\n\n### Run this code separately: KNN w/bagging ###\n\nimport pandas as pd\nimport numpy as np\nfrom sklearn.ensemble import BaggingClassifier \nfrom sklearn import tree\nfrom sklearn.cross_validation import cross_val_score\nfrom sklearn.neighbors import KNeighborsClassifier\n\ndf = pd.read_csv('https://s3-us-west-2.amazonaws.com/ga-dat-2015-suneel/datasets/iris.csv')\n\nfeatures = [\"sepal_length\", \"sepal_width\", \"petal_length\", \"petal_width\"]\n\nclf = KNeighborsClassifier(n_neighbors=5)\n\n\nbagging_clf = BaggingClassifier(\n clf,\n #you can pass other classifiers here.\n # bag using 20 trees\n n_estimators=20,\n # the max number of samples to draw from the training set for each tree\n # there are 105 training samples, so each tree will have .8 * 105\n # data points each to train on, chosen randomly with replacement\n max_samples=0.8,\n)\n\nscore2 = cross_val_score(bagging_clf, df[features], df[\"target\"], cv=5)\n\nprint score2\n# print the average accuracy\nprint score2.mean()\n# print the standard deviation of the scores\nprint np.std(score2)\n\n### Run this code separately: Logisitc Regression ###\n\nimport pandas as pd\nimport numpy as np\nfrom sklearn.ensemble import BaggingClassifier \nfrom sklearn import tree\nfrom sklearn.cross_validation import cross_val_score\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn import linear_model\nfrom sklearn.cross_validation import train_test_split\n\n\ndf = pd.read_csv('https://s3-us-west-2.amazonaws.com/ga-dat-2015-suneel/datasets/iris.csv')\n\nfeatures = [\"sepal_length\", \"sepal_width\", \"petal_length\", \"petal_width\"]\n\nlogistic_clf = linear_model.LogisticRegression()\nscores = cross_val_score(logistic_clf, df[features], df[\"target\"], cv=5)\nprint \"Mean: {}\".format(scores.mean())\nprint \"Std Dev: {}\".format(np.std(scores))\n\n\n"
},
{
"alpha_fraction": 0.7900000214576721,
"alphanum_fraction": 0.79666668176651,
"avg_line_length": 297,
"blob_id": "7470353fb47f097f5bd3f84e393b06d93218aba4",
"content_id": "5552f4301a68561e6d64249e1fa803dc44f55f36",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 300,
"license_type": "no_license",
"max_line_length": 297,
"num_lines": 1,
"path": "/dat-chapter-7/README.md",
"repo_name": "jmore2290/supervised-learning-algos",
"src_encoding": "UTF-8",
"text": "Contained in the file solution.py are the answers and explanations for the NLP Programming Exercises section of Lesson 7: SVM, CTD and Recap. There are 5 programming problems in total, the solutions are stacked one on top of the other. Please run each body of code separately where it indicates. \n"
},
{
"alpha_fraction": 0.7876631021499634,
"alphanum_fraction": 0.8007117509841919,
"avg_line_length": 119.42857360839844,
"blob_id": "4f16ca835847209adcaac19b84fca8535fa20121",
"content_id": "724522ace1b4a1cd27e2c081c60fb802c8e69ea8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1686,
"license_type": "no_license",
"max_line_length": 466,
"num_lines": 14,
"path": "/supervised-learning-algos/practicum_01/README.md",
"repo_name": "jmore2290/supervised-learning-algos",
"src_encoding": "UTF-8",
"text": "The two files LabelEncoder.py and DictVectorizer.py both describe different coding techniques in dealing with the census data present in the file adult.data. Specifically, LabelEncoding and DictVectorizing are methods for ennumerating categorical data that is non-numerical. I have also answered the questions in the lab 1 of the practicum by changing the parameters in each model. I have found the following:\n\nAltering the value of c for SVC (tuning):\n Changing C to 85 results in greatly improved accuracy for SVC (from .63 to .77). However, changing C to around 25, also results in good accuracy measures .79.\n\nAltering the value of n_estimators for the tree based classifiers:\n Changing the n_estimators parameter results in slightly different accuracies when dealing with labelencoder and dictvectorizer. In general the accuracies for labelencoder are higher with fairly low standard deviations, compared to dictvectorizer. For example, @ n_estimators = 30: labelencoder is .857 and dictvectorizer is .837. Also, in general increasing the n_estimators variable leads to slightly higher accuracies and slightly lower standard deviations. \n\nAltering the value of cv when running models:\n In general increasing the value of cv (I ran all the models on a value of 3), made everything worse (accuracies and standard deviation). I guess becuase you are slicing the test data into smaller sizes when you increase cv.\n\nAltering the Logisitic Penalty from l2 to l1:\n\n This leads to a small increase in mean accuracy in logisitic regression for label encoder. However, it seems to have greatly improved Dictvectorizer's logisitic regression (w/small increase in std dev.)\n"
},
{
"alpha_fraction": 0.6524187326431274,
"alphanum_fraction": 0.6593294143676758,
"avg_line_length": 33.27193069458008,
"blob_id": "647372835f3ec4c7a15f042022e44b062d5e620d",
"content_id": "2167114ecc09d048c08bce992b2ce70348bb0746",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3908,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 114,
"path": "/supervised-learning-algos/naive-bayes/solution.py",
"repo_name": "jmore2290/supervised-learning-algos",
"src_encoding": "UTF-8",
"text": "import csv \nimport nltk\nimport random\nimport time\n\n\ndef sms_features(message):\n \"\"\"\n This method returns a dictionary of features that we want out model to be based on. See return statement to see exactly which \n features are being included in our model.\n \"\"\"\n return{\n \"contains_poundcurrency\": \"£\" in message,\n \"contains_free\": \"Free\" in message or \"free\" in message,\n \"contains_clickhere\": \"Click Here\" in message or \"click here\" in message or \"Click here\" in message,\n \"contains_dotcomandnet\": \".net\" in message or \".com\" in message,\n \"contains_XXX\": \"xxx\" in message or \"XXX\" in message or \"XxX\" in message,\n \"contains_TXT\": \"TxT\" in message or \"txt\" in message or \"TXT\" in message,\n }\n\n\n\ndef get_feature_sets():\n \"\"\"\n # Step 1: This reads in the rows from the csv file which look like this:\n ['ham', 'I had askd u a question some hours before. Its answer']\n ['spam', \"Win your free tickets to Sunday's game, just text 4589 back to our studio.\"]\n\n where the first row is the label; ham, spam\n and the second row is the body of the sms message\n\n # Step 2: Turn the csv rows into feature dictionaries using `sms_features` function above.\n\n The output of this function run on the example in Step 1 will look like this:\n [\n ({\"contains_poundcurrency\": true}, spam), # this corresponds to spam, \"Win your free tickets to Sunday's game, just text 4589..\n ({\"contains_poundcurrency\": false}, ham) # this corresponds to ham, 'I had askd u a question some hours before. Its answer'\n ]\n\n You can think about this more abstractly as this:\n [\n (feature_dictionary, label), # corresponding to row 0\n ... # corresponding to row 1 ... n\n ]\n \"\"\"\n f = open('/home/vagrant/repos/datasets/sms_spam_or_ham.csv', 'rb')\n # let's read in the rows from the csv file\n rows = []\n \n for row in csv.reader( f ):\n rows.append( row )\n\n rows = rows[1:]\n \n output_data = []\n \n # Currently using half of the dataset, will apply to entire dataset when I am more confident of my feature's accuracy. \n for row in rows[850:2500]:\n try:\n indicator = row[0]\n feature_dict = sms_features(row[1])\n except:\n pass\n data = (feature_dict, indicator)\n output_data.append(data)\n \n f.close()\n return output_data\n\ndef get_training_and_validation_sets(feature_sets):\n \n random.shuffle(feature_sets)\n \n count = len(feature_sets)\n \n slicing_point = int(.20 * count)\n \n training_set = feature_sets[:slicing_point]\n \n validation_set = feature_sets[slicing_point:]\n \n return training_set, validation_set\n\ndef run_classification(training_set, validation_set):\n # train the NaiveBayesClassifier on the training_set\n classifier = nltk.NaiveBayesClassifier.train(training_set)\n # let's see how accurate it was\n accuracy = nltk.classify.accuracy(classifier, validation_set)\n print \"The accuracy was.... {}\".format(accuracy)\n return classifier\n\ndef predict(classifier, new_tweet):\n \"\"\"\n Given a trained classifier and a fresh data point (an SMS),\n this will predict its label, either 0 or 1 (spam or ham).\n \"\"\"\n return classifier.classify(sms_features(new_tweet))\n\n\nstart_time = time.time()\n\nprint \"Let's use Naive Bayes!\"\n\nour_feature_sets = get_feature_sets()\nour_training_set, our_validation_set = get_training_and_validation_sets(our_feature_sets)\nprint len(get_feature_sets())\n\nprint \"Now training the classifier and testing the accuracy...\"\nclassifier = run_classification(our_training_set, our_validation_set)\n\nend_time = time.time()\ncompletion_time = end_time - start_time\nprint \"It took {} seconds to run the algorithm\".format(completion_time)\nprint \"It took {} seconds to run the algorithm\".format(completion_time)\n"
},
{
"alpha_fraction": 0.783197820186615,
"alphanum_fraction": 0.7886179089546204,
"avg_line_length": 367,
"blob_id": "2a935e61bf664a9bb911343caa1e0c52d56a45e0",
"content_id": "1c7bed624cb4f7001bf25af342512b1d3a0b89c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 369,
"license_type": "no_license",
"max_line_length": 367,
"num_lines": 1,
"path": "/supervised-learning-algos/naive-bayes/README.md",
"repo_name": "jmore2290/supervised-learning-algos",
"src_encoding": "UTF-8",
"text": "\nPresented here, I am using a Naive Bayes Classifier to accurately classify SMSs as either spam or ham. I have managed to get ~ 92% accuracy by taking advantage of the fact that many SMS messages in the data set want the mobile user to click on a link or take some critical action. The way I actually managed to classify my data can be seen in the method sms_features.\n"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.7727272510528564,
"avg_line_length": 21,
"blob_id": "61f2c70447788c89a90e41a2a0a2e599ebbfc956",
"content_id": "66845ed415b3cd612d653a65f0a4e5a819354a1e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 44,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 2,
"path": "/README.md",
"repo_name": "jmore2290/supervised-learning-algos",
"src_encoding": "UTF-8",
"text": "# supervised-learning-algos\n# dat-chapter-7\n"
}
] | 9 |
Baba-Bob-Soile/trinity-clock
|
https://github.com/Baba-Bob-Soile/trinity-clock
|
27e8665f2af4a9f980a25b4959cc16459b860d80
|
3a81a25802307f7bc910dd02652f6e7c4fdaab5c
|
86c3ec3232c4746c7e79f8e84e7831942ea3cc4f
|
refs/heads/master
| 2021-01-11T10:48:17.624769 | 2017-03-20T00:40:07 | 2017-03-20T00:40:07 | 76,178,523 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5841643810272217,
"alphanum_fraction": 0.6035056114196777,
"avg_line_length": 32.76530456542969,
"blob_id": "ce8306e869b7e20d5655a0a9c5ddb38e3d4c96dd",
"content_id": "8cad5df1ec6e0e4b8b928efa7b1e5c407e289195",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3309,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 98,
"path": "/temperature/trinity_tem.py",
"repo_name": "Baba-Bob-Soile/trinity-clock",
"src_encoding": "UTF-8",
"text": "import time\nimport datetime\nimport matplotlib.pyplot as plt\nimport matplotlib.dates as md\nimport numpy as np\nimport os\nimport os.path\nfrom ds18b20 import DS18B20\n\ndef plot_temp():\n results_data=np.loadtxt(txt_name,skiprows=1)\n rows=results_data.size/(no_of_sensors+1)\n if rows > 1:\n unix_time=results_data[0:,0]\n date_time= [None] * len(unix_time)\n for index,time_inst in enumerate(unix_time):\n datetime_data=datetime.datetime.fromtimestamp(unix_time[index])\n date_time[index]=datetime_data\n \n plt.figure()\n xfmt = md.DateFormatter('%H:%M')\n xfmtb= md.HourLocator(interval=2)\n legendlabel=[None]*len(np.arange(no_of_sensors))\n for index in np.arange(no_of_sensors):\n legendlabel[index]=\"Probe {}\".format(index+1)\n lineobjects=plt.plot(date_time,results_data[0:,1:])\n plt.title(\"Temperature vs Time\")\n plt.legend(lineobjects,legendlabel)\n plt.ylabel(\"Temperature (degree Celsius)\")\n plt.xlabel(\"Time in seconds since \"+start_time_formatted)\n ax=plt.gca()\n ax.xaxis.set_major_formatter(xfmt)\n ax.xaxis.set_major_locator(xfmtb)\n plt.savefig(image_name)\n plt.close()\n return\n\nsensors = DS18B20.get_all_sensors()\nno_of_sensors=len(DS18B20.get_available_sensors())\nsensor =np.array([])\nsensor_header=\"unixtime Probe1(bottom) #2 #3 #4 #5 #6(top)\\n\"\nprint(sensor_header)\ntic=time.time()\n\nprint(\"In While Loop...\")\npath=\"/home/pi/Temperature/\"\nsensor_data= sensor_header\n\nwhile True:\n start_time=datetime.datetime.now()\n start_time_formatted=start_time.strftime(\"%Y-%m-%d\")\n year_month=start_time.strftime(\"%Y/%m/\")\n new_path=\"{}{}\".format(path,year_month)\n \n #start_time_formatted=\"test_fixed\"\n image_name=\"{}{}.png\".format(new_path,start_time_formatted)\n txt_name=\"{}{}.txt\".format(new_path,start_time_formatted)\n\n #Makes directory if it doesn't exist\n if not os.path.exists(new_path):\n os.makedirs(new_path)\n #Writes header to file if it did not exist previously\n if os.path.isfile(txt_name) != True: \n f=open(\"{}\".format(txt_name), \"a+\")\n f.write(\"{}\".format(sensor_header))\n f=open(\"{}\".format(txt_name), \"a+\")\n \n data=np.array([])\n unixtime=time.time()\n tic=unixtime\n data=np.append(data,[unixtime])\n\n for index,sensor in enumerate(sensors):\n data=np.append(data, sensor.get_temperature())\n\n #rearranges the data to txt file arrange in physical order\n probe_data= [None] * len(data)\n probe_data[0]=data[0]\n probe_data[1]=round(data[5],4)\n probe_data[2]=round(data[6],4)\n probe_data[3]=round(data[3],4)\n probe_data[4]=round(data[2],4)\n probe_data[5]=round(data[4],4)\n probe_data[6]=round(data[1],4)\n print probe_data[1:]\n\n f.write(\"{} {} {} {} {} {} {} \\n\".format(probe_data[0],probe_data[1],\n probe_data[2],probe_data[3],\n probe_data[4],probe_data[5],\n probe_data[6]))\n f.close #saves file\n \n f=open(\"{}\".format(txt_name), \"a+\")\n plot_temp()\n\n #Waits for a minute before plotting next data\n while time.time()-tic<60:\n time.sleep(0.01)\n"
},
{
"alpha_fraction": 0.5373334884643555,
"alphanum_fraction": 0.5623570680618286,
"avg_line_length": 37.858638763427734,
"blob_id": "0a132c58be4017da37be629b2f832a6efe719f34",
"content_id": "28b66dc648358b363ed945db99a135e580f345d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7433,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 191,
"path": "/laser_detection/video/trinity_vid.py",
"repo_name": "Baba-Bob-Soile/trinity-clock",
"src_encoding": "UTF-8",
"text": "#Python 3.2.3 (default, Mar 1 2013, 11:53:50) \n#[GCC 4.6.3] on linux2\n#Type \"copyright\", \"credits\" or \"license()\" for more information.\nimport os\nfrom subprocess import call\nimport datetime\nimport picamera\nimport numpy as np\nimport imageio\nimport matplotlib as mpl\nmpl.use('Agg')\nfrom PIL import Image\nfrom matplotlib import pyplot as plt\nfrom matplotlib import patches as patch\nfrom time import sleep\nimport cv2\n\ndef clean_image (image):\n image =cv2.GaussianBlur(image,(9,9),0) \n thresh = cv2.threshold(image, 200, 255, cv2.THRESH_BINARY)[1]\n thresh = cv2.erode(thresh, None, iterations=1)\n thresh = cv2.dilate(thresh, None, iterations=2)\n im_clean = thresh\n\n return im_clean\ndef find_first_blob_coords(contours,imCopy):\n contour_areas = [cv2.contourArea(contour) for contour in contours]\n max_index = np.argmax(contour_areas)\n max_contour=contours[max_index]\n\n contour_moment = cv2.moments(max_contour)\n cx = (contour_moment['m10']/contour_moment['m00'])\n cy = (contour_moment['m01']/contour_moment['m00'])\n## (x,y),radius = cv2.minEnclosingCircle(max_contour)\n## center = (int(x),int(y))\n## radius = int(radius)\n## cv2.circle(imCopy,center,radius,(0,0,255),1)\n## cv2.drawContours(imCopy, max_contour, -1, (0,255,0), 1)\n\n return cx, cy\n \ndef find_blob_coords (frame,index,video_name):\n \n global cx, cy, blob_found, radius, height, width\n #Load Image, Resize and Convert To Grayscale\n im = frame\n image_name=\"{}-index{}cleaned.png\".format(video_name,index)\n #im_name=\"{}-index{}.png\".format(video_name,index)\n #im =cv2.resize(im,None,fx=0.5, fy=0.5, interpolation = cv2.INTER_AREA)\n height, width, channels = im.shape\n im =cv2.cvtColor(im, cv2.COLOR_RGB2GRAY )\n #cv2.imwrite(im_name,im)\n \n if blob_found==True:\n #If Blob found in Previous Frame\n #Set Region of Interest (roi) to look for blob in frame\n xmin = max(0,cx-20)\n ymin = max(0,cy-20)\n xmax = min(width, cx +20)\n ymax = min(height, cy+20)\n\n roi = im[ymin:ymax,\n xmin:xmax]\n thresh = clean_image (roi)\n imCopy = cv2.cvtColor(thresh, cv2.COLOR_GRAY2RGB)\n contours, hierarchy= cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,\n cv2.CHAIN_APPROX_NONE)\n \n if len(contours)!=0:\n cropped_cx, cropped_cy= find_first_blob_coords(contours, imCopy)\n cx = cropped_cx+ xmin\n cy = cropped_cy+ ymin\n blob_found=True\n return np.array([index,cx,cy])\n else:\n #cv2.imwrite(image_name,roi)#Change im to roi for troubleshooting\n blob_found=False\n print \"no blob found in cropped frame #{}\".format(index)\n return []\n\n else:\n #If Blob not found in Previous Frame\n #searches whole image rather than ROI\n thresh = clean_image (im)\n imCopy = cv2.cvtColor(thresh, cv2.COLOR_GRAY2RGB )\n contours, hierarchy= cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,\n cv2.CHAIN_APPROX_NONE)\n \n if len(contours)!=0: \n cx, cy= find_first_blob_coords(contours, imCopy)\n #cv2.imwrite(image_name,imCopy)\n blob_found=True\n return np.array([index,cx,cy])\n else:\n #cv2.imwrite(image_name,im)\n blob_found=False\n print \"no blob found in frame #{}\".format(index)\n return []\ndef plot_trajectory(xy_coords):\n global index, height, width\n plt.figure()\n #plt.axis((0,width,0,height))\n plt.scatter(xy_coords[0:,0],xy_coords[0:,1])\n numberOfBlobsDetected=xy_coords[0:,0].size\n plt.title(\"Laser Trajectory-{}/{}blobs found\".format(numberOfBlobsDetected\n ,index))\n plt.xlabel(\"x_coords\")\n plt.ylabel(\"y_coords\")\n## plt.xlim(xmin=0)\n## plt.ylim(ymin=0)\n plt.savefig(\"{}-trajectory.png\".format(video_name))\ndef trajectory_analysis(results):\n \n frame_no=results[1:,0]\n #time= frame_no/5\n x_coords=results[1:,1]\n y_coords=results[1:,2]\n plt.close('all')\n\n fig, axarr = plt.subplots(2, sharex=True)\n\n axarr[0].plot(frame_no, x_coords)\n axarr[0].set_title(\"Trajectory Coordinates vs Frame Number\")\n axarr[0].set_xlabel(\"Frame Number\")\n axarr[0].set_ylabel(\"x coordinate\")\n axarr[1].set_xlabel(\"Frame Number\")\n axarr[1].set_ylabel(\"y coordinate\")\n axarr[1].plot(frame_no, y_coords)\n\n fig.savefig(\"{}_analysis.png\".format(video_name))\n \ntic= datetime.datetime.now()\nwhile True:\n print(\"start\")\n #Initialise Variables to be used by functions\n blob_found=False\n cx=cy=radius=index=height=width=0\n #Names image to be saved with timestamp so it is unique\n tic=datetime.datetime.now()\n time_now=datetime.datetime.now()\n## time_formatted=time_now.strftime(\"%Y-%m-%d_%H-%M-%S\")\n #time_formatted=\"2V_1Hz_10cm_1640x1232\"\n time_formatted=\"fixed_vertical_2V\"\n \n video_name= \"/home/pi/camera/{}\".format(time_formatted)\n video_name_h264= \"{}.h264\".format(video_name)\n video_name_mp4= \"{}.mp4\".format(video_name)\n video_name_txt= \"{}.txt\".format(video_name)\n #Camera takes picture and saves its name as the time stamp\n print(\"taking video\")\n with picamera.PiCamera() as camera:\n camera.resolution=(1640,1232)\n camera.framerate= 30\n camera.start_recording(\"{}\".format(video_name_h264))\n camera.wait_recording(5)\n camera.stop_recording()\n #convert h264 to mp4 using gpac wrapper so it can be watched on PC/Mac\n## call(\"MP4Box -fps 30 -add {} {}\".format(video_name_h264,video_name_mp4),shell=True)\n\n\n #Loads Video\n\n #vid = cv2.VideoCapture(video_name_mp4)\n vid = cv2.VideoCapture(video_name_h264)\n results=np.array([\"index\",\"x-coord\",\"y-coord\"])\n\n #Check if Video was Loaded Properly\n if not vid.isOpened():\n print \"can't open video\"\n #Iterates through each video frame and finds blob\n while(vid.isOpened()):\n index=index+ 1\n ret, frame = vid.read() \n if ret==True:\n frame=cv2.flip(frame,0)\n index_results=find_blob_coords(frame,index,video_name)\n if index_results!=[]:\n results=np.vstack((results, index_results))\n else:\n break\n print\"results {}\".format(results)\n np.savetxt(video_name_txt,results, delimiter=\" \", fmt=\"%s\")\n\n xy_coords=results[1:,1:]\n plot_trajectory(xy_coords)\n trajectory_analysis(results)\n toc=datetime.datetime.now()\n programtime=toc-tic\n print\"Time: {}\".format(programtime.seconds)\n print \"sleeping for 30 secs\"\n sleep(30)\n \n \n\n"
},
{
"alpha_fraction": 0.5317885875701904,
"alphanum_fraction": 0.5637686848640442,
"avg_line_length": 35.09090805053711,
"blob_id": "e3d31cc24e4701a8a442010abbae00cccf40367e",
"content_id": "220e595ec4676e2b0f6268d24abd0861e682244c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5222,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 143,
"path": "/tilt/trinity_tilt.py",
"repo_name": "Baba-Bob-Soile/trinity-clock",
"src_encoding": "UTF-8",
"text": "from __future__ import print_function\nfrom time import sleep\nfrom scipy import signal\nimport numpy as np\nimport time\nimport datetime\nimport spidev\nimport matplotlib.pyplot as plt\n \n# Open SPI bus\nspi = spidev.SpiDev()\nspi.close()\nspi.open(0,0)\nspi.max_speed_hz = 10000#150000\nspi.cshigh = False\n\ndef twos_complement(input_value, num_bits):\n\t#Calculates a two's complement integer\n #from the given input value's bits\n\tmask = 2**(num_bits - 1)\n\treturn -(input_value & mask) + (input_value & ~mask)\ndef ConvertVolts(data,places):\n offset= 0 #0.007\n volts = (data * 4.096) / float(pow(2,16))\n volts = round(volts,places)+offset\n return volts\n\ndef noise_filter(input_signal):\n b, a = signal.butter(4, 0.67, 'low', analog=True)\n output_signal = signal.filtfilt(b, a,input_signal)\n \ndef movingaverage(interval, window_size):\n window = np.ones(int(window_size))/float(window_size)\n return np.convolve(interval, window, 'same')\n\ndef plot_conv_ma():\n fig, axarr = plt.subplots(4, sharex=True)\n axarr[0].set_title(\"Tilt Measurements\")\n axarr[0].set_ylabel(\"Inst.\")\n axarr[0].plot(time_noise, inst)\n axarr[1].set_ylabel(\"1 MA\")\n axarr[1].plot(time_noise, mov_ave)\n axarr[2].set_ylabel(\"2 MA\")\n axarr[2].plot(time_noise, mov_ave_second)\n axarr[3].set_ylabel(\"3 MA\")\n axarr[3].plot(time_noise, mov_ave_third) \n fig.savefig(\"Noise_in_Tilt_Comparison_{}_conv.png\".format(time_formatted))\n plt.close(fig)\n\n#Function to read SPI data from LTC1867 chip\n# Channel must be an integer 0-7\ndef ReadChannel():\n #Performs an SPI transaction.\n #Chip-select should be held active between blocks.\n #pi.spi_xfer([XXXXXXX,0])#sends 2 bytes 1st contains DIN, second is irrelevant\n #See http://cds.linear.com/docs/en/datasheet/18637fc.pdf for more info\n #pin 7-GND=[244,0] connected to ground\n #pin 6-GND=[180,0]\n #pin 5-GND=[228,0] connected to 2.5V\n #pin 1-GND=[196,0]\n #pin 1-pin 2= [0,0]connected to analog level\n #pin 6-pin 7= [48,0] should be 2.5V\n\n channel_six = spi.xfer2([180,0])\n channel_seven = spi.xfer2([244,0])\n tilt = spi.xfer2([0,0])\n \n six_data = (channel_six[0]<<8) + channel_six[1]\n sev_data = (channel_seven[0]<<8) + channel_seven[1]\n\n tilt_data = (tilt[0]<<8) + tilt[1]\n dummy=six_data\n six_data=sev_data\n sev_data=tilt_data\n tilt_data=dummy\n tilt_data = twos_complement(tilt_data,16)\n tilt_measured=ConvertVolts(tilt_data,4)\n tilt_corrected=tilt_measured*float(40000/six_data)\n return tilt_corrected\n\nprint(\"Reading LTC1867 values, press Ctrl-C to quit...\")\n\ndelay=0.05\nreading=ReadChannel()\nindex=0\nsaved=False\nwritten=0\nheader=\"time inst.\\n\"\n\ntic= time.time()\ndatetime_now=datetime.datetime.now()\ntime_formatted=datetime_now.strftime(\"%Y-%m-%d_%H-%M-%S\")\n##time_formatted=\"49_60_batt\"\nfilename=\"tilt_{}\".format(time_formatted)\nfilename_txt= \"{}_1_hr_after.txt\".format(filename,0)\nf=open(\"{}\".format(filename_txt), \"a+\")\nf.write(\"{}\".format(header))\nwhile True:\n time_now=time.time()\n tilt_inst = ReadChannel()\n index=index +1\n sleep(delay)\n \n f.write(\"{} {}\\n\".format(time_now, tilt_inst))\n \n timediff=time_now-tic\n timediff_secs=int(timediff)\n no_hours= timediff_secs/3600\n if timediff_secs%5==0 and timediff_secs>4:\n print(index, timediff, no_hours, tilt_inst)\n f.close\n f=open(\"{}\".format(filename_txt), \"a+\")\n if timediff_secs%3600==0 and no_hours>0 and written != no_hours:\n print(\"Saving new hour data to new file\")\n results=[time_now,tilt_inst]\n written=no_hours\n if no_hours==24:\n break\n filename_txt=\"{}_{}_hr_after.txt\".format(filename,no_hours+1)\n f=open(\"{}\".format(filename_txt), \"a+\")\n f.write(\"{}\".format(header))\n \n if saved:\n## tictic=datetime.datetime.now()\n## tilt_noise=np.loadtxt(\"{}\".\n## format(filename_txt),skiprows=2)\n## time_noise=tilt_noise[0:,0]\n## inst=tilt_noise[0:,1]\n## mov_ave=movingaverage(inst,10)\n## mov_ave_second=movingaverage(mov_ave,10)\n## mov_ave_third=movingaverage(mov_ave_second,10)\n## plot_conv_ma()\n## toctoc=datetime.datetime.now()\n## time_taken=toctoc-tictic\n## time_secs=time_taken.total_seconds()\n## print \"time taken{}\".format(time_secs)\n## smoothresults=np.hstack((results, [mov_ave,\n## mov_ave_second,\n## mov_ave_third]))\n## np.savetxt(\"{}_smooth.txt\".format(filename),results,\n## delimiter=\" \", fmt=\"%s\",\n## header=\"time inst. 1st MA 2nd MA 3rd MA\")\n saved=False\n \n\n \n \n\n\n \n"
},
{
"alpha_fraction": 0.6275011897087097,
"alphanum_fraction": 0.6447184681892395,
"avg_line_length": 36.130435943603516,
"blob_id": "fd45b1fa8765059c0ba3691b2e9e5993c0d10d6f",
"content_id": "7b63a5368ac780bdfd250262aeab6c8e3ad54b2a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4298,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 115,
"path": "/tilt/tilt_analysis.py",
"repo_name": "Baba-Bob-Soile/trinity-clock",
"src_encoding": "UTF-8",
"text": "from time import sleep\nimport time\nimport datetime\nimport spidev\nimport matplotlib.pyplot as plt\nimport matplotlib.dates as md\nfrom scipy import signal\nimport numpy as np\nimport os\n\ndef noise_filter(input_signal):\n b, a = signal.butter(4, 160, 'low', analog=True)\n output_signal = signal.filtfilt(b, a,input_signal)\n return output_signal\ndef movingaverage(interval, window_size):\n window = np.ones(int(window_size))/float(window_size)\n return np.convolve(interval, window, 'same')\ndef three_moving_average(interval,window_size):\n window = np.ones(int(window_size))/float(window_size)\n first=np.convolve(interval, window, 'same')\n second=np.convolve(first, window, 'same')\n third=np.convolve(second, window, 'same')\n return third\ndef fifteen_moving_average(interval,window_size):\n third=three_moving_average(interval,window_size)\n sixth=three_moving_average(third,window_size)\n ninth=three_moving_average(sixth,window_size)\n twelfth=three_moving_average(ninth,window_size)\n fifteenth=three_moving_average(twelfth,window_size)\n return fifteenth\ndef plot_weighted_ma():\n fig, axarr = plt.subplots(4, sharex=True)\n axarr[0].set_title(\"Tilt Measurements\")\n axarr[0].set_ylabel(\"Inst.\")\n axarr[0].plot(time_noise, inst)\n axarr[1].set_ylabel(\"1st Ave\")\n axarr[1].plot(time_noise, first_ave)\n axarr[2].set_ylabel(\"2nd Ave\")\n axarr[2].plot(time_noise, second_ave)\n axarr[3].set_ylabel(\"Clean\")\n axarr[3].plot(time_clean, clean)\n ##axarr[4].set_ylabel(\"Filtered\")\n ##axarr[4].plot(time_noise, filtered)\n fig.savefig(\"Noise_in_Tilt_Comparison{}_weighted.png\".format(filename))\ndef plot_conv_ma(): \n xfmt = md.DateFormatter('%H:%M')\n xfmtb= md.HourLocator()\n xfmtc= md.MinuteLocator(interval=15)\n fig, axarr = plt.subplots(4, sharex=True)\n time_start=time.strftime(\"%Y-%m-%d\",time.localtime(time_noise[1]))\n axarr[0].set_title(\"Tilt Measurements from {}\".format(time_start))\n axarr[0].set_ylabel(\"Inst.\")\n axarr[0].plot(datetime_noise, inst)\n axarr[1].set_ylabel(\"3 MA\")\n axarr[1].plot(datetime_noise, mov_ave)\n axarr[2].set_ylabel(\"18 MA\")\n axarr[2].plot(datetime_noise, mov_ave_second)\n axarr[3].set_ylabel(\"33 MA\")\n axarr[3].plot(datetime_noise, mov_ave_three)\n \n ax=plt.gca()\n ax.xaxis.set_major_formatter(xfmt)\n ax.xaxis.set_major_locator(xfmtb)\n #ax.xaxis.set_minor_locator(xfmtc)\n \n fig.savefig(\"Noise_in_Tilt_Comparison_{}_conv.png\".format(name))\n\nprint \"Enter a file name:\",\nname = raw_input()\ntic=time.time()\npath=\"/home/pi/\"\n#name=\"tilt8b\"\n#name=\"2017-02-22_16-41-00\"\nprefix=\"tilt_{}\".format(name)\nsuffix=\"_after.txt\"\ndirs = os.listdir( path )\nfilenamelist=[]\nfor f in dirs:\n if f.startswith(prefix) and f.endswith(suffix):\n filenamelist.extend([f])\nfilenamelist.sort()\n\nfor index, filename in enumerate(filenamelist):\n print index, filename\n new_data=np.loadtxt(filename,skiprows=1)\n if index==0:\n tilt_noise=new_data\n else:\n tilt_noise=np.vstack((tilt_noise, new_data))\n\ntime_noise=tilt_noise[0:,0]\ndatetime_noise= [None] * len(tilt_noise)\nfor index,time_noise_inst in enumerate(time_noise):\n unix_time_f=time_noise[index]\n datetime_data=datetime.datetime.fromtimestamp(unix_time_f)\n datetime_noise[index]=datetime_data\ninst=tilt_noise[0:,1]\n#To select certain regions\n##start=1000\n##end=start+3600*16\n##datetime_noise=datetime_noise[start:end]\n##inst=inst[start:end]\n\nwindow=10*16\nmov_ave=three_moving_average(inst,window)\nmov_ave_second=fifteen_moving_average(mov_ave,window)\nmov_ave_three=fifteen_moving_average(mov_ave_second,window)\nplot_conv_ma()\n\nsmooth_results=np.column_stack((time_noise, datetime_noise, inst, mov_ave, mov_ave_second, mov_ave_three))\nnp.savetxt(\"{}_smooth.txt\".format(prefix),smooth_results,\n delimiter=\" \", fmt=\"%s\",\n header=\"unixtime datetime inst. Filter1 Filter2 Filter 3 \")\ntoc=time.time()\nprint \"Runtime:{}\".format(toc-tic)\n\n \n\n\n \n"
},
{
"alpha_fraction": 0.8016529083251953,
"alphanum_fraction": 0.8099173307418823,
"avg_line_length": 39,
"blob_id": "311bce18d875005b4d731692d64a59cc31e6a957",
"content_id": "482e07bb3b7f078f7c762d5aca984653ad716cd3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 121,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 3,
"path": "/README.md",
"repo_name": "Baba-Bob-Soile/trinity-clock",
"src_encoding": "UTF-8",
"text": "# trinity-clock\n4th Year Project\nContains files to measure twist, tilt and temperature and other parameters of project. \n"
},
{
"alpha_fraction": 0.6579766273498535,
"alphanum_fraction": 0.6743190884590149,
"avg_line_length": 32.81578826904297,
"blob_id": "38c31535f502294da3f252f1cbf5037014677195",
"content_id": "f30210fc9e434f5f76dadaed16411cd6462152f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2570,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 76,
"path": "/laser_detection/photo/trinity_cam.py",
"repo_name": "Baba-Bob-Soile/trinity-clock",
"src_encoding": "UTF-8",
"text": "#Python 3.2.3 (default, Mar 1 2013, 11:53:50) \n#[GCC 4.6.3] on linux2\n#Type \"copyright\", \"credits\" or \"license()\" for more information.\nimport datetime\nimport picamera\nimport numpy\nimport matplotlib as mpl\nmpl.use('Agg')\nfrom PIL import Image\nfrom skimage import data\nfrom skimage.feature import blob_doh, blob_log, blob_dog\nfrom matplotlib import pyplot as plt\nfrom matplotlib import patches as patch\nfrom math import sqrt\nfrom skimage.color import rgb2gray\nfrom time import sleep, perf_counter\nimport math\n\ndef roundup(x):\n return int(math.ceil(x/5.0))*5\n\nwhile True:\n print(\"start\")\n #Names image to be saved with timestamp so it is unique\n tic=perf_counter()\n time_now=datetime.datetime.now()\n time_formatted=time_now.strftime(\"%Y-%m-%d_%H-%M-%S\")\n image_name= \"/home/pi/camera/{}.png\".format(time_formatted)\n #image_name=\"/home/pi/red5.jpg\"\n \n #Camera takes picture and saves its name as the time stamp\n print(\"taking picture\")\n camera=picamera.PiCamera()\n sleep(2)\n\n camera.capture(\"{}\".format(image_name))\n #Copies Image and resises it so processing is faster (reduces precision)\n img_orig=Image.open(\"{}\".format(image_name))\n img=img_orig.copy()\n width_orig, height_orig= img.size\n reduction_factor=5\n width=roundup(width_orig/reduction_factor)\n height=roundup(height_orig/reduction_factor)\n print(\"picture resized\")\n img=img.resize((width,height))\n img.save(\"{}\".format(image_name))\n width, height= img.size\n print(\"width\", width, \"\\nheight\", height)\n\n #Converts from colored image to greyscale for easier processing\n image=data.imread((\"{}\".format(image_name)))\n image_gray=rgb2gray(image)\n camera.close()\n\n #Finds laser using difference of Hessian algorithm\n blobs_doh=blob_doh(image_gray, max_sigma=30, threshold=.01)#30,0.01\n\n #Plots circle of blob found on original image\n fig=plt.figure()\n ax=fig.add_subplot(111)\n plt.imshow(image, interpolation=\"nearest\")\n for blob in blobs_doh:\n y,x,r= blob\n print(\"x-\",x,\"\\ny-\",y, \"\\nr-\",r)\n circ=patch.Circle((x,y),r,color=\"black\",linewidth=4, fill=False)\n ax.add_patch(circ)\n ax.text(x,y,\"X\", horizontalalignment=\"center\",\n verticalalignment=\"center\",\n fontsize=10,color=\"black\")\n #Saves picture, ends timer\n image_edited_name= \"/home/pi/camera/{}edited.png\".format(time_formatted)\n fig.savefig((\"{}\".format(image_edited_name)))\n sleep(5)\n toc=perf_counter()\n total_time=toc-tic\n print(\"Total time:\",total_time)\n"
}
] | 6 |
Anirudh1313/TenSpy
|
https://github.com/Anirudh1313/TenSpy
|
a10f3d576c95b53553064658d92815e96d505c42
|
8245a150b80ae7b1f44bdf5e5e901a3fb2e62186
|
4517143e479fdc84708846e99d7003dc75c1b767
|
refs/heads/master
| 2020-04-13T00:36:47.637657 | 2018-12-23T00:00:08 | 2018-12-23T00:00:08 | 162,850,103 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.470085471868515,
"alphanum_fraction": 0.5641025900840759,
"avg_line_length": 12.764705657958984,
"blob_id": "355350c9436efd71e9b4cc0a51809e30910e63a2",
"content_id": "1666b5a725ac027b80e89a40d33c8e7da18a60c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 234,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 17,
"path": "/tester.py",
"repo_name": "Anirudh1313/TenSpy",
"src_encoding": "UTF-8",
"text": "from tenspy import *\n\non = ones((2, 4, 4))\nprint(on)\n\nprint(reshape(on, (2, 2, 8)))\n\nprint(ones((1, 1, 1, 1, 1, 1)))\n\nk = tenspy([1,3,2])\nk._pri = 2\nprint(k)\n\nprint(k._tenspy__build_ones(1,3,(2,2,2,2)))\n\n#print(k.ten)\n#print(k.dtype)\n"
},
{
"alpha_fraction": 0.5411157011985779,
"alphanum_fraction": 0.5537189841270447,
"avg_line_length": 22.5,
"blob_id": "c2fa106a8017ad768ffef32dee860bd52af634c5",
"content_id": "dd4db20b69958fd68d040eafb4ad32692aad8d9d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4840,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 206,
"path": "/tenspy.py",
"repo_name": "Anirudh1313/TenSpy",
"src_encoding": "UTF-8",
"text": "class tenspy:\n\n def __init__(self, ten):\n\n self.ten = ten\n\n self.__pri = 1\n\n self.dtype = \"dtype = tenspy\"\n\n def ones(self, t):\n '''\n returns a tensor of 1's with the specified shape.\n\n :param t: tuple of tensor shape\n :return: tensor of 1's\n '''\n\n l = len(t)\n self.ten = 1\n return _tenspy__build_ones(self.ten, l - 1, t)\n\n\n\n def __build_ones(self, inp, j, t):\n '''\n recursive functions called for every dimension i.e. len(shape tuple)\n in which computed output tensor is sent as input and its reused for further computation.\n\n :param inp: tensor of 1's\n :param j: dimension counter\n :param t: shape tuple\n :return: computed tensor\n '''\n if j < 0:\n return inp\n\n out = []\n for i in range(t[j]):\n out.append(inp)\n\n return build_ones(out, j - 1, t)\n\n def reshape(self, t):\n '''\n The input tensor is converted into a 1 dimensional tensor (i.e. 1D python list)\n and the 1D tensor is reshaped as per the input shape tuple parameter.\n\n :param inp: input tensor\n :param t: tuple of desired output shape\n :return: reshaped tensor as per input provided shape tuple\n '''\n out_list, out_reshaped = [], []\n\n _tenspy__build_list(self.ten, out_list)\n\n # print('list', out_list)\n\n order = 1\n for t1 in t:\n order *= t1\n\n assert len(out_list) == order, 'reshaping not possible due to tensor size mismatch'\n\n return _tenspy__reshape_tensor_from_list(out_list, t)\n\n def __build_list(inp, out):\n '''\n\n :param inp: input tensor\n :param out: empty tensor being reshaped as 1D tensor in this function.\n '''\n for j in inp:\n if type(j) is list:\n build_list(j, out)\n else:\n out.append(j)\n\n def __reshape_tensor_from_list(inp, t, j=0, ci=[0]):\n '''\n recursive function which creates a tensor as per the shape specified.\n\n :param inp: 1D tensor\n :param t: shape tuple\n :param j: dimension counter used to stop recursive calls\n :param ci: index for 1D tensor\n :return: reshaped tensor\n '''\n out = []\n for i in range(t[j]):\n if j < len(t) - 1:\n out.append(reshape_tensor_from_list(inp, t, j + 1, ci))\n else:\n out.append(inp[ci[0]])\n ci[0] += 1\n\n del inp\n return out\n\n\n\n\ndef ones(t):\n '''\n returns a tensor of 1's with the specified shape.\n\n :param t: tuple of tensor shape\n :return: tensor of 1's\n '''\n\n l = len(t)\n inp = 1\n return build_ones(inp, l - 1, t)\n\n\ndef build_ones(inp, j, t):\n '''\n recursive functions called for every dimension i.e. len(shape tuple)\n in which computed output tensor is sent as input and its reused for further computation.\n\n :param inp: tensor of 1's\n :param j: dimension counter\n :param t: shape tuple\n :return: computed tensor\n '''\n if j < 0:\n return inp\n\n out = []\n for i in range(t[j]):\n out.append(inp)\n\n return build_ones(out, j - 1, t)\n\n\ndef reshape(inp, t):\n '''\n The input tensor is converted into a 1 dimensional tensor (i.e. 1D python list)\n and the 1D tensor is reshaped as per the input shape tuple parameter.\n\n :param inp: input tensor\n :param t: tuple of desired output shape\n :return: reshaped tensor as per input provided shape tuple\n '''\n out_list, out_reshaped = [], []\n\n build_list(inp, out_list)\n\n # print('list', out_list)\n\n order = 1\n for t1 in t:\n order *= t1\n\n assert len(out_list) == order, 'reshaping not possible due to tensor size mismatch'\n\n return reshape_tensor_from_list(out_list, t)\n\n\n\ndef build_list(inp, out):\n '''\n\n :param inp: input tensor\n :param out: empty tensor being reshaped as 1D tensor in this function.\n '''\n for j in inp:\n if type(j) is list:\n build_list(j, out)\n else:\n out.append(j)\n\n\ndef reshape_tensor_from_list(inp, t, j=0, ci=[0]):\n '''\n recursive function which creates a tensor as per the shape specified.\n\n :param inp: 1D tensor\n :param t: shape tuple\n :param j: dimension counter used to stop recursive calls\n :param ci: index for 1D tensor\n :return: reshaped tensor\n '''\n out = []\n for i in range(t[j]):\n if j < len(t) - 1:\n out.append(reshape_tensor_from_list(inp, t, j + 1, ci))\n else:\n out.append(inp[ci[0]])\n ci[0] += 1\n\n del inp\n return out\n\n#def dot(inp1, inp2):\n\n\n\n\n\n# on = ones((2, 4, 4))\n# print(on)\n#\n# print(reshape(on, (2, 2, 8)))\n#\n# print(ones((1, 1, 1, 1, 1, 1)))"
}
] | 2 |
tbrixen/stadssb
|
https://github.com/tbrixen/stadssb
|
7651cf5c7e0c74a6f1863b8691074680d843031e
|
8d5d6a41fc999bff86d4d501f702cad8dfaf3674
|
4076df9e320a0031ef0407f7ea236e41e36956c6
|
refs/heads/master
| 2021-01-01T19:02:09.508006 | 2014-07-14T16:05:50 | 2014-07-14T16:05:50 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7575757503509521,
"alphanum_fraction": 0.7575757503509521,
"avg_line_length": 21,
"blob_id": "97f43d189053a1f99444b75d2d971c4330ba0bb5",
"content_id": "99b7bf38c512d3a46bea1a7058c21cfcc0e32db6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 132,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 6,
"path": "/README.md",
"repo_name": "tbrixen/stadssb",
"src_encoding": "UTF-8",
"text": "stadssb\n=======\n\nA scraper for the stassb system to get a message when getting new grades\n\nEdit the config.ini for your credentials\n"
},
{
"alpha_fraction": 0.6552606225013733,
"alphanum_fraction": 0.6658138632774353,
"avg_line_length": 25.72649574279785,
"blob_id": "fe65cc47478b776eece96e27c67893984619144c",
"content_id": "c87444810e6107b89d52956c0657c6c9e45ed332",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3128,
"license_type": "permissive",
"max_line_length": 138,
"num_lines": 117,
"path": "/stadssb.py",
"repo_name": "tbrixen/stadssb",
"src_encoding": "UTF-8",
"text": "# -*- coding: ISO-8859-1 -*-\nfrom time import gmtime, strftime\nimport urllib, urllib2, cookielib\nimport os, sys\nfrom HTMLParser import HTMLParser\nimport ConfigParser\n\nclass MyParser(HTMLParser):\n\tstartPoint = 0 #When should we start parsing\n\tnewCourse = 0 #Have we found a new course?\n\ttdCount = 99 #How many TD's have we seen?\n\tresults = [] #The list of results\n\n\tdef handle_starttag(self, tag, attrs):\n\t\t#If we've passed the startingpoint, we start parsing\n\t\tif self.startPoint == 1:\n\t\t\tif tag == \"tr\":\n\t\t\t#We've found a new course\n\t\t\t\tself.newCourse = 1\n\t\t\t\tself.tdCount = 0\n\t\t\tif tag == \"td\":\n\t\t\t\tself.tdCount = self.tdCount + 1\n\n\tdef handle_data(self, data):\n\t\tglobal results\n\t\t#We've found the table, and starts our search\n\t\tif data == \"ECTS\":\n\t\t\tself.startPoint = 1\n\n\t\t#1 TD's from the tr lays the coursename\n\t\t#4 TD's from the tr lays the grade\n\t\tif self.tdCount == 1:\n\t\t\tself.tdCount = self.tdCount + 1\n\t\t\tself.results.append(data.strip())\n\n\t\tif self.tdCount == 4:\n\t\t\tself.tdCount = self.tdCount + 1\n\t\t\tself.results.append(data)\n\nclass Fetcher():\n\n\thtml = \"\"\n\tusername = \"\"\n\tpassword = \"\"\n\n\tdef __init__(self, username, password):\n\t\tself.username = username\n\t\tself.password = password\n\n\tdef fetch(self):\n\t\t#We start by getting initial cookie, from stads\n\t\tcj = cookielib.CookieJar()\n\t\topener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))\n\t\topener.open('https://stadssb.au.dk/sb_STAP/sb/index.jsp')\n\n\t\tprint \"Brugernavn: \", self.username\n\t\tprint \"Kode: \", self.password\n\n\t\t#And then we craft our post request to get our login token\n\t\tlogin_data = urllib.urlencode({'lang' : 'null', 'submit_action' : 'login', 'brugernavn' : self.username, 'adgangskode' : self.password})\n\t\topener.open('https://stadssb.au.dk/sb_STAP/sb/index.jsp', login_data)\n\t\tresp = opener.open('https://stadssb.au.dk/sb_STAP/sb/resultater/studresultater.jsp')\n\t\tself.html = resp.read()\n\nif __name__ == '__main__':\n\n\t#Config\n\tconfig = ConfigParser.ConfigParser()\n\tconfig.read(\"config.ini\")\n\tuser = config.get(\"stadssb\", \"username\")\n\tpassword = config.get(\"stadssb\", \"password\")\n\n\tif (user == '') or (password == ''):\n\t\tsys.exit('Error:\\tEmpty username or password\\n\\tYou need to edit the config.ini')\n\n\tresults = []\n\tscriptDir = os.path.dirname(os.path.abspath(__file__))\n\n\t### Fetch the html\n\tfetcher = Fetcher(user, password)\n\tfetcher.fetch()\n\thtml = fetcher.html\n\n\t### Parse the html\n\tparser = MyParser()\n\tparser.feed(html)\n\tresults = parser.results\n\n\t### See if theres any change\n\t## Previous number of courses\n\tf = open(scriptDir + '/gradedCourses.log', 'a+')\n\tprevCourses = int('0' + f.read())\n\tf.close()\n\n\t## Current number of courses\n\tcurrCourses = len(results)/2\n\n\tnewGrades = currCourses - prevCourses\n\n\tif (newGrades > 0) and (currCourses != 0):\n\t\tmessage = \"Der er kommet nye karakterer. \"\n\t\tmessage += \"Du har fået \"\n\n\t\tfor i in range(0, newGrades):\n\t\t\tmessage += results[1 + i*2]\n\t\t\tmessage += \" i \"\n\t\t\tmessage += results[0 + i*2]\n\t\t\tmessage += \", \"\n\n\t\tmessage = message[:-2]\n\t\tmessage += \".\"\n\n\t\tprint message\n\n\t\tf = open (scriptDir + '/gradedCourses.log', 'w')\n\t\tf.write(str(currCourses))\n\t\tf.close()\n"
},
{
"alpha_fraction": 0.6583333611488342,
"alphanum_fraction": 0.7250000238418579,
"avg_line_length": 16.14285659790039,
"blob_id": "e3bb2567d41bdb04d66705bbff55168285687efa",
"content_id": "79b80316b216ef948351e8cf2dc872b0eb001720",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 120,
"license_type": "permissive",
"max_line_length": 31,
"num_lines": 7,
"path": "/config.ini",
"repo_name": "tbrixen/stadssb",
"src_encoding": "UTF-8",
"text": "# Logininformation for stadssb.\n# format:\n# \tusername: 12345678\n#\tpassword: thePassword \n[stadssb]\nusername: \npassword:\n"
}
] | 3 |
P-CAST/python_web_req_test
|
https://github.com/P-CAST/python_web_req_test
|
03a0c30445c2437052b44ad920d7127543e1649f
|
f7f2bee2762fa568da36dd0c13676055bcd6a95c
|
812b37f3922ce1cf2ce5649114b20740debdc3e2
|
refs/heads/main
| 2023-07-20T23:59:41.098642 | 2021-08-30T15:17:29 | 2021-08-30T15:17:29 | 400,445,808 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5848303437232971,
"alphanum_fraction": 0.5954757332801819,
"avg_line_length": 23.25806427001953,
"blob_id": "6796fab95c216ba389409930fd1e5060a491c181",
"content_id": "2de7c1a0d142ce076977eec7b6011eb897ed8ce7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1503,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 62,
"path": "/main.py",
"repo_name": "P-CAST/python_web_req_test",
"src_encoding": "UTF-8",
"text": "import requests\nimport logging\nimport datetime\nimport os\nfrom multiprocessing import Process\n\ndef get_url():\n get_url.url = input('Enter url (full path): ')\n confirm_url = input('Confirm this url?(y/N): ')\n\n if confirm_url == 'y' or confirm_url == 'Y':\n main(get_url.url)\n elif confirm_url == 'n' or confirm_url == 'N' or confirm_url == '':\n print('abort')\n get_url()\n else:\n print('abort with error')\n get_url()\n\ndef main(url):\n response = requests.get(url)\n \n if response.status_code == 200:\n print('Connected')\n elif response.status_code == 404:\n print('Not found')\n elif response.status_code == 500:\n print('Server error')\n else:\n print(\"Can't connect to server\")\n\n concurrency = int(input('Enter concurrency: '))\n print('Worker1 up')\n print('Worker2 up\\n')\n for _ in range(concurrency):\n print('On going...')\n Process(target=worker1(url)).start()\n Process(target=worker2(url)).start()\n print('Done')\n log(url,concurrency)\n finish_task()\n\ndef finish_task(): \n os.system('pause')\n\ndef log(url,concurrency):\n date = datetime.datetime.now()\n logging.basicConfig(\n filename='LogFile.log',\n encoding='utf-8',\n level=logging.INFO\n )\n logging.info('url: %s\\t concurrency: %d\\t time: %s',url,concurrency,date)\n\ndef worker1(url):\n requests.get(url)\n\ndef worker2(url):\n requests.get(url)\n\nif __name__ == '__main__':\n get_url()"
}
] | 1 |
twiden/sagas
|
https://github.com/twiden/sagas
|
145ab742fe7f952da58c98d97ab73121ce6e488c
|
b3ca67bbe1b11e5d65d533a3a88a787f9e83e4a9
|
92718a2eb3a2506d74fa182ddfa8654bc7a6b5e6
|
refs/heads/master
| 2021-01-10T02:25:34.865370 | 2015-11-22T11:44:55 | 2015-11-22T11:44:55 | 46,588,777 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.675000011920929,
"alphanum_fraction": 0.699999988079071,
"avg_line_length": 19,
"blob_id": "7ce964d74fbec1db059c649eae3b8c0f68f76d9d",
"content_id": "e3cfc8336f737e39cea8e25cfae0b55fc6d23bc2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 160,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 8,
"path": "/Makefile",
"repo_name": "twiden/sagas",
"src_encoding": "UTF-8",
"text": "start:\n\tpython sagas/sagas.py\n\nexample:\n\tcurl -L -H \"Content-Type: application/json\" -X POST -d \"@data/saga.json\" http://localhost:8080/\n\ntest:\n\tpy.test tests/\n"
},
{
"alpha_fraction": 0.7258567214012146,
"alphanum_fraction": 0.7258567214012146,
"avg_line_length": 21.928571701049805,
"blob_id": "cbb474e0650dfeff35871d58d52d58e8be5a2006",
"content_id": "7847649a3c98b22a2bd0e454953d02be3e44c74c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 321,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 14,
"path": "/README.md",
"repo_name": "twiden/sagas",
"src_encoding": "UTF-8",
"text": "# sagas\nExperiment with sagas pattern.\n\nIt is a series of actions to be performed on data. Here we add, subtract, divide and multiply numbers by passing the list of actions along.\n\n## Make targets \n```make start```\nstart the web app\n\n```make example```\ncall the web app with sample data.\n\n```make test```\nrun test suite.\n"
},
{
"alpha_fraction": 0.6289041638374329,
"alphanum_fraction": 0.6352567672729492,
"avg_line_length": 24.18666648864746,
"blob_id": "cd1e2d386f7b1efd5a4d036abe3ba02b8aaf3c3e",
"content_id": "14a3dfa80ea6c2569d74d51ce128f773eee962c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1889,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 75,
"path": "/sagas/sagas.py",
"repo_name": "twiden/sagas",
"src_encoding": "UTF-8",
"text": "import cherrypy\nimport requests\nimport operator\n\n\ndef modify(saga, what):\n value = saga['value']\n pointer = saga['pointer']\n operation = saga['story'][pointer]\n saga['pointer'] += 1\n saga['value'] = what(float(value), float(operation['operand']))\n return saga\n\n\ndef next(saga):\n headers = {'Content-type': 'application/json', 'Accept': 'application/json'}\n next_handler = saga['story'][saga['pointer']]['chapter']\n return requests.post(next_handler, json=saga, headers=headers)\n\n\ndef result(resp):\n if resp.status_code == 200:\n return resp.json()\n else:\n return {'errors': [{'url': resp.url, 'status_code': resp.status_code}]}\n\n\ndef apply(operator):\n return result(next(modify(cherrypy.request.json, operator)))\n\n\nclass Math(object):\n\n @cherrypy.tools.json_out()\n @cherrypy.tools.json_in()\n @cherrypy.expose\n def add(self):\n return apply(operator.add)\n\n @cherrypy.tools.json_out()\n @cherrypy.tools.json_in()\n @cherrypy.expose\n def subtract(self):\n return apply(operator.sub)\n\n @cherrypy.tools.json_out()\n @cherrypy.tools.json_in()\n @cherrypy.expose\n def multiply(self, ):\n return apply(operator.mul)\n\n @cherrypy.tools.json_out()\n @cherrypy.tools.json_in()\n @cherrypy.expose\n def divide(self):\n return apply(operator.div)\n\n @cherrypy.tools.json_out()\n @cherrypy.tools.json_in()\n @cherrypy.expose\n def stop(self):\n return {'result': cherrypy.request.json['value'], 'errors': []}\n\n @cherrypy.tools.json_out()\n @cherrypy.tools.json_in()\n @cherrypy.expose\n def index(self):\n return result(next(cherrypy.request.json))\n\n\nif __name__ == \"__main__\":\n cherrypy.config.update({'server.socket_port': 8080, 'server.socket_host': '0.0.0.0'})\n cherrypy.tree.mount(Math(), \"/\")\n cherrypy.engine.start()\n cherrypy.engine.block()\n"
},
{
"alpha_fraction": 0.40008577704429626,
"alphanum_fraction": 0.43224701285362244,
"avg_line_length": 27.439023971557617,
"blob_id": "2bf1333f1d80279008b82a29c4fc2a30ccb374bc",
"content_id": "93b71f56893180f4f11971eabd30bc11e646a023",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2332,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 82,
"path": "/tests/test_sagas.py",
"repo_name": "twiden/sagas",
"src_encoding": "UTF-8",
"text": "import cherrypy\nimport requests\nfrom sagas.sagas import Math\n\nheaders = lambda: {'Content-type': 'application/json', 'Accept': 'application/json'}\nurl = lambda x='': 'http://127.0.0.1:4711/{}/'.format(x)\n\ndef saga():\n return {\n \"story\":\n [\n {\n \"chapter\": url('add'),\n \"operand\": 7\n },\n {\n \"chapter\": url('subtract'),\n \"operand\": 2\n },\n {\n \"chapter\": url('multiply'),\n \"operand\": 4\n },\n {\n \"chapter\": url('add'),\n \"operand\": 89\n },\n {\n \"chapter\": url('divide'),\n \"operand\": 12\n },\n {\n \"chapter\": url('subtract'),\n \"operand\": 7\n },\n {\n \"chapter\": url('add'),\n \"operand\": 72\n },\n {\n \"chapter\": url('divide'),\n \"operand\": 2\n },\n {\n \"chapter\": url('stop')\n }\n ],\n \"value\": 9.3,\n \"pointer\": 0\n }\n\n\ndef setup_module():\n cherrypy.tree.mount(Math(), \"/\")\n cherrypy.config.update({'server.socket_port': 4711})\n cherrypy.engine.start()\n\n\ndef teardown_module():\n cherrypy.engine.stop()\n\n\ndef test_performing_a_series_of_operations_as_the_story_of_a_saga():\n result = requests.post(url(), json=saga(), headers=headers()).json()\n expected = {'result': 38.59166666666667, 'errors': []}\n assert expected == result\n\n\ndef test_handling_malformed_saga():\n s = saga()\n s['story'][5]['operand'] = 'foobar'\n result = requests.post(url(), json=s, headers=headers()).json()\n expected = {'errors': [{'status_code': 500, 'url': 'http://127.0.0.1:4711/subtract/'}]}\n assert expected == result\n\n\ndef test_handling_malformed_url():\n s = saga()\n s['story'][5]['chapter'] = url('foobar')\n result = requests.post(url(), json=s, headers=headers()).json()\n expected = {'errors': [{'status_code': 404, 'url': 'http://127.0.0.1:4711/foobar/'}]}\n assert expected == result\n"
},
{
"alpha_fraction": 0.44186046719551086,
"alphanum_fraction": 0.6511628031730652,
"avg_line_length": 13.333333015441895,
"blob_id": "3cf32f7b662c185eb542b512106b3525ded8a38c",
"content_id": "d3fc66c9b89056d1133372b1bed57ea5dda45201",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 86,
"license_type": "no_license",
"max_line_length": 15,
"num_lines": 6,
"path": "/requirements.txt",
"repo_name": "twiden/sagas",
"src_encoding": "UTF-8",
"text": "CherryPy==3.8.0\npy==1.4.30\npytest==2.8.3\nrequests==2.8.1\ntest-pkg==0.0\nwsgiref==0.1.2\n"
}
] | 5 |
Kortika/ISBI_Ass1
|
https://github.com/Kortika/ISBI_Ass1
|
5457f4916d9f9e47e3dad774c8a4b6f508afef09
|
7d2b91222f2f28e9f7d0add022c2b832783a3a71
|
8acb9ef0490207b37144aee1a7e8ef36501c4c82
|
refs/heads/master
| 2020-09-09T11:08:17.903301 | 2019-11-19T15:21:37 | 2019-11-19T15:21:37 | 221,431,040 | 0 | 1 | null | 2019-11-13T10:17:09 | 2019-11-13T10:21:26 | 2019-11-13T12:11:25 | null |
[
{
"alpha_fraction": 0.708375096321106,
"alphanum_fraction": 0.7246740460395813,
"avg_line_length": 84.73912811279297,
"blob_id": "8176fe3e997492ddf5275ce41571783acaa4d029",
"content_id": "02df7a3306d2d57b71e8f5f5f495b1fa4b5a5f43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 3993,
"license_type": "no_license",
"max_line_length": 192,
"num_lines": 46,
"path": "/graphploting.R",
"repo_name": "Kortika/ISBI_Ass1",
"src_encoding": "ISO-8859-7",
"text": "#Initializations\r\ndirpath='C:/Users/Μαρία/Desktop/ISBI/ISBI_Ass1/pyresults/'#Specify project directory\r\nfilenames=c('google.csv.result', 'duckduckgo.csv.result', 'webcrawler.csv.result', 'google_interpolated.csv.result', 'duckduckgo_interpolated.csv.result', 'webcrawler_interpolated.csv.result')\r\n#Read Inputs\r\ngoogle.prcsn_rcl.frame=read.table(file=paste(dirpath, filenames[1], sep=\"\"), header = TRUE, sep=\",\", na.strings=\"NA\", strip.white = TRUE, stringsAsFactors = FALSE)\r\ngoogle.interpolated.frame=read.table(file=paste(dirpath, filenames[4], sep=\"\"), header = TRUE, sep=\",\", na.strings=\"0.0\", strip.white = TRUE, stringsAsFactors = FALSE)\r\nduckduckgo.prcsn_rcl.frame=read.table(file=paste(dirpath, filenames[2], sep=\"\"), header = TRUE, sep=\",\", na.strings=\"NA\", strip.white = TRUE, stringsAsFactors = FALSE)\r\nduckduckgo.interpolated.frame=read.table(file=paste(dirpath, filenames[5], sep=\"\"), header = TRUE, sep=\",\", na.strings=\"0.0\", strip.white = TRUE, stringsAsFactors = FALSE)\r\nwebcrawler.prcsn_rcl.frame=read.table(file=paste(dirpath, filenames[3], sep=\"\"), header = TRUE, sep=\",\", na.strings=\"NA\", strip.white = TRUE, stringsAsFactors = FALSE)\r\nwebcrawler.interpolated.frame=read.table(file=paste(dirpath, filenames[6], sep=\"\"), header = TRUE, sep=\",\", na.strings=\"0.0\", strip.white = TRUE, stringsAsFactors = FALSE)\r\n\r\n\r\n#Clear NA values\r\nna.omit(google.prcsn_rcl.frame)\r\nna.omit(google.interpolated.frame)\r\nna.omit(duckduckgo.prcsn_rcl.frame)\r\nna.omit(duckduckgo.interpolated.frame)\r\nna.omit(webcrawler.prcsn_rcl.frame)\r\nna.omit(webcrawler.interpolated.frame)\r\n\r\n#Plot graph for Google\r\nplot(google.prcsn_rcl.frame$q1_recall, google.prcsn_rcl.frame$q1_precision, type='o', col='blue', ylim=c(0,1), xlim=c(0,1), main='Google', xlab='Recall', ylab='precision')\r\nlines(google.prcsn_rcl.frame$q2_recall, google.prcsn_rcl.frame$q2_precision, type='o', col='red')\r\nlines(google.prcsn_rcl.frame$q3_recall, google.prcsn_rcl.frame$q3_precision, type='o', col='green')\r\nlines(google.prcsn_rcl.frame$q4_recall, google.prcsn_rcl.frame$q4_precision, type='o', col='yellow')\r\nlegend('bottomright', legend=c('q1', 'q2','q3','q4'), fill=c('blue', 'red', 'green', 'yellow'))\r\n\r\n#Plot graph for duckduckgo\r\nplot(duckduckgo.prcsn_rcl.frame$q1_recall, duckduckgo.prcsn_rcl.frame$q1_precision, type='o', col='blue', ylim=c(0,1), xlim=c(0,1), main='DuckDuckGo', xlab='Recall', ylab='precision')\r\nlines(duckduckgo.prcsn_rcl.frame$q2_recall, duckduckgo.prcsn_rcl.frame$q2_precision, type='o', col='red')\r\nlines(duckduckgo.prcsn_rcl.frame$q3_recall, duckduckgo.prcsn_rcl.frame$q3_precision, type='o', col='green')\r\nlines(duckduckgo.prcsn_rcl.frame$q4_recall, duckduckgo.prcsn_rcl.frame$q4_precision, type='o', col='yellow')\r\nlegend('bottomright', legend=c('q1', 'q2','q3','q4'), fill=c('blue', 'red', 'green', 'yellow'))\r\n\r\n#Plot graph for webcrawler\r\nplot(webcrawler.prcsn_rcl.frame$q1_recall, webcrawler.prcsn_rcl.frame$q1_precision, type='o', col='blue', ylim=c(0,1), xlim=c(0,1), main='Webcrawler', xlab='Recall', ylab='precision')\r\nlines(webcrawler.prcsn_rcl.frame$q2_recall, webcrawler.prcsn_rcl.frame$q2_precision, type='o', col='red')\r\nlines(webcrawler.prcsn_rcl.frame$q3_recall, webcrawler.prcsn_rcl.frame$q3_precision, type='o', col='green')\r\nlines(webcrawler.prcsn_rcl.frame$q4_recall, webcrawler.prcsn_rcl.frame$q4_precision, type='o', col='yellow')\r\nlegend('bottomright', legend=c('q1', 'q2','q3','q4'), fill=c('blue', 'red', 'green', 'yellow'))\r\n\r\n#Plot intepolation Graph\r\nplot(google.interpolated.frame$std_recall, google.interpolated.frame$average, type='o', col='blue', ylab='Precission', ylim=c(0, 1), xlim=c(0, 1), main='Average Interpolated', xlab='Recall' )\r\nlines(duckduckgo.interpolated.frame$std_recall, duckduckgo.interpolated.frame$average, type='o', col='red')\r\nlines(webcrawler.interpolated.frame$std_recall, webcrawler.interpolated.frame$average, type='o', col='green')\r\nlegend('topright', legend=c('Google', 'DuckDuckGo', 'Webcrawler'), fill=c('blue', 'red', 'green'))"
},
{
"alpha_fraction": 0.5081062912940979,
"alphanum_fraction": 0.5154604911804199,
"avg_line_length": 31.80225944519043,
"blob_id": "8082d84c0bdc71e90bab77ec1de4e7a634ccee81",
"content_id": "200c2df3085584f4bdc3ee414e25532e47fbbc13",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5983,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 177,
"path": "/extract_data.py",
"repo_name": "Kortika/ISBI_Ass1",
"src_encoding": "UTF-8",
"text": "import os\r\nimport numpy as np\r\n\r\n\r\ndef readDirectory(directory=\"./data\"):\r\n result = []\r\n\r\n for file_name in os.listdir(directory):\r\n if(file_name.endswith(\".csv\")):\r\n result.append(readFile(\"%s/%s\" % (directory, file_name)))\r\n\r\n return result\r\n\r\n\r\ndef readFile(filename):\r\n name = filename.split('.csv')[0]\r\n question, engine = name.split('-')[0].lower(), name.split('-')[1].lower()\r\n question = question.split('/')[-1].lower()\r\n with open(filename, 'r') as fh:\r\n fh.readline() # Ingore first line we don't need col names\r\n raw_data = fh.readlines()\r\n data = []\r\n for i in range(0, len(raw_data)):\r\n line = raw_data[i]\r\n if not (i+1 == len(raw_data)):\r\n data.append(\r\n (i, line.split(',')[0].strip(), int(line.split(',')[1][:-1])))\r\n else:\r\n data.append(\r\n (i, line.split(',')[0].strip(), int(line.split(',')[1])))\r\n return (question, engine, data)\r\n\r\n\r\ndef calculateRecallPrecision(data, pool_dict):\r\n engine_query_dict = dict()\r\n for question, engine, links in data:\r\n try:\r\n engine_query_dict[engine]\r\n except KeyError:\r\n engine_query_dict[engine] = dict()\r\n\r\n engine_query_dict[engine][question] = []\r\n precision_divider = 0\r\n numerator = 0\r\n recall = 0\r\n precision = 0\r\n\r\n for index, link, relevance in links:\r\n precision_divider += 1\r\n\r\n if relevance == 1:\r\n numerator += 1\r\n\r\n precision = round(numerator/precision_divider, 3)\r\n recall = round(numerator/pool_dict[question], 3)\r\n\r\n if (precision == 0):\r\n precision = \"NA\"\r\n recall = \"NA\"\r\n engine_query_dict[engine][question].append([precision, recall])\r\n\r\n for engine in engine_query_dict:\r\n with open(\"pyresults/%s.csv.result\" % engine, \"w+\") as output:\r\n text = []\r\n for query in engine_query_dict[engine]:\r\n query_text = [\"%s_precision,%s_recall\" % (query, query)]\r\n query_text += map(lambda x: \",\".join(str(z)\r\n for z in x), engine_query_dict[engine][query])\r\n\r\n if len(text) == 0:\r\n text = query_text\r\n else:\r\n for i in range(0, len(query_text)):\r\n text[i] += \",\" + query_text[i]\r\n\r\n output.write(\"\\n\".join(text))\r\n\r\n return engine_query_dict\r\n\r\n\r\ndef interpolate_query(engine_query_dict):\r\n\r\n result = dict()\r\n std_recall_list = np.around(np.arange(0.1, 1.1, 0.1),decimals=1)\r\n for engine in engine_query_dict:\r\n with open(\"pyresults/%s_interpolated.csv.result\" % engine, \"w+\") as output:\r\n header = list()\r\n header.append(\"std_recall\")\r\n result[engine] = dict()\r\n write_matrix = list() \r\n for query in engine_query_dict[engine]:\r\n header.append(\"%s_interpolated\" % query)\r\n print(engine, query)\r\n result[engine][query] = list()\r\n query_precision_recalls = [ x if x[1] != \"NA\" else [0,-1] for x in engine_query_dict[engine][query]]\r\n for std_recall_val in std_recall_list:\r\n\r\n filtered_precision = [\r\n x[0] for x in query_precision_recalls if x[1] >= std_recall_val]\r\n\r\n highest_precision= 0\r\n if len(filtered_precision) != 0:\r\n highest_precision = max(filtered_precision)\r\n\r\n result[engine][query].append(highest_precision)\r\n\r\n write_matrix.append(result[engine][query])\r\n print(\"\\n\".join([str(x) for x in result[engine][query]]))\r\n \r\n header.append(\"average\")\r\n output.write(\",\".join(header)+\"\\n\")\r\n average = np.mean(write_matrix, axis = 0 )\r\n write_matrix.append(average)\r\n write_matrix.insert(0,std_recall_list)\r\n write_matrix = np.transpose(write_matrix)\r\n \r\n for row in write_matrix:\r\n output.write(\",\".join([str(x) for x in row]))\r\n output.write(\"\\n\")\r\n\r\n result[engine][\"average\"] = average\r\n\r\n\r\n return result\r\n\r\n\r\ndef calculatePool(data):\r\n query_dict = dict()\r\n for question, engine, links in data:\r\n relevant_links = filter(lambda x: x[2] == 1, links)\r\n try:\r\n query_dict[question]\r\n except KeyError:\r\n query_dict[question] = dict()\r\n\r\n for linkTuple in relevant_links:\r\n link = linkTuple[1]\r\n try:\r\n query_dict[question][link]\r\n except KeyError:\r\n query_dict[question][link] = set()\r\n\r\n query_dict[question][link].add(engine)\r\n\r\n result = dict()\r\n for question in query_dict.keys():\r\n with open(\"pyresults/%s.csv.pool\" % question, \"w+\") as output:\r\n output.write(\"Link,Engines\\n\")\r\n pool_output = []\r\n result[question] = len(query_dict[question])\r\n for link in query_dict[question]:\r\n engine = query_dict[question][link]\r\n pool_output.append(\"%s,%s\" % (link, \"-\".join(engine)))\r\n\r\n output.write(\"%s\" % (\"\\n\".join(pool_output)))\r\n\r\n return result\r\n\r\n\r\ndef readData(questions, engines, dirpath='./data'):\r\n filenames = []\r\n for r, d, f in os.walk(dirpath):\r\n for file in f:\r\n filenames.append(file)\r\n\r\n unusefullData = []\r\n for filename in filenames:\r\n if filename.endswith(\".csv\"):\r\n unusefullData.append(readFile(dirpath+'/'+filename))\r\n\r\n commonpools = calculatePool(unusefullData)\r\n\r\n engine_query_dict = calculateRecallPrecision(unusefullData, commonpools)\r\n interpolate_query(engine_query_dict)\r\n\r\n\r\nreadData(2, 2)\r\n"
},
{
"alpha_fraction": 0.6930533051490784,
"alphanum_fraction": 0.7059773802757263,
"avg_line_length": 33.38888931274414,
"blob_id": "8e1d2027473d98be09a476e22e812a76b5352f56",
"content_id": "b64527064bbc6f2e2d16b76b284fe9796faa1139",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1238,
"license_type": "no_license",
"max_line_length": 241,
"num_lines": 36,
"path": "/README.md",
"repo_name": "Kortika/ISBI_Ass1",
"src_encoding": "UTF-8",
"text": "# First Assignment in course Internet Search Techniques and Business Intelligence (2019-2020)<br>\n__Group Members:__<br>\n * Ignatius Patrick\n * Dare Gbenga Christopher Akinboyewa\n * [Sitt Min Oo](https://github.com/Kortika)\n * [Vasileios Mormoris](https://github.com/VMormoris)\n\n\nWe look 4 queries in 3 different search engines. For each search engine we check for the top 30 suggestions that each made the relevance to the respective query. After that we calculated the precision and recall and the Average interpolated.\n\n## Queries\n\n * __q1:__ _Fall of the Soviet Union_\n * __q2:__ _What is the tinder algorithm?_\n * __q3:__ _What is the population of Sierra Leone?_\n * __q4:__ _How banks transfer money?_\n\n## Search Engines\n\n * [Google](https://www.google.com)\n * [DuckDuckGo](https://www.duckduckgo.com)\n * [Webcrawler](https://www.webcrawler.com)\n\n## Results(Graphs)\n\n<br><br>\n\n<br><br>\n\n<br><br>\n\n\n\n## Notes about the source code\n__Currently working directory in R is not the same with the directory that the file is located.__\n_Change dirpath value on graphloting.R in order for the R script to work properly._\n"
},
{
"alpha_fraction": 0.6656050682067871,
"alphanum_fraction": 0.6671974658966064,
"avg_line_length": 25.125,
"blob_id": "ce1c9388858a8b4fbdf1bf7a84c83d7dad060d68",
"content_id": "93518f39c9d76374d408cea6c2c988e512e18fb6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 628,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 24,
"path": "/main.py",
"repo_name": "Kortika/ISBI_Ass1",
"src_encoding": "UTF-8",
"text": "\nimport os\nimport sys\nimport argparse\nimport extract_data\n\ndef main(arguments):\n\n parser = argparse.ArgumentParser(\n description=__doc__,\n formatter_class=argparse.RawDescriptionHelpFormatter)\n parser.add_argument('directory', help=\"Data links directory\", type=str)\n parser.add_argument('-o', '--outfile', help=\"Output file\",\n default=sys.stdout, type=argparse.FileType('w'))\n\n args = parser.parse_args(arguments)\n\n extracted_data_dict = extract_data.readDirectory(args.directory)\n\n print(extracted_data_dict)\n\n\n\nif __name__ == '__main__':\n sys.exit(main(sys.argv[1:]))\n"
}
] | 4 |
zerogravity1990/Web-Scraper
|
https://github.com/zerogravity1990/Web-Scraper
|
3620fb5daeaac7f2d635efa08d0cf6eb6aceca1e
|
960f34ea00a84c38a09e871a4a7c423aa2d96506
|
d5a5147af0f887004c70996ca22009cb58a35daa
|
refs/heads/master
| 2021-05-14T16:26:02.900303 | 2019-06-18T14:25:01 | 2019-06-18T14:25:01 | 116,021,477 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5887265205383301,
"alphanum_fraction": 0.592901885509491,
"avg_line_length": 28.9375,
"blob_id": "eeb5ddaad9bd7dc4b5bb101d8d7b112e8a4327e0",
"content_id": "692620a71a02a77d7c275ad0b399ddac488c8c88",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 479,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 16,
"path": "/mangascraper/mangascraper/images/immortale/full/directory.py",
"repo_name": "zerogravity1990/Web-Scraper",
"src_encoding": "UTF-8",
"text": "import os\n\n\nfiles_list = os.listdir('.')\nbase_path = os.getcwd()\nfor f in files_list:\n if f.split('.')[1] in ['py','pyc']:\n continue\n chapter_folder_name = f.split('-')[0]\n folder_chapter = 'Capitolo ' + chapter_folder_name\n folder_path = base_path + \"/\" + folder_chapter\n if not os.path.exists(folder_path):\n os.mkdir(folder_path)\n file_path = base_path + \"/\" + f\n new_file_path = folder_path + \"/\" + f\n os.rename(file_path, new_file_path)\n"
},
{
"alpha_fraction": 0.6753731369972229,
"alphanum_fraction": 0.6800373196601868,
"avg_line_length": 34.733333587646484,
"blob_id": "4d98a92854a4eee709e1cf1b10922d49b1c01e71",
"content_id": "9ed0f655d04ebe2226227a308e509ed224bf323c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1072,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 30,
"path": "/mangascraper/mangascraper/pipelines.py",
"repo_name": "zerogravity1990/Web-Scraper",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Define your item pipelines here\n#\n# Don't forget to add your pipeline to the ITEM_PIPELINES setting\n# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html\n\nimport scrapy\nfrom scrapy.pipelines.images import ImagesPipeline\nfrom scrapy.utils.project import get_project_settings\nfrom scrapy.exceptions import DropItem\nimport os\n\nclass MyImagesPipeline(ImagesPipeline):\n\n # IMAGES_STORE = get_project_settings().get(\"IMAGES_STORE\")\n\n # def item_completed(self, result, item, info):\n # image_path = [x[\"path\"] for ok, x in result if ok]\n # os.rename(self.IMAGES_STORE + \"/\" + image_path[0], self.IMAGES_STORE + \"/full/\" + item[\"image_names\"][0] + \".jpg\")\n # return item\n\n# TODO: try to override file_path instead of os.rename --DONE--\n\n\n def get_media_requests(self, item, info):\n return [scrapy.Request(url, meta={'f1':item.get('image_names')}) for url in item.get(self.images_urls_field, [])]\n\n def file_path(self, request, response=None, info=None):\n return '%s.jpg' % (request.meta['f1'])\n"
},
{
"alpha_fraction": 0.5737179517745972,
"alphanum_fraction": 0.5833333134651184,
"avg_line_length": 36.439998626708984,
"blob_id": "3bef71a2c2a89d8667dccc783ec9e0ad3540b3de",
"content_id": "189c6c5baa9ddf5e9593a71969ae5b7dc646cd24",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 936,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 25,
"path": "/mangascraper/mangascraper/spiders/immortale.py",
"repo_name": "zerogravity1990/Web-Scraper",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport scrapy\nfrom .. import items\n\nclass ImmortaleSpider(scrapy.Spider):\n name = 'immortale'\n allowed_domains = ['www.mangaeden.com']\n start_urls = ['https://www.mangaeden.com/en/it-manga/limmortale/0/1/']\n\n\n def parse(self, response):\n item = items.MangascraperItem()\n urls_list = []\n for url in response.xpath('//img[@id=\"mainImg\"]/@src').extract():\n urls_list.append(\"https:\" + url)\n item['image_urls'] = urls_list\n item['image_names'] = response.url.split(\"/\")[-3] + \"-\" + response.url.split(\"/\")[-2] #result is like \"chapter-page\", \"1-25\"\n yield item\n\n next_page = response.xpath('//a[@class=\"ui-state-default next\"]/@href').extract()\n if next_page:\n next_href = next_page[0]\n next_page_url = response.urljoin(next_href)\n request = scrapy.Request(url=next_page_url)\n yield request\n"
}
] | 3 |
B-Griffinn/text-based-RPG
|
https://github.com/B-Griffinn/text-based-RPG
|
6e03c32236f8b12f9c8636b9104597ec2320853d
|
c3bbfaee926e377342786b56aa6d0386dbb16c9b
|
5c9183896f23582e74f8b5e31db303c3129e5ca6
|
refs/heads/master
| 2022-10-03T10:59:39.712220 | 2020-05-30T21:03:55 | 2020-05-30T21:03:55 | 268,132,400 | 0 | 0 | null | 2020-05-30T17:55:06 | 2020-05-30T21:02:15 | 2020-05-30T21:03:56 |
Python
|
[
{
"alpha_fraction": 0.5098356604576111,
"alphanum_fraction": 0.5219123363494873,
"avg_line_length": 26.043771743774414,
"blob_id": "a2aa0cd8e299d70e0da0739fe039c209152ec044",
"content_id": "95c38bdf6465b2f2af05b40811d3992d02738dcb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8032,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 297,
"path": "/game.py",
"repo_name": "B-Griffinn/text-based-RPG",
"src_encoding": "UTF-8",
"text": "# Python Text RPG - Ben Griffin\n\n# Imports\nimport cmd\nimport textwrap\nimport sys\nimport os\nimport time\nimport random\n\n# Our screen width\nscreen_width = 100\n\n#### Player Class Setup ####\n\n\nclass Player:\n def __init__(self):\n self.name = ''\n self.job = ''\n self.hp = 0\n self.mp = 0\n self.status_effects = []\n self.location = 'b2'\n self.game_over = False\n\n\n# Initialize a player\nmyPlayer = Player()\n\n#### Title Screen ####\n\n\ndef title_screen_selections():\n # select menu options and lowercase it\n option = input(\"~~> \")\n\n if option.lower() == (\"play\"):\n setup_game() # TODO - placeholder\n elif option.lower() == (\"help\"):\n help_menu() # TODO - placeholder\n elif option.lower() == (\"quit\"):\n sys.exit()\n\n while option.lower() not in ['play', 'help', 'quit']:\n print(\"Please enter a valid command.\")\n option = input(\"~~> \")\n\n if option.lower() == (\"play\"):\n setup_game() # TODO - placeholder\n elif option.lower() == (\"help\"):\n help_menu() # TODO - placeholder\n elif option.lower() == (\"quit\"):\n sys.exit()\n\n\ndef title_screen():\n os.system('clear')\n print('######################################')\n print('# Welcome to the Text RPG!')\n print('######################################')\n print(' -Play- ')\n print(' -Help- ')\n print(' -Quit- ')\n print(' Copyright Ben Griffin ')\n title_screen_selections()\n\n\ndef help_menu():\n os.system('clear')\n print('######################################')\n print('# Welcome to the Text RPG!')\n print('######################################')\n print('- Use up, down, left, right to move ')\n print('- Type your commands to run them ')\n print('- Good luck and have fun ')\n title_screen_selections()\n\n#### Game Interactivity ####\n\n\ndef print_location():\n print('\\n' + ('#' * (4 + len(myPlayer.location))))\n print('# ' + myPlayer.location.upper() + ' #')\n print('# ' + zone_map[myPlayer.location][DESCRIPTION] + ' #')\n print('\\n' + ('#' * (4 + len(myPlayer.location))))\n\n\ndef prompt():\n print(\"\\n\" + \"===============\")\n print(\"What would you like to do?\")\n action = input(\"~~> \")\n acceptable_actions = ['move', 'go', 'travel', 'walk', 'quit',\n 'examine', 'inspect', 'interact', 'look']\n while action.lower() not in acceptable_actions:\n print(\"Please use a known action\")\n action = input(\"~~> \")\n if action.lower() == 'quit':\n sys.exit()\n elif action.lower() in ['move', 'go', 'travel', 'walk']:\n player_move(action.lower()) # TODO\n elif action.lower() in ['examine', 'inspect', 'interact', 'look']:\n player_examine(action.lower()) # TODO\n\n\ndef player_move(myAction):\n ask = \"Where would you like to move to?\\n\"\n dest = input(ask)\n if dest in ['up', 'north']:\n destination = zone_map[myPlayer.location][UP]\n movement_handler(destination)\n elif dest in ['down', 'south']:\n destination = zone_map[myPlayer.location][DOWN]\n movement_handler(destination)\n elif dest in ['left', 'west']:\n destination = zone_map[myPlayer.location][LEFT]\n movement_handler(destination)\n elif dest in ['right', 'east']:\n destination = zone_map[myPlayer.location][RIGHT]\n movement_handler(destination)\n\n\ndef movement_handler(destination):\n print(f\"\\n You have moved to the {destination}.\")\n myPlayer.location = destination\n print_location()\n\n\ndef player_examine(action):\n if zone_map[myPlayer.location][SOLVED]:\n print(\"You have already exhausted this zone.\")\n else:\n print(\"You can trigger puzzle here.\")\n\n#### Game Functionality ####\n\n\ndef main_game_loop():\n while myPlayer.game_over is False:\n prompt()\n # here handle if puzzles have been solved, boss defeated, explored etc.\n\n\n#### MAP ####\nZONENAME = ''\nDESCRIPTION = 'description'\nEXAMINATION = 'examine'\nSOLVED = False\nUP = 'up, north'\nDOWN = 'down, south'\nLEFT = 'left, west'\nRIGHT = 'right, east'\n\nsolved_places = {'a1': False, 'a2': False, 'a3': False, 'a4': False,\n 'b1': False, 'b2': False, 'b3': False, 'b4': False,\n 'c1': False, 'c2': False, 'c3': False, 'c4': False,\n 'd1': False, 'd2': False, 'd3': False, 'd4': False}\n\nzone_map = {\n 'a1': {\n ZONENAME: \"Town Market\",\n DESCRIPTION: 'description',\n EXAMINATION: 'examine',\n SOLVED: False,\n UP: '',\n DOWN: 'b1',\n LEFT: '',\n RIGHT: 'a2',\n },\n 'a2': {\n ZONENAME: \"Town Entrance\",\n DESCRIPTION: 'description',\n EXAMINATION: 'examine',\n SOLVED: False,\n UP: '',\n DOWN: 'b2',\n LEFT: 'a1',\n RIGHT: 'a3',\n },\n 'a3': {\n ZONENAME: \"Town Square\",\n DESCRIPTION: 'description',\n EXAMINATION: 'examine',\n SOLVED: False,\n UP: '',\n DOWN: 'b3',\n LEFT: 'a2',\n RIGHT: 'a4',\n },\n 'a4': {\n ZONENAME: \"Town Hall\",\n DESCRIPTION: 'description',\n EXAMINATION: 'examine',\n SOLVED: False,\n UP: '',\n DOWN: 'b4',\n LEFT: 'a3',\n RIGHT: '',\n },\n 'b1': {\n ZONENAME: \"\",\n DESCRIPTION: 'description',\n EXAMINATION: 'examine',\n SOLVED: False,\n UP: 'a1',\n DOWN: 'c1',\n LEFT: '',\n RIGHT: 'b2',\n },\n 'b2': {\n ZONENAME: 'Home',\n DESCRIPTION: 'This is your home.',\n EXAMINATION: 'Your home looks the same - nothing has changed.',\n SOLVED: False,\n UP: 'a2',\n DOWN: 'c2',\n LEFT: 'b1',\n RIGHT: 'b3',\n },\n # TODO map remainder of map\n}\n\n\ndef setup_game():\n os.system('clear')\n\n # name collecting\n question1 = \"Hello Whats your name?\\n\"\n for char in question1:\n sys.stdout.write(char)\n sys.stdout.flush()\n time.sleep(0.02)\n player_name = input(\"~~> \")\n myPlayer.name = player_name\n\n # job collecting\n question2 = \"Hello, what role do you want to play?\\n\"\n question2added = \"You can play as 'warrior', 'mage', 'priest'.\\n\"\n for char in question2:\n sys.stdout.write(char)\n sys.stdout.flush()\n time.sleep(0.05)\n for char2 in question2added:\n sys.stdout.write(char2)\n sys.stdout.flush()\n time.sleep(0.10)\n player_job = input(\"~~> \")\n valid_jobs = ['warrior', 'mage', 'priest']\n if player_job.lower() in valid_jobs:\n myPlayer.job = player_job\n print(f\"You are now a {player_job}\\n\")\n while player_job.lower() not in valid_jobs:\n player_job = input(\"~~> \")\n if player_job.lower() in valid_jobs:\n myPlayer.job = player_job\n print(f\"You are now a {player_job}\\n\")\n # PLayer stats\n if myPlayer.job == 'warrior':\n myPlayer.hp = 100\n myPlayer.mp = 15\n elif myPlayer.job == 'mage':\n myPlayer.hp = 95\n myPlayer.mp = 65\n elif myPlayer.job == 'priest':\n myPlayer.hp = 50\n myPlayer.mp = 50\n # Introduction\n question3 = f\"Weclome {player_name} the {player_job}.\\n\"\n for char in question3:\n sys.stdout.write(char)\n sys.stdout.flush()\n time.sleep(0.02)\n\n speech1 = \"Welcome to this fantasy world.\\n\"\n speech2 = \"Enjoy the adventure.\\n\"\n speech3 = \"Just make sure to not lose your way...\\n\"\n\n for char in speech1:\n sys.stdout.write(char)\n sys.stdout.flush()\n time.sleep(0.01)\n for char in speech2:\n sys.stdout.write(char)\n sys.stdout.flush()\n time.sleep(0.01)\n for char in speech3:\n sys.stdout.write(char)\n sys.stdout.flush()\n time.sleep(0.02)\n os.system('clear')\n print(\"#############\")\n print(\"Let's start now.\")\n print(\"#############\")\n main_game_loop()\n\n\ntitle_screen()\n"
}
] | 1 |
preetida/decart_linear_algebra_2019
|
https://github.com/preetida/decart_linear_algebra_2019
|
a659bfd47dbdbac1eb9f86a55893b35d590b13b3
|
446e0fca4cd78fd0ea63205014d306c56807d8d1
|
97bf49669ebfec3bc1853873fb25e1995f1c600d
|
refs/heads/master
| 2020-06-17T08:58:45.339345 | 2019-07-08T04:48:34 | 2019-07-08T04:48:34 | 195,871,371 | 1 | 1 | null | 2019-07-08T19:08:45 | 2019-07-08T04:48:41 | 2019-07-08T04:48:40 | null |
[
{
"alpha_fraction": 0.748155951499939,
"alphanum_fraction": 0.754478394985199,
"avg_line_length": 36.91999816894531,
"blob_id": "46f3574a5b2dc057c549879c3a8a4f323b167bc3",
"content_id": "a509dfc0428b8ac9dd43201fff0acf24ccf73a67",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 949,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 25,
"path": "/day1/gaussian_elimination.md",
"repo_name": "preetida/decart_linear_algebra_2019",
"src_encoding": "UTF-8",
"text": "\n# Gaussian Elimination\n\n\n## Algorithm (from http://www.math-cs.gordon.edu/courses/ma342/handouts/gauss.pdf)\n\nFollowing the pseudocode available at the above link, we are going to break our algorithm into three parts:\n\n1. Gaussian Elimination\n2. Forward Elimination\n3. Backward Solve\n\n### Gaussian Elimination\n\nThe gist of this step is to transform our matrix to an upper triangular matrix by finding **pivots**, using the pivots to determine multiplicative factors\n\n\n\n**Note:** this pseudocode assumes indexing starts at one. We will need to modify this for Python which starts at zero.\n\nFor the $k^{th}$ row we identify the $k^{th}$ column; this is the **pivot**. For each row $i; i > k$, we find the multiplier ($f_{ki}$) such that when we multiply row $k$ by\n\n\n\n## Backward Substitution\n\n"
},
{
"alpha_fraction": 0.5440860390663147,
"alphanum_fraction": 0.6033794283866882,
"avg_line_length": 17.384180068969727,
"blob_id": "6c993872f7c188716f212e0382def427c3282cf1",
"content_id": "0c8ecaca1a1c5be3a84150935abd9f57abd13f27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3255,
"license_type": "no_license",
"max_line_length": 248,
"num_lines": 177,
"path": "/LAProblems1.md",
"repo_name": "preetida/decart_linear_algebra_2019",
"src_encoding": "UTF-8",
"text": "\n# Linear Algebra and Biomedical Data Science\n\n## Homework - Work by hand\n\n### Problem 1.1\nUsing Gaussian elimination solve the following system of equations.\n\na)\n\\begin{eqnarray*}\nx_1+5x_2&= 7\\\\\n-2x_1-7x_2&=-5\n\\end{eqnarray*}\n\nb)\nFind the point of intersection of the two lines $x_1+5x_2=7$ and $x_1-2x_2=-2$.\n\nc)\n\\begin{eqnarray*}\nx_2+4x_3&= -5\\\\\nx_1+3x_2+5x_3&=-2\\\\\n3x_1+7x_2+7x_3&=6\n\\end{eqnarray*}\n\n#### Using Python\nRedo a), b), and c).\n\n### Problem 1.2\nDetermine if the system is consistent and if it has a unique solution. Each matrix represents an augmented matrix.\n\na)\n\\begin{equation*}\n\\begin{bmatrix}\nx & * & * & * \\\\ \n0 & x & * & *\\\\ \n0& 0 &x &0\n\\end{bmatrix}\n\\end{equation*}\n\nb)\n\\begin{equation*}\n\\begin{bmatrix}\n0 &x& * & * & * \\\\ \n0 &0& x & * & *\\\\ \n0& 0&0 &0 &x\n\\end{bmatrix}\n\\end{equation*}\n\n\nFind the general form of the solution for the following augmented matrix\n\nc)\n\\begin{equation*}\n\\begin{bmatrix}\n1 &-3& 0 & -1 & 0 &-2 \\\\ \n0 &1&0& 0 & -4 & 1\\\\ \n0&0& 0&1 &9 &4\\\\\n0&0&0&0&0&0\n\\end{bmatrix}\n\\end{equation*}\n\n\n### Problem 1.3\nLet $\\mathbf{x}=\\begin{bmatrix}\n1 \\\\ 2 \\\\ 3\\\\ 4\n\\end{bmatrix}$, $\\mathbf{y}=\\begin{bmatrix}\n-2 \\\\ 1\\\\ 2\\\\ 1\n\\end{bmatrix}$, and $\\mathbf{z}=\\begin{bmatrix}\n-2 \\\\ 1\\\\ 2\n\\end{bmatrix}$ . \n\na) Find $\\mathbf{x}+2\\mathbf{y}$ and $-2\\mathbf{x}+\\mathbf{z}$.\n\nb) Let $\\mathbf{x}=\\begin{bmatrix}\n1 \\\\ -2 \\\\ 0\n\\end{bmatrix}$, $\\mathbf{y}=\\begin{bmatrix}\n0\\\\ 1\\\\ 2\n\\end{bmatrix}$, and $\\mathbf{z}=\\begin{bmatrix}\n5 \\\\ -6\\\\ 8\n\\end{bmatrix}$. Is $\\mathbf{b}= \\begin{bmatrix}\n2 \\\\ -1\\\\ 6\n\\end{bmatrix}$ a linear combination of $\\mathbf{x}$, $\\mathbf{y}$, and $\\mathbf{z}$?\n\nc) List 4 vectors which are in the span of $\\{\\mathbf{v_1},\\mathbf{v_2}\\}$ where $\\mathbf{v_1}=\\begin{bmatrix}\n2 \\\\ 2\\\\ 6\n\\end{bmatrix}$ and $\\{\\mathbf{v_2}=\\begin{bmatrix}\n-2 \\\\ 2\\\\ 6\n\\end{bmatrix}$\n\n\n#### Using Python \nLet $\\mathbf{x}$ be a vector in $\\mathbb{R}^{10}$ whose $i$th component is $i$, let $\\mathbf{y}$ also be a vector in $\\mathbb{R}^{10}$ whose $i$th component is $i^2$, and let $\\mathbf{z}$ be a vector in $\\mathbb{R}^{11}$ whose components are all 1.\n\nFind $\\mathbf{y}+3\\mathbf{x}$, $-2\\mathbf{z}$, and $\\mathbf{x}+\\mathbf{z}$.\n\n### Problem 1.4\n\nCompute the product $A\\mathbf{x}$ using linear combination of columns and dots products.\n\na) $A=\\begin{bmatrix}\n-4& 2\\\\\n1&6\\\\\n0& 1\n\\end{bmatrix}$ and $\\mathbf{x}=\\begin{bmatrix}\n3\\\\\n-2\\\\\n7\n\\end{bmatrix}$\n\nb) $A=\\begin{bmatrix}\n5& 1&-8&4\\\\\n-2 &-7&3&-5\n\\end{bmatrix}$ and $\\mathbf{x}=\\begin{bmatrix}\n5\\\\\n-1\\\\\n3\\\\\n-2\n\\end{bmatrix}$\n\nc) a) $A=\\begin{bmatrix}\n-4& 2\\\\\n1&6\\\\\n0& 1\n\\end{bmatrix}$ and $\\mathbf{x}=\\begin{bmatrix}\n3\\\\\n-2\n\\end{bmatrix}$\n\nd) Is $\\mathbf{x}=\\begin{bmatrix}\n0\\\\\n4\\\\\n4\n\\end{bmatrix}$ in the span of the columns of \n$A=\\begin{bmatrix}\n3& -5\\\\\n-2&6\\\\\n1& 1\n\\end{bmatrix}$?\n\n#### Using Python \nRedo a), b) and c) using python.\n\n### Problem 1.5\n\na) Determine if the system has a non-trivial solution.\n\n\\begin{eqnarray*}\n2x_1-5x_2+8x_3&= 0\\\\\n-2x_1-7x_2+x_3&=0\\\\\n-4x_1+2x_2+7x_3&=0\\\\\n\\end{eqnarray*}\n\n### Problem 1.6\na) Find the values of $h$ which make the following vectors linearly dependent.\n$\\begin{bmatrix}\n1\\\\\n-1\\\\\n4\n\\end{bmatrix}$, $\\begin{bmatrix}\n3\\\\\n-5\\\\\n7\n\\end{bmatrix}$, and \n$\\begin{bmatrix}\n-1\\\\\n5\\\\\nh\n\\end{bmatrix}$\n\n\n```python\n\n```\n\n\n```python\n\n```\n"
},
{
"alpha_fraction": 0.7889294624328613,
"alphanum_fraction": 0.7889294624328613,
"avg_line_length": 30.01886749267578,
"blob_id": "e2b3c69bc09f5efe4a9c762380d4e377cda58167",
"content_id": "425cb8658fba28bd53c2112343e08c4248f1c478",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1644,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 53,
"path": "/README.md",
"repo_name": "preetida/decart_linear_algebra_2019",
"src_encoding": "UTF-8",
"text": "# Principles of Linear Algebra for Data Science\n\nThis course introduces students to linear algebra principles that form the\nfoundation of data science. Students will use Python to write simple programs\nto implement linear algebra concepts. Linear algebra concepts will be connected\nto important biomedical data science problems, such as text representation.\n\n## Linear Algebra Topics\n\n* Vector and matrix representation and basic mathematical operations\n* Vector spaces\n* Gaussian elimination\n* Basis vectors, dimensionality, norm\n* Null space, column space, and row space\n* Orthogonal projections\n* Least squares\n\n## Python Topics\n\nAs part of this class, students will develop a simple Python package that implements vectors, matrices, and linear algebra functions. Because the\nobjective of the programming is to reinforce linear algebra principles,\nprograms will be developed from native Python data structures rather than\nnumpy, which would be used in practice.\n\n## Prerequisities\n\nStudents should have prior Python programming experience (such as the\nDeCART Python boot camp or equivalent).\n\n## Course Schedule\n\n* Linear Equations\n * Systems of linear equations\n * Row reduction - Gaussian elimination\n * Vector equations\n * Matrix equations\n * Solutions sets\n * Linear independence\n* Matrices\n * Linear transformations\n * Matrix operations\n * Inverses of matrices\n* Vector Spaces\n * Vector spaces\n * Null space\n * Column space, row space\n * Linearly independent sets, bases\n * Coordinate systems, dimension\n* Orthogonality and Least Squares\n * Inner products\n * Orthogonal sets\n * Orthogonal projections\n * Least-Squares\n"
},
{
"alpha_fraction": 0.5564892888069153,
"alphanum_fraction": 0.5807656645774841,
"avg_line_length": 21.3125,
"blob_id": "0b873f33751d47570b1d4b0833374b47ee9ab840",
"content_id": "5c108ebf1043edc403d6c85966bd69f005b420bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1071,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 48,
"path": "/myla/plotting.py",
"repo_name": "preetida/decart_linear_algebra_2019",
"src_encoding": "UTF-8",
"text": "from sympy.plotting import plot\nimport sympy as sp\nfrom sympy import solve, symbols\nimport collections\n\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport numpy.linalg as la\n\n\ndef plot_lines(*eqs, solvefor='y'):\n plot(*[solve(e,solvefor)[0] for e in eqs])\n\n\ndef create_vd(v):\n if isinstance(v[0], collections.Sequence):\n return (v[0][0], v[0][1], v[1][0], v[1][1])\n else:\n return (0,0,v[0],v[1])\ndef extract_color(v):\n if isinstance(v[0], np.ndarray):\n return v[1]\n else:\n return v[2]\n\ndef draw_vectors(*v, ax=None):\n\n vs = [create_vd(vv) for vv in v]\n soa =np.array(vs)\n X, Y, U, V = zip(*soa)\n if ax == None:\n plt.figure()\n ax = plt.gca()\n\n maxx = np.abs(soa.max())\n\n\n colors = [extract_color(vv) for vv in v]\n ax.quiver(X, Y, U, V, color = colors, angles='uv', scale_units='xy', scale=1)\n\n ax.set_xlim([-1.2*maxx, 1.2*maxx])\n ax.set_ylim([-1.2*maxx, 1.2*maxx])\n ax.set_aspect(\"equal\")\n plt.xlabel(\"x\")\n plt.ylabel(\"y\")\n plt.grid(True)\n plt.draw()\n plt.show()\n"
},
{
"alpha_fraction": 0.7894737124443054,
"alphanum_fraction": 0.7894737124443054,
"avg_line_length": 18,
"blob_id": "46600cbc0144ad3f53c51ead008064f4f7d49c3d",
"content_id": "af6ea217e36566e368278e63bd0b954a8d1746d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 19,
"license_type": "no_license",
"max_line_length": 18,
"num_lines": 1,
"path": "/day1/README.md",
"repo_name": "preetida/decart_linear_algebra_2019",
"src_encoding": "UTF-8",
"text": "# Linear Equations\n"
}
] | 5 |
RoenAronson/pokemonSpawner
|
https://github.com/RoenAronson/pokemonSpawner
|
19c7b6aa47d06e54f9a58cdff98dfc74b3bb3b44
|
1d7d2a37f6b3062813ef77bc9180048444d332c1
|
14c8c3942f2157c57aebabd83162847a073ae6ce
|
refs/heads/master
| 2022-06-20T03:14:54.195553 | 2020-05-09T21:39:03 | 2020-05-09T21:39:03 | 262,663,009 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5723684430122375,
"alphanum_fraction": 0.6019737124443054,
"avg_line_length": 19.266666412353516,
"blob_id": "125c25ed7692b373e876eb7dc3d02435e1ccef3e",
"content_id": "0ae26bac72381cb40e49878b3c9d0d61e5bf435d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 608,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 30,
"path": "/ImageCreator.py",
"repo_name": "RoenAronson/pokemonSpawner",
"src_encoding": "UTF-8",
"text": "import Pokemon\nimport os\nimport random\nimport math\nfrom pathlib import Path\nfrom PIL import Image\n\npCoords = [] # Previous Coordinates\n\n\ndef generateCoordinate():\n x = random.randint(0, 1000)\n y = random.randint(0, 1000)\n available = True\n if not pCoords:\n pCoords.append([x, y])\n else:\n for c in pCoords:\n if math.fabs(c[0] - x) < 30 and math.fabs(c[1] - y) < 30:\n available = False\n if available:\n pCoords.append([x, y])\n\n\nfor i in range(10):\n generateCoordinate()\n\nif __name__ == '__main__':\n generateCoordinate()\n print(pCoords)\n"
},
{
"alpha_fraction": 0.6515093445777893,
"alphanum_fraction": 0.6572411060333252,
"avg_line_length": 30.16666603088379,
"blob_id": "770ce84634a06e3b499c26081f6d4c02d75c5b1a",
"content_id": "abe1c84aa134be7850fc8156e5f6b1880d3e06d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2617,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 84,
"path": "/PokemonListGenerator.py",
"repo_name": "RoenAronson/pokemonSpawner",
"src_encoding": "UTF-8",
"text": "import Pokemon\nimport os\nimport random\nimport math\nfrom pathlib import Path\nfrom PIL import Image\n\npokemonImages = 'D:\\PycharmProjects\\PokemonRandomizer\\pokemon_sprites';\npokemonList = [] # List of all of the pokemon objects, they have a weight for random encounter,\n# name, and associated image.\n\nweightList = [] # List of all of the pokemon's weights, this is only used to actually choose\n# a pokemon, the weights are generated when the list of pokemon is generated\n# at the start of the program.\n\ncoordinateList = [] # Coordinates that a pokemon has already spawned at, used to make sure they don't\n\ncanvasSize = 600\n\n# spawn on top of each other\n\ndef generatePokemonList():\n for pokemon in os.listdir(pokemonImages):\n p = Pokemon.Pokemon()\n p.name = Path(pokemon).stem\n p.image = Image.open(os.path.join('D:\\PycharmProjects\\PokemonRandomizer\\pokemon_sprites', pokemon))\n p.weight = random.random()\n pokemonList.append(p)\n\n\n# def calculatePreviousCoords(x, y, sizeOfSprite):\n# new = True\n# print(len(coordinateList))\n# for coord in coordinateList:\n# if coord is None:\n# return False\n# new = True\n# if x in range(coord[0] - sizeOfSprite, coord[0] + sizeOfSprite) and \\\n# y in range(coord[1] - sizeOfSprite, coord[1] + sizeOfSprite):\n# new = False\n# return new\n# return new\n\n\ndef generateCoordinate(canvasSize, distance):\n x = random.randint(0, canvasSize)\n y = random.randint(0, canvasSize)\n available = True\n if not coordinateList:\n coordinateList.append([x, y])\n return [x, y]\n else:\n for c in coordinateList:\n if math.fabs(c[0] - x) < distance and math.fabs(c[1] - y) < distance:\n available = False\n if available:\n coordinateList.append([x, y])\n return [x, y]\n else:\n generateCoordinate(canvasSize, distance)\n\ndef choosePokemon():\n imageX = canvasSize\n imageY = canvasSize\n combinedPokemonImage = Image.new('RGB', (imageX, imageY))\n for p in pokemonList:\n weightList.append(p.weight)\n for choice in random.choices(population=pokemonList, weights=weightList, k=10):\n imageCoordinate = generateCoordinate(canvasSize, 50)\n combinedPokemonImage.paste(choice.image, imageCoordinate)\n combinedPokemonImage.show()\n\n\ndef printPokemonList():\n for p in pokemonList:\n print(p.name)\n print(p.weight)\n\n\nif __name__ == '__main__':\n generatePokemonList()\n choosePokemon()\n print(len(coordinateList))\n print(coordinateList)"
},
{
"alpha_fraction": 0.5231788158416748,
"alphanum_fraction": 0.5231788158416748,
"avg_line_length": 20.14285659790039,
"blob_id": "2ac01a47c8594b46166fe0106468e61f9c033761",
"content_id": "67a9dc5105ad2732d2419d420dc11d15e252cb15",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 151,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 7,
"path": "/Pokemon.py",
"repo_name": "RoenAronson/pokemonSpawner",
"src_encoding": "UTF-8",
"text": "class Pokemon:\n\n def __init__(self):\n self.name = None\n self.image = None\n self.weight = None\n self.spawnArea = None\n\n\n\n"
}
] | 3 |
drorspei/ipython-adbcompleter
|
https://github.com/drorspei/ipython-adbcompleter
|
300cf6a7b7556c97434c08f89b88dec90d5c09d3
|
1e96b35658d7e7636734be36a88e8bebded7cc6e
|
d63ef9aa1349fb45fa03636aa787bef33d44e24f
|
refs/heads/master
| 2021-03-30T21:16:20.944910 | 2018-04-23T16:13:32 | 2018-04-23T16:13:32 | 124,942,849 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4810996651649475,
"alphanum_fraction": 0.48562127351760864,
"avg_line_length": 26.783920288085938,
"blob_id": "91b93f2dc07bf64e169159187c129aa515d3b7c9",
"content_id": "acae13be91cb59a6513d53737008d2309f2acc15",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5529,
"license_type": "permissive",
"max_line_length": 134,
"num_lines": 199,
"path": "/ipython_adbcompleter.py",
"repo_name": "drorspei/ipython-adbcompleter",
"src_encoding": "UTF-8",
"text": "\"\"\"IPython completer for adb commands.\n\nTo activate, pip-install and append the output of `ipython -m ipython_adbcompleter`\nto `~/.ipython/profile_default/ipython_config.py`.\n\"\"\"\nimport os\nimport re\nimport subprocess\n\n\ntry:\n import _ipython_adbcompleter_version\nexcept ImportError:\n from pip._vendor import pkg_resources\n __version__ = pkg_resources.get_distribution(\"ipython-adbcompleter\").version\nelse:\n __version__ = _ipython_adbcompleter_version.get_versions()[\"version\"]\n\n\ndef slash_chr(s, c):\n sc = '\\\\%c' % c\n return sc.join(ss.replace(c, sc) for ss in s.split(sc))\n\ndef unslash_chr(s, c):\n sc = '\\\\%c' % c\n while True:\n s2 = s.replace(sc, c)\n if s != s2:\n return s2\n s = s2\n\n\ndef adb_completer(self, event):\n \"\"\"\n A simple completer that returns the arguments that adb accepts\n \"\"\"\n adb_completer.event = event\n subs = event.text_until_cursor[event.text_until_cursor.find('adb ') + 4:]\n\n if re.match(r\"(^|^.*\\s)-s\\s+[^\\s]*$\", subs):\n return adb_devices()\n elif re.match(r\"^(-s [^\\s]*\\s+)?[^\\s]*$\", subs):\n return [\n '-a',\n '-d',\n '-e',\n '--help',\n '-s',\n '-p',\n '-H',\n '-P',\n 'devices',\n 'connect',\n 'disconnect',\n 'push',\n 'pull',\n 'sync',\n 'shell',\n 'emu',\n 'logcat',\n 'forward',\n 'reverse',\n 'jdwp',\n 'install',\n 'uninstall',\n 'bugreport',\n 'backup',\n 'restore',\n 'help',\n 'version',\n 'wait-for-device',\n 'start-server',\n 'kill-server',\n 'get-state',\n 'get-serialno',\n 'get-devpath',\n 'status-window',\n 'remount',\n 'reboot',\n 'reboot-bootloader',\n 'root',\n 'usb',\n 'tcpip',\n 'ppp',\n ]\n\n pathname = None\n\n for nr, pattern, in_quotes in [\n (3, r\"^(-s ([^\\s]*)\\s+)?pull\\s+(([^\\s\\\"']|(?<=\\\\)[ \\\"'])*)$\", False),\n (3, r\"^(-s ([^\\s]*)\\s+)?pull\\s+\\\"(([^\\\"]|(?<=\\\\)\\\")*)$\", True),\n (5, r\"^(-s ([^\\s]*)\\s+)?push\\s+\\\"(([^\\\"]|(?<=\\\\)\\\")*)\\\"\\s+(([^\\s\\\"']|(?<=\\\\)[ \\\"'])*)$\", False),\n (5, r\"^(-s ([^\\s]*)\\s+)?push\\s+(([^\\s\\\"']|(?<=\\\\)[ \\\"'])*)\\s+(([^\\s\\\"']|(?<=\\\\)[ \\\"'])*)$\", False),\n (5, r\"^(-s ([^\\s]*)\\s+)?push\\s+(([^\\s\\\"']|(?<=\\\\)[ \\\"'])*)\\s+\\\"(([^\\\"]|(?<=\\\\)\\\")*)$\", True),\n (5, r\"^(-s ([^\\s]*)\\s+)?push\\s+\\\"(([^\\\"]|(?<=\\\\)\\\")*)\\\"\\s+\\\"(([^\\\"]|(?<=\\\\)\\\")*)$\", True)\n ]:\n m = re.match(pattern, subs)\n if m:\n pathname = m.group(nr)\n res = [slash_chr(slash_chr(slash_chr(s, '\"'), \"'\"), ' ') for s in parse_and_ls(pathname, m.group(1))]\n\n if not in_quotes:\n res = [slash_chr(s, ' ') for s in res]\n\n return [p[len(pathname) - len(event.symbol):] for p in res]\n \n return []\n\n\n_enabled = False\n\n\ndef parse_and_ls(pathname, device):\n if pathname.endswith('/'):\n return shell_ls(pathname, '', device)\n else:\n last_slash = pathname.rfind('/')\n if last_slash == -1:\n return [f[1:] for f in shell_ls('/', pathname, device)]\n else:\n return shell_ls(pathname[:pathname.rfind('/') + 1], pathname[pathname.rfind('/') + 1:], device)\n\n\ndef shell_ls(pathbase, filename, device):\n if device is None:\n device = ''\n try:\n files = subprocess.check_output('adb %sshell ls \"%s\"' % (device, pathbase), shell=True, stderr=subprocess.STDOUT).splitlines()\n except Exception:\n return []\n \n paths = []\n if (len(files) > 1 or \n (len(files) == 1 and files[0] != 'error: device not found' and \n files[0] != \"opendir failed, Permission denied\" and \n not files[0].endswith('No such file or directory'))):\n for f in files:\n try:\n if f.startswith(filename):\n paths.append('%s%s%s' % (pathbase, '' if pathbase.endswith('/') else '/', f))\n except Exception:\n pass\n\n return paths\n\n\ndef adb_devices():\n try:\n lines = [line for line in subprocess.check_output('adb devices', shell=True, stderr=subprocess.STDOUT).splitlines() if line]\n except Exception:\n return []\n\n if len(lines) <= 1 or lines[0] != 'List of devices attached':\n return []\n\n lines = lines[1:]\n devices = [line.split()[0] for line in lines]\n\n return devices\n\n\nif __name__ != \"__main__\":\n from IPython.core.magic import register_line_magic\n\n @register_line_magic\n def adb(arg):\n \"\"\"Conveniance magic for running adb\"\"\"\n os.system('adb %s' % arg)\n\n\ndef load_ipython_extension(ipython):\n \"\"\"\n Load the extension.\n \"\"\"\n global _enabled\n _enabled = True\n ipython.set_hook('complete_command', adb_completer, re_key='.*adb ')\n\n\ndef unload_ipython_extension(ipython):\n \"\"\"\n Unload the extension\n \"\"\"\n global _enabled\n _enabled = False\n\n\nif __name__ == \"__main__\":\n import sys\n\n if os.isatty(sys.stdout.fileno()):\n print(\"\"\"\\\n# Please append the output of this command to the\n# output of `ipython profile locate` (typically\n# `~/.ipython/profile_default/ipython_config.py`)\n\"\"\")\n print(\"\"\"\\\nc.InteractiveShellApp.exec_lines.append(\n \"try:\\\\n %load_ext ipython_adbcompleter\\\\nexcept ImportError: pass\")\"\"\")\n"
},
{
"alpha_fraction": 0.5582586526870728,
"alphanum_fraction": 0.5685019493103027,
"avg_line_length": 31.54166603088379,
"blob_id": "39e908aefc4c29876d20b1f84273d1f3e1b0ff4b",
"content_id": "55da5d865396aeaf9fb9ea7830eb513a994e3478",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 781,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 24,
"path": "/setup.py",
"repo_name": "drorspei/ipython-adbcompleter",
"src_encoding": "UTF-8",
"text": "from setuptools import setup\nimport versioneer\n\n\nif __name__ == \"__main__\":\n setup(\n name=\"ipython-adbcompleter\",\n version=versioneer.get_version(),\n cmdclass=versioneer.get_cmdclass(),\n description=\"IPython completer for adb commands\",\n long_description=open(\"README.md\").read(),\n author=\"Dror Speiser\",\n url=\"https://github.com/drorspei/ipython-adbcompleter\",\n license=\"MIT\",\n classifiers=[\n \"Development Status :: 1 - Beta\",\n \"Framework :: IPython\",\n \"License :: OSI Approved :: MIT License\",\n \"Programming Language :: Python :: 3\",\n ],\n py_modules=[\"ipython_adbcompleter\"],\n python_requires=\">=2.7.10\",\n install_requires=[\"ipython>=4.0\"],\n )\n"
},
{
"alpha_fraction": 0.7307692170143127,
"alphanum_fraction": 0.7455621361732483,
"avg_line_length": 27.97142791748047,
"blob_id": "6587232571d2a93308c5fed1141593db7db3bb79",
"content_id": "a437bba162c3be5a5eb64efcca0c38474db22979",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1014,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 35,
"path": "/README.md",
"repo_name": "drorspei/ipython-adbcompleter",
"src_encoding": "UTF-8",
"text": "# ipython-adbcompleter\nAn IPython completer for adb commands\n\nBeyond the basic argument completion, this extension also adds completions for file/directory paths:\n\n```\nIn [1]: adb p # hit tab!\npull\npush\nIn [1]: adb pull /storage/ # hit tab!\n6432-6235\nemulated\nenc_emulated\nPrivate\nself\nIn [1]: adb pull /storage/emu # hit tab!\nIn [1]: adb pull /storage/emulated\n```\n\nAmazing! This will save me so much time!\n\nNotes:\n1. The android path must start with `/`. This is to reduce queries to the phone when you want a path on your computer.\n2. Unicode characters in paths mess up my ipython, so for now adbcompleter just skips them.\n3. adbcompleter now supports multiple connected devices!\n\n# Install\nUse pip like this:\n`pip install git+https://github.com/drorspei/ipython-adbcompleter`\n\nThen add the following lines to your `ipython_config.py` file (usually in `~/.ipython/profile_default/`):\n```\nc.InteractiveShellApp.exec_lines.append(\n \"try:\\n %load_ext ipython_adbcompleter\\nexcept ImportError: pass\")\n```\n"
}
] | 3 |
jmichaelseri/flask-todolist
|
https://github.com/jmichaelseri/flask-todolist
|
6cda52dd8daae069dfcbfc9a143e6e1d15e75202
|
bc0bfb447c23cc422385c948a2fe2c5a72d652d5
|
b5b1bb2c47ffd9dc640906242096ca8e3091dd54
|
refs/heads/master
| 2020-05-28T11:53:47.806183 | 2019-07-25T13:27:32 | 2019-07-25T13:27:32 | 188,991,401 | 0 | 1 | null | 2019-05-28T08:52:55 | 2019-07-25T13:27:47 | 2021-03-20T01:07:10 |
Python
|
[
{
"alpha_fraction": 0.7398374080657959,
"alphanum_fraction": 0.7502903342247009,
"avg_line_length": 22.243244171142578,
"blob_id": "d0d9c228d3482a4809d3a9396b1b861838229d34",
"content_id": "7c11baa1d59d5f150ffdb5fa6633dfc95961ac45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 861,
"license_type": "no_license",
"max_line_length": 170,
"num_lines": 37,
"path": "/README.md",
"repo_name": "jmichaelseri/flask-todolist",
"src_encoding": "UTF-8",
"text": "# Flask Todo List app\n\nThis is a simple todo list app in flask. It uses the following dependencies:\n1. Flask-login\n2. Flask-sqlalchemy\n3. SQLite3\n4. Flask-migrate\n5. Flask-wtf\n6. python-dotenv\n7. Flask-debugtoolbar\n\nThere is a basic CRUD functionality as well as login/logout and registration.\n\n# Installation notes\n\nIn order to set up the app after having cloned the repository, do the following to install the required dependencies. Make sure that `pip` and `virtualenv` are installed.\n\n* In the folder run \n```\npython3 -m virtualenv venv\n```` \nwhere `venv` is the folder name of the virtual environment.\n\n* Then activate the virtual environment\n\n```\nsource /venv/bin/activate\n```\nThe command line prompt will then look like\n```\n(venv) {machine-name}:flask-todolist {username}$\n```\n\n* Finally install the requirements\n```\npip install -r requirements.txt\n```\n\n"
},
{
"alpha_fraction": 0.6691218018531799,
"alphanum_fraction": 0.6691218018531799,
"avg_line_length": 34.64646530151367,
"blob_id": "2611548d90004d4e75ca4c56fde54dff7eae4e37",
"content_id": "5961eb0e2601d5d946f86b2121de4fea7669e887",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3530,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 99,
"path": "/app/routes.py",
"repo_name": "jmichaelseri/flask-todolist",
"src_encoding": "UTF-8",
"text": "from flask import render_template, redirect, url_for, request, flash, request\nfrom app import app, db\nfrom app.forms import LoginForm, TaskFrom, RegistrationForm\nfrom werkzeug.urls import url_parse\nfrom app.models import User, Task\n\nfrom flask_login import current_user, login_user, logout_user, login_required\n\n\n# Lists of incomplete tasks\[email protected]('/', methods=('GET', 'POST'))\[email protected]('/index', methods=('GET', 'POST'))\n@login_required\ndef index():\n itasks = Task.query.filter_by(completed=False).all()\n form = TaskFrom()\n if form.validate_on_submit():\n task = Task(body=form.task.data, author=current_user)\n db.session.add(task)\n db.session.commit()\n return redirect(url_for('index'))\n return render_template('index.html', title='Home', form=form, itasks=itasks)\n\n# list of completed tasks and other informations\[email protected]('/completed/tasks')\n@login_required\ndef completed_tasks():\n ctasks = Task.query.filter_by(completed=True).all()\n return render_template('/completed.html', title='Completed Tasks', ctasks=ctasks )\n\n\n# logging into the application\[email protected]('/login', methods=['GET', 'POST'])\ndef login():\n if current_user.is_authenticated:\n return redirect(url_for('index'))\n form = LoginForm()\n if form.validate_on_submit():\n user = User.query.filter_by(username=form.username.data).first()\n if user is None or not user.check_password(form.password.data):\n flash('Invalid username or password.')\n return redirect(url_for('login'))\n login_user(user, remember=form.remember_me.data)\n next_page = request.args.get('next')\n if not next_page or url_parse(next_page).netloc != '':\n next_page = url_for('index')\n return redirect(next_page)\n return render_template('login.html', title='Sign In', form=form)\n\n# logging out of the application\[email protected]('/logout')\ndef logout():\n logout_user()\n return redirect(url_for('index'))\n\n# Registering with the application in order to login\[email protected]('/register', methods=['GET', 'POST'])\ndef register():\n if current_user.is_authenticated:\n return redirect(url_for('index'))\n form = RegistrationForm()\n if form.validate_on_submit():\n user = User(username=form.username.data, email=form.email.data)\n user.set_password(form.password.data)\n db.session.add(user)\n db.session.commit()\n flash('Congratulations, you are now a registered user!')\n return redirect(url_for('login'))\n return render_template('register.html', title='Regiser', form=form)\n\n# complete a task so that it appears in the completed task list\[email protected]('/complete/<int:id>', methods=('GET', 'POST'))\n@login_required\ndef complete(id):\n task = Task.query.get(int(id))\n task.completed = not task.completed\n db.session.commit()\n return redirect(url_for('index'))\n\n# Delete a task from the database\[email protected]('/delete/<int:id>', methods=('GET', 'POST'))\n@login_required\ndef delete(id):\n task = Task.query.get(int(id))\n db.session.delete(task)\n db.session.commit()\n return redirect(url_for('completed_tasks'))\n\n# Update a todo\[email protected]('/update/<string:id>', methods=('GET', 'POST'))\ndef update(id):\n task = Task.query.get(id)\n form = TaskFrom()\n if form.validate_on_submit():\n task.body = form.task.data\n db.session.commit()\n flash('Task updated!')\n return redirect(url_for('index'))\n return render_template('update.html', form=form, task=task)\n\n"
},
{
"alpha_fraction": 0.8620689511299133,
"alphanum_fraction": 0.8620689511299133,
"avg_line_length": 28.5,
"blob_id": "78ded1704895edbd4c968008dc1d6144de60b038",
"content_id": "54b5c134cb959dce70fb9921e930e6c352445a01",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 58,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 2,
"path": "/.flaskenv",
"repo_name": "jmichaelseri/flask-todolist",
"src_encoding": "UTF-8",
"text": "export FLASK_APP=flasktodo.py\nexport FLASK_ENV=development"
}
] | 3 |
carmanm/Blackjack-Console-Game
|
https://github.com/carmanm/Blackjack-Console-Game
|
2936817d8c7f9bb4a57701d6451a3d9956d946b3
|
45614f23fe2f42c368e7b5f9fc1047e6ad19e090
|
dfd9647f8bb13724e4b03af8d4aa940939f421ba
|
refs/heads/master
| 2020-04-14T14:51:57.221009 | 2016-09-18T21:08:40 | 2016-09-18T21:08:40 | 68,152,793 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.766094446182251,
"alphanum_fraction": 0.7725321650505066,
"avg_line_length": 45.599998474121094,
"blob_id": "cd9948a693d25ee941d90af518547551a9cc54f2",
"content_id": "08256782d331dd159eab5807e24c759e13541e21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 466,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 10,
"path": "/README.md",
"repo_name": "carmanm/Blackjack-Console-Game",
"src_encoding": "UTF-8",
"text": "# Blackjack-Console-Game\nWant to look like you're coding, but are actually trying your hand at a riveting game of blackjack? Well now you can with this console game.\nJust install python 3.5.1 to get started. All the instructions are given in the game. Have fun!\n\nCOMING SOON:\n-Next commit will have the ability to split\n\nBUGS:\n-Aces don't always work properly for the dealer\n-I have noted a bug giving a random blackjack to the player, but have only seen it once\n"
},
{
"alpha_fraction": 0.3629712164402008,
"alphanum_fraction": 0.3934771716594696,
"avg_line_length": 21.276243209838867,
"blob_id": "213aac0fc99e1b91f12d7201b0cf9b61c5683904",
"content_id": "2c79ca29880aca01463dc12c734409a84ffa15a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8064,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 362,
"path": "/Blackjack.py",
"repo_name": "carmanm/Blackjack-Console-Game",
"src_encoding": "UTF-8",
"text": "from tkinter import ttk\nfrom tkinter import *\nimport random\nimport time\n\n\nclass blackjack:\n def __init__(self): \n global money\n \n money = 100\n \n begin = input(\"Welcome to the console version of blackjack, press enter to begin. . .\")\n if begin == \"\": \n self.placeBet()\n else:\n really = input(\"That is not pressing enter. . . PRESS ENTER TO BEGIN. . .\")\n if really == \"\":\n self.placeBet()\n else:\n print(\"Goodbye. . .\")\n time.sleep(3)\n \n\n def placeBet(self):\n global money\n global bet\n \n print(\"you have $\" + str(money))\n\n if money <= 0:\n print(\"Sorry, you're out of money. . .\")\n print(\"Goodbye. . .\")\n time.sleep(3)\n exit()\n \n time.sleep(0.5)\n print(\"_____________________________________________________________________\")\n bet = input(\"Enter your bet: \")\n\n if bet == \"\" or bet.isalpha():\n print(\"Enter a number . . .\")\n self.placeBet()\n\n if int(bet) > money:\n print(\"You don't have enough money. . . \")\n self.placeBet()\n \n money = money - int(bet)\n time.sleep(0.5)\n print(\"Remaining balance: \", money)\n time.sleep(0.5)\n getCards = input(\"Press enter to deal cards. . . \")\n if getCards == \"\":\n self.dealCards()\n else:\n ye = input(\"Press enter. . .\")\n if ye == \"\":\n self.dealCards()\n else:\n print(\"You messed it all up. . .\")\n \n def dealCards(self):\n global deck\n global total\n global deal1\n global deal2\n global currentHand\n global aceHand\n \n \n deck = {2:2, 3:3, 4:4, 5:5, 6:6, 7:7, 8:8, 9:9, 10:10, \"J\":\"J\", \"K\":\"K\", \"Q\":\"Q\", \"A\":\"A\"}\n\n \n \n print(\"Cards Dealt:\")\n\n time.sleep(0.5)\n \n deal1 = random.choice(list(deck.keys()))\n deal2 = random.choice(list(deck.keys()))\n pair = print(deal1, \",\", deal2)\n\n currentHand = [deal1, deal2]\n \n if deal1 == \"J\":\n deal1 = 10\n if deal1 == \"K\":\n deal1 = 10\n if deal1 == \"Q\":\n deal1 = 10\n if deal1 == \"A\":\n deal1 = 11\n\n if deal2 == \"J\":\n deal2 = 10\n if deal2 == \"K\":\n deal2 = 10\n if deal2 == \"Q\":\n deal2 = 10\n if deal2 == \"A\":\n deal2 = 11\n \n #acehand\n if deal1 == 11:\n ace1 = 1\n else:\n ace1 = deal1\n\n if deal2 == 11:\n ace2 = 1\n else:\n ace2 = deal2\n\n aceHand = [ace1, ace2]\n\n \n \n #print(aceHand)\n total = deal1 + deal2\n\n \n \n #print(total)\n if total == 21:\n time.sleep(1)\n print(\"BLACKJACK\")\n self.playerWin()\n else:\n self.hitStay()\n\n\n \n def hitStay(self):\n time.sleep(0.5)\n HS = input(\"Would you like to hit or stay? 'h' for hit, 's' for stay. . .\")\n \n if HS == \"h\" or HS == \"H\":\n self.hit()\n\n if HS == \"s\" or HS == \"S\":\n self.dealer1()\n\n if HS !=\"h\" or HS != \"H\" or HS != \"s\" or HS != \"S\":\n print(\"You must type 'h' or 's'\")\n time.sleep(0.5)\n self.hitStay()\n \n \n def hit(self):\n global deck\n global total\n global deal1\n global deal2\n global currentHand\n global aceHand\n \n deal3 = random.choice(list(deck.keys()))\n\n currentHand.insert(0, deal3)\n for value in currentHand:\n print(value, end = \" , \")\n \n print(\"\\n\")\n \n if deal3 == \"J\":\n deal3 = 10\n if deal3 == \"K\":\n deal3 = 10\n if deal3 == \"Q\":\n deal3 = 10\n if deal3 == \"A\":\n deal3 = 11\n \n if total > 21 and deal3 == \"A\":\n deal3 = 1 \n \n \n total = total + deal3\n #print(total)\n\n if deal3 == 11:\n ace3 = 1\n else:\n ace3 = deal3 \n\n for i in aceHand:\n if i == \"A\":\n i = 1\n \n aceHand.insert(0, ace3)\n\n if \"A\" in currentHand:\n total = sum(aceHand)\n \n #print(aceHand)\n #print(\"CURRENT: \", currentHand)\n #print(\"SUM: \", total)\n \n \n if total > 21:\n time.sleep(1)\n print(\"BUST\")\n print(\"Dealer wins. . .\")\n self.placeBet()\n if total == 21:\n time.sleep(1)\n print(\"BLACKJACK\")\n self.playerWin()\n if total < 21:\n self.hitStay()\n\n \n\n def playerWin(self):\n global money\n global bet\n \n money = money + (int(bet) * 2)\n\n self.placeBet() \n\n def dealer1(self):\n global deck\n global total\n global _total\n global _deal1\n global _deal2\n\n time.sleep(1) \n \n print(\"Dealer's turn:\")\n\n time.sleep(0.5)\n \n _deal1 = random.choice(list(deck.keys()))\n _deal2 = random.choice(list(deck.keys()))\n _pair = print(_deal1, _deal2)\n\n time.sleep(0.5)\n\n if _deal1 == \"J\":\n _deal1 = 10\n if _deal1 == \"K\":\n _deal1 = 10\n if _deal1 == \"Q\":\n _deal1 = 10\n if _deal1 == \"A\":\n _deal1 = 11\n\n if _deal2 == \"J\":\n _deal2 = 10\n if _deal2 == \"K\":\n _deal2 = 10\n if _deal2 == \"Q\":\n _deal2 = 10\n if _deal2 == \"A\":\n _deal2 = 11\n\n _total = _deal1 + _deal2\n\n \n if _total == 21:\n time.sleep(1)\n print(\"BLACKJACK\")\n print(\"Dealer wins. . .\")\n self.placeBet()\n \n else:\n self.dealerPonders()\n\n\n \n \n \n\n\n def dealerPonders(self):\n global deck\n global total\n global _total\n global deal1\n global deal2\n global bet\n global money\n\n if total > _total:\n self.dealerHit()\n elif total == _total:\n time.sleep(1)\n print(\"Push. . .\")\n\n money = money + int(bet)\n \n self.placeBet()\n\n if _total > total:\n print(\"Dealer wins. . .\")\n self.placeBet()\n \n\n def dealerHit(self):\n global deck\n global total\n global _total\n global _deal1\n global _deal2\n \n _deal3 = random.choice(list(deck.keys()))\n\n print(\"HIT:\", _deal3)\n\n if _deal3 == \"J\":\n _deal3 = 10\n if _deal3 == \"K\":\n _deal3 = 10\n if _deal3 == \"Q\":\n _deal3 = 10\n if _deal3 == \"A\":\n _deal3 = 11\n \n _total = _total + _deal3\n\n time.sleep(1)\n \n \n\n time.sleep(1)\n if _total > 21 and _deal3 == \"A\":\n _deal3 = 1 \n if _total > 21 and _deal1 == \"A\":\n _deal1 = 1\n #print(_total)\n self.dealerPonders()\n if _total > 21 and _deal2 == \"A\":\n _deal2 = 1\n #print(_total)\n self.dealerPonders()\n if _total > 21:\n time.sleep(1)\n print(\"BUST\")\n self.playerWin()\n if _total == 21:\n time.sleep(1)\n print(\"BLACKJACK\")\n print(\"Dealer wins. . .\")\n self.placeBet()\n if _total < 21:\n self.dealerPonders()\n \n time.sleep(0.5)\n\n \n \n \n \ndef main():\n blackjack()\n\n exit()\n\nif __name__ == \"__main__\": main()\n"
}
] | 2 |
Jaroslove/LessonDjango111
|
https://github.com/Jaroslove/LessonDjango111
|
903c68d7ecbca0a274e33b5fc4063072e88ed6ac
|
f51fbdae7be1c15fa3f52edf5084efbc03823e8e
|
e9957ffb1071a77c42f4e68e887c4869a72de3fd
|
refs/heads/master
| 2021-08-07T05:58:17.187313 | 2017-11-07T17:54:57 | 2017-11-07T17:54:57 | 108,690,301 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6543624401092529,
"alphanum_fraction": 0.6543624401092529,
"avg_line_length": 50.826087951660156,
"blob_id": "3718addfe0981d04f0189601ece506fbf0c6e9b6",
"content_id": "45d98ef0cc606d31ffcde8b70ac0aa96d7c24bda",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1192,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 23,
"path": "/TrOneONeOne/urls.py",
"repo_name": "Jaroslove/LessonDjango111",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url, include\nfrom django.contrib import admin\nfrom restoran import views\nfrom django.contrib.auth.views import LoginView\n\nurlpatterns = [\n url(r'^admin/', admin.site.urls),\n url(r'^restoran/', include('restoran.urls')),\n url(r'^items/', include('menus.urls')),\n # url(r'^restoran/$', views.RestoranListView.as_view(), name='restoran'),\n # url(r'^restoran/create/$', views.RestoranCreateView.as_view(), name='create_restoran'),\n # url(r'^restoran/create/$', views.restoran_createview),\n # url(r'^restoran/(?P<slug>\\w+)$', views.SearchRestoranListView.as_view()),\n # url(r'^restoran/(?P<pk>\\w+)$', views.DetailRestoranListView.as_view()),\n # url(r'^restoran/(?P<slug>[\\w-]+)/$', views.DetailRestoranListView.as_view(), name='restoran_details'),\n # use rest_id instead pk\n # url(r'^restoran/spb/$', views.SRestoranlist.as_view()),\n # url(r'^restoran/moscow/$', views.MRestoranlist.as_view()),\n # url(r'^home/', views.restorant_listview),\n # url(r'^home/(?P<id>\\d+)', views.ContactTemplateView.as_view()),\n # url(r'^home/(?P<id>\\d+)', views.ContactView.as_view()),\n url(r'login/', LoginView.as_view(), name='login'),\n]\n"
},
{
"alpha_fraction": 0.5900216698646545,
"alphanum_fraction": 0.5943601131439209,
"avg_line_length": 19.954545974731445,
"blob_id": "7900da7fa3069da5f222debacc82485013d61020",
"content_id": "abe1d1f469d76431a06ffa221155533ce45e3649",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 461,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 22,
"path": "/restoran/validation.py",
"repo_name": "Jaroslove/LessonDjango111",
"src_encoding": "UTF-8",
"text": "from django.core.exceptions import ValidationError\n\n\ndef valid_even(value):\n if value % 2 != 0:\n raise ValidationError('%(value)s',\n params={'value': value}, )\n\n\ndef valid_email(value):\n email = value\n if '.edu' in email:\n raise ValidationError('we dont')\n\n\nLOCATION = ['Spb', 'Moscow']\n\n\ndef valid_location(value):\n # cat = value.capitalize()\n if value in LOCATION:\n raise ValidationError('no')\n"
},
{
"alpha_fraction": 0.6972891688346863,
"alphanum_fraction": 0.704066276550293,
"avg_line_length": 29.88372039794922,
"blob_id": "7e60fb299400c168ec5279f22351404014135672",
"content_id": "b40ba8330ec34c752e892f96d89d9341dbeea152",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1328,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 43,
"path": "/restoran/models.py",
"repo_name": "Jaroslove/LessonDjango111",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.db.models.signals import pre_save, post_save\nfrom .utils import unique_slag_generator\nfrom django.conf import settings\nfrom django.core.urlresolvers import reverse\n\nUser = settings.AUTH_USER_MODEL\n\n\nclass Restorant(models.Model):\n owner = models.ForeignKey(User)\n name = models.CharField(max_length=120)\n location = models.CharField(max_length=120, null=True, blank=True)\n category = models.CharField(max_length=120, null=True, blank=True)\n timestamp = models.DateTimeField(auto_now_add=True)\n update = models.DateTimeField(auto_now=True)\n slug = models.SlugField(null=True, blank=True)\n\n def __str__(self):\n return self.name\n\n def get_absolute_url(self):\n return reverse('details_restoran', kwargs={'slug': self.slug})\n\n @property\n def title(self):\n return self.name # obj.title\n\n\ndef r_pre_save_receiver(sender, instance, *args, **kwargs):\n # print('saving...')\n # print(instance.timestamp)\n if not instance.slug:\n instance.slug = unique_slag_generator(instance)\n\n\n# def r_post_save_receiver(sender, created, instance, *args, **kwargs):\n# print('saved')\n# print(instance.timestamp)\n\n\npre_save.connect(r_pre_save_receiver, sender=Restorant)\n# post_save.connect(r_post_save_receiver, sender=Restorant)\n"
},
{
"alpha_fraction": 0.6830309629440308,
"alphanum_fraction": 0.6862326860427856,
"avg_line_length": 29.225807189941406,
"blob_id": "2f2d0f4fa6ef4a0f287e1f11eb265f403dc7c40c",
"content_id": "b593e98a2508e746ce1a1b8e431818cb751a8bfe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 937,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 31,
"path": "/menus/models.py",
"repo_name": "Jaroslove/LessonDjango111",
"src_encoding": "UTF-8",
"text": "from django.conf import settings\nfrom django.db import models\nfrom django.urls import reverse\n\nfrom restoran.models import Restorant\n\n\nclass Item(models.Model):\n user = models.ForeignKey(settings.AUTH_USER_MODEL)\n restoran = models.ForeignKey(Restorant)\n name = models.CharField(max_length=120)\n contents = models.TextField(help_text='this is help')\n excludes = models.TextField(blank=True, null=True, help_text='another')\n public = models.BooleanField(default=True)\n timestamp = models.DateTimeField(auto_now_add=True)\n update = models.DateTimeField(auto_now=True)\n\n def __str__(self):\n return self.name\n\n def get_absolute_url(self):\n return reverse('details_menus', kwargs={'pk': self.pk})\n\n class Meta:\n ordering = ['-timestamp', '-update']\n\n def get_content(self):\n return self.contents.split(', ')\n\n def get_excludes(self):\n return self.excludes.split(', ')\n"
},
{
"alpha_fraction": 0.6776119470596313,
"alphanum_fraction": 0.6776119470596313,
"avg_line_length": 40.875,
"blob_id": "695599f9f03a5bdc6cfbacdb4a9aaf2099317dea",
"content_id": "0fa16d834930e063f6a932ba8b36352d3bec4198",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 335,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 8,
"path": "/menus/urls.py",
"repo_name": "Jaroslove/LessonDjango111",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\nfrom .views import ItemListView, ItemCreateView, ItemDetailView, ItemUpdateView\n\nurlpatterns = [\n url(r'^$', ItemListView.as_view(), name='menus'),\n url(r'^create/$', ItemCreateView.as_view(), name='create_menus'),\n url(r'^(?P<pk>[\\w-]+)/$', ItemDetailView.as_view(), name='details_menus'),\n]\n"
},
{
"alpha_fraction": 0.6942148804664612,
"alphanum_fraction": 0.6942148804664612,
"avg_line_length": 28.512195587158203,
"blob_id": "14e8a1d0d969530b3cf99092933d86eb31079755",
"content_id": "c3095a0d4c1f5dc8d07352dd1d3accdf33655770",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1210,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 41,
"path": "/menus/views.py",
"repo_name": "Jaroslove/LessonDjango111",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom django.views.generic import ListView, CreateView, DetailView, UpdateView\nfrom .models import Item\nfrom .forms import ItemForm\n\n\nclass ItemListView(ListView):\n def get_queryset(self):\n return Item.objects.filter(user=self.request.user)\n\n\nclass ItemDetailView(DetailView):\n def get_queryset(self):\n return Item.objects.filter(user=self.request.user)\n\n\nclass ItemCreateView(CreateView):\n template_name = 'restoran/form.html'\n form_class = ItemForm\n success_url = '/restoran/'\n\n def get_queryset(self):\n return Item.objects.filter(user=self.request.user)\n\n def get_context_data(self, *args, **kwargs):\n context = super(ItemCreateView, self).get_context_data(*args, **kwargs)\n context['title'] = 'Create item'\n return context\n\n\nclass ItemUpdateView(UpdateView):\n template_name = 'restoran/form.html'\n form_class = ItemForm\n\n def get_queryset(self):\n return Item.objects.filter(user=self.request.user)\n\n def get_context_data(self, *args, **kwargs):\n context = super(ItemUpdateView, self).get_context_data(*args, **kwargs)\n context['title'] = 'Update item'\n return context\n"
},
{
"alpha_fraction": 0.6756272315979004,
"alphanum_fraction": 0.6756272315979004,
"avg_line_length": 25.571428298950195,
"blob_id": "9a46782b8348381b8f41b265a534cf7e3a2e1605",
"content_id": "9273e98a536183a3b27edc626d3bca83f7fc5bc9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 558,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 21,
"path": "/restoran/forms.py",
"repo_name": "Jaroslove/LessonDjango111",
"src_encoding": "UTF-8",
"text": "from django import forms\nfrom .models import Restorant\nfrom .validation import valid_email, valid_even, valid_location\n\n\nclass RestoranCreateForm(forms.Form):\n name = forms.CharField(required=True)\n location = forms.CharField(required=False)\n category = forms.CharField(required=False)\n\n\nclass RestoranCreateFromTwo(forms.ModelForm):\n location = forms.CharField(required=False, validators=[valid_location])\n\n class Meta:\n model = Restorant\n fields = [\n 'name',\n 'location',\n 'category'\n ]\n"
},
{
"alpha_fraction": 0.6373850703239441,
"alphanum_fraction": 0.6373850703239441,
"avg_line_length": 50.52631759643555,
"blob_id": "f926f590edf653fe3863dbb383d092bb24f39fdb",
"content_id": "80ff1460bd258222aa6d620ce38294687582af89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 979,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 19,
"path": "/restoran/urls.py",
"repo_name": "Jaroslove/LessonDjango111",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\nfrom restoran import views\n\nurlpatterns = [\n # url(r'^admin/', admin.site.urls),\n url(r'^$', views.RestoranListView.as_view(), name='restoran'),\n url(r'^create/$', views.RestoranCreateView.as_view(), name='create_restoran'),\n # url(r'^restoran/create/$', views.restoran_createview),\n # url(r'^restoran/(?P<slug>\\w+)$', views.SearchRestoranListView.as_view()),\n # url(r'^restoran/(?P<pk>\\w+)$', views.DetailRestoranListView.as_view()),\n url(r'^(?P<slug>[\\w-]+)/$', views.DetailRestoranListView.as_view(), name='details_restoran'),\n # use rest_id instead pk\n # url(r'^restoran/spb/$', views.SRestoranlist.as_view()),\n # url(r'^restoran/moscow/$', views.MRestoranlist.as_view()),\n # url(r'^home/', views.restorant_listview),\n # url(r'^home/(?P<id>\\d+)', views.ContactTemplateView.as_view()),\n # url(r'^home/(?P<id>\\d+)', views.ContactView.as_view()),\n # url(r'login/', LoginView.as_view(), name='login'),\n]\n"
},
{
"alpha_fraction": 0.6415747404098511,
"alphanum_fraction": 0.6493619084358215,
"avg_line_length": 31.10416603088379,
"blob_id": "efdb3a5f7dfe3843c93bfbec76ea51804c0ee52c",
"content_id": "fb7586ceb7356bbd61ac59394957fdd1da83400b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4623,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 144,
"path": "/restoran/views.py",
"repo_name": "Jaroslove/LessonDjango111",
"src_encoding": "UTF-8",
"text": "from django.contrib.auth.decorators import login_required\nfrom django.contrib.auth.mixins import LoginRequiredMixin\nfrom django.db.models import Q\nfrom django.shortcuts import render, get_object_or_404\nfrom django.views import View\nfrom django.views.generic import TemplateView, ListView, DetailView, CreateView\nfrom .models import Restorant\nfrom .forms import RestoranCreateForm, RestoranCreateFromTwo\nfrom django.http import HttpResponse, HttpResponseRedirect\n\n\n@login_required()\ndef restoran_createview(request):\n form = RestoranCreateFromTwo(request.POST or None)\n if form.is_valid():\n if request.user.is_authenticated():\n instance = form.save(commit=False)\n instance.owner = request.user\n instance.save()\n return HttpResponseRedirect('/restoran/')\n if form.errors:\n print(form.errors)\n template_name = 'restoran/form.html'\n context = {'form': form}\n return render(request, template_name, context)\n\n\n# def restoran_createview(request):\n# form = RestoranCreateForm(request.POST or None)\n# if form.is_valid():\n# obj = Restorant.objects.create(\n# name=form.cleaned_data.get('name'),\n# location=form.cleaned_data.get('location'),\n# category=form.cleaned_data.get('category')\n# )\n# return HttpResponseRedirect('/restoran/')\n# if form.errors:\n# print(form.errors)\n# template_name = 'restoran/form.html'\n# context = {'form': form}\n# return render(request, template_name, context)\n\n\nclass DetailRestoranListView(DetailView):\n queryset = Restorant.objects.all()\n\n # def get_context_data(self, *args, **kwargs):\n # print(self.kwargs)\n # context = super(DetailRestoranListView, self).get_context_data(*args, **kwargs)\n # print(context)\n # return context\n\n # def get_object(self, *args, **kwargs):\n # rest_id = self.kwargs.get('rest_id')\n # obj = get_object_or_404(Restorant, id=rest_id)\n # return obj\n\n\nclass SearchRestoranListView(ListView):\n template_name = 'restoran/home.html'\n\n def get_queryset(self):\n # print(self.kwargs)\n slug = self.kwargs.get('slug')\n print(slug)\n if slug:\n return Restorant.objects.filter(\n Q(location__iexact=slug) |\n Q(location__contains=slug)\n )\n else:\n return Restorant.objects.all()\n\n\nclass RestoranListView(ListView):\n queryset = Restorant.objects.all() # use object_list as list in templates\n template_name = 'restoran/home.html'\n\n\nclass SRestoranlist(ListView):\n queryset = Restorant.objects.filter(location__iexact='spb') # use object_list as list in templates\n template_name = 'restoran/home.html'\n\n\nclass MRestoranlist(ListView):\n queryset = Restorant.objects.filter(location__iexact='moscow') # use object_list as list in templates\n template_name = 'restoran/home.html'\n\n\ndef restorant_listview(request):\n template_name = 'restoran/home.html'\n queryset = Restorant.objects.filter(location__iexact='spb')\n context = {\n 'list_restoran': queryset # queryset.filter(location__iexact='spb')\n }\n return render(request, template_name, context)\n\n\ndef index(request):\n template = 'restoran/home.html'\n context = {\n 'ee': [3, 24, 525, 35, 35]\n }\n return render(request, template, context)\n\n\nclass ContactView(View):\n def get(self, request, *args, **kwargs):\n print(kwargs)\n template = 'restoran/home.html'\n context = {\n 'ee': [3, 24, 525, 35, 35]\n }\n return render(request, template, context)\n\n\nclass ContactTemplateView(TemplateView):\n template_name = 'restoran/home.html'\n\n def get_context_data(self, *args, **kwargs):\n # context = super(ContactTemplateView, self).get_context_data(*args, **kwargs) show me the example of context\n context = {\n 'ee': [3, 24, 525, 35, 35]\n }\n # print(context)\n return context\n\n\nclass RestoranCreateView(LoginRequiredMixin, CreateView):\n form_class = RestoranCreateFromTwo\n login_url = '/login/'\n template_name = 'form.html'\n success_url = '/restoran/'\n\n def form_valid(self, form):\n instance = form.save(commit=False)\n instance.owner = self.request.user\n # instance.save()\n return super(RestoranCreateView, self).form_valid(form)\n\n def get_context_data(self, *args, **kwargs):\n context = super(RestoranCreateView, self).get_context_data(*args, **kwargs)\n context['title'] = 'Add restoran'\n return context\n"
},
{
"alpha_fraction": 0.8315789699554443,
"alphanum_fraction": 0.8315789699554443,
"avg_line_length": 22.75,
"blob_id": "b45dd88217395cc60fc02fa57dc3135319932d2b",
"content_id": "e7952c24e1751205ae8539a3a613337a61a27809",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 95,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 4,
"path": "/restoran/admin.py",
"repo_name": "Jaroslove/LessonDjango111",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import Restorant\n\nadmin.site.register(Restorant)\n"
},
{
"alpha_fraction": 0.3928571343421936,
"alphanum_fraction": 0.3973214328289032,
"avg_line_length": 31.071428298950195,
"blob_id": "bc82247db304f61a65cbfe37c664a6dd9c882b06",
"content_id": "134672203047729263402e2cbc1c6b1abffcbdb5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 448,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 14,
"path": "/templates/restoran/restorant_detail.html",
"repo_name": "Jaroslove/LessonDjango111",
"src_encoding": "UTF-8",
"text": "{% extends 'restoran/base.html' %}\n{% block main %}\n <h5>Hello from base</h5>\n {% for item in object_list %}\n <ul>\n <il>\n {# <a href=\"{% url 'restoran_details' slug=item.slug %}\"></a><br/>#}\n <a href=\"{{ item.get_absolute_url }}\"></a><br/>\n {{ item.location }} </br>\n {{ item.update }}\n </il>\n </ul>\n {% endfor %}\n{% endblock %}"
}
] | 11 |
oamunozr/Capstone
|
https://github.com/oamunozr/Capstone
|
e0e0dd1f29225453c7956449e4e1254c55cc5dfa
|
d0c0067cf28fea079217a27f921bed99cb0576aa
|
f635bd1b930e9636f6a657e3db8ac7004ed1122b
|
refs/heads/main
| 2023-04-25T00:18:06.252795 | 2021-05-14T17:40:47 | 2021-05-14T17:40:47 | 367,399,609 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6657650470733643,
"alphanum_fraction": 0.6676970720291138,
"avg_line_length": 34.97142791748047,
"blob_id": "6fd76d30fe945abb62801e380268fdd0c11f0298",
"content_id": "4f842390c96252edb443753cf54ac900a1ec282b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2588,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 70,
"path": "/script.py",
"repo_name": "oamunozr/Capstone",
"src_encoding": "UTF-8",
"text": "# based on: https://github.com/aws/amazon-sagemaker-examples/blob/master/sagemaker-python-sdk/scikit_learn_randomforest/Sklearn_on_SageMaker_end2end.ipynb\r\nimport argparse\r\nimport joblib\r\nimport os\r\n\r\nimport numpy as np\r\nimport pandas as pd\r\nfrom sklearn.ensemble import RandomForestClassifier\r\nfrom sklearn.metrics import accuracy_score\r\n\r\n\r\n# inference functions ---------------\r\ndef model_fn(model_dir):\r\n clf = joblib.load(os.path.join(model_dir, \"model.joblib\"))\r\n return clf\r\n\r\n\r\nif __name__ == \"__main__\":\r\n\r\n print(\"extracting arguments\")\r\n parser = argparse.ArgumentParser()\r\n\r\n # hyperparameters sent by the client are passed as command-line arguments to the script.\r\n # to simplify the demo we don't use all sklearn RandomForest hyperparameters\r\n parser.add_argument(\"--n-estimators\", type=int, default=10)\r\n parser.add_argument(\"--min-samples-leaf\", type=int, default=3)\r\n\r\n # Data, model, and output directories\r\n parser.add_argument(\"--model-dir\", type=str, default=os.environ.get(\"SM_MODEL_DIR\"))\r\n parser.add_argument(\"--train\", type=str, default=os.environ.get(\"SM_CHANNEL_TRAIN\"))\r\n parser.add_argument(\"--test\", type=str, default=os.environ.get(\"SM_CHANNEL_TEST\"))\r\n parser.add_argument(\"--train-file\", type=str, default=\"train.csv\")\r\n parser.add_argument(\"--test-file\", type=str, default=\"test.csv\")\r\n parser.add_argument(\r\n \"--features\", type=str\r\n ) # in this script we ask user to explicitly name features\r\n parser.add_argument(\r\n \"--target\", type=str\r\n ) # in this script we ask user to explicitly name the target\r\n\r\n args, _ = parser.parse_known_args()\r\n\r\n print(\"reading data\")\r\n train_df = pd.read_csv(os.path.join(args.train, args.train_file))\r\n test_df = pd.read_csv(os.path.join(args.test, args.test_file))\r\n\r\n print(\"building training and testing datasets\")\r\n X_train = train_df[args.features.split()]\r\n X_test = test_df[args.features.split()]\r\n y_train = train_df[args.target]\r\n y_test = test_df[args.target]\r\n\r\n # train\r\n print(\"training model\")\r\n model = RandomForestClassifier(\r\n n_estimators=args.n_estimators, min_samples_leaf=args.min_samples_leaf, n_jobs=-1\r\n )\r\n\r\n model.fit(X_train, y_train)\r\n\r\n # Calculate and print the accuracy \r\n accuracy = accuracy_score(y_test, model.predict(X_test))\r\n\r\n print('Accuracy is:', accuracy)\r\n \r\n # persist model\r\n path = os.path.join(args.model_dir, \"model.joblib\")\r\n joblib.dump(model, path)\r\n print(\"model persisted at \" + path)\r\n print(args.min_samples_leaf)\r\n"
}
] | 1 |
BNMetrics/bnmetrics-utils
|
https://github.com/BNMetrics/bnmetrics-utils
|
0082377da3b66bba4eb121938d4aa460f4a26784
|
7087181ea871a9e379781446e8f076853fb3eb13
|
f69b4a6373b62fe189e0fd272bd010e8c9c25834
|
refs/heads/master
| 2021-06-02T16:52:52.734022 | 2018-12-21T15:41:52 | 2018-12-21T15:41:52 | 135,461,695 | 0 | 0 |
NOASSERTION
| 2018-05-30T15:19:11 | 2018-12-21T15:41:59 | 2021-04-29T19:58:37 |
Python
|
[
{
"alpha_fraction": 0.6754807829856873,
"alphanum_fraction": 0.6802884340286255,
"avg_line_length": 24.212121963500977,
"blob_id": "af87f1141060cf54629bbff27df2ab18a94462da",
"content_id": "c4812ea4d5b6f8add35479b7f8de5704e9417d3a",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 832,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 33,
"path": "/setup.py",
"repo_name": "BNMetrics/bnmetrics-utils",
"src_encoding": "UTF-8",
"text": "from pathlib import Path\n\nfrom importlib.machinery import SourceFileLoader\n\nfrom setuptools import setup, find_packages\n\n\nver_module_path = Path(__file__).parent / Path('bnmutils/__version__.py')\nver_module_obj = SourceFileLoader('bnmutils', str(ver_module_path)).load_module()\n\nversion = ver_module_obj.__version__\n\n\nrequires = [\n]\n\nwith open('README.rst', 'r', encoding='utf-8') as f:\n readme = f.read()\n\nsetup(\n name='bnmutils',\n packages=find_packages(exclude=['tests*']),\n install_requires=requires,\n version=version,\n description='Compilations of various utilities',\n long_description=readme,\n author='Luna Chen',\n url='https://github.com/BNMetrics/bnmetrics-utils',\n author_email='[email protected]',\n keywords=['configparser', '.ini', 'docstring'],\n python_requires='>=3',\n license='Apache 2.0',\n)\n"
},
{
"alpha_fraction": 0.6032906770706177,
"alphanum_fraction": 0.6307129859924316,
"avg_line_length": 14.657142639160156,
"blob_id": "01f1ed44d71d067cabe00bb7689deff394fdcddf",
"content_id": "e36e19bdd9d884c65b5626c68b6388cbc3027332",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 547,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 35,
"path": "/tests/test_configparser/dummy_config.ini",
"repo_name": "BNMetrics/bnmetrics-utils",
"src_encoding": "UTF-8",
"text": "[my_config]\nprofile =\n name: Luna\n profession:software engineer\n Hobby: Marine fish\nprojects = [\"hello\", 1, 3]\nActive = True\nPosts = None\nUsers = 5\n\n\n[Fish_Profiles]\nTank_type = Reef Tank\nTank_size = 50 gal\nAge = 1 year\nFish =\n clownfish: 2\n chalk_goby: 1\n yellow_clown_goby: 1\ninvertebrates =\n snails: 3\n Shrimps: 1\nOthers =\n Liverock: 1\nCorals =\n toadstool: 2\n ricordia: 1\n euphyllia: 2\n\n[date_format]\nformatter =\n\tfmt: {asctime} - {name} - {levelname} - {message}\n\tdatefmt: '%Y/%m/%d'\n\tstyle: {\nActive = True"
},
{
"alpha_fraction": 0.6160194277763367,
"alphanum_fraction": 0.6160194277763367,
"avg_line_length": 23.819276809692383,
"blob_id": "9121fac87a2e143bd1281b8780de66a41fc26b07",
"content_id": "f252cb23b201f93be815578a3533e931c0d663c5",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2060,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 83,
"path": "/bnmutils/novelty.py",
"repo_name": "BNMetrics/bnmetrics-utils",
"src_encoding": "UTF-8",
"text": "import os\nimport ast\nfrom pathlib import Path\nfrom functools import wraps\nfrom contextlib import contextmanager\n\nfrom typing import Callable\n\n\ndef doc_parametrize(**parameters) -> Callable:\n \"\"\"\n Decorator for allowing parameters to be passed into docstring\n\n :param parameters: key value pair that corresponds to the params in docstring\n \"\"\"\n def decorator_(callable_):\n new_doc = callable_.__doc__.format(**parameters)\n callable_.__doc__ = new_doc\n\n @wraps(callable_)\n def wrapper(*args, **kwargs):\n return callable_(*args, **kwargs)\n\n return wrapper\n\n return decorator_\n\n\n@contextmanager\ndef cd(dir_path: str):\n \"\"\"\n Context manager for cd, change back to original directory when done\n \"\"\"\n cwd = os.getcwd()\n try:\n os.chdir(os.path.expanduser(dir_path))\n yield\n finally:\n os.chdir(cwd)\n\n\ndef strip_blank_recursive(nested_list: list, evaluate: bool=False):\n \"\"\"\n Strip blank space or newline characters recursively for a nested list\n\n *This updates the original list passed in*\n\n \"\"\"\n if not isinstance(nested_list, list):\n raise ValueError(f\"iterable passed must be type of list. not '{type(nested_list).__name__}'\")\n\n for i, v in enumerate(nested_list):\n if isinstance(v, list):\n strip_blank_recursive(v, evaluate)\n elif isinstance(v, str):\n if not evaluate:\n val_ = v.strip()\n else:\n val_ = str_eval(v)\n\n nested_list[i] = val_\n\n\ndef str_eval(parse_str: str):\n \"\"\"\n Evaluate string, return the respective object if evaluation is successful,\n \"\"\"\n try:\n val = ast.literal_eval(parse_str.strip())\n except (ValueError, SyntaxError): # SyntaxError raised when passing in \"{asctime}::{message}\"\n val = parse_str.strip()\n\n return val\n\n\ndef is_pypkg(path: Path) -> bool:\n \"\"\"\n Check if the input path is a python package\n \"\"\"\n if (path / '__init__.py').exists():\n return True\n\n return False\n"
},
{
"alpha_fraction": 0.30122214555740356,
"alphanum_fraction": 0.31200575828552246,
"avg_line_length": 28.617021560668945,
"blob_id": "78a4a75b6d0b16b40d91fb76729ee11392419833",
"content_id": "c3c34d7bb76b73e382b91839132cfd7e1e4d9271",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1391,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 47,
"path": "/tests/test_configparser/data.py",
"repo_name": "BNMetrics/bnmetrics-utils",
"src_encoding": "UTF-8",
"text": "from pathlib import Path\n\ncurrent_dir = Path(__file__).parent\n\nconfig_path = current_dir / 'dummy_config.ini'\n\nconfig_dict = {\n 'my_config': {\n 'profile': {\n 'name': 'Luna',\n 'profession': 'software engineer',\n 'Hobby': 'Marine fish'\n },\n 'projects': ['hello', 1, 3],\n 'Active': True,\n 'Posts': None,\n 'Users': 5,\n },\n 'Fish_Profiles': {\n 'Tank_type': 'Reef Tank',\n 'Tank_size': '50 gal',\n 'Age': '1 year',\n 'Fish': {\n 'clownfish': 2,\n 'chalk_goby': 1,\n 'yellow_clown_goby': 1\n },\n 'invertebrates': {\n 'snails': 3,\n 'Shrimps': 1\n },\n 'Others': {'Liverock': 1},\n 'Corals': {\n 'toadstool': 2,\n 'ricordia': 1,\n 'euphyllia': 2}\n },\n 'date_format': {\n 'formatter': {\n 'fmt': '{asctime} - {name} - {levelname} - {message}',\n 'datefmt': '%Y/%m/%d',\n 'style': '{'\n },\n 'Active': True\n }\n\n }"
},
{
"alpha_fraction": 0.5719146728515625,
"alphanum_fraction": 0.5746369957923889,
"avg_line_length": 32.64885330200195,
"blob_id": "01d1f162a9fb155226ca4a575d36aaf34132580c",
"content_id": "f6f102e5143aa561edc51c3a98839cc8495ea04e",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4408,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 131,
"path": "/bnmutils/configparser.py",
"repo_name": "BNMetrics/bnmetrics-utils",
"src_encoding": "UTF-8",
"text": "import os\n\nfrom typing import Iterable, Union, List\n\nfrom configparser import RawConfigParser as BuiltinConfigParser\n\nfrom .exceptions import InvalidConfig, InvalidConfigOption\nfrom .novelty import strip_blank_recursive, str_eval\n\n\nclass ConfigParser(BuiltinConfigParser):\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n\n # Preserve casing for options\n self.optionxform = str\n\n @classmethod\n def from_files(cls, filenames: Union[str, os.PathLike, Iterable],\n encoding=None, *args, **kwargs):\n\n # Transforming filenames into string format to work with older versions of python, e.g. python 3.6.0\n if isinstance(filenames, Iterable) and \\\n not isinstance(filenames, str):\n filenames = [str(i) for i in filenames]\n\n obj = cls(*args, **kwargs)\n obj.read(filenames, encoding)\n\n if not obj.sections():\n raise InvalidConfig(f\"Invalid config file/files: {filenames}.\")\n\n return obj\n\n @classmethod\n def from_dict(cls, parse_dict: dict, *args, **kwargs):\n obj = cls(*args, **kwargs)\n\n flattened_dict = {}\n\n for section, val in parse_dict.items():\n flattened_dict[section] = obj._flatten_section_dict(val)\n\n obj.read_dict(flattened_dict)\n\n return obj\n\n def to_dict(self, section: str=None, option: str=None, **kwargs):\n \"\"\"\n\n :param section:\n :param option:\n :return:\n \"\"\"\n if option and not section:\n raise ValueError(\"Option cannot be passed on its own.\")\n\n if section and option:\n option_str = self.get(section, option)\n return self._option_to_dict(option_str)\n\n if section:\n section_list = self.items(section, **kwargs)\n return self._section_to_dict(section_list)\n\n config_dict = {}\n for i in self.sections():\n config_dict[i] = self._section_to_dict(self.items(i))\n\n return config_dict\n\n def _option_to_dict(self, parse_option: str) -> dict:\n \"\"\"\n Map the configuration option to dict.\n * Do not pass in the whole config section!*\n\n :param: parse_option: values from config.get('section', 'option')\n \"\"\"\n try:\n str_split = parse_option.strip().split('\\n') # raise AttributeError\n mapped_list = list(map(lambda x: x.split(':', 1), str_split))\n\n strip_blank_recursive(mapped_list, evaluate=True)\n\n return dict(mapped_list) # raises ValueError\n except AttributeError:\n raise InvalidConfigOption(f\"option passed must be a string value, \"\n f\"not type of '{type(parse_option).__name__}'.\")\n except ValueError:\n if '\\n' not in parse_option:\n raise ValueError(f\"'{parse_option}' cannot be converted to dict. alternatively, \"\n f\"use ConfigParser.get(section, value) to get the value.\")\n\n raise InvalidConfigOption(f\"{parse_option} is not a valid option, \"\n f\"please follow the convention of 'key: value'\")\n\n def _section_to_dict(self, config_section: Union[List[tuple], dict]) -> dict:\n \"\"\"\n Converting the ConfigParser *section* to a dictionary format\n\n :param config_section: values from config.items('section') or dict(config['section'])\n \"\"\"\n if isinstance(config_section, dict):\n return {k: self._option_to_dict(v) if '\\n' in v else str_eval(v)\n for k, v in config_section.items()}\n\n if isinstance(config_section, list):\n return {i[0]: self._option_to_dict(i[1]) if '\\n' in i[1] else str_eval(i[1])\n for i in config_section}\n\n raise ValueError(f\"Invalid section type '{type(config_section).__name__}'\")\n\n def _flatten_section_dict(self, parse_dict: dict):\n \"\"\"\n flatten nested dict config options for configuration file *sections*\n \"\"\"\n flattened = {}\n\n for k, v in parse_dict.items():\n\n if isinstance(v, dict):\n val_list = [f'{k1}: {v1}' for k1, v1 in v.items()]\n\n str_val = '\\n' + '\\n'.join(val_list)\n else:\n str_val = str(v)\n\n flattened[k] = str_val\n\n return flattened\n"
},
{
"alpha_fraction": 0.7403314709663391,
"alphanum_fraction": 0.7403314709663391,
"avg_line_length": 29.16666603088379,
"blob_id": "d22a8acecb7826941b3dfed36b7d3c23854ccbe5",
"content_id": "78ffb60db2399c5b3ffe95d26182bbfaca1d7c2d",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 181,
"license_type": "permissive",
"max_line_length": 56,
"num_lines": 6,
"path": "/bnmutils/exceptions.py",
"repo_name": "BNMetrics/bnmetrics-utils",
"src_encoding": "UTF-8",
"text": "class InvalidConfigOption(Exception):\n \"\"\"Used when the option in config file is invalid\"\"\"\n\n\nclass InvalidConfig(Exception):\n \"\"\"Used when invalid configuration is passed\"\"\"\n"
},
{
"alpha_fraction": 0.4567052125930786,
"alphanum_fraction": 0.46389496326446533,
"avg_line_length": 40.54545593261719,
"blob_id": "0aaf360169476e31933374a20b78cc1ee1738a2d",
"content_id": "697b7cdb552b4279a84fc0bab7950a105fa5df83",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3199,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 77,
"path": "/tests/test_novelty.py",
"repo_name": "BNMetrics/bnmetrics-utils",
"src_encoding": "UTF-8",
"text": "import pytest\nfrom pathlib import Path\n\nfrom bnmutils.novelty import doc_parametrize, cd, strip_blank_recursive, str_eval, is_pypkg\n\n\ndef test_doc_parametrize():\n @doc_parametrize(val1='hello', val2='world')\n def dummy_func():\n \"\"\"\n This is my docstring, {val1}, {val2}\n \"\"\"\n\n assert dummy_func.__doc__.strip() == 'This is my docstring, hello, world'\n\n\ndef test_cd(tmpdir):\n\n original_cwd = Path.cwd()\n\n with cd(tmpdir):\n assert Path.cwd() == tmpdir\n assert Path.cwd() != original_cwd\n\n assert original_cwd == Path.cwd()\n\n\[email protected]('iterable_, expected, evaluate',\n [pytest.param(['hello ', '\\nhi ', '1'], ['hello', 'hi', 1],\n True,\n id='when the iterable passed is not nested, evaluate=True'),\n pytest.param([[' hello ', 'hi \\n'], ['1', ' blah ', ' bye']],\n [['hello', 'hi'], [1, 'blah', 'bye']],\n True,\n id='when the iterable passed has nested list, evaluate=True'),\n pytest.param([[' hello ', 'hi \\n'], ['2.5', ' blah ', ' bye'], 'greet '],\n [['hello', 'hi'], [2.5, 'blah', 'bye'], 'greet'],\n True,\n id='when a tuple is passed and it has nested list and string, '\n 'evaluate=True'),\n pytest.param([['True', 'False', '2.5'], 'False'],\n [['True', 'False', '2.5'], 'False'],\n False,\n id='Nested list and String, evaluate=False')\n ])\ndef test_strip_blank_recursive(iterable_, expected, evaluate):\n strip_blank_recursive(iterable_, evaluate=evaluate)\n\n assert iterable_ == expected\n\n\[email protected]('parse_arg', [pytest.param(1, id='int value passed'),\n pytest.param('hello foo bar', id='string value passed'),\n pytest.param(('hello', 'hi'), id='tuple value passed')\n ])\ndef test_strip_blank_recursive_raise(parse_arg):\n with pytest.raises(ValueError):\n strip_blank_recursive(parse_arg)\n\n\[email protected]('parse_str, expected',\n [\n pytest.param('None', None, id='Passing a None value'),\n pytest.param('False', False, id='Passing a boolean value'),\n pytest.param('Hello world', 'Hello world', id='Passing a regular string'),\n pytest.param('[1, 2, 3]', [1,2,3], id='Passing a list value'),\n ])\ndef test_str_eval(parse_str, expected):\n result = str_eval(parse_str)\n\n assert result == expected\n\n\ndef test_is_pypkg():\n path = Path(__file__).parent / 'test_configparser'\n assert is_pypkg(path)\n assert not is_pypkg(Path(__file__))\n"
},
{
"alpha_fraction": 0.695035457611084,
"alphanum_fraction": 0.695035457611084,
"avg_line_length": 34.33333206176758,
"blob_id": "3fc69bfb5a01df04bedd246ceefa7867d45f0394",
"content_id": "bf5284f0b28820a795c3fceab777368d4d01afb5",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 423,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 12,
"path": "/README.rst",
"repo_name": "BNMetrics/bnmetrics-utils",
"src_encoding": "UTF-8",
"text": "============\nCOMING SOON!\n============\n\n.. image:: https://travis-ci.org/BNMetrics/bnmetrics-utils.svg?branch=master\n :target: https://travis-ci.org/BNMetrics/bnmetrics-utils\n\n.. image:: https://codecov.io/gh/BNMetrics/bnmetrics-utils/branch/master/graph/badge.svg\n :target: https://codecov.io/gh/BNMetrics/bnmetrics-utils\n\n.. image:: https://badge.fury.io/py/bnmutils.svg\n :target: https://badge.fury.io/py/bnmutils"
},
{
"alpha_fraction": 0.8500000238418579,
"alphanum_fraction": 0.8500000238418579,
"avg_line_length": 38,
"blob_id": "73ef8eaf1cd0b1e2a59221a0820f4f6b7e0d4b8d",
"content_id": "8383d97573346df62774242eef6933e132ade64e",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 40,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 1,
"path": "/bnmutils/__init__.py",
"repo_name": "BNMetrics/bnmetrics-utils",
"src_encoding": "UTF-8",
"text": "from .configparser import ConfigParser\n\n"
},
{
"alpha_fraction": 0.4784323275089264,
"alphanum_fraction": 0.48052749037742615,
"avg_line_length": 40.60512924194336,
"blob_id": "8477ce346f623336d114fdd261490a3197a3a50d",
"content_id": "47722697eae128bbfa738df78a20040ebec5f3fb",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8114,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 195,
"path": "/tests/test_configparser/test_configparser.py",
"repo_name": "BNMetrics/bnmetrics-utils",
"src_encoding": "UTF-8",
"text": "import pytest\nfrom pathlib import Path\n\nfrom bnmutils import ConfigParser\nfrom bnmutils.exceptions import InvalidConfig, InvalidConfigOption\n\nfrom . import data\n\n\nclass TestConfigParser:\n\n @classmethod\n def setup_class(cls):\n cls.config = ConfigParser()\n\n @pytest.mark.parametrize('filenames',\n [\n pytest.param(data.config_path,\n id='parse with pathlib.Path object'),\n pytest.param(str(data.config_path),\n id='parse with string'),\n pytest.param([data.config_path],\n id='parse as list')\n ])\n def test_init_from_files(self, filenames):\n config = ConfigParser.from_files(filenames)\n assert set(config.sections()) == {'my_config', 'Fish_Profiles', 'date_format'}\n\n def test_init_from_files_empty(self, tmpdir):\n file = tmpdir.join('foo.ini')\n file.open('w').close()\n\n assert Path(file).exists()\n\n with pytest.raises(InvalidConfig):\n ConfigParser.from_files(file)\n\n def test_init_from_files_non_exist(self):\n with pytest.raises(InvalidConfig):\n ConfigParser.from_files('blah.ini')\n\n def test_init_from_files_raise(self, tmpdir):\n ini_path = tmpdir.join('test.ini')\n\n with pytest.raises(InvalidConfig):\n ConfigParser.from_files(ini_path)\n\n def test_init_from_dict(self):\n config = ConfigParser.from_dict(data.config_dict)\n\n assert set(config.sections()) == {'my_config', 'Fish_Profiles', 'date_format'}\n\n # ---------------------------------------------------------------------------\n # Tests for .to_dict() and helper methods\n # ---------------------------------------------------------------------------\n\n @pytest.mark.parametrize('parse_args, expected',\n [\n pytest.param({'section': 'my_config'},\n data.config_dict['my_config'],\n id='when section is passed'),\n pytest.param({'section': 'my_config', 'option': 'profile'},\n data.config_dict['my_config']['profile'],\n id='when both section and option are passed'),\n # pytest.param({'section': 'my_config', 'option': 'Active'},\n # True,\n # id='when both value passed. return value is none dict'),\n pytest.param({}, data.config_dict,\n id='when no args passed')\n ])\n def test_to_dict(self, parse_args, expected):\n config = ConfigParser.from_files(data.config_path)\n\n assert config.to_dict(**parse_args) == expected\n\n def test_to_dict_raise(self):\n config = ConfigParser.from_files(data.config_path)\n\n with pytest.raises(ValueError):\n config.to_dict(option='profile')\n\n def test_to_dict_with_datefmt(self):\n config = ConfigParser.from_files(data.config_path)\n expected = {\n 'formatter': {\n 'fmt': '{asctime} - {name} - {levelname} - {message}',\n 'datefmt': '%Y/%m/%d',\n 'style': '{'\n },\n 'Active': True\n }\n assert config.to_dict(section='date_format') == expected\n\n def test_option_to_dict(self):\n parse_option = \"\\nclownfish: 2\\nchalk_goby:1\\nyellow_clown_goby: 1\"\n\n expected = {\n 'clownfish': 2,\n 'chalk_goby': 1,\n 'yellow_clown_goby': 1,\n }\n\n result = self.config._option_to_dict(parse_option)\n\n assert result == expected\n\n @pytest.mark.parametrize('parse_option',\n [pytest.param(\" \\ntype: option \\n second_val : my_val \",\n id='config options with blank space in the beginning and middle'),\n pytest.param(\"\\n type : option \\n second_val : my_val \\n\",\n id='config option with blank space after new line, '\n 'and new line after last option'),\n pytest.param(\"\\ntype: option \\nsecond_val: my_val \",\n id='config option with no blank space')])\n def test_conf_item_to_dict(self, parse_option):\n expected_dict = {'type': 'option',\n 'second_val': 'my_val'}\n output = self.config._option_to_dict(parse_option)\n\n assert expected_dict == output\n\n def test_option_to_dict_multiple_colons(self):\n parse_item = '\\nactive: True' \\\n '\\nlevel: INFO' \\\n '\\nformatter: {funcName} :: {levelname} :: {message}'\n\n expected = {\n 'active': True,\n 'level': 'INFO',\n 'formatter': '{funcName} :: {levelname} :: {message}',\n }\n\n assert self.config._option_to_dict(parse_item) == expected\n\n @pytest.mark.parametrize('parse_option',\n [pytest.param(['blah', 'test'], id='when option passed is a list'),\n pytest.param(20, id='when option passed is an int'),\n pytest.param({'blah': 'test'}, id='when option passed is a dict'),\n pytest.param(\"\\nhello\\nbye\", id='when string option passed is in invalid format'),\n pytest.param(\"\\nhello: hi\\nbye\", id='when string option passed is in invalid format'),\n ])\n def test_option_to_dict_raise_invalidoption(self, parse_option):\n with pytest.raises(InvalidConfigOption):\n self.config._option_to_dict(parse_option)\n\n def test_option_to_dict_raise_option_none_dict(self):\n with pytest.raises(ValueError) as e_info:\n self.config._option_to_dict('HELLO')\n\n assert e_info.value.args[0] == \"'HELLO' cannot be converted to dict. alternatively, \" \\\n \"use ConfigParser.get(section, value) to get the value.\"\n\n def test_section_to_dict(self):\n parse_section = [('profile', '\\nname: Luna\\nprofession:software engineer\\nHobby: Marine fish'),\n ('projects', '[\"hello\", 1, 3]'),\n ('Active', 'True'),\n ('Posts', 'None')]\n\n expected = {\n 'profile': {\n 'name': 'Luna',\n 'profession': 'software engineer',\n 'Hobby': 'Marine fish'\n },\n 'projects': ['hello', 1, 3],\n 'Posts': None,\n 'Active': True\n }\n\n result = self.config._section_to_dict(parse_section)\n assert result == expected\n\n def test_section_to_dict_raise(self):\n with pytest.raises(ValueError) as e_info:\n self.config._section_to_dict('\\nname: Luna\\nprofession: software engineer\\nHobby: Marine fish')\n\n assert e_info.value.args[0] == \"Invalid section type 'str'\"\n\n # ---------------------------------------------------------------------------\n # Test helpers\n # ---------------------------------------------------------------------------\n\n def test_flatten_section_dict(self):\n expected = {\n 'profile': '\\nname: Luna\\nprofession: software engineer\\nHobby: Marine fish',\n 'projects': \"['hello', 1, 3]\",\n 'Active': 'True',\n 'Posts': 'None',\n 'Users': '5',\n }\n\n output = self.config._flatten_section_dict(data.config_dict['my_config'])\n\n assert output == expected\n assert self.config._section_to_dict(output) == data.config_dict['my_config']\n\n"
}
] | 10 |
finpapa/kore_GSheet
|
https://github.com/finpapa/kore_GSheet
|
aeab4f58a1d5f36d4eb8697c3da81245db3e3b7b
|
41ee0e1ea8d120b3b86e5b871ae575347b3a7af3
|
513b57433b5d8ac4c56532b8046d05bc678a6534
|
refs/heads/master
| 2017-11-03T10:35:08.859230 | 2012-06-07T11:00:46 | 2012-06-07T11:00:46 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5319832563400269,
"alphanum_fraction": 0.5373406410217285,
"avg_line_length": 34.22264099121094,
"blob_id": "64dfeef356836a4da23d1a9b86d707e314a3416b",
"content_id": "3132d2e3adf2b0cd4d0088b5146ff2286a2d4359",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9477,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 265,
"path": "/verifiers/sentenceReading.py",
"repo_name": "finpapa/kore_GSheet",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport re\n\nfrom deckQuery import DeckQuery\n\ndq = DeckQuery()\nc = dq.getDbCursor()\n\n\ndef isKana(s):\n if s < u'\\u3041' or s > u'\\u30FF':\n return False\n return True\n\ndef checkInnerComma(doFix=False):\n '''\n Prints out and optionally fixes all cases of a poorly placed comma.\n E.g., 今日、[きょう] will be fixed as 今日[きょう]、\n '''\n innerComma_re = re.compile(ur'、(\\[.+?])', re.UNICODE)\n\n print '######### Poorly placed commas #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n factDict = dq.getFactDict(fact_id)\n sentKanaField = factDict['Reading']\n \n commaPortion = innerComma_re.search(sentKanaField)\n if commaPortion is not None:\n # Comma inside furiganafied word!\n found += 1\n print factDict['Core-Index'], '\\t::\\t', sentKanaField\n if doFix:\n fixedComma = commaPortion.group(1) + '、'\n fixed = re.sub(innerComma_re, fixedComma, sentKanaField)\n print '\\t-->\\t', fixed\n dq.updateFieldByCoreIndex(factDict['Core-Index'],\n 'Reading', fixed)\n print \"Found: \", found \n \n\ndef checkSpacedByCommaFurigana(doFix=False):\n '''\n Prints out and optionally fixes all cases of poorly combined furigana\n there resulted from commas (most likely confusing some automated tool) \n E.g., 最近、銀行[さいきん ぎんこう] will be fixed as \n 最近[さいきん]、 銀行[ぎんこう]\n '''\n innerSpace_re = re.compile(ur'(\\w+)、(\\w+)\\[(\\w+)\\s+(\\w+)\\]', re.UNICODE)\n\n print '######### Space inside furigana #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n factDict = dq.getFactDict(fact_id)\n sentKanaField = factDict['Reading']\n \n spaceMatch = innerSpace_re.search(sentKanaField)\n if spaceMatch is not None:\n # Space inside furiganafied word!\n found += 1\n print factDict['Core-Index'], '\\t::\\t', sentKanaField\n if doFix:\n firstWord = spaceMatch.group(1)\n secondWord = spaceMatch.group(2)\n firstFuri = spaceMatch.group(3)\n secondFuri = spaceMatch.group(4)\n \n fixedFuri = '%s[%s]、 %s[%s]' % (firstWord, firstFuri,\n secondWord, secondFuri) \n \n fixed = re.sub(innerSpace_re, fixedFuri, sentKanaField)\n print '\\t-->\\t', fixed\n dq.updateFieldByCoreIndex(factDict['Core-Index'],\n 'Reading', fixed)\n print \"Found: \", found \n\ndef extraSpace1(doFix=False):\n '''\n Prints out all cases of multiple spaces appearing together and\n optionally fix them.\n '''\n hasSpaces_re = re.compile(ur'\\s\\s+', re.UNICODE)\n\n print '######### Extra spaces1 #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n factDict = dq.getFactDict(fact_id)\n sentKanaField = factDict['Reading']\n \n spacedPortion = hasSpaces_re.search(sentKanaField)\n if spacedPortion is not None:\n found += 1\n print factDict['Core-Index'], '\\t::\\t', sentKanaField\n if doFix:\n #TODO: add a fix rule for this case\n pass\n print \"Found: \", found \n\ndef extraSpace2(doFix=False):\n '''\n Prints out all cases of multiple spaces occurring because one was\n inside <b> tags, and optionally fix them.\n '''\n hasSpaces_re = re.compile(ur'\\s(<b>)\\s', re.UNICODE)\n\n print '######### Extra spaces2 #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n factDict = dq.getFactDict(fact_id)\n sentKanaField = factDict['Reading']\n \n spacedPortion = hasSpaces_re.search(sentKanaField)\n if spacedPortion is not None:\n found += 1\n print factDict['Core-Index'], '\\t::\\t', sentKanaField\n if doFix:\n fixedSpace = spacedPortion.group(1) + ' ' \n fixed = re.sub(hasSpaces_re, fixedSpace, sentKanaField)\n print '\\t-->\\t', fixed\n dq.updateFieldByCoreIndex(factDict['Core-Index'],\n 'Reading', fixed)\n print \"Found: \", found \n\ndef extraSpace3(doFix=False):\n '''\n Prints out all cases of a space after a </b>, where the next\n character is a kana (so no space should be there).\n From: <b>昨日[さくじつ]</b> は 雨[あめ]でしたね。\n To : <b>昨日[さくじつ]</b>は 雨[あめ]でしたね。\n '''\n hasSpaces_re = re.compile(ur'(</b>)\\s(\\w)', re.UNICODE)\n\n print '######### Extra spaces3 #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n factDict = dq.getFactDict(fact_id)\n sentKanaField = factDict['Reading']\n \n spacedPortion = hasSpaces_re.search(sentKanaField)\n if spacedPortion is not None:\n nextChar = spacedPortion.group(2)\n if isKana(nextChar):\n found += 1\n print factDict['Core-Index'], '\\t::\\t', sentKanaField\n if doFix:\n fixedSpace = spacedPortion.group(1) + spacedPortion.group(2) \n fixed = re.sub(hasSpaces_re, fixedSpace, sentKanaField)\n print '\\t-->\\t', fixed\n dq.updateFieldByCoreIndex(factDict['Core-Index'],\n 'Reading', fixed)\n pass\n print \"Found: \", found \n\ndef extraSpace4(doFix=False):\n '''\n Prints out all cases of a space after a ], where the next\n character is a kana (so no space should be there).\n '''\n hasSpaces_re = re.compile(ur'(\\])\\s(\\w)', re.UNICODE)\n\n print '######### Extra spaces4 #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n factDict = dq.getFactDict(fact_id)\n sentKanaField = factDict['Reading']\n \n spacedPortion = hasSpaces_re.search(sentKanaField)\n if spacedPortion is not None:\n nextChar = spacedPortion.group(2)\n if isKana(nextChar):\n found += 1\n print factDict['Core-Index'], '\\t::\\t', sentKanaField\n if doFix:\n fixedSpace = spacedPortion.group(1) + spacedPortion.group(2) \n fixed = re.sub(hasSpaces_re, fixedSpace, sentKanaField)\n print '\\t-->\\t', fixed\n dq.updateFieldByCoreIndex(factDict['Core-Index'],\n 'Reading', fixed)\n pass\n print \"Found: \", found \n\ndef checkFirstBoldSpace(doFix=False):\n '''\n Prints out all cases of a space after a ], where the next\n character is a kana (so no space should be there).\n '''\n hasSpaces_re = re.compile(ur'<b>(.+)</b>', re.UNICODE)\n\n print '######### No space in first bold #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n factDict = dq.getFactDict(fact_id)\n sentKanaField = factDict['Reading']\n \n spacedPortion = hasSpaces_re.search(sentKanaField)\n if spacedPortion is not None:\n firstBoldChar = spacedPortion.group(1)[0]\n if not isKana(firstBoldChar) and not firstBoldChar == ' ':\n found += 1\n print factDict['Core-Index'], '\\t::\\t', sentKanaField\n if doFix:\n fixedSpace = '<b> ' + spacedPortion.group(1) + '</b>' \n fixed = re.sub(hasSpaces_re, fixedSpace, sentKanaField)\n print '\\t-->\\t', fixed\n dq.updateFieldByCoreIndex(factDict['Core-Index'],\n 'Reading', fixed)\n\n print \"Found: \", found \n \n\ndef checkNoBold(doFix=False):\n '''\n Prints out all cases where the key word isn't emboldened\n '''\n hasSpaces_re = re.compile(ur'<b>.+</b>', re.UNICODE)\n\n print '######### No bold #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n factDict = dq.getFactDict(fact_id)\n sentKanaField = factDict['Reading']\n \n spacedPortion = hasSpaces_re.search(sentKanaField)\n if spacedPortion is None:\n found += 1\n print factDict['Core-Index'], '\\t::\\t', sentKanaField\n\n print \"Found: \", found \n \nif __name__ == \"__main__\":\n\n checkInnerComma(doFix=False)\n checkSpacedByCommaFurigana(doFix=False)\n extraSpace1(doFix=False)\n extraSpace2(doFix=True)\n extraSpace3(doFix=False)\n extraSpace4(doFix=False)\n checkNoBold(doFix=False)\n checkFirstBoldSpace(doFix=True)\n# dq.commit()"
},
{
"alpha_fraction": 0.44081974029541016,
"alphanum_fraction": 0.4458385705947876,
"avg_line_length": 29.278480529785156,
"blob_id": "253045f25170fc92290c8536e2f9e24f3ef202f8",
"content_id": "d22a43ca9c4facb541bc005e7f39724a9d422eeb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2391,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 79,
"path": "/verifiers/tagSoup.py",
"repo_name": "finpapa/kore_GSheet",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport re\nfrom deckQuery import DeckQuery\n\ndq = DeckQuery()\nc = dq.getDbCursor()\n\n\ndef removeRichTextEmpty(doFix=False):\n empty_span = re.compile(ur'<span style=\"font-weight:600;\"> </span>',\n re.UNICODE)\n \n print '######### Tag soup (empty) #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n s = '''\n SELECT * FROM fields\n WHERE factId=?\n '''\n fields = c.execute(s, [fact_id]).fetchall() \n \n for field in fields:\n field_value = field['value']\n hasJunk = empty_span.search(field_value)\n if hasJunk is not None:\n print \"Fixing: \", field_value\n found += 1\n clean_field = re.sub(empty_span, '', field_value)\n \n s = '''UPDATE fields\n SET value=?\n WHERE id=?\n '''\n c.execute(s, [clean_field, field['id']])\n print \"Found: \", found \n\n\ndef removeRichTextWithContent(doFix=False):\n span_re = re.compile(ur'<span style=\"font-weight:600;\">(.+)</span>',\n re.UNICODE)\n \n print '######### Tag soup (with content) #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n s = '''\n SELECT * FROM fields\n WHERE factId=?\n '''\n fields = c.execute(s, [fact_id]).fetchall() \n \n for field in fields:\n field_value = field['value']\n span = span_re.search(field_value)\n if span is not None:\n print \"Fixing: \", field_value\n found += 1\n clean_field = re.sub(span_re, '<b>'+span.group(1)+'</b>',\n field_value)\n \n s = '''UPDATE fields\n SET value=?\n WHERE id=?\n '''\n c.execute(s, [clean_field, field['id']])\n print \"Found: \", found \n\n\nif __name__ == \"__main__\":\n \n #removeRichTextEmpty(doFix=False)\n #removeRichTextWithContent(doFix=False)\n #dq.commit()"
},
{
"alpha_fraction": 0.5563387870788574,
"alphanum_fraction": 0.5579655170440674,
"avg_line_length": 35.86399841308594,
"blob_id": "ed35afb8db94dde862fafbdcbd6c2b12c65156a6",
"content_id": "52d42e0156b2b3657abf274b07d2731c7d6a1441",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9221,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 250,
"path": "/gSheetSync.py",
"repo_name": "finpapa/kore_GSheet",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python2\n\nimport time\nimport gdata.spreadsheet.service\nimport deckQuery\nimport localConfig\nfrom fieldToColumnMapper import gColumnToField, fieldToGColumn\n\n\nclass DiffablePrint:\n \n origFilename = 'spreadsheet.txt'\n newFilename = 'deck.txt'\n \n columnOrder = [\n 'core-index',\n 'opt-voc-index',\n 'opt-sen-index',\n 'vocab-expression',\n 'vocab-kana',\n 'vocab-meaning',\n 'vocab-sound-local',\n 'vocab-pos',\n 'sentence-expression',\n 'sentence-kana',\n 'sentence-meaning',\n 'sentence-sound-local',\n 'sentence-image-local',\n 'vocab-furigana',\n 'sentence-furigana',\n 'sentence-cloze',\n 'jlpt',\n 'sent-ko-index',\n 'vocab-ko-index',\n ]\n \n def __init__(self):\n self.oldColumnValues = {}\n self.newColumnValues = {}\n \n def prepareFiles(self):\n orig = open(self.origFilename, 'w')\n new = open(self.newFilename, 'w')\n for column in self.columnOrder:\n orig.write(column + '\\t')\n new.write(column + '\\t')\n orig.write('\\n')\n new.write('\\n')\n \n def prepareConsole(self):\n for column in self.columnOrder:\n print column + '\\t',\n print\n \n def addColumnValue(self, column, oldValue, newValue): \n self.oldColumnValues[column] = oldValue\n self.newColumnValues[column] = newValue\n \n def printToFile(self):\n orig = open(self.origFilename, 'a')\n new = open(self.newFilename, 'a')\n\n for column in self.columnOrder:\n try:\n orig.write(self.oldColumnValues.get(column, '') + '\\t')\n except:\n orig.write('' + '\\t')\n\n new.write(self.newColumnValues.get(column, '') + '\\t')\n\n orig.write('\\n')\n new.write('\\n')\n \n def printToConsole(self):\n print '-',\n for column in self.columnOrder:\n try:\n print self.oldColumnValues.get(column, '') + '\\t',\n except:\n print '' + '\\t',\n print\n print '+',\n for column in self.columnOrder:\n print self.newColumnValues.get(column, '') + '\\t',\n print\n\n \ndq = deckQuery.DeckQuery()\nfactsOfInterest = dq.getAllFactsWithTag(deckQuery.tag_clozeFIX)\nfactDictByCoreIndex = {}\n\nfor fact in factsOfInterest:\n factDictByCoreIndex[fact['Core-Index']] = fact\n\ndef changeCells(gd_client, spreadsheet_id, worksheet_id, deck):\n print 'Accessing spreadsheet...'\n rows = gd_client.GetListFeed(spreadsheet_id, worksheet_id).entry\n print 'Making changes to the spreadsheet...'\n for row in rows:\n coreIndex = row.custom['core-index'].text\n optVocIndex = row.custom['opt-voc-index'].text\n try:\n factDict = deck.getFactByCoreIndex(coreIndex)\n except:\n print \"Tried to access invalid fact id for coreIndex \", coreIndex\n continue\n \n if factDict['Sentence-Image'] is not None and\\\n factDict['Sentence-Image'] != \"\":\n row.custom['sentence-image-local'].text = factDict['Sentence-Image']\n newData = getNewRowDictFromExistingRow(row.custom)\n saved = False\n while not saved:\n try:\n nrow = gd_client.UpdateRow(row, newData)\n print \"Saved: opt-voc-index[%s]\\tcore-index[%s]\" %\\\n (optVocIndex, coreIndex)\n saved = True\n except gdata.service.RequestError, e:\n print \"Error saving row: %s\\t::\\t%s\" % (e.message,\n optVocIndex) \n print \"Retrying in 30 seconds\"\n time.sleep(32)\n print \"Done!\"\n \n\ndef uploadDeckToGSheet(gd_client, spreadsheet_id, worksheet_id, deck):\n print 'Accessing spreadsheet...'\n rows = gd_client.GetListFeed(spreadsheet_id, worksheet_id).entry\n print 'Making changes to the spreadsheet...'\n for row in rows:\n coreIndex = row.custom['core-index'].text\n optVocIndex = row.custom['opt-voc-index'].text\n try:\n factDict = deck.getFactByCoreIndex(coreIndex)\n except:\n print \"Tried to access invalid fact id for coreIndex \", coreIndex\n continue\n \n for field in row.custom:\n # Only update fields that exist on the sheet and also in the deck.\n # I hesitate to modify core-index. In the event I screw things up,\n # I'll still have a valid index to fix rows against\n if field in gColumnToField.keys() and\\\n not field == 'core-index':\n if gColumnToField[field] is not None:\n deckField = gColumnToField[field]\n row.custom[field].text = factDict[deckField]\n \n newData = getNewRowDictFromExistingRow(row.custom)\n saved = False\n while not saved:\n try:\n nrow = gd_client.UpdateRow(row, newData)\n print \"Saved: opt-voc-index[%s]\\tcore-index[%s]\" %\\\n (optVocIndex, coreIndex)\n saved = True\n except gdata.service.RequestError, e:\n print \"Error saving row: %s\\t::\\t%s\" % (e.message,\n optVocIndex) \n print \"Retrying in 30 seconds\"\n time.sleep(32)\n print 'Done!'\n \ndef getNewRowDictFromExistingRow(rowDict):\n newDict = {}\n for k,v in rowDict.iteritems():\n newDict[k] = v.text\n return newDict\n \n\ndef findDifferences(gd_client, spreadsheet_id, worksheet_id):\n rows = gd_client.GetListFeed(spreadsheet_id, worksheet_id).entry\n \n dp = DiffablePrint()\n dp.prepareConsole()\n \n for row in rows:\n coreIndex = row.custom['core-index'].text \n if coreIndex in factDictByCoreIndex.keys():\n dp = DiffablePrint()\n gSheetValue = None\n deckValue = None\n \n for field in row.custom:\n gSheetValue = row.custom[field].text\n \n if field not in gColumnToField.keys():\n deckValue = ''\n else:\n deckFieldName = gColumnToField[field]\n if deckFieldName is None:\n deckValue = ''\n else:\n deckValue = factDictByCoreIndex[coreIndex][deckFieldName]\n \n dp.addColumnValue(field, gSheetValue, deckValue)\n dp.printToConsole()\n \ndef mergeColumnGsheetToDeck(gd_client, spreadsheet_id, worksheet_id, deck,\n deckFieldName):\n rows = gd_client.GetListFeed(spreadsheet_id, worksheet_id).entry\n gSheetColumnName = fieldToGColumn[deckFieldName]\n dp = DiffablePrint()\n for row in rows:\n coreIndex = row.custom['core-index'].text\n if row.custom[gSheetColumnName] is not None:\n fieldValue = row.custom[gSheetColumnName].text\n if fieldValue is not None: \n deck.updateFieldByCoreIndex(coreIndex, deckFieldName,\n fieldValue)\n print \"Updated %s\\t::\\t%s\" % (coreIndex, fieldValue)\n\n# Ignore or delete this\ndef mergeColumnGsheetToDeckTweak(gd_client, spreadsheet_id, worksheet_id, deck,\n deckFieldName):\n rows = gd_client.GetListFeed(spreadsheet_id, worksheet_id).entry\n gSheetColumnName = fieldToGColumn[deckFieldName]\n dp = DiffablePrint()\n for row in rows:\n coreIndex = row.custom['core-index'].text\n optVocIndex = row.custom['opt-voc-index'].text\n\n if row.custom[gSheetColumnName] is not None:\n fieldValue = row.custom[gSheetColumnName].text\n if fieldValue is not None: \n deck.updateFieldByCoreIndex(optVocIndex, deckFieldName,\n fieldValue)\n print \"Updated %s\\t::\\t%s\" % (coreIndex, fieldValue)\n\n\nif __name__ == \"__main__\":\n gd_client = gdata.spreadsheet.service.SpreadsheetsService()\n gd_client.email = localConfig.GOOGLE_USERNAME\n gd_client.password = localConfig.GOOGLE_PASSWORD\n gd_client.source = \"The Matrix\"\n gd_client.ProgrammaticLogin()\n \n q = gdata.spreadsheet.service.DocumentQuery()\n q['title'] = localConfig.DOC_NAME\n q['title-exact'] = 'true'\n feed = gd_client.GetSpreadsheetsFeed(query=q)\n spreadsheet_id = feed.entry[0].id.text.rsplit('/',1)[1]\n feed = gd_client.GetWorksheetsFeed(spreadsheet_id)\n worksheet_id = feed.entry[0].id.text.rsplit('/',1)[1]\n \n #findDifferences(gd_client, spreadsheet_id, worksheet_id)\n #changeCells(gd_client, spreadsheet_id, worksheet_id, dq)\n #mergeColumnGsheetToDeckTweak(gd_client, spreadsheet_id, worksheet_id, dq, 'Sentence-Image')\n uploadDeckToGSheet(gd_client, spreadsheet_id, worksheet_id, dq)\n \n"
},
{
"alpha_fraction": 0.5727506279945374,
"alphanum_fraction": 0.578920304775238,
"avg_line_length": 26.408451080322266,
"blob_id": "5335869f33188bf9b5488ffce6e21edd2e3f99cc",
"content_id": "f0284addf00d59e44ad87ea0633c297142a0f7a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1945,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 71,
"path": "/verifiers/sentenceKana.py",
"repo_name": "finpapa/kore_GSheet",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport re\n\nfrom deckQuery import DeckQuery\n\ndq = DeckQuery()\nc = dq.getDbCursor()\n\n\ndef isKana(s):\n if s < u'\\u3041' or s > u'\\u30FF':\n return False\n return True\n\n\ndef checkInnerSpace(doFix=False):\n '''\n Checks for spaces inside bold tags. We don't want them in the kana field\n '''\n hasSpacesLeft_re = re.compile(ur'<b>\\s.+</b>', re.UNICODE)\n hasSpacesRight_re = re.compile(ur'<b>.+\\s</b>', re.UNICODE)\n\n print '######### Inner spaces #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n factDict = dq.getFactDict(fact_id)\n sentKanaField = factDict['Sentence-Kana']\n \n leftSpacePortion = hasSpacesLeft_re.search(sentKanaField)\n rightSpacePortion = hasSpacesRight_re.search(sentKanaField)\n if leftSpacePortion is not None:\n found += 1\n print factDict['Core-Index'], '\\t::\\t', sentKanaField\n if rightSpacePortion is not None:\n found += 1\n print factDict['Core-Index'], '\\t::\\t', sentKanaField\n\n print \"Found: \", found \n\n\ndef checkNoBold(doFix=False):\n '''\n Prints out all cases where the key word isn't emboldened\n '''\n hasSpaces_re = re.compile(ur'<b>.+</b>', re.UNICODE)\n\n print '######### No bold #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n factDict = dq.getFactDict(fact_id)\n sentKanaField = factDict['Sentence-Kana']\n \n spacedPortion = hasSpaces_re.search(sentKanaField)\n if spacedPortion is None:\n found += 1\n print factDict['Core-Index'], '\\t::\\t', sentKanaField\n\n print \"Found: \", found \n \nif __name__ == \"__main__\":\n\n checkInnerSpace(doFix=False)\n checkNoBold(doFix=False)\n #dq.commit()"
},
{
"alpha_fraction": 0.5361452102661133,
"alphanum_fraction": 0.5412706732749939,
"avg_line_length": 32.45000076293945,
"blob_id": "26ba5ff360bdfda530e9fe166962da9dbf8c0f09",
"content_id": "49b689971ad8d3ab213d78fcea51a5911b391b08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9449,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 280,
"path": "/verifiers/sentenceCloze.py",
"repo_name": "finpapa/kore_GSheet",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport re\n\nfrom deckQuery import DeckQuery\n\ndq = DeckQuery()\nc = dq.getDbCursor()\n\n\ndef isKana(s):\n if s < u'\\u3041' or s > u'\\u30FF':\n return False\n return True\n\ndef checkInnerComma(doFix=False):\n '''\n Prints out and optionally fixes all cases of a poorly placed comma.\n E.g., 今日、[きょう] will be fixed as 今日[きょう]、\n '''\n innerComma_re = re.compile(ur'、(\\[.+?])', re.UNICODE)\n\n print '######### Poorly placed commas #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n factDict = dq.getFactDict(fact_id)\n clozeField = factDict['Sentence-Clozed']\n \n commaPortion = innerComma_re.search(clozeField)\n if commaPortion is not None:\n # Comma inside furiganafied word!\n found += 1\n print factDict['Core-Index'], '\\t::\\t', clozeField\n if doFix:\n fixedComma = commaPortion.group(1) + '、'\n fixed = re.sub(innerComma_re, fixedComma, clozeField)\n print '\\t-->\\t', fixed\n dq.updateFieldByCoreIndex(factDict['Core-Index'],\n 'Sentence-Clozed', fixed)\n print \"Found: \", found \n \n\ndef checkSpacedByCommaFurigana(doFix=False):\n '''\n Prints out and optionally fixes all cases of poorly combined furigana\n there resulted from commas (most likely confusing some automated tool) \n E.g., 最近、銀行[さいきん ぎんこう] will be fixed as \n 最近[さいきん]、 銀行[ぎんこう]\n '''\n innerSpace_re = re.compile(ur'(\\w+)、(\\w+)\\[(\\w+)\\s+(\\w+)\\]', re.UNICODE)\n\n print '######### Space inside furigana #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n factDict = dq.getFactDict(fact_id)\n clozeField = factDict['Sentence-Clozed']\n \n spaceMatch = innerSpace_re.search(clozeField)\n if spaceMatch is not None:\n # Space inside furiganafied word!\n found += 1\n print factDict['Core-Index'], '\\t::\\t', clozeField\n if doFix:\n firstWord = spaceMatch.group(1)\n secondWord = spaceMatch.group(2)\n firstFuri = spaceMatch.group(3)\n secondFuri = spaceMatch.group(4)\n \n fixedFuri = '%s[%s]、 %s[%s]' % (firstWord, firstFuri,\n secondWord, secondFuri) \n \n fixed = re.sub(innerSpace_re, fixedFuri, clozeField)\n print '\\t-->\\t', fixed\n dq.updateFieldByCoreIndex(factDict['Core-Index'],\n 'Sentence-Clozed', fixed)\n print \"Found: \", found \n\ndef checkNoCloze():\n '''\n Prints out all cases of a missing cloze deletion\n '''\n hasCloze_re = re.compile(ur'<b>(.+)</b>', re.UNICODE)\n\n print '######### No cloze deletions #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n factDict = dq.getFactDict(fact_id)\n clozeField = factDict['Sentence-Clozed']\n \n clozedPortion = hasCloze_re.search(clozeField)\n if clozedPortion is None:\n # No cloze deletion in this field!\n found += 1\n print factDict['Core-Index'], '\\t::\\t', clozeField\n \n print \"Found: \", found \n\ndef extraSpace1(doFix=False):\n '''\n Prints out all cases of multiple spaces appearing together and\n optionally fix them.\n '''\n hasSpaces_re = re.compile(ur'\\s\\s+', re.UNICODE)\n\n print '######### Extra spaces1 #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n factDict = dq.getFactDict(fact_id)\n clozeField = factDict['Sentence-Clozed']\n \n spacedPortion = hasSpaces_re.search(clozeField)\n if spacedPortion is not None:\n found += 1\n print factDict['Core-Index'], '\\t::\\t', clozeField\n if doFix:\n #TODO: add a fix rule for this case\n pass\n print \"Found: \", found \n\ndef extraSpace2(doFix=False):\n '''\n Prints out all cases of multiple spaces occurring because one was\n inside <b> tags, and optionally fix them.\n '''\n hasSpaces_re = re.compile(ur'\\s<b>\\s', re.UNICODE)\n\n print '######### Extra spaces2 #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n factDict = dq.getFactDict(fact_id)\n clozeField = factDict['Sentence-Clozed']\n \n spacedPortion = hasSpaces_re.search(clozeField)\n if spacedPortion is not None:\n found += 1\n print factDict['Core-Index'], '\\t::\\t', clozeField\n if doFix:\n #TODO: add a fix rule for this case\n pass\n print \"Found: \", found \n\ndef extraSpace3(doFix=False):\n '''\n Prints out all cases of a space after a </b>, where the next\n character is a kana (so no space should be there).\n \n '''\n hasSpaces_re = re.compile(ur'</b>\\s(\\w)', re.UNICODE)\n\n print '######### Extra spaces3 #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n factDict = dq.getFactDict(fact_id)\n clozeField = factDict['Sentence-Clozed']\n \n spacedPortion = hasSpaces_re.search(clozeField)\n if spacedPortion is not None:\n nextChar = spacedPortion.group(1)\n if isKana(nextChar):\n found += 1\n print factDict['Core-Index'], '\\t::\\t', clozeField\n if doFix:\n fixedSpace = spacedPortion.group(1) + spacedPortion.group(2) \n fixed = re.sub(hasSpaces_re, fixedSpace, clozeField)\n print '\\t-->\\t', fixed\n dq.updateFieldByCoreIndex(factDict['Core-Index'],\n 'Sentence-Clozed', fixed)\n pass\n print \"Found: \", found \n\ndef extraSpace4(doFix=False):\n '''\n Prints out all cases of a space after a ], where the next\n character is a kana (so no space should be there).\n '''\n hasSpaces_re = re.compile(ur'(\\])\\s(\\w)', re.UNICODE)\n\n print '######### Extra spaces4 #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n factDict = dq.getFactDict(fact_id)\n clozeField = factDict['Sentence-Clozed']\n \n spacedPortion = hasSpaces_re.search(clozeField)\n if spacedPortion is not None:\n nextChar = spacedPortion.group(2)\n if isKana(nextChar):\n found += 1\n print factDict['Core-Index'], '\\t::\\t', clozeField\n if doFix:\n fixedSpace = spacedPortion.group(1) + spacedPortion.group(2) \n fixed = re.sub(hasSpaces_re, fixedSpace, clozeField)\n print '\\t-->\\t', fixed\n dq.updateFieldByCoreIndex(factDict['Core-Index'],\n 'Sentence-Clozed', fixed)\n pass\n print \"Found: \", found \n\ndef spaceInFurigana(doFix=False):\n '''\n \n '''\n innerSpace_re = re.compile(ur'(\\w+)\\[(\\w+)\\s+(\\w+)\\]', re.UNICODE)\n\n print '######### Space inside furigana #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n factDict = dq.getFactDict(fact_id)\n clozeField = factDict['Sentence-Clozed']\n \n spaceMatch = innerSpace_re.search(clozeField)\n if spaceMatch is not None:\n # Space inside furiganafied word!\n found += 1\n print factDict['Core-Index'], '\\t::\\t', clozeField\n \n print \"Found: \", found \n\ndef checkWrongCloze(doFix=False):\n '''\n Finds cards with an incorrect cloze deletion. There are some\n false positives. They need to be fixed manually anyway.\n '''\n\n print '######### Incorrect cloze #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n factDict = dq.getFactDict(fact_id)\n clozeField = factDict['Sentence-Clozed']\n vocabField = factDict['Vocabulary-Kanji']\n \n if vocabField in clozeField:\n found += 1\n print factDict['Core-Index'], '\\t::\\t', \n print vocabField, '\\t::\\t', clozeField\n\n print \"Found: \", found \n\n\nif __name__ == \"__main__\":\n #It is likely that the order is important. It's best to follow this order,\n #just to be sure.\n \n checkNoCloze()\n checkInnerComma(doFix=False)\n checkSpacedByCommaFurigana(doFix=False)\n extraSpace1(doFix=False)\n extraSpace2(doFix=False)\n checkWrongCloze(doFix=False)\n extraSpace3(doFix=False)\n extraSpace4(doFix=False)\n\n #dq.commit()"
},
{
"alpha_fraction": 0.5393028259277344,
"alphanum_fraction": 0.5399863123893738,
"avg_line_length": 36.512821197509766,
"blob_id": "1bdbc5dfc6fe0b999b166ae8b328cee3a4f4c3b0",
"content_id": "d85bd44d713e3503586ffe3d11ce8f57f953d947",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1463,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 39,
"path": "/fieldToColumnMapper.py",
"repo_name": "finpapa/kore_GSheet",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n#spreadsheet order\nfieldToGColumn = {\n 'Core-Index' : 'core-index',\n None : 'vocab-ko-index',\n None : 'sent-ko-index', \n 'Optimized-Voc-Index' : 'opt-voc-index',\n 'Optimized-Sent-Index' : 'opt-sen-index',\n None : 'jlpt',\n 'Vocabulary-Kanji' : 'vocab-expression',\n 'Vocabulary-Kana' : 'vocab-kana',\n 'Vocabulary-English' : 'vocab-meaning',\n 'Vocabulary-Audio' : 'vocab-sound-local',\n 'Vocabulary-Pos' : 'vocab-pos',\n 'Expression' : 'sentence-expression',\n 'Sentence-Kana' : 'sentence-kana',\n 'Sentence-English' : 'sentence-meaning',\n 'Sentence-Audio' : 'sentence-sound-local',\n 'Sentence-Image' : 'sentence-image-local',\n 'Vocabulary-Furigana' : 'vocab-furigana',\n 'Reading' : 'sentence-furigana',\n 'Sentence-Clozed' : 'sentence-cloze',\n \n ## In deck, not in spreadsheet ##\n 'Notes' : None,\n 'Hint' : None,\n}\n\n# Another dict with the keys/values swapped\ngColumnToField = {}\nfor key, value in fieldToGColumn.iteritems():\n gColumnToField[value] = key\n\ndef getGSheetColumnFromDeckField(fieldName):\n return fieldToGColumn[fieldName]\n\ndef getDeckFieldFromGSheetColumn(column):\n return gColumnToField[column]\n"
},
{
"alpha_fraction": 0.7554388642311096,
"alphanum_fraction": 0.776444137096405,
"avg_line_length": 165.75,
"blob_id": "30f1da164588c7fecb714f3313dd445b9282a995",
"content_id": "3f707e4360d503440dd9c7d6317efae57dc4cde8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1333,
"license_type": "no_license",
"max_line_length": 538,
"num_lines": 8,
"path": "/README.md",
"repo_name": "finpapa/kore_GSheet",
"src_encoding": "UTF-8",
"text": "kore_GSheet\n===========\n\nThe scripts I am using to find and fix errors in the Optimized Core 2k/6k deck ([courtesy of Nukemarine from the RevTK forums](http://forum.koohii.com/viewtopic.php?pid=95122#p95122)). It's also what I use to maintain parity between [my Core 2k/6k anki deck](http://forum.koohii.com/viewtopic.php?pid=177610#p177610) and the [main Google Spreadsheet](https://docs.google.com/spreadsheet/ccc?key=0AscWM0WNU3s4dHE3R0M0VG5JMndrMEpiNTdnRjhtYnc#gid=0) from which new versions of that deck are ultimately generated. (That is, I sync between the two using the Google spreadsheet API).\n\nThis is mostly throwaway code, which explains why it's so hideous (I did a copy+paste every time I needed a new function. Contain your derision, please!). There's really no use for it after the deck has been cleaned and the updates pushed to the main spreadsheet (which I've done now).\n\nThe code that talks to the Google Spreadsheet can serve as a useful reference in the future. Unfortunately, Google Spreadsheets have proven to be somewhat unwieldy for this task (even more so for such a large spreadsheet -- it's so slow!). In the future, it'd be nice to create some resource to provide an online service for collaboratively editing anki decks that can then generate and/or sync actively used decks (unless anki2 does something like that already, I'm not too sure)."
},
{
"alpha_fraction": 0.5564878582954407,
"alphanum_fraction": 0.5582858920097351,
"avg_line_length": 28.79464340209961,
"blob_id": "cb6189be1d263a59e1e1152f528a14dea375a1c0",
"content_id": "ffc79937b0ee9272058c6a46df5b902dd561f8b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3337,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 112,
"path": "/deckQuery.py",
"repo_name": "finpapa/kore_GSheet",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport sqlite3\nimport localConfig\n\ntag_clozeFIX = 1 # hardcoding: it's like magic, but worse!\n\nclass DeckQuery:\n \n def __init__(self):\n self.conn = sqlite3.connect(localConfig.DECK_PATH)\n self.conn.row_factory = sqlite3.Row\n self.c = self.conn.cursor()\n \n self.fieldIds = {}\n self.fieldNames = {}\n \n s = 'SELECT id, name FROM fieldModels'\n fieldsModels = self.c.execute(s)\n for fieldModel in fieldsModels:\n self.fieldIds[fieldModel['name']] = fieldModel['id']\n self.fieldNames[fieldModel['id']] = fieldModel['name']\n \n \n def getDbCursor(self):\n return self.c\n \n \n def getFieldModelIdOfField(self, fieldName):\n s = '''SELECT id\n FROM fieldModels\n WHERE name=?\n '''\n row = self.c.execute(s, [fieldName]).fetchone()\n return row['id'] \n \n \n def getAllFactsWithTag(self, tag):\n facts = []\n s = '''\n SELECT cards.factId\n FROM cardTags\n LEFT OUTER JOIN cards\n ON cardTags.cardId=cards.id\n WHERE tagId=?\n '''\n cards = self.c.execute(s, [tag]).fetchall()\n for card in cards:\n factId = card['factId'].__str__()\n fact = self.getFactDict(factId)\n facts.append(fact)\n return facts \n\n\n def getFactByCoreIndex(self, coreIndex):\n factId = self.getFactIdForCoreIndex(coreIndex)\n return self.getFactDict(factId)\n\n\n def getFactIdForCoreIndex(self, coreIndex):\n fieldModelId = self.getFieldModelIdOfField('Core-Index')\n s = '''\n SELECT factId\n FROM fields\n WHERE fieldModelId=? AND value=?'''\n row = self.c.execute(s, [fieldModelId, coreIndex]).fetchone()\n return row['factId']\n\n\n def getFactDict(self, factId):\n s = '''\n SELECT fields.value, fieldModels.name\n FROM fields\n LEFT OUTER JOIN fieldModels\n ON fields.fieldModelId=fieldModels.id\n WHERE factId=?\n '''\n fieldsOfFact = self.c.execute(s, [factId]).fetchall()\n fact = {}\n for fields in fieldsOfFact:\n fact[fields['name']] = fields['value']\n return fact\n\n\n def updateFieldByCoreIndex(self, coreIndex, fieldName, fieldValue):\n factId = self.getFactIdForCoreIndex(coreIndex)\n fieldModelId = self.getFieldModelIdOfField(fieldName)\n s = '''\n UPDATE fields\n SET value=?\n WHERE factId=? AND fieldModelId=?\n '''\n field = self.c.execute(s, [fieldValue, factId, fieldModelId]) \n #self.conn.commit()\n \n\n def printCoreIndexOfClozeFixed(self):\n clozeFixFacts = self.getAllFactsWithTag(tag_clozeFIX)\n for fixedFact in clozeFixFacts:\n print \"\\n -------- \", fixedFact['Core-Index'], \" -------- \" \n for (fieldName, fieldValue) in fixedFact.items():\n print fieldName, \" :: \", fieldValue\n\n\n def commit(self):\n self.conn.commit()\n\nif __name__ == \"__main__\":\n dq = DeckQuery()\n #dq.printCoreIndexOfClozeFixed()\n factId = dq.getFactIdForCoreIndex('1')\n dq.updateField(factId, 'Hint', 'TESTING STUFF!')\n"
},
{
"alpha_fraction": 0.5458851456642151,
"alphanum_fraction": 0.5523978471755981,
"avg_line_length": 23.852941513061523,
"blob_id": "455ac6a94c9b4c2561a3281d21fcf93f904bdda7",
"content_id": "16f79e1040ddc2b78fbc1903eeba4aa4d831853c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1689,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 68,
"path": "/verifiers/expression.py",
"repo_name": "finpapa/kore_GSheet",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport re\n\nfrom deckQuery import DeckQuery\n\ndq = DeckQuery()\nc = dq.getDbCursor()\n\n\ndef isKana(s):\n if s < u'\\u3041' or s > u'\\u30FF':\n return False\n return True\n\n\ndef checkSpace(doFix=False):\n '''\n There should be no spaces in the expression field\n '''\n hasSpaces_re = re.compile(ur'\\s+', re.UNICODE)\n\n print '######### Contain spaces #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n factDict = dq.getFactDict(fact_id)\n exprField = factDict['Expression']\n \n spacedPortion = hasSpaces_re.search(exprField)\n if spacedPortion is not None:\n found += 1\n print factDict['Core-Index'], '\\t::\\t', exprField\n if doFix:\n #TODO: add a fix rule for this case\n pass\n print \"Found: \", found \n\ndef checkNoBold(doFix=False):\n '''\n Prints out all cases where the key word isn't emboldened\n '''\n hasSpaces_re = re.compile(ur'<b>.+</b>', re.UNICODE)\n\n print '######### No bold #########'\n found = 0\n s = 'SELECT id FROM facts'\n facts = c.execute(s).fetchall()\n for fact in facts:\n fact_id = fact['id'].__str__()\n factDict = dq.getFactDict(fact_id)\n exprField = factDict['Expression']\n \n spacedPortion = hasSpaces_re.search(exprField)\n if spacedPortion is None:\n found += 1\n print factDict['Core-Index'], '\\t::\\t', exprField\n\n print \"Found: \", found \n\n\nif __name__ == \"__main__\":\n\n checkSpace(doFix=False)\n checkNoBold(doFix=False)\n #dq.commit()"
},
{
"alpha_fraction": 0.6808510422706604,
"alphanum_fraction": 0.695035457611084,
"avg_line_length": 27.399999618530273,
"blob_id": "c39183b62e1e2a0788885ce8c976b8e40ea87895",
"content_id": "b2c4d85a4c311b8a850c4c75221dcb3f8622805a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 141,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 5,
"path": "/localConfig.py",
"repo_name": "finpapa/kore_GSheet",
"src_encoding": "UTF-8",
"text": "DECK_PATH = '/home/ntsp/.anki/decks/Core 2k6k.anki'\n\nGOOGLE_USERNAME = '[email protected]'\nGOOGLE_PASSWORD = 'topSecret++'\nDOC_NAME = 'Optimized Kore'"
}
] | 10 |
ribeiro-ucl/UCLGoProject
|
https://github.com/ribeiro-ucl/UCLGoProject
|
7b81ba963c9a8c113f0dd79b0bc279243a6c0c2a
|
f9a2ef0be11f7559c08e1257f56ce95e2c8bcceb
|
5bb91761bb7a72a90de209f07fb19ba3f0848518
|
refs/heads/master
| 2019-01-31T00:54:20.044121 | 2017-10-10T19:27:40 | 2017-10-10T19:27:40 | 98,745,443 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5230496525764465,
"alphanum_fraction": 0.5372340679168701,
"avg_line_length": 37.23728942871094,
"blob_id": "2c878d4167005a98662a165d9154a9fe177a3e33",
"content_id": "515b8d11cefc8684d3b7c6dbdd423cd595e87025",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2258,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 59,
"path": "/UCLGo/migrations/0013_auto_20170802_0046.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.3 on 2017-08-02 03:46\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('UCLGo', '0012_remove_resultado_computado'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Cidade',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('nome', models.CharField(max_length=50)),\n ],\n options={\n 'verbose_name': 'Cidade',\n 'verbose_name_plural': 'Cidades',\n },\n ),\n migrations.CreateModel(\n name='Endereco',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('logradouro', models.CharField(max_length=100)),\n ('complemento', models.CharField(blank=True, max_length=50, null=True)),\n ('cep', models.CharField(max_length=8, verbose_name='CEP')),\n ('cidade', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='UCLGo.Cidade')),\n ('participante', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='UCLGo.Participante')),\n ],\n options={\n 'verbose_name': 'Endereço',\n 'verbose_name_plural': 'Endereços',\n },\n ),\n migrations.CreateModel(\n name='Estado',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('nome', models.CharField(max_length=50)),\n ('sigla', models.CharField(max_length=2, verbose_name='UF')),\n ],\n options={\n 'verbose_name': 'Estado',\n 'verbose_name_plural': 'Estados',\n },\n ),\n migrations.AddField(\n model_name='cidade',\n name='estado',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='UCLGo.Estado'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5334685444831848,
"alphanum_fraction": 0.5598376989364624,
"avg_line_length": 40.08333206176758,
"blob_id": "ad54a0ef116b3dad39a2c60de3f4e7b5ba0a29e8",
"content_id": "c4aefebc6c595643cb2b6005e23e565429f8a4bd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1488,
"license_type": "permissive",
"max_line_length": 344,
"num_lines": 36,
"path": "/UCLGo/migrations/0022_auto_20170919_1938.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.4 on 2017-09-19 22:38\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('UCLGo', '0021_tarefa_tarefa_cadastro'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Banda',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('nome', models.CharField(max_length=50)),\n ],\n options={\n 'verbose_name': 'Banda',\n 'verbose_name_plural': 'Bandas',\n },\n ),\n migrations.AlterField(\n model_name='participante',\n name='escolaridade',\n field=models.SmallIntegerField(blank=True, choices=[(1, 'Ensino Fundamental Incompleto'), (2, 'Ensino Fundamental Completo'), (3, 'Ensino Médio Incompleto'), (4, 'Ensino Médio Completo'), (5, 'Ensino Superior Incompleto'), (6, 'Ensino Superior Completo'), (7, 'Pós-graduação Incompleta'), (8, 'Pós-graduação Completa')], null=True),\n ),\n migrations.AlterField(\n model_name='participante',\n name='tipo_sanguineo',\n field=models.SmallIntegerField(blank=True, choices=[(1, 'A+'), (2, 'A-'), (3, 'B+'), (4, 'B-'), (5, 'AB+'), (6, 'AB-'), (7, 'O+'), (8, 'O-')], null=True, verbose_name='Tipo Sanguíneo'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5736767053604126,
"alphanum_fraction": 0.6037195920944214,
"avg_line_length": 28.125,
"blob_id": "06b63efe2337180e4de71d15c74f492874757ab5",
"content_id": "3ef32754cf7309dc98245d72373221cdf9b24cf5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 703,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 24,
"path": "/UCLGo/migrations/0029_auto_20171010_1615.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.4 on 2017-10-10 19:15\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('UCLGo', '0028_tipotarefa_data_encerramento'),\n ]\n\n operations = [\n migrations.AlterModelOptions(\n name='instituicao',\n options={'ordering': ['papel', 'nome'], 'verbose_name': 'Instituição', 'verbose_name_plural': 'Instituições'},\n ),\n migrations.AddField(\n model_name='resultado',\n name='registro_ok',\n field=models.BooleanField(default=True, verbose_name='Registro Ok'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7411764860153198,
"alphanum_fraction": 0.7411764860153198,
"avg_line_length": 16,
"blob_id": "f4ba80b36ddba6f29354f1f7bafa865b004f20d7",
"content_id": "e82870788a580f6e1c9362513be1bccc2b0eba42",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 85,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/UCLGo/apps.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass UclgoConfig(AppConfig):\n name = 'UCLGo'\n"
},
{
"alpha_fraction": 0.655562162399292,
"alphanum_fraction": 0.6702855229377747,
"avg_line_length": 29.844036102294922,
"blob_id": "c6e6d4f4300131d8dacde1f6f9948aaaa5679f2a",
"content_id": "e01ffc741cda0c71c12f786a5bd2b03b05c0dc4d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6727,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 218,
"path": "/UCLGoProject/settings.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "\"\"\"\nDjango settings for UCLGoProject project.\n\nGenerated by 'django-admin startproject' using Django 1.11.3.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.11/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.11/ref/settings/\n\"\"\"\n\nimport os\nfrom decouple import config\nfrom dj_database_url import parse as db_url\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n\n\nLOGIN_URL = '/admin/login/'\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/1.11/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret! Generate one with:\n# import random\n# ''.join(random.SystemRandom().choice('abcdefghijklmnopqrstuvwxyz0123456789!@#$%^&*(-_=+)') for i in range(50))\n\n\nSECRET_KEY = config('SECRET_KEY')\n\n#Senha padrão para criação de participante:\nSENHA_PADRAO_USER = config('SENHA_PADRAO_USER', default='0948753045#5@9586$#%*')\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = config('DEBUG', default=False, cast=bool)\n\n# AWS S3 backend used to serve static files:\nAWS_S3 = config('AWS_S3', default=False, cast=bool)\n\n\nALLOWED_HOSTS = ['uclgo.sa-east-1.elasticbeanstalk.com',\n 'uclgo-test.sa-east-1.elasticbeanstalk.com',\n '127.0.0.1', 'localhost',\n 'uclgo-test.agora.vix.br',\n 'uclgo.agora.vix.br']\n\n\n# Application definition\n\nINSTALLED_APPS = [\n 'admin_tools.menu',\n 'dal',\n 'dal_select2',\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'storages',\n 'rest_framework',\n 'rest_framework_tracking',\n 'UCLGo.apps.UclgoConfig',\n # 'debug_toolbar',\n]\n\n# INTERNAL_IPS = ['127.0.0.1',]\n\nMIDDLEWARE = [\n # 'debug_toolbar.middleware.DebugToolbarMiddleware',\n 'django.middleware.security.SecurityMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n]\n\nROOT_URLCONF = 'UCLGoProject.urls'\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [os.path.join(BASE_DIR, 'templates')]\n ,\n # 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n 'loaders': [\n # 'django.template.loaders.filesystem.load_template_source',\n # 'django.template.loaders.app_directories.load_template_source',\n 'admin_tools.template_loaders.Loader',\n 'django.template.loaders.app_directories.Loader',\n 'django.template.loaders.filesystem.Loader',\n ],\n },\n },\n]\n\nWSGI_APPLICATION = 'UCLGoProject.wsgi.application'\n\n\n# Database\n# https://docs.djangoproject.com/en/1.11/ref/settings/#databases\n\n# DATABASES = {\n# 'default': {\n# 'ENGINE': 'django.db.backends.sqlite3',\n# 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),\n# }\n# }\n\n\nDATABASES = {\n 'default': config('DATABASE_URL',\n default='sqlite:///' + os.path.join(BASE_DIR, 'db.sqlite3'),\n cast=db_url\n ),\n}\n\nif DATABASES['default']['ENGINE'] == 'django.db.backends.mysql':\n DATABASES['default']['OPTIONS'] = {'init_command': \"SET sql_mode='STRICT_TRANS_TABLES'\",}\n\n# Password validation\n# https://docs.djangoproject.com/en/1.11/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',\n },\n]\n\nREST_FRAMEWORK = {\n 'DEFAULT_PERMISSION_CLASSES': (config('API_AUTH', default='rest_framework.permissions.AllowAny', cast=str),),\n 'DEFAULT_AUTHENTICATION_CLASSES': (\n 'rest_framework_jwt.authentication.JSONWebTokenAuthentication',\n 'rest_framework.authentication.SessionAuthentication',\n 'rest_framework.authentication.BasicAuthentication',\n ),\n}\n\nJWT_AUTH = {\n 'JWT_VERIFY_EXPIRATION': False,\n}\n\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.11/topics/i18n/\n\nLANGUAGE_CODE = 'pt-br'\n\n# TIME_ZONE = 'UTC'\nTIME_ZONE = 'America/Sao_Paulo'\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n\n# https://stackoverflow.com/questions/6418072/accessing-media-files-in-django\n# https://timmyomahony.com/blog/static-vs-media-and-root-vs-path-in-django/\n# MEDIA_ROOT = os.path.join(BASE_DIR, 'media')\n# MEDIA_URL = '/media/'\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.11/howto/static-files/\n# STATIC_URL = '/static/'\n# STATIC_ROOT = 'static'\n\n\nif AWS_S3:\n DEFAULT_FILE_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage'\n STATICFILES_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage'\n AWS_STORAGE_BUCKET_NAME = config('AWS_STORAGE_BUCKET_NAME')\n AWS_ACCESS_KEY_ID = config('AWS_ACCESS_KEY_ID')\n AWS_SECRET_ACCESS_KEY = config('AWS_SECRET_ACCESS_KEY')\n\n AWS_S3_CUSTOM_DOMAIN = '%s.s3.amazonaws.com' % AWS_STORAGE_BUCKET_NAME\n STATICFILES_LOCATION = 'static'\n\n STATIC_URL = \"https://%s/%s/\" % (AWS_S3_CUSTOM_DOMAIN, STATICFILES_LOCATION)\n MEDIAFILES_LOCATION = 'media'\n MEDIA_URL = \"https://%s/%s/\" % (AWS_S3_CUSTOM_DOMAIN, MEDIAFILES_LOCATION)\n\n STATICFILES_STORAGE = 'UCLGoProject.custom_storages.StaticStorage'\n DEFAULT_FILE_STORAGE = 'UCLGoProject.custom_storages.MediaStorage'\n\nelse:\n default_staticurl = '/static/'\n default_mediaurl = '/media/'\n STATIC_URL = config('STATIC_URL', default=default_staticurl)\n STATIC_ROOT = os.path.join(BASE_DIR, \"..\", \"static\")\n MEDIA_URL = config('MEDIA_URL', default=default_mediaurl)\n MEDIA_ROOT = os.path.join(BASE_DIR, \"..\" ,\"media\")\n\n\n\nADMIN_TOOLS_MENU = 'UCLGoProject.menu.CustomMenu'\n"
},
{
"alpha_fraction": 0.6528662443161011,
"alphanum_fraction": 0.7738853693008423,
"avg_line_length": 15.526315689086914,
"blob_id": "8ad80dd8577d4849fe498b7f595d5738605c4523",
"content_id": "6d58af05ab75c95e23b23cba1e4736e164e5dc9d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 314,
"license_type": "permissive",
"max_line_length": 31,
"num_lines": 19,
"path": "/requirements.txt",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "boto3\nDjango==1.11.4\ndj-database-url\ndjango-autocomplete-light\ndjango-admin-tools\ndjango-choices==1.6.0\npython-decouple\ndjangorestframework==3.6.3\ndjangorestframework-jwt==1.11.0\ndjango-storages\ndrf-tracking\nMarkdown==2.6.8\nmysqlclient\nolefile==0.44\nPillow==4.2.1\nPyJWT==1.5.2\npytz==2017.2\nqrcode==5.3\nsix==1.10.0\n"
},
{
"alpha_fraction": 0.5568627715110779,
"alphanum_fraction": 0.6215686202049255,
"avg_line_length": 24.5,
"blob_id": "e9df2a9536f9aab639385303ea5d01de8da12419",
"content_id": "d426c1dfcf8d7bd6210976d9ca2f3040d9c111d0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 510,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 20,
"path": "/UCLGo/migrations/0021_tarefa_tarefa_cadastro.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.4 on 2017-09-11 19:43\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('UCLGo', '0020_auto_20170815_1415'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='tarefa',\n name='tarefa_cadastro',\n field=models.BooleanField(default=False, verbose_name='Tarefa de Cadastro do Participante'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5102996230125427,
"alphanum_fraction": 0.5220037698745728,
"avg_line_length": 35.82758712768555,
"blob_id": "6d49c2590b4fb09c81c69198444f8768e58a22a4",
"content_id": "b0e96f63a83add4ce8e30f5db2556df11b5818cf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2137,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 58,
"path": "/UCLGoProject/menu.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "\"\"\"\nThis file was generated with the custommenu management command, it contains\nthe classes for the admin menu, you can customize this class as you want.\n\nTo activate your custom menu add the following to your settings.py::\n ADMIN_TOOLS_MENU = 'UCLGoProject.menu.CustomMenu'\n\"\"\"\n\ntry:\n from django.urls import reverse\nexcept ImportError:\n from django.core.urlresolvers import reverse\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom admin_tools.menu import items, Menu\n\n\nclass CustomMenu(Menu):\n \"\"\"\n Custom Menu for UCLGoProject admin site.\n \"\"\"\n def __init__(self, **kwargs):\n Menu.__init__(self, **kwargs)\n self.children += [\n # items.MenuItem(_('Dashboard'), reverse('admin:index')),\n # items.Bookmarks(),\n # items.AppList(\n # _('Applications'),\n # exclude=('django.contrib.*',)\n # ),\n\n # items.MenuItem('Tarefas',\n # children=[\n # items.MenuItem('Impressão de QR Codes', reverse('tarefa_impressao_geral')),\n # ]\n # ),\n\n items.MenuItem('Ranking',\n children=[\n items.MenuItem('Alunos UCL', reverse('ranking_ucl', args=[15000,1])),\n items.MenuItem('Escolas', reverse('ranking_escolas', args=[15000,1])),\n items.MenuItem('Empresas', reverse('ranking_empresas', args=[15000,1])),\n items.MenuItem('Individual', reverse('ranking_individual', args=[15000,1])),\n items.MenuItem('Bandas', reverse('ranking_bandas', args=[1])),\n ]\n ),\n\n # items.AppList(\n # _('Administration'),\n # models=('django.contrib.*',)\n # )\n ]\n\n def init_with_context(self, context):\n \"\"\"\n Use this method if you need to access the request context.\n \"\"\"\n return super(CustomMenu, self).init_with_context(context)\n"
},
{
"alpha_fraction": 0.6910401582717896,
"alphanum_fraction": 0.7075180411338806,
"avg_line_length": 43.181819915771484,
"blob_id": "99dafdf1f2030f2b65ac1d6998bcc4897c29c300",
"content_id": "fccf87695bfce40bd486571df0c833073e488c92",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 979,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 22,
"path": "/UCLGo/constants.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "from djchoices import DjangoChoices, ChoiceItem\n\nclass ESCOLARIDADE(DjangoChoices):\n fundamental_incompleto = ChoiceItem(1, 'Ensino Fundamental Incompleto')\n fundamental_completo = ChoiceItem(2, 'Ensino Fundamental Completo')\n medio_incompleto = ChoiceItem(3, 'Ensino Médio Incompleto')\n medio_completo = ChoiceItem(4, 'Ensino Médio Completo')\n superior_incompleto = ChoiceItem(5, 'Ensino Superior Incompleto')\n superior_completo = ChoiceItem(6, 'Ensino Superior Completo')\n pos_graduacao_incompleta = ChoiceItem(7, 'Pós-graduação Incompleta')\n pos_graduacao_completa = ChoiceItem(8, 'Pós-graduação Completa')\n\n\nclass TIPOSANGUINEO(DjangoChoices):\n a_positivo = ChoiceItem(1, 'A+')\n a_negativo = ChoiceItem(2, 'A-')\n b_positivo = ChoiceItem(3, 'B+')\n b_negativo = ChoiceItem(4, 'B-')\n ab_positivo = ChoiceItem(5, 'AB+')\n ab_negativo = ChoiceItem(6, 'AB-')\n o_positivo = ChoiceItem(7, 'O+')\n o_negativo = ChoiceItem(8, 'O-')"
},
{
"alpha_fraction": 0.5680933594703674,
"alphanum_fraction": 0.575875461101532,
"avg_line_length": 35.57143020629883,
"blob_id": "2f32a6442694d7f9e0f812f8f2d690051077e089",
"content_id": "94e12a13542757cf8889d69a6ed8849f07728486",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 257,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 7,
"path": "/UCLGo/templates/admin/UCLGo/tarefa/change_list.html",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "{% extends \"admin/change_list.html\" %} {% load i18n %}\n{% block object-tools-items %}\n {{ block.super }}\n <li>\n <a target=\"_blank\" class=\"historylink\" href={% url 'tarefa_impressao_geral' %}> Imprimir QR Codes </a>\n </li>\n{% endblock %}\n\n"
},
{
"alpha_fraction": 0.5573770403862,
"alphanum_fraction": 0.6086065769195557,
"avg_line_length": 23.399999618530273,
"blob_id": "5b3cc720220fe2a54e369f704cdcf88f484b41d0",
"content_id": "06b21fdb30649451c546e2007c408d760561f18a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 488,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 20,
"path": "/UCLGo/migrations/0020_auto_20170815_1415.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.3 on 2017-08-15 17:15\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('UCLGo', '0019_participante_user'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='tarefa',\n name='carga_horaria',\n field=models.DecimalField(decimal_places=1, default=0.0, max_digits=4),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5666400790214539,
"alphanum_fraction": 0.5937749147415161,
"avg_line_length": 31.973684310913086,
"blob_id": "ad0c955d225404fa0728a0c1d46d05ef142cbf00",
"content_id": "38db24c5db1ed8228d634594974c40fa8add81f9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1255,
"license_type": "permissive",
"max_line_length": 121,
"num_lines": 38,
"path": "/UCLGo/migrations/0003_auto_20170728_1549.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.3 on 2017-07-28 18:49\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('UCLGo', '0002_auto_20170728_1016'),\n ]\n\n operations = [\n migrations.AlterModelOptions(\n name='participante',\n options={'verbose_name': 'Participante', 'verbose_name_plural': 'Participantes'},\n ),\n migrations.AlterModelOptions(\n name='resultado',\n options={'verbose_name': 'Resultado', 'verbose_name_plural': 'Resultados'},\n ),\n migrations.AlterModelOptions(\n name='tarefa',\n options={'verbose_name': 'Tarefa', 'verbose_name_plural': 'Tarefas'},\n ),\n migrations.AlterModelOptions(\n name='vinculo',\n options={'verbose_name': 'Vínculo', 'verbose_name_plural': 'Vínculos'},\n ),\n migrations.AddField(\n model_name='instituicao',\n name='papel',\n field=models.ForeignKey(default=1, on_delete=django.db.models.deletion.CASCADE, to='UCLGo.PapelInstituicao'),\n preserve_default=False,\n ),\n ]\n"
},
{
"alpha_fraction": 0.550684928894043,
"alphanum_fraction": 0.5844748616218567,
"avg_line_length": 30.285715103149414,
"blob_id": "c634c7317bb4b69474cba6a74edaaadca4bfea09",
"content_id": "9d4e60d2aa43f22051ffe4e0e1789c2e36e9b758",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1097,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 35,
"path": "/UCLGo/migrations/0005_auto_20170728_1609.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.3 on 2017-07-28 19:09\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('UCLGo', '0004_auto_20170728_1605'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='tarefa',\n name='data_fim',\n field=models.DateTimeField(blank=True, null=True, verbose_name='Data de Fim'),\n ),\n migrations.AlterField(\n model_name='tarefa',\n name='data_inicio',\n field=models.DateTimeField(blank=True, null=True, verbose_name='Data de Início'),\n ),\n migrations.AlterField(\n model_name='tarefa',\n name='instrutor',\n field=models.TextField(blank=True, max_length=50, null=True, verbose_name='Instrutor/Palestrante'),\n ),\n migrations.AlterField(\n model_name='tarefa',\n name='responsavel',\n field=models.CharField(max_length=50, verbose_name='Responsável'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5281873345375061,
"alphanum_fraction": 0.56027752161026,
"avg_line_length": 30.16216278076172,
"blob_id": "a2eb8f7a471828fcf3c00f7251c7264e5844cd11",
"content_id": "38ccb8ef39f649c2986d0c9a079ecf0f6e3b8647",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1153,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 37,
"path": "/UCLGo/migrations/0015_auto_20170808_1550.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.3 on 2017-08-08 18:50\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('UCLGo', '0014_auto_20170802_0109'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='TipoTarefa',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('descricao', models.CharField(max_length=50)),\n ],\n options={\n 'verbose_name': 'Tipo de Tarefa',\n 'verbose_name_plural': 'Tipos de Tarefas',\n },\n ),\n migrations.AlterField(\n model_name='participante',\n name='e_mail',\n field=models.CharField(max_length=50, unique=True),\n ),\n migrations.AlterField(\n model_name='tarefa',\n name='arena',\n field=models.ForeignKey(null=True, on_delete=django.db.models.deletion.CASCADE, to='UCLGo.TipoTarefa'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5779092907905579,
"alphanum_fraction": 0.6193293929100037,
"avg_line_length": 24.350000381469727,
"blob_id": "62a06a1fd3e5c20d1c4063302597f7b95fd3c121",
"content_id": "ae200d829bd536d5c88a7a6b7e5b6146d431fed9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 507,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 20,
"path": "/UCLGo/migrations/0028_tipotarefa_data_encerramento.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.4 on 2017-09-28 16:30\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('UCLGo', '0027_resultado_user'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='tipotarefa',\n name='data_encerramento',\n field=models.DateTimeField(blank=True, null=True, verbose_name='Data de Encerramento'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.4633123576641083,
"alphanum_fraction": 0.49056604504585266,
"avg_line_length": 28.204082489013672,
"blob_id": "2d002bee1f68180e7c612aa934417a0e249c3deb",
"content_id": "c7c1045094b73081fefc7bbbfd76d5885129e8a8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1433,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 49,
"path": "/UCLGo/migrations/0026_auto_20170923_1858.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.4 on 2017-09-23 21:58\nfrom __future__ import unicode_literals\n\nimport django.contrib.auth.models\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('auth', '0008_alter_user_username_max_length'),\n ('UCLGo', '0025_auto_20170922_0054'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='ParticipanteApoio',\n fields=[\n ],\n options={\n 'verbose_name': 'Participante (Apoio UCL Go)',\n 'verbose_name_plural': 'Participantes (Apoio UCL Go)',\n 'proxy': True,\n 'indexes': [],\n },\n bases=('UCLGo.participante',),\n ),\n migrations.CreateModel(\n name='UsuarioApoio',\n fields=[\n ],\n options={\n 'verbose_name': 'Usuário (Apoio UCL Go)',\n 'verbose_name_plural': 'Usuários (Apoio UCL Go)',\n 'proxy': True,\n 'indexes': [],\n },\n bases=('auth.user',),\n managers=[\n ('objects', django.contrib.auth.models.UserManager()),\n ],\n ),\n migrations.AlterField(\n model_name='participante',\n name='e_mail',\n field=models.EmailField(max_length=50, unique=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5698729753494263,
"alphanum_fraction": 0.6297640800476074,
"avg_line_length": 25.238094329833984,
"blob_id": "8b7d93feb0f5579609c0886a1cd73aa3ea582395",
"content_id": "686df5c3f25d5f2a068ba23056af8ae9e2ec8a2d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 551,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 21,
"path": "/UCLGo/migrations/0023_tarefa_banda.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.4 on 2017-09-19 22:49\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('UCLGo', '0022_auto_20170919_1938'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='tarefa',\n name='banda',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.CASCADE, to='UCLGo.Banda'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.49058592319488525,
"alphanum_fraction": 0.5206056833267212,
"avg_line_length": 19.419355392456055,
"blob_id": "a48a2a80f51ca272fb143deac8228dd5773d1042",
"content_id": "c343df5009388f253150316a09113506b61533ac",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 7612,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 372,
"path": "/UCLGo/templates/tarefa_impressao_geral.html",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "{% load static %}\n<!DOCTYPE html>\n<html>\n\n<head>\n <title>UCL Go - Impressão de Tarefas</title>\n <meta charset=\"utf-8\" />\n <meta name=\"viewport\" content=\"initial-scale=1.0; maximum-scale=1.0; width=device-width;\">\n{# <link rel=\"stylesheet\" type=\"text/css\" href=\"{% static 'UCLGo/css/ranking.css' %}\">#}\n\n <style type=\"text/css\">\n\n @import url(https://fonts.googleapis.com/css?family=Roboto:400,500,700,300,100);\n\n body {\n font-family: \"Roboto\", helvetica, arial, sans-serif;\n width: 19cm;\n }\n\n .wrap1{\n border: 1px solid #ccc;\n width: 45%;\n height: 350px;\n padding: 10px;\n float: left;\n margin: 5px 5px 10px 5px;\n }\n\n .wrap2{\n border: 1px solid #ccc;\n width: 45%;\n height: 350px;\n padding: 10px;\n float: right;\n margin: 5px 5px 10px 5px;\n }\n\n\n .descricao p{\n font-size: 12px;\n text-align: justify;\n }\n\n .resumo{\n font-size: 12px;\n }\n\n\n h3, h4, h5, h6{\n margin: 0px;\n }\n\n h2{\n font-size: 20px;\n margin: 4px;\n }\n\n h3{\n text-transform: uppercase;\n }\n\n @media print {\n footer {page-break-after: always;}\n }\n\n @page{\n margin: 05mm 05mm 05mm 05mm\n }\n\n</style>\n\n</head>\n\n<body style=\"background: none\">\n\n{% for grupo in tarefas_list %}\n\n<div class=\"wrap1\">\n\n <h3 align=\"center\"> {{ grupo.0.arena}}</h3>\n <hr>\n\n<div class=\"table-title\">\n <h5 align=\"center\"> * TAREFA # {{ grupo.0.codigo_simples }} * </h5>\n <h2 align=\"center\">{{ grupo.0.nome }}</h2>\n {% if grupo.0.instrutor %}\n <h4 align=\"center\">{{ grupo.0.instrutor }}</h4>\n {% endif %}\n {% if grupo.0.data_inicio %}\n <h5 align=\"center\">{{ grupo.0.data_inicio }}</h5>\n {% endif %}\n</div>\n\n\n<div align=\"center\">\n <img width=\"40%\" height=\"40%\" src=\"{{ grupo.0.qrcode.url }}\">\n</div>\n\n{#<div class=\"descricao\">#}\n{# <p> {{ grupo.0.descricao}}</p>#}\n{#</div>#}\n\n{% if grupo.0.responsavel %}\n<div class=\"table-title\">\n <h4 align=\"center\"> Responsável: {{ grupo.0.responsavel }}</h4>\n</div>\n{% endif %}\n\n<br/>\n\n<table class=\"resumo\" width=\"100%\" align=\"center\">\n<thead>\n <tr>\n <th>Pontos</th>\n <th>Ocorrências</th>\n <th>Conquista</th>\n <th>Carga Horária</th>\n </tr>\n</thead>\n <tr align=\"center\">\n <td>{{ grupo.0.pontuacao }}</td>\n <td>{{ grupo.0.ocorrencia_maxima }}</td>\n <td>{% if grupo.0.conquista %} Sim {% else %} Não {% endif %}</td>\n <td>{{ grupo.0.carga_horaria }}</td>\n </tr>\n</table>\n\n{% if grupo.0.exclusividades.exists %}\n <br/>\n <table width=\"50%\" align=\"center\">\n <thead>\n <tr>\n <th>Tarefa Exclusiva</th>\n </tr>\n </thead>\n\n <tr align=\"center\">\n <td>\n {% for item in grupo.0.exclusividades.all %}\n {{ item }} <br/>\n {% endfor %}\n </td>\n </tr>\n </table>\n{% endif %}\n\n</div>\n\n\n<div class=\"wrap2\">\n\n <h3 align=\"center\"> {{ grupo.1.arena}}</h3>\n <hr>\n\n<div class=\"table-title\">\n <h5 align=\"center\"> * TAREFA # {{ grupo.1.codigo_simples }} * </h5>\n <h2 align=\"center\">{{ grupo.1.nome }}</h2>\n {% if grupo.1.instrutor %}\n <h4 align=\"center\">{{ grupo.1.instrutor }}</h4>\n {% endif %}\n {% if grupo.1.data_inicio %}\n <h5 align=\"center\">{{ grupo.1.data_inicio }}</h5>\n {% endif %}\n</div>\n\n\n<div align=\"center\">\n <img width=\"40%\" height=\"40%\" src=\"{{ grupo.1.qrcode.url }}\">\n</div>\n\n{#<div class=\"descricao\">#}\n{# <p> {{ grupo.1.descricao}}</p>#}\n{#</div>#}\n\n{% if grupo.1.responsavel %}\n<div class=\"table-title\">\n <h4 align=\"center\"> Responsável: {{ grupo.1.responsavel }}</h4>\n</div>\n{% endif %}\n\n<br/>\n\n<table class=\"resumo\" width=\"100%\" align=\"center\">\n<thead>\n <tr>\n <th>Pontos</th>\n <th>Ocorrências</th>\n <th>Conquista</th>\n <th>Carga Horária</th>\n </tr>\n</thead>\n <tr align=\"center\">\n <td>{{ grupo.1.pontuacao }}</td>\n <td>{{ grupo.1.ocorrencia_maxima }}</td>\n <td>{% if grupo.1.conquista %} Sim {% else %} Não {% endif %}</td>\n <td>{{ grupo.1.carga_horaria }}</td>\n </tr>\n</table>\n\n{% if grupo.1.exclusividades.exists %}\n <br/>\n <table width=\"50%\" align=\"center\">\n <thead>\n <tr>\n <th>Tarefa Exclusiva</th>\n </tr>\n </thead>\n\n <tr align=\"center\">\n <td>\n {% for item in grupo.1.exclusividades.all %}\n {{ item }} <br/>\n {% endfor %}\n </td>\n </tr>\n </table>\n{% endif %}\n\n</div>\n\n\n\n<div class=\"wrap1\">\n\n <h3 align=\"center\"> {{ grupo.2.arena}}</h3>\n <hr>\n\n<div class=\"table-title\">\n <h5 align=\"center\"> * TAREFA # {{ grupo.2.codigo_simples }} * </h5>\n <h2 align=\"center\">{{ grupo.2.nome }}</h2>\n {% if grupo.2.instrutor %}\n <h4 align=\"center\">{{ grupo.2.instrutor }}</h4>\n {% endif %}\n {% if grupo.2.data_inicio %}\n <h5 align=\"center\">{{ grupo.2.data_inicio }}</h5>\n {% endif %}\n</div>\n\n\n<div align=\"center\">\n <img width=\"40%\" height=\"40%\" src=\"{{ grupo.2.qrcode.url }}\">\n</div>\n\n{#<div class=\"descricao\">#}\n{# <p> {{ grupo.2.descricao}}</p>#}\n{#</div>#}\n\n{% if grupo.2.responsavel %}\n<div class=\"table-title\">\n <h4 align=\"center\"> Responsável: {{ grupo.2.responsavel }}</h4>\n</div>\n{% endif %}\n\n<br/>\n\n<table class=\"resumo\" width=\"100%\" align=\"center\">\n<thead>\n <tr>\n <th>Pontos</th>\n <th>Ocorrências</th>\n <th>Conquista</th>\n <th>Carga Horária</th>\n </tr>\n</thead>\n <tr align=\"center\">\n <td>{{ grupo.2.pontuacao }}</td>\n <td>{{ grupo.2.ocorrencia_maxima }}</td>\n <td>{% if grupo.2.conquista %} Sim {% else %} Não {% endif %}</td>\n <td>{{ grupo.2.carga_horaria }}</td>\n </tr>\n</table>\n\n{% if grupo.2.exclusividades.exists %}\n <br/>\n <table width=\"50%\" align=\"center\">\n <thead>\n <tr>\n <th>Tarefa Exclusiva</th>\n </tr>\n </thead>\n\n <tr align=\"center\">\n <td>\n {% for item in grupo.2.exclusividades.all %}\n {{ item }} <br/>\n {% endfor %}\n </td>\n </tr>\n </table>\n{% endif %}\n\n</div>\n\n\n<div class=\"wrap2\">\n\n <h3 align=\"center\"> {{ grupo.3.arena}}</h3>\n <hr>\n\n<div class=\"table-title\">\n <h5 align=\"center\"> * TAREFA # {{ grupo.3.codigo_simples }} * </h5>\n <h2 align=\"center\">{{ grupo.3.nome }}</h2>\n {% if grupo.3.instrutor %}\n <h4 align=\"center\">{{ grupo.3.instrutor }}</h4>\n {% endif %}\n {% if grupo.3.data_inicio %}\n <h5 align=\"center\">{{ grupo.3.data_inicio }}</h5>\n {% endif %}\n</div>\n\n\n<div align=\"center\">\n <img width=\"40%\" height=\"40%\" src=\"{{ grupo.3.qrcode.url }}\">\n</div>\n\n{#<div class=\"descricao\">#}\n{# <p> {{ grupo.3.descricao}}</p>#}\n{#</div>#}\n\n{% if grupo.3.responsavel %}\n<div class=\"table-title\">\n <h4 align=\"center\"> Responsável: {{ grupo.3.responsavel }}</h4>\n</div>\n{% endif %}\n\n<br/>\n\n<table class=\"resumo\" width=\"100%\" align=\"center\">\n<thead>\n <tr>\n <th>Pontos</th>\n <th>Ocorrências</th>\n <th>Conquista</th>\n <th>Carga Horária</th>\n </tr>\n</thead>\n <tr align=\"center\">\n <td>{{ grupo.3.pontuacao }}</td>\n <td>{{ grupo.3.ocorrencia_maxima }}</td>\n <td>{% if grupo.3.conquista %} Sim {% else %} Não {% endif %}</td>\n <td>{{ grupo.3.carga_horaria }}</td>\n </tr>\n</table>\n\n{% if grupo.3.exclusividades.exists %}\n <br/>\n <table width=\"50%\" align=\"center\">\n <thead>\n <tr>\n <th>Tarefa Exclusiva</th>\n </tr>\n </thead>\n\n <tr align=\"center\">\n <td>\n {% for item in grupo.3.exclusividades.all %}\n {{ item }} <br/>\n {% endfor %}\n </td>\n </tr>\n </table>\n{% endif %}\n\n</div>\n\n<footer> </footer>\n\n{% endfor %}\n\n</body>\n\n</html>"
},
{
"alpha_fraction": 0.6409925818443298,
"alphanum_fraction": 0.6545279026031494,
"avg_line_length": 48.25396728515625,
"blob_id": "c3a196dc9c541bc2f59a34080ac4445bb6f036b4",
"content_id": "80bde6b4d55cb3c73112ce70e760b259e701024a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3103,
"license_type": "permissive",
"max_line_length": 131,
"num_lines": 63,
"path": "/UCLGo/api/urls.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\nfrom rest_framework.urlpatterns import format_suffix_patterns\nfrom rest_framework_jwt.views import obtain_jwt_token\n\nfrom UCLGo.api import views\n\nurlpatterns = [\n # url(r'^tarefas/$', views.TarefaList.as_view()),\n url(r'^tarefas/(?P<pk>[0-9]+)/$', views.TarefaDetail.as_view()),\n url(r'^tarefas/participante/(?P<pk>[0-9]+)/$', views.TarefaParticipanteList.as_view()),\n url(r'^tarefas/participante/(?P<pk>[0-9]+)/flat/$', views.TarefaParticipanteFlatList.as_view()),\n url(r'^tarefas/participante/(?P<pk>[0-9]+)/paged/$', views.TarefaParticipantePagedList.as_view()),\n url(r'^tarefas/codigo_cadastro/$', views.TarefaCadastroParticipante.as_view()),\n\n # url(r'^participantes/$', views.ParticipanteList.as_view()),\n\n url(r'^participantes/(?P<pk>[0-9]+)/$', views.ParticipanteDetail.as_view()),\n url(r'^participantes/(?P<username>[\\w.%+-]+@[A-Za-z0-9.-]+\\.[A-Za-z]{2,4})/$', views.ParticipanteUserDetail.as_view()),\n\n url(r'^participantes/(?P<pk>[0-9]+)/flat$', views.ParticipanteDetailFlat.as_view()),\n url(r'^participantes/(?P<username>[\\w.%+-]+@[A-Za-z0-9.-]+\\.[A-Za-z]{2,4})/flat$', views.ParticipanteUserDetailFlat.as_view()),\n\n url(r'^participantes/create$', views.ParticipanteCreate.as_view()),\n\n url(r'^participantes/(?P<pk>[0-9]+)/update$', views.ParticipanteUpdate.as_view()),\n url(r'^participantes/(?P<pk>[0-9]+)/update/flat$', views.ParticipanteUpdateFlat.as_view()),\n\n url(r'^participantes/(?P<pk>[0-9]+)/pontos$', views.ParticipantePontos.as_view()),\n url(r'^participantes/(?P<pk>[0-9]+)/vinculos$', views.ParticipanteVinculoList.as_view()),\n url(r'^participantes/(?P<pk>[0-9]+)/enderecos$', views.ParticipanteEnderecoList.as_view()),\n url(r'^participantes/(?P<pk>[0-9]+)/realizar_tarefa$', views.ParticipanteTarefa.as_view()),\n url(r'^participantes/(?P<pk>[0-9]+)/execucoes_tarefa$', views.ParticipanteExecucoesTarefa.as_view()),\n\n url(r'^vinculos/create$', views.VinculoCreate.as_view()),\n\n url(r'^enderecos/create', views.EnderecoCreate.as_view()),\n url(r'^enderecos/(?P<pk>[0-9]+)/update$', views.EnderecoUpdate.as_view()),\n\n url(r'^cidades/$', views.CidadeList.as_view()),\n\n url(r'^estados/$', views.EstadoList.as_view()),\n\n url(r'^instituicoes/$', views.InstituicaoList.as_view()),\n url(r'^instituicoes/(?P<pk>[0-9]+)/$', views.InstituicaoDetail.as_view()),\n\n url(r'^arenas/$', views.ArenaList.as_view()),\n url(r'^tipos_tarefas/$', views.TipoTarefaList.as_view()),\n\n url(r'^users/register', views.CreateUserView.as_view()),\n url(r'^users/(?P<username>[\\w.%+-]+@[A-Za-z0-9.-]+\\.[A-Za-z]{2,4})/$', views.UserDetail.as_view()),\n url(r'^users/login', obtain_jwt_token),\n url(r'^users/password/$', views.ChangeUserPassword.as_view()),\n\n url(r'^escolaridades/$', views.EscolaridadeList.as_view()),\n url(r'^tipos_sanguineos/$', views.TipoSanguineoList.as_view()),\n]\n\n# urlpatterns += [\n# url(r'^api-auth/', include('rest_framework.urls',\n# namespace='rest_framework')),\n# ]\n\nurlpatterns = format_suffix_patterns(urlpatterns)\n"
},
{
"alpha_fraction": 0.6342877745628357,
"alphanum_fraction": 0.6361000537872314,
"avg_line_length": 30.112781524658203,
"blob_id": "1dd826fbd3903ee9866ec446501b4d1b46a46fc4",
"content_id": "011db99f906d8175f29b9447ea2b7ed741ddfe8d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8284,
"license_type": "permissive",
"max_line_length": 123,
"num_lines": 266,
"path": "/UCLGo/admin.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import *\nfrom .forms import *\nfrom django.utils.html import format_html\nfrom django.urls import reverse\n\nfrom random import randint\n\n\nadmin.site.site_header = 'UCL GO - Site de Administração'\n\n# Register your models here.\n\nclass TipoTarefaAdmin(admin.ModelAdmin):\n list_display = ['descricao', 'data_encerramento']\nadmin.site.register(TipoTarefa, TipoTarefaAdmin)\n\nclass ArenaAdmin(admin.ModelAdmin):\n list_display = ['nome','responsavel']\nadmin.site.register(Arena, ArenaAdmin)\n\nclass BandaAdmin(admin.ModelAdmin):\n list_display = ['nome']\nadmin.site.register(Banda, BandaAdmin)\n\n\nclass TarefaAdmin(admin.ModelAdmin):\n\n def print_qrcode(self, obj):\n return format_html('<a href=\"%s\" target=\"_blank\">%s</a>' % (reverse('tarefa_impressao',args=[obj.id] ), 'QR Code'))\n print_qrcode.short_description = 'QR Code'\n\n def print_fichas(self, obj):\n return format_html('<a href=\"%s\" target=\"_blank\">%s</a>' % (reverse('tarefa_fichas',args=[obj.id] ), 'Fichas'))\n print_fichas.short_description = 'Fichas'\n\n list_display_links = ['codigo_simples', 'nome']\n list_display = ['codigo_simples', 'nome', 'responsavel', 'pontuacao', 'ocorrencia_maxima', 'data_inicio', 'arena',\n 'print_qrcode', 'print_fichas']\n search_fields = ['codigo_simples','nome', 'responsavel', 'instrutor','arena__nome']\n readonly_fields = ['codigo','qrcode_tag', 'codigo_simples']\n exclude = ['qrcode']\nadmin.site.register(Tarefa, TarefaAdmin)\n\n\nclass ResultadoInline(admin.TabularInline):\n model = Resultado\n form = ResultadoInlineForm\n\n # def formfield_for_foreignkey(self, db_field, request=None, **kwargs):\n #\n # field = super(ResultadoInline, self).formfield_for_foreignkey(db_field, request, **kwargs)\n # # field.label_from_instance = self.label_pre_requisito\n #\n # if db_field.name == 'tarefa':\n # try:\n # parent_obj_id = request.resolver_match.args[0]\n # except IndexError:\n # parent_obj_id = None\n #\n # if parent_obj_id is not None:\n # tarefas_participante = Participante.objects.get(id=parent_obj_id).tarefas_habilitadas()\n # field.queryset = Tarefa.objects.filter(id__in=tarefas_participante)\n # field.widget.attrs['style'] = 'width:500px;'\n # else:\n # field.queryset = field.queryset.none()\n #\n # return field\n\n\n\n def pontuacao(self, obj):\n if obj:\n return obj.tarefa.pontuacao\n return 0\n pontuacao.short_description = 'Pontuação'\n\n readonly_fields = ['pontuacao', 'registro']\n extra = 0\n\n\nclass VinculoInline(admin.TabularInline):\n model = Vinculo\n extra = 0\n\n readonly_fields = ['total_pontos']\n\n\nclass EnderecoInline(admin.TabularInline):\n model = Endereco\n extra = 0\n\n\nclass ParticipanteAdmin(admin.ModelAdmin):\n list_display = ['nome', 'data_nascimento', 'e_mail', 'telefone', 'escolaridade']\n search_fields = ['nome', 'e_mail']\n\n inlines = [VinculoInline, EnderecoInline, ResultadoInline]\n\nadmin.site.register(Participante, ParticipanteAdmin)\n\nfrom django.conf import settings\n\nclass ParticipanteApoioAdmin(admin.ModelAdmin):\n list_display = ['nome', 'data_nascimento', 'e_mail', 'telefone', 'escolaridade']\n search_fields = ['nome', 'e_mail']\n readonly_fields = ['user']\n\n inlines = [VinculoInline, EnderecoInline]\n\n actions = ['reset_password']\n\n def reset_password(self, request, queryset):\n cont = 0\n for participante in queryset:\n user = participante.user\n if user:\n passwd = settings.SENHA_PADRAO_USER\n user.set_password(passwd)\n user.save()\n cont += 1\n\n self.message_user(request, \"Senha resetada para %s participante(s)!\" % str(cont))\n\n reset_password.short_description = \"Realizar Reset de Senha do Usuário\"\n\n def get_actions(self, request):\n actions = super(ParticipanteApoioAdmin, self).get_actions(request)\n\n if request.user.is_superuser == False:\n if 'delete_selected' in actions:\n del actions['delete_selected']\n\n return actions\n\n def save_model(self, request, obj, form, change):\n\n if not change:\n with transaction.atomic():\n UserModel = get_user_model()\n\n # Configura uma senha padrão para os participantes criados pelo apoio:\n passwd = settings.SENHA_PADRAO_USER\n\n user = UserModel.objects.create(\n username=obj.e_mail\n )\n user.set_password(passwd)\n user.save()\n\n # Associa o usuário criado ao cadastro do participante:\n obj.user = user\n\n super(ParticipanteApoioAdmin, self).save_model(request, obj, form, change)\n\n # self.message_user(request, \"Participante criado com sucesso! Senha: %s\" % passwd)\n else:\n super(ParticipanteApoioAdmin, self).save_model(request, obj, form, change)\n\n\nadmin.site.register(ParticipanteApoio, ParticipanteApoioAdmin)\n\nfrom django.contrib.auth.admin import UserAdmin as BaseUserAdmin\n\nclass UsuarioApoioAdmin(BaseUserAdmin):\n list_display = ['username', 'date_joined', 'resultados']\n readonly_fields = ['resultados']\n\n def resultados(self, obj):\n if obj:\n return obj.participante.resultado_set.count()\n\n return 0;\n\n resultados.short_description = 'Resultados'\n\n\n fieldsets = (\n (None, {'fields': ('username', 'password')}),\n # (_('Personal info'), {'fields': ('first_name', 'last_name', 'email')}),\n # (_('Permissions'), {'fields': ('is_active', 'is_staff', 'is_superuser',\n # 'groups', 'user_permissions')}),\n # (_('Important dates'), {'fields': ('last_login', 'date_joined')}),\n )\n\n\nadmin.site.register(UsuarioApoio, UsuarioApoioAdmin)\n\n\nclass InstituicaoAdmin(admin.ModelAdmin):\n list_display = ['nome', 'cnpj', 'representante', 'e_mail', 'telefone', 'papel']\nadmin.site.register(Instituicao, InstituicaoAdmin)\n\n\nadmin.site.register(PapelInstituicao)\n\n\nclass VinculoAdmin(admin.ModelAdmin):\n list_display = ['participante','instituicao']\nadmin.site.register(Vinculo, VinculoAdmin)\n\n\nclass ResultadoAdmin(admin.ModelAdmin):\n form = ExecucaoTarefaForm\n search_fields = ['participante__nome', 'participante__e_mail', 'tarefa__nome', 'user__username']\n list_display = ['participante', 'participante_email', 'id_tarefa', 'tarefa', 'pontos', 'registro', 'user']\n\n # list_filter = ['registro']\n\n readonly_fields = ['registro', 'pontos', 'id_tarefa', 'user', 'participante_email']\n\n def participante_email(self, obj):\n if obj:\n return obj.participante.e_mail\n return ''\n participante_email.short_description = 'E-mail'\n\n def save_model(self, request, obj, form, change):\n if not change:\n obj.user = request.user\n\n super(ResultadoAdmin, self).save_model(request, obj, form, change)\n\n def id_tarefa(self, obj):\n if obj:\n return '{0:03d}'.format(obj.tarefa.id)\n return ''\n id_tarefa.short_description = 'ID Tarefa'\n\n def pontos(self, obj):\n if obj:\n return obj.tarefa.pontuacao\n return 0\n pontos.short_description = 'Pontos'\n\n def get_queryset(self, request):\n qs = super(ResultadoAdmin, self).get_queryset(request)\n if request.user.is_superuser:\n return qs\n return qs.filter(user=request.user)\n\nadmin.site.register(Resultado, ResultadoAdmin)\n\n\nclass ExecucaoTarefaAdmin(ResultadoAdmin):\n readonly_fields = ['registro', 'pontos', 'id_tarefa', 'user', 'participante_email', 'registro_ok']\n\n\nadmin.site.register(ExecucaoTarefa, ExecucaoTarefaAdmin)\n\n\n\n\nclass EnderecoAdmin(admin.ModelAdmin):\n list_display = ['logradouro', 'cidade', 'cep']\nadmin.site.register(Endereco, EnderecoAdmin)\n\n\nclass CidadeAdmin(admin.ModelAdmin):\n list_display = ['nome', 'estado']\nadmin.site.register(Cidade, CidadeAdmin)\n\n\nclass EstadoAdmin(admin.ModelAdmin):\n list_display = ['nome', 'sigla']\nadmin.site.register(Estado, EstadoAdmin)\n\n"
},
{
"alpha_fraction": 0.6022835373878479,
"alphanum_fraction": 0.6336821913719177,
"avg_line_length": 32.90322494506836,
"blob_id": "b3a422f68eda50dea23a75b46f6aad6eb4bab4c9",
"content_id": "765d95b8f4e66c707d2a3903d9f6b76cfd9798a8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1057,
"license_type": "permissive",
"max_line_length": 144,
"num_lines": 31,
"path": "/UCLGo/migrations/0007_auto_20170728_1635.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.3 on 2017-07-28 19:35\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('UCLGo', '0006_auto_20170728_1612'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='tarefa',\n name='exclusividades',\n field=models.ManyToManyField(help_text='A tarefa se aplica exclusivamente aos papeis instituicionais', to='UCLGo.PapelInstituicao'),\n ),\n migrations.AlterField(\n model_name='tarefa',\n name='ocorrencia_maxima',\n field=models.SmallIntegerField(help_text='Número máximo de ocorrências', verbose_name='Ocorrências'),\n ),\n migrations.AlterField(\n model_name='vinculo',\n name='instituicao',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='UCLGo.Instituicao', verbose_name='Instituição'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5433070659637451,
"alphanum_fraction": 0.6082677245140076,
"avg_line_length": 24.399999618530273,
"blob_id": "1816faddcb075d026415ea40f5ceed409d2dac62",
"content_id": "3992cf66e8f54f023d1639fa299112a2055f14a2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 508,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 20,
"path": "/UCLGo/migrations/0009_tarefa_qrcode.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.3 on 2017-07-29 18:19\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('UCLGo', '0008_auto_20170728_1635'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='tarefa',\n name='qrcode',\n field=models.ImageField(blank=True, null=True, upload_to='qrcodes', verbose_name='Imagem QR Code'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5610687136650085,
"alphanum_fraction": 0.5728825926780701,
"avg_line_length": 50.42055892944336,
"blob_id": "17f75304f02e1e9a0942e2c17be04a6ae35d2757",
"content_id": "7b710b4954e204794e9fe31e49479a63dd7f47ff",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5529,
"license_type": "permissive",
"max_line_length": 360,
"num_lines": 107,
"path": "/UCLGo/migrations/0001_initial.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.3 on 2017-07-28 04:23\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\nimport uuid\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='Instituicao',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('nome', models.CharField(max_length=50)),\n ('cnpj', models.CharField(max_length=13)),\n ('e_mail', models.CharField(max_length=50)),\n ('telefone', models.CharField(max_length=30)),\n ('representante', models.CharField(max_length=50)),\n ],\n options={\n 'verbose_name': 'Instituição',\n 'verbose_name_plural': 'Instituições',\n },\n ),\n migrations.CreateModel(\n name='PapelInstituicao',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('descricao', models.CharField(max_length=50)),\n ],\n options={\n 'verbose_name': 'Papel da Instituição',\n 'verbose_name_plural': 'Papeis da Instituição',\n },\n ),\n migrations.CreateModel(\n name='Participante',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('nome', models.CharField(max_length=50)),\n ('e_mail', models.CharField(max_length=50)),\n ('data_nascimento', models.DateField(blank=True, null=True, verbose_name='Data de Nascimento')),\n ('telefone', models.CharField(blank=True, max_length=30, null=True)),\n ('escolaridade', models.SmallIntegerField(blank=True, choices=[(1, 'Ensino Fundamental Incompleto'), (2, 'Ensino Fundamental Completo'), (3, 'Ensino Médio Incompleto'), (4, 'Ensino Médio Completo'), (5, 'Ensino Superior Incompleto'), (5, 'Ensino Superior Completo'), (6, 'Pós-graduação Incompleta'), (7, 'Pós-graduação Completa')], null=True)),\n ('tipo_sanguineo', models.SmallIntegerField(choices=[(1, 'A+'), (2, 'A-'), (1, 'B+'), (2, 'B-'), (1, 'AB+'), (2, 'AB-'), (1, 'O+'), (2, 'O-')], verbose_name='Tipo Sanguíneo')),\n ('telefone_emergencia', models.CharField(blank=True, max_length=30, null=True, verbose_name='Telefone para Emergências')),\n ('pessoa_emergencia', models.CharField(blank=True, max_length=30, null=True, verbose_name='Pessoa para Emergências')),\n ],\n ),\n migrations.CreateModel(\n name='Resultado',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('computado', models.BooleanField()),\n ('participante', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='UCLGo.Participante')),\n ],\n ),\n migrations.CreateModel(\n name='Tarefa',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('nome', models.CharField(max_length=50)),\n ('descricao', models.TextField(verbose_name='Descrição')),\n ('data_inicio', models.DateTimeField(verbose_name='Data de Início')),\n ('data_fim', models.DateTimeField(verbose_name='Data de Fim')),\n ('responsavel', models.TextField(max_length=50, verbose_name='Responsável')),\n ('pontuacao', models.SmallIntegerField(verbose_name='Pontuação')),\n ('ocorrencia_maxima', models.SmallIntegerField(verbose_name='Pontuação')),\n ('conquista', models.BooleanField()),\n ('codigo', models.UUIDField(default=uuid.uuid4, editable=False)),\n ('carga_horaria', models.DecimalField(blank=True, decimal_places=1, max_digits=4, null=True)),\n ('instrutor', models.TextField(blank=True, max_length=50, null=True)),\n ],\n ),\n migrations.CreateModel(\n name='Vinculo',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('total_pontos', models.IntegerField(default=0, verbose_name='Total de Pontos')),\n ('instituicao', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='UCLGo.Instituicao')),\n ('participante', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='UCLGo.Participante')),\n ],\n ),\n migrations.AddField(\n model_name='resultado',\n name='tarefa',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='UCLGo.Tarefa'),\n ),\n migrations.AddField(\n model_name='participante',\n name='tarefas',\n field=models.ManyToManyField(through='UCLGo.Resultado', to='UCLGo.Tarefa'),\n ),\n migrations.AddField(\n model_name='participante',\n name='vinculos',\n field=models.ManyToManyField(through='UCLGo.Vinculo', to='UCLGo.Instituicao'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.4708589017391205,
"alphanum_fraction": 0.5030674934387207,
"avg_line_length": 23.148147583007812,
"blob_id": "1c87ff2576cb31cd8b56a60fbbfee247aabe33a3",
"content_id": "e07da895defed7cd01f2c5aa53f973c18fc3bdda",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 656,
"license_type": "permissive",
"max_line_length": 62,
"num_lines": 27,
"path": "/UCLGo/migrations/0024_execucaotarefa.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.4 on 2017-09-22 02:35\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('UCLGo', '0023_tarefa_banda'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='ExecucaoTarefa',\n fields=[\n ],\n options={\n 'verbose_name': 'Execução de Tarefa',\n 'verbose_name_plural': 'Execuções de Tarefas',\n 'proxy': True,\n 'indexes': [],\n },\n bases=('UCLGo.resultado',),\n ),\n ]\n"
},
{
"alpha_fraction": 0.669442355632782,
"alphanum_fraction": 0.6709563732147217,
"avg_line_length": 33.61135482788086,
"blob_id": "97f69cb669639ba464a5fbaad56fabe9109aeddc",
"content_id": "b377bd19b23bce7c3d559d02e7b85225b5e60bcf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7926,
"license_type": "permissive",
"max_line_length": 162,
"num_lines": 229,
"path": "/UCLGo/api/serializers.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "from rest_framework import serializers\nfrom django.db import transaction\n\nfrom UCLGo.models import Tarefa, Participante, Vinculo, Instituicao, TipoTarefa, Arena, Endereco, Cidade, Estado\nfrom UCLGo.constants import ESCOLARIDADE, TIPOSANGUINEO\n\n\nclass ArenaSerializer(serializers.ModelSerializer):\n class Meta:\n model = Arena\n fields = ('id', 'nome', 'responsavel')\n\n\nclass TipoTarefaSerializer(serializers.ModelSerializer):\n class Meta:\n model = TipoTarefa\n fields = ('id', 'descricao')\n\nclass TarefaParticipanteSerializerFlat(serializers.ModelSerializer):\n arena_id = serializers.SerializerMethodField()\n arena_nome = serializers.SerializerMethodField()\n\n tipo_id = serializers.SerializerMethodField()\n tipo_nome = serializers.SerializerMethodField()\n\n num_execucoes = serializers.SerializerMethodField()\n\n def get_tipo_id(self, tarefa):\n tarefa_obj = Tarefa.objects.get(id=tarefa.id)\n return tarefa_obj.tipo_id\n\n def get_tipo_nome(self, tarefa):\n tarefa_obj = Tarefa.objects.get(id=tarefa.id)\n if tarefa_obj.tipo:\n return tarefa_obj.tipo.descricao\n return ''\n\n def get_arena_id(self, tarefa):\n tarefa_obj = Tarefa.objects.get(id=tarefa.id)\n return tarefa_obj.arena_id\n\n def get_arena_nome(self, tarefa):\n tarefa_obj = Tarefa.objects.get(id=tarefa.id)\n return tarefa_obj.arena.nome\n\n def get_num_execucoes(self, tarefa):\n participante = Participante.objects.get(id=self.pk_participante)\n num_execucoes = participante.execucoes_tarefa(tarefa.codigo)\n return num_execucoes\n\n class Meta:\n model = Tarefa\n fields = ('id', 'arena_id', 'arena_nome', 'tipo_id', 'tipo_nome', 'nome', 'descricao', 'responsavel', 'pontuacao', 'data_inicio', 'data_fim', 'instrutor',\n 'carga_horaria', 'codigo', 'ocorrencia_maxima', 'num_execucoes', 'conquista')\n\n def __init__(self, *args, **kwargs):\n super(TarefaParticipanteSerializerFlat, self).__init__(*args, **kwargs)\n\n request = self.context.get(\"request\")\n if request:\n self.pk_participante = self.context.get(\"pk\")\n\n\n\nclass TarefaParticipanteSerializer(serializers.ModelSerializer):\n arena = ArenaSerializer()\n tipo = TipoTarefaSerializer()\n num_execucoes = serializers.SerializerMethodField()\n\n def get_num_execucoes(self, tarefa):\n participante = Participante.objects.get(id=self.pk_participante)\n num_execucoes = participante.execucoes_tarefa(tarefa.codigo)\n return num_execucoes\n\n class Meta:\n model = Tarefa\n fields = ('id', 'arena', 'tipo', 'nome', 'descricao', 'responsavel', 'pontuacao', 'data_inicio', 'data_fim', 'instrutor',\n 'carga_horaria', 'codigo', 'ocorrencia_maxima', 'num_execucoes', 'conquista')\n\n def __init__(self, *args, **kwargs):\n super(TarefaParticipanteSerializer, self).__init__(*args, **kwargs)\n\n request = self.context.get(\"request\")\n if request:\n self.pk_participante = self.context.get(\"pk\")\n\n\nclass EscolaridadeSerializer(serializers.Serializer):\n id = serializers.IntegerField()\n descricao = serializers.CharField(max_length=50)\n\nclass TipoSanguineoSerializer(serializers.Serializer):\n id = serializers.IntegerField()\n descricao = serializers.CharField(max_length=50)\n\nclass TarefaSerializer(serializers.ModelSerializer):\n arena = ArenaSerializer()\n tipo = TipoTarefaSerializer()\n\n class Meta:\n model = Tarefa\n fields = ('id', 'arena', 'tipo', 'nome', 'descricao', 'responsavel', 'pontuacao', 'data_inicio', 'data_fim', 'instrutor',\n 'carga_horaria', 'codigo')\n\n\n\nclass VinculoSerializer(serializers.ModelSerializer):\n instituicao = serializers.StringRelatedField(read_only=True)\n\n instituicao_id = serializers.IntegerField()\n participante_id = serializers.IntegerField()\n\n class Meta:\n model = Vinculo\n fields = ('participante_id', 'instituicao_id', 'instituicao', 'total_pontos',)\n\n\nclass EstadoSerializer(serializers.ModelSerializer):\n\n class Meta:\n model = Estado\n fields = ('id', 'nome', 'sigla')\n\n\n\nclass CidadeSerializer(serializers.ModelSerializer):\n estado_id = serializers.IntegerField()\n\n class Meta:\n model = Cidade\n fields = ('id', 'nome', 'estado_id')\n\n\nclass EnderecoSerializer(serializers.ModelSerializer):\n participante_id = serializers.IntegerField()\n cidade_id = serializers.IntegerField()\n\n class Meta:\n model = Endereco\n fields = ('id', 'participante_id', 'logradouro', 'complemento', 'cidade_id', 'cep')\n\n\nclass ParticipanteSerializerFlat(serializers.ModelSerializer):\n escolaridade = serializers.ChoiceField(ESCOLARIDADE.choices, required=False, allow_null=True)\n tipo_sanguineo = serializers.ChoiceField(TIPOSANGUINEO.choices, required=False, allow_null=True)\n username = serializers.SerializerMethodField()\n\n def get_username(self, participante):\n if participante.user:\n return participante.user.username\n return None\n\n class Meta:\n model = Participante\n fields = ('id', 'nome', 'username', 'e_mail', 'data_nascimento', 'telefone', 'escolaridade', 'tipo_sanguineo',\n 'telefone_emergencia', 'pessoa_emergencia',)\n\n\nclass ParticipanteSerializer(serializers.ModelSerializer):\n vinculos = VinculoSerializer(many=True, read_only=True, source='vinculo_set', required=False)\n escolaridade = serializers.ChoiceField(ESCOLARIDADE.choices, required=False)\n tipo_sanguineo = serializers.ChoiceField(TIPOSANGUINEO.choices, required=False)\n\n username = serializers.SerializerMethodField()\n\n def get_username(self, participante):\n if participante.user:\n return participante.user.username\n return None\n\n class Meta:\n model = Participante\n fields = ('id', 'nome', 'username', 'e_mail', 'data_nascimento', 'telefone', 'escolaridade', 'tipo_sanguineo',\n 'telefone_emergencia', 'pessoa_emergencia', 'vinculos')\n\n # http://www.django-rest-framework.org/api-guide/relations/#writable-nested-serializers\n # def create(self, validated_data):\n # participante = Participante.objects.create(**validated_data)\n #\n # if 'vinculos' in validated_data:\n # vinculos_data = validated_data.pop('vinculos')\n # for vinculo in vinculos_data:\n # Vinculo.objects.create(participante=participante, **vinculo)\n #\n # return participante\n\n\nclass InstituicaoSerializer(serializers.ModelSerializer):\n papel = serializers.StringRelatedField()\n\n class Meta:\n model = Instituicao\n fields = ('id', 'nome', 'cnpj', 'e_mail', 'telefone', 'representante', 'papel')\n\n\nclass ParticipanteTarefaSerializer(serializers.Serializer):\n codigo = serializers.UUIDField(format='hex_verbose')\n\n\n# https://stackoverflow.com/questions/16857450/how-to-register-users-in-django-rest-framework\nfrom rest_framework import serializers\nfrom django.contrib.auth import get_user_model # If used custom user model\n\nUserModel = get_user_model()\n\nclass UserSerializer(serializers.ModelSerializer):\n username = serializers.EmailField()\n password = serializers.CharField(write_only=True)\n\n def create(self, validated_data):\n with transaction.atomic():\n user = UserModel.objects.create(\n username=validated_data['username']\n )\n user.set_password(validated_data['password'])\n user.save()\n\n participante = Participante.objects.create(\n nome = validated_data['username'],\n e_mail = validated_data['username'],\n user = user\n )\n participante.save()\n\n return user\n\n class Meta:\n model = UserModel\n fields = ('username', 'password',)\n"
},
{
"alpha_fraction": 0.5615276098251343,
"alphanum_fraction": 0.608203649520874,
"avg_line_length": 26.19230842590332,
"blob_id": "56e088dbb443b56028fe01a53bf3e4a16d1d51b1",
"content_id": "d13dfedbf6abd5457741f5042abcee6b62fb6c4c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 707,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 26,
"path": "/UCLGo/migrations/0011_auto_20170801_2349.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.3 on 2017-08-02 02:49\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.utils.timezone\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('UCLGo', '0010_auto_20170729_2055'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='resultado',\n name='registro',\n field=models.DateTimeField(auto_now_add=True, default=django.utils.timezone.now),\n preserve_default=False,\n ),\n migrations.AlterUniqueTogether(\n name='vinculo',\n unique_together=set([('participante', 'instituicao')]),\n ),\n ]\n"
},
{
"alpha_fraction": 0.667370617389679,
"alphanum_fraction": 0.6737064123153687,
"avg_line_length": 37.65306091308594,
"blob_id": "dfa4ae104737ea7d7154380fd3afd8779e2d2775",
"content_id": "7477efd014089f4311cded6b962a96856047876d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1904,
"license_type": "permissive",
"max_line_length": 125,
"num_lines": 49,
"path": "/UCLGo/forms.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "from django.forms import ModelForm\nfrom django import forms\nfrom UCLGo.models import Instituicao, Participante, Resultado, ExecucaoTarefa, Tarefa\nfrom dal import autocomplete\n\n\nclass ExecucaoTarefaForm(ModelForm):\n participante = forms.ModelChoiceField(\n queryset=Participante.objects.all(),\n widget=autocomplete.ModelSelect2(url='participante-autocomplete', attrs={'style': 'width:500px'})\n )\n\n tarefa = forms.ModelChoiceField(\n queryset=Tarefa.objects.all(),\n widget=autocomplete.ModelSelect2(url='tarefa-autocomplete', attrs={'style': 'width:700px'},forward=['participante'])\n )\n\n def clean(self):\n cleaned_data = super(ExecucaoTarefaForm, self).clean()\n participante = cleaned_data.get(\"participante\")\n tarefa = cleaned_data.get(\"tarefa\")\n\n insert = self.instance.pk == None\n\n if insert or (not insert and self.instance.tarefa != tarefa):\n if participante and tarefa:\n if participante.execucoes_tarefa(tarefa.codigo) >= tarefa.ocorrencia_maxima:\n raise forms.ValidationError(\"O número máximo de execuções para esta tarefa já foi atingido!\" )\n\n if insert or (not insert and self.instance.participante != participante):\n if participante and tarefa:\n if participante.execucoes_tarefa(tarefa.codigo) >= tarefa.ocorrencia_maxima:\n raise forms.ValidationError(\"O número máximo de execuções para esta tarefa já foi atingido!\" )\n\n class Meta:\n model = ExecucaoTarefa\n fields = '__all__'\n\n\nclass ResultadoInlineForm(ModelForm):\n\n tarefa = forms.ModelChoiceField(\n queryset=Tarefa.objects.all(),\n widget=autocomplete.ModelSelect2(url='tarefa-autocomplete', attrs={'style': 'width:700px'}, forward=['participante'])\n )\n\n class Meta:\n model = Resultado\n fields = '__all__'\n"
},
{
"alpha_fraction": 0.6331305503845215,
"alphanum_fraction": 0.6378099918365479,
"avg_line_length": 32.643043518066406,
"blob_id": "3e90290f55a8c53fd474505efbd185a631ce019c",
"content_id": "a67dcfe52c684338c6ae4c15fddc2fe3ef33d8a9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12866,
"license_type": "permissive",
"max_line_length": 135,
"num_lines": 381,
"path": "/UCLGo/views.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "import pytz\n\nfrom django.http import HttpResponse\nfrom django.contrib.auth.decorators import login_required\n\nfrom django.shortcuts import render\nfrom UCLGo.models import Tarefa, Participante, Resultado, Vinculo, Instituicao, PapelInstituicao, Banda\nfrom django.db.models import Sum, Max, Count\nfrom django.template import loader\nfrom django.core.paginator import Paginator, EmptyPage, PageNotAnInteger\n\nfrom UCLGo.forms import *\n\nfrom datetime import datetime\n\n\"\"\"\n4 classificações:\n\nPapel: Instituição Empresarial (listar 10)\nPosição - Nome - Pontos - Última tarefa\n\nPapel: Instituição de Ensino (listar 10)\nPosição - Nome - Pontos - Última tarefa\n\nAlunos UCL (listar 25):\nPosição - Nome - Pontos - Última tarefa\n\nIndividual (listar 25):\nPosição - Nome - Pontos - Última tarefa\n\n\"\"\"\n\n\n\"\"\"\nRanking \n\"\"\"\nfrom operator import itemgetter, attrgetter\n\nclass Ranking():\n\n papel_UCL = 1\n papel_Escolas = 2\n papel_Empresas = 3\n\n\n\n def get_ranking_bandas(self):\n lista = []\n for b in Banda.objects.all():\n qsResult = Resultado.objects.filter(registro_ok=True, tarefa__banda=b).aggregate(Sum('tarefa__pontuacao'), Max('registro'))\n pontos = qsResult.get('tarefa__pontuacao__sum')\n ultimo_registro = qsResult.get('registro__max')\n\n if pontos is None:\n pontos = 0\n\n if ultimo_registro:\n lista.append((b.nome, pontos, ultimo_registro.astimezone().strftime(\"%d/%m/%Y %H:%M:%S\")))\n\n lista_ranking = []\n if( len(lista) > 0):\n lista_temp = sorted(lista, key=itemgetter(2)) #ordem pelo critério de desempate\n lista_ranking = sorted(lista_temp, key=itemgetter(1), reverse=True) #ordena por pontuacao\n\n return lista_ranking\n\n\n def get_ranking_individual(self):\n lista = []\n for p in Participante.objects.exclude(vinculos__papel=self.papel_UCL):\n qsResult = Resultado.objects.filter(registro_ok=True, participante_id=p.id)\\\n .aggregate(Sum('tarefa__pontuacao'), Max('registro'))\n pontos = qsResult.get('tarefa__pontuacao__sum')\n ultimo_registro = qsResult.get('registro__max')\n\n if pontos is None:\n pontos = 0\n\n if ultimo_registro:\n lista.append((p.e_mail, pontos, ultimo_registro.astimezone().strftime(\"%d/%m/%Y %H:%M:%S\")))\n\n lista_ranking = []\n if( len(lista) > 0):\n lista_temp = sorted(lista, key=itemgetter(2)) #ordem pelo critério de desempate\n lista_ranking = sorted(lista_temp, key=itemgetter(1), reverse=True) #ordena por pontuacao\n\n return lista_ranking[:42]\n\n\n def get_ranking_UCL(self):\n lista = []\n\n lista_outros_papeis = PapelInstituicao.objects.exclude(id=self.papel_UCL)\n\n for p in Participante.objects.filter(vinculo__instituicao__papel_id=self.papel_UCL):\n qsResultInicial = Resultado.objects.filter(participante_id=p.id)\n\n # Exclusão dos resultados gerados para tarefas que possuem exclusividades de outros papeis:\n qsResultSemExclusividades = qsResultInicial.exclude(tarefa__exclusividades__in=lista_outros_papeis)\n\n # Apenas os resultados de tarefas excluvivas da UCL.\n qsResultExclusivoInstituicao = Resultado.objects.filter(participante_id=p.id,\n tarefa__exclusividades__instituicao__papel_id=self.papel_UCL)\n\n # Inclui novamente os resultados exclusivos da UCL (podem ter sido retirados anteriormente):\n # Prepara a Lista de ids para fazer a união entre os dois conjuntos acima:\n qsResultIds1 = qsResultSemExclusividades.values_list('id', flat=True)\n qsResultIds2 = qsResultExclusivoInstituicao.values_list('id', flat=True)\n\n qsResult = Resultado.objects.filter(registro_ok=True, id__in=(qsResultIds1|qsResultIds2))\n\n # Soma da pontuação e verificação do momento da última realização da terefa:\n qsResult = qsResult.aggregate(Sum('tarefa__pontuacao'), Max('registro'))\n\n pontos = qsResult.get('tarefa__pontuacao__sum')\n ultimo_registro = qsResult.get('registro__max')\n\n if pontos is None:\n pontos = 0\n\n if ultimo_registro:\n lista.append((p.e_mail, pontos, ultimo_registro.astimezone().strftime(\"%d/%m/%Y %H:%M:%S\")))\n\n lista_ranking = []\n if( len(lista) > 0):\n lista_temp = sorted(lista, key=itemgetter(2)) #ordem pelo critério de desempate\n lista_ranking = sorted(lista_temp, key=itemgetter(1), reverse=True) #ordena por pontuacao\n\n return lista_ranking[:42]\n\n\n def get_ranking_vinculo(self, papel_instituicao):\n\n lista = []\n\n lista_outros_papeis = PapelInstituicao.objects.exclude(id=papel_instituicao)\n # print('Outos Papeis:', lista_outros_papeis)\n\n for i in Instituicao.objects.filter(papel_id=papel_instituicao):\n pontos_instituicao = 0\n\n # Resultados gerados com participantes que possuem vínculo com a instituicao:\n qsResultInicial = Resultado.objects.filter(registro_ok=True, participante__vinculo__instituicao=i)\n\n # Exclusão dos resultados gerados para tarefas que possuem exclusividades de outros papeis:\n qsResultSemExclusividades = qsResultInicial.exclude(tarefa__exclusividades__in=lista_outros_papeis)\n\n # Apenas os resultados de tarefas exclusivas da Instituição.\n qsResultExclusivoInstituicao = Resultado.objects.filter(registro_ok=True, participante__vinculo__instituicao=i,\n tarefa__exclusividades__instituicao__papel_id=papel_instituicao)\n\n # Prepara a Lista de ids para fazer a união entre os dois conjuntos acima:\n qsResultIds1 = qsResultSemExclusividades.values_list('id', flat=True)\n qsResultIds2 = qsResultExclusivoInstituicao.values_list('id', flat=True)\n\n qsResult = Resultado.objects.filter(id__in=(qsResultIds1|qsResultIds2))\n\n # Soma da pontuação e verificação do momento da última realização da terefa:\n qsResult = qsResult.aggregate(Sum('tarefa__pontuacao'), Count('participante', distinct=True), Max('registro'))\n\n pontos_instituicao = qsResult.get('tarefa__pontuacao__sum')\n qtd_participantes = qsResult.get('participante__count')\n ultimo_registro = qsResult.get('registro__max')\n\n if pontos_instituicao is None:\n pontos_instituicao = 0\n\n if qtd_participantes is None:\n qtd_participantes = 0\n\n if papel_instituicao == self.papel_Escolas:\n if qtd_participantes > 0:\n lista.append((i.nome, pontos_instituicao, qtd_participantes))\n else:\n if ultimo_registro:\n lista.append((i.nome, pontos_instituicao, ultimo_registro.astimezone().strftime(\"%d/%m/%Y %H:%M:%S\")))\n\n\n lista_ranking = []\n if( len(lista) > 0):\n if papel_instituicao == self.papel_Escolas:\n lista_temp = sorted(lista, key=itemgetter(2), reverse=True) # ordem pelo critério de desempate\n else:\n lista_temp = sorted(lista, key=itemgetter(2)) # ordem pelo critério de desempate\n\n lista_ranking = sorted(lista_temp, key=itemgetter(1), reverse=True) #ordena por pontuacao\n\n return lista_ranking[:28]\n\n\n@login_required()\ndef get_ranking_view(request):\n ranking = Ranking()\n\n template = loader.get_template('ranking.html')\n context = {\n 'ranking_individual': ranking.get_ranking_individual(),\n 'ranking_empresa': ranking.get_ranking_vinculo(ranking.papel_Empresas),\n 'ranking_ucl': ranking.get_ranking_UCL(),\n 'ranking_ensino': ranking.get_ranking_vinculo(ranking.papel_Escolas),\n 'ranking_bandas': ranking.get_ranking_bandas(),\n }\n return HttpResponse(template.render(context, request))\n\n\n@login_required()\ndef get_ranking_escolas_view(request, tipo, page):\n ranking = Ranking()\n\n paginator = Paginator(ranking.get_ranking_vinculo(ranking.papel_Escolas), 14)\n lista = paginator.page(page)\n\n context = {\n 'ranking_ensino': lista,\n 'titulo': 'Escolas',\n 'tipo': tipo,\n 'page': page,\n 'atualizacao': datetime.now(pytz.UTC).astimezone(),\n }\n\n template = loader.get_template('ranking_escolas.html')\n\n return HttpResponse(template.render(context, request))\n\n\n@login_required()\ndef get_ranking_empresas_view(request, tipo, page):\n ranking = Ranking()\n\n paginator = Paginator(ranking.get_ranking_vinculo(ranking.papel_Empresas), 14)\n lista = paginator.page(page)\n\n context = {\n 'ranking': lista,\n 'titulo': 'Empresas',\n 'tipo': tipo,\n 'page' : page,\n 'atualizacao': datetime.now(pytz.UTC).astimezone(),\n }\n\n template = loader.get_template('ranking_empresas.html')\n\n return HttpResponse(template.render(context, request))\n\n@login_required()\ndef get_ranking_individual_view(request, tipo, page):\n ranking = Ranking()\n\n paginator = Paginator(ranking.get_ranking_individual(), 14)\n try:\n lista = paginator.page(page)\n except EmptyPage:\n lista = paginator.page(paginator.num_pages)\n\n context = {\n 'ranking': lista,\n 'titulo': 'Visitantes',\n 'page': page,\n 'tipo': tipo,\n 'atualizacao': datetime.now(pytz.UTC).astimezone(),\n }\n\n template = loader.get_template('ranking_individual.html')\n return HttpResponse(template.render(context, request))\n\n\n@login_required()\ndef get_ranking_ucl_view(request, tipo, page):\n ranking = Ranking()\n\n paginator = Paginator(ranking.get_ranking_UCL(), 14)\n lista = paginator.page(page)\n\n context = {\n 'ranking': lista,\n 'titulo' : 'Alunos UCL',\n 'page' : page,\n 'tipo': tipo,\n 'atualizacao': datetime.now(pytz.UTC).astimezone(),\n }\n\n template = loader.get_template('ranking_ucl.html')\n return HttpResponse(template.render(context, request))\n\n\n@login_required()\ndef get_ranking_bandas_view(request, tipo):\n ranking = Ranking()\n\n template = loader.get_template('ranking_bandas.html')\n context = {\n 'ranking_bandas': ranking.get_ranking_bandas(),\n 'tipo': tipo,\n }\n return HttpResponse(template.render(context, request))\n\n\n@login_required()\ndef tarefa_impressao_view(request, pk):\n template = loader.get_template('tarefa_impressao.html')\n\n context = {\n 'tarefa': Tarefa.objects.get(id=pk),\n }\n\n return HttpResponse(template.render(context, request))\n\n\ndef grouped(l, n):\n for i in range(0, len(l), n):\n yield l[i:i+n]\n\n@login_required()\ndef tarefa_impressao_geral_view(request):\n template = loader.get_template('tarefa_impressao_geral.html')\n\n # Agrupa a lista de 4 em 4 objetos.\n context = {\n 'tarefas_list': grouped(Tarefa.objects.all().order_by('id'), 4),\n }\n\n return HttpResponse(template.render(context, request))\n\n\n@login_required()\ndef tarefa_fichas_view(request, pk):\n template = loader.get_template('tarefa_fichas.html')\n\n context = {\n 'tarefa': Tarefa.objects.get(id=pk),\n }\n\n return HttpResponse(template.render(context, request))\n\n\n\n\n\"\"\"\nAuto-complete views:\n\n\"\"\"\nfrom dal import autocomplete\nfrom django.db.models import Q\n\n\nclass ParticipanteAutocomplete(autocomplete.Select2QuerySetView):\n def get_queryset(self):\n # Don't forget to filter out results depending on the visitor !\n if not self.request.user.is_authenticated():\n return Participante.objects.none()\n\n qs = Participante.objects.all()\n\n if self.q:\n qs = qs.filter( Q(nome__icontains=self.q) | Q(e_mail__icontains=self.q))\n\n return qs\n\n def get_result_label(self, result):\n return '%s - <%s>' % (result.nome, result.e_mail)\n\n\nclass TarefaAutocomplete(autocomplete.Select2QuerySetView):\n def get_queryset(self):\n # Don't forget to filter out results depending on the visitor !\n if not self.request.user.is_authenticated():\n return Tarefa.objects.none()\n\n participante = self.forwarded.get('participante', None)\n\n ids_tarefas = []\n if participante:\n participante_obj = Participante.objects.get(id=participante)\n ids_tarefas = participante_obj.tarefas_habilitadas()\n\n qs = Tarefa.objects.filter(id__in=ids_tarefas).order_by('codigo_simples')\n\n if self.q:\n qs = qs.filter( Q(nome__icontains=self.q) | Q(codigo_simples__exact=self.q))\n\n return qs\n\n\n\n\n"
},
{
"alpha_fraction": 0.5608646273612976,
"alphanum_fraction": 0.5858930349349976,
"avg_line_length": 30.39285659790039,
"blob_id": "40cc44d488b1fc233b96d180890961ed62794d1f",
"content_id": "44707e2f81610314487373e63496fdd5a5fc5b4c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 879,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 28,
"path": "/UCLGo/migrations/0025_auto_20170922_0054.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.4 on 2017-09-22 03:54\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('UCLGo', '0024_execucaotarefa'),\n ]\n\n operations = [\n migrations.AlterModelOptions(\n name='participante',\n options={'ordering': ('nome',), 'verbose_name': 'Participante', 'verbose_name_plural': 'Participantes'},\n ),\n migrations.AlterModelOptions(\n name='tarefa',\n options={'ordering': ('nome',), 'verbose_name': 'Tarefa', 'verbose_name_plural': 'Tarefas'},\n ),\n migrations.AddField(\n model_name='tarefa',\n name='codigo_simples',\n field=models.CharField(max_length=4, null=True, unique=True, verbose_name='# Tarefa'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.632020115852356,
"alphanum_fraction": 0.6504610180854797,
"avg_line_length": 50.826087951660156,
"blob_id": "d2038630e1d6e7a4c333eec1b62d8f3c7cb5e905",
"content_id": "3a34a702b5b3a21d1182420320fae7f05868528a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1193,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 23,
"path": "/UCLGo/urls.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url, include\nfrom UCLGo.views import *\n\nurlpatterns = [\n url(r'^api/', include('UCLGo.api.urls')),\n\n url(r'^ranking/bandas/(?P<tipo>[0-9]+)/$', get_ranking_bandas_view, name='ranking_bandas'),\n url(r'^ranking/escolas/(?P<tipo>[0-9]+)/(?P<page>[0-9]+)/$', get_ranking_escolas_view, name='ranking_escolas'),\n url(r'^ranking/empresas/(?P<tipo>[0-9]+)/(?P<page>[0-9]+)/$', get_ranking_empresas_view, name='ranking_empresas'),\n\n url(r'^ranking/ucl/(?P<tipo>[0-9]+)/(?P<page>[0-9]+)/$', get_ranking_ucl_view, name='ranking_ucl'),\n url(r'^ranking/individual/(?P<tipo>[0-9]+)/(?P<page>[0-9]+)/$', get_ranking_individual_view, name='ranking_individual'),\n\n url(r'^impressao/(?P<pk>[0-9]+)$', tarefa_impressao_view, name='tarefa_impressao'),\n url(r'^impressao_tarefas/$', tarefa_impressao_geral_view, name='tarefa_impressao_geral'),\n\n url(r'^fichas/(?P<pk>[0-9]+)$', tarefa_fichas_view, name='tarefa_fichas'),\n\n #URL Auto-complete:\n url(r'^participante-autocomplete/$', ParticipanteAutocomplete.as_view(),name='participante-autocomplete',),\n url(r'^tarefa-autocomplete/$', TarefaAutocomplete.as_view(), name='tarefa-autocomplete', ),\n\n]\n\n"
},
{
"alpha_fraction": 0.5075125098228455,
"alphanum_fraction": 0.5559265613555908,
"avg_line_length": 28.950000762939453,
"blob_id": "abeac9008f71561197d151ee7fe20e13f4732ff7",
"content_id": "703ce46e1757ac4cedd9a06f9fae2fc2fc41bde6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 600,
"license_type": "permissive",
"max_line_length": 197,
"num_lines": 20,
"path": "/UCLGo/migrations/0002_auto_20170728_1016.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.3 on 2017-07-28 13:16\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('UCLGo', '0001_initial'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='participante',\n name='tipo_sanguineo',\n field=models.SmallIntegerField(blank=True, choices=[(1, 'A+'), (2, 'A-'), (1, 'B+'), (2, 'B-'), (1, 'AB+'), (2, 'AB-'), (1, 'O+'), (2, 'O-')], null=True, verbose_name='Tipo Sanguíneo'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6687090992927551,
"alphanum_fraction": 0.6726778745651245,
"avg_line_length": 31.49547576904297,
"blob_id": "0dc2e6eb008ca7f7c1abd2a59c66cc2600770e63",
"content_id": "9977079f92142a2414030bf4135e2c091abd1713",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14385,
"license_type": "permissive",
"max_line_length": 182,
"num_lines": 442,
"path": "/UCLGo/api/views.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "from django.http import HttpResponse\nfrom django.shortcuts import render\nfrom django.http import Http404\nfrom django.contrib.auth import get_user_model # If used custom user model\n\nfrom rest_framework import status\nfrom rest_framework.pagination import PageNumberPagination\n\nfrom UCLGo.constants import *\nfrom UCLGo.models import Tarefa, Participante, Instituicao, Arena, TipoTarefa, Vinculo, Endereco, Cidade, Estado\nfrom UCLGo.api.serializers import TarefaSerializer, ParticipanteSerializer, InstituicaoSerializer, \\\n ParticipanteTarefaSerializer, ArenaSerializer, TipoTarefaSerializer, \\\n TarefaParticipanteSerializer, TarefaParticipanteSerializerFlat, VinculoSerializer, \\\n ParticipanteSerializerFlat, UserSerializer, EscolaridadeSerializer, \\\n TipoSanguineoSerializer, EnderecoSerializer, CidadeSerializer, EstadoSerializer\n\nfrom rest_framework.views import APIView\nfrom rest_framework.response import Response\nfrom rest_framework import permissions\nfrom rest_framework.permissions import IsAuthenticatedOrReadOnly\nfrom rest_framework.generics import ListAPIView, RetrieveAPIView, UpdateAPIView, CreateAPIView\n\nfrom rest_framework_tracking.mixins import LoggingMixin\n\nfrom UCLGo.models import TarefaMaxOcorrenciaAtingido, TarefaNaoHabilitadaParticipante, TarefaDataFimExpirada\n\n# Create your views here.\n\nclass ParticipanteVinculoList(ListAPIView):\n \"\"\"\n Lista todas os vínculos de um participante\n \"\"\"\n serializer_class = VinculoSerializer\n\n def get_queryset(self):\n pk = self.kwargs.get('pk')\n vinculos = Vinculo.objects.filter(participante_id=pk)\n return vinculos\n\nclass VinculoCreate(CreateAPIView):\n queryset = Vinculo.objects.all()\n serializer_class = VinculoSerializer\n\n\nclass TarefaParticipanteFlatList(ListAPIView):\n \"\"\"\n Lista todas as tarefas de um participante\n \"\"\"\n serializer_class = TarefaParticipanteSerializerFlat\n\n def get_serializer(self, *args, **kwargs):\n \"\"\"\n sobrecarregado aqui para passas o parâmetro 'pk' para filtrar o serializer.\n \"\"\"\n serializer_class = self.get_serializer_class()\n kwargs['context'] = self.get_serializer_context()\n kwargs['context']['pk'] = self.kwargs.get('pk')\n\n return serializer_class(*args, **kwargs)\n\n def get_queryset(self):\n pk = self.kwargs.get('pk')\n participante = Participante.objects.get(id=pk)\n tarefas = Tarefa.objects.filter(id__in=participante.tarefas_habilitadas())\n return tarefas\n\n\nclass TarefaParticipanteList(ListAPIView):\n \"\"\"\n Lista todas as tarefas de um participante\n \"\"\"\n serializer_class = TarefaParticipanteSerializer\n\n def get_serializer(self, *args, **kwargs):\n \"\"\"\n Return the serializer instance that should be used for validating and\n deserializing input, and for serializing output.\n\n sobrecarregado aqui para passas o parâmetro 'pk' para filtrar o serializer.\n \"\"\"\n serializer_class = self.get_serializer_class()\n kwargs['context'] = self.get_serializer_context()\n kwargs['context']['pk'] = self.kwargs.get('pk')\n\n return serializer_class(*args, **kwargs)\n\n def get_queryset(self):\n pk = self.kwargs.get('pk')\n participante = Participante.objects.get(id=pk)\n tarefas = Tarefa.objects.filter(id__in=participante.tarefas_habilitadas())\n return tarefas\n\nclass StandardResultsSetPagination(PageNumberPagination):\n page_size = 1\n # page_size_query_param = 'page_size'\n max_page_size = 1000\n\nclass TarefaParticipantePagedList(TarefaParticipanteList):\n pagination_class = StandardResultsSetPagination\n\n\nclass EscolaridadeList(APIView):\n \"\"\"\n Lista as escolaridades disponíveis\n \"\"\"\n def get(self, request, format=None):\n escolaridades = []\n for esc in ESCOLARIDADE.choices:\n e = {'id': esc[0], 'descricao': esc[1]}\n escolaridades.append(e)\n\n serializer = EscolaridadeSerializer(escolaridades, many=True)\n return Response(serializer.data)\n\n permission_classes = (IsAuthenticatedOrReadOnly,)\n\n\nclass TipoSanguineoList(APIView):\n \"\"\"\n Lista os tipos sanguíneos disponíveis\n \"\"\"\n def get(self, request, format=None):\n tipos_sanguineos = []\n for ts in TIPOSANGUINEO.choices:\n e = {'id': ts[0], 'descricao': ts[1]}\n tipos_sanguineos.append(e)\n\n serializer = TipoSanguineoSerializer(tipos_sanguineos, many=True)\n return Response(serializer.data)\n\n permission_classes = (IsAuthenticatedOrReadOnly,)\n\n\nclass TarefaList(APIView):\n \"\"\"\n Lista todas as tarefas.\n \"\"\"\n def get(self, request, format=None):\n tarefas = Tarefa.objects.all()\n serializer = TarefaSerializer(tarefas, many=True)\n return Response(serializer.data)\n\n\nclass TarefaDetail(APIView):\n \"\"\"\n Retorna uma tarefa.\n \"\"\"\n def get_object(self, pk):\n try:\n return Tarefa.objects.get(pk=pk)\n except Tarefa.DoesNotExist:\n raise Http404\n\n def get(self, request, pk, format=None):\n tarefa = self.get_object(pk)\n serializer = TarefaSerializer(tarefa)\n return Response(serializer.data)\n\n\n\n\nclass CidadeList(ListAPIView):\n \"\"\"\n Lista todas as cidades\n \"\"\"\n serializer_class = CidadeSerializer\n\n def get_queryset(self):\n cidades = Cidade.objects.all()\n return cidades\n\n permission_classes = (IsAuthenticatedOrReadOnly,)\n\n\nclass EstadoList(ListAPIView):\n \"\"\"\n Lista todas os Estados\n \"\"\"\n serializer_class = EstadoSerializer\n\n def get_queryset(self):\n estados = Estado.objects.all()\n return estados\n\n permission_classes = (IsAuthenticatedOrReadOnly,)\n\n\nclass ParticipanteEnderecoList(ListAPIView):\n \"\"\"\n Lista todos os endereços de um participante\n \"\"\"\n serializer_class = EnderecoSerializer\n\n def get_queryset(self):\n pk = self.kwargs.get('pk')\n enderecos = Endereco.objects.filter(participante_id=pk)\n return enderecos\n\n\nclass EnderecoCreate(CreateAPIView):\n queryset = Endereco.objects.all()\n serializer_class = EnderecoSerializer\n\nclass EnderecoUpdate(UpdateAPIView):\n queryset = Endereco.objects.all()\n serializer_class = EnderecoSerializer\n\n\nclass ParticipanteList(ListAPIView):\n queryset = Participante.objects.all()\n serializer_class = ParticipanteSerializer\n\nclass ParticipanteDetailFlat(RetrieveAPIView):\n queryset = Participante.objects.all()\n serializer_class = ParticipanteSerializerFlat\n\nclass ParticipanteDetail(RetrieveAPIView):\n queryset = Participante.objects.all()\n serializer_class = ParticipanteSerializer\n\nclass ParticipanteUserDetailFlat(RetrieveAPIView):\n queryset = Participante.objects.all()\n serializer_class = ParticipanteSerializerFlat\n\n def get_queryset(self):\n username = self.kwargs.get('username')\n participantes = Participante.objects.filter(user__username=username)\n return participantes\n\n lookup_field = 'user__username'\n lookup_url_kwarg = 'username'\n\n\n\nclass ParticipanteUserDetail(RetrieveAPIView):\n queryset = Participante.objects.all()\n serializer_class = ParticipanteSerializer\n\n def get_queryset(self):\n username = self.kwargs.get('username')\n participantes = Participante.objects.filter(user__username=username)\n\n return participantes\n\n lookup_field = 'user__username'\n lookup_url_kwarg = 'username'\n\n\nclass ParticipanteCreate(CreateAPIView):\n queryset = Participante.objects.all()\n serializer_class = ParticipanteSerializer\n\nclass ParticipanteUpdate(UpdateAPIView):\n queryset = Participante.objects.all()\n serializer_class = ParticipanteSerializer\n\nclass ParticipanteUpdateFlat(UpdateAPIView):\n queryset = Participante.objects.all()\n serializer_class = ParticipanteSerializerFlat\n\n\nclass TarefaCadastroParticipante(APIView):\n \"\"\"\n Retorna o código da tarefa cadastrada como sendo de cadastro completo do participante.\n \"\"\"\n def get_object(self):\n try:\n qsTarefa = Tarefa.objects.filter(tarefa_cadastro=True)\n if qsTarefa:\n return qsTarefa.first()\n\n raise Http404\n\n except Participante.DoesNotExist:\n raise Http404\n\n def get(self, request, format=None):\n tarefa_cadastro = self.get_object()\n return Response({'codigo':tarefa_cadastro.codigo})\n\n permission_classes = (IsAuthenticatedOrReadOnly,)\n\n\nclass ParticipanteExecucoesTarefa(APIView):\n \"\"\"\n Retorna o número de vezes que uma tarefa foi executada por um participante.\n \"\"\"\n def get_object(self, pk):\n try:\n return Participante.objects.get(pk=pk)\n except Participante.DoesNotExist:\n raise Http404\n\n def put(self, request, pk, format=None):\n participante = self.get_object(pk)\n serializer = ParticipanteTarefaSerializer(data=request.data)\n if serializer.is_valid():\n try:\n codigo = serializer.validated_data['codigo']\n num_execucoes = participante.execucoes_tarefa(codigo)\n\n return Response({\"num_execucoes\":num_execucoes, \"erro\":False})\n\n except Exception as e:\n return Response({\"erro\": True, \"mensagem\":str(e)})\n\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n\nclass ParticipantePontos(APIView):\n \"\"\"\n Retorna o total de pontos de um participante.\n \"\"\"\n def get_object(self, pk):\n try:\n return Participante.objects.get(pk=pk)\n except Tarefa.DoesNotExist:\n raise Http404\n\n def get(self, request, pk, format=None):\n participante = self.get_object(pk)\n return Response({'pontos':participante.pontos_obtidos()})\n\n\nclass ParticipanteTarefa(APIView):\n \"\"\"\n Realiza a contabilização da tarefa para o participante, caso seja uma tarefa válida para ele e caso o número\n de ocorrências não tenha atingido o limite.\n \"\"\"\n def get_object(self, pk):\n try:\n return Participante.objects.get(pk=pk)\n except Participante.DoesNotExist:\n raise Http404\n\n def put(self, request, pk, format=None):\n participante = self.get_object(pk)\n serializer = ParticipanteTarefaSerializer(data=request.data)\n if serializer.is_valid():\n try:\n codigo = serializer.validated_data['codigo']\n\n api_user = None\n if request.user.is_authenticated():\n api_user = request.user\n\n pontuacao = participante.contabilizar_tarefa(codigo, user_responsavel=api_user)\n\n id_tarefa = Tarefa.objects.filter(codigo=codigo).first().id\n pontuacao_total = participante.pontos_obtidos()\n\n num_execucoes = participante.execucoes_tarefa(codigo)\n return Response({\"score\":pontuacao_total, \"id_tarefa\":id_tarefa, \"num_execucoes\":num_execucoes, \"pontos\":pontuacao, \"erro\":False, \"mensagem\":\"Tarefa contabilizada!\"})\n except TarefaMaxOcorrenciaAtingido:\n return Response({\"erro\": True, \"mensagem\":\"Número máximo de ocorrências atingido para a tarefa.\"},\n status=status.HTTP_400_BAD_REQUEST)\n except TarefaDataFimExpirada:\n return Response({\"erro\": True, \"mensagem\":\"A data/hora de encerramento da tarefa foi atingida.\"},\n status=status.HTTP_400_BAD_REQUEST)\n except TarefaNaoHabilitadaParticipante:\n return Response({\"erro\": True, \"mensagem\":\"A tarefa informada não está habilitada para o participante.\"},\n status=status.HTTP_400_BAD_REQUEST)\n except Exception as e:\n return Response({\"erro\": True, \"mensagem\":str(e)},\n status=status.HTTP_400_BAD_REQUEST)\n\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n\nclass ArenaList(ListAPIView):\n queryset = Arena.objects.all()\n serializer_class = ArenaSerializer\n\n permission_classes = (IsAuthenticatedOrReadOnly,)\n\nclass TipoTarefaList(ListAPIView):\n queryset = TipoTarefa.objects.all()\n serializer_class = TipoTarefaSerializer\n\n permission_classes = (IsAuthenticatedOrReadOnly,)\n\nclass InstituicaoList(ListAPIView):\n queryset = Instituicao.objects.all()\n serializer_class = InstituicaoSerializer\n\nclass InstituicaoDetail(RetrieveAPIView):\n queryset = Instituicao.objects.all()\n serializer_class = InstituicaoSerializer\n\n\nclass UserDetail(RetrieveAPIView):\n user_model = get_user_model()\n queryset = user_model.objects.all()\n serializer_class = UserSerializer\n\n # Habilitar para pesquisar o Participante por email:\n lookup_field = 'username'\n lookup_url_kwarg = 'username'\n\n permission_classes = (IsAuthenticatedOrReadOnly,)\n\n\nclass CreateUserView(CreateAPIView):\n\n model = get_user_model()\n permission_classes = [\n permissions.AllowAny # Or anon users can't register\n ]\n serializer_class = UserSerializer\n\n\nclass ChangeUserPassword(APIView):\n \"\"\"\n Realiza a alteração da senha de um usuário para a senha informada em password\n \"\"\"\n\n # permission_classes = (IsAuthenticatedOrReadOnly,)\n\n def get_object(self, username):\n try:\n UserModel = get_user_model()\n return UserModel.objects.get(username=username)\n except UserModel.DoesNotExist:\n raise Http404\n\n def put(self, request, format=None):\n serializer = UserSerializer(data=request.data)\n if serializer.is_valid():\n try:\n username = serializer.validated_data['username']\n user = self.get_object(username)\n\n passwd = serializer.validated_data['password']\n user.set_password(passwd)\n user.save()\n\n return Response({\"erro\":False, \"mensagem\":\"Senha Alterada!\"})\n\n except Exception as e:\n return Response({\"erro\": True, \"mensagem\":str(e)}, status=status.HTTP_400_BAD_REQUEST)\n\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)"
},
{
"alpha_fraction": 0.6582712531089783,
"alphanum_fraction": 0.6632917523384094,
"avg_line_length": 34.24483871459961,
"blob_id": "7a312dbe07c063186c3788ec65344027e8f50f56",
"content_id": "9f52805c21d2e0f874585a1c7be825ab5f03358d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12005,
"license_type": "permissive",
"max_line_length": 130,
"num_lines": 339,
"path": "/UCLGo/models.py",
"repo_name": "ribeiro-ucl/UCLGoProject",
"src_encoding": "UTF-8",
"text": "import uuid\nimport qrcode\nimport pytz\n\nfrom io import BytesIO\nfrom django.core.files.base import ContentFile\n\nfrom django.db import models\nfrom django.db.models import Sum, Count\nfrom django.db import transaction\n\nfrom django.contrib.auth import get_user_model # If used custom user model\n\nfrom .constants import ESCOLARIDADE, TIPOSANGUINEO\n\n#Obtem a classe usada para usuarios:\nUserModel = get_user_model()\n\nclass PapelInstituicao(models.Model):\n descricao = models.CharField(max_length=50)\n\n class Meta:\n verbose_name = 'Papel da Instituição'\n verbose_name_plural = 'Papeis da Instituição'\n\n def __str__(self):\n return self.descricao\n\n\nclass Instituicao(models.Model):\n papel = models.ForeignKey(PapelInstituicao)\n nome = models.CharField(max_length=50)\n cnpj = models.CharField(max_length=13)\n e_mail = models.CharField(max_length=50)\n telefone = models.CharField(max_length=30)\n representante = models.CharField(max_length=50)\n\n class Meta:\n verbose_name = 'Instituição'\n verbose_name_plural = 'Instituições'\n ordering = ['papel', 'nome']\n\n def __str__(self):\n return '%s - %s' % (self.papel.descricao, self.nome)\n\nclass TipoTarefa(models.Model):\n descricao = models.CharField(max_length=50)\n data_encerramento = models.DateTimeField(verbose_name='Data de Encerramento', blank=True, null=True)\n\n class Meta:\n verbose_name = 'Tipo de Tarefa'\n verbose_name_plural = 'Tipos de Tarefas'\n\n def __str__(self):\n return self.descricao\n\n\nclass Arena(models.Model):\n nome = models.CharField(max_length=50)\n responsavel = models.CharField(max_length=50)\n\n class Meta:\n verbose_name = 'Arena'\n verbose_name_plural = 'Arenas'\n\n def __str__(self):\n return self.nome\n\n\nclass Banda(models.Model):\n nome = models.CharField(max_length=50)\n\n class Meta:\n verbose_name = 'Banda'\n verbose_name_plural = 'Bandas'\n\n def __str__(self):\n return self.nome\n\n\nclass TarefaMaxOcorrenciaAtingido(Exception):\n \"\"\"Indica que o número máximo de ocorrências de uma tarefa foi atingida para um determinado participante\"\"\"\n\nclass TarefaNaoHabilitadaParticipante(Exception):\n \"\"\"Indica que a tarefa não está habilitada para um determinado participante\"\"\"\n\nclass TarefaDataFimExpirada(Exception):\n \"\"\"Indica que a tarefa não está habilitada pois a data de fim já foi atingida. \"\"\"\n\n\nclass Tarefa(models.Model):\n codigo_simples = models.CharField(max_length=4, unique=True, verbose_name='# Tarefa', null=True)\n arena = models.ForeignKey(Arena, blank=False, null=True)\n tipo = models.ForeignKey(TipoTarefa, blank=False, null=True)\n nome = models.CharField(max_length=100)\n descricao = models.TextField(verbose_name='Descrição')\n responsavel = models.CharField(max_length=50, verbose_name='Responsável')\n pontuacao = models.PositiveSmallIntegerField(verbose_name='Pontuação')\n ocorrencia_maxima = models.PositiveSmallIntegerField(verbose_name='Ocorrências',\n help_text='Número máximo de ocorrências')\n\n conquista = models.BooleanField()\n\n banda = models.ForeignKey(Banda, blank=True, null=True)\n\n data_inicio = models.DateTimeField(verbose_name='Data de Início', blank=True, null=True)\n data_fim = models.DateTimeField(verbose_name='Data de Fim', blank=True, null=True)\n instrutor = models.CharField(max_length=50, blank=True, null=True, verbose_name='Instrutor/Palestrante')\n\n codigo = models.UUIDField(default=uuid.uuid4, editable=False)\n\n carga_horaria = models.DecimalField(max_digits=4, decimal_places=1, default=0.0, blank=False, null=False)\n\n exclusividades = models.ManyToManyField(PapelInstituicao, blank=True,\n help_text='A tarefa se aplica exclusivamente aos papeis instituicionais')\n\n qrcode = models.ImageField(upload_to='qrcodes',verbose_name='Imagem QR Code', blank=True, null=True)\n\n tarefa_cadastro = models.BooleanField(default=False, verbose_name='Tarefa de Cadastro do Participante')\n\n def qrcode_tag(self):\n if self.qrcode:\n return u'<img src=\"%s\" />' % self.qrcode.url\n\n return ''\n qrcode_tag.short_description = 'QR Code'\n qrcode_tag.allow_tags = True\n\n def gerar_qrcode(self):\n if self.codigo:\n #Gera o QR Code:\n imagem = qrcode.make(self.codigo)\n\n #Transforma em bytes para aplicar ao campo do django:\n imagem_io = BytesIO()\n imagem.save(imagem_io, format='png')\n\n #salva o qrcode gerado no model/sistema de arquivos:\n self.qrcode.save(str(self.id)+'_qr.png', ContentFile(imagem_io.getvalue()),save=False)\n # print('gerar_qrcode...')\n\n\n def save(self, force_insert=False, force_update=False, using=None, update_fields=None):\n super(Tarefa, self).save()\n\n #Gera o QR Code apenas se o mesmo não existe.\n if not self.qrcode:\n self.gerar_qrcode()\n super(Tarefa, self).save()\n\n if not self.codigo_simples:\n self.codigo_simples = '{0:03d}'.format(self.id)\n super(Tarefa, self).save()\n\n class Meta:\n verbose_name = 'Tarefa'\n verbose_name_plural = 'Tarefas'\n ordering = ('nome',)\n\n def __str__(self):\n return '%s - #%s' % (self.nome, self.codigo_simples)\n\nfrom datetime import datetime\n\nclass Participante(models.Model):\n nome = models.CharField(max_length=50)\n e_mail = models.EmailField(max_length=50, unique=True)\n data_nascimento = models.DateField(verbose_name='Data de Nascimento', blank=True, null=True)\n telefone = models.CharField(max_length=30, blank=True, null=True)\n escolaridade = models.SmallIntegerField(choices=ESCOLARIDADE.choices, blank=True, null=True)\n tipo_sanguineo = models.SmallIntegerField(verbose_name='Tipo Sanguíneo', choices=TIPOSANGUINEO.choices, blank=True, null=True)\n telefone_emergencia = models.CharField(verbose_name='Telefone para Emergências', max_length=30, blank=True, null=True)\n pessoa_emergencia = models.CharField('Pessoa para Emergências', max_length=30, blank=True, null=True)\n tarefas = models.ManyToManyField(Tarefa, through='Resultado')\n vinculos = models.ManyToManyField(Instituicao, through='Vinculo')\n\n user = models.OneToOneField(UserModel, blank=True, null=True)\n\n\n def contabilizar_tarefa(self, codigo_tarefa, user_responsavel=None):\n tarefa = Tarefa.objects.filter(codigo=codigo_tarefa).first()\n\n if self.id and tarefa:\n if tarefa.id in self.tarefas_habilitadas():\n\n # Se a data de fim estiver preenchida compara com a data atual, senão libera a tarefa:\n data_agora = datetime.now(pytz.UTC)\n data_limite = tarefa.tipo.data_encerramento\n\n if data_limite is None or data_limite.astimezone(pytz.UTC) >= data_agora:\n # contar resultados existentes para a tarefa atual\n resultados_existentes = self.tarefas.filter(codigo=tarefa.codigo)\n\n # criar novo resultado apenas se o limite não foi atingido.\n if resultados_existentes.count() < tarefa.ocorrencia_maxima:\n resultado = Resultado.objects.create(participante=self, tarefa=tarefa, user=user_responsavel)\n return tarefa.pontuacao\n else:\n raise TarefaMaxOcorrenciaAtingido\n else:\n raise TarefaDataFimExpirada\n else:\n raise TarefaNaoHabilitadaParticipante\n else:\n raise Tarefa.DoesNotExist(\"Tarefa não encontrada!\")\n\n return 0\n\n def pontos_obtidos(self):\n \"\"\" Total de pontos obtidos até o momento em todas as tarefas que executou \"\"\"\n pontos = self.tarefas.filter(registro_ok=True).aggregate(Sum('pontuacao'))['pontuacao__sum']\n if pontos is None:\n pontos = 0\n\n return pontos\n\n def execucoes_tarefa(self, codigo_tarefa):\n \"\"\" Número de vezes que o participante executou uma determinada tarefa \"\"\"\n return self.tarefas.filter(registro_ok=True, codigo=codigo_tarefa).aggregate(Count('codigo'))['codigo__count']\n\n def tarefas_habilitadas(self):\n #Apenas tarefas exclusivas para o participante com base em seus vínculos:\n papeis = self.vinculos.values_list('papel', flat=True)\n tarefas_exclusivas = list(Tarefa.objects.filter(exclusividades__id__in=papeis).values_list('id', flat=True))\n\n #Tarefas que não possuem exclusividade (válido para todos os participantes):\n tarefas_sem_exclusividade = list(Tarefa.objects.filter(exclusividades__id=None).values_list('id', flat=True))\n\n tarefas_participante = list(set(tarefas_exclusivas + tarefas_sem_exclusividade))\n\n return tarefas_participante\n\n class Meta:\n verbose_name = 'Participante'\n verbose_name_plural = 'Participantes'\n ordering = ('nome',)\n\n def __str__(self):\n return '%s' % (self.nome)\n\n\nclass Resultado(models.Model):\n participante = models.ForeignKey(Participante)\n tarefa = models.ForeignKey(Tarefa)\n registro = models.DateTimeField(auto_now_add=True)\n user = models.ForeignKey(UserModel, null=True, verbose_name='Responsável')\n registro_ok = models.BooleanField(null=False, blank=False, default=True, verbose_name='Registro Ok')\n\n class Meta:\n verbose_name = 'Resultado'\n verbose_name_plural = 'Resultados'\n\n def __str__(self):\n return '%s - %s' %(self.participante.nome, self.tarefa.nome)\n\n\nclass ExecucaoTarefa(Resultado):\n\n class Meta:\n proxy = True\n verbose_name = 'Execução de Tarefa'\n verbose_name_plural = 'Execuções de Tarefas'\n\n\nclass ParticipanteApoio(Participante):\n\n class Meta:\n proxy = True\n verbose_name = 'Participante (Apoio UCL Go)'\n verbose_name_plural = 'Participantes (Apoio UCL Go)'\n\n def __str__(self):\n return '%s - %s' % (self.nome, self.e_mail)\n\n\nclass UsuarioApoio(UserModel):\n\n class Meta:\n proxy = True\n verbose_name = 'Usuário (Apoio UCL Go)'\n verbose_name_plural = 'Usuários (Apoio UCL Go)'\n\n def __str__(self):\n return self.username\n\n\nclass Vinculo(models.Model):\n participante = models.ForeignKey(Participante)\n instituicao = models.ForeignKey(Instituicao, verbose_name='Instituição')\n\n # Mantido apenas por questões de compatibilidade com a API/Apps. Não está sendo atualizado:\n total_pontos = models.IntegerField(verbose_name='Total de Pontos', default=0)\n\n class Meta:\n verbose_name = 'Vínculo'\n verbose_name_plural = 'Vínculos'\n unique_together = ['participante', 'instituicao']\n\n def __str__(self):\n return '%s - %s' %(self.participante.nome, self.instituicao.nome)\n\n\nclass Estado(models.Model):\n nome = models.CharField(max_length=50)\n sigla = models.CharField(max_length=2, verbose_name='UF')\n\n class Meta:\n verbose_name = 'Estado'\n verbose_name_plural = 'Estados'\n\n def __str__(self):\n return self.sigla\n\n\nclass Cidade(models.Model):\n nome = models.CharField(max_length=50)\n estado = models.ForeignKey(Estado)\n\n class Meta:\n verbose_name = 'Cidade'\n verbose_name_plural = 'Cidades'\n\n def __str__(self):\n return self.nome\n\n\nclass Endereco(models.Model):\n participante = models.ForeignKey(Participante)\n logradouro = models.CharField(max_length=100)\n complemento = models.CharField(max_length=50, blank=True, null=True)\n cidade = models.ForeignKey(Cidade)\n cep = models.CharField(max_length=8, verbose_name='CEP')\n\n class Meta:\n verbose_name = 'Endereço'\n verbose_name_plural = 'Endereços'\n\n def __str__(self):\n return '%s - %s - %s' %(self.logradouro, self.cidade, str(self.cidade.estado))\n\n\n\n"
}
] | 33 |
TheRealRhyle/WFRP-2e-Char-Gen
|
https://github.com/TheRealRhyle/WFRP-2e-Char-Gen
|
8d99c3284266abb273119eda88631d163bad4839
|
e7f580f22ac058caf6f67debe96c56874cfecde8
|
3922492332368074bbe89ab18b66cebf22185d52
|
refs/heads/master
| 2020-03-22T18:57:44.152015 | 2018-10-11T01:12:21 | 2018-10-11T01:12:21 | 140,494,552 | 2 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5700912475585938,
"alphanum_fraction": 0.5744208097457886,
"avg_line_length": 31.49429702758789,
"blob_id": "d1e15a6a2d5c1918f9e69a1da671a28307247f7d",
"content_id": "6d0b84668f01ce84e56944d0442c183b92afdf2e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8546,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 263,
"path": "/genchar.py",
"repo_name": "TheRealRhyle/WFRP-2e-Char-Gen",
"src_encoding": "UTF-8",
"text": "# WFRP Character generator\n# Created as a personal project\nimport pickle\nimport random\nimport re\nimport careers\nimport personal_details as pd\nimport races\nimport skills\nimport career_listf as cl\nimport export_to_html\n\nrace = ['dwarf', 'elf', 'halfling', 'human']\ngender = ('male', 'female')\n\ndef build_random_char():\n rand_race = race[random.randint(0, 3)]\n rand_gender = gender[random.randint(0, 1)]\n\n # Get starting Skills and Talents based on rand_race\n ski, tal = skills.skills_talents(rand_race)\n\n ski = sorted(ski)\n tal = sorted(tal)\n\n ski = select_option(ski)\n tal = select_option(tal)\n\n mp_key, mp_value, sp_key, sp_value = random_stat_blocks(rand_race, tal)\n\n # Select random career\n sel_career_name = careers.starting_career(rand_race)\n\n #get career info for selected career\n sel_career = cl.career_selection(sel_career_name + ' Advance Scheme')\n mp_adv = list(sel_career['Statblock'])[0:8]\n sec_adv = list(sel_career['Statblock'])[8:]\n mp_adv = '\\t'.join(str(li) for li in mp_adv)\n sec_adv = '\\t'.join(str(li) for li in sec_adv)\n adv_skill = sorted(sel_career['Skills'])\n adv_talent = sorted(sel_career['Talents'])\n trappings = sorted(sel_career['Trappings'])\n career_entries =sel_career['Career Entries']\n career_exits =sel_career['Career Exits']\n\n trappings = select_option(trappings)\n\n charout = {}\n charout['name'] = pd.get_names(rand_race, rand_gender)\n charout['career'] = sel_career_name\n charout['race'] = rand_race.title()\n charout['gender'] = rand_gender.title()\n charout['height'] = pd.height(rand_race, rand_gender)\n charout['hair_color'] = pd.hair_color(rand_race)\n charout['weight'] = pd.weight(rand_race)\n charout['eye_color'] = pd.eye_color(rand_race)\n charout['marks'] = pd.distinctive_marks()\n charout['age'] = pd.age(rand_race)\n charout['siblings'] = pd.number_siblings(rand_race)\n charout['birthplace'] = pd.birthplace(rand_race)\n charout['starsign'] = pd.star_sign()\n charout['skills'] = sorted(ski)\n charout['talents'] = sorted(tal)\n charout['main_profile_header'] = mp_key\n charout['main_profile'] = mp_value\n charout['main_profile_adv'] = mp_adv\n charout['secondary_profile_header'] = sp_key\n charout['secondary_profile'] = sp_value\n charout['secondary_profile_adv'] = sec_adv\n charout['adv_skill'] = adv_skill\n charout['adv_talent'] = adv_talent\n charout['trappings'] = trappings\n charout['career_entries'] = career_entries\n charout['career_exits'] = career_exits\n return charout\n\ndef perm_talen_adj(tal, mp_value, sp_value):\n # Test for perm stat adjustments\n perm_adjust_talents = {'Coolheaded': ('WP', 5), 'Fleet Footed': ('M', 1), 'Hardy': ('W', 1),\n 'Lightning Reflexes': ('Ag', 5), 'Marksman': ('BS', 5), 'Savvy': ('Int', 5),\n 'Suave': ('Fel', 5), 'Very Resilient': ('T', 5), 'Very Strong': ('S', 5),\n 'Warrior Born': ('WS', 5)}\n\n tal_count = 0\n while tal_count < len(tal):\n # for x in range(len(tal)-1):\n if tal[tal_count] in perm_adjust_talents:\n talent_adj = perm_adjust_talents[tal[tal_count]]\n\n if talent_adj[0] in mp_value.keys():\n mp_value[talent_adj[0]] = mp_value[talent_adj[0]] + talent_adj[1]\n elif talent_adj[0] in sp_value.keys():\n sp_value[talent_adj[0]] = sp_value[talent_adj[0]] + talent_adj[1]\n\n tal_count += 1\n return mp_value, sp_value\n\ndef random_stat_blocks(race, tal):\n # Generate Main and Secondary Profiles\n mp, sp = races.profiles(race)\n str_bonus, tough_bonus = '', ''\n\n perm_talen_adj(tal, mp, sp)\n\n mp_key, mp_value = '', ''\n for key, value in mp.items():\n mp_key = mp_key + key + '\\t'\n\n for key, value in mp.items():\n if key == 'S':\n str_bonus = int(value/10)\n if key == 'T':\n tough_bonus = int(value/10)\n mp_value = str(mp_value) + str(value) + '\\t'\n\n sp_key, sp_value = '', ''\n for key, value in sp.items():\n sp_key = sp_key + key + '\\t'\n\n for key, value in sp.items():\n if key == 'SB':\n value = str_bonus\n if key == 'TB':\n value = tough_bonus\n sp_value = str(sp_value) + str(value) + '\\t'\n\n\n\n return (mp_key, mp_value, sp_key, sp_value)\n\ndef select_option(stt_selection):\n options = 0\n while options < len(stt_selection):\n if ' or ' in stt_selection[options]:\n\n talent_selection = [ts for ts in stt_selection[options].split(\" or \")]\n\n for item in range(len(talent_selection)):\n print(str(item+1) + ': ' + talent_selection[item])\n\n selection = input('Please select one of the above options: ')\n\n\n stt_selection.remove(stt_selection[options])\n stt_selection.append(talent_selection[int(selection)-1])\n options -= 1\n options += 1\n return stt_selection\n\ndef save_character(charout):\n with open('characters\\{}.dat'.format(charout['name']), 'wb') as f:\n pickle.dump(charout, f)\n\ndef load_character(char):\n with open('characters\\{}.dat'.format(char), 'rb') as f:\n charin = pickle.load(f)\n return charin\n\ndef format_sheet(charin):\n charin['weight'] = str(charin['weight'])\n\n # skills = charin['skills']\n skills = ', '.join(sorted(charin['skills']))\n talents = ', '.join(sorted(charin['talents']))\n adv_skill = ', '.join(sorted(charin['adv_skill']))\n adv_talent = ', '.join(sorted(charin['adv_talent']))\n trappings = ', '.join(sorted(charin['trappings']))\n career_entries = ', '.join(sorted(charin['career_entries']))\n career_exits = ', '.join(sorted(charin['career_exits']))\n\n sheet = \"\"\"Name: {name} the {career}\n Race: {race} Gender: {gender} Age: {age}\n Height: {height} Hair Color: {hair_color} Siblings: {siblings}\n Weight: {weight} Eye Color: {eye_color}\n Birthplace: {birthplace}\n Star Sign: {starsign}\n Distinguishing Marks: {marks}\n \n Main Profile:\\t{main_profile_header}\n Main Profile:\\t{main_profile}\n Main Advance:\\t{main_profile_adv}\n Advance Taken: [ ][ ][ ][ ][ ][ ][ ][ ]\n \n Sec Profile:\\t{secondary_profile_header}\n Sec Profile:\\t{secondary_profile}\n Sec Advance:\\t{secondary_profile_adv}\n Advance Taken: [ ][ ][ ][ ][ ][ ][ ][ ]\n \n Trappings:\n -------\n {}\n \n Skills:\n -------\n {}\n \n Talents:\n -------\n {}\n \n Skill Advancements:\n -------\n {}\n \n Talent Advancements:\n -------\n {}\n \n Career Entries\n -------\n {}\n \n Career Exits\n -------\n {}\n \n \"\"\".format(trappings, skills, talents, adv_skill, adv_talent, career_entries,career_exits, **charin).replace(' ','')\n\n # sheet_as_html = sheet.replace('\\n','<br>')\n # header = '<html><title>{name}</title><body>'.format(**charin)\n # with open('characters\\{name}.html'.format(**charin),'w+') as file:\n # file.write(header)\n # file.write(sheet_as_html)\n # file.write('</body></html>')\n return sheet\n\ndef mainloop(option):\n if option.lower() == 'g':\n charout = build_random_char()\n print(format_sheet(charout))\n ser = input('[S]ave,[E]xit,[R]eroll: ')\n print('')\n if ser.lower() == 's':\n save_character(charout)\n saved=('Character: {} has been saved to characters\\{}.dat').format(charout['name'],charout['name'])\n print(saved)\n input('Press [ENTER] key to continue...')\n mainloop('g')\n elif ser.lower() == 'r':\n mainloop('g')\n elif ser.lower() == 'h':\n export_to_html.format_sheet(charout)\n print(('Character: {} has been saved to characters\\{}.html').format(charout['name'],charout['name']))\n mainloop('g')\n elif ser.lower() == 'e':\n print('Now exiting.')\n else:\n ser = input('[S]ave,[E]xit,[R]eroll: ')\n mainloop(ser)\n\n elif option.lower() == 'l':\n char = input('Character name: ')\n lc = load_character(char)\n print(format_sheet(lc))\n else:\n print('Not a valid selection, please try again.')\n option = input('Would you like to [G]enerate a Random Character or [L]oad a character? ')\n mainloop(option)\n\nif __name__=='__main__':\n option = input('Would you like to [G]enerate a Random Character or [L]oad a character? ')\n print('')\n mainloop(option)\n"
},
{
"alpha_fraction": 0.571747899055481,
"alphanum_fraction": 0.572641909122467,
"avg_line_length": 76.13793182373047,
"blob_id": "bb740b952ebcc520c8df72dfe2335bdcac1b5916",
"content_id": "c0d797ed9dbcf197e99ed6a16ba088561890da61",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2237,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 29,
"path": "/careers.py",
"repo_name": "TheRealRhyle/WFRP-2e-Char-Gen",
"src_encoding": "UTF-8",
"text": "from random import randint\n\n\ndef starting_career(race):\n dict_careers = {\n 'dwarf': ['Agitator', 'Bodyguard', 'Burgher', 'Coachman', 'Entertainer', 'Jailer', 'Marine', 'Mercenary',\n 'Militiaman', 'Miner', 'Noble', 'Outlaw', 'Pit Fighter', 'Protagonist', 'Rat Catcher', 'Runebearer',\n 'Scribe', 'Seaman', 'Servant', 'Shieldbreaker', 'Smuggler', 'Soldier', 'Student', 'Thief',\n 'Toll Keeper', 'Tomb Robber', 'Tradesman', 'Troll Slayer', 'Watchman'],\n 'elf': ['Apprentice Wizard', 'Entertainer', 'Envoy', 'Hunter', 'Kithband Warrior', 'Mercenary', 'Messenger',\n 'Outlaw', 'Outrider', 'Rogue', 'Scribe', 'Seaman', 'Student', 'Thief', 'Tradesman', 'Vagabond'],\n 'halfling': ['Agitator', 'Barber-Surgeon', 'Bone Picker', 'Bounty Hunter', 'Burgher', 'Camp Follower',\n 'Charcoal-Burner', 'Entertainer', 'Ferryman', 'Fieldwarden', 'Fisherman', 'Grave Robber', 'Hunter',\n 'Mercenary', 'Messenger', 'Militiaman', 'Outlaw', 'Peasant', 'Rat Catcher', 'Rogue', 'Servant',\n 'Smuggler', 'Soldier', 'Student', 'Thief', 'Toll Keeper', 'Tomb Robber', 'Tradesman', 'Vagabond',\n 'Valet', 'Watchman'],\n 'human': ['Agitator', 'Apprentice Wizard', 'Bailiff', 'Barber-Surgeon', 'Boatman', 'Bodyguard', 'Bone Picker',\n 'Bounty Hunter', 'Burgher', 'Camp Follower', 'Charcoal-Burner', 'Coachman', 'Entertainer',\n 'Estalian Diestro', 'Ferryman', 'Fisherman', 'Grave Robber', 'Hedge Wizard', 'Hunter', 'Initiate',\n 'Jailer', 'Kislevite Kossar', 'Marine', 'Mercenary', 'Messenger', 'Militiaman', 'Miner', 'Noble',\n 'Norse Berserker', 'Outlaw', 'Outrider', 'Peasant', 'Pit Fighter', 'Protagonist', 'Rat Catcher',\n 'Roadwarden', 'Rogue', 'Scribe', 'Seaman', 'Servant', 'Smuggler', 'Soldier', 'Squire', 'Student',\n 'Thief', 'Thug', 'Toll Keeper', 'Tomb Robber', 'Tradesman', 'Vagabond', 'Valet', 'Watchman',\n 'Woodsman', 'Zealot']\n }\n rand_career = randint(0, len(dict_careers[race]) - 1)\n startingcareer = dict_careers[race][rand_career]\n\n return startingcareer\n"
},
{
"alpha_fraction": 0.5673359036445618,
"alphanum_fraction": 0.5827169418334961,
"avg_line_length": 50,
"blob_id": "39e217acc490bec27f519a3d7a6eda47bcf4c6f4",
"content_id": "fc647ee7d578dab726bc6e750c78c445394a0676",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8517,
"license_type": "no_license",
"max_line_length": 880,
"num_lines": 167,
"path": "/personal_details.py",
"repo_name": "TheRealRhyle/WFRP-2e-Char-Gen",
"src_encoding": "UTF-8",
"text": "from random import randint\n\n\ndef height(race, gender):\n if race == 'dwarf':\n height = 50\n elif race == 'elf':\n height = 64\n elif race == 'halfling':\n height = 38\n elif race == 'human':\n height = 61\n\n if gender == 'male':\n height = height + 2\n\n height = height + randint(1, 10)\n\n height = str(int(height / 12)) + \"'\" + str(int(height % 12)) + '\"'\n\n return(height)\n\n\ndef weight(race):\n if race == 'dwarf':\n race_base_weight = 90\n if race == 'elf':\n race_base_weight = 90\n if race == 'halfling':\n race_base_weight = 90\n if race == 'human':\n race_base_weight = 90\n\n weight_selection = randint(1, 20)\n weight_list = [(race_base_weight + i) for i in range(1, 100) if i % 5 == 0]\n weight_list.insert(0, race_base_weight)\n weight = weight_list[weight_selection - 1]\n\n return weight\n\n\ndef hair_color(race):\n rand_hc = randint(0, 10)\n if race == 'dwarf':\n hair_color = ['Ash-blond', 'Yellow', 'Red', 'Copper', 'Light Brown', 'Brown', 'Brown', 'Dark Brown', 'Blue-black', 'Black']\n elif race == 'elf':\n hair_color = ['Silver', 'Ash-blond', 'Corn', 'Yellow', 'Copper', 'Light Brown', 'Light Brown', 'Brown', 'Dark Brown', 'Black']\n elif race == 'halfling':\n hair_color = ['Ash-blond', 'Corn', 'Yellow', 'Yellow', 'Copper', 'Red', 'Light Brown', 'Brown', 'Dark Brown', 'Black']\n elif race == 'human':\n hair_color = ['Ash-blond', 'Corn', 'Yellow', 'Copper', 'Red', 'Light Brown', 'Brown', 'Brown', 'Dark Brown', 'Black']\n else:\n hair_color = ['Bald', 'Bald', 'Bald', 'Bald', 'Bald', 'Bald', 'Bald', 'Bald', 'Bald', 'Bald']\n\n hc = hair_color[rand_hc - 1]\n return hc\n\n\ndef eye_color(race):\n rand_ec = randint(0, 10)\n if race == 'dwarf':\n eye_color = ['Pale Grey', 'Blue', 'Copper', 'Light Brown', 'Light Brown', 'Brown', 'Brown', 'Dark Brown', 'Dark Brown', 'Purple']\n elif race == 'elf':\n eye_color = ['Grey-blue', 'Blue', 'Green', 'Copper', 'Light Brown', 'Brown', 'Dark Brown', 'Silver', 'Purple', 'Black']\n elif race == 'halfling':\n eye_color = ['Blue', 'Hazel', 'Hazel', 'Light Brown', 'Light Brown', 'Brown', 'Brown', 'Dark Brown', 'Dark Brown', 'Dark Brown']\n elif race == 'human':\n eye_color = ['Pale Grey', 'Grey-blue', 'Blue', 'Green', 'Copper', 'Light Brown', 'Brown', 'Dark Brown', 'Purple', 'Black']\n\n ec = eye_color[rand_ec - 1]\n return ec\n\n\ndef distinctive_marks():\n distinctive_marks = ['Pox Marks', 'Ruddy Faced', 'Scar', 'Tattoo', 'Earring', 'Ragged Ear', 'Nose Ring', 'Wart', 'Broken Nose', 'Missing tooth', 'Snaggle Teeth', 'Lazy Eye', 'Missing Eyebrow(s)', 'Missing digit', 'Missing Nail', 'Distinctive Gait', 'Curious Smell', 'Huge Nose', 'Large Mole', 'Small Bald Patch', 'Strange Colord Eye(s)']\n rand_dm = randint(0, len(distinctive_marks) - 1)\n dm = distinctive_marks[rand_dm]\n return dm\n\n\ndef number_siblings(race):\n sibling_roll = randint(0, 5)\n dict_siblings = {\n 'dwarf': [0, 0, 1, 1, 2, 3],\n 'elf': [0, 1, 1, 2, 2, 3],\n 'halfling': [1, 2, 3, 4, 5, 6],\n 'human': [0, 1, 2, 3, 4, 5]\n }\n sib = dict_siblings[race][sibling_roll]\n return sib\n\n\ndef age(race):\n age_roll = randint(0, 19)\n base_age_dh = 20\n base_age_e = 30\n base_age_hu = 16\n dict_age = {\n 'dwarf': [(base_age_dh + i) for i in range(0, 100) if i % 5 == 0],\n 'elf': [(base_age_e + i) for i in range(0, 100) if i % 5 == 0],\n 'halfling': [(base_age_dh + i) for i in range(0, 41) if i % 2 == 0],\n 'human': [(base_age_hu + i) for i in range(0, 20)]\n\n # weight_list = [(race_base_weight + i) for i in range(1, 100) if i % 5 == 0]\n }\n age_list = dict_age[race]\n _age = age_list[age_roll]\n return _age\n\n\ndef birthplace(race):\n dict_sl = {\n 'human': [['Averland', 'Hochland', 'Middenland', 'Nordland', 'Ostermark', 'Ostland', 'Reikland', 'Stirland', 'Talabecland', 'Wissenland'], ['City', 'Prosperous Town', 'Market Town', 'Fortified Town', 'Farming Village', 'Poor Village', 'Small Settlement', 'Pig/Cattle Farm', 'Arable Farm', 'Hovel']],\n 'dwarf': ['Roll on Human', 'Karak Norn (Grey Mountains)', 'Karak Izor (the Vaults)', 'Karak Hirn (Black Mountains)', 'Karak Kadrin (World\\'s Edge Mountians)', 'Karaz-a-Karak (World\\'s Edge Mountians)', 'Zhufbar (World\\'s Edge Mountians)', 'Barak Varr (the Black Gulf)'],\n 'elf': ['City of Altdorf', 'City of Marienburg', 'Laurelorn Forest', 'The Great Forest', 'Reikwald Forest'],\n 'halfling': ['The Moot', 'Roll on Human']\n }\n\n hl_roll = randint(0, len(dict_sl[race]) - 1)\n\n if race == 'human' or dict_sl[race][hl_roll] == 'Roll on Human':\n region = randint(0, len(dict_sl['human'][0]) - 1)\n pop = randint(0, len(dict_sl['human'][1]) - 1)\n if str(dict_sl['human'][1][pop])[0] == 'A':\n sl = str('An ' + str(dict_sl['human'][1][pop]) + ' in the province of ' + str(dict_sl['human'][0][region]))\n else:\n sl = str('A ' + str(dict_sl['human'][1][pop]) + ' in the province of ' + str(dict_sl['human'][0][region]))\n else:\n sl = dict_sl[race][hl_roll]\n\n return sl\n\n\ndef get_names(race, gender):\n dict_names = {\n 'dwarf': [['Anika', 'Asta', 'Astrid', 'Berta', 'Birgit', 'Dagmar', 'Elsa', 'Erika', 'Franziska', 'Greta', 'Hunni', 'Ingrid', 'Janna', 'Karin', 'Petra', 'Sigrid', 'Sigrun', 'Silma', 'Thylda', 'Ulla'], ['Bardin', 'Brokk', 'Dimzad', 'Durak', 'Garil', 'Gottri', 'Grundi', 'Hargin', 'Imrak', 'Kargun', 'Jotunn', 'Magnar', 'Mordrin', 'Nargond', 'Orzad', 'Ragnar', 'Snorri', 'Storri', 'Thingrim', 'Urgrim']],\n 'elf': [['Alane', 'Altronia', 'Davandrel', 'Eldril', 'Eponia', 'Fanriel', 'Gallina', 'Halion', 'Iludil', 'Ionor', 'Lindara', 'Lorandara', 'Maruviel', 'Pelgrana', 'Siluvaine', 'Tallana', 'Ulliana', 'Vivandrel', 'Yuviel'], ['Aluthol', 'Amendil', 'Angran', 'Cavindel', 'Dolwen', 'Eldillor', 'Falandar', 'Farnoth', 'Gildiril', 'Harrond', 'Imhol', 'Larandar', 'Laurenor', 'Mellion', 'Mormacar', 'Ravandil', 'Torendil', 'Yavandir']],\n 'halfling': [['Agnes', 'Alice', 'Elena', 'Eva', 'Frida', 'Greta', 'Hanna', 'Heidi', 'Hilda', 'Janna', 'Karin', 'Lendi', 'Marie', 'Petra', 'Silma', 'Sophia', 'Susi', 'Theda', 'Ulla', 'Wanda'], ['Adam', 'Albert', 'Alfred', 'Axel', 'Carl', 'Edgar', 'Hugo', 'Jakob', 'Ludo', 'Max', 'Nuiklaus', 'Oskar', 'Paul', 'Ralf', 'Rudi', 'heo', 'Thomas', 'Udo', 'Viktor', 'Walter', ]],\n 'human': [['Alexa', 'Alfrida', 'Beatrix', 'Bianka', 'Carlott', 'Elfrida', 'Elise', 'Gabrielle', 'Gretchen', 'Hanna', 'Ilsa', 'Klara', 'Jarla', 'Ludmilla', 'Mathilde', 'Regina', 'Solveig', 'Theodora', 'Ulrike', 'Wertha'], ['Adelbert', 'Albrecht', 'Berthold', 'Dieter', 'Eckhardt', 'Felix', 'Gottfried', 'Gustav', 'Heinz', 'Johann', 'Konrad', 'Leopold', 'Magnus', 'Otto', 'Pieter', 'Rudiger', 'Siegfried', 'Ulrich', 'Waldenmar', 'Wolfgang']]\n }\n\n first_name_list = []\n last_name_list = []\n\n if gender == 'male':\n first_name_list = dict_names[race][1]\n last_name_list = dict_names[race][0]\n if gender == 'female':\n first_name_list = dict_names[race][0]\n last_name_list = dict_names[race][1]\n\n first_name_roll = randint(0, len(first_name_list) - 1)\n last_name_roll = randint(0, len(last_name_list) - 1)\n\n char_name = (first_name_list[first_name_roll] + ' ' + last_name_list[last_name_roll])\n return char_name\n\n\ndef star_sign():\n ssign = ['Wymund the Anchorite - Sign of Enduring','The Big Cross - Sign of Clarity','The Limner\\'s line - Sign of Percision','Gnuthus the Ox - Sign of Dutiful Service','Dragonmas the Drake - Sign of Courage','The Gloaming - Sign of Illusion and Mastery','Grungi\\'s Baldric - Sign of Martial Pursuits','Mammit the Wise - Sign of Wisdom','Mummit the Fool - Sign of Instinct','The Two Bullocks - Sign of Fertility and Craftsmanship','The Dancer - Sign of Love and Attraction','The Drummer - Sign of Excess and Hedonism','The Piper - Sign of the Trickster','Vobist the Faint - Sign of Darkness and Uncertainty','The Broken Cart - Sign of Pride','The Greased Goat - Sign of Denied Passions','Rhya\\'s Cauldron - Sign of Mercy, Death and Creation','Cackelfax the Cockerel - Sign of Money and Merchants','The Bonesaw - Sign of Skill and Learning','The Witching Star - Sign of Magic']\n random_ssign = randint(0, len(ssign)-1)\n\n return ssign[random_ssign]\n\nif __name__ == '__main__':\n for i in range(9):\n print(get_names('human','male'))\n"
},
{
"alpha_fraction": 0.7232704162597656,
"alphanum_fraction": 0.7260656952857971,
"avg_line_length": 37.67567443847656,
"blob_id": "238751b584f9710739494233a5a183b053ab9dcb",
"content_id": "2ef6b51523cc2af935a352549cfc5ac1529f41e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1435,
"license_type": "no_license",
"max_line_length": 152,
"num_lines": 37,
"path": "/README.md",
"repo_name": "TheRealRhyle/WFRP-2e-Char-Gen",
"src_encoding": "UTF-8",
"text": "# WFRP-2e-Char-Gen\nProject status can be found here: http://changer-of-ways.blogspot.com/<br>\nI can be contacted on <a href = \"http://Twitch.tv/DarkXilde\">Twitch.tv/DarkXilde</a>, or Steam at DarkXilde\n\n<font size = \"1\">\nStatus at a glance:<br>\n#TODO<br>\n<list>\n <li>Random ‘Free Raise’\n <li>Adjust the starting characteristic profile based on the racial skills/talents\n <li>Based on the advancement scheme randomly choose one of the advancements to take.\n</list> <br>\n#Done<br>\n<list>\n <li>Randomly choose one of the 4 races\n <li>Randomly select the gender\n <li>First and Last names, separately randomized (R, G)\n <li>Age (R)\n <li>Height (R, G)\n <li>Weight (R, G)\n <li>Hair Color (R)\n <li>Eye Color (R)\n <li>Skills and Talents (R)\n <li>Distinctive Marks\n <li>The number of Siblings the character has (R)\n <li>The characters birthplace (R)\n <li>The racially modified Main, and Secondary stat profiles. (R)\n <li>What Star sight the character was born under\n <li>The characters Starting Career\n <li>Saving and Loading characters.\n <li>Add the skills for the starting career.\n <li>Add the Talents for the starting career.\n <li>Add the Trappings allotted by the starting career.\n <li>Stat line modifications based on the starting career. We added a 3rd statline: The Advancement Scheme stat line for the currently selected career.\n <li>Read in the Advancement line for the starting career.\n</list><br>\n</font>\n"
},
{
"alpha_fraction": 0.7235979437828064,
"alphanum_fraction": 0.7279679775238037,
"avg_line_length": 41.261539459228516,
"blob_id": "6dc6f317a26d2ae852b0a5516a2e759e13522a11",
"content_id": "f525caa12b5cd4e21bff338d760f225c3a25db47",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2746,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 65,
"path": "/guiButtons.py",
"repo_name": "TheRealRhyle/WFRP-2e-Char-Gen",
"src_encoding": "UTF-8",
"text": "def generate_character(self):\n charout = genchar.build_random_char()\n print(charout['name'])\n self.txtName.setPlainText(charout['name'])\n self.txtRace.setPlainText(charout['race'])\n self.txtCCareer.setPlainText(charout['career'])\n self.txtAge.setPlainText(str(charout['age']))\n self.txtGender.setPlainText(charout['gender'])\n self.txtEyeColor.setPlainText(charout['eye_color'])\n self.txtWeight.setPlainText(str(charout['weight']) + \" lbs\")\n self.txtHaircolor.setPlainText(charout['hair_color'])\n self.txtHeight.setPlainText(charout['height'])\n self.txtStarSign.setPlainText(charout['starsign'])\n self.txtNoofSib.setPlainText(str(charout['siblings']))\n self.txtBirthplace.setPlainText(charout['birthplace'])\n self.txtDMarks.setPlainText(charout['marks'])\n\ndef exitbutton(self):\n weapon = ['Foil','40','Fencing','SB-2','-','-','Fast, Precise']\n rowPosition = self.tableWidget.rowCount()\n self.tableWidget.insertRow(rowPosition)\n for item in range(len(weapon)):\n self.tableWidget.setItem(self.tableWidget.rowCount()-1, item,\n QtWidgets.QTableWidgetItem(str(weapon[item])))\n\n\n\n self.pb_Quit.clicked.connect(self.exitbutton)\n self.pb_Rando.clicked.connect(self.generate_character)\n\ndef generate_character(self):\n charout = genchar.build_random_char()\n print(charout['name'])\n self.txtName.setText(charout['name'])\n self.le_Race.setText(charout['race'])\n self.le_CurrentCar.setText(charout['career'])\n self.le_Age.setText(str(charout['age']))\n self.le_Gender.setText(charout['gender'])\n self.le_EyeC.setText(charout['eye_color'])\n self.le_Weight.setText(str(charout['weight']) + \" lbs\")\n self.le_HairC.setText(charout['hair_color'])\n self.le_Height.setText(charout['height'])\n self.le_StarSign.setText(charout['starsign'])\n self.le_NoofSib.setText(str(charout['siblings']))\n self.le_Birthplace.setText(charout['birthplace'])\n self.le_Distinguish.setText(charout['marks'])\n\ndef exitbutton(self):\n exit()\n\n# \"\"\"\n# Add to Ui_MainWindow\n# \"\"\"\n#\n#\n# header = self.tableWidget.horizontalHeader()\n# header.setSectionResizeMode(0, QtWidgets.QHeaderView.Stretch)\n# header.setSectionResizeMode(1, QtWidgets.QHeaderView.ResizeToContents)\n# header.setSectionResizeMode(2, QtWidgets.QHeaderView.ResizeToContents)\n# header.setSectionResizeMode(3, QtWidgets.QHeaderView.ResizeToContents)\n# header.setSectionResizeMode(4, QtWidgets.QHeaderView.ResizeToContents)\n# header.setSectionResizeMode(5, QtWidgets.QHeaderView.ResizeToContents)\n# header.setSectionResizeMode(6, QtWidgets.QHeaderView.Stretch)\n# self.pushButton.clicked.connect(self.exitbutton)\n# self.pushButton_2.clicked.connect(self.generate_character)"
},
{
"alpha_fraction": 0.6468977928161621,
"alphanum_fraction": 0.6510036587715149,
"avg_line_length": 65.42424011230469,
"blob_id": "d42bdee1bd7229fd79a6d0950aa3a473bc487ed0",
"content_id": "4e32c14691b61b1195630a131d87dd62b16a5332",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2192,
"license_type": "no_license",
"max_line_length": 384,
"num_lines": 33,
"path": "/skills.py",
"repo_name": "TheRealRhyle/WFRP-2e-Char-Gen",
"src_encoding": "UTF-8",
"text": "from random import randint\n\n\ndef skills_talents(rce):\n # Build the Random talent list.\n random_talent_list = ['Acute Hearing', 'Ambidexterous', 'Coolheaded', 'Excellent Vision', 'Fleet Footed', 'Hardy', 'Lightning Reflexes', 'Luck', 'Marksman', 'Mimic', 'Night Vision', 'Resistance to Disease', 'Resistance to Magic', 'Resistance to Poison', 'Savvy', 'Sixth Sense', 'Strong-minded', 'Sturdy', 'Suave', 'Super Numerate', 'Very Resilient', 'Very Strong', 'Warrior Born']\n\n if rce.lower() == 'dwarf':\n skills = ['Common Knowledge (Dwarfs)', 'Speak language (Khazalid)', 'Speak Language (Reikspiel)', 'Trade (Miner) or Trade (Smith) or Trade (Stonworker)']\n talents = ['Dwarfcraft', 'Grudge-born Fury', 'Night Vision', 'Resistance to Magic', 'Stout-hearted', 'Sturdy']\n elif rce.lower() == 'elf':\n skills = ['Common Knowledge (Elves)', 'Speak Language (Eltharin)', 'Speak Language (Reikspiel)']\n talents = ['Aethyric Attunement or Specialist Weapon Group (Longbow)', 'Coolheaded or Savvy', 'Excellent Vision', 'Night Vision']\n elif rce.lower() == 'halfling':\n skills = ['Academic Knowledge (Geneology/Heraldry)', 'Common Knowledge (Halflings)', 'Gossip', 'Speak Language (Halfling)', 'Speak Language (Reikspiel)', 'Trade (Cook) or Trade (Farmer)']\n talents = ['Night Vision', 'Resistance to Chaos', 'Specialist Weapon Group (Sling)']\n # Halflings get one random talent\n _halfling_random_talent = random_talent_list[randint(0, len(random_talent_list) - 1)]\n if _halfling_random_talent == 'Night Vision':\n _halfling_random_talent = random_talent_list[randint(0, len(random_talent_list) - 1)]\n talents.append(_halfling_random_talent)\n elif rce.lower() == 'human':\n skills = ['Common Knowledge (the Empire)', 'Gossip', 'Speak Language (Reikspiel)']\n talents = []\n # Humans get 2 random talents\n for rndTalent in range(0, 2):\n _human_random_talent = random_talent_list[randint(0, len(random_talent_list) - 1)]\n talents.append(_human_random_talent)\n else:\n skills = 'Invalid Race'\n talents = 'Invalid Race'\n\n return(skills, talents)\n"
},
{
"alpha_fraction": 0.5156484246253967,
"alphanum_fraction": 0.5436794757843018,
"avg_line_length": 80.59039306640625,
"blob_id": "2a56fb62bc1c39323aa7967171d6a449e3bc21a6",
"content_id": "542da36116877477791941ff31429b8ff4b45e93",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 86692,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 1062,
"path": "/career_listf.py",
"repo_name": "TheRealRhyle/WFRP-2e-Char-Gen",
"src_encoding": "UTF-8",
"text": "\ndef career_selection(career_name):\n\n career_dict = {'Agitator Advance Scheme': {\n 'Statblock': [5, 5, 0, 0, 5, 10, 0, 10, 0, 2, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (History) or Gossip', 'Academic Knowledge(Law) or Common Knowledge (the Empire)',\n 'Concealment', 'Charm', 'Perception', 'Read/Write', 'Speak Language (Breton or Tilean)',\n 'Speak Language (Reikspiel)'],\n 'Talents': ['Coolheaded or Street Fighting', 'Flee!', 'Public Speaking'],\n 'Trappings': ['Light Armour (Leather Jack)', 'One set of Good Craftsmanship Clothes',\n '2d10 leaflets for various causes'],\n 'Career Entries': ['Burgher', 'Captain', 'Herald', 'Highwayman', 'Scribe', 'Servant', 'Student', 'Zealot'],\n 'Career Exits': ['Charlatan', 'Demagogue', 'Outlaw', 'Politician,Rogue, Zealot']},\n 'Apprentice Wizard Advance Scheme': {\n 'Statblock': [0, 0, 0, 0, 5, 10, 15, 5, 0, 2, 0, 0, 0, 1, 0, 0],\n 'Skills': ['Academic Knowledge (Magic)', 'Channelling', 'Magical Sense', 'Perception', 'Read/Write',\n 'Search', 'Speak Arcane Language (Magick)', 'Speak Language (Classical)'],\n 'Talents': ['Aethyric Attunement or Fast Hands', 'Petty Magic (Arcane)', 'Savvy or Very Resilient'],\n 'Trappings': ['Quarter Staff', 'Backpack', 'Printed Book'],\n 'Career Entries': ['Hedge Wizard', 'Scholar', 'Scribe', 'Student'],\n 'Career Exits': ['Journeyman Wizard', 'Scholar', 'Scribe']},\n 'Bailiff Advance Scheme': {\n 'Statblock': [5, 5, 5, 0, 0, 10, 5, 10, 0, 2, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Law)', 'Animal Care or Gossip', 'Charm', 'Command or Navigation',\n 'Intimidate or Common Knowledge (the Empire)', 'Perception', 'Read/Write', 'Ride'],\n 'Talents': ['Etiquette or Super Numerate', 'Public Speaking'],\n 'Trappings': ['Light Armour (Leather Jack and Leather Skullcap)', 'Riding Horse with Saddle and Harness',\n 'One Set of Good Craftsmanship Clothing'],\n 'Career Entries': ['Bodyguard', 'Jailer'],\n 'Career Exits': ['Militiaman', 'Politician', 'Protagonist', 'Racketeer', 'Smuggler', 'Toll Keeper']},\n 'Barber-Surgeon Advance Scheme': {\n 'Statblock': [5, 0, 0, 0, 10, 10, 10, 5, 0, 2, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Charm', 'Drive or Swim', 'Haggle', 'Heal', 'Read/Write',\n 'Speak Language (Breton or Reikspiel or Tilean)', 'Trade (Apothecary)'],\n 'Talents': ['Resistance to Disease or Savvy', 'Suave or Very Resilient', 'Surgery'],\n 'Trappings': ['Trade Tools (Barber-Surgeon)'],\n 'Career Entries': ['Initiate', 'Student'],\n 'Career Exits': ['Interrogator', 'Grave Robber', 'Tradesman', 'Vagabond']},\n 'Boatman Advance Scheme': {\n 'Statblock': [10, 5, 5, 5, 10, 5, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Common Knowledge (The Empire or Kislev)', 'Consume Alcohol or Gossip', 'Navigation',\n 'Outdoor Survival', 'Perception', 'Row', 'Sail',\n 'Secret Language (Ranger) or Speak Language (Kislevian)', 'Swim'],\n 'Talents': ['Orientation', 'Seasoned Traveller'],\n 'Trappings': ['Light Armour (Leather Jack)', 'Row Boat'],\n 'Career Entries': ['Ferryman', 'Smuggler'],\n 'Career Exits': ['Fisherman', 'Marine', 'Navigator', 'Smuggler']},\n 'Bodyguard Advance Scheme': {\n 'Statblock': [10, 0, 5, 5, 5, 0, 0, 0, 1, 3, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Dodge Blow', 'Heal', 'Intimidate', 'Perception'],\n 'Talents': ['Disarm or Quick Draw', 'Specialist Weapon Group (Parrying)',\n 'Specialist Weapon Group (Throwing)', 'Street Fighting', 'Strike to Stun',\n 'Very Strong or Very Resilient'],\n 'Trappings': ['Buckler', 'Knuckle-dusters', 'A Pair of Throwing Axes or Throwing Knives',\n 'Light Armour (Leather Jack)'],\n 'Career Entries': ['Estalian Diestro', 'Jailer', 'Mercenary', 'Thug'],\n 'Career Exits': ['Bailiff', 'Bounty Hunter', 'Interrogator', 'Mercenary', 'Protagonist', 'Racketeer']},\n 'Bone Picker Advance Scheme': {\n 'Statblock': [5, 0, 5, 10, 5, 0, 5, 5, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Animal Care', 'Charm or Gossip', 'Drive', 'Common Knowledge (the Empire)', 'Evaluate', 'Haggle',\n 'Search'],\n 'Talents': ['Coolheaded or Streetwise', 'Hardy or Resistance to Disease'],\n 'Trappings': ['Cart', '3 Sacks'],\n 'Career Entries': ['Peasant', 'Rat Catcher', 'Vagabond'],\n 'Career Exits': ['Camp Follower', 'Cat Burglar', 'Fence', 'Grave Robber', 'Smuggler']},\n 'Bounty Hunter Advance Scheme': {\n 'Statblock': [5, 10, 5, 0, 10, 0, 5, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Follow Trail', 'Intimidate', 'Outdoor Perception', 'Search', 'Shadowing', 'Silent Move'],\n 'Talents': ['Marksman or Strike to Stun', 'Rover', 'Specialist Weapon Group (Entangling)',\n 'Sharpshooter or Strike Mighty Blow'],\n 'Trappings': ['Crossbow with 10 bolts', 'Net', 'Light Armour (Leather Jerkin and Leather Skullcap)',\n 'Manacles', '10 Yards of Rope'],\n 'Career Entries': ['Bodyguard', 'Fieldwarden', 'Kislevite Kossar', 'Mercenary', 'Pit Fighter'],\n 'Career Exits': ['Mercenary', 'Protagonist', 'Scout', 'Vampire Hunter']},\n 'Burgher Advance Scheme': {\n 'Statblock': [5, 0, 0, 0, 5, 10, 5, 5, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Common Knowledge (the Empire) or Consume Alcohol', 'Drive', 'Evaluate', 'Gossip or Read/Write',\n 'Haggle', 'Perception', 'Search', 'Speak Language ( Kislevian', 'or Tilean)',\n 'Speak Language (Reikspiel)'],\n 'Talents': ['Dealmaker', 'Savvy or Suave'],\n 'Trappings': ['Abacus', 'Lantern', 'One Set of Good Clothing'],\n 'Career Entries': ['Innkeeper', 'Servant'],\n 'Career Exits': ['Agitator', 'Fence', 'Innkeeper', 'Militiaman', 'Tradesman', 'Valet']},\n 'Camp Follower Advance Scheme': {\n 'Statblock': [0, 0, 0, 5, 10, 5, 5, 10, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Animal Care or Drive', 'Charm or Gossip', 'Haggle', 'Perception', 'Search',\n 'Any one of: Trade (Armourer', 'Bowyer', 'Cartographer', 'Gunsmith', 'Herbalist', 'Merchant',\n 'Smith', 'Tailor', 'or Weaponsmith)', 'Speak Language (Breton', 'or Tilean)', 'Sleight of Hand'],\n 'Talents': ['Dealmaker or Street Fighter', 'Flee!', 'Hardy or Resistance to Disease or Seasoned Traveller'],\n 'Trappings': ['Lucky Charm or Trade Tools', 'Pouch', 'Tent'],\n 'Career Entries': ['Bone Picker', 'Servant'],\n 'Career Exits': ['Charcoal-Burner', 'Charlatan', 'Smuggler', 'Spy', 'Tradesman', 'Vagabond']},\n 'Charcoal-Burner Advance Scheme': {\n 'Statblock': [5, 0, 5, 5, 5, 5, 5, 5, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Common Knowledge (the Empire) or Drive or Gossip', 'Haggle', 'Outdoor Perception',\n 'Scale Sheer Surface', 'Search', 'Secret Signs (Ranger)'],\n 'Trappings': ['3 Torches', 'Tinderbox', 'Hand Weapon (Hatchet)'],\n 'Career Entries': ['Camp Follower', 'Hunter', 'Miner', 'Peasant'],\n 'Career Exits': ['Hunter', 'Miner', 'Scout', 'Vagabond', 'Woodsman']},\n 'Coachman Advance Scheme': {\n 'Statblock': [5, 10, 0, 0, 10, 0, 5, 5, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Animal Care', 'Drive', 'Gossip or Haggle', 'Heal or Navigation', 'Perception',\n 'Secret Signs (Ranger)', 'Speak Language (Breton', 'Kislevian', 'or Tilean)'],\n 'Talents': ['Quick Draw or Seasoned Traveller', 'Specialist Weapon Group (Gunpowder)'],\n 'Trappings': ['Blunderbuss with powder/ammunition enough for 10 shots',\n 'Medium Armour (Mail Shirt and Leather Jack)', 'Instrument (Coach Horn)'],\n 'Career Entries': ['Outrider', 'Messenger'],\n 'Career Exits': ['Ferryman', 'Highwayman', 'Outlaw', 'Scout', 'Smuggler', 'Toll Keeper']},\n 'Entertainer Advance Scheme': {\n 'Statblock': [5, 10, 0, 0, 10, 0, 5, 10, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Animal Care or Swim', 'Charm', 'Common Knowledge (the Empire)', 'Evaluate or Gossip',\n 'Perception', 'Performer (any two)', 'Speak Language (Reikspiel)', 'Any one of:',\n 'Animal Training', 'Blather', 'Charm Animal', 'Hypnotism', 'Ride', 'Scale Sheer Surface',\n 'Sleight of Hand', 'Ventriloquism'],\n 'Talents': ['Any two of:', 'Contortionist', 'Lightning Reflexes', 'Public Speaking', 'Quick Draw',\n 'Sharpshooter', 'Specialist Weapon Group (Throwing)', 'Trick Riding', 'Very Wrestling'],\n 'Trappings': ['Light Armour (Leather Jerkin)', 'Any one of: Instrument (any one)',\n 'Trade Tools (Performer)', '3 Throwing Knives', '2 Throwing Axes', 'Any one of: Costume',\n 'One Set of Good Craftsmanship Clothes'],\n 'Career Entries': ['Herald', 'Rogue', 'Thief', 'Vagabond'],\n 'Career Exits': ['Charlatan', 'Minstrel', 'Rogue', 'Thief', 'Vagabond']},\n 'Envoy Advance Scheme': {\n 'Statblock': [5, 5, 0, 0, 5, 10, 5, 10, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Charm', 'Common Knowledge (the Empire or the Wasteland)', 'Evaluate', 'Gossip', 'Haggle',\n 'Read/Write', 'Secret Language (Guild Tongue)', 'Trade (Merchant)'],\n 'Talents': ['Dealmaker or Seasoned Traveller'],\n 'Trappings': ['Light Armour (Leather Jack)', '2 sets of Good Craftsmanship Clothes', 'Writing Kit'],\n 'Career Entries': ['Student', 'Tradesman'],\n 'Career Exits': ['Charlatan', 'Merchant', 'Rogue', 'Seaman', 'Vagabond']},\n 'Estalian Diestro Advance Scheme': {\n 'Statblock': [15, 0, 5, 5, 10, 5, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Science)', 'Common Knowledge (Estalia)', 'Dodge Blow',\n 'Read/ Speak Language (Estalian)'],\n 'Talents': ['Lightning Reflexes or Quick Draw or Strike to Injure', 'Specialist Weapon Group (Fencing)',\n 'Strike Mighty Blow'],\n 'Trappings': ['Foil or Rapier', 'One set of Best Craftsmanship Clothes', 'Perfume or Healing Draught'],\n 'Career Entries': ['None'],\n 'Career Exits': ['Bodyguard', 'Duellist', 'Protagonist', 'Rogue']},\n 'Ferryman Advance Scheme': {\n 'Statblock': [5, 5, 10, 5, 5, 5, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Charm', 'Common Knowledge (the Empire)', 'Evaluate or Secret Language (Ranger Tongue)',\n 'Gossip orIntimidate', 'Haggle', 'Perception', 'Row', 'Swim'],\n 'Talents': ['Marksman or Suave', 'Specialist Weapon Group (Gunpowder) or Street Fighting'],\n 'Trappings': ['Crossbow with 10 bolts or Blunderbuss with powder/ammunition enough for 10 shots',\n 'LightArmour (Leather Jack)'],\n 'Career Entries': ['Coachman', 'Smuggler', 'Toll Keeper'],\n 'Career Exits': ['Boatman', 'Highwayman', 'Roadwarden', 'Smuggler']},\n 'Fieldwarden Advance Scheme': {\n 'Statblock': [5, 10, 0, 5, 10, 0, 10, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Necromancy) or Common Knowledge (the Empire)', 'Concealment',\n 'Follow Outdoor Survival', 'Perception', 'Search', 'Silent Move'],\n 'Talents': ['Fleet Footed or Savvy', 'Mighty Shot or Rapid Reload', 'Rover or Quick Draw'],\n 'Trappings': ['Sling with Ammunition', 'Lantern', 'Lamp Spade', 'Pony with Saddle and Harness'],\n 'Career Entries': ['Hunter', 'Militiaman', 'Toll Keeper'],\n 'Career Exits': ['Bounty Hunter', 'Mercenary', 'Scout', 'Vampire Hunter']},\n 'Fisherman Advance Scheme': {\n 'Statblock': [0, 5, 10, 5, 10, 5, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Common Knowledge (the Empire or the Wasteland)', 'Consume Alcohol or Haggle',\n 'Navigationor Trade (Merchant)', 'Outdoor Survival', 'Row', 'Sail',\n 'Speak Language (Reikspiel or Norse)', 'Swim'],\n 'Talents': ['Hardy or Savvy', 'Orientation or Street Fighting'],\n 'Trappings': ['Fish Hook and Line', 'Spear'],\n 'Career Entries': ['Boatman', 'Peasant'],\n 'Career Exits': ['Marine', 'Merchant', 'Navigator', 'Seaman']},\n 'Grave Robber Advance Scheme': {\n 'Statblock': [5, 5, 5, 0, 10, 0, 10, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Drive', 'Gossip or Haggle', 'Perception', 'Scale Sheer Surface', 'Search',\n 'Secret Signs (Thief)', 'Silent Move'],\n 'Talents': ['Flee!', 'Resistance to Disease', 'Streetwise or Strongminded'],\n 'Trappings': ['Lantern', 'Lamp Oil', 'Pick', 'Sack', 'Spade'],\n 'Career Entries': ['Barber-Surgeon', 'Bone Picker', 'Rat Catcher'],\n 'Career Exits': ['Cat Burglar', 'Fence', 'Rat Catcher', 'Thief']},\n 'Hedge Wizard Advance Scheme': {\n 'Statblock': [0, 0, 0, 5, 5, 5, 10, 10, 2, 0, 0, 0, 1, 0, 0, 0],\n 'Skills': ['Animal Care or Haggle', 'Charm or Channelling', 'Charm Animal or Trade (Apothecary)',\n 'Heal or Hypnotism', 'Magical Sense', 'Perception', 'Search'],\n 'Talents': ['Hedge Magic', 'Petty Magic (Hedge)'],\n 'Trappings': ['Healing Draught', 'Hood'],\n 'Career Entries': ['None'],\n 'Career Exits': ['Apprentice Wizard', 'Charlatan', 'Outlaw', 'Vagabond']},\n 'Hunter Advance Scheme': {\n 'Statblock': [0, 15, 0, 5, 10, 5, 0, 0, 3, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Concealment', 'Follow Trail', 'Outdoor Perception', 'Search or Swim', 'Secret Signs (Ranger)',\n 'Silent Move or Set Trap'],\n 'Talents': ['Hardy or Specialist Weapon Group (Longbow)', 'Lightning Reflexes or Very Resilient',\n 'Marksman or Rover', 'Rapid Reload'],\n 'Trappings': ['Longbow with 10 arrows', '2 Animal Antitoxin Kit'],\n 'Career Entries': ['Charcoal-Burner', 'Kithband Woodsman'],\n 'Career Exits': ['Bounty Hunter', 'Charcoal- Fieldwarden', 'Kithband Warrior', 'Miner', 'Soldier',\n 'Targeteer']},\n 'Initiate Advance Scheme': {\n 'Statblock': [5, 5, 0, 5, 0, 10, 10, 10, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Astronomy or History)', 'Academic Knowledge (Theology)', 'Charm', 'Heal',\n 'Perception', 'Read/Write', 'Speak Language (Classical)', 'Speak Language(Reikspiel)'],\n 'Talents': ['Lightning Reflexes or Very Strong', 'Public Speaking', 'Suave or Warrior Born'],\n 'Trappings': ['Religious Symbol (see Chapter 8,: Religion and Belief for types), Robes'],\n 'Career Entries': ['Hedge Wizard', 'Knight', 'Scribe', 'Vampire Hunter', 'Witch Hunter', 'Zealot'],\n 'Career Exits': ['Barber-Surgeon', 'Demagogue', 'Friar', 'Priest', 'Zealot']},\n 'Jailer Advance Scheme': {\n 'Statblock': [10, 0, 10, 10, 0, 0, 5, 0, 3, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Command', 'Consume Alcohol', 'Dodge Blow', 'Heal or Sleight of Hand', 'Intimidate',\n 'Perception', 'Search'],\n 'Talents': ['Resistance to Disease', 'Resistance to Specialist Weapon Group (Entangling)', 'Wrestling'],\n 'Trappings': ['Bottle of Common Wine', 'Tankard', 'Any one of: Bola', 'Lasso', 'Net'],\n 'Career Entries': ['Bodyguard', 'Rat Catcher'],\n 'Career Exits': ['Bailiff', 'Bodyguard', 'Interrogator', 'Rat Watchman Kislevite']},\n 'Kossar Advance Scheme': {\n 'Statblock': [10, 10, 0, 10, 0, 0, 10, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Common Knowledge (Kislev)', 'Consume Dodge Blow', 'Gamble or Gossip', 'Outdoor Perception',\n 'Search', 'Speak Language (Kislevian)'],\n 'Talents': ['Specialist Weapon Group (Two-handed)', 'Strike to Injure'],\n 'Trappings': ['Bow with 10 arrows', 'Great Weapon (Two-handed Axe)',\n 'Medium Armour (Mail Leather Jack and Leather Leggings)'],\n 'Career Entries': ['None'],\n 'Career Exits': ['Bounty Hunter', 'Mercenary', 'Shieldbreaker', 'Veteran']},\n 'Kithband Warrior Advance Scheme': {\n 'Statblock': [5, 5, 0, 0, 10, 10, 5, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Concealment', 'Dodge Blow', 'Follow Trail', 'Heal or Search', 'Outdoor Survival', 'Perception',\n 'Scale SheerSurface', 'Silent Move'],\n 'Talents': ['Marksman or Rover', 'Rapid Reload or Warrior Born'],\n 'Trappings': ['Elfbow with 10 arrows', 'Light Armour (Leather Jack)'],\n 'Career Entries': ['Hunter', 'Messenger'],\n 'Career Exits': ['Hunter', 'Outrider', 'Vagabond', 'Veteran']},\n 'Marine Advance Scheme': {\n 'Statblock': [10, 10, 10, 0, 5, 0, 5, 0, 3, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Common Knowledge (the Wasteland) or Consume Alcohol', 'Dodge Blow',\n 'Gossip or Secret Language (Battle Tongue)', 'Intimidate', 'Row', 'Swim'],\n 'Talents': ['Disarm or Quick Draw', 'Strike Mighty Strike to Stun'],\n 'Trappings': ['Bow or Crossbow with 10 Arrows or Bolts', 'Light Armour (Leather Jack)', 'Shield',\n 'Grappling Hook', '10 Yards of Rope'],\n 'Career Entries': ['Boatman', 'Fisherman', 'Seaman'],\n 'Career Exits': ['Mate', 'Outlaw', 'Sergeant', 'Smuggler', 'Thug']},\n 'Mercenary Advance Scheme': {\n 'Statblock': [10, 10, 5, 5, 5, 0, 5, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Animal Care or Gamble', 'Common Knowledge ( Kislev', 'or Tilea)', 'Dodge Blow', 'Drive or Ride',\n 'Gossip or Haggle', 'Perception or Search', 'Secret Language (BattleTongue)',\n 'Speak Language (Tilean) or Swim'],\n 'Talents': ['Disarm or Quick Draw', 'Rapid Reload or Strike Mighty Blow', 'Sharpshooter or Strike to Stun'],\n 'Trappings': ['Crossbow with 10 Bolts', 'Shield', 'Medium Armour (Mail Shirt and Leather Jack)',\n 'Healing Draught'],\n 'Career Entries': ['Bodyguard', 'Bounty Hunter', 'Fieldwarden', 'Kislevite Kossar', 'Militiaman',\n 'Norse Berserker', 'Outrider', 'Pit Fighter', 'Soldier', 'Watchman'],\n 'Career Exits': ['Bodyguard', 'Bounty Hunter', 'Outlaw', 'Shieldbreaker', 'Veteran']},\n 'Messenger Advance Scheme': {\n 'Statblock': [5, 5, 0, 5, 10, 5, 5, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Animal Care', 'Common Knowledge (the Empire or the Wasteland) or Gossip', 'Navigation',\n 'Outdoor Survival', 'Secret Signs (Scout)', 'Perception', 'Speak Language (Reikspiel)', 'Swim'],\n 'Talents': ['Orientation', 'Seasoned Traveller'],\n 'Trappings': ['Light Armour (Leather Jack)', 'Riding Horse with Saddle and Harness or Pony(for Halflings)',\n 'Map Case', 'Shield'],\n 'Career Entries': ['Militiaman', 'Roadwarden', 'Servant'],\n 'Career Exits': ['Coachman', 'Herald', 'Kithband Warrior', 'Outrider', 'Roadwarden', 'Scout', 'Soldier']},\n 'Militiaman Advance Scheme': {\n 'Statblock': [10, 5, 5, 5, 10, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Animal Care', 'Dodge Blow', 'Drive or Swim', 'Gamble or Gossip', 'Outdoor Survival',\n 'Perception', 'Search', 'Trade(any one)'],\n 'Talents': ['Specialist Weapon Group (Two-handed) or Rapid Reload', 'Strike Mighty Blow'],\n 'Career Entries': ['Artisan', 'Bailiff', 'Burgher', 'Merchant', 'Peasant', 'Tradesman', 'Woodsman'],\n 'Trappings': ['Halberd or Bow with 10 arrows', 'Light Armour (Leather Jack and Leather Skullcap)',\n 'Uniform'],\n 'Career Exits': ['Artisan', 'Fieldwarden', 'Mercenary', 'Outlaw', 'Sergeant', 'Thief']},\n 'Miner Advance Scheme': {\n 'Statblock': [5, 5, 10, 5, 0, 5, 5, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Animal Care', 'Concealment or Evaluate or Outdoor Survival', 'Perception',\n 'Scale Sheer Surface', 'Trade (Miner or Prospector)'],\n 'Talents': ['Orientation', 'Specialist Weapon Group (Two-handed)', 'Very Resilient or Warrior Born'],\n 'Trappings': ['Great Weapon (Two-handed Pick)', 'Light Armour (Leather Jack)', 'Pick', 'Spade',\n 'Storm Lantern', 'Lamp Oil'],\n 'Career Entries': ['Charcoal-Burner', 'Hunter'],\n 'Career Exits': ['Charcoal-Burner', 'Engineer', 'Mercenary', 'Shieldbreaker', 'Smuggler']},\n 'Noble Advance Scheme': {\n 'Statblock': [10, 5, 0, 0, 5, 5, 5, 10, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Blather or Command', 'Common Knowledge (the Empire)', 'Consume Alcohol or Performer (Musician)',\n 'Charm', 'Gamble or Gossip', 'Read/Write', 'Ride', 'SpeakLanguage (Reikspiel)'],\n 'Talents': ['Etiquette', 'Luck or Public Speaking', 'Savvy or Specialist Weapon (Fencing)',\n 'Schemer or SpecialistWeapon (Parrying)'],\n 'Trappings': ['Foil', 'Main Gauche', 'Noble’s Garb', 'Riding Horse with Saddle and Harness', '1d10 gc',\n 'Jewellery worth 6d10 gc'],\n 'Career Entries': ['Squire', 'Steward'],\n 'Career Exits': ['Courtier', 'Pistolier', 'Politician', 'Rogue', 'Student']},\n 'Norse Berserker Advance Scheme': {\n 'Statblock': [15, 0, 10, 10, 0, 0, 10, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Common Knowledge (Norsca)', 'Consume Intimidate', 'Performer (Storyteller)',\n 'Speak Language (Norse)', 'Swim'],\n 'Talents': ['Frenzy', 'Menacing', 'Quick Draw', 'Specialist Weapon Group (Two-handed)'],\n 'Trappings': ['Light Armour (Leather Jerkin)', 'Bottle of Good Craftsmanship Spirits', 'Great Weapon or Shield'],\n 'Career Entries': ['None'],\n 'Career Exits': ['Mercenary', 'Pit Fighter', 'Seaman', 'Veteran']},\n 'Outlaw Advance Scheme': {\n 'Statblock': [10, 10, 0, 0, 10, 5, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Animal Care or Common Knowledge (the Empire)', 'Concealment', 'Dodge Blow', 'Drive or Ride',\n 'Gossip or Secret Signs (Thief)', 'Perception', 'Scale Sheer Set Trap or Swim', 'Silent Move'],\n 'Talents': ['Rover or Streetwise', 'Sharpshooter or Strike to Stun'],\n 'Trappings': ['Bow with 10 arrows', 'Light Armour (Leather Jerkin)', 'Shield'],\n 'Career Entries': ['Agitator', 'Charlatan', 'Coachman', 'Hedge Wizard', 'Innkeeper', 'Marine', 'Mercenary',\n 'Peasant', 'Roadwarden', 'Rogue', 'Squire', 'Toll Woodsman', 'Zealot'],\n 'Career Exits': ['Demagogue', 'Highwayman', 'Thief', 'Veteran']},\n 'Outrider Advance Scheme': {\n 'Statblock': [5, 10, 0, 0, 10, 10, 5, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Animal Care', 'Follow Trail', 'Outdoor Survival', 'Perception', 'Ride', 'Search',\n 'Silent Move'],\n 'Talents': ['Coolheaded or Very Orientation', 'Specialist Weapon Group (Entangling)'],\n 'Trappings': ['Bow or Crossbow with 10 arrows or Bolts', 'Net', 'Whip or Lasso',\n 'Light Armour(Leather Jack)', 'Shield', '10 Yards of Rope',\n 'Riding Horse with Saddle and Harness OR Pony(for Halflings)'],\n 'Career Entries': ['Kithband Warrior', 'Roadwarden', 'Soldier'],\n 'Career Exits': ['Coachman', 'Highwayman', 'Roadwarden', 'Scout']},\n 'Peasant Advance Scheme': {\n 'Statblock': [5, 5, 5, 10, 5, 0, 5, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Animal Care or Charm', 'Animal Training or Charm Animal or Trade (Cook)', 'Concealment',\n 'Drive or Trade (Bowyer)', 'Gamble or Performer (Dancer orSinger)',\n 'Outdoor Survival or Trade (Farmer)', 'Row orSet Trap', 'Scale Sheer Surface or Silent Move'],\n 'Talents': ['Hardy or Rover', 'Flee! or Specialist Weapon Group (Sling)'],\n 'Trappings': ['Sling or Quarter Staff', 'Leather Flask'],\n 'Career Entries': ['None'],\n 'Career Exits': ['Bone Picker', 'Charcoal-Burner', 'Militiaman', 'Outlaw', 'Politician', 'Servant',\n 'Zealot']},\n 'Pit Fighter Advance Scheme': {\n 'Statblock': [15, 0, 0, 10, 10, 0, 10, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Dodge Blow', 'Intimidate'],\n 'Talents': ['Disarm or Wrestling', 'Quick Draw or Strike to Injure', 'Specialist Weapon Group (Flail)',\n 'SpecialistWeapon Group (Parrying)', 'Specialist Weapon Group(Two-handed)',\n 'Strike Mighty Blow', 'Very Strong orStrong-minded'],\n 'Trappings': ['Flail or Great Weapon', 'Knuckle-duster', 'Shield or Buckler',\n 'Medium Armour (Mail Shirt and LeatherJack)'],\n 'Career Entries': ['Norse Berserker', 'Protagonist', 'Thug'],\n 'Career Exits': ['Bounty Hunter', 'Mercenary', 'Protagonist', 'Troll Slayer', 'Veteran']},\n 'Protagonist Advance Scheme': {\n 'Statblock': [10, 0, 10, 0, 10, 0, 10, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Dodge Blow', 'Gossip or Haggle', 'Intimidate', 'Ride'],\n 'Talents': ['Disarm or Quick Draw', 'Menacing or Suave', 'Street Fighting', 'Strike Mighty Blow',\n 'Strike to Injure', 'Strike to Stun'],\n 'Trappings': ['Medium Armour (Mail Shirt and Leather Jack)', 'Shield',\n 'Riding Horse with Saddle and Harness'],\n 'Career Entries': ['Bailiff', 'Bodyguard', 'Bounty Hunter', 'Estalian Diestro', 'Pit Fighter'],\n 'Career Exits': ['Duellist', 'Pit Fighter', 'Racketeer', 'Thief', 'Thug']},\n 'Rat Catcher Advance Scheme': {\n 'Statblock': [5, 10, 0, 5, 10, 0, 10, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Animal Care', 'Animal Trainer', 'Perception', 'Search', 'Set Trap', 'Silent Move'],\n 'Talents': ['Resistance to Disease', 'Resistance to Specialist Weapon Group (Sling)', 'Tunnel Rat'],\n 'Trappings': ['Sling with Ammunition', '4 Animal Traps', 'Pole with 1d10 dead rats',\n 'Small but Vicious Dog'],\n 'Career Entries': ['Grave Robber', 'Jailer', 'Runebearer', 'Tomb Robber'],\n 'Career Exits': ['Bone Picker', 'Cat Burglar', 'Grave Jailer', 'Shieldbreaker', 'Thief']},\n 'Roadwarden Advance Scheme': {\n 'Statblock': [10, 10, 5, 0, 10, 5, 5, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Animal Care', 'Common Knowledge (the Empire) or Gossip', 'Drive',\n 'Follow Trail or Secret Signs (Scout)', 'Navigation', 'Outdoor Survival', 'Perception', 'Ride',\n 'Search'],\n 'Talents': ['Quick Draw or Rapid Reload', 'Specialist Weapons Group (Gunpowder)'],\n 'Trappings': ['Pistol with 10 Firearm Balls and Medium Armour (Mail Shirt and Leather Jack)', 'Shield',\n '10 Yards of Rope', 'Light Warhorse with Saddle and Harness (or Pony for Halfling)'],\n 'Career Entries': ['Coachman', 'Ferryman', 'Outrider', 'Watchman'],\n 'Career Exits': ['Highwayman', 'Messenger', 'Outlaw', 'Scout', 'Sergeant', 'Toll Keeper']},\n 'Rogue Advance Scheme': {\n 'Statblock': [5, 5, 0, 0, 10, 5, 5, 10, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Blather', 'Charm', 'Evaluate', 'Gamble or Secret Signs (Thief)', 'Gossip or Haggle',\n 'Perception', 'Performer(Actor or Storyteller)', 'Search or Secret Language(Thieves’ Tongue)',\n 'Speak Language (Reikspiel)'],\n 'Talents': ['Flee! or Streetwise', 'Luck or Sixth Sense', 'Public Speaking'],\n 'Trappings': ['One set of Best Craftsmanship Clothing or Dice or Deck of Cards', '1d10 gc'],\n 'Career Entries': ['Agitator', 'Assassin', 'Duellist', 'Envoy', 'Estalian Diestro', 'Noble', 'Seaman',\n 'Thief', 'Valet'],\n 'Career Exits': ['Charlatan', 'Demagogue', 'Entertainer', 'Servant', 'Thief']},\n 'Runebearer Advance Scheme': {\n 'Statblock': [10, 0, 5, 5, 10, 5, 5, 0, 2, 0, 0, 1, 0, 0, 0, 0],\n 'Skills': ['Dodge Blow', 'Navigation', 'Outdoor Survival', 'Secret Signs (Scout)', 'Perception', 'Swim'],\n 'Talents': ['Flee!', 'Fleet Footed or Sixth Sense', 'Rapid Reload', 'Very Resilient or Very Strong'],\n 'Trappings': ['Crossbow and 10 Bolts', 'Light Armour (Leather Jerkin)', 'Healing Draught', 'Lucky Charm'],\n 'Career Entries': ['Shieldbreaker'],\n 'Career Exits': ['Rat Catcher', 'Scout', 'Shieldbreaker', 'Tomb Robber', 'Veteran']},\n 'Scribe Advance Scheme': {\n 'Statblock': [0, 0, 0, 0, 10, 10, 10, 5, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (any one)', 'Common Knowledge (the Empire) or Gossip', 'Perception',\n 'Read/ Secret Language (Guild Tongue)', 'Speak Language(Breton)', 'Speak Language (Classical)',\n 'Speak Language(Reikspiel or Tilean)', 'Trade (Calligrapher)'],\n 'Talents': ['Linguistics'],\n 'Trappings': ['Knife', 'A Pair of Candles', 'Wax', '5 Illuminated Book', 'Writing Kit'],\n 'Career Entries': ['Apprentice Wizard', 'Initiate'],\n 'Career Exits': ['Agitator', 'Apprentice Wizard', 'Navigator', 'Scholar']},\n 'Seaman Advance Scheme': {\n 'Statblock': [10, 5, 10, 0, 10, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Common Knowledge (Bretonnia', 'Tilea or the Wasteland)', 'Consume Alcohol or Perception',\n 'Dodge Blow', 'Row', 'Sail', 'Scale SheerSurface', 'Speak Language (Breton', 'Norse or Tilean)',\n 'Swim'],\n 'Talents': ['Hardy or Street Fighting', 'Seasoned Traveller', 'Strike Mighty Blow or Swashbuckler'],\n 'Trappings': ['Leather Jerkin', 'Bottle of Poor Craftsmanship Spirits'],\n 'Career Entries': ['Boatman', 'Envoy', 'Ferryman', 'Norse Berserker', 'Smuggler'],\n 'Career Exits': ['Marine', 'Mate', 'Navigator', 'Rogue', 'Smuggler']},\n 'Servant Advance Scheme': {\n 'Statblock': [5, 0, 5, 0, 10, 5, 10, 5, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Animal Care or Trade (Cook)', 'Blather', 'Dodge Blow', 'Drive or Search', 'Evaluate or Haggle',\n 'Perception', 'Read/Write or Sleight of Hand'],\n 'Talents': ['Acute Hearing or Flee!', 'Etiquette or Lightning Reflexes or Very Resilient'],\n 'Trappings': ['One Set of Good Craftsmanship Clothing', 'Pewter Tankard', 'Tinderbox', 'Storm Lantern',\n 'Lamp Oil'],\n 'Career Entries': ['Camp Follower', 'Peasant', 'Rogue'],\n 'Career Exits': ['Agitator', 'Burgher', 'Camp Follower', 'Messenger', 'Spy', 'Thief', 'Valet']},\n 'Shieldbreaker Advance Scheme': {\n 'Statblock': [10, 0, 5, 5, 10, 0, 5, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Dodge Blow', 'Navigation', 'Perception', 'Scale Sheer Surface', 'Shadowing'],\n 'Talents': ['Acute Hearing or Coolheaded', 'Strike Mighty Blow', 'Strike to Injure', 'Strike to Stun'],\n 'Trappings': ['Crossbow with 10 bolts', 'Medium Armour (Mail Coat', 'Leather Jack and LeatherLeggings)',\n 'Shield', 'Grappling Hook', '10 Yards ofRope', 'Water Skin'],\n 'Career Entries': ['Kislevite Kossar', 'Miner', 'Rat Catcher', 'Runebearer', 'Smuggler', 'Tomb Robber'],\n 'Career Exits': ['Pit Fighter', 'Runebearer', 'Smuggler', 'Tomb Robber', 'Veteran']},\n 'Smuggler Advance Scheme': {\n 'Statblock': [5, 5, 0, 0, 10, 10, 0, 10, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Drive', 'Evaluate', 'Gossip or Secret Language (Thieves’ Tongue)', 'Haggle', 'Perception',\n 'Row', 'Search', 'SilentMove', 'Speak Language (Breton or Kislevian) or Secret Signs (Thief)',\n 'Swim'],\n 'Talents': ['Dealmaker or Streetwise'],\n 'Trappings': ['Light Armour (Leather Jack)', '2 Torches', 'Draft Horse and Cart or Rowing Boat'],\n 'Career Entries': ['Bailiff', 'Boatman', 'Bone Picker', 'Camp Follower', 'Coachman', 'Engineer', 'Ferryman',\n 'Marine', 'Miner', 'Seaman', 'Shieldbreaker'],\n 'Career Exits': ['Boatman', 'Charlatan', 'Fence', 'Seaman', 'Shieldbreaker', 'Thief']},\n 'Soldier Advance Scheme': {\n 'Statblock': [10, 10, 0, 0, 10, 0, 5, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Animal Care or Heal', 'Common Knowledge (the Empire) or Perception', 'Dodge Blow',\n 'Drive or Gamble or Gossip', 'Intimidate'],\n 'Talents': ['Disarm or Quick Draw', 'Sharpshooter or Strike Mighty Blow',\n 'Specialist Weapon Group (Gunpowderor Two-handed)',\n 'Strike to Injure or Rapid Strike to Stun or Mighty Shot'],\n 'Trappings': ['Great Weapon (Halberd) or Firearm with ammunition for 10 shots', 'Shield',\n 'Light Armour (FullLeather Armour)', 'Uniform'],\n 'Career Entries': ['Flagellant', 'Hunter', 'Messenger', 'Toll Watchman'],\n 'Career Exits': ['Mercenary', 'Outrider', 'Sergeant', 'Veteran', 'Watchman']},\n 'Squire Advance Scheme': {\n 'Statblock': [10, 5, 5, 5, 5, 0, 0, 5, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Genealogy/Heraldry) or Common Knowledge (Bretonnia)', 'Animal Care',\n 'Animal Training', 'Charm or Gossip', 'Dodge Ride', 'Speak Language (Breton or Reikspiel)'],\n 'Talents': ['Etiquette', 'Specialist Weapon Group (Cavalry)', 'Strike Mighty Blow'],\n 'Trappings': ['Demilance', 'Medium Armour (Mail Shirt', 'Mail Coif', 'Leather Jack)', 'Shield',\n 'Horse with Saddle and Harness'],\n 'Career Entries': ['Herald', 'Noble', 'Valet'],\n 'Career Exits': ['Knight', 'Noble', 'Outlaw', 'Sergeant', 'Veteran']},\n 'Student Advance Scheme': {\n 'Statblock': [0, 0, 0, 0, 10, 10, 5, 10, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (any one)', 'Academic Knowledge (any one) or Gossip',\n 'Charm or Consume Alcohol', 'Heal or Search', 'Perception', 'Read/Write',\n 'Speak Language (Classical)', 'Speak Language(Reikspiel)'],\n 'Talents': ['Etiquette or Linguistics', 'Savvy or Suave', 'Seasoned Traveller or Super Numerate'],\n 'Trappings': ['Two Textbooks corresponding to Knowledge Skills', 'Writing Kit'],\n 'Career Entries': ['Envoy', 'Grave Robber', 'Minstrel', 'Valet'],\n 'Career Exits': ['Agitator', 'Apprentice Wizard', 'Barber- Surgeon', 'Engineer', 'Envoy', 'Initiate',\n 'Physician', 'Scholar']},\n 'Thief Advance Scheme': {\n 'Statblock': [5, 5, 0, 0, 15, 5, 0, 10, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Charm or Scale Sheer Surface', 'Evaluate or Disguise', 'Gamble or Pick Lock',\n 'Read/Write or Sleight of Hand', 'Search',\n 'Secret Language (Thieves’ Tongue) or Secret Signs (Thief)', 'Silent Move'],\n 'Talents': ['Alley Cat or Streetwise', 'Super Numerate or Trapfinder'],\n 'Trappings': ['Light Armour (Leather Jerkin)', 'Sack', 'Lock picks', '10 Yards of Rope'],\n 'Career Entries': ['Entertainer', 'Grave Interrogator', 'Militiaman', 'Outlaw', 'Rat Catcher', 'Rogue',\n 'Servant', 'Smuggler', 'Toll Keeper', 'Tomb Robber', 'Vagabond'],\n 'Career Exits': ['Cat Burglar', 'Entertainer', 'Fence', 'Rogue', 'Tomb Robber']},\n 'Thug Advance Scheme': {\n 'Statblock': [10, 0, 5, 5, 0, 0, 5, 5, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Consume Alcohol', 'Dodge Blow', 'Gamble', 'Secret Language (Thieves’ Tongue)'],\n 'Talents': ['Coolheaded or Lightning Reflexes', 'Resistance to Poison or Quick Draw',\n 'Strike to Injure or Wrestling', 'Strike to Stun'],\n 'Trappings': ['Knuckle-dusters', 'Medium Armour (Mail Shirt and Leather Jerkin)'],\n 'Career Entries': ['Marine', 'Protagonist'],\n 'Career Exits': ['Bodyguard', 'Interrogator', 'Mercenary', 'Pit Fighter', 'RacketeerToll']},\n 'Toll Keeper Advance Scheme': {\n 'Statblock': [10, 5, 5, 10, 5, 0, 5, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Dodge Blow', 'Evaluate', 'Gossip or Haggle', 'Read/Write', 'Search', 'Speak Language(Kislevian',\n 'or Tilean)'],\n 'Talents': ['Lightning Reflexes or Marksman'],\n 'Trappings': ['Chest', 'Crossbow with 10 Bolts', 'Medium Armour (Mail Shirt and Leather Jerkin)', 'Shield',\n '1d10 gc'],\n 'Career Entries': ['Bailiff', 'Coachman', 'Roadwarden'],\n 'Career Exits': ['Ferryman', 'Fieldwarden', 'Highwayman', 'Soldier', 'Politician', 'Thief']},\n 'Tomb Robber Advance Scheme': {\n 'Statblock': [10, 0, 0, 0, 10, 10, 10, 5, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Common Knowledge (the Empire) or Secret Signs (Thief)', 'Concealment or Outdoor Survival',\n 'Perception', 'Pick Lock or Silent Move', 'Read/ Scale Sheer Surface', 'Search',\n 'Speak Language ( Khazalid or Eltharin)'],\n 'Talents': ['Luck or Sixth Sense', 'Trapfinder or Tunnel Rat'],\n 'Trappings': ['Light Armour (Leather Jack)', 'Crowbar', 'Lamp Oil', '10 Yards of Rope', '2 Sacks'],\n 'Career Entries': ['Runebearer', 'Shieldbreaker', 'Thief'],\n 'Career Exits': ['Fence', 'Rat Catcher', 'Shieldbreaker', 'Vampire Hunter']},\n 'Tradesman Advance Scheme': {\n 'Statblock': [0, 0, 5, 5, 10, 5, 10, 0, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Animal Care or Gossip', 'Drive', 'Haggle', 'Perception', 'Read/Write',\n 'Secret Language (Guild Tongue)', 'Trade (any two)'],\n 'Talents': ['Dealmaker or Savvy'],\n 'Trappings': ['Light Armour (Leather Jerkin)', '1d10 gc'],\n 'Career Entries': ['Barber-Surgeon', 'Burgher', 'Camp Peasant', 'Watchman'],\n 'Career Exits': ['Artisan', 'Engineer', 'Envoy', 'Militiaman', 'Zealot']},\n 'Troll Slayer Advance Scheme': {\n 'Statblock': [10, 0, 5, 5, 5, 0, 10, 0, 3, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Consume Alcohol', 'Dodge Blow', 'Intimidate'],\n 'Talents': ['Disarm or Quick Draw', 'Hardy', 'Lightning Reflexes or Very Resilient',\n 'Specialist Weapon Group (Two-handed)', 'Street Fighter', 'Strike Mighty Blow'],\n 'Trappings': ['Great Weapon', 'Light Armour (Leather Jerkin)', 'One Bottle of Poor Craftsmanship Spirits'],\n 'Career Entries': ['Pit Fighter'],\n 'Career Exits': ['Giant Slayer']},\n 'Vagabond Advance Scheme': {\n 'Statblock': [5, 10, 0, 0, 10, 5, 0, 5, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Common Knowledge (Bretonnia', 'Estalia', 'Kislev', 'or Tilea)',\n 'Gossip or Secret Language (Ranger Tongue orThieves’ Tongue)', 'Haggle or Swim',\n 'Heal or Navigation', 'Outdoor Survival', 'Performer ( Singer or Storyteller) or Secret Signs '\n '(Ranger or Thief)', 'Silent Move'],\n 'Talents': ['Fleet Footed or Rover', 'Marksman or Seasoned Traveller'],\n 'Trappings': ['Back Pack', 'Rations (1 week)', 'Tent', 'Water Skin'],\n 'Career Entries': ['Barber-Surgeon', 'Camp Follower', 'Cat Charcoal-Burner', 'Entertainer', 'Envoy',\n 'Fieldwarden', 'Hedge Wizard', 'Kithband Warrior', 'Outlaw', 'Soldier', 'Woodsman'],\n 'Career Exits': ['Bone Picker', 'Entertainer', 'Friar', 'Scout', 'Woodsman']},\n 'Valet Advance Scheme': {\n 'Statblock': [0, 0, 0, 0, 10, 10, 5, 10, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Genealogy/Heraldry)', 'Evaluate',\n 'Gossip or Speak Language (Breton or Reikspiel)', 'Haggle', 'Perception', 'Read/Write',\n 'Search'],\n 'Talents': ['Coolheaded or Suave', 'Dealmaker or Seasoned Traveller', 'Etiquette'],\n 'Trappings': ['Cologne', 'Purse', 'Two sets of Best Craftsmanship Clothing', 'Uniform'],\n 'Career Entries': ['Burgher', 'Servant'],\n 'Career Exits': ['Herald', 'Rogue', 'Squire', 'Steward', 'Student']},\n 'Watchman Advance Scheme': {\n 'Statblock': [10, 5, 5, 0, 5, 10, 0, 5, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Law)', 'Dodge Blow', 'Follow Trail', 'Gossip', 'Intimidate', 'Perception',\n 'Search'],\n 'Talents': ['Coolheaded or Savvy', 'Disarm or Street Strike Mighty Blow', 'Strike to Stun'],\n 'Trappings': ['Light Armour (Leather Jack)', 'Lantern and Lamp Oil', 'Uniform'],\n 'Career Entries': ['Jailer', 'Soldier'],\n 'Career Exits': ['Mercenary', 'Racketeer', 'Sergeant', 'Soldier', 'Tradesman']},\n 'Woodsman Advance Scheme': {\n 'Statblock': [10, 0, 10, 0, 5, 0, 10, 0, 3, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Concealment', 'Follow Trail or Set Perception', 'Scale Sheer Surface',\n 'Secret Language (Ranger Tongue)', 'Secret Signs (Ranger)', 'Silent Move'],\n 'Talents': ['Fleet Footed or Very Resilient', 'Rover', 'Specialist Weapon Group (Two-handed)'],\n 'Trappings': ['Great Weapon (Two-handed Axe)', 'Light Armour (Leather Jack)', 'Antitoxin Kit'],\n 'Career Entries': ['Charcoal-Burner', 'Vagabond'],\n 'Career Exits': ['Hunter', 'Militiaman', 'Outlaw', 'Vagabond']},\n 'Zealot Advance Scheme': {\n 'Statblock': [10, 0, 5, 10, 0, 0, 10, 5, 2, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Theology)', 'Charm', 'Common Knowledge (the Empire)', 'Intimidate',\n 'Read/Write'],\n 'Talents': ['Coolheaded or Very Strong', 'Hardy or Public Speaking', 'Specialist Weapon Group (Flail)'],\n 'Trappings': ['Flail or Morning Star', 'Light Armour (Leather Jack)',\n 'Bottle of Good Craftsmanship Spirits'],\n 'Career Entries': ['Agitator', 'Initiate', 'Judicial Peasant', 'Tradesman'],\n 'Career Exits': ['Agitator', 'Initiate', 'Flagellant', 'Friar', 'Outlaw']},\n 'Anointed Priest Advance Scheme': {\n 'Statblock': [15, 15, 10, 10, 10, 15, 25, 20, 5, 0, 0, 0, 2, 0, 0, 0],\n 'Skills': ['Academic Knowledge (any two)', 'Academic Knowledge (Theology)', 'Channelling', 'Charm',\n 'CommonKnowledge (any two)', 'Gossip', 'Heal', 'Magical Ride or Swim',\n 'Speak Arcane Language (Magick)', 'Speak Language (any two)'],\n 'Talents': ['Aethyric Attunement or Meditation', 'Armoured Casting or Fast Hands', 'Divine Lore (any one)',\n 'LesserMagic (any two)', 'Seasoned Traveller or Strike MightyBlow'],\n 'Trappings': ['Noble’s Garb'],\n 'Career Entries': ['Priest'],\n 'Career Exits': ['Demagogue', 'Flagellant', 'High Priest', 'Witch Hunter']},\n 'Artisan Advance Scheme': {\n 'Statblock': [0, 0, 10, 10, 20, 10, 10, 10, 3, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Drive', 'Evaluate', 'Gossip', 'Haggle', 'Perception', 'Secret Language (Guild Tongue)',\n 'Speak Language ( Breton', 'or Tilean)', 'Trade (any three)'],\n 'Talents': ['Artistic or Etiquette'],\n 'Trappings': ['Trade Tools (according to Trade)', '15 gc'],\n 'Career Entries': ['Engineer', 'Militiaman', 'Navigator', 'Tradesman'],\n 'Career Exits': ['Demagogue', 'Engineer', 'Guild Merchant', 'Militiaman']},\n 'Assassin Advance Scheme': {\n 'Statblock': [25, 25, 10, 10, 30, 20, 10, 20, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Concealment', 'Disguise', 'Gossip', 'Perception', 'Prepare Poison', 'Scale Sheer Surface',\n 'Secret Signs (Thief)', 'Shadowing', 'Silent Move'],\n 'Talents': ['Quick Draw', 'Lightning Parry', 'Sharpshooter', 'Specialist Weapon Group (Entangling)',\n 'Specialist Weapon Group(Parrying)', 'Specialist Weapon Group (Throwing)', 'StreetFighting',\n 'Streetwise', 'Swashbuckler'],\n 'Trappings': ['Net', '4 Throwing Knives', 'Grappling 10 Yards of Rope', '1 dose of Poison (any)'],\n 'Career Entries': ['Champion', 'Duellist', 'Judicial Champion', 'Outlaw Chief', 'Spy', 'Targeteer'],\n 'Career Exits': ['Champion', 'Outlaw', 'Rogue', 'Sergeant', 'Witch Hunter']},\n 'Captain Advance Scheme': {\n 'Statblock': [30, 20, 20, 20, 20, 15, 15, 25, 7, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Strategy/ Tactics)', 'Animal Care', 'Common Knowledge (any three)',\n 'DodgeBlow', 'Gossip', 'Read/Write', 'Ride', 'SecretLanguage (Battle Tongue)',\n 'Speak Language(Kislevian or Tilean)'],\n 'Talents': ['Disarm or Quick Draw', 'Lightning Specialist Weapon Group (Cavalry or Two-handed Weapon)',\n 'Specialist Weapon Group (Flail or Parrying)'],\n 'Trappings': ['Flail or Sword-breaker', 'Lance or Great Weapon', 'Medium Armour (Full Mail Armour)',\n 'Shield',\n 'Destrier with Saddle andHarness', 'Unit of Troops'],\n 'Career Entries': ['Explorer', 'Ghost Strider', 'Knight', 'Knight of the Inner Circle', 'Noble Lord',\n 'Outlaw Chief', 'Sergeant', 'Witch Hunter'],\n 'Career Exits': ['Agitator', 'Explorer', 'Merchant', 'Outlaw', 'Politician']},\n 'Cat Burglar Advance Scheme': {\n 'Statblock': [10, 10, 5, 5, 25, 10, 10, 0, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Concealment', 'Evaluate', 'Gossip', 'Haggle', 'Pick Lock', 'Scale Sheer Surface', 'Search',\n 'Secret Language (Thieves’ Tongue)', 'Secret Signs (Thief)', 'Silent Move'],\n 'Talents': ['Alley Cat', 'Street Fighting', 'Streetwise', 'Trapfinder'],\n 'Trappings': ['Grappling Hook', 'Lock Picks', '10 Yards of Rope'],\n 'Career Entries': ['Bone Picker', 'Charlatan', 'Grave Rat Catcher', 'Thief'],\n 'Career Exits': ['Crime Lord', 'Fence', 'Master Thief', 'Vagabond']},\n 'Champion Advance Scheme': {\n 'Statblock': [40, 40, 25, 25, 30, 0, 20, 0, 8, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Dodge Blow', 'Evaluate', 'Intimidate', 'Perception'],\n 'Talents': ['Fleet Footed or Lightning Reflexes', 'Lightning Parry', 'Master Gunner', 'Mighty Shot',\n 'Quick Rapid Reload', 'Specialist Weapon Group (any three)', 'Wrestling'],\n 'Trappings': ['Any Six Weapons (all of Best Craftsmanship)', 'Medium Armour (Mail Shirt and Leather Jack)'],\n 'Career Entries': ['Assassin', 'Duellist', 'Judicial Knight of the Inner Circle', 'Targeteer', 'Veteran',\n 'Witch Hunter'],\n 'Career Exits': ['Assassin', 'Scout', 'Sergeant', 'Witch Hunter']},\n 'Charlatan Advance Scheme': {\n 'Statblock': [10, 10, 5, 10, 15, 15, 15, 25, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Blather', 'Charm', 'Common Knowledge (Bretonnia or Tilea)', 'Disguise', 'Evaluate', 'Gamble',\n 'Gossip', 'Perception', 'Secret Language (Thieves’ Tongue)', 'Sleightof Hand',\n 'Speak Language (Breton or Tilean)', 'SpeakLanguage (Reikspiel)'],\n 'Talents': ['Flee!', 'Mimic', 'Public Speaking', 'Schemer or Seasoned Traveller'],\n 'Trappings': ['6 sets of Common Clothes', '4 sets of Best Craftsmanship Clothes', 'Forged Document',\n '4 bottles of variously coloured water', '4 bottles of variously coloured powder'],\n 'Career Entries': ['Agitator', 'Camp Follower', 'Courtier', 'Envoy', 'Fence', 'Hedge Wizard',\n 'Journeyman Minstrel', 'Rogue', 'Smuggler', 'Thief'],\n 'Career Exits': ['Cat Burglar', 'Demagogue', 'Outlaw', 'Politician', 'Spy']},\n 'Coutier Advance Scheme': {\n 'Statblock': [5, 5, 0, 0, 10, 20, 20, 20, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (the Arts or History) or Gamble', 'Blather', 'Charm',\n 'Command or Performer(any one)', 'Common Knowledge (Bretonnia or Tilea)', 'Evaluate', 'Gossip',\n 'Perception', 'Read/Write', 'Speak Language (Breton or Tilean)', 'Speak Language(Reikspiel)'],\n 'Talents': ['Dealmaker or Etiquette', 'Public Speaking', 'Savvy or Suave',\n 'Schemer or Specialist Weapon Group (Fencing)'],\n 'Trappings': ['4 Sets of Noble’s Garb', '100 gc', 'Valet'],\n 'Career Entries': ['Noble', 'Herald', 'Pistolier', 'Politician'],\n 'Career Exits': ['Charlatan', 'Duellist', 'Noble Politician', 'Steward', 'Spy']},\n 'Daemon Slayer Advance Scheme': {\n 'Statblock': [40, 0, 30, 30, 20, 0, 30, 0, 8, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Common Knowledge (any two)', 'Consume Alcohol', 'Dodge Blow', 'Intimidate',\n 'Scale SheerSurface'],\n 'Talents': ['Lightning Parry', 'Unsettling'],\n 'Trappings': ['Great Weapon'],\n 'Career Entries': ['Giant Slayer'],\n 'Career Exits': ['Glorious death']},\n 'Demagogue Advance Scheme': {\n 'Statblock': [10, 10, 0, 10, 15, 20, 15, 30, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (History)', 'Academic Knowledge (Law)', 'Blather', 'Charm', 'Command',\n 'Common Knowledge(the Empire)', 'Concealment', 'Disguise', 'Dodge Blow', 'Intimidate',\n 'Perception', 'Speak Language (Reikspiel)'],\n 'Talents': ['Etiquette or Streetwise', 'Master Orator', 'Public Speaking', 'Street Fighting'],\n 'Trappings': ['Light Armour (Leather Jack and Leather Skullcap)'],\n 'Career Entries': ['Agitator', 'Anointed Priest', 'Artisan', 'Crime Lord', 'Flagellant', 'Friar',\n 'Initiate', 'Minstrel', 'Outlaw Chief', 'Politician', 'Rogue', 'Vampire Witch Hunter'],\n 'Career Exits': ['Crime Lord', 'Friar', 'Mercenary', 'Outlaw', 'Politician']},\n 'Duellist Advance Scheme': {\n 'Statblock': [20, 20, 10, 20, 20, 15, 15, 10, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Charm', 'Dodge Blow', 'Gamble', 'Gossip', 'Perception', 'Sleight of Hand'],\n 'Talents': ['Ambidextrous or Disarm', 'Etiquette', 'Master Mighty Shot', 'Quick Draw', 'Sharpshooter',\n 'Specialist Weapon Group (Fencing)', 'Specialist Weapon Group(Gunpowder)',\n 'Specialist Weapon Group (Parrying)', 'Strike Mighty Blow', 'Strike to Injure', 'Swashbuckler'],\n 'Trappings': ['Main Gauche', 'Pistol with Powder and Ammunition for 10 Shots', 'Rapier'],\n 'Career Entries': ['Courtier', 'Estalian Diestro', 'Pistolier', 'Protagonist', 'Sergeant', 'Targeteer'],\n 'Career Exits': ['Assassin', 'Champion', 'Highwayman', 'Sergeant']},\n 'Engineer Advance Scheme': {\n 'Statblock': [10, 15, 5, 5, 10, 20, 10, 0, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Engineering)', 'Academic Knowledge (Science)',\n 'Common Knowledge (Dwarfs or Tilea)', 'Drive or Ride', 'Perception', 'Read/Write',\n 'SpeakLanguage (Khazalid or Tilean)', 'Trade (Gunsmith)'],\n 'Talents': ['Master Gunner', 'Specialist Weapon Group (Engineer or Gunpowder)'],\n 'Trappings': ['Light Armour (Leather Jack)', 'Engineer’s Kit', '6 Spikes'],\n 'Career Entries': ['Artisan', 'Miner', 'Student', 'Tradesman'],\n 'Career Exits': ['Artisan', 'Explorer', 'Guild Master', 'Smuggler']},\n 'Explorer Advance Scheme': {\n 'Statblock': [20, 20, 10, 15, 15, 25, 20, 15, 6, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (History or Law)', 'Common Knowledge (any three)', 'Drive', 'Follow Trail', \n 'Navigation', 'Outdoor Survival', 'Read/Write', 'Ride', 'Scale Sheer Surface', \n 'Secret Language (Ranger Tongue)', 'Secret Signs (Scout)', 'Speak Language(any three)', 'Swim', \n 'Trade (Cartographer)'],\n 'Talents': ['Orientation or Linguistics', 'Seasoned Traveller'],\n 'Trappings': ['Bow or Crossbow with 10 arrows or bolts', 'Hand Weapon', \n 'Medium Armour (Mail Shirt and Leather Jack)', 'Shield', '6 Maps', \n '1,000 gc in coin and trade goods', 'Riding Horse with saddle and harness'],\n 'Career Entries': ['Captain', 'Engineer', 'Herald', 'Master Master Wizard', 'Mate', 'Navigator', 'Scholar',\n 'Scout', 'Sea Captain', 'Spy', 'Wizard Lord'],\n 'Career Exits': ['Captain', 'Merchant', 'Sea Captain', 'Spy']},\n 'Fence Advance Scheme': {\n 'Statblock': [15, 10, 10, 5, 10, 5, 10, 10, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Evaluate', 'Gamble', 'Gossip', 'Haggle', 'Perception', 'Sleight of Hand'],\n 'Talents': ['Dealmaker or Streetwise', 'Strike to Stun', 'Super Numerate'],\n 'Trappings': ['Trade Tools (Engraver’s Kit)', 'Writing Kit'],\n 'Career Entries': ['Bone Picker', 'Burgher', 'Cat Burglar', 'Grave Robber', 'Innkeeper', 'Racketeer',\n 'Smuggler', 'Thief', 'Tomb Robber'],\n 'Career Exits': ['Charlatan', 'Crime Lord', 'Master Thief', 'Racketeer']},\n 'Flagellant Advance Scheme': {\n 'Statblock': [15, 0, 10, 15, 5, 0, 20, 10, 6, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Theology)', 'Charm', 'Intimidate', 'Speak Language (Classical)'],\n 'Talents': ['Fearless', 'Specialist Weapon Group (Flail or Two-handed Weapon)', 'Strike Mighty Blow'],\n 'Trappings': ['Flail or Great Weapon', 'Bottle of Good Craftsmanship Spirits', 'Religious Symbol', \n 'Religious Relic'],\n 'Career Entries': ['Anointed Priest', 'Friar', 'Priest', 'Zealot'],\n 'Career Exits': ['Demagogue', 'Interrogator', 'Priest', 'Veteran']},\n 'Friar Advance Scheme': {\n 'Statblock': [10, 0, 5, 10, 0, 15, 15, 15, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Theology)', 'Animal Care', 'Common Knowledge (any two)', 'Outdoor Survival',\n 'Perception', 'Speak Language(Breton', 'Estalian', 'Kislevian', 'or Tilean)',\n 'SpeakLanguage (Classical)', 'Speak Language (Reikspiel)'],\n 'Talents': ['Seasoned Traveller'],\n 'Trappings': ['Healing Draught', 'Religious Religious Relic', 'Robes'],\n 'Career Entries': ['Demagogue', 'Initiate', 'Physician', 'Vagabond', 'Zealot'],\n 'Career Exits': ['Demagogue', 'Flagellant', 'Priest', 'Scholar']},\n 'Ghost Strider Advance Scheme': {\n 'Statblock': [20, 30, 15, 15, 25, 20, 20, 0, 6, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Concealment', 'Dodge Blow', 'Follow Intimidate', 'Lip Reading', 'Navigation',\n 'Outdoor Survival', 'Perception', 'Secret Language (RangerTongue)', 'Secret Signs (Ranger)',\n 'Set Shadowing', 'Silent Move'],\n 'Talents': ['Hardy or Fleet Footed', 'Lightning Parry', 'Mighty Shot', 'Quick Draw', 'RapidReload',\n 'Sure Shot'],\n 'Trappings': ['Elfbow with 10 arrows', 'Light Armour (Best Craftsmanship Full LeatherArmour)'],\n 'Career Entries': ['Scout'],\n 'Career Exits': ['Captain', 'Outlaw Chief', 'Targeteer', 'Vampire Hunter']},\n 'Giant Slayer Advance Scheme': {\n 'Statblock': [25, 0, 15, 15, 10, 0, 20, 0, 6, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Common Knowledge (any one)', 'Consume Dodge Blow', 'Intimidate', 'Perception'],\n 'Talents': ['Fearless', 'Resistance to Poison', 'Specialist Weapon Group (Flail)', 'Strike to Injure'],\n 'Trappings': ['Great Weapon'],\n 'Career Entries': ['Troll Slayer'],\n 'Career Exits': ['Daemon Slayer']},\n 'Guild Master Advance Scheme': {\n 'Statblock': [10, 10, 0, 10, 15, 30, 20, 35, 5, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (History)', 'Charm', 'Common Knowledge (the Empire)', 'Evaluate', 'Haggle', \n 'Perception', 'Secret Language (Guild Tongue)', 'Speak Language (Breton, Estalian, Kislevian, or'\n ' Norse)', 'Speak Language (Reikspiel)', \n 'Trade (any two)'],\n 'Talents': ['Dealmaker', 'Etiquette', 'Linguistics'],\n 'Trappings': ['Writing Kit', '100 gc', 'Guild'],\n 'Career Entries': ['Artisan', 'Engineer', 'Merchant', 'Wizard Lord'],\n 'Career Exits': ['Crime Lord', 'Politician', 'Racketeer']},\n 'Herald Advance Scheme': {\n 'Statblock': [10, 10, 5, 5, 15, 15, 10, 20, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Genealogy/Heraldry)', 'Academic Knowledge (History)', 'Blather', 'Charm',\n 'CommonKnowledge (Bretonnia', 'Kislev', 'or Tilea)', 'CommonKnowledge (the Empire)', 'Evaluate',\n 'Gossip', 'Perception', 'Read/Write', 'Ride', 'Speak Language(Breton', 'Kislevian', 'or Tilean)',\n 'Speak Language(Reikspiel)'],\n 'Talents': ['Etiquette', 'Master Orator', 'Public Speaking'],\n 'Trappings': ['Cologne', 'Purse', 'Two sets of Best Craftsmanship Clothing', 'Uniform'],\n 'Career Entries': ['Messenger', 'Valet'],\n 'Career Exits': ['Agitator', 'Courtier', 'Entertainer', 'Politician', 'Squire']},\n 'High Priest Advance Scheme': {\n 'Statblock': [20, 20, 15, 15, 15, 20, 30, 25, 6, 0, 0, 0, 3, 0, 0, 0],\n 'Skills': ['Academic Knowledge (any three)', 'Academic Knowledge (Theology)', 'Channelling', \n 'Common Knowledge (any two)', 'Gossip', 'Intimidate', 'Magical Sense', 'Ride or Swim', \n 'Speak Arcane Language (Magick)', 'Speak Language (anythree)'],\n 'Talents': ['Aethyric Attunement or Meditation', 'Armoured Casting or Mighty Missile', 'Etiquette', \n 'Fast Hands orStrong-minded', 'Lesser Magic (any two)'],\n 'Trappings': ['Religious Relic'],\n 'Career Entries': ['Anointed Priest'],\n 'Career Exits': ['Politician', 'Scholar', 'Witch Hunter']},\n 'Highwayman Advance Scheme': {\n 'Statblock': [20, 20, 10, 10, 30, 20, 15, 25, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Animal Care', 'Animal Training', 'Common Knowledge (the Empire)', 'Gossip', 'Ride', \n 'Silent Move'],\n 'Talents': ['Ambidextrous', 'Etiquette', 'Master Gunner', 'Mighty Shot', 'Sharpshooter', \n 'SpecialistWeapon Group (Fencing)', 'Specialist WeaponGroup (Gunpowder)', 'Swashbuckler', \n 'Trick Riding'],\n 'Trappings': ['Pair of Pistols with Powder and Ammunition for 20 Shots', 'Noble’s Garb', 'Hood orMask', \n 'Riding Horse with Saddle and Harness'],\n 'Career Entries': ['Coachman', 'Duellist', 'Estalian Ferryman', 'Minstrel', 'Outlaw', 'Outrider', \n 'Toll Keeper'],\n 'Career Exits': ['Agitator', 'Duellist', 'Master Theif', 'Outlaw Chief', 'Sergeant']},\n 'Innkeeper Advance Scheme': {\n 'Statblock': [10, 5, 5, 10, 20, 10, 10, 20, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Blather or Lip Reading', 'Charm', 'Common Knowledge (the Empire)', 'Consume Evaluate', \n 'Gossip', 'Haggle', 'Perception', 'Read/Write or Sleight of Hand', \n 'Speak Language ( Kislevian, Reikspiel or Tilean)', 'Trade (Cook)'],\n 'Talents': ['Etiquette or Streetwise', 'Dealmaker or Street Fighting', 'Strike to Stun'],\n 'Trappings': ['Inn', '1 or more Servants'],\n 'Career Entries': ['Burgher', 'Servant'],\n 'Career Exits': ['Burgher', 'Fence', 'Merchant', 'Outlaw', 'Smuggle']},\n 'Interrogator Advance Scheme': {\n 'Statblock': [15, 0, 20, 10, 10, 10, 20, 15, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Charm', 'Heal', 'Intimidate', 'Perception', 'Torture'],\n 'Talents': ['Menacing', 'Specialist Weapon Group (Flail)', 'Wrestling'],\n 'Trappings': ['5 knives', 'Flail', '3 sets of manacles'],\n 'Career Entries': ['Barber-Surgeon', 'Bodyguard', 'Jailer', 'Thug'],\n 'Career Exits': ['Physician', 'Racketeer', 'Thief']},\n 'Journeyman Wizard Advance Scheme': {\n 'Statblock': [5, 5, 0, 5, 10, 20, 25, 10, 3, 0, 0, 0, 2, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Magic)', 'Academic Knowledge (any one)', 'Channelling', \n 'Charm or Intimidate', 'Common Knowledge (any two)', 'Magical Sense', 'Read/Write', \n 'Ride or Swim', 'SpeakArcane Language (Magick)', 'Speak Language(any two)'],\n 'Talents': ['Arcane Lore (any one) or Dark Lore (any one)', 'Aethyric Attunementor Dark Magic', \n 'Fast Hands or Very Resilient', 'Lesser Magic (any two)', 'Meditation or Mighty Missile'],\n 'Trappings': ['Grimoire', 'Writing Kit'],\n 'Career Entries': ['Apprentice Wizard'],\n 'Career Exits': ['Charlatan', 'Master Wizard', 'Scholar']},\n 'Judicial Champion Advance Scheme': {\n 'Statblock': [35, 0, 15, 15, 20, 10, 15, 0, 6, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Dodge Blow', 'Perception'],\n 'Talents': ['Lightning Parry', 'Specialist Weapon Group (Fencing)', 'Specialist Weapon Group (Flail)', \n 'SpecialistWeapon Group (Parrying)', 'Specialist Weapon Group(Two-handed)'],\n 'Trappings': ['Great Weapon', 'Flail or Morning Star', 'Rapier or Foil', 'Buckler or Main Gauche', \n '10 Yards of Rope'],\n 'Career Entries': ['Sergeant', 'Veteran'],\n 'Career Exits': ['Assassin', 'Champion', 'Sergeant', 'Witch Hunter', 'Zealot']},\n 'Knight Advance Scheme': {\n 'Statblock': [25, 0, 15, 15, 15, 5, 15, 5, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Genealogy/Heraldry or Religion)', 'Academic Knowledge (Strategy/Tactics)',\n 'Dodge Blow', 'Perception', 'Ride', 'Secret Language(Battle Tongue)', \n 'Speak Language (any two)'],\n 'Talents': ['Specialist Weapon Group (Cavalry)', 'Specialist Weapon Group (Flail)', \n 'Specialist Weapon Group(Two-handed)', 'Strike Mighty Blow'],\n 'Trappings': ['Flail or Morning Star', 'Lance', 'Heavy Armour (Full Plate Armour)', 'Shield', \n 'Religious Symbol', '25 Destrier with Saddle and Harness'],\n 'Career Entries': ['Noble Lord', 'Pistolier', 'Sergeant', 'Vampire Hunter'],\n 'Career Exits': ['Captain', 'Initiate', 'Knight of the Inner Noble Lord', 'Vampire Hunter']},\n 'Knight of the Inner Circle Advance Scheme': {\n 'Statblock': [35, 10, 20, 20, 20, 15, 25, 15, 8, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Genealogy/Heraldry or Religion)', 'Academic Knowledge (Strategy/Tactics)', \n 'Animal Training', 'Charm', 'Command', 'CommonKnowledge (any three)', 'Dodge Blow', 'Perception',\n 'Read/Write', 'Ride', 'Secret Language (Battle Tongue)', 'SecretSigns (Scout or Templar)', \n 'Speak Language ( Estalian', 'Kislevian', 'or Tilean)'],\n 'Talents': ['Etiquette', 'Lightning Parry', 'Seasoned Specialist Weapon Group (Fencing)', \n 'Specialist Weapon Group (Parrying)', 'Stout-hearted', 'Strike to Strike to Stun'],\n 'Trappings': ['Buckler or Main Gauche', 'Rapier or Heavy Armour (Best Craftsmanship Full Plate Armour)',\n 'Religious Symbol', '50 gc'],\n 'Career Entries': ['Knight', 'Witch Hunter'],\n 'Career Exits': ['Captain', 'Champion', 'Noble Lord', 'Witch Hunter']},\n 'Master Thief Advance Scheme': {\n 'Statblock': [20, 20, 10, 10, 40, 25, 20, 25, 6, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Charm', 'Concealment', 'Disguise', 'Dodge Blow', 'Evaluate', 'Gamble or Lip Reading', 'Gossip',\n 'Perception', 'Pick Lock', 'Read/ Scale Sheer Surface', 'Secret Language (Thieves’ Tongue)', \n 'SecretSigns (Thief)', 'Search', 'Silent Move', 'Sleight of Hand', 'Swim'],\n 'Talents': ['Specialist Weapon Group (Crossbow)', 'Specialist Weapon Group (Throwing)', \n 'Street Fighting or Streetwise', 'Trapfinder'],\n 'Trappings': ['Crossbow Pistol with 10 Bolts', '2 Throwing Axes/ Hammer or 3 Throwing Daggers/Stars', \n 'Best Craftsmanship Lock Picks', 'Cloak', 'Sack', 'Best Craftsmanship Rope (10 Yards)'],\n 'Career Entries': ['Cat Burglar', 'Crime Lord', 'Highwayman', 'Racketeer', 'Spy'],\n 'Career Exits': ['Crime Lord', 'Explorer', 'Outlaw', 'Targeteer']},\n 'Master Wizard Advance Scheme': {\n 'Statblock': [10, 10, 0, 10, 15, 30, 35, 15, '=4', 0, 0, 0, 3, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Magic)', 'Academic Knowledge (any two)', 'Channelling', \n 'Charm or Common Knowledge (any two)', 'Gossip or Magical Sense', 'Read/Write', \n 'Speak Arcane Language(Magick)', 'Speak Arcane Language (Daemonic orArcane Elf)', \n 'Speak Language (any three)'],\n 'Talents': ['Aethyric Attunement or Meditation', 'Dark Magic or Strong-minded', \n 'Fast Hands or Mighty Missile', 'Lesser Magic (any two)'],\n 'Trappings': ['Trade Tools (Apothecary)', 'Two magic items'],\n 'Career Entries': ['Journeyman Wizard'],\n 'Career Exits': ['Explorer', 'Scholar', 'Wizard Lord']},\n 'Mate Advance Scheme': {\n 'Statblock': [15, 15, 10, 15, 10, 10, 10, 10, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Command', 'Common Knowledge (any two)', 'Consume Alcohol', 'Dodge Blow', 'Gamble', 'Gossip', \n 'Row', 'Sail', 'Speak Language (Breton', 'Kislevian', 'orNorse)', 'Swim', 'Trade (Shipwright)'],\n 'Talents': ['Resistance to Disease', 'Seasoned Traveller', 'Street Fighting'],\n 'Trappings': ['Light Armour (Leather Jack)'],\n 'Career Entries': ['Marine', 'Seaman'],\n 'Career Exits': ['Explorer', 'Merchant', 'Navigator', 'Sea Captain']},\n 'Merchant Advance Scheme': {\n 'Statblock': [10, 10, 5, 5, 10, 25, 20, 20, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Charm', 'Common Knowledge (any two)', 'Evaluate', 'Gossip', 'Haggle', 'Read/Write', 'Ride', \n 'Secret Language (Guild Tongue)', 'Speak Language ( Estalian', 'Kislevian', 'or Norse)', \n 'Speak Language(Reikspiel)', 'Trade (Merchant)'],\n 'Talents': ['Dealmaker or Streetwise', 'Super Numerate'],\n 'Trappings': ['Town House', 'Warehouse', '1,,000 gc in coin or trade goods'],\n 'Career Entries': ['Artisan', 'Burgher', 'Captain', 'Envoy', 'Fisherman', 'Innkeeper', 'Mate', 'Scholar', \n 'Tradesman'],\n 'Career Exits': ['Guild Master', 'Militiaman', 'Racketeer', 'Spy']},\n 'Minstrel Advance Scheme': {\n 'Statblock': [10, 10, 0, 0, 15, 10, 5, 25, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Charm', 'Common Knowledge (any two)', 'Perception', 'Performer (Musician)', \n 'Performer (Singer)', 'Read/Write', 'Speak Language (Breton', 'Eltharin or Tilean)'],\n 'Talents': ['Etiquette', 'Pubic Speaking'],\n 'Trappings': ['Entertainer’s Garb', 'Musical Instrument (Lute or Mandolin)'],\n 'Career Entries': ['Entertainer'],\n 'Career Exits': ['Charlatan', 'Demagogue', 'Highwayman', 'Student']},\n 'Navigator Advance Scheme': {\n 'Statblock': [10, 10, 5, 5, 10, 25, 10, 5, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Astronomy)', 'Common Knowledge (any two)', 'Navigation', 'Perception', \n 'Read/Write', 'Speak Language (Classical)', 'Swim', 'Trade(Cartographer)'],\n 'Talents': ['Orientation'],\n 'Trappings': ['6 Maps and Charts, Trade Tools (Navigator’s Instruments)'],\n 'Career Entries': ['Boatman', 'Fisherman', 'Mate', 'Scribe', 'Seaman'],\n 'Career Exits': ['Artisan', 'Explorer', 'Scholar', 'Sea Captain']},\n 'Noble Lord Advance Scheme': {\n 'Statblock': [25, 15, 10, 10, 10, 20, 20, 30, 6, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (History or Strategy/Tactics)', 'Academic Knowledge (Genealogy/Heraldry)', \n 'Command', 'Common Knowledge (the Empire)', 'Gossip', 'Perception', 'Read/Write', 'Ride',\n 'Speak Language (Classical)', 'Speak Language (Reikspiel)'],\n 'Talents': ['Master Orator', 'Public Speaking', 'Specialist Weapon Group (Fencing)'],\n 'Trappings': ['Best Craftsmanship Rapier or Foil', 'Best Craftsmanship Noble’s Garb', '500gc',\n 'Jewellery worth 500gc', 'Destrier with Saddle and Harness'],\n 'Career Entries': ['Courtier', 'Knight', 'Knight of the Inner Politician', 'Sea Captain'],\n 'Career Exits': ['Captain', 'Knight', 'Scholar', 'Sea Captain']},\n 'Outlaw Chief Advance Scheme': {\n 'Statblock': [20, 30, 10, 20, 10, 10, 10, 20, 6, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Strategy/Tactics)', 'Common Knowledge (the Empire)', 'Concealment', \n 'Follow Trail', 'Perception', 'Ride', 'Scale Sheer Surface', 'SecretLanguage (Battle Tongue)', \n 'Secret Language (Thieves’Tongue)', 'Secret Signs (Scout or Thief)', 'Silent Move'],\n 'Talents': ['Lightning Parry', 'Mighty Shot', 'Quick Draw', 'Rapid Reload', 'Sure Shot'],\n 'Trappings': ['Bow or Crossbow with 10 arrows or Bolts', \n 'Medium Armour (Sleeved Mail Shirt and Leather Jack)', 'Horse with Saddle and Harness',\n 'Band of Outlaws'],\n 'Career Entries': ['Crime Lord', 'Demagogue', 'Ghost Highwayman', 'Master Thief', 'Racketeer', 'Scout', \n 'Veteran'],\n 'Career Exits': ['Assassin', 'Captain', 'Crime Lord', 'Demagogue']},\n 'Physician Advance Scheme': {\n 'Statblock': [0, 0, 10, 10, 15, 30, 20, 15, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Science)', 'Heal', 'Perception', 'Prepare Poison', 'Read/Write', \n 'Speak Language (Classical)', 'Trade (Apothecary)'],\n 'Talents': ['Resistance to Disease', 'Strike to Stun', 'Surgery'],\n 'Trappings': ['4 Healing Draughts, Trade Tools (Medical Instruments)'],\n 'Career Entries': ['Barber-Surgeon', 'Interrogator', 'Student'],\n 'Career Exits': ['Friar', 'Guild Master', 'Scholar', 'Spy']},\n 'Pistolier Advance Scheme': {\n 'Statblock': [20, 20, 10, 10, 15, 0, 15, 15, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Animal Care', 'Dodge Evaluate or Gossip', 'Perception', 'Secret Signs (Scout)'],\n 'Talents': ['Master Gunner', 'Quick Draw', 'Rapid Reload', 'Sharpshooter', \n 'Specialist WeaponGroup (Gunpowder)', 'Mighty Shot', 'SureShot'],\n 'Trappings': ['Pair of Pistols with Ammunition and Gunpowder for 20 Shots', 'Best CraftsmanshipClothing',\n 'Light Warhorse'],\n 'Career Entries': ['Engineer', 'Noble'],\n 'Career Exits': ['Courtier', 'Duellist', 'Knight', 'Veteran']},\n 'Politician Advance Scheme': {\n 'Statblock': [5, 5, 5, 10, 0, 20, 10, 20, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (History or Genealogy/Heraldry)', 'Academic Knowledge (Law)', 'Blather', \n 'Charm', 'Common Knowledge (the Empire)', 'Evaluate', 'Haggle', 'Perception', \n 'Performer (Actor)', 'Read/ Speak Language (Reikspiel)'],\n 'Talents': ['Dealmaker or r', 'Etiquette or Streetwise', 'Master Orator', 'Public Speaking'],\n 'Trappings': ['Best Craftsmanship Hand Weapon', 'Best Craftsmanship Leather Jack', 'Pamphlets'],\n 'Career Entries': ['Agitator', 'Bailiff', 'Captain', 'Charlatan', 'Crime Lord', 'Demagogue', 'Guild Master',\n 'Herald', 'High Priest', 'Merchant', 'Noble', 'Peasant', 'Racketeer', 'Toll Keeper'],\n 'Career Exits': ['Courtier', 'Crime Lord', 'Demagogue', 'Noble Racketeer', 'Steward']},\n 'Priest Advance Scheme': {\n 'Statblock': [10, 10, 5, 10, 5, 10, 20, 15, 4, 0, 0, 0, 1, 0, 0, 0],\n 'Skills': ['Academic Knowledge (any one)', 'Academic Knowledge (Theology)', 'Channelling', \n 'Common Knowledge (any two)', 'Gossip', 'Magical Sense', 'Perception', 'Read/Write', \n 'Ride orSwim', 'Speak Arcane Language (Magick)', 'SpeakLanguage (any two)'],\n 'Talents': ['Armoured Caster or Master Orator', 'Petty Magic(Divine)',\n 'Strike to Injure or Strike to Stun'],\n 'Trappings': ['Prayer Book', 'Writing Kit'],\n 'Career Entries': ['Flagellant', 'Friar', 'Initiate'],\n 'Career Exits': ['Anointed Priest', 'Flagellant', 'Steward']},\n 'Racketeer Advance Scheme': {\n 'Statblock': [20, 15, 15, 10, 10, 0, 15, 10, 5, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Command', 'Common Knowledge (the Empire)', 'Dodge Blow', 'Evaluate', 'Gossip', 'Haggle',\n 'Perception', 'Shadowing'],\n 'Talents': ['Menacing', 'Street Fighting', 'Streetwise', 'Strike Mighty Blow', 'Strike to Stun'],\n 'Trappings': ['Knuckle-dusters', 'Good Quality Clothing', 'Hat'],\n 'Career Entries': ['Bailiff', 'Bodyguard', 'Cat Burglar', 'Guild Master', 'Interrogator', 'Merchant', \n 'Protagonist', 'Spy', 'Thug'],\n 'Career Exits': ['Fence', 'Master Thief', 'Politician', 'Outlaw Chief']},\n 'Scholar Advance Scheme': {\n 'Statblock': [5, 5, 5, 5, 10, 30, 15, 15, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (any three)', 'Common Knowledge (any three)', \n 'Evaluate or Trade (Cartographer)', 'Perception', 'Read/Write', 'SpeakLanguage (any three)',\n 'Speak Language (Classical)'],\n 'Talents': ['Linguistics'],\n 'Trappings': ['Writing Kit'],\n 'Career Entries': ['Anointed Priest', 'Apprentice Friar', 'High Priest', 'Journeyman Wizard', \n 'Master Wizard', 'Navigator', 'Noble Lord', 'Physician', 'Scribe', 'Sea Captain',\n 'Student'],\n 'Career Exits': ['Apprentice Wizard', 'Explorer', 'Merchant', 'Physician', 'Steward']},\n 'Scout Advance Scheme': {\n 'Statblock': [20, 20, 10, 10, 15, 20, 15, 0, 6, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Animal Care', 'Common Knowledge (any two)', 'Concealment', 'Dodge Blow', 'Follow Trail', \n 'Perception', 'Ride', 'Secret Language (Ranger Tongue)', 'Secret Signs (Scout)', 'Silent Move', \n 'Speak Language (any two)'],\n 'Talents': ['Charm Animal', 'Mighty Shot or Sure Shot', 'Rapid Reload', \n 'Specialist Weapon (Crossbow or Longbow)'],\n 'Trappings': ['Medium Armour (Mail Shirt and Leather Jack)', 'Shield', '10 Yards of Rope', \n 'Horse with Saddle and Harness'],\n 'Career Entries': ['Bounty Hunter', 'Champion', 'Charcoal- Coachman', 'Fieldwarden', 'Hunter', \n 'Kithband Messenger', 'Miner', 'Outrider', 'Roadwarden', 'Vagabond', 'Woodsman'],\n 'Career Exits': ['Explorer', 'Outlaw Chief', 'Sergeant', 'Vampire Hunter', 'Ghost Strider']},\n 'Sea Captain Advance Scheme': {\n 'Statblock': [25, 20, 15, 20, 20, 20, 25, 30, 6, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Strategy/Tactics)', 'Animal Training', 'Command', \n 'Common Knowledge (anythree)', 'Dodge Blow', 'Perception', 'Sail', 'SpeakLanguage (any three)',\n 'Swim', 'Trade (Cartographer orShipwright)'],\n 'Talents': ['Disarm', 'Lightning Parry or Seasoned Traveller', 'Specialist Weapon Group (Fencing)', \n 'Strike Mighty Blow'],\n 'Trappings': ['Rapier', 'Light Armour (Leather Jack)', 'Ship'],\n 'Career Entries': ['Explorer', 'Mate', 'Navigator', 'Noble Lord'],\n 'Career Exits': ['Explorer', 'Noble Lord', 'Scholar', 'Spy']},\n 'Sergeant Advance Scheme': {\n 'Statblock': [20, 15, 10, 10, 10, 10, 10, 20, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Strategy/Tactics)', 'Common Knowledge (any two)', 'Dodge Blow', \n 'Intimidate', 'Perception', 'Ride or Swim', 'Secret Language (Battle Tongue)', \n 'Speak Language (Tilean)'],\n 'Talents': ['Menacing or Seasoned Traveller', 'Street Fighting or Wrestling', 'Strike Mighty Blow', \n 'Strike to Stun'],\n 'Trappings': ['Medium Armour (Full Mail Armour)', 'Shield'],\n 'Career Entries': ['Assassin', 'Champion', 'Duellist', 'Judicial Champion', 'Kislevite Kossar', 'Marine',\n 'Militiaman', 'Norse Berserker', 'Pistolier', 'Scout', 'Shieldbreaker', 'Soldier',\n 'Squire', 'Targeteer', 'Watchman'],\n 'Career Exits': ['Captain', 'Duellist', 'Judicial Champion', 'Knight']},\n 'Spy Advance Scheme': {\n 'Statblock': [15, 15, 5, 10, 20, 20, 35, 20, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Charm', 'Common Knowledge (any two)', 'Disguise', 'Gossip', 'Lip Reading', 'Performer (Actor)',\n 'Pick Lock', 'Shadowing', 'Sleight of Hand', 'Secret Language (any one)', 'Silent Move',\n 'Speak Language (anythree)'],\n 'Talents': ['Flee!', 'Linguistics', 'r', 'Suave or Sixth Sense'],\n 'Trappings': ['Disguise Kit', '4 Homing Pigeons'],\n 'Career Entries': ['Camp Follower', 'Charlatan', 'Explorer', 'Merchant', 'Minstrel', 'Physician', \n 'Sea Servant'],\n 'Career Exits': ['Assassin', 'Explorer', 'Master Thief', 'Racketeer']},\n 'Steward Advance Scheme': {\n 'Statblock': [10, 10, 10, 10, 0, 30, 20, 25, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Law)', 'Charm', 'Common Knowledge (the Empire)', 'Evaluate', 'Haggle', \n 'Intimidate', 'Perception', 'Read/Write', 'Search', 'Speak Language (Reikspiel)', \n 'Trade (Merchant)'],\n 'Talents': ['Public Speaking', 'Super Numerate'],\n 'Trappings': ['2 Sets of Best Craftsmanship Noble’s Writing Kit'],\n 'Career Entries': ['Courtier', 'Politician', 'Priest', 'Scholar', 'Valet'],\n 'Career Exits': ['Crime Lord', 'Fence', 'Merchant', 'Noble']},\n 'Targeteer Advance Scheme': {\n 'Statblock': [0, 35, 10, 10, 25, 10, 20, 15, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Common Knowledge (the Empire)', 'Gossip', 'Outdoor Survival', 'Perception', 'Search',\n 'Sleight of Hand'],\n 'Talents': ['Mighty Shot', 'Rapid Reload', 'Sharpshooter', 'Specialist Weapon Group (Longbow)',\n 'Specialist Weapon Group(Crossbow or Throwing)', 'Sure Shot'],\n 'Trappings': ['Longbow or Crossbow with 10 arrows or Light Armour (Leather Jack)'],\n 'Career Entries': ['Bounty Hunter', 'Hunter', 'Ghost Strider', 'Master Thief', 'Vampire Hunter', 'Veteran'],\n 'Career Exits': ['Assassin', 'Champion', 'Duellist', 'Sergeant']},\n 'Vampire Hunter Advance Scheme': {\n 'Statblock': [20, 20, 10, 20, 15, 15, 20, 0, 4, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (History or Necromancy)', 'Common Knowledge (the Empire)', 'Concealment',\n 'Dodge Blow', 'Follow Trail', 'Perception', 'Scale Sheer Shadowing', 'Search', 'Silent Move', \n 'Speak Language(Classical)'],\n 'Talents': ['Mighty Shot or Rapid Reload', 'Specialist Weapon Group (Crossbow)', 'Stout-hearted', \n 'Strike Mighty Strike to Injure', 'Tunnel Rat'],\n 'Trappings': ['Repeater Crossbow with 10 Bolts', 'Medium Armour (Full Mail Armour)', 'Blessed Water', \n '4 Stakes'],\n 'Career Entries': ['Bounty Hunter', 'Field Warden', 'Ghost Strider', 'Knight', 'Scout', 'Tomb Robber'],\n 'Career Exits': ['Demagogue', 'Initiate', 'Knight', 'Targeteer', 'Witch Hunter']},\n 'Veteran Advance Scheme': {\n 'Statblock': [20, 20, 10, 10, 15, 0, 15, 0, 6, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Common Knowledge (the Empire)', 'Consume Dodge Blow', 'Gamble', 'Gossip', 'Intimidate', \n 'Secret Language (Battle Tongue)'],\n 'Talents': ['Mighty Shot or Strike Mighty Blow', 'Rapid Reload or Strike to Injure', \n 'Specialist Weapon Group (anytwo)', 'Very Resilient or Very Strong'],\n 'Trappings': ['Any two weapons', 'Medium Armour(Full Mail Armour)', 'Bottle of Good Craftsmanship Spirits'],\n 'Career Entries': ['Flagellant', 'Kislevite Kossar', 'Kithband Warrior', 'Mercenary', 'Norse Berserker',\n 'Pistolier', 'Pit Fighter', 'Runebearer', 'Soldier', 'Squire'],\n 'Career Exits': ['Champion', 'Judicial Champion', 'Outlaw', 'Sergeant', 'Targeteer']},\n 'Witch Hunter Advance Scheme': {\n 'Statblock': [30, 30, 15, 15, 15, 15, 35, 20, 6, 0, 0, 0, 0, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Magic)', 'Academic Knowledge (Necromancy)', 'Academic Knowledge (Theology)',\n 'Command', 'Common Knowledge (the Empire)', 'Intimidate', 'Perception', 'Ride', 'Search',\n 'Silent Move', 'SpeakLanguage (any one)'],\n 'Talents': ['Lightning Parry', 'Lightning Reflexes or Marksman', 'Public Speaking', 'Sixth Sense', \n 'Specialist Weapon Group (Crossbow)', 'Specialist Weapon Group (Entangling)', \n 'SpecialistWeapon Group (Throwing)', 'Stout-hearted', 'Strike Mighty Blow'],\n 'Trappings': ['Crossbow Pistol with 10 bolts', 'Best Craftsmanship Hand Weapon', '4 Throwing Knives/Stars', \n 'Heavy Armour (Full PlateArmour)', '10 Yards of Rope'],\n 'Career Entries': ['Anointed Priest', 'Assassin', 'Champion', 'High Judicial Champion', \n 'Knight of the Inner Circle', 'Vampire Hunter'],\n 'Career Exits': ['Captain', 'Champion', 'Demagogue', 'Initiate', 'Knight of the Inner Circle']},\n 'Wizard Lord Advance Scheme': {\n 'Statblock': [15, 15, 5, 15, 20, 35, 40, 20, 5, 0, 0, 0, 4, 0, 0, 0],\n 'Skills': ['Academic Knowledge (Magic)', 'Academic Knowledge (any three)', 'Channelling', \n 'Charm or Intimidate', 'CommonKnowledge (any three)', 'Magical Sense', 'Read/Write', \n 'Speak Arcane Language (Magick)', 'Speak Arcane Language(Daemonic or Arcane Elf)', \n 'Speak Language (any four)'],\n 'Talents': ['Aethyric Attunement or Mighty Missile', 'Dark Magic or Meditation', 'Fast Hands or Hardy', \n 'Lesser Magic (any two)'],\n 'Trappings': ['Three magic items', '12 Grimoires'],\n 'Career Entries': ['Master Wizard'],\n 'Career Exits': ['Explorer', 'Guild Master']},\n }\n\n return (career_dict[career_name])\n\n\nif __name__ == '__main__':\n\n career_selection\n\n\n\n\n"
},
{
"alpha_fraction": 0.6700596213340759,
"alphanum_fraction": 0.7082253098487854,
"avg_line_length": 56.795372009277344,
"blob_id": "d4bbb2a76e9e6cc26805fb10af1f9da8b4bf9abb",
"content_id": "15ef88cff663d50baeb64da03a0edfb7780d0f8a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 47451,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 821,
"path": "/WFRP 2e.py",
"repo_name": "TheRealRhyle/WFRP-2e-Char-Gen",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file 'WFRP 2e.ui'\n#\n# Created by: PyQt5 UI code generator 5.11.2\n#\n# WARNING! All changes made in this file will be lost!\n\nfrom PyQt5 import QtCore, QtGui, QtWidgets\n\nclass Ui_MainWindow(object):\n def setupUi(self, MainWindow):\n MainWindow.setObjectName(\"MainWindow\")\n MainWindow.resize(874, 861)\n MainWindow.setAutoFillBackground(False)\n self.centralwidget = QtWidgets.QWidget(MainWindow)\n self.centralwidget.setObjectName(\"centralwidget\")\n self.groupBox = QtWidgets.QGroupBox(self.centralwidget)\n self.groupBox.setGeometry(QtCore.QRect(0, 0, 391, 141))\n self.groupBox.setObjectName(\"groupBox\")\n self.label = QtWidgets.QLabel(self.groupBox)\n self.label.setGeometry(QtCore.QRect(10, 20, 47, 21))\n self.label.setObjectName(\"label\")\n self.label_2 = QtWidgets.QLabel(self.groupBox)\n self.label_2.setGeometry(QtCore.QRect(10, 50, 47, 21))\n self.label_2.setObjectName(\"label_2\")\n self.label_3 = QtWidgets.QLabel(self.groupBox)\n self.label_3.setGeometry(QtCore.QRect(10, 80, 81, 21))\n self.label_3.setObjectName(\"label_3\")\n self.label_4 = QtWidgets.QLabel(self.groupBox)\n self.label_4.setGeometry(QtCore.QRect(10, 110, 81, 21))\n self.label_4.setScaledContents(False)\n self.label_4.setObjectName(\"label_4\")\n self.txtName = QtWidgets.QPlainTextEdit(self.groupBox)\n self.txtName.setGeometry(QtCore.QRect(60, 20, 320, 21))\n self.txtName.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtName.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtName.setPlainText(\"\")\n self.txtName.setObjectName(\"txtName\")\n self.txtRace = QtWidgets.QPlainTextEdit(self.groupBox)\n self.txtRace.setGeometry(QtCore.QRect(60, 50, 320, 21))\n self.txtRace.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtRace.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtRace.setPlainText(\"\")\n self.txtRace.setObjectName(\"txtRace\")\n self.txtCCareer = QtWidgets.QPlainTextEdit(self.groupBox)\n self.txtCCareer.setGeometry(QtCore.QRect(90, 80, 290, 21))\n self.txtCCareer.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCCareer.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCCareer.setPlainText(\"\")\n self.txtCCareer.setObjectName(\"txtCCareer\")\n self.txtPCareer = QtWidgets.QPlainTextEdit(self.groupBox)\n self.txtPCareer.setGeometry(QtCore.QRect(90, 110, 290, 21))\n self.txtPCareer.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtPCareer.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtPCareer.setPlainText(\"\")\n self.txtPCareer.setObjectName(\"txtPCareer\")\n self.groupBox_2 = QtWidgets.QGroupBox(self.centralwidget)\n self.groupBox_2.setGeometry(QtCore.QRect(0, 140, 391, 201))\n self.groupBox_2.setObjectName(\"groupBox_2\")\n self.label_5 = QtWidgets.QLabel(self.groupBox_2)\n self.label_5.setGeometry(QtCore.QRect(10, 20, 47, 21))\n self.label_5.setObjectName(\"label_5\")\n self.label_6 = QtWidgets.QLabel(self.groupBox_2)\n self.label_6.setGeometry(QtCore.QRect(10, 50, 47, 21))\n self.label_6.setObjectName(\"label_6\")\n self.label_7 = QtWidgets.QLabel(self.groupBox_2)\n self.label_7.setGeometry(QtCore.QRect(10, 80, 81, 21))\n self.label_7.setObjectName(\"label_7\")\n self.label_8 = QtWidgets.QLabel(self.groupBox_2)\n self.label_8.setGeometry(QtCore.QRect(10, 110, 81, 21))\n self.label_8.setScaledContents(False)\n self.label_8.setObjectName(\"label_8\")\n self.txtAge = QtWidgets.QPlainTextEdit(self.groupBox_2)\n self.txtAge.setGeometry(QtCore.QRect(60, 20, 131, 21))\n self.txtAge.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAge.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAge.setPlainText(\"\")\n self.txtAge.setObjectName(\"txtAge\")\n self.txtEyeColor = QtWidgets.QPlainTextEdit(self.groupBox_2)\n self.txtEyeColor.setGeometry(QtCore.QRect(60, 50, 131, 21))\n self.txtEyeColor.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtEyeColor.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtEyeColor.setPlainText(\"\")\n self.txtEyeColor.setObjectName(\"txtEyeColor\")\n self.txtHaircolor = QtWidgets.QPlainTextEdit(self.groupBox_2)\n self.txtHaircolor.setGeometry(QtCore.QRect(60, 80, 131, 21))\n self.txtHaircolor.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtHaircolor.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtHaircolor.setPlainText(\"\")\n self.txtHaircolor.setObjectName(\"txtHaircolor\")\n self.txtStarSign = QtWidgets.QPlainTextEdit(self.groupBox_2)\n self.txtStarSign.setGeometry(QtCore.QRect(60, 110, 130, 21))\n self.txtStarSign.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtStarSign.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtStarSign.setPlainText(\"\")\n self.txtStarSign.setObjectName(\"txtStarSign\")\n self.label_9 = QtWidgets.QLabel(self.groupBox_2)\n self.label_9.setGeometry(QtCore.QRect(10, 140, 81, 21))\n self.label_9.setScaledContents(False)\n self.label_9.setObjectName(\"label_9\")\n self.label_10 = QtWidgets.QLabel(self.groupBox_2)\n self.label_10.setGeometry(QtCore.QRect(10, 170, 101, 21))\n self.label_10.setScaledContents(False)\n self.label_10.setObjectName(\"label_10\")\n self.label_11 = QtWidgets.QLabel(self.groupBox_2)\n self.label_11.setGeometry(QtCore.QRect(210, 50, 47, 21))\n self.label_11.setObjectName(\"label_11\")\n self.label_12 = QtWidgets.QLabel(self.groupBox_2)\n self.label_12.setGeometry(QtCore.QRect(210, 110, 91, 21))\n self.label_12.setScaledContents(False)\n self.label_12.setObjectName(\"label_12\")\n self.label_13 = QtWidgets.QLabel(self.groupBox_2)\n self.label_13.setGeometry(QtCore.QRect(210, 20, 47, 21))\n self.label_13.setObjectName(\"label_13\")\n self.label_14 = QtWidgets.QLabel(self.groupBox_2)\n self.label_14.setGeometry(QtCore.QRect(210, 80, 41, 21))\n self.label_14.setObjectName(\"label_14\")\n self.txtHeight = QtWidgets.QPlainTextEdit(self.groupBox_2)\n self.txtHeight.setGeometry(QtCore.QRect(260, 80, 121, 21))\n self.txtHeight.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtHeight.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtHeight.setPlainText(\"\")\n self.txtHeight.setObjectName(\"txtHeight\")\n self.txtNoofSib = QtWidgets.QPlainTextEdit(self.groupBox_2)\n self.txtNoofSib.setGeometry(QtCore.QRect(310, 110, 71, 21))\n self.txtNoofSib.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtNoofSib.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtNoofSib.setPlainText(\"\")\n self.txtNoofSib.setObjectName(\"txtNoofSib\")\n self.txtWeight = QtWidgets.QPlainTextEdit(self.groupBox_2)\n self.txtWeight.setGeometry(QtCore.QRect(260, 50, 121, 21))\n self.txtWeight.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtWeight.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtWeight.setPlainText(\"\")\n self.txtWeight.setObjectName(\"txtWeight\")\n self.txtGender = QtWidgets.QPlainTextEdit(self.groupBox_2)\n self.txtGender.setGeometry(QtCore.QRect(260, 20, 121, 21))\n self.txtGender.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtGender.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtGender.setPlainText(\"\")\n self.txtGender.setObjectName(\"txtGender\")\n self.txtBirthplace = QtWidgets.QPlainTextEdit(self.groupBox_2)\n self.txtBirthplace.setGeometry(QtCore.QRect(60, 140, 321, 21))\n self.txtBirthplace.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtBirthplace.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtBirthplace.setPlainText(\"\")\n self.txtBirthplace.setObjectName(\"txtBirthplace\")\n self.txtDMarks = QtWidgets.QPlainTextEdit(self.groupBox_2)\n self.txtDMarks.setGeometry(QtCore.QRect(110, 170, 271, 21))\n self.txtDMarks.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtDMarks.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtDMarks.setPlainText(\"\")\n self.txtDMarks.setObjectName(\"txtDMarks\")\n self.pushButton = QtWidgets.QPushButton(self.centralwidget)\n self.pushButton.setGeometry(QtCore.QRect(220, 770, 160, 40))\n self.pushButton.setObjectName(\"pushButton\")\n self.groupBox_3 = QtWidgets.QGroupBox(self.centralwidget)\n self.groupBox_3.setGeometry(QtCore.QRect(0, 340, 391, 201))\n self.groupBox_3.setObjectName(\"groupBox_3\")\n self.label_25 = QtWidgets.QLabel(self.groupBox_3)\n self.label_25.setGeometry(QtCore.QRect(10, 20, 47, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_25.sizePolicy().hasHeightForWidth())\n self.label_25.setSizePolicy(sizePolicy)\n self.label_25.setLineWidth(1)\n self.label_25.setScaledContents(False)\n self.label_25.setObjectName(\"label_25\")\n self.label_26 = QtWidgets.QLabel(self.groupBox_3)\n self.label_26.setGeometry(QtCore.QRect(10, 110, 61, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_26.sizePolicy().hasHeightForWidth())\n self.label_26.setSizePolicy(sizePolicy)\n self.label_26.setLineWidth(1)\n self.label_26.setScaledContents(False)\n self.label_26.setObjectName(\"label_26\")\n self.txtSBS = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSBS.setGeometry(QtCore.QRect(110, 40, 31, 21))\n self.txtSBS.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSBS.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSBS.setPlainText(\"\")\n self.txtSBS.setObjectName(\"txtSBS\")\n self.txtSS = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSS.setGeometry(QtCore.QRect(150, 40, 31, 21))\n self.txtSS.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSS.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSS.setPlainText(\"\")\n self.txtSS.setObjectName(\"txtSS\")\n self.txtST = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtST.setGeometry(QtCore.QRect(190, 40, 31, 21))\n self.txtST.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtST.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtST.setPlainText(\"\")\n self.txtST.setObjectName(\"txtST\")\n self.txtSAg = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSAg.setGeometry(QtCore.QRect(230, 40, 31, 21))\n self.txtSAg.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSAg.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSAg.setPlainText(\"\")\n self.txtSAg.setObjectName(\"txtSAg\")\n self.txtSInt = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSInt.setGeometry(QtCore.QRect(270, 40, 31, 21))\n self.txtSInt.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSInt.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSInt.setPlainText(\"\")\n self.txtSInt.setObjectName(\"txtSInt\")\n self.txtSWP = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSWP.setGeometry(QtCore.QRect(310, 40, 31, 21))\n self.txtSWP.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSWP.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSWP.setPlainText(\"\")\n self.txtSWP.setObjectName(\"txtSWP\")\n self.txtSFel = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSFel.setGeometry(QtCore.QRect(350, 40, 31, 21))\n self.txtSFel.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSFel.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSFel.setPlainText(\"\")\n self.txtSFel.setObjectName(\"txtSFel\")\n self.txtSWS = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSWS.setGeometry(QtCore.QRect(70, 40, 31, 21))\n self.txtSWS.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSWS.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSWS.setPlainText(\"\")\n self.txtSWS.setObjectName(\"txtSWS\")\n self.txtAInt = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAInt.setGeometry(QtCore.QRect(270, 60, 31, 21))\n self.txtAInt.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAInt.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAInt.setPlainText(\"\")\n self.txtAInt.setObjectName(\"txtAInt\")\n self.txtAAg = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAAg.setGeometry(QtCore.QRect(230, 60, 31, 21))\n self.txtAAg.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAAg.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAAg.setPlainText(\"\")\n self.txtAAg.setObjectName(\"txtAAg\")\n self.txtAWS = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAWS.setGeometry(QtCore.QRect(70, 60, 31, 21))\n self.txtAWS.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAWS.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAWS.setPlainText(\"\")\n self.txtAWS.setObjectName(\"txtAWS\")\n self.txtAFel = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAFel.setGeometry(QtCore.QRect(350, 60, 31, 21))\n self.txtAFel.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAFel.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAFel.setPlainText(\"\")\n self.txtAFel.setObjectName(\"txtAFel\")\n self.txtABS = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtABS.setGeometry(QtCore.QRect(110, 60, 31, 21))\n self.txtABS.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtABS.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtABS.setPlainText(\"\")\n self.txtABS.setObjectName(\"txtABS\")\n self.txtAT = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAT.setGeometry(QtCore.QRect(190, 60, 31, 21))\n self.txtAT.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAT.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAT.setPlainText(\"\")\n self.txtAT.setObjectName(\"txtAT\")\n self.txtAS = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAS.setGeometry(QtCore.QRect(150, 60, 31, 21))\n self.txtAS.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAS.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAS.setPlainText(\"\")\n self.txtAS.setObjectName(\"txtAS\")\n self.txtAWP = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAWP.setGeometry(QtCore.QRect(310, 60, 31, 21))\n self.txtAWP.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAWP.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAWP.setPlainText(\"\")\n self.txtAWP.setObjectName(\"txtAWP\")\n self.txtCInt = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCInt.setGeometry(QtCore.QRect(270, 80, 31, 21))\n self.txtCInt.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCInt.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCInt.setPlainText(\"\")\n self.txtCInt.setObjectName(\"txtCInt\")\n self.txtCAg = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCAg.setGeometry(QtCore.QRect(230, 80, 31, 21))\n self.txtCAg.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCAg.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCAg.setPlainText(\"\")\n self.txtCAg.setObjectName(\"txtCAg\")\n self.txtCWS = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCWS.setGeometry(QtCore.QRect(70, 80, 31, 21))\n self.txtCWS.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCWS.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCWS.setPlainText(\"\")\n self.txtCWS.setObjectName(\"txtCWS\")\n self.txtCFel = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCFel.setGeometry(QtCore.QRect(350, 80, 31, 21))\n self.txtCFel.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCFel.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCFel.setPlainText(\"\")\n self.txtCFel.setObjectName(\"txtCFel\")\n self.txtCBS = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCBS.setGeometry(QtCore.QRect(110, 80, 31, 21))\n self.txtCBS.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCBS.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCBS.setPlainText(\"\")\n self.txtCBS.setObjectName(\"txtCBS\")\n self.txtCT = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCT.setGeometry(QtCore.QRect(190, 80, 31, 21))\n self.txtCT.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCT.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCT.setPlainText(\"\")\n self.txtCT.setObjectName(\"txtCT\")\n self.txtCS = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCS.setGeometry(QtCore.QRect(150, 80, 31, 21))\n self.txtCS.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCS.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCS.setPlainText(\"\")\n self.txtCS.setObjectName(\"txtCS\")\n self.txtCWP = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCWP.setGeometry(QtCore.QRect(310, 80, 31, 21))\n self.txtCWP.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCWP.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCWP.setPlainText(\"\")\n self.txtCWP.setObjectName(\"txtCWP\")\n self.txtSA = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSA.setGeometry(QtCore.QRect(70, 130, 31, 21))\n self.txtSA.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSA.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSA.setPlainText(\"\")\n self.txtSA.setObjectName(\"txtSA\")\n self.txtSB = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSB.setGeometry(QtCore.QRect(150, 130, 31, 21))\n self.txtSB.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSB.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSB.setPlainText(\"\")\n self.txtSB.setObjectName(\"txtSB\")\n self.txtAIp = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAIp.setGeometry(QtCore.QRect(310, 150, 31, 21))\n self.txtAIp.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAIp.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAIp.setPlainText(\"\")\n self.txtAIp.setObjectName(\"txtAIp\")\n self.txtAA = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAA.setGeometry(QtCore.QRect(70, 150, 31, 21))\n self.txtAA.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAA.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAA.setPlainText(\"\")\n self.txtAA.setObjectName(\"txtAA\")\n self.txtSTB = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSTB.setGeometry(QtCore.QRect(190, 130, 31, 21))\n self.txtSTB.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSTB.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSTB.setPlainText(\"\")\n self.txtSTB.setObjectName(\"txtSTB\")\n self.txtSIP = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSIP.setGeometry(QtCore.QRect(310, 130, 31, 21))\n self.txtSIP.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSIP.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSIP.setPlainText(\"\")\n self.txtSIP.setObjectName(\"txtSIP\")\n self.txtCTB = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCTB.setGeometry(QtCore.QRect(190, 170, 31, 21))\n self.txtCTB.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCTB.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCTB.setPlainText(\"\")\n self.txtCTB.setObjectName(\"txtCTB\")\n self.txtSW = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSW.setGeometry(QtCore.QRect(110, 130, 31, 21))\n self.txtSW.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSW.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSW.setPlainText(\"\")\n self.txtSW.setObjectName(\"txtSW\")\n self.txtAMag = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAMag.setGeometry(QtCore.QRect(270, 150, 31, 21))\n self.txtAMag.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAMag.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAMag.setPlainText(\"\")\n self.txtAMag.setObjectName(\"txtAMag\")\n self.txtAM = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAM.setGeometry(QtCore.QRect(230, 150, 31, 21))\n self.txtAM.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAM.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAM.setPlainText(\"\")\n self.txtAM.setObjectName(\"txtAM\")\n self.txtCA = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCA.setGeometry(QtCore.QRect(70, 170, 31, 21))\n self.txtCA.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCA.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCA.setPlainText(\"\")\n self.txtCA.setObjectName(\"txtCA\")\n self.txtSM = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSM.setGeometry(QtCore.QRect(230, 130, 31, 21))\n self.txtSM.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSM.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSM.setPlainText(\"\")\n self.txtSM.setObjectName(\"txtSM\")\n self.txtCW = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCW.setGeometry(QtCore.QRect(110, 170, 31, 21))\n self.txtCW.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCW.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCW.setPlainText(\"\")\n self.txtCW.setObjectName(\"txtCW\")\n self.txtCMag = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCMag.setGeometry(QtCore.QRect(270, 170, 31, 21))\n self.txtCMag.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCMag.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCMag.setPlainText(\"\")\n self.txtCMag.setObjectName(\"txtCMag\")\n self.txtAW = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAW.setGeometry(QtCore.QRect(110, 150, 31, 21))\n self.txtAW.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAW.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAW.setPlainText(\"\")\n self.txtAW.setObjectName(\"txtAW\")\n self.txtCFP = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCFP.setGeometry(QtCore.QRect(350, 170, 31, 21))\n self.txtCFP.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCFP.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCFP.setPlainText(\"\")\n self.txtCFP.setObjectName(\"txtCFP\")\n self.txtASB = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtASB.setGeometry(QtCore.QRect(150, 150, 31, 21))\n self.txtASB.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtASB.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtASB.setPlainText(\"\")\n self.txtASB.setObjectName(\"txtASB\")\n self.txtCIP = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCIP.setGeometry(QtCore.QRect(310, 170, 31, 21))\n self.txtCIP.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCIP.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCIP.setPlainText(\"\")\n self.txtCIP.setObjectName(\"txtCIP\")\n self.txtCSB = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCSB.setGeometry(QtCore.QRect(150, 170, 31, 21))\n self.txtCSB.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCSB.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCSB.setPlainText(\"\")\n self.txtCSB.setObjectName(\"txtCSB\")\n self.txtSFP = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSFP.setGeometry(QtCore.QRect(350, 130, 31, 21))\n self.txtSFP.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSFP.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSFP.setPlainText(\"\")\n self.txtSFP.setObjectName(\"txtSFP\")\n self.txtATB = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtATB.setGeometry(QtCore.QRect(190, 150, 31, 21))\n self.txtATB.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtATB.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtATB.setPlainText(\"\")\n self.txtATB.setObjectName(\"txtATB\")\n self.txtCM = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCM.setGeometry(QtCore.QRect(230, 170, 31, 21))\n self.txtCM.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCM.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCM.setPlainText(\"\")\n self.txtCM.setObjectName(\"txtCM\")\n self.txtAFP = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAFP.setGeometry(QtCore.QRect(350, 150, 31, 21))\n self.txtAFP.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAFP.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAFP.setPlainText(\"\")\n self.txtAFP.setObjectName(\"txtAFP\")\n self.txtSMag = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSMag.setGeometry(QtCore.QRect(270, 130, 31, 21))\n self.txtSMag.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSMag.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSMag.setPlainText(\"\")\n self.txtSMag.setObjectName(\"txtSMag\")\n self.label_27 = QtWidgets.QLabel(self.groupBox_3)\n self.label_27.setGeometry(QtCore.QRect(70, 20, 31, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_27.sizePolicy().hasHeightForWidth())\n self.label_27.setSizePolicy(sizePolicy)\n self.label_27.setLineWidth(1)\n self.label_27.setScaledContents(False)\n self.label_27.setAlignment(QtCore.Qt.AlignCenter)\n self.label_27.setObjectName(\"label_27\")\n self.label_28 = QtWidgets.QLabel(self.groupBox_3)\n self.label_28.setGeometry(QtCore.QRect(110, 20, 31, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_28.sizePolicy().hasHeightForWidth())\n self.label_28.setSizePolicy(sizePolicy)\n self.label_28.setLineWidth(1)\n self.label_28.setScaledContents(False)\n self.label_28.setAlignment(QtCore.Qt.AlignCenter)\n self.label_28.setObjectName(\"label_28\")\n self.label_29 = QtWidgets.QLabel(self.groupBox_3)\n self.label_29.setGeometry(QtCore.QRect(150, 20, 31, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_29.sizePolicy().hasHeightForWidth())\n self.label_29.setSizePolicy(sizePolicy)\n self.label_29.setLineWidth(1)\n self.label_29.setScaledContents(False)\n self.label_29.setAlignment(QtCore.Qt.AlignCenter)\n self.label_29.setObjectName(\"label_29\")\n self.label_30 = QtWidgets.QLabel(self.groupBox_3)\n self.label_30.setGeometry(QtCore.QRect(270, 20, 30, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_30.sizePolicy().hasHeightForWidth())\n self.label_30.setSizePolicy(sizePolicy)\n self.label_30.setLineWidth(1)\n self.label_30.setScaledContents(False)\n self.label_30.setAlignment(QtCore.Qt.AlignCenter)\n self.label_30.setObjectName(\"label_30\")\n self.label_31 = QtWidgets.QLabel(self.groupBox_3)\n self.label_31.setGeometry(QtCore.QRect(310, 20, 30, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_31.sizePolicy().hasHeightForWidth())\n self.label_31.setSizePolicy(sizePolicy)\n self.label_31.setLineWidth(1)\n self.label_31.setScaledContents(False)\n self.label_31.setAlignment(QtCore.Qt.AlignCenter)\n self.label_31.setObjectName(\"label_31\")\n self.label_32 = QtWidgets.QLabel(self.groupBox_3)\n self.label_32.setGeometry(QtCore.QRect(350, 20, 30, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_32.sizePolicy().hasHeightForWidth())\n self.label_32.setSizePolicy(sizePolicy)\n self.label_32.setLineWidth(1)\n self.label_32.setScaledContents(False)\n self.label_32.setAlignment(QtCore.Qt.AlignCenter)\n self.label_32.setObjectName(\"label_32\")\n self.label_33 = QtWidgets.QLabel(self.groupBox_3)\n self.label_33.setGeometry(QtCore.QRect(190, 20, 30, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_33.sizePolicy().hasHeightForWidth())\n self.label_33.setSizePolicy(sizePolicy)\n self.label_33.setLineWidth(1)\n self.label_33.setScaledContents(False)\n self.label_33.setAlignment(QtCore.Qt.AlignCenter)\n self.label_33.setObjectName(\"label_33\")\n self.label_35 = QtWidgets.QLabel(self.groupBox_3)\n self.label_35.setGeometry(QtCore.QRect(230, 20, 30, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_35.sizePolicy().hasHeightForWidth())\n self.label_35.setSizePolicy(sizePolicy)\n self.label_35.setLineWidth(1)\n self.label_35.setScaledContents(False)\n self.label_35.setAlignment(QtCore.Qt.AlignCenter)\n self.label_35.setObjectName(\"label_35\")\n self.label_34 = QtWidgets.QLabel(self.groupBox_3)\n self.label_34.setGeometry(QtCore.QRect(20, 40, 47, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_34.sizePolicy().hasHeightForWidth())\n self.label_34.setSizePolicy(sizePolicy)\n self.label_34.setLineWidth(1)\n self.label_34.setScaledContents(False)\n self.label_34.setObjectName(\"label_34\")\n self.label_36 = QtWidgets.QLabel(self.groupBox_3)\n self.label_36.setGeometry(QtCore.QRect(20, 60, 47, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_36.sizePolicy().hasHeightForWidth())\n self.label_36.setSizePolicy(sizePolicy)\n self.label_36.setLineWidth(1)\n self.label_36.setScaledContents(False)\n self.label_36.setObjectName(\"label_36\")\n self.label_37 = QtWidgets.QLabel(self.groupBox_3)\n self.label_37.setGeometry(QtCore.QRect(20, 80, 47, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_37.sizePolicy().hasHeightForWidth())\n self.label_37.setSizePolicy(sizePolicy)\n self.label_37.setLineWidth(1)\n self.label_37.setScaledContents(False)\n self.label_37.setObjectName(\"label_37\")\n self.label_38 = QtWidgets.QLabel(self.groupBox_3)\n self.label_38.setGeometry(QtCore.QRect(20, 170, 47, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_38.sizePolicy().hasHeightForWidth())\n self.label_38.setSizePolicy(sizePolicy)\n self.label_38.setLineWidth(1)\n self.label_38.setScaledContents(False)\n self.label_38.setObjectName(\"label_38\")\n self.label_39 = QtWidgets.QLabel(self.groupBox_3)\n self.label_39.setGeometry(QtCore.QRect(20, 150, 47, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_39.sizePolicy().hasHeightForWidth())\n self.label_39.setSizePolicy(sizePolicy)\n self.label_39.setLineWidth(1)\n self.label_39.setScaledContents(False)\n self.label_39.setObjectName(\"label_39\")\n self.label_40 = QtWidgets.QLabel(self.groupBox_3)\n self.label_40.setGeometry(QtCore.QRect(20, 130, 47, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_40.sizePolicy().hasHeightForWidth())\n self.label_40.setSizePolicy(sizePolicy)\n self.label_40.setLineWidth(1)\n self.label_40.setScaledContents(False)\n self.label_40.setObjectName(\"label_40\")\n self.label_41 = QtWidgets.QLabel(self.groupBox_3)\n self.label_41.setGeometry(QtCore.QRect(70, 110, 31, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_41.sizePolicy().hasHeightForWidth())\n self.label_41.setSizePolicy(sizePolicy)\n self.label_41.setLineWidth(1)\n self.label_41.setScaledContents(False)\n self.label_41.setAlignment(QtCore.Qt.AlignCenter)\n self.label_41.setObjectName(\"label_41\")\n self.label_42 = QtWidgets.QLabel(self.groupBox_3)\n self.label_42.setGeometry(QtCore.QRect(350, 110, 30, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_42.sizePolicy().hasHeightForWidth())\n self.label_42.setSizePolicy(sizePolicy)\n self.label_42.setLineWidth(1)\n self.label_42.setScaledContents(False)\n self.label_42.setAlignment(QtCore.Qt.AlignCenter)\n self.label_42.setObjectName(\"label_42\")\n self.label_43 = QtWidgets.QLabel(self.groupBox_3)\n self.label_43.setGeometry(QtCore.QRect(230, 110, 30, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_43.sizePolicy().hasHeightForWidth())\n self.label_43.setSizePolicy(sizePolicy)\n self.label_43.setLineWidth(1)\n self.label_43.setScaledContents(False)\n self.label_43.setAlignment(QtCore.Qt.AlignCenter)\n self.label_43.setObjectName(\"label_43\")\n self.label_44 = QtWidgets.QLabel(self.groupBox_3)\n self.label_44.setGeometry(QtCore.QRect(150, 110, 31, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_44.sizePolicy().hasHeightForWidth())\n self.label_44.setSizePolicy(sizePolicy)\n self.label_44.setLineWidth(1)\n self.label_44.setScaledContents(False)\n self.label_44.setAlignment(QtCore.Qt.AlignCenter)\n self.label_44.setObjectName(\"label_44\")\n self.label_45 = QtWidgets.QLabel(self.groupBox_3)\n self.label_45.setGeometry(QtCore.QRect(270, 110, 30, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_45.sizePolicy().hasHeightForWidth())\n self.label_45.setSizePolicy(sizePolicy)\n self.label_45.setLineWidth(1)\n self.label_45.setScaledContents(False)\n self.label_45.setAlignment(QtCore.Qt.AlignCenter)\n self.label_45.setObjectName(\"label_45\")\n self.label_46 = QtWidgets.QLabel(self.groupBox_3)\n self.label_46.setGeometry(QtCore.QRect(310, 110, 30, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_46.sizePolicy().hasHeightForWidth())\n self.label_46.setSizePolicy(sizePolicy)\n self.label_46.setLineWidth(1)\n self.label_46.setScaledContents(False)\n self.label_46.setAlignment(QtCore.Qt.AlignCenter)\n self.label_46.setObjectName(\"label_46\")\n self.label_47 = QtWidgets.QLabel(self.groupBox_3)\n self.label_47.setGeometry(QtCore.QRect(110, 110, 31, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_47.sizePolicy().hasHeightForWidth())\n self.label_47.setSizePolicy(sizePolicy)\n self.label_47.setLineWidth(1)\n self.label_47.setScaledContents(False)\n self.label_47.setAlignment(QtCore.Qt.AlignCenter)\n self.label_47.setObjectName(\"label_47\")\n self.label_48 = QtWidgets.QLabel(self.groupBox_3)\n self.label_48.setGeometry(QtCore.QRect(190, 110, 30, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_48.sizePolicy().hasHeightForWidth())\n self.label_48.setSizePolicy(sizePolicy)\n self.label_48.setLineWidth(1)\n self.label_48.setScaledContents(False)\n self.label_48.setAlignment(QtCore.Qt.AlignCenter)\n self.label_48.setObjectName(\"label_48\")\n self.pushButton_2 = QtWidgets.QPushButton(self.centralwidget)\n self.pushButton_2.setGeometry(QtCore.QRect(20, 770, 151, 41))\n self.pushButton_2.setObjectName(\"pushButton_2\")\n self.groupBox_4 = QtWidgets.QGroupBox(self.centralwidget)\n self.groupBox_4.setGeometry(QtCore.QRect(0, 540, 390, 130))\n self.groupBox_4.setObjectName(\"groupBox_4\")\n self.tableWidget = QtWidgets.QTableWidget(self.groupBox_4)\n self.tableWidget.setGeometry(QtCore.QRect(10, 20, 370, 100))\n self.tableWidget.setObjectName(\"tableWidget\")\n self.tableWidget.setColumnCount(7)\n self.tableWidget.setRowCount(0)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setHorizontalHeaderItem(0, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setHorizontalHeaderItem(1, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setHorizontalHeaderItem(2, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setHorizontalHeaderItem(3, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setHorizontalHeaderItem(4, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setHorizontalHeaderItem(5, item)\n item = QtWidgets.QTableWidgetItem()\n self.tableWidget.setHorizontalHeaderItem(6, item)\n self.groupBox_5 = QtWidgets.QGroupBox(self.centralwidget)\n self.groupBox_5.setGeometry(QtCore.QRect(0, 670, 390, 90))\n self.groupBox_5.setObjectName(\"groupBox_5\")\n self.label_15 = QtWidgets.QLabel(self.groupBox_5)\n self.label_15.setGeometry(QtCore.QRect(100, 40, 47, 13))\n self.label_15.setObjectName(\"label_15\")\n MainWindow.setCentralWidget(self.centralwidget)\n self.menubar = QtWidgets.QMenuBar(MainWindow)\n self.menubar.setGeometry(QtCore.QRect(0, 0, 874, 21))\n self.menubar.setObjectName(\"menubar\")\n MainWindow.setMenuBar(self.menubar)\n self.statusbar = QtWidgets.QStatusBar(MainWindow)\n self.statusbar.setObjectName(\"statusbar\")\n MainWindow.setStatusBar(self.statusbar)\n\n self.retranslateUi(MainWindow)\n QtCore.QMetaObject.connectSlotsByName(MainWindow)\n\n def retranslateUi(self, MainWindow):\n _translate = QtCore.QCoreApplication.translate\n MainWindow.setWindowTitle(_translate(\"MainWindow\", \"MainWindow\"))\n self.groupBox.setTitle(_translate(\"MainWindow\", \"Character\"))\n self.label.setText(_translate(\"MainWindow\", \"Name\"))\n self.label_2.setText(_translate(\"MainWindow\", \"Race\"))\n self.label_3.setText(_translate(\"MainWindow\", \"Current Career\"))\n self.label_4.setText(_translate(\"MainWindow\", \"Previous Career\"))\n self.groupBox_2.setTitle(_translate(\"MainWindow\", \"Personal Details\"))\n self.label_5.setText(_translate(\"MainWindow\", \"Age\"))\n self.label_6.setText(_translate(\"MainWindow\", \"Eye Color\"))\n self.label_7.setText(_translate(\"MainWindow\", \"Hair Color\"))\n self.label_8.setText(_translate(\"MainWindow\", \"Star Sign\"))\n self.label_9.setText(_translate(\"MainWindow\", \"Birthplace\"))\n self.label_10.setText(_translate(\"MainWindow\", \"Distinguishing Marks\"))\n self.label_11.setText(_translate(\"MainWindow\", \"Weight\"))\n self.label_12.setText(_translate(\"MainWindow\", \"Number of Siblings\"))\n self.label_13.setText(_translate(\"MainWindow\", \"Gender\"))\n self.label_14.setText(_translate(\"MainWindow\", \"Height\"))\n self.pushButton.setText(_translate(\"MainWindow\", \"Fake exit button here\"))\n self.groupBox_3.setTitle(_translate(\"MainWindow\", \"Character Profile\"))\n self.label_25.setText(_translate(\"MainWindow\", \"Main\"))\n self.label_26.setText(_translate(\"MainWindow\", \"Secondary\"))\n self.label_27.setText(_translate(\"MainWindow\", \"WS\"))\n self.label_28.setText(_translate(\"MainWindow\", \"BS\"))\n self.label_29.setText(_translate(\"MainWindow\", \"S\"))\n self.label_30.setText(_translate(\"MainWindow\", \"Int\"))\n self.label_31.setText(_translate(\"MainWindow\", \"WP\"))\n self.label_32.setText(_translate(\"MainWindow\", \"Fel\"))\n self.label_33.setText(_translate(\"MainWindow\", \"T\"))\n self.label_35.setText(_translate(\"MainWindow\", \"Ag\"))\n self.label_34.setText(_translate(\"MainWindow\", \"Starting\"))\n self.label_36.setText(_translate(\"MainWindow\", \"Advance\"))\n self.label_37.setText(_translate(\"MainWindow\", \"Current\"))\n self.label_38.setText(_translate(\"MainWindow\", \"Current\"))\n self.label_39.setText(_translate(\"MainWindow\", \"Advance\"))\n self.label_40.setText(_translate(\"MainWindow\", \"Starting\"))\n self.label_41.setText(_translate(\"MainWindow\", \"A\"))\n self.label_42.setText(_translate(\"MainWindow\", \"FP\"))\n self.label_43.setText(_translate(\"MainWindow\", \"M\"))\n self.label_44.setText(_translate(\"MainWindow\", \"SB\"))\n self.label_45.setText(_translate(\"MainWindow\", \"Mag\"))\n self.label_46.setText(_translate(\"MainWindow\", \"IP\"))\n self.label_47.setText(_translate(\"MainWindow\", \"W\"))\n self.label_48.setText(_translate(\"MainWindow\", \"TB\"))\n self.pushButton_2.setText(_translate(\"MainWindow\", \"Generate Character\"))\n self.groupBox_4.setTitle(_translate(\"MainWindow\", \"Weapons\"))\n item = self.tableWidget.horizontalHeaderItem(0)\n item.setText(_translate(\"MainWindow\", \"Name\"))\n item = self.tableWidget.horizontalHeaderItem(1)\n item.setText(_translate(\"MainWindow\", \"Enc\"))\n item = self.tableWidget.horizontalHeaderItem(2)\n item.setText(_translate(\"MainWindow\", \"Group\"))\n item = self.tableWidget.horizontalHeaderItem(3)\n item.setText(_translate(\"MainWindow\", \"Damage\"))\n item = self.tableWidget.horizontalHeaderItem(4)\n item.setText(_translate(\"MainWindow\", \"Range\"))\n item = self.tableWidget.horizontalHeaderItem(5)\n item.setText(_translate(\"MainWindow\", \"Reload\"))\n item = self.tableWidget.horizontalHeaderItem(6)\n item.setText(_translate(\"MainWindow\", \"Qualities\"))\n self.groupBox_5.setTitle(_translate(\"MainWindow\", \"Armor\"))\n self.label_15.setText(_translate(\"MainWindow\", \"TODO\"))\n\nimport asdf_rc\n\nif __name__ == \"__main__\":\n import sys\n app = QtWidgets.QApplication(sys.argv)\n MainWindow = QtWidgets.QMainWindow()\n ui = Ui_MainWindow()\n ui.setupUi(MainWindow)\n MainWindow.show()\n sys.exit(app.exec_())\n\n"
},
{
"alpha_fraction": 0.6053639650344849,
"alphanum_fraction": 0.6130267977714539,
"avg_line_length": 28.11111068725586,
"blob_id": "6670d86cebb6fc9644c10819fc829a6387f66b0a",
"content_id": "f7c8a4498ed1958029305c2c2b8f737889eceda6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 261,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 9,
"path": "/compile_ui.py",
"repo_name": "TheRealRhyle/WFRP-2e-Char-Gen",
"src_encoding": "UTF-8",
"text": "import os\nfrom subprocess import call\n\nfor filename in os.listdir('D:\\GHRepo\\WFRP-2e-Char-Gen'):\n\n if '.ui' in filename:\n print(\"UI File: \" + filename)\n pyfname = filename.replace('.ui','.py')\n call(['pyuic5','-x',filename,'-o',pyfname])"
},
{
"alpha_fraction": 0.43851131200790405,
"alphanum_fraction": 0.5285868644714355,
"avg_line_length": 30.965517044067383,
"blob_id": "70e69d523950083f862019bd8210d642ff9838ee",
"content_id": "f7b1494d23850cc457ae89172f0ad615af3f0948",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1854,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 58,
"path": "/races.py",
"repo_name": "TheRealRhyle/WFRP-2e-Char-Gen",
"src_encoding": "UTF-8",
"text": "import random\nfrom random import randint\n\n\ndef profiles(rce):\n main_profile_dict = {'WS': 0, 'BS': 0, 'S': 0, 'T': 0, 'Ag': 0, 'Int': 0, 'WP': 0, 'Fel': 0}\n secondary_profile_dict = {'A': 0, 'W': 0, 'SB': 0, 'TB': 0, 'M': 0, 'Mag': 0, 'IP': 0, 'FP': 0}\n main_profile = []\n secondary_profile = []\n\n if rce.lower() == 'dwarf':\n main_profile = [30, 20, 20, 30, 10, 20, 20, 10]\n secondary_profile = [1, 0, 0, 0, 3, 0, 0, 0]\n\n elif rce.lower() == 'elf':\n main_profile = [20, 30, 20, 20, 30, 20, 20, 20]\n secondary_profile = [1, 0, 0, 0, 5, 0, 0, 0]\n\n elif rce.lower() == 'halfling':\n main_profile = [10, 30, 10, 10, 30, 20, 20, 30]\n secondary_profile = [1, 0, 0, 0, 4, 0, 0, 0]\n\n elif rce.lower() == 'human':\n main_profile = [20, 20, 20, 20, 20, 20, 20, 20]\n secondary_profile = [1, 0, 0, 0, 4, 0, 0, 0]\n\n # Set starting fate points.\n f_roll = randint(0, 2)\n dict_fate = {\n 'dwarf': [1, 2, 3],\n 'elf': [1, 2, 2],\n 'halfling': [2, 2, 3],\n 'human': [2, 3, 3]\n }\n\n # Determine starting Wounds based on Race\n w_roll = randint(0, 3)\n dict_wounds = {\n 'dwarf': [11, 12, 13, 14],\n 'elf': [9, 10, 11, 12],\n 'halfling': [8, 9, 10, 11],\n 'human': [10, 11, 12, 13]\n }\n\n fate = dict_fate[rce][f_roll]\n wound = dict_wounds[rce][w_roll]\n # main_random = [randint(2, 20) for stat in range(len(main_profile))]\n mp = [main_profile[stat] + randint(2, 20) for stat in range(len(main_profile))]\n\n secondary_profile.insert(7, fate)\n secondary_profile.pop(-1)\n secondary_profile.pop(3)\n secondary_profile.insert(1, wound)\n\n main_profile = dict(zip(main_profile_dict, mp))\n secondary_profile = dict(zip(secondary_profile_dict, secondary_profile))\n\n return(main_profile, secondary_profile)\n"
},
{
"alpha_fraction": 0.6289424896240234,
"alphanum_fraction": 0.646567702293396,
"avg_line_length": 27.394737243652344,
"blob_id": "05c0da174a8cb116a265ef13747e6ad687bf8958",
"content_id": "e65ed8db58419a4cb9605286be23e1c6d196f21a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1078,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 38,
"path": "/career list test.py",
"repo_name": "TheRealRhyle/WFRP-2e-Char-Gen",
"src_encoding": "UTF-8",
"text": "import career_listf as cf\n\ncareer_name = 'Outrider'\nscheme_name = career_name + ' Advance Scheme'\nmain_profile_dict = {'WS': 0, 'BS': 0, 'S': 0, 'T': 0, 'Ag': 0, 'Int': 0, 'WP': 0, 'Fel': 0}\nsecondary_profile_dict = {'A': 0, 'W': 0, 'SB': 0, 'TB': 0, 'M': 0, 'Mag': 0, 'IP': 0, 'FP': 0}\n\n#career_name = cf.career_selection(scheme_name)\n\n#print(scheme_name)\n#print(career_name['Skills'])\ncareer = cf.career_selection(scheme_name)\n\ncareer['Skills'] = ', '.join(career['Skills'])\ncareer['Talents'] = ', '.join(career['Talents'])\ncareer['Trappings'] = ', '.join(career['Trappings'])\ncareer['Career Entries'] = ', '.join(career['Career Entries'])\ncareer['Career Exits'] = ', '.join(career['Career Exits'])\nliststat = list(career['Statblock'])\nmain_profile_adv = liststat[0:7]\nsecondary_profile_adv = liststat[7:]\n\n\nmp = dict(zip(main_profile_dict,main_profile_adv))\nsp = dict(zip(secondary_profile_dict,secondary_profile_adv))\n\n\nscheme_output = '''{}\n{}\n{}\n{Skills}\n{Talents}\n{Trappings}\n{Career Entries}\n{Career Exits}\n'''.format(scheme_name, mp, sp, **career)\n\nprint(scheme_output)"
},
{
"alpha_fraction": 0.5615584254264832,
"alphanum_fraction": 0.5864934921264648,
"avg_line_length": 45.92683029174805,
"blob_id": "4b4fc37ab2feb001e994bbfa299d9f7b9496f2a7",
"content_id": "0cfd8639f2a0b7d0f4471329ceeea50d37c8d836",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1925,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 41,
"path": "/rand.py",
"repo_name": "TheRealRhyle/WFRP-2e-Char-Gen",
"src_encoding": "UTF-8",
"text": "# import pickle\n#\n# char = {\n# 'starsign': 'The Drummer - Sign of Excess and Hedonism',\n# 'skills': ['Common Knowledge (Elves)', 'Speak Language (Eltharin)', 'Speak Language (Reikspiel)'],\n# 'talents': ['Aethyric Attunement or Specialist Weapon Group (Longbow)', 'Coolheaded or Savvy', 'Excellent Vision',\n# 'Night Vision'],\n# 'main_profile_header': 'WS\\tBS\\tS\\tT\\tAg\\tInt\\tWP\\tFel\\t',\n# 'main_profile': '35\\t40\\t35\\t31\\t41\\t29\\t24\\t39\\t',\n# 'main_profile_adv': '5\\t5\\t0\\t0\\t10\\t10\\t5\\t0',\n# 'secondary_profile_header': 'A\\tW\\tSB\\tTB\\tM\\tMag\\tIP\\tFP\\t',\n# 'secondary_profile': '1\\t11\\t3\\t3\\t5\\t0\\t0\\t2\\t',\n# 'secondary_profile_adv': '2\\t0\\t0\\t0\\t0\\t0\\t0\\t0',\n# 'adv_skill': ['Concealment', 'Dodge Blow', 'Follow Trail', 'Heal or Search', 'Outdoor Survival', 'Perception',\n# 'Scale SheerSurface', 'Silent Move'],\n# 'adv_talent': ['Marksman or Rover', 'Rapid Reload or Warrior Born'],\n# 'trappings': ['Elfbow with 10 arrows', 'Light Armour (Leather Jack)'],\n# 'career_entries': ['Hunter', 'Messenger'],\n# 'career_exits': ['Hunter', 'Outrider', 'Vagabond', 'Veteran']\n# }\n#\n# skill = 0\n# while skill < len(char['talents']):\n# if ' or ' in char['talents'][skill]:\n# print(char['talents'][skill])\n# selection = input('A selection must be made: ' + char['talents'][skill] + \": \")\n# char['talents'].remove(char['talents'][skill])\n# char['talents'].append(selection)\n# skill -= 1\n# skill += 1\n#\n# print(sorted(char['talents']))\n#\n#\n# # for skill in range(len(sorted(char['talents']))):\n# # print(char['talents'][skill])\n# # if ' or ' in char['talents'][skill]:\n# # selection = input('A selection must be made: ' + char['talents'][skill])\n# # char['talents'].remove(char['talents'][skill])\n# # char['talents'].append(selection)\n# # print(char['talents'])\n\n"
},
{
"alpha_fraction": 0.6662184000015259,
"alphanum_fraction": 0.7044508457183838,
"avg_line_length": 57.047088623046875,
"blob_id": "b7178c0b3eed02bacdd93b3dc2ac6aacbf28f474",
"content_id": "4cf6293ab60e64ad91bc1a2c8b6e376fee5efe45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 46845,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 807,
"path": "/testui.py",
"repo_name": "TheRealRhyle/WFRP-2e-Char-Gen",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file 'testui.ui'\n#\n# Created by: PyQt5 UI code generator 5.11.2\n#\n# WARNING! All changes made in this file will be lost!\n\nfrom PyQt5 import QtCore, QtGui, QtWidgets\n\nclass Ui_MainWindow(object):\n def setupUi(self, MainWindow):\n MainWindow.setObjectName(\"MainWindow\")\n MainWindow.setWindowModality(QtCore.Qt.ApplicationModal)\n MainWindow.resize(633, 487)\n self.centralwidget = QtWidgets.QWidget(MainWindow)\n self.centralwidget.setObjectName(\"centralwidget\")\n self.IconPlaceholder = QtWidgets.QFrame(self.centralwidget)\n self.IconPlaceholder.setGeometry(QtCore.QRect(6, 6, 120, 50))\n self.IconPlaceholder.setFrameShape(QtWidgets.QFrame.StyledPanel)\n self.IconPlaceholder.setFrameShadow(QtWidgets.QFrame.Raised)\n self.IconPlaceholder.setObjectName(\"IconPlaceholder\")\n self.nameButton = QtWidgets.QPushButton(self.centralwidget)\n self.nameButton.setGeometry(QtCore.QRect(130, 10, 41, 40))\n self.nameButton.setObjectName(\"nameButton\")\n self.txtName = QtWidgets.QPlainTextEdit(self.centralwidget)\n self.txtName.setGeometry(QtCore.QRect(180, 10, 450, 40))\n font = QtGui.QFont()\n font.setFamily(\"Comic Sans MS\")\n font.setPointSize(18)\n font.setBold(True)\n font.setWeight(75)\n self.txtName.setFont(font)\n self.txtName.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtName.setHorizontalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtName.setLineWrapMode(QtWidgets.QPlainTextEdit.WidgetWidth)\n self.txtName.setPlainText(\"\")\n self.txtName.setBackgroundVisible(False)\n self.txtName.setObjectName(\"txtName\")\n self.tabWidget = QtWidgets.QTabWidget(self.centralwidget)\n self.tabWidget.setGeometry(QtCore.QRect(130, 50, 501, 391))\n self.tabWidget.setObjectName(\"tabWidget\")\n self.tabIdent = QtWidgets.QWidget()\n self.tabIdent.setObjectName(\"tabIdent\")\n self.label = QtWidgets.QLabel(self.tabIdent)\n self.label.setGeometry(QtCore.QRect(-1, 10, 51, 20))\n self.label.setAlignment(QtCore.Qt.AlignRight|QtCore.Qt.AlignTrailing|QtCore.Qt.AlignVCenter)\n self.label.setObjectName(\"label\")\n self.label_2 = QtWidgets.QLabel(self.tabIdent)\n self.label_2.setGeometry(QtCore.QRect(0, 32, 51, 31))\n self.label_2.setAlignment(QtCore.Qt.AlignRight|QtCore.Qt.AlignTrailing|QtCore.Qt.AlignVCenter)\n self.label_2.setWordWrap(True)\n self.label_2.setObjectName(\"label_2\")\n self.label_3 = QtWidgets.QLabel(self.tabIdent)\n self.label_3.setGeometry(QtCore.QRect(0, 62, 51, 31))\n self.label_3.setAlignment(QtCore.Qt.AlignRight|QtCore.Qt.AlignTrailing|QtCore.Qt.AlignVCenter)\n self.label_3.setWordWrap(True)\n self.label_3.setObjectName(\"label_3\")\n self.label_4 = QtWidgets.QLabel(self.tabIdent)\n self.label_4.setGeometry(QtCore.QRect(190, 10, 61, 20))\n self.label_4.setAlignment(QtCore.Qt.AlignRight|QtCore.Qt.AlignTrailing|QtCore.Qt.AlignVCenter)\n self.label_4.setObjectName(\"label_4\")\n self.label_5 = QtWidgets.QLabel(self.tabIdent)\n self.label_5.setGeometry(QtCore.QRect(190, 40, 61, 20))\n self.label_5.setAlignment(QtCore.Qt.AlignRight|QtCore.Qt.AlignTrailing|QtCore.Qt.AlignVCenter)\n self.label_5.setObjectName(\"label_5\")\n self.label_6 = QtWidgets.QLabel(self.tabIdent)\n self.label_6.setGeometry(QtCore.QRect(190, 70, 61, 20))\n self.label_6.setAlignment(QtCore.Qt.AlignRight|QtCore.Qt.AlignTrailing|QtCore.Qt.AlignVCenter)\n self.label_6.setObjectName(\"label_6\")\n self.label_7 = QtWidgets.QLabel(self.tabIdent)\n self.label_7.setGeometry(QtCore.QRect(-10, 100, 61, 20))\n self.label_7.setAlignment(QtCore.Qt.AlignRight|QtCore.Qt.AlignTrailing|QtCore.Qt.AlignVCenter)\n self.label_7.setObjectName(\"label_7\")\n self.label_8 = QtWidgets.QLabel(self.tabIdent)\n self.label_8.setGeometry(QtCore.QRect(190, 130, 60, 20))\n self.label_8.setAlignment(QtCore.Qt.AlignRight|QtCore.Qt.AlignTrailing|QtCore.Qt.AlignVCenter)\n self.label_8.setObjectName(\"label_8\")\n self.label_9 = QtWidgets.QLabel(self.tabIdent)\n self.label_9.setGeometry(QtCore.QRect(10, 130, 41, 20))\n self.label_9.setAlignment(QtCore.Qt.AlignRight|QtCore.Qt.AlignTrailing|QtCore.Qt.AlignVCenter)\n self.label_9.setObjectName(\"label_9\")\n self.label_10 = QtWidgets.QLabel(self.tabIdent)\n self.label_10.setGeometry(QtCore.QRect(340, 10, 61, 20))\n self.label_10.setAlignment(QtCore.Qt.AlignRight|QtCore.Qt.AlignTrailing|QtCore.Qt.AlignVCenter)\n self.label_10.setObjectName(\"label_10\")\n self.label_11 = QtWidgets.QLabel(self.tabIdent)\n self.label_11.setGeometry(QtCore.QRect(340, 40, 61, 20))\n self.label_11.setAlignment(QtCore.Qt.AlignRight|QtCore.Qt.AlignTrailing|QtCore.Qt.AlignVCenter)\n self.label_11.setObjectName(\"label_11\")\n self.label_12 = QtWidgets.QLabel(self.tabIdent)\n self.label_12.setGeometry(QtCore.QRect(340, 70, 61, 20))\n self.label_12.setAlignment(QtCore.Qt.AlignRight|QtCore.Qt.AlignTrailing|QtCore.Qt.AlignVCenter)\n self.label_12.setObjectName(\"label_12\")\n self.label_13 = QtWidgets.QLabel(self.tabIdent)\n self.label_13.setGeometry(QtCore.QRect(340, 90, 61, 31))\n self.label_13.setAlignment(QtCore.Qt.AlignRight|QtCore.Qt.AlignTrailing|QtCore.Qt.AlignVCenter)\n self.label_13.setWordWrap(True)\n self.label_13.setObjectName(\"label_13\")\n self.le_Race = QtWidgets.QLineEdit(self.tabIdent)\n self.le_Race.setGeometry(QtCore.QRect(60, 10, 130, 20))\n self.le_Race.setObjectName(\"le_Race\")\n self.le_CurrentCar = QtWidgets.QLineEdit(self.tabIdent)\n self.le_CurrentCar.setGeometry(QtCore.QRect(60, 40, 130, 20))\n self.le_CurrentCar.setObjectName(\"le_CurrentCar\")\n self.le_previousCar = QtWidgets.QLineEdit(self.tabIdent)\n self.le_previousCar.setGeometry(QtCore.QRect(60, 70, 130, 20))\n self.le_previousCar.setObjectName(\"le_previousCar\")\n self.le_Age = QtWidgets.QLineEdit(self.tabIdent)\n self.le_Age.setGeometry(QtCore.QRect(260, 10, 81, 20))\n self.le_Age.setObjectName(\"le_Age\")\n self.le_Gender = QtWidgets.QLineEdit(self.tabIdent)\n self.le_Gender.setGeometry(QtCore.QRect(410, 10, 81, 20))\n self.le_Gender.setObjectName(\"le_Gender\")\n self.le_EyeC = QtWidgets.QLineEdit(self.tabIdent)\n self.le_EyeC.setGeometry(QtCore.QRect(260, 40, 81, 20))\n self.le_EyeC.setObjectName(\"le_EyeC\")\n self.le_Weight = QtWidgets.QLineEdit(self.tabIdent)\n self.le_Weight.setGeometry(QtCore.QRect(410, 40, 81, 20))\n self.le_Weight.setObjectName(\"le_Weight\")\n self.le_HairC = QtWidgets.QLineEdit(self.tabIdent)\n self.le_HairC.setGeometry(QtCore.QRect(260, 70, 81, 20))\n self.le_HairC.setObjectName(\"le_HairC\")\n self.le_Height = QtWidgets.QLineEdit(self.tabIdent)\n self.le_Height.setGeometry(QtCore.QRect(410, 70, 81, 20))\n self.le_Height.setObjectName(\"le_Height\")\n self.le_StarSign = QtWidgets.QLineEdit(self.tabIdent)\n self.le_StarSign.setGeometry(QtCore.QRect(60, 100, 280, 20))\n self.le_StarSign.setObjectName(\"le_StarSign\")\n self.le_NoofSib = QtWidgets.QLineEdit(self.tabIdent)\n self.le_NoofSib.setGeometry(QtCore.QRect(410, 100, 81, 20))\n self.le_NoofSib.setObjectName(\"le_NoofSib\")\n self.le_Birthplace = QtWidgets.QLineEdit(self.tabIdent)\n self.le_Birthplace.setGeometry(QtCore.QRect(260, 130, 230, 20))\n self.le_Birthplace.setObjectName(\"le_Birthplace\")\n self.le_Distinguish = QtWidgets.QLineEdit(self.tabIdent)\n self.le_Distinguish.setGeometry(QtCore.QRect(61, 130, 130, 20))\n self.le_Distinguish.setObjectName(\"le_Distinguish\")\n self.groupBox_3 = QtWidgets.QGroupBox(self.tabIdent)\n self.groupBox_3.setGeometry(QtCore.QRect(0, 160, 391, 201))\n self.groupBox_3.setAlignment(QtCore.Qt.AlignCenter)\n self.groupBox_3.setObjectName(\"groupBox_3\")\n self.label_25 = QtWidgets.QLabel(self.groupBox_3)\n self.label_25.setGeometry(QtCore.QRect(10, 20, 47, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_25.sizePolicy().hasHeightForWidth())\n self.label_25.setSizePolicy(sizePolicy)\n self.label_25.setLineWidth(1)\n self.label_25.setScaledContents(False)\n self.label_25.setObjectName(\"label_25\")\n self.label_26 = QtWidgets.QLabel(self.groupBox_3)\n self.label_26.setGeometry(QtCore.QRect(10, 110, 61, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_26.sizePolicy().hasHeightForWidth())\n self.label_26.setSizePolicy(sizePolicy)\n self.label_26.setLineWidth(1)\n self.label_26.setScaledContents(False)\n self.label_26.setObjectName(\"label_26\")\n self.txtSBS = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSBS.setGeometry(QtCore.QRect(110, 40, 31, 21))\n self.txtSBS.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSBS.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSBS.setPlainText(\"\")\n self.txtSBS.setObjectName(\"txtSBS\")\n self.txtSS = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSS.setGeometry(QtCore.QRect(150, 40, 31, 21))\n self.txtSS.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSS.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSS.setPlainText(\"\")\n self.txtSS.setObjectName(\"txtSS\")\n self.txtST = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtST.setGeometry(QtCore.QRect(190, 40, 31, 21))\n self.txtST.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtST.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtST.setPlainText(\"\")\n self.txtST.setObjectName(\"txtST\")\n self.txtSAg = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSAg.setGeometry(QtCore.QRect(230, 40, 31, 21))\n self.txtSAg.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSAg.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSAg.setPlainText(\"\")\n self.txtSAg.setObjectName(\"txtSAg\")\n self.txtSInt = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSInt.setGeometry(QtCore.QRect(270, 40, 31, 21))\n self.txtSInt.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSInt.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSInt.setPlainText(\"\")\n self.txtSInt.setObjectName(\"txtSInt\")\n self.txtSWP = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSWP.setGeometry(QtCore.QRect(310, 40, 31, 21))\n self.txtSWP.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSWP.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSWP.setPlainText(\"\")\n self.txtSWP.setObjectName(\"txtSWP\")\n self.txtSFel = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSFel.setGeometry(QtCore.QRect(350, 40, 31, 21))\n self.txtSFel.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSFel.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSFel.setPlainText(\"\")\n self.txtSFel.setObjectName(\"txtSFel\")\n self.txtSWS = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSWS.setGeometry(QtCore.QRect(70, 40, 31, 21))\n self.txtSWS.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSWS.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSWS.setPlainText(\"\")\n self.txtSWS.setObjectName(\"txtSWS\")\n self.txtAInt = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAInt.setGeometry(QtCore.QRect(270, 60, 31, 21))\n self.txtAInt.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAInt.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAInt.setPlainText(\"\")\n self.txtAInt.setObjectName(\"txtAInt\")\n self.txtAAg = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAAg.setGeometry(QtCore.QRect(230, 60, 31, 21))\n self.txtAAg.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAAg.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAAg.setPlainText(\"\")\n self.txtAAg.setObjectName(\"txtAAg\")\n self.txtAWS = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAWS.setGeometry(QtCore.QRect(70, 60, 31, 21))\n self.txtAWS.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAWS.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAWS.setPlainText(\"\")\n self.txtAWS.setObjectName(\"txtAWS\")\n self.txtAFel = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAFel.setGeometry(QtCore.QRect(350, 60, 31, 21))\n self.txtAFel.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAFel.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAFel.setPlainText(\"\")\n self.txtAFel.setObjectName(\"txtAFel\")\n self.txtABS = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtABS.setGeometry(QtCore.QRect(110, 60, 31, 21))\n self.txtABS.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtABS.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtABS.setPlainText(\"\")\n self.txtABS.setObjectName(\"txtABS\")\n self.txtAT = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAT.setGeometry(QtCore.QRect(190, 60, 31, 21))\n self.txtAT.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAT.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAT.setPlainText(\"\")\n self.txtAT.setObjectName(\"txtAT\")\n self.txtAS = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAS.setGeometry(QtCore.QRect(150, 60, 31, 21))\n self.txtAS.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAS.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAS.setPlainText(\"\")\n self.txtAS.setObjectName(\"txtAS\")\n self.txtAWP = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAWP.setGeometry(QtCore.QRect(310, 60, 31, 21))\n self.txtAWP.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAWP.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAWP.setPlainText(\"\")\n self.txtAWP.setObjectName(\"txtAWP\")\n self.txtCInt = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCInt.setGeometry(QtCore.QRect(270, 80, 31, 21))\n self.txtCInt.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCInt.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCInt.setPlainText(\"\")\n self.txtCInt.setObjectName(\"txtCInt\")\n self.txtCAg = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCAg.setGeometry(QtCore.QRect(230, 80, 31, 21))\n self.txtCAg.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCAg.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCAg.setPlainText(\"\")\n self.txtCAg.setObjectName(\"txtCAg\")\n self.txtCWS = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCWS.setGeometry(QtCore.QRect(70, 80, 31, 21))\n self.txtCWS.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCWS.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCWS.setPlainText(\"\")\n self.txtCWS.setObjectName(\"txtCWS\")\n self.txtCFel = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCFel.setGeometry(QtCore.QRect(350, 80, 31, 21))\n self.txtCFel.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCFel.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCFel.setPlainText(\"\")\n self.txtCFel.setObjectName(\"txtCFel\")\n self.txtCBS = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCBS.setGeometry(QtCore.QRect(110, 80, 31, 21))\n self.txtCBS.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCBS.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCBS.setPlainText(\"\")\n self.txtCBS.setObjectName(\"txtCBS\")\n self.txtCT = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCT.setGeometry(QtCore.QRect(190, 80, 31, 21))\n self.txtCT.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCT.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCT.setPlainText(\"\")\n self.txtCT.setObjectName(\"txtCT\")\n self.txtCS = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCS.setGeometry(QtCore.QRect(150, 80, 31, 21))\n self.txtCS.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCS.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCS.setPlainText(\"\")\n self.txtCS.setObjectName(\"txtCS\")\n self.txtCWP = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCWP.setGeometry(QtCore.QRect(310, 80, 31, 21))\n self.txtCWP.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCWP.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCWP.setPlainText(\"\")\n self.txtCWP.setObjectName(\"txtCWP\")\n self.txtSA = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSA.setGeometry(QtCore.QRect(70, 130, 31, 21))\n self.txtSA.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSA.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSA.setPlainText(\"\")\n self.txtSA.setObjectName(\"txtSA\")\n self.txtSB = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSB.setGeometry(QtCore.QRect(150, 130, 31, 21))\n self.txtSB.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSB.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSB.setPlainText(\"\")\n self.txtSB.setObjectName(\"txtSB\")\n self.txtAIp = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAIp.setGeometry(QtCore.QRect(310, 150, 31, 21))\n self.txtAIp.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAIp.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAIp.setPlainText(\"\")\n self.txtAIp.setObjectName(\"txtAIp\")\n self.txtAA = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAA.setGeometry(QtCore.QRect(70, 150, 31, 21))\n self.txtAA.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAA.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAA.setPlainText(\"\")\n self.txtAA.setObjectName(\"txtAA\")\n self.txtSTB = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSTB.setGeometry(QtCore.QRect(190, 130, 31, 21))\n self.txtSTB.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSTB.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSTB.setPlainText(\"\")\n self.txtSTB.setObjectName(\"txtSTB\")\n self.txtSIP = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSIP.setGeometry(QtCore.QRect(310, 130, 31, 21))\n self.txtSIP.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSIP.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSIP.setPlainText(\"\")\n self.txtSIP.setObjectName(\"txtSIP\")\n self.txtCTB = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCTB.setGeometry(QtCore.QRect(190, 170, 31, 21))\n self.txtCTB.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCTB.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCTB.setPlainText(\"\")\n self.txtCTB.setObjectName(\"txtCTB\")\n self.txtSW = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSW.setGeometry(QtCore.QRect(110, 130, 31, 21))\n self.txtSW.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSW.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSW.setPlainText(\"\")\n self.txtSW.setObjectName(\"txtSW\")\n self.txtAMag = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAMag.setGeometry(QtCore.QRect(270, 150, 31, 21))\n self.txtAMag.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAMag.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAMag.setPlainText(\"\")\n self.txtAMag.setObjectName(\"txtAMag\")\n self.txtAM = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAM.setGeometry(QtCore.QRect(230, 150, 31, 21))\n self.txtAM.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAM.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAM.setPlainText(\"\")\n self.txtAM.setObjectName(\"txtAM\")\n self.txtCA = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCA.setGeometry(QtCore.QRect(70, 170, 31, 21))\n self.txtCA.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCA.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCA.setPlainText(\"\")\n self.txtCA.setObjectName(\"txtCA\")\n self.txtSM = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSM.setGeometry(QtCore.QRect(230, 130, 31, 21))\n self.txtSM.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSM.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSM.setPlainText(\"\")\n self.txtSM.setObjectName(\"txtSM\")\n self.txtCW = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCW.setGeometry(QtCore.QRect(110, 170, 31, 21))\n self.txtCW.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCW.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCW.setPlainText(\"\")\n self.txtCW.setObjectName(\"txtCW\")\n self.txtCMag = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCMag.setGeometry(QtCore.QRect(270, 170, 31, 21))\n self.txtCMag.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCMag.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCMag.setPlainText(\"\")\n self.txtCMag.setObjectName(\"txtCMag\")\n self.txtAW = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAW.setGeometry(QtCore.QRect(110, 150, 31, 21))\n self.txtAW.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAW.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAW.setPlainText(\"\")\n self.txtAW.setObjectName(\"txtAW\")\n self.txtCFP = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCFP.setGeometry(QtCore.QRect(350, 170, 31, 21))\n self.txtCFP.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCFP.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCFP.setPlainText(\"\")\n self.txtCFP.setObjectName(\"txtCFP\")\n self.txtASB = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtASB.setGeometry(QtCore.QRect(150, 150, 31, 21))\n self.txtASB.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtASB.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtASB.setPlainText(\"\")\n self.txtASB.setObjectName(\"txtASB\")\n self.txtCIP = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCIP.setGeometry(QtCore.QRect(310, 170, 31, 21))\n self.txtCIP.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCIP.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCIP.setPlainText(\"\")\n self.txtCIP.setObjectName(\"txtCIP\")\n self.txtCSB = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCSB.setGeometry(QtCore.QRect(150, 170, 31, 21))\n self.txtCSB.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCSB.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCSB.setPlainText(\"\")\n self.txtCSB.setObjectName(\"txtCSB\")\n self.txtSFP = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSFP.setGeometry(QtCore.QRect(350, 130, 31, 21))\n self.txtSFP.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSFP.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSFP.setPlainText(\"\")\n self.txtSFP.setObjectName(\"txtSFP\")\n self.txtATB = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtATB.setGeometry(QtCore.QRect(190, 150, 31, 21))\n self.txtATB.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtATB.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtATB.setPlainText(\"\")\n self.txtATB.setObjectName(\"txtATB\")\n self.txtCM = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtCM.setGeometry(QtCore.QRect(230, 170, 31, 21))\n self.txtCM.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtCM.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtCM.setPlainText(\"\")\n self.txtCM.setObjectName(\"txtCM\")\n self.txtAFP = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtAFP.setGeometry(QtCore.QRect(350, 150, 31, 21))\n self.txtAFP.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtAFP.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtAFP.setPlainText(\"\")\n self.txtAFP.setObjectName(\"txtAFP\")\n self.txtSMag = QtWidgets.QPlainTextEdit(self.groupBox_3)\n self.txtSMag.setGeometry(QtCore.QRect(270, 130, 31, 21))\n self.txtSMag.setVerticalScrollBarPolicy(QtCore.Qt.ScrollBarAlwaysOff)\n self.txtSMag.setLineWrapMode(QtWidgets.QPlainTextEdit.NoWrap)\n self.txtSMag.setPlainText(\"\")\n self.txtSMag.setObjectName(\"txtSMag\")\n self.label_27 = QtWidgets.QLabel(self.groupBox_3)\n self.label_27.setGeometry(QtCore.QRect(70, 20, 31, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_27.sizePolicy().hasHeightForWidth())\n self.label_27.setSizePolicy(sizePolicy)\n self.label_27.setLineWidth(1)\n self.label_27.setScaledContents(False)\n self.label_27.setAlignment(QtCore.Qt.AlignCenter)\n self.label_27.setObjectName(\"label_27\")\n self.label_28 = QtWidgets.QLabel(self.groupBox_3)\n self.label_28.setGeometry(QtCore.QRect(110, 20, 31, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_28.sizePolicy().hasHeightForWidth())\n self.label_28.setSizePolicy(sizePolicy)\n self.label_28.setLineWidth(1)\n self.label_28.setScaledContents(False)\n self.label_28.setAlignment(QtCore.Qt.AlignCenter)\n self.label_28.setObjectName(\"label_28\")\n self.label_29 = QtWidgets.QLabel(self.groupBox_3)\n self.label_29.setGeometry(QtCore.QRect(150, 20, 31, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_29.sizePolicy().hasHeightForWidth())\n self.label_29.setSizePolicy(sizePolicy)\n self.label_29.setLineWidth(1)\n self.label_29.setScaledContents(False)\n self.label_29.setAlignment(QtCore.Qt.AlignCenter)\n self.label_29.setObjectName(\"label_29\")\n self.label_30 = QtWidgets.QLabel(self.groupBox_3)\n self.label_30.setGeometry(QtCore.QRect(270, 20, 30, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_30.sizePolicy().hasHeightForWidth())\n self.label_30.setSizePolicy(sizePolicy)\n self.label_30.setLineWidth(1)\n self.label_30.setScaledContents(False)\n self.label_30.setAlignment(QtCore.Qt.AlignCenter)\n self.label_30.setObjectName(\"label_30\")\n self.label_31 = QtWidgets.QLabel(self.groupBox_3)\n self.label_31.setGeometry(QtCore.QRect(310, 20, 30, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_31.sizePolicy().hasHeightForWidth())\n self.label_31.setSizePolicy(sizePolicy)\n self.label_31.setLineWidth(1)\n self.label_31.setScaledContents(False)\n self.label_31.setAlignment(QtCore.Qt.AlignCenter)\n self.label_31.setObjectName(\"label_31\")\n self.label_32 = QtWidgets.QLabel(self.groupBox_3)\n self.label_32.setGeometry(QtCore.QRect(350, 20, 30, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_32.sizePolicy().hasHeightForWidth())\n self.label_32.setSizePolicy(sizePolicy)\n self.label_32.setLineWidth(1)\n self.label_32.setScaledContents(False)\n self.label_32.setAlignment(QtCore.Qt.AlignCenter)\n self.label_32.setObjectName(\"label_32\")\n self.label_33 = QtWidgets.QLabel(self.groupBox_3)\n self.label_33.setGeometry(QtCore.QRect(190, 20, 30, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_33.sizePolicy().hasHeightForWidth())\n self.label_33.setSizePolicy(sizePolicy)\n self.label_33.setLineWidth(1)\n self.label_33.setScaledContents(False)\n self.label_33.setAlignment(QtCore.Qt.AlignCenter)\n self.label_33.setObjectName(\"label_33\")\n self.label_35 = QtWidgets.QLabel(self.groupBox_3)\n self.label_35.setGeometry(QtCore.QRect(230, 20, 30, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_35.sizePolicy().hasHeightForWidth())\n self.label_35.setSizePolicy(sizePolicy)\n self.label_35.setLineWidth(1)\n self.label_35.setScaledContents(False)\n self.label_35.setAlignment(QtCore.Qt.AlignCenter)\n self.label_35.setObjectName(\"label_35\")\n self.label_34 = QtWidgets.QLabel(self.groupBox_3)\n self.label_34.setGeometry(QtCore.QRect(20, 40, 47, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_34.sizePolicy().hasHeightForWidth())\n self.label_34.setSizePolicy(sizePolicy)\n self.label_34.setLineWidth(1)\n self.label_34.setScaledContents(False)\n self.label_34.setObjectName(\"label_34\")\n self.label_36 = QtWidgets.QLabel(self.groupBox_3)\n self.label_36.setGeometry(QtCore.QRect(20, 60, 47, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_36.sizePolicy().hasHeightForWidth())\n self.label_36.setSizePolicy(sizePolicy)\n self.label_36.setLineWidth(1)\n self.label_36.setScaledContents(False)\n self.label_36.setObjectName(\"label_36\")\n self.label_37 = QtWidgets.QLabel(self.groupBox_3)\n self.label_37.setGeometry(QtCore.QRect(20, 80, 47, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_37.sizePolicy().hasHeightForWidth())\n self.label_37.setSizePolicy(sizePolicy)\n self.label_37.setLineWidth(1)\n self.label_37.setScaledContents(False)\n self.label_37.setObjectName(\"label_37\")\n self.label_38 = QtWidgets.QLabel(self.groupBox_3)\n self.label_38.setGeometry(QtCore.QRect(20, 170, 47, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_38.sizePolicy().hasHeightForWidth())\n self.label_38.setSizePolicy(sizePolicy)\n self.label_38.setLineWidth(1)\n self.label_38.setScaledContents(False)\n self.label_38.setObjectName(\"label_38\")\n self.label_39 = QtWidgets.QLabel(self.groupBox_3)\n self.label_39.setGeometry(QtCore.QRect(20, 150, 47, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_39.sizePolicy().hasHeightForWidth())\n self.label_39.setSizePolicy(sizePolicy)\n self.label_39.setLineWidth(1)\n self.label_39.setScaledContents(False)\n self.label_39.setObjectName(\"label_39\")\n self.label_40 = QtWidgets.QLabel(self.groupBox_3)\n self.label_40.setGeometry(QtCore.QRect(20, 130, 47, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_40.sizePolicy().hasHeightForWidth())\n self.label_40.setSizePolicy(sizePolicy)\n self.label_40.setLineWidth(1)\n self.label_40.setScaledContents(False)\n self.label_40.setObjectName(\"label_40\")\n self.label_41 = QtWidgets.QLabel(self.groupBox_3)\n self.label_41.setGeometry(QtCore.QRect(70, 110, 31, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_41.sizePolicy().hasHeightForWidth())\n self.label_41.setSizePolicy(sizePolicy)\n self.label_41.setLineWidth(1)\n self.label_41.setScaledContents(False)\n self.label_41.setAlignment(QtCore.Qt.AlignCenter)\n self.label_41.setObjectName(\"label_41\")\n self.label_42 = QtWidgets.QLabel(self.groupBox_3)\n self.label_42.setGeometry(QtCore.QRect(350, 110, 30, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_42.sizePolicy().hasHeightForWidth())\n self.label_42.setSizePolicy(sizePolicy)\n self.label_42.setLineWidth(1)\n self.label_42.setScaledContents(False)\n self.label_42.setAlignment(QtCore.Qt.AlignCenter)\n self.label_42.setObjectName(\"label_42\")\n self.label_43 = QtWidgets.QLabel(self.groupBox_3)\n self.label_43.setGeometry(QtCore.QRect(230, 110, 30, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_43.sizePolicy().hasHeightForWidth())\n self.label_43.setSizePolicy(sizePolicy)\n self.label_43.setLineWidth(1)\n self.label_43.setScaledContents(False)\n self.label_43.setAlignment(QtCore.Qt.AlignCenter)\n self.label_43.setObjectName(\"label_43\")\n self.label_44 = QtWidgets.QLabel(self.groupBox_3)\n self.label_44.setGeometry(QtCore.QRect(150, 110, 31, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_44.sizePolicy().hasHeightForWidth())\n self.label_44.setSizePolicy(sizePolicy)\n self.label_44.setLineWidth(1)\n self.label_44.setScaledContents(False)\n self.label_44.setAlignment(QtCore.Qt.AlignCenter)\n self.label_44.setObjectName(\"label_44\")\n self.label_45 = QtWidgets.QLabel(self.groupBox_3)\n self.label_45.setGeometry(QtCore.QRect(270, 110, 30, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_45.sizePolicy().hasHeightForWidth())\n self.label_45.setSizePolicy(sizePolicy)\n self.label_45.setLineWidth(1)\n self.label_45.setScaledContents(False)\n self.label_45.setAlignment(QtCore.Qt.AlignCenter)\n self.label_45.setObjectName(\"label_45\")\n self.label_46 = QtWidgets.QLabel(self.groupBox_3)\n self.label_46.setGeometry(QtCore.QRect(310, 110, 30, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_46.sizePolicy().hasHeightForWidth())\n self.label_46.setSizePolicy(sizePolicy)\n self.label_46.setLineWidth(1)\n self.label_46.setScaledContents(False)\n self.label_46.setAlignment(QtCore.Qt.AlignCenter)\n self.label_46.setObjectName(\"label_46\")\n self.label_47 = QtWidgets.QLabel(self.groupBox_3)\n self.label_47.setGeometry(QtCore.QRect(110, 110, 31, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_47.sizePolicy().hasHeightForWidth())\n self.label_47.setSizePolicy(sizePolicy)\n self.label_47.setLineWidth(1)\n self.label_47.setScaledContents(False)\n self.label_47.setAlignment(QtCore.Qt.AlignCenter)\n self.label_47.setObjectName(\"label_47\")\n self.label_48 = QtWidgets.QLabel(self.groupBox_3)\n self.label_48.setGeometry(QtCore.QRect(190, 110, 30, 16))\n sizePolicy = QtWidgets.QSizePolicy(QtWidgets.QSizePolicy.Minimum, QtWidgets.QSizePolicy.Minimum)\n sizePolicy.setHorizontalStretch(0)\n sizePolicy.setVerticalStretch(0)\n sizePolicy.setHeightForWidth(self.label_48.sizePolicy().hasHeightForWidth())\n self.label_48.setSizePolicy(sizePolicy)\n self.label_48.setLineWidth(1)\n self.label_48.setScaledContents(False)\n self.label_48.setAlignment(QtCore.Qt.AlignCenter)\n self.label_48.setObjectName(\"label_48\")\n self.groupBox = QtWidgets.QGroupBox(self.tabIdent)\n self.groupBox.setGeometry(QtCore.QRect(400, 160, 90, 201))\n self.groupBox.setAlignment(QtCore.Qt.AlignCenter)\n self.groupBox.setObjectName(\"groupBox\")\n self.l_GC = QtWidgets.QLabel(self.groupBox)\n self.l_GC.setGeometry(QtCore.QRect(10, 10, 71, 31))\n self.l_GC.setAlignment(QtCore.Qt.AlignCenter)\n self.l_GC.setWordWrap(True)\n self.l_GC.setObjectName(\"l_GC\")\n self.l_GC_2 = QtWidgets.QLabel(self.groupBox)\n self.l_GC_2.setGeometry(QtCore.QRect(10, 70, 70, 31))\n self.l_GC_2.setAlignment(QtCore.Qt.AlignCenter)\n self.l_GC_2.setWordWrap(True)\n self.l_GC_2.setObjectName(\"l_GC_2\")\n self.l_GC_3 = QtWidgets.QLabel(self.groupBox)\n self.l_GC_3.setGeometry(QtCore.QRect(10, 130, 70, 31))\n self.l_GC_3.setAlignment(QtCore.Qt.AlignCenter)\n self.l_GC_3.setWordWrap(True)\n self.l_GC_3.setObjectName(\"l_GC_3\")\n self.le_GC = QtWidgets.QLineEdit(self.groupBox)\n self.le_GC.setGeometry(QtCore.QRect(9, 50, 70, 20))\n self.le_GC.setObjectName(\"le_GC\")\n self.le_S = QtWidgets.QLineEdit(self.groupBox)\n self.le_S.setGeometry(QtCore.QRect(10, 110, 70, 20))\n self.le_S.setObjectName(\"le_S\")\n self.le_P = QtWidgets.QLineEdit(self.groupBox)\n self.le_P.setGeometry(QtCore.QRect(10, 170, 70, 20))\n self.le_P.setObjectName(\"le_P\")\n self.tabWidget.addTab(self.tabIdent, \"\")\n self.tabSkills = QtWidgets.QWidget()\n self.tabSkills.setObjectName(\"tabSkills\")\n self.tabWidget.addTab(self.tabSkills, \"\")\n self.tabTrappings = QtWidgets.QWidget()\n self.tabTrappings.setObjectName(\"tabTrappings\")\n self.tabWidget.addTab(self.tabTrappings, \"\")\n self.pb_Rando = QtWidgets.QPushButton(self.centralwidget)\n self.pb_Rando.setGeometry(QtCore.QRect(30, 380, 75, 23))\n self.pb_Rando.setObjectName(\"pb_Rando\")\n self.pb_Quit = QtWidgets.QPushButton(self.centralwidget)\n self.pb_Quit.setGeometry(QtCore.QRect(30, 410, 75, 23))\n self.pb_Quit.setObjectName(\"pb_Quit\")\n self.listView = QtWidgets.QListView(self.centralwidget)\n self.listView.setGeometry(QtCore.QRect(10, 60, 111, 311))\n self.listView.setObjectName(\"listView\")\n MainWindow.setCentralWidget(self.centralwidget)\n self.menubar = QtWidgets.QMenuBar(MainWindow)\n self.menubar.setGeometry(QtCore.QRect(0, 0, 633, 21))\n self.menubar.setObjectName(\"menubar\")\n MainWindow.setMenuBar(self.menubar)\n self.statusbar = QtWidgets.QStatusBar(MainWindow)\n self.statusbar.setAutoFillBackground(False)\n self.statusbar.setSizeGripEnabled(False)\n self.statusbar.setObjectName(\"statusbar\")\n MainWindow.setStatusBar(self.statusbar)\n\n self.retranslateUi(MainWindow)\n self.tabWidget.setCurrentIndex(0)\n QtCore.QMetaObject.connectSlotsByName(MainWindow)\n\n def retranslateUi(self, MainWindow):\n _translate = QtCore.QCoreApplication.translate\n MainWindow.setWindowTitle(_translate(\"MainWindow\", \"MainWindow\"))\n self.nameButton.setText(_translate(\"MainWindow\", \"Name\"))\n self.txtName.setPlaceholderText(_translate(\"MainWindow\", \"Test Name\"))\n self.label.setText(_translate(\"MainWindow\", \"Race:\"))\n self.label_2.setText(_translate(\"MainWindow\", \"Current Career:\"))\n self.label_3.setText(_translate(\"MainWindow\", \"Previous Career:\"))\n self.label_4.setText(_translate(\"MainWindow\", \"Age:\"))\n self.label_5.setText(_translate(\"MainWindow\", \"Eye Color:\"))\n self.label_6.setText(_translate(\"MainWindow\", \"Hair Color:\"))\n self.label_7.setText(_translate(\"MainWindow\", \"Star Sign:\"))\n self.label_8.setText(_translate(\"MainWindow\", \"Birthplace:\"))\n self.label_9.setText(_translate(\"MainWindow\", \"Marks:\"))\n self.label_10.setText(_translate(\"MainWindow\", \"Gender:\"))\n self.label_11.setText(_translate(\"MainWindow\", \"Weight:\"))\n self.label_12.setText(_translate(\"MainWindow\", \"Height:\"))\n self.label_13.setText(_translate(\"MainWindow\", \"Numner of Siblings:\"))\n self.groupBox_3.setTitle(_translate(\"MainWindow\", \"Character Profile\"))\n self.label_25.setText(_translate(\"MainWindow\", \"Main\"))\n self.label_26.setText(_translate(\"MainWindow\", \"Secondary\"))\n self.label_27.setText(_translate(\"MainWindow\", \"WS\"))\n self.label_28.setText(_translate(\"MainWindow\", \"BS\"))\n self.label_29.setText(_translate(\"MainWindow\", \"S\"))\n self.label_30.setText(_translate(\"MainWindow\", \"Int\"))\n self.label_31.setText(_translate(\"MainWindow\", \"WP\"))\n self.label_32.setText(_translate(\"MainWindow\", \"Fel\"))\n self.label_33.setText(_translate(\"MainWindow\", \"T\"))\n self.label_35.setText(_translate(\"MainWindow\", \"Ag\"))\n self.label_34.setText(_translate(\"MainWindow\", \"Starting\"))\n self.label_36.setText(_translate(\"MainWindow\", \"Advance\"))\n self.label_37.setText(_translate(\"MainWindow\", \"Current\"))\n self.label_38.setText(_translate(\"MainWindow\", \"Current\"))\n self.label_39.setText(_translate(\"MainWindow\", \"Advance\"))\n self.label_40.setText(_translate(\"MainWindow\", \"Starting\"))\n self.label_41.setText(_translate(\"MainWindow\", \"A\"))\n self.label_42.setText(_translate(\"MainWindow\", \"FP\"))\n self.label_43.setText(_translate(\"MainWindow\", \"M\"))\n self.label_44.setText(_translate(\"MainWindow\", \"SB\"))\n self.label_45.setText(_translate(\"MainWindow\", \"Mag\"))\n self.label_46.setText(_translate(\"MainWindow\", \"IP\"))\n self.label_47.setText(_translate(\"MainWindow\", \"W\"))\n self.label_48.setText(_translate(\"MainWindow\", \"TB\"))\n self.groupBox.setTitle(_translate(\"MainWindow\", \"Purse\"))\n self.l_GC.setText(_translate(\"MainWindow\", \"Gold Crowns (gc)\"))\n self.l_GC_2.setText(_translate(\"MainWindow\", \"Silver Shillings (s)\"))\n self.l_GC_3.setText(_translate(\"MainWindow\", \"Brass Pennies (p)\"))\n self.tabWidget.setTabText(self.tabWidget.indexOf(self.tabIdent), _translate(\"MainWindow\", \"Identity\"))\n self.tabWidget.setTabText(self.tabWidget.indexOf(self.tabSkills), _translate(\"MainWindow\", \"Skills and Talents\"))\n self.tabWidget.setTabText(self.tabWidget.indexOf(self.tabTrappings), _translate(\"MainWindow\", \"Trappings and Magic\"))\n self.pb_Rando.setText(_translate(\"MainWindow\", \"TestButton\"))\n self.pb_Quit.setText(_translate(\"MainWindow\", \"Quit\"))\n\n\nif __name__ == \"__main__\":\n import sys\n app = QtWidgets.QApplication(sys.argv)\n MainWindow = QtWidgets.QMainWindow()\n ui = Ui_MainWindow()\n ui.setupUi(MainWindow)\n MainWindow.show()\n sys.exit(app.exec_())\n\n"
},
{
"alpha_fraction": 0.5447036027908325,
"alphanum_fraction": 0.5456753969192505,
"avg_line_length": 28.399999618530273,
"blob_id": "70ef97746e3820f75cdf72a0f4d551b0fdd9870a",
"content_id": "d8ced6d75c204936c6b66d8deef3b2bc9d34e1b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2058,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 70,
"path": "/export_to_html.py",
"repo_name": "TheRealRhyle/WFRP-2e-Char-Gen",
"src_encoding": "UTF-8",
"text": "def format_sheet(charin):\n charin['weight'] = str(charin['weight'])\n\n # skills = charin['skills']\n skills = ', '.join(sorted(charin['skills']))\n talents = ', '.join(sorted(charin['talents']))\n adv_skill = ', '.join(sorted(charin['adv_skill']))\n adv_talent = ', '.join(sorted(charin['adv_talent']))\n trappings = ', '.join(sorted(charin['trappings']))\n career_entries = ', '.join(sorted(charin['career_entries']))\n career_exits = ', '.join(sorted(charin['career_exits']))\n\n sheet = \"\"\"Name: {name} the {career}\n Race: {race} Gender: {gender} Age: {age}\n Height: {height} Hair Color: {hair_color} Siblings: {siblings}\n Weight: {weight} Eye Color: {eye_color}\n Birthplace: {birthplace}\n Star Sign: {starsign}\n Distinguishing Marks: {marks}\n \n Main Profile:\\t{main_profile_header}\n Main Profile:\\t{main_profile}\n Main Advance:\\t{main_profile_adv}\n Advance Taken: [ ][ ][ ][ ][ ][ ][ ][ ]\n \n Sec Profile:\\t{secondary_profile_header}\n Sec Profile:\\t{secondary_profile}\n Sec Advance:\\t{secondary_profile_adv}\n Advance Taken: [ ][ ][ ][ ][ ][ ][ ][ ]\n \n Trappings:\n -------\n {}\n \n Skills:\n -------\n {}\n \n Talents:\n -------\n {}\n \n Skill Advancements:\n -------\n {}\n \n Talent Advancements:\n -------\n {}\n \n Career Entries\n -------\n {}\n \n Career Exits\n -------\n {}\n \n \"\"\".format(trappings, skills, talents, adv_skill, adv_talent, career_entries,career_exits, **charin).replace(' ','')\n\n sheet_as_html = sheet.replace('\\n','<br>')\n header = '<html><title>{name}</title><body>'.format(**charin)\n with open('characters\\{name}.html'.format(**charin),'w+') as file:\n file.write(header)\n file.write(sheet_as_html)\n file.write('<font size=\"1\"> Character auto generated bt WFRP-2e-Char-Gen by Phillip W. (<a href = \"http://twitch'\n '.tv/darkxilde\">twitch.tv/darkxilde</a>)</font>')\n file.write('</body></html>')\n\n return sheet\n"
}
] | 14 |
lizalexandrita/kyd-scraper
|
https://github.com/lizalexandrita/kyd-scraper
|
837c36f2ca26fef961805b2fe178961affcafccb
|
f82c49d7ddfbe0ec3eef51f51fc354fe75b9d1e6
|
6c4c952e2624f2194a3ed25b5a04be8a2e95a2af
|
refs/heads/master
| 2021-01-21T08:51:31.944669 | 2013-12-18T11:08:50 | 2013-12-18T11:08:50 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5899621248245239,
"alphanum_fraction": 0.5980113744735718,
"avg_line_length": 21.68817138671875,
"blob_id": "de47b15a1ddcb9e5859cdf5c0b760e5df72f2a34",
"content_id": "ef69f2852bb19a0bb256aa179999e8a1fbe6fd30",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2112,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 93,
"path": "/try_meta.py",
"repo_name": "lizalexandrita/kyd-scraper",
"src_encoding": "UTF-8",
"text": "import inspect\nimport pprint\n\nclass Attr(object):\n\tdef __init__(self):\n\t\tself.value = None\n\t\n\tdef __set__(self, obj, value):\n\t\tprint('set', obj, value)\n\t\tself.value = value\n\t\n\tdef __get__(self, obj, typo):\n\t\tprint('get', obj, typo)\n\t\treturn self.value\n\t\t\n\tdef __delete__(self, obj):\n\t\tself.value = None\n\nclass MetaClass(type):\n\tdef __new__(mcls, name, bases, classdict):\n\t\tattrs = {}\n\t\tnew_classdict = {}\n\t\tfor n, v in classdict.iteritems():\n\t\t\tif isinstance(v, Attr):\n\t\t\t\tattrs[n] = v\n\t\t\telse:\n\t\t\t\tnew_classdict[n] = v\n\t\tcls = type.__new__(mcls, name, bases, new_classdict)\n\t\tcls.attrs = cls.attrs.copy()\n\t\tcls.attrs.update(attrs)\n\t\treturn cls\n\nimport copy\n\nclass A(object):\n\t# attrs = {}\n\t# __metaclass__ = MetaClass\n\tdef __new__(cls, *args, **kwargs):\n\t\tobj = super(A, cls).__new__(cls, *args, **kwargs)\n\t\tfor n, v in cls.__dict__.iteritems():\n\t\t\tif isinstance(v, Attr):\n\t\t\t\tprint(n,v)\n\t\t\t\tsetattr(obj, n, copy.copy(v))\n\t\t# for prop_name, prop_value in obj.attrs.items():\n\t\t# \tsetattr(obj, prop_name, copy.copy(prop_value))\n\t\treturn obj\n\t\n\tdef __init__(self, **kwargs):\n\t\tfor prop_name, prop_value in kwargs.items():\n\t\t\tsetattr(self, prop_name, prop_value)\n\t\n\tdef __getattribute__(self, key):\n\t\t\"Emulate type_getattro() in Objects/typeobject.c\"\n\t\tv = object.__getattribute__(self, key)\n\t\tif hasattr(v, '__get__'):\n\t\t\treturn v.__get__(self, type(self))\n\t\treturn v\n\t\n\tdef __setattr__(self, key, value):\n\t\ttry:\n\t\t\tv = object.__getattribute__(self, key)\n\t\t\tif hasattr(v, '__set__'):\n\t\t\t\tv.__set__(self, value)\n\t\t\telse:\n\t\t\t\tself.__dict__[key] = value\n\t\texcept AttributeError, err:\n\t\t\tself.__dict__[key] = value\n\n\t# def __delattr__(self, name):\n\t# \tpass\n\t\n\t# def __repr__(self):\n\t# \tprop_names = [prop_name for prop_name, prop_type in inspect.getmembers(self)\n\t# \t\tif not prop_name.startswith('__')]\n\t# \td = {}\n\t# \tfor prop_name in prop_names:\n\t# \t\td[prop_name] = getattr(self, prop_name)\n\t# \treturn pprint.pformat(d)\n\nclass C(A):\n\tx = Attr()\n\ty = Attr()\n\nc0 = C()\n# print(c0.x)\n# c0.x = 1\n# print(c0.x)\n# print dir(c0)\n# c1 = C(x=1, y=2)\n# c2 = C(x=2)\n# print(c0.x, c0.y)\n# print(c1.x, c1.y)\n# print(c2.x, c2.y)\n\n\n"
},
{
"alpha_fraction": 0.6626029014587402,
"alphanum_fraction": 0.6846104860305786,
"avg_line_length": 33.50273132324219,
"blob_id": "54fe3a05f78b6724e0167776103d1d58bcc46d4c",
"content_id": "3713c123e1eb0da77375ddb3898705e9d607fe37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6316,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 183,
"path": "/test_scrap.py",
"repo_name": "lizalexandrita/kyd-scraper",
"src_encoding": "UTF-8",
"text": "\nimport unittest\nimport scraps\n\nclass TestScrap(unittest.TestCase):\n\tdef test_Scrap(self):\n\t\t\"\"\"it should create and instanciate a Scrap class\"\"\"\n\t\tclass MyScrap(scraps.Scrap):\n\t\t\ta1 = scraps.Attribute()\n\t\t\n\t\tmyScrap = MyScrap()\n\t\tself.assertEquals(myScrap.a1, None)\n\t\t\n\t\tmyScrap.a1 = 1\n\t\tself.assertEquals(myScrap.a1, 1)\n\t\t\n\t\tdel(myScrap.a1)\n\t\tself.assertEquals(myScrap.a1, None)\n\t\n\tdef test_Scrap_instanciation(self):\n\t\t\"\"\"it should instanciate a Scrap passing parameter.\"\"\"\n\t\timport inspect\n\t\tclass MyScrap(scraps.Scrap):\n\t\t\ttitle = scraps.Attribute()\n\t\tmyScrap = MyScrap(title='Normstron')\n\t\tself.assertEquals(myScrap.title, 'Normstron')\n\t\t\n\tdef test_Scrap_instanciation2(self):\n\t\t\"\"\"it should instanciate a Scrap passing an invalid parameter.\"\"\"\n\t\timport inspect\n\t\tclass MyScrap(scraps.Scrap):\n\t\t\ttitle = scraps.Attribute()\n\t\twith self.assertRaises(Exception):\n\t\t\tmyScrap = MyScrap(title1='Normstron')\n\t\t\t\n\tdef test_Scrap_errorisnone(self):\n\t\t\"\"\"it should instanciate a Scrap passing an invalid parameter.\"\"\"\n\t\timport inspect\n\t\tclass MyScrap(scraps.Scrap):\n\t\t\tfloat_attr = scraps.FloatAttr()\n\t\t\terror_is_none = True\n\t\tmyScrap = MyScrap(float_attr='--')\n\t\tclass MyScrap(scraps.Scrap):\n\t\t\tfloat_attr = scraps.FloatAttr()\n\t\twith self.assertRaises(Exception):\n\t\t\tmyScrap = MyScrap(float_attr='--')\n\nclass TestAttribute(unittest.TestCase):\n\tdef test_Attribute(self):\n\t\t\"\"\"\tit should instanciate an Attribute class and its descriptor \n\t\t\tmethods\n\t\t\"\"\"\n\t\ta = scraps.Attribute()\n\t\tself.assertEquals(a.__get__(None, None), None)\n\t\ta.__set__(None, 1)\n\t\tself.assertEquals(a.__get__(None, None), 1)\n\t\ta.__delete__(None)\n\t\tself.assertEquals(a.__get__(None, None), None)\n\t\t\n\tdef test_Attribute_repeat(self):\n\t\t\"\"\"it should instanciate a repeated Attribute\"\"\"\n\t\ta = scraps.Attribute(repeat=True)\n\t\ta.__set__(None, 1)\n\t\ta.__set__(None, 2)\n\t\tself.assertEquals(a.__get__(None, None), [1,2])\n\t\n\tdef test_Attribute_transform(self):\n\t\t\"\"\"\tit should instanciate an Attribute that should be transformed by some\n\t\t\tfunction while is set\n\t\t\"\"\"\n\t\ta = scraps.Attribute(transform=lambda x: x*100)\n\t\ta.__set__(None, 1)\n\t\tself.assertEquals(a.__get__(None, None), 100)\n\t\nclass TestFloatAttr(unittest.TestCase):\n\tdef test_FloatAttr(self):\n\t\t\"\"\"it should instanciate the FloatAttr class and set it with a valid string.\"\"\"\n\t\ta = scraps.FloatAttr()\n\t\ta.__set__(None, '2.2')\n\t\tself.assertAlmostEqual(a.__get__(None, None), 2.2)\n\t\t\n\tdef test_FloatAttr_int(self):\n\t\t\"\"\"it should instanciate the FloatAttr class and set it with an int.\"\"\"\n\t\ta = scraps.FloatAttr()\n\t\ta.__set__(None, 2)\n\t\tself.assertAlmostEqual(a.__get__(None, None), 2.0)\n\n\tdef test_FloatAttr_float(self):\n\t\t\"\"\"it should instanciate the FloatAttr class and set it with a float.\"\"\"\n\t\ta = scraps.FloatAttr()\n\t\ta.__set__(None, 2.2)\n\t\tself.assertAlmostEqual(a.__get__(None, None), 2.2)\n\n\tdef test_FloatAttr_decimal(self):\n\t\t\"\"\"it should instanciate the FloatAttr class and set it with a decimal.\"\"\"\n\t\tfrom decimal import Decimal\n\t\ta = scraps.FloatAttr()\n\t\ta.__set__(None, Decimal(2.2))\n\t\tself.assertAlmostEqual(a.__get__(None, None), 2.2)\n\t\t\n\tdef test_FloatAttr_comma(self):\n\t\t\"\"\"\tit should instanciate the FloatAttr class and set it with a string\n\t\t\twhich represents a float but uses comma as decimal separator.\"\"\"\n\t\ta = scraps.FloatAttr(decimalsep=',')\n\t\ta.__set__(None, '2,2')\n\t\tself.assertAlmostEqual(a.__get__(None, None), 2.2)\n\t\n\tdef test_FloatAttr_percentage(self):\n\t\t\"\"\"\tit should instanciate the FloatAttr class and set it with a string\n\t\t\twhich represents a percentage, ie, a float followed by the symbol '%'.\"\"\"\n\t\ta = scraps.FloatAttr(percentage=True)\n\t\ta.__set__(None, '22 %')\n\t\tself.assertAlmostEqual(a.__get__(None, None), 22./100)\n\t\n\tdef test_FloatAttr_percentage_comma(self):\n\t\t\"\"\"\tit should instanciate the FloatAttr class and set it with a string\n\t\t\twhich represents a percentage and uses comma as decimal separator.\"\"\"\n\t\ta = scraps.FloatAttr(decimalsep=',', percentage=True)\n\t\ta.__set__(None, '22,5 %')\n\t\tself.assertAlmostEqual(a.__get__(None, None), 22.5/100)\n\n\tdef test_FloatAttr_thousand(self):\n\t\t\"\"\"\tit should instanciate the FloatAttr class and set it with a string\n\t\t\twhich represents a float with thousand separators.\"\"\"\n\t\ta = scraps.FloatAttr(thousandsep=',')\n\t\ta.__set__(None, '2,222.22')\n\t\tself.assertAlmostEqual(a.__get__(None, None), 2222.22)\n\t\ta = scraps.FloatAttr(thousandsep='.', decimalsep=',')\n\t\ta.__set__(None, '2.222,22')\n\t\tself.assertAlmostEqual(a.__get__(None, None), 2222.22)\n\t\n\tdef test_FloatAttr_repeat(self):\n\t\t\"\"\"\tit should instanciate the FloatAttr class and set the repeat parameter\n\t\t\tfrom Attribute.\"\"\"\n\t\ta = scraps.FloatAttr(repeat=True)\n\t\ta.__set__(None, '22.5')\n\t\ta.__set__(None, '22.5')\n\t\tself.assertEquals(a.__get__(None, None), [22.5, 22.5])\n\n\tdef test_FloatAttr_error(self):\n\t\t\"\"\"\tit should instanciate the FloatAttr class with an invalid string.\"\"\"\n\t\ta = scraps.FloatAttr()\n\t\twith self.assertRaises(Exception):\n\t\t\ta.__set__(None, '--')\n\t\nclass TestDatetimeAttr(unittest.TestCase):\n\tdef test_DatetimeAttr(self):\n\t\t\"\"\"\tit should instanciate the DatetimeAttr class and set it with a \n\t\t\tvalid string.\"\"\"\n\t\tfrom datetime import datetime\n\t\ta = scraps.DatetimeAttr(formatstr='%Y-%m-%d')\n\t\ta.__set__(None, '2013-01-01')\n\t\tself.assertEquals(a.__get__(None, None), datetime(2013,1,1))\n\t\t\n\tdef test_DatetimeAttr_locale(self):\n\t\t\"\"\"\tit should instanciate the DatetimeAttr class and set it with a \n\t\t\tvalid string and locale.\"\"\"\n\t\tfrom datetime import datetime\n\t\ta = scraps.DatetimeAttr(formatstr='%d/%b/%Y', locale='pt_BR')\n\t\ta.__set__(None, '11/Dez/2013')\n\t\tself.assertEquals(a.__get__(None, None), datetime(2013,12,11))\n\t\t# Check if locale have been restored\n\t\ta = scraps.DatetimeAttr(formatstr='%d/%b/%Y')\n\t\ta.__set__(None, '11/Dec/2013')\n\t\tself.assertEquals(a.__get__(None, None), datetime(2013,12,11))\n\t\t\nclass TestFetcher(unittest.TestCase):\n\tdef test_Fetcher(self):\n\t\t\"\"\"\tit should create a Fetcher.\"\"\"\n\t\tclass MyFetcher(scraps.Fetcher):\n\t\t\tname = 'test'\n\t\t\turl = 'http://httpbin.org/html'\n\t\t\tdef parse(self, content):\n\t\t\t\tfrom bs4 import BeautifulSoup\n\t\t\t\tsoup = BeautifulSoup(content)\n\t\t\t\tclass MockScrap(object):\n\t\t\t\t\ttitle = soup.html.body.h1.string\n\t\t\t\treturn MockScrap()\n\t\tfetcher = MyFetcher()\n\t\tret = fetcher.fetch()\n\t\tself.assertEquals(ret.title, 'Herman Melville - Moby-Dick')\n\nif __name__ == '__main__':\n\tunittest.main(verbosity=1)\n\n"
},
{
"alpha_fraction": 0.695557177066803,
"alphanum_fraction": 0.714129626750946,
"avg_line_length": 35.573333740234375,
"blob_id": "fbc2bf2fa73488c6bbda4bdb289e92412321d45f",
"content_id": "f8720e2ff8f76d9e93634013f0275ecd8b5fab75",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2746,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 75,
"path": "/merc_sec_tit_pub.py",
"repo_name": "lizalexandrita/kyd-scraper",
"src_encoding": "UTF-8",
"text": "# encoding: utf-8\n\nfrom bs4 import BeautifulSoup\nimport bs4\nimport urllib2\nimport cookielib\nimport pprint\nimport scraps\n\nclass TituloNtnbScrap(scraps.Scrap):\n\t\"\"\"This represents scrapss of information from Anbima's NTN-B page\"\"\"\n\terror_is_none = True\n\tcodigo_selic = scraps.Attribute()\n\tdata_base = scraps.DatetimeAttr(formatstr='%d/%m/%Y')\n\tdata_vencimento = scraps.DatetimeAttr(formatstr='%d/%m/%Y')\n\ttaxa_max = scraps.FloatAttr(decimalsep=',', transform=lambda x: x/100.0)\n\ttaxa_min = scraps.FloatAttr(decimalsep=',', transform=lambda x: x/100.0)\n\ttaxa_ind = scraps.FloatAttr(decimalsep=',', transform=lambda x: x/100.0)\n\tpu = scraps.FloatAttr(thousandsep='.', decimalsep=',')\n\t\nclass AnbimaNtnbScrap(scraps.Scrap):\n\t\"\"\"This represents scrapss of information from Anbima's NTN-B page\"\"\"\n\tdata_atual = scraps.DatetimeAttr(formatstr='%d/%b/%Y', locale='pt_BR')\n\tipca_final = scraps.FloatAttr(decimalsep=',', percentage=True)\n\tnome = scraps.Attribute()\n\ttitulos = scraps.Attribute(repeat=True)\n\t\nclass AnbimaNTNBFetcher(scraps.Fetcher):\n\tname = 'anbima-ntn-b'\n\turl = 'http://www.anbima.com.br/merc_sec/resultados/msec_16dez2013_ntn-b.asp'\n\tdef parse(self, content):\n\t\tsoup = BeautifulSoup(content)\n\t\ttables = soup.html.body.table.tr.td.div.find_all('table')\n\t\tdata_atual = tables[2].tr.td.next_sibling.next_sibling.string\n\t\tnome = tables[2].tr.next_sibling.next_sibling.td.next_sibling.next_sibling.string\n\t\tipca_final = tables[7].tr.td.contents[0].string.split(':')[1]\n\t\tscraps = AnbimaNtnbScrap(data_atual=data_atual, nome=nome, \n\t\t\tipca_final=ipca_final)\n\t\tfor sib in tables[2].tr.next_sibling.next_sibling.next_sibling.next_sibling.next_siblings:\n\t\t\trow = [str(elm.string) for elm in sib.contents if str(elm.string).strip() is not '']\n\t\t\tprint(row)\n\t\t\ttit = TituloNtnbScrap(codigo_selic=row[0], data_base=row[1],\n\t\t\t\tdata_vencimento=row[2], taxa_max=row[3], taxa_min=row[4],\n\t\t\t\ttaxa_ind=row[5], pu=row[6])\n\t\t\t# print(scraps.titulos)\n\t\t\tprint(tit)\n\t\t\tscraps.titulos = tit\n\t\treturn scraps\n\nfetcher = AnbimaNTNBFetcher()\nret = fetcher.fetch()\n# print ret\n\n# cj = cookielib.LWPCookieJar()\n# proc = urllib2.HTTPCookieProcessor(cj)\n# url = 'http://www.anbima.com.br/merc_sec/resultados/msec_16dez2013_ntn-b.asp'\n# \n# opener = urllib2.build_opener()\n# req = urllib2.Request(url)\n# ret = opener.open(req)\n# \n# soup = BeautifulSoup(ret.read())\n# \n# tables = soup.html.body.table.tr.td.div.find_all('table')\n# \n# # td = tables[2].tr.find_all('td')\n# # print len(td)\n# # print td[0].string\n# # print td[1].string\n# \n# # print tables[2].tr.td.string\n# print tables[2].tr.td.next_sibling.next_sibling.string\n# \n# print tables[2].tr.next_sibling.next_sibling.td.string\n# print tables[2].tr.next_sibling.next_sibling.td.next_sibling.next_sibling.string\n\n\n\n"
},
{
"alpha_fraction": 0.6805375814437866,
"alphanum_fraction": 0.6820883750915527,
"avg_line_length": 28.922481536865234,
"blob_id": "074ece110fff7ad67fc70099507ac4c18f5318e3",
"content_id": "c84de10426c8a44bdc5f984ad82ec3977a6ac624",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3869,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 129,
"path": "/scraps.py",
"repo_name": "lizalexandrita/kyd-scraper",
"src_encoding": "UTF-8",
"text": "\nimport pprint\nimport inspect\nimport urllib2\nfrom datetime import datetime\n\nclass Fetcher(object):\n\t\"\"\"\tFetcher class represents the request handler. It defines the URL to be\n\t\trequested so as the method to parse.\n\t\"\"\"\n\tdef fetch(self):\n\t\topener = urllib2.build_opener()\n\t\treq = urllib2.Request(self.url)\n\t\treturn self.parse(opener.open(req))\n\t\n\tdef parse(self, content):\n\t\t\"\"\"\tit receives the fetched content, parses it and returns a Scrap.\"\"\"\n\t\traise NotImplemented('This method must be inherited.')\n\nclass MetaScraps(type):\n\tdef __new__(mcls, name, bases, classdict):\n\t\tattrs = {}\n\t\tnew_classdict = {}\n\t\tfor n, v in classdict.iteritems():\n\t\t\tif isinstance(v, Attribute):\n\t\t\t\tattrs[n] = v\n\t\t\telse:\n\t\t\t\tnew_classdict[n] = v\n\t\tcls = type.__new__(mcls, name, bases, new_classdict)\n\t\tcls.attrs = cls.attrs.copy()\n\t\tcls.attrs.update(attrs)\n\t\treturn cls\n\t\t\nclass Scrap(object):\n\t\"\"\"\tScrap class represents a bunch of data collected from information\n\t\tsources.\n\t\"\"\"\n\t__metaclass__ = MetaScraps\n\tdef __init__(self, **kwargs):\n\t\tprop_names = [prop_name for prop_name, prop_type in inspect.getmembers(self)\n\t\t\tif not prop_name.startswith('__')]\n\t\tif 'error_is_none' not in prop_names:\n\t\t\tself.error_is_none = False\n\t\tfor prop_name, prop_value in kwargs.items():\n\t\t\tif prop_name not in prop_names:\n\t\t\t\traise KeyError('Invalid attribute: ' + prop_name)\n\t\t\ttry:\n\t\t\t\tsetattr(self, prop_name, prop_value)\n\t\t\texcept Exception, e:\n\t\t\t\tif not self.error_is_none:\n\t\t\t\t\traise e\n\t\n\tdef __repr__(self):\n\t\tprop_names = [prop_name for prop_name, prop_type in inspect.getmembers(self)\n\t\t\tif not prop_name.startswith('__')]\n\t\td = {}\n\t\tfor prop_name in prop_names:\n\t\t\td[prop_name] = getattr(self, prop_name)\n\t\treturn pprint.pformat(d)\n\nclass Attribute(object):\n\t\"\"\"\tAttribute class is a descriptor which represents each chunk of\n\t\tdata extracted from a source of information.\n\t\"\"\"\n\tdef __init__(self, repeat=False, transform=lambda x: x):\n\t\tself.value = None\n\t\tself.repeat = repeat\n\t\tself.transform = transform\n\t\n\tdef __set__(self, obj, value):\n\t\t\"\"\"sets attribute's value\"\"\"\n\t\tvalue = self.transform(value)\n\t\tif self.repeat:\n\t\t\ttry:\n\t\t\t\tself.value.append(value)\n\t\t\texcept:\n\t\t\t\tself.value = [value]\n\t\telse:\n\t\t\tself.value = value\n\t\n\tdef __get__(self, obj, typo):\n\t\t\"\"\"gets attribute's value\"\"\"\n\t\treturn self.value\n\t\t\n\tdef __delete__(self, obj):\n\t\t\"\"\"resets attribute's initial state\"\"\"\n\t\tself.value = None\n\nclass FloatAttr(Attribute):\n\t\"\"\"\tFloatAttr class is an Attribute descriptor which tries to convert to \n\t\tfloat every value set. It should convert mainly strings though numeric \n\t\ttypes such as int and decimal could be set.\n\t\"\"\"\n\tdef __init__(self, thousandsep=None, decimalsep=None, percentage=False, **kwargs):\n\t\tsuper(FloatAttr, self).__init__(**kwargs)\n\t\tself.decimalsep = decimalsep\n\t\tself.percentage = percentage\n\t\tself.thousandsep = thousandsep\n\t\n\tdef __set__(self, obj, value):\n\t\tif type(value) in (str, unicode):\n\t\t\tif self.thousandsep is not None:\n\t\t\t\tvalue = value.replace(self.thousandsep, '')\n\t\t\tif self.decimalsep is not None:\n\t\t\t\tvalue = value.replace(self.decimalsep, '.')\n\t\t\tif self.percentage:\n\t\t\t\tvalue = value.replace('%', '')\n\t\tif self.percentage:\n\t\t\tvalue = float(value)/100\n\t\telse:\n\t\t\tvalue = float(value)\n\t\tsuper(FloatAttr, self).__set__(obj, value)\n\t\nclass DatetimeAttr(Attribute):\n\t\"\"\"\tDatetimeAttr class is an Attribute descriptor which tries to convert to\n\t\tdatetime.datetime every value set.\n\t\"\"\"\n\tdef __init__(self, formatstr=None, locale=None, **kwargs):\n\t\tsuper(DatetimeAttr, self).__init__(**kwargs)\n\t\tself.formatstr = formatstr\n\t\tself.locale = locale\n\t\t\n\tdef __set__(self, obj, value):\n\t\tif self.locale is not None:\n\t\t\timport locale\n\t\t\tlocale.setlocale(locale.LC_TIME, 'pt_BR')\n\t\tvalue = datetime.strptime(value, self.formatstr)\n\t\tif self.locale is not None:\n\t\t\tlocale.setlocale(locale.LC_TIME, '')\n\t\tsuper(DatetimeAttr, self).__set__(obj, value)\n\t\t\n\t\t\n\t\t"
}
] | 4 |
abusofiuan/asib-mail
|
https://github.com/abusofiuan/asib-mail
|
db8a711e0366b2b03b965ef9a91e9098c82a4210
|
37254371e4af8c57333fefce7a4ea682e2c406c4
|
372fd7753595f317d27a58b9fb6995342d5bcc32
|
refs/heads/main
| 2023-02-20T21:50:16.165796 | 2021-01-20T05:44:43 | 2021-01-20T05:44:43 | 331,019,135 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 11,
"blob_id": "a7a612719d2bb29246a6d17f21220dcfe6b99f80",
"content_id": "e37c3274d76af1515efea471ec5c2ed7a3160f35",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12,
"license_type": "no_license",
"max_line_length": 11,
"num_lines": 1,
"path": "/Asib.py",
"repo_name": "abusofiuan/asib-mail",
"src_encoding": "UTF-8",
"text": "# asib-mail\n"
}
] | 1 |
t0mmyt/puppet-nsd
|
https://github.com/t0mmyt/puppet-nsd
|
8ecb54f4114929990637b4cdbeb353e820a581a6
|
f3a7d73973535ae4c310b4949f95cd0afecaa9e1
|
d766cb52c11662bd86e37b2db9e4a313c0df2cd2
|
refs/heads/master
| 2020-04-06T07:07:03.621339 | 2015-03-30T16:15:55 | 2015-03-30T16:15:55 | 32,988,337 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5676382780075073,
"alphanum_fraction": 0.5710014700889587,
"avg_line_length": 26.875,
"blob_id": "ad87b621201bc3ef4e9415637828b8a4af9bb459",
"content_id": "f49afe42b254aa0b37f0d7fb09caf6344509f866",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2676,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 96,
"path": "/files/scripts/update_zones.py",
"repo_name": "t0mmyt/puppet-nsd",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nimport os\nimport sys\nimport socket\nimport subprocess\nimport re\n\nworking_dir = '/etc/nsd/zones'\n\nclass zone:\n def __init__(self):\n self.name = None\n self.zonefile = None\n\n def is_complete(self):\n if self.name and self.zonefile:\n return True\n\n def check_zone(self):\n do_command(['/usr/sbin/nsd-checkzone', self.name, self.zonefile])\n\n\ndef fatal(s):\n for line in s.rstrip().split('\\n'):\n print \"%10s: %s\" % (s_host, line)\n sys.exit(1)\n\ndef output(s):\n for line in s.rstrip().split('\\n'):\n print \"%10s: %s\" % (s_host, line)\n\ndef do_command(command):\n ''' function to run a command and return output or die with output '''\n output(\"RUNNING: \" + \" \".join(command))\n\n p = subprocess.Popen(command, stdout=subprocess.PIPE)\n out, err = p.communicate()\n\n if out:\n output(out)\n if err:\n output(err)\n\n if p.returncode != 0:\n fatal(\"Nonzero return code: %d\" % p.returncode)\n\n# cd to working dir\ntry:\n os.chdir(working_dir)\nexcept OSError as e:\n fatal(\"Error: %s\" % e)\n\n# Store our hostname for verbose output\nf_host = socket.gethostname()\ns_host = f_host[:f_host.find('.')]\n\n# Are we root? (bad!)\nif os.getuid() == 0:\n fatal(\"You don't really want to be running this as root!!!\")\n\n# Git pull\n#do_command(['/bin/sh', '-c', 'eval $(ssh-agent) && ssh-add ../.ssh/id_nameserver && git pull >/dev/null'])\ndo_command(['/usr/bin/git', 'pull'])\n\n# Check nsd.conf\ndo_command(['/usr/sbin/nsd-checkconf', '/etc/nsd/nsd.conf'])\n\ntry:\n with open('/etc/nsd/zones/zones.conf') as zoneconfig:\n is_zone_start = re.compile('^zone:')\n is_zone_name = re.compile('\\s+name: \"(.*)\"')\n is_zone_file = re.compile('\\s+zonefile: \"(.*)\"')\n this_zone = None\n for line in zoneconfig:\n # Are we starting a zone definition?\n m = is_zone_start.match(line)\n if m:\n this_zone = zone()\n # Is this the name of a zone?\n m = is_zone_name.match(line)\n if this_zone and m:\n this_zone.name = m.group(1)\n # Is this the filename of a zone?\n m = is_zone_file.match(line)\n if this_zone and m:\n this_zone.zonefile = m.group(1)\n # Is the zone definition complete? If so then check\n if this_zone and this_zone.is_complete():\n this_zone.check_zone()\n this_zone = None\nexcept OSError as e:\n fatal(\"Error: %s\" % e)\n\n# Got this far ... must be good for a reload\ndo_command(['/usr/sbin/nsd-control', 'reconfig'])\ndo_command(['/usr/sbin/nsd-control', 'reload'])\n"
}
] | 1 |
Marco2018/learning_note
|
https://github.com/Marco2018/learning_note
|
bde07d6af71bdd595b564065f6863b11b156ac15
|
99f708f92a6e5b30731447316669aa53623a6037
|
8376885b97c2288dc444e038ee34365653461c76
|
refs/heads/master
| 2020-02-15T14:08:08.677992 | 2020-02-11T13:28:21 | 2020-02-11T13:28:21 | 125,012,863 | 3 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6171454191207886,
"alphanum_fraction": 0.6427289247512817,
"avg_line_length": 14.367647171020508,
"blob_id": "c0fd68d8feae940eb26342e7eb3e8caa618775e7",
"content_id": "bba61e16be242ed79592444508c29048b59feeb4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3622,
"license_type": "no_license",
"max_line_length": 301,
"num_lines": 136,
"path": "/books/python100天.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 100 天 python\r\n\r\n##### Day0-15\r\n\r\n##### 函数与模块的使用\r\nPython中使用def来定义函数。函数是绝大多数编程语言中都支持的一个代码的“构建块”,但是Python中的函数与其他语言中的函数还是有很多不太相同的地方,其中一个显著的区别就是Python对函数参数的处理。在Python中,函数的参数可以有默认值,也支持使用可变参数,所以Python并不需要像其他语言一样支持函数的重载。\r\n\r\n默认值:\r\n\r\n\r\n\r\n```python\r\ndef roll_dice(n=2):\r\n\t\"\"\"\r\n\t摇色子\r\n\r\n\tparam n: 色子的个数\r\n\treturn: n颗色子点数之和\r\n\t\"\"\"\r\n\ttotal = 0\r\n\tfor _ in range(n):\r\n\t\ttotal += randint(1, 6)\r\n\treturn total \r\n\r\ndef add(a=0, b=0, c=0):\r\n\treturn a + b + c\r\n\r\nprint(roll_dice(3))\r\nprint(add())\r\nprint(add(1))\r\nprint(add(1, 2))\r\nprint(add(1, 2, 3))\r\n```\r\n\r\n可变参数\r\n\r\n```python\r\ndef add(*args):\r\n\ttotal = 0\r\n\tfor val in args:\r\n\t\ttotal += val\r\n\treturn total\r\n\r\nprint(add())\r\nprint(add(1))\r\nprint(add(1, 2))\r\nprint(add(1, 2, 3))\r\nprint(add(1, 3, 5, 7, 9))\r\n```\r\n\r\n\r\n\r\n##### 用模块管理函数:\r\n由于Python没有函数重载的概念,那么后面的定义会覆盖之前的定义。Python中每个文件就代表了一个模块(module),我们在不同的模块中可以有同名的函数,在使用函数的时候我们通过import关键字导入指定的模块就可以区分到底要使用的是哪个模块中的foo函数。\r\n\r\nmodule1.py\r\n\r\n```python\r\ndef foo():\r\n print('hello, world!')\r\n```\r\n\r\n\r\nmodule2.py\r\n\r\n```python\r\ndef foo():\r\n print('goodbye, world!')\r\n```\r\n\r\n\r\ntest.py\r\n\r\n```python\r\nfrom module1 import foo\r\n```\r\n\r\n输出hello, world!\r\n\r\n```python\r\nfrom module2 import foo\r\n```\r\n\r\n输出goodbye, world!\r\n\r\ntest.py\r\n\r\nimport module1 as m1\r\nimport module2 as m2\r\n\r\nm1.foo()\r\nm2.foo()\r\n\r\n\r\n\r\n##### 变量作用域\r\n\r\n最后,我们来讨论一下Python中有关变量作用域的问题。\r\n\r\n\r\n\r\n```python\r\ndef foo():\r\n b = 'hello'\r\n \r\ndef bar(): # Python中可以在函数内部再定义函数\r\n c = True\r\n print(a)\r\n print(b)\r\n print(c)\r\n \r\nbar()\r\n# print(c) # NameError: name 'c' is not defined\r\n\r\nif __name__ == '__main__':\r\n a = 100\r\n # print(b) # NameError: name 'b' is not defined\r\n foo()\r\n```\r\n\r\n 上面的代码能够顺利的执行并且打印出100和“hello”,但我们注意到了,在bar函数的内部并没有定义a和b两个变量,那么a和b是从哪里来的。我们在上面代码的if分支中定义了一个变量a,这是一个全局变量(global variable),属于全局作用域,因为它没有定义在任何一个函数中。在上面的foo函数中我们定义了变量b,这是一个定义在函数中的局部变量(local variable),属于局部作用域,在foo函数的外部并不能访问到它;但对于foo函数内部的bar函数来说,变量b属于嵌套作用域,在bar函数中我们是可以访问到它的。bar函数中的变量c属于局部作用域,在bar函数之外是无法访问的。\r\n\r\n事实上,Python查找一个变量时会按照“局部作用域”、“嵌套作用域”、“全局作用域”和“内置作用域”的顺序进行搜索。\r\n\r\n前三者我们在上面的代码中已经看到了,所谓的“内置作用域”就是Python内置的那些隐含标识符min、len等都属于内置作用域)。\r\n\r\n再看看下面这段代码,我们希望通过函数调用修改全局变量a的值,但实际上下面的代码是做不到的。\r\n\r\n```python\r\ndef foo():\r\n a = 200\r\n print(a) # 200\r\n\r\nif __name__ == '__main__':\r\n a = 100\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.5130823254585266,
"alphanum_fraction": 0.5432177782058716,
"avg_line_length": 23.968692779541016,
"blob_id": "7b81382c58097907bed7d78da7fd7572d0fb9f84",
"content_id": "b4ca180ca8067778d533009fa2c6991ef94163b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 14437,
"license_type": "no_license",
"max_line_length": 444,
"num_lines": 543,
"path": "/leetcode_note/Union set.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "并查集的应用 (LeetCode 547)\r\n\r\nUnion常规实现\r\n\r\n```python\r\nclass DSU:\r\n def __init__(self):\r\n self.parents = {}\r\n \r\n def find(self, x):\r\n if x != self.parents[x]:\r\n self.parents[x] = self.find(self.parents[x])\r\n return self.parents[x]\r\n\r\n def union(self, x, y):\r\n par_x, par_y = self.find(x), self.find(y)\r\n if par_x != par_y:\r\n self.parents[par_y] = par_x\r\n```\r\n\r\n上述版本没有path compression\r\n\r\n```python\r\nclass DSU:\r\n def __init__(self):\r\n self.parents = {}\r\n\r\n\r\n def find(self, x): #compression\r\n while x != self.parents[x]:\r\n self.parents[x] = self.parents[self.parents[x]]\r\n x = self.parents[x]\r\n return x\r\n\r\n def union(self, x, y):\r\n par_x, par_y = self.find(x), self.find(y)\r\n if par_x != par_y:\r\n self.parents[par_y] = par_x\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 305 Number of Islands II\r\n\r\nA 2d grid map of `m` rows and `n` columns is initially filled with water. We may perform an *addLand* operation which turns the water at position (row, col) into a land. Given a list of positions to operate, **count the number of islands after each addLand operation**. An island is surrounded by water and is formed by connecting adjacent lands horizontally or vertically. You may assume all four edges of the grid are all surrounded by water.\r\n\r\n**Example:**\r\n\r\n```\r\nInput: m = 3, n = 3, positions = [[0,0], [0,1], [1,2], [2,1]]\r\nOutput: [1,1,2,3]\r\n```\r\n\r\n**Explanation:**\r\n\r\nInitially, the 2d grid `grid` is filled with water. (Assume 0 represents water and 1 represents land).\r\n\r\n```\r\n0 0 0\r\n0 0 0\r\n0 0 0\r\n```\r\n\r\nOperation #1: addLand(0, 0) turns the water at grid[0][0] into a land.\r\n\r\n```\r\n1 0 0\r\n0 0 0 Number of islands = 1\r\n0 0 0\r\n```\r\n\r\nOperation #2: addLand(0, 1) turns the water at grid[0][1] into a land.\r\n\r\n```\r\n1 1 0\r\n0 0 0 Number of islands = 1\r\n0 0 0\r\n```\r\n\r\nOperation #3: addLand(1, 2) turns the water at grid[1][2] into a land.\r\n\r\n```\r\n1 1 0\r\n0 0 1 Number of islands = 2\r\n0 0 0\r\n```\r\n\r\nOperation #4: addLand(2, 1) turns the water at grid[2][1] into a land.\r\n\r\n```\r\n1 1 0\r\n0 0 1 Number of islands = 3\r\n0 1 0\r\n```\r\n\r\n Number of Islands 可以用DFS做 但是这道题比较适合用Union\r\n\r\n```python\r\nclass DSU:\r\n def __init__(self):\r\n self.parents = {}\r\n self.count = 0\r\n\r\n def find(self, x):\r\n if x != self.parents[x]:\r\n self.parents[x] = self.find(self.parents[x])\r\n return self.parents[x]\r\n\r\n def union(self, x, y):\r\n par_x, par_y = self.find(x), self.find(y)\r\n if par_x != par_y:\r\n self.count -= 1\r\n self.parents[par_y] = par_x\r\n\r\n def setParent(self, x):\r\n self.parents[x] = x\r\n self.count += 1\r\n\r\n\r\nclass Solution:\r\n def numIslands2(self, m, n, positions):\r\n \"\"\"\r\n :type m: int\r\n :type n: int\r\n :type positions: List[List[int]]\r\n :rtype: List[int]\r\n \"\"\"\r\n dsu = DSU()\r\n ans = []\r\n for po in positions:\r\n idx = po[0] * n + po[1]\r\n if idx not in dsu.parents:\r\n dsu.setParent(idx)\r\n for di in [(1, 0), (-1, 0), (0, 1), (0, -1)]:\r\n x, y = po[0] + di[0], po[1] + di[1]\r\n if 0 <= x < m and 0 <= y < n and x * n + y in dsu.parents:\r\n dsu.union(idx, x * n + y)\r\n ans.append(dsu.count)\r\n return ans\r\n```\r\n\r\n\r\n\r\n##### leetcode 261 Graph Valid Tree\r\n\r\nGiven `n` nodes labeled from `0` to `n-1` and a list of undirected edges (each edge is a pair of nodes), write a function to check whether these edges make up a valid tree.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: n = 5, and edges = [[0,1], [0,2], [0,3], [1,4]]\r\nOutput: true\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: n = 5, and edges = [[0,1], [1,2], [2,3], [1,3], [1,4]]\r\nOutput: false\r\n```\r\n\r\n**Note**: you can assume that no duplicate edges will appear in `edges`. Since all edges are undirected, `[0,1]` is the same as `[1,0]` and thus will not appear together in `edges`.\r\n\r\n```python\r\nclass DSU:\r\n def __init__(self):\r\n self.parents = {}\r\n\r\n\r\n def find(self, x):\r\n while x != self.parents[x]:\r\n self.parents[x] = self.parents[self.parents[x]]\r\n x = self.parents[x]\r\n return x\r\n\r\n def union(self, x, y):\r\n par_x, par_y = self.find(x), self.find(y)\r\n if par_x != par_y:\r\n self.parents[par_y] = par_x\r\n\r\n\r\nclass Solution:\r\n def validTree(self, n: int, edges):\r\n dst = DSU()\r\n if len(edges) != n-1:\r\n return False\r\n for i in range(n):\r\n dst.parents[i] = i\r\n for s, e in edges:\r\n if dst.find(s) != dst.find(e):\r\n dst.union(s, e)\r\n else:\r\n return False\r\n return True\r\n```\r\n\r\n判断一个图是否是tree的充要条件是是否有环\r\n\r\n通过union的方式来判断是否有环\r\n\r\n如果有环 则会出现 dst.find(s) == dst.find(e)\r\n\r\n但是要注意 首先要判断len(edges) != n-1\r\n\r\n同时这道题必须使用path compression,反例n=4, edges = [[2,3],[1,2],[1,3]]\r\n\r\n\r\n\r\n##### leetcide 323 Number of Connected Components in an Undirected Graph\r\n\r\nGiven `n` nodes labeled from `0` to `n - 1` and a list of undirected edges (each edge is a pair of nodes), write a function to find the number of connected components in an undirected graph.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: n = 5 and edges = [[0, 1], [1, 2], [3, 4]]\r\n\r\n 0 3\r\n | |\r\n 1 --- 2 4 \r\n\r\nOutput: 2\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: n = 5 and edges = [[0, 1], [1, 2], [2, 3], [3, 4]]\r\n\r\n 0 4\r\n | |\r\n 1 --- 2 --- 3\r\n\r\nOutput: 1\r\n```\r\n\r\n**Note:**\r\nYou can assume that no duplicate edges will appear in `edges`. Since all edges are undirected, `[0, 1]` is the same as `[1, 0]` and thus will not appear together in `edges`.\r\n\r\n```python\r\nclass DSU:\r\n def __init__(self, n):\r\n self.parents = {}\r\n self.count = n\r\n\r\n def find(self, x):\r\n while x != self.parents[x]:\r\n self.parents[x] = self.parents[self.parents[x]]\r\n x = self.parents[x]\r\n return x\r\n\r\n def union(self, x, y):\r\n par_x, par_y = self.find(x), self.find(y)\r\n if par_x != par_y:\r\n self.parents[par_y] = par_x\r\n\r\n\r\nclass Solution:\r\n def countComponents(self, n: int, edges):\r\n dst = DSU(n)\r\n for i in range(n):\r\n dst.parents[i] = i\r\n for s, e in edges:\r\n if dst.find(s) != dst.find(e):\r\n dst.union(s, e)\r\n dst.count-=1\r\n return dst.count\r\n```\r\n\r\n使用路径压缩,如果dst.find(s) != dst.find(e): 说明这条边将两个graph连了起来\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 128 Longest Consecutive Sequence\r\n\r\nSET\r\n\r\n* Given an unsorted array of integers, find the length of the longest consecutive elements sequence. Your algorithm should run in O(*n*) complexity.\r\n\r\n```\r\nInput: [100, 4, 200, 1, 3, 2]\r\nOutput: 4\r\nExplanation: The longest consecutive elements sequence is [1, 2, 3, 4]. Therefore its length is 4.\r\n```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution(object):\r\n def longestConsecutive(self, nums):\r\n \"\"\"\r\n :type nums: List[int]\r\n :rtype: int\r\n \"\"\"\r\n res=0\r\n nums_set = set(nums)\r\n for num in nums:\r\n if num-1 not in nums_set:\r\n temp=1\r\n while num+1 in nums_set:\r\n num+=1\r\n temp+=1\r\n if temp>res:\r\n res=temp\r\n return res\r\n```\r\n\r\nset 的使用减少了时间复杂度\r\n\r\n如果num在nums_set内就不断查看num+1是否在nums_set内\r\n\r\n在这之间如果num-1也在set内说明num已经被查过了\r\n\r\n\r\n\r\n###### leetcode 1202 Smallest String With Swaps\r\n\r\nYou are given a string `s`, and an array of pairs of indices in the string `pairs` where `pairs[i] = [a, b]` indicates 2 indices(0-indexed) of the string.\r\n\r\nYou can swap the characters at any pair of indices in the given `pairs` **any number of times**.\r\n\r\nReturn the lexicographically smallest string that `s` can be changed to after using the swaps.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: s = \"dcab\", pairs = [[0,3],[1,2]]\r\nOutput: \"bacd\"\r\nExplaination: \r\nSwap s[0] and s[3], s = \"bcad\"\r\nSwap s[1] and s[2], s = \"bacd\"\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: s = \"dcab\", pairs = [[0,3],[1,2],[0,2]]\r\nOutput: \"abcd\"\r\nExplaination: \r\nSwap s[0] and s[3], s = \"bcad\"\r\nSwap s[0] and s[2], s = \"acbd\"\r\nSwap s[1] and s[2], s = \"abcd\"\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: s = \"cba\", pairs = [[0,1],[1,2]]\r\nOutput: \"abc\"\r\nExplaination: \r\nSwap s[0] and s[1], s = \"bca\"\r\nSwap s[1] and s[2], s = \"bac\"\r\nSwap s[0] and s[1], s = \"abc\"\r\n```\r\n\r\n**Constraints:**\r\n\r\n- `1 <= s.length <= 10^5`\r\n- `0 <= pairs.length <= 10^5`\r\n- `0 <= pairs[i][0], pairs[i][1] < s.length`\r\n- `s` only contains lower case English letters.\r\n\r\nUnion Find:\r\n\r\n基本思想: if (0, 1) is an exchange pair and (0, 2) is an exchange pair, then any 2 in (0, 1, 2) can be exchanged.\r\n\r\n相当于 0,1,2内部联通了\r\n\r\n```python\r\n def smallestStringWithSwaps(self, s: str, pairs: List[List[int]]) -> str:\r\n class UF:\r\n def __init__(self, n): self.p = list(range(n))\r\n def union(self, x, y): self.p[self.find(x)] = self.find(y)\r\n def find(self, x):\r\n if x != self.p[x]: self.p[x] = self.find(self.p[x])\r\n return self.p[x]\r\n uf, res, m = UF(len(s)), [], defaultdict(list)\r\n for x,y in pairs: \r\n uf.union(x,y)\r\n for i in range(len(s)): \r\n m[uf.find(i)].append(s[i])\r\n for comp_id in m.keys(): \r\n m[comp_id].sort(reverse=True)\r\n for i in range(len(s)): \r\n res.append(m[uf.find(i)].pop())\r\n return ''.join(res)\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 1319 Number of Operations to Make Network Connected\r\n\r\nThere are `n` computers numbered from `0` to `n-1` connected by ethernet cables `connections` forming a network where `connections[i] = [a, b]` represents a connection between computers `a` and `b`. Any computer can reach any other computer directly or indirectly through the network.\r\n\r\nGiven an initial computer network `connections`. You can extract certain cables between two directly connected computers, and place them between any pair of disconnected computers to make them directly connected. Return the *minimum number of times* you need to do this in order to make all the computers connected. If it's not possible, return -1. \r\n\r\n**Example 1:**\r\n\r\n****\r\n\r\n```\r\nInput: n = 4, connections = [[0,1],[0,2],[1,2]]\r\nOutput: 1\r\nExplanation: Remove cable between computer 1 and 2 and place between computers 1 and 3.\r\n```\r\n\r\n**Example 2:**\r\n\r\n****\r\n\r\n```\r\nInput: n = 6, connections = [[0,1],[0,2],[0,3],[1,2],[1,3]]\r\nOutput: 2\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: n = 6, connections = [[0,1],[0,2],[0,3],[1,2]]\r\nOutput: -1\r\nExplanation: There are not enough cables.\r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: n = 5, connections = [[0,1],[0,2],[3,4],[2,3]]\r\nOutput: 0\r\n```\r\n\r\n \r\n\r\n**Constraints:**\r\n\r\n- `1 <= n <= 10^5`\r\n- `1 <= connections.length <= min(n*(n-1)/2, 10^5)`\r\n- `connections[i].length == 2`\r\n- `0 <= connections[i][0], connections[i][1] < n`\r\n- `connections[i][0] != connections[i][1]`\r\n- There are no repeated connections.\r\n- No two computers are connected by more than one cable.\r\n\r\n```python\r\nclass DSU:\r\n def __init__(self):\r\n self.parents = {}\r\n\r\n def find(self, x): # compression\r\n while x != self.parents[x]:\r\n self.parents[x] = self.parents[self.parents[x]]\r\n x = self.parents[x]\r\n return x\r\n\r\n def union(self, x, y):\r\n par_x, par_y = self.find(x), self.find(y)\r\n if par_x != par_y:\r\n self.parents[par_y] = par_x\r\n\r\n\r\nclass Solution:\r\n def makeConnected(self, n, connections) -> int:\r\n if len(connections) < n - 1:\r\n return -1\r\n dst = DSU()\r\n for i in range(n):\r\n dst.parents[i] = i\r\n root = set()\r\n for a, b in connections:\r\n dst.union(a, b)\r\n for i in range(n):\r\n p = dst.find(i)\r\n root.add(p)\r\n return len(root) - 1\r\n```\r\n\r\n\r\n\r\n##### leetcode 684 Redundant Connection\r\n\r\nIn this problem, a tree is an **undirected** graph that is connected and has no cycles.\r\n\r\nThe given input is a graph that started as a tree with N nodes (with distinct values 1, 2, ..., N), with one additional edge added. The added edge has two different vertices chosen from 1 to N, and was not an edge that already existed.\r\n\r\nThe resulting graph is given as a 2D-array of `edges`. Each element of `edges` is a pair `[u, v]` with `u < v`, that represents an **undirected** edge connecting nodes `u` and `v`.\r\n\r\nReturn an edge that can be removed so that the resulting graph is a tree of N nodes. If there are multiple answers, return the answer that occurs last in the given 2D-array. The answer edge `[u, v]` should be in the same format, with `u < v`.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [[1,2], [1,3], [2,3]]\r\nOutput: [2,3]\r\nExplanation: The given undirected graph will be like this:\r\n 1\r\n / \\\r\n2 - 3\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [[1,2], [2,3], [3,4], [1,4], [1,5]]\r\nOutput: [1,4]\r\nExplanation: The given undirected graph will be like this:\r\n5 - 1 - 2\r\n | |\r\n 4 - 3\r\n```\r\n\r\n```python\r\nclass DSU:\r\n def __init__(self):\r\n self.parents = {}\r\n\r\n def find(self, x): #compression\r\n while x != self.parents[x]:\r\n self.parents[x] = self.parents[self.parents[x]]\r\n x = self.parents[x]\r\n return x\r\n\r\n def union(self, x, y):\r\n par_x, par_y = self.find(x), self.find(y)\r\n if par_x != par_y:\r\n self.parents[par_y] = par_x\r\n \r\nclass Solution:\r\n def findRedundantConnection(self, edges: List[List[int]]) -> List[int]:\r\n dst = DSU()\r\n n = len(edges)\r\n for i in range(1, n+1):\r\n dst.parents[i] = i\r\n for edge in edges:\r\n if dst.find(edge[0]) == dst.find(edge[1]):\r\n return edge\r\n dst.union(edge[0], edge[1])\r\n return \r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.450937956571579,
"alphanum_fraction": 0.5028859972953796,
"avg_line_length": 18.057971954345703,
"blob_id": "82d2a343295612bcf28b3065a315623a95117686",
"content_id": "8761a5db2f16dbf82b193f6a59284dc34f995a9a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1540,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 69,
"path": "/leetcde_note_cpp/others.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### Prexfix Count\r\n\r\n##### leetcode 440 K-th Smallest in Lexicographical Order\r\n\r\nGiven integers `n` and `k`, find the lexicographically k-th smallest integer in the range from `1` to `n`.\r\n\r\nNote: 1 ≤ k ≤ n ≤ 109.\r\n\r\n**Example:**\r\n\r\n```\r\nInput:\r\nn: 13 k: 2\r\n\r\nOutput:\r\n10\r\n\r\nExplanation:\r\nThe lexicographical order is [1, 10, 11, 12, 13, 2, 3, 4, 5, 6, 7, 8, 9], so the second smallest number is 10.\r\n```\r\n\r\n\r\n\r\n一般来说可能会想到binary search,但是本题中求得是Lexicographical Order,并不适用\r\n\r\n核心是如何计算在n以内有多少个以prefix开头的数字\r\n\r\n\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int between_nums(int n, long first, long last){\r\n int count = 0;\r\n while(first<=n){\r\n count += min((long)n+1, last) - first;\r\n first *= 10; last *= 10;\r\n }\r\n return count;\r\n }\r\n int findKthNumber(int n, int k) {\r\n int result = 1;\r\n k--;\r\n while(k>0){\r\n int count = between_nums(n, result, result+1);\r\n if(k >= count){\r\n k -= count;\r\n result++;\r\n }\r\n else{\r\n result *= 10;\r\n k--;\r\n }\r\n }\r\n return result; \r\n }\r\n};\r\n```\r\n\r\nbetween_nums 返回在1-n中 有多少个在$[first, last)$区间中的数字\r\n\r\n如果count>k则 需要将前缀乘以10,进一步搜索\r\n\r\n```\r\nn = 13, k=2\r\n1.result = 1,k->1\r\nbetween_nums(13,1,2)=5 (1,10,11,12,13)\r\nresult->10 k->0\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.7330096960067749,
"alphanum_fraction": 0.7330096960067749,
"avg_line_length": 16.18181800842285,
"blob_id": "74634ab1f8537b541c29f967f20a7d60532635a4",
"content_id": "c362d5da781bbe616caa2bc4b39bbd840358611a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 374,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 11,
"path": "/云计算.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 云计算\r\n\r\n第三次IT革命:个人计算机的出现,互联网的使用\r\n\r\n简单的来说,云计算是基于互联网将规模化资源池的计算、存储、开发平台和软件能力提供给用户的服务。\r\n\r\nIaaS: Infrastructure as a Service 基础设施即服务\r\n\r\nPaaS: Platform as a Service 平台即服务\r\n\r\nSaaS: Software as a Service\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5962092876434326,
"alphanum_fraction": 0.619663417339325,
"avg_line_length": 14.47258472442627,
"blob_id": "c144ac93182a06dcad3d1946f2164c00f7de9ef0",
"content_id": "7e39777c8c2d229da83941284d7bb2587704d15d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 46625,
"license_type": "no_license",
"max_line_length": 171,
"num_lines": 1915,
"path": "/books/c++primer.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### C++ Primer\r\n\r\n#### 1 开始\r\n\r\n##### 编写一个简单的C++程序\r\n\r\nc++函数必须包含四部分:返回类型 函数名 形参列表 函数体\r\n\r\n##### 编译 运行\r\n\r\n最常用的使用GNU编译器\r\n\r\n```\r\ng++ -o hello hello.cpp\r\n```\r\n\r\n-o是表示输出的参数,生成一个名为hello或是hello.exe的可执行文件\r\n\r\n在unix系统中 可执行文件没有后缀,window中可执行文件的后缀exe,生成可执行文件后使用如下命令运行\r\n\r\n```\r\n.\\hello.exe\r\n```\r\n\r\n\r\n\r\n##### 初始输入输出\r\n\r\n标准IO库 iostream定义了四个IO对象 cin cout cerr clog\r\n\r\ncerr一般用来输出错误 警告等信息,而clog一般用来输出程序运行时的一般性信息\r\n\r\n如果要使用cout endl等符号需要使用作用域运算符::,或者using namespace std\r\n\r\nendl 操纵符,表示将与设备关联的缓冲区中的内容都刷到设备中。\r\n\r\n\r\n\r\n##### 1.3 注释\r\n\r\nc++中有两种注释方法://与/**/\r\n\r\n\r\n\r\n##### 1.4控制流\r\n\r\nwhile\r\n\r\n```c++\r\nwhile(i<20){\r\n val+=i;\r\n}\r\n```\r\n\r\n\r\n\r\nfor\r\n\r\n```c++\r\nfor(i=0;i<10;i++){\r\n\tsum+=i;\r\n}\r\n```\r\n\r\n\r\n\r\n读取数量不定的输入数据\r\n\r\n```\r\nwhile(cin>>value){\r\n sum+=value;\r\n}\r\n```\r\n\r\nif else\r\n\r\n\r\n\r\n##### 1.5 类简介\r\n\r\n使用文件重定向:\r\n\r\n```\r\naddItem.exe <infile >outfile\r\n```\r\n\r\n执行addItem.exe 从infile文件中读入,输出在outfile文件中\r\n\r\n\r\n\r\n#### 2.变量和基本类型\r\n\r\n常量:20(十进制)024(八进制)0x14(十六进制)\r\n\r\n字符串和字符串字面值:\r\n\r\n字符串字面值是由字符组成的数组,实际长度比字符数组长度多1,多了一个结尾的空字符‘\\0‘\r\n\r\n变量初始化,将units_sold初始化为0,可以有以下四种形式:\r\n\r\n```c++\r\nint units_sold=0;\r\nint units_sold={0};\r\nint units_sold{0};\r\nint units_sold(0);\r\n```\r\n\r\n默认初始化:\r\n\r\n如果没有初始化,则变量的值会被默认初始化,默认值与变量类型和变量位置有关。定义在任何函数外的变量会被初始化为0,定义在函数内的变量不被初始化,试图拷贝或者是访问这个值会引发错误。\r\n\r\n\r\n\r\n变量申明与变量定义:\r\n可以在c++中对某个量在多个文件中使用,这样的话就需要使用extern\r\n\r\nextern int i;表示申明了int i,其定义在其他文件中\r\n\r\n如果extern int i=0;则是定义了i ,定义的同时也消除了extern关键词的意义。\r\n\r\n\r\n\r\n作用域:\r\n\r\n定义在main函数外面的变量是全局变量\r\n\r\n```c++\r\nint i=0;\r\nvoid func(){\r\n cout<<i;\r\n}\r\nint main(){\r\n cout<<i;\r\n return 0;\r\n}\r\n```\r\n\r\n如果定义在for循环里面,块作用域,出了for循环则不能访问了\r\n\r\n```c++\r\nint reuse=42;\r\nint main(){\r\n cout<<reuse; //42\r\n int reuse=0;\r\n cout<<reuse; //0\r\n cout<<::reuse;//42,显示调用全局变量\r\n}\r\n```\r\n\r\n##### 引用与指针:\r\n\r\nint &ref; 报错,引用必须被初始化\r\n\r\nint &ref=10;报错,引用类型的初始值必须是一个对象\r\n\r\n引用是为对象创建了另一个名字;\r\n\r\n```c++\r\nint ival=10;\r\nint &reival=ival;\r\nreival--;\r\ncout<<ival; //9\r\n```\r\n\r\n指针也是创建了对其他对象的间接访问,指针与引用不同,首先指针本身就是一个对象,允许对指针赋值拷贝等等,如果指针没有被初始化则将拥有一个不确定的值。\r\n\r\n```c++\r\nint *p=&ival;\r\n```\r\n\r\n使用解引用符*来访问;\r\n\r\n*p即为ival\r\n\r\n空指针nullptr或者NULL不知向任何东西\r\n\r\n```\r\nint *p1=nullptr;\r\nint *p2=0;\r\nint *p3=NULL;\r\n```\r\n\r\n但是不能用int类型的变量对指针赋值\r\n\r\n```c++\r\nint zero=0;\r\nint *p=zero; //不行\r\n```\r\n\r\n建议对所有的指针都进行初始化,否则比较容易出现问题;\r\n\r\nvoid* 是一种特殊类型的指针,能够存放任何类型的对象。\r\n\r\n注意\r\n\r\n```c++\r\nint* p1,p2; p1是指针,p2是int\r\n* 可以多层使用\r\nint **pp1=&p1; pp1是指向指针的指针\r\n```\r\n\r\n##### const限定符\r\n\r\n被const限定的变量的数值不能被改变\r\n\r\n因此const类型的变量在创建的时候必须初始化。\r\n\r\n编译器在编译的过程中会把const变量直接替换成对应的值。\r\n\r\n##### 顶层const与底层const\r\n\r\n由于指针本身就是一个对象,我们用顶层const表示指针本身是个常量不可改变,底层const表示指针所指的对象是常量。\r\n\r\n```c++\r\nint i=0;\r\nint *const pi=&i; pi是顶层const\r\nconst int ci=42;\r\nconst int *p2=&ci; p2是底层const 可以改变\r\n```\r\n\r\n##### typedef 类型别名\r\n\r\n```c++\r\ntypedef longlong ll;\r\nusing ll=longlong;\r\n```\r\n\r\n##### auto类型\r\n\r\n```c++\r\nauto item =val1+val2;\r\n```\r\n\r\n编译器会根据val1 val2相加的结果决定推断item的类型\r\n\r\n##### decltype类型指示符\r\n\r\n```\r\nconst int ci=0;\r\ndecltype(ci) a; //将a定义为const int类型;\r\n```\r\n\r\n##### 自定义数据结构\r\n\r\n```c++\r\nstruct Sales_data{\r\n string bookNO;\r\n unsigned units_sold ;\r\n double revenue;\r\n};\r\n```\r\n\r\nc++11新标准规定可以给数据成员一个类内初始值,例如bookNO被初始化为空字符串,units_sold revenue被初始化为0\r\n\r\n##### 使用数据结构\r\n\r\n```c++\r\nSales_data data1,data2;\r\ncin>>data1.revenue>>data2.revenue;\r\n```\r\n\r\n##### 编写自己的头文件\r\n\r\n我们应该将struct Sales_data的定义放在Sales_data.h文件中\r\n\r\n```\r\n#ifndef SALES_DATA_H\r\n#define SALES_DATA_H\r\n#include <string>\r\nstruct Sales_data{\r\n std::string bookNO;\r\n unsigned units_sold=0;\r\n double revenue=0.0;\r\n};\r\n#endif\r\n```\r\n\r\n使用预处理器,进行头文件保护,避免重复包含\r\n\r\n在cpp文件中加上\r\n\r\n```c++\r\n#include \"Sales_data.h\"\r\n```\r\n\r\n\r\n\r\n\r\n\r\n#### 字符串 数组和向量\r\n\r\n##### 字符串\r\n\r\n```c++\r\n//初始化字符串\r\nstring s1; //默认初始化为空字符串\r\nstring s2(s1); //s2是s1的副本\r\nstring s2=s1; //等价于拷贝\r\nstring s3(\"value\");//初始化为value\r\nstring s3=\"value\";//初始化为\"value\"\r\nstring s4(n,'c');//初始化为n个'c'\r\n```\r\n\r\n字符串的基本操作\r\n\r\n```c++\r\nos<<s //将s写到os中\r\nis>>s //从is中读取字符串给s\r\ngetline(is,s) //从is中读一行给s\r\ns.empty() //判断是否为空\r\ns.size()\r\ns[n] //访问第n个元素\r\ns1+s2 //拼接\r\n<,<= //利用字符在字典中的顺序进行比较,注意大小写\r\n```\r\n\r\ncin>>s;\r\n\r\n程序会自动忽略之前的空白,直到遇到了下一处空白\r\n\r\n例如输入\r\n\r\n```\r\n hello world!\r\n```\r\n\r\n程序中s的值是“hello”\r\n\r\n```c++\r\nwhile(getline(cin,line)){\r\n cout<<line<<endl;\r\n}\r\n```\r\n\r\n##### 处理字符串中的字符\r\n\r\n```c++\r\nisalnum(c) //检测字符或者数字\r\nisalpha(c)//检测字符\r\niscntrl(c) //检测控制字符\r\nisdigit(c) //检测数字\r\nislower(c) //检测小写字符\r\nisupper(c) //检测大写字符\r\ntolower(c) //转换成小写字符\r\ntoupper(c) //转成大写字符\r\nispunct(c) //检测是否为标点\r\n```\r\n\r\n基本范围的for语句\r\n\r\n```c++\r\nstr=\"lower\";\r\nfor(auto c:str)\r\n c=toupper(c);\r\n cout<<c<<endl;\r\ncout<<str; //lower\r\n\r\nstr=\"lower\";\r\nfor(auto &c:str)\r\n c=toupper(c);\r\n cout<<c<<endl;\r\ncout<<str; //LOWER\r\n```\r\n\r\n\r\n\r\n##### 标准库vector\r\n\r\n使用时需要加上\r\n\r\n#include<vector>\r\n\r\n初始化\r\n\r\n```c++\r\nvector<int> v1; //空vector\r\nvector<int> v2(v1) //v1的拷贝\r\nvector<int> v2=v1; //v1拷贝\r\nvector<int> v3(n,val)//n个val元素\r\nvector<int>v5={a,b,c} //初始化为a,b,c\r\nvector<int>v5{a,b,c} //初始化为a,b,c\r\n```\r\n\r\n二维vector的初始化\r\n\r\n```c++\r\nvector<vector<int>> nums(5,vector<int>(5,1));\r\n```\r\n\r\n\r\n\r\nvector支持的操作\r\n\r\n```c++\r\nv.empty() //是否为空\r\nv.size() //返回元素个数\r\nv.push_back() //尾部添加元素\r\nv1==v2 判断两个vector是否完全相同\r\n< > <= 按照字典顺序进行比较\r\n```\r\n\r\n使用迭代器\r\n\r\nend返回的是尾后迭代器,如果容器为空,则begin end返回的是尾后迭代器\r\n\r\n```\r\nvector<int>::iterator it;\r\nstring::iterator it2;\r\n```\r\n\r\n\r\n\r\n迭代器的运算\r\n\r\n```\r\n*iter //取值\r\n++iter //向后移动一个\r\n--iter //向前移动一个\r\niter+n //向后移动n个位置\r\niter1-iter2 //得到二者之间的距离\r\n< > <= //判断两个迭代器之间的大小关系,在位置较前的迭代器小\r\n\r\nauto mid=v.begin()+v.size()/2;\r\nauto mid=v.begin()+(end-begin)/2;\r\nauto mid=(begin+end)/2; //这种是错误的,begin+end没有意义\r\n```\r\n\r\n\r\n\r\n某些对vector对象的操作会使得迭代器失效,例如在for循环中对vector添加元素等\r\n\r\n\r\n\r\n#### 表达式\r\n\r\n##### 左值和右值\r\n\r\nc++表达式不是左值就是右值。归纳:当一个对象被用作右值的时候,用的是对象的值(内容),用作左值的时候用的是对象的身份(在内存中的位置)。\r\n\r\n有几种我们熟悉的运算符是要用到左值的:\r\n\r\n赋值运算符一个左值作为左侧运算对象,返回的结果也是一个左值\r\n\r\n取地址符作用于一个左值运算对象,返回一个指向该运算对象的指针这个指针是右值。\r\n\r\n\r\n\r\n##### 算术运算符\r\n\r\n一元运算符\r\n\r\n```\r\nbool b=true;\r\nbool b2=-b; //b2为true,-1转换为bool为true\r\n\r\n```\r\n\r\n溢出:当数值超出了范围之后,符号位会发生改变。\r\n\r\n余数运算:\r\n\r\n(-m)/n m/(-n)等价于-(m/n)\r\n\r\n(-m)%n等价于-(m%n)\r\n\r\nm%(-n)等价于m%n\r\n\r\n```c++\r\n-21%10 -1\r\n21%-5 1\r\n```\r\n\r\n##### 类型转换 \r\n\r\n隐式转换,例如int+char 得到int等\r\n\r\n强制类型转换:\r\n\r\nint i,j;\r\n\r\ndouble slope=static_cast<double>(j)/i;\r\n\r\n建议避免使用强制类型转换\r\n\r\n\r\n\r\n#### 语句\r\n\r\nif语句 if else语句 else语句\r\n\r\n```c++\r\nswitch(ch){\r\n case 'a':case 'e':case 'i': case 'o': case 'u':\r\n ++vowelcnt;\r\n break;\r\n default:\r\n ++othercnt;\r\n break;\r\n}\r\n```\r\n\r\n##### try语句和异常处理\r\n\r\nc++中异常处理机制:遇到异常,throw抛出异常,catch语句会处理异常。\r\n\r\n异常:\r\n\r\n```c++\r\nif(item1.isbbn()==item2.isbn()){\r\n cout<<item1+item2<<endl;\r\n return 0;\r\n}\r\nelse{\r\n cerr<<\"Data must refer to same ISBN\"<<endl;\r\n return -1;\r\n}\r\n```\r\n\r\n```c++\r\nif(item1.isbn()!=item2.isbn())\r\n throw runtime_error(\"Data must refer to same ISBN\");\r\n```\r\n\r\n抛出异常将终止当前的函数\r\n\r\n```c++\r\nwhile(cin>>item1>>item2){\r\n try{\r\n if(item1.isbn()!=item2.isbn())\r\n throw runtime_error(\"Data must refer to same ISBN\");\r\n }\r\n catch(runtime_error err){\r\n cout<<err.what()<<\"Try Again Enter Y or N\"<<endl;\r\n char c;\r\n cin>>c;\r\n if(!cin||c=='n')\r\n break;\r\n }\r\n}\r\n```\r\n\r\n如果最终没有找到任何匹配的catch语句,程序转移到terminate函数\r\n\r\n##### 标准异常\r\n\r\nc++库定义了例如exception,runtime_error overflow_error等类型的异常\r\n\r\n异常类型只定义了一个名为what的函数,没有参数,用于提供一些异常的文本信息。\r\n\r\n\r\n\r\n#### 函数\r\n\r\n一个典型的函数包括返回类型、函数名、形参、函数体等部分。\r\n\r\n实参与形参:实参是形参的初始值。\r\n\r\n对象有生命周期,形参是一种自动对象。\r\n\r\n##### 局部静态对象\r\n\r\n局部静态对象在程序经过时初始化,并且直到程序终止时才会被销毁。\r\n\r\n##### 参数传递\r\n\r\n参数传递分为传值参数与传引用参数。\r\n\r\n```c++\r\nvoid reset(int i){\r\n i=0; //传值参数,返回之后int i的值没有改变;\r\n}\r\nvoid reset(int &i){\r\n i=0; //传引用参数, 返回之后int i值变;\r\n}\r\n```\r\n\r\n一个函数只能返回一个值,有时需要返回多个值,引用参数为我们异常返回多个结果提供了有效的途径。\r\n\r\n\r\n\r\n数组形参\r\n\r\n```c++\r\nvoid print(const int*);\r\nvoid print(const int[]);\r\nvoid print(const int[10]);\r\n```\r\n\r\n##### 传递多维数组\r\n\r\nc++中没有多维数组\r\n\r\nint matrix[10,10];\r\n\r\n```c++\r\nvoid print(int (*matrix)[10],int rowsize){};\r\nvoid print(int maxtrix[][10],int rowsize){};\r\n```\r\n\r\n\r\n\r\n##### main 处理命令行\r\n\r\n若main函数位于可执行prog之内\r\n\r\n```c++\r\nprog -d -o ofile data0\r\nint main(int argc,char *argv[]){}\r\n\r\nargc=5;\r\nargv[0]=\"prog\";\r\nargv[1]=\"-d\";\r\nargv[2]=\"-o\";\r\nargv[3]=\"ofile\";\r\nargv[4]=\"data0\";\r\nargv[5]=0;\r\n```\r\n\r\n\r\n\r\n##### 含有可变形参的函数\r\n\r\n有时我们无法提前预知应该像函数传递几个实参。如果所有的实参的类型相同,则使用initializer_list,如果实参的类型不同,则使用一种特殊的函数,也就是可变参数模板。\r\n\r\n ```c++\r\nvoid error_msg(initializer_list<string> i1){\r\n for(auto beg=i1.begin();beg!=i1.end();++beg){\r\n cout<<*beg<<\" \";\r\n }\r\n cout<<endl;\r\n}\r\n ```\r\n\r\n##### 函数重载\r\n\r\n如果同一作用域内的几个函数名字先沟通但形参不同,称之为重载函数。\r\n\r\n```c++\r\nvoid print(const char*cp);\r\nvoid print(const int *beg,const int *end);\r\nvoid print(const int ia[],size_t size);\r\n\r\nprint(\"Hello World\");\r\nprint(j,end(j)-begin(j));\r\nprint(begin(j),end(j));\r\n```\r\n\r\n##### 确定重载的函数\r\n\r\n 函数匹配是一个过程,在这个过程中我们把函数调用与一组重载函数的某个关联起来,这种匹配也叫做重载确定。重载确定有三种可能的结果:\r\n\r\n* 找到一个最佳匹配函数\r\n* 找不到任何一个匹配,发出无匹配的错误信息。\r\n* 有多余一个函数可以匹配,但是每一个都不是最佳匹配,此时也发生错误,二义性调用。\r\n\r\n\r\n\r\n##### 重载和作用域\r\n\r\n重载函数需要定义在一起\r\n\r\n```c++\r\nvoid print(const string &);\r\nvoid print(double);\r\nvoid print(int);\r\n```\r\n\r\n```c++\r\nvoid print(const string &);\r\nvoid print(double);\r\nvoid foo(int ival){\r\n bool read=false;\r\n string s=read();\r\n void print(int); //新作用域 覆盖了之前的print函数 不是重载\r\n}\r\n```\r\n\r\n##### 默认实参\r\n\r\n如果我们要使用默认实参,只要在调用函数的时候忽略这个参数就可以了。\r\n\r\n```c++\r\nstring screen(int ht=24,int int wid=80,char background=' ');\r\nwindow=screen(); //使用默认参数\r\n```\r\n\r\n默认实参负责填补缺少的尾部实参;\r\n\r\n```c++\r\nwindow=screen(,,'?'); //错误 只能忽略尾部的参数\r\nwindow=screen('?'); //错误 相当于调用screen('?',80,' ');\r\n```\r\n\r\n\r\n\r\n##### 函数匹配\r\n\r\n```c++\r\nvoid f();\r\nvoid f(int);\r\nvoid f(int,int);\r\nvoid f(double,double=3.14);\r\nf(5.6);\r\n```\r\n\r\n对于f(5.6)而言,有4个候选函数,考察实参5.6发现有两个可行函数\r\n\r\n```c++\r\nvoid f(int);\r\nvoid f(double,double=3.14);\r\n```\r\n\r\n5.6可以通过类型转换double到int,或者可以将第二个参数视为默认实参\r\n\r\n\r\n\r\n##### 函数指针\r\n\r\n函数指针指向的是函数而非对象。\r\n\r\n```c++\r\nbool lengthCompare(const string &,const string &); //函数\r\nbool (*pf)(const string &,const string &); //pf 是一个函数指针,*pf两端的括号不可少,不写的话pf是一个返回值为bool *的函数\r\n\r\n//使用函数指针\r\npf=lengthCompare; //pf指向lengthCompare函数\r\npf=&lengthCompare //与上一句等价\r\n\r\nbool b1=pf(\"hello\",\"goodbye\"); //调用lengthCompare函数\r\nbool b2=(*pf)(\"hello\",\"goodbye\"); //一个等价的调用\r\nbool b3=lengthCompare(\"hello\",\"goodbye\"); //一个等价调用\r\n\r\nstring sumLength(const string&, const string&);\r\nbool cstringCompare(const char*,const char*);\r\npf=0; //pf不指向任何函数\r\npf=sumLength; //错误,返回类型不匹配\r\npf=cstringCompare //错误 形参不匹配\r\npf=lengthCompare // 正确 函数和指针匹配\r\n```\r\n\r\n\r\n\r\n#### 类\r\n\r\n##### 7.1 定义抽象数据类型\r\n\r\n类的基本思想是数据抽象和封装。数据抽象是一种依赖于接口和实现分离的编程技术。\r\n\r\n##### 引入this\r\n\r\nthis是一个常量指针,在类内使用this这个指向自己的指针。例如在类内调用成员变量。\r\n\r\n例如成员函数\r\n\r\n```c++\r\nstring isbn(){return bookNO;}\r\n```\r\n\r\n相当于使用this.bookNO;\r\n\r\n```c++\r\nclass Sales_data{\r\n friend Sales_data add(const Sales_data&, const Sales_data&);\r\n friend std::isream &read(std::istream&, Sales_data&);\r\n friend std::ostream &print(std::ostream&, const Sales_data&);\r\npublic:\r\n Sales_data()=default;\r\n Sales_data(const std::string &s,unsigned n, double p):bookNO(s),units_sold(n),revenue(p*n){}\r\n Sales_data(const std::string &s):bookNO(s){}\r\n Sales_data(std::istream);\r\n std::string isbn() const{return bookNO;}\r\n cSales_data &combine(const Sales_data&);\r\nprivate:\r\n std::string bookNO;\r\n unsigned units_sold=0;\r\n double revenue=0.0;\r\n};\r\nSales_data add(const Sales_data&, const Sales_data&);\r\nstd::istream &read(std::istream&, Sales_data&);\r\nstd::ostream &print(std::ostream&, const Sales_data&);\r\n```\r\n\r\n##### 构造函数\r\n\r\n```c++\r\nSales_data(const std::string &s,unsigned n, double p):bookNO(s),units_sold(n),revenue(p*n){}\r\nSales_data(const std::string &s):bookNO(s){}\r\n```\r\n\r\n注意构造函数的冒号以及冒号与花括号之间的语句。\r\n\r\n类之间也可以进行拷贝等操作\r\n\r\n```c++\r\ntotal=trans;\r\n```\r\n\r\n等价于\r\n\r\n```\r\ntotal.bookNO=trans.bookNO;\r\ntotal.units_sold=trans.units_sold;\r\ntotal.revenue=trans.revenue;\r\n```\r\n\r\n##### 访问控制与封装\r\n\r\n* 定义在public后面的成员在整个程序中都可以访问,public成员的定义了类的接口。\r\n* 定义在private后面的成员可以被类内的成员函数访问,但不能被使用该类的代码访问,private部分是类所隐藏的实现细节。\r\n\r\n\r\n\r\n##### 友元\r\n\r\n由于其他代码不能访问类内的private成员,则例如add 等函数也不能编译了。为了使得add print等函数能够成功运行,可以将add等函数作为Sales_data类的友元。只需要增加一条friend语句即可。\r\n\r\n\r\n\r\n\r\n\r\n#### IO库\r\n\r\nIO库中有istream类型 ostream类型,cin是一个istream对象 ostream对象\r\n\r\n流对象不能拷贝或者赋值\r\n\r\n```c++\r\nofstream out1,out2;\r\nout1=out2; //错误\r\n```\r\n\r\n确定一个流对象的状态最好的方法是将它作为一个条件来使用:\r\n\r\n```c++\r\nwhile(cin>>word)\r\n```\r\n\r\n每个输出流都管理一个缓冲区,用来曹村程序读写的数据。导致缓冲刷新(数据真正写到输出设备上时)的原因可能有:\r\n\r\n* 程序正常结束\r\n* 缓冲区满的时候刷新缓冲区\r\n* 使用endl等操作符\r\n\r\n类似于endl操作符的还有ends flush\r\n\r\n```\r\nendl;//输出缓冲区的内容并换行\r\nends;//输出缓冲区的内容并加一个空格\r\nflush;// 输出缓冲区的内容\r\n```\r\n\r\n##### unitbuf\r\n\r\n```\r\ncout<<unitbuf;//所有的输出操作之后都自动帅新缓存区\r\ncout<<nounitbuf;//回到正常输出的模式\r\n```\r\n\r\n##### 文件输入输出\r\n\r\n头文件fstream定义了三个类型来支持文件IO,ifstream ofstream fstream\r\n\r\n```c++\r\n#include <fstream>\r\nusing namespace std;\r\nint main(){\r\n string ifle=\"ifile\";\r\n ifstream in(ifile); //定义了一个ifstream类并将其打开给指定文件ifile\r\n ostream out;\r\n out.open(\"ofile\") //out打开或是新建ofile\r\n string s;\r\n while(in>>s){\r\n cout<<s<<endl;\r\n out<<s;\r\n }\r\n}\r\n\r\n```\r\n\r\n```c++\r\nifile:\r\nline1 line1\r\nline2 line2\r\n\r\n屏幕:\r\nline1\r\nline1\r\nline2\r\nline2\r\n\r\nofile:\r\nline1line1line2line2\r\n```\r\n\r\n```c++\r\n//按行读取\r\n#include <fstream>\r\nusing namespace std;\r\nint main(){\r\n string ifle=\"ifile\";\r\n ifstream in(ifile); //定义了一个ifstream类并将其打开给指定文件ifile\r\n ostream out;\r\n out.open(\"ofile\") //out打开或是新建ofile\r\n string s;\r\n while(getline(in,s)){\r\n cout<<s<<endl;\r\n out<<s;\r\n }\r\n}\r\n```\r\n\r\n\r\n\r\n##### 实现python中getline split效果\r\n\r\n```c++\r\n#include <sstream>\r\nusing namespace std;\r\nint main(){\r\n string ifile=\"ifile\";\r\n ifstream in(ifile);\r\n string line,s;\r\n while(getline(in,line)){\r\n istringstream record(line);\r\n while(record>>s)\r\n cout<<s<<endl;\r\n }\r\n return 0;\r\n}\r\n```\r\n\r\n按照行先读入到line中 \"line1 line1\"\r\n\r\n利用istringstream将line中按照空格一个个分开,读到s中\r\n\r\n\r\n\r\n#### 顺序容器\r\n\r\n顺序容器的基本属性\r\n\r\n```c++\r\n构造函数:\r\nC c; //默认构造函数 构造空容器\r\nC c1(c2); //构造c2的拷贝c1\r\nC c(b,e); //构造c将迭代器b e指定的范围内的元素拷贝到c\r\nC c{a,b,c}; //列表初始化;\r\n\r\n赋值与swap操作:\r\nc1=c2; //将c1中的元素替换为c2;\r\nc1={a,b,c} //将c1中的元素替换为列表\r\na.swap(b); //交换a,b中的元素\r\nswap(a,b); //交换a,b中的元素\r\n\r\n大小:\r\nc.size(); //返回c中的元素数\r\nc.max_size(); //c可保存的最大元素数目\r\nc.empty(); //c是否空\r\n\r\n添加 删除元素\r\nc.insert(); //增加元素\r\nc.emplace()\r\nc.erase(); //删除某个元素\r\nc.clear(); // 清除所有的元素\r\n\r\n关系运算符:\r\n==,!= 所有的容器都支持相等 不等运算符\r\n<,<=,>,>= 关系运算符(无序容器不支持)\r\n\r\n迭代器:\r\nc.begin(),c.end();\r\nc.cbegin(),c.cend(); const iterator\r\nc.rbegin(),c.rend();//指向c的尾元素与首元素\r\nc.crbegin(),c.crend();\r\n```\r\n\r\n\r\n\r\n使用迭代器\r\n\r\n```c++\r\nwhile(begin!=end){\r\n *begin=val;\r\n ++begin;\r\n}\r\n```\r\n\r\n如果begin==end,区间为空\r\n\r\n```c++\r\nseq.assign(b,e); //将seq中的元素替换为迭代器b和e所表示的范围中的元素\r\nseq.assign(i1); //将seq中的元素替换为列表i1中的元素\r\nseq.assign(n,t); //将seq中的元素天魂为n个值为t的元素\r\n```\r\n\r\n对容器操作可能使迭代器失效。向容器添加元素之后,如果容器时vector或者string,且存储空间被重新分配,则指向容器的迭代器、指针和引用都会失效。如果存储空间未重新分配,指向插入位置之前的元素的迭代器、指针和引用会失效,而指向插入位置之后的元素的迭代器、指针和引用会继续有作用。对于deque,插入在除了首尾两端的位置都会使得迭代器失效。\r\n\r\n\r\n\r\n##### 额外的string操作\r\n\r\n构造string的其他方法:\r\n\r\n```\r\nstring s(cp,n); //s是cp指向的数组前n个字符的拷贝\r\nstring s(s2,pos2); //s是string s2从下标pos2开始的字符的拷贝;\r\nstring s(s2,pos2,len2); //s是string s2从下标pos2开始的len2个字符拷贝\r\n```\r\n\r\nsubstr\r\n\r\n```c++\r\nstring s(\"hello world\");\r\nstring s2=s.substr(0,5); hello\r\nstring s3=s.substr(6); world\r\nstring s4=s.substr(6,5); world\r\nstring s5=s.substr(12); 报出错误\r\n```\r\n\r\n改变string的函数:\r\n\r\n```c++\r\ns.insert(s.size(),5,'!'); //在末尾加上5个\"!\"\r\ns.erase(s.size()-5,5); //在后面删除最后5个;\r\n```\r\n\r\n##### string 搜索操作\r\n\r\nstring类提供了6个不同的搜索函数,每个函数都有4个重载版本。\r\n\r\n```c++\r\ns.find(args); //查找s中args第一次出现的位置\r\ns.rfind(args); // 查找s中args最后一次出现的位置;\r\ns.find_first_of(args); //在s中找args中任何一个字符第一次出现的位置;\r\ns.find_last_of(args); //在s中找args中任何一个字符最后一次出现的位置;\r\ns.find_first_not_of(args); //在s中查找第一个不在args中的字符;\r\ns.find_last_of(args); //在s中查找最后一个不在args中的字符;\r\n\r\nstring name(\"AnnaBelle\");\r\nauto pos1=name.find(\"Anna\"); //返回0\r\n\r\nstring numbers(\"0123456789\"),name(\"r2d2\");\r\nauto pos=name.find_first_of(numbers);\r\n\r\n每个字符都可以接收第二个参数用来指出从什么位置开始搜索。\r\n```\r\n\r\n#####compare函数\r\n\r\n```c++\r\ns.compare\r\npos1,n1,s2,pos2,n2; //s从pos1开始的n1个字符与s2中从pos2开始的n2个字符比较\r\n```\r\n\r\n根据s是等于 大于还是小于参数指的字符串,返回0 正数或负数\r\n\r\n##### 数值转换\r\n\r\n```c++\r\nstring s=to_string(i); int to string\r\ndouble d=stod(s)//string to double\r\n```\r\n\r\n\r\n\r\n#### 泛型算法\r\n\r\n标准库容器定义的操作集合很小,而是提供了一组算法,这些算法的大多数能够在任何容器中使用。这些算法大多数都定义在algorithm文件中。这些算法都不执行容器的操作,而是作用在迭代器上。\r\n\r\n```\r\nresult=find(vec.cbegin(),vec.cend(),val);\r\n```\r\n\r\n前两个参数是用来表示元素范围的迭代器。find函数会按照顺序依次比较。\r\n\r\n##### 只读算法\r\n\r\n```c++\r\ncount(v.begin(), v.end(), 1);//count有多少个1;\r\nint sum=accumulate(vec.begin(),vec.end(),0); //求和,初始值为0;\r\nstring sum=accumulate(v.cbegin(),v.cend(),string(\"\")); //将v中所有的string连起来\r\nstring sum=accumulate(v.begin(),v.end(),\"\");//错误,char* 没有定义+运算\r\n\r\nequal(roster1.cbegin(),roster1.cend(),roster.cbegin()); //比较是否相同\r\n```\r\n\r\n##### 写元素的算法\r\n\r\n```c++\r\nfill(vec.begin(),vec.end(),0); // 将所有元素重置0;\r\nfill_n(vec.begin(),vec.size(),0);//fill_n假定写入指定个元素是安全的;\r\n\r\n//back_inserter\r\nvec<int> vec;\r\nfill_n(back_inserter(vec),10,0); //添加10个元素到末尾\r\n\r\n//copy\r\nvector<int> v = {1,2,3};\r\nvector<int> cv(3) ;\r\ncopy(v.begin(),v.end(),cv.begin());\r\n\r\nreplace(ilist.begin(),ilist.end(),0,42); 将所有的0替换为42;\r\n```\r\n\r\n##### 重排\r\n\r\n```c++\r\n\"the quick red fox jumps over the slow red turtle\"\r\nsort(words.begin(),words.end());\r\n\"fox jumps over quick red red slow the the turtle\"\r\nauto end_unique=unique(words.begin(),words.end()); //unique并未删除元素\r\n\"fox jumps over quick red slow the turtle ??? ???\"\r\nwords.erase(end_unique,words.end());\r\n\"fox jumps over quick red slow the turtle\"\r\n```\r\n\r\n```\r\nbool isshorter(const string &s1,const string &s2){\r\n return s1.size()<s2.size();\r\n}\r\nsort(words.begin(),words.end(),isshorter);\r\nstable_sort(words.begin(),words.end(),isshorter);//保持了相同擦汗高难度的单词按字典序排列\r\n```\r\n\r\n\r\n\r\nwhat is泛型算法:\r\n\r\ngeneral type algorithm\r\n\r\n对于不同的数据类型,都可以适用,例如sort可以适用于不同类型的元素(int double float)和多种多种容器类型(只要容器提供了算法所需的接口即iterator)\r\n\r\n\r\n\r\niterator可以理解为经过包装过的指针(void*,void *可以适配所有类型),区别在于iterator能够更好地与容器兼容,对于非连续空间的容器,例如set(实现机制红黑树),指针自增是没有意义的,而iterator自增可以找到下一个元素。\r\n\r\n同时使用iterator具有智能指针的效果,即不需要程序员手动释放内存,当变量的生命周期结束之后自动回收内存。如果是void *,搭配malloc或者new--在堆上分配数据,则需要手动释放内存。\r\n\r\n\r\n\r\n#### 关联容器\r\n\r\n关联容器和顺序容器有着根本的不同,关联容器中的元素是按照关键字来保存和访问的,顺序容器中的元素是按照他们在容器中的顺序来保存和访问的。\r\n\r\n##### map\r\n\r\n```c++\r\nmap是关键字-值对的集合,与之相对set仅仅是关键字的简单集合\r\n// 统计每个单词在输入中出现的次数\r\nmap <string,size_t> word_count;\r\nwhile(cin>>word)\r\n ++word_count[word];\r\nfor(const auto &w:word_count)\r\n cout<<w.first<<\" occurs\"<<w.second<<\" times\"<<endl;\r\n```\r\n\r\n如果word未在map中,下标运算符会创建一个新元素,其关键字为word,值为0.\r\n\r\n\r\n\r\n##### set\r\n\r\n```\r\nset<string> exclude={\"The\",\"But\",\"And\",\"Or\",\"An\",\"A\"};\r\n```\r\n\r\n##### map\r\n\r\nmap的初始化方法\r\n\r\n```c++\r\nmap<string,size_t> word_count; //空容器\r\nmap<string,string>authors={{\"Jyoce\",\"James\"},{\"Austen\",\"Jane\"},{\"Dickens\",\"Charles\"}};\r\n\r\n{key,value}\r\n```\r\n\r\n一个map或者一个set的关键字必须是唯一的,容器multiset和multimap没有这样的限制,他们都允许多个元素具有相同的关键字。\r\n\r\n```\r\nvector<int> ivec={0,0,1,1};\r\nset<int> iset(ivec.cbegin(),ivec.cend()); //0,1\r\nmultiset<int> miset(ivec.cbegin(),ivec.cend());//0,0,1,1 \r\n```\r\n\r\n##### 关联容器内部的排序\r\n\r\n可以向一个算法提供我们自己定义的比较操作,用来代替<运算符。这个操作要求满足严格弱续,可以将严格弱续视为小于等于。这个小于等于可能不是数值上的。\r\n例如我们可以定义一个compare函数用来比较。\r\n\r\n```c++\r\n#include<set>\r\nbool compare(const pair<int, int> &a, const pair<int, int> &b) {\r\n\treturn a.second < b.second;\r\n}\r\nint main() {\r\n\tset<pair<int,int>,decltype(compare)*> iset(compare);\r\n\tpair<int, int> a{ 2,1 };\r\n\tpair<int, int> b{ 0,2 };\r\n\tpair<int, int> c{ -3,3 };\r\n\tiset.insert(a);\r\n\tiset.insert(b); \r\n\tiset.insert(c);\r\n\tfor (auto &it : iset)\r\n\t\tcout << it.first << \" \" << it.second << endl;\r\n\tsystem(\"pause\");\r\n\treturn 0;\r\n};\r\n```\r\n\r\n上述代码实现在set中所有元素按照compare的方式进行排序:a b c,正常的话是c b a\r\n\r\n\r\n\r\n##### pair类型\r\n\r\npair在头文件utility中\r\n\r\n````\r\npair<T1,T2> P;//定义了一个空pair;\r\npair<T1,T2> P(V1,V2); //初始化为v1v2\r\npair<T1,T2> ={v1,v2}; //作用同上\r\nmake_pair(v1,v2); //返回一个用v1 v2初始化的pair\r\np.first;\r\np.second;\r\n````\r\n\r\n关联容器还定义了key_value,mapped_type,value_type这三个类型\r\n\r\nset的迭代器是const的,可以使用set迭代器来读取元素的值,但不能修改。\r\n\r\n##### 遍历关联容器\r\n\r\n```c++\r\nauto map it=word_count.cbegin();\r\nwhile(map_it!=word_count.cend()){\r\n cout<<map_it->first<<\" occurs \"<<map_it->second<<\" times\"<<endl;\r\n ++map_it;\r\n}\r\n```\r\n\r\n##### 添加元素\r\n\r\n关联容器使用insert函数向容器中添加一个元素或者一个元素范围。map和set中插入一个已经存在的元素对容器没有任何影响。\r\n\r\n```c++\r\nvector<int> ivec={2,4,6,8,2,4,6,8};\r\nset<int> set2;\r\nset2.insert(ivec.cbegin(),ivec.cend()); //2,4,6,8\r\nset2.insert({1,3,5,7,1,3,5,7});//1,3,5,7\r\n\r\nword_count.insert({word,1});\r\nword_count.insert(make_pair(word,1));\r\nword_count.insert(pair<string,size_t>(word,1));\r\n```\r\n\r\n如果容器中没有这个元素,则插入并返回true,如果已经存在了则不做任何操作,返回false\r\n\r\n```c++\r\nmultimap<string,string> authors;\r\nauthors.insert({\"a,b\",\"1\"});\r\nauthors.insert({\"a,b\",\"2\"});\r\n```\r\n\r\n\r\n\r\n##### 删除元素\r\n\r\n```\r\nc.erase(k); //删除每个关键字为k的元素;\r\nc.erase(p); //从c中删除迭代器p指定的元素;\r\nc.erase(b,e); 删除迭代器b和e所表示的范围\r\n\r\nerase返回删除元素的数量\r\n```\r\n\r\nmap和unordered_map支持下标操作,multimap不支持下标操作。\r\n\r\n下标操作:\r\n\r\n```c++\r\nc[k];\r\nc.at(k)\r\n```\r\n\r\nc[k]:与vector不同的是,如果k不在c中,会添加k元素到c中\r\n\r\nc.at(k)如果k不在c中会报out of range 错误\r\n\r\n\r\n\r\n##### 访问元素\r\n\r\nfind函数与count函数\r\n\r\n```\r\nset<int> iset={0,1,2,3,4,5,6,7,8};\r\niset.find(1); //返回一个迭代器,指向key==1的元素\r\niset.find(11); //返回一个迭代器,iset.end()\r\niset.count(1); //返回1\r\niset.count(0); //返回0\r\n\r\nc.lower_bound(k);//返回一个迭代器,指向第一个不小于k的元素\r\nc.upper_bound(k);//返回一个迭代器,指向第一个大于k的元素\r\nc.equal_range(k);//返回一个迭代器pair,关键字等于k的元素范围,若k不存在则返回两个c.end()\r\n```\r\n\r\n\r\n\r\n##### 无序容器\r\n\r\n定义了unordered_map,unordered_set等无序容器\r\n\r\n容器使用一个哈希函数与关键字类型==运算符来组织元素\r\n\r\nfind insert等函数也适用于无序容器。无序容器在组织上为一组桶,每个桶保存零个或者多个元素。\r\n\r\n```c++\r\nc.bucket_count() ;// 正在使用的桶数目\r\nc.max_bucket_count();//容器能容纳的最多桶的数目\r\nc.bucket_size(n);//第n个桶中有多少个元素\r\nc.bucket(k);//元素k在哪个桶中\r\n```\r\n\r\n可以用自己定义的函数hasher来重新定义==符号\r\n\r\n\r\n\r\n#### 拷贝控制\r\n\r\n```c++\r\nclass Foo(){\r\npublic:\r\n Foo(); //默认初始化\r\n Foo(const Foo&); //拷贝初始化\r\n //...\r\n};\r\n```\r\n\r\n````c++\r\nstring dots(10,'.'); //直接初始化\r\nstring s(dots); //直接初始化\r\nstring s2=dots; //拷贝初始化\r\nstring null_book=\"9-9999-99999-9\"; //拷贝初始化\r\nstring nines=string(100,'9'); //拷贝初始化\r\n````\r\n\r\n##### 析构函数\r\n\r\n析构函数与构造函数执行相反的操作。\r\n\r\n```c++\r\nclass Foo(){\r\npublic:\r\n ~Foo();\r\n}\r\n```\r\n\r\n什么时候会调用析构函数:无论何时,一个对象对销毁时会自动调用其析构函数。\r\n\r\n* 一个变量离开其作用域时\r\n* 一个对象被销毁时,其成员被销毁\r\n\r\n等等\r\n\r\n\r\n\r\n\r\n\r\n#### 重载运算&&类型转换\r\n\r\n重载+号运算符\r\n\r\n```c++\r\n#include <iostream>\r\nusing namespace std;\r\nclass Box{\r\n public:\r\n double getVolume(void){\r\n return length * breadth * height;\r\n }\r\n void setLength( double len ){\r\n length = len;\r\n }\r\n void setBreadth( double bre ){\r\n breadth = bre;\r\n }\r\n void setHeight( double hei ){\r\n height = hei;\r\n }\r\n // 重载 + 运算符,用于把两个 Box 对象相加\r\n Box operator+(const Box& b){\r\n Box box;\r\n box.length = this->length + b.length;\r\n box.breadth = this->breadth + b.breadth;\r\n box.height = this->height + b.height;\r\n return box;\r\n }\r\n private:\r\n double length; // 长度\r\n double breadth; // 宽度\r\n double height; // 高度\r\n};\r\nint main( ){\r\n Box Box1; // 声明 Box1,类型为 Box\r\n Box Box2; // 声明 Box2,类型为 Box\r\n Box Box3; // 声明 Box3,类型为 Box\r\n double volume = 0.0; // 把体积存储在该变量中\r\n // Box1 详述\r\n Box1.setLength(6.0); \r\n Box1.setBreadth(7.0); \r\n Box1.setHeight(5.0);\r\n // Box2 详述\r\n Box2.setLength(12.0); \r\n Box2.setBreadth(13.0); \r\n Box2.setHeight(10.0);\r\n // Box1 的体积\r\n volume = Box1.getVolume();\r\n cout << \"Volume of Box1 : \" << volume <<endl;\r\n // Box2 的体积\r\n volume = Box2.getVolume();\r\n cout << \"Volume of Box2 : \" << volume <<endl;\r\n // 把两个对象相加,得到 Box3\r\n Box3 = Box1 + Box2;\r\n // Box3 的体积\r\n volume = Box3.getVolume();\r\n cout << \"Volume of Box3 : \" << volume <<endl;\r\n \r\n return 0;\r\n}\r\n```\r\n\r\noperator+ 运算符\r\n\r\noperator<< 符号\r\n\r\n```c++\r\nostream &operator<<(ostream &os,const Sales_data &item){\r\n os<<item.isbn()<<\" \"<<item.units_sold<<\" \"<<item.revenue<<\" \"<<item.avg_price();\r\n return os;\r\n}\r\n\r\ncout<<data;\r\n```\r\n\r\noperator>>符号\r\n\r\n```c++\r\nistream &operator>>(istream &is,Sales_data &item){\r\n double price;\r\n is>>item.bookNo>>item>>units_sold()>>price;\r\n if(is)\r\n item.revenue=tiem.units_sold*price;\r\n else\r\n item=Sales_data();\r\n return is;\r\n}\r\n```\r\n\r\n##### 算术和关系运算符重载\r\n\r\n```c++\r\nSales_data operator+(const Sales_data 7lhs,const Sales_data &rhs){\r\n Sales_data sum=lhs;\r\n sum+=rhs;\r\n return sum;\r\n}\r\n\r\nbool operator==(const Sales_data &lhs,const Sales_data &rhs){\r\n return lhs.isbn()==rhs.isbn()&&lhs.units_sold==rhs.units_sold&&lhs.revenue==rhs.revenue;\r\n}\r\nbool operator!=(const Sales_data &lhs,const Sales_data &rhs){\r\n return !(lhs==rhs);\r\n}\r\n```\r\n\r\n\r\n\r\n\r\n\r\n### 面向对象程序设计\r\n\r\n面向对象程序设计基于三个基本的概念:数据抽象、继承和动态绑定\r\n\r\n##### 继承:\r\n\r\n通过继承联系在一起的类构成一种层次关系。通常在层次关系的根部有一个基类,其他类通过基类继承而来,这些类称为派生类。\r\n\r\n基类Quote\r\n\r\n```\r\nclass Quote{\r\npublic:\r\n std::string isbn() const;\r\n virtual double net_price(std::size_t n) const;\r\n};\r\n```\r\n\r\n对于某些函数,基类希望它的派生类各自定义适合自身的版本,此时基类就将这些函数声明为虚函数。\r\n\r\n派生类通过类派生列表明确指出它是从哪个基类继承而来的。\r\n\r\n```c++\r\nclass Bulk_quote:public Quote{\r\npublic:\r\n double net_price(std::size_t) const override;\r\n}\r\n```\r\n\r\n派生类可以显示地注明它将使用哪个成员函数改写基类的虚函数,具体的措施是在该函数的形参列表后写一个override关键字。\r\n\r\n\r\n\r\n##### 动态绑定\r\n\r\n函数print_total基于net_price函数。\r\n\r\n```c++\r\n//basic 的类型是Quote,bulk的类型是Bulk_quote;\r\nprint_totall(cout,basic,20);//调用Quote的net_price函数\r\nprint_total(cout,bulk,20);//调用Bulk_quote的net_price函数\r\n```\r\n\r\n动态绑定:\r\n\r\n函数的运行版本由实参决定,即在运行时选择函数的版本,动态绑定又被称为运行时绑定。\r\n\r\n\r\n\r\n#### 基类:\r\n\r\n```c++\r\nclass Quote{\r\npublic:\r\n Quote()=default;\r\n Quote(const std::string &book,double sales_price):bookNo(book),price(sales_price){}\r\n std::string isbn() const{return bookNo;}\r\n virtual double net_price(std::size_t n)const{return n*price};//虚函数\r\n virtual ~Quote()=default;\r\nprivate:\r\n std::string bookNo;\r\nprotected:\r\n double price=0.0;\r\n};\r\n```\r\n\r\n在c++语言中,基类将它的两种成员函数区分开来:一种是基类希望其派生类进行覆盖的函数,另一种是基类希望派生类直接继承而不要改变的函数。对于前者,基类通常将其定义为虚函数virtual。\r\n\r\n基类的public成员能被其他用户访问,private不能被其他用户访问,protected类表示它的派生类可以访问但是其他用户不能访问。\r\n\r\n##### 派生类\r\n\r\n```c++\r\nclass Bulk_quote:public Quote{//继承自Quote\r\npublic:\r\n Bulk_quote()=default;\r\n Bulk_quote(const std::string&,double,std::size_t,double);\r\n \r\n double net_price(std::size_t) const override;\r\nprivate:\r\n std::size_t min_qty=0;\r\n double discount=0.0;\r\n};\r\n```\r\n\r\n派生类必须将其继承而来的成员函数中需要覆盖的那些重新声明。如果没有覆盖则会继承在基类的版本。\r\n\r\nBulk_quote类从Quote类继承了bookNo price 等数据成员,重新定义了net_price的版本,增加了两个min_qty discount成员。\r\n\r\n##### 防止继承的发生\r\n\r\n有时我们需要有些类不能被其他类所继承,使用final关键字\r\n\r\n```c++\r\nclass NoDerived final{}; // 不能继承\r\n```\r\n\r\n##### 类型转换与继承\r\n\r\n我们在使用指针或者引用时,指针或者引用的类型应与对象的类型一致,但是继承关系的类时一个重要的例外。我们可以将基类的指针或引用绑定到派生类对象上,例如可以用Quote&引用,Quote*指针指向Bulk_quote对象。\r\n\r\n\r\n\r\n#### 虚函数\r\n\r\n对虚函数的调用可能在运行时才被解析\r\n\r\n##### 多态性\r\n\r\nOOP的核心思想是多态性,表示多种形态。我们把具有继承关系的多个类型称为多态类型,我们能够使用这些类型的多种形式而不需要注意它们的差异。当我们使用基类的引用或者是指针调用基类的一个函数时,不知道该函数真正作用的对象是什么类型,因为可能是基类的对象或者是一个派生类的对象。如果这个函数是虚函数,则知道运行时才会决定到底执行哪个版本。\r\n\r\n\r\n\r\n##### 抽象基类与纯虚函数\r\n\r\n和普通的虚函数不一样,纯虚函数不需要定义,直接书写=0即可。\r\n\r\n```c++\r\ndouble net_price(std::size t) const=0;\r\n```\r\n\r\n含有纯虚函数的类是抽象基类,抽象基类负责定义接口,我们不能直接创建一个抽象基类对象。\r\n\r\n例子:\r\n\r\n抽象基类:动物,纯虚函数是进食。动物不能直接创建一个对象。\r\n\r\n基类:猫,虚函数:进食(具体表现为吃鱼)\r\n\r\n派生类:虎,override的虚函数 进食(具体表现为吃羊等)\r\n\r\n\r\n\r\n##### 直接基类与间接基类\r\n\r\n```c++\r\nclass Base{...};\r\nclass D1: public Base{...};\r\nclass D2:public D1{...};\r\n```\r\n\r\nBase是D1类的直接基类,同时是D2的间接基类。直接基类出现在派生列表中。最终的派生类将包含它的直接基类的子对象以及每个间接基类的子对象。(直接基类有点像father 间接基类比较像grandfather)\r\n\r\n\r\n\r\n##### 公有继承 私有继承 受保护继承\r\n\r\n```c++\r\nclass D2:public Pal{...};//公有继承\r\nclass Derived: private Base{...};//私有继承\r\n```\r\n\r\n在私有继承中,基类的公有成员和受保护成员是派生类的私有成员。\r\n\r\n在公有继承中,积累的公有接口时派生类公有接口的组成部分。\r\n\r\n在受保护的继承中,基类的公有成员和受保护成员是派生类的受保护成员。\r\n\r\n\r\n\r\n##### 重构\r\n\r\n在继承体系中将相关代码搜集到单独的抽象类中,替换原来的代码。\r\n\r\n\r\n\r\n##### 切掉\r\n\r\n```c++\r\nBulk_quote bulk;\r\nQuote item(bulk);\r\nitem =bulk;\r\n```\r\n\r\n用一个派生类对象去初始化一个基类对象时,对象的派生类部分(bulk中的Bulk_quote部分)被切掉,只剩下基类部分(Quote部分)赋值给基类对象。\r\n\r\n\r\n\r\n### 标准库的特殊设施\r\n\r\n#### tuple\r\n\r\ntuple是一个轻松而又随机的数据结构,与pair类似。pair中每个成员的类型可以不相同,但是只能有两个成员。tuple中可以有任何数量的成员,每个成员的类型可以不相同。\r\n\r\ntuple头文件\r\n\r\n```c++\r\ntuple<T1,T2,T3...,Tn> t;\r\ntuple<T1,T2,T3,...,Tn> t(v1,v2,...,vn);\r\nmake_tuple(v1,v2,...,vn);\r\nt1==t2;\r\nt1 relop t2;//按照字典序比较t1 t2中对应的元素\r\nget<i>(t);//返回t的第i个数据成员的引用\r\n```\r\n\r\n```c++\r\ntuple<string,vector<double>,int,list<int>>someVal(\"constants\",{3.14,2.718},42,{0,1,2,3,4,5});\r\nauto item=make_tuple(\"0-999-78345-X\",3,20.00);\r\nauto book=get<0>(item);\r\nauto cnt=get<1>(item);\r\nauto price=get<2>(item)/cnt;\r\nget<2>(item)*=0.8;\r\n```\r\n\r\n只有当tuple内成员数量和类型相同时才可以使用关系和相等关系符\r\n\r\ntuple的一个常见用途是用来返回多个值\r\n\r\n#### bitset\r\n\r\n#include<bitset>\r\n\r\n使得位运算更加容易\r\n\r\n```c++\r\nbitset<32>bitvec(1U); //32位,低位为1其余为0\r\nbitset<n> b; //b有n位,每位均为0\r\n//用unsigned 值初始化bitset\r\nbitset<13> bitvec1(0xbeef);// 二进制序列为1111011101111 (初始值高位被丢弃)\r\nbitset<20>bitvec2(0xbeef);//二进制为000010111111011101111 (初始高位补零)\r\n//用string初始化bitset\r\nbitset<32> bitset4(\"1100\");\r\n```\r\n\r\n```c++\r\nb.any(); //b中是否有置为=位的二进制位\r\nb.all(); //是否b中所有的位都置位了\r\nb.none();//b中是否不存在置位的二进制位\r\nb.count;//统计b中置位的二进制位数量\r\nb.size(); //位数\r\n\r\nb.test(pos); //判断pos位置是否被置位\r\nb.set(pos,v); //置为v,默认为1\r\nb.set();//全部置位\r\nb.reset(pos);//将pos位置复位\r\nb.reset();//全部复位\r\nb.flip(pos);//将pos位置翻转\r\nb.flip();//全部翻转\r\nb.to_ulong();\r\n\r\nb.to_string(zero,one); //zero和one默认为0和1\r\nos<<b;\r\n```\r\n\r\n```c++\r\nunsigned long quizA=0;\r\nquizA|=1UL<<27; //指出第27个学生通过了测试\r\nstatus=quizA&(1UL<<27);//检查第27个学生是否通过测试\r\nquizA &=~(1UL<<27);//第27个学生没通过测试\r\n1UL 无符号长整形1\r\n```\r\n\r\n\r\n\r\n#### 正则表达式\r\n\r\n正则表达式是用来描述字符串的强大方法。\r\n\r\n```c++\r\nstring pattern(\"[^c]ei\");//查找不在字符c后面的字符串ei\r\npattern=\"[[:alpha:]]*\"+pattern+\"[[:alpha:]]*\";\r\nregex r(pattern);//构造一个regex\r\nsmatch results; //定义一个对象保存结果\r\nstring test_str=\"receipt freind theif receive\";\r\nif(regex_search(test_str,results,r))\r\n cout<<results.str()<<endl; //打印结果 freind\r\n```\r\n\r\n\r\n\r\n#### 随机数\r\n\r\n定义在random头文件中的随机数库通过一组写作的类:随机数引擎类和随机数分布类来解决问题。\r\n\r\n```c++\r\ndefault_random_engine e;//生成随机无符号数\r\nfor(size_t i=0;i<10;i++){\r\n cout<<e()<<\" \";//16807 282475249 ... ....\r\n}\r\n```\r\n\r\n```c++\r\nEngineer e;//默认构造函数\r\nEngineer e(s);以s作为种子\r\ne.min()\r\ne.max()\r\n```\r\n\r\n```c++\r\nuniform_int_distribution<unsigned>u(0,9); //均匀分布的0-9整数\r\ndefault_random_engine e;\r\nfor(size_t i=0;i<10;i++){\r\n cout<<u(e)<<\" \";//0 1 7 4 5 2 0 6 6 9\r\n}\r\n\r\n```\r\n\r\n随机数发生器:即使看起来生成的数看起来是随机的,但是对一个给定的发生器,每次运行程序它都会返回相同的数值序列。\r\n\r\n```c++\r\nvector<unsigned> bad_randVec(){\r\n default_random_engine e;\r\n uniform_int_distribution<unsigned>u(0,9);\r\n vector<unsigned>ret;\r\n for(size_t i=0;i<100;i++){\r\n ret.push_back(u(e));\r\n }\r\n return ret;\r\n}\r\nvector<unsigned>v1(bad_randVec());\r\nvector<unsigned>v2(bad_randVec());\r\nv1==v2\r\n```\r\n\r\n编写此函数正确的方法是使用static\r\n\r\n```c++\r\nvector<unsigned> bad_randVec(){\r\n static default_random_engine e;\r\n static uniform_int_distribution<unsigned>u(0,9);\r\n vector<unsigned>ret;\r\n for(size_t i=0;i<100;i++){\r\n ret.push_back(u(e));\r\n }\r\n return ret;\r\n}\r\nvector<unsigned>v1(bad_randVec());\r\nvector<unsigned>v2(bad_randVec());\r\nv1!=v2\r\n```\r\n\r\n设置随机数发生器种子就是让引擎从一个序列中一个新位置重新开始生成随机数。\r\n\r\n```c++\r\ndefault_random_engine e1;\r\ne1.seed(32767);\r\ndefault_random_engine e2(32767);\r\ndefault_random_engine e3(time(0));\r\n```\r\n\r\ne1 e2 两个发生器产生的随机数列相同\r\n\r\n一般使用time作为种子,在头文件ctime里\r\n\r\n```c++\r\nuniform_real_distribution<double> u(0,1);//0-1real number\r\nnormal_distribution<double> n(4,15);//均值为4标准差为1.5的正态分布\r\nbernoulli_distribution b(0.7);//默认实50 50/true false分布\r\n```\r\n\r\n#### IO库再探\r\n\r\n标准库中定义了一组操纵符来控制\r\n\r\n##### 布尔值的格式:\r\n\r\nboolalpha noboolalpha\r\n\r\n默认情况下true的值是1,使用boolalpha之后输出就是string “true”\r\n\r\n##### 整型值的进制:\r\n\r\n```c++\r\ncout<<\"hex\"<<hex<<20<<\" \"<<1024<<endl; //16进制 14 400\r\n```\r\n\r\nhex oct dec 分别表示使用十六 8 10进制\r\n\r\n##### 显示进制\r\n\r\n```c++\r\ncout<<showbase<<\"in hex\"<< hex<<20<<endl;//0x14\r\n```\r\n\r\n使用showbase显示进制,noshowbase恢复\r\n\r\nuppercase nouppercase 显示0X14\r\n\r\n##### 控制浮点数格式\r\n\r\n精度:\r\n\r\n```c++\r\ncout.precision(12);//设置为12精度\r\nsetprecision(12);//效果相同\r\ncout<<sqrt(2.0)<<endl; //1.41421356237\r\ncout<<scientific://使用科学计数法\r\n```\r\n\r\n##### 小数点\r\n\r\n````c++\r\ncout<<10.0<<endl; //10\r\ncout<<showpoint<<10.0<<noshowpoint<<endl;//10.0000\r\n````\r\n\r\n##### 输出补白\r\n\r\n* setw指定下一个数字和字符串值的最小空间\r\n* left表示左对齐输出\r\n* right表示右对齐输出,这是默认格式\r\n* internal 控制负数的符号的位置,它左对齐符号,右对齐数值,空格填满中间的空隙\r\n* setfill允许一个字符代替空格\r\n\r\n\r\n\r\n##### 控制输入格式\r\n\r\n默认情况下会忽略空白符\r\n\r\na b c d\r\n\r\n```c++\r\nchar ch;\r\nwhile(cin>>ch){\r\n cout<<ch;\r\n}// abcd\r\ncin>>noshipws;\r\nwhile(cin>>ch){\r\n cout<<ch;\r\n}//a b c d\r\n```\r\n\r\n##### 从输入操作中返回int值\r\n\r\n```c++\r\nint ch;\r\nwhile((ch=cin.get())!=EOF){\r\n cout.put(ch);\r\n}//正确\r\nchar ch;\r\nwhile((ch=cin.get()!=EOF)){\r\n cout.put(ch)//永远读\r\n}\r\n```\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.554347813129425,
"alphanum_fraction": 0.5891304612159729,
"avg_line_length": 10.678898811340332,
"blob_id": "0abe19d6fda84c5b3a3fe7a0e026a0f9678d35f3",
"content_id": "aaf999d6bc1f1bf52feb30ba2035ae51dcc6a2f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1802,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 109,
"path": "/latex.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Latex\r\n\r\n使用Texstudio软件,F5快捷键 compile and view可以看到预览效果\r\n\r\n##### 最简单的latex文档\r\n\r\n````latex\r\n\\documentclass{article}\r\n\\begin{document}\r\nHere comes \\LaTeX!\r\n\\end{document}\r\n````\r\n\r\n\r\n\r\n##### 数学公式\r\n\r\n1.使用 `$ ... $` 可以插入行内公式,使用 `$$ ... $$` 可以插入行间公式\r\n\r\n2.求和等符号:\\sum\r\n\r\n3.上下标,_{},^{}\r\n\r\n##### 中文支持\r\n\r\n引用CJK宏包,应用CKJK环境\r\n\r\n```latex\r\n\\documentclass[11pt]{article} %百分号表示注释\r\n\\usepackage{CJK} %引入CJK宏包\r\n\\begin{document} %begin与end成对出现\r\n\\begin{CJK}{UTF8}{song} %应用CJK环境\r\n你好\r\n\\end{CJK}\r\n\\end{document}\r\n```\r\n\r\n##### 格式控制\r\n\r\n1.表示一个段落\r\n\r\n**\\ begin{XXX}…..\\end{XXX}**\r\n\r\n2.新起一页\r\n\r\n**\\newpage**\r\n\r\n3.设置计数器,从开始之后每页开始加上页码\r\n\r\n**\\setcounter{page}{1}**\r\n\r\n4.子段落\r\n\r\n**\\subsection{XXX}**\r\n\r\n\r\n\r\n1.缩进\r\n\r\n**\\indent…….**\r\n\r\n\\noindent 无缩进\r\n\r\n2.换行\r\n\r\n**\\\\\\\\** 换行不另起一段\r\n\r\n**\\par** 换行另起一段\r\n\r\n**\\textbf{}** 加粗\r\n\r\n\r\n\r\n##### 配置latex环境\r\n\r\nhttps://blog.csdn.net/qq_33826564/article/details/81490478\r\n\r\n##### 配置中文环境\r\n\r\nhttps://blog.csdn.net/qizaijie/article/details/79564079\r\n\r\n##### 配置中文论文模板\r\n\r\nhttps://blog.csdn.net/simmel_92/article/details/81233286\r\n\r\n\r\n\r\ntex文件是latex的主文件(源文件),cls文件是latex格式文件,决定了latex文件的排版布局\r\n\r\n\r\n\r\n##### 插入图片\r\n\r\n```\r\n\\begin{figure}[h]\r\n\t\\centering\r\n\t\\includegraphics[width=\\linewidth]{sample-franklin}\r\n\t\\caption{This is the description}\r\n\t\\Description{This is the description. just for writer}\r\n\\end{figure}\r\n```\r\n\r\n\r\n\r\n插入参考文献\r\n\r\nBibTex\r\n\r\n\\cite{ref}"
},
{
"alpha_fraction": 0.6966068148612976,
"alphanum_fraction": 0.7604790329933167,
"avg_line_length": 29.3125,
"blob_id": "461aab9c1ee5250432d3c4078ee3faeebdbb50b7",
"content_id": "63a531fa679afb25f8b45ee913f532b3ceb70a0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 803,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 16,
"path": "/c++/静态编译与动态编译.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "#### 静态编译与动态编译\r\n使用opencv 带的dll 以及opencv_world330d.lib这种是动态编译\r\n\r\n想要在没有安装opencv的电脑上使用exe, \r\n先使用cmake生成静态opencv lib,教程如下\r\nhttps://blog.csdn.net/woainishifu/article/details/77472123\r\n将得到的IlmImfd.lib等文件放到\r\nD:\\opencv33\\opencv\\new_build\\install\\x64\\vc15\\staticlib下 \r\n\r\nhttps://blog.csdn.net/skeeee/article/details/32130763 \r\n```\r\n1、右键属性表->属性->VC++目录->包含目录,然后添加opencv的h文件目录\r\n2、C/C++->代码生成->运行库->多线程调试(/MTd)\r\n3、连接器->输入->依赖项 把IlmImfd.lib等文件放进去(参考少了这一步,会无法解析一些代码)\r\n```\r\n在/x64/debug下面有可以独立运行的exe文件,大小大约在40M左右\r\n"
},
{
"alpha_fraction": 0.5776081681251526,
"alphanum_fraction": 0.6030534505844116,
"avg_line_length": 18.6842098236084,
"blob_id": "cf3e0ffcaea28a9ee8e2d5ccbfaaed6a3291955b",
"content_id": "11adf101ed7aa476c4667bf2d42497f84819fc43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 393,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 19,
"path": "/books/test.cpp",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "#include <iostream>\r\n#include <string.h>\r\n#include<vector>\r\n#include <fstream>\r\n#include <sstream>\r\nusing namespace std;\r\nint main(){\r\n string ifile=\"ifile12345\";\r\n string s1=ifile.substr(3,5);\r\n cout<<s1;\r\n ifstream in(ifile);\r\n string line,s;\r\n while(getline(in,line)){\r\n istringstream record(line);\r\n\twhile(record>>s)\r\n\t cout<<s<<endl;\r\n }\r\n return 0;\r\n}\r\n"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.7833333611488342,
"avg_line_length": 41.14285659790039,
"blob_id": "cee7106687446cbb34446ef6ca41009bea1af5a4",
"content_id": "d621646a6e1e6f8547da4c5356168779e75c45cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 566,
"license_type": "no_license",
"max_line_length": 233,
"num_lines": 7,
"path": "/computer_science_knowledge/computer composition/computer composition.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 计算机组成\r\n\r\n\r\n\r\nSIMD:Single Instruction Multiple Data,单指令多数据流。\r\n\r\nSIMD更适合于数据密集型计算:单指令单数据([SISD](https://baike.baidu.com/item/SISD))的CPU对加法指令译码后,执行部件先访问内存,取得第一个[操作数](https://baike.baidu.com/item/%E6%93%8D%E4%BD%9C%E6%95%B0);之后再一次访问内存,取得第二个操作数;随后才能进行求和运算。而在SIMD型的CPU中,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算。"
},
{
"alpha_fraction": 0.5846154093742371,
"alphanum_fraction": 0.7230769395828247,
"avg_line_length": 10,
"blob_id": "fc1ee8a0c509dc0c87bfe3d12f9cb8ee40fbd307",
"content_id": "2e03125f44e86e886942633a40161cda8469bf8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 278,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 11,
"path": "/algorithm/strange_algorithm.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### 如何用O(1)时间判断一个数是否为2的幂数\r\n\r\n判断n与n的补码求并之后得到的结果,如果与n相同则n为2的幂数\r\n\r\n10000 \r\n\r\n补码等于求返加一 ->10000,求并 10000\r\n\r\n\r\n\r\n是不是只要n与自己的补码相同就可以判断了?"
},
{
"alpha_fraction": 0.7692307829856873,
"alphanum_fraction": 0.7692307829856873,
"avg_line_length": 25,
"blob_id": "8720150afe89c9312f789bf3e0822c6587eed143",
"content_id": "097b03f765026f35f09e052eb079dc5cd2db1906",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 52,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 2,
"path": "/README.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "## tensorflow_learing_note\r\nthis is my cs study note"
},
{
"alpha_fraction": 0.7094370722770691,
"alphanum_fraction": 0.7127483487129211,
"avg_line_length": 29.0256404876709,
"blob_id": "0546dca57c693eb35a4c54d7d8d64dc04cebd829",
"content_id": "dbda7aad776a8212b9d2bd1c3604337000b3f26e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1834,
"license_type": "no_license",
"max_line_length": 193,
"num_lines": 39,
"path": "/computer_science_knowledge/ADS/ADS.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### ADS\r\n\r\n##### AVL Trees, Splay Trees, and Amortized Analysis\r\n\r\n##### AVL Tree\r\n\r\ntarget:speed up searching,for normal trees\r\n\r\nT=O(height),but the height can be as bad as O(N)\r\n\r\nAdelson-Velskii-Landis (AVL) Trees :\r\n\r\n【Definition】An empty binary tree is height balanced. If T is a nonempty binary tree with $T_L$ and $T_R$ as its left and right subtrees, then T is height balanced if:\r\n\r\n (1) $T_L$ and $T_R$ are height balanced, and\r\n\r\n (2) $|h_L-h_R|<=1$ where $h_L$ and $h_R$ are the heights of $T_L$ and $T_R$ , respectively.\r\n\r\n\r\n\r\nInsertion: Rotation\r\n\r\nThe trouble maker Nov is in the right subtree’s right subtree of the trouble finder Mar. Hence it is called an RR rotation.\r\n\r\n\r\n\r\nThe height for a AVL tree\r\n\r\n$h = O(ln n)$\r\n\r\n\r\n\r\n##### Splay Trees 伸展树\r\n\r\nAny M consecutive tree operations starting from an empty tree take at most O(M log N) time.\r\n\r\n它的主要特点是不会保证树一直是平衡的,但各种操作的平摊时间复杂度是O(log n),因而,从平摊复杂度上看,二叉查找树也是一种平衡二叉树。另外,相比于其他树状数据结构(如红黑树,AVL树等),伸展树的空间要求与编程复杂度要小得多。\r\n\r\n伸展树的出发点是这样的:考虑到局部性原理(刚被访问的内容下次可能仍会被访问,查找次数多的内容可能下一次会被访问),为了使整个查找时间更小,被查频率高的那些节点应当经常处于靠近树根的位置。这样,很容易得想到以下这个方案:每次查找节点之后对树进行重构,把被查找的节点搬移到树根,这种自调整形式的二叉查找树就是伸展树。每次对伸展树进行操作后,它均会通过旋转的方法把被访问节点旋转到树根的位置。"
},
{
"alpha_fraction": 0.7966386675834656,
"alphanum_fraction": 0.8184874057769775,
"avg_line_length": 23.60869598388672,
"blob_id": "72132b4723f0613fbaffd416b981a6644261369d",
"content_id": "9715ae4ba5bef00a1fabc02e7fdf7ffa07500706",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1621,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 23,
"path": "/贝叶斯 频率.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "#### 贝叶斯学派和频率学派\r\n\r\n贝叶斯学派认为:频率学派认为任何事情都不存在先验。而先验是贝叶斯学派中一个非常重要的概念。\r\n\r\n**频率学派认为模型的参数是固定的,一个模型在经过无数次的抽样之后,参数可以被准确的估计出来,而贝叶斯学派则认为参数是变化的,应该用观测来估计参数。**\r\n\r\n\r\n\r\n频率学派认为数据就是事实,贝叶斯学派考虑了参数的概率性。\r\n\r\n对于抛硬币问题,如果前10次都是正面,那下一次是正面?\r\n\r\n如果频率学派学者知道硬币的特性是正反1/2 他就认为说,参数就是1/2,不会随着数据的改变而改变。如果他不知道硬币1/2这个特点,他只知道参数是固定的,那仅从有限的实验数据来看,概率为1。而贝叶斯学派则会考虑到先验,一般的硬币都是接近于1/2的,所以概率会更接近于1/2.\r\n\r\n对于一个黑盒 输出正负两种情况。\r\n\r\n频率学派研究的是客观概率,参数不变。这个客观概率是通过无数的历史数据所构成的,贝叶斯学派认为参数本身是概率分布。\r\n\r\n频率学派最大的缺点:在研究很多情况下,没有明显的先验知识。\r\n\r\n如果大量历史数据的结论和少量实验数据的结论冲突,频率学派认为我们坚持历史数据(参数不变),贝叶斯学派认为应该考虑到参数变化的情况。\r\n\r\n极大似然概率认为参数不变,通过数据去不断拟合参数,最大后验概率则是更倾向于贝叶斯学派,认为参数可变。\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5206611752510071,
"alphanum_fraction": 0.5785123705863953,
"avg_line_length": 8.434782981872559,
"blob_id": "ae3c1cea8088a4e051f416b3ef45fe2fb66f02dd",
"content_id": "84738af04cd9c233101ef87dfdc03f29a7ed5756",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 312,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 23,
"path": "/leetcde_note_cpp/vscode环境配置.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### VSCODE 调试运行c++\r\n\r\n1. 安装vscode\r\n\r\n2. 装c/c++插件\r\n3. 修改环境变量,注意bin后面加斜杠\r\n4. 修改vscode配置文件\r\n\r\n```\r\nhttps://www.cnblogs.com/zhuzhenwei918/p/9057289.html\r\n\r\n```\r\n\r\n\r\n\r\n运行调试\r\n\r\n打开terminal ctrl ~\r\n\r\n```\r\ng++ test.cpp -o test.exe\r\n./test.exe\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.45235857367515564,
"alphanum_fraction": 0.4728434383869171,
"avg_line_length": 23.820388793945312,
"blob_id": "dc53074f621ddb2076b38b8cd16eb1a101065247",
"content_id": "46beb5c4406e9bbcfa3999a33e7097f0a60c1536",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5467,
"license_type": "no_license",
"max_line_length": 279,
"num_lines": 206,
"path": "/leetcde_note_cpp/string.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### leetcode 1249 Minimum Remove to Make Valid Parentheses\r\n\r\nGiven a string s of `'('` , `')'` and lowercase English characters. \r\n\r\nYour task is to remove the minimum number of parentheses ( `'('` or `')'`, in any positions ) so that the resulting *parentheses string* is valid and return **any** valid string.\r\n\r\nFormally, a *parentheses string* is valid if and only if:\r\n\r\n- It is the empty string, contains only lowercase characters, or\r\n- It can be written as `AB` (`A` concatenated with `B`), where `A` and `B` are valid strings, or\r\n- It can be written as `(A)`, where `A` is a valid string.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: s = \"lee(t(c)o)de)\"\r\nOutput: \"lee(t(c)o)de\"\r\nExplanation: \"lee(t(co)de)\" , \"lee(t(c)ode)\" would also be accepted.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: s = \"a)b(c)d\"\r\nOutput: \"ab(c)d\"\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: s = \"))((\"\r\nOutput: \"\"\r\nExplanation: An empty string is also valid.\r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: s = \"(a(b(c)d)\"\r\nOutput: \"a(b(c)d)\"\r\n```\r\n\r\n \r\n\r\n**Constraints:**\r\n\r\n- `1 <= s.length <= 10^5`\r\n- `s[i]` is one of `'('` , `')'` and lowercase English letters`.`\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n string minRemoveToMakeValid(string s) {\r\n int i = 0, count = 0;\r\n // left;\r\n count = 0;\r\n while(i<s.size()){\r\n if (s[i] =='(') count++;\r\n else{\r\n if(s[i] == ')'){\r\n if(count <= 0){\r\n s.erase(i, 1);\r\n i--;\r\n }\r\n else{\r\n count--;\r\n }\r\n }\r\n }\r\n i++;\r\n }\r\n //right\r\n count = 0; i = s.size() - 1;\r\n while(i>=0){\r\n if (s[i] == ')') count++;\r\n else{\r\n if(s[i] == '('){\r\n if(count<=0){\r\n s.erase(i, 1);\r\n }\r\n else{\r\n count--;\r\n }\r\n }\r\n }\r\n i--;\r\n }\r\n return s;\r\n }\r\n};\r\n```\r\n\r\n从左边检测一遍是否有多余的) 从右边检测一遍是否有多余的(\r\n\r\n注意erase执行完之后 string i右侧的部分会左移一格\r\n\r\n因此要注意从左到右时要i--;但是从右到左时不用 \r\n\r\n\r\n\r\n##### leetcode 243. Shortest Word Distance\r\n\r\nGiven a list of words and two words *word1* and *word2*, return the shortest distance between these two words in the list.\r\n\r\n**Example:**\r\nAssume that words = `[\"practice\", \"makes\", \"perfect\", \"coding\", \"makes\"]`.\r\n\r\n```\r\nInput: word1 = “coding”, word2 = “practice”\r\nOutput: 3\r\nInput: word1 = \"makes\", word2 = \"coding\"\r\nOutput: 1\r\n```\r\n\r\n**Note:**\r\nYou may assume that *word1* **does not equal to** *word2*, and *word1* and *word2* are both in the list.\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int shortestDistance(vector<string>& words, string word1, string word2) {\r\n map<string, vector<int>> m1;\r\n int n = words.size(), i = 0, j = 0, res = INT_MAX;\r\n for(i=0;i<n;i++){\r\n if (m1.find(words[i]) == m1.end()){\r\n vector<int> index;\r\n m1[words[i]] = index;\r\n }\r\n m1[words[i]].push_back(i); \r\n }\r\n vector<int> nums1 = m1[word1], nums2 = m1[word2];\r\n i = 0;\r\n while(i < nums1.size() && j < nums2.size()){\r\n if(nums1[i] > nums2[j]){\r\n res = min(res, nums1[i]- nums2[j]);\r\n j += 1;\r\n }\r\n else{\r\n res = min(res, nums2[j]- nums1[i]);\r\n i+= 1;\r\n }\r\n }\r\n return res;\r\n }\r\n};\r\n```\r\n\r\n\r\n\r\n##### leetcode 244 Shortest Word Distance II\r\n\r\nDesign a class which receives a list of words in the constructor, and implements a method that takes two words *word1* and *word2* and return the shortest distance between these two words in the list. Your method will be called *repeatedly* many times with different parameters. \r\n\r\n**Example:**\r\nAssume that words = `[\"practice\", \"makes\", \"perfect\", \"coding\", \"makes\"]`.\r\n\r\n```\r\nInput: word1 = “coding”, word2 = “practice”\r\nOutput: 3\r\nInput: word1 = \"makes\", word2 = \"coding\"\r\nOutput: 1\r\n```\r\n\r\n**Note:**\r\nYou may assume that *word1* **does not equal to** *word2*, and *word1* and *word2* are both in the list.\r\n\r\n```c++\r\nclass WordDistance {\r\nmap<string, vector<int>> m1;\r\npublic:\r\n WordDistance(vector<string>& words) {\r\n int n = words.size(), i = 0;\r\n for(i=0;i<n;i++){\r\n if (m1.find(words[i]) == m1.end()){\r\n vector<int> index;\r\n m1[words[i]] = index;\r\n }\r\n m1[words[i]].push_back(i); \r\n }\r\n return;\r\n }\r\n int shortest(string word1, string word2) {\r\n vector<int> nums1 = m1[word1], nums2 = m1[word2];\r\n int i = 0, j = 0, res = INT_MAX;\r\n while(i < nums1.size() && j < nums2.size()){\r\n if(nums1[i] > nums2[j]){\r\n res = min(res, nums1[i]- nums2[j]);\r\n j += 1;\r\n }\r\n else{\r\n res = min(res, nums2[j]- nums1[i]);\r\n i+= 1;\r\n }\r\n }\r\n return res;\r\n }\r\n};\r\n\r\n/**\r\n * Your WordDistance object will be instantiated and called as such:\r\n * WordDistance* obj = new WordDistance(words);\r\n * int param_1 = obj->shortest(word1,word2);\r\n */\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.5520912408828735,
"alphanum_fraction": 0.5720532536506653,
"avg_line_length": 38.4461555480957,
"blob_id": "2cb1a5cb83d8bdecbd1426c7fb6f43e9b9adb504",
"content_id": "43685dce4dcd5de0cf13b67cc2ddb4254bae9086",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5402,
"license_type": "no_license",
"max_line_length": 374,
"num_lines": 130,
"path": "/leetcode_note/bitmap.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### A simple tutorial on this bitmasking problem\r\n\r\n\r\n\r\n[](https://leetcode.com/zerotrac2)[zerotrac2](https://leetcode.com/zerotrac2)237\r\n\r\nLast Edit: 7 hours ago\r\n\r\n1.5K VIEWS\r\n\r\nBitmasking DP rarely appears in weekly contests. This tutorial will introduce my own perspective of bitmasking DP as well as several coding tricks when dealing with bitmasking problems. I will also give my solution to this problem at the end of this tutorial.\r\n\r\n\r\n\r\nWhat is bitmasking? Bitmasking is something related to **bit** and **mask**. For the **bit** part, everything is encoded as a single **bit**, so the whole state can be encoded as a group of **bits**, i.e. a binary number. For the **mask** part, we use 0/1 to represent the state of something. In most cases, 1 stands for the valid state while 0 stands for the invalid state.\r\n\r\n\r\n\r\nLet us consider an example. There are 4 cards on the table and I am going to choose several of them. We can encode the 4 cards as 4 bits. Say, if we choose cards 0, 1 and 3, we will use the binary number \"1011\" to represent the state. If we choose card 2, we will use the binary number \"0100\" then. The bits on the right represent cards with smaller id.\r\n\r\n\r\n\r\nAs we all know, integers are stored as binary numbers in the memory but appear as decimal numbers when we are coding. As a result, we tend to use a decimal number instead of a binary number to represent a state. In the previous example, we would use \"11\" and \"4\" instead of \"1011\" and \"0100\".\r\n\r\n\r\n\r\nWhen doing Bitmasking DP, we are always handling problems like \"what is the i-th bit in the state\" or \"what is the number of valid bits in a state\". These problems can be very complicated if we do not handle them properly. I will show some coding tricks below which we can make use of and solve this problem.\r\n\r\n\r\n\r\n- We can use **(x >> i) & 1** to get i-th bit in state **x**, where **>>** is the right shift operation. If we are doing this in an if statement (i.e. to check whether the i-th bit is 1), we can also use **x & (1 << i)**, where the **<<** is the left shift operation.\r\n\r\n- We can use **(x & y) == x** to check if **x** is a subset of **y**. The subset means every state in **x** could be 1 only if the corresponding state in **y** is 1.\r\n\r\n- We can use **(x & (x >> 1)) == 0** to check if there are no adjancent valid states in **x**.\r\n\r\n\r\n\r\n##### leetcode 1349. Maximum Students Taking Exam\r\n\r\nGiven a `m * n` matrix `seats` that represent seats distributions in a classroom. If a seat is broken, it is denoted by `'#'` character otherwise it is denoted by a `'.'` character.\r\n\r\nStudents can see the answers of those sitting next to the left, right, upper left and upper right, but he cannot see the answers of the student sitting directly in front or behind him. Return the **maximum** number of students that can take the exam together without any cheating being possible..\r\n\r\nStudents must be placed in seats in good condition.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: seats = [[\"#\",\".\",\"#\",\"#\",\".\",\"#\"],\r\n [\".\",\"#\",\"#\",\"#\",\"#\",\".\"],\r\n [\"#\",\".\",\"#\",\"#\",\".\",\"#\"]]\r\nOutput: 4\r\nExplanation: Teacher can place 4 students in available seats so they don't cheat on the exam. \r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: seats = [[\".\",\"#\"],\r\n [\"#\",\"#\"],\r\n [\"#\",\".\"],\r\n [\"#\",\"#\"],\r\n [\".\",\"#\"]]\r\nOutput: 3\r\nExplanation: Place all students in available seats. \r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: seats = [[\"#\",\".\",\".\",\".\",\"#\"],\r\n [\".\",\"#\",\".\",\"#\",\".\"],\r\n [\".\",\".\",\"#\",\".\",\".\"],\r\n [\".\",\"#\",\".\",\"#\",\".\"],\r\n [\"#\",\".\",\".\",\".\",\"#\"]]\r\nOutput: 10\r\nExplanation: Place students in available seats in column 1, 3 and 5.\r\n```\r\n\r\n**Constraints:**\r\n\r\n- `seats` contains only characters `'.' and``'#'.`\r\n- `m == seats.length`\r\n- `n == seats[i].length`\r\n- `1 <= m <= 8`\r\n- `1 <= n <= 8`\r\n\r\n```python\r\nclass Solution:\r\n def maxStudents(self, seats) -> int:\r\n m, n = len(seats), len(seats[0])\r\n validity = []\r\n\r\n for i in range(m):\r\n cur = 0\r\n for j in range(n):\r\n cur = (cur << 1) + (seats[i][j] == '.')\r\n validity.append(cur)\r\n\r\n def count_bits(n):\r\n cnt = 0\r\n while n:\r\n cnt += 1\r\n n = n & (n - 1)\r\n return cnt\r\n\r\n dp = [[0] * (1 << n) for _ in range(m + 1)]\r\n for i in range(1, m + 1):\r\n valid = validity[i - 1]\r\n for j in range(1 << n):\r\n # check 1. if x is a subset of y, 2. no adjancent valid states.\r\n if (j & valid) == j and not (j & (j >> 1)):\r\n for k in range(1 << n):\r\n # no students in the upper left&right position\r\n if not (j & (k >> 1)) and not (j & (k << 1)):\r\n dp[i][j] = max(dp[i][j], dp[i - 1][k] + count_bits(j))\r\n\r\n return max(dp[-1])\r\n```\r\n\r\n用j来表示某一行的状态 例如5 表示 101 (1表示有人坐着)\r\n\r\n一共有1<<n种可能状态\r\n\r\n转移方程为\r\n\r\ndp[i,j] = max(dp[i,j], dp[i - 1,k] + count_bits(j))\r\n\r\n第i行在以j这种形式坐的情况下 和上一排中以k这种形式坐不冲突, count_bits(j))表示坐了多少个人\r\n\r\n"
},
{
"alpha_fraction": 0.554858922958374,
"alphanum_fraction": 0.6081504821777344,
"avg_line_length": 11.25,
"blob_id": "884f9b75cba6c505b1e8e5ab2a852ee87678ee81",
"content_id": "3d8b853c6b20e5a9bfda106cc160b314ca97d66e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1263,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 48,
"path": "/ina/inter.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### redux 前端的数据存储器\r\n\r\n##### 春风十里香水\r\n\r\n##### 函数式编程\r\n\r\n函数式编程是一种编程范式,支持函数作为第一对象。函数是\"第一等公民\",可以被赋值,可以被用于返回类型。\r\n\r\n最重要的基础是λ演算。\r\n\r\n指令式编程相比,函数式编程强调函数的计算比指令的执行重要。\r\n\r\n和过程化编程相比,函数式编程里函数的计算可随时调用。\r\n\r\n**惰性计算** \r\n\r\n表达式不是在绑定到变量时立即计算,而是在求值程序需要产生表达式的值时进行计算。\r\n\r\n**引用透明性**\r\n\r\n引用透明性是惰性计算的前提。即如果提供同样的输入,那么函数总是返回同样的结果。就是说,表达式的值不依赖于可以改变值的全局状态。\r\n\r\n**没有\"副作用\"**\r\n\r\n所谓\"副作用\"(side effect),指的是函数内部与外部互动(最典型的情况,就是修改全局变量的值),产生运算以外的其他结果。\r\n\r\n没有副作用:\r\n\r\n```\r\nvar xs=[1,2,3,4,5];\r\nxs.slice(0,3); [1,2,3]\r\nxs.slice(0,3); [1,2,3]\r\nxs.slice(0,3); [1,2,3]\r\n```\r\n\r\n有副作用:\r\n\r\n```\r\nxs.splice(0,3);[1,2,3]\r\nxs.splice(0,3);[4,5]\r\nxs.splice(0,3);[]\r\n```\r\n\r\n\r\n\r\n\r\n\r\n32\r\n\r\n"
},
{
"alpha_fraction": 0.4118942618370056,
"alphanum_fraction": 0.45154184103012085,
"avg_line_length": 26.25,
"blob_id": "072ba5d406c4db9027c206dd727839cbac7ec1a1",
"content_id": "6adbf0e4db67f15664d448613381469ce096422b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 454,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 16,
"path": "/leetcode_note/Suffix Array.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Suffix Array\r\n\r\nA suffix array is a sorted array of all suffixes of a given string.\r\n\r\n```\r\nLet the given string be \"banana\".\r\n\r\n0 banana 5 a\r\n1 anana Sort the Suffixes 3 ana\r\n2 nana ----------------> 1 anana \r\n3 ana alphabetically 0 banana \r\n4 na 4 na \r\n5 a 2 nana\r\n\r\nSo the suffix array for \"banana\" is {5, 3, 1, 0, 4, 2}\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.8168317079544067,
"alphanum_fraction": 0.8316831588745117,
"avg_line_length": 21.44444465637207,
"blob_id": "4011d27925425e761a3d290768ac394e0d6e0b20",
"content_id": "82540b7bdab5ab71df2a2c4330f3e31a6e688793",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 384,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 9,
"path": "/os_instructions/linux/grep.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "grep(global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具\ngrep搜索文件夹中所有文件的内容:\nexample:\ngrep -R \"123\" ./\n其中-R表示d递归搜索\n\nawk是文本解析器,也可以用于解析所有的文件中的文本\n\nfind是用来查找文件而非文件中的内容的\n"
},
{
"alpha_fraction": 0.7473683953285217,
"alphanum_fraction": 0.7473683953285217,
"avg_line_length": 18.88888931274414,
"blob_id": "0833c4cd31432cf4650f3804639f29a30eb522b5",
"content_id": "e653043e9f57ece0ec312e84e333a24d635d712e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 272,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 9,
"path": "/java/java_cookbook.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### JAVA\r\n\r\n##### JDK,JRE,JVM\r\n\r\nJDK: java develop toolkit java开发包,提供java的开发环境与运行环境\r\n\r\nJRE:java running environment 提供java的运行环境,是java使用者用的\r\n\r\nJVM: java virtual machine JVM是java跨平台性好的原因所在\r\n\r\n"
},
{
"alpha_fraction": 0.502498209476471,
"alphanum_fraction": 0.5289078950881958,
"avg_line_length": 19.859375,
"blob_id": "852fb212991f41186a430d37166f7a003eedbd72",
"content_id": "52712d9bc78b8d3dd8e4a207028c7503afa93e7d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1515,
"license_type": "no_license",
"max_line_length": 227,
"num_lines": 64,
"path": "/leetcde_note_cpp/stack.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### leetcode 316 Remove Duplicate Letters\r\n\r\nGiven a string which contains only lowercase letters, remove duplicate letters so that every letter appears once and only once. You must make sure your result is the smallest in lexicographical order among all possible results.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: \"bcabc\"\r\nOutput: \"abc\"\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: \"cbacdcbc\"\r\nOutput: \"acdb\"\r\n```\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n string removeDuplicateLetters(string s) {\r\n string res = \"0\";\r\n unordered_map<char, int> m1;\r\n vector<int> visited(26, 0);\r\n for(char c : s){\r\n auto it = m1.find(c);\r\n if(it!=m1.end())\r\n m1[c]++;\r\n else m1[c] = 1;\r\n }\r\n for (char c : s) {\r\n m1[c]--;\r\n if (visited[c-'a']) continue;\r\n while (res.back()>c && m1[res.back()]>0) {\r\n visited[res.back()-'a'] = 0;\r\n res.pop_back();\r\n }\r\n res += c;\r\n visited[c-'a'] = 1;\r\n }\r\n return res.substr(1);\r\n }\r\n}; \r\n```\r\n\r\n这道题和[\r\nLargest Rectangle in Histogram](https://leetcode.com/problems/largest-rectangle-in-histogram) 有些类似\r\n\r\n用map记录每个词有多少遍\r\n\r\n'a'>0 在res中补个0 这样就可以避免每次都需要判断res.back()是否存在\r\n\r\nbcabc\r\n\r\n```\r\n1.res = 0b\r\n2.res=0bc\r\n3.由于后面还有c c弹出,res=0b\r\n4.由于后面还有b b弹出 res=0\r\n5.res=0a\r\n6.res=0ab\r\n7.res=0abc\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.5179703831672668,
"alphanum_fraction": 0.5449259877204895,
"avg_line_length": 29.53333282470703,
"blob_id": "af2dcdb6b9cf49cdb4364c478946caf185e91810",
"content_id": "24931df76a5b750a50f9595cfa2d59560ea5bc75",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1898,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 60,
"path": "/math&&deeplearning/test.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "#代码块\r\n```javascript\r\ndropout_p=0.5;\r\nif dropout_p>0\r\n mask=rand(size(nn.a{k-1}))<dropout_p;\r\n nn.a{k-1}=nn.a{k-1}.*mask/dropout_p;\r\nend\r\n```\r\n\r\n\r\n```javascript\r\nif strcmp(nn.optimization_method,'RMSProp_NestrovMonoment')\r\n alpha=0.01;\r\n nn.W2{k-1}=nn.W{k-1};\r\n nn.W{k-1}=nn.W{k-1}+alpha*nn.vW{k-1};\r\n nn.b2{k-1}=nn.b{k-1};\r\n nn.b{k-1}=nn.b{k-1}+alpha*nn.vb{k-1};\r\n if nn.batch_normalization\r\n nn.Gamma2{k-1}=nn.Gamma{k-1};\r\n nn.Beta2{k-1}=nn.Beta{k-1};\r\n nn.Gamma{k-1}=nn.Gamma{k-1}+alpha*nn.vGamma{k-1};\r\n nn.Beta{k-1}=nn.Beta{k-1}+alpha*nn.vBeta{k-1};\r\n end\r\nend\r\n```\r\n\r\n```javascript\r\nelseif strcmp(nn.optimization_method, 'RMSProp_NestrovMonoment')\r\n alpha = 0.9;\r\n rho = 0.9;\r\n nn.rW{k} = rho*nn.rW{k} + (1-rho)*nn.W_grad{k}.^2;\r\n nn.rb{k} = rho*nn.rb{k} + (1-rho)*nn.b_grad{k}.^2;\r\n nn.rGamma{k} = rho*nn.rGamma{k} + (1-rho)*nn.Gamma_grad{k}^2;\r\n nn.rBeta{k} = rho*nn.rBeta{k} + (1-rho)*nn.Beta_grad{k}^2;\r\n \r\n nn.vW{k} = alpha*nn.vW{k} - nn.learning_rate*nn.W_grad{k}./sqrt(nn.rW{k});\r\n nn.vb{k} = alpha*nn.vb{k} - nn.learning_rate*nn.b_grad{k}./sqrt(nn.rb{k});\r\n nn.vGamma{k} = alpha*nn.vGamma{k} - nn.learning_rate*nn.Gamma_grad{k}/sqrt(nn.rGamma{k});\r\n nn.vBeta{k} = alpha*nn.vBeta{k} - nn.learning_rate*nn.Beta_grad{k}/sqrt(nn.rBeta{k});\r\n \r\n nn.W{k} = nn.W{k} + nn.vW{k};\r\n nn.b{k} = nn.b{k} + nn.vb{k};\r\n nn.Gamma{k} = nn.Gamma{k}+ nn.vGamma{k};\r\n nn.Beta{k}= nn.Beta{k} + nn.vBeta{k};\r\n```\r\n\r\n```javascript\r\nif strcmp(nn.optimization_method,'RMSProp_NestrovMonoment')\r\n nn.rW{k} = zeros(height,width);\r\n nn.rb{k} = zeros(height,1);\r\n nn.vW{k} = zeros(height,width);\r\n nn.vb{k} = zeros(height,1);\r\n if nn.batch_normalization\r\n nn.rGamma{k} = 0;\r\n nn.rBeta{k} = 0;\r\n nn.vGamma{k} = 1;\r\n nn.vBeta{k} = 0;\r\n end\r\nend\r\n```\r\n"
},
{
"alpha_fraction": 0.621169924736023,
"alphanum_fraction": 0.6518105864524841,
"avg_line_length": 20.87234115600586,
"blob_id": "5d87c22c81cb06b66ff61822d8720d73c56ef60e",
"content_id": "a6a382d3a3c290cba37a810616232f6429f3e813",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1429,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 47,
"path": "/os_instructions/linux/cuda.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "nvcc -V查看cuda的版本\r\n编译方法:\r\n```\r\nnvcc test1.cu -o test\r\n./test\r\n```\r\nfirst cuda code:\r\n```\r\n#include <iostream>\r\n#include <string>\r\n#include <cuda.h>\r\n#include <cuda_runtime.h>\r\n__global__ void kernel(void){\r\n}\r\nint main(){\r\n kernel<<<1,1>>>();\r\n std::cout<<\"hello\"<<std::endl;\r\n return 0;\r\n}\r\n```\r\n```\r\n__global__ - Runs on the GPU, called from the CPU. Executed with <<<dim3>>> arguments.\r\n__device__ - Runs on the GPU, called from the GPU. Can be used with variabiles too.\r\n__host__ - Runs on the CPU, called from the CPU.\r\n```\r\n\r\n同一个服务器上的memory可能会有不同人占用\r\n\r\n\r\n使用命令\r\n```\r\nnivdia-smi\r\n```\r\n```\r\n* GPU:编号 \r\n* Fan:风扇转速,在0到100%之间变动,这里是42% \r\n* Name:显卡名,这里是TITAN X \r\n* Temp:显卡温度,这里是69摄氏度 \r\n* Perf:性能状态,从P0到P12,P0性能最大,P12最小 \r\n* Persistence-M:持续模式的状态开关,该模式耗能大,但是启动新GPU应用时比较快,这里是off \r\n* Pwr:能耗 \r\n* Bus-Id:涉及GPU总线的东西 \r\n* Disp.A:表示GPU的显示是否初始化 \r\n* Memory-Usage:现存使用率,这里已经快满了 (前面数字表示已经使用的memory)\r\n* GPU-Util:GPU利用率 \r\n* Compute M.:计算模式\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.6790123581886292,
"alphanum_fraction": 0.6913580298423767,
"avg_line_length": 9.255813598632812,
"blob_id": "ccc966be575085082ac3f4a6f3743eaa940fd523",
"content_id": "aaba4f6d2ba6e446b1b65d06289a9f92b0f35e79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 762,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 43,
"path": "/javascript/javascript小技巧.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### JavaScript小技巧\r\n\r\nctrl u 打开html源码\r\n\r\nctrl+shift+i打开页面module,页面对象是document\r\n\r\nctrl+shift+c 将文档与源高亮对应\r\n\r\nctrl+f对当前文档搜索\r\n\r\nctrl+shift+f:全局搜索\r\n\r\n整个html源码是以一棵树的架构组织起来的。\r\n\r\n\r\n\r\n##### html css js\r\n\r\nhtml是web的基础\r\n\r\ncss是为了显示的更好\r\n\r\njs是用于动态的交互-> 事件驱动编程\r\n\r\n##### 事件驱动编程\r\n\r\n分为三部分:EVENT LISTENER HANDLER\r\n\r\n\r\n\r\n304: not modified( still in cache)\r\n\r\n200: load ok\r\n\r\n\r\n\r\nwindow对象\r\n\r\nwindow对象下主要又document navigator location history这四个重要子属性。history下面的back go函数相当于前进和后退。\r\n\r\n##### 句柄\r\n\r\n句柄就是对资源的引用\r\n\r\n"
},
{
"alpha_fraction": 0.651583731174469,
"alphanum_fraction": 0.7264867424964905,
"avg_line_length": 9.841148376464844,
"blob_id": "a0e2b0ed9d164b086c989b05294c23e64822b9e8",
"content_id": "730aa0d2cd9ba11a89fcb7cf8b5ce8fb1900b67c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 25206,
"license_type": "no_license",
"max_line_length": 156,
"num_lines": 1045,
"path": "/computer_science_knowledge/Operating System.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 操作系统\r\n\r\n\r\n\r\n操作系统是一个控制程序,控制程序执行过程,给用户提供各种服务,方便用户使用计算机系统。操作系统是一个资源管理器,是应用程序和硬件之间的中间层,用来管理计算机软硬件。解决资源访问冲突,确保资源公平使用。\r\n\r\n\r\n\r\n\r\n\r\n操作系统组成:\r\n\r\n1.kernel:执行各种资源管理等功能\r\n\r\n2.shell命令行接口\r\n\r\n3.GUI 图形用户接口 \r\n\r\n\r\n\r\n操作系统内核特征:\r\n\r\n1.并发: 操作系统同时管理调度多个运行的程序\r\n\r\n2.共享:宏观上实现多个程序能同时访问资源,微观上实现互斥共享\r\n\r\n3.虚拟:利用多道程序设计技术,让每个用户觉得有一个计算机专门为他服务\r\n\r\n4.异步:程序的执行是走走停停,每次前进的程度不可知。只要运行环境相同,输入相同得到相同的结果。\r\n\r\n\r\n\r\n##### 常见操作系统\r\n\r\nunix家族 linux等:开源开放 ios android\r\n\r\nwindows系列:封闭式的\r\n\r\n\r\n\r\n\r\n\r\n##### BOIS \r\n\r\n计算机接上电之后第一行代码从内存(ROM)从中读取运行(RAM:断电即丢失,ROM:只读,断电不丢失)\r\n\r\n计算机由CS(代码段寄存器)和IP(指令指针寄存器)决定运行哪条程序。在初始化完成时,CS和IP的值是约定好的。\r\n\r\nBIOS:\r\n\r\n将加载程序从磁盘加载到0x7c00这个位置。然后跳转到0x7c00\r\n\r\n加载程序:\r\n\r\n将操作系统的代码和数据从硬盘加载到内存中\r\n\r\n跳转到操作系统的起始地址\r\n\r\n\r\n\r\n##### 中断 异常 系统调用\r\n\r\n中断是硬件设备对操作系统提出的处理请求\r\n\r\n异常时由于非法指令或者其他原因导致当前指令执行失败(内存出错等)后的处理请求。\r\n\r\n系统调用则是应用程序主动向操作系统发出的请求。(例如请求操作系统调用数据)\r\n\r\n\r\n\r\n源头:\r\n\r\n中断:外设\r\n\r\n异常:程序意想不到的行为\r\n\r\n系统调用:引用程序的请求\r\n\r\n\r\n\r\n响应方式与处理机制:\r\n\r\n中断:异步,对用户应用程序是透明的\r\n\r\n异常:同步(需要处理完异常才能继续运行),杀死出现异常的程序\r\n\r\n系统调用:引用程序的请求,等待再继续\r\n\r\n\r\n\r\n中断异常的处理机制:\r\n\r\n1.现场保护\r\n\r\n2.中断服务处理\r\n\r\n3.清除中断标记\r\n\r\n4.现场恢复\r\n\r\n\r\n\r\n异常和中断是可以被嵌套的。\r\n\r\n\r\n\r\n##### 内存层次\r\n\r\n\r\n\r\n抽象:将物理地址空间抽象到逻辑地址空间\r\n\r\n保护:独立地址空间\r\n\r\n共享:访问相同内存\r\n\r\n虚拟化:更大的地址空间\r\n\r\n\r\n\r\n操作系统中采用的内存管理方式:\r\n\r\n1.重定位\r\n\r\n2.分页\r\n\r\n3.分块\r\n\r\n\r\n\r\n##### 连续内存分配\r\n\r\n给进程分配一块不小于指定大小的连续的物理内存空间\r\n\r\n##### 内存碎片\r\n\r\n空闲碎片不能被利用\r\n\r\n\r\n\r\n外部碎片:\r\n\r\n分配单元之间未被使用的内存\r\n\r\n\r\n\r\n内部碎片:\r\n\r\n分配单元内部的未被使用的内存\r\n\r\n\r\n\r\n\r\n\r\n操作系统需要维护的数据结构:\r\n\r\n1.所有进程的已分配分区\r\n\r\n2.空闲分区\r\n\r\n\r\n\r\n##### 动态分区匹配策略:\r\n\r\n1.最佳分配(Best Fit)找比指定要求的大小稍微大一点的空间\r\n\r\n2.最先分配(First Fit)\r\n\r\n3.最差匹配(Worst Fit)每次都用最大的\r\n\r\n\r\n\r\n\r\n\r\n最先匹配:依次寻找,找到第一块比需求空间大的空间\r\n\r\n1.空闲分区是按照地址顺序排列的\r\n\r\n2.分配时找第一个合适的分区\r\n\r\n3.释放时检查是否有可以合并的空闲分区\r\n\r\n简单,但是容易产生外部碎片,分配大块时比较慢\r\n\r\n\r\n\r\n最佳分配:\r\n\r\n1.空闲分区是按照大小排列的\r\n\r\n2.分配是按照大小从小到大找第一个合适的\r\n\r\n3.在合并时检测地址周围是否有可以合并的空闲分区\r\n\r\n\r\n\r\n可以避免大块分区被拆分,减少外部碎片,简单\r\n\r\n释放分区比较慢\r\n\r\n\r\n\r\n最差分配:\r\n\r\n1.空闲分区是按照大小排列的\r\n\r\n2.分配选最大的分区\r\n\r\n3.在合并时检测地址周围是否有可以合并的空闲分区\r\n\r\n\r\n\r\n中等大小分配较多时效果好,避免出现太多小碎片\r\n\r\n释放分区较慢,容易破坏大的空闲分区\r\n\r\n\r\n\r\n##### 碎片整理\r\n\r\n紧凑:通过调整进程占用的分区位置来减少碎片\r\n\r\n条件:可动态重定位(程序中不能引用绝对地址)\r\n\r\n什么时候移动:一般是在等待的时候移动\r\n\r\n同时移动需要开销\r\n\r\n分区对换:\r\n\r\n抢占那些处于等待状态进程的分区(将等待状态的进程数据放到外存中)\r\n\r\n\r\n\r\n实例:伙伴系统\r\n\r\n整个可分配的分区大小时$2^U$\r\n\r\n如果需要的分区大小$s \\le2^{i - 1}$ 将大小为$2^i$ 的空间划分为两个大小为$2^{i - 1}$的空间,最大可能的空闲块为$2^{U - 1} - 1$ \r\n\r\n数据结构:(二叉树)\r\n\r\n1.空闲块按照大小和地址组织成二维数组\r\n\r\n2.初始为一个大小为$2^U$的空闲块\r\n\r\n3.分配时由小到大寻找合适的空闲块, 如果最小的空闲块太大就对半分\r\n\r\n4.在释放时检测能否和周围的空闲块合并成大小为$2^i$的空闲块\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n##### 非连续内存分配\r\n\r\n非连续内存分配需要实现 虚拟地址和物理地址的转换\r\n\r\n1.软件实现\r\n\r\n2.硬件实现\r\n\r\n\r\n\r\n如何选择非连续分配中的内存分块大小\r\n\r\n1.段式分配\r\n\r\n2.页式分配\r\n\r\n\r\n\r\n##### 段式分配\r\n\r\n段表示访问方式和储存数据等属性相同的一段地址空间\r\n\r\n进程的段地址空间由多个段组成\r\n\r\n一般来说,代码段、数据段、堆栈、堆之间不会跨段访问,因此段不连续的影响是比较小的。因此我们可以以段为单位,将程序的代码段、数据段等分开存放。段可以由(段号,段偏移)来表示。\r\n\r\n\r\n\r\n##### 页式分配\r\n\r\n把物理地址空间划为大小相同的基本分配单位(2的n次方)帧\r\n\r\n物理地址由二元组表示(f,o)f表示帧号,o表示帧内偏移\r\n\r\n进程逻辑地址空间划分为基本分配单位 页\r\n\r\n逻辑地址由二元组表示(p, o)p表示页号,o表示页内偏移\r\n\r\n帧内偏移 = 页内偏移 但是帧号和页号不相同(页连续 帧不连续)\r\n\r\n\r\n\r\n每个进程都有一个页表,每个页面对应一个页表项。常用页表项标志:存在位,修改位,引用位\r\n\r\n页表做的事情就是做地址转换\r\n\r\n\r\n\r\n快表(TLB):通过缓存的方式减少页表所占的开销\r\n\r\n将近期访问过的页表项存到CPU里面\r\n\r\n如果TLB命中,物理页号可以很快夺取\r\n\r\n如果不命中,则在内存中查询,并存到CPU中\r\n\r\n\r\n\r\n多级页表:通过多级来减少页表的大小\r\n\r\n通过间接引用将页号分为多级\r\n\r\n\r\n\r\n反置页表和页寄存器也是为了减少大量页表项所占的内存空间的开销。\r\n\r\n\r\n\r\n二者都通过HASH来做\r\n\r\n\r\n\r\n段页式存储管理:段式存储在保护方面有优势,页式存储在利用内存等方面有优势\r\n\r\n二者能不能结合呢?\r\n\r\n将程序分为多段,每个段中使用页表对应到物理地址。\r\n\r\n\r\n\r\n\r\n\r\n#### 虚拟存储\r\n\r\n增长迅速的存储需求\r\n\r\n实际当中的存储器有层次结构\r\n\r\n\r\n\r\n##### 覆盖技术\r\n\r\n目标:在较小的内存中运行较大的程序\r\n\r\n将程序分为必要部分(常用代码和常用数据),可选部分(只在需要时放入)\r\n\r\n不存在调用关系的模块可以相互覆盖。\r\n\r\n\r\n\r\n##### 交换技术\r\n\r\n将暂时不用的程序放到外存\r\n\r\n\r\n\r\n##### 局部性原理\r\n\r\n程序在执行过程中的一个较短时期,所执行的指令地址和指令的操作数地址,分别局限于一定区域。\r\n\r\n时间局部性:本次执行和下次执行在一个较短的时间\r\n\r\n空间局部性:当前指令和邻近指令,当前访问的数据和临近几个数据都只集中在一个小区域内\r\n\r\n分支局部性:一条跳转指令的两次执行很可能跳转到相同位置\r\n\r\n局部性原理从理论上保证了虚拟存储技术是能够实现的\r\n\r\n\r\n\r\n虚拟存储:(物理内存+磁盘=虚拟存储)\r\n\r\n在装载程序时只将需要执行的部分页面或段装入内存\r\n\r\n在执行过程中需要的指令或数据不在内存中(缺页)则调入内存\r\n\r\n操作系统将内存中暂时不用的保存到外面\r\n\r\n\r\n\r\n虚拟页式存储管理:\r\n\r\n在页式存储管理上增加请求调页和页面置换\r\n\r\n在程序启动时,只装入部分页面。在需要的时候再载入。\r\n\r\n\r\n\r\n##### 缺页\r\n\r\n缺页异常(中断)的处理流程\r\n\r\n\r\n\r\n虚拟页式存储管理的性能:\r\n\r\nEAT(有效存储访问时间) = 访问时间$\\times$(1-p)+缺页异常处理时间$\\times$缺页率p\r\n\r\n\r\n\r\n##### 页面置换算法\r\n\r\n概念:当出现缺页异常需要调入新页面而内存已满时,置换算法选择被置换的物理页面,要求尽可能减少页面调入调出次数,将未来不再访问的页面调出。\r\n\r\n页面锁定:部分重要的逻辑页面不能被调出\r\n\r\n\r\n\r\n局部页面置换算法:\r\n\r\n置换页面的选择范围仅仅限于当前进程占用的物理页面\r\n\r\n全局页面置换算法:\r\n\r\n置换范围为所有可换的页面\r\n\r\n\r\n\r\n最优页面置换算法:\r\n\r\n缺页时,计算所有逻辑页面的下一次访问时间,选择最长不访问的页面\r\n\r\n特点是无法预知未来的访问\r\n\r\n可以作为其他置换算法的性能评价依据\r\n\r\n\r\n\r\n先进先出算法\r\n\r\n选择在内存驻留时间最长的页面进行置换\r\n\r\n维护一个逻辑页面链表,链首是时间最长的\r\n\r\n特点:简单实现,性能较差\r\n\r\n\r\n\r\n最近最久未使用算法:\r\n\r\n选择最长时间没有被引用的页面进行置换\r\n\r\n特点 这是最优置换算法的一种近似\r\n\r\n\r\n\r\nLRU算法\r\n\r\n维护一个按最近一次访问时间的链表\r\n\r\n首是最近使用过的页面\r\n\r\n置换时置换链尾元素,每次访问的时候将最新访问的点放到链接、首\r\n\r\n\r\n\r\n时钟置换算法:\r\n\r\n仅对页面的访问情况进行大致统计\r\n\r\n在页表项中增加访问位,各页面组织成环形链表,指针指向最先调入的页面\r\n\r\n缺页时从指针处开始查找最近未被访问的页面(如果是该页面访问位为1则改为0继续寻找)\r\n\r\n时钟算法时LRU和FIFO的折中\r\n\r\n改进的clock算法:加入修改位\r\n\r\n如果该页面被读,访问位置1,被写 访问位 修改位置1\r\n\r\n缺页时 跳过有修改的页面,将访问位置0\r\n\r\n\r\n\r\n最不常用算法:\r\n\r\n每个页面设置一个访问计数器\r\n\r\n访问时计数加1\r\n\r\nLRU关注过去最近访问的时间,LFU关注最近访问次数\r\n\r\n\r\n\r\nBelady现象\r\n\r\n一般来说随着分配给进程的内存增加,缺页率下降。\r\n\r\nbelady现象指的是随着分配给进程的内存增加,缺页率上升。(FIFO) \r\n\r\n\r\n\r\n\r\n\r\nLRU算法没有belady算法\r\n\r\n\r\n\r\nLRU,FIFO,Clock本质上都是先进先出的思路\r\n\r\nLRU 根据页面最近访问时间来排序,同时需要动态调整顺序\r\n\r\nFIFO是根据页面进入内存的时间排序,相对顺序不变\r\n\r\n\r\n\r\n全局置换算法:给进程分配可变数目的物理页面\r\n\r\n局部置换算法没有考虑进程差异\r\n\r\n工作集置换算法 \r\n\r\n工作集指的是当前一段时间内进程访问的页面集合\r\n\r\n\r\n\r\n\r\n\r\n缺页率置换算法\r\n\r\n缺页率一般用缺页平均时间间隔进行表示\r\n\r\n\r\n\r\n\r\n\r\n抖动:\r\n\r\n抖动指的是系统运行的进程太多使得每个进程的物理页面太少,造成大量缺页,频繁置换,进程运行速度变慢。\r\n\r\n操作系统希望能在并发水平和缺页率之间进行一个平衡\r\n\r\n\r\n\r\n负载控制:通过调节并发进程数来进行系统负载控制\r\n\r\n\r\n\r\n若缺页间隔时间大于处理时间,说明是来得及进行处理的 \r\n\r\n\r\n\r\n### 进程 线程\r\n\r\n进程指的是具有一定功能得程序在一个数据集合上得一次动态执行过程\r\n\r\n进程包含了一个程序执行得所有状态信息,例如代码数据 状态寄存器 通用寄存器,内存等\r\n\r\n同一个程序的多次执行对应的是不同的进程\r\n\r\nPCB 进程控制块,进程创建时生成其PCB,进程结束回收PCB,进程运行时PCB控制。\r\n\r\n\r\n\r\n进程的状态:\r\n\r\n\r\n\r\n进程的状态分为 创建 就绪 等待 运行 退出等\r\n\r\n\r\n\r\n三状态进程模型\r\n\r\n创建-就绪:创建工作结束,准备就绪\r\n\r\n就绪-运行:就绪状态的进程被调度运行\r\n\r\n运行-结束:回收\r\n\r\n运行-就绪:时间片用完 让出资源 处理机\r\n\r\n运行-等待:等待某个资源或数据\r\n\r\n等待-就绪:进程等待的资源等到来,转成就绪状态\r\n\r\n\r\n\r\n进程挂起模型:处于挂起状态的进程存在磁盘上,目的是减少进程占用内存\r\n\r\n\r\n\r\n挂起:进程从内存转到外存(等待到等待挂起,就绪到就绪挂起,运行到就绪挂起)\r\n\r\n等待挂起到就绪挂起:等待事件出现\r\n\r\n激活:\r\n\r\n就绪挂起到就绪\r\n\r\n等待挂起到等待:有进程释放了大量的空间\r\n\r\n\r\n\r\n##### 线程\r\n\r\n为什么要引入线程:在进程内部进一步提高并发性\r\n\r\n例子:有一个mp3播放软件,核心功能有三个:1.从mp3文件中读取 2.解压 3.播放\r\n\r\n如果是单进程工作的话效率并不高,事实上可以并发进行 多进程实现\r\n\r\n存在的问题:进程之间如何通信\r\n\r\n\r\n\r\n增加一种实体:1.能够并发执行 2.共享空间 这种实体就是线程\r\n\r\n线程:是进程中的一部分,是指令执行流的最小单元,是CPU的基本调度单位\r\n\r\n一个进程内部可以存在多个线程,线程之间可以并发进行,共享地址空间和文件等等。可以实现上述mp3播放软件的功能\r\n\r\n进程是资源分配的单位,线程是CPU调度单位。\r\n\r\n线程同样具有就绪 等待 运行着三种基本状态以及转换关系。\r\n\r\n\r\n\r\n线程的三种实现方式:用户线程、内核线程、轻量级进程\r\n\r\n用户线程:\r\n\r\n用户库来完成创建、终止、同步、调度等。\r\n\r\n内核线程:\r\n\r\n内核通过系统调用来实现创建终止和管理。\r\n\r\n\r\n\r\n### 处理机调度\r\n\r\nCPU资源是时分复用的。调度算法,调度时机:非抢占式系统、抢占式系统\r\n\r\n调度准则:\r\n\r\n比较调度算法的准则:\r\n\r\nCPU利用率(处于繁忙时间的百分比)\r\n\r\n吞吐量:单位时间完成的进程数量\r\n\r\n周转时间:进程从初始化倒结束的总时间\r\n\r\n等待时间:进程在就绪队列中的总时间\r\n\r\n响应时间:从提交请求倒产生响应的总时间\r\n\r\n\r\n\r\n##### 调度算法\r\n\r\n先来先服务算法:\r\n\r\n根据进程进入就绪状态的先后顺序排队。算法的周转时间和先后顺序有关\r\n\r\n例子 12,3,3\r\n\r\n(12+15+18)/3 = 15\r\n\r\n3,3,12\r\n\r\n(3+6+18)/3 = 9\r\n\r\n资源的资源利用率比较低\r\n\r\n\r\n\r\n短进程优先算法:\r\n\r\n选择就绪队列中按照执行时间期望最短的进程\r\n\r\n变种:短剩余时间优先算法:如果在执行进程A 突然来了新的更短的进程B,可以抢占。具有最优平均周转时间特点。\r\n\r\n可能会导致饥饿:连续的短进程使得长进程无法获得CPU资源\r\n\r\n\r\n\r\n最高响应比优先算法\r\n\r\n 响应比r = (w+s)/s w是等待时间,s为执行时间\r\n\r\n可以避免进程无限期等待\r\n\r\n\r\n\r\n时间片轮转算法\r\n\r\n时间片是分配处理机资源的基本时间单元\r\n\r\n时间片结束时时间片轮转算法切换到下一个就绪进程\r\n\r\n例子:\r\n\r\n\r\n\r\n时间片轮转有额外的上下文切换开销\r\n\r\n时间片太大时退化为先来先服务算法\r\n\r\n\r\n\r\n\r\n\r\n多级队列调度算法\r\n\r\n就绪队列被划分为多个独立的子队列,每个队列有自己的调度策略,队列之间也调度策略(固定优先级,时间片轮转)\r\n\r\n\r\n\r\n多级反馈队列算法:\r\n\r\n时间片大小随着优先级级别增加而增加,进程在一个时间片没有完成之后下降优先级\r\n\r\nCPU密集型的进程优先级下降很快\r\n\r\n\r\n\r\n公平共享调度算法:强调资源访问公平\r\n\r\n一些用户组比其他用户组更重要\r\n\r\n未使用的资源按照比例分配\r\n\r\n\r\n\r\n##### 实时调度\r\n\r\n指某些任务必须在某个时间之前完成\r\n\r\n软时限(尽量满足要求) 硬时限(必须验证在最坏情况下满足要求)\r\n\r\n速率单调调度算法:周期越短的优先级越高\r\n\r\n最早截至时间优先算法:截至时间越早优先级越高\r\n\r\n\r\n\r\n多处理机调度算法\r\n\r\n进程分配:将进程分配到哪个处理器上运行\r\n\r\n静态分配:每个处理机都有队列,可能会导致每个处理机忙闲不均\r\n\r\n动态分配:进程在执行中可被分配到任意空闲处理机,所有的处理机共享一个队列,导致调度开销大,各处理机的负载时均衡的\r\n\r\n\r\n\r\n优先级反置\r\n\r\n指的是高优先级进程长时间等待等待低优先级进程所占用资源的现象\r\n\r\n\r\n\r\nT1占用了临界资源,不能被抢占(例如打印机等)\r\n\r\n基于优先级的可抢占的算法都会存在优先级反置:\r\n\r\n解决方法\r\n\r\n优先级继承:占用资源的低优先级进程继承申请资源的高优先级进程的优先级\r\n\r\n优先级天花板协议:占用资源的进程优先级和所有可能使用该资源的优先级的最大值相同\r\n\r\n\r\n\r\n\r\n\r\n#### 同步互斥\r\n\r\n背景:\r\n\r\n并发进程使得有资源的共享\r\n\r\n##### 原子操作\r\n\r\n一次不存在任何中断的操作\r\n\r\n操作系统需要利用同步机制在并发执行的同时,保证一些操作是原子操作。\r\n\r\n\r\n\r\n临界区:\r\n\r\n空闲等待\r\n\r\n忙则等待\r\n\r\n有限等待:等待进入临界区的进程不能无限等待\r\n\r\n让权等待(可选):不能进入临界区的进程让出CPU等\r\n\r\n\r\n\r\n实现方法:\r\n\r\n方法1:禁用硬件中断:没有中断 没有上下文切换,没有并发\r\n\r\n方法2:基于软件 可以用一些共享变量实现\r\n\r\nPeterson算法\r\n\r\n\r\n\r\n\r\n\r\n##### 信号量\r\n\r\n用信号量实现临界区的互斥访问\r\n\r\n每类资源设置一个信号量,初值为1。PV操作必须同步使用。P操作保证互斥访问,V操作在使用后释放保证下一个能使用\r\n\r\n\r\n\r\n用信号量实现条件同步\r\n\r\n条件同步设置一个信号量,其初始值为0.\r\n\r\n\r\n\r\n线程A需要等待线程B执行完X模块之后才能执行N模块\r\n\r\n\r\n\r\n管程:\r\n\r\n管程是一种用于多线程互斥访问共享资源的结构\r\n\r\n\r\n\r\n经典同步问题\r\n\r\n哲学家就餐问题\r\n\r\n\r\n\r\n\r\n\r\n为了避免死锁的情况(5个人同时拿左边的叉子,进入等待右边叉子的状态,即死锁)\r\n\r\n\r\n\r\n读者-写者问题\r\n\r\n\r\n\r\n用信号量来解决该问题: \r\n\r\n信号量writerMutex初始化为1\r\n\r\n读者计数Rcount,初始化为0\r\n\r\n信号量CountMutex,用来控制堆Rcount的修改,初始化1\r\n\r\n\r\n\r\n第一个读者进入的时候 占住writerMutex,之后的读者进入的时候只是增加Rcount\r\n\r\n\r\n\r\n另一个策略是写者优先\r\n\r\n\r\n\r\n管程实现\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n##### 死锁\r\n\r\n由于竞争资源或者是通信关系,两个或者更多线程在执行中出现,永远相互等待的事件\r\n\r\n例如单向通向桥梁\r\n\r\n出现死锁的四个条件:\r\n\r\n互斥:有一个资源任何时刻只能被一个进程占有\r\n\r\n持有并等待:进程持有至少一个资源同时在等待别的进程占有的资源\r\n\r\n非抢占:资源不能被抢占\r\n\r\n循环等待\r\n\r\n\r\n\r\n死锁处理方法:\r\n\r\n1.死锁预防:破坏四个必要条件\r\n\r\n2.死锁避免:在使用前进行判断\r\n\r\n3.死锁检测和恢复\r\n\r\n\r\n\r\n银行家算法:\r\n\r\n银行家算法是一种死锁避免的算法。n=线程数量,m=资源类型数量\r\n\r\n数据结构:\r\n\r\n\r\n\r\nNeed = Max - Allocation\r\n\r\n安全状态判定:\r\n\r\n\r\n\r\n本质上是判断如果某进程可以安全运行,则分配给其资源,运行完之后回收资源,将标志置为true,否则为false\r\n\r\n最后检测是不是所有的进程的状态都是true\r\n\r\n\r\n\r\n死锁检测\r\n\r\n允许系统进入死锁状态\r\n\r\n\r\n\r\n\r\n\r\n##### 进程通信\r\n\r\n进程通信指的是进程之间进行通信和同步的机制,有两个基本操作:发送操作和接收操作。\r\n\r\n通信方式分为间接通信和直接通信。\r\n\r\n直接通信会建立一条消息链路,间接通信通过操作系统维护的消息队列实现消息接收和发送。\r\n\r\n进程通信分为阻塞通信(同步),非阻塞通信(异步)\r\n\r\n阻塞通信:\r\n\r\n发送者在发送消息后进入等待,直接接收者成功接收到\r\n\r\n接收者在请求接收消息后进入等待直接成功收到消息\r\n\r\n\r\n\r\n非阻塞通信:\r\n\r\n发送者在发送消息后直接做别的事\r\n\r\n接收者在请求接收消息后可能不会等到一条消息\r\n\r\n\r\n\r\n通信链路缓冲:\r\n\r\n0容量:发送发必须等待接收方\r\n\r\n有限容量:当链路满了之后发送方必须等待\r\n\r\n无限容量:发送方无需等待\r\n\r\n\r\n\r\n##### 信号和管道\r\n\r\n信号:进程间的软件中断和处理机制\r\n\r\nSIGKILL等\r\n\r\n信号的处理:\r\n\r\n捕获:信号处理函数被调用\r\n\r\n屏蔽:登录时 信号被屏蔽\r\n\r\n\r\n\r\n##### 管道\r\n\r\n进程间基于内存文件的通信机制\r\n\r\n进程不关心管道的另一端是谁\r\n\r\n与管道相关的系统调用:read write\r\n\r\n\r\n\r\n消息队列和共享内存\r\n\r\n消息队列是操作系统维护的间接通信机制\r\n\r\n共享内存是把同一个物理内存区域同时映射到多个进程的内存地址空间的通信机制\r\n\r\n\r\n\r\n#### 文件系统和文件\r\n\r\n文件系统是操作系统中管理持久性数据的子系统\r\n\r\n文件是具有符号名,由字节序列构成的数据项集合\r\n\r\n\r\n\r\n文件描述符\r\n\r\n进程访问文件前必须要打开文件\r\n\r\n文件描述符是操作系统所打开文件的状态和信息\r\n\r\n文件指针\r\n\r\n文件打开计数:最后一个进程关闭文件时,可以从内存中移除\r\n\r\n文件的磁盘位置\r\n\r\n访问权限\r\n\r\n\r\n\r\n文件的用户视图:持久的数据结构\r\n\r\n系统视图:字节序列\r\n\r\n\r\n\r\n文件别名:多个文件名关联同一个文件,方便共享\r\n\r\n硬链接:多个文件项指向一个文件\r\n\r\n软链接:软连接文件中存的是另一个文件的路径\r\n\r\n\r\n\r\n虚拟文件系统\r\n\r\n对不同的文件系统进行抽象,提供相同的文件和文件系统接口\r\n\r\n"
},
{
"alpha_fraction": 0.4858657121658325,
"alphanum_fraction": 0.5318021178245544,
"avg_line_length": 18.032447814941406,
"blob_id": "7f47a7b2be6da71bf8f1719be3f843b58abcbb36",
"content_id": "286f732f5f09562e583926cbd947450ee2d2ca79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 14464,
"license_type": "no_license",
"max_line_length": 162,
"num_lines": 678,
"path": "/c++/c++_cookbook.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### c++ 笔记\r\n\r\n#### c++创建数组\r\n\r\n```\r\nint dp[n][n];\r\nfill(dp[0], dp[0]+n*n, 0);\r\nfill(dp,dp+n*n,0) 会出错,因为dp不是dp[0][0]的地址,dp[0]才是dp[0][0]的地址\r\nmemset(dp,0,sizeof(dp))\r\n```\r\n数组sum accumulate\r\n\r\n```\r\nint sum1 = accumulate(A.begin() , A.end() , 0);\r\n```\r\n\r\n#### c++ split\r\n\r\n```\r\nstring line;\r\ngetline(in, line);\r\nchar* p;\r\nchar line_cstr[1000];\r\nstrcpy(line_cstr,line.c_str());\r\np = strtok(line_cstr, \" \"); str1 = p;\r\np = strtok(NULL, \" \"); str2 = p;\r\na = stoi(str1); b = stoi(str2);\r\n```\r\n\r\n#### string与int double等类型的转化\r\n\r\nstoi,stod函数 \r\n\r\nto_string函数\r\n\r\n```c++\r\nstring str1=\"125\";\r\nint a;\r\na=stoi(str1);\r\nstring str2=to_string(a);\r\n```\r\n\r\n#### 二维vector初始化\r\n\r\n```\r\nvector<vector <int> > ivec(5, vector<int>(6,1)); ### 初始化为1 的5*6二维vector\r\n二维vector不能用fill来初始化\r\nint nums[2][3] = { {1,2,7},{3,6,7}};\r\nint nums2[6] = { 1,1,1,1,1,1 };\r\nvector <int> a;\r\na.assign(nums2, nums2 + 6);\r\nvector<vector<int> > num(2);\r\nfor (int i = 0; i < 2; i++) {\r\n\tnum[i].assign(nums[i], nums[i] + 3);\r\n}\r\n```\r\n\r\n#### c++ string\r\n\r\n```\r\nstring不能直接相减,可以比较大小\r\n\"xa\"<\"xc\" true\r\n```\r\n##### 大小写转换问题\r\n\r\n```\r\nstring s1 = \"123asx\";\r\ntransform(s1.begin(), s1.end(), s1.begin(), ::toupper); 注意是::toupper和::tolower\r\n```\r\n\r\n如果要生成新的语句,则第二个s1.begin()换成s2.begin();\r\n\r\n#### sstream\r\n\r\n```\r\n#include<sstream>\r\nstreamstring ss;\r\nss.str(\"\"); #clear\r\nss << A[0] << A[1] << \":\" << A[2] << A[3];\r\nstr1=ss.str(); #讲stream中的内容存到str1中\r\n```\r\n\r\n#### permutation\r\n\r\n#### c++union find\r\n```c++\r\nclass Solution {\r\npublic:\r\n int find(int x) {\r\n return id[x];\r\n }\r\nvoid union1(int x, int y, int n) {# 这种union方式效率比较低\r\n int xid = find(x);\r\n int yid = find(y);\r\n if (xid == yid) return;\r\n for (int i = 0;i <n;i++) {\r\n if (id[i]==xid) id[i]=yid;\r\n }\r\n islands--;\r\n return;\r\n}\r\nint removeStones(vector<vector<int>>& stones) {\r\n int i = 0,j;\r\n int n = stones.size();\r\n for (i = 0;i < n;i++) {\r\n id[i] = i;\r\n }\r\n islands = n;\r\n for (i = 0;i < n;i++) {\r\n for (j = i + 1;j < n;j++) {\r\n\t if (stones[i][0] == stones[j][0] || stones[i][1] == stones[j][1]) {\r\n\t union1(i, j, n);\r\n\t }\r\n\t}\r\n }\r\n return n - islands;\r\n}\r\nprivate:\r\n int id[1000];\r\n int islands = 0;\r\n};\r\n```\r\n#### permutation\r\n```\r\nnext_permutation(A.begin(), A.end()) #增序\r\nprev_permutation(A.begin(), A.end()) #减序\r\n```\r\n\r\n#### 并查集 union find+路径压缩\r\n```c++\r\nvector<int> id(20000,0);\r\nvector<int> size1(20000, 0);\r\nclass Solution {\r\npublic:\r\n int find(int x) {\r\n if (id[x] == x) return x;\r\n else return id[x] = find(id[x]);\r\n }\r\n void union1(int a, int b) {\r\n int f_x = find(a), f_y = find(b);\r\n if (f_x == f_y) return;\r\n id[f_x] = f_y;\r\n size1[f_y] += size1[f_x];\r\n max_len = max(max_len, size1[f_y]);\r\n }\r\n int largestComponentSize(vector<int>& A) {\r\n int n = A.size(),i,j;\r\n int temp;\r\n\t\t\r\n for (i = 0; i < n; i++) {\r\n id[i] = i;\r\n size1[i] = 1;\r\n }\r\n for (i = 0; i < n; i++) {\r\n for (j = i+1; j < n; j++) {\r\n temp = maxfactor(A[i], A[j]);\r\n\t if (temp>1)\r\n\t\tunion1(i, j);\r\n\t }\r\n }\r\n return max_len;\r\n}\r\nprivate: \r\n int max_len = 1;\r\n};\r\n```\r\n时间复杂度为O(N2)\r\n\r\n要实现O(N) leetcode952 \r\n\r\n##### max_element,min_element\r\n```\r\nint num_max=*max_element(nums.begin(),nums.end());\r\n```\r\n##### for循环的方式 C++11特性\r\n```\r\nfor(int& a: A){ #这种更好\r\n}\r\nfor(int i=0;i<n;i++){\r\n}\r\n```\r\n#### c++ sort \r\n使用自己定义的函数\r\n\r\n```c++\r\nchar op(char ch){\r\n if(ch>='A'&&ch<='Z')\r\n return ch+32;\r\n else\r\n return ch;\r\n}\r\ntransform(first.begin(),first.end(),second.begin(),op);\r\n```\r\n```c++\r\nstruct node{\r\n int x;\r\n int y;\r\n};\r\nbool cmp(node& a, node& b) {\r\n if (a.x != b.x)\r\n return a.x > b.x;\r\n else\r\n return a.y < b.y;\r\n}\r\nsort(nums.begin(), nums.end(), cmp);\r\nsort(nums.begin(), nums.end());\r\n```\r\ncmp要放在solution外面\r\n```c++\r\nint issorted(vector<string>& str) {\r\n int j;\r\n for (j = 1; j < str.size(); j++) {\r\n if (str[j - 1] > str[j]) return -1;\r\n }\r\n for (j = 1; j < str.size(); j++) {\r\n if (str[j - 1] == str[j]) return 0;\r\n }\r\n return 1;\r\n}\r\nclass Solution {\r\npublic:\r\n int minDeletionSize(vector<string>& A) {\r\n \tint i,j, n = A.size();\r\n \tbool flag = true;\r\n \tvector<string> str(n, \"\");\r\n \tvector<string> str2(n, \"\");\r\n \tint count = 0;\r\n \tif (n <=1) return count;\r\n \tfor (i = 0; i < A[0].size(); i++) {\r\n for (j = 0; j < A.size(); j++) {\r\n str2[j] += A[j][i];\r\n\t }\r\n\t int res = issorted(str2);\r\n if (res==1) return count;\r\n\t else {\r\n\t if (res == 0) {\r\n\t\t str = str2;\r\n\t }\r\n\t else {\r\n\t\t str2 = str;\r\n\t\t count++;\r\n\t }\r\n }\r\n }\r\n return count;\r\n }\r\n};\r\n```\r\n##### algorithm\r\nall_of,any_of,none_of\r\n```\r\nall_of(foo.begin(), foo.end(), [](int i){return i%2;}) #lambda表达式 表示是否都是奇数\r\n```\r\nequal\r\n```\r\nequal:Compares the elements in the range [first1,last1) with those in the range beginning at first2, and returns true if all of the elements in both ranges match.\r\nint myints[] = {20,40,60,80,100};\r\nstd::vector<int>myvector (myints,myints+5);\r\nstd::equal (myvector.begin(), myvector.end(), myints);\r\n```\r\ncount\r\n```\r\nint myints[] = {10,20,30,30,20,10,10,20};\r\nint mycount = std::count (myints, myints+8, 10);\r\n```\r\nmismatch\r\n```\r\nint myints[] = {10,20,80,320,1024}; \r\nfor (int i=1; i<6; i++) myvector.push_back (i*10);\r\nstd::pair<std::vector<int>::iterator,int*> mypair;\r\n\r\nmypair = std::mismatch (myvector.begin(), myvector.end(), myints);\r\nstd::cout << \"First mismatching elements: \" << *mypair.first;\r\nstd::cout << \" and \" << *mypair.second << '\\n';\r\n\r\nFirst mismatching elements: 30 and 80\r\n```\r\nsearch\r\n```\r\nsearch:Searches the range [first1,last1) for the first occurrence of the sequence defined by [first2,last2)\r\nfor (int i=1; i<10; i++) haystack.push_back(i*10);\r\nint needle1[] = {40,50,60,70};\r\nstd::vector<int>::iterator it;\r\nit = std::search (haystack.begin(), haystack.end(), needle1, needle1+4);\r\nif (it!=haystack.end())\r\n std::cout << \"needle1 found at position \" << (it-haystack.begin()) << '\\n';\r\n else\r\n std::cout << \"needle1 not found\\n\";\r\n```\r\nis_permutation\r\n```\r\nis_permutation:Compares the elements in the range [first1,last1) with those in the range beginning at first2 两个数组是否元素相同\r\nstd::array<int,5> foo = {1,2,3,4,5};\r\nstd::array<int,5> bar = {3,1,4,5,2};\r\nstd::is_permutation (foo.begin(), foo.end(), bar.begin())\r\n```\r\ncopy\r\n```\r\nint myints[]={10,20,30,40,50,60,70};\r\nstd::vector<int> myvector (7);\r\nstd::copy ( myints, myints+7, myvector.begin() );\r\n```\r\nmove\r\n```\r\nstd::vector<std::string> foo = {\"air\",\"water\",\"fire\",\"earth\"};\r\nstd::vector<std::string> bar (4);\r\n\r\nstd::move ( foo.begin(), foo.begin()+4, bar.begin() );\r\n或者\r\nfoo = std::move (bar);\r\n```\r\n\r\nswap\r\n```\r\nint x=10, y=20; // x:10 y:20\r\nstd::swap(x,y);\r\n```\r\nremove\r\n```\r\nremove all the items equal to val\r\nint myints[] = {10,20,30,30,20,10,10,20};\r\nvector<int> nums(myints,myints+8);\r\nstd::remove (nums.begin(), nums.end(), 20);\r\n```\r\nunique\r\n```\r\nunique 删除所有连续的相同元素\r\n\r\nint myints[] = {10,20,30,30,20,10,10,20};\r\nvector<int> nums(myints,myints+8);\r\nunique (myvector.begin(), myvector.end()); // 10 20 30 20 10\r\n```\r\n\r\nreverse\r\n```\r\nstd::vector<int> myvector;\r\n// set some values:\r\nfor (int i=1; i<10; ++i) myvector.push_back(i); // 1 2 3 4 5 6 7 8 9\r\nstd::reverse(myvector.begin(),myvector.end()); // 9 8 7 6 5 4 3 2 1\r\n```\r\n\r\nrotate\r\n```\r\nstd::vector<int> myvector;\r\n\r\n// set some values:\r\nfor (int i=1; i<10; ++i) myvector.push_back(i); // 1 2 3 4 5 6 7 8 9\r\nstd::rotate(myvector.begin(),myvector.begin()+3,myvector.end());\r\n // 4 5 6 7 8 9 1 2 3\r\n```\r\n\r\nshuffle\r\n```\r\nstd::array<int,5> foo {1,2,3,4,5};\r\n\r\n// obtain a time-based seed:\r\nunsigned seed = std::chrono::system_clock::now().time_since_epoch().count();\r\nshuffle (foo.begin(), foo.end(), std::default_random_engine(seed));\r\n```\r\n\r\nstring 比较大小\r\n```\r\nstring s1 = \"123Bsx\";\r\nstring s2 = \"123b\";\r\nbool is=s1 < s2;\r\ncout << is;\r\n```\r\nascii code int转换\r\n```\r\nint a = 97,b;\r\nchar ch;\r\nch = a;\r\nb = ch;\r\ncout << ch<<\" \"<<b<< 'a'<<\" \"<<\"a\";\r\n\r\na 97 a a \r\n```\r\n\r\n#### c++file读写\r\n```\r\n#include <iostream>\r\nifstream in(\"123.txt\");\r\nofstream out(\"a.out\");\r\nstring line;\r\ngetline(in,line);\r\nn=stoi(line); #int\r\n```\r\n\r\n#### bitset\r\n```\r\nbitset<4> bitset1; //无参构造,长度为4,默认每一位为0\r\nbitset<8> bitset2(12); //长度为8,二进制保存,前面用0补充\r\n\r\nstring s = \"100101\";\r\nbitset<10> bitset3(s); //长度为10,前面用0补充\r\nchar s2[] = \"10101\";\r\nbitset<13> bitset4(s2); //长度为13,前面用0补充\r\n\r\ncout << bitset1 << endl; //0000\r\ncout << bitset2 << endl; //00001100\r\ncout << bitset3 << endl; //0000100101\r\ncout << bitset4 << endl; //0000000010101\r\n```\r\n\r\n```\r\nbitset<10>(h << 6 | m).count() leetcode401\r\n```\r\n\r\ntime: test for c++ and python:\r\n\r\n```\r\nimport time\r\nt1=time.time()\r\na=[i for i in range(10000001)]\r\nfor i in range(100000):\r\n nums=list(a[i*100:i*100+100])\r\nt2=time.time()\r\nprint(t2-t1)\r\n```\r\n\r\n73.6ms \r\n\r\nc++: \r\n\r\n```\r\n#include \"time.h\"\r\nusing namespace std;\r\nint main() {\r\n vector<int> temp(10002000,1);\r\n clock_t start,finish;\r\n start=clock();\r\n for(int i =0;i<100000;i++){\r\n vector<int> num(temp.begin() + 100 * i, temp.begin() + 100 * i + 100);\r\n }\r\n finish=clock();\r\n cout<<finish-start;\r\n return 0;\r\n}\r\n```\r\n\r\n29ms \r\n\r\n```\r\n#include \"time.h\"\r\nusing namespace std;\r\nint main() {\r\n vector<int> temp(10002000,1);\r\n clock_t start,finish;\r\n start=clock();\r\n for(int i =0;i<100000;i++){\r\n vector<int> num;\r\n for (int j=0;j<100;j++){\r\n num.push_back(j);\r\n }\r\n }\r\n finish=clock();\r\n cout<<finish-start;\r\n return 0;\r\n}\r\n```\r\n\r\n342ms \r\n\r\n结论:python[i:j] 这种形式是用vector<int> num(temp.begin() + i, temp.begin() + j);最好 \r\ntemp.begin()+i ~ temp.begin()+j-1\r\n\r\n\r\n\r\nc++中的max_int\r\n\r\n```c++\r\n#include <limits.h>\r\nint a=INT_MAX;\r\nint b=INT_MIN;\r\n```\r\n\r\n\r\n\r\nc++ set,map unordered_set,unordered_map\r\n\r\nc++中set和map实现的数据结构是红黑树,因此查询一个元素是否在set或者map中需要O(logN)\r\n\r\nunordered_set和unordered_map是基于hash的,所以查询一个元素是否在ordered_set ordered_map中需要O(1)时间 \r\n\r\n##### unordered_map\r\n\r\n```c++\r\n#include <iostream>\r\n#include <vector>\r\n#include <unordered_map>\r\n#include <string>\r\nusing namespace std;\r\nint main() {\r\n\tunordered_map<string, int> m1;\r\n\tunordered_map<string, int>::iterator it;\r\n\tm1[\"A\"] = 1;\r\n\tm1[\"B\"] = 2; \r\n\tit=m1.find(\"A\");\r\n\tif(it!=m1.end())\r\n\t\tcout << \"True \"<<it->first<<\" \"<<it->second;\r\n\tsystem(\"pause\");\r\n\treturn 0;\r\n}\r\n```\r\n\r\n##### unordered_set\r\n\r\n```c++\r\n#include <iostream>\r\n#include <vector>\r\n#include <unordered_set>\r\n#include <string>\r\nusing namespace std;\r\nint main() {\r\n\tunordered_set<int> m1;\r\n\tunordered_set<int>::iterator it;\r\n\tm1.insert(1);m1.insert(2);\r\n\tit = m1.find(1);\r\n\tif (it != m1.end())\r\n\t\tcout << \"True \" << *it;\r\n\tsystem(\"pause\");\r\n\treturn 0;\r\n}\r\n```\r\n\r\n\r\n\r\n在map中使用红黑树为底层数据结构,因此是存在固定顺序的\r\n\r\n```c++\r\n#include <iostream>\r\n#include <map>\r\n#include <string>\r\nusing namespace std;\r\nint main() {\r\n\tmap<string, int> m1;\r\n\tmap<string, int>::iterator it;\r\n\tm1[\"A\"] = 1;\r\n m1[\"C\"] = 2;\r\n\tm1[\"B\"] = 2; \r\n\tfor(auto it = m1.begin();it!=m1.end();++it){\r\n cout<<it->first<<\" \"<<it->second<<\" \";\r\n }\r\n return 0;\r\n}\r\n\r\nA 1 B 2 C 2\r\n```\r\n\r\nmap的两种遍历方式\r\n\r\n```c++\r\nmap<int,int> p;\r\np[0] = 1;\r\np[1] = 2;\r\np[3] = 4;\r\nmap<int,int>::iterator it;\r\nfor(it = p.begin(); it != p.end(); it++) {\r\n\tcout<<it->first<<\" \"<<it->second<<endl;\r\n}\r\nfor(auto it:p) {\r\n\tcout<<it.first<<\" \"<<it.second<<endl;\r\n}\r\n```\r\n\r\nunordered_map的两种遍历方式\r\n\r\n```c++\r\nunordered_map<int,int> p;\r\np[0] = 1;\r\np[1] = 2;\r\np[3] = 4;\r\nunordered_map<int,int>::iterator it;\r\nfor(it = p.begin(); it != p.end(); it++) {\r\n\tcout<<it->first<<\" \"<<it->second<<endl;\r\n}\r\nfor(auto it:p) {\r\n\tcout<<it.first<<\" \"<<it.second<<endl;\r\n}\r\n```\r\n\r\n但是没有python中的get方法\r\n\r\n\r\n\r\n按照键值进行排序\r\n\r\n也可以通过自己定义的函数来决定排列顺序 CmpByKeyLength\r\n\r\n```c++\r\nstruct CmpByKeyLength {\r\n bool operator()(const string& k1, const string& k2)const {\r\n return k1.length() < k2.length();\r\n }\r\n};\r\n\r\nint main(){\r\n map<string, int, CmpByKeyLength> name_score_map;\r\n\r\n name_score_map[\"LiMin\"] = 90;\r\n name_score_map[\"ZiLinMi\"] = 79;\r\n name_score_map[\"BoB\"] = 92;\r\n name_score_map.insert(make_pair(\"Bing\", 99));\r\n name_score_map.insert(make_pair(\"Albert\", 86));\r\n\r\n map<string, int>::iterator iter;\r\n for ( iter = name_score_map.begin();iter != name_score_map.end();++iter) {\r\n cout << (*iter).first << endl;\r\n }\r\n return 0;\r\n}\r\n```\r\n\r\n\r\n\r\nset与map一样同样存在键值顺序\r\n\r\n```c++\r\n#include <iostream>\r\n#include <set>\r\n#include <string>\r\nusing namespace std;\r\nint main() {\r\n\tset<string> s1;\r\n\tset<string>::iterator it;\r\n\ts1.insert(\"test\");\r\n s1.insert(\"1test\");\r\n s1.insert(\"asdgesadsd\");\r\n\tfor(auto it = s1.begin();it!=s1.end();++it){\r\n cout<<*it<<\" \";\r\n }\r\n for(auto &it: s1){\r\n cout<<it<<\" \";\r\n }\r\n return 0;\r\n}\r\n```\r\n\r\n1test asdgesadsd test 1test asdgesadsd test\r\n\r\n同样可以自己定义键值大小顺序\r\n\r\n```c++\r\n#include <iostream>\r\n#include <set>\r\n#include <string>\r\nusing namespace std;\r\nstruct CmpByKeyLength {\r\n bool operator()(const string& k1, const string& k2)const {\r\n return k1.length() < k2.length();\r\n }\r\n};\r\n\r\nint main(){\r\n set<string, CmpByKeyLength> s1;\r\n s1.insert(\"LiMin\");\r\n s1.insert(\"ZiLinMi\");\r\n s1.insert(\"ZBoB\");\r\n\r\n set<string>::iterator iter;\r\n for ( iter = s1.begin();iter != s1.end();++iter) {\r\n cout << (*iter) << endl;\r\n }\r\n for ( auto& it : s1) {\r\n cout << it << endl;\r\n }\r\n return 0;\r\n}\r\n```\r\n\r\n\r\n\r\nint double转换\r\n\r\n```c++\r\ndouble s=1/2; 0\r\ndouble s=1.0*1/2; 0.5\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.7698412537574768,
"alphanum_fraction": 0.7936508059501648,
"avg_line_length": 22.799999237060547,
"blob_id": "819c6c05057a2037f55155f09e82ee56f9c88e43",
"content_id": "f2b5eb021483144516cf9187992d48d75aa0130f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 162,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 5,
"path": "/papers/struct2vec.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### struct2vec: Learning Node Representation from Structural Identity\r\n\r\nstruct2vec:只考虑了网络结构特征\r\n\r\ndeepwalk node2vec还考虑了什么?\r\n\r\n"
},
{
"alpha_fraction": 0.5517241358757019,
"alphanum_fraction": 0.8574712872505188,
"avg_line_length": 435,
"blob_id": "65d55acaefb4b04cb184fc1b97be2d6eb96102ae",
"content_id": "e93daeefd92a5b385e5faed17f6a16a926d68637",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 435,
"license_type": "no_license",
"max_line_length": 435,
"num_lines": 1,
"path": "/social_network/pics.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "https://mp.weixin.qq.com/s?__biz=MzIwMTgwNjgyOQ==&mid=2247489386&idx=1&sn=45c7243c7aa5ce936c223433a60bbf11&chksm=96e911e8a19e98febfa6646616752f911c2340afbc2c6b07c5ac3e368c6c9e4e6991c3d97009&mpshare=1&scene=1&srcid=&sharer_sharetime=1574667828081&sharer_shareid=23f70eb49ae0d31904e96e52dd7556a7&key=d2b64b7a8020292cde69c2e7986ad6629c7026b9a7bfcf035e413b85d65fe644cebd65ff02dce36718878cc8fc0d55ec073e709c5eb7e105227a5c19011bf7805697c3b26f1ee403a16a8ac356bb147e&ascene=1&uin=Mjk1MDE5NTEyNg%3D%3D&devicetype=Windows+10&version=62070158&lang=zh_CN&pass_ticket=42zaUq%2Bu4H9cwGMIO5IOi4aoamNleilY9ct6EjyO%2BNX5UEgNAv5C9Uhj3nLuFK8H"
},
{
"alpha_fraction": 0.6284469962120056,
"alphanum_fraction": 0.6821480393409729,
"avg_line_length": 25.479999542236328,
"blob_id": "68ea2f2bfdbe473cab782f64c19e3790fa1598b6",
"content_id": "44ec5c38614bcfc64c412d8ecf9541f03388eafe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1095,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 25,
"path": "/math&&deeplearning/math/极大似然估计与最大后验概率.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 极大似然估计与最大后验概率\r\n\r\n极大似然估计是最大后验概率中认为先验概率为均分时的特殊情况。\r\n\r\n经典例子:\r\n\r\nYou have a coin, you flip it 10 times (a sample of 10 observations) and count the number of times if landed on \"Heads\", e.g. X=3.\r\n\r\n我们的目标是求解硬币向上的概率$p_0$\r\n\r\n对于频率学派的极大似然估计方法来说,相当于求解某个参数,使得模型在这个参数下呈现出当前观察到的数据的可能性最大。\r\n$$\r\nf(p)=(_{3}^{10})p^3(1-p)^7\r\n$$\r\nlog, derive ->$p_{MLE}$=0.3\r\n\r\n最大后验概率是贝叶斯学派的方法,贝叶斯学派不认为参数p是一个固定的值,而是认为p也具有概率分布,这个概率分布即为先验分布。在本题中,我们有理由认为硬币仍一次朝上的概率为$p\\sim Normal(0.5,1)$ \r\n\r\n则有\r\n$$\r\nP(X|p)P(p)=(_{3}^{10})p^3(1-p)^7\\frac{1}{\\sqrt{2\\pi}}exp(-\\frac{(p-0.5)^2}{2})\r\n$$\r\nlog,derive ->$p_{MAP}$=0.3\r\n\r\n<https://stats.stackexchange.com/questions/199701/intuitive-example-for-mle-map-and-naive-bayes-classifier>\r\n\r\n"
},
{
"alpha_fraction": 0.4715968370437622,
"alphanum_fraction": 0.5043914914131165,
"avg_line_length": 26.68674659729004,
"blob_id": "2962265a07bcce4389743cff6eee48a372c7b99e",
"content_id": "45b78bf92e54c17636a324c877ac1474326847fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 57355,
"license_type": "no_license",
"max_line_length": 295,
"num_lines": 1909,
"path": "/leetcode_note/BFS&&DFS.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "深搜题目 (LeetCode 200)\r\n\r\n深搜题目 (LeetCode 473)\r\n\r\n深搜题目 (LeetCode 491)\r\n\r\n广搜题目 (LeetCode 126,127)\r\n\r\n广搜题目 (LeetCode 417)\r\n\r\n广搜题目 (LeetCode 407)\r\n\r\n\r\n\r\n核心:xx到xx的最少步数 马上想到BFS\r\n\r\n##### leetcode 200 Number of Islands\r\n\r\n- Given a 2d grid map of `'1'`s (land) and `'0'`s (water), count the number of islands. An island is surrounded by water and is formed by connecting adjacent lands horizontally or vertically. You may assume all four edges of the grid are all surrounded by water.\r\n\r\n```\r\nInput:\r\n11110\r\n11010\r\n11000\r\n00000\r\n\r\nOutput: 1\r\n\r\nInput:\r\n11000\r\n11000\r\n00100\r\n00011\r\n\r\nOutput: 3\r\n```\r\n\r\n- Mysolution:\r\n\r\n```python\r\nclass Solution(object):\r\n def numIslands(self, grid):\r\n if grid==[]:\r\n return 0\r\n m,n=len(grid),len(grid[0])\r\n def dfs(i,j):\r\n if 0<=i<m and 0<=j<n and grid[i][j]=='1':\r\n grid[i][j]='0'\r\n dfs(i-1,j)\r\n dfs(i+1,j)\r\n dfs(i,j-1)\r\n dfs(i,j+1)\r\n return\r\n\r\n count=0\r\n for i in range(m):\r\n for j in range(n):\r\n if grid[i][j]=='1':\r\n count+=1\r\n dfs(i,j)\r\n return count\r\n```\r\n\r\nDFS\r\n\r\n\r\n\r\n##### leetcode 286 Walls and Gates\r\n\r\nMedium\r\n\r\nYou are given a *m x n* 2D grid initialized with these three possible values.\r\n\r\n1. `-1` - A wall or an obstacle.\r\n2. `0` - A gate.\r\n3. `INF` - Infinity means an empty room. We use the value `231 - 1 = 2147483647` to represent `INF` as you may assume that the distance to a gate is less than `2147483647`.\r\n\r\nFill each empty room with the distance to its *nearest* gate. If it is impossible to reach a gate, it should be filled with `INF`.\r\n\r\n**Example:** \r\n\r\nGiven the 2D grid:\r\n\r\n```\r\nINF -1 0 INF\r\nINF INF INF -1\r\nINF -1 INF -1\r\n 0 -1 INF INF\r\n```\r\n\r\nAfter running your function, the 2D grid should be:\r\n\r\n```\r\n 3 -1 0 1\r\n 2 2 1 -1\r\n 1 -1 2 -1\r\n 0 -1 3 4\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def wallsAndGates(self, rooms):\r\n \"\"\"\r\n Do not return anything, modify rooms in-place instead.\r\n \"\"\"\r\n if len(rooms) == 0 or len(rooms[0]) == 0:return\r\n m, n = len(rooms), len(rooms[0])\r\n visited = [[0 for i in range(n)] for j in range(m)]\r\n level, next_level = [], []\r\n for i in range(m):\r\n for j in range(n):\r\n if rooms[i][j] == 0:\r\n level.append([i, j])\r\n visited[i][j] = 1\r\n directions = [[-1, 0], [1, 0], [0, -1], [0, 1]]\r\n count = 1\r\n while level or next_level:\r\n while level:\r\n i, j = level.pop()\r\n for ii, jj in directions:\r\n if 0<=i+ii<m and 0<=j+jj<n:\r\n if visited[i+ii][j+jj] == 0 and rooms[i+ii][j+jj] == 2147483647:\r\n next_level.append([i+ii, j+jj])\r\n visited[i + ii][j + jj] = 1\r\n rooms[i+ii][j+jj] = count\r\n count += 1\r\n level = copy.deepcopy(next_level)\r\n next_level = []\r\n return\r\n```\r\n\r\n计算每个点到0 的最短路径 BFS\r\n\r\n如果觉得level和next_level太麻烦 可以使用queue\r\n\r\n```python\r\nwhile queue:\r\n i, j, val = queue.popleft()\r\n if 0 <= i + ii < n and 0 <= j +jj < m and (i+ii, j+jj) not in visited:\r\n if rooms[i+ii, j+jj] == 0 or rooms[i+ii, j+jj] == -1:\r\n visited.add((i + ii, j + jj))\r\n queue.append((i + ii, j + jj, val+1))\r\n```\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 419 Battleships in a Board\r\n\r\nGiven an 2D board, count how many battleships are in it. The battleships are represented with \r\n\r\n```\r\n'X'\r\n```\r\n\r\ns, empty slots are represented with \r\n\r\n```\r\n'.'\r\n```\r\n\r\ns. You may assume the following rules:\r\n\r\n- You receive a valid board, made of only battleships or empty slots.\r\n- Battleships can only be placed horizontally or vertically. In other words, they can only be made of the shape `1xN` (1 row, N columns) or `Nx1` (N rows, 1 column), where N can be of any size.\r\n- At least one horizontal or vertical cell separates between two battleships - there are no adjacent battleships.\r\n\r\n**Example:**\r\n\r\n```\r\nX..X\r\n...X\r\n...X\r\n```\r\n\r\nIn the above board there are 2 battleships.\r\n\r\n**Invalid Example:**\r\n\r\n```\r\n...X\r\nXXXX\r\n...X\r\n```\r\n\r\nThis is an invalid board that you will not receive - as battleships will always have a cell separating between them.\r\n\r\n**Follow up:**\r\nCould you do it in **one-pass**, using only **O(1) extra memory** and **without modifying** the value of the board?\r\n\r\n```python\r\nclass Solution:\r\n def countBattleships(self, board):\r\n \"\"\"\r\n :type board: List[List[str]]\r\n :rtype: int\r\n \"\"\"\r\n def goright(isvisited,board,i,j):\r\n if j>=len(board[0]) or isvisited[i][j]:\r\n return\r\n isvisited[i][j]=1\r\n if board[i][j]==\"X\":\r\n goright(isvisited,board,i,j+1)\r\n return\r\n def godown(isvisited,board,i,j):\r\n if i>=len(board) or isvisited[i][j]:\r\n return\r\n isvisited[i][j]=1\r\n if board[i][j]==\"X\":\r\n godown(isvisited,board,i+1,j)\r\n return\r\n if board ==None or board[0]==None:\r\n return 0\r\n ans=0\r\n n,m=len(board),len(board[0])\r\n isvisited=[[0 for i in range(m)]for j in range(n)]\r\n for i in range(n):\r\n for j in range(m):\r\n if isvisited[i][j]==1:\r\n continue\r\n if isvisited[i][j]==0:\r\n isvisited[i][j] = 1\r\n if board[i][j] == \"X\":\r\n ans+=1\r\n goright(isvisited,board,i,j+1)\r\n godown(isvisited,board,i+1,j)\r\n return ans\r\n```\r\n\r\n现在看来用DFS的方法更加直接一些\r\n\r\n```python\r\ndef countBattleships(self, board):\r\n \"\"\"\r\n :type board: List[List[str]]\r\n :rtype: int\r\n \"\"\"\r\n ans = 0\r\n self.newboard = board\r\n m = len(board)\r\n n = len(board[0])\r\n for i in range(m):\r\n for j in range(n): \r\n if self.newboard[i][j] == '.':\r\n continue\r\n else:\r\n ans += 1\r\n self.dfs(i, j)\r\n return ans\r\n \r\ndef dfs(self, i, j):\r\n if 0 <= i < len(self.newboard) and 0 <= j < len(self.newboard[0]) and self.newboard[i][j] == 'X':\r\n self.newboard[i][j] = '.'\r\n else:\r\n return False\r\n self.dfs(i+1, j)\r\n self.dfs(i-1, j)\r\n self.dfs(i, j+1)\r\n self.dfs(i, j-1)\r\n```\r\n\r\n找到一个X之后用DFS将所有的X置为. 相当于找到了一艘battle ship\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 127 Word Ladder\r\n\r\nGiven two words (*beginWord* and *endWord*), and a dictionary's word list, find the length of shortest transformation sequence from *beginWord* to *endWord*, such that:\r\n\r\n1. Only one letter can be changed at a time.\r\n2. Each transformed word must exist in the word list. Note that *beginWord* is *not* a transformed word.\r\n\r\n**Note:**\r\n\r\n- Return 0 if there is no such transformation sequence.\r\n- All words have the same length.\r\n- All words contain only lowercase alphabetic characters.\r\n- You may assume no duplicates in the word list.\r\n- You may assume *beginWord* and *endWord* are non-empty and are not the same.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput:\r\nbeginWord = \"hit\",\r\nendWord = \"cog\",\r\nwordList = [\"hot\",\"dot\",\"dog\",\"lot\",\"log\",\"cog\"]\r\n\r\nOutput: 5\r\n\r\nExplanation: As one shortest transformation is \"hit\" -> \"hot\" -> \"dot\" -> \"dog\" -> \"cog\",\r\nreturn its length 5.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput:\r\nbeginWord = \"hit\"\r\nendWord = \"cog\"\r\nwordList = [\"hot\",\"dot\",\"dog\",\"lot\",\"log\"]\r\n\r\nOutput: 0\r\n\r\nExplanation: The endWord \"cog\" is not in wordList, therefore no possible transformation.\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def ladderLength(self, beginWord, endWord, wordList):\r\n queue = [(beginWord, 1)]\r\n visited = set()\r\n wordList = set(wordList)\r\n while queue:\r\n word, dist = queue.pop(0)\r\n if word == endWord:\r\n return dist\r\n for i in range(len(word)):\r\n for j in 'abcdefghijklmnopqrstuvwxyz':\r\n tmp = word[:i] + j + word[i+1:]\r\n if tmp not in visited and tmp in wordList:\r\n queue.append((tmp, dist+1))\r\n visited.add(tmp)\r\n return 0\r\n```\r\n\r\n虽然本题说不会出现重复的词语,但是实际运算时还需要加上wordList = set(wordList)\r\n\r\n本题只要求计算两词距离,因此使用BFS即可,使用queue结构来实现BFS\r\n\r\n```\r\nfor j in 'abcdefghijklmnopqrstuvwxyz':\r\n\ttmp = word[:i] + j + word[i+1:]\r\n\tif tmp not in visited and tmp in wordList:\r\n```\r\n\r\n该方法也值得学习\r\n\r\n\r\n\r\n##### leetcode 126 Word Ladder II\r\n\r\nGiven two words (*beginWord* and *endWord*), and a dictionary's word list, find all shortest transformation sequence(s) from *beginWord* to *endWord*, such that:\r\n\r\n1. Only one letter can be changed at a time\r\n2. Each transformed word must exist in the word list. Note that *beginWord* is *not* a transformed word.\r\n\r\n**Note:**\r\n\r\n- Return an empty list if there is no such transformation sequence.\r\n- All words have the same length.\r\n- All words contain only lowercase alphabetic characters.\r\n- You may assume no duplicates in the word list.\r\n- You may assume *beginWord* and *endWord* are non-empty and are not the same.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput:\r\nbeginWord = \"hit\",\r\nendWord = \"cog\",\r\nwordList = [\"hot\",\"dot\",\"dog\",\"lot\",\"log\",\"cog\"]\r\n\r\nOutput:\r\n[\r\n [\"hit\",\"hot\",\"dot\",\"dog\",\"cog\"],\r\n [\"hit\",\"hot\",\"lot\",\"log\",\"cog\"]\r\n]\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput:\r\nbeginWord = \"hit\"\r\nendWord = \"cog\"\r\nwordList = [\"hot\",\"dot\",\"dog\",\"lot\",\"log\"]\r\n\r\nOutput: []\r\n\r\nExplanation: The endWord \"cog\" is not in wordList, therefore no possible transformation.\r\n```\r\n\r\n使用BFS+DFS\r\n\r\n```python\r\nclass Solution:\r\n def bfs(self, beginWord, endWord, wordList):\r\n queue = [(beginWord, 1)]\r\n visited = set()\r\n wordList = set(wordList)\r\n while queue:\r\n word, dist = queue.pop(0)\r\n if word == endWord:\r\n return dist\r\n for i in range(len(word)):\r\n for j in 'abcdefghijklmnopqrstuvwxyz':\r\n tmp = word[:i] + j + word[i+1:]\r\n if tmp not in visited and tmp in wordList:\r\n queue.append((tmp, dist+1))\r\n visited.add(tmp)\r\n return 0\r\n \r\n def dfs(self, path, visited, endword, wordList, dis):\r\n if len(path) > dis:\r\n return\r\n word = path[-1]\r\n if word == endword:\r\n self.res.append(path)\r\n return\r\n for i in range(len(word)):\r\n for j in 'abcdefghijklmnopqrstuvwxyz':\r\n tmp = word[:i] + j + word[i+1:]\r\n if tmp not in visited and tmp in wordList:\r\n visited.add(tmp)\r\n self.dfs(path+[tmp], visited, endword, wordList, dis)\r\n visited.remove(tmp)\r\n return\r\n \r\n def findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]:\r\n if beginWord == endWord:\r\n return []\r\n dis = self.bfs(beginWord, endWord, wordList)\r\n if dis == 0: return []\r\n self.res = []\r\n visited = set()\r\n wordList = set(wordList)\r\n self.dfs([beginWord], visited, endWord, wordList, dis)\r\n return self.res\r\n```\r\n\r\n先用BFS求出distance然后使用DFS求出符合最短路径的路径\r\n\r\n但是这样会超时,使用memorization在BFS的时候就将路径记录下来\r\n\r\n```python\r\n\r\nclass Solution:\r\n def bfs(self, beginWord, endWord, wordList):\r\n queue = [beginWord]\r\n visited = set()\r\n while queue:\r\n word = queue.pop(0)\r\n if word == endWord:\r\n break\r\n for i in range(len(word)):\r\n for j in 'abcdefghijklmnopqrstuvwxyz':\r\n tmp = word[:i] + j + word[i + 1:]\r\n if tmp in wordList:\r\n if tmp not in visited:\r\n queue.append(tmp)\r\n visited.add(tmp)\r\n if self.distance[word] + 1 < self.distance[tmp]:\r\n self.distance[tmp] = self.distance[word] + 1\r\n self.pathes[tmp] = set([word])\r\n elif self.distance[word] + 1 == self.distance[tmp]:\r\n self.pathes[tmp].add(word)\r\n return\r\n\r\n def dfs(self, path, word, beginword):\r\n if word == beginword:\r\n self.res.append(path)\r\n return\r\n for word_x in self.pathes[word]:\r\n self.dfs([word_x] + path, word_x, beginword)\r\n return\r\n\r\n def findLadders(self, beginWord, endWord, wordList):\r\n self.pathes = {}\r\n self.distance = {}\r\n max_int = 100000000\r\n wordList = set(wordList)\r\n for word in wordList:\r\n self.distance[word] = max_int\r\n self.distance[beginWord] = 1\r\n if beginWord == endWord or endWord not in wordList:\r\n return []\r\n self.bfs(beginWord, endWord, wordList)\r\n if self.distance[endWord] == max_int:\r\n return []\r\n self.res = []\r\n\r\n self.dfs([endWord], endWord, beginWord)\r\n return self.res\r\n```\r\n\r\nself.pathes = {}, 记录在最短路径下,每个节点的上个节点是什么\r\n\r\nself.distance = {}记录在最短路径下 每个节点与beginword的距离\r\n\r\n注意在126题下 存在多个路径,因此对于if tmp not in visited:的判断也不同了\r\n\r\n如果tmp不在visited中则queue.append(tmp),如果在visited中仍然可能会产生新的路径 但是由于不妨到queue中了 所以不会有无限重复\r\n\r\n\r\n\r\n##### leetcode 301 Remove Invalid Parentheses\r\n\r\n* Remove the minimum number of invalid parentheses in order to make the input string valid. Return all possible results.\r\n\r\n **Note:** The input string may contain letters other than the parentheses `(` and `)`.\r\n\r\n```\r\nInput: \"()())()\"\r\nOutput: [\"()()()\", \"(())()\"]\r\n\r\nInput: \"(a)())()\"\r\nOutput: [\"(a)()()\", \"(a())()\"]\r\n\r\nInput: \")(\"\r\nOutput: [\"\"]\r\n```\r\n\r\n```python\r\ndef removeInvalidParentheses(self, s):\r\n self.allstr=set()\r\n def check(str1):\r\n count=0\r\n for i in range(len(str1)):\r\n if str1[i]==\"(\":\r\n count+=1\r\n if str1[i]==\")\":\r\n count-=1\r\n if count<0:\r\n return False\r\n if count!=0:\r\n return False\r\n return True\r\n\r\n def helper(s,temp):\r\n if temp not in self.allstr and check(temp):\r\n self.allstr.add(temp)\r\n if s!=\"\":\r\n helper(s[1:], temp + s[0])\r\n helper(s[1:],temp)\r\n return\r\n helper(s,\"\")\r\n maxlen=-1\r\n for item in self.allstr:\r\n maxlen=max(maxlen,len(item))\r\n res=[tmp for tmp in self.allstr if len(tmp)==maxlen]\r\n return res\r\n```\r\n\r\n先用递归得到所有符合check的subarray\r\n\r\n然后取长度最长的,但是这样会得到TLE\r\n\r\n```python\r\nclass Solution:\r\n def removeInvalidParentheses(self, s):\r\n \"\"\"\r\n :type s: str\r\n :rtype: List[str]\r\n \"\"\"\r\n self.res=set()\r\n def helper_left(s,last_i,last_j):\r\n count=0\r\n for i in range(len(s)):\r\n if s[i] == \"(\":\r\n count -= 1\r\n elif s[i] == \")\":\r\n count += 1\r\n else:\r\n continue\r\n if count <0:\r\n for j in range(last_j,i+1):\r\n if s[j]==\"(\":\r\n helper_left(s[:j]+s[j+1:],i,j)\r\n return\r\n self.res.add(s[::-1])\r\n def helper_right(s,last_i,last_j):\r\n count=0\r\n for i in range(len(s)):\r\n if s[i]==\"(\":\r\n count+=1\r\n elif s[i]==\")\":\r\n count-=1\r\n else:\r\n continue\r\n if count<0:\r\n for j in range(last_j,i+1,1):\r\n if s[j]==\")\":\r\n helper_right(s[:j]+s[j+1:],i,j)\r\n return\r\n helper_left(s[::-1],0,0)\r\n helper_right(s,0,0)\r\n return list(self.res)\r\n```\r\n\r\nDFS\r\n\r\n先考虑从左往右,删除多余的“)”,当count<0时说明需要删除“(”,前面任意一个(删除都可以(DFS)\r\n\r\n然后从右往左,删除多余的“(”\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 417 Pacific Atlantic Water Flow\r\n\r\nGiven an `m x n` matrix of non-negative integers representing the height of each unit cell in a continent, the \"Pacific ocean\" touches the left and top edges of the matrix and the \"Atlantic ocean\" touches the right and bottom edges.\r\n\r\nWater can only flow in four directions (up, down, left, or right) from a cell to another one with height equal or lower.\r\n\r\nFind the list of grid coordinates where water can flow to both the Pacific and Atlantic ocean.\r\n\r\n**Note:**\r\n\r\n1. The order of returned grid coordinates does not matter.\r\n2. Both *m* and *n* are less than 150.\r\n\r\n \r\n\r\n**Example:**\r\n\r\n```\r\nGiven the following 5x5 matrix:\r\n\r\n Pacific ~ ~ ~ ~ ~ \r\n ~ 1 2 2 3 (5) *\r\n ~ 3 2 3 (4) (4) *\r\n ~ 2 4 (5) 3 1 *\r\n ~ (6) (7) 1 4 5 *\r\n ~ (5) 1 1 2 4 *\r\n * * * * * Atlantic\r\n\r\nReturn:\r\n\r\n[[0, 4], [1, 3], [1, 4], [2, 2], [3, 0], [3, 1], [4, 0]] (positions with parentheses in above matrix).\r\n```\r\n\r\n```python\r\nimport numpy as np\r\nclass Solution:\r\n #反向逆流\r\n def pacificAtlantic(self, matrix):\r\n def dfs(matrix, x, y, visited, m, n):\r\n visited[x][y] = 1\r\n directions = [[-1, 0], [1, 0], [0, -1], [0, 1]]\r\n for dx, dy in directions:\r\n xx, yy = x+dx, y+dy\r\n if xx<0 or xx>=m or yy<0 or yy>=n or visited[xx][yy] or matrix[xx][yy]<matrix[x][y]:\r\n continue\r\n dfs(matrix, xx, yy, visited, m, n)\r\n return\r\n\r\n if not matrix or len(matrix) == 0: return []\r\n res = []\r\n m, n = len(matrix), len(matrix[0])\r\n avisited, pvisited = np.zeros((m, n)), np.zeros((m, n))\r\n for i in range(m):\r\n dfs(matrix, i, 0, pvisited, m, n)\r\n dfs(matrix, i, n-1, avisited, m, n)\r\n for j in range(n):\r\n dfs(matrix, 0, j, pvisited, m, n)\r\n dfs(matrix, m-1, j, avisited, m, n)\r\n for i in range(m):\r\n for j in range(n):\r\n if avisited[i][j] == 1 and pvisited[i][j] == 1:\r\n res.append([i ,j])\r\n return res\r\n```\r\n\r\n反过来思考会简单很多,流入太平洋的只能是左侧和上面两侧,从那些点做dfs找 哪些地方的水能够由此流入太平洋,大西洋同理。\r\n\r\n注意本题中avisited和pvisited的传递\r\n\r\n\r\n\r\n##### leetcode 742 Closest Leaf in a Binary Tree\r\n\r\nGiven a binary tree **where every node has a unique value**, and a target key `k`, find the value of the nearest leaf node to target `k` in the tree.\r\n\r\nHere, *nearest* to a leaf means the least number of edges travelled on the binary tree to reach any leaf of the tree. Also, a node is called a *leaf* if it has no children.\r\n\r\nIn the following examples, the input tree is represented in flattened form row by row. The actual `root` tree given will be a TreeNode object.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput:\r\nroot = [1, 3, 2], k = 1\r\nDiagram of binary tree:\r\n 1\r\n / \\\r\n 3 2\r\n\r\nOutput: 2 (or 3)\r\n\r\nExplanation: Either 2 or 3 is the nearest leaf node to the target of 1.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput:\r\nroot = [1], k = 1\r\nOutput: 1\r\n\r\nExplanation: The nearest leaf node is the root node itself\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput:\r\nroot = [1,2,3,4,null,null,null,5,null,6], k = 2\r\nDiagram of binary tree:\r\n 1\r\n / \\\r\n 2 3\r\n /\r\n 4\r\n /\r\n 5\r\n /\r\n 6\r\n\r\nOutput: 3\r\nExplanation: The leaf node with value 3 (and not the leaf node with value 6) is nearest to the node with value 2\r\n```\r\n\r\n**Note:**\r\n\r\n1. `root` represents a binary tree with at least `1` node and at most `1000` nodes.\r\n2. Every node has a unique `node.val` in range `[1, 1000]`.\r\n3. There exists some node in the given binary tree for which `node.val == k`.\r\n\r\n```python\r\nfrom collections import defaultdict\r\nimport copy\r\nclass Solution:\r\n def init(self, root):\r\n if root.left == None and root.right == None:\r\n self.isleaf[root.val] = 1\r\n else:\r\n self.isleaf[root.val] = 0\r\n if root.left:\r\n self.graph[root.val].append(root.left.val)\r\n self.graph[root.left.val].append(root.val)\r\n self.init(root.left)\r\n if root.right:\r\n self.graph[root.val].append(root.right.val)\r\n self.graph[root.right.val].append(root.val)\r\n self.init(root.right)\r\n return\r\n\r\n def findClosestLeaf(self, root, target):\r\n self.isleaf = {}\r\n self.graph = defaultdict(list)\r\n seen = set()\r\n seen.add(target)\r\n self.init(root)\r\n if not root:\r\n return -1\r\n level, next_level = [target], []\r\n while level or next_level:\r\n while level:\r\n node = level.pop()\r\n if self.isleaf[node] == 1:\r\n return node\r\n for item in self.graph[node]:\r\n if item not in seen:\r\n next_level.append(item)\r\n seen.add(item)\r\n level = copy.deepcopy(next_level)\r\n next_level = []\r\n return -1\r\n```\r\n\r\n在tree结构上不太好做BFS\r\n\r\n因此先用init函数将tree结构转化为graph结果,同时记录下哪些点是leaf\r\n\r\n然后用基本的BFS得到结果\r\n\r\n\r\n\r\n##### leetcode 752 Open the Lock\r\n\r\n* You have a lock in front of you with 4 circular wheels. Each wheel has 10 slots: `'0', '1', '2', '3', '4', '5', '6', '7', '8', '9'`. The wheels can rotate freely and wrap around: for example we can turn `'9'` to be `'0'`, or `'0'` to be `'9'`. Each move consists of turning one wheel one slot.\r\n\r\n The lock initially starts at `'0000'`, a string representing the state of the 4 wheels.\r\n\r\n You are given a list of `deadends` dead ends, meaning if the lock displays any of these codes, the wheels of the lock will stop turning and you will be unable to open it.\r\n\r\n Given a `target` representing the value of the wheels that will unlock the lock, return the minimum total number of turns required to open the lock, or -1 if it is impossible.\r\n\r\n```\r\nInput: deadends = [\"0201\",\"0101\",\"0102\",\"1212\",\"2002\"], target = \"0202\"\r\nOutput: 6\r\nExplanation:\r\nA sequence of valid moves would be \"0000\" -> \"1000\" -> \"1100\" -> \"1200\" -> \"1201\" -> \"1202\" -> \"0202\".\r\nNote that a sequence like \"0000\" -> \"0001\" -> \"0002\" -> \"0102\" -> \"0202\" would be invalid,\r\nbecause the wheels of the lock become stuck after the display becomes the dead end \"0102\".\r\n\r\nInput: deadends = [\"8888\"], target = \"0009\"\r\nOutput: 1\r\nExplanation:\r\nWe can turn the last wheel in reverse to move from \"0000\" -> \"0009\".\r\n\r\nInput: deadends = [\"8887\",\"8889\",\"8878\",\"8898\",\"8788\",\"8988\",\"7888\",\"9888\"], target = \"8888\"\r\nOutput: -1\r\nExplanation:\r\nWe can't reach the target without getting stuck.\r\n```\r\n\r\n```c++\r\nstruct point {\r\n\tint a;\r\n\tint b;\r\n\tint c;\r\n\tint d;\r\n\tpoint(int a, int b, int c, int d) :a(a), b(b), c(c), d(d) {}\r\n};\r\n\r\nclass Solution {\r\npublic:\r\n\tint openLock(vector<string>& deadends, string target) {\r\n\t\tint dp[10][10][10][10];\r\n\t\tmemset(dp, -1, sizeof(dp));\r\n\t\tpoint tar=point(target[0] - '0', target[1] - '0', target[2] - '0', target[3] - '0');\r\n\t\tqueue<point> que;\r\n\t\tint a, b, c, d;\r\n\t\tint da[8] = {1,-1,0,0,0,0,0,0};\r\n\t\tint db[8] = {0,0,1,-1,0,0,0,0};\r\n\t\tint dc[8] = {0,0,0,0,1,-1,0,0};\r\n\t\tint dd[8] = {0,0,0,0,0,0,1,-1};\r\n\t\tint i,n=deadends.size();\r\n dp[0][0][0][0] = 0;\r\n\t\tfor (i = 0; i < n; i++) {\r\n\t\t\ta = deadends[i][0] - '0';\r\n\t\t\tb = deadends[i][1] - '0';\r\n\t\t\tc = deadends[i][2] - '0';\r\n\t\t\td = deadends[i][3] - '0';\r\n\t\t\tdp[a][b][c][d] = INT_MAX;\r\n\t\t}\r\n if(dp[0][0][0][0]!=0)return -1;\r\n\t\tque.push(point(0, 0, 0, 0));\r\n\t\twhile (que.size()) {\r\n\t\t\tpoint tmp = que.front();\r\n\t\t\tque.pop();\r\n\t\t\tif (tmp.a == tar.a&&tmp.b == tar.b&&tmp.c == tar.c&&tmp.d == tar.d)\r\n\t\t\t\tbreak;\r\n\t\t\tfor (i = 0; i < 8; i++) {\r\n\t\t\t\tint na = (tmp.a + da[i])%10, nb = (tmp.b + db[i])%10, nc = (tmp.c + dc[i])%10, nd = (tmp.d + dd[i])%10;\r\n\t\t\t\tif (na < 0) na += 10;\r\n\t\t\t\tif (nb < 0) nb += 10;\r\n\t\t\t\tif (nc < 0) nc += 10;\r\n\t\t\t\tif (nd < 0) nd += 10;\r\n\t\t\t\tif (dp[na][nb][nc][nd] == -1) {\r\n\t\t\t\t\tque.push(point(na, nb, nc, nd));\r\n\t\t\t\t\tdp[na][nb][nc][nd] = dp[tmp.a][tmp.b][tmp.c][tmp.d] + 1;\r\n\t\t\t\t}\r\n\t\t\t}\r\n\t\t}\r\n\t\treturn dp[tar.a][tar.b][tar.c][tar.d];\r\n\t}\r\n};\r\n```\r\n\r\n将这个问题转化成BFS 最短路径问题\r\n\r\n值得注意的是本题中struct与构成函数的用法\r\n\r\n与一般的图问题不同的是本题中0-9,9-0的存在,因此要对na nb nc nd等进行判断\r\n\r\n\r\n\r\n##### leetcode 968 Binary Tree Cameras\r\n\r\n- Given a binary tree, we install cameras on the nodes of the tree. \r\n\r\n Each camera at a node can monitor **its parent, itself, and its immediate children**.\r\n\r\n Calculate the minimum number of cameras needed to monitor all nodes of the tree.\r\n\r\n \r\n\r\n\r\n\r\n ```\r\n Input: [0,0,null,0,0]\r\n Output: 1\r\n Explanation: One camera is enough to monitor all nodes if placed as shown.\r\n ```\r\n\r\n \r\n\r\n ```\r\n Input: [0,0,null,0,null,0,null,null,0]\r\n Output: 2\r\n Explanation: At least two cameras are needed to monitor all nodes of the tree. The above image shows one of the valid configurations of camera placement.\r\n ```\r\n\r\n ```python\r\n class Solution:\r\n def minCameraCover(self, root):\r\n self.res=0\r\n def dfs(root):\r\n if not root:\r\n return 2\r\n if not root.left and not root.right:\r\n return 0\r\n left,right=dfs(root.left),dfs(root.right)\r\n if left==0 or right==0: #child is leaf\r\n self.res+=1\r\n return 1\r\n if left==1 or right==1:\r\n return 2 #its child has a camera\r\n return 0 #becomes a leaf\r\n if root==None:\r\n return 0\r\n if dfs(root)==0: #still has a root to camera\r\n return self.res+1\r\n return self.res\r\n ```\r\n\r\n 本题属于DFS\r\n\r\n 考虑到在节点上放置camera效果必然不如在节点的parent节点上放置\r\n\r\n 因此在所有的叶子parent节点上放置camera\r\n\r\n 如果节点是叶子节点则用0表示\r\n\r\n 如果节点是叶子节点的parent 需要放置camera,用1表示\r\n\r\n 如果节点子节点放置了camera,则用2 表示\r\n\r\n\r\n\r\n\tleft==0 or right==0 表示该节点是叶子节点的parent 需要放置camera\r\n\r\n\tleft==1 or right==1 说明该节点的子节点放置了camera 返回2 收到2 的上一层相当于把这一分支置为none\r\n\r\n\t如果还没有执行操作说明该节点的子节点均通过camera被消除(left==right==2),返回0 将其视为叶子节点\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 1162 As Far from Land as Possible\r\n\r\nGiven an N x N `grid` containing only values `0` and `1`, where `0` represents water and `1` represents land, find a water cell such that its distance to the nearest land cell is maximized and return the distance.\r\n\r\nThe distance used in this problem is the *Manhattan distance*: the distance between two cells `(x0, y0)` and `(x1, y1)` is `|x0 - x1| + |y0 - y1|`.\r\n\r\nIf no land or water exists in the grid, return `-1`.\r\n\r\n**Example 1:**\r\n\r\n****\r\n\r\n```\r\nInput: [[1,0,1],[0,0,0],[1,0,1]]\r\nOutput: 2\r\nExplanation: \r\nThe cell (1, 1) is as far as possible from all the land with distance 2.\r\n```\r\n\r\n**Example 2:**\r\n\r\n****\r\n\r\n```\r\nInput: [[1,0,0],[0,0,0],[0,0,0]]\r\nOutput: 4\r\nExplanation: \r\nThe cell (2, 2) is as far as possible from all the land with distance 4.\r\n```\r\n\r\n**Note:**\r\n\r\n1. `1 <= grid.length == grid[0].length <= 100`\r\n2. `grid[i][j]` is `0` or `1`\r\n\r\n```python\r\nimport copy\r\nclass Solution:\r\n def maxDistance(self, grid):\r\n n = len(grid)\r\n visited = [[0 for i in range(n)] for j in range(n)]\r\n level = []\r\n for i in range(n):\r\n for j in range(n):\r\n if grid[i][j]==1:\r\n level.append([i, j])\r\n visited[i][j] = 1\r\n if len(level) == 0 or len(level) == n*n: return -1\r\n next_level = []\r\n d = 0\r\n while level or next_level:\r\n dirs = [[-1, 0], [1, 0], [0, -1], [0, 1]]\r\n while level:\r\n i, j = level.pop(0)\r\n for ii, jj in dirs:\r\n if i+ii>=0 and i+ii<n and j+jj>=0 and j+jj<n and visited[i+ii][j+jj] == 0:\r\n next_level.append([i+ii, j+jj])\r\n visited[i+ii][j+jj] = 1\r\n level = copy.deepcopy(next_level)\r\n next_level = []\r\n if level:\r\n d += 1\r\n return d\r\n```\r\n\r\n使用BFS 把所有的陆地节点放入list\r\n\r\n把临近的水域节点放入next_level\r\n\r\n\r\n\r\n##### leetcode 827 Making A Large Island\r\n\r\nIn a 2D grid of `0`s and `1`s, we change at most one `0` to a `1`.\r\n\r\nAfter, what is the size of the largest island? (An island is a 4-directionally connected group of `1`s).\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [[1, 0], [0, 1]]\r\nOutput: 3\r\nExplanation: Change one 0 to 1 and connect two 1s, then we get an island with area = 3.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [[1, 1], [1, 0]]\r\nOutput: 4\r\nExplanation: Change the 0 to 1 and make the island bigger, only one island with area = 4.\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: [[1, 1], [1, 1]]\r\nOutput: 4\r\nExplanation: Can't change any 0 to 1, only one island with area = 4.\r\n```\r\n\r\nNotes:\r\n\r\n- `1 <= grid.length = grid[0].length <= 50`.\r\n- `0 <= grid[i][j] <= 1`.\r\n\r\n思路:\r\n\r\n先用DFS对每个1的点做一遍,数出这个island上有哪些点,并用path保存下来\r\n\r\n然后把每个点标上所在岛屿的大小用dp数组表示,以及该岛的出发节点坐标由 position表示\r\n\r\n然后做一遍循环,如果grid,坐标i,j == 0则判断左右上下四个点是否为岛屿,如果是的话判断是否是同一个岛,不是则把面积加起来(用temp_pos表示 已经加进来的岛屿(用岛屿的初始节点表示))\r\n\r\n注意:有可能全是陆地,所以grid,坐标i,j == 1 也要max\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n void dfs(int n, int m, int i, int j, vector<vector<int>>& path, vector<vector<int>>& visited, vector<vector<int>>& grid){\r\n vector<vector<int>> directions = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}};\r\n int ii, jj;\r\n visited[i][j] = 1;\r\n path.push_back({i, j});\r\n for(auto dir:directions){\r\n ii = dir[0]; jj = dir[1];\r\n if(i+ii>=0 && i+ii<n && j+jj>=0 && j+jj<m){\r\n if(grid[i+ii][j+jj] == 1 && visited[i+ii][j+jj] == 0){\r\n dfs(n, m, i+ii, j+jj, path, visited, grid);\r\n }\r\n }\r\n }\r\n return;\r\n }\r\n int largestIsland(vector<vector<int>>& grid) {\r\n if(grid.size() == 0) return 0;\r\n int n = grid.size(), m = grid[0].size();\r\n vector<vector <int> > visited(n, vector<int>(m,0));\r\n vector<vector <int> > dp(n, vector<int>(m,0));\r\n vector<vector <vector<int>>> position(n, vector<vector<int>>(m, vector<int> (2, -1)));\r\n int i, j;\r\n int num;\r\n for(i=0;i<n;i++){\r\n for(j=0;j<m;j++){\r\n if(grid[i][j] == 1 && visited[i][j] == 0){\r\n vector<vector<int>> path;\r\n dfs(n, m, i, j, path, visited, grid);\r\n num = path.size();\r\n for(auto pos:path){\r\n dp[pos[0]][pos[1]] = num;\r\n position[pos[0]][pos[1]] = {i, j};\r\n }\r\n }\r\n }\r\n }\r\n vector<vector<int>> directions = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}};\r\n int ii, jj, res = 0, temp;\r\n for(i=0;i<n;i++){\r\n for(j=0;j<m;j++){\r\n if(grid[i][j]==0){\r\n temp = 1;\r\n vector<vector<int>> temp_pos;\r\n for(auto dir:directions){\r\n ii = dir[0]; jj = dir[1];\r\n if(i+ii>=0 && i+ii<n && j+jj>=0 && j+jj<m){\r\n if(dp[i+ii][j+jj]!=0){\r\n auto it = find(temp_pos.begin(), temp_pos.end(), position[i+ii][j+jj]);\r\n if( it==temp_pos.end()){\r\n temp_pos.push_back(position[i+ii][j+jj]);\r\n temp += dp[i+ii][j+jj];\r\n }\r\n }\r\n }\r\n }\r\n res = max(res, temp);\r\n }\r\n else{\r\n res = max(res, dp[i][j]);\r\n }\r\n }\r\n }\r\n return res; \r\n }\r\n};\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 1087 Brace Expansion\r\n\r\nMedium\r\n\r\nA string `S` represents a list of words.\r\n\r\nEach letter in the word has 1 or more options. If there is one option, the letter is represented as is. If there is more than one option, then curly braces delimit the options. For example, `\"{a,b,c}\"` represents options `[\"a\", \"b\", \"c\"]`.\r\n\r\nFor example, `\"{a,b,c}d{e,f}\"` represents the list `[\"ade\", \"adf\", \"bde\", \"bdf\", \"cde\", \"cdf\"]`.\r\n\r\nReturn all words that can be formed in this manner, in lexicographical order.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: \"{a,b}c{d,e}f\"\r\nOutput: [\"acdf\",\"acef\",\"bcdf\",\"bcef\"]\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: \"abcd\"\r\nOutput: [\"abcd\"]\r\n```\r\n\r\n**Note:**\r\n\r\n1. `1 <= S.length <= 50`\r\n2. There are no nested curly brackets.\r\n3. All characters inside a pair of consecutive opening and ending curly brackets are different.\r\n\r\n```\r\nclass Solution:\r\n def dfs(self, chars, path):\r\n if not chars:\r\n self.res.append(path)\r\n return\r\n if len(chars[0]) == 1:\r\n self.dfs(chars[1:], path + chars[0][0])\r\n else:\r\n for i in range(len(chars[0])):\r\n self.dfs(chars[1:], path + chars[0][i])\r\n return\r\n\r\n def expand(self, S):\r\n chars = []\r\n n, i = len(S), 0\r\n temp = []\r\n while i<n:\r\n if S[i] == \"{\":\r\n temp = []\r\n i += 1\r\n while S[i]!=\"}\":\r\n if S[i] != \",\":\r\n temp.append(S[i])\r\n i += 1\r\n if S[i] == \"}\":\r\n temp.sort()\r\n chars.append(temp)\r\n i += 1\r\n else:\r\n chars.append([S[i]])\r\n i += 1\r\n self.res = []\r\n self.dfs(chars, \"\")\r\n return self.res\r\n```\r\n\r\n```python\r\n\"{a,b}{z,x,y}\"- > [[a,b],[x,y,z]]\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### 1254. Number of Closed Islands\r\n\r\nGiven a 2D `grid` consists of `0s` (land) and `1s` (water). An *island* is a maximal 4-directionally connected group of `0s` and a *closed island* is an island **totally** (all left, top, right, bottom) surrounded by `1s.`\r\n\r\nReturn the number of *closed islands*.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n\r\n\r\n```\r\nInput: grid = [[1,1,1,1,1,1,1,0],[1,0,0,0,0,1,1,0],[1,0,1,0,1,1,1,0],[1,0,0,0,0,1,0,1],[1,1,1,1,1,1,1,0]]\r\nOutput: 2\r\nExplanation: \r\nIslands in gray are closed because they are completely surrounded by water (group of 1s).\r\n```\r\n\r\n**Example 2:**\r\n\r\n\r\n\r\n```\r\nInput: grid = [[0,0,1,0,0],[0,1,0,1,0],[0,1,1,1,0]]\r\nOutput: 1\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: grid = [[1,1,1,1,1,1,1],\r\n [1,0,0,0,0,0,1],\r\n [1,0,1,1,1,0,1],\r\n [1,0,1,0,1,0,1],\r\n [1,0,1,1,1,0,1],\r\n [1,0,0,0,0,0,1],\r\n [1,1,1,1,1,1,1]]\r\nOutput: 2\r\n```\r\n\r\n \r\n\r\n**Constraints:**\r\n\r\n- `1 <= grid.length, grid[0].length <= 100`\r\n- `0 <= grid[i][j] <=1`\r\n\r\n```python\r\nclass Solution(object):\r\n def closedIsland(self, grid):\r\n \"\"\"\r\n :type grid: List[List[int]]\r\n :rtype: int\r\n \"\"\"\r\n def dfs(grid, i, j, isvisited, n, m):\r\n directions = [[-1,0], [1,0],[0,-1],[0,1]]\r\n for ii, jj in directions:\r\n if i+ii<0 or i+ii>=n or j+jj<0 or j+jj>=m:\r\n self.touch_corner = True\r\n\r\n else:\r\n if grid[i+ii][j+jj] == 0 and isvisited[i+ii][j+jj] == 0:\r\n isvisited[i+ii][j+jj] = 1\r\n dfs(grid, i+ii, j+jj, isvisited, n, m)\r\n return\r\n \r\n if not grid or len(grid[0]) == 0:\r\n return 0\r\n count = 0\r\n n, m = len(grid), len(grid[0])\r\n isvisited = [[0 for i in range(m)] for j in range(n)]\r\n for i in range(n):\r\n for j in range(m):\r\n if grid[i][j] == 0 and isvisited[i][j] == 0:\r\n isvisited[i][j] = 1\r\n self.touch_corner = False\r\n dfs(grid, i, j, isvisited, n, m)\r\n if not self.touch_corner:\r\n count += 1\r\n return count\r\n \r\n```\r\n\r\n使用isvisited函数,对每个没有访问过的点 使用dfs进行访问,通过 self.touch_corner判断是否完全被水包围\r\n\r\n\r\n\r\n##### leetcode 1129 Shortest Path with Alternating Colors\r\n\r\nConsider a directed graph, with nodes labelled `0, 1, ..., n-1`. In this graph, each edge is either red or blue, and there could be self-edges or parallel edges.\r\n\r\nEach `[i, j]` in `red_edges` denotes a red directed edge from node `i` to node `j`. Similarly, each `[i, j]` in `blue_edges` denotes a blue directed edge from node `i` to node `j`.\r\n\r\nReturn an array `answer` of length `n`, where each `answer[X]` is the length of the shortest path from node `0` to node `X` such that the edge colors alternate along the path (or `-1` if such a path doesn't exist).\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: n = 3, red_edges = [[0,1],[1,2]], blue_edges = []\r\nOutput: [0,1,-1]\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: n = 3, red_edges = [[0,1]], blue_edges = [[2,1]]\r\nOutput: [0,1,-1]\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: n = 3, red_edges = [[1,0]], blue_edges = [[2,1]]\r\nOutput: [0,-1,-1]\r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: n = 3, red_edges = [[0,1]], blue_edges = [[1,2]]\r\nOutput: [0,1,2]\r\n```\r\n\r\n**Example 5:**\r\n\r\n```\r\nInput: n = 3, red_edges = [[0,1],[0,2]], blue_edges = [[1,0]]\r\nOutput: [0,1,1]\r\n```\r\n\r\n**Constraints:**\r\n\r\n- `1 <= n <= 100`\r\n- `red_edges.length <= 400`\r\n- `blue_edges.length <= 400`\r\n- `red_edges[i].length == blue_edges[i].length == 2`\r\n- `0 <= red_edges[i][j], blue_edges[i][j] < n`\r\n\r\n变种BFS题,路径必须要一红一蓝这样子\r\n\r\n我们用二维数组来存储0到某个点的最短路径\r\n\r\n```python\r\nimport copy\r\nclass Solution:\r\n def shortestAlternatingPaths(self, n, red_edges, blue_edges):\r\n G = [[[], []] for i in range(n)]\r\n for i, j in red_edges: G[i][0].append(j)\r\n for i, j in blue_edges: G[i][1].append(j)\r\n res = [[0, 0]] + [[float(\"inf\"), float(\"inf\")] for i in range(n - 1)]\r\n level, next_level = [[0, 0], [0 ,1]], [] #[node, through which color to get here]\r\n while level or next_level:\r\n while level:\r\n start, color = level.pop()\r\n for node in G[start][1-color]:\r\n if res[node][1-color] == float(\"inf\"):\r\n res[node][1 - color] = res[start][color] + 1\r\n next_level.append([node, 1-color])\r\n level = copy.deepcopy(next_level)\r\n next_level = []\r\n ans = [0]\r\n for i in range(1, n):\r\n if min(res[i]) == float(\"inf\"):\r\n ans.append(-1)\r\n else:\r\n ans.append(min(res[i]))\r\n return ans\r\n```\r\n\r\n$res[i][j]$ 表示通过j颜色的路径走到i点需要的步数\r\n\r\n在bfs的时候注意红色蓝色的颜色变换\r\n\r\n\r\n\r\n##### leetcode 1255 Maximum Score Words Formed by Letters\r\n\r\nGiven a list of `words`, list of single `letters` (might be repeating) and `score` of every character.\r\n\r\nReturn the maximum score of **any** valid set of words formed by using the given letters (`words[i]` cannot be used two or more times).\r\n\r\nIt is not necessary to use all characters in `letters` and each letter can only be used once. Score of letters `'a'`, `'b'`, `'c'`, ... ,`'z'` is given by `score[0]`, `score[1]`, ... , `score[25]` respectively.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: words = [\"dog\",\"cat\",\"dad\",\"good\"], letters = [\"a\",\"a\",\"c\",\"d\",\"d\",\"d\",\"g\",\"o\",\"o\"], score = [1,0,9,5,0,0,3,0,0,0,0,0,0,0,2,0,0,0,0,0,0,0,0,0,0,0]\r\nOutput: 23\r\nExplanation:\r\nScore a=1, c=9, d=5, g=3, o=2\r\nGiven letters, we can form the words \"dad\" (5+1+5) and \"good\" (3+2+2+5) with a score of 23.\r\nWords \"dad\" and \"dog\" only get a score of 21.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: words = [\"xxxz\",\"ax\",\"bx\",\"cx\"], letters = [\"z\",\"a\",\"b\",\"c\",\"x\",\"x\",\"x\"], score = [4,4,4,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,5,0,10]\r\nOutput: 27\r\nExplanation:\r\nScore a=4, b=4, c=4, x=5, z=10\r\nGiven letters, we can form the words \"ax\" (4+5), \"bx\" (4+5) and \"cx\" (4+5) with a score of 27.\r\nWord \"xxxz\" only get a score of 25.\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: words = [\"leetcode\"], letters = [\"l\",\"e\",\"t\",\"c\",\"o\",\"d\"], score = [0,0,1,1,1,0,0,0,0,0,0,1,0,0,1,0,0,0,0,1,0,0,0,0,0,0]\r\nOutput: 0\r\nExplanation:\r\nLetter \"e\" can only be used once.\r\n```\r\n\r\n**Constraints:**\r\n\r\n- `1 <= words.length <= 14`\r\n- `1 <= words[i].length <= 15`\r\n- `1 <= letters.length <= 100`\r\n- `letters[i].length == 1`\r\n- `score.length == 26`\r\n- `0 <= score[i] <= 10`\r\n- `words[i]`, `letters[i]` contains only lower case English letters.\r\n\r\n```python\r\nfrom collections import Counter\r\n\r\nclass Solution(object):\r\n def maxScoreWords(self, words, letters, score):\r\n\r\n def dfs(i, curr_score, letter_counter):\r\n if curr_score + sum(words_score[i:]) <= self.max_score:\r\n return\r\n self.max_score = max(self.max_score, curr_score)\r\n for j, wordcounter in enumerate(words_counter[i:], i):\r\n if all(n <= letter_counter.get(c, 0) for c, n in wordcounter.items()):\r\n new_counter = {}\r\n for c, n in letter_counter.items():\r\n new_counter[c] = n - wordcounter.get(c, 0)\r\n dfs(j + 1, curr_score + words_score[j], new_counter)\r\n\r\n self.max_score = 0\r\n words_score = [sum(score[ord(c) - ord('a')] for c in word) for word in words]\r\n words_counter = [Counter(word) for word in words]\r\n\r\n dfs(0, 0, Counter(letters))\r\n return self.max_score\r\n```\r\n\r\n对每个words中的word依次进行判断\r\n\r\n```python\r\nall(n <= letter_counter.get(c, 0) for c, n in wordcounter.items())\r\n```\r\n\r\nletter_counter.get(c, 0) 返回c的数量,如果不存在c则返回0\r\n\r\nDFS的思路是如果letters中目前的letter还能够word 那就对word进行DFS搜索\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 1263 Minimum Moves to Move a Box to Their Target Location\r\n\r\nStorekeeper is a game, in which the player pushes boxes around in a warehouse, trying to get them to target locations.\r\n\r\nThe game is represented by a `grid` of size `n*``m`, where each element is a wall, floor or a box.\r\n\r\nYour task is move the box `'B'` to the target position `'T'` under the following rules:\r\n\r\n- Player is represented by character `'S'` and can move up, down, left, right in the `grid` if its a floor (empy cell).\r\n- Floor is represented by character `'.'` that means free cell to walk.\r\n- Wall is represented by character `'#'` that means obstacle (impossible to walk there). \r\n- There is only one box `'B'` and one target cell `'T'` in the `grid`.\r\n- The box can be moved to an adjacent free cell by standing next to the box and then moving in the direction of the box. This is a **push**.\r\n- The player cannot walk through the box.\r\n\r\nReturn the minimum number of **pushes** to move the box to the target. If there is no way to reach the target, return `-1`.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n****\r\n\r\n```\r\nInput: grid = [[\"#\",\"#\",\"#\",\"#\",\"#\",\"#\"],\r\n [\"#\",\"T\",\"#\",\"#\",\"#\",\"#\"],\r\n [\"#\",\".\",\".\",\"B\",\".\",\"#\"],\r\n [\"#\",\".\",\"#\",\"#\",\".\",\"#\"],\r\n [\"#\",\".\",\".\",\".\",\"S\",\"#\"],\r\n [\"#\",\"#\",\"#\",\"#\",\"#\",\"#\"]]\r\nOutput: 3\r\nExplanation: We return only the number of times the box is pushed.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: grid = [[\"#\",\"#\",\"#\",\"#\",\"#\",\"#\"],\r\n [\"#\",\"T\",\"#\",\"#\",\"#\",\"#\"],\r\n [\"#\",\".\",\".\",\"B\",\".\",\"#\"],\r\n [\"#\",\"#\",\"#\",\"#\",\".\",\"#\"],\r\n [\"#\",\".\",\".\",\".\",\"S\",\"#\"],\r\n [\"#\",\"#\",\"#\",\"#\",\"#\",\"#\"]]\r\nOutput: -1\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: grid = [[\"#\",\"#\",\"#\",\"#\",\"#\",\"#\"],\r\n [\"#\",\"T\",\".\",\".\",\"#\",\"#\"],\r\n [\"#\",\".\",\"#\",\"B\",\".\",\"#\"],\r\n [\"#\",\".\",\".\",\".\",\".\",\"#\"],\r\n [\"#\",\".\",\".\",\".\",\"S\",\"#\"],\r\n [\"#\",\"#\",\"#\",\"#\",\"#\",\"#\"]]\r\nOutput: 5\r\nExplanation: push the box down, left, left, up and up.\r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: grid = [[\"#\",\"#\",\"#\",\"#\",\"#\",\"#\",\"#\"],\r\n [\"#\",\"S\",\"#\",\".\",\"B\",\"T\",\"#\"],\r\n [\"#\",\"#\",\"#\",\"#\",\"#\",\"#\",\"#\"]]\r\nOutput: -1\r\n```\r\n\r\n \r\n\r\n**Constraints:**\r\n\r\n- `1 <= grid.length <= 20`\r\n- `1 <= grid[i].length <= 20`\r\n- `grid` contains only characters `'.'`, `'#'`, `'S'` , `'T'`, or `'B'`.\r\n- There is only one character `'S'`, `'B'` and `'T'` in the `grid`.\r\n\r\n\r\n\r\n```python\r\nclass Solution:\r\n def minPushBox(self, grid) -> int:\r\n def bfs_to_reach_S(r, c, x_B, y_B, x_S, y_S):\r\n curr_level = {(r, c)}\r\n visited = set()\r\n while curr_level:\r\n next_level = set()\r\n for i, j in curr_level:\r\n visited.add((i, j))\r\n if i == x_S and j == y_S:\r\n return True\r\n for di, dj in [(0, 1), (0, -1), (1, 0), (-1, 0)]:\r\n i1, j1 = i + di, j + dj\r\n if 0 <= i1 < n and 0 <= j1 < m and (i1, j1) not in visited and (i1, j1) != (x_B, y_B) and \\\r\n grid[i1][j1] != '#':\r\n next_level.add((i1, j1))\r\n curr_level = next_level\r\n return False\r\n\r\n def valid_moves(grid, x_B, y_B, x_S, y_S):\r\n next_moves = []\r\n for dx, dy in [(0, 1), (1, 0), (-1, 0), (0, -1)]:\r\n r1, c1 = x_B + dx, y_B + dy #人走到推箱子的位置\r\n r2, c2 = x_B - dx, y_B - dy #箱子移动到下一个地点\r\n if 0 <= r1 < n and 0 <= c1 < m and grid[r1][c1] != '#' and 0 <= r2 < n and 0 <= c2 < m and grid[r2][\r\n c2] != '#':\r\n if bfs_to_reach_S(r1, c1, x_B, y_B, x_S, y_S):\r\n next_moves.append((r2, c2, x_B, y_B))\r\n return next_moves\r\n\r\n n, m = len(grid), len(grid[0])\r\n for i in range(n):\r\n for j in range(m):\r\n if grid[i][j] == 'B':\r\n x_B, y_B = i, j\r\n elif grid[i][j] == 'S':\r\n x_S, y_S = i, j\r\n grid[x_B][y_B], grid[x_S][y_S] = '.', '.'\r\n curr_level = {(x_B, y_B, x_S, y_S)}\r\n visited = set()\r\n moves = 0\r\n while curr_level:\r\n next_level = set()\r\n for i_B, j_B, i_S, j_S in curr_level:\r\n visited.add((i_B, j_B, i_S, j_S))\r\n if grid[i_B][j_B] == 'T':\r\n return moves\r\n for i_B1, j_B1, i_S1, j_S1 in valid_moves(grid, i_B, j_B, i_S, j_S):\r\n if (i_B1, j_B1, i_S1, j_S1) not in visited:\r\n next_level.add((i_B1, j_B1, i_S1, j_S1))\r\n curr_level = next_level\r\n moves += 1\r\n return -1\r\n```\r\n\r\n推箱子问题\r\n\r\n由于需要知道人的位置与箱子的位置表示一个state,因此使用$(x_B, y_B, x_S, y_S)$ 来表示state\r\n\r\ncur_level和next_level表示这一步可能走到的state和下一步可能可以走到的状态\r\n\r\n如果能走到target则返回步数,如果出了while循环还没有达到就返回-1\r\n\r\nbfs_to_reach_S表示人能不能走到推箱子的那个位置\r\n\r\n\r\n\r\n##### leetcode 1293 Shortest Path in a Grid with Obstacles Elimination\r\n\r\nGiven a `m * n` grid, where each cell is either `0` (empty) or `1` (obstacle). In one step, you can move up, down, left or right from and to an empty cell.\r\n\r\nReturn the minimum number of steps to walk from the upper left corner `(0, 0)` to the lower right corner `(m-1, n-1)` given that you can eliminate **at most** `k` obstacles. If it is not possible to find such walk return -1.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: \r\ngrid = \r\n[[0,0,0],\r\n [1,1,0],\r\n [0,0,0],\r\n [0,1,1],\r\n [0,0,0]], \r\nk = 1\r\nOutput: 6\r\nExplanation: \r\nThe shortest path without eliminating any obstacle is 10. \r\nThe shortest path with one obstacle elimination at position (3,2) is 6. Such path is (0,0) -> (0,1) -> (0,2) -> (1,2) -> (2,2) -> (3,2) -> (4,2).\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: \r\ngrid = \r\n[[0,1,1],\r\n [1,1,1],\r\n [1,0,0]], \r\nk = 1\r\nOutput: -1\r\nExplanation: \r\nWe need to eliminate at least two obstacles to find such a walk.\r\n```\r\n\r\n**Constraints:**\r\n\r\n- `grid.length == m`\r\n- `grid[0].length == n`\r\n- `1 <= m, n <= 40`\r\n- `1 <= k <= m*n`\r\n- `grid[i][j] == 0 **or** 1`\r\n- `grid[0][0] == grid[m-1][n-1] == 0`\r\n\r\n```python\r\nimport heapq\r\nclass Solution:\r\n def shortestPath(self, grid, k):\r\n n, m = len(grid), len(grid[0])\r\n dp = [[[float(\"inf\") for a in range(m+1)] for i in range(n+1)] for j in range(k+1)]\r\n q = [(0, 1, 1)]\r\n dp[0][1][1] = 0\r\n stopped = {(1, 1): 0}\r\n while q:\r\n dist, i, j = heapq.heappop(q)\r\n for ii, jj in ((-1, 0), (1, 0), (0, -1), (0, 1)):\r\n if 0 < i+ii<= n and 0 < j+jj <= m and grid[i+ii-1][j+jj-1] != 1:\r\n if (i+ii, j+jj) not in stopped or dist + 1 < stopped[(i+ii, j+jj)]:\r\n stopped[(i+ii, j+jj)] = dist + 1\r\n dp[0][i+ii][j+jj] = dist + 1\r\n heapq.heappush(q, (dist + 1, i+ii, j+jj))\r\n for a in range(1, k+1):\r\n for i in range(1, n+1):\r\n for j in range(1, m+1):\r\n if grid[i-1][j-1] == 0:\r\n dp[a][i][j] = min(min(dp[a][i - 1][j], dp[a][i][j-1]) + 1, dp[a-1][i][j])\r\n else:\r\n dp[a][i][j] = min(min(dp[a-1][i - 1][j], dp[a-1][i][j-1]) + 1, dp[a-1][i][j])\r\n if dp[k][n][m] == float(\"inf\"): return -1\r\n return dp[k][n][m]\r\n```\r\n\r\ndp有k+1层,第一层用简单的BFS得到所有点的距离\r\n\r\n$if grid[i-1][j-1] == 0:$ 说明这一点不需要移除障碍,因此可以使用第a层的结果\r\n\r\n即用$min(dp[a][i - 1][j], dp[a][i][j-1]) + 1$ 尝试优化$dp[a-1][i][j]$ 作为$dp[a][i][j]$ \r\n\r\n$if grid[i-1][j-1] == 1:$ 说明这一点需要移除障碍,只能用第a-1层的结果\r\n\r\n\r\n\r\n更进一步的方式是不保存k+1的结果,只保留两层,level和next_level 空间复杂度上更好\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 694. Number of Distinct Islands\r\n\r\nGiven a non-empty 2D array `grid` of 0's and 1's, an **island** is a group of `1`'s (representing land) connected 4-directionally (horizontal or vertical.) You may assume all four edges of the grid are surrounded by water.\r\n\r\nCount the number of **distinct** islands. An island is considered to be the same as another if and only if one island can be translated (and not rotated or reflected) to equal the other.\r\n\r\n**Example 1:**\r\n\r\n```\r\n11000\r\n11000\r\n00011\r\n00011\r\n```\r\n\r\nGiven the above grid map, return \r\n\r\n```\r\n1\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\n11011\r\n10000\r\n00001\r\n11011\r\n```\r\n\r\nGiven the above grid map, return \r\n\r\n```\r\n3\r\n```\r\n\r\nNotice that:\r\n\r\n```\r\n11\r\n1\r\n```\r\n\r\nand\r\n\r\n```\r\n 1\r\n11\r\n```\r\n\r\n\r\n\r\n```python\r\nclass Solution:\r\n def dfs(self, grid, i, j, x, y, visited, n, m, temp_path):\r\n directions = [[-1, 0], [1, 0], [0, -1], [0, 1]]\r\n temp_path.append(x)\r\n temp_path.append(y)\r\n for ii, jj in directions:\r\n if 0 <= i + ii < n and 0 <= j + jj < m and grid[i + ii][j + jj] == 1 and visited[i + ii][j + jj] == 0:\r\n visited[i + ii][j + jj] = 1\r\n self.dfs(grid, i + ii, j + jj, x + ii, y + jj, visited, n, m, temp_path)\r\n return\r\n\r\n def numDistinctIslands(self, grid):\r\n if len(grid) == 0 or len(grid[0]) == 0: return 0\r\n n, m = len(grid), len(grid[0])\r\n visited = [[0 for i in range(m)] for j in range(n)]\r\n self.res = 0\r\n self.set1 = set()\r\n for i in range(n):\r\n for j in range(m):\r\n if grid[i][j] == 1 and visited[i][j] == 0:\r\n visited[i][j] = 1\r\n temp_path = []\r\n self.dfs(grid, i, j, 0, 0, visited, n, m, temp_path)\r\n self.set1.add(tuple(temp_path))\r\n return len(self.set1)\r\n```\r\n\r\n用path记录下island每个节点的位置\r\n\r\n\r\n\r\n##### leetcode 1197 Minimum Knight Moves\r\n\r\nIn an **infinite** chess board with coordinates from `-infinity` to `+infinity`, you have a **knight** at square `[0, 0]`.\r\n\r\nA knight has 8 possible moves it can make, as illustrated below. Each move is two squares in a cardinal direction, then one square in an orthogonal direction.\r\n\r\n\r\n\r\nReturn the minimum number of steps needed to move the knight to the square `[x, y]`. It is guaranteed the answer exists.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: x = 2, y = 1\r\nOutput: 1\r\nExplanation: [0, 0] → [2, 1]\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: x = 5, y = 5\r\nOutput: 4\r\nExplanation: [0, 0] → [2, 1] → [4, 2] → [3, 4] → [5, 5]\r\n```\r\n\r\n\r\n\r\n````python\r\nclass Solution:\r\n def minKnightMoves(self, x: int, y: int) -> int:\r\n x, y =abs(x), abs(y)\r\n q = collections.deque()\r\n q.append([0, 0, 0])\r\n seen = set({(0, 0)})\r\n directions = [[1, 2], [2, 1], [2, -1], [1, -2], [-1, 2], [-2, 1], [-2, -1], [-1, -2]]\r\n if [x, y] == [0, 0]: return 0\r\n while q:\r\n i, j, step = q.popleft()\r\n for ii, jj in directions:\r\n if [i+ii, j+jj] == [x, y]:\r\n return step + 1\r\n elif (i+ii, j+jj) not in seen and i+ii>-2 and j+jj>-2:\r\n seen.add((i+ii, j+jj))\r\n q.append([i+ii, j+jj, step+1])\r\n return 0\r\n````\r\n\r\n使用对称性质简化计算\r\n\r\n\r\n\r\n##### leetcode 1146 Snapshot Array\r\n\r\nImplement a SnapshotArray that supports the following interface:\r\n\r\n- `SnapshotArray(int length)` initializes an array-like data structure with the given length. **Initially, each element equals 0**.\r\n- `void set(index, val)` sets the element at the given `index` to be equal to `val`.\r\n- `int snap()` takes a snapshot of the array and returns the `snap_id`: the total number of times we called `snap()` minus `1`.\r\n- `int get(index, snap_id)` returns the value at the given `index`, at the time we took the snapshot with the given `snap_id`\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [\"SnapshotArray\",\"set\",\"snap\",\"set\",\"get\"]\r\n[[3],[0,5],[],[0,6],[0,0]]\r\nOutput: [null,null,0,null,5]\r\nExplanation: \r\nSnapshotArray snapshotArr = new SnapshotArray(3); // set the length to be 3\r\nsnapshotArr.set(0,5); // Set array[0] = 5\r\nsnapshotArr.snap(); // Take a snapshot, return snap_id = 0\r\nsnapshotArr.set(0,6);\r\nsnapshotArr.get(0,0); // Get the value of array[0] with snap_id = 0, return 5\r\n```\r\n\r\n```python\r\nclass SnapshotArray(object):\r\n\r\n def __init__(self, n):\r\n self.A = [[[-1, 0]] for _ in range(n)]\r\n self.snap_id = 0\r\n self.n = n\r\n\r\n def set(self, index, val):\r\n self.A[index].append([self.snap_id, val])\r\n\r\n def snap(self):\r\n self.snap_id += 1\r\n return self.snap_id - 1\r\n\r\n def get(self, index, snap_id):\r\n i = bisect.bisect(self.A[index], [snap_id + 1]) - 1\r\n return self.A[index][i][1]\r\n\r\n\r\n# Your SnapshotArray object will be instantiated and called as such:\r\n# obj = SnapshotArray(length)\r\n# obj.set(index,val)\r\n# param_2 = obj.snap()\r\n# param_3 = obj.get(index,snap_id)\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.4994298815727234,
"alphanum_fraction": 0.5332098007202148,
"avg_line_length": 18.68436622619629,
"blob_id": "e2e668bfae1d1ee35714ea8bf6dac6d5f89f64f3",
"content_id": "ecd718031925e6ae15324f98ad95ab15a8996bb0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 8521,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 339,
"path": "/math&&deeplearning/math/math_concept.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "## 拉普拉斯算子 \r\n拉普拉斯算子代表的是梯度的旋度 \r\n$$\r\n\\Delta f={\\nabla}^{2}f=\\nabla·\\nabla f\r\n$$\r\nf(x1,x2,.....,xn) \r\n拉普拉斯算子表示xi中所有的非混合二阶偏导数 \r\n$$\r\n\\Delta f=\\sum_{i=1}^{n}\\frac{\\partial^2f}{\\partial x_{i}^{2}}\r\n$$\r\n\r\n对于三维空间的情况而言: \r\n$$\r\n\\Delta f=\\frac{\\partial^2f}{\\partial x^{2}}+\\frac{\\partial^2f}{\\partial y^{2}}+\\frac{\\partial^2f}{\\partial z^{2}}\r\n$$\r\n\r\n\r\n## 梯度 \r\n梯度代表的是标量对向量的求导,物理意义是标量场中标量变化最快的方向函数\r\n$$\r\n\\varphi=2x+3y^2-\\sin(z)\r\n$$\r\n的梯度为:\r\n$$\r\n\\nabla\\varphi=(\\frac{\\partial\\varphi}{\\partial x},\\frac{\\partial\\varphi}{\\partial y},\\frac{\\partial\\varphi}{\\partial z})=(2,6y-\\cos(z))\r\n$$\r\n梯度常用倒三角形符号或者是grad表示 \r\n\r\n\r\n## 矩阵向量的求导 \r\n\r\n常量 常向量 常矩阵的导数均为0 \r\n\r\n### 1.1、标量y对标量x的求导:\r\n$$\r\n\\frac{\\partial y}{\\partial x}\r\n$$\r\n\r\n\r\n\r\n### 1.2、向量y对标量x求导\r\n下一步 我们有向量y:\r\n\r\n$$\r\nY=\\begin{bmatrix}\r\ny_{1} \\\\\r\ny_{2} \\\\\r\n. \\\\\r\n. \\\\\r\n. \\\\\r\ny_{n} \\\\\r\n\\end{bmatrix}\r\n$$\r\n向量对标量的导数:\r\n$$\r\n\\frac{\\partial Y}{\\partial x}=\\begin{bmatrix}\r\n\\frac{\\partial y_{1}}{\\partial x} \\\\\r\n\\frac{\\partial y_{2}}{\\partial x} \\\\\r\n. \\\\\r\n. \\\\\r\n. \\\\\r\n\\frac{\\partial y_{n}}{\\partial x} \\\\\r\n\\end{bmatrix}\r\n$$\r\n\r\n\r\n### 1.3、矩阵对标量求导\r\n矩阵y:\r\n$$\r\nY=\\begin{bmatrix}\r\ny_{11}&y_{12}&.&.&y_{1n} \\\\\r\ny_{21}&y_{22}&.&.&y_{2n} \\\\\r\n.&.&.&.&. \\\\\r\n.&.&.&.&. \\\\\r\ny_{n1}&y_{n2}&.&.&y_{nn}\\\\\r\n\\end{bmatrix}\r\n$$\r\n矩阵对标量的导数:\r\n$$\r\n\\frac{\\partial Y}{\\partial x}=\\begin{bmatrix}\r\n\\frac{\\partial y_{11}}{\\partial x} &\\frac{\\partial y_{12}}{\\partial x}&.&\\frac{\\partial y_{1n}}{\\partial x}\\\\\r\n\\frac{\\partial y_{21}}{\\partial x} &\\frac{\\partial y_{22}}{\\partial x}&.&\\frac{\\partial y_{2n}}{\\partial x}\\\\\r\n. &.&.&.\\\\\r\n. &.&.&.\\\\\r\n\\frac{\\partial y_{n1}}{\\partial x} &\\frac{\\partial y_{n2}}{\\partial x}&.&\\frac{\\partial y_{nn}}{\\partial x}\\\\\r\n\\end{bmatrix}\r\n$$\r\n\r\n\r\n### 2.1 标量对向量求导\r\n我们有向量x: \r\n\r\n$$\r\nX=\\begin{bmatrix}\r\nx_{1} \\\\\r\nx_{2} \\\\\r\n. \\\\\r\n. \\\\\r\n. \\\\\r\nx_{n} \\\\\r\n\\end{bmatrix}\r\n$$\r\n标量y对向量x求导: \r\n\r\n$$\r\n\\frac{\\partial y}{\\partial X}=\\begin{bmatrix}\r\n\\frac{\\partial y}{\\partial x_{1}} &\r\n\\frac{\\partial y}{\\partial x_{2}} &\r\n. &\r\n. &\r\n\\frac{\\partial y}{\\partial x_{n}}\r\n\\end{bmatrix}\r\n$$\r\n此时叫梯度向量,反映了标量y在以x为基的空间中的梯度 \r\n\r\n### 2.2 向量对向量求导\r\n对向量y,x: \r\n\r\n$$\r\nX=\\begin{bmatrix}\r\nx_{1} \\\\\r\nx_{2} \\\\\r\n. \\\\\r\n. \\\\\r\n. \\\\\r\nx_{n} \\\\\r\n\\end{bmatrix}\r\n$$\r\n\r\n$$\r\nY=\\begin{bmatrix}\r\ny_{1} \\\\\r\ny_{2} \\\\\r\n. \\\\\r\n. \\\\\r\n. \\\\\r\ny_{n} \\\\\r\n\\end{bmatrix}\r\n$$\r\n\r\n求导: \r\n\r\n$$\r\n\\frac{\\partial Y}{\\partial X}=\\begin{bmatrix}\r\n\\frac{\\partial y_{1}}{\\partial x_{1}} &\\frac{\\partial y_{1}}{\\partial x_{2}}&.&\\frac{\\partial y_{1}}{\\partial x_{n}}\\\\\r\n\\frac{\\partial y_{2}}{\\partial x_{1}} &\\frac{\\partial y_{2}}{\\partial x_{2}}&.&\\frac{\\partial y_{2}}{\\partial x_n}\\\\\r\n. &.&.&.\\\\\r\n. &.&.&.\\\\\r\n\\frac{\\partial y_{n}}{\\partial x_{1}} &\\frac{\\partial y_{n}}{\\partial x_{2}}&.&\\frac{\\partial y_{n}}{\\partial x_{n}}\\\\\r\n\\end{bmatrix}\r\n$$\r\n此时的矩阵为雅可比矩阵 \r\n\r\n### 2.3 矩阵向量求导:\r\n对矩阵Y: \r\n\r\n$$\r\nY=\\begin{bmatrix}\r\ny_{11}&y_{12}&.&.&y_{1n} \\\\\r\ny_{21}&y_{22}&.&.&y_{2n} \\\\\r\n.&.&.&.&. \\\\\r\n.&.&.&.&. \\\\\r\ny_{n1}&y_{n2}&.&.&y_{nn}\\\\\r\n\\end{bmatrix}\r\n$$\r\n \r\n\r\n求导: \r\n\r\n$$\r\n\\frac{\\partial Y}{\\partial x}=\\begin{bmatrix}\r\n\\frac{\\partial y_{11}}{\\partial x_{1}} &\\frac{\\partial y_{12}}{\\partial x_{2}}&.&\\frac{\\partial y_{1n}}{\\partial x_{n}}\\\\\r\n\\frac{\\partial y_{21}}{\\partial x_{1}} &\\frac{\\partial y_{22}}{\\partial x_{2}}&.&\\frac{\\partial y_{2n}}{\\partial x_{n}}\\\\\r\n. &.&.&.\\\\\r\n. &.&.&.\\\\\r\n\\frac{\\partial y_{n1}}{\\partial x_{1}} &\\frac{\\partial y_{n2}}{\\partial x_{2}}&.&\\frac{\\partial y_{nn}}{\\partial x_{n}}\\\\\r\n\\end{bmatrix}\r\n$$\r\n\r\n\r\n### 3.1关于矩阵的导数一般只考虑标量矩阵的情况:\r\n$$\r\n\\frac{\\partial y}{\\partial X}=\\begin{bmatrix}\r\n\\frac{\\partial y}{\\partial x_{11}} &\\frac{\\partial y}{\\partial x_{21}}&.&\\frac{\\partial y}{\\partial x_{n1}}\\\\\r\n\\frac{\\partial y}{\\partial x_{12}} &\\frac{\\partial y}{\\partial x_{22}}&.&\\frac{\\partial y}{\\partial x_{n2}}\\\\\r\n. &.&.&.\\\\\r\n. &.&.&.\\\\\r\n\\frac{\\partial y}{\\partial x_{1n}} &\\frac{\\partial y}{\\partial x_{2n}}&.&\\frac{\\partial y}{\\partial x_{nn}}\\\\\r\n\\end{bmatrix}\r\n$$\r\n\r\n\r\n\r\n\r\n## 雅可比矩阵\r\n反映某函数从Rn到Rm的线性映射(从n维空间映射到m维空间),这个函数由m个实函数构成: \r\n\r\ny1(x1,x2,....x,n),......,ym(x1,x2,.....,xn) \r\n\r\n这些函数的偏导数构成雅可比矩阵,例子如下 \r\n\r\n由球坐标系到直角坐标系的转化:\r\n$$\r\nx_{1}=r\\sin\\theta \\cos\\phi \\\\\r\nx_{2}=r\\sin\\theta \\sin\\phi \\\\\r\nx_{3}=r\\cos\\theta\r\n$$\r\n此坐标变换的雅可比矩阵\r\n$$\r\nJ_{F}(r,\\theta,\\phi)=\\begin{bmatrix}\r\n\\frac{\\partial x_{1}}{\\partial r} &\\frac{\\partial x_{1}}{\\partial \\theta}&.&\\frac{\\partial x_{1}}{\\partial \\phi}\\\\\r\n\\frac{\\partial x_{2}}{\\partial r} &\\frac{\\partial x_{2}}{\\partial \\theta}&.&\\frac{\\partial x_{2}}{\\partial \\phi}\\\\\r\n\\frac{\\partial x_{3}}{\\partial r} &\\frac{\\partial x_{3}}{\\partial \\theta}&.&\\frac{\\partial x_{3}}{\\partial \\phi}\\\\\r\n\\end{bmatrix}=\\begin{bmatrix}\r\n\\sin\\theta\\cos\\phi&r\\cos\\theta\\cos\\phi& -r\\sin\\theta\\sin\\phi \\\\\r\n\\sin\\theta\\sin\\phi&r\\cos\\theta\\sin\\phi& r\\sin\\theta\\cos\\phi \\\\\r\n\\cos\\theta&-r\\sin\\theta& 0\\\\\r\n\\end{bmatrix}\r\n$$\r\n\r\n\r\n## 拉格朗日乘子法 \r\n拉格朗日乘子法用于求解在函数有约束条件时的极大值和极小值,尤其时函数的显示表达式表达很困难的时候 \r\nb比如,要求\r\n$$\r\nf(x,y)在g(x,y)=c\r\n$$\r\n时的最大值,我们可以引入新变量拉格朗日乘数\r\n$$\r\n\\lambda\r\n$$\r\n这时我们只需要下列拉格朗日函数的极值:\r\n$$\r\nL(x,y,\\lambda)=f(x,y)+\\lambda·(g(x,y)-c)\r\n$$\r\n例子:求方程最小值:\r\n$$\r\nf(x,y)=x^2y\r\n$$\r\n同时未知数满足\r\n$$\r\nx^2+y^2=1\r\n$$\r\n因为只有一个未知数的限制条件,我们只需要用一个乘数\r\n$$\r\n\\lambda\r\n$$\r\n\r\n$$\r\ng(x,y)=x^2+y^2-1 \\\\\r\n\\psi(x,y,\\lambda)=f(x,y)+\\lambda g(x,y)=x^2y+\\lambda(x^2+y^2-1)\r\n$$\r\n\r\n将所有\r\n$$\r\n\\psi\r\n$$\r\n方程的偏微分设为零,得到一个方程组,最小值是以下方程组的解中的一个:\r\n$$\r\n2xy+2\\lambda x=0 \\\\\r\nx^2+2\\lambda y=0 \\\\\r\nx^2+y^2 -1=0\r\n$$\r\n可见上述三个未知数三个方程,可以求出解(x,y,lambda),利用求出的(x,y)得到最值 \r\n\r\n# 优化算法\r\n## 随机梯度下降算法 SGD\r\n定义: \r\n$$\r\n\\omega:=\\omega-\\eta\\nabla Q(\\omega)\r\n$$\r\n\r\n例子: \r\n回归问题:\r\n$$\r\ny=\\omega_{1}+\\omega_{2}x\r\n$$\r\n 最小化目标函数:\r\n$$\r\nQ(\\omega)=\\sum_{i=1}^{n}Q_{i}(\\omega)=\\sum_{i=1}^{n}(\\hat{y_{i}}-y_{i})^2=\\sum_{i=1}^{n}(\\omega_{1}+\\omega_{2}x_{i}-y_{i})^2\r\n$$\r\n\r\n$$\r\n\\begin{bmatrix}\r\n\\omega_{1} \\\\\r\n\\omega_{2} \\\\\r\n\\end{bmatrix}:=\\begin{bmatrix}\r\n\\omega_{1} \\\\\r\n\\omega_{2} \\\\\r\n\\end{bmatrix}-\\eta\\begin{bmatrix}\r\n\\frac{\\partial}{\\partial \\omega_{1}}(\\omega_{1}+\\omega_{2}x_{i}-y_{i})^2 \\\\\r\n\\frac{\\partial}{\\partial \\omega_{1}}(\\omega_{1}+\\omega_{2}x_{i}-y_{i})^2 \\\\\r\n\\end{bmatrix}=\\begin{bmatrix}\r\n\\omega_{1} \\\\\r\n\\omega_{2} \\\\\r\n\\end{bmatrix}-\\eta\\begin{bmatrix}\r\n2(\\omega_{1}+\\omega_{2}x_{i}-y_{i})^2 \\\\\r\n2x_{i}(\\omega_{1}+\\omega_{2}x_{i}-y_{i})^2 \\\\\r\n\\end{bmatrix}\r\n$$\r\n\r\npython代码: \r\n\r\n```python\r\n>>> import numpy as np\r\n>>> from sklearn import linear_model\r\n>>> X = np.array([[-1, -1], [-2, -1], [1, 1], [2, 1]])\r\n>>> Y = np.array([1, 1, 2, 2])\r\n>>> clf = linear_model.SGDClassifier(max_iter=1000)\r\n>>> clf.fit(X, Y)\r\n... \r\nSGDClassifier(alpha=0.0001, average=False, class_weight=None,\r\n early_stopping=False, epsilon=0.1, eta0=0.0, fit_intercept=True,\r\n l1_ratio=0.15, learning_rate='optimal', loss='hinge', max_iter=1000,\r\n n_iter=None, n_iter_no_change=5, n_jobs=None, penalty='l2',\r\n power_t=0.5, random_state=None, shuffle=True, tol=None,\r\n validation_fraction=0.1, verbose=0, warm_start=False)\r\n>>>\r\n>>> print(clf.predict([[-0.8, -1]]))\r\n[1]\r\n```\r\n\r\n\r\n\r\n### 数学符号与读法\r\n```\r\nα( 阿而法)\r\nβ( 贝塔)\r\nγ(伽马)\r\nδ(德尔塔)\r\nε(艾普西龙)\r\nζ(截塔)\r\nη(艾塔) θ(西塔) ι约塔) κ(卡帕)\r\nλ(兰姆达) μ(米尤) ν(纽) ξ(可系) ο(奥密克戎)\r\nπ (派)ρ (若)σ (西格马)τ (套)υ (英文或拉丁字母)\r\nφ(斐) χ(喜) ψ(普西)) ω(欧米伽)\r\n```\r\nσ(x) sigmoid激活函数 \r\n⊙ 点乘 \r\n\r\n"
},
{
"alpha_fraction": 0.6365073323249817,
"alphanum_fraction": 0.645594596862793,
"avg_line_length": 11.056700706481934,
"blob_id": "df4c14342977ce55cd2b4c801cf369ac21f4c3c1",
"content_id": "316e3f10c4c5fc0d37f378969e72c33f0f6bf6fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4037,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 194,
"path": "/books/javascript DOM编程艺术.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Javascript DOM\r\n\r\n当网页设计人员谈起web标准时,一般HTML(超文本标记语言)和CSS(层叠样式表)通常占据核心地位。不过W3C已经批准了DOM技术,所有与标准相容的浏览器都支持DOM。\r\n\r\n\r\n\r\n##### javascript语法\r\n\r\n编写JavaScript脚本不需要任何特殊的软件,一个普通的文本编译器和一个web浏览器就可以了。\r\n\r\njavascript代码必须通过HTML文档或者是DHTML文档才能执行,有两种方式可以做到这一点。第一种是将javascript代码放到文档head标签中的script标签中。\r\n\r\n```javascript\r\n<head>\r\n\t<script>\r\n\t Javascript goes here\r\n\t<script>\r\n<head>\r\n```\r\n\r\n一个更好的方式是将javascript代码存为一个拓展名为.js的独立文件。\r\n\r\n```javascript\r\n<script src=\"file.js\"></script>\r\n```\r\n\r\n\r\n\r\n实践:两个文件,test.html,example.js\r\n\r\n```html\r\n<!DOCTYPE html>\r\n<html lang=\"en\">\r\n\t<head>\r\n\t <meta charset=\"utf-8\" />\r\n\t <title>Just a text</title>\r\n\t</head>\r\n\t<body>\r\n\t <script src=\"example.js\"></script>\r\n\t<body>\r\n</html>\r\n\t \r\n```\r\n\r\n将任何一个实例都可以复制到example.js中\r\n\r\n\r\n\r\n程序设计语言分为解释型和编译型,例如c++/java等编译型语言需要一个编译器,编译器是一种程序,能够将java等高级语言编写的源代码直接翻译为在计算机上能执行的文件,解释型语言不需要编译器,对于javascript而言,浏览器中的javascript解释器直接读入源代码执行。 \r\n\r\n\r\n\r\n##### 语句\r\n\r\n```\r\nfirst statement;\r\nsecond statement;\r\n```\r\n\r\n多条语句在同一行上则必须要有;否则可以没有 \r\n\r\n\r\n\r\n##### 注释\r\n\r\n// 注释单行\r\n\r\n/**/ 注释多行\r\n\r\n<!-- javascript 注释\r\n\r\n<!-- HTML注释>\r\n\r\n\r\n\r\n##### 变量\r\n\r\njavascript中可以直接对变量进行赋值而无需声明。不过提前声明变量是一个良好的习惯。\r\n\r\n```\r\nvar mood=\"happy\",age=33;\r\n```\r\n\r\n必须声明变量类型的语言是强类型语言,二不需声明的语言是弱类型语言。\r\n\r\n##### 数组\r\n\r\n```\r\nvar beattles=Array(\"John\",\"Paul\",\"George\",\"Ringo\")\r\nvar leon=[\"john\",1940,true] //类似tuple\r\n```\r\n\r\n关联数组\r\n\r\n```\r\nvar lennon=Array()\r\nlenoon[\"name\"]=\"john\"\r\nlenoon[\"year\"]=1940\r\n```\r\n\r\n类似于dict结构\r\n\r\n##### 对象\r\n\r\n对象也是用一个名字来表示一组值,每个值都是对象中的一个属性。\r\n\r\n```\r\nvar lennon=Object()\r\nlenoon.name=\"john\"\r\nlenoon.year=1940\r\n```\r\n\r\n##### 操作\r\n\r\n例如加减乘除等基本操作符\r\n\r\n字符串之间存在首尾连接在一起的拼接。\r\n\r\n##### 条件语句\r\n\r\n```\r\nif(){}\r\nelse{}\r\n```\r\n\r\n##### while循环,for循环\r\n\r\n```javascript\r\nwhile(condition){\r\n state;\r\n}\r\nfor(var count=1;count<11;count++){\r\n\tstate;\r\n}\r\n```\r\n\r\n##### 全局变量和局部变量\r\n\r\n```\r\nfunction square(num){\r\n total=num*num;\r\n return total;\r\n}\r\nvar total=50;\r\nvar number=square(20);\r\nalert(total);\r\n```\r\n\r\n全局变量total变化\r\n\r\n```javascript\r\nfunction square(num){\r\n var total=num*num;\r\n return total;\r\n}\r\n```\r\n\r\n为局部变量,全局变量total没有变化\r\n\r\n##### 对象\r\n\r\n对象是一个非常重要的数据类型,属性(property)和方法(method)\r\n\r\n属性是隶属于某个特定对象的变量\r\n\r\n方法是只有某个特定对象才能调用的函数\r\n\r\nPerson.mood,Person.age\r\n\r\nPerson.wal(),Person.sleep() 方法\r\n\r\nvar jeremy=new Person; //使用new关键字来创建对象\r\n\r\n\r\n\r\n##### 内建对象\r\n\r\njavascript脚本,内建对象可以帮助我们快速简单完成许多任务\r\n\r\n常见的内建对象有array math date等\r\n\r\n\r\n\r\n##### 宿主对象\r\n\r\n除了内建对象,还有宿主对象。宿主对象不是有javascript语言提供的,是由运行环境提供的。document对象可以用来获得网页上表单、图像等信息。此外常用的还有Form Image Element这几个宿主对象。\r\n\r\n\r\n\r\n#### DOM\r\n\r\n##### 节点的概念\r\n\r\n根元素是html,代表整个文档,深入一层是head和body两个分支。head元素有两个子元素 分别是meta和title"
},
{
"alpha_fraction": 0.6828358173370361,
"alphanum_fraction": 0.7014925479888916,
"avg_line_length": 18.980392456054688,
"blob_id": "8631de76d5df32db7a8027f4f448197a6e8c34f5",
"content_id": "afd85ad928c35d09123693df68e5c1befdd6cc19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1326,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 51,
"path": "/leetcode_note/leetcode_sql.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### SQL leetcode\r\n\r\n##### leetcode 175 两个表的联结\r\n\r\n使用left join on ;on后面表示条件\r\n\r\n \r\n\r\n```mysql\r\nSELECT Person.FirstName, Person.LastName, Address.City, Address.State FROM Person LEFT JOIN Address \r\nON Person.PersonId = Address.PersonId;\r\n```\r\n\r\n\r\n\r\n选区person表中的firstname lastname address表中的city state,用left join... on ... 词,on表示条件。\r\n\r\n\r\n\r\n##### leetcode 176 second highest salary\r\n\r\n\r\n\r\n这题不能直接用order by 然后输出第二行数据这样\r\n\r\n因为存在两个salary相同的情况或者是只有一条数据的情况\r\n\r\n```mysql\r\nSELECT MAX(Salary) AS SecondHighestSalary FROM Employee WHERE Salary < (SELECT MAX(Salary) FROM Employee); \r\n```\r\n\r\n先利用max找到最大salary 然后用salary<进行筛选\r\n\r\n然后在新的数据中找max salary即为second highest salary\r\n\r\n##### leetcode 177 Nth Highest Salary\r\n\r\n\r\n\r\n本题要求返回一个函数\r\n\r\n```mysql\r\nCREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT\r\nBEGIN\r\n SET N = N-1; #因为limit后面不能跟表达式,所以要在之前完成\r\n RETURN (\r\n # Write your MySQL query statement below.\r\n SELECT DISTINCT Salary FROM Employee ORDER BY Salary DESC LIMIT N,1\r\n );\r\nEND \r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.6388993859291077,
"alphanum_fraction": 0.6701846718788147,
"avg_line_length": 25.905263900756836,
"blob_id": "81a60df19f97c438d43f2ba82200c31b330edaec",
"content_id": "5474ae19e6801af3e6d69715dfa4e409a0d1c885",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2779,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 95,
"path": "/javascript/爬虫实践.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Web Scraping\r\n\r\n1. Beautiful Soup\r\n\r\n Beautiful Soup 是一个python库,用来解析网页HTML内容。\r\n\r\n Beautiful Soup直接解析网页,不需要login等,但是运行速度较慢\r\n\r\n ```python\r\n from urllib.request import urlopen\r\n from bs4 import BeautifulSoup\r\n \r\n html = urlopen(\"http://www.pythonscraping.com/pages/page3.html\")\r\n bsObj = BeautifulSoup(html)\r\n images = bsObj.findall(\"img\",{\"src\":re.compile(\"\\.\\.\\/img\\/gifts/img.*\\.jpg\")})\r\n for image in images:\r\n print(image[\"src\"])\r\n ```\r\n\r\n2. 使用request python库\r\n\r\n ```python\r\n import requests\r\n login_url = 'https://openid.cc98.org/connect/token'\r\n username = 'comma_d'\r\n password = 'www.1230'\r\n scope = 'cc98-api openid offline_access'\r\n client_id = '9a1fd200-8687-44b1-4c20-08d50a96e5cd'\r\n client_secret = '8b53f727-08e2-4509-8857-e34bf92b27f2'\r\n grant_type = 'password'\r\n user_agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.80 Safari/537.36'\r\n form = {\r\n \"username\":username,\r\n \"password\":password,\r\n \"scope\":scope,\r\n \"grant_type\":grant_type,\r\n \"client_id\":client_id,\r\n \"client_secret\":client_secret\r\n }\r\n ```\r\n\r\n 模拟cc98的登陆界面\r\n\r\n\r\n```python\r\nlogin_result = requests.post(login_url, headers={\"user_agent\":user_agent}, data=form)\r\nlogin_result.status_code\r\nlogin_result.headers\r\ncookies = login_result.cookies\r\n```\r\n\r\n\r\n\r\n```python\r\nfirst_page = 'https://www.cc98.org'\r\nfirstpage_result = requests.get(first_page, cookies=cookies)\r\nfirstpage_result.status_code\r\nfirstpage_result.content\r\nfirstpage_result.headers\r\nfirstpage_result.encoding = firstpage_result.apparent_encoding\r\nfirstpage_result.text\r\n\r\nindex_url = 'https://api.cc98.org/config/index'\r\nindex_result = requests.get(index_url, cookies=cookies)\r\n\r\nindex_result.headers\r\nindex_result.encoding=index_result.apparent_encoding\r\n\r\nimport json\r\nindex_json = json.loads(index_result.text)\r\n\r\ntopic_url = 'https://api.xxx.org/Topic/4850852/post?from=0&size=10'\r\ntopic_result = requests.get(topic_url, cookies=cookies)\r\ntopic_result.encoding=topic_result.apparent_encoding\r\ntopic_json = json.loads(topic_result.text)\r\ntopic_content = topic_json[0][\"content\"]\r\n\r\nimport re\r\nimg_urls = re.findall(r'\\[img\\](.*)\\[\\/img\\]', topic_content)\r\n\r\nfrom PIL import Image\r\nimg_filename = 'img{0}.{1}'\r\ni = 0\r\nfor img_url in img_urls:\r\n i = i + 1\r\n img_response = requests.get(img_url, cookies=cookies)\r\n ext = img_response.headers['Content-Type'].split('/')[1]\r\n file = open(img_filename.format(i, ext), 'wb')\r\n file.write(img_response.content)\r\n file.close()\r\n \r\nimg_response = requests.get(img_urls[0], cookies=cookies)\r\n```\r\n\r\n在98上找到某个网页,将网页上的jpg文件保存下来\r\n\r\n"
},
{
"alpha_fraction": 0.41009464859962463,
"alphanum_fraction": 0.4658254384994507,
"avg_line_length": 19.613636016845703,
"blob_id": "ac9f1ad3045985fad08d1b757b907a9357b0f202",
"content_id": "a3074e42f8e44a66df810ed947e118fafcbb7139",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1519,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 44,
"path": "/algorithm/acm/100dp方程.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "## 100个bp方程\r\nhttps://blog.csdn.net/liuqiyao_01/article/details/8765812\r\n### 1、机器分配问题\r\nDescription\r\n总公司拥有高效设备M台,准备分给下属的N个分公司。各分公司若获得这些设备,可以为国家提供一定的盈利。 \r\n问:如何分配这M台设备才能使国家得到的盈利最大?求出最大盈利值。其中M≤15,N≤10。分配原则: \r\n每个公司有权获得任意数目的设备,但总台数不超过设备数M。 \r\n\r\nInput \r\n输入数据文件格式为:第一行有两个数,第一个数是分公司数N,第二个数是设备台数M。 \r\n接下来是一个N*M的矩阵,表明了第 I个公司分配 J台机器的盈利。 \r\n\r\nOutput \r\n输出第一行为最大盈利值 \r\n接下来有n行,分别为各分公司分配的机器数。 \r\n\r\nSample Input \r\n\r\n3 3 \r\n\r\n30 40 50 \r\n\r\n20 30 50 \r\n\r\n20 25 30 \r\n\r\nSample Output \r\n\r\n70 {最大盈利值为70} \r\n\r\n1 1 {第一分公司分1台} \r\n\r\n2 1 {第二分公司分1台} \r\n\r\n3 1 {第三分公司分1台} \r\n\r\n\r\ndp方程 \r\n\r\ndp[n+1][m+1] \r\n\r\ndp[i,j]=max(dp[i-1,k]+w[i,j-k]) \r\n\r\ndp[i,j]表示用i个分公司,j台机器得到的最大效益,w[i][j-k]表示公司i用j-k台机器得到的效益。\r\n"
},
{
"alpha_fraction": 0.6366227269172668,
"alphanum_fraction": 0.6483790278434753,
"avg_line_length": 12.930850982666016,
"blob_id": "58cc5d564bfa0fb83e92c40ab92dce042ab95574",
"content_id": "cca8bdd0467c7b75f6ab3b9429a9b0b00cc5970a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3369,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 188,
"path": "/social_network/Heterogeneous Information Network Embedding and applications.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Heterogeneous Information Network Embedding and applications\r\n\r\nGraph Embedding\r\n\r\n1. 邻接矩阵 (过于稀疏,维度大)\r\n\r\nNetwork Embedding: Embed each node of a network into a low-dimensional vector space.\r\n\r\n**Applications**:\r\n\r\n1. Node Importance\r\n2. Community Detection\r\n3. Network distance\r\n4. Node classification\r\n5. Network evolution\r\n\r\n\r\n\r\nEmbedding methods:\r\n\r\n1. Shadow models:\r\n\r\n Factorization-based approaches, Laplacian method\r\n\r\n Random walk Approach: Deepwalk, node2vec\r\n\r\n2. Deep Model\r\n\r\n Autoencoder: DNGR, SDNE\r\n\r\n Graph Convolution network: GCN, GraphSage\r\n\r\n Graph Attention network\r\n\r\n\r\n\r\n##### Deepwalk\r\n\r\nContext: truncated random walks\r\n\r\nModel:word embedding (skip-gram)\r\n$$\r\nmax_{\\phi}Pr(\\{v_{i-w},...,v_{i+w})\\}/v_i)|\\phi(v_i)=\\prod^{i+w}_{j=i-w,j\\ne i}Pr(v_j|\\phi(v_i)\r\n$$\r\n$\\phi(v_i)$ 表示node i的embedding vector\r\n\r\n表示不断修改$\\phi$ 使得$v_{i-w},...v_{i+w}$ 这些点around $v_i$ 的概率大\r\n\r\n$Pr(v_j|\\phi(v_i)) = sim(\\phi(v_i),\\phi(v_j))$ \r\n\r\n\r\n\r\n**Node2vec**\r\n\r\n\r\n\r\n\r\n\r\n使用一个参数来调节BFS 与 DFS游走\r\n\r\nDeepwalk Node2vec训练的结果是越近的节点的embedding越像\r\n\r\n\r\n\r\n**LINE**\r\n\r\n\r\n\r\nLINE考虑了一阶相似度与二阶相似度\r\n\r\nfirst-order: 直接相连\r\n\r\nsecond-order:非直接相连(5,6) 结构相似\r\n\r\n\r\n\r\n**Graph Neural Network** \r\n\r\nAverage neighbor information and apply a neural network\r\n\r\n\r\n\r\n**Graph Attention**\r\n\r\n聚合不同邻居的特征时考虑权重\r\n\r\n\r\n\r\n\r\n\r\n**Heterogeneous Information Networks**\r\n\r\nBasic Concepts:\r\n\r\nNetwork schema: 元机描述\r\n\r\nMeta Path: 元路径\r\n\r\n\r\n\r\nMeta path: APA (author paper author), APVPA(author paper venue paper author), APV(author paper venue)\r\n\r\n不同的元路径研究不同的网络信息\r\n\r\n如何选择元路径?:\r\n\r\n1.简单网络:根据专业知识\r\n\r\n2.复杂网络比较困难\r\n\r\n\r\n\r\n##### metaPath2vec\r\n\r\n类似randomwalk,根据选定的元路径进行游走\r\n\r\n在计算softmax也会有不同:\r\n\r\nskip-gram:所有节点\r\n$$\r\np(c_t|v;\\theta)=\\frac{e^{x_u}e^{x_v}}{\\sum_{u\\in V}e^{x_u}e^{x_v}}\r\n$$\r\nHIN skip-gram:只考虑元路径下某一类型的点\r\n$$\r\np(c_t|v;\\theta)=\\frac{e^{x_u}e^{x_v}}{\\sum_{u\\in V_t}e^{x_u}e^{x_v}}\r\n$$\r\n\r\n\r\n\r\n\r\n##### HIN2vec\r\n\r\n寻找大量训练样例\r\n\r\n<x,y,r,L(x,y,r)>\r\n\r\nnode x,y; r:relation; L(x,y,r)=0,1\r\n\r\n训练得到node embedding, meta-path embedding\r\n\r\n\r\n\r\n##### HERec\r\n\r\n将异质网络转化为同质网络,\r\n\r\n基于对称的元路径得到多个同质网络,在每个网络中利用LINE等方法得到embedding vector,对于每个node在不同网络中得到的embedding vector融合起来。\r\n\r\n\r\n\r\n##### Hyperbolic Heterogeneous Information Network Embedding\r\n\r\n\r\n\r\n从欧式空间到非欧空间\r\n\r\nHyperbolic geometry:\r\n\r\n1.model data with power-law distribution naturally\r\n\r\n2.reflected the hierarchy\r\n\r\n\r\n\r\nMethod:\r\n\r\n1.use meta-path guided random walks\r\n\r\n2.use distance in hyperbolic spaces to measure the similarity between nodes.\r\n\r\n3.Design optimization objective based on the skip-gram\r\n\r\n\r\n\r\n#### Deep Model\r\n\r\n##### Autoencoder Neural Network\r\n\r\n\r\n\r\nlayer L1-layer L2: encoder (embedding)\r\n\r\nlayer L2- layer L3:decoder\r\n\r\nloss:\r\n$$\r\nloss=||X-\\widehat{X}||\r\n$$\r\n"
},
{
"alpha_fraction": 0.42537057399749756,
"alphanum_fraction": 0.474319189786911,
"avg_line_length": 21.53346824645996,
"blob_id": "b83c3164eef5dbf7c075dfc5b6e957c43eb7f953",
"content_id": "447e2bb627245fc67f07b7bfe85aa7b8f0fca062",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 15302,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 493,
"path": "/computer_science_knowledge/database/liaoxuefengMysql_tutorial.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "<https://www.liaoxuefeng.com/wiki/1177760294764384>\r\n\r\n##### download\r\n\r\n<https://dev.mysql.com/downloads/mysql/>\r\n\r\n选择5.7.23版本,安装完之后 需要在PATH环境中设置的路径:\r\n\r\nC:/Program Files/MySQL/MySQL Server 5.1/bin\r\n\r\n运行:\r\n\r\n在cmd输入\r\n\r\n```mysql\r\nmysql -u root -p\r\n```\r\n\r\n用exit退出\r\n\r\n\r\n\r\n数据库根据数据结构来组织、存储和管理数据。数据库一共有三种模型,\r\n\r\n数据库中一对一,一对多,多对多的关系:\r\n\r\n一对一关系:一个人对应一张身份证,一张身份证对应一个人\r\n\r\n主键:数据库中任意两条记录不能重复,可以通过某个字段唯一区分出不同记录,这个字段称为主键。一旦插入数据库中,主键最好不要修改,最好不使用任何业务相关的字段作为主键,因为主键不建议修改,一般可以用id等作为主键。\r\n\r\n\r\n\r\n##### 查询数据\r\n\r\n```\r\nmysql -u root -p < init-test-data.sql\r\nmysql> USE test\r\n```\r\n\r\n##### 基本查询:\r\n\r\n```\r\nSELECT * FROM students;\r\n```\r\n\r\n`SELECT`是关键字,表示将要执行一个查询,`*`表示“所有列”,`FROM`表示将要从哪个表查询,本例中是`students`表。\r\n\r\n```mysql\r\nSELECT 100+200;\r\n```\r\n\r\n\r\n\r\n##### 条件查询\r\n\r\n```mysql\r\nSELECT * FROM students WHERE score >= 80;\r\n\r\n+----+----------+------+--------+-------+\r\n| id | class_id | name | gender | score |\r\n+----+----------+------+--------+-------+\r\n| 1 | 1 | Ming | M | 90 |\r\n| 2 | 1 | Hong | F | 95 |\r\n| 3 | 1 | Jun | M | 88 |\r\n| 5 | 2 | Bai | F | 81 |\r\n| 7 | 2 | Lin | M | 85 |\r\n| 8 | 3 | Xin | F | 91 |\r\n| 9 | 3 | Wang | M | 89 |\r\n| 10 | 3 | Li | F | 85 |\r\n+----+----------+------+--------+-------+\r\n```\r\n\r\n通过`WHERE`条件来设定查询条件 `WHERE`关键字后面的`score >= 80`就是条件\r\n\r\n```mysql\r\nSELECT * FROM students WHERE score >= 80 AND gender = 'M';\r\nSELECT * FROM students WHERE score >= 80 OR gender = 'M';\r\nSELECT * FROM students WHERE NOT class_id = 2;\r\n```\r\n\r\n查询分数在60分(含)~90分(含)之间的学生可以使用的WHERE语句是:\r\n\r\n```\r\nWHERE score >= 60 AND score <= 90\r\nWHERE score BETWEEN 60 AND 90\r\n\r\n\r\nWHERE score IN (60, 90) #查询分数为60分或者90分的\r\nWHERE 60 <= score <= 90 #这样写不对,等于查询所有的\r\n\r\n```\r\n\r\n\r\n\r\n##### 投影查询\r\n\r\n可以只返回数列的数据\r\n\r\n```mysql\r\nmysql> SELECT id, score, name FROM students;\r\n+----+-------+------+\r\n| id | score | name |\r\n+----+-------+------+\r\n| 1 | 90 | Ming |\r\n| 2 | 95 | Hong |\r\n| 3 | 88 | Jun |\r\n| 4 | 73 | Mi |\r\n| 5 | 81 | Bai |\r\n| 6 | 55 | Bing |\r\n| 7 | 85 | Lin |\r\n| 8 | 91 | Xin |\r\n| 9 | 89 | Wang |\r\n| 10 | 85 | Li |\r\n+----+-------+------+\r\n10 rows in set (0.00 sec)\r\n```\r\n\r\n```\r\n-- 使用投影查询,并将列名重命名:\r\nmysql> SELECT id, score points, name FROM students;\r\n+----+--------+------+\r\n| id | points | name |\r\n+----+--------+------+\r\n| 1 | 90 | Ming |\r\n| 2 | 95 | Hong |\r\n| 3 | 88 | Jun |\r\n| 4 | 73 | Mi |\r\n| 5 | 81 | Bai |\r\n| 6 | 55 | Bing |\r\n| 7 | 85 | Lin |\r\n| 8 | 91 | Xin |\r\n| 9 | 89 | Wang |\r\n| 10 | 85 | Li |\r\n+----+--------+------+\r\n10 rows in set (0.00 sec)\r\n```\r\n\r\n注意这没有修改数据库\r\n\r\n\r\n\r\n```mysql\r\nSELECT id, score points, name FROM students WHERE gender = 'M';\r\n+----+--------+------+\r\n| id | points | name |\r\n+----+--------+------+\r\n| 1 | 90 | Ming |\r\n| 3 | 88 | Jun |\r\n| 6 | 55 | Bing |\r\n| 7 | 85 | Lin |\r\n| 9 | 89 | Wang |\r\n+----+--------+------+\r\n5 rows in set (0.00 sec)\r\n```\r\n\r\n\r\n\r\n##### 排序\r\n\r\n```\r\n-- 按score从低到高\r\nSELECT id, name, gender, score FROM students ORDER BY score;\r\n\r\n如果score列有相同的数据,要进一步排序,可以继续添加列名。例如,使用ORDER BY score DESC, gender表示先按score列倒序,如果有相同分数的,再按gender列排序\r\nSELECT id, name, gender, score FROM students ORDER BY score DESC, gender;\r\n```\r\n\r\n```\r\n默认的排序规则是ASC:“升序”,即从小到大。ASC可以省略,即ORDER BY score ASC和ORDER BY score效果一样。\r\n\r\n如果有WHERE子句,那么ORDER BY子句要放到WHERE子句后面。例如,查询一班的学生成绩,并按照倒序排序:\r\n\r\nSELECT id, name, gender, score\r\nFROM students\r\nWHERE class_id = 1\r\nORDER BY score DESC;\r\n```\r\n\r\n\r\n\r\n##### 分页查询\r\n\r\n使用SELECT查询时,结果往往都很大,可以使用分页功能只显示其中的一部分\r\n\r\n```mysql\r\nSELECT id, name, gender, score\r\nFROM students\r\nORDER BY score DESC\r\nLIMIT 3 OFFSET 0;\r\n```\r\n\r\n表示每页3条,从第0条开始显示\r\n\r\n\r\n\r\n##### 聚合查询\r\n\r\n聚合查询可以用来统计一张表的数量\r\n\r\n`COUNT(*)`表示查询所有列的行数,要注意聚合的计算结果虽然是一个数字,但查询的结果仍然是一个二维表\r\n\r\n```mysql\r\nSELECT COUNT(*) num FROM students;\r\n+-----+\r\n| num |\r\n+-----+\r\n| 10 |\r\n+-----+\r\n1 row in set (0.00 sec)\r\n```\r\n\r\n聚合查询同样可以使用`WHERE`条件,因此我们可以方便地统计出有多少男生、多少女生、多少80分以上的学生等:\r\n\r\n```mysql\r\nmysql> SELECT COUNT(*) boys FROM students WHERE gender = 'M';\r\n+------+\r\n| boys |\r\n+------+\r\n| 5 |\r\n+------+\r\n1 row in set (0.00 sec)\r\n```\r\n\r\n```mysql\r\n-- 使用聚合查询计算男生平均成绩:\r\nSELECT AVG(score) average FROM students WHERE gender = 'M';\r\n+---------+\r\n| average |\r\n+---------+\r\n| 81.4000 |\r\n+---------+\r\n1 row in set (0.00 sec)\r\n```\r\n\r\n\r\n\r\n##### 多表查询\r\n\r\n查询多张表的语法是:`SELECT * FROM <表1> <表2>`。\r\n\r\n例如,同时从`students`表和`classes`表的“乘积”\r\n\r\n```\r\nSELECT * FROM students, classes;\r\n+----+----------+------+--------+-------+----+-------------+\r\n| id | class_id | name | gender | score | id | name |\r\n+----+----------+------+--------+-------+----+-------------+\r\n| 1 | 1 | Ming | M | 90 | 1 | one class |\r\n| 1 | 1 | Ming | M | 90 | 2 | two class |\r\n| 1 | 1 | Ming | M | 90 | 3 | three class |\r\n| 1 | 1 | Ming | M | 90 | 4 | four class |\r\n| 2 | 1 | Hong | F | 95 | 1 | one class |\r\n| 2 | 1 | Hong | F | 95 | 2 | two class |\r\n| 2 | 1 | Hong | F | 95 | 3 | three class |\r\n| 2 | 1 | Hong | F | 95 | 4 | four class |\r\n| 3 | 1 | Jun | M | 88 | 1 | one class |\r\n| 3 | 1 | Jun | M | 88 | 2 | two class |\r\n| 3 | 1 | Jun | M | 88 | 3 | three class |\r\n| 3 | 1 | Jun | M | 88 | 4 | four class |\r\n| 4 | 1 | Mi | F | 73 | 1 | one class |\r\n| 4 | 1 | Mi | F | 73 | 2 | two class |\r\n| 4 | 1 | Mi | F | 73 | 3 | three class |\r\n| 4 | 1 | Mi | F | 73 | 4 | four class |\r\n| 5 | 2 | Bai | F | 81 | 1 | one class |\r\n| 5 | 2 | Bai | F | 81 | 2 | two class |\r\n| 5 | 2 | Bai | F | 81 | 3 | three class |\r\n| 5 | 2 | Bai | F | 81 | 4 | four class |\r\n| 6 | 2 | Bing | M | 55 | 1 | one class |\r\n| 6 | 2 | Bing | M | 55 | 2 | two class |\r\n| 6 | 2 | Bing | M | 55 | 3 | three class |\r\n| 6 | 2 | Bing | M | 55 | 4 | four class |\r\n| 7 | 2 | Lin | M | 85 | 1 | one class |\r\n| 7 | 2 | Lin | M | 85 | 2 | two class |\r\n| 7 | 2 | Lin | M | 85 | 3 | three class |\r\n| 7 | 2 | Lin | M | 85 | 4 | four class |\r\n| 8 | 3 | Xin | F | 91 | 1 | one class |\r\n| 8 | 3 | Xin | F | 91 | 2 | two class |\r\n| 8 | 3 | Xin | F | 91 | 3 | three class |\r\n| 8 | 3 | Xin | F | 91 | 4 | four class |\r\n| 9 | 3 | Wang | M | 89 | 1 | one class |\r\n| 9 | 3 | Wang | M | 89 | 2 | two class |\r\n| 9 | 3 | Wang | M | 89 | 3 | three class |\r\n| 9 | 3 | Wang | M | 89 | 4 | four class |\r\n| 10 | 3 | Li | F | 85 | 1 | one class |\r\n| 10 | 3 | Li | F | 85 | 2 | two class |\r\n| 10 | 3 | Li | F | 85 | 3 | three class |\r\n| 10 | 3 | Li | F | 85 | 4 | four class |\r\n+----+----------+------+--------+-------+----+-------------+\r\n```\r\n\r\n`students`表的每一行与`classes`表的每一行都两两拼在一起返回。\r\n\r\n\r\n\r\n```mysql\r\nSELECT\r\n students.id sid,\r\n students.name,\r\n students.gender,\r\n students.score,\r\n classes.id cid,\r\n classes.name cname\r\nFROM students, classes;\r\n\r\n```\r\n\r\n用两张表中的数据拼成新的表\r\n\r\n\r\n\r\n##### 修改数据\r\n\r\n对数据库的基本操作时是增删改查,查的基本操作如上所示\r\n\r\n##### INSERT\r\n\r\n```\r\nINSERT INTO students (class_id, name, gender, score) VALUES\r\n (1, '大宝', 'M', 87),\r\n (2, '二宝', 'M', 81);\r\n\r\nSELECT * FROM students;\r\n```\r\n\r\n我们并没有列出`id`字段,也没有列出`id`字段对应的值,这是因为`id`字段是一个自增主键,它的值可以由数据库自己推算出来。字段顺序不必和数据库表的字段顺序一致,但值的顺序必须和字段顺序一致。\r\n\r\n\r\n\r\n##### UPDATE\r\n\r\n```\r\nUPDATE <表名> SET 字段1=值1, 字段2=值2, ... WHERE ...;\r\n\r\nUPDATE students SET name='大牛', score=66 WHERE id=1;\r\n-- 查询并观察结果:\r\nSELECT * FROM students WHERE id=1;\r\n\r\n+----+----------+------+--------+-------+\r\n| id | class_id | name | gender | score |\r\n+----+----------+------+--------+-------+\r\n| 1 | 1 | 大牛 | M | 66 |\r\n+----+----------+------+--------+-------+\r\n```\r\n\r\n更新`students`表`id=1`的记录的`name`和`score`这两个字段,先写出`UPDATE students SET name='大牛', score=66`,然后在`WHERE`子句中写出需要更新的行的筛选条件`id=1`\r\n\r\n\r\n\r\n```\r\nUPDATE students SET score=score+10 WHERE score<80;\r\n-- 查询并观察结果:\r\nSELECT * FROM students;\r\n```\r\n\r\n`SET score=score+10`就是给当前行的`score`字段的值加上了10。\r\n\r\n\r\n\r\n##### DELETE\r\n\r\n```mysql\r\nDELETE FROM students WHERE id=1;\r\n-- 查询并观察结果:\r\nSELECT * FROM students;\r\n\r\n+----+----------+------+--------+-------+\r\n| id | class_id | name | gender | score |\r\n+----+----------+------+--------+-------+\r\n| 2 | 1 | Hong | F | 95 |\r\n| 3 | 1 | Jun | M | 88 |\r\n| 4 | 1 | Mi | F | 73 |\r\n| 5 | 2 | Bai | F | 81 |\r\n| 6 | 2 | Bing | M | 55 |\r\n| 7 | 2 | Lin | M | 85 |\r\n| 8 | 3 | Xin | F | 91 |\r\n| 9 | 3 | Wang | M | 89 |\r\n| 10 | 3 | Li | F | 85 |\r\n| 11 | 2 | 大牛 | M | 80 |\r\n| 12 | 1 | 大宝 | M | 87 |\r\n| 13 | 2 | 二宝 | M | 81 |\r\n+----+----------+------+--------+-------+\r\n```\r\n\r\n\r\n\r\n##### 管理MySql\r\n\r\n在运行的MySQL服务器上可以有多个数据库\r\n\r\n其中,`information_schema`、`mysql`、`performance_schema`和`sys`是系统库,不要去改动它们。\r\n\r\n ```\r\n要创建一个新数据库,使用命令:\r\n\r\nmysql> CREATE DATABASE test;\r\nQuery OK, 1 row affected (0.01 sec)\r\n要删除一个数据库,使用命令:\r\n\r\nmysql> DROP DATABASE test;\r\nQuery OK, 0 rows affected (0.01 sec)\r\n注意:删除一个数据库将导致该数据库的所有表全部被删除。\r\n\r\n对一个数据库进行操作时,要首先将其切换为当前数据库:\r\n\r\nmysql> USE test;\r\nDatabase changed\r\n\r\n表\r\n列出当前数据库的所有表,使用命令:\r\n\r\nmysql> SHOW TABLES;\r\n ```\r\n\r\n\r\n\r\n在编写SQL时,灵活运用一些技巧,可以大大简化程序逻辑。\r\n\r\n### 插入或替换\r\n\r\n如果我们希望插入一条新记录(INSERT),但如果记录已经存在,就先删除原记录,再插入新记录。此时,可以使用`REPLACE`语句,这样就不必先查询,再决定是否先删除再插入:\r\n\r\n```\r\nREPLACE INTO students (id, class_id, name, gender, score) VALUES (1, 1, '小明', 'F', 99);\r\n```\r\n\r\n若`id=1`的记录不存在,`REPLACE`语句将插入新记录,否则,当前`id=1`的记录将被删除,然后再插入新记录。\r\n\r\n### 插入或更新\r\n\r\n如果我们希望插入一条新记录(INSERT),但如果记录已经存在,就更新该记录,此时,可以使用`INSERT INTO ... ON DUPLICATE KEY UPDATE ...`语句:\r\n\r\n```\r\nINSERT INTO students (id, class_id, name, gender, score) VALUES (1, 1, '小明', 'F', 99) ON DUPLICATE KEY UPDATE name='小明', gender='F', score=99;\r\n```\r\n\r\n若`id=1`的记录不存在,`INSERT`语句将插入新记录,否则,当前`id=1`的记录将被更新,更新的字段由`UPDATE`指定。\r\n\r\n### 插入或忽略\r\n\r\n如果我们希望插入一条新记录(INSERT),但如果记录已经存在,就啥事也不干直接忽略,此时,可以使用`INSERT IGNORE INTO ...`语句:\r\n\r\n```\r\nINSERT IGNORE INTO students (id, class_id, name, gender, score) VALUES (1, 1, '小明', 'F', 99);\r\n```\r\n\r\n若`id=1`的记录不存在,`INSERT`语句将插入新记录,否则,不执行任何操作。\r\n\r\n### 快照\r\n\r\n如果想要对一个表进行快照,即复制一份当前表的数据到一个新表,可以结合`CREATE TABLE`和`SELECT`:\r\n\r\n```\r\n-- 对class_id=1的记录进行快照,并存储为新表students_of_class1:\r\nCREATE TABLE students_of_class1 SELECT * FROM students WHERE class_id=1;\r\n```\r\n\r\n新创建的表结构和`SELECT`使用的表结构完全一致\r\n\r\n\r\n\r\n##### 事物\r\n\r\n在执行SQL语句的时候,有些业务要求一系列操作必须全部执行或者全都不执行,例如\r\n\r\n```\r\n-- 从id=1的账户给id=2的账户转账100元\r\n-- 第一步:将id=1的A账户余额减去100\r\nUPDATE accounts SET balance = balance - 100 WHERE id = 1;\r\n-- 第二步:将id=2的B账户余额加上100\r\nUPDATE accounts SET balance = balance + 100 WHERE id = 2;\r\n```\r\n\r\n如果第二步骤失败则需要全部撤销\r\n\r\n这种把多条语句作为一个整体进行操作的功能,被称为数据库*事务*。\r\n\r\n事务具有四个特性:\r\n\r\n- A:Atomic,原子性,将所有SQL作为原子工作单元执行,要么全部执行,要么全部不执行;\r\n- C:Consistent,一致性,事务完成后,所有数据的状态都是一致的,即A账户只要减去了100,B账户则必定加上了100;\r\n- I:Isolation,隔离性,如果有多个事务并发执行,每个事务作出的修改必须与其他事务隔离;\r\n- D:Duration,持久性,即事务完成后,对数据库数据的修改被持久化存储\r\n\r\n单条SQL语句,数据库系统自动将其作为一个事务执行,这种事务被称为*隐式事务*。\r\n\r\n要手动把多条SQL语句作为一个事务执行,使用`BEGIN`开启一个事务,使用`COMMIT`提交一个事务,这种事务被称为*显式事务*,例如,把上述的转账操作作为一个显式事务:\r\n\r\n```\r\nBEGIN;\r\nUPDATE accounts SET balance = balance - 100 WHERE id = 1;\r\nUPDATE accounts SET balance = balance + 100 WHERE id = 2;\r\nCOMMIT;\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.45004802942276,
"alphanum_fraction": 0.4682997167110443,
"avg_line_length": 16.738739013671875,
"blob_id": "bbc4525ef51065b88357b6f039c34840c5cf287b",
"content_id": "0aed762995454da9ec79515720a3dd1ec5d63728",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2530,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 111,
"path": "/interview/others.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "#### Others\r\n\r\n问在pass里面添加代码,使输出123和456\r\n\r\n```c++\r\nvoid pass(){ \r\n} \r\nint main( ) { \r\n\tint x; \r\n\tx = 123; \r\n\tprintf(\"%d \\n\",x); \r\n\tpass(); \r\n\tprintf(\"%d \\n\",x); \r\n\treturn 0; \r\n} \r\n// 123 \r\n// 456\r\n```\r\n\r\n堆栈操作\r\n\r\n堆栈使用一个空间,栈从后往前\r\n\r\n```c++\r\nvoid pass(){\r\n int temp = 0; // 定一个变量为temp\r\n int *p = &temp; // 取temp的地址p\r\n while (*p!=123){// 比较*p和x的值,让p移动到x的地址,\r\n p++;\r\n }\r\n *p = 456; // 修改当前地址的值,也就是x的值。\r\n}\r\n```\r\n\r\n`x`和`temp`都是保存在栈区的,`x`在高地址,`temp`在低地址,所以让temp往上走找就行了。\r\n\r\n```c++\r\nprintf(\"456 \\n\"); \r\nexit(1);\r\n```\r\n\r\n\r\n\r\n简历上的问题:\r\n\r\n做过的项目都说一遍\r\n\r\nlinux常见命令\r\n\r\n\r\n\r\n如何用python实现hashmap即python中dict这个功能\r\n\r\n方法1:\r\n使用TrieTree,例如apple这个单词\r\n\r\na-p-p-l-e这样储存,在e这边储存apple的数值,同时标注其为end节点\r\n\r\n但是这样不好实现,更好的方式是基于hash函数利用广度换速度O(1)put get remove操作\r\n\r\n利用gethash函数得到word的哈希值,利用开链的方式解决冲突问题\r\n\r\n```python\r\nclass ListNode():\r\n def __init__(self,word,value):\r\n self.word=word\r\n self.value=value\r\n self.next=NULL\r\n \r\n\r\n class dict1():\r\n def__init__(self):\r\n self.nodes=[ListNode(\"\",0) for i in range(10000)]\r\n def put(word,value):\r\n key=get_hash(word)\r\n it=self.nodes[key]\r\n while it!=NULL:\r\n if it.word==word:\r\n it.value=value # 实现revise功能 put(apple,2),put(apple,3)\r\n return\r\n else:\r\n it=it.next\r\n it=ListNode(word,value)\r\n \t return\r\n def get(word):\r\n key=get_hash(word)\r\n it=self.nodes[key]\r\n while it!=NULL:\r\n if it.word==word:\r\n return it.value\r\n else:\r\n it=it.next\r\n print(\"no such word\")\r\n return \r\n def remove(word):\r\n key=get_hash(word)\r\n it=self.nodes[key]\r\n if it.word==word:\r\n it=NULL\r\n return\r\n pre,it=it,it.next\r\n while it!=NULL:\r\n if it.word==word:\r\n pre.next=it.next\r\n return\r\n else:\r\n pre=it\r\n it=it.next\r\n return\r\n \r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.5357142686843872,
"alphanum_fraction": 0.5357142686843872,
"avg_line_length": 6.666666507720947,
"blob_id": "7afb95c6c9a4c7bbc6ce313a6d408973ad7460fb",
"content_id": "fe1ab74e2d18a4ee1b504a4fb9629648721b8868",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 60,
"license_type": "no_license",
"max_line_length": 14,
"num_lines": 3,
"path": "/books/others/逆转.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 逆转\r\n\r\n大卫与歌利亚:以弱胜强的故事\r\n\r\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5455604195594788,
"avg_line_length": 23.9212589263916,
"blob_id": "7a33fc8b72ee1151af537bb2ca6be563ecdb5143",
"content_id": "58bda2f2b0f129fdada0576380dce0ea97029575",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 20732,
"license_type": "no_license",
"max_line_length": 346,
"num_lines": 762,
"path": "/leetcode_note/heap.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "栈、队列知识要点与实现(数组、链表)\r\n\r\n\r\n\r\n数组中第K大的数(堆的应用) (LeetCode 215)\r\n\r\n寻找中位数(堆的应用)( LeetCode 295)\r\n\r\n```python\r\nimport heapq\r\nnums = [2,1,5,7,3,6]\r\n\r\nheapq.heapify(nums) #创建堆 都是最小堆\r\nnums[0] #Nums[0]永远表示最小值,类似于top的功能 1\r\n\r\nheapq.heappush(nums,5) #push\r\nheapq.heappop(nums) #弹出最小值\r\n\r\nheapq.nlargest(n , heapq, key=None) \r\nheapq.nsmallest(n , heapq, key=None) \r\n从堆中找出做大的N个数,key的作用和sorted( )方法里面的key类似\r\na = [0, 1, 2, 3, 4, 5, 5, 7, 8, 10, 15, 20, 25]\r\nheapq.nlargest(5,a)\r\n```\r\n\r\n\r\n\r\n##### leetcode 215. Kth Largest Element in an Array\r\n\r\n- Find the **k**th largest element in an unsorted array. Note that it is the kth largest element in the sorted order, not the kth distinct element.\r\n\r\n```\r\nInput: [3,2,1,5,6,4] and k = 2\r\nOutput: 5\r\n\r\nInput: [3,2,3,1,2,4,5,5,6] and k = 4\r\nOutput: 4\r\n\r\n```\r\n\r\n- Mysolution:\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int findKthLargest(vector<int>& nums, int k) {\r\n priority_queue<int,vector<int>,myCmp> num;\r\n int n =nums.size();\r\n for (int i=0;i<n;i++){\r\n num.push(nums[i]);\r\n }\r\n for (int i=0;i<k-1;i++){\r\n num.pop();\r\n }\r\n return num.top();\r\n }\r\n};\r\n```\r\n\r\n找第k个大的数字 使用堆排 priority_queue\r\n\r\n也可以用改良版的快排\r\n\r\n\r\n\r\n##### leetcode 272 Closest Binary Search Tree Value II\r\n\r\nGiven a non-empty binary search tree and a target value, find *k* values in the BST that are closest to the target.\r\n\r\n**Note:**\r\n\r\n- Given target value is a floating point.\r\n- You may assume *k* is always valid, that is: *k* ≤ total nodes.\r\n- You are guaranteed to have only one unique set of *k* values in the BST that are closest to the target.\r\n\r\n**Example:**\r\n\r\n```\r\nInput: root = [4,2,5,1,3], target = 3.714286, and k = 2\r\n\r\n 4\r\n / \\\r\n 2 5\r\n / \\\r\n1 3\r\n\r\nOutput: [4,3]\r\n```\r\n\r\n用两个list存储数组,利用heap,弹出的是最小值,所以小于target的数组我们存其相反数 这样弹出来的就是小于target中的最大值\r\n\r\n```python\r\n\r\nclass Solution:\r\n def find_value(self, root, target):\r\n if not root: return\r\n if root.val <= target:\r\n self.smaller.append(-root.val)\r\n else:\r\n self.bigger.append(root.val)\r\n self.find_value(root.right, target)\r\n self.find_value(root.left, target)\r\n return\r\n def closestKValues(self, root, target, k):\r\n self.bigger = [float(\"inf\")]\r\n self.smaller = [float(\"inf\")]\r\n self.find_value(root, target)\r\n res = []\r\n heapq.heapify(self.bigger)\r\n heapq.heapify(self.smaller)\r\n while k > 0:\r\n if abs(-self.smaller[0]-target) < abs(self.bigger[0]-target):\r\n res.append(-heapq.heappop(self.smaller))\r\n else:\r\n res.append(heapq.heappop(self.bigger))\r\n k -= 1\r\n return res\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 407 Trapping Rain Water II\r\n\r\nHard\r\n\r\nGiven an `m x n` matrix of positive integers representing the height of each unit cell in a 2D elevation map, compute the volume of water it is able to trap after raining.\r\n\r\n**Note:**\r\n\r\nBoth *m* and *n* are less than 110. The height of each unit cell is greater than 0 and is less than 20,000.\r\n\r\n**Example:**\r\n\r\n```\r\nGiven the following 3x6 height map:\r\n[\r\n [1,4,3,1,3,2],\r\n [3,2,1,3,2,4],\r\n [2,3,3,2,3,1]\r\n]\r\n\r\nReturn 4.\r\n```\r\n\r\n\r\n\r\nThe above image represents the elevation map `[[1,4,3,1,3,2],[3,2,1,3,2,4],[2,3,3,2,3,1]]` before the rain.\r\n\r\n\r\n\r\nAfter the rain, water is trapped between the blocks. The total volume of water trapped is 4.\r\n\r\n```python\r\nclass Solution:\r\n\r\n def trapRainWater(self, grid):\r\n \"\"\"\r\n :type heightMap: List[List[int]]\r\n :rtype: int\r\n \"\"\"\r\n if len(grid) == 0:\r\n return 0\r\n m = len(grid)\r\n n = len(grid[0])\r\n heap = []\r\n visit = set()\r\n # init , put surrounding into heap\r\n for i in [0, m - 1]:\r\n for j in range(n):\r\n heap.append((grid[i][j], i, j))\r\n visit.add((i, j))\r\n\r\n for j in [0, n - 1]:\r\n for i in range(1, m-1):\r\n heap.append((grid[i][j], i, j))\r\n visit.add((i, j))\r\n\r\n heapq.heapify(heap)\r\n\r\n dxy = [[0, 1], [1, 0], [0, -1], [-1, 0]]\r\n ans = 0\r\n mx = float('-inf')\r\n\r\n while heap:\r\n\r\n h, x, y = heapq.heappop(heap)\r\n mx = max(h, mx)\r\n\r\n for dx, dy in dxy:\r\n nx = x + dx\r\n ny = y + dy\r\n\r\n if not (0 <= nx < m and 0 <= ny < n):\r\n continue\r\n\r\n if (nx, ny) in visit:\r\n continue\r\n\r\n if mx > grid[nx][ny]:\r\n ans += mx - grid[nx][ny]\r\n\r\n itm = (grid[nx][ny], nx, ny)\r\n heapq.heappush(heap, itm)\r\n visit.add((nx, ny))\r\n\r\n return ans\r\n```\r\n\r\n视频解析:\r\n\r\n<https://www.youtube.com/watch?v=cJayBq38VYw>\r\n\r\n使用heap,将最外围一圈放入heap中,每次弹出heap中最小的值,使用mx记录弹出的最大值,弹出某个位置的值后若其周围格子的点没有被访问过则放入其中 如果弹出的值比mx小 说明这个位置是可以存储雨水的\r\n\r\n\r\n\r\n类似:\r\n\r\n##### leetcode 778 Swim in Rising Water\r\n\r\nOn an N x N `grid`, each square `grid[i][j]` represents the elevation at that point `(i,j)`.\r\n\r\nNow rain starts to fall. At time `t`, the depth of the water everywhere is `t`. You can swim from a square to another 4-directionally adjacent square if and only if the elevation of both squares individually are at most `t`. You can swim infinite distance in zero time. Of course, you must stay within the boundaries of the grid during your swim.\r\n\r\nYou start at the top left square `(0, 0)`. What is the least time until you can reach the bottom right square `(N-1, N-1)`?\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [[0,2],[1,3]]\r\nOutput: 3\r\nExplanation:\r\nAt time 0, you are in grid location (0, 0).\r\nYou cannot go anywhere else because 4-directionally adjacent neighbors have a higher elevation than t = 0.\r\n\r\nYou cannot reach point (1, 1) until time 3.\r\nWhen the depth of water is 3, we can swim anywhere inside the grid.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [[0,1,2,3,4],[24,23,22,21,5],[12,13,14,15,16],[11,17,18,19,20],[10,9,8,7,6]]\r\nOutput: 16\r\nExplanation:\r\n 0 1 2 3 4\r\n24 23 22 21 5\r\n12 13 14 15 16\r\n11 17 18 19 20\r\n10 9 8 7 6\r\n\r\nThe final route is marked in bold.\r\nWe need to wait until time 16 so that (0, 0) and (4, 4) are connected.\r\n```\r\n\r\n**Note:**\r\n\r\n1. `2 <= N <= 50`.\r\n2. grid[i][j] is a permutation of [0, ..., N*N - 1].\r\n\r\n```python\r\nimport heapq\r\nclass Solution:\r\n def swimInWater(self, grid):\r\n n = len(grid)\r\n if n == 0: return 0\r\n visited = [[0 for i in range(n)] for j in range(n)]\r\n max_number = 0\r\n q = [[grid[0][0], 0, 0]]\r\n directions = [[0, 1], [1, 0], [0, -1], [-1, 0]]\r\n visited[0][0] = 1\r\n while len(q)!=0:\r\n heapq.heapify(q)\r\n val, i, j = heapq.heappop(q)\r\n max_number = max(max_number, val)\r\n if i==n-1 and j==n-1: return max_number\r\n for ii, jj in directions:\r\n x = i+ii\r\n y = j+jj\r\n if not(0<=x<n and 0<=y<n):\r\n continue\r\n if visited[x][y] == 0:\r\n visited[x][y] = 1\r\n q.append([grid[x][y], x, y])\r\n return max_number\r\n```\r\n\r\n本题的核心就是找到从左上角到右下角的路径中的最大值,使用queue将初始点放进去,然后弹出grid值最小的邻居,并且记录下最大值max_number,直到弹出右下角的点 表示其被访问到了\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 692. Top K Frequent Words\r\n\r\nGiven a non-empty list of words, return the *k* most frequent elements.\r\n\r\nYour answer should be sorted by frequency from highest to lowest. If two words have the same frequency, then the word with the lower alphabetical order comes first.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [\"i\", \"love\", \"leetcode\", \"i\", \"love\", \"coding\"], k = 2\r\nOutput: [\"i\", \"love\"]\r\nExplanation: \"i\" and \"love\" are the two most frequent words.\r\n Note that \"i\" comes before \"love\" due to a lower alphabetical order.\r\n```\r\n\r\n\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [\"the\", \"day\", \"is\", \"sunny\", \"the\", \"the\", \"the\", \"sunny\", \"is\", \"is\"], k = 4\r\nOutput: [\"the\", \"is\", \"sunny\", \"day\"]\r\nExplanation: \"the\", \"is\", \"sunny\" and \"day\" are the four most frequent words,\r\n with the number of occurrence being 4, 3, 2 and 1 respectively.\r\n```\r\n\r\n**Note:**\r\n\r\n1. You may assume *k* is always valid, 1 ≤ *k* ≤ number of unique elements.\r\n2. Input words contain only lowercase letters.\r\n\r\n```python\r\nclass Solution(object):\r\n def topKFrequent(self, words, k):\r\n \"\"\"\r\n :type words: List[str]\r\n :type k: int\r\n :rtype: List[str]\r\n \"\"\"\r\n import collections,heapq \r\n dic=collections.defaultdict(int)\r\n heap=[]\r\n for word in words:\r\n dic[word]+=1\r\n for key,val in dic.items():\r\n heapq.heappush(heap,(-val,key))\r\n\r\n res=[]\r\n while k:\r\n va,key=heapq.heappop(heap)\r\n res+=key,\r\n k-=1\r\n \t \treturn res\r\n```\r\n\r\n1.统计频率 2.构建heap(按照频率)3.弹出k次\r\n\r\n\r\n\r\n##### leetcode 239 Sliding Window Maximum\r\n\r\n* Given an array *nums*, there is a sliding window of size *k* which is moving from the very left of the array to the very right. You can only see the *k* numbers in the window. Each time the sliding window moves right by one position. Return the max sliding window.\r\n\r\n```\r\nInput: nums = [1,3,-1,-3,5,3,6,7], and k = 3\r\nOutput: [3,3,5,5,6,7] \r\nExplanation: \r\n\r\nWindow position Max\r\n--------------- -----\r\n[1 3 -1] -3 5 3 6 7 3\r\n 1 [3 -1 -3] 5 3 6 7 3\r\n 1 3 [-1 -3 5] 3 6 7 5\r\n 1 3 -1 [-3 5 3] 6 7 5\r\n 1 3 -1 -3 [5 3 6] 7 6\r\n 1 3 -1 -3 5 [3 6 7] 7\r\n```\r\n\r\n```python\r\nimport heapq\r\nclass Solution(object):\r\n def maxSlidingWindow(self, nums, k):\r\n \"\"\"\r\n :type nums: List[int]\r\n :type k: int\r\n :rtype: List[int]\r\n \"\"\"\r\n n=len(nums)\r\n if n==0:\r\n return []\r\n ans=[]\r\n heap1=[]\r\n for i in range(k-1):\r\n heapq.heappush(heap1,nums[i])\r\n for i in range(n-k+1):\r\n heap1.append(nums[i+k-1])\r\n ans.append(heapq.nlargest(1,heap1)[0])\r\n heap1.remove(nums[i])\r\n return ans\r\n```\r\n\r\nO(N)\r\n\r\nheap append,remove,以及找maxelement操作都是O(1)\r\n\r\n\r\n\r\n##### leetcode 295 Find Median from Data Stream\r\n\r\nMedian is the middle value in an ordered integer list. If the size of the list is even, there is no middle value. So the median is the mean of the two middle value.\r\n\r\nFor example,\r\n\r\n```\r\n[2,3,4]`, the median is `3\r\n[2,3]`, the median is `(2 + 3) / 2 = 2.5\r\n```\r\n\r\nDesign a data structure that supports the following two operations:\r\n\r\n- void addNum(int num) - Add a integer number from the data stream to the data structure.\r\n- double findMedian() - Return the median of all elements so far.\r\n\r\n```python\r\nfrom heapq import *\r\n\r\n\r\nclass MedianFinder:\r\n def __init__(self):\r\n self.small = [] # the smaller half of the list, max heap (invert min-heap)\r\n self.large = [] # the larger half of the list, min heap\r\n\r\n def addNum(self, num):\r\n if len(self.small) == len(self.large):\r\n heappush(self.large, -heappushpop(self.small, -num))\r\n else:\r\n heappush(self.small, -heappushpop(self.large, num))\r\n\r\n def findMedian(self):\r\n if len(self.small) == len(self.large):\r\n return float(self.large[0] - self.small[0]) / 2.0\r\n else:\r\n return float(self.large[0])\r\n```\r\n\r\n用两个堆来记数\r\n\r\n常见的堆都是min-heap,要用最大堆需要invert min-heap\r\n\r\n\r\n\r\n##### leetcode 1054. Distant Barcodes\r\n\r\nIn a warehouse, there is a row of barcodes, where the `i`-th barcode is `barcodes[i]`.\r\n\r\nRearrange the barcodes so that no two adjacent barcodes are equal. You may return any answer, and it is guaranteed an answer exists. \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [1,1,1,2,2,2]\r\nOutput: [2,1,2,1,2,1]\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [1,1,1,1,2,2,3,3]\r\nOutput: [1,3,1,3,2,1,2,1]\r\n```\r\n\r\n**Note:**\r\n\r\n1. `1 <= barcodes.length <= 10000`\r\n2. `1 <= barcodes[i] <= 10000`\r\n\r\n```python\r\nclass Solution:\r\n def rearrangeBarcodes(self, barcodes):\r\n count = collections.Counter(barcodes)\r\n res = []\r\n q = []\r\n for item, val in count.items():\r\n q.append([-val, item])\r\n heapq.heapify(q)\r\n while q:\r\n val, item = heapq.heappop(q)\r\n if len(res) == 0 or res[-1]!=item:\r\n res.append(item)\r\n if val != -1:\r\n heapq.heappush(q, [val + 1, item])\r\n else:\r\n val2, item2 = heapq.heappop(q)\r\n heapq.heappush(q, [val, item])\r\n res.append(item2)\r\n if val2 != -1:\r\n heapq.heappush(q, [val2 + 1, item2])\r\n return res\r\n```\r\n\r\n最有利的就是先把目前剩的最多的元素放进去,但是要做个判断如果前一个就是这个元素,就放目前第二多的元素\r\n\r\n\r\n\r\n##### 1341. The K Weakest Rows in a Matrix\r\n\r\n```\r\nGiven a m * n matrix mat of ones (representing soldiers) and zeros (representing civilians), return the indexes of the k weakest rows in the matrix ordered from the weakest to the strongest.\r\n\r\nA row i is weaker than row j, if the number of soldiers in row i is less than the number of soldiers in row j, or they have the same number of soldiers but i is less than j. Soldiers are always stand in the frontier of a row, that is, always ones may appear first and then zeros.\r\n\r\n \r\n\r\nExample 1:\r\n\r\nInput: mat = \r\n[[1,1,0,0,0],\r\n [1,1,1,1,0],\r\n [1,0,0,0,0],\r\n [1,1,0,0,0],\r\n [1,1,1,1,1]], \r\nk = 3\r\nOutput: [2,0,3]\r\nExplanation: \r\nThe number of soldiers for each row is: \r\nrow 0 -> 2 \r\nrow 1 -> 4 \r\nrow 2 -> 1 \r\nrow 3 -> 2 \r\nrow 4 -> 5 \r\nRows ordered from the weakest to the strongest are [2,0,3,1,4]\r\nExample 2:\r\n\r\nInput: mat = \r\n[[1,0,0,0],\r\n [1,1,1,1],\r\n [1,0,0,0],\r\n [1,0,0,0]], \r\nk = 2\r\nOutput: [0,2]\r\nExplanation: \r\nThe number of soldiers for each row is: \r\nrow 0 -> 1 \r\nrow 1 -> 4 \r\nrow 2 -> 1 \r\nrow 3 -> 1 \r\nRows ordered from the weakest to the strongest are [0,2,3,1]\r\n```\r\n\r\n```python\r\nimport heapq\r\nclass Solution:\r\n def kWeakestRows(self, mat: List[List[int]], k: int) -> List[int]:\r\n nums = []\r\n n, m = len(mat), len(mat[0])\r\n for i in range(n):\r\n num = sum(mat[i])\r\n heapq.heappush(nums, ([num, i]))\r\n k_small = heapq.nsmallest(k, nums)\r\n return [x[1] for x in k_small]\r\n```\r\n\r\n\r\n\r\n##### 1342. Reduce Array Size to The Half\r\n\r\nGiven an array `arr`. You can choose a set of integers and remove all the occurrences of these integers in the array.\r\n\r\nReturn *the minimum size of the set* so that **at least** half of the integers of the array are removed.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: arr = [3,3,3,3,5,5,5,2,2,7]\r\nOutput: 2\r\nExplanation: Choosing {3,7} will make the new array [5,5,5,2,2] which has size 5 (i.e equal to half of the size of the old array).\r\nPossible sets of size 2 are {3,5},{3,2},{5,2}.\r\nChoosing set {2,7} is not possible as it will make the new array [3,3,3,3,5,5,5] which has size greater than half of the size of the old array.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: arr = [7,7,7,7,7,7]\r\nOutput: 1\r\nExplanation: The only possible set you can choose is {7}. This will make the new array empty.\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: arr = [1,9]\r\nOutput: 1\r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: arr = [1000,1000,3,7]\r\nOutput: 1\r\n```\r\n\r\n**Example 5:**\r\n\r\n```\r\nInput: arr = [1,2,3,4,5,6,7,8,9,10]\r\nOutput: 5\r\n```\r\n\r\n**Constraints:**\r\n\r\n- `1 <= arr.length <= 10^5`\r\n- `arr.length` is even.\r\n- `1 <= arr[i] <= 10^5`\r\n\r\n```python\r\nclass Solution:\r\n def minSetSize(self, arr: List[int]) -> int:\r\n target = int(len(arr) / 2)\r\n times = collections.defaultdict(int)\r\n for num in arr:\r\n times[num] += 1\r\n nums = []\r\n for item, val in times.items():\r\n heapq.heappush(nums, -val)\r\n count = 0\r\n while target > 0:\r\n target += heapq.heappop(nums)\r\n count += 1\r\n return count\r\n```\r\n\r\n\r\n\r\n##### 1102. Path With Maximum Minimum Value\r\n\r\nGiven a matrix of integers `A` with R rows and C columns, find the **maximum** score of a path starting at `[0,0]` and ending at `[R-1,C-1]`.\r\n\r\nThe *score* of a path is the **minimum** value in that path. For example, the value of the path 8 → 4 → 5 → 9 is 4.\r\n\r\nA *path* moves some number of times from one visited cell to any neighbouring unvisited cell in one of the 4 cardinal directions (north, east, west, south).\r\n\r\n**Example 1:**\r\n\r\n****\r\n\r\n```\r\nInput: [[5,4,5],[1,2,6],[7,4,6]]\r\nOutput: 4\r\nExplanation: \r\nThe path with the maximum score is highlighted in yellow. \r\n```\r\n\r\n**Example 2:**\r\n\r\n****\r\n\r\n```\r\nInput: [[2,2,1,2,2,2],[1,2,2,2,1,2]]\r\nOutput: 2\r\n```\r\n\r\n**Example 3:**\r\n\r\n****\r\n\r\n```\r\nInput: [[3,4,6,3,4],[0,2,1,1,7],[8,8,3,2,7],[3,2,4,9,8],[4,1,2,0,0],[4,6,5,4,3]]\r\nOutput: 3\r\n```\r\n\r\n**Note:**\r\n\r\n1. `1 <= R, C <= 100`\r\n2. `0 <= A[i][j] <= 10^9`\r\n\r\n\r\n\r\n```python\r\nimport heapq\r\nclass Solution: \r\n def maximumMinimumPath(self, A: List[List[int]]) -> int:\r\n n, m = len(A), len(A[0])\r\n visited = [[0 for i in range(m)] for j in range(n)]\r\n visited[n-1][m-1] = 1\r\n q = [[-A[n-1][m-1], n-1, m-1]]\r\n heapq.heapify(q)\r\n while q:\r\n score, i, j = heapq.heappop(q)\r\n if i == 0 and j == 0: return -score\r\n dirs = [[-1, 0], [1, 0], [0, 1], [0, -1]]\r\n for ii, jj in dirs:\r\n if 0 <= i+ii < n and 0 <= j+jj < m and visited[i+ii][j+jj] == 0:\r\n visited[i+ii][j+jj] = 1\r\n temp = max(-A[i+ii][j+jj], score)\r\n heapq.heappush(q, [temp, i+ii, j+jj])\r\n return\r\n \r\n \r\n```\r\n\r\n有趣的是 反过来走一般会更快一些\r\n\r\n可能的原因是出题者可能更习惯于将需要绕着走的部分设置在start节点附近\r\n\r\n保持优先队列,score表示走到这里时路径中的最小值\r\n\r\n\r\n\r\n##### leetcode \\1091. Shortest Path in Binary Matrix\r\n\r\nIn an N by N square grid, each cell is either empty (0) or blocked (1).\r\n\r\nA *clear path from top-left to bottom-right* has length `k` if and only if it is composed of cells `C_1, C_2, ..., C_k` such that:\r\n\r\n- Adjacent cells `C_i` and `C_{i+1}` are connected 8-directionally (ie., they are different and share an edge or corner)\r\n- `C_1` is at location `(0, 0)` (ie. has value `grid[0][0]`)\r\n- `C_k` is at location `(N-1, N-1)` (ie. has value `grid[N-1][N-1]`)\r\n- If `C_i` is located at `(r, c)`, then `grid[r][c]` is empty (ie. `grid[r][c] == 0`).\r\n\r\nReturn the length of the shortest such clear path from top-left to bottom-right. If such a path does not exist, return -1.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [[0,1],[1,0]]\r\n\r\n\r\nOutput: 2\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [[0,0,0],[1,1,0],[1,1,0]]\r\n\r\n\r\nOutput: 4\r\n```\r\n\r\n**Note:**\r\n\r\n1. `1 <= grid.length == grid[0].length <= 100`\r\n2. `grid[r][c]` is `0` or `1`\r\n\r\n```python\r\nclass Solution:\r\n def shortestPathBinaryMatrix(self, grid: List[List[int]]) -> int:\r\n if grid[0][0] == 1: return -1 \r\n n = len(grid)\r\n q, seen = [[1, 0, 0]], set()\r\n seen.add((0, 0))\r\n heapq.heapify(q)\r\n dirs = [[-1, -1], [-1, 0], [-1, 1], [0, -1], [1, 0],[0, 1], [1, -1], [1, 1]]\r\n while q:\r\n length, i, j = heapq.heappop(q)\r\n if i == n-1 and j == n-1: return length\r\n for ii, jj in dirs:\r\n if 0 <= i+ii < n and 0 <= j+jj < n and grid[i+ii][j+jj] == 0 and (i+ii, j+jj) not in seen:\r\n seen.add((i+ii, j+jj))\r\n heapq.heappush(q, [length+1, i+ii, j+jj])\r\n return -1\r\n \r\n \r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.769784152507782,
"alphanum_fraction": 0.769784152507782,
"avg_line_length": 28.55555534362793,
"blob_id": "a3f6162c297af7db1dbd30ee4f041292f7c4001b",
"content_id": "cd78e07f1a4c885319a36a201b7fcde8d26624a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 278,
"license_type": "no_license",
"max_line_length": 158,
"num_lines": 9,
"path": "/papers/Deepwalk.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Deepwalk\r\n\r\nDeepwalk: online learning of social representations\r\n\r\nget node features by transforming the graph into a lower dimensional latent representation using the deep learning techniques developed for language modeling.\r\n\r\n\r\n\r\n##### Short random walks = sentences \r\n\r\n"
},
{
"alpha_fraction": 0.5096067786216736,
"alphanum_fraction": 0.5630027055740356,
"avg_line_length": 9.91978645324707,
"blob_id": "6cfe6590dad26966e85778349166f79ede07badb",
"content_id": "f719b1f0e368692244b1446b964c18b0e1f952f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5694,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 374,
"path": "/正则表达式.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 正则表达式\r\n\r\npython中使用re模块\r\n\r\n匹配与搜索\r\n\r\n匹配re.match()\r\n\r\n从第一个字符开始找,如果第一个字符不匹配就返回None 不继续匹配,速度快\r\n\r\n搜索re.search()\r\n\r\n如果第一个字符不匹配,会继续寻找直到找到一个匹配\r\n\r\n\r\n\r\n\r\n\r\n##### 特殊字符\r\n\r\nliteral 字面匹配\r\n\r\n```python\r\ns=\"1something\"\r\nre.search('some',s).group()\r\n'some'\r\n```\r\n\r\nre1|re2 或\r\n\r\n```python\r\ns=\"1something\"\r\npattern = \"some|1some\"\r\nre.search(pattern,s).group()\r\n'1some'\r\n```\r\n\r\n. 匹配任何字符\r\n\r\n```python\r\ns='abcdefg'\r\npattern='b.d'\r\nre.search(pattern,s).group()\r\n'bcd'\r\n```\r\n\r\n^ 字符串的起始部分\r\n\r\n```python\r\ns='abcdefg'\r\npattern='^b.d'\r\nre.search(pattern,s).group()\r\nNone\r\n```\r\n\r\n$ 终止部分\r\n\r\n```python\r\ns='abcdefg'\r\npattern='e.g$'\r\nre.search(pattern,s).group()\r\n'efg'\r\n```\r\n\r\n*匹配前面出现的0次或者多次的正则表达式\r\n\r\n```python\r\ns='111222'\r\npattern='1*'\r\nre.search(pattern,s).group()\r\n'111'\r\n```\r\n\r\n+匹配前面出现的1次或者多次的正则表达式\r\n\r\n```python\r\ns='111222'\r\npattern='1+'\r\nre.search(pattern,s).group()\r\n'111'\r\n```\r\n\r\n\r\n\r\n?匹配一次或者0次前面出现的正则表达式\r\n\r\n```python\r\ns='111222'\r\npattern='1?'\r\nre.search(pattern,s).group()\r\n'1'\r\n```\r\n\r\n{N} 匹配N次前面出现的正则表达式\r\n\r\n```python\r\ns='111222'\r\npattern='1{3}'\r\nre.search(pattern,s).group()\r\n'111'\r\n```\r\n\r\n{M,N}匹配N-M次前面出现的正则表达式\r\n\r\n```python\r\ns='111222'\r\npattern='1{3,4}'\r\nre.search(pattern,s).group()\r\n'111'\r\n```\r\n\r\n[...]匹配来自字符集的任意单一字符\r\n\r\n```python\r\ns='111222'\r\npattern='[12345]'\r\nre.search(pattern,s).group()\r\n'1'\r\n```\r\n\r\n[...x-y...]匹配x-y的范围内的任意单一字符\r\n\r\n```python\r\ns='111222'\r\npattern='[1-5,a]'\r\nre.search(pattern,s).group()\r\n'1'\r\n\r\ns=\"a12345\"\r\nre.search(pattern,s).group()\r\n'a'\r\n```\r\n\r\n[^....]不匹配这个字符集中出现的字符\r\n\r\n```python\r\ns=\"123456\"\r\npattern='[^1-5]'\r\nre.search(pattern,s).group()\r\n'6'\r\n```\r\n\r\n(...)匹配封闭的表达式,另存为子组\r\n\r\n```python\r\ns=\"123123\"\r\npattern='([123]){3}'\r\nre.search(pattern,s).group()\r\n'123'\r\n```\r\n\r\n\\d 任何十进制字符,与[0-9]等价\r\n\r\n```python\r\ns='123'\r\npattern='\\d'\r\nre.search(pattern,s).group()\r\n'1'\r\n```\r\n\r\n\\w 任何字符数字,与[A-Za-z0-9]\r\n\r\n\\s匹配任何空的字符,[\\n\\t\\r\\v\\f]相同\r\n\r\n使用转义符\r\n\r\n```python\r\ns=\"12...\"\r\npattern='\\.'\r\nre.search(pattern,s).group()\r\n'.'\r\n```\r\n\r\n字符集\r\n\r\n```\r\n[cr][12][cr][12]\r\n```\r\n\r\n第一个字符是c或r\r\n\r\n第二个字符是1或2\r\n\r\n第三个字符是c或r\r\n\r\n第四个字符是1或2\r\n\r\n\r\n\r\n```python\r\ns='a123-1-1'\r\npattern='.+(\\d+-\\d+-\\d+)'\r\nre.search(pattern,s).group()\r\n'a123-1-1'\r\nre.match(pattern,s).group()\r\n'a123-1-1'\r\n```\r\n\r\n\r\n\r\nre模块的函数\r\n\r\ncompile\r\n\r\n编译正则表达式的模式,返回一个正则表达式的对象\r\n\r\n```python\r\nprog = re.compile(pattern)\r\nresult = prog.match(string)\r\n```\r\n\r\n\r\n\r\nsearch() match()\r\n\r\n```python\r\nre.match('foo','seafood') None\r\nre.search('foo','seafood') 'foo'\r\n```\r\n\r\n\r\n\r\nfindall()函数与finditer()函数\r\n\r\n```python\r\ns=\"this and that\"\r\nre.findall(\"th\\w+\",s)\r\n['this', 'that']\r\n\r\nit=re.finditer(\"th\\w+\",s,re.I)\r\nit.next().group()\r\n'this'\r\nit.next().group()\r\n'that'\r\n```\r\n\r\n\r\n\r\ngroup()函数与groups()函数\r\n\r\n```python\r\np=re.compile('\\d-\\d-\\d')\r\nm=p.match('2-3-1')\r\nm.groups()\r\n()\r\nm.group()\r\n'2-3-1'\r\nm.group(0)\r\n'2-3-1'\r\nm.group(1)\r\nTraceback (most recent call last)\r\n File \"<stdin>\", line 1, in <module>\r\nIndexError: no such group\r\n\r\np=re.compile('(\\d)-(\\d)-(\\d)')\r\nm.groups()\r\n()\r\nm=p.match('2-3-1')\r\nm.groups()\r\n('2', '3', '1')\r\nm.group()\r\n'2-3-1'\r\nm.group(0)\r\n'2-3-1'\r\nm.group(1)\r\n'2'\r\nm.group(2)\r\n'3'\r\nm.group(3)\r\n'1'\r\n```\r\n\r\n\r\n\r\nsub函数与subn函数\r\n\r\n```python\r\nre.sub('[ae]','X','abcdefg')\r\n'XbcdXfg'\r\nre.subn('[ae],'X','abcdefg')\r\n('XbcdXfg',2)\r\n```\r\n\r\n\r\n\r\n\r\n\r\n贪婪匹配 非贪婪匹配\r\n\r\n```python\r\ns=\"this is a that 123-1-1\"\r\npattern='\\d+-\\d+-\\d+'\r\nre.search(pattern,s).group()\r\n'123-1-1'\r\n只能匹配到123-1-1\r\n\r\n\r\n.+ 表示0个或多个任意字符,这些字符不一定要相同\r\npattern='.+\\d+-\\d+-\\d+'\r\nre.search(pattern,s).group()\r\n'this is a that 123-1-1'\r\n\r\npattern='.+(\\d+-\\d+-\\d+)'\r\nre.search(pattern,s).group(1)\r\n'3-1-1'\r\nre.search(pattern,s).group(0)\r\n'this is a that 12'\r\n\r\n\r\npattern='.+?(\\d+-\\d+-\\d+)'\r\nre.search(pattern,s).group(1)\r\n'123-1-1'\r\nre.search(pattern,s).group(0)\r\n'this is a that 123-1-1'\r\n```\r\n\r\n.+是贪婪匹配 会将尽可能多的字符匹配给它\r\n\r\n后面加上?表示.+?是非贪婪匹配\r\n\r\n\r\n\r\n\r\n\r\nfind 指令\r\n\r\nfind -path -type regex\r\n\r\n```shell\r\nfind . -name \"result_[0-9].txt\"\r\n```\r\n\r\n表示在当前文件夹下搜索result_0.txt-result_9.txt的文件\r\n\r\n\r\n\r\n```shell\r\nfind . -type f -exec cat {} \\;>all_files.txt\r\n```\r\n\r\n合并文件夹下所有的文件\r\n\r\n\r\n\r\nfind后面可以根据name搜索 可以根据type搜索不同的文件\r\n\r\n不过这些命令后面跟的正则表达式不是标准正则,例如不能识别如下命令:\r\n\r\n```shell\r\nfind . -name \"result_\\([0-9]\\|[1-2][0-9]\\).txt\"\r\n```\r\n\r\n\r\n\r\n需要使用标准正则表达式应该使用-regex\r\n\r\n```shell\r\nfind . -regex \".*/result_\\([0-9]\\|[1-2][0-9]\\).txt\"\r\n```\r\n\r\n寻找result0.txt-result29.txt的文件\r\n\r\n值得注意的是 -regex将会从路径开始匹配,不是从文件名开始匹配,因此需要在result前面加上.*/\r\n\r\n\r\n\r\nfind找到文件后可以使用-exec 执行\r\n\r\n```shell\r\nfind . -regex \".*/result_\\([0-9]\\|[1-2][0-9]\\).txt\" -exec cat {} \\; >\r\n../all_data4.txt \r\n```\r\n\r\n执行将找到的文件合并的操作,-exec 需要有一个;作为结尾,前面应该有转义符,同时前面要有空格。\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.49967846274375916,
"alphanum_fraction": 0.517041802406311,
"avg_line_length": 20.507246017456055,
"blob_id": "63e7fa0ae05bf2d8b33d44d9ec8eb8829633e582",
"content_id": "4870eb3f338947e418d1138d6ecb1a9894b433af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1691,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 69,
"path": "/leetcode_note/Segment tree.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "线段树与树状数组\r\n\r\n线段树与树状数组的应用(LeetCode 307)\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 307 Range Sum Query - Mutable\r\n\r\nGiven an integer array *nums*, find the sum of the elements between indices *i* and *j* (*i* ≤ *j*), inclusive.\r\n\r\nThe *update(i, val)* function modifies *nums* by updating the element at index *i* to *val*.\r\n\r\n**Example:**\r\n\r\n```\r\nGiven nums = [1, 3, 5]\r\n\r\nsumRange(0, 2) -> 9\r\nupdate(1, 2)\r\nsumRange(0, 2) -> 8\r\n```\r\n\r\n**Note:**\r\n\r\n1. The array is only modifiable by the *update* function.\r\n2. You may assume the number of calls to *update* and *sumRange* function is distributed evenly.\r\n\r\n```c++\r\nclass NumArray {\r\npublic:\r\n NumArray(vector<int> &nums) {\r\n array = vector<int>(nums.begin(), nums.end());\r\n int len = array.size(), tmpSum = 0;\r\n for (int i = 0; i < len; ++i)\r\n {\r\n tmpSum += array[i];\r\n allSum.push_back(tmpSum);\r\n }//for\r\n }\r\n\r\n void update(int i, int val) {\r\n if (i < 0 || i >= array.size())\r\n return;\r\n int tmp = val - array[i];\r\n array[i] = val;\r\n for (; i < array.size(); ++i)\r\n allSum[i] += tmp; \r\n }\r\n\r\n int sumRange(int i, int j) {\r\n if (i < 0 || i >= array.size() || j<0 || j >= array.size() || i>j)\r\n return 0;\r\n if (0 == i)\r\n return allSum[j];\r\n else\r\n return allSum[j] - allSum[i - 1];\r\n }\r\n\r\nprivate:\r\n vector<int> array;\r\n vector<int> allSum;\r\n};\r\n```\r\n\r\n常规方法,先求一个accumulate数组出来,要update就把所有和数组中的元素也update\r\n\r\n可以用高级方法例如线段树或者树冠装数组解决\r\n\r\n"
},
{
"alpha_fraction": 0.475220263004303,
"alphanum_fraction": 0.5110132098197937,
"avg_line_length": 10.865248680114746,
"blob_id": "e79c78143e0215e654a5d6dfd91e51024ca9f56e",
"content_id": "2cffa03af8b2f655df783b135f28b784d50e0b17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1946,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 141,
"path": "/leetcde_note_cpp/cpp.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### c++中传参函数\r\n\r\nc++中string类\r\n\r\n类型也是可以改变的,\r\n\r\n```c++\r\nint change(string& nums) {\r\n\tnums = \"abc\";\r\n\treturn 0;\r\n}\r\nint change(vector<int>& nums) {\r\n\tnums[0] = 2;\r\n\treturn 0;\r\n}\r\n```\r\n\r\n传指针,nums对象改变\r\n\r\n\r\n\r\n```c++\r\nint change(string nums) {\r\n\tnums = \"abc\";\r\n\treturn 0;\r\n}\r\nint change(vector<int> nums) {\r\n\tnums[0] = 2;\r\n\treturn 0;\r\n}\r\n```\r\n\r\n传数值,对象不改变\r\n\r\n\r\n\r\n\r\n\r\n##### map\r\n\r\n```c++\r\n#include <iostream>\r\n#include <map>\r\nusing namespace std;\r\nint main() {\r\n\tmap<int, int> m1;\r\n\tm1[1] = 11;\r\n\tfor (auto c : m1) {\r\n\t\tcout << c.first << \" \" << c.second;\r\n\t}\r\n}\r\n\r\nint main() {\r\n\tmap<vector<int>, vector<int>> m1;\r\n\tvector<int> c = { 1,2,3 }, cc = {11, 12, 13};\r\n\tm1[c] = cc;\r\n\tfor (auto c : m1) {\r\n\t\tcout << c.first[0] << \" \" << c.second[0];\r\n\t}\r\n\tsystem(\"pause\");\r\n}\r\n```\r\n\r\n可以实现vector-vector 底层是红黑树\r\n\r\n##### unordered_map\r\n\r\n```\r\n#include <unordered_map>\r\nusing namespace std;\r\nint main() {\r\n\tunordered_map <int, vector<int>> m1;\r\n\tvector<int> c = { 1,2,3 }, cc = {11, 12, 13};\r\n\tm1[0] = cc;\r\n\tfor (auto c : m1) {\r\n\t\tcout << c.first << \" \" << c.second[0];\r\n\t}\r\n\tsystem(\"pause\");\r\n}\r\n```\r\n\r\nunordered_map底层为hash 不能用vector做键值\r\n\r\nc++中不支持hash (vector tuple pair)\r\n\r\n\r\n\r\n##### set\r\n\r\n```c++\r\n#include <set>\r\nusing namespace std;\r\nint main() {\r\n\tset <int> s1;\r\n\ts1.insert(1);\r\n\ts1.insert(0);\r\n\ts1.erase(1);\r\n\tfor (auto c : s1) {\r\n\t\tcout << c;\r\n\t}\r\n}\r\n\r\nusing namespace std;\r\nint main() {\r\n\tset <pair<int, int>> s1;\r\n\ts1.insert(make_pair(1, 1));\r\n\ts1.insert(make_pair(0, 0));\r\n\ts1.erase(make_pair(1, 1));\r\n}\r\n```\r\n\r\n表示in\r\n\r\n```\r\nif (set1.find(x) != set1.end()){\r\n \r\n}\r\n```\r\n\r\n\r\n\r\nmax min int:\r\n\r\n```\r\nINT_MAX, INT_MIN\r\n```\r\n\r\n\r\n\r\n全局变量\r\n\r\n```c++\r\nclass WordDistance {\r\nmap<string, vector<int>> m1;\r\npublic:\r\n WordDistance(vector<string>& words) {\r\n }\r\n int shortest(string word1, string word2) {\r\n }\r\n};\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.5587629079818726,
"alphanum_fraction": 0.6178694367408752,
"avg_line_length": 15.457831382751465,
"blob_id": "7ace436f15f8e7006f00b454177a6205e6dc0318",
"content_id": "c054e40c9164bba75221f94f4c100ad2e3ddd3f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1515,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 83,
"path": "/python/opencv.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "open image:\r\n```\r\n Image.open(filename)\r\n```\r\nRGB image and gray image:\r\n```\r\nimg1 = img0.convert(\"L\")\r\nimg0 = img1.convert(\"RGB\")\r\n```\r\nimage resize:\r\n```\r\nimg0 = img0.resize((512,512))\r\n```\r\n\r\nchoose a region of the image:\r\n```\r\nbox = (100, 100, 400, 400)\r\nregion = im.crop(box)\r\n```\r\n区域由一个4元组定义,表示为坐标是 (left, upper, right, lower)。\r\n\r\ntwo pictures blend together:\r\n```\r\nimg3 = Image.blend(img0, img2, 0.4)\r\n```\r\n\r\nstitch two picture together:\r\n```\r\n image = Image.new('RGB',(512*3,512*1))\r\n image.paste(img2,(0,0))\r\n image.paste(img0,(512,0))\r\n image.paste(img3,(512*2,0))\r\n```\r\nselect ROI of image selectRect function and setonMouse\r\n必须执行:\r\n```\r\n Mat frame\r\n Rect selectRect=selectROI(\"ball\", frame);\r\n\timshow(\"ROI\", frame(selectRect));\r\n```\r\n\r\n中断:\r\n```\r\nvoid onMouse(int event,int x,int y,int,void*){\r\n namedWindow(\"camera\",1);\r\n setMouseCallback(\"camera\",onMouse,0);\r\n}\r\n```\r\n\r\nImage 模块:\r\n```\r\nfrom PIL import Image\r\nim= Image.open(\"test.png\")\r\nim.size\r\nim.show()\r\nim.save()\r\n```\r\n\r\ncv2模块:\r\n```\r\ncv2.imread()\r\ncv2.imshow()\r\ncv2.imwrite()\r\n```\r\n\r\n\r\n\r\nimage_overlap\r\n\r\n```\r\nimport cv2\r\nimg1=cv2.imread(img1.jpg\")\r\ncv2.imshow('img1',img1)\r\nimg2=cv2.imread(\"img2.jpg\")\r\ncv2.imshow('img2',img2)\r\n\r\nshape=img1.shape\r\nprint(\"shape\",shape)\r\nimg_new=cv2.resize(img2,(shape[1],shape[0]),interpolation=cv2.INTER_CUBIC)\r\ncv2.imshow('img_new',img_new)\r\nimg_mix = cv2.addWeighted(img1, 0.5, img_new, 0.5, 0)\r\ncv2.imshow(\"img_mix\",img_mix)\r\n```\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.4499332308769226,
"alphanum_fraction": 0.6395193338394165,
"avg_line_length": 15.372093200683594,
"blob_id": "315aa5aed2b534abfffeb6a38411baa48c8059c9",
"content_id": "79fa0a76e82ae147e2fe93ccb9097958d6d80af0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 781,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 43,
"path": "/python/python效率.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### 构造list\r\n\r\n\r\n\r\n```python\r\nstart_time = time.time()\r\ntest1 = [0 for i in range(100000000)]\r\nend_time = time.time()\r\nprint(end_time - start_time)\r\n\r\nstart1_time = time.time()\r\ntest2 = np.zeros(100000000)\r\nend1_time = time.time()\r\nprint(end1_time - start1_time)\r\n\r\n6.414020776748657\r\n0.0019986629486083984\r\n\r\n```\r\n\r\n显然使用np.zeros快得多\r\n\r\n\r\n\r\n##### 求和\r\n\r\n```python\r\nstart1_time = time.time()\r\nsum(test2[i] for i in range(1, 100000000, 2))\r\nend1_time = time.time()\r\nprint(end1_time - start1_time)\r\nsum1 = 0\r\nstart1_time = time.time()\r\nfor i in range(1, 100000000, 2):\r\n sum1 += test2[i]\r\nend1_time = time.time()\r\nprint(end1_time - start1_time)\r\n\r\n10.446698427200317\r\n11.892154932022095\r\n```\r\n\r\nsum(test2[i] for i in range(1, 100000000, 2)) 稍微快一点\r\n\r\n"
},
{
"alpha_fraction": 0.5016655921936035,
"alphanum_fraction": 0.5391594171524048,
"avg_line_length": 21.789207458496094,
"blob_id": "834c14762b0fa19d42505dbd3fdef8125d510722",
"content_id": "0144f671d3f55b36ed22f6f65b04bd9ecfcb78ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 15021,
"license_type": "no_license",
"max_line_length": 313,
"num_lines": 593,
"path": "/leetcde_note_cpp/Binary_search.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### Binary_search\r\n\r\n必须要用在sort后的数组中使用upper_bound与lower_bound\r\n\r\n从小到大\r\n\r\nupper_bound (大于的数), lower_bound (大于等于的数)\r\n\r\n\r\n\r\n```c++\r\n#include <iostream>\r\n#include <vector>\r\n#include <algorithm>\r\nusing namespace std;\r\nint main() {\r\n\tvector<int> nums = { 2, 1, 5, 3, 4 };\r\n\tsort(nums.begin(), nums.end());\r\n\tint pos = upper_bound(nums.begin(), nums.end(), 2) - nums.begin();\r\n\tcout << pos << \" \";\r\n\tcout << *upper_bound(nums.begin(), nums.end(), 2);\r\n}\r\n```\r\n\r\n如果要找比num小于或者小于等于的数:\r\n\r\n```c++\r\n#include <iostream>\r\n#include <vector>\r\n#include <algorithm>\r\n#include<functional>\r\nusing namespace std;\r\nint cmp(int a, int b) {\r\n\treturn a > b;\r\n}\r\nint main() {\r\n\tvector<int> nums = { 2, 1, 5, 3, 4 };\r\n\tsort(nums.begin(), nums.end(), cmp); 5 4 3 2 1\r\n\tint pos3 = upper_bound(nums.begin(), nums.end(), 2, greater<int>()) - nums.begin();\r\n\tcout << pos3 << \" \"; //输出比2小于的数的位置,lower_bound 小于等于\r\n\t//cout << *upper_bound(nums.begin(), nums.end(), 3, greater<int>());\r\n\tsystem(\"pause\");\r\n}\r\n```\r\n\r\n\r\n\r\n````c++\r\nint upper_bound(vector<int>& nums, int target) {\r\n\tint left = 0, right = nums.size() - 1;\r\n\tint mid;\r\n\twhile (left < right) {\r\n\t\tmid = (left + right) / 2;\r\n\t\tif (nums[mid] == target) return mid;\r\n\t\telse\r\n\t\t\tif (nums[mid] < target) {\r\n\t\t\t\tleft = mid + 1;\r\n\t\t\t}\r\n\t\t\telse {\r\n\t\t\t\tright = mid;\r\n\t\t\t}\r\n\t}\r\n\treturn left;\r\n}\r\n````\r\n\r\n实现binary search\r\n\r\n\r\n\r\n##### leetcode 354 Russian Doll Envelopes\r\n\r\nYou have a number of envelopes with widths and heights given as a pair of integers `(w, h)`. One envelope can fit into another if and only if both the width and height of one envelope is greater than the width and height of the other envelope.\r\n\r\nWhat is the maximum number of envelopes can you Russian doll? (put one inside other)\r\n\r\n**Note:**\r\nRotation is not allowed.\r\n\r\n**Example:**\r\n\r\n```\r\nInput: [[5,4],[6,4],[6,7],[2,3]]\r\nOutput: 3 \r\nExplanation: The maximum number of envelopes you can Russian doll is 3 ([2,3] => [5,4] => [6,7]).\r\n```\r\n\r\nYou can solve this problem in this way :\r\n\r\nlet's suppose the values are given as... $[2,3],[4,6],[3,9],[4,8]$\r\n\r\nIf we **Sort** this envelopes in a tricky way that *Sort the envelopes according to width BUT when the values of height are same, we can sort it in reverse way* like this :\r\n\r\n $[2,3],[3,9],[4,8],[4,6]$\r\n\r\nNow just **Do LIS on the all height values, you will get the answer**\r\n\r\n先按照宽度排,相同宽度 按照高度倒着排\r\n\r\n\r\n\r\n为什么要这样:\r\n\r\n在LIS流程中 如果4,6先出现则 会把collector[1]中的元素改掉,这样等到4,8出现的时候就会出现4,8套着4,6的情况\r\n\r\n\r\n\r\n $[2,3],[3,9],[4,8],[4,6]$ 按照如下代码得到2\r\n\r\n $[2,3],[3,9],[4,6],[4,8]$ 得到3\r\n\r\n\r\n\r\n```\r\nclass Solution {\r\npublic:\r\n int maxEnvelopes(vector<vector<int>>& envelopes){\r\n int size = envelopes.size();\r\n sort(envelopes.begin(), envelopes.end(), [](vector<int> a, vector<int>b){\r\n return a[0]<b[0] || (a[0]==b[0] && a[1]>b[1]);\r\n });\r\n vector<int> collector;\r\n for(auto pair: envelopes){\r\n auto iter = lower_bound(collector.begin(), collector.end(), pair[1]);\r\n if(iter == collector.end()) collector.push_back(pair[1]);\r\n else if(*iter > pair[1]) *iter = pair[1];\r\n }\r\n return collector.size();\r\n }\r\n}; \r\n```\r\n\r\n本问题中有个子问题LIS leetcode 300\r\n\r\n##### leetcode 300 Longest Increasing Subsequence\r\n\r\n- Given an unsorted array of integers, find the length of longest increasing subsequence.\r\n\r\n```\r\nInput: [10,9,2,5,3,7,101,18]\r\nOutput: 4 \r\nExplanation: The longest increasing subsequence is [2,3,7,101], therefore the length is 4.\r\n\r\n```\r\n\r\n**Note:**\r\n\r\n- There may be more than one LIS combination, it is only necessary for you to return the length.\r\n- Your algorithm should run in O(*n2*) complexity.\r\n\r\n\r\n\r\n```python\r\nclass Solution:\r\n def lengthOfLIS(self, nums):\r\n tails = [0] * len(nums)\r\n size = 0\r\n for x in nums:\r\n i, j = 0, size\r\n while i != j:#二分法找比x的lower bound,最小的大于等于x的元素\r\n m = int((i + j) / 2)\r\n if tails[m] < x:\r\n i = m + 1\r\n else:\r\n j = m\r\n tails[i] = x\r\n size = max(i + 1, size)\r\n return size\r\n```\r\n\r\n`tails` is an array storing the smallest tail of all increasing subsequences with length `i+1` in `tails[i]`.\r\nFor example, say we have `nums = [4,5,6,3]`, then all the available increasing subsequences are:\r\n\r\n\r\n\r\n```\r\nlen = 1 : [4], [5], [6], [3] => tails[0] = 3\r\nlen = 2 : [4, 5], [5, 6] => tails[1] = 5\r\nlen = 3 : [4, 5, 6] => tails[2] = 6\r\n\r\n```\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 410 Split Array Largest Sum\r\n\r\nHard\r\n\r\nGiven an array which consists of non-negative integers and an integer *m*, you can split the array into *m* non-empty continuous subarrays. Write an algorithm to minimize the largest sum among these *m* subarrays.\r\n\r\n**Note:**\r\nIf *n* is the length of array, assume the following constraints are satisfied:\r\n\r\n- 1 ≤ *n* ≤ 1000\r\n- 1 ≤ *m* ≤ min(50, *n*)\r\n\r\n\r\n\r\n**Examples:**\r\n\r\n```\r\nInput:\r\nnums = [7,2,5,10,8]\r\nm = 2\r\n\r\nOutput:\r\n18\r\n\r\nExplanation:\r\nThere are four ways to split nums into two subarrays.\r\nThe best way is to split it into [7,2,5] and [10,8],\r\nwhere the largest sum among the two subarrays is only 18.\r\n```\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n bool cansplit(vector<int>& nums, int m, int sum1){\r\n long long n = nums.size(), i = 0, temp = 0, k = 1;\r\n while(i < n){\r\n temp += nums[i];\r\n if(temp<=sum1) i++;\r\n else{\r\n temp = 0; k++;\r\n }\r\n }\r\n if(k<=m) return true;\r\n return false;\r\n }\r\n int splitArray(vector<int>& nums, int m) {\r\n long long left = 0, right = 0, mid;\r\n for(auto num: nums){\r\n left = max(left, (long long)num);\r\n right += num;\r\n }\r\n while (left< right){\r\n mid = (left+right)/2;\r\n if(cansplit(nums, m, mid)){\r\n right = mid;//right一直是可以作为阈值的, left用于逼近\r\n }\r\n else{\r\n left = mid + 1;//mid太小 所以下一个尝试的是mid+1\r\n }\r\n }\r\n return left;\r\n }\r\n}; \r\n```\r\n\r\n正常的思路是把所有k种拆分的方法试一遍找最小值,\r\n\r\n跳出这个思维 我们发现这个每个分组的阈值必然在nums中的最大元素和nums数组和之间\r\n\r\n(注意这边是最大元素而非最小元素,不然可能nums = [1, 219210291920912] 这样TLE\r\n\r\n然后二分法去尝试mid是否可以作为阈值\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 436 Find Right Interval\r\n\r\nGiven a set of intervals, for each of the interval i, check if there exists an interval j whose start point is bigger than or equal to the end point of the interval i, which can be called that j is on the \"right\" of i.\r\n\r\nFor any interval i, you need to store the minimum interval j's index, which means that the interval j has the minimum start point to build the \"right\" relationship for interval i. If the interval j doesn't exist, store -1 for the interval i. Finally, you need output the stored value of each interval as an array.\r\n\r\n**Note:**\r\n\r\n1. You may assume the interval's end point is always bigger than its start point.\r\n2. You may assume none of these intervals have the same start point.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [ [1,2] ]\r\n\r\nOutput: [-1]\r\n\r\nExplanation: There is only one interval in the collection, so it outputs -1.\r\n```\r\n\r\n \r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [ [3,4], [2,3], [1,2] ]\r\n\r\nOutput: [-1, 0, 1]\r\n\r\nExplanation: There is no satisfied \"right\" interval for [3,4].\r\nFor [2,3], the interval [3,4] has minimum-\"right\" start point;\r\nFor [1,2], the interval [2,3] has minimum-\"right\" start point.\r\n```\r\n\r\n \r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: [ [1,4], [2,3], [3,4] ]\r\n\r\nOutput: [-1, 2, -1]\r\n\r\nExplanation: There is no satisfied \"right\" interval for [1,4] and [3,4].\r\nFor [2,3], the interval [3,4] has minimum-\"right\" start point.\r\n```\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n vector<int> findRightInterval(vector<vector<int>>& intervals) {\r\n vector<int> res, start_times;\r\n map<int, int> map1;\r\n int n = intervals.size();\r\n int i, start, end;\r\n for(i=n-1;i>-1;i--){\r\n start = intervals[i][0]; end = intervals[i][1];\r\n start_times.push_back(start);\r\n map1[start] = i;\r\n }\r\n sort(start_times.begin(), start_times.end());\r\n int time;\r\n for(i=0;i<n;i++){\r\n time = intervals[i][1];\r\n auto q = lower_bound(start_times.begin(), start_times.end(), time);\r\n if(q!=start_times.end()) res.push_back(map1[*q]);\r\n else res.push_back(-1);\r\n }\r\n return res;\r\n }\r\n};\r\n```\r\n\r\n把所有的start_time集合起来,然后用lower_bound找到不小于其的最小值,通过map映射到下标,注意一开始反过来这样可以使得map1映射出的下标是所有满足条件中最小的\r\n\r\n\r\n\r\n##### leetcode 719 Find K-th Smallest Pair Distance\r\n\r\nHard\r\n\r\nGiven an integer array, return the k-th smallest **distance** among all the pairs. The distance of a pair (A, B) is defined as the absolute difference between A and B.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput:\r\nnums = [1,3,1]\r\nk = 1\r\nOutput: 0 \r\nExplanation:\r\nHere are all the pairs:\r\n(1,3) -> 2\r\n(1,1) -> 0\r\n(3,1) -> 2\r\nThen the 1st smallest distance pair is (1,1), and its distance is 0.\r\n```\r\n\r\n**Note:**\r\n\r\n1. `2 <= len(nums) <= 10000`.\r\n2. `0 <= nums[i] < 1000000`.\r\n3. `1 <= k <= len(nums) * (len(nums) - 1) / 2`.\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int smallestDistancePair(vector<int>& nums, int k) {\r\n sort(nums.begin(), nums.end());\r\n int n = nums.size(), low = 0, high = 1000000;\r\n while (low < high) {\r\n int mid = (low + high)/2, cnt = 0;\r\n for (int i = 0, j = 0; i < n; i++) {\r\n while (j < n && nums[j]-nums[i] <= mid) j++;\r\n cnt += j-i-1;\r\n }\r\n if (cnt < k) \r\n low = mid+1;\r\n else\r\n high = mid;\r\n }\r\n return low;\r\n }\r\n};\r\n```\r\n\r\nmid表示 差值,统计在nums中比mid小的差值的数量cnt,\r\n\r\n时间的复杂度O(NlogN)\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 1201. Ugly Number III\r\n\r\nWrite a program to find the `n`-th ugly number.\r\n\r\nUgly numbers are **positive integers** which are divisible by `a` **or** `b` **or** `c`.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: n = 3, a = 2, b = 3, c = 5\r\nOutput: 4\r\nExplanation: The ugly numbers are 2, 3, 4, 5, 6, 8, 9, 10... The 3rd is 4.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: n = 4, a = 2, b = 3, c = 4\r\nOutput: 6\r\nExplanation: The ugly numbers are 2, 3, 4, 6, 8, 9, 10, 12... The 4th is 6.\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: n = 5, a = 2, b = 11, c = 13\r\nOutput: 10\r\nExplanation: The ugly numbers are 2, 4, 6, 8, 10, 11, 12, 13... The 5th is 10.\r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: n = 1000000000, a = 2, b = 217983653, c = 336916467\r\nOutput: 1999999984\r\n```\r\n\r\n \r\n\r\n**Constraints:**\r\n\r\n- `1 <= n, a, b, c <= 10^9`\r\n- `1 <= a * b * c <= 10^18`\r\n- It's guaranteed that the result will be in range `[1, 2 * 10^9]`\r\n\r\n\r\n\r\n```c++\r\nclass Solution {\r\npublic: \r\n int nthUglyNumber(int k, int A, int B, int C) {\r\n int lo = 1, hi = 2 * (int) 1e9;\r\n long a = long(A), b = long(B), c = long(C);\r\n long ab = a * b / __gcd(a, b);\r\n long bc = b * c / __gcd(b, c);\r\n long ac = a * c / __gcd(a, c);\r\n long abc = a * bc / __gcd(a, bc);\r\n while(lo < hi) {\r\n int mid = lo + (hi - lo)/2;\r\n int cnt = mid/a + mid/b + mid/c - mid/ab - mid/bc - mid/ac + mid/abc;\r\n if(cnt < k) \r\n lo = mid + 1;\r\n else\r\n\t\t\t //the condition: F(N) >= k\r\n hi = mid;\r\n }\r\n return lo;\r\n }\r\n};\r\n```\r\n\r\n1.1*e9超过了int的范围,因此需要使用long\r\n\r\n2.从1开始一个个去判断是否为ugly number时间复杂度非常高,因此使用二分法\r\n\r\n通过cnt = mid/a + mid/b + mid/c - mid/ab - mid/bc - mid/ac + mid/abc\r\n\r\n计算在mid之前有多少个ugly number\r\n\r\n\r\n\r\n##### leetcode 1095 Find in Mountain Array\r\n\r\nHard\r\n\r\n*(This problem is an \\**interactive problem**.)*\r\n\r\nYou may recall that an array `A` is a *mountain array* if and only if:\r\n\r\n- `A.length >= 3`\r\n\r\n- There exists some \r\n\r\n ```\r\n i\r\n ```\r\n\r\n with \r\n\r\n ```\r\n 0 < i < A.length - 1\r\n ```\r\n\r\n such that:\r\n\r\n - `A[0] < A[1] < ... A[i-1] < A[i]`\r\n - `A[i] > A[i+1] > ... > A[A.length - 1]`\r\n\r\nGiven a mountain array `mountainArr`, return the **minimum** `index` such that `mountainArr.get(index) == target`. If such an `index` doesn't exist, return `-1`.\r\n\r\n**You can't access the mountain array directly.** You may only access the array using a `MountainArray` interface:\r\n\r\n- `MountainArray.get(k)` returns the element of the array at index `k` (0-indexed).\r\n- `MountainArray.length()` returns the length of the array.\r\n\r\nSubmissions making more than `100` calls to `MountainArray.get` will be judged *Wrong Answer*. Also, any solutions that attempt to circumvent the judge will result in disqualification.\r\n\r\n\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: array = [1,2,3,4,5,3,1], target = 3\r\nOutput: 2\r\nExplanation: 3 exists in the array, at index=2 and index=5. Return the minimum index, which is 2.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: array = [0,1,2,4,2,1], target = 3\r\nOutput: -1\r\nExplanation: 3 does not exist in the array, so we return -1.\r\n```\r\n\r\n \r\n\r\n**Constraints:**\r\n\r\n1. `3 <= mountain_arr.length() <= 10000`\r\n2. `0 <= target <= 10^9`\r\n3. `0 <= mountain_arr.get(index) <= 10^9`\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int findInMountainArray(int target, MountainArray &mountainArr) {\r\n int n = A.length(), l, r, m, peak = 0;\r\n l = 0;\r\n r = n-1;\r\n while(l<r){\r\n m = (l+r)/2;\r\n if(A.get(m)<A.get(m+1)) l =peak = m+1;\r\n else r=m;\r\n }\r\n //find in left of the peak\r\n l = 0;\r\n r = peak;\r\n while (l <= r) {\r\n m = (l + r) / 2;\r\n if (A.get(m) < target)\r\n l = m + 1;\r\n else if (A.get(m) > target)\r\n r = m - 1;\r\n else\r\n return m;\r\n }\r\n // find target in the right of peak\r\n l = peak;\r\n r = n - 1;\r\n while (l <= r) {\r\n m = (l + r) / 2;\r\n if (A.get(m) > target)\r\n l = m + 1;\r\n else if (A.get(m) < target)\r\n r = m - 1;\r\n else\r\n return m;\r\n }\r\n return -1;\r\n }\r\n};\r\n```\r\n\r\n思想很简单 做三次binary search\r\n\r\n先找到peak 然后在left侧中找target,找不到的话就在right侧找target\r\n\r\n"
},
{
"alpha_fraction": 0.585185170173645,
"alphanum_fraction": 0.6395061612129211,
"avg_line_length": 9.852941513061523,
"blob_id": "8ba192abc9cbe47abb885189682d72eb1b4fb3fc",
"content_id": "28d6c16e4288848074ada9b0cdaaf41b714c2261",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 427,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 34,
"path": "/os_instructions/linux/interesting_techs.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "```\r\n1.sudo apt-get install hollywood\r\nhollywood #hollywood movies scenes\r\n2.cmatrix #黑客帝国\r\nsudo apt-get install cmatrix\r\ncmatrix\r\n```\r\n\r\n2.cmatrix #黑客帝国\r\n\r\n```\r\nsudo apt-get install cmatrix\r\ncmatrix\r\n```\r\n\r\n3.oneko 猫\r\n\r\n```\r\nsudo apt-get install oneko\r\noneko\r\n```\r\n\r\n4.火焰\r\n\r\n```\r\nsudo apt-get install libaa-bin\r\naafire\r\n```\r\n\r\n\r\n\r\n```\r\nhttps://blog.csdn.net/u014028063/article/details/81978804\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.7491319179534912,
"alphanum_fraction": 0.7598379850387573,
"avg_line_length": 22.524822235107422,
"blob_id": "982c2d8e95db56cec3c7fb3f60ba26280b8b0b26",
"content_id": "1c755cb59f8589d05c0f052e978bfcfb70bc783a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4296,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 141,
"path": "/network_embedding.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Network Embedding\r\n\r\n值得细读的paper:\r\n\r\n* [DeepWalk: Online Learning of Social Representations](https://arxiv.org/abs/1403.6652) 2014\r\n* [node2vec: Scalable Feature Learning for Networks](https://arxiv.org/abs/1607.00653) 2016\r\n* *Max*-*Margin DeepWalk*:*Discriminative Learning of Network Representation* 2016\r\n* \r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n#### Deepwalk\r\n\r\n* DeepWalk (online learning of social representations)\r\n\r\n* Deepwalk是对一个节点使用random walk来生成文本一样的序列数据,将节点作为一个词,使用skip gram训练得到词向量 \r\n\r\n###### Node2vec(Scalable Feature Learning for Networks)\r\n\r\n* node2vec在DW的基础上定义了一个bias random walk的策略生成序列\r\n\r\n##### MMDW(Max-Margin DeepWalk Discriminative Learning of Network Representation)\r\n\r\n* 引入了SVM,将SVM和DeepWalk结合\r\n\r\n##### TADW(Network Representation Learning with Rich Text Information)\r\n\r\n* DeepWalk等价于对矩阵的分解,在实际情况中一些节点上有丰富的文本信息,在这篇文章中使用将文本以一个子矩阵的方式加入,使得向量学到更多的信息。\r\n\r\n\r\n\r\n##### GraRep(Learning Graph Representations with Global Structural Information)\r\n\r\n* 沿用了矩阵分解的思路,分析了不同k-step所刻画的信息是不一样的\r\n\r\n##### LINE(Large scale information network embedding)\r\n\r\n* 以较高的效率将大型网络embedding到低维空间\r\n\r\n\r\n\r\n#### Extra Info\r\n\r\n* 真实世界中节点和边往往带有丰富的信息\r\n\r\n\r\n\r\n##### CANE(context-Aware Network Embedding for relation modeling)\r\n\r\n* 考虑了节点上的文本,学习对每个节点产出文本向量Vt和结构向量Vs\r\n\r\n##### CENE(A General Framework for Content-enhanced Network Representation Learning)\r\n\r\n* 将文本转化为特殊的节点,这样就包含两种边,(节点-节点),(节点-文档),对两种边一起建模,损失函数包括两种\r\n\r\n\r\n\r\n#### Deeplearning\r\n\r\n##### GCN(semi-supervised classification with graph convolutional networks)\r\n\r\n##### SDNE(structural deep network embedding)\r\n\r\n\r\n\r\n\r\n#### Heterogenous\r\n\r\n* 真实世界的网络都是异构的,节点和边的类型是不一样的\r\n\r\n\r\n\r\n##### PTE(Predictive Text Embedding through Large-scale Heterogeneous Text Networks)\r\n\r\n* 定义了word-word,word-document,word-label三个network\r\n\r\n\r\n\r\n##### HINES(Heterogeneous Information Network Embedding for Meta Path based Proximity)\r\n\r\n* 对多元异构网络进行了embedding,图中有不同类型的点,不同类型的连边。引入了meta\r\n path的概念,就是不同点之间的连边是按照一定的元信息连起来的\r\n\r\n\r\n\r\n\r\n\r\n#### github\r\n\r\n```\r\nDeepWalk: Online Learning of Social Representations.\r\nhttps://github.com/phanein/deepwalk\r\n\r\nGraRep: Learning Graph Representations with Global Structural Information.\r\nhttps://github.com/ShelsonCao/GraRep\r\n\r\nLINE: Large-scale Information Network Embedding.\r\nhttps://github.com/tangjianpku/LINE\r\n\r\nNetwork Representation Learning with Rich Text Information.\r\nhttps://github.com/thunlp/tadw\r\n\r\n\r\nPTE: Predictive Text Embedding through Large-scale Heterogeneous Text Networks.\r\nhttps://github.com/mnqu/PTE\r\n\r\n\r\nDeep Neural Networks for Learning Graph Representations.\r\nhttps://github.com/ShelsonCao/DNGR\r\n\r\nnode2vec: Scalable Feature Learning for Networks.\r\nhttps://github.com/aditya-grover/node2vec\r\n\r\nMax-Margin DeepWalk: Discriminative Learning of Network Representation.\r\nhttps://github.com/thunlp/mmdw\r\n\r\nSemi-supervised Classification with Graph Convolutional Networks.\r\nhttps://github.com/tkipf/gcn\r\n\r\nCANE: Context-Aware Network Embedding for Relation Modeling.\r\nhttps://github.com/thunlp/cane\r\n\r\nFast Network Embedding Enhancement via High Order Proximity Approximation.\r\nhttps://github.com/thunlp/neu\r\n\r\nTransNet: Translation-Based Network Representation Learning for Social Relation Extraction.\r\nhttps://github.com/thunlp/transnet\r\n\r\nmetapath2vec: Scalable Representation Learning for Heterogeneous Networks.\r\nhttps://ericdongyx.github.io/metapath2vec/m2v.html\r\n```\r\n\r\n\r\n\r\n#### What is Network Embedding\r\n\r\n将网络中的节点表示成低维、实值、稠密的向量形式,使得向量具有表示与推理的能力。"
},
{
"alpha_fraction": 0.4929453134536743,
"alphanum_fraction": 0.5088183283805847,
"avg_line_length": 5.753424644470215,
"blob_id": "b828931e3736f77353fb71941c29fa06414c3631",
"content_id": "cf72d97145c1dc5851f82929ec8163739719c50c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1902,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 146,
"path": "/os_instructions/linux/vim.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "## vim\r\n```\r\nhttps://www.cnblogs.com/usergaojie/p/4583796.html\r\n```\r\n\r\n\r\n\r\n##### 模式转换:\r\n\r\n1. i:在当前字符的前面,转为输入模式\r\n2. esc 输入模式到编辑模式\r\n\r\n##### 打开文件\r\n\r\n1. vim filename 打开文件\r\n2. vim # filename:打开文件,定位到#行\r\n\r\n##### 关闭文件\r\n\r\n\t:q 退出\r\n\r\n\t:wq 保存并退出\r\n\r\n\t:q! 强制退出\r\n\r\n\t:w 保存\r\n\r\n\r\n\r\n##### 移动光标\r\n\r\n逐字符移动:\r\n\r\n\th: 左 l:右 j:下 k:上 #h: 移动#个字符\r\n\r\n以单词为单位移动:\r\n\r\n\tw:移动到下一个单词的词首,e:移动到下一个单词的词尾\r\n\r\n\tb:跳到当前或前一个单词的词首\r\n\r\n\t#w: 移动#个单词\r\n\r\n\r\n\r\n##### 翻屏\r\n\r\nctrl+f: 向下翻一页\r\n\r\nctrl+b: 向上翻一页\r\n\r\n\r\n\r\n##### 删除单个字符\r\n\r\nx:删除光标所在处的单个字符\r\n\r\n#x:删除光标所在处以及后的#个字符\r\n\r\n\r\n\r\n##### 删除命令:d\r\n\r\nd命令和跳转命令结合: #dw\r\n\r\ndd:删除当前光标所在行\r\n\r\n#dd:删除包括当前光标所在行在内的#行\r\n\r\n\r\n\r\n##### 复制 粘贴\r\n\r\n复制命令:y 用法与d相同\r\n\r\nyw #yw yy #yy\r\n\r\n粘贴 p\r\n\r\n例如\r\n\r\n```\r\n2yy\r\np\r\n#### 复制两行\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### 替换\r\n\r\nr:单字符替换\r\n\r\n#r:光标后#个字符全替换\r\n\r\nR:替换模式\r\n\r\n\r\n\r\n##### 撤销指令\r\n\r\nu:撤销前一次的编辑\r\n\r\n#u:撤销前n次的编辑\r\n\r\n\r\n\r\n##### 查找\r\n\r\n/pattern 或?pattern \r\n\r\nn上一个 N下一个\r\n\r\n\r\n\r\n##### 高级设置\r\n\r\n显示或取消行号:\r\n\r\n:set nu\r\n\r\n:set nonu\r\n\r\n文本高亮: :set hlsearch\r\n\r\n显示vim中的tab与空格\r\n:set list\r\n如果遇到tab space混用的问题\r\n则可以使用\r\n:1,$/\t/ /g\r\n将文本中所有的tab都替换了 g表示global\r\n\r\n\r\n##### 跳转到某一行\r\n\r\n: 12 跳转到12行\r\n\r\nG 跳转到最后一行\r\n\r\n\r\n\r\ntabstop=shiftwidth=4\r\n\r\nset expandtab\r\n\r\n"
},
{
"alpha_fraction": 0.6203561425209045,
"alphanum_fraction": 0.6682469248771667,
"avg_line_length": 16.275726318359375,
"blob_id": "d8c54ebb272013a0e5688e7b903d9d7ee5c4d499",
"content_id": "52c4e531166968a52250ee5e5049bfaa903b7670",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 134353,
"license_type": "no_license",
"max_line_length": 591,
"num_lines": 4305,
"path": "/interview/INTERVIEW.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "1.语言python c++ 云计算概念 2.项目(尤其是embedding) 简历 3. leetcode (不包括在本文件中)4.计算机知识 操作系统 计算机网络\r\n\r\n### 语言\r\n\r\n#### 1.python c++常见面试问题,二者的不同\r\n\r\n##### (1)Python如何进行内存管理\r\n\r\n垃圾回收:\r\n\r\n**python采用的是引用计数机制为主,标记-清除和分代收集两种机制为辅的策略**\r\n\r\n在python中 对象的引用计数为0的时候,该对象生命就结束了。\r\n\r\n1.引用计数机制:\r\n\r\n优点:1.简单实用\r\n\r\n缺点:1.引用计数消耗资源 2.无法解决循环引用的问题\r\n\r\n2.标记清除\r\n\r\n\r\n\r\n确认一个根节点对象,然后迭代寻找根节点的引用对象,以及被引用对象的引用对象(标为灰色),然后将那些没有被引用的对象(白色)回收清除。\r\n\r\n3.分代回收\r\n\r\n分代回收是一种空间换时间的操作方式。python将内存根据对象划分为不同的集合。分别为年轻代0 中年代1 老年代2,对应三个链表。新创建的对象都会分配在新生代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象。\r\n\r\n\r\n\r\n##### (2) 什么是lambda函数\r\n\r\nlambda函数也叫匿名函数\r\n\r\n最大的优点是非常轻便,不用特别命名,很适合为map sort等函数做服务\r\n\r\n```\r\npeople.sort(key=lambda x:(-x[0],x[1]))\r\n```\r\n\r\n\r\n\r\n##### (3)python中的深拷贝与浅拷贝与赋值\r\n\r\n深拷贝和浅拷贝的区别\r\n\r\n深拷贝是将对象本身完全复制给另一个对象包括子对象,浅拷贝(copy):拷贝父对象,不会拷贝对象的内部的子对象。赋值是将对象的引用复制给另一个对象,如果对引用进行更改会改变原对象。\r\n\r\n首先对于,在python中对于不可变对象,例如int,str等 = 赋值操作和拷贝没区别\r\n\r\n对于list dict等可变对象\r\n\r\n1、**b = a:** 赋值引用,a 和 b 都指向同一个对象。\r\n\r\n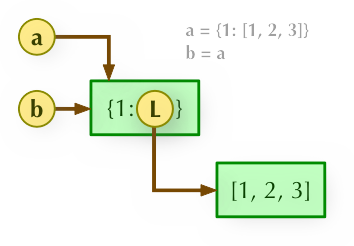\r\n\r\n**2、b = a.copy():** 浅拷贝, a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象(是引用)。\r\n\r\n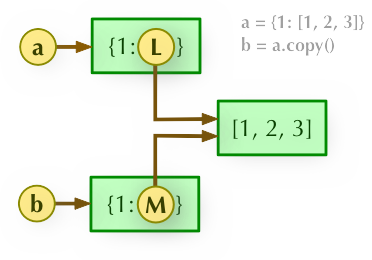\r\n\r\n**b = copy.deepcopy(a):** 深度拷贝, a 和 b 完全拷贝了父对象及其子对象,两者是完全独立的。\r\n\r\n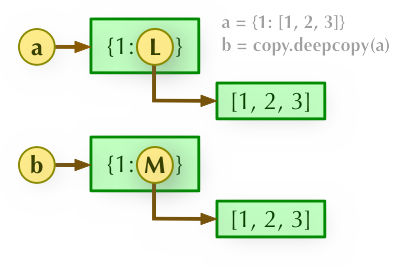\r\n\r\n更多实例\r\n\r\n使用 copy 模块的 copy.copy( 浅拷贝 )和(copy.deepcopy ):\r\n\r\n```\r\n#!/usr/bin/python # -*-coding:utf-8 -*- \r\nimport copy a = [1, 2, 3, 4, ['a', 'b']] #原始对象 \r\nb = a #赋值,传对象的引用 \r\nc = copy.copy(a) #对象拷贝,浅拷贝 \r\nd = copy.deepcopy(a) #对象拷贝,深拷贝 \r\na.append(5) #修改对象a \r\na[4].append('c') #修改对象a中的['a', 'b']数组对象 \r\nprint( 'a = ', a ) \r\nprint( 'b = ', b ) \r\nprint( 'c = ', c ) \r\nprint( 'd = ', d )\r\n```\r\n\r\n以上实例执行输出结果为:\r\n\r\n```\r\n('a = ', [1, 2, 3, 4, ['a', 'b', 'c'], 5])\r\n('b = ', [1, 2, 3, 4, ['a', 'b', 'c'], 5])\r\n('c = ', [1, 2, 3, 4, ['a', 'b', 'c']])\r\n('d = ', [1, 2, 3, 4, ['a', 'b']])\r\n```\r\n\r\nc++中 = 表示值语义,a=b是将b的值赋给a,python中=是引用语义\r\n\r\na=b是将b所指向的东西赋给a\r\n\r\nc++中对于普通类型的对象来说,复制是简单的浅拷贝,对于类对象而言\r\n\r\n某些情况下类内成员变量需要动态开辟堆内存,如果B中有一个成员变量指针已经申请了内存,那A中的那个成员变量也指向同一块内存,如果B把内存释放了,A中的指针就是野指针了。\r\n\r\n\r\n\r\n##### (4)如何理解python的动态特性\r\n\r\npython是门动态语言,程序的运行过程中定义变量的类型并分配内存空间,所以python没有int溢出之类的问题\r\n\r\npython的封装、继承和多态:\r\n\r\n封装:数据和具体实现的代码放在对象内部,细节不被外界所知,只能通过接口使用该对象。\r\n\r\n继承:子类继承了父类所有的函数和方法,同时可以根据需要进行修改 拓展:\r\n\r\n- 子类在调用某个方法或变量的时候,首先在自己内部查找,如果没有找到,则开始根据继承机制在父类里查找。\r\n- 根据父类定义中的顺序,以**深度优先**的方式逐一查找父类!\r\n\r\n设想有下面的继承关系:\r\n\r\n\r\n\r\n```\r\nclass D:\r\n pass\r\n\r\nclass C(D):\r\n pass\r\n\r\nclass B(C): \r\n def show(self):\r\n print(\"i am B\")\r\n pass\r\n\r\nclass G:\r\n pass\r\n\r\nclass F(G):\r\n pass\r\n\r\nclass E(F): \r\n def show(self):\r\n print(\"i am E\")\r\n pass\r\n\r\nclass A(B, E):\r\n pass\r\n\r\na = A()\r\na.show()\r\n```\r\n\r\n运行结果是\"i am B\"。在类A中,没有show()这个方法,于是它只能去它的父类里查找,它首先在B类中找,结果找到了,于是直接执行B类的show()方法。可见,在A的定义中,继承参数的书写有先后顺序,写在前面的被优先继承。\r\n\r\n------\r\n\r\n那如果B没有show方法,而是D有呢?\r\n\r\n```\r\nclass D:\r\n def show(self):\r\n print(\"i am D\")\r\n pass\r\n\r\nclass C(D):\r\n pass\r\n\r\nclass B(C):\r\n\r\n pass\r\n\r\nclass G:\r\n pass\r\n\r\nclass F(G):\r\n pass\r\n\r\nclass E(F): \r\n def show(self):\r\n print(\"i am E\")\r\n pass\r\n\r\nclass A(B, E):\r\n pass\r\n\r\na = A()\r\na.show()\r\n```\r\n\r\n执行结果是\"i am D\",左边具有深度优先权\r\n\r\nsuper()函数:\r\n\r\n在子类中如果有与父类同名的成员,那就会覆盖掉父类里的成员。那如果想强制调用父类的成员呢?使用super()函数\r\n\r\n多态:\r\n\r\npython这里的多态性是指具有不同功能的函数可 以使用相同的函数名,这样就可以用一个函数名调用不同内容的函数\r\n\r\n###### 当我们使用基类的引用调用某个函数时,由于基类可能有多种派生类,我们不知道该函数真正作用的对象是什么类型,只有在运行时才会决定到底执行哪个版本。这样这样就可以用一个函数名调用不同内容的函数\r\n\r\n```\r\nclass Animal:\r\n\r\n def kind(self):\r\n print(\"i am animal\")\r\n\r\nclass Dog(Animal):\r\n\r\n def kind(self):\r\n print(\"i am a dog\")\r\n\r\nclass Cat(Animal):\r\n\r\n def kind(self):\r\n print(\"i am a cat\")\r\n\r\nclass Pig(Animal):\r\n\r\n def kind(self):\r\n print(\"i am a pig\")\r\n# 这个函数接收一个animal参数,并调用它的kind方法\r\ndef show_kind(animal):\r\n animal.kind()\r\n\r\nd = Dog()\r\nc = Cat()\r\np = Pig()\r\n\r\nshow_kind(d)\r\nshow_kind(c)\r\nshow_kind(p)\r\n------------------\r\n打印结果:\r\ni am a dog\r\ni am a cat\r\ni am a pig\r\n```\r\n\r\n\r\n\r\n##### (5) 什么是闭包\r\n\r\n闭包又称词法闭包、函数闭包。\r\n\r\n```python\r\ndef test():\r\n x = [1]\r\n def test2():\r\n x[0] += 1\r\n print(\"x is \",x)\r\n return\r\n return test2\r\n\r\na = test()\r\na()\r\na()\r\n```\r\n\r\n```python\r\n('x is ', [2])\r\n('x is ', [3])\r\n```\r\n\r\ntest是一个闭包,分为外部函数,自由变量和内部函数。\r\n\r\n闭包可以很好地保存当前程序的运行环境,使得每次程序执行时的起点都是上次执行结束的终点。例如点赞程序,一篇文章统计点赞数量,点赞之后就是点赞数在原先点赞数的数量上加1,这可以用闭包实现。\r\n\r\n\r\n\r\n注意的是 如果test函数中x=1 这样的话会报错,test2中x = x+1 既是local variable,又是外部变量。在python中int float str是不可变类型,变的只是其引用。改成list可以解决这个问题\r\n\r\n\r\n\r\n##### (6)python中的切片与负索引\r\n\r\nlist切片\r\n\r\n\r\n\r\n##### (7)args和kwargs\r\n\r\npython中的可变参数。*args表示任何多个无名参数,它是一个tuple;**kwargs表示关键字参数,它是一个dict\r\n\r\n\r\n\r\n##### (8)什么是生成器,迭代器,装饰器\r\n\r\n##### 迭代器与生成器\r\n\r\npython中迭代器从集合的第一个元素开始访问,直到最后一个元素。\r\n\r\n迭代器基本的方法:iter(),next()\r\n\r\n```python\r\nlist=[1,2,3,4]\r\nit = iter(list) # 创建迭代器对象\r\nprint (next(it)) # 输出迭代器的下一个元素\r\n1\r\nprint (next(it))\r\n2\r\n```\r\n\r\n生成器\r\n\r\n使用了yield函数的称为生成器\r\n\r\n生成器是一个返回迭代器的函数,每次遇到yield的时候会暂停并保存所有的信息,返回yield值,在下一次执行next的时候从当前位置继续执行。\r\n\r\n```python\r\nimport sys\r\n \r\ndef fibonacci(n): # 生成器函数 - 斐波那契\r\n a, b, counter = 0, 1, 0\r\n while True:\r\n if (counter > n): \r\n return\r\n yield a\r\n a, b = b, a + b\r\n counter += 1\r\nf = fibonacci(10) # f 是一个迭代器,由生成器返回生成\r\n \r\nwhile True:\r\n try:\r\n print (next(f), end=\" \")\r\n except StopIteration:\r\n sys.exit()\r\n```\r\n\r\n\r\n\r\n##### 装饰器\r\n\r\n```python\r\ndef print_add(add):\r\n def warp(x):\r\n print(\"start adding\")\r\n add(x)\r\n return warp\r\n\r\n@print_add\r\ndef add(x):\r\n x += 1\r\n print(x)\r\n return\r\n\r\nadd(1)\r\n```\r\n\r\n```python\r\nstart adding\r\n2\r\n```\r\n\r\n函数add相当于一个接口,print_add则是在这个接口外面包装了一下。\r\n\r\n这样做的好处在于将主体的代码逻辑和副线(打印)分开来,逻辑清晰。\r\n\r\n\r\n\r\n##### C++ Primer\r\n\r\nc++函数必须包含四部分:返回类型 函数名 形参列表 函数体\r\n\r\n##### 编译 运行\r\n\r\n最常用的使用GNU编译器\r\n\r\n```\r\ng++ -o hello hello.cpp\r\n```\r\n\r\n-o是表示输出的参数,生成一个名为hello或是hello.exe的可执行文件\r\n\r\n在unix系统中 可执行文件没有后缀,window中可执行文件的后缀exe,生成可执行文件后使用如下命令运行\r\n\r\n```\r\n.\\hello.exe\r\n```\r\n\r\n\r\n\r\n##### 初始输入输出\r\n\r\n标准IO库 iostream定义了四个IO对象 cin cout cerr clog\r\n\r\ncerr一般用来输出错误 警告等信息,而clog一般用来输出程序运行时的一般性信息\r\n\r\n如果要使用cout endl等符号需要使用作用域运算符::,或者using namespace std\r\n\r\nendl 操纵符,表示将与设备关联的缓冲区中的内容都刷到设备中。\r\n\r\n\r\n\r\n读取数量不定的输入数据\r\n\r\n```\r\nwhile(cin>>value){\r\n sum+=value;\r\n}\r\n```\r\n\r\n\r\n\r\n##### 1.5 类简介\r\n\r\n使用文件重定向:\r\n\r\n```\r\naddItem.exe <infile >outfile\r\n```\r\n\r\n执行addItem.exe 从infile文件中读入,输出在outfile文件中\r\n\r\n\r\n\r\n#### 2.变量和基本类型\r\n\r\n常量:20(十进制)024(八进制)0x14(十六进制)\r\n\r\n字符串和字符串字面值:\r\n\r\n字符串字面值是由字符组成的数组,实际长度比字符数组长度多1,多了一个结尾的空字符‘\\0‘\r\n\r\n变量初始化,将units_sold初始化为0,可以有以下四种形式:\r\n\r\n```c++\r\nint units_sold=0;\r\nint units_sold={0};\r\nint units_sold{0};\r\nint units_sold(0);\r\n```\r\n\r\n默认初始化:\r\n\r\n如果没有初始化,则变量的值会被默认初始化,默认值与变量类型和变量位置有关。定义在任何函数外的变量会被初始化为0,定义在函数内的变量不被初始化,试图拷贝或者是访问这个值会引发错误。\r\n\r\n\r\n\r\n变量申明与变量定义:\r\n可以在c++中对某个量在多个文件中使用,这样的话就需要使用extern\r\n\r\nextern int i;表示申明了int i,其定义在其他文件中\r\n\r\n如果extern int i=0;则是定义了i ,定义的同时也消除了extern关键词的意义。\r\n\r\n\r\n\r\n作用域:\r\n\r\n定义在main函数外面的变量是全局变量\r\n\r\n```c++\r\nint i=0;\r\nvoid func(){\r\n cout<<i;\r\n}\r\nint main(){\r\n cout<<i;\r\n return 0;\r\n}\r\n```\r\n\r\n如果定义在for循环里面,块作用域,出了for循环则不能访问了\r\n\r\n```c++\r\nint reuse=42;\r\nint main(){\r\n cout<<reuse; //42\r\n int reuse=0;\r\n cout<<reuse; //0\r\n cout<<::reuse;//42,显示调用全局变量\r\n}\r\n```\r\n\r\n##### 引用与指针:\r\n\r\nint &ref; 报错,引用必须被初始化\r\n\r\nint &ref=10;报错,引用类型的初始值必须是一个对象\r\n\r\n引用是为对象创建了另一个名字;\r\n\r\n```c++\r\nint ival=10;\r\nint &reival=ival;\r\nreival--;\r\ncout<<ival; //9\r\n```\r\n\r\n指针也是创建了对其他对象的间接访问,指针与引用不同,首先指针本身就是一个对象,允许对指针赋值拷贝等等,如果指针没有被初始化则将拥有一个不确定的值。\r\n\r\n```c++\r\nint *p=&ival;\r\n```\r\n\r\n使用解引用符*来访问;\r\n\r\n*p即为ival\r\n\r\n空指针nullptr或者NULL不知向任何东西\r\n\r\n```\r\nint *p1=nullptr;\r\nint *p2=0;\r\nint *p3=NULL;\r\n```\r\n\r\n但是不能用int类型的变量对指针赋值\r\n\r\n```c++\r\nint zero=0;\r\nint *p=zero; //不行\r\n```\r\n\r\n建议对所有的指针都进行初始化,否则比较容易出现问题;\r\n\r\nvoid* 是一种特殊类型的指针,能够存放任何类型的对象。\r\n\r\n注意\r\n\r\n```c++\r\nint* p1,p2; p1是指针,p2是int\r\n* 可以多层使用\r\nint **pp1=&p1; pp1是指向指针的指针\r\n```\r\n\r\n##### const限定符\r\n\r\n被const限定的变量的数值不能被改变\r\n\r\n因此const类型的变量在创建的时候必须初始化。\r\n\r\n编译器在编译的过程中会把const变量直接替换成对应的值。\r\n\r\n##### 顶层const与底层const\r\n\r\n由于指针本身就是一个对象,我们用顶层const表示指针本身是个常量不可改变,底层const表示指针所指的对象是常量。\r\n\r\n```c++\r\nint i=0;\r\nint *const pi=&i; pi是顶层const\r\nconst int ci=42;\r\nconst int *p2=&ci; p2是底层const 可以改变\r\n```\r\n\r\n##### typedef 类型别名\r\n\r\n```c++\r\ntypedef longlong ll;\r\nusing ll=longlong;\r\n```\r\n\r\n##### auto类型\r\n\r\n```c++\r\nauto item =val1+val2;\r\n```\r\n\r\n编译器会根据val1 val2相加的结果决定推断item的类型\r\n\r\n##### decltype类型指示符\r\n\r\n```\r\nconst int ci=0;\r\ndecltype(ci) a; //将a定义为const int类型;\r\n```\r\n\r\n##### 自定义数据结构\r\n\r\n```c++\r\nstruct Sales_data{\r\n string bookNO;\r\n unsigned units_sold ;\r\n double revenue;\r\n};\r\n```\r\n\r\nc++11新标准规定可以给数据成员一个类内初始值,例如bookNO被初始化为空字符串,units_sold revenue被初始化为0\r\n\r\n##### 使用数据结构\r\n\r\n```c++\r\nSales_data data1,data2;\r\ncin>>data1.revenue>>data2.revenue;\r\n```\r\n\r\n##### 编写自己的头文件\r\n\r\n我们应该将struct Sales_data的定义放在Sales_data.h文件中\r\n\r\n```\r\n#ifndef SALES_DATA_H\r\n#define SALES_DATA_H\r\n#include <string>\r\nstruct Sales_data{\r\n std::string bookNO;\r\n unsigned units_sold=0;\r\n double revenue=0.0;\r\n};\r\n#endif\r\n```\r\n\r\n使用预处理器,进行头文件保护,避免重复包含\r\n\r\n在cpp文件中加上\r\n\r\n```c++\r\n#include \"Sales_data.h\"\r\n```\r\n\r\n\r\n\r\n#### 字符串 数组和向量\r\n\r\n##### 字符串\r\n\r\n```c++\r\n//初始化字符串\r\nstring s1; //默认初始化为空字符串\r\nstring s2(s1); //s2是s1的副本\r\nstring s2=s1; //等价于拷贝\r\nstring s3(\"value\");//初始化为value\r\nstring s3=\"value\";//初始化为\"value\"\r\nstring s4(n,'c');//初始化为n个'c'\r\n```\r\n\r\n字符串的基本操作\r\n\r\n```c++\r\nos<<s //将s写到os中\r\nis>>s //从is中读取字符串给s\r\ngetline(is,s) //从is中读一行给s\r\ns.empty() //判断是否为空\r\ns.size()\r\ns[n] //访问第n个元素\r\ns1+s2 //拼接\r\n<,<= //利用字符在字典中的顺序进行比较,注意大小写\r\n```\r\n\r\ncin>>s;\r\n\r\n程序会自动忽略之前的空白,直到遇到了下一处空白\r\n\r\n例如输入\r\n\r\n```\r\n hello world!\r\n```\r\n\r\n程序中s的值是“hello”\r\n\r\n```c++\r\nwhile(getline(cin,line)){\r\n cout<<line<<endl;\r\n}\r\n```\r\n\r\n##### 处理字符串中的字符\r\n\r\n```c++\r\nisalnum(c) //检测字符或者数字\r\nisalpha(c)//检测字符\r\niscntrl(c) //检测控制字符\r\nisdigit(c) //检测数字\r\nislower(c) //检测小写字符\r\nisupper(c) //检测大写字符\r\ntolower(c) //转换成小写字符\r\ntoupper(c) //转成大写字符\r\nispunct(c) //检测是否为标点\r\n```\r\n\r\n基本范围的for语句\r\n\r\n```c++\r\nstr=\"lower\";\r\nfor(auto c:str)\r\n c=toupper(c);\r\n cout<<c<<endl;\r\ncout<<str; //lower\r\n\r\nstr=\"lower\";\r\nfor(auto &c:str)\r\n c=toupper(c);\r\n cout<<c<<endl;\r\ncout<<str; //LOWER\r\n```\r\n\r\n\r\n\r\n##### 标准库vector\r\n\r\n使用时需要加上\r\n\r\n#include<vector>\r\n\r\n初始化\r\n\r\n```c++\r\nvector<int> v1; //空vector\r\nvector<int> v2(v1) //v1的拷贝\r\nvector<int> v2=v1; //v1拷贝\r\nvector<int> v3(n,val)//n个val元素\r\nvector<int>v5={a,b,c} //初始化为a,b,c\r\nvector<int>v5{a,b,c} //初始化为a,b,c\r\n```\r\n\r\n二维vector的初始化\r\n\r\n```c++\r\nvector<vector<int>> nums(5,vector<int>(5,1));\r\n```\r\n\r\n\r\n\r\nvector支持的操作\r\n\r\n```c++\r\nv.empty() //是否为空\r\nv.size() //返回元素个数\r\nv.push_back() //尾部添加元素\r\nv1==v2 判断两个vector是否完全相同\r\n< > <= 按照字典顺序进行比较\r\n```\r\n\r\n使用迭代器\r\n\r\nend返回的是尾后迭代器,如果容器为空,则begin end返回的是尾后迭代器\r\n\r\n```\r\nvector<int>::iterator it;\r\nstring::iterator it2;\r\n\r\n```\r\n\r\n\r\n\r\n迭代器的运算\r\n\r\n```\r\n*iter //取值\r\n++iter //向后移动一个\r\n--iter //向前移动一个\r\niter+n //向后移动n个位置\r\niter1-iter2 //得到二者之间的距离\r\n< > <= //判断两个迭代器之间的大小关系,在位置较前的迭代器小\r\n\r\nauto mid=v.begin()+v.size()/2;\r\nauto mid=v.begin()+(end-begin)/2;\r\nauto mid=(begin+end)/2; //这种是错误的,begin+end没有意义\r\n\r\n```\r\n\r\n\r\n\r\n某些对vector对象的操作会使得迭代器失效,例如在for循环中对vector添加元素等\r\n\r\n\r\n\r\n#### 表达式\r\n\r\n##### 左值和右值\r\n\r\nc++表达式不是左值就是右值。归纳:当一个对象被用作右值的时候,用的是对象的值(内容),用作左值的时候用的是对象的身份(在内存中的位置)。\r\n\r\n有几种我们熟悉的运算符是要用到左值的:\r\n\r\n赋值运算符一个左值作为左侧运算对象,返回的结果也是一个左值\r\n\r\n取地址符作用于一个左值运算对象,返回一个指向该运算对象的指针这个指针是右值。\r\n\r\n\r\n\r\n##### 算术运算符\r\n\r\n一元运算符\r\n\r\n```\r\nbool b=true;\r\nbool b2=-b; //b2为true,-1转换为bool为true\r\n\r\n\r\n```\r\n\r\n溢出:当数值超出了范围之后,符号位会发生改变。\r\n\r\n余数运算:\r\n\r\n(-m)/n m/(-n)等价于-(m/n)\r\n\r\n(-m)%n等价于-(m%n)\r\n\r\nm%(-n)等价于m%n\r\n\r\n```c++\r\n-21%10 -1\r\n21%-5 1\r\n```\r\n\r\n##### 类型转换 \r\n\r\n隐式转换,例如int+char 得到int等\r\n\r\n强制类型转换:\r\n\r\nint i,j;\r\n\r\ndouble slope=static_cast<double>(j)/i;\r\n\r\n建议避免使用强制类型转换\r\n\r\n\r\n\r\n#### 语句\r\n\r\nif语句 if else语句 else语句\r\n\r\n```c++\r\nswitch(ch){\r\n case 'a':case 'e':case 'i': case 'o': case 'u':\r\n ++vowelcnt;\r\n break;\r\n default:\r\n ++othercnt;\r\n break;\r\n}\r\n```\r\n\r\n##### try语句和异常处理\r\n\r\nc++中异常处理机制:遇到异常,throw抛出异常,catch语句会处理异常。\r\n\r\n异常:\r\n\r\n```c++\r\nif(item1.isbbn()==item2.isbn()){\r\n cout<<item1+item2<<endl;\r\n return 0;\r\n}\r\nelse{\r\n cerr<<\"Data must refer to same ISBN\"<<endl;\r\n return -1;\r\n}\r\n```\r\n\r\n```c++\r\nif(item1.isbn()!=item2.isbn())\r\n throw runtime_error(\"Data must refer to same ISBN\");\r\n```\r\n\r\n抛出异常将终止当前的函数\r\n\r\n```c++\r\nwhile(cin>>item1>>item2){\r\n try{\r\n if(item1.isbn()!=item2.isbn())\r\n throw runtime_error(\"Data must refer to same ISBN\");\r\n }\r\n catch(runtime_error err){\r\n cout<<err.what()<<\"Try Again Enter Y or N\"<<endl;\r\n char c;\r\n cin>>c;\r\n if(!cin||c=='n')\r\n break;\r\n }\r\n}\r\n```\r\n\r\n如果最终没有找到任何匹配的catch语句,程序转移到terminate函数\r\n\r\n##### 标准异常\r\n\r\nc++库定义了例如exception,runtime_error overflow_error等类型的异常\r\n\r\n异常类型只定义了一个名为what的函数,没有参数,用于提供一些异常的文本信息。\r\n\r\n\r\n\r\n#### 函数\r\n\r\n一个典型的函数包括返回类型、函数名、形参、函数体等部分。\r\n\r\n实参与形参:实参是形参的初始值。\r\n\r\n对象有生命周期,形参是一种自动对象。\r\n\r\n##### 局部静态对象\r\n\r\n局部静态对象在程序经过时初始化,并且直到程序终止时才会被销毁。\r\n\r\n##### 参数传递\r\n\r\n参数传递分为传值参数与传引用参数。\r\n\r\n```c++\r\nvoid reset(int i){\r\n i=0; //传值参数,返回之后int i的值没有改变;\r\n}\r\nvoid reset(int &i){\r\n i=0; //传引用参数, 返回之后int i值变;\r\n}\r\n```\r\n\r\n一个函数只能返回一个值,有时需要返回多个值,引用参数为我们异常返回多个结果提供了有效的途径。\r\n\r\n\r\n\r\n数组形参\r\n\r\n```c++\r\nvoid print(const int*);\r\nvoid print(const int[]);\r\nvoid print(const int[10]);\r\n```\r\n\r\n##### 传递多维数组\r\n\r\nc++中没有多维数组\r\n\r\nint matrix[10,10];\r\n\r\n```c++\r\nvoid print(int (*matrix)[10],int rowsize){};\r\nvoid print(int maxtrix[][10],int rowsize){};\r\n```\r\n\r\n\r\n\r\n##### main 处理命令行\r\n\r\n若main函数位于可执行prog之内\r\n\r\n```c++\r\nprog -d -o ofile data0\r\nint main(int argc,char *argv[]){}\r\n\r\nargc=5;\r\nargv[0]=\"prog\";\r\nargv[1]=\"-d\";\r\nargv[2]=\"-o\";\r\nargv[3]=\"ofile\";\r\nargv[4]=\"data0\";\r\nargv[5]=0;\r\n```\r\n\r\n\r\n\r\n##### 含有可变形参的函数\r\n\r\n有时我们无法提前预知应该像函数传递几个实参。如果所有的实参的类型相同,则使用initializer_list,如果实参的类型不同,则使用一种特殊的函数,也就是可变参数模板。\r\n\r\n```c++\r\nvoid error_msg(initializer_list<string> i1){\r\n for(auto beg=i1.begin();beg!=i1.end();++beg){\r\n cout<<*beg<<\" \";\r\n }\r\n cout<<endl;\r\n}\r\n```\r\n\r\n##### 函数重载\r\n\r\npython不支持函数重载\r\n\r\n如果同一作用域内的几个函数名字先沟通但形参不同,称之为重载函数。\r\n\r\n```c++\r\nvoid print(const char*cp);\r\nvoid print(const int *beg,const int *end);\r\nvoid print(const int ia[],size_t size);\r\n\r\nprint(\"Hello World\");\r\nprint(j,end(j)-begin(j));\r\nprint(begin(j),end(j));\r\n```\r\n\r\n##### 确定重载的函数\r\n\r\n 函数匹配是一个过程,在这个过程中我们把函数调用与一组重载函数的某个关联起来,这种匹配也叫做重载确定。重载确定有三种可能的结果:\r\n\r\n- 找到一个最佳匹配函数\r\n- 找不到任何一个匹配,发出无匹配的错误信息。\r\n- 有多余一个函数可以匹配,但是每一个都不是最佳匹配,此时也发生错误,二义性调用。\r\n\r\n\r\n\r\n##### 重载和作用域\r\n\r\n重载函数需要定义在一起\r\n\r\n```c++\r\nvoid print(const string &);\r\nvoid print(double);\r\nvoid print(int);\r\n```\r\n\r\n```c++\r\nvoid print(const string &);\r\nvoid print(double);\r\nvoid foo(int ival){\r\n bool read=false;\r\n string s=read();\r\n void print(int); //新作用域 覆盖了之前的print函数 不是重载\r\n}\r\n```\r\n\r\n##### 默认实参\r\n\r\n如果我们要使用默认实参,只要在调用函数的时候忽略这个参数就可以了。\r\n\r\n```c++\r\nstring screen(int ht=24,int int wid=80,char background=' ');\r\nwindow=screen(); //使用默认参数\r\n```\r\n\r\n默认实参负责填补缺少的尾部实参;\r\n\r\n```c++\r\nwindow=screen(,,'?'); //错误 只能忽略尾部的参数\r\nwindow=screen('?'); //错误 相当于调用screen('?',80,' ');\r\n```\r\n\r\n\r\n\r\n##### 函数匹配\r\n\r\n```c++\r\nvoid f();\r\nvoid f(int);\r\nvoid f(int,int);\r\nvoid f(double,double=3.14);\r\nf(5.6);\r\n```\r\n\r\n对于f(5.6)而言,有4个候选函数,考察实参5.6发现有两个可行函数\r\n\r\n```c++\r\nvoid f(int);\r\nvoid f(double,double=3.14);\r\n```\r\n\r\n5.6可以通过类型转换double到int,或者可以将第二个参数视为默认实参\r\n\r\n\r\n\r\n##### 函数指针\r\n\r\n函数指针指向的是函数而非对象。\r\n\r\n```c++\r\nbool lengthCompare(const string &,const string &); //函数\r\nbool (*pf)(const string &,const string &); //pf 是一个函数指针,*pf两端的括号不可少,不写的话pf是一个返回值为bool *的函数\r\n\r\n//使用函数指针\r\npf=lengthCompare; //pf指向lengthCompare函数\r\npf=&lengthCompare //与上一句等价\r\n\r\nbool b1=pf(\"hello\",\"goodbye\"); //调用lengthCompare函数\r\nbool b2=(*pf)(\"hello\",\"goodbye\"); //一个等价的调用\r\nbool b3=lengthCompare(\"hello\",\"goodbye\"); //一个等价调用\r\n\r\nstring sumLength(const string&, const string&);\r\nbool cstringCompare(const char*,const char*);\r\npf=0; //pf不指向任何函数\r\npf=sumLength; //错误,返回类型不匹配\r\npf=cstringCompare //错误 形参不匹配\r\npf=lengthCompare // 正确 函数和指针匹配\r\n```\r\n\r\n\r\n\r\n#### 类\r\n\r\n##### 7.1 定义抽象数据类型\r\n\r\n类的基本思想是数据抽象和封装。数据抽象是一种依赖于接口和实现分离的编程技术。\r\n\r\n##### 引入this\r\n\r\nthis是一个常量指针,在类内使用this这个指向自己的指针。例如在类内调用成员变量。\r\n\r\n例如成员函数\r\n\r\n```c++\r\nstring isbn(){return bookNO;}\r\n```\r\n\r\n相当于使用this.bookNO;\r\n\r\n```c++\r\nclass Sales_data{\r\n friend Sales_data add(const Sales_data&, const Sales_data&);\r\n friend std::isream &read(std::istream&, Sales_data&);\r\n friend std::ostream &print(std::ostream&, const Sales_data&);\r\npublic:\r\n Sales_data()=default;\r\n Sales_data(const std::string &s,unsigned n, double p):bookNO(s),units_sold(n),revenue(p*n){}\r\n Sales_data(const std::string &s):bookNO(s){}\r\n Sales_data(std::istream);\r\n std::string isbn() const{return bookNO;}\r\n cSales_data &combine(const Sales_data&);\r\nprivate:\r\n std::string bookNO;\r\n unsigned units_sold=0;\r\n double revenue=0.0;\r\n};\r\nSales_data add(const Sales_data&, const Sales_data&);\r\nstd::istream &read(std::istream&, Sales_data&);\r\nstd::ostream &print(std::ostream&, const Sales_data&);\r\n```\r\n\r\n##### 构造函数\r\n\r\n```c++\r\nSales_data(const std::string &s,unsigned n, double p):bookNO(s),units_sold(n),revenue(p*n){}\r\nSales_data(const std::string &s):bookNO(s){}\r\n```\r\n\r\n注意构造函数的冒号以及冒号与花括号之间的语句。\r\n\r\n类之间也可以进行拷贝等操作\r\n\r\n```c++\r\ntotal=trans;\r\n```\r\n\r\n等价于\r\n\r\n```\r\ntotal.bookNO=trans.bookNO;\r\ntotal.units_sold=trans.units_sold;\r\ntotal.revenue=trans.revenue;\r\n\r\n```\r\n\r\n##### 访问控制与封装\r\n\r\n- 定义在public后面的成员在整个程序中都可以访问,public成员的定义了类的接口。\r\n- 定义在private后面的成员可以被类内的成员函数访问,但不能被使用该类的代码访问,private部分是类所隐藏的实现细节。\r\n\r\n\r\n\r\n##### 友元\r\n\r\n由于其他代码不能访问类内的private成员,则例如add 等函数也不能编译了。为了使得add print等函数能够成功运行,可以将add等函数作为Sales_data类的友元。只需要增加一条friend语句即可。\r\n\r\n\r\n\r\n\r\n\r\n#### IO库\r\n\r\nIO库中有istream类型 ostream类型,cin是一个istream对象 ostream对象\r\n\r\n流对象不能拷贝或者赋值\r\n\r\n```c++\r\nofstream out1,out2;\r\nout1=out2; //错误\r\n```\r\n\r\n确定一个流对象的状态最好的方法是将它作为一个条件来使用:\r\n\r\n```c++\r\nwhile(cin>>word)\r\n```\r\n\r\n每个输出流都管理一个缓冲区,用来曹村程序读写的数据。导致缓冲刷新(数据真正写到输出设备上时)的原因可能有:\r\n\r\n- 程序正常结束\r\n- 缓冲区满的时候刷新缓冲区\r\n- 使用endl等操作符\r\n\r\n类似于endl操作符的还有ends flush\r\n\r\n```\r\nendl;//输出缓冲区的内容并换行\r\nends;//输出缓冲区的内容并加一个空格\r\nflush;// 输出缓冲区的内容\r\n\r\n```\r\n\r\n##### unitbuf\r\n\r\n```\r\ncout<<unitbuf;//所有的输出操作之后都自动帅新缓存区\r\ncout<<nounitbuf;//回到正常输出的模式\r\n\r\n```\r\n\r\n##### 文件输入输出\r\n\r\n头文件fstream定义了三个类型来支持文件IO,ifstream ofstream fstream\r\n\r\n```c++\r\n#include <fstream>\r\nusing namespace std;\r\nint main(){\r\n string ifle=\"ifile\";\r\n ifstream in(ifile); //定义了一个ifstream类并将其打开给指定文件ifile\r\n ostream out;\r\n out.open(\"ofile\") //out打开或是新建ofile\r\n string s;\r\n while(in>>s){\r\n cout<<s<<endl;\r\n out<<s;\r\n }\r\n}\r\n\r\n```\r\n\r\n```c++\r\nifile:\r\nline1 line1\r\nline2 line2\r\n\r\n屏幕:\r\nline1\r\nline1\r\nline2\r\nline2\r\n\r\nofile:\r\nline1line1line2line2\r\n```\r\n\r\n```c++\r\n//按行读取\r\n#include <fstream>\r\nusing namespace std;\r\nint main(){\r\n string ifle=\"ifile\";\r\n ifstream in(ifile); //定义了一个ifstream类并将其打开给指定文件ifile\r\n ostream out;\r\n out.open(\"ofile\") //out打开或是新建ofile\r\n string s;\r\n while(getline(in,s)){\r\n cout<<s<<endl;\r\n out<<s;\r\n }\r\n}\r\n```\r\n\r\n\r\n\r\n##### 实现python中getline split效果\r\n\r\n```c++\r\n#include <sstream>\r\nusing namespace std;\r\nint main(){\r\n string ifile=\"ifile\";\r\n ifstream in(ifile);\r\n string line,s;\r\n while(getline(in,line)){\r\n istringstream record(line);\r\n while(record>>s)\r\n cout<<s<<endl;\r\n }\r\n return 0;\r\n}\r\n```\r\n\r\n按照行先读入到line中 \"line1 line1\"\r\n\r\n利用istringstream将line中按照空格一个个分开,读到s中\r\n\r\n\r\n\r\n#### 顺序容器\r\n\r\n顺序容器的基本属性\r\n\r\n```c++\r\n构造函数:\r\nC c; //默认构造函数 构造空容器\r\nC c1(c2); //构造c2的拷贝c1\r\nC c(b,e); //构造c将迭代器b e指定的范围内的元素拷贝到c\r\nC c{a,b,c}; //列表初始化;\r\n\r\n赋值与swap操作:\r\nc1=c2; //将c1中的元素替换为c2;\r\nc1={a,b,c} //将c1中的元素替换为列表\r\na.swap(b); //交换a,b中的元素\r\nswap(a,b); //交换a,b中的元素\r\n\r\n大小:\r\nc.size(); //返回c中的元素数\r\nc.max_size(); //c可保存的最大元素数目\r\nc.empty(); //c是否空\r\n\r\n添加 删除元素\r\nc.insert(); //增加元素\r\nc.emplace()\r\nc.erase(); //删除某个元素\r\nc.clear(); // 清除所有的元素\r\n\r\n关系运算符:\r\n==,!= 所有的容器都支持相等 不等运算符\r\n<,<=,>,>= 关系运算符(无序容器不支持)\r\n\r\n迭代器:\r\nc.begin(),c.end();\r\nc.cbegin(),c.cend(); const iterator\r\nc.rbegin(),c.rend();//指向c的尾元素与首元素\r\nc.crbegin(),c.crend();\r\n```\r\n\r\n\r\n\r\n使用迭代器\r\n\r\n```c++\r\nwhile(begin!=end){\r\n *begin=val;\r\n ++begin;\r\n}\r\n```\r\n\r\n如果begin==end,区间为空\r\n\r\n```c++\r\nseq.assign(b,e); //将seq中的元素替换为迭代器b和e所表示的范围中的元素\r\nseq.assign(i1); //将seq中的元素替换为列表i1中的元素\r\nseq.assign(n,t); //将seq中的元素天魂为n个值为t的元素\r\n```\r\n\r\n对容器操作可能使迭代器失效。向容器添加元素之后,如果容器时vector或者string,且存储空间被重新分配,则指向容器的迭代器、指针和引用都会失效。如果存储空间未重新分配,指向插入位置之前的元素的迭代器、指针和引用会失效,而指向插入位置之后的元素的迭代器、指针和引用会继续有作用。对于deque,插入在除了首尾两端的位置都会使得迭代器失效。\r\n\r\n\r\n\r\n##### 额外的string操作\r\n\r\n构造string的其他方法:\r\n\r\n```\r\nstring s(cp,n); //s是cp指向的数组前n个字符的拷贝\r\nstring s(s2,pos2); //s是string s2从下标pos2开始的字符的拷贝;\r\nstring s(s2,pos2,len2); //s是string s2从下标pos2开始的len2个字符拷贝\r\n\r\n```\r\n\r\nsubstr\r\n\r\n```c++\r\nstring s(\"hello world\");\r\nstring s2=s.substr(0,5); hello\r\nstring s3=s.substr(6); world\r\nstring s4=s.substr(6,5); world\r\nstring s5=s.substr(12); 报出错误\r\n```\r\n\r\n改变string的函数:\r\n\r\n```c++\r\ns.insert(s.size(),5,'!'); //在末尾加上5个\"!\"\r\ns.erase(s.size()-5,5); //在后面删除最后5个;\r\n```\r\n\r\n##### string 搜索操作\r\n\r\nstring类提供了6个不同的搜索函数,每个函数都有4个重载版本。\r\n\r\n```c++\r\ns.find(args); //查找s中args第一次出现的位置\r\ns.rfind(args); // 查找s中args最后一次出现的位置;\r\ns.find_first_of(args); //在s中找args中任何一个字符第一次出现的位置;\r\ns.find_last_of(args); //在s中找args中任何一个字符最后一次出现的位置;\r\ns.find_first_not_of(args); //在s中查找第一个不在args中的字符;\r\ns.find_last_of(args); //在s中查找最后一个不在args中的字符;\r\n\r\nstring name(\"AnnaBelle\");\r\nauto pos1=name.find(\"Anna\"); //返回0\r\n\r\nstring numbers(\"0123456789\"),name(\"r2d2\");\r\nauto pos=name.find_first_of(numbers);\r\n\r\n每个字符都可以接收第二个参数用来指出从什么位置开始搜索。\r\n```\r\n\r\n#####compare函数\r\n\r\n```c++\r\ns.compare\r\npos1,n1,s2,pos2,n2; //s从pos1开始的n1个字符与s2中从pos2开始的n2个字符比较\r\n```\r\n\r\n根据s是等于 大于还是小于参数指的字符串,返回0 正数或负数\r\n\r\n##### 数值转换\r\n\r\n```c++\r\nstring s=to_string(i); int to string\r\ndouble d=stod(s)//string to double\r\n```\r\n\r\n\r\n\r\n#### 泛型算法\r\n\r\n标准库容器定义的操作集合很小,而是提供了一组算法,这些算法的大多数能够在任何容器中使用。这些算法大多数都定义在algorithm文件中。这些算法都不执行容器的操作,而是作用在迭代器上。\r\n\r\n```\r\nresult=find(vec.cbegin(),vec.cend(),val);\r\n\r\n```\r\n\r\n前两个参数是用来表示元素范围的迭代器。find函数会按照顺序依次比较。\r\n\r\n##### 只读算法\r\n\r\n```c++\r\ncount(v.begin(), v.end(), 1);//count有多少个1;\r\nint sum=accumulate(vec.begin(),vec.end(),0); //求和,初始值为0;\r\nstring sum=accumulate(v.cbegin(),v.cend(),string(\"\")); //将v中所有的string连起来\r\nstring sum=accumulate(v.begin(),v.end(),\"\");//错误,char* 没有定义+运算\r\n\r\nequal(roster1.cbegin(),roster1.cend(),roster.cbegin()); //比较是否相同\r\n```\r\n\r\n##### 写元素的算法\r\n\r\n```c++\r\nfill(vec.begin(),vec.end(),0); // 将所有元素重置0;\r\nfill_n(vec.begin(),vec.size(),0);//fill_n假定写入指定个元素是安全的;\r\n\r\n//back_inserter\r\nvec<int> vec;\r\nfill_n(back_inserter(vec),10,0); //添加10个元素到末尾\r\n\r\n//copy\r\nvector<int> v = {1,2,3};\r\nvector<int> cv(3) ;\r\ncopy(v.begin(),v.end(),cv.begin());\r\n\r\nreplace(ilist.begin(),ilist.end(),0,42); 将所有的0替换为42;\r\n```\r\n\r\n##### 重排\r\n\r\n```c++\r\n\"the quick red fox jumps over the slow red turtle\"\r\nsort(words.begin(),words.end());\r\n\"fox jumps over quick red red slow the the turtle\"\r\nauto end_unique=unique(words.begin(),words.end()); //unique并未删除元素\r\n\"fox jumps over quick red slow the turtle ??? ???\"\r\nwords.erase(end_unique,words.end());\r\n\"fox jumps over quick red slow the turtle\"\r\n```\r\n\r\n```\r\nbool isshorter(const string &s1,const string &s2){\r\n return s1.size()<s2.size();\r\n}\r\nsort(words.begin(),words.end(),isshorter);\r\nstable_sort(words.begin(),words.end(),isshorter);//保持了相同擦汗高难度的单词按字典序排列\r\n\r\n```\r\n\r\n\r\n\r\nwhat is泛型算法:\r\n\r\ngeneral type algorithm\r\n\r\n对于不同的数据类型,都可以适用,例如sort可以适用于不同类型的元素(int double float)和多种多种容器类型(只要容器提供了算法所需的接口即iterator)\r\n\r\n\r\n\r\niterator可以理解为经过包装过的指针(void*,void *可以适配所有类型),区别在于iterator能够更好地与容器兼容,对于非连续空间的容器,例如set(实现机制红黑树),指针自增是没有意义的,而iterator自增可以找到下一个元素。\r\n\r\n同时使用iterator具有智能指针的效果,即不需要程序员手动释放内存,当变量的生命周期结束之后自动回收内存。如果是void *,搭配malloc或者new--在堆上分配数据,则需要手动释放内存。\r\n\r\n\r\n\r\n#### 关联容器\r\n\r\n关联容器和顺序容器有着根本的不同,关联容器中的元素是按照关键字来保存和访问的,顺序容器中的元素是按照他们在容器中的顺序来保存和访问的。\r\n\r\n##### map\r\n\r\n```c++\r\nmap是关键字-值对的集合,与之相对set仅仅是关键字的简单集合\r\n// 统计每个单词在输入中出现的次数\r\nmap <string,size_t> word_count;\r\nwhile(cin>>word)\r\n ++word_count[word];\r\nfor(const auto &w:word_count)\r\n cout<<w.first<<\" occurs\"<<w.second<<\" times\"<<endl;\r\n```\r\n\r\n如果word未在map中,下标运算符会创建一个新元素,其关键字为word,值为0.\r\n\r\n\r\n\r\n##### set\r\n\r\n```\r\nset<string> exclude={\"The\",\"But\",\"And\",\"Or\",\"An\",\"A\"};\r\n\r\n```\r\n\r\n##### map\r\n\r\nmap的初始化方法\r\n\r\n```c++\r\nmap<string,size_t> word_count; //空容器\r\nmap<string,string>authors={{\"Jyoce\",\"James\"},{\"Austen\",\"Jane\"},{\"Dickens\",\"Charles\"}};\r\n\r\n{key,value}\r\n```\r\n\r\n一个map或者一个set的关键字必须是唯一的,容器multiset和multimap没有这样的限制,他们都允许多个元素具有相同的关键字。\r\n\r\n```\r\nvector<int> ivec={0,0,1,1};\r\nset<int> iset(ivec.cbegin(),ivec.cend()); //0,1\r\nmultiset<int> miset(ivec.cbegin(),ivec.cend());//0,0,1,1 \r\n\r\n```\r\n\r\n##### 关联容器内部的排序\r\n\r\n可以向一个算法提供我们自己定义的比较操作,用来代替<运算符。这个操作要求满足严格弱续,可以将严格弱续视为小于等于。这个小于等于可能不是数值上的。\r\n例如我们可以定义一个compare函数用来比较。\r\n\r\n```c++\r\n#include<set>\r\nbool compare(const pair<int, int> &a, const pair<int, int> &b) {\r\n\treturn a.second < b.second;\r\n}\r\nint main() {\r\n\tset<pair<int,int>,decltype(compare)*> iset(compare);\r\n\tpair<int, int> a{ 2,1 };\r\n\tpair<int, int> b{ 0,2 };\r\n\tpair<int, int> c{ -3,3 };\r\n\tiset.insert(a);\r\n\tiset.insert(b); \r\n\tiset.insert(c);\r\n\tfor (auto &it : iset)\r\n\t\tcout << it.first << \" \" << it.second << endl;\r\n\tsystem(\"pause\");\r\n\treturn 0;\r\n};\r\n```\r\n\r\n上述代码实现在set中所有元素按照compare的方式进行排序:a b c,正常的话是c b a\r\n\r\n\r\n\r\n##### pair类型\r\n\r\npair在头文件utility中\r\n\r\n```\r\npair<T1,T2> P;//定义了一个空pair;\r\npair<T1,T2> P(V1,V2); //初始化为v1v2\r\npair<T1,T2> ={v1,v2}; //作用同上\r\nmake_pair(v1,v2); //返回一个用v1 v2初始化的pair\r\np.first;\r\np.second;\r\n\r\n```\r\n\r\n关联容器还定义了key_value,mapped_type,value_type这三个类型\r\n\r\nset的迭代器是const的,可以使用set迭代器来读取元素的值,但不能修改。\r\n\r\n##### 遍历关联容器\r\n\r\n```c++\r\nauto map it=word_count.cbegin();\r\nwhile(map_it!=word_count.cend()){\r\n cout<<map_it->first<<\" occurs \"<<map_it->second<<\" times\"<<endl;\r\n ++map_it;\r\n}\r\n```\r\n\r\n##### 添加元素\r\n\r\n关联容器使用insert函数向容器中添加一个元素或者一个元素范围。map和set中插入一个已经存在的元素对容器没有任何影响。\r\n\r\n```c++\r\nvector<int> ivec={2,4,6,8,2,4,6,8};\r\nset<int> set2;\r\nset2.insert(ivec.cbegin(),ivec.cend()); //2,4,6,8\r\nset2.insert({1,3,5,7,1,3,5,7});//1,3,5,7\r\n\r\nword_count.insert({word,1});\r\nword_count.insert(make_pair(word,1));\r\nword_count.insert(pair<string,size_t>(word,1));\r\n```\r\n\r\n如果容器中没有这个元素,则插入并返回true,如果已经存在了则不做任何操作,返回false\r\n\r\n```c++\r\nmultimap<string,string> authors;\r\nauthors.insert({\"a,b\",\"1\"});\r\nauthors.insert({\"a,b\",\"2\"});\r\n```\r\n\r\n\r\n\r\n##### 删除元素\r\n\r\n```\r\nc.erase(k); //删除每个关键字为k的元素;\r\nc.erase(p); //从c中删除迭代器p指定的元素;\r\nc.erase(b,e); 删除迭代器b和e所表示的范围\r\n\r\nerase返回删除元素的数量\r\n\r\n```\r\n\r\nmap和unordered_map支持下标操作,multimap不支持下标操作。\r\n\r\n下标操作:\r\n\r\n```c++\r\nc[k];\r\nc.at(k)\r\n```\r\n\r\nc[k]:与vector不同的是,如果k不在c中,会添加k元素到c中\r\n\r\nc.at(k)如果k不在c中会报out of range 错误\r\n\r\n\r\n\r\n##### 访问元素\r\n\r\nfind函数与count函数\r\n\r\n```\r\nset<int> iset={0,1,2,3,4,5,6,7,8};\r\niset.find(1); //返回一个迭代器,指向key==1的元素\r\niset.find(11); //返回一个迭代器,iset.end()\r\niset.count(1); //返回1\r\niset.count(0); //返回0\r\n\r\nc.lower_bound(k);//返回一个迭代器,指向第一个不小于k的元素\r\nc.upper_bound(k);//返回一个迭代器,指向第一个大于k的元素\r\nc.equal_range(k);//返回一个迭代器pair,关键字等于k的元素范围,若k不存在则返回两个c.end()\r\n\r\n```\r\n\r\n\r\n\r\n##### 无序容器\r\n\r\n定义了unordered_map,unordered_set等无序容器\r\n\r\n容器使用一个哈希函数与关键字类型==运算符来组织元素\r\n\r\nfind insert等函数也适用于无序容器。无序容器在组织上为一组桶,每个桶保存零个或者多个元素。\r\n\r\n```c++\r\nc.bucket_count() ;// 正在使用的桶数目\r\nc.max_bucket_count();//容器能容纳的最多桶的数目\r\nc.bucket_size(n);//第n个桶中有多少个元素\r\nc.bucket(k);//元素k在哪个桶中\r\n```\r\n\r\n可以用自己定义的函数hasher来重新定义==符号\r\n\r\n\r\n\r\n#### 拷贝控制\r\n\r\n```c++\r\nclass Foo(){\r\npublic:\r\n Foo(); //默认初始化\r\n Foo(const Foo&); //拷贝初始化\r\n //...\r\n};\r\n```\r\n\r\n```c++\r\nstring dots(10,'.'); //直接初始化\r\nstring s(dots); //直接初始化\r\nstring s2=dots; //拷贝初始化\r\nstring null_book=\"9-9999-99999-9\"; //拷贝初始化\r\nstring nines=string(100,'9'); //拷贝初始化\r\n```\r\n\r\n##### 析构函数\r\n\r\n析构函数与构造函数执行相反的操作。\r\n\r\n```c++\r\nclass Foo(){\r\npublic:\r\n ~Foo();\r\n}\r\n```\r\n\r\n什么时候会调用析构函数:无论何时,一个对象对销毁时会自动调用其析构函数。\r\n\r\n- 一个变量离开其作用域时\r\n- 一个对象被销毁时,其成员被销毁\r\n\r\n等等\r\n\r\n\r\n\r\n\r\n\r\n#### 重载运算&&类型转换\r\n\r\n重载+号运算符\r\n\r\n```c++\r\n#include <iostream>\r\nusing namespace std;\r\nclass Box{\r\n public:\r\n double getVolume(void){\r\n return length * breadth * height;\r\n }\r\n void setLength( double len ){\r\n length = len;\r\n }\r\n void setBreadth( double bre ){\r\n breadth = bre;\r\n }\r\n void setHeight( double hei ){\r\n height = hei;\r\n }\r\n // 重载 + 运算符,用于把两个 Box 对象相加\r\n Box operator+(const Box& b){\r\n Box box;\r\n box.length = this->length + b.length;\r\n box.breadth = this->breadth + b.breadth;\r\n box.height = this->height + b.height;\r\n return box;\r\n }\r\n private:\r\n double length; // 长度\r\n double breadth; // 宽度\r\n double height; // 高度\r\n};\r\nint main( ){\r\n Box Box1; // 声明 Box1,类型为 Box\r\n Box Box2; // 声明 Box2,类型为 Box\r\n Box Box3; // 声明 Box3,类型为 Box\r\n double volume = 0.0; // 把体积存储在该变量中\r\n // Box1 详述\r\n Box1.setLength(6.0); \r\n Box1.setBreadth(7.0); \r\n Box1.setHeight(5.0);\r\n // Box2 详述\r\n Box2.setLength(12.0); \r\n Box2.setBreadth(13.0); \r\n Box2.setHeight(10.0);\r\n // Box1 的体积\r\n volume = Box1.getVolume();\r\n cout << \"Volume of Box1 : \" << volume <<endl;\r\n // Box2 的体积\r\n volume = Box2.getVolume();\r\n cout << \"Volume of Box2 : \" << volume <<endl;\r\n // 把两个对象相加,得到 Box3\r\n Box3 = Box1 + Box2;\r\n // Box3 的体积\r\n volume = Box3.getVolume();\r\n cout << \"Volume of Box3 : \" << volume <<endl;\r\n \r\n return 0;\r\n}\r\n```\r\n\r\noperator+ 运算符\r\n\r\noperator<< 符号\r\n\r\n```c++\r\nostream &operator<<(ostream &os,const Sales_data &item){\r\n os<<item.isbn()<<\" \"<<item.units_sold<<\" \"<<item.revenue<<\" \"<<item.avg_price();\r\n return os;\r\n}\r\n\r\ncout<<data;\r\n```\r\n\r\noperator>>符号\r\n\r\n```c++\r\nistream &operator>>(istream &is,Sales_data &item){\r\n double price;\r\n is>>item.bookNo>>item>>units_sold()>>price;\r\n if(is)\r\n item.revenue=tiem.units_sold*price;\r\n else\r\n item=Sales_data();\r\n return is;\r\n}\r\n```\r\n\r\n##### 算术和关系运算符重载\r\n\r\n```c++\r\nSales_data operator+(const Sales_data 7lhs,const Sales_data &rhs){\r\n Sales_data sum=lhs;\r\n sum+=rhs;\r\n return sum;\r\n}\r\n\r\nbool operator==(const Sales_data &lhs,const Sales_data &rhs){\r\n return lhs.isbn()==rhs.isbn()&&lhs.units_sold==rhs.units_sold&&lhs.revenue==rhs.revenue;\r\n}\r\nbool operator!=(const Sales_data &lhs,const Sales_data &rhs){\r\n return !(lhs==rhs);\r\n}\r\n```\r\n\r\n面向对象程序设计\r\n\r\n面向对象程序设计基于三个基本的概念:数据抽象、继承和动态绑定\r\n\r\n##### 继承:\r\n\r\n通过继承联系在一起的类构成一种层次关系。通常在层次关系的根部有一个基类,其他类通过基类继承而来,这些类称为派生类。\r\n\r\n基类Quote\r\n\r\n```\r\nclass Quote{\r\npublic:\r\n std::string isbn() const;\r\n virtual double net_price(std::size_t n) const;\r\n};\r\n\r\n```\r\n\r\n对于某些函数,基类希望它的派生类各自定义适合自身的版本,此时基类就将这些函数声明为虚函数。\r\n\r\n派生类通过类派生列表明确指出它是从哪个基类继承而来的。\r\n\r\n```c++\r\nclass Bulk_quote:public Quote{\r\npublic:\r\n double net_price(std::size_t) const override;\r\n}\r\n```\r\n\r\n派生类可以显示地注明它将使用哪个成员函数改写基类的虚函数,具体的措施是在该函数的形参列表后写一个override关键字。\r\n\r\n\r\n\r\n##### 动态绑定\r\n\r\n函数print_total基于net_price函数。\r\n\r\n```c++\r\n//basic 的类型是Quote,bulk的类型是Bulk_quote;\r\nprint_totall(cout,basic,20);//调用Quote的net_price函数\r\nprint_total(cout,bulk,20);//调用Bulk_quote的net_price函数\r\n```\r\n\r\n动态绑定:\r\n\r\n函数的运行版本由实参决定,即在运行时选择函数的版本,动态绑定又被称为运行时绑定。\r\n\r\n\r\n\r\n#### 基类:\r\n\r\n```c++\r\nclass Quote{\r\npublic:\r\n Quote()=default;\r\n Quote(const std::string &book,double sales_price):bookNo(book),price(sales_price){}\r\n std::string isbn() const{return bookNo;}\r\n virtual double net_price(std::size_t n)const{return n*price};//虚函数\r\n virtual ~Quote()=default;\r\nprivate:\r\n std::string bookNo;\r\nprotected:\r\n double price=0.0;\r\n};\r\n```\r\n\r\n在c++语言中,基类将它的两种成员函数区分开来:一种是基类希望其派生类进行覆盖的函数,另一种是基类希望派生类直接继承而不要改变的函数。对于前者,基类通常将其定义为虚函数virtual。\r\n\r\n基类的public成员能被其他用户访问,private不能被其他用户访问,protected类表示它的派生类可以访问但是其他用户不能访问。\r\n\r\n##### 派生类\r\n\r\n```c++\r\nclass Bulk_quote:public Quote{//继承自Quote\r\npublic:\r\n Bulk_quote()=default;\r\n Bulk_quote(const std::string&,double,std::size_t,double);\r\n \r\n double net_price(std::size_t) const override;\r\nprivate:\r\n std::size_t min_qty=0;\r\n double discount=0.0;\r\n};\r\n```\r\n\r\n派生类必须将其继承而来的成员函数中需要覆盖的那些重新声明。如果没有覆盖则会继承在基类的版本。\r\n\r\nBulk_quote类从Quote类继承了bookNo price 等数据成员,重新定义了net_price的版本,增加了两个min_qty discount成员。\r\n\r\n##### 防止继承的发生\r\n\r\n有时我们需要有些类不能被其他类所继承,使用final关键字\r\n\r\n```c++\r\nclass NoDerived final{}; // 不能继承\r\n```\r\n\r\n##### 类型转换与继承\r\n\r\n我们在使用指针或者引用时,指针或者引用的类型应与对象的类型一致,但是继承关系的类时一个重要的例外。我们可以将基类的指针或引用绑定到派生类对象上,例如可以用Quote&引用,Quote*指针指向Bulk_quote对象。\r\n\r\n\r\n\r\n#### 虚函数\r\n\r\n对虚函数的调用可能在运行时才被解析\r\n\r\n##### 多态性\r\n\r\nOOP的核心思想是多态性,表示多种形态。我们把具有继承关系的多个类型称为多态类型,我们能够使用这些类型的多种形式而不需要注意它们的差异。当我们使用基类的引用或者是指针调用基类的一个函数时,不知道该函数真正作用的对象是什么类型,因为可能是基类的对象或者是一个派生类的对象。如果这个函数是虚函数,则知道运行时才会决定到底执行哪个版本。\r\n\r\n\r\n\r\n##### 抽象基类与纯虚函数\r\n\r\n和普通的虚函数不一样,纯虚函数不需要定义,直接书写=0即可。\r\n\r\n```c++\r\ndouble net_price(std::size t) const=0;\r\n```\r\n\r\n含有纯虚函数的类是抽象基类,抽象基类负责定义接口,我们不能直接创建一个抽象基类对象。\r\n\r\n例子:\r\n\r\n抽象基类:动物,纯虚函数是进食。动物不能直接创建一个对象。\r\n\r\n基类:猫,虚函数:进食(具体表现为吃鱼)\r\n\r\n派生类:虎,override的虚函数 进食(具体表现为吃羊等)\r\n\r\n\r\n\r\n##### 直接基类与间接基类\r\n\r\n```c++\r\nclass Base{...};\r\nclass D1: public Base{...};\r\nclass D2:public D1{...};\r\n```\r\n\r\nBase是D1类的直接基类,同时是D2的间接基类。直接基类出现在派生列表中。最终的派生类将包含它的直接基类的子对象以及每个间接基类的子对象。(直接基类有点像father 间接基类比较像grandfather)\r\n\r\n\r\n\r\n##### 公有继承 私有继承 受保护继承\r\n\r\n```c++\r\nclass D2:public Pal{...};//公有继承\r\nclass Derived: private Base{...};//私有继承\r\n```\r\n\r\n在私有继承中,基类的公有成员和受保护成员是派生类的私有成员。\r\n\r\n在公有继承中,积累的公有接口时派生类公有接口的组成部分。\r\n\r\n在受保护的继承中,基类的公有成员和受保护成员是派生类的受保护成员。\r\n\r\n\r\n\r\n##### 重构\r\n\r\n在继承体系中将相关代码搜集到单独的抽象类中,替换原来的代码。\r\n\r\n\r\n\r\n##### 切掉\r\n\r\n```c++\r\nBulk_quote bulk;\r\nQuote item(bulk);\r\nitem =bulk;\r\n```\r\n\r\n用一个派生类对象去初始化一个基类对象时,对象的派生类部分(bulk中的Bulk_quote部分)被切掉,只剩下基类部分(Quote部分)赋值给基类对象。\r\n\r\n\r\n\r\n### 标准库的特殊设施\r\n\r\n#### tuple\r\n\r\ntuple是一个轻松而又随机的数据结构,与pair类似。pair中每个成员的类型可以不相同,但是只能有两个成员。tuple中可以有任何数量的成员,每个成员的类型可以不相同。\r\n\r\ntuple头文件\r\n\r\n```c++\r\ntuple<T1,T2,T3...,Tn> t;\r\ntuple<T1,T2,T3,...,Tn> t(v1,v2,...,vn);\r\nmake_tuple(v1,v2,...,vn);\r\nt1==t2;\r\nt1 relop t2;//按照字典序比较t1 t2中对应的元素\r\nget<i>(t);//返回t的第i个数据成员的引用\r\n```\r\n\r\n```c++\r\ntuple<string,vector<double>,int,list<int>>someVal(\"constants\",{3.14,2.718},42,{0,1,2,3,4,5});\r\nauto item=make_tuple(\"0-999-78345-X\",3,20.00);\r\nauto book=get<0>(item);\r\nauto cnt=get<1>(item);\r\nauto price=get<2>(item)/cnt;\r\nget<2>(item)*=0.8;\r\n```\r\n\r\n只有当tuple内成员数量和类型相同时才可以使用关系和相等关系符\r\n\r\ntuple的一个常见用途是用来返回多个值\r\n\r\n#### bitset\r\n\r\n#include<bitset>\r\n\r\n使得位运算更加容易\r\n\r\n```c++\r\nbitset<32>bitvec(1U); //32位,低位为1其余为0\r\nbitset<n> b; //b有n位,每位均为0\r\n//用unsigned 值初始化bitset\r\nbitset<13> bitvec1(0xbeef);// 二进制序列为1111011101111 (初始值高位被丢弃)\r\nbitset<20>bitvec2(0xbeef);//二进制为000010111111011101111 (初始高位补零)\r\n//用string初始化bitset\r\nbitset<32> bitset4(\"1100\");\r\n```\r\n\r\n```c++\r\nb.any(); //b中是否有置为=位的二进制位\r\nb.all(); //是否b中所有的位都置位了\r\nb.none();//b中是否不存在置位的二进制位\r\nb.count;//统计b中置位的二进制位数量\r\nb.size(); //位数\r\n\r\nb.test(pos); //判断pos位置是否被置位\r\nb.set(pos,v); //置为v,默认为1\r\nb.set();//全部置位\r\nb.reset(pos);//将pos位置复位\r\nb.reset();//全部复位\r\nb.flip(pos);//将pos位置翻转\r\nb.flip();//全部翻转\r\nb.to_ulong();\r\n\r\nb.to_string(zero,one); //zero和one默认为0和1\r\nos<<b;\r\n```\r\n\r\n```c++\r\nunsigned long quizA=0;\r\nquizA|=1UL<<27; //指出第27个学生通过了测试\r\nstatus=quizA&(1UL<<27);//检查第27个学生是否通过测试\r\nquizA &=~(1UL<<27);//第27个学生没通过测试\r\n1UL 无符号长整形1\r\n```\r\n\r\n\r\n\r\n#### 正则表达式\r\n\r\n正则表达式是用来描述字符串的强大方法。\r\n\r\n```c++\r\nstring pattern(\"[^c]ei\");//查找不在字符c后面的字符串ei\r\npattern=\"[[:alpha:]]*\"+pattern+\"[[:alpha:]]*\";\r\nregex r(pattern);//构造一个regex\r\nsmatch results; //定义一个对象保存结果\r\nstring test_str=\"receipt freind theif receive\";\r\nif(regex_search(test_str,results,r))\r\n cout<<results.str()<<endl; //打印结果 freind\r\n```\r\n\r\n\r\n\r\n#### 随机数\r\n\r\n定义在random头文件中的随机数库通过一组写作的类:随机数引擎类和随机数分布类来解决问题。\r\n\r\n```c++\r\ndefault_random_engine e;//生成随机无符号数\r\nfor(size_t i=0;i<10;i++){\r\n cout<<e()<<\" \";//16807 282475249 ... ....\r\n}\r\n```\r\n\r\n```c++\r\nEngineer e;//默认构造函数\r\nEngineer e(s);以s作为种子\r\ne.min()\r\ne.max()\r\n```\r\n\r\n```c++\r\nuniform_int_distribution<unsigned>u(0,9); //均匀分布的0-9整数\r\ndefault_random_engine e;\r\nfor(size_t i=0;i<10;i++){\r\n cout<<u(e)<<\" \";//0 1 7 4 5 2 0 6 6 9\r\n}\r\n\r\n```\r\n\r\n随机数发生器:即使看起来生成的数看起来是随机的,但是对一个给定的发生器,每次运行程序它都会返回相同的数值序列。\r\n\r\n```c++\r\nvector<unsigned> bad_randVec(){\r\n default_random_engine e;\r\n uniform_int_distribution<unsigned>u(0,9);\r\n vector<unsigned>ret;\r\n for(size_t i=0;i<100;i++){\r\n ret.push_back(u(e));\r\n }\r\n return ret;\r\n}\r\nvector<unsigned>v1(bad_randVec());\r\nvector<unsigned>v2(bad_randVec());\r\nv1==v2\r\n```\r\n\r\n编写此函数正确的方法是使用static\r\n\r\n```c++\r\nvector<unsigned> bad_randVec(){\r\n static default_random_engine e;\r\n static uniform_int_distribution<unsigned>u(0,9);\r\n vector<unsigned>ret;\r\n for(size_t i=0;i<100;i++){\r\n ret.push_back(u(e));\r\n }\r\n return ret;\r\n}\r\nvector<unsigned>v1(bad_randVec());\r\nvector<unsigned>v2(bad_randVec());\r\nv1!=v2\r\n```\r\n\r\n设置随机数发生器种子就是让引擎从一个序列中一个新位置重新开始生成随机数。\r\n\r\n```c++\r\ndefault_random_engine e1;\r\ne1.seed(32767);\r\ndefault_random_engine e2(32767);\r\ndefault_random_engine e3(time(0));\r\n```\r\n\r\ne1 e2 两个发生器产生的随机数列相同\r\n\r\n一般使用time作为种子,在头文件ctime里\r\n\r\n```c++\r\nuniform_real_distribution<double> u(0,1);//0-1real number\r\nnormal_distribution<double> n(4,15);//均值为4标准差为1.5的正态分布\r\nbernoulli_distribution b(0.7);//默认实50 50/true false分布\r\n```\r\n\r\n#### IO库再探\r\n\r\n标准库中定义了一组操纵符来控制\r\n\r\n##### 布尔值的格式:\r\n\r\nboolalpha noboolalpha\r\n\r\n默认情况下true的值是1,使用boolalpha之后输出就是string “true”\r\n\r\n##### 整型值的进制:\r\n\r\n```c++\r\ncout<<\"hex\"<<hex<<20<<\" \"<<1024<<endl; //16进制 14 400\r\n```\r\n\r\nhex oct dec 分别表示使用十六 8 10进制\r\n\r\n##### 显示进制\r\n\r\n```c++\r\ncout<<showbase<<\"in hex\"<< hex<<20<<endl;//0x14\r\n```\r\n\r\n使用showbase显示进制,noshowbase恢复\r\n\r\nuppercase nouppercase 显示0X14\r\n\r\n##### 控制浮点数格式\r\n\r\n精度:\r\n\r\n```c++\r\ncout.precision(12);//设置为12精度\r\nsetprecision(12);//效果相同\r\ncout<<sqrt(2.0)<<endl; //1.41421356237\r\ncout<<scientific://使用科学计数法\r\n```\r\n\r\n##### 小数点\r\n\r\n```c++\r\ncout<<10.0<<endl; //10\r\ncout<<showpoint<<10.0<<noshowpoint<<endl;//10.0000\r\n```\r\n\r\n##### 输出补白\r\n\r\n- setw指定下一个数字和字符串值的最小空间\r\n- left表示左对齐输出\r\n- right表示右对齐输出,这是默认格式\r\n- internal 控制负数的符号的位置,它左对齐符号,右对齐数值,空格填满中间的空隙\r\n- setfill允许一个字符代替空格\r\n\r\n\r\n\r\n##### 控制输入格式\r\n\r\n默认情况下会忽略空白符\r\n\r\na b c d\r\n\r\n```c++\r\nchar ch;\r\nwhile(cin>>ch){\r\n cout<<ch;\r\n}// abcd\r\ncin>>noshipws;\r\nwhile(cin>>ch){\r\n cout<<ch;\r\n}//a b c d\r\n```\r\n\r\n##### 从输入操作中返回int值\r\n\r\n```c++\r\nint ch;\r\nwhile((ch=cin.get())!=EOF){\r\n cout.put(ch);\r\n}//正确\r\nchar ch;\r\nwhile((ch=cin.get()!=EOF)){\r\n cout.put(ch)//永远读\r\n}\r\n```\r\n\r\n\r\n\r\n2.实现一些常见的数据结构\r\n\r\nstack\r\n\r\nempty,top,pop,append\r\n\r\n```\r\nclass Stack(object):\r\n # 初始化栈为空列表\r\n def __init__(self):\r\n self.items = []\r\n # 判断栈是否为空,返回布尔值\r\n def is_empty(self):\r\n return self.items == []\r\n # 返回栈顶元素\r\n def peek(self):\r\n return self.items[len(self.items) - 1]\r\n # 返回栈的大小\r\n def size(self):\r\n return len(self.items)\r\n # 把新的元素堆进栈里面(程序员喜欢把这个过程叫做压栈,入栈,进栈……)\r\n def push(self, item):\r\n self.items.append(item)\r\n # 把栈顶元素丢出去(程序员喜欢把这个过程叫做出栈……)\r\n def pop(self, item):\r\n return self.items.pop()\r\n```\r\n\r\nqueue\r\n\r\n```\r\nclass MyQueue:\r\n def __init__(self):\r\n \"\"\"\r\n Initialize your data structure here.\r\n \"\"\"\r\n self.nums=[]\r\n def push(self, x):\r\n \"\"\"\r\n Push element x to the back of queue.\r\n :type x: int\r\n :rtype: void\r\n \"\"\"\r\n self.nums.append(x)\r\n def pop(self):\r\n \"\"\"\r\n Removes the element from in front of queue and returns that element.\r\n :rtype: int\r\n \"\"\"\r\n res=self.nums[0]\r\n self.nums=self.nums[1:]\r\n return res\r\n def peek(self):\r\n \"\"\"\r\n Get the front element.\r\n :rtype: int\r\n \"\"\"\r\n return self.nums[0]\r\n def empty(self):\r\n \"\"\"\r\n Returns whether the queue is empty.\r\n :rtype: bool\r\n \"\"\"\r\n if self.nums==[]:\r\n return True\r\n else:\r\n return False\r\n\r\n```\r\n\r\ndict\r\n\r\n```\r\npython 使用hash函数来得到一个很大的hash值\r\n这个hash值与输入有关 也可能与保存位置有关\r\n自己实现一个简单的hash函数:\r\n>>> def myhash(a):\r\n... if type(int)==int:\r\n... return a\r\n... return ord(a)<<32%1000000007\r\n\r\nPyDict_SetItem: key = ‘a’, value = 1\r\n hash = hash(‘a’) = 12416037344\r\n insertdict\r\n lookdict_string\r\n slot index = hash & mask = 12416037344 & 7 = 0\r\n slot 0 is not used so return it\r\n init entry at index 0 with key, value and hashma_used = 1, ma_fill = 1\r\n\r\nPyDict_SetItem: key = ‘b’, value = 2\r\n hash = hash(‘b’) = 12544037731\r\n insertdict\r\n lookdict_string\r\n slot index = hash & mask = 12544037731 & 7 = 3\r\n slot 3 is not used so return it\r\n init entry at index 3 with key, value and hashma_used = 2, ma_fill = 2\r\n\r\nPyDict_SetItem: key = ‘z’, value = 26\r\n hash = hash(‘z’) = 15616046971\r\n insertdict\r\n lookdict_string\r\n slot index = hash & mask = 15616046971 & 7 = 3\r\n slot 3 is used so probe for a different slot: 5 is free\r\n init entry at index 5 with key, value and hashma_used = 3, ma_fill = 3\r\n```\r\n\r\n \r\n\r\n处理冲突的时候,可以选用open address method或者linked method\r\n\r\nheap\r\n\r\n```python\r\nclass MaxHeap(object):\r\n \r\n def __init__(self):\r\n self._data = []\r\n self._count = len(self._data)\r\n \r\n def size(self):\r\n return self._count\r\n \r\n def isEmpty(self):\r\n return self._count == 0\r\n \r\n def add(self, item):\r\n # 插入元素入堆\r\n self._data.append(item)\r\n self._count += 1\r\n self._shiftup(self._count-1)\r\n \r\n def pop(self):\r\n # 出堆\r\n if self._count > 0:\r\n ret = self._data[0]\r\n self._data[0] = self._data[self._count-1]\r\n self._count -= 1\r\n self._shiftDown(0)\r\n return ret\r\n \r\n def _shiftup(self, index):\r\n # 上移self._data[index],以使它不大于父节点\r\n parent = (index-1)>>1\r\n while index > 0 and self._data[parent] < self._data[index]:\r\n # swap\r\n self._data[parent], self._data[index] = self._data[index], self._data[parent]\r\n index = parent\r\n parent = (index-1)>>1\r\n \r\n def _shiftDown(self, index):\r\n # 上移self._data[index],以使它不小于子节点\r\n j = (index << 1) + 1\r\n while j < self._count :\r\n # 有子节点\r\n if j+1 < self._count and self._data[j+1] > self._data[j]:\r\n # 有右子节点,并且右子节点较大\r\n j += 1\r\n if self._data[index] >= self._data[j]:\r\n # 堆的索引位置已经大于两个子节点,不需要交换了\r\n break\r\n self._data[index], self._data[j] = self._data[j], self._data[index]\r\n index = j\r\n j = (index << 1) + 1\r\n\r\n```\r\n\r\n\r\n\r\nC++与python相同不同\r\n\r\n传值还是传引用\r\n\r\n```python\r\ndef foo(arg):\r\n arg = 2\r\n print(arg)\r\n\r\na = 1\r\nfoo(a) # 输出:2\r\nprint(a) # 输出:1\r\n```\r\n\r\n```python\r\ndef bar(args):\r\n args.append(1)\r\n\r\nb = []\r\nprint(b)# 输出:[]\r\nprint(id(b)) # 输出:4324106952\r\nbar(b)\r\nprint(b) # 输出:[1]\r\nprint(id(b)) # 输出:4324106952\r\n```\r\n\r\npython中函数参数既可以是传值也可以是传引用(都不准确),python中一切皆对象,函数参数传的也是对象。如果传的是不可变对象,例如int,string等 就会表现出传值的性质(第一段代码),如果传的是可变对象就表现出传引用的性质(第二段代码),例如[]\r\n\r\n\r\n\r\n在设置函数默认参数时,最好不要使用可变对象作为默认值,函数定义好之后默认参数就会指向(绑定)一个空列表对象,每次调用函数时都是对同一个对象进行操作。\r\n\r\n\r\n\r\n```python\r\ndef bad_append(new_item, a_list=[]):\r\n a_list.append(new_item)\r\n return a_list\r\n \r\n>>> print bad_append('one')\r\n['one']\r\n>>> print bad_append('one')\r\n['one', 'one']\r\n```\r\n\r\n\r\n\r\nC++中函数有值传递、指针传递、引用传递这三种。\r\n\r\n**值传递:**形参是实参的拷贝,改变形参的值并不会影响外部实参的值。\r\n\r\n**指针传递:**形参为指向实参地址的指针,当对形参的指向操作时,就相当于对实参本身进行的操作\r\n\r\n**引用传递:**形参相当于是实参的“别名”,对形参的操作其实就是对实参的操作\r\n\r\n\r\n\r\npython中没有自增自减符,++i等\r\n\r\n\r\n\r\n对函数中return的限制\r\n\r\n在c/c++中有一个常见的错误:\"Not all control paths return a value\",如果有任何一条路径没有返回值,会报错。\r\n\r\n```c++\r\n// Error: not all control paths returns\r\nint f(bool flag)\r\n{\r\n if (flag)\r\n {\r\n return 1;\r\n }\r\n}\r\n```\r\n\r\n但对应的Python程序没有任何问题:\r\n\r\n```python\r\ndef f(flag):\r\n if flag:\r\n return 1\r\n \r\n>>> print (f(True))\r\n>>> 1\r\n>>> print (f(False))\r\n>>> None\r\n```\r\n\r\n\r\n\r\n##### 作用域\r\n\r\nC/C++中for loop循环变量的作用域仅限于for及对应的{}本身,for结束后该作用域消失。\r\n\r\n```c++\r\nfor (int i = 0; i < 10; ++i){\r\n ..\r\n}\r\n// v--- undeclared variable \"i\"\r\nif (i == 10)\r\n\r\n```\r\n\r\nPython中,for语句(以及while、if等)没有自己单独的作用域。循环变量i的作用域就是包含它的函数f的作用域。\r\n\r\n```python\r\ndef f():\r\n for i in range(10):\r\n ..\r\n // Ok!\r\n if i == 10:\r\n\r\n```\r\n\r\nPython作为一种动态语言,一个名字只要在使用前赋过值,就可以使用。\r\n\r\n\r\n\r\n##### for循环的最后一个值\r\n\r\npython和c++中for循环结束之后的i数值是不一样的。C++在每次循环结束后会++i,即使是最后一次循环。而由于Python有着不同的循环方式。\r\n\r\n```c++\r\nint i;\r\nfor (i = 0; i < 10; ++i)\r\n{\r\n ..\r\n if (found)\r\n break\r\n}\r\n// Not found\r\nif (i == 10)\r\n```\r\n\r\n```python\r\nfor i in range(10):\r\n if found:\r\n break\r\nelse:\r\n # Not found\r\n ..\r\nprint (i) # 9\r\n```\r\n\r\n\r\n\r\n##### 垃圾回收\r\n\r\n高级语言例如python,java,c#都采用了垃圾回收机制,不再是c,c++那种用户自己管理内存的方式。c/c++对内存的管理非常自由,但是存在内存泄漏等风险。\r\n\r\n**python采用的是引用计数机制为主,标记-清除和分代收集两种机制为辅的策略**\r\n\r\n在python中 对象的引用计数为0的时候,该对象生命就结束了。\r\n\r\n1.引用计数机制:\r\n\r\n优点:1.简单实用\r\n\r\n缺点:1.引用计数消耗资源 2.无法解决循环引用的问题\r\n\r\n2.标记清除\r\n\r\n\r\n\r\n确认一个根节点对象,然后迭代寻找根节点的引用对象,以及被引用对象的引用对象(标为灰色),然后将那些没有被引用的对象(白色)回收清除。\r\n\r\n3.分代回收\r\n\r\n分代回收是一种空间换时间的操作方式。python将内存根据对象划分为不同的集合。分别为年轻代0 中年代1 老年代2,对应三个链表。新创建的对象都会分配在新生代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象。\r\n\r\n\r\n\r\nGC系统提供了1.为新对象分配内存 2.识别哪些对象是垃圾 3.将垃圾的内存回收\r\n\r\n\r\n\r\n\r\n\r\nc++垃圾回收机制\r\n\r\nc语言中显然没有GC(Garbage Collection)系统,C语言使用mallloc进行分配,free回收。\r\n\r\nc++中提供了基于引用计算算法的智能指针进行内存管理。\r\n\r\n\r\n\r\n##### 运行效率\r\n\r\nc++是一种编译型语言,运行效率高,python是一种解释型语言,运行效率低\r\n\r\npython比c++慢的原因主要在于:\r\n\r\n1.动态类型\r\n\r\n在运行时需要不断判断数据类型,带来一定的开销\r\n\r\n2.python执行的时候通过python解释器(Interpreter)一条条翻译成字节码文件\r\n\r\n3.由虚拟机来执行刚刚解释器得到的字节码文件,需要开销\r\n\r\n4.GIL Global Interpreter Lock\r\n\r\nGIL 只允许一个线程拥有python解释器,因此带来了伪多线程问题,效率低\r\n\r\n\r\n\r\nc++则是直接编译为二进制可执行文件,效率高\r\n\r\n\r\n\r\nint类型字节数 大小\r\n\r\n在c++和java中,int类型占据了4个字节的大小,\r\n\r\n在python中int类型的大小可以用`sys.getsizeof`这个API知道\r\n\r\n```\r\nprint(sys.getsizeof(0)) # 24\r\nprint(sys.getsizeof(1)) # 28\r\nprint(sys.getsizeof(2)) # 28\r\nprint(sys.getsizeof(2**15)) # 28\r\nprint(sys.getsizeof(2**30)) # 32\r\nprint(sys.getsizeof(2**128)) # 44\r\n```\r\n\r\n\r\n\r\n一个整型最少要占24字节(0),1开始就要占用28个字节,到了2的30次方开始要占用32个字节,而2的128次方则要占用44个字节。\r\n\r\n1. 字节数随着数字增大而增大。\r\n2. 每次的增量是4个字节。\r\n\r\npython64与python32不同\r\n\r\n\r\n\r\n### 项目\r\n\r\nembedding问题\r\n\r\n如果和cnn有关,熟悉卷积网络的内容\r\n\r\n\r\n\r\n### Mapreduce\r\n\r\nmapreduce可以分为input,split,map,shuffle,reduce,finalize六个步骤。本质上map是分解的过程,reduce是组合的过程。\r\n\r\n\r\n\r\n经典例子:\r\n1.distributed grep(查找): map(如果某个文件匹配到了,则输出被匹配到的结果),reduce(将所有的被匹配到的结果合起来)\r\n\r\n2.count of URL Access Frequency:map(将link输出为<URL,1>),reduce(将相同的key对应的组合,生成<URL,totalcount>)\r\n\r\n3.reverse web-link graph(从source->target,统计有多少source指向target):map(输出<target,source>),reduce:(将相同的key组合,得到<target,list(source)>)\r\n\r\n4.term-vector per host\r\n\r\n5.Inverted Index(倒排索引) 根据某个词找出出现该词的document\r\n\r\nmap:(输出<word, document ID>)\r\n\r\nreduce:(输出<word, list(document ID)>)\r\n\r\n6.distributed sort大数据排序\r\n\r\nmap:(输出<key,NULL>) 将数字作为key\r\n\r\nreduce:(将所有的map输出合起来即可)\r\n\r\nmapreduce中默认以key的顺序排序为序,因此利用这一点可以轻松实现distributed sort\r\n\r\n\r\n\r\n##### First non repeating word in a file? File size can be 100GB.\r\n\r\nGiven a text file of size say 100GB? Task is to find first non repeating word in this file?\r\nconstraints: You can traverse the file only once.\r\n\r\n###### Mapreduce\r\n\r\n本题的问题主要在于100G 可能不能由一个server存下,因此需要使用多个server\r\n\r\n1.map:将100G文件平均分成100份,输送到100个server,每个server会用一个hashmap来统计不同单词的个数,key is word, value is count\r\n\r\n2.reduce:将每个server上只出现一次的单词发给一个server进行统计(hashmap)\r\n\r\n如果一个server太小的话就先用26个server 分别存A-Z的出现过一次的单词,先用这26个server reduce一遍,然后再发给一个server\r\n\r\n\r\n\r\n### 计算机知识问题\r\n\r\n操作系统:\r\n\r\n操作系统是一个控制程序,控制程序执行过程,给用户提供各种服务,方便用户使用计算机系统。操作系统是一个资源管理器,是应用程序和硬件之间的中间层,用来管理计算机软硬件。解决资源访问冲突,确保资源公平使用。\r\n\r\n\r\n\r\n\r\n\r\n操作系统组成:\r\n\r\n1.kernel:执行各种资源管理等功能\r\n\r\n2.shell命令行接口\r\n\r\n3.GUI 图形用户接口 \r\n\r\n\r\n\r\n操作系统内核特征:\r\n\r\n1.并发: 操作系统同时管理调度多个运行的程序\r\n\r\n2.共享:宏观上实现多个程序能同时访问资源,微观上实现互斥共享\r\n\r\n3.虚拟:利用多道程序设计技术,让每个用户觉得有一个计算机专门为他服务\r\n\r\n4.异步:程序的执行是走走停停,每次前进的程度不可知。只要运行环境相同,输入相同得到相同的结果。\r\n\r\n\r\n\r\n##### 常见操作系统\r\n\r\nunix家族 linux等:开源开放 ios android\r\n\r\nwindows系列:封闭式的\r\n\r\n\r\n\r\n\r\n\r\n##### BIOS \r\n\r\n计算机接上电之后第一行代码从内存(ROM)从中读取运行(RAM:断电即丢失,ROM:只读,断电不丢失)\r\n\r\n计算机由CS(代码段寄存器)和IP(指令指针寄存器)决定运行哪条程序。在初始化完成时,CS和IP的值是约定好的。\r\n\r\nBIOS:\r\n\r\n将加载程序从磁盘加载到0x7c00这个位置。然后跳转到0x7c00\r\n\r\n加载程序:\r\n\r\n将操作系统的代码和数据从硬盘加载到内存中\r\n\r\n跳转到操作系统的起始地址\r\n\r\n\r\n\r\n##### 中断 异常 系统调用\r\n\r\n中断是硬件设备对操作系统提出的处理请求\r\n\r\n异常时由于非法指令或者其他原因导致当前指令执行失败(内存出错等)后的处理请求。\r\n\r\n系统调用则是应用程序主动向操作系统发出的请求。(例如请求操作系统调用数据)\r\n\r\n\r\n\r\n源头:\r\n\r\n中断:外设\r\n\r\n异常:程序意想不到的行为\r\n\r\n系统调用:引用程序的请求\r\n\r\n\r\n\r\n响应方式与处理机制:\r\n\r\n中断:异步,对用户应用程序是透明的\r\n\r\n异常:同步(需要处理完异常才能继续运行),杀死出现异常的程序\r\n\r\n系统调用:引用程序的请求,等待再继续\r\n\r\n\r\n\r\n中断异常的处理机制:\r\n\r\n1.现场保护\r\n\r\n2.中断服务处理\r\n\r\n3.清除中断标记\r\n\r\n4.现场恢复\r\n\r\n\r\n\r\n异常和中断是可以被嵌套的。\r\n\r\n\r\n\r\n##### 内存层次\r\n\r\n\r\n\r\n抽象:将物理地址空间抽象到逻辑地址空间\r\n\r\n保护:独立地址空间\r\n\r\n共享:访问相同内存\r\n\r\n虚拟化:更大的地址空间\r\n\r\n\r\n\r\n操作系统中采用的内存管理方式:\r\n\r\n1.重定位\r\n\r\n2.分页\r\n\r\n3.分块\r\n\r\n\r\n\r\n##### 连续内存分配\r\n\r\n给进程分配一块不小于指定大小的连续的物理内存空间\r\n\r\n##### 内存碎片\r\n\r\n空闲碎片不能被利用\r\n\r\n\r\n\r\n外部碎片:\r\n\r\n分配单元之间未被使用的内存\r\n\r\n\r\n\r\n内部碎片:\r\n\r\n分配单元内部的未被使用的内存\r\n\r\n\r\n\r\n\r\n\r\n操作系统需要维护的数据结构:\r\n\r\n1.所有进程的已分配分区\r\n\r\n2.空闲分区\r\n\r\n\r\n\r\n##### 动态分区匹配策略:\r\n\r\n1.最佳分配(Best Fit)找比指定要求的大小稍微大一点的空间\r\n\r\n2.最先分配(First Fit)\r\n\r\n3.最差匹配(Worst Fit)每次都用最大的\r\n\r\n\r\n\r\n\r\n\r\n最先匹配:依次寻找,找到第一块比需求空间大的空间\r\n\r\n1.空闲分区是按照地址顺序排列的\r\n\r\n2.分配时找第一个合适的分区\r\n\r\n3.释放时检查是否有可以合并的空闲分区\r\n\r\n简单,但是容易产生外部碎片,分配大块时比较慢\r\n\r\n\r\n\r\n最佳分配:\r\n\r\n1.空闲分区是按照大小排列的\r\n\r\n2.分配是按照大小从小到大找第一个合适的\r\n\r\n3.在合并时检测地址周围是否有可以合并的空闲分区\r\n\r\n\r\n\r\n可以避免大块分区被拆分,减少外部碎片,简单\r\n\r\n释放分区比较慢\r\n\r\n\r\n\r\n最差分配:\r\n\r\n1.空闲分区是按照大小排列的\r\n\r\n2.分配选最大的分区\r\n\r\n3.在合并时检测地址周围是否有可以合并的空闲分区\r\n\r\n\r\n\r\n中等大小分配较多时效果好,避免出现太多小碎片\r\n\r\n释放分区较慢,容易破坏大的空闲分区\r\n\r\n\r\n\r\n##### 碎片整理\r\n\r\n紧凑:通过调整进程占用的分区位置来减少碎片\r\n\r\n条件:可动态重定位(程序中不能引用绝对地址)\r\n\r\n什么时候移动:一般是在等待的时候移动\r\n\r\n同时移动需要开销\r\n\r\n分区对换:\r\n\r\n抢占那些处于等待状态进程的分区(将等待状态的进程数据放到外存中)\r\n\r\n\r\n\r\n实例:伙伴系统\r\n\r\n整个可分配的分区大小时$2^U$\r\n\r\n如果需要的分区大小$s \\le2^{i - 1}$ 将大小为$2^i$ 的空间划分为两个大小为$2^{i - 1}$的空间,最大可能的空闲块为$2^{U - 1} - 1$ \r\n\r\n数据结构:(二叉树)\r\n\r\n1.空闲块按照大小和地址组织成二维数组\r\n\r\n2.初始为一个大小为$2^U$的空闲块\r\n\r\n3.分配时由小到大寻找合适的空闲块, 如果最小的空闲块太大就对半分\r\n\r\n4.在释放时检测能否和周围的空闲块合并成大小为$2^i$的空闲块\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n##### 非连续内存分配\r\n\r\n非连续内存分配需要实现 虚拟地址和物理地址的转换\r\n\r\n1.软件实现\r\n\r\n2.硬件实现\r\n\r\n\r\n\r\n如何选择非连续分配中的内存分块大小\r\n\r\n1.段式分配\r\n\r\n2.页式分配\r\n\r\n\r\n\r\n##### 段式分配\r\n\r\n段表示访问方式和储存数据等属性相同的一段地址空间\r\n\r\n进程的段地址空间由多个段组成\r\n\r\n一般来说,代码段、数据段、堆栈、堆之间不会跨段访问,因此段不连续的影响是比较小的。因此我们可以以段为单位,将程序的代码段、数据段等分开存放。段可以由(段号,段偏移)来表示。\r\n\r\n\r\n\r\n##### 页式分配\r\n\r\n把物理地址空间划为大小相同的基本分配单位(2的n次方)帧\r\n\r\n物理地址由二元组表示(f,o)f表示帧号,o表示帧内偏移\r\n\r\n进程逻辑地址空间划分为基本分配单位 页\r\n\r\n逻辑地址由二元组表示(p, o)p表示页号,o表示页内偏移\r\n\r\n帧内偏移 = 页内偏移 但是帧号和页号不相同(页连续 帧不连续)\r\n\r\n\r\n\r\n每个进程都有一个页表,每个页面对应一个页表项。常用页表项标志:存在位,修改位,引用位\r\n\r\n页表做的事情就是做地址转换\r\n\r\n\r\n\r\n快表(TLB):通过缓存的方式减少页表所占的开销\r\n\r\n将近期访问过的页表项存到CPU里面\r\n\r\n如果TLB命中,物理页号可以很快夺取\r\n\r\n如果不命中,则在内存中查询,并存到CPU中\r\n\r\n\r\n\r\n多级页表:通过多级来减少页表的大小\r\n\r\n通过间接引用将页号分为多级\r\n\r\n\r\n\r\n反置页表和页寄存器也是为了减少大量页表项所占的内存空间的开销。\r\n\r\n\r\n\r\n二者都通过HASH来做\r\n\r\n\r\n\r\n段页式存储管理:段式存储在保护方面有优势,页式存储在利用内存等方面有优势\r\n\r\n二者能不能结合呢?\r\n\r\n将程序分为多段,每个段中使用页表对应到物理地址。\r\n\r\n\r\n\r\n\r\n\r\n#### 虚拟存储\r\n\r\n增长迅速的存储需求\r\n\r\n实际当中的存储器有层次结构\r\n\r\n\r\n\r\n##### 覆盖技术\r\n\r\n目标:在较小的内存中运行较大的程序\r\n\r\n将程序分为必要部分(常用代码和常用数据),可选部分(只在需要时放入)\r\n\r\n不存在调用关系的模块可以相互覆盖。\r\n\r\n\r\n\r\n##### 交换技术\r\n\r\n将暂时不用的程序放到外存\r\n\r\n\r\n\r\n##### 局部性原理\r\n\r\n程序在执行过程中的一个较短时期,所执行的指令地址和指令的操作数地址,分别局限于一定区域。\r\n\r\n时间局部性:本次执行和下次执行在一个较短的时间\r\n\r\n空间局部性:当前指令和邻近指令,当前访问的数据和临近几个数据都只集中在一个小区域内\r\n\r\n分支局部性:一条跳转指令的两次执行很可能跳转到相同位置\r\n\r\n局部性原理从理论上保证了虚拟存储技术是能够实现的\r\n\r\n\r\n\r\n虚拟存储:(物理内存+磁盘=虚拟存储)\r\n\r\n在装载程序时只将需要执行的部分页面或段装入内存\r\n\r\n在执行过程中需要的指令或数据不在内存中(缺页)则调入内存\r\n\r\n操作系统将内存中暂时不用的保存到外面\r\n\r\n\r\n\r\n虚拟页式存储管理:\r\n\r\n在页式存储管理上增加请求调页和页面置换\r\n\r\n在程序启动时,只装入部分页面。在需要的时候再载入。\r\n\r\n\r\n\r\n##### 缺页\r\n\r\n缺页异常(中断)的处理流程\r\n\r\n\r\n\r\n虚拟页式存储管理的性能:\r\n\r\nEAT(有效存储访问时间) = 访问时间$\\times$(1-p)+缺页异常处理时间$\\times$缺页率p\r\n\r\n\r\n\r\n##### 页面置换算法\r\n\r\n概念:当出现缺页异常需要调入新页面而内存已满时,置换算法选择被置换的物理页面,要求尽可能减少页面调入调出次数,将未来不再访问的页面调出。\r\n\r\n页面锁定:部分重要的逻辑页面不能被调出\r\n\r\n\r\n\r\n局部页面置换算法:\r\n\r\n置换页面的选择范围仅仅限于当前进程占用的物理页面\r\n\r\n全局页面置换算法:\r\n\r\n置换范围为所有可换的页面\r\n\r\n\r\n\r\n最优页面置换算法:\r\n\r\n缺页时,计算所有逻辑页面的下一次访问时间,选择最长不访问的页面\r\n\r\n特点是无法预知未来的访问\r\n\r\n可以作为其他置换算法的性能评价依据\r\n\r\n\r\n\r\n先进先出算法\r\n\r\n选择在内存驻留时间最长的页面进行置换\r\n\r\n维护一个逻辑页面链表,链首是时间最长的\r\n\r\n特点:简单实现,性能较差\r\n\r\n\r\n\r\n最近最久未使用算法:\r\n\r\n选择最长时间没有被引用的页面进行置换\r\n\r\n特点 这是最优置换算法的一种近似\r\n\r\n\r\n\r\nLRU算法\r\n\r\n维护一个按最近一次访问时间的链表\r\n\r\n首是最近使用过的页面\r\n\r\n置换时置换链尾元素,每次访问的时候将最新访问的点放到链接、首\r\n\r\n\r\n\r\n时钟置换算法:\r\n\r\n仅对页面的访问情况进行大致统计\r\n\r\n在页表项中增加访问位,各页面组织成环形链表,指针指向最先调入的页面\r\n\r\n缺页时从指针处开始查找最近未被访问的页面(如果是该页面访问位为1则改为0继续寻找)\r\n\r\n时钟算法时LRU和FIFO的折中\r\n\r\n改进的clock算法:加入修改位\r\n\r\n如果该页面被读,访问位置1,被写 访问位 修改位置1\r\n\r\n缺页时 跳过有修改的页面,将访问位置0\r\n\r\n\r\n\r\n最不常用算法:\r\n\r\n每个页面设置一个访问计数器\r\n\r\n访问时计数加1\r\n\r\nLRU关注过去最近访问的时间,LFU关注最近访问次数\r\n\r\n\r\n\r\nBelady现象\r\n\r\n一般来说随着分配给进程的内存增加,缺页率下降。\r\n\r\nbelady现象指的是随着分配给进程的内存增加,缺页率上升。(FIFO) \r\n\r\n\r\n\r\n\r\n\r\nLRU算法没有belady算法\r\n\r\n\r\n\r\nLRU,FIFO,Clock本质上都是先进先出的思路\r\n\r\nLRU 根据页面最近访问时间来排序,同时需要动态调整顺序\r\n\r\nFIFO是根据页面进入内存的时间排序,相对顺序不变\r\n\r\n\r\n\r\n全局置换算法:给进程分配可变数目的物理页面\r\n\r\n局部置换算法没有考虑进程差异\r\n\r\n工作集置换算法 \r\n\r\n工作集指的是当前一段时间内进程访问的页面集合\r\n\r\n\r\n\r\n\r\n\r\n缺页率置换算法\r\n\r\n缺页率一般用缺页平均时间间隔进行表示\r\n\r\n\r\n\r\n\r\n\r\n抖动:\r\n\r\n抖动指的是系统运行的进程太多使得每个进程的物理页面太少,造成大量缺页,频繁置换,进程运行速度变慢。\r\n\r\n操作系统希望能在并发水平和缺页率之间进行一个平衡\r\n\r\n\r\n\r\n负载控制:通过调节并发进程数来进行系统负载控制\r\n\r\n\r\n\r\n若缺页间隔时间大于处理时间,说明是来得及进行处理的 \r\n\r\n\r\n\r\n### 进程 线程\r\n\r\n进程指的是具有一定功能得程序在一个数据集合上得一次动态执行过程\r\n\r\n进程包含了一个程序执行得所有状态信息,例如代码数据 状态寄存器 通用寄存器,内存等\r\n\r\n同一个程序的多次执行对应的是不同的进程\r\n\r\nPCB 进程控制块,进程创建时生成其PCB,进程结束回收PCB,进程运行时PCB控制。\r\n\r\n\r\n\r\n进程的状态:\r\n\r\n\r\n\r\n进程的状态分为 创建 就绪 等待 运行 退出等\r\n\r\n\r\n\r\n三状态进程模型\r\n\r\n创建-就绪:创建工作结束,准备就绪\r\n\r\n就绪-运行:就绪状态的进程被调度运行\r\n\r\n运行-结束:回收\r\n\r\n运行-就绪:时间片用完 让出资源 处理机\r\n\r\n运行-等待:等待某个资源或数据\r\n\r\n等待-就绪:进程等待的资源等到来,转成就绪状态\r\n\r\n\r\n\r\n进程挂起模型:处于挂起状态的进程存在磁盘上,目的是减少进程占用内存\r\n\r\n\r\n\r\n挂起:进程从内存转到外存(等待到等待挂起,就绪到就绪挂起,运行到就绪挂起)\r\n\r\n等待挂起到就绪挂起:等待事件出现\r\n\r\n激活:\r\n\r\n就绪挂起到就绪\r\n\r\n等待挂起到等待:有进程释放了大量的空间\r\n\r\n\r\n\r\n##### 线程\r\n\r\n为什么要引入线程:在进程内部进一步提高并发性\r\n\r\n例子:有一个mp3播放软件,核心功能有三个:1.从mp3文件中读取 2.解压 3.播放\r\n\r\n如果是单进程工作的话效率并不高,事实上可以并发进行 多进程实现\r\n\r\n存在的问题:进程之间如何通信\r\n\r\n\r\n\r\n增加一种实体:1.能够并发执行 2.共享空间 这种实体就是线程\r\n\r\n线程:是进程中的一部分,是指令执行流的最小单元,是CPU的基本调度单位\r\n\r\n一个进程内部可以存在多个线程,线程之间可以并发进行,共享地址空间和文件等等。可以实现上述mp3播放软件的功能\r\n\r\n进程是资源分配的单位,线程是CPU调度单位。\r\n\r\n线程同样具有就绪 等待 运行着三种基本状态以及转换关系。\r\n\r\n\r\n\r\n线程的三种实现方式:用户线程、内核线程、轻量级进程\r\n\r\n用户线程:\r\n\r\n用户库来完成创建、终止、同步、调度等。\r\n\r\n内核线程:\r\n\r\n内核通过系统调用来实现创建终止和管理。\r\n\r\n\r\n\r\n### 处理机调度\r\n\r\nCPU资源是时分复用的。调度算法,调度时机:非抢占式系统、抢占式系统\r\n\r\n调度准则:\r\n\r\n比较调度算法的准则:\r\n\r\nCPU利用率(处于繁忙时间的百分比)\r\n\r\n吞吐量:单位时间完成的进程数量\r\n\r\n周转时间:进程从初始化倒结束的总时间\r\n\r\n等待时间:进程在就绪队列中的总时间\r\n\r\n响应时间:从提交请求倒产生响应的总时间\r\n\r\n\r\n\r\n##### 调度算法\r\n\r\n先来先服务算法:\r\n\r\n根据进程进入就绪状态的先后顺序排队。算法的周转时间和先后顺序有关\r\n\r\n例子 12,3,3\r\n\r\n(12+15+18)/3 = 15\r\n\r\n3,3,12\r\n\r\n(3+6+18)/3 = 9\r\n\r\n资源的资源利用率比较低\r\n\r\n\r\n\r\n短进程优先算法:\r\n\r\n选择就绪队列中按照执行时间期望最短的进程\r\n\r\n变种:短剩余时间优先算法:如果在执行进程A 突然来了新的更短的进程B,可以抢占。具有最优平均周转时间特点。\r\n\r\n可能会导致饥饿:连续的短进程使得长进程无法获得CPU资源\r\n\r\n\r\n\r\n最高响应比优先算法\r\n\r\n 响应比r = (w+s)/s w是等待时间,s为执行时间\r\n\r\n可以避免进程无限期等待\r\n\r\n\r\n\r\n时间片轮转算法\r\n\r\n时间片是分配处理机资源的基本时间单元\r\n\r\n时间片结束时时间片轮转算法切换到下一个就绪进程\r\n\r\n例子:\r\n\r\n\r\n\r\n时间片轮转有额外的上下文切换开销\r\n\r\n时间片太大时退化为先来先服务算法\r\n\r\n\r\n\r\n\r\n\r\n多级队列调度算法\r\n\r\n就绪队列被划分为多个独立的子队列,每个队列有自己的调度策略,队列之间也调度策略(固定优先级,时间片轮转)\r\n\r\n\r\n\r\n多级反馈队列算法:\r\n\r\n时间片大小随着优先级级别增加而增加,进程在一个时间片没有完成之后下降优先级\r\n\r\nCPU密集型的进程优先级下降很快\r\n\r\n\r\n\r\n公平共享调度算法:强调资源访问公平\r\n\r\n一些用户组比其他用户组更重要\r\n\r\n未使用的资源按照比例分配\r\n\r\n\r\n\r\n##### 实时调度\r\n\r\n指某些任务必须在某个时间之前完成\r\n\r\n软时限(尽量满足要求) 硬时限(必须验证在最坏情况下满足要求)\r\n\r\n速率单调调度算法:周期越短的优先级越高\r\n\r\n最早截至时间优先算法:截至时间越早优先级越高\r\n\r\n\r\n\r\n多处理机调度算法\r\n\r\n进程分配:将进程分配到哪个处理器上运行\r\n\r\n静态分配:每个处理机都有队列,可能会导致每个处理机忙闲不均\r\n\r\n动态分配:进程在执行中可被分配到任意空闲处理机,所有的处理机共享一个队列,导致调度开销大,各处理机的负载时均衡的\r\n\r\n\r\n\r\n优先级反置\r\n\r\n指的是高优先级进程长时间等待等待低优先级进程所占用资源的现象\r\n\r\n\r\n\r\nT1占用了临界资源,不能被抢占(例如打印机等)\r\n\r\n基于优先级的可抢占的算法都会存在优先级反置:\r\n\r\n解决方法\r\n\r\n优先级继承:占用资源的低优先级进程继承申请资源的高优先级进程的优先级\r\n\r\n优先级天花板协议:占用资源的进程优先级和所有可能使用该资源的优先级的最大值相同\r\n\r\n\r\n\r\n\r\n\r\n#### 同步互斥\r\n\r\n背景:\r\n\r\n并发进程使得有资源的共享\r\n\r\n##### 原子操作\r\n\r\n一次不存在任何中断的操作\r\n\r\n操作系统需要利用同步机制在并发执行的同时,保证一些操作是原子操作。\r\n\r\n\r\n\r\n临界区:\r\n\r\n空闲等待\r\n\r\n忙则等待\r\n\r\n有限等待:等待进入临界区的进程不能无限等待\r\n\r\n让权等待(可选):不能进入临界区的进程让出CPU等\r\n\r\n\r\n\r\n实现方法:\r\n\r\n方法1:禁用硬件中断:没有中断 没有上下文切换,没有并发\r\n\r\n方法2:基于软件 可以用一些共享变量实现\r\n\r\nPeterson算法\r\n\r\n\r\n\r\n\r\n\r\n##### 信号量\r\n\r\n用信号量实现临界区的互斥访问\r\n\r\n每类资源设置一个信号量,初值为1。PV操作必须同步使用。P操作保证互斥访问,V操作在使用后释放保证下一个能使用\r\n\r\n\r\n\r\n用信号量实现条件同步\r\n\r\n条件同步设置一个信号量,其初始值为0.\r\n\r\n\r\n\r\n线程A需要等待线程B执行完X模块之后才能执行N模块\r\n\r\n\r\n\r\n管程:\r\n\r\n管程是一种用于多线程互斥访问共享资源的结构\r\n\r\n\r\n\r\n经典同步问题\r\n\r\n哲学家就餐问题\r\n\r\n\r\n\r\n\r\n\r\n为了避免死锁的情况(5个人同时拿左边的叉子,进入等待右边叉子的状态,即死锁)\r\n\r\n\r\n\r\n读者-写者问题\r\n\r\n\r\n\r\n用信号量来解决该问题: \r\n\r\n信号量writerMutex初始化为1\r\n\r\n读者计数Rcount,初始化为0\r\n\r\n信号量CountMutex,用来控制堆Rcount的修改,初始化1\r\n\r\n\r\n\r\n第一个读者进入的时候 占住writerMutex,之后的读者进入的时候只是增加Rcount\r\n\r\n\r\n\r\n另一个策略是写者优先\r\n\r\n\r\n\r\n管程实现\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n##### 死锁\r\n\r\n由于竞争资源或者是通信关系,两个或者更多线程在执行中出现,永远相互等待的事件\r\n\r\n例如单向通向桥梁\r\n\r\n出现死锁的四个条件:\r\n\r\n互斥:有一个资源任何时刻只能被一个进程占有\r\n\r\n持有并等待:进程持有至少一个资源同时在等待别的进程占有的资源\r\n\r\n非抢占:资源不能被抢占\r\n\r\n循环等待\r\n\r\n\r\n\r\n死锁处理方法:\r\n\r\n1.死锁预防:破坏四个必要条件\r\n\r\n2.死锁避免:在使用前进行判断\r\n\r\n3.死锁检测和恢复\r\n\r\n\r\n\r\n银行家算法:\r\n\r\n银行家算法是一种死锁避免的算法。n=线程数量,m=资源类型数量\r\n\r\n数据结构:\r\n\r\n\r\n\r\nNeed = Max - Allocation\r\n\r\n安全状态判定:\r\n\r\n\r\n\r\n本质上是判断如果某进程可以安全运行,则分配给其资源,运行完之后回收资源,将标志置为true,否则为false\r\n\r\n最后检测是不是所有的进程的状态都是true\r\n\r\n\r\n\r\n死锁检测\r\n\r\n允许系统进入死锁状态\r\n\r\n\r\n\r\n\r\n\r\n##### 进程通信\r\n\r\n进程通信指的是进程之间进行通信和同步的机制,有两个基本操作:发送操作和接收操作。\r\n\r\n通信方式分为间接通信和直接通信。\r\n\r\n直接通信会建立一条消息链路,间接通信通过操作系统维护的消息队列实现消息接收和发送。\r\n\r\n进程通信分为阻塞通信(同步),非阻塞通信(异步)\r\n\r\n阻塞通信:\r\n\r\n发送者在发送消息后进入等待,直接接收者成功接收到\r\n\r\n接收者在请求接收消息后进入等待直接成功收到消息\r\n\r\n\r\n\r\n非阻塞通信:\r\n\r\n发送者在发送消息后直接做别的事\r\n\r\n接收者在请求接收消息后可能不会等到一条消息\r\n\r\n\r\n\r\n通信链路缓冲:\r\n\r\n0容量:发送发必须等待接收方\r\n\r\n有限容量:当链路满了之后发送方必须等待\r\n\r\n无限容量:发送方无需等待\r\n\r\n\r\n\r\n##### 信号和管道\r\n\r\n信号:进程间的软件中断和处理机制\r\n\r\nSIGKILL等\r\n\r\n信号的处理:\r\n\r\n捕获:信号处理函数被调用\r\n\r\n屏蔽:登录时 信号被屏蔽\r\n\r\n\r\n\r\n##### 管道\r\n\r\n进程间基于内存文件的通信机制\r\n\r\n进程不关心管道的另一端是谁\r\n\r\n与管道相关的系统调用:read write\r\n\r\n\r\n\r\n消息队列和共享内存\r\n\r\n消息队列是操作系统维护的间接通信机制\r\n\r\n共享内存是把同一个物理内存区域同时映射到多个进程的内存地址空间的通信机制\r\n\r\n\r\n\r\n#### 文件系统和文件\r\n\r\n文件系统是操作系统中管理持久性数据的子系统\r\n\r\n文件是具有符号名,由字节序列构成的数据项集合\r\n\r\n\r\n\r\n文件描述符\r\n\r\n进程访问文件前必须要打开文件\r\n\r\n文件描述符是操作系统所打开文件的状态和信息\r\n\r\n文件指针\r\n\r\n文件打开计数:最后一个进程关闭文件时,可以从内存中移除\r\n\r\n文件的磁盘位置\r\n\r\n访问权限\r\n\r\n\r\n\r\n文件的用户视图:持久的数据结构\r\n\r\n系统视图:字节序列\r\n\r\n\r\n\r\n文件别名:多个文件名关联同一个文件,方便共享\r\n\r\n硬链接:多个文件项指向一个文件\r\n\r\n软链接:软连接文件中存的是另一个文件的路径\r\n\r\n\r\n\r\n虚拟文件系统\r\n\r\n对不同的文件系统进行抽象,提供相同的文件和文件系统接口\r\n\r\n\r\n\r\n计算机网络:\r\n\r\n计算机网络协议同我们的语言一样,多种多样。而ARPA公司与1977年到1979年推出了一种名为ARPANET的网络协议受到了广泛的热捧,其中最主要的原因就是它推出了人尽皆知的TCP/IP标准网络协议。目前TCP/IP协议已经成为Internet中的“通用语言”,下图为不同计算机群之间利用TCP/IP进行通信的示意图。\r\n\r\n\r\n\r\n##### 1. 网络层次划分\r\n\r\n国际标准化组织(ISO)在1978年提出了“开放系统互联参考模型”,即著名的OSI/RM模型(Open System Interconnection/Reference Model)。它将计算机网络体系结构的通信协议划分为七层,自下而上依次为:物理层(Physics Layer)、数据链路层(Data Link Layer)、网络层(Network Layer)、传输层(Transport Layer)、会话层(Session Layer)、表示层(Presentation Layer)、应用层(Application Layer)。其中第四层完成数据传送服务,上面三层面向用户。\r\n\r\n 除了标准的OSI七层模型以外,常见的网络层次划分还有TCP/IP四层协议以及TCP/IP五层协议,它们之间的对应关系如下图所示:\r\n\r\n \r\n\r\n\r\n\r\n \r\n\r\n### 2. OSI七层网络模型\r\n\r\nPlease do not tell stupid people anything\r\n\r\n TCP/IP协议毫无疑问是互联网的基础协议,没有它就根本不可能上网,任何和互联网有关的操作都离不开TCP/IP协议。不管是OSI七层模型还是TCP/IP的四层、五层模型,每一层中都要自己的专属协议,完成自己相应的工作以及与上下层级之间进行沟通。由于OSI七层模型为网络的标准层次划分,所以我们以OSI七层模型为例从下向上进行一一介绍。\r\n\r\n\r\n\r\n \r\n\r\n **1)物理层(Physical Layer)** Please\r\n\r\n 激活、维持、关闭通信端点之间的机械特性、电气特性、功能特性以及过程特性。**该层为上层协议提供了一个传输数据的可靠的物理媒体。简单的说,物理层确保原始的数据可在各种物理媒体上传输。**物理层记住两个重要的设备名称,中继器(Repeater,也叫放大器)和集线器。\r\n\r\n **2)数据链路层(Data Link Layer)**Do\r\n\r\n 数据链路层在物理层提供的服务的基础上向网络层提供服务,其最基本的服务是将源自网络层来的数据可靠地传输到相邻节点的目标机网络层。为达到这一目的,数据链路必须具备一系列相应的功能,主要有:如何将数据组合成数据块,在数据链路层中称这种数据块为帧(frame),帧是数据链路层的传送单位;如何控制帧在物理信道上的传输,包括如何处理传输差错,如何调节发送速率以使与接收方相匹配;以及在两个网络实体之间提供数据链路通路的建立、维持和释放的管理。数据链路层在不可靠的物理介质上提供可靠的传输。该层的作用包括:物理地址寻址、数据的成帧、流量控制、数据的检错、重发等。\r\n\r\n 有关数据链路层的重要知识点:\r\n\r\n **1> 数据链路层为网络层提供可靠的数据传输;**\r\n\r\n **2> 基本数据单位为帧;**\r\n\r\n **3> 主要的协议:以太网协议;**\r\n\r\n **4> 两个重要设备名称:网桥和交换机。**\r\n\r\n **3)网络层(Network Layer)**Not\r\n\r\n 网络层的目的是实现两个端系统之间的数据透明传送,具体功能包括寻址和路由选择、连接的建立、保持和终止等。它提供的服务使传输层不需要了解网络中的数据传输和交换技术。如果您想用尽量少的词来记住网络层,那就是“路径选择、路由及逻辑寻址”。\r\n\r\n 网络层中涉及众多的协议,其中包括最重要的协议,也是TCP/IP的核心协议——IP协议。IP协议非常简单,仅仅提供不可靠、无连接的传送服务。IP协议的主要功能有:无连接数据报传输、数据报路由选择和差错控制。与IP协议配套使用实现其功能的还有地址解析协议ARP、逆地址解析协议RARP、因特网报文协议ICMP、因特网组管理协议IGMP。具体的协议我们会在接下来的部分进行总结,有关网络层的重点为:\r\n\r\n **1> 网络层负责对子网间的数据包进行路由选择。此外,网络层还可以实现拥塞控制、网际互连等功能;**\r\n\r\n **2> 基本数据单位为IP数据报;**\r\n\r\n **3> 包含的主要协议:**\r\n\r\n **IP协议(Internet Protocol,因特网互联协议);**\r\n\r\n **ICMP协议(Internet Control Message Protocol,因特网控制报文协议);**\r\n\r\n **ARP协议(Address Resolution Protocol,地址解析协议);**\r\n\r\n **RARP协议(Reverse Address Resolution Protocol,逆地址解析协议)。**\r\n\r\n **4> 重要的设备:路由器。**\r\n\r\n **4)传输层(Transport Layer)**Tell\r\n\r\n 第一个端到端,即主机到主机的层次。传输层负责将上层数据分段并提供端到端的、可靠的或不可靠的传输。此外,传输层还要处理端到端的差错控制和流量控制问题。\r\n\r\n 传输层的任务是根据通信子网的特性,最佳的利用网络资源,为两个端系统的会话层之间,提供建立、维护和取消传输连接的功能,负责端到端的可靠数据传输。在这一层,信息传送的协议数据单元称为段或报文。\r\n\r\n 网络层只是根据网络地址将源结点发出的数据包传送到目的结点,而传输层则负责将数据可靠地传送到相应的端口。\r\n\r\n 有关网络层的重点:\r\n\r\n **1> 传输层负责将上层数据分段并提供端到端的、可靠的或不可靠的传输以及端到端的差错控制和流量控制问题;**\r\n\r\n **2> 包含的主要协议:TCP协议(Transmission Control Protocol,传输控制协议)、UDP协议(User Datagram Protocol,用户数据报协议);**\r\n\r\n **3> 重要设备:网关。**\r\n\r\n **5)会话层Session ** Stupid\r\n\r\n 会话层管理主机之间的会话进程,即负责建立、管理、终止进程之间的会话。会话层还利用在数据中插入校验点来实现数据的同步。\r\n\r\n **6)表示层 Presentation ** People\r\n\r\n 表示层对上层数据或信息进行变换以保证一个主机应用层信息可以被另一个主机的应用程序理解。表示层的数据转换包括数据的加密、压缩、格式转换等。\r\n\r\n **7)应用层 Application ** Anything\r\n\r\n 为操作系统或网络应用程序提供访问网络服务的接口。\r\n\r\n 会话层、表示层和应用层重点:\r\n\r\n **1> 数据传输基本单位为报文;**\r\n\r\n **2> 包含的主要协议:FTP(文件传送协议)、Telnet(远程登录协议)、DNS(域名解析协议)、SMTP(邮件传送协议),POP3协议(邮局协议),HTTP协议(Hyper Text Transfer Protocol)。**\r\n\r\n\r\n\r\n##### 2.IP地址\r\n\r\n **1)网络地址**\r\n\r\n IP地址由网络号(包括子网号)和主机号组成,网络地址的主机号为全0,网络地址代表着整个网络。\r\n\r\n **2)广播地址**\r\n\r\n 广播地址通常称为直接广播地址,是为了区分受限广播地址。\r\n\r\n 广播地址与网络地址的主机号正好相反,广播地址中,主机号为全1。当向某个网络的广播地址发送消息时,该网络内的所有主机都能收到该广播消息。\r\n\r\n **3)组播地址**\r\n\r\n D类地址就是组播地址。\r\n\r\n 先回忆下A,B,C,D类地址吧:\r\n\r\n A类地址以0开头,第一个字节作为网络号,地址范围为:0.0.0.0~127.255.255.255;(**modified @2016.05.31**)\r\n\r\n B类地址以10开头,前两个字节作为网络号,地址范围是:128.0.0.0~191.255.255.255;\r\n\r\n C类地址以110开头,前三个字节作为网络号,地址范围是:192.0.0.0~223.255.255.255。\r\n\r\n D类地址以1110开头,地址范围是224.0.0.0~239.255.255.255,D类地址作为组播地址(一对多的通信);\r\n\r\n E类地址以1111开头,地址范围是240.0.0.0~255.255.255.255,E类地址为保留地址,供以后使用。\r\n\r\n 注:只有A,B,C有网络号和主机号之分,D类地址和E类地址没有划分网络号和主机号。\r\n\r\n **4)255.255.255.255**\r\n\r\n 该IP地址指的是受限的广播地址。受限广播地址与一般广播地址(直接广播地址)的区别在于,受限广播地址只能用于本地网络,路由器不会转发以受限广播地址为目的地址的分组;一般广播地址既可在本地广播,也可跨网段广播。例如:主机192.168.1.1/30上的直接广播数据包后,另外一个网段192.168.1.5/30也能收到该数据报;若发送受限广播数据报,则不能收到。\r\n\r\n 注:一般的广播地址(直接广播地址)能够通过某些路由器(当然不是所有的路由器),而受限的广播地址不能通过路由器。\r\n\r\n **5)0.0.0.0**\r\n\r\n 常用于寻找自己的IP地址,例如在我们的RARP,BOOTP和DHCP协议中,若某个未知IP地址的无盘机想要知道自己的IP地址,它就以255.255.255.255为目的地址,向本地范围(具体而言是被各个路由器屏蔽的范围内)的服务器发送IP请求分组。\r\n\r\n **6)回环地址**\r\n\r\n 127.0.0.0/8被用作回环地址,回环地址表示本机的地址,常用于对本机的测试,用的最多的是127.0.0.1。\r\n\r\n **7)A、B、C类私有地址**\r\n\r\n 私有地址(private address)也叫专用地址,它们不会在全球使用,只具有本地意义。\r\n\r\n A类私有地址:10.0.0.0/8,范围是:10.0.0.0~10.255.255.255\r\n\r\n B类私有地址:172.16.0.0/12,范围是:172.16.0.0~172.31.255.255\r\n\r\n C类私有地址:192.168.0.0/16,范围是:192.168.0.0~192.168.255.255\r\n\r\n\r\n\r\n##### 3.子网掩码及网络划分\r\n\r\n 随着互连网应用的不断扩大,原先的IPv4的弊端也逐渐暴露出来,即网络号占位太多,而主机号位太少,所以其能提供的主机地址也越来越稀缺,目前除了使用NAT在企业内部利用保留地址自行分配以外,通常都对一个高类别的IP地址进行再划分,以形成多个子网,提供给不同规模的用户群使用。\r\n\r\n 这里主要是为了在网络分段情况下有效地利用IP地址,通过对主机号的高位部分取作为子网号,从通常的网络位界限中扩展或压缩子网掩码,用来创建某类地址的更多子网。但创建更多的子网时,在每个子网上的可用主机地址数目会比原先减少。\r\n\r\n **什么是子网掩码?**\r\n\r\n 子网掩码是标志两个IP地址是否同属于一个子网的,也是32位二进制地址,其每一个为1代表该位是网络位,为0代表主机位。它和IP地址一样也是使用点式十进制来表示的。如果两个IP地址在子网掩码的按位与的计算下所得结果相同,即表明它们共属于同一子网中。\r\n\r\n **在计算子网掩码时,我们要注意IP地址中的保留地址,即“ 0”地址和广播地址,它们是指主机地址或网络地址全为“ 0”或“ 1”时的IP地址,它们代表着本网络地址和广播地址,一般是不能被计算在内的。**\r\n\r\n **子网掩码的计算:**\r\n\r\n 对于无须再划分成子网的IP地址来说,其子网掩码非常简单,即按照其定义即可写出:如某B类IP地址为 10.12.3.0,无须再分割子网,则该IP地址的子网掩码255.255.0.0。如果它是一个C类地址,则其子网掩码为 255.255.255.0。其它类推,不再详述。下面我们关键要介绍的是一个IP地址,还需要将其高位主机位再作为划分出的子网网络号,剩下的是每个子网的主机号,这时该如何进行每个子网的掩码计算。\r\n\r\n 下面总结一下有关子网掩码和网络划分常见的面试考题:\r\n\r\n **1)利用子网数来计算**\r\n\r\n 在求子网掩码之前必须先搞清楚要划分的子网数目,以及每个子网内的所需主机数目。\r\n\r\n (1) 将子网数目转化为二进制来表示;\r\n\r\n 如欲将B类IP地址168.195.0.0划分成27个子网:27=11011;\r\n\r\n (2) 取得该二进制的位数,为N;\r\n\r\n 该二进制为五位数,N = 5\r\n\r\n (3) 取得该IP地址的类子网掩码,将其主机地址部分的的前N位置1即得出该IP地址划分子网的子网掩码。\r\n\r\n 将B类地址的子网掩码255.255.0.0的主机地址前5位置 1,得到 255.255.248.0\r\n\r\n **2)利用主机数来计算**\r\n\r\n 如欲将B类IP地址168.195.0.0划分成若干子网,每个子网内有主机700台:\r\n\r\n (1) 将主机数目转化为二进制来表示;\r\n\r\n 700=1010111100;\r\n\r\n (2) 如果主机数小于或等于254(注意去掉保留的两个IP地址),则取得该主机的二进制位数,为N,这里肯定 N<8。如果大于254,则 N>8,这就是说主机地址将占据不止8位;\r\n\r\n 该二进制为十位数,N=10;\r\n\r\n (3) 使用255.255.255.255来将该类IP地址的主机地址位数全部置1,然后从后向前的将N位全部置为 0,即为子网掩码值。\r\n\r\n 将该B类地址的子网掩码255.255.0.0的主机地址全部置1,得到255.255.255.255,然后再从后向前将后 10位置0,即为:11111111.11111111.11111100.00000000,即255.255.252.0。这就是该欲划分成主机为700台的B类IP地址 168.195.0.0的子网掩码。\r\n\r\n **3)还有一种题型,要你根据每个网络的主机数量进行子网地址的规划和****计算子网掩码。这也可按上述原则进行计算。**\r\n\r\n 比如一个子网有10台主机,那么对于这个子网需要的IP地址是:\r\n\r\n 10+1+1+1=13\r\n\r\n **注意:加的第一个1是指这个网络连接时所需的网关地址,接着的两个1分别是指网****络地址和广播地址。**\r\n\r\n 因为13小于16(16等于2的4次方),所以主机位为4位。而256-16=240,所以该子网掩码为255.255.255.240。\r\n\r\n 如果一个子网有14台主机,不少人常犯的错误是:依然分配具有16个地址空间的子网,而忘记了给网关分配地址。这样就错误了,因为14+1+1+1=17,17大于16,所以我们只能分配具有32个地址(32等于2的5次方)空间的子网。这时子网掩码为:255.255.255.224。\r\n\r\n##### 4.ARP/RARP协议\r\n\r\n **地址解析协议,即ARP(Address Resolution Protocol),是根据IP地址获取物理地址的一个TCP/IP协议。**主机发送信息时将包含目标IP地址的ARP请求广播到网络上的所有主机,并接收返回消息,以此确定目标的物理地址;收到返回消息后将该IP地址和物理地址存入本机ARP缓存中并保留一定时间,下次请求时直接查询ARP缓存以节约资源。地址解析协议是建立在网络中各个主机互相信任的基础上的,网络上的主机可以自主发送ARP应答消息,其他主机收到应答报文时不会检测该报文的真实性就会将其记入本机ARP缓存;由此攻击者就可以向某一主机发送伪ARP应答报文,使其发送的信息无法到达预期的主机或到达错误的主机,这就构成了一个ARP欺骗。**ARP命令可用于查询本机ARP缓存中IP地址和MAC地址的对应关系、添加或删除静态对应关系等。**\r\n\r\n ARP工作流程举例:\r\n\r\n 主机A的IP地址为192.168.1.1,MAC地址为0A-11-22-33-44-01;\r\n\r\n 主机B的IP地址为192.168.1.2,MAC地址为0A-11-22-33-44-02;\r\n\r\n 当主机A要与主机B通信时,地址解析协议可以将主机B的IP地址(192.168.1.2)解析成主机B的MAC地址,以下为工作流程:\r\n\r\n (1)根据主机A上的路由表内容,IP确定用于访问主机B的转发IP地址是192.168.1.2。然后A主机在自己的本地ARP缓存中检查主机B的匹配MAC地址。\r\n\r\n (2)如果主机A在ARP缓存中没有找到映射,它将询问192.168.1.2的硬件地址,从而将ARP请求帧广播到本地网络上的所有主机。源主机A的IP地址和MAC地址都包括在ARP请求中。本地网络上的每台主机都接收到ARP请求并且检查是否与自己的IP地址匹配。如果主机发现请求的IP地址与自己的IP地址不匹配,它将丢弃ARP请求。\r\n\r\n (3)主机B确定ARP请求中的IP地址与自己的IP地址匹配,则将主机A的IP地址和MAC地址映射添加到本地ARP缓存中。\r\n\r\n (4)主机B将包含其MAC地址的ARP回复消息直接发送回主机A。\r\n\r\n (5)当主机A收到从主机B发来的ARP回复消息时,会用主机B的IP和MAC地址映射更新ARP缓存。本机缓存是有生存期的,生存期结束后,将再次重复上面的过程。主机B的MAC地址一旦确定,主机A就能向主机B发送IP通信了。\r\n\r\n **逆地址解析协议,即RARP,功能和ARP协议相对,其将局域网中某个主机的物理地址转换为IP地址**,比如局域网中有一台主机只知道物理地址而不知道IP地址,那么可以通过RARP协议发出征求自身IP地址的广播请求,然后由RARP服务器负责回答。\r\n\r\n RARP协议工作流程:\r\n\r\n (1)给主机发送一个本地的RARP广播,在此广播包中,声明自己的MAC地址并且请求任何收到此请求的RARP服务器分配一个IP地址;\r\n\r\n (2)本地网段上的RARP服务器收到此请求后,检查其RARP列表,查找该MAC地址对应的IP地址;\r\n\r\n (3)如果存在,RARP服务器就给源主机发送一个响应数据包并将此IP地址提供给对方主机使用;\r\n\r\n (4)如果不存在,RARP服务器对此不做任何的响应;\r\n\r\n (5)源主机收到从RARP服务器的响应信息,就利用得到的IP地址进行通讯;如果一直没有收到RARP服务器的响应信息,表示初始化失败。\r\n\r\n##### 5. 路由选择协议\r\n\r\n 常见的路由选择协议有:RIP协议、OSPF协议。\r\n\r\n **RIP****协议** :底层是贝尔曼福特算法,它选择路由的度量标准(metric)是跳数,最大跳数是15跳,如果大于15跳,它就会丢弃数据包。\r\n\r\n **OSPF****协议** :Open Shortest Path First开放式最短路径优先,底层是迪杰斯特拉算法,是链路状态路由选择协议,它选择路由的度量标准是带宽,延迟。\r\n\r\n\r\n\r\n##### 6. TCP/IP协议\r\n\r\n **TCP/IP协议是Internet最基本的协议、Internet国际互联网络的基础,由网络层的IP协议和传输层的TCP协议组成。通俗而言:TCP负责发现传输的问题,一有问题就发出信号,要求重新传输,直到所有数据安全正确地传输到目的地。而IP是给因特网的每一台联网设备规定一个地址。**\r\n\r\n IP层接收由更低层(网络接口层例如以太网设备驱动程序)发来的数据包,并把该数据包发送到更高层---TCP或UDP层;相反,IP层也把从TCP或UDP层接收来的数据包传送到更低层。IP数据包是不可靠的,因为IP并没有做任何事情来确认数据包是否按顺序发送的或者有没有被破坏,IP数据包中含有发送它的主机的地址(源地址)和接收它的主机的地址(目的地址)。\r\n\r\n TCP是面向连接的通信协议,通过三次握手建立连接,通讯完成时要拆除连接,由于TCP是面向连接的所以只能用于端到端的通讯。TCP提供的是一种可靠的数据流服务,采用“带重传的肯定确认”技术来实现传输的可靠性。TCP还采用一种称为“滑动窗口”的方式进行流量控制,所谓窗口实际表示接收能力,用以限制发送方的发送速度。\r\n\r\n **TCP报文首部格式:**\r\n\r\n\r\n\r\n **TCP协议的三次握手和四次挥手:**\r\n\r\n\r\n\r\n \r\n\r\n **注:seq**:\"sequance\"序列号;**ack**:\"acknowledge\"确认号;**SYN**:\"synchronize\"请求同步标志;**;ACK**:\"acknowledge\"确认标志\"**;****FIN**:\"Finally\"结束标志。\r\n\r\n **TCP连接建立过程:**首先Client端发送连接请求报文,Server段接受连接后回复ACK报文,并为这次连接分配资源。Client端接收到ACK报文后也向Server段发生ACK报文,并分配资源,这样TCP连接就建立了。\r\n\r\n **TCP连接断开过程:**假设Client端发起中断连接请求,也就是发送FIN报文。Server端接到FIN报文后,意思是说\"我Client端没有数据要发给你了\",但是如果你还有数据没有发送完成,则不必急着关闭Socket,可以继续发送数据。所以你先发送ACK,\"告诉Client端,你的请求我收到了,但是我还没准备好,请继续你等我的消息\"。这个时候Client端就进入FIN_WAIT状态,继续等待Server端的FIN报文。当Server端确定数据已发送完成,则向Client端发送FIN报文,\"告诉Client端,好了,我这边数据发完了,准备好关闭连接了\"。Client端收到FIN报文后,\"就知道可以关闭连接了,但是他还是不相信网络,怕Server端不知道要关闭,所以发送ACK后进入TIME_WAIT状态,如果Server端没有收到ACK则可以重传。“,Server端收到ACK后,\"就知道可以断开连接了\"。Client端等待了2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,我Client端也可以关闭连接了。Ok,TCP连接就这样关闭了!\r\n\r\n **为什么要三次挥手?**\r\n\r\n 在只有两次“握手”的情形下,假设Client想跟Server建立连接,但是却因为中途连接请求的数据报丢失了,故Client端不得不重新发送一遍;这个时候Server端仅收到一个连接请求,因此可以正常的建立连接。但是,有时候Client端重新发送请求不是因为数据报丢失了,而是有可能数据传输过程因为网络并发量很大在某结点被阻塞了,这种情形下Server端将先后收到2次请求,并持续等待两个Client请求向他发送数据...问题就在这里,Cient端实际上只有一次请求,而Server端却有2个响应,极端的情况可能由于Client端多次重新发送请求数据而导致Server端最后建立了N多个响应在等待,因而造成极大的资源浪费!所以,“三次握手”很有必要!\r\n\r\n **为什么要四次挥手?**\r\n\r\n 试想一下,假如现在你是客户端你想断开跟Server的所有连接该怎么做?第一步,你自己先停止向Server端发送数据,并等待Server的回复。但事情还没有完,虽然你自身不往Server发送数据了,但是因为你们之前已经建立好平等的连接了,所以此时他也有主动权向你发送数据;故Server端还得终止主动向你发送数据,并等待你的确认。其实,说白了就是保证双方的一个合约的完整执行!\r\n\r\n 使用TCP的协议:FTP(文件传输协议)、Telnet(远程登录协议)、SMTP(简单邮件传输协议)、POP3(和SMTP相对,用于接收邮件)、HTTP协议等。\r\n\r\n\r\n\r\n\r\n\r\n##### 7. UDP协议 \r\n\r\n **UDP用户数据报协议,是面向无连接的通讯协议,UDP数据包括目的端口号和源端口号信息,由于通讯不需要连接,所以可以实现广播发送。****UDP通讯时不需要接收方确认,属于不可靠的传输,可能会出现丢包现象,实际应用中要求程序员编程验证。**\r\n\r\n UDP与TCP位于同一层,但它不管数据包的顺序、错误或重发。因此,UDP不被应用于那些使用虚电路的面向连接的服务,UDP主要用于那些面向查询---应答的服务,例如NFS。相对于FTP或Telnet,这些服务需要交换的信息量较小。\r\n\r\n 每个UDP报文分UDP报头和UDP数据区两部分。报头由四个16位长(2字节)字段组成,分别说明该报文的源端口、目的端口、报文长度以及校验值。UDP报头由4个域组成,其中每个域各占用2个字节,具体如下:\r\n (1)源端口号;\r\n\r\n (2)目标端口号;\r\n\r\n (3)数据报长度;\r\n\r\n (4)校验值。\r\n\r\n 使用UDP协议包括:TFTP(简单文件传输协议)、SNMP(简单网络管理协议)、DNS(域名解析协议)、NFS、BOOTP。\r\n\r\n **TCP** **与** **UDP** **的区别:**TCP是面向连接的,可靠的字节流服务;UDP是面向无连接的,不可靠的数据报服务。\r\n\r\n\r\n\r\n##### 8. DNS协议\r\n\r\n DNS是域名系统(DomainNameSystem)的缩写,该系统用于命名组织到域层次结构中的计算机和网络服务,**可以简单地理解为将URL转换为IP地址**。域名是由圆点分开一串单词或缩写组成的,每一个域名都对应一个惟一的IP地址,在Internet上域名与IP地址之间是一一对应的,DNS就是进行域名解析的服务器。DNS命名用于Internet等TCP/IP网络中,通过用户友好的名称查找计算机和服务。\r\n\r\n\r\n\r\n##### 9. DHCP协议\r\n\r\n DHCP动态主机设置协议(Dynamic Host Configuration Protocol)是一个局域网的网络协议,使用UDP协议工作,主要有两个用途:给内部网络或网络服务供应商自动分配IP地址,给用户或者内部网络管理员作为对所有计算机作中央管理的手段。\r\n\r\n\r\n\r\n##### 10. HTTP协议\r\n\r\n 超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议。所有的WWW文件都必须遵守这个标准。\r\n\r\n **HTTP** **协议包括哪些请求?**\r\n\r\n GET:请求读取由URL所标志的信息。\r\n\r\n POST:给服务器添加信息(如注释)。\r\n\r\n PUT:在给定的URL下存储一个文档。\r\n\r\n DELETE:删除给定的URL所标志的资源。\r\n\r\n **HTTP** **中,** **POST** **与** **GET** **的区别**\r\n\r\n 1)Get是从服务器上获取数据,Post是向服务器传送数据。\r\n\r\n 2)Get是把参数数据队列加到提交表单的Action属性所指向的URL中,值和表单内各个字段一一对应,在URL中可以看到。\r\n\r\n 3)Get传送的数据量小,不能大于2KB;Post传送的数据量较大,一般被默认为不受限制。\r\n\r\n 4)根据HTTP规范,GET用于信息获取,而且应该是安全的和幂等的。\r\n\r\n I. 所谓 **安全的** 意味着该操作用于获取信息而非修改信息。换句话说,GET请求一般不应产生副作用。就是说,它仅仅是获取资源信息,就像数据库查询一样,不会修改,增加数据,不会影响资源的状态。\r\n\r\n II. **幂等** 的意味着对同一URL的多个请求应该返回同样的结果。\r\n\r\n\r\n\r\n##### 11. 一个举例\r\n\r\n **在浏览器中输入** [**www.baidu.com** ](http://www.baidu.com/) **后执行的全部过程**\r\n\r\n 现在假设如果我们在客户端(客户端)浏览器中输入http://www.baidu.com,而baidu.com为要访问的服务器(服务器),下面详细分析客户端为了访问服务器而执行的一系列关于协议的操作:\r\n\r\n 1)客户端浏览器通过DNS解析到www.baidu.com的IP地址220.181.27.48,通过这个IP地址找到客户端到服务器的路径。客户端浏览器发起一个HTTP会话到220.161.27.48,然后通过TCP进行封装数据包,输入到网络层。\r\n\r\n 2)在客户端的传输层,把HTTP会话请求分成报文段,添加源和目的端口,如服务器使用80端口监听客户端的请求,客户端由系统随机选择一个端口如5000,与服务器进行交换,服务器把相应的请求返回给客户端的5000端口。然后使用IP层的IP地址查找目的端。\r\n\r\n 3)客户端的网络层不用关系应用层或者传输层的东西,主要做的是通过查找路由表确定如何到达服务器,期间可能经过多个路由器,这些都是由路由器来完成的工作,不作过多的描述,无非就是通过查找路由表决定通过那个路径到达服务器。\r\n\r\n 4)客户端的链路层,包通过链路层发送到路由器,通过邻居协议查找给定IP地址的MAC地址,然后发送ARP请求查找目的地址,如果得到回应后就可以使用ARP的请求应答交换的IP数据包现在就可以传输了,然后发送IP数据包到达服务器的地址。\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n### Math\r\n\r\n1.二孩悖论\r\n\r\n一对夫妇有两个孩子,考虑以下几个条件,求另一个孩子也是男孩的概率\r\n\r\n(1)第一个孩子是男孩 1/2\r\n\r\n\r\n\r\n\r\n\r\n(2)其中一个是男孩,1/3\r\n\r\n\r\n\r\n(3) 至少一个男孩在星期二出生 13/27\r\n\r\n\r\n\r\n\r\n\r\n2.希尔伯特旅馆悖论\r\n\r\n假设有个可数无限多个房间的旅馆,且所有房间都已经客满了\r\n\r\n(1)有限个客人\r\n\r\n设想此时有一个客人想要入住该旅馆。由于旅馆拥有无穷个房间,因而我们可以将原先在1号房 间原有的客人安置到2号房间、2号房间原有的客人安置到3号房间,以此类推,这样就空出了1号 房间留给新的客人。重复这一过程,我们就能够使任意有限个客人入住到旅馆内。\r\n\r\n(2)无限个客人\r\n\r\n将1号房间原有的客人安置到2号房间、2号房间原有的客人安置到4号房间、![[公式]](https://www.zhihu.com/equation?tex=n)号房间原有的客 人安置到![[公式]](https://www.zhihu.com/equation?tex=2n)号房间,这样所有的奇数房间就都能够空出来以容纳新的客人。因此偶数集合和整 数集合等势(你可以认为偶数和整数“一样多”。)\r\n\r\n(3)\r\n\r\n- 无限个客车且每个客车上有无限个新客人\r\n\r\n 这需要有一个前提条件:所有客车上的每个座位都已经编好了次序(即旅馆管理员对客人的安排 满足[选择公理](https://link.zhihu.com/?target=https%3A//zh.wikipedia.org/wiki/%25E9%2580%2589%25E6%258B%25A9%25E5%2585%25AC%25E7%2590%2586))。首先,如同前面一样将所有奇数房间都清空,再将第一辆客车上的客人安排在 第![[公式]](https://www.zhihu.com/equation?tex=3%5En)号房间![[公式]](https://www.zhihu.com/equation?tex=%28n%3D1%2C2%2C3...%29)、第二辆客车上的客人安排在第![[公式]](https://www.zhihu.com/equation?tex=5%5En)号房间,以此类推,将第*i*辆客 车上的客人安排在第![[公式]](https://www.zhihu.com/equation?tex=p%5En)号房间(其中,![[公式]](https://www.zhihu.com/equation?tex=p)是第![[公式]](https://www.zhihu.com/equation?tex=i%2B1)个质数)。\r\n\r\n\r\n\r\n3.生日问题\r\n\r\n23个人 没有同月同日的概率\r\n\r\n\r\n\r\n4.i\r\n\r\n\r\n\r\n5.**信息瀑布**\r\n\r\n一个课室的讲台上有一个箱子,里面有两种颜色的小球:**红色**和**蓝色**,各自种类数量不相同,我们假设蓝色球数量为![[公式]](https://www.zhihu.com/equation?tex=A),红色球数量为![[公式]](https://www.zhihu.com/equation?tex=B),并且一种球的数量要比另外一种要多,即有两种情况,一种是红多,一种是蓝多,而且出现这两种情况的概率分别概率是1/2。我们假设![[公式]](https://www.zhihu.com/equation?tex=p)为抽到一个小球等于数量多的那个球的概率,显然![[公式]](https://www.zhihu.com/equation?tex=p%3E0.5)。现在班上的同学开始排队取小球。按照顺序,每一个人取了一个小球,**自己偷偷看**然后放回箱子(这样后面的同学抽**蓝色的球**概率不变),并且**宣布**一个自己的对**箱子中主要的球的主要颜色的猜测**(**即猜A大还是B大**),假设这个猜测是根据自己所掌握的信息(**自己抽出小球颜色**和**之前的人宣布的猜测**)最大化自己猜测的正确性。\r\n\r\n那么问题来了:\r\n\r\n1. 如果**前面两个人**的猜测都是**蓝色**,那么第3,第4到第n个人宣布自己猜测为蓝色的概率是多少?\r\n2. 从第![[公式]](https://www.zhihu.com/equation?tex=2n)个人之后的所有人宣布相同的猜测的概率是多少?\r\n\r\n\r\n\r\n为了方便表示,我们用![[公式]](https://www.zhihu.com/equation?tex=X_i%3D%5C%7B0%2C1%5C%7D),和![[公式]](https://www.zhihu.com/equation?tex=Y_i%3D%5C%7B0%2C1%5C%7D)分别来表示第![[公式]](https://www.zhihu.com/equation?tex=i)个人的偷**偷看的球的颜色**和他**宣布的猜测的颜色**。![[公式]](https://www.zhihu.com/equation?tex=0)为红色,![[公式]](https://www.zhihu.com/equation?tex=1)为蓝色。\r\n\r\n如果你是第一个人,你该怎么做?很简单,![[公式]](https://www.zhihu.com/equation?tex=X_1)是1就写1,是0就写0,即![[公式]](https://www.zhihu.com/equation?tex=Y_1%5Cleftarrow+X_1),因为猜中的概率![[公式]](https://www.zhihu.com/equation?tex=p)超过0.5。\r\n\r\n如果你是第二个人,你所掌握的信息有![[公式]](https://www.zhihu.com/equation?tex=X_2)和![[公式]](https://www.zhihu.com/equation?tex=Y_1),注意到第二个人是知道第一个人是做决策的,即![[公式]](https://www.zhihu.com/equation?tex=Y_1%3DX_1),这个时候你要稍微考虑一下了,有以下两种情形:\r\n\r\n- 如果![[公式]](https://www.zhihu.com/equation?tex=Y_1%3DX_1%3DX_2),则![[公式]](https://www.zhihu.com/equation?tex=Y_2%5Cleftarrow+X_1%3DX_2)。\r\n- 如果![[公式]](https://www.zhihu.com/equation?tex=Y_1%3DX_1%5Cneq+X_2),扔一个硬币,如果正面朝上,则![[公式]](https://www.zhihu.com/equation?tex=Y_2%5Cleftarrow+X_1);如果朝下,则\r\n\r\n如果你是第三个人,那么情况开始就有点难处理了,两种情况\r\n\r\n- 如果![[公式]](https://www.zhihu.com/equation?tex=Y_1%3DY_2),那么无论![[公式]](https://www.zhihu.com/equation?tex=X_3)等于什么,第三个人都会忽略自己的私密信息![[公式]](https://www.zhihu.com/equation?tex=X_3)并且选择,跟随别人,即![[公式]](https://www.zhihu.com/equation?tex=Y_3%5Cleftarrow+Y_1)\r\n- 如果![[公式]](https://www.zhihu.com/equation?tex=Y_1%5Cneq+Y_2),则![[公式]](https://www.zhihu.com/equation?tex=Y_3%5Cleftarrow+X_3)。\r\n\r\n注意到,\r\n\r\n- ![[公式]](https://www.zhihu.com/equation?tex=Y_1%3DY_2)的情况下,第三个人释放的信号![[公式]](https://www.zhihu.com/equation?tex=Y_3)是没有任何信息量的,因为在任何条件下,![[公式]](https://www.zhihu.com/equation?tex=Y_3)都等于![[公式]](https://www.zhihu.com/equation?tex=Y_1)和![[公式]](https://www.zhihu.com/equation?tex=Y_2)。因此后面第四个人开始,所以人面临的选择都跟第三个人一毛一样,并且都会选择![[公式]](https://www.zhihu.com/equation?tex=Y_i%3DY_2%3DY_1),这样以来,**信息****瀑布**就开始了。信息瀑布的产生,只需要两个人。\r\n\r\n- ![[公式]](https://www.zhihu.com/equation?tex=Y_1%5Cneq+Y_2)的情况下,后面所以人会自动忽略掉这两个信号,因此你考虑把队列前面两个人移除然后把**第三个人**看成是一个**新的队列的第一个人**,因此如果![[公式]](https://www.zhihu.com/equation?tex=Y_3%3DY_4), 那么依然可能产生信息瀑布。如果![[公式]](https://www.zhihu.com/equation?tex=Y_3%5Cneq+Y_4),同理,移除他们,把后面的人当成新的队列的第一个人。\r\n\r\n- 可以计算第二个人之后没有**信息****瀑布**的概率是\r\n\r\n![[公式]](https://www.zhihu.com/equation?tex=Pr_%7Bno%7D%3DPr%5C%7BY_1%5Cneq+Y_2%5C%7D%3Dp%281-p%29)\r\n\r\n并且产生错误和正确的信息瀑布的概率相同,为\r\n\r\n![[公式]](https://www.zhihu.com/equation?tex=Pr_%7Berr%7D%3DPr_%7Bcor%7D%3D%5Cfrac%7B1-p%281-p%29%7D%7B2%7D)\r\n\r\n同理,第2n个人之后没有产生信息瀑布的概率是\r\n\r\n![[公式]](https://www.zhihu.com/equation?tex=Pr_%7Bno%7D%3DPr%5C%7BY_1%5Cneq+Y_2%2C+Y_3%5Cneq+Y_4%2C...%2CY_%7B2n-1%7D%5Cneq+Y_%7B2n%7D%5C%7D%3D%28p%281-p%29%29%5En)\r\n\r\n这个数越来越小,当![[公式]](https://www.zhihu.com/equation?tex=n%5Crightarrow+%5Cinfty),![[公式]](https://www.zhihu.com/equation?tex=Pr_%7Bno%7D%5Crightarrow+0),因此信息瀑布总会发生。\r\n\r\n \r\n\r\n6.出硬币\r\n\r\n\r\n\r\n作者:张萌\r\n\r\n链接:https://www.zhihu.com/question/41408857/answer/100016873\r\n\r\n来源:知乎\r\n\r\n著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。\r\n\r\n> 有一天,一位陌生美女主动过来和你搭讪,并要求和你一起玩个游戏。她提议:“让我们各自**亮出硬币的一面**。如果我们都是正面,那么我给你3元,如果我们都是反面,我给你1元,剩下的情况你给我2元就可以了。”那么该不该和这位姑娘玩这个游戏呢?这基本是废话,当然该。**问题是,这个游戏公平吗?**\r\n\r\n简单一算,都是正面的概率是![[公式]](https://www.zhihu.com/equation?tex=1%2F4),都是反面也是![[公式]](https://www.zhihu.com/equation?tex=1%2F4),一正一反的概率是![[公式]](https://www.zhihu.com/equation?tex=1%2F2),那么通过这个游戏,我获得的奖励的期望是\r\n\r\n![[公式]](https://www.zhihu.com/equation?tex=E%3D%5Cfrac%7B1%7D%7B4%7D%5Ccdot+3%2B%5Cfrac%7B1%7D%7B4%7D%5Ccdot+1-%5Cfrac%7B1%7D%7B2%7D%5Ccdot+2%3D0)\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n这游戏很公平啊,美女竟然跟我玩这么无趣的游戏,不是美女寂寞了,就是我太有魅力。\r\n\r\n不过,仔细一想,这不对啊!\r\n\r\n\r\n\r\n\r\n\r\n我们是亮硬币,不是拋硬币,因此这个以什么概率亮出硬币的概率是\r\n\r\n可以控制的\r\n\r\n!经过我大脑飞速的运算,我发现,如果我以\r\n\r\n\r\n\r\n的概率出正面,而美女以\r\n\r\n\r\n\r\n的概率出正面,那么我的期望收益为\r\n\r\n\r\n\r\n![[公式]](https://www.zhihu.com/equation?tex=E%3D%5Cfrac%7B3%7D%7B8%7D%5Ccdot+3%5Ccdot+x%2B%5Cfrac%7B5%7D%7B8%7D%5Ccdot+%281-x%29+%5Ccdot1+-%5Cleft%28%5Cfrac%7B3%7D%7B8%7D%5Ccdot+%281-x%29%2B%5Cfrac%7B5%7D%7B8%7D%5Ccdot+x%5Cright%29%5Ccdot+2%3D-%5Cfrac%7B1%7D%7B8%7D)\r\n\r\n也就是说在这种情况下,无论我怎么选择亮硬币的概率,我平均每轮都要亏![[公式]](https://www.zhihu.com/equation?tex=-%5Cfrac%7B1%7D%7B8%7D)块钱\r\n\r\n其实这道题不是简单的概率问题,而是一个经典的零和(Zero-sum)混合策略(Mixed Strategies)博弈问题,假设你出正面的概率是![[公式]](https://www.zhihu.com/equation?tex=p_1),她出正面的概率是![[公式]](https://www.zhihu.com/equation?tex=p_2),那么你的平均收益则为\r\n\r\n![[公式]](https://www.zhihu.com/equation?tex=E_1%3D+3%5Ccdot+p_1%5Ccdot+p_2%2B+1+%5Ccdot+%281-p_1%29%5Ccdot+%281-p_2%29+-+2%5Ccdot+%5Cleft%28p_2%5Ccdot+%281-p_1%29%2B%281-p_2%29%5Ccdot+p_1+%5Cright%29)\r\n\r\n"
},
{
"alpha_fraction": 0.5668073296546936,
"alphanum_fraction": 0.5935302376747131,
"avg_line_length": 12.469388008117676,
"blob_id": "d9d15309b7ca7d9f6dc3385657c5dde4e0863cf1",
"content_id": "f7438991bec5cc0c0bce4d944f14cfae24eee0d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1053,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 49,
"path": "/os_instructions/linux/awk.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### awk命令读取文件某一行或者某一列\r\n\r\nhttps://linux.cn/article-3945-1.html\r\n\r\n读取文件第一行\r\n\r\n```\r\nawk 'NR==1{print}' test.file\r\n```\r\n\r\n读取文件第一列\r\n\r\n```\r\nawk '{print $1}' test.file\r\n```\r\n\r\n读取文件第一行的第三列\r\n\r\n```\r\nawk 'NR==1{print $3}' test.file\r\n```\r\n\r\n\r\n如果输入不是由空格分隔怎么办?只需用awk中的'-F'标志指定分隔符:\r\n\r\n```\r\n$ echo 'one mississippi,two mississippi,three mississippi,four mississippi' | awk -F , '{print $4}' \r\n```\r\n\r\n偶尔间,发现正在处理字段数量不同的数据,只知道想要的最后字段。 awk中内置的$NF变量代表字段的数量,这样你就可以用它来抓取最后一个元素:\r\n\r\n```\r\n$ echo 'one two three four' | awk '{print $NF}' \r\n```\r\n\r\n\r\n\r\nawk的一个特性,维持跨行状态。\r\n\r\n```\r\n$ echo -e 'one 1\\ntwo 2' | awk '{print $2}' \r\n1\r\n2\r\n$ echo -e 'one 1\\ntwo 2' | awk '{sum+=$2} END {print sum}' \r\n3\r\n```\r\n\r\n\r\n(END代表的是我们在执行完每行的处理之后只处理下面的代码块)\r\n\r\n"
},
{
"alpha_fraction": 0.6384022235870361,
"alphanum_fraction": 0.694113552570343,
"avg_line_length": 19.4436092376709,
"blob_id": "e5b3486674dd70171e85f6d6bd1333720d3b11eb",
"content_id": "7b0e9cc3255873836d38ebef7f1fb2e1f37a16ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5612,
"license_type": "no_license",
"max_line_length": 193,
"num_lines": 133,
"path": "/interview/INA.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "####questions\r\n1.C++11的新特性\r\n```\r\n(1)nullptr\r\n传统意义上C++会把NULL 和0 视为同一个东西,这个要看编译器是怎么处理的\r\nc++ 11里面提出了nullptr专门用来区别空指针和0\r\nnullptr 的类型为 nullptr_t\r\n\r\n(2)类型推导 auto\r\nauto 类型推导\r\nauto i = 5; // i 被推导为 int\r\n主要应用于迭代器\r\nfor(vector<int>::const_iterator itr = vec.cbegin(); itr != vec.cend(); ++itr)\r\nfor(auto itr = vec.cbegin(); itr != vec.cend(); ++itr);\r\n\r\n(3)区间迭代\r\nfor(auto &i : arr) { \r\n std::cout << i << std::endl;\r\n}\r\n(4)C++11 提供了统一的语法来初始化任意的对象\r\nstruct A {\r\n int a;\r\n float b;\r\n};\r\nA a {1, 1.1}; \r\nLambda 表达式\r\n```\r\n2.auto a=1;a=3.5;a的类型是什么?\r\n```\r\n类型为int\r\n```\r\n3.std::vector,实现和扩容时分别使用什么构造函数?\r\n4.std::map的原理\r\n```\r\n\r\n```\r\n5.有一个随机数发生器,以概率P产生0,概率(1-P)产生1,请问能否利用这个随机数发生器,构造出新的发生器,以1/2的概率产生0和1\r\n```\r\n(1)思路是叠加多个原始构造器,通过每次叠加的和与期望值对比,来决定是0和1,思路得到了面试官的采纳。具体如下:\r\n迭代N次,则期望E=( (1-p)*1 + p*0) * N 。比较累加N次的和Sum和E,Sum大则返回0,Sum小则返回1。\r\n\r\n拓展1:用等概率生成(0,1)的构造器等概率生成(0,1,2,3)。\r\n假设,原始构造器为Rand2(),则Rand2()*2为(0,2),Rand2()*2 + Rand2()则可以生成(0,1,2,3)。注意Rand2()*2 + Rand2()不等于Rand2()*3,后者等于(0,3),只用了一次构造器。前者由part1:(0,2)和part2:(0,1)构成。最终结果(0,1,2,3)任何一个数字都由part1和part2中唯一的数字相加得到。\r\n用Rand4(等概率生成0,1,2,3)可以进一步生成Rand16。方法为:Rand4()*4 + Rand4()\r\n\r\n拓展2:用等概率生成(0,1)的构造器等概率生成(0,1,2,3,...,N)。\r\n思路同上相似。由(0,1)的构造器可以生成(0,...,2^n)的构造器,其中每次构造生成的随机数个数是上一次的平方。只需要构造到保证2^n>N即可。当得到的随机数处于[N, 2^n)时,递归生成一次,直到构造数为[0,N)时,退出本次随机数生成。\r\n\r\n(2)\r\nrandp()以概率p产生0,概率(1-p)产生1;\r\n a=0,b=1的概率为p(1-p),将其视为0\r\na=1,b=0的概率也为p(1-p),将其视为1\r\n则产生0和1的概率相等 \r\n int randequal() { ;int a=randp(); \r\nint b=randp(); \r\nif(a==0;b==1) return 0; \r\nif(a==1;b==0)\r\nreturn 1; \r\nreturn randequal(); \r\n } \r\n```\r\n6.spark为什么比map-reduce快\r\n```\r\n一致性哈希\r\n```\r\n7.一个int型数组寻找第k个最大的元素\r\n```\r\n堆排nlogn,O(N)级别的 改良过的快排(最好)\r\n构建堆的时间复杂度为O(N) 每个元素都要比对一下nums[n]与nums[n/2]\r\n堆排复杂度是NlogN\r\n每次上浮或是下沉的复杂度为O(logN) sortN次 nlogn\r\n```\r\n8.C++面向对象体现在哪里?\r\n```\r\n三个基本特征:封装、继承、多态\r\n```\r\n9.SVM为什么要求对偶形式?\r\n```\r\nSVM为什么要求对偶形式?\r\n在不改变最优解的情况下,改变求解的时间复杂度\r\n原问题的求解时间和数据的量有关,对偶形式的求解时间和数据的维度有关\r\n```\r\n10.线性回归\r\n```\r\n线性回归是数学中用来确定两种或者两种以上变量之间相互依赖定量关系的统计分析方法\r\nY=WX+b\r\n如果只包含一个自变量,且二者的关系可以用一条直线近似表示则这种回归分析可以成为一元线性回归,如果包含多个自变量则称为多元线性回归\r\n```\r\n\r\n11.决策树算法,随机森林和GBDT的区别\r\n```\r\n二者的相同点:\r\n都是由多棵树组成\r\n最终的结果是由多棵树一起决定的\r\n\r\n随机森林:\r\n随机森林是一个包含多个决策树的分类器,随机森林就是希望构建多个臭皮匠,希望最终的分类效果能够超过单个大师的一种算法。\r\n\r\n那随机森林具体如何构建呢?有两个方面:数据的随机性选取,以及待选特征的随机选取\r\n(1)第一,从原始的数据集中采取有放回的抽样,构造子数据集,子数据集的数据量是和原始数据集相同的。\r\n(2)每棵树所使用的决策特征都是不同的,这样可以使得每棵决策树彼此不同,提升多样性\r\n\r\nGBDT(Gradient Boost Decision Tree)梯度决策提升树\r\n在上一棵树的残差的梯度方向上前进\r\n```\r\n\r\n12.LSTM与RNN 梯度消散问题,LSTM在结构上做了什么设计?\r\n```\r\nRNN采用tanh激活函数,映射在-1 到1 之间,如果经过很多层之后RNN会丧失连接到很远的信息能力(梯度消失),很多个小于1的连乘会很快逼近0\r\n使用Relu激活函数可能会出现梯度爆炸\r\nLSTM使用sigmoid和tanh,避免了梯度爆炸的问题\r\nLSTM 遗忘门 输入门 输出门,很多相加的形式,因此避免了0的出现,从而避免了梯度消失\r\n```\r\n13.Deeplearning 几个激活函数的优缺点\r\n```\r\ntahn [-1,1]\r\nRelu 可能出现梯度爆炸问题\r\nsigmoid 常见\r\n```\r\n\r\n14.避免过拟合?\r\n```\r\ndropout 正则项\r\n```\r\nL1正则 L2正则优缺点\r\n```\r\nL1正则,L1范数 是对应参数向量绝对值之和,具有稀疏性\r\nL2正则 L2范数是对应参数向量的平方和,再求平方根\r\n```\r\n\r\nL1正则化的稀疏性在于会让大多数参数为0,为什么会有这样的性质呢?\r\n\r\n因为L1正则化的导数永远是1,即使在参数接近于0的时候仍然为1,而L2正则化的导数是2x\r\n\r\n"
},
{
"alpha_fraction": 0.7344262003898621,
"alphanum_fraction": 0.7377049326896667,
"avg_line_length": 33.882354736328125,
"blob_id": "27d17801834bb055b893df4266909fc07a49c7ae",
"content_id": "ca4d2201d53a2c6d3290617d417600aeea9c3bd7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 838,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 17,
"path": "/os_instructions/linux/probelms.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "通过终端安装程序sudo apt-get install xxx时出错:\r\nE: Could not get lock /var/lib/dpkg/lock - open (11: Resource temporarily unavailable)\r\nE: Unable to lock the administration directory (/var/lib/dpkg/), is another process using it?\r\n\r\n```\r\n出现这个问题可能是有另外一个程序正在运行,导致资源被锁不可用。而导致资源被锁的原因可能是上次运行安装或更新时没有正常完成,进而出现此状况,解决的办法其实很简单:\r\n在终端中敲入以下两句\r\nsudo rm /var/cache/apt/archives/lock\r\nsudo rm /var/lib/dpkg/lock\r\n```\r\n\r\n发现报错 Please put eval $(thefuck --alias) in your ~/.bashrc and apply changes with source ~/.bashrc or restart your shell.\r\n#not configure\r\n```\r\n使用 sudo gedit ~/.bashrc \r\n在 .bashrc 文件中添加 eval $(thefuck --alias)\r\n```\r\n"
},
{
"alpha_fraction": 0.7073456645011902,
"alphanum_fraction": 0.7195494174957275,
"avg_line_length": 12.115894317626953,
"blob_id": "ecf391b52a2e0d5bfb0690cb4a9db663ce0c8163",
"content_id": "b0e90ea498970da3b1d260d96831b6117647b658",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 7959,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 302,
"path": "/computer_science_knowledge/linux/linux.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### linux\r\n\r\n看linux课程PPT自学笔记\r\n\r\n##### 第二章 linux基础\r\n\r\nlinux软件体系结构:\r\n\r\n\r\n\r\n硬件->驱动->linux内核->调用接口(函数)->linux shell->应用程序用户接口\r\n\r\nlinux系统运行级别:\r\n\r\n0: 停机 1: 单用户模式 2:多用户模式 3:完整的多用户模式 4:保留 5 X Window系统 6 重启\r\n\r\n登陆与退出:\r\nctrl-D logout\r\n\r\nshutdown; halt; init 0;poweroff\r\n\r\n\r\n\r\nshutdown -h 8:00 早上8点关机\r\n\r\nshutdown -h +3 三分钟后\r\n\r\nshell 是linux系统的用户界面,提供了用户与内核进行交互操作的一种接口,它接收用户输入的命令并把它送入内核中执行。\r\n\r\nshell to accept human's command in 'readable' form and translates them into 1 and 0 stream.\r\n\r\n\r\n\r\n常用的shell有:csh zsh等\r\n\r\nbash是linux主要的shell\r\n\r\n\r\n\r\nshell搜索的目录的名字都保存再一个shell变量PATH中,echo $PATH\r\n\r\n目录名用冒号分开\r\n\r\n查看环境变量:\r\n\r\nset\r\n\r\n\r\n\r\nbash中的一些启动文件\r\n\r\n/etc/profile,~/.bash_profile, ~/.profile 登陆时自动执行\r\n\r\n~/.bashrc shell登陆时自动执行\r\n\r\n\r\n\r\n修改~/.bashrc文件更为安全,可以将使用的环境变量的权限控制在用户级别。\r\n\r\n\r\n\r\n##### 常用linux命令:\r\n\r\nwhatis得到任何LINUX命令更短的描述命令\r\n\r\nwhoami显示用户名\r\n\r\nhostname显示主机的名字\r\n\r\ncat 显示一个或多个文件内容\r\n\r\ncal 显示日历\r\n\r\n\r\n\r\n##### linux标准目录与文件\r\n\r\n/bin 二进制目录,包含了供使用的bash cat chmod等命令的可执行文件\r\n\r\n/boot包含了系统启动时所要用到的程序\r\n\r\n/dev 设备的缩写,包含了所有使用的外部设备,但是不是存放外部设备的驱动程序\r\n\r\n/etc 存放系统管理时用到的配置文件和子目录\r\n\r\n\r\n\r\n\r\n\r\n删除重复行\r\n\r\nuniq sample\r\n\r\n\r\n\r\nlinux与windows文件格式转化\r\n\r\nwindos文件的转行符位\\r\\n\r\n\r\nlinux文件的转行符为\\n\r\n\r\n\r\n\r\ndos2unix wintolinuF.txt 将Windows转化为linux文件\r\n\r\nunix2dos LinuxtowinF.txt 将Linux转化为Windows文件\r\n\r\n\r\n\r\n##### 文件安全\r\n\r\n用户分类:所有者、组、其他人\r\n\r\n在linux系统中文件有三种权限:读r 写r执行x\r\n\r\n目录也有三种权限 读r写w执行x\r\n\r\nchmod用来改变文件的访问权限\r\n\r\n```\r\nchmod 700 * 文件拥有者对当前目录下所有文件和子目录拥有读写执行的权限,其他用户没有特权\r\nchmod 740 courses 对courses的拥有者设定读、写和执行的特权,对组设定读访问的特权,其他用户没有任何特权\r\nchmod -R 可以递归更改目录与子目录内的所有文件的访问特权\r\n```\r\n\r\n对于目录而言,读意味着可以读取目录的内容,写意味着可以在目录下创建或者删除一个文件,执行意味着可以检索这个目录\r\n\r\n\r\n\r\n默认新创建的文件 执行文件为777,文本文件为666\r\n\r\n使用umask 013命令并运行成功,对于新创建的可执行文件的特权就是764(777-013)\r\n\r\n\r\n\r\ntouch命令用于修改文件或者目录的时间属性,如果文件不存在会创建新的文件\r\n\r\n文件共享\r\n\r\n硬链接与软链接(符号)\r\n\r\n软链接相当于快捷方式,软链接文件的大小和创建时间和源文件不同。\r\n\r\n特点是可跨越文件系统,如果链接指向的文件移动了则无法通过软链接访问,占有少量空间用来存inode信息。\r\n\r\n硬链接相当于创建了一份copy文件,同时与源文件永远保持同步。如果源文件被删除,硬链接就像正常文件一样。\r\n\r\n硬链接特点:不可跨越文件系统,只有超级文件才可以建立硬链接(目录) 不占用空间。\r\n\r\n\r\n\r\n##### 进程\r\n\r\nAn executing program = a process\r\n\r\nshell可以是内部或者是外部命令,内部命令本身就是shell进程的一部分例如cd echo等\r\n\r\n外部命令的代码是以文件形式出现的,例如grep more等\r\n\r\n\r\n\r\n输入重定向<\r\n\r\n输出重定向>\r\n\r\n文件描述符0表示输入,1表示输出,2表示错误\r\n\r\n\r\n\r\n##### 网络\r\n\r\nfinger, ftp, ifconfig, nslookup, ping, rcp, rlogin, rsh, ruptime, rusers, rwho,\r\ntalk, telnet, traceroute\r\n\r\nifconfig命令可以查看主机IP地址和一些关于网络接口的信息。\r\n\r\nhostname命令或者uname命令可以显示登陆主机名\r\n\r\nping命令 向hostname发送一个IP数据包,测试它是否在网络上;如果对应的\r\n主机在网络上,它将响应该请求。\r\n\r\n文件传输ftp命令\r\n\r\n\r\n\r\n##### linux软件开发\r\n\r\n**make程序:是一个命令工具,是一个解释makefile中指令的命令工具**\r\n\r\nmake程序提供一种可以用于构建大规模工程的强劲而灵活的机制。\r\n\r\n**Makefile是一个文本形式的数据库文件,其中包含了一些规则告诉make处理那些文件以及如何处理这些文件**,这些规则主要是描述哪些文件(target目标文件)是从哪些别的文件(dependency依赖文件)中产生的,以及用什么命令(command)来执行这个过程。\r\n\r\nmake会对磁盘上的文件进行检测,如果目标文件的生成或者改动时间(时间戳)至少比它一个依赖文件还旧的话,则make执行相应的命令,以更新目标文件。目标文件不一定是最后的可执行文件,可以是任何中间文件并作为其他目标文件的依赖文件。\r\n\r\n```\r\ntest:prog.o code.o\r\n\tgcc –o test prog.o code.o\r\nprog.o:prog.c prog.h code.h\r\n\tgcc –c prog.c –o prog.o\r\ncode.o:code.c code.h\r\n\tgcc –c code.c –o code.o\r\nclean:\r\n\trm –f *.o \r\n```\r\n\r\n上述的Makefile文件共定义了四个目标,test、prog.o、code.o 、clean\r\n\r\n目标从每行的最左边开始写,后面跟一个冒号,后面跟依赖文件\r\n\r\nmake命令的起始字符为TAB\r\n\r\n一般情况下调用make命令可输入:$ make target, 如果省略target make命令就等于make test\r\n\r\nmake找到prog.c prog.h code.h通过gcc生成prog.o\r\n\r\n找到code.c code.h 通过gcc生成code.o\r\n\r\n然后gcc命令将code.o prog.o连接成目标文件test\r\n\r\nclean目标用于删除所有的目标模块。\r\n\r\n使用变量(需要大写),则上述Makefile文件变为\r\n\r\n```\r\nOBJS=prog.o code.o\r\nCC=gcc\r\ntest:$(OBJS)\r\n\t$(CC) –o test $(OBJS)\r\nprog.o:prog.c prog.h code.h\r\n\t$(CC) –c prog.c –o prog.o\r\ncode.o:code.c code.h\r\n\t$(CC) –c code.c –o code.o\r\nclean:\r\n\trm –f *.o \r\n```\r\n\r\n\r\n\r\n使用GDB工具调试代码\r\n\r\n\r\n\r\n##### BASH 编程\r\n\r\n常用的BASH环境变量如下:BASH, bash完整路径名\r\n\r\n双引号“”将值括起来,则允许使用$符对变量进行替换。\r\n如果用单引号‘’将值括起来,则不允许有变量替换,而不对它做shell解释。\r\n\r\n给shell脚本传递参数\r\n\r\n变量的前9个包含在\\$1-\\$9中,$0表示shell文件本身的名字\r\n\r\n使用source filename或者 . filename来执行filename中的命令\r\n\r\nshell中使用\r\n\r\nif then else fi\r\n\r\n```shell\r\nif test -d 'gems'\r\nthen\r\n echo 'true'\r\nelse\r\n echo 'false'\r\nfi\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### 系统程序设计\r\n\r\nfork exec\r\n\r\nfork:创建一个新子进程\r\n\r\n用fork函数创建子进程后,子进程往往要调用一种exec函数以执行另一个程序。\r\n当进程调用一种exec函数时,该进程完全由新程序代换,而新程序则从其main函数开始执行。\r\n调用exec并不创建新进程,所以前后的进程I D并未改变。exec只是用另一个新程序替换了当前进程的正文、数据、堆和栈段。\r\n\r\n\r\n\r\nlinux进程之间互相通信的方法有:\r\n\r\n1.System V IPC机制\r\n\r\n\t信号量 消息队列 共享内存\r\n\r\n2.管道\r\n\r\n3.套接字\r\n\r\n4.信号\r\n\r\n\r\n\r\n消息队列:就是一个消息的链表,是一系列保存在内核中的消息的列表。用户进程可以向消息队列添加消息,也可以从消息队列读取消息。\r\n\r\n管道是指用于连接一个读进程和一个写进程,以实现它们之间通信的共享文件,又称为pipe文件。"
},
{
"alpha_fraction": 0.6196213364601135,
"alphanum_fraction": 0.6471600532531738,
"avg_line_length": 24.409090042114258,
"blob_id": "2d9557c8116c1165bd244f65047fcc4694dba8a6",
"content_id": "f2d236851c7c7ef841afc703b794765a1770365e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 601,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 22,
"path": "/c++/opencv.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "create video files with images:\r\n```\r\nint Color = 1;\r\nint fps = 10;\r\nint frameWidth = src.cols;\r\nint frameHeight = src.rows;\r\nVideoWriter writer(\"test.avi\", VideoWriter::fourcc('M', 'J', 'P', 'G'), fps,Size(frameWidth, frameHeight), Color);\r\n\r\nwhile(xxxxx){\r\n\t\tsrc=\r\n resize(src, src, Size(frameWidth, frameHeight));\r\n\t\timshow(\"src\", src);\r\n\t\twaitKey(50);\r\n\t\twriter.write(src);\r\n} \r\n```\r\n```\r\nint frameWidth = img1.cols; 表示宽度 列\r\nint frameHeight = img1.rows; 表示高度 行\r\nMat img2(frameHeight,frameWidth*2, CV_8UC3, Scalar(0, 0, 0));\r\nimg.copyTo(img2.colRange(0, frameWidth));\r\n```\r\n"
},
{
"alpha_fraction": 0.5030303001403809,
"alphanum_fraction": 0.5151515007019043,
"avg_line_length": 11.692307472229004,
"blob_id": "5709c02f1881f5504e79597e0a44f223c917d949",
"content_id": "d0c386080bb929c74d1fee2feb602c5f65af0c1e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 165,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 13,
"path": "/test.py",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "def print_add(add):\n def warp(x):\n print(\"start adding\")\n add(x)\n return warp\n\n@print_add\ndef add(x):\n x += 1\n print(x)\n return\n\nadd(1)\n"
},
{
"alpha_fraction": 0.4779151976108551,
"alphanum_fraction": 0.5357773900032043,
"avg_line_length": 21.5625,
"blob_id": "d3cf811cf90271c60db30df165975fd46af3baeb",
"content_id": "0e5a3c90a032f095f4d66abe06bef7d93f03e68b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2622,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 96,
"path": "/c++/c++ sort .md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### C++中的sort\r\n\r\n```c++\r\n#include <iostream> // cout\r\n#include <algorithm> // sort\r\n#include <vector> // vector\r\nusing namespace std;\r\nbool myfunction (int i,int j) { return (i<j); }\r\n\r\nstruct myclass {\r\n bool operator() (int i,int j) { return (i<j);}\r\n} myobject;\r\n\r\nint main () {\r\n int myints[] = {32,71,12,45,26,80,53,33};\r\n vector<int> myvector (myints, myints+8); // 32 71 12 45 26 80 53 33\r\n // using default comparison (operator <):\r\n sort (myvector.begin(), myvector.begin()+4); //(12 32 45 71)26 80 53 33\r\n // using function as comp\r\n sort (myvector.begin()+4, myvector.end(), myfunction); // 12 32 45 71(26 33 53 80)\r\n\r\n // using object as comp\r\n sort (myvector.begin(), myvector.end(), myobject); //(12 26 32 33 45 53 71 80)\r\n sort (myvector.begin(), myvector.end(), greater<int>()); //80 71 53 45 33 32 26 12\r\n // print out content:\r\n cout << \"myvector contains:\";\r\n for (std::vector<int>::iterator it=myvector.begin(); it!=myvector.end(); ++it)\r\n cout << ' ' << *it;\r\n cout << '\\n';\r\n return 0;\r\n}\r\n```\r\n\r\n1.新建数组vector使用{}\r\n\r\n2.自定义比较大小的function,返回bool\r\n\r\n如果返回值是 True,表示 要把 序列 (X,Y),X放Y前。这边需要注意的是在 c++中 -1为true,因此\r\n\r\n要使用a[0]<b[0] 表示从大到小而不是 a[0]-b[0],否则会出现很乱的数组 因为正负都是true\r\n\r\n默认的是从小到大排序,使用从大到小: \r\n\r\n ```c++\r\nsort (myvector.begin(), myvector.end(), greater<int>());\r\n ```\r\n\r\n这是对int数组的排序\r\n\r\n自定义的可以是比较函数也可以是lambda体\r\n\r\n```\r\nauto func=[](int i, int j) { return abs(i) < abs(j); };\r\n```\r\n\r\n使用lambda体更方便(可以在[]中传参数)\r\n\r\n例如leetcode 1030,比较数组到某个点的距离排序\r\n\r\n```c++\r\nvector<vector<int>> allCellsDistOrder(int R, int C, int r0, int c0) {\r\n auto comp = [r0, c0](vector<int> &a, vector<int> &b){\r\n return abs(a[0]-r0) + abs(a[1]-c0) < abs(b[0]-r0) + abs(b[1]-c0);\r\n };\r\n \r\n vector<vector<int>> resp;\r\n for(int i=0 ; i<R ; i++){\r\n for(int j=0; j<C ; j++){\r\n resp.push_back({i, j});\r\n }\r\n }\r\n\r\n sort(resp.begin(), resp.end(), comp);\r\n\r\n return resp;\r\n }\r\n```\r\n\r\n可以将r0, c0作为参数传进去\r\n\r\n注意lambda表达式是 auto开头\r\n\r\n\r\n\r\n3. print vector<vector<int>>\r\n\r\n for(auto& row:myvector){\r\n for(auto& col:row){\r\n cout<<col<<\" \";\r\n }\r\n cout<<\"\\n\";\r\n }\r\n\r\n\r\n\r\n注意在c++中i=3,i/2==1\r\n\r\n"
},
{
"alpha_fraction": 0.7442273497581482,
"alphanum_fraction": 0.7690941095352173,
"avg_line_length": 17.789474487304688,
"blob_id": "8be3cb2b7d6dc6ed99aba1bb67c55eee19577ceb",
"content_id": "d18fa876dc3ec8bb650f41ee7437ec2e9c5c48e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2074,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 57,
"path": "/Learning to Rank.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Learning to Rank\r\n\r\nhttps://www.cnblogs.com/bentuwuying/p/6681943.html\r\n\r\nhttps://www.cnblogs.com/bentuwuying/p/6690836.html\r\n\r\n##### 排序问题\r\n\r\n在信息检索中,给定一个query,模型f(q,d)对不同的document进行排序,这个模型可以是人工设定的参数模型也可以是机器学习算法自动训练出来的模型。\r\n\r\n在排序问题中,最关注的是Documents之间的相对顺序关系,而不是各个Documents的预测分最准确。\r\n\r\n##### 1.1Training data的获取\r\n\r\n第一种方式是人工标注,第二种方式是通过日志获取。搜索日志记录了人们实际生活中实际的搜索行为和相应的点击行为,点击行为实际上隐含了query-doc pair的相关性。但是这种情况是存在position-bias的,即用户偏向于点击位置靠前的doc。\r\n\r\n##### 1.2 feature生成\r\n\r\nfeature主要分为两大类,relevance(query-doc pair的相关性feature)和importance(doc本身热门程度)。两者有代表性的是BM25和PageRank。\r\n\r\n##### BM25\r\n\r\nBM25 模型是一种用来评价搜索词和文档之间相关性的算法\r\n\r\n##### PageRank\r\n\r\nPageRank算法通过不断地迭代,基于网页之间相互彼此间的引用计算网页的热度。\r\n\r\n##### 1.3 Evaluation\r\n\r\nGBN\r\n\r\nMAP(Mean Average Precision)\r\n\r\n\r\n\r\n\r\n\r\nrank algorithm的损失函数主要可以分为,\r\n\r\npointwise pairwise listwise\r\n\r\npointwise 单文档处理对象是单独一篇文档。损失例如square loss:\r\n$$\r\nL=\\sum_{i=1}^n(f(x_i)-y_i)^2\r\n$$\r\npointwise方法没有对先后顺序的优劣性进行惩罚。\r\n\r\n\r\n\r\npairwise将文档的排序问题转化为多个pair的排序问题,比较不同文章之间的先后顺序。\r\n\r\n\r\n\r\nlistwise:\r\n\r\n单文档方法将训练集里每一个文档当做一个训练实例,文档对方法将同一个査询的搜索结果里任意两个文档对作为一个训练实例,文档列表方法与上述两种方法都不同,ListWise方法直接考虑整体序列,针对Ranking评价指标进行优化。比如常用的MAP, NDCG。"
},
{
"alpha_fraction": 0.5605536103248596,
"alphanum_fraction": 0.6020761132240295,
"avg_line_length": 17.266666412353516,
"blob_id": "90ed6f19494c6de3dbae91312921f1187871e7ba",
"content_id": "a0e735ddb3d99ff460b5011b33f5643cc1684d2a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 289,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 15,
"path": "/books/hello.cpp",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "#include <iostream>\r\n#include \"Sales_data.h\"\r\nusing namespace std;\r\nint i=0;\r\nvoid pri(){\r\n std::cout<<i;\r\n}\r\nint main(){\r\n Sales_data data1,data2;\r\n data1.revenue=1.0;\r\n data2.revenue=2.0;\r\n cout<<data1.revenue+data2.revenue;\r\n printf(\"hello world\");\r\n return 0;\r\n}\r\n"
},
{
"alpha_fraction": 0.7286224961280823,
"alphanum_fraction": 0.739620566368103,
"avg_line_length": 21.55194854736328,
"blob_id": "b764665ecef2ee97d37e88d28595766789f32dcb",
"content_id": "41330ac452c57b09e0724d6221bda38fcd30ec9c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5063,
"license_type": "no_license",
"max_line_length": 193,
"num_lines": 154,
"path": "/books/OSTEP.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Operating systems: Three Easy Pieces\r\n\r\nThree pieces:\r\n\r\nvirtualization(虚拟化),concurrency(并发性) and persistence(持久性)\r\n\r\n##### what happens when a program runs:\r\n\r\n**Von Neumann** model:先将整个程序加载到内存中,然后进程fetch(取)一个指令(instruction),解析这个指令(decode),再执行该指令 executes。这个指令可以是将两个数相加或者是将变量存到内存中或者是跳转到某个位置等等。执行完一个指令后就执行下一个指令。\r\n\r\n\r\n\r\n**virtualization**:\r\n\r\nprimary goal of virtualization:easy to use\r\n\r\nOS takes a physical resource (such as the processor, or memory, or a disk) and transforms it into a more general, powerful, and easy-to-use virtual form of itself.\r\n\r\n操作系统将进程、内存、磁盘等资源转化成一个更广义的更易使用的虚拟形式。\r\n\r\nvirtualization allows many programs to run.\r\n\r\n如果只有一个CPU,通过时间片轮换虚拟出了多个cpu,“同时”允许多个进程运行。\r\n\r\n**virtulization CPU**\r\nTurning a single CPU (or small set of them) into a seemingly infinite number of CPUs and thus allowing many programs to seemingly run at once is what we call virtualizing the CPU.\r\n\r\n\r\n\r\n**virtulization memory**\r\n\r\nOS is virtualizing memory. Each process accesses its own private virtual address space (sometimes just called its address space)\r\n\r\n\r\n\r\nWe see from the example that each running program has allocated memory at the same address (00200000), and yet each seems to be updating the value at 00200000 independently!\r\n\r\n每个程序都在00200000这个位置更改数值\r\n\r\n如何将大小为4GB的内存通过虚拟化的方式得到16G的效果?\r\n\r\n通过页表的结构,12G内容存在硬盘里,当需要使用的时候将硬盘中相关的数据导入到内存中,从而达到16G内存的效果。\r\n\r\n\r\n\r\n##### Concurrency\r\n\r\nthe curx of the problem:how to build correct concurrent programs?\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n当loop较大时,可能出现问题,原因在于\r\n\r\n执行操作分为三个部分:取出counter,加1,放回counter。但是这三个步骤不是自动地连续执行的,这就是并发可能会出现的问题。\r\n\r\n\r\n\r\n##### persistence\r\n\r\n持久存储\r\n\r\nthe crux of the problem:\r\n\r\nhow to store data persistently?\r\n\r\nwhat techniques are needed to do so correctly? what mechanisms and policies are required to do so?\r\n\r\n\r\n\r\nwhat is the design goal?\r\n\r\nAbstraction:makes it possible to write a large program by dividing it into small and understandable pieces.\r\n\r\nhigh performance\r\n\r\nsecurity\r\n\r\nmobiklity\r\n\r\nenergy-efficiency\r\n\r\n\r\n\r\n### virtualization\r\n\r\n##### Process\r\n\r\nthe process is a bunch of instructions to be acted.\r\n\r\nOS creates illusion by virtualizing CPU. By running one process, then stopping it and running another. OS promote the illusion that many virtual CPUS exist when there is only one or a few CPUs.\r\n\r\nThis basic technique, known as **time sharing** of the CPU.\r\n\r\n##### 上下文切换 context switch\r\n\r\n上下文切换指的是CPU从一个进程(线程)切换到另一个进程(线程)。\r\n\r\n1. 暂停当前进程执行流程,将各个寄存器内容存到内存中;\r\n2. 从内存中取出下一个将要执行的进程的上下文,存进各个寄存器中;\r\n3. 返回程序计数器记录的指令地址,用于恢复进程执行\r\n\r\n##### process creation\r\n\r\nwhat happen when program turn into process?\r\n\r\n1. load code and static data into memory\r\n\r\n \told way:eargely\r\n\r\n \tmodern way:load what is needed: paging and swapping\r\n\r\n2. OS allocate memory for stack(local variables, function parameters, and return addresses) and heap(linked list,hash tables...)\r\n\r\n3. start to run from the entry point (main)\r\n\r\n \r\n\r\n##### process state\r\n\r\n三种state:running,ready,blocked\r\n\r\n\r\n\r\nrunning:executing instructions\r\n\r\nready:is ready to run but OS chose not run \r\n\r\nblocked: example: a process needs IO device, but other process is using: blocked. When it is ready, it become running.\r\n\r\n\r\n\r\n##### PCB: process control block\r\n\r\n存放进程的管理和控制信息的数据结构称为进程控制块,是进程实体的一部分,是最重要的记录性数据结构,每个进程都有PCB,在创建进程时创建PCB,进程结束时,PCB结束。\r\n\r\n\r\n\r\n##### system(),fork(),exec()函数\r\n\r\nunix系统中对进程进行操作的系统函数。\r\n\r\nsystem()函数会调用fork()等函数,用来创建一个与当前进程几乎完全相同的紫禁城,父进程中调用wait()等待子进程的执行,子进程使用exec()在新的空间中运行,然父进程再运行,值得注意的是子进程不是从main开始运行的,从fork()点开始运行。\r\n\r\nfork()函数用于产生一个新的进程(复制),这两个进程的数据相同,空间不同\r\n\r\nexec():替换函数,将某个进程的数据等复制替换到新空间。\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5090847015380859,
"alphanum_fraction": 0.5338495969772339,
"avg_line_length": 21.335651397705078,
"blob_id": "5622b6a1482c6d76cc6fbf1c132235b0a94ade8b",
"content_id": "126de60c8c4cd3d40dcf99986949260b91185867",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 24917,
"license_type": "no_license",
"max_line_length": 295,
"num_lines": 1007,
"path": "/leetcode_note/stack.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "使用队列实现栈(LeetCode 232)\r\n\r\n使用栈实现队列(LeetCode 225)\r\n\r\n包含min函数的栈(LeetCode 155)\r\n\r\n简单的计算器(栈的应用)( LeetCode 224)\r\n\r\n##### leetcode 20 Valid Parentheses\r\n\r\n* Given a string containing just the characters `'('`, `')'`, `'{'`, `'}'`, `'['` and `']'`, determine if the input string is valid.\r\n\r\n An input string is valid if:\r\n\r\n 1. Open brackets must be closed by the same type of brackets.\r\n 2. Open brackets must be closed in the correct order.\r\n\r\n Note that an empty string is also considered valid.\r\n\r\n ```\r\n Input: \"()\"\r\n Output: true\r\n \r\n Input: \"()[]{}\"\r\n Output: true\r\n \r\n Input: \"(]\"\r\n Output: false\r\n \r\n Input: \"([)]\"\r\n Output: false\r\n \r\n Input: \"{[]}\"\r\n Output: true\r\n ```\r\n\r\n Solution:\r\n\r\n ```python\r\n class Solution:\r\n def isValid(s):\r\n n=len(s)\r\n stack=[]\r\n dict={')':'(',']':'[','}':'{'}\r\n for i in range(n):\r\n if s[i] in dict:\r\n if len(stack)==0:\r\n return False\r\n elif stack[-1]==dict[s[i]]:\r\n stack.pop()\r\n else:\r\n return False\r\n else:\r\n stack.append(s[i])\r\n if len(stack)==0:\r\n return True\r\n else:\r\n return False\r\n ```\r\n\r\n符号分为两种,结束符号] }) 开始符[{(\r\n\r\n将开始符压入栈,如果出现结束符则将栈顶的元素弹出。如果不对应则返回False\r\n\r\n\r\n\r\n##### leetcode 32 Longest Valid Parentheses\r\n\r\n* Given a string containing just the characters `'('` and `')'`, find the length of the longest valid (well-formed) parentheses substring.\r\n\r\n```\r\nInput: \"(()\"\r\nOutput: 2\r\nExplanation: The longest valid parentheses substring is \"()\"\r\n\r\nInput: \")()())\"\r\nOutput: 4\r\nExplanation: The longest valid parentheses substring is \"()()\"\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def longestValidParentheses(self, s):\r\n \"\"\"\r\n :type s: str\r\n :rtype: int\r\n \"\"\"\r\n max_len=0\r\n stack=[-1]\r\n for i in range(len(s)):\r\n if stack[-1]!=-1 and s[i]==\")\" and s[stack[-1]]==\"(\":\r\n stack.pop()\r\n max_len = max(max_len, i - stack[-1])\r\n else:\r\n stack.append(i)\r\n return max_len\r\n```\r\n\r\n本题要求substring (连续) 考虑stack结构,\r\n\r\n如果不要求substring,则考虑从右往左去掉多余的),从左往右去掉多余的(\r\n\r\n本解法的优点在于使用了i-stack[-1]:stack[-1]之后的全都用上了\r\n\r\n如果简单将所有的(放入stack中,对于()()这种情况只能识别到length=2\r\n\r\n因此将所有杂七杂八的情况都放进stack中,仅if stack[-1]!=-1 and s[i]==\")\" and s[stack[-1]]==\"(\": pop出来\r\n\r\n\r\n\r\n#### 单调栈\r\n\r\n##### leetcode 84 Largest Rectangle in Histogram\r\n\r\n* Given *n* non-negative integers representing the histogram's bar height where the width of each bar is 1, find the area of largest rectangle in the histogram.\r\n\r\n \r\n\r\n Above is a histogram where width of each bar is 1, given height = `[2,1,5,6,2,3]`.\r\n\r\n \r\n\r\n The largest rectangle is shown in the shaded area, which has area = `10` unit.\r\n\r\n```python\r\nclass Solution:\r\n def largestRectangleArea(self, heights):\r\n ans = 0\r\n n=len(heights)\r\n heights.append(0)\r\n stack = [-1]\r\n for i in range(n + 1):\r\n while heights[i] < heights[stack[-1]]:\r\n h = heights[stack.pop()]\r\n w = i - 1 - stack[-1]\r\n ans = max(ans, h * w)\r\n stack.append(i)\r\n return ans\r\n```\r\n\r\n单调栈 O(N)\r\n\r\nstack中放置 -1,height最后加0 防止出现单调的情况\r\n\r\nstack中的情况\r\n\r\n-1 2\r\n\r\n-1 1\r\n\r\n-1 1 5\r\n\r\n-1 1 5 6\r\n\r\n-1 1 2\r\n\r\n-1 1 2 3(遇到0 全都弹出)\r\n\r\n-1\r\n\r\n例如当压进nums[4]的时候,因为以后再考虑高度也最高到nums[4]即为2,前面的5,6都可以视为2,因此可以弹出\r\n\r\n\r\n\r\n##### leetcode 85 Maximal Rectangle\r\n\r\n* Given a 2D binary matrix filled with 0's and 1's, find the largest rectangle containing only 1's and return its area.\r\n\r\n```\r\nInput:\r\n[\r\n [\"1\",\"0\",\"1\",\"0\",\"0\"],\r\n [\"1\",\"0\",\"1\",\"1\",\"1\"],\r\n [\"1\",\"1\",\"1\",\"1\",\"1\"],\r\n [\"1\",\"0\",\"0\",\"1\",\"0\"]\r\n]\r\nOutput: 6\r\n```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution:\r\n def maximalRectangle(self, matrix):\r\n if not matrix or not matrix[0]:\r\n return 0\r\n n = len(matrix[0])\r\n height = [0] * (n + 1)\r\n ans = 0\r\n for row in matrix:\r\n for i in range(n):\r\n height[i] = height[i] + 1 if row[i] == '1' else 0\r\n stack = [-1]\r\n for i in range(n + 1):\r\n while height[i] < height[stack[-1]]:\r\n h = height[stack.pop()]\r\n w = i - 1 - stack[-1]\r\n ans = max(ans, h * w)\r\n stack.append(i)\r\n return ans\r\n```\r\n\r\nThe solution is based on largest rectangle in histogram solution.Every row in the matrix is viewed as the ground with some buildings on it.The building height is the count of consecutive 1s from that row to above rows.The rest is then the same as this solution for largest rectangle in histogram\r\n\r\n\r\n\r\n##### leetcode 155 Min Stack\r\n\r\nDesign a stack that supports push, pop, top, and retrieving the minimum element in constant time.\r\n\r\n- push(x) -- Push element x onto stack.\r\n- pop() -- Removes the element on top of the stack.\r\n- top() -- Get the top element.\r\n- getMin() -- Retrieve the minimum element in the stack.\r\n\r\n**Example:**\r\n\r\n```\r\nMinStack minStack = new MinStack();\r\nminStack.push(-2);\r\nminStack.push(0);\r\nminStack.push(-3);\r\nminStack.getMin(); --> Returns -3.\r\nminStack.pop();\r\nminStack.top(); --> Returns 0.\r\nminStack.getMin(); --> Returns -2.\r\n```\r\n\r\n```python\r\nclass MinStack:\r\n\r\n def __init__(self):\r\n \"\"\"\r\n initialize your data structure here.\r\n \"\"\"\r\n self.stack = []\r\n self.stack1 = []\r\n\r\n def push(self, x):\r\n \"\"\"\r\n :type x: int\r\n :rtype: void\r\n \"\"\"\r\n self.stack.append(x)\r\n self.stack1.append(x)\r\n self.stack1.sort()\r\n\r\n def pop(self):\r\n \"\"\"\r\n :rtype: void\r\n \"\"\"\r\n key = self.stack[-1]\r\n self.stack.pop()\r\n self.stack1.remove(key)\r\n\r\n def top(self):\r\n \"\"\"\r\n :rtype: int\r\n \"\"\"\r\n return self.stack[-1]\r\n\r\n def getMin(self):\r\n \"\"\"\r\n :rtype: int\r\n \"\"\"\r\n return self.stack1[0]\r\n```\r\n\r\n\r\n\r\n##### leetcode 224 Basic Calculator\r\n\r\nImplement a basic calculator to evaluate a simple expression string.\r\n\r\nThe expression string may contain open `(` and closing parentheses `)`, the plus `+` or minus sign `-`, **non-negative** integers and empty spaces ``.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: \"1 + 1\"\r\nOutput: 2\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: \" 2-1 + 2 \"\r\nOutput: 3\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: \"(1+(4+5+2)-3)+(6+8)\"\r\nOutput: 23\r\n```\r\n\r\nNote:\r\n\r\n- You may assume that the given expression is always valid.\r\n- **Do not** use the `eval` built-in library function.\r\n\r\n```python\r\ndef calculate(self, s):\r\n res, num, sign, stack = 0, 0, 1, [1]\r\n for i in s+\"+\":\r\n if i.isdigit():\r\n num = 10*num + int(i)\r\n elif i in \"+-\":\r\n res += num * sign * stack[-1]\r\n sign = 1 if i==\"+\" else -1\r\n num = 0\r\n elif i == \"(\":\r\n stack.append(sign * stack[-1])\r\n sign = 1\r\n elif i == \")\":\r\n res += num * sign * stack[-1]\r\n num = 0\r\n stack.pop()\r\n return res\r\n```\r\n\r\n\r\n\r\n##### leetcode 225 Implement Stack using Queues\r\n\r\nImplement the following operations of a stack using queues.\r\n\r\n- push(x) -- Push element x onto stack.\r\n- pop() -- Removes the element on top of the stack.\r\n- top() -- Get the top element.\r\n- empty() -- Return whether the stack is empty.\r\n\r\n**Example:**\r\n\r\n```\r\nMyStack stack = new MyStack();\r\n\r\nstack.push(1);\r\nstack.push(2); \r\nstack.top(); // returns 2\r\nstack.pop(); // returns 2\r\nstack.empty(); // returns false\r\n```\r\n\r\n```python\r\nclass MyStack(object):\r\n\r\n def __init__(self):\r\n \"\"\"\r\n Initialize your data structure here.\r\n \"\"\"\r\n self.q = collections.deque()\r\n \r\n\r\n def push(self, x):\r\n \"\"\"\r\n Push element x onto stack.\r\n :type x: int\r\n :rtype: None\r\n \"\"\"\r\n self.q.appendleft(x)\r\n \r\n\r\n def pop(self):\r\n \"\"\"\r\n Removes the element on top of the stack and returns that element.\r\n :rtype: int\r\n \"\"\"\r\n return self.q.popleft()\r\n \r\n\r\n def top(self):\r\n \"\"\"\r\n Get the top element.\r\n :rtype: int\r\n \"\"\"\r\n return self.q[0]\r\n \r\n\r\n def empty(self):\r\n \"\"\"\r\n Returns whether the stack is empty.\r\n :rtype: bool\r\n \"\"\"\r\n return not self.q\r\n```\r\n\r\n\r\n\r\n##### leetcode 232 Implement Queue using Stacks\r\n\r\nImplement the following operations of a queue using stacks.\r\n\r\n- push(x) -- Push element x to the back of queue.\r\n- pop() -- Removes the element from in front of queue.\r\n- peek() -- Get the front element.\r\n- empty() -- Return whether the queue is empty.\r\n\r\n**Example:**\r\n\r\n```\r\nMyQueue queue = new MyQueue();\r\n\r\nqueue.push(1);\r\nqueue.push(2); \r\nqueue.peek(); // returns 1\r\nqueue.pop(); // returns 1\r\nqueue.empty(); // returns false\r\n```\r\n\r\n```python\r\nclass MyQueue:\r\n\r\n def __init__(self):\r\n \"\"\"\r\n Initialize your data structure here.\r\n \"\"\"\r\n self.nums=[]\r\n \r\n\r\n def push(self, x):\r\n \"\"\"\r\n Push element x to the back of queue.\r\n :type x: int\r\n :rtype: void\r\n \"\"\"\r\n self.nums.append(x)\r\n \r\n\r\n def pop(self):\r\n \"\"\"\r\n Removes the element from in front of queue and returns that element.\r\n :rtype: int\r\n \"\"\"\r\n res=self.nums[0]\r\n self.nums=self.nums[1:]\r\n return res\r\n\r\n def peek(self):\r\n \"\"\"\r\n Get the front element.\r\n :rtype: int\r\n \"\"\"\r\n return self.nums[0]\r\n \r\n\r\n def empty(self):\r\n \"\"\"\r\n Returns whether the queue is empty.\r\n :rtype: bool\r\n \"\"\"\r\n if self.nums==[]:\r\n return True\r\n else:\r\n return False\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 907 Sum of Subarray Minimums\r\n\r\n* Given an array of integers `A`, find the sum of `min(B)`, where `B` ranges over every (contiguous) subarray of `A`.\r\n\r\n Since the answer may be large, **return the answer modulo 10^9 + 7.\r\n\r\n **Note:**\r\n\r\n 1. `1 <= A.length <= 30000`\r\n 2. `1 <= A[i] <= 30000`\r\n\r\n```\r\nInput: [3,1,2,4]\r\nOutput: 17\r\nExplanation: Subarrays are [3], [1], [2], [4], [3,1], [1,2], [2,4], [3,1,2], [1,2,4], [3,1,2,4]. \r\nMinimums are 3, 1, 2, 4, 1, 1, 2, 1, 1, 1. Sum is 17.\r\n```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution:\r\n def sumSubarrayMins(self, A):\r\n res,n=0,len(A)\r\n left,right=[0 for i in range(n)],[0 for i in range(n)]\r\n stack=[0]\r\n left[0]=1\r\n for i in range(1,n):\r\n if A[i]>=A[stack[-1]]:\r\n stack.append(i)\r\n for j in range(len(stack)):\r\n left[stack[j]]+=1\r\n else:\r\n while stack and A[i]<A[stack[-1]]:\r\n stack.pop()\r\n stack.append(i)\r\n for j in range(len(stack)):\r\n left[stack[j]] += 1\r\n stack = [n-1]\r\n right[n-1] = 1\r\n for i in range(n-2,-1,-1):\r\n if A[i] > A[stack[-1]]:\r\n stack.append(i)\r\n for j in range(len(stack)):\r\n right[stack[j]] += 1\r\n else:\r\n while stack and A[i] <= A[stack[-1]]:\r\n stack.pop()\r\n stack.append(i)\r\n for j in range(len(stack)):\r\n right[stack[j]] += 1\r\n for i in range(n):\r\n res+=A[i]*left[i]*right[i]\r\n return res%(10**9 + 7)\r\n```\r\n\r\n\r\n\r\n由于长度在30000,因此肯定不能用递归法将所有的subarray都求解出来\r\n\r\nres=sum(A[i]*left[i] *right[i])\r\n\r\n注意由于存在相同的数字,因此我的方法中对于left和right的处理在等号上是不一样的\r\n\r\nleft[i] 表示从左向右考虑,在[i]后面有多少个小于等于nums[i]的数字\r\n\r\nright[I]表示从右向左考虑,在后面有多少个小于num[i]的数字\r\n\r\n但是我的方法会超时\r\n\r\n```python\r\nclass Solution:\r\n def sumSubarrayMins(self, A):\r\n res = 0\r\n stack = [] # non-decreasing\r\n A = [float('-inf')] + A + [float('-inf')]\r\n for i, n in enumerate(A):\r\n while stack and A[stack[-1]] > n:\r\n cur = stack.pop()\r\n res += A[cur] * (i - cur) * (cur - stack[-1])\r\n stack.append(i)\r\n return res % (10**9 + 7)\r\n```\r\n\r\nO(N)\r\n\r\n对于19 19 62 66\r\n\r\nres=19* 4* 1+19* 3 * 1 + 62 * 2 * 1 + 66 * 1 * 1\r\n\r\ni-cur 表示比cur更小的前一个数的距离\r\n\r\nstack[-1]表示比cur更小的后一个数的距离\r\n\r\n\r\n\r\n##### leetcode 155 Min Stack\r\n\r\n* Design a stack that supports push, pop, top, and retrieving the minimum element in constant time.\r\n - push(x) -- Push element x onto stack.\r\n - pop() -- Removes the element on top of the stack.\r\n - top() -- Get the top element.\r\n - getMin() -- Retrieve the minimum element in the stack.\r\n\r\n```\r\nMinStack minStack = new MinStack();\r\nminStack.push(-2);\r\nminStack.push(0);\r\nminStack.push(-3);\r\nminStack.getMin(); --> Returns -3.\r\nminStack.pop();\r\nminStack.top(); --> Returns 0.\r\nminStack.getMin(); --> Returns -2.\r\n```\r\n\r\n```python\r\nclass MinStack:\r\n def __init__(self):\r\n \"\"\"\r\n initialize your data structure here.\r\n \"\"\"\r\n self.stack = []\r\n self.stack1 = []\r\n def push(self, x):\r\n \"\"\"\r\n :type x: int\r\n :rtype: void\r\n \"\"\"\r\n self.stack.append(x)\r\n self.stack1.append(x)\r\n self.stack1.sort()\r\n def pop(self):\r\n \"\"\"\r\n :rtype: void\r\n \"\"\"\r\n key = self.stack[-1]\r\n self.stack.pop()\r\n self.stack1.remove(key)\r\n def top(self):\r\n \"\"\"\r\n :rtype: int\r\n \"\"\"\r\n return self.stack[-1]\r\n def getMin(self):\r\n \"\"\"\r\n :rtype: int\r\n \"\"\"\r\n return self.stack1[0]\r\n```\r\n\r\n要实现的功能是实现基本stack push pop的同时实现得到最小值的功能\r\n\r\n利用两个stack来实现这一功能,stack1用来得到最小值\r\n\r\nstack实现基本push pop操作\r\n\r\n\r\n\r\n##### leetcode 962 Maximum Width Ramp\r\n\r\n* Given an array `A` of integers, a *ramp* is a tuple `(i, j)` for which `i < j` and `A[i] <= A[j]`. The width of such a ramp is `j - i`.\r\n\r\n Find the maximum width of a ramp in `A`. If one doesn't exist, return 0.\r\n\r\n ```\r\n Input: [6,0,8,2,1,5]\r\n Output: 4\r\n Explanation: \r\n The maximum width ramp is achieved at (i, j) = (1, 5): A[1] = 0 and A[5] = 5.\r\n \r\n Input: [9,8,1,0,1,9,4,0,4,1]\r\n Output: 7\r\n Explanation: \r\n The maximum width ramp is achieved at (i, j) = (2, 9): A[2] = 1 and A[9] = 1.\r\n \r\n 2 <= A.length <= 50000\r\n 0 <= A[i] <= 50000\r\n ```\r\n\r\n\r\n* Mysolution:\r\n\r\n ```python\r\n class Solution:\r\n def maxWidthRamp(self, A):\r\n \t\tn=len(A)\r\n if n==0:\r\n return 0\r\n if A[n-1]>=A[0]:\r\n return n-1\r\n else:\r\n return max(self.maxWidthRamp(A[1:]),self.maxWidthRamp(A[:n-1]))\r\n ```\r\n\r\n 最长的情况是A[n-1]>=A[0]\r\n\r\n 递归方法 但是得到TLE\r\n\r\nO(N) 单调栈\r\n\r\n```python\r\nclass Solution:\r\n def maxWidthRamp(self, A):\r\n s=[]\r\n res,n=0,len(A)\r\n for i in range(n):\r\n if not s or A[s[-1]]>A[i]:\r\n s.append(i)\r\n for j in range(n-1,-1,-1):\r\n while s and A[s[-1]]<=A[j]:\r\n res=max(res,j-s[-1])\r\n s.pop()\r\n return res\r\n```\r\n\r\n将元素从前往后放入递减栈中,如果有个元素比前面的元素大,则在计算ramp长度的时候可以只考虑前面那个小的元素,因此只用递减栈。\r\n\r\nlength在50000这种级别的,基本上只有O(N)的解法可以考虑\r\n\r\n\r\n\r\n##### leetcode 1081 Smallest Subsequence of Distinct Characters\r\n\r\nReturn the lexicographically smallest subsequence of `text` that contains all the distinct characters of `text` exactly once.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: \"cdadabcc\"\r\nOutput: \"adbc\"\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: \"abcd\"\r\nOutput: \"abcd\"\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: \"ecbacba\"\r\nOutput: \"eacb\"\r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: \"leetcode\"\r\nOutput: \"letcod\"\r\n```\r\n\r\n**Note:**\r\n\r\n1. `1 <= text.length <= 1000`\r\n2. `text` consists of lowercase English letters.\r\n\r\nstack\r\n\r\n```python\r\nclass Solution:\r\n def smallestSubsequence(self, text):\r\n dict = {}\r\n for i, c in enumerate(text):\r\n dict[c] = i\r\n stack = []\r\n for i,c in enumerate(text):\r\n if c in stack: continue\r\n while stack and stack[-1] > c and i < dict[stack[-1]]:\r\n stack.pop()\r\n stack.append(c)\r\n return \"\".join(stack)\r\n```\r\n\r\n首先记录不同字符在string中最后出现的位置\r\n\r\n进行比较如果c比stack中最后一个字符小,且该字符在i之后还有出现则弹出\r\n\r\n```\r\ncdadabcc:\r\n第一轮:c\r\n第二轮:cd\r\n第三轮 弹出cd a\r\n第四轮:ad\r\n第五轮:ad\r\n第六轮:adb\r\n第七轮:adbc\r\n```\r\n\r\n\r\n\r\n##### leetcode 1047 Remove All Adjacent Duplicates In String\r\n\r\nGiven a string `S` of lowercase letters, a *duplicate removal* consists of choosing two adjacent and equal letters, and removing them.\r\n\r\nWe repeatedly make duplicate removals on S until we no longer can.\r\n\r\nReturn the final string after all such duplicate removals have been made. It is guaranteed the answer is unique.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: \"abbaca\"\r\nOutput: \"ca\"\r\nExplanation: \r\nFor example, in \"abbaca\" we could remove \"bb\" since the letters are adjacent and equal, and this is the only possible move. The result of this move is that the string is \"aaca\", of which only \"aa\" is possible, so the final string is \"ca\".\r\n```\r\n\r\n用一个stack去存储,如果c和res[-1]一样就表示要弹出\r\n\r\n```python\r\nclass Solution:\r\n def removeDuplicates(self, s):\r\n res = []\r\n for c in s:\r\n if res and res[-1] == c:\r\n res.pop()\r\n else:\r\n res.append(c)\r\n return \"\".join(res)\r\n```\r\n\r\n\r\n\r\n##### leetcode 1209 Remove All Adjacent Duplicates in String II\r\n\r\nGiven a string `s`, a *k* *duplicate removal* consists of choosing `k` adjacent and equal letters from `s` and removing them causing the left and the right side of the deleted substring to concatenate together.\r\n\r\nWe repeatedly make `k` duplicate removals on `s` until we no longer can.\r\n\r\nReturn the final string after all such duplicate removals have been made.\r\n\r\nIt is guaranteed that the answer is unique.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: s = \"abcd\", k = 2\r\nOutput: \"abcd\"\r\nExplanation: There's nothing to delete.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: s = \"deeedbbcccbdaa\", k = 3\r\nOutput: \"aa\"\r\nExplanation: \r\nFirst delete \"eee\" and \"ccc\", get \"ddbbbdaa\"\r\nThen delete \"bbb\", get \"dddaa\"\r\nFinally delete \"ddd\", get \"aa\"\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: s = \"pbbcggttciiippooaais\", k = 2\r\nOutput: \"ps\"\r\n```\r\n\r\n**Constraints:**\r\n\r\n- `1 <= s.length <= 10^5`\r\n- `2 <= k <= 10^4`\r\n- `s` only contains lower case English letters.\r\n\r\n```python\r\nclass Solution:\r\n def removeDuplicates(self, s, k):\r\n res = [[\"#\", 0]]\r\n for c in s:\r\n if res and res[-1][0] == c:\r\n res[-1][1] += 1\r\n if res[-1][1] == k:\r\n res.pop()\r\n else:\r\n res.append([c,1])\r\n return \"\".join(c*k for c, k in res)\r\n```\r\n\r\n注意到k有可能是一个比较大的值\r\n\r\n如果每次都检查某个位置前k-1个元素就时间复杂度很高\r\n\r\n在stack中加一个元素表示之前相同的元素有多少个\r\n\r\n这个就能省很多计算量\r\n\r\n```python\r\nclass Solution:\r\n def removeDuplicates(self, s, k):\r\n res = [[\"#\", 0]]\r\n for c in s:\r\n if res and res[-1][0] == c:\r\n res[-1][1] += 1\r\n if res[-1][1] == k:\r\n res.pop()\r\n else:\r\n res.append([c,1])\r\n return \"\".join(c*k for c, k in res)\r\n```\r\n\r\n\r\n\r\n##### leetcode 388 Longest Absolute File Path\r\n\r\nSuppose we abstract our file system by a string in the following manner:\r\n\r\nThe string `\"dir\\n\\tsubdir1\\n\\tsubdir2\\n\\t\\tfile.ext\"` represents:\r\n\r\n```\r\ndir\r\n subdir1\r\n subdir2\r\n file.ext\r\n\r\n```\r\n\r\nThe directory `dir` contains an empty sub-directory `subdir1` and a sub-directory `subdir2` containing a file `file.ext`.\r\n\r\nThe string `\"dir\\n\\tsubdir1\\n\\t\\tfile1.ext\\n\\t\\tsubsubdir1\\n\\tsubdir2\\n\\t\\tsubsubdir2\\n\\t\\t\\tfile2.ext\"` represents:\r\n\r\n```\r\ndir\r\n subdir1\r\n file1.ext\r\n subsubdir1\r\n subdir2\r\n subsubdir2\r\n file2.ext\r\n\r\n```\r\n\r\nThe directory `dir` contains two sub-directories `subdir1` and `subdir2`. `subdir1` contains a file `file1.ext` and an empty second-level sub-directory `subsubdir1`. `subdir2` contains a second-level sub-directory `subsubdir2` containing a file `file2.ext`.\r\n\r\nWe are interested in finding the longest (number of characters) absolute path to a file within our file system. For example, in the second example above, the longest absolute path is `\"dir/subdir2/subsubdir2/file2.ext\"`, and its length is `32` (not including the double quotes).\r\n\r\nGiven a string representing the file system in the above format, return the length of the longest absolute path to file in the abstracted file system. If there is no file in the system, return `0`.\r\n\r\n**Note:**\r\n\r\n- The name of a file contains at least a `.` and an extension.\r\n- The name of a directory or sub-directory will not contain a `.`.\r\n\r\nTime complexity required: `O(n)` where `n` is the size of the input string.\r\n\r\nNotice that `a/aa/aaa/file1.txt` is not the longest file path, if there is another path `aaaaaaaaaaaaaaaaaaaaa/sth.png`.\r\n\r\n```python\r\nclass Solution:\r\n def lengthLongestPath(self, input: str) -> int:\r\n pathes = input.split(\"\\n\")\r\n stack, length = [], 0\r\n for path in pathes:\r\n depth = 0\r\n while len(path)!=0 and path[0] == \"\\t\":\r\n depth += 1\r\n path = path[1:]\r\n while depth < len(stack):\r\n stack.pop()\r\n stack.append(path)\r\n if \".\" in path:\r\n length = max(length, sum(len(x) for x in stack) + len(stack) - 1)\r\n return length\r\n```\r\n\r\n\r\n\r\n##### leetcode 735. Asteroid Collision\r\n\r\nWe are given an array `asteroids` of integers representing asteroids in a row.\r\n\r\nFor each asteroid, the absolute value represents its size, and the sign represents its direction (positive meaning right, negative meaning left). Each asteroid moves at the same speed.\r\n\r\nFind out the state of the asteroids after all collisions. If two asteroids meet, the smaller one will explode. If both are the same size, both will explode. Two asteroids moving in the same direction will never meet.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: \r\nasteroids = [5, 10, -5]\r\nOutput: [5, 10]\r\nExplanation: \r\nThe 10 and -5 collide resulting in 10. The 5 and 10 never collide.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: \r\nasteroids = [8, -8]\r\nOutput: []\r\nExplanation: \r\nThe 8 and -8 collide exploding each other.\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: \r\nasteroids = [10, 2, -5]\r\nOutput: [10]\r\nExplanation: \r\nThe 2 and -5 collide resulting in -5. The 10 and -5 collide resulting in 10.\r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: \r\nasteroids = [-2, -1, 1, 2]\r\nOutput: [-2, -1, 1, 2]\r\nExplanation: \r\nThe -2 and -1 are moving left, while the 1 and 2 are moving right.\r\nAsteroids moving the same direction never meet, so no asteroids will meet each other.\r\n```\r\n\r\n**Note:**\r\n\r\nThe length of `asteroids` will be at most `10000`.\r\n\r\nEach asteroid will be a non-zero integer in the range `[-1000, 1000].`\r\n\r\n```python\r\nclass Solution:\r\n def asteroidCollision(self, asteroids: List[int]) -> List[int]:\r\n stack = []\r\n n = len(asteroids)\r\n for num in asteroids:\r\n while stack and stack[-1] > 0 and num < 0:\r\n out = stack.pop()\r\n if abs(num) < abs(out):\r\n stack.append(out)\r\n num = 0\r\n break\r\n elif abs(num) == abs(out):\r\n num = 0\r\n break\r\n if num != 0:\r\n stack.append(num)\r\n return stack\r\n \r\n \r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.6359223127365112,
"alphanum_fraction": 0.7184466123580933,
"avg_line_length": 38.79999923706055,
"blob_id": "98e3ff2d41786b4e953fbbcc8e9bcf6746723a17",
"content_id": "710828c516f1e4f4c9be876f3254f121db48eed9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 222,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 5,
"path": "/math&&deeplearning/math/ml_datamining10大算法.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "###数据挖掘10大算法 \r\n\r\nhttps://wizardforcel.gitbooks.io/dm-algo-top10/content/adaboost.html \r\n### PCA等\r\nhttps://yoyoyohamapi.gitbooks.io/mit-ml/content/%E7%89%B9%E5%BE%81%E9%99%8D%E7%BB%B4/articles/PCA.html \r\n"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.75,
"avg_line_length": 26.66666603088379,
"blob_id": "b07a9a196722bdf8c38076d405b416d62588a8f6",
"content_id": "23fe447d562c352856a650f3ffe55a0c8fdaf76a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 88,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 3,
"path": "/social_network/Geometric deep learning on graphs and manifolds.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### Non-Euclidean domains\r\n\r\nGraph-wise classification, Vertex-wise classification\r\n\r\n"
},
{
"alpha_fraction": 0.6491120457649231,
"alphanum_fraction": 0.6527862548828125,
"avg_line_length": 10.41984748840332,
"blob_id": "3e72d81f2496501365aee44a8fde55b37c16eb32",
"content_id": "cacde7e51d76167cc6ac5306c9e4665273b85306",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2577,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 131,
"path": "/books/Github入门与实践.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Github入门与实践\r\n\r\nGithub上公开的软件源代码全都由Git进行管理\r\n\r\nGithub带来了SOCIAL CODING的概念\r\n\r\nISSUE:每个讨论或修正都会有一个issue\r\n\r\nPR: pull request开发者通过pull request向别人的仓库提出申请,请求对方合并\r\n\r\n\r\n\r\nGit是分散型软件开发版本管理系统\r\n\r\n集中型管理系统: subversion\r\n\r\n\r\n\r\n分散型系统:\r\n\r\n\r\n\r\n在电脑上要先安装Git\r\n\r\n初始设置:\r\n\r\n```\r\n$ git config --global user.name \"Firstname Lastname\"\r\n$ git config --global user.email \"[email protected]\"\r\n```\r\n\r\n\r\n\r\n##### copy 代码:\r\n\r\ngit clone + [email protected]:hirocastest/Hello-World.git\r\n\r\n##### 提交\r\n\r\ngit add --all\r\n\r\n将所有的改动放入暂存区\r\n\r\ngit commit -m \"xxx\"\r\n\r\n提交所有的改动\r\n\r\n##### push操作\r\n\r\n只要进行push,github上面的仓库就会更新\r\n\r\n\r\n\r\n#### Git基本操作\r\n\r\ngit init #初始化仓库\r\n\r\n通过git init初始化仓库,生成.git目录\r\n\r\ngit status #查看当前git仓库的状态\r\n\r\ngit add #向暂存区添加文件\r\n\r\ngit commit #保存仓库的历史纪录\r\n\r\n如果使用-m会只提交一行信息,如果不用 -m会进入编辑器界面 可以添加更多信息\r\n\r\ngit log #可以用来查看提交日志\r\n\r\ngit diff #查看当前工作树和暂存区的差别\r\n\r\n\r\n\r\n##### 分支\r\n\r\n在同时进行多个作业时,会用到分支\r\n\r\nmaster是Git默认创建的分支\r\n\r\ngit branch #可以用来查看所有的分支列表\r\n\r\ngit checkout -b #用来创建或者切换分支\r\n\r\n```\r\n$ git checkout -b feature-A\r\nSwitched to a new branch 'feature-A'\r\n```\r\n\r\ngit merge #合并分支\r\n\r\ngit log --graph #以图表的形式输出日志\r\n\r\ngit reset --hard xxxx #将仓库的HEAD 暂存区以及工作树等回到指定的状态\r\n\r\n##### 添加远程仓库\r\n\r\n如果想将本地的仓库放到远程,先在github上创建一个新仓库,最好与本地仓库同名,然后不要创建readme\r\n\r\n```\r\n$ git remote add origin [email protected]:github-book/git-tutorial.git\r\n```\r\n\r\ngit push\r\n\r\n\r\n\r\n\r\n\r\n#### Pull Request\r\n\r\n\r\n\r\n1. 将他的远程仓库fork到自己的远程仓库\r\n\r\n2. 将自己的远程仓库clone到本地 pull\r\n\r\n3. 在本地创建一个work分支,在work分支下进行修改\r\n\r\n4. 切换到work分支后,add commit\r\n\r\n5. 在自己的远程仓库创建本地work分支对应的远程分支 git push origin work\r\n\r\n 用 git branch -a 可以看到remote /origin/work应该已经被创建\r\n\r\n6. 登录github,切换分支,创建PR\r\n\r\n\r\n\r\n\r\n\r\n#### 接收Pull request\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.534821629524231,
"alphanum_fraction": 0.5731618404388428,
"avg_line_length": 32.17499923706055,
"blob_id": "78ea02b8264367ae55824af52b578b27d634b675",
"content_id": "1becdf7fa034813c7dd5225f0ddeafc2880c0b62",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4121,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 120,
"path": "/math&&deeplearning/pytorch/pytorch.py",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "import os\r\nimport torch\r\nimport torch.nn as nn\r\nimport torch.nn.functional as F\r\nimport random\r\nimport torch.optim as optim\r\n\r\nimport torch.optim as optim\r\nimport torch.utils.data as Data\r\nfrom torch.utils.data import DataLoader as DataLoader\r\nfrom torch.autograd import Variable\r\n\r\nfrom PIL import Image\r\nimport numpy as np\r\nfrom torchvision import transforms as T\r\n\r\n\r\n\r\nclass FaceDataSet(Data.Dataset):\r\n def __init__(self, set_config, transforms=None):\r\n self.transform = transforms\r\n self.imgs = open(set_config).readlines()\r\n\r\n def __getitem__(self, index):\r\n img_path, label = self.imgs[index].split()\r\n data = Image.open(img_path)\r\n if self.transform:\r\n data = self.transform(data)\r\n return data, int(label)\r\n def __len__(self):\r\n return len(self.imgs)\r\n\r\n \r\n\r\n\r\nclass Model(nn.Module):\r\n def __init__(self):\r\n super(Model,self).__init__()\r\n self.conv1=nn.Conv2d(3,20,4)\r\n self.bn1 = nn.BatchNorm2d(20)\r\n self.conv2=nn.Conv2d(20,40,3)\r\n self.bn2 = nn.BatchNorm2d(40)\r\n self.conv3=nn.Conv2d(40,60,3)\r\n self.bn3 = nn.BatchNorm2d(60)\r\n self.conv4=nn.Conv2d(60,80,2)\r\n self.fc1=nn.Linear(80*2*1,160)\r\n self.fc2=nn.Linear(60*2*3,160)\r\n self.fc3=nn.Linear(160,10000)\r\n\r\n def forward(self,x):\r\n# print(\"the shape of input is {fuck}\".format(fuck=x.size()))\r\n x=F.max_pool2d(F.relu(self.conv1(x)),(2,2))\r\n x=self.bn1(x)\r\n# print(\"the shape after max-pooling layer 1 is {fuck}\".format(fuck=x.size()))\r\n x=F.max_pool2d(F.relu(self.conv2(x)),(2,2))\r\n x=self.bn2(x)\r\n# print(\"the shape after max-pooling layer 2 is {fuck}\".format(fuck=x.size()))\r\n x1=F.max_pool2d(F.relu(self.conv3(x)),(2,2))\r\n x1=self.bn3(x1)\r\n# print(\"the shape after max-pooling layer 3 is {fuck}\".format(fuck=x1.size()))\r\n x2=F.relu(self.conv4(x1))\r\n# print(\"the shape after conv layer 4 is {fuck}\".format(fuck=x2.size()))\r\n# print(\"Linear layer 1 is {fuck}\".format(fuck=self.fc1))\r\n x2 = x2.view(-1, 80*2*1)\r\n x1 = x1.view(-1, 60*2*3)\r\n x3=F.relu(self.fc1(x2))\r\n x4=F.relu(self.fc2(x1))\r\n x5=F.relu(self.fc3(x3+x4))\r\n return x5\r\n\r\nif __name__ == \"__main__\":\r\n trainset_config = \"./dataset_config/trainconfig.txt\"\r\n testset_config = \"./dataset_config/valconfig.txt\"\r\n\r\n device = torch.device(\"cuda:1\" if torch.cuda.is_available() else \"cpu\")\r\n print(device)\r\n net = Model()\r\n net = net.to(device)\r\n\r\n BATCH_SIZE=128\r\n EPOCHES = 1000\r\n INTERVAL = 100\r\n transform = T.Compose([\r\n T.Resize([39, 31]),\r\n T.ToTensor(),\r\n T.Normalize(mean=[.5, .5, .5], std=[.5, .5, .5])\r\n ])\r\n criterion = nn.CrossEntropyLoss()\r\n optimizer = optim.Adam(net.parameters(), lr=0.001)\r\n\r\n trainset = FaceDataSet(trainset_config, transform)\r\n testset = FaceDataSet(testset_config, transform)\r\n\r\n trainset_loader = DataLoader(trainset, batch_size = BATCH_SIZE, shuffle = True, num_workers=2, pin_memory = False)\r\n testset_loader = DataLoader(testset, batch_size = BATCH_SIZE, num_workers=2, pin_memory = False)\r\n\r\n for epoch in range(EPOCHES):\r\n running_loss = 0\r\n for i, data in enumerate(trainset_loader, 0):\r\n inputs, label = data\r\n inputs, label = inputs.to(device), label.to(device)\r\n optimizer.zero_grad()\r\n outputs = net(inputs)\r\n\r\n label = label.long()\r\n loss = criterion(outputs, label)\r\n loss.backward()\r\n optimizer.step()\r\n\r\n\r\n predicted = torch.argmax(outputs, 1)\r\n total = len(label)\r\n correct = (predicted == label).sum().float()\r\n accuracy = 100 * correct / total\r\n\r\n running_loss += loss.item()\r\n if i % INTERVAL == INTERVAL-1:\r\n print(\"[%d, %5d] loss : %3f, accuracy : %3f\" % (epoch + 1, i + 1, running_loss/INTERVAL, accuracy))\r\n running_loss = 0\r\n print(\"Finish Trainning\")\r\n\r\n \r\n\r\n\r\n"
},
{
"alpha_fraction": 0.43077272176742554,
"alphanum_fraction": 0.4484477639198303,
"avg_line_length": 21.59893035888672,
"blob_id": "6cdc3ce0b8e22c779c61df2b7025b943c147649c",
"content_id": "4e19281760cfeb2d7ec7bb9b44ee813bf1fd625a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4435,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 187,
"path": "/python/python_tree.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "```\r\nclass Node:\r\n def __init__(self,val):\r\n self.l=None\r\n self.r=None\r\n self.v=val\r\n\r\nclass Tree:\r\n def __init__(self):\r\n self.root=None\r\n\r\n def getRoot(self):\r\n return self.root\r\n\r\n def add(self, val): #构建二叉树\r\n if (self.root == None):\r\n self.root = Node(val)\r\n else:\r\n self._add(val, self.root)\r\n\r\n def _add(self, val, node):\r\n if (val < node.v):\r\n if node.l != None:\r\n self._add(val, node.l)\r\n else:\r\n node.l = Node(val)\r\n else:\r\n if node.r != None:\r\n self._add(val, node.r)\r\n else:\r\n node.r = Node(val)\r\n\r\n def find(self,val):\r\n if(self.root!=None):\r\n return self._find(val,self.root)\r\n else:\r\n return None\r\n\r\n def _find(self,val,node):\r\n if val==node.v:\r\n return node\r\n elif val<node.v:\r\n if node.l!=None:\r\n self._find(val,node.l)\r\n else:\r\n print(\"no exist\")\r\n elif val>node.v:\r\n if node.r!=None:\r\n self._find(val,node.r)\r\n else:\r\n print(\"no exist\")\r\n\r\n def deleteTree(self):\r\n self.root=None\r\n\r\n def printTree(self):\r\n if self.root!=None:\r\n self._printTree(self.root)\r\n\r\n def _printTree(self,node):\r\n if node!=None:\r\n self._printTree(node.l)\r\n print(\" \"+str(node.v)+\" \")\r\n self._printTree(node.r)\r\n \r\n def add2(self, num): #add2 构建满二叉树\r\n if num==-1:\r\n node=None\r\n else:\r\n node = Node(num)\r\n if self.root is None:\r\n self.root = node\r\n else:\r\n q = [self.root]\r\n\r\n while True:\r\n pop_node = q.pop(0)\r\n if pop_node.l is None:\r\n pop_node.l = node\r\n return\r\n elif pop_node.r is None:\r\n pop_node.r = node\r\n return\r\n else:\r\n q.append(pop_node.l)\r\n q.append(pop_node.r)\r\n```\r\n```\r\ntree = Tree()\r\ntree.add(3)\r\ntree.add(4)\r\ntree.add(0)\r\ntree.add(8)\r\ntree.add(2)\r\ntree.printTree()\r\nprint ((tree.find(3)).v)\r\nprint (tree.find(10))\r\ntree.deleteTree()\r\ntree.printTree()\r\n```\r\n\r\n```\r\n 0 \r\n 2 \r\n 3 \r\n 4 \r\n 8 \r\n3\r\nno exist\r\nNone\r\n```\r\n```\r\nclass Solution(object):\r\n def isSymmetric(self, root):\r\n \"\"\"\r\n :type root: TreeNode\r\n :rtype: bool\r\n \"\"\"\r\n def issame(root1, root2):\r\n if root1==None and root2==None:\r\n return True\r\n elif (root1==None and root2!=None) or (root2==None and root1!=None):\r\n return False\r\n if root1.v!=root2.v:\r\n return False\r\n else:\r\n return issame(root1.l, root2.r) and issame(root1.r, root2.l)\r\n if root==None:\r\n return True\r\n return issame(root.l,root.r)\r\ns=Solution()\r\ntree = Tree()\r\nnums=[1,2,2,3,4,4,3]\r\ntree.add2(1)\r\ntree.add2(2)\r\ntree.add2(2)\r\ntree.add2(3)\r\ntree.add2(4)\r\ntree.add2(4)\r\n#tree.add2(3)\r\ntree.printTree()\r\nroot=tree.getRoot()\r\nprint(s.isSymmetric(root))\r\n```\r\n\r\n104: depth of tree\r\n```\r\nclass Solution(object):\r\n def maxDepth(self, root):\r\n \"\"\"\r\n :type root: TreeNode\r\n :rtype: int\r\n \"\"\"\r\n count=0\r\n def returndep(root,count):\r\n if root==None:\r\n return count\r\n else:\r\n return max(returndep(root.l,count+1),returndep(root.r,count+1))\r\n return returndep(root,count)\r\n```\r\n226:\r\ninvert binary tree:\r\n```\r\nclass Solution(object):\r\n def invertTree(self, root):\r\n \"\"\"\r\n :type root: TreeNode\r\n :rtype: TreeNode\r\n \"\"\"\r\n def invert(root1,root2):\r\n if root1==None:\r\n return\r\n else:\r\n root2.val=root1.val\r\n if root1.left!=None:\r\n root2.right=TreeNode(-1)\r\n invert(root1.left,root2.right)\r\n if root1.right!=None:\r\n root2.left=TreeNode(-1)\r\n invert(root1.right,root2.left)\r\n if root==None:\r\n return\r\n root_new=TreeNode(-1)\r\n invert(root,root_new)\r\n return root_new\r\n```\r\n"
},
{
"alpha_fraction": 0.5764706134796143,
"alphanum_fraction": 0.5983193516731262,
"avg_line_length": 12.560976028442383,
"blob_id": "92c06c5f6061caf09ac975f0cff54a7577ac4da2",
"content_id": "c76d08015e1f11423eec41fb504814471391631a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1091,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 41,
"path": "/computer_science_knowledge/CS.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### 闭包\r\n\r\n闭包又称词法闭包、函数闭包。\r\n\r\n```python\r\ndef test():\r\n x = [1]\r\n def test2():\r\n x[0] += 1\r\n print(\"x is \",x)\r\n return\r\n return test2\r\n\r\na = test()\r\na()\r\na()\r\n```\r\n\r\n```python\r\n('x is ', [2])\r\n('x is ', [3])\r\n```\r\n\r\ntest是一个闭包,分为外部函数,自由变量和内部函数。\r\n\r\n闭包可以很好地保存当前程序的运行环境,使得每次程序执行时的起点都是上次执行结束的终点。例如点赞程序,一篇文章统计点赞数量,点赞之后就是点赞数在原先点赞数的数量上加1,这可以用闭包实现。\r\n\r\n\r\n\r\n注意的是 如果test函数中x=1 这样的话会报错,test2中x = x+1 既是local variable,又是外部变量。在python中int float str是不可变类型,变的只是其引用。改成list可以解决这个问题\r\n\r\n```\r\nx = 1\r\nx += 1 #变了x的引用\r\n```\r\n\r\n\r\n\r\n\r\n\r\n在支持闭包的语言中,通常讲函数作为第一类对象(一等公民),即可以被当作参数传递、也可以作为函数返回值、绑定到变量名。"
},
{
"alpha_fraction": 0.7034700512886047,
"alphanum_fraction": 0.7034700512886047,
"avg_line_length": 9.666666984558105,
"blob_id": "8d04871d8a2e56a55b4df9f8fa5cd0f111fb76b7",
"content_id": "e806830ed5fb707fcf94ab0762fd3d7cb220a7c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 549,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 27,
"path": "/blog/jekyll.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "jekyll是一个简单的静态网页生成工具,不需要数据库支持。jekyll可以免费部署在github上,可以绑定自己的域名。\r\n\r\n\r\n\r\n_sass _variable.scss:\r\n\r\npic\r\n\r\n\r\n\r\n_posts:\r\n\r\nyear-month-day-title.md\r\n\r\n\r\n\r\nblog line:\r\n\r\n_config.yml\r\n\r\n\r\n\r\n_includes这里面的就是可以重复利用的文件。这个文件可以被其他的文件包含,重复利用。{% include file.ext %},就是引用file.ext的格式。\r\n\r\n_layouts这里存放的是模板文件。\r\n\r\n_site这个文件夹存放的是最终生成的文件。\r\n\r\n"
},
{
"alpha_fraction": 0.8070175647735596,
"alphanum_fraction": 0.8070175647735596,
"avg_line_length": 20.399999618530273,
"blob_id": "9dd19621c208056c470a23fe85d2ae11411a41b2",
"content_id": "42392a15e6f0e84c403b8dfe5f55dccf71ae2c6b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 224,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 5,
"path": "/computer_science_knowledge/database/sql.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### SQL\r\n\r\nsql与mysql的关系类似于shell与linux操作系统的关系,通过shell来操纵linux操作系统,用户通过sql来操纵mysql软件。\r\n\r\nmy是瑞典语的单词前缀,不代表我的这个意思\r\n\r\n"
},
{
"alpha_fraction": 0.48705190420150757,
"alphanum_fraction": 0.5182831883430481,
"avg_line_length": 28,
"blob_id": "d8fdabe9c5344ee3ae5f5611e9ae0a0102864bce",
"content_id": "aba5286edc97ffed533aeee0f4ff5678aab78d94",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 16772,
"license_type": "no_license",
"max_line_length": 803,
"num_lines": 556,
"path": "/leetcode_note/Google面经.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### 1. Given a `2-D matrix` containing only 1's or 0's. Find the number of sub-matrices containing only 0's.\r\n\r\nFor eg.,\r\n[[0, 1, 0], [1, 0, 0], [0, 0, 0]]\r\nAns => 15\r\n[[0]] => 7\r\n[[0, 0]] => 3\r\n[[0], [0]] => 3\r\n[[0, 0, 0]] => 1\r\n[[0], [0], [0]] => 1\r\n\r\n\r\n\r\n7 + 3 + 3 + 1 + 1 = 15\r\n\r\n```python\r\nclass Solution:\r\n def count(self, nums):\r\n n, m = len(nums), len(nums[0])\r\n dp = [[0 for i in range(m+1)]for j in range(n+1)]\r\n res = 0\r\n for i in range(1, n+1):\r\n for j in range(1, m+1):\r\n if nums[i-1][j-1] == 0:\r\n dp[i][j] = dp[i-1][j] + dp[i][j-1] + 1\r\n if dp[i][j-1] != 0:\r\n dp[i][j]-= dp[i-1][j-1]\r\n if dp[i-1][j] != 0:\r\n dp[i][j]-= dp[i-1][j-1]\r\n res += dp[i][j]\r\n return res\r\n```\r\n\r\n\r\n\r\n##### 2 Question on Job scheduling. Given a list of jobs (each with id, start time and duration) which are currently running. You have to write a program to check if a random job can be scheduled.\r\n**Current job list**- [(A, 1, 4), (B, 10, 3), (C, 6, 2)]\r\n\r\nNew job(D, 2, 3)- Cannot be scheduled because the job A would be running at that time.\r\n(E, 14, 6)- Can be scheduled as no other job is running during that duration.\r\n\r\n```python\r\nclass Solution:\r\n def canSchedule(self, lists, job):\r\n start_time, end_time = job[1], job[1] + job[2]\r\n for item in lists:\r\n if start_time >= item[2] or end_time <= item[1]:\r\n continue\r\n else:\r\n return False\r\n return True\r\n```\r\n\r\n**Round 2-**\r\nYou are given a n * n matrix with grid values of either 0 or 1. 0 means you **can** travel and 1 means you **cannot** travel through that grid. You are provided a starting coordinate(**start**) and an ending coordinate (**end**). Your code should return the shortest path from **start** to **end**. The catch is, you have some special power which lets you change the value of grids from 1 to 0, hence, making it accessable. But, This special power **can not** be used more than **once**.\r\n\r\n\r\n\r\n```python\r\nimport copy\r\nclass Solution:\r\n def accessable(self, grid, start, end):\r\n if not grid or len(grid) == 0: return\r\n n, m = len(grid), len(grid[0])\r\n visited, dp, dp2 = [[0 for i in range(m)] for j in range(n)], [[float(\"inf\") for i in range(m+1)] for j in range(n+1)], [[float(\"inf\") for i in range(m+1)] for j in range(n+1)]\r\n level, next_level = [start + [0]], []\r\n visited[start[0]][start[1]],dp[start[0]+1][start[1]+1], dp2[start[0]+1][start[1]+1] = 1, 0, 0\r\n\r\n dirs = [[0, 1], [0, -1], [1, 0], [-1, 0]]\r\n while level or next_level:\r\n while level:\r\n i, j, val = level.pop()\r\n for ii, jj in dirs:\r\n if 0<=i+ii<n and 0<=j+jj<m and grid[i+ii][j+jj] == 0 and visited[i+ii][j+jj] == 0:\r\n visited[i + ii][j + jj] = 1\r\n next_level.append([i+ii, j+jj, val + 1])\r\n dp[i+ii+1][j+jj+1] = min(dp[i+ii+1][j+jj+1], val + 1)\r\n level = copy.deepcopy(next_level)\r\n next_level = []\r\n\r\n for i in range(n):\r\n for j in range(m):\r\n if [i, j] == start:\r\n continue\r\n for ii, jj in dirs:\r\n if 0 <= i + ii < n and 0 <= j + jj < m:\r\n if grid[i][j] == 0:\r\n dp2[i+1][j+1] = min(dp2[i+1][j+1], dp2[i+ii+1][j+jj+1])\r\n else:\r\n dp2[i+1][j+1] = min(dp2[i+1][j+1], dp[i+ii+1][j+jj+1])\r\n dp2[i + 1][j + 1] += 1\r\n print(dp2)\r\n return dp2[end[0]+1][end[1]+1]\r\n\r\ns1 = Solution()\r\ngrid = [[0, 1, 0, 0], [0, 0, 1, 0], [1, 0, 0, 0], [1, 0, 0, 0]]\r\nstart, end = [0, 0], [1, 3]\r\nprint(s1.accessable(grid,start, end))\r\n```\r\n\r\n\r\n\r\n##### Given a char grid (`o` represents an empty cell and `x` represents a target object) and an API `getResponse` which would give you a response w.r.t. to your previous position. Write a program to find the object. You can move to any position.\r\n\r\n```\r\nenum Response {\r\n\tHOTTER, // Moving closer to target\r\n\tCOLDER, // Moving farther from target\r\n\tSAME, // Same distance from the target as your previous guess\r\n\tEXACT; // Reached destination\r\n}\r\n\r\n// Throws an error if 'row' or 'col' is out of bounds\r\npublic Response getResponse(int row, int col) {\r\n\t// black box\r\n}\r\n```\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput:\r\n[['o', 'o', 'o'],\r\n ['o', 'o', 'o'],\r\n ['x', 'o', 'o']]\r\n\r\nOutput: [2, 0]\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput:\r\n[['o', 'o', 'o', 'o', 'o'],\r\n ['o', 'o', 'o', 'o', 'o'],\r\n ['o', 'o', 'o', 'o', 'o'],\r\n ['o', 'o', 'o', 'o', 'o'],\r\n ['o', 'o', 'o', 'x', 'o'],\r\n ['o', 'o', 'o', 'o', 'o']]\r\n\r\nOutput: [4, 3]\r\n```\r\n\r\n```python\r\n def getResponse(self, row, col):\r\n target_row, target_col = 4, 3\r\n if row == target_row and col == target_col:\r\n return \"EXACT\"\r\n if abs(target_row - row) + abs(target_col - col) < abs(self.prev_row - target_row) + abs(self.prev_col - target_col):\r\n self.prev_row, self.prev_col = row, col\r\n return \"HOTTER\"\r\n elif abs(target_row - row) + abs(target_col - col) > abs(self.prev_row - target_row) + abs(self.prev_col - target_col):\r\n return \"COLDER\"\r\n else:\r\n return \"SAME\"\r\n\r\n def find_object(self, grid):\r\n if not grid or len(grid) == 0: return\r\n self.prev_row, self.prev_col = 0, 0\r\n n, m = len(grid), len(grid[0])\r\n left_row, right_row = 0, n - 1\r\n left_col, right_col = 0, m - 1\r\n while left_row < right_row:\r\n self.getResponse(left_row, left_col)\r\n s = self.getResponse(right_row, left_col)\r\n mid = int((left_row + right_row)/2)\r\n if s == \"HOTTER\":\r\n left_row = mid + 1\r\n elif s == \"HOTTER\":\r\n right_row = mid\r\n elif s == \"SAME\":\r\n left_row = mid\r\n break\r\n else:\r\n left_row = right_row\r\n break\r\n while left_col < right_col:\r\n self.getResponse(left_row, left_col)\r\n s = self.getResponse(left_row, right_col)\r\n mid = int((left_col + right_col)/2)\r\n if s == \"HOTTER\":\r\n left_col = mid + 1\r\n elif s == \"HOTTER\":\r\n right_col = mid\r\n elif s == \"SAME\":\r\n left_col = mid\r\n break\r\n else:\r\n left_col = right_col\r\n break\r\n return (left_row, left_col)\r\n\r\ns1 = Solution()\r\ngrid = [['o', 'o', 'o', 'o', 'o'],\r\n ['o', 'o', 'o', 'o', 'o'],\r\n ['o', 'o', 'o', 'o', 'o'],\r\n ['o', 'o', 'o', 'o', 'o'],\r\n ['o', 'o', 'o', 'x', 'o'],\r\n ['o', 'o', 'o', 'o', 'o']]\r\nprint(s1.find_object(grid))\r\n```\r\n\r\n先二分查找找row 再二分查找找col\r\n\r\n\r\n\r\n##### Given a binary 2D grid (each element can either be a `1` or a `0`). You have the ability to choose any element and flip its value. The only condition is that when you choose to flip any element at index `(r, c)`, the 4 neighbors of that element also get flipped. Find the minimum number of flips that you need to do in order to set all the elements in the matrix equal to `0`. If it's not possible, return `-1`.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput:\r\n[[0, 0, 0],\r\n [0, 0, 0],\r\n [0, 0, 0]]\r\n\r\nOutput: 0\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput:\r\n[[0, 1, 0],\r\n [1, 1, 1],\r\n [0, 1, 0]]\r\n\r\nOutput: 1\r\nExplanation: Flip (1, 1) to make the whole matrix consisting of only 0s.\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput:\r\n[[0, 1, 0],\r\n [1, 1, 0],\r\n [0, 1, 1]]\r\n\r\nOutput: 4\r\nExplanation:\r\n1. Flip (0, 0)\r\n[[1, 0, 0],\r\n [0, 1, 0],\r\n [0, 1, 1]]\r\n\r\n2. Flip (0, 1)\r\n[[0, 1, 1],\r\n [0, 0, 0],\r\n [0, 1, 1]]\r\n\r\n3. Flip (0, 2)\r\n[[0, 0, 0],\r\n [0, 0, 1],\r\n [0, 1, 1]]\r\n\r\n4. Flip (2, 2)\r\n[[0, 0, 0],\r\n [0, 0, 0],\r\n [0, 0, 0]]\r\n```\r\n\r\ntoo hard\r\n\r\n考虑用graph做 把grid中不同的情况视为一个个node\r\n\r\n从graph中表示全0的点开始找最短路径\r\n\r\n\r\n\r\n##### leetcode 894. All Possible Full Binary Trees\r\n\r\nA *full binary tree* is a binary tree where each node has exactly 0 or 2 children.\r\n\r\nReturn a list of all possible full binary trees with `N` nodes. Each element of the answer is the root node of one possible tree.\r\n\r\nEach `node` of each tree in the answer **must** have `node.val = 0`.\r\n\r\nYou may return the final list of trees in any order.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: 7\r\nOutput: [[0,0,0,null,null,0,0,null,null,0,0],[0,0,0,null,null,0,0,0,0],[0,0,0,0,0,0,0],[0,0,0,0,0,null,null,null,null,0,0],[0,0,0,0,0,null,null,0,0]]\r\nExplanation:\r\n```\r\n\r\n**Note:**\r\n\r\n- `1 <= N <= 20`\r\n\r\n```python\r\n# Definition for a binary tree node.\r\n# class TreeNode:\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.left = None\r\n# self.right = None\r\n\r\nclass Solution:\r\n def allPossibleFBT(self, N: int):\r\n nodes = []\r\n if N % 2 == 0:\r\n return []\r\n if N == 1: return [TreeNode(0)]\r\n for i in range(1, N - 1, 2):\r\n for left in self.allPossibleFBT(i):\r\n for right in self.allPossibleFBT(N - 1 - i):\r\n node = TreeNode(0)\r\n node.left = left\r\n node.right = right\r\n nodes.append(node)\r\n return nodes\r\n \r\n```\r\n\r\n\r\n\r\n##### Treap\r\n\r\nA binary tree has the binary search tree property (BST property) if, for every node, the keys in its left subtree are smaller than its own key, and the keys in its right subtree are larger than its own key. It has the heap property if, for every node, the keys of its children are all smaller than its own key. You are given a set of binary tree nodes `(i, j)` where each node contains an integer `i` and an integer `j`. No two `i` values are equal and no two `j` values are equal. We must assemble the nodes into a single binary tree where the `i` values obey the BST property and the `j` values obey the heap property. If you pay attention only to the second key in each node, the tree looks like a heap, and if you pay attention only to the first key in each node, it looks like a binary search tree.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [(1, 6), (3, 7), (2, 4)]\r\nOutput:\r\n\r\n\t\t(3, 7)\r\n\t\t/\r\n\t (1, 6)\r\n\t\t\\\r\n\t (2, 4)\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [(1, 4), (8, 5), (3, 6), (10, -1), (4, 7)]\r\nOutput:\r\n\r\n\t\t(4, 7)\r\n\t\t/ \\\r\n\t(3, 6) (8, 5)\r\n\t / \\\r\n (1, 4) (10, -1)\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def treap(self, nums):\r\n if not nums: return\r\n index, max = -1, -float(\"inf\")\r\n for i in range(len(nums)):\r\n if nums[i][1] > max:\r\n index, max = i, nums[i][1]\r\n node = TreapNode(nums[index][0], nums[index][1])\r\n nums.pop()\r\n left, right = [], []\r\n for x, y in nums:\r\n if x < node.i:\r\n left.append((x, y))\r\n else:\r\n right.append((x, y))\r\n node.left, node.right = self.treap(left), self.treap(right)\r\n return node\r\n```\r\n\r\n\r\n\r\n##### leetcode 1145 Binary Tree Coloring Game\r\n\r\nTwo players play a turn based game on a binary tree. We are given the `root` of this binary tree, and the number of nodes `n` in the tree. `n` is odd, and each node has a distinct value from `1` to `n`.\r\n\r\nInitially, the first player names a value `x` with `1 <= x <= n`, and the second player names a value `y` with `1 <= y <= n` and `y != x`. The first player colors the node with value `x` red, and the second player colors the node with value `y` blue.\r\n\r\nThen, the players take turns starting with the first player. In each turn, that player chooses a node of their color (red if player 1, blue if player 2) and colors an **uncolored** neighbor of the chosen node (either the left child, right child, or parent of the chosen node.)\r\n\r\nIf (and only if) a player cannot choose such a node in this way, they must pass their turn. If both players pass their turn, the game ends, and the winner is the player that colored more nodes.\r\n\r\nYou are the second player. If it is possible to choose such a `y` to ensure you win the game, return `true`. If it is not possible, return `false`.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: root = [1,2,3,4,5,6,7,8,9,10,11], n = 11, x = 3\r\nOutput: true\r\nExplanation: The second player can choose the node with value 2.\r\n```\r\n\r\n\r\n\r\n##### Most Booked Hotel Room\r\n\r\n\r\n\r\nGiven a hotel which has 10 floors `[0-9]` and each floor has 26 rooms `[A-Z]`. You are given a sequence of rooms, where `+` suggests room is booked, `-` room is freed. You have to find which room is booked maximum number of times.\r\n\r\nYou may assume that the list describe a correct sequence of bookings in chronological order; that is, only free rooms can be booked and only booked rooms can be freeed. All rooms are initially free. Note that this does not mean that all rooms have to be free at the end. In case, 2 rooms have been booked the same number of times, return the lexographically smaller room.\r\n\r\nYou may assume:\r\n\r\n- N (length of input) is an integer within the range [1, 600]\r\n- each element of array A is a string consisting of three characters: \"+\" or \"-\"; a digit \"0\"-\"9\"; and uppercase English letter \"A\" - \"Z\"\r\n- the sequence is correct. That is every booked room was previously free and every freed room was previously booked.\r\n\r\n**Example:**\r\n\r\n```\r\nInput: [\"+1A\", \"+3E\", \"-1A\", \"+4F\", \"+1A\", \"-3E\"]\r\nOutput: \"1A\"\r\nExplanation: 1A as it has been booked 2 times.\r\n```\r\n\r\n```python\r\nimport collections\r\nclass Solution:\r\n def most_booked(self, books):\r\n times = collections.defaultdict(int)\r\n for book in books:\r\n if book[0] == \"+\":\r\n times[book[1:]] += 1\r\n index, max = \"\", -float(\"inf\")\r\n for num, val in times.items():\r\n if val > max:\r\n index, max = num, val\r\n elif val == max:\r\n index = num\r\n return index\r\n```\r\n\r\n\r\n\r\n##### Maximum Time\r\n\r\nYou are given a string that represents time in the format `hh:mm`. Some of the digits are blank (represented by `?`). Fill in `?` such that the time represented by this string is the maximum possible. Maximum time: `23:59`, minimum time: `00:00`. You can assume that input string is always valid.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: \"?4:5?\"\r\nOutput: \"14:59\"\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: \"23:5?\"\r\nOutput: \"23:59\"\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: \"2?:22\"\r\nOutput: \"23:22\"\r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: \"0?:??\"\r\nOutput: \"09:59\"\r\n```\r\n\r\n**Example 5:**\r\n\r\n```\r\nInput: \"??:??\"\r\nOutput: \"23:59\"\r\n```\r\n\r\n\r\n\r\n```python\r\nclass Solution:\r\n def maximum_time(self, time):\r\n hour, minute = time[:2], time[3:]\r\n if hour == \"??\":\r\n hour = \"24\"\r\n elif hour[0] == \"?\":\r\n if int(hour[1]) < 4:\r\n hour = \"2\"+hour[1]\r\n else:\r\n hour = \"1\"+hour[1]\r\n elif hour[1] == \"?\":\r\n if int(hour[0]) < 2:\r\n hour = hour[0] + \"9\"\r\n else:\r\n hour = hour[0] + \"3\"\r\n if minute == \"??\":\r\n minute = \"59\"\r\n elif minute[0] == \"?\":\r\n minute = \"5\"+minute[1]\r\n elif minute[1] == \"?\":\r\n minute = minute[0] + \"9\"\r\n return hour + \":\" + minute\r\n```\r\n\r\n\r\n\r\n##### Ranking\r\n\r\nGiven a series of game results such as `xxxx beats yyyy`, output the final ranking.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [\"a beats b\", \"b beats c\", \"c beats d\"]\r\nOutput: [\"a\", \"b\", \"c\", \"d\"]\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [\"a beats b\", \"a beats c\"]\r\nOutput: [\"a\", \"b\", \"c\"] or [\"a\", \"c\", \"b\"]\r\n```\r\n\r\ntypical topological sort problem:\r\n\r\n\r\n\r\n```python\r\nimport collections\r\nclass Solution:\r\n def dfs(self, graph, stack, visited, node):\r\n visited[node] = 0\r\n for nei in graph[node]:\r\n if visited[nei] == 0:\r\n print(\"loop\")\r\n return\r\n elif visited[nei] == -1:\r\n self.dfs(graph, stack, visited, nei)\r\n visited[node] = 1\r\n stack.insert(0, node)\r\n return\r\n\r\n def Ranking(self, beats):\r\n nodes, graph = set(), collections.defaultdict(set)\r\n for beat in beats:\r\n chars = beat.split(\" beats \")\r\n a, b = chars[0], chars[1]\r\n graph[a].add(b)\r\n nodes.add(a)\r\n nodes.add(b)\r\n n = len(graph)\r\n stack, visited = [], {}\r\n for node in nodes:\r\n visited[node] = -1\r\n for node in nodes:\r\n if visited[node] == -1:\r\n self.dfs(graph, stack, visited, node)\r\n return stack\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.646766185760498,
"alphanum_fraction": 0.6567164063453674,
"avg_line_length": 9.941176414489746,
"blob_id": "7b7a4ba1215209519c78b3b20e9625236d4f5fc5",
"content_id": "6ff29ddd0b759e1e6dcab38433d11a6a28f7b2c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 283,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 17,
"path": "/URL.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### URL\r\n\r\nurl:统一资源定位符\r\n\r\nhttp://www.sohu.com/test/HXW\r\n\r\nhttp://表示资源类型,ftp://表示ftp服务器\r\n\r\nwww.sohu.com 表示host,也是site\r\n\r\n/test/HXW 表示访问path\r\n\r\ndomain:sohu.com\r\n\r\nanchor:表示页面中的跳转链接\r\n\r\npattern:[a-z],[0-9]"
},
{
"alpha_fraction": 0.6417489647865295,
"alphanum_fraction": 0.6798307299613953,
"avg_line_length": 14.534883499145508,
"blob_id": "ccf77f45e0c970571e93575f03dcc64a0c500b40",
"content_id": "3e9f193bb6b146aaac03b9aba057212e7cb041b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1373,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 43,
"path": "/python和c++的区别.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### python和c++区别\r\n\r\n##### 编译执行的过程\r\n\r\npython类似于java是一种解释性语言,c/c++则是编译性语言。\r\n\r\n使用c/c++语言时需要将源文件经过预处理、编译、汇编、链接等四个步骤转换为计算机使用的机器语言,形成可执行的二进制文件,运行该程序的时候将程序从硬盘载入内存中去并运行。\r\n\r\n对于python而言,不需要编译为二进制代码,直接从源代码运行程序,当我们在运行python文件的时候,python解释器将源代码转换为字节码(pyc文件),然后由python解释器来执行这些字节码。\r\n\r\n对于python解释语言,有下面几个特性:\r\n\r\n1.每次运行都需要转换为字节码,与编译性语言相比每次在运行时多出了编译和链接的过程。\r\n\r\n2.由于不用担心程序编译和链接的问题,开发的工作更轻松\r\n\r\n3.python代码与底层更远,python程序更易于平台移植。\r\n\r\n\r\n\r\npython中的for循环问题\r\n\r\npython中有时可以用向量化代替for循环,从而优化运行时间。\r\n\r\n```python\r\n>>> for i in range(10):\r\n... if i == 3:\r\n... i = i + 3\r\n... print ('i:', i)\r\n...\r\ni: 0\r\ni: 1\r\ni: 2\r\ni: 6\r\ni: 4\r\ni: 5\r\ni: 6\r\ni: 7\r\ni: 8\r\ni: 9\r\n```\r\n\r\npython中的for循环没有迭代索引这个概念,for循环相当于foreach循环,即 for n in [0,1,2,3,4,5,6,7,8,9]"
},
{
"alpha_fraction": 0.4252873659133911,
"alphanum_fraction": 0.4321839213371277,
"avg_line_length": 15.359999656677246,
"blob_id": "7411e9769501e8d5998966cd2599f590bbbeb470",
"content_id": "ae6c8cca767d2a0c22a423c101f0f830b8a74d0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1098,
"license_type": "no_license",
"max_line_length": 175,
"num_lines": 50,
"path": "/leetcode_note/STDIO.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Python 标准IO\r\n\r\npython提供了raw_input, input两个函数来从键盘中读取一行\r\n\r\n```python\r\nstr = input()\r\nstr = raw_input()\r\n```\r\ninput函数可以处理python表达式\r\n\r\n打开关闭文件:\r\n\r\n```\r\nfo = open(\"foo.txt\") fo.write( \"www.runoob.com!\\nVery good site!\\n\")\r\nfo.close() \r\n```\r\n\r\nread()函数可以从头读取n个字节的内容\r\n\r\n```\r\nstr = fo.read(10)\r\nprint \"读取的字符串是 : \", str\r\nfo.close()\r\n```\r\n\r\n以上实例输出结果:\r\n\r\n```\r\n读取的字符串是 : www.runoob\r\n```\r\n\r\n重命名删除文件\r\n\r\n```\r\nimport os\r\n \r\n# 重命名文件test1.txt到test2.txt。\r\nos.rename( \"test1.txt\", \"test2.txt\" )\r\n\r\nos.remove(file_name) #删除文件\r\n```\r\n\r\n对目录进行操作\r\n\r\n```\r\nos.mkdir(\"test\") #创建一个目录\r\nos.chdir(\"newdir\") #更换目录\r\nos.getcwd() #当前路径\r\nos.rmdir(\"dirname\") #删除目录\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.6603148579597473,
"alphanum_fraction": 0.6677713394165039,
"avg_line_length": 22.67346954345703,
"blob_id": "4cc2ab11913d1300b121580a0b3103c6683bc43e",
"content_id": "ec9de0fdebbd83805a9aaa606a400d3438d81c6b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1229,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 49,
"path": "/papers/BiNE Bipartite Network Embedding.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### BiNE: Bipartite Network Embedding\r\n\r\n##### Related work\r\n\r\nmatrix factorization methods and neural network-based methods\r\n\r\n**In MF methods**:\r\n\r\nSVD, kernel PCA, spectral embeddings\r\n\r\nmost MF methods drawbacks: 1.computationally expensive, 2. sensitive to the proximity method.\r\n\r\n**Neural network method**:\r\n\r\nDeepwalk and Node2vec extend the idea of Skip-gram to model homogeneous network.\r\n\r\nAdd 1st-order and 2nd-order proximities to embed node: LINE, SDNE, GraRep\r\n\r\n\r\n\r\nBINE Problem\r\n\r\n$G=(U,V,E)$ 其中U,V分别表示不同的两类vertices\r\n\r\n**Model**\r\n\r\njoint probability:\r\n\r\n$P(i,j)=\\frac{w_{i,j}}{\\sum_{e_{i,j}\\in E}w_{ij}}$, $w_{ij}$ is the weight of edge $e_{ij}$\r\n\r\n$\\widehat{P}(i,j)=\\frac{1}{+exp({-\\vec{u_i}^T\\vec{v_j})}}$ \r\n\r\nMinimize \r\n\r\n$O_1=KL(P||\\widehat{P})=\\sum_{e_{ij}\\in E} P(i,j) log(\\frac{P(i,j)}{\\widehat{P}(i,j)})$\r\n\r\n\r\n\r\n**Constructing Corpus of Vertex Sequence** \r\n\r\nIf directly preform random walks on the network, could fail.\r\n\r\nConsider performing random walks on two homogeneous networks that contain 2nd-order proximities between vertices of the same type.\r\n\r\nthe 2nd-order proximity between two vertices:\r\n\r\n$w_{ij}^U=\\sum_{k\\in V}w_{ik}w_{jk}$\r\n\r\n$w_{ij}^V=\\sum_{k\\in U}w_{ik}w_{jk}$"
},
{
"alpha_fraction": 0.5020653605461121,
"alphanum_fraction": 0.533931314945221,
"avg_line_length": 24.12952995300293,
"blob_id": "e7a5ae5223e40e342ab1040c4f95652176135ef6",
"content_id": "c257a533b5f49f2e97ebd189e8128be3ce3fd078",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 35920,
"license_type": "no_license",
"max_line_length": 479,
"num_lines": 1297,
"path": "/leetcode_note/string.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "#### String\r\n\r\n字符串的匹配 string s, string t\r\n\r\n其中t是s的字串 简单匹配算法需要O(mn)\r\n\r\n例如s=“ababcabcacbab”,t=\"abcac\"\r\n\r\n\r\n\r\n```\r\n第一次匹配\r\na b a b c a b c a c b a b \r\na b c 匹配不对\r\n第二次匹配\r\na b a b c a b c a c b a b \r\n a 匹配不对\r\n第三次匹配\r\na b a b c a b c a c b a b \r\n a b c a c 匹配不对\r\n第四次匹配\r\na b a b c a b c a c b a b \r\n a 匹配不对\r\n第五次匹配\r\na b a b c a b c a c b a b \r\n a 匹配不对\r\n第六次匹配\r\na b a b c a b c a c b a b \r\n a b c a c\r\n```\r\n\r\n\r\n\r\n改进的模式匹配算法---KMP算法\r\n\r\n字符串的前串 后串 部分匹配值\r\n\r\n以ababa为例\r\n\r\n 前串 后串 部分匹配值\r\n\r\n'a' ‘’ ‘’ 0\r\n\r\n‘ab' 'a' 'b' 0\r\n\r\n’aba' 'a,ab' 'a,ba' 1\r\n\r\n’abab' 'a,ab,aba' 'b,ab,bab' 2\r\n\r\n’ababa' 'a,ab,aba.abab' 'a,ba,aba,baba' 3\r\n\r\n\r\n\r\n回到t=abcac\r\n\r\n部分匹配数为0 0 0 1 0\r\n\r\n使用next数组进行匹配\r\n\r\n```\r\n第一次匹配\r\na b a b c a b c a c b a b \r\na b c 匹配不对\r\n向前移动位数=已匹配字符数-对应的部分匹配值=2-0=2\r\n第二次匹配\r\na b a b c a b c a c b a b \r\n a b c a c 配不对\r\n向前移动位数=已匹配字符数-对应的部分匹配值=4-1=3\r\n第三次匹配\r\na b a b c a b c a c b a b \r\n a b c a c\r\n```\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n字符串题目 (LeetCode 459)\r\n\r\n字符串题目 (LeetCode 468)\r\n\r\nthis file does not include string problem which can be solved by DP\r\n\r\n##### leetcode 3 Longest Substring Without Repeating Characters\r\n\r\n- Given a string, find the length of the **longest substring** without repeating characters.\r\n\r\n```\r\nInput: \"abcabcbb\"\r\nOutput: 3 \r\nExplanation: The answer is \"abc\", with the length of 3. \r\nInput: \"bbbbb\"\r\nOutput: 1\r\nExplanation: The answer is \"b\", with the length of 1.\r\nInput: \"pwwkew\"\r\nOutput: 3\r\nExplanation: The answer is \"wke\", with the length of 3. \r\nNote that the answer must be a substring, \"pwke\" is a subsequence and not a substring. \r\n```\r\n\r\n* Mysolution:\r\n\r\n ```python\r\n def lengthOfLongestSubstring(s):\r\n start = maxLength = 0\r\n usedChar = {}\r\n for i in range(len(s)):\r\n if s[i] in usedChar and start <= usedChar[s[i]]:\r\n start = usedChar[s[i]] + 1\r\n else:\r\n maxLength = max(maxLength, i - start + 1)\r\n usedChar[s[i]] = i\r\n return maxLength\r\n ```\r\n\r\n O(N) 找到maxlen\r\n\r\n start从下标为0开始,用hash记录出现的字符的位置,如果s[i]出现过并且出现的位置usedChar[s[i]]>=start,则这一段结束,start=usedChar[s[i]]+1,即使更新usedChar[s[i]]\r\n\r\n\r\n\r\n##### leetcode 6 ZigZag Conversion\r\n\r\n* The string `\"PAYPALISHIRING\"` is written in a zigzag pattern on a given number of rows like this: (you may want to display this pattern in a fixed font for better legibility)\r\n\r\n ```python\r\n P A H N\r\n A P L S I I G\r\n Y I R\r\n ```\r\n\r\n And then read line by line: `\"PAHNAPLSIIGYIR\"`\r\n\r\n Write the code that will take a string and make this conversion given a number of rows:\r\n\r\n ```\r\n string convert(string s, int numRows);\r\n ```\r\n\r\n```\r\nInput: s = \"PAYPALISHIRING\", numRows = 3\r\nOutput: \"PAHNAPLSIIGYIR\"\r\n\r\nInput: s = \"PAYPALISHIRING\", numRows = 4\r\nOutput: \"PINALSIGYAHRPI\"\r\nExplanation:\r\n\r\nP I N\r\nA L S I G\r\nY A H R\r\nP I\r\n```\r\n\r\n\r\n\r\nMysolution:\r\n\r\n```python\r\nfrom collections import defaultdict\r\nclass Solution:\r\n def convert(self, s, numRows):\r\n if len(s)<=1 or numRows<=1:\r\n return s\r\n n=2*numRows-2\r\n dict1=defaultdict(list)\r\n for i in range(len(s)):\r\n j=i%n\r\n if j<numRows:\r\n dict1[j].append(s[i])\r\n else:\r\n j-=numRows\r\n dict1[numRows-2-j].append(s[i])\r\n string=\"\"\r\n for i in range(numRows):\r\n for char in dict1[i]:\r\n string+=char\r\n return string\r\n```\r\n\r\n找规律,把每一行都看作一个list 把对应的字符保存进去\r\n\r\n\r\n\r\n##### leetcode 7 Reverse Integer\r\n\r\n* Given a 32-bit signed integer, reverse digits of an integer\r\n\r\n ```\r\n Input: 123\r\n Output: 321\r\n Input: -123\r\n Output: -321\r\n Input: 120\r\n Output: 21\r\n ```\r\n\r\n```python\r\nclass Solution:\r\n def reverse(self,x):\r\n if x<0:\r\n y=-int(str(-x)[::-1])\r\n else:\r\n y=int(str(x)[::-1])\r\n if y<-2147483648 or y> 2147483648: return 0\r\n return y\r\n```\r\n\r\n考察reverse,easy\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 12 Integer to Roman\r\n\r\n* Roman numerals are represented by seven different symbols: `I`, `V`, `X`, `L`, `C`, `D` and `M`.\r\n\r\n* For example, two is written as `II` in Roman numeral, just two one's added together. Twelve is written as, `XII`, which is simply `X` + `II`. The number twenty seven is written as `XXVII`, which is `XX` + `V` + `II`.\r\n\r\n Roman numerals are usually written largest to smallest from left to right. However, the numeral for four is not `IIII`. Instead, the number four is written as `IV`. Because the one is before the five we subtract it making four. The same principle applies to the number nine, which is written as `IX`. There are six instances where subtraction is used:\r\n\r\n - `I` can be placed before `V` (5) and `X` (10) to make 4 and 9. \r\n - `X` can be placed before `L` (50) and `C` (100) to make 40 and 90. \r\n - `C` can be placed before `D` (500) and `M` (1000) to make 400 and 900.\r\n\r\n Given an integer, convert it to a roman numeral. Input is guaranteed to be within the range from 1 to 3999.\r\n\r\n ```\r\n Symbol Value\r\n I 1\r\n V 5\r\n X 10\r\n L 50\r\n C 100\r\n D 500\r\n M 1000\r\n ```\r\n\r\n ```\r\n Input: 3\r\n Output: \"III\"\r\n \r\n Input: 4\r\n Output: \"IV\"\r\n \r\n Input: 9\r\n Output: \"IX\"\r\n \r\n Input: 58\r\n Output: \"LVIII\"\r\n Explanation: L = 50, V = 5, III = 3.\r\n \r\n Input: 1994\r\n Output: \"MCMXCIV\"\r\n Explanation: M = 1000, CM = 900, XC = 90 and IV = 4.\r\n ```\r\n\r\n* Mysolution:\r\n\r\n ```python\r\n class Solution:\r\n def intToRoman(self, num):\r\n #1000\r\n n=len(str(num))\r\n str1=\"\"\r\n number_1000=number_100=number_10=number_1=0\r\n if n==4:\r\n number_1000=int(num/1000)\r\n str1+=\"M\"*number_1000\r\n if n>=3:\r\n number_100=int((num-1000*number_1000)/100)\r\n if number_100==9:\r\n str1+=\"CM\"\r\n elif number_100>=5:\r\n str1+=\"D\"\r\n str1+=\"C\"*(number_100-5)\r\n elif number_100==4:\r\n str1+=\"CD\"\r\n else:\r\n str1+=\"C\"*number_100\r\n if n>=2:\r\n number_10 = int((num - 1000 * number_1000-100*number_100) / 10)\r\n if number_10==9:\r\n str1+=\"XC\"\r\n elif number_10>=5:\r\n str1+=\"L\"\r\n str1+=\"X\"*(number_10-5)\r\n elif number_10==4:\r\n str1+=\"XL\"\r\n else:\r\n str1+=\"X\"*number_10\r\n number_1=num - 1000 * number_1000-100*number_100-10*number_10\r\n if number_1 == 9:\r\n str1 += \"IX\"\r\n elif number_1 >= 5:\r\n str1 += \"V\"\r\n str1 += \"I\" * (number_1 - 5)\r\n elif number_1 == 4:\r\n str1 += \"IV\"\r\n else:\r\n str1 += \"I\" * number_1\r\n return str1\r\n \r\n ```\r\n\r\n这是一道考察分情况讨论的问题,首先看有几位\r\n\r\n对于每一位首先判断是否>=5,接着看是否==4?\r\n\r\n\r\n\r\n##### leetcode 14 Longest Common Prefix\r\n\r\n* Write a function to find the longest common prefix string amongst an array of strings.\r\n\r\n If there is no common prefix, return an empty string `\"\"`.\r\n\r\n ```\r\n Input: [\"flower\",\"flow\",\"flight\"]\r\n Output: \"fl\"\r\n \r\n Input: [\"dog\",\"racecar\",\"car\"]\r\n Output: \"\"\r\n Explanation: There is no common prefix among the input strings.\r\n ```\r\n\r\n\r\n* Mysolution:\r\n\r\n ```python\r\n class Solution:\r\n def longestCommonPrefix(self,strs):\r\n n,i = len(strs),0\r\n if n == 0:\r\n return \"\"\r\n if n==1:\r\n return strs[0]\r\n min_len= len(min(strs,key=len))\r\n for i in range(min_len):\r\n char=strs[0][i]\r\n for j in range(1,len(strs),1):\r\n if char!=strs[j][i]:\r\n return strs[0][:i]\r\n return strs[0][:min_len]\r\n ```\r\n\r\n找到nums中长度最短的string\r\n\r\n然后从index0 开始对每个string上index的元素进行比较,如果不同则返回,如果一直都相同则返回strs[0,:min_len]\r\n\r\n\r\n\r\n##### leetcode 17 Letter Combinations of a Phone Number\r\n\r\n* Given a string containing digits from `2-9` inclusive, return all possible letter combinations that the number could represent.\r\n\r\n A mapping of digit to letters (just like on the telephone buttons) is given below. Note that 1 does not map to any letters.\r\n\r\n \r\n\r\n ```\r\n Input: \"23\"\r\n Output: [\"ad\", \"ae\", \"af\", \"bd\", \"be\", \"bf\", \"cd\", \"ce\", \"cf\"].\r\n ```\r\n\r\n* Solutions\r\n\r\n ```python\r\n class Solution:\r\n def letterCombinations(self,digits):\r\n if len(digits)==0:\r\n return []\r\n dict={'2':'abc','3':'def','4':'ghi','5':'jkl','6':'mno','7':'pqrs','8':'tuv','9':'wxyz'}\r\n return [\"\".join(s) for s in itertools.product(*[dict[dig] for dig in digits])]\r\n ```\r\n\r\n ```\r\n import itertools\r\n itertools.product()表示求笛卡尔积\r\n list1 = ['a', 'b']\r\n list2 = ['c', 'd']\r\n for i in itertools.product(list1, list2):\r\n print i\r\n ('a', 'c')\r\n ('a', 'd')\r\n ('b', 'c')\r\n ('b', 'd')\r\n 但是如果不确定有几个list,则可以使用*解包\r\n *[dict[dig] for dig in digits] 这一步相当于把[]中的多个list都解了出来\r\n 下一步使用itertools.product(),得到\r\n ('a', 'c')\r\n ('a', 'd')\r\n ('b', 'c')\r\n ('b', 'd')\r\n 使用\"\".join(s)将这些字母串起来\r\n ```\r\n\r\n 递归1:\r\n\r\n ```python\r\n class Solution:\r\n def letterCombinations(self,digits):\r\n def comb(temp,digits):\r\n if len(digits)==0:\r\n self.nums.append(temp)\r\n return\r\n for i in range(len(self.dict1[digits[0]])):\r\n comb(temp+self.dict1[digits[0]][i],digits[1:])\r\n return\r\n if len(digits)==0:\r\n return []\r\n self.nums,temp=[],\"\"\r\n self.dict1={'2':'abc','3':'def','4':'ghi','5':'jkl','6':'mno','7':'pqrs','8':'tuv','9':'wxyz'}\r\n comb(temp,digits)\r\n return self.nums\r\n ```\r\n\r\n 递归2\r\n\r\n ```python\r\n class Solution:\r\n def letterCombinations(self,digits):\r\n def comb(temp,digits):\r\n if len(digits)==0:\r\n self.nums.append(temp)\r\n return\r\n for i in range(len(self.dict1[digits[0]])):\r\n temp+=self.dict1[digits[0]][i]\r\n comb(temp,digits[1:])\r\n temp=temp[:-1]\r\n return\r\n if len(digits)==0:\r\n return []\r\n self.nums,temp=[],\"\"\r\n self.dict1={'2':'abc','3':'def','4':'ghi','5':'jkl','6':'mno','7':'pqrs','8':'tuv','9':'wxyz'}\r\n comb(temp,digits)\r\n return self.nums\r\n ```\r\n\r\n 注意两种递归方法的不同,即如果使用temp一个字符放进去之后要拿出来\r\n\r\n\r\n\r\n##### leetcode 49 Group Anagrams\r\n\r\n* Given an array of strings, group anagrams together.\r\n\r\n\r\n```\r\nInput: [\"eat\", \"tea\", \"tan\", \"ate\", \"nat\", \"bat\"],\r\nOutput:\r\n[\r\n [\"ate\",\"eat\",\"tea\"],\r\n [\"nat\",\"tan\"],\r\n [\"bat\"]\r\n]\r\n```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution:\r\n def groupAnagrams(self, strs):\r\n sorted_str,dict1,result=[],{},[]\r\n for i in range(len(strs)):\r\n a=list(strs[i])\r\n a.sort()\r\n sorted_str.append(\"\".join(a))\r\n for j in range(len(sorted_str)):\r\n if sorted_str[j] not in dict1:\r\n dict1[sorted_str[j]]=[]\r\n dict1[sorted_str[j]].append(strs[j])\r\n for key in dict1:\r\n result.append(dict1[key])\r\n return result\r\n```\r\n\r\n先将每个str按照字符的顺序重新排列好\r\n\r\nsorted_str: ['aet', 'aet', 'ant', 'aet', 'ant', 'abt']\r\n\r\n\r\n\r\n##### leetcode 76 Minimum Window Substring\r\n\r\n* Given a string S and a string T, find the minimum window in S which will contain all the characters in T in complexity O(n).\r\n\r\n```\r\nInput: S = \"ADOBECODEBANC\", T = \"ABC\"\r\nOutput: \"BANC\"\r\n```\r\n\r\n**Note:**\r\n\r\n- If there is no such window in S that covers all characters in T, return the empty string `\"\"`.\r\n- If there is such window, you are guaranteed that there will always be only one unique minimum window in S.\r\n\r\n```c++\r\nstring minWindow(string s, string t) {\r\n vector<int> map(128,0);\r\n for(auto c: t) map[c]++;\r\n int counter=t.size(), begin=0, end=0, d=INT_MAX, head=0;\r\n while(end<s.size()){\r\n if(map[s[end++]]-->0) counter--; //in t\r\n while(counter==0){ //valid\r\n if(end-begin<d) d=end-(head=begin);\r\n if(map[s[begin++]]++==0) counter++; //make it invalid\r\n } \r\n }\r\n return d==INT_MAX? \"\":s.substr(head, d);\r\n }\r\n```\r\n\r\n每当扫过一个map中map[s[i]]>0的字符时,count-=1 表示距离目标近了一步\r\n\r\n当count==0 开始缩start,找到最小长度\r\n\r\n//template\r\n\r\n```c++\r\nint findSubstring(string s){\r\n vector<int> map(128,0);\r\n int counter; // check whether the substring is valid\r\n int begin=0, end=0; //two pointers, one point to tail and one head\r\n int d; //the length of substring\r\n\r\n for() { /* initialize the hash map here */ }\r\n\r\n while(end<s.size()){\r\n\r\n if(map[s[end++]]-- ?){ /* modify counter here */ }\r\n\r\n while(/* counter condition */){ \r\n \r\n /* update d here if finding minimum*/\r\n\r\n //increase begin to make it invalid/valid again\r\n \r\n if(map[s[begin++]]++ ?){ /*modify counter here*/ }\r\n } \r\n\r\n /* update d here if finding maximum*/\r\n }\r\n return d;\r\n }\r\n```\r\n\r\n\r\n\r\n##### leetcode 186 Reverse Words in a String II\r\n\r\nGiven an input string , reverse the string word by word. \r\n\r\n**Example:**\r\n\r\n```\r\nInput: [\"t\",\"h\",\"e\",\" \",\"s\",\"k\",\"y\",\" \",\"i\",\"s\",\" \",\"b\",\"l\",\"u\",\"e\"]\r\nOutput: [\"b\",\"l\",\"u\",\"e\",\" \",\"i\",\"s\",\" \",\"s\",\"k\",\"y\",\" \",\"t\",\"h\",\"e\"]\r\n```\r\n\r\n**Note:** \r\n\r\n- A word is defined as a sequence of non-space characters.\r\n- The input string does not contain leading or trailing spaces.\r\n- The words are always separated by a single space.\r\n\r\n**Follow up:** Could you do it *in-place* without allocating extra space?\r\n\r\n```python\r\nclass Solution:\r\n def reverseWords(self, s):\r\n \"\"\"\r\n Do not return anything, modify s in-place instead.\r\n \"\"\"\r\n words, temp = [], []\r\n for item in s:\r\n if item == \" \":\r\n words.append(temp)\r\n temp = []\r\n else:\r\n temp.append(item)\r\n if len(temp): words.append(temp)\r\n start = 0\r\n for word in words[::-1]:\r\n s[start:start+len(word)] = word\r\n if start+len(word)<len(s):\r\n s[start+len(word)] = \" \"\r\n start += len(word) + 1\r\n return\r\n```\r\n\r\nreverse word\r\n\r\n\r\n\r\n##### leetcode 438 Find All Anagrams in a String\r\n\r\n* Given a string **s** and a **non-empty** string **p**, find all the start indices of **p**'s anagrams in **s**.\r\n\r\n Strings consists of lowercase English letters only and the length of both strings **s** and **p** will not be larger than 20,100.\r\n\r\n The order of output does not matter.\r\n\r\n```\r\nInput:\r\ns: \"cbaebabacd\" p: \"abc\"\r\n\r\nOutput:\r\n[0, 6]\r\n\r\nExplanation:\r\nThe substring with start index = 0 is \"cba\", which is an anagram of \"abc\".\r\nThe substring with start index = 6 is \"bac\", which is an anagram of \"abc\".\r\n\r\nInput:\r\ns: \"abab\" p: \"ab\"\r\n\r\nOutput:\r\n[0, 1, 2]\r\n\r\nExplanation:\r\nThe substring with start index = 0 is \"ab\", which is an anagram of \"ab\".\r\nThe substring with start index = 1 is \"ba\", which is an anagram of \"ab\".\r\nThe substring with start index = 2 is \"ab\", which is an anagram of \"ab\".\r\n```\r\n\r\n\r\n\r\n```python\r\nimport collections\r\nclass Solution(object):\r\n def findAnagrams(self, s, p):\r\n res = []\r\n length = len(p)\r\n dic_p = collections.Counter(p)\r\n dic_s = collections.Counter(s[:length])\r\n prev = dic_p == dic_s\r\n if prev:\r\n res.append(0)\r\n for i in range(1,len(s)-length+1):\r\n if s[i-1] == s[i+length-1]:\r\n if prev:\r\n res.append(i)\r\n else:\r\n old_char = s[i-1]\r\n dic_s[old_char] -= 1\r\n if dic_s[old_char] == 0:\r\n del dic_s[old_char]\r\n new_char = s[i+length-1]\r\n if new_char in dic_s:\r\n dic_s[new_char] += 1\r\n else:\r\n dic_s[new_char] = 1\r\n prev = dic_s == dic_p\r\n if prev:\r\n res.append(i)\r\n return res\r\n```\r\n\r\n\r\n\r\n两个dict直接比较是否相同\r\n\r\n```python\r\nclass Solution:\r\n def findAnagrams(self, s: str, p: str) -> List[int]:\r\n c, res, temp = collections.Counter(p), [], collections.Counter(s[:len(p)])\r\n if c == temp: res.append(0)\r\n for i in range(len(p), len(s)):\r\n if s[i] not in temp:\r\n temp[s[i]] = 1\r\n else:\r\n temp[s[i]] += 1\r\n if temp[s[i-len(p)]] == 1:\r\n temp.pop(s[i-len(p)])\r\n else:\r\n temp[s[i-len(p)]] -= 1\r\n if c == temp: res.append(i-len(p)+1)\r\n return res\r\n```\r\n\r\n注意用pop弹出键值对,如果不弹出则temp和c不会视为相等\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 459 Repeated Substring Pattern\r\n\r\nGiven a non-empty string check if it can be constructed by taking a substring of it and appending multiple copies of the substring together. You may assume the given string consists of lowercase English letters only and its length will not exceed 10000.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: \"abab\"\r\nOutput: True\r\nExplanation: It's the substring \"ab\" twice.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: \"aba\"\r\nOutput: False\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: \"abcabcabcabc\"\r\nOutput: True\r\nExplanation: It's the substring \"abc\" four times. (And the substring \"abcabc\" twice.)\r\n```\r\n\r\n```python\r\nclass Solution(object):\r\n def repeatedSubstringPattern(self, s):\r\n \"\"\"\r\n :type s: str\r\n :rtype: bool\r\n \"\"\"\r\n for i in range(1,int(len(s)/2)+1):\r\n if len(s)%i==0:\r\n x=s[:i]\r\n index=0\r\n for j in range(0,len(s),i):\r\n if x!=s[j:j+i]:\r\n index=1\r\n break\r\n if index==0:\r\n return True\r\n return False\r\n```\r\n\r\n显然这个题长度为多少都有可能,不适用于二分法因此,从1-len/2长度一个一个试过去\r\n\r\n\r\n\r\n##### leetcode 468 Validate IP Address\r\n\r\nWrite a function to check whether an input string is a valid IPv4 address or IPv6 address or neither.\r\n\r\n**IPv4** addresses are canonically represented in dot-decimal notation, which consists of four decimal numbers, each ranging from 0 to 255, separated by dots (\".\"), e.g.,`172.16.254.1`;\r\n\r\nBesides, leading zeros in the IPv4 is invalid. For example, the address `172.16.254.01` is invalid.\r\n\r\n**IPv6** addresses are represented as eight groups of four hexadecimal digits, each group representing 16 bits. The groups are separated by colons (\":\"). For example, the address `2001:0db8:85a3:0000:0000:8a2e:0370:7334` is a valid one. Also, we could omit some leading zeros among four hexadecimal digits and some low-case characters in the address to upper-case ones, so `2001:db8:85a3:0:0:8A2E:0370:7334` is also a valid IPv6 address(Omit leading zeros and using upper cases).\r\n\r\nHowever, we don't replace a consecutive group of zero value with a single empty group using two consecutive colons (::) to pursue simplicity. For example, `2001:0db8:85a3::8A2E:0370:7334` is an invalid IPv6 address.\r\n\r\nBesides, extra leading zeros in the IPv6 is also invalid. For example, the address `02001:0db8:85a3:0000:0000:8a2e:0370:7334` is invalid.\r\n\r\n**Note:** You may assume there is no extra space or special characters in the input string.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: \"172.16.254.1\"\r\n\r\nOutput: \"IPv4\"\r\n\r\nExplanation: This is a valid IPv4 address, return \"IPv4\".\r\n```\r\n\r\n\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: \"2001:0db8:85a3:0:0:8A2E:0370:7334\"\r\n\r\nOutput: \"IPv6\"\r\n\r\nExplanation: This is a valid IPv6 address, return \"IPv6\".\r\n```\r\n\r\n\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: \"256.256.256.256\"\r\n\r\nOutput: \"Neither\"\r\n\r\nExplanation: This is neither a IPv4 address nor a IPv6 address.\r\n```\r\n\r\n```python\r\ndef validIPAddress(self, IP):\r\n \r\n def isIPv4(s):\r\n try: return str(int(s)) == s and 0 <= int(s) <= 255\r\n except: return False\r\n \r\n def isIPv6(s):\r\n if len(s) > 4: return False\r\n try: return int(s, 16) >= 0 and s[0] != '-'\r\n except: return False\r\n\r\n if IP.count(\".\") == 3 and all(isIPv4(i) for i in IP.split(\".\")): \r\n return \"IPv4\"\r\n if IP.count(\":\") == 7 and all(isIPv6(i) for i in IP.split(\":\")): \r\n return \"IPv6\"\r\n return \"Neither\"\r\n```\r\n\r\n\r\n\r\n##### leetcode 647 Palindromic Substrings\r\n\r\n* Given a string, your task is to count how many palindromic substrings in this string.\r\n\r\n The substrings with different start indexes or end indexes are counted as different substrings even they consist of same characters.\r\n\r\n```\r\nInput: \"abc\"\r\nOutput: 3\r\nExplanation: Three palindromic strings: \"a\", \"b\", \"c\".\r\n\r\nInput: \"aaa\"\r\nOutput: 6\r\nExplanation: Six palindromic strings: \"a\", \"a\", \"a\", \"aa\", \"aa\", \"aaa\".\r\n```\r\n\r\n**Note:**\r\n\r\n1. The input string length won't exceed 1000.\r\n\r\n```python\r\nclass Solution(object):\r\n def countSubstrings(self, s):\r\n \"\"\"\r\n :type s: str\r\n :rtype: int\r\n \"\"\"\r\n n=len(s)\r\n num=0\r\n for center in range(n):\r\n length=0\r\n while center-length>=0 and center+length<n:\r\n if s[center-length]==s[center+length]:\r\n num+=1\r\n else:\r\n break\r\n length+=1\r\n if center<n-1 and s[center]==s[center+1]:\r\n length2=0\r\n while center-length2>=0 and center+1+length2<n:\r\n if s[center-length2]==s[center+1+length2]:\r\n num+=1\r\n else:\r\n break\r\n length2+=1\r\n return num\r\n```\r\n\r\n1. 该方法遍历string,时间复杂度O(N2),考虑了palid长度为奇数与偶数两种情况\r\n\r\nOther ways:\r\nDP:\r\n\r\n```python\r\nclass Solution:\r\n # DP solution\r\n # countSubstrings(s[:i]) = countSubstrings(s[:i-1]) + \r\n # all palindromic strings in s[:i] containing s[i]\r\n # Time Complexity = O(n^2)\r\n # Space Complexity = O(n)\r\n def countSubstrings(self, s):\r\n \"\"\"\r\n :type s: str\r\n :rtype: int\r\n \"\"\"\r\n dp = [1]\r\n for i in range(1, len(s)):\r\n count = 0\r\n for j in range(i+1):\r\n substring = s[j : i+1]\r\n if substring == substring[::-1]:##判断substring是否palind\r\n count += 1\r\n dp.append(count + dp[i-1])\r\n return dp[-1]\r\n```\r\n\r\n```\r\ncountSubstrings(s[:i]) = countSubstrings(s[:i-1]) + all palindromic strings in s[:i] containing s[i]\r\n```\r\n\r\n\r\n\r\nManacher's algorithm\r\n\r\n```python\r\ndef ManacherAlgm(self, s):\r\n # Transform S into T.\r\n # For example, S = \"abba\", T = \"^#a#b#b#a#$\".\r\n # ^ and $ signs are sentinels appended to each end to avoid bounds checking\r\n T = '#'.join('^{}$'.format(s))\r\n n = len(T)\r\n P = [0] * n\r\n C = R = 0\r\n for i in range (1, n-1):\r\n # (R > i) and min(R - i, P[2*C - i]) considering Case1 and Case2\r\n P[i] = (R > i) and min(R - i, P[2*C - i])\r\n # Attempt to expand palindrome centered at i\r\n while T[i + 1 + P[i]] == T[i - 1 - P[i]]:\r\n P[i] += 1\r\n\r\n # If palindrome centered at i expand past R,\r\n # adjust center based on expanded palindrome.\r\n if i + P[i] > R:\r\n C, R = i, i + P[i]\r\n return (sum(P) + len(s)) // 2\r\n```\r\n\r\n使用“#”是为了不考虑palind string是奇数还是偶数的情况\r\n\r\nC表示center,R表示在此center下覆盖的最右端,半径为R-C\r\n\r\n\r\n\r\nP数组表示每个点作为中心时能向外扩张多少长度(保持palind)\r\n\r\nsum(P)+len(s) len(s)表示不扩张,自己长度为1 算palind的情况\r\n\r\n除以2是因为有“#”多算了一倍\r\n\r\n\r\n\r\n之所以该算法的复杂度为O(N)\r\n\r\n在于 P[i] = (R > i) and min(R - i, P[2*C - i]) 如果符合R>i 则P[i]=min(R-i,P[2C-i])\r\n\r\nP[2C-i]是P[i]关于P[C]之中心对称点\r\n\r\n因为在R之内,所以P[i]至少是P[2C-i] 但是这个范围不能出了R,如果出了R则 这个center周围的对称效果就没了 需要重新计算\r\n\r\n\r\n\r\n##### leetcode 771 Jewels and Stones\r\n\r\n* You're given strings `J` representing the types of stones that are jewels, and `S` representing the stones you have. Each character in `S` is a type of stone you have. You want to know how many of the stones you have are also jewels.\r\n\r\n The letters in `J` are guaranteed distinct, and all characters in `J` and `S` are letters. Letters are case sensitive, so `\"a\"` is considered a different type of stone from `\"A\"`.\r\n\r\n\r\n```\r\nInput: J = \"aA\", S = \"aAAbbbb\"\r\nOutput: 3\r\n\r\nInput: J = \"z\", S = \"ZZ\"\r\nOutput: 0\r\n```\r\n\r\n```python\r\nclass Solution(object):\r\n def numJewelsInStones(self, J, S):\r\n \"\"\"\r\n :type J: str\r\n :type S: str\r\n :rtype: int\r\n \"\"\"\r\n jew=set(J)\r\n nums,count=list(S),0\r\n for i in range(len(nums)):\r\n if S[i] in jew:\r\n count+=1\r\n return count\r\n```\r\n\r\n使用set 使得S[i] in jew在O(1)级别实现\r\n\r\n```python\r\nclass Solution(object):\r\n def numJewelsInStones(self, J, S):\r\n \"\"\"\r\n :type J: str\r\n :type S: str\r\n :rtype: int\r\n \"\"\"\r\n \r\n tot_jewels = 0\r\n for j in J:\r\n \r\n tot_jewels += S.count(j)\r\n \r\n return tot_jewels\r\n```\r\n\r\n该方法更快\r\n\r\n\r\n\r\n##### leetcode 856 Score of Parentheses\r\n\r\n* Given a balanced parentheses string `S`, compute the score of the string based on the following rule:\r\n - `()` has score 1\r\n - `AB` has score `A + B`, where A and B are balanced parentheses strings.\r\n - `(A)` has score `2 * A`, where A is a balanced parentheses string.\r\n\r\n```\r\nInput: \"()\"\r\nOutput: 1\r\n\r\nInput: \"(())\"\r\nOutput: 2\r\n\r\nInput: \"()()\"\r\nOutput: 2\r\n```\r\n\r\n```c++\r\n#include <math.h>\r\nclass Solution {\r\npublic:\r\n int scoreOfParentheses(string S) {\r\n int res=0,layer=0,i,n=S.length();\r\n for(i=0;i<n-1;i++){\r\n if(S[i]=='('){\r\n layer++;\r\n if(S[i+1]==')')\r\n res+=pow(2,layer-1);\r\n } \r\n else layer--;\r\n }\r\n return res;\r\n }\r\n};\r\n```\r\n\r\n将所有的乘法消为加法\r\n\r\n如果在某个层级的()里面 ,()不表示为1,直接表示为pow(2,layer-1)\r\n\r\n\r\n\r\n##### leetcode 972 Equal Rational Numbers\r\n\r\n* Given two strings `S` and `T`, each of which represents a non-negative rational number, return **True** if and only if they represent the same number. The strings may use parentheses to denote the repeating part of the rational number.\r\n\r\n In general a rational number can be represented using up to three parts: an *integer part*, a *non-repeating part,* and a *repeating part*. The number will be represented in one of the following three ways:\r\n\r\n - `<IntegerPart>` (e.g. 0, 12, 123)\r\n - `<IntegerPart><.><NonRepeatingPart>` (e.g. 0.5, 1., 2.12, 2.0001)\r\n - `<IntegerPart><.><NonRepeatingPart><(><RepeatingPart><)>` (e.g. 0.1(6), 0.9(9), 0.00(1212))\r\n\r\n The repeating portion of a decimal expansion is conventionally denoted within a pair of round brackets. For example:\r\n\r\n 1 / 6 = 0.16666666... = 0.1(6) = 0.1666(6) = 0.166(66)\r\n\r\n Both 0.1(6) or 0.1666(6) or 0.166(66) are correct representations of 1 / 6.\r\n\r\n```\r\nInput: S = \"0.(52)\", T = \"0.5(25)\"\r\nOutput: true\r\nExplanation:\r\nBecause \"0.(52)\" represents 0.52525252..., and \"0.5(25)\" represents 0.52525252525..... , the strings represent the same number.\r\n\r\nInput: S = \"0.1666(6)\", T = \"0.166(66)\"\r\nOutput: true\r\n\r\nInput: S = \"0.9(9)\", T = \"1.\"\r\nOutput: true\r\nExplanation: \r\n\"0.9(9)\" represents 0.999999999... repeated forever, which equals 1. [See this link for an explanation.]\r\n\"1.\" represents the number 1, which is formed correctly: (IntegerPart) = \"1\" and (NonRepeatingPart) = \"\".\r\n```\r\n\r\n1. Each part consists only of digits.\r\n2. The `<IntegerPart>` will not begin with 2 or more zeros. (There is no other restriction on the digits of each part.)\r\n3. `1 <= <IntegerPart>.length <= 4`\r\n4. `0 <= <NonRepeatingPart>.length <= 4`\r\n5. `1 <= <RepeatingPart>.length <= 4`\r\n\r\n```python\r\nclass Solution:\r\n def isRationalEqual(self, S, T):\r\n \"\"\"\r\n :type S: str\r\n :type T: str\r\n :rtype: bool\r\n \"\"\"\r\n def f(S):\r\n i=S.find('(')\r\n if i>0:\r\n s1=S[:i]+S[i+1:len(S)-1]*20\r\n return float(s1)\r\n else:\r\n return float(S)\r\n return\r\n return f(S)==f(T)\r\n```\r\n\r\n在python中:\r\n>>> 0.9999999999999==1\r\n>>> False\r\n>>> 0.999999999999999999999999999999999999999999==1\r\n>>> True\r\n\r\n首先判断是否存在循环,否则直接利用float(s1)返回数值\r\n如果存在循环则将循环拉长20倍 这样可以使得0.999999=1\r\n\r\n当然这题的本意应该不是这样考察的\r\n应该是两个string搭配两个指针\r\n两个指针一起移动,如果数值不同返回False 直到移动到循环部分之后再继续二者循环部分的最小公倍数次后 返回True\r\n\r\n\r\n\r\n##### leetcode 1156 Swap For Longest Repeated Character Substring\r\n\r\nGiven a string `text`, we are allowed to swap two of the characters in the string. Find the length of the longest substring with repeated characters.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: text = \"ababa\"\r\nOutput: 3\r\nExplanation: We can swap the first 'b' with the last 'a', or the last 'b' with the first 'a'. Then, the longest repeated character substring is \"aaa\", which its length is 3.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: text = \"aaabaaa\"\r\nOutput: 6\r\nExplanation: Swap 'b' with the last 'a' (or the first 'a'), and we get longest repeated character substring \"aaaaaa\", which its length is 6.\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: text = \"aaabbaaa\"\r\nOutput: 4\r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: text = \"aaaaa\"\r\nOutput: 5\r\nExplanation: No need to swap, longest repeated character substring is \"aaaaa\", length is 5.\r\n```\r\n\r\n**Example 5:**\r\n\r\n```\r\nInput: text = \"abcdef\"\r\nOutput: 1\r\n```\r\n\r\n```python\r\nimport itertools\r\nimport collections\r\nclass Solution:\r\n def maxRepOpt1(self, S):\r\n # We get the group's key and length first, e.g. 'aaabaaa' -> [[a , 3], [b, 1], [a, 3]\r\n A = [[c, len(list(g))] for c, g in itertools.groupby(S)]\r\n # We also generate a count dict for easy look up e.g. 'aaabaaa' -> {a: 6, b: 1}\r\n count = collections.Counter(S)\r\n # only extend 1 more, use min here to avoid the case that there's no extra char to extend\r\n res = max(min(k + 1, count[c]) for c, k in A)\r\n # merge 2 groups together\r\n for i in range(1, len(A) - 1):\r\n # if both sides have the same char and are separated by only 1 char\r\n if A[i - 1][0] == A[i + 1][0] and A[i][1] == 1:\r\n # min here serves the same purpose\r\n res = max(res, min(A[i - 1][1] + A[i + 1][1] + 1, count[A[i + 1][0]]))\r\n return res\r\n```\r\n\r\n只要考虑这种情况: 1.存在aabaa这种一个单独的元素将两列隔开的情况就换他\r\n\r\n但是不能超出总数\r\n\r\n\r\n\r\n##### leetcode 1190 Reverse Substrings Between Each Pair of Parentheses\r\n\r\nYou are given a string `s` that consists of lower case English letters and brackets. \r\n\r\nReverse the strings in each pair of matching parentheses, starting from the innermost one.\r\n\r\nYour result should **not** contain any brackets.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: s = \"(abcd)\"\r\nOutput: \"dcba\"\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: s = \"(u(love)i)\"\r\nOutput: \"iloveu\"\r\nExplanation: The substring \"love\" is reversed first, then the whole string is reversed.\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: s = \"(ed(et(oc))el)\"\r\nOutput: \"leetcode\"\r\nExplanation: First, we reverse the substring \"oc\", then \"etco\", and finally, the whole string.\r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: s = \"a(bcdefghijkl(mno)p)q\"\r\nOutput: \"apmnolkjihgfedcbq\"\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def upper_bound(self, nums, target):\r\n left, right = 0, len(nums)-1\r\n while left < right:\r\n mid = int((left+right)/2)\r\n if nums[mid] <= target:\r\n left = mid + 1\r\n else:\r\n right = mid\r\n return left\r\n\r\n def reverseParentheses(self, s):\r\n n= len(s)\r\n lefts, rights, chars = [], [], []\r\n for i in range(n):\r\n if s[i] == \"(\":\r\n lefts.append(i)\r\n elif s[i] == \")\":\r\n rights.append(i)\r\n chars.append(s[i])\r\n while len(lefts) and len(rights):\r\n left = lefts.pop()\r\n index = self.upper_bound(rights, left)\r\n right = rights[index]\r\n del rights[index]\r\n chars[left+1:right] = chars[left+1:right][::-1]\r\n res = \"\"\r\n for i in range(n):\r\n if chars[i]!=\"(\" and chars[i]!=\")\":\r\n res+=chars[i]\r\n return res\r\n```\r\n\r\n第一遍把所有的(和)的位置记录下来。\r\n\r\n对每个(寻找其对应的) 使用upper_bound\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 1048 Longest String Chain\r\n\r\nGiven a list of words, each word consists of English lowercase letters.\r\n\r\nLet's say `word1` is a predecessor of `word2` if and only if we can add exactly one letter anywhere in `word1` to make it equal to `word2`. For example, `\"abc\"` is a predecessor of `\"abac\"`.\r\n\r\nA *word chain* is a sequence of words `[word_1, word_2, ..., word_k]` with `k >= 1`, where `word_1` is a predecessor of `word_2`, `word_2` is a predecessor of `word_3`, and so on.\r\n\r\nReturn the longest possible length of a word chain with words chosen from the given list of `words`.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [\"a\",\"b\",\"ba\",\"bca\",\"bda\",\"bdca\"]\r\nOutput: 4\r\nExplanation: one of the longest word chain is \"a\",\"ba\",\"bda\",\"bdca\".\r\n```\r\n\r\n**Note:**\r\n\r\n1. `1 <= words.length <= 1000`\r\n2. `1 <= words[i].length <= 16`\r\n3. `words[i]` only consists of English lowercase letters.\r\n\r\n```python\r\nclass Solution:\r\n def longestStrChain(self, words: List[str]) -> int:\r\n words.sort(key = lambda x: len(x))\r\n seen, res = {}, 0\r\n for word in words:\r\n for i in range(len(word)):\r\n pre = word[:i] + word[i+1:]\r\n val = seen.get(pre, 0) \r\n res = max(res, val+1)\r\n seen[word] = max(seen.get(word, 0), val + 1)\r\n return res\r\n \r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.7605285048484802,
"alphanum_fraction": 0.8150289058685303,
"avg_line_length": 39.75862121582031,
"blob_id": "a667678bf6db0387703e770da8c2be36966ef245",
"content_id": "c216ce0d826dd2f54eb213e5a4c51ce96cd890ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1591,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 29,
"path": "/math&&deeplearning/tensorflow_object_detection.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "使用tensorflow_object_detection api,参考:\r\nhttps://blog.csdn.net/xiaoxiao123jun/article/details/76605928\r\n安装所需环境:\r\n```\r\npython tensorflow(仅用CPU+ native pip) pip install tensorflow\r\n安装protoc,git,pillow,lxml,jupyter,matplotlib\r\n下载 tensorflow models\r\n1、在cmd中输入:git clone http://github.com/tensorflow/models.git\r\n\r\n2、在cmd进入到models/research文件夹,编译Object Detection API的代码:\r\n使用protoc object_detection/protocs/*.proto --python_out=.\r\n注意:可能会出现 找不到file的情况,这是由于protoc 3.5不稳定,改成3.4 可以解决这个问题,不然可能会出现\r\nImportError: cannot import name string_int_label_map_pb2这个问题\r\nhttps://github.com/google/protobuf/releases/tag/v3.4.0\r\nprotoc-3.4.0-win32.zip\r\n\r\n3、在models文件夹下运行 jupyter-notebook,浏览器自动开启\r\n可能会出现No module named 'markupsafe._compat'错误\r\n使用git先卸载markupsafe再安装markupsafe\r\n在git base中运行pip uninstall markupsafe卸载markupsafe模块,再在git base中输入pip install markupsafe,成功安装后再输入jupyter notebook成功启动jupyter\r\n\r\n4、进入object_detection文件夹中的object_detection_tutorial.ipynb:\r\n点击Cell内 Run All\r\n出现显示原图没有结果的情况,这是因为最新的model:ssd_mobilenet_v1_coco_2017_11_08 不好,换成\r\nfaster_rcnn_resnet101_coco_2017_11_08或者ssd_mobilenet_v1_coco_11_06_2017\r\nhttps://stackoverflow.com/questions/47237388/nothing-is-being-detected-in-tensorflow-object-detection-api\r\n\r\n5、得到结果\r\n```\r\n"
},
{
"alpha_fraction": 0.48138028383255005,
"alphanum_fraction": 0.5103145241737366,
"avg_line_length": 24.70243263244629,
"blob_id": "33d1aeb954a8108d384699a776961e6d836e4692",
"content_id": "5c0b23372bd3721cc1456425d5029d69e6a89f2c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 19614,
"license_type": "no_license",
"max_line_length": 310,
"num_lines": 699,
"path": "/leetcode_note/back_tracking.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "#### 递归\r\n\r\n生成组合数(LeetCode 39)\r\n\r\n生成排列数(LeetCode 46)\r\n\r\nN皇后问题(LeetCode 51)\r\n\r\n不同的加括号方法(LeetCode 241)\r\n\r\n两个数组的中位数(LeetCode 4)\r\n\r\n##### leetcode 22 Generate Parentheses\r\n\r\n- Given *n* pairs of parentheses, write a function to generate all combinations of well-formed parentheses.\r\n\r\n For example, given *n* = 3, a solution set is:\r\n\r\n ```\r\n [\r\n \"((()))\",\r\n \"(()())\",\r\n \"(())()\",\r\n \"()(())\",\r\n \"()()()\"\r\n ]\r\n ```\r\n\r\nMysolution:\r\n\r\n```python\r\nclass Solution(object):\r\n def generateParenthesis(self, n):\r\n def backtrack(n,score,cur,ans):\r\n if len(cur)>n*2 or score<0:\r\n return\r\n if len(cur)==n*2 and score==0:\r\n ans.append(cur)\r\n return\r\n backtrack(n,score+1,cur+\"(\",ans)\r\n backtrack(n,score-1,cur+\")\",ans)\r\n ans=[]\r\n backtrack(n,0,\"\",ans)\r\n return ans\r\n```\r\n\r\n递归解决,两种情况,分别插入(或者)\r\n\r\n如果score<0 表示)的数量多于(,返回false\r\n\r\n\r\n\r\n##### leetcode 39 Combination Sum\r\n\r\n- Given a **set** of candidate numbers (`candidates`) **(without duplicates)** and a target number (`target`), find all unique combinations in `candidates` where the candidate numbers sums to `target`.\r\n\r\n The **same** repeated number may be chosen from `candidates` unlimited number of times.\r\n\r\n **Note:**\r\n\r\n - All numbers (including `target`) will be positive integers.\r\n - The solution set must not contain duplicate combinations.\r\n\r\n```\r\nInput: candidates = [2,3,6,7], target = 7,\r\nA solution set is:\r\n[\r\n [7],\r\n [2,2,3]\r\n]\r\n\r\nInput: candidates = [2,3,5], target = 8,\r\nA solution set is:\r\n[\r\n [2,2,2,2],\r\n [2,3,3],\r\n [3,5]\r\n]\r\n```\r\n\r\n- Mysolution:\r\n\r\n```python\r\nclass Solution:\r\n def combinationSum(self, candidates, target):\r\n def helper(candi,target,path):\r\n if target<0:\r\n return\r\n elif target==0:\r\n self.ans.append(path)\r\n else:\r\n for i in range(len(candi)):\r\n helper(candi[i:],target-candi[i],path+[candi[i]])\r\n\r\n self.ans=[]\r\n helper(candidates,target,[])\r\n return self.ans\r\n```\r\n\r\n注意由于本题元素可以重复使用,因此在递归中使用candi[i:] 并不去掉任何元素\r\n\r\n如果本题元素只能使用一次,在递归中应该写candi[i+1:]表示使用过之后就不再使用相同元素了\r\n\r\nfor i in range(len(candi)): 考虑path中是否含有candi[i] 如果不含有candi[i]则path中之后的递归也不适用candi[i]了\r\n\r\n\r\n\r\n##### leetcode 46 Permutations\r\n\r\n- Given a collection of **distinct** integers, return all possible permutations.\r\n\r\n```\r\nInput: [1,2,3]\r\nOutput:\r\n[\r\n [1,2,3],\r\n [1,3,2],\r\n [2,1,3],\r\n [2,3,1],\r\n [3,1,2],\r\n [3,2,1]\r\n]\r\n```\r\n\r\n- Mysolution:\r\n\r\n```python\r\nimport itertools\r\nclass Solution:\r\n def permute(self, nums):\r\n return list(itertools.permutations(nums))\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def permute(self, nums):\r\n self.ans=[]\r\n def helper(nums,path):\r\n if len(nums)==0:\r\n self.ans.append(path)\r\n return\r\n for i in range(len(nums)):\r\n helper(nums[:i]+nums[i+1:],path+[nums[i]])\r\n helper(nums,[])\r\n return self.ans\r\n```\r\n\r\n可以使用itertools.permutations 也可以使用递归\r\n\r\n\r\n\r\n##### leetcode 967 Numbers With Same Consecutive Differences\r\n\r\n- Return all **non-negative** integers of length `N` such that the absolute difference between every two consecutive digits is `K`.\r\n\r\n Note that **every** number in the answer **must not** have leading zeros **except** for the number `0` itself. For example, `01` has one leading zero and is invalid, but `0` is valid.\r\n\r\n You may return the answer in any order.\r\n\r\n 1. `1 <= N <= 9`\r\n 2. `0 <= K <= 9`\r\n\r\n ```\r\n Input: N = 3, K = 7\r\n Output: [181,292,707,818,929]\r\n Explanation: Note that 070 is not a valid number, because it has leading zeroes.\r\n \r\n Input: N = 2, K = 1\r\n Output: [10,12,21,23,32,34,43,45,54,56,65,67,76,78,87,89,98]\r\n ```\r\n\r\n```python\r\nclass Solution:\r\n def numsSameConsecDiff(self, N, K):\r\n self.nums=[]\r\n def helper(path,n):\r\n if n==N:\r\n if path not in self.nums:\r\n self.nums.append(path)\r\n return\r\n if int(path[-1])+K<10:\r\n temp=int(path[-1])+K\r\n helper(path+str(temp),n+1)\r\n if int(path[-1])-K>=0:\r\n temp=int(path[-1])-K\r\n helper(path+str(temp),n+1)\r\n if N==0:\r\n return []\r\n if N==1:\r\n return [0,1,2,3,4,5,6,7,8,9]\r\n for i in range(1,10,1):\r\n helper(str(i),1)\r\n return [int(x) for x in self.nums]\r\n```\r\n\r\nN,K<=9 这种题很适合用递归来完成\r\n\r\n注意N=0,1的特殊情况\r\n\r\n\r\n\r\n##### leetcode 698. Partition to K Equal Sum Subsets\r\n\r\nGiven an array of integers `nums` and a positive integer `k`, find whether it's possible to divide this array into `k` non-empty subsets whose sums are all equal.\r\n\r\n **Example 1:**\r\n\r\n```\r\nInput: nums = [4, 3, 2, 3, 5, 2, 1], k = 4\r\nOutput: True\r\nExplanation: It's possible to divide it into 4 subsets (5), (1, 4), (2,3), (2,3) with equal sums.\r\n```\r\n\r\n **Note:**\r\n\r\n- `1 <= k <= len(nums) <= 16`.\r\n- `0 < nums[i] < 10000`.\r\n\r\n```python\r\nimport numpy as np\r\nclass Solution:\r\n def canPartitionKSubsets(self, nums, k) -> bool:\r\n def helper(nums, temp_sum, target, start, k, visited):\r\n if temp_sum > target:\r\n return False\r\n if k == 1:\r\n return True\r\n if temp_sum == target:\r\n return helper(nums, 0, target, 0, k - 1, visited)\r\n for i in range(start, len(nums)):\r\n if visited[i] == 1:\r\n continue\r\n if nums[i] <= target - temp_sum:\r\n visited[i] = 1\r\n if helper(nums, temp_sum + nums[i], target, i + 1, k, visited):\r\n return True\r\n visited[i] = 0\r\n return False\r\n\r\n sums = sum(nums)\r\n if sums % k != 0:\r\n return False\r\n visited = np.zeros(len(nums))\r\n nums = sorted(nums, reverse = True)\r\n return helper(nums, 0, int(sums / k), 0, k, visited)\r\n```\r\n\r\n\r\n\r\n回溯法\r\n\r\n先将nums排序 会效率高一些\r\n\r\nhelper(nums, temp_sum + nums[i], target, i + 1, k, visited)\r\n\r\n\r\n\r\n如果k==1 return True\r\n\r\n如果target==sum则完成一组,进入下一组\r\n\r\n如果nums[i] <= target - temp_sum 说明可以放i\r\n\r\n就将nums[i] 放进\r\n\r\n\r\n\r\n注意各种return的条件\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 36 Valid Sudoku\r\n\r\nDetermine if a 9x9 Sudoku board is valid. Only the filled cells need to be validated **according to the following rules**:\r\n\r\n1. Each row must contain the digits `1-9` without repetition.\r\n2. Each column must contain the digits `1-9` without repetition.\r\n3. Each of the 9 `3x3` sub-boxes of the grid must contain the digits `1-9` without repetition.\r\n\r\n\r\n\r\nThe Sudoku board could be partially filled, where empty cells are filled with the character `'.'`.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput:\r\n[\r\n [\"5\",\"3\",\".\",\".\",\"7\",\".\",\".\",\".\",\".\"],\r\n [\"6\",\".\",\".\",\"1\",\"9\",\"5\",\".\",\".\",\".\"],\r\n [\".\",\"9\",\"8\",\".\",\".\",\".\",\".\",\"6\",\".\"],\r\n [\"8\",\".\",\".\",\".\",\"6\",\".\",\".\",\".\",\"3\"],\r\n [\"4\",\".\",\".\",\"8\",\".\",\"3\",\".\",\".\",\"1\"],\r\n [\"7\",\".\",\".\",\".\",\"2\",\".\",\".\",\".\",\"6\"],\r\n [\".\",\"6\",\".\",\".\",\".\",\".\",\"2\",\"8\",\".\"],\r\n [\".\",\".\",\".\",\"4\",\"1\",\"9\",\".\",\".\",\"5\"],\r\n [\".\",\".\",\".\",\".\",\"8\",\".\",\".\",\"7\",\"9\"]\r\n]\r\nOutput: true\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput:\r\n[\r\n [\"8\",\"3\",\".\",\".\",\"7\",\".\",\".\",\".\",\".\"],\r\n [\"6\",\".\",\".\",\"1\",\"9\",\"5\",\".\",\".\",\".\"],\r\n [\".\",\"9\",\"8\",\".\",\".\",\".\",\".\",\"6\",\".\"],\r\n [\"8\",\".\",\".\",\".\",\"6\",\".\",\".\",\".\",\"3\"],\r\n [\"4\",\".\",\".\",\"8\",\".\",\"3\",\".\",\".\",\"1\"],\r\n [\"7\",\".\",\".\",\".\",\"2\",\".\",\".\",\".\",\"6\"],\r\n [\".\",\"6\",\".\",\".\",\".\",\".\",\"2\",\"8\",\".\"],\r\n [\".\",\".\",\".\",\"4\",\"1\",\"9\",\".\",\".\",\"5\"],\r\n [\".\",\".\",\".\",\".\",\"8\",\".\",\".\",\"7\",\"9\"]\r\n]\r\nOutput: false\r\nExplanation: Same as Example 1, except with the 5 in the top left corner being \r\n modified to 8. Since there are two 8's in the top left 3x3 sub-box, it is invalid.\r\n```\r\n\r\n**Note:**\r\n\r\n- A Sudoku board (partially filled) could be valid but is not necessarily solvable.\r\n- Only the filled cells need to be validated according to the mentioned rules.\r\n- The given board contain only digits `1-9` and the character `'.'`.\r\n- The given board size is always `9x9`.\r\n\r\n```python\r\nclass Solution:\r\n def isValidSudoku(self, board):\r\n return self.iscolvalid(board) and self.isrowvalid(board) and self.issquarevalid(board)\r\n\r\n def iscolvalid(self,board):\r\n for i in range(9):\r\n line=[]\r\n for j in range(9):\r\n line.append(board[j][i])\r\n if not self.isvalid(line):\r\n return False\r\n return True\r\n\r\n def isrowvalid(self,board):\r\n for line in board:\r\n if not self.isvalid(line):\r\n return False\r\n return True\r\n\r\n def issquarevalid(self,board):\r\n for i in range(0,9,3):\r\n for j in range(0,9,3):\r\n line=[]\r\n line+=board[i][j:j+3]\r\n line += board[i+1][j:j + 3]\r\n line += board[i+2][j:j + 3]\r\n if not self.isvalid(line):\r\n return False\r\n return True\r\n\r\n def isvalid(self,line):\r\n seen=set()\r\n for item in line:\r\n if item != \".\":\r\n if item in seen:\r\n return False\r\n else:\r\n seen.add(item)\r\n return True\r\n \r\n```\r\n\r\n考虑全局,行,列,方针中是否有重复元素,不用考虑深层次有无可能生成一个sodu\r\n\r\n\r\n\r\n从严格意义上说本题并不是使用回溯法的题目,但是37是经典的使用回溯法的题目 放在一起\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 37 Sudoku Solver\r\n\r\nWrite a program to solve a Sudoku puzzle by filling the empty cells.\r\n\r\nA sudoku solution must satisfy **all of the following rules**:\r\n\r\n1. Each of the digits `1-9` must occur exactly once in each row.\r\n2. Each of the digits `1-9` must occur exactly once in each column.\r\n3. Each of the the digits `1-9` must occur exactly once in each of the 9 `3x3` sub-boxes of the grid.\r\n\r\nEmpty cells are indicated by the character `'.'`.\r\n\r\n\r\n\r\n**Note:**\r\n\r\n- The given board contain only digits `1-9` and the character `'.'`.\r\n- You may assume that the given Sudoku puzzle will have a single unique solution.\r\n- The given board size is always `9x9`.\r\n\r\n本题是要具体将sodu写出来,采用回溯法,非常经典的题目\r\n\r\n```python\r\nclass Solution:\r\n def isvalid(self,board,row,col,c):\r\n for i in range(9):\r\n if board[i][col]==c: return False\r\n if board[row][i]==c: return False\r\n if board[3*(row//3)+i//3][3*(col//3)+i%3]==c:return False\r\n return True\r\n\r\n def solveSudoku(self, board):\r\n self.solve(board)\r\n return\r\n\r\n def solve(self, board):\r\n \"\"\"\r\n Do not return anything, modify board in-place instead.\r\n \"\"\"\r\n for i in range(9):\r\n for j in range(9):\r\n if board[i][j]==\".\":\r\n for item in range(9):\r\n c=chr(ord(\"1\")+item)\r\n if self.isvalid(board,i,j,c):\r\n board[i][j]=c\r\n if self.solve(board):\r\n return True\r\n else:\r\n board[i][j]=\".\"\r\n return False\r\n return True\r\n```\r\n\r\n首先为了速度起见,不用上一题中判断sodu是否solid的函数。因为上一题中的判断函数是判断全局的,这题中我们只需要的函数是判断在某个点填入值c是否会使得该sodu仍然成立。\r\n\r\n\r\n\r\n##### leetcode 51 N-Queens\r\n\r\nThe *n*-queens puzzle is the problem of placing *n* queens on an *n*×*n* chessboard such that no two queens attack each other.\r\n\r\n\r\n\r\nGiven an integer *n*, return all distinct solutions to the *n*-queens puzzle.\r\n\r\nEach solution contains a distinct board configuration of the *n*-queens' placement, where `'Q'` and `'.'` both indicate a queen and an empty space respectively.\r\n\r\n**Example:**\r\n\r\n```\r\nInput: 4\r\nOutput: [\r\n [\".Q..\", // Solution 1\r\n \"...Q\",\r\n \"Q...\",\r\n \"..Q.\"],\r\n\r\n [\"..Q.\", // Solution 2\r\n \"Q...\",\r\n \"...Q\",\r\n \".Q..\"]\r\n]\r\nExplanation: There exist two distinct solutions to the 4-queens puzzle as shown above.\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def solveNQueens(self, n):\r\n \"\"\"\r\n :type n: int\r\n :rtype: List[List[str]]\r\n \"\"\"\r\n def check(queen,i,j,row,col,n):\r\n #col\r\n for a in range(i):\r\n if queen[a][j]==\"Q\":\r\n return False\r\n #45\r\n a,b=i-1,j+1\r\n while a>=0 and b<n:\r\n if queen[a][b]==\"Q\":\r\n return False\r\n a-=1\r\n b+=1\r\n #135\r\n a,b=i-1,j-1\r\n while a>=0 and b>=0:\r\n if queen[a][b]==\"Q\":\r\n return False\r\n a-=1\r\n b-=1\r\n return True\r\n def placequeen(res,queen,row,col,index,n):\r\n if index==n:\r\n queen2=[]\r\n for i in range(n):\r\n string=\"\".join(x for x in queen[i])\r\n queen2.append(string)\r\n res.append(queen2)\r\n for i in range(col):\r\n if check(queen,index,i,row,col,n):\r\n queen[index][i]=\"Q\"\r\n placequeen(res,queen,row,col,index+1,n)\r\n queen[index][i]=\".\"\r\n return\r\n queen=[[\".\" for i in range(n)]for i in range(n)]\r\n res=[]\r\n placequeen(res,queen,n,n,0,n)\r\n return res\r\n```\r\n\r\n使用回溯法放置Queen,关键在于\r\n\r\n```\r\nqueen[index][i]=\"Q\"\r\nplacequeen(res,queen,row,col,index+1,n)\r\nqueen[index][i]=\".\"\r\n```\r\n\r\n\r\n\r\n##### leetcode 79 Word Search\r\n\r\n- Given a 2D board and a word, find if the word exists in the grid.\r\n\r\n The word can be constructed from letters of sequentially adjacent cell, where \"adjacent\" cells are those horizontally or vertically neighboring. The same letter cell may not be used more than once.\r\n\r\n```\r\nboard =\r\n[\r\n ['A','B','C','E'],\r\n ['S','F','C','S'],\r\n ['A','D','E','E']\r\n]\r\n\r\nGiven word = \"ABCCED\", return true.\r\nGiven word = \"SEE\", return true.\r\nGiven word = \"ABCB\", return false.\r\n```\r\n\r\n- Mysolution:\r\n\r\n```python\r\nclass Solution:\r\n def exist(self, board, word):\r\n \"\"\"\r\n :type board: List[List[str]]\r\n :type word: str\r\n :rtype: bool\r\n \"\"\"\r\n if word==\"\":\r\n return True\r\n m=len(board)\r\n if m==0:\r\n return False\r\n n=len(board[0])\r\n isvisited=[[0 for i in range(n)]for j in range(m)]\r\n def dfs(board,isvisited,word,m,n,i,j):\r\n if word==\"\":\r\n return True\r\n if i<0 or i>=m or j<0 or j>=n or word[0]!=board[i][j] or isvisited[i][j]==1:\r\n return False\r\n else:\r\n isvisited[i][j]=1\r\n res=dfs(board,isvisited,word[1:],m,n,i+1,j) or dfs(board,isvisited,word[1:],m,n,i-1,j)or dfs(board,isvisited,word[1:],m,n,i,j-1) or dfs(board,isvisited,word[1:],m,n,i,j+1)\r\n isvisited[i][j]=0\r\n return res\r\n for i in range(m):\r\n for j in range(n):\r\n if dfs(board,isvisited,word,m,n,i,j):\r\n return True\r\n return False\r\n```\r\n\r\n注意将isvisited置为1 运算结束后置为1\r\n\r\n回溯法\r\n\r\n212 是该题的进阶版,需要使用Trie\r\n\r\n\r\n\r\n##### leetcode 1219 Path with Maximum Gold\r\n\r\nIn a gold mine `grid` of size `m * n`, each cell in this mine has an integer representing the amount of gold in that cell, `0` if it is empty.\r\n\r\nReturn the maximum amount of gold you can collect under the conditions:\r\n\r\n- Every time you are located in a cell you will collect all the gold in that cell.\r\n- From your position you can walk one step to the left, right, up or down.\r\n- You can't visit the same cell more than once.\r\n- Never visit a cell with `0` gold.\r\n- You can start and stop collecting gold from **any** position in the grid that has some gold.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: grid = [[0,6,0],[5,8,7],[0,9,0]]\r\nOutput: 24\r\nExplanation:\r\n[[0,6,0],\r\n [5,8,7],\r\n [0,9,0]]\r\nPath to get the maximum gold, 9 -> 8 -> 7.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: grid = [[1,0,7],[2,0,6],[3,4,5],[0,3,0],[9,0,20]]\r\nOutput: 28\r\nExplanation:\r\n[[1,0,7],\r\n [2,0,6],\r\n [3,4,5],\r\n [0,3,0],\r\n [9,0,20]]\r\nPath to get the maximum gold, 1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7.\r\n```\r\n\r\n**Constraints:**\r\n\r\n- `1 <= grid.length, grid[i].length <= 15`\r\n- `0 <= grid[i][j] <= 100`\r\n- There are at most **25** cells containing gold.\r\n\r\n```python\r\nclass Solution:\r\n def dfs(self, grid, i, j, n, m):\r\n temp = 0\r\n dirs = [[-1, 0], [1, 0], [0, -1], [0, 1]]\r\n for ii, jj in dirs:\r\n if i+ii>=0 and i+ii<n and j+jj>=0 and j+jj<m:\r\n if grid[i+ii][j+jj] != 0 and self.visited[i+ii][j+jj] == 0:\r\n self.visited[i + ii][j + jj] = 1\r\n temp = max(temp, self.dfs(grid, i+ii, j+jj, n, m))\r\n self.visited[i + ii][j + jj] = 0\r\n return temp+grid[i][j]\r\n def getMaximumGold(self, grid):\r\n if len(grid) == 0:return 0\r\n n, m = len(grid), len(grid[0])\r\n self.visited = [[0 for i in range(m)] for j in range(n)]\r\n self.res = 0\r\n for i in range(n):\r\n for j in range(m):\r\n if grid[i][j]!=0:\r\n self.visited[i][j] = 1\r\n temp = self.dfs(grid, i, j, n, m)\r\n self.res = max(temp, self.res)\r\n self.visited[i][j] = 0\r\n return self.res\r\n```\r\n\r\n使用back tracking\r\n\r\ndfs(i, j)返回从i j出发最大能获取的gold数量\r\n\r\n注意self.visited的使用\r\n\r\n\r\n\r\n##### leetcode 294. Flip Game II\r\n\r\nYou are playing the following Flip Game with your friend: Given a string that contains only these two characters: `+` and `-`, you and your friend take turns to flip two **consecutive** `\"++\"` into `\"--\"`. The game ends when a person can no longer make a move and therefore the other person will be the winner.\r\n\r\nWrite a function to determine if the starting player can guarantee a win.\r\n\r\n**Example:**\r\n\r\n```\r\nInput: s = \"++++\"\r\nOutput: true \r\nExplanation: The starting player can guarantee a win by flipping the middle \"++\" to become \"+--+\".\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def helper(self, s1, dict1):\r\n if s1 in dict1:\r\n return dict1[s1]\r\n for i in range(len(s1) - 1):\r\n if s1[i] == \"+\" and s1[i+1] == \"+\":\r\n t = s1[:i] + \"--\" + s1[i+2:]\r\n if not self.helper(t, dict1):\r\n dict1[s1] = True\r\n return True\r\n dict1[s1] = False\r\n return False\r\n def canWin(self, s: str) -> bool:\r\n if len(s) < 2: return False\r\n dict1 = {}\r\n return self.helper(s, dict1)\r\n```\r\n\r\n用dict记录,去尝试每一种翻++的可能"
},
{
"alpha_fraction": 0.5658766031265259,
"alphanum_fraction": 0.5874439477920532,
"avg_line_length": 11.767646789550781,
"blob_id": "91b201e47a00d500e750753c0574eb180650fa87",
"content_id": "01f6354220ebb2e4a818173607e907e5529525d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5289,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 340,
"path": "/computer_science_knowledge/database/mysql.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Creating and Selecting a Database \r\n```\r\nmysql> CREATE DATABASE menagerie;\r\n\r\nmysql> USE menagerie\r\nDatabase changed\r\n```\r\n\r\n### create a table \r\n```\r\nmysql> SHOW TABLES;\r\nEmpty set (0.00 sec) \r\nmysql> CREATE TABLE pet (name VARCHAR(20), owner VARCHAR(20),\r\n -> species VARCHAR(20), sex CHAR(1), birth DATE, death DATE);\r\n\r\nmysql> SHOW TABLES;\r\nmysql> DESCRIBE pet;\r\n```\r\n\r\n### Loading Data into a Table \r\n```\r\n1 load from txt\r\nmysql> LOAD DATA LOCAL INFILE '/path/pet.txt' INTO TABLE pet;\r\nin txt:\r\nWhistler Gwen bird \\N 1997-12-09 \\N 用tab隔开\r\n\r\n2 手动加入\r\nmysql> INSERT INTO pet\r\n -> VALUES ('Puffball','Diane','hamster','f','1999-03-30',NULL);\r\n```\r\n### Retrieving Information from a table\r\n```\r\nSELECT what_to_select\r\nFROM which_table\r\nWHERE conditions_to_satisfy;\r\n\r\nSelecting All Data:\r\nmysql> SELECT * FROM pet;\r\n```\r\n\r\n\r\n```\r\nmysql> SELECT owner FROM pet;\r\n```\r\n### correct information:\r\n```\r\nmysql> UPDATE pet SET birth = '1989-08-31' WHERE name = 'Bowser';\r\nor\r\nmysql> DELETE FROM pet;\r\nmysql> LOAD DATA LOCAL INFILE '/path/pet.txt' INTO TABLE pet;\r\n```\r\n\r\n### 使用限定条件搜索\r\n```\r\nmysql> SELECT * FROM pet WHERE birth >= '1998-1-1';\r\n```\r\n```\r\nmysql> SELECT * FROM pet WHERE species = 'dog' AND sex = 'f';\r\n```\r\n```\r\nmysql> SELECT * FROM pet WHERE species = 'snake' OR species = 'bird';\r\n```\r\n```\r\nmysql> SELECT * FROM pet WHERE (species = 'cat' AND sex = 'm')\r\n -> OR (species = 'dog' AND sex = 'f');\r\n```\r\n### sort rows\r\norder by birth 升序\r\n```\r\nmysql> SELECT name, birth FROM pet ORDER BY birth;\r\n```\r\n降序: \r\n```\r\nmysql> SELECT name, birth FROM pet ORDER BY birth DESC;\r\n```\r\n多种排序: \r\n```\r\nmysql> SELECT name, species, birth FROM pet\r\n -> ORDER BY species, birth DESC;\r\n```\r\n\r\n\r\n\r\n### MYSQL Workbench\r\n\r\nmysql workbench is the official graphical interface GUI tool for Mysql.\r\n\r\n##### Mysql connections (其中一个是local,connect上修改数据)\r\n\r\nsetup new connection form\r\n\r\n##### Models\r\n\r\n##### Mysql migration\r\n\r\n\r\n\r\n##### Import Data\r\n\r\nworkbench可以import json csv sql等文件\r\n\r\n### query 关键字\r\n\r\nhttp://www.mysqltutorial.org/basic-mysql-tutorial.aspx\r\n\r\n末尾加;号\r\n\r\nSELECT, FROM, JOIN, WHERE, GROUP BY, HAVING, ORDER BY,LIMIT\r\n\r\n```\r\nSELECT \r\n lastname, firstname, jobtitle\r\nFROM\r\n employees;\r\n```\r\n\r\n\r\n\r\n从employee表格中选取了last name,first name以及jobtitle这三列\r\n\r\n\r\n\r\n```\r\nSELECT * FROM employees;\r\n```\r\n\r\n\r\n\r\n选取所有的列\r\n\r\n\r\n\r\nJOIN:\r\n\r\n分为 CROSS JOIN, INNER JOIN, LEFT JOIN,RIGHT JOIN\r\n\r\n```\r\nINSERT INTO t1(id, pattern)\r\nVALUES(1,'Divot'),\r\n (2,'Brick'),\r\n (3,'Grid');\r\n \r\nINSERT INTO t2(id, pattern)\r\nVALUES('A','Brick'),\r\n ('B','Grid'),\r\n ('C','Diamond');\r\n```\r\n\r\n\r\n\r\n```\r\nSELECT \r\n t1.id, t2.id\r\nFROM\r\n t1\r\nCROSS JOIN t2;\r\n```\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n##### WHERE\r\n\r\n\r\n\r\nWHERE 后面加conditions\r\n\r\n=,!=,<,>,<=,>=\r\n\r\n\r\n\r\n##### DISTINCT\r\n\r\nSELECT DISTINCT key FROM XXX ORDER BY time ASC;\r\n\r\nDISTINCT只保留第一个 同类型的记录\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n##### GROUP BY\r\n\r\n\r\n\r\ngroup by state, 按照state进行分类,配上count(*) 表示不同的state各有多少条记录\r\n\r\n\r\n\r\n##### ORDER BY\r\n\r\n\r\n\r\nDESC,ASC\r\n\r\n\r\n\r\n##### AND\r\n\r\n\r\n\r\nAND 单词表示bool语句的并关系\r\n\r\n```mysql\r\nSELECT customername,\r\n country,\r\n state,\r\n creditlimit\r\nFROM customers\r\nWHERE country = 'USA'\r\n AND state = 'CA'\r\n AND creditlimit > 100000;\r\n```\r\n\r\n类似的还有OR\r\n\r\n\r\n\r\n##### IN\r\n\r\n\r\n\r\ncountry in ('USA','FRANCE'),在集合中找\r\n\r\n\r\n\r\n##### BETWEEN\r\n\r\n表示<and<这个意思\r\n\r\n\r\n\r\n```mysql\r\nSELECT \r\n productCode, \r\n productName, \r\n buyPrice\r\nFROM\r\n products\r\nWHERE\r\n buyPrice NOT BETWEEN 20 AND 100;\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### LIKE\r\n\r\n有时需要寻找字段中带“on'”的,like关键字可以很好的满足这一要求。\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n```\r\nWHERE lastname LIKE 'a%';// 表示寻找以a开头的字段\r\nWHERE lastname LIKE '%on';//表示找on结尾的字段\r\nWHERE lastname LIKE '%on%';//表示有on的字段\r\n```\r\n\r\n\r\n\r\n##### LIMIT\r\n\r\n表示查询结果限制的长度,\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n##### IS NULL\r\n\r\n to test whether a value is NULL or not.\r\n\r\n\r\n\r\n\r\n\r\n##### HAVING\r\n\r\nhaving语句和where非常相似,都是表示条件condition\r\n\r\n区别如下:\r\n\r\n```mysql\r\nselect empno,ename,job,mgr\r\nfrom emp\r\nwhere deptno=20\r\n```\r\n\r\n不会报错\r\n\r\n\r\n\r\n```mysql\r\nselect empno,ename,job,mgr\r\nfrom emp\r\nhaving deptno=20\r\n```\r\n\r\n这时会出错,因为前面并没有筛选出deptno字段 他会先查询出所有的记录到内存,形成了一个表,在对表进行操作,这是只能操作表中的字段,也就是select中有的字段。\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n##### CREATE DATABASE\r\n\r\n```\r\nmysql> create DATABASE TESTDB;\r\n```\r\n\r\n在TESTDB下创建新的数据表\r\n\r\n```mysql\r\nmysql> use TESTDB;\r\nmysql> create TABLE t(\r\n -> FIRSTNAME varchar(20),\r\n -> LASTNAME varchar(20),\r\n -> AGE int,\r\n -> SEX int);\r\n```\r\n\r\n\r\n\r\n<https://www.runoob.com/mysql/mysql-create-database.html>\r\n\r\n"
},
{
"alpha_fraction": 0.4753451645374298,
"alphanum_fraction": 0.47731754183769226,
"avg_line_length": 8.140000343322754,
"blob_id": "842daeb5857009d1b9afc997fd3c0fcc3da55d50",
"content_id": "f37426e2a191350cb9280f362b7685ce3566709e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 831,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 50,
"path": "/books/深度学习.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 深度学习\r\n\r\n##### 概率与信息论\r\n\r\n概率分布用来描述随机变量在每个可能取到状态的可能性大小。\r\n\r\n**离散性变量和概率分布律函数**\r\n\r\n```\r\nx~P(x) 用波浪号表示\r\n```\r\n\r\n联合概率分布\r\n\r\nP(X=x,Y=y)表示X=x Y=y同时发生的概率\r\n\r\n**连续型变量和概率密度函数**\r\n$$\r\n\\int p(x)dx=1\r\n$$\r\n**边缘概率**\r\n\r\nP(x)表示只与x有关,与其他变量无关的概率分布\r\n$$\r\nP(X=x)=\\sum _yP(X=x,Y=y)\r\n$$\r\n**条件概率**\r\n\r\n给定X=x时,Y=y时的概率\r\n$$\r\nP(Y=y|X=x)=\\frac{P(Y=y,X=x)}{P(X=x)}\r\n$$\r\n条件概率的链式法则\r\n$$\r\nP(a,b,c)=P(a|b,c)P(b|c)P(c)\r\n$$\r\n独立性:\r\n\r\n如果存在\r\n$$\r\nP(X=x,Y=y)=P(X=x)*P(Y=y)\r\n$$\r\n则X Y两个因子条件独立的。\r\n\r\n\r\n\r\n**期望**\r\n$$\r\nE_{X\\sim P }[f(x)]=\\sum_xP(x)f(x)\r\n$$\r\n"
},
{
"alpha_fraction": 0.6733958125114441,
"alphanum_fraction": 0.6770007014274597,
"avg_line_length": 13.57677936553955,
"blob_id": "93d3f055501929cc2d0eb1b8c1857e7e3276acf1",
"content_id": "5dc758c8deb6d58d37ef16392e78d29ec3733ff1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6175,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 267,
"path": "/spark/spark.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Spark\r\n\r\n##### 什么是hadoop?\r\n\r\nHadoop是一种可靠的可扩展的开源的分布式计算框架工程。\r\n\r\nApache Hadoop软件库是一个允许使用简单编程模型处理大数据集合的框架。\r\n\r\nHadoop工程包含:\r\n\r\nPig:高级数据流语言并且支持并行计算的框架\r\n\r\nSpark:用于Hadoop数据的快速计算引擎\r\n\r\n\r\n\r\n##### Hadoop生态家族如此庞大,为什么要使用Spark呢?\r\n\r\n* 速度快\r\n* 易用性(可以使用java scala python r sql快速写spark应用)\r\n* 通用性\r\n\r\n\r\n\r\n##### Hadoop和Spark之间的关系是什么?\r\n\r\n这个要从Hadoop的MapReduce编程框架说起,如果说MapReduce是第一代计算引擎,那spark就是第二代计算引擎。Mapreduce相对而言效率更低,不够灵活。Spark计算速度快,高效,同时易用(提供了较为丰富的API)\r\n\r\n\r\n\r\nspark本身基于scala,所以安装spark需要先安装scala(java)\r\n\r\n\r\n\r\n##### Spark可以做什么?\r\n\r\n\r\n\r\n##### spark 常见考题\r\n\r\n\r\n\r\nSpark例程\r\n\r\n```\r\nbin/pyspark 进入spark\r\n```\r\n\r\npython行数统计\r\n\r\n```\r\nlines = sc.textFile(\"README.md\") 创建一个名为lines的RDD\r\nlines.count() #统计RDD中元素的个数\r\nlines.first() #RDD中第一个元素\r\n```\r\n\r\n\r\n\r\nSpark核心概念介绍\r\n\r\n每个Spark应用都由一个驱动器程序发起。驱动器程序通过一个SparkContext对象来访问Spark。\r\n\r\n##### 筛选功能\r\n\r\n```\r\npythonlines=lines.filter(lambda line: \"Python\" in line)\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### RDD 编程\r\n\r\nRDD是spark中的核心概念,RDD是一个不可变的分布式对象集合。\r\n\r\nRDD支持两种类型的操作,转化操作与行动操作。转化操作会由一个RDD生成一个新的RDD,例如之前使用的filter()函数,行动操作会对RDD计算出一个结果,例如之前使用的first()函数。\r\n\r\n##### 创建RDD\r\n\r\n创建RDD有两种方式,最简单的方式是将程序中一个已有的集合传给SparkContext的parallelize()方法\r\n\r\n```python\r\nlines = sc.parallelize([\"pandas\",\"i like pandas\"])\r\n```\r\n\r\n使用textFile直接读取外部数据\r\n\r\n```\r\nlines = sc.textFile(\"README.md\")\r\n```\r\n\r\n##### RDD 转化操作\r\n\r\nfilter()\r\n\r\n```\r\ninputRDD = sc.textFile(\"log.txt\")\r\nerrorsRDD = inputRDD.filter(lambda x: \"error\" in x)\r\n```\r\n\r\nfilter操作不会改变inputRDD中的数据,该操作会返回一个全新的RDD\r\n\r\nunion()\r\n\r\n```\r\nerrorsRDD = inputRDD.filter(lambda x: \"error\" in x)\r\nwarningsRDD = inputRDD.filter(lambda x: \"warning\" in x)\r\nbadLinesRDD = errorsRDD.union(warningsRDD)\r\n```\r\n\r\nmap()函数\r\n\r\n```\r\nnums = sc.parallelize([1, 2, 3, 4])\r\nsquared = nums.map(lambda x: x * x).collect()\r\nfor num in squared:\r\n print \"%i \" % (num)\r\n```\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n##### RDD行动操作\r\n\r\ntake()获取RDD中少量元素\r\n\r\n```\r\nprint \"Input had \" + badLinesRDD.count() + \" concerning lines\"\r\nprint \"Here are 10 examples:\"\r\nfor line in badLinesRDD.take(10):\r\n\tprint line\r\n```\r\n\r\n需要注意的是,每当要调用一个新的行动操作时,整个RDD都会从头计算,要避免这种低效的行为,用户可以将中间结果持久化。(适合大数据的特点,RDD转化操作并不会有实质的运算)\r\n\r\n\r\n\r\n\r\n\r\n##### 惰性求值\r\n\r\nRDD的转化操作都是惰性求值的,在被调用行动操作之前spark不会开始计算,例如在使用sc.textFile()读入数据时,数据并没有被立刻读进来,而是在必要的时候才会操作。\r\n\r\n\r\n\r\n##### RDD不同类型\r\n\r\n有些函数只能作用在特定类型的RDD上,例如mean()和variable()函数只能作用在数值RDD上,join()只能作用在键值对RDD上。\r\n\r\n\r\n\r\n##### RDD持久化\r\n\r\n有时我们希望能够多次使用同一个RDD,这是可以对这个RDD持久化,放入缓存。\r\n\r\npersist()函数与unpersist()函数\r\n\r\n```\r\nlines = sc.textFile(\"README.md\")\r\nlines.persist()\r\nREADME.md MapPartitionsRDD[1] at textFile at NativeMethodAccessorImpl.java:0\r\nlines.unpersist()\r\n```\r\n\r\n若缓存中的数据太多放不下,Spark会自动利用最近最少使用LRU的缓存策略将最不常用的分区从内存中移除。\r\n\r\n\r\n\r\n##### 键值对操作\r\n\r\n我们通过一些的初始操作,例如抽取 转化 装载,将数据转化为键值对形式,键值对RDD常用来聚合。\r\n\r\n创建Pair RDD\r\n\r\n```\r\npairs = lines.map(lambda x: (x.split(\" \")[0], x))\r\n```\r\n\r\n键:第一个词,值:行\r\n\r\n\r\n\r\n##### pair RDD的转化操作\r\n\r\n\r\n\r\n数据分组\r\n\r\ngroupByKey()函数会使用RDD中的键对数据进行分组\r\n\r\n\r\n\r\n### 数据读取与保存\r\n\r\n有时数据量可能大到无法放在一台机器中,spark支持很多种输入输出源\r\n\r\n将文本文件的一行视为一条记录\r\n\r\n##### 读入文本文件\r\n\r\n```\r\ninput = sc.textFile(filename)\r\n```\r\n\r\n##### 输出文本文件\r\n\r\n```\r\nresult.saveAsTextFile(outputfile)\r\n```\r\n\r\n\r\n\r\n##### 读取JSON文件\r\n\r\n```\r\nimport json\r\ndata = input.map(lambda x:json.loads(x))\r\n```\r\n\r\n##### 输出JSON文件\r\n\r\n```\r\n(data.filter(lambda x:x[\"lovesPandas\"])).map(lambda x:json.dumps(x)).saveAsTextFile(outputFile)\r\n```\r\n\r\n\r\n\r\nCSV文件种使用逗号进行分隔,在读取CSV文件时,同样需要先把文件当作普通文本文件来处理,然后再对数据进行处理。\r\n\r\n##### 读取CSV\r\n\r\n```python\r\ndef loadRecords(fileNameContents):\r\n\t\"\"\"读取给定文件中的所有记录\"\"\"\r\n\tinput = StringIO.StringIO(fileNameContents[1])\r\n\treader = csv.DictReader(input, fieldnames=[\"name\", \"favoriteAnimal\"])\r\n\treturn reader\r\nfullFileData = sc.wholeTextFiles(inputFile).flatMap(loadRecords)\r\n```\r\n\r\n##### 输出 CSV\r\n\r\n```python\r\ndef writeRecords(records):\r\n\t\"\"\"写出一些CSV记录\"\"\"\r\n\toutput = StringIO.StringIO()\r\n\twriter = csv.DictWriter(output, fieldnames=[\"name\", \"favoriteAnimal\"])\r\n\tfor record in records:\r\n\t\twriter.writerow(record)\r\n\treturn [output.getvalue()]\r\npandaLovers.mapPartitions(writeRecords).saveAsTextFile(outputFile)\r\n```\r\n\r\n\r\n\r\nSequenceFile是由没有相对关系结构的键值对文件组成的常用Hadoop格式\r\n\r\n##### 读取SequenceFile\r\n\r\n```python\r\n data = sc.sequenceFile(inFile,\r\n \"org.apache.hadoop.io.Text\", \"org.apache.hadoop.io.IntWritable\")\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.7333984375,
"alphanum_fraction": 0.7861328125,
"avg_line_length": 19.5744686126709,
"blob_id": "cb46ffd516531bfca1fb25cd881f4a58773a75aa",
"content_id": "828a36b237c3c392b2a9b03badcf46b0b159ed20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2520,
"license_type": "no_license",
"max_line_length": 217,
"num_lines": 47,
"path": "/interview/五分钟学算法.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 五分钟学算法\r\n\r\n1. 3的幂,leetcode,给定一个整数 要求判断是否为3的幂\r\n\r\n进阶:如何用不使用循环的方法验证?\r\n\r\nint类型,最大是2^31<3^20:\r\n\r\n判断3^20能否整除n\r\n\r\n\r\n\r\n2. 给定一个排序数组,你需要在原地删除重复元素,返回移除之后的数组新长度。\r\n\r\n 要求只能使用O(1)额外空间。\r\n\r\n 使用快慢指针来记录遍历坐标\r\n\r\n (1)开始时这两个指针都指向第一个数字\r\n\r\n (2)如果这两个指针指向的数字相同,则快指针向前走一步(表示重复元素)\r\n\r\n (3)如果不同则两个指针都向前一步(不重复元素)\r\n\r\n (4)当快指针走完的时候,慢指针当前坐标加1就是不同元素个数。\r\n\r\n\r\n\r\n3.海量数据查找中位数:海量数据的容量已经超过了内存的限制\r\n\r\n采用基于二进制位比较的方法:\r\n\r\n假如将着10亿个数字放在一个超大文件中,依次将这些数读到内存中,按照这些数字的第一位 分,如果第一位是1就放到file1中,第一位是0就放到file0中,加入一共是10亿个元素,如果file0中有6亿个元素,就到file0中去寻找第5亿个大的元素。\r\n\r\n\r\n\r\n4.在海量数据中判断数字是否存在?例如有10亿个数\r\n\r\n常规的方法是使用散列表\r\n\r\n但是10亿个数太多了,加上用来解决散列冲突的空间,需要太多的内存空间。\r\n\r\n位图法:如果所有的数字都在1-10亿之间,构建一个长度为10亿的数组,数字a出现了则将nums[a]置为1。但是位图法最大的问题在于其空间随着最大元素的增加而增加,为了解决这个问题可以考虑使用布隆过滤器:\r\n\r\n一开始布隆过滤器是一个长度为m的数组,一开始全是0,还有K个哈希函数。对于某个数,经过K个哈希函数得到K个哈希映射值,例如三个哈希值n1 n2 n3,将位数组arr[n1],arr[n2],arr[n3]置为1.当要判断某个数在不在布隆过滤器中时就进行K次哈希计算,如果每个数都为1则应该在布隆过滤器中,如果某个值不在则说明该元素不在布隆过滤器中。但是可能存在误判:总结是布隆过滤器说某个数不在则一定不在,如果其说某个数在,则不一定。\r\n\r\n常见的补救方法是建立白名单。例如判断判断某个邮箱是不是在10亿个垃圾邮箱中,是否为垃圾邮箱:如果不是则一定不是垃圾邮箱,如果是则扔到垃圾堆里(白名单 没有删除)\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.531737744808197,
"alphanum_fraction": 0.5338189601898193,
"avg_line_length": 20.880952835083008,
"blob_id": "bc457cc40e3cd2f914f58f65439cacaa880f7183",
"content_id": "e041ef90c7b8e5fb6e8d5e8ad83cc0a53c441fb6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2400,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 84,
"path": "/c++/c++_Tree.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "```c++\r\n#include <iostream> \r\nusing namespace std;\r\nstruct TreeNode {\r\n\tint val;\r\n\tTreeNode *left;\r\n\tTreeNode *right;\r\n\tTreeNode(int x) : val(x), left(NULL), right(NULL) {}\r\n\t\r\n};\r\nTreeNode*T;\r\nvoid CreateBiTree(TreeNode* &T);\r\nvoid Inorder(TreeNode* &T);\r\nvoid PreOrderTraverse(TreeNode* &T);\r\nvoid Posorder(TreeNode* &T);\r\n\r\nint main() {\r\n\tcout << \"创建一颗树,其中A->Z字符代表树的数据,用“#”表示空树:\" << endl;\r\n\tCreateBiTree(T);\r\n\tcout << \"先序递归遍历:\" << endl;\r\n\tPreOrderTraverse(T);\r\n\tcout << endl;\r\n\tcout << \"中序递归遍历:\" << endl;\r\n\tInorder(T);\r\n\tcout << endl;\r\n\tcout << \"后序递归遍历:\" << endl;\r\n\tPosorder(T);\r\n\tcout << endl;\r\n\tsystem(\"pause\");\r\n\treturn 1;\r\n}\r\n\r\n//=============================================先序递归创建二叉树树 \r\nvoid CreateBiTree(TreeNode* &T) {\r\n\t//按先序输入二叉树中结点的值(一个字符),空格字符代表空树, \r\n\t//构造二叉树表表示二叉树T。 \r\n\tchar ch;\r\n\tif ((ch = getchar()) == '#')T = NULL;//其中getchar()为逐个读入标准库函数 \r\n\telse {\r\n\t\tT = new TreeNode(1);//产生新的子树 \r\n\t\tT->val = ch;//由getchar()逐个读入来 \r\n\t\tCreateBiTree(T->left);//递归创建左子树 \r\n\t\tCreateBiTree(T->right);//递归创建右子树 \r\n\t}\r\n}//CreateTree \r\n\r\n//===============================================先序递归遍历二叉树 \r\nvoid PreOrderTraverse(TreeNode* &T) {\r\n\t//先序递归遍历二叉树 \r\n\tif (T) {//当结点不为空的时候执行 \r\n\t\tcout << T->val;\r\n\t\tPreOrderTraverse(T->left);// \r\n\t\tPreOrderTraverse(T->right);\r\n\t}\r\n\telse cout << \"\";\r\n}//PreOrderTraverse \r\n\r\n//================================================中序遍历二叉树 \r\nvoid Inorder(TreeNode* &T) {//中序递归遍历二叉树 \r\n\tif (T) {//bt=null退层 \r\n\t\tInorder(T->left);//中序遍历左子树 \r\n\t\tcout << T->val;//访问参数 \r\n\t\tInorder(T->right);//中序遍历右子树 \r\n\t}\r\n\telse cout << \"\";\r\n}//Inorder \r\n\r\n//=================================================后序递归遍历二叉树 \r\nvoid Posorder(TreeNode* &T) {\r\n\tif (T) {\r\n\t\tPosorder(T->left);//后序递归遍历左子树 \r\n\t\tPosorder(T->right);//后序递归遍历右子树 \r\n\t\tcout << T->val;//访问根结点 \r\n\t}\r\n\telse cout << \"\";\r\n}\r\n```\r\n\r\n构造函数\r\n```\r\nTreeNode(int x) : val(x), left(NULL), right(NULL) {}\r\nTreeNode* root = new TreeNode(1);\r\nroot->left = new TreeNode(2);\r\n```\r\n"
},
{
"alpha_fraction": 0.6041868329048157,
"alphanum_fraction": 0.6373327970504761,
"avg_line_length": 10.764851570129395,
"blob_id": "45af0126027a196fd7eb3435edd9b1890efa993c",
"content_id": "14c762ec88e0263dd07c49734ff0980e4b77818c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 7955,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 404,
"path": "/books/linux_command_line.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### The Linux Command Line\r\n\r\n分为5个部分\r\n\r\n* 学习shell基本命令行语言,包括命令组成结构,文件系统浏览,查找命令行帮助文档等等\r\n* 配置文件与环境\r\n* 常见任务与主要工具\r\n* shell编程\r\n\r\n\r\n\r\n命令行指的是Shell,bash是shell的一种\r\n\r\n$ shell提示符\r\n\r\n#超级用户权限的shell提示符\r\n\r\n在终端中ctrl C,ctrl V是没有复制黏贴效果的\r\n\r\n几个简单命令\r\n\r\n```\r\ndate #显示日期\r\ncal #显示月历\r\ndf #查看磁盘剩余空间的数量\r\nfree 显示空闲内存的数量\r\nexit 终止一个会话\r\n```\r\n\r\n\r\n\r\n##### 文件系统跳转\r\n\r\n```\r\npwd 打印出当前工作目录名\r\ncd 更改目录\r\ncd 可以搭配绝对路径或相对路径\r\ncd /usr/bin\r\ncd ./bin\r\n.表示当前文件夹,..表示父目录\r\ncd — 表示回到刚才的工作目录\r\ncd ~ 表示回到用户主目录\r\nls 列出目录内容\r\n```\r\n\r\n\r\n\r\n##### 探究操作系统\r\n\r\n```\r\nls 列出目录类型\r\nls -l以长类型输出\r\n```\r\n\r\n要看得懂长输出的格式、\r\n\r\n-rw-r--r-- -表示是普通文件 d表示是文件夹其后三个字符是文件所有者的访问权限,再其后的\r\n三个字符是文件所属组中成员的访问权限,最后三个字符是其他所有人的访问权限\r\n\r\n```\r\nless file #浏览文件中的内容\r\n```\r\n\r\n\r\n\r\n##### 操作文件和目录\r\n\r\n```\r\ncp -复制文件和目录\r\nmv -移动/重命名文件/目录\r\nmkdir 创建目录\r\nrm 删除文件和目录\r\nln 创建硬链接和符号链接\r\n\r\n使用* .等通配符能更加快捷\r\ncp ./test1/*.jpg ./test2\r\nls 也可以用通配符\r\n./test1/2.jpg\r\n```\r\n\r\n\r\n\r\n##### 使用命令\r\n\r\n```\r\ntype 显示命令的类型\r\nwhich 显示会执行哪个可执行程序 which python\r\nman 显示命令手册\r\napropos 显示一系列合适的命令\r\ninfo 显示命令\r\nwhatis 显示一个命令的简介描述\r\nalias 别名\r\n```\r\n\r\n\r\n\r\n##### 重定向\r\n\r\nI/O输入输出重定向\r\n\r\n```\r\ncat 连接文件\r\nsort 排序文本行\r\nuniq \r\ngrep\r\nwc\r\nhead\r\ntail\r\n\r\n```\r\n\r\n\r\n\r\n重定向符#\r\n\r\nls -l /usr/bin > ls-output.txt\r\n\r\n将输出重定向到ls-output.txt文件中\r\n\r\n每次使用>都会重新开始写文件\r\n\r\nls -l /usr/bin >> ls-output.txt\r\n\r\n在文件的后面接下去写\r\n\r\n\r\n\r\n重定向错误 2\r\n\r\nls -l /bin/usr 2> ls-error.txt\r\n\r\n\r\n\r\n##### cat\r\n\r\ncat可以读取一个或多个文件,将他们复制到标准输出\r\n\r\ncat filename\r\n\r\n屏幕上会显示文件中的所有文本信息,因此cat常用来显示简短的文本文件\r\n\r\n<重定向输入\r\n\r\n```\r\n[me@linuxbox ~]$ cat < lazy_dog.txt\r\nThe quick brown fox jumped over the lazy dog.\r\n```\r\n\r\n\r\n\r\n##### 管道线\r\n\r\ncommand1 | command2\r\n\r\n```\r\nls /bin /usr/bin | sort | uniq | less\r\n将两个目录中的文件名排序 删除重复的部分再less出来\r\n```\r\n\r\n\r\n\r\nwc ls-output.txt\r\n\r\n7902 64566 503634 ls-output.txt 行数 单词数 字节数\r\n\r\ngrep 打印匹配行\r\n\r\ngrep pattern [file ...]\r\n\r\nls -l | grep txt 查找匹配所有的txt文件‘’\r\n\r\n用head/tail打印文件开头/结尾的部分\r\n\r\n\r\n\r\n\r\n\r\n```\r\necho 1234 #echo 打印一行文本\r\n1234\r\n\r\nhistory #查看之前执行的命令\r\nclear #清空\r\n```\r\n\r\n\r\n\r\n##### 权限\r\n\r\n文件权限 rwx 读取 写入 执行\r\n\r\nchmod 777 filename\r\n\r\n7 表示赋予读取 写入执行的权限\r\n\r\n777:对文件所有者、用户组、其他用户的权限进行设置\r\n\r\nsudo 使用超级用户权限\r\n\r\nchown #更改文件所有者和用户组 #chgrp 更改用户组所有权\r\n\r\n使用passwd 更改用户密码\r\n\r\n\r\n\r\n##### 进程\r\n\r\n```\r\nps #显示当前的进程\r\nkill #杀死某个进程\r\n```\r\n\r\n\r\n\r\n```\r\n[me@linuxbox ~]$ ps\r\nPID TTY TIME CMD\r\n5198 pts/1 00:00:00 bash\r\n10129 pts/1 00:00:00 ps\r\n```\r\n\r\n上例中,列出了两个进程,进程5198 和进程10129\r\n\r\nps-aux 列出更多的信息\r\n\r\nps -A 列出所有的进程\r\n\r\nps -A | grep bash 列出所有的bash进程\r\n\r\nkill n 关闭进程n\r\n\r\n\r\n\r\n##### shell环境\r\n\r\n登录系统之后,系统会自动运行一些配置文件\r\n\r\n~/.bashrc 用户私有的启动文件,可以用来配置设置\r\n\r\nsource .bashrc 激活刚刚的修改\r\n\r\n\r\n\r\n##### 软件安装管理\r\n\r\nsudo apt-get update/upgrade\r\n\r\nsudo apt-get remove ...\r\n\r\n\r\n\r\n\r\n\r\n##### 网络系统\r\n\r\nping www.baidu.com\r\n\r\n向百度网站发送ICMP ECHO_REQUEST 软件包到网络主机,如果连接到会有回应\r\n\r\nssh 远程连接服务器\r\n\r\n远程在服务端之间传文件:\r\n\r\nscp file.txt [email protected]:file.txt\r\n\r\n将file传到249服务器上\r\n\r\nscp [email protected]:loss.txt ./loss.txt\r\n\r\n将文件从服务器上下载下来\r\n\r\nnetstat -ie 查看系统中的网络设置\r\n\r\nnetstat -r查看显示网络路由表\r\n\r\nwget 用来下载文件的命令程序\r\n\r\n例如下载github上的单个文件\r\n\r\n在github上选择transform.py 点击raw\r\n\r\n```\r\nwget https://raw.githubusercontent.com/Marco2018/fast-style-transfer/master/src/transform.py\r\n```\r\n\r\n如果下载了一半中断了\r\n\r\nwget -c断点续传 重现启动中断的文件\r\n\r\n\r\n\r\n##### 查找文件\r\n\r\nlocate 程序可以快速搜索路径数据库\r\n\r\nlocate需要update db 同时不能用正则表达式\r\n\r\n\r\n\r\nfind命令\r\n\r\n```\r\nfind ./ -type d #查找当前目录下的所有目录而非文件\r\nfind ./ -type f -name *.txt #查找当前目录下 的文件(f) 名字中.txt结尾的文件\r\nfind ./ -name *.txt #查找当前目录下 名字中.txt结尾的文件或目录\r\nfind ./ -maxdepth 5 -name *.txt #从当前目录开始查找5层 中名字带有.txt的文件 目录\r\nfind ./ -maxdepth 5 -regex *rc #从当前目录开始查找5层 使用正则表达式\r\nfind ./ -maxdepth 5 -regex \".*txt\"\r\nfind ./ -maxdepth 5 -size -10000 #查找size小于10000的文件,+表达大于\r\nfind ./ -type f -maxdepth 1\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### 归档和备份\r\n\r\n文件压缩: gzip filename 压缩为filename.gz\r\n\r\n解压: gunzip filename\r\n\r\n文件压缩: bzip2 filename 压缩为filename.bz2 压缩效率更高\r\n\r\n解压: bunzip2 filename\r\n\r\nzip filename.zip filename\r\n\r\nunzip filename.zip\r\n\r\n归档的作用是将很多个小文件归成一个大文件来存储使用\r\n\r\n```\r\ntar cf playground.tar playground #归档\r\ntar xf playground.tar #抽取\r\n```\r\n\r\n\r\n\r\n##### 正则表达式\r\n\r\n```\r\ngrep ‘.zip’ dirlist*.txt 在dirlist-bin.txt等文件中查找符合.zip的\r\n.可以匹配任何字符\r\n'^zip' 表示匹配开头的zip\r\n‘zip$’ 表示匹配结尾的zip\r\n'[bg]zip' 文件名包含字符串zip并且前一个字符是bg中的一个字符\r\n'[^bg]zip'文件名包含字符串zip并且前一个字符不是bg中的一个字符\r\n'^[ABCDEFGHIJKLMNOPQRSTUVWXZY]' 从列表中找到大写字母开头的文件\r\n'^[A-Za-z0-9]' 匹配所有以字母和数字开头的文件名\r\n?表示前一个字符匹配1个或0个\r\n'^\\(?[0-9][0-9][0-9]\\)? [0-9][0-9][0-9]$' 匹配(555)123-4567或555 123-4567\r\n'^\\(?[0-9]{3}\\)? [0-9]{3}-[0-9]{4}$'\r\n{n}表示出现n次\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### 文本处理\r\n\r\n```\r\ncat --连接文件并打印到输出\r\ncat -ns foo.txt 将多余的空白行删除,并对保留的文本进行编号\r\nsort --给文本行排序\r\nuniq --省略重复行\r\ndiff file1 file2 > diff_file\r\n```\r\n\r\n```\r\nsed 流编辑器\r\nMacBook-Pro:tmp maxincai$ cat test.txt\r\nmy cat's name is betty\r\nThis is your dog\r\nmy dog's name is frank\r\nThis is your fish\r\nmy fish's name is george\r\nThis is your goat\r\nmy goat's name is adam\r\n\r\ns替换命令\r\nsed 's/This/aaa/' test.txt\r\nmy cat's name is betty\r\naaa is your dog\r\nmy dog's name is frank\r\naaa is your fish\r\nmy fish's name is george\r\naaa is your goat\r\nmy goat's name is adam\r\n\r\nsed -n 's/This/aaa/p' test.txt 只打印有改动的行\r\naaa is your dog\r\naaa is your fish\r\naaa is your goat\r\n\r\nsed -i 's/This/this/' test.txt 只编辑不打印\r\nsed '/^$/d' test.txt 删除空行\r\nsed '2d' test.txt 删除第2行\r\nsed '2,$d' test.txt 删除第2行到最后一行\r\nsed '$d' test.txt 删除最后一行\r\nsed '/^my/'d test.txt 删除以my开头的行\r\n\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.4489402770996094,
"alphanum_fraction": 0.459216445684433,
"avg_line_length": 11.033613204956055,
"blob_id": "562b149b788ef4efc36d2c9086892e715e5c9acc",
"content_id": "573083a0e46bead701b45b45520f2754cc618efd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1597,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 119,
"path": "/math&&deeplearning/reinforcement_learning/CS294.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### Reinforcement Learning\r\n\r\n$o_{t}$ observation, $x_{t}$ state, $u_t$ action\r\n\r\nreward function is just reverse of cost function\r\n\r\n##### optimization:\r\n\r\n$$\r\nmin_{u_{1},...u_{T}}\\sum_{t=1}^Tc(x_t,u_t) s.t. x_t=f(x_{t-1},u_{t-1})\r\n$$\r\n\r\n$$\r\nmin_{u_{1},...u_{T}} (c(x_1,u_1)+c(f(x_1,u_1),u_2)+...+c(f(...)u_T)\r\n$$\r\n\r\n\r\n\r\n##### Linear case:LQR\r\n\r\nassume the cost is a quadratic function\r\n$$\r\nf(x_t,u_t)=F_t\r\n \\left[\r\n \\begin{matrix}\r\n x_t\\\\\r\n u_t\\\\\r\n \\end{matrix}\r\n \\right]+f_t\r\n$$\r\n\r\n$$\r\nc(x_t,u_t)=\\frac{1}{2}\r\n \\left[\r\n \\begin{matrix}\r\n x_t\\\\\r\n u_t\\\\\r\n \\end{matrix}\r\n \\right]^T C_t\\left[\r\n \\begin{matrix}\r\n x_t\\\\\r\n u_t\\\\\r\n \\end{matrix}\r\n \\right]+\r\n \\left[\r\n \\begin{matrix}\r\n x_t\\\\\r\n u_t\\\\\r\n \\end{matrix}\r\n \\right]^Tc_t\r\n$$\r\n\r\nt时刻的Q值\r\n$$\r\nQx_T,u_T)=const+\\frac{1}{2}\r\n \\left[\r\n \\begin{matrix}\r\n x_T\\\\\r\n u_T\\\\\r\n \\end{matrix}\r\n \\right]^T C_t\\left[\r\n \\begin{matrix}\r\n x_T\\\\\r\n u_T\\\\\r\n \\end{matrix}\r\n \\right]+\r\n \\left[\r\n \\begin{matrix}\r\n x_T\\\\\r\n u_T\\\\\r\n \\end{matrix}\r\n \\right]^Tc_T\r\n$$\r\n\r\n$$\r\n\\nabla_{u_T}Q(x_T,u_T)=C_{u_T,x_T}x_T+C_{u_T,u_T}u_T+c_{u_T}^T=0 \r\n$$\r\n\r\n$$\r\nC_T=\r\n \\left[\r\n \\begin{matrix}\r\n C_{x_T,x_T} & C_{x_T,u_T}\\\\\r\n C_{u_T,x_T} & C_{u_T,u_T}\\\\\r\n \\end{matrix}\r\n \\right]\r\n$$\r\n\r\n$$\r\nc_T=\r\n \\left[\r\n \\begin{matrix}\r\n c_{x_T}\\\\\r\n c_{u_T}\\\\\r\n \\end{matrix}\r\n \\right]\r\n$$\r\n\r\n$$\r\nu_T=-C_{u_T,u_T}^{-1}(C_{u_T,x_T}x_T+c_{u_T})\r\n$$\r\n\r\n求解出t时刻的action\r\n\r\n\r\n\r\n\r\n\r\nbackward即更新参数\r\n\r\nforward得到结果\r\n\r\n\r\n\r\n#### Nonlinear case:\r\n\r\n\r\n\r\nNonlinear case use iterate method\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.4946911334991455,
"alphanum_fraction": 0.5255791544914246,
"avg_line_length": 18.65999984741211,
"blob_id": "8e92c1b621aa9e9dbf98d952651f87a514ab1a5a",
"content_id": "13b30ee0736322f463a57dd225f7a7d5312055d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2276,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 100,
"path": "/leetcode_note/To_type.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Binary_search\r\n\r\npython\r\n\r\n```python\r\n# upper_bound\r\ndef upper_bound(self, nums, target):\r\n left, right = 0, len(nums)-1\r\n while left < right:\r\n mid = int((left+right)/2)\r\n if nums[mid] <= target:\r\n left = mid + 1\r\n else:\r\n right = mid\r\n return left\r\n# lower_bound\r\ndef lower_bound(self, nums, target):\r\n left, right = 0, len(nums)-1\r\n while left < right:\r\n mid = int((left+right)/2)\r\n if nums[mid] < target:\r\n left = mid + 1\r\n else:\r\n right = mid\r\n return left \r\n```\r\n\r\n\r\n\r\n\r\n\r\n```python\r\nimport heapq\r\nnums = [2,1,5,7,3,6]\r\n\r\nheapq.heapify(nums) #创建堆 都是最小堆\r\nnums[0] #Nums[0]永远表示最小值,类似于top的功能 1\r\n\r\nheapq.heappush(nums,5) #push\r\nheapq.heappop(nums) #弹出最小值\r\n\r\nheapq.nlargest(n , heapq, key=None) \r\nheapq.nsmallest(n , heapq, key=None) \r\n从堆中找出做大的N个数,key的作用和sorted( )方法里面的key类似\r\na = [0, 1, 2, 3, 4, 5, 5, 7, 8, 10, 15, 20, 25]\r\nheapq.nlargest(5,a)\r\n```\r\n\r\n\r\n\r\nsort与 lambda表达式结合起来:\r\n\r\n```\r\npeople.sort(key=lambda x:(-x[0],x[1]))\r\n[[7,0], [4,4], [7,1], [5,0], [6,1], [5,2]]\r\n表示按照 x[0]降序 x[1]增序排序\r\n[[7, 0], [7, 1], [6, 1], [5, 0], [5, 2], [4, 4]]\r\n```\r\n\r\n自定义sort cmp\r\n\r\n```\r\nfrom functools import cmp_to_key\r\ndef cmp(x,y):\r\n if x.isvisited!=y.isvisited:\r\n return x.isvisited-y.isvisited\r\n elif (x.capital<=W)!=(y.capital<=W):\r\n return -(x.capital<=W)+(y.capital<=W)\r\n return y.profit-x.profit\r\nnodes.sort(key=cmp_to_key(cmp))\r\n```\r\n\r\npython提供了raw_input, input两个函数来从键盘中读取一行\r\n\r\n```python\r\nstr = input()\r\nstr = raw_input()\r\n```\r\n\r\ninput函数可以处理python表达式\r\n\r\n上述版本没有path compression\r\n\r\n```python\r\nclass DSU:\r\n def __init__(self):\r\n self.parents = {}\r\n\r\n\r\n def find(self, x): #compression\r\n while x != self.parents[x]:\r\n self.parents[x] = self.parents[self.parents[x]]\r\n x = self.parents[x]\r\n return x\r\n\r\n def union(self, x, y):\r\n par_x, par_y = self.find(x), self.find(y)\r\n if par_x != par_y:\r\n self.parents[par_y] = par_x\r\n```\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.4986737370491028,
"alphanum_fraction": 0.5258620977401733,
"avg_line_length": 13.171717643737793,
"blob_id": "80ffab671c8cad8ad7f6f884f77d9fdfab130108",
"content_id": "92a6aea5e9d86fb5e89b1ea8113f85974c3151a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2357,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 99,
"path": "/math&&deeplearning/math/随机过程.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 随机过程\r\n\r\n概念:\r\n\r\n随机变量:表示随机实验各种结果的实值单值函数\r\n\r\n随机变量的分布函数F:\r\n\r\n$F(x) = P\\{X \\le x\\}$\r\n\r\n如果随机变量是离散的\r\n\r\n$F(x) = \\sum_{y\\le x} P\\{X=y\\}$\r\n\r\n如果变量是连续的,存在概率密度函数f(x)\r\n\r\n$F(x) = \\int_{-\\infin}^xf(x)dx$ \r\n\r\n\r\n\r\n两个随机变量X,Y的联合分布函数:\r\n\r\n$F(x,y) = P\\{X\\le x,Y\\le y\\}$\r\n\r\n如果有$F(x,y) = F_x(x)F_y(y)$则两个变量X,Y独立\r\n\r\n $F(x,y) = \\int_{-\\infin}^x\\int_{-\\infin}^yf(x,y)dydx$ 联合概率密度函数\r\n\r\n\r\n\r\n期望:均值 $E[X]$\r\n\r\n方差: $VarX = E[(X-E[X])^2] = E[X^2]-E^2[X]$ \r\n\r\n如果两个随机变量是不相关的,则协方差为0\r\n\r\n$Cov(X,Y) = E[(X-E[X])(Y-E[Y])]=E[XY]-E[X]E[Y] = 0$ \r\n\r\n独立随机变量不相关,不相关的两个随机变量不一样独立\r\n\r\n\r\n\r\n随机变量之和的期望等于期望之和\r\n\r\n$E[\\sum_{i=1}^nX_i] = \\sum_{i=1}^nE[X_i]$\r\n\r\n$Var[\\sum_{i=1}^nX_i] = \\sum_{i=1}^nVar[X_i]+2\\sum \\sum_{i<j}Cov(X_i,X_j)$\r\n\r\n\r\n\r\n##### 矩母函数,特征函数,拉普拉斯变换\r\n\r\n矩母函数,特征函数,拉普拉斯变换唯一决定了分布\r\n\r\n$\\varphi(t) = E[e^{tX}]$\r\n\r\nt = 0时:\r\n\r\n$\\varphi^n(0) = E[X^n]$\r\n\r\n例题:矿井有三扇门:第一扇门花2小时出去,第二扇门花三小时回到矿井,第三扇门花5小时回到矿井,算期望\r\n\r\n$E[X] = 1/3·E[X|Y=1]+1/3·E[X|Y=2]+1/3·E[X|Y=3]]$\r\n\r\n$E[X] = 2/3+3/3+1/3·E[X]+5/3+1/3·E[X]$\r\n\r\n$E[X] = 10$\r\n\r\n\r\n\r\n##### 指数分布,无记忆性,失效率函数\r\n\r\n概率密度函数为\r\n\r\n$f(x) = \\lambda e^{-\\lambda x},x \\ge 0,if x<0, f(x) = 0$\r\n\r\n$F(x) = 1- e^{-\\lambda x},x \\ge 0$\r\n\r\n称为指数分布,指数分布无记忆性,定于:\r\n\r\n$P\\{X>s+t|X>t\\} = P\\{X>s\\}$\r\n\r\n$\\frac{\\overline{F(s+t)}}{\\overline{F(s)}} =\\overline{F(t)} ,\\overline{F(t)} = 1-F(t)$\r\n\r\n一台机器已经工作了t小时的条件下,其继续工作s小时的概率分布和新机器工作s小时的概率分布是相同的\r\n\r\n失效函数$\\lambda (t) = \\frac{f(t)}{\\overline{F(t)}}$\r\n\r\n用来表示已经工作了t时间的原件失效的概率强度\r\n\r\n对于指数分布的随机变量而言,其失效函数为\r\n\r\n$\\lambda (t) = \\lambda$ \r\n\r\n\r\n\r\n随机过程$X=\\{X(t),t\\in T\\}$是一族随机变量,X(t)表示过程在t时刻的状态\r\n\r\nX的任一现实称为一条样本路径\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.6338729858398438,
"alphanum_fraction": 0.6363636255264282,
"avg_line_length": 19.648649215698242,
"blob_id": "1a869393dc16ff21bc6eab747d6952c97afa8037",
"content_id": "c910a7e49900dea3fdeba71cf286206ad1b652ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1069,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 37,
"path": "/pyparsing.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Pyparsing\r\n\r\npyparsing是由纯python编写的,易于使用。pyparsing提供了一些列包用来文本解析。\r\n\r\n```python\r\nfrom pyparsing import *\r\ntest=[\"Hello, World!\",\"Good morning, miss!\"]\r\n\r\nword=Word(alphas+\"'.\")\r\nsalutation=OneOrMore(word)\r\ncomma=Literal(\",\")\r\ngreetee=OneOrMore(word)\r\nendpunc=oneOf(\"! ?\")\r\ngreeting = salutation+comma+greetee+endpunc\r\n\r\nfor t in test:\r\n results=greeting.parseString(t)\r\n print(results)\r\n salutation=[]\r\n for token in results:\r\n if token==\",\":\r\n break\r\n salutation.append(token)\r\n print(salutation)\r\n['Hello', ',', 'World', '!']\r\n['Hello']\r\n['Good', 'morning', ',', 'miss', '!']\r\n['Good', 'morning']\r\n```\r\n\r\n\r\n\r\n##### LL 1文法 \r\n\r\nLL(k)文法,表示使用k个词法单元向前探查,对于某个文法,如果存在某个分析器可以在不用回溯法回溯的情况下处理该文法,则称为LL(k)文法。严格的LL1文法相当受欢迎。\r\n\r\n正则表达式与pyparsing相比,正则表达式不能处理递归,这是其解析时的受限所在。\r\n\r\n"
},
{
"alpha_fraction": 0.524104654788971,
"alphanum_fraction": 0.5488981008529663,
"avg_line_length": 8.5,
"blob_id": "5d2b8bf3ce53c1138d20e5dda9d53c99a4868447",
"content_id": "22a403626621d9f050bbf8d621842930304693d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2098,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 138,
"path": "/os_instructions/linux/shell脚本.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": " #### shell脚本\r\n\r\necho 在输出打印 \r\n\r\n```\r\necho \"start style transfering\"\r\necho $count\r\n```\r\n\r\nfor 循环\r\n\r\n```\r\nfor content in 10 11 12 13 14\r\ndo\r\necho \"test\"\r\ndone\r\n```\r\n\r\nstr生成\r\n\r\n```\r\nstr_content=\"content_image\"$content\".jpg\"\r\n```\r\n\r\n加1\r\n\r\n```\r\ncount=$(($count+1))\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### 目标:统计文件中不同word的数量\r\n\r\n```\r\ncat cora.cites |tr -cs \"[0-9]\" \"\\n\"| sort |uniq -c| wc\r\n```\r\n\r\ncat cora.cites表示将文件中的内容读进来\r\n\r\ntr -cs \"[0-9]\" \"\\n\" 表示将文件中除了0-9的数字之外的其他符号用\\n替换\r\n\r\nsort表示将所有的行按照某顺序排列\r\n\r\nuniq -c表示去除重复的行(只在上下两行间比较,因此要配合之前的sort使用)\r\n\r\nwc 表示word count 分别输出表示行数、词数、字符数\r\n\r\n\r\n\r\n##### 统计文件的行数\r\n\r\n```\r\ncat test_book.txt | wc\r\n```\r\n\r\n输出表示行数、词数、字符数\r\n\r\n\r\n\r\n##### 统计文件的不同单词的数量\r\n\r\n```\r\ncat test_book.txt |tr -cs \"[0-9][a-z][A-Z]\" \"\\n\"|sort|uniq -c\r\n```\r\n\r\n\r\n\r\n```\r\n1 12\r\n3 a\r\n1 book\r\n1 book1\r\n1 book2\r\n3 is\r\n3 test\r\n3 this\r\n```\r\n\r\n\r\n\r\n##### 统计当前文件夹下文件的个数\r\n\r\n```\r\nls -l |grep \"^-\"|wc -l\r\n```\r\n\r\n**grep \"^-\"** \r\n\r\n将长列表输出信息过滤一部分,只保留一般文件,如果只保留目录就是 ^d\r\n\r\n\r\n\r\n**统计当前文件夹下目录的个数**\r\n\r\n```\r\nls -l |grep \"^d\"|wc -l\r\n```\r\n\r\n\r\n\r\n##### 统计当前文件夹下文件的个数,包括子文件夹里的** \r\n\r\n```\r\nls -lR|grep \"^-\"|wc -l\r\n```\r\n\r\n\r\n\r\n**统计文件夹下目录的个数,包括子文件夹里的**\r\n\r\n```\r\nls -lR|grep \"^d\"|wc -l\r\nfind ./ -type f | wc -l\r\n```\r\n\r\n\r\n\r\nfind 查找\r\n\r\n./当前的文件下\r\n\r\n-type f 文件\r\n\r\nfind 自动查找子文件夹下的文件,如果只要招当前文件夹下\r\n\r\n```\r\nfind ./ -type f -maxdepth 1\r\n```\r\n\r\nDifference of Bash and Dash\r\nUbuntu目前都默认使用dash 更快 效率更高,但是shell还是bash\r\n解决兼容性问题:\r\n1. 在bash脚本的y第一行加上 \"#!/bin/bash\"\r\n2. Makefile中设置 SHELL=/bin/bash\r\n3. sudo dpkg-reconfigure dash 选择NO\r\n\r\n"
},
{
"alpha_fraction": 0.6514455676078796,
"alphanum_fraction": 0.682248055934906,
"avg_line_length": 16.984615325927734,
"blob_id": "236031f853c62022592978540171ac03ec2af2cd",
"content_id": "efacc83e09be4abf77550993f64b4b1c7c3cc3e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 10819,
"license_type": "no_license",
"max_line_length": 235,
"num_lines": 390,
"path": "/产品业界.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 常识\r\n\r\n##### AB test\r\n\r\nab test指的是为同一个优化目标制定的两个方案,让一部分用户使用a方案,让另一些用户使用b方案,统计并对比不同方案的转化率,点击量等指标,从而提升优化目标。\r\n\r\n\r\n\r\n##### SS Table\r\n\r\nSS Table (sorted String) Table is a file of key/value strin pairs,sorted by keys.\r\n\r\n适合场景:\r\n\r\n1.需要高效地存储大量的键-值对数据\r\n2.数据是顺序写入\r\n3.要求高效地顺序读写\r\n4.没有随机读取或者对随机读取性能要求不高\r\n\r\n\r\n\r\nSS Table内部包含了任意长度、排好序的键值对<key,value>集合\r\n\r\n由两部分数据组成:索引和键值对数据。所有的key和value都是紧凑地存放在一起的,如果要读取某个键对应的值,需要通过索引中的key:offset来定位。\r\n\r\nSSTable文件中所有的键值对<key,value>是存放到一起的,所以SSTable在序列化成文件之后,是不可变的,因为此时的SSTable,就类似于一个数组一样,如果插入或者删除,需要移动一大片数据,开销比较大。\r\n顺序读取整个文件,就拿到了一个排好序的索引。如果文件很大,还可以为了加速访问而追加或者单独建立一个独立的key:offset的索引。\r\n\r\n\r\n\r\n### Mapreduce\r\n\r\nmapreduce可以分为input,split,map,shuffle,reduce,finalize六个步骤。本质上map是分解的过程,reduce是组合的过程。\r\n\r\n\r\n\r\n经典例子:\r\n1.distributed grep(查找): map(如果某个文件匹配到了,则输出被匹配到的结果),reduce(将所有的被匹配到的结果合起来)\r\n\r\n2.count of URL Access Frequency:map(将link输出为<URL,1>),reduce(将相同的key对应的组合,生成<URL,totalcount>)\r\n\r\n3.reverse web-link graph(从source->target,统计有多少source指向target):map(输出<target,source>),reduce:(将相同的key组合,得到<target,list(source)>)\r\n\r\n4.term-vector per host\r\n\r\n5.Inverted Index(倒排索引) 根据某个词找出出现该词的document\r\n\r\nmap:(输出<word, document ID>)\r\n\r\nreduce:(输出<word, list(document ID)>)\r\n\r\n6.distributed sort大数据排序\r\n\r\nmap:(输出<key,NULL>) 将数字作为key\r\n\r\nreduce:(将所有的map输出合起来即可)\r\n\r\nmapreduce中默认以key的顺序排序为序,因此利用这一点可以轻松实现distributed sort\r\n\r\n\r\n\r\n\r\n\r\n一个好用的画图工具:\r\n\r\nhttps://csacademy.com/app/graph_editor/\r\n\r\n##### cmder 调用bash后方向键无法使用?\r\n\r\nchoose your start up: shell:cmd\r\nstart up: command line %windir%\\system32\\bash.exe ~ -cur_console:p5\r\n\r\n\r\n\r\n##### O(n)时间复杂度找中位数\r\n\r\n主要利用快排递归划分的思想,可以在期望复杂度为O(n)的条件下求第k大数。快排的期望复杂度为O(nlogn),因为快排会递归处理划分的两边,而求第k大数则只需要处理划分的一边,其期望复杂度将是O(n)。详细的证明见《算法导论》\r\n\r\n我们可以这样粗略的思考:\r\n\r\n假设我们的数据足够的随机,每次划分都在数据序列的中间位置,那么第一次划分我们需要遍历约n个数,第二次需要遍历约n/2个数,...,这样递归下去,最后:n+n/2+n/(2^2)+n/(2^3)+...+n/(2^k)+... = (1+1/2+1/(2^2)+1/(2^3)+...+1/(2^k)+...)*n, 当k趋于无穷大的时候,上式的极限为2n。\r\n\r\n\r\n\r\n##### 在/etc文件夹下查找“logread”字符串\r\n\r\ngrep \"logread\" /etc -nr \r\n\r\n##### 查找文件\r\n\r\nfind -name \"inlink_statistics_util.cpp\" \r\n\r\n\r\n\r\nfirst hadoop program\r\n\r\nhttps://www.guru99.com/create-your-first-hadoop-program.html\r\n\r\n\r\n\r\nOpenCV panorama stitching\r\n\r\nhttps://www.pyimagesearch.com/2016/01/11/opencv-panorama-stitching/\r\n\r\nhttp://ppwwyyxx.com/2013/SIFT-and-Image-Stiching/\r\n\r\n##### 主要技术点:\r\n\r\n- **Step #1:** Detect keypoints (DoG, Harris, etc.) and extract local invariant descriptors (SIFT, SURF, etc.) from the two input images.\r\n\r\n- \r\n\r\n DOG: difference of Gaussian: 高斯金字塔\r\n\r\n 高斯金字塔构建过程:\r\n\r\n 1. 先将原图像扩大一倍之后作为高斯金字塔的第1组第1层,将第1组第1层图像经高斯卷积(其实就是高斯平滑或称高斯滤波)之后作为第1组金字塔的第2层\r\n\r\n 2. 一组图像下采样得到下一组图像\r\n\r\n DOG 高斯滤波之后做差相当于在原图上检测边缘,(高斯滤波的效果是使得边缘模糊,做差即为检测边缘)\r\n\r\n- **Step #2:** Match the descriptors between the two images.\r\n\r\n- **Step #3:** Use the [RANSAC algorithm](https://en.wikipedia.org/wiki/RANSAC) to estimate a [homography matrix](https://en.wikipedia.org/wiki/Homography_(computer_vision)) using our matched feature vectors.\r\n\r\n 在两幅图的Feature匹配上之后, 要算一个转移矩阵出来, 大家都说用一个[RANSAC](http://en.wikipedia.org/wiki/RANSAC) 算法. 名字听上去好NB啊: Random Sample Consensus, 其实很SB..大致就是: 先随机取些匹配点, 把矩阵解出来, 看这个矩阵Match了多少个点. 嗯, 这没问题, 然后..再随机取些点, 再解出来, 再随机取点, 再解出来..最后用 最好的那个.....给这算法跪了.\r\n\r\n- **Step #4:** Apply a warping transformation using the homography matrix obtained from **Step #3**.\r\n\r\n\r\n\r\n\r\n##### 统计文件行数\r\n\r\ncat a.txt | wc -l\r\n\r\n##### 统计文件非空行数\r\n\r\ncat a.txt | grep -v ^$ | wc -l\r\n\r\ngrep -v表示取反\r\n\r\n正则表达式中 ^表示行首 $表示行尾\r\n\r\n^$表示行首和行尾之间没有空\r\n\r\n\r\n\r\npython写脚本抢票\r\n\r\nhttps://zhuanlan.zhihu.com/p/25214682\r\n\r\n```python\r\n#12306秒抢Python代码\r\nfrom splinter.browser import Browser\r\nx = Browser(driver_name=\"chrome\")\r\nurl = “https://kyfw.12306.cn/otn/leftTicket/init”\r\nx = Browser(driver_name=\"chrome\")\r\nx.visit(url)\r\n#填写登陆账户、密码\r\nx.find_by_text(u\"登录\").click()\r\nx.fill(\"loginUserDTO.user_name\",\"your login name\")\r\nx.fill(\"userDTO.password\",\"your password\")\r\n#填写出发点目的地\r\nx.cookies.add({\"_jc_save_fromStation\":\"%u4E0A%u6D77%2CSHH\"})\r\nx.cookies.add({\"_jc_save_fromDate\":\"2016-01-20\"})\r\nx.cookies.add({u'_jc_save_toStation':'%u6C38%u5DDE%2CAOQ'})\r\n#加载查询\r\nx.reload()\r\nx.find_by_text(u\"查询\").click()\r\n#预定\r\nx.find_by_text(u\"预订\")[1].click()\r\n#选择乘客\r\nx.find_by_text(u\"数据分析侠\")[1].click()\r\n```\r\n\r\n\r\n\r\n##### lightgbm模型画出feature name\r\n\r\n```python\r\ndtrain=lgb.Dataset('./newlink_score_new.txt.train',feature_name=feature_names)\r\ndval=lgb.Dataset('./newlink_score_new.txt.val',feature_name=feature_names)\r\n\r\nparam = {'learning_rate': 0.1,'num_leaves':63, 'objective': 'regression'}\r\nbst = lgb.train(param, dtrain, 2000,valid_sets=dval, feature_name=feature_names, early_stopping_rounds=5)\r\nax=lgb.plot_importance(bst,xlabel='Feature names',ylabel='Features')\r\n```\r\n\r\n\r\nIf you have a validation set, you can use early stopping to find the optimal number of boosting rounds. Early stopping requires at least one set in valid_sets. \r\n\r\n\r\n\r\n##### 软链\r\n\r\n创建软链:文件夹建立软链接(用绝对地址)\r\n看起来在地址A工作但是实际操作都是在B执行\r\n\r\n```\r\nsudo ln -s /apsarapangu/disk3/wb-sp542977/ /home/wb-sp542977/ \r\n```\r\n\r\n\r\ndf -h 显示文件系统上的可用空间(df 命令)\r\n\r\n\r\n\r\n工程向\r\n\r\nscons 相当于编译\r\n\r\nabxp 相当于下载相应的库,同时编译\r\n\r\n两者都需要在特定的目录下执行 \r\n\r\n\r\n\r\n##### python3 for循环中list与迭代器的区别:\r\n\r\nreadlines()\r\n\r\n```python\r\nf=open(\"a.txt\")\r\ntype(f.readlines())\r\n\r\n#list\r\n```\r\n\r\n\r\n\r\n若要使用迭代器则使用\r\n\r\n```python\r\nf=open(\"a.txt\")\r\nfor line in f:\r\n print line\r\n```\r\n\r\n\r\n\r\nvim中跳转到指定行数\r\n\r\n:n\r\n\r\n跳到第n行\r\n\r\n\r\n\r\n\r\n\r\npython zip函数\r\n\r\nzip函数将可迭代的对象作为参数,将对象中对应的元素打包成一个元组,然后返回这些元组构成的list\r\n\r\n```python\r\na=[1,2,3]\r\nb=[4,5,6]\r\nc=[7,8,9]\r\nzip(a,b,c)\r\n\r\n[(1,4,7),(2,5,8),(3,6,9)]\r\n\r\na=[1,2,3,0]\r\nb=[4,5,6]\r\nc=[7,8,9]\r\nzip(a,b,c)\r\n#如果每个迭代器长度不一,则取最短的\r\n[(1,4,7),(2,5,8),(3,6,9)]\r\n```\r\n\r\n查看linux内存的命令\r\n\r\n```\r\ncat /proc/meminfo\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### 余弦相似度与皮尔逊相似度:\r\n\r\n皮尔逊相似度具有平移不变性与尺度不变性\r\n$$\r\nCorr(x,y)=\\frac{\\sum_i(x_i-\\overline{x})(y_i-\\overline{y})}{\\sqrt{(x_i-\\overline{x})^2} \\sqrt{(y_i-\\overline{y})^2}}=\r\n\\\\\r\n\\frac{<x-\\overline{x},y-\\overline{y}>}{||x-\\overline{x}|·|y-\\overline{y}||}=\r\n\r\nCosSim(x-\\overline{x},y-\\overline{y})\r\n$$\r\n而余弦相似度具有尺度不变性 \r\n$$\r\ncos(\\theta)=\\frac{\\sum_{k=1}^n x_{k}y_{k}}{\\sqrt{\\sum x_i^2} \\sqrt{\\sum y_i^2}}\r\n$$\r\n\r\n\r\n\r\nLearning to Rank简介\r\n\r\n\r\nhttps://www.cnblogs.com/bentuwuying/p/6681943.html\r\n\r\n\r\nall dataset:https://ls11-www.cs.tu-dortmund.de/staff/morris/graphkerneldatasets\r\n\r\n\r\n\r\n##### 位 字节 字\r\n\r\n位是最小的单位,只能表示01,一般字节包括8个位\r\n\r\n\r\n字:有些编码是2个字节表示,有些是4个字节表示\r\n\r\n\r\n\r\npython setup.py install意味着什么\r\n\r\nhttps://www.kancloud.cn/tuna_dai_/day01/535536\r\n\r\n两本书\r\n\r\nFBI教你读心术\r\n\r\n别生气啦\r\n\r\n\r\n\r\n\r\n\r\n\r\n##### vim中强大的替换功能解决python中space和tab混用的问题\r\n\r\n:1,$s/^I/ /\r\n\r\n表示从第一行到最后一行,执行替换操作,将tab替换为四个空格\r\n\r\n\r\n\r\n\r\n\r\n##### base64 加密解密\r\nhttps://codebeautify.org/base64-to-image-converter\r\n\r\nhttps://www.base64-image.de/\r\n\r\nBase64是一种可逆的编码方式,且不算是加密方式,简单来说base64是一种用64个ascii字符来表示任意二进制数据的方法。 \r\n\r\n```python\r\nimport base64\r\nf = open('./MAP.png','rb')\r\ndata = f.read()\r\nstr1 = data.encode(\"base64\")\r\nprint(str1)\r\n\r\noutput = open(\"./output.png\",\"wb\")\r\noutput.write(base64.decodestring(str1))\r\n```\r\n\r\n\r\n\r\n论坛 stackoverflow, Cross Validated\r\n\r\n\r\n\r\nweight:weight = np.array([1,2,2,2,2,2,2])\r\nweight = torch.from_numpy(weight).float()\r\nloss_val = F.cross_entropy(output[idx_val], labels[idx_val],weight)\r\n\r\n\r\n\r\n##### tf.gfile\r\n\r\ntf.gfile模块将常用的大数据分布时平台的文件读写接口统一起来\r\n\r\n利用gfile 可以很方便的去操作类似 hdfs(hadoop file system), oss(阿里云Object Storage Service),pangu(阿里云)的读写接口\r\n\r\n\r\n\r\nsh x.sh 文件在执行过程中会打开一个subshell在其中运行,结束后退出,比如在sh文件中有cd等操作,运行结束后会回到原来的位置,如果是. x.sh或者source x.sh就会完全执行,结束后会到一个新的路径下\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n强化学习很多需要online测试,因此很多应用场景是游戏、棋类等不太会有较大负面影响的领域,带有业务的场景很多不适用于强化学习。"
},
{
"alpha_fraction": 0.6575149297714233,
"alphanum_fraction": 0.6994016170501709,
"avg_line_length": 16.09554100036621,
"blob_id": "22e719e995b8b1dd81230f9d945c898ff52b49b2",
"content_id": "e69e86683f3c1a6630b1b7d6a2321a5ad7e58488",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3489,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 157,
"path": "/envirment.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Enviroments\r\n\r\nthis file includes methods how to configure or install\r\n\r\n#### opengl with vs2017\r\n\r\nhttps://blog.csdn.net/qq_19003345/article/details/76098781\r\n\r\n1. 下载:\r\n http://www.opengl.org/resources/libraries/glut/glutdlls37beta.zip\r\n2. 将.dll文件放到系统目录下,C:\\Windows\\System32(32位) C:\\Windows\\SysWOW64(64位)\r\n3. 将所有的.lib文件放VS安装目录下D:\\vs2017\\VC\\Tools\\MSVC\\14.12.25827\\lib x86 x64 都放一份\r\n4. .h文件全部放在VS安装目录下D:\\vs2017\\VC\\Tools\\MSVC\\14.12.25827\\include 中,如果无GL文件夹,则新建一个\r\n5. 新建vs项目,选择属性,在链接器中选择输入,在附加依赖项中填入如下:glut.lib;GLUT32.LIB;Opengl32.lib;Glu32.lib\r\n6. 测试:\r\n\r\n```\r\n#include<windows.h> \r\n#include<gl\\GL.h> \r\n#include<gl\\GLU.h> \r\n注意要把windows.h放在第一\r\n```\r\n\r\n#### mingw \r\n```\r\nmingw-developer-toolkit\r\nmingw32-base\r\nmingw32-gcc-g++\r\nmsys-base\r\n```\r\n\r\ninstallation apply changes\r\n\r\n\r\n\r\n#### mysql\r\n\r\nHow to install mysql on ubuntu:\r\n\r\nhttps://www.digitalocean.com/community/tutorials/how-to-install-mysql-on-ubuntu-18-04 \r\nhttps://stackoverflow.com/questions/11990708/error-cant-connect-to-local-mysql-server-through-socket-var-run-mysqld-mysq\r\n\r\n```\r\nsudo apt update\r\nsudo apt install mysql-server\r\nsudo service mysql start\r\nsudo mysql_secure_installation\r\n```\r\n\r\nenter:\r\n\r\n```\r\nsudo mysql\r\n\\q\r\n```\r\n\r\n#### python\r\n\r\n安装pip\r\n\r\n```\r\npip install requests\r\n```\r\n\r\npip install requirments.txt\r\n\r\n```\r\n安装依赖: pip install -r requirements.txt\r\n```\r\n\r\n#### 使用douban镜像快速安装\r\n\r\n```python\r\npip install -i http://pypi.douban.com/simple --trusted-host pypi.douban.com numpy\r\n```\r\n\r\n需要创建或修改配置文件(一般都是创建)\r\nlinux的文件在~/.pip/pip.conf\r\nwindows在%HOMEPATH%\\pip\\pip.ini)\r\n\r\n```\r\n[global]\r\nindex-url = http://pypi.douban.com/simple\r\n[install]\r\ntrusted-host=pypi.douban.com\r\n\r\n```\r\n\r\nsudo apt install 加速 https://mirrors.zju.edu.cn/\r\n\r\n将/etc/apt/sources.list替换\r\n\r\n安装python2 and python3\r\n\r\n```\r\nwget https://www.python.org/ftp/python/3.6.0/Python-3.6.0.tgz\r\ntar -zxf Python-3.6.0.tgz\r\ncd Python-3.6.0\r\n./configure\r\nmake\r\n\r\npython #进入python2\r\npython3 #进入python3\r\n```\r\n\r\n一般可以使用anaconda虚拟环境\r\n\r\n\r\n\r\n#### windows 环境变量配置\r\n\r\n1. 电脑右键 属性-高级系统设置-环境变量-双击系统变量 将python.exe文件所在的路径添加进去 例如D:\\python36\r\n2. 安装完python之后 安装pip:在D:\\python36文件夹下检查是否有easy_install.exe文件\r\n 然后在cmd里面打开,easy_install.exe pip 安装pip\r\n 然后也要将pip.exe所在的文件夹的路径添加到环境变量中去D:\\python36\\Scripts\r\n\r\n\r\n\r\n#### Anaconda\r\n\r\n```\r\nconda create -n your_env_name python=X.X(2.7、3.6等)命令创建python版本为X.X\r\nactivate py #windows\r\nsource activate py #linux 进入虚拟环境\r\nsource deactivate xxx\r\n```\r\n\r\n\r\n安装好之后要把路径配置好 \r\n\r\n```\r\nexport PATH=/home/shg/anaconda3/bin:$PATH\r\n```\r\n\r\n加到/home 下 .bashrc文件中,该文件表示在进入bash之前会执行的程序\r\n\r\n测试:\r\n\r\n```\r\nconda --version\r\n```\r\n\r\n下载:\r\n\r\n```\r\nconda install xxx\r\n```\r\n\r\n需要安装的库:\r\n\r\n```\r\nconda install opencv\r\npython numpy matplotlib scipy scikit-learn opencv jupyter pillow( pip3 install --user Pillow,pandas\r\n#install pytorch:\r\nconda install pytorch torchvision -c pytorch\r\nhttps://pytorch.org/get-started/locally/\r\n```\r\n"
},
{
"alpha_fraction": 0.699680507183075,
"alphanum_fraction": 0.7092651724815369,
"avg_line_length": 18.733333587646484,
"blob_id": "d3f46f441dab9dd60e5b2fbcbb718252d3dace4a",
"content_id": "5382811feb9e74009ac9d564e095f98685dbf3ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 329,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 15,
"path": "/BAT.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "bat脚本 在windows系统上运行\r\n\r\n\r\n\r\n```bat\r\nset data_path=ca-CondMat\r\ncd data\r\npython create_undirected2.py %data_path%\r\ncd ..\r\nset new_file=undirected_%data_path%.edges\r\nset output_file=%data_path%_counts.out\r\norca.exe node 4 data/%new_file% output/%output_file%\r\npython create_motif_count2.py %data_path%\r\npause\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.4946575462818146,
"alphanum_fraction": 0.5370467901229858,
"avg_line_length": 21.538145065307617,
"blob_id": "8b862ecff23b1496215e444b943a85b1a31f1a45",
"content_id": "034767bf8f3208e4aea3d14e651df74dd1a29164",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 11828,
"license_type": "no_license",
"max_line_length": 178,
"num_lines": 485,
"path": "/leetcode_note/Sliding Windows.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Sliding Windows\r\n\r\nsliding windows techniques有时可用于substring等问题上\r\n\r\n\r\n\r\n##### leetcode 159. Longest Substring with At Most Two Distinct Characters\r\n\r\nGiven a string **s** , find the length of the longest substring **t** that contains **at most** 2 distinct characters.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: \"eceba\"\r\nOutput: 3\r\nExplanation: t is \"ece\" which its length is 3.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: \"ccaabbb\"\r\nOutput: 5\r\nExplanation: t is \"aabbb\" which its length is 5\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def lengthOfLongestSubstringTwoDistinct(self, s):\r\n num_chars, start, n, res = 2, 0, len(s), 0\r\n seen = {}\r\n for end in range(n):\r\n val = seen.get(s[end], 0)\r\n if val == 0:\r\n num_chars -= 1\r\n seen[s[end]] = 1\r\n else:\r\n seen[s[end]] += 1\r\n while num_chars < 0:\r\n if seen[s[start]] == 1:\r\n num_chars += 1\r\n seen[s[start]] -= 1\r\n start += 1\r\n res = max(res, end-start+1)\r\n return res\r\n```\r\n\r\n这边almost 2也可以换成k\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 424 Longest Repeating Character Replacement\r\n\r\nGiven a string `s` that consists of only uppercase English letters, you can perform at most `k` operations on that string.\r\n\r\nIn one operation, you can choose **any** character of the string and change it to any other uppercase English character.\r\n\r\nFind the length of the longest sub-string containing all repeating letters you can get after performing the above operations.\r\n\r\n**Note:**\r\nBoth the string's length and *k* will not exceed 104.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput:\r\ns = \"ABAB\", k = 2\r\n\r\nOutput:\r\n4\r\n\r\nExplanation:\r\nReplace the two 'A's with two 'B's or vice versa.\r\n```\r\n\r\n \r\n\r\n**Example 2:**\r\n\r\n```\r\nInput:\r\ns = \"AABABBA\", k = 1\r\n\r\nOutput:\r\n4\r\n\r\nExplanation:\r\nReplace the one 'A' in the middle with 'B' and form \"AABBBBA\".\r\nThe substring \"BBBB\" has the longest repeating letters, which is 4.\r\n```\r\n\r\n\r\n\r\n```python\r\nfrom collections import defaultdict\r\nclass Solution:\r\n def characterReplacement(self, s, k):\r\n count = defaultdict(int)\r\n res = max_count = left = 0\r\n for right in range(len(s)):\r\n count[s[right]] = count.get(s[right], 0) + 1\r\n max_count = max(max_count, count[s[right]])\r\n if right - left + 1 - max_count>k:\r\n count[s[left]] -= 1\r\n left += 1\r\n res = max(res, right-left+1)\r\n return res\r\n```\r\n\r\nsliding window\r\n\r\nright表示所探究的子字符串的右侧\r\n\r\n例如子字符串AAABC,max_count=3 right-left+1-max_count=2 即如果要将这个字符串转变为同一个字符需要两次操作,如果次数大于k则需要left后移\r\n\r\n\r\n\r\n##### leetcode 1004. Max Consecutive Ones III\r\n\r\nGiven an array `A` of 0s and 1s, we may change up to `K` values from 0 to 1.\r\n\r\nReturn the length of the longest (contiguous) subarray that contains only 1s. \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: A = [1,1,1,0,0,0,1,1,1,1,0], K = 2\r\nOutput: 6\r\nExplanation: \r\n[1,1,1,0,0,1,1,1,1,1,1]\r\nBolded numbers were flipped from 0 to 1. The longest subarray is underlined.\r\n\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: A = [0,0,1,1,0,0,1,1,1,0,1,1,0,0,0,1,1,1,1], K = 3\r\nOutput: 10\r\nExplanation: \r\n[0,0,1,1,1,1,1,1,1,1,1,1,0,0,0,1,1,1,1]\r\nBolded numbers were flipped from 0 to 1. The longest subarray is underlined.\r\n```\r\n\r\n**Note:**\r\n\r\n1. `1 <= A.length <= 20000`\r\n2. `0 <= K <= A.length`\r\n3. `A[i]` is `0` or `1` \r\n\r\nnums array中如果有K个xxx的要求,例如替换K个,K个不同字母之类的都考虑使用sliding windows\r\n\r\n```python\r\nclass Solution:\r\n def longestOnes(self, A, K):\r\n start, n, res = 0, len(A), 0\r\n for end in range(n):\r\n if A[end] == 0:\r\n K -= 1\r\n while K < 0:\r\n if A[start] == 0:\r\n K += 1\r\n start += 1\r\n res = max(res, end - start + 1)\r\n return res\r\n```\r\n\r\n\r\n\r\n##### leetcode 1100 Find K-Length Substrings With No Repeated Characters\r\n\r\nGiven a string `S`, return the number of substrings of length `K` with no repeated characters.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: S = \"havefunonleetcode\", K = 5\r\nOutput: 6\r\nExplanation: \r\nThere are 6 substrings they are : 'havef','avefu','vefun','efuno','etcod','tcode'.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: S = \"home\", K = 5\r\nOutput: 0\r\nExplanation: \r\nNotice K can be larger than the length of S. In this case is not possible to find any substring.\r\n```\r\n\r\n**Note:**\r\n\r\n1. `1 <= S.length <= 10^4`\r\n2. All characters of S are lowercase English letters.\r\n3. `1 <= K <= 10^4`\r\n\r\n```python\r\nclass Solution:\r\n def numKLenSubstrNoRepeats(self, S, K):\r\n n = len(S)\r\n if n < K: return 0\r\n res, seen = 0, {}\r\n for i in range(K):\r\n val = seen.get(S[i], 0)\r\n if val == 0:\r\n seen[S[i]] = 1\r\n else:\r\n seen[S[i]] += 1\r\n if len(seen) == K: res += 1\r\n for step in range(n-K):\r\n val = seen.get(S[step], 0)\r\n if val == 1:\r\n seen.pop(S[step])\r\n else:\r\n seen[S[step]] -= 1\r\n val = seen.get(S[step + K], 0)\r\n if val == 0:\r\n seen[S[step + K]] = 1\r\n else:\r\n seen[S[step + K]] += 1\r\n if len(seen) == K: res += 1\r\n return res\r\n```\r\n\r\n\r\n\r\n##### leetcode 1151 Minimum Swaps to Group All 1's Together\r\n\r\nGiven a binary array `data`, return the minimum number of swaps required to group all `1`’s present in the array together in **any place** in the array.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [1,0,1,0,1]\r\nOutput: 1\r\nExplanation: \r\nThere are 3 ways to group all 1's together:\r\n[1,1,1,0,0] using 1 swap.\r\n[0,1,1,1,0] using 2 swaps.\r\n[0,0,1,1,1] using 1 swap.\r\nThe minimum is 1.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [0,0,0,1,0]\r\nOutput: 0\r\nExplanation: \r\nSince there is only one 1 in the array, no swaps needed.\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: [1,0,1,0,1,0,0,1,1,0,1]\r\nOutput: 3\r\nExplanation: \r\nOne possible solution that uses 3 swaps is [0,0,0,0,0,1,1,1,1,1,1].\r\n```\r\n\r\n**Note**\r\n\r\n1. `1 <= data.length <= 10^5`\r\n2. `0 <= data[i] <= 1`\r\n\r\n```python\r\nclass Solution:\r\n def minSwaps(self, data):\r\n n, one = len(data), sum(data)\r\n temp_sum = sum(data[:one])\r\n res = one - temp_sum\r\n for start in range(n - one):\r\n temp_sum = temp_sum - data[start] + data[start+one]\r\n res = min(res, one - temp_sum)\r\n return res\r\n```\r\n\r\n控制一个宽度为one的window,one是data中1的数量\r\n\r\n\r\n\r\n\r\n\r\n#### leetcode 1248 Count Number of Nice Subarrays\r\n\r\nGiven an array of integers `nums` and an integer `k`. A subarray is called **nice** if there are `k` odd numbers on it.\r\n\r\nReturn the number of **nice** sub-arrays.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: nums = [1,1,2,1,1], k = 3\r\nOutput: 2\r\nExplanation: The only sub-arrays with 3 odd numbers are [1,1,2,1] and [1,2,1,1].\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: nums = [2,4,6], k = 1\r\nOutput: 0\r\nExplanation: There is no odd numbers in the array.\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: nums = [2,2,2,1,2,2,1,2,2,2], k = 2\r\nOutput: 16\r\n```\r\n\r\n \r\n\r\n**Constraints:**\r\n\r\n- `1 <= nums.length <= 50000`\r\n- `1 <= nums[i] <= 10^5`\r\n- `1 <= k <= nums.length`\r\n\r\n```python\r\nclass Solution(object):\r\n def numberOfSubarrays(self, nums, k):\r\n def subarray(k):\r\n ans, i = 0, 0\r\n n = len(nums)\r\n for j in range(n):\r\n k -= nums[j]%2\r\n while (k < 0):\r\n k += nums[i]%2\r\n i += 1\r\n ans += j - i + 1\r\n return ans\r\n return subarray(k) - subarray(k-1)\r\n```\r\n\r\n正好有k个奇数= k个或以下奇数的substring个数-k-1个或以下substring个数\r\n\r\n\r\n\r\n##### leetcode 992. Subarrays with K Different Integers\r\n\r\nGiven an array `A` of positive integers, call a (contiguous, not necessarily distinct) subarray of `A` *good* if the number of different integers in that subarray is exactly `K`.\r\n\r\n(For example, `[1,2,3,1,2]` has `3` different integers: `1`, `2`, and `3`.)\r\n\r\nReturn the number of good subarrays of `A`.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: A = [1,2,1,2,3], K = 2\r\nOutput: 7\r\nExplanation: Subarrays formed with exactly 2 different integers: [1,2], [2,1], [1,2], [2,3], [1,2,1], [2,1,2], [1,2,1,2].\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: A = [1,2,1,3,4], K = 3\r\nOutput: 3\r\nExplanation: Subarrays formed with exactly 3 different integers: [1,2,1,3], [2,1,3], [1,3,4].\r\n```\r\n\r\n \r\n\r\n**Note:**\r\n\r\n1. `1 <= A.length <= 20000`\r\n2. `1 <= A[i] <= A.length`\r\n3. `1 <= K <= A.length`\r\n\r\n```python\r\nclass Solution(object):\r\n def subarraysWithKDistinct(self, A, K):\r\n \"\"\"\r\n :type A: List[int]\r\n :type K: int\r\n :rtype: int\r\n \"\"\"\r\n def subarray(K):\r\n nums = [0 for i in range(len(A) + 1)]\r\n i = 0\r\n ans = 0\r\n for j in range(len(A)):\r\n if nums[A[j]] == 0: #如果A[j]是第一次出现,则K-1\r\n K -= 1\r\n nums[A[j]] += 1\r\n while (K < 0): #如果在i,j 之间的数字已经超过K个了 则开始移动i\r\n if nums[A[i]] == 1: #如果==1 则当i右移时A[i]这个数字将会从substring中移除\r\n K += 1\r\n nums[A[i]] -= 1\r\n i += 1\r\n ans += j - i + 1 # 一共有j-i+1 substring\r\n return ans\r\n return subarray(K) - subarray(K-1)\r\n```\r\n\r\n在闭包内不用传递A\r\n\r\ni,j分别表示起始位置与终点\r\n\r\n\r\n\r\n##### leetcode 904 Fruit Into Baskets\r\n\r\nIn a row of trees, the `i`-th tree produces fruit with type `tree[i]`.\r\n\r\nYou **start at any tree of your choice**, then repeatedly perform the following steps:\r\n\r\n1. Add one piece of fruit from this tree to your baskets. If you cannot, stop.\r\n2. Move to the next tree to the right of the current tree. If there is no tree to the right, stop.\r\n\r\nNote that you do not have any choice after the initial choice of starting tree: you must perform step 1, then step 2, then back to step 1, then step 2, and so on until you stop.\r\n\r\nYou have two baskets, and each basket can carry any quantity of fruit, but you want each basket to only carry one type of fruit each.\r\n\r\nWhat is the total amount of fruit you can collect with this procedure?\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [1,2,1]\r\nOutput: 3\r\nExplanation: We can collect [1,2,1].\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [0,1,2,2]\r\nOutput: 3\r\nExplanation: We can collect [1,2,2].\r\nIf we started at the first tree, we would only collect [0, 1].\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: [1,2,3,2,2]\r\nOutput: 4\r\nExplanation: We can collect [2,3,2,2].\r\nIf we started at the first tree, we would only collect [1, 2].\r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: [3,3,3,1,2,1,1,2,3,3,4]\r\nOutput: 5\r\nExplanation: We can collect [1,2,1,1,2].\r\nIf we started at the first tree or the eighth tree, we would only collect 4 fruits.\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def totalFruit(self, tree: List[int]) -> int:\r\n if len(tree) <= 2: return len(tree)\r\n left, seen, kind = 0, {}, 2\r\n res = 0\r\n for right in range(len(tree)):\r\n if seen.get(tree[right], 0) == 0:\r\n kind -= 1\r\n if tree[right] not in seen:\r\n seen[tree[right]] = 1\r\n else:\r\n seen[tree[right]] += 1\r\n while kind < 0:\r\n seen[tree[left]] -= 1\r\n if seen[tree[left]] == 0:\r\n kind += 1\r\n left += 1\r\n res = max(res, right - left + 1)\r\n return res\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.5401213765144348,
"alphanum_fraction": 0.5590020418167114,
"avg_line_length": 22.71666717529297,
"blob_id": "a54969c4d67a2d7996fd3e377c166c79b69b0634",
"content_id": "fa793f2370147967ed0f4aec86bf06c1189efbf0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1729,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 60,
"path": "/math&&deeplearning/tensorflow.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "常量:\r\n```\r\ntf.constant()\r\nsess = tf.Session()\r\nprint sess.run(hello)\r\n```\r\n首先,通过tf.constant创建一个常量,然后启动Tensorflow的Session,调用sess的run方法来启动整个graph\r\n\r\n实现加减乘除:\r\n```\r\na = tf.constant(2)\r\nb = tf.constant(3)\r\nwith tf.Session() as sess:\r\n sess.run(a+b)\r\n sess.run(a*b)\r\n\r\na = tf.placeholder(tf.int16)\r\nb = tf.placeholder(tf.int16)\r\nadd = tf.add(a, b)\r\nmul = tf.mul(a, b)\r\nwith tf.Session() as sess:\r\n print \"Addition with variables: %i\" % sess.run(add, feed_dict={a: 2, b: 3})\r\n print \"Multiplication with variables: %i\" % sess.run(mul, feed_dict={a: 2, b: 3})\r\n```\r\n\r\nlinux下进入python 退出python的命令:\r\n进入:python\r\n使用 quit(), exit(), 或者Ctrl-D退出命令行\r\n\r\n在终端命令查看TensorFlow版本号及路径:\r\n```\r\npython\r\nimport tensorflow as tf\r\ntf.__version__\r\ntf.__path__\r\n```\r\ncp命令用来将一个或多个源文件或者目录复制到指定的目的文件或目录\r\n\r\n在object detection框出人物之后,得到其坐标\r\n```\r\nwidth=image.size[0]\r\n height=image.size[1]\r\n ymin = boxes[0][0][0]*height\r\n xmin = boxes[0][0][1]*width\r\n ymax = boxes[0][0][2]*height\r\n xmax = boxes[0][0][3]*width\r\n print ('Top left')\r\n print (xmin,ymin,)\r\n print ('Bottom right')\r\n print (xmax,ymax)\r\n posi=['position:',(xmax+xmin)/2,(ymax+ymin)/2]\r\n```\r\n\r\n写csv文件:\r\n```\r\nwith open(\"position.csv\",\"w\") as csvfile:\r\n writer = csv.writer(csvfile)\r\n posi=['position:',(xmax+xmin)/2,(ymax+ymin)/2]\r\n writer.writerow(posi) #写一行\r\n```\r\n"
},
{
"alpha_fraction": 0.5131086111068726,
"alphanum_fraction": 0.5173532962799072,
"avg_line_length": 23.993507385253906,
"blob_id": "c114b2f85fa78d6c26a3182fed3371519d63291b",
"content_id": "30a1e5e5b0ccdcfa13b874dfe82e3bfe662841eb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4029,
"license_type": "no_license",
"max_line_length": 209,
"num_lines": 154,
"path": "/leetcode_note/Trie.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### leetcode 208 Implement Trie (Prefix Tree)\r\n\r\n- Implement a trie with `insert`, `search`, and `startsWith` methods.\r\n\r\n```\r\nTrie trie = new Trie();\r\n\r\ntrie.insert(\"apple\");\r\ntrie.search(\"apple\"); // returns true\r\ntrie.search(\"app\"); // returns false\r\ntrie.startsWith(\"app\"); // returns true\r\ntrie.insert(\"app\"); \r\ntrie.search(\"app\"); // returns true\r\n```\r\n\r\n**Note:**\r\n\r\n- You may assume that all inputs are consist of lowercase letters `a-z`.\r\n- All inputs are guaranteed to be non-empty strings.\r\n- Mysolution:\r\n\r\n```python\r\nfrom collections import defaultdict\r\nclass TrieNode:\r\n def __init__(self):\r\n self.children = defaultdict(TrieNode)\r\n self.isword = False\r\n\t\t\r\nclass Trie:\r\n\r\n def __init__(self):\r\n \"\"\"\r\n Initialize your data structure here.\r\n \"\"\"\r\n self.root = TrieNode()\r\n\r\n def insert(self, word):\r\n \"\"\"\r\n Inserts a word into the trie.\r\n :type word: str\r\n :rtype: void\r\n \"\"\"\r\n cur = self.root\r\n for letter in word:\r\n cur = cur.children[letter]\r\n cur.isword = True\r\n\r\n def search(self, word):\r\n \"\"\"\r\n Returns if the word is in the trie.\r\n :type word: str\r\n :rtype: bool\r\n \"\"\"\r\n cur = self.root\r\n for letter in word:\r\n if letter in cur.children:\r\n cur = cur.children[letter]\r\n else:\r\n return False\r\n return cur.isword\r\n\r\n def startsWith(self, prefix):\r\n \"\"\"\r\n Returns if there is any word in the trie that starts with the given prefix.\r\n :type prefix: str\r\n :rtype: bool\r\n \"\"\"\r\n cur = self.root\r\n for letter in prefix:\r\n if letter in cur.children:\r\n cur = cur.children[letter]\r\n else:\r\n return False\r\n return True\r\n```\r\n\r\n\r\n\r\n##### leetcode 212 Word Search II\r\n\r\nGiven a 2D board and a list of words from the dictionary, find all words in the board.\r\n\r\nEach word must be constructed from letters of sequentially adjacent cell, where \"adjacent\" cells are those horizontally or vertically neighboring. The same letter cell may not be used more than once in a word.\r\n\r\n**Example:**\r\n\r\n```\r\nInput: \r\nboard = [\r\n ['o','a','a','n'],\r\n ['e','t','a','e'],\r\n ['i','h','k','r'],\r\n ['i','f','l','v']\r\n]\r\nwords = [\"oath\",\"pea\",\"eat\",\"rain\"]\r\n\r\nOutput: [\"eat\",\"oath\"]\r\n```\r\n\r\n用上述79的方法会得到TLE,使用TRIE\r\n\r\n```python\r\nclass TrieNode():\r\n def __init__(self):\r\n self.children = collections.defaultdict(TrieNode)\r\n self.isWord = False\r\n \r\nclass Trie():\r\n def __init__(self):\r\n self.root = TrieNode()\r\n \r\n def insert(self, word):\r\n node = self.root\r\n for w in word:\r\n node = node.children[w]\r\n node.isWord = True\r\n \r\n def search(self, word):\r\n node = self.root\r\n for w in word:\r\n node = node.children.get(w)\r\n if not node:\r\n return False\r\n return node.isWord\r\n \r\nclass Solution(object):\r\n def findWords(self, board, words):\r\n res = []\r\n trie = Trie()\r\n node = trie.root\r\n for w in words:\r\n trie.insert(w)\r\n for i in range(len(board)):\r\n for j in range(len(board[0])):\r\n self.dfs(board, node, i, j, \"\", res)\r\n return res\r\n \r\n def dfs(self, board, node, i, j, path, res):\r\n if node.isWord:\r\n res.append(path)\r\n node.isWord = False\r\n if i < 0 or i >= len(board) or j < 0 or j >= len(board[0]):\r\n return \r\n tmp = board[i][j]\r\n node = node.children.get(tmp)\r\n if not node:\r\n return \r\n board[i][j] = \"#\"\r\n self.dfs(board, node, i+1, j, path+tmp, res)\r\n self.dfs(board, node, i-1, j, path+tmp, res)\r\n self.dfs(board, node, i, j-1, path+tmp, res)\r\n self.dfs(board, node, i, j+1, path+tmp, res)\r\n board[i][j] = tmp\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.6438547372817993,
"alphanum_fraction": 0.6475791335105896,
"avg_line_length": 18.065420150756836,
"blob_id": "ac1e874b893c15ce0fdb2250ab569a6b0659b18f",
"content_id": "8273300bfa9ca632d7b6ff9628487ac0d2098431",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4520,
"license_type": "no_license",
"max_line_length": 494,
"num_lines": 214,
"path": "/OOD.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### OOD\r\n\r\n##### parking lot\r\n\r\n这道题让我们实现一个停车位的数据结构,由于题目没给任何多余的信息,所以自由度很大,比如能停放什么种类的车,或是否是多层的等等。根据书中描述,这里我们做如下假设:\r\n\r\n1. 停车场有多层,每层有多行停车位\r\n\r\n2. 停车场可以停摩托车,小轿车和公交车\r\n\r\n```c++\r\nclass Vehicle;\r\nclass Level;\r\n\r\nclass ParkingSpot {\r\npublic:\r\n ParkingSpot(Level *lvl, int r, int n, VehicleSize s): _level(lvl), _row(r), _spotNumber(n), _spotSize(s) {} // ...\r\n bool isAvailable() { return _vehicle == nullptr; };\r\n bool canFitVehicle(Vehicle *vehicle) {} // ...\r\n bool park(Vehicle *v) {} // ...\r\n int getRow() { return _row; }\r\n int getSpotNumber() { return _spotNumber; }\r\n void removeVehicle() {} // ... \r\n\r\nprivate:\r\n Vehicle *_vehicle = nullptr;\r\n VehicleSize _spotSize;\r\n int _row;\r\n int _spotNumber;\r\n Level *_level = nullptr;\r\n};\r\n\r\nclass Vehicle {\r\npublic:\r\n Vehicle() {}\r\n int getSpotsNeeded() { return _spotsNeeded; }\r\n VehicleSize getSize() { return _size; }\r\n void parkInSpot(ParkingSpot s) { _parkingSpots.push_back(s); }\r\n void clearSpots() {} // ...\r\n virtual bool canFitInSpot(ParkingSpot spot) {}\r\n\r\nprotected:\r\n vector<ParkingSpot> _parkingSpots;\r\n string _licensePlate;\r\n int _spotsNeeded;\r\n VehicleSize _size;\r\n};\r\n\r\nclass Bus: public Vehicle {\r\npublic:\r\n Bus() {\r\n _spotsNeeded = 5;\r\n _size = VehicleSize::Large;\r\n }\r\n bool canFitInSpot(ParkingSpot spot) { }\r\n};\r\n\r\nclass Car: public Vehicle {\r\npublic:\r\n Car() {\r\n _spotsNeeded = 1;\r\n _size = VehicleSize::Compact;\r\n }\r\n bool canFitInSpot(ParkingSpot spot) { }\r\n};\r\n\r\nclass Motorcycle: public Vehicle {\r\npublic:\r\n Motorcycle() {\r\n _spotsNeeded = 1;\r\n _size = VehicleSize::Motorcycle;\r\n }\r\n bool canFitInSpot(ParkingSpot spot) { }\r\n};\r\n\r\nclass ParkingLot {\r\npublic:\r\n ParkingLot() {} // ...\r\n bool parkVehicle(Vehicle vehicle) {} // ...\r\n\r\nprivate:\r\n vector<Level> _levels;\r\n const int _NUM_LEVELS = 5;\r\n};\r\n```\r\n\r\n\r\n\r\n##### elevator program\r\n\r\n```\r\nYou have several functions to control elevator:\r\nmoveUp()\r\nmoveDown()\r\nstopAndOpenDoor()\r\ncloseDoor()\r\n\r\nNote:I forgot some parts, but I believe you can figure out which functions are necessary as well - However, you should think about situation that multiple users pushing buttons in different floors. So, obviously you should keep record of buttons pushed, inside and outside of the elevator, sort them, and move the way the elevator should work. You can suppose we have N>1 floors, and currently elevator is in 1 <= m <=N floor, and initialize your class with these numbers and elevator is empty.\r\n\r\nFor example, I will tell you we have 10 floors and at start the elevator is in floor 2 and empty.\r\n\r\nNow, complete these functions using above basic elevator actions to have a fully functional elevator, you can use a class, and for example for at_floor() save the state of elevator in a class variable:\r\n\r\nvoid on_push_button(int num)// When user push in each floor\r\n{\r\n}\r\n\r\nvoid at_floor() // Gives you current floor number\r\n{\r\n}\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### Design an online hotel booking system\r\n\r\nMy Solution :\r\n\r\n\r\n\r\nMain Classes :\r\n\r\n\r\n\r\n1. User\r\n2. Room\r\n3. Hotel\r\n4. Booking\r\n5. Adress\r\n\r\n```java\r\nEnums :\r\n\r\npublic enum RoomStatus {\r\n EMPTY\r\n NOT_EMPTY;\r\n}\r\n\r\npublic enum RoomType{\r\n SINGLE,\r\n DOUBLE,\r\n TRIPLE;\r\n}\r\n\r\npublic enum PaymentStatus {\r\n PAID,\r\n UNPAID;\r\n}\r\n\r\nclass User{\r\n\r\nint userId;\r\nString name;\r\nDate dateOfBirth;\r\nString mobNo;\r\nString emailId;\r\nString sex;\r\n}\r\n\r\n// For the room in any hotel\r\nclass Room{\r\n\r\nint roomId;\r\nint hotelId;\r\nRoomType roomType;\r\nRoomStatus roomStatus;\r\n}\r\n\r\nclass Hotel{\r\n\r\nint hotelId;\r\nString hotelName;\r\nAdress adress;\r\nList<Room> rooms; // hotel contains the list of rooms\r\nfloat rating;\r\nFacilities facilities;\r\n}\r\n\r\n// a new booking is created for each booking done by any user\r\nclass Booking{\r\n int bookingId;\r\n int userId;\r\n int hotelId; \r\n List<Rooms> bookedRooms; \r\n int amount;\r\n PaymentStatus status_of_payment;\r\n Time bookingTime;\r\n Duration duration;\r\n}\r\n\r\nclass Adress{\r\n\r\nstring city;\r\nstring pinCode;\r\nstring streetNo;\r\nstring landmark;\r\n}\r\n\r\nclass Duration{\r\n\r\nTime from;\r\nTiime to;\r\n}\r\n\r\nclass Facilities{\r\n\r\nbool provides_lift;\r\nbool provides_power_backup;\r\nbool provides_hot_water;\r\nbool provides_breakfast_free;\r\n}\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.6696600317955017,
"alphanum_fraction": 0.6767158508300781,
"avg_line_length": 9.533333778381348,
"blob_id": "7197847e113f65d6c301da4c7c91e177f87bbf7c",
"content_id": "d1ceae957da1a3a56ec79c67efe6b13563104d81",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3303,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 135,
"path": "/social_network/SMP.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 智慧金融\r\n\r\n##### 高文 边缘计算:\r\n\r\n目前大多数交通监控系统将得到的图像或视频数据传到数据中心,但数据量极大。近些年来,出现边缘计算后很多系统在摄像头端进行对象识别和事件分析,由此形成的数据一定程度上提升了检索分析的效率。\r\n\r\n硬件嵌入式\r\n\r\n1.模型足够小,硬件端\r\n\r\n2.stream update\r\n\r\n\r\n\r\n##### 方滨兴:主流疲劳\r\n\r\n多渠道发布避免主流疲劳\r\n\r\n\r\n\r\n##### 杨强 数据孤岛 联邦学习\r\n\r\n部门与机构之间的隔阂使得部门墙成为数据孤岛间难以逾越的障碍。法律、金融、医疗等领域数据分布分散。基于此提出了联邦学习,建立机构之间的桥梁,联合建立AI模型而各方数据可以不出本地,用户隐私可以等到最好的保护。\r\n\r\n\r\n\r\n\r\n\r\n##### 李金龙 招商银行\r\n\r\n银行要点:1.信用创造 2.支付 \r\n\r\n社会媒体技术促进银行风险管理。\r\n\r\n低成本技术(打电话 很多是电脑) vs 打扰客户问题\r\n\r\n\r\n\r\n### 情感分析\r\n\r\n##### 权小军 情感分析\r\n\r\n\r\n\r\n##### 梁吉业 面向大数据的粒计算理论与方法\r\n\r\n粒计算: 97年提出,Granular Computing, 用信息粒代替了复杂信息,将复杂问题抽象划分而专程若干个简单的问题。\r\n\r\n大数据情况下具有超大规模、多源多模态的特点。\r\n\r\n一般粒计算框架:信息粒化(聚类)、粒空间构建、多粒度模式发现 多粒度关联挖掘\r\n\r\n不平衡数据的K-Means方法会导致出现均匀效应:多中心聚类方法\r\n\r\n\r\n\r\n##### 冯仕政 互联网、社会互动和群体行为\r\n\r\n互联网深刻改变了社会,整个社会日渐散众化。散众的基本特征是基于互联网时代信息的过载、自闭和高频流动,社会各成员之间难以形成深入的情感交流和价值共识。\r\n\r\n散众:地理不集中、无深入互动\r\n\r\n高流动性、高组合型(啸聚)、高流离性\r\n\r\n互联网:信息的选择与自闭\r\n\r\n\r\n\r\n##### 端到端模型 刘康\r\n\r\n端到端:input 数据, output:直接用于任务中\r\n\r\n非端到端:input 数据 output:非直接应用的结果(embedding)\r\n\r\n\r\n\r\n##### 表示学习论坛\r\n\r\n图神经网络 GNN\r\n\r\n2018年后兴起了深度学+图结构\r\n\r\nCNN: 欧式空间数据,GNN:非欧空间数据\r\n\r\n谱方法是空间卷积方法 的特殊情况\r\n\r\n\r\n\r\n##### 魏忠钰 计算金融学\r\n\r\n预测股票价格:\r\n\r\nGCN(联系不同公司特征)+LSTM(时序信号)\r\n\r\n特征:<开盘价、高点、低点、收盘价、交易量>\r\n\r\n通过对金融事件(公告事件,自然事件,政治事件)进行建模\r\n\r\n\r\n\r\n##### 塔娜 社交网络上议题社群的公共焦虑研究\r\n\r\nemotion: happiness, anger, suprise, sadness, fear, disgust\r\n\r\nsentiment: negative, positive, neural\r\n\r\nmoods:很多\r\n\r\n\r\n\r\n##### 数据挖掘论坛\r\n\r\n李晓林\r\n\r\ngood question:如何从学术界到工业界\r\n\r\n\r\n\r\n陈为 可视化\r\n\r\n可视化:创建并研究数据的实觉表达,\r\n\r\n表示数据、分析数据、交流数据\r\n\r\n应用:大工程仿真、物联网智慧城市\r\n\r\n\r\n\r\n宋国杰\r\n\r\nSepNE:在网络中寻找几个基准点来确定embedding vector\r\n\r\nTag2vec model:网络Tag表示\r\n\r\nSpaceNE model:社群-> 子空间\r\n\r\n"
},
{
"alpha_fraction": 0.5273560285568237,
"alphanum_fraction": 0.5487322807312012,
"avg_line_length": 26.425912857055664,
"blob_id": "c1b325953c624ab5b39a70ed407bbae819515fd6",
"content_id": "1f2013566edd16cb81c39ee2b6c59f2930e8e764",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 41727,
"license_type": "no_license",
"max_line_length": 323,
"num_lines": 1397,
"path": "/leetcode_note/Graph.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "\r\n\r\n图的复制(LeetCode 133)\r\n\r\n图的搜索与应用(LeetCode 207)\r\n\r\n##### Graph Algorithm\r\n\r\ntree is a special graph with no loop\r\n\r\nrooted tree: tree with a root, other nodes all come in or out from the root\r\n\r\nDAG: dtrected acyclic graphs\r\n\r\nbipartite graph: nodes can be divided into set u and v, all edges are connected between one u and one v.\r\n\r\ncomplete graph\r\n\r\n\r\n\r\ncommon graph theory problem:\r\n\r\n##### shortest path problem:\r\n\r\nBFS, Dijkstra, Bellman-Ford, Floyd-Warshall\r\n\r\n<img src=\"shorest_path_problem.png\" width=\"600\">\r\n\r\n\r\n\r\n##### connectivity poblem:\r\n\r\nis a path between node a and node b?\r\n\r\nFind-Union, BFS, DFS\r\n\r\n\r\n\r\n##### negative cycles\r\n\r\ndoes negative cycles exists, where?\r\n\r\nbellman-ford and floyd-warshall\r\n\r\n\r\n\r\n##### strongly connected components\r\n\r\ntarjan, kosaraju algorithm\r\n\r\n<img src=\"scc.png\" width=\"600\">\r\n\r\n\r\n\r\n##### TSP traveling Salesman Problem\r\n\r\nWhat is the shortest possible route that visits each city exactly once and returns to the origin city?\r\n\r\n<img src=\"tsp.png\" width=\"600\">\r\n\r\nNP hard\r\n\r\nHeld-Karp algorithm\r\n\r\n\r\n\r\n##### Finding bridges\r\n\r\nA bridge is any edge in a graph whose removal increases the number of connected components\r\n\r\narticulation points\r\n\r\nis any point in a graph whose removal increases the number of connected components\r\n\r\n\r\n\r\n##### MST\r\n\r\nA minimun spanning tree is a subset of edges that connects all the vertices without cycles with the minimum edge weight.\r\n\r\nKruskal's, Prim's and Boruvka's algorithm\r\n\r\n\r\n\r\n##### Max flow\r\n\r\n<img src=\"flow.png\" width=\"600\">\r\n\r\nwith infinite input source how much flow can we push through the network\r\n\r\nFord-Fulkerson, Edmonds-Karp& Dinic's algorithm\r\n\r\n\r\n\r\n##### Basic Algorithm\r\n\r\n### DFS\r\n\r\n常见问题:\r\n\r\n1.leetcode 1254. Number of Closed Islands(在水域中数有多少个小岛)\r\n\r\n2.graph中有多少个连通图\r\n\r\n3.compute a graph's minimum spanning tree?\r\n\r\n4.detect and find cycles in a graph?\r\n\r\n5.check if a graph is bipartite?\r\n\r\n6.topologically sort the nodes of a graph?\r\n\r\n7.find bridges and articulation points?\r\n\r\n8.find augmenting paths in a flow network?\r\n\r\n9.generate mazes?\r\n\r\n\r\n\r\n```python\r\n# on grid\r\ndef dfs(grid, i, j, isvisited, n, m):\r\n directions = [[-1,0], [1,0],[0,-1],[0,1]]\r\n for ii, jj in directions:\r\n if i+ii<0 or i+ii>=n or j+jj<0 or j+jj>=m:\r\n continue\r\n else:\r\n if grid[i+ii][j+jj] == 0 and isvisited[i+ii][j+jj] == 0:\r\n isvisited[i+ii][j+jj] = 1\r\n dfs(grid, i+ii, j+jj, isvisited, n, m)\r\n return\r\n\r\n# on graph\r\ndef dfs(graph, start, isvisited):\r\n isvisited.add(start)\r\n for node in graph[start]:\r\n if node not in isvisited:\r\n dfs(graph, node, isvisited)\r\n return\r\n```\r\n\r\n\r\n\r\n##### BFS \r\n\r\nfind shortest path, find shortest path value for weighted or unweighted graph\r\n\r\n如果要获得全部的最短路径 可以讲prev换为default(set)格式\r\n\r\n```python\r\nclass Solution(object):\r\n def bfs(self, graph, start, end, n):\r\n q = [start]\r\n visited = [0 for i in range(n)]\r\n visited[start] = 1\r\n distance = [float(\"inf\") for i in range(n)]\r\n distance[start] = 0\r\n prev = [None for i in range(n)]\r\n while len(q) != 0:\r\n node = q.pop(0)\r\n for nei, val in graph[node]:\r\n if visited[nei] == 0:\r\n q.append(nei)\r\n visited[nei] = 1\r\n if distance[node] + val < distance[nei]:\r\n distance[nei] = distance[node] + val\r\n prev[nei] = node\r\n return prev\r\n\r\n def reconstruct_path(self, start, end, prev):\r\n\r\n path = []\r\n pos = end\r\n while pos!=None:\r\n path.append(pos)\r\n pos = prev[pos]\r\n path = path[::-1]\r\n if path[0] == start: # connected or not\r\n return path\r\n return []\r\n\r\n def min_path(self, n ,graph, start, end):\r\n prev = self.bfs(graph, start, end, n)\r\n return self.reconstruct_path(start, end, prev)\r\n```\r\n\r\n用prev记录上一个节点,用distance表示节点到start节点的距离\r\n\r\nfor find the longest path in DAG:\r\n\r\n所有的边乘以-1,找shortest path 然后把结果乘-1\r\n\r\n\r\n\r\nBFS on grid(dungeon problem)\r\n\r\n<img src=\"dungeon.png\" width=\"600\">\r\n\r\n\r\n\r\n```python\r\nimport copy\r\nclass Solution(object):\r\n def bfs(self, grid, start, end):\r\n this_level = [start]\r\n n, m = len(grid), len(grid[0])\r\n visited = [[0 for i in range(m)] for j in range(n)]\r\n visited[start[0]][start[1]] = 1\r\n directions = [[-1, 0], [1, 0], [0, -1], [0, 1]]\r\n step = 0\r\n next_level = []\r\n while len(this_level) != 0 or len(next_level) != 0:\r\n while len(this_level) != 0:\r\n i, j = this_level.pop(0)\r\n if grid[i][j] == \"E\":\r\n return step \r\n for ii, jj in directions:\r\n if i+ii<0 or i+ii>=n or j+jj<0 or j+jj>=m:\r\n continue\r\n if visited[i+ii][j+jj] == 0 and grid[i+ii][j+jj] != \"#\":\r\n next_level.append([i+ii, j+jj])\r\n visited[i+ii][j+jj] = 1\r\n this_level = copy.deepcopy(next_level)\r\n next_level = []\r\n step += 1\r\n return -1\r\n```\r\n\r\n\r\n\r\n##### Tree\r\n\r\nproblem 1:what is the sum of all leaves? Pre-order traversal\r\n\r\nproblem: 2.height of a tree? BFS this_level, next_level\r\n\r\nor h(x) = max(h(x.left),h(x.right))+1\r\n\r\n\r\n\r\n##### Topological sort\r\n\r\nclass scheduing\r\n\r\nonly DAG(directed acyclic graph) has topological sort.\r\n\r\n典型问题:得到一组符合要求的topological sort array\r\n\r\n```python\r\nclass Solution(object):\r\n def dfs(self, graph, start, isvisited, stack):\r\n isvisited[start] = 1\r\n for node in graph[start]:\r\n if isvisited[node] == 0:\r\n self.dfs(graph, node, isvisited, stack)\r\n stack.insert(0, start)\r\n return\r\n\r\n def top(self, graph, n):\r\n visited = [0 for i in range(n)]\r\n stack = []\r\n for i in range(n):\r\n if visited[i] == 0:\r\n self.dfs(graph, i, visited, stack)\r\n return stack\r\n```\r\n\r\n<img src=\"top.png\" width=\"300\">\r\n\r\n[5, 4, 2, 3, 1, 0]\r\n\r\n1. pick an unvisited node\r\n2. begin with this node DFS only unvisited nodes\r\n3. when return from the DFS, add the current node to the topological array in reverse order.(保证了current node后续的节点即 需要current node作为前置节点的node都已经被DFS访问了,即都在topological array中了)\r\n\r\n上述版本无法检测loop\r\n\r\n```python\r\nclass Solution:\r\n def dfs(self, graph, start, isvisited, stack):\r\n isvisited[start] = 0\r\n for node in graph[start]:\r\n if isvisited[node] == -1:\r\n self.dfs(graph, node, isvisited, stack)\r\n if isvisited[node] == 0:\r\n self.flag = False\r\n return\r\n stack.insert(0, start)\r\n isvisited[start] = 1\r\n return\r\n\r\n def minimumSemesters(self, N, relations):\r\n visited = [-1 for i in range(N+1)]\r\n graph = defaultdict(set)\r\n for s, e in relations:\r\n graph[s].add(e)\r\n stack = []\r\n self.flag = True\r\n for i in range(1, N+1):\r\n if visited[i] == -1:\r\n self.dfs(graph, i, visited, stack)\r\n```\r\n\r\n-1 表示未访问,0表示正在访问,1表示已经访问过了\r\n\r\n\r\n\r\n\r\n\r\n##### Dijkstra\r\n\r\n适用于single source shortest path problem with no negative edges\r\n\r\n```python\r\n# dijkstra算法实现\r\ndef dijkstra(graph, src):\r\n # 判断图是否为空\r\n if graph is None:\r\n return None\r\n nodes = [i for i in range(len(graph))] # 获取图中所有节点\r\n visited = [] # 表示已经路由到最短路径的节点集合\r\n if src in nodes:\r\n visited.append(src)\r\n nodes.remove(src)\r\n else:return None\r\n distance = {src: 0} # 记录源节点到各个节点的距离\r\n for i in nodes:\r\n distance[i] = graph[src][i] # 初始化\r\n path = {src: {src: []}} # 记录源节点到每个节点的路径\r\n\r\n while nodes:\r\n temp_distance = float('inf')\r\n # 遍历所有的v(visited)与d(unvisited),寻找最短的temp_distance,即最小的distance[k](其中k unvisited),接着将k作为新的点visit,d是k点的pre,用于记录path\r\n for v in visited:\r\n for d in nodes:\r\n if graph[src][v] + graph[v][d] < temp_distance:\r\n temp_distance = graph[src][v] + graph[v][d]\r\n graph[src][d] = graph[src][v] + graph[v][d] # 进行距离更新\r\n k = d\r\n pre = v\r\n distance[k] = temp_distance # 最短路径\r\n path[src][k] = [i for i in path[src][pre]]\r\n path[src][k].append(k)\r\n # 更新两个节点集合\r\n visited.append(k)\r\n nodes.remove(k)\r\n #print(visited, nodes) # 输出节点的添加过程\r\n return distance, path\r\n\r\n\r\nif __name__ == '__main__':\r\n graph_list = [[0, 2, 1, 4, 5, 1],\r\n [1, 0, 4, 2, 3, 4],\r\n [2, 1, 0, 1, 2, 4],\r\n [3, 5, 2, 0, 3, 3],\r\n [2, 4, 3, 4, 0, 1],\r\n [3, 4, 7, 3, 1, 0]]\r\n\r\n distance, path = dijkstra(graph_list, 0) # 查找从源点0开始带其他节点的最短路径\r\n```\r\n\r\n\r\n\r\n##### Bellman-Ford \r\n\r\nis a single source shortest path algorithm. 时间复杂度比dijkstra大很多,但是可以应对负边的情况。\r\n\r\n同时可以检测negative cycles的存在\r\n\r\n1.set every node to float(\"inf\")\r\n\r\n2.set dist[start]=0\r\n\r\n3.relax each edge n-1 times\r\n\r\n```python\r\ndef bellman(self, edges, n):\r\n distance = [float(\"inf\") for i in range(n)]\r\n distance[0] = 0\r\n for it in range(n-1):\r\n # relax each edge n-1 times\r\n for start, end ,val in edges:\r\n if distance[start] + val < distance[end]:\r\n distance[end] = distance[start] + val\r\n print(distance)\r\n # check if there is a negative loop\r\n for it in range(n-1):\r\n for start, end ,val in edges:\r\n if distance[start] + val < distance[end]:\r\n print(\"true\")\r\n return\r\n print(\"false\")\r\n return\r\n```\r\n\r\n<img src=\"negative_cycle.png\" width=\"500\">\r\n\r\n<img src=\"graph_algorithm.png\" width=\"500\">\r\n\r\n##### Floyd-warshall algorithm\r\n\r\nis an all-pair shortest path algorithm\r\n\r\n```python\r\ndef floydwarshall(m):\r\n setup(m)\r\n for k in range(n):\r\n for i in range(n):\r\n for j in range(n):\r\n if dp[i][k] + dp[k][j] < dp[i][j]:\r\n dp[i][j] = dp[i][k] + dp[k][j]\r\n next[i][j] = next[i][k]\r\n```\r\n\r\n\r\n\r\n##### Find bridges\r\n\r\n```python\r\nclass Solution(object):\r\n def dfs(self, at, parent, graph):\r\n self.visited[at] = 1\r\n self.low[at] = self.ids[at] = self.id\r\n self.id += 1\r\n for node in graph[at]:\r\n if node == parent:continue\r\n if self.visited[node] == 0:\r\n self.dfs(node, at, graph)\r\n self.low[at] = min(self.low[at], self.low[node]) #dfs 返回时传递min low值\r\n if self.ids[at] < self.low[node]: #目前节点的id比后续节点的low还要小,说明后续节点只能通过at节点传递\r\n self.bridges.append([at, node])\r\n else:\r\n self.low[at] = min(self.low[at], self.ids[node])#已经被访问了则传递ids值\r\n return\r\n\r\n def findbridge(self, graph, n):\r\n self.id = 0\r\n self.ids = [0 for i in range(n)]\r\n self.low = [0 for i in range(n)]\r\n self.visited = [0 for i in range(n)]\r\n self.bridges = []\r\n for i in range(n):\r\n if self.visited[i] == 0:\r\n self.dfs(i, -1, graph)\r\n return self.bridges\r\n```\r\n\r\nbridges是那些删除了之后子图的数量增加的边\r\n\r\n\r\n\r\n##### find articulation point\r\n\r\n删除了某些节点后,子图的数量增加\r\n\r\n```python\r\nclass Solution(object):\r\n def dfs(self, root, at, parent, graph):\r\n if parent == root: self.outEdgeCount += 1\r\n self.visited[at] = 1\r\n self.low[at] = self.ids[at] = self.id\r\n self.id += 1\r\n for node in graph[at]:\r\n if node == parent:continue\r\n if self.visited[node] == 0:\r\n self.dfs(root, node, at, graph)\r\n self.low[at] = min(self.low[at], self.low[node]) #dfs 返回时传递min low值\r\n # find articulation point via bridge\r\n if self.ids[at] < self.low[node]:\r\n self.isArt[at] = True\r\n # find articulation point via cycle\r\n if self.ids[at] == self.low[node]:\r\n self.isArt[at] = True\r\n else:\r\n self.low[at] = min(self.low[at], self.ids[node])\r\n return\r\n\r\n def findbridge(self, graph, n):\r\n self.id = 0\r\n self.ids = [0 for i in range(n)]\r\n self.low = [0 for i in range(n)]\r\n self.visited = [0 for i in range(n)]\r\n self.isArt = [False for i in range(n)]\r\n for i in range(n):\r\n if self.visited[i] == 0:\r\n self.outEdgeCount = 0\r\n self.dfs(i, i, -1,graph)\r\n self.isArt[i] = (self.outEdgeCount > 1)\r\n return self.isArt\r\n```\r\n\r\n<img src=\"articulation_bridge.png\" width=\"400\">\r\n\r\n##### TSP 问题 旅行家\r\n\r\nn city visit only once with least cost and return to start point\r\n\r\nDP\r\n\r\n\r\n\r\n##### Minimum Spanning Tree\r\n\r\nPrim algorithm\r\n\r\n```python\r\nfrom heapq import *\r\ndef prim(n, edges, start):\r\n # graph edge: weight v1, v2\r\n mst_edges, val_cost = [], 0\r\n visited = set({start})\r\n q = graph[start]\r\n heapify(q)\r\n while q:\r\n w, v1, v2 = heappop(q)\r\n if v2 not in visited:\r\n visited.add(v2)\r\n mst_edges.append([v1, v2, w])\r\n val_cost += w\r\n for edge in graph[v2]:\r\n if edge[2] not in visited: #v2\r\n heappush(q, edge)\r\n return val_cost, mst_edges\r\n\r\nn = 6\r\ngraph = {0:[[1, 0, 1],[2, 0,2]], 1:[[1, 1, 0],[2, 1, 4],[4,1,3]],2:[[2,2,0], [3,2,3]], 3:[[4,3,1],[3,3,2],[1,3,5]],4:[[2,4,1],[4,4,5]],5:[[1,5,3],[4,5,4]]}\r\nprint(prim(n, graph,0))\r\n```\r\n\r\n<img src=\"mst.png\" width=\"500\">\r\n\r\n\r\n\r\n维持一个queue队列,每次弹出weight最小的edge,只有edge中的v2节点没有被访问过才会被放入queue中\r\n\r\n\r\n\r\n##### MaxFlow\r\n\r\nFord Fulkerson algorithm\r\n\r\n<img src=\"maxflow.png\" width=\"500\">\r\n\r\n\r\n\r\n\r\n\r\n```python\r\nclass Graph:\r\n def BFS(self, s, t, prev, n):\r\n visited = [False] * (n)\r\n queue = []\r\n queue.append(s)\r\n visited[s] = True\r\n while queue:\r\n u = queue.pop(0)\r\n # Get all adjacent vertices of the dequeued vertex u\r\n # If a adjacent has not been visited, then mark it \r\n # visited and enqueue it \r\n for index, val in enumerate(self.graph[u]):\r\n if visited[index] == False and val > 0:\r\n queue.append(index)\r\n visited[index] = True\r\n prev[index] = u\r\n return True if visited[t] else False\r\n def FordFulkerson(self, graph, source, sink, n):\r\n self.graph = graph # residual graph\r\n prev = [-1] * n\r\n max_flow = 0\r\n # Augment the flow while there is path from source to sink\r\n while self.BFS(source, sink, prev, n):\r\n path_flow = float(\"inf\")\r\n s = sink\r\n while (s != source):\r\n path_flow = min(path_flow, self.graph[prev[s]][s])\r\n s = prev[s]\r\n max_flow += path_flow\r\n v = sink\r\n while (v != source):\r\n u = prev[v]\r\n self.graph[u][v] -= path_flow #reduce by bottleneck\r\n self.graph[v][u] += path_flow #create residual edges\r\n v = prev[v]\r\n return max_flow\r\n\r\ngraph = [[0, 16, 13, 0, 0, 0],\r\n [0, 0, 10, 12, 0, 0],\r\n [0, 4, 0, 0, 14, 0],\r\n [0, 0, 9, 0, 0, 20],\r\n [0, 0, 0, 7, 0, 4],\r\n [0, 0, 0, 0, 0, 0]]\r\nsource = 0\r\nsink = 5\r\ng = Graph()\r\nprint(\"The maximum possible flow is %d \" % g.FordFulkerson(graph, source, sink, 6))\r\n```\r\n\r\n\r\n\r\nalgorithm: To find maximum flow, the algorithm repeatedly finds augmenting paths through the residual network until there is no augmenting paths.\r\n\r\nAugementing path is a path of edges in residual graph with unused capacity grater than zero.\r\n\r\n每发现一条augmenting path就找到其capacity最小的bottleneck, 然后改变residual graph,构建residual edges\r\n\r\n<img src=\"maxflow_1.png\" width=\"500\">\r\n\r\n<img src=\"maxflow_2.png\" width=\"500\">\r\n\r\n\r\n\r\nresidual edges和正常的edge一样,也可以走,其存在的意义是为了undo the bad augmenting paths which do not lead to a maximum Flow.\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\nstrong connected components:强连通子图中的每个点出发可以通过若干步走到另外的所有节点\r\n\r\ntarjan algorithm:\r\n\r\ninput:graph\r\n\r\noutput:strong connected component\r\n\r\n先使用DFS对graph中的每个节点进行编号\r\n\r\n某个节点的low-link value指的是从这个节点出发能达到的节点中编号最小的值(包括自己)\r\n\r\n\r\n\r\n##### leetcode 133 Clone Graph\r\n\r\nGiven a reference of a node in a **connected** undirected graph, return a [**deep copy**](https://en.wikipedia.org/wiki/Object_copying#Deep_copy) (clone) of the graph. Each node in the graph contains a val (`int`) and a list (`List[Node]`) of its neighbors.\r\n\r\n```python\r\n\"\"\"\r\n# Definition for a Node.\r\nclass Node:\r\n def __init__(self, val, neighbors):\r\n self.val = val\r\n self.neighbors = neighbors\r\n\"\"\"\r\nclass Solution:\r\n def cloneGraph(self, node: 'Node') -> 'Node':\r\n self.node_dict = {}\r\n def clone(node):\r\n if not node: return\r\n if node not in self.node_dict:\r\n self.node_dict[node] = Node(node.val,[])\r\n for nei in node.neighbors:\r\n # self.node_dict[nei].neighbors.append(node)\r\n clone(nei)\r\n return\r\n clone(node)\r\n for key in self.node_dict:\r\n self.node_dict[key].neighbors = [self.node_dict[nei] for nei in key.neighbors]\r\n return self.node_dict[node]\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 207 Course Schedule\r\n\r\n* There are a total of *n* courses you have to take, labeled from `0` to `n-1`.\r\n\r\n Some courses may have prerequisites, for example to take course 0 you have to first take course 1, which is expressed as a pair: `[0,1]`\r\n\r\n Given the total number of courses and a list of prerequisite **pairs**, is it possible for you to finish all courses?\r\n\r\n```\r\nInput: 2, [[1,0]] \r\nOutput: true\r\nExplanation: There are a total of 2 courses to take. \r\n To take course 1 you should have finished course 0. So it is possible.\r\n \r\nInput: 2, [[1,0],[0,1]]\r\nOutput: false\r\nExplanation: There are a total of 2 courses to take. \r\n To take course 1 you should have finished course 0, and to take course 0 you should\r\n also have finished course 1. So it is impossible.\r\n```\r\n\r\n**Note:**\r\n\r\n1. The input prerequisites is a graph represented by **a list of edges**, not adjacency matrices. Read more about [how a graph is represented](https://www.khanacademy.org/computing/computer-science/algorithms/graph-representation/a/representing-graphs).\r\n2. You may assume that there are no duplicate edges in the input prerequisites.\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution:\r\n def canFinish(self, numCourses, prerequisites):\r\n graph = [[] for _ in range(numCourses)]\r\n visit = [0 for _ in range(numCourses)]\r\n for x, y in prerequisites:\r\n graph[x].append(y)\r\n def dfs(i):\r\n if visit[i] == -1:\r\n return False\r\n if visit[i] == 1:\r\n return True\r\n visit[i] = -1\r\n for j in graph[i]:\r\n if not dfs(j):\r\n return False\r\n visit[i] = 1\r\n return True\r\n for i in range(numCourses):\r\n if not dfs(i):\r\n return False\r\n return True\r\n```\r\n\r\ngraph 中保存的是对于每节课的预置要求 \r\n\r\nvisit数组初始为0,visit 1表示这节课已经被修过了 \r\n\r\ndfs(i)表示探讨i这节课能不能被修掉\r\n\r\n-1表示这节课正在被探讨,如果访问到-1 则表明出现了循环的预置要求,例如[0,1],[1,2],[2,0]则 return false\r\n\r\n\r\n\r\n##### leetcode 210 Course Schedule II\r\n\r\nThere are a total of *n* courses you have to take, labeled from `0` to `n-1`.\r\n\r\nSome courses may have prerequisites, for example to take course 0 you have to first take course 1, which is expressed as a pair: `[0,1]`\r\n\r\nGiven the total number of courses and a list of prerequisite **pairs**, return the ordering of courses you should take to finish all courses.\r\n\r\nThere may be multiple correct orders, you just need to return one of them. If it is impossible to finish all courses, return an empty array.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: 2, [[1,0]] \r\nOutput: [0,1]\r\nExplanation: There are a total of 2 courses to take. To take course 1 you should have finished \r\n course 0. So the correct course order is [0,1] .\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: 4, [[1,0],[2,0],[3,1],[3,2]]\r\nOutput: [0,1,2,3] or [0,2,1,3]\r\nExplanation: There are a total of 4 courses to take. To take course 3 you should have finished both \r\n courses 1 and 2. Both courses 1 and 2 should be taken after you finished course 0. \r\n So one correct course order is [0,1,2,3]. Another correct ordering is [0,2,1,3] .\r\n```\r\n\r\n\r\n\r\n```python\r\nfrom collections import defaultdict\r\nclass Solution:\r\n def findOrder(self, numCourses, prerequisites):\r\n graph = defaultdict(set)\r\n visit = [0 for _ in range(numCourses)]\r\n for x, y in prerequisites:\r\n graph[x].add(y)\r\n def dfs(i, path):\r\n if visit[i] == -1:\r\n return False\r\n if visit[i] == 1:\r\n return True\r\n visit[i] = -1\r\n for j in graph[i]:\r\n flag = dfs(j, path)\r\n if not flag:\r\n return False\r\n else:\r\n if visit[j] != 1:\r\n path.append(j)\r\n visit[j] = 1\r\n return True\r\n path = []\r\n for i in range(numCourses):\r\n flag = dfs(i, path)\r\n if not flag:\r\n return []\r\n else:\r\n if visit[i] != 1:\r\n path.append(i)\r\n visit[i] = 1\r\n if len(path) != numCourses:\r\n return []\r\n return path\r\n```\r\n\r\ndfs(i)表示探讨i这节课能不能被修掉 如果能被成功修掉同时且没有修过则加入path\r\n\r\n有i的前置课程则会在dfs(i)中运行中运行dfs(j)\r\n\r\n\r\n\r\n##### leetcode 289. Game of Life\r\n\r\nAccording to the [Wikipedia's article](https://en.wikipedia.org/wiki/Conway%27s_Game_of_Life): \"The **Game of Life**, also known simply as **Life**, is a cellular automaton devised by the British mathematician John Horton Conway in 1970.\"\r\n\r\nGiven a *board* with *m* by *n* cells, each cell has an initial state *live* (1) or *dead* (0). Each cell interacts with its [eight neighbors](https://en.wikipedia.org/wiki/Moore_neighborhood) (horizontal, vertical, diagonal) using the following four rules (taken from the above Wikipedia article):\r\n\r\n1. Any live cell with fewer than two live neighbors dies, as if caused by under-population.\r\n2. Any live cell with two or three live neighbors lives on to the next generation.\r\n3. Any live cell with more than three live neighbors dies, as if by over-population..\r\n4. Any dead cell with exactly three live neighbors becomes a live cell, as if by reproduction.\r\n\r\nWrite a function to compute the next state (after one update) of the board given its current state. The next state is created by applying the above rules simultaneously to every cell in the current state, where births and deaths occur simultaneously.\r\n\r\n**Example:**\r\n\r\n```\r\nInput: \r\n[\r\n [0,1,0],\r\n [0,0,1],\r\n [1,1,1],\r\n [0,0,0]\r\n]\r\nOutput: \r\n[\r\n [0,0,0],\r\n [1,0,1],\r\n [0,1,1],\r\n [0,1,0]\r\n]\r\n```\r\n\r\n**Follow up**:\r\n\r\n1. Could you solve it in-place? Remember that the board needs to be updated at the same time: You cannot update some cells first and then use their updated values to update other cells.\r\n2. In this question, we represent the board using a 2D array. In principle, the board is infinite, which would cause problems when the active area encroaches the border of the array. How would you address these problems?\r\n\r\n```python\r\nclass Solution:\r\n def gameOfLife(self, board):\r\n \"\"\"\r\n Do not return anything, modify board in-place instead.\r\n \"\"\"\r\n\r\n def get_number(i, j, m, n, board):\r\n count = 0\r\n di = [-1, 0, 1, -1, 1, -1, 0, 1]\r\n dj = [-1, -1, -1, 0, 0, 1, 1, 1]\r\n for k in range(8):\r\n if i + di[k] < 0 or i + di[k] >= m or j + dj[k] < 0 or j + dj[k] >= n:\r\n continue\r\n else:\r\n if board[di[k] + i][dj[k] + j] == 1:\r\n count += 1\r\n return count\r\n\r\n if board == None or board[0] == None: return\r\n m, n = len(board), len(board[0])\r\n board2 = [[0 for i in range(n)] for j in range(m)]\r\n for i in range(m):\r\n for j in range(n):\r\n number = get_number(i, j, m, n, board)\r\n if board[i][j] == 1:\r\n if number == 2 or number == 3:\r\n board2[i][j] = 1\r\n else:\r\n if number == 3:\r\n board2[i][j] = 1\r\n for i in range(m):\r\n for j in range(n):\r\n board[i][j] = board2[i][j]\r\n return\r\n```\r\n\r\n\r\n\r\n##### leetcode 310 Minimum Height Trees\r\n\r\nFor an undirected graph with tree characteristics, we can choose any node as the root. The result graph is then a rooted tree. Among all possible rooted trees, those with minimum height are called minimum height trees (MHTs). Given such a graph, write a function to find all the MHTs and return a list of their root labels.\r\n\r\n**Format**\r\nThe graph contains `n` nodes which are labeled from `0` to `n - 1`. You will be given the number `n` and a list of undirected `edges` (each edge is a pair of labels).\r\n\r\nYou can assume that no duplicate edges will appear in `edges`. Since all edges are undirected, `[0, 1]` is the same as `[1, 0]` and thus will not appear together in `edges`.\r\n\r\n**Example 1 :**\r\n\r\n```\r\nInput: n = 4, edges = [[1, 0], [1, 2], [1, 3]]\r\n\r\n 0\r\n |\r\n 1\r\n / \\\r\n 2 3 \r\n\r\nOutput: [1]\r\n```\r\n\r\n**Example 2 :**\r\n\r\n```\r\nInput: n = 6, edges = [[0, 3], [1, 3], [2, 3], [4, 3], [5, 4]]\r\n\r\n 0 1 2\r\n \\ | /\r\n 3\r\n |\r\n 4\r\n |\r\n 5 \r\n\r\nOutput: [3, 4]\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def findMinHeightTrees(self,n, edges):\r\n if n <= 1:\r\n return [0]\r\n degrees = [0] * n\r\n graph = {x: [] for x in range(n)}\r\n for p in edges:\r\n degrees[p[1]] += 1\r\n degrees[p[0]] += 1\r\n graph[p[1]].append(p[0])\r\n graph[p[0]].append(p[1])\r\n queue = [x for x in range(0, n) if degrees[x] == 1]\r\n ret = []\r\n #先找叶子节点 然后假装将叶子节点去掉找上一层的节点\r\n while queue:\r\n temp = []\r\n ret = queue[:]\r\n for x in queue:\r\n for n in graph[x]:\r\n degrees[n] -= 1\r\n if degrees[n] == 1:\r\n temp.append(n)\r\n queue = temp\r\n\r\n return ret\r\n```\r\n\r\n\r\n\r\n##### leetcode 332 Reconstruct Itinerary\r\n\r\nGiven a list of airline tickets represented by pairs of departure and arrival airports `[from, to]`, reconstruct the itinerary in order. All of the tickets belong to a man who departs from `JFK`. Thus, the itinerary must begin with `JFK`.\r\n\r\n**Note:**\r\n\r\n1. If there are multiple valid itineraries, you should return the itinerary that has the smallest lexical order when read as a single string. For example, the itinerary `[\"JFK\", \"LGA\"]` has a smaller lexical order than `[\"JFK\", \"LGB\"]`.\r\n2. All airports are represented by three capital letters (IATA code).\r\n3. You may assume all tickets form at least one valid itinerary.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [[\"MUC\", \"LHR\"], [\"JFK\", \"MUC\"], [\"SFO\", \"SJC\"], [\"LHR\", \"SFO\"]]\r\nOutput: [\"JFK\", \"MUC\", \"LHR\", \"SFO\", \"SJC\"]\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [[\"JFK\",\"SFO\"],[\"JFK\",\"ATL\"],[\"SFO\",\"ATL\"],[\"ATL\",\"JFK\"],[\"ATL\",\"SFO\"]]\r\nOutput: [\"JFK\",\"ATL\",\"JFK\",\"SFO\",\"ATL\",\"SFO\"]\r\nExplanation: Another possible reconstruction is [\"JFK\",\"SFO\",\"ATL\",\"JFK\",\"ATL\",\"SFO\"].\r\n But it is larger in lexical order.\r\n```\r\n\r\n```python\r\nimport collections\r\nclass Solution:\r\n def findItinerary(self, tickets):\r\n targets = collections.defaultdict(list)\r\n for a, b in sorted(tickets)[::-1]:\r\n targets[a] += b,\r\n route = []\r\n\r\n def visit(airport):\r\n while targets[airport]:\r\n visit(targets[airport].pop())\r\n route.append(airport)\r\n\r\n visit('JFK')\r\n return route[::-1]\r\n```\r\n\r\n要注意本题要求顺序, 使用sorted(tickets)[::-1], targets[airport].pop()来保证\r\n\r\n另一点 本题要求必须从JFK开始 但是没要求在哪里结束,因此采用倒叙的方式,最后把route倒过来\r\n\r\n\r\n\r\n##### leetcode 399 Evaluate Division\r\n\r\nEquations are given in the format `A / B = k`, where `A` and `B` are variables represented as strings, and `k` is a real number (floating point number). Given some queries, return the answers. If the answer does not exist, return `-1.0`.\r\n\r\n**Example:**\r\nGiven `a / b = 2.0, b / c = 3.0.`\r\nqueries are: `a / c = ?, b / a = ?, a / e = ?, a / a = ?, x / x = ? .`\r\nreturn `[6.0, 0.5, -1.0, 1.0, -1.0 ].`\r\n\r\nThe input is: `vector<pair<string, string>> equations, vector<double>& values, vector<pair<string, string>> queries `, where `equations.size() == values.size()`, and the values are positive. This represents the equations. Return `vector<double>`.\r\n\r\nAccording to the example above:\r\n\r\n```\r\nequations = [ [\"a\", \"b\"], [\"b\", \"c\"] ],\r\nvalues = [2.0, 3.0],\r\nqueries = [ [\"a\", \"c\"], [\"b\", \"a\"], [\"a\", \"e\"], [\"a\", \"a\"], [\"x\", \"x\"] ]. \r\n```\r\n\r\n```python\r\nclass Solution:\r\n def calcEquation(self, equations, values, queries):\r\n quot = collections.defaultdict(dict)\r\n for (num, den), val in zip(equations, values):\r\n quot[num][num] = quot[den][den] = 1.0\r\n quot[num][den] = val\r\n quot[den][num] = 1 / val\r\n for k, i, j in itertools.permutations(quot, 3):\r\n if k in quot[i] and j in quot[k]:\r\n quot[i][j] = quot[i][k] * quot[k][j]\r\n return [quot[num].get(den, -1.0) for num, den in queries]\r\n```\r\n\r\n关键在于for k, i, j in itertools.permutations(quot, 3):\r\n\r\n在query之前把能计算的值都计算了\r\n\r\n\r\n\r\n##### leetcode 886 Possible Bipartition\r\n\r\n* Given a set of `N` people (numbered `1, 2, ..., N`), we would like to split everyone into two groups of **any** size.\r\n\r\n Each person may dislike some other people, and they should not go into the same group. \r\n\r\n Formally, if `dislikes[i] = [a, b]`, it means it is not allowed to put the people numbered `a` and `b` into the same group.\r\n\r\n Return `true` if and only if it is possible to split everyone into two groups in this way.\r\n\r\n```\r\nInput: N = 4, dislikes = [[1,2],[1,3],[2,4]]\r\nOutput: true\r\nExplanation: group1 [1,4], group2 [2,3]\r\n\r\nInput: N = 5, dislikes = [[1,2],[2,3],[3,4],[4,5],[1,5]]\r\nOutput: false\r\n```\r\n\r\n对每个点,统计和他相互讨厌的点\r\n\r\n对每个未访问过的点DFS(BFS也行),如果遇到矛盾则说明不能分,如果没有遇到,说明可以分\r\n\r\n本题和将图染成两种色问题基本一致\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n\tbool DFS(int source,int color) {\r\n\t\tbool res = true;\r\n\t\tnums[source] = color;\r\n\t\tfor (int i = 0; i < no_samegroup[source].size(); i++) {\r\n\t\t\tif (nums[no_samegroup[source][i]] == color)\r\n\t\t\t\treturn false;\r\n\t\t\telse if (nums[no_samegroup[source][i]] == 0) {\r\n\t\t\t\tres = res && DFS(no_samegroup[source][i], -color);\r\n\t\t\t}\r\n\t\t}\r\n\t\treturn res;\r\n\t}\r\n\tbool possibleBipartition(int N, vector<vector<int>>& dislikes) {\r\n\t\tif (dislikes.size() == 0)\r\n\t\t\treturn true;\r\n\t\tno_samegroup.resize(N);\r\n\t\tnums.resize(N);\r\n\t\tfor (int i = 0; i < dislikes.size(); i++) {\r\n\t\t\tno_samegroup[dislikes[i][0]-1].push_back(dislikes[i][1]-1);\r\n\t\t\tno_samegroup[dislikes[i][1]-1].push_back(dislikes[i][0]-1);\r\n\t\t}\r\n\t\tbool res;\r\n\t\tfor (int j = 0; j < N; j++) {\r\n\t\t\tif (nums[j] == 0)\r\n\t\t\t\tres = DFS(j, 1);\r\n\t\t\tif (!res) return false;\r\n\t\t}\r\n\t\treturn true;\r\n\t}\r\nprivate:\r\n\tvector<int> nums;\r\n\tvector<vector<int>> no_samegroup;\r\n};\r\n```\r\n\r\n\r\n\r\n##### leetcode 743 Network Delay Time\r\n\r\nThere are `N` network nodes, labelled `1` to `N`.\r\n\r\nGiven `times`, a list of travel times as **directed** edges `times[i] = (u, v, w)`, where `u` is the source node, `v` is the target node, and `w` is the time it takes for a signal to travel from source to target.\r\n\r\nNow, we send a signal from a certain node `K`. How long will it take for all nodes to receive the signal? If it is impossible, return `-1`.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n\r\n\r\n```\r\nInput: times = [[2,1,1],[2,3,1],[3,4,1]], N = 4, K = 2\r\nOutput: 2\r\n```\r\n\r\n \r\n\r\n**Note:**\r\n\r\n1. `N` will be in the range `[1, 100]`.\r\n2. `K` will be in the range `[1, N]`.\r\n3. The length of `times` will be in the range `[1, 6000]`.\r\n4. All edges `times[i] = (u, v, w)` will have `1 <= u, v <= N` and `0 <= w <= 100`.\r\n\r\n```python\r\nclass Solution:\r\n def networkDelayTime(self, times, N, K):\r\n nodes, distance = set(), [float(\"inf\") for i in range(N+1)]\r\n distance[0] = 0\r\n for i in range(1, N+1):\r\n if i == K:\r\n distance[K] = 0\r\n else:\r\n nodes.add(i)\r\n while nodes:\r\n temp_distance = float('inf')\r\n temp = -1\r\n for start, end, w in times:\r\n if end in nodes:\r\n if distance[start] + w < temp_distance:\r\n temp_distance = distance[start] + w\r\n temp = end\r\n if temp_distance == float(\"inf\"): return -1\r\n distance[temp] = temp_distance\r\n nodes.remove(temp)\r\n return max(distance)\r\n```\r\n\r\n单源到其他点的最短距离,dijkstra\r\n\r\n\r\n\r\n##### leetcode 1245 Tree Diameter\r\n\r\nGiven an undirected tree, return its diameter: the number of **edges** in a longest path in that tree.\r\n\r\nThe tree is given as an array of `edges` where `edges[i] = [u, v]` is a bidirectional edge between nodes `u` and `v`. Each node has labels in the set `{0, 1, ..., edges.length}`.\r\n\r\n**Example 1:**\r\n\r\n\r\n\r\n```\r\nInput: edges = [[0,1],[0,2]]\r\nOutput: 2\r\nExplanation: \r\nA longest path of the tree is the path 1 - 0 - 2.\r\n```\r\n\r\n**Example 2:**\r\n\r\n\r\n\r\n```\r\nInput: edges = [[0,1],[1,2],[2,3],[1,4],[4,5]]\r\nOutput: 4\r\nExplanation: \r\nA longest path of the tree is the path 3 - 2 - 1 - 4 - 5.\r\n```\r\n\r\n**Constraints:**\r\n\r\n- `0 <= edges.length < 10^4`\r\n- `edges[i][0] != edges[i][1]`\r\n- `0 <= edges[i][j] <= edges.length`\r\n- The given edges form an undirected tree.\r\n\r\n```\r\nclass Solution:\r\n def treeDiameter(self, edges):\r\n n = len(edges) + 1\r\n dp = [[float(\"inf\") for i in range(n)]for i in range(n)]\r\n for s, e in edges:\r\n dp[s][e] = dp[e][s] = 1\r\n for k in range(n):\r\n for i in range(n):\r\n for j in range(n):\r\n if dp[i][k] + dp[k][j] < dp[i][j]:\r\n dp[i][j] = dp[i][k] + dp[k][j]\r\n res = 0\r\n for i in range(n):\r\n for j in range(n):\r\n res = max(dp[i][j], res)\r\n return res\r\n```\r\n\r\n##### Floyd-warshall algorithm\r\n\r\nis an all-pair shortest path algorithm 超过时间\r\n\r\n\r\n\r\n```python\r\nimport collections\r\nclass Solution:\r\n def depth(self, node, parent, graph):\r\n d1 = d2 = 0\r\n for nei in graph[node]:\r\n if nei != parent:\r\n d = self.depth(nei, node, graph)\r\n if d > d1:\r\n d1, d2 = d, d1\r\n elif d > d2:\r\n d2 = d\r\n self.diameter = max(self.diameter, d1 + d2)\r\n return d1 + 1\r\n def treeDiameter(self, edges):\r\n n = len(edges) + 1\r\n self.diameter = 0\r\n graph = collections.defaultdict(set)\r\n for a, b in edges:\r\n graph[a].add(b)\r\n graph[b].add(a)\r\n self.depth(0, None, graph)\r\n return self.diameter\r\n```\r\n\r\n从0节点开始对每个节点求depth,这边要注意depth函数中要传进去parent节点,不能往回计算depth\r\n\r\n根节点的depth为1\r\n\r\n要计算直径就是在计算depth时记录每个节点的两个depth最大的子节点,之和即为该节点的直径\r\n\r\n\r\n\r\n##### leetcode 785. Is Graph Bipartite?\r\n\r\nGiven an undirected `graph`, return `true` if and only if it is bipartite.\r\n\r\nRecall that a graph is *bipartite* if we can split it's set of nodes into two independent subsets A and B such that every edge in the graph has one node in A and another node in B.\r\n\r\nThe graph is given in the following form: `graph[i]` is a list of indexes `j` for which the edge between nodes `i` and `j` exists. Each node is an integer between `0` and `graph.length - 1`. There are no self edges or parallel edges: `graph[i]` does not contain `i`, and it doesn't contain any element twice.\r\n\r\n```\r\nExample 1:\r\nInput: [[1,3], [0,2], [1,3], [0,2]]\r\nOutput: true\r\nExplanation: \r\nThe graph looks like this:\r\n0----1\r\n| |\r\n| |\r\n3----2\r\nWe can divide the vertices into two groups: {0, 2} and {1, 3}.\r\nExample 2:\r\nInput: [[1,2,3], [0,2], [0,1,3], [0,2]]\r\nOutput: false\r\nExplanation: \r\nThe graph looks like this:\r\n0----1\r\n| \\ |\r\n| \\ |\r\n3----2\r\nWe cannot find a way to divide the set of nodes into two independent subsets.\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def put(self, node, graph, index):\r\n self.index_dict[node] = index\r\n for nei in graph[node]:\r\n if nei not in self.index_dict:\r\n if not self.put(nei, graph, 1-index):\r\n return False\r\n else:\r\n if self.index_dict[nei] != 1-index:\r\n return False\r\n return True\r\n \r\n def isBipartite(self, graph: List[List[int]]) -> bool:\r\n self.set0, self.set1 = set(), set()\r\n self.index_dict = {}\r\n for i in range(len(graph)):\r\n if i not in self.index_dict:\r\n if not self.put(i, graph, 0):\r\n return False\r\n return True\r\n```\r\n\r\n先把node放入一个set,然后把其所有的邻居都变为1-index\r\n\r\n\r\n\r\n##### leetcode 269 Alien Dictionary\r\n\r\nThere is a new alien language which uses the latin alphabet. However, the order among letters are unknown to you. You receive a list of **non-empty** words from the dictionary, where **words are sorted lexicographically by the rules of this new language**. Derive the order of letters in this language.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput:\r\n[\r\n \"wrt\",\r\n \"wrf\",\r\n \"er\",\r\n \"ett\",\r\n \"rftt\"\r\n]\r\n\r\nOutput: \"wertf\"\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput:\r\n[\r\n \"z\",\r\n \"x\"\r\n]\r\n\r\nOutput: \"zx\"\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput:\r\n[\r\n \"z\",\r\n \"x\",\r\n \"z\"\r\n] \r\n\r\nOutput: \"\" \r\n\r\nExplanation: The order is invalid, so return \"\".\r\n```\r\n\r\n**Note:**\r\n\r\n1. You may assume all letters are in lowercase.\r\n2. You may assume that if a is a prefix of b, then a must appear before b in the given dictionary.\r\n3. If the order is invalid, return an empty string.\r\n4. There may be multiple valid order of letters, return any one of them is fine.\r\n\r\n```python\r\nimport collections\r\nclass Solution:\r\n def dfs(self, node, graph, stack, visited):\r\n visited[node] = 0\r\n for nei in graph[node]:\r\n if visited[nei] == 0:\r\n return False\r\n elif visited[nei] == -1:\r\n if not self.dfs(nei, graph, stack, visited):\r\n return False\r\n visited[node] = 1\r\n stack.insert(0, node)\r\n return True\r\n\r\n def alienOrder(self, words) -> str:\r\n n, graph = len(words), collections.defaultdict(set)\r\n nodes = set()\r\n for i in range(n):\r\n nodes |= set(words[i])\r\n for j in range(i + 1, n):\r\n length = min(len(words[i]), len(words[j]))\r\n for k in range(length):\r\n if words[i][k] != words[j][k]:\r\n graph[words[i][k]].add(words[j][k])\r\n break\r\n stack, visited = [], {}\r\n for node in nodes:\r\n visited[node] = -1\r\n for node in nodes:\r\n if visited[node] == -1:\r\n if not self.dfs(node, graph, stack, visited):\r\n return \"\"\r\n return \"\".join(x for x in stack)\r\n```\r\n\r\n典型的Toplogical sort 但是需要根据words来主动发现edges\r\n\r\n"
},
{
"alpha_fraction": 0.7312273383140564,
"alphanum_fraction": 0.7358881235122681,
"avg_line_length": 12.335821151733398,
"blob_id": "eeb2c0993e493790dc2590fc55cfd06bb60679c6",
"content_id": "fdd7df482c5673cf54a3290f937a5ac212e5e2ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4055,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 134,
"path": "/interview/常见问题.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "#### python常见问题\r\n\r\npython的特点是什么?\r\n\r\n解释性、动态、面向对象等\r\n\r\n\r\n\r\n深拷贝和浅拷贝的区别\r\n\r\n深拷贝是将对象本身复制给另一个对象,浅拷贝是将对象的引用复制给另一个对象,如果对引用进行更改会改变原对象。\r\n\r\npython中使用deepcopy进行深拷贝,copy进行浅拷贝。\r\n\r\npython与c++在这一点上的不同在于python是引用语义的而c++是值语义的。\r\n\r\n\r\n\r\n列表和元祖有什么不同?\r\n\r\npython中:列表是可变的,但是元祖是不可变的,不能够通过赋值来改变元祖中某个对象的值。\r\n\r\nc++中的元祖tuple和vector的区别在于:tuple更加宽松,tuple中的对象可以是不同类型的,但是vector必须是同一类型的。\r\n\r\n\r\n\r\npython中的三元表达式\r\n\r\na,b=2,3\r\n\r\nmin=a if a<b else b\r\n\r\n\r\n\r\npython中的with ...结构和try: finally结构是一样的\r\n\r\n如果直接使用open函数,可能会出现一些问题,例如IOError。\r\n\r\n\r\n\r\n#### C++ 常见面试\r\n\r\nnew/delete 与malloc/free的区别\r\n\r\n都是在做内存分配方面的工作\r\n\r\nnew/delete是c++的运算符,malloc和free是库函数。\r\n\r\nnew/delete这些运算符会调用构造函数和析构函数来对对象进行初始化、析构\r\n\r\n\r\n\r\n析构函数必须是virtual的,否则在用父类的指针指向子类对象时,不会调用子类的析构函数。\r\n\r\n\r\n\r\n多态、虚函数、纯虚函数\r\n\r\n多态:一种接口,多种方法。多态包括运行时多态和编译时多态。我们把具有继承关系的多个类型称为多态类型。\r\n\r\n编译时的多态:运算符重载,多个同名函数,参数不同,在编译期具体绑定为哪个函数。\r\n\r\n运行时多态:通过继承与虚函数来实现的。虚函数:运行时类型分派,对于具有继承关系的多个类,具体使用的是哪个类要到运行时才会被解析。\r\n\r\n虚函数:虚函数用virtual表示。派生类对基类的虚函数进行重新定义或者不重新定义。虚函数是用来实现多态的重要的机制。\r\n\r\n纯虚函数:纯虚函数的类是抽象类,纯虚函数后面接一个=0,抽象类不可以实例化。\r\n\r\nc++中抽象类就是接口。\r\n\r\n\r\n\r\n重载和重写\r\n\r\n函数重载:相同范围(同一个类下),函数名相同,参数不同,例如\r\n\r\nbase::f(int),base::f(float)\r\n\r\n函数重写:不同范围(不同类),函数名相同,参数不同\r\n\r\nbase::f(int),derived::f(int)\r\n\r\n\r\n\r\n堆栈:\r\n\r\n内存中堆和栈是最重要的两块内存空间,其中栈中存放基本类型的变量数据和对象的引用,例如指针等,局部变量也存放在栈中。\r\n\r\n堆中主要存放的是new 创建的对象。\r\n\r\n\r\n\r\n```c++\r\nint test=0; //全局静态存储区\r\nint* ptr=&test;//全局变量存储区\r\nint main(){\r\n int a=2;//栈\r\n int* ptr2=&a; //ptr2是在栈上,指向的内容也是栈上\r\n \r\n int* ptrheap=new int(2);//new 是堆上申请的内存,但是ptrheap在栈上\r\n}\r\n```\r\n\r\n\r\n\r\nstatic关键字\r\n\r\n表示静态变量,如果static修饰局部变量,则改变了其存储位置(栈到静态存储区),同时改变了其生命周期,如果static修饰全局变量则没有改变其位置和生命周期,但是让别的源文件无法访问该变量。\r\n\r\nstatic强调这是唯一的拷贝,下次调用static变量的时候维持了上次的值\r\n\r\n\r\n\r\nconst关键字\r\n\r\n限定变量不可更改\r\n\r\nconst char* p,p指向的内容不能变\r\n\r\nchar *const p,p声明为常指针,地址不能变,内容可变\r\n\r\n\r\n\r\nvector中size和capacity的区别:\r\n\r\nsize表示vector中有多少元素,capacity则表示vector目前的最大能容纳的元素数量,一般capacity是2的幂。\r\n\r\n\r\n\r\n结构体struct和共同体union的区别\r\n\r\n结构体是将不同类型的数据组合成一个整体,是自定义类型\r\n\r\nsizeof(struct)是所有成员的长度和,sizeof(union)是内存对齐猴最长数据成员的长度,union共同体中所有成员占用了同一段内存。\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.8199513554573059,
"alphanum_fraction": 0.8199513554573059,
"avg_line_length": 24.516128540039062,
"blob_id": "99e518ae66b78ad2139588713b3ebbb86ac26ef1",
"content_id": "25c8ed7b3ee71d5f99e195471c40bbefd9747fcd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2174,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 31,
"path": "/computer_science_knowledge/database/数据库常考概念.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "## 数据库: \r\n### 事物: 事物指一个单元的工作,这些工作要么不做要么全做\r\n```\r\n事物机制保证一组数据要么全部执行要么全部不执行\r\nACID 指的是数据库正确执行的四个要素缩写\r\n原子性Atomicity、一致性 Consistency\r\n隔离性(Isolation)、持久性(Durability)。\r\n原子性 整个事务中的全部操作要么全部完成要么全部不完成 如果执行中发生错误,回滚。\r\n一致性 在事务开始前和在结束后 数据库的完整性约束没有被破坏\r\n隔离性 两个事务是互不干扰的, 一个事务不可能看到其他事务运行时中的数据。\r\n持久性 在事务完成之后,该事务对数据库的更改持久。\r\n```\r\n### 数据库的死锁: \r\n```\r\n两个或者是两个以上进程在执行的过程中,因相互争夺资源而导致二者都无法继续进行的现象,\r\n若无外力推动,都将无法进行下去,此时成为死锁。\r\n\r\n死锁出现的四个必要条件:\r\n互斥性:进程要求的资源具有互斥性\r\n不剥夺条件:进程获得的资源在没有使用完成之前,不能被其他进程所强行夺走,只能由进程自己释放。\r\n请求与保持条件:进程每次申请一部分所需要的资源的时候,在等待时保留其目前有的资源。\r\n循环等待条件:存在一个循环等待链。\r\n死锁处理:预防死锁 避免死锁 死锁检测与解除\r\n为了避免死锁,可以考虑破坏死锁成立的条件之一以及在分配资源时考虑其安全性。\r\n银行家算法是最著名的死锁避免算法。将操作系统看成银行家,而操作系统的资源则\r\n被看成是用来贷款的资金。在进程首次向操作系统申请资源的时候,检测其所需的最\r\n\\大资源,如果其所需的最大资源量超过了现在操作系统中有的资源则推迟分配。进\r\n程在执行过程中向操作系统申请资源的时候,先检测已占有的资源加本次申请的资源\r\n是否超过最大所需资源总和,若没超过则检测现存的资源能否满足该进程还需要的最\r\n大资源量,若能满足则继续按照分配。\r\n```\r\n"
},
{
"alpha_fraction": 0.6644295454025269,
"alphanum_fraction": 0.7382550239562988,
"avg_line_length": 19.285715103149414,
"blob_id": "13931a3a235e4f8cfd9d201e257a65be1376eea3",
"content_id": "ebdb62e75131d20766d7d1af725eb72b453c28f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 205,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 7,
"path": "/interview/indeed.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "ExpiringMap:\r\nhttp://www.1point3acres.com/bbs/thread-197737-1-1.html\r\n使用time 对每个元素进入map的时间进行标记 仔使用时判断是否过期即可\r\n```\r\nimport time\r\nt1=time.clock()\r\n```\r\n"
},
{
"alpha_fraction": 0.472517728805542,
"alphanum_fraction": 0.48771530389785767,
"avg_line_length": 22.43962860107422,
"blob_id": "84bd19fd9ff20c80b315611988637cae062296c4",
"content_id": "e51274f1e5e961f51fa1458fa95d5e6620048aee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 8046,
"license_type": "no_license",
"max_line_length": 188,
"num_lines": 323,
"path": "/leetcode_note/Palindrome.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### leetocde 5 Longest Palindromic Substring\r\n\r\n- Given a string **s**, find the longest palindromic substring in **s**. You may assume that the maximum length of **s** is 1000.\r\n\r\n ```\r\n Input: \"babad\"\r\n Output: \"bab\"\r\n Note: \"aba\" is also a valid answer.\r\n \r\n Input: \"cbbd\"\r\n Output: \"bb\"mysolution \r\n ```\r\n\r\n```python\r\nclass Solution(object):\r\n def longestPalindrome(self, s):\r\n n=len(s)\r\n if n==0:\r\n return \"\"\r\n num,i=1,0\r\n res=s[0]\r\n while i<n-1:\r\n pivot=i+1\r\n while pivot<n and s[i]==s[pivot]:\r\n pivot+=1\r\n temp=s[i:pivot] #temp str\r\n left,right=i-1,pivot\r\n while left>=0 and right<=n-1:\r\n if s[left]==s[right]:\r\n temp=s[left]+temp+s[right]\r\n else:\r\n break\r\n left-=1\r\n right+=1\r\n i=pivot\r\n if len(temp)>num:\r\n num,res=len(temp),temp\r\n return res\r\n```\r\n\r\nstart从0开始\r\n\r\n```python\r\npivot=i+1\r\nwhile pivot<n and s[i]==s[pivot]:\r\n pivot+=1\r\n```\r\n\r\n考虑到偶数核心和奇数核心的问题,然后开始left,right向两边拓(本题也可以使用DP)\r\n\r\n\r\n\r\n##### leetcode 9 Palindrome Number\r\n\r\n- Determine whether an integer is a palindrome. An integer is a palindrome when it reads the same backward as forward.\r\n\r\n ```\r\n Input: 121\r\n Output: true\r\n Input: -121\r\n Output: false\r\n ```\r\n\r\n Mysolution:\r\n\r\n ```python\r\n class Solution:\r\n def isPalindrome(self, x):\r\n str1=str(x)\r\n return str1==str1[::-1]\r\n ```\r\n\r\n 考察str1[::-1] reverse功能\r\n\r\n\r\n##### leetcode 131 Palindrome Partitioning\r\n\r\nGiven a string *s*, partition *s* such that every substring of the partition is a palindrome.\r\n\r\nReturn all possible palindrome partitioning of *s*.\r\n\r\n**Example:**\r\n\r\n```\r\nInput: \"aab\"\r\nOutput:\r\n[\r\n [\"aa\",\"b\"],\r\n [\"a\",\"a\",\"b\"]\r\n]\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def partition(self, s):\r\n \"\"\"\r\n :type s: str\r\n :rtype: List[List[str]]\r\n \"\"\"\r\n def helper(s,path):\r\n if not s:\r\n self.res.append(path)\r\n for i in range(1,len(s)+1,1):\r\n if ispal(s[:i]):\r\n helper(s[i:],path+[s[:i]])\r\n def ispal(s):\r\n return s==s[::-1]\r\n self.res=[]\r\n helper(s,[])\r\n return self.res\r\n```\r\n\r\nback-tracking\r\n\r\n用s==s[::-1]判断是否回文\r\n\r\n然后如果s[:i] 是回文就尝试将s[:i]放入path\r\n\r\n\r\n\r\n##### leetcode 132 Palindrome Partitioning II\r\n\r\nGiven a string *s*, partition *s* such that every substring of the partition is a palindrome.\r\n\r\nReturn the minimum cuts needed for a palindrome partitioning of *s*.\r\n\r\n**Example:**\r\n\r\n```\r\nInput: \"aab\"\r\nOutput: 1\r\nExplanation: The palindrome partitioning [\"aa\",\"b\"] could be produced using 1 cut.\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def minCut(self, s):\r\n cut = [x for x in range(-1,len(s))]\r\n for i in range(0,len(s)):\r\n for j in range(i,len(s)):\r\n if s[i:j] == s[j:i:-1]:\r\n cut[j+1] = min(cut[j+1],cut[i]+1)\r\n return cut[-1]\r\n```\r\n\r\n\r\n\r\n##### leetcode 1278. Palindrome Partitioning III\r\n\r\nYou are given a string `s` containing lowercase letters and an integer `k`. You need to :\r\n\r\n- First, change some characters of `s` to other lowercase English letters.\r\n- Then divide `s` into `k` non-empty disjoint substrings such that each substring is palindrome.\r\n\r\nReturn the minimal number of characters that you need to change to divide the string.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: s = \"abc\", k = 2\r\nOutput: 1\r\nExplanation: You can split the string into \"ab\" and \"c\", and change 1 character in \"ab\" to make it palindrome.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: s = \"aabbc\", k = 3\r\nOutput: 0\r\nExplanation: You can split the string into \"aa\", \"bb\" and \"c\", all of them are palindrome.\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: s = \"leetcode\", k = 8\r\nOutput: 0\r\n```\r\n\r\n \r\n\r\n**Constraints:**\r\n\r\n- `1 <= k <= s.length <= 100`.\r\n- `s` only contains lowercase English letters.\r\n\r\nAccepted\r\n\r\n```python\r\nclass Solution(object):\r\n def palindromePartition(self, s, k):\r\n def num_change(w):#how many need to change to become palindrome\r\n l,r=0,len(w)-1\r\n count=0\r\n while l<r:\r\n if w[l]!=w[r]:\r\n count+=1\r\n l+=1\r\n r-=1\r\n return count\r\n \r\n def dp(i,k):\r\n if (i,k) not in memo:\r\n if k==1:\r\n memo[i,k]=num_change(s[:i+1])\r\n else:\r\n memo[i,k]=min(dp(j,k-1)+num_change(s[j+1:i+1]) for j in range(k-2,i))\r\n return memo[i,k]\r\n memo={} \r\n n=len(s)\r\n return dp(n-1,k)\r\n```\r\n\r\n\r\n\r\n##### leetcode 336 Palindrome Pairs\r\n\r\nHard\r\n\r\nGiven a list of **unique** words, find all pairs of **distinct** indices `(i, j)` in the given list, so that the concatenation of the two words, i.e. `words[i] + words[j]` is a palindrome.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [\"abcd\",\"dcba\",\"lls\",\"s\",\"sssll\"]\r\nOutput: [[0,1],[1,0],[3,2],[2,4]] \r\nExplanation: The palindromes are [\"dcbaabcd\",\"abcddcba\",\"slls\",\"llssssll\"]\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [\"bat\",\"tab\",\"cat\"]\r\nOutput: [[0,1],[1,0]] \r\nExplanation: The palindromes are [\"battab\",\"tabbat\"]\r\n```\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n vector<vector<int>> palindromePairs(vector<string>& words) {\r\n vector<vector<int>> result;\r\n unordered_map<string, int> dict;\r\n for(int i = 0; i < words.size(); i++) {\r\n dict[words[i]] = i;\r\n }\r\n for(int i = 0; i < words.size(); i++) {\r\n for(int j = 0; j <= words[i].length(); j++) {\r\n //check the suffix word\r\n if(is_palindrome(words[i], j, words[i].size() - 1)) {\r\n /** the suffix word can be null to all the word **/\r\n string suffix = words[i].substr(0, j);\r\n reverse(suffix.begin(), suffix.end());\r\n if(dict.find(suffix) != dict.end() && i != dict[suffix]) {\r\n result.push_back({i, dict[suffix]});\r\n }\r\n }\r\n //check the prefix word \r\n if(j > 0 && is_palindrome(words[i], 0, j - 1)) {\r\n string prefix = words[i].substr(j);\r\n reverse(prefix.begin(), prefix.end());\r\n if(dict.find(prefix) != dict.end() && dict[prefix] != i) {\r\n result.push_back({dict[prefix], i});\r\n }\r\n }\r\n }\r\n }\r\n return result;\r\n }\r\n \r\n bool is_palindrome(string& s, int start, int end) {\r\n while(start < end) {\r\n if(s[start++] != s[end--]) {\r\n return false;\r\n }\r\n }\r\n return true;\r\n \r\n }\r\n};\r\n```\r\n\r\n流程\r\n\r\nfor abcd\r\n\r\n```\r\n拆开\r\na check \"a\" pali?-> find \"dcb\" no check \"bcd\" pali? no\r\nab check \"ab\" pali? no check \"cd\" pali? no\r\nabc check \"abc\" pali? no check \"d\" pali? yes find \"cba\" no\r\nabcd check \"abcd\" pali? no check \"\" pali? yes find \"dcba\" yes, push_back\r\n```\r\n\r\n原本自己的方法会超时\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n bool ispali(string word1, string word2){\r\n word1 += word2;\r\n int n=word1.size();\r\n int i=0, j=n-1;\r\n while(i<j){\r\n if(word1[i]!=word1[j]) return false;\r\n i++;j--;\r\n }\r\n return true;\r\n }\r\n vector<vector<int>> palindromePairs(vector<string>& words) {\r\n int n = words.size(), i, j;\r\n vector<vector<int>> res;\r\n for(i=0;i<n;i++){\r\n for(j=0;j<n;j++){\r\n if(i!=j){\r\n if(ispali(words[i], words[j])) res.push_back({i, j});\r\n }\r\n }\r\n }\r\n return res;\r\n }\r\n};\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.6232557892799377,
"alphanum_fraction": 0.682170569896698,
"avg_line_length": 25.4255313873291,
"blob_id": "e224098bfa13f3aaf00cf9b509119f59ff8e9eae",
"content_id": "ca98c5899c0fd718c744f7d50bd468c258604460",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1400,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 47,
"path": "/programs/zhangkang.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "retrain.py occlusion.py train.py utils.py\r\nutils.py 读取数据、保存数据等\r\n```\r\ndef get_image_files(image_dir):\r\n fs = glob(\"{}/*.jpg\".format(image_dir))\r\n fs = [os.path.basename(filename) for filename in fs]\r\n return sorted(fs)\r\n```\r\n读取文件夹下所有后缀名为jpg的文件\r\n```\r\ndef download_pretrained_weights(inception_url, dest_dir)\r\n```\r\n用来下载transfer learning中的原模型\r\n\r\ntrain.py\r\n```\r\ndef get_model_config():\r\n inception_url = \"http://download.tensorflow.org/models/image/imagenet/inception-2015-12-05.tgz\"\r\n```\r\ntgz文件夹里面是classify_image_graph_def.pb文件\r\n\r\n下载model\r\n```\r\n inception_url = \"http://download.tensorflow.org/models/image/imagenet/inception-2015-12-05.tgz\"\r\n bottleneck_tensor_name = \"pool_3/_reshape:0\"\r\n bottleneck_tensor_size = 2048\r\n input_width = 299 \r\n input_height = 299\r\n input_depth = 3\r\n resized_input_tensor_name = \"Mul:0\"\r\n model_file_name = \"classify_image_graph_def.pb\"\r\n input_mean = 128\r\n input_std = 128\r\n```\r\nmodel 参数\r\n\r\nretrain.py\r\n\r\nprint log infomation\r\n```\r\nINFO:tensorflow:Step 660: loss = 0.04849398136138916 train acc = 1.0 val acc = 0.7446808218955994\r\n```\r\n```\r\ntf.logging.info(\"Step {}: loss = {} train acc = {} val acc = {}\". format(\r\n i, cross_entropy_value, train_accuracy, validation_accuracy))\r\n```\r\ntf.logging.set_verbosity(tf.logging.INFO)就开始打印配置信息 \r\n"
},
{
"alpha_fraction": 0.5151382088661194,
"alphanum_fraction": 0.5493637323379517,
"avg_line_length": 19.704761505126953,
"blob_id": "663696cdb102b4e59ac02f96dce5ccb12becc276",
"content_id": "a78dc0e63de7010605b302d4933c14b5298d8e6e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2601,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 105,
"path": "/interview/google.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "多和面试官沟通,可以通过注释代码的方式来进行沟通\r\n\r\n题目:\r\nhttp://www.1point3acres.com/bbs/thread-435292-1-1.html \r\n有一个n*n的棋盘,上面有m个糖果,最开始有一个人在棋盘左上角,他可以向左向右或者向下移动,但不能向上移动,问他最少需要多少步吃完所有糖果\r\nhttp://www.1point3acres.com/bbs/forum.php?mod=viewthread&tid=101600&ctid=92\r\n```\r\n把一个list的字符串 编码成 一个字符串 \r\n再把这个编码过的字符串 转回原来的list\r\n```\r\n\r\n```\r\n>>> list=[\"a\",\"b\",\"c\",\"d\"]\r\n>>> str1=\"\".join(x for x in list)\r\n>>> str1\r\n'abcd'\r\n>>> list1=[]\r\n>>> for i in range(len(str1)):\r\n... list1.append(str1[i])\r\n...\r\n>>> list1\r\n['a', 'b', 'c']\r\n```\r\npython字符串种的编码与解码\r\nencode decode\r\n```\r\n>>> str1=\"abc\"\r\n>>> code=str1.encode('utf-8')\r\n>>> str2=code.decode('utf-8')\r\n>>> str2\r\n'abc'\r\nencode decode的编码系统应该要相同\r\n```\r\n\r\n``` \r\n+1 North America\r\n...\r\n+1950 Northern Cal\r\n…\r\n+44 UK\r\n+4420 London\r\n+447 UK Mobile\r\n+44750 Vodafoned\r\n…\r\nand we have a phone number, for instance\r\n+447507439854795\r\n+44989045454\r\nreturn where the number is from\r\n各种data structure猜了一轮以后,猜中trie。然后要求implement\r\n```\r\n```\r\nfrom collections import defaultdict\r\nclass TrieNode:\r\n def __init__(self):\r\n self.children = defaultdict(TrieNode)\r\n self.isword = False\r\n\r\n\r\nclass Trie:\r\n\r\n def __init__(self):\r\n \"\"\"\r\n Initialize your data structure here.\r\n \"\"\"\r\n self.root = TrieNode()\r\n\r\n def insert(self, word):\r\n \"\"\"\r\n Inserts a word into the trie.\r\n :type word: str\r\n :rtype: void\r\n \"\"\"\r\n cur = self.root\r\n for letter in word:\r\n cur = cur.children[letter]\r\n cur.isword = True\r\n\r\n def search(self, word):\r\n \"\"\"\r\n Returns if the word is in the trie.\r\n :type word: str\r\n :rtype: bool\r\n \"\"\"\r\n cur = self.root\r\n for letter in word:\r\n if letter in cur.children:\r\n cur = cur.children[letter]\r\n else:\r\n return False\r\n return cur.isword\r\n\r\n def startsWith(self, prefix):\r\n \"\"\"\r\n Returns if there is any word in the trie that starts with the given prefix.\r\n :type prefix: str\r\n :rtype: bool\r\n \"\"\"\r\n cur = self.root\r\n for letter in prefix:\r\n if letter in cur.children:\r\n cur = cur.children[letter]\r\n else:\r\n return False\r\n return True\r\n```\r\n"
},
{
"alpha_fraction": 0.5409941673278809,
"alphanum_fraction": 0.6233053803443909,
"avg_line_length": 11.402597427368164,
"blob_id": "2dad7b251122a07651d17e76419365968cdbafc6",
"content_id": "c4728596f20e4c2fc661ec4903eb6ec991b7106f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3668,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 231,
"path": "/books/Sed and awk.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Sed and awk\r\n\r\nsed代表stream editor 流编辑器\r\n\r\nsed基本语法:\r\n\r\nsed [options] {sed-commands}{input-file}\r\n\r\nsed 每次从input-file中读取一行记录,并在该记录上执行sed-commands\r\n\r\nempolyee.txt\r\n\r\n```\r\n101,John Doe,CEO\r\n102,Jason Smith,IT Manager\r\n103,Raj Reddy,Sysadmin\r\n104,Anand Ram,Developer\r\n105,Jane Miller,Sales Manager\r\n```\r\n\r\n\r\n\r\np命令来打印\r\n\r\noptions:\r\n\r\n\t-n 只打印模式匹配的行\r\n\r\n\r\n\r\nsed 'p' emploee.txt\r\n\r\n```\r\n101,John Doe,CEO\r\n101,John Doe,CEO\r\n102,Jason Smith,IT Manager\r\n102,Jason Smith,IT Manager\r\n103,Raj Reddy,Sysadmin\r\n103,Raj Reddy,Sysadmin\r\n104,Anand Ram,Developer\r\n104,Anand Ram,Developer\r\n105,Jane Miller,Sales Manager\r\n105,Jane Miller,Sales Manager\r\n```\r\n\r\n会打印两遍\r\n\r\n\r\n\r\n```\r\nsed -n 'p' employee.txt\r\n101,John Doe,CEO\r\n102,Jason Smith,IT Manager\r\n103,Raj Reddy,Sysadmin\r\n104,Anand Ram,Developer\r\n105,Jane Miller,Sales Manager\r\n```\r\n\r\n打印第 1 至第 4 行:\r\n\r\n```\r\n$ sed -n '1,4 p' employee.txt\r\n101,John Doe,CEO\r\n102,Jason Smith,IT Manager\r\n103,Raj Reddy,Sysadmin\r\n104,Anand Ram,Developer\r\n```\r\n\r\n打印第 2 行至最后一行($代表最后一行):\r\n\r\n```\r\n$ sed -n '2,$ p' employee.txt\r\n102,Jason Smith,IT Manager\r\n103,Raj Reddy,Sysadmin\r\n104,Anand Ram,Developer\r\n105,Jane Miller,Sales Manager\r\n```\r\n\r\n每隔m行打印\r\n\r\n1~2 匹配 1,3,5,7,……\r\n2~2 匹配 2,4,6,8,……\r\n1~3 匹配 1,4,7,10,…..\r\n2~3 匹配 2,5,8,11,…..\r\n\r\n```\r\n$ sed -n '1~2 p' employee.txt\r\n101,John Doe,CEO\r\n103,Raj Reddy,Sysadmin\r\n105,Jane Miller,Sales Manager\r\n```\r\n\r\n\r\n\r\n打印匹配到了Jane的行\r\n\r\n```\r\nsed -n '/Jane/p' employee.txt\r\n105,Jane Miller,Sales Manager\r\n```\r\n\r\n打印自匹配 Raj 的行开始到匹配 Jane 的行之间的所有内容:\r\n\r\n```\r\n$ sed -n '/Raj/,/Jane/ p' employee.txt\r\n103,Raj Reddy,Sysadmin\r\n104,Anand Ram,Developer\r\n105,Jane Miller,Sales Manager\r\n```\r\n\r\n打印匹配 Jason 的行和其后面的两行:\r\n\r\n```\r\n$ sed -n '/Jane/,+2 p' employee.txt\r\n105,Jane Miller,Sales Manager\r\n```\r\n\r\n\r\n\r\nd命令表示删除\r\n\r\n```\r\nsed '/Jane/d' employee.txt\r\n101,John Doe,CEO\r\n102,Jason Smith,IT Manager\r\n103,Raj Reddy,Sysadmin\r\n104,Anand Ram,Developer\r\n\r\n删除了Jane那一行,但是本身不会删除txt文件中的一行\r\n\r\nsed 'p' employee.txt\r\n101,John Doe,CEO\r\n101,John Doe,CEO\r\n102,Jason Smith,IT Manager\r\n102,Jason Smith,IT Manager\r\n103,Raj Reddy,Sysadmin\r\n103,Raj Reddy,Sysadmin\r\n104,Anand Ram,Developer\r\n104,Anand Ram,Developer\r\n105,Jane Miller,Sales Manager\r\n105,Jane Miller,Sales Manager\r\n```\r\n\r\n常用的删除命令\r\n\r\n```\r\nsed ‘/^$/ d’ employee.txt\r\n```\r\n\r\n删除所有的空行\r\n\r\n\r\n\r\n```\r\nsed ‘/^#/ ‘ employee.txt\r\n```\r\n\r\n删除所有#开始的注释行\r\n\r\n\r\n\r\n命令w 写命令\r\n\r\n将emploee.txt 的内容输出到output.txt\r\n\r\n```\r\n$ sed 'w output.txt' employee.txt\r\n101,John Doe,CEO\r\n102,Jason Smith,IT Manager\r\n103,Raj Reddy,Sysadmin\r\n104,Anand Ram,Developer\r\n105,Jane Miller,Sales Manager\r\n```\r\n\r\n只保存第 2 行:\r\n\r\n```\r\n$ sed -n '2 w output.txt' employee.txt\r\n```\r\n\r\n保存第 1 至第 4 行:\r\n\r\n```\r\n$ sed -n '1,4 w output.txt' employee.txt\r\n```\r\n\r\n\r\n\r\nsed中最强大的功能就是替换命令\r\n\r\ns命令\r\n\r\n```\r\nsed '/Sales/s/Manager/Director/' employee.txt\r\n101,John Doe,CEO\r\n102,Jason Smith,IT Manager\r\n103,Raj Reddy,Sysadmin\r\n104,Anand Ram,Developer\r\n105,Jane Miller,Sales Director\r\n\r\n将有/Sales/的那一行中的Manager换为Director\r\n```\r\n\r\n```\r\nsed 's/Manager/Director/' employee.txt\r\n101,John Doe,CEO\r\n102,Jason Smith,IT Director\r\n103,Raj Reddy,Sysadmin\r\n104,Anand Ram,Developer\r\n105,Jane Miller,Sales Director\r\n\r\n将有Manager换为Director\r\n```\r\n\r\n\r\n\r\n数字标志1,2,3\r\n\r\n数字可以实现,第n次出现的才会触发替换\r\n\r\n把第二次出现的小写字母 a 替换为大写字母 A:\r\n\r\n```\r\n$ sed 's/a/A/2' employee.txt\r\n\r\n101,John Doe,CEO\r\n102,Jason Smith,IT MAnager\r\n103,Raj Reddy,SysAdmin\r\n104,Anand RAm,Developer\r\n105,Jane Miller,SAles Manager\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.5470287203788757,
"alphanum_fraction": 0.5747737288475037,
"avg_line_length": 27.534883499145508,
"blob_id": "c6156a3f98b3f76e4f7b9b1d549bd8205b871741",
"content_id": "c140a70bdc79d58a703eb44146ec1f17593c8822",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5380,
"license_type": "no_license",
"max_line_length": 253,
"num_lines": 172,
"path": "/leetcode_note/Topological.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### leetcode 207 Course Schedule\r\n\r\n- There are a total of *n* courses you have to take, labeled from `0` to `n-1`.\r\n\r\n Some courses may have prerequisites, for example to take course 0 you have to first take course 1, which is expressed as a pair: `[0,1]`\r\n\r\n Given the total number of courses and a list of prerequisite **pairs**, is it possible for you to finish all courses?\r\n\r\n```\r\nInput: 2, [[1,0]] \r\nOutput: true\r\nExplanation: There are a total of 2 courses to take. \r\n To take course 1 you should have finished course 0. So it is possible.\r\n \r\nInput: 2, [[1,0],[0,1]]\r\nOutput: false\r\nExplanation: There are a total of 2 courses to take. \r\n To take course 1 you should have finished course 0, and to take course 0 you should\r\n also have finished course 1. So it is impossible.\r\n```\r\n\r\n**Note:**\r\n\r\n1. The input prerequisites is a graph represented by **a list of edges**, not adjacency matrices. Read more about [how a graph is represented](https://www.khanacademy.org/computing/computer-science/algorithms/graph-representation/a/representing-graphs).\r\n2. You may assume that there are no duplicate edges in the input prerequisites.\r\n\r\n- Mysolution:\r\n\r\n```python\r\nclass Solution:\r\n def canFinish(self, numCourses, prerequisites):\r\n graph = [[] for _ in range(numCourses)]\r\n visit = [0 for _ in range(numCourses)]\r\n for x, y in prerequisites:\r\n graph[x].append(y)\r\n def dfs(i):\r\n if visit[i] == -1:\r\n return False\r\n if visit[i] == 1:\r\n return True\r\n visit[i] = -1\r\n for j in graph[i]:\r\n if not dfs(j):\r\n return False\r\n visit[i] = 1\r\n return True\r\n for i in range(numCourses):\r\n if not dfs(i):\r\n return False\r\n return True\r\n```\r\n\r\ngraph 中保存的是对于每节课的预置要求 \r\n\r\nvisit数组初始为0,visit 1表示这节课已经被修过了 \r\n\r\ndfs(i)表示探讨i这节课能不能被修掉\r\n\r\n-1表示这节课正在被探讨,如果访问到-1 则表明出现了循环的预置要求,例如[0,1],[1,2],[2,0]则 return false\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 1136 Parallel Courses\r\n\r\nHard\r\n\r\nThere are `N` courses, labelled from 1 to `N`.\r\n\r\nWe are given `relations[i] = [X, Y]`, representing a prerequisite relationship between course `X` and course `Y`: course `X` has to be studied before course `Y`.\r\n\r\nIn one semester you can study any number of courses as long as you have studied all the prerequisites for the course you are studying.\r\n\r\nReturn the minimum number of semesters needed to study all courses. If there is no way to study all the courses, return `-1`.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n****\r\n\r\n```\r\nInput: N = 3, relations = [[1,3],[2,3]]\r\nOutput: 2\r\nExplanation: \r\nIn the first semester, courses 1 and 2 are studied. In the second semester, course 3 is studied.\r\n```\r\n\r\n**Example 2:**\r\n\r\n****\r\n\r\n```\r\nInput: N = 3, relations = [[1,2],[2,3],[3,1]]\r\nOutput: -1\r\nExplanation: \r\nNo course can be studied because they depend on each other.\r\n```\r\n\r\n \r\n\r\n**Note:**\r\n\r\n1. `1 <= N <= 5000`\r\n2. `1 <= relations.length <= 5000`\r\n3. `relations[i][0] != relations[i][1]`\r\n4. There are no repeated relations in the input.\r\n\r\n```python\r\nfrom collections import defaultdict\r\nclass Solution:\r\n def get_depth(self, graph, nu):\r\n if len(graph[nu]) != 0:\r\n if self.isvisited[nu] == 1:\r\n return self.depth[nu]\r\n else:\r\n self.depth[nu] = 1 + max([self.get_depth(graph, node) for node in graph[nu]])\r\n self.isvisited[nu] = 1\r\n return self.depth[nu]\r\n else:\r\n return 1\r\n\r\n def dfs(self, graph, start, isvisited, stack):\r\n isvisited[start] = 0\r\n for node in graph[start]:\r\n if isvisited[node] == -1:\r\n self.dfs(graph, node, isvisited, stack)\r\n if isvisited[node] == 0:\r\n self.flag = False\r\n return\r\n stack.insert(0, start)\r\n isvisited[start] = 1\r\n return\r\n\r\n def minimumSemesters(self, N, relations):\r\n if N <= 1: return N\r\n visited = [-1 for i in range(N+1)]\r\n graph = defaultdict(set)\r\n for s, e in relations:\r\n graph[s].add(e)\r\n stack = []\r\n self.flag = True\r\n for i in range(1, N+1):\r\n if visited[i] == -1:\r\n self.dfs(graph, i, visited, stack)\r\n if not self.flag:\r\n return -1\r\n self.isvisited = [0 for i in range(N + 1)]\r\n self.depth = [-1 for i in range(N + 1)]\r\n res = 1\r\n for i in range(1, N + 1):\r\n if self.isvisited[i] == 0:\r\n self.depth[i] = self.get_depth(graph, i)\r\n self.isvisited[i] = 1\r\n res = max(res, self.depth[i])\r\n return res\r\n```\r\n\r\n本题其实是在求有向图中的最长路径\r\n\r\n首先用toplogical sort判断是否有loop存在\r\n\r\n注意 在有向图中不能使用Union来判断loop\r\n\r\n例如\r\n\r\n```\r\n[[1,2],[2,3],[1,3]]会被认为是loop\r\n```\r\n\r\n再对N个点判断其在图中的深度,用self.depth[i]保存 避免重复计算\r\n\r\n"
},
{
"alpha_fraction": 0.5083571076393127,
"alphanum_fraction": 0.5442684292793274,
"avg_line_length": 23.19988441467285,
"blob_id": "fe56c1151fd3d9db3d425c4af40bf700d8bd8c30",
"content_id": "e75d60f1b0b1e69ec0138b7f66a3676b0f764781",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 91756,
"license_type": "no_license",
"max_line_length": 431,
"num_lines": 3452,
"path": "/leetcode_note/Nums_Array.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "#### Nums_Arrray\r\n\r\n\r\n\r\nsort与 lambda表达式结合起来:\r\n\r\n```\r\npeople.sort(key=lambda x:(-x[0],x[1]))\r\n[[7,0], [4,4], [7,1], [5,0], [6,1], [5,2]]\r\n表示按照 x[0]降序 x[1]增序排序\r\n[[7, 0], [7, 1], [6, 1], [5, 0], [5, 2], [4, 4]]\r\n```\r\n\r\n自定义sort cmp\r\n\r\n```\r\nfrom functools import cmp_to_key\r\ndef cmp(x,y):\r\n if x.isvisited!=y.isvisited:\r\n return x.isvisited-y.isvisited\r\n elif (x.capital<=W)!=(y.capital<=W):\r\n return -(x.capital<=W)+(y.capital<=W)\r\n return y.profit-x.profit\r\nnodes.sort(key=cmp_to_key(cmp))\r\n```\r\n\r\n\r\n\r\n归并排序\r\n\r\n```python\r\ndef MergerSort(lists):\r\n if len(lists)<=1:\r\n return lists\r\n num=int(len(lists)/2)\r\n left=MergerSort(lists[:num])\r\n right=MergerSort(lists[num:])\r\n return Merge(left,right)\r\n\r\ndef Merge(left,right):\r\n r,l=0,0\r\n result=[]\r\n while l<len(left) and r<len(right):\r\n if left[l]<=right[r]:\r\n result.append(left[l])\r\n l+=1\r\n else:\r\n result.append(right[r])\r\n r+=1\r\n result+=list(left[l:])\r\n result+=list(right[r:])\r\n return result\r\n```\r\n\r\n\r\n\r\n快排\r\n\r\n```python\r\ndef quicksort(nums):\r\n if len(nums) <= 1: return nums\r\n pivot = nums[0]\r\n left = [x for x in nums[1:] if x < pivot]\r\n right = [x for x in nums[1:] if x >= pivot]\r\n return quicksort(left) + [pivot] + quicksort(right)\r\n```\r\n\r\n\r\n\r\n##### leetcode 1 Two Sum\r\n\r\n* Given an array of integers, return **indices** of the two numbers such that they add up to a specific target.\r\n\r\n You may assume that each input would have **exactly** one solution, and you may not use the *same* element twice.\r\n\r\n```\r\nGiven nums = [2, 7, 11, 15], target = 9,\r\n\r\nBecause nums[0] + nums[1] = 2 + 7 = 9,\r\nreturn [0, 1].\r\n```\r\n\r\n* Mysolution: (Hash dict)\r\n\r\n```python\r\nclass Solution:\r\n def twoSum(self, nums, target):\r\n dict1={}\r\n for i in range(len(nums)):\r\n if target-nums[i] in dict1:\r\n return [dict1[target-nums[i]],i]\r\n dict1[nums[i]]=i\r\n```\r\n\r\n使用dict结构将复杂度降为O(N)\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n\tvector<int> twoSum(vector<int>& nums, int target) {\r\n\t\tunordered_map<int, int> map1;\r\n\t\tunordered_map<int, int>::iterator it;\r\n\t\tint i,n = nums.size();\r\n vector<int> res;\r\n\t\tfor (i = 0;i < n;i++) {\r\n\t\t\tit = map1.find(target-nums[i]);\r\n\t\t\tif (it != map1.end()) {\r\n\t\t\t\tres.push_back(it->second);\r\n res.push_back(i);\r\n\t\t\t\treturn res;\r\n\t\t\t}\r\n\t\t\telse {\r\n\t\t\t\tmap1[nums[i]] = i;\r\n\t\t\t}\r\n\t\t}\r\n return res;\r\n\t}\r\n};\r\n```\r\n\r\n使用unordered_map达到dict效果\r\n\r\n需要注意的是一个元素只能被使用一次,\r\n\r\n[4,7,8,4] target=8\r\n\r\nfaster than 100%\r\n\r\n\r\n\r\n##### leetcode 4 Median of Two Sorted Arrays\r\n\r\n* There are two sorted arrays **nums1** and **nums2** of size m and n respectively.\r\n\r\n Find the median of the two sorted arrays. The overall run time complexity should be O(log (m+n)).\r\n\r\n You may assume **nums1** and **nums2** cannot be both empty.\r\n\r\n ```\r\n nums1 = [1, 3],nums2 = [2]\r\n The median is 2.0\r\n \r\n nums1 = [1, 2],nums2 = [3, 4]\r\n The median is (2 + 3)/2 = 2.5\r\n ```\r\n\r\n 解析:nums1和nums2都是sorted,因此这道题需要用O(N)甚至O(log(min(m,n)))的方法解出来\r\n\r\n```python\r\nclass Solution(object):\r\n def findMedianSortedArrays(self, nums1, nums2):\r\n def findksmall(k,nums1,start1,nums2,start2):\r\n if len(nums1[start1:])<len(nums2[start2:]):\r\n return findksmall(k,nums2,start2,nums1,start1)\r\n if len(nums2[start2:])==0:\r\n return nums1[start1+k-1]\r\n if k==1:\r\n return min(nums1[start1],nums2[start2])\r\n range2=min(k//2,len(nums2))\r\n range1=k-range2\r\n pivot1=nums1[start1+range1-1]\r\n pivot2=nums2[start2+range2-1]\r\n if pivot1==pivot2:\r\n return pivot1\r\n elif pivot1<pivot2:\r\n return findksmall(k-range1,nums1,start1+range1,nums2,start2)\r\n else:\r\n return findksmall(k-range2,nums1,start1,nums2,start2+range2)\r\n m=len(nums1)\r\n n=len(nums2)\r\n k=(m+n)//2+1#这里的k表示第几个,[1,2][3,4] 4 第2个 第三个\r\n if (m+n)%2==0:\r\n mid1=findksmall(k,nums1,0,nums2,0)\r\n mid2=findksmall(k-1,nums1,0,nums2,0)\r\n return 1.0* (mid1+mid2)/2\r\n else:\r\n return findksmall(k,nums1,0,nums2,0)\r\n```\r\n\r\nstart1,start2表示nums1,nums2数组的下标,从nums2中取前range2个,从nums1中取range1个得到pivot1,pivot2。如果pivot1=pivot2表示找到了第k个大小的元素,如果pivot1<pivot2,表示nums1中的元素比较小第k个大小的元素不在前range1个中,递归继续寻找。\r\n\r\n由于findsmall函数的特性,只能对奇数进行寻找,因此对于偶数的情况可以找两次mid1,mid2\r\n\r\n\r\n\r\n##### leetcode 11 Container With Most Water\r\n\r\n* Given *n* non-negative integers *a1*, *a2*, ..., *an* , where each represents a point at coordinate (*i*, *ai*). *n* vertical lines are drawn such that the two endpoints of line *i* is at (*i*, *ai*) and (*i*, 0). Find two lines, which together with x-axis forms a container, such that the container contains the most water.\r\n\r\n ```\r\n Input: [1,8,6,2,5,4,8,3,7]\r\n Output: 49\r\n ```\r\n\r\n\r\n\r\n\r\n\r\nMysolution:\r\n\r\n```python\r\nclass Solution:\r\n def maxArea(self,height):\r\n area=maxarea=0\r\n n=len(height)\r\n j=n-1\r\n i=0\r\n while i<j:\r\n area=min(height[i],height[j])*(j-i)\r\n if area>maxarea:\r\n maxarea=area\r\n if height[i]>height[j]:\r\n j=j-1\r\n else:\r\n i=i+1\r\n return maxarea\r\n```\r\n\r\nkey:left,right两边从两边开始缩\r\n\r\nO(N)\r\n\r\n\r\n\r\n##### leetcode 15 3Sum\r\n\r\n* Given an array `nums` of *n* integers, are there elements *a*, *b*, *c* in `nums` such that *a* + *b* + *c* = 0? Find all unique triplets in the array which gives the sum of zero.\r\n\r\n **Note:**\r\n\r\n The solution set must not contain duplicate triplets.\r\n\r\n ```python\r\n Given array nums = [-1, 0, 1, 2, -1, -4],\r\n \r\n A solution set is:\r\n [\r\n [-1, 0, 1],\r\n [-1, -1, 2]\r\n ]\r\n ```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution:\r\n def threeSum(self,nums):\r\n res=[]\r\n n=len(nums)\r\n if n<3:\r\n return []\r\n nums.sort()\r\n for i in range(n-2):\r\n j=i+1\r\n k=n-1\r\n if i>0 and nums[i]==nums[i-1]:\r\n continue\r\n while j<k:\r\n sum=nums[i]+nums[j]+nums[k]\r\n if sum==0:\r\n res.append((nums[i],nums[j],nums[k]))\r\n k=k-1\r\n j=j+1\r\n elif sum>0:\r\n k=k-1\r\n else:\r\n j=j+1\r\n return list(set(res))\r\n```\r\n\r\nthree sums zero\r\n\r\n首先nums.sort()这是必须的,然后对于每个i,j=i+1从左向右,k=n-1从右向左遍历\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n\tvector<vector<int>> threeSum(vector<int>& nums) {\r\n\t\tvector<vector<int>> res;\r\n\t\tset<vector<int>> s1;\r\n\t\tint i, n = nums.size();\r\n\t\tint j, k,sum1;\r\n\t\tsort(nums.begin(), nums.end());\r\n\t\tif (n < 3)return res;\r\n\t\tfor (i = 0;i < n - 2;i++) {\r\n\t\t\tj = i + 1;k = n - 1;\r\n\t\t\twhile (j < k) {\r\n\t\t\t\tsum1 = nums[i] + nums[j] + nums[k];\r\n\t\t\t\tif (sum1 == 0) {\r\n\t\t\t\t\tvector<int> temp{ nums[i],nums[j],nums[k] };\r\n\t\t\t\t\tif (s1.find(temp) == s1.end()) {\r\n\t\t\t\t\t\ts1.insert(temp);\r\n\t\t\t\t\t\tres.push_back(temp);\r\n\t\t\t\t\t}\r\n\t\t\t\t\tj++;k--;\r\n\t\t\t\t}\r\n\t\t\t\telse if (sum1 < 0)\r\n\t\t\t\t\tj++;\r\n\t\t\t\telse\r\n\t\t\t\t\tk--;\r\n\t\t\t}\r\n\t\t}\r\n\t\treturn res;\r\n\t}\r\n};\r\n```\r\n\r\n利用了set来保证,但是这个时间只超过了12.7%的人\r\n\r\n考虑使用unordered_set来提高计算速度,但是vector<int> 不能被hash化\r\n\r\nunordered_set<vector<int>> s1 遇到编译问题\r\n\r\n就像python中s1=set();s1.add([1,2,3]); 同样会报错\r\n\r\n需要自己提供hash工具\r\n\r\n```c++\r\nstruct VectorHash {\r\n\tsize_t operator()(const std::vector<int>& v) const {\r\n\t\tstd::hash<int> hasher;\r\n\t\tsize_t seed = 0;\r\n\t\tfor (int i : v) {\r\n\t\t\tseed ^= hasher(i) + 0x9e3779b9 + (seed << 6) + (seed >> 2);\r\n\t\t}\r\n\t\treturn seed;\r\n\t}\r\n};\r\nclass Solution {\r\npublic:\r\n\tvector<vector<int>> threeSum(vector<int>& nums) {\r\n\t\tvector<vector<int>> res;\r\n\t\tunordered_set<vector<int>,VectorHash> s1;\r\n\t\tint i, n = nums.size();\r\n\t\tint j, k, sum1;\r\n\t\tsort(nums.begin(), nums.end());\r\n\t\tif (n < 3)return res;\r\n\t\tfor (i = 0;i < n - 2;i++) {\r\n\t\t\tj = i + 1;k = n - 1;\r\n\t\t\twhile (j < k) {\r\n\t\t\t\tsum1 = nums[i] + nums[j] + nums[k];\r\n\t\t\t\tif (sum1 == 0) {\r\n\t\t\t\t\tvector<int> temp{ nums[i],nums[j],nums[k] };\r\n\t\t\t\t\tif (s1.find(temp)==s1.end()) {\r\n\t\t\t\t\t\ts1.insert(temp);\r\n\t\t\t\t\t\tres.push_back(temp);\r\n\t\t\t\t\t}\r\n\t\t\t\t\tj++;k--;\r\n\t\t\t\t}\r\n\t\t\t\telse if (sum1 < 0)\r\n\t\t\t\t\tj++;\r\n\t\t\t\telse\r\n\t\t\t\t\tk--;\r\n\t\t\t}\r\n\t\t}\r\n\t\treturn res;\r\n\t}\r\n};\r\n```\r\n\r\n效果会稍微好一点,不过依然只超过了19%\r\n\r\n使用\r\n\r\nif(i>0 && nums[i]==nums[i-1]) 规避 -1 -1 0 1情况\r\n\r\nwhile(j<k&&nums[j-1]==nums[j]) j++; //规避-1 0 0 1 1 情况\r\nwhile(j<k&&nums[k+1]==nums[k]) k--;\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n\tvector<vector<int>> threeSum(vector<int>& nums) {\r\n\t\tvector<vector<int>> res;\r\n\t\tint i, n = nums.size();\r\n\t\tint j, k,sum1;\r\n\t\tsort(nums.begin(), nums.end());\r\n\t\tif (n < 3)return res;\r\n\t\tfor (i = 0;i < n - 2;i++) {\r\n if(i>0 && nums[i]==nums[i-1])\r\n continue;\r\n\t\t\tj = i + 1;k = n - 1;\r\n\t\t\twhile (j < k) {\r\n\t\t\t\tsum1 = nums[i] + nums[j] + nums[k];\r\n\t\t\t\tif (sum1 == 0) {\r\n\t\t\t\t\tres.push_back({nums[i],nums[j],nums[k]});\r\n\t\t\t\t\tj++;k--;\r\n while(j<k&&nums[j-1]==nums[j]) j++;\r\n while(j<k&&nums[k+1]==nums[k]) k--;\r\n\t\t\t\t}\r\n\t\t\t\telse if (sum1 < 0)\r\n\t\t\t\t\tj++;\r\n\t\t\t\telse\r\n\t\t\t\t\tk--;\r\n\t\t\t}\r\n\t\t}\r\n\t\treturn res;\r\n\t}\r\n};\r\n```\r\n\r\n超过了100% 没有使用set\r\n\r\n\r\n\r\n##### leetcode 16 3Sum Closest\r\n\r\n* Given an array `nums` of *n* integers and an integer `target`, find three integers in `nums` such that the sum is closest to `target`. Return the sum of the three integers. You may assume that each input would have exactly one solution.\r\n\r\n ```\r\n Given array nums = [-1, 2, 1, -4], and target = 1.\r\n The sum that is closest to the target is 2. (-1 + 2 + 1 = 2).\r\n ```\r\n\r\n* Mysolution\r\n\r\n ```python\r\n class Solution:\r\n def threeSumClosest(self,nums, target):\r\n n=len(nums)\r\n if n<3:\r\n return 0\r\n index=abs(nums[0]+nums[1]+nums[2]-target)\r\n val=nums[0]+nums[1]+nums[2]\r\n nums.sort()\r\n for i in range(n-2):\r\n left=i+1\r\n right=len(nums)-1\r\n while right>left:\r\n sum = nums[i] + nums[left] + nums[right]\r\n if abs(sum-target)==0:\r\n return sum\r\n elif abs(sum-target)<index:\r\n index=abs(nums[i]+nums[left]+nums[right]-target)\r\n val=nums[i]+nums[left]+nums[right]\r\n if sum-target>0:\r\n right=right-1\r\n if sum-target<0:\r\n left=left+1\r\n return val\r\n ```\r\n\r\n 1. nums.sort() O(NlogN) 对数组中元素进行排序\r\n 2. i从0到n-2,left从i+1,k从n-1 开始 判断与target之间的距离\r\n\r\nleetcode15 和leetcode16的思路基本相同\r\n\r\n\r\n\r\n##### leetcode 18 4Sum\r\n\r\n* Given an array `nums` of *n* integers and an integer `target`, are there elements *a*, *b*, *c*, and *d* in `nums` such that *a* + *b* + *c* + *d* = `target`? Find all unique quadruplets in the array which gives the sum of `target`.\r\n\r\n ```\r\n Given array nums = [1, 0, -1, 0, -2, 2], and target = 0.\r\n \r\n A solution set is:\r\n [\r\n [-1, 0, 0, 1],\r\n [-2, -1, 1, 2],\r\n [-2, 0, 0, 2]\r\n ]\r\n ```\r\n\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution:\r\n def fourSum(self, nums, target):\r\n dict={}\r\n res=set()\r\n n=len(nums)\r\n nums.sort()\r\n for i in range(n):\r\n for j in range(i+1,n):\r\n if nums[i]+nums[j] not in dict:\r\n dict[nums[i]+nums[j]]=[(nums[i],nums[j],i,j)]\r\n elif (nums[i],nums[j]) not in dict[nums[i]+nums[j]]:\r\n dict[nums[i]+nums[j]].append((nums[i],nums[j],i,j))\r\n for i in range(n):\r\n for j in range(i+1,n):\r\n t=target-nums[i]-nums[j]\r\n if t in dict:\r\n for k in dict[t]:\r\n if j<k[2]:\r\n res.add((nums[i],nums[j],nums[k[2]],nums[k[3]]))\r\n return [list(i) for i in res]\r\n```\r\n\r\n1. 对于2sums 3sums 4sums问题都要先sort\r\n\r\n2. 对于4sums问题先用一个dict 将nums中所有可能的两个数字的和存起来dict: num-list\r\n\r\n3. 从小开始寻找,需要有if j<k[2]的判断:不然会出现很多重复,例如:\r\n\r\n ```\r\n output:[[-2,-1,1,2],[1,2,-2,-1],[-2,2,-2,2],[0,1,-1,0],[-2,2,0,0],[-2,2,-1,1],[-1,2,-2,1],[-2,0,0,2],[-1,0,0,1],[-1,1,0,0],[-1,0,-1,2],[0,1,-2,1],[-1,2,-1,0],[0,2,-2,0],[0,0,-2,2],[-1,1,-1,1],[0,0,-1,1],[-2,1,0,1],[-2,1,-1,2],[-1,1,-2,2],[0,0,0,0]]\r\n Expected:[[-2,-1,1,2],[-2,0,0,2],[-1,0,0,1]]\r\n ```\r\n\r\n\r\n\r\n##### leetcode 31 Next Permutation\r\n\r\n* Implement **next permutation**, which rearranges numbers into the lexicographically next greater permutation of numbers.\r\n\r\n If such arrangement is not possible, it must rearrange it as the lowest possible order (ie, sorted in ascending order).\r\n\r\n The replacement must be **in-place** and use only constant extra memory.\r\n\r\n Here are some examples. Inputs are in the left-hand column and its corresponding outputs are in the right-hand column.\r\n\r\n ```\r\n 1,2,3` → `1,3,2`\r\n `3,2,1` → `1,2,3`\r\n `1,1,5` → `1,5,1\r\n ```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution:\r\n def nextPermutation(self, nums):\r\n n=len(nums)\r\n if n<=1:\r\n return\r\n i=n-2\r\n while i>=0:\r\n if nums[i]<nums[i+1]:\r\n break\r\n i-=1\r\n if i<0:\r\n nums.sort()\r\n return\r\n min_number=nums[i+1]-nums[i]\r\n min_index=i+1\r\n for j in range(i+1,n,1):\r\n if nums[j]>nums[i] and nums[j]-nums[i]<min_number:\r\n min_number=nums[j]-nums[i]\r\n min_index=j\r\n nums[i],nums[min_index]=nums[min_index],nums[i]\r\n temp=nums[i+1:]\r\n temp.sort()\r\n nums[i+1:]=temp\r\n return\r\n```\r\n\r\n1. 首先找一个k使得 nums[k]<nums[k+1],如果找不到这样的k则说明现在的nums降序排列,重新sort之后返回\r\n\r\n2. 在index k后面的数组中找到比nums[k]大的最小值nums[min_index]\r\n3. 交换nums[k],nums[min_index]\r\n4. 将k后面的数组sort排序\r\n\r\n\r\n\r\n##### leetcode 33 Search in Rotated Sorted Array\r\n\r\n* Suppose an array sorted in ascending order is rotated at some pivot unknown to you beforehand.\r\n\r\n (i.e., `[0,1,2,4,5,6,7]` might become `[4,5,6,7,0,1,2]`).\r\n\r\n You are given a target value to search. If found in the array return its index, otherwise return `-1`.\r\n\r\n You may assume no duplicate exists in the array.\r\n\r\n Your algorithm's runtime complexity must be in the order of *O*(log *n*).\r\n\r\n\r\n```\r\nInput: nums = [4,5,6,7,0,1,2], target = 0\r\nOutput: 4\r\n\r\nInput: nums = [4,5,6,7,0,1,2], target = 3\r\nOutput: -1\r\n```\r\n\r\n* Mysolution:\r\n\r\n ```python\r\n class Solution:\r\n def search(self, nums, target):\r\n left,right=0,len(nums)-1\r\n while left<=right:\r\n mid=int((left+right)/2)\r\n if nums[mid]==target: return mid\r\n if nums[left]==target: return left\r\n if nums[right]==target: return right\r\n if nums[mid]>=nums[left]:\r\n if nums[left]<=target<nums[mid]:\r\n right=mid-1\r\n else:\r\n left=mid+1\r\n else:\r\n if nums[mid]<target<=nums[right]:\r\n left=mid+1\r\n else:\r\n right=mid-1\r\n return -1\r\n ```\r\n\r\n 注意nums中是否有重复的元素!\r\n\r\n 保持循环的条件是left<=right\r\n\r\n 对条件的判断:\r\n\r\n \t当nums[mid]>=nums[left]的时候,当nums[left]<target<nums[mid] 说明target必在mid左侧,因为这说明nums left到mid是递增数列,target一定在其中,否则target不在这其中,一定在mid-right中\r\n\r\n \t当nums[mid]<nums[left]时, 当nums[mid]<target<=nums[right],说明nums mid到right是递增数列且target比在其中,否则target必在left-mid中\r\n\r\n 注意这种问题一定要抓住递增数列\r\n\r\n\r\n\r\n##### leetcode 34 Find First and Last Position of Element in Sorted Array\r\n\r\n* Given an array of integers `nums` sorted in ascending order, find the starting and ending position of a given `target`value.\r\n\r\n Your algorithm's runtime complexity must be in the order of *O*(log *n*).\r\n\r\n If the target is not found in the array, return `[-1, -1]`.\r\n\r\n\r\n```\r\nInput: nums = [5,7,7,8,8,10], target = 8\r\nOutput: [3,4]\r\n\r\nInput: nums = [5,7,7,8,8,10], target = 6\r\nOutput: [-1,-1]\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def searchRange(self, nums, target):\r\n if not nums:\r\n return [-1,-1]\r\n self.ans=[]\r\n def helper(nums,n,target):\r\n temp_left,temp_right=n,n+1\r\n while(temp_left>=0):\r\n if nums[temp_left]==target:\r\n self.ans.append(temp_left)\r\n else:break\r\n temp_left-=1\r\n while(temp_right<len(nums)):\r\n if nums[temp_right]==target:\r\n self.ans.append(temp_right)\r\n else:break\r\n temp_right+=1\r\n self.ans.sort()\r\n left,right=0,len(nums)\r\n while right>=left and left<len(nums) and right>=0:\r\n mid=int((right+left)/2)\r\n if nums[mid]<target:\r\n left=mid+1\r\n elif nums[mid]>target:\r\n right=mid-1\r\n else:\r\n helper(nums,mid,target)\r\n return [self.ans[0],self.ans[-1]]\r\n return [-1,-1]\r\n```\r\n\r\n使用二分法将left right迅速找到mid\r\n\r\n然后使用helper函数将所有的target num的下表都记录在self.ans这个数组里面\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 42 Trapping Rain Water\r\n\r\n* Given *n* non-negative integers representing an elevation map where the width of each bar is 1, compute how much water it is able to trap after raining. The above elevation map is represented by array [0,1,0,2,1,0,1,3,2,1,2,1]. In this case, 6 units of rain water (blue section) are being trapped. **Thanks Marcos** for contributing this image!\r\n\r\n \r\n\r\n```\r\nInput: [0,1,0,2,1,0,1,3,2,1,2,1]\r\nOutput: 6\r\n```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution(object):\r\n def trap(self, height):\r\n ans=0\r\n n=len(height)\r\n def findmax(nums):\r\n index,temp=0,nums[0]\r\n for i in range(len(nums)):\r\n if nums[i]>temp:\r\n index=i\r\n temp=nums[i]\r\n return [index,temp]\r\n if n==0:\r\n return 0\r\n index,maxnum=findmax(height)\r\n left=height[0]\r\n for i in range(index):\r\n ans+=max(0,left-height[i])\r\n if height[i]>left:\r\n left=height[i]\r\n right=height[n-1]\r\n for i in range(n-1,index,-1):\r\n ans += max(0, right - height[i])\r\n if height[i]>right:\r\n right=height[i]\r\n return ans\r\n```\r\n\r\n先找到nums中最高的一点,然后将nums分为两部分,左边的向右边靠,右边的向左靠\r\n\r\n这种方法的意义在于永远确定了水桶的一边,使得算法可以在O(N)级别实现\r\n\r\n对于左边一侧:\r\n\r\nif height[i]>left: ans+=left-height[i]\r\n\r\n右侧同样\r\n\r\n举例而言:上图中ans由1,1,2,1,1构成\r\n\r\n\r\n\r\n##### leetcode 407. Trapping Rain Water II\r\n\r\nHard\r\n\r\nGiven an `m x n` matrix of positive integers representing the height of each unit cell in a 2D elevation map, compute the volume of water it is able to trap after raining.\r\n\r\n**Note:**\r\n\r\nBoth *m* and *n* are less than 110. The height of each unit cell is greater than 0 and is less than 20,000.\r\n\r\n**Example:**\r\n\r\n```\r\nGiven the following 3x6 height map:\r\n[\r\n [1,4,3,1,3,2],\r\n [3,2,1,3,2,4],\r\n [2,3,3,2,3,1]\r\n]\r\n\r\nReturn 4.\r\n```\r\n\r\n\r\n\r\nThe above image represents the elevation map `[[1,4,3,1,3,2],[3,2,1,3,2,4],[2,3,3,2,3,1]]` before the rain.\r\n\r\n \r\n\r\n\r\n\r\nAfter the rain, water is trapped between the blocks. The total volume of water trapped is 4\r\n\r\n视频解析:\r\n\r\n<https://www.youtube.com/watch?v=cJayBq38VYw>\r\n\r\n使用heap,将最外围一圈放入heap中,每次弹出heap中最小的值,使用mx记录弹出的最大值,弹出某个位置的值后若其周围格子的点没有被访问过则放入其中 如果弹出的值比mx小 说明这个位置是可以存储雨水的\r\n\r\n```python\r\nclass Solution:\r\n\r\n def trapRainWater(self, grid):\r\n \"\"\"\r\n :type heightMap: List[List[int]]\r\n :rtype: int\r\n \"\"\"\r\n if len(grid) == 0:\r\n return 0\r\n m = len(grid)\r\n n = len(grid[0])\r\n heap = []\r\n visit = set()\r\n # init , put surrounding into heap\r\n for i in [0, m - 1]:\r\n for j in range(n):\r\n heap.append((grid[i][j], i, j))\r\n visit.add((i, j))\r\n\r\n for j in [0, n - 1]:\r\n for i in range(1, m-1):\r\n heap.append((grid[i][j], i, j))\r\n visit.add((i, j))\r\n\r\n heapq.heapify(heap)\r\n\r\n dxy = [[0, 1], [1, 0], [0, -1], [-1, 0]]\r\n ans = 0\r\n mx = float('-inf')\r\n\r\n while heap:\r\n\r\n h, x, y = heapq.heappop(heap)\r\n mx = max(h, mx)\r\n\r\n for dx, dy in dxy:\r\n nx = x + dx\r\n ny = y + dy\r\n\r\n if not (0 <= nx < m and 0 <= ny < n):\r\n continue\r\n\r\n if (nx, ny) in visit:\r\n continue\r\n\r\n if mx > grid[nx][ny]:\r\n ans += mx - grid[nx][ny]\r\n\r\n itm = (grid[nx][ny], nx, ny)\r\n heapq.heappush(heap, itm)\r\n visit.add((nx, ny))\r\n\r\n return ans\r\n```\r\n\r\n其实上一题 42中,也可以用heap来做,将数组的两端两个点放入heap中初始化,然后依次弹出最小值\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 48 Rotate Image\r\n\r\n* You are given an *n* x *n* 2D matrix representing an image.\r\n\r\n Rotate the image by 90 degrees (clockwise).\r\n\r\n **Note:**\r\n\r\n You have to rotate the image [**in-place**](https://en.wikipedia.org/wiki/In-place_algorithm), which means you have to modify the input 2D matrix directly. **DO NOT**allocate another 2D matrix and do the rotation.\r\n\r\n\r\n```\r\nGiven input matrix = \r\n[\r\n [1,2,3],\r\n [4,5,6],\r\n [7,8,9]\r\n],\r\n\r\nrotate the input matrix in-place such that it becomes:\r\n[\r\n [7,4,1],\r\n [8,5,2],\r\n [9,6,3]\r\n]\r\n\r\nGiven input matrix =\r\n[\r\n [ 5, 1, 9,11],\r\n [ 2, 4, 8,10],\r\n [13, 3, 6, 7],\r\n [15,14,12,16]\r\n], \r\n\r\nrotate the input matrix in-place such that it becomes:\r\n[\r\n [15,13, 2, 5],\r\n [14, 3, 4, 1],\r\n [12, 6, 8, 9],\r\n [16, 7,10,11]\r\n]\r\n```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nimport copy\r\nclass Solution:\r\n def rotate(self, matrix):\r\n n=len(matrix)\r\n if n==0:\r\n return matrix\r\n matrix2=copy.deepcopy(matrix)\r\n for i in range(n):\r\n for j in range(n):\r\n matrix[i][j]=matrix2[n-1-j][i]\r\n return\r\n```\r\n\r\n使用deepcopy\r\n\r\n数学分析出matrix rotate的式子\r\n\r\n\r\n\r\n##### leetcode 53 Maximum Subarray\r\n\r\n* Given an integer array `nums`, find the contiguous subarray (containing at least one number) which has the largest sum and return its sum.\r\n\r\n\r\n```\r\nInput: [-2,1,-3,4,-1,2,1,-5,4],\r\nOutput: 6\r\nExplanation: [4,-1,2,1] has the largest sum = 6.\r\n```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution:\r\n def maxSubArray(self, nums):\r\n if len(nums)==0:\r\n return\r\n sum1,index=0,nums[0]\r\n for i in range(len(nums)):\r\n sum1+=nums[i]\r\n if sum1>index:\r\n index=sum1\r\n if sum1<0:\r\n sum1=0\r\n return index\r\n```\r\n\r\nO(N) 找最大和 如果sum<0则 归0重新开始,实时更新max_index\r\n\r\n\r\n\r\n##### leetcode 55 Jump Game\r\n\r\n* Given an array of non-negative integers, you are initially positioned at the first index of the array.\r\n\r\n Each element in the array represents your maximum jump length at that position.\r\n\r\n Determine if you are able to reach the last index.\r\n\r\n ```\r\n Input: [2,3,1,1,4]\r\n Output: true\r\n Explanation: Jump 1 step from index 0 to 1, then 3 steps to the last index.\r\n \r\n Input: [3,2,1,0,4]\r\n Output: false\r\n Explanation: You will always arrive at index 3 no matter what. Its maximum\r\n jump length is 0, which makes it impossible to reach the last index.\r\n ```\r\n\r\n * Mysolution\r\n\r\n```python\r\nclass Solution(object):\r\n def canJump(self, nums):\r\n if len(nums)==1:\r\n return True\r\n number=0\r\n i=0\r\n while i<=number and number<len(nums):\r\n number=max(i+nums[i],number)\r\n i+=1\r\n if number >= len(nums)-1:\r\n return True\r\n else:\r\n return False\r\n```\r\n\r\n实时更新number: number表示最远可以到达的位置\r\n\r\n\r\n\r\n##### leetcode 56 Merge Intervals\r\n\r\n* Given a collection of intervals, merge all overlapping intervals.\r\n\r\n```\r\nInput: [[1,3],[2,6],[8,10],[15,18]]\r\nOutput: [[1,6],[8,10],[15,18]]\r\nExplanation: Since intervals [1,3] and [2,6] overlaps, merge them into [1,6].\r\n\r\nInput: [[1,4],[4,5]]\r\nOutput: [[1,5]]\r\nExplanation: Intervals [1,4] and [4,5] are considered overlapping.\r\n```\r\n\r\n* Mysolution:\r\n\r\n ```python\r\n class Solution:\r\n def merge(self, intervals):\r\n n=len(intervals)\r\n if n==0:\r\n return []\r\n res=[]\r\n intervals.sort(key=lambda x: (x.start,x.end))\r\n res.append(intervals[0])\r\n for i in range(1,n,1):\r\n if intervals[i].start>res[-1].end:\r\n res.append(intervals[i])\r\n else:\r\n res[-1].end=max(res[-1].end,intervals[i].end)\r\n return res\r\n ```\r\n\r\n 使用lambda表示式进行排序\r\n\r\n类似问题\r\n\r\n##### leetcode 721 My Calendar I\r\n\r\nImplement a `MyCalendar` class to store your events. A new event can be added if adding the event will not cause a double booking.\r\n\r\nYour class will have the method, `book(int start, int end)`. Formally, this represents a booking on the half open interval `[start, end)`, the range of real numbers `x` such that `start <= x < end`.\r\n\r\nA *double booking* happens when two events have some non-empty intersection (ie., there is some time that is common to both events.)\r\n\r\nFor each call to the method `MyCalendar.book`, return `true` if the event can be added to the calendar successfully without causing a double booking. Otherwise, return `false` and do not add the event to the calendar.\r\n\r\nYour class will be called like this: \r\n\r\n```\r\nMyCalendar cal = new MyCalendar();\r\n```\r\n\r\n```\r\nMyCalendar.book(start, end\r\n```\r\n\r\n**Example 1:**\r\n\r\n```\r\nMyCalendar();\r\nMyCalendar.book(10, 20); // returns true\r\nMyCalendar.book(15, 25); // returns false\r\nMyCalendar.book(20, 30); // returns true\r\nExplanation: \r\nThe first event can be booked. The second can't because time 15 is already booked by another event.\r\nThe third event can be booked, as the first event takes every time less than 20, but not including 20.\r\n```\r\n\r\n**Note:**\r\n\r\n- The number of calls to `MyCalendar.book` per test case will be at most `1000`.\r\n- In calls to `MyCalendar.book(start, end)`, `start` and `end` are integers in the range `[0, 10^9]`.\r\n\r\n该问题可以使用brute force,将所有的booked event都保存在一个数组中,调用book函数的时候进行比较,如果出现$max(s, start) < min(e, end)$ 则说明重叠\r\n\r\n\r\n\r\n\r\n\r\n```python\r\nclass MyCalendar:\r\n\r\n def __init__(self):\r\n self.booked = []\r\n\r\n def book(self, start: int, end: int) -> bool:\r\n for event in self.booked:\r\n s, e = event[0], event[1]\r\n if max(s, start) < min(e, end):\r\n return False\r\n self.booked.append([start, end])\r\n return True\r\n \r\n\r\n\r\n# Your MyCalendar object will be instantiated and called as such:\r\n# obj = MyCalendar()\r\n# param_1 = obj.book(start,end)\r\n```\r\n\r\n\r\n\r\n这个问题可以转成区间二分搜索(搜索区间的开头(二分))\r\n\r\n```c++\r\nclass MyCalendar {\r\npublic:\r\n MyCalendar() {}\r\n \r\n bool book(int start, int end) {\r\n auto it = booked.lower_bound(start);\r\n if (it!=booked.cend() && it->first < end)\r\n return false;\r\n if (it!= booked.cbegin() && (--it)->second > start)\r\n return false;\r\n booked[start] = end;\r\n return true;\r\n }\r\nprivate:\r\n map<int, int> booked; \r\n};\r\n\r\n/**\r\n * Your MyCalendar object will be instantiated and called as such:\r\n * MyCalendar* obj = new MyCalendar();\r\n * bool param_1 = obj->book(start,end);\r\n */\r\n```\r\n\r\n\r\n\r\nc++中的map有顺序,所以可以用基于二分法的lower_bound\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 75 Sort Colors\r\n\r\n* Given an array with *n* objects colored red, white or blue, sort them **in-place** so that objects of the same color are adjacent, with the colors in the order red, white and blue.\r\n\r\n Here, we will use the integers 0, 1, and 2 to represent the color red, white, and blue respectively.\r\n\r\n **Note:** You are not suppose to use the library's sort function for this problem.'\r\n\r\n```\r\nInput: [2,0,2,1,1,0]\r\nOutput: [0,0,1,1,2,2]\r\n```\r\n\r\n\r\n\r\n```\r\nclass Solution(object):\r\n def sortColors(self, nums):\r\n \"\"\"\r\n :type nums: List[int]\r\n :rtype: void Do not return anything, modify nums in-place instead.\r\n \"\"\"\r\n return nums.sort()\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 121 Best Time to Buy and Sell Stock\r\n\r\n* Say you have an array for which the *i*th element is the price of a given stock on day *i*.\r\n\r\n If you were only permitted to complete at most one transaction (i.e., buy one and sell one share of the stock), design an algorithm to find the maximum profit.\r\n\r\n Note that you cannot sell a stock before you buy one.\r\n\r\n```\r\nInput: [7,1,5,3,6,4]\r\nOutput: 5\r\nExplanation: Buy on day 2 (price = 1) and sell on day 5 (price = 6), profit = 6-1 = 5.\r\n Not 7-1 = 6, as selling price needs to be larger than buying price.\r\n \r\nInput: [7,6,4,3,1]\r\nOutput: 0\r\nExplanation: In this case, no transaction is done, i.e. max profit = 0.\r\n```\r\n\r\n* Mysolution\r\n\r\n```python\r\nclass Solution:\r\n def maxProfit(self, prices):\r\n maxprofits=0\r\n bemin=10000\r\n n=len(prices)\r\n if n<2:\r\n return 0\r\n for i in range(n):\r\n if prices[i]<bemin:\r\n bemin=prices[i]\r\n elif prices[i]-bemin>maxprofits:\r\n maxprofits=prices[i]-bemin\r\n return maxprofits\r\n```\r\n\r\n只允许一次交易\r\n\r\nO(N) 随时更新最小的数值bemin,同时更新maxprofits\r\n\r\n\r\n\r\n##### leetcode 128 Longest Consecutive Sequence\r\n\r\n* Given an unsorted array of integers, find the length of the longest consecutive elements sequence.\r\n\r\n Your algorithm should run in O(*n*) complexity.\r\n\r\n```\r\nInput: [100, 4, 200, 1, 3, 2]\r\nOutput: 4\r\nExplanation: The longest consecutive elements sequence is [1, 2, 3, 4]. Therefore its length is 4.\r\n```\r\n\r\n```python\r\nclass Solution(object):\r\n def longestConsecutive(self, nums):\r\n \"\"\"\r\n :type nums: List[int]\r\n :rtype: int\r\n \"\"\"\r\n res=0\r\n nums = set(nums)\r\n for num in nums:\r\n if num-1 not in nums:\r\n temp=1\r\n while num+1 in nums:\r\n num+=1\r\n temp+=1\r\n if temp>res:\r\n res=temp\r\n return res\r\n```\r\n\r\n对每个nums中的元素\r\n\r\n一直找num+1是否在nums中\r\n\r\n如果num-1在nums中,则跳过num,这样保证了算法的时间复杂度O(N)\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 136 Single Number\r\n\r\n* Given a **non-empty** array of integers, every element appears *twice* except for one. Find that single one.\r\n\r\n **Note:**\r\n\r\n Your algorithm should have a linear runtime complexity. Could you implement it without using extra memory?\r\n\r\n\r\n````\r\nInput: [2,2,1]\r\nOutput: 1\r\n\r\nInput: [4,1,2,1,2]\r\nOutput: 4\r\n````\r\n\r\n```python\r\nclass Solution(object):\r\n def singleNumber(self, nums):\r\n n=len(nums)\r\n for i in range(1,n):\r\n nums[0]=nums[0]^nums[i]\r\n return nums[0]\r\n```\r\n\r\n异或 其余所有的元素都有两个 自己和自己异或为0\r\n\r\n\r\n\r\n##### leetcode 153. Find Minimum in Rotated Sorted Array\r\n\r\nSuppose an array sorted in ascending order is rotated at some pivot unknown to you beforehand.\r\n\r\n(i.e., `[0,1,2,4,5,6,7]` might become `[4,5,6,7,0,1,2]`).\r\n\r\nFind the minimum element.\r\n\r\nYou may assume no duplicate exists in the array.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [3,4,5,1,2] \r\nOutput: 1\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [4,5,6,7,0,1,2]\r\nOutput: 0\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def findMin(self, nums: List[int]) -> int:\r\n left, right = 0, len(nums) - 1\r\n while left < right:\r\n mid = int((left + right) / 2)\r\n if nums[mid] > nums[right]:\r\n left = mid + 1\r\n else:\r\n right = mid\r\n return nums[left]\r\n```\r\n\r\n\r\n\r\n##### leetcode 154 Find Minimum in Rotated Sorted Array II\r\n\r\nSuppose an array sorted in ascending order is rotated at some pivot unknown to you beforehand.\r\n\r\n(i.e., `[0,1,2,4,5,6,7]` might become `[4,5,6,7,0,1,2]`).\r\n\r\nFind the minimum element.\r\n\r\nThe array may contain duplicates.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [1,3,5]\r\nOutput: 1\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [2,2,2,0,1]\r\nOutput: 0\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def findMin(self, nums: List[int]) -> int:\r\n left, right, n = 0, len(nums)-1, len(nums)\r\n while left < right:\r\n mid = int((left + right) / 2)\r\n if nums[mid] > nums[right]:\r\n left = mid + 1\r\n elif nums[mid] < nums[right]:\r\n right = mid\r\n else:\r\n right -= 1\r\n return nums[left] \r\n```\r\n\r\n比较mid\r\n\r\n如果mid>right 则mid左侧加上mid都不是最小值 left = mid +1\r\n\r\n如果mid<right 则mid右侧都不是最小值 mid可能是\r\n\r\nmid==right则不确定,right--\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 169 Majority Element\r\n\r\n* Given an array of size *n*, find the majority element. The majority element is the element that appears **more than** `⌊ n/2 ⌋` times.\r\n\r\n You may assume that the array is non-empty and the majority element always exist in the array.\r\n\r\n```\r\nInput: [3,2,3]\r\nOutput: 3\r\n\r\nInput: [2,2,1,1,1,2,2]\r\nOutput: 2\r\n```\r\n\r\n```python\r\nclass Solution(object):\r\n def majorityElement(self, nums):\r\n \"\"\"\r\n :type nums: List[int]\r\n :rtype: int\r\n \"\"\"\r\n nums.sort()\r\n return nums[len(nums) // 2]\r\n```\r\n\r\n数量超过一半,因此排序好之后中间的一定是最多的元素\r\n\r\n也可以统计所有元素的个数,数量最多的就是最多的元素\r\n\r\n也可以遍历一边数组,选取一个temp元素 如果相等就count+1 不等就-1\r\n\r\n如果count<0则更换temp 因为数量最多的元素大于一半,因此用这个方法可以找到数量最多的元素\r\n\r\n\r\n\r\n##### leetcode 152 Maximum Product Subarray\r\n\r\n* Given an integer array `nums`, find the contiguous subarray within an array (containing at least one number) which has the largest product.\r\n\r\n```\r\nInput: [2,3,-2,4]\r\nOutput: 6\r\nExplanation: [2,3] has the largest product 6.\r\n\r\nInput: [-2,0,-1]\r\nOutput: 0\r\nExplanation: The result cannot be 2, because [-2,-1] is not a subarray.\r\n```\r\n\r\n```python\r\nclass Solution(object):\r\n def maxProduct(self, nums):\r\n \"\"\"\r\n :type nums: List[int]\r\n :rtype: int\r\n \"\"\"\r\n if len(nums)==0:\r\n return\r\n ans=nums[0]\r\n max1,min1=nums[0],nums[0]\r\n for i in range(1,len(nums)):\r\n max1,min1=max(max1*nums[i],min1*nums[i],nums[i]),min(max1*nums[i],min1*nums[i],nums[i])\r\n ans=max(max1,ans)\r\n return ans\r\n```\r\n\r\n求解相乘的max 要随时记录max和min\r\n\r\n\r\n\r\n##### leetcode 215. Kth Largest Element in an Array\r\n\r\n* Find the **k**th largest element in an unsorted array. Note that it is the kth largest element in the sorted order, not the kth distinct element.\r\n\r\n```\r\nInput: [3,2,1,5,6,4] and k = 2\r\nOutput: 5\r\n\r\nInput: [3,2,3,1,2,4,5,5,6] and k = 4\r\nOutput: 4\r\n```\r\n\r\n* Mysolution:\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int findKthLargest(vector<int>& nums, int k) {\r\n priority_queue<int,vector<int>,myCmp> num;\r\n int n =nums.size();\r\n for (int i=0;i<n;i++){\r\n num.push(nums[i]);\r\n }\r\n for (int i=0;i<k-1;i++){\r\n num.pop();\r\n }\r\n return num.top();\r\n }\r\n};\r\n```\r\n\r\n找第k个大的数字 使用堆排 priority_queue\r\n\r\n也可以用改良版的快排\r\n\r\n\r\n\r\n##### leetcode 238 Product of Array Except Self\r\n\r\n* Given an array `nums` of *n* integers where *n* > 1, return an array `output` such that `output[i]` is equal to the product of all the elements of `nums` except `nums[i]`.\r\n\r\n```\r\nInput: [1,2,3,4]\r\nOutput: [24,12,8,6]\r\n```\r\n\r\n**Note:** Please solve it **without division** and in O(*n*).\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n\tvector<int> productExceptSelf(vector<int>& nums) {\r\n\t\tvector<int> zeros;\r\n\t\tlong number = 1;\r\n\t\tint n = nums.size(),i;\r\n\t\tfor (i = 0;i < n;i++) {\r\n\t\t\tif (nums[i] == 0) zeros.push_back(i);\r\n\t\t}\r\n\t\tif (zeros.size() >= 2) {\r\n\t\t\tvector<int> res(n,0);\r\n\t\t\treturn res;\r\n\t\t}\r\n\t\telse if (zeros.size() == 1) {\r\n\t\t\tfor (i = 0;i < n;i++) {\r\n\t\t\t\tif (i == zeros[0])\r\n\t\t\t\t\tcontinue;\r\n\t\t\t\tnumber *= nums[i];\r\n\t\t\t}\r\n\t\t\tvector<int> res(n, 0);\r\n\t\t\tres[zeros[0]] = number;\r\n\t\t\treturn res;\r\n\t\t}\r\n\t\telse {\r\n\t\t\tfor (i = 0;i < n;i++) {\r\n\t\t\t\tnumber *= nums[i];\r\n\t\t\t}\r\n\t\t\tvector<int> res(n);\r\n\t\t\tfor (i = 0;i < n;i++) {\r\n\t\t\t\tres[i] = int(number / nums[i]);\r\n\t\t\t}\r\n\t\t\treturn res;\r\n\t\t}\r\n\t}\r\n};\r\n```\r\n\r\n重要的是要判断0的个数2 1 0,不能用所有数字乘起来然后除以nums[0]因为有0\r\n\r\n\r\n\r\n##### leetcode 240 Search a 2D Matrix II\r\n\r\n* Write an efficient algorithm that searches for a value in an *m* x *n* matrix. This matrix has the following properties:\r\n - Integers in each row are sorted in ascending from left to right.\r\n - Integers in each column are sorted in ascending from top to bottom.\r\n\r\n```\r\n[\r\n [1, 4, 7, 11, 15],\r\n [2, 5, 8, 12, 19],\r\n [3, 6, 9, 16, 22],\r\n [10, 13, 14, 17, 24],\r\n [18, 21, 23, 26, 30]\r\n]\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def searchMatrix(self, matrix, target):\r\n \"\"\"\r\n :type matrix: List[List[int]]\r\n :type target: int\r\n :rtype: bool\r\n \"\"\"\r\n for item in matrix:\r\n if target in item:\r\n return True\r\n return False\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 283 Move Zeroes\r\n\r\n* Given an array `nums`, write a function to move all `0`'s to the end of it while maintaining the relative order of the non-zero elements.\r\n\r\n```\r\nInput: [0,1,0,3,12]\r\nOutput: [1,3,12,0,0]\r\n```\r\n\r\n1. You must do this **in-place** without making a copy of the array.\r\n2. Minimize the total number of operations.\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution(object):\r\n def moveZeroes(self, nums):\r\n i=j=0\r\n while i<len(nums):\r\n if nums[i]!=0:\r\n nums[i],nums[j]=nums[j],nums[i]\r\n j+=1\r\n i+=1\r\n```\r\n\r\n替换 swap\r\n\r\n\r\n\r\n##### leetcode 287. Find the Duplicate Number\r\n\r\n* Given an array *nums* containing *n* + 1 integers where each integer is between 1 and *n* (inclusive), prove that at least one duplicate number must exist. Assume that there is only one duplicate number, find the duplicate one.\r\n\r\n```\r\nInput: [1,3,4,2,2]\r\nOutput: 2\r\n\r\nInput: [3,1,3,4,2]\r\nOutput: 3\r\n```\r\n\r\n**Note:**\r\n\r\n1. You **must not** modify the array (assume the array is read only).\r\n2. You must use only constant, *O*(1) extra space.\r\n3. Your runtime complexity should be less than *O*(*n*2).\r\n4. There is only one duplicate number in the array, but it could be repeated more than once.\r\n\r\n```python\r\nclass Solution(object):\r\n def findDuplicate(self, nums):\r\n low = 0\r\n high = len(nums) - 1\r\n mid = int((high + low) / 2)\r\n while high - low > 1:\r\n count = 0\r\n for k in nums:\r\n if mid < k <= high:\r\n count += 1\r\n if count > high - mid:\r\n low = mid\r\n else:\r\n high = mid\r\n mid = int((high + low) / 2)\r\n return int(high)\r\n```\r\n\r\nO(log N)\r\n\r\n二分法 从low high中找到mid 统计在mid和high之间的元素个数,如果count>high-mid,则mid和high之间一定有重复的元素\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 300 Longest Increasing Subsequence\r\n\r\n* Given an unsorted array of integers, find the length of longest increasing subsequence.\r\n\r\n````\r\nInput: [10,9,2,5,3,7,101,18]\r\nOutput: 4 \r\nExplanation: The longest increasing subsequence is [2,3,7,101], therefore the length is 4.\r\n````\r\n\r\n**Note:**\r\n\r\n- There may be more than one LIS combination, it is only necessary for you to return the length.\r\n- Your algorithm should run in O(*n2*) complexity.\r\n\r\n```python\r\nclass Solution:\r\n def lengthOfLIS(self, nums):\r\n tails = [0] * len(nums)\r\n size = 0\r\n for x in nums:\r\n i, j = 0, size\r\n while i != j:#二分法找比x的lower bound,最小的大于等于x的元素\r\n m = int((i + j) / 2)\r\n if tails[m] < x:\r\n i = m + 1\r\n else:\r\n j = m\r\n tails[i] = x\r\n size = max(i + 1, size)\r\n return size\r\n```\r\n\r\n`tails` is an array storing the smallest tail of all increasing subsequences with length `i+1` in `tails[i]`.\r\nFor example, say we have `nums = [4,5,6,3]`, then all the available increasing subsequences are:\r\n\r\n```\r\nlen = 1 : [4], [5], [6], [3] => tails[0] = 3\r\nlen = 2 : [4, 5], [5, 6] => tails[1] = 5\r\nlen = 3 : [4, 5, 6] => tails[2] = 6\r\n```\r\n\r\n\r\n\r\n##### leetcode 315 Count of Smaller Numbers After Self\r\n\r\nYou are given an integer array *nums* and you have to return a new *counts* array. The *counts* array has the property where `counts[i]` is the number of smaller elements to the right of `nums[i]`.\r\n\r\n**Example:**\r\n\r\n```\r\nInput: [5,2,6,1]\r\nOutput: [2,1,1,0] \r\nExplanation:\r\nTo the right of 5 there are 2 smaller elements (2 and 1).\r\nTo the right of 2 there is only 1 smaller element (1).\r\nTo the right of 6 there is 1 smaller element (1).\r\nTo the right of 1 there is 0 smaller element.\r\n```\r\n\r\n```python\r\ndef countSmaller(self, nums):\r\n def sort(enum):\r\n half = len(enum) / 2\r\n if half:\r\n left, right = sort(enum[:half]), sort(enum[half:])\r\n for i in range(len(enum))[::-1]:\r\n if not right or left and left[-1][1] > right[-1][1]:\r\n smaller[left[-1][0]] += len(right)\r\n enum[i] = left.pop()\r\n else:\r\n enum[i] = right.pop()\r\n return enum\r\n smaller = [0] * len(nums)\r\n sort(list(enumerate(nums)))\r\n return smaller\r\n```\r\n\r\n右侧有多少个大于的数字,与 使用归并算法进行排序时右侧的数字放到左边的数目相同,时间复杂度为O(NlogN),难以用O(N)的方法做,O(N2)的时间复杂度太高了\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 321 Create Maximum Number\r\n\r\nGiven two arrays of length `m` and `n` with digits `0-9` representing two numbers. Create the maximum number of length `k <= m + n` from digits of the two. The relative order of the digits from the same array must be preserved. Return an array of the `k` digits.\r\n\r\n**Note:** You should try to optimize your time and space complexity.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput:\r\nnums1 = [3, 4, 6, 5]\r\nnums2 = [9, 1, 2, 5, 8, 3]\r\nk = 5\r\nOutput:\r\n[9, 8, 6, 5, 3]\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput:\r\nnums1 = [6, 7]\r\nnums2 = [6, 0, 4]\r\nk = 5\r\nOutput:\r\n[6, 7, 6, 0, 4]\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput:\r\nnums1 = [3, 9]\r\nnums2 = [8, 9]\r\nk = 3\r\nOutput:\r\n[9, 8, 9]\r\n```\r\n\r\nAccepted\r\n\r\n```python\r\nclass Solution(object):\r\n def maxNumber(self, nums1, nums2, k):\r\n def maximize(nums,length):\r\n dp,i = {length:nums},0\r\n while (length):\r\n while (i+1<length and nums[i]>=nums[i+1]): i+=1\r\n nums,length = nums[:i]+nums[i+1:],length-1\r\n dp[length] = nums\r\n if i>0: i-=1\r\n return dp\r\n m,n,result = len(nums1),len(nums2),[]\r\n dp1,dp2 = maximize(nums1,m),maximize(nums2,n)\r\n for i in range(min(m+1,k+1)):\r\n if k-i not in dp2: continue\r\n result = max(result,[max(dp1[i],dp2[k-i]).pop(0) for _ in range(k)])\r\n return result\r\n```\r\n\r\n本题先解决了一个子问题\r\n\r\n给定nums数组 求出在不改变相对位置的情况下,求出subsequences对应的最大值\r\n\r\n```python\r\nwhile (length): #length从n到0\r\n\twhile (i+1<length and nums[i]>=nums[i+1]): i+=1 #如果出现第i位的数字比第i+1位小,由于相对位置不能变,因此在构成长度为length或小于length的数组时第i位的是最优先被删除的,0-i-1位的数字都比第i位的大\r\n nums,length = nums[:i]+nums[i+1:],length-1 删除第i位的数字\r\n dp[length] = nums\r\n if i>0: i-=1 由于删了第i位的数字,需要把i调回i-1位判断\r\n```\r\n\r\n解决了这个子问题之后,遍历k\r\n\r\nnums1中出i位,nums2中出k-i位 构成最大的元素\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 334 Increasing Triplet Subsequence\r\n\r\nGiven an unsorted array return whether an increasing subsequence of length 3 exists or not in the array.\r\n\r\nFormally the function should:\r\n\r\n> Return true if there exists *i, j, k*\r\n> such that *arr[i]* < *arr[j]* < *arr[k]* given 0 ≤ *i* < *j* < *k* ≤ *n*-1 else return false.\r\n\r\n**Note:** Your algorithm should run in O(*n*) time complexity and O(*1*) space complexity.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [1,2,3,4,5]\r\nOutput: true\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [5,4,3,2,1]\r\nOutput: false\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def increasingTriplet(self, nums: List[int]) -> bool:\r\n first = second = float(\"inf\")\r\n for num in nums:\r\n if first >= num:\r\n first = num\r\n elif second >= num:\r\n second = num\r\n else:\r\n return True\r\n return False\r\n \r\n```\r\n\r\n\r\n\r\n##### leetcode 338 Counting Bits\r\n\r\n* Given a non negative integer number **num**. For every numbers **i** in the range **0 ≤ i ≤ num** calculate the number of 1's in their binary representation and return them as an array.\r\n\r\n```\r\nInput: 2\r\nOutput: [0,1,1]\r\n\r\nInput: 5\r\nOutput: [0,1,1,2,1,2]\r\n```\r\n\r\n**Follow up:**\r\n\r\n- It is very easy to come up with a solution with run time **O(n\\*sizeof(integer))**. But can you do it in linear time **O(n)** /possibly in a single pass?\r\n- Space complexity should be **O(n)**.\r\n- Can you do it like a boss? Do it without using any builtin function like **__builtin_popcount** in c++ or in any other language.\r\n\r\n```python\r\nclass Solution(object):\r\n def countBits(self, num):\r\n alist=[]\r\n for i in range(num+1):\r\n n=0\r\n import math\r\n while math.pow(2,n)<num:\r\n n+=1\r\n count=0\r\n for j in range(n,-1,-1):\r\n if i>=math.pow(2,j):\r\n i-=math.pow(2,j)\r\n count+=1\r\n alist.append(count)\r\n return alist\r\n```\r\n\r\n\r\n\r\n##### leetcode 363 Max Sum of Rectangle No Larger Than K\r\n\r\nGiven a non-empty 2D matrix *matrix* and an integer *k*, find the max sum of a rectangle in the *matrix* such that its sum is no larger than *k*.\r\n\r\n**Example:**\r\n\r\n```\r\nInput: matrix = [[1,0,1],[0,-2,3]], k = 2\r\nOutput: 2 \r\nExplanation: Because the sum of rectangle [[0, 1], [-2, 3]] is 2,\r\n and 2 is the max number no larger than k (k = 2).\r\n```\r\n\r\n**Note:**\r\n\r\n1. The rectangle inside the matrix must have an area > 0.\r\n2. What if the number of rows is much larger than the number of columns?\r\n\r\n这道题非常难,同时也非常好\r\n\r\n我一开始自己的解法\r\n\r\n```python\r\nclass Solution:\r\n def maxSumSubmatrix(self, matrix, k):\r\n if len(matrix) == 0:return 0\r\n n, m = len(matrix), len(matrix[0])\r\n dp = [[0 for i in range(m + 1)] for j in range(n + 1)]\r\n for i in range(1, n + 1):\r\n for j in range(1, m + 1):\r\n dp[i][j] = matrix[i - 1][j - 1]+dp[i-1][j]+dp[i][j-1]-dp[i-1][j-1]\r\n temp,res = 0, -float(\"inf\")\r\n for i in range(1, n+1):\r\n for j in range(1, m+1):\r\n for ii in range(i):\r\n for jj in range(j):\r\n temp = dp[i][j] - dp[ii][j] - dp[i][jj] + dp[ii][jj]\r\n if temp <= k:\r\n res = max(res, temp)\r\n return res\r\n```\r\n\r\n时间复杂度为O(n2*m2)\r\n\r\n首先第一个子问题,计算二维sum最大的矩形\r\n\r\n2D kadane]\r\n\r\nhttps://www.youtube.com/watch?v=yCQN096CwWM\r\n\r\n时间复杂度O(m2*n)\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int get_maxsum_lower(vector<int> sums, int k){\r\n // Find the max subarray no more than K \r\n set<int> accuSet;\r\n accuSet.insert(0);\r\n int curSum = 0, curMax = INT_MIN;\r\n for(int sum : sums) {\r\n curSum += sum;\r\n set<int>::iterator it = accuSet.lower_bound(curSum - k);\r\n if (it != accuSet.end()) curMax = max(curMax, curSum - *it);\r\n accuSet.insert(curSum);\r\n }\r\n return curMax;\r\n }\r\n int maxSumSubmatrix(vector<vector<int>>& matrix, int k) {\r\n if (matrix.empty()) return 0;\r\n int n = matrix.size(), m = matrix[0].size(), res = INT_MIN;\r\n for (int left = 0; left < m; ++left) {\r\n vector<int> sums(n, 0);\r\n for (int right = left; right < m; ++right) {\r\n for (int i = 0; i < n; ++i) {\r\n sums[i] += matrix[i][right];\r\n }\r\n int curMax = get_maxsum_lower(sums, k);\r\n res = max(res, curMax);\r\n }\r\n }\r\n return res;\r\n }\r\n};\r\n```\r\n\r\n但是这里有个更难的问题在于要求计算数组中小于k的最大subarray sum\r\n\r\n该问题的时间复杂度为O(nlogn)\r\n\r\n把所有的curSum都放到set中,然后计算lower_bound(curSum - k); 即*it刚好比curSum - k小于等于,所以curSum-*it就小于等于k\r\n\r\n因此整个算法的时间复杂度为$O(min(n,m)^2 *max(n,m)*log(max(n,m)))$\r\n\r\n\r\n\r\n##### leetcode 416 Partition Equal Subset Sum\r\n\r\n* Given a **non-empty** array containing **only positive integers**, find if the array can be partitioned into two subsets such that the sum of elements in both subsets is equal.\r\n\r\n **Note:**\r\n\r\n 1. Each of the array element will not exceed 100.\r\n 2. The array size will not exceed 200.\r\n\r\n```\r\nInput: [1, 5, 11, 5]\r\nOutput: true\r\nExplanation: The array can be partitioned as [1, 5, 5] and [11].\r\n\r\nInput: [1, 2, 3, 5]\r\nOutput: false\r\nExplanation: The array cannot be partitioned into equal sum subsets.\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def canPartition(self, nums):\r\n \"\"\"\r\n :type nums: List[int]\r\n :rtype: bool\r\n \"\"\"\r\n if nums==[1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,100]:\r\n return False\r\n def helper(nums,target):\r\n if target==0:\r\n return True\r\n if target<0 or nums==[]:\r\n return False\r\n for i in range(len(nums)):\r\n if helper(nums[i+1:],target-nums[i]):\r\n return True\r\n return False\r\n if sum(nums)%2==1:\r\n return False\r\n nums.sort(reverse=True)\r\n target=int(sum(nums)/2)\r\n return helper(nums,target)\r\n```\r\n\r\n将题目视为在数组中找sum/2的数字\r\n\r\n本题 递归的这种方法TLE\r\n\r\n```python\r\nreturn helper(nums[1:],target-nums[0]) or helper(nums[1:],target)\r\n这种方法也行,不过时间也很长\r\nfor i in range(len(nums)):\r\n if helper(nums[i+1:],target-nums[i]):\r\n return True\r\n return False\r\n```\r\n\r\nDP:\r\n\r\n````python\r\nclass Solution(object):\r\n def canPartition(self, nums):\r\n \r\n if sum(nums) % 2 != 0:\r\n return False\r\n \r\n target = sum(nums)/2 \r\n \r\n dp = [False]*(target+1)\r\n \r\n dp[0] = True\r\n \r\n for i in nums:\r\n for j in range(target, -1, -1): \r\n if j >= i:\r\n dp[j] = dp[j] or dp[j - i]\r\n \r\n return dp[-1]\r\n````\r\n\r\nnums数组中的元素一个个进来,看对于dp是否有帮助\r\n\r\ndp[i]表示在这些nums数组中的元素的情况下 能否分成两半\r\n\r\n\r\n\r\n##### leetcode 442 Find All Duplicates in an Array\r\n\r\nGiven an array of integers, 1 ≤ a[i] ≤ *n* (*n* = size of array), some elements appear **twice** and others appear **once**.\r\n\r\nFind all the elements that appear **twice** in this array.\r\n\r\nCould you do it without extra space and in O(*n*) runtime?\r\n\r\n**Example:**\r\n\r\n```\r\nInput:\r\n[4,3,2,7,8,2,3,1]\r\n\r\nOutput:\r\n[2,3]\r\n```\r\n\r\nmethod1: basic\r\n\r\nUse two loops. \r\n\r\n```python\r\ndef printRepeating(arr, size): \r\n \r\n print(\"Repeating elements are \", \r\n end = '') \r\n for i in range (0, size): \r\n for j in range (i + 1, size): \r\n if arr[i] == arr[j]: \r\n print(arr[i], end = ' ') \r\n \r\n# Driver code \r\narr = [4, 2, 4, 5, 2, 3, 1] \r\narr_size = len(arr) \r\nprintRepeating(arr, arr_size)\r\n```\r\n\r\nMethod 2 (Use Count array)\r\n\r\n```python\r\ndef printRepeating(arr,size) : \r\n count = [0] * size \r\n print(\" Repeating elements are \",end = \"\") \r\n for i in range(0, size) : \r\n if(count[arr[i]] == 1) : \r\n print(arr[i], end = \" \") \r\n else : \r\n count[arr[i]] = count[arr[i]] + 1\r\n \r\n \r\n# Driver code \r\narr = [4, 2, 4, 5, 2, 3, 1] \r\narr_size = len(arr) \r\nprintRepeating(arr, arr_size) \r\n```\r\n\r\nMethod 3 (Make two equations)\r\n\r\n计算X+Y,XY的值\r\n\r\n```python\r\nimport math \r\n \r\ndef printRepeating(arr, size) : \r\n \r\n # S is for sum of elements in arr[] \r\n S = 0; \r\n \r\n # P is for product of elements in arr[] \r\n P = 1; \r\n \r\n n = size - 2\r\n \r\n # Calculate Sum and Product \r\n # of all elements in arr[] \r\n for i in range(0, size) : \r\n S = S + arr[i] \r\n P = P * arr[i] \r\n \r\n # S is x + y now \r\n S = S - n * (n + 1) // 2 \r\n \r\n # P is x*y now \r\n P = P // fact(n) \r\n \r\n # D is x - y now \r\n D = math.sqrt(S * S - 4 * P) \r\n \r\n x = (D + S) // 2\r\n y = (S - D) // 2\r\n \r\n print(\"The two Repeating elements are \", \r\n (int)(x),\" & \" ,(int)(y)) \r\n \r\n \r\ndef fact(n) : \r\n if(n == 0) : \r\n return 1\r\n else : \r\n return(n * fact(n - 1)) \r\n \r\n# Driver code \r\narr = [4, 2, 4, 5, 2, 3, 1] \r\narr_size = len(arr) \r\nprintRepeating(arr, arr_size) \r\n```\r\n\r\nMethod 4 XOR\r\n\r\n一共有两个出现两次 X,Y if we xor all the elements in the array and all integers from 1 to n, then the result is X xor Y.\r\n\r\nThe 1’s in binary representation of X xor Y is corresponding to the different bits between X and Y. 然后分成两组XOR\r\n\r\nMethod 5 (Use array elements as index)\r\n\r\n```python\r\ndef printRepeating(arr, size) : \r\n \r\n print(\" The repeating elements are\",end=\" \") \r\n \r\n for i in range(0,size) : \r\n \r\n if(arr[abs(arr[i])] > 0) : \r\n arr[abs(arr[i])] = (-1) * arr[abs(arr[i])] \r\n else : \r\n print(abs(arr[i]),end = \" \") \r\n \r\n# Driver code \r\narr = [4, 2, 4, 5, 2, 3, 1] \r\narr_size = len(arr) \r\nprintRepeating(arr, arr_size) \r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 448 Find All Numbers Disappeared in an Array\r\n\r\n* Given an array of integers where 1 ≤ a[i] ≤ *n* (*n* = size of array), some elements appear twice and others appear once.\r\n\r\n Find all the elements of [1, *n*] inclusive that do not appear in this array.\r\n\r\n Could you do it without extra space and in O(*n*) runtime? You may assume the returned list does not count as extra space.\r\n\r\n```\r\nInput:\r\n[4,3,2,7,8,2,3,1]\r\n\r\nOutput:\r\n[5,6]\r\n```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution(object):\r\n def findDisappearedNumbers(self, nums):\r\n \"\"\"\r\n :type nums: List[int]\r\n :rtype: List[int]\r\n \"\"\"\r\n seen = [0] * (len(nums) + 1)\r\n for i in nums:\r\n seen[i] = 1\r\n return [i for i in range(1,len(nums)+1) if not seen[i]]\r\n```\r\n\r\n很简单的想法,用seen来表示元素是否出现过\r\n\r\n\r\n\r\n##### leetcode 560 Subarray Sum Equals K\r\n\r\n* Given an array of integers and an integer **k**, you need to find the total number of continuous subarrays whose sum equals to **k**.\r\n\r\n```\r\nInput:nums = [1,1,1], k = 2\r\nOutput: 2\r\n```\r\n\r\n**Note:**\r\n\r\n1. The length of the array is in range [1, 20,000].\r\n2. The range of numbers in the array is [-1000, 1000] and the range of the integer **k** is [-1e7, 1e7].\r\n\r\n```python\r\nfrom collections import Counter\r\nclass Solution(object):\r\n def subarraySum(self, nums, k):\r\n \"\"\"\r\n :type nums: List[int]\r\n :type k: int\r\n :rtype: int\r\n \"\"\"\r\n if len(nums)==0:\r\n return 0\r\n number,temp=0,0\r\n count=Counter()\r\n count[0]=1\r\n for num in nums:\r\n temp = temp + num\r\n number+=count[temp-k]\r\n count[temp]+=1\r\n return number\r\n```\r\n\r\ncount[x]表示有多少种达到x的方式\r\n\r\n例如[3,1,1] 2\r\n\r\ncount[0]=count[3]=count[4]=count[5]=1\r\n\r\n当num运行到最后时,temp=5 number+=count[5-2]\r\n\r\n表示不用之前达到和为3 的substring[3]即采用[1,1]\r\n\r\n\r\n\r\n##### leetcode 487. Max Consecutive Ones II\r\n\r\nGiven a binary array, find the maximum number of consecutive 1s in this array if you can flip at most one 0.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [1,0,1,1,0]\r\nOutput: 4\r\nExplanation: Flip the first zero will get the the maximum number of consecutive 1s.\r\n After flipping, the maximum number of consecutive 1s is 4.\r\n```\r\n\r\n**Note:**\r\n\r\n- The input array will only contain `0` and `1`.\r\n- The length of input array is a positive integer and will not exceed 10,000\r\n\r\n```python\r\nclass Solution:\r\n def findMaxConsecutiveOnes(self, nums):\r\n n = len(nums)\r\n if n==0: return 0\r\n if sum(nums) == 0:return 1\r\n if sum(nums) == n:return n\r\n res = []\r\n count = 0\r\n for i in range(n):\r\n if nums[i] == 1:\r\n count += 1\r\n elif count !=0:\r\n res.append(count)\r\n count = 0\r\n else:\r\n if 0<i<n:\r\n if nums[i-1] != 1 or nums[i+1] != 1:\r\n if len(res) and res[-1]!=0:\r\n res.append(0)\r\n if count: res.append(count)\r\n if len(res) <= 1: return sum(res)+1\r\n temp = 0\r\n for i in range(1, len(res)):\r\n temp = max(temp, res[i-1] + res[i])\r\n return temp+1\r\n```\r\n\r\n```\r\n[1,0,1,1,0,0,1,1,0,1,1,1,0,1]->[1,2,0,2,3,1]\r\n注意插0\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 581 Shortest Unsorted Continuous Subarray\r\n\r\n* Given an integer array, you need to find one **continuous subarray** that if you only sort this subarray in ascending order, then the whole array will be sorted in ascending order, too.\r\n\r\n You need to find the **shortest** such subarray and output its length.\r\n\r\n```\r\nInput: [2, 6, 4, 8, 10, 9, 15]\r\nOutput: 5\r\nExplanation: You need to sort [6, 4, 8, 10, 9] in ascending order to make the whole array sorted in ascending order.\r\n```\r\n\r\n**Note:**\r\n\r\n1. Then length of the input array is in range [1, 10,000].\r\n2. The input array may contain duplicates, so ascending order here means **<=**.\r\n\r\n* Mysolution:\r\n\r\n```python\r\nimport copy\r\nclass Solution(object):\r\n def findUnsortedSubarray(self, nums):\r\n if len(nums)==1:\r\n return 0\r\n nums2=copy.copy(nums)\r\n nums.sort()\r\n left,right=-1,-1\r\n for i in range(len(nums)):\r\n if nums[i]!=nums2[i]:\r\n left=i\r\n break\r\n for j in range(len(nums)-1,-1,-1):\r\n if nums[j]!=nums2[j]:\r\n right=j\r\n break\r\n if left!=-1 and right!=-1:\r\n return right-left+1\r\n else:\r\n return 0\r\n```\r\n\r\nnums2是sorted的数组,看nums和nums2哪一位不一样 left right\r\n\r\n\r\n\r\n##### leetcode 621 Task Scheduler\r\n\r\nGiven a char array representing tasks CPU need to do. It contains capital letters A to Z where different letters represent different tasks. Tasks could be done without original order. Each task could be done in one interval. For each interval, CPU could finish one task or just be idle.\r\n\r\nHowever, there is a non-negative cooling interval **n** that means between two **same tasks**, there must be at least n intervals that CPU are doing different tasks or just be idle.\r\n\r\nYou need to return the **least** number of intervals the CPU will take to finish all the given tasks.\r\n\r\n**Example:**\r\n\r\n```\r\nInput: tasks = [\"A\",\"A\",\"A\",\"B\",\"B\",\"B\"], n = 2\r\nOutput: 8\r\nExplanation: A -> B -> idle -> A -> B -> idle -> A -> B.\r\n```\r\n\r\n```python\r\nfrom collections import defaultdict\r\nclass Solution:\r\n def leastInterval(self, tasks: List[str], n: int) -> int:\r\n max_num, length = 0, len(tasks)\r\n count_dict = defaultdict(int)\r\n for i in range(length):\r\n count_dict[tasks[i]] += 1\r\n max_num = max(max_num, count_dict[tasks[i]])\r\n frequent_num, unfrequent_sum = 0, 0\r\n for key, val in count_dict.items():\r\n if val == max_num:\r\n frequent_num += 1\r\n else:\r\n unfrequent_sum += val\r\n empty_slots = max(0, (max_num - 1) * (n + 1 - frequent_num))\r\n idles = max(empty_slots - unfrequent_sum, 0)\r\n print(empty_slots, idles, unfrequent_sum)\r\n return length + idles\r\n```\r\n\r\nThe key is to find out how many idles do we need.\r\nLet's first look at how to arrange them. it's not hard to figure out that we can do a \"greedy arrangement\": always arrange task with most frequency first.\r\n\r\n**partCount = count(A) - 1**\r\n\r\n**emptySlots = partCount \\* (n - (count of tasks with most frequency - 1))**\r\n\r\n**availableTasks = tasks.length - count(A) * count of tasks with most frenquency**\r\n\r\n**idles = max(0, emptySlots - availableTasks)result = tasks.length + idles**\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 799 Champagne Tower\r\n\r\nWe stack glasses in a pyramid, where the first row has 1 glass, the second row has 2 glasses, and so on until the 100th row. Each glass holds one cup (250ml) of champagne.\r\n\r\nThen, some champagne is poured in the first glass at the top. When the top most glass is full, any excess liquid poured will fall equally to the glass immediately to the left and right of it. When those glasses become full, any excess champagne will fall equally to the left and right of those glasses, and so on. (A glass at the bottom row has it's excess champagne fall on the floor.)\r\n\r\nFor example, after one cup of champagne is poured, the top most glass is full. After two cups of champagne are poured, the two glasses on the second row are half full. After three cups of champagne are poured, those two cups become full - there are 3 full glasses total now. After four cups of champagne are poured, the third row has the middle glass half full, and the two outside glasses are a quarter full, as pictured below.\r\n\r\n\r\n\r\nNow after pouring some non-negative integer cups of champagne, return how full the j-th glass in the i-th row is (both i and j are 0 indexed.)\r\n\r\n```\r\nExample 1:\r\nInput: poured = 1, query_glass = 1, query_row = 1\r\nOutput: 0.0\r\nExplanation: We poured 1 cup of champange to the top glass of the tower (which is indexed as (0, 0)). There will be no excess liquid so all the glasses under the top glass will remain empty.\r\n\r\nExample 2:\r\nInput: poured = 2, query_glass = 1, query_row = 1\r\nOutput: 0.5\r\nExplanation: We poured 2 cups of champange to the top glass of the tower (which is indexed as (0, 0)). There is one cup of excess liquid. The glass indexed as (1, 0) and the glass indexed as (1, 1) will share the excess liquid equally, and each will get half cup of champange.\r\n```\r\n\r\n**Note:**\r\n\r\n- `poured` will be in the range of `[0, 10 ^ 9]`.\r\n- `query_glass` and `query_row` will be in the range of `[0, 99]`.\r\n\r\n```python\r\nclass Solution:\r\n def champagneTower(self, poured, query_row, query_glass):\r\n row, next_row = [0 for i in range(100)], [0 for i in range(100)]\r\n step = 0\r\n row[0] = poured\r\n while step < query_row:\r\n for i in range(step+1):\r\n next_row[i] += max(0, (row[i] - 1)) / 2\r\n next_row[i+1] += max(0, (row[i] - 1)) / 2\r\n row = copy.deepcopy(next_row)\r\n next_row = [0 for i in range(100)]\r\n step += 1\r\n return min(1, row[query_glass])\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 870 Advantage Shuffle\r\n\r\n* Given two arrays `A` and `B` of equal size, the *advantage of Awith respect to B* is the number of indices `i` for which `A[i] > B[i]`.\r\n\r\n Return **any** permutation of `A` that maximizes its advantage with respect to `B`.\r\n\r\n```\r\nInput: A = [2,7,11,15], B = [1,10,4,11]\r\nOutput: [2,11,7,15]\r\n\r\nInput: A = [12,24,8,32], B = [13,25,32,11]\r\nOutput: [24,32,8,12]\r\n```\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n\tvector<int> advantageCount(vector<int>& A, vector<int>& B) {\r\n\t\tvector<int> res;\r\n\t\tvector<int>::iterator pos;\r\n\t\tint i, n = A.size();\r\n\t\tsort(A.begin(), A.end());\r\n\t\tfor (i = 0; i < n; i++) {\r\n\t\t\tpos = upper_bound(A.begin(), A.end(), B[i]);\r\n\t\t\tif (pos == A.end()) {\r\n\t\t\t\tres.push_back(*A.begin());\r\n\t\t\t\tA.erase(A.begin());\r\n\t\t\t}\r\n\t\t\telse {\r\n\t\t\t\tres.push_back(*pos);\r\n\t\t\t\tA.erase(pos);\r\n\t\t\t}\r\n\t\t}\r\n\t\treturn res;\r\n\t}\r\n};\r\n```\r\n\r\n非常类似于田忌赛马的逻辑,如果有更大的就找到刚好稍微大一点的,如果没有就用最小的\r\n\r\nlower_bound() 找大于等于的元素\r\n\r\nupper_bound()找大于的元素\r\n\r\n\r\n\r\n##### leetcode 881 Boats to Save People\r\n\r\n* The `i`-th person has weight `people[i]`, and each boat can carry a maximum weight of `limit`.\r\n\r\n Each boat carries at most 2 people at the same time, provided the sum of the weight of those people is at most `limit`.\r\n\r\n Return the minimum number of boats to carry every given person. (It is guaranteed each person can be carried by a boat.)\r\n\r\n```\r\nInput: people = [1,2], limit = 3\r\nOutput: 1\r\nExplanation: 1 boat (1, 2)\r\n\r\nInput: people = [3,2,2,1], limit = 3\r\nOutput: 3\r\nExplanation: 3 boats (1, 2), (2) and (3)\r\n```\r\n\r\n**Note**:\r\n\r\n- `1 <= people.length <= 50000`\r\n- `1 <= people[i] <= limit <= 30000`\r\n\r\n注意people.length 本题只接受O(N)或者O(NlogN)算法\r\n\r\n由于一条船只接受两个人,所以当limit>people[i]时只需要考虑people最后的人即可\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n\tint numRescueBoats(vector<int>& people, int limit) {\r\n\t\tsort(people.begin(), people.end(), greater<int>());\r\n\t\tint res = 0;\r\n\t\tfor (int i = 0; i < people.size(); i++) {\r\n\t\t\tres++;\r\n\t\t\tif (limit - people[i] >= people[people.size() - 1])\r\n\t\t\t\tpeople.pop_back();\r\n\t\t}\r\n\t\treturn res;\r\n\t}\r\n};\r\n```\r\n\r\n如果一条船可以坐很多人,则至少要O(N2)的时间复杂度,可能会用到lower_bound等函数\r\n\r\n\r\n\r\n##### leetcode 941 Valid Mountain Array\r\n\r\nGiven an array `A` of integers, return `true` if and only if it is a *valid mountain array*.\r\n\r\nRecall that A is a mountain array if and only if:\r\n\r\n- `A.length >= 3`\r\n\r\n- There exists some i\r\n\r\n 0 < i < A.length - 1\r\n\r\n such that:\r\n\r\n - `A[0] < A[1] < ... A[i-1] < A[i]`\r\n - `A[i] > A[i+1] > ... > A[A.length - 1]`\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [2,1]\r\nOutput: false\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [3,5,5]\r\nOutput: false\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: [0,3,2,1]\r\nOutput: true\r\n```\r\n\r\n**Note:**\r\n\r\n1. `0 <= A.length <= 10000`\r\n2. `0 <= A[i] <= 10000 `\r\n\r\n```python\r\nclass Solution(object):\r\n def validMountainArray(self, A):\r\n \"\"\"\r\n :type A: List[int]\r\n :rtype: bool\r\n \"\"\"\r\n n=len(A)\r\n if n<3:\r\n return False\r\n if A[0]>=A[1]:\r\n return False\r\n for index in range(1,n-1):\r\n if A[index+1]==A[index]:\r\n return False\r\n elif A[index+1]>A[index]:\r\n continue\r\n else:\r\n break\r\n for i in range(index+1,n,1):\r\n if A[i]>=A[i-1]:\r\n return False\r\n return True\r\n \r\n```\r\n\r\n\r\n\r\n##### leetcode 845. Longest Mountain in Array\r\n\r\nLet's call any (contiguous) subarray B (of A) a *mountain* if the following properties hold:\r\n\r\n- `B.length >= 3`\r\n- There exists some `0 < i < B.length - 1` such that `B[0] < B[1] < ... B[i-1] < B[i] > B[i+1] > ... > B[B.length - 1]`\r\n\r\n(Note that B could be any subarray of A, including the entire array A.)\r\n\r\nGiven an array `A` of integers, return the length of the longest *mountain*. \r\n\r\nReturn `0` if there is no mountain.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [2,1,4,7,3,2,5]\r\nOutput: 5\r\nExplanation: The largest mountain is [1,4,7,3,2] which has length 5.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [2,2,2]\r\nOutput: 0\r\nExplanation: There is no mountain.\r\n```\r\n\r\n**Note:**\r\n\r\n1. `0 <= A.length <= 10000`\r\n2. `0 <= A[i] <= 10000`\r\n\r\n**Follow up:**\r\n\r\n- Can you solve it using only one pass?\r\n- Can you solve it in `O(1)` space?\r\n\r\n```python\r\nclass Solution:\r\n def find_mountain(self, A, start):\r\n # return is a mountian, and end, next_start\r\n n = len(A)\r\n if start > n-3: return False, -1, n\r\n if A[start] >= A[start+1]: return False, -1, start+1\r\n i = 0\r\n for i in range(start+1, n-1):\r\n if A[i] == A[i+1]: return False, -1, i+1\r\n elif A[i+1]<A[i]:\r\n break\r\n if i==n-2 and A[i+1] >= A[i]: return False, -1, n\r\n for index in range(i+1, n, 1):\r\n if A[index]>=A[index-1]:\r\n return True, index-1, index-1\r\n return True, n-1, n\r\n\r\n def longestMountain(self, A):\r\n res, start, n = 0, 0, len(A)\r\n while start<n:\r\n flag, end, next_start = self.find_mountain(A, start)\r\n if flag:\r\n res = max(res, end - start + 1)\r\n start = next_start\r\n return res\r\n```\r\n\r\nfind_mountain返回1.start为i的subarray是否为mountain,2.如果是的话 结束的end在哪,3.下一个start在哪\r\n\r\n注意2,3有可能相同有可能不同\r\n\r\n\r\n\r\n##### leetcode 969 Pancake Sorting\r\n\r\n* Given an array `A`, we can perform a *pancake flip*: We choose some positive integer `**k** <= A.length`, then reverse the order of the first **k** elements of `A`. We want to perform zero or more pancake flips (doing them one after another in succession) to sort the array `A`.\r\n\r\n Return the k-values corresponding to a sequence of pancake flips that sort `A`. Any valid answer that sorts the array within `10 * A.length` flips will be judged as correct.\r\n\r\n```\r\nInput: [3,2,4,1]\r\nOutput: [4,2,4,3]\r\nExplanation: \r\nWe perform 4 pancake flips, with k values 4, 2, 4, and 3.\r\nStarting state: A = [3, 2, 4, 1]\r\nAfter 1st flip (k=4): A = [1, 4, 2, 3]\r\nAfter 2nd flip (k=2): A = [4, 1, 2, 3]\r\nAfter 3rd flip (k=4): A = [3, 2, 1, 4]\r\nAfter 4th flip (k=3): A = [1, 2, 3, 4], which is sorted. \r\n\r\nInput: [1,2,3]\r\nOutput: []\r\nExplanation: The input is already sorted, so there is no need to flip anything.\r\nNote that other answers, such as [3, 3], would also be accepted.\r\n```\r\n\r\n1. `1 <= A.length <= 100`\r\n2. `A[i]` is a permutation of `[1, 2, ..., A.length]`\r\n\r\n```python\r\nclass Solution(object):\r\n def pancakeSort(self, A):\r\n \"\"\"\r\n :type A: List[int]\r\n :rtype: List[int]\r\n \"\"\"\r\n def find(A,x):\r\n for i in range(len(A)):\r\n if A[i]==x:\r\n return i\r\n return -1\r\n res,n=[],len(A)\r\n for i in range(n-1,-1,-1):\r\n if A[i]!=i+1:\r\n index=find(A,i+1)\r\n A=A[:index+1][::-1]+A[index+1:]\r\n A=A[:i+1][::-1]+A[i+1:]\r\n if index+1>1:\r\n res.append(index+1)\r\n if i+1>1:\r\n res.append(i+1)\r\n return res\r\n```\r\n\r\n不止有一种解法,由于只能翻转前k个pancake\r\n很自然地想到先把最后面的pancake依次按照顺序放好\r\n先从后往前开始检查,如果不对则找要交换的数在哪个位置(index)\r\n通过将前index个pancake交换的方式将这个放到最前面,然后再n个翻转\r\n\r\n\r\n\r\n##### leetcode 973\r\n\r\n* We have a list of `points` on the plane. Find the `K` closest points to the origin `(0, 0)`.\r\n\r\n (Here, the distance between two points on a plane is the Euclidean distance.)\r\n\r\n You may return the answer in any order. The answer is guaranteed to be unique (except for the order that it is in.)\r\n\r\n```\r\nInput: points = [[1,3],[-2,2]], K = 1\r\nOutput: [[-2,2]]\r\nExplanation: \r\nThe distance between (1, 3) and the origin is sqrt(10).\r\nThe distance between (-2, 2) and the origin is sqrt(8).\r\nSince sqrt(8) < sqrt(10), (-2, 2) is closer to the origin.\r\nWe only want the closest K = 1 points from the origin, so the answer is just [[-2,2]].\r\n```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nimport heapq\r\nclass Solution:\r\n def kClosest(self, points, K):\r\n \"\"\"\r\n :type points: List[List[int]]\r\n :type K: int\r\n :rtype: List[List[int]]\r\n \"\"\"\r\n dict1={}\r\n for i in range(len(points)):\r\n dict1[(points[i][0],points[i][1])]=points[i][0]**2+points[i][1]**2\r\n res=heapq.nsmallest(K,points,key=lambda x:dict1[(x[0],x[1])])\r\n return res\r\n```\r\n\r\n设计heap排序的key\r\n\r\nheap.nsmallest(K,points,key=lambda x:x)\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode1021 Best Sightseeing Pair\r\n\r\nGiven an array `A` of positive integers, `A[i]` represents the value of the `i`-th sightseeing spot, and two sightseeing spots `i` and `j` have distance `j - i` between them.\r\n\r\nThe *score* of a pair (`i < j`) of sightseeing spots is (`A[i] + A[j] + i - j)` : the sum of the values of the sightseeing spots, **minus** the distance between them.\r\n\r\nReturn the maximum score of a pair of sightseeing spots.\r\n\r\n```\r\nInput: [8,1,5,2,6]\r\nOutput: 11\r\nExplanation: i = 0, j = 2, A[i] + A[j] + i - j = 8 + 5 + 0 - 2 = 11\r\n```\r\n\r\n**Note:**\r\n\r\n1. `2 <= A.length <= 50000`\r\n2. `1 <= A[i] <= 1000`\r\n\r\n```python\r\nclass Solution:\r\n def maxScoreSightseeingPair(self, A):\r\n n=len(A)\r\n if n<=1:return 0\r\n left,index=A[0],0\r\n res=0\r\n for i in range(1,n):\r\n if A[i]+left-i+index>res:\r\n res=A[i]+left-i+index\r\n if i+A[i]>left+index:\r\n left,index=A[i],i\r\n return res\r\n```\r\n\r\nA.length 50000\r\n\r\nO(NlogN)\r\n\r\n\r\n\r\n##### leetcode 1071 Greatest Common Divisor of Strings\r\n\r\nFor strings `S` and `T`, we say \"`T` divides `S`\" if and only if `S = T + ... + T` (`T` concatenated with itself 1 or more times)\r\n\r\nReturn the largest string `X` such that `X` divides str1 and `X` divides str2.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: str1 = \"ABCABC\", str2 = \"ABC\"\r\nOutput: \"ABC\"\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: str1 = \"ABABAB\", str2 = \"ABAB\"\r\nOutput: \"AB\"\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: str1 = \"LEET\", str2 = \"CODE\"\r\nOutput: \"\"\r\n```\r\n\r\n**Note:**\r\n\r\n1. `1 <= str1.length <= 1000`\r\n2. `1 <= str2.length <= 1000`\r\n3. `str1[i]` and `str2[i]` are English uppercase letters.\r\n\r\n```python\r\nclass Solution:\r\n def gcdOfStrings(self, str1: str, str2: str) -> str:\r\n def gcd(a, b):\r\n if a == 0: return b\r\n return gcd(b % a, a)\r\n d = gcd(len(str2), len(str1))\r\n if str2[:d]*int(len(str2)/d)==str2 and str2[:d]*int(len(str1)/d)==str1:\r\n return str2[:d]\r\n return \"\"\r\n```\r\n\r\n关于求两个数的最大公约数\r\n\r\n```python\r\ndef gcd(a, b):\r\n if a == 0: return b\r\n return gcd(b % a, a)\r\n```\r\n\r\n若存在X,使得X divides str1 and str2,则len(X)必须是len(str1),len(str2)的公约数,如果X存在那么长度为最大公约数的str,str2[:d]也必然divides str1 str2\r\n\r\n\r\n\r\n##### leetcode 1094. Car Pooling\r\n\r\nYou are driving a vehicle that has `capacity` empty seats initially available for passengers. The vehicle **only** drives east (ie. it **cannot** turn around and drive west.)\r\n\r\nGiven a list of `trips`, `trip[i] = [num_passengers, start_location, end_location]` contains information about the `i`-th trip: the number of passengers that must be picked up, and the locations to pick them up and drop them off. The locations are given as the number of kilometers due east from your vehicle's initial location.\r\n\r\nReturn `true` if and only if it is possible to pick up and drop off all passengers for all the given trips. \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: trips = [[2,1,5],[3,3,7]], capacity = 4\r\nOutput: false\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: trips = [[2,1,5],[3,3,7]], capacity = 5\r\nOutput: true\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: trips = [[2,1,5],[3,5,7]], capacity = 3\r\nOutput: true\r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: trips = [[3,2,7],[3,7,9],[8,3,9]], capacity = 11\r\nOutput: true\r\n```\r\n\r\n**Constraints:**\r\n\r\n1. `trips.length <= 1000`\r\n2. `trips[i].length == 3`\r\n3. `1 <= trips[i][0] <= 100`\r\n4. `0 <= trips[i][1] < trips[i][2] <= 1000`\r\n5. `1 <= capacity <= 100000`\r\n\r\n```python\r\nclass Solution:\r\n def carPooling(self, trips, capacity):\r\n nums = [0 for i in range(1000)]\r\n for trip in trips:\r\n for i in range(trip[1], trip[2]):\r\n nums[i] += trip[0]\r\n if nums[i] > capacity:\r\n return False\r\n return True\r\n```\r\n\r\n这边start 和end length都不超过1000,因此可以用这种方法 但是时间复杂度还是挺高的\r\n\r\n时间复杂度O(length*max(end))\r\n\r\n```python\r\nclass Solution:\r\n\tdef carPooling(self, trips, capacity):\r\n for i, v in sorted(x for n, i, j in trips for x in [[i, n], [j, - n]]):\r\n capacity -= v\r\n if capacity < 0:\r\n return False\r\n return True\r\n```\r\n\r\n将trip拆分为两个事件,上车n 下车-n\r\n\r\nO(length*log(length))\r\n\r\n\r\n\r\n##### leetcode 1186 Maximum Subarray Sum with One Deletion\r\n\r\nGiven an array of integers, return the maximum sum for a **non-empty** subarray (contiguous elements) with at most one element deletion. In other words, you want to choose a subarray and optionally delete one element from it so that there is still at least one element left and the sum of the remaining elements is maximum possible.\r\n\r\nNote that the subarray needs to be **non-empty** after deleting one element.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: arr = [1,-2,0,3]\r\nOutput: 4\r\nExplanation: Because we can choose [1, -2, 0, 3] and drop -2, thus the subarray [1, 0, 3] becomes the maximum value.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: arr = [1,-2,-2,3]\r\nOutput: 3\r\nExplanation: We just choose [3] and it's the maximum sum.\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: arr = [-1,-1,-1,-1]\r\nOutput: -1\r\nExplanation: The final subarray needs to be non-empty. You can't choose [-1] and delete -1 from it, then get an empty subarray to make the sum equals to 0.\r\n```\r\n\r\n```python\r\nimport copy\r\nclass Solution:\r\n def maximumSum(self, arr):\r\n n, temp = len(arr), 0\r\n left, right = [-float(\"inf\") for i in range(n)], [-float(\"inf\") for i in range(n)]\r\n for i in range(n):\r\n temp += arr[i]\r\n right[i] = max(arr[i], temp)\r\n if temp < 0:\r\n temp = 0\r\n temp = 0\r\n for i in range(n-1, -1, -1):\r\n temp += arr[i]\r\n left[i] = max(arr[i], temp)\r\n if temp < 0:\r\n temp = 0\r\n res = max(max(left), max(right))\r\n for i in range(1, n-1, 1):\r\n res = max(res, right[i-1] + left[i+1])\r\n return res\r\n\r\ns1 = Solution()\r\narr = [2,1,-2,-5,-2]\r\nprint(s1.maximumSum(arr))\r\n\r\n```\r\n\r\nright[i]数组表示最右边的num为arr[i]时的Maximum Subarray Sum\r\n\r\nleft[i]数组表示最左边的num为arr[i]时的Maximum Subarray Sum\r\n\r\n\r\n\r\n但是值得注意的是 如果是可以删除K个,那只能用DP?\r\n\r\n\r\n\r\n##### leetcode 1252. Cells with Odd Values in a Matrix\r\n\r\nGiven `n` and `m` which are the dimensions of a matrix initialized by zeros and given an array `indices` where `indices[i] = [ri, ci]`. For each pair of `[ri, ci]` you have to increment all cells in row `ri` and column `ci` by 1.\r\n\r\nReturn *the number of cells with odd values* in the matrix after applying the increment to all `indices`.\r\n\r\n\r\n\r\n\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: n = 2, m = 3, indices = [[0,1],[1,1]]\r\nOutput: 6\r\nExplanation: Initial matrix = [[0,0,0],[0,0,0]].\r\nAfter applying first increment it becomes [[1,2,1],[0,1,0]].\r\nThe final matrix will be [[1,3,1],[1,3,1]] which contains 6 odd numbers.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: n = 2, m = 2, indices = [[1,1],[0,0]]\r\nOutput: 0\r\nExplanation: Final matrix = [[2,2],[2,2]]. There is no odd number in the final matrix.\r\n```\r\n\r\n**Constraints:**\r\n\r\n- `1 <= n <= 50`\r\n- `1 <= m <= 50`\r\n- `1 <= indices.length <= 100`\r\n- `0 <= indices[i][0] < n`\r\n- `0 <= indices[i][1] < m`\r\n\r\n```python\r\nimport numpy as np\r\nclass Solution(object):\r\n def oddCells(self, n, m, indices):\r\n \"\"\"\r\n :type n: int\r\n :type m: int\r\n :type indices: List[List[int]]\r\n :rtype: int\r\n \"\"\"\r\n nums = np.zeros((n, m))\r\n for r,c in indices:\r\n nums[r] = 1-nums[r]\r\n nums[:,c] = 1-nums[:,c]\r\n return int(sum(sum(nums)))\r\n \r\n \r\n```\r\n\r\n表示行 列nums[r], nums[:,c]\r\n\r\n但是nums必须是array 如果是list则不行\r\n\r\n\r\n\r\n##### leetcode 1262 Greatest Sum Divisible by Three\r\n\r\nGiven an array `nums` of integers, we need to find the maximum possible sum of elements of the array such that it is divisible by three.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: nums = [3,6,5,1,8]\r\nOutput: 18\r\nExplanation: Pick numbers 3, 6, 1 and 8 their sum is 18 (maximum sum divisible by 3).\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: nums = [4]\r\nOutput: 0\r\nExplanation: Since 4 is not divisible by 3, do not pick any number.\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: nums = [1,2,3,4,4]\r\nOutput: 12\r\nExplanation: Pick numbers 1, 3, 4 and 4 their sum is 12 (maximum sum divisible by 3).\r\n```\r\n\r\n**Constraints:**\r\n\r\n- `1 <= nums.length <= 4 * 10^4`\r\n- `1 <= nums[i] <= 10^4`\r\n\r\n```python\r\nimport heapq\r\nclass Solution:\r\n def maxSumDivThree(self, nums):\r\n ones = []\r\n twos = []\r\n total = sum(nums)\r\n total_yu = total % 3\r\n for num in nums:\r\n yu = num % 3\r\n if yu == 1:\r\n heapq.heappush(ones, num)\r\n elif yu == 2:\r\n heapq.heappush(twos, num)\r\n\r\n if total_yu == 0:\r\n return total\r\n elif total_yu == 1:\r\n remove = float(\"inf\")\r\n if len(ones) > 0:\r\n remove = min(remove, ones[0])\r\n if len(twos) > 1:\r\n remove = min(remove, sum(heapq.nsmallest(2, twos)))\r\n return total-remove\r\n else:\r\n remove = float(\"inf\")\r\n if len(twos) > 0:\r\n remove = min(remove, twos[0])\r\n if len(ones) > 1:\r\n remove = min(remove, sum(heapq.nsmallest(2, ones)))\r\n return total-remove\r\n```\r\n\r\n从余数的角度考虑\r\n\r\n如果和余1,则需要去掉一个1或者两个2\r\n\r\n如果和余2, 则需要去掉两个1或者一个2\r\n\r\n\r\n\r\n##### leetcode 788. Rotated Digits\r\n\r\nX is a good number if after rotating each digit individually by 180 degrees, we get a valid number that is different from X. Each digit must be rotated - we cannot choose to leave it alone.\r\n\r\nA number is valid if each digit remains a digit after rotation. 0, 1, and 8 rotate to themselves; 2 and 5 rotate to each other; 6 and 9 rotate to each other, and the rest of the numbers do not rotate to any other number and become invalid.\r\n\r\nNow given a positive number `N`, how many numbers X from `1` to `N` are good?\r\n\r\n```\r\nExample:\r\nInput: 10\r\nOutput: 4\r\nExplanation: \r\nThere are four good numbers in the range [1, 10] : 2, 5, 6, 9.\r\nNote that 1 and 10 are not good numbers, since they remain unchanged after rotating.\r\n```\r\n\r\n**Note:**\r\n\r\n- N will be in range `[1, 10000]`.\r\n\r\nO(N) 方法\r\n\r\n```python\r\nclass Solution:\r\n def rotatedDigits(self, N):\r\n def isrotated(str1):\r\n n=len(str1)\r\n index=0\r\n set1=['1','0','2','5','6','8','9']\r\n set2=['2','5','6','9']\r\n for i in range(n):\r\n if str1[i] not in set1:\r\n return 0\r\n if str1[i] in set2:\r\n index=1\r\n if index==1:\r\n return 1\r\n else:\r\n return 0\r\n count=0\r\n for j in range(1,N+1):\r\n count+=isrotated(str(j))\r\n return count \r\n \r\n```\r\n\r\nO(logN)\r\n\r\n```python\r\ndef rotatedDigits(self, N):\r\n s1 = set([0, 1, 8])\r\n s2 = set([0, 1, 8, 2, 5, 6, 9])\r\n s = set()\r\n res = 0\r\n N = map(int, str(N))\r\n for i, v in enumerate(N):\r\n for j in range(v):\r\n if s.issubset(s2) and j in s2:\r\n res += 7**(len(N) - i - 1)\r\n if s.issubset(s1) and j in s1:\r\n res -= 3**(len(N) - i - 1)\r\n if v not in s2:\r\n return res\r\n s.add(v)\r\n return res + (s.issubset(s2) and not s.issubset(s1))\r\n```\r\n\r\n\r\n\r\n##### leetcode \\829. Consecutive Numbers Sum\r\n\r\nGiven a positive integer `N`, how many ways can we write it as a sum of consecutive positive integers?\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: 5\r\nOutput: 2\r\nExplanation: 5 = 5 = 2 + 3\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: 9\r\nOutput: 3\r\nExplanation: 9 = 9 = 4 + 5 = 2 + 3 + 4\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: 15\r\nOutput: 4\r\nExplanation: 15 = 15 = 8 + 7 = 4 + 5 + 6 = 1 + 2 + 3 + 4 + 5\r\n```\r\n\r\n**Note:** `1 <= N <= 10 ^ 9`.\r\n\r\n```python\r\nclass Solution:\r\n def consecutiveNumbersSum(self, N: int) -> int:\r\n seen, temp, res = set(), 0, 0\r\n for i in range(N + 1):\r\n temp += i\r\n if temp - N in seen:\r\n # print(i)\r\n res += 1\r\n seen.add(temp)\r\n return res\r\n```\r\n\r\n用seen储存之前见过的1-N之和\r\n\r\nTLE\r\n\r\n```python\r\nclass Solution:\r\n def consecutiveNumbersSum(self, N: int) -> int:\r\n n = int(math.sqrt(N*2))\r\n res = 0\r\n for i in range(1, n+1):\r\n if (N-(i+1)*i/2)%i==0:\r\n res += 1\r\n return res\r\n```\r\n\r\nO(log n)\r\n\r\n9=2+3+4-> 1+2+3+3\r\n\r\n=4+5 ->1+2+4*2\r\n\r\n\r\n\r\n##### leetcode 1344. Jump Game V\r\n\r\nGiven an array of integers `arr` and an integer `d`. In one step you can jump from index `i` to index:\r\n\r\n- `i + x` where: `i + x < arr.length` and `0 < x <= d`.\r\n- `i - x` where: `i - x >= 0` and `0 < x <= d`.\r\n\r\nIn addition, you can only jump from index `i` to index `j` if `arr[i] > arr[j]` and `arr[i] > arr[k]` for all indices `k` between `i` and `j` (More formally `min(i, j) < k < max(i, j)`).\r\n\r\nYou can choose any index of the array and start jumping. Return *the maximum number of indices* you can visit.\r\n\r\nNotice that you can not jump outside of the array at any time.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: arr = [6,4,14,6,8,13,9,7,10,6,12], d = 2\r\nOutput: 4\r\nExplanation: You can start at index 10. You can jump 10 --> 8 --> 6 --> 7 as shown.\r\nNote that if you start at index 6 you can only jump to index 7. You cannot jump to index 5 because 13 > 9. You cannot jump to index 4 because index 5 is between index 4 and 6 and 13 > 9.\r\nSimilarly You cannot jump from index 3 to index 2 or index 1.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: arr = [3,3,3,3,3], d = 3\r\nOutput: 1\r\nExplanation: You can start at any index. You always cannot jump to any index.\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: arr = [7,6,5,4,3,2,1], d = 1\r\nOutput: 7\r\nExplanation: Start at index 0. You can visit all the indicies. \r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: arr = [7,1,7,1,7,1], d = 2\r\nOutput: 2\r\n```\r\n\r\n**Example 5:**\r\n\r\n```\r\nInput: arr = [66], d = 1\r\nOutput: 1\r\n```\r\n\r\n**Constraints:**\r\n\r\n- `1 <= arr.length <= 1000`\r\n- `1 <= arr[i] <= 10^5`\r\n- `1 <= d <= arr.length`\r\n\r\n```python\r\nclass Solution:\r\n def jump(self, i, d, arr):\r\n if self.dp[i] != -1: return self.dp[i]\r\n for di in [-1, 1]:\r\n for j in range(1, d + 1):\r\n index = i + di * j\r\n if index < 0 or index >= len(arr) or arr[i] <= arr[index]: break\r\n self.dp[i] = max(self.dp[i], 1 + self.jump(index, d, arr))\r\n self.dp[i] = max(self.dp[i], 0)\r\n return self.dp[i]\r\n\r\n def maxJumps(self, arr, d):\r\n self.dp = [-1 for i in range(len(arr))]\r\n self.res = 0\r\n for i in range(len(arr)):\r\n self.res = max(self.res, 1 + self.jump(i, d, arr))\r\n return self.res\r\n```\r\n\r\nself.dp[i]表示除了自己之外还可以跳多少步\r\n\r\n如果self.dp[i]!=-1表示其已经访问过了\r\n\r\nO(ND)\r\n\r\n\r\n\r\n##### leetcode 644 Maximum Average Subarray II\r\n\r\nGiven an array consisting of `n` integers, find the contiguous subarray whose **length is greater than or equal to** `k` that has the maximum average value. And you need to output the maximum average value.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [1,12,-5,-6,50,3], k = 4\r\nOutput: 12.75\r\nExplanation:\r\nwhen length is 5, maximum average value is 10.8,\r\nwhen length is 6, maximum average value is 9.16667.\r\nThus return 12.75.\r\n```\r\n\r\n\r\n\r\n**Note:**\r\n\r\n1. 1 <= `k` <= `n` <= 10,000.\r\n2. Elements of the given array will be in range [-10,000, 10,000].\r\n3. The answer with the calculation error less than 10-5 will be accepted.\r\n\r\n```python\r\nclass Solution:\r\n def findMaxAverage(self, nums: List[int], k: int) -> float:\r\n n=len(nums)\r\n def isbigger(target):\r\n cur=0\r\n for i in range(k):\r\n cur+=nums[i]-target\r\n if cur>=0:\r\n return True\r\n prev=0\r\n prevmin=0\r\n for i in range(k,n):\r\n cur+=nums[i]-target\r\n prev+=nums[i-k]-target\r\n prevmin=min(prevmin,prev)\r\n if cur>=prevmin:\r\n return True\r\n return False\r\n i,j=min(nums),max(nums)\r\n while j-i>=0.000004:\r\n mid=(i+j)/2.0\r\n if isbigger(mid):\r\n i=mid\r\n else:\r\n j=mid\r\n return i\r\n```\r\n\r\n使用二分法\r\n\r\n注意prevmin这种形式,prevmin就对应着某种长度的max subarray sum\r\n\r\n"
},
{
"alpha_fraction": 0.5265265107154846,
"alphanum_fraction": 0.5576052069664001,
"avg_line_length": 22.967857360839844,
"blob_id": "34ae124a2aeff1e7b6b0daa7cdd578e7a560d227",
"content_id": "6fe9ea6408e18ff520c7ef3b50268e880f94b516",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 21953,
"license_type": "no_license",
"max_line_length": 323,
"num_lines": 840,
"path": "/leetcode_note/Linked-list.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "#### Linked-list\r\n\r\n链表逆序(LeetCode 92,206)\r\n求两个链表的交点(LeetCode 160)\r\n\r\n链表的节点交换(LeetCode 24)\r\n\r\n链表求环(LeetCode 141,142)\r\n\r\n链表重新构造(LeetCode 86) \r\n\r\n复杂的链表复制(LeetCode 138)\r\n\r\n排序链表合并(2个与多个) (LeetCode 21,23)\r\n\r\n##### leetcode 2 Add Two Numbers\r\n\r\n* You are given two **non-empty** linked lists representing two non-negative integers. The digits are stored in **reverse order** and each of their nodes contain a single digit. Add the two numbers and return it as a linked list.\r\n\r\n ```\r\n Input: (2 -> 4 -> 3) + (5 -> 6 -> 4)\r\n Output: 7 -> 0 -> 8\r\n Explanation: 342 + 465 = 807.\r\n ```\r\n\r\n* Mysolution:\r\n\r\n ```python\r\n class ListNode:\r\n def __init__(self, x):\r\n self.val = x\r\n self.next = None\r\n \r\n class Solution:\r\n def addTwoNumbers(self, l1, l2):\r\n if not l1:return l2\r\n if not l2:return l1\r\n head=cur=ListNode(-1)\r\n carry=0\r\n while l1 and l2:\r\n value=l1.val+l2.val+carry\r\n if value>=10:\r\n carry=1\r\n value-=10\r\n else:\r\n carry=0\r\n node=ListNode(value)\r\n cur.next=node\r\n cur=cur.next\r\n l1=l1.next\r\n l2=l2.next\r\n while l1:\r\n value=l1.val+carry\r\n if value>=10:\r\n carry=1\r\n value-=10\r\n else:\r\n carry=0\r\n node=ListNode(value)\r\n cur.next=node\r\n cur=cur.next\r\n l1=l1.next\r\n while l2:\r\n value=l2.val+carry\r\n if value>=10:\r\n carry=1\r\n value-=10\r\n else:\r\n carry=0\r\n node=ListNode(value)\r\n cur.next=node\r\n cur=cur.next\r\n l2=l2.next\r\n if carry:\r\n node=ListNode(1)\r\n cur.next=node\r\n return head.next\r\n ```\r\n\r\n better solution:\r\n\r\n ```python\r\n def addTwoNumbers(self, l1, l2):\r\n dummy = cur = ListNode(0)\r\n carry = 0\r\n while l1 or l2 or carry:\r\n if l1:\r\n carry += l1.val\r\n l1 = l1.next\r\n if l2:\r\n carry += l2.val\r\n l2 = l2.next\r\n cur.next = ListNode(carry%10)\r\n cur = cur.next\r\n carry //= 10\r\n return dummy.next\r\n ```\r\n\r\n每次做加法之前对l1 l2进行判断是否为空,carry\r\n\r\n\r\n\r\n##### leetcode 19 Remove Nth Node From End of List\r\n\r\n* Given a linked list, remove the *n*-th node from the end of list and return its head.\r\n\r\n **Example:**\r\n\r\n ```\r\n Given linked list: 1->2->3->4->5, and n = 2.\r\n \r\n After removing the second node from the end, the linked list becomes 1->2->3->5.\r\n ```\r\n\r\n **Note:**\r\n\r\n Given *n* will always be valid.\r\n\r\n **Follow up:**\r\n\r\n Could you do this in one pass?\r\n\r\n Mysolution:\r\n\r\n ```python\r\n class Solution(object):\r\n def removeNthFromEnd(self, head, n):\r\n root=copy=ListNode(0)\r\n root.next=head\r\n lists=[]\r\n while root:\r\n lists.append(root)\r\n root=root.next\r\n number=len(lists)\r\n if n==1:\r\n lists[number-n-1].next=None\r\n else:\r\n lists[number-n-1].next=lists[number-n+1]\r\n return copy.next\r\n ```\r\n\r\n用python做linked-list题,先用一个list将元素保存下来,然后对list进行操作,最后根据list返回\r\n\r\n\r\n\r\n##### leetcode 21 Merge Two Sorted Lists\r\n\r\n* Merge two sorted linked lists and return it as a new list. The new list should be made by splicing together the nodes of the first two lists.\r\n\r\n ```\r\n Input: 1->2->4, 1->3->4\r\n Output: 1->1->2->3->4->4\r\n ```\r\n\r\n ```python\r\n class Solution(object):\r\n def mergeTwoLists(self, l1, l2):\r\n if l1==None:\r\n return l2\r\n elif l2==None:\r\n return l1\r\n cur=head=ListNode(-1)\r\n while l1!=None and l2!=None:\r\n if l1.val<=l2.val:\r\n cur.next=l1\r\n l1=l1.next\r\n else:\r\n cur.next=l2\r\n l2=l2.next\r\n cur=cur.next\r\n cur.next = l1 or l2\r\n return head.next\r\n ```\r\n\r\n分两段,第一段是l1和l2都存在的时候,比较l1.val与l2.val的大小\r\n\r\n第二段是把剩余的l1或者剩余的l2拼接上去 cur.next=l1 or l2\r\n\r\n\r\n\r\n##### leetcode 23 Merge k Sorted Lists\r\n\r\n* Merge *k* sorted linked lists and return it as one sorted list. Analyze and describe its complexity.\r\n\r\n ```\r\n Input:\r\n [\r\n 1->4->5,\r\n 1->3->4,\r\n 2->6\r\n ]\r\n Output: 1->1->2->3->4->4->5->6\r\n ```\r\n\r\n* Mysolution:\r\n\r\n ```python\r\n class Solution(object):\r\n def mergeKLists(self, lists):\r\n import heapq\r\n lists=[(node.val,node)for node in lists if node]\r\n heapq.heapify(lists)\r\n pre=pre2=ListNode(-1)\r\n while lists:\r\n val,node=heapq.heappop(lists)\r\n if node.next:\r\n heapq.heappush(lists,(node.next.val,node.next))\r\n pre.next=node\r\n pre=pre.next\r\n return pre2.next\r\n ```\r\n\r\n本题的难点在于不知道k的大小,那么问题就转化为了如何在最短的时间内从k个数中(k个list的开头元素)找到最小的元素,因此使用heap。\r\n\r\nval,node=heapq.heappop(lists)弹出来的是最小的val 然后如果node存在next就把node.next放进去\r\n\r\n\r\n\r\n##### leetocde 25 Reverse Nodes in k-Group\r\n\r\n* Given a linked list, reverse the nodes of a linked list *k* at a time and return its modified list.\r\n\r\n *k* is a positive integer and is less than or equal to the length of the linked list. If the number of nodes is not a multiple of *k* then left-out nodes in the end should remain as it is.\r\n\r\n **Example:**\r\n\r\n Given this linked list: `1->2->3->4->5`\r\n\r\n For *k* = 2, you should return: `2->1->4->3->5`\r\n\r\n For *k* = 3, you should return: `3->2->1->4->5`\r\n\r\n **Note:**\r\n\r\n - Only constant extra memory is allowed.\r\n\r\n - You may not alter the values in the list's nodes, only nodes itself may be changed.\r\n\r\n\r\n* Mysolution:\r\n\r\n ```python\r\n class Solution:\r\n def reverseKGroup(self, head, k):\r\n cur=head\r\n nums=[]\r\n while cur:\r\n nums.append(cur.val)\r\n cur=cur.next\r\n i,n=0,len(nums)\r\n while i+k<=n:\r\n nums=nums[:i]+nums[i:i+k][::-1]+nums[i+k:]\r\n i+=k\r\n new_head=ListNode(-1)\r\n cur=new_head\r\n i=0\r\n for i in range(n):\r\n temp=ListNode(nums[i])\r\n cur.next=temp\r\n cur=cur.next\r\n return new_head.next\r\n ```\r\n\r\n\r\n1. 在python中 list-node问题可以先用list[]把所有元素都保存下来\r\n\r\n2. reverse:\r\n\r\n ```python\r\n nums[i:i+k][::-1] [::-1] return reversed nums\r\n nums[i:i+k].reverse() return None\r\n \r\n nums[len(nums):] return [] 这样不报错\r\n ```\r\n\r\n\r\n\r\n##### leetcode 92 Reverse Linked List II\r\n\r\nReverse a linked list from position *m* to *n*. Do it in one-pass.\r\n\r\n**Note:** 1 ≤ *m* ≤ *n* ≤ length of list.\r\n\r\n**Example:**\r\n\r\n```\r\nInput: 1->2->3->4->5->NULL, m = 2, n = 4\r\nOutput: 1->4->3->2->5->NULL\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def reverseBetween(self, head, m, n):\r\n \"\"\"\r\n :type head: ListNode\r\n :type m: int\r\n :type n: int\r\n :rtype: ListNode\r\n \"\"\"\r\n res,res1=[],[]\r\n while head:\r\n res.append(head)\r\n head=head.next\r\n temp=res[m-1:n]\r\n temp.reverse()\r\n res1=res[:m-1]+temp+res[n:]\r\n ans=pre=ListNode(-1)\r\n for i in range(len(res1)):\r\n pre.next=res1[i]\r\n pre=pre.next\r\n pre.next=None\r\n return ans.next\r\n```\r\n\r\n```python\r\ndef reverseBetween(self, head, m, n):\r\n if m == n:\r\n return head\r\n\r\n dummyNode = ListNode(0)\r\n dummyNode.next = head\r\n pre = dummyNode\r\n\r\n for i in range(m - 1):\r\n pre = pre.next\r\n \r\n # reverse the [m, n] nodes\r\n reverse = None\r\n cur = pre.next\r\n for i in range(n - m + 1):\r\n next = cur.next\r\n cur.next = reverse\r\n reverse = cur\r\n cur = next\r\n\r\n pre.next.next = cur\r\n pre.next = reverse\r\n\r\n return dummyNode.next\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 141 Linked List Cycle\r\n\r\n* Given a linked list, determine if it has a cycle in it.\r\n\r\n To represent a cycle in the given linked list, we use an integer `pos` which represents the position (0-indexed) in the linked list where tail connects to. If `pos` is `-1`, then there is no cycle in the linked list.\r\n\r\n```\r\nInput: head = [3,2,0,-4], pos = 1\r\nOutput: true\r\nExplanation: There is a cycle in the linked list, where tail connects to the second node.\r\n```\r\n\r\n\r\n\r\n```\r\nInput: head = [1,2], pos = 0\r\nOutput: true\r\nExplanation: There is a cycle in the linked list, where tail connects to the first node.\r\n```\r\n\r\n\r\n\r\n```\r\nInput: head = [1], pos = -1\r\nOutput: false\r\nExplanation: There is no cycle in the linked list.\r\n```\r\n\r\n\r\n\r\n* Mysolution\r\n\r\n```python\r\nclass Solution(object):\r\n def hasCycle(self, head):\r\n if head==None:\r\n return False\r\n slow,fast=head,head\r\n while fast.next!=None and fast.next.next!=None:\r\n fast=fast.next.next\r\n slow=slow.next\r\n if fast==slow:\r\n return True\r\n return False\r\n```\r\n\r\n如果存在circle,利用一个slow 一个fast,fast必然会追上slow\r\n\r\n\r\n\r\n##### leetcode 142 Linked List Cycle II\r\n\r\n* Given a linked list, return the node where the cycle begins. If there is no cycle, return `null`. To represent a cycle in the given linked list, we use an integer `pos` which represents the position (0-indexed) in the linked list where tail connects to. If `pos` is `-1`, then there is no cycle in the linked list. \r\n* **Note:** Do not modify the linked list.\r\n\r\n```\r\nInput: head = [3,2,0,-4], pos = 1\r\nOutput: tail connects to node index 1\r\nExplanation: There is a cycle in the linked list, where tail connects to the second node.\r\n```\r\n\r\n\r\n\r\n```\r\nInput: head = [1,2], pos = 0\r\nOutput: tail connects to node index 0\r\nExplanation: There is a cycle in the linked list, where tail connects to the first node.\r\n```\r\n\r\n\r\n\r\n```\r\nInput: head = [1], pos = -1\r\nOutput: no cycle\r\nExplanation: There is no cycle in the linked list.\r\n```\r\n\r\n\r\n\r\n\r\n\r\n* Mysolution:\r\n\r\n ```python\r\n class Solution(object):\r\n def detectCycle(self, head):\r\n \"\"\"\r\n :type head: ListNode\r\n :rtype: ListNode\r\n \"\"\"\r\n if not head:\r\n return\r\n iscircle=0\r\n fast=slow=head\r\n while fast and fast.next:\r\n fast=fast.next.next\r\n slow=slow.next\r\n if fast==slow:\r\n iscircle=1\r\n break\r\n if iscircle==0:\r\n return\r\n first=head\r\n while first!=slow:\r\n first=first.next\r\n slow=slow.next\r\n return first\r\n ```\r\n\r\n\r\n\r\n检测linked list中是否有loop,采用一个fast 一个slow看fast能不能追上slow\r\n\r\n\r\n\r\n##### leetcode 160 Intersection of Two Linked Lists\r\n\r\n* Write a program to find the node at which the intersection of two singly linked lists begins.\r\n\r\n For example, the following two linked lists:\r\n\r\n begin to intersect at node c1.\r\n\r\n\r\n\r\n```\r\nInput: intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3\r\nOutput: Reference of the node with value = 8\r\nInput Explanation: The intersected node's value is 8 (note that this must not be 0 if the two lists intersect). From the head of A, it reads as [4,1,8,4,5]. From the head of B, it reads as [5,0,1,8,4,5]. There are 2 nodes before the intersected node in A; There are 3 nodes before the intersected node in B.\r\n```\r\n\r\n\r\n\r\n\r\n```\r\nInput: intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1\r\nOutput: Reference of the node with value = 2\r\nInput Explanation: The intersected node's value is 2 (note that this must not be 0 if the two lists intersect). From the head of A, it reads as [0,9,1,2,4]. From the head of B, it reads as [3,2,4]. There are 3 nodes before the intersected node in A; There are 1 node before the intersected node in B.\r\n```\r\n\r\n\r\n\r\n```\r\nInput: intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2\r\nOutput: null\r\nInput Explanation: From the head of A, it reads as [2,6,4]. From the head of B, it reads as [1,5]. Since the two lists do not intersect, intersectVal must be 0, while skipA and skipB can be arbitrary values.\r\nExplanation: The two lists do not intersect, so return null.\r\n```\r\n\r\n\r\n\r\n- If the two linked lists have no intersection at all, return `null`.\r\n- The linked lists must retain their original structure after the function returns.\r\n- You may assume there are no cycles anywhere in the entire linked structure.\r\n- Your code should preferably run in O(n) time and use only O(1) memory.\r\n\r\n\r\n\r\n```python\r\nclass Solution(object):\r\n def getIntersectionNode(self, headA, headB):\r\n if not headA or not headB:\r\n return None\r\n p, q = headA, headB\r\n while p and q and p != q:\r\n p = p.next\r\n q = q.next\r\n if p == q:\r\n return q\r\n if not p:\r\n p = headB\r\n if not q:\r\n q = headA\r\n return p\r\n```\r\n\r\n对于两个不知道长度的linked list而言 求公共点的时候不知道要让p=p.next还是q=q.next\r\n\r\n对于两个不一样长的list 让p先走lista 再走listb 让q先走listb再走lista\r\n\r\n如果存在公共点,则会在p q 均为None之前相等\r\n\r\n如果不存在公共点则二者会走到 None\r\n\r\n本题不考虑先合并再字符串分开的情况\r\n\r\n\r\n\r\n##### leetcode 206 Reverse Linked List\r\n\r\n* Reverse a singly linked list\r\n\r\n```\r\nInput: 1->2->3->4->5->NULL\r\nOutput: 5->4->3->2->1->NULL\r\n```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution(object):\r\n def reverseList(self, head):\r\n pre,cur,next1=None,head,head\r\n while next1:\r\n cur=next1\r\n next1=next1.next\r\n cur.next=pre\r\n pre=cur\r\n return pre\r\n```\r\n\r\niter 的方法或者可以将所有的元素都放到list中再生成新的list\r\n\r\n\r\n\r\n##### leetcode 234 Palindrome Linked List\r\n\r\n* Given a singly linked list, determine if it is a palindrome.\r\n\r\n```\r\nInput: 1->2\r\nOutput: false\r\n\r\nInput: 1->2->2->1\r\nOutput: true\r\n```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution:\r\n def isPalindrome(self, head):\r\n val=[]\r\n while head:\r\n val.append(head.val)\r\n head=head.next\r\n return val==val[::-1]\r\n```\r\n\r\n对于python遇到linked list问题先用list保存下来再做\r\n\r\n\r\n\r\n##### leetcode 237 Delete Node in a Linked List\r\n\r\nWrite a function to delete a node (except the tail) in a singly linked list, given only access to that node.\r\n\r\nGiven linked list -- head = [4,5,1,9], which looks like following:\r\n\r\n\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: head = [4,5,1,9], node = 5\r\nOutput: [4,1,9]\r\nExplanation: You are given the second node with value 5, the linked list should become 4 -> 1 -> 9 after calling your function.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: head = [4,5,1,9], node = 1\r\nOutput: [4,5,9]\r\nExplanation: You are given the third node with value 1, the linked list should become 4 -> 5 -> 9 after calling your function.\r\n```\r\n\r\n```python\r\n# Definition for singly-linked list.\r\n# class ListNode:\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.next = None\r\n\r\nclass Solution:\r\n def deleteNode(self, node):\r\n \"\"\"\r\n :type node: ListNode\r\n :rtype: void Do not return anything, modify node in-place instead.\r\n \"\"\"\r\n if node is not None and node.next is not None:\r\n node.val = node.next.val\r\n node.next = node.next.next\r\n```\r\n\r\n第一眼看好像没有head\r\n\r\n\r\n\r\n##### leetcode 138. Copy List with Random Pointer\r\n\r\nA linked list is given such that each node contains an additional random pointer which could point to any node in the list or null.\r\n\r\nReturn a [**deep copy**](https://en.wikipedia.org/wiki/Object_copying#Deep_copy) of the list.\r\n\r\nThe Linked List is represented in the input/output as a list of `n` nodes. Each node is represented as a pair of `[val, random_index]` where:\r\n\r\n- `val`: an integer representing `Node.val`\r\n- `random_index`: the index of the node (range from `0` to `n-1`) where random pointer points to, or `null` if it does not point to any node.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: head = [[7,null],[13,0],[11,4],[10,2],[1,0]]\r\nOutput: [[7,null],[13,0],[11,4],[10,2],[1,0]]\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: head = [[1,1],[2,1]]\r\nOutput: [[1,1],[2,1]]\r\n```\r\n\r\n**Example 3:**\r\n\r\n****\r\n\r\n```\r\nInput: head = [[3,null],[3,0],[3,null]]\r\nOutput: [[3,null],[3,0],[3,null]]\r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: head = []\r\nOutput: []\r\nExplanation: Given linked list is empty (null pointer), so return null.\r\n```\r\n\r\n```python\r\n\"\"\"\r\n# Definition for a Node.\r\nclass Node:\r\n def __init__(self, val, next, random):\r\n self.val = val\r\n self.next = next\r\n self.random = random\r\n\"\"\"\r\nclass Solution:\r\n def copyRandomList(self, head: 'Node') -> 'Node':\r\n dummy = Node(0, None, None)\r\n cur, tmp, nodes, origin_nodes = dummy, head, [], []\r\n while head:\r\n next_node = Node(head.val, None, None)\r\n nodes.append(next_node)\r\n origin_nodes.append(head)\r\n head = head.next\r\n cur.next = next_node\r\n cur = next_node\r\n cur = dummy.next\r\n while tmp:\r\n random = tmp.random\r\n if random:\r\n index = origin_nodes.index(random)\r\n cur.random = nodes[index]\r\n cur = cur.next\r\n tmp = tmp.next\r\n return dummy.next\r\n\r\n```\r\n\r\n与其他的不同的地方在于 多了一个random,而且要注意不能指向原来list中的节点\r\n\r\n因此用两个【】保存下来\r\n\r\n\r\n\r\n##### leetcode 430. Flatten a Multilevel Doubly Linked List\r\n\r\nYou are given a doubly linked list which in addition to the next and previous pointers, it could have a child pointer, which may or may not point to a separate doubly linked list. These child lists may have one or more children of their own, and so on, to produce a multilevel data structure, as shown in the example below.\r\n\r\nFlatten the list so that all the nodes appear in a single-level, doubly linked list. You are given the head of the first level of the list.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: head = [1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]\r\nOutput: [1,2,3,7,8,11,12,9,10,4,5,6]\r\nExplanation:\r\n\r\nThe multilevel linked list in the input is as follows:\r\n\r\n\r\n\r\nAfter flattening the multilevel linked list it becomes:\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: head = [1,2,null,3]\r\nOutput: [1,3,2]\r\nExplanation:\r\n\r\nThe input multilevel linked list is as follows:\r\n\r\n 1---2---NULL\r\n |\r\n 3---NULL\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: head = []\r\nOutput: []\r\n```\r\n\r\n**How multilevel linked list is represented in test case:**\r\n\r\nWe use the multilevel linked list from **Example 1** above:\r\n\r\n```\r\n 1---2---3---4---5---6--NULL\r\n |\r\n 7---8---9---10--NULL\r\n |\r\n 11--12--NULL\r\n```\r\n\r\nThe serialization of each level is as follows:\r\n\r\n```\r\n[1,2,3,4,5,6,null]\r\n[7,8,9,10,null]\r\n[11,12,null]\r\n```\r\n\r\nTo serialize all levels together we will add nulls in each level to signify no node connects to the upper node of the previous level. The serialization becomes:\r\n\r\n```\r\n[1,2,3,4,5,6,null]\r\n[null,null,7,8,9,10,null]\r\n[null,11,12,null]\r\n```\r\n\r\nMerging the serialization of each level and removing trailing nulls we obtain:\r\n\r\n```\r\n[1,2,3,4,5,6,null,null,null,7,8,9,10,null,null,11,12]\r\n```\r\n\r\n**Constraints:**\r\n\r\n- Number of Nodes will not exceed 1000.\r\n- `1 <= Node.val <= 10^5`\r\n\r\n\r\n\r\n```python\r\nclass Solution:\r\n def flat(self, head):\r\n while head:\r\n self.nodes.append(head)\r\n if head.child:\r\n self.flat(head.child)\r\n head = head.next\r\n return\r\n def flatten(self, head: 'Node') -> 'Node':\r\n if not head: return\r\n self.nodes = []\r\n self.flat(head)\r\n if len(self.nodes)<2: return head\r\n last = None\r\n for i in range(len(self.nodes) -1):\r\n self.nodes[i].next, self.nodes[i].prev, self.nodes[i].child = self.nodes[i+1], last, None\r\n last = self.nodes[i]\r\n self.nodes[-1].next, self.nodes[-1].prev, self.nodes[i].child = None, self.nodes[-2], None\r\n return self.nodes[0]\r\n```\r\n\r\n用【】将所有的node都保存下来\r\n\r\n但是一定要用last将前面一个节点保存下来\r\n\r\n否则会遇到not valid doubly linked list报错\r\n\r\n```python\r\ndef flatten(self, head: 'Node') -> 'Node':\r\n if not head: return\r\n self.nodes = []\r\n self.flat(head)\r\n if len(self.nodes)<2: return self.nodes[0]\r\n self.nodes[0].next, self.nodes[0].prev = self.nodes[1], None\r\n for i in range(1, len(self.nodes) -1):\r\n self.nodes[i].next, self.nodes[i].prev = self.nodes[i+1], self.nodes[i-1]\r\n self.nodes[-1].next, self.nodes[-1].prev = None, self.nodes[-2]\r\n for i in range(n):\r\n print(self.nodes[i].val)\r\n return self.nodes[0]\r\n```\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.526437520980835,
"alphanum_fraction": 0.5703899264335632,
"avg_line_length": 16.782608032226562,
"blob_id": "dd130497e28803d44b062b248fbbd90c158e6b62",
"content_id": "623550fc70f6841ed4f8f518904ed0b8a0271432",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3370,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 161,
"path": "/c++/algorithm.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### Algorithm\r\n\r\n```\r\nhttps://www.geeksforgeeks.org/algorithms-library-c-stl/\r\n```\r\n\r\n```c++\r\nint arr[] = {10, 20, 5, 23 ,42 , 15}; \r\n```\r\n\r\n1.sort\r\n\r\n```c++\r\n// Sorting the Vector in Ascending order \r\n sort(vect.begin(), vect.end()); \r\n```\r\n\r\n\r\n\r\n2.reverse\r\n\r\n```c++\r\nreverse(vect.begin(), vect.end());\r\n```\r\n\r\n\r\n\r\n3.找最大最小值\r\n\r\nmax_element, min_element 这两个函数返回iterator\r\n\r\n```c++\r\nauto it = max_element(vect.begin(), vect.end()); \r\ncout << *it;\r\naudo it = min_element(vect.begin(), vect.end()); \r\n```\r\n\r\n\r\n\r\n4.找最大最小值的下标\r\n\r\n使用distance,输入iterator\r\n\r\n```c++\r\ndistance(vect.begin(), max_element(vect.begin(), vect.end()))\r\n```\r\n\r\n\r\n\r\n5.count 计算某元素的出现次数\r\n\r\n```c++\r\ncout << count(vect.begin(), vect.end(), 20); \r\n2\r\n```\r\n\r\n\r\n\r\n6. find寻找某元素,返回iterator,如果没找到则返回end()\r\n\r\n```c++\r\nfind(vect.begin(), vect.end(),5) != vect.end()? \r\n cout << \"\\nElement found\": \t\t\t\t\t\t\t cout << \"\\nElement not found\"; \r\n```\r\n\r\n\r\n\r\n7. Binary_search(iterator, iterator, x)用二分法检测x是否存在\r\n\r\n lower_bound(iterator, iterator, x) 二分法返回第一个不小于x的iterator\r\n\r\n upper_bound(iterator, iterator, x)二分法返回第一个大于x的iterator\r\n\r\n 这三个算法都需要在已经排好序的数组上运行\r\n\r\n ```c++\r\n sort(vect.begin(), vect.end()); \r\n // Returns the first occurrence of 20 \r\n auto q = lower_bound(vect.begin(), vect.end(), 20); \r\n \r\n // Returns the last occurrence of 20 \r\n auto p = upper_bound(vect.begin(), vect.end(), 20); \r\n \r\n cout << \"The lower bound is at position: \"; \r\n cout << q-vect.begin() << endl; \r\n \r\n cout << \"The upper bound is at position: \"; \r\n cout << p-vect.begin() << endl;\r\n ```\r\n\r\n8. arr.erase(pos)\r\n\r\n```c++\r\nvect.erase(vect.begin()+1); \r\n```\r\n\r\n删除第二个元素\r\n\r\narr.erase(unique(arr.begin(),arr.end()),arr.end())\r\n\r\n删除arr中连续的重复元素\r\n\r\n```c++\r\nusing namespace std; \r\nint main(){ \r\n // Initializing vector with array values \r\n int arr[] = {10, 10, 20, 5,5,10,10,23 ,42 , 15};\r\n int n = sizeof(arr)/sizeof(arr[0]);\r\n vector<int> vect = {arr, arr+n};\r\n vect.erase(unique(vect.begin(),vect.end()),vect.end());\r\n int i;\r\n cout << \"Vector is: \"; \r\n for (i=0; i<vect.size(); i++) \r\n cout << vect[i] << \" \";\r\n return 0;\r\n}\r\n\r\nVector is: 10 20 5 10 23 42 15\r\n```\r\n\r\nunique运算会将重复的元素剔除,后面的元素向前移动,但是数组的大小没有改变,erase改变了大小\r\n\r\n\r\n\r\n9.size\r\n\r\narray的大小 \r\n\r\n```c++\r\nint n = sizeof(arr)/sizeof(arr[0]);\r\n```\r\n\r\n\r\n\r\nvector大小\r\n\r\n```c++\r\nvect.size()\r\n```\r\n\r\n\r\n\r\n10.permutation\r\n\r\n1. **next_permutation(first_iterator, last_iterator)** – This modified the vector to its next permutation.\r\n2. **prev_permutation(first_iterator, last_iterator)** – This modified the vector to its previous permutation.\r\n\r\n\r\n\r\n```c++\r\nint arr[] = {5, 10, 15, 20, 20, 23, 42, 45}; \r\nint n = sizeof(arr)/sizeof(arr[0]); \r\nvector<int> vect(arr, arr+n); \r\n \r\n// modifies vector to its next permutation order next_permutation(vect.begin(), vect.end()); \r\n5, 10, 15, 20, 20, 23, 45, 42\r\nprev_permutation(vect.begin(), vect.end());\r\n5, 10, 15, 20, 20, 23, 42, 45\r\nprev_permutation(vect.begin(), vect.end());\r\n45 42 23 20 20 15 10 5\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.5849246382713318,
"alphanum_fraction": 0.6020100712776184,
"avg_line_length": 12.701492309570312,
"blob_id": "0ded9678d8a9d963765e0a9339e0e838bc57cce9",
"content_id": "7dd035653c3a45ca99b616a3058b08109d5dbebd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1797,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 67,
"path": "/math&&deeplearning/math/Distance.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Distance\r\n\r\n几个概念:熵(Entropy), 交叉熵(Cross-Entropy),KL松散度(KL Divergence)\r\n\r\n如何去衡量y与y'的接近程度呢?\r\n\r\n##### 熵\r\n\r\n对信息的测度:\r\n$$\r\nI=-log_2p\r\n$$\r\n该公式只能用来研究一个单独的消息,表示信息量与概率为负关系,概率越大信息量越小。\r\n\r\n例如:\r\n\r\n巴西队进入世界杯 (概率大 信息量小)\r\n\r\n中国队不进入世界杯(概率大 信息量小)\r\n\r\n中国队进入世界杯 (概率小 信息量大)\r\n\r\n但是这个信息的熵减不高?【0.1,0.9】->【1,0】\r\n\r\n\r\n\r\n即为信息熵。香农在通信的数学原理中指出,信息是用来消除随机不确定的东西。信息熵用来反应不确定性的大小。\r\n\r\n**Input** :概率分布(可能是离散的概率分布例如vector),**Output**:0-1 float\r\n$$\r\nEntropy,H(x)=-\\sum_{i=1}^np(x_i)log_2p(x_i)\r\n$$\r\n\r\n\r\n不确定性越大,熵越大 不确定性越小,熵越小。\r\n\r\n例如A班对B班,胜率分别为[x, 1-x]\r\n\r\n当x=1/2时,熵最大\r\n\r\n\r\n\r\n##### 交叉熵\r\n\r\n在信息论中,交叉熵用于度量两个概率分布之间的差异性信息。\r\n$$\r\nH(P,Q)=-\\sum_i{P(i)log_aQ(i)}\r\n$$\r\n交叉熵大于熵,当预测的概率分布等于实际的概率分布时,交叉熵等于熵。\r\n\r\n**Input** :两个概率分布(可能是离散的概率分布例如vector),**Output**:>=熵 float 差异\r\n\r\n\r\n\r\n\r\n\r\n##### KL 松散度\r\n\r\n又为相对熵,从定义中很好看出区别,相当于交叉熵减去熵\r\n\r\n**Input** :两个概率分布(可能是离散的概率分布例如vector),**Output**:0- float 表示差异\r\n$$\r\nKL(y,y')=H(y,y')-H(y)=\\sum_i y_ilog\\frac{1}{y_i'}-\\sum_i y_ilog\\frac{1}{y_i}=\\sum_i y_ilog\\frac{y_i}{y_i'}\r\n$$\r\nKL不具有相对性\r\n\r\nKL(y,y')!=KL(y',y)\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.49186602234840393,
"alphanum_fraction": 0.5138756036758423,
"avg_line_length": 14.296875,
"blob_id": "eb3d253c4f7503f87c7f384d9adb1431a3e35589",
"content_id": "67a1afdd5ee722cc23a0ce124c07bdb55a0dc5e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1239,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 64,
"path": "/social_network/Network Embedding Method.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### SDNE: Structural Deep Network Embedding\r\n\r\n\r\n\r\n\r\n\r\nAutoENcoder Framework\r\n\r\n\r\n\r\nloss function:\r\n$$\r\nL=L_{2nd}+\\alpha L_{1st}+vL_{reg}\r\n$$\r\n\r\n$$\r\nL_{2nd}=\\sum_{i=1}^{n}||(\\hat{x_i}-x_i) \\odot b_i||_2^2\r\n$$\r\n\r\n$b_i=\\{b_{i,j}\\}_{j=1}^n$ if $s_{i,j}=0, b_{i,j}=1$, else $b_{i,j}=\\beta>1$\r\n$$\r\nL_{1st}=\\sum_{i,j=1}^n s_{i,j}||y_i^{(K)}-y_j^{(K)}||_2^2\r\n$$\r\n\r\n$$\r\nL_{reg}=\\frac{1}{2}\\sum_{k=1}^K(||W^{(k)}||_F^2+||\\hat{W}^{(k)}||_F^2)\r\n$$\r\n\r\n矩阵的F范数\r\n\r\n$||A||_F=\\sqrt{\\sum_{i=1}^m\\sum_{j=1}^na_{ij}^2}$ \r\n\r\n\r\n\r\n##### DeepWalk\r\n\r\n将网络中的节点模拟为语言模型中的单词,而节点序列模拟为语言中的句子作为skip-gram的输入\r\n\r\n\r\n\r\n\r\n\r\nrandom walk完全随机生成序列,并以此来学习节点的向量表示\r\n\r\n\r\n\r\n\r\n\r\n$\\Phi(v_i)$ is the representation vector of vi\r\n\r\n$W_{v_i}$ 表示$v_i$边上的一次游走,w is window size\r\n\r\n$Pr(u_k|\\Phi(v_j))$ 计算方法如下:\r\n\r\n\r\n\r\n假设文本序列是 the man loves his son.\r\n$$\r\nP(the,man,his,son∣loves)=P(the∣loves)⋅P(man∣loves)⋅P(his∣loves)⋅P(son∣loves)\r\n$$\r\n\r\n$$\r\nP(w_o|w_c)=\\frac{exp(u_o^Tv_c)}{\\sum_{i\\in v}exp(u_i^Tv_c)}\r\n$$\r\n\r\n"
},
{
"alpha_fraction": 0.4695431590080261,
"alphanum_fraction": 0.48368382453918457,
"avg_line_length": 23.757009506225586,
"blob_id": "3dc73358a808c254d9b5abd0ed0bf4dd0d0ad0c3",
"content_id": "ea3859eb446876aeac9a35be07bfb0bd368b1060",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3138,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 107,
"path": "/leetcode_note/Line Sweep.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Line sweep\r\n\r\n扫描线算法\r\n\r\n问题:从互不相同的N个点中找出最近的两个。这个问题可以通过暴力枚举每两个点解决,不过这样复杂度为O(N2)\r\n\r\n现在想象我们已经扫描过1至N-1,令h为我们得到的最短距离。对第N个点,我们想要找到距离小于等于h的点,而对于横坐标,只有横坐标范围在$x_N-h,x$内,纵坐标范围在$x_N−h,x_N+h$内的才是我们需要担心的点。\r\n\r\n```c++\r\n#define px second\r\n#define py first\r\ntypedef pair<long long, long long> pairll;\r\npairll pnts [MAX];\r\nint compare(pairll a, pairll b{ \r\n return a.px<b.px; \r\n}\r\ndouble closest_pair(pairll pnts[],int n){\r\n sort(pnts,pnts+n,compare);\r\n double best=INF;\r\n set<pairll> box;\r\n box.insert(pnts[0]);\r\n int left = 0;\r\n for (int i=1;i<n;++i){\r\n while (left<i && pnts[i].px-pnts[left].px > best)\r\n box.erase(pnts[left++]);\r\n for(typeof(box.begin()) it=box.lower_bound(make_pair(pnts[i].py-best, pnts[i].px-best));it!=box.end() && pnts[i].py+best>=it->py;it++)\r\n best = min(best, sqrt(pow(pnts[i].py - it->py, 2.0)+pow(pnts[i].px - it->px, 2.0)));\r\n box.insert(pnts[i]);\r\n }\r\n return best;\r\n}\r\n```\r\n\r\nO(NlogN)\r\n\r\n\r\n\r\n难在要建立一个高效的数据结构\r\n\r\n\r\n\r\nspecial case\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n如果大楼是进入事件,需要从大到小(高度进行排序)\r\n\r\n如果是离开事件,需要从小到大进行排序\r\n\r\n```c++\r\n// Time Complexity: O(nlogn)\r\n// Space Complexity: O(n)\r\n// Running Time: 22 ms\r\nclass Solution {\r\npublic:\r\n vector<pair<int, int>> getSkyline(vector<vector<int>>& buildings) {\r\n typedef pair<int, int> Event; \r\n // events, x, h\r\n vector<Event> es; \r\n hs_.clear();\r\n \r\n for (const auto& b : buildings) {\r\n es.emplace_back(b[0], b[2]);\r\n es.emplace_back(b[1], -b[2]);\r\n }\r\n \r\n // Sort events by x\r\n sort(es.begin(), es.end(), [](const Event& e1, const Event& e2){\r\n if (e1.first == e2.first) return e1.second > e2.second;\r\n return e1.first < e2.first;\r\n });\r\n \r\n vector<pair<int, int>> ans;\r\n \r\n // Process all the events\r\n for (const auto& e: es) { \r\n int x = e.first;\r\n bool entering = e.second > 0;\r\n int h = abs(e.second);\r\n \r\n if (entering) { \r\n if (h > this->maxHeight()) \r\n ans.emplace_back(x, h);\r\n hs_.insert(h);\r\n } else {\r\n hs_.erase(hs_.equal_range(h).first);\r\n if (h > this->maxHeight())\r\n ans.emplace_back(x, this->maxHeight());\r\n } \r\n }\r\n \r\n return ans;\r\n }\r\nprivate:\r\n int maxHeight() const {\r\n if (hs_.empty()) return 0;\r\n return *hs_.rbegin();\r\n }\r\n multiset<int> hs_;\r\n};\r\n```\r\n\r\n<https://www.youtube.com/watch?v=8Kd-Tn_Rz7s>\r\n\r\n"
},
{
"alpha_fraction": 0.6528462171554565,
"alphanum_fraction": 0.6698139309883118,
"avg_line_length": 14.671233177185059,
"blob_id": "aafd4f75a2777acc1680b9c72b53355697d3b54d",
"content_id": "d90c3c05f9b9b55e11d926f737fbba80153f7cd6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 11074,
"license_type": "no_license",
"max_line_length": 155,
"num_lines": 438,
"path": "/os_instructions/linux/linux_shell.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "指令\r\n```\r\nls -l /var \r\n```\r\n#输出文件var的详细信息\r\nBIOS UEFI:\r\nBIOS 就是在开机的时候,计算机系统会主动执行的第一个程序\r\nUEFI 主要是想要取代BIOS 这个韧体界面,因此我们也称UEFI 为UEFI BIOS 就是了。UEFI 使\r\n用C 程序语言,比起使用汇编语言的传统BIOS 要更容易开发!也因为使用C 语言来撰写,因此\r\n如果开发者够厉害,甚至可以在UEFI 开机阶段就让该系统了解TCP/IP 而直接上网! 根本不需要\r\n进入操作系统耶!这让小型系统的开发充满各式各样的可能性!\r\n\r\n日期指令:\r\n```\r\ndate #显示时间星期几等等\r\ncal #显示本月日历 cal X #显示X年的日历 cal [month] [year]\r\nbc #进入简单计算器\r\n```\r\n如果要输出小数点下位数,那么就必须要执行scale=number ,那个number 就是小数点位数\r\n\r\nctrl+c 中止目前运行的程序 ctrl+d 停止键盘输入\r\ndate --help或者 man date 说明\r\ninfo指令也是类似\r\n 说明文件都在/usr/share/doc 这个目录下\r\n\r\n linux 文本编辑器:\r\n ```\r\n nano text.txt\r\n ```\r\n 常用的关机 重启指令:\r\n shutdown 但是linux下不建议经常使用\r\n reboot等\r\n\r\n vi\r\n ```\r\n vi test.txt\r\n 进入vi一般模式,如果要对txt文件进行修改则需要按i a o等键,进入编辑模式之后会在下方显示INSERT\r\n 在编辑模式中ctrl+c 复制 ctrl+v黏贴都可以用\r\n 按Esc会退回到一般模式\r\n 在一般模式在输入:wq可以exit\r\n vim 环境设定与记录: ~/.vimrc, ~/.viminfo\r\n vim ~/.vimrc\r\n alias 别名 vi=vim\r\n ```\r\n\r\n认识BASH 这个Shell\r\n用env 观察环境变量与常见环境变量说明\r\n变量的取用与设定:echo\r\n```\r\necho $PATH\r\nbash配置文件 ~/.bashrc\r\n修改bashrc\r\nvi ~/.bashrc\r\n```\r\ncat命令是linux下的一个文本输出命令,通常是用于观看某个文件的内容的;\r\ncat主要有三大功能:\r\n```\r\n1.一次显示整个文件/读取 不用加引号。\r\n$ cat filename\r\n2.从键盘创建一个文件。\r\n$ cat > filename\r\n只能创建新文件,不能编辑已有文件.\r\n3.将几个文件合并为一个文件。\r\n$cat file1 file2 > file\r\n宣告变量类型:\r\n(py) shaoping@ubuntu3:~$ sum=50+100+200\r\n(py) shaoping@ubuntu3:~$ echo $sum\r\n50+100+200\r\n(py) shaoping@ubuntu3:~$ declare -i sum=50+100+200\r\n(py) shaoping@ubuntu3:~$ echo $sum\r\n350\r\n```\r\n```\r\ngrep(global search regular expression(RE) and print out the line\r\necho this is a test line | grep -o -E \"[a-z]\"\r\nt\r\nh\r\ni\r\ns\r\ni\r\ns\r\na\r\nt\r\ne\r\ns\r\nt\r\nl\r\ni\r\nn\r\ne\r\n\r\nshaoping@ubuntu3:~$ echo this is a test line | grep -o -E \"[a-z]+\" (这个+号表示按照word的形式来检索)\r\nthis\r\nis\r\na\r\ntest\r\nline\r\n\r\n$ echo this is a test line | grep -o \"[a-z]+\" (少了E没有输出,少了o按照整句话输出)\r\n$ echo this is a test line | grep -E \"[a-z]+\"\r\nthis is a test line\r\n```\r\nnetstat 用来显示所有的网络接口情况\r\n\r\n将文件file复制到目录/usr/men/tmp下,并改名为file1\r\ncp file /usr/men/tmp/file1\r\n- f 删除已经存在的目标文件而不提示\r\n删除文件\r\n$ rm test.txt\r\n\r\ntar\r\ntar命令可以用来压缩打包单文件、多个文件、单个目录、多个目录。\r\n常用格式:\r\n```\r\n单个文件压缩打包 tar czvf my.tar file1\r\n多个文件压缩打包 tar czvf my.tar file1 file2,...\r\n单个目录压缩打包 tar czvf my.tar dir1\r\n多个目录压缩打包 tar czvf my.tar dir1 dir2\r\n解包至当前目录:tar xzvf my.tar\r\n```\r\nlinux编译运行:\r\n```\r\n~/cuda$ vi test.cpp\r\n~/cuda$ g++ test.cpp -o test(将cpp文件编译为可执行文件test)\r\n~/cuda$ ./test(执行文件test)\r\nhello\r\n```\r\n在shell编程中使用echo 输出\r\n使用一个定义过的变量,只要在变量名前面加美元符号即可,如:\r\n```\r\nyour_name=\"qinjx\"\r\necho $your_name\r\necho ${your_name}\r\n```\r\n变量名外面的花括号是可选的,加不加都行,加花括号是为了帮助解释器识别变量的边界\r\n只读变量\r\n使用 readonly 命令可以将变量定义为只读变量,只读变量的值不能被改变。\r\n```\r\n#!/bin/bash\r\nmyUrl=\"http://www.w3cschool.cc\"\r\nreadonly myUrl\r\n```\r\n使用 unset 命令可以删除变量。语法:\r\n```\r\nunset variable_name\r\n```\r\n\r\nshell字符串\r\n单引号与双引号的区别\r\n单引号里的任何字符都会原样输出,单引号字符串中的变量是无效的\r\n双引号里可以有变量\r\n双引号里可以出现转义字符\r\n```\r\npython中单引号与双引号没有区别,只是不能混用\r\n\r\nstr='this is a string'\r\nyour_name='qinjx'\r\nstr=\"Hello, I know you are \\\"$your_name\\\"! \\n\"\r\nshaoping@ubuntu3:~$ echo ${str}\r\nHello, I know you are \"qinjx\"! \\n\r\n```\r\n拼接字符串\r\n```\r\nyour_name=\"qinjx\"\r\ngreeting=\"hello, \"$your_name\" !\"\r\ngreeting_1=\"hello, ${your_name} !\"\r\necho $greeting $greeting_1\r\n```\r\n获取字符串长度\r\n```\r\nstring=\"abcd\"\r\necho ${#string} #输出 4\r\n```\r\n提取子字符串\r\n以下实例从字符串第 2 个字符开始截取 4 个字符:\r\n```\r\nstring=\"runoob is a great site\"\r\necho ${string:1:4} # 输出 unoo\r\n```\r\n查找子字符串\r\n查找字符 \"i 或 s\" 的位置:\r\n```\r\nstring=\"runoob is a great company\"\r\necho `expr index \"$string\" is` # 输出 8\r\n```\r\n\r\nshell数组:\r\n用括号来表示数组,数组元素用\"空格\"符号分割开\r\n```\r\narray_name=(value0 value1 value2 value3)\r\n```\r\n还可以单独定义数组的各个分量:\r\n```\r\narray_name[0]=value0\r\narray_name[1]=value1\r\narray_name[n]=valuen\r\n```\r\n使用@符号可以获取数组中的所有元素,例如:\r\n```\r\necho ${array_name[@]}\r\n```\r\n获取数组的长度\r\n获取数组长度的方法与获取字符串长度的方法相同,例如:\r\n\r\n#### 取得数组元素的个数\r\n\r\n```\r\nlength=${#array_name[@]}\r\n# 或者\r\nlength=${#array_name[*]}\r\n# 取得数组单个元素的长度\r\nlengthn=${#array_name[n]}\r\n```\r\nexpr表达式:可以实现数值运算、数值或字符串比较、字符串匹配、字符串提取、字符串长度计算等功能。\r\nval=`expr 2 + 2`\r\necho \"两数之和为 : $val\"\r\n\r\nshell编程与正则表达式\r\n\r\nawk sed与grep命令类似\r\nawk优秀的文本处理命令,主要用于模板patter匹配\r\nsed (stream editer)与awk功能类似 sed功能更加简单一些\r\n\r\nsed\r\n```\r\nsed -n '6p' test.txt #读取test.txt文件中的第6行并打印\r\n\r\nsed '2d' test.txt #删除test.txt文件中的第二行\r\n```\r\nsed替换(替换文件中所有的匹配项)\r\nsed处理过的输出时直接输出到屏幕上的,使用参数-i直接在文件中替换\r\n```\r\nsed -i 's/原字符串/替换字符串/g' filename\r\n```\r\n\r\n\r\nfor循环与while循环:\r\n```\r\nfor ((i=1;i<=10;i++));\r\n> do\r\n> echo ${i}\r\n> done\r\n\r\nfor i in $(seq 1 10);\r\n> do\r\n> echo $i\r\n> done\r\n```\r\n```\r\nsum=0\r\ni=2\r\nwhile(($i<=100))\r\n> do\r\n> sum=$(($sum+$i))\r\n> i=$(($i+2))\r\n> done\r\n注意这边的两个括号\r\n```\r\n\r\n[]可以用来执行算术运算:\r\n```\r\na=5 b=6\r\nresult=$[a+b]\r\n11\r\n```\r\nShell中的 test 命令用于检查某个条件是否成立,它可以进行数值、字符和文件三个方面的测试。\r\n\r\n数值测试\r\n参数\t说明\r\n-eq\t等于则为真\r\n-ne\t不等于则为真\r\n-gt\t大于则为真\r\n-ge\t大于等于则为真\r\n-lt\t小于则为真\r\n-le\t小于等于则为真\r\n实例演示:\r\n```\r\nnum1=100\r\nnum2=100\r\nif test $[num1] -eq $[num2]\r\nthen\r\n echo '两个数相等!'\r\nelse\r\n echo '两个数不相等!'\r\nfi\r\n```\r\n screen:这样可以退出cmder之后程序继续运行\r\n```\r\n screen -ls#显示所有的screen\r\n screen -S thyroid#创建以thyroid为名的screen\r\n screen -r thyroid#进入到以thyroid为名的screen\r\n screen -d#退出当前screen\r\n ctrl+a+d 回到前一级\r\n exit#删除该screen\r\n```\r\n\r\n```\r\ntop\r\nhtop\r\n查看服务器中进程情况\r\n\r\nkill 12345\r\n```\r\npip install requirments.txt\r\n```\r\n安装依赖: pip install -r requirements.txt\r\n```\r\npip install 加速\r\n```\r\npip install web.py -i http://pypi.douban.com/simple\r\n如果报错则使用\r\npip install web.py -i http://pypi.douban.com/simple --trusted-host pypi.douban.com\r\n```\r\n需要创建或修改配置文件(一般都是创建)\r\nlinux的文件在~/.pip/pip.conf\r\nwindows在%HOMEPATH%\\pip\\pip.ini)\r\n```\r\n[global]\r\nindex-url = http://pypi.douban.com/simple\r\n[install]\r\ntrusted-host=pypi.douban.com\r\n```\r\nsudo apt install 加速\r\n```\r\nhttps://mirrors.zju.edu.cn/\r\n```\r\n将/etc/apt/sources.list替换\r\n\r\n#### 挂载\r\n```\r\n挂载的意义是操作系统设备管理系统对块设备(U盘 硬盘等)的识别\r\n主要会识别块设备的文件系统的格式,例如FAT32,以及块设备的分区等\r\n```\r\n#### linux各主要目录的作用\r\n```\r\n/bin 启动系统时需要的二进制程序等\r\n/home 用户主目录\r\n/dev 这是一个包含设备节点的特殊目录,不能通过dev目录直接对设备进行访问\r\n/etc 该目录包含了所有的系统配置文件,常见的有:\r\n /etc/crontab 定义自动运行的任务\r\n /etc/fstab 包含存储设备的列表\r\n /etc/passwd 包含用户的账号列表\r\n /etc/shadow 包含了用户的密码(加密)\r\n /etc/resolv.conf 包含了解析器的域名\r\n /etc/apt/source.list 包含了apt命令的源\r\n/lib 包含了程序系统的库文件\r\n/media USB挂载点\r\n/mnt 包含挂载点,在windows系统的ubuntu子系统中cde盘就挂载在这里,因为linux系统的文件系统是ext,但是windows的文件系统是FAT所以只能以挂载的形式\r\n/opt 该目录用来安装可选的软件\r\n/root root账户主目录\r\n/tmp 每次重启都会重置\r\n/usr 普通用户的目录 unix software resource\r\n/usr/bin 包含系统安装的可执行程序 常见命令cd ls python llvm等\r\n/home 下 .bashrc文件表示在进入bash之前会执行的程序\r\n```\r\n\r\n\r\n\r\n##### 利用X Ming &&putty实现在远程服务器上显示图片\r\n\r\nhttps://uisapp2.iu.edu/confluence-prd/pages/viewpage.action?pageId=280461906\r\n\r\n```\r\n1.Install the Xming software.\r\n2.download putty.exe from the PuTTY site and install it.\r\n3.Run Xming on your PC to start the X server.\r\n4.Run PuTTY and set things up as follows:\r\n\t- Enter the server name in Host Name\r\n\t- Make sure the Connection type is set to SSH\r\n\t- Enable X11 forwarding (Connection > SSH > X11)\r\n5.Log in using your normal IU username and passphrase\r\n6.Once you are logged into the linux system, you can just run the GUI program of your choice (ie. matlab, mathematics, etc) and it will display on your PC.\r\n```\r\n\r\n查看内存memory等\r\n\r\n```\r\nfree -m\r\n```\r\n\r\n显示目录下文件大小\r\n\r\n```\r\ndu -h\r\n```\r\n\r\n-a显示目录和目录下子文件占磁盘的大小\r\n\r\n-s仅仅显示目录的大小\r\n\r\n\r\n\r\n```\r\nCUDA_VISIBLE_DEVICES=1\r\n```\r\n\r\n只有编号为1的GPU对程序是可见的,\r\n\r\nCUDA_VISIBLE_DEVICES=1 python test.py\r\n\r\n\r\n\r\n\r\n\r\n查看版本\r\n\r\ntensorflow\r\n\r\n```\r\npython\r\nimport tensorflow as tf\r\ntf.__version__\r\n```\r\n\r\npytorch\r\n\r\n```\r\nimport torch\r\nprint(torch.__version__)\r\n```\r\n\r\nCUDA\r\n\r\n```\r\nnvcc -V\r\n```\r\n\r\n\r\n\r\n#### 一起学Shell\r\n\r\n合并文件夹下所有的文件\r\n\r\n```shell\r\nfind . -type f -exec cat {} \\;>all_files.txt\r\n```\r\n\r\n找到所有的普通文件,然后执行cat命令 都输出到all_files.txt文件\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5770348906517029,
"alphanum_fraction": 0.5893895626068115,
"avg_line_length": 9.743589401245117,
"blob_id": "ebb5a543be4500cc274f4e8da5d1f5305639833e",
"content_id": "1072c6c88736aeda17855adca9bd5abb79516bd3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1698,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 117,
"path": "/javascript/javascript.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Javascript\r\n\r\n菜鸟教程\r\n\r\njavascript是一种网络脚本语言。\r\n\r\n#### 基础Javascript实例\r\n\r\n##### 用javascript输出文本\r\n\r\n```javascript\r\n<h1>我的第一个 Web 页面78</h1>\r\n<p>我的第一个段落。</p>\r\n<script>\r\ndocument.write(Date());\r\n</script>\r\n```\r\n\r\nh1到h6表示标题的大小,h1最大,h6最小\r\n\r\np表示段落\r\n\r\nscript表示脚本语句\r\n\r\n```javascript\r\n<script>\r\ndocument.write(\"<h1>这是一个标题</h1>\");\r\ndocument.write(\"<p>这是一个段落。</p>\");\r\n</script>\r\n```\r\n\r\n\r\n\r\n##### button\r\n\r\n```javascript\r\n<script>\r\nfunction myFunction(){\r\n\tdocument.getElementById(\"demo\").innerHTML=\"我的第一个 JavaScript 函数\";\r\n}\r\n</script>\r\n\r\n<h1>我的 Web 页面</h1>\r\n<p id=\"demo\">一个段落。</p>\r\n<button type=\"button\" onclick=\"myFunction()\">点击这里</button>\r\n```\r\n\r\n\r\n\r\n\r\n\r\n点一下显示\r\n\r\n\r\n\r\n#### javascript输出\r\n\r\nwindow.alert()\r\n\r\n通过弹出警告框来显示数据\r\n\r\n```javascript\r\n<script>\r\nwindow.alert(5 + 6);\r\n</script>\r\n```\r\n\r\ndocument.write();\r\n\r\n```javascript\r\n<script>\r\ndocument.write(Date());\r\n</script>\r\n```\r\n\r\ninnerHTML 来获取或插入元素内容\r\n\r\n```javascript\r\n<p id=\"demo\">我的第一个段落。</p>\r\n<script>\r\ndocument.getElementById(\"demo\").innerHTML=\"段落已修改。\";\r\n</script>\r\n```\r\n\r\n console.log()在控制台输出\r\n\r\n```javascript\r\n<script>\r\na = 5;\r\nb = 6;\r\nc = a + b;\r\nconsole.log(c);\r\n</script>\r\n```\r\n\r\n\r\n\r\n注释\r\n\r\n单行注释://\r\n\r\n多行注释: /* */\r\n\r\n\r\n\r\n##### 定义变量\r\n\r\n```javascript\r\n<script>\r\nvar firstname;\r\nfirstname=\"Hege\";\r\ndocument.write(firstname);\r\ndocument.write(\"<br>\"); //换行\r\nfirstname=\"Tove\";\r\ndocument.write(firstname);\r\n</script>\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.5398482084274292,
"alphanum_fraction": 0.5640417337417603,
"avg_line_length": 8.057415962219238,
"blob_id": "1ef54471110e6cf1b1953514b8f3dd6b04e4b761",
"content_id": "231aff73e331cc1d5548bccdf5df1d7cd265a014",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3380,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 209,
"path": "/interview/newcoder.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### python\r\n\r\n1. 闭包\r\n\r\n ```python\r\n def adder(x):\r\n def wrapper(y):\r\n return x+y\r\n return wrapper\r\n adder5 = adder(5)\r\n print(adder5(adder5(6)))\r\n ```\r\n\r\n运行结束的值是多少 16\r\n\r\nadder5相当于x=5的wrapper\r\n\r\n\r\n\r\n2.小整数对象池\r\n\r\n```python\r\na = [1,2,3]\r\nb = [1,2,4]\r\nid(a[1]) == id(b[1]) True\r\n```\r\n\r\n范围在[-5, 257)之间的数,python不会新建对象,直接从小整数对象池中取\r\n\r\n\r\n\r\n3.\r\n\r\nprint_func.py\r\n\r\n```python\r\nprint('Hello world!')\r\nprint('__name__:', __name__)\r\ndef main():\r\n print(\"this is message from main function\")\r\n\r\nif __name__ == '__main__':\r\n main()\r\n```\r\n\r\nprint_module.py\r\n\r\n```python\r\nimport print_func\r\nprint('Done')\r\n```\r\n\r\n输出结果为\r\n\r\n```\r\nHello world!\r\n__name__: print_func\r\nDone\r\n```\r\n\r\nimport module的时候会执行module中的代码\r\n\r\n对于\r\n\r\n```python\r\nif __name__ == '__main__':\r\n```\r\n\r\n如果该文件是主执行文件则$\\_\\_name\\_\\_$ =$\\_\\_main\\_\\_$ \r\n\r\n如果不是主执行文件,则其值为module名\r\n\r\n\r\n\r\n4.\r\n\r\n```python\r\na = 'a'\r\nprint(a > 'b' or 'c') 'c'\r\n```\r\n\r\nx or y\r\n\r\n若x为true则返回x的值,x为false则返回y值\r\n\r\n\r\n\r\n\r\n\r\n##### c++\r\n\r\n1. 私有继承 derived类从student类\r\n\r\n ```\r\n class derived:: private student{};\r\n ```\r\n\r\n 基类中的共有成员的保护成员变为私有\r\n\r\n\r\n\r\n2. ```c++\r\n Class A *pclassa = new ClassA[5];\r\n delete pclassa;\r\n ```\r\n\r\n classA的构造函数被调用5次 析构函数被调用1次\r\n\r\n\r\n\r\n3.合法调用\r\n\r\n```\r\nviud f4(int **p);\r\nint a[4] = {1,2,3,4};\r\nint *q[3] = {b[0],b[1],b[2]};\r\n```\r\n\r\nf4(a) 不合法 相当于&a[0]数组首元素的地址\r\n\r\nf4(q) 成立\r\n\r\nf4(&a) 转化为&a[0]\r\n\r\n\r\n\r\n\r\n\r\n##### 操作系统\r\n\r\n程序有三种链接方式:\r\n\r\n静态链接:在程序运行前链接成一个可执行程序\r\n\r\n装入时动态链接:在装入内存时链接\r\n\r\n运行时链接:在运行时链接\r\n\r\n\r\n\r\n数据传送方式:\r\n\r\n程序控制:CPU和硬件同步,浪费CPU资源多\r\n\r\n程序中断:CPU硬件异步同坐\r\n\r\nDMA:直接内存读取 不依赖 CPU仅和硬件相关\r\n\r\n\r\n\r\n文件结构不同,可以被顺序访问或者随机访问(数组)\r\n\r\n每一个文件对应一个文件控制块FCB (进程, PCB)\r\n\r\n\r\n\r\n一级目录结构:这是一层的目录 所有文件不能同名\r\n\r\n二级目录结构:主目录,用户目录\r\n\r\n多级目录结构\r\n\r\n\r\n\r\n\r\n\r\n##### 计算机网络\r\n\r\nMAC放在每台计算机的网卡上\r\n\r\nDNS:域名解析\r\n\r\nFTP:文件传输\r\n\r\nWWW:信息查询\r\n\r\nADSL:非对称数字用户线路 数据传输\r\n\r\nRIP:距离向量内部网关协议\r\n\r\nOSPF:链路状态内部网关协议\r\n\r\n\r\n\r\n运输层:不同主机进程到进程的通信 端到端\r\n\r\n网络层:不同主机通信 点到点\r\n\r\n\r\n\r\n以集线器组件的以太网上某个主机发送一个帧到此网络上的另一主机,则:\r\n\r\n该网络上的所有主机都会收到\r\n\r\n集线器仅有放大功能,没有寻址功能,交换机有寻址功能\r\n\r\n\r\n\r\n三次握手建立连接的时候:\r\n\r\n甲方发送SYN=1,SEQ=X\r\n\r\n乙方发送SYN=1 表示收到 SEQ=Y乙方初始报文序号 ACK=X+1表示下次希望收到的\r\n\r\n\r\n\r\n正交调幅:\r\n\r\n两个频率相等 香味相差90的正交载波进行调幅,然后再矢量相加,得到的信号称为正交调幅信号,振幅和相位会发生改变\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.6089559197425842,
"alphanum_fraction": 0.6391283273696899,
"avg_line_length": 23.740739822387695,
"blob_id": "031832c0e9e100aa93c5cd08c0262e78ebf08e94",
"content_id": "28b045ea0f9974d837e59d033b6d4d248bd35e16",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5036,
"license_type": "no_license",
"max_line_length": 181,
"num_lines": 162,
"path": "/System Design.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### System Design\r\n\r\n**Problem:** Design a service like TinyURL, a URL shortening service, a web service that provides short aliases for redirection of long URLs.\r\n\r\n<https://leetcode.com/discuss/interview-question/system-design/124658/Design-URL-Shortening-service-like-TinyURL>\r\n\r\n```python\r\nclass Solution():\r\n def __init__(self):\r\n self.map = \"abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789\"\r\n\r\n def url2id(self, string):\r\n num = 0\r\n for i in range(len(string)):\r\n if string[i] >= 'a' and string[i] <= 'z':\r\n num = num * 62 + ord(string[i]) - ord('a')\r\n elif string[i] >= 'A' and string[i] <= 'Z':\r\n num = num * 62 + ord(string[i]) - ord('A') + 26\r\n elif string[i] >= '0' and string[i] <= '9':\r\n num = num * 62 + ord(string[i]) - ord('0') + 52\r\n return num\r\n\r\n def id2url(self, num, list):\r\n string = \"\"\r\n while num:\r\n string += self.map[num % 62]\r\n num = int((num - (num % 62)) / 62)\r\n print(list)\r\n return string[::-1]\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### First non repeating word in a file? File size can be 100GB.\r\n\r\nGiven a text file of size say 100GB? Task is to find first non repeating word in this file?\r\nconstraints: You can traverse the file only once.\r\n\r\n###### Mapreduce\r\n\r\n本题的问题主要在于100G 可能不能由一个server存下,因此需要使用多个server\r\n\r\n1.map:将100G文件平均分成100份,输送到100个server,每个server会用一个hashmap来统计不同单词的个数,key is word, value is count\r\n\r\n2.reduce:将每个server上只出现一次的单词发给一个server进行统计(hashmap)\r\n\r\n如果一个server太小的话就先用26个server 分别存A-Z的出现过一次的单词,先用这26个server reduce一遍,然后再发给一个server\r\n\r\n\r\n\r\n##### Amazon's \"Customers who bought this item also bought\" recommendation system\r\n\r\n功能:\r\n\r\n1.在顾客浏览商品时显示recommendation\r\n\r\n2.数量:最多5个\r\n\r\n3.系统规模:开始时数量小,后期可以异步增加\r\n\r\n\r\n\r\n数据结构:\r\n\r\nhashtable:\r\n\r\n(itema, itemb), value\r\n\r\n注意itema和itemb两个的购买时间应该在一年之内。\r\n\r\n存储时,要求item_A_id < item_B_id\r\n\r\n\r\n\r\n工作流程:\r\n\r\n1.当顾客购买了itemA的时候,从hashmap中抽取pair itema==itemA or itemb==itemA,根据count排序找出前5个\r\n\r\n2.对这位顾客一年内的购买记录(B,C,D,E) 增加这些pair 1 (A,B),(A,C),...\r\n\r\n\r\n\r\n优化:\r\n\r\n1.对于最常用被购买的商品的各项记录存在cache中\r\n\r\n2.将所有的商品在推荐时按照商品类别进行分类\r\n\r\n\r\n\r\n##### Uber | Rate Limiter\r\n\r\nWhenever you expose a web service / api endpoint, you need to implement a rate limiter to prevent abuse of the service (DOS attacks).\r\n\r\nImplement a RateLimiter Class with an isAllow method. Every request comes in with a unique clientID, deny a request if that client has made more than 100 requests in the past second\r\n\r\n\r\n\r\n使用一个hashtable\r\n\r\n每个id对应一个list list中保存的是访问的时间,如果list已经有100个了就比较当前时刻与list中最后一个节点的时间差,从而判断是否为DOS\r\n\r\n\r\n\r\n```python\r\nimport time\r\nfrom time import sleep\r\n\r\nclass PreciseRateLimiter(object):\r\n def __init__(self, max_requests, time_interval_ms):\r\n self._max_requests = max_requests\r\n self._time_interval_ms = time_interval_ms\r\n self._clientIDs = {}\r\n \r\n def is_allowed(self, clientID):\r\n current_ms_time = int(round(time.time() * 1000))\r\n if clientID in self._clientIDs:\r\n if len(self._clientIDs[clientID]) >= self._max_requests:\r\n time_diff = current_ms_time - self._clientIDs[clientID][-1]\r\n self._clientIDs[clientID].pop()\r\n self._clientIDs[clientID].append(current_ms_time)\r\n if time_diff < self._time_interval_ms:\r\n return False\r\n else:\r\n self._clientIDs[clientID].append(current_ms_time)\r\n else:\r\n self._clientIDs[clientID] = list()\r\n self._clientIDs[clientID].append(current_ms_time)\r\n return True\r\n \r\nmyLimiter = PreciseRateLimiter(100, 1000)\r\nmax_counter = 101\r\ncounter = 1\r\nwhile counter <= max_counter:\r\n sleep(0.01)\r\n print 'counter: {} result: {}'.format(counter, myLimiter.is_allowed(1))\r\n counter += 1\r\n```\r\n\r\n\r\n\r\n#### Design a crawler\r\n\r\n流程:\r\n\r\n1.初始一些较有名的大网站\r\n\r\n2.避免进入死循环\r\n\r\n\r\n\r\n在nosql中维护两个数据结构:links_to_crawl, crawled_links\r\n\r\n从links_to_crawl中选取最优先级的link去爬,如果crawled_links中存在相似的则减低其优先级\r\n\r\n如果不存在则抓取该链接,将新的links加入到links_to_crawl\r\n\r\n在links_to_crawl中删除这个链接\r\n\r\n在crawled_links中加入该链接\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5366336703300476,
"alphanum_fraction": 0.5584158301353455,
"avg_line_length": 6.3114752769470215,
"blob_id": "ca607aa7cc5014a57289661ae1b7ad512d316ea5",
"content_id": "89310d6e6239a7934278bfb68238f0419d19ca66",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 891,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 61,
"path": "/leetcode_note/Time Complexity.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "常见数据结构:\r\n\r\nBinary Tree\r\n\r\n平均查找时间为O(N)\r\n\r\nBinary Search Tree\r\n\r\n平均查找时间为$O(log_2N)$,最坏的情况是O(N) (所有的子树都在一边)\r\n\r\nHash Table\r\n\r\n平均查找O(1)\r\n\r\nAVL\r\n\r\n平衡二叉树 平均查找时间为$O(log_2N)$ 任何节点左右子树高度差小于等于1\r\n\r\nlinked list\r\n\r\n平均查找O(N)\r\n\r\nArray\r\n\r\n平均查找O(N)\r\n\r\n\r\n\r\n\r\n\r\n排序:\r\n\r\n插入排序:\r\n\r\n直接插入排序 $O(n^2)$\r\n\r\n希尔排序(缩小增量排序) 一般情况下 $O(n^{1.3})$ 最坏是$O(n^2)$\r\n\r\n\r\n\r\n交换排序:\r\n\r\n冒泡排序 平均时间$O(n^2)$\r\n\r\n快速排序 平均时间$O(nlogn)$ ,最坏$O^2$\r\n\r\n\r\n\r\n选择排序:\r\n\r\n简单选择排序:从L[i...n]选择最小值与L[i]交换 $O( n^2)$\r\n\r\n堆排序:建队时间$O(n)$,排序时间 平均和最坏$O(nlogn)$\r\n\r\n\r\n\r\n归并排序\r\n\r\n\r\n\r\n基数排序"
},
{
"alpha_fraction": 0.5847293734550476,
"alphanum_fraction": 0.6378865838050842,
"avg_line_length": 17.658227920532227,
"blob_id": "d1878fb3140a77b947b7ac014d5e3ec497808099",
"content_id": "6f52f22f8a0ad185fb99a0a37c4b471802deb9b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4324,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 158,
"path": "/books/python核心编程.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### python核心编程\r\n\r\n##### 多线程编程\r\n\r\n同步(Synchronous)异步(Asynchronous)\r\n\r\n在计算机网络中同步传输与异步传输的区别在于同步传输中发送方和接收方的时钟是统一的,而异步传输中接收方和发送方的时钟不统一。\r\n\r\n##### 进程与线程\r\n\r\n程序是储存在磁盘上的可执行二进制文件,只有把它们加载到内存中被操作系统调用,采用生命期。进程,有时被称为重量级进程是一个执行中的程序。每个进程都拥有自己的地址空间、内存、数据栈等。\r\n\r\n线程被称为轻量级进程。一个进程中的各个线程与主线程共享同一片数据空间。\r\n\r\n\r\n\r\n##### 全局解释器锁\r\n\r\npython的代码是由python虚拟机执行的,python对虚拟机的访问是由全局解释器锁来控制的。\r\n\r\npython解释器中可以运行多个线程,但是任意给定时刻只有一个线程会被解释器执行。\r\n\r\n```python\r\nimport thread\r\nfrom time import sleep, ctime\r\n\r\ndef loop0():\r\n print('start loop 0 at:',ctime())\r\n sleep(4)\r\n print('loop 0 done at:',ctime())\r\n\r\n\r\ndef loop1():\r\n print('start loop 1 at:',ctime())\r\n sleep(2)\r\n print('loop 1 done at:',ctime())\r\n\r\ndef main():\r\n print(\"starting at:\",ctime())\r\n thread.start_new_thread(loop0,())\r\n thread.start_new_thread(loop1,())\r\n sleep(6)\r\n print(\"all done at:\",ctime())\r\n\r\nif __name__=='__main__':\r\n main()\r\n('starting at:', 'Sat Jun 1 15:21:13 2019')\r\n('start loop 0 at:', 'Sat Jun 1 15:21:13 2019')\r\n ('start loop 1 at:', 'Sat Jun 1 15:21:13 2019')\r\n('loop 1 done at:', 'Sat Jun 1 15:21:15 2019')\r\n('loop 0 done at:', 'Sat Jun 1 15:21:17 2019')\r\n('all done at:', 'Sat Jun 1 15:21:19 2019')\r\n```\r\n\r\n使用start_new_thread函数之后可见loop0和loop1是分别执行的\r\n\r\n为何要在main中增加一个sleep6呢,因为如果不阻止主进线程的执行,它会显示all done然后退出,loop线程就直接终止。\r\n\r\n\r\n\r\n如果我们不知道线程要执行多久呢?使用锁结构\r\n\r\n```python\r\nimport thread\r\nfrom time import sleep, ctime\r\n\r\nloops=[4,2]\r\n\r\ndef loop(nloop, nsec, lock):\r\n print('start loop',nloop, 'at:',ctime())\r\n sleep(nsec)\r\n print('loop' ,nloop,'done at:',ctime())\r\n lock.release()\r\n\r\ndef main():\r\n print(\"starting at:\",ctime())\r\n locks=[]\r\n nloops=range(len(loops))\r\n\r\n for i in nloops:\r\n lock=thread.allocate_lock()\r\n lock.acquire()\r\n locks.append(lock)\r\n\r\n for i in nloops:\r\n thread.start_new_thread(loop,(i,loops[i],locks[i]))\r\n\r\n for i in nloops:\r\n while locks[i].locked(): pass\r\n\r\n print(\"all done at:\",ctime())\r\n\r\nif __name__=='__main__':\r\n main()\r\n \r\n('starting at:', 'Sat Jun 1 15:41:41 2019')\r\n('start loop', 0, 'at:'('start loop', 1, 'at:', 'Sat Jun 1 15:41:41 2019'), 'Sat Jun 1 15:41:41 2019')\r\n('loop', 1, 'done at:', 'Sat Jun 1 15:41:43 2019')\r\n('loop', 0, 'done at:', 'Sat Jun 1 15:41:45 2019')\r\n('all done at:', 'Sat Jun 1 15:41:45 2019')\r\n```\r\n\r\n使用allocate_lock()函数得到锁结构,然后使用acquire相当于将锁锁上。当每个线程执行完之后,它会释放自己的锁对象。最后一个for循环相当于检查所有的锁是否都被释放了。\r\n\r\n\r\n\r\n##### python如何实现并行\r\n\r\npython提供thread,threading等模块支持创建多个线程\r\n\r\n还提供了基本的同步数据结构:锁\r\n\r\n同步同样可以通过信号量实现\r\n\r\n \r\n\r\n\r\n\r\n##### 数据库\r\n\r\n<https://www.runoob.com/python3/python3-mysql.html>\r\n\r\n```python\r\nimport pymysql\r\ndb = pymysql.connect(\"localhost\",\"root\",\"123456\",\"TESTDB\" )\r\n```\r\n\r\nconnect 四个参数分别是host user password table\r\n\r\n可以通过\r\n\r\n```mysqql\r\nmysql> SHOW DATABASES;\r\n\r\nmysql> use mysql;\r\n\r\nmysql> select host,user from mysql.user;\r\n```\r\n\r\n查看user\r\n\r\n\r\n\r\npython3中使用pymysql库来操控Mysql\r\n\r\npython使用connect通过Connect对象访问数据库。\r\n\r\n连接建立之后,就可以和数据库进行通信了,Cursor对象即游标对象可以让用户提交数据库命令,并获得查询的结果行。游标对象最重要的属性是execute()函数与fetch()。\r\n\r\n\r\n\r\n##### 关系型数据库与非关系型数据库\r\n\r\npython几乎支持所有的数据库\r\n\r\n关系型数据库:Mysql,SQL\r\n\r\n非关系型数据库:MongoDB, BigTable"
},
{
"alpha_fraction": 0.7545816898345947,
"alphanum_fraction": 0.7689242959022522,
"avg_line_length": 14.311688423156738,
"blob_id": "41fefac6c6a87d5ee6653e538cd0b5b57f1a9e5d",
"content_id": "6ea79ba77e9eff0c480b5915e00807bef81af902",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3341,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 77,
"path": "/books/others/枪炮、病菌与钢铁.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 枪炮、病菌与钢铁\r\n\r\n耶利的问题:为什么白人制造了那么多的货物并把它运到了新几内亚来,而我们黑人却几乎没有属于我们自己的货物呢?\r\n\r\n气候的作用:高纬度严寒的多变齐猴比恒定的热带齐猴提出了更多的挑战。\r\n\r\n不同民族的历史遵循不同的道路前进,其原因是民族环境的差异,而不是民族自身在生物学上的差异。\r\n\r\n\r\n\r\n莫里奥里人与毛利人都是源于1000年前的波利尼西亚人。莫里奥里人去了查塔姆群岛,天气更加寒冷,只能重新回到狩猎工作中,不能产出多余的农作物用于重新分配与储藏作用,不能养活专门的手艺人、军队、首领,因而他们只能学会和平相处,宣布放弃战争。而毛利人则相反,他们在局部地区形成了密集的人口,从事残酷的战争。\r\n\r\n\r\n\r\n卡哈马卡的冲突:168人的西班牙小队击败了8万人的印加军队,俘虏了国王阿塔瓦尔帕。\r\n\r\n阿塔瓦尔帕对西班牙人的行为、以及目的毫无所知\r\n\r\n\r\n\r\n皮萨罗俘虏阿塔瓦尔帕这件事的直接原因包括了以枪炮、钢铁武器和马匹为基础的军事技术,欧亚大陆的传染性流行病、欧洲的航海技术,统一集中的行政组织和文字。\r\n\r\n\r\n\r\n终极问题是:为什么是欧洲白人殖民了全世界登陆了美洲杀光了印第安土著,而不是印第安人登陆欧洲殖民欧洲?\r\n\r\n人类发展的差异并不是因为人基因的不同,而是由于地利!\r\n\r\n作者的推导过程:\r\n\r\n为什么是欧洲人侵略了美洲并取得了成功?\r\n\r\n直接原因是\r\n\r\n1.技术(枪炮 钢刀,远洋船只)\r\n\r\n2.马(骑兵作战的巨大优势)\r\n\r\n3.病菌(流行性传染病杀死了大量的土著)\r\n\r\n4.文字(沟通便利,技术传播,技术积累)\r\n\r\n5.集中统一的政府\r\n\r\n\r\n\r\n因为:\r\n\r\n1.技术:\r\n\r\n\t巨大而稠密的人口(粮食积累,供养多余人员进行技术开发),定居的方式等等\r\n\r\n2. 马和病菌\r\n\r\n 欧亚大陆广袤的面积拥有众多的齐猴和物种\r\n\r\n3.政府和文字:\r\n\r\n\t这一点和1相同\r\n\r\n\r\n\r\n这些原因的根本原因是因为地利。这片土地上气候合适粮食耕作吗? 这片土地有适合发展成作物的植物吗? 这片土地有适合发展成牲畜的动物吗? 这片土地能到达其他地方吗?其他地方的人能到达我们这来吗?\r\n\r\n\r\n\r\n为什么亚欧大陆得天独厚,但是中国在欧洲殖民全世界的时候中国落后了?\r\n\r\n因为中国经常是统一的而欧洲始终是分裂的。\r\n\r\n中央集权的君主由于党政、喜好等等因素,轻而易举就会下令停止某项技术,造成不可逆转的技术倒退(郑和航海、钟表、纺纱机等等)。 而在分裂的欧洲,如果某一国的君主拒绝了某项新技术,那在该领域该国会被周围采用/发展该技术的国家超越,从而迫使该国不得不接受这项技术。\r\n\r\n\r\n\r\n为什么中国式统一的?**地理**\r\n\r\n中国:海岸线平直,几乎无大半岛(朝鲜),无近邻大岛(台湾海南太小,日本太远) 欧洲:海岸线曲折,五大半岛(希腊、意大利、伊比利亚、丹麦、挪威瑞典),两个近邻大岛(大不列颠、爱尔兰) "
},
{
"alpha_fraction": 0.6969696879386902,
"alphanum_fraction": 0.7037037014961243,
"avg_line_length": 11.155555725097656,
"blob_id": "b7c920624e1c1f7745def8151efe9b5d1f38bc7b",
"content_id": "c7d22e14dcc76801a597b9eec08caad72471ede1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 607,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 45,
"path": "/papers/Graph 综述.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "Graph非常常见\r\n\r\n1. social networks\r\n2. proteins\r\n3. chemical compounds\r\n4. program file graph\r\n\r\n\r\n\r\nHow to analysis graph\r\n\r\nNode-level representaion learning:\r\nshallow structure: Deepwalk LIne\r\n\r\nDeep: SDNE GCN Graphsage\r\n\r\nGraph-level:\r\n\r\nGCN Graphsage GIN\r\n\r\n\r\n\r\nConsider graph-level similarity search\r\n\r\ngraph query in graph database -> descending similarity graph\r\n\r\nTwo types of graph-level opeartors:\r\n\r\nGraph similarity opeartor\r\n$$\r\nG×G -> R\r\n$$\r\nGraph embedding \r\n$$\r\nG->R^d\r\n$$\r\ndeeplearning + embedding更快\r\n\r\n\r\n\r\nGraph Edit Distance:(np HARD)\r\n\r\n\r\n\r\nfeature engineering: graphlets\r\n\r\n"
},
{
"alpha_fraction": 0.6559515595436096,
"alphanum_fraction": 0.6836711168289185,
"avg_line_length": 17.504545211791992,
"blob_id": "61f17bd99198ab4b26916d5a2188d5e5c3575100",
"content_id": "7e36df8c857eca59e0e6b5806fd3c87f130b9aa2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4931,
"license_type": "no_license",
"max_line_length": 192,
"num_lines": 220,
"path": "/docker.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Docker\r\n\r\n## WSL中安装Docker\r\n\r\n启动WSL控制台,执行以下指令\r\n\r\n```bash\r\nsudo apt update\r\nsudo apt install docker.io\r\nsudo usermod -aG docker $USER\r\n```\r\n\r\n随后再以管理员启动WSL控制台,执行\r\n\r\n```bash\r\nsudo cgroupfs-mount\r\nsudo service docker start\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### Docker Document\r\n\r\nOrientations\r\n\r\nDocker is a platform for developers and sysadmins to **develop, deploy, and run** applications with containers. \r\n\r\nA container is launched by running an image. An image is an executable package that includes everything needed to run an application.\r\n\r\nA **container** is a runtime instance of an image--what the image becomes in memory when executed.\r\n\r\n#### Container and virtual machine\r\n\r\nA container runs natively on Linux. It runs a discrete process, taking no more memory than any other executable, lightweight virtual machine.\r\n\r\nA virtual machine runs a full-blown guest operating system with virtual access host resources through a hypervisor. VMs provide an environment with more resources than most applications need.\r\n\r\n\r\n\r\n\r\n\r\n##### Test docker version\r\n\r\n```shell\r\ndocker --version\r\n```\r\n\r\nDocker version 18.09.5, build e8ff056\r\n\r\n##### Test Docker installation\r\n\r\n```\r\ndocker run hello-world\r\n\r\nUnable to find image 'hello-world:latest' locally\r\nlatest: Pulling from library/hello-world\r\nca4f61b1923c: Pull complete\r\nDigest: sha256:ca0eeb6fb05351dfc8759c20733c91def84cb8007aa89a5bf606bc8b315b9fc7\r\nStatus: Downloaded newer image for hello-world:latest\r\n\r\nHello from Docker!\r\nThis message shows that your installation appears to be working correctly.\r\n...\r\n```\r\n\r\nlist image\r\n\r\n```\r\ndocker image ls\r\n```\r\n\r\n\r\n\r\n##### Containers\r\n\r\nWith Docker, you can grab a portable python runtime as an image, no installation necessary.\r\n\r\nThese portable images are defined by Dockerfile.\r\n\r\nexample:\r\n\r\n```python\r\n# Use an official Python runtime as a parent image\r\nFROM python:2.7-slim\r\n\r\n# Set the working directory to /app\r\nWORKDIR /app\r\n\r\n# Copy the current directory contents into the container at /app\r\nCOPY . /app\r\n\r\n# Install any needed packages specified in requirements.txt\r\nRUN pip install --trusted-host pypi.python.org -r requirements.txt\r\n\r\n# Make port 80 available to the world outside this container\r\nEXPOSE 80\r\n\r\n# Define environment variable\r\nENV NAME World\r\n\r\n# Run app.py when the container launches\r\nCMD [\"python\", \"app.py\"]\r\n```\r\n\r\n### `requirements.txt`\r\n\r\n```python\r\nFlask\r\nRedis\r\n```\r\n\r\n### `app.py`\r\n\r\n\r\n\r\n```python\r\nfrom flask import Flask\r\nfrom redis import Redis, RedisError\r\nimport os\r\nimport socket\r\n\r\n# Connect to Redis\r\nredis = Redis(host=\"redis\", db=0, socket_connect_timeout=2, socket_timeout=2)\r\n\r\napp = Flask(__name__)\r\n\r\[email protected](\"/\")\r\ndef hello():\r\n try:\r\n visits = redis.incr(\"counter\")\r\n except RedisError:\r\n visits = \"<i>cannot connect to Redis, counter disabled</i>\"\r\n\r\n html = \"<h3>Hello {name}!</h3>\" \\\r\n \"<b>Hostname:</b> {hostname}<br/>\" \\\r\n \"<b>Visits:</b> {visits}\"\r\n return html.format(name=os.getenv(\"NAME\", \"world\"), hostname=socket.gethostname(), visits=visits)\r\n\r\nif __name__ == \"__main__\":\r\n app.run(host='0.0.0.0', port=80)\r\n```\r\ndocker run -v /apsarapangu/disk3/:/apsarapangu/disk3/ --net=host --cpuset-cpus=\"0-23\" -v \"/home/wb-sp542977:/home/wb-sp542977\" -it reg.docker.alibaba-inc.com/sm/tensorflow_r1.4:2018_07_09 bash\r\n\r\n\r\n\r\n\r\n\r\n<https://www.runoob.com/docker/docker-container-usage.html>\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\nDocker的核心目的是构建轻量级的虚拟化操作系统\r\n\r\n传统虚拟化方式是通过hypervisor在硬件层面连接host OS 和guest OS\r\n\r\nDocker则是通过Docker Engine在host OS层面上实现虚拟化\r\n\r\n\r\n\r\nDocker构架:\r\n\r\n\r\n\r\n核心概念:\r\n\r\n**镜像**:镜像就是一个只读的模板,镜像可以用来创建Docker容器 \r\n\r\n**仓库**: 仓库是集中存放镜像文件的场所\r\n\r\n**容器**: 容器是从镜像创建的运行实例,每个容器都是互相隔离的平台,容器最上面一层是可读可写的。\r\n\r\n\r\n\r\n\r\n\r\n## 容器使用\r\n\r\n### 获取镜像\r\n\r\n如果我们本地没有 ubuntu 镜像,我们可以使用 docker pull 命令来载入 ubuntu 镜像:\r\n\r\n```\r\ndocker images:查看已经下载好的镜像 \r\ndocker pull ubuntu:16.04: 下载ubuntu镜像\r\n```\r\n\r\n### 启动容器\r\n\r\n以下命令使用 ubuntu 镜像启动一个容器,参数为以命令行模式进入该容器:\r\n\r\n```\r\ndocker run -it ubuntu:16.04 /bin/bash\r\n```\r\n\r\n参数说明:\r\n\r\n- **-i**: 交互式操作。\r\n- **-t**: 终端。\r\n- **ubuntu**: ubuntu 镜像。\r\n- **/bin/bash**:放在镜像名后的是命令,这里我们希望有个交互式 Shell,因此用的是 /bin/bash。\r\n\r\n要退出终端,直接输入 **exit**:\r\n\r\n```\r\nroot@ed09e4490c57:/# exit\r\n```\r\n\r\n\r\n\r\n进入python容器\r\n\r\n```\r\ndocker run -it python\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.3759123980998993,
"alphanum_fraction": 0.4133211672306061,
"avg_line_length": 7.116666793823242,
"blob_id": "9fe26e2b033d2b0557c3555429ed87b5c97cdc9a",
"content_id": "a4865735af13347b1717e88ce0dfe8cb7f11204d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1158,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 120,
"path": "/markdown.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "#### Markdown\r\n\r\n```\r\nhttps://math.meta.stackexchange.com/questions/5020/mathjax-basic-tutorial-and-quick-reference/5044%20MathJax%20basic%20tutorial%20and%20quick%20reference\r\n```\r\n\r\n```\r\nhttps://steemit.com/utopian-io/@jubi/typora-typora-tutorial-mathematical-formula\r\n```\r\n\r\n\r\n\r\n快捷键\r\n\r\nctrl shift m\r\n\r\nctrl shit i\r\n\r\n上标 \r\n\r\n```\r\na^2\r\n```\r\n\r\n下标\r\n\r\n```\r\na_{i}\r\n```\r\n\r\n分数\r\n$$\r\n\\frac{1}{2}\r\n$$\r\n\r\n\r\n```\r\n\\frac{}{}\r\n```\r\n\r\n\r\n\r\n连乘,连加\r\n\r\n```\r\n\\prod \\sum\r\n```\r\n\r\n\r\n\r\n转置符号:\r\n$$\r\na \\top\r\n$$\r\n\r\n\r\n```python\r\na \\top\r\n```\r\n\r\n矩阵\r\n$$\r\n\\begin{matrix}\r\n 1 & x & x^2 \\\\\r\n 1 & y & y^2 \\\\\r\n 1 & z & z^2 \\\\\r\n\\end{matrix}\r\n$$\r\n\r\n```\r\n \\begin{matrix}\r\n 1 & x & x^2 \\\\\r\n 1 & y & y^2 \\\\\r\n 1 & z & z^2 \\\\\r\n \\end{matrix}\r\n```\r\n\r\n$$\r\n\\sqrt[3]{15}\r\n$$\r\n\r\n```\r\n\\left[\r\n \\begin{matrix}\r\n x_t\\\\\r\n u_t\\\\\r\n \\end{matrix}\r\n \\right]\r\n```\r\n\r\n$$\r\n\\left[\r\n \\begin{matrix}\r\n x_t\\\\\r\n u_t\\\\\r\n \\end{matrix}\r\n \\right]\r\n$$\r\n\r\n常用希腊字符\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\nmarkdown语法 表格\r\n\r\n| a | b | c |\r\n| ---- | ---- | ---- |\r\n| | | |\r\n\r\n```\r\n|a|b|c|\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.6404697299003601,
"alphanum_fraction": 0.6648600101470947,
"avg_line_length": 26.384614944458008,
"blob_id": "9b9e79c944cc701c6079b3269ee7c620e5c4518e",
"content_id": "fc67e067295ab46591bfc1fcccff4054f0295fe3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1107,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 39,
"path": "/programs/mnist.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "```\r\n#!/usr/bin/python\r\nimport tensorflow as tf\r\nimport sys\r\nimport pandas\r\nfrom tensorflow.examples.tutorials.mnist import input_data\r\n \r\nmnist = input_data.read_data_sets(\"MNIST_data/\", one_hot=True)\r\n \r\nx = tf.placeholder(\"float\", [None, 784])\r\nW = tf.Variable(tf.zeros([784,10]))\r\nb = tf.Variable(tf.zeros([10]))\r\n \r\ny = tf.nn.softmax(tf.matmul(x,W) + b)\r\n \r\ny_ = tf.placeholder(\"float\", [None,10])\r\ncross_entropy = -tf.reduce_sum(y_*tf.log(y))\r\n \r\ntrain_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)\r\n \r\ninit = tf.initialize_all_variables()\r\nsess = tf.Session()\r\nsess.run(init)\r\n \r\nfor i in range(1000):\r\n if i % 20 == 0:\r\n sys.stdout.write('.')\r\n batch_xs, batch_ys = mnist.train.next_batch(100)\r\n sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})\r\nprint(\"\")\r\n \r\ncorrect_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))\r\naccuracy = tf.reduce_mean(tf.cast(correct_prediction, \"float\"))\r\n \r\nprint (sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))\r\n```\r\n\r\nerror:module 'pandas' has no attribute 'computation'\r\nconda update dask\r\n"
},
{
"alpha_fraction": 0.5916061401367188,
"alphanum_fraction": 0.6029055714607239,
"avg_line_length": 23.163265228271484,
"blob_id": "3d4e53b601c41ac799a544636d01fdce51d7cb8c",
"content_id": "6fa8c3690b17f32c2f154932c865cf43306fc9f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1297,
"license_type": "no_license",
"max_line_length": 175,
"num_lines": 49,
"path": "/leetcde_note_cpp/Tree.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### leetcode 530 Minimum Absolute Difference in BST\r\n\r\nGiven a binary search tree with non-negative values, find the minimum [absolute difference](https://en.wikipedia.org/wiki/Absolute_difference) between values of any two nodes.\r\n\r\n**Example:**\r\n\r\n```\r\nInput:\r\n\r\n 1\r\n \\\r\n 3\r\n /\r\n 2\r\n\r\nOutput:\r\n1\r\n\r\nExplanation:\r\nThe minimum absolute difference is 1, which is the difference between 2 and 1 (or between 2 and 3).\r\n```\r\n\r\n```c++\r\n/**\r\n * Definition for a binary tree node.\r\n * struct TreeNode {\r\n * int val;\r\n * TreeNode *left;\r\n * TreeNode *right;\r\n * TreeNode(int x) : val(x), left(NULL), right(NULL) {}\r\n * };\r\n */\r\nclass Solution {\r\npublic:\r\n void inorderTraverse(TreeNode* root, int& val, int& min_dif) {\r\n if (root->left != NULL) inorderTraverse(root->left, val, min_dif);\r\n if (val >= 0) min_dif = min(min_dif, root->val - val);\r\n val = root->val;\r\n if (root->right != NULL) inorderTraverse(root->right, val, min_dif);\r\n }\r\n int getMinimumDifference(TreeNode* root) {\r\n auto min_dif = INT_MAX, val = -1;\r\n inorderTraverse(root, val, min_dif);\r\n return min_dif;\r\n }\r\n};\r\n```\r\n\r\n因为是BST,因此通过inordertraverse可以得到sorted数组然后依次相减就可以得到最小差值\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.7923875451087952,
"alphanum_fraction": 0.8027681708335876,
"avg_line_length": 25.88596534729004,
"blob_id": "141319421f51e9f590d337e2e4c16c4674f5a62f",
"content_id": "f56bdd217419e422dd6a591afce067a7e2b0fd0c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 7583,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 114,
"path": "/c++/c++_常考概念.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "https://wenku.baidu.com/view/300950270722192e4536f61a.html \r\n\r\n### 多态与动态链接: \r\n```\r\n多态是OOP(面向对象程序设计)中非常重要的概念, 实现多态在很多情况下都是通过虚函数来实现的。多态分为静态多态与动态多态,\r\n静态多态是函数重载,在编译时就可以确定使用哪个函数,动态多态需要用到虚函数。虚函数的意义是使得父类对象可以使用子类接口。\r\n例如父类animal类,定义有eat函数这个函数是不能被animal类的对象实现的(因为没有意义),这个就是纯虚函数,通过虚函数可以\r\n实现使得父类animal的对象实现子类dog类的中eat的功能。 \r\n\r\n关于基类与继承:几个类构成一种层次关系,在底部有一个基类,其他类直接亦或是间接从基类继承而来,称为派生类。基类中与类型\r\n无关的函数,可以直接继承的函数与类型有关的函数区分对待。 函数与类型有关,则在基类中定义为是虚函数。Virtual动态链接与\r\n静态链接相对,静态链接是将要调用的程序与函数等直接链接到可执行文件中,成为可执行文件的一部分,相对而言浪费资源。而动态\r\n链接则是并不将函数放到应用程序的可执行文件中去,而是加入一些描述信息比如定位信息等,等到执行的时候再去调用。 \r\n\r\n动态绑定: 所谓动态绑定与静态绑定相对,一个基类有虚函数,在编译时会生成一个虚函数表,然后又一个指针指向虚函数表,静态绑定\r\n理解为在编译时已经知道了对象名,就知道了调用哪一个虚函数,动态绑定则是函数的版本是由参数来决定的,不运行到哪一bu是不知道虚函数的版本\r\n```\r\n\r\n### 内存泄漏: \r\n```\r\n因为程序中已经分配的动态内存无法释放导致内存浪费,造成运行变缓等后果。\r\n可能导致内存泄漏的原因:使用动态内存,但是没有用delete函数销毁对象 释放内存\r\n动态内存:通过new来分配内存空间,并返回一个指向的指针;用delete销毁对象,释放内存。\r\n可以使用智能指针来自动销毁对象,释放内存。\r\n动态分配的对象生存的周期与他们在哪里被创建无关,只有被显示的释放时,这些对象才会被销毁。\r\n```\r\n\r\n### 重载 \r\n```\r\nc++中函数重载就是在同一作用域内可以有一组具有相同函数名,不同参数列表的函数,这组函数就是重载函数。这样可以减少\r\n函数名的数量,是的程序的可读性增强。比如print函数,既可以打印int型 也可以打印string型变量。编译器在编译的时候\r\n函数名讳发生变化,新的函数名和原函数名以及其参数类型有关。\r\n重载函数如何进行匹配?\r\n有一系列规则,按照规则进行匹配,例如精准匹配(参数完全对应),提升匹配,例如将bool提升到int型等等。\r\n```\r\n\r\n虚拟机:虚拟机的好处(可移植性,安全) 效率低\r\nJTM BEA JRockit\t\r\nC++ 封装继承多态的特点,支持面向对象编程 泛型编程(利用模板,代码运行以及在编写代码的时候数据类型 不考虑)\r\n泛型算法的具体实现方法:通过迭代器来访问容器,这些容器中存有数据。迭代器访问数据的方式与数据类型无关。使得泛型算法不依赖容器。 \r\n\r\n### 防止内存泄漏: \r\n```\r\nC++ 异常处理机制: 遇到异常抛出,捕捉异常\r\njava中也是非常类似,不过java中有finally 垃圾回收\r\nC语言面向过程,c++既可面向过程又面向对象\r\n内存泄露就是c++程序由于疏忽或是错误没能释放部分内存导致内存被浪费了。\r\nJava处理对象分配与释放问题:\r\nJava将内存分为两种,一种栈内存与堆内存\r\n函数中基本类型的变量与对象引用变量都在栈内存中分配,定义了一个变量之后,java在栈内分配空间。当超过该变量的作用域之后就释放该\r\n变量的内存。堆内存用来存放数组以及new创建的对象,全局变量等等。\r\nJava中有垃圾回收机制,自动释放不被程序使用的对象,实现自动资源回收功能,c++中需要程序员自己使用delete或者是析构函数来回收内存。\r\nJava是纯面向对象的,而c++\r\n ```\r\n \r\n### 面向对象的特点: \r\n```\r\n1 对象的唯一性,每个对象都有一个标识,通过找标识可以找到相应的对象。\r\n2 分类性 将具有一样的数据结构和行为的对象抽象为类\r\n3 继承性 类与类之间的关系,在定义一个新的类的时候能够在已经有的类的基础上来进行,加入若干新的内容,继承性是面向对象\r\n最重要的特点,减少了重复性增加了可重性。\r\n4 多态性 用相同的操作或者是相同的函数作用于不同类型的对象上获得不同的结果。多态性增加了软件的灵活性与重用性。\r\n ```\r\n \r\n \r\n### C++ 与c中字符串 \r\n```\r\nC中字符串是个基本数据类型而c++是一个类\r\n c++中IO口\r\nc++不直接处理输入输出,而是定义在标准库中的类型还处理IO。 这些类型支持从设备读取或者写入数据。比如有istream类提供\r\n输入操作,ostream类提供输出操作。cin是一个istream对象而cout是一个ostream对象。标准库通过继承机制让我们可以忽略不\r\n同类型流之间的差异。IO对象是不能拷贝或者赋值的,IO操作可能会处理错误状态,例如本来应该读入int型变量,但是后来读入\r\n了字符等等。当流处于没有错的情况下才能够正常读取数据。\r\n```\r\n文件模式:每个流都有与之对应的文件模式,是一组标志,用来指出给定流是否可用。\r\n文件流:用来读写命名文件的流对象,字符串流是用来读写string类型的流对象。\r\n\r\n### 友元函数\r\n```\r\n关键字friend,友元函数不属于类,可以实现在类外访问类内的私有成员的非成员函数\r\n ```\r\n\r\n### 关于public private protected继承 \r\n```\r\nhttp://www.jb51.net/article/54224.htm\r\npublic可以被类外访问,protected不可以被类外访问,可以被仿生类访问,private不可以被类外 仿生类访问。\r\nPublic继承, 类中public protected private成员属性不变\r\nProtected继承 类中public protected private成员属性变为protected protected private\r\nPrivate继承 类中public protected private成员属性变为private private private\r\n```\r\n\r\n### 纯虚函数与虚函数 \r\n```\r\n一个函数为虚函数,并不意味着其不能被实现,定义其为虚函数是为了允许基类的指针来调用子类的这个函数。定义一个函数为\r\n纯虚函数,则说明这个函数不能被实现,纯虚函数是基类申明的虚函数,引入虚函数是为了方便使用多态这一特性,但是有时候\r\n基类本身是不能产生对象的,例如基类动物,,本身不能产生实体有意义的对象,因此有些函数也是没有意义的,为了解决这一\r\n问题就引入了纯虚函数。含有纯虚函数的类是抽象基类。\r\n```\r\n\r\n#### 翁恺课程\r\n构造与析构\r\n```\r\nC++中一般没有初始化为0的步骤,java 中有这个功能\r\nC++中这个和编译器有关\r\n\r\n使用构造函数 constructor来确保初始化的进行\r\n构造函数与析构函数:\r\nclass Foo{\r\npublic:\r\n Foo(); //构造函数\r\n ~Foo(); //析构函数\r\n}\r\n当对象被销毁时例如离开作用域或者是当一个对象被销毁时其成员被销毁,使用析构函数\r\n```\r\n"
},
{
"alpha_fraction": 0.4564102590084076,
"alphanum_fraction": 0.5753846168518066,
"avg_line_length": 19.15217399597168,
"blob_id": "03c841aaa3265bb21df5066b7de726131a436b9b",
"content_id": "dad9afcb7544d60141158e0c6016a4e1999303e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1127,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 46,
"path": "/leetcde_note_cpp/heap.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### heap\r\n\r\nmake_heap\r\n\r\n```c++\r\nusing namespace std;\r\nint cmp(int a, int b) {\r\n\treturn a > b; //这里和sort有些不同,a大就把a往下沉 因此是最小堆\r\n}\r\nint cmp2(int a, int b) {\r\n\treturn a < b;\r\n}\r\nint main() {\r\n\tvector<int> nums = { 10,20,30,5,15 };\r\n\tmake_heap(nums.begin(), nums.end()); //默认为构建最大堆 30 20 10 5 15\r\n\tmake_heap(nums.begin(), nums.end(), cmp); //构建最小堆 5 10 30 20 15\r\n\tmake_heap(nums.begin(), nums.end(), cmp2); //构建最大堆 30 20 10 5 15\r\n}\r\n\r\n```\r\n\r\npop_heap\r\n\r\n```c++\r\nvector<int> nums = { 10,20,30,5,15 };\r\nmake_heap(nums.begin(), nums.end()); //30 20 10 5 15\r\npop_heap(nums.begin(), nums.end()); //最大元素放到最后,最后的元素放到队首下沉 20 15 10 5 30\r\nnums.pop_back(); //20 15 10 5\r\n```\r\n\r\npush_heap\r\n\r\n```c++\r\nvector<int> nums = { 10,20,30,5,15 };\r\nmake_heap(nums.begin(), nums.end());\r\nnums.push_back(99); //30 20 10 5 15 99\r\npush_heap(nums.begin(), nums.end()); //99 20 30 5 15 10\r\n```\r\n\r\nsort_heap\r\n\r\n```c++\r\nsort_heap(nums.begin(), nums.end()); // 5 10 15 20 30 99 \r\n```\r\n\r\n只能作用于最大堆,形成从小到大的数组\r\n\r\n"
},
{
"alpha_fraction": 0.5335041880607605,
"alphanum_fraction": 0.5742066502571106,
"avg_line_length": 24.690141677856445,
"blob_id": "27cb1dd6553e8722e396ef60e139e9db6ba7f76e",
"content_id": "e7ece6e3d130b4c14afe64dd21a88d84a9d08ba0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 13711,
"license_type": "no_license",
"max_line_length": 454,
"num_lines": 497,
"path": "/leetcode_note/Greedy.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "贪心题目1(LeetCode 455)\r\n\r\n贪心题目2(LeetCode 402)\r\n\r\n贪心题目3(LeetCode 134)\r\n\r\n贪心题目4(LeetCode 135)\r\n\r\n贪心题目5(LeetCode 502)\r\n\r\n贪心题目6(LeetCode 321)\r\n\r\n\r\n\r\n##### leetcode 134 Gas Station\r\n\r\nThere are *N* gas stations along a circular route, where the amount of gas at station *i* is `gas[i]`.\r\n\r\nYou have a car with an unlimited gas tank and it costs `cost[i]` of gas to travel from station *i* to its next station (*i*+1). You begin the journey with an empty tank at one of the gas stations.\r\n\r\nReturn the starting gas station's index if you can travel around the circuit once in the clockwise direction, otherwise return -1.\r\n\r\n**Note:**\r\n\r\n- If there exists a solution, it is guaranteed to be unique.\r\n- Both input arrays are non-empty and have the same length.\r\n- Each element in the input arrays is a non-negative integer.\r\n\r\n```\r\nInput: \r\ngas = [1,2,3,4,5]\r\ncost = [3,4,5,1,2]\r\n\r\nOutput: 3\r\n\r\nExplanation:\r\nStart at station 3 (index 3) and fill up with 4 unit of gas. Your tank = 0 + 4 = 4\r\nTravel to station 4. Your tank = 4 - 1 + 5 = 8\r\nTravel to station 0. Your tank = 8 - 2 + 1 = 7\r\nTravel to station 1. Your tank = 7 - 3 + 2 = 6\r\nTravel to station 2. Your tank = 6 - 4 + 3 = 5\r\nTravel to station 3. The cost is 5. Your gas is just enough to travel back to station 3.\r\nTherefore, return 3 as the starting index.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: \r\ngas = [2,3,4]\r\ncost = [3,4,3]\r\n\r\nOutput: -1\r\n\r\nExplanation:\r\nYou can't start at station 0 or 1, as there is not enough gas to travel to the next station.\r\nLet's start at station 2 and fill up with 4 unit of gas. Your tank = 0 + 4 = 4\r\nTravel to station 0. Your tank = 4 - 3 + 2 = 3\r\nTravel to station 1. Your tank = 3 - 3 + 3 = 3\r\nYou cannot travel back to station 2, as it requires 4 unit of gas but you only have 3.\r\nTherefore, you can't travel around the circuit once no matter where you start.\r\n```\r\n\r\n```python\r\nclass Solution(object):\r\n def canCompleteCircuit(self, gas, cost):\r\n n=len(gas)\r\n cha=[0 for i in range(n)]\r\n for i in range(n):\r\n cha[i]=gas[i]-cost[i]\r\n for i in range(n):\r\n res,start=0,i\r\n res+=cha[i]\r\n start+=1\r\n while res>=0:\r\n if start>=n:\r\n start-=n\r\n if start==i:\r\n return i\r\n res+=cha[start]\r\n start+=1\r\n return -1\r\n```\r\n\r\n\r\n\r\n##### leetcode 135 Candy\r\n\r\nThere are *N* children standing in a line. Each child is assigned a rating value.\r\n\r\nYou are giving candies to these children subjected to the following requirements:\r\n\r\n- Each child must have at least one candy.\r\n- Children with a higher rating get more candies than their neighbors.\r\n\r\nWhat is the minimum candies you must give?\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [1,0,2]\r\nOutput: 5\r\nExplanation: You can allocate to the first, second and third child with 2, 1, 2 candies respectively.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [1,2,2]\r\nOutput: 4\r\nExplanation: You can allocate to the first, second and third child with 1, 2, 1 candies respectively.\r\n The third child gets 1 candy because it satisfies the above two conditions.\r\n```\r\n\r\n```python\r\nclass Solution(object):\r\n def candy(self, ratings):\r\n \"\"\"\r\n :type ratings: List[int]\r\n :rtype: int\r\n \"\"\"\r\n n=len(ratings)\r\n if n==0:\r\n return 0\r\n if n==1:\r\n return 1\r\n nums=[1 for i in range(n)]\r\n for i in range(1,n-1,1):\r\n if ratings[i]>ratings[i+1]:\r\n nums[i]=max(nums[i],nums[i+1]+1)\r\n if ratings[i]>ratings[i-1]:\r\n nums[i]=max(nums[i],nums[i-1]+1)\r\n for i in range(n-2,0,-1):\r\n if ratings[i]>ratings[i-1]:\r\n nums[i]=max(nums[i],nums[i-1]+1)\r\n if ratings[i]>ratings[i+1]:\r\n nums[i]=max(nums[i],nums[i+1]+1)\r\n if ratings[0]>ratings[1]:\r\n nums[0]=max(nums[0],nums[1]+1)\r\n if ratings[n-1]>ratings[n-2]:\r\n nums[n-1]=max(nums[n-1],nums[n-2]+1)\r\n return sum(nums)\r\n```\r\n\r\n\r\n\r\n##### leetcode 321 Create Maximum Number\r\n\r\nGiven two arrays of length `m` and `n` with digits `0-9` representing two numbers. Create the maximum number of length `k <= m + n` from digits of the two. The relative order of the digits from the same array must be preserved. Return an array of the `k` digits.\r\n\r\n**Note:** You should try to optimize your time and space complexity.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput:\r\nnums1 = [3, 4, 6, 5]\r\nnums2 = [9, 1, 2, 5, 8, 3]\r\nk = 5\r\nOutput:\r\n[9, 8, 6, 5, 3]\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput:\r\nnums1 = [6, 7]\r\nnums2 = [6, 0, 4]\r\nk = 5\r\nOutput:\r\n[6, 7, 6, 0, 4]\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput:\r\nnums1 = [3, 9]\r\nnums2 = [8, 9]\r\nk = 3\r\nOutput:\r\n[9, 8, 9]\r\n```\r\n\r\nSo there're 3 steps:\r\n\r\n1. **iterate i from 0 to k.**\r\n2. **find max number from num1, num2 by select i , k-i numbers, denotes as left, right**\r\n3. **find max merge of left, right**\r\n\r\n```python\r\nclass Solution(object):\r\n def maxNumber(self, nums1, nums2, k):\r\n \"\"\"\r\n :type nums1: List[int]\r\n :type nums2: List[int]\r\n :type k: int\r\n :rtype: List[int]\r\n \"\"\"\r\n n, m= len(nums1),len(nums2)\r\n ret = [0] * k\r\n for i in range(0, k+1):\r\n j = k - i\r\n if i > n or j > m: continue\r\n left = self.maxSingleNumber(nums1, i)\r\n right = self.maxSingleNumber(nums2, j)\r\n num = self.mergeMax(left, right)\r\n ret = max(num, ret)\r\n return ret\r\n\r\n\r\n def mergeMax(self, nums1, nums2):\r\n ans = []\r\n while nums1 or nums2:\r\n if nums1 > nums2:\r\n ans += nums1[0],\r\n nums1 = nums1[1:]\r\n else:\r\n ans += nums2[0],\r\n nums2 = nums2[1:]\r\n return ans\r\n\r\n def maxSingleNumber(self, nums, selects):\r\n n = len(nums)\r\n ret = [-1]\r\n if selects > n : return ret\r\n while selects > 0:\r\n start = ret[-1] + 1 #search start\r\n end = n-selects + 1 #search end\r\n ret.append( max(range(start, end), key = nums.__getitem__))\r\n selects -= 1\r\n ret = [nums[item] for item in ret[1:]]\r\n return ret\r\n```\r\n\r\n\r\n\r\n##### leetcode 337 House Robber III\r\n\r\n* The thief has found himself a new place for his thievery again. There is only one entrance to this area, called the \"root.\" Besides the root, each house has one and only one parent house. After a tour, the smart thief realized that \"all houses in this place forms a binary tree\". It will automatically contact the police if two directly-linked houses were broken into on the same night.\r\n\r\n Determine the maximum amount of money the thief can rob tonight without alerting the police.\r\n\r\n```\r\nInput: [3,2,3,null,3,null,1]\r\n\r\n 3\r\n / \\\r\n 2 3\r\n \\ \\ \r\n 3 1\r\n\r\nOutput: 7 \r\nExplanation: Maximum amount of money the thief can rob = 3 + 3 + 1 = 7.\r\n\r\nInput: [3,4,5,1,3,null,1]\r\n\r\n 3\r\n / \\\r\n 4 5\r\n / \\ \\ \r\n 1 3 1\r\n\r\nOutput: 9\r\nExplanation: Maximum amount of money the thief can rob = 4 + 5 = 9.\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def rob(self, root):\r\n \"\"\"\r\n :type root: TreeNode\r\n :rtype: int\r\n \"\"\"\r\n def rob_skip(root):\r\n if not root:\r\n return 0,0\r\n rob_left,skip_left=rob_skip(root.left)\r\n rob_right,skip_right=rob_skip(root.right)\r\n rob=root.val+skip_left+skip_right\r\n skip = max(rob_left, skip_left) + max(rob_right, skip_right)\r\n return rob,skip\r\n return max(rob_skip(root))\r\n```\r\n\r\ngreedy 算法,rob或者skip两种选择\r\n\r\n\r\n\r\n##### leetcode 406 Queue Reconstruction by Height\r\n\r\n* Suppose you have a random list of people standing in a queue. Each person is described by a pair of integers `(h, k)`, where `h` is the height of the person and `k` is the number of people in front of this person who have a height greater than or equal to `h`. Write an algorithm to reconstruct the queue.\r\n\r\n **Note:**\r\n The number of people is less than 1,100\r\n\r\n```\r\nInput:\r\n[[7,0], [4,4], [7,1], [5,0], [6,1], [5,2]]\r\n\r\nOutput:\r\n[[5,0], [7,0], [5,2], [6,1], [4,4], [7,1]]\r\n```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution:\r\n def reconstructQueue(self, people):\r\n \"\"\"\r\n :type people: List[List[int]]\r\n :rtype: List[List[int]]\r\n \"\"\"\r\n people.sort(key=lambda x:(-x[0],x[1]))\r\n queue=[]\r\n for p in people:\r\n queue.insert(p[1],p)\r\n return queue\r\n```\r\n\r\n[[7,0], [4,4], [7,1], [5,0], [6,1], [5,2]]\r\n表示按照 x[0]降序 x[1]增序排序\r\n[[7, 0], [7, 1], [6, 1], [5, 0], [5, 2], [4, 4]]\r\n矮个子对于高个子的x[1]这个数值没有影响 所以可以先将高个子的人插到队列中\r\n\r\n\r\n\r\n##### leetcode 455 Assign Cookies\r\n\r\nAssume you are an awesome parent and want to give your children some cookies. But, you should give each child at most one cookie. Each child i has a greed factor gi, which is the minimum size of a cookie that the child will be content with; and each cookie j has a size sj. If sj >= gi, we can assign the cookie j to the child i, and the child i will be content. Your goal is to maximize the number of your content children and output the maximum number.\r\n\r\n**Note:**\r\nYou may assume the greed factor is always positive.\r\nYou cannot assign more than one cookie to one child.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [1,2,3], [1,1]\r\n\r\nOutput: 1\r\n\r\nExplanation: You have 3 children and 2 cookies. The greed factors of 3 children are 1, 2, 3. \r\nAnd even though you have 2 cookies, since their size is both 1, you could only make the child whose greed factor is 1 content.\r\nYou need to output 1.\r\n```\r\n\r\n\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [1,2], [1,2,3]\r\n\r\nOutput: 2\r\n\r\nExplanation: You have 2 children and 3 cookies. The greed factors of 2 children are 1, 2. \r\nYou have 3 cookies and their sizes are big enough to gratify all of the children, \r\nYou need to output 2.\r\n```\r\n\r\n```python\r\nclass Solution(object):\r\n def findContentChildren(self, g, s):\r\n g=sorted(g,reverse=True)\r\n s=sorted(s,reverse=True)\r\n count=0;i=0;j=0\r\n while i<len(g) and j<len(s):\r\n if s[j]>=g[i]:\r\n i+=1;j+=1;count+=1\r\n else:\r\n i+=1;\r\n return count\r\n```\r\n\r\nGreedy:\r\n\r\n每个小孩只能给一块,所以从最大的饼干开始看能给到哪个孩子\r\n\r\n\r\n\r\n##### leetcode 402 Remove K Digits\r\n\r\nGiven a non-negative integer *num* represented as a string, remove *k* digits from the number so that the new number is the smallest possible.\r\n\r\n**Note:**\r\n\r\n- The length of *num* is less than 10002 and will be ≥ *k*.\r\n- The given *num* does not contain any leading zero.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: num = \"1432219\", k = 3\r\nOutput: \"1219\"\r\nExplanation: Remove the three digits 4, 3, and 2 to form the new number 1219 which is the smallest.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: num = \"10200\", k = 1\r\nOutput: \"200\"\r\nExplanation: Remove the leading 1 and the number is 200. Note that the output must not contain leading zeroes.\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def removeKdigits(self, num: str, k: int) -> str:\r\n stack = []\r\n for x in num:\r\n while k and stack and stack[-1] > x:\r\n k -= 1\r\n stack.pop()\r\n stack.append(x)\r\n res = \"\".join(stack)[:len(stack) - k].lstrip(\"0\")\r\n if res == \"\":\r\n return \"0\"\r\n else:\r\n return res\r\n```\r\n\r\n使用stack\r\n\r\n```\r\nInput: num = \"1432219\", k = 3\r\n\r\nFor example, now in stringbuilder is 14. We check '3', 3 is smaller than 4, remove 4, append 3.\r\nnow stringbuilder is 13, we check '2', 2 is smaller than 3, remove 3, append 2.\r\nnow stringbuilder is 12, we check '2', 2 is equal to 2, append 2.\r\nnow stringbuilder is 122, we check `1`, 1 is smaller than 2, remove 2, append 1.\r\nnow stringbuilder is 121, now k is 0, we append 9.\r\n\r\nOutput: \"1219\"\r\n```\r\n\r\n如果k还大于0,同时stack中最后一个元素大于x则弹出,这样可以保证stack中的元素是从小到大排列的\r\n\r\n如果k还有剩则res不取最后k位。同时注意返回“0”以及去掉最坐边的0\r\n\r\n\r\n\r\n##### leetcode 659. Split Array into Consecutive Subsequences\r\n\r\nGiven an array `nums` sorted in ascending order, return `true` if and only if you can split it into 1 or more subsequences such that each subsequence consists of consecutive integers and has length at least 3.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [1,2,3,3,4,5]\r\nOutput: True\r\nExplanation:\r\nYou can split them into two consecutive subsequences : \r\n1, 2, 3\r\n3, 4, 5\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [1,2,3,3,4,4,5,5]\r\nOutput: True\r\nExplanation:\r\nYou can split them into two consecutive subsequences : \r\n1, 2, 3, 4, 5\r\n3, 4, 5\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: [1,2,3,4,4,5]\r\nOutput: False\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def isPossible(self, nums):\r\n left = collections.Counter(nums)\r\n end = collections.Counter()\r\n for i in nums:\r\n if not left[i]: continue\r\n left[i] -= 1\r\n if end[i - 1] > 0:\r\n end[i - 1] -= 1\r\n end[i] += 1\r\n elif left[i + 1] and left[i + 2]:\r\n left[i + 1] -= 1\r\n left[i + 2] -= 1\r\n end[i + 2] += 1\r\n else:\r\n return False\r\n return True\r\n```\r\n\r\n最优策略就是一个数num,如果有个以num-1结尾的数组就把num放到这个数组中,如果没有就检验是否有num+1 num+2可以组成新的数组\r\n\r\n"
},
{
"alpha_fraction": 0.5100692510604858,
"alphanum_fraction": 0.5433138012886047,
"avg_line_length": 20.709444046020508,
"blob_id": "0bf9fe39e626830b009856e3365b25ff21fb46ec",
"content_id": "556858ac3df6c8cd3199e8aaeb8b4b2e2d61dd65",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 9787,
"license_type": "no_license",
"max_line_length": 257,
"num_lines": 413,
"path": "/leetcode_note/binary_search.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Binary_search\r\n\r\npython\r\n\r\n```python\r\n# upper_bound\r\ndef upper_bound(self, nums, target):\r\n left, right = 0, len(nums)-1\r\n while left < right:\r\n mid = int((left+right)/2)\r\n if nums[mid] <= target:\r\n left = mid + 1\r\n else:\r\n right = mid\r\n return left\r\n# lower_bound\r\ndef lower_bound(self, nums, target):\r\n left, right = 0, len(nums)-1\r\n while left < right:\r\n mid = int((left+right)/2)\r\n if nums[mid] < target:\r\n left = mid + 1\r\n else:\r\n right = mid\r\n return left \r\n```\r\n\r\npython bisect模块\r\n\r\n```python\r\nnums = [2, 4, 7, 9]\r\nbisect.insort(nums, 3)\r\nnums [2,3,4,7,9]\r\nbisect.bisect(nums, 4) :其目的在于查找该数值将会插入的位置并返回,而不会插入 3\r\nbisect.bisect_left(nums, 4) 2\r\nbisect.bisect_right(nums, 4) 3\r\n\r\nbisect和bisect_right等价 相当于找> 4的数的位置\r\nbisect_left 相当于找>= 4的数的位置\r\n\r\n```\r\n\r\n\r\n\r\n数组的二分查找(LeetCode 33,81)\r\n\r\n区间二分查找(LeetCode 34)\r\n\r\n##### 1014. Capacity To Ship Packages Within D Days\r\n\r\nA conveyor belt has packages that must be shipped from one port to another within `D` days.\r\n\r\nThe `i`-th package on the conveyor belt has a weight of `weights[i]`. Each day, we load the ship with packages on the conveyor belt (in the order given by `weights`). We may not load more weight than the maximum weight capacity of the ship.\r\n\r\nReturn the least weight capacity of the ship that will result in all the packages on the conveyor belt being shipped within `D` days.\r\n\r\n```\r\nInput: weights = [1,2,3,4,5,6,7,8,9,10], D = 5\r\nOutput: 15\r\nExplanation: \r\nA ship capacity of 15 is the minimum to ship all the packages in 5 days like this:\r\n1st day: 1, 2, 3, 4, 5\r\n2nd day: 6, 7\r\n3rd day: 8\r\n4th day: 9\r\n5th day: 10\r\n\r\nNote that the cargo must be shipped in the order given, so using a ship of capacity 14 and splitting the packages into parts like (2, 3, 4, 5), (1, 6, 7), (8), (9), (10) is not allowed. \r\n\r\nInput: weights = [3,2,2,4,1,4], D = 3\r\nOutput: 6\r\nExplanation: \r\nA ship capacity of 6 is the minimum to ship all the packages in 3 days like this:\r\n1st day: 3, 2\r\n2nd day: 2, 4\r\n3rd day: 1, 4\r\n\r\nInput: weights = [1,2,3,1,1], D = 4\r\nOutput: 3\r\nExplanation: \r\n1st day: 1\r\n2nd day: 2\r\n3rd day: 3\r\n4th day: 1, 1\r\n```\r\n\r\n* Mysolution\r\n\r\n```python\r\nclass Solution:\r\n def shipWithinDays(self, weights, D):\r\n capacity_left, capacity_right, n = max(weights), sum(weights), len(weights)\r\n while capacity_left < capacity_right:\r\n capacity = (capacity_left + capacity_right) // 2\r\n count, temp, i = 1, 0, 0\r\n while i < n:\r\n if capacity < temp + weights[i]:\r\n temp = 0\r\n count += 1\r\n else:\r\n temp += weights[i]\r\n i += 1\r\n if count > D:\r\n capacity_left = capacity + 1\r\n else:\r\n capacity_right = capacity\r\n return capacity_left\r\n```\r\n\r\n注意本题要求放到一个箱子里货物是连续的。\r\n\r\n如果没有这个要求,可以考虑从大到小放,每次选出目前放的货物量最小的箱子来放\r\n\r\nTLE:\r\n\r\n```python\r\nclass Solution:\r\n def shipWithinDays(self, weights,D):\r\n capacity,n=max(weights),len(weights)\r\n while True:\r\n count,temp,i,n_capacity=1,0,0,float(\"inf\")\r\n while i<n:\r\n if capacity<temp+weights[i]:\r\n n_capacity=min(n_capacity,temp+weights[i])\r\n temp=0\r\n count+=1\r\n else:\r\n temp+=weights[i]\r\n i+=1\r\n if count<=D:\r\n return capacity\r\n else:\r\n capacity=n_capacity\r\n```\r\n\r\n尝试在capacity的容量下需要用count个箱子,如果数量大于D则说明需要更大的capacity,(n_capacity)\r\n\r\n但是会得到TLE,需要用binary search\r\n\r\n```python\r\nwhile left<right:\r\n\t...\r\n\t...\r\n\tif count > D:\r\n \tcapacity_left = capacity + 1\r\n else:\r\n \tcapacity_right = capacity\r\n```\r\n\r\n相似问题:\r\n\r\n875.Koko Eating Bananas \r\n\r\n774.Minimize Max Distance to Gas Station\r\n\r\n\r\n\r\n##### leetcode 875. Koko Eating Bananas\r\n\r\nKoko loves to eat bananas. There are `N` piles of bananas, the `i`-th pile has `piles[i]` bananas. The guards have gone and will come back in `H` hours.\r\n\r\nKoko can decide her bananas-per-hour eating speed of `K`. Each hour, she chooses some pile of bananas, and eats K bananas from that pile. If the pile has less than `K` bananas, she eats all of them instead, and won't eat any more bananas during this hour.\r\n\r\nKoko likes to eat slowly, but still wants to finish eating all the bananas before the guards come back.\r\n\r\nReturn the minimum integer `K` such that she can eat all the bananas within `H` hours.\r\n\r\n\r\n\r\n```\r\nInput: piles = [3,6,7,11], H = 8\r\nOutput: 4\r\n\r\nInput: piles = [30,11,23,4,20], H = 5\r\nOutput: 30\r\n\r\nInput: piles = [30,11,23,4,20], H = 6\r\nOutput: 23\r\n```\r\n\r\n**Note:**\r\n\r\n- `1 <= piles.length <= 10^4`\r\n- `piles.length <= H <= 10^9`\r\n- `1 <= piles[i] <= 10^9`\r\n\r\n\r\n\r\n```python\r\nclass Solution:\r\n def minEatingSpeed(self, piles, H):\r\n \"\"\"\r\n :type piles: List[int]\r\n :type H: int\r\n :rtype: int\r\n \"\"\"\r\n def helper(piles,H,k):\r\n sum1=0\r\n for i in range(len(piles)):\r\n if piles[i]%k==0:\r\n sum1+=piles[i]/k\r\n else:\r\n sum1+=int(piles[i]/k)+1\r\n if sum1<=H:\r\n return True\r\n return False\r\n left,right,n=1,max(piles),len(piles)\r\n if n==0:\r\n return\r\n while left<right:\r\n mid=int((left+right)/2)\r\n if helper(piles,H,mid):\r\n right=mid \r\n else:\r\n left=mid+1\r\n return left\r\n```\r\n\r\n\r\n\r\n\r\n\r\n###### 1231 Divide Chocolate\r\n\r\nYou have one chocolate bar that consists of some chunks. Each chunk has its own sweetness given by the array `sweetness`.\r\n\r\nYou want to share the chocolate with your `K` friends so you start cutting the chocolate bar into `K+1` pieces using `K` cuts, each piece consists of some **consecutive** chunks.\r\n\r\nBeing generous, you will eat the piece with the **minimum total sweetness** and give the other pieces to your friends.\r\n\r\nFind the **maximum total sweetness** of the piece you can get by cutting the chocolate bar optimally.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: sweetness = [1,2,3,4,5,6,7,8,9], K = 5\r\nOutput: 6\r\nExplanation: You can divide the chocolate to [1,2,3], [4,5], [6], [7], [8], [9]\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: sweetness = [5,6,7,8,9,1,2,3,4], K = 8\r\nOutput: 1\r\nExplanation: There is only one way to cut the bar into 9 pieces.\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: sweetness = [1,2,2,1,2,2,1,2,2], K = 2\r\nOutput: 5\r\nExplanation: You can divide the chocolate to [1,2,2], [1,2,2], [1,2,2]\r\n```\r\n\r\n \r\n\r\n**Constraints:**\r\n\r\n- `0 <= K < sweetness.length <= 10^4`\r\n- `1 <= sweetness[i] <= 10^5`\r\n\r\n\r\n\r\n```python\r\nclass Solution:\r\n def issplit(self, sweetness, K, target):\r\n temp, count = 0, 0\r\n for num in sweetness:\r\n temp += num\r\n if temp > target:\r\n count += 1\r\n temp = 0\r\n if count >= K: return True\r\n return False\r\n \r\n def maximizeSweetness(self, sweetness: List[int], K: int) -> int:\r\n if K+1 > len(sweetness): return 0\r\n left, right = min(sweetness), sum(sweetness)\r\n while left < right:\r\n mid = int((left+right)/2)\r\n if self.issplit(sweetness, K+1, mid):\r\n left = mid + 1\r\n else:\r\n right = mid\r\n print(mid, left, right)\r\n return left\r\n \r\n```\r\n\r\nissplit 表示能否将巧克力分为K+1堆,同时最少的也至少有mid\r\n\r\n\r\n\r\n##### leetcode 410. Split Array Largest Sum\r\n\r\nGiven an array which consists of non-negative integers and an integer *m*, you can split the array into *m* non-empty continuous subarrays. Write an algorithm to minimize the largest sum among these *m* subarrays.\r\n\r\n**Note:**\r\nIf *n* is the length of array, assume the following constraints are satisfied:\r\n\r\n- 1 ≤ *n* ≤ 1000\r\n- 1 ≤ *m* ≤ min(50, *n*\r\n\r\n**Examples:**\r\n\r\n```\r\nInput:\r\nnums = [7,2,5,10,8]\r\nm = 2\r\n\r\nOutput:\r\n18\r\n\r\nExplanation:\r\nThere are four ways to split nums into two subarrays.\r\nThe best way is to split it into [7,2,5] and [10,8],\r\nwhere the largest sum among the two subarrays is only 18.\r\n```\r\n\r\n```\r\nclass Solution {\r\npublic:\r\n bool cansplit(vector<int>& nums, int m, int sum1){\r\n long long n = nums.size(), i = 0, temp = 0, k = 1;\r\n while(i < n){\r\n temp += nums[i];\r\n if(temp<=sum1) i++;\r\n else{\r\n temp = 0; k++;\r\n }\r\n }\r\n if(k<=m) return true;\r\n return false;\r\n }\r\n int splitArray(vector<int>& nums, int m) {\r\n long long left = 0, right = 0, mid;\r\n for(auto num: nums){\r\n left = max(left, (long long)num);\r\n right += num;\r\n }\r\n while (left< right){\r\n mid = (left+right)/2;\r\n if(cansplit(nums, m, mid)){\r\n right = mid;\r\n }\r\n else{\r\n left = mid + 1;\r\n }\r\n }\r\n return left;\r\n }\r\n}; \r\n```\r\n\r\n\r\n\r\nSplit Array Largest Sum 这类问题都是binary search\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n二分法 永远是\r\n\r\n```\r\nwhile left <right:\r\n\tmid=int((left+right)/2)\r\n if :\r\n right=mid \r\n else:\r\n left=mid+1\r\nreturn left\r\n```\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.512637197971344,
"alphanum_fraction": 0.548506498336792,
"avg_line_length": 20.833818435668945,
"blob_id": "aa0e003f5197d17b293a73b7201a29906cac9a1d",
"content_id": "6e1ca073448085e9a7a3beef74ae9ba2d6d72341",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 8030,
"license_type": "no_license",
"max_line_length": 258,
"num_lines": 343,
"path": "/leetcode_note/BrainTeaser.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### leetcode1267 Count Servers that Communicate\r\n\r\nYou are given a map of a server center, represented as a `m * n` integer matrix `grid`, where 1 means that on that cell there is a server and 0 means that it is no server. Two servers are said to communicate if they are on the same row or on the same column.\r\n\r\nReturn the number of servers that communicate with any other server.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n\r\n\r\n```\r\nInput: grid = [[1,0],[0,1]]\r\nOutput: 0\r\nExplanation: No servers can communicate with others.\r\n```\r\n\r\n**Example 2:**\r\n\r\n****\r\n\r\n```\r\nInput: grid = [[1,0],[1,1]]\r\nOutput: 3\r\nExplanation: All three servers can communicate with at least one other server.\r\n```\r\n\r\n**Example 3:**\r\n\r\n\r\n\r\n```\r\nInput: grid = [[1,1,0,0],[0,0,1,0],[0,0,1,0],[0,0,0,1]]\r\nOutput: 4\r\nExplanation: The two servers in the first row can communicate with each other. The two servers in the third column can communicate with each other. The server at right bottom corner can't communicate with any other server.\r\n```\r\n\r\n \r\n\r\n**Constraints:**\r\n\r\n- `m == grid.length`\r\n- `n == grid[i].length`\r\n- `1 <= m <= 250`\r\n- `1 <= n <= 250`\r\n- `grid[i][j] == 0 or `\r\n\r\n\r\n\r\n```python\r\nclass Solution:\r\n def countServers(self, grid: List[List[int]]) -> int:\r\n m = len(grid)\r\n if m==0:return 0\r\n n, res = len(grid[0]), 0\r\n rows, cols =[0 for i in range(m)], [0 for i in range(n)]\r\n for i in range(m):\r\n for j in range(n):\r\n if grid[i][j]==1:\r\n rows[i]+=1\r\n cols[j]+=1\r\n for i in range(m):\r\n for j in range(n):\r\n if grid[i][j]==1:\r\n if rows[i]>=2 or cols[j]>=2:\r\n res+=1\r\n return res\r\n \r\n \r\n```\r\n\r\n统计每条row 每个col分别有多少台server\r\n\r\n然后再遍历一遍 如果有rows[i]>2,或者cols[j]>2则说明这台server是连着的\r\n\r\n\r\n\r\n##### leetcode 470. Implement Rand10() Using Rand7()\r\n\r\nGiven a function `rand7` which generates a uniform random integer in the range 1 to 7, write a function `rand10` which generates a uniform random integer in the range 1 to 10.\r\n\r\nDo NOT use system's `Math.random()` \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: 1\r\nOutput: [7]\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: 2\r\nOutput: [8,4]\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: 3\r\nOutput: [8,1,10]\r\n```\r\n\r\n**Note:**\r\n\r\n1. `rand7` is predefined.\r\n2. Each testcase has one argument: `n`, the number of times that `rand10` is called.\r\n\r\n```python\r\n# The rand7() API is already defined for you.\r\n# def rand7():\r\n# @return a random integer in the range 1 to 7\r\n\r\nclass Solution:\r\n def rand10(self):\r\n \"\"\"\r\n :rtype: int\r\n \"\"\"\r\n r40 = (rand7() - 1) * 7 + (rand7() - 1)\r\n if r40 < 40:\r\n return r40 % 10 + 1\r\n \r\n return self.rand10()\r\n```\r\n\r\nrand7->rand48\r\n\r\n小于40的%10,大于40的重新来\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 1007 Minimum Domino Rotations For Equal Row\r\n\r\nIn a row of dominoes, `A[i]` and `B[i]` represent the top and bottom halves of the `i`-th domino. (A domino is a tile with two numbers from 1 to 6 - one on each half of the tile.)\r\n\r\nWe may rotate the `i`-th domino, so that `A[i]` and `B[i]` swap values.\r\n\r\nReturn the minimum number of rotations so that all the values in `A` are the same, or all the values in `B` are the same.\r\n\r\nIf it cannot be done, return `-1`.\r\n\r\n**Example 1:**\r\n\r\n\r\n\r\n```\r\nInput: A = [2,1,2,4,2,2], B = [5,2,6,2,3,2]\r\nOutput: 2\r\nExplanation: \r\nThe first figure represents the dominoes as given by A and B: before we do any rotations.\r\nIf we rotate the second and fourth dominoes, we can make every value in the top row equal to 2, as indicated by the second figure.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: A = [3,5,1,2,3], B = [3,6,3,3,4]\r\nOutput: -1\r\nExplanation: \r\nIn this case, it is not possible to rotate the dominoes to make one row of values equal.\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def minDominoRotations(self, A: List[int], B: List[int]) -> int:\r\n n, possi = len(A), set({1,2,3,4,5,6})\r\n for i in range(n):\r\n possi = possi & set({A[i], B[i]})\r\n if len(possi) == 0: return -1\r\n res = n\r\n for num in possi:\r\n count_a, count_b = 0, 0\r\n for i in range(n):\r\n if A[i] == num:\r\n count_a += 1\r\n if B[i] == num:\r\n count_b += 1\r\n res = min(res, n - count_a, n - count_b)\r\n return res\r\n \r\n \r\n```\r\n\r\n\r\n\r\n##### leetcode 418 Sentence Screen Fitting\r\n\r\nGiven a `rows x cols` screen and a sentence represented by a list of **non-empty** words, find **how many times** the given sentence can be fitted on the screen.\r\n\r\n**Note:**\r\n\r\n1. A word cannot be split into two lines.\r\n2. The order of words in the sentence must remain unchanged.\r\n3. Two consecutive words **in a line** must be separated by a single space.\r\n4. Total words in the sentence won't exceed 100.\r\n5. Length of each word is greater than 0 and won't exceed 10.\r\n6. 1 ≤ rows, cols ≤ 20,000.\r\n\r\n\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput:\r\nrows = 2, cols = 8, sentence = [\"hello\", \"world\"]\r\n\r\nOutput: \r\n1\r\n\r\nExplanation:\r\nhello---\r\nworld---\r\n\r\nThe character '-' signifies an empty space on the screen.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput:\r\nrows = 3, cols = 6, sentence = [\"a\", \"bcd\", \"e\"]\r\n\r\nOutput: \r\n2\r\n\r\nExplanation:\r\na-bcd- \r\ne-a---\r\nbcd-e-\r\n\r\nThe character '-' signifies an empty space on the screen\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput:\r\nrows = 4, cols = 5, sentence = [\"I\", \"had\", \"apple\", \"pie\"]\r\n\r\nOutput: \r\n1\r\n\r\nExplanation:\r\nI-had\r\napple\r\npie-I\r\nhad--\r\n\r\nThe character '-' signifies an empty space on the screen.\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def wordsTyping(self, sentence: List[str], rows: int, cols: int) -> int:\r\n line, left, i, count = 1, cols, 0, 0\r\n while line <= rows:\r\n if left >= len(sentence[i]):\r\n left -= len(sentence[i]) + 1\r\n i += 1\r\n else:\r\n left = cols\r\n line += 1\r\n if i == len(sentence):\r\n i = 0 \r\n count += 1\r\n return count\r\n```\r\n\r\nnaive 方法 TLE\r\n\r\n```python\r\nclass Solution:\r\n def wordsTyping(self, sentence, rows, cols):\r\n s = ' '.join(sentence)+' '\r\n start, l = 0,len(s)\r\n for i in range(rows):\r\n start+=cols\r\n while s[start % l]!=' ':\r\n start-=1\r\n start+=1\r\n return int(start/l)\r\n```\r\n\r\nstart表示每一行能真正用来print的长度之和 删除那些最后因为一个单词挤不下而舍弃的空格\r\n\r\n\r\n\r\n##### leetcode 41 First Missing Positive\r\n\r\nGiven an unsorted integer array, find the smallest missing positive integer.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [1,2,0]\r\nOutput: 3\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [3,4,-1,1]\r\nOutput: 2\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: [7,8,9,11,12]\r\nOutput: 1\r\n```\r\n\r\n**Note:**\r\n\r\nYour algorithm should run in *O*(*n*) time and uses constant extra space.\r\n\r\n```python\r\nclass Solution:\r\n def firstMissingPositive(self, nums: List[int]) -> int:\r\n temp = float(\"inf\")\r\n for num in nums:\r\n if num > 0:\r\n temp = min(temp, num)\r\n n = len(nums)\r\n for i in range(n):\r\n if nums[i] <= 0:\r\n nums[i] = temp\r\n for i in range(n):\r\n if abs(nums[i]) <= n:\r\n nums[abs(nums[i]) - 1] = -abs(nums[abs(nums[i]) - 1])\r\n print(nums)\r\n for i in range(n):\r\n if nums[i] > 0:\r\n return i + 1\r\n return n + 1\r\n \r\n```\r\n\r\n难度在于用nums记录,从而达到O(1) space complexity\r\n\r\n"
},
{
"alpha_fraction": 0.5877587795257568,
"alphanum_fraction": 0.5994599461555481,
"avg_line_length": 14.552238464355469,
"blob_id": "27fb4d30fbb3bb5aea45e735a755b0a511a91e73",
"content_id": "361f19cf9ca1b84b4c83d3fb80bfc21e8a30a48c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1188,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 67,
"path": "/social_network/Graph Laplacian.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Spectral Partitioning\r\n\r\nGraph Laplacian\r\n\r\nGraph G, \r\n\r\n**邻接矩阵A** Adjacency matrix\r\n\r\n如果$v_i,v_j$ 有边则$A(i,j)=1$ 否则$A(i,j)=0$ \r\n\r\n**邻接权重矩阵W** \r\n\r\n当所有的权重为1时, **A=W** \r\n\r\n**度矩阵D**\r\n\r\n只有对角线有值,$A(i,i)=Degree(i)$ \r\n\r\n\r\n\r\n\r\n\r\nGraph laplacian:\r\n$L(G)=D(G)-W(G)$\r\n\r\n\r\n\r\n##### eigenvalues and eigenvectors of Graph\r\n\r\n$A·x=\\lambda ·x$\r\n\r\n$x$ is the vector of labels \r\n\r\n$x=\\{...,x_i,..,x_j...\\} $, $x_i$ is the label of node i\r\n\r\n$A·x=y$ $y=\\{y_0,y_1,...y_n\\}$ \r\n\r\n$y_i$ is the sum of labels of neighbors of node i\r\n\r\nFor undirected graph, \r\n\r\n1. adjacency matrix is symmetric matrix \r\n2. eigenvectors are real and orthogonal\r\n\r\n\r\n\r\n##### Use laplacian to find a partition\r\n\r\nthe second smallest eigenvalue $\\lambda_2$\r\n\r\n \r\n$$\r\n\\lambda_2=min_x\r\n$$\r\n$x$ is an eigenvector\r\n\r\nwhat is the meaning of $x^TLx$ \r\n$$\r\nx^TLx=\\sum_{(i,j)\\in E} (x_i-x_j)^2\r\n$$\r\nall eigenvalues are positive or zero.\r\n\r\nthe smallest eigenvalue is zero\r\n\r\nIf the second smallest eigenvalue $\\lambda _2=0$ ,the graph is not connected.\r\n\r\nAnd if $\\lambda _2$is **small**, this suggests the graph is **nearly** disconnected.\r\n\r\n"
},
{
"alpha_fraction": 0.5528925657272339,
"alphanum_fraction": 0.5768595337867737,
"avg_line_length": 30.23214340209961,
"blob_id": "6aeaa59aaed42f5b558fc27867d8ae967bdac069",
"content_id": "38085424538bb108d9e581e82ada502f0e33ba64",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3630,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 112,
"path": "/math&&deeplearning/pytorch/pytorch_resnet.py",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "import os\r\nimport torch\r\nimport torch.nn as nn\r\nimport torch.nn.functional as F\r\nimport random\r\nimport time\r\nimport torch.optim as optim\r\nimport torch.utils.data as Data\r\nfrom torch.utils.data import DataLoader as DataLoader\r\nfrom torch.autograd import Variable\r\n\r\nfrom PIL import Image\r\nimport numpy as np\r\nfrom torchvision import transforms as T\r\nimport pretrainedmodels\r\n\r\n\r\nclass FaceDataSet(Data.Dataset):\r\n def __init__(self, set_config, transforms=None):\r\n self.transform = transforms\r\n self.imgs = open(set_config).readlines()\r\n\r\n def __getitem__(self, index):\r\n img_path, label = self.imgs[index].split()\r\n data = Image.open(img_path)\r\n if self.transform:\r\n data = self.transform(data)\r\n return data, int(label)\r\n def __len__(self):\r\n return len(self.imgs)\r\n\r\n \r\n\r\n\r\nclass Net(nn.Module):\r\n def __init__(self, model):\r\n super(Net,self).__init__()\r\n self.model = model\r\n self.fc1=nn.Linear(2048, 4096)\r\n self.fc2=nn.Linear(4096,10000)\r\n\r\n def forward(self,x):\r\n x=self.model.conv1(x)\r\n x=self.model.bn1(x)\r\n x=self.model.relu(x)\r\n x=self.model.maxpool(x)\r\n\r\n x=self.model.layer1(x)\r\n x=self.model.layer2(x)\r\n x=self.model.layer3(x)\r\n x=self.model.layer4(x)\r\n x1=self.model.avgpool(x)\r\n x1 = x1.view(-1, 2048)\r\n x2=self.fc1(x1)\r\n x3=self.fc2(x2)\r\n# print(\"the shape after max-pooling layer 1 is {fuck}\".format(fuck=x.size()))\r\n return x3\r\n\r\nif __name__ == \"__main__\":\r\n trainset_config = \"./dataset_config/trainconfig.txt\"\r\n testset_config = \"./dataset_config/valconfig.txt\"\r\n\r\n device = torch.device(\"cuda:2\" if torch.cuda.is_available() else \"cpu\")\r\n print(device)\r\n #net = Model()\r\n model_name='resnet18'\r\n model = pretrainedmodels.__dict__[model_name](num_classes=1000, pretrained='imagenet')\r\n net = Net(model)\r\n net = net.to(device)\r\n\r\n BATCH_SIZE=128\r\n EPOCHES = 10000\r\n INTERVAL = 10\r\n transform = T.Compose([\r\n T.Resize([256,256]),\r\n T.ToTensor(),\r\n T.Normalize(mean=[.5, .5, .5], std=[.5, .5, .5])\r\n ])\r\n criterion = nn.CrossEntropyLoss()\r\n optimizer = optim.Adadelta(net.parameters(), lr=1e-1)\r\n\r\n trainset = FaceDataSet(trainset_config, transform)\r\n testset = FaceDataSet(testset_config, transform)\r\n\r\n trainset_loader = DataLoader(trainset, batch_size = BATCH_SIZE, shuffle = True, num_workers=2, pin_memory = False)\r\n testset_loader = DataLoader(testset, batch_size = BATCH_SIZE, num_workers=2, pin_memory = False)\r\n\r\n for epoch in range(EPOCHES):\r\n running_loss = 0\r\n for i, data in enumerate(trainset_loader, 0):\r\n inputs, label = data\r\n inputs, label = inputs.to(device), label.to(device)\r\n optimizer.zero_grad()\r\n outputs = net(inputs)\r\n\r\n label = label.long()\r\n loss = criterion(outputs, label)\r\n loss.backward()\r\n optimizer.step()\r\n\r\n\r\n predicted = torch.argmax(outputs, 1)\r\n total = len(label)\r\n correct = (predicted == label).sum().float()\r\n accuracy = 100 * correct / total\r\n\r\n running_loss += loss.item()\r\n if i % INTERVAL == INTERVAL-1:\r\n print(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())), end=\" \")\r\n print(\"[%d, %5d] loss : %3f, accuracy : %3f\" % (epoch + 1, i + 1, running_loss/INTERVAL, accuracy))\r\n running_loss = 0\r\n print(\"Finish Trainning\")\r\n\r\n \r\n\r\n\r\n"
},
{
"alpha_fraction": 0.4625914990901947,
"alphanum_fraction": 0.49091893434524536,
"avg_line_length": 14.524663925170898,
"blob_id": "e8028badc85534fbacc8bf355df61156e7219bed",
"content_id": "6856e1a647d0af992a2ea8c2fe487fdfda2ebbcd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 10410,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 446,
"path": "/books/挑战程序设计竞赛.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 挑战程序设计竞赛\r\n\r\n##### DFS\r\n\r\n池塘积水 \r\n\r\n有一个大小为N×M的园子,雨后积起了水。八连通的积水被认为是连接在一起的。请求出\r\n园子里总共有多少水洼?\r\n\r\n使用DFS,从任意一个W开始将周围的W(水)都换成.(地),执行几次DFS就有几滩积水。\r\n\r\n```c++\r\n// 输入\r\nint N, M;\r\nchar field[MAX_N][MAX_M + 1]; // 园子\r\n// 现在位置(x,y)\r\nvoid dfs(int x, int y) {\r\n\t// 将现在所在位置替换为.\r\n\tfield[x][y] = '.';\r\n\t// 循环遍历移动的8个方向\r\n\tfor (int dx = -1; dx <= 1; dx++) {\r\n\t\tfor (int dy = -1; dy <= 1; dy++) {\r\n\t\t// 向x方向移动dx,向y方向移动dy,移动的结果为(nx,ny)\r\n\t\t\tint nx = x + dx, ny = y + dy;\r\n\t\t\t// 判断(nx,ny)是不是在园子内,以及是否有积水\r\n\t\t\tif (0 <= nx && nx < N && 0 <= ny && ny < M && field[nx][ny] == 'W')\r\n dfs(nx, ny);\r\n\t\t\t}\r\n\t\t}\r\n\treturn ;\r\n}\r\nvoid solve() {\r\n\tint res = 0;\r\n for (int i = 0; i < N; i++) {\r\n\t\tfor (int j = 0; j < M; j++) {\r\n\t\t\tif (field[i][j] == 'W') {\r\n\t\t\t// 从有W的地方开始dfs\r\n\t\t\tdfs(i, j);\r\n\t\t\tres++;\r\n\t\t\t}\r\n\t\t}\r\n\t}\r\n\tprintf(\"%d\\n\", res);\r\n}\r\n```\r\n\r\n\r\n\r\n##### BFS\r\n\r\n给定一个大小为N×M的迷宫。迷宫由通道和墙壁组成,每一步可以向邻接的上下左右四格\r\n的通道移动。请求出从起点到终点所需的最小步数。请注意,本题假定从起点一定可以移动\r\n到终点。\r\n\r\n\r\n\r\n```c++\r\nconst int INF = 100000000;\r\n// 使用pair表示状态时,使用typedef会更加方便一些\r\ntypedef pair<int, int> P;\r\n// 输入\r\nchar maze[MAX_N][MAX_M + 1]; // 表示迷宫的字符串的数组\r\nint N, M;\r\nint sx, sy; // 起点坐标\r\nint gx, gy; // 终点坐标\r\nint d[MAX_N][MAX_M]; // 到各个位置的最短距离的数组\r\n// 4个方向移动的向量\r\nint dx[4] = {1, 0, -1, 0}, dy[4] = {0, 1, 0, -1};\r\n// 求从(sx, sy)到(gx, gy)的最短距离\r\n// 如果无法到达,则是INF\r\nint bfs() {\r\n\tqueue<P> que;\r\n\t// 把所有的位置都初始化为INF\r\n\tfor (int i = 0; i < N; i++)\r\n\t\tfor (int j = 0; j < M; j++) d[i][j] = INF;\r\n\t\t// 将起点加入队列,并把这一地点的距离设置为0\r\n\t\t\tque.push(P(sx, sy));\r\n\t\t\td[sx][sy] = 0;\r\n\t\t\t// 不断循环直到队列的长度为0\r\n\t\t\twhile (que.size()) {\r\n\t\t\t\t// 从队列的最前端取出元素\r\n\t\t\t\tP p = que.front(); que.pop();\r\n\t\t\t\t// 如果取出的状态已经是终点,则结束搜索\r\n\t\t\t\tif (p.first == gx && p.second == gy) break;\r\n\t\t\t\t// 四个方向的循环\r\n\t\t\t\tfor (int i = 0; i < 4; i++) {\r\n\t\t\t\t\t// 移动之后的位置记为(nx, ny)\r\n\t\t\t\t\tint nx = p.first + dx[i], ny = p.second + dy[i];\r\n\t\t\t\t\t// 判断是否可以移动以及是否已经访问过(d[nx][ny]!=INF即为已经访问过)\r\n\t\t\t\t\tif (0 <= nx && nx < N && 0 <= ny && ny < M && maze[nx][ny] != '#' &&d[nx][ny] == INF) {\r\n\t\t\t\t\t\t// 可以移动的话,则加入到队列,并且到该位置的距离确定为到p的距离+1\r\n\t\t\t\t\t\tque.push(P(nx, ny));\r\n\t\t\t\t\t\td[nx][ny] = d[p.first][p.second] + 1;\r\n\t\t\t\t\t}\r\n\t\t\t\t}\r\n\t\t\t}\r\n\treturn d[gx][gy];\r\n}\r\nvoid solve() {\r\n\tint res = bfs();\r\n\tprintf(\"%d\\n\", res);\r\n}\r\n```\r\n\r\n走出迷宫最短步数,使用BFS,因此当某个点不是INF时(已经被访问过了),之后再访问同一个点不会更新最短的路径,这是BFS的特点。\r\n\r\n\r\n\r\n#### 贪心算法\r\n\r\n##### 硬币问题\r\n\r\n有1元 5元 10元 50元 100元 500元的硬币各C1 C5 C10 C50 C100 C500枚来支付A元,最少需要多少枚硬币,假设最少有一种解\r\n\r\n贪心:优先使用面值大的硬币\r\n\r\n```c++\r\nconst int V[6]={1,5,10,50,100,500};\r\nint C[6];\r\nint A;\r\nvoid solve(){\r\n int ans=0;\r\n for(int =5;i>=0;i--){\r\n int t=min(A/V[i],C[i]);\r\n A-=t*V[i];\r\n ans=ans+t\r\n }\r\n printf(\"%d\\n\",ans);\r\n}\r\n```\r\n\r\n\r\n\r\n##### 区间调度问题\r\n\r\n有n项工作,每项工作分别在si时间开始,在ti时间结束,可以选择是否参与,如果参与则需要从头做到尾。开始和结束的时间不能重合(瞬间重合也不行)\r\n\r\n\r\n\r\n这个问题的贪心算法可以想到很多种,例如:\r\n\r\n\t1.在可选的工作中选择开始时间最早的\r\n\r\n\t2.在可选的工作中选择结束时间最早的\r\n\r\n\t3.在可选的工作中选择用时最短的\r\n\r\n\t4.在可选的工作中选择重复最少的\r\n\r\n可以简单证明2是正确的算法\r\n\r\n```c++\r\npair<int,int>itv[MAX_N];\r\nvoid solve(){\r\n for(int i-0;i<N;i++){\r\n itv[i].first=T[i];\r\n itv[i].second=S[i];\r\n }\r\n sort(itv,itv+N);\r\n \r\n int ans=0,t=0;\r\n for(int i=0;i<N;i++){\r\n if(t<itv[i].seond){\r\n ans++;\r\n t=itv[i].first;\r\n }\r\n }\r\n printf(\"%d\\n\",ans);\r\n}\r\n```\r\n\r\n\r\n\r\n##### 字典序最小问题\r\n\r\n给定长度为N的字符串S,要构成一个长度N的字符串T,起初T损失一个空串,随后进行若干如下的操作:\r\n\r\n* 从S的头部删除一个字符,加到T的尾部\r\n* 从S的尾部删除一个字符,加到T的尾部\r\n\r\n目标是要构造尽可能小的字符串\r\n\r\n贪心:\r\n\r\n比较S的头部和尾部,选择较小的一个加到T的尾部\r\n\r\n\r\n\r\n#### DP\r\n\r\n##### 背包问题\r\n\r\nn个重量和价值为wi vi的物品,从这些物品中,从这些物品中挑出总重量不超过W的物品,求所选价值总和最大值\r\n\r\ndp[i,j]表示使用前i个物品,总重量不超过j\r\n\r\n```\r\n当j<w[i]: dp[i+1]=dp[i][j]\r\nelse:dp[i+1][j]=max(dp[i][j],dp[i][j-w[i]]]+v[i])\r\n```\r\n\r\n\r\n\r\n##### 最长公共子序列问题\r\n\r\n给定两个字符串,s和t,求出这两个字符串最长的公共子序列的长度。\r\n\r\ndp[i,j]表示长度前i的s和长度前j的t的最长公共字符串\r\n\r\n```\r\ndp[i+1][j+1]=dp[i][j]+1 si+1=tj+1\r\ndp[i+1][j+1]=max(dp[i][j+1],dp[i+1][j]) si+1!=tj+1\r\n```\r\n\r\n\r\n\r\n##### 最长上升子序列\r\n\r\n长度为n的数列 a0,a1.....,an-1,求出该序列中最长的上升子序列的长度。\r\n\r\na={4,2,3,1,5}最长上升子序列为2 3 5\r\n\r\n利用dp在O(n2)的时间复杂度内解决问题\r\n\r\n```\r\ndp[i]=max(1,dp[j]+1) j<i且aj<ai\r\n对每个i j从1~i-1遍历\r\n```\r\n\r\n\r\n\r\n### 树等数据结构\r\n\r\n##### 并查集\r\n\r\n\r\n\r\n\r\n\r\n#### 图\r\n\r\n给定一个具有n个顶点的图,给每个顶点上色,并且要使相邻的顶点颜色不同。是否能用最多两种颜色进行染色?\r\n\r\n如果只用两种颜色则意味着当某个顶点的颜色确定了之后其邻居的颜色也就确定了,因此可以用DFS或者BFS求解。\r\n\r\n```\r\nbool dfs(int v,int c){\r\n color[v]=c;\r\n for(int i=0;i<G[v].size();i++){\r\n\t\tif(color[G[v][i]]==c)return false;//相邻顶点同色,则false\r\n\t\tif(color[G[v][i]]==0&&!dfs(G[v][i],-c))//相邻顶点没被染色,则染色成-c\r\n\t\t\treturn false;\r\n\t}\r\n\treturn true;\r\n}\r\nvoid solve(){\r\n \tfor(int i=0;i<v;i++){\r\n if(color[i]==0){\r\n if(!dfs(i,1)){\r\n printf(\"NO\\n\");\r\n return;\r\n }\r\n }\r\n \t} \r\n \tprintf(\"YES\\n\");\r\n}\r\n```\r\n\r\n\r\n\r\n##### 最短路径问题\r\n\r\n##### 单源最短路径问题\r\n\r\n1.Bellman-Ford算法\r\n\r\n````c++\r\nvoid shortest_path(int s){\r\n\tfor(int i=0;i<V;i++)\r\n\t\td[i]=INF;\r\n\td[source]=0;\r\n\twhile(true){\r\n bool update=false;\r\n for(int i=0;i<E;i++){//遍历每条边更新,直到没有更新为止\r\n edge e=es[i];\r\n if(d[e.from]!=INF&&d[e.to]>d[e.from]+e.cost){\r\n d[e.to]=d[e.from]+e.cost;\r\n update=true;\r\n }\r\n }\r\n if(!update)break!;\r\n\t}\r\n}\r\n````\r\n\r\nO(VE)\r\n\r\n2. disjkstra算法\r\n\r\n```c++\r\nvoid dijkstra(int s){\r\n fill(d,d+V,INF);\r\n fill(used,used+V,false)\r\n \r\n\twhile(true){\r\n \tint v=-1;\r\n \t//从尚未使用过的顶点中选择一个距离最小的顶点\r\n \tfor(int u=0;u<V;u++){\r\n if(!used[u]&&(v==-1||d[u]<d[v]))v=u;//找到最短距离v\r\n \t}\r\n \tif(v==-1)break;//找不到最小距离的点;\r\n \tused[v]=true;\r\n \tfor(int u=0;u<V;u++){\r\n d[u]=min(d[u],d[v]+cost[v][u]);\r\n \t}\r\n }\r\n}\r\n```\r\n\r\nO(ElogV)\r\n\r\n##### 任意两点之间的最短路问题\r\n\r\n1. floyd-warshall\r\n\r\n```\r\nint d[MAX_V][MAX_V];\r\nint V;\r\n\r\nvoid warshall_floyd(){\r\n for(int k=0;k<V;k++){//先循环k\r\n for(int i=0;i<V;i++){\r\n for(int j=0;j<V;j++){\r\n d[i][j]=min(d[i][j],d[i][k]+d[k][j]);\r\n }\r\n }\r\n }\r\n}\r\n```\r\n\r\nO(V3)\r\n\r\n路径还原\r\n\r\n使用prev数组来记载前驱\r\n\r\n```\r\nvoid dijkstra(int s){\r\n fill(d,d+V,INF);\r\n fill(used,used+V,false)\r\n fill(prev,prev+V,-1)\r\n \r\n\twhile(true){\r\n \tint v=-1;\r\n \t//从尚未使用过的顶点中选择一个距离最小的顶点\r\n \tfor(int u=0;u<V;u++){\r\n if(!used[u]&&(v==-1||d[u]<d[v]))v=u;//找到最短距离v\r\n \t}\r\n \tif(v==-1)break;//找不到最小距离的点;\r\n \tused[v]=true;\r\n \tfor(int u=0;u<V;u++){\r\n \t\tif(d[u]>d[v]+cost[v][u]){\r\n \td[u]=d[v]+cost[v][u]\r\n \tprev[u]=v;\r\n \t\t}\r\n \t}\r\n }\r\n}\r\n```\r\n\r\n\r\n\r\n#### 数学技巧\r\n\r\n##### 线段上格点的个数\r\n\r\n给定平面上两个点P1=(x1,y1),P2=(x2,y2),线段P1P2上除了P1和P2之外还有几个点?\r\n\r\n1.检查所有min(x1,x2)<x<max(x1,x2),min(y1,y2)<y<max(y1,y2)的点\r\n\r\n复杂度太高\r\n\r\n答案是|x1-x2|,|y1-y2|的最大公约数-1\r\n\r\n\r\n\r\n#### 最小生成树\r\n\r\n将一个无向图展成一棵的形式\r\n\r\nprim算法\r\n\r\n```\r\nint prim(){\r\n for(int i=0;i<V;i++){\r\n mincost[i]=INF;\r\n used[i]=false;\r\n }\r\n while(true){\r\n\t\tint v=-1;\r\n\t\t//从没有连接的顶点中选择cost最小的\r\n\t\tfor(int u=0;u<V;u++){\r\n\t\t\tif(!used[u]&&(v==-1||mincost[u]<mincost[v]))\r\n\t\t\t\tv=u;\r\n\t\t}\r\n\t\tif(v==-1)break;\r\n\t\tused[v]=true;\r\n\t\tres+=mincost[v];\r\n\t\tfor(int u=0;u<V;u++){//将新的点加入之后更新距离数组\r\n mincost[u]=min(mincost[u],cost[v][u]);\r\n\t\t}\r\n\t}\r\n\treturn res;\r\n}\r\n```\r\n\r\n\r\n\r\n### ACM题目\r\n\r\n##### minimum scalar product\r\n\r\n有两个向量v1=(x1,x2,.....,xn),v2=(y1,y2,....,yn),可以调整向量中分量的位置,求两个向量相乘得到的最小积是多少。\r\n\r\n将v1升序排列 将v2降序排列\r\n\r\n##### bribe the prisoners\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n请输出(3+sqrt(5))^n 整数部分的最后三位\r\n\r\nn<=200000000\r\n\r\n朴素的计算在时间上肯定是不行的,多项式展开之后得到a+bsqrt(5)的形式\r\n$$\r\na_{i+1}=3a_i+5b_i\\\\\r\nb_{i+1}=a_{i}+3b_i\\\\\r\na_0=1,b_0=0\r\n$$\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.7331730723381042,
"alphanum_fraction": 0.7331730723381042,
"avg_line_length": 35.272727966308594,
"blob_id": "6e53beb7bdd144655cb7d2afee94191992c0ebaa",
"content_id": "1db89a35a8a9a865e4a83abb80a9c5bc75a33982",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 416,
"license_type": "no_license",
"max_line_length": 271,
"num_lines": 11,
"path": "/books/cracking coding interview.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Cracking coding interview\r\n\r\n##### interview\r\n\r\n```\r\n\"Why do you want to work for Microsoft?\"\r\n```\r\n\r\npassionate about technology\r\n\r\n\"I've been using Microsoft software as long as I can remember, and I'm really impressed at how Microsoft manages to create a product that is universally excellent. For example, I've been using Visual Studio recently to learn game programming, and its APls are excellent:'\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.600403904914856,
"alphanum_fraction": 0.6330063343048096,
"avg_line_length": 12.820512771606445,
"blob_id": "82fff38cfdef55bbed9c61f20e4fd45ee8cbdb5f",
"content_id": "0292a70c67111392eea8c326211a5970220f0b28",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6070,
"license_type": "no_license",
"max_line_length": 170,
"num_lines": 234,
"path": "/python/C++与python相同不同_32.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### C++与python相同不同\r\n\r\n传值还是传引用\r\n\r\n```python\r\ndef foo(arg):\r\n arg = 2\r\n print(arg)\r\n\r\na = 1\r\nfoo(a) # 输出:2\r\nprint(a) # 输出:1\r\n```\r\n\r\n```python\r\ndef bar(args):\r\n args.append(1)\r\n\r\nb = []\r\nprint(b)# 输出:[]\r\nprint(id(b)) # 输出:4324106952\r\nbar(b)\r\nprint(b) # 输出:[1]\r\nprint(id(b)) # 输出:4324106952\r\n```\r\n\r\npython中函数参数既可以是传值也可以是传引用(都不准确),python中一切皆对象,函数参数传的也是对象。如果传的是不可变对象,例如int,string等 就会表现出传值的性质(第一段代码),如果传的是可变对象就表现出传引用的性质(第二段代码),例如[]\r\n\r\n\r\n\r\n在设置函数默认参数时,最好不要使用可变对象作为默认值,函数定义好之后默认参数就会指向(绑定)一个空列表对象,每次调用函数时都是对同一个对象进行操作。\r\n\r\n\r\n\r\n```python\r\ndef bad_append(new_item, a_list=[]):\r\n a_list.append(new_item)\r\n return a_list\r\n \r\n>>> print bad_append('one')\r\n['one']\r\n>>> print bad_append('one')\r\n['one', 'one']\r\n```\r\n\r\n\r\n\r\nC++中函数有值传递、指针传递、引用传递这三种。\r\n\r\n**值传递:**形参是实参的拷贝,改变形参的值并不会影响外部实参的值。\r\n\r\n**指针传递:**形参为指向实参地址的指针,当对形参的指向操作时,就相当于对实参本身进行的操作\r\n\r\n**引用传递:**形参相当于是实参的“别名”,对形参的操作其实就是对实参的操作\r\n\r\n\r\n\r\npython中没有自增自减符,++i等\r\n\r\n\r\n\r\n对函数中return的限制\r\n\r\n在c/c++中有一个常见的错误:\"Not all control paths return a value\",如果有任何一条路径没有返回值,会报错。\r\n\r\n```c++\r\n// Error: not all control paths returns\r\nint f(bool flag)\r\n{\r\n if (flag)\r\n {\r\n return 1;\r\n }\r\n}\r\n```\r\n\r\n但对应的Python程序没有任何问题:\r\n\r\n```python\r\ndef f(flag):\r\n if flag:\r\n return 1\r\n \r\n>>> print (f(True))\r\n>>> 1\r\n>>> print (f(False))\r\n>>> None\r\n```\r\n\r\n\r\n\r\n##### 作用域\r\n\r\nC/C++中for loop循环变量的作用域仅限于for及对应的{}本身,for结束后该作用域消失。\r\n\r\n```c++\r\nfor (int i = 0; i < 10; ++i){\r\n ..\r\n}\r\n// v--- undeclared variable \"i\"\r\nif (i == 10)\r\n\r\n```\r\n\r\nPython中,for语句(以及while、if等)没有自己单独的作用域。循环变量i的作用域就是包含它的函数f的作用域。\r\n\r\n```python\r\ndef f():\r\n for i in range(10):\r\n ..\r\n // Ok!\r\n if i == 10:\r\n\r\n```\r\n\r\nPython作为一种动态语言,一个名字只要在使用前赋过值,就可以使用。\r\n\r\n\r\n\r\n##### for循环的最后一个值\r\n\r\npython和c++中for循环结束之后的i数值是不一样的。C++在每次循环结束后会++i,即使是最后一次循环。而由于Python有着不同的循环方式。\r\n\r\n```c++\r\nint i;\r\nfor (i = 0; i < 10; ++i)\r\n{\r\n ..\r\n if (found)\r\n break\r\n}\r\n// Not found\r\nif (i == 10)\r\n```\r\n\r\n```python\r\nfor i in range(10):\r\n if found:\r\n break\r\nelse:\r\n # Not found\r\n ..\r\nprint (i) # 9\r\n```\r\n\r\n\r\n\r\n##### 垃圾回收\r\n\r\n高级语言例如python,java,c#都采用了垃圾回收机制,不再是c,c++那种用户自己管理内存的方式。c/c++对内存的管理非常自由,但是存在内存泄漏等风险。\r\n\r\n**python采用的是引用计数机制为主,标记-清除和分代收集两种机制为辅的策略**\r\n\r\n在python中 对象的引用计数为0的时候,该对象生命就结束了。\r\n\r\n1.引用计数机制:\r\n\r\n优点:1.简单实用\r\n\r\n缺点:1.引用计数消耗资源 2.无法解决循环引用的问题\r\n\r\n2.标记清除\r\n\r\n\r\n\r\n确认一个根节点对象,然后迭代寻找根节点的引用对象,以及被引用对象的引用对象(标为灰色),然后将那些没有被引用的对象(白色)回收清除。\r\n\r\n3.分代回收\r\n\r\n分代回收是一种空间换时间的操作方式。python将内存根据对象划分为不同的集合。分别为年轻代0 中年代1 老年代2,对应三个链表。新创建的对象都会分配在新生代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象。\r\n\r\n\r\n\r\nGC系统提供了1.为新对象分配内存 2.识别哪些对象是垃圾 3.将垃圾的内存回收\r\n\r\n\r\n\r\n\r\n\r\nc++垃圾回收机制\r\n\r\nc语言中显然没有GC(Garbage Collection)系统,C语言使用mallloc进行分配,free回收。\r\n\r\nc++中提供了基于引用计算算法的智能指针进行内存管理。\r\n\r\n\r\n\r\n##### 运行效率\r\n\r\nc++是一种编译型语言,运行效率高,python是一种解释型语言,运行效率低\r\n\r\npython比c++慢的原因主要在于:\r\n\r\n1.动态类型\r\n\r\n在运行时需要不断判断数据类型,带来一定的开销\r\n\r\n2.python执行的时候通过python解释器(Interpreter)一条条翻译成字节码文件\r\n\r\n3.由虚拟机来执行刚刚解释器得到的字节码文件,需要开销\r\n\r\n4.GIL Global Interpreter Lock\r\n\r\nGIL 只允许一个线程拥有python解释器,因此带来了伪多线程问题,效率低\r\n\r\n\r\n\r\nc++则是直接编译为二进制可执行文件,效率高\r\n\r\n\r\n\r\nint类型字节数 大小\r\n\r\n在c++和java中,int类型占据了4个字节的大小,\r\n\r\n在python中int类型的大小可以用`sys.getsizeof`这个API知道\r\n\r\n```\r\nprint(sys.getsizeof(0)) # 24\r\nprint(sys.getsizeof(1)) # 28\r\nprint(sys.getsizeof(2)) # 28\r\nprint(sys.getsizeof(2**15)) # 28\r\nprint(sys.getsizeof(2**30)) # 32\r\nprint(sys.getsizeof(2**128)) # 44\r\n```\r\n\r\n\r\n\r\n一个整型最少要占24字节(0),1开始就要占用28个字节,到了2的30次方开始要占用32个字节,而2的128次方则要占用44个字节。\r\n\r\n1. 字节数随着数字增大而增大。\r\n2. 每次的增量是4个字节。\r\n\r\npython64与python32不同"
},
{
"alpha_fraction": 0.4747356176376343,
"alphanum_fraction": 0.5031055808067322,
"avg_line_length": 23.233051300048828,
"blob_id": "6b208264ab1867a38d18decf4de8f6f9b3412e8d",
"content_id": "50b1dbfe0ab34a9934867b871c006c87a5f44a88",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6813,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 236,
"path": "/algorithm/algorithm.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 回溯法 Dijkstra算法 topilogical sort BFS DFS\r\n#### dijkstra:\r\n\r\n```python\r\n# dijkstra算法实现\r\ndef dijkstra(graph, src):\r\n # 判断图是否为空\r\n if graph is None:\r\n return None\r\n nodes = [i for i in range(len(graph))] # 获取图中所有节点\r\n visited = [] # 表示已经路由到最短路径的节点集合\r\n if src in nodes:\r\n visited.append(src)\r\n nodes.remove(src)\r\n else:return None\r\n distance = {src: 0} # 记录源节点到各个节点的距离\r\n for i in nodes:\r\n distance[i] = graph[src][i] # 初始化\r\n path = {src: {src: []}} # 记录源节点到每个节点的路径\r\n\r\n while nodes:\r\n temp_distance = float('inf')\r\n # 遍历所有的v(visited)与d(unvisited),寻找最短的temp_distance,即最小的distance[k](其中k unvisited),接着将k作为新的点visit,d是k点的pre,用于记录path\r\n for v in visited:\r\n for d in nodes:\r\n if graph[src][v] + graph[v][d] < temp_distance:\r\n temp_distance = graph[src][v] + graph[v][d]\r\n graph[src][d] = graph[src][v] + graph[v][d] # 进行距离更新\r\n k = d\r\n pre = v\r\n distance[k] = temp_distance # 最短路径\r\n path[src][k] = [i for i in path[src][pre]]\r\n path[src][k].append(k)\r\n # 更新两个节点集合\r\n visited.append(k)\r\n nodes.remove(k)\r\n #print(visited, nodes) # 输出节点的添加过程\r\n return distance, path\r\n\r\n\r\nif __name__ == '__main__':\r\n graph_list = [[0, 2, 1, 4, 5, 1],\r\n [1, 0, 4, 2, 3, 4],\r\n [2, 1, 0, 1, 2, 4],\r\n [3, 5, 2, 0, 3, 3],\r\n [2, 4, 3, 4, 0, 1],\r\n [3, 4, 7, 3, 1, 0]]\r\n\r\n distance, path = dijkstra(graph_list, 0) # 查找从源点0开始带其他节点的最短路径\r\n print(\"the distance\")\r\n print(distance)\r\n print(\"path\")\r\n print(path)\r\n```\r\n\r\n```\r\nthe distance\r\n{0: 0, 1: 2, 2: 1, 3: 2, 4: 2, 5: 1}\r\npath\r\n{0: {0: [], 2: [2], 5: [5], 1: [1], 3: [2, 3], 4: [5, 4]}}\r\n```\r\n\r\ndijkstra算法的核心思想是将所有的点分为visited和unvisited两类\r\n\r\n对于利用所有的visited点来寻找unvisited中距离src点最近的点k,并将其并入visited中\r\n\r\n```\r\nfor v in visited:\r\n for d in nodes:\r\n if graph[src][v] + graph[v][d] < temp_distance:\r\n temp_distance = graph[src][v] + graph[v][d]\r\n graph[src][d] = graph[src][v] + graph[v][d] # 进行距离更新\r\n k = d\r\n```\r\n\r\n这一步就是在寻找k,体会如何利用所有的visited点寻找unvisited中距离src最近的k\r\n\r\n```\r\nhttps://zh.wikipedia.org/wiki/%E6%88%B4%E5%85%8B%E6%96%AF%E7%89%B9%E6%8B%89%E7%AE%97%E6%B3%95\r\n```\r\n\r\n\r\n\r\nmatrix:\r\n\r\n```\r\nhttps://en.wikipedia.org/wiki/Dijkstra%27s_algorithm\r\n```\r\n\r\n\r\n\r\n* ```\r\n graph_list2=[[0,0,1,2],[1,3,2,1],[1000,1000,5,1000],[1,2,3,4]]\r\n ```\r\n\r\n```python\r\n# dijkstra算法实现\r\ndef dijkstra(graph,rows,cols,src_row,src_col,t_row,t_col):\r\n visited,unvisited=set(),set() #visited,unvisited set\r\n for i in range(rows):\r\n for j in range(cols):\r\n unvisited.add((i,j))\r\n if (src_row,src_col) not in unvisited:\r\n return\r\n dist=[[float(\"inf\") for i in range(cols)]for j in range(rows)]\r\n dist[src_row][src_col]=0 #dist[i][j]表示 从source点到[i][j]点所需的距离\r\n\r\n unvisited.remove((src_row,src_col))\r\n visited.add((src_row,src_col))\r\n\r\n while unvisited:\r\n temp_dis=float(\"inf\")\r\n temp=(src_row,src_col)\r\n for (i,j) in visited:#对每一个visited点拿出来考虑,看其周围的unvisited的邻居,选择一个距离source点最近的作为新纳入visited集合中的点\r\n if (i-1,j) in unvisited:\r\n if dist[i][j]+graph[i-1][j]<temp_dis:\r\n temp,temp_dis=(i-1,j),dist[i][j]+graph[i-1][j]\r\n if (i+1,j) in unvisited:\r\n if dist[i][j]+graph[i+1][j]<temp_dis:\r\n temp,temp_dis=(i+1,j),dist[i][j]+graph[i+1][j]\r\n if (i,j-1) in unvisited:\r\n if dist[i][j]+graph[i][j-1]<temp_dis:\r\n temp,temp_dis=(i,j-1),dist[i][j]+graph[i][j-1]\r\n if (i,j+1) in unvisited:\r\n if dist[i][j]+graph[i][j+1]<temp_dis:\r\n temp,temp_dis=(i,j+1),dist[i][j]+graph[i][j+1]\r\n if temp_dis>=1000: #wall,只剩下wall \r\n break\r\n dist[temp[0]][temp[1]]=temp_dis \r\n visited.add(temp)#visit\r\n unvisited.remove(temp)\r\n #if temp==(t_row,t_col):\r\n #break\r\n return dist[t_row][t_col],dist\r\n```\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n```c++\r\nbool TopSort(LGraph G,int TopOrder[]){\r\n\tint nums[MaxVertexNum];\r\n\tint i=0,j=0;\r\n\tPtrToAdjVNode temp;\r\n\tfor(i=0;i<G->Nv;i++){\r\n\t\tnums[i]=0;\r\n\t}\r\n\tfor(i=0;i<G->Nv;i++){\r\n\t\ttemp=(G->G[i]).FirstEdge;\r\n\t\twhile(temp!=NULL){\r\n\t\t\tnums[temp->AdjV]++;\r\n\t\t\ttemp=temp->Next;\r\n\t\t}\r\n\t}\r\n\tfor(i=0;i<G->Nv;i++){\r\n\t\tfor(i=0;i<G->Nv;i++){\r\n\t\t\tif(nums[i]==0){\r\n\t\t\t\tTopOrder[j]=i;j++;\r\n\t\t\t}\r\n\t\t}\r\n\t\tfor(i=0;i<G->Nv;i++){\r\n \t\t\ttemp=(G->G[TopOrder[i]]).FirstEdge;\r\n \t\t\twhile(temp!=NULL){\r\n \t\t\tnums[temp->AdjV]--;\r\n \t\t\tif(nums[temp->AdjV]==0){\r\n \t\t\t\tTopOrder[j]=temp->AdjV;\r\n \t\t\t\tj++;\r\n \t\t\t\t}\r\n \t\t\t\ttemp=temp->Next;\r\n\t\t\t}\r\n \t\t\tif(i==j)\r\n\t\t\t\treturn false;\r\n \t\t}\r\n\t}\r\n\treturn true;\r\n}\r\n```\r\n\r\n#### 回溯法\r\n\r\n```c++\r\n#include <iostream>\r\n#include <vector>\r\nusing namespace std;\r\nvoid find(vector<int> &a,vector<int> &t,int index,int n,vector<vector<int>>& ans,int length){\r\n if(t.size() == length){\r\n ans.push_back(t);\r\n return;\r\n }\r\n for(int i=index;i<n;i++){\r\n t.push_back(a[i]);\r\n find(a,t,i+1,n,ans,length);\r\n t.pop_back();\r\n }\r\n}\r\nint main() {\r\n vector<vector<int>> ans;\r\n vector<int> a,t;\r\n a.push_back(2);\r\n a.push_back(1);\r\n a.push_back(3);\r\n int length=0;\r\n int n=a.size();\r\n for(int i=1;i<=n;i++){\r\n length++;\r\n find(a,t,0,n,ans,length);\r\n }\r\n for(int i=0;i<ans.size();i++){\r\n for(int j=0;j<ans[i].size();j++)\r\n cout<<ans[i][j]<<\" \";\r\n cout<<endl;\r\n }\r\n return 0;\r\n}\r\n```\r\n\r\n\r\n\r\n##### 逆序数计算\r\n\r\n什么是逆序数:逆序对:数列a[1],a[2],a[3]…中的任意两个数a[i],a[j] (i<j),如果a[i]>a[j],那么我们就说这两个数构成了一个逆序对。\r\n\r\n1.O(N2)对于数列中每个a[i],遍历a[j],如果a[i]>a[j]则逆序数+1\r\n\r\n2.O(NlogN)归并排序的拓展\r\n\r\n将数列分成两部分递归,整个数组的逆序数=左侧数组的逆序数+右侧数组的逆序数+左右两个数组merge时产生的逆序数\r\n\r\n\r\n\r\n变种:两个数组的逆序数对\r\n\r\na[i]>a[j], b[i]<b[j]\r\n\r\n"
},
{
"alpha_fraction": 0.7580645084381104,
"alphanum_fraction": 0.7903226017951965,
"avg_line_length": 18.66666603088379,
"blob_id": "a51c55583aa9ef888a223a7a1e957c7bf8f9571f",
"content_id": "6c7ee522c0d7b944048ab45d6ca0bb3d39ffd76c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 148,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 3,
"path": "/algorithm/techniques.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "#小技巧\r\n对于每个数都必须加K或者减K 的时候可以改成\r\n加2*K或者0 这样可以保持很多数不变,在O(n)的时间完成\r\n"
},
{
"alpha_fraction": 0.8104575276374817,
"alphanum_fraction": 0.8104575276374817,
"avg_line_length": 48.33333206176758,
"blob_id": "e0ef7090da9c4437bdbbfc48c8394d32ced243e4",
"content_id": "3c4cbdcf6430231eab3dd052859bec16279503cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 153,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 3,
"path": "/papers/A Survey of Heterogeneous Information Network Analysis.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### A Survey of Heterogeneous Information Network Analysis\r\n\r\nMost real systems consists multi typed components as Heterogeneous information network.\r\n\r\n"
},
{
"alpha_fraction": 0.516515851020813,
"alphanum_fraction": 0.5513574481010437,
"avg_line_length": 19.240385055541992,
"blob_id": "777e7059e82bbbd8799202af1b2a4d152f1089a1",
"content_id": "6319776da04bc362876a9beb7e8c4e9a42c2294e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5222,
"license_type": "no_license",
"max_line_length": 174,
"num_lines": 208,
"path": "/leetcode_note/Bit.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "使用位运算表示集合(LeetCode 78)\r\n\r\n位运算应用题目(LeetCode 136,137,260)\r\n\r\n##### leetcode 78 Subsets\r\n\r\nGiven a set of **distinct** integers, *nums*, return all possible subsets (the power set).\r\n\r\n**Note:** The solution set must not contain duplicate subsets.\r\n\r\n**Example:**\r\n\r\n```\r\nInput: nums = [1,2,3]\r\nOutput:\r\n[\r\n [3],\r\n [1],\r\n [2],\r\n [1,2,3],\r\n [1,3],\r\n [2,3],\r\n [1,2],\r\n []\r\n]\r\n```\r\n\r\n```python\r\ndef get_subset(mask, nums):\r\n ans = []\r\n bin_ = bin(mask)[2:] #转化为二进制\r\n bin_ = '0' * (len(nums) - len(bin_)) + bin_\r\n for i in range(len(bin_)):\r\n if bin_[i] == '1':\r\n ans.append(nums[i])\r\n return ans\r\n\r\n\r\nclass Solution:\r\n def subsets(self, nums):\r\n \"\"\"\r\n :type nums: List[int]\r\n :rtype: List[List[int]]\r\n \"\"\"\r\n ans = []\r\n mask = (2 ** len(nums)) - 1\r\n\r\n while mask >= 0:\r\n ans.append(get_subset(mask, nums))\r\n mask -= 1\r\n return ans\r\n\r\ns1 = Solution()\r\nnums = [1,2,3]\r\nprint(s1.subsets(nums))\r\n```\r\n\r\n\r\n\r\n##### leetcode 136. Single Number\r\n\r\nGiven a **non-empty** array of integers, every element appears *twice* except for one. Find that single one.\r\n\r\n**Note:**\r\n\r\nYour algorithm should have a linear runtime complexity. Could you implement it without using extra memory?\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [2,2,1]\r\nOutput: 1\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [4,1,2,1,2]\r\nOutput: 4\r\n```\r\n\r\n```python\r\nclass Solution(object):\r\n def singleNumber(self, nums):\r\n n=len(nums)\r\n for i in range(1,n):\r\n nums[0]=nums[0]^nums[i]\r\n return nums[0]\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 137 Single Number II\r\n\r\nGiven a **non-empty** array of integers, every element appears *three* times except for one, which appears exactly once. Find that single one.\r\n\r\n**Note:**\r\n\r\nYour algorithm should have a linear runtime complexity. Could you implement it without using extra memory?\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [2,2,3,2]\r\nOutput: 3\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [0,1,0,1,0,1,99]\r\nOutput: 99\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def singleNumber(self, nums):\r\n \"\"\"\r\n :type nums: List[int]\r\n :rtype: int\r\n \"\"\"\r\n n,dict1=len(nums),{}\r\n for i in range(n):\r\n if nums[i] not in dict1:\r\n dict1[nums[i]]=1\r\n else:\r\n dict1[nums[i]]+=1\r\n for key,value in dict1.items():\r\n if value==1:\r\n return key\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def singleNumber(self, nums):\r\n ones, twos = 0, 0\r\n for i in range(len(nums)):\r\n ones = (ones ^ nums[i]) & ~twos\r\n twos = (twos ^ nums[i]) & ~ones\r\n return ones\r\n\r\ns1 = Solution()\r\nnums = [2,2,3,2]\r\nprint(s1.singleNumber(nums))\r\n```\r\n\r\n\r\n\r\n##### leetcode 260 Single Number III\r\n\r\nGiven an array of numbers `nums`, in which exactly two elements appear only once and all the other elements appear exactly twice. Find the two elements that appear only once.\r\n\r\n**Example:**\r\n\r\n```\r\nInput: [1,2,1,3,2,5]\r\nOutput: [3,5]\r\n```\r\n\r\n**Note**:\r\n\r\n1. The order of the result is not important. So in the above example, `[5, 3]` is also correct.\r\n2. Your algorithm should run in linear runtime complexity. Could you implement it using only constant space complexity?\r\n\r\n```\r\n这个题的初级版本中 ,只有一个数出现一次,xor 一遍即可得到答案。为什么呢?\r\n\r\nA xor A=0\r\n0 xor A=A\r\n并且 xor 满足交换律和结合律。\r\n比如 2 2 3 1 3,2 xor 2 xor 3 xor 1 xor 3\r\n= 2 xor 2 xor 3 xor 3 xor 1\r\n=(2 xor 2) xor (3 xor 3) xor 1\r\n= 0 xor 0 xor 1\r\n= 1\r\n\r\n在这道加强版的题目里,也会很自然的想到 xor 一遍,那结果是什么呢。假设只出现一次的两个数是 A、B,那我们最后只能得到一个值 = A xor B,但没有办法知道 A 是多少,B 是多少。\r\n那得到的这个值有没有用呢?有,xor 是按位比较,相同为0,不同为1,也就是说得到的这个值里,所有的1都代表了:在这个位置上,A 和 B 是不同的,这给我们区分 A B 提供了一个方法:\r\n\r\n我们随便找一个是1的位置(也就是 A和B 在这个位置上的值反正有一个是0 有一个是1),再次遍历一遍数组,按照这个位置上是0还是1分成两组,那么 A 和 B 一定会被分开。而对于其他的数字,无论他们在这个位置上是0还是1,总之他们会两两一对分到两个组中的任意一个组里去。\r\n\r\n这就转化成了初级版本的问题了,每个组中都只有一个数出现1次,对两个组分别做一次xor ,得到两个数就是 A 和 B。\r\n```\r\n\r\n```python\r\nclass Solution(object):\r\n def singleNumber(self, nums):\r\n \"\"\"\r\n :type nums: List[int]\r\n :rtype: List[int]\r\n \"\"\"\r\n xor = 0\r\n a = 0\r\n b = 0\r\n for num in nums:\r\n xor ^= num\r\n mask = 1\r\n while(xor&mask == 0): #找xor不为0的一位,接着分成两个数组异或\r\n mask = mask << 1\r\n for num in nums:\r\n if num&mask:\r\n a ^= num\r\n else:\r\n b ^= num\r\n return [a, b]\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.6603606343269348,
"alphanum_fraction": 0.669524073600769,
"avg_line_length": 19.15625,
"blob_id": "62922189bd4dda6c36db7192f0511914a940a636",
"content_id": "e0dab0218956e63587639ec3a2f399060fce91f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4599,
"license_type": "no_license",
"max_line_length": 190,
"num_lines": 160,
"path": "/python/cc++ 与python通信.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "https://www.zhihu.com/question/23003213\r\n\r\n##### c/c++ 调用python\r\n\r\nPython 本身就是一个C库。\r\n\r\n```c++\r\n//my_python.c\r\n#include <Python.h>\r\n\r\nint main(int argc, char *argv[])\r\n{\r\n Py_SetProgramName(argv[0]);\r\n Py_Initialize();\r\n PyRun_SimpleString(\"print 'Hello Python!'\\n\");\r\n Py_Finalize();\r\n return 0;\r\n}\r\n```\r\n\r\n在Windows平台下,打开Visual Studio命令提示符,编译命令为\r\n\r\n```text\r\ncl my_python.c -IC:\\Python27\\include C:\\Python27\\libs\\python27.lib\r\n```\r\n\r\n在Linux下编译命令为\r\n\r\n```text\r\ngcc my_python.c -o my_python -I/usr/include/python2.7/ -lpython2.7\r\n```\r\n\r\n首先,复用Python模块得做‘import’,这里也不例外。所以我们把great_function放到一个module里,比如说,这个module名字叫 great_module.py\r\n\r\n接下来就要用C来调用Python了,完整的代码如下:\r\n\r\n```c\r\n#include <Python.h>\r\n\r\nint great_function_from_python(int a) {\r\n int res;\r\n PyObject *pModule,*pFunc;\r\n PyObject *pArgs, *pValue;\r\n \r\n /* import */\r\n pModule = PyImport_Import(PyString_FromString(\"great_module\"));\r\n\r\n /* great_module.great_function */\r\n pFunc = PyObject_GetAttrString(pModule, \"great_function\"); \r\n \r\n /* build args */\r\n pArgs = PyTuple_New(1);\r\n PyTuple_SetItem(pArgs,0, PyInt_FromLong(a));\r\n \r\n /* call */\r\n pValue = PyObject_CallObject(pFunc, pArgs);\r\n \r\n res = PyInt_AsLong(pValue);\r\n return res;\r\n}\r\n```\r\n\r\n从上述代码可以窥见Python内部运行的方式:\r\n\r\n- 所有Python元素,module、function、tuple、string等等,实际上都是PyObject。C语言里操纵它们,一律使用PyObject *。\r\n- Python的类型与C语言类型可以相互转换。Python类型XXX转换为C语言类型YYY要使用PyXXX_AsYYY函数;C类型YYY转换为Python类型XXX要使用PyXXX_FromYYY函数。\r\n- 也可以创建Python类型的变量,使用PyXXX_New可以创建类型为XXX的变量。\r\n- 若a是Tuple,则a[i] = b对应于 PyTuple_SetItem(a,i,b),有理由相信还有一个函数PyTuple_GetItem完成取得某一项的值。\r\n- 不仅Python语言很优雅,Python的库函数API也非常优雅。\r\n\r\n现在我们得到了一个C语言的函数了,可以写一个main测试它\r\n\r\n```c\r\n#include <Python.h>\r\n\r\nint great_function_from_python(int a); \r\n\r\nint main(int argc, char *argv[]) {\r\n Py_Initialize();\r\n printf(\"%d\",great_function_from_python(2));\r\n Py_Finalize();\r\n}\r\n```\r\n\r\n编译的方式就用本节开头使用的方法。\r\n\r\n在Linux/Mac OSX运行此示例之前,可能先需要设置环境变量:\r\n\r\nbash:\r\n\r\n```text\r\nexport PYTHONPATH=.:$PYTHONPATH\r\n```\r\n\r\ncsh:\r\n\r\n```text\r\nsetenv PYTHONPATH .:$PYTHONPATH\r\n```\r\n\r\n2 Python 调用 C/C++(基础篇)\r\n\r\n这种做法称为Python扩展。\r\n\r\n比如说,我们有一个功能强大的C函数:\r\n\r\n```text\r\nint great_function(int a) {\r\n return a + 1;\r\n}\r\n```\r\n\r\n期望在Python里这样使用:\r\n\r\n```text\r\n>>> from great_module import great_function \r\n>>> great_function(2)\r\n3\r\n```\r\n\r\n考虑最简单的情况。我们把功能强大的函数放入C文件 great_module.c 中。\r\n\r\n```c\r\n#include <Python.h>\r\n\r\nint great_function(int a) {\r\n return a + 1;\r\n}\r\n\r\nstatic PyObject * _great_function(PyObject *self, PyObject *args)\r\n{\r\n int _a;\r\n int res;\r\n\r\n if (!PyArg_ParseTuple(args, \"i\", &_a))\r\n return NULL;\r\n res = great_function(_a);\r\n return PyLong_FromLong(res);\r\n}\r\n\r\nstatic PyMethodDef GreateModuleMethods[] = {\r\n {\r\n \"great_function\",\r\n _great_function,\r\n METH_VARARGS,\r\n \"\"\r\n },\r\n {NULL, NULL, 0, NULL}\r\n};\r\n\r\nPyMODINIT_FUNC initgreat_module(void) {\r\n (void) Py_InitModule(\"great_module\", GreateModuleMethods);\r\n}\r\n```\r\n\r\n除了功能强大的函数great_function外,这个文件中还有以下部分:\r\n\r\n- 包裹函数_great_function。它负责将Python的参数转化为C的参数(PyArg_ParseTuple),调用实际的great_function,并处理great_function的返回值,最终返回给Python环境。\r\n- 导出表GreateModuleMethods。它负责告诉Python这个模块里有哪些函数可以被Python调用。导出表的名字可以随便起,每一项有4个参数:第一个参数是提供给Python环境的函数名称,第二个参数是_great_function,即包裹函数。第三个参数的含义是参数变长,第四个参数是一个说明性的字符串。导出表总是以{NULL, NULL, 0, NULL}结束。\r\n- 导出函数initgreat_module。这个的名字不是任取的,是你的module名称添加前缀init。导出函数中将模块名称与导出表进行连接。"
},
{
"alpha_fraction": 0.4761904776096344,
"alphanum_fraction": 0.6218487620353699,
"avg_line_length": 5.317406177520752,
"blob_id": "af3238db525ede6c955850efea8a6b6bd3b2ae4b",
"content_id": "3d3b48d99e0542089e60f32cf98f255544725eae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3762,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 293,
"path": "/books/算法导论.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 算法导论\r\n\r\n重要问题与算法:\r\n\r\n插入排序 P9\r\n\r\n归并排序 P17\r\n\r\n在归并排序中对小数组采用插入排序P22 2-1\r\n\r\n逆序对 P24 2-4\r\n\r\n最大子数组问题 P38\r\n\r\nstrassen 矩阵乘法方法 P45\r\n\r\n堆排序(建堆 堆排序)P84\r\n\r\nd叉堆 P93\r\n\r\n快排 P95\r\n\r\n相同元素的快排 P104\r\n\r\n三数取中 P105\r\n\r\n对区间的模糊排序 P106\r\n\r\n计数排序 P108\r\n\r\n基数排序 P110\r\n\r\n桶排序 P112\r\n\r\n有序数列的i个最大数 P125\r\n\r\n栈 P129\r\n\r\n队列 P130\r\n\r\n链表 P131\r\n\r\n搜索已排序的紧凑链表 P139\r\n\r\n散列 P152\r\n\r\n二叉搜索树 P160\r\n\r\n带有相同关键字的二叉搜索树 P171\r\n\r\n红黑树 P175\r\n\r\nAVL树 P189\r\n\r\ntreap树 P189\r\n\r\n区间树 P198\r\n\r\n动态规划:\r\n\r\n\t钢条切割问题 P204\r\n\r\n\t矩阵链乘法 P210\r\n\r\n最长公共子序列问题 P222\r\n\r\n最优二叉搜索树 P226\r\n\r\n有向无环图的最长简单路径 P231\r\n\r\n最长回文子序列 P231\r\n\r\n活动选择问题 P237\r\n\r\n贪心算法:\r\n\r\n\t01背包问题 P243\r\n\r\n\t分数背包问题 P243\r\n\r\n赫夫曼编码 P245\r\n\r\n用拟阵求解任务调度问题 P253\r\n\r\n找零问题、最小平均完成时间调度问题、无环子图、调度问题变形、离线缓存\r\n\r\nB树 P281\r\n\r\n斐波那契堆 P291\r\n\r\nVEB树 P306\r\n\r\n不相交集合P324\r\n\r\nBFS P343\r\n\r\n最短路径 P346\r\n\r\nDFS P349\r\n\r\n拓扑排序 P355\r\n\r\n最小生成树 P362\r\n\r\n\tKruskal算法\r\n\r\n\tPrim算法\r\n\r\n单源最短路径 P374\r\n\r\n\tBellman-Ford算法\r\n\r\n\tDijkstra算法\r\n\r\n最大流问题 P415\r\n\r\n最大二分类问题 P428\r\n\r\n逃逸问题、最小路径覆盖问题\r\n\r\n字符串匹配 P577\r\n\r\n寻找凸包 P605\r\n\r\nNP问题\r\n\r\n\t团问题\r\n\r\n\t顶点覆盖问题\r\n\r\n\t哈密顿回路问题\r\n\r\n\t旅行商问题\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n插入排序 P9\r\n\r\n归并排序 P17\r\n\r\n在归并排序中对小数组采用插入排序P22 2-1\r\n\r\n##### 逆序对 P24 2-4\r\n\r\n归并算法计算逆序数\r\n\r\n\r\n\r\n##### 最大子数组问题 P38\r\n\r\nif sum<0:\r\n\r\n\tsum=0\r\n\r\n\r\n\r\n##### strassen 矩阵乘法方法 P45\r\n\r\n普通矩阵乘法:C=A*B\r\n\r\n如果A,B都是n*n的矩阵,C中的每个元素都需要n次乘法与n次加法。时间复杂度为O(n^3)。\r\n\r\nstrassen算法只递归进行7次而不是8次n/2*n/2矩阵的乘法\r\n\r\nO(N^(lg7))\r\n\r\n\r\n\r\n堆排序(建堆 堆排序)P84\r\n\r\nd叉堆 P93\r\n\r\n快排 P95\r\n\r\n相同元素的快排 P104\r\n\r\n三数取中 P105\r\n\r\n对区间的模糊排序 P106\r\n\r\n计数排序 P108\r\n\r\n基数排序 P110\r\n\r\n桶排序 P112\r\n\r\n有序数列的i个最大数 P125\r\n\r\n栈 P129\r\n\r\n队列 P130\r\n\r\n链表 P131\r\n\r\n搜索已排序的紧凑链表 P139\r\n\r\n散列 P152\r\n\r\n二叉搜索树 P160\r\n\r\n带有相同关键字的二叉搜索树 P171\r\n\r\n红黑树 P175\r\n\r\nAVL树 P189\r\n\r\ntreap树 P189\r\n\r\n区间树 P198\r\n\r\n动态规划:\r\n\r\n\t钢条切割问题 P204\r\n\r\n\t矩阵链乘法 P210\r\n\r\n最长公共子序列问题 P222\r\n\r\n最优二叉搜索树 P226\r\n\r\n有向无环图的最长简单路径 P231\r\n\r\n最长回文子序列 P231\r\n\r\n活动选择问题 P237\r\n\r\n贪心算法:\r\n\r\n\t01背包问题 P243\r\n\r\n\t分数背包问题 P243\r\n\r\n赫夫曼编码 P245\r\n\r\n用拟阵求解任务调度问题 P253\r\n\r\n找零问题、最小平均完成时间调度问题、无环子图、调度问题变形、离线缓存\r\n\r\nB树 P281\r\n\r\n斐波那契堆 P291\r\n\r\nVEB树 P306\r\n\r\n不相交集合P324\r\n\r\nBFS P343\r\n\r\n最短路径 P346\r\n\r\nDFS P349\r\n\r\n拓扑排序 P355\r\n\r\n最小生成树 P362\r\n\r\n\tKruskal算法\r\n\r\n\tPrim算法\r\n\r\n单源最短路径 P374\r\n\r\n\tBellman-Ford算法\r\n\r\n\tDijkstra算法\r\n\r\n最大流问题 P415\r\n\r\n最大二分类问题 P428\r\n\r\n逃逸问题、最小路径覆盖问题\r\n\r\n字符串匹配 P577\r\n\r\n寻找凸包 P605\r\n\r\nNP问题\r\n\r\n\t团问题\r\n\r\n\t顶点覆盖问题\r\n\r\n\t哈密顿回路问题\r\n\r\n\t旅行商问题"
},
{
"alpha_fraction": 0.7231638431549072,
"alphanum_fraction": 0.7288135886192322,
"avg_line_length": 15.5,
"blob_id": "a9537c9ae37feb7d0620ac1101648f30db9dbd4f",
"content_id": "2569e5df335847f1bf140919b52890e34458d627",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 263,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 10,
"path": "/books/javascript高级程序设计.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Javascript高级程序设计\r\n\r\n#### 第1 章“JavaScript 简介”\r\n\r\n讲述了JavaScript 的起源\r\n\r\nJavaScript 与ECMAScript 之间的关系\r\n\r\nDOM(Document Object Model,文档对象模型)\r\nBOM(Browser Object Model,浏览器对象模型)\r\n\r\n"
},
{
"alpha_fraction": 0.4926251769065857,
"alphanum_fraction": 0.5433560609817505,
"avg_line_length": 22.980165481567383,
"blob_id": "30a28cdffd8d10b1207272201ff54587fedebcdb",
"content_id": "24f64af3a6bbfce9cd031b154f7cab41bd9b83fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 16011,
"license_type": "no_license",
"max_line_length": 382,
"num_lines": 605,
"path": "/leetcde_note_cpp/DP.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "\r\n\r\n##### leetcode 576 Out of Boundary Paths\r\n\r\nThere is an **m** by **n** grid with a ball. Given the start coordinate **(i,j)** of the ball, you can move the ball to **adjacent** cell or cross the grid boundary in four directions (up, down, left, right). However, you can **at most** move **N** times. Find out the number of paths to move the ball out of grid boundary. The answer may be very large, return it after mod 109 + 7.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: m = 2, n = 2, N = 2, i = 0, j = 0\r\nOutput: 6\r\nExplanation:\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: m = 1, n = 3, N = 3, i = 0, j = 1\r\nOutput: 12\r\nExplanation:\r\n```\r\n\r\n \r\n\r\n**Note:**\r\n\r\n1. Once you move the ball out of boundary, you cannot move it back.\r\n2. The length and height of the grid is in range [1,50].\r\n3. N is in range [0,50].\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int findPaths(int m, int n, int N, int i, int j) {\r\n uint dp[51][50][50] = {};\r\n for (auto Ni = 1; Ni <= N; ++Ni)\r\n for (auto mi = 0; mi < m; ++mi)\r\n for (auto ni = 0; ni < n; ++ni)\r\n dp[Ni][mi][ni] = ((mi == 0 ? 1 : dp[Ni - 1][mi - 1][ni]) + (mi == m - 1? 1 : dp[Ni - 1][mi + 1][ni])\r\n + (ni == 0 ? 1 : dp[Ni - 1][mi][ni - 1]) + (ni == n - 1 ? 1 : dp[Ni - 1][mi][ni + 1])) % 1000000007;\r\n return dp[N][i][j];\r\n\t}\r\n};\r\n```\r\n\r\nThe number of paths for N moves is the sum of paths for N - 1 moves from the adjacent cells. If an adjacent cell is out of the border, the number of paths is 1.\r\n\r\n如果[i,j]的adjacent cells在第Ni步出界了,说明在第Ni-1步在[i,j]有一种方式可以出界\r\n\r\n\r\n\r\n##### leetcode 887 Super Egg Drop\r\n\r\nYou are given `K` eggs, and you have access to a building with `N` floors from `1` to `N`. \r\n\r\nEach egg is identical in function, and if an egg breaks, you cannot drop it again.\r\n\r\nYou know that there exists a floor `F` with `0 <= F <= N` such that any egg dropped at a floor higher than `F` will break, and any egg dropped at or below floor `F` will not break.\r\n\r\nEach *move*, you may take an egg (if you have an unbroken one) and drop it from any floor `X` (with `1 <= X <= N`). \r\n\r\nYour goal is to know **with certainty** what the value of `F` is.\r\n\r\nWhat is the minimum number of moves that you need to know with certainty what `F` is, regardless of the initial value of `F`?\r\n\r\n \r\n\r\n\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: K = 1, N = 2\r\nOutput: 2\r\nExplanation: \r\nDrop the egg from floor 1. If it breaks, we know with certainty that F = 0.\r\nOtherwise, drop the egg from floor 2. If it breaks, we know with certainty that F = 1.\r\nIf it didn't break, then we know with certainty F = 2.\r\nHence, we needed 2 moves in the worst case to know what F is with certainty.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: K = 2, N = 6\r\nOutput: 3\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: K = 3, N = 14\r\nOutput: 4\r\n```\r\n\r\n \r\n\r\n**Note:**\r\n\r\n1. `1 <= K <= 100`\r\n2. `1 <= N <= 10000`\r\n\r\n```c++\r\nint superEggDrop(int K, int N) {\r\n vector<vector<int>> dp(N + 1, vector<int>(K + 1, 0));\r\n int m = 0;\r\n while (dp[m][K] < N) {\r\n m++;\r\n for (int k = 1; k <= K; ++k)\r\n dp[m][k] = dp[m - 1][k - 1] + dp[m - 1][k] + 1;\r\n }\r\n return m;\r\n}\r\n```\r\n\r\n\r\n\r\n$dp[m][k]$表示在有m step k个鸡蛋的情况下能够check多少层楼\r\n\r\ndp equtaion如下\r\n\r\n$dp[m][k] = dp[m - 1][k - 1] + dp[m - 1][k] + 1;$\r\n\r\n仍一次,check一层楼(+1)有两种情况,如果鸡蛋碎了 那还有m-1步 k-1个鸡蛋($dp[m-1][k-1]$)\r\n\r\n鸡蛋没碎$dp[m-1][k]$ m-1步 k个鸡蛋\r\n\r\n这边是+ 因为无论鸡蛋碎不碎这些楼层都可以被check到\r\n\r\n例子\r\n\r\n```\r\ndp\r\nm = 0 0 0 0\r\nm = 1 0 1 1\r\nm = 2 0 2 3\r\nm = 3 0 3 6\r\n```\r\n\r\n$dp[3][2] = 6$ 第一次check第三层 这表示+1( 碎了$dp[2][1]=2$ 一个鸡蛋两步 check第1层和第2层) 没碎 ($dp[2][2] $ 两鸡蛋 两步 check第5层,然后下一步check6或者4)\r\n\r\n\r\n\r\n##### leetcode 1187 Make Array Strictly Increasing\r\n\r\nGiven two integer arrays `arr1` and `arr2`, return the minimum number of operations (possibly zero) needed to make `arr1` strictly increasing.\r\n\r\nIn one operation, you can choose two indices `0 <= i < arr1.length` and `0 <= j < arr2.length` and do the assignment `arr1[i] = arr2[j]`.\r\n\r\nIf there is no way to make `arr1` strictly increasing, return `-1`.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: arr1 = [1,5,3,6,7], arr2 = [1,3,2,4]\r\nOutput: 1\r\nExplanation: Replace 5 with 2, then arr1 = [1, 2, 3, 6, 7].\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: arr1 = [1,5,3,6,7], arr2 = [4,3,1]\r\nOutput: 2\r\nExplanation: Replace 5 with 3 and then replace 3 with 4. arr1 = [1, 3, 4, 6, 7].\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: arr1 = [1,5,3,6,7], arr2 = [1,6,3,3]\r\nOutput: -1\r\nExplanation: You can't make arr1 strictly increasing.\r\n```\r\n\r\n**Constraints:**\r\n\r\n- `1 <= arr1.length, arr2.length <= 2000`\r\n- `0 <= arr1[i], arr2[i] <= 10^9`\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n //how many operations is needed\r\n int dp[2001][2001];\r\n int dfs(vector<int>& arr1, vector<int>& arr2, int index1, int index2, int prev){\r\n //prev 表示之前已经固定的元素中的最大值\r\n int r1, r2;\r\n if(index1>=arr1.size()) return 0; //finish\r\n //operation on arr1[index1]\r\n index2 = upper_bound(arr2.begin()+index2, arr2.end(), prev) - arr2.begin();\r\n if(dp[index1][index2]) return dp[index1][index2];\r\n if(index2>=arr2.size()) r1 = arr2.size()+1; //can not do opeartions\r\n else r1 = 1+dfs(arr1, arr2, index1+1, index2, arr2[index2]);\r\n //no opeartions\r\n if(prev<arr1[index1]) r2 = dfs(arr1, arr2, index1+1, index2, arr1[index1]);\r\n else r2 = arr2.size() + 1;\r\n \r\n dp[index1][index2] = min(r1, r2);\r\n return min(r1, r2);\r\n }\r\n int makeArrayIncreasing(vector<int>& arr1, vector<int>& arr2) {\r\n sort(arr2.begin(), arr2.end());\r\n auto res = dfs(arr1, arr2, 0, 0, -100000);\r\n if(res<=arr2.size()) return res;\r\n return -1;\r\n\r\n }\r\n}; \r\n```\r\n\r\n对于arr1中的每一位数字有两种情况,替换与不替换,并用dp数组记录 防止重复情况的出现\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 1218 Longest Arithmetic Subsequence of Given Difference\r\n\r\nMedium\r\n\r\nGiven an integer array `arr` and an integer `difference`, return the length of the longest subsequence in `arr` which is an arithmetic sequence such that the difference between adjacent elements in the subsequence equals `difference`.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: arr = [1,2,3,4], difference = 1\r\nOutput: 4\r\nExplanation: The longest arithmetic subsequence is [1,2,3,4].\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: arr = [1,3,5,7], difference = 1\r\nOutput: 1\r\nExplanation: The longest arithmetic subsequence is any single element.\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: arr = [1,5,7,8,5,3,4,2,1], difference = -2\r\nOutput: 4\r\nExplanation: The longest arithmetic subsequence is [7,5,3,1].\r\n```\r\n\r\n \r\n\r\n**Constraints:**\r\n\r\n- `1 <= arr.length <= 10^5`\r\n- `-10^4 <= arr[i], difference <= 10^4`\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int longestSubsequence(vector<int>& arr, int difference) {\r\n int n = arr.size(), res = 1;\r\n map<int, int> map1;\r\n if(n<=1) return n;\r\n for(auto num: arr){\r\n auto it = map1.find(num - difference);\r\n if(it!=map1.end()){\r\n map1[num] = map1[num-difference]+1;\r\n res = max(res, map1[num]);\r\n }\r\n else{\r\n map1[num] = 1;\r\n }\r\n }\r\n return res;\r\n }\r\n}; \r\n```\r\n\r\n用map来充当DP 记录功能\r\n\r\nmap[num]表示num及以前的数组能构成差为difference的等差数列的长度\r\n\r\n\r\n\r\n ##### leetcode 1269 Number of Ways to Stay in the Same Place After Some Steps\r\n\r\nYou have a pointer at index `0` in an array of size `arrLen`. At each step, you can move 1 position to the left, 1 position to the right in the array or stay in the same place (The pointer should not be placed outside the array at any time).\r\n\r\nGiven two integers `steps` and `arrLen`, return the number of ways such that your pointer still at index `0` after **exactly** `steps` steps.\r\n\r\nSince the answer may be too large, return it **modulo** `10^9 + 7`.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: steps = 3, arrLen = 2\r\nOutput: 4\r\nExplanation: There are 4 differents ways to stay at index 0 after 3 steps.\r\nRight, Left, Stay\r\nStay, Right, Left\r\nRight, Stay, Left\r\nStay, Stay, Stay\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: steps = 2, arrLen = 4\r\nOutput: 2\r\nExplanation: There are 2 differents ways to stay at index 0 after 2 steps\r\nRight, Left\r\nStay, Stay\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: steps = 4, arrLen = 2\r\nOutput: 8\r\n```\r\n\r\n \r\n\r\n**Constraints:**\r\n\r\n- `1 <= steps <= 500`\r\n- `1 <= arrLen <= 10^6`\r\n\r\n\r\n\r\n首先可以简单的发现可以使用DP,二维数组,$DP[step][pos]$ 并发现转移方程\r\n\r\n$ivec[step][pos] = (ivec[step][pos-1]+ivec[step][pos]+ivec[step][pos+1])%1000000007;$\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int numWays(int steps, int arrLen) {\r\n vector<vector <int> > ivec(steps+1, vector<int>(arrLen,0));\r\n int step, pos;\r\n ivec[0][0] = 1;\r\n for (step=1;step<=steps;step++){\r\n ivec[step][0] = ivec[step-1][0]+ivec[step-1][1];\r\n ivec[step][arrLen-1] = ivec[step-1][arrLen-1]+ivec[step-1][arrLen-2];\r\n for(pos = 1;pos<arrLen-1;pos++){\r\n ivec[step][pos] = ivec[step-1][pos-1]+ivec[step-1][pos]+ivec[step-1][pos+1];\r\n }\r\n }\r\n return ivec[steps][0];\r\n }\r\n};\r\n```\r\n\r\n 上述方法的问题在于 answer可能很大没有**modulo** `10^9 + 7`, 因此使用int也是不合适的 应该用long\r\n\r\n然后不需要step+1层DP 太占空间了,只需要记录这一层和上一层就可以了\r\n\r\n同时在时间复杂度方面注意到arrLen可以很大,我们可以取sz=min(step/2,arrLen)\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int numWays(int steps, int arrLen) {\r\n int sz = min(steps / 2 + 1, arrLen);\r\n vector<long> ivec(sz,0);\r\n int step, pos;\r\n ivec[0] = 1;\r\n for (step=1;step<=steps;step++){\r\n vector<long> new_vec(sz,0);\r\n new_vec[0] = (ivec[0]+ivec[1])%1000000007;\r\n new_vec[sz-1] = (ivec[sz-1]+ivec[sz-2])%1000000007;\r\n for(pos = 1;pos<sz-1;pos++){\r\n new_vec[pos] = (ivec[pos-1]+ivec[pos]+ivec[pos+1])%1000000007;\r\n }\r\n ivec = new_vec;\r\n }\r\n return ivec[0];\r\n }\r\n};\r\n```\r\n\r\nc++中vector的赋值\r\n\r\n```\r\nivec = new_vec;\r\nnew_vec.assign(ivec.begin(), ivec.end());\r\n```\r\n\r\n\r\n\r\n##### leetcode 1235 Maximum Profit in Job Scheduling\r\n\r\nHard\r\n\r\nWe have `n` jobs, where every job is scheduled to be done from `startTime[i]` to `endTime[i]`, obtaining a profit of `profit[i]`.\r\n\r\nYou're given the `startTime` , `endTime` and `profit` arrays, you need to output the maximum profit you can take such that there are no 2 jobs in the subset with overlapping time range.\r\n\r\nIf you choose a job that ends at time `X` you will be able to start another job that starts at time `X`.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n****\r\n\r\n```\r\nInput: startTime = [1,2,3,3], endTime = [3,4,5,6], profit = [50,10,40,70]\r\nOutput: 120\r\nExplanation: The subset chosen is the first and fourth job. \r\nTime range [1-3]+[3-6] , we get profit of 120 = 50 + 70.\r\n```\r\n\r\n**Example 2:**\r\n\r\n****\r\n\r\n```\r\nInput: startTime = [1,2,3,4,6], endTime = [3,5,10,6,9], profit = [20,20,100,70,60]\r\nOutput: 150\r\nExplanation: The subset chosen is the first, fourth and fifth job. \r\nProfit obtained 150 = 20 + 70 + 60.\r\n```\r\n\r\n**Example 3:**\r\n\r\n****\r\n\r\n```\r\nInput: startTime = [1,1,1], endTime = [2,3,4], profit = [5,6,4]\r\nOutput: 6\r\n```\r\n\r\n \r\n\r\n**Constraints:**\r\n\r\n- `1 <= startTime.length == endTime.length == profit.length <= 5 * 10^4`\r\n- `1 <= startTime[i] < endTime[i] <= 10^9`\r\n- `1 <= profit[i] <= 10^4`\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int jobScheduling(vector<int>& startTime, vector<int>& endTime, vector<int>& profit) {\r\n int n = startTime.size();\r\n vector<vector<int>> jobs;\r\n for (int i = 0; i < n; ++i) {\r\n jobs.push_back({endTime[i], startTime[i], profit[i]});\r\n }\r\n sort(jobs.begin(), jobs.end());\r\n map<int, int> dp = {{0, 0}};\r\n for (auto job : jobs) {\r\n int cur = prev(dp.upper_bound(job[1]))->second + job[2];\r\n if (cur > dp.rbegin()->second)\r\n dp[job[0]] = cur;\r\n }\r\n return dp.rbegin()->second;\r\n }\r\n}; \r\n```\r\n\r\n这个题和传统的DP不一样的地方在于使用map作为dp\r\n\r\n转移方程为\r\n\r\n$dp[job[0]]=max(dp.rbegin()->second, prev(dp.upper_bound(job[1]))->second + job[2])$\r\n\r\n前者表示不做这个job,则此时的最大收益和上一个job判断完的收益相同,后者表示做这个job的收益+在做这个job开始时间前的最大收益\r\n\r\n注意prev和upper_bound用法\r\n\r\n\r\n\r\n##### leetcode 1277. Count Square Submatrices with All Ones\r\n\r\nGiven a `m * n` matrix of ones and zeros, return how many **square** submatrices have all ones.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: matrix =\r\n[\r\n [0,1,1,1],\r\n [1,1,1,1],\r\n [0,1,1,1]\r\n]\r\nOutput: 15\r\nExplanation: \r\nThere are 10 squares of side 1.\r\nThere are 4 squares of side 2.\r\nThere is 1 square of side 3.\r\nTotal number of squares = 10 + 4 + 1 = 15.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: matrix = \r\n[\r\n [1,0,1],\r\n [1,1,0],\r\n [1,1,0]\r\n]\r\nOutput: 7\r\nExplanation: \r\nThere are 6 squares of side 1. \r\nThere is 1 square of side 2. \r\nTotal number of squares = 6 + 1 = 7.\r\n```\r\n\r\n \r\n\r\n**Constraints:**\r\n\r\n- `1 <= arr.length <= 300`\r\n- `1 <= arr[0].length <= 300`\r\n- `0 <= arr[i][j] <= 1`\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int check_left(int i, int j,vector<vector<int>>& matrix, int x){\r\n int a, res = 0;\r\n for(a=1;a<=x;a++){\r\n if(matrix[i-a][j] != 1)\r\n return res;\r\n else res += 1;\r\n }\r\n return res;\r\n }\r\n int check_top(int i, int j,vector<vector<int>>& matrix, int x){\r\n int a, res = 0;\r\n for(a=1;a<=x;a++){\r\n if(matrix[i][j-a] != 1)\r\n return res;\r\n else res += 1;\r\n }\r\n return res;\r\n }\r\n int countSquares(vector<vector<int>>& matrix) {\r\n int m = matrix.size(); \r\n if(m==0) return 0;\r\n int n = matrix[0].size();\r\n vector<vector<int>> dp(m+1, vector<int>(n+1, 0));\r\n int i,j,res=0;\r\n for(i=1;i<=m;i++){\r\n for(j=1;j<=n;j++){\r\n if (matrix[i-1][j-1] == 1){\r\n int x = dp[i-1][j-1];\r\n int top = check_top(i-1,j-1,matrix,x);\r\n int left = check_left(i-1,j-1,matrix,x);\r\n dp[i][j] = min(top, left) + 1;\r\n res += dp[i][j];\r\n }\r\n }\r\n }\r\n return res;\r\n }\r\n};\r\n\r\n```\r\n\r\n\r\n\r\n\r\n\r\n```\r\nclass Solution {\r\npublic:\r\n int countSquares(vector<vector<int>>& matrix) {\r\n int m = matrix.size(); \r\n if(m==0) return 0;\r\n int n = matrix[0].size();\r\n vector<vector<int>> dp(m+1, vector<int>(n+1, 0));\r\n int i,j,res=0;\r\n for(i=1;i<=m;i++){\r\n for(j=1;j<=n;j++){\r\n if (matrix[i-1][j-1] == 1){\r\n int x = min(dp[i-1][j], dp[i][j-1]);\r\n if(matrix[i-1-x][j-1-x] == 1)\r\n dp[i][j] = x+1;\r\n else dp[i][j] = x;\r\n res += dp[i][j];\r\n }\r\n }\r\n }\r\n return res;\r\n }\r\n};\r\n```\r\n\r\nDP\r\n\r\n对于$DP[i][j]$的值,两种方法,先看$x = dp[i-1][j-1]$ ,然后check长度为x的左边和上面两条\r\n\r\n或者看$min(dp[i-1][j], dp[i][j-1])$, check $matrix[i-1-x][j-1-x]$ \r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.33887043595314026,
"alphanum_fraction": 0.33887043595314026,
"avg_line_length": 7.612903118133545,
"blob_id": "95931371bf5c9509fbb2bf23f5b5201cb1276c90",
"content_id": "d269baa5af94b3784524418304e2fec7f6078956",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 301,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 31,
"path": "/leetcode_note/leetcode.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "#### leetcode_note\r\n\r\n* ##### DP\r\n\r\n* ##### BFS && DFS\r\n\r\n* ##### Back-track\r\n\r\n* ##### Greedy \r\n\r\n* ##### Hash\r\n\r\n* ##### Linked-list \r\n\r\n* ##### String\r\n\r\n* ##### Topological\r\n\r\n* ###### Tree \r\n\r\n* ##### Graph\r\n\r\n* ##### Union set\r\n\r\n* ##### Nums_Array\r\n\r\n* ##### math \r\n\r\n* ##### others \r\n\r\n* \r\n\r\n"
},
{
"alpha_fraction": 0.5962843894958496,
"alphanum_fraction": 0.6277241706848145,
"avg_line_length": 14.074712753295898,
"blob_id": "373976e89f777d29de24343735c632a73abbd4d2",
"content_id": "d6c2d1ad429b1e9cda23ab99a17eaac78d315a1b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5385,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 174,
"path": "/books/背包九讲.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 背包九讲\r\n\r\n1 0-1 背包问题\r\n\r\n将N件物品和一个容量为V的背包。物品的费用为Ci,得到的价值为Wi,每个物体只有一件,求解放入哪些物品使得总价值和最大。\r\n\r\n```\r\nF[i,v]=max{F[i-1,v],F[i-1,v-Ci]+Wi}\r\n```\r\n\r\ni表示只考虑前i个物品,有两种情况,一种是不放 F[i-1,v],一种是放第i个,F[i-1,v-Ci]+Wi\r\n\r\n时间和空间复杂度均为O(VN),其中空间复杂度可以优化到O(V)\r\n\r\n```\r\nF[v]=max(F[v],F[v-Ci]+Wi)\r\n```\r\n\r\n能够这样优化,需要将循环中V改为从V到0的递减顺序\r\n\r\n```\r\nF[0,...V]=0\r\nfor i:1to N\r\n for v:V to 0:\r\n F[v]=max(F[v],F[v-Ci]+Wi)\r\n```\r\n\r\n\r\n\r\n细节问题,有两种不同的问法,第一种是要求把背包装满,另一种没有这个要求\r\n\r\n对于恰好装满背包,则在初始化的时候将F[0]设为0,其余的F[1-V]都设为负无穷。可以这样理解,如果要求背包装满,则此时只有容量为0的背包符合条件,其余的背包都是不符合条件的,因此在上述方程中,如果一种物品排列方式不能占满包,就会有一个负无穷。\r\n\r\n对于不要求恰好装满包,则初始化的时候设置F[o-V]为0\r\n\r\n\r\n\r\n2 完全背包问题\r\n\r\n有N件物品和一个容量为V的背包,物品的费用为Ci,得到的价值为Wi,每种物品有无数件,求解放入哪些物品使得得到的总价值最大。\r\n\r\n经典思路:\r\n\r\n```\r\nF[i,v]=max{F[i-1,v-k*Ci]+k*Wi} 0<=kCi<=v\r\n```\r\n\r\n时间复杂度为O(NV sum(V/Ci))\r\n\r\n简单的优化:将满足Ci<=Cj,Wi>=Wj 的j物品去掉,同时去掉所有Cj大于V的物品。\r\n\r\n转化为01背包问题:\r\n\r\n将第i件物品拆成费用为$C_i2^k$ 价值为$W_i2^k$ 若干件物品,k满足$C_i2^k<=v$ 非负整数,这是一个很大改进,因为选n个同类型的物品相当于选了$C_i2^n$ 这一个物品\r\n\r\n\r\n\r\n3 多重背包问题\r\n\r\n有N种物品和一个容量为V的背包,物品的费用为Ci,得到的价值为Wi,每种物品有Mi件,求解放入哪些物品使得得到的总价值最大。\r\n\r\n```\r\nF[i,v]=max{F[i-1,v-k*Ci]+k*Wi} 0<=k<=Mi\r\n```\r\n\r\n\r\n\r\n4 混合三种背包问题\r\n\r\n将前面的1,2,3三种背包问题混合起来,就是说有些物品可以取一次,有的物品可以获取Mi次,有的物品可以获取无数次。\r\n\r\n这个问题可以当作第三个问题\r\n\r\n\r\n\r\n5 二维费用的背包问题\r\n\r\n对于每件物品具有两种不同的费用,选择这个物品必须符出这两种费用。对于每种费用都有一个可付出的最大值,问怎样选择物品可以达到最大值。\r\n\r\n设第i件物品所需的两种费用分别为Ci和Di。两种费用可付出的最大值为V和U,物品的价值为Wi。\r\n\r\n费用加了一维,只需要状态也加一维即可。设F[i,v,u]表示前i件物品可付出两种费用分别为v u时候可获得的最大值。\r\n\r\n```\r\nF[i,v,u]=max{F[i-1,v,u],F[i-1,v-Ci,u-Di]+Wi}\r\n```\r\n\r\n\r\n\r\n6.分组的背包问题\r\n\r\n有N个物品和一个容量为V的背包,第i件物品的费用是Ci,价值是Wi,这些物品被划分为K组,每组的物品是相互冲突的,最多选一件。求解将哪些物品装入背包可使得这些物品的总费用和不超过背包容量且价值总和最大。\r\n\r\n```\r\nF[k,v]=max{F[k-1,v],F[k-1,v-Ci]+Wi|item i in group k}\r\n```\r\n\r\nfor k:1-K:\r\n\r\n for v: V-0:\r\n\r\n for all item i in group k\r\n\r\n F[v]=max(F[v],F[v-Ci]+Wi)\r\n\r\n\r\n\r\n7 有依赖的背包问题\r\n\r\n物品两两间可能存在依赖,比如物品i依赖于物品j,表示若选物品i,则必须选物品j。\r\n\r\n对于一件主件k以及他的很多附件所构成的附件集合。如果有n个附件,则总共有2^n+1中策略\r\n\r\n由于这些策略本质上都是互斥的,因此一个主件和它的附件集是互斥的。一个主件和它的附件集是对应的一个物品集。仅仅是这一步转化是不够的,因为物品组里面的物品还是和策略数一样多。\r\n\r\n考虑下一步的优化,对于同样的cost 我们肯定会只选择价值最大的那种,因此对于主件k的附件集合可以先进行一次0-1背包,得到费用为0....V-Ck的所有值对应的最大价值Fk[0...V-Ck],因此通过这种优化可以将主件k以及其附件转化为V-Ck+1个物品的物品组,就可以直接应用6的算法解决问题。\r\n\r\n\r\n\r\n9 背包问题的问法变化\r\n\r\n9.1 输出背包\r\n\r\n以0 1背包为例,以数组G[i,v]记录i,v情况下的选择,如果没有选择i物品,则F[i,v]=F[i-1,v] G[i,v]=0\r\n\r\nG[i,v]=1, 则表示F[i,v]=F[i-1,v-Ci]+Wi\r\n\r\n9.2 输出字典序最小的最优方案\r\n\r\n\r\n\r\n9.3 求方案总数\r\n\r\n```\r\nF[i,v]=sum{F[i-1,v],F[i,v-Ci]}\r\n```\r\n\r\nF[0,0]=1\r\n\r\n\r\n\r\n9.4 最优方案总数\r\n\r\n用F[i,v]表示该状态的最大值,用G[i,v]表示这个问题下最优方案的总数\r\n\r\n```\r\nG[0,0]=1\r\nfor i:1-N\r\n for v:0-V\r\n F[i,v]=max(F[i1-,v],F[i-1,v-Ci]+Wi)\r\n G[i,v]=0\r\n if F[i,v]==F[i-1,v]:\r\n G[i,v]=G[i,v]+G[i-1][v]\r\n if F[i,v]==F[i-1,v-Ci]+Wi:\r\n G[i,v]=G[i,v]+G[i-1][v-Ci]\r\n```\r\n\r\n\r\n\r\n9.5第K优解\r\n\r\n总的时间复杂度为O(VNK)\r\n\r\n状态转移方程:\r\n\r\n```\\\r\nF[i-1,v]=max(F[i-1,v],F[i-1,v-Ci]+Wi)\r\n```\r\n\r\nF[i,v]是一个大小为K的队列\r\n\r\n原方程解释为,由F[i-1,v]和F[i-1,v-Ci]+Wi这两个队列所构成的\r\n\r\n合并这两个队列取前K项\r\n\r\n"
},
{
"alpha_fraction": 0.6712828278541565,
"alphanum_fraction": 0.6858600378036499,
"avg_line_length": 9.913043022155762,
"blob_id": "2df445529aa638750154291faa85d4c74147d8ee",
"content_id": "830ef95471c46071ac6c8d9c4e79744aa0bc6c00",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2206,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 115,
"path": "/word_embedding.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### NLP历史突破!快速解读Google BERT模型 + Word Embedding\r\n\r\nyoutube视频\r\n\r\n##### One Hot Encoding\r\n\r\nGiven a collection of unique N words\r\n\r\nWord-> a vector of size N.\r\n\r\n\r\n\r\n缺点:\r\n\r\n1.sparse\r\n\r\n2.dimensions are independent\r\n\r\n\r\n\r\n##### Bag of Words\r\n\r\n将文章看成一个包,统计文章中不同词语出现的次数\r\n\r\n\r\n\r\n将一个文章用一个vector表示,第i维表示第i种单词在该文章中出现了多少次\r\n\r\n\r\n\r\n##### Neural Network Based NNLM\r\n\r\n上述两个模型种每一个单词都代表了一个维度,但是不同单词之间有些是非常接近的,因此我们希望学习词语之间共同的性质,用更少的维度来表示这些词\r\n\r\n即distributed representations\r\n\r\n模型1:\r\n\r\n\r\n\r\n其中code就是embedding向量\r\n\r\n训练$min|X-X'|$\r\n\r\n\r\n\r\n\r\n\r\n模型2:\r\n\r\nNLM 根据上文推测下文\r\n\r\n\r\n\r\n##### Word2Vec\r\n\r\n\r\n\r\nCBOW:\r\n\r\nGiven 上下文,预测单词(单词的意义由上下文决定)\r\n\r\nSkip-Gram 给定单词 预测单词的上下文\r\n\r\n\r\n\r\nword2vec最主要的缺点在于计算量太大\r\n\r\n使用hierarchical softmax, negative sampling\r\n\r\n\r\n\r\n将高频词放到接近root的位置,这样可以减少计算量\r\n\r\n\r\n\r\n有趣的性质:\r\n\r\nking-man = queen-woman\r\n\r\n\r\n\r\n##### GloVe\r\n\r\nglobal vectors for word representation\r\n\r\nmust be trained offline\r\n\r\n与word2vec非常接近\r\n\r\n\r\n\r\n##### ELMo\r\n\r\n解决了NLP中多义词的问题,数值型网络很难训练出多意义的向量\r\n\r\n一般的模型都是生成一个常量向量,ELMo对每个单词生成三个向量,实际问题中的上下文决定三个向量的权重。\r\n\r\n\r\n\r\n 有两层LSTM模型,由于LSTM是由方向的,因此一个LSTM只能预测上文到下文或者是下文到上文,因此这边用了双向LSTM,分别学习上文到下文,下文到上文\r\n\r\npretrain:对每个单词得到$(v_1,v_2,v_3)$\r\n\r\nfine tuning: 实际环境中根据上下文得到$w_1,w_2,w_3$\r\n\r\nthe final embedding $w_1v_1+w_2v_2+w_3v_3$\r\n\r\n\r\n\r\n##### BERT\r\n\r\n从变形器得到双向编码器的表示\r\n\r\nBERT中将所有的RNN换成了Transformer\r\n\r\n"
},
{
"alpha_fraction": 0.5963391065597534,
"alphanum_fraction": 0.6382466554641724,
"avg_line_length": 20.171123504638672,
"blob_id": "012afafe6f2bf5b1b659905ad05801e270e1088d",
"content_id": "bd4311a7d6e161fef2f10eabe8779c9202f16d20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4804,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 187,
"path": "/math&&deeplearning/pytorch/pytorch.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### pytorch note\r\n\r\n深度学习框架的比较:\r\npytorch facebook\r\ntensorflow google\r\n\r\npytorch基础结构:\r\n定义矩阵:\r\n\r\n```\r\na=torch.Tensor([[2,3],[4,8],[7,9]])\r\nprint ('a is {}'.format(a))\r\nprint('a size is {}'.format(a.size()))\r\nc=torch.zeros((3,2))\r\n```\r\n将第一行第二列的数改成 100\r\n```\r\na[0,1]=100\r\n```\r\nnumpy与Tensor间切换\r\n```\r\nnumpy_b=b.numpy()\r\ntorch_e=torch.from_numpy(e)\r\n```\r\nGPU:\r\n```\r\na_cuda()=a.cuda()\r\n```\r\n\r\nvariable量:\r\n```\r\nx=Variable(torch.Tensor([1]),requires_grad=True)\r\nVariable 变量可以直接求导数\r\nx.grad\r\ny=wx+b\r\ny.backward(torch.FloatTensor([1,0.1,0.01]))\r\n对y中的w x b分别求导,并将梯度分别乘以1,0.1,0.01\r\n```\r\n\r\n读取数据dataset\r\n```\r\ndset=ImageFolder(root='root_path',transform=None,loader=default_loader)\r\nroot表示根目录,这个目录下面有几个文件夹,每个文件夹表示一个类别\r\n```\r\nmodule(所有的模型都是通过torch.nn所继承的)\r\n```\r\n求得loss\r\ncriterion=nn.CrossEntropyLoss()\r\nloss=criterion(output,target)\r\n```\r\n优化\r\n```\r\noptimizer=torch.optim.SGD(model.parameters(),lr=0.1,momentum=0.9)\r\n```\r\n保存模型、加载模型\r\n```\r\ntorch.save(model,'./model.pth')\r\ntorch.load('model_state.pth')\r\n```\r\n\r\ndata augmentation:\r\npytorch\r\n```\r\nimport torch\r\nfrom torchvision import transforms, datasets\r\n\r\ndata_transform = transforms.Compose([\r\n transforms.RandomSizedCrop(224),\r\n transforms.RandomHorizontalFlip(),\r\n transforms.ToTensor(),\r\n transforms.Normalize(mean=[0.485, 0.456, 0.406],\r\n std=[0.229, 0.224, 0.225])\r\n ])\r\nhymenoptera_dataset = datasets.ImageFolder(root='hymenoptera_data/train',\r\n transform=data_transform)\r\ndataset_loader = torch.utils.data.DataLoader(hymenoptera_dataset,\r\n batch_size=4, shuffle=True,\r\n num_workers=4)\r\n```\r\n\r\npytorch卷积神经网络\r\n```\r\nnn.Conv2d() 表示Pytorch中的卷积模块\r\n其中可以使用的参数有5个:input_channel,output_channel,kernel_size,strde,padding\r\n例如nn.Conv2d(3,32,3,1,padding=1)\r\n\r\nnn.MaxPool2d()表示最大值池化\r\nnn.AvgPool2d()表示均值池化\r\n参数:kernel_size,stride,padding,dilation\r\ndilation表示数据在空间方面的膨胀\r\n例如nn.MaxPool2d(2,2)\r\n\r\nnn.ReLU(True) 激活函数\r\n\r\nnn.Linear(4096,4096) #线性变换 从4096维向量变换到4096维\r\n```\r\n\r\nAlexNet:\r\n```\r\nAlexnet分为两部分:features和Classifly两个部分\r\nfeatures:顺序:\r\nConv2d,ReLU,MaxPool2d *n\r\nclassifier:\r\nnn.Dropout(),nn.Linear(),nn.ReLU(),nn.Dropout(),nn.Linear(),nn.ReLU(),nn.Linear()\r\n\r\nview is to reshape a tensor\r\nx = torch.randn(2, 3, 4)\r\nprint(x)\r\nprint(x.view(2, 12)) # Reshape to 2 rows, 12 columns\r\n# Same as above. If one of the dimensions is -1, its size can be inferred\r\nprint(x.view(2, -1))\r\n\r\nsqueeze()与unsqueeze()函数分别表示对某一维度上数据进行压缩与解压\r\n```\r\n\r\nVGG与Alexnet比较相似\r\nGoogleNet:\r\n```\r\nnn.BatchNorm2d(output_channels)# 归一化\r\n```\r\n\r\nRNN 循环神经网络\r\n```\r\nRNN: \r\nbasic_rnn=nn.RNN(input_size=20,hidden_size=50(outpputsize),num_layers=2)\r\nLSTM:\r\nlstm=nn.lstm(input_size=20,hidden_size=50,num_layers=2)\r\nGRU:与lstm类似\r\n\r\n词嵌入:\r\n通过nn.Embedding(m,n)来实现,m表示所有的单词数目,n是词嵌入的维度\r\nword_to_ix={'hello':0,'world':1}\r\nembeds=nn.Embedding(2,5)\r\nhello_idx=torch.LongTensor([word_to_ix['hello']])\r\nhello_idx=Variable(hello_idx)\r\nhello_embed=embeds(hello_idx)\r\nprint(hello_embed)\r\n```\r\n```\r\ntransfer learning and fine tune:\r\ntransfer learning:\r\nclass Net(nn.Module):\r\n def __init__(self):\r\n super(Net, self).__init__()\r\n self.bn1 = nn.BatchNorm1d(1258)\r\n self.fc1 = nn.Linear(1258, 2048)\r\n self.bn2 = nn.BatchNorm1d(2048)\r\n self.fc2 = nn.Linear(2048, 256)\r\n self.bn3 = nn.BatchNorm1d(256)\r\n self.fc3 = nn.Linear(256, 2)\r\n\r\n def forward(self, x):\r\n x = F.relu(self.fc1(self.bn1(x)))\r\n x = F.relu(self.fc2(self.bn2(x)))\r\n x = F.log_softmax(self.fc3(self.bn3(x)))\r\n return x\r\n先定义后面的全连接层,然后将模型resnet得到的features:\r\noutput_features = model.features(input)\r\n将data(features)作为输入:\r\noutput = net(data)\r\n\r\n\r\nfinetune:\r\noutput = model(data)\r\n\r\nloss = criterion(output, target)\r\ntotal_loss += loss.item()\r\ntotal_size += data.size(0)\r\nloss.backward()\r\noptimizer.step()\r\n```\r\n\r\npython文件调用另一个python文件中的函数\r\n```\r\nimport xxxx\r\nxxx.func()\r\n```\r\n\r\n\r\n\r\n权重:\r\n\r\n```python\r\nweight:weight = np.array([1,2,2,2,2,2,2])\r\nweight = torch.from_numpy(weight).float()\r\nloss_val = F.cross_entropy(output[idx_val], labels[idx_val],weight)\r\n```\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.2777777910232544,
"alphanum_fraction": 0.33183184266090393,
"avg_line_length": 11.098039627075195,
"blob_id": "9d9b2cc358a55f9650221caab710f9ef5312cacd",
"content_id": "325ce5c7458a5d76881f05b0dff714f25f7b3185",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 897,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 51,
"path": "/books/矩阵分析与应用.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 矩阵分析与应用\r\n\r\n##### 矩阵基本代数基础\r\n\r\n1. 线性无关 {u1,u2,u3...,un} ,当且仅当\r\n $$\r\n c_{1}u_{1}+...+c_{n}u_{n}=0\r\n $$\r\n 仅有0解 $c_{1}$ = $c_{2} $ = 0使得上述方程成立,则向量组u1 u2..... 线性无关\r\n\r\n2. 非奇异 n×n 矩阵A ,当且仅当其n个列向量a1 a2..... an线性无关\r\n\r\n3. 内积\r\n\r\n 向量x,y的内积为\r\n $$\r\n (x,y)=x^Ty=\\sum_{i=1}^nx_{i}*y_{i}\r\n $$\r\n 称为典范内积\r\n\r\n 范数:\r\n\r\n L0范数\r\n $$\r\n ||x||_{0}=非零个数\r\n $$\r\n L1范数\r\n $$\r\n ||x||_{1}=|x_1|+...+|x_m|\r\n $$\r\n\r\n\r\n L2范数\r\n $$\r\n ||x||_{2}={(|x_1|^2+|x_{2}|^2+...+|x_{n}|^2)}^{1/2}\r\n $$\r\n\r\n\r\n L 无穷\r\n $$\r\n ||x||_{∞}=max\\{|x_1|,...,|x_n|\\}\r\n $$\r\n\r\n\r\n Lp\r\n $$\r\n ||x||_p=(\\sum_{i=1}^m|x_i|^p)^{1/p}, p≥1\r\n $$\r\n\r\n\r\n矩阵之间的内积,矩阵A,B的内积定义为将A拉长 向量"
},
{
"alpha_fraction": 0.5481441617012024,
"alphanum_fraction": 0.6009951829910278,
"avg_line_length": 26.910505294799805,
"blob_id": "f90abe1d31e1afd8dc0c175e0c346fe533a728e2",
"content_id": "0aeac74b462c811083521c3dc82fc72b35cc3c27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 7506,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 257,
"path": "/math&&deeplearning/pytorch/vgg.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "```\r\nimport torch\r\nimport torch.nn as tnn\r\nimport torchvision.datasets as dsets\r\nimport torchvision.transforms as transforms\r\nimport torch.nn.functional as F\r\nfrom torch.autograd import Variable\r\nfrom PIL import Image\r\nfrom myloader import ImageFolderWithPaths\r\nimport os\r\nBATCH_SIZE = 64\r\nLEARNING_RATE = 0.1\r\nEPOCH = 50\r\n\r\ntransform = transforms.Compose([\r\n transforms.RandomResizedCrop(224),\r\n transforms.RandomHorizontalFlip(),\r\n transforms.ToTensor(),\r\n \r\n transforms.Normalize(mean = [ 0.5485348371, 0.2952247873, 0.2488217890 ],\r\n std = [ 0.2206798556, 0.5122815546, 0.5363560231 ]),\r\n ])\r\n\r\n#trainData = dsets.ImageFolder('../data/Train', transform)\r\n#testData = dsets.ImageFolder('../data/Test', transform)\r\n\r\ntrainData = ImageFolderWithPaths('/mnt/data/kongming/MILData/Data/Data5_2/train', transform)\r\ntestData = ImageFolderWithPaths('/mnt/data/kongming/MILData/Data/Data5_2/test', transform)\r\n\r\n\r\ntrainLoader = torch.utils.data.DataLoader(dataset=trainData, batch_size=BATCH_SIZE, shuffle=True, drop_last=False)\r\ntestLoader = torch.utils.data.DataLoader(dataset=testData, batch_size=BATCH_SIZE, shuffle=False, drop_last=False)\r\n\r\nclass VGG16(tnn.Module):\r\n def __init__(self):\r\n super(VGG16, self).__init__()\r\n self.layer1 = tnn.Sequential(\r\n\r\n # 1-1 conv layer\r\n tnn.Conv2d(3, 64, kernel_size=3, padding=1),\r\n tnn.BatchNorm2d(64),\r\n tnn.ReLU(),\r\n\r\n # 1-2 conv layer\r\n tnn.Conv2d(64, 64, kernel_size=3, padding=1),\r\n tnn.BatchNorm2d(64),\r\n tnn.ReLU(),\r\n\r\n # 1 Pooling layer\r\n tnn.MaxPool2d(kernel_size=2, stride=2))\r\n\r\n self.layer2 = tnn.Sequential(\r\n\r\n # 2-1 conv layer\r\n tnn.Conv2d(64, 128, kernel_size=3, padding=1),\r\n tnn.BatchNorm2d(128),\r\n tnn.ReLU(),\r\n\r\n # 2-2 conv layer\r\n tnn.Conv2d(128, 128, kernel_size=3, padding=1),\r\n tnn.BatchNorm2d(128),\r\n tnn.ReLU(),\r\n\r\n # 2 Pooling lyaer\r\n tnn.MaxPool2d(kernel_size=2, stride=2))\r\n\r\n self.layer3 = tnn.Sequential(\r\n\r\n # 3-1 conv layer\r\n tnn.Conv2d(128, 256, kernel_size=3, padding=1),\r\n tnn.BatchNorm2d(256),\r\n tnn.ReLU(),\r\n\r\n # 3-2 conv layer\r\n tnn.Conv2d(256, 256, kernel_size=3, padding=1),\r\n tnn.BatchNorm2d(256),\r\n tnn.ReLU(),\r\n\r\n # 3 Pooling layer\r\n tnn.MaxPool2d(kernel_size=2, stride=2))\r\n\r\n self.layer4 = tnn.Sequential(\r\n\r\n # 4-1 conv layer\r\n tnn.Conv2d(256, 512, kernel_size=3, padding=1),\r\n tnn.BatchNorm2d(512),\r\n tnn.ReLU(),\r\n\r\n # 4-2 conv layer\r\n tnn.Conv2d(512, 512, kernel_size=3, padding=1),\r\n tnn.BatchNorm2d(512),\r\n tnn.ReLU(),\r\n\r\n # 4 Pooling layer\r\n tnn.MaxPool2d(kernel_size=2, stride=2))\r\n\r\n self.layer5 = tnn.Sequential(\r\n\r\n # 5-1 conv layer\r\n tnn.Conv2d(512, 512, kernel_size=3, padding=1),\r\n tnn.BatchNorm2d(512),\r\n tnn.ReLU(),\r\n\r\n # 5-2 conv layer\r\n tnn.Conv2d(512, 512, kernel_size=3, padding=1),\r\n tnn.BatchNorm2d(512),\r\n tnn.ReLU(),\r\n\r\n # 5 Pooling layer\r\n tnn.MaxPool2d(kernel_size=2, stride=2))\r\n\r\n self.layer6 = tnn.Sequential(\r\n\r\n # 6 Fully connected layer\r\n # Dropout layer omitted since batch normalization is used.\r\n tnn.Linear(512*7*7, 4096),\r\n tnn.BatchNorm1d(4096),\r\n tnn.ReLU())\r\n \r\n\r\n self.layer7 = tnn.Sequential(\r\n\r\n # 7 Fully connected layer\r\n # Dropout layer omitted since batch normalization is used.\r\n tnn.Linear(4096, 4096),\r\n tnn.BatchNorm1d(4096),\r\n tnn.ReLU())\r\n\r\n self.layer8 = tnn.Sequential(\r\n\r\n # 8 output layer\r\n tnn.Linear(4096, 4),\r\n tnn.BatchNorm1d(4),\r\n tnn.Softmax(dim=1))\r\n\r\n def forward(self, x):\r\n out = self.layer1(x)\r\n out = self.layer2(out)\r\n out = self.layer3(out)\r\n out = self.layer4(out)\r\n out = self.layer5(out)\r\n vgg16_features = out.view(out.size(0), -1)\r\n #print(vgg16_features)\r\n #print(vgg16_features.size())\r\n out = self.layer6(vgg16_features)\r\n out = self.layer7(out)\r\n out = self.layer8(out)\r\n\r\n return vgg16_features,out\r\n \r\nvgg16 = VGG16()\r\nvgg16.cuda()\r\nvgg16=tnn.DataParallel(vgg16)\r\n# Loss and Optimizer\r\ncost = tnn.CrossEntropyLoss()\r\noptimizer = torch.optim.Adam(vgg16.parameters(), lr=LEARNING_RATE)\r\n\r\n# Train the model\r\nprint(\"Start Training...\")\r\n#To Train the model\r\nfor epoch in range(EPOCH):\r\n vgg16.train()\r\n count=0\r\n train_loss=0\r\n for images, target, paths in trainLoader:\r\n images = Variable(images).cuda()\r\n target = Variable(target).cuda()\r\n # Forward + Backward + Optimize\r\n optimizer.zero_grad()\r\n _, outputs = vgg16.forward(images)\r\n loss = cost(outputs, target)\r\n train_loss+=loss.data[0]\r\n loss.backward()\r\n optimizer.step()\r\n count+=1\r\n if count % 20 == 0 :\r\n print ('Epoch [%d/%d], Iter[%d] Loss. %.4f' %\r\n (epoch+1, EPOCH, count, train_loss/count))\r\n\r\n# Test the model\r\n vgg16.eval()\r\n# Evaluation mode\r\n correct = 0\r\n total = 0\r\n count = 0\r\n print(\"Start Testing...\")\r\n for images, target, paths in testLoader:\r\n images = Variable(images).cuda()\r\n _, outputs = vgg16.forward(images)\r\n _, predicted = torch.max(outputs.data, 1)\r\n total += target.size(0)\r\n correct += (predicted.cpu() == target).sum()\r\n count+=1\r\n print('Test Accuracy of the model on the 10000 test images: %d %%' % (100 * correct / total))\r\n\r\n#output the test result of classification \r\nvgg16.eval()\r\nincorrect = 0\r\ncount_right = [0]*4\r\ncount_tot = [0]*4\r\nmatrix = [[0] * 4 for row in range(4)]\r\ntot = 0\r\nsave_rec = True\r\nprint(\"Start Testing...\")\r\nfor data, target, paths in testLoader:\r\n data, target = Variable(data, volatile=True), Variable(target)\r\n _, output = vgg16.forward(data)\r\n for i in range(target.cpu().data.size()[0]):\r\n curr_max = torch.max(output.cpu().data[i])\r\n curr_min = torch.min(output.cpu().data[i])\r\n index = target.cpu().data[i]#actually right\r\n count_tot[index]+=1\r\n for j in range(4):\r\n if output.cpu().data[i][j] == curr_max:\r\n pred = j\r\n matrix[index][pred]+=1\r\n if pred == index:\r\n count_right[index]+=1 \r\n tot+=1\r\n if save_rec:\r\n num=index.cpu().data.numpy()\r\n file_name = \"./rec_data5_2/\"+str(num)+\"_\"+str(pred)+\".txt\"\r\n file = open(file_name,\"a\")\r\n file.write(paths[i]+\"\\t\"+str(curr_max)+\"\\t\"+str(output.cpu().data[i][num])+\"\\n\")\r\n file.close()\r\n pred = output.data.max(1)[1] # get the index of the max log-probability\r\n incorrect += pred.ne(target.cuda().data).cpu().sum()\r\n\r\nnTotal = len(testLoader.dataset)\r\nerr = 100.*incorrect/nTotal\r\nprint('\\nError: {}/{} ({:.0f}%)\\n'.format(\r\n incorrect, nTotal, err))\r\nprint(count_right)\r\nprint(count_tot)\r\nprint(matrix)\r\nprint(\"{}/{}\".format(tot,nTotal))\r\ntorch.save(vgg16.state_dict(), 'cnn_data5_2.pkl')\r\n```\r\n前面的部分是vgg网络的定义\r\ntrain部分:\r\n```\r\nvgg16.train()\r\n count=0\r\n train_loss=0\r\n for images, target, paths in trainLoader:\r\n images = Variable(images).cuda()\r\n target = Variable(target).cuda()\r\n # Forward + Backward + Optimize\r\n optimizer.zero_grad()\r\n _, outputs = vgg16.forward(images)\r\n loss = cost(outputs, target)\r\n train_loss+=loss.data[0]\r\n loss.backward()\r\n optimizer.step()\r\n count+=1\r\n ```\r\n 作差计算loss,loss向后传播loss.backward()更改参数,这样是一次训练\r\n \r\n \r\n"
},
{
"alpha_fraction": 0.5557917356491089,
"alphanum_fraction": 0.595111608505249,
"avg_line_length": 8.477777481079102,
"blob_id": "6b6f9ab75a7239ec1ccf42b0fff2522bf1990d3f",
"content_id": "7ff23859a15d448ebefc4350cf3bee815e2e16c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1331,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 90,
"path": "/os_instructions/linux/tmux.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "#### tmux\r\n\r\n```\r\nhttps://blog.csdn.net/ZCF1002797280/article/details/51859524\r\n```\r\n\r\n进入tmux:tmux\r\n\r\n下一个动作用加号隔开\r\n\r\nctrl b + ?: 显示快捷键帮助\r\n\r\nctrl b+o 切换到下一个分隔窗口\r\n\r\nctrl b+p:前一个窗口\r\n\r\nctrl b+n:下一个窗口\r\n\r\nctrl b+%:水平分隔\r\n\r\nctrl b+“:垂直分隔\r\n\r\nctrl b+d:退出tmux,并保存当前会话\r\n\r\n\r\n\r\ntmux new -s 会话名:启动新会话\r\n\r\ntmux attach -t 会话: 进入指定会话中\r\n\r\ntmux kill-session -t 会话名:关闭会话\r\n\r\ntmux ls | grep : | cut -d. -f1 | awk '{print substr($1, 0, length($1)-1)}' | xargs kill: 关闭所有会话\r\n\r\ntmux ls 列出存在的所有会话\r\n\r\nctrl b+[ 进入翻页模式,此时光标可以上下自由移动\r\n\r\n退出:exit\r\n\r\n\r\n\r\nrun.sh\r\n\r\n```\r\npython wait.py\r\npython print.py\r\n```\r\n\r\nwait.py\r\n\r\n```\r\nimport time\r\n\r\nprint(\"start\")\r\ntime.sleep(10)\r\nprint(\"time is: 1\")\r\n```\r\n\r\nprint.py\r\n\r\n```\r\nprint(\"time is: 1\")\r\n```\r\n\r\n正常运行:\r\n\r\n```\r\nstart\r\ntime is: 1\r\ntime is: 1\r\n```\r\n\r\n如果开始运行之后讲print.py中的1改成2则\r\n\r\n````\r\nstart\r\ntime is: 1\r\ntime is: 2\r\n````\r\n\r\n如果开始运行之后讲wait.py中的1改成2则\r\n\r\n```\r\nstart\r\ntime is: 1\r\ntime is: 2\r\n```\r\n\r\ntmux开始运行某个文件之后,对这个文件的代码进行改动并不会影响代码的运行"
},
{
"alpha_fraction": 0.5186991691589355,
"alphanum_fraction": 0.5430894494056702,
"avg_line_length": 16.08823585510254,
"blob_id": "47af0b47207681fefa0419baa4696996e8ba8770",
"content_id": "8eb991974c8dd5329aeb25c3b748952309567692",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1918,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 68,
"path": "/machine_learning/PCA.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### PCA \r\n\r\nPCA 主成分分析 principal Components Analysis\r\n\r\nPCA的目的是在于寻找到数据中的主成分。我们认为数据分布的更为分散,也意味着数在这个方向上的方差更大。在信号处理领域,我们认为数据具有更大的方差而噪声具有较小的方差。\r\n\r\n对于给定的一组数据点\r\n$$\r\n\\{v_1,v_2,...,v_n\\}\r\n$$\r\n首先进行中心化,即\r\n$$\r\n\\{x_1,x_2,...,x_n\\}=\\{v_1-\\mu,v_2-\\mu,...,v_n-\\mu\\}\r\n$$\r\n其中\r\n$$\r\n\\mu=\\frac{1}{n}\\sum_{i=1}^nv_i\r\n$$\r\nx经过投影之后的数据的方差就是协方差矩阵的特征值。我们要找到最大的方差也就是协方差矩阵最大的特征值,最佳投影方向就是最大特征值所对应的特征向量。\r\n\r\n\r\n\r\n##### 样本协方差矩阵\r\n\r\n假设有m个样本,n个随机变量,即样本是n维的。第k维的特征与第l维的特征的协方差矩阵是:\r\n$$\r\n\\sigma(x_k,x_l)=\\frac{1}{m-1}\\sum_{i=1}^m(x_{ki}-\\overline{x_k})(x_{li}-\\overline{x_l})\r\n$$\r\n协方差矩阵为:\r\n$$\r\n\\left[\r\n \\begin{matrix}\r\n \\sigma(x_1,x_1) & . & . & . & \\sigma(x_1,x_n)\\\\\r\n . & & & & .\\\\\r\n . & & & & . \\\\\r\n . & & & & . \\\\\r\n \\sigma(x_n,x_1) & . & . & . & \\sigma(x_n,x_n)\r\n \\end{matrix}\r\n \\right] \\tag{3}\r\n$$\r\n\r\n\r\n因此PCA算法的求解流程如下:\r\n1.对样本数据进行中心化处理\r\n\r\n2.求样本协方差矩阵\r\n\r\n3.对协方差矩阵进行特征值分解,将特征值从大到小排列\r\n\r\n4.去特征值中前k个特征向量$\\omega_1,\\omega_2,...,\\omega_k$\r\n\r\n5.做下列映射将n维样本$x_i$映射到k维\r\n$$\r\nx'_i=\r\n\\left[\r\n \\begin{matrix}\r\n \\omega_1^Tx_i\\\\\r\n \\omega_2^Tx_i \\\\\r\n . \\\\\r\n . \\\\\r\n \\omega_k^Tx_i\r\n \\end{matrix}\r\n \\right] \\tag{3}\r\n$$\r\n新的样本$x_i'$的第d维即为样本在第d个主成分方向$\\omega_d$方向上的投影。降维后信息占比为\r\n$$\r\n\\eta=\\sqrt{\\frac{\\sum_{i=1}^k\\lambda_i^2}{\\sum_{i=1}^n\\lambda_i^2}}\r\n$$\r\n"
},
{
"alpha_fraction": 0.5700598955154419,
"alphanum_fraction": 0.6119760274887085,
"avg_line_length": 10.753846168518066,
"blob_id": "6721ae846118d7b45cfc1a3137312ef8492d75dc",
"content_id": "7c5c5f745a1b5454278b2f7ad914ddcaa7548ebc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1025,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 65,
"path": "/git.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Git\r\n\r\n##### git clone\r\n\r\n```\r\ngit config --global http.proxy http://127.0.0.1:1080\r\ngit clone + [email protected]:hirocastest/Hello-World.git\r\n```\r\n\r\n##### 日常\r\n\r\n```\r\ngit fetch origin\r\n\r\ngit add --all\r\n\r\ngit commit -m \"xxx\"\r\n\r\ngit push origin\r\n```\r\n\r\n\r\n\r\n##### 添加远程仓库\r\n\r\n如果想将本地的仓库放到远程,先在github上创建一个新仓库,最好与本地仓库同名,然后不要创建readme\r\n\r\n```\r\n$ git remote add origin [email protected]:github-book/git-tutorial.git\r\ngit push\r\n```\r\n\r\n\r\n\r\n##### linux服务器与window本地通过Git相互关联\r\n\r\n1.先在linux上创建远程仓库\r\n\r\n```\r\nmkdir test\r\ncd test\r\ngit init --bare\r\n```\r\n\r\n2.windows克隆远程仓库\r\n\r\n```\r\ngit clone [email protected]:/home/..../test\r\n#新加test.txt\r\ngit add --add \r\ngit commit -m \"first commit\"\r\ngit push\r\n```\r\n\r\n3.再到linux端接收\r\n\r\n```\r\n在/test文件夹下\r\ngit clone [email protected]:/home/..../test\r\ngit pull\r\n#在linux端口进行修改\r\ngit add --add \r\ngit commit -m \"second commit\"\r\ngit push\r\n```\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5574101209640503,
"alphanum_fraction": 0.5849229693412781,
"avg_line_length": 13.694524765014648,
"blob_id": "a630a5ef715e5e2fa350189ac83f7e00f8ec2b86",
"content_id": "546e2c1c896eb9c0f2bf24d0449f9586d3290c2c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 8658,
"license_type": "no_license",
"max_line_length": 170,
"num_lines": 347,
"path": "/python/python基础面试题.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "\r\n\r\n### Python基础面试题\r\n\r\n##### 1.Python如何进行内存管理\r\n\r\n垃圾回收:\r\n\r\n**python采用的是引用计数机制为主,标记-清除和分代收集两种机制为辅的策略**\r\n\r\n在python中 对象的引用计数为0的时候,该对象生命就结束了。\r\n\r\n1.引用计数机制:\r\n\r\n优点:1.简单实用\r\n\r\n缺点:1.引用计数消耗资源 2.无法解决循环引用的问题\r\n\r\n2.标记清除\r\n\r\n\r\n\r\n确认一个根节点对象,然后迭代寻找根节点的引用对象,以及被引用对象的引用对象(标为灰色),然后将那些没有被引用的对象(白色)回收清除。\r\n\r\n3.分代回收\r\n\r\n分代回收是一种空间换时间的操作方式。python将内存根据对象划分为不同的集合。分别为年轻代0 中年代1 老年代2,对应三个链表。新创建的对象都会分配在新生代,年轻代链表的总数达到上限时,Python垃圾收集机制就会被触发,把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推,老年代中的对象是存活时间最久的对象。\r\n\r\n\r\n\r\n##### 2. 什么是lambda函数\r\n\r\nlambda函数也叫匿名函数\r\n\r\n最大的优点是非常轻便,不用特别命名,很适合为map sort等函数做服务\r\n\r\n```\r\npeople.sort(key=lambda x:(-x[0],x[1]))\r\n```\r\n\r\n\r\n\r\n##### 3. python中的深拷贝与浅拷贝与赋值\r\n\r\n深拷贝和浅拷贝的区别\r\n\r\n深拷贝是将对象本身完全复制给另一个对象包括子对象,浅拷贝(copy):拷贝父对象,不会拷贝对象的内部的子对象。赋值是将对象的引用复制给另一个对象,如果对引用进行更改会改变原对象。\r\n\r\n首先对于,在python中对于不可变对象,例如int,str等 = 赋值操作和拷贝没区别\r\n\r\n对于list dict等可变对象\r\n\r\n1、**b = a:** 赋值引用,a 和 b 都指向同一个对象。\r\n\r\n\r\n\r\n**2、b = a.copy():** 浅拷贝, a 和 b 是一个独立的对象,但他们的子对象还是指向统一对象(是引用)。\r\n\r\n\r\n\r\n**b = copy.deepcopy(a):** 深度拷贝, a 和 b 完全拷贝了父对象及其子对象,两者是完全独立的。\r\n\r\n\r\n\r\n### 更多实例\r\n\r\n以下实例是使用 copy 模块的 copy.copy( 浅拷贝 )和(copy.deepcopy ):\r\n\r\n## 实例\r\n\r\n```\r\n#!/usr/bin/python # -*-coding:utf-8 -*- \r\nimport copy a = [1, 2, 3, 4, ['a', 'b']] #原始对象 \r\nb = a #赋值,传对象的引用 \r\nc = copy.copy(a) #对象拷贝,浅拷贝 \r\nd = copy.deepcopy(a) #对象拷贝,深拷贝 \r\na.append(5) #修改对象a \r\na[4].append('c') #修改对象a中的['a', 'b']数组对象 \r\nprint( 'a = ', a ) \r\nprint( 'b = ', b ) \r\nprint( 'c = ', c ) \r\nprint( 'd = ', d )\r\n```\r\n\r\n\r\n\r\n以上实例执行输出结果为:\r\n\r\n```\r\n('a = ', [1, 2, 3, 4, ['a', 'b', 'c'], 5])\r\n('b = ', [1, 2, 3, 4, ['a', 'b', 'c'], 5])\r\n('c = ', [1, 2, 3, 4, ['a', 'b', 'c']])\r\n('d = ', [1, 2, 3, 4, ['a', 'b']])\r\n```\r\n\r\n\r\n\r\n4. 如何理解python的动态特性\r\n\r\npython是门动态语言,程序的运行过程中定义变量的类型并分配内存空间,所以python没有int溢出之类的问题\r\n\r\npython的封装、继承和多态:\r\n\r\n封装:数据和具体实现的代码放在对象内部,细节不被外界所知,只能通过接口使用该对象。\r\n\r\n继承:子类继承了父类所有的函数和方法,同时可以根据需要进行修改 拓展:\r\n\r\n- 子类在调用某个方法或变量的时候,首先在自己内部查找,如果没有找到,则开始根据继承机制在父类里查找。\r\n- 根据父类定义中的顺序,以**深度优先**的方式逐一查找父类!\r\n\r\n设想有下面的继承关系:\r\n\r\n\r\n\r\n```\r\nclass D:\r\n pass\r\n\r\nclass C(D):\r\n pass\r\n\r\nclass B(C): \r\n def show(self):\r\n print(\"i am B\")\r\n pass\r\n\r\nclass G:\r\n pass\r\n\r\nclass F(G):\r\n pass\r\n\r\nclass E(F): \r\n def show(self):\r\n print(\"i am E\")\r\n pass\r\n\r\nclass A(B, E):\r\n pass\r\n\r\na = A()\r\na.show()\r\n```\r\n\r\n运行结果是\"i am B\"。在类A中,没有show()这个方法,于是它只能去它的父类里查找,它首先在B类中找,结果找到了,于是直接执行B类的show()方法。可见,在A的定义中,继承参数的书写有先后顺序,写在前面的被优先继承。\r\n\r\n------\r\n\r\n那如果B没有show方法,而是D有呢?\r\n\r\n```\r\nclass D:\r\n def show(self):\r\n print(\"i am D\")\r\n pass\r\n\r\nclass C(D):\r\n pass\r\n\r\nclass B(C):\r\n\r\n pass\r\n\r\nclass G:\r\n pass\r\n\r\nclass F(G):\r\n pass\r\n\r\nclass E(F): \r\n def show(self):\r\n print(\"i am E\")\r\n pass\r\n\r\nclass A(B, E):\r\n pass\r\n\r\na = A()\r\na.show()\r\n```\r\n\r\n执行结果是\"i am D\",左边具有深度优先权\r\n\r\n### super()函数:\r\n\r\n在子类中如果有与父类同名的成员,那就会覆盖掉父类里的成员。那如果想强制调用父类的成员呢?使用super()函数\r\n\r\n多态:\r\n\r\npython这里的多态性是指具有不同功能的函数可以使用相同的函数名,这样就可以用一个函数名调用不同内容的函数\r\n\r\n```\r\nclass Animal:\r\n\r\n def kind(self):\r\n print(\"i am animal\")\r\n\r\nclass Dog(Animal):\r\n\r\n def kind(self):\r\n print(\"i am a dog\")\r\n\r\nclass Cat(Animal):\r\n\r\n def kind(self):\r\n print(\"i am a cat\")\r\n\r\nclass Pig(Animal):\r\n\r\n def kind(self):\r\n print(\"i am a pig\")\r\n# 这个函数接收一个animal参数,并调用它的kind方法\r\ndef show_kind(animal):\r\n animal.kind()\r\n\r\nd = Dog()\r\nc = Cat()\r\np = Pig()\r\n\r\nshow_kind(d)\r\nshow_kind(c)\r\nshow_kind(p)\r\n------------------\r\n打印结果:\r\ni am a dog\r\ni am a cat\r\ni am a pig\r\n```\r\n\r\n\r\n\r\n##### 5 什么是闭包\r\n\r\n闭包又称词法闭包、函数闭包。\r\n\r\n```python\r\ndef test():\r\n x = [1]\r\n def test2():\r\n x[0] += 1\r\n print(\"x is \",x)\r\n return\r\n return test2\r\n\r\na = test()\r\na()\r\na()\r\n```\r\n\r\n```python\r\n('x is ', [2])\r\n('x is ', [3])\r\n```\r\n\r\ntest是一个闭包,分为外部函数,自由变量和内部函数。\r\n\r\n闭包可以很好地保存当前程序的运行环境,使得每次程序执行时的起点都是上次执行结束的终点。例如点赞程序,一篇文章统计点赞数量,点赞之后就是点赞数在原先点赞数的数量上加1,这可以用闭包实现。\r\n\r\n\r\n\r\n注意的是 如果test函数中x=1 这样的话会报错,test2中x = x+1 既是local variable,又是外部变量。在python中int float str是不可变类型,变的只是其引用。改成list可以解决这个问题\r\n\r\n\r\n\r\n6. python中的切片与负索引\r\n\r\nlist切片\r\n\r\n\r\n\r\n7. args和kwargs\r\n\r\npython中的可变参数。*args表示任何多个无名参数,它是一个tuple;**kwargs表示关键字参数,它是一个dict\r\n\r\n\r\n\r\n8. 什么是生成器,迭代器,装饰器\r\n\r\n\r\n\r\n##### 迭代器与生成器\r\n\r\npython中迭代器从集合的第一个元素开始访问,直到最后一个元素。\r\n\r\n迭代器基本的方法:iter(),next()\r\n\r\n```python\r\nlist=[1,2,3,4]\r\nit = iter(list) # 创建迭代器对象\r\nprint (next(it)) # 输出迭代器的下一个元素\r\n1\r\nprint (next(it))\r\n2\r\n```\r\n\r\n生成器\r\n\r\n使用了yield函数的称为生成器\r\n\r\n生成器是一个返回迭代器的函数,每次遇到yield的时候会暂停并保存所有的信息,返回yield值,在下一次执行next的时候从当前位置继续执行。\r\n\r\n```python\r\nimport sys\r\n \r\ndef fibonacci(n): # 生成器函数 - 斐波那契\r\n a, b, counter = 0, 1, 0\r\n while True:\r\n if (counter > n): \r\n return\r\n yield a\r\n a, b = b, a + b\r\n counter += 1\r\nf = fibonacci(10) # f 是一个迭代器,由生成器返回生成\r\n \r\nwhile True:\r\n try:\r\n print (next(f), end=\" \")\r\n except StopIteration:\r\n sys.exit()\r\n```\r\n\r\n\r\n\r\n##### 装饰器\r\n\r\n```python\r\ndef print_add(add):\r\n def warp(x):\r\n print(\"start adding\")\r\n add(x)\r\n return warp\r\n\r\n@print_add\r\ndef add(x):\r\n x += 1\r\n print(x)\r\n return\r\n\r\nadd(1)\r\n```\r\n\r\n```python\r\nstart adding\r\n2\r\n```\r\n\r\n函数add相当于一个接口,print_add则是在这个接口外面包装了一下。\r\n\r\n这样做的好处在于将主体的代码逻辑和副线(打印)分开来,逻辑清晰。\r\n\r\n"
},
{
"alpha_fraction": 0.5194823741912842,
"alphanum_fraction": 0.5648087859153748,
"avg_line_length": 28.87276840209961,
"blob_id": "12a33459566d1f01a80e6c7c6a489c8e71f2e3a7",
"content_id": "5de75ffae87288a930293ec89da7cd5f544c747b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 14999,
"license_type": "no_license",
"max_line_length": 498,
"num_lines": 448,
"path": "/leetcode_note/Math&&Geo.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "#### Math \r\n\r\n##### leetcode 963 Minimum Area Rectangle II\r\n\r\n* Given a set of points in the xy-plane, determine the minimum area of **any** rectangle formed from these points, with sides **not necessarily parallel** to the x and y axes. If there isn't any rectangle, return 0.\r\n\r\n```\r\nInput: [[1,2],[2,1],[1,0],[0,1]]\r\nOutput: 2.00000\r\nExplanation: The minimum area rectangle occurs at [1,2],[2,1],[1,0],[0,1], with an area of 2.\r\n```\r\n\r\n\r\n\r\n```\r\nInput: [[0,1],[2,1],[1,1],[1,0],[2,0]]\r\nOutput: 1.00000\r\nExplanation: The minimum area rectangle occurs at [1,0],[1,1],[2,1],[2,0], with an area of 1.\r\n```\r\n\r\n\r\n\r\n```\r\nInput: [[0,3],[1,2],[3,1],[1,3],[2,1]]\r\nOutput: 0\r\nExplanation: There is no possible rectangle to form from these points.\r\n```\r\n\r\n\r\n\r\n\r\n\r\n* Mysolution:\r\n\r\n ```python\r\n class Solution:\r\n def minAreaFreeRect(self, points):\r\n res=float(\"inf\")\r\n n=len(points)\r\n if n<=3: return 0\r\n for i in range(n):\r\n for j in range(i+1,n):\r\n for k in range(j+1,n):\r\n [x1,y1]=points[i][0],points[i][1]\r\n [x2, y2] = points[j][0], points[j][1]\r\n [x3, y3] = points[k][0], points[k][1]\r\n if [x2+x3-x1,y2+y3-y1] in points:\r\n vec1=[x2-x1,y2-y1]\r\n vec2=[x3-x1,y3-y1]\r\n if vec1[0]*vec2[0]+vec1[1]*vec2[1]==0:\r\n res=min(res,(vec1[0]*vec1[0]+vec1[1]*vec1[1])**0.5*(vec2[0]*vec2[0]+vec2[1]*vec2[1])**0.5)\r\n return res\r\n ```\r\n\r\n\r\n1. 判断第四个点在不在points中\r\n2. 判断向量[x2-x1,y2-y1]与[x3-x1,y3-y1]是否垂直\r\n\r\n\r\n\r\n和上一题不同,如果存在边必须与x轴或者y轴平行等要求,则复杂度可以明显降低到O(N)\r\n\r\n##### leetcode 939 Minimum Area Rectangle\r\n\r\n* Given a set of points in the xy-plane, determine the minimum area of a rectangle formed from these points, with sides parallel to the x and y axes.\r\n\r\n If there isn't any rectangle, return 0.\r\n\r\n **Note**:\r\n\r\n 1. `1 <= points.length <= 500`\r\n 2. `0 <= points[i][0] <= 40000`\r\n 3. `0 <= points[i][1] <= 40000`\r\n 4. All points are distinct.\r\n\r\n ```\r\n Input: [[1,1],[1,3],[3,1],[3,3],[2,2]]\r\n Output: 4\r\n \r\n Input: [[1,1],[1,3],[3,1],[3,3],[4,1],[4,3]]\r\n Output: 2\r\n ```\r\n\r\n\r\n```python\r\nclass Solution:\r\n def minAreaRect(self, points):\r\n seen = set()\r\n res = float('inf')\r\n for x1, y1 in points:\r\n for x2, y2 in seen:\r\n if (x1, y2) in seen and (x2, y1) in seen:\r\n area = abs(x1 - x2) * abs(y1 - y2)\r\n if area and area < res:\r\n res = area\r\n seen.add((x1, y1))\r\n return res if res < float('inf') else 0\r\n```\r\n\r\n首先使用set,使得查询在O(1)数量级\r\n\r\n使用seen,如果用for x2,y2 in points: if (x1,y2) in points and (x2,y1) in points:会出现 x1,y1=1,1, x2,y2=1,3的情况,但是使用seen则会避免这种情况,因为在执行的时候(1,3)还没有放到seen里面\r\n\r\nlist 不能hash化\r\n\r\n```\r\nnums\r\n[[1, 1], [1, 3], [2, 2], [3, 1], [3, 3]]\r\ndict1={(x[0],x[1])for x in nums}\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 964 Least Operators to Express Number\r\n\r\n* Given a single positive integer `x`, we will write an expression of the form `x (op1) x (op2) x (op3) x ...` where each operator `op1`, `op2`, etc. is either addition, subtraction, multiplication, or division (`+`, `-`, `*`, or `/)`. For example, with `x = 3`, we might write `3 * 3 / 3 + 3 - 3` which is a value of 3.\r\n\r\n When writing such an expression, we adhere to the following conventions:\r\n\r\n 1. The division operator (`/`) returns rational numbers.\r\n 2. There are no parentheses placed anywhere.\r\n 3. We use the usual order of operations: multiplication and division happens before addition and subtraction.\r\n 4. It's not allowed to use the unary negation operator (`-`). For example, \"`x - x`\" is a valid expression as it only uses subtraction, but \"`-x + x`\" is not because it uses negation.\r\n\r\n We would like to write an expression with the least number of operators such that the expression equals the given `target`. Return the least number of expressions used.\r\n\r\n```\r\nInput: x = 3, target = 19\r\nOutput: 5\r\nExplanation: 3 * 3 + 3 * 3 + 3 / 3. The expression contains 5 operations.\r\n```\r\n\r\n* Solution:\r\n\r\n ```python\r\n class Solution(object):\r\n def leastOpsExpressTarget(self, x, target):\r\n rl = list()\r\n while target:\r\n rl.append(target%x)\r\n target=int(target/x)\r\n n = len(rl)\r\n pos = rl[0] * 2\r\n neg = (x-rl[0]) * 2\r\n for i in range(1,n):\r\n pos, neg = min(rl[i] * i + pos, rl[i] * i + i + neg), min((x - rl[i]) * i + pos, (x-rl[i]) * i + i + neg - 2 * i)\r\n return min(pos-1, n+neg-1)\r\n ```\r\n\r\n 1. 在个位的时候,必须用x/x表示1,所以*2,但其它位不用,所以单独先提出\r\n\r\n 2. 正数表示时,可用自己+剩下的正数表示或者多加一个本位然后减去上一位的余数表示\r\n #负数表示时,可用自己的余数加上剩下的正数表示或者用自己的余数+剩下的余数,但此时可以合并同级项减少运算符\r\n\r\n 如在10进制下,86可表示为\r\n\r\n 80 + 6 (6 为下一位正数表示\r\n\r\n 80 + 10 - 4 (4 为下一位负数表示)\r\n\r\n 100 - 20 + 6 (100-20为本位余数表示,6为下一位正数表示\r\n\r\n 100 - 20 + 10 - 4 (100-20为本位余数表示,10 -4 为下一位余数表示\r\n\r\n 在此时, 20 和 10注定为同一位且符号相反,可以省去两个符号(一个符号在该位用i 个符号表示(如100为第二位,所以表示为+10 * 10,用两个符号,在此时所有符号均带自己的正负号\r\n\r\n 因为在前面算法中所有位都带自己的正负号,所以第一位应该减去自己的符号,所以总量减1\r\n 或者在余数表示法中,加上一个更高位的减去自己表示本位余数\r\n\r\n\r\n\r\n##### leetcode 1022. Smallest Integer Divisible by K\r\n\r\nGiven a positive integer `K`, you need find the **smallest** positive integer `N` such that `N` is divisible by `K`, and `N` only contains the digit **1**.\r\n\r\nReturn the length of `N`. If there is no such `N`, return -1.\r\n\r\n```\r\nInput: 1\r\nOutput: 1\r\nExplanation: The smallest answer is N = 1, which has length 1.\r\n\r\nInput: 2\r\nOutput: -1\r\nExplanation: There is no such positive integer N divisible by 2.\r\n\r\nInput: 3\r\nOutput: 3\r\nExplanation: The smallest answer is N = 111, which has length 3.\r\n```\r\n\r\n**Note:**\r\n\r\n- `1 <= K <= 10^5`\r\n\r\n```python\r\nclass Solution:\r\n def smallestRepunitDivByK(self, K):\r\n if K==1:return 1\r\n yu,seen,count=0,set(),0\r\n while True:\r\n yu=(10*yu+1)%K\r\n count+=1\r\n if yu==0:\r\n return count\r\n if yu in seen:\r\n return -1\r\n else:\r\n seen.add(yu)\r\n```\r\n\r\n所有的整除问题都考虑**余数**\r\n\r\nyu=10*yu+1\r\n\r\n利用抽屉原理,如果出现余数的循环说明不可能被整除\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 1138 Alphabet Board Path\r\n\r\nOn an alphabet board, we start at position `(0, 0)`, corresponding to character `board[0][0]`.\r\n\r\nHere, `board = [\"abcde\", \"fghij\", \"klmno\", \"pqrst\", \"uvwxy\", \"z\"]`, as shown in the diagram below.\r\n\r\n\r\n\r\nWe may make the following moves:\r\n\r\n- `'U'` moves our position up one row, if the position exists on the board;\r\n- `'D'` moves our position down one row, if the position exists on the board;\r\n- `'L'` moves our position left one column, if the position exists on the board;\r\n- `'R'` moves our position right one column, if the position exists on the board;\r\n- `'!'` adds the character `board[r][c]` at our current position `(r, c)` to the answer.\r\n\r\n(Here, the only positions that exist on the board are positions with letters on them.)\r\n\r\nReturn a sequence of moves that makes our answer equal to `target` in the minimum number of moves. You may return any path that does so.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: target = \"leet\"\r\nOutput: \"DDR!UURRR!!DDD!\"\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: target = \"code\"\r\nOutput: \"RR!DDRR!UUL!R!\"\r\n```\r\n\r\n \r\n\r\n**Constraints:**\r\n\r\n- `1 <= target.length <= 100`\r\n- `target` consists only of English lowercase letters.\r\n\r\n```python\r\nclass Solution:\r\n def alphabetBoardPath(self, target: str) -> str:\r\n pos = {}\r\n for i in range(26):\r\n r, c = int(i/5), i % 5\r\n pos[chr(i+97)] = [r,c]\r\n pos_x, pos_y = 0, 0\r\n res = \"\"\r\n for i in range(len(target)):\r\n target_pos_x, target_pos_y = pos[target[i]]\r\n dr, dc = target_pos_x - pos_x, target_pos_y - pos_y\r\n if target_pos_x == 5 and target_pos_y == 0:\r\n if dc > 0:\r\n res += \"R\"*dc\r\n elif dc < 0:\r\n res += \"L\"*(-dc)\r\n if dr > 0:\r\n res += \"D\"*dr\r\n elif dr < 0:\r\n res += \"U\"*(-dr)\r\n else:\r\n if dr > 0:\r\n res += \"D\"*dr\r\n elif dr < 0:\r\n res += \"U\"*(-dr)\r\n if dc > 0:\r\n res += \"R\"*dc\r\n elif dc < 0:\r\n res += \"L\"*(-dc)\r\n res += \"!\"\r\n pos_x, pos_y = target_pos_x, target_pos_y\r\n return res\r\n \r\n \r\n```\r\n\r\n需要注意board其实不是一个完整的矩形,因此可能移出边界,分别考虑移向z和从z移出的时候可能存在的边界问题\r\n\r\n\r\n\r\n##### leetcode 1057 Campus Bikes\r\n\r\nOn a campus represented as a 2D grid, there are `N` workers and `M` bikes, with `N <= M`. Each worker and bike is a 2D coordinate on this grid.\r\n\r\nOur goal is to assign a bike to each worker. Among the available bikes and workers, we choose the (worker, bike) pair with the shortest Manhattan distance between each other, and assign the bike to that worker. (If there are multiple (worker, bike) pairs with the same shortest Manhattan distance, we choose the pair with the smallest worker index; if there are multiple ways to do that, we choose the pair with the smallest bike index). We repeat this process until there are no available workers.\r\n\r\nThe Manhattan distance between two points `p1` and `p2` is `Manhattan(p1, p2) = |p1.x - p2.x| + |p1.y - p2.y|`.\r\n\r\nReturn a vector `ans` of length `N`, where `ans[i]` is the index (0-indexed) of the bike that the `i`-th worker is assigned to.\r\n\r\n**Example 1:**\r\n\r\n\r\n\r\n```\r\nInput: workers = [[0,0],[2,1]], bikes = [[1,2],[3,3]]\r\nOutput: [1,0]\r\nExplanation: \r\nWorker 1 grabs Bike 0 as they are closest (without ties), and Worker 0 is assigned Bike 1. So the output is [1, 0].\r\n```\r\n\r\n**Example 2:**\r\n\r\n\r\n\r\n```\r\nInput: workers = [[0,0],[1,1],[2,0]], bikes = [[1,0],[2,2],[2,1]]\r\nOutput: [0,2,1]\r\nExplanation: \r\nWorker 0 grabs Bike 0 at first. Worker 1 and Worker 2 share the same distance to Bike 2, thus Worker 1 is assigned to Bike 2, and Worker 2 will take Bike 1. So the output is [0,2,1].\r\n```\r\n\r\n**Note:**\r\n\r\n1. `0 <= workers[i][j], bikes[i][j] < 1000`\r\n2. All worker and bike locations are distinct.\r\n3. `1 <= workers.length <= bikes.length <= 1000`\r\n\r\n```python\r\nclass Solution:\r\n def assignBikes(self, workers, bikes):\r\n nums = []\r\n for i in range(len(workers)):\r\n for j in range(len(bikes)):\r\n d = abs(workers[i][0] - bikes[j][0]) + abs(workers[i][1] - bikes[j][1])\r\n nums.append([d, i, j])\r\n nums.sort()\r\n res = [0 for i in range(len(workers))]\r\n seen_workers, seen_bikes = set(), set()\r\n for d, i, j in nums:\r\n if i not in seen_workers and j not in seen_bikes:\r\n seen_workers.add(i)\r\n seen_bikes.add(j)\r\n res[i] = j\r\n return res\r\n```\r\n\r\n这题是抢车,每个worker同时开始抢\r\n\r\n因此排序的顺序是$[distance, worker,bike ]$ \r\n\r\n\r\n\r\n##### leetcode 1066 Campus Bikes II\r\n\r\nOn a campus represented as a 2D grid, there are `N` workers and `M` bikes, with `N <= M`. Each worker and bike is a 2D coordinate on this grid.\r\n\r\nWe assign one unique bike to each worker so that the sum of the Manhattan distances between each worker and their assigned bike is minimized.\r\n\r\nThe Manhattan distance between two points `p1` and `p2` is `Manhattan(p1, p2) = |p1.x - p2.x| + |p1.y - p2.y|`.\r\n\r\nReturn the minimum possible sum of Manhattan distances between each worker and their assigned bike.\r\n\r\n**Example 1:**\r\n\r\n\r\n\r\n```\r\nInput: workers = [[0,0],[2,1]], bikes = [[1,2],[3,3]]\r\nOutput: 6\r\nExplanation: \r\nWe assign bike 0 to worker 0, bike 1 to worker 1. The Manhattan distance of both assignments is 3, so the output is 6.\r\n```\r\n\r\n**Example 2:**\r\n\r\n\r\n\r\n```\r\nInput: workers = [[0,0],[1,1],[2,0]], bikes = [[1,0],[2,2],[2,1]]\r\nOutput: 4\r\nExplanation: \r\nWe first assign bike 0 to worker 0, then assign bike 1 to worker 1 or worker 2, bike 2 to worker 2 or worker 1. Both assignments lead to sum of the Manhattan distances as 4.\r\n```\r\n\r\n**Note:**\r\n\r\n1. `0 <= workers[i][0], workers[i][1], bikes[i][0], bikes[i][1] < 1000`\r\n2. All worker and bike locations are distinct.\r\n3. `1 <= workers.length <= bikes.length <= 10`\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int min_num = INT_MAX; \r\n int distance(vector<int>& worker, vector<int>& bike){\r\n return abs(worker[0] - bike[0]) + abs(worker[1] - bike[1]);\r\n }\r\n void dfs(int worker_index, vector<vector<int>>& workers, vector<vector<int>>& bikes, int sum_num, vector<int>& used){\r\n if(worker_index == workers.size()){\r\n min_num = min(min_num, sum_num);\r\n return;\r\n }\r\n if(sum_num > min_num) return;\r\n int i;\r\n for(i=0;i<bikes.size();i++){\r\n if(used[i] == 0){\r\n used[i] = 1;\r\n int d = distance(workers[worker_index], bikes[i]);\r\n dfs(worker_index + 1, workers, bikes, sum_num + d, used);\r\n used[i] = 0;\r\n }\r\n }\r\n return;\r\n }\r\n int assignBikes(vector<vector<int>>& workers, vector<vector<int>>& bikes) {\r\n int n = workers.size(), m = bikes.size();\r\n vector<int> used(m ,0);\r\n dfs(0, workers, bikes, 0, used);\r\n return min_num;\r\n }\r\n};\r\n```\r\n\r\n求拿车的最小距离之和\r\n\r\n使用back-track\r\n\r\n用used记录车被使用的情况\r\n\r\n然后尝试将没有被分配的车分配给workers\r\n\r\n"
},
{
"alpha_fraction": 0.6529080867767334,
"alphanum_fraction": 0.6829268336296082,
"avg_line_length": 14.090909004211426,
"blob_id": "459241feb40e04315681db689384e9156fa815f9",
"content_id": "29acc820e1e0d7bcc73da7d1f38df5e20f3d2eac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 599,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 33,
"path": "/computer_science_knowledge/database/mysql_install.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Mysql install\r\n\r\n如何在服务器上ubuntu环境,安装mysql\r\n\r\n<https://blog.csdn.net/weixx3/article/details/80782479>\r\n\r\n\r\n\r\n```python\r\nsudo apt-get update\r\nsudo apt-get install mysql-server\r\nsudo mysql_secure_installation\r\n\r\nno no no\r\n```\r\n\r\n登陆\r\n\r\n```\r\nmysql -u root -p \r\n```\r\n\r\n可能遇到的错误\r\n\r\nERROR 2002 (HY000): Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock'问题\r\n\r\n这个错误是文件`/var/run/mysqld/mysqld.sock` 不存在\r\n\r\n```\r\nsudo mkdir -p /var/run/mysqld\r\nsudo chown mysql /var/run/mysqld/\r\nsudo service mysql restart\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.5603827238082886,
"alphanum_fraction": 0.5929903388023376,
"avg_line_length": 36.93916320800781,
"blob_id": "230de316827c93ac17ee3ad51f90804de68bedd1",
"content_id": "1bc4804b240f52230e77eabed6c6031bef96fba7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 10419,
"license_type": "no_license",
"max_line_length": 523,
"num_lines": 263,
"path": "/leetcode_note/maze.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### Maze\r\n\r\nBFS\r\n\r\n##### leetcode 490 The Maze\r\n\r\nThere is a **ball** in a maze with empty spaces and walls. The ball can go through empty spaces by rolling **up**, **down**, **left** or **right**, but it won't stop rolling until hitting a wall. When the ball stops, it could choose the next direction.\r\n\r\nGiven the ball's **start position**, the **destination** and the **maze**, determine whether the ball could stop at the destination.\r\n\r\nThe maze is represented by a binary 2D array. 1 means the wall and 0 means the empty space. You may assume that the borders of the maze are all walls. The start and destination coordinates are represented by row and column indexes.\r\n\r\n **Example 1:**\r\n\r\n```\r\nInput 1: a maze represented by a 2D array\r\n\r\n0 0 1 0 0\r\n0 0 0 0 0\r\n0 0 0 1 0\r\n1 1 0 1 1\r\n0 0 0 0 0\r\n\r\nInput 2: start coordinate (rowStart, colStart) = (0, 4)\r\nInput 3: destination coordinate (rowDest, colDest) = (4, 4)\r\n\r\nOutput: true\r\n\r\nExplanation: One possible way is : left -> down -> left -> down -> right -> down -> right.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput 1: a maze represented by a 2D array\r\n\r\n0 0 1 0 0\r\n0 0 0 0 0\r\n0 0 0 1 0\r\n1 1 0 1 1\r\n0 0 0 0 0\r\n\r\nInput 2: start coordinate (rowStart, colStart) = (0, 4)\r\nInput 3: destination coordinate (rowDest, colDest) = (3, 2)\r\n\r\nOutput: false\r\n\r\nExplanation: There is no way for the ball to stop at the destination.\r\n```\r\n\r\n **Note:**\r\n\r\n1. There is only one ball and one destination in the maze.\r\n2. Both the ball and the destination exist on an empty space, and they will not be at the same position initially.\r\n3. The given maze does not contain border (like the red rectangle in the example pictures), but you could assume the border of the maze are all walls.\r\n4. The maze contains at least 2 empty spaces, and both the width and height of the maze won't exceed 100.\r\n\r\n ```python\r\nimport copy\r\nclass Solution:\r\n def hasPath(self, maze, start, destination):\r\n if len(maze) == 0 or len(maze[0]) == 0: return False\r\n n, m = len(maze), len(maze[0])\r\n level, next_level = [], []\r\n level.append(start)\r\n directions = [[-1, 0], [1, 0], [0, -1], [0, 1]]\r\n visited = [[0 for i in range(m)] for j in range(n)]\r\n visited[start[0]][start[1]] = 1\r\n while level or next_level:\r\n while level:\r\n i, j = level.pop()\r\n if i == destination[0] and j == destination[1]:\r\n return True\r\n for ii, jj in directions:\r\n temp_i, temp_j = i, j\r\n while 0<=temp_i+ii<n and 0<=temp_j+jj<m:\r\n if maze[temp_i+ii][temp_j+jj] == 0:\r\n temp_i += ii\r\n temp_j += jj\r\n else:\r\n break\r\n if visited[temp_i][temp_j] == 0:\r\n visited[temp_i][temp_j] = 1\r\n next_level.append([temp_i, temp_j])\r\n level = copy.deepcopy(next_level)\r\n next_level = []\r\n return False\r\n ```\r\n\r\n与普通的BFS不同的是 这次小球不碰到wall不停,因此多了一个while\r\n\r\n这种使用next_level, level两个list的比较适合用来求解小球需要多少步运行到destination,如果是要求start到destination的绝对长度的话,需要使用heap(优先队列)优先弹出那些距离start点较近的节点\r\n\r\n\r\n\r\n##### leetcode 505 The Maze II\r\n\r\nThere is a **ball** in a maze with empty spaces and walls. The ball can go through empty spaces by rolling **up**, **down**, **left** or **right**, but it won't stop rolling until hitting a wall. When the ball stops, it could choose the next direction.\r\n\r\nGiven the ball's **start position**, the **destination** and the **maze**, find the shortest distance for the ball to stop at the destination. The distance is defined by the number of **empty spaces** traveled by the ball from the start position (excluded) to the destination (included). If the ball cannot stop at the destination, return -1.\r\n\r\nThe maze is represented by a binary 2D array. 1 means the wall and 0 means the empty space. You may assume that the borders of the maze are all walls. The start and destination coordinates are represented by row and column indexes.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput 1: a maze represented by a 2D array\r\n\r\n0 0 1 0 0\r\n0 0 0 0 0\r\n0 0 0 1 0\r\n1 1 0 1 1\r\n0 0 0 0 0\r\n\r\nInput 2: start coordinate (rowStart, colStart) = (0, 4)\r\nInput 3: destination coordinate (rowDest, colDest) = (4, 4)\r\n\r\nOutput: 12\r\n\r\nExplanation: One shortest way is : left -> down -> left -> down -> right -> down -> right.\r\n The total distance is 1 + 1 + 3 + 1 + 2 + 2 + 2 = 12.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput 1: a maze represented by a 2D array\r\n\r\n0 0 1 0 0\r\n0 0 0 0 0\r\n0 0 0 1 0\r\n1 1 0 1 1\r\n0 0 0 0 0\r\n\r\nInput 2: start coordinate (rowStart, colStart) = (0, 4)\r\nInput 3: destination coordinate (rowDest, colDest) = (3, 2)\r\n\r\nOutput: -1\r\n\r\nExplanation: There is no way for the ball to stop at the destination.\r\n```\r\n\r\n**Note:**\r\n\r\n1. There is only one ball and one destination in the maze.\r\n2. Both the ball and the destination exist on an empty space, and they will not be at the same position initially.\r\n3. The given maze does not contain border (like the red rectangle in the example pictures), but you could assume the border of the maze are all walls.\r\n4. The maze contains at least 2 empty spaces, and both the width and height of the maze won't exceed 100.\r\n\r\n```python\r\nimport heapq\r\nclass Solution:\r\n def shortestDistance(self, maze, start, destination):\r\n if len(maze) == 0 or len(maze[0]) == 0: return False\r\n n, m = len(maze), len(maze[0])\r\n directions = [[-1, 0], [1, 0], [0, -1], [0, 1]]\r\n visited = [[0 for i in range(m)] for j in range(n)]\r\n distance = [[float(\"inf\") for i in range(m)] for j in range(n)]\r\n visited[start[0]][start[1]] = 1\r\n distance[start[0]][start[1]] = 0\r\n q = [(0, start[0], start[1])]\r\n while q:\r\n dist, i, j = heapq.heappop(q)\r\n if i == destination[0] and j == destination[1]:\r\n return distance[i][j]\r\n for ii, jj in directions:\r\n temp_i, temp_j = i, j\r\n step = 0\r\n while 0<=temp_i+ii<n and 0<=temp_j+jj<m:\r\n if maze[temp_i+ii][temp_j+jj] == 0:\r\n step += 1\r\n temp_i += ii\r\n temp_j += jj\r\n else:\r\n break\r\n if visited[temp_i][temp_j] == 0 or distance[temp_i][temp_j] > distance[i][j] + step:\r\n visited[temp_i][temp_j] = 1\r\n distance[temp_i][temp_j] = min(distance[temp_i][temp_j], distance[i][j] + step)\r\n heapq.heappush(q, (distance[temp_i][temp_j], temp_i, temp_j))\r\n return -1\r\n```\r\n\r\n\r\n\r\nball, hole:\r\n\r\n##### leetcode 499\r\n\r\n There is a **ball** in a maze with empty spaces and walls. The ball can go through empty spaces by rolling **up** (u), **down** (d), **left** (l) or **right** (r), but it won't stop rolling until hitting a wall. When the ball stops, it could choose the next direction. There is also a **hole** in this maze. The ball will drop into the hole if it rolls on to the hole.\r\n\r\nGiven the **ball position**, the **hole position** and the **maze**, find out how the ball could drop into the hole by moving the **shortest distance**. The distance is defined by the number of **empty spaces** traveled by the ball from the start position (excluded) to the hole (included). Output the moving **directions** by using 'u', 'd', 'l' and 'r'. Since there could be several different shortest ways, you should output the **lexicographically smallest** way. If the ball cannot reach the hole, output \"impossible\".\r\n\r\nThe maze is represented by a binary 2D array. 1 means the wall and 0 means the empty space. You may assume that the borders of the maze are all walls. The ball and the hole coordinates are represented by row and column indexes.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput 1: a maze represented by a 2D array\r\n\r\n0 0 0 0 0\r\n1 1 0 0 1\r\n0 0 0 0 0\r\n0 1 0 0 1\r\n0 1 0 0 0\r\n\r\nInput 2: ball coordinate (rowBall, colBall) = (4, 3)\r\nInput 3: hole coordinate (rowHole, colHole) = (0, 1)\r\n\r\nOutput: \"lul\"\r\n\r\nExplanation: There are two shortest ways for the ball to drop into the hole.\r\nThe first way is left -> up -> left, represented by \"lul\".\r\nThe second way is up -> left, represented by 'ul'.\r\nBoth ways have shortest distance 6, but the first way is lexicographically smaller because 'l' < 'u'. So the output is \"lul\".\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput 1: a maze represented by a 2D array\r\n\r\n0 0 0 0 0\r\n1 1 0 0 1\r\n0 0 0 0 0\r\n0 1 0 0 1\r\n0 1 0 0 0\r\n\r\nInput 2: ball coordinate (rowBall, colBall) = (4, 3)\r\nInput 3: hole coordinate (rowHole, colHole) = (3, 0)\r\n\r\nOutput: \"impossible\"\r\n\r\nExplanation: The ball cannot reach the hole.\r\n```\r\n\r\n**Note:**\r\n\r\n1. There is only one ball and one hole in the maze.\r\n2. Both the ball and hole exist on an empty space, and they will not be at the same position initially.\r\n3. The given maze does not contain border (like the red rectangle in the example pictures), but you could assume the border of the maze are all walls.\r\n4. The maze contains at least 2 empty spaces, and the width and the height of the maze won't exceed 30.\r\n\r\n```python\r\nclass Solution:\r\n def findShortestWay(self, maze, ball, hole):\r\n m, n, q, stopped = len(maze), len(maze[0]), [(0, \"\", ball[0], ball[1])], {(ball[0], ball[1]): [0, \"\"]}\r\n while q:\r\n dist, pattern, x, y = heapq.heappop(q)\r\n if [x, y] == hole:\r\n return pattern\r\n for i, j, p in ((-1, 0, \"u\"), (1, 0, \"d\"), (0, -1, \"l\"), (0, 1, \"r\")):\r\n newX, newY, d = x, y, 0\r\n while 0 <= newX + i < m and 0 <= newY + j < n and maze[newX + i][newY + j] != 1:\r\n newX += i\r\n newY += j\r\n d += 1\r\n if [newX, newY] == hole:\r\n break\r\n if (newX, newY) not in stopped or [dist + d, pattern + p] < stopped[(newX, newY)]:\r\n stopped[(newX, newY)] = [dist + d, pattern + p]\r\n heapq.heappush(q, (dist + d, pattern + p, newX, newY))\r\n return \"impossible\"\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.5338930487632751,
"alphanum_fraction": 0.5824005007743835,
"avg_line_length": 24.04453468322754,
"blob_id": "bf5cc60fd2a0a6ba9a00d1d4025edddaf3895f2e",
"content_id": "73cf59cef9a26d4bb884eba6900c1863b488ae4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 13417,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 494,
"path": "/math&&deeplearning/pytorch/pytorch_nn.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### How to load data\r\n#### data 结构:\r\n```\r\ndata:\r\n train:\r\n class a\r\n class b\r\n test:\r\n class a\r\n class b\r\n```\r\n#### load data:\r\n```\r\n# Data augmentation and normalization for training\r\n# Just normalization for validation\r\ndata_transforms = {\r\n 'train': transforms.Compose([\r\n transforms.RandomResizedCrop(224),\r\n transforms.RandomHorizontalFlip(),\r\n transforms.ToTensor(),\r\n transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])\r\n ]),\r\n 'val': transforms.Compose([\r\n transforms.Resize(256),\r\n transforms.CenterCrop(224),\r\n transforms.ToTensor(),\r\n transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])\r\n ]),\r\n}\r\n\r\ndata_dir = '/home/shaoping/data/hymenoptera_data'\r\nimage_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),\r\n data_transforms[x])\r\n for x in ['train', 'val']}\r\ndataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,\r\n shuffle=True, num_workers=4)\r\n for x in ['train', 'val']}\r\ndataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}\r\nclass_names = image_datasets['train'].classes\r\n```\r\n\r\n#### train model\r\n```\r\ndef train_model(model, criterion, optimizer, scheduler, num_epochs=25):\r\n since = time.time()\r\n\r\n best_model_wts = copy.deepcopy(model.state_dict())\r\n best_acc = 0.0\r\n\r\n for epoch in range(num_epochs):\r\n print('Epoch {}/{}'.format(epoch, num_epochs - 1))\r\n print('-' * 10)\r\n\r\n # Each epoch has a training and validation phase\r\n for phase in ['train', 'val']:\r\n if phase == 'train':\r\n scheduler.step()\r\n model.train() # Set model to training mode\r\n else:\r\n model.eval() # Set model to evaluate mode\r\n\r\n running_loss = 0.0\r\n running_corrects = 0\r\n\r\n # Iterate over data.\r\n for inputs, labels in dataloaders[phase]:\r\n inputs = inputs.to(device)\r\n labels = labels.to(device)\r\n\r\n # zero the parameter gradients\r\n optimizer.zero_grad()\r\n\r\n # forward\r\n # track history if only in train\r\n with torch.set_grad_enabled(phase == 'train'):\r\n outputs = model(inputs)\r\n _, preds = torch.max(outputs, 1)\r\n loss = criterion(outputs, labels)\r\n\r\n # backward + optimize only if in training phase\r\n if phase == 'train':\r\n loss.backward()\r\n optimizer.step()\r\n\r\n # statistics\r\n running_loss += loss.item() * inputs.size(0)\r\n running_corrects += torch.sum(preds == labels.data)\r\n\r\n epoch_loss = running_loss / dataset_sizes[phase]\r\n epoch_acc = running_corrects.double() / dataset_sizes[phase]\r\n\r\n print('{} Loss: {:.4f} Acc: {:.4f}'.format(\r\n phase, epoch_loss, epoch_acc))\r\n\r\n # deep copy the model\r\n if phase == 'val' and epoch_acc > best_acc:\r\n best_acc = epoch_acc\r\n best_model_wts = copy.deepcopy(model.state_dict())\r\n\r\n print()\r\n\r\n time_elapsed = time.time() - since\r\n print('Training complete in {:.0f}m {:.0f}s'.format(\r\n time_elapsed // 60, time_elapsed % 60))\r\n print('Best val Acc: {:4f}'.format(best_acc))\r\n\r\n # load best model weights\r\n model.load_state_dict(best_model_wts)\r\n return model\r\n```\r\n\r\n #### finetune\r\n ```\r\n model_ft = models.resnet101(pretrained=True)\r\nnum_ftrs = model_ft.fc.in_features\r\nmodel_ft.fc = nn.Linear(num_ftrs, 2)\r\n\r\nmodel_ft = model_ft.to(device)\r\n\r\ncriterion = nn.CrossEntropyLoss()\r\n\r\n# Observe that all parameters are being optimized\r\noptimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)\r\n\r\n# Decay LR by a factor of 0.1 every 7 epochs\r\nexp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)\r\n\r\nmodel_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,\r\n num_epochs=25)\r\n ```\r\n\r\n#### freeze all the network except the final layer\r\n```\r\nmodel_conv = torchvision.models.resnet101(pretrained=True)\r\nfor param in model_conv.parameters():\r\n param.requires_grad = False\r\n\r\n# Parameters of newly constructed modules have requires_grad=True by default\r\nnum_ftrs = model_conv.fc.in_features\r\nmodel_conv.fc = nn.Linear(num_ftrs, 2)\r\n\r\nmodel_conv = model_conv.to(device)\r\n\r\ncriterion = nn.CrossEntropyLoss()\r\n\r\n# Observe that only parameters of final layer are being optimized as\r\n# opoosed to before.\r\noptimizer_conv = optim.SGD(model_conv.fc.parameters(), lr=0.001, momentum=0.9)\r\n\r\n# Decay LR by a factor of 0.1 every 7 epochs\r\nexp_lr_scheduler = lr_scheduler.StepLR(optimizer_conv, step_size=7, gamma=0.1)\r\n\r\nmodel_conv = train_model(model_conv, criterion, optimizer_conv,\r\n exp_lr_scheduler, num_epochs=25)\r\n```\r\n\r\n#### CPU GPU\r\n```\r\ndevice = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\r\n```\r\n\r\n#### Resnet do not have attribute feature\r\n##### vgg19直接用feature\r\n```\r\ncnn = models.vgg19(pretrained=True).features.to(device).eval()\r\n```\r\n##### resnet\r\n```\r\nimport torch\r\nimport torch.nn as nn\r\nfrom torchvision import models\r\n\r\nmodel = models.alexnet(pretrained=True)\r\n\r\n# remove last fully-connected layer\r\nnew_classifier = nn.Sequential(*list(model.classifier.children())[:-1])\r\nmodel.classifier = new_classifier\r\n```\r\n\r\n#### what does num of workers mean:\r\n```\r\nnum of works=0 means batches of data will be load by the main process\r\nnum of works>0 means is used to preprocess batches of data before the next batch is ready to load \r\nmore num of works would consume more memory but speed up IO process\r\n```\r\n\r\n\r\n\r\n网络结构:\r\n\r\n1. con1 input 3 output 20,Relu,max_pool,batchnorm\r\n2. conv2 input 20 output 40,Relu,max_pool,batchnorm\r\n3. conv3 input 40 output 60,Relu,max_pool,batchnorm\r\n4. conv4 input 60 output 80,Relu\r\n5. fc1 input 80×2×1 output 160 \r\n6. fc2 input 60×2×3 output 160\r\n7. fc3 input 160 output 10000\r\n\r\n注意:本图中fc1 由conv4经过relu之后映射到160维,fc2由conv3经过relu和maxpooling norm之后映射到160维\r\n\r\n```\r\nclass Model(nn.Module):\r\n def __init__(self):\r\n super(Model,self).__init__()\r\n self.conv1=nn.Conv2d(3,20,4)\r\n self.bn1 = nn.BatchNorm2d(20)\r\n self.conv2=nn.Conv2d(20,40,3)\r\n self.bn2 = nn.BatchNorm2d(40)\r\n self.conv3=nn.Conv2d(40,60,3)\r\n self.bn3 = nn.BatchNorm2d(60)\r\n self.conv4=nn.Conv2d(60,80,2)\r\n self.fc1=nn.Linear(80*2*1,160)\r\n self.fc2=nn.Linear(60*2*3,160)\r\n self.fc3=nn.Linear(160,10000)\r\n\r\n def forward(self,x):\r\n x=F.max_pool2d(F.relu(self.conv1(x)),(2,2))\r\n x=self.bn1(x)\r\n x=F.max_pool2d(F.relu(self.conv2(x)),(2,2))\r\n x=self.bn2(x)\r\n x1=F.max_pool2d(F.relu(self.conv3(x)),(2,2))\r\n x1=self.bn3(x1)\r\n x2=F.relu(self.conv4(x1))\r\n x2 = x2.view(-1, 80*2*1)\r\n x1 = x1.view(-1, 60*2*3)\r\n x3=F.relu(self.fc1(x2))\r\n x4=F.relu(self.fc2(x1))\r\n x5=F.relu(self.fc3(x3+x4))\r\n return x5\r\n```\r\n\r\ninit中定义了网络层\r\n\r\n```python\r\nx1 = x1.view(-1, 60*2*3)\r\n```\r\n\r\n-1 的意义是自动填充BATCH的数量,这一步是必须的,这样使得conv层和fc层能够连接起来。60×2×3即为fc层input\r\n\r\n#### transform\r\n\r\n```\r\ntransform = T.Compose([\r\n T.Resize([39, 31]),\r\n T.ToTensor(),\r\n T.Normalize(mean=[.5, .5, .5], std=[.5, .5, .5])\r\n ])\r\n```\r\n\r\nresize input到39×31 size\r\n\r\n归一化\r\n\r\n\r\n\r\n```\r\ncriterion = nn.CrossEntropyLoss()\r\noptimizer = optim.Adam(net.parameters(), lr=0.001)\r\n```\r\n\r\n使用Adam优化\r\n\r\n\r\n\r\n#### Data \r\n\r\n```\r\nclass FaceDataSet(Data.Dataset):\r\n def __init__(self, set_config, transforms=None):\r\n self.transform = transforms\r\n self.imgs = open(set_config).readlines()\r\n\r\n def __getitem__(self, index):\r\n img_path, label = self.imgs[index].split()\r\n data = Image.open(img_path)\r\n if self.transform:\r\n data = self.transform(data)\r\n return data, int(label)\r\n def __len__(self):\r\n return len(self.imgs)\r\n```\r\n\r\n```python\r\ntrainset_config = \"./dataset_config/trainconfig.txt\"\r\ntestset_config = \"./dataset_config/valconfig.txt\"\r\ntrainset = FaceDataSet(trainset_config, transform)\r\ntestset = FaceDataSet(testset_config, transform)\r\n\r\ntrainset_loader = DataLoader(trainset, batch_size = BATCH_SIZE, shuffle = True, num_workers=2, pin_memory = False)\r\ntestset_loader = DataLoader(testset, batch_size = BATCH_SIZE, num_workers=2, pin_memory = False)\r\n```\r\n\r\n```\r\ntrainconfig.txt:\r\n\t0004266/538.jpg 0\r\n\t0004266/629.jpg 0\r\n\t0004266/108.jpg 0\r\n\t0000439/082.jpg 1\r\n\t....\r\nvalconfig.txt:\r\n\t0004266/009.jpg 0\r\n\t0004266/156.jpg 0\r\n\t0004266/134.jpg 0\r\n\t0001774/333.jpg 2\r\n\t...\r\n```\r\n\r\n0004266/538.jpg 0 #表示0004266文件夹下538.jpg这张图片对应的分类是0\r\n\r\n\r\n\r\n\r\n\r\n#### Train\r\n\r\n```\r\nfor epoch in range(EPOCHES):\r\n running_loss = 0\r\n for i, data in enumerate(trainset_loader, 0):\r\n inputs, label = data\r\n inputs, label = inputs.to(device), label.to(device)\r\n optimizer.zero_grad()\r\n outputs = net(inputs)\r\n\r\n label = label.long()\r\n loss = criterion(outputs, label)\r\n loss.backward()\r\n optimizer.step()\r\n\r\n\r\n predicted = torch.argmax(outputs, 1)\r\n total = len(label)\r\n correct = (predicted == label).sum().float()\r\n accuracy = 100 * correct / total\r\n\r\n running_loss += loss.item()\r\n if i % INTERVAL == INTERVAL-1:\r\n print(\"[%d, %5d] loss : %3f, accuracy : %3f\" % (epoch + 1, i + 1, running_loss/INTERVAL, accuracy))\r\n running_loss = 0\r\n print(\"Finish Trainning\")\r\n```\r\n\r\n得到Accuracy:\r\n\r\n```\r\npredicted = torch.argmax(outputs, 1)\r\ntotal = len(label)\r\ncorrect = (predicted == label).sum().float()\r\naccuracy = 100 * correct / total\r\n```\r\n\r\noutputs 输出的是128×10000的Tensor 128为BATCH_SIZE,10000为分类总数\r\n\r\npredicted为128×1 的int 类型的Tensor (数值从0-9999 下标 表示哪一类)\r\n\r\nlabel为128×1的 Tensor 表示ground truth(数值从0-9999 表示哪一类)\r\n\r\n(predicted == label) 得到的是128×1的0,1Tensor\r\n\r\n```\r\n>>> import torch\r\n>>> a=torch.Tensor([[1,2],[3,4],[5,6]])\r\n>>> torch.argmax(a,1)\r\ntensor([1, 1, 1])\r\n```\r\n\r\n\r\n\r\n\r\n\r\n#### GPU\r\n\r\n```\r\ndevice = torch.device(\"cuda:1\" if torch.cuda.is_available() else \"cpu\")\r\nprint(device)\r\nnet = Model()\r\nnet = net.to(device)\r\n\r\ninputs, label = data\r\ninputs, label = inputs.to(device), label.to(device)\r\n```\r\n\r\n\r\n\r\n#### Pretrained Models\r\n\r\n```\r\nimport pretrainedmodels\r\nmodel_name='resnet18'\r\nmodel = pretrainedmodels.__dict__[model_name](num_classes=1000, pretrained='imagenet')\r\n```\r\n\r\ntransform resize不应过小,否则难以运行完net\r\n\r\n```\r\ntransform = T.Compose([\r\n T.Resize([256,256]),\r\n T.ToTensor(),\r\n T.Normalize(mean=[.5, .5, .5], std=[.5, .5, .5])\r\n ])\r\n```\r\n\r\n#### Model Structure\r\n\r\n```\r\nmodel.conv1\r\nmodel.bn1\r\nmodel.relu()\r\nmodel.maxpool()\r\n\r\nmodel.layer1()\r\nmodel.layer2()\r\nmodel.layer3()\r\nmodel.layer4()\r\nmodel.avgpool()\r\nmodel.last_Linear() #512->1000\r\n```\r\n\r\n这里我们不用最后的1000分类linear层\r\n\r\n```python\r\nclass Net(nn.Module):\r\n def __init__(self, model):\r\n super(Net,self).__init__()\r\n self.model = model\r\n self.fc1=nn.Linear(2048, 4096)\r\n self.fc2=nn.Linear(4096,10000)\r\n\r\n def forward(self,x):\r\n x=self.model.conv1(x)\r\n x=self.model.bn1(x)\r\n x=self.model.relu(x)\r\n x=self.model.maxpool(x)\r\n\r\n x=self.model.layer1(x)\r\n x=self.model.layer2(x)\r\n x=self.model.layer3(x)\r\n x=self.model.layer4(x)\r\n x1=self.model.avgpool(x)\r\n x1 = x1.view(-1, 2048)\r\n x2=self.fc1(x1)\r\n x3=self.fc2(x2)\r\n return x3\r\n```\r\n\r\n仅使用\r\n\r\n```\r\nmodel.conv1\r\nmodel.bn1\r\nmodel.relu()\r\nmodel.maxpool()\r\n\r\nmodel.layer1()\r\nmodel.layer2()\r\nmodel.layer3()\r\nmodel.layer4()\r\nmodel.avgpool()\r\n```\r\n\r\n这些层,注意x1 = x1.view(-1, 2048) -1 表示自动补全batch_size 2048为了与fc1 input结合\r\n\r\n#### load and save model\r\n\r\n```\r\n#save\r\ntorch.save(model,\"model_name\")\r\n#load\r\ntorch.load(\"model_name\")\r\n```\r\n\r\n注意:\r\n\r\n1. 如果使用自己定义的Net 在使用load函数之前要将自己定义的网路结构先载入 才能load model\r\n\r\n2. 如果使用了pretrained model,则在自定义model中应该具体这样写\r\n\r\n ```\r\n class Net(nn.Module):\r\n def __init__(self, model):\r\n super(Net,self).__init__()\r\n self.conv1 = model.conv1\r\n self.bn1 = model.bn1\r\n self.relu = model.relu\r\n self.maxpool = model.maxpool\r\n self.layer1 = model.layer1\r\n self.layer2 = model.layer2\r\n self.layer3 = model.layer3\r\n self.layer4 = model.layer4\r\n self.avgpool = model.avgpool\r\n self.fc1=nn.Linear(2048, 10000)\r\n ```\r\n\r\n3.如果使用了多块GPU net会成为DataParalle类 model会保存在net.module下"
},
{
"alpha_fraction": 0.701533854007721,
"alphanum_fraction": 0.7072858810424805,
"avg_line_length": 16.661354064941406,
"blob_id": "7d6876dafbabd8c00b54272820bb92df4264c2f6",
"content_id": "e2c2b730d6750f1d32fcca43036bd07798933054",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 7700,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 251,
"path": "/books/Spark快速大数据分析.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Spark快速大数据分析\r\n\r\n#### 第一章 spark数据分析导论\r\n\r\nSpark提供了功能丰富的数据操作库(MLlib),研究数据集大小超过单机所能处理极限的数据问题。与此同时,工程师们则可以从书中学习和利用spark编写通用的分布式程序并运维这些应用。\r\n\r\n##### spark的目标\r\n\r\n* spark是一个用来实现快速而通用的集群计算的平台。处理大规模数据时速度是非常重要的。速度快意味着可以进行交互,spark一个主要特点是可以在内存中进行计算,不过即使在磁盘上进行计算,spark依然比mapreduce更加高效。\r\n* spark提供得接口非常丰富,同时可以适用于各种各样原先需要分布式平台得场景。\r\n* spark core包含了spark的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等,还包含了对弹性分布式数据集\r\n* spark sql用来操作结构化的数据,用来执行查找等操作\r\n* spark streaming对实时数据进行流式计算组件\r\n* Mllib里面包含了对常见机器学习算法的支持\r\n* GraphX操作图(例如社交网络的朋友关系图)\r\n\r\n##### spark的安装\r\n\r\n##### spark shell工具\r\n\r\n* RDD(弹性分布式数据集)是spark对数据的核心抽象\r\n* 用户可以用两种方法创建RDD:读取一个外部数据集,或者在程序中分发驱动器程序中的对象集合list set\r\n\r\nRDD支持转化操作和行动操作,转化操作会产生一个新的RDD,行动操作会计算树一个结果。\r\n\r\n转化操作只会让Spark去惰性计算这些RDD,不是真正去计算它,只有当它被第一次实际用到的时候才会被计算,这个策略在大数据背景下是有意义的。\r\n\r\n```scala\r\nlines = sc.textFile(\"README.md\")\r\npythonLines = lines.filter(lambda line: \"Python\" in line) //惰性计算\r\npythonLines.first() //计算\r\n```\r\n\r\n第二行执行的时候,程序没有真正将所有行都进来,而是在第三行时扫描整个文件找到第一个匹配的位置即可。这样节省了大量的空间等。\r\n\r\n因此就导致了持久化问题的出现:\r\n\r\n如果一个RDD需要被多次操作则可以使用函数将RDD内容读到内存中,并反复查询这部分的数据\r\n\r\n```\r\npythonLines.persist\r\npythonLines.count()\r\n2\r\npythonLines.first()\r\nu'## Interactive Python Shell'\r\n```\r\n\r\n##### RDD 操作\r\n\r\n转化操作:返回RDD\r\n\r\n```\r\ninputRDD = sc.textFile(\"log.txt\")\r\nerrorsRDD = inputRDD.filter(lambda x: \"error\" in x)\r\n```\r\n\r\n转化操作 filter()\r\n\r\n```\r\nerrorsRDD = inputRDD.filter(lambda x: \"error\" in x)\r\nwarningsRDD = inputRDD.filter(lambda x: \"warning\" in x)\r\nbadLinesRDD = errorsRDD.union(warningsRDD)\r\n```\r\n\r\nunion操作\r\n\r\n行动操作:可能返回其他类型的数据,会执行实际操作\r\n\r\n```\r\nprint \"Input had \" + badLinesRDD.count() + \" concerning lines\"\r\nprint \"Here are 10 examples:\"\r\nfor line in badLinesRDD.take(10):\r\n\tprint line\r\n```\r\n\r\n利用count对错误数进行计数。\r\n\r\nRDD常见操作:\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n有些函数只能作用在特定类型的RDD,例如mean()和variance()只能作用在RDD数值类型上\r\n\r\n\r\n\r\n#### 键值对操作\r\n\r\n键值对RDD,pair RDD是一宗spark中非常常见的数据类型。\r\n\r\n对于一个简单的RDD,如何创建pair RDD?\r\n\r\n很多存储键值对的数据格式会在读取时直接返回由其键值对数据组成的 pair RDD。此外,当需要把一个普通的 RDD 转为 pair RDD 时,可以调用 map() 函数来实现\r\n\r\n```\r\npairs = lines.map(lambda x: (x.split(\" \")[0], x))\r\n```\r\n\r\n对pair RDD的操作\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\nRDD的一些基本函数同样适用于pair RDD,\r\n\r\n```\r\nresult = pairs.filter(lambda keyValue: len(keyValue[1]) < 20)\r\n```\r\n\r\n\r\n\r\n##### 聚合操作\r\n\r\n在RDD中,聚合具有相同键的元素是很常见的操作。基础RDD上有fold,combine,reduce等操作\r\n\r\n对于pair RDD同样具有foldByKey(), reduceByKey等操作。\r\n\r\n\r\n\r\n```python\r\nrdd = sc.textFile(\"s3://...\")\r\nwords = rdd.flatMap(lambda x: x.split(\" \"))\r\nresult = words.map(lambda x: (x, 1)).reduceByKey(lambda x, y: x + y)\r\n```\r\n\r\n单词计数\r\n\r\n##### 数据分组\r\n\r\nRDD经常会根据数据的特性,要根据键进行分组,groupByKey() 就会使用RDD 中的键来对数据进行\r\n分组。\r\n\r\n##### 连接\r\n\r\n##### 数据排序\r\n\r\n```python\r\nrdd.sortByKey(ascending=True, numPartitions=None, keyfunc = lambda x: str(x))\r\n```\r\n\r\n如果需要对数据进行按照复杂比较规则进行排序则可以自己编写排序函数\r\n\r\n\r\n\r\n##### 数据分区\r\n\r\n在分布式程序中,通信的代价是很大的。spark程序可以通过控制RDD分区来减少通信开销。\r\n\r\n##### 数据读取与保存\r\n\r\nspark支持很多种输入输出源。\r\n\r\n输入格式:\r\n\r\n文本文件:非结构化文件\r\n\r\nJSON:半结构化\r\n\r\nCSV:结构化\r\n\r\nSequenceFiles:结构化文件 用于键值对数据的常见Hadoop文件格式\r\n\r\nProtocol buffers:结构化文件,快速、节约的跨语言格式\r\n\r\n```python\r\n//文本\r\ninput = sc.textFile(\"file:///home/holden/repos/spark/README.md\") //用python读取文本文件\r\nresult.saveAsTextFile(outputFile) //用python保存文本文件\r\n\r\n//json\r\nimport json\r\ndata = input.map(lambda x: json.loads(x)) //用python读取json文件\r\nwriter = csv.DictWriter(output, fieldnames=[\"name\", \"favoriteAnimal\"])\r\n\r\n//sequencefile\r\nval data = sc.sequenceFile(inFile,\"org.apache.hadoop.io.Text\",\"org.apache.hadoop.io.IntWritable\") \r\n\r\n```\r\n\r\n通过数据库提供的Hadoop连接器或者系定义的spark连接器,spark可以访问一些常用的数据库系统。\r\n\r\nJava数据库连接、Cassandra连接器、HBase,Elasticsearch\r\n\r\n\r\n\r\n#### Spark编程进阶\r\n\r\n进一步介绍两种类型的共享变量:累加器和广播变量,累加器用于对信息进行聚合,二广播变更两则用来高效分发较大的对象。\r\n\r\n累加器对空行进行计数:\r\n\r\n```python\r\nfile = sc.textFile(inputFile)\r\n# 创建Accumulator[Int]并初始化为0\r\nblankLines = sc.accumulator(0)\r\ndef extractCallSigns(line):\r\n global blankLines # 访问全局变量\r\n if (line == \"\"):\r\n blankLines += 1\r\n return line.split(\" \")\r\ncallSigns = file.flatMap(extractCallSigns)\r\ncallSigns.saveAsTextFile(outputDir + \"/callsigns\")\r\nprint \"Blank lines: %d\" % blankLines.valu\r\n```\r\n\r\n\r\n\r\n##### 将spark 应用运行在集群上\r\n\r\nspark可以通过增加机器的数量并使用集群模式运行。\r\n\r\nspark在集群上运行时的架构:spark采用的是一个主从结构。中央协调节点被称为驱动器节点,与之对应的工作节点被称为执行器节点。驱动器节点和所有的执行器节点一起被称为spark应用。\r\n\r\n##### 驱动器节点\r\n\r\nspark驱动器是执行程序中main()方法的进程。spark依赖于集群管理器来启动执行器的节点,在某些情况下也用集群管理器来启动驱动器节点。。除了spark自带的独立集群管理器,spark也可以运行在其他的外部集群管理器上。\r\n\r\n##### spark-submit\r\n\r\nspark使用spark-submit来提交作业 \r\n\r\n一般格式:\r\n\r\n```\r\nbin/spark-submit [options] <app jar | python file> [app options]\r\nbin/spark-submit --master spark://host:7077 --executor-memory 10g my_script.py\r\n```\r\n\r\n\r\n\r\n常见的集群管理器:\r\n\r\nYARN(Hadoop 2.0中引入的集群管理器)\r\n\r\nMesos(Mesos是一个通用的集群管理器)\r\n\r\n\r\n\r\n\r\n\r\n##### spark所提供的高层程序支持\r\n\r\n##### Spark SQL\r\n\r\nspark sql可以实现对各种结构化数据进行读取,同时对结构化数据进行查询功能(query)\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5856031179428101,
"alphanum_fraction": 0.6132295727729797,
"avg_line_length": 21.363636016845703,
"blob_id": "7ba3ab8329d890533e42383fc89de14973ce1b5d",
"content_id": "6f5b9bf2d5ad3bf105c146bfe46ae3ba604106ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 9284,
"license_type": "no_license",
"max_line_length": 156,
"num_lines": 330,
"path": "/c++/stl.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### c++中的stl:vector,list,deque,stack,queue,heap,priority_queue,slist,tree,set,map,multiset,multimap,hashtable,,hash_set,hash_map,hash_multiset,hash_multimap\r\n#### vector,vector维护的是一个连续空间\r\n创建\r\n```\r\nvector<int> nums(2,9)\r\nvector中的iterator start #表示空间的头\r\niterator finish #表示使用空间的尾\r\niterator end_of_storage #表示可用空间的尾\r\n```\r\n#### begin(),end(),front(),back(),size(),capacity(),empty()\r\n```\r\niterator nums.begin() 指向第一个元素\r\niterator nums.end() 指向最后一个元素的后一个\r\nint nums.back() return *(nums.end()-1);\r\nint nums.front() return *begin();\r\nint nums.size() 返回vector目前的大小\r\nint nums.capacity()返回容量 2的幂数\r\nbool nums.empty()判断是否为空\r\n```\r\n#### push_back,pop_back(),insert(),erase(),resize(),clean(),find()\r\n```\r\nvector<int> ::iterator it;\r\nfor (it = nums.begin(); it != nums.end(); it++) {\r\n cout << *it;\r\n}\r\n\r\n\r\nvoid push_back(int x){\r\n if(finish!=end_of_story) construct(finish,x);++finish;\r\n else inset_aux(end(),x);\r\n}\r\nvoid pop_back(){--finish; destroy(finish);}\r\niterator erase(iterator position) #清除某个位置的元素,然后将后面的元素向前移动\r\niterator insert(iterator pos,int x) #将某个元素插入到某个位置\r\nvector<int>::iterator ivit=find(vector.begin(),vector.end(),1);查找1这个元素的位置\r\nif (ivit!=vector.end()) \r\n vector.erase(ivit);#将ivit对应的元素删除;\r\n vector.insert(ivit,3);#插入3;\r\n vector.insert(ivit,2,3)#插入2个3;\r\nvoid nums.clear();\r\nvoid nums.resize(5);\r\n```\r\n如果vector要转移到新的两倍大小的位置,所有的iterator都会失效\r\n#### list,双向链表,list维护的是一个不连续的数据结构\r\n#### 创建,\r\n```\r\nlist<int> nums = { 1,2,3 };\r\nint iv[5]={5,6,7,8,9}\r\nlist<int> ilist2(iv,iv+5);\r\n```\r\n#### begin(),end(),front(),back(),size(),empty()# 没有capacity\r\n```\r\niterator nums.begin() 指向第一个元素\r\niterator nums.end() 指向最后一个元素的后一个\r\nint nums.back() return *(nums.end()-1);\r\nint nums.front() return *begin();\r\nint nums.size() 返回vector目前的大小\r\nbool nums.empty()判断是否为空\r\n```\r\n#### 元素操作 push_front(),push_back(),pop_front(),pop_back(),clear(),unique(),remove(),empty()\r\n```\r\nvoid nums.push_front(int x); {insert(begin(),x);}\r\nvoid nums.push_back(int x);{insert(end(),x);}\r\nvoid nums.pop_front(){erase(begin());}\r\nvoid nums.pop_back(){iterator tmp=end();erase(--tmp);}\r\nvoid nums.clear();\r\n\r\nbool nums.empty();\r\nvoid nums.remove(int value); 将数值为value的所有元素移除\r\nvoid nums.unique();将数值相同的连续元素移除;\r\n```\r\n#### find(),reverse(),sort(),merge(),splice(),merge()\r\n```\r\nint iv[5]={5,6,7,8,9};\r\nlist<int> ilist2(iv,iv+5);\r\n\r\n//目前ilist为 0 2 99 3 4\r\nite=find(ilist.begin(),ilist.end(),99) 找到99\r\nilist.splice(ite,ilist2) #将ilist2拼接到ite后面 0 2 5 6 7 8 9 99 3 4\r\nilist.reverse(); 4 3 99 9 8 7 6 5 2 0\r\nilist.sort(); 0 2 3 4 5 6 7 8 9 99\r\n```\r\n\r\n#### merge与splice\r\n```\r\nmerge函数是将两个已经按照递增排序之后的list,再按照顺序排列\r\nsplice是自由拼接\r\n```\r\n\r\n#### deque 双向开口的连续线性空间,与vector相比,deque 没有capacity的概念,同时可以在常数时间内对头端元素进行操作 \r\ndeque由多段连续空间构成,通过一块map作为主控\r\n#### begin(),end(),front(),back(),size(),empty()# 没有capacity\r\n创建\r\n```\r\n#include<deque>\r\ndeque<int>ideq(20, 9);\r\n```\r\n```\r\niterator nums.begin() 指向第一个元素\r\niterator nums.end() 指向最后一个元素的后一个\r\nint nums.back() return *(nums.end()-1);\r\nint nums.front() return *begin();\r\nint nums.size() 返回vector目前的大小\r\nbool nums.empty()判断是否为空\r\n```\r\n\r\n#### 元素操作 push_front(),push_back(),pop_front(),pop_back(),clear(),insert(),erase(),find()\r\n```\r\nvoid nums.push_front(int x); {insert(begin(),x);}\r\nvoid nums.push_back(int x);{insert(end(),x);}\r\nvoid nums.pop_front(){erase(begin());}\r\nvoid nums.pop_back(){iterator tmp=end();erase(--tmp);}\r\nvoid nums.clear();\r\nbool nums.empty();\r\niterator insert(iterator it,x);\r\niterator erase(iterator it);\r\n\r\ndeque<int>::iterator itr;\r\nit=find(ide.begin(),ide.end(),9);\r\ncout<<*it<<\" \";\r\nide.insert(it,99);\r\nide.erase(it);\r\n```\r\n\r\n#### stack FILO stack没有迭代器\r\n#### stack push(),pop(),empty(),size(),top(),back()\r\n```\r\nvoid istack.pop();\r\nvoid istack.push(int x);\r\nint istack.top();\r\nint istack.size();\r\nbool istack.empty();\r\nint istack.back();\r\n```\r\n\r\n#### queue FIFO \r\nqueue没有迭代器 没有遍历的方法,不能存取queue除顶端和最前的元素 \r\n#### empty(),size(),front(),back(),push(),pop()\r\n```\r\nbool ique.empty()\r\nint ique.size()\r\nint ique.front()\r\nint ique.back()\r\nvoid ique.push()\r\nvoid ique.pop()\r\n```\r\n#### heap \r\nheap扮演着priority queue的作用,用户以任何顺序将任何元素放入容器中,取出时是按照优先级最高的元素开始取。 \r\nheap分为max-heap min-heap两种\r\n```\r\n#include<algorithm>\r\n```\r\nheap中所有的元素都遵循特别的排列规则,所以不提供遍历功能也不提供迭代器 \r\nmake_heap,最大值在最上面 \r\n```\r\nint ia[9] = { 0,1,2,3,4,8,9,3,5 };\r\nvector<int> ivec(ia, ia + 9);\r\nmake_heap(ivec.begin(), ivec.end());\r\nfor (int i = 0; i < ivec.size(); i++) {\r\n\tcout << ivec[i] << \" \";\r\n}\r\ncout << endl;\r\n9 5 8 3 4 0 2 3 1 //最大的元素在最前面,其余的数字按照二叉树排列\r\n```\r\npush_heap \r\n```\r\nivec.push_back(7);\r\npush_heap(ivec.begin(), ivec.end());\r\nfor (int i = 0; i < ivec.size(); i++) {\r\n\tcout << ivec[i] << \" \";\r\n}\r\ncout << endl;\r\n存到heap里\r\n9 7 8 3 5 0 2 3 1 4\r\n```\r\npop_heap\r\n```\r\npop_heap(ivec.begin(), ivec.end());\r\ncout << ivec.back(); 9\r\nivec.pop_back(); //排出9\r\nfor (int i = 0; i < ivec.size(); i++) {\r\n\tcout << ivec[i] << \" \";\r\n}\r\npop_heap之后 9就到了ivec中最后的位置\r\n```\r\nsort_heap\r\n```\r\nsort_heap(ivec.begin(), ivec.end());\r\nfor (int i = 0; i < ivec.size(); i++) {\r\n\tcout << ivec[i] << \" \";\r\n}\r\ncout << endl;\r\n0 1 2 3 3 4 5 7 8\r\n```\r\n\r\n#### priority_queue \r\n只有queue顶端的元素才能被外界取用 \r\n```\r\nint ia[9]={0,1,2,3,4,8,9,3,5};\r\npriority_queue<int> ipq(ia,ia+9);\r\n```\r\n#### size(),top(),pop(),empty()\r\n```\r\nint ipq.top() //最大值\r\nvoid ipq.pop();\r\n```\r\n\r\nexample:\r\n\r\n```\r\n#include <iostream>\r\n#include <vector>\r\n#include <queue>\r\nusing namespace std;\r\nstruct myCmp{\r\n bool operator ()(const int &a,const int &b){\r\n return a<b;\r\n }\r\n};\r\nclass Solution {\r\n\r\npublic:\r\n int findKthLargest(vector<int>& nums, int k) {\r\n priority_queue<int,vector<int>,myCmp> num;\r\n int n =nums.size();\r\n for (int i=0;i<n;i++){\r\n num.push(nums[i]);\r\n }\r\n for (int i=0;i<k-1;i++){\r\n num.pop();\r\n }\r\n return num.top();\r\n }\r\n};\r\nint main() {\r\n vector<int> nums={2,3,1,5,4};\r\n Solution s;\r\n int k=2;\r\n printf(\"%d\",s.findKthLargest(nums,k));\r\n return 0;\r\n}\r\n```\r\n\r\n```\r\n最大堆 priority_queue<int,vector<int>,less<int>> num;\r\n最小堆 priority_queue<int,vector<int>,greater<int>> num;\r\n```\r\n\r\n### 关联式容器\r\n主要关联式容器可分为set和map两大类 \r\n这些容器的底层机制都以红黑树完成 \r\n#### set 中所有的元素都会根据键值自动排序,set元素的实值就是键值,不允许多个元素有相同的键值 \r\n#### count(),insert(),erase(),begin(),end()\r\nset 中 insert(),erase() 参数为int 不是iterator\r\n```\r\n#include<set>\r\nint ia[5]={0,1,2,3,4};\r\nset<int> iset(ia,ia+5);\r\nint iset.size(); 5\r\niset.insert(3) int x;\r\niset.count(3) // 1; \r\niset.erase(1);\r\n```\r\nset也可以用iterator\r\n```\r\nite1=find(iset.begin(),iset.end(),3);\r\nset<int> ::iterator ite1;\r\nfor(ite1=iset.begin();ite1!=iset.end();ite1++){\r\n \r\n}\r\n```\r\nset count()\r\n```\r\nmyset.count(i)!=0 #判断myset中是否有i\r\n```\r\n\r\nset中所有的元素按照键值排序但是unordered_set没有顺序\r\nset底层基于RB-Tree,天然的有序结构,而unordered_set底层则是hashtable\r\n```\r\nint main(){\r\n set<int>s1;\r\n unordered_set<int>s2;\r\n s1.insert(4);s1.insert(2);s1.insert(3);s1.insert(1);\r\n s2.insert(4);s2.insert(2);s2.insert(3);s2.insert(1);\r\n for(auto it=s1.begin();it!=s1.end();++it)\r\n cout<<*it<<\" \";\r\n cout<<endl;\r\n for(auto it=s2.begin();it!=s2.end();++it)\r\n cout<<*it<<\" \";\r\n cout<<endl;\r\n}\r\n//输出:\r\n//1 2 3 4\r\n//1 3 2 4\r\n```\r\nmultiset 同样采用RB-Tree 但是底层稍微有些不同,因此允许存在相同的键值,比如可以有多个1\r\n\r\n\r\n#### map\r\nmap的特性是,所有的元素都会根据元素的键值自动排序,map不允许两个元素有相同的键值 \r\npair 1:键值,pair 2:实值 \r\n#### insert(),find(),erase()\r\n```\r\nvoid insert(pair);\r\niterator find(key);\r\niterator erase(iterator);\r\n\r\nmap<string,int> simap;\r\nsimap[string(\"jjhou\")]=1;\r\nsimap[string(\"jerry\")]=2;\r\nsimap[string(\"jason\")]=3;\r\nsimap[string(\"jimmy\")]=4;\r\n\r\npair<string,int> value(string(\"davide\"),5);\r\nsimap.insert(value);\r\n\r\nmap<string, int>::iterator ite1;\r\nite1 = simap.find(string(\"jjhou\"));\r\nsimap.erase(ite1);\r\n```\r\n\r\n#### hash\r\nhashset,hashmap等结构是基于hashtable的set,map数据结构 \r\n\r\n#### 数值方法\r\n```\r\n#include<numeric>\r\npower(int x,int n); x的n次方\r\n\r\n```\r\n"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.6235294342041016,
"avg_line_length": 9.466666221618652,
"blob_id": "55323efe1138d55ad4fe5caf99d8ecc55336bc01",
"content_id": "4348a1b480d864dbcf3ff92548c7b863527e12dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 348,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 15,
"path": "/books/算法设计与分析.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 算法设计与分析\r\n\r\n#### 递归与分治策略\r\n\r\n* 2.4 n个元素排列问题\r\n* 2.5整数划分问题\r\n* Hanoi塔问题\r\n* 二分搜索问题\r\n* 大整数乘法问题\r\n* strassen矩阵乘法问题\r\n* 棋盘覆盖问题\r\n* 快排\r\n* 线性时间选择问题(找到第k大的元素)\r\n* 最接近点对问题\r\n* 循环赛日程表问题"
},
{
"alpha_fraction": 0.6752577424049377,
"alphanum_fraction": 0.7603092789649963,
"avg_line_length": 16.571428298950195,
"blob_id": "b2f1114dedcd52e3c33f4814817d07654beabc3f",
"content_id": "415e4609b41cf8d8bb88785870effb45857fa7cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 634,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 21,
"path": "/social_network/GCN.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### GCN\r\n\r\n什么是卷积?\r\n\r\n离散卷积的本质是加权求和。\r\n\r\n```\r\nhttps://www.zhihu.com/question/54504471\r\n```\r\n\r\nGNN的本质是提取拓扑图中的空间特征,主流的有vertex domain和spectral domain两种。\r\n\r\n(1)vertex domain 主要考虑按照什么条件去找中心节点的neighbors,如何处理包含数量不同的neighrbos的特征。\r\n\r\n\r\n\r\n\r\n\r\n(2)**spectral domain**\r\n\r\n从时间上来说,学者先定义了graph上的傅里叶变换,进而定义了graph上的卷积,然后和深度学习结合提出了GCN"
},
{
"alpha_fraction": 0.7568442225456238,
"alphanum_fraction": 0.7685415744781494,
"avg_line_length": 18.68041229248047,
"blob_id": "f1cc5f73d91c8ebca2c2f4a72cfed0ce33cbd175",
"content_id": "8ce14e167718aaee28a1cb004b45a12b29263536",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 9568,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 194,
"path": "/books/程序员的自我修养.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 程序员的自我修养\r\n\r\n\r\n\r\n##### 简介\r\n\r\nhelloworld的运行可以分解为四个过程,预处理、编译、汇编、链接\r\n\r\n##### 预编译:\r\n\r\n第一步 源代码文件hello.c以及相关头文件stdio.h等经过预编译器cpp预编译成.i文件\r\n\r\nhpp文件预编译之后为.ii文件\r\n\r\n预编译的主要内容是处理所有的宏,删除所有注释\r\n\r\n保留#pragma编译器指令等\r\n\r\n```\r\ncpp hello.c > hello.i\r\n```\r\n\r\n<<<<<<< HEAD\r\n##### 编译\r\n\r\n编译过程就是将预处理完的文件进行一系列词法分析等产生相应的汇编代码文件\r\n\r\n```\r\ngcc -S hello.i -o hello.s\r\n```\r\n\r\n=======\r\n##### 编译:\r\n编译这一步的工作就是将预处理完的文本进行一系列词法分析、语义分析等等后生成相应的汇编代码文件,这个部分是最核心也是最复杂的一部分。\r\n>>>>>>> 3aae38bf1e2d2b08a291fc5451d0db13935d5333\r\n\r\n```\r\ngcc -S hello.i -o hello.s\r\n```\r\n\r\n##### 汇编\r\n汇编器会将汇编代码生成机器可以执行的指令,只需要将汇编指令与机器指令的对照表一一对应即可\r\n```\r\nas hello.s -o hello.o\r\n```\r\n##### 链接\r\n将汇编生成的目标文件链接起来得到最终的可执行文件。现代软件开发的代码量都很大,经常有几百万行代码,现代大型软件经常有很多模块。程序被分成很多模块之后,如何将模块拼接起来得到最终的可执行文件就是链接。\r\n\r\n#### 编译器做了什么?\r\n直观的说,编译器做的是将高级的语言翻译为机器可以理解的语言。\r\n\r\n#### 模块拼装——————静态链接\r\n链接的主要过程包括了地址和空间分配、符号决议、重定位等功能\r\n什么是符号决议:\r\n符号表给链接器提供了当前目标文件可以提供给其他文件使用的符号,以及其他文件需要提供给当前文件的使用的符号,对每个目标文件定义\r\n\r\n重定位:比如在编译某个目标文件a的时候,如果该文件中有引用其他文件b中定义的变量var,则在编译a的时候我们不知道var的地址是多少,所以在编译器没法确定的情况下,会等待链接器将目标文件a和b链接起来的时候再修正,这个将逻辑地址改为实际物理地址的过程被称为重定位。\r\n\r\n#### 装载和动态链接\r\n静态链接会带来很多问题,例如浪费空间、模块更新困难等\r\n操作系统中有着数量极大的程序,如果每个程序都配有相应的库文件,那么这些库文件就会重复很多次,造成空间上的浪费。\r\n同时如果要更新一个静态链接的文件program1中的一个小文件,需要厂商将整个program1重新链接好之后再发布给所有用户,比较不方便\r\n动态链接的思想是将程序的模块相互分割开来,形成独立的文件,在程序运行的时候再进行链接,就是说将链接这个过程推迟到了程序运行的时候\r\n\r\n##### cmake与make\r\n1. make是用来执行Makefile的,Makefile是在类unix环境下的脚本文件,make指令+Makefile是类unix环境下的项目管理工具\r\n2. cmake是跨平台管理工具,用来执行CMakeLists.txt文件\r\n```\r\n\r\nmkdir build\r\ncd build\r\ncmake ..\r\nmake\r\nmake install\r\n```\r\ncmake指令执行CMakeLists.txt生成Makefile\r\nmake指令执行Makefile\r\n\r\n\r\n本书提出来的值得思考的问题:\r\n1.程序为什么要被编译器编译了之后才可以运行?\r\n\r\n2. 编译器把C语言程序转换成可以执行的机器码中过程中做了什么,怎么做的?\r\n3. 最后编译出来的可执行文件里面是什么?除了 机器码还有什么?它们是怎么存放的,怎么组织的?\r\n4. #include<stdio.h>是什么意思,把这个文件含进来意味着什么?C语言库又是什么?它是怎么实现的?\r\n5. 不同的编译器(VC,GCC)和不同的硬件平台(x86 ARM)以及不同的操作系统windows linux编译出来的结果是相同的么?为什么?\r\n6. hello world程序是怎么运行起来的?操作系统是怎么样装载的?它从哪里开始执行,到哪里结束?main函数之前发生了什么?main函数结束了之后又发生了什么?\r\n7. 如果没有操作系统,hello world可以运行么?如果要在一台没有操作系统的机器上运行hello world需要什么,应该怎么实现?\r\n8. printf是怎么实现的?它为什么可以有不定数量的参数,为什么能够在终端输出字符串?\r\n9. hello world程序在运行时,它在内存中时什么样子的?\r\n\r\n#### 第一章 温故而知新\r\n\r\n计算机最重要的部件:中央处理器CPU,内存,I/O控制芯片\r\n\r\n##### 北桥 南桥\r\n\r\n为了协调CPU、内存和高速的图形设备,人们设计了高速的北桥,用来高效的交换数据。\r\n\r\n部分较为低速的设别不能直接连到北桥上,(磁盘、鼠标、键盘等)于是人们设计了南桥,南桥将这些汇总后连到北桥上。\r\n\r\n##### 多核\r\n\r\n人们希望处理器速度越来越快,CPU的频率不断提高,但是已经逐渐接近瓶颈,因此人们从另一个角度去提高处理速度,使用多核处理器。\r\n\r\n#### 操作系统做什么?\r\n\r\n操作系统的功能是提供抽象的接口,用来管理硬件资源。CPU资源非常宝贵,分时系统\r\n\r\n##### 多任务系统 抢占式\r\n\r\n多任务系统:操作系统本身运行在一个受硬件保护的级别,所有程序都以进程的方式运行在操作系统权限更低的级别。每个进程都有自己的操作空间,相互独立,CPU根据进程优先级的高低都有机会得到CPU,如果运行时间超过一定时间,操作系统就会暂停该进程,将CPU资源分配给其他等待的进程。这种CPU分配方式即为抢占式。\r\n\r\n\r\n\r\n##### 设备驱动\r\n\r\n操作系统作为硬件层的上层,是对硬件的管理和抽象。对于操作系统上的运行库和应用程序来说,希望看到统一的接口。这些繁琐的硬件细节都交给了硬件驱动程序。\r\n\r\n\r\n\r\n##### 内存不够\r\n\r\n如果将内存直接分配给进程,会有如下几个问题:\r\n\r\n1. 地址空间不隔离:恶意程序可能会改写其他程序的数据\r\n\r\n2. 内存使用效率低\r\n\r\n3. 程序运行的地址不确定(每次当程序载入的时候需要从内存中分配一块足够大的空间,这块空间的位置是不确定的)\r\n\r\n 解决方法:使用虚拟地址,增加一层中间层\r\n\r\n\r\n\r\n一、分段\r\n\r\n把一段和程序所需的内存空间大小相同的虚拟空间映射到某个地址空间。不过分段没有解决第二个问题,分段的内存区域的映射是以程序为单位,如果内存不足,整个程序的内存都会被换出,造成大量的浪费。因此人们想到了更小粒度的内存分割方法,即为分页。\r\n\r\n二、分页\r\n\r\n分页的基本方法是将地址空间人为地等分为固定大小地页,每一页的大小由硬件决定。我们将内存按页分割,将常用的数据和代码放在内存,将不常用的数据和代码保存在磁盘,需要用的时候再拿出来即可。虚拟存储需要MMU(memory management unit)实现。\r\n\r\n##### 线程\r\n\r\n线程有时被称为轻量级进程,是程序执行流的最小单元。线程通常有三种状态:运行、就绪、等待。处于运行中的线程有一段可以执行的时间,这段时间被称为时间片,当时间片用完的时候则进入等待状态。\r\n\r\n\r\n\r\n##### 优先级调度和轮转法\r\n\r\n轮转法:让各个线程轮流执行一小段时间。\r\n\r\n优先调度法:线程都有各自的优先级,具有高优先级的线程会更早地被执行。在优先级调度下,存在饿死现象,即长时间得不到执行,对于长时间得不到执行的线程,我们需要改变其线程优先级。\r\n\r\n\r\n\r\n##### 抢占\r\n\r\n当某个线程的时间片结束之后,其他线程将抢占其继续执行的权力。\r\n\r\n\r\n\r\n##### 线程安全\r\n\r\n竞争与原子操作:例如自增操作被编译之后不止一条指令,如果自增操作进行到一半被打断会出现错误。因此我们将这些操作称为**原子** 的。\r\n\r\n为了避免多个进程读写同一个数据,我们要将各个线程对同一个数据的访问同步,即在某个线程访问数据未结束时其他线程不能对同一个数据进行访问。\r\n\r\n同步最常见的额实现方法是使用锁。\r\n\r\n\r\n\r\n### 编译和链接\r\n\r\n1. 编译器把C语言程序转换成可以执行的机器码中过程中做了什么,怎么做的?\r\n\r\n上述过程可以分为四个步骤:预处理、编译、汇编、链接。\r\n\r\n**预编译**:.ii文件 处理代码中所有#开头的指令\r\n\r\n**编译**:.c文件 通过一些词法分析,产生相应的汇编代码文件。\r\n\r\n**汇编**:.o文件 将汇编代码变成机器指令\r\n\r\n**链接**:将一大堆目标文件链接起来生成最终的可执行文件。 .out\r\n\r\n\r\n\r\n2. 最后编译出来的可执行文件里面是什么?除了 机器码还有什么?它们是怎么存放的,怎么组织的?\r\n\r\n目标文件中包含编译后的机器指令、数据,这些信息按照不同的属性,以节或者段的形式存储。代码段:常见后缀.text, .code,数据段.data\r\n\r\n.bss:初始化后的全局变量和局部静态变量都保存在.data段,未初始化的变量都存在.bss内,因为未初始化即为0,在.data中存全为0的变量是没有意义的,.bss文件不占空间,只是为未初始化的全局变量和局部静态变量预留位置而已。\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.508614182472229,
"alphanum_fraction": 0.5483952164649963,
"avg_line_length": 22.281707763671875,
"blob_id": "6ab2f7420857263d9a221cc932e6e5b00924ee75",
"content_id": "0a25a2fd5ab38534f969021717243dae9eb837ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 20783,
"license_type": "no_license",
"max_line_length": 324,
"num_lines": 820,
"path": "/leetcde_note_cpp/Nums.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "构建多维数组\r\n\r\n```c++\r\nvector<vector <int> > ivec(5, vector<int>(6, 1)); // 初始化为1 的5 * 6二维vector\r\nvector<vector < vector<int>> > ivec(5, vector<vector<int>>(6, vector<int>(4, 1))); // 初始化为1 的5 * 6 * 4二维vector\r\n初始化5个,每个都是vector<vector<int>>\r\n里面一层 初始化 6个每个都是vector<int>\r\n再里面一层,初始化4个每个都是int 1\r\n```\r\n\r\n\r\n\r\n##### leetcode 252 Meeting Rooms\r\n\r\nGiven an array of meeting time intervals consisting of start and end times `[[s1,e1],[s2,e2],...]` (si < ei), determine if a person could attend all meetings.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [[0,30],[5,10],[15,20]]\r\nOutput: false\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [[7,10],[2,4]]\r\nOutput: true\r\n```\r\n\r\n使用自定义的lambda表达式作为sort比较函数\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n bool canAttendMeetings(vector<vector<int>>& intervals) {\r\n auto cmp = [](vector<int>& a, vector<int>& b){\r\n return a[0] < b[0];\r\n };\r\n sort(intervals.begin(), intervals.end(),cmp);\r\n int end_time = INT_MIN;\r\n for (auto meet:intervals){\r\n if(meet[0]>=end_time){\r\n end_time = meet[1];\r\n }\r\n else{\r\n return false;\r\n }\r\n }\r\n return true;\r\n }\r\n};\r\n```\r\n\r\n\r\n\r\n##### leetcode 253 Meeting Rooms II\r\n\r\nGiven an array of meeting time intervals consisting of start and end times `[[s1,e1],[s2,e2],...]` (si < ei), find the minimum number of conference rooms required.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [[0, 30],[5, 10],[15, 20]]\r\nOutput: 2\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [[7,10],[2,4]]\r\nOutput: 1\r\n```\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int minMeetingRooms(vector<vector<int>>& intervals) {\r\n auto cmp = [](vector<int>& a, vector<int>& b){\r\n return a[0] < b[0];\r\n };\r\n sort(intervals.begin(), intervals.end(),cmp);\r\n vector<int> times;\r\n priority_queue<int, vector<int>, greater<int>> q(times.begin(),times.end());\r\n int count = 1;\r\n if(intervals.size()==0) return 0;\r\n q.emplace(INT_MIN);\r\n for (auto meet:intervals){\r\n int last_time = q.top();\r\n if(last_time<=meet[0]){\r\n q.pop();\r\n q.emplace(meet[1]);\r\n }\r\n else{\r\n count++;\r\n q.emplace(meet[1]);\r\n }\r\n }\r\n return count;\r\n }\r\n};\r\n```\r\n\r\n使用heap\r\n\r\nheap中每个数字表示一个meeting room目前预约到的最后时间\r\n\r\n如果新的interval的开始时间要比heap中弹出来的最小值还要小,说明必须要增加一个room\r\n\r\n如果开始时间大于等于heap中弹出来的,则说明可以在这个room中进行会议,将最小值弹出,放入结束时间\r\n\r\n\r\n\r\n##### leetcode 594 Longest Harmonious Subsequence\r\n\r\nWe define a harmounious array as an array where the difference between its maximum value and its minimum value is **exactly** 1.\r\n\r\nNow, given an integer array, you need to find the length of its longest harmonious subsequence among all its possible [subsequences](https://en.wikipedia.org/wiki/Subsequence).\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [1,3,2,2,5,2,3,7]\r\nOutput: 5\r\nExplanation: The longest harmonious subsequence is [3,2,2,2,3].\r\n```\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int findLHS(vector<int>& nums) {\r\n unordered_map<int, int> freqs;\r\n for (int n : nums) {\r\n freqs[n]++;\r\n }\r\n\r\n int longest = 0;\r\n int lastNum = 0;\r\n int lastFreq = 0;\r\n for (pair<int, int> p : freqs) {\r\n int freq2 = 0;\r\n if (lastFreq && p.first == lastNum + 1) {\r\n freq2 = p.second + lastFreq;\r\n }\r\n longest = max(longest, freq2);\r\n lastNum = p.first;\r\n lastFreq = p.second;\r\n }\r\n return longest;\r\n }\r\n};\r\n```\r\n\r\n思路是先统计array中不同数字出现的次数\r\n\r\n然后遍历找两个差为1的或者为0的数字数量和的最大值\r\n\r\nc++中没有python的counter和dict get,需要用lastnum和lastfreq来记录\r\n\r\n\r\n\r\n##### leetcode 599 Minimum Index Sum of Two Lists\r\n\r\nSuppose Andy and Doris want to choose a restaurant for dinner, and they both have a list of favorite restaurants represented by strings.\r\n\r\nYou need to help them find out their **common interest** with the **least list index sum**. If there is a choice tie between answers, output all of them with no order requirement. You could assume there always exists an answer.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput:\r\n[\"Shogun\", \"Tapioca Express\", \"Burger King\", \"KFC\"]\r\n[\"Piatti\", \"The Grill at Torrey Pines\", \"Hungry Hunter Steakhouse\", \"Shogun\"]\r\nOutput: [\"Shogun\"]\r\nExplanation: The only restaurant they both like is \"Shogun\".\r\n```\r\n\r\n\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput:\r\n[\"Shogun\", \"Tapioca Express\", \"Burger King\", \"KFC\"]\r\n[\"KFC\", \"Shogun\", \"Burger King\"]\r\nOutput: [\"Shogun\"]\r\nExplanation: The restaurant they both like and have the least index sum is \"Shogun\" with index sum 1 (0+1).\r\n```\r\n\r\n\r\n\r\n**Note:**\r\n\r\n1. The length of both lists will be in the range of [1, 1000].\r\n2. The length of strings in both lists will be in the range of [1, 30].\r\n3. The index is starting from 0 to the list length minus 1.\r\n4. No duplicates in both lists.\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n vector<string> findRestaurant(vector<string>& list1, vector<string>& list2) {\r\n map<string, int> map1, map2;\r\n int n1 = list1.size(), n2 = list2.size(), i;\r\n for(i=0;i<n1;i++){\r\n map1[list1[i]] = i; \r\n }\r\n vector<string> res;\r\n int min_sum = INT_MAX;\r\n map<string, int>::iterator it;\r\n for(i=0;i<n2;i++){\r\n string str = list2[i];\r\n it = map1.find(str);\r\n if(it!=map1.end())\r\n\t\t if (min_sum>map1[str] +i){\r\n min_sum = map1[str]+i;\r\n res = {list2[i]};\r\n }\r\n else{\r\n if(min_sum == map1[str]+i){\r\n res.push_back({list2[i]});\r\n }\r\n }\r\n }\r\n return res;\r\n }\r\n};\r\n```\r\n\r\n注意c++中list的iterator不能相减,map等数据结构的iterator相减意义和常规理解的相减不同\r\n\r\n\r\n\r\n##### leetcode 1002 Find Common Characters\r\n\r\nGiven an array `A` of strings made only from lowercase letters, return a list of all characters that show up in all strings within the list **(including duplicates)**. For example, if a character occurs 3 times in all strings but not 4 times, you need to include that character three times in the final answer.\r\n\r\nYou may return the answer in any order.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [\"bella\",\"label\",\"roller\"]\r\nOutput: [\"e\",\"l\",\"l\"]\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [\"cool\",\"lock\",\"cook\"]\r\nOutput: [\"c\",\"o\"]\r\n```\r\n\r\n \r\n\r\n**Note:**\r\n\r\n1. `1 <= A.length <= 100`\r\n2. `1 <= A[i].length <= 100`\r\n3. `A[i][j]` is a lowercase letter\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n vector<string> commonChars(vector<string>& A) {\r\n vector<int> cnt(26, INT_MAX); //#include <bits/stdc++.h> \r\n\t\tvector<string> res;\r\n\t\tfor (auto s: A) {\r\n\t\t\tvector<int> cnt1(26, 0);\r\n\t\t\tfor (auto c:s) ++cnt1[c-'a'];\r\n\t\t\tfor(int i=0;i<26;i++) cnt[i] = min(cnt[i], cnt1[i]);\r\n\t\t}\r\n\t\tfor(int i =0;i<26;i++){\r\n\t\t\tfor(int j=0;j<cnt[i];j++){\r\n\t\t\t\tres.push_back(string(1, i + 'a'));\r\n\t\t\t}\r\n\t\t}\r\n\t\treturn res;\r\n }\r\n};\r\n```\r\n\r\npython中可以使用counter很快的写出来\r\n\r\nc++中正常使用cnt这个vector去统计\r\n\r\n对每个字符串用cnt1暂时记录下来,然后比较cnt与cnt1,26位取小的\r\n\r\n\r\n\r\n##### leetcode 1018 Binary Prefix Divisible By 5\r\n\r\nGiven an array `A` of `0`s and `1`s, consider `N_i`: the i-th subarray from `A[0]` to `A[i]` interpreted as a binary number (from most-significant-bit to least-significant-bit.)\r\n\r\nReturn a list of booleans `answer`, where `answer[i]` is `true` if and only if `N_i` is divisible by 5.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [0,1,1]\r\nOutput: [true,false,false]\r\nExplanation: \r\nThe input numbers in binary are 0, 01, 011; which are 0, 1, and 3 in base-10. Only the first number is divisible by 5, so answer[0] is true.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [1,1,1]\r\nOutput: [false,false,false]\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: [0,1,1,1,1,1]\r\nOutput: [true,false,false,false,true,false]\r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: [1,1,1,0,1]\r\nOutput: [false,false,false,false,false]\r\n```\r\n\r\n \r\n\r\n**Note:**\r\n\r\n1. `1 <= A.length <= 30000`\r\n2. `A[i]` is `0` or `1`\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n vector<bool> prefixesDivBy5(vector<int>& A) {\r\n int n = A.size(), temp = 0;\r\n vector<bool> res;\r\n for(int i=0;i<n;i++){\r\n temp = (2*temp+A[i])%5;\r\n if (temp%5==0) res.push_back(true);\r\n else res.push_back(false);\r\n }\r\n return res;\r\n }\r\n};\r\n```\r\n\r\ntemp = (2*temp+A[i])%5; 用这个来表示当前A【0】-A【i】构成的二进制\r\n\r\n\r\n\r\n##### leetcode 1029. Two City Scheduling \r\n\r\nThere are `2N` people a company is planning to interview. The cost of flying the `i`-th person to city `A` is `costs[i][0]`, and the cost of flying the `i`-th person to city `B` is `costs[i][1]`.\r\n\r\nReturn the minimum cost to fly every person to a city such that exactly `N` people arrive in each city.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [[10,20],[30,200],[400,50],[30,20]]\r\nOutput: 110\r\nExplanation: \r\nThe first person goes to city A for a cost of 10.\r\nThe second person goes to city A for a cost of 30.\r\nThe third person goes to city B for a cost of 50.\r\nThe fourth person goes to city B for a cost of 20.\r\n\r\nThe total minimum cost is 10 + 30 + 50 + 20 = 110 to have half the people interviewing in each city.\r\n```\r\n\r\n \r\n\r\n**Note:**\r\n\r\n1. `1 <= costs.length <= 100`\r\n2. It is guaranteed that `costs.length` is even.\r\n3. `1 <= costs[i][0], costs[i][1] <= 1000`\r\n\r\nAccepted\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int twoCitySchedCost(vector<vector<int>>& costs) {\r\n auto cmp=[](vector<int> &a, vector<int> &b){\r\n return a[0]-a[1]<b[0]-b[1];\r\n };\r\n int res = 0, n = costs.size();\r\n sort(costs.begin(), costs.end(), cmp);\r\n int i;\r\n for(i=0;i<n/2;i++) res+=costs[i][0];\r\n for(i=n/2;i<n;i++) res+=costs[i][1];\r\n return res;\r\n }\r\n};\r\n```\r\n\r\n关键在于利用元素0 和元素1的差排序\r\n\r\n\r\n\r\n##### leetcode 1030 Matrix Cells in Distance Order\r\n\r\nWe are given a matrix with `R` rows and `C` columns has cells with integer coordinates `(r, c)`, where `0 <= r < R` and `0 <= c < C`.\r\n\r\nAdditionally, we are given a cell in that matrix with coordinates `(r0, c0)`.\r\n\r\nReturn the coordinates of all cells in the matrix, sorted by their distance from `(r0, c0)` from smallest distance to largest distance. Here, the distance between two cells `(r1, c1)` and `(r2, c2)` is the Manhattan distance, `|r1 - r2| + |c1 - c2|`. (You may return the answer in any order that satisfies this condition.)\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: R = 1, C = 2, r0 = 0, c0 = 0\r\nOutput: [[0,0],[0,1]]\r\nExplanation: The distances from (r0, c0) to other cells are: [0,1]\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: R = 2, C = 2, r0 = 0, c0 = 1\r\nOutput: [[0,1],[0,0],[1,1],[1,0]]\r\nExplanation: The distances from (r0, c0) to other cells are: [0,1,1,2]\r\nThe answer [[0,1],[1,1],[0,0],[1,0]] would also be accepted as correct.\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: R = 2, C = 3, r0 = 1, c0 = 2\r\nOutput: [[1,2],[0,2],[1,1],[0,1],[1,0],[0,0]]\r\nExplanation: The distances from (r0, c0) to other cells are: [0,1,1,2,2,3]\r\nThere are other answers that would also be accepted as correct, such as [[1,2],[1,1],[0,2],[1,0],[0,1],[0,0]].\r\n```\r\n\r\n \r\n\r\n**Note:**\r\n\r\n1. `1 <= R <= 100`\r\n2. `1 <= C <= 100`\r\n3. `0 <= r0 < R`\r\n4. `0 <= c0 < C`\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n vector<vector<int>> allCellsDistOrder(int R, int C, int r0, int c0) {\r\n auto comp = [r0, c0](vector<int> &a, vector<int> &b){\r\n return abs(a[0]-r0) + abs(a[1]-c0) < abs(b[0]-r0) + abs(b[1]-c0);\r\n };\r\n \r\n vector<vector<int>> resp;\r\n for(int i=0 ; i<R ; i++){\r\n for(int j=0; j<C ; j++){\r\n resp.push_back({i, j});\r\n }\r\n }\r\n\r\n sort(resp.begin(), resp.end(), comp);\r\n\r\n return resp;\r\n }\r\n};\r\n```\r\n\r\n使用lambda体作为cmp的比较函数\r\n\r\n这样可以 传递r0, c0进去\r\n\r\n\r\n\r\n##### leetcode 1084 Distance Between Bus Stops\r\n\r\n\r\n\r\nA bus has `n` stops numbered from `0` to `n - 1` that form a circle. We know the distance between all pairs of neighboring stops where `distance[i]` is the distance between the stops number `i` and `(i + 1) % n`.\r\n\r\nThe bus goes along both directions i.e. clockwise and counterclockwise.\r\n\r\nReturn the shortest distance between the given `start` and `destination` stops.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n\r\n\r\n```\r\nInput: distance = [1,2,3,4], start = 0, destination = 1\r\nOutput: 1\r\nExplanation: Distance between 0 and 1 is 1 or 9, minimum is 1.\r\n```\r\n\r\n \r\n\r\n**Example 2:**\r\n\r\n\r\n\r\n```\r\nInput: distance = [1,2,3,4], start = 0, destination = 2\r\nOutput: 3\r\nExplanation: Distance between 0 and 2 is 3 or 7, minimum is 3.\r\n```\r\n\r\n \r\n\r\n**Example 3:**\r\n\r\n\r\n\r\n```\r\nInput: distance = [1,2,3,4], start = 0, destination = 3\r\nOutput: 4\r\nExplanation: Distance between 0 and 3 is 6 or 4, minimum is 4.\r\n```\r\n\r\n \r\n\r\n**Constraints:**\r\n\r\n- `1 <= n <= 10^4`\r\n- `distance.length == n`\r\n- `0 <= start, destination < n`\r\n- `0 <= distance[i] <= 10^4`\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int distanceBetweenBusStops(vector<int>& distance, int start, int destination) {\r\n int n = distance.size();\r\n vector<int> accu(n+1, 0);\r\n for(auto i=1;i<n+1;i++){\r\n accu[i] = accu[i-1]+distance[i-1];\r\n }\r\n int clock_dis = abs(accu[destination]-accu[start]);\r\n int unclock_dis = accu[n]-clock_dis;\r\n return min(clock_dis, unclock_dis); \r\n }\r\n};\r\n```\r\n\r\n典型的accumulate功能应用\r\n\r\n用\r\n\r\n```\r\nabs(accu[destination]-accu[start])\r\n```\r\n\r\n表示距离\r\n\r\n\r\n\r\n##### leetcode1160. Find Words That Can Be Formed by Characters\r\n\r\nYou are given an array of strings `words` and a string `chars`.\r\n\r\nA string is *good* if it can be formed by characters from `chars` (each character can only be used once).\r\n\r\nReturn the sum of lengths of all good strings in `words`.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: words = [\"cat\",\"bt\",\"hat\",\"tree\"], chars = \"atach\"\r\nOutput: 6\r\nExplanation: \r\nThe strings that can be formed are \"cat\" and \"hat\" so the answer is 3 + 3 = 6.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: words = [\"hello\",\"world\",\"leetcode\"], chars = \"welldonehoneyr\"\r\nOutput: 10\r\nExplanation: \r\nThe strings that can be formed are \"hello\" and \"world\" so the answer is 5 + 5 = 10.\r\n```\r\n\r\n \r\n\r\n**Note:**\r\n\r\n1. `1 <= words.length <= 1000`\r\n2. `1 <= words[i].length, chars.length <= 100`\r\n3. All strings contain lowercase English letters only.\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int countCharacters(vector<string>& words, string chars) {\r\n vector<int> cnt(26, 0); //#include <bits/stdc++.h>\r\n for(auto c : chars){\r\n ++cnt[c-'a'];\r\n }\r\n int res = 0;\r\n bool flag;\r\n\t\tfor (auto word: words) {\r\n\t\t\tvector<int> cnt1(26, 0);\r\n\t\t\tfor (auto c:word) ++cnt1[c-'a'];\r\n\t\t\tflag = true;\r\n for (int i=0;i<26;i++){\r\n if (cnt1[i]>cnt[i]){\r\n flag = false;\r\n break;\r\n }\r\n }\r\n if (flag) res+=word.size();\r\n\t\t}\r\n\t\treturn res;\r\n }\r\n};\r\n```\r\n\r\n用cnt记录chars中每个字符有多少个,然后一个一个word进行比较\r\n\r\n\r\n\r\n##### leetcode 1191 K-Concatenation Maximum Sum\r\n\r\nMedium\r\n\r\nGiven an integer array `arr` and an integer `k`, modify the array by repeating it `k` times.\r\n\r\nFor example, if `arr = [1, 2]` and `k = 3 `then the modified array will be `[1, 2, 1, 2, 1, 2]`.\r\n\r\nReturn the maximum sub-array sum in the modified array. Note that the length of the sub-array can be `0` and its sum in that case is `0`.\r\n\r\nAs the answer can be very large, return the answer **modulo** `10^9 + 7`.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: arr = [1,2], k = 3\r\nOutput: 9\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: arr = [1,-2,1], k = 5\r\nOutput: 2\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: arr = [-1,-2], k = 7\r\nOutput: 0\r\n```\r\n\r\n \r\n\r\n**Constraints:**\r\n\r\n- `1 <= arr.length <= 10^5`\r\n- `1 <= k <= 10^5`\r\n- `-10^4 <= arr[i] <= 10^4`\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int kConcatenationMaxSum(vector<int>& arr, int k) {\r\n int n = arr.size(), i;\r\n long long sum1=0, left=0, right = 0, temp=0, left_temp=0, right_temp=0;\r\n long long res;\r\n long long sig_sum = 0;\r\n for(i=0;i<n;i++){\r\n temp+=arr[i];\r\n if(temp<0)temp=0;\r\n if(temp>sig_sum){\r\n sig_sum = temp;\r\n }\r\n }\r\n sig_sum = sig_sum%1000000007;\r\n for(i=0;i<n;i++){\r\n left_temp+=arr[i];\r\n sum1 += arr[i];\r\n if(left_temp>left){\r\n left = left_temp;\r\n }\r\n }\r\n for(i=n-1;i>=0;i--){\r\n right_temp+=arr[i];\r\n if(right_temp>right){\r\n right = right_temp;\r\n }\r\n }\r\n sum1 = sum1%1000000007; left = left%1000000007; right = right%1000000007;\r\n if(sum1>=0){\r\n if(k>=2) res = (k*sum1 + max((long long)0, right-sum1) + max((long long)0, left-sum1))%1000000007;\r\n else{\r\n int bigger = max(right, left);\r\n res = (k*sum1 + max(0, bigger))%1000000007;\r\n }\r\n }\r\n else{\r\n \r\n res = (max((long long)0, right) + max((long long)0, left))%1000000007;\r\n }\r\n return max(res, sig_sum);\r\n }\r\n}; \r\n```\r\n\r\n注意long long型变量的用法,可以直接返回 c++会视为int\r\n\r\nsum1表述数组的和,left表示从左边开始的最大和,right表示从右边开始的substring的最大和\r\n\r\nsig_sum表示数组的substring的最大和\r\n\r\n\r\n\r\n##### leetcode 251. Flatten 2D Vector\r\n\r\nDesign and implement an iterator to flatten a 2d vector. It should support the following operations: `next` and `hasNext`.\r\n\r\n**Example:**\r\n\r\n```\r\nVector2D iterator = new Vector2D([[1,2],[3],[4]]);\r\n\r\niterator.next(); // return 1\r\niterator.next(); // return 2\r\niterator.next(); // return 3\r\niterator.hasNext(); // return true\r\niterator.hasNext(); // return true\r\niterator.next(); // return 4\r\niterator.hasNext(); // return false\r\n```\r\n\r\n**Notes:**\r\n\r\n1. Please remember to **RESET** your class variables declared in Vector2D, as static/class variables are **persisted across multiple test cases**. Please see [here](https://leetcode.com/faq/) for more details.\r\n2. You may assume that `next()` call will always be valid, that is, there will be at least a next element in the 2d vector when `next()` is called.\r\n\r\n```c++\r\nclass Vector2D {\r\nvector<int> nums;\r\nint index = 0;\r\npublic:\r\n Vector2D(vector<vector<int>>& v) {\r\n for(auto vec:v){\r\n for(auto c:vec){\r\n nums.push_back(c);\r\n }\r\n }\r\n }\r\n \r\n int next() {\r\n int res = nums[index];\r\n index += 1;\r\n return res;\r\n }\r\n \r\n bool hasNext() {\r\n if (index < nums.size()) return true;\r\n return false;\r\n }\r\n};\r\n```\r\n\r\n\r\n\r\n##### leetcode 259. 3Sum Smaller\r\n\r\nGiven an array of *n* integers *nums* and a *target*, find the number of index triplets `i, j, k` with `0 <= i < j < k < n` that satisfy the condition `nums[i] + nums[j] + nums[k] < target`.\r\n\r\n**Example:**\r\n\r\n```\r\nInput: nums = [-2,0,1,3], and target = 2\r\nOutput: 2 \r\nExplanation: Because there are two triplets which sums are less than 2:\r\n [-2,0,1]\r\n [-2,0,3]\r\n```\r\n\r\n**Follow up:** Could you solve it in *O*(*n*2) runtime?\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int threeSumSmaller(vector<int>& nums, int target) {\r\n sort(nums.begin(), nums.end());\r\n int n = nums.size();\r\n int left, right, res = 0;\r\n for(int i = 0; i<n-2;i++){\r\n left = i+1; right = n - 1;\r\n while(left < right){\r\n if(nums[i] + nums[left] + nums[right] < target){\r\n res += right - left;\r\n left += 1;\r\n }\r\n else{\r\n right -= 1;\r\n }\r\n }\r\n }\r\n return res;\r\n }\r\n};\r\n```\r\n\r\n *O*(*n*2)"
},
{
"alpha_fraction": 0.8281887173652649,
"alphanum_fraction": 0.8281887173652649,
"avg_line_length": 19.759492874145508,
"blob_id": "0897fc75ce5a90ffe10d8a4fe1b4800543ff228d",
"content_id": "dd19dcee28b44f1a58b774756b157de06eb72b82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4803,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 79,
"path": "/books/others/人生的智慧.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 人生的智慧\r\n\r\n叔本华\r\n\r\n这世界上存在着三种力:明智、力量和运气。我相信运气至为重要。\r\n\r\n一个人所能得到的属于他的快乐,从一开始就已经由这个人的个性规定了。一个人的精神能力的范围决定性地限定了他领略高级快乐地能力。如果一个人的精神能力相当有限,那么所有来自外在的努力----别人或者运气所能为他做的一切----都不会使他超越只能领略平庸无奇、夹杂着动物性的快乐的范围。\r\n\r\n对于人的幸福快乐而言,主体远远比客体来的重要。饥饿才是最好的调味品,衰老之人对青春美色再难一见钟情。\r\n\r\n我们唯一能够做到的就是尽可能充分利用我们既定的个性。因此,我们应该循着符合我们个性的方向,努力争取适合个性的发展,除此之外则一概避免。\r\n\r\n痛苦和无聊时人类幸福的两个死敌,每当我们感到快活,在我们远离上述的一个敌人的时候,我们就接近了另一个敌人。\r\n\r\n闲暇是人生的精华。\r\n\r\n无论我们身在何处,我们只能在我们自身寻找或者获得幸福。\r\n\r\n拥有丰富内在的人就像在冬月的晚上,在漫天冰雪中拥有一间明亮、温暖、愉快的圣诞小屋。\r\n\r\n精神上的享受---对美的追求。\r\n\r\n伊比鸠鲁将人的需要分为三类:天然的需求:例如食品和衣物;性需求;对奢侈、排场的需求。\r\n\r\n一个习惯处理钱财的有钱女人,会小心翼翼的花钱,但一个结婚后才首次获得金钱的支配权力的女人,会在用钱的时候大胆妄为。\r\n\r\n把别人的意见和看法看得太过重要是人们常犯的错误,这一错误或者根植于我们的本性。\r\n\r\n跟奴隶开玩笑,奴隶就会对你不屑,不要拒绝贺拉斯的这句话:你必须强迫自己接受应有的骄傲。谦虚是美德是蠢人的发明。\r\n\r\n最廉价的骄傲就是民族自豪感。\r\n\r\n\r\n\r\n如何保持快乐?\r\n\r\n理性的人寻求的不是快乐而是没有痛苦。\r\n\r\n所有的快乐,本质都是否定的,所有的痛苦,本质都是肯定的。如果有一件事情违反了我们的意愿,尽管是件微不足道的事情,我们就会惦记着这件事情,而不会想到其他已经让我们如愿的事情。谁要从幸福论的角度衡量自己是否过的幸福,他需要一一列举自己所躲避的不幸,所谓幸福的生活应当理解为减少了不幸的生活。\r\n\r\n柏拉图:没有什么人、事值得我们过分的操心。\r\n\r\n欢乐就像澳大利亚的金砂:它们分散在各处,没有任何的规则和定律,找到它们纯粹是偶然机会,并且每次也只能找到一小撮,因为它们甚少大量聚集在一起。\r\n\r\n\r\n\r\n衡量一个人是否幸福,我们不应该向他询问那些令他高兴的事情,而应该了解那些让他烦恼操心的事情,因为烦扰他的事情越少,越微不足道,那么他也就生活的越幸福。\r\n\r\n\r\n\r\n一般来说,人们最常做的一件大蠢事就是过分地为生活未雨绸缪了---无论这种绸缪是以何种方式进行。计划都有太多阻滞的机会,甚少真能达致成功。就算我们的目标都实现,我们可能当目标实现的时候我们取得的成果已经不再适合我们的需要了。\r\n\r\n\r\n\r\n如何对待自己:\r\n\r\n人生智慧重要的一点就是关注现在和计划将来这两者之间达致恰到好处的平衡。这样,现在与将来才不至于互相干扰。\r\n\r\n我们应该愉快地迎接现在此刻,从而有意识地享受每一可忍受地、没有直接烦恼和痛苦地短暂时光,也就是说,不要由于在过去我们的希望落空现在就变得犹豫寡欢,或者为了将来操心而败坏现时。\r\n\r\n已经发生的事情:无论多么悲痛,我们必须让过去的事情过去。\r\n\r\n将来的事情:在上帝的安排之中\r\n\r\n现在:把每一天视为一段特别的生活\r\n\r\n我们应该珍惜每一刻可以忍受的现在。生活流淌就像一条波澜不惊、漩涡不起的小溪。\r\n\r\n只有当一个人独处的时候他才是自由的。青年人首先要学习的第一课就是承受孤独,因为孤独是幸福、安乐的源泉。\r\n\r\n人们单调的个性使他们无法忍受自己,人们只有凑到一块、联合起来的时候才能有所作为。\r\n\r\n节制与人交往会使我们心灵平静,要是谁能在早年就能适应独处,并且喜欢独处,那他就发现了一个金矿。\r\n\r\n当我们看到某样东西时,很轻易会产生一个念头:呀,我能拥有它就好了,由此我们感到了有所缺欠。我们更应该这么想,如果我失去了某样东西,那将是怎么样的场景。\r\n\r\n\r\n\r\n如何对待与他人的关系:"
},
{
"alpha_fraction": 0.5046913027763367,
"alphanum_fraction": 0.5634581446647644,
"avg_line_length": 15.1864652633667,
"blob_id": "ad8a645d13d7b80e6ee6007179a4dc0638f56b54",
"content_id": "3ab422a19ed76600c2aa80d66ba77f60c0c08d7d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 28678,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 1389,
"path": "/python/python_cookbook.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "#### python cookbook\r\n\r\n\r\n\r\npython cpython,jython\r\n\r\ncpython是基于c语言开发的python解释器,所以叫cpython\r\n\r\njython是运行在java平台上的python解释器,可以直接把python代码编译成java字节码运行。\r\n\r\npython 运算:\r\n\r\n```\r\n// 表示除法取整运算\r\n** 表示乘方运算\r\n```\r\n文本 list\r\nthelist=list(thestring)\r\n\r\n字符与文本之间的转化:\r\n```python\r\nprint(ord('a'))\r\n97\r\nprint(chr(97))\r\na\r\n```\r\nmap函数:\r\n```python\r\nmap1=map(ord,'ciao')\r\nprint(map1)\r\n<map object at 0x00000230FB925CF8>\r\nprint(list(map1))\r\n[99, 105, 97, 111]\r\n```\r\n判断字符串的类型\r\n```python\r\nisinstance(\"123\",str)\r\nTrue\r\nisinstance(1,int)\r\nTrue\r\n```\r\n字符串的对齐填充\r\n```\r\ncenter(),.ljust(),rjust()\r\nprint('hej'.center(20,'+'))\r\n++++++++hej+++++++++\r\n```\r\n去除字符串首尾的空格\r\n```\r\nstr.lstrip(),.rstrip(),.strip()\r\n```\r\n字符串连接\r\n```\r\n>>> pieces=['a','b','c']\r\n>>> largepieces=\"\".join(pieces)\r\n或者使用+\r\nlargepieces+=piece\r\nimport operator\r\nlargestring=reduce(operator.add,pieces,\"\")\r\n```\r\n```\r\nfor c in seq:(检测seq中是否有aset中的项)\r\n if c in aset:\r\n return true\r\n else:\r\n return false\r\n```\r\n difference\r\n set(L1).difference(L2)\r\n 寻找L1中不属于L2的\r\n\r\npython set:\r\n```python\r\nset是一个没有序的集合,因此it is not callable set(0) set[0]是没有意义的\r\ns=set([1,2,3,2])\r\nfor i in s: (set 遍历)\r\n\tprint(i)\r\n1\r\n2\r\n3\r\n\r\nset之间表示包含关系\r\nset1=set({1,2,3}),set2=set({1,2}),set3=set({1,4})\r\nset1>set2 True\r\nset1>set3 False\r\n\r\n>>> x = set('spam')\r\n>>> y = set(['h','a','m'])\r\n>>> x, y\r\n(set(['a', 'p', 's', 'm']), set(['a', 'h', 'm']))\r\n>>> x & y # 交集\r\nset(['a', 'm'])\r\n>>> x | y # 并集\r\nset(['a', 'p', 's', 'h', 'm'])\r\n>>> x - y # 差集\r\nset(['p', 's'])\r\n```\r\n\r\n将字符串中的字符进行反转:\r\n```\r\nrevchars=astring[::-1] 或者\r\nrevwords=astring.split()\r\nrevwords.reverse()\r\nrevwords=\"\".join(revwords)\r\n```\r\n在字符串中删除所有的特殊字符:\r\n```python\r\nimport string\r\nl=\"hello, this\"\r\nl2=\"\".join(i for i in l if i not in string.punctuation)\r\nl2\r\n'hello this'\r\n```\r\n\r\ntranslate方法:\r\n```python\r\nfrom string import maketrans # 引用 maketrans 函数。 \r\nintab = \"aeiou\"\r\nouttab = \"12345\"\r\ntrantab = maketrans(intab, outtab)\r\nstr = \"this is string example....wow!!!\";\r\nprint str.translate(trantab);\r\n以上实例输出结果如下:\r\n\r\nth3s 3s str3ng 2x1mpl2....w4w!!!\r\n以上实例去除字符串中的 'x' 和 'm' 字符:\r\n\r\n实例(Python 2.0+)\r\nfrom string import maketrans # Required to call maketrans function.\r\n \r\nintab = \"aeiou\"\r\nouttab = \"12345\"\r\ntrantab = maketrans(intab, outtab)\r\n \r\nstr = \"this is string example....wow!!!\";\r\nprint str.translate(trantab, 'xm');\r\n以上实例输出结果:\r\n\r\nth3s 3s str3ng 21pl2....w4w!!!\r\n```\r\n字符的大小写\r\n```python\r\nlittle.upper()\r\nbig.lower()\r\n\r\nstring.captalize() # 第一个字符被改为大写,其余的改为小写\r\nstring.title() #每个单词的首字母大写\r\n```\r\n\r\nreduce方法:\r\n```python\r\na=np.array([1,2,3,4])\r\nnp.add.reduce(a)\r\n10\r\n\r\na = np.array([[1,2,3],[4,5,6]])\r\nnp.add.reduce(a)\r\narray([5, 7, 9])\r\n\r\n指定维度:\r\nnp.add.reduce(a, 1)\r\narray([ 6, 15])\r\n```\r\n作用他于字符串:\r\n```python\r\na=np.array(['ab','cd','ef'],np.object)\r\nnp.add.reduce(a)\r\n其中如果不加 np.object 会出现\r\nTypeError: cannot perform reduce with flexible type\r\n```\r\n\r\naccumulate方法:\r\n```python\r\naccumulate 可视为每一步保存reduce的结果形成的数组\r\na=np.array([1,2,3,4])\r\nnp.add.accumulate(a)\r\n\r\narray([1,3,6,10])\r\n\r\na = np.array(['ab', 'cd', 'ef'], np.object)\r\nnp.add.accumulate(a)\r\nOut[11]:\r\narray(['ab', 'abcd', 'abcdef'], dtype=object)\r\n```\r\n\r\n利用python插值计算:\r\n```\r\nfrom scipy import interpolate\r\nx = np.arange(0, 10)\r\ny = np.exp(-x/3.0)\r\nf = interpolate.interp1d(x, y)\r\n\r\nxnew = np.arange(0,9, 0.1)\r\nynew = f(xnew) # use interpolation function returned by `interp1d`\r\nplt.plot(x, y, 'o', xnew, ynew, '-')\r\nplt.show()\r\n```\r\ninterp1d 线性插值\r\npython图像插值:\r\nhttps://blog.csdn.net/u010096025/article/details/53780623\r\n\r\n概率数学统计:\r\n```\r\n导入 numpy 和 matplotlib:\r\nheights = numpy.array([1.46, 1.79, 2.01, 1.75, 1.56, 1.69, 1.88, 1.76, 1.88, 1.78])\r\nprint 'mean, ', heights.mean()\r\nprint 'min, ', heights.min()\r\nprint 'max, ', heights.max()\r\nprint 'standard deviation, ', heights.std()\r\nprint 'median, ', heights.median()\r\nprint 'nan median, ', heights.nanmedian() #除了nan之外的median\r\n\r\n导入 Scipy 的统计模块:\r\n\r\nIn [4]:\r\nimport scipy.stats.stats as st\r\n其他统计量:\r\n\r\nIn [5]:\r\nprint 'median, ', st.nanmedian(heights) # 忽略nan值之后的中位数\r\nprint 'mode, ', st.mode(heights) # 众数及其出现次数\r\nprint 'skewness, ', st.skew(heights) # 偏度\r\nprint 'kurtosis, ', st.kurtosis(heights) # 峰度\r\nprint 'and so many more...'\r\n```\r\n\r\n分布:\r\n```\r\n按照正态分布产生500个点\r\nfrom scipy.stats import norm\r\nx_norm = norm.rvs(size=500)\r\n\r\n在这组数据下,正态分布参数的最大似然估计值为:\r\nx_mean, x_std = norm.fit(x_norm)\r\nprint 'mean, ', x_mean\r\nprint 'x_std, ', x_std\r\n```\r\n\r\n文件格式:\r\n```\r\ninput=open('data.txt','r')\r\noutput=open('data.txt','w')\r\ninput.close()\r\n\r\n逐行读取\r\nlines=input.readlines()\r\n\r\n一次性读取全部内容\r\nlines=input.read()\r\n\r\n写入内容\r\noutput.write(data)\r\n```\r\n搜索和替换文件中的文本:\r\n```\r\ninput=open(\"test.txt\")\r\noutput=open(\"test2.txt\",\"w\")\r\noutput.write(input.read().replace(\"test\",\"test2\"))\r\noutput.close()\r\n\r\n从文件中读取指定的行:\r\nimport linecache\r\ntheline=linecache.getline(thefile,linenumber)\r\n计算文件的行数\r\n比较小的文件:\r\ncount=len(open(path,\"r\").readlines())\r\n对于比较大的文件:\r\ncount=0\r\nthefile=open(path,'rb')\r\nwhile True:\r\n buffer=thefile.read(8192*1024)\r\n if not buffer:\r\n break\r\n count+=buffer.count('\\n')\r\n thefile.close()\r\n```\r\n\r\nlist:\r\n```\r\nlist count\r\nT=['a','b','c']\r\nT.count('a')\r\n统计一共有多少个\r\n```\r\n字典:\r\n```\r\nmax(words.values()) #2\r\nmax(words.key()) #was\r\n for key,value in words.items():\r\n if value==max(words.values()):\r\n return key\r\n# ball\r\n```\r\n 从字典中读取value最大的对应的key\r\n```\r\nkey = max(dict1, key=dict1.get)\r\n```\r\nenumerate:\r\n```\r\nfor i, x in enumerate(nums):\r\nnums 表示数组\r\ni是下标,x是数组中的元素\r\n```\r\n\r\npython heap:\r\n```\r\nPython heapq 堆模块\r\nlist=[2,1,3,4,5,6,7,8]\r\n对于已经存在的列表:\r\nheapq.heapify(list) #创建堆\r\nlist[0] #最小值\r\n1\r\n\r\nheapq.heappush(list,5) #push\r\nheappop(h) #弹出最小值\r\n\r\nnlargest(n , iterbale, key=None) \r\n从堆中找出做大的N个数,key的作用和sorted( )方法里面的key类似,用列表元素的某个属性和函数作为关键字。\r\na = [0, 1, 2, 3, 4, 5, 5, 7, 8, 10, 15, 20, 25]\r\nheapq.nlargest(5,a)\r\n[25, 20, 15, 10, 8]\r\n\r\nnsmallest(n,data)\r\nres=heapq.nsmallest(K,points,key=lambda x:dict1[(x[0],x[1])])\r\n#从堆中找出最小的n个值,可以设计按照key值或者cmp函数来找到nsmallest\r\n但是heapify好像不行,不能设计key或者cmp\r\n\r\n找最小/大的第某个值\r\nlist.sort()\r\nlist.sort(reverse=True)\r\nlist[n]\r\nitem = heapreplace(heap,item) #弹出并返回最小值,然后将heapqreplace方法中item的值插入到堆中\r\n```\r\nsort与 lambda表达式结合起来:\r\n```\r\npeople.sort(key=lambda x:(-x[0],x[1]))\r\n[[7,0], [4,4], [7,1], [5,0], [6,1], [5,2]]\r\n表示按照 x[0]降序 x[1]增序排序\r\n[[7, 0], [7, 1], [6, 1], [5, 0], [5, 2], [4, 4]]\r\n```\r\n自定义sort cmp\r\n```\r\nfrom functools import cmp_to_key\r\ndef cmp(x,y):\r\n if x.isvisited!=y.isvisited:\r\n return x.isvisited-y.isvisited\r\n elif (x.capital<=W)!=(y.capital<=W):\r\n return -(x.capital<=W)+(y.capital<=W)\r\n return y.profit-x.profit\r\nnodes.sort(key=cmp_to_key(cmp))\r\n```\r\nstack:# 在python中用append和pop实现stack功能\r\n```\r\nstack=[1,2,3,4]\r\nstack.append(5)\r\nstack.append(6)\r\nstack.pop()\r\n6\r\n```\r\n\r\nqueue:#使用deque模块中的append和popleft\r\n```\r\nfrom collections import deque\r\nlist=deque([1,2,3,4,5])\r\nlist.append(7)\r\nlist.popleft()\r\n1\r\n```\r\n\r\n```\r\ninsert方法\r\nqueue.insert(x,item)\r\n表示将item插到队列中的下标为x的位置\r\n```\r\n##### OrderedDict\r\n\r\n使用dict的时候可以注意到dict中的元素是无序的\r\n\r\n\r\n\r\n\r\n\r\n树:\r\n\r\n```python\r\nfrom bintrees import BinaryTree # 二叉树\r\nfrom bintrees import AVLTree #平衡AVL\r\nfrom bintrees import RBTree #平衡红黑树\r\n```\r\n\r\npython defaultdict方法:\r\n在Python中如果访问字典中不存在的键,会引发KeyError异常\r\n可以通过defaultdict设置字典中的每个键都存在默认值\r\n\r\n```\r\nfor kw in strings:\r\n if kw not in counts:\r\n counts[kw] = 1\r\n else:\r\n counts[kw] += 1\r\n```\r\n\r\n使用set默认值\r\n```\r\nfor kw in strings:\r\n counts[kw] = counts.setdefault(kw, 0) + 1\r\n\r\n使用defaultdict\r\nfrom collections import defaultdict\r\ndd=defaultdict(int)\r\ndd[0]\r\n0 #默认所有值一开始 0\r\ndd=defaultdict(list)\r\n[] #默认所有值一开始 []\r\n```\r\n\r\npython collections集成模块:\r\n```python\r\nnamedtuple\r\np=(1,2)\r\np[1]\r\n2\r\n\r\nfrom collections import namedtuple\r\nPoint = namedtuple('Point', ['x', 'y'])\r\np = Point(1, 2)\r\np.x\r\n1\r\np.y\r\n2\r\nnamedtuple 定义一个集合类\r\n\r\n\r\nCounter 计数器\r\nfrom collections import Counter\r\nc = Counter('programming')\r\nc: ({'r': 2, 'g': 2, 'm': 2, 'p': 1, 'o': 1, 'a': 1, 'i': 1, 'n': 1})\r\nc.get('p') # 1\r\nc.get('t') # None\r\nc.get('t', 0) # 如果没有就返回0\r\n\r\nc = {}\r\nfor ch in 'programming':\r\n c[ch]=c[ch]+1\r\nc\r\nCounter({'r': 2, 'g': 2, 'm': 2, 'p': 1, 'o': 1, 'a': 1, 'i': 1, 'n': 1})\r\n```\r\n\r\npython hashlib\r\n```python\r\nfrom hashlib import md5\r\nm1=hashlib.md5()\r\nstr='hello'\r\nm1.update(str.encode(\"utf8\"))\r\nprint(m1.hexdigest)\r\n<built-in method hexdigest of _hashlib.HASH object at 0x0000029B5A0903C8>\r\n```\r\npython itertools\r\n```\r\nimport itertools\r\nnatuals = itertools.count(1)\r\n#count创建无限的迭代器\r\ncs = itertools.cycle('ABC')\r\n#无限循环\r\nns = itertools.repeat('A', 10)\r\n#重复10 times\r\n```\r\n\r\n排列组合迭代器\r\n\r\n```\r\nproduction() #相当于嵌套的for循环\r\npermutations()\r\np[, r] 长度r元组,所有可能的排列,无重复元素\r\ncombinations()\r\np, r 长度r元组,有序,无重复元素\r\ncombinations_with_replacement()\r\np, r 长度r元组,有序,元素可重复\r\n\r\nproduct('ABCD', repeat=2)\r\nAA AB AC AD BA BB BC BD CA CB CC CD DA DB DC DD\r\npermutations('ABCD', 2)\r\nAB AC AD BA BC BD CA CB CD DA DB DC\r\ncombinations('ABCD', 2)\r\nAB AC AD BC BD CD\r\ncombinations_with_replacement('ABCD',2)\r\nAA AB AC AD BB BC BD CC CD DD\r\n```\r\n\r\ngroupby\r\n\r\n```\r\nimport pandas as pd\r\nimport numpy as np\r\ndf = pd.DataFrame({'key1':list('aabba'),\r\n 'key2': ['one','two','one','two','one'],\r\n 'data1': np.random.randn(5),\r\n 'data2': np.random.randn(5)})\r\n```\r\n\r\n```\r\nfor i in df.groupby('key1'):\r\n print(i)\r\n# 输出:\r\n('a', data1 data2 key1 key2\r\n0 -0.293828 0.571930 a one\r\n1 1.872765 1.085445 a two\r\n4 -1.943001 0.106842 a one)\r\n('b', data1 data2 key1 key2\r\n2 -0.466504 1.262140 b one\r\n3 -1.125619 -0.836119 b two)\r\n```\r\n\r\n```\r\nfor i in df.groupby(['key1','key2']):\r\n print(i)\r\n# 输出:\r\n(('a', 'one'), data1 data2 key1 key2\r\n0 -0.293828 0.571930 a one\r\n4 -1.943001 0.106842 a one)\r\n(('a', 'two'), data1 data2 key1 key2\r\n1 1.872765 1.085445 a two)\r\n(('b', 'one'), data1 data2 key1 key2\r\n2 -0.466504 1.26214 b one)\r\n(('b', 'two'), data1 data2 key1 key2\r\n3 -1.125619 -0.836119 b two)\r\n\r\n```\r\n\r\n\r\n\r\npython 对象拷贝\r\n\"=\" 与copy 拷贝不同\r\n\r\n```\r\nimport copy\r\na=[1,2,3]\r\nb=copy.copy(a)\r\na.append(4)\r\nb\r\n[1, 2, 3]\r\n\r\n>>> a=b=1\r\n>>> b+=1\r\n>>> a\r\n1\r\n>>> b\r\n2\r\n\r\n>>> a=[1,2,3]\r\n>>> b=a\r\n>>> b.append(4)\r\n>>> print(a,b)\r\n[1, 2, 3, 4] [1, 2, 3, 4]\r\n```\r\n通过列表推导列表:\r\n```\r\nl=[min(x,100) x for x in l]\r\n```\r\n通过enumerate不用循环实现遍历\r\n```\r\nfor index,item in enumerate(sequence)\r\n```\r\n创建全为0的2维数组\r\n```\r\n[[0 for i in range(5)]for j in range(6)]\r\n```\r\n\r\n\r\nyield:\r\n```\r\ndef fab(max): \r\n n, a, b = 0, 0, 1 \r\n while n < max: \r\n yield b \r\n # print b \r\n a, b = b, a + b \r\n n = n + 1 \r\n \r\n```\r\n在遇到yield之后 暂时返回 类似于return\r\n但是下一次调用fab函数时从yield的下一行开始运行\r\n\r\n\r\n三行代码python实现快速排序:\r\n```\r\ndef qsort(L):\r\n if len(L)<=1:return L\r\n return qsort([left for left in L[1:] if left<L[0]])+L[0]+qsort([right for right in L[:1] if right >=L[1:)\r\n```\r\n\r\npython print之后不换行: 默认的end是换行\r\n```\r\n>>> for i in range(10):\r\n... print(i,end=\" \")\r\n...\r\n0 1 2 3 4 5 6 7 8 9 \r\n```\r\n\r\nsplit函数详解:\r\n```\r\ns=\" \"\r\ns.split() #默认是将多余的空格全部去掉\r\n[]\r\n```\r\n```\r\n>>> s=\" 1 2 3\"\r\n>>> print(s.split(\" \")) #存在多个空格连续的情况不能处理\r\n['', '', '', '1', '', '', '2', '', '', '', '', '', '3']\r\n```\r\n#hash table 对应list\r\n\r\n```\r\nfrom collections import defaultdict\r\ndict = defaultdict(list)\r\n```\r\n\r\nfilter\r\n```\r\nfilter(function, iterable)\r\ndef is_odd(n):\r\n return n % 2 == 1\r\n \r\nnewlist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])\r\nprint(newlist)\r\n\r\nleecode771\r\nJ = \"aA\"\r\nS = \"aAAbbbb\"\r\nfilter(lambda x:x in J,list(S))\r\n这里lambda充当了一个可以用于 iteration函数\r\n```\r\n\r\npython linked list:\r\n考虑将其转换为list对象进行操作\r\n```\r\nwhile head:\r\n val.append(head.val)\r\n head=head.next\r\nreturn val==val[::-1]\r\n[::-1] 反转\r\n```\r\n对linked list进行删除操作:\r\n```\r\nleetcode203\r\n对于输入的head,先创建一个节点\r\ncur=ListNode(-1)\r\ncur.next=head\r\ncurrent=cur\r\n通过迭代current节点,最后返回的时候就返回cur.next就可以了\r\n```\r\n\r\nlinked list中循环:\r\n```\r\n slow,fast=head,head\r\n while fast.next!=None and fast.next.next!=None:\r\n fast=fast.next.next\r\n slow=slow.next\r\n if fast==slow:\r\n return True\r\n return False\r\nfast slow\r\n```\r\nlinked list:\r\n合并list\r\n```\r\nwhile l1!=None and l2!=None:\r\n if l1.val<=l2.val:\r\n cur.next=l1\r\n l1=l1.next\r\n else:\r\n cur.next=l2\r\n l2=l2.next\r\n cur=cur.next\r\ncur.next = l1 or l2#直接把后面没有弄完的list连上\r\n```\r\npython math:\r\n```\r\ncount digits :1 2 3 4 5 6 7 8 9 10 \r\ndef nth(n):\r\n count=0\r\n while n>10**count*9*(count+1):\r\n n-=10**count*9*(count+1)\r\n count+=1\r\nreturn count,n\r\n```\r\npython 迅速找到所有的质因数\r\n```\r\nfrom functools import reduce\r\ndef factors(n):\r\n return set(reduce(list.__add__,([i, n // i] for i in range(1, int(n ** 0.5) + 1) if n % i == 0)))\r\n返回set格式 包括n \r\n```\r\n\r\nmax int\r\n```\r\nimport sys\r\ni = sys.maxint\r\n```\r\n\r\npermutation:\r\n```\r\nimport itertools\r\nclass Solution:\r\n def permute(self, nums):\r\n \"\"\"\r\n :type nums: List[int]\r\n :rtype: List[List[int]]\r\n \"\"\"\r\n return list(itertools.permutations(nums))\r\nInput: [1,2,3]\r\nOutput:[[1,2,3], [1,3,2], [2,1,3], [2,3,1],[3,1,2], [3,2,1]] \r\n```\r\n使用nums当中一部分元素 permutation:\r\n```\r\n>>> nums=[1,2,3,4,5]\r\n>>> import itertools\r\n>>> for i, j, k in itertools.combinations(nums, 3):\r\n... print(i,j,k)\r\n...\r\n1 2 3\r\n1 2 4\r\n1 2 5\r\n1 3 4\r\n1 3 5\r\n1 4 5\r\n2 3 4\r\n2 3 5\r\n2 4 5\r\n3 4 5\r\n可以看出这个时候 对于选择的三个元素不再调换其位置视为新一种\r\n```\r\n\r\n如果可以不出现全部数据的情况则:\r\n```\r\nclass Solution:\r\n def permute(self, nums):\r\n res = []\r\n self.dfs(nums, [], res)\r\n return res\r\n\r\n def dfs(self, nums, path, res):\r\n if not nums:\r\n if path not in res:\r\n res.append(path)\r\n # return # backtracking\r\n for i in range(len(nums)):\r\n self.dfs(nums[:i] + nums[i + 1:], path + [nums[i]], res)\r\n self.dfs(nums[:i] + nums[i + 1:], path, res)\r\n \r\n [[1, 2, 3], [1, 2], [1, 3], [1], [1, 3, 2], [2, 3], [2], [3], [], [3, 2], [2, 1, 3], [2, 1], [2, 3, 1], [3, 1], [3, 1, 2], [3, 2, 1]]\r\n```\r\n如果要求顺序:\r\n```\r\nclass Solution:\r\n def permute(self, nums):\r\n self.res = []\r\n self.dfs(nums, [])\r\n return self.res\r\n\r\n def dfs(self, nums, path):\r\n if not nums:\r\n self.res.append(path)\r\n return\r\n self.dfs(nums[1:], path)\r\n self.dfs(nums[1:], path+[nums[0]])\r\n[[], [3], [2], [2, 3], [1], [1, 3], [1, 2], [1, 2, 3]] \r\n```\r\nleetcode 84 85 递增栈\r\n\r\nbisect\r\n```\r\nimport bisect\r\ndata=[2,3,4,7,9]\r\nbisect.bisect(data,1)\r\n0\r\nbisect.bisect(data,5)\r\n3\r\nbisect.bisect(data,8)\r\n4\r\n返回比他大的最小的元素的下标\r\n```\r\n\r\npython union find 并查集\r\n```\r\nhttps://www.jianshu.com/p/72da76a34db1\r\nquick find,quick union算法\r\n```\r\n\r\narray:\r\n\r\n数据结构:\r\n数组(ndarray from numpy)\r\n\r\n```\r\ndata.shape (2,3) (rows,cols)\r\ndata.dtype 'float64'\r\n```\r\n\r\n创建ndarray:\r\n\r\n```\r\ndata1=[6,7.5,8,0,1]\r\narr1=np.array(data1)\r\narr1:([6.0,7.5,8.0,0.,1.])\r\n\r\nnp.zeros(10)\r\n([0.,0.,0.,.....0.])\r\nnp.zeros((3,6))\r\n```\r\n\r\n数组与标量之间的运算是元素级的:\r\n\r\n```\r\narr=([1,.2.,3.],[4.,5.,6.])\r\narr*arr=([1,.4.,9.],[16.,25.,36.])\r\n```\r\n\r\narange函数 slice函数\r\n\r\n```\r\narr=np.arange(10)\r\narray([0,1,2,3,4,5,6,7,8,9])\r\narr[5:8]\r\narray([5,6,7])\r\n```\r\n\r\n与列表不同的地方在于数据不会被复制,也就是说对数组复制之后再赋值,原数组的数值也会改变\r\n如果需要只是一个copy 则可以用 arr[5:8].copy()\r\n\r\n数组的切片索引:\r\n\r\n```\r\narr=array([1,2,3],[4,5,6],[7,8,9])\r\narr[:2,1:]\r\narray([[2,3],[5,6]])\r\n```\r\n\r\nnumpy randn函数\r\n\r\n```\r\nnumpy.random.randn(7,4)\r\n```\r\n\r\n布尔型索引:\r\n\r\n```\r\nnames=np.array(['Bob','Joe','Will','Bob','Will','Joe','Joe'])\r\ndata\r\narray([1,2,3,4],[5,6,7,8],[9,10,11,12],[13,14,15,16],[17,18,19,20],[21,22,23,24],[25,26,27,28])\r\n\r\nnames=='Bob'\r\narray([True,False,False,True,False,False,False],dtpye=bool)\r\n\r\ndata[names=='Bob']\r\narray([1,2,3,4],[13,14,15,16])\r\ndata[names=='Bob',2:]\r\narray([3,4],[15,16])\r\n\r\ndata[names!='Bob'] 或者data[-(names=='Bob')]\r\narray([5,6,7,8],[9,10,11,12],[17, 18,19,20],[21,22,23,24],[25,26,27,28])\r\n```\r\n\r\n布尔条件可以通过| &等进行组合\r\n\r\n```\r\ndata[data<10]=0\r\narray([0,0,0,0],[0,0,0,0],[0,10,11,12],[13,14,15,16],[17,18,19,20],[21,22,23,24],[25,26,27,28])\r\narray([1,2,3,4],[13,14,15,16])\r\n```\r\n\r\n数组的转置\r\n\r\n```\r\narr.T\r\n```\r\n\r\narray 排序\r\n\r\n```\r\narr.sort() 表示从小到大进行排序,这个既可以对float int类型的数据进行排序也可以直接对字符串数组进行排序\r\narr.sort(1)表示对二维数组按照每一行进行从小到大排序\r\narr.sort(reverse = True) 从大到小排序\r\n>>> arr=numpy.array(['a','c','b'])\r\n>>> arr.sort()\r\narray(['a', 'b', 'c'], dtype='<U1')\r\n```\r\n\r\n对字符串进行排序\r\n\r\n```\r\n>>> s = \"string\"\r\n>>> l = list(s)\r\n>>> l.sort()\r\n>>> s = \"\".join(l)\r\n>>> s\r\n'ginrst'\r\n```\r\n\r\n逻辑集合:\r\n\r\n```\r\nnp.unique(arr)或者sorted(set(arr))表示对求唯一\r\n```\r\n\r\n随机数生成可以用numpy.random\r\n\r\n```\r\nsample=np.random.normal(size=(4,4)) 按照高斯分布生成4,4 的数列\r\n\r\nnumpy mask 数组 图像\r\n>>> arr=numpy.random.randint(1,10,size=[1,5,5])\r\n>>> arr\r\narray([[[6, 1, 8, 9, 9],\r\n [3, 2, 5, 3, 5],\r\n [2, 8, 3, 9, 3],\r\n [2, 1, 4, 4, 8],\r\n [9, 2, 9, 8, 3]]])\r\n>>> mask=arr<5\r\n>>> arr[mask]=0\r\n>>> arr\r\narray([[[6, 0, 8, 9, 9],\r\n [0, 0, 5, 0, 5],\r\n [0, 8, 0, 9, 0],\r\n [0, 0, 0, 0, 8],\r\n [9, 0, 9, 8, 0]]])\r\n```\r\n\r\n正则表达式FLAGS\r\n在运行时可以在命令行中输入参数,例如在运行时 python xxx.py --A one --B two --C three\r\n则FLAGS.A表示one FLAGS.B表示two FLAGS.C表示three\r\n\r\npython 遍历文件夹中的所有文件:\r\n\r\n```\r\nfile=os.listdir(path)#得到paht下所有文件的名称\r\nfor file in files:\r\n f=.......\r\n```\r\n\r\n```\r\nos.path.isdir(x) 来判断x是否是文件夹\r\n```\r\n\r\nipython:交互式python\r\n\r\nencode_decode\r\n\r\n```\r\n>>> s.decode('utf-8')\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\nAttributeError: 'str' object has no attribute 'decode'\r\n```\r\n\r\npython有两种形式 一种是str 另一种是unicode\r\nstr->unicode 即为encode\r\nunicode->str 即为decode\r\n\r\n```\r\ns='中文'\r\ns1=s.encode() #str->unicode\r\ns1\r\nb'\\xe4\\xb8\\xad\\xe6\\x96\\x87' \r\ns1.decode(\"utf-8\") #unicode->str\r\n'中文'\r\n```\r\n\r\n\r\n\r\n##### matplotlib \r\n\r\n```python\r\nplt.title(\"Training and Testing Accuracy Curve\")\r\nplt.xlabel(\"Epoches\")\r\nplt.ylabel(\"Accuracy\")\r\nplt.plot(iters, accuracy, 'r')\r\nplt.plot(iters, test_accuracy, 'y')\r\nplt.savefig(\"acc-iter.png\")\r\nplt.show()\r\n```\r\n\r\n##### lru_cache\r\n\r\n```python\r\nfrom functools import lru_cache\r\n@lru_cache(None)\r\ndef add(x, y):\r\n print(\"calculating: %s + %s\" % (x, y))\r\n return x + y\r\n\r\nprint(add(1, 2))\r\nprint(add(1, 2))\r\nprint(add(2, 3))\r\n\r\ncalculating: 1 + 2\r\n3\r\n3\r\ncalculating: 2 + 3\r\n5\r\n```\r\n\r\n从结果可以看出,当第二次调用 add(1, 2) 时,并没有真正执行函数体,而是直接返回缓存的结果\r\n\r\n\r\n\r\n##### python argv\r\n\r\npython test.py a.jpg b.jpg\r\n\r\n```\r\nimport sys\r\nprint(sys.argv[0],sys.argv[1],sys.argv[2])\r\n```\r\n\r\nsys.argv[0] test.py\r\n\r\nsys.argv[1] a.jpg\r\n\r\nsys.argv[2] b.jpg\r\n\r\n\r\n\r\n##### assert 用法\r\n\r\n```py\r\nassert True # nothing happens\r\nassert False\r\nRaise AssertionError\r\n```\r\n\r\n```python\r\nassert 1==2,\"this is asserting\"\r\nTraceback (most recent call last):\r\nFile \"<stdin>\", line 1, in <module>\r\nAssertionError: this is asserting\r\n```\r\n\r\n\r\n\r\n\r\n\r\n### Brief Tour of STL\r\n\r\n##### os\r\n\r\n```\r\nimport os\r\nos.getcwd() #get the current working directory\r\nos.chdir('path') #change work directory into path\r\n```\r\n\r\n##### shutil\r\n\r\n```python\r\nimport shutil\r\nshutil.copyfile('data.db', 'archive.db')\r\n'archive.db'\r\nshutil.move('/build/executables', 'installdir')\r\n'installdir'\r\n```\r\n\r\n##### glob\r\n\r\n```python\r\nimport glob\r\nglob.glob('*.py')\r\n['primes.py', 'random.py', 'quote.py']\r\n```\r\n\r\n##### re\r\n\r\n```\r\n正则表达式\r\n```\r\n\r\n##### random\r\n\r\n```\r\n>>> import random\r\n>>> random.choice(['apple', 'pear', 'banana'])\r\n'apple'\r\n>>> random.sample(range(100), 10) # sampling without replacement\r\n[30, 83, 16, 4, 8, 81, 41, 50, 18, 33]\r\n>>> random.random() # random float\r\n0.17970987693706186\r\n>>> random.randrange(6) # random integer chosen from range(6)\r\n4\r\n```\r\n\r\n##### statistics\r\n\r\n```\r\n>>> import statistics\r\n>>> data = [2.75, 1.75, 1.25, 0.25, 0.5, 1.25, 3.5]\r\n>>> statistics.mean(data)\r\n1.6071428571428572\r\n>>> statistics.median(data)\r\n1.25\r\n>>> statistics.variance(data)\r\n1.3720238095238095\r\n```\r\n\r\n\r\n\r\n##### python读入n行数据\r\n\r\n```python\r\nwhile True:\r\n line = sys.stdin.readline().strip()\r\n if line == '':\r\n break\r\n nums = [int(x) for x in list(line)]\r\n map1.append(nums)\r\n```\r\n\r\n\r\n\r\n##### 反射 getattr基于string调用函数\r\n\r\n```python\r\nclass a:\r\n def asay():\r\n print(\"12\")\r\n\r\nf=getattr(a,'asay')\r\nf()\r\n```\r\n\r\ngetattr函数可以实现利用一个字符串得到这个字符串对应的函数的对象,然后就可以执行。\r\n\r\n在工程中,常常会遇到传递过来的是一个字符串,需要调用这个字符串对应的函数。c++ 等语言需要构建一个dict,将字符串与函数实体一一对应起来,但是python是天然基于dict实现的,可以直接通过getattr函数得到字符串对应的函数对象实体。\r\n\r\njava也存在反射机制\r\n\r\n\r\n\r\n##### 装饰器\r\n\r\n```python\r\ndef print_add(add):\r\n def warp(x):\r\n print(\"start adding\")\r\n add(x)\r\n return warp\r\n\r\n@print_add\r\ndef add(x):\r\n x += 1\r\n print(x)\r\n return\r\n\r\nadd(1)\r\n```\r\n\r\n```python\r\nstart adding\r\n2\r\n```\r\n\r\n函数add相当于一个接口,print_add则是在这个接口外面包装了一下。\r\n\r\n这样做的好处在于将主体的代码逻辑和副线(打印)分开来,逻辑清晰。\r\n\r\n\r\n\r\n##### 迭代器与生成器\r\n\r\npython中迭代器从集合的第一个元素开始访问,直到最后一个元素。\r\n\r\n迭代器基本的方法:iter(),next()\r\n\r\n```python\r\nlist=[1,2,3,4]\r\nit = iter(list) # 创建迭代器对象\r\nprint (next(it)) # 输出迭代器的下一个元素\r\n1\r\nprint (next(it))\r\n2\r\n```\r\n\r\n生成器\r\n\r\n使用了yield函数的称为生成器\r\n\r\n生成器是一个返回迭代器的函数,每次遇到yield的时候会暂停并保存所有的信息,返回yield值,在下一次执行next的时候从当前位置继续执行。\r\n\r\n```python\r\nimport sys\r\n \r\ndef fibonacci(n): # 生成器函数 - 斐波那契\r\n a, b, counter = 0, 1, 0\r\n while True:\r\n if (counter > n): \r\n return\r\n yield a\r\n a, b = b, a + b\r\n counter += 1\r\nf = fibonacci(10) # f 是一个迭代器,由生成器返回生成\r\n \r\nwhile True:\r\n try:\r\n print (next(f), end=\" \")\r\n except StopIteration:\r\n sys.exit()\r\n```\r\n\r\n\r\n\r\n##### python与c++不同\r\n\r\nc++中int 等类型存在溢出的情况,而python不存在这样的情况。c++中的variable分配在栈上面,编译之后大小就确定了,不能再动态增加空间大小,因此可能会溢出。\r\n\r\npython是动态类型的语言,在运行时才能确定类型,因此不存在溢出的问题,如果32位的长度不够就在前面再补足一些长度。同时这也是python语言运行效率低的重要原因。\r\n\r\n\r\n\r\n##### zip\r\n\r\n创建一个聚合来自每个可迭代对象中元素的迭代器\r\n\r\n```\r\ndef zip(*iterables):\r\n # zip('ABCD', 'xy') --> Ax By\r\n sentinel = object()\r\n iterators = [iter(it) for it in iterables]\r\n while iterators:\r\n result = []\r\n for it in iterators:\r\n elem = next(it, sentinel)\r\n if elem is sentinel:\r\n return\r\n result.append(elem)\r\n yield tuple(result)\r\n```\r\n\r\n```\r\nx = [1, 2, 3]\r\ny = [4, 5, 6]\r\nzipped = zip(x, y)\r\nlist(zipped)\r\n[(1, 4), (2, 5), (3, 6)]\r\n```\r\n\r\n用*可以拆解一个迭代器\r\n\r\n```\r\n>>> x2, y2 = zip(*zip(x, y))\r\n>>> x == list(x2) and y == list(y2)\r\nTrue\r\n```\r\n\r\n\r\n\r\n比较 Compare\r\n\r\n```\r\n1 < 2\r\n'1' <'2'\r\n'10' < '2'\r\n```\r\n\r\n\r\n\r\n用于序列化的两个模块 pickle json\r\n\r\npickle用于python特有类型和数据类型转型\r\n\r\n主要有dumps dump loads load四个函数\r\n\r\n```\r\nimport pickle\r\n\r\n# dumps 转为python认识的字符串\r\ndata = ['aa', 'bb', 'cc']\r\np_str = pickle.dumps(data)\r\n\r\n# loads \r\nmes = pickle.loads(p_str)\r\nprint(mes)\r\n['aa', 'bb', 'cc']\r\n\r\n# dump功能 将数据通过特殊的形式转换为只有python语言认识的字符串,并写入文件\r\nwith open('D:/tmp.pk', 'w') as f:\r\n pickle.dump(data, f)\r\n \r\n# load功能 从数据文件中读取数据,并转换为python的数据结构\r\nwith open('D:/tmp.pk', 'r') as f:\r\n data = pickle.load(f)\r\n```\r\n\r\n\r\n\r\n##### Python print all substrings or subarrays\r\n\r\nsubstrings必须连续,而且不适合用子函数迭代求解(容易出现重复)\r\n\r\n简单使用两个for循环可以求解\r\n\r\n```python\r\nclass Solution(object):\r\n def allsubstrings(self, nums):\r\n for length in range(1, len(nums)+1):\r\n for i in range(len(nums)-length+1):\r\n print(nums[i:i+length])\r\n return \r\nnums = [1,2, 3,4,5]\r\ns1 = Solution()\r\ns1.allsubstrings(nums)\r\n\r\n[1]\r\n[2]\r\n[3]\r\n[4]\r\n[5]\r\n[1, 2]\r\n[2, 3]\r\n[3, 4]\r\n[4, 5]\r\n[1, 2, 3]\r\n[2, 3, 4]\r\n[3, 4, 5]\r\n[1, 2, 3, 4]\r\n[2, 3, 4, 5]\r\n[1, 2, 3, 4, 5]\r\n\r\n```\r\n\r\n\r\n\r\n ##### Python print all subsequences\r\n\r\n可以不连续\r\n\r\n```\r\nclass Solution(object):\r\n def subsequences(self, nums):\r\n def sub(temp, nums):\r\n if not nums: #要先判断是否到底,不然会出现很多重复\r\n if temp:\r\n print(temp)\r\n return\r\n sub(temp, nums[1:])\r\n sub(temp+[nums[0]], nums[1:])\r\n sub([], nums)\r\n return\r\nnums = [1,2, 3,4, 5]\r\ns1 = Solution()\r\ns1.subsequences(nums)\r\n\r\n[5]\r\n[4]\r\n[4, 5]\r\n[3]\r\n[3, 5]\r\n[3, 4]\r\n[3, 4, 5]\r\n[2]\r\n[2, 5]\r\n[2, 4]\r\n[2, 4, 5]\r\n[2, 3]\r\n[2, 3, 5]\r\n[2, 3, 4]\r\n[2, 3, 4, 5]\r\n[1]\r\n[1, 5]\r\n[1, 4]\r\n[1, 4, 5]\r\n[1, 3]\r\n[1, 3, 5]\r\n[1, 3, 4]\r\n[1, 3, 4, 5]\r\n[1, 2]\r\n[1, 2, 5]\r\n[1, 2, 4]\r\n[1, 2, 4, 5]\r\n[1, 2, 3]\r\n[1, 2, 3, 5]\r\n[1, 2, 3, 4]\r\n[1, 2, 3, 4, 5]\r\n\r\n```\r\n\r\n\r\n\r\n##### python值传递和引用传递\r\n\r\n如果函数传递的是可变类型对象例如列表 字典等,则使用的是引用传递,即在函数中改变对象的值,在主函数中也会改变。如果传递的是不可变对象,例如字符串 整型变量则在主函数中对象的值不会改变。本质上是复制了一个对象到函数中\r\n\r\n"
},
{
"alpha_fraction": 0.5036987662315369,
"alphanum_fraction": 0.5444899797439575,
"avg_line_length": 26.76947593688965,
"blob_id": "d067c69f2dc2a6e015e17336f837e6751839793f",
"content_id": "bd53d60645af6a8b4f1b9cdce81b1cb3c5c7b81f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 84473,
"license_type": "no_license",
"max_line_length": 364,
"num_lines": 2824,
"path": "/leetcode_note/DP.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "#### DP\r\n\r\n动态规划题目1(LeetCode 120)\r\n\r\n动态规划题目2(LeetCode 53)\r\n\r\n动态规划题目3(LeetCode 198,213)\r\n\r\n动态规划题目4(LeetCode 322)\r\n\r\n动态规划题目5(LeetCode 72)\r\n\r\n动态规划题目6(LeetCode 174)\r\n\r\n动态规划题目7(codeforces 711C)\r\n\r\n\r\n\r\n##### Grid DP\r\n\r\n```python\r\ndef print_path(prev, path, i, j):\r\n if prev[i][j] == None:\r\n path.insert(0, [0 ,0])\r\n return\r\n prev_i, prev_j = prev[i][j]\r\n path.insert(0, [prev_i, prev_j])\r\n print_path(prev, path, prev_i, prev_j)\r\n return\r\n\r\ndef dp(grid):\r\n n = len(grid)\r\n dp = [[0 for i in range(n+1)] for j in range(n+1)]\r\n prev = [[None for i in range(n)] for j in range(n)]\r\n for i in range(1, n+1):\r\n for j in range(1, n+1):\r\n if grid[i-1][j-1] != -1:\r\n if dp[i-1][j] == -1 and dp[i][j-1] == -1:\r\n dp[i][j] = -1\r\n continue\r\n if dp[i-1][j] > dp[i][j-1]:\r\n dp[i][j] = dp[i - 1][j] + grid[i - 1][j - 1]\r\n if i>=2:\r\n prev[i-1][j-1] = [i-2, j-1]\r\n else:\r\n dp[i][j] = dp[i][j-1] + grid[i-1][j-1]\r\n if j>=2:\r\n prev[i-1][j-1] = [i-1, j-2]\r\n else:\r\n dp[i][j] = -1\r\n print(dp[n][n])\r\n if dp[n][n] != -1:\r\n path = [[n-1, n-1]]\r\n print_path(prev, path, n-1, n-1)\r\n print(path)\r\n return\r\n\r\ngrid = [[0, 1, -1], [1, 0, -1], [1, 1, 1]]\r\nprint(dp(grid))\r\n\r\ngrid = [[1, 1, -1], [1, -1, 1], [-1, 1, 1]]\r\nprint(dp(grid))\r\n```\r\n\r\n-1表示障碍物\r\n\r\nprev表示走到这里时取得最大值的 前一步在哪个位置\r\n\r\n\r\n\r\n##### leetcode 5 Longest Palindromic Substring\r\n\r\n* Given a string **s**, find the longest palindromic substring in **s**. You may assume that the maximum length of **s** is 1000.\r\n\r\n ```\r\n Input: \"babad\"\r\n Output: \"bab\"\r\n Note: \"aba\" is also a valid answer.\r\n \r\n Input: \"cbbd\"\r\n Output: \"bb\"mysolution \r\n ```\r\n\r\n```python\r\nclass Solution:\r\n def longestPalindrome(self, s):\r\n n=len(s)\r\n dp=[[0 for i in range(n)]for j in range(n)]\r\n for i in range(n):\r\n dp[i][i]=1\r\n if i<n-1 and s[i]==s[i+1]:\r\n dp[i][i+1]=1\r\n for i in range(n-3,-1,-1):\r\n for j in range(i+2,n,1):\r\n dp[i][j]=dp[i+1][j-1] and s[i]==s[j]\r\n # get max_str\r\n max_len=0\r\n maxstr=\"\"\r\n for i in range(n):\r\n for j in range(i,n):\r\n if dp[i][j] and j-i+1>max_len:\r\n max_len=j-i+1\r\n maxstr=s[i:j+1]\r\n return maxstr\r\n```\r\n\r\n初始化要考虑中心“a”和“aa”的情况:\r\n\r\nif i<n-1 and s[i]==s[i+1]:\r\n dp[i+1]=1\r\n\r\ndp[i,j]表示从s[i]开始到s[j]的string是否为palindr,注意i要逆序\r\n\r\ndp[i,j] 为true需要:\r\n\r\n1. dp[i+1,j-1]==1\r\n\r\n2. s[i]=s[j]\r\n\r\n\r\n\r\n##### leetcode 10 Regular Expression Matching\r\n\r\n* Given an input string (`s`) and a pattern (`p`), implement regular expression matching with support for `'.'` and `'*'`.\r\n\r\n ```\r\n '.' Matches any single character.\r\n '*' Matches zero or more of the preceding element.\r\n ```\r\n\r\n ```\r\n Input:\r\n s = \"aa\"\r\n p = \"a\"\r\n Output: false\r\n Explanation: \"a\" does not match the entire string \"aa\".\r\n \r\n Input:\r\n s = \"aa\"\r\n p = \"a*\"\r\n Output: true\r\n Explanation: '*' means zero or more of the precedeng element, 'a'. Therefore, by repeating 'a' once, it becomes \"aa\".\r\n \r\n Input:\r\n s = \"ab\"\r\n p = \".*\"\r\n Output: true\r\n Explanation: \".*\" means \"zero or more (*) of any character (.)\".\r\n \r\n Input:\r\n s = \"aab\"\r\n p = \"c*a*b\"\r\n Output: true\r\n Explanation: c can be repeated 0 times, a can be repeated 1 time. Therefore it matches \"aab\".\r\n \r\n Input:\r\n s = \"mississippi\"\r\n p = \"mis*is*p*.\"\r\n Output: false\r\n ```\r\n\r\n\r\n* Mysolution:\r\n\r\n ```python\r\n class Solution:\r\n def isMatch(self, s,p):\r\n dp=[[False]*(len(s)+1) for i in range(len(p)+1)]\r\n dp[0][0]=True\r\n # update then s is empty and p is not\r\n for i in range(2,len(p)+1):\r\n dp[i][0]=dp[i-2][0] and p[i-1]=='*'\r\n \r\n for i in range(1,len(p)+1):\r\n for j in range(1,len(s)+1):\r\n # not *\r\n if p[i-1]!=\"*\":\r\n dp[i][j]=dp[i-1][j-1] and (p[i-1]==s[j-1] or p[i-1]=='.')\r\n # p[i-1]==\"*\"\r\n else:\r\n # eliminate: * stands for 0 char or 1 char\r\n dp[i][j]=dp[i-2][j] or dp[i-1][j]\r\n if p[i-2]==s[j-1] or p[i-2]=='.':\r\n # if p[i-2] the char before \"*\" ==s[j-1],dp[i][j]=dp[i][j] or dp[i][j-1]: use * to represent s[i-1] char\r\n dp[i][j]=dp[i][j] or dp[i][j-1]\r\n return dp[len(p)][len(s)]\r\n ```\r\n\r\n 经典DP 分别考虑“.”和“*”的作用\r\n\r\n 对于“*” \r\n\r\n ```python\r\n dp[i][j]=dp[i-2][j] or dp[i-1][j] #表示 a* 视为a 或空 的时候的情况\r\n 如果*前面的字符p[i-2]与s[j-1]相同则,考虑s[j-1]用*来表示\r\n dp[i][j]=dp[i][j] or dp[i][j-1]\r\n ```\r\n\r\n\r\n\r\n##### leetcode 53 Maximum Subarray\r\n\r\nGiven an integer array `nums`, find the contiguous subarray (containing at least one number) which has the largest sum and return its sum.\r\n\r\n**Example:**\r\n\r\n```\r\nInput: [-2,1,-3,4,-1,2,1,-5,4],\r\nOutput: 6\r\nExplanation: [4,-1,2,1] has the largest sum = 6.\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def maxSubArray(self, nums: List[int]) -> int:\r\n n=len(nums)\r\n if n==0:return 0\r\n max_sum,temp=nums[0],0\r\n for i in range(n):\r\n temp+=nums[i]\r\n if temp>max_sum:\r\n max_sum=temp\r\n if temp<0:\r\n temp=0\r\n return max_sum\r\n```\r\n\r\n\r\n\r\n##### leetcode 62 Unique Paths\r\n\r\n* A robot is located at the top-left corner of a *m* x *n* grid (marked 'Start' in the diagram below).\r\n\r\n The robot can only move either down or right at any point in time. The robot is trying to reach the bottom-right corner of the grid (marked 'Finish' in the diagram below).\r\n\r\n How many possible unique paths are there?\r\n\r\n```\r\nInput: m = 3, n = 2\r\nOutput: 3\r\nExplanation:\r\nFrom the top-left corner, there are a total of 3 ways to reach the bottom-right corner:\r\n1. Right -> Right -> Down\r\n2. Right -> Down -> Right\r\n3. Down -> Right -> Right\r\n\r\nInput: m = 7, n = 3\r\nOutput: 28\r\n```\r\n\r\n\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution:\r\n def uniquePaths(self, m, n):\r\n if n<=0 or m<=0:\r\n return 0\r\n if n==1 or m==1:\r\n return 1\r\n num = [[0 for i in range(m)] for j in range(n)]\r\n for i in range(m):\r\n num[0][i] = 1\r\n for i in range(n):\r\n num[i][0] = 1\r\n for i in range(1, n, 1):\r\n for j in range(1, m, 1):\r\n num[i][j] = num[i - 1][j] + num[i][j - 1]\r\n return num[n - 1][m - 1]\r\n```\r\n\r\n转移方程:\r\n\r\nnum[i,j]=nums[i-1,j]+nums[i,j-1]\r\n\r\n\r\n\r\n##### leetcode 64 Minimum Path Sum\r\n\r\nGiven a *m* x *n* grid filled with non-negative numbers, find a path from top left to bottom right which *minimizes* the sum of all numbers along its path.\r\n\r\n**Note:** You can only move either down or right at any point in time.\r\n\r\n```\r\nInput:\r\n[\r\n [1,3,1],\r\n [1,5,1],\r\n [4,2,1]\r\n]\r\nOutput: 7\r\nExplanation: Because the path 1→3→1→1→1 minimizes the sum.\r\n```\r\n\r\n```python\r\nimport sys\r\nclass Solution(object):\r\n def minPathSum(self, grid):\r\n \"\"\"\r\n :type grid: List[List[int]]\r\n :rtype: int\r\n \"\"\"\r\n if len(grid)==0 or len(grid[0])==0:\r\n return 0\r\n rows,cols=len(grid),len(grid[0])\r\n dp=[[sys.maxsize for i in range(cols+1)]for j in range(rows+1)]\r\n for i in range(1,rows+1):\r\n for j in range(1,cols+1):\r\n if i==1 and j==1:\r\n dp[i][j]=grid[i-1][j-1]\r\n continue\r\n dp[i][j]=grid[i-1][j-1]+min(dp[i-1][j],dp[i][j-1])\r\n return dp[rows][cols]\r\n```\r\n\r\n转移方程:\r\n\r\n```\r\n dp[i][j]=grid[i-1][j-1]+min(dp[i-1][j],dp[i][j-1])\r\n```\r\n\r\ndp[i,j]表示走到这一格子需要的最小点\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 70 Climbing Stairs\r\n\r\n* You are climbing a stair case. It takes *n* steps to reach to the top.\r\n\r\n Each time you can either climb 1 or 2 steps. In how many distinct ways can you climb to the top? \r\n\r\n **Note:** Given *n* will be a positive integer.\r\n\r\n\r\n```\r\nInput: 2\r\nOutput: 2\r\nExplanation: There are two ways to climb to the top.\r\n1. 1 step + 1 step\r\n2. 2 steps\r\n\r\nInput: 3\r\nOutput: 3\r\nExplanation: There are three ways to climb to the top.\r\n1. 1 step + 1 step + 1 step\r\n2. 1 step + 2 steps\r\n3. 2 steps + 1 step\r\n```\r\n\r\n* Mysolution\r\n\r\n```python\r\nclass Solution:\r\n def climbStairs(self, n):\r\n dp = [0] + [1] + [2] + [0] * (n - 2)\r\n for i in range(3, n+1):\r\n dp[i] = dp[i-1] + dp[i-2]\r\n return dp[n]\r\n```\r\n\r\n状态转移方程\r\n\r\ndp[i]=dp[i-1]+dp[i-2]\r\n\r\n注意当n=0,1,2的时候\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 72 Edit Distance\r\n\r\n* Given two words *word1* and *word2*, find the minimum number of operations required to convert *word1* to *word2*.\r\n\r\n You have the following 3 operations permitted on a word:\r\n\r\n 1. Insert a character\r\n 2. Delete a character\r\n 3. Replace a character\r\n\r\n```\r\nInput: word1 = \"horse\", word2 = \"ros\"\r\nOutput: 3\r\nExplanation: \r\nhorse -> rorse (replace 'h' with 'r')\r\nrorse -> rose (remove 'r')\r\nrose -> ros (remove 'e')\r\n\r\nInput: word1 = \"intention\", word2 = \"execution\"\r\nOutput: 5\r\nExplanation: \r\nintention -> inention (remove 't')\r\ninention -> enention (replace 'i' with 'e')\r\nenention -> exention (replace 'n' with 'x')\r\nexention -> exection (replace 'n' with 'c')\r\nexection -> execution (insert 'u')\r\n```\r\n\r\n\r\n\r\n```python\r\nclass Solution(object):\r\n def minDistance(self, word1, word2):\r\n \"\"\"\r\n :type word1: str\r\n :type word2: str\r\n :rtype: int\r\n \"\"\"\r\n m=len(word1)\r\n n=len(word2)\r\n dp=[[0 for i in range(n+1)]for j in range(m+1)]\r\n for i in range(m+1):\r\n for j in range(n+1):\r\n if i ==0:\r\n dp[i][j]=j\r\n elif j==0:\r\n dp[i][j]=i\r\n elif word1[i-1]==word2[j-1]:\r\n dp[i][j]=dp[i-1][j-1]\r\n else:\r\n dp[i][j]=1+min(dp[i-1][j],dp[i][j-1],dp[i-1][j-1])\r\n return dp[m][n]\r\n```\r\n\r\nDP\r\n\r\ndp[i,j] 表示长度为i的word1和长度为j的word2distance\r\n\r\nword[i-1] 这里 因为长度为3的word最后一位是2\r\n\r\n\r\n\r\n##### leetcode 139 Word Break\r\n\r\n* Given a **non-empty** string *s* and a dictionary *wordDict* containing a list of **non-empty** words, determine if *s* can be segmented into a space-separated sequence of one or more dictionary words.\r\n\r\n **Note:**\r\n\r\n - The same word in the dictionary may be reused multiple times in the segmentation.\r\n - You may assume the dictionary does not contain duplicate words.\r\n\r\n```\r\nInput: s = \"leetcode\", wordDict = [\"leet\", \"code\"]\r\nOutput: true\r\nExplanation: Return true because \"leetcode\" can be segmented as \"leet code\".\r\n\r\nInput: s = \"applepenapple\", wordDict = [\"apple\", \"pen\"]\r\nOutput: true\r\nExplanation: Return true because \"applepenapple\" can be segmented as \"apple pen apple\".Note that you are allowed to reuse a dictionary word.\r\n \r\nInput: s = \"catsandog\", wordDict = [\"cats\", \"dog\", \"sand\", \"and\", \"cat\"]\r\nOutput: false \r\n```\r\n\r\n```python\r\nclass Solution(object):\r\n def wordBreak(self, s, wordDict):\r\n \"\"\"\r\n :type s: str\r\n :type wordDict: List[str]\r\n :rtype: bool\r\n \"\"\"\r\n n=len(s)\r\n dp=[False for i in range(n+1)]\r\n dp[0]=True\r\n for i in range(1,n+1):\r\n for j in range(i):\r\n if s[j:i] in wordDict:\r\n if dp[j]==True:\r\n dp[i]=True\r\n break\r\n return dp[n]\r\n```\r\n\r\nDP, if s[j:i] in wordDict and dp[j]==true dp[i]=true\r\n\r\n\r\n\r\n##### leetcode 140 Word Break II\r\n\r\nGiven a **non-empty** string *s* and a dictionary *wordDict* containing a list of **non-empty** words, add spaces in *s* to construct a sentence where each word is a valid dictionary word. Return all such possible sentences.\r\n\r\n**Note:**\r\n\r\n- The same word in the dictionary may be reused multiple times in the segmentation.\r\n- You may assume the dictionary does not contain duplicate words.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput:\r\ns = \"catsanddog\"\r\nwordDict = [\"cat\", \"cats\", \"and\", \"sand\", \"dog\"]\r\nOutput:\r\n[\r\n \"cats and dog\",\r\n \"cat sand dog\"\r\n]\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput:\r\ns = \"pineapplepenapple\"\r\nwordDict = [\"apple\", \"pen\", \"applepen\", \"pine\", \"pineapple\"]\r\nOutput:\r\n[\r\n \"pine apple pen apple\",\r\n \"pineapple pen apple\",\r\n \"pine applepen apple\"\r\n]\r\nExplanation: Note that you are allowed to reuse a dictionary word.\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput:\r\ns = \"catsandog\"\r\nwordDict = [\"cats\", \"dog\", \"sand\", \"and\", \"cat\"]\r\nOutput:\r\n[]\r\n```\r\n\r\n```python\r\ndef wordBreak(self, s, wordDict):\r\n res = []\r\n self.dfs(s, wordDict, '', res)\r\n return res\r\n\r\ndef dfs(self, s, dic, path, res):\r\n# Before we do dfs, we check whether the remaining string \r\n# can be splitted by using the dictionary,\r\n# in this way we can decrease unnecessary computation greatly.\r\n if self.check(s, dic): # prunning\r\n if not s:\r\n res.append(path[:-1])\r\n return # backtracking\r\n for i in range(1, len(s)+1):\r\n if s[:i] in dic:\r\n # dic.remove(s[:i])\r\n self.dfs(s[i:], dic, path+s[:i]+\" \", res)\r\n\r\n# DP code to check whether a string can be splitted by using the \r\n# dic, this is the same as word break I. \r\ndef check(self, s, dic):\r\n dp = [False for i in range(len(s)+1)]\r\n dp[0] = True\r\n for i in range(1, len(s)+1):\r\n for j in range(i):\r\n if dp[j] and s[j:i] in dic:\r\n dp[i] = True\r\n return dp[-1]\r\n```\r\n\r\n前一题的内容作为check函数\r\n\r\n在dfs中如果check false那就返回\r\n\r\n如果check成功就说明s可以被dict所匹配,则尝试匹配词语\r\n\r\n\r\n\r\n##### leetcode 198 House Robber\r\n\r\n- You are a professional robber planning to rob houses along a street. Each house has a certain amount of money stashed, the only constraint stopping you from robbing each of them is that adjacent houses have security system connected and **it will automatically contact the police if two adjacent houses were broken into on the same night**.\r\n\r\n Given a list of non-negative integers representing the amount of money of each house, determine the maximum amount of money you can rob tonight **without alerting the police**.\r\n\r\n```\r\nInput: [1,2,3,1]\r\nOutput: 4\r\nExplanation: Rob house 1 (money = 1) and then rob house 3 (money = 3).\r\n Total amount you can rob = 1 + 3 = 4.\r\n \r\nInput: [2,7,9,3,1]\r\nOutput: 12\r\nExplanation: Rob house 1 (money = 2), rob house 3 (money = 9) and rob house 5 (money = 1).\r\n Total amount you can rob = 2 + 9 + 1 = 12.\r\n```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution:\r\n def rob(self, nums):\r\n n=len(nums)\r\n dp=[0 for i in range(n+2)]\r\n for i in range(2,n+2):\r\n dp[i]=max(dp[i-1],dp[i-2]+nums[i-2])\r\n return dp[n+1]\r\n```\r\n\r\n转移方程为\r\n\r\ndp[i]=max(dp[i-1],dp[i-2]+nums[i-2]) \r\n\r\n\r\n\r\n##### leetcode 221 Maximal Square\r\n\r\n* Given a 2D binary matrix filled with 0's and 1's, find the largest square containing only 1's and return its area.\r\n\r\n```\r\nInput: \r\n\r\n1 0 1 0 0\r\n1 0 1 1 1\r\n1 1 1 1 1\r\n1 0 0 1 0\r\n\r\nOutput: 4\r\n```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution(object):\r\n def maximalSquare(self, matrix):\r\n \"\"\"\r\n :type matrix: List[List[str]]\r\n :rtype: int\r\n \"\"\"\r\n if len(matrix)==0 or len(matrix[0])==0:\r\n return 0\r\n row,col=len(matrix),len(matrix[0])\r\n dp=[[0 for i in range(col+1)]for j in range(row+1)]\r\n maxlen=0\r\n for i in range(1,row+1):\r\n for j in range(1,col+1):\r\n if matrix[i-1][j-1]==1:\r\n dp[i][j]=1+min(dp[i-1][j-1],dp[i][j-1],dp[i-1][j])\r\n maxlen=max(maxlen,dp[i][j])\r\n return maxlen**2\r\n```\r\n\r\ndp[i,j]=n表示[i,j]以及之前(左上角)的n*n的矩阵都为1\r\n\r\n转移方程:\r\n\r\n```python\r\ndp[i][j]=1+min(dp[i-1][j-1],dp[i][j-1],dp[i-1][j])\r\n```\r\n\r\n\r\n\r\n##### leetcode 256 House Painting\r\n\r\nThere are a row of *n* houses, each house can be painted with one of the three colors: red, blue or green. The cost of painting each house with a certain color is different. You have to paint all the houses such that no two adjacent houses have the same color.\r\n\r\nThe cost of painting each house with a certain color is represented by a `*n* x *3*` cost matrix. For example, `costs[0][0]` is the cost of painting house 0 with color red; `costs[1][2]` is the cost of painting house 1 with color green, and so on... Find the minimum cost to paint all houses.\r\n\r\nNote:\r\nAll costs are positive integers.\r\n\r\n```python\r\nimport numpy as np\r\nclass Solution(object):\r\n def mincost(self, houses, costs):\r\n \"\"\"\r\n :type bookings: List[List[int]]\r\n :type n: int\r\n :rtype: List[int]\r\n \"\"\"\r\n n = len(houses)\r\n dp = np.zeros((n+1, 3))\r\n for i in range(1, n+1):\r\n dp[i][0] = min(dp[i - 1][1], dp[i - 1][2]) + costs[i][0] # paint red\r\n dp[i][1] = min(dp[i - 1][0], dp[i - 1][2]) + costs[i][1] # paint green\r\n dp[i][2] = min(dp[i - 1][0], dp[i - 1][1]) + costs[i][2] # paint blue\r\n return min(dp[n][0], dp[n][1], dp[n][2])\r\n\r\ns1=Solution()\r\nres=s1.mincost([4,2],1)\r\nprint(res)\r\n```\r\n\r\n$dp[i][j]$ 表示前i个房子所需的花费,其中第i个房子用了第j个颜色\r\n\r\n\r\n\r\n##### leetcode 265 Paint House2\r\n\r\nThere are a row of *n* houses, each house can be painted with one of the *k* colors. The cost of painting each house with a certain color is different. You have to paint all the houses such that no two adjacent houses have the same color.\r\n\r\nThe cost of painting each house with a certain color is represented by a `*n* x *k*` cost matrix. For example, `costs[0][0]` is the cost of painting house 0 with color 0; `costs[1][2]`is the cost of painting house 1 with color 2, and so on... Find the minimum cost to paint all houses.\r\n\r\nNote:\r\nAll costs are positive integers.\r\n\r\nFollow up:\r\nCould you solve it in *O*(*nk*) runtime?\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int minCostII(vector<vector<int>>& costs) {\r\n if (costs.empty() || costs[0].empty()) return 0;\r\n int min1 = 0, min2 = 0, idx1 = -1;\r\n for (int i = 0; i < costs.size(); ++i) {\r\n int m1 = INT_MAX, m2 = m1, id1 = -1;\r\n for (int j = 0; j < costs[i].size(); ++j) {\r\n int cost = costs[i][j] + (j == idx1 ? min2 : min1);\r\n if (cost < m1) {\r\n m2 = m1; m1 = cost; id1 = j;\r\n } else if (cost < m2) {\r\n m2 = cost;\r\n }\r\n }\r\n min1 = m1; min2 = m2; idx1 = id1;\r\n }\r\n return min1;\r\n }\r\n};\r\n```\r\n\r\n这题还需要琢磨一下\r\n\r\n这一题与上一题不同在于颜色变成了k种,如果还是使用相同的方法会得到TLE\r\n\r\n其实要得到最小的paint cost并不需要尝试全部的颜色,只要记录最小值和次小值以及二者对应的颜色即可,(记录次小值是为了保证能够用不同的颜色进行paint)\r\n\r\n\r\n\r\n##### leetcode 279 Perfect Squares\r\n\r\n* Given a positive integer *n*, find the least number of perfect square numbers (for example, `1, 4, 9, 16, ...`) which sum to *n*.\r\n\r\n```\r\nInput: n = 12\r\nOutput: 3 \r\nExplanation: 12 = 4 + 4 + 4.\r\n\r\nInput: n = 13\r\nOutput: 2\r\nExplanation: 13 = 4 + 9.\r\n```\r\n\r\n* Mysolution:\r\n\r\n````python\r\nimport sys\r\nclass Solution(object):\r\n def numSquares(self, n):\r\n \"\"\"\r\n :type n: int\r\n :rtype: int\r\n \"\"\"\r\n dp=[float('inf')] * (n+1)\r\n m=int(n**(0.5)+1)\r\n dp[0]=0\r\n for x in range(1,m):\r\n for i in range(n+1):\r\n if i>=x**2:\r\n dp[i]=min(dp[i],1+dp[i-x**2])\r\n print(dp)\r\n return dp[n]\r\n````\r\n\r\nDP\r\n\r\n\r\n\r\n##### leetcode 309. Best Time to Buy and Sell Stock with Cooldown\r\n\r\n* Say you have an array for which the *i*th element is the price of a given stock on day *i*.\r\n\r\n Design an algorithm to find the maximum profit. You may complete as many transactions as you like (ie, buy one and sell one share of the stock multiple times) with the following restrictions:\r\n\r\n - You may not engage in multiple transactions at the same time (ie, you must sell the stock before you buy again).\r\n - After you sell your stock, you cannot buy stock on next day. (ie, cooldown 1 day)\r\n\r\n```\r\nInput: [1,2,3,0,2]\r\nOutput: 3 \r\nExplanation: transactions = [buy, sell, cooldown, buy, sell]\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def maxProfit(self, prices):\r\n \"\"\"\r\n :type prices: List[int]\r\n :rtype: int\r\n \"\"\"\r\n n=len(prices)\r\n if n<2:\r\n return 0\r\n buy,sell=[0 for i in range(n)],[0 for i in range(n)]\r\n buy[0],buy[1]=-prices[0],max(-prices[0],-prices[1])\r\n sell[0],sell[1]=0,max(0,prices[1]-prices[0])\r\n for i in range(2,n):\r\n buy[i]=max(buy[i-1],sell[i-2]-prices[i])\r\n sell[i]=max(buy[i-1]+prices[i],sell[i-1])\r\n return sell[n-1]\r\n```\r\n\r\nbuy[i]: The maximum profit can be made if the first i days end with buy or wait.\r\n\"buy, cooldown, cooldown\",\"buy sell cool,buy\"\r\nso :buy[i]=max(buy[[i-1]],sell[i-2]-price)\r\nsell[i]: The maximum profit can be made if the first i days end with sell or wait\r\n\"buy, sell\" or \"buy, cooldown, sell\" or \"buy sell cool\"\r\nsell[i]=max(buy[i-1]+price,sell[i-1])\r\n\r\n\r\n\r\n##### leetcode 312 Burst Balloons \r\n\r\n* Given `n` balloons, indexed from `0` to `n-1`. Each balloon is painted with a number on it represented by array `nums`. You are asked to burst all the balloons. If the you burst balloon `i` you will get `nums[left] * nums[i] * nums[right]` coins. Here `left` and `right` are adjacent indices of `i`. After the burst, the `left` and `right` then becomes adjacent.\r\n\r\n Find the maximum coins you can collect by bursting the balloons wisely.\r\n\r\n **Note:**\r\n\r\n - You may imagine `nums[-1] = nums[n] = 1`. They are not real therefore you can not burst them.\r\n - 0 ≤ `n` ≤ 500, 0 ≤ `nums[i]` ≤ 100\r\n\r\n```\r\nInput: [3,1,5,8]\r\nOutput: 167 \r\nExplanation: nums = [3,1,5,8] --> [3,5,8] --> [3,8] --> [8] --> []\r\n coins = 3*1*5 + 3*5*8 + 1*3*8 + 1*8*1 = 167\r\n```\r\n\r\n```python\r\nclass Solution(object):\r\n def maxCoins(self, nums):\r\n nums1=[1]+[i for i in nums if i>0]+[1]\r\n n=len(nums1)\r\n dp=[[0]*n for j in range(n)]\r\n for k in range(2,n,1):\r\n for left in range(0,n-k):\r\n right=left+k\r\n for i in range(left+1,right):\r\n dp[left][right]=max(dp[left][right],nums1[left]*nums1[i]*nums1[right]+dp[left][i]+dp[i][right])\r\n return dp[0][n-1]\r\n```\r\n\r\ndp[0,n-1]表示刺破下标为0到n-1的气球得到的数\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 322 Coin Change\r\n\r\n* You are given coins of different denominations and a total amount of money *amount*. Write a function to compute the fewest number of coins that you need to make up that amount. If that amount of money cannot be made up by any combination of the coins, return `-1`.\r\n\r\n```\r\nInput: coins = [1, 2, 5], amount = 11\r\nOutput: 3 \r\nExplanation: 11 = 5 + 5 + 1\r\n\r\nInput: coins = [2], amount = 3\r\nOutput: -1\r\n```\r\n\r\n```python\r\nclass Solution(object):\r\n def coinChange(self, coins, amount):\r\n \"\"\"\r\n :type coins: List[int]\r\n :type amount: int\r\n :rtype: int\r\n \"\"\"\r\n MAX=amount+1\r\n dp=[MAX for i in range(amount+1)]\r\n dp[0]=0\r\n coins.sort()\r\n for item in coins:\r\n for i in range(amount+1):\r\n if i-item>=0:\r\n dp[i]=min(dp[i-item]+1,dp[i])\r\n if dp[amount]==MAX:\r\n return -1\r\n else:\r\n return dp[amount]\r\n```\r\n\r\nfor items in coins:\r\n\r\n如果只用1元coin 有多少种,加上可以使用2元,加上可以使用5元\r\n\r\n\r\n\r\n##### leetcode 329 Longest Increasing Path in a Matrix\r\n\r\nGiven an integer matrix, find the length of the longest increasing path.\r\n\r\nFrom each cell, you can either move to four directions: left, right, up or down. You may NOT move diagonally or move outside of the boundary (i.e. wrap-around is not allowed).\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: nums = \r\n[\r\n [9,9,4],\r\n [6,6,8],\r\n [2,1,1]\r\n] \r\nOutput: 4 \r\nExplanation: The longest increasing path is [1, 2, 6, 9].\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: nums = [\r\n [7,8,9],\r\n [9,7,6],\r\n [7,2,3]\r\n]\r\nOutput: 6\r\nExplanation: The longest increasing path is [2, 3, 6, 7, 8, 9]. Moving diagonally is not allowed.\r\n```\r\n\r\n```\r\nclass Solution:\r\n def longestIncreasingPath(self, matrix) -> int:\r\n def dfs(matrix, i, j, n, m, temp):\r\n self.res = max(self.res, temp)\r\n direct = [[-1, 0], [1, 0], [0, -1], [0, 1]]\r\n for ii, jj in direct:\r\n if i + ii < 0 or i + ii >= n or j + jj < 0 or j + jj >= m:\r\n continue\r\n if matrix[i + ii][j + jj] > matrix[i][j]:\r\n dfs(matrix, i + ii, j + jj, n, m, temp + 1)\r\n return\r\n\r\n if not matrix or len(matrix[0]) == 0:\r\n return 0\r\n self.res = 0\r\n n, m = len(matrix), len(matrix[0])\r\n for i in range(n):\r\n for j in range(m):\r\n dfs(matrix, i, j, n, m, 1)\r\n return self.res\r\n```\r\n\r\nDFS\r\n\r\n由于本题中的只能向更大的点前进,因此不需要isvisited数组来确保不会无限循环\r\n\r\n但是这样会出现大量的重复计算导致TLE,因此考虑DP来实现memorization\r\n\r\n```python\r\nclass Solution:\r\n def longestIncreasingPath(self, matrix) -> int:\r\n def dfs(dp, matrix, i, j, n, m):\r\n if dp[i][j] != 1:\r\n return dp[i][j]\r\n\r\n direct = [[-1, 0], [1, 0], [0, -1], [0, 1]]\r\n for ii, jj in direct:\r\n if i + ii < 0 or i + ii >= n or j + jj < 0 or j + jj >= m:\r\n continue\r\n if matrix[i + ii][j + jj] > matrix[i][j]:\r\n dp[i][j] = max(dp[i][j], 1 + dfs(dp, matrix, i+ii, j+jj, n, m))\r\n self.res = max(self.res, dp[i][j])\r\n return dp[i][j]\r\n\r\n if not matrix or len(matrix[0]) == 0:\r\n return 0\r\n self.res = 0\r\n n, m = len(matrix), len(matrix[0])\r\n dp = [[1 for i in range(m)] for j in range(n)]\r\n for i in range(n):\r\n for j in range(m):\r\n dfs(dp, matrix, i, j, n, m)\r\n return self.res\r\n```\r\n\r\n用DP来保存各个位置的DFS值,如果DP不等于1说明已经运行过一遍了直接返回DFS值即可,注意这边DP的初始值设为1\r\n\r\n\r\n\r\n##### leetcode 403. Frog Jump\r\n\r\nA frog is crossing a river. The river is divided into x units and at each unit there may or may not exist a stone. The frog can jump on a stone, but it must not jump into the water.\r\n\r\nGiven a list of stones' positions (in units) in sorted ascending order, determine if the frog is able to cross the river by landing on the last stone. Initially, the frog is on the first stone and assume the first jump must be 1 unit.\r\n\r\nIf the frog's last jump was *k* units, then its next jump must be either *k* - 1, *k*, or *k* + 1 units. Note that the frog can only jump in the forward direction.\r\n\r\n**Note:**\r\n\r\n- The number of stones is ≥ 2 and is < 1,100.\r\n- Each stone's position will be a non-negative integer < 231.\r\n- The first stone's position is always 0.\r\n\r\n**Example 1:**\r\n\r\n```\r\n[0,1,3,5,6,8,12,17]\r\n\r\nThere are a total of 8 stones.\r\nThe first stone at the 0th unit, second stone at the 1st unit,\r\nthird stone at the 3rd unit, and so on...\r\nThe last stone at the 17th unit.\r\n\r\nReturn true. The frog can jump to the last stone by jumping \r\n1 unit to the 2nd stone, then 2 units to the 3rd stone, then \r\n2 units to the 4th stone, then 3 units to the 6th stone, \r\n4 units to the 7th stone, and 5 units to the 8th stone.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\n[0,1,2,3,4,8,9,11]\r\n\r\nReturn false. There is no way to jump to the last stone as \r\nthe gap between the 5th and 6th stone is too large.\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def canCross(self, stones):\r\n self.memo = set()\r\n self.target = stones[-1]\r\n self.stones_set = set(stones)\r\n self.res = False\r\n def jump(start, step):\r\n if (start, step) in self.memo:\r\n return\r\n self.memo.add((start, step))\r\n if start == self.target:\r\n self.res = True\r\n return\r\n if start + step - 1 in self.stones_set and step - 1 > 0:\r\n jump(start + step - 1, step - 1)\r\n if start + step in self.stones_set and step > 0:\r\n jump(start + step, step)\r\n if start + step + 1 in self.stones_set:\r\n jump(start + step + 1, step + 1)\r\n return\r\n jump(stones[0], 0)\r\n return self.res\r\n```\r\n\r\n首先由于本题在记录postion的同时还要记录speed(k) 因此仅仅使用dp来记录是不够的\r\n\r\n```\r\n0 - 1(k=1) - 2 (k=1) - 3(k=1) -\r\n - 4(k=2) (no)\r\n - 3 (k=2) - 4(k=1) (no)\r\n - 5(k=2) \r\n - 6(k=3) \r\n```\r\n\r\n思路如上图所示,使用DFS\r\n\r\n注意这边不要用dp=[0 for i in range(stones[-1])] 这种思路\r\n\r\n因为有可能stones=[0 21201020122222122] 这样\r\n\r\n##### \r\n\r\n\r\n\r\n##### leetcode494 Target Sum\r\n\r\n* You are given a list of non-negative integers, a1, a2, ..., an, and a target, S. Now you have 2 symbols `+` and `-`. For each integer, you should choose one from `+` and `-` as its new symbol.\r\n\r\n Find out how many ways to assign symbols to make sum of integers equal to target S.\r\n\r\n```\r\nInput: nums is [1, 1, 1, 1, 1], S is 3. \r\nOutput: 5\r\nExplanation: \r\n\r\n-1+1+1+1+1 = 3\r\n+1-1+1+1+1 = 3\r\n+1+1-1+1+1 = 3\r\n+1+1+1-1+1 = 3\r\n+1+1+1+1-1 = 3\r\n\r\nThere are 5 ways to assign symbols to make the sum of nums be target 3.\r\n```\r\n\r\n**Note:**\r\n\r\n1. The length of the given array is positive and will not exceed 20.\r\n2. The sum of elements in the given array will not exceed 1000.\r\n3. Your output answer is guaranteed to be fitted in a 32-bit integer.\r\n\r\n```python\r\nclass Solution(object):\r\n def findTargetSumWays(self, nums, S):\r\n \"\"\"\r\n :type nums: List[int]\r\n :type S: int\r\n :rtype: int\r\n \"\"\"\r\n dict1={}\r\n if nums[0]!=0:\r\n dict1[nums[0]]=1\r\n dict1[-nums[0]]=1\r\n else:\r\n dict1[0]=2\r\n for i in range(1,len(nums)):\r\n dict2={}\r\n for key,val in dict1.items():\r\n if key+nums[i] not in dict2:\r\n dict2[key+nums[i]]=val\r\n else:\r\n dict2[key+nums[i]]+=val\r\n if key-nums[i] not in dict2:\r\n dict2[key-nums[i]]=val\r\n else:\r\n dict2[key-nums[i]]+=val\r\n dict1=dict2\r\n if S in dict1:\r\n return dict1[S]\r\n else:\r\n return 0\r\n```\r\n\r\ndict[num]=count 表示达到num有count种方式\r\n\r\n对于num,可加可减\r\n\r\ndict新的元素有: for key,val in dict1.items(): key+nums[i],key-nums[i]\r\n\r\n\r\n\r\n##### leetcode 688 Knight Probability in Chessboard\r\n\r\nOn an `N`x`N` chessboard, a knight starts at the `r`-th row and `c`-th column and attempts to make exactly `K` moves. The rows and columns are 0 indexed, so the top-left square is `(0, 0)`, and the bottom-right square is `(N-1, N-1)`.\r\n\r\nA chess knight has 8 possible moves it can make, as illustrated below. Each move is two squares in a cardinal direction, then one square in an orthogonal direction.\r\n\r\n \r\n\r\n\r\n\r\n \r\n\r\nEach time the knight is to move, it chooses one of eight possible moves uniformly at random (even if the piece would go off the chessboard) and moves there.\r\n\r\nThe knight continues moving until it has made exactly `K` moves or has moved off the chessboard. Return the probability that the knight remains on the board after it has stopped moving.\r\n\r\n \r\n\r\n**Example:**\r\n\r\n```\r\nInput: 3, 2, 0, 0\r\nOutput: 0.0625\r\nExplanation: There are two moves (to (1,2), (2,1)) that will keep the knight on the board.\r\nFrom each of those positions, there are also two moves that will keep the knight on the board.\r\nThe total probability the knight stays on the board is 0.0625.\r\n```\r\n\r\n \r\n\r\n**Note:**\r\n\r\n- `N` will be between 1 and 25.\r\n- `K` will be between 0 and 100.\r\n- The knight always initially starts on the board.\r\n\r\n```python\r\nclass Solution(object):\r\n def knightProbability(self, N, K, r, c):\r\n \"\"\"\r\n :type N: int\r\n :type K: int\r\n :type r: int\r\n :type c: int\r\n :rtype: float\r\n \"\"\"\r\n self.inside = 0.0\r\n self.outside = 0.0\r\n def jump(N, K, r, c, index, num):\r\n if index == K:\r\n self.inside += num\r\n return\r\n directions = [[-2, -1], [2, -1], [-2, 1], [2, 1], [-1, -2], [1, -2], [-1, 2], [1, 2]]\r\n for ii, jj in directions:\r\n if r+ii<0 or r+ii>=N or c+jj<0 or c+jj>=N:\r\n self.outside += 1.0*num/8\r\n else:\r\n jump(N,K,r+ii,c+jj,index+1,1.0*num/8)\r\n return\r\n jump(N,K,r,c,0,1)\r\n if (self.inside+self.outside) == 0:\r\n return 0\r\n return self.inside/(self.inside+self.outside)\r\n```\r\n\r\n用递归做,但是会TLE,没有使用memorization会有大量重复计算的情况\r\n\r\n使用DP改进\r\n\r\n```python\r\nimport numpy as np\r\nclass Solution(object):\r\n def knightProbability(self, N, K, r, c):\r\n \"\"\"\r\n :type N: int\r\n :type K: int\r\n :type r: int\r\n :type c: int\r\n :rtype: float\r\n \"\"\"\r\n directions = [[1, 2], [2, 1], [2, -1], [1, -2], [-1, -2], [-2, -1], [-2, 1], [-1, 2]]\r\n dp = [[[0 for i in range(N)] for j in range(N)] for k in range(K + 1)]\r\n dp[0][r][c] = 1\r\n for step in range(1, K+1):\r\n for i in range(N):\r\n for j in range(N):\r\n for ii, jj in directions:\r\n x, y = i - ii, j - jj\r\n if x<0 or x>=N or y<0 or y>=N:\r\n continue\r\n else:\r\n dp[step][i][j] += dp[step-1][x][y]*0.125\r\n \r\n return sum(sum(np.array(dp[K])))\r\n```\r\n\r\n一共有K+1层\r\n\r\n$dp[step][i][j]$ 表示第step步出现在i j的概率 由$dp[step-1][x][y]*0.125$ 之和计算得到\r\n\r\n\r\n\r\n##### leetcode 718 Maximum Length of Repeated Subarray\r\n\r\nGiven two integer arrays `A` and `B`, return the maximum length of an subarray that appears in both arrays.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput:\r\nA: [1,2,3,2,1]\r\nB: [3,2,1,4,7]\r\nOutput: 3\r\nExplanation: \r\nThe repeated subarray with maximum length is [3, 2, 1].\r\n```\r\n\r\n **Note:**\r\n\r\n1. 1 <= len(A), len(B) <= 1000\r\n2. 0 <= A[i], B[i] < 100\r\n\r\n```python\r\nimport numpy as np\r\n\r\nclass Solution:\r\n def findLength(self, A: List[int], B: List[int]) -> int:\r\n n, m = len(A), len(B)\r\n dp = [[0 for _ in range(len(B) + 1)] for _ in range(len(A) + 1)]\r\n res = 0\r\n for i in range(1, n+1):\r\n for j in range(1, m+1):\r\n if A[i-1] == B[j-1]:\r\n dp[i][j] = dp[i-1][j-1] + 1\r\n res = max(res, int(dp[i][j]))\r\n return res\r\n```\r\n\r\n使用numpy的运行时间较长(在m n不大的情况下)\r\n\r\nDP,$DP[i][j]$ 表示公共子串在A[i-1] B[j-1]处同时结尾的长度\r\n\r\n因此如果$A[i-1]!= B[j-1]$ 则$DP[i][j]=0$\r\n\r\n否则$dp[i][j] = dp[i-1][j-1] + 1$\r\n\r\npython的运行时间较慢这题中可以体现出来,用cpp会快很多\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int findLength(vector<int>& A, vector<int>& B) {\r\n int m = A.size(), n = B.size(), ans = 0;\r\n vector<vector<int>> dp(m + 1, vector<int>(n + 1, 0));\r\n for (int i = 1; i <= m; i++) {\r\n for (int j = 1; j <= n; j++) {\r\n if (A[i - 1] == B[j - 1]) {\r\n dp[i][j] = dp[i - 1][j - 1] + 1;\r\n ans = max(ans, dp[i][j]);\r\n }\r\n }\r\n }\r\n return ans;\r\n }\r\n};\r\n```\r\n\r\n\r\n\r\n##### leetcode 741 Cherry Pickup\r\n\r\nIn a N x N `grid` representing a field of cherries, each cell is one of three possible integers.\r\n\r\n- 0 means the cell is empty, so you can pass through;\r\n- 1 means the cell contains a cherry, that you can pick up and pass through;\r\n- -1 means the cell contains a thorn that blocks your way.\r\n\r\nYour task is to collect maximum number of cherries possible by following the rules below:\r\n\r\n- Starting at the position (0, 0) and reaching (N-1, N-1) by moving right or down through valid path cells (cells with value 0 or 1);\r\n- After reaching (N-1, N-1), returning to (0, 0) by moving left or up through valid path cells;\r\n- When passing through a path cell containing a cherry, you pick it up and the cell becomes an empty cell (0);\r\n- If there is no valid path between (0, 0) and (N-1, N-1), then no cherries can be collected.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: grid =\r\n[[0, 1, -1],\r\n [1, 0, -1],\r\n [1, 1, 1]]\r\nOutput: 5\r\nExplanation: \r\nThe player started at (0, 0) and went down, down, right right to reach (2, 2).\r\n4 cherries were picked up during this single trip, and the matrix becomes [[0,1,-1],[0,0,-1],[0,0,0]].\r\nThen, the player went left, up, up, left to return home, picking up one more cherry.\r\nThe total number of cherries picked up is 5, and this is the maximum possible.\r\n```\r\n\r\n**Note:**\r\n\r\n- `grid` is an `N` by `N` 2D array, with `1 <= N <= 50`.\r\n- Each `grid[i][j]` is an integer in the set `{-1, 0, 1}`.\r\n- It is guaranteed that $grid[0][0]$ and $grid[N-1][N-1]$ are not -1.\r\n\r\n```python\r\nclass Solution:\r\n def print_path(self, prev, path, i, j):\r\n if prev[i][j] == None:\r\n path.insert(0, [0, 0])\r\n return\r\n prev_i, prev_j = prev[i][j]\r\n path.insert(0, [prev_i, prev_j])\r\n self.print_path(prev, path, prev_i, prev_j)\r\n return\r\n def cherryPickup(self, grid):\r\n n = len(grid)\r\n dp = [[0 for i in range(n + 1)] for j in range(n + 1)]\r\n prev = [[None for i in range(n)] for j in range(n)]\r\n for i in range(1, n + 1):\r\n for j in range(1, n + 1):\r\n if grid[i - 1][j - 1] != -1:\r\n if dp[i - 1][j] == -1 and dp[i][j - 1] == -1:\r\n dp[i][j] = -1\r\n continue\r\n if dp[i - 1][j] > dp[i][j - 1]:\r\n dp[i][j] = dp[i - 1][j] + grid[i - 1][j - 1]\r\n if i >= 2:\r\n prev[i - 1][j - 1] = [i - 2, j - 1]\r\n else:\r\n dp[i][j] = dp[i][j - 1] + grid[i - 1][j - 1]\r\n if j >= 2:\r\n prev[i - 1][j - 1] = [i - 1, j - 2]\r\n else:\r\n dp[i][j] = -1\r\n res = dp[n][n]\r\n if res == -1: return 0\r\n path = [[n - 1, n - 1]]\r\n self.print_path(prev, path, n - 1, n - 1)\r\n for i, j in path:\r\n grid[i][j] = 0\r\n dp = [[0 for i in range(n + 1)] for j in range(n + 1)]\r\n for i in range(n-1, -1, -1):\r\n for j in range(n-1, -1, -1):\r\n if grid[i][j] != -1:\r\n dp[i][j] = max(dp[i+1][j], dp[i][j+1]) + grid[i][j]\r\n return res + dp[0][0]\r\n```\r\n\r\n分成两次 但是这样是存在问题的\r\n\r\n```\r\n1 1 1 1 0 0 0 \r\n0 0 0 1 0 0 0 \r\n0 0 0 1 0 0 1\r\n1 0 0 1 0 0 0\r\n0 0 0 1 0 0 0 \r\n0 0 0 1 0 0 0 \r\n0 0 0 1 1 1 1\r\n```\r\n\r\n\r\n\r\n#### Approach #2: Dynamic Programming (Top Down) [Accepted]\r\n\r\n**Intuition**\r\n\r\nInstead of walking from end to beginning, let's reverse the second leg of the path, so we are only considering two paths from the beginning to the end.\r\n\r\nNotice after `t` steps, each position `(r, c)` we could be, is on the line `r + c = t`. So if we have two people at positions `(r1, c1)` and `(r2, c2)`, then `r2 = r1 + c1 - c2`. That means the variables `r1, c1, c2` uniquely determine 2 people who have walked the same `r1 + c1` number of steps. This sets us up for dynamic programming quite nicely.\r\n\r\n**Algorithm**\r\n\r\nLet `dp[r1][c1][c2]` be the most number of cherries obtained by two people starting at `(r1, c1)` and `(r2, c2)` and walking towards `(N-1, N-1)` picking up cherries, where `r2 = r1+c1-c2`.\r\n\r\nIf `grid[r1][c1]` and `grid[r2][c2]` are not thorns, then the value of `dp[r1][c1][c2]` is `(grid[r1][c1] + grid[r2][c2])`, plus the maximum of `dp[r1+1][c1][c2]`, `dp[r1][c1+1][c2]`, `dp[r1+1][c1][c2+1]`, `dp[r1][c1+1][c2+1]` as appropriate. We should also be careful to not double count in case `(r1, c1) == (r2, c2)`.\r\n\r\nWhy did we say it was the maximum of `dp[r+1][c1][c2]` etc.? It corresponds to the 4 possibilities for person 1 and 2 moving down and right:\r\n\r\n- Person 1 down and person 2 down: `dp[r1+1][c1][c2]`;\r\n- Person 1 right and person 2 down: `dp[r1][c1+1][c2]`;\r\n- Person 1 down and person 2 right: `dp[r1+1][c1][c2+1]`;\r\n- Person 1 right and person 2 right: `dp[r1][c1+1][c2+1]`;\r\n\r\n```python\r\nclass Solution(object):\r\n def cherryPickup(self, grid):\r\n N = len(grid)\r\n memo = [[[None] * N for _1 in xrange(N)] for _2 in xrange(N)]\r\n def dp(r1, c1, c2):\r\n r2 = r1 + c1 - c2\r\n if (N == r1 or N == r2 or N == c1 or N == c2 or\r\n grid[r1][c1] == -1 or grid[r2][c2] == -1):\r\n return float('-inf')\r\n elif r1 == c1 == N-1:\r\n return grid[r1][c1]\r\n elif memo[r1][c1][c2] is not None:\r\n return memo[r1][c1][c2]\r\n else:\r\n ans = grid[r1][c1] + (c1 != c2) * grid[r2][c2]\r\n ans += max(dp(r1, c1+1, c2+1), dp(r1+1, c1, c2+1),\r\n dp(r1, c1+1, c2), dp(r1+1, c1, c2))\r\n\r\n memo[r1][c1][c2] = ans\r\n return ans\r\n\r\n return max(0, dp(0, 0, 0))\r\n```\r\n\r\n\r\n\r\n##### leetcode 764 Largest Plus Sign\r\n\r\nIn a 2D `grid` from (0, 0) to (N-1, N-1), every cell contains a `1`, except those cells in the given list `mines` which are `0`. What is the largest axis-aligned plus sign of `1`s contained in the grid? Return the order of the plus sign. If there is none, return 0.\r\n\r\nAn \"*axis-aligned plus sign of 1s* of order **k**\" has some center `grid[x][y] = 1` along with 4 arms of length `k-1` going up, down, left, and right, and made of `1`s. This is demonstrated in the diagrams below. Note that there could be `0`s or `1`s beyond the arms of the plus sign, only the relevant area of the plus sign is checked for 1s.\r\n\r\n**Examples of Axis-Aligned Plus Signs of Order k:**\r\n\r\n```\r\nOrder 1:\r\n000\r\n010\r\n000\r\n\r\nOrder 2:\r\n00000\r\n00100\r\n01110\r\n00100\r\n00000\r\n\r\nOrder 3:\r\n0000000\r\n0001000\r\n0001000\r\n0111110\r\n0001000\r\n0001000\r\n0000000\r\n```\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: N = 5, mines = [[4, 2]]\r\nOutput: 2\r\nExplanation:\r\n11111\r\n11111\r\n11111\r\n11111\r\n11011\r\nIn the above grid, the largest plus sign can only be order 2. One of them is marked in bold.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: N = 2, mines = []\r\nOutput: 1\r\nExplanation:\r\nThere is no plus sign of order 2, but there is of order 1.\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: N = 1, mines = [[0, 0]]\r\nOutput: 0\r\nExplanation:\r\nThere is no plus sign, so return 0.\r\n```\r\n\r\n**Note:**\r\n\r\n1. `N` will be an integer in the range `[1, 500]`.\r\n2. `mines` will have length at most `5000`.\r\n3. `mines[i]` will be length 2 and consist of integers in the range `[0, N-1]`.\r\n4. *(Additionally, programs submitted in C, C++, or C# will be judged with a slightly smaller time limit.)*\r\n\r\n```python\r\nclass Solution:\r\n def orderOfLargestPlusSign(self, N, mines):\r\n # left, up, right, down\r\n\r\n mines = {(i, j) for i,j in mines}\r\n dp = [[[0, 0, 0, 0] for i in range(N)]for j in range(N)]\r\n for i in range(N):\r\n if (i, 0) not in mines:\r\n dp[i][0] = [1, 1, 1, 1]\r\n if (0, i) not in mines:\r\n dp[0][i] = [1, 1, 1, 1]\r\n for i in range(N):\r\n if (i, N-1) not in mines:\r\n dp[i][N-1] = [1, 1, 1, 1]\r\n if (N-1, i) not in mines:\r\n dp[N-1][i] = [1, 1, 1, 1]\r\n\r\n for i in range(1, N):\r\n for j in range(1, N):\r\n if (i,j) not in mines:\r\n dp[i][j][0] = dp[i][j-1][0] + 1\r\n dp[i][j][1] = dp[i-1][j][1] + 1\r\n\r\n\r\n for i in range(N-2, -1, -1):\r\n for j in range(N-2, -1, -1):\r\n if (i,j) not in mines:\r\n dp[i][j][2] = dp[i][j + 1][2] + 1\r\n dp[i][j][3] = dp[i + 1][j][3] + 1\r\n res = 0\r\n for i in range(N):\r\n for j in range(N):\r\n res = max(res, min(dp[i][j]))\r\n return res\r\n```\r\n\r\nplus需要考虑上下左右四个方向\r\n\r\n两个for循环正常来看上左比较方便,因此先从上左来一遍,再从右下来一遍\r\n\r\n\r\n\r\n##### leetcode 787 Cheapest Flights Within K Stops\r\n\r\nThere are `n` cities connected by `m` flights. Each fight starts from city `u `and arrives at `v` with a price `w`.\r\n\r\nNow given all the cities and flights, together with starting city `src` and the destination `dst`, your task is to find the cheapest price from `src` to `dst` with up to `k` stops. If there is no such route, output `-1`.\r\n\r\n```\r\nExample 1:\r\nInput: \r\nn = 3, edges = [[0,1,100],[1,2,100],[0,2,500]]\r\nsrc = 0, dst = 2, k = 1\r\nOutput: 200\r\nExplanation: \r\nThe graph looks like this:\r\n\r\n\r\nThe cheapest price from city 0 to city 2 with at most 1 stop costs 200, as marked red in the picture.\r\nExample 2:\r\nInput: \r\nn = 3, edges = [[0,1,100],[1,2,100],[0,2,500]]\r\nsrc = 0, dst = 2, k = 0\r\nOutput: 500\r\nExplanation: \r\nThe graph looks like this:\r\n\r\n\r\nThe cheapest price from city 0 to city 2 with at most 0 stop costs 500, as marked blue in the picture.\r\n```\r\n\r\n**Note:**\r\n\r\n- The number of nodes `n` will be in range `[1, 100]`, with nodes labeled from `0` to `n`` - 1`.\r\n- The size of `flights` will be in range `[0, n * (n - 1) / 2]`.\r\n- The format of each flight will be `(src, ``dst``, price)`.\r\n- The price of each flight will be in the range `[1, 10000]`.\r\n- `k` is in the range of `[0, n - 1]`.\r\n- There will not be any duplicated flights or self cycles.\r\n\r\n```python\r\nclass Solution:\r\n def findCheapestPrice(self, n, flights, src, dst, K):\r\n if src==dst: return 0\r\n status = K + 1\r\n dp = [[float(\"inf\") for i in range(n)] for j in range(status+1)]\r\n dp[0][src] = 0\r\n for i in range(1,status+1):\r\n for s, d, value in flights:\r\n dp[i][d] = min(dp[i][d], dp[i-1][d], dp[i-1][s]+value)\r\n\r\n if dp[status][dst] == float(\"inf\"):\r\n return -1\r\n return dp[status][dst]\r\n\r\n```\r\n\r\nDP \r\n\r\n$DP[i][d]$ 表示在stop i次以内的情况下到d位置最小的花费\r\n\r\n$min(dp[i][d](表示其他方法到达d的花费), dp[i-1][d]表示在d不动, dp[i-1][s]+value 表示从s飞到d)$ \r\n\r\n\r\n\r\n##### leetcode 801 Minimum Swaps To Make Sequences Increasing\r\n\r\nMedium\r\n\r\nWe have two integer sequences `A` and `B` of the same non-zero length.\r\n\r\nWe are allowed to swap elements `A[i]` and `B[i]`. Note that both elements are in the same index position in their respective sequences.\r\n\r\nAt the end of some number of swaps, `A` and `B` are both strictly increasing. (A sequence is *strictly increasing* if and only if `A[0] < A[1] < A[2] < ... < A[A.length - 1]`.)\r\n\r\nGiven A and B, return the minimum number of swaps to make both sequences strictly increasing. It is guaranteed that the given input always makes it possible.\r\n\r\n```\r\nExample:\r\nInput: A = [1,3,5,4], B = [1,2,3,7]\r\nOutput: 1\r\nExplanation: \r\nSwap A[3] and B[3]. Then the sequences are:\r\nA = [1, 3, 5, 7] and B = [1, 2, 3, 4]\r\nwhich are both strictly increasing.\r\n```\r\n\r\n**Note:**\r\n\r\n- `A, B` are arrays with the same length, and that length will be in the range `[1, 1000]`.\r\n- `A[i], B[i]` are integer values in the range `[0, 2000]`.\r\n\r\n```python\r\nclass Solution:\r\n def minSwap(self, A, B) -> int:\r\n n = len(A)\r\n no_swap, swap = [0 for i in range(n)], [0 for i in range(n)]\r\n swap[0] = 1\r\n for i in range(1, n):\r\n if A[i-1]<A[i] and B[i-1]<B[i] and B[i-1]<A[i] and A[i-1]<B[i]:\r\n no_swap[i]=min(no_swap[i-1], swap[i-1])\r\n swap[i]=min(no_swap[i-1], swap[i-1])+1\r\n elif A[i-1]<A[i] and B[i-1]<B[i]:\r\n no_swap[i]=no_swap[i-1]\r\n swap[i]=swap[i-1]+1\r\n else:\r\n no_swap[i]=swap[i-1]\r\n swap[i]=no_swap[i-1]+1\r\n return min(no_swap[-1],swap[-1])\r\n```\r\n\r\n分别用no_swap[i]表示在第i位不使用swap下使得条件成立需要的swap次数\r\n\r\nswap[i]表示在第i位使用swap下使得条件成立需要的swap次数\r\n\r\n情况可分为三种:\r\n\r\n1.$A[i-1]<A[i] and B[i-1]<B[i] and B[i-1]<A[i] and A[i-1]<B[i] (A:1,3, B:2,4)$ \r\n\r\n对于这种情况无论i-1 swap与否都不影响第i位(swap no swap都可以)\r\n\r\n2.$elif A[i-1]<A[i] and B[i-1]<B[i]: (A:1,2;B:3,4)$\r\n\r\n对于这种情况如果第i-1位没有swap则第i位也不swap 如果第i-1位swap则第i位也swap\r\n\r\n3.$else: (A:1,4;B:3,2)$\r\n\r\n对于这种情况第i-1位和第i位必须有一个进行swap\r\n\r\n\r\n\r\n##### leetcode 838 Push Dominoes\r\n\r\nMedium\r\n\r\nThere are `N` dominoes in a line, and we place each domino vertically upright.\r\n\r\nIn the beginning, we simultaneously push some of the dominoes either to the left or to the right.\r\n\r\n\r\n\r\nAfter each second, each domino that is falling to the left pushes the adjacent domino on the left.\r\n\r\nSimilarly, the dominoes falling to the right push their adjacent dominoes standing on the right.\r\n\r\nWhen a vertical domino has dominoes falling on it from both sides, it stays still due to the balance of the forces.\r\n\r\nFor the purposes of this question, we will consider that a falling domino expends no additional force to a falling or already fallen domino.\r\n\r\nGiven a string \"S\" representing the initial state. `S[i] = 'L'`, if the i-th domino has been pushed to the left; `S[i] = 'R'`, if the i-th domino has been pushed to the right; `S[i] = '.'`, if the `i`-th domino has not been pushed.\r\n\r\nReturn a string representing the final state. \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: \".L.R...LR..L..\"\r\nOutput: \"LL.RR.LLRRLL..\"\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: \"RR.L\"\r\nOutput: \"RR.L\"\r\nExplanation: The first domino expends no additional force on the second domino.\r\n```\r\n\r\n**Note:**\r\n\r\n1. `0 <= N <= 10^5`\r\n2. String `dominoes` contains only `'L`', `'R'` and `'.'`\r\n\r\n```python\r\nclass Solution:\r\n def pushDominoes(self, dominoes):\r\n dominoes = list(dominoes)\r\n right, left = set(), set()\r\n n = len(dominoes)\r\n for i in range(len(dominoes)):\r\n if dominoes[i]==\"R\":\r\n right.add(i)\r\n elif dominoes[i]==\"L\":\r\n left.add(i)\r\n while right or left:\r\n new_right, new_left = set(), set()\r\n for num in right:\r\n if num+2<n:\r\n if num+2 not in left and dominoes[num+1]==\".\":\r\n dominoes[num+1]=\"R\"\r\n new_right.add(num+1)\r\n elif num == n-2 and dominoes[num+1]==\".\":\r\n dominoes[num + 1] = \"R\"\r\n\r\n for num in left:\r\n if num-2>=0:\r\n if num-2 not in right and dominoes[num-1]==\".\":\r\n dominoes[num-1]=\"L\"\r\n new_left.add(num-1)\r\n elif num == 1 and dominoes[0] == \".\":\r\n dominoes[0]=\"L\"\r\n right, left = new_right, new_left\r\n return ''.join(x for x in dominoes)\r\n \r\n```\r\n\r\n首先我们发现只有原来是直立的“.”才会变动,需要注意的是所有的翻到都是同时的\r\n\r\n因此我们用两个set来存储,一个right 表示这些多尼诺牌在下一时刻会向右边倒,left表示向左边倒\r\n\r\n例如num在right中要判断num+2是否在left中,从而判断num+1是否被抵消\r\n\r\n然后用两个新数组来记录有新倒下的多米诺骨牌以及方向\r\n\r\n直到right和left皆为空则停止\r\n\r\n\r\n\r\n##### leetcode 974 Subarray Sums Divisible by K\r\n\r\n* Given an array `A` of integers, return the number of (contiguous, non-empty) subarrays that have a sum divisible by `K`.\r\n\r\n```\r\nInput: A = [4,5,0,-2,-3,1], K = 5\r\nOutput: 7\r\nExplanation: There are 7 subarrays with a sum divisible by K = 5:\r\n[4, 5, 0, -2, -3, 1], [5], [5, 0], [5, 0, -2, -3], [0], [0, -2, -3], [-2, -3]\r\n```\r\n\r\n**Note:**\r\n\r\n1. `1 <= A.length <= 30000`\r\n2. `-10000 <= A[i] <= 10000`\r\n3. `2 <= K <= 10000`\r\n\r\n如果要穷举,时间复杂度为O(N2)\r\n\r\n* Mysolution:DP \r\n\r\n```python\r\nclass Solution:\r\n def subarraysDivByK(self, A, K):\r\n \"\"\"\r\n :type A: List[int]\r\n :type K: int\r\n :rtype: int\r\n \"\"\"\r\n dp=[0]*K\r\n dp[0]=1\r\n sum1,count=0,0\r\n for i in range(len(A)):\r\n sum1+=A[i]\r\n count+=dp[sum1%K]\r\n dp[sum1%K]+=1\r\n return count\r\n```\r\n\r\ndp[i]表示实现%K余数为i的有多少种不同的情况\r\n\r\nA[i:]和A[j:] %K的余数相同,那么A[i:j+1]就是一种subarray\r\n\r\n\r\n\r\n##### leetcode 975 Odd Even Jump\r\n\r\n* You are given an integer array `A`. From some starting index, you can make a series of jumps. The (1st, 3rd, 5th, ...) jumps in the series are called *odd numbered jumps*, and the (2nd, 4th, 6th, ...) jumps in the series are called *even numbered jumps*.\r\n\r\n You may from index `i` jump forward to index `j` (with `i < j`) in the following way:\r\n\r\n - During odd numbered jumps (ie. jumps 1, 3, 5, ...), you jump to the index j such that `A[i] <= A[j]` and `A[j]`is the smallest possible value. If there are multiple such indexes `j`, you can only jump to the **smallest** such index `j`.\r\n - During even numbered jumps (ie. jumps 2, 4, 6, ...), you jump to the index j such that `A[i] >= A[j]` and `A[j]` is the largest possible value. If there are multiple such indexes `j`, you can only jump to the **smallest** such index `j`.\r\n - (It may be the case that for some index `i,` there are no legal jumps.)\r\n\r\n A starting index is *good* if, starting from that index, you can reach the end of the array (index `A.length - 1`) by jumping some number of times (possibly 0 or more than once.)\r\n\r\n Return the number of good starting indexes.\r\n\r\n```\r\nInput: [10,13,12,14,15]\r\nOutput: 2\r\nExplanation: \r\nFrom starting index i = 0, we can jump to i = 2 (since A[2] is the smallest among A[1], A[2], A[3], A[4] that is greater or equal to A[0]), then we can't jump any more.\r\nFrom starting index i = 1 and i = 2, we can jump to i = 3, then we can't jump any more.\r\nFrom starting index i = 3, we can jump to i = 4, so we've reached the end.\r\nFrom starting index i = 4, we've reached the end already.\r\nIn total, there are 2 different starting indexes (i = 3, i = 4) where we can reach the end with some number of jumps.\r\n\r\nInput: [2,3,1,1,4]\r\nOutput: 3\r\nExplanation: \r\nFrom starting index i = 0, we make jumps to i = 1, i = 2, i = 3:\r\n\r\nDuring our 1st jump (odd numbered), we first jump to i = 1 because A[1] is the smallest value in (A[1], A[2], A[3], A[4]) that is greater than or equal to A[0].\r\n\r\nDuring our 2nd jump (even numbered), we jump from i = 1 to i = 2 because A[2] is the largest value in (A[2], A[3], A[4]) that is less than or equal to A[1]. A[3] is also the largest value, but 2 is a smaller index, so we can only jump to i = 2 and not i = 3.\r\n\r\nDuring our 3rd jump (odd numbered), we jump from i = 2 to i = 3 because A[3] is the smallest value in (A[3], A[4]) that is greater than or equal to A[2].\r\n\r\nWe can't jump from i = 3 to i = 4, so the starting index i = 0 is not good.\r\n\r\nIn a similar manner, we can deduce that:\r\nFrom starting index i = 1, we jump to i = 4, so we reach the end.\r\nFrom starting index i = 2, we jump to i = 3, and then we can't jump anymore.\r\nFrom starting index i = 3, we jump to i = 4, so we reach the end.\r\nFrom starting index i = 4, we are already at the end.\r\nIn total, there are 3 different starting indexes (i = 1, i = 3, i = 4) where we can reach the end with some number of jumps.\r\n\r\nInput: [5,1,3,4,2]\r\nOutput: 3\r\nExplanation: \r\nWe can reach the end from starting indexes 1, 2, and 4.\r\n```\r\n\r\n* Mysolution:\r\n\r\n```c++\r\nclass Solution {\r\npublic:\r\n int oddEvenJumps(vector<int>& A) {\r\n int n=A.size();\r\n vector<vector<int>> dp(n,vector<int>(2));\r\n dp[n-1][0]=dp[n-1][1]=1;\r\n map<int,int> m;\r\n m[A[n-1]]=n-1;\r\n int ans=1;\r\n for (int i=n-2;i>=0;i--){\r\n auto o=m.lower_bound(A[i]);\r\n if (o!=m.end()) dp[i][0]=dp[o->second][1];\r\n auto e=m.upper_bound(A[i]);\r\n if(e!=m.begin()) dp[i][1]=dp[prev(e)->second][0];\r\n if(dp[i][0]) ans++;\r\n m[A[i]]=i;\r\n }\r\n return ans;\r\n }\r\n};\r\n```\r\n\r\n利用二分法实现lower_bound与upper_bound 配合map\r\n\r\n可以在乱序的数组中用O(NlogN)的时间找到所有数的上下界,python难以做到这点\r\n\r\n\r\n\r\n##### leetcode 983 Minimum Cost For Tickets\r\n\r\nIn a country popular for train travel, you have planned some train travelling one year in advance. The days of the year that you will travel is given as an array `days`. Each day is an integer from `1` to `365`.\r\n\r\nTrain tickets are sold in 3 different ways:\r\n\r\n- a 1-day pass is sold for `costs[0]` dollars;\r\n- a 7-day pass is sold for `costs[1]` dollars;\r\n- a 30-day pass is sold for `costs[2]` dollars.\r\n\r\nThe passes allow that many days of consecutive travel. For example, if we get a 7-day pass on day 2, then we can travel for 7 days: day 2, 3, 4, 5, 6, 7, and 8.\r\n\r\nReturn the minimum number of dollars you need to travel every day in the given list of `days`.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: days = [1,4,6,7,8,20], costs = [2,7,15]\r\nOutput: 11\r\nExplanation: \r\nFor example, here is one way to buy passes that lets you travel your travel plan:\r\nOn day 1, you bought a 1-day pass for costs[0] = $2, which covered day 1.\r\nOn day 3, you bought a 7-day pass for costs[1] = $7, which covered days 3, 4, ..., 9.\r\nOn day 20, you bought a 1-day pass for costs[0] = $2, which covered day 20.\r\nIn total you spent $11 and covered all the days of your travel.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: days = [1,2,3,4,5,6,7,8,9,10,30,31], costs = [2,7,15]\r\nOutput: 17\r\nExplanation: \r\nFor example, here is one way to buy passes that lets you travel your travel plan:\r\nOn day 1, you bought a 30-day pass for costs[2] = $15 which covered days 1, 2, ..., 30.\r\nOn day 31, you bought a 1-day pass for costs[0] = $2 which covered day 31.\r\nIn total you spent $17 and covered all the days of your travel.\r\n```\r\n\r\n**Note:**\r\n\r\n1. `1 <= days.length <= 365`\r\n2. `1 <= days[i] <= 365`\r\n3. `days` is in strictly increasing order.\r\n4. `costs.length == 3`\r\n5. `1 <= costs[i] <= 1000`\r\n\r\n```python\r\nclass Solution:\r\n def mincostTickets(self, days, costs):\r\n n = days[-1]\r\n dp = [0 for i in range(n+31)]\r\n days = set(days)\r\n for i in range(30, n+31):\r\n if i-30 in days:\r\n dp[i] = min(dp[i-1]+costs[0], dp[i-7]+costs[1], dp[i-30]+costs[2])\r\n else:\r\n dp[i] = dp[i-1]\r\n return dp[-1]\r\n```\r\n\r\ndp[i]表示第i天及以前所有的花费,如果i不在days中,则dp[i]=dp[i-1]\r\n\r\n如果在days中则考虑最便宜的方式\r\n\r\nmin(dp[i-1]+costs[0], dp[i-7]+costs[1], dp[i-30]+costs[2])\r\n\r\n\r\n\r\n##### leetcode 1105 Filling Bookcase Shelves\r\n\r\nWe have a sequence of `books`: the `i`-th book has thickness `books[i][0]` and height `books[i][1]`.\r\n\r\nWe want to place these books **in order** onto bookcase shelves that have total width `shelf_width`.\r\n\r\nWe choose some of the books to place on this shelf (such that the sum of their thickness is `<= shelf_width`), then build another level of shelf of the bookcase so that the total height of the bookcase has increased by the maximum height of the books we just put down. We repeat this process until there are no more books to place.\r\n\r\nNote again that at each step of the above process, the order of the books we place is the same order as the given sequence of books. For example, if we have an ordered list of 5 books, we might place the first and second book onto the first shelf, the third book on the second shelf, and the fourth and fifth book on the last shelf.\r\n\r\nReturn the minimum possible height that the total bookshelf can be after placing shelves in this manner.\r\n\r\n \r\n\r\n\r\n\r\n**Example 1:**\r\n\r\n\r\n\r\n```\r\nInput: books = [[1,1],[2,3],[2,3],[1,1],[1,1],[1,1],[1,2]], shelf_width = 4\r\nOutput: 6\r\nExplanation:\r\nThe sum of the heights of the 3 shelves are 1 + 3 + 2 = 6.\r\nNotice that book number 2 does not have to be on the first shelf.\r\n```\r\n\r\n \r\n\r\n**Constraints:**\r\n\r\n- `1 <= books.length <= 1000`\r\n- `1 <= books[i][0] <= shelf_width <= 1000`\r\n- `1 <= books[i][1] <= 1000`\r\n\r\n```python\r\nclass Solution:\r\n def minHeightShelves(self, books, shelf_width):\r\n n = len(books)\r\n dp = [float(\"inf\") for x in range(n + 1)]\r\n dp[0] = 0\r\n for i in range(1, n+1):\r\n j = i-1\r\n width, max_height = shelf_width, 0\r\n while j>=0 and width >= books[j][0]:\r\n width -= books[j][0]\r\n max_height = max(max_height, books[j][1])\r\n dp[i] = min(dp[i], dp[j] + max_height)\r\n j -= 1\r\n return dp[n]\r\n```\r\n\r\n\r\n\r\n##### leetcode 1024 Video Stitching\r\n\r\nYou are given a series of video clips from a sporting event that lasted `T` seconds. These video clips can be overlapping with each other and have varied lengths.\r\n\r\nEach video clip `clips[i]` is an interval: it starts at time `clips[i][0]` and ends at time `clips[i][1]`. We can cut these clips into segments freely: for example, a clip `[0, 7]` can be cut into segments `[0, 1] + [1, 3] + [3, 7]`.\r\n\r\nReturn the minimum number of clips needed so that we can cut the clips into segments that cover the entire sporting event (`[0, T]`). If the task is impossible, return `-1`.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: clips = [[0,2],[4,6],[8,10],[1,9],[1,5],[5,9]], T = 10\r\nOutput: 3\r\nExplanation: \r\nWe take the clips [0,2], [8,10], [1,9]; a total of 3 clips.\r\nThen, we can reconstruct the sporting event as follows:\r\nWe cut [1,9] into segments [1,2] + [2,8] + [8,9].\r\nNow we have segments [0,2] + [2,8] + [8,10] which cover the sporting event [0, 10].\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: clips = [[0,1],[1,2]], T = 5\r\nOutput: -1\r\nExplanation: \r\nWe can't cover [0,5] with only [0,1] and [0,2].\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: clips = [[0,1],[6,8],[0,2],[5,6],[0,4],[0,3],[6,7],[1,3],[4,7],[1,4],[2,5],[2,6],[3,4],[4,5],[5,7],[6,9]], T = 9\r\nOutput: 3\r\nExplanation: \r\nWe can take clips [0,4], [4,7], and [6,9].\r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: clips = [[0,4],[2,8]], T = 5\r\nOutput: 2\r\nExplanation: \r\nNotice you can have extra video after the event ends.\r\n```\r\n\r\n**Note:**\r\n\r\n1. `1 <= clips.length <= 100`\r\n2. `0 <= clips[i][0], clips[i][1] <= 100`\r\n3. `0 <= T <= 100`\r\n\r\n```python\r\nclass Solution:\r\n def videoStitching(self, clips, T):\r\n if T == 0:return 0\r\n clips.sort(key=lambda x:(x[0],x[0]-x[1]))\r\n print(clips)\r\n dp = [float(\"inf\") for i in range(T+1)]\r\n dp[0] = 0\r\n if clips[0][0] != 0: return -1\r\n for start, end in clips:\r\n if start>=T:\r\n continue\r\n if end>=T:\r\n end=T\r\n for i in range(start+1, end+1):\r\n dp[i] = min(dp[i], 1 + dp[start])\r\n if dp[-1] == float(\"inf\"): return -1\r\n return dp[-1]\r\n```\r\n\r\ndp[i]表示得到0-i的clip最少需要多少片\r\n\r\n首先对clips进行排序,start小的clips放到前面,length长的放前面\r\n\r\n对于clip[2,8] 从3-8开始判断 min(dp[i], 1 + dp[start])\r\n\r\n1 + dp[start] 表示使用这个切片 其中start=2\r\n\r\n\r\n\r\n##### leetcode 1027 Longest Arithmetic Sequence\r\n\r\nGiven an array `A` of integers, return the **length** of the longest arithmetic subsequence in `A`.\r\n\r\nRecall that a *subsequence* of `A` is a list `A[i_1], A[i_2], ..., A[i_k]` with `0 <= i_1 < i_2 < ... < i_k <= A.length - 1`, and that a sequence `B` is *arithmetic* if `B[i+1] - B[i]` are all the same value (for `0 <= i < B.length - 1`).\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [3,6,9,12]\r\nOutput: 4\r\nExplanation: \r\nThe whole array is an arithmetic sequence with steps of length = 3.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [9,4,7,2,10]\r\nOutput: 3\r\nExplanation: \r\nThe longest arithmetic subsequence is [4,7,10].\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: [20,1,15,3,10,5,8]\r\nOutput: 4\r\nExplanation: \r\nThe longest arithmetic subsequence is [20,15,10,5].\r\n```\r\n\r\n**Note:**\r\n\r\n1. `2 <= A.length <= 2000`\r\n2. `0 <= A[i] <= 10000`\r\n\r\n```python\r\nclass Solution:\r\n def longestArithSeqLength(self, A):\r\n dp = {}\r\n for i in range(len(A)):\r\n for j in range(i+1, len(A)):\r\n # 站在j处向A[:j+1]探索\r\n dp[j, A[j]-A[i]] = dp.get((i, A[j]-A[i]), 1) + 1\r\n return max(dp.values())\r\n```\r\n\r\ndp[j,x]表示A[:j+1]的子字符串中差为x的等差数列的最长长度\r\n\r\n\r\n\r\n##### leetcode 1049 Last Stone Weight II\r\n\r\nWe have a collection of rocks, each rock has a positive integer weight.\r\n\r\nEach turn, we choose **any two rocks** and smash them together. Suppose the stones have weights `x` and `y` with `x <= y`. The result of this smash is:\r\n\r\n- If `x == y`, both stones are totally destroyed;\r\n- If `x != y`, the stone of weight `x` is totally destroyed, and the stone of weight `y` has new weight `y-x`.\r\n\r\nAt the end, there is at most 1 stone left. Return the **smallest possible** weight of this stone (the weight is 0 if there are no stones left.)\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [2,7,4,1,8,1]\r\nOutput: 1\r\nExplanation: \r\nWe can combine 2 and 4 to get 2 so the array converts to [2,7,1,8,1] then,\r\nwe can combine 7 and 8 to get 1 so the array converts to [2,1,1,1] then,\r\nwe can combine 2 and 1 to get 1 so the array converts to [1,1,1] then,\r\nwe can combine 1 and 1 to get 0 so the array converts to [1] then that's the optimal value.\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def lastStoneWeightII(self, stones: List[int]) -> int: \r\n mem = {} #Mem\r\n def explore(a, b, stones):\r\n if len(stones) == 0:\r\n return abs(a-b)\r\n entry = (a, b, len(stones)) #Mem\r\n if entry in mem:\r\n return mem[entry]\r\n s = stones.pop()\r\n m = min(explore(a+s, b, stones), explore(a, b+s, stones))\r\n stones.append(s)\r\n \r\n mem[entry] = m #Mem\r\n return m\r\n \r\n return explore(0, 0, stones)\r\n```\r\n\r\n类似于背包问题,放到a堆或者放到b堆\r\n\r\n\r\n\r\n##### leetcode 1143 Longest Common Subsequence\r\n\r\nGiven two strings `text1` and `text2`, return the length of their longest common subsequence.\r\n\r\nA *subsequence* of a string is a new string generated from the original string with some characters(can be none) deleted without changing the relative order of the remaining characters. (eg, \"ace\" is a subsequence of \"abcde\" while \"aec\" is not). A *common subsequence* of two strings is a subsequence that is common to both strings.\r\n\r\nIf there is no common subsequence, return 0.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: text1 = \"abcde\", text2 = \"ace\" \r\nOutput: 3 \r\nExplanation: The longest common subsequence is \"ace\" and its length is 3.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: text1 = \"abc\", text2 = \"abc\"\r\nOutput: 3\r\nExplanation: The longest common subsequence is \"abc\" and its length is 3.\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: text1 = \"abc\", text2 = \"def\"\r\nOutput: 0\r\nExplanation: There is no such common subsequence, so the result is 0.\r\n```\r\n\r\n**Constraints:**\r\n\r\n- `1 <= text1.length <= 1000`\r\n- `1 <= text2.length <= 1000`\r\n- The input strings consist of lowercase English characters only.\r\n\r\n```python\r\nclass Solution:\r\n def longestCommonSubsequence(self, text1, text2):\r\n n, m = len(text1), len(text2)\r\n dp = [[0 for i in range(m+1)] for j in range(n+1)]\r\n for i in range(1, n+1):\r\n for j in range(1, m+1):\r\n if text1[i-1] == text2[j-1]:\r\n dp[i][j] = dp[i-1][j-1] + 1\r\n else:\r\n dp[i][j] = max(dp[i][j-1], dp[i-1][j])\r\n return dp[n][m]\r\n```\r\n\r\n典型DP问题\r\n\r\n如果这道题不是subsequence而是substring\r\n\r\n改成\r\n\r\n```\r\nelse:\r\n dp[i][j] = max(dp[i][j-1], dp[i-1][j])\r\n```\r\n\r\n\r\n\r\n##### leetcode 1289 Minimum Falling Path Sum II\r\n\r\nGiven a square grid of integers `arr`, a *falling path with non-zero shifts* is a choice of exactly one element from each row of `arr`, such that no two elements chosen in adjacent rows are in the same column.\r\n\r\nReturn the minimum sum of a falling path with non-zero shifts.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: arr = [[1,2,3],[4,5,6],[7,8,9]]\r\nOutput: 13\r\nExplanation: \r\nThe possible falling paths are:\r\n[1,5,9], [1,5,7], [1,6,7], [1,6,8],\r\n[2,4,8], [2,4,9], [2,6,7], [2,6,8],\r\n[3,4,8], [3,4,9], [3,5,7], [3,5,9]\r\nThe falling path with the smallest sum is [1,5,7], so the answer is 13.\r\n```\r\n\r\n**Constraints:**\r\n\r\n- `1 <= arr.length == arr[i].length <= 200`\r\n- `-99 <= arr[i][j] <= 99`\r\n\r\n```python\r\nclass Solution:\r\n def get_small(self, nums):\r\n min1, min2 = float(\"inf\"), float(\"inf\")\r\n index1, index2 = -1, -1\r\n for i in range(len(nums)):\r\n if nums[i] < min1:\r\n min2, index2 = min1, index1\r\n min1, index1 = nums[i], i\r\n elif min1 <= nums[i] < min2:\r\n min2, index2 = nums[i], i\r\n return min1, index1, min2, index2\r\n\r\n def minFallingPathSum(self, arr):\r\n n = len(arr)\r\n min_sum1, min_sum2 = 0, 0\r\n index1, index2 = -1, -1\r\n for i in range(n):\r\n min1, temp_index1, min2, temp_index2 = self.get_small(arr[i])\r\n if temp_index1!=index1:\r\n min_sum1 += min1\r\n index1 = temp_index1\r\n else:\r\n min_sum1 += min2\r\n index1 = temp_index2\r\n if temp_index1!=index2:\r\n min_sum2 += min1\r\n index2 = temp_index1\r\n else:\r\n min_sum2 += min2\r\n index2 = temp_index2\r\n if min_sum1 > min_sum2:\r\n min_sum1, min_sum2 = min_sum2, min_sum1\r\n index1, index2 = index2, index1\r\n return min_sum1\r\n```\r\n\r\n从顶向下的DP,所有的最小值都来自于最小的两个数(有可能不能取到最小的一个数因为列要不同)\r\n\r\n这个会遇到问题\r\n\r\n```\r\n[[-37,51,-36,34,-22]\r\n [82, 4, 30,14, 38],\r\n [-68,-52,-92,65,-85],\r\n [-49,-3,-77,8,-19],\r\n [-60,-71,-21,-62,-73]] \r\n```\r\n\r\n第三行选-92和-85的问题\r\n\r\n\r\n\r\n```python\r\nclass Solution:\r\n def minFallingPathSum(self, A):\r\n for i in range(1, len(A)):\r\n r = heapq.nsmallest(2, A[i - 1])\r\n for j in range(len(A[0])):\r\n A[i][j] += r[1] if A[i - 1][j] == r[0] else r[0]\r\n return min(A[-1])\r\n```\r\n\r\n从底向上才能得到正确答案\r\n\r\n$A[i][j]$ 表示走到A的第i行,最后一个数取到第j个的时候\r\n\r\n\r\n\r\n##### leetcode 1155 Number of Dice Rolls With Target Sum\r\n\r\nYou have `d` dice, and each die has `f` faces numbered `1, 2, ..., f`.\r\n\r\nReturn the number of possible ways (out of `fd` total ways) **modulo 10^9 + 7** to roll the dice so the sum of the face up numbers equals `target`.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: d = 1, f = 6, target = 3\r\nOutput: 1\r\nExplanation: \r\nYou throw one die with 6 faces. There is only one way to get a sum of 3.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: d = 2, f = 6, target = 7\r\nOutput: 6\r\nExplanation: \r\nYou throw two dice, each with 6 faces. There are 6 ways to get a sum of 7:\r\n1+6, 2+5, 3+4, 4+3, 5+2, 6+1.\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: d = 2, f = 5, target = 10\r\nOutput: 1\r\nExplanation: \r\nYou throw two dice, each with 5 faces. There is only one way to get a sum of 10: 5+5.\r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: d = 1, f = 2, target = 3\r\nOutput: 0\r\nExplanation: \r\nYou throw one die with 2 faces. There is no way to get a sum of 3.\r\n```\r\n\r\n**Example 5:**\r\n\r\n```\r\nInput: d = 30, f = 30, target = 500\r\nOutput: 222616187\r\nExplanation: \r\nThe answer must be returned modulo 10^9 + 7.\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def numRollsToTarget(self, d, f, target):\r\n memo = {}\r\n def dp(d, target):\r\n if d==0:\r\n if target != 0:\r\n return 0\r\n else:\r\n return 1\r\n if (d, target) in memo:\r\n return memo[(d, target)]\r\n res = 0\r\n for i in range(1, min(f, target)+1):\r\n res += dp(d-1, target - i)\r\n memo[(d, target)] = res\r\n return res\r\n return dp(d, target) % (10**9 + 7)\r\n```\r\n\r\n由于有每个筛子最大面值的存在限制,不能视为排列组合问题,因此需要列举\r\n\r\nDP记录,这样时间复杂度上就来得及\r\n\r\n\r\n\r\n##### leetcode 1220. Count Vowels Permutation\r\n\r\nGiven an integer `n`, your task is to count how many strings of length `n` can be formed under the following rules:\r\n\r\n- Each character is a lower case vowel (`'a'`, `'e'`, `'i'`, `'o'`, `'u'`)\r\n- Each vowel `'a'` may only be followed by an `'e'`.\r\n- Each vowel `'e'` may only be followed by an `'a'` or an `'i'`.\r\n- Each vowel `'i'` **may not** be followed by another `'i'`.\r\n- Each vowel `'o'` may only be followed by an `'i'` or a `'u'`.\r\n- Each vowel `'u'` may only be followed by an `'a'.`\r\n\r\nSince the answer may be too large, return it modulo `10^9 + 7.`\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: n = 1\r\nOutput: 5\r\nExplanation: All possible strings are: \"a\", \"e\", \"i\" , \"o\" and \"u\".\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: n = 2\r\nOutput: 10\r\nExplanation: All possible strings are: \"ae\", \"ea\", \"ei\", \"ia\", \"ie\", \"io\", \"iu\", \"oi\", \"ou\" and \"ua\".\r\n```\r\n\r\n**Example 3:** \r\n\r\n```\r\nInput: n = 5\r\nOutput: 68\r\n```\r\n\r\n**Constraints:**\r\n\r\n- `1 <= n <= 2 * 10^4`\r\n\r\n```python\r\nclass Solution:\r\n def VowelPermutation(self, path, n):\r\n if len(path) == n:\r\n self.res += 1\r\n return \r\n for c in self.follow[path[-1]]:\r\n self.VowelPermutation(path + c, n)\r\n return\r\n def countVowelPermutation(self, n: int) -> int:\r\n self.follow = {'a':{'e'}, 'e':{'a','i'}, 'i':{'a','e','o','u'}, 'o':{'i','u'}, 'u':{'a'}}\r\n chars = ['a', 'e', 'i', 'o', 'u']\r\n if n == 0: return 0\r\n self.res = 0\r\n for c in chars:\r\n self.VowelPermutation(c, n)\r\n return self.res % 1000000007\r\n```\r\n\r\n穷举的方法会导致TLE\r\n\r\n\r\n\r\n```python\r\nclass Solution:\r\n def countVowelPermutation(self, n: int) -> int:\r\n mod=1000000007\r\n dp= [[0]*5 for i in range(n+1)]\r\n \r\n for i in range(5):\r\n dp[1][i] = 1\r\n for j in range(2,n+1):\r\n for i in range(5):\r\n if i == 0:\r\n dp[j][i] += dp[j-1][1] %mod\r\n if i == 1:\r\n dp[j][i] += (dp[j-1][0] + dp[j-1][2]) %mod\r\n if i == 2:\r\n dp[j][i] += (dp[j-1][0] + dp[j-1][1] + dp[j-1][3] + dp[j-1][4]) %mod\r\n if i == 3:\r\n dp[j][i] += ( dp[j-1][2] + dp[j-1][4]) %mod\r\n if i == 4:\r\n dp[j][i] += ( dp[j-1][0]) %mod\r\n \r\n return sum(dp[n]) %mod\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 1320. Minimum Distance to Type a Word Using Two Fingers\r\n\r\n\r\n\r\nYou have a keyboard layout as shown above in the XY plane, where each English uppercase letter is located at some coordinate, for example, the letter **A** is located at coordinate **(0,0)**, the letter **B** is located at coordinate **(0,1)**, the letter **P** is located at coordinate **(2,3)** and the letter **Z** is located at coordinate **(4,1)**.\r\n\r\nGiven the string `word`, return the minimum total distance to type such string using only two fingers. The distance between coordinates **(x1,y1)** and **(x2,y2)** is **|x1 - x2| + |y1 - y2|**. \r\n\r\nNote that the initial positions of your two fingers are considered free so don't count towards your total distance, also your two fingers do not have to start at the first letter or the first two letters.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: word = \"CAKE\"\r\nOutput: 3\r\nExplanation: \r\nUsing two fingers, one optimal way to type \"CAKE\" is: \r\nFinger 1 on letter 'C' -> cost = 0 \r\nFinger 1 on letter 'A' -> cost = Distance from letter 'C' to letter 'A' = 2 \r\nFinger 2 on letter 'K' -> cost = 0 \r\nFinger 2 on letter 'E' -> cost = Distance from letter 'K' to letter 'E' = 1 \r\nTotal distance = 3\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: word = \"HAPPY\"\r\nOutput: 6\r\nExplanation: \r\nUsing two fingers, one optimal way to type \"HAPPY\" is:\r\nFinger 1 on letter 'H' -> cost = 0\r\nFinger 1 on letter 'A' -> cost = Distance from letter 'H' to letter 'A' = 2\r\nFinger 2 on letter 'P' -> cost = 0\r\nFinger 2 on letter 'P' -> cost = Distance from letter 'P' to letter 'P' = 0\r\nFinger 1 on letter 'Y' -> cost = Distance from letter 'A' to letter 'Y' = 4\r\nTotal distance = 6\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: word = \"NEW\"\r\nOutput: 3\r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: word = \"YEAR\"\r\nOutput: 7\r\n```\r\n\r\n```python\r\nimport copy\r\nclass Solution:\r\n def distance(self, a, b):\r\n if a == -1:\r\n return 0\r\n a, b = ord(a) - ord(\"A\"), ord(b) - ord(\"A\")\r\n return abs(int(a / 6) - int(b / 6)) + abs(a % 6 - b % 6)\r\n\r\n def minimumDistance(self, word: str) -> int:\r\n dp, next_dp = {(-1, -1): 0}, {}\r\n for c in word:\r\n for (a, b), val in dp.items():\r\n next_dp[(a, c)] = min(next_dp.get((c, a), float(\"inf\")), val + self.distance(b, c))\r\n next_dp[(c, b)] = min(next_dp.get((b, c), float(\"inf\")), val + self.distance(a, c))\r\n dp = copy.deepcopy(next_dp)\r\n next_dp = {}\r\n return min(dp.values())\r\n```\r\n\r\n可以简单的发现,这类问题必须要穷尽所有的情况,因此可以通过DP进行优化,减少重复计算\r\n\r\n因为有两只手,用二维数组表示其现在所在的位置\r\n\r\n\r\n\r\n##### leetcode 1043 Partition Array for Maximum Sum\r\n\r\nGiven an integer array `A`, you partition the array into (contiguous) subarrays of length at most `K`. After partitioning, each subarray has their values changed to become the maximum value of that subarray.\r\n\r\nReturn the largest sum of the given array after partitioning.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: A = [1,15,7,9,2,5,10], K = 3\r\nOutput: 84\r\nExplanation: A becomes [15,15,15,9,10,10,10]\r\n```\r\n\r\n**Note:**\r\n\r\n1. `1 <= K <= A.length <= 500`\r\n2. `0 <= A[i] <= 10^6`\r\n\r\n```python\r\nclass Solution:\r\n def maxSumAfterPartitioning(self, A: List[int], K: int) -> int:\r\n n = len(A)\r\n dp = [0 for i in range(n+1)]\r\n for i in range(K):\r\n dp[i+1] = max(A[:i+1])*(i+1)\r\n for i in range(K+1, n+1):\r\n for k in range(1, K+1):\r\n dp[i] = max(dp[i], dp[i-k]+k*max(A[i-k:i]))\r\n return dp[n]\r\n```\r\n\r\ndp[i]表示前i个数的最大值\r\n\r\ndp[i-k]+k*max(A[i-k:i]) 表示最后k个数max一下\r\n\r\n但是这样时间复杂度比较高\r\n\r\nO(kN)\r\n\r\n\r\n\r\n##### leetcode 1292 Maximum Side Length of a Square with Sum Less than or Equal to Threshold\r\n\r\nMedium\r\n\r\nGiven a `m x n` matrix `mat` and an integer `threshold`. Return the maximum side-length of a square with a sum less than or equal to `threshold` or return **0** if there is no such square.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n\r\n\r\n```\r\nInput: mat = [[1,1,3,2,4,3,2],[1,1,3,2,4,3,2],[1,1,3,2,4,3,2]], threshold = 4\r\nOutput: 2\r\nExplanation: The maximum side length of square with sum less than 4 is 2 as shown.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: mat = [[2,2,2,2,2],[2,2,2,2,2],[2,2,2,2,2],[2,2,2,2,2],[2,2,2,2,2]], threshold = 1\r\nOutput: 0\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: mat = [[1,1,1,1],[1,0,0,0],[1,0,0,0],[1,0,0,0]], threshold = 6\r\nOutput: 3\r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: mat = [[18,70],[61,1],[25,85],[14,40],[11,96],[97,96],[63,45]], threshold = 40184\r\nOutput: 2\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def maxSideLength(self, mat: List[List[int]], threshold: int) -> int:\r\n n = len(mat)\r\n m = len(mat[0])\r\n dp = [[0] * (m+1) for _ in range(n+1)]\r\n res = 0\r\n for r in range(1, n+1):\r\n for c in range(1, m+1):\r\n dp[r][c] = dp[r-1][c] + dp[r][c-1] - dp[r-1][c-1] + mat[r-1][c-1]\r\n k = res + 1\r\n if r >= k and c >= k and threshold >= dp[r][c] - dp[r-k][c] - dp[r][c-k] + dp[r-k][c-k]:\r\n res = k\r\n return res\r\n```\r\n\r\npresum\r\n\r\n用dp[r,c] - dp[r-k, c] - dp[r,c-k] + dp[r-k,c-k]表示一个矩形的面积\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 673. Number of Longest Increasing Subsequence\r\n\r\nGiven an unsorted array of integers, find the number of longest increasing subsequence.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: [1,3,5,4,7]\r\nOutput: 2\r\nExplanation: The two longest increasing subsequence are [1, 3, 4, 7] and [1, 3, 5, 7].\r\n```\r\n\r\n\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: [2,2,2,2,2]\r\nOutput: 5\r\nExplanation: The length of longest continuous increasing subsequence is 1, and there are 5 subsequences' length is 1, so output 5.\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def findNumberOfLIS(self, nums: List[int]) -> int:\r\n dp, max_length, n = [[1, 1]], 1, len(nums)\r\n if n == 0: return 0\r\n for i in range(1, n):\r\n temp_length, count = 1, 1\r\n for j in range(i):\r\n if nums[j] < nums[i]:\r\n if dp[j][0] + 1 > temp_length:\r\n temp_length = dp[j][0] + 1\r\n count = dp[j][1]\r\n elif dp[j][0] == temp_length - 1:\r\n count += dp[j][1]\r\n dp.append([temp_length, count])\r\n max_length = max(max_length, temp_length)\r\n print(dp)\r\n return sum([item[1] for item in dp if item[0] == max_length])\r\n \r\n```\r\n\r\n时间复杂度O(n2)\r\n\r\ntemp_length记录当前该节点的最长路径,而max_length表示全局最长路径\r\n\r\n\r\n\r\n##### leetcode 651. 4 Keys Keyboard\r\n\r\nImagine you have a special keyboard with the following keys:\r\n\r\n`Key 1: (A)`: Print one 'A' on screen.\r\n\r\n`Key 2: (Ctrl-A)`: Select the whole screen.\r\n\r\n`Key 3: (Ctrl-C)`: Copy selection to buffer.\r\n\r\n`Key 4: (Ctrl-V)`: Print buffer on screen appending it after what has already been printed.\r\n\r\nNow, you can only press the keyboard for **N** times (with the above four keys), find out the maximum numbers of 'A' you can print on screen.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: N = 3\r\nOutput: 3\r\nExplanation: \r\nWe can at most get 3 A's on screen by pressing following key sequence:\r\nA, A, A\r\n```\r\n\r\n\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: N = 7\r\nOutput: 9\r\nExplanation: \r\nWe can at most get 9 A's on screen by pressing following key sequence:\r\nA, A, A, Ctrl A, Ctrl C, Ctrl V, Ctrl V\r\n```\r\n\r\n\r\n\r\n**Note:**\r\n\r\n1. 1 <= N <= 50\r\n2. Answers will be in the range of 32-bit signed integer.\r\n\r\n```python\r\nclass Solution:\r\n def maxA(self, N):\r\n best = [0, 1]\r\n for x in range(2, N+1):\r\n cur = best[x-1] + 1\r\n for y in range(x-1):\r\n cur = max(cur, best[y] * (x-y-1))\r\n best.append(cur)\r\n return best[N]\r\n \r\n```\r\n\r\n当前最大值 可能是best[x-1] + 1 (A)\r\n\r\n max(cur, best[y] * (x-y-1)) 表示从第y次开始一直按黏贴"
},
{
"alpha_fraction": 0.6177024245262146,
"alphanum_fraction": 0.7080979347229004,
"avg_line_length": 16.379310607910156,
"blob_id": "0d7715e93c3f7a57e86e00bdf6a1cb907cc5839b",
"content_id": "4cabc0d81e8216daebb59f2bd18bbf83d9d4f784",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 621,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 29,
"path": "/Anaconda.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "先要搞清楚自己的电脑上适配的是什么CUDA\r\n\r\n1060->cuda9.\r\n\r\n##### Win10下安装Anaconda+PyTorch+pycharm\r\n\r\n<https://zhuanlan.zhihu.com/p/35255076>\r\n\r\n##### Conda 下载镜像加速\r\n\r\n```\r\nconda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/\r\n\r\nconda config --set show_channel_urls yes\r\n```\r\n\r\n\r\n\r\n版本:[Anaconda3-2018.12-Linux-x86_64.sh](https://repo.continuum.io/archive/Anaconda3-2018.12-Linux-x86_64.sh)\r\n\r\n\r\n\r\nanaconda python版本变化之后遇到的问题\r\n\r\nImportError: No module named conda.cli\r\n\r\n解决方法:\r\n\r\nbash Anaconda3-2018.12-Linux-x86_64.sh -u"
},
{
"alpha_fraction": 0.4801171123981476,
"alphanum_fraction": 0.5108563303947449,
"avg_line_length": 24.2756404876709,
"blob_id": "096c1897ffdd7757926fff5bafedafd9917d7975",
"content_id": "6e7c8b2ab9a91f851ccaec3c3b9860479f27392d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4567,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 156,
"path": "/python/python实现数据结构.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "## stack\r\n### empty,top,pop,append\r\n```\r\nclass Stack(object):\r\n # 初始化栈为空列表\r\n def __init__(self):\r\n self.items = []\r\n # 判断栈是否为空,返回布尔值\r\n def is_empty(self):\r\n return self.items == []\r\n # 返回栈顶元素\r\n def peek(self):\r\n return self.items[len(self.items) - 1]\r\n # 返回栈的大小\r\n def size(self):\r\n return len(self.items)\r\n # 把新的元素堆进栈里面(程序员喜欢把这个过程叫做压栈,入栈,进栈……)\r\n def push(self, item):\r\n self.items.append(item)\r\n # 把栈顶元素丢出去(程序员喜欢把这个过程叫做出栈……)\r\n def pop(self, item):\r\n return self.items.pop()\r\n```\r\n\r\n### queue\r\n```\r\nclass MyQueue:\r\n def __init__(self):\r\n \"\"\"\r\n Initialize your data structure here.\r\n \"\"\"\r\n self.nums=[]\r\n def push(self, x):\r\n \"\"\"\r\n Push element x to the back of queue.\r\n :type x: int\r\n :rtype: void\r\n \"\"\"\r\n self.nums.append(x)\r\n def pop(self):\r\n \"\"\"\r\n Removes the element from in front of queue and returns that element.\r\n :rtype: int\r\n \"\"\"\r\n res=self.nums[0]\r\n self.nums=self.nums[1:]\r\n return res\r\n def peek(self):\r\n \"\"\"\r\n Get the front element.\r\n :rtype: int\r\n \"\"\"\r\n return self.nums[0]\r\n def empty(self):\r\n \"\"\"\r\n Returns whether the queue is empty.\r\n :rtype: bool\r\n \"\"\"\r\n if self.nums==[]:\r\n return True\r\n else:\r\n return False\r\n\r\n```\r\n### dict\r\n```\r\npython 使用hash函数来得到一个很大的hash值\r\n这个hash值与输入有关 也可能与保存位置有关\r\n自己实现一个简单的hash函数:\r\n>>> def myhash(a):\r\n... if type(int)==int:\r\n... return a\r\n... return ord(a)<<32%1000000007\r\n\r\nPyDict_SetItem: key = ‘a’, value = 1\r\n hash = hash(‘a’) = 12416037344\r\n insertdict\r\n lookdict_string\r\n slot index = hash & mask = 12416037344 & 7 = 0\r\n slot 0 is not used so return it\r\n init entry at index 0 with key, value and hashma_used = 1, ma_fill = 1\r\n\r\nPyDict_SetItem: key = ‘b’, value = 2\r\n hash = hash(‘b’) = 12544037731\r\n insertdict\r\n lookdict_string\r\n slot index = hash & mask = 12544037731 & 7 = 3\r\n slot 3 is not used so return it\r\n init entry at index 3 with key, value and hashma_used = 2, ma_fill = 2\r\n\r\nPyDict_SetItem: key = ‘z’, value = 26\r\n hash = hash(‘z’) = 15616046971\r\n insertdict\r\n lookdict_string\r\n slot index = hash & mask = 15616046971 & 7 = 3\r\n slot 3 is used so probe for a different slot: 5 is free\r\n init entry at index 5 with key, value and hashma_used = 3, ma_fill = 3\r\n```\r\n \r\n\r\n处理冲突的时候,可以选用open address method或者linked method\r\n\r\n### heap\r\n```python\r\nclass MaxHeap(object):\r\n \r\n def __init__(self):\r\n self._data = []\r\n self._count = len(self._data)\r\n \r\n def size(self):\r\n return self._count\r\n \r\n def isEmpty(self):\r\n return self._count == 0\r\n \r\n def add(self, item):\r\n # 插入元素入堆\r\n self._data.append(item)\r\n self._count += 1\r\n self._shiftup(self._count-1)\r\n \r\n def pop(self):\r\n # 出堆\r\n if self._count > 0:\r\n ret = self._data[0]\r\n self._data[0] = self._data[self._count-1]\r\n self._count -= 1\r\n self._shiftDown(0)\r\n return ret\r\n \r\n def _shiftup(self, index):\r\n # 上移self._data[index],以使它不大于父节点\r\n parent = (index-1)>>1\r\n while index > 0 and self._data[parent] < self._data[index]:\r\n # swap\r\n self._data[parent], self._data[index] = self._data[index], self._data[parent]\r\n index = parent\r\n parent = (index-1)>>1\r\n \r\n def _shiftDown(self, index):\r\n # 上移self._data[index],以使它不小于子节点\r\n j = (index << 1) + 1\r\n while j < self._count :\r\n # 有子节点\r\n if j+1 < self._count and self._data[j+1] > self._data[j]:\r\n # 有右子节点,并且右子节点较大\r\n j += 1\r\n if self._data[index] >= self._data[j]:\r\n # 堆的索引位置已经大于两个子节点,不需要交换了\r\n break\r\n self._data[index], self._data[j] = self._data[j], self._data[index]\r\n index = j\r\n j = (index << 1) + 1\r\n\r\n```\r\n"
},
{
"alpha_fraction": 0.5158945322036743,
"alphanum_fraction": 0.5424368381500244,
"avg_line_length": 22.743318557739258,
"blob_id": "1c74726b32b8af5953865e4b4b3e3678e00fdde2",
"content_id": "c0c6096f21050b795dcc3bca76ea31d705b54315",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 60484,
"license_type": "no_license",
"max_line_length": 692,
"num_lines": 2357,
"path": "/leetcode_note/Tree.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "树与链表的转换(LeetCode 114)\r\n\r\n最近的公共祖先(LeetCode 236)\r\n\r\n树的层次遍历应用(LeetCode 199)\r\n\r\n树的改造(LeetCode 117)\r\n\r\n\r\n\r\n 排序链表转换为二叉排序树(LeetCode 109)\r\n\r\n二叉排序树的遍历与改造(LeetCode 538 )\r\n\r\n二叉排序树中的第K大的数(LeetCode 230)\r\n\r\n##### leetcode 94 Binary Tree Inorder Traversal\r\n\r\n* Given a binary tree, return the *inorder* traversal of its nodes' values.\r\n\r\n```\r\nInput: [1,null,2,3]\r\n 1\r\n \\\r\n 2\r\n /\r\n 3\r\n\r\nOutput: [1,3,2]\r\n```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution:\r\n def inorderTraversal(self, root):\r\n \"\"\"\r\n :type root: TreeNode\r\n :rtype: List[int]\r\n \"\"\"\r\n self.ans=[]\r\n def helper(root):\r\n if root.left:\r\n helper(root.left)\r\n self.ans.append(root.val)\r\n if root.right:\r\n helper(root.right)\r\n return\r\n if not root:\r\n return []\r\n else:\r\n helper(root)\r\n return self.ans\r\n```\r\n\r\nleft node.val right\r\n\r\n##### leetcode 95Unique Binary Search Trees II\r\n\r\nGiven an integer *n*, generate all structurally unique **BST's** (binary search trees) that store values 1 ... *n*.\r\n\r\n**Example:**\r\n\r\n```\r\nInput: 3\r\nOutput:\r\n[\r\n [1,null,3,2],\r\n [3,2,null,1],\r\n [3,1,null,null,2],\r\n [2,1,3],\r\n [1,null,2,null,3]\r\n]\r\nExplanation:\r\nThe above output corresponds to the 5 unique BST's shown below:\r\n\r\n 1 3 3 2 1\r\n \\ / / / \\ \\\r\n 3 2 1 1 3 2\r\n / / \\ \\\r\n 2 1 2 3\r\n```\r\n\r\n```python\r\n# Definition for a binary tree node.\r\n# class TreeNode:\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.left = None\r\n# self.right = None\r\n\r\nclass Solution(object):\r\n def generateTrees(self, n):\r\n def buildBST(nums):\r\n if not nums: \r\n return [None]\r\n res=[]\r\n for i in range(len(nums)):\r\n for left in buildBST(nums[:i]):\r\n for right in buildBST(nums[i+1:]):\r\n root, root.left, root.right=TreeNode(nums[i]), left, right\r\n res += [root]\r\n return res\r\n if n == 0:\r\n return []\r\n return buildBST(list(range(1, n+1)))\r\n```\r\n\r\n需要穷举出所有的情况,对nums list中的每个点都讨论其有无成为根节点的情况\r\n\r\n注意本题中left right 的求得方式与别的题不太一样\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 96 Unique Binary Search Trees\r\n\r\n* Given *n*, how many structurally unique **BST's** (binary search trees) that store values 1 ... *n*?\r\n\r\n```\r\nInput: 3\r\nOutput: 5\r\nExplanation:\r\nGiven n = 3, there are a total of 5 unique BST's:\r\n\r\n 1 3 3 2 1\r\n \\ / / / \\ \\\r\n 3 2 1 1 3 2\r\n / / \\ \\\r\n 2 1 2 3\r\n```\r\n\r\n\r\n\r\n* Mysolution:\r\n\r\n```\r\nclass Solution:\r\n def numTrees(self, n):\r\n \"\"\"\r\n :type n: int\r\n :rtype: int\r\n \"\"\"\r\n dp=[0 for i in range(n+1)]\r\n dp[0]=1\r\n for i in range(1,n+1,1):\r\n for j in range(i):\r\n dp[i]+=dp[j]*dp[i-1-j]\r\n return dp[n]\r\n```\r\n\r\n转移方程:\r\n\r\n```\r\ndp[i]+=dp[j]*dp[i-1-j]\r\n```\r\n\r\nj: 表示左边有j个点,则右边有i-1-j个点\r\n\r\n\r\n\r\n##### leetcode 98. Validate Binary Search Tree\r\n\r\n* Given a binary tree, determine if it is a valid binary search tree (BST).\r\n\r\n Assume a BST is defined as follows:\r\n\r\n - The left subtree of a node contains only nodes with keys **less than** the node's key.\r\n - The right subtree of a node contains only nodes with keys **greater than** the node's key.\r\n - Both the left and right subtrees must also be binary search trees.\r\n\r\n```\r\nInput:\r\n 2\r\n / \\\r\n 1 3\r\nOutput: true\r\n```\r\n\r\n```python\r\nclass Solution(object):\r\n def isValidBST(self, root):\r\n \"\"\"\r\n :type root: TreeNode\r\n :rtype: bool\r\n \"\"\"\r\n if root==None:\r\n return True\r\n def isvalid(root,min,max):\r\n if root==None:\r\n return True\r\n if root.val<=min or root.val>=max:\r\n return False\r\n return isvalid(root.left,min,root.val) and isvalid(root.right,root.val,max)\r\n return isvalid(root,-float(\"inf\"),float(\"inf\"))\r\n```\r\n\r\n对于每一层将min max传下去,检查是否满足要求\r\n\r\n对于node left:min=min,max=node .val\r\n\r\n对于node right:min=node.val,max=max\r\n\r\n\r\n\r\n##### leetcode 101 Symmetric Tree\r\n\r\n* Given a binary tree, check whether it is a mirror of itself (ie, symmetric around its center).\r\n\r\n For example, this binary tree `[1,2,2,3,4,4,3]` is symmetric:\r\n\r\n\r\n\r\n```\r\n 1\r\n / \\\r\n 2 2\r\n / \\ / \\\r\n3 4 4 3\r\n```\r\n\r\nBut the following `[1,2,2,null,3,null,3]` is not:\r\n\r\n```\r\n 1\r\n / \\\r\n 2 2\r\n \\ \\\r\n 3 3\r\n```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution(object):\r\n def isSymmetric(self, root):\r\n def issame(root1, root2):\r\n if root1==None and root2==None:\r\n return True\r\n elif (root1==None and root2!=None) or (root2==None and root1!=None):\r\n return False\r\n if root1.v!=root2.v:\r\n return False\r\n else:\r\n return issame(root1.l, root2.r) and issame(root1.r, root2.l)\r\n if root==None:\r\n return True\r\n return issame(root.l,root.r)\r\n```\r\n\r\neasy 使用递归,注意none的情况即可\r\n\r\n\r\n\r\n##### leetcode 102. Binary Tree Level Order Traversal\r\n\r\n* Given a binary tree, return the *level order* traversal of its nodes' values. (ie, from left to right, level by level).\r\n\r\n For example:\r\n Given binary tree `[3,9,20,null,null,15,7]`,\r\n\r\n```\r\n 3\r\n / \\\r\n 9 20\r\n / \\\r\n 15 7\r\n```\r\n\r\n```\r\n[\r\n [3],\r\n [9,20],\r\n [15,7]\r\n]\r\n```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nfrom collections import deque\r\nclass Solution:\r\n def levelOrder(self, root):\r\n \"\"\"\r\n :type root: TreeNode\r\n :rtype: List[List[int]]\r\n \"\"\"\r\n if not root:\r\n return []\r\n level1,level2,nums,ans=deque(),deque(),[],[]\r\n level1.append(root)\r\n while level1 or level2:\r\n while level1:\r\n temp=level1[0]\r\n nums.append(temp.val)\r\n level1.popleft()\r\n if temp.left:\r\n level2.append(temp.left)\r\n if temp.right:\r\n level2.append(temp.right)\r\n ans.append(nums.copy())\r\n level1=level2.copy()\r\n level2.clear()\r\n nums.clear()\r\n return ans\r\n```\r\n\r\n使用两个deque 来保存node节点\r\n\r\n\r\n\r\n##### leetcode 104 Maximum Depth of Binary Tree\r\n\r\n* Given a binary tree, find its maximum depth.\r\n\r\n The maximum depth is the number of nodes along the longest path from the root node down to the farthest leaf node.\r\n\r\n **Note:** A leaf is a node with no children.\r\n\r\n **Example:**\r\n\r\n Given binary tree `[3,9,20,null,null,15,7]`\r\n\r\n```\r\n 3\r\n / \\\r\n 9 20\r\n / \\\r\n 15 7\r\n```\r\n\r\nreturn its depth = 3.\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution(object):\r\n def maxDepth(self, root):\r\n count=0\r\n def returndep(root,count):\r\n if root==None:\r\n return count\r\n else:\r\n return max(returndep(root.l,count+1),returndep(root.r,count+1))\r\n return returndep(root,count)\r\n```\r\n\r\n```python\r\ndef maxDepth(self, root):\r\n return 1 + max(map(self.maxDepth, (root.left, root.right))) if root else 0\r\n```\r\n\r\n递归,1+max(左支的depth,右支的depth)\r\n\r\n\r\n\r\n##### leetcode 105. Construct Binary Tree from Preorder and Inorder Traversal\r\n\r\n* Given preorder and inorder traversal of a tree, construct the binary tree.\r\n\r\n **Note:**\r\n You may assume that duplicates do not exist in the tree.\r\n\r\n For example, given\r\n\r\n```\r\npreorder = [3,9,20,15,7]\r\ninorder = [9,3,15,20,7]\r\n\r\n 3\r\n / \\\r\n 9 20\r\n / \\\r\n 15 7\r\n```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution:\r\n def buildTree(self, preorder, inorder):\r\n \"\"\"\r\n :type preorder: List[int]\r\n :type inorder: List[int]\r\n :rtype: TreeNode\r\n \"\"\"\r\n if not inorder:\r\n return\r\n i=0\r\n for i in range(len(inorder)):\r\n if inorder[i]==preorder[0]:\r\n break\r\n root=TreeNode(preorder[0])\r\n root.left=self.buildTree(preorder[1:i+1],inorder[:i])\r\n root.right=self.buildTree(preorder[i+1:],inorder[i+1:])\r\n return root\r\n```\r\n\r\npreorder[0]是最上面节点的元素\r\n\r\n找到inorder[i]\r\n\r\n将前面的i个递归到root.left进行生成\r\n\r\n将其余的递归到root.right进行生成\r\n\r\n\r\n\r\n##### leetcode 106 Construct Binary Tree from Inorder and Postorder Traversal\r\n\r\nGiven inorder and postorder traversal of a tree, construct the binary tree.\r\n\r\n**Note:**\r\nYou may assume that duplicates do not exist in the tree.\r\n\r\nFor example, given\r\n\r\n```\r\ninorder = [9,3,15,20,7]\r\npostorder = [9,15,7,20,3]\r\n```\r\n\r\nReturn the following binary tree:\r\n\r\n```\r\n 3\r\n / \\\r\n 9 20\r\n / \\\r\n 15 7\r\n```\r\n\r\n```python\r\n# Definition for a binary tree node.\r\n# class TreeNode:\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.left = None\r\n# self.right = None\r\n\r\nclass Solution:\r\n def buildTree(self, inorder: List[int], postorder: List[int]) -> TreeNode:\r\n if not postorder:\r\n return\r\n num = postorder[-1]\r\n for i in range(len(inorder)):\r\n if inorder[i] == num:\r\n break\r\n root = TreeNode(num)\r\n root.left = self.buildTree(inorder[:i], postorder[:i])\r\n root.right = self.buildTree(inorder[i+1:], postorder[i:-1])\r\n return root\r\n```\r\n\r\n上述方法的时间复杂度是O(N2)\r\n\r\n```python\r\nclass Solution:\r\n def buildTree(self, inorder, postorder):\r\n map_inorder = {}\r\n for i, val in enumerate(inorder): map_inorder[val] = i\r\n def recur(low, high):\r\n if low > high: return None\r\n x = TreeNode(postorder.pop())\r\n mid = map_inorder[x.val]\r\n x.right = recur(mid+1, high)\r\n x.left = recur(low, mid-1)\r\n return x\r\n return recur(0, len(inorder)-1)\r\n```\r\n\r\nO(N)\r\n\r\n\r\n\r\n##### leetcode 889 Construct Binary Tree from Preorder and Postorder Traversal\r\n\r\nReturn any binary tree that matches the given preorder and postorder traversals.\r\n\r\nValues in the traversals `pre` and `post` are distinct positive integers \r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: pre = [1,2,4,5,3,6,7], post = [4,5,2,6,7,3,1]\r\nOutput: [1,2,3,4,5,6,7]\r\n```\r\n\r\n**Note:**\r\n\r\n- `1 <= pre.length == post.length <= 30`\r\n- `pre[]` and `post[]` are both permutations of `1, 2, ..., pre.length`.\r\n- It is guaranteed an answer exists. If there exists multiple answers, you can return any of them.\r\n\r\n```python\r\nclass Solution:\r\n def constructFromPrePost(self, pre, post):\r\n if not pre or not post: return None\r\n root = TreeNode(pre[0])\r\n if len(post) == 1: return root\r\n idx = pre.index(post[-2])\r\n root.left = self.constructFromPrePost(pre[1: idx], post[:(idx - 1)])\r\n root.right = self.constructFromPrePost(pre[idx: ], post[(idx - 1):-1])\r\n return root\r\n```\r\n\r\npre中的第一个元素也就是post里面的最后一个元素, 找到post中倒数第二个\r\n\r\nindex,分为左右子树\r\n\r\n从pre和post重建tree是有可能出现多个解的\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 107 Binary Tree Level Order Traversal II\r\n\r\nGiven a binary tree, return the *bottom-up level order* traversal of its nodes' values. (ie, from left to right, level by level from leaf to root).\r\n\r\nFor example:\r\nGiven binary tree `[3,9,20,null,null,15,7]`,\r\n\r\n```\r\n 3\r\n / \\\r\n 9 20\r\n / \\\r\n 15 7\r\n```\r\n\r\nreturn its bottom-up level order traversal as:\r\n\r\n```\r\n[\r\n [15,7],\r\n [9,20],\r\n [3]\r\n]\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def levelOrderBottom(self, root):\r\n if not root:\r\n return []\r\n level=0\r\n stack,res,nums=[],[],[]\r\n stack.append([root,level])\r\n while stack:\r\n if stack[-1][1]>level:\r\n res.append(nums)\r\n nums=[]\r\n level=stack[-1][1]\r\n temp,temp_level=stack.pop()\r\n nums.append(temp.val)\r\n if temp.left:\r\n stack.insert(0,[temp.left,level+1])\r\n if temp.right:\r\n stack.insert(0,[temp.right,level+1])\r\n if nums:\r\n res.append(nums)\r\n return res[::-1]\r\n```\r\n\r\n\r\n\r\n##### leetcode 108 Convert Sorted Array to Binary Search Tree\r\n\r\nGiven an array where elements are sorted in ascending order, convert it to a height balanced BST.\r\n\r\nFor this problem, a height-balanced binary tree is defined as a binary tree in which the depth of the two subtrees of *every* node never differ by more than 1.\r\n\r\n**Example:**\r\n\r\n```\r\nGiven the sorted array: [-10,-3,0,5,9],\r\n\r\nOne possible answer is: [0,-3,9,-10,null,5], which represents the following height balanced BST:\r\n\r\n 0\r\n / \\\r\n -3 9\r\n / /\r\n -10 5\r\n```\r\n\r\n```python\r\n# Definition for a binary tree node.\r\n# class TreeNode:\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.left = None\r\n# self.right = None\r\n\r\nclass Solution:\r\n def sortedArrayToBST(self, nums: List[int]) -> TreeNode:\r\n def buildBST(nums):\r\n if not nums:\r\n return\r\n mid = int(len(nums)/2)\r\n root = TreeNode(nums[mid])\r\n root.left = buildBST(nums[:mid])\r\n root.right = buildBST(nums[mid+1:])\r\n return root\r\n return buildBST(nums)\r\n \r\n```\r\n\r\n所求的是一颗平衡树,因此将中间的那个值作为root 小于的部分放到左边 大于的部分放到右侧\r\n\r\n\r\n\r\n##### leetcode 109 Convert Sorted List to Binary Search Tree\r\n\r\nGiven a singly linked list where elements are sorted in ascending order, convert it to a height balanced BST.\r\n\r\nFor this problem, a height-balanced binary tree is defined as a binary tree in which the depth of the two subtrees of *every* node never differ by more than 1.\r\n\r\n**Example:**\r\n\r\n```\r\nGiven the sorted linked list: [-10,-3,0,5,9],\r\n\r\nOne possible answer is: [0,-3,9,-10,null,5], which represents the following height balanced BST:\r\n\r\n 0\r\n / \\\r\n -3 9\r\n / /\r\n -10 5\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def sortedListToBST(self, head: ListNode) -> TreeNode:\r\n def buildBST(nums):\r\n if not nums:\r\n return\r\n mid = int(len(nums)/2)\r\n root = TreeNode(nums[mid])\r\n root.left = buildBST(nums[:mid])\r\n root.right = buildBST(nums[mid+1:])\r\n return root\r\n nums = []\r\n while head:\r\n nums.append(head.val)\r\n head = head.next\r\n return buildBST(nums)\r\n```\r\n\r\n和108解题思路一样,只是用list先储存一下linked-list的值\r\n\r\n\r\n\r\n##### leetcode 114 Flatten Binary Tree to Linked List\r\n\r\n* Given a binary tree, flatten it to a linked list in-place.\r\n\r\n For example, given the following tree:\r\n\r\n```\r\n 1\r\n / \\\r\n 2 5\r\n / \\ \\\r\n3 4 6\r\n\r\n1\r\n \\\r\n 2\r\n \\\r\n 3\r\n \\\r\n 4\r\n \\\r\n 5\r\n \\\r\n 6\r\n```\r\n\r\n\r\n\r\n```python\r\nclass Solution:\r\n def flatten(self, root):\r\n \"\"\"\r\n :type root: TreeNode\r\n :rtype: void Do not return anything, modify root in-place instead.\r\n \"\"\"\r\n if root: \r\n self.flatten(root.left)\r\n self.flatten(root.right)\r\n if root.left:\r\n l, r = root.left, root.right\r\n root.left = None\r\n root.right = l\r\n while l.right:\r\n l = l.right\r\n l.right = r\r\n```\r\n\r\nDFS递归\r\n\r\nflatten函数相当于将root 下面的节点捋直\r\n\r\n因此对于root 先将其root.left root.right捋直,再拼接起来\r\n\r\n先让root.right=l\r\n\r\n然后指针一直沿着l走下去,最后用l.right=r将r接上 \r\n\r\n\r\n\r\n##### leetcode 124 Binary Tree Maximum Path Sum\r\n\r\n* Given a **non-empty** binary tree, find the maximum path sum.\r\n\r\n For this problem, a path is defined as any sequence of nodes from some starting node to any node in the tree along the parent-child connections. The path must contain **at least one node** and does not need to go through the root.\r\n\r\n```\r\nInput: [1,2,3]\r\n\r\n 1\r\n / \\\r\n 2 3\r\n\r\nOutput: 6\r\n\r\nInput: [-10,9,20,null,null,15,7]\r\n\r\n -10\r\n / \\\r\n 9 20\r\n / \\\r\n 15 7\r\n\r\nOutput: 42\r\n```\r\n\r\n```python\r\nclass Solution:\r\n def maxPathSum(self, root):\r\n self.res=-float(\"inf\")\r\n def helper(root):\r\n if not root:\r\n return 0\r\n left=helper(root.left)\r\n right=helper(root.right)\r\n if left<0: left=0\r\n if right<0: right=0\r\n self.res=max(self.res,root.val+left+right)\r\n return root.val+max(left,right)\r\n helper(root)\r\n return self.res\r\n```\r\n\r\n自底向上\r\n\r\n\r\n\r\n##### leetcode 208 Implement Trie (Prefix Tree)\r\n\r\n* Implement a trie with `insert`, `search`, and `startsWith` methods.\r\n\r\n```\r\nTrie trie = new Trie();\r\n\r\ntrie.insert(\"apple\");\r\ntrie.search(\"apple\"); // returns true\r\ntrie.search(\"app\"); // returns false\r\ntrie.startsWith(\"app\"); // returns true\r\ntrie.insert(\"app\"); \r\ntrie.search(\"app\"); // returns true\r\n```\r\n\r\n**Note:**\r\n\r\n- You may assume that all inputs are consist of lowercase letters `a-z`.\r\n- All inputs are guaranteed to be non-empty strings.\r\n\r\n* Mysolution:\r\n\r\n```python\r\nfrom collections import defaultdict\r\nclass TrieNode:\r\n def __init__(self):\r\n self.children = defaultdict(TrieNode)\r\n self.isword = False\r\n\t\t\r\nclass Trie:\r\n\r\n def __init__(self):\r\n \"\"\"\r\n Initialize your data structure here.\r\n \"\"\"\r\n self.root = TrieNode()\r\n\r\n def insert(self, word):\r\n \"\"\"\r\n Inserts a word into the trie.\r\n :type word: str\r\n :rtype: void\r\n \"\"\"\r\n cur = self.root\r\n for letter in word:\r\n cur = cur.children[letter]\r\n cur.isword = True\r\n\r\n def search(self, word):\r\n \"\"\"\r\n Returns if the word is in the trie.\r\n :type word: str\r\n :rtype: bool\r\n \"\"\"\r\n cur = self.root\r\n for letter in word:\r\n if letter in cur.children:\r\n cur = cur.children[letter]\r\n else:\r\n return False\r\n return cur.isword\r\n\r\n def startsWith(self, prefix):\r\n \"\"\"\r\n Returns if there is any word in the trie that starts with the given prefix.\r\n :type prefix: str\r\n :rtype: bool\r\n \"\"\"\r\n cur = self.root\r\n for letter in prefix:\r\n if letter in cur.children:\r\n cur = cur.children[letter]\r\n else:\r\n return False\r\n return True\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 222 Count Complete Tree Nodes\r\n\r\nGiven a **complete** binary tree, count the number of nodes.\r\n\r\n**Note:**\r\n\r\n**Definition of a complete binary tree from Wikipedia:**\r\nIn a complete binary tree every level, except possibly the last, is completely filled, and all nodes in the last level are as far left as possible. It can have between 1 and 2h nodes inclusive at the last level h.\r\n\r\n**Example:**\r\n\r\n```\r\nInput: \r\n 1\r\n / \\\r\n 2 3\r\n / \\ /\r\n4 5 6\r\n\r\nOutput: 6\r\n```\r\n\r\n```python\r\n# Definition for a binary tree node.\r\n# class TreeNode:\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.left = None\r\n# self.right = None\r\n\r\nclass Solution:\r\n def countNodes(self, root: TreeNode) -> int:\r\n self.count = 0\r\n def count(root):\r\n if not root:\r\n return\r\n self.count += 1\r\n count(root.left)\r\n count(root.right)\r\n count(root)\r\n return self.count\r\n \r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 226 Invert Binary Tree\r\n\r\n* Invert a binary tree.\r\n\r\n```\r\ninput:\r\n 4\r\n / \\\r\n 2 7\r\n / \\ / \\\r\n1 3 6 9\r\noutput:\r\n 4\r\n / \\\r\n 7 2\r\n / \\ / \\\r\n9 6 3 1\r\n```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution(object):\r\n def invertTree(self, root):\r\n def invert(root1,root2):\r\n if root1==None:\r\n return\r\n else:\r\n root2.val=root1.val\r\n if root1.left!=None:\r\n root2.right=TreeNode(-1)\r\n invert(root1.left,root2.right)\r\n if root1.right!=None:\r\n root2.left=TreeNode(-1)\r\n invert(root1.right,root2.left)\r\n if root==None:\r\n return\r\n root_new=TreeNode(-1)\r\n invert(root,root_new)\r\n return root_new\r\n```\r\n\r\n递归生成root_new\r\n\r\n\r\n\r\n##### leetcode 230 Kth Smallest Element in a BST\r\n\r\nGiven a binary search tree, write a function `kthSmallest` to find the **k**th smallest element in it.\r\n\r\n**Note:**\r\nYou may assume k is always valid, 1 ≤ k ≤ BST's total elements.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: root = [3,1,4,null,2], k = 1\r\n 3\r\n / \\\r\n 1 4\r\n \\\r\n 2\r\nOutput: 1\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: root = [5,3,6,2,4,null,null,1], k = 3\r\n 5\r\n / \\\r\n 3 6\r\n / \\\r\n 2 4\r\n /\r\n 1\r\nOutput: 3\r\n```\r\n\r\n```python\r\n# Definition for a binary tree node.\r\n# class TreeNode:\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.left = None\r\n# self.right = None\r\n\r\nclass Solution:\r\n def kthSmallest(self, root: TreeNode, k: int) -> int:\r\n self.nums = []\r\n def pre_order(root):\r\n if not root:\r\n return\r\n pre_order(root.left)\r\n self.nums.append(root.val)\r\n pre_order(root.right)\r\n return\r\n pre_order(root)\r\n return self.nums[k-1]\r\n```\r\n\r\n这是我一开始想到的方法 先得到所有nums得到的数组,取第k个\r\n\r\n但是这样的复杂度其实比较高,有iterative的方法 更好\r\n\r\n```python\r\n class Solution:\r\n # @param {TreeNode} root\r\n # @param {integer} k\r\n # @return {integer}\r\n def kthSmallest(self, root, k):\r\n i=0\r\n stack=[]\r\n node=root\r\n while node or stack:\r\n while node:\r\n stack.append(node)\r\n node=node.left\r\n node=stack.pop()\r\n i+=1\r\n if i==k:\r\n return node.val\r\n node=node.right\r\n```\r\n\r\n用stack来存已经发现的节点\r\n\r\n每次弹出节点后先把其left的节点都拿过来,直到遇到node==None, 然后弹出node(同时+1) 再判断右侧有没有\r\n\r\n\r\n\r\n##### leetcode 236 Lowest Common Ancestor\r\n\r\n* Given a binary tree, find the lowest common ancestor (LCA) of two given nodes in the tree.\r\n\r\n According to the [definition of LCA on Wikipedia](https://en.wikipedia.org/wiki/Lowest_common_ancestor): “The lowest common ancestor is defined between two nodes p and q as the lowest node in T that has both p and q as descendants (where we allow **a node to be a descendant of itself**).”\r\n\r\n Given the following binary tree: root = [3,5,1,6,2,0,8,null,null,7,4]\r\n\r\n\r\n\r\n```\r\nInput: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1\r\nOutput: 3\r\nExplanation: The LCA of nodes 5 and 1 is 3.\r\n\r\nInput: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4\r\nOutput: 5\r\nExplanation: The LCA of nodes 5 and 4 is 5, since a node can be a descendant of itself according to the LCA definition.\r\n```\r\n\r\n\r\n\r\n```python\r\nclass Solution:\r\n def lowestCommonAncestor(self, root, p, q):\r\n \"\"\"\r\n :type root: TreeNode\r\n :type p: TreeNode\r\n :type q: TreeNode\r\n :rtype: TreeNode\r\n \"\"\"\r\n if not root:\r\n return\r\n if root==p or root==q:\r\n return root\r\n left=self.lowestCommonAncestor(root.left,p,q)\r\n right=self.lowestCommonAncestor(root.right,p,q)\r\n if left and right:\r\n return root\r\n if left:\r\n return left\r\n else:\r\n return right\r\n```\r\n\r\n如果left和right非null表示 p q在两边\r\n如果一个是空,则返回另一个(表示pq都在另一侧 这个也是从下面传上来的)\r\n\r\n\r\n\r\n##### leetcode 297 Serialize and Deserialize Binary Tree\r\n\r\n* Serialization is the process of converting a data structure or object into a sequence of bits so that it can be stored in a file or memory buffer, or transmitted across a network connection link to be reconstructed later in the same or another computer environment.\r\n\r\n Design an algorithm to serialize and deserialize a binary tree. There is no restriction on how your serialization/deserialization algorithm should work. You just need to ensure that a binary tree can be serialized to a string and this string can be deserialized to the original tree structure.、\r\n\r\n```\r\nYou may serialize the following tree:\r\n\r\n 1\r\n / \\\r\n 2 3\r\n / \\\r\n 4 5\r\n\r\nas \"[1,2,3,null,null,4,5]\"\r\n```\r\n\r\n```python\r\nclass Codec:\r\n def serialize(self, root):\r\n def doit(node):\r\n if node:\r\n vals.append(str(node.val))\r\n doit(node.left)\r\n doit(node.right)\r\n else:\r\n vals.append('#')\r\n vals = []\r\n doit(root)\r\n return ' '.join(vals)\r\n def deserialize(self, data):\r\n def doit():\r\n val = next(vals)\r\n if val == '#':\r\n return None\r\n node = TreeNode(int(val))\r\n node.left = doit()\r\n node.right = doit()\r\n return node\r\n vals = iter(data.split())\r\n return doit()\r\n```\r\n\r\n\r\n\r\nserialize: '1 2 # # 3 4 # 6 # # 5 # #'\r\n\r\ndeserialize 恢复原图\r\n\r\n本题对于serialize的格式没有要求\r\n\r\n\r\n\r\n##### leetcode 112 Path Sum\r\n\r\nEasy\r\n\r\nGiven a binary tree and a sum, determine if the tree has a root-to-leaf path such that adding up all the values along the path equals the given sum.\r\n\r\n**Note:** A leaf is a node with no children.\r\n\r\n**Example:**\r\n\r\nGiven the below binary tree and `sum = 22`,\r\n\r\n```\r\n 5\r\n / \\\r\n 4 8\r\n / / \\\r\n 11 13 4\r\n / \\ \\\r\n7 2 1\r\n```\r\n\r\nreturn true, as there exist a root-to-leaf path `5->4->11->2` which sum is 22.\r\n\r\n```python\r\n# Definition for a binary tree node.\r\n# class TreeNode(object):\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.left = None\r\n# self.right = None\r\n\r\nclass Solution(object):\r\n def hasPathSum(self, root, sum):\r\n \"\"\"\r\n :type root: TreeNode\r\n :type sum: int\r\n :rtype: bool\r\n \"\"\"\r\n def pathsum(root,sum):\r\n if root.left==None and root.right==None:\r\n if sum==root.val:\r\n return True\r\n else:\r\n return False\r\n index1=index2=False\r\n if root.left:\r\n index1=pathsum(root.left,sum-root.val)\r\n if root.right:\r\n index2=pathsum(root.right,sum-root.val)\r\n return index1 or index2\r\n if root==None:\r\n return False\r\n return pathsum(root,sum)\r\n \r\n \r\n```\r\n\r\n\r\n\r\n##### leetcode 113 Path Sum II\r\n\r\nGiven a binary tree and a sum, find all root-to-leaf paths where each path's sum equals the given sum.\r\n\r\n**Note:** A leaf is a node with no children.\r\n\r\n**Example:**\r\n\r\nGiven the below binary tree and `sum = 22`,\r\n\r\n```\r\n 5\r\n / \\\r\n 4 8\r\n / / \\\r\n 11 13 4\r\n / \\ / \\\r\n7 2 5 1\r\n```\r\n\r\nReturn:\r\n\r\n```\r\n[\r\n [5,4,11,2],\r\n [5,8,4,5]\r\n]\r\n```\r\n\r\n```python\r\n# Definition for a binary tree node.\r\n# class TreeNode:\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.left = None\r\n# self.right = None\r\n\r\nclass Solution:\r\n def pathSum(self, root, sum):\r\n \"\"\"\r\n :type root: TreeNode\r\n :type sum: int\r\n :rtype: List[List[int]]\r\n \"\"\"\r\n def helper(root,sum,path,res):\r\n if root==None:\r\n return\r\n if root.left==None and root.right==None and sum==root.val:\r\n path.append(root.val)\r\n res.append(path)\r\n return\r\n helper(root.left,sum-root.val,path+[root.val],res)\r\n helper(root.right,sum-root.val,path+[root.val],res)\r\n if not root:\r\n return []\r\n res=[]\r\n helper(root,sum,[],res)\r\n return res\r\n```\r\n\r\n\r\n\r\n##### leetcode 437 Path Sum III\r\n\r\n- You are given a binary tree in which each node contains an integer value.\r\n\r\n Find the number of paths that sum to a given value.\r\n\r\n The path does not need to start or end at the root or a leaf, but it must go downwards (traveling only from parent nodes to child nodes).\r\n\r\n The tree has no more than 1,000 nodes and the values are in the range -1,000,000 to 1,000,000.\r\n\r\n```\r\nroot = [10,5,-3,3,2,null,11,3,-2,null,1], sum = 8\r\n\r\n 10\r\n / \\\r\n 5 -3\r\n / \\ \\\r\n 3 2 11\r\n / \\ \\\r\n3 -2 1\r\n\r\nReturn 3. The paths that sum to 8 are:\r\n\r\n1. 5 -> 3\r\n2. 5 -> 2 -> 1\r\n3. -3 -> 11\r\n```\r\n\r\n\r\n\r\n- Mysolution:\r\n\r\n```python\r\nclass Solution(object):\r\n def pathSum(self, root, sum):\r\n def find_path(root,sum):\r\n if not root:\r\n return 0\r\n if root.val==sum:\r\n index=1\r\n else:\r\n index=0\r\n return index+find_path(root.left,sum-root.val)+find_path(root.right,sum-root.val)\r\n if root:\r\n return find_path(root,sum)+self.pathSum(root.left,sum)+self.pathSum(root.right,sum)\r\n return 0\r\n```\r\n\r\nfind_path(root,sum):在本节点考虑path,即path包含了root节点,因此才需要\r\n\r\n```python\r\nfind_path(root,sum)+self.pathSum(root.left,sum)+self.pathSum(root.right,sum)\r\n```\r\n\r\n\r\n\r\n##### leetcode 366 Find Leaves of Binary Tree\r\n\r\nGiven a binary tree, collect a tree's nodes as if you were doing this: Collect and remove all leaves, repeat until the tree is empty.\r\n\r\n**Example:**\r\n\r\n```\r\nInput: [1,2,3,4,5]\r\n \r\n 1\r\n / \\\r\n 2 3\r\n / \\ \r\n 4 5 \r\n\r\nOutput: [[4,5,3],[2],[1]]\r\n```\r\n\r\n**Explanation:**\r\n\r\n\\1. Removing the leaves `[4,5,3]` would result in this tree:\r\n\r\n```\r\n 1\r\n / \r\n 2 \r\n```\r\n\r\n\\2. Now removing the leaf `[2]` would result in this tree:\r\n\r\n```\r\n 1 \r\n```\r\n\r\n\\3. Now removing the leaf `[1]` would result in the empty tree:\r\n\r\n```\r\n [] \r\n```\r\n\r\n这其实就是在统计所有节点的高度\r\n\r\n```python\r\n# Definition for a binary tree node.\r\n# class TreeNode:\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.left = None\r\n# self.right = None\r\n\r\nclass Solution(object):\r\n def findLeaves(self, root):\r\n def order(root, dic):\r\n if not root:\r\n return 0\r\n left = order(root.left, dic)\r\n right = order(root.right, dic)\r\n lev = max(left, right) + 1\r\n dic[lev] += root.val,\r\n return lev\r\n dic, ret = collections.defaultdict(list), []\r\n order(root, dic)\r\n for i in range(1, len(dic) + 1):\r\n ret.append(dic[i])\r\n return ret\r\n \r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 968 Binary Tree Cameras\r\n\r\n* Given a binary tree, we install cameras on the nodes of the tree. \r\n\r\n Each camera at a node can monitor **its parent, itself, and its immediate children**.\r\n\r\n Calculate the minimum number of cameras needed to monitor all nodes of the tree.\r\n\r\n \r\n\r\n ```\r\n Input: [0,0,null,0,0]\r\n Output: 1\r\n Explanation: One camera is enough to monitor all nodes if placed as shown.\r\n ```\r\n\r\n \r\n\r\n ```\r\n Input: [0,0,null,0,null,0,null,null,0]\r\n Output: 2\r\n Explanation: At least two cameras are needed to monitor all nodes of the tree. The above image shows one of the valid configurations of camera placement.\r\n ```\r\n\r\n\r\n\r\n ```python\r\n class Solution:\r\n def minCameraCover(self, root):\r\n self.res=0\r\n def dfs(root):\r\n if not root:\r\n return 2\r\n if not root.left and not root.right:\r\n return 0\r\n left,right=dfs(root.left),dfs(root.right)\r\n if left==0 or right==0: #child is leaf\r\n self.res+=1\r\n return 1\r\n if left==1 or right==1:\r\n return 2 #its child has a camera\r\n return 0 #becomes a leaf\r\n if root==None:\r\n return 0\r\n if dfs(root)==0: #still has a root to camera\r\n return self.res+1\r\n return self.res\r\n ```\r\n\r\n 本题属于DFS\r\n\r\n 考虑到在节点上放置camera效果必然不如在节点的parent节点上放置\r\n\r\n 因此在所有的叶子parent节点上放置camera\r\n\r\n 如果节点是叶子节点则用0表示\r\n\r\n 如果节点是叶子节点的parent 需要放置camera,用1表示\r\n\r\n 如果节点子节点放置了camera,则用2 表示\r\n\r\n\r\n\r\n\tleft==0 or right==0 表示该节点是叶子节点的parent 需要放置camera\r\n\r\n\tleft==1 or right==1 说明该节点的子节点放置了camera 返回2 收到2 的上一层相当于把这一分支置为none\r\n\r\n\t如果还没有执行操作说明该节点的子节点均通过camera被消除(left==right==2),返回0 将其视为叶子节点\r\n\r\n\r\n\r\n##### leetcode 538 Convert BST to Greater Tree\r\n\r\n* Given a Binary Search Tree (BST), convert it to a Greater Tree such that every key of the original BST is changed to the original key plus sum of all keys greater than the original key in BST.\r\n\r\n```\r\nInput: The root of a Binary Search Tree like this:\r\n 5\r\n / \\\r\n 2 13\r\n\r\nOutput: The root of a Greater Tree like this:\r\n 18\r\n / \\\r\n 20 13\r\n```\r\n\r\n* Mysolution:\r\n\r\n```python\r\n# Definition for a binary tree node.\r\nclass TreeNode(object):\r\n def __init__(self, x):\r\n self.val = x\r\n self.left = None\r\n self.right = None\r\n\r\nclass Solution(object):\r\n def convertBST(self, root):\r\n self.nums=[]\r\n self.s=0\r\n def helper_nums(root):\r\n if not root:\r\n return\r\n helper_nums(root.left)\r\n self.nums.append(root.val)\r\n helper_nums(root.right)\r\n return\r\n def helper_tree(root):\r\n if not root:\r\n return\r\n helper_tree(root.right)\r\n self.s+=self.nums.pop()\r\n root.val=self.s\r\n helper_tree(root.left)\r\n return\r\n helper_nums(root)\r\n self.nums.sort()\r\n helper_tree(root)\r\n return root\r\n```\r\n\r\n利用BST的性质\r\n不然每次找比root.val大的数字 复杂度比较高\r\n\r\nhelper_nums把所有的nums都保存下来\r\n\r\n从树的右节点开始 结束程序之后,每个节点上的val都等于self.s self.s是随着nums不断弹出不断增大,利用了二叉树的性质\r\n\r\n\r\n\r\n##### leetcode 543 Diameter of Binary Tree\r\n\r\n* Given a binary tree, you need to compute the length of the diameter of the tree. The diameter of a binary tree is the length of the **longest**path between any two nodes in a tree. This path may or may not pass through the root.\r\n\r\nReturn **3**, which is the length of the path [4,2,1,3] or [5,2,1,3].\r\n\r\n**Note:** The length of path between two nodes is represented by the number of edges between them.\r\n\r\n```\r\n 1\r\n / \\\r\n 2 3\r\n / \\ \r\n 4 5 \r\n```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution(object):\r\n def diameterOfBinaryTree(self, root):\r\n \"\"\"\r\n :type root: TreeNode\r\n :rtype: int\r\n \"\"\"\r\n self.ans = 0\r\n\r\n def depth(p):\r\n if not p: return 0\r\n left, right = depth(p.left), depth(p.right)\r\n self.ans = max(self.ans, left + right)\r\n return 1 + max(left, right)\r\n\r\n depth(root)\r\n return self.ans\r\n```\r\n\r\n递归BFS\r\n\r\nleft+right为该节点的diameter\r\n\r\n1+max(left,right)为该节点的height\r\n\r\n\r\n\r\n##### leetcode 572 Subtree of Another Tree\r\n\r\n* Given two non-empty binary trees **s** and **t**, check whether tree **t** has exactly the same structure and node values with a subtree of **s**. A subtree of **s** is a tree consists of a node in **s** and all of this node's descendants. The tree **s** could also be considered as a subtree of itself.\r\n\r\n**Example 1:**\r\nGiven tree s:\r\n\r\n```\r\n 3\r\n / \\\r\n 4 5\r\n / \\\r\n 1 2\r\n```\r\n\r\nGiven tree t:\r\n\r\n```\r\n 4 \r\n / \\\r\n 1 2\r\n```\r\n\r\nReturn \r\n\r\ntrue\r\n\r\n, because t has the same structure and node values with a subtree of s.\r\n\r\n**Example 2:**\r\nGiven tree s:\r\n\r\n```\r\n 3\r\n / \\\r\n 4 5\r\n / \\\r\n 1 2\r\n /\r\n 0\r\n```\r\n\r\nGiven tree t:\r\n\r\n```\r\n 4\r\n / \\\r\n 1 2\r\n```\r\n\r\nReturn **false**\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution(object):\r\n def isSubtree(self, s, t):\r\n def check(s,t):\r\n if s==None and t==None:\r\n return True\r\n elif (s==None and t!=None) or (s!=None and t==None):\r\n return False\r\n if s.val!=t.val:\r\n return False\r\n return check(s.left,t.left) and check(s.right,t.right)\r\n\r\n def dfs(s,t):\r\n if s==None:\r\n return False\r\n if s.val==t.val and check(s,t):\r\n return True\r\n return dfs(s.left,t) or dfs(s.right,t)\r\n if t==None:\r\n return True\r\n return dfs(s,t)\r\n```\r\n\r\ncheck函数表示检测两个tree是否相同\r\n\r\ndfs遍历节点,同时利用check进行检测\r\n\r\n\r\n\r\n##### leetcode 617 Merge Two Binary Trees\r\n\r\n* Given two binary trees and imagine that when you put one of them to cover the other, some nodes of the two trees are overlapped while the others are not.\r\n\r\n You need to merge them into a new binary tree. The merge rule is that if two nodes overlap, then sum node values up as the new value of the merged node. Otherwise, the NOT null node will be used as the node of new tree.\r\n\r\n```\r\nInput: \r\n\tTree 1 Tree 2 \r\n 1 2 \r\n / \\ / \\ \r\n 3 2 1 3 \r\n / \\ \\ \r\n 5 4 7 \r\nOutput: \r\nMerged tree:\r\n\t 3\r\n\t / \\\r\n\t 4 5\r\n\t / \\ \\ \r\n\t 5 4 7\r\n```\r\n\r\n**Note:** The merging process must start from the root nodes of both trees.\r\n\r\n\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution(object):\r\n def mergeTrees(self, t1, t2):\r\n \"\"\"\r\n :type t1: TreeNode\r\n :type t2: TreeNode\r\n :rtype: TreeNode\r\n \"\"\"\r\n if t1==None and t2==None:\r\n return\r\n elif t1!=None and t2==None:\r\n return t1\r\n elif t2!=None and t1==None:\r\n return t2\r\n else:\r\n node=Node(t1.v+t2.v)\r\n node.left=self.mergeTrees(t1.l,t2.l)\r\n node.right=self.mergeTrees(t1.r,t2.r)\r\n return node\r\n```\r\n\r\n将两个binary tree merge起来 \r\n\r\nif t1==None: return t2\r\n\r\nif t2==None:return t1\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 971 Flip Binary Tree To Match Preorder Traversal\r\n\r\n* Given a binary tree with `N` nodes, each node has a different value from `{1, ..., N}`.\r\n\r\n A node in this binary tree can be *flipped* by swapping the left child and the right child of that node.\r\n\r\n Consider the sequence of `N` values reported by a preorder traversal starting from the root. Call such a sequence of `N` values the *voyage* of the tree.\r\n\r\n (Recall that a *preorder traversal* of a node means we report the current node's value, then preorder-traverse the left child, then preorder-traverse the right child.)\r\n\r\n Our goal is to flip the **least number** of nodes in the tree so that the voyage of the tree matches the `voyage` we are given.\r\n\r\n If we can do so, then return a list of the values of all nodes flipped. You may return the answer in any order.\r\n\r\n If we cannot do so, then return the list `[-1]`.\r\n\r\n```\r\nInput: root = [1,2], voyage = [2,1]\r\nOutput: [-1]\r\n\r\nInput: root = [1,2,3], voyage = [1,3,2]\r\nOutput: [1]\r\n\r\nInput: root = [1,2,3], voyage = [1,2,3]\r\nOutput: []\r\n```\r\n\r\n1. `1 <= N <= 100`\r\n\r\n```python\r\nclass Solution(object):\r\n def flipMatchVoyage(self, root, voyage):\r\n self.next=0\r\n self.res=[]\r\n def dfs(root):\r\n if not root:#如果root到了None 则返回True\r\n return True\r\n if root.val!=self.nums[self.next]:\r\n return False\r\n else:\r\n self.next+=1\r\n if root.left and self.nums[self.next]==root.left.val:##要考虑root.left是否存在\r\n return dfs(root.left) and dfs(root.right)\r\n if root.right and self.nums[self.next]==root.right.val:\r\n if root.left:##如果root.left存在还执行到这一步 说明需要flip,否则可能存在left==None的情况\r\n self.res.append(root.val)\r\n return dfs(root.right) and dfs(root.left)\r\n return root.left==root.right==None##这边需要判断是已经执行到最后了 返回True 还是在root.left和root.right中都找不到nums[self.next]返回False\r\n\r\n self.nums=voyage\r\n if dfs(root):\r\n return self.res\r\n return [-1]\r\n```\r\n\r\n##### leetcode 1161 Maximum Level Sum of a Binary Tree\r\n\r\nGiven the `root` of a binary tree, the level of its root is `1`, the level of its children is `2`, and so on.\r\n\r\nReturn the **smallest** level `X` such that the sum of all the values of nodes at level `X` is **maximal**.\r\n\r\n**Example 1:**\r\n\r\n****\r\n\r\n```\r\nInput: [1,7,0,7,-8,null,null]\r\nOutput: 2\r\nExplanation: \r\nLevel 1 sum = 1.\r\nLevel 2 sum = 7 + 0 = 7.\r\nLevel 3 sum = 7 + -8 = -1.\r\nSo we return the level with the maximum sum which is level 2.\r\n```\r\n\r\n**Note:**\r\n\r\n1. The number of nodes in the given tree is between `1` and `10^4`.\r\n2. `-10^5 <= node.val <= 10^5`\r\n\r\n```python\r\n# Definition for a binary tree node.\r\n# class TreeNode:\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.left = None\r\n# self.right = None\r\n\r\nclass Solution:\r\n def maxLevelSum(self, root):\r\n if not root:\r\n return 0\r\n level, next_level = [], []\r\n level.append(root)\r\n max_sum, index = -float(\"inf\"), -1\r\n step = 0\r\n while level or next_level:\r\n step += 1\r\n tmp_sum = 0\r\n while level:\r\n node = level.pop()\r\n tmp_sum += node.val\r\n if node.left:\r\n next_level.append(node.left)\r\n if node.right:\r\n next_level.append(node.right)\r\n level = copy.deepcopy(next_level)\r\n next_level = []\r\n if max_sum < tmp_sum:\r\n max_sum, index = tmp_sum, step\r\n return index\r\n \r\n```\r\n\r\n这样的方法会导致TLE\r\n\r\n```python\r\n# Definition for a binary tree node.\r\n# class TreeNode:\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.left = None\r\n# self.right = None\r\n\r\nclass Solution:\r\n def maxLevelSum(self, root):\r\n if not root:\r\n return 0\r\n level = collections.deque()\r\n level.append(root)\r\n max_sum, index = -float(\"inf\"), -1\r\n step = 0\r\n while level:\r\n step += 1\r\n tmp_sum = 0\r\n for i in range(len(level)):\r\n node = level.popleft()\r\n tmp_sum += node.val\r\n if node.left:\r\n level.append(node.left)\r\n if node.right:\r\n level.append(node.right)\r\n if max_sum < tmp_sum:\r\n max_sum, index = tmp_sum, step\r\n return index\r\n```\r\n\r\n改进方法如上所示\r\n\r\n使用deque, 第二层用for循环 这样的话就不用copy了 \r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 1261 Find Elements in a Contaminated Binary Tree\r\n\r\nGiven a binary tree with the following rules:\r\n\r\n1. `root.val == 0`\r\n2. If `treeNode.val == x` and `treeNode.left != null`, then `treeNode.left.val == 2 * x + 1`\r\n3. If `treeNode.val == x` and `treeNode.right != null`, then `treeNode.right.val == 2 * x + 2`\r\n\r\nNow the binary tree is contaminated, which means all `treeNode.val` have been changed to `-1`.\r\n\r\nYou need to first recover the binary tree and then implement the `FindElements` class:\r\n\r\n- `FindElements(TreeNode* root)` Initializes the object with a contamined binary tree, you need to recover it first.\r\n- `bool find(int target)` Return if the `target` value exists in the recovered binary tree.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n****\r\n\r\n```\r\nInput\r\n[\"FindElements\",\"find\",\"find\"]\r\n[[[-1,null,-1]],[1],[2]]\r\nOutput\r\n[null,false,true]\r\nExplanation\r\nFindElements findElements = new FindElements([-1,null,-1]); \r\nfindElements.find(1); // return False \r\nfindElements.find(2); // return True \r\n```\r\n\r\n**Example 2:**\r\n\r\n****\r\n\r\n```\r\nInput\r\n[\"FindElements\",\"find\",\"find\",\"find\"]\r\n[[[-1,-1,-1,-1,-1]],[1],[3],[5]]\r\nOutput\r\n[null,true,true,false]\r\nExplanation\r\nFindElements findElements = new FindElements([-1,-1,-1,-1,-1]);\r\nfindElements.find(1); // return True\r\nfindElements.find(3); // return True\r\nfindElements.find(5); // return False\r\n```\r\n\r\n**Example 3:**\r\n\r\n****\r\n\r\n```\r\nInput\r\n[\"FindElements\",\"find\",\"find\",\"find\",\"find\"]\r\n[[[-1,null,-1,-1,null,-1]],[2],[3],[4],[5]]\r\nOutput\r\n[null,true,false,false,true]\r\nExplanation\r\nFindElements findElements = new FindElements([-1,null,-1,-1,null,-1]);\r\nfindElements.find(2); // return True\r\nfindElements.find(3); // return False\r\nfindElements.find(4); // return False\r\nfindElements.find(5); // return True\r\n```\r\n\r\n \r\n\r\n**Constraints:**\r\n\r\n- `TreeNode.val == -1`\r\n- The height of the binary tree is less than or equal to `20`\r\n- The total number of nodes is between `[1, 10^4]`\r\n- Total calls of `find()` is between `[1, 10^4]`\r\n- `0 <= target <= 10^6`\r\n\r\n```python\r\nclass FindElements:\r\n\r\n def __init__(self, root: TreeNode):\r\n if not root:\r\n return\r\n self.nums = set()\r\n self.root = self.build(root, 0)\r\n return\r\n\r\n def build(self, root, val):\r\n if not root:\r\n return\r\n root.val = val\r\n self.nums.add(val)\r\n root.left = self.build(root.left, val*2+1)\r\n root.right = self.build(root.right, val*2+2)\r\n return root\r\n\r\n def find(self, target: int) -> bool:\r\n if target in self.nums:\r\n return True\r\n return False\r\n```\r\n\r\n\r\n\r\n##### leetcode 988 Smallest String Starting From Leaf\r\n\r\n- Given the `root` of a binary tree, each node has a value from `0` to `25` representing the letters `'a'` to `'z'`: a value of `0` represents `'a'`, a value of `1` represents `'b'`, and so on.\r\n\r\n Find the lexicographically smallest string that starts at a leaf of this tree and ends at the root.\r\n\r\n *(As a reminder, any shorter prefix of a string is lexicographically smaller: for example, \"ab\" is lexicographically smaller than \"aba\". A leaf of a node is a node that has no children.)*\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n```\r\nInput: [0,1,2,3,4,3,4]\r\nOutput: \"dba\"\r\n\r\nInput: [25,1,3,1,3,0,2]\r\nOutput: \"adz\"\r\n\r\nInput: [2,2,1,null,1,0,null,0]\r\nOutput: \"abc\"\r\n\r\n```\r\n\r\n**Note:**\r\n\r\n1. The number of nodes in the given tree will be between `1` and `1000`.\r\n2. Each node in the tree will have a value between `0` and `25`.\r\n\r\n```python\r\nclass Solution: \r\n def smallestFromLeaf(self, root: 'TreeNode') -> 'str':\r\n if root==None:\r\n return \"\"\r\n left=self.smallestFromLeaf(root.left)\r\n right=self.smallestFromLeaf(root.right)\r\n if right==\"\" or (left!=\"\" and left<right):\r\n return left+chr(97+root.val)\r\n else:\r\n return right+chr(97+root.val)\r\n```\r\n\r\n\r\n\r\n##### leetcode 510 Inorder Successor in BST II\r\n\r\nGiven a binary search tree and a node in it, find the in-order successor of that node in the BST.\r\n\r\nThe successor of a node `p` is the node with the smallest key greater than `p.val`.\r\n\r\nYou will have direct access to the node but not to the root of the tree. Each node will have a reference to its parent node.\r\n\r\n**Example 1:**\r\n\r\n\r\n\r\n```\r\nInput: \r\nroot = {\"$id\":\"1\",\"left\":{\"$id\":\"2\",\"left\":null,\"parent\":{\"$ref\":\"1\"},\"right\":null,\"val\":1},\"parent\":null,\"right\":{\"$id\":\"3\",\"left\":null,\"parent\":{\"$ref\":\"1\"},\"right\":null,\"val\":3},\"val\":2}\r\np = 1\r\nOutput: 2\r\nExplanation: 1's in-order successor node is 2. Note that both p and the return value is of Node type.\r\n```\r\n\r\n**Example 2:**\r\n\r\n\r\n\r\n```\r\nInput: \r\nroot = {\"$id\":\"1\",\"left\":{\"$id\":\"2\",\"left\":{\"$id\":\"3\",\"left\":{\"$id\":\"4\",\"left\":null,\"parent\":{\"$ref\":\"3\"},\"right\":null,\"val\":1},\"parent\":{\"$ref\":\"2\"},\"right\":null,\"val\":2},\"parent\":{\"$ref\":\"1\"},\"right\":{\"$id\":\"5\",\"left\":null,\"parent\":{\"$ref\":\"2\"},\"right\":null,\"val\":4},\"val\":3},\"parent\":null,\"right\":{\"$id\":\"6\",\"left\":null,\"parent\":{\"$ref\":\"1\"},\"right\":null,\"val\":6},\"val\":5}\r\np = 6\r\nOutput: null\r\nExplanation: There is no in-order successor of the current node, so the answer is null.\r\n```\r\n\r\n**Example 3:**\r\n\r\n\r\n\r\n```\r\nInput: \r\nroot = {\"$id\":\"1\",\"left\":{\"$id\":\"2\",\"left\":{\"$id\":\"3\",\"left\":{\"$id\":\"4\",\"left\":null,\"parent\":{\"$ref\":\"3\"},\"right\":null,\"val\":2},\"parent\":{\"$ref\":\"2\"},\"right\":{\"$id\":\"5\",\"left\":null,\"parent\":{\"$ref\":\"3\"},\"right\":null,\"val\":4},\"val\":3},\"parent\":{\"$ref\":\"1\"},\"right\":{\"$id\":\"6\",\"left\":null,\"parent\":{\"$ref\":\"2\"},\"right\":{\"$id\":\"7\",\"left\":{\"$id\":\"8\",\"left\":null,\"parent\":{\"$ref\":\"7\"},\"right\":null,\"val\":9},\"parent\":{\"$ref\":\"6\"},\"right\":null,\"val\":13},\"val\":7},\"val\":6},\"parent\":null,\"right\":{\"$id\":\"9\",\"left\":{\"$id\":\"10\",\"left\":null,\"parent\":{\"$ref\":\"9\"},\"right\":null,\"val\":17},\"parent\":{\"$ref\":\"1\"},\"right\":{\"$id\":\"11\",\"left\":null,\"parent\":{\"$ref\":\"9\"},\"right\":null,\"val\":20},\"val\":18},\"val\":15}\r\np = 15\r\nOutput: 17\r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: \r\nroot = {\"$id\":\"1\",\"left\":{\"$id\":\"2\",\"left\":{\"$id\":\"3\",\"left\":{\"$id\":\"4\",\"left\":null,\"parent\":{\"$ref\":\"3\"},\"right\":null,\"val\":2},\"parent\":{\"$ref\":\"2\"},\"right\":{\"$id\":\"5\",\"left\":null,\"parent\":{\"$ref\":\"3\"},\"right\":null,\"val\":4},\"val\":3},\"parent\":{\"$ref\":\"1\"},\"right\":{\"$id\":\"6\",\"left\":null,\"parent\":{\"$ref\":\"2\"},\"right\":{\"$id\":\"7\",\"left\":{\"$id\":\"8\",\"left\":null,\"parent\":{\"$ref\":\"7\"},\"right\":null,\"val\":9},\"parent\":{\"$ref\":\"6\"},\"right\":null,\"val\":13},\"val\":7},\"val\":6},\"parent\":null,\"right\":{\"$id\":\"9\",\"left\":{\"$id\":\"10\",\"left\":null,\"parent\":{\"$ref\":\"9\"},\"right\":null,\"val\":17},\"parent\":{\"$ref\":\"1\"},\"right\":{\"$id\":\"11\",\"left\":null,\"parent\":{\"$ref\":\"9\"},\"right\":null,\"val\":20},\"val\":18},\"val\":15}\r\np = 13\r\nOutput: 15\r\n```\r\n\r\n```python\r\n\"\"\"\r\n# Definition for a Node.\r\nclass Node:\r\n def __init__(self, val, left, right, parent):\r\n self.val = val\r\n self.left = left\r\n self.right = right\r\n self.parent = parent\r\n\"\"\"\r\nclass Solution:\r\n def inorderSuccessor(self, node: 'Node') -> 'Node':\r\n if node.right:#如果node节点有右儿子,则找到右侧中最左边的节点\r\n temp = node.right\r\n while temp.left:\r\n temp = temp.left\r\n return temp\r\n else:\r\n temp = node #否则,向上找parent节点\r\n while temp.val <= node.val and temp.parent:\r\n temp = temp.parent\r\n if temp.parent == None and temp.val <= node.val: #没有找到更大的parent节点 返回None\r\n return None\r\n return temp\r\n```\r\n\r\n##### leetcode 863 All Nodes Distance K in Binary Tree\r\n\r\nWe are given a binary tree (with root node `root`), a `target` node, and an integer value `K`.\r\n\r\nReturn a list of the values of all nodes that have a distance `K` from the `target` node. The answer can be returned in any order.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: root = [3,5,1,6,2,0,8,null,null,7,4], target = 5, K = 2\r\n\r\nOutput: [7,4,1]\r\n\r\nExplanation: \r\nThe nodes that are a distance 2 from the target node (with value 5)\r\nhave values 7, 4, and 1.\r\n\r\n\r\n\r\nNote that the inputs \"root\" and \"target\" are actually TreeNodes.\r\nThe descriptions of the inputs above are just serializations of these objects.\r\n```\r\n\r\n**Note:**\r\n\r\n1. The given tree is non-empty.\r\n2. Each node in the tree has unique values `0 <= node.val <= 500`.\r\n3. The `target` node is a node in the tree.\r\n4. `0 <= K <= 1000`.\r\n\r\n如果不是在tree结构中这题就是简单的BFS就可以解决,因此 先将结构转化为graph然后再使用BFS\r\n\r\n```python\r\n# Definition for a binary tree node.\r\n# class TreeNode:\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.left = None\r\n# self.right = None\r\n\r\nclass Solution:\r\n def build_graph(self, root):\r\n if not root: return\r\n if root.left:\r\n self.graph[root.val].add(root.left.val)\r\n self.graph[root.left.val].add(root.val)\r\n self.build_graph(root.left)\r\n if root.right:\r\n self.graph[root.val].add(root.right.val)\r\n self.graph[root.right.val].add(root.val)\r\n self.build_graph(root.right)\r\n return\r\n def distanceK(self, root: TreeNode, target: TreeNode, K: int) -> List[int]:\r\n self.graph = collections.defaultdict(set)\r\n self.build_graph(root)\r\n seen = set([target.val])\r\n level, next_level = [target.val], [] \r\n while level and K>0:\r\n while level:\r\n node = level.pop()\r\n for nei in self.graph[node]:\r\n if nei not in seen:\r\n seen.add(nei)\r\n next_level.append(nei)\r\n level = copy.deepcopy(next_level)\r\n next_level = []\r\n K -= 1\r\n return level\r\n```\r\n\r\n\r\n\r\n##### leetcode Maximum Difference Between Node and Ancestor\r\n\r\nGiven the `root` of a binary tree, find the maximum value `V` for which there exists **different** nodes `A` and `B` where `V = |A.val - B.val|` and `A` is an ancestor of `B`.\r\n\r\n(A node A is an ancestor of B if either: any child of A is equal to B, or any child of A is an ancestor of B.)\r\n\r\n**Example 1:**\r\n\r\n\r\n\r\n```\r\nInput: [8,3,10,1,6,null,14,null,null,4,7,13]\r\nOutput: 7\r\nExplanation: \r\nWe have various ancestor-node differences, some of which are given below :\r\n|8 - 3| = 5\r\n|3 - 7| = 4\r\n|8 - 1| = 7\r\n|10 - 13| = 3\r\nAmong all possible differences, the maximum value of 7 is obtained by |8 - 1| = 7.\r\n```\r\n\r\n**Note:**\r\n\r\n1. The number of nodes in the tree is between `2` and `5000`.\r\n2. Each node will have value between `0` and `100000`.\r\n\r\n```python\r\n# Definition for a binary tree node.\r\n# class TreeNode:\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.left = None\r\n# self.right = None\r\n\r\nclass Solution:\r\n def maxdiff(self, root, max_ances_val, min_ances_val):\r\n if not root: return\r\n self.res = max(self.res, abs(root.val-max_ances_val), abs(root.val-min_ances_val))\r\n self.maxdiff(root.left, max(max_ances_val, root.val), min(min_ances_val, root.val))\r\n self.maxdiff(root.right, max(max_ances_val, root.val), min(min_ances_val, root.val))\r\n return\r\n def maxAncestorDiff(self, root: TreeNode) -> int:\r\n self.res = 0\r\n if root.left:\r\n self.maxdiff(root.left, root.val, root.val)\r\n if root.right:\r\n self.maxdiff(root.right, root.val, root.val)\r\n return self.res\r\n```\r\n\r\n目标求最大的差值,因此对于每个节点而言,传递其ancestor节点中的最大值与小值\r\n\r\n\r\n\r\n##### 1343. Maximum Product of Splitted Binary Tree\r\n\r\nGiven a binary tree `root`. Split the binary tree into two subtrees by removing 1 edge such that the product of the sums of the subtrees are maximized.\r\n\r\nSince the answer may be too large, return it modulo 10^9 + 7.\r\n\r\n \r\n\r\n**Example 1:**\r\n\r\n****\r\n\r\n```\r\nInput: root = [1,2,3,4,5,6]\r\nOutput: 110\r\nExplanation: Remove the red edge and get 2 binary trees with sum 11 and 10. Their product is 110 (11*10)\r\n```\r\n\r\n**Example 2:**\r\n\r\n\r\n\r\n```\r\nInput: root = [1,null,2,3,4,null,null,5,6]\r\nOutput: 90\r\nExplanation: Remove the red edge and get 2 binary trees with sum 15 and 6.Their product is 90 (15*6)\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: root = [2,3,9,10,7,8,6,5,4,11,1]\r\nOutput: 1025\r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: root = [1,1]\r\nOutput: 1\r\n```\r\n\r\n**Constraints:**\r\n\r\n- Each tree has at most `50000` nodes and at least `2` nodes.\r\n- Each node's value is between `[1, 10000]`.\r\n\r\n```python\r\n# Definition for a binary tree node.\r\n# class TreeNode:\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.left = None\r\n# self.right = None\r\n\r\nclass Solution:\r\n def pre_order(self, root):\r\n if not root:\r\n return\r\n self.all_sum += root.val\r\n self.pre_order(root.left)\r\n self.pre_order(root.right)\r\n return\r\n \r\n def set_sun(self, root):\r\n if not root: return 0\r\n left = self.set_sun(root.left)\r\n self.res = max(self.res, left*(self.all_sum - left))\r\n right = self.set_sun(root.right)\r\n self.res = max(self.res, right*(self.all_sum - right))\r\n return root.val + left + right\r\n \r\n def maxProduct(self, root: TreeNode) -> int:\r\n self.all_sum, self.res = 0, 0\r\n self.pre_order(root)\r\n self.set_sun(root)\r\n return self.res % 1000000007\r\n```\r\n\r\n\r\n\r\n##### leetcode 508 Most Frequent Subtree Sum\r\n\r\n\r\n\r\nGiven the root of a tree, you are asked to find the most frequent subtree sum. The subtree sum of a node is defined as the sum of all the node values formed by the subtree rooted at that node (including the node itself). So what is the most frequent subtree sum value? If there is a tie, return all the values with the highest frequency in any order.\r\n\r\n**Examples 1**\r\nInput:\r\n\r\n```\r\n 5\r\n / \\\r\n2 -3\r\n```\r\n\r\nreturn [2, -3, 4], since all the values happen only once, return all of them in any order.\r\n\r\n\r\n\r\n**Examples 2**\r\nInput:\r\n\r\n```\r\n 5\r\n / \\\r\n2 -5\r\n```\r\n\r\nreturn [2], since 2 happens twice, however -5 only occur once.\r\n\r\n```python\r\n# Definition for a binary tree node.\r\n# class TreeNode:\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.left = None\r\n# self.right = None\r\n\r\nclass Solution:\r\n def helper(self, root):\r\n if not root:\r\n return -float(\"inf\") \r\n left = self.helper(root.left)\r\n right = self.helper(root.right)\r\n num = root.val\r\n if left != -float(\"inf\") :\r\n self.sums[left] += 1\r\n num += left\r\n if right != -float(\"inf\") :\r\n self.sums[right] += 1\r\n num += right\r\n return num\r\n def findFrequentTreeSum(self, root: TreeNode) -> List[int]:\r\n self.sums = collections.defaultdict(int)\r\n sum1 = self.helper(root)\r\n if sum1 != -float(\"inf\") :\r\n self.sums[sum1] += 1\r\n else:\r\n return []\r\n # print(self.sums)\r\n max_val = max(self.sums.values())\r\n res = []\r\n for key, val in self.sums.items():\r\n if val == max_val:\r\n res.append(key)\r\n return res\r\n \r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.5549019575119019,
"alphanum_fraction": 0.5954248309135437,
"avg_line_length": 16.987577438354492,
"blob_id": "7d9eb550e9ffcd0fde031b973d4c8b3230eaff70",
"content_id": "8f76d28b8c95a3ce25cd77cb524ceebe8b9dc05a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 7198,
"license_type": "no_license",
"max_line_length": 175,
"num_lines": 322,
"path": "/python/Python3 Tutorial.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Python3 Tutorial\r\n\r\nShell 介于使用者与操作系统之间。shell中使用_存储最近得到的变量\r\n\r\n```python\r\n>>> 3 + 2 * 4\r\n11\r\n>>> _\r\n11\r\n>>> _ * 3\r\n33\r\n>>> \r\n```\r\n\r\n一般来说,python是一种解释型语言。python解释器解释python源码为字节码(非机器码),通过python虚拟机PVM运行。这一过程与java相似。python中也可以使用module py_compile对python源代码文件进行编译\r\n\r\n```python\r\n>>> import py_compile\r\n>>> py_compile.compile('my_first_simple_program.py')\r\n\r\n\r\npython -m py_compile my_first_simple_program.py\r\n```\r\n\r\n会得到 __ pycache __ 文件夹,然后会有一个.PYC文件,这是编译得到的二进制文件。但是这个二进制文件与c++编译得到的二进制文件仍然不同,python只有当运行时才能确定数据的类型等。\r\n\r\n在运行python程序的时候,python会检查.pyc文件是否存在,如果存在python会先判断时间戳然后加载pyc这个二进制文件, 从而加速,若没有字节码则会由python解释器解释python源码得到字节码然后由PVM执行。\r\n\r\n编译器:编译器将高级语言源码文件转化到计算机可以理解的语言,多数情况下是可执行二进制文件。\r\n\r\n解释器:解释器可以1.直接执行源码文件或者2.将源码文件转化到一种效率更高的形式再执行文件\r\n\r\n\r\n\r\nVariable\r\n\r\n```python\r\n>>> x=1\r\n>>> id(x)\r\n271541344\r\n>>> y=2\r\n>>> id(y)\r\n271541360\r\n>>> y=x\r\n>>> id(y)\r\n271541344\r\n```\r\n\r\n在python中 1,2这些都是不可变量,x=1相当于将x指向了1,可以看到y=x之后,y和x指向了同一个\r\n\r\n\r\n\r\nlist 运行时间\r\n\r\n```python\r\nimport time\r\n\r\nn= 100000\r\n\r\nstart_time = time.time()\r\nl = []\r\nfor i in range(n):\r\n l = l + [i * 2]\r\nprint(time.time() - start_time)\r\n\r\nstart_time = time.time()\r\nl = []\r\nfor i in range(n):\r\n l += [i * 2]\r\nprint(time.time() - start_time)\r\n\r\nstart_time = time.time()\r\nl = []\r\nfor i in range(n):\r\n l.append(i * 2)\r\nprint(time.time() - start_time)\r\nThis program returns shocking results:\r\n26.3175041676\r\n0.0305399894714\r\n0.0207479000092\r\n```\r\n\r\nl = l + [i * 2] 最慢 相当于多了一步将新的list赋值给l 将原来的list remove,+=和append速度相似\r\n\r\n\r\n\r\n浅拷贝与深拷贝\r\n\r\nlist\r\n\r\n```python\r\n>>> colours1 = [\"red\", \"blue\"]\r\n>>> colours2 = colours1 ['red', 'blue'],['red', 'blue']\r\n>>> print(id(colours1),id(colours2))\r\n43444416 43444416\r\n>>> colours2 = [\"rouge\", \"vert\"] ['red', 'blue'],['rouge', 'vert']\r\n>>> print(id(colours1),id(colours2))\r\n43444416 43444200\r\n```\r\n\r\ncolours1,2一开始指向的是同一个list,\r\n\r\n后来经过colours2 = [\"rouge\", \"vert\"] ,colours2指向了新的list\r\n\r\n```python\r\n>>> colours1 = [\"red\", \"blue\"]\r\n>>> colours2 = colours1\r\n>>> print(id(colours1),id(colours2))\r\n14603760 14603760\r\n>>> colours2[1] = \"green\"\r\n>>> print(id(colours1),id(colours2))\r\n14603760 14603760\r\n>>> print(colours1)\r\n['red', 'green']\r\n>>> print(colours2)\r\n['red', 'green']\r\n```\r\n\r\n由于list是可变对象,在改了colours2[1]之后 colours1也变了(指向的对象变了)\r\n\r\n\r\n\r\nlist可通过slice生成新的list\r\n\r\n```python\r\n>>> list1 = ['a','b','c','d']\r\n>>> list2 = list1[:]\r\n>>> list2[1] = 'x'\r\n>>> print(list2)\r\n['a', 'x', 'c', 'd']\r\n>>> print(list1)\r\n['a', 'b', 'c', 'd']\r\n```\r\n\r\n但是如果list中有sublist则只拷贝了sublist的引用\r\n\r\n```python\r\n>>> lst1 = ['a','b',['ab','ba']]\r\n>>> lst2 = lst1[:]\r\n>>> lst2[0] = 'c'\r\n>>> print(lst1)\r\n['a', 'b', ['ab', 'ba']]\r\n>>> print(lst2)\r\n['c', 'b', ['ab', 'ba']]\r\n\r\n>>> lst2[2][1] = 'd'\r\n>>> print(lst1)\r\n['a', 'b', ['ab', 'd']]\r\n>>> print(lst2)\r\n['c', 'b', ['ab', 'd']]\r\n```\r\n\r\n\r\n\r\n\r\n\r\ndict\r\n\r\noperators in dict:\r\n\r\nlen(d), del d[k], k in d, k not in d\r\n\r\npop() and popitem()\r\n\r\n```python\r\ncapitals = {\"Austria\":\"Vienna\", \"Germany\":\"Berlin\", \"Netherlands\":\"Amsterdam\"}\r\n>>> capital = capitals.pop(\"Austria\")\r\n>>> print(capital)\r\nVienna\r\n\r\n>>> capitals = {\"Springfield\":\"Illinois\", \"Augusta\":\"Maine\", \"Boston\": \"Massachusetts\", \"Lansing\":\"Michigan\", \"Albany\":\"New York\", \"Olympia\":\"Washington\", \"Toronto\":\"Ontario\"}\r\n>>> (city, state) = capitals.popitem()\r\n>>> (city, state)\r\n('Olympia', 'Washington')\r\n```\r\n\r\nD.pop(k) removes the key k with its value from the dictionary D and returns the corresponding value as the return value, i.e. D[k]. \r\n\r\npopitem() is a method of dict, which doesn't take any parameter and removes and returns an arbitrary (key,value) pair as a 2-tuple. \r\n\r\n\r\n\r\nhow to get key,value\r\n\r\n直接读locations[\"Ottawa\"]\r\n如果Ottawa关键字不存在的话会报错\r\n\r\n可以使用in 来防止这种错误\r\n\r\n```\r\n>>> if \"Ottawa\" in locations: print(locations[\"Ottawa\"])\r\n... \r\n>>> if \"Toronto\" in locations: print(locations[\"Toronto\"])\r\n... \r\nOntario\r\n```\r\n\r\n或者使用get()方法\r\n\r\n```python\r\n>>> proj_language = {\"proj1\":\"Python\", \"proj2\":\"Perl\", \"proj3\":\"Java\"}\r\n>>> proj_language[\"proj1\"]\r\n'Python'\r\n>>> proj_language.get(\"proj2\")\r\n'Perl'\r\n>>> proj_language.get(\"proj4\")\r\n>>> print(proj_language.get(\"proj4\"))\r\nNone\r\n```\r\n\r\nmethod copy():\r\n\r\n```python\r\n>>> w = words.copy()\r\n>>> words[\"cat\"]=\"chat\"\r\n>>> print(w)\r\n{'house': 'Haus', 'cat': 'Katze'}\r\n>>> print(words)\r\n{'house': 'Haus', 'cat': 'chat'}\r\n```\r\n\r\ncopy函数是浅拷贝函数\r\n\r\n如果dict中的对象是list等可变对象的话,则会发生同时改变的情况\r\n\r\n```python\r\n>>> dict1[\"cat\"]=[1,2]\r\n>>> dict2=dict1.copy()\r\n>>> dict2[\"cat\"][1]=3\r\n>>> dict1\r\n{'cat': [1, 3]}\r\n>>> dict2\r\n{'cat': [1, 3]}\r\n```\r\n\r\n### Update: Merging Dictionaries\r\n\r\n```python\r\n>>> knowledge = {\"Frank\": {\"Perl\"}, \"Monica\":{\"C\",\"C++\"}}\r\n>>> knowledge2 = {\"Guido\":{\"Python\"}, \"Frank\":{\"Perl\", \"Python\"}}\r\n>>> knowledge.update(knowledge2)\r\n>>> knowledge\r\n{'Frank': {'Python', 'Perl'}, 'Guido': {'Python'}, 'Monica': {'C', 'C++'}}\r\n```\r\n\r\n\r\n\r\ndict中的迭代器 d.keys(),d.values(),d.items()\r\n\r\n\r\n\r\nlists转化为dict\r\n\r\n```python\r\n>>> dishes = [\"pizza\", \"sauerkraut\", \"paella\", \"hamburger\"]\r\n>>> countries = [\"Italy\", \"Germany\", \"Spain\", \"USA\"]\r\n>>> country_specialities_iterator = zip(countries, dishes)\r\ncountry_specialities = list(country_specialities_iterator)\r\n>>> print(country_specialities)\r\n[('Italy', 'pizza'), ('Germany', 'sauerkraut'), ('Spain', 'paella'), ('USA', 'hamburger')]\r\n\r\n>>> country_specialities_dict = dict(country_specialities)\r\n>>> print(country_specialities_dict)\r\n{'USA': 'hamburger', 'Germany': 'sauerkraut', 'Spain': 'paella', 'Italy': 'pizza'}\r\n```\r\n\r\n\r\n\r\nset集合\r\n\r\n```python\r\n>>> x = set(\"A Python Tutorial\")\r\n>>> x\r\n{'A', ' ', 'i', 'h', 'l', 'o', 'n', 'P', 'r', 'u', 't', 'a', 'y', 'T'}\r\n```\r\n\r\nset opeartion\r\n\r\nadd(), clear(), copy()(浅拷贝)\r\n\r\n\r\n\r\nget input from keyboard\r\n\r\n```python\r\nname = input(\"What's your name? \")\r\n```\r\n\r\n\r\n\r\nprint Function\r\n\r\n```python\r\nprint(value1, ..., sep=' ', end='\\n', file=sys.stdout, flush=False)\r\n```\r\n\r\nolder way for printf\r\n\r\n```python\r\nprint(\"Art: %5d, Price per Unit: %8.2f\"%(453,59.058))\r\nArt: 453, Price per Unit: 59.06\r\n```\r\n\r\n\r\n\r\nCommand Line Arguments\r\n\r\nimport sys\r\n\r\nsys.argv\r\n\r\n```python\r\npython argumente.py python course for beginners\r\n\r\nThis call creates the following output:\r\n\r\nargumente.py\r\npython\r\ncourse\r\nfor\r\nbeginners\r\n```\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.7798131108283997,
"alphanum_fraction": 0.7813084125518799,
"avg_line_length": 21.619468688964844,
"blob_id": "b531c52ef2d43c76b8cb10443c0243b427c4eeb1",
"content_id": "f87d6b594981a54dfe9039df963ab9a97902f692",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6283,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 113,
"path": "/books/深入理解Java虚拟机 JVM高级特性与最佳实践.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 深入理解JAVA虚拟机\r\n\r\n##### 什么是java虚拟机\r\n\r\n所有的java代码,都编译为字节码在java虚拟机上执行。虚拟机是一种抽象的计算机。java虚拟机屏蔽了与具体操作系统平台相关的信息,使得java代码只需要考虑java虚拟机即可,即有着较强的可移植性。\r\n\r\njava虚拟机和c++ 编译器的不同点:JVM垄断了所有从源码到底层硬件的所有工作,而c++的编译器只是将源码编译成了目标文件,目标文件在执行时还需要结合RE(runtime environment)例如DLL等文件。\r\n\r\n例如我在自己的电脑上编译c++文件成exe文件,在自己的电脑上可以执行但是换到别人的电脑上不能执行(缺少对应的DLL库),java就没有这个问题。c++程序员需要管到DLL这一层。\r\n\r\n从操作系统的层面来理解,虚拟机是运行在操作系统当中的,虚拟机是一个特殊的进程。\r\n\r\n```java\r\npublic class HelloWorld { \r\n public static void main(String[] args) { \r\n System.out.println(\"HelloWorld\"); \r\n } \r\n} \r\nzhangjg@linux:/deve/workspace/HelloJava/src$ javac HelloWorld.java \r\n```\r\n\r\n对于helloworld.java 在运行的时候\r\n\r\njava命令首先启动虚拟机进程,然偶读取参数helloworld,把它作为出示类加载到内存中,对这个类进行初始化和动态链接,然后从这个类的额main方法开始执行。换而言之,在执行java程序的时候真正执行的是一个java虚拟机的进程。\r\n\r\n\r\n\r\njava虚拟机会根据程序的需要,将其他类加载进来。注意这边的根据需要,只有当程序运行时才会加载,正如人只有饿的时候才会去吃饭。\r\n\r\njava虚拟机会自动进行内存管理,不需要程序员编写代码来分配释放内存,这部分工作由u垃圾收集子系统负责。\r\n\r\n从上面的论述中可知,java虚拟机有三个子系统来保障其运行,分别是类加载器子系统,执行引擎子系统和垃圾收集子系统。\r\n\r\n\r\n\r\n内存区分为如下几个部分:\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n##### Java内存区域与内存溢出异常\r\n\r\njava与c++之间有一堵由内存动态分配和垃圾回收技术围城的高墙。\r\n\r\n对于c++程序员而言,在内存管理区域既是有最高权限同时又担任对每个对象生命开始到终结的维护责任\r\n\r\njava程序员利用虚拟机自动内存管理机制进行内存管理,不容易出现内存泄漏和内存溢出问题。\r\n\r\n\r\n\r\njava运行时数据区域大致可分为:方法区、虚拟机栈、本地方法栈、堆、程序计数器\r\n\r\n有很多人会简单分为堆和栈,这样是非常粗的划分。\r\n\r\n##### 程序计数器\r\n\r\n可以看作是当前线程所执行的字节码的行号指示器。字节码(是java虚拟机执行的一种指令格式)\r\n\r\n##### java虚拟机栈\r\n\r\njava中栈指的是虚拟机栈,或者说是局部变量表部分。java虚拟机栈与本地方法栈的作用非常相近,很多虚拟机会将二者视为一物。局部变量表中存放的是对象引用类型,它不等同于对象本身,可能是一个指向对象起始地址的指针。\r\n\r\n##### java堆\r\n\r\njava堆是被所有线程共享的一块,所有的对象实例都在这里分配内存。java堆是垃圾收集器管理的主要区域。\r\n\r\n\r\n\r\n##### Hotspot虚拟机\r\n\r\n对象的创建\r\n\r\n\r\n\r\n##### 垃圾收集器与内存分配策略\r\n\r\n如何判断对象已死?\r\n\r\n经典的判断对象是否存活的算法是这样的(**引用计数算法**):给对象中添加一个引用计数器,每当一个地方引用他,计数器值加1,当引用失效时计数器值减1。任何时刻计数器值为0时就是不能被再使用的。\r\n\r\n很多地方都会使用引用计数算法,效率也很高。不过java虚拟机中没有使用引用计数算法,原因是其无法解决对象之间循环引用的例子。例如\r\n\r\n```\r\nobjA.instance=objB\r\nobjB.instance=objA\r\n```\r\n\r\n现在主流的商用程序设计语言主要是通过**可达性分析算法**实现的。基本思路是从GC Root对象作为起点,向下搜索,如果某个对象是不可到达的,则说明该对象是不可用的。\r\n\r\n**引用细分** 单纯以有引用和无引用来区分过于直接,为了处理这样一些对象。当内存空间还足够的情况下可以保留在内存中,如果内存空间非常紧张则处理掉这些对象,因此java堆引用的概念进行了扩充,引入了**强引用** 、**软引用**、**弱引用**、**虚引用** \r\n\r\n即使是可达性算法不可达的对象,也并非非死不可,处于缓刑阶段。\r\n\r\n**垃圾回收算法** \r\n\r\n**标记-清楚算法** 算法分为两个阶段,“标记”和“清楚”,不足之处主要在于这两个过程的效率都不够高,同时标记清除之后会产生大量不连续的内存碎片。\r\n\r\n**复制算法** 将内存分为大小相同的两块,每次只使用一块,当一块的内存用完了就把对象复制到另一块的地方上,同时将使用过的内存空间一次性清理掉。\r\n\r\n**标记-整理** 和标记-清除算法比较相似,只是而所有存活的对象都向一端移动,以解决空间的问题。\r\n\r\njava由于自动垃圾回收的存在,因此java的效率不够高,对于科技金融(量化交易)、游戏开发等领域并不适合(垃圾回收系统有时会导致xxms的暂停)。这些领域比较适合C++等没有自动垃圾回收机制的语言。\r\n\r\n**垃圾收集器** 垃圾收集算法是内存回收的方法论,垃圾收集器是具体执行的方法。例如Serial收集器等等。\r\n\r\n\r\n\r\njava技术所倡导的自动内存管理最终可以归结为自动化解决了两个问题:给对象分配内存和回收分配给对象的内存。大方向说,对象在堆上分配。\r\n\r\n一般来说对象优先在新生代Eden区中分配,当新生代Eden去中没有足够空间来进行分配的话,虚拟机会启动一个minor GC,来获得足够的内存。大对象例如很长的字符串或者是数组将会直接进入老年代空间。(因为新生代空间用的多也就是说空间比较琐碎,难以存放一些大对象)长期存活的对象将进入老年代。\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.7850678563117981,
"alphanum_fraction": 0.7850678563117981,
"avg_line_length": 34.75,
"blob_id": "c5e1e8437d02643f9e760f92f3facdc6ca88b698",
"content_id": "ed2225df6189808a9b0cfef69e3f3ec19cc80791",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 900,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 24,
"path": "/bash.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### Bash\r\n\r\ncmder:cmd\r\n\r\nubuntu VM:Bash\r\n\r\n将/etc/apt/sources.list中的内容替换为\r\n\r\n```\r\ndeb http://mirrors.zju.edu.cn/ubuntu bionic main universe restricted multiverse\r\ndeb http://mirrors.zju.edu.cn/ubuntu bionic-security main universe restricted multiverse\r\ndeb http://mirrors.zju.edu.cn/ubuntu bionic-updates main universe restricted multiverse\r\ndeb http://mirrors.zju.edu.cn/ubuntu bionic-backports main universe restricted multiverse\r\ndeb-src http://mirrors.zju.edu.cn/ubuntu bionic main universe restricted multiverse\r\ndeb-src http://mirrors.zju.edu.cn/ubuntu bionic-security main universe restricted multiverse\r\ndeb-src http://mirrors.zju.edu.cn/ubuntu bionic-updates main universe restricted multiverse\r\ndeb-src http://mirrors.zju.edu.cn/ubuntu bionic-backports main universe restricted multiverse\r\n```\r\n\r\nsudo apt update\r\n\r\nsudo apt install ipython\r\n\r\nsudo apt install python-pip\r\n\r\n"
},
{
"alpha_fraction": 0.5816571116447449,
"alphanum_fraction": 0.5966235399246216,
"avg_line_length": 28.571428298950195,
"blob_id": "7270202c349e3dba7efe88b6997c99ab1b183890",
"content_id": "243c18448bd47eefcd3954bc7c9bb7fe0d6ac8c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 8756,
"license_type": "no_license",
"max_line_length": 180,
"num_lines": 273,
"path": "/leetcode_note/Hash.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "\r\n\r\n哈希题目 (LeetCode 290)\r\n\r\n哈希与字符串综合 (LeetCode 3)\r\n\r\n哈希与字符串综合 (LeetCode 76)\r\n\r\n哈希与字符串综合 (LeetCode 30)\r\n\r\n用pop删除键值对\r\n\r\n\r\n\r\n##### leetcode 290 Word Pattern\r\n\r\nGiven a `pattern` and a string `str`, find if `str` follows the same pattern.\r\n\r\nHere **follow** means a full match, such that there is a bijection between a letter in `pattern` and a **non-empty** word in `str`.\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: pattern = \"abba\", str = \"dog cat cat dog\"\r\nOutput: true\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput:pattern = \"abba\", str = \"dog cat cat fish\"\r\nOutput: false\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: pattern = \"aaaa\", str = \"dog cat cat dog\"\r\nOutput: false\r\n```\r\n\r\n**Example 4:**\r\n\r\n```\r\nInput: pattern = \"abba\", str = \"dog dog dog dog\"\r\nOutput: false\r\n```\r\n\r\n**Notes:**\r\nYou may assume `pattern` contains only lowercase letters, and `str` contains lowercase letters that may be separated by a single space.\r\n\r\n```python\r\nclass Solution:\r\n def wordPattern(self, pattern, str):\r\n \"\"\"\r\n :type pattern: str\r\n :type str: str\r\n :rtype: bool\r\n \"\"\"\r\n str=str.split()\r\n if len(pattern)!=len(str):\r\n return False\r\n if pattern==\"\":\r\n return True\r\n dict,dict1={},{}\r\n for i in range(len(str)):\r\n if pattern[i] not in dict:\r\n dict[pattern[i]]=str[i]\r\n else:\r\n if dict[pattern[i]]!=str[i]:\r\n return False\r\n if str[i] not in dict1:\r\n dict1[str[i]]=pattern[i]\r\n else:\r\n if dict1[str[i]]!=pattern[i]:\r\n return False\r\n return True\r\n```\r\n\r\n\r\n\r\n\r\n\r\n##### leetcode 966 Vowel Spellchecker\r\n\r\n* Given a `wordlist`, we want to implement a spellchecker that converts a query word into a correct word.\r\n\r\n For a given `query` word, the spell checker handles two categories of spelling mistakes:\r\n\r\n - Capitalization: If the query matches a word in the wordlist (\r\n\r\n case-insensitive\r\n\r\n ), then the query word is returned with the same case as the case in the wordlist.\r\n\r\n - Example: `wordlist = [\"yellow\"]`, `query = \"YellOw\"`: `correct = \"yellow\"`\r\n - Example: `wordlist = [\"Yellow\"]`, `query = \"yellow\"`: `correct = \"Yellow\"`\r\n - Example: `wordlist = [\"yellow\"]`, `query = \"yellow\"`: `correct = \"yellow\"`\r\n\r\n - Vowel Errors: If after replacing the vowels ('a', 'e', 'i', 'o', 'u') of the query word with any vowel individually, it matches a word in the wordlist (\r\n\r\n case-insensitive\r\n\r\n ), then the query word is returned with the same case as the match in the wordlist.\r\n\r\n - Example: `wordlist = [\"YellOw\"]`, `query = \"yollow\"`: `correct = \"YellOw\"`\r\n - Example: `wordlist = [\"YellOw\"]`, `query = \"yeellow\"`: `correct = \"\"` (no match)\r\n - Example: `wordlist = [\"YellOw\"]`, `query = \"yllw\"`: `correct = \"\"` (no match)\r\n\r\n In addition, the spell checker operates under the following precedence rules:\r\n\r\n - When the query exactly matches a word in the wordlist (**case-sensitive**), you should return the same word back.\r\n - When the query matches a word up to capitlization, you should return the first such match in the wordlist.\r\n - When the query matches a word up to vowel errors, you should return the first such match in the wordlist.\r\n - If the query has no matches in the wordlist, you should return the empty string.\r\n\r\n Given some `queries`, return a list of words `answer`, where `answer[i]` is the correct word for `query = queries[i]`.\r\n\r\n```\r\nInput: wordlist = [\"KiTe\",\"kite\",\"hare\",\"Hare\"], queries = [\"kite\",\"Kite\",\"KiTe\",\"Hare\",\"HARE\",\"Hear\",\"hear\",\"keti\",\"keet\",\"keto\"]\r\nOutput: [\"kite\",\"KiTe\",\"KiTe\",\"Hare\",\"hare\",\"\",\"\",\"KiTe\",\"\",\"KiTe\"]\r\n```\r\n\r\n```\r\nimport re\r\nclass Solution:\r\n def spellchecker(self, wordlist, queries):\r\n words = {w: w for w in wordlist}\r\n cap = {w.lower(): w for w in wordlist[::-1]}\r\n vowel = {re.sub(\"[aeiou]\", '#', w.lower()): w for w in wordlist[::-1]}\r\n return [words.get(w) or cap.get(w.lower()) or vowel.get(re.sub(\"[aeiou]\", '#', w.lower()), \"\") for w in queries]\r\n```\r\n\r\n1. dict的使用\r\n\r\n初始化完成之后\r\n\r\n```\r\ncap={'hare': 'hare', 'kite': 'KiTe'}\r\nwords={'KiTe': 'KiTe', 'kite': 'kite', 'hare': 'hare', 'Hare': 'Hare'}\r\nvowel={'h#r#': 'hare', 'k#t#': 'KiTe'}\r\n```\r\n\r\n注意这边对于cap和vowel逆序,因为存在覆盖的现象,逆序的话保证最后初始化完成之后大小写和vowel hash里面保存的都是符合要求的第一个元素\r\n\r\n2. str.lower()\r\n\r\n3. re.sub(\"[aeiou]\", '#', w.lower()) 将w.lower()中属于\"[aeiou]\"的其他元素用#代替\r\n\r\n4. dict.get(key) return key对应的value或者找不到return None\r\n\r\n\r\n\r\n##### leetcode 981 Time Based Key-Value Store\r\n\r\n* Create a timebased key-value store class `TimeMap`, that supports two operations.\r\n\r\n 1. `set(string key, string value, int timestamp)`\r\n\r\n - Stores the `key` and `value`, along with the given `timestamp`.\r\n\r\n 2. `get(string key, int timestamp)`\r\n\r\n - Returns a value such that `set(key, value, timestamp_prev)` was called previously, with `timestamp_prev <= timestamp`.\r\n - If there are multiple such values, it returns the one with the largest `timestamp_prev`.\r\n - If there are no values, it returns the empty string (`\"\"`).\r\n\r\n\r\n\r\n```\r\nInput: inputs = [\"TimeMap\",\"set\",\"get\",\"get\",\"set\",\"get\",\"get\"], inputs = [[],[\"foo\",\"bar\",1],[\"foo\",1],[\"foo\",3],[\"foo\",\"bar2\",4],[\"foo\",4],[\"foo\",5]]\r\nOutput: [null,null,\"bar\",\"bar\",null,\"bar2\",\"bar2\"]\r\nExplanation: \r\nTimeMap kv; \r\nkv.set(\"foo\", \"bar\", 1); // store the key \"foo\" and value \"bar\" along with timestamp = 1 \r\nkv.get(\"foo\", 1); // output \"bar\" \r\nkv.get(\"foo\", 3); // output \"bar\" since there is no value corresponding to foo at timestamp 3 and timestamp 2, then the only value is at timestamp 1 ie \"bar\" \r\nkv.set(\"foo\", \"bar2\", 4); \r\nkv.get(\"foo\", 4); // output \"bar2\" \r\nkv.get(\"foo\", 5); //output \"bar2\" \r\n\r\nInput: inputs = [\"TimeMap\",\"set\",\"set\",\"get\",\"get\",\"get\",\"get\",\"get\"], inputs = [[],[\"love\",\"high\",10],[\"love\",\"low\",20],[\"love\",5],[\"love\",10],[\"love\",15],[\"love\",20],[\"love\",25]]\r\nOutput: [null,null,null,\"\",\"high\",\"high\",\"low\",\"low\"]\r\n```\r\n\r\n**Note:**\r\n\r\n1. All key/value strings are lowercase.\r\n2. All key/value strings have length in the range `[1, 100]`\r\n3. The `timestamps` for all `TimeMap.set` operations are strictly increasing.\r\n4. `1 <= timestamp <= 10^7`\r\n5. `TimeMap.set` and `TimeMap.get` functions will be called a total of `120000` times (combined) per test case.\r\n\r\n* Solution:\r\n\r\n```python\r\nfrom collections import defaultdict,deque\r\nclass TimeMap:\r\n def __init__(self):\r\n self.values = defaultdict(deque)\r\n def set(self, key: 'str', value: 'str', timestamp: 'int') -> 'None':\r\n self.values[key].appendleft((value, timestamp))\r\n def get(self, key: 'str', timestamp: 'int') -> 'str':\r\n vs = self.values[key]\r\n for i in range(len(vs)):\r\n if vs[i][1] <= timestamp:\r\n return vs[i][0]\r\n return \"\"\r\n```\r\n\r\n并不一定要用deque,利用所有的操作的时间都依次增加这一点,将最新的操作(时间大)的排在对应的list前面\r\n\r\n检查当timestamp>=vs[i,1]时,key对应着的value是vs[i,0]\r\n\r\n\r\n\r\n##### leetcode 1171 Remove Zero Sum Consecutive Nodes from Linked List\r\n\r\nRemove Zero Sum Consecutive Nodes from Linked List\r\n\r\nGiven the `head` of a linked list, we repeatedly delete consecutive sequences of nodes that sum to `0` until there are no such sequences.\r\n\r\nAfter doing so, return the head of the final linked list. You may return any such answer.\r\n\r\n(Note that in the examples below, all sequences are serializations of `ListNode` objects.)\r\n\r\n**Example 1:**\r\n\r\n```\r\nInput: head = [1,2,-3,3,1]\r\nOutput: [3,1]\r\nNote: The answer [1,2,1] would also be accepted.\r\n```\r\n\r\n**Example 2:**\r\n\r\n```\r\nInput: head = [1,2,3,-3,4]\r\nOutput: [1,2,4]\r\n```\r\n\r\n**Example 3:**\r\n\r\n```\r\nInput: head = [1,2,3,-3,-2]\r\nOutput: [1]\r\n```\r\n\r\n使用OrderDict\r\n\r\n保存了dict存进去的顺序,同时可以使用popitem根据加入的顺序删除\r\n\r\n```python\r\n# Definition for singly-linked list.\r\n# class ListNode:\r\n# def __init__(self, x):\r\n# self.val = x\r\n# self.next = None\r\n\r\nclass Solution:\r\n def removeZeroSumSublists(self, head):\r\n cur = dummy = ListNode(0)\r\n dummy.next = head\r\n prefix = 0\r\n seen = collections.OrderedDict()\r\n while cur:\r\n prefix += cur.val\r\n node = seen.get(prefix, cur)\r\n while prefix in seen:\r\n seen.popitem()\r\n seen[prefix] = node\r\n node.next = cur = cur.next\r\n return dummy.next\r\n \r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.7896950840950012,
"alphanum_fraction": 0.7944269180297852,
"avg_line_length": 22.063291549682617,
"blob_id": "05cca179d9a398d08da7ebcf0baa4e352ef665ef",
"content_id": "fec39f54e93522c3724333250cbeda386db36684",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4484,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 79,
"path": "/computer_science_knowledge/computer_network/计算机网络常考概念.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "## 计算机网络\r\n### OSI体系结构\r\n```\r\n7层 应用层 表示层 会话层 运输层 网络层 数据链路层 物理层\r\n应用层 运输层 网际层 网络接口层\r\n应用层 运输层 网络层 数据链路层 物理层\r\n应用层:SMTP POP3 FTP\r\n运输层:UDP TCP\r\n网际层(网络层):IP\r\n数据链路层:PPP\r\n```\r\n\r\n### 电子邮件(POP3协议与SMTP协议)\r\n```\r\n电子邮件系统有三部分构成,用户代理、邮件服务器以及邮件发送协议(smtp)和邮件读取协议(pop3)。\r\n用户代理就是用户与电子邮件系统的接口,一般是PC中运行的一个程序。\r\nSMTP simple mail transfer protocol 简单邮件传送协议\r\n作用于发件人用户代理与发送方邮件服务器以及发送方邮件服务器与接收方邮件服务器间。\r\nPOP3邮件读取协议 post office protocol 用来读取邮件内容\r\nIMAP Internet Message Access Protocol 网际报文存取协议\r\n比POP3复杂很多\r\n网络(http协议www和ftp协议)\r\nHTTP 超文本传送协议 面向事务的应用层协议,可以可靠地传送交换文件。\r\nFTP 文件传送协议 file transfer protocol 用的最广的文件传送协议\r\nwww 万维网 万维网是超媒体系统,是超文本系统的扩充,所谓超文本就是包括指向了其他文件的连接的文本,而超媒体指的是在超文本的基础上,所指向的可以不是文本信息。\r\n```\r\n\r\n### TCP与UDP PPP\r\n```\r\nTCP 运输层协议 非常复杂的协议,面向连接\r\n在使用TCP协议之前必须建立TCP连接 TCP必须是点对点的,提供全双工通信\r\nTCP面向连接 需要确认\r\nUDP尽力传送的传送方式,不需要确认\r\nTCP比UDP数据开销更大,保证数据准确到达,按照顺序接收,提供流量控制与拥塞控制\r\nUDP不提供顺序接收功能以及不能流量控制、拥塞控制。\r\n```\r\n\r\n### TCP建立连接的三次握手\r\n```\r\n为什么要三次握手其实是因为信息在传送的过程中可能是会丢失的,而TCP则要确保数据能够传送到。\r\n三次具体如下:有AB两个客户端,A先向B发送连接请求报文段,B收到之后同意连接,向A发出确认,\r\n这一条是为了确认B可以接收到A,A收到之后也向B发出确认,确认A可以接收到B。这样就是三次握手\r\n建立连接。\r\n```\r\n\r\n### 释放链接四次握手\r\n```\r\n当AB之间停止通信的时候,A先向B发出释放链接报文段,表示A已经没有要发的报文段了,B接收到之后\r\n发出确认,这样A到B这个链接就关闭了,B进入了等待关闭状态,B若还有数据要发送,这样的话A就要继\r\n续接收数据。知道B也发完了数据之后,B向A发送连接释放报文段,A接收到之后发出确认。B接收到确认\r\n之后就正式关闭,A还需要再等待2MSL的时间(最长报文段寿命)的时间确保B接收到了,A也关闭,这样\r\n就是四次握手。\r\n```\r\n\r\n### TCP/IP 体系\r\n```\r\n分为应用层 运输层 网际层 网络接口层\r\n网络接口层之上的网际层有IP协议 运输层有TCP/UDP协议\r\n应用层是HTTP SMTP 协议\r\n IP协议:\r\nIP层协议是TCP/IP系统中最重要的协议之一,是属于网际层的。使用IP协议将性能各异的网络连接成一个\r\n虚拟的网络,这个网络就是IP网络。每一个主机都会被分配一个唯一的32位标识符。IP地址被分为ABC三类。\r\nIP地址是网络层及以上使用的逻辑地址,物理地址是数据链路层以及物理层的地址。\r\n通过转发器 网桥或者是路由器 网关等设备将不同网络连接起来。\r\nPPP 点对点协议应用广泛的数据链路层协议 无连接\r\n最大特点 简单,封装成帧\r\n总之这种数据链路层协议非常简单,接收方每接收到一个帧,就进行CRC检验,如果CRC检验正确就接收下,如果不正确就丢弃。\r\nPPP不需要纠错 不需要流量控制 序号等功能\r\n ```\r\n \r\n### 广域网与局域网的区别\r\n```\r\n广域网作用范围大,作用半径常常在几十公里到几百公里,广域网是因特网中的核心部分,主要任务是长距离运输数据,\r\n链路主要是高速链路,通信容量大。\r\n局域网作用范围小\r\n虚拟局域网 VLAN\r\n虚拟局域网指的是一组逻辑上的设备与用户,这组设备和用户不受物理网段的限制,可以根据功能等将他们组织起来,\r\n好像在一个网段中工作一样,因此得名虚拟局域网。\r\n``` \r\n"
},
{
"alpha_fraction": 0.6830601096153259,
"alphanum_fraction": 0.7122039794921875,
"avg_line_length": 14.454545021057129,
"blob_id": "b5a986e8942e5f8fe610c1bfb94f7e475c3b2558",
"content_id": "84cc1d7ec4d7e6c39ad690c336f126a617811c1c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1259,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 33,
"path": "/books/百面机器学习.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### 百面机器学习\r\n\r\n特征归一化\r\n\r\n为了消除数据特征之间的量纲影响,我们需要对特征进行归一化操作。例如分析一个人身高和体重对健康的影响,使用米和千克作为单位,那么身高会在1.6-1.8之间,体重在50-100之间 那么结果会倾向于数值偏差较大的体重特征。\r\n\r\n归一化方法:\r\n\r\n线性:\r\n$$\r\nX_{norm}=\\frac{X-X_{min}}{X_{max}-X_{min}}\r\n$$\r\n零均值归一化:\r\n$$\r\nz=\\frac{x-\\mu}{\\sigma}\r\n$$\r\n映射到均值为0,标准差为1的分布上\r\n\r\n\r\n\r\n数据归一化不是万能的,通过梯度下降法求解的方法都是需要归一化的,包括线性回归、逻辑回归、SVM、神经网络等。但是数据归一化对于决策树模型不适用,决策树在节点分裂时主要依据数据集D关于特征x的信息增益比,这个与是否归一化无关。\r\n\r\n\r\n\r\n##### 类别型特征\r\n\r\n类别型特征指的是类似于男女、血型等通常用字符串进行表示的特征。除了决策树等少数模型可以处理字符串形式的输入,对于逻辑回归、支持向量机等模型来说,类别型特征需要进行特别的处理。\r\n\r\n如何处理呢?\r\n\r\n1.序号编码,例如 高中低->321\r\n\r\n2.独热编码 one hot\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.528192937374115,
"alphanum_fraction": 0.5495923757553101,
"avg_line_length": 24.070796966552734,
"blob_id": "57e39729749a9a5327ba5e32b78dc73932034fa8",
"content_id": "b3f8c08b458b83901bb7b21366eff655ba42aead",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3000,
"license_type": "no_license",
"max_line_length": 231,
"num_lines": 113,
"path": "/leetcode_note/others.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "##### leetcode 146 LRU Cache\r\n\r\n* Share\r\n\r\n Design and implement a data structure for [Least Recently Used (LRU) cache](https://en.wikipedia.org/wiki/Cache_replacement_policies#LRU). It should support the following operations: `get` and `put`.\r\n\r\n `get(key)` - Get the value (will always be positive) of the key if the key exists in the cache, otherwise return -1.\r\n `put(key, value)` - Set or insert the value if the key is not already present. When the cache reached its capacity, it should invalidate the least recently used item before inserting a new item.\r\n\r\n **Follow up:**\r\n Could you do both operations in **O(1)** time complexity?\r\n\r\n```\r\nLRUCache cache = new LRUCache( 2 /* capacity */ );\r\n\r\ncache.put(1, 1);\r\ncache.put(2, 2);\r\ncache.get(1); // returns 1\r\ncache.put(3, 3); // evicts key 2\r\ncache.get(2); // returns -1 (not found)\r\ncache.put(4, 4); // evicts key 1\r\ncache.get(1); // returns -1 (not found)\r\ncache.get(3); // returns 3\r\ncache.get(4); // returns 4\r\n```\r\n\r\n```python\r\nclass LRUCache:\r\n def __init__(self, capacity):\r\n self.nums = {}\r\n self.stack = []\r\n self.capacity = capacity\r\n def get(self, key):\r\n if key in self.nums:\r\n self.stack.remove(key)\r\n self.stack = [key] + self.stack\r\n return self.nums[key]\r\n else:\r\n return -1\r\n def put(self, key, value):\r\n if key in self.stack:\r\n self.nums[key] = value\r\n self.stack.remove(key)\r\n self.stack = [key] + self.stack\r\n return\r\n if len(self.stack) == self.capacity:\r\n key1 = self.stack[-1]\r\n self.stack.pop()\r\n self.nums.pop(key1)\r\n self.stack = [key] + self.stack\r\n self.nums[key] = value\r\n```\r\n\r\n\r\n\r\n\r\n\r\n### Bit opeartion\r\n\r\n##### leetcode 461 Hamming Distance\r\n\r\n* The [Hamming distance](https://en.wikipedia.org/wiki/Hamming_distance) between two integers is the number of positions at which the corresponding bits are different. Given two integers `x` and `y`, calculate the Hamming distance.\r\n\r\n0 ≤ `x`, `y` < 231.\r\n\r\n```\r\nInput: x = 1, y = 4\r\n\r\nOutput: 2\r\n\r\nExplanation:\r\n1 (0 0 0 1)\r\n4 (0 1 0 0)\r\n ↑ ↑\r\n\r\nThe above arrows point to positions where the corresponding bits are different.\r\n```\r\n\r\n* Mysolution:\r\n\r\n```python\r\nclass Solution(object):\r\n def hammingDistance(self, x, y):\r\n count=0\r\n while x or y:\r\n a=x%2\r\n b=y%2\r\n if a!=b:\r\n count=count+1\r\n x=(x-a)/2\r\n y=(y-b)/2\r\n return count\r\n```\r\n\r\na b表示x y除以2的余数,表示二进制的0 1\r\n\r\n```python\r\nclass Solution(object):\r\n def hammingDistance(self, x, y):\r\n \"\"\"\r\n :type x: int\r\n :type y: int\r\n :rtype: int\r\n \"\"\"\r\n z=x^y\r\n count=0\r\n while z:\r\n count+=z%2\r\n z=z/2\r\n return count\r\n```\r\n\r\nx y某一位不同,z在那一位为1"
},
{
"alpha_fraction": 0.4117647111415863,
"alphanum_fraction": 0.44117647409439087,
"avg_line_length": 8.666666984558105,
"blob_id": "5e34d0fb881c177b7473a4c40c1b176161a4e790",
"content_id": "c3a4ae12632b4135c09c0a860e1b9d686caacf93",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 50,
"license_type": "no_license",
"max_line_length": 16,
"num_lines": 3,
"path": "/books/python从入门到实践/python从入门到实践.md",
"repo_name": "Marco2018/learning_note",
"src_encoding": "UTF-8",
"text": "### python从入门到实践\r\n\r\n##### 8 函数\r\n\r\n"
}
] | 176 |
Dragon-Dane/networkx-graph-theory
|
https://github.com/Dragon-Dane/networkx-graph-theory
|
3fab46323681d47d2bedd31b105e362b40056ff0
|
7033abd622a5098312ed3fd054f6f76a4c15a885
|
04b2158ea57063f00c64ea9f4e0cfc2a3f7f3466
|
refs/heads/main
| 2023-02-03T14:32:42.623818 | 2020-12-19T14:35:11 | 2020-12-19T14:35:11 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6259328126907349,
"alphanum_fraction": 0.6492537260055542,
"avg_line_length": 31.4375,
"blob_id": "28f13ab28c72818062ab5cd77ee1ca8cf0522630",
"content_id": "ff7e4d920bd700659587b692981d46d28c138855",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1072,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 32,
"path": "/distance and diameter.py",
"repo_name": "Dragon-Dane/networkx-graph-theory",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Tue Oct 20 11:08:24 2020\r\n\r\n@author: shrey\r\n\"\"\"\r\n\r\nimport networkx as nx \r\nl=int(input(\"Enter no. of nodes\"))\r\nG=nx.Graph()#creating a graph\r\nH=nx.path_graph(l) #creating a graph having l no. of nodes\r\n\r\nnodes=input(\"enter nodes separated by comma\").split(',')\r\nfor i in range(l):\r\n G.add_node(nodes[i])#adding the nodes in G and H\r\n H.add_node(nodes[i])\r\nno_of_edges=int(input(\"enter no. of edges\"))\r\nprint(\"enter the pair of nodes, where the edge is present\")\r\nfor i in range(no_of_edges):\r\n b=input()#consists of the list of nodes where an edge is present between them\r\n #so, if, there exists an edge between 1 and 3, then b=[1,3], where b[0]=1,b[1]=3\r\n G.add_edge(b[0],b[1])\r\n H.add_edge(b[0],b[1])\r\n \r\nprint(\"the diameter of the graph is \", nx.diameter(G))\r\n\r\nprint(\"enter the pair of nodes you want to find the distance between\")\r\na=input(\"enter first node \")\r\nb=input(\"enter second node \")\r\n\r\n\r\nprint(\"the shortest distance between\",a,\"and\",b, \"is\",nx.shortest_path_length(H, source=a, target=b ))\r\n\r\n"
},
{
"alpha_fraction": 0.5345473885536194,
"alphanum_fraction": 0.5516871809959412,
"avg_line_length": 27.564516067504883,
"blob_id": "9c6073be6848a7aba9bc92cc05e3eedd537392b3",
"content_id": "e7744507d5a78698e78129654d61bb1f26360542",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1867,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 62,
"path": "/path matrix using warshall's algorithm.py",
"repo_name": "Dragon-Dane/networkx-graph-theory",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Wed Nov 11 15:20:15 2020\r\n\r\n@author: shrey\r\n\"\"\"\r\n#Shreya Srivastava\r\n#19BCP123\r\nimport numpy as np\r\n#numpy library will help us create arrays/matrices\r\nimport networkx as nx\r\n\r\n\r\n\r\nnodes=input(\"enter the nodes/vertices of the graph separated by comma\").split(',')\r\nG=nx.DiGraph()\r\nfor i in range(len(nodes)):\r\n G.add_node(nodes[i])#adding the node in G\r\nno_of_edges=int(input(\"enter no. of edges\"))\r\nprint(\"enter the pair of nodes, where the edge is present\")\r\nfor i in range(no_of_edges):\r\n b=input().split(',')#consists of list of nodes where an edge is present, so, if\r\n #there is an edge between A and B, then b=[A,B], and b[0]=A, b[1]=B\r\n G.add_edge(b[0],b[1])\r\n\r\nA=np.zeros((len(nodes),len(nodes)))\r\nfor i in range(len(nodes)):\r\n for j in range(len(nodes)):\r\n if (G.has_successor(nodes[i],nodes[j])):\r\n A[i][j]=1\r\n else:\r\n A[i][j]=0\r\n\r\nprint(\"P0 is \\n\", A)\r\n\r\n\r\nB=A\r\n\r\nl=list(nx.simple_cycles(G))#list of nodes forming a cycle\r\n\r\nfor i in range(len(nodes)):\r\n for j in range(len(nodes)):\r\n if nodes[i]!=nodes[j]:#since nx.all_simple_paths() function doesn't work when\r\n #source node and destination node is same, we check in the else statement if the\r\n #node is a part of cycle\r\n \r\n if list(nx.all_simple_paths(G,nodes[i],nodes[j]))!=[]:#checks whether there\r\n #exists a path between 2 nodes\r\n \r\n B[i][j]=1\r\n \r\n \r\n \r\n else:\r\n for r in range(len(l)):\r\n if nodes[i] in l[r]:#checks whether the nodes are a part of cycle\r\n B[i][j]=1\r\n\r\nprint(\"THIS IS P\",len(nodes),\"\\n\",B)\r\n\r\nprint(\"the graph looks like this \\n\")\r\nnx.draw(G, node_size=1000,with_labels=True) \r\n \r\n \r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.6553784608840942,
"alphanum_fraction": 0.677689254283905,
"avg_line_length": 36.61538314819336,
"blob_id": "59921c558b4326fba3659a48407e158858a7e6c5",
"content_id": "1716a2f9885c1a4643620e83a41cef6060773904",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2510,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 65,
"path": "/Minimum spanning tree using Kruskal algorithm.py",
"repo_name": "Dragon-Dane/networkx-graph-theory",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Sat Oct 31 09:53:11 2020\r\n\r\n@author: shrey\r\n\"\"\"\r\n\r\nimport networkx as nx\r\n\r\n\r\nG=nx.Graph()#creating a graph G\r\nl=int(input(\"Enter no. of nodes\"))\r\nnodes=input(\"enter nodes\").split(',')\r\nfor i in range(l):\r\n G.add_node(nodes[i])\r\nno_of_edges=int(input(\"enter no. of edges\"))\r\n\r\nprint(\"enter the pair of nodes, where the edge is present and the edge-weight separated by comma \")\r\nprint(\"\\n\")\r\nprint(\"Enter the edges in ascending order of their weights\")\r\n\r\n#Therefore, the user will enter the edges in ascending order of their weights, edges having the\r\n#least weights will be entered first and then the edges with greater weights will be entered by\r\n#the user\r\n\r\nedge_with_weight=[] #creating an empty list\r\nfor i in range(no_of_edges):\r\n \r\n b=input().split(',')#consists a list of edges and weights separated by comma\r\n #if there is an edge present between 1 and 2 of weight 10, b=[1,2,10]\r\n #where b[0]=1, b[1]=2, b[2]=10\r\n \r\n G.add_edge(b[0],b[1], weight=int(b[2]))\r\n edge_with_weight.append((b[0],b[1],int(b[2])))#if we consider the example above, one of\r\n #the elements of edge_with_weight list can be (1,2,10), which is a tuple\r\n\r\nprint(\"The list of edges with their weights:-\") \r\nprint(edge_with_weight)\r\n\r\nH=nx.Graph()\r\nH.add_nodes_from(G) #creating a new graph that already has the nodes \r\n#from the graph entered by the user\r\n\r\nfor i in range(len(edge_with_weight)):\r\n (node1, node2, weightt)=edge_with_weight[i]#we are extracting data from the \r\n #edge_with_weight list elements one by one and storing it in LHS\r\n #so, if there was an element (1,2,10) in the list then, node1=1, node2=2, weightt=10\r\n \r\n H.add_edge(node1, node2, weight= weightt)\r\n #Now we check if any cycle was created after adding this edge\r\n \r\n if nx.cycle_basis(H)!=[]:\r\n #checking if the list of cycles is empty or not\r\n # and removing the edge that was recently added if the list is not empty\r\n H.remove_edge(node1,node2)\r\n\r\n#After creating graph H(which is the minimum spanning tree), all we have to do\r\n# is add the weights of edges\r\nb=list(H.edges(data='weight'))#we get a list of the edges in H with weights\r\nmin_weight=0#declaring a variable with initial value 0\r\nfor i in range(len(b)):\r\n (src,dest,weightt)=b[i]#since b is a list of tuples, we extract data from tuple first\r\n #and then add the weight below\r\n min_weight=min_weight+weightt\r\nprint(\"Minimum weight of spanning tree is\",min_weight)\r\n"
},
{
"alpha_fraction": 0.5400862097740173,
"alphanum_fraction": 0.5625,
"avg_line_length": 36.517242431640625,
"blob_id": "0e737e33fe5d3fb8009231c0da94d20b4e47cd17",
"content_id": "a509161c0dad5a0ddf952a339e0dce2dd44578e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2320,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 58,
"path": "/shortest path matrix warshall.py",
"repo_name": "Dragon-Dane/networkx-graph-theory",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Fri Nov 13 10:18:32 2020\r\n\r\n@author: shrey\r\n\"\"\"\r\n#Shreya Srivastava\r\n#19BCP123\r\nimport networkx as nx\r\nimport numpy as np\r\n\r\n\r\nnodes=input(\"enter the nodes/vertices of the graph separated by comma\").split(',')\r\nG=nx.DiGraph()\r\nfor i in range(len(nodes)):\r\n G.add_node(nodes[i])#adding the node in G\r\nno_of_edges=int(input(\"enter no. of edges\"))\r\nprint(\"enter the pair of nodes, where the edge is present, with the weight,all separated by comma\")\r\nfor i in range(no_of_edges):\r\n b=input().split(',')#consists of list of nodes where an edge is present, so, if\r\n #there is an edge between A and B, then b=[A,B,4], and b[0]=A, b[1]=B, b[2]=4(the edge weight)\r\n G.add_edge(b[0],b[1], weight=int(b[2]))\r\n \r\na=nx.floyd_warshall_numpy(G)#returns a shortest path matrix using warshall's algorithm\r\n#but this matrix doesn't provide shortest path where the source and the destination node is same\r\n\r\n#if there is a cycle between 1,2,3; then, we can traverse from 1 to 1 or 2 to2 or 3 to 3 via this\r\n#cycle, but in the matrix the value of 1st row-1st col =0; similarly for 2nd and 3rd row and cols\r\n\r\nC=np.asarray(a)#converting it into an array\r\n\r\nm=[]\r\nl=list(nx.simple_cycles(G))#returns a list of nodes forming a cycle\r\nf=0\r\nfor i in range(len(nodes)):\r\n \r\n for r in range(len(l)):\r\n \r\n if nodes[i] in l[r]:#if the node is in the list containing cycles\r\n k=l[r]\r\n \r\n for s in range(len(k)):#say, k=[1,2,3], so, len(k)=3, but 2 is the last index\r\n #that is, k[3] doesn't exist\r\n if (s+1)!=len(k):#thus, the if conditions check whether index is in range\r\n \r\n f=f+G.get_edge_data(k[s],k[s+1])['weight']#adding the weight as we proceed\r\n #from one edge to another in a cycle\r\n \r\n if (s+1)==len(k):\r\n \r\n f=f+G.get_edge_data(k[s],k[0])['weight']\r\n m.append(f)#appending the value of the shortest path obtained in the list\r\n f=0\r\n if m!=[]:\r\n C[i][i]=min(m)#assigning the minimum value in the list\r\n m=[]\r\n \r\nprint(\"shortest path matrix \\n\", C)\r\n \r\n \r\n \r\n "
},
{
"alpha_fraction": 0.6068090796470642,
"alphanum_fraction": 0.628170907497406,
"avg_line_length": 32.88372039794922,
"blob_id": "3fa650abdc226709ec1b3e4eec9dbe3e0747354c",
"content_id": "bd8a0c299785a88044c6e7c25b5636fe270f678a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1498,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 43,
"path": "/path matrix.py",
"repo_name": "Dragon-Dane/networkx-graph-theory",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Tue Nov 3 13:55:54 2020\r\n\r\n@author: shrey\r\n\"\"\"\r\n#Shreya Srivastava\r\n#19BCP123\r\nimport numpy as np\r\n#numpy library will help us create arrays\r\n\r\nrow=int(input(\"enter no. of rows\"))#since it is a square matrix\r\n#so, only no. of rows is needed\r\n\r\nA=np.zeros((row,row))#creating a zero matrix of the size (no. of rows) x (no. of rows)\r\nB=np.zeros((row,row))\r\nC=np.zeros((row,row))\r\nfor i in range(row):\r\n for j in range(row):\r\n print(\"enter 1 if there is a direct edge present between\",i,\"row and\",j,\"column else enter 0\")\r\n \r\n b=int(input())#taking the input from the user\r\n A[i][j]=b #and assigning the value of the element present at \r\n #i'th row and j'th column in A matrix\r\nB=A\r\nC=A\r\nprint(\"length 1\\n\",B)\r\nfor i in range(row-1):\r\n B=B.dot(A)#multiplying two matrices and storing the result in variable B\r\n #since B was A earlier, so it becomes A*A=A^2 and this A^2 is stored in B\r\n #so for the next multiplication, B is A^2, so A^2 * A= A^3 and this is stored in B, and so on..\r\n print(\"LENGTH\",i+2,B,\"\\n\")\r\n C=C+B #adding two matrices and storing it in C\r\n #therefore, C will be composed of A+A^2+A^3+...\r\n\r\npath_matrix=np.zeros((row,row))#so, initially all the elements in path matrix are zeros\r\nfor i in range(row):\r\n for j in range(row):\r\n if C[i][j]!=0:\r\n path_matrix[i][j]=1 #changing the element to 1, if the corresponding element \r\n #in C is non-zero\r\n\r\nprint(path_matrix)"
},
{
"alpha_fraction": 0.8252873420715332,
"alphanum_fraction": 0.8252873420715332,
"avg_line_length": 71.5,
"blob_id": "ff4d9c9e216ab0aa389855a197f39f04986886b1",
"content_id": "4ecb108a6615dea41bc8ac3343f69875efebc5c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 435,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 6,
"path": "/README.md",
"repo_name": "Dragon-Dane/networkx-graph-theory",
"src_encoding": "UTF-8",
"text": "# networkx-graph-theory\nImplementing graph theory concepts using networkx library.\nThe concepts implemented are-:\nisomorphism, degree of a node, distance and diameter in a graph, Eulerian path and cycle,\nminimum spanning tree using Kruskal's algorithm, finding out path matrix using powers of adjacency matrix,\npath matrix and shortest path matrix using Warshall's algorithm, finding out chromatic number using Welsh-Powell Algorithm.\n"
},
{
"alpha_fraction": 0.6458519101142883,
"alphanum_fraction": 0.6726137399673462,
"avg_line_length": 33.03125,
"blob_id": "58859a1c95ddf6795f19234529f0026b27350080",
"content_id": "2f1d7554b998504321287b910019939ecd91e688",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1121,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 32,
"path": "/welsh-powell.py",
"repo_name": "Dragon-Dane/networkx-graph-theory",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Fri Nov 13 11:56:40 2020\r\n\r\n@author: shrey\r\n\"\"\"\r\n\r\n\r\nimport networkx as nx \r\n\r\nnodes=input(\"enter the nodes/vertices of the graph separated by comma\").split(',')\r\nG=nx.Graph()\r\n\r\nfor i in range(len(nodes)):\r\n G.add_node(nodes[i])#adding the node in G\r\nno_of_edges=int(input(\"enter no. of edges\"))\r\nprint(\"enter the pair of nodes, where the edge is present,all separated by comma\")\r\n\r\nfor i in range(no_of_edges):\r\n b=input().split(',')#consists of list of nodes where an edge is present, so, if\r\n #there is an edge between A and B, then b=[A,B], and b[0]=A, b[1]=B\r\n G.add_edge(b[0],b[1])\r\n\r\nd=nx.greedy_color(G,strategy=\"random_sequential\")#assigns colours to nodes\r\n#such that no two adjacent nodes have the same colour\r\n# say there are 3 nodes, A,B,C , in a cycle, then d={A:0,B:1,C:2}\r\n#where 0,1,2 are the colours assigned\r\n\r\nl=list(d.values())#we will extract those values from the dictionary and convert it into a list\r\nprint(\"chromatic number is\", max(l)+1)#since the colour starts from zero, we have to add 1\r\n\r\nnx.draw(G, node_size=1000, with_labels=True)\r\n"
},
{
"alpha_fraction": 0.6088019609451294,
"alphanum_fraction": 0.6242868900299072,
"avg_line_length": 26.511627197265625,
"blob_id": "d483a98719815fcaa17adfd11e7d9d11076f1877",
"content_id": "c698c9ada7636de65a3ae5386c9594bb3237f27b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2454,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 86,
"path": "/isomorphism_in_graphs.py",
"repo_name": "Dragon-Dane/networkx-graph-theory",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Thu Jul 30 12:48:30 2020\r\n\r\n@author: shrey\r\n\"\"\"\r\n\r\n\r\nimport networkx as nx \r\n\r\nG=nx.Graph()#creating an undirected graph G\r\n\r\nno_of_nodes=input(\"enter no. of nodes\")\r\n\r\nnodes=input(\"enter nodes\").split(',')#like 1,2,3.. or a,b,c..\r\nfor i in range(len(no_of_nodes)):\r\n G.add_node(nodes[i])#adding the node in G\r\nno_of_edges=int(input(\"enter no. of edges\"))\r\nprint(\"enter the pair of nodes, where the edge is present\")\r\nfor i in range(no_of_edges):\r\n b=input()#consists of list of nodes where an edge is present, so, if\r\n #there is an edge between A and B, then b=[A,B], and b[0]=A, b[1]=B\r\n G.add_edge(b[0],b[1])\r\n\r\nprint(\"Second Graph\")\r\n\r\nH=nx.Graph()\r\n\r\nno_of_second_nodes=input(\"enter no. of nodes\")\r\n\r\nnodes_second=input(\"enter nodes\").split(',')\r\nfor i in range(len(no_of_second_nodes)):\r\n H.add_node(nodes_second[i])\r\n \r\nno_of_second_edges=int(input(\"enter no. of edges\"))\r\nprint(\"enter the pair of nodes, where the edge is present\")\r\nfor i in range(no_of_second_edges):\r\n b=input()\r\n H.add_edge(b[0],b[1])\r\n\r\nprint(\"Now, to compare\")\r\ncount=0\r\nl=list(G.nodes)#consists of list of nodes of graph G\r\nm=list(H.nodes)#same with H\r\n\r\n\r\nif(len(l)==len(m)):#checking whether the length of the lists of nodes of G and H are same or not\r\n \r\n print(\"no. of nodes is same\")\r\n count=count+1\r\nelse:\r\n \r\n print(\"different number of nodes\")\r\nif(G.number_of_edges()==H.number_of_edges()):\r\n print(\"no. of edges is same\")\r\n count=count+1\r\nelse:\r\n print(\"no. of edges are different\")\r\n \r\nif(G.number_of_selfloops()==H.number_of_selfloops()):\r\n print(\"no. of self-loops is same\")\r\n count=count+1\r\nelse:\r\n \r\n print(\"different no. of self-loops\")\r\n\r\ntemp=0\r\n\r\nfor i in range(len(l)):\r\n \r\n if(G.degree[l[i]])!=(H.degree[m[i]]):#comparing the degree of the corresponding nodes in G and H\r\n print(\"degree of\", l[i], \" in first graph is not equal to that of \", m[i], \" in second graph\")\r\n print(\"degree of\",l[i], \" in first graph is\", G.degree[l[i]])\r\n print(\"degree of\",m[i], \"in second graph is\", H.degree[m[i]])\r\n temp=temp-1\r\n\r\nif(temp==0 and count==3):\r\n print(\"the graphs are isomorphic\")\r\nelse:\r\n print(\"the graphs are not isomorphic\")\r\n\r\n#drawing the graphs\r\nnx.draw(H, node_color='green',node_size=1000,with_labels=True, font_weight='bold')\r\nprint()\r\n\r\nnx.draw(G, node_size=1000,with_labels=True, font_weight='bold')\r\n\r\n"
},
{
"alpha_fraction": 0.616143524646759,
"alphanum_fraction": 0.6466367840766907,
"avg_line_length": 31.84848403930664,
"blob_id": "c7dd1f0838f099e18800f60094f63e13b5bb4c1c",
"content_id": "2cab6f5bd005efcb5a1c12e4d6c1046025b73cce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1115,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 33,
"path": "/eulerian path and cycle.py",
"repo_name": "Dragon-Dane/networkx-graph-theory",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Sat Oct 24 10:57:37 2020\r\n\r\n@author: shrey\r\n\"\"\"\r\n\r\nimport networkx as nx \r\n\r\nG=nx.Graph()#creating a graph G\r\nl=int(input(\"Enter no. of nodes\"))\r\nnodes=input(\"enter nodes\").split(',')#like 1,2,3.. or a,b,c..\r\nfor i in range(l):\r\n G.add_node(nodes[i])#adding the node in graph G\r\nno_of_edges=int(input(\"enter no. of edges\"))\r\nprint(\"enter the pair of nodes, where the edge is present\")\r\nfor i in range(no_of_edges):\r\n b=input()#consists of a list of nodes where an edge is present\r\n #if,say, there exists an edge between 1 and 2, then b=[1,2], where b[0]=1, b[1]=2\r\n G.add_edge(b[0],b[1])\r\neven=0\r\nodd=0\r\nfor i in range(l):\r\n if G.degree(nodes[i])%2==0:#checking whether the degree of i'th node is even or odd\r\n even=even+1#if it is even then increment the variable by 1\r\n else:\r\n odd=odd+1#same with odd\r\nif even==len(nodes):#if the value of variable even is equal to the total no. of nodes\r\n print('eulerian cycle exits')\r\nelif odd==2:\r\n print('eulerian path exits')\r\nelse:\r\n print(\"neither eulerian cycle nor eulerian path exists\")"
},
{
"alpha_fraction": 0.6209773421287537,
"alphanum_fraction": 0.641239583492279,
"avg_line_length": 33.04166793823242,
"blob_id": "b6dc894b5aadc6f1798585ce4c753da688db6669",
"content_id": "310a11c8a3bc0f561850c7673aecbaef7eac7e12",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 839,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 24,
"path": "/degree of node in graph.py",
"repo_name": "Dragon-Dane/networkx-graph-theory",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Tue Oct 20 10:58:25 2020\r\n\r\n@author: shrey\r\n\"\"\"\r\n\r\nimport networkx as nx \r\n\r\nG=nx.Graph()#creating a graph G\r\nl=int(input(\"Enter no. of nodes\"))\r\nnodes=input(\"enter the nodes separated by comma\").split(',')\r\nfor i in range(l):\r\n G.add_node(nodes[i])#adding the node in G\r\nno_of_edges=int(input(\"enter no. of edges\"))\r\nprint(\"enter the pair of nodes, where the edge is present,separated by comma\")\r\nfor i in range(no_of_edges):\r\n b=input().split(',')#consists of list of nodes where an edge is present, so, if\r\n #there is an edge between A and B, then b=[A,B], and b[0]=A, b[1]=B\r\n #the next time the loop runs again, b becomes empty list\r\n G.add_edge(b[0],b[1])\r\n \r\nfor i in range(l):\r\n print(\"The degree of\",nodes[i],\"is\",G.degree(nodes[i]))# tells the degree of the i'th node"
}
] | 10 |
samsonovkirill/codebattle
|
https://github.com/samsonovkirill/codebattle
|
76b309cdb55c5b70ba7ff235542daaae8d94a28d
|
5a45d1e39663ffdb6cf677bfb1fa9dd3402fffbf
|
d033025089c333da8674368af8881f01ded0ab18
|
refs/heads/master
| 2020-06-04T09:55:33.783490 | 2019-06-14T12:01:52 | 2019-06-14T12:01:52 | 191,976,493 | 1 | 0 | null | 2019-06-14T16:41:38 | 2019-06-14T12:01:55 | 2019-06-14T12:01:53 | null |
[
{
"alpha_fraction": 0.5578424334526062,
"alphanum_fraction": 0.5660042762756348,
"avg_line_length": 27.18000030517578,
"blob_id": "7052347bf9cd52a7985dcdff3d272e70a579f808",
"content_id": "a07c1f5a3f6f3400d1c99dc4055f7da7ee2d681c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2818,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 100,
"path": "/services/app/assets/js/widgets/containers/RatingList.jsx",
"repo_name": "samsonovkirill/codebattle",
"src_encoding": "UTF-8",
"text": "import React from 'react';\nimport { connect } from 'react-redux';\nimport _ from 'lodash';\nimport Pagination from 'react-pagination-library';\nimport UserInfo from './UserInfo';\nimport { getUsersList } from '../selectors';\nimport * as UsersMiddlewares from '../middlewares/Users';\nimport Loading from '../components/Loading';\n\nclass UsersRating extends React.Component {\n componentDidMount() {\n const { getRatingPage } = this.props;\n getRatingPage(1);\n }\n\n renderUser = (user, index) => {\n const { usersRatingPage: { pageInfo } } = this.props;\n return (\n <tr key={user.id}>\n <td className=\"p-3 align-middle\">\n {pageInfo.page_number > 1\n ? index + 1 + (pageInfo.page_number - 1) * pageInfo.page_size\n : index + 1}\n </td>\n <td className=\"tex-left p-3 align-middle\">\n <UserInfo user={_.omit(user, 'rating')} />\n </td>\n <td className=\"p-3 align-middle\">{user.rating}</td>\n <td className=\"p-3 align-middle\">{user.game_count}</td>\n <td className=\"p-3 align-middle\">\n <a className=\"text-muted\" href={`https://github.com/${user.name}`}>\n <span className=\"h3\">\n <i className=\"fab fa-github\" />\n </span>\n </a>\n </td>\n </tr>\n );\n }\n\n renderPaginationUi = () => {\n const {\n getRatingPage,\n usersRatingPage:\n { pageInfo: { page_number: current, total_pages: total } },\n } = this.props;\n return (\n <Pagination\n currentPage={current}\n totalPages={total}\n changeCurrentPage={getRatingPage}\n theme=\"bottom-border\"\n />\n );\n }\n\n render() {\n const { usersRatingPage } = this.props;\n if (!usersRatingPage) {\n return <Loading />;\n }\n\n return (\n <div className=\"text-center\">\n <h2 className=\"font-weight-normal\">Users rating</h2>\n <p>\n {`Total: ${usersRatingPage.pageInfo.total_entries}`}\n </p>\n <table className=\"table\">\n <thead className=\"text-left\">\n <tr>\n <th className=\"p-3 border-0\">Rank</th>\n <th className=\"p-3 border-0\">User</th>\n <th className=\"p-3 border-0\">Rating</th>\n <th className=\"p-3 border-0\">Games played</th>\n <th className=\"p-3 border-0\">Github</th>\n </tr>\n </thead>\n <tbody className=\"text-left\">\n {usersRatingPage.users.map(this.renderUser)}\n </tbody>\n </table>\n {this.renderPaginationUi()}\n </div>\n );\n }\n}\n\nconst mapStateToProps = state => ({\n usersRatingPage: getUsersList(state),\n});\n\nconst mapDispatchToProps = {\n getRatingPage: UsersMiddlewares.getUsersRatingPage,\n};\n\nexport default connect(\n mapStateToProps,\n mapDispatchToProps,\n)(UsersRating);\n"
},
{
"alpha_fraction": 0.739130437374115,
"alphanum_fraction": 0.7424749135971069,
"avg_line_length": 16.58823585510254,
"blob_id": "a2a30f23fa21ae22a2c22a8e55c57687a1faf691",
"content_id": "bae5e31a2bb5e79143cb74e6e00b0b4bc805a4af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 299,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 17,
"path": "/services/app/dockers/haskell/Dockerfile",
"repo_name": "samsonovkirill/codebattle",
"src_encoding": "UTF-8",
"text": "FROM alpine:latest\n\nRUN apk update \\\n && apk add cabal ghc gmp-dev make wget musl-dev libc6-compat\n\nWORKDIR /usr/src/app\n\nADD HOwl.cabal .\nADD checker.hs .\nADD magic.hs .\nADD Types.hs .\nADD Solution.hs Check/Solution.hs\nADD Makefile .\n\nRUN ln -s check Check\nRUN cabal new-update\nRUN cabal new-build\n"
},
{
"alpha_fraction": 0.7377049326896667,
"alphanum_fraction": 0.7377049326896667,
"avg_line_length": 14.5,
"blob_id": "464911459de99cc662267d28056ee10c9dab601f",
"content_id": "be8bd7c0a7f3f782984bbb669a880e86ebe76cac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 61,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 4,
"path": "/services/app/dockers/python/Makefile",
"repo_name": "samsonovkirill/codebattle",
"src_encoding": "UTF-8",
"text": "test:\n\tcat check/data.jsons | python checker.py\n\n.PHONY: test"
},
{
"alpha_fraction": 0.6804123520851135,
"alphanum_fraction": 0.7010309100151062,
"avg_line_length": 23.25,
"blob_id": "6a2cb477400588443815d2f2659c734c5e9a1ce3",
"content_id": "0bd62b35d0c610be16ff7d172c9f7523824d4301",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 97,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 4,
"path": "/services/app/dockers/haskell/Makefile",
"repo_name": "samsonovkirill/codebattle",
"src_encoding": "UTF-8",
"text": "test:\n\tcabal new-run Magic -v0 && cat Check/data.jsons | cabal new-run Checker -v0\n\n.PHONY: test\n"
},
{
"alpha_fraction": 0.6905660629272461,
"alphanum_fraction": 0.7056604027748108,
"avg_line_length": 21.08333396911621,
"blob_id": "1acd560145e67873484b6b4a069cd26eefc192bb",
"content_id": "0edbc02e1cb227c1a919c03faac458eb5a773c3f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 265,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 12,
"path": "/services/app/dockers/js/Dockerfile",
"repo_name": "samsonovkirill/codebattle",
"src_encoding": "UTF-8",
"text": "FROM node:11.6.0\n\nRUN apt-get update && apt-get install -y build-essential --no-install-recommends && apt-get clean && rm -rf /var/lib/apt/lists/*\n\nRUN npm i -g chai\n\nENV NODE_PATH /usr/local/lib/node_modules/\n\nWORKDIR /usr/src/app\n\nADD checker.js .\nADD Makefile .\n"
},
{
"alpha_fraction": 0.5582655668258667,
"alphanum_fraction": 0.5627822875976562,
"avg_line_length": 20.288461685180664,
"blob_id": "52e2a14f2cc04872a087ca2feb2051a36e80f6f6",
"content_id": "898dda9b0874b1edce4376779196b20ffadc5b6d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 1107,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 52,
"path": "/services/app/dockers/php/checker.php",
"repo_name": "samsonovkirill/codebattle",
"src_encoding": "UTF-8",
"text": "<?php\n\nregister_shutdown_function(function() {\n $stdout = STDERR;\n $last_error = error_get_last();\n $errors = array(E_ERROR, E_CORE_ERROR, E_COMPILE_ERROR);\n\n if (in_array($last_error['type'], $errors)) {\n if (isset($last_error['message'])) {\n list($message) = explode(PHP_EOL, $last_error['message']);\n } else {\n $message = $last_error['message'];\n }\n\n fwrite($stdout, json_encode(array(\n 'status' => 'error',\n 'result' => $message\n )));\n exit(0);\n }\n});\n\ninclude 'check/solution.php';\n\nassert_options(ASSERT_ACTIVE, 1);\nassert_options(ASSERT_WARNING, 0);\nassert_options(ASSERT_QUIET_EVAL, 1);\n\n$stdout = STDERR;\n\nwhile ($line = fgets(STDIN)) {\n $json = json_decode($line);\n\n if (isset($json->check)) {\n fwrite($stdout, json_encode(array(\n 'status' => 'ok',\n 'result' => $json->check\n )));\n } else {\n $result = solution(...$json->arguments);\n\n if (assert($result !== $json->expected)) {\n fwrite($stdout, json_encode(array(\n 'status' => 'failure',\n 'result' => $json->arguments\n )));\n exit(0);\n }\n }\n}\n\n?>\n"
},
{
"alpha_fraction": 0.5784061551094055,
"alphanum_fraction": 0.5809768438339233,
"avg_line_length": 17.975608825683594,
"blob_id": "6067b39079a4b2985b81785cf2395bf6d3c28ab0",
"content_id": "c3e531ce816cf1ab563e53a31c1aa2d5ba6bfdd4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 778,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 41,
"path": "/services/app/dockers/ruby/checker.rb",
"repo_name": "samsonovkirill/codebattle",
"src_encoding": "UTF-8",
"text": "require 'json'\nrequire 'test/unit'\n$stdout = STDERR\n\nextend Test::Unit::Assertions\n\nchecks = []\n\nSTDIN.read.split(\"\\n\").each do |line|\n checks.push(JSON.parse(line))\nend\n\nbegin\n require './check/solution'\n\n checks.each do |element|\n if element['check']\n puts JSON.dump(\n status: :ok,\n result: element['check']\n )\n else\n result = method(:solution).call(*element['arguments'])\n begin\n assert_equal(element['expected'], result)\n rescue Test::Unit::AssertionFailedError\n puts JSON.dump(\n status: :failure,\n result: element['arguments']\n )\n exit(0)\n end\n end\n end\nrescue Exception => e\n puts(JSON.dump(\n status: :error,\n result: e.message\n ))\n exit(0)\nend\n"
},
{
"alpha_fraction": 0.7166666388511658,
"alphanum_fraction": 0.7166666388511658,
"avg_line_length": 14,
"blob_id": "9537f59cffcfcb2b01b1cc5d4f441c0120304724",
"content_id": "0ddf032563fe1ba90675c8f9cf0d199423e135b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 60,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 4,
"path": "/services/app/dockers/js/Makefile",
"repo_name": "samsonovkirill/codebattle",
"src_encoding": "UTF-8",
"text": "test:\n\tcat check/data.jsons | node checker.js\n\n.PHONY: test\n"
},
{
"alpha_fraction": 0.71875,
"alphanum_fraction": 0.71875,
"avg_line_length": 15,
"blob_id": "a8e9dfb98bd06c9f1e03eb6fdb8d3352d9089231",
"content_id": "0a3ab06f8414dc9700ea6c1c3f7354674ef805f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 64,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 4,
"path": "/services/app/dockers/elixir/Makefile",
"repo_name": "samsonovkirill/codebattle",
"src_encoding": "UTF-8",
"text": "test:\n\tcat check/data.jsons | mix run checker.exs\n\n.PHONY: test\n"
},
{
"alpha_fraction": 0.6778846383094788,
"alphanum_fraction": 0.7211538553237915,
"avg_line_length": 17.909090042114258,
"blob_id": "9762be95ff938c0c86cb3d65b5f9109f2e38fb30",
"content_id": "1576d37e368d7e7b100d90b82c04efcdb855b31b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 208,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 11,
"path": "/services/app/dockers/clojure/Dockerfile",
"repo_name": "samsonovkirill/codebattle",
"src_encoding": "UTF-8",
"text": "FROM clojure:openjdk-11-tools-deps-1.10.0.408\n\nRUN apt-get update && apt-get install -y build-essential\n\n\nWORKDIR /usr/src/app\n\nADD deps.edn .\nRUN clojure -e \"(prn :install)\"\nADD checker.clj .\nADD Makefile .\n"
},
{
"alpha_fraction": 0.7166666388511658,
"alphanum_fraction": 0.7166666388511658,
"avg_line_length": 14,
"blob_id": "61dbe1ee2f6f2c297a1cc2af56e3a5ba7c16d7ff",
"content_id": "0288c4c833a880956c88e46fba14ac096e99ab17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 60,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 4,
"path": "/services/app/dockers/ruby/Makefile",
"repo_name": "samsonovkirill/codebattle",
"src_encoding": "UTF-8",
"text": "test:\n\tcat check/data.jsons | ruby checker.rb\n\n.PHONY: test\n"
},
{
"alpha_fraction": 0.694915235042572,
"alphanum_fraction": 0.694915235042572,
"avg_line_length": 13.75,
"blob_id": "5a5a02c8f40cfcd8e66f7466857d39f1bb67f0a0",
"content_id": "daa71837770622e6b3cc07b2e24cdae8e5a9ee5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 59,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 4,
"path": "/services/app/dockers/clojure/Makefile",
"repo_name": "samsonovkirill/codebattle",
"src_encoding": "UTF-8",
"text": "test:\n\tcat check/data.jsons | clj -m checker\n\n.PHONY: test\n"
},
{
"alpha_fraction": 0.5346820950508118,
"alphanum_fraction": 0.5390173196792603,
"avg_line_length": 23.714284896850586,
"blob_id": "857a694c020e15deea2c0a986ca7405ee48282e6",
"content_id": "263e852b6e220dd247f8da4a5b7e36aed403bc2f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 692,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 28,
"path": "/services/app/dockers/python/checker.py",
"repo_name": "samsonovkirill/codebattle",
"src_encoding": "UTF-8",
"text": "import sys\nimport json\n\nchecks = [json.loads(l) for l in sys.stdin.read().split(\"\\n\")]\n\ntry:\n from check.solution import solution\n for element in checks:\n if 'check' in element.keys():\n print(json.dumps({\n 'status': 'ok',\n 'result': element['check'],\n }))\n else:\n assert solution(*element['arguments']) == element['expected'], element['arguments']\n\nexcept AssertionError as exc:\n print(json.dumps({\n 'status': 'failure',\n 'result': exc.args[0],\n }))\n exit(0)\nexcept Exception as exc:\n print(json.dumps({\n 'status': 'error',\n 'result': 'unexpected',\n }))\n exit(0)\n"
}
] | 13 |
F713ND5/spammer
|
https://github.com/F713ND5/spammer
|
1ecd1464ec11d73b99fac407311f530f6117cc84
|
e6163e1aed590464392adf29397ab45ce2ed8e61
|
32b1ce4bb9d3f96f4d9bf478e1f3f9e89e310952
|
refs/heads/master
| 2021-04-23T12:57:10.344260 | 2020-03-25T08:59:52 | 2020-03-25T08:59:52 | 249,926,905 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6683168411254883,
"alphanum_fraction": 0.6881188154220581,
"avg_line_length": 27.85714340209961,
"blob_id": "b082c5d15f3e9e1cdb944708c77393df146b6331",
"content_id": "b8e6ef49beba753cc5c975e4c1f33e8fddb4825c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 406,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 14,
"path": "/jalan.py",
"repo_name": "F713ND5/spammer",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nimport random\nimport sys\nimport time\ndef mengetik(s):\n for c in s + '\\n':\n sys.stdout.write(c)\n sys.stdout.flush()\n time.sleep(random.random() * 0.3)\nmengetik(' Selamat datang di tools spammer sms')\nmengetik(' Saya sudah mendapatkan persetujuan dari team black coder crush untuk menyatukan ulang tools ini')\nprint \"\\033[96m[√] TUNGGU SEBENTAR...\"\ntime.sleep(3)\n"
}
] | 1 |
kevin335200/iliasScraper
|
https://github.com/kevin335200/iliasScraper
|
b73b0225434525327118cb35f5335b9579d87881
|
f1b751ced37c9df2ab056f4e3f3eea5f02b72099
|
cbd9133498a0020edf010be6595e174ad637b057
|
refs/heads/main
| 2023-04-20T12:50:43.305843 | 2021-04-26T09:15:56 | 2021-04-26T09:15:56 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5362062454223633,
"alphanum_fraction": 0.5389610528945923,
"avg_line_length": 35.03546142578125,
"blob_id": "825f2b5a46fd60d30bfbc82230a30966a5c2a4db",
"content_id": "6d2d966e874d451ffaf13a8f4a0d863dd1cbb955",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5083,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 141,
"path": "/iliasScraper/file_parser.py",
"repo_name": "kevin335200/iliasScraper",
"src_encoding": "UTF-8",
"text": "\nimport re\nfrom tqdm import tqdm\nfrom colorama import Fore, Back, Style\n\nclass FileParser:\n \"\"\"\n docstring for FileParser.\n \"\"\"\n\n def __init__(self, request_handler, skip_existing_files=True, existing_files=[]):\n self.parser = 'html.parser'\n self.ignore = [\"weblink\", \"test\", \"forum\", \"übung\", \"inhaltsseite\"]\n self.file_id = \"datei\"\n self.folder_id = \"ordner\"\n self.current_path = \"/\"\n self.dir_dict = {}\n self.done_folders = []\n self.folder_todo = []\n self.todo_folders_index = 0\n self.layer = 0\n self.request_handler = request_handler\n self.all_urls = []\n self.skip_existing_files = skip_existing_files\n self.existing_files = existing_files\n\n\n def filter_ignored(self, img_list):\n def filter_(title):\n return any(map(lambda el: el in title.lower(), self.ignore))\n return [tag for tag in img_list if not filter_(tag[\"title\"])]\n\n def _extract_href(self, img):\n element = list(img.parent.parent.find_all(\"a\"))[0]\n return element[\"href\"]\n\n def _pathify_folder_name(self, folder_name):\n folder_name = \"_\".join(folder_name.split(\" \"))\n folder_name = \"_\".join(folder_name.split(\"|\"))\n folder_name = \"_\".join(folder_name.split(\"'\"))\n folder_name = \"_\".join(folder_name.split(\":\"))\n folder_name = re.sub(\"_+\", \"_\", folder_name)\n return folder_name\n\n def _extract_file_name(self, img):\n # why was index = 1 ????\n element = list(img.parent.parent.parent.find_all(\"a\"))[0]\n return element.text\n\n def _extract_symbol_name(self, a_tag):\n imgs = a_tag.find_all(\"img\")\n if imgs:\n return str(imgs[0][\"title\"].lower())\n return \"\"\n\n def update_dir_dict(self, img_list, path):\n \"\"\"\n \"\"\"\n dir_dict = {}\n for img in img_list:\n img_title = img[\"title\"].lower()\n # print(f\"{img_title=}\")\n if self.file_id in img_title:\n if not path in dir_dict:\n dir_dict[path] = []\n filename = self._extract_file_name(img)\n # print(f\"{filename=}\")\n if self.skip_existing_files and filename in self.existing_files:\n print(\"continue\")\n continue\n dir_dict[path].append({\n \"url\": self._extract_href(img),\n \"file_name\": filename\n })\n return dir_dict\n\n def _is_sitzung(self, tag, soup, add_q=False):\n if add_q:\n sitzungen = soup.find_all(\"img\", title=\"Symbol Sitzung\")\n sitzungen_no = len(sitzungen)\n if sitzungen_no == 1:\n return True\n return False\n\n img = tag.parent.parent.parent.parent.parent.find_all(\"img\", class_=\"ilListItemIcon\")\n if img:\n img = img[0]\n title = img[\"title\"].lower()\n if \"sitzung\" in title or \"session\" in title:\n return True\n return False\n\n def get_all_urls(self, url):\n # print(40*\"~\")\n # print(f\"{url=}\")\n soup = self.request_handler.get_soup(url)\n links = soup.find_all('a', class_=\"il_ContainerItemTitle\")\n if not links or url in self.all_urls:\n self.all_urls.append(url)\n return 1\n else:\n sitzung_q = self._is_sitzung(url, soup=soup, add_q=True)\n # print(f\"{sitzung_q=}\")\n if \"fold\" in url or sitzung_q:\n self.all_urls.append(url)\n print(Style.DIM + url + Style.RESET_ALL)\n for link in links:\n if not link.has_attr(\"href\") or link in self.all_urls:\n continue\n href = link['href']\n if not \"https\" in href:\n href = f\"https://ilias.uni-konstanz.de/ilias/{href}\"\n\n if \"fold\" in href or self._is_sitzung(link, soup=soup):\n self.get_all_urls(href)\n\n return list(set(self.all_urls))\n\n def extract_path_from_breadcrumb(self, breadcrumb_string):\n total_path_list = breadcrumb_string.split(\"\\n\")\n split_index = list(map(lambda item: \"Lehrveranstaltung\" in item, total_path_list)).index(True)\n path_list = total_path_list[split_index+1:][:-1]\n return path_list\n\n def parse(self, soup):\n breadcrumb_string = soup.find_all(\"ol\", class_=\"breadcrumb\")\n if not breadcrumb_string:\n return {}\n breadcrumb_string = breadcrumb_string[0].text\n path = \"/\".join(list(map(lambda x: self._pathify_folder_name(x),\n self.extract_path_from_breadcrumb(breadcrumb_string))))\n\n # ilContainerListItemOuter\n # - ilContainerListItemIcon\n # - ilContainerListItemContent\n\n all_img_tags = soup.find_all(\"img\", class_=\"ilListItemIcon\")\n f_img_tags = self.filter_ignored(all_img_tags)\n\n dir_dict = self.update_dir_dict(f_img_tags, path)\n\n return dir_dict\n"
},
{
"alpha_fraction": 0.6395779848098755,
"alphanum_fraction": 0.6421442627906799,
"avg_line_length": 31.462963104248047,
"blob_id": "baa43fd3da68ff065d4372e711c30cfdd9fc6753",
"content_id": "310acbd4351aa48e7cfcc5045bba500b07cb9076",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3507,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 108,
"path": "/iliasScraper/cli.py",
"repo_name": "kevin335200/iliasScraper",
"src_encoding": "UTF-8",
"text": "\nimport os\nimport sys\nimport glob\nimport click\nfrom pathlib import Path\nfrom colorama import Fore, Back, Style\n\nfrom .scraper import Scraper\nfrom .auth_manager import remove_pwd\n\nCONFIG_FILE = \".config\"\nHOME = str(Path.home())\nPATH = os.path.join(HOME, \".iliasScraper\")\n\nversion_path = os.path.join(os.path.dirname(__file__),\"VERSION\")\n\nwith open(version_path) as f:\n line = f.readline()\n __version__ = line\n\[email protected]()\[email protected]_option(__version__)\ndef main():\n \"\"\"CLI for the ilias-scraper\"\"\"\n if not os.path.exists(PATH):\n os.makedirs(PATH)\n\n\[email protected]()\[email protected](\"-u\", '--url', help='Ilias course url', required=True)\[email protected](\"-n\", '--username', help='Your Ilias username', required=True)\[email protected](\"-c\", '--course-name', help='The name of the course, will be used as the name of this scraper', required=True)\[email protected](\"-d\", '--target-dir', help=\"The ABSOLUTE path for this course folder\", required=False)\n# @click.option('--ignore', help=\"Files you want to ignore, seperated by ,\")\ndef create(url, username, course_name, target_dir):\n \"\"\"\n Create a new scraper with a url and name\n \"\"\"\n # ignore = ignore.split(\",\")\n scraper_source = f\"\"\"\nimport sys\nfrom iliasScraper import scraper\nif len(sys.argv) == 2:\n skip = sys.argv[1]\n\nuser = '{username}'\nsc = scraper.Scraper(url='{url}', name='{course_name}', target_dir='{target_dir}')\nsc.setup(user)\nsc.run()\"\"\"\n if course_name == None:\n print(\"please use \")\n return 0\n course_name = course_name.replace(\" \", \"_\")\n with open(f\"{PATH}/{course_name}.py\", \"w\") as scraper_file:\n scraper_file.write(scraper_source)\n print(Fore.GREEN + f\"Scraper {course_name} has been created!\")\n\n\[email protected]()\[email protected](\"-n\", '--name', help='Name of the scraper', required=True)\[email protected](\"-s\", '--skip', help='Skip existing files, default=True', required=False)\[email protected](\"-e\", '--fallback-extension', required=False)\ndef run(name, skip=True, fallback_extension=\"txt\"):\n \"\"\"\n Run a previously created scraper, name can be specified with\n and without the .py ending\n \"\"\"\n scraper_file = f\"{PATH}/{name}\"\n if not \".py\" in scraper_file:\n scraper_file += \".py\"\n if not os.path.exists(scraper_file):\n print(Fore.RED + \"The specified name does not match any configured scrapers.\")\n print(\"Use <<iliasScraper list>> to list all current scrapers.\")\n return 0\n os.system(f\"python3 {scraper_file} {skip}\")\n\[email protected]()\ndef list(**kwargs):\n \"\"\"\n List all existing scraper\n \"\"\"\n files = [f for f in glob.glob(PATH+\"/*.py\", recursive=True)]\n if not files:\n print(Fore.RED+\"There are no scrapers configured.\"+Style.RESET_ALL)\n return 0\n print(Fore.BLUE + \"Currently configured scrapers:\"+Style.RESET_ALL)\n for f in files:\n filename_printable = f.split(\"/\")[-1:][0]\n print(f\"- {filename_printable}\")\n\n\[email protected]()\[email protected]('--username', required=True)\ndef remove_password(username):\n \"\"\"\n Remove the stored password\n \"\"\"\n remove_pwd(username)\n print(Fore.RED + f\"Password for {username} has been removed!\")\n\nif __name__ == '__main__':\n args = sys.argv\n if \"--help\" in args or len(args) == 1:\n print(Fore.BLUE + \"ILIAS SCRAPER\")\n print(Style.RESET)\n print(Style.DIM + \"scraper for ilias platform of of the uni constance\")\n print(\"create a scraper via <create> <url> <title> or run via <run> <name>\")\n main()\n"
},
{
"alpha_fraction": 0.7136752009391785,
"alphanum_fraction": 0.7158119678497314,
"avg_line_length": 25.714284896850586,
"blob_id": "4ca7210f498751950161509c651d1528358f8d6a",
"content_id": "905b47944248fd701dd369f71c53109c955c20d3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 936,
"license_type": "permissive",
"max_line_length": 140,
"num_lines": 35,
"path": "/iliasScraper/auth_manager.py",
"repo_name": "kevin335200/iliasScraper",
"src_encoding": "UTF-8",
"text": "\n# -*- coding: utf-8 -*-\n\nimport sys\nimport getpass\nimport keyring\nfrom .config import SCRAPER_NAME\nfrom colorama import Fore, Back, Style\n\nPASSWORD = \"\"\n\ndef store_pwd(pwd,username):\n\tkeyring.set_password(SCRAPER_NAME, username, pwd)\n\ndef read_pwd(username):\n\treturn keyring.get_password(SCRAPER_NAME, username)\n\ndef set_auth(username):\n\tglobal PASSWORD\n\n\tif read_pwd(username) != None:\n\t\tPASSWORD = read_pwd(username)\n\telse:\n\t\tprint(Fore.RED + \"For your first run you have to set a password, you can choose to store it or enter it for every run.\" + Style.RESET_ALL)\n\t\tprint(\">> Please enter your password: \")\n\t\tPASSWORD = getpass.getpass()\n\t\tprint(\">> Would you like to store the password encrpyted for the future? [y/N]\")\n\t\tshould_store = str(sys.stdin.readline()[:-1])\n\t\tif should_store == \"y\":\n\t\t\tstore_pwd(PASSWORD, username)\n\ndef remove_pwd(username):\n\tkeyring.delete_password(SCRAPER_NAME, username)\n\ndef get_pwd():\n\treturn PASSWORD\n"
},
{
"alpha_fraction": 0.5553655624389648,
"alphanum_fraction": 0.5643437504768372,
"avg_line_length": 32.884056091308594,
"blob_id": "19691d2af3c642a3acaaa8fa5b6144324caa11c0",
"content_id": "fd350a730ed8e713ca995479b4e21a7bcb706404",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2339,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 69,
"path": "/iliasScraper/download_handler.py",
"repo_name": "kevin335200/iliasScraper",
"src_encoding": "UTF-8",
"text": "\nimport os\nimport fleep\n\nfrom .config import PATH_DELIMITER\n\nclass DownloadHandler:\n \"\"\"\n docstring for RequestHandler.\n \"\"\"\n\n def __init__(self, request_handler, target_dir):\n self.request_handler = request_handler\n self.target_dir = target_dir\n\n def _determine_extension(self, file_loc):\n with open(file_loc, \"rb\") as file:\n info = fleep.get(file.read(256))\n if not info.extension:\n # default extension\n extension = \"txt\"\n else:\n extension = info.extension[0]\n if extension == \"ai\":\n extension = \"pdf\"\n elif extension == \"pages\":\n extension = \"zip\"\n return extension\n\n def download(self, file_dict, file_path, ignore_endings):\n # print(f\"download <{file_dict=}>, <{file_path=}>\")\n path = \"\"\n print(f\"{self.target_dir=}\")\n if self.target_dir[-1] != PATH_DELIMITER:\n # print(self.target_dir[:-1])\n self.target_dir += PATH_DELIMITER\n\n # print(f\"{self.target_dir=}\")\n # relative path in script execution dir\n if self.target_dir == PATH_DELIMITER:\n path += os.getcwd()\n\n # else: an absolute path has been set and will be used\n path += self.target_dir + file_path\n\n # create path if does not exist\n self._verify_path(path)\n url = file_dict[\"url\"]\n file_name = file_dict[\"file_name\"]\n file = self.request_handler.get_file(url)\n file_loc = path+PATH_DELIMITER+file_name\n # save file without file-ending\n with open(file_loc, \"wb\") as file_we:\n file_we.write(file.content)\n # set file-ending\n extension = self._determine_extension(file_loc)\n # if extension in ignore_endings:\n # # delete file\n os.rename(r\"\"+file_loc,r\"\"+file_loc+\".\"+extension)\n\n def _verify_path(self, path):\n folder_list = path.split(PATH_DELIMITER)\n for i in range(0, len(folder_list)):\n sub_path = PATH_DELIMITER+PATH_DELIMITER.join(folder_list[1:i+3])\n if not os.path.exists(sub_path):\n # todo check windows\n original_umask = os.umask(000)\n os.makedirs(sub_path, mode=0o777), #mode = 0o666)\n os.umask(original_umask)\n return 1\n"
},
{
"alpha_fraction": 0.6192842721939087,
"alphanum_fraction": 0.6259940266609192,
"avg_line_length": 38.05825424194336,
"blob_id": "3a85432a12bb2e498627db215e9438b399db42d0",
"content_id": "1acbb5abbf3d742a3a5fa931b82fbafb681f7911",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4024,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 103,
"path": "/iliasScraper/controller.py",
"repo_name": "kevin335200/iliasScraper",
"src_encoding": "UTF-8",
"text": "\nimport os\nimport glob\nfrom tqdm import tqdm\nfrom colorama import Fore, Back, Style\n\nfrom .config import PATH_DELIMITER\nfrom .login_handler import LoginHandler\nfrom .file_parser import FileParser\nfrom .request_handler import RequestHandler\nfrom .download_handler import DownloadHandler\n\n\nclass Controller:\n \"\"\"\n The controller of the package - here comes everything together\n \"\"\"\n\n def __init__(self, username, target_dir=\"/\", skip_existing_files=True, ignore=[]):\n self.request_handler = RequestHandler()\n self.username = username\n self.target_dir = target_dir\n self.ignore_endings = ignore\n self._check_version()\n self.skip_existing_files = skip_existing_files\n if self.skip_existing_files:\n print(\"getting files\")\n self.existing_files = self.get_existing_files()\n else:\n self.existing_files = []\n print(self.existing_files)\n\n\n self.login_handler = LoginHandler(self.username)\n\n self.test_course_url = \"https://ilias.uni-konstanz.de/ilias/goto_ilias_uni_crs_1078392.html\"\n self.test_file1 = \"https://ilias.uni-konstanz.de/ilias/goto_ilias_uni_file_1078407_download.html\"\n self.test_file2 = \"https://ilias.uni-konstanz.de/ilias/goto_ilias_uni_file_1091580_download.html\"\n\n def _check_version(self):\n version_path = os.path.join(os.path.dirname(__file__),\"VERSION\")\n with open(version_path) as f:\n line = f.readline()\n local_version = line.replace(\"\\n\", \"\")\n remote_version = self.request_handler.get_version()\n if remote_version != local_version:\n print(Fore.RED + Style.BRIGHT + Back.BLACK \\\n + f\"You are using version {local_version}, however version {remote_version} is available.\\n\" \\\n + \"THIS VERSION IS DEPRECATED AND POSSIBLY UNSTABLE.\\n\" \\\n + \"PLEASE UPDATE VIA:\\n\" \\\n + Style.NORMAL + Fore.BLACK + Back.WHITE \\\n + \"pip install iliasScraper --upgrade\" + Style.RESET_ALL \\\n + \"\\n\"+(50*\"-\")+\"\\n\")\n\n def get_existing_files(self):\n # existing_files = []\n directory = self.target_dir\n if directory == PATH_DELIMITER:\n directory = os.getcwd()\n\n # filename.split(PATH_DELIMITER)[-1]\n existing_files = [os.path.join(dp, f) for dp, dn, filenames in os.walk(directory) for f in filenames]\n return existing_files\n\n\n def collect(self, url):\n file_dict = {}\n print(\">> Getting all folder and session urls...\")\n all_urls = self.file_parser.get_all_urls(url)#.append(url)\n all_urls.append(url)\n print(Style.RESET_ALL)\n for link in all_urls:\n soup = self.request_handler.get_soup(link)\n file_dict_for_link = self.file_parser.parse(soup)\n file_dict.update(file_dict_for_link)\n return file_dict\n\n def init_controller(self):\n self.session = self.login_handler.login()\n self.request_handler.init_session(self.session)\n self.file_parser = FileParser(self.request_handler, self.skip_existing_files, self.existing_files)\n self.download_handler = DownloadHandler(self.request_handler, self.target_dir)\n\n def download(self, url, name=\"course name\"):\n print(Fore.BLUE + \"\\t\\t ILIAS SCRAPER\")\n print(Fore.GREEN + f\" - {name} -\")\n print(Style.RESET_ALL)\n files = self.collect(url)\n print(\">> Starting download\")\n for path in files.keys():\n files_for_path = files[path]\n print(Style.DIM + path)\n for file in files_for_path:\n print(file[\"file_name\"])\n self.download_handler.download(file, path, self.ignore_endings)\n\n def test(self):\n self.download_handler.download({\"url\":self.test_file2, \"file_name\":\"testfile\"}, \"\")\n\n\n# controller = Controller(\"tilman.kerl\", \"\", ignore=\"None\")\n# controller.init_controller()\n# controller.download(controller.test_course_url, \"bsc\")\n# controller.test()\n"
},
{
"alpha_fraction": 0.7301625609397888,
"alphanum_fraction": 0.7393836379051208,
"avg_line_length": 29.52592658996582,
"blob_id": "7bb0b19f2f78e73a26487e0d32f5ada5466f938a",
"content_id": "59474ed7c013dfb1f860b6a5e4c5beab5fd6c0f4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4121,
"license_type": "permissive",
"max_line_length": 195,
"num_lines": 135,
"path": "/README.md",
"repo_name": "kevin335200/iliasScraper",
"src_encoding": "UTF-8",
"text": "# iliasScraper: revised\n\n**Package is still in development, so make sure you have the latest version installed or update via:** <br>\n`pip install iliasScraper --upgrade`\n\niliasScraper is as the name already states, a web scraper which downloads your\nmaterials from any Ilias course. Designed for the university Constance and written in python. <br>\n**The folder structure from the Ilias course is kept!** <br>\nMy initial approach can be found here: [MisterXY89/iliasSpider](https://github.com/MisterXY89/iliasSpider). However this is outdated and doesn't really work anymore. Further this scraper\nnow supports:\n - keep-structure of the ilias course\n - recursively finding all folders, not only custom specified ones\n - specicy a target dir\n - CLI and package mode\n - file extension detection\n - sessions/sitzungen are now supported\n\nThis package uses the old `request` and `bs4`, instead of `scrapy`.\n\n*There is a fork of my old approach [mawenzy/iliasSpider](https://github.com/mawenzy/iliasSpider)\nwhich is actively maintained, if you prefer scrapy.*\n\nFor password storing I'll be using the `keyring` package.\n\n**The CLI-mode does currently only support linux-systems.**\n\n## Install\n\n`pip3 install iliasScraper`\nor clone, cd into folder and `pip3 install .`.\n\n### MacOS\nTo get it working on a mac you need `Python 3.9.4`,\n\n## Usage\nThere are two modes: the *package* and the *cli* mode. Both modes download all files for the respective course in the current directory.\n\n\n### Package\n\n```python\n\nfrom iliasScraper import scraper\n\n# your Ilias username, without the @uni-konstanz.de ending\nusername = \"tilman.kerl\"\n# this is used to identify and later run the configured scraper\ncourse_name = \"Bsc Seminar\" # -> will be changed to bsc_seminar\n# your course url\nurl = \"https://ilias.uni-konstanz.de/ilias/goto_ilias_uni_crs_1078392.html\"\n\n# if target_dir is not set, the current path is used\n# an absolute path has to be used\ntarget_dir = \"/home/dragonfly/Documents/Uni/WS201\"\n\nsc = scraper.Scraper(\n url = url,\n name = course_name,\n target_dir = target_dir\n)\n\n# setup your scraper, on your first usage you will be asked for a password\n# if the user is set to \"\" or something not valid, you will be prompted\n# an input to enter your username\nsc.setup(username)\n\n# this then runs the scraper and downloads all files and folders in the\n# target directory\nsc.run()\n\n# if you choose to store your password previously and want to remove it,\n# you can simply to so via\nsc.remove_password(username)\n```\n\n\n### CLI\n```bash\nUsage: iliasScraper [OPTIONS] COMMAND [ARGS]...\n\n CLI for the ilias-scraper\n\nOptions:\n --version Show the version and exit.\n --help Show this message and exit.\n\nCommands:\n create Create a new scraper with a url and name\n list List all existing scraper\n remove-password Remove the stored password\n run Run a previously created scraper\n```\n#### Example usage\n\n##### Mac\n\nFor Macs the creation is a little different:\n\n```bash\n# the url needs to be put in quotes\niliasScraper create --url \"https://ilias.uni-konstanz.de/ilias/goto.php?target=crs_1186878\" --username tilman.kerl --course-name \"Vertragsrecht\" --target-dir \"/Users/tilman/Desktop/UNI/Jura\"\n```\n\n##### Linux\n\n```bash\n# create a new scraper like this, the name will be changed to \"bsc_seminar\"\n# the scraper will be stored in ~/.iliasScraper/\n# the target_dir has to be an ABSOLUTE PATH!\n$ iliasScraper create --url https://ilias.uni-konstanz.de/ilias/goto_ilias_uni_crs_1078392.html --username tilman.kerl --course-name \"bsc seminar\" --target-dir /home/dragonfly/Documents/Uni/WS201\n> Scraper 'bsc_seminar' has been created!\n# you can now run the scraper via\n$ iliasScraper run --name bsc_seminar\n# to list all currently configured scraper\n$ iliasScraper list\n> Currently configured scrapers:\n> - bsc_seminar.py\n# if you choose to store your password previously and want to remove it,\n# you can simply to so via\n$ iliasScraper remove-password --username tilman.kerl\n> The password for tilman.kerl has been removed!\n```\n\n\n\n## Requirements\n```\nbs4\nrequests\nfleep\ntqdm\ncolorama\nkeyring\nclick\n```\n"
},
{
"alpha_fraction": 0.623344361782074,
"alphanum_fraction": 0.623344361782074,
"avg_line_length": 31.648649215698242,
"blob_id": "fd2faff36e7fde97321ba07ea8768e845ec5d916",
"content_id": "de33010ddaf3d5b3e2d7eb9f957923c6d762f1dd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1208,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 37,
"path": "/iliasScraper/scraper.py",
"repo_name": "kevin335200/iliasScraper",
"src_encoding": "UTF-8",
"text": "\"\"\"\ninterface for user & comandline tool\n\"\"\"\n\nfrom colorama import Fore, Back, Style\n\nfrom .controller import Controller\nfrom .auth_manager import set_auth, remove_pwd\n\nclass Scraper:\n \"\"\"\n docstring for Scraper.\n \"\"\"\n\n def __init__(self, url=\"\", name=\"\", target_dir=\"/\", ignore=[], skip_existing_files=True):\n self.url = url\n self.name = name.replace(\" \", \"_\").lower()\n self.target_dir = target_dir\n self.ignore = ignore\n self.skip_existing_files = skip_existing_files\n\n def setup(self, username=\"\"):\n if not username or not \".\" in username:\n print(Fore.BLUE + \"ILIAS SCRAPER\" + Style.RESET_ALL)\n print(Style.DIM + \"You did not specicy a username so please to it now.\" + Style.RESET_ALL)\n self.username = input(\">> Enter your username: \")\n else:\n self.username = username\n set_auth(username)\n self.controller = Controller(self.username, self.target_dir, self.skip_existing_files, self.ignore)\n\n def run(self):\n self.controller.init_controller()\n self.controller.download(self.url, name=self.name)\n\n def remove_password(self, username):\n remove_pwd(username)\n"
},
{
"alpha_fraction": 0.6022727489471436,
"alphanum_fraction": 0.6022727489471436,
"avg_line_length": 16.399999618530273,
"blob_id": "7b7df577eb40ee6a60f40f21557b091bcb1d0558",
"content_id": "eb4c0f3e9f35ed881e55687668bafaf4522b01d3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 88,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 5,
"path": "/iliasScraper/ilias_exceptions.py",
"repo_name": "kevin335200/iliasScraper",
"src_encoding": "UTF-8",
"text": "\nclass LoginFailedError(Exception):\n \"\"\"\n Raise for failed login\n \"\"\"\n pass\n"
},
{
"alpha_fraction": 0.7184466123580933,
"alphanum_fraction": 0.7216828465461731,
"avg_line_length": 29.799999237060547,
"blob_id": "2f022834b4f5cf1cc04544b5dcf9ce3d6ee45f85",
"content_id": "7e3dc982317005158b021f301f29c76af8545c0b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 309,
"license_type": "permissive",
"max_line_length": 165,
"num_lines": 10,
"path": "/iliasScraper/config.py",
"repo_name": "kevin335200/iliasScraper",
"src_encoding": "UTF-8",
"text": "\nimport platform\n\nSCRAPER_NAME = \"ilias-scraper\"\nLOGIN_POST_URL = \"https://ilias.uni-konstanz.de/ilias/ilias.php?lang=de&client_id=ilias_uni&cmd=post&cmdClass=ilstartupgui&cmdNode=y1&baseClass=ilStartUpGUI&rtoken=\"\n\n\nif platform.system() == \"windows\":\n PATH_DELIMITER = \"\\\\\"\nelse:\n PATH_DELIMITER = \"/\"\n"
},
{
"alpha_fraction": 0.5501012206077576,
"alphanum_fraction": 0.556174099445343,
"avg_line_length": 30.854839324951172,
"blob_id": "a9b8c493daf571fe4bc1bfc309435a55e2005178",
"content_id": "6407951670c9961d576109c7afe9b6d65993232a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1976,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 62,
"path": "/iliasScraper/request_handler.py",
"repo_name": "kevin335200/iliasScraper",
"src_encoding": "UTF-8",
"text": "\nimport requests\nfrom bs4 import BeautifulSoup\n\nclass RequestHandler:\n \"\"\"\n docstring for RequestHandler.\n \"\"\"\n\n def __init__(self):\n self.parser = \"html.parser\"\n\n def init_session(self, session):\n self.session = session\n\n def get_soup(self, url):\n if not self.session:\n return False\n try:\n response = self.session.get(url)\n except Exception as err:\n print(f\"Error: {err}\")\n # raise err\n print(f\"WITH FOLLOWING URL: {url=}\")\n raise err\n return False\n if response.status_code == 200:\n soup = BeautifulSoup(response.content, self.parser)\n # print(f\"OK! Url: {url}\")\n return soup\n else:\n print(f'Something went wrong. Got the following response code: {response.status_code}')\n return None\n\n def get_file(self, url):\n if not self.session:\n return False\n try:\n response = self.session.get(url, allow_redirects=True)\n except Exception as err:\n print(f\"Error: {err}\")\n print(f\"With the following: {url=}\")\n raise err\n return False\n if response.status_code == 200:\n return response\n else:\n print(f'Something went wrong. Got the following response code: {response.status_code}')\n return None\n\n def get_version(self):\n try:\n response = requests.get(\"https://raw.githubusercontent.com/MisterXY89/iliasScraper/main/iliasScraper/VERSION\")\n except Exception as err:\n print(f\"Error: {err}\")\n print(f\"With the following: {url=}\")\n raise err\n return False\n if response.status_code == 200:\n return response.text.replace(\"\\n\", \"\")\n else:\n print(f'Something went wrong. Got the following response code: {response.status_code}')\n return None\n"
},
{
"alpha_fraction": 0.6002673506736755,
"alphanum_fraction": 0.6042780876159668,
"avg_line_length": 28.8799991607666,
"blob_id": "9b94d2a03c97d8c1c9b09014b0643e21cdbb6d7f",
"content_id": "c1860ea2b0116f9533e25fee5a573fb59d68bdd1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 748,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 25,
"path": "/iliasScraper/login_handler.py",
"repo_name": "kevin335200/iliasScraper",
"src_encoding": "UTF-8",
"text": "\nimport requests\n\nfrom .ilias_exceptions import LoginFailedError\nfrom .config import LOGIN_POST_URL\nfrom .auth_manager import get_pwd\n\nclass LoginHandler:\n \"\"\"\n Handle login with\n \"\"\"\n\n def __init__(self, username):\n self.payload = {\n \"username\": username,\n \"password\": get_pwd(),\n \"cmd[doStandardAuthentication]\": \"Anmelden\"\n }\n self.session = requests.Session()\n\n def login(self):\n with self.session as session_r:\n login_resp = session_r.post(LOGIN_POST_URL, data=self.payload)\n if login_resp.status_code != 200:\n raise LoginFailedError(f\"Login failed with status_code {login_resp.status_code}\")\n return session_r\n"
},
{
"alpha_fraction": 0.7362086176872253,
"alphanum_fraction": 0.7462387084960938,
"avg_line_length": 31.161291122436523,
"blob_id": "6730347de9b9cb3650c8eb54ca92e74f0861f38a",
"content_id": "92be8c755dd0904693aa75eb84ad2f6c43625d3f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 997,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 31,
"path": "/example.py",
"repo_name": "kevin335200/iliasScraper",
"src_encoding": "UTF-8",
"text": "from iliasScraper import scraper\n\n# your Ilias username, without the @uni-konstanz.de ending\nusername = \"tilman.kerl\"\n# this is used to identify and later run the configured scraper\ncourse_name = \"Bsc Seminar\" # -> will be changed to bsc_seminar\n# your course url\nurl = \"https://ilias.uni-konstanz.de/ilias/goto_ilias_uni_crs_1078392.html\"\n\n# if target_dir is not set, the current path is used\n# an absolute path has to be used\ntarget_dir = \"/home/dragonfly/Documents/Uni/WS201\"\n\nsc = scraper.Scraper(\n url = url,\n name = course_name,\n target_dir = target_dir\n)\n\n# setup your scraper, on your first usage you will be asked for a password\n# if the user is set to \"\" or something not valid, you will be prompted\n# an input to enter your username\nsc.setup(username)\n\n# this then runs the scraper and downloads all files and folders in the\n# target directory\nsc.run()\n\n# if you choose to store your password previously and want to remove it,\n# you can simply to so via\nsc.remove_password(username)\n"
}
] | 12 |
tjddn2615/GazeTracking
|
https://github.com/tjddn2615/GazeTracking
|
903cf055700517e6eee9c12a9810f50bd9fe423c
|
60ef5f5797cb9a61f42bb0257800b2de0de40bce
|
6b03032f00e94aa74b4bfab1f46d5edf6ff15d05
|
refs/heads/master
| 2023-01-09T07:52:41.645263 | 2020-11-18T06:41:58 | 2020-11-18T06:41:58 | 263,603,661 | 4 | 0 |
MIT
| 2020-05-13T10:56:38 | 2020-05-13T00:37:49 | 2020-04-25T20:02:33 | null |
[
{
"alpha_fraction": 0.48801299929618835,
"alphanum_fraction": 0.5306785702705383,
"avg_line_length": 26.043956756591797,
"blob_id": "ab9e8c14ce1c94a29b3a6bf51cfd1607ede64b63",
"content_id": "fd1f916d982d2144167284293ad27246e64345e5",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2461,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 91,
"path": "/gaze_tracking.py",
"repo_name": "tjddn2615/GazeTracking",
"src_encoding": "UTF-8",
"text": "\"\"\"\nDemonstration of the GazeTracking library.\nCheck the README.md for complete documentation.\n\"\"\"\n\nimport cv2\nimport dlib\nfrom gaze_tracking import GazeTracking\n\ngaze = GazeTracking()\nwebcam = cv2.VideoCapture(0)\nface_detector = dlib.get_frontal_face_detector()\n\nwhile True:\n # We get a new frame from the webcam\n _, frame = webcam.read()\n\n #print(\"in\")\n \n frame2 = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)\n faces = face_detector(frame2)\n\n right_cnt=0\n left_cnt=0\n center_cnt=0\n text=\"\"\n focusing=0\n\n if faces:\n print(\"faces found\")\n for face in faces:\n\n #if face:\n #print(\"face found\")\n\n gaze.refresh(frame, face)\n\n frame = gaze.annotated_frame()\n\n #for each people\n if gaze.is_blinking():\n text = \"Blinking\"\n elif gaze.is_right():\n text = \"Looking right\"\n right_cnt+=1\n elif gaze.is_left():\n text = \"Looking left\"\n left_cnt+=1\n elif gaze.is_center():\n text = \"Looking center\"\n center_cnt+=1\n elif gaze.is_up():\n text = \"Looking up\"\n elif gaze.is_down():\n text = \"Looking down\"\n\n left_pupil = gaze.pupil_left_coords()\n right_pupil = gaze.pupil_right_coords()\n\n focusing=0\n\n # if(text==\"Blinking\"):\n # text=\"Blinking\"\n if(right_cnt>left_cnt and right_cnt>center_cnt):\n cv2.rectangle(frame, (0, 0), (640, 1080), (0, 0, 255), 3)\n text = \"Looking right\"\n focusing=right_cnt\n elif(left_cnt>right_cnt and left_cnt>center_cnt):\n cv2.rectangle(frame, (1280, 0), (1920, 1080), (0, 0, 255), 3)\n text = \"Looking left\"\n focusing=left_cnt\n elif(center_cnt>right_cnt and center_cnt>left_cnt):\n cv2.rectangle(frame, (640, 0), (1280, 1080), (0, 0, 255), 3)\n text = \"Looking center\"\n focusing=center_cnt\n else:\n text = \"None\"\n\n\n else:\n gaze.refresh(frame,None)\n frame = gaze.annotated_frame()\n\n\n cv2.putText(frame, \"Current people: \" + str(focusing), (90, 200), cv2.FONT_HERSHEY_DUPLEX, 1.6, (0, 0, 0), 2)\n cv2.putText(frame, text, (90, 60), cv2.FONT_HERSHEY_DUPLEX, 1.6, (147, 58, 31), 2)\n cv2.imshow(\"Demo\", frame)\n\n\n if cv2.waitKey(1) == 27:\n break\n"
},
{
"alpha_fraction": 0.40944230556488037,
"alphanum_fraction": 0.5267807841300964,
"avg_line_length": 31.339284896850586,
"blob_id": "6d9c1d7fc2ac43436119d2fcfe12a61be3469732",
"content_id": "f92a06e15b84dcdef2c4f28203003bbef7cdf486",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3622,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 112,
"path": "/window.py",
"repo_name": "tjddn2615/GazeTracking",
"src_encoding": "UTF-8",
"text": "\"\"\"\nDemonstration of the GazeTracking library.\nCheck the README.md for complete documentation.\n\"\"\"\n\nimport cv2\nimport numpy as np\nfrom gaze_tracking import GazeTracking\n\ngaze = GazeTracking()\nwebcam = cv2.VideoCapture(0)\n\nwhile True:\n # We get a new frame from the webcam\n _, frame = webcam.read()\n\n # We send this frame to GazeTracking to analyze it\n gaze.refresh(frame)\n\n frame = gaze.annotated_frame()\n text = \"\"\n\n width = 500\n height = 500\n bpp = 3\n\n\n if gaze.is_window_8():\n text = \"window_8\"\n cv2.rectangle(frame, (400, 440), (800, 660), (0, 0, 255), 3)\n elif gaze.is_window_2():\n text = \"window_2\"\n cv2.rectangle(frame, (400, 0), (800, 220), (0, 0, 255), 3)\n elif gaze.is_window_5():\n text = \"window_5\"\n cv2.rectangle(frame, (400, 220), (800, 440), (0, 0, 255), 3)\n elif gaze.is_window_7():\n text = \"window_7\"\n cv2.rectangle(frame, (800, 440), (1200, 660), (0, 0, 255), 3)\n elif gaze.is_window_9():\n text = \"window_9\"\n cv2.rectangle(frame, (0, 440), (400, 660), (0, 0, 255), 3)\n elif gaze.is_window_1():\n text = \"window_1\"\n cv2.rectangle(frame, (800, 0), (1200, 220), (0, 0, 255), 3)\n elif gaze.is_window_3():\n text = \"window_3\"\n cv2.rectangle(frame, (0, 0), (400, 220), (0, 0, 255), 3)\n elif gaze.is_window_4():\n text = \"window_4\"\n cv2.rectangle(frame, (800, 220), (1200, 440), (0, 0, 255), 3)\n elif gaze.is_window_6():\n text = \"window_6\"\n cv2.rectangle(frame, (0, 220), (400, 440), (0, 0, 255), 3)\n \n\n \n \n # if gaze.is_window_1():\n # text = \"window_1\"\n # cv2.rectangle(frame, (800, 0), (1200, 220), (0, 0, 255), 3)\n # elif gaze.is_window_2():\n # text = \"window_2\"\n # cv2.rectangle(frame, (400, 0), (800, 220), (0, 0, 255), 3)\n # elif gaze.is_window_3():\n # text = \"window_3\"\n # cv2.rectangle(frame, (0, 0), (400, 220), (0, 0, 255), 3)\n # elif gaze.is_window_4():\n # text = \"window_4\"\n # cv2.rectangle(frame, (800, 220), (1200, 440), (0, 0, 255), 3)\n # elif gaze.is_window_5():\n # text = \"window_5\"\n # cv2.rectangle(frame, (400, 220), (800, 440), (0, 0, 255), 3)\n # elif gaze.is_window_6():\n # text = \"window_6\"\n # cv2.rectangle(frame, (0, 220), (400, 440), (0, 0, 255), 3)\n # elif gaze.is_window_7():\n # text = \"window_7\"\n # cv2.rectangle(frame, (800, 440), (1200, 660), (0, 0, 255), 3)\n # elif gaze.is_window_8():\n # text = \"window_8\"\n # cv2.rectangle(frame, (400, 440), (800, 660), (0, 0, 255), 3)\n # elif gaze.is_window_9():\n # text = \"window_9\"\n # cv2.rectangle(frame, (0, 440), (400, 660), (0, 0, 255), 3)\n\n # if gaze.is_blinking():\n # text = \"Blinking\"\n # elif gaze.is_right():\n # text = \"Looking right\"\n # elif gaze.is_left():\n # text = \"Looking left\"\n # elif gaze.is_up():\n # text = \"Looking up\"\n # elif gaze.is_down():\n # text = \"Looking down\"\n # elif gaze.is_center():\n # text = \"Looking center\"\n\n cv2.putText(frame, text, (90, 60), cv2.FONT_HERSHEY_DUPLEX, 1.6, (147, 58, 31), 2)\n\n left_pupil = gaze.pupil_left_coords()\n right_pupil = gaze.pupil_right_coords()\n\n cv2.putText(frame, \"Left pupil: \" + str(left_pupil), (90, 130), cv2.FONT_HERSHEY_DUPLEX, 0.9, (147, 58, 31), 1)\n cv2.putText(frame, \"Right pupil: \" + str(right_pupil), (90, 165), cv2.FONT_HERSHEY_DUPLEX, 0.9, (147, 58, 31), 1)\n\n\n cv2.imshow(\"Demo\", frame)\n\n if cv2.waitKey(1) == 27:\n break\n"
}
] | 2 |
Aziz-T/django-ile-E-Ticaret-Sitesi-projesi--E-Commerce-Web-Site-with-django
|
https://github.com/Aziz-T/django-ile-E-Ticaret-Sitesi-projesi--E-Commerce-Web-Site-with-django
|
374f14f2b47881876db90235ee2ea5a064918f48
|
cef5e2da46d7b5bc2abbc3d642797518d1b82c33
|
a43e24eca5ec318c6e32349541e34ae8dda79eda
|
refs/heads/master
| 2023-03-27T17:05:31.152851 | 2021-03-30T12:19:03 | 2021-03-30T12:19:03 | 321,477,176 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7477965950965881,
"alphanum_fraction": 0.7647457718849182,
"avg_line_length": 42.35293960571289,
"blob_id": "bcc75cc2bb8799b57c6a1917372e53bda74144e0",
"content_id": "94f86d1b196c10babdfc81106e911b33ae7fe711",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1475,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 34,
"path": "/eCom/models.py",
"repo_name": "Aziz-T/django-ile-E-Ticaret-Sitesi-projesi--E-Commerce-Web-Site-with-django",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n\n# Create your models here.\n\nclass Customer(models.Model):\n name = models.CharField(max_length=200, null=True)\n email = models.CharField(max_length=200,null=True)\n\nclass Product(models.Model):\n name= models.CharField(max_length=200,null=True)\n price=models.FloatField()\n digital = models.BooleanField(default=False,null=True,blank=False)\n\nclass Order(models.Model):\n customer=models.ForeignKey(Customer,on_delete=models.SET_NULL,blank=True,null=True)\n date_order=models.DateTimeField(auto_now_add=True)\n complete=models.BooleanField(default=False,null=True,blank=False)\n transaction_id=models.CharField(max_length=200,null=True)\n\nclass OrderItem(models.Model):\n product=models.ForeignKey(Product,on_delete=models.SET_NULL,blank=True,null=True)\n order=models.ForeignKey(Order,on_delete=models.SET_NULL,blank=True,null=True)\n quantity= models.IntegerField(default=0,null=True,blank=True)\n date_added=models.DateTimeField(auto_now_add=True)\n\nclass ShippingAddress(models.Model):\n customer = models.ForeignKey(Customer,on_delete=models.SET_NULL,null=True)\n order=models.ForeignKey(Order, on_delete=models.SET_NULL,null=True)\n address=models.CharField(max_length=200,null=False)\n city=models.CharField(max_length=200,null=False)\n state = models.CharField(max_length=200,null=False)\n zipcode = models.CharField(max_length=200,null=False)\n date_added=models.DateTimeField(auto_now_add=True)\n\n"
},
{
"alpha_fraction": 0.7954545617103577,
"alphanum_fraction": 0.7954545617103577,
"avg_line_length": 42.66666793823242,
"blob_id": "293bca2041c4eeafe1202ec506f1d4ede99dd38a",
"content_id": "74562e40f39717fafcbcb573f61a45ba11a49179",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 136,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 3,
"path": "/README.md",
"repo_name": "Aziz-T/django-ile-E-Ticaret-Sitesi-projesi--E-Commerce-Web-Site-with-django",
"src_encoding": "UTF-8",
"text": "# django-ile-E-Ticaret-Sitesi-projesi--E-Commerce-Web-Site-with-django\n\nOkul projesi için Django ile yapılmış e-ticaret sitesidir. \n"
},
{
"alpha_fraction": 0.6845528483390808,
"alphanum_fraction": 0.6910569071769714,
"avg_line_length": 38.67741775512695,
"blob_id": "a2dac26cb32f54689afa536366ff35e15a95201a",
"content_id": "d634653d804064bda3a6be47717ac7ffdbef0ed9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1230,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 31,
"path": "/ecommerce/urls.py",
"repo_name": "Aziz-T/django-ile-E-Ticaret-Sitesi-projesi--E-Commerce-Web-Site-with-django",
"src_encoding": "UTF-8",
"text": "\"\"\"ecommerce URL Configuration\n\nThe `urlpatterns` list routes URLs to views. For more information please see:\n https://docs.djangoproject.com/en/3.1/topics/http/urls/\nExamples:\nFunction views\n 1. Add an import: from my_app import views\n 2. Add a URL to urlpatterns: path('', views.home, name='home')\nClass-based views\n 1. Add an import: from other_app.views import Home\n 2. Add a URL to urlpatterns: path('', Home.as_view(), name='home')\nIncluding another URLconf\n 1. Import the include() function: from django.urls import include, path\n 2. Add a URL to urlpatterns: path('blog/', include('blog.urls'))\n\"\"\"\nfrom django.contrib import admin\nfrom django.urls import path\nfrom eCom import views\n\nurlpatterns = [\n path('admin/', admin.site.urls),\n path('', views.index, name='index'),\n path('index.html', views.index, name='index'),\n path('contact.html', views.contact, name='contact'),\n path('checkout.html', views.checkout, name='checkout'),\n path('cart.html', views.cart, name='cart'),\n path('product_detail.html', views.product_detail, name='product_detail'),\n path('products.html', views.products, name='products'),\n path('register.html', views.register, name='register'),\n\n]\n"
},
{
"alpha_fraction": 0.34324324131011963,
"alphanum_fraction": 0.34864863753318787,
"avg_line_length": 29.83333396911621,
"blob_id": "d2ad2938878bd024faad1b720987e7ad88f976a5",
"content_id": "fa35f2d7728cf3d248fe2a0b5830516dab5ae2b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 370,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 12,
"path": "/venv/Lib/site-packages/my.py",
"repo_name": "Aziz-T/django-ile-E-Ticaret-Sitesi-projesi--E-Commerce-Web-Site-with-django",
"src_encoding": "UTF-8",
"text": "def print_aa(_list,intend=True,level=0):\n for each_on in _list:\n\n if isinstance(each_on,list):\n\n print_aa(each_on,intend,level+1)\n else:\n if intend:\n \n print(\"\\t\"*level,end='')\n \n print(each_on)\n"
},
{
"alpha_fraction": 0.7357414364814758,
"alphanum_fraction": 0.7357414364814758,
"avg_line_length": 21.913043975830078,
"blob_id": "b3cda2d47693865c80b8a5cc8d55a1ee45095f90",
"content_id": "59b1d89b7eacee9d7d6c873d691e8764694cc321",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 526,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 23,
"path": "/eCom/views.py",
"repo_name": "Aziz-T/django-ile-E-Ticaret-Sitesi-projesi--E-Commerce-Web-Site-with-django",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\n\n\ndef index(request):\n return render(request,'index.html')\n# Create your views here.\ndef contact(request):\n return render(request,'contact.html')\n\ndef cart(request):\n return render(request,'cart.html')\n\ndef checkout(request):\n return render(request,'checkout.html')\n\ndef products(request):\n return render(request,'products.html')\n\ndef product_detail(request):\n return render(request,'product_detail.html')\n\ndef register(request):\n return render(request,'register.html')"
}
] | 5 |
ThePurpleOneTpo/Python
|
https://github.com/ThePurpleOneTpo/Python
|
75253e8611c06c4b72e2133432cdb76a2e5cfe5c
|
8b0b3d746b6f92bbcf1a4fffaa044fc2a43de486
|
683507bb798664d6532f6064cdd413776e46e3ea
|
refs/heads/master
| 2019-08-12T14:54:59.271783 | 2016-08-23T16:23:46 | 2016-08-23T16:23:46 | 66,382,710 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4264150857925415,
"alphanum_fraction": 0.43207547068595886,
"avg_line_length": 32.0625,
"blob_id": "6c9a17d7a2f2ac2879480299492fefed1f8e21b9",
"content_id": "e7a2d03d766eea5032333585e30dcbf4a470ea47",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 531,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 16,
"path": "/main.py",
"repo_name": "ThePurpleOneTpo/Python",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3.4\n#coding: utf-8\n\n#---------------------------------------------------------\nprint(\"-----------------------\")\nprint(\"------ Variables ------\")\nprint(\"-----------------------\")\nprint(\"Entier (int)|\")\nprint(\"Decimal (float)|\")\nprint(\"booléen (bool)|\")\nprint(\"Chaine (string)|\")\n#----------------------------------------------------------\nAge = input(\"quel est ton age ?\")\nPlayer_name = input(\"Que veux-tu choisir comme pseudo ?\")\nstr(Player_name)\nprint(\"tu as donc \", Age, \"ans \", \"et tu t'appeles\",Player_name)\n\n"
},
{
"alpha_fraction": 0.42090970277786255,
"alphanum_fraction": 0.44467073678970337,
"avg_line_length": 24.842105865478516,
"blob_id": "65c15d82c9be6c3c048c1c3c221ef0614a9839b2",
"content_id": "9d651db486cf6a8309fde457e3263e3050d9fa52",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1475,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 57,
"path": "/conditions",
"repo_name": "ThePurpleOneTpo/Python",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3.4\n#coding: utf-8\n\nprint(\"Nous\", \"sommes\", \"en\", \"France\", sep='__')#sep =\"UUU\" remplace par exemple les espaces par UUU\n\ni=1\nwhile i<5:\n\tprint(\"alllAhuAKBAR!\", end =\" \")\n\ti += 1\n#---------------------------------------------------------\nHP = 100\n\nif HP == 100:\n\tprint(\"Tu es full life\")\nelif HP <= 0:\n\tprint(\"VOUS ETES MORT\")\nelif HP == 50:\n\tprint(\"Tu es Mid life\")\nelif HP < 100 and HP != 100 and HP != 50 and HP != 0:\n\tprint(\"Tu as \", HP, \"Points de vie!\")\n#---------------------------------------------------------\nLetter = \"j\"\n\nif Letter in \"aeiouy\":#si letter (j) appartient à \"aeiouy\"\n\tprint(\"c'est une voyelle!\")\nelse:\n\tprint(\"c'est une consonne!\")\n#---------------------------------------------------------\nLettre = \"a\"\n\nif Lettre not in \"aeiouy\":\n\tprint(\"C'EST UNE CONSONNE!\")\nelse:\n\tprint(\"C'EST UNE VOYELLE!\")\n#---------------------------------------------------------\n\ni = 1\n\nwhile i != 11:\n\tprint(\"ligne n°\",i)\n\ti += 1\n#----------------------------------------------------------\ndef dire(nom, message):\n\tprint(nom, \":\", message)\n\ndire(\"Jonas\", \"Naoumy je t'aime\")\n#----------------------------------------------------------\ndef create_perso(nom ,mana=9000 ,arme='Pioche' ,vie=100):\n\tprint(\"mana :\",mana)\n\tprint(\"nom :\",nom)\n\tprint(\"arme :\",arme)\n\tprint(\"vie :\",vie)\n\ncreate_perso(nom=input(\"Votre nom :\") ,mana=input(\"Votre mana :\"))\n#----------------------------------------------------------\nnom_perso=input('Nom ?')\nprint(len(nom_perso))\n"
}
] | 2 |
KevinL10/Linear-Cryptanalysis
|
https://github.com/KevinL10/Linear-Cryptanalysis
|
9baaf2be86750083ea7dae76169bde71d643ff2e
|
0f7a8ff8aa0e1473662a662252833cb5bf57c89d
|
10d5c2b6edbd889ecfce57f70c9765770ac7847c
|
refs/heads/main
| 2023-09-04T01:14:01.239274 | 2021-11-11T05:48:29 | 2021-11-11T05:48:29 | 388,955,210 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5635309815406799,
"alphanum_fraction": 0.6272848844528198,
"avg_line_length": 23.933332443237305,
"blob_id": "20de9b306a3a30001ac1b21fe0aa3ab519f908fc",
"content_id": "d33133a389c8cd8938373d5977c95a018545e801",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2243,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 90,
"path": "/cipher.py",
"repo_name": "KevinL10/Linear-Cryptanalysis",
"src_encoding": "UTF-8",
"text": "from random import randint\n\nROUNDS = 4\n\ns_box = (\n\t0xE, 0x4, 0xD, 0x1, \n\t0x2, 0xF, 0xB, 0x8, \n\t0x3, 0xA, 0x6, 0xC, \n\t0x5, 0x9, 0x0, 0x7,\n)\n\ninv_s_box = (\n\t0xE, 0x3, 0x4, 0x8,\n\t0x1, 0xC, 0xA, 0xF,\n\t0x7, 0xD, 0x9, 0x6,\n\t0xB, 0x2, 0x0, 0x5,\n)\n\n# Note that our P-box is a self-inverse function\np_box = (\n\t0x0, 0x4, 0x8, 0xC, \n\t0x1, 0x5, 0x9, 0xD, \n\t0x2, 0x6, 0xA, 0xE, \n\t0x3, 0x7, 0xB, 0xF,\n)\n\n# Divide input into 4 blocks of 4 bits each; perform S-box substitutions on each block\ndef substitute(s):\n\ts_blocks = [(s >> 12) & 0xf, (s >> 8) & 0xf, (s >> 4) & 0xf, s & 0xf]\n\ts_blocks = [s_box[b] for b in s_blocks]\n\treturn (s_blocks[0] << 12) | (s_blocks[1] << 8) | (s_blocks[2] << 4) | s_blocks[3]\n\n# Divide input into 4 blocks of 4 bits each; perform inverse S-box substitutions on each block\ndef inv_substitute(s):\n\ts_blocks = [(s >> 12) & 0xf, (s >> 8) & 0xf, (s >> 4) & 0xf, s & 0xf]\n\ts_blocks = [inv_s_box[b] for b in s_blocks]\n\treturn (s_blocks[0] << 12) | (s_blocks[1] << 8) | (s_blocks[2] << 4) | s_blocks[3]\n\n# Permute input bit-by-bit according to the P-box\ndef permute(p):\n\tp_permuted = 0\n\tfor i in range(16):\n\t\tif p & (1 << i):\n\t\t\tp_permuted |= (1 << p_box[i])\n\treturn p_permuted\n\n# Encrypt 16-bit plaintext with five (ROUNDS + 1) 16-bit keys\ndef encrypt(plaintext, keys):\n\tassert(len(keys) == ROUNDS + 1)\n\tdata = plaintext\n\n\tfor i in range(ROUNDS - 1):\n\t\t# Key mixing\n\t\tdata ^= keys[i]\n\t\t# Substitution\n\t\tdata = substitute(data)\n\t\t# Permutation\n\t\tdata = permute(data)\n\t\n\t# Perform last round separately (no permutation)\n\tdata ^= keys[ROUNDS - 1]\n\tdata = substitute(data)\n\tdata ^= keys[ROUNDS]\n\n\treturn data\n\ndef decrypt(ciphertext, keys):\n\tassert(len(keys) == ROUNDS + 1)\n\tdata = ciphertext\n\n\t# Decrypt last round separately (no permutation)\n\tdata ^= keys[ROUNDS]\n\tdata = inv_substitute(data)\n\tdata ^= keys[ROUNDS - 1]\n\n\tfor i in reversed(range(0, ROUNDS - 1)):\n\t\t# Undo permutation (permute is a self-inverse function)\n\t\tdata = permute(data)\n\t\t# Undo substitution\n\t\tdata = inv_substitute(data)\n\t\t# Undo key mixing\n\t\tdata ^= keys[i]\n\n\treturn data\n\n# Check that encryption/decryption works\npt = randint(1, (1 << 16) - 1)\nkeys = [randint(1, (1 << 16) - 1) for i in range(ROUNDS + 1)]\nct = encrypt(pt, keys)\nassert(pt == decrypt(ct, keys))"
},
{
"alpha_fraction": 0.588166356086731,
"alphanum_fraction": 0.6315172910690308,
"avg_line_length": 24.878787994384766,
"blob_id": "2b433b5b5bb833e7fb4fddf6b521fa89f1976b71",
"content_id": "d2f076df2da571d7a6c7d181409eb77b10ce9334",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1707,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 66,
"path": "/attack.py",
"repo_name": "KevinL10/Linear-Cryptanalysis",
"src_encoding": "UTF-8",
"text": "from cipher import *\nfrom math import fabs\nfrom random import randint\nimport numpy as np\nimport sys, timeit\n\ndef getBit(num, idx):\n\treturn (num >> idx) & 0x1\n\nstart_time = timeit.default_timer()\nSAMPLES = 10 ** 4\n\n# Set DEBUG to True to see all biases for different keys\nDEBUG = False\n\n# Generate random keys\nkeys = [randint(1, (1 << 16) - 1) for i in range(ROUNDS + 1)]\nplaintexts, ciphertexts = [], []\n\n# Collect plaintext/ciphertext samples\nfor i in range(SAMPLES):\n\tn = randint(1, (1 << 16) - 1)\n\tplaintexts.append(n)\n\tciphertexts.append(encrypt(n, keys))\n\nprint(\"Keys:\", [hex(key) for key in keys])\n\nbiases = np.zeros((16, 16))\nbest_keys = (0,)\n\nfor i in range(256):\n\tsys.stdout.write(f\"[x] Progress: {i}/256\\r\")\n\n\tk2 = (i >> 4) & 0xF\n\tk4 = i & 0xF\n\tcnt = 0\n\n\tfor a in range(SAMPLES):\n\t\tpt = plaintexts[a]\n\t\tct = ciphertexts[a]\n\n\t\t# Calculate the bits before the last S-box\n\t\tV = [((ct >> 8) & 0xF) ^ k2, ((ct >> 0) & 0xF) ^ k4]\n\t\tU = [inv_s_box[nib] for nib in V]\n\n\t\tval = getBit(U[0], 0) ^ getBit(U[0], 2) ^ getBit(U[1], 0) ^ getBit(U[1], 2)\n\t\tval ^= getBit(pt, 8) ^ getBit(pt, 9) ^ getBit(pt, 11)\n\n\t\t# If the linear approximation holds, then increment the counter\n\t\tif val == 0:\n\t\t\tcnt += 1\n\n\t# Keep track of the (k2, k4) pair that has the greatest bias\n\tbias = fabs(cnt/SAMPLES - 0.5)\n\tif bias > best_keys[0]:\n\t\tbest_keys = (bias, k2, k4)\n\tbiases[k2][k4] = bias\n\nprint(f\"[+] Expected: {hex((keys[-1] >> 8) & 0xF)} and {hex(keys[-1] & 0xF)}\")\nprint(f\"[+] Found: {hex(best_keys[1])} and {hex(best_keys[2])}\")\nprint(f\"[+] Time taken: {timeit.default_timer() - start_time}\")\n\n# Display biases for all the possible (two-bit) keys\nif DEBUG:\n\tnp.set_printoptions(edgeitems=10,linewidth=180)\n\tprint(biases)"
},
{
"alpha_fraction": 0.7747875452041626,
"alphanum_fraction": 0.7861189842224121,
"avg_line_length": 53.38461685180664,
"blob_id": "4d13e51c230d3721004ed838a3e548f82b83c83d",
"content_id": "f1d368dc978dd28b12642aa331319b0b1077e90f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 706,
"license_type": "no_license",
"max_line_length": 190,
"num_lines": 13,
"path": "/README.md",
"repo_name": "KevinL10/Linear-Cryptanalysis",
"src_encoding": "UTF-8",
"text": "# Linear-Cryptanalysis\nImplementations and linear cryptanalysis of a substitution-permutation network, based off [this paper](http://www.cs.bc.edu/~straubin/crypto2017/heys.pdf) by Howard M. Heys.\n\nRead my blog post [here](https://kevinl10.github.io/posts/Linear-Cryptanalysis-Pt-1/) for a more detailed explanation of the attack.\n\n# Usage\n`python3 attack.py` generates a random key, along with a specified number of plaintext/ciphertext samples. To see the biases for all possible key bit pairs, set the `DEBUG` option to `True`.\n\n# Todo\n\nExamine the relationships between:\n- The number of samples and the accuracy of the attack\n- The magnitude of the bias and the number of samples needed for consistent accuracy"
}
] | 3 |
goodza/pyscrapin
|
https://github.com/goodza/pyscrapin
|
97c63ca9e515c920e65ba7d81c6a54038bd5b122
|
d967dd2ec057a46de549f4bef3d57ca2ee43c39e
|
9b1b7be94f05a14039b7f190fe22679a94f268b9
|
refs/heads/master
| 2022-11-08T12:41:17.967405 | 2020-06-25T16:22:15 | 2020-06-25T16:22:15 | 274,961,040 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6570397019386292,
"alphanum_fraction": 0.6687725782394409,
"avg_line_length": 31.58823585510254,
"blob_id": "1aa0ebefcaedddf26c4e9018dcbd8f12a44c59a0",
"content_id": "6cf4049d9d28bcb67a269aed17b9f5f31850cca6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1108,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 34,
"path": "/index.py",
"repo_name": "goodza/pyscrapin",
"src_encoding": "UTF-8",
"text": "from selenium import webdriver\nimport json\nimport os\n\ndef handler(event, context):\n \n print(str(os.getcwd()))\n print('#HANDLER::2::')\n options = webdriver.ChromeOptions()\n options.binary_location = \"./bin/headless-chromium\"\n options.add_argument(\"--headless\")\n options.add_argument(\"--disable-gpu\")\n options.add_argument(\"--window-size=1280x1696\")\n options.add_argument(\"--disable-application-cache\")\n options.add_argument(\"--disable-infobars\")\n options.add_argument(\"--no-sandbox\")\n options.add_argument(\"--hide-scrollbars\")\n options.add_argument(\"--enable-logging\")\n options.add_argument(\"--log-level=0\")\n options.add_argument(\"--single-process\")\n options.add_argument(\"--homedir=/tmp\")\n options.add_argument(\"--ignore-certificate-errors\")\n chrome = webdriver.Chrome('./bin/chromedriver',chrome_options=options)\n #chrome = webdriver.Chrome(chrome_options=options) \n chrome.get('https://yandex.ru')\n title = chrome.title\n chrome.quit()\n return {\n 'statusCode': 200,\n 'body': json.dumps(title)\n }\n\n\n#print(handler('',''))\n"
},
{
"alpha_fraction": 0.6983739733695984,
"alphanum_fraction": 0.7081300616264343,
"avg_line_length": 28.285715103149414,
"blob_id": "6ff53c3370e9efd5fa45352dc0fa15dd5fb4b4f1",
"content_id": "948db900c3b1ddcc0e8f5fff9db3ea8073a0eb5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1230,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 42,
"path": "/app.py",
"repo_name": "goodza/pyscrapin",
"src_encoding": "UTF-8",
"text": "from selenium import webdriver\nfrom flask import Flask, jsonify\nimport json\n\nGOOGLE_CHROME_PATH = '/usr/bin/google-chrome'\nCHROMEDRIVER_PATH = '/root/.pyenv/shims/chromedriver'\n\nchrome_options = webdriver.ChromeOptions()\n\n\noptions = webdriver.ChromeOptions()\noptions.binary_location = \"./bin/headless-chromium\"\noptions.add_argument(\"--headless\")\noptions.add_argument(\"--disable-gpu\")\noptions.add_argument(\"--window-size=1280x1696\")\noptions.add_argument(\"--disable-application-cache\")\noptions.add_argument(\"--disable-infobars\")\noptions.add_argument(\"--no-sandbox\")\noptions.add_argument(\"--hide-scrollbars\")\noptions.add_argument(\"--enable-logging\")\noptions.add_argument(\"--log-level=0\")\noptions.add_argument(\"--single-process\")\noptions.add_argument(\"--homedir=/tmp\")\noptions.add_argument(\"--ignore-certificate-errors\")\nchrome = webdriver.Chrome('./bin/chromedriver',chrome_options=options)\n\napp = Flask(__name__)\n\[email protected]('/')\ndef hello():\n chrome.get(\"https://mlcourse.ai/roadmap\")\n title = chrome.title\n #chrome.quit()\n #return jsonify({\"len\":len(driver.find_elements_by_tag_name('tbody'))})\n return {\n 'statusCode': 200,\n 'body': json.dumps(title)\n\n }\n\nif __name__ == '__main__':\n app.run()\n"
},
{
"alpha_fraction": 0.875,
"alphanum_fraction": 0.875,
"avg_line_length": 7,
"blob_id": "50c23136208478ac1f7979b0e7d11477ea5fe80b",
"content_id": "f64729f04537107bb575cb9233389d489226f1ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 32,
"license_type": "no_license",
"max_line_length": 8,
"num_lines": 4,
"path": "/requirements.txt",
"repo_name": "goodza/pyscrapin",
"src_encoding": "UTF-8",
"text": "gunicorn\nflask\njsonify\nselenium\n"
}
] | 3 |
Amar56/amar65
|
https://github.com/Amar56/amar65
|
0559d6f6922e4aecb0ccc7fbccfdcf3063d5729f
|
4f548bd293ec266e7ec9606655398c4d59b08a2a
|
22635a9bbe6bf4143c543c5701c508335a172a5f
|
refs/heads/master
| 2021-07-15T08:15:03.458505 | 2017-10-22T20:41:19 | 2017-10-22T20:41:19 | 107,896,843 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7004830837249756,
"alphanum_fraction": 0.7198067903518677,
"avg_line_length": 24.875,
"blob_id": "4f97067a1e77641b937647034652709f9804ffe5",
"content_id": "c55eeb4dfffed108f6bbc019f67bd2f7a45e4e0a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 207,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 8,
"path": "/amars coding dont lose.py",
"repo_name": "Amar56/amar65",
"src_encoding": "UTF-8",
"text": "print(\"hello world\")\nname=input(\"hi there what is your name?\")\nprint(name)\nprint(\"how are you?\")\nnum1=input(\"enter first number:\")\nnum2=input(\"enter secound number:\")\nsum= float(num1)+float(num2)\nprint(sum)\n"
}
] | 1 |
lewisdk/blogz
|
https://github.com/lewisdk/blogz
|
7ac6648657c4072905399d506b95e78097ebe973
|
1e60db4f9033edd44db9a74f5aa248bc916d67c6
|
41e0d360b3454edd0f83ea55764368a73fca720b
|
refs/heads/master
| 2020-04-25T22:22:10.488033 | 2019-03-04T04:57:53 | 2019-03-04T04:57:53 | 173,107,568 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5952034592628479,
"alphanum_fraction": 0.5976744294166565,
"avg_line_length": 29.995494842529297,
"blob_id": "d552c2e1ba3f90f9ae3dd166b9f6e753949b7bda",
"content_id": "eda5f98165d844d70653da859c236bedae75d532",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6880,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 222,
"path": "/main.py",
"repo_name": "lewisdk/blogz",
"src_encoding": "UTF-8",
"text": "from datetime import datetime\nfrom flask import Flask, request, redirect, render_template, url_for, flash, session\nfrom flask_sqlalchemy import SQLAlchemy\nfrom flask_bcrypt import Bcrypt\nfrom flask_login import current_user, LoginManager, login_user, logout_user\nimport cgi\nimport os\nimport jinja2\n\napp = Flask(__name__)\napp.config['DEBUG'] = True\napp.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://blogz:MyNewPass@localhost:8889/blogz'\napp.config['SQLALCHEMY_ECHO'] = True\ndb = SQLAlchemy(app)\napp.secret_key = \"super secret key\"\nbcrypt = Bcrypt(app)\nlogin_manager = LoginManager(app)\n\nclass User(db.Model):\n\n id = db.Column(db.Integer, primary_key=True)\n username = db.Column(db.String(15), unique=True, nullable=False)\n password = db.Column(db.String(15), nullable=False)\n blogs = db.relationship('Blog', backref='owner', lazy=True)\n\n def __init__(self, username, password):\n self.username = username\n self.password = password \n \n def __repr__(self):\n return f\"User('{self.username}')\"\n \n def is_authenticated(self):\n return True\n\n def is_active(self):\n return True\n\n def get_id(self):\n return self.id\n\nclass Blog(db.Model):\n\n id = db.Column(db.Integer, primary_key=True)\n blogtitle = db.Column(db.String(50))\n date_posted = db.Column(db.DateTime, nullable=False, default=datetime.utcnow)\n content = db.Column(db.Text, nullable=False)\n owner_id = db.Column(db.Integer, db.ForeignKey('user.id'), nullable=False)\n\n def __init__(self, blogtitle, content, owner):\n self.blogtitle = blogtitle\n self.content = content\n self.owner = owner\n\n def __repr__(self):\n return f\"Blog('{self.blogtitle}', '{self.date_posted}'', {self.content}', '{self.owner}')\"\n\n@login_manager.user_loader\ndef load_user(user_id):\n return User.query.get(int(user_id))\n\n\nblogs = []\nusers = []\n\[email protected]_request\ndef require_login():\n\n allowed_routes = ['login', 'index', 'signup', 'singleUser,' 'base']\n if request.endpoint not in allowed_routes and 'username' not in session:\n return redirect('/login')\n\[email protected]('/', methods=['POST', 'GET'])\ndef index():\n users = User.query.order_by(User.username.desc()).all()\n\n return render_template('index.html', users=users)\n\ndef logged_in_user():\n owner = User.query.filter_by(username=session['user']).first()\n return owner\n\[email protected]('/signup', methods=['POST', 'GET'])\ndef signup():\n if current_user.is_authenticated:\n return redirect('/')\n if request.method == 'POST':\n username = request.form['username']\n password = request.form['password']\n verify = request.form['verify']\n existing_user = User.query.filter_by(username=username).first()\n username_error = ''\n password_error = ''\n verify_error = ''\n\n def good_username(username):\n username = request.form['username']\n\n if (len(username) > 3 and len(username) < 20):\n return True\n else:\n return False\n\n def good_password(password):\n password = request.form['password']\n\n if (len(password) > 3 and len(password) < 20):\n if (\" \") in password:\n return True\n else:\n return False \n\n def password_match(verify):\n verify = request.form['verify']\n password = request.form['password']\n\n if [password] == [verify]:\n return True\n else:\n return False\n\n if existing_user:\n username_error = \"Username exists. Try harder.\"\n return render_template('signup.html', username_error=username_error)\n \n\n if good_username(username) == False:\n username_error = 'That is not a valid username.' \n return render_template('signup.html', username_error=username_error, username = '') \n\n if good_password(password) == False:\n password_error = 'That is not a valid password.'\n return render_template('signup.html', password_error=password_error, password = '')\n\n if password_match(verify) == False:\n verify_error = 'Passwords do not match.'\n return render_template('signup.html', verify_error=verify_error, verify = '')\n\n else:\n user = User(username=username, password=password)\n db.session.add(user)\n db.session.commit()\n session['username'] = username\n flash('Your account has been created. You are now able to log in.')\n return redirect('login')\n \n return render_template('signup.html') \n\[email protected]('/login', methods=['POST', 'GET'])\ndef login():\n if request.method == 'POST':\n username = request.form['username']\n password = request.form['password']\n user = User.query.filter_by(username=username).first()\n if user and user.password == password:\n session['username'] = username\n flash(\"Logged in\")\n return redirect('/')\n else:\n if not user:\n flash('User does not exist', 'error')\n return redirect('/signup')\n else:\n flash('Password is incorrect', 'error')\n return redirect('/login')\n \n return render_template('login.html', title='login') \n\n# @app.route('/add')\n# def add():\n# return render_template('newpost.html')\n\[email protected]('/newpost', methods=['POST', 'GET'])\ndef add_new_post():\n if request.method == 'POST':\n blogtitle = request.form[\"blogtitle\"]\n content = request.form[\"content\"]\n owner = session['usernamer']\n \n if not blogtitle or not content:\n flash(\"All fields are required. Please try again.\")\n return redirect(url_for('/newpost.html'))\n else:\n post = Blog(blogtitle, content, owner)\n\n db.session.add(post)\n db.session.commit()\n\n posted = '/blog/'+ str(post.id)\n \n flash('New entry was successfully posted!')\n\n return redirect(posted)\n return render_template('newpost.html')\n\[email protected]('/singleUser/<username>')\ndef singleUser(username):\n user = User.query.filter_by(username=User.username).first()\n \n return render_template('singleUser.html', title='singleUser', user=user)\n\[email protected]('/blog/<int:blog_id>')\ndef blog(blog_id):\n blog = Blog.query.filter_by(id=blog_id).one()\n\n return render_template('blog.html', blog=blog)\n\[email protected]('/base')\ndef all_blogs():\n blogs = Blog.query.all()\n return render_template('base.html', blogs=blogs)\n\n\[email protected]('/logout')\ndef logout():\n del session['username']\n return redirect('/base')\n\n\n\nif __name__ == '__main__':\n app.run()"
}
] | 1 |
michaelriedl/Pic2Paint
|
https://github.com/michaelriedl/Pic2Paint
|
fb3670c90f13940f73b6979f076f5f852dab4640
|
e34f618d338d44ff570f3860fb67be7b8f2b840b
|
835c111c66ff2638205d4a2a657aff0322f7d22d
|
refs/heads/master
| 2021-04-19T03:04:51.390176 | 2020-03-24T03:02:50 | 2020-03-24T03:02:50 | 249,573,507 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.644673764705658,
"alphanum_fraction": 0.6562845706939697,
"avg_line_length": 35.3624153137207,
"blob_id": "fa79fc3820ad94e902cc50e1ffad9777c286047e",
"content_id": "e924fef54da52cbf1ba9dfbae9c2bec3b9f6ae31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5426,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 149,
"path": "/run_pic2paint.py",
"repo_name": "michaelriedl/Pic2Paint",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nStreamlit app for Pic2Paint\n\nAuthor: Michael Riedl\nLast Updated: March 18, 2020\n\"\"\"\n\nimport torch\nimport scipy.linalg\nimport numpy as np\nimport streamlit as st\nimport torch.optim as optim\nimport torchvision.transforms as transforms\nfrom PIL import Image, ImageOps\nfrom utils.models import StyleTransferNet\n\ndef load_model(device, content_img, style_img):\n loader = transforms.Compose([transforms.ToTensor()])\n return StyleTransferNet(device, loader(style_img).unsqueeze(0), loader(content_img).unsqueeze(0))\n\ndef color_balance(content_img, style_img):\n # Store the size of the original style image\n imsize = style_img.size\n # Convert the content and style images to tensors\n loader = transforms.Compose([transforms.ToTensor()])\n content_img = loader(content_img)\n style_img = loader(style_img)\n # Create the style covariance\n style_vec = np.moveaxis(style_img.cpu().numpy(), 0 , -1).reshape(-1, 3)\n style_mean = np.mean(style_vec, axis=0)\n style_cov = 1/style_vec.shape[0]*np.matmul(np.transpose(style_vec - style_mean), style_vec - style_mean)\n # Create the content covariance\n content_vec = np.moveaxis(content_img.cpu().numpy(), 0 , -1).reshape(-1, 3)\n content_mean = np.mean(content_vec, axis=0)\n content_cov = 1/content_vec.shape[0]*np.matmul(np.transpose(content_vec - content_mean), content_vec - content_mean)\n # Apply the color balance to the style image\n style_img_conv = np.reshape(style_img.cpu().numpy(), (3, -1))\n A = np.matmul(scipy.linalg.sqrtm(content_cov), scipy.linalg.sqrtm(np.linalg.inv(style_cov)))\n b = content_mean - np.matmul(A, style_mean)\n style_img_conv = np.clip(np.matmul(A, style_img_conv) + b[:, None], 0, 1)\n style_img_conv = torch.tensor(np.reshape(style_img_conv, (3, imsize[1], imsize[0])))\n saver = transforms.Compose([transforms.ToPILImage()])\n style_img_conv = saver(style_img_conv)\n \n return style_img_conv\n \n# Remove old variables\nmodel = None\n\n# Create the headers\nst.title(\"Pic2Paint\")\nst.header(\"Upload images to start.\")\n\n# Initialize the sidebar view\nst.sidebar.header(\"Processing Status\")\nprogress_bar = st.sidebar.progress(0)\nstatus_text = st.sidebar.empty()\nstatus_text.text(\"Waiting to process...\")\n\n# Create the file uploaders\nst.sidebar.header(\"Choose the pictures to use\")\ncontent_img_file = st.sidebar.file_uploader(\"Content Image\")\nstyle_img_file = st.sidebar.file_uploader(\"Style Image\")\n\n# Create the resize options\nresize_flag = st.sidebar.selectbox(\"Resizing\", [\"None\", \"Content\", \"Style\"])\ncolor_flag = st.sidebar.checkbox(\"Maintain content color\")\n\n# Display the chosen images and enable run if valid\nif(content_img_file is not None and style_img_file is not None):\n content_img = Image.open(content_img_file)\n style_img = Image.open(style_img_file)\n # Perform resizing\n if(resize_flag == 'Content'):\n style_img = ImageOps.fit(style_img, content_img.size, Image.ANTIALIAS)\n if(resize_flag == 'Style'):\n content_img = ImageOps.fit(content_img, style_img.size, Image.ANTIALIAS)\n # Perform color balance\n if(color_flag):\n style_img = color_balance(content_img, style_img)\n st.image([content_img, style_img], \n caption=['Content Image', 'Style Image'], \n width=256)\n st.sidebar.header(\"Run style transfer\")\n proc_flag = st.sidebar.button(\"Run\")\nelif(content_img_file is not None):\n content_img = Image.open(content_img_file)\n st.image([content_img], \n caption=['Content Image'], \n width=256)\nelif(style_img_file is not None):\n style_img = Image.open(style_img_file)\n st.image([style_img], \n caption=['Style Image'], \n width=256)\n \n# Run the style transfer\nif(content_img_file is not None and style_img_file is not None and proc_flag):\n \n # Set the device to use\n device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')\n \n # Load the model\n model = load_model(device, content_img, style_img)\n \n # Change the status text\n status_text.text(\"Processing...\")\n # Set the number of processing steps\n max_steps = 60\n \n # Initialize list for creating gif\n final_gif = []\n saver = transforms.Compose([transforms.ToPILImage()])\n\n # Create the input\n loader = transforms.Compose([transforms.ToTensor()])\n input_img = loader(content_img).unsqueeze(0).to(device)\n optimizer = optim.LBFGS([input_img.requires_grad_()], max_iter=1, history_size=1)\n step = [0]\n while step[0] < max_steps:\n \n def closure():\n input_img.data.clamp_(0, 1)\n optimizer.zero_grad()\n model(input_img)\n model.loss.backward()\n step[0] += 1\n return model.loss.item()\n \n optimizer.step(closure)\n progress_bar.progress(step[0]/max_steps)\n # Store the intermediate image for the gif\n input_img.data.clamp_(0, 1)\n final_gif.append(saver(input_img.cpu().squeeze(0)))\n \n # Change the status text\n status_text.text(\"Complete!\")\n \n # Plot the final image\n final_img = saver(input_img.cpu().squeeze(0))\n st.image([final_img], \n caption=['Stylized Image'], \n width=256)\n \n # Save the image\n final_img.save(\"output.png\")\n # Save the gif\n final_gif[0].save(\"output.gif\", save_all=True, append_images=final_gif[1:])\n "
},
{
"alpha_fraction": 0.7170668244361877,
"alphanum_fraction": 0.7261518239974976,
"avg_line_length": 32.5,
"blob_id": "5ce432d43f297e957746c88d709723b2e4837336",
"content_id": "01819e2a5d0dd5114da1347c6ccc451bc24ec146",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1541,
"license_type": "no_license",
"max_line_length": 323,
"num_lines": 46,
"path": "/README.md",
"repo_name": "michaelriedl/Pic2Paint",
"src_encoding": "UTF-8",
"text": "# Pic2Paint\nA Streamlit app for neural style transfer.\n\n## Running the App\n\nTo run the app you will first need to setup your environment. I use Anaconda to manage my environments and have included a YAML file to recreate the environment I used. To create the environment, run the command below:\n```\nconda env create -n myenv -f environment.yml\n```\nTo activate the environment you can use the command:\n```\nconda activate myenv\n```\n\nOnce you have the environment setup you can run the Streamlit app. You can run the app with the following command:\n```\nstreamlit run run_pic2paint.py \n```\n\n## Processing Images\n\nIt is important to note that both the content and style image need to be the same size. If they are not, you can use the options in the sidebar to choose how to resize the images. Also, high resolution images may cause an error if using a GPU, since the processing may take up more memory than what is available on the GPU.\n\n## Hardware Acceleration\n\nI have written the code to utilize the system GPU if it is configured correctly. This app will still run without a GPU but will be much slower.\n\n## Examples\n\nBelow are some examples of the style transfer output.\n\n| <img src=\"/examples/picasso.jpg\" width=\"250\"> | \n|:--:| \n| *Style Image* |\n\n| <img src=\"/examples/hard_scene.jpg\" width=\"250\"> | \n|:--:| \n| *Content Image* |\n\n| <img src=\"/examples/hard_scene_output.png\" width=\"250\"> | \n|:--:| \n| *Output Image* |\n\n| <img src=\"/examples/hard_scene_output_color.png\" width=\"250\"> | \n|:--:| \n| *Output Image with Color Preservation* |\n"
},
{
"alpha_fraction": 0.5875475406646729,
"alphanum_fraction": 0.5989575982093811,
"avg_line_length": 36.96791458129883,
"blob_id": "3e5c209ea3580ff4f96834a99d3d510a3d52827b",
"content_id": "f650d2660d3088e841972acb1c147bc9357ea425",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7099,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 187,
"path": "/utils/models.py",
"repo_name": "michaelriedl/Pic2Paint",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nNeural transfer network definitions\n\nAuthor: Michael Riedl\nLast Updated: December 8, 2019\n\"\"\"\n\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torchvision.models as models\n\ndef gram_matrix(input):\n \"\"\" Function for calculating the normalized Gram matrix from layer activations \n \n Parameters\n ----------\n input : torch.Tensor\n The layer activation tensor\n \n Returns\n -------\n torch.Tensor\n A tensor containing the Gram matrix\n \n Notes\n -----\n This code was modified from: \n https://github.com/pytorch/tutorials/blob/master/advanced_source/neural_style_tutorial.py\n \"\"\"\n a, b, c, d = input.size()\n features = input.view(a * b, c * d)\n G = torch.mm(features, features.t())\n\n return G.div(a * b * c * d)\n\nclass Normalization(nn.Module):\n \"\"\" A neural module that takes an input image tensor and normalizes it for\n the pretrained network\n \n Extended Summary\n ----------------\n A :class:`Normalization` module takes an input image tensor and normalizes it \n for the pretrained neural network. This module is placed in front of the \n pretrained network so that the input data does not need to be preprocessed.\n \n Attributes\n ----------\n mean : torch.Tensor\n A tensor of means for each channel\n \n std : torch.Tensor\n A tensor of standard deviations for each channel\n \n Notes\n -----\n The means and variances should be moved to the desired device before \n initializing the module.\n This code was modified from: \n https://github.com/pytorch/tutorials/blob/master/advanced_source/neural_style_tutorial.py\n \"\"\"\n def __init__(self, mean, std):\n super(Normalization, self).__init__()\n self.mean = mean.view(-1, 1, 1)\n self.std = std.view(-1, 1, 1)\n\n def forward(self, img):\n return (img - self.mean) / self.std\n\nclass StyleTransferNet(nn.Module):\n \"\"\" A neural module that implements neural style transfer using the pretrained\n VGG19 network. The implementation follows that of Gatys et. al.\n \n Extended Summary\n ----------------\n A :class:`StyleTransferNet` transfers the sytle of the style image to the\n content image. The inputs are the style image, the style loss weight, the\n content image, the content loss weight, and the device to be used for\n training.\n \n Attributes\n ----------\n device : str\n The device to use for training.\n \n style_img : torch.Tensor\n The style image to be used to transfer style to the content image.\n \n content_img : torch.Tensor\n The content image to be re-styled/\n \n style_weight : float\n The weight applied to the style loss.\n \n content_weight : float\n The weight applied to the content loss.\n \n Notes\n -----\n This module was designed to minimize the memory overhead required when\n training on a GPU.\n This code was modified from: \n https://github.com/pytorch/tutorials/blob/master/advanced_source/neural_style_tutorial.py\n \"\"\"\n def __init__(self, device, style_img, content_img, style_weight=1e6, content_weight=1):\n super(StyleTransferNet, self).__init__()\n # Store the device to run the network\n self.device = device\n # Move the style and content images to the device\n style_img = style_img.requires_grad_(False).to(self.device)\n content_img = content_img.requires_grad_(False).to(self.device)\n # Store the weights\n self.style_weight = style_weight\n self.content_weight = content_weight\n # Set the default layers to use (CHANGING REQUIRES MODIFICATION OF FORWARD PASS)\n max_conv_layer = 5\n content_layers = ['conv_4']\n style_layers = ['conv_1', 'conv_2', 'conv_3', 'conv_4', 'conv_5']\n # Set the normalization parameters for VGG19\n self.norm_mean = torch.tensor([0.485, 0.456, 0.406]).to(self.device)\n self.norm_std = torch.tensor([0.229, 0.224, 0.225]).to(self.device)\n # Store the needed VGG19 layers\n self.conv_layers = nn.ModuleList()\n self.relu_layers = nn.ModuleList()\n self.pool_layers = nn.ModuleList()\n self.style_loss_dict = dict()\n self.content_loss_dict = dict()\n cnn = models.vgg19(pretrained=True).features.to(self.device).eval()\n self.normalization = Normalization(self.norm_mean, self.norm_std)\n model = nn.Sequential(self.normalization)\n i = 0\n for layer in cnn.children():\n if isinstance(layer, nn.Conv2d):\n i += 1\n name = 'conv_{}'.format(i)\n self.conv_layers.append(layer)\n elif isinstance(layer, nn.ReLU):\n name = 'relu_{}'.format(i)\n layer = nn.ReLU(inplace=False)\n self.relu_layers.append(layer)\n elif isinstance(layer, nn.MaxPool2d):\n name = 'pool_{}'.format(i)\n layer = nn.AvgPool2d(kernel_size=2, stride=2, padding=0, ceil_mode=False)\n self.pool_layers.append(layer)\n elif isinstance(layer, nn.BatchNorm2d):\n name = 'bn_{}'.format(i)\n else:\n raise RuntimeError('Unrecognized layer: {}'.format(layer.__class__.__name__)) \n model.add_module(name, layer.requires_grad_(False))\n # Add content loss\n if name in content_layers: \n self.content_loss_dict[name] = model(content_img).detach()\n # Add style loss\n if name in style_layers:\n self.style_loss_dict[name] = model(style_img).detach() \n # Stop after the 5th conv layer\n if(i == max_conv_layer):\n break\n \n def forward(self, img):\n x = self.normalization(img)\n x = self.conv_layers[0](x)\n # Style loss\n self.loss = self.style_weight*F.mse_loss(gram_matrix(x), gram_matrix(self.style_loss_dict['conv_1']))\n x = self.relu_layers[0](x)\n x = self.conv_layers[1](x)\n # Style loss\n self.loss += self.style_weight*F.mse_loss(gram_matrix(x), gram_matrix(self.style_loss_dict['conv_2']))\n x = self.relu_layers[1](x)\n x = self.pool_layers[0](x)\n x = self.conv_layers[2](x)\n # Style loss\n self.loss += self.style_weight*F.mse_loss(gram_matrix(x), gram_matrix(self.style_loss_dict['conv_3']))\n x = self.relu_layers[2](x)\n x = self.conv_layers[3](x)\n # Style loss\n self.loss += self.style_weight*F.mse_loss(gram_matrix(x), gram_matrix(self.style_loss_dict['conv_4']))\n # Content loss\n self.loss += self.content_weight*F.mse_loss(x, self.content_loss_dict['conv_4'])\n x = self.relu_layers[3](x)\n x = self.pool_layers[1](x)\n x = self.conv_layers[4](x)\n # Style loss\n self.loss += self.style_weight*F.mse_loss(gram_matrix(x), gram_matrix(self.style_loss_dict['conv_5']))\n \n return x"
}
] | 3 |
philz/crepo
|
https://github.com/philz/crepo
|
2064d65b3786d1229d990220e5f4a730f0ade8a0
|
e33ffb21e55f12f730658c8142a851e4300feff7
|
22107424936519d95d8861735158878886a9d45e
|
refs/heads/master
| 2021-01-16T21:36:33.940176 | 2009-08-26T21:07:34 | 2009-08-26T21:07:34 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6273870468139648,
"alphanum_fraction": 0.6316720843315125,
"avg_line_length": 27.857526779174805,
"blob_id": "5072a3beebf40980678afc0691690f42d04844b2",
"content_id": "ef938c1ea34a631a176b9426e36e9c6c0b77620a",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10735,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 372,
"path": "/crepo.py",
"repo_name": "philz/crepo",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python2.5\n# (c) Copyright 2009 Cloudera, Inc.\n\nimport os\nimport sys\nimport optparse\nimport manifest\nimport logging\nimport textwrap\nfrom git_command import GitCommand\nfrom git_repo import GitRepo\n\nLOADED_MANIFEST = None\ndef load_manifest():\n global LOADED_MANIFEST\n if not LOADED_MANIFEST:\n LOADED_MANIFEST = manifest.load_manifest(\"manifest.json\")\n return LOADED_MANIFEST\n\ndef help(args):\n \"\"\"Shows help\"\"\"\n if len(args) == 1:\n command = args[0]\n doc = COMMANDS[command].__doc__\n if doc:\n print >>sys.stderr, \"Help for command %s:\\n\" % command\n print >>sys.stderr, doc\n sys.exit(1)\n usage()\n\n\ndef init(args):\n \"\"\"Initializes repository - DEPRECATED - use sync\"\"\"\n print >>sys.stderr, \"crepo init is deprecated - use crepo sync\"\n sync(args)\n\ndef sync(args):\n \"\"\"Synchronize your local repository with the manifest and the real world.\n This includes:\n - ensures that all projects are cloned\n - ensures that they have the correct remotes set up\n - fetches from the remotes\n - checks out the correct tracking branches\n - if the local branch is not dirty and it is a fast-forward update, merges\n the remote branch's changes in\n\n Process exit code will be 0 if all projects updated correctly.\n \"\"\"\n \n man = load_manifest()\n\n for (name, project) in man.projects.iteritems():\n if not project.is_cloned():\n project.clone()\n ensure_remotes([])\n fetch([])\n checkout_branches([])\n\n retcode = 0\n \n for project in man.projects.itervalues():\n repo = project.git_repo\n if repo.is_workdir_dirty() or repo.is_index_dirty():\n print >>sys.stderr, \"Not syncing project %s - it is dirty.\" % project.name\n retcode = 1\n continue\n (left, right) = project.tracking_status\n if left > 0:\n print >>sys.stderr, \\\n (\"Not syncing project %s - you have %d unpushed changes.\" % \n (project.name, left))\n retcode = 1\n continue\n elif right > 0:\n repo.check_command([\"merge\", project.remote_ref])\n else:\n print >>sys.stderr, \"Project %s needs no update\" % project.name\n\n return retcode\n\ndef ensure_remotes(args):\n \"\"\"Ensure that remotes are set up\"\"\"\n man = load_manifest()\n for (proj_name, project) in man.projects.iteritems():\n project.ensure_remotes()\n\n\ndef ensure_tracking_branches(args):\n \"\"\"Ensures that the tracking branches are set up\"\"\"\n man = load_manifest()\n for (name, project) in man.projects.iteritems():\n project.ensure_tracking_branch()\n\ndef check_dirty(args):\n \"\"\"Prints output if any projects have dirty working dirs or indexes.\"\"\"\n man = load_manifest()\n any_dirty = False\n for (name, project) in man.projects.iteritems():\n repo = project.git_repo\n any_dirty = check_dirty_repo(repo) or any_dirty\n return any_dirty\n\ndef check_dirty_repo(repo, indent=0):\n workdir_dirty = repo.is_workdir_dirty()\n index_dirty = repo.is_index_dirty()\n\n name = repo.name\n if workdir_dirty:\n print \" \" * indent + \"Project %s has a dirty working directory (unstaged changes).\" % name\n if index_dirty:\n print \" \" * indent + \"Project %s has a dirty index (staged changes).\" % name\n\n return workdir_dirty or index_dirty\n\n\ndef checkout_branches(args):\n \"\"\"Checks out the tracking branches listed in the manifest.\"\"\"\n\n if check_dirty([]) and '-f' not in args:\n raise Exception(\"Cannot checkout new branches with dirty projects.\")\n \n man = load_manifest()\n for (name, project) in man.projects.iteritems():\n print >>sys.stderr, \"Checking out tracking branch in project: %s\" % name\n project.checkout_tracking_branch()\n\ndef hard_reset_branches(args):\n \"\"\"Hard-resets your tracking branches to match the remotes.\"\"\"\n checkout_branches(args)\n man = load_manifest()\n for (name, project) in man.projects.iteritems():\n print >>sys.stderr, \"Hard resetting tracking branch in project: %s\" % name\n project.git_repo.check_command([\"reset\", \"--hard\", project.remote_ref])\n \n\ndef do_all_projects(args):\n \"\"\"Run the given git-command in every project\n\n Pass -p to do it in parallel\"\"\"\n man = load_manifest()\n\n if args[0] == '-p':\n parallel = True\n del args[0]\n else:\n parallel = False\n\n towait = []\n\n for (name, project) in man.projects.iteritems():\n print >>sys.stderr, \"In project: \", name, \" running \", \" \".join(args)\n p = project.git_repo.command_process(args)\n if not parallel:\n p.Wait()\n print >>sys.stderr\n else:\n towait.append(p)\n\n for p in towait:\n p.Wait()\n \ndef do_all_projects_remotes(args):\n \"\"\"Run the given git-command in every project, once for each remote.\n\n Pass -p to do it in parallel\"\"\"\n man = load_manifest()\n\n if args[0] == '-p':\n parallel = True\n del args[0]\n else:\n parallel = False\n towait = []\n\n for (name, project) in man.projects.iteritems():\n for remote_name in project.remotes.keys():\n cmd = [arg % {\"remote\": remote_name} for arg in args]\n print >>sys.stderr, \"In project: \", name, \" running \", \" \".join(cmd)\n p = project.git_repo.command_process(cmd)\n if not parallel:\n p.Wait()\n print >>sys.stderr\n else:\n towait.append(p)\n for p in towait:\n p.Wait()\n\n\ndef fetch(args):\n \"\"\"Run git-fetch in every project\"\"\"\n do_all_projects_remotes(\n args + [\"fetch\", \"-t\", \"%(remote)s\",\n \"refs/heads/*:refs/remotes/%(remote)s/*\"])\n\ndef pull(args):\n \"\"\"Run git-pull in every project\"\"\"\n do_all_projects(args + [\"pull\", \"-t\"])\n\ndef _format_tracking(local_branch, remote_branch,\n left, right):\n \"\"\"\n Takes a tuple returned by repo.tracking_status and outputs a nice string\n describing the state of the repository.\n \"\"\"\n if (left,right) == (0,0):\n return \"Your tracking branch and remote branches are up to date.\"\n elif left == 0:\n return (\"The remote branch %s is %d revisions ahead of tracking branch %s.\" %\n (remote_branch, right, local_branch))\n elif right == 0:\n return (\"Your tracking branch %s is %s revisions ahead of remote branch %s.\" %\n (local_branch, left, remote_branch))\n else:\n return ((\"Your local branch %s and remote branch %s have diverged by \" +\n \"%d and %d revisions.\") %\n (local_branch, remote_branch, left, right))\n\ndef project_status(project, indent=0):\n repo = project.git_repo\n repo_status(repo, project.tracking_branch, project.remote_ref, indent=indent)\n\ndef repo_status(repo, tracking_branch, remote_ref, indent=0):\n # Make sure the right branch is checked out\n if repo.current_branch() != tracking_branch:\n print \" \" * indent + (\"Checked out branch is %s instead of %s\" %\n (repo.current_branch(), tracking_branch))\n\n # Make sure the branches exist\n has_tracking = repo.has_ref(tracking_branch)\n has_remote = repo.has_ref(remote_ref)\n\n if not has_tracking:\n print \" \" * indent + \"You appear to be missing the tracking branch \" + \\\n tracking_branch\n if not has_remote:\n print \" \" * indent + \"You appear to be missing the remote branch \" + \\\n remote_ref\n\n if not has_tracking or not has_remote:\n return\n\n # Print tracking branch status\n (left, right) = repo.tracking_status(tracking_branch, remote_ref)\n text = _format_tracking(tracking_branch, remote_ref, left, right)\n indent_str = \" \" * indent\n print textwrap.fill(text, initial_indent=indent_str, subsequent_indent=indent_str)\n\ndef status(args):\n \"\"\"Shows where your branches have diverged from the specified remotes.\"\"\"\n ensure_tracking_branches([])\n man = load_manifest()\n first = True\n for (name, project) in man.projects.iteritems():\n if not first: print\n first = False\n\n print \"Project %s:\" % name\n project_status(project, indent=2)\n check_dirty_repo(project.git_repo,\n indent=2)\n\n man_repo = get_manifest_repo()\n if man_repo:\n print\n print \"Manifest repo:\"\n repo_status(man_repo,\n man_repo.current_branch(),\n \"origin/\" + man_repo.current_branch(),\n indent=2)\n check_dirty_repo(man_repo, indent=2)\n\n\ndef get_manifest_repo():\n \"\"\"\n Return a GitRepo object pointing to the repository that contains\n the crepo manifest.\n \"\"\"\n # root dir is cwd for now\n cdup = GitRepo(\".\").command_process([\"rev-parse\", \"--show-cdup\"],\n capture_stdout=True,\n capture_stderr=True)\n if cdup.Wait() != 0:\n return None\n cdup_path = cdup.stdout.strip()\n if cdup_path:\n return GitRepo(cdup_path)\n else:\n return GitRepo(\".\")\n\ndef dump_refs(args):\n \"\"\"\n Output a list of all repositories along with their\n checked out branches and their hashes.\n \"\"\"\n man = load_manifest()\n first = True\n for (name, project) in man.projects.iteritems():\n if not first: print\n first = False\n print \"Project %s:\" % name\n\n repo = project.git_repo\n print \" HEAD: %s\" % repo.rev_parse(\"HEAD\")\n print \" Symbolic: %s\" % repo.current_branch()\n project_status(project, indent=2)\n\n repo = get_manifest_repo()\n if repo:\n print\n print \"Manifest repo:\"\n print \" HEAD: %s\" % repo.rev_parse(\"HEAD\")\n print \" Symbolic: %s\" % repo.current_branch()\n repo_status(repo,\n repo.current_branch(),\n \"origin/\" + repo.current_branch(),\n indent=2)\n check_dirty_repo(repo, indent=2)\n \n\n\nCOMMANDS = {\n 'help': help,\n 'init': init,\n 'sync': sync,\n 'checkout': checkout_branches,\n 'hard-reset': hard_reset_branches,\n 'do-all': do_all_projects,\n 'fetch': fetch,\n 'pull': pull,\n 'status': status,\n 'check-dirty': check_dirty,\n 'setup-remotes': ensure_remotes,\n 'dump-refs': dump_refs\n }\n\ndef usage():\n print >>sys.stderr, \"you screwed up. here are the commands:\"\n print >>sys.stderr\n\n max_comlen = 0\n out = []\n for (command, function) in COMMANDS.iteritems():\n docs = function.__doc__ or \"no docs\"\n docs = docs.split(\"\\n\")[0]\n if len(command) > max_comlen:\n max_comlen = len(command)\n\n out.append( (command, docs) )\n\n for (command, docs) in sorted(out):\n command += \" \" * (max_comlen - len(command))\n available_len = 80 - max_comlen - 5\n output_docs = []\n cur_line = \"\"\n for word in docs.split(\" \"):\n if cur_line and len(cur_line + \" \" + word) > available_len:\n output_docs.append(cur_line)\n cur_line = \" \" * (max_comlen + 5)\n cur_line += \" \" + word\n if cur_line: output_docs.append(cur_line)\n print >>sys.stderr, \" %s %s\" % (command, \"\\n\".join(output_docs))\n sys.exit(1)\n\ndef main():\n args = sys.argv[1:]\n if len(args) == 0 or args[0] not in COMMANDS:\n usage()\n command = COMMANDS[args[0]]\n sys.exit(command.__call__(args[1:]))\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.5924398899078369,
"alphanum_fraction": 0.5941580533981323,
"avg_line_length": 31.45353126525879,
"blob_id": "8547606822d225602262f01ba2b11646cc45626d",
"content_id": "989a7bdb66212e9aafcd503bd742defc00e2e429",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8730,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 269,
"path": "/manifest.py",
"repo_name": "philz/crepo",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python2.5\n# (c) Copyright 2009 Cloudera, Inc.\nimport logging\nimport os\nimport simplejson\n\nfrom git_command import GitCommand\nfrom git_repo import GitRepo\n\n\nclass Manifest(object):\n def __init__(self,\n base_dir=None,\n remotes=[],\n projects={},\n default_ref=\"master\",\n default_remote=\"origin\"):\n self.base_dir = base_dir or os.getcwd()\n self.remotes = remotes\n self.projects = projects\n self.default_ref = default_ref\n self.default_remote = default_remote\n\n @staticmethod\n def from_dict(data, base_dir=None):\n remotes = dict([(name, Remote.from_dict(d)) for (name, d) in data.get('remotes', {}).iteritems()])\n\n default_remote = data.get(\"default-remote\", \"origin\")\n assert default_remote in remotes\n\n man = Manifest(\n base_dir=base_dir,\n default_ref=data.get(\"default-revision\", \"master\"),\n default_remote=default_remote,\n remotes=remotes)\n \n for (name, d) in data.get('projects', {}).iteritems():\n man.add_project(Project.from_dict(\n manifest=man,\n name=name,\n data=d))\n return man\n\n @classmethod\n def from_json_file(cls, path):\n data = simplejson.load(file(path))\n return cls.from_dict(data, base_dir=os.path.abspath(os.path.dirname(path)))\n\n def add_project(self, project):\n if project.name in self.projects:\n raise Exception(\"Project %s already in manifest\" % project.name)\n self.projects[project.name] = project\n\n def to_json(self):\n return simplejson.dumps(self.data_for_json(), indent=2)\n\n def data_for_json(self):\n return {\n \"default-revision\": self.default_ref,\n \"default-remote\": self.default_remote,\n \"remotes\": dict( [(name, remote.data_for_json()) for (name, remote) in self.remotes.iteritems()] ),\n \"projects\": dict( [(name, project.data_for_json()) for (name, project) in self.projects.iteritems()] ),\n }\n\n def __repr__(self):\n return self.to_json()\n\n\nclass Remote(object):\n def __init__(self,\n fetch):\n self.fetch = fetch\n\n @staticmethod\n def from_dict(data):\n return Remote(fetch=data.get('fetch'))\n\n def to_json(self):\n return simplejson.dumps(self.data_for_json(), indent=2)\n\n def data_for_json(self):\n return {'fetch': self.fetch}\n\nclass Project(object):\n def __init__(self,\n name=None,\n manifest=None,\n remotes=None,\n tracking_branch=None, # the name of the tracking branch\n remote_ref=\"master\", # what ref to track\n tracks_remote_ref=True,\n from_remote=\"origin\", # where to pull from\n dir=None,\n remote_project_name = None\n ):\n self.name = name\n self.manifest = manifest\n self.remotes = remotes if remotes else []\n self._dir = dir if dir else name\n self.from_remote = from_remote\n self.remote_ref = remote_ref\n self.tracks_remote_ref = tracks_remote_ref\n self.tracking_branch = tracking_branch\n self.remote_project_name = remote_project_name if remote_project_name else name\n\n @staticmethod\n def from_dict(manifest, name, data):\n my_remote_names = data.get('remotes', [manifest.default_remote])\n my_remotes = dict([ (r, manifest.remotes[r])\n for r in my_remote_names])\n\n from_remote = data.get('from-remote')\n if not from_remote:\n if len(my_remote_names) == 1:\n from_remote = my_remote_names[0]\n elif manifest.default_remote in my_remote_names:\n from_remote = manifest.default_remote\n else:\n raise Exception(\"no from-remote listed for project %s, and more than one remote\" %\n name)\n \n assert from_remote in my_remote_names\n remote_project_name = data.get('remote-project-name')\n\n track_tag = data.get('track-tag')\n track_branch = data.get('track-branch')\n track_hash = data.get('track-hash')\n\n\n if len([ x for x in [track_tag, track_branch, track_hash] if x]) != 1:\n raise Exception(\"Cannot specify more than one of track-branch, track-tag, or track-hash for project %s\" %\n name)\n\n # This is old and deprecated\n ref = data.get('refspec')\n if not track_tag and not track_branch and not track_hash:\n if ref:\n logging.warn(\"'ref' is deprecated - use either track-branch or track-tag \" +\n \"for project %s\" % name)\n track_branch = ref\n else:\n track_branch = \"master\"\n \n if track_tag:\n remote_ref = \"refs/tags/\" + track_tag\n tracks_remote_ref = True\n tracking_branch = track_tag\n elif track_branch:\n remote_ref = \"%s/%s\" % (from_remote, track_branch)\n tracks_remote_ref = True\n tracking_branch = track_branch\n elif track_hash:\n remote_ref = track_hash\n tracks_remote_ref = False\n tracking_branch = \"crepo\"\n else:\n assert False and \"Cannot get here!\"\n \n\n return Project(name=name,\n manifest=manifest,\n remotes=my_remotes,\n remote_ref=remote_ref,\n tracks_remote_ref=tracks_remote_ref,\n tracking_branch=tracking_branch,\n dir=data.get('dir', name),\n from_remote=from_remote,\n remote_project_name=remote_project_name)\n\n\n @property\n def tracking_status(self):\n return self.git_repo.tracking_status(\n self.tracking_branch, self.remote_ref)\n\n def to_json(self):\n return simplejson.dumps(self.data_for_json())\n\n def data_for_json(self):\n return {'name': self.name,\n 'remotes': self.remotes.keys(),\n 'ref': self.ref,\n 'from-remote': self.from_remote,\n 'dir': self.dir}\n\n @property\n def dir(self):\n return os.path.join(self.manifest.base_dir, self._dir)\n\n @property\n def git_repo(self):\n return GitRepo(self.dir)\n\n def is_cloned(self):\n return self.git_repo.is_cloned()\n\n ############################################################\n # Actual actions to be taken on a project\n ############################################################\n\n def clone(self):\n if self.is_cloned():\n return\n logging.warn(\"Initializing project: %s\" % self.name)\n clone_remote = self.manifest.remotes[self.from_remote]\n clone_url = clone_remote.fetch % {\"name\": self.remote_project_name}\n p = GitCommand([\"clone\", \"-o\", self.from_remote, \"-n\", clone_url, self.dir])\n p.Wait()\n\n repo = self.git_repo\n if repo.command([\"show-ref\", \"-q\", \"HEAD\"]) != 0:\n # There is no HEAD (maybe origin/master doesnt exist) so check out the tracking\n # branch\n if self.tracks_remote_ref:\n repo.check_command([\"checkout\", \"--track\", \"-b\", self.tracking_branch,\n self.remote_ref])\n else:\n repo.check_command([\"checkout\", \"-b\", self.tracking_branch,\n self.remote_ref])\n else:\n repo.check_command([\"checkout\"])\n \n\n def ensure_remotes(self):\n repo = self.git_repo\n for remote_name in self.remotes:\n remote = self.manifest.remotes[remote_name]\n new_url = remote.fetch % { \"name\": self.remote_project_name }\n\n p = repo.command_process([\"config\", \"--get\", \"remote.%s.url\" % remote_name],\n capture_stdout=True)\n if p.Wait() == 0:\n cur_url = p.stdout.strip()\n if cur_url != new_url:\n repo.check_command([\"config\", \"--replace-all\", \"remote.%s.url\" % remote_name, new_url])\n else:\n repo.check_command([\"remote\", \"add\", remote_name, new_url])\n\n def ensure_tracking_branch(self):\n \"\"\"Ensure that the tracking branch exists.\"\"\"\n if not self.is_cloned():\n self.init()\n\n branch_missing = self.git_repo.command(\n [\"rev-parse\", \"--verify\", \"-q\", \"refs/heads/%s\" % self.tracking_branch],\n capture_stdout=True)\n\n if branch_missing:\n logging.warn(\"Branch %s does not exist in project %s. checking out.\" %\n (self.tracking_branch, self.name))\n if self.tracks_remote_ref:\n self.git_repo.command([\"branch\", \"--track\",\n self.tracking_branch, self.remote_ref])\n else:\n self.git_repo.command([\"branch\", self.tracking_branch, self.remote_ref])\n \n\n def checkout_tracking_branch(self):\n \"\"\"Check out the correct tracking branch.\"\"\"\n self.ensure_tracking_branch()\n self.git_repo.check_command([\"checkout\", self.tracking_branch])\n\ndef load_manifest(path):\n return Manifest.from_json_file(path)\n\n\ndef test_json_load_store():\n man = load_manifest(os.path.join(os.path.dirname(__file__), 'test', 'test_manifest.json'))\n assert len(man.to_json()) > 10\n"
},
{
"alpha_fraction": 0.6217765212059021,
"alphanum_fraction": 0.6346704959869385,
"avg_line_length": 24.851852416992188,
"blob_id": "f7e0e57b0bbab5d58ed00bc901e1b53042be1b4c",
"content_id": "b292f49f7e777b3b4911ad80d65f9c49e62e1adf",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 698,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 27,
"path": "/test.py",
"repo_name": "philz/crepo",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python2.5\n# (c) Copyright 2009 Cloudera, Inc.\n\nimport unittest\nfrom unittest import TestCase\nimport os\nimport subprocess\nimport re\n\nTESTS_DIR=os.path.join(os.path.dirname(__file__), \"shell-tests\")\n\nclass ShellTests(TestCase):\n def _run_shell_test(self, path):\n print \"running: \" + path\n ret = subprocess.call([os.path.join(TESTS_DIR, path)])\n self.assertEquals(ret, 0)\n\ndef __add_tests():\n for x in os.listdir(TESTS_DIR):\n if x.startswith(\".\"): continue\n t = lambda self,x=x: self._run_shell_test(x)\n t.__name__ = 'test' + re.sub('[^a-zA-Z0-9]', '_', 'test' + x)\n setattr(ShellTests, t.__name__, t)\n__add_tests()\n\nif __name__ == \"__main__\":\n unittest.main()\n"
}
] | 3 |
zouxiaoyu/myOwn_codeStyle
|
https://github.com/zouxiaoyu/myOwn_codeStyle
|
4875fe2b809cb7c52ea7e8ecc0f00ff8d35f8cb9
|
018bffd14ba26cfe7724c5be5a8920622163ce01
|
c47c3783b1adcb3f24e175a600ea6d02f67e3f86
|
refs/heads/master
| 2021-01-12T06:43:25.601797 | 2017-05-18T01:43:30 | 2017-05-18T01:43:30 | 77,421,391 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5884100794792175,
"alphanum_fraction": 0.689450204372406,
"avg_line_length": 73.77777862548828,
"blob_id": "8c6f99f20714954c056501a65bc215afb95418e6",
"content_id": "afa0aeb70d9c73e16d2dbd8fbeda58502409dcb4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 673,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 9,
"path": "/get_prCmitUrl.sh",
"repo_name": "zouxiaoyu/myOwn_codeStyle",
"src_encoding": "UTF-8",
"text": "./exportMongDat.sh \"127.0.0.1\" 35repos pulls \"fn,number,commits_url\" 35repos_pr\n./exportMongDat.sh \"127.0.0.1\" another75repos pulls \"fn,number,commits_url\" 40repos_pr\n./exportMongDat.sh \"127.0.0.1\" another75repos pullcommits \"fn,pn\" 40repos_prcmit\n./exportMongDat.sh \"127.0.0.1\" 35repos pullcommits \"fn,pn\" 35repos_prcmit\nawk 'BEGIN{FS=\",\";OFS=\",\"}{if(NR==FNR){arr[$1$2]=1}else{if(!($1$2 in arr)){print $0}}}' 35repos_prcmit 35repos_pr | sort -u > 35repos_prCmitUrl \nsed -i '$d' 35repos_prCmitUrl\n\nawk 'BEGIN{FS=\",\";OFS=\",\"}{if(NR==FNR){arr[$1$2]=1}else{if(!($1$2 in arr)){print $0}}}' 40repos_prcmit 40repos_pr | sort -u > 40repos_prCmitUrl\nsed -i '$d' 40repos_prCmitUrl\n"
},
{
"alpha_fraction": 0.5925791263580322,
"alphanum_fraction": 0.6074936389923096,
"avg_line_length": 29.208791732788086,
"blob_id": "a82f41a9cb35e507018f05da2e2a02a7c3c4c08d",
"content_id": "8450b1735bb4fda3c0b35dd5d07b0b507602c111",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2749,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 91,
"path": "/filterRepo.sh",
"repo_name": "zouxiaoyu/myOwn_codeStyle",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nstartDate=$1\nendDate=$2\nwhichHour=$3\nclientAccount=$4\nclientCnt=$(cat $clientAccount | wc -l)\ninterval_s=12 #12 hours\ninterval_e=1 #1 hour\nprefix=\"https://api.github.com/search/repositories?\"\nquery=\"q=language:Java+created:\"\npageLimit=100\n\n\n\n#one_search $startTime $endTime\nfunction one_search(){\n start=$1\n end=$2\n timeRange=$start\"..\"$end\n\n gotFn=0\n cnt=1\n clientNum=$((cnt%clientCnt + 1))\n client=$(sed -n \"${clientNum}p\" $clientAccount)\n pageCnt=1\n url=${prefix}${query}\"\\\"${timeRange}\\\"&page=${pageCnt}&per_page=${pageLimit}&${client}\"\n curl -m 120 $url -o ${whichHour}/tmpFilter\n\n grep \"\\\"full_name\\\":\" ${whichHour}/tmpFilter | awk '{print $NF}' | cut -f1 -d \",\" > ${whichHour}/tmpFilterFn\n totalCnt=$(grep \"\\\"total_count\\\":\" ${whichHour}/tmpFilter | awk '{print $NF}' | cut -f1 -d \",\")\n echo $timeRange $totalCnt >> ${whichHour}/${whichHour}_totalCnt\n cat ${whichHour}/tmpFilterFn >>${whichHour}/${whichHour}_fn\n fnCnt=$(cat ${whichHour}/tmpFilterFn | wc -l)\n gotFn=$((gotFn+fnCnt))\n\n rm ${whichHour}/tmpFilter\n if [ \"$totalCnt\" = \"\" ];then\n return \n fi\n\n if [ \"$gotFn\" -eq \"$totalCnt\" ];then\n return\n fi\n\n while [ \"$gotFn\" -lt \"$totalCnt\" ]\n do\n pageCnt=$((pageCnt+1))\n cnt=$((cnt+1))\n clientNum=$((cnt%clientCnt + 1))\n client=$(sed -n \"${clientNum}p\" $clientAccount)\nurl=${prefix}${query}\"\\\"${timeRange}\\\"&page=${pageCnt}&per_page=${pageLimit}&${client}\"\n\n curl -m 120 $url -o ${whichHour}/tmpFilter\n\n grep \"\\\"full_name\\\":\" ${whichHour}/tmpFilter | awk '{print $NF}' | cut -f1 -d \",\" > ${whichHour}/tmpFilterFn\n fnCnt=$(cat ${whichHour}/tmpFilterFn | wc -l)\n gotFn=$((gotFn+fnCnt))\n cat ${whichHour}/tmpFilterFn >>${whichHour}/${whichHour}_fn\n rm ${whichHour}/tmpFilter\n done\n}\n\n#example run_filter $startDate $stopDate\nfunction run_filter(){\n mkdir -p $whichHour \n rm ${whichHour}/${whichHour}_fn\n rm ${whichHour}/${whichHour}_totalCnt\n startTime=$startDate\"T\"$whichHour\":00:00Z\"\n stopTime=$endDate\"T00:00:00Z\"\n if [ \"$startTime\" \\> \"$stopTime\" ];then\n return\n fi\n endTime=$(python everyNhours.py $startTime $interval_e)\n if [ \"$endTime\" \\> \"$stopTime\" ];then\n endTime=$stopTime\n fi\n one_search $startTime $endTime\n startTime=$(python everyNhours.py $startTime $interval_s)\n while [ \"$startTime\" \\< \"$stopTime\" ]\n do\n endTime=$(python everyNhours.py $startTime $interval_e)\n if [ \"$endTime\" \\> \"$stopTime\" ];then\n endTime=$stopTime\n fi\n one_search $startTime $endTime \n startTime=$(python everyNhours.py $startTime $interval_s)\n\n done\n}\nrun_filter $startDate $endDate\n"
},
{
"alpha_fraction": 0.5647059082984924,
"alphanum_fraction": 0.6078431606292725,
"avg_line_length": 22.090909957885742,
"blob_id": "f6bfc4c2b1b1521049fb657b138d51c2efcf41ba",
"content_id": "00ca6874a51f41d9222045d04e09588a14106032",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 255,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 11,
"path": "/exportMongDat.sh",
"repo_name": "zouxiaoyu/myOwn_codeStyle",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nip=$1\ndb=$2\ncol=$3\nfield=$4\nout=$5\n\n#mongoexport -h \"127.0.0.1\" -d onlyTest -c pullcommits --type=csv -o ttpr -f fn,pn\n\n#mongoexport -h $ip -d $db -c $col --type=csv -o $out -f $field\nmongoexport -h $ip -d $db -c $col --csv -o $out -f $field\n\n"
},
{
"alpha_fraction": 0.579285740852356,
"alphanum_fraction": 0.5978571176528931,
"avg_line_length": 30.11111068725586,
"blob_id": "db97b6e4723e4e0b8bb11a00baac88e25bb046a6",
"content_id": "e97faa1cf0f54ee6fb683061ae42107de87d25e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1400,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 45,
"path": "/filter_PRissues.sh",
"repo_name": "zouxiaoyu/myOwn_codeStyle",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nfnList=$1\nclientAccount=$2\nclientCnt=$(cat $clientAccount | wc -l)\nprLimit=200 #closed PR number >=200\nissueLimit=20 #closed issues number >=20\n\ncnt=1\n#rm failed prIssueOk_fn filteredFn\nfor fn in $(cat $fnList)\ndo\n\n clientNum=$((cnt%clientCnt + 1))\n client=$(sed -n \"${clientNum}p\" $clientAccount)\n issueUrl=\"https://api.github.com/search/issues?q=type:issue+repo:${fn}+state:closed&${client}&per_page=1\"\n prUrl=\"https://api.github.com/search/issues?q=type:pr+repo:${fn}+state:closed&${client}&per_page=1\"\n\n rm prtmp issuetmp\n curl -m 120 $prUrl -o prtmp\n cnt=$((cnt+1))\n cldPrCnt=0\n cldPrCnt=$(grep \"\\\"total_count\\\":\" prtmp | awk '{print $NF}' | cut -f1 -d \",\")\n if [ \"$cldPrCnt\" = \"\" ];then\n echo \"$fn:curl prs failed\" >>failed\n continue\n fi\n\n cldIssueCnt=\"no_need_to_search\"\n if [ $cldPrCnt -ge $prLimit ];then\n curl -m 120 $issueUrl -o issuetmp\n cldIssueCnt=$(grep \"\\\"total_count\\\":\" issuetmp | awk '{print $NF}' | cut -f1 -d \",\")\n if [ \"$cldIssueCnt\" = \"\" ];then\n echo \"$fn:curl issues failed\" >>failed\n continue\n fi\n if [ $cldIssueCnt -ge $issueLimit ];then\n echo $fn $cldPrCnt $cldIssueCnt >> prIssueOk_fn\n fi\n echo $fn $cldPrCnt $cldIssueCnt >> filteredFn\n else\n echo $fn $cldPrCnt $cldIssueCnt >> filteredFn\n fi\n \ndone\n"
},
{
"alpha_fraction": 0.45528456568717957,
"alphanum_fraction": 0.46904316544532776,
"avg_line_length": 24.79032325744629,
"blob_id": "2046b9b36529fa1d95ca15945b4219db7af485df",
"content_id": "4bc935471a750c8dcade7039e304b6eb09d7cf8d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1601,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 62,
"path": "/getB4chgFile.py",
"repo_name": "zouxiaoyu/myOwn_codeStyle",
"src_encoding": "UTF-8",
"text": "# -*- encoding:utf-8 -*-\nimport sys\nreload(sys)\nsys.setdefaultencoding('utf-8')\nimport re\nimport traceback\n\ndef getBlock(patch_str):\n chgP=re.compile(r\"@@ .*? @@\")\n b4P=re.compile(r\"^[-| ]\")\n p=patch_str.replace(\"去\",\"\\n\").split(\"\\n\")\n block={}\n endLineNum={}\n unit=''\n for pi in p:\n try:\n if chgP.search(pi):\n if unit!='':\n block[start]=unit[:-1]\n unit=''\n f=pi.split()[2].split(\",\")\n (start,num)=(int(f[0]),int(f[1]))\n endLineNum[start]=start+num-1\n continue\n if b4P.search(pi):\n unit=unit+pi[1:]+'\\n'\n except:\n traceback.print_exc()\n block[start]=unit[:-1]\n endLineNum[start]=start+num-1\n return block,endLineNum\n\ndef getB4file(after_fin,patch_str):\n (block,endLineNum)=getBlock(patch_str)\n lineNum=0\n start=0\n flag=0\n for line in after_fin.xreadlines():\n try:\n lineNum+=1\n line=line.strip('\\n')\n if lineNum in block:\n flag=1\n print block[lineNum]\n start=lineNum\n continue\n if flag:\n if lineNum>start and lineNum<=endLineNum[start]:\n continue\n else:\n print line\n flag=0\n else:\n print line\n except:\n traceback.print_exc()\n\n\nif __name__ == \"__main__\":\n after_fin=sys.argv[1]\n patch=sys.argv[2]\n getB4file(file(after_fin,'r'),patch)\n"
},
{
"alpha_fraction": 0.35960590839385986,
"alphanum_fraction": 0.5763546824455261,
"avg_line_length": 21.55555534362793,
"blob_id": "fd2ebd5fdef942a713267605f284c04ff3bbd01a",
"content_id": "21d37e82730219688519c1b0c5cc35b8bad6e871",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 203,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 9,
"path": "/run_filter1.sh",
"repo_name": "zouxiaoyu/myOwn_codeStyle",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nstart=\"2014-11-24\"\nend=\"2016-01-01\"\n\nfor hour in \"00\" \"01\" \"02\" \"03\" \"04\" \"05\" \"06\" \"08\" \"09\" \"10\" \"11\" \"07\"\ndo\n ./filterRepo.sh $start $end $hour 12client_secret > ${hour}.log 2>&1\ndone\n"
},
{
"alpha_fraction": 0.5602791905403137,
"alphanum_fraction": 0.5894669890403748,
"avg_line_length": 33.260868072509766,
"blob_id": "6e4b5fbaac0723b9b2c2c2d0fde186e997b30caf",
"content_id": "ed9adbe3b9fe39518cc5baa605fb07c010dbd8ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1598,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 46,
"path": "/save_b4after_java.sh",
"repo_name": "zouxiaoyu/myOwn_codeStyle",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nresDir=$1\nidx=$2 #the idx loop for a given start and end\ncmitChgFile=$3\nclientAccount=$4\nmkdir -p $resDir\nrm ${resDir}/${idx}_curlFailed.res\n\nclientCnt=$(cat $clientAccount | wc -l)\ntotal=$(cat $cmitChgFile | wc -l)\nfor cnt in `seq 1 $total`\ndo\n c=$(sed -n \"$cnt p\" $cmitChgFile)\n fn=$(echo \"$c\" | awk -F \"邹\" '{print $1}')\n prID=$(echo \"$c\" | awk -F \"邹\" '{print $2}')\n sha=$(echo \"$c\" | awk -F \"邹\" '{print $3}')\n chgLine=$(echo \"$c\" | awk -F \"邹\" '{print $4}')\n fname=$(echo \"$c\" | awk -F \"邹\" '{print $5}')\n patch=$(echo \"$c\" | awk -F \"邹\" '{print $6}')\n\n clientNum=$((cnt%clientCnt + 1))\n client=$(sed -n \"${clientNum}p\" $clientAccount)\n\n prefix=\"https://raw.githubusercontent.com/\"\n relaF=$(echo $fname | cut -f7- -d \"/\")\n furl=${prefix}${fn}\"/\"${relaF}\"?\"$client\n #https://raw.githubusercontent.com/guardianproject/ChatSecureAndroid/20ce719f40b9fb747c20f3bc95b11f5c85ae60ee/res/xml/account_settings.xml\n curl $furl -o ${resDir}/${idx}_after.java\n if [ $? -ne 0 ];then\n echo $fn邹$prID邹$sha邹\"$chgLine\"邹$fname邹\"$patch\" >> ${resDir}/${idx}_curlFailed.res\n continue\n fi\n \n python getB4chgFile.py ${resDir}/${idx}_after.java \"$patch\" >${resDir}/${idx}_b4.java\n \n repo=$(echo ${fn} | cut -f2 -d \"/\")\n shortSha=${sha:0:6}\n fbaseName=$(basename $fname)\n b4File=\"b4_\"${repo}\"_\"${prID}\"_\"${shortSha}\"_\"${fbaseName}\n afterFile=\"after_\"${repo}\"_\"${prID}\"_\"${shortSha}\"_\"${fbaseName}\n\n mv ${resDir}/${idx}_b4.java ${resDir}/${b4File}\n mv ${resDir}/${idx}_after.java ${resDir}/${afterFile}\n\ndone\n"
},
{
"alpha_fraction": 0.6123853325843811,
"alphanum_fraction": 0.6215596199035645,
"avg_line_length": 19.761905670166016,
"blob_id": "c77f6fda43d7ab6491caeade9b5712267babeab5",
"content_id": "af1e3530de742dcb005ff388d7d0bb5daac1a6d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 436,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 21,
"path": "/clone_newRepo.sh",
"repo_name": "zouxiaoyu/myOwn_codeStyle",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n#example:./clone_newRepo.sh newRepo_list reposDir\nnewRepoList=$1\n\nreposDir=$2 #\"./repos\"\nmkdir -p $reposDir\nrm $reposDir/failedClone\nfor fn in $(cat $newRepoList)\ndo\n #clone the new repo\n repo=$(echo $fn | awk -F \"/\" '{print $2}')\n rm -rf $reposDir/$repo\n\n repoUrl=\"[email protected]:\"\"$fn\"\".git\"\n git clone $repoUrl $reposDir/$repo\n\n if [ $? -ne 0 ];then\n echo $repoUrl >> $reposDir/failedClone\n fi\ndone\n"
},
{
"alpha_fraction": 0.4564934968948364,
"alphanum_fraction": 0.4694805145263672,
"avg_line_length": 28.056604385375977,
"blob_id": "b5271b2ac349f1741c9f01672a8824727bdfaad7",
"content_id": "042501efb8c02879647413a929be90146548abe2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1544,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 53,
"path": "/get_pullCommit.py",
"repo_name": "zouxiaoyu/myOwn_codeStyle",
"src_encoding": "UTF-8",
"text": "# -*- encoding:utf-8 -*-\nimport io\nimport sys\nimport traceback\nreload(sys)\nsys.setdefaultencoding('utf-8')\nimport os\nimport json\nimport re\nfrom pymongo import *\n\ndef get_prcmit_file(db,chgFile_fout):\n lineP=re.compile(r\"@@ .*? @@\")\n javaP=re.compile(r\"\\.java$\")\n unit=100000 #every 10w change file record into a single file\n cnt=0\n for cmit in db.pullcommits.find({}):\n try:\n repoName=cmit[\"fn\"]\n prID=str(cmit[\"pn\"])\n sha=cmit[\"sha\"]\n chgF=cmit[\"files\"]\n for f in chgF:\n try:\n rawUrl=f[\"raw_url\"]\n if javaP.search(rawUrl):\n p=f[\"patch\"]\n chgLine=str(lineP.findall(p))\n p=p.replace(\"\\n\",\"去\")\n chgRes=(repoName,prID,sha,chgLine,rawUrl,p)\n chgRes=\"邹\".join(chgRes)\n cnt+=1\n num=cnt/(unit)\n out=chgFile_fout+\"_\"+str(num)\n print>>file(out,\"a\"), chgRes\n except:\n traceback.print_exc()\n continue\n except:\n traceback.print_exc()\n continue\n\nif __name__ == '__main__':\n try:\n ip=sys.argv[1]\n client=MongoClient(ip,27017)\n dbName=sys.argv[2]\n chgFile_fout=sys.argv[3]\n db=client[dbName]\n get_prcmit_file(db, chgFile_fout)\n client.close()\n except:\n traceback.print_exc()\n"
},
{
"alpha_fraction": 0.5781759023666382,
"alphanum_fraction": 0.5928338766098022,
"avg_line_length": 29.700000762939453,
"blob_id": "aaea0fec0c36bc0c742e4ff3c4d98541079c692d",
"content_id": "7a6cbd4991582cf69ff1c9973d75fdef0ae1cdd6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1228,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 40,
"path": "/get_contri_collabo.sh",
"repo_name": "zouxiaoyu/myOwn_codeStyle",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nfnList=$1\nclientAccount=$2\nclientCnt=$(cat $clientAccount | wc -l)\ncontriLimit=10 #contributors number >=10\n\ncnt=1\nrm failed developerOk_fn\nfor fn in $(cat $fnList)\ndo\n clientNum=$((cnt%clientCnt + 1))\n client=$(sed -n \"${clientNum}p\" $clientAccount)\n fnUrl=\"https://github.com/${fn}?${client}\"\n \n rm fntmp\n curl -m 120 $fnUrl -o fntmp\n contriCnt=$(grep -B2 \"^ *contributors$\" fntmp | head -1 | awk '{print $NF}' | sed 's/,//g')\n if [ \"$contriCnt\" = \"\" ];then\n echo \"$fn:curl contributors failed\" >>failed\n continue\n fi\n\n if [ $contriCnt -ge $contriLimit ];then\n collaUrl=\"https://github.com/${fn}/issues/show_menu_content?partial=issues/filters/authors_content?${client}\"\n rm collatmp\n curl -m 120 $collaUrl -o collatmp\n collaCnt=$(grep \"\\\"select-menu-item-text\\\"\" collatmp | wc -l)\n if [ \"$collaCnt\" = \"\" ];then\n echo \"$fn:curl collaborators failed\" >>failed\n continue\n fi\n half=$(awk -v count=$contriCnt 'BEGIN{print count/2}')\n if [ $colla -le $half ];then\n echo $fn $cldPrCnt $cldIssueCnt >> developerOk_fn\n fi\n fi\n cnt=$((cnt+1))\n echo $contriCnt $collaCnt\ndone\n"
},
{
"alpha_fraction": 0.6354581713676453,
"alphanum_fraction": 0.6832669377326965,
"avg_line_length": 34.85714340209961,
"blob_id": "89d1815f8e9579e57ff01c3aafdd011842a4b6b8",
"content_id": "1fcc0ee950dcfc480399009ef3481652dc82ee20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 502,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 14,
"path": "/everyNhours.py",
"repo_name": "zouxiaoyu/myOwn_codeStyle",
"src_encoding": "UTF-8",
"text": "import sys\nimport datetime\n\n'''python every12hours.py '2012-12-12T12:23:34Z' 12'''\n'''add N hours to an existing timestamp and return the added timestamp'''\ndef addedNhours(startTime, interval):\n dayHours=24\n delta=int(interval)*1.0/dayHours\n endTime=(datetime.datetime.strptime(startTime, '%Y-%m-%dT%H:%M:%SZ')+datetime.timedelta(days=delta)).strftime('%Y-%m-%dT%H:%M:%SZ')\n print endTime\nif __name__ == '__main__':\n start=sys.argv[1]\n inter=sys.argv[2]\n addedNhours(start,inter)\n"
}
] | 11 |
algadoreo/starcam-simulator
|
https://github.com/algadoreo/starcam-simulator
|
0d5406f392957f3220be8d4a008cecf2af6c8e2e
|
4c1c8e5f8740577d1eec491827e912a6a30a81da
|
6b2abb445b61be3b76fd40b214c4328a060eca57
|
refs/heads/master
| 2021-03-31T07:35:31.137993 | 2020-04-28T23:10:40 | 2020-04-28T23:10:40 | 248,089,099 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5760787129402161,
"alphanum_fraction": 0.6003028154373169,
"avg_line_length": 29.022727966308594,
"blob_id": "5c27580699b70b107b1984b24fd0ac06976d4045",
"content_id": "22f60e04044f3a5d77822cda6c98807aa30bc35f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1321,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 44,
"path": "/projections.py",
"repo_name": "algadoreo/starcam-simulator",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n\"\"\"\nMap projections to convert between sky (RA, Dec) and pixel coordinates.\n\"\"\"\n\nimport numpy as np\nimport astropy.units as u\n\n__all__ = ['s2x_Gnomonic']\n\ndef s2x_Gnomonic(mu, obj_coords, cen_coords=(0*u.deg, 90*u.deg)):\n \"\"\"Converts RA and Dec to pixel coordinates using the Gnomonic projection.\n\n Parameters\n ----------\n mu : float\n Plate scale of image, in arcsec/pixel\n obj_coords: (float, float)\n RA, Dec of the object, in degrees\n cen_coords: (float, float)\n RA, Dec of the centre of projection, in degrees (default: 0, 90)\n\n Returns\n -------\n float, float\n Row, column to place the object\n \"\"\"\n\n if len(obj_coords) != 2:\n raise RuntimeError(\"Object coordinates must be of length 2\")\n elif len(cen_coords) != 2:\n raise RuntimeError(\"Reference coordinates must be of length 2\")\n\n ra = np.deg2rad(obj_coords[0]); de = np.deg2rad(obj_coords[1])\n ra0 = np.deg2rad(cen_coords[0]); de0 = np.deg2rad(cen_coords[1])\n\n A = np.cos(de) * np.cos(ra - ra0)\n F = 180.*u.deg/np.pi * 1./(mu.to(u.deg/u.pixel) * ( np.sin(de0) * np.sin(de) + A * np.cos(de0) ))\n\n x = -F * np.cos(de) * np.sin(ra - ra0)\n y = -F * ( np.cos(de0) * np.sin(de) - A * np.sin(de0) )\n\n return x.to(u.pixel).value, y.to(u.pixel).value\n"
},
{
"alpha_fraction": 0.6016355156898499,
"alphanum_fraction": 0.6308411359786987,
"avg_line_length": 40.253013610839844,
"blob_id": "55acbe5d5627507362dd6a2ed875e85f8a1b48ea",
"content_id": "275daa15e79d71497d22c8714c5fc9532c2a34b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3424,
"license_type": "no_license",
"max_line_length": 164,
"num_lines": 83,
"path": "/main.py",
"repo_name": "algadoreo/starcam-simulator",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n\"\"\"\nRetrieve objects from a catalogue and project them correctly onto an image.\n\"\"\"\n\nimport argparse\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport astropy.coordinates as coord\nimport astropy.units as u\nfrom astroquery.vizier import Vizier\nimport projections as proj\n\n# Input parameters from user\nparser = argparse.ArgumentParser()\nparser.add_argument(\"-c\", dest='coords', nargs=2, type=float,\n default=[0., 0.],\n metavar=(\"RA\", \"DEC\"),\n help=\"RA and Dec of image centre, in degrees (default: 0 0)\")\nparser.add_argument(\"-n\", dest='npix', nargs=2, type=int,\n default=[6576, 4384], # from SuperBIT scicam\n metavar=(\"NPIX_X\", \"NPIX_Y\"),\n help=\"size of image, in pixels (default: 6576 4384)\")\nparser.add_argument(\"-p\", dest='plate_scale', type=float,\n help=\"plate scale of image, in arcsec/pix (default: 0.206265)\")\nparser.add_argument(\"-m\", dest='max_mag',\n default=\"15\",\n help=\"magnitude of dimmest star to plot (default: 15)\")\nparser.add_argument(\"-f\", dest='filename',\n default=\"simage.png\",\n help=\"output file name (default: %(default)s)\")\nargv = parser.parse_args()\n\nif argv.plate_scale == None:\n # Default values: SuperBIT scicam\n ccd_pix_size = 5.5 * u.micrometer\n focal_length = 5.5 * u.meter\n plate_scale = (206265 * u.arcsecond) * (ccd_pix_size / u.pixel) / focal_length\nelse:\n plate_scale = argv.plate_scale * u.arcsec / u.pixel\n\nactive_pixels_x = argv.npix[0] * u.pixel\nactive_pixels_y = argv.npix[1] * u.pixel\n\nfov_x = (active_pixels_x * plate_scale).to(u.deg)\nfov_y = (active_pixels_y * plate_scale).to(u.deg)\n\nprint('Field of view in x axis: {} = {}'.format(fov_x, (fov_x).to(u.arcmin)))\nprint('Field of view in y axis: {} = {}'.format(fov_y, (fov_y).to(u.arcmin)))\nprint('Plate scale: {}'.format(plate_scale.to(u.arcsec/u.pixel)))\n\n# Catalogue info\ncat = 'I/345/gaia2'\ncent_ra, cent_dec = argv.coords[0], argv.coords[1]\nv = Vizier(columns = ['_RAJ2000', '_DEJ2000', 'BPmag', 'e_BPmag', '+FBP', 'e_FBP'], column_filters = {'BPmag': '<'+argv.max_mag}, row_limit=-1)\n\n# Extract rectangular region the side of fov_x times fov_y\nquery = v.query_region(coord.SkyCoord(ra=cent_ra, dec=cent_dec, unit=(u.deg, u.deg), frame='icrs'), height=fov_y, width=fov_x, catalog=cat)\ndata = query[0]\nprint(data['_RAJ2000', '_DEJ2000', 'BPmag', 'e_BPmag', 'FBP', 'e_FBP'])\n\ncoords_idx = np.array([proj.s2x_Gnomonic(plate_scale.to(u.deg/u.pixel), obj_coords, cen_coords=(cent_ra, cent_dec)) for obj_coords in data['_RAJ2000', '_DEJ2000']])\ncoords_idx[:,0] = np.array(coords_idx[:,0] + active_pixels_x.value/2, dtype=int)\ncoords_idx[:,1] = np.array(coords_idx[:,1] + active_pixels_y.value/2, dtype=int)\n\n# Initialize image array\nimg = np.zeros((int(active_pixels_y.value), int(active_pixels_x.value)))\n\n# Populate image array with stars\nfor i, (ri, di) in enumerate(coords_idx):\n if ri >= 0 and di >= 0:\n ri = int(ri); di = int(di)\n img[di:di+1, ri:ri+1] = data['FBP'][i]\n\n# Plot figure and save to disk\nfig = plt.figure(figsize=(active_pixels_x.value/100, active_pixels_y.value/100))\nax = plt.Axes(fig, [0., 0., 1., 1.])\nax.set_axis_off()\nfig.add_axes(ax)\nax.imshow(img, cmap='gray', vmax=min(5e5, max(data['FBP'])))\nplt.savefig(argv.filename)\nplt.close()\n"
}
] | 2 |
Siyouardi/GitSavvy
|
https://github.com/Siyouardi/GitSavvy
|
5eea3107deaf9aee96475e2cb9c621eda6d4d72e
|
1ac83c8c66e914eaf1585d3e48b8c10a284f8285
|
d281fe7bbbcf2918838907c53b2ef1fff3e68a39
|
refs/heads/master
| 2022-07-27T01:52:48.970755 | 2020-05-04T20:32:49 | 2020-05-04T20:32:49 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6501614451408386,
"alphanum_fraction": 0.6519554853439331,
"avg_line_length": 31.4069766998291,
"blob_id": "f024976dbe01d5f4bb9ada2c72b96dd69f341788",
"content_id": "4d70dca1acd3a1310a2e1d90730b20a7c266f12f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2787,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 86,
"path": "/common/util/file.py",
"repo_name": "Siyouardi/GitSavvy",
"src_encoding": "UTF-8",
"text": "import sublime\nimport threading\nimport yaml\nimport os\nfrom contextlib import contextmanager\n\n\nif 'syntax_file_map' not in globals():\n syntax_file_map = {}\n\nif 'determine_syntax_thread' not in globals():\n determine_syntax_thread = None\n\n\ndef determine_syntax_files():\n global determine_syntax_thread\n if not syntax_file_map:\n determine_syntax_thread = threading.Thread(\n target=_determine_syntax_files)\n determine_syntax_thread.start()\n\n\ndef _determine_syntax_files():\n syntax_files = sublime.find_resources(\"*.sublime-syntax\")\n for syntax_file in syntax_files:\n try:\n # Use `sublime.load_resource`, in case Package is `*.sublime-package`.\n resource = sublime.load_resource(syntax_file)\n for extension in yaml.safe_load(resource)[\"file_extensions\"]:\n if extension not in syntax_file_map:\n syntax_file_map[extension] = []\n extension_list = syntax_file_map[extension]\n extension_list.append(syntax_file)\n except Exception:\n continue\n\n\ndef get_syntax_for_file(filename):\n if not determine_syntax_thread or determine_syntax_thread.is_alive():\n return \"Packages/Text/Plain text.tmLanguage\"\n extension = get_file_extension(filename)\n syntaxes = syntax_file_map.get(filename, None) or syntax_file_map.get(extension, None)\n return syntaxes[-1] if syntaxes else \"Packages/Text/Plain text.tmLanguage\"\n\n\ndef get_file_extension(filename):\n period_delimited_segments = filename.split(\".\")\n return \"\" if len(period_delimited_segments) < 2 else period_delimited_segments[-1]\n\n\ndef get_file_contents_binary(repo_path, file_path):\n \"\"\"\n Given an absolute file path, return the binary contents of that file\n as a string.\n \"\"\"\n file_path = os.path.join(repo_path, file_path)\n with safe_open(file_path, \"rb\") as f:\n binary = f.read()\n binary = binary.replace(b\"\\r\\n\", b\"\\n\")\n binary = binary.replace(b\"\\r\", b\"\")\n return binary\n\n\ndef get_file_contents(repo_path, file_path):\n \"\"\"\n Given an absolute file path, return the text contents of that file\n as a string.\n \"\"\"\n binary = get_file_contents_binary(repo_path, file_path)\n try:\n return binary.decode('utf-8')\n except UnicodeDecodeError:\n return binary.decode('latin-1')\n\n\n@contextmanager\ndef safe_open(filename, mode, *args, **kwargs):\n try:\n with open(filename, mode, *args, **kwargs) as file:\n yield file\n except PermissionError as e:\n sublime.ok_cancel_dialog(\"GitSavvy could not access file: \\n{}\".format(e))\n raise e\n except OSError as e:\n sublime.ok_cancel_dialog(\"GitSavvy encountered an OS error: \\n{}\".format(e))\n raise e\n"
}
] | 1 |
prashant87/hilotof
|
https://github.com/prashant87/hilotof
|
4511dfa46440c4db96a037fe4288839ba87362aa
|
b8da9f34b16ad41913327e3a95673a476d53d4c0
|
224e58879b48541069003a2b5acd10af9daa1d2c
|
refs/heads/master
| 2021-10-16T09:05:18.742834 | 2019-02-09T17:42:31 | 2019-02-09T17:42:31 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.750684916973114,
"alphanum_fraction": 0.7625570893287659,
"avg_line_length": 46.65217208862305,
"blob_id": "519f7f297e80f5f1517fc669fb285417b5d72927",
"content_id": "9d6ee7a75887d11147a34643ee95e3d87c33da56",
"detected_licenses": [
"ISC"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1095,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 23,
"path": "/README.md",
"repo_name": "prashant87/hilotof",
"src_encoding": "UTF-8",
"text": "# HiLoTOF -- Hardware-in-the-Loop Test framework for Open FPGAs\n\nThis is a project to develop a fully automated, hardware-in-the-loop, framework for\ntesting open source FPGA flows. Its first target is the Yosys, nextpnr and Trellis\nflow for Lattice ECP5 FPGAs.\n\nAt the moment, the framework wraps a \"DUT\" Verilog module providing 32-bit input\nand output over a UART. 32-bit words are sent and received over the UART\nhex-encoded and terminated with \\r\\n. Sending \"R\" will reset the DUT. The\nstate machine for this is implemented in `rtl/framework.v` and the wrapper\nfor the ECP5 in `ecp5/common/wrapper.v`.\n\nPython scripts have a few library functions (to be extended) to send, receive\nand check data over the UART.\n\nFor a simple implementation of a test, see `ecp5/tests/001-loop`.\n\nTo run all ECP5 tests, run `cd ecp5 && ./all.sh`. `build.sh <test>` performs\nsynthesis, place-and-route and SVF generation for a given test inside `build/<test>`.\n`run.sh <test>` will then load that test onto the target and run the checker Python\nscript.\n\n**This is a work-in-progress. Expect breaking changes!**"
},
{
"alpha_fraction": 0.5176056623458862,
"alphanum_fraction": 0.5721830725669861,
"avg_line_length": 17.96666717529297,
"blob_id": "450cd0a841013eca978bb881798089ce04724640",
"content_id": "546a151672e60a256d0723badcac3990fe6a9d93",
"detected_licenses": [
"ISC"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 568,
"license_type": "permissive",
"max_line_length": 46,
"num_lines": 30,
"path": "/ecp5/tests/020-ram/checker.py",
"repo_name": "prashant87/hilotof",
"src_encoding": "UTF-8",
"text": "from interface import DUTInterface\n\ndef xorshift32(x):\n\tx ^= x << 13\n\tx &= 0xFFFFFFFF\n\tx ^= x >> 17\n\tx &= 0xFFFFFFFF\n\tx ^= x << 5\n\treturn x & 0xFFFFFFFF\n\ndef main():\n\twith DUTInterface() as dut:\n\t\tdef write(addr, data):\n\t\t\tdut.set_din((1 << 31) | (addr << 8) | data)\n\t\tdef verify(addr, data):\n\t\t\tdut.assert_result(addr << 18, data)\n\t\tx = 1\n\n\t\tram = []\n\t\tfor i in range(1024):\n\t\t\tx = xorshift32(x)\n\t\t\tram.append(x & 0xFF)\n\t\t\twrite(i, x & 0xFF)\n\n\t\tfor i in range(32):\n\t\t\tx = xorshift32(x)\n\t\t\taddr = x & 0x3FF\n\t\t\tverify(addr, ram[addr])\nif __name__ == \"__main__\":\n\tmain()"
},
{
"alpha_fraction": 0.6945946216583252,
"alphanum_fraction": 0.7108108401298523,
"avg_line_length": 32.727272033691406,
"blob_id": "f44719c81a7f9a9b08b402511c3efbbe3c7d183e",
"content_id": "5ef98d793f86bb23e323a23ce05d645149bbbd5c",
"detected_licenses": [
"ISC"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 370,
"license_type": "permissive",
"max_line_length": 214,
"num_lines": 11,
"path": "/ecp5/sim.sh",
"repo_name": "prashant87/hilotof",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -ex\nmkdir -p build/$1\n\nUSER_DEFINES=\nif [ -f tests/$1/defines.v ]; then\n\tUSER_DEFINES=tests/$1/defines.v\nfi\n\niverilog -o build/$1/testbench common/defines.v $USER_DEFINES ../rtl/framework.v ../rtl/instruments.v ../rtl/uart_baud_tick_gen.v ../rtl/uart_rx.v ../rtl/uart_tx.v common/wrapper.v tests/$1/dut.v common/testbench.v\nvvp build/$1/testbench"
},
{
"alpha_fraction": 0.5723684430122375,
"alphanum_fraction": 0.6776315569877625,
"avg_line_length": 20.85714340209961,
"blob_id": "47a3f79ade968452b64e78490f295e0ae38c97cf",
"content_id": "ea0c6cd0a43a39a482009c5783ee1c714110dce1",
"detected_licenses": [
"ISC"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 152,
"license_type": "permissive",
"max_line_length": 40,
"num_lines": 7,
"path": "/ecp5/tests/046-clkdiv3p5/checker.py",
"repo_name": "prashant87/hilotof",
"src_encoding": "UTF-8",
"text": "from interface import DUTInterface\n\ndef main():\n\twith DUTInterface() as dut:\n\t\tdut.assert_freq(28.571428571e6, 0.001)\nif __name__ == \"__main__\":\n\tmain()"
},
{
"alpha_fraction": 0.6126760840415955,
"alphanum_fraction": 0.6619718074798584,
"avg_line_length": 19.428571701049805,
"blob_id": "206bd05f68c4bd73673d8416f16e58bc3bc69c4e",
"content_id": "d65e524de60cfb4ad674a481476a878dd0ab3f5b",
"detected_licenses": [
"ISC"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 142,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 7,
"path": "/ecp5/tests/045-clkdiv2/checker.py",
"repo_name": "prashant87/hilotof",
"src_encoding": "UTF-8",
"text": "from interface import DUTInterface\n\ndef main():\n\twith DUTInterface() as dut:\n\t\tdut.assert_freq(50e6, 0.001)\nif __name__ == \"__main__\":\n\tmain()"
},
{
"alpha_fraction": 0.6065258979797363,
"alphanum_fraction": 0.6257197856903076,
"avg_line_length": 19.038461685180664,
"blob_id": "6d22fd69650a0f5712dc9d5df62c371542012bf5",
"content_id": "c560508bbd7518e7724ed541e3655626c5dd4658",
"detected_licenses": [
"ISC"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 521,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 26,
"path": "/ecp5/all.sh",
"repo_name": "prashant87/hilotof",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\nresult=0\n\nfor f in tests/*; do\n\ttest=$(basename $f)\n\techo \"Building $test...\"\n\t./build.sh $test > build/$1/build.log 2>&1\n\tbuild_result=$?\n\tif [ $build_result -ne 0 ]; then\n\t\techo \"***** Building $test failed, see build/$test/build.log\"\n\t\tresult=1\n\t\tcontinue\n\tfi\n\techo \"Running $test...\"\n\t./run.sh $test > build/$test/run.log 2>&1\n\ttest_result=$?\n\tif [ $test_result -ne 0 ]; then\n\t\techo \"***** $test failed, see build/$test/run.log\"\n\t\tresult=1\n\t\tcontinue\n\tfi\n\techo \"$test passed!\"\ndone\n\nexit $result\n"
},
{
"alpha_fraction": 0.5347222089767456,
"alphanum_fraction": 0.7395833134651184,
"avg_line_length": 25.272727966308594,
"blob_id": "2db34edc110847294bfc41e4189e6597c49b01a1",
"content_id": "72da3a4dad586cca623f976a0698dcaa06e766d2",
"detected_licenses": [
"ISC"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 288,
"license_type": "permissive",
"max_line_length": 43,
"num_lines": 11,
"path": "/ecp5/tests/010-add/checker.py",
"repo_name": "prashant87/hilotof",
"src_encoding": "UTF-8",
"text": "from interface import DUTInterface\n\ndef main():\n\twith DUTInterface() as dut:\n\t\tdut.assert_result(0x00010001, 0x00000002)\n\t\tdut.assert_result(0x1234ABCD, 0x0000BE01)\n\t\tdut.assert_result(0x00FF0001, 0x00000100)\n\t\tdut.assert_result(0xFFFF0010, 0x0001000F)\n\nif __name__ == \"__main__\":\n\tmain()"
},
{
"alpha_fraction": 0.5186335444450378,
"alphanum_fraction": 0.5714285969734192,
"avg_line_length": 18,
"blob_id": "cd0e8f5f910a684aac31bd339f042658fc0150ac",
"content_id": "b3b6239a11b9927592796282f72dbe9dde206de2",
"detected_licenses": [
"ISC"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 322,
"license_type": "permissive",
"max_line_length": 62,
"num_lines": 17,
"path": "/ecp5/tests/030-dsp/checker.py",
"repo_name": "prashant87/hilotof",
"src_encoding": "UTF-8",
"text": "from interface import DUTInterface\n\ndef xorshift32(x):\n\tx ^= x << 13\n\tx &= 0xFFFFFFFF\n\tx ^= x >> 17\n\tx &= 0xFFFFFFFF\n\tx ^= x << 5\n\treturn x & 0xFFFFFFFF\n\ndef main():\n\twith DUTInterface() as dut:\n\t\tx = 1\n\t\tfor i in range(64):\n\t\t\tdut.assert_result(x, ((x & 0xFFFF) * ((x >> 16) & 0xFFFF)))\nif __name__ == \"__main__\":\n\tmain()"
},
{
"alpha_fraction": 0.6660929322242737,
"alphanum_fraction": 0.7005163431167603,
"avg_line_length": 47.5,
"blob_id": "46f94fe91d749d9c28dbb81186100ecd749b24bd",
"content_id": "b604fdaa231a522798684c6ae20f00c4a3bfce49",
"detected_licenses": [
"ISC"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 581,
"license_type": "permissive",
"max_line_length": 242,
"num_lines": 12,
"path": "/ecp5/build.sh",
"repo_name": "prashant87/hilotof",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -ex\nmkdir -p build/$1\n\nUSER_DEFINES=\nif [ -f tests/$1/defines.v ]; then\n\tUSER_DEFINES=tests/$1/defines.v\nfi\n\nyosys -p \"synth_ecp5 -json build/$1/top.json -top top\" -ql build/$1/yosys.log common/defines.v $USER_DEFINES ../rtl/framework.v ../rtl/instruments.v ../rtl/uart_baud_tick_gen.v ../rtl/uart_rx.v ../rtl/uart_tx.v common/wrapper.v tests/$1/dut.v\nnextpnr-ecp5 --um5g-45k --json build/$1/top.json --lpf common/versa.lpf --textcfg build/$1/top.config -ql build/$1/nextpnr.log --freq 100\necppack --svf build/$1/top.svf build/$1/top.config build/$1/top.bit"
},
{
"alpha_fraction": 0.6170212626457214,
"alphanum_fraction": 0.652482271194458,
"avg_line_length": 19.285715103149414,
"blob_id": "def4745c87c6b62649d2bc6157cd08aadac2b18d",
"content_id": "26f6a234f65255dceb757a821f11974fab4aa565",
"detected_licenses": [
"ISC"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 141,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 7,
"path": "/ecp5/tests/040-intosc2p4/checker.py",
"repo_name": "prashant87/hilotof",
"src_encoding": "UTF-8",
"text": "from interface import DUTInterface\n\ndef main():\n\twith DUTInterface() as dut:\n\t\tdut.assert_freq(2.4e6, 0.1)\nif __name__ == \"__main__\":\n\tmain()"
},
{
"alpha_fraction": 0.6877636909484863,
"alphanum_fraction": 0.7383966445922852,
"avg_line_length": 58.5,
"blob_id": "0bb8af3d7f93b7a573a51aed053e161983ba5891",
"content_id": "9c8a3bc413610451df6e5d97e3bc53e083fbe8a2",
"detected_licenses": [
"ISC"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 237,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 4,
"path": "/ecp5/run.sh",
"repo_name": "prashant87/hilotof",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -ex\nopenocd -f ../../prjtrellis/misc/openocd/ecp5-versa5g.cfg -c \"transport select jtag; init; svf quiet build/$1/top.svf; exit\"\nPYTHONPATH=../py UART_PORT=/dev/ttyUSB1 UART_BAUD=115200 python3 tests/$1/checker.py"
},
{
"alpha_fraction": 0.5316293835639954,
"alphanum_fraction": 0.5482428073883057,
"avg_line_length": 28.547170639038086,
"blob_id": "b8492ef2ad9c389b78be6ad94e3e378014e58b18",
"content_id": "a901d82b420b24981f7a856f27b25ad03773d310",
"detected_licenses": [
"ISC"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1565,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 53,
"path": "/py/interface.py",
"repo_name": "prashant87/hilotof",
"src_encoding": "UTF-8",
"text": "from serial import Serial\nimport os, sys, time\n\nclass DUTInterface:\n def __init__(self):\n pass\n\n def __enter__(self):\n self.port = Serial(os.environ[\"UART_PORT\"], os.environ[\"UART_BAUD\"])\n self.port.timeout = 1\n self.port.reset_input_buffer()\n self.port.write(b'R') # Reset DUT\n self.port.reset_input_buffer()\n return self\n\n def __exit__(self, *args):\n self.port.close()\n\n def set_din(self, val):\n # Write value\n self.port.write((\"%08X\" % val).encode('utf-8'))\n # Write newline to set valid\n self.port.write(b\"\\n\")\n self.port.flush()\n\n def purge(self):\n oldto = self.port.timeout\n self.port.timeout = 0.01\n for i in range(4):\n data = self.port.read(4096)\n self.port.timeout = oldto\n\n def check_dout(self, val):\n self.port.reset_input_buffer()\n self.port.readline()\n line = self.port.readline().strip()\n assert val == int(line, 16), (\"%s != %08X\" % (line, val))\n\n def assert_result(self, din, dout):\n self.set_din(din)\n self.purge()\n self.check_dout(dout)\n\n def assert_freq(self, freq, tol=0.001):\n time.sleep(1)\n self.purge()\n self.port.reset_input_buffer()\n self.port.readline()\n line = self.port.readline().strip()\n upper = freq + tol * freq\n lower = freq - tol * freq\n actual = 10.0 * int(line, 16)\n assert (actual >= lower and actual <= upper), (\"%f Hz not in [%f, %f]\" % (actual, lower, upper))"
},
{
"alpha_fraction": 0.6065573692321777,
"alphanum_fraction": 0.7295082211494446,
"avg_line_length": 23.5,
"blob_id": "1b008a60937edce83bebc81f9e05e0f861364e17",
"content_id": "0e9a152459bd8d4a9e20dbbb0d77bf7c6752fe5a",
"detected_licenses": [
"ISC"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 244,
"license_type": "permissive",
"max_line_length": 43,
"num_lines": 10,
"path": "/ecp5/tests/001-loop/checker.py",
"repo_name": "prashant87/hilotof",
"src_encoding": "UTF-8",
"text": "from interface import DUTInterface\n\ndef main():\n\twith DUTInterface() as dut:\n\t\tdut.assert_result(0x00000000, 0xFFFFFFFF)\n\t\tdut.assert_result(0x00000001, 0xFFFFFFFE)\n\t\tdut.assert_result(0xDEADBEEF, 0x21524110)\n\nif __name__ == \"__main__\":\n\tmain()"
}
] | 13 |
zgyunyunyunyun/ITproject
|
https://github.com/zgyunyunyunyun/ITproject
|
e3400c6df4e4a20b1214a55b042e46e98558751c
|
0a58bead59580c17e08cce8957d300d03d554d32
|
f2b33350633bdbf2042ed8412a22dc37a4339174
|
refs/heads/master
| 2020-04-10T20:26:05.599766 | 2018-12-10T18:15:00 | 2018-12-10T18:15:00 | 161,267,823 | 0 | 0 | null | 2018-12-11T02:51:08 | 2018-12-10T18:15:26 | 2018-12-10T18:15:24 | null |
[
{
"alpha_fraction": 0.6796875,
"alphanum_fraction": 0.6796875,
"avg_line_length": 14.5,
"blob_id": "237d3a277da517646f24fa1fdc9e60270a691700",
"content_id": "448cbf5f78418cc5972bbaf031ed299e28cccd62",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 128,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 8,
"path": "/server/DBmanagement/UserDBmanagement.py",
"repo_name": "zgyunyunyunyun/ITproject",
"src_encoding": "UTF-8",
"text": "\n\nfrom server.data.DBContext import DBContext\n\ndef check_login(acct, pwd):\n pass\n\n\ndef reg_user(acct, pwd, more):\n pass\n\n\n"
},
{
"alpha_fraction": 0.6900662183761597,
"alphanum_fraction": 0.6913907527923584,
"avg_line_length": 26.962963104248047,
"blob_id": "5aeee4ec6df605518db1c68272385f6295fd272a",
"content_id": "6060176274fedb321e0e12be39c646373dbe5b0a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 755,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 27,
"path": "/server/management/OrderManagement.py",
"repo_name": "zgyunyunyunyun/ITproject",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nsys.path.append(os.path.dirname(os.path.dirname(__file__)))\nfrom server.DBmanagement.OrderDBmanagement import OrderDBmanagement\n\n\nclass OrderManagement:\n odbm = 0\n\n def __init__(self):\n self.odbm = OrderDBmanagement()\n\n def purchaseBook(self, buyerid, bookid, number):\n orderid = self.odbm.addNewOrder(buyerid, bookid, number)\n return orderid\n\n def viewOrders(self, userid):\n orders = self.odbm.viewOrders(userid)\n return orders\n\n def viewOrderDetail(self, orderid):\n orderDetail = self.odbm.viewOrderDetail(orderid)\n return orderDetail\n\n def changeOrderState(self, orderid, state):\n boolean = self.odbm.changeOrderState(orderid, state)\n return boolean\n"
},
{
"alpha_fraction": 0.5774496793746948,
"alphanum_fraction": 0.5817449688911438,
"avg_line_length": 44.98765563964844,
"blob_id": "79477b814821ec3d34364ba7987776e27aa40512",
"content_id": "759e8c9b137a6bac350f431c27ada00bf91d79c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3831,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 81,
"path": "/server/DBmanagement/OrderDBmanagement.py",
"repo_name": "zgyunyunyunyun/ITproject",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nsys.path.append(os.path.dirname(os.path.dirname(__file__)))\nfrom server.data.DBContext import DBContext\nimport time\n\n\nclass OrderDBmanagement:\n def __init__(self):\n pass\n\n def addNewOrder(self, buyerid, bookid, number):\n t = time.time()\n t = int(round(t * 1000)) # 毫秒级时间戳\n orderid = buyerid + str(t)\n state = \"待付款\"\n with DBContext() as context:\n for i in range(len(bookid)):\n context.get_cursor().execute(\"SELECT price from book where bookid=?\", (bookid[i], ))\n result = context.get_cursor().fetchone()[0]\n print(\"书的单价为\", result)\n total = int(number[i])*result\n context.get_cursor().execute(\"INSERT INTO orders values(?,?,?,?,?,?)\", (bookid[i], orderid, t, number, total, state))\n result = context.get_cursor().fetchone()\n print(\"将订单写入数据库Orders\", result)\n context.get_cursor().execute(\"SELECT userid from user_book_publish where bookid=?\", (bookid[i], ))\n result = context.get_cursor().fetchone()[0]\n print(\"当前书的发布者id是\", result)\n context.get_cursor().execute(\"INSERT INTO user_order values(?,?,?,?)\", (bookid[i], orderid, buyerid, result))\n result = context.get_cursor().fetchone()\n print(\"将订单写入数据库User_Order\", result)\n return orderid\n\n def viewOrders(self, userid):\n temp = []\n with DBContext() as context:\n context.get_cursor().execute(\"SELECT orderid from user_order where buyerid=? \", (userid, ))\n result = context.get_cursor().fetchall()\n for i in range(len(result)):\n # context.get_cursor().execute(\"SELECT * from orders where orderid=? \", (result[i][0],))\n temp[i] = result[i][0] # 订单号数组\n return temp\n\n def viewOrderDetail(self, orderid):\n with DBContext() as context:\n context.get_cursor().execute(\"SELECT * from orders where orderid=? \", (orderid, ))\n result = context.get_cursor().fetchone() # 订单详情\n return result\n\n def changeOrderState(self, orderid, state):\n with DBContext() as context:\n context.get_cursor().execute(\"SELECT * FROM orders where orderid=?\", (orderid,))\n result = context.get_cursor().fetchone()\n context.get_cursor().execute(\"UPDATE orders set state=? where orderid=? \", (state, orderid))\n if not result:\n boolean = False\n else:\n boolean = True\n print(\"是否存在订单\", boolean)\n return boolean\n\nif __name__ == '__main__':\n pass\n #with DBContext() as context:\n #context.get_cursor().execute(\"INSERT INTO user_order values(?,?,?,?)\", (\"BOOK1\", \"ORDER1\", \"BUYERID\", \"SELLERID\"))\n #context.get_cursor().execute(\"INSERT INTO user_order values(?,?,?,?)\", (\"BOOK2\", \"ORDER2\", \"BUYERID\", \"SELLERID\"))\n #context.get_cursor().execute(\"INSERT INTO user_order values(?,?,?,?)\", (\"BOOK3\", \"ORDER3\", \"BUYERID\", \"SELLERID\"))\n #with DBContext() as context:\n #context.get_cursor().execute(\"SELECT orderid from user_order where buyerid=?\", (\"BUYERID\",))\n #result = context.get_cursor().fetchall()\n #print(result)\n #OrderDBmanagement().viewOrders(userid=\"BUYERID\")\n #with DBContext() as context:\n #context.get_cursor().execute(\"SELECT * from orders\", ())\n #result = context.get_cursor().fetchall()\n #print(result)\n #OrderDBmanagement().changeOrderState(\"11\",\"hh\")\n #with DBContext() as context:\n #context.get_cursor().execute(\"SELECT * from orders\", ())\n #result = context.get_cursor().fetchall()\n #print(result)\n"
}
] | 3 |
Bkukov/Fix-Parser
|
https://github.com/Bkukov/Fix-Parser
|
108318c2315b450583ecc84fc0d9c40d93c44adc
|
2fc94b6ee2f6f302e8fcef28eadb6e95f4ac7961
|
b69f359245917664f303367f970c8b89f646a11c
|
refs/heads/master
| 2019-06-17T18:05:52.466228 | 2017-08-13T16:20:44 | 2017-08-13T16:20:44 | 100,188,390 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5799576640129089,
"alphanum_fraction": 0.589621365070343,
"avg_line_length": 38.6129035949707,
"blob_id": "330352cadcf3170ed012a95a10ec476747fab55a",
"content_id": "71e34ee264d24606edc29dfbd829e5d66bc18ceb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7554,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 186,
"path": "/Full_Parse.py",
"repo_name": "Bkukov/Fix-Parser",
"src_encoding": "UTF-8",
"text": "import time\r\nfrom collections import defaultdict\r\nimport re\r\nimport random\r\n\r\n\r\ndef qsort(l):\r\n \"\"\" In place qsort, takes in a list and then sorts it for use of gettting earliest contract dates. \"\"\"\r\n\r\n if not l: return l\r\n pivot = l[random.choice(range(0, len(l)))]\r\n head = qsort([elem for elem in l if elem < pivot])\r\n tail = qsort([elem for elem in l if elem > pivot])\r\n return head + [elem for elem in l if elem == pivot] + tail\r\n\r\n\r\ndef load_dict():\r\n\r\n \"\"\" Splits a line by delimiter then further by the equals sign, then feeds the output of the split\r\n into a dictionary which establishes a line of dictionaries which are then copied to a list. \"\"\"\r\n\r\n fList = []\r\n record = defaultdict(lambda: '0')\r\n with open('secdef.dat') as file:\r\n for line in file:\r\n j = 1\r\n i = 0\r\n fields = re.split(r'[\\001=]', line.strip())\r\n while i < len(fields) - 1:\r\n record[fields[i]] = fields[j]\r\n i += 2\r\n j += 2\r\n fList.append(record.copy())\r\n return fList\r\n\r\n\r\ndef count_tags(dict_list,tag_list):\r\n\r\n \"\"\" Uses list of dictionaries to count any tag which is given as input through nested dictionaries.\r\n Can count multiple tags at a time. Defaultdict allows for tags that don't exist to not break the program. \"\"\"\r\n\r\n i = len(tag_list)\r\n tag_counter = defaultdict(int)\r\n n=0\r\n while i>0:\r\n for line in dict_list:\r\n tag_counter[line[tag_list[n]]]+=1\r\n print(\"Tag %s results: \" % tag_list[n] + str(tag_counter))\r\n i-=1\r\n n+=1\r\n tag_counter.clear()\r\n return\r\n\r\n\r\ndef single_filter(dict_list, filtertag, value, tag):\r\n\r\n \"\"\" Similar to the count_tags, counts tags within a single filter that's applied. Parameters include\r\n the list of dictionaries, the tag which is used to filter along with its value and the tag you're\r\n looking to count. \"\"\"\r\n\r\n filter_counter = defaultdict(int)\r\n for line in dict_list:\r\n if line[filtertag]==value:\r\n filter_counter[line[tag]]+=1\r\n print(\"Filter results for tag \"+tag+\" within filter tag \"+filtertag+\": \"+str(filter_counter))\r\n return\r\n\r\n\r\ndef tag_list_load():\r\n \"\"\" Adds tags to a list and checks if they already exist, if they exist doesn't add, if they don't exist\r\n adds them. Returns list of tags for later use in either filter or sorts.\"\"\"\r\n tag_list=[]\r\n tag_count_var = input().replace(' ','').split(',')\r\n for tag in tag_count_var:\r\n if tag not in tag_list:\r\n tag_list.append(tag)\r\n return tag_list\r\n\r\ndef filter_tuple_load():\r\n\r\n \"\"\" Creates tuples out of inputs by user. Tuples are then stripped mostly and added as key values for later use\r\n as parameters in the multi_sort_filter. Returns a list of tuples created by user. \"\"\"\r\n\r\n mlist=[]\r\n multi_sort_list =[]\r\n while multi_sort_list!= 'done':\r\n multi_sort_list = input(\"Enter key value pairs which you would like to use as filter parameters\\n\"\r\n \"Format expected, key,value\").replace(' ','').split(',')\r\n if multi_sort_list[0].lower() == 'done':\r\n break\r\n if len(multi_sort_list)!=2 or multi_sort_list[0]=='' or multi_sort_list[1]=='':\r\n print(\"Not entered in proper format.\")\r\n continue\r\n key_val = (multi_sort_list[0],multi_sort_list[1].upper())\r\n if key_val not in mlist:\r\n mlist.append(key_val)\r\n else:\r\n print(\"Key value pair already in list\")\r\n print(\"Loaded to list currently: \")\r\n print(mlist)\r\n multi_sort_list.clear()\r\n return mlist\r\n\r\n\r\ndef multi_sort_filter(dict_list,filter_tags,date_product_tag,how_many,sort_choice):\r\n\r\n \"\"\" A more generalized version of the previous filtering in single_filter. Takes in the list of dictionaries\r\n numerous filter tags and a date and product tag due to the requirements of the prompt. There's also a\r\n sort_choice which decides if the program is going to display the earliest or latest expiration dates.\r\n The program looks to see if all the filter conditions pass and if they do the date and product tags are\r\n appended to a list which is then sorted using qsort(). Generalized for wide usage since any filters tags can\r\n be applied. \"\"\"\r\n\r\n filter_list=[]\r\n while sort_choice == 1:\r\n for line in dict_list:\r\n i=0\r\n j=0\r\n while i<len(filter_tags):\r\n for k,v in filter_tags:\r\n i+=1\r\n if line[k]==v:\r\n j+=1\r\n if j == len(filter_tags):\r\n filter_list.append((line[date_product_tag[0]], line[date_product_tag[1]]))\r\n early_sort = qsort(filter_list)\r\n if len(early_sort) == 0:\r\n return print(\"No matches under given parameters:\")\r\n else:\r\n return print(early_sort[0:how_many])\r\n while sort_choice == 2:\r\n for line in dict_list:\r\n i=0\r\n j=0\r\n while i<len(filter_tags):\r\n for k,v in filter_tags:\r\n i+=1\r\n if line[k]==v:\r\n j+=1\r\n if j == len(filter_tags):\r\n filter_list.append((line[date_product_tag[0]], line[date_product_tag[1]]))\r\n early_sort = qsort(filter_list)\r\n if len(early_sort) == 0:\r\n return print(\"No matches under given parameters\")\r\n else:\r\n return print(early_sort[(-how_many):])\r\n\r\ndef main():\r\n \"\"\" Main with test parameters input, I don't believe that a 167='FUT' + 555:'0' + 461='GE' exists though. \"\"\"\r\n\r\n \"\"\" Initially splits strings line by line and creates dictionaries out of each key value pair and then adds them to\r\n a list which it then returns for later use in the filters.\"\"\"\r\n\r\n print(\"Loading dictionary list.\")\r\n start_time = time.time()\r\n dlist = load_dict()\r\n print(\"Load Time \\n --- %s seconds ---\" % (time.time() - start_time))\r\n\r\n \"\"\" First question given in prompt answered here. \"\"\"\r\n\r\n print(\"Enter keys to be counted, comma delimited, key1, key2, ... format: \")\r\n tag_list=tag_list_load()\r\n start_time = time.time()\r\n count_tags(dlist, tag_list)\r\n print(\"Tag Count Time \\n --- %s seconds ---\" % (time.time() - start_time))\r\n\r\n \"\"\" Second question answered here, not that flexible but you could easily change the tag numbers. \"\"\"\r\n\r\n print(\"Counts for tag 462 within 167=FUT\")\r\n single_filter(dlist,'167','FUT','462')\r\n\r\n \"\"\" Third question answered here, pretty flexible filtering and input, choices given for different sorts in terms\r\n of latest or earliest expiration. Could also have different filters and as many filters as wanted. Has no\r\n verification beyond what is input though as I don't have an xml dictionary on hand for the CME FIX format. \"\"\"\r\n\r\n multi_sort_list=filter_tuple_load()\r\n #print(\"Enter tags for date and product name, x,y format: \") #provided if sorting wants to be done by other tags\r\n #d_p_t = tag_list_load()\r\n pick_choice = int(input(\"Enter 1 for earliest 4 expiration dates or 2 for latest 4 expiration dates: \"))\r\n start_time = time.time()\r\n multi_sort_filter(dlist,multi_sort_list,['200','55'],4,pick_choice)\r\n print(\"Execution Time \\n --- %s seconds ---\" % (time.time() - start_time))\r\n\r\n\r\nif __name__=='__main__':\r\n main()\r\n"
},
{
"alpha_fraction": 0.7907425165176392,
"alphanum_fraction": 0.7965284585952759,
"avg_line_length": 73,
"blob_id": "b8f6f7fc74eabdd7bc65fe961ba2011bc648a4d4",
"content_id": "ab370d7fcb9077299fec88b8ad15d663306cbf6d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1037,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 14,
"path": "/README.md",
"repo_name": "Bkukov/Fix-Parser",
"src_encoding": "UTF-8",
"text": "# Fix-Parser\nFIX Parser Created for Interview\n\nThis parser works in a very direct way as can be seen in the code itself.\n\nThe parser takes in lines from a given file, which can be changed in the code itself and the file is then scanned for each individual line.\nThe lines are then broken up by delimeters and then a line of dicitonaries is created using defaultdict() from the Python libraries. \n\nThe lines of dictionaries are then loaded up to a list and that list is utilized in order to complete the prompt provided. Using nested\ndictionaries I was able to count, filter and sort through my list of 250,000 lines in order to find the exact values of given key-value\npairs. Multiple counts can be done by understanding the meaning of each key on the line and adjusting the code for multiple counts.\n\nIt was a project given to me to be completed in a couple of days and it demonstrates the power of dictionaries in terms of speed for look\nups and the ability to sort and filter large sets of data using Python and nested dictionaries. \n"
}
] | 2 |
gigasurgeon/Multivariate_Linear_Regression_from_scratch
|
https://github.com/gigasurgeon/Multivariate_Linear_Regression_from_scratch
|
a58b553a5960c12f6a8f1daa1e6857cfe13b72c8
|
175be5b623e0d8b95887809baf35f98883c38bfd
|
e93c5d4b0db7960417fc11451bc7ae77802400c4
|
refs/heads/master
| 2023-02-24T23:14:36.841986 | 2019-01-06T17:18:11 | 2019-01-06T17:18:11 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8527607321739197,
"alphanum_fraction": 0.8527607321739197,
"avg_line_length": 80.5,
"blob_id": "5ba5ecdae96855af9d0b1609faf62e52a62727b2",
"content_id": "7147ac888ae26052b80a525fd296986eca34ea4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 163,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 2,
"path": "/README.md",
"repo_name": "gigasurgeon/Multivariate_Linear_Regression_from_scratch",
"src_encoding": "UTF-8",
"text": "# Multivariate-Linear-Regression\nIt is the implementation of Multivariate Linear Regression without the use of Library Functions of SciKit or TensorFlow libraries\n"
},
{
"alpha_fraction": 0.5452151298522949,
"alphanum_fraction": 0.5812115669250488,
"avg_line_length": 20.294116973876953,
"blob_id": "8da9a12e941959cffdb04b81eac13dbc51cc8fdd",
"content_id": "8dd1a743a9ecd881b5f4b2c21874c8879fc1e897",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1139,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 51,
"path": "/MLR.py",
"repo_name": "gigasurgeon/Multivariate_Linear_Regression_from_scratch",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Sun Oct 14 22:28:18 2018\r\n\r\n@author: CAPTAIN \r\n\"\"\"\r\n\r\nimport numpy as np\r\nimport pandas as pd\r\nimport matplotlib.pyplot as plt\r\n\r\nnp.set_printoptions(suppress=True)\r\n\r\n\r\nx,y,alpha,theta,data,one=None,None,None,None,None,None\r\n\r\ndef data_preprocess():\r\n global x,y,one,data,theta,alpha\r\n data=pd.read_csv(\"abc.txt\",names=[\"size\",\"bedroom\",\"price\"])\r\n data.dropna()\r\n data=(data-data.mean())/(data.std())\r\n x=np.array(data.iloc[:,0:2])\r\n y=np.array(data[\"price\"])\r\n theta=np.random.randn(3,1)\r\n alpha=0.01\r\n y=y.reshape(-1,1)\r\n one=np.ones((x.shape[0])).reshape(-1,1)\r\n x=np.hstack((one,x))\r\n\r\n\r\ndef gradient(x,y):\r\n global theta\r\n iter=1000\r\n for i in range(iter):\r\n yhat=np.matmul(x,theta)\r\n theta=theta-(alpha/len(x))*(np.matmul(x.T,(yhat-y)))\r\n c2=cost(x,y)\r\n if(iter%100==0):\r\n print(c2)\r\n return theta\r\n\r\ndef cost(x,y):\r\n yhat=np.matmul(x,theta)\r\n c1=(1/(2*len(x)))*(np.sum(np.power(np.subtract(yhat,y),2)))\r\n return c1\r\n\r\ndata_preprocess()\r\ngradient(x,y)\r\nprint(theta)\r\n\r\ny1=np.array(x@theta)\r\n\r\n"
}
] | 2 |
KonEco2006/ALO-AutoLinkOpener
|
https://github.com/KonEco2006/ALO-AutoLinkOpener
|
98664b624f052ec35e6cac9736d8d63def5ec648
|
0526120407c5772991438f3fd7771564712571dd
|
5f4f1638a9d97044dcbface9fd36d877f43ff09b
|
refs/heads/main
| 2023-06-09T06:30:05.377004 | 2021-07-05T10:50:10 | 2021-07-05T10:50:10 | 383,106,232 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7872697114944458,
"alphanum_fraction": 0.7872697114944458,
"avg_line_length": 297.5,
"blob_id": "0a97bf01fca85f8087b054a93f97db2bb220953e",
"content_id": "4b88841bb120515b20aea0ef2b6ea135ceb996c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 598,
"license_type": "no_license",
"max_line_length": 575,
"num_lines": 2,
"path": "/README.md",
"repo_name": "KonEco2006/ALO-AutoLinkOpener",
"src_encoding": "UTF-8",
"text": "# ALO-AutoLinkOpener\nThese days, many people(mostly students) attend meetings almost every day and sometimes they are late, because they are looking for the links. ALO(Auto Link Opener) was designed to solve this problem. It is an application that can automatically attend your meetings, open your e-mails and do every other task that can be done by opening a link. The only thing that you have to do, is to insert the links, the day and the time you want to open them, and the program is going to open the links on the day and time you have inserted, automatically, for as many weeks you want.\n"
},
{
"alpha_fraction": 0.3321724236011505,
"alphanum_fraction": 0.37822774052619934,
"avg_line_length": 61.1081428527832,
"blob_id": "634c82aaff1dc8a618e68379e8fe686ab4ab9d38",
"content_id": "c9fda48e458b5770db0ba2aa4aeaa1ef5f1aaac8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 413177,
"license_type": "no_license",
"max_line_length": 163,
"num_lines": 6547,
"path": "/ALO(AutoLinkOpener).py",
"repo_name": "KonEco2006/ALO-AutoLinkOpener",
"src_encoding": "UTF-8",
"text": "import schedule \r\nimport time\r\nimport webbrowser\r\nimport clock\r\nimport plan\r\nimport apscheduler\r\nimport sched\r\nimport day\r\nimport datetime\r\nimport calendar\r\nimport tkinter\r\nfrom tkinter import *\r\nimport tkinter as tk\r\nfrom tkinter import ttk\r\nfrom PIL import ImageTk,Image\r\n\r\n \r\n\r\n \r\nroot = Tk()\r\nroot.title(\"ALO(AutoLinkOpener)\")\r\nroot.geometry(\"800x600\")\r\nroot.iconbitmap(r\"icon.ico\")\r\n\r\nmain_frame = Frame(root)\r\nmain_frame.pack(fill=BOTH, expand=1)\r\n\r\nmy_canvas = Canvas(main_frame)\r\nmy_canvas.pack(side=LEFT, fill=BOTH, expand=1)\r\n\r\nmy_scrollbar = ttk.Scrollbar(main_frame, orient=VERTICAL, command=my_canvas.yview)\r\nmy_scrollbar.pack(side=RIGHT, fill=Y)\r\n\r\nmy_canvas.configure(yscrollcommand=my_scrollbar.set)\r\nmy_canvas.bind('<Configure>', lambda e: my_canvas.configure(scrollregion = my_canvas.bbox(\"all\")))\r\n\r\nsecond_frame = Frame(my_canvas)\r\n\r\nmy_canvas.create_window((0,0), window=second_frame, anchor=\"nw\")\r\n\r\ndef _on_mousewheel(event):\r\n my_canvas.yview_scroll(int(-1*(event.delta/120)), \"units\")\r\nmy_canvas.bind_all(\"<MouseWheel>\", _on_mousewheel)\r\n\r\ndef open1():\r\n global my_img\r\n top1 = Toplevel()\r\n top1.title('ALO(AutoLinkOpener)-Instructions')\r\n top1.iconbitmap(r'icon.ico')\r\n \r\n my_img = ImageTk.PhotoImage(Image.open(r'ALO(AutoLinkOpener)-Instructions.png'))\r\n my_label1 = Label(top1, image=my_img).pack()\r\n btn2 = Button(top1, text=\"Close Instructions\", command=top1.destroy, bg=\"WHITE\", cursor=\"hand2\").pack()\r\n\r\n\r\nbtn = Button(second_frame, text=\"Instructions\", command=open1, bg=\"WHITE\", cursor=\"hand2\").pack()\r\n\r\n \r\n\r\n\r\n\r\nlabel=Label(second_frame, text= \"Insert the link1:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink1= Entry(second_frame, width=100)\r\nlink1.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link1:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday1= Entry(second_frame)\r\nday1.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link1:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime1= Entry(second_frame)\r\ntime1.pack()\r\nlabel=Label(second_frame, text= \"Insert the link2:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink2= Entry(second_frame, width=100)\r\nlink2.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link2:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday2= Entry(second_frame)\r\nday2.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link2:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime2= Entry(second_frame)\r\ntime2.pack()\r\nlabel=Label(second_frame, text= \"Insert the link3:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink3= Entry(second_frame, width=100)\r\nlink3.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link3:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday3= Entry(second_frame)\r\nday3.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link3:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime3= Entry(second_frame)\r\ntime3.pack()\r\nlabel=Label(second_frame, text= \"Insert the link4:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink4= Entry(second_frame, width=100)\r\nlink4.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link4:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday4= Entry(second_frame)\r\nday4.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link4:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime4= Entry(second_frame)\r\ntime4.pack()\r\nlabel=Label(second_frame, text= \"Insert the link5:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink5= Entry(second_frame, width=100)\r\nlink5.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link5:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday5= Entry(second_frame)\r\nday5.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link5:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime5= Entry(second_frame)\r\ntime5.pack()\r\nlabel=Label(second_frame, text= \"Insert the link6:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink6= Entry(second_frame, width=100)\r\nlink6.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link6:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday6= Entry(second_frame)\r\nday6.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link6:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime6= Entry(second_frame)\r\ntime6.pack()\r\nlabel=Label(second_frame, text= \"Insert the link7:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink7= Entry(second_frame, width=100)\r\nlink7.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link7:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday7= Entry(second_frame)\r\nday7.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link7:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime7= Entry(second_frame)\r\ntime7.pack()\r\nlabel=Label(second_frame, text= \"Insert the link8:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink8= Entry(second_frame, width=100)\r\nlink8.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link8:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday8= Entry(second_frame)\r\nday8.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link8:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime8= Entry(second_frame)\r\ntime8.pack()\r\nlabel=Label(second_frame, text= \"Insert the link9:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink9= Entry(second_frame, width=100)\r\nlink9.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link9:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday9= Entry(second_frame)\r\nday9.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link9:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime9= Entry(second_frame)\r\ntime9.pack()\r\nlabel=Label(second_frame, text= \"Insert the link10:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink10= Entry(second_frame, width=100)\r\nlink10.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link10:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday10= Entry(second_frame)\r\nday10.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link10:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime10= Entry(second_frame)\r\ntime10.pack()\r\nlabel=Label(second_frame, text= \"Insert the link11:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink11= Entry(second_frame, width=100)\r\nlink11.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link11:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday11= Entry(second_frame)\r\nday11.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link11:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime11= Entry(second_frame)\r\ntime11.pack()\r\nlabel=Label(second_frame, text= \"Insert the link12:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink12= Entry(second_frame, width=100)\r\nlink12.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link12:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday12= Entry(second_frame)\r\nday12.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link12:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime12= Entry(second_frame)\r\ntime12.pack()\r\nlabel=Label(second_frame, text= \"Insert the link13:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink13= Entry(second_frame, width=100)\r\nlink13.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link13:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday13= Entry(second_frame)\r\nday13.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link13:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime13= Entry(second_frame)\r\ntime13.pack()\r\nlabel=Label(second_frame, text= \"Insert the link14:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink14= Entry(second_frame, width=100)\r\nlink14.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link14:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday14= Entry(second_frame)\r\nday14.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link14:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime14= Entry(second_frame)\r\ntime14.pack()\r\nlabel=Label(second_frame, text= \"Insert the link15:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink15= Entry(second_frame, width=100)\r\nlink15.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link15:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday15= Entry(second_frame)\r\nday15.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link15:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime15= Entry(second_frame)\r\ntime15.pack()\r\nlabel=Label(second_frame, text= \"Insert the link16:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink16= Entry(second_frame, width=100)\r\nlink16.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link16:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday16= Entry(second_frame)\r\nday16.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link16:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime16= Entry(second_frame)\r\ntime16.pack()\r\nlabel=Label(second_frame, text= \"Insert the link17:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink17= Entry(second_frame, width=100)\r\nlink17.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link17:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday17= Entry(second_frame)\r\nday17.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link17:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime17= Entry(second_frame)\r\ntime17.pack()\r\nlabel=Label(second_frame, text= \"Insert the link18:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink18= Entry(second_frame, width=100)\r\nlink18.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link18:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday18= Entry(second_frame)\r\nday18.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link18:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime18= Entry(second_frame)\r\ntime18.pack()\r\nlabel=Label(second_frame, text= \"Insert the link19:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink19= Entry(second_frame, width=100)\r\nlink19.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link19:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday19= Entry(second_frame)\r\nday19.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link19:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime19= Entry(second_frame)\r\ntime19.pack()\r\nlabel=Label(second_frame, text= \"Insert the link20:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink20= Entry(second_frame, width=100)\r\nlink20.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link20:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday20= Entry(second_frame)\r\nday20.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link20:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime20= Entry(second_frame)\r\ntime20.pack()\r\nlabel=Label(second_frame, text= \"Insert the link21:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink21= Entry(second_frame, width=100)\r\nlink21.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link21:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday21= Entry(second_frame)\r\nday21.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link21:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime21= Entry(second_frame)\r\ntime21.pack()\r\nlabel=Label(second_frame, text= \"Insert the link22:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink22= Entry(second_frame, width=100)\r\nlink22.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link22:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday22= Entry(second_frame)\r\nday22.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link22:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime22= Entry(second_frame)\r\ntime22.pack()\r\nlabel=Label(second_frame, text= \"Insert the link23:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink23= Entry(second_frame, width=100)\r\nlink23.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link23:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday23= Entry(second_frame)\r\nday23.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link23:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime23= Entry(second_frame)\r\ntime23.pack()\r\nlabel=Label(second_frame, text= \"Insert the link24:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink24= Entry(second_frame, width=100)\r\nlink24.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link24:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday24= Entry(second_frame)\r\nday24.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link24:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime24= Entry(second_frame)\r\ntime24.pack()\r\nlabel=Label(second_frame, text= \"Insert the link25:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink25= Entry(second_frame, width=100)\r\nlink25.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link25:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday25= Entry(second_frame)\r\nday25.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link25:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime25= Entry(second_frame)\r\ntime25.pack()\r\nlabel=Label(second_frame, text= \"Insert the link26:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink26= Entry(second_frame, width=100)\r\nlink26.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link26:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday26= Entry(second_frame)\r\nday26.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link26:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime26= Entry(second_frame)\r\ntime26.pack()\r\nlabel=Label(second_frame, text= \"Insert the link27:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink27= Entry(second_frame, width=100)\r\nlink27.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link27:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday27= Entry(second_frame)\r\nday27.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link27:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime27= Entry(second_frame)\r\ntime27.pack()\r\nlabel=Label(second_frame, text= \"Insert the link28:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink28= Entry(second_frame, width=100)\r\nlink28.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link28:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday28= Entry(second_frame)\r\nday28.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link28:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime28= Entry(second_frame)\r\ntime28.pack()\r\nlabel=Label(second_frame, text= \"Insert the link29:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink29= Entry(second_frame, width=100)\r\nlink29.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link29:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday29= Entry(second_frame)\r\nday29.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link29:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime29= Entry(second_frame)\r\ntime29.pack()\r\nlabel=Label(second_frame, text= \"Insert the link30:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink30= Entry(second_frame, width=100)\r\nlink30.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link30:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday30= Entry(second_frame)\r\nday30.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link30:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime30= Entry(second_frame)\r\ntime30.pack()\r\nlabel=Label(second_frame, text= \"Insert the link31:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink31= Entry(second_frame, width=100)\r\nlink31.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link31:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday31= Entry(second_frame)\r\nday31.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link31:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime31= Entry(second_frame)\r\ntime31.pack()\r\nlabel=Label(second_frame, text= \"Insert the link32:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink32= Entry(second_frame, width=100)\r\nlink32.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link32:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday32= Entry(second_frame)\r\nday32.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link32:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime32= Entry(second_frame)\r\ntime32.pack()\r\nlabel=Label(second_frame, text= \"Insert the link33:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink33= Entry(second_frame, width=100)\r\nlink33.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link33:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday33= Entry(second_frame)\r\nday33.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link33:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime33= Entry(second_frame)\r\ntime33.pack()\r\nlabel=Label(second_frame, text= \"Insert the link34:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink34= Entry(second_frame, width=100)\r\nlink34.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link34:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday34= Entry(second_frame)\r\nday34.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link34:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime34= Entry(second_frame)\r\ntime34.pack()\r\nlabel=Label(second_frame, text= \"Insert the link35:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink35= Entry(second_frame, width=100)\r\nlink35.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link35:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday35= Entry(second_frame)\r\nday35.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link35:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime35= Entry(second_frame)\r\ntime35.pack()\r\nlabel=Label(second_frame, text= \"Insert the link36:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink36= Entry(second_frame, width=100)\r\nlink36.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link36:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday36= Entry(second_frame)\r\nday36.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link36:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime36= Entry(second_frame)\r\ntime36.pack()\r\nlabel=Label(second_frame, text= \"Insert the link37:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink37= Entry(second_frame, width=100)\r\nlink37.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link37:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday37= Entry(second_frame)\r\nday37.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link37:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime37= Entry(second_frame)\r\ntime37.pack()\r\nlabel=Label(second_frame, text= \"Insert the link38:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink38= Entry(second_frame, width=100)\r\nlink38.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link38:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday38= Entry(second_frame)\r\nday38.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link38:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime38= Entry(second_frame)\r\ntime38.pack()\r\nlabel=Label(second_frame, text= \"Insert the link39:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink39= Entry(second_frame, width=100)\r\nlink39.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link39:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday39= Entry(second_frame)\r\nday39.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link39:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime39= Entry(second_frame)\r\ntime39.pack()\r\nlabel=Label(second_frame, text= \"Insert the link40:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink40= Entry(second_frame, width=100)\r\nlink40.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link40:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday40= Entry(second_frame)\r\nday40.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link40:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime40= Entry(second_frame)\r\ntime40.pack()\r\nlabel=Label(second_frame, text= \"Insert the link41:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink41= Entry(second_frame, width=100)\r\nlink41.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link41:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday41= Entry(second_frame)\r\nday41.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link41:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime41= Entry(second_frame)\r\ntime41.pack()\r\nlabel=Label(second_frame, text= \"Insert the link42:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink42= Entry(second_frame, width=100)\r\nlink42.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link42:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday42= Entry(second_frame)\r\nday42.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link42:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime42= Entry(second_frame)\r\ntime42.pack()\r\nlabel=Label(second_frame, text= \"Insert the link43:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink43= Entry(second_frame, width=100)\r\nlink43.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link43:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday43= Entry(second_frame)\r\nday43.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link43:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime43= Entry(second_frame)\r\ntime43.pack()\r\nlabel=Label(second_frame, text= \"Insert the link44:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink44= Entry(second_frame, width=100)\r\nlink44.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link44:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday44= Entry(second_frame)\r\nday44.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link44:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime44= Entry(second_frame)\r\ntime44.pack()\r\nlabel=Label(second_frame, text= \"Insert the link45:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink45= Entry(second_frame, width=100)\r\nlink45.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link45:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday45= Entry(second_frame)\r\nday45.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link45:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime45= Entry(second_frame)\r\ntime45.pack()\r\nlabel=Label(second_frame, text= \"Insert the link46:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink46= Entry(second_frame, width=100)\r\nlink46.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link46:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday46= Entry(second_frame)\r\nday46.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link46:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime46= Entry(second_frame)\r\ntime46.pack()\r\nlabel=Label(second_frame, text= \"Insert the link47:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink47= Entry(second_frame, width=100)\r\nlink47.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link47:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday47= Entry(second_frame)\r\nday47.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link47:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime47= Entry(second_frame)\r\ntime47.pack()\r\nlabel=Label(second_frame, text= \"Insert the link48:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink48= Entry(second_frame, width=100)\r\nlink48.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link48:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday48= Entry(second_frame)\r\nday48.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link48:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime48= Entry(second_frame)\r\ntime48.pack()\r\nlabel=Label(second_frame, text= \"Insert the link49:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink49= Entry(second_frame, width=100)\r\nlink49.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link49:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday49= Entry(second_frame)\r\nday49.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link49:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime49= Entry(second_frame)\r\ntime49.pack()\r\nlabel=Label(second_frame, text= \"Insert the link50:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink50= Entry(second_frame, width=100)\r\nlink50.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link50:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday50= Entry(second_frame)\r\nday50.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link50:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime50= Entry(second_frame)\r\ntime50.pack()\r\nlabel=Label(second_frame, text= \"Insert the link51:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink51= Entry(second_frame, width=100)\r\nlink51.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link51:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday51= Entry(second_frame)\r\nday51.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link51:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime51= Entry(second_frame)\r\ntime51.pack()\r\nlabel=Label(second_frame, text= \"Insert the link52:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink52= Entry(second_frame, width=100)\r\nlink52.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link52:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday52= Entry(second_frame)\r\nday52.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link52:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime52= Entry(second_frame)\r\ntime52.pack()\r\nlabel=Label(second_frame, text= \"Insert the link53:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink53= Entry(second_frame, width=100)\r\nlink53.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link53:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday53= Entry(second_frame)\r\nday53.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link53:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime53= Entry(second_frame)\r\ntime53.pack()\r\nlabel=Label(second_frame, text= \"Insert the link54:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink54= Entry(second_frame, width=100)\r\nlink54.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link54:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday54= Entry(second_frame)\r\nday54.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link54:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime54= Entry(second_frame)\r\ntime54.pack()\r\nlabel=Label(second_frame, text= \"Insert the link55:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink55= Entry(second_frame, width=100)\r\nlink55.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link55:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday55= Entry(second_frame)\r\nday55.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link55:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime55= Entry(second_frame)\r\ntime55.pack()\r\nlabel=Label(second_frame, text= \"Insert the link56:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink56= Entry(second_frame, width=100)\r\nlink56.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link56:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday56= Entry(second_frame)\r\nday56.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link56:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime56= Entry(second_frame)\r\ntime56.pack()\r\nlabel=Label(second_frame, text= \"Insert the link57:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink57= Entry(second_frame, width=100)\r\nlink57.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link57:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday57= Entry(second_frame)\r\nday57.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link57:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime57= Entry(second_frame)\r\ntime57.pack()\r\nlabel=Label(second_frame, text= \"Insert the link58:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink58= Entry(second_frame, width=100)\r\nlink58.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link58:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday58= Entry(second_frame)\r\nday58.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link58:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime58= Entry(second_frame)\r\ntime58.pack()\r\nlabel=Label(second_frame, text= \"Insert the link59:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink59= Entry(second_frame, width=100)\r\nlink59.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link59:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday59= Entry(second_frame)\r\nday59.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link59:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime59= Entry(second_frame)\r\ntime59.pack()\r\nlabel=Label(second_frame, text= \"Insert the link60:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink60= Entry(second_frame, width=100)\r\nlink60.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link60:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday60= Entry(second_frame)\r\nday60.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link60:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime60= Entry(second_frame)\r\ntime60.pack()\r\nlabel=Label(second_frame, text= \"Insert the link61:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink61= Entry(second_frame, width=100)\r\nlink61.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link61:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday61= Entry(second_frame)\r\nday61.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link61:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime61= Entry(second_frame)\r\ntime61.pack()\r\nlabel=Label(second_frame, text= \"Insert the link62:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink62= Entry(second_frame, width=100)\r\nlink62.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link62:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday62= Entry(second_frame)\r\nday62.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link62:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime62= Entry(second_frame)\r\ntime62.pack()\r\nlabel=Label(second_frame, text= \"Insert the link63:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink63= Entry(second_frame, width=100)\r\nlink63.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link63:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday63= Entry(second_frame)\r\nday63.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link63:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime63= Entry(second_frame)\r\ntime63.pack()\r\nlabel=Label(second_frame, text= \"Insert the link64:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink64= Entry(second_frame, width=100)\r\nlink64.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link64:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday64= Entry(second_frame)\r\nday64.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link64:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime64= Entry(second_frame)\r\ntime64.pack()\r\nlabel=Label(second_frame, text= \"Insert the link65:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink65= Entry(second_frame, width=100)\r\nlink65.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link65:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday65= Entry(second_frame)\r\nday65.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link65:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime65= Entry(second_frame)\r\ntime65.pack()\r\nlabel=Label(second_frame, text= \"Insert the link66:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink66= Entry(second_frame, width=100)\r\nlink66.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link66:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday66= Entry(second_frame)\r\nday66.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link66:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime66= Entry(second_frame)\r\ntime66.pack()\r\nlabel=Label(second_frame, text= \"Insert the link67:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink67= Entry(second_frame, width=100)\r\nlink67.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link67:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday67= Entry(second_frame)\r\nday67.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link67:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime67= Entry(second_frame)\r\ntime67.pack()\r\nlabel=Label(second_frame, text= \"Insert the link68:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink68= Entry(second_frame, width=100)\r\nlink68.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link68:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday68= Entry(second_frame)\r\nday68.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link68:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime68= Entry(second_frame)\r\ntime68.pack()\r\nlabel=Label(second_frame, text= \"Insert the link69:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink69= Entry(second_frame, width=100)\r\nlink69.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link69:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday69= Entry(second_frame)\r\nday69.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link69:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime69= Entry(second_frame)\r\ntime69.pack()\r\nlabel=Label(second_frame, text= \"Insert the link70:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink70= Entry(second_frame, width=100)\r\nlink70.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link70:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday70= Entry(second_frame)\r\nday70.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link70:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime70= Entry(second_frame)\r\ntime70.pack()\r\nlabel=Label(second_frame, text= \"Insert the link71:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink71= Entry(second_frame, width=100)\r\nlink71.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link71:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday71= Entry(second_frame)\r\nday71.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link71:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime71= Entry(second_frame)\r\ntime71.pack()\r\nlabel=Label(second_frame, text= \"Insert the link72:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink72= Entry(second_frame, width=100)\r\nlink72.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link72:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday72= Entry(second_frame)\r\nday72.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link72:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime72= Entry(second_frame)\r\ntime72.pack()\r\nlabel=Label(second_frame, text= \"Insert the link73:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink73= Entry(second_frame, width=100)\r\nlink73.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link73:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday73= Entry(second_frame)\r\nday73.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link73:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime73= Entry(second_frame)\r\ntime73.pack()\r\nlabel=Label(second_frame, text= \"Insert the link74:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink74= Entry(second_frame, width=100)\r\nlink74.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link74:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday74= Entry(second_frame)\r\nday74.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link74:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime74= Entry(second_frame)\r\ntime74.pack()\r\nlabel=Label(second_frame, text= \"Insert the link75:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink75= Entry(second_frame, width=100)\r\nlink75.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link75:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday75= Entry(second_frame)\r\nday75.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link75:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime75= Entry(second_frame)\r\ntime75.pack()\r\nlabel=Label(second_frame, text= \"Insert the link76:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink76= Entry(second_frame, width=100)\r\nlink76.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link76:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday76= Entry(second_frame)\r\nday76.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link76:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime76= Entry(second_frame)\r\ntime76.pack()\r\nlabel=Label(second_frame, text= \"Insert the link77:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink77= Entry(second_frame, width=100)\r\nlink77.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link77:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday77= Entry(second_frame)\r\nday77.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link77:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime77= Entry(second_frame)\r\ntime77.pack()\r\nlabel=Label(second_frame, text= \"Insert the link78:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink78= Entry(second_frame, width=100)\r\nlink78.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link78:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday78= Entry(second_frame)\r\nday78.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link78:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime78= Entry(second_frame)\r\ntime78.pack()\r\nlabel=Label(second_frame, text= \"Insert the link79:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink79= Entry(second_frame, width=100)\r\nlink79.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link79:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday79= Entry(second_frame)\r\nday79.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link79:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime79= Entry(second_frame)\r\ntime79.pack()\r\nlabel=Label(second_frame, text= \"Insert the link80:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink80= Entry(second_frame, width=100)\r\nlink80.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link80:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday80= Entry(second_frame)\r\nday80.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link80:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime80= Entry(second_frame)\r\ntime80.pack()\r\nlabel=Label(second_frame, text= \"Insert the link81:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink81= Entry(second_frame, width=100)\r\nlink81.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link81:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday81= Entry(second_frame)\r\nday81.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link81:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime81= Entry(second_frame)\r\ntime81.pack()\r\nlabel=Label(second_frame, text= \"Insert the link82:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink82= Entry(second_frame, width=100)\r\nlink82.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link82:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday82= Entry(second_frame)\r\nday82.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link82:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime82= Entry(second_frame)\r\ntime82.pack()\r\nlabel=Label(second_frame, text= \"Insert the link83:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink83= Entry(second_frame, width=100)\r\nlink83.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link83:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday83= Entry(second_frame)\r\nday83.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link83:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime83= Entry(second_frame)\r\ntime83.pack()\r\nlabel=Label(second_frame, text= \"Insert the link84:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink84= Entry(second_frame, width=100)\r\nlink84.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link84:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday84= Entry(second_frame)\r\nday84.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link84:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime84= Entry(second_frame)\r\ntime84.pack()\r\nlabel=Label(second_frame, text= \"Insert the link85:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink85= Entry(second_frame, width=100)\r\nlink85.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link85:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday85= Entry(second_frame)\r\nday85.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link85:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime85= Entry(second_frame)\r\ntime85.pack()\r\nlabel=Label(second_frame, text= \"Insert the link86:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink86= Entry(second_frame, width=100)\r\nlink86.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link86:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday86= Entry(second_frame)\r\nday86.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link86:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime86= Entry(second_frame)\r\ntime86.pack()\r\nlabel=Label(second_frame, text= \"Insert the link87:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink87= Entry(second_frame, width=100)\r\nlink87.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link87:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday87= Entry(second_frame)\r\nday87.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link87:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime87= Entry(second_frame)\r\ntime87.pack()\r\nlabel=Label(second_frame, text= \"Insert the link88:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink88= Entry(second_frame, width=100)\r\nlink88.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link88:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday88= Entry(second_frame)\r\nday88.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link88:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime88= Entry(second_frame)\r\ntime88.pack()\r\nlabel=Label(second_frame, text= \"Insert the link89:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink89= Entry(second_frame, width=100)\r\nlink89.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link89:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday89= Entry(second_frame)\r\nday89.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link89:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime89= Entry(second_frame)\r\ntime89.pack()\r\nlabel=Label(second_frame, text= \"Insert the link90:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink90= Entry(second_frame, width=100)\r\nlink90.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link90:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday90= Entry(second_frame)\r\nday90.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link90:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime90= Entry(second_frame)\r\ntime90.pack()\r\nlabel=Label(second_frame, text= \"Insert the link91:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink91= Entry(second_frame, width=100)\r\nlink91.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link91:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday91= Entry(second_frame)\r\nday91.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link91:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime91= Entry(second_frame)\r\ntime91.pack()\r\nlabel=Label(second_frame, text= \"Insert the link92:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink92= Entry(second_frame, width=100)\r\nlink92.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link92:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday92= Entry(second_frame)\r\nday92.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link92:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime92= Entry(second_frame)\r\ntime92.pack()\r\nlabel=Label(second_frame, text= \"Insert the link93:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink93= Entry(second_frame, width=100)\r\nlink93.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link93:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday93= Entry(second_frame)\r\nday93.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link93:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime93= Entry(second_frame)\r\ntime93.pack()\r\nlabel=Label(second_frame, text= \"Insert the link94:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink94= Entry(second_frame, width=100)\r\nlink94.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link94:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday94= Entry(second_frame)\r\nday94.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link94:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime94= Entry(second_frame)\r\ntime94.pack()\r\nlabel=Label(second_frame, text= \"Insert the link95:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink95= Entry(second_frame, width=100)\r\nlink95.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link95:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday95= Entry(second_frame)\r\nday95.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link95:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime95= Entry(second_frame)\r\ntime95.pack()\r\nlabel=Label(second_frame, text= \"Insert the link96:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink96= Entry(second_frame, width=100)\r\nlink96.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link96:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday96= Entry(second_frame)\r\nday96.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link96:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime96= Entry(second_frame)\r\ntime96.pack()\r\nlabel=Label(second_frame, text= \"Insert the link97:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink97= Entry(second_frame, width=100)\r\nlink97.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link97:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday97= Entry(second_frame)\r\nday97.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link97:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime97= Entry(second_frame)\r\ntime97.pack()\r\nlabel=Label(second_frame, text= \"Insert the link98:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink98= Entry(second_frame, width=100)\r\nlink98.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link98:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday98= Entry(second_frame)\r\nday98.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link98:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime98= Entry(second_frame)\r\ntime98.pack()\r\nlabel=Label(second_frame, text= \"Insert the link99:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink99= Entry(second_frame, width=100)\r\nlink99.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link99:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday99= Entry(second_frame)\r\nday99.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link99:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime99= Entry(second_frame)\r\ntime99.pack()\r\nlabel=Label(second_frame, text= \"Insert the link100:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink100= Entry(second_frame, width=100)\r\nlink100.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link100:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday100= Entry(second_frame)\r\nday100.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link100:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime100= Entry(second_frame)\r\ntime100.pack()\r\nlabel=Label(second_frame, text= \"Insert the link101:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink101= Entry(second_frame, width=100)\r\nlink101.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link101:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday101= Entry(second_frame)\r\nday101.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link101:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime101= Entry(second_frame)\r\ntime101.pack()\r\nlabel=Label(second_frame, text= \"Insert the link102:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink102= Entry(second_frame, width=100)\r\nlink102.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link102:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday102= Entry(second_frame)\r\nday102.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link102:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime102= Entry(second_frame)\r\ntime102.pack()\r\nlabel=Label(second_frame, text= \"Insert the link103:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink103= Entry(second_frame, width=100)\r\nlink103.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link103:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday103= Entry(second_frame)\r\nday103.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link103:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime103= Entry(second_frame)\r\ntime103.pack()\r\nlabel=Label(second_frame, text= \"Insert the link104:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink104= Entry(second_frame, width=100)\r\nlink104.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link104:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday104= Entry(second_frame)\r\nday104.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link104:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime104= Entry(second_frame)\r\ntime104.pack()\r\nlabel=Label(second_frame, text= \"Insert the link105:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink105= Entry(second_frame, width=100)\r\nlink105.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link105:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday105= Entry(second_frame)\r\nday105.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link105:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime105= Entry(second_frame)\r\ntime105.pack()\r\nlabel=Label(second_frame, text= \"Insert the link106:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink106= Entry(second_frame, width=100)\r\nlink106.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link106:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday106= Entry(second_frame)\r\nday106.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link106:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime106= Entry(second_frame)\r\ntime106.pack()\r\nlabel=Label(second_frame, text= \"Insert the link107:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink107= Entry(second_frame, width=100)\r\nlink107.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link107:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday107= Entry(second_frame)\r\nday107.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link107:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime107= Entry(second_frame)\r\ntime107.pack()\r\nlabel=Label(second_frame, text= \"Insert the link108:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink108= Entry(second_frame, width=100)\r\nlink108.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link108:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday108= Entry(second_frame)\r\nday108.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link108:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime108= Entry(second_frame)\r\ntime108.pack()\r\nlabel=Label(second_frame, text= \"Insert the link109:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink109= Entry(second_frame, width=100)\r\nlink109.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link109:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday109= Entry(second_frame)\r\nday109.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link109:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime109= Entry(second_frame)\r\ntime109.pack()\r\nlabel=Label(second_frame, text= \"Insert the link110:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink110= Entry(second_frame, width=100)\r\nlink110.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link110:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday110= Entry(second_frame)\r\nday110.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link110:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime110= Entry(second_frame)\r\ntime110.pack()\r\nlabel=Label(second_frame, text= \"Insert the link111:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink111= Entry(second_frame, width=100)\r\nlink111.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link111:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday111= Entry(second_frame)\r\nday111.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link111:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime111= Entry(second_frame)\r\ntime111.pack()\r\nlabel=Label(second_frame, text= \"Insert the link112:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink112= Entry(second_frame, width=100)\r\nlink112.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link112:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday112= Entry(second_frame)\r\nday112.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link112:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime112= Entry(second_frame)\r\ntime112.pack()\r\nlabel=Label(second_frame, text= \"Insert the link113:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink113= Entry(second_frame, width=100)\r\nlink113.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link113:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday113= Entry(second_frame)\r\nday113.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link113:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime113= Entry(second_frame)\r\ntime113.pack()\r\nlabel=Label(second_frame, text= \"Insert the link114:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink114= Entry(second_frame, width=100)\r\nlink114.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link114:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday114= Entry(second_frame)\r\nday114.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link114:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime114= Entry(second_frame)\r\ntime114.pack()\r\nlabel=Label(second_frame, text= \"Insert the link115:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink115= Entry(second_frame, width=100)\r\nlink115.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link115:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday115= Entry(second_frame)\r\nday115.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link115:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime115= Entry(second_frame)\r\ntime115.pack()\r\nlabel=Label(second_frame, text= \"Insert the link116:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink116= Entry(second_frame, width=100)\r\nlink116.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link116:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday116= Entry(second_frame)\r\nday116.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link116:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime116= Entry(second_frame)\r\ntime116.pack()\r\nlabel=Label(second_frame, text= \"Insert the link117:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink117= Entry(second_frame, width=100)\r\nlink117.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link117:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday117= Entry(second_frame)\r\nday117.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link117:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime117= Entry(second_frame)\r\ntime117.pack()\r\nlabel=Label(second_frame, text= \"Insert the link118:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink118= Entry(second_frame, width=100)\r\nlink118.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link118:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday118= Entry(second_frame)\r\nday118.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link118:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime118= Entry(second_frame)\r\ntime118.pack()\r\nlabel=Label(second_frame, text= \"Insert the link119:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink119= Entry(second_frame, width=100)\r\nlink119.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link119:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday119= Entry(second_frame)\r\nday119.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link119:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime119= Entry(second_frame)\r\ntime119.pack()\r\nlabel=Label(second_frame, text= \"Insert the link120:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink120= Entry(second_frame, width=100)\r\nlink120.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link120:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday120= Entry(second_frame)\r\nday120.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link120:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime120= Entry(second_frame)\r\ntime120.pack()\r\nlabel=Label(second_frame, text= \"Insert the link121:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink121= Entry(second_frame, width=100)\r\nlink121.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link121:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday121= Entry(second_frame)\r\nday121.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link121:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime121= Entry(second_frame)\r\ntime121.pack()\r\nlabel=Label(second_frame, text= \"Insert the link122:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink122= Entry(second_frame, width=100)\r\nlink122.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link122:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday122= Entry(second_frame)\r\nday122.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link122:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime122= Entry(second_frame)\r\ntime122.pack()\r\nlabel=Label(second_frame, text= \"Insert the link123:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink123= Entry(second_frame, width=100)\r\nlink123.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link123:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday123= Entry(second_frame)\r\nday123.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link123:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime123= Entry(second_frame)\r\ntime123.pack()\r\nlabel=Label(second_frame, text= \"Insert the link124:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink124= Entry(second_frame, width=100)\r\nlink124.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link124:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday124= Entry(second_frame)\r\nday124.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link124:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime124= Entry(second_frame)\r\ntime124.pack()\r\nlabel=Label(second_frame, text= \"Insert the link125:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink125= Entry(second_frame, width=100)\r\nlink125.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link125:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday125= Entry(second_frame)\r\nday125.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link125:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime125= Entry(second_frame)\r\ntime125.pack()\r\nlabel=Label(second_frame, text= \"Insert the link126:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink126= Entry(second_frame, width=100)\r\nlink126.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link126:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday126= Entry(second_frame)\r\nday126.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link126:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime126= Entry(second_frame)\r\ntime126.pack()\r\nlabel=Label(second_frame, text= \"Insert the link127:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink127= Entry(second_frame, width=100)\r\nlink127.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link127:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday127= Entry(second_frame)\r\nday127.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link127:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime127= Entry(second_frame)\r\ntime127.pack()\r\nlabel=Label(second_frame, text= \"Insert the link128:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink128= Entry(second_frame, width=100)\r\nlink128.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link128:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday128= Entry(second_frame)\r\nday128.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link128:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime128= Entry(second_frame)\r\ntime128.pack()\r\nlabel=Label(second_frame, text= \"Insert the link129:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink129= Entry(second_frame, width=100)\r\nlink129.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link129:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday129= Entry(second_frame)\r\nday129.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link129:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime129= Entry(second_frame)\r\ntime129.pack()\r\nlabel=Label(second_frame, text= \"Insert the link130:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink130= Entry(second_frame, width=100)\r\nlink130.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link130:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday130= Entry(second_frame)\r\nday130.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link130:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime130= Entry(second_frame)\r\ntime130.pack()\r\nlabel=Label(second_frame, text= \"Insert the link131:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink131= Entry(second_frame, width=100)\r\nlink131.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link131:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday131= Entry(second_frame)\r\nday131.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link131:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime131= Entry(second_frame)\r\ntime131.pack()\r\nlabel=Label(second_frame, text= \"Insert the link132:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink132= Entry(second_frame, width=100)\r\nlink132.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link132:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday132= Entry(second_frame)\r\nday132.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link132:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime132= Entry(second_frame)\r\ntime132.pack()\r\nlabel=Label(second_frame, text= \"Insert the link133:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink133= Entry(second_frame, width=100)\r\nlink133.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link133:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday133= Entry(second_frame)\r\nday133.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link133:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime133= Entry(second_frame)\r\ntime133.pack()\r\nlabel=Label(second_frame, text= \"Insert the link134:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink134= Entry(second_frame, width=100)\r\nlink134.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link134:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday134= Entry(second_frame)\r\nday134.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link134:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime134= Entry(second_frame)\r\ntime134.pack()\r\nlabel=Label(second_frame, text= \"Insert the link135:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink135= Entry(second_frame, width=100)\r\nlink135.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link135:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday135= Entry(second_frame)\r\nday135.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link135:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime135= Entry(second_frame)\r\ntime135.pack()\r\nlabel=Label(second_frame, text= \"Insert the link136:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink136= Entry(second_frame, width=100)\r\nlink136.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link136:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday136= Entry(second_frame)\r\nday136.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link136:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime136= Entry(second_frame)\r\ntime136.pack()\r\nlabel=Label(second_frame, text= \"Insert the link137:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink137= Entry(second_frame, width=100)\r\nlink137.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link137:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday137= Entry(second_frame)\r\nday137.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link137:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime137= Entry(second_frame)\r\ntime137.pack()\r\nlabel=Label(second_frame, text= \"Insert the link138:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink138= Entry(second_frame, width=100)\r\nlink138.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link138:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday138= Entry(second_frame)\r\nday138.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link138:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime138= Entry(second_frame)\r\ntime138.pack()\r\nlabel=Label(second_frame, text= \"Insert the link139:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink139= Entry(second_frame, width=100)\r\nlink139.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link139:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday139= Entry(second_frame)\r\nday139.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link139:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime139= Entry(second_frame)\r\ntime139.pack()\r\nlabel=Label(second_frame, text= \"Insert the link140:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink140= Entry(second_frame, width=100)\r\nlink140.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link140:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday140= Entry(second_frame)\r\nday140.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link140:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime140= Entry(second_frame)\r\ntime140.pack()\r\nlabel=Label(second_frame, text= \"Insert the link141:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink141= Entry(second_frame, width=100)\r\nlink141.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link141:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday141= Entry(second_frame)\r\nday141.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link141:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime141= Entry(second_frame)\r\ntime141.pack()\r\nlabel=Label(second_frame, text= \"Insert the link142:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink142= Entry(second_frame, width=100)\r\nlink142.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link142:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday142= Entry(second_frame)\r\nday142.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link142:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime142= Entry(second_frame)\r\ntime142.pack()\r\nlabel=Label(second_frame, text= \"Insert the link143:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink143= Entry(second_frame, width=100)\r\nlink143.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link143:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday143= Entry(second_frame)\r\nday143.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link143:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime143= Entry(second_frame)\r\ntime143.pack()\r\nlabel=Label(second_frame, text= \"Insert the link144:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink144= Entry(second_frame, width=100)\r\nlink144.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link144:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday144= Entry(second_frame)\r\nday144.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link144:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime144= Entry(second_frame)\r\ntime144.pack()\r\nlabel=Label(second_frame, text= \"Insert the link145:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink145= Entry(second_frame, width=100)\r\nlink145.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link145:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday145= Entry(second_frame)\r\nday145.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link145:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime145= Entry(second_frame)\r\ntime145.pack()\r\nlabel=Label(second_frame, text= \"Insert the link146:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink146= Entry(second_frame, width=100)\r\nlink146.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link146:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday146= Entry(second_frame)\r\nday146.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link146:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime146= Entry(second_frame)\r\ntime146.pack()\r\nlabel=Label(second_frame, text= \"Insert the link147:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink147= Entry(second_frame, width=100)\r\nlink147.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link147:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday147= Entry(second_frame)\r\nday147.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link147:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime147= Entry(second_frame)\r\ntime147.pack()\r\nlabel=Label(second_frame, text= \"Insert the link148:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink148= Entry(second_frame, width=100)\r\nlink148.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link148:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday148= Entry(second_frame)\r\nday148.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link148:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime148= Entry(second_frame)\r\ntime148.pack()\r\nlabel=Label(second_frame, text= \"Insert the link149:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink149= Entry(second_frame, width=100)\r\nlink149.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link149:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday149= Entry(second_frame)\r\nday149.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link149:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime149= Entry(second_frame)\r\ntime149.pack()\r\nlabel=Label(second_frame, text= \"Insert the link150:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink150= Entry(second_frame, width=100)\r\nlink150.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link150:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday150= Entry(second_frame)\r\nday150.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link150:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime150= Entry(second_frame)\r\ntime150.pack()\r\nlabel=Label(second_frame, text= \"Insert the link151:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink151= Entry(second_frame, width=100)\r\nlink151.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link151:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday151= Entry(second_frame)\r\nday151.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link151:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime151= Entry(second_frame)\r\ntime151.pack()\r\nlabel=Label(second_frame, text= \"Insert the link152:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink152= Entry(second_frame, width=100)\r\nlink152.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link152:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday152= Entry(second_frame)\r\nday152.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link152:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime152= Entry(second_frame)\r\ntime152.pack()\r\nlabel=Label(second_frame, text= \"Insert the link153:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink153= Entry(second_frame, width=100)\r\nlink153.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link153:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday153= Entry(second_frame)\r\nday153.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link153:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime153= Entry(second_frame)\r\ntime153.pack()\r\nlabel=Label(second_frame, text= \"Insert the link154:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink154= Entry(second_frame, width=100)\r\nlink154.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link154:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday154= Entry(second_frame)\r\nday154.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link154:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime154= Entry(second_frame)\r\ntime154.pack()\r\nlabel=Label(second_frame, text= \"Insert the link155:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink155= Entry(second_frame, width=100)\r\nlink155.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link155:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday155= Entry(second_frame)\r\nday155.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link155:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime155= Entry(second_frame)\r\ntime155.pack()\r\nlabel=Label(second_frame, text= \"Insert the link156:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink156= Entry(second_frame, width=100)\r\nlink156.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link156:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday156= Entry(second_frame)\r\nday156.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link156:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime156= Entry(second_frame)\r\ntime156.pack()\r\nlabel=Label(second_frame, text= \"Insert the link157:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink157= Entry(second_frame, width=100)\r\nlink157.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link157:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday157= Entry(second_frame)\r\nday157.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link157:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime157= Entry(second_frame)\r\ntime157.pack()\r\nlabel=Label(second_frame, text= \"Insert the link158:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink158= Entry(second_frame, width=100)\r\nlink158.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link158:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday158= Entry(second_frame)\r\nday158.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link158:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime158= Entry(second_frame)\r\ntime158.pack()\r\nlabel=Label(second_frame, text= \"Insert the link159:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink159= Entry(second_frame, width=100)\r\nlink159.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link159:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday159= Entry(second_frame)\r\nday159.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link159:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime159= Entry(second_frame)\r\ntime159.pack()\r\nlabel=Label(second_frame, text= \"Insert the link160:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink160= Entry(second_frame, width=100)\r\nlink160.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link160:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday160= Entry(second_frame)\r\nday160.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link160:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime160= Entry(second_frame)\r\ntime160.pack()\r\nlabel=Label(second_frame, text= \"Insert the link161:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink161= Entry(second_frame, width=100)\r\nlink61.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link161:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday161= Entry(second_frame)\r\nday161.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link161:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime161= Entry(second_frame)\r\ntime161.pack()\r\nlabel=Label(second_frame, text= \"Insert the link162:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink162= Entry(second_frame, width=100)\r\nlink162.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link162:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday162= Entry(second_frame)\r\nday162.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link162:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime162= Entry(second_frame)\r\ntime162.pack()\r\nlabel=Label(second_frame, text= \"Insert the link163:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink163= Entry(second_frame, width=100)\r\nlink63.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link163:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday163= Entry(second_frame)\r\nday163.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link163:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime163= Entry(second_frame)\r\ntime163.pack()\r\nlabel=Label(second_frame, text= \"Insert the link164:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink164= Entry(second_frame, width=100)\r\nlink164.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link164:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday164= Entry(second_frame)\r\nday164.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link164:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime164= Entry(second_frame)\r\ntime164.pack()\r\nlabel=Label(second_frame, text= \"Insert the link165:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink165= Entry(second_frame, width=100)\r\nlink165.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link165:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday165= Entry(second_frame)\r\nday165.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link165:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime165= Entry(second_frame)\r\ntime165.pack()\r\nlabel=Label(second_frame, text= \"Insert the link166:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink166= Entry(second_frame, width=100)\r\nlink166.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link166:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday166= Entry(second_frame)\r\nday166.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link166:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime166= Entry(second_frame)\r\ntime166.pack()\r\nlabel=Label(second_frame, text= \"Insert the link167:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink167= Entry(second_frame, width=100)\r\nlink167.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link167:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday167= Entry(second_frame)\r\nday167.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link167:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime167= Entry(second_frame)\r\ntime167.pack()\r\nlabel=Label(second_frame, text= \"Insert the link168:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink168= Entry(second_frame, width=100)\r\nlink168.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link168:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday168= Entry(second_frame)\r\nday168.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link168:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime168= Entry(second_frame)\r\ntime168.pack()\r\nlabel=Label(second_frame, text= \"Insert the link169:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink169= Entry(second_frame, width=100)\r\nlink169.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link169:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday169= Entry(second_frame)\r\nday169.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link169:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime169= Entry(second_frame)\r\ntime169.pack()\r\nlabel=Label(second_frame, text= \"Insert the link170:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink170= Entry(second_frame, width=100)\r\nlink170.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link170:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday170= Entry(second_frame)\r\nday170.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link170:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime170= Entry(second_frame)\r\ntime170.pack()\r\nlabel=Label(second_frame, text= \"Insert the link171:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink171= Entry(second_frame, width=100)\r\nlink171.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link171:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday171= Entry(second_frame)\r\nday171.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link171:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime171= Entry(second_frame)\r\ntime171.pack()\r\nlabel=Label(second_frame, text= \"Insert the link172:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink172= Entry(second_frame, width=100)\r\nlink172.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link172:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday172= Entry(second_frame)\r\nday172.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link172:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime172= Entry(second_frame)\r\ntime172.pack()\r\nlabel=Label(second_frame, text= \"Insert the link173:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink173= Entry(second_frame, width=100)\r\nlink173.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link173:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday173= Entry(second_frame)\r\nday173.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link173:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime173= Entry(second_frame)\r\ntime173.pack()\r\nlabel=Label(second_frame, text= \"Insert the link174:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink174= Entry(second_frame, width=100)\r\nlink174.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link174:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday174= Entry(second_frame)\r\nday174.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link174:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime174= Entry(second_frame)\r\ntime174.pack()\r\nlabel=Label(second_frame, text= \"Insert the link175:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink175= Entry(second_frame, width=100)\r\nlink175.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link175:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday175= Entry(second_frame)\r\nday175.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link175:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime175= Entry(second_frame)\r\ntime175.pack()\r\nlabel=Label(second_frame, text= \"Insert the link176:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink176= Entry(second_frame, width=100)\r\nlink176.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link176:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday176= Entry(second_frame)\r\nday176.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link176:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime176= Entry(second_frame)\r\ntime176.pack()\r\nlabel=Label(second_frame, text= \"Insert the link177:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink177= Entry(second_frame, width=100)\r\nlink177.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link177:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday177= Entry(second_frame)\r\nday177.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link177:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime177= Entry(second_frame)\r\ntime177.pack()\r\nlabel=Label(second_frame, text= \"Insert the link178:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink178= Entry(second_frame, width=100)\r\nlink178.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link178:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday178= Entry(second_frame)\r\nday178.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link178:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime178= Entry(second_frame)\r\ntime178.pack()\r\nlabel=Label(second_frame, text= \"Insert the link179:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink179= Entry(second_frame, width=100)\r\nlink179.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link179:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday179= Entry(second_frame)\r\nday179.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link179:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime179= Entry(second_frame)\r\ntime179.pack()\r\nlabel=Label(second_frame, text= \"Insert the link180:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink180= Entry(second_frame, width=100)\r\nlink180.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link180:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday180= Entry(second_frame)\r\nday180.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link180:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime180= Entry(second_frame)\r\ntime180.pack()\r\nlabel=Label(second_frame, text= \"Insert the link181:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink181= Entry(second_frame, width=100)\r\nlink181.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link181:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday181= Entry(second_frame)\r\nday181.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link181:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime181= Entry(second_frame)\r\ntime181.pack()\r\nlabel=Label(second_frame, text= \"Insert the link182:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink182= Entry(second_frame, width=100)\r\nlink182.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link182:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday182= Entry(second_frame)\r\nday182.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link182:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime182= Entry(second_frame)\r\ntime182.pack()\r\nlabel=Label(second_frame, text= \"Insert the link183:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink183= Entry(second_frame, width=100)\r\nlink183.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link183:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday183= Entry(second_frame)\r\nday183.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link183:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime183= Entry(second_frame)\r\ntime183.pack()\r\nlabel=Label(second_frame, text= \"Insert the link184:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink184= Entry(second_frame, width=100)\r\nlink184.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link184:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday184= Entry(second_frame)\r\nday184.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link184:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime184= Entry(second_frame)\r\ntime184.pack()\r\nlabel=Label(second_frame, text= \"Insert the link185:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink185= Entry(second_frame, width=100)\r\nlink185.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link185:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday185= Entry(second_frame)\r\nday185.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link185:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime185= Entry(second_frame)\r\ntime185.pack()\r\nlabel=Label(second_frame, text= \"Insert the link186:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink186= Entry(second_frame, width=100)\r\nlink186.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link186:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday186= Entry(second_frame)\r\nday186.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link186:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime186= Entry(second_frame)\r\ntime186.pack()\r\nlabel=Label(second_frame, text= \"Insert the link187:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink187= Entry(second_frame, width=100)\r\nlink187.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link187:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday187= Entry(second_frame)\r\nday187.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link187:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime187= Entry(second_frame)\r\ntime187.pack()\r\nlabel=Label(second_frame, text= \"Insert the link188:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink188= Entry(second_frame, width=100)\r\nlink188.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link188:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday188= Entry(second_frame)\r\nday188.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link188:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime188= Entry(second_frame)\r\ntime188.pack()\r\nlabel=Label(second_frame, text= \"Insert the link189:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink189= Entry(second_frame, width=100)\r\nlink189.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link189:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday189= Entry(second_frame)\r\nday189.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link189:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime189= Entry(second_frame)\r\ntime189.pack()\r\nlabel=Label(second_frame, text= \"Insert the link190:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink190= Entry(second_frame, width=100)\r\nlink190.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link190:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday190= Entry(second_frame)\r\nday190.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link190:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime190= Entry(second_frame)\r\ntime190.pack()\r\nlabel=Label(second_frame, text= \"Insert the link191:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink191= Entry(second_frame, width=100)\r\nlink191.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link191:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday191= Entry(second_frame)\r\nday191.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link191:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime191= Entry(second_frame)\r\ntime191.pack()\r\nlabel=Label(second_frame, text= \"Insert the link192:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink192= Entry(second_frame, width=100)\r\nlink192.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link192:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday192= Entry(second_frame)\r\nday192.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link192:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime192= Entry(second_frame)\r\ntime192.pack()\r\nlabel=Label(second_frame, text= \"Insert the link193:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink193= Entry(second_frame, width=100)\r\nlink193.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link193:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday193= Entry(second_frame)\r\nday193.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link193:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime193= Entry(second_frame)\r\ntime193.pack()\r\nlabel=Label(second_frame, text= \"Insert the link194:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink194= Entry(second_frame, width=100)\r\nlink194.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link194:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday194= Entry(second_frame)\r\nday194.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link194:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime194= Entry(second_frame)\r\ntime194.pack()\r\nlabel=Label(second_frame, text= \"Insert the link195:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink195= Entry(second_frame, width=100)\r\nlink195.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link195:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday195= Entry(second_frame)\r\nday195.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link195:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime195= Entry(second_frame)\r\ntime195.pack()\r\nlabel=Label(second_frame, text= \"Insert the link196:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink196= Entry(second_frame, width=100)\r\nlink196.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link196:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday196= Entry(second_frame)\r\nday196.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link196:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime196= Entry(second_frame)\r\ntime196.pack()\r\nlabel=Label(second_frame, text= \"Insert the link197:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink197= Entry(second_frame, width=100)\r\nlink197.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link197:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday197= Entry(second_frame)\r\nday197.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link197:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime197= Entry(second_frame)\r\ntime197.pack()\r\nlabel=Label(second_frame, text= \"Insert the link198:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink198= Entry(second_frame, width=100)\r\nlink198.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link198:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday198= Entry(second_frame)\r\nday198.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link198:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime198= Entry(second_frame)\r\ntime198.pack()\r\nlabel=Label(second_frame, text= \"Insert the link199:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink199= Entry(second_frame, width=100)\r\nlink199.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link199:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday199= Entry(second_frame)\r\nday199.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link199:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime199= Entry(second_frame)\r\ntime199.pack()\r\nlabel=Label(second_frame, text= \"Insert the link200:\", font=(\"Calibri\", 12), fg ='blue')\r\nlabel.pack()\r\nlink200= Entry(second_frame, width=100)\r\nlink200.pack()\r\nlabel=Label(second_frame, text= \"Insert the day you want to open the link200:\", font=(\"Calibri\", 12), fg ='orange')\r\nlabel.pack()\r\nday200= Entry(second_frame)\r\nday200.pack()\r\nlabel=Label(second_frame, text= \"Insert the time you want to open the link200:\", font=(\"Calibri\", 12), fg ='red')\r\nlabel.pack()\r\ntime200= Entry(second_frame)\r\ntime200.pack()\r\n\r\n\r\n\r\n\r\ndef job1():\r\n webbrowser.open (link1.get())\r\n \r\ndef job2():\r\n webbrowser.open (link2.get())\r\n \r\ndef job3():\r\n webbrowser.open (link3.get()) \r\n\r\ndef job4():\r\n webbrowser.open (link4.get())\r\n \r\ndef job5():\r\n webbrowser.open (link5.get())\r\n\r\ndef job6():\r\n webbrowser.open (link6.get())\r\n\r\ndef job7():\r\n webbrowser.open (link7.get())\r\n\r\ndef job8():\r\n webbrowser.open (link8.get())\r\n \r\ndef job9():\r\n webbrowser.open (link9.get())\r\n\r\ndef job10():\r\n webbrowser.open (link10.get())\r\n\r\ndef job11():\r\n webbrowser.open (link11.get())\r\n \r\ndef job12():\r\n webbrowser.open (link12.get())\r\n \r\ndef job13():\r\n webbrowser.open (link13.get()) \r\n\r\ndef job14():\r\n webbrowser.open (link14.get())\r\n \r\ndef job15():\r\n webbrowser.open (link15.get())\r\n\r\ndef job16():\r\n webbrowser.open (link16.get())\r\n\r\ndef job17():\r\n webbrowser.open (link17.get())\r\n\r\ndef job18():\r\n webbrowser.open (link18.get())\r\n \r\ndef job19():\r\n webbrowser.open (link19.get())\r\n\r\ndef job20():\r\n webbrowser.open (link20.get())\r\n\r\ndef job21():\r\n webbrowser.open (link21.get())\r\n \r\ndef job22():\r\n webbrowser.open (link22.get())\r\n \r\ndef job23():\r\n webbrowser.open (link23.get()) \r\n\r\ndef job24():\r\n webbrowser.open (link24.get())\r\n \r\ndef job25():\r\n webbrowser.open (link25.get())\r\n\r\ndef job26():\r\n webbrowser.open (link26.get())\r\n\r\ndef job27():\r\n webbrowser.open (link27.get())\r\n\r\ndef job28():\r\n webbrowser.open (link28.get())\r\n \r\ndef job29():\r\n webbrowser.open (link29.get())\r\n\r\ndef job30():\r\n webbrowser.open (link30.get())\r\n\r\ndef job31():\r\n webbrowser.open (link31.get())\r\n \r\ndef job32():\r\n webbrowser.open (link32.get())\r\n \r\ndef job33():\r\n webbrowser.open (link33.get()) \r\n\r\ndef job34():\r\n webbrowser.open (link34.get())\r\n \r\ndef job35():\r\n webbrowser.open (link35.get())\r\n\r\ndef job36():\r\n webbrowser.open (link36.get())\r\n\r\ndef job37():\r\n webbrowser.open (link37.get())\r\n\r\ndef job38():\r\n webbrowser.open (link38.get())\r\n \r\ndef job39():\r\n webbrowser.open (link39.get())\r\n\r\ndef job40():\r\n webbrowser.open (link40.get())\r\n\r\ndef job41():\r\n webbrowser.open (link41.get())\r\n \r\ndef job42():\r\n webbrowser.open (link42.get())\r\n \r\ndef job43():\r\n webbrowser.open (link43.get()) \r\n\r\ndef job44():\r\n webbrowser.open (link44.get())\r\n \r\ndef job45():\r\n webbrowser.open (link45.get())\r\n\r\ndef job46():\r\n webbrowser.open (link46.get())\r\n\r\ndef job47():\r\n webbrowser.open (link47.get())\r\n\r\ndef job48():\r\n webbrowser.open (link48.get())\r\n \r\ndef job49():\r\n webbrowser.open (link49.get())\r\n\r\ndef job50():\r\n webbrowser.open (link50.get())\r\n\r\ndef job51():\r\n webbrowser.open (link51.get())\r\n \r\ndef job52():\r\n webbrowser.open (link52.get())\r\n \r\ndef job53():\r\n webbrowser.open (link53.get()) \r\n\r\ndef job54():\r\n webbrowser.open (link54.get())\r\n \r\ndef job55():\r\n webbrowser.open (link55.get())\r\n\r\ndef job56():\r\n webbrowser.open (link56.get())\r\n\r\ndef job57():\r\n webbrowser.open (link57.get())\r\n\r\ndef job58():\r\n webbrowser.open (link58.get())\r\n \r\ndef job59():\r\n webbrowser.open (link59.get())\r\n\r\ndef job60():\r\n webbrowser.open (link60.get())\r\n\r\ndef job61():\r\n webbrowser.open (link61.get())\r\n \r\ndef job62():\r\n webbrowser.open (link62.get())\r\n \r\ndef job63():\r\n webbrowser.open (link63.get()) \r\n\r\ndef job64():\r\n webbrowser.open (link64.get())\r\n \r\ndef job65():\r\n webbrowser.open (link65.get())\r\n\r\ndef job66():\r\n webbrowser.open (link66.get())\r\n\r\ndef job67():\r\n webbrowser.open (link67.get())\r\n\r\ndef job68():\r\n webbrowser.open (link68.get())\r\n \r\ndef job69():\r\n webbrowser.open (link69.get())\r\n\r\ndef job70():\r\n webbrowser.open (link70.get())\r\n\r\ndef job71():\r\n webbrowser.open (link71.get())\r\n \r\ndef job72():\r\n webbrowser.open (link72.get())\r\n \r\ndef job73():\r\n webbrowser.open (link73.get()) \r\n\r\ndef job74():\r\n webbrowser.open (link74.get())\r\n \r\ndef job75():\r\n webbrowser.open (link75.get())\r\n\r\ndef job76():\r\n webbrowser.open (link76.get())\r\n\r\ndef job77():\r\n webbrowser.open (link77.get())\r\n\r\ndef job78():\r\n webbrowser.open (link78.get())\r\n \r\ndef job79():\r\n webbrowser.open (link79.get())\r\n\r\ndef job80():\r\n webbrowser.open (link80.get())\r\n\r\ndef job81():\r\n webbrowser.open (link81.get())\r\n \r\ndef job82():\r\n webbrowser.open (link82.get())\r\n \r\ndef job83():\r\n webbrowser.open (link83.get()) \r\n\r\ndef job84():\r\n webbrowser.open (link84.get())\r\n \r\ndef job85():\r\n webbrowser.open (link85.get())\r\n\r\ndef job86():\r\n webbrowser.open (link86.get())\r\n\r\ndef job87():\r\n webbrowser.open (link87.get())\r\n\r\ndef job88():\r\n webbrowser.open (link88.get())\r\n \r\ndef job89():\r\n webbrowser.open (link89.get())\r\n\r\ndef job90():\r\n webbrowser.open (link90.get())\r\n\r\ndef job91():\r\n webbrowser.open (link91.get())\r\n \r\ndef job92():\r\n webbrowser.open (link92.get())\r\n \r\ndef job93():\r\n webbrowser.open (link93.get()) \r\n\r\ndef job94():\r\n webbrowser.open (link94.get())\r\n \r\ndef job95():\r\n webbrowser.open (link95.get())\r\n\r\ndef job96():\r\n webbrowser.open (link96.get())\r\n\r\ndef job97():\r\n webbrowser.open (link97.get())\r\n\r\ndef job98():\r\n webbrowser.open (link98.get())\r\n \r\ndef job99():\r\n webbrowser.open (link99.get())\r\n\r\ndef job100():\r\n webbrowser.open (link100.get())\r\n\r\ndef job101():\r\n webbrowser.open (link101.get())\r\n \r\ndef job102():\r\n webbrowser.open (link102.get())\r\n \r\ndef job103():\r\n webbrowser.open (link103.get()) \r\n\r\ndef job104():\r\n webbrowser.open (link104.get())\r\n \r\ndef job105():\r\n webbrowser.open (link105.get())\r\n\r\ndef job106():\r\n webbrowser.open (link106.get())\r\n\r\ndef job107():\r\n webbrowser.open (link107.get())\r\n\r\ndef job108():\r\n webbrowser.open (link108.get())\r\n \r\ndef job109():\r\n webbrowser.open (link109.get())\r\n\r\ndef job110():\r\n webbrowser.open (link110.get())\r\n\r\ndef job111():\r\n webbrowser.open (link111.get())\r\n \r\ndef job112():\r\n webbrowser.open (link112.get())\r\n \r\ndef job113():\r\n webbrowser.open (link113.get()) \r\n\r\ndef job114():\r\n webbrowser.open (link114.get())\r\n \r\ndef job115():\r\n webbrowser.open (link115.get())\r\n\r\ndef job116():\r\n webbrowser.open (link116.get())\r\n\r\ndef job117():\r\n webbrowser.open (link117.get())\r\n\r\ndef job118():\r\n webbrowser.open (link118.get())\r\n \r\ndef job119():\r\n webbrowser.open (link119.get())\r\n\r\ndef job120():\r\n webbrowser.open (link120.get())\r\n\r\ndef job121():\r\n webbrowser.open (link121.get())\r\n \r\ndef job122():\r\n webbrowser.open (link122.get())\r\n \r\ndef job123():\r\n webbrowser.open (link123.get()) \r\n\r\ndef job124():\r\n webbrowser.open (link124.get())\r\n \r\ndef job125():\r\n webbrowser.open (link125.get())\r\n\r\ndef job126():\r\n webbrowser.open (link126.get())\r\n\r\ndef job127():\r\n webbrowser.open (link127.get())\r\n\r\ndef job128():\r\n webbrowser.open (link128.get())\r\n \r\ndef job129():\r\n webbrowser.open (link129.get())\r\n\r\ndef job130():\r\n webbrowser.open (link130.get())\r\n\r\ndef job131():\r\n webbrowser.open (link131.get())\r\n \r\ndef job132():\r\n webbrowser.open (link132.get())\r\n \r\ndef job133():\r\n webbrowser.open (link133.get()) \r\n\r\ndef job134():\r\n webbrowser.open (link134.get())\r\n \r\ndef job135():\r\n webbrowser.open (link135.get())\r\n\r\ndef job136():\r\n webbrowser.open (link136.get())\r\n\r\ndef job137():\r\n webbrowser.open (link137.get())\r\n\r\ndef job138():\r\n webbrowser.open (link138.get())\r\n \r\ndef job139():\r\n webbrowser.open (link139.get())\r\n\r\ndef job140():\r\n webbrowser.open (link140.get())\r\n\r\ndef job141():\r\n webbrowser.open (link141.get())\r\n \r\ndef job142():\r\n webbrowser.open (link142.get())\r\n \r\ndef job143():\r\n webbrowser.open (link143.get()) \r\n\r\ndef job144():\r\n webbrowser.open (link144.get())\r\n \r\ndef job145():\r\n webbrowser.open (link145.get())\r\n\r\ndef job146():\r\n webbrowser.open (link146.get())\r\n\r\ndef job147():\r\n webbrowser.open (link147.get())\r\n\r\ndef job148():\r\n webbrowser.open (link148.get())\r\n \r\ndef job149():\r\n webbrowser.open (link149.get())\r\n\r\ndef job150():\r\n webbrowser.open (link150.get())\r\n\r\ndef job151():\r\n webbrowser.open (link151.get())\r\n \r\ndef job152():\r\n webbrowser.open (link152.get())\r\n \r\ndef job153():\r\n webbrowser.open (link153.get()) \r\n\r\ndef job154():\r\n webbrowser.open (link154.get())\r\n \r\ndef job155():\r\n webbrowser.open (link155.get())\r\n\r\ndef job156():\r\n webbrowser.open (link156.get())\r\n\r\ndef job157():\r\n webbrowser.open (link157.get())\r\n\r\ndef job158():\r\n webbrowser.open (link158.get())\r\n \r\ndef job159():\r\n webbrowser.open (link159.get())\r\n\r\ndef job160():\r\n webbrowser.open (link160.get())\r\n\r\ndef job161():\r\n webbrowser.open (link161.get())\r\n \r\ndef job162():\r\n webbrowser.open (link162.get())\r\n \r\ndef job163():\r\n webbrowser.open (link163.get()) \r\n\r\ndef job164():\r\n webbrowser.open (link164.get())\r\n \r\ndef job165():\r\n webbrowser.open (link165.get())\r\n\r\ndef job166():\r\n webbrowser.open (link166.get())\r\n\r\ndef job167():\r\n webbrowser.open (link167.get())\r\n\r\ndef job168():\r\n webbrowser.open (link168.get())\r\n \r\ndef job169():\r\n webbrowser.open (link169.get())\r\n\r\ndef job170():\r\n webbrowser.open (link170.get())\r\n\r\ndef job171():\r\n webbrowser.open (link171.get())\r\n \r\ndef job172():\r\n webbrowser.open (link172.get())\r\n \r\ndef job173():\r\n webbrowser.open (link173.get()) \r\n\r\ndef job174():\r\n webbrowser.open (link174.get())\r\n \r\ndef job175():\r\n webbrowser.open (link175.get())\r\n\r\ndef job176():\r\n webbrowser.open (link176.get())\r\n\r\ndef job177():\r\n webbrowser.open (link177.get())\r\n\r\ndef job178():\r\n webbrowser.open (link178.get())\r\n \r\ndef job179():\r\n webbrowser.open (link179.get())\r\n\r\ndef job180():\r\n webbrowser.open (link180.get())\r\n\r\ndef job181():\r\n webbrowser.open (link181.get())\r\n \r\ndef job182():\r\n webbrowser.open (link182.get())\r\n \r\ndef job183():\r\n webbrowser.open (link183.get()) \r\n\r\ndef job184():\r\n webbrowser.open (link184.get())\r\n \r\ndef job185():\r\n webbrowser.open (link185.get())\r\n\r\ndef job186():\r\n webbrowser.open (link186.get())\r\n\r\ndef job187():\r\n webbrowser.open (link187.get())\r\n\r\ndef job188():\r\n webbrowser.open (link188.get())\r\n \r\ndef job189():\r\n webbrowser.open (link189.get())\r\n\r\ndef job190():\r\n webbrowser.open (link190.get())\r\n\r\ndef job191():\r\n webbrowser.open (link191.get())\r\n \r\ndef job192():\r\n webbrowser.open (link192.get())\r\n \r\ndef job193():\r\n webbrowser.open (link193.get()) \r\n\r\ndef job194():\r\n webbrowser.open (link194.get())\r\n \r\ndef job195():\r\n webbrowser.open (link195.get())\r\n\r\ndef job196():\r\n webbrowser.open (link196.get())\r\n\r\ndef job197():\r\n webbrowser.open (link197.get())\r\n\r\ndef job198():\r\n webbrowser.open (link198.get())\r\n \r\ndef job199():\r\n webbrowser.open (link199.get())\r\n\r\ndef job200():\r\n webbrowser.open (link200.get())\r\n\r\ndef job409():\r\n \r\n if day181.get()==\"1\":\r\n schedule.every().monday.at(time181.get()).do(job181)\r\n elif day181.get()==\"2\":\r\n schedule.every().tuesday.at(time181.get()).do(job181)\r\n elif day181.get()==\"3\":\r\n schedule.every().wednesday.at(time181.get()).do(job181)\r\n elif day181.get()==\"4\":\r\n schedule.every().thursday.at(time181.get()).do(job181)\r\n elif day181.get()==\"5\":\r\n schedule.every().friday.at(time181.get()).do(job181)\r\n elif day181.get()==\"6\":\r\n schedule.every().saturday.at(time181.get()).do(job181)\r\n elif day181.get()==\"7\":\r\n schedule.every().sunday.at(time181.get()).do(job181)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day182.get()==\"1\":\r\n schedule.every().monday.at(time182.get()).do(job182)\r\n elif day182.get()==\"2\":\r\n schedule.every().tuesday.at(time182.get()).do(job182)\r\n elif day182.get()==\"3\":\r\n schedule.every().wednesday.at(time182.get()).do(job182)\r\n elif day182.get()==\"4\":\r\n schedule.every().thursday.at(time182.get()).do(job182)\r\n elif day182.get()==\"5\":\r\n schedule.every().friday.at(time182.get()).do(job182)\r\n elif day182.get()==\"6\":\r\n schedule.every().saturday.at(time182.get()).do(job182)\r\n elif day182.get()==\"7\":\r\n schedule.every().sunday.at(time182.get()).do(job182)\r\n\r\n while True:\r\n schedule.run_pending() \r\n if day183.get()==\"1\":\r\n schedule.every().monday.at(time183.get()).do(job183)\r\n elif day183.get()==\"2\":\r\n schedule.every().tuesday.at(time183.get()).do(job183)\r\n elif day183.get()==\"3\":\r\n schedule.every().wednesday.at(time183.get()).do(job183)\r\n elif day183.get()==\"4\":\r\n schedule.every().thursday.at(time183.get()).do(job183)\r\n elif day183.get()==\"5\":\r\n schedule.every().friday.at(time183.get()).do(job183)\r\n elif day183.get()==\"6\":\r\n schedule.every().saturday.at(time183.get()).do(job183)\r\n elif day183.get()==\"7\":\r\n schedule.every().sunday.at(time183.get()).do(job183)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day184.get()==\"1\":\r\n schedule.every().monday.at(time184.get()).do(job184)\r\n elif day184.get()==\"2\":\r\n schedule.every().tuesday.at(time184.get()).do(job184)\r\n elif day184.get()==\"3\":\r\n schedule.every().wednesday.at(time184.get()).do(job184)\r\n elif day184.get()==\"4\":\r\n schedule.every().thursday.at(time184.get()).do(job184)\r\n elif day184.get()==\"5\":\r\n schedule.every().friday.at(time184.get()).do(job184)\r\n elif day184.get()==\"6\":\r\n schedule.every().saturday.at(time184.get()).do(job184)\r\n elif day184.get()==\"7\":\r\n schedule.every().sunday.at(time184.get()).do(job184)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day185.get()==\"1\":\r\n schedule.every().monday.at(time185.get()).do(job185)\r\n elif day185.get()==\"2\":\r\n schedule.every().tuesday.at(time185.get()).do(job185)\r\n elif day185.get()==\"3\":\r\n schedule.every().wednesday.at(time185.get()).do(job185)\r\n elif day185.get()==\"4\":\r\n schedule.every().thursday.at(time185.get()).do(job185)\r\n elif day185.get()==\"5\":\r\n schedule.every().friday.at(time185.get()).do(job185)\r\n elif day185.get()==\"6\":\r\n schedule.every().saturday.at(time185.get()).do(job185)\r\n elif day185.get()==\"7\":\r\n schedule.every().sunday.at(time185.get()).do(job185)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day186.get()==\"1\":\r\n schedule.every().monday.at(time186.get()).do(job186)\r\n elif day186.get()==\"2\":\r\n schedule.every().tuesday.at(time186.get()).do(job186)\r\n elif day186.get()==\"3\":\r\n schedule.every().wednesday.at(time186.get()).do(job186)\r\n elif day186.get()==\"4\":\r\n schedule.every().thursday.at(time186.get()).do(job186)\r\n elif day186.get()==\"5\":\r\n schedule.every().friday.at(time186.get()).do(job186)\r\n elif day186.get()==\"6\":\r\n schedule.every().saturday.at(time186.get()).do(job186)\r\n elif day186.get()==\"7\":\r\n schedule.every().sunday.at(time186.get()).do(job186)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day187.get()==\"1\":\r\n schedule.every().monday.at(time187.get()).do(job187)\r\n elif day187.get()==\"2\":\r\n schedule.every().tuesday.at(time187.get()).do(job187)\r\n elif day187.get()==\"3\":\r\n schedule.every().wednesday.at(time187.get()).do(job187)\r\n elif day187.get()==\"4\":\r\n schedule.every().thursday.at(time187.get()).do(job187)\r\n elif day187.get()==\"5\":\r\n schedule.every().friday.at(time187.get()).do(job187)\r\n elif day187.get()==\"6\":\r\n schedule.every().saturday.at(time187.get()).do(job187)\r\n elif day187.get()==\"7\":\r\n schedule.every().sunday.at(time187.get()).do(job187)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day188.get()==\"1\":\r\n schedule.every().monday.at(time188.get()).do(job188)\r\n elif day188.get()==\"2\":\r\n schedule.every().tuesday.at(time188.get()).do(job188)\r\n elif day188.get()==\"3\":\r\n schedule.every().wednesday.at(time188.get()).do(job188)\r\n elif day188.get()==\"4\":\r\n schedule.every().thursday.at(time188.get()).do(job188)\r\n elif day188.get()==\"5\":\r\n schedule.every().friday.at(time188.get()).do(job188)\r\n elif day188.get()==\"6\":\r\n schedule.every().saturday.at(time188.get()).do(job188)\r\n elif day188.get()==\"7\":\r\n schedule.every().sunday.at(time188.get()).do(job188)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day189.get()==\"1\":\r\n schedule.every().monday.at(time189.get()).do(job189)\r\n elif day189.get()==\"2\":\r\n schedule.every().tuesday.at(time189.get()).do(job189)\r\n elif day189.get()==\"3\":\r\n schedule.every().wednesday.at(time189.get()).do(job189)\r\n elif day189.get()==\"4\":\r\n schedule.every().thursday.at(time189.get()).do(job189)\r\n elif day189.get()==\"5\":\r\n schedule.every().friday.at(time189.get()).do(job189)\r\n elif day189.get()==\"6\":\r\n schedule.every().saturday.at(time189.get()).do(job189)\r\n elif day189.get()==\"7\":\r\n schedule.every().sunday.at(time189.get()).do(job189)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day190.get()==\"1\":\r\n schedule.every().monday.at(time190.get()).do(job190)\r\n elif day190.get()==\"2\":\r\n schedule.every().tuesday.at(time190.get()).do(job190)\r\n elif day190.get()==\"3\":\r\n schedule.every().wednesday.at(time190.get()).do(job190)\r\n elif day190.get()==\"4\":\r\n schedule.every().thursday.at(time190.get()).do(job190)\r\n elif day190.get()==\"5\":\r\n schedule.every().friday.at(time190.get()).do(job190)\r\n elif day190.get()==\"6\":\r\n schedule.every().saturday.at(time190.get()).do(job190)\r\n elif day190.get()==\"7\":\r\n schedule.every().sunday.at(time190.get()).do(job190)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day191.get()==\"1\":\r\n schedule.every().monday.at(time191.get()).do(job191)\r\n elif day191.get()==\"2\":\r\n schedule.every().tuesday.at(time191.get()).do(job191)\r\n elif day191.get()==\"3\":\r\n schedule.every().wednesday.at(time191.get()).do(job191)\r\n elif day191.get()==\"4\":\r\n schedule.every().thursday.at(time191.get()).do(job191)\r\n elif day191.get()==\"5\":\r\n schedule.every().friday.at(time191.get()).do(job191)\r\n elif day191.get()==\"6\":\r\n schedule.every().saturday.at(time191.get()).do(job191)\r\n elif day191.get()==\"7\":\r\n schedule.every().sunday.at(time191.get()).do(job191)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day192.get()==\"1\":\r\n schedule.every().monday.at(time192.get()).do(job192)\r\n elif day192.get()==\"2\":\r\n schedule.every().tuesday.at(time192.get()).do(job192)\r\n elif day192.get()==\"3\":\r\n schedule.every().wednesday.at(time192.get()).do(job192)\r\n elif day192.get()==\"4\":\r\n schedule.every().thursday.at(time192.get()).do(job192)\r\n elif day192.get()==\"5\":\r\n schedule.every().friday.at(time192.get()).do(job192)\r\n elif day192.get()==\"6\":\r\n schedule.every().saturday.at(time192.get()).do(job192)\r\n elif day192.get()==\"7\":\r\n schedule.every().sunday.at(time192.get()).do(job192)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day193.get()==\"1\":\r\n schedule.every().monday.at(time193.get()).do(job193)\r\n elif day193.get()==\"2\":\r\n schedule.every().tuesday.at(time193.get()).do(job193)\r\n elif day193.get()==\"3\":\r\n schedule.every().wednesday.at(time193.get()).do(job193)\r\n elif day193.get()==\"4\":\r\n schedule.every().thursday.at(time193.get()).do(job193)\r\n elif day193.get()==\"5\":\r\n schedule.every().friday.at(time193.get()).do(job193)\r\n elif day193.get()==\"6\":\r\n schedule.every().saturday.at(time193.get()).do(job193)\r\n elif day193.get()==\"7\":\r\n schedule.every().sunday.at(time193.get()).do(job193)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day194.get()==\"1\":\r\n schedule.every().monday.at(time194.get()).do(job194)\r\n elif day194.get()==\"2\":\r\n schedule.every().tuesday.at(time194.get()).do(job194)\r\n elif day194.get()==\"3\":\r\n schedule.every().wednesday.at(time194.get()).do(job194)\r\n elif day194.get()==\"4\":\r\n schedule.every().thursday.at(time194.get()).do(job194)\r\n elif day194.get()==\"5\":\r\n schedule.every().friday.at(time194.get()).do(job194)\r\n elif day194.get()==\"6\":\r\n schedule.every().saturday.at(time194.get()).do(job194)\r\n elif day194.get()==\"7\":\r\n schedule.every().sunday.at(time194.get()).do(job194)\r\n\r\n while True:\r\n schedule.run_pending() \r\n if day195.get()==\"1\":\r\n schedule.every().monday.at(time195.get()).do(job195)\r\n elif day195.get()==\"2\":\r\n schedule.every().tuesday.at(time195.get()).do(job195)\r\n elif day195.get()==\"3\":\r\n schedule.every().wednesday.at(time195.get()).do(job195)\r\n elif day195.get()==\"4\":\r\n schedule.every().thursday.at(time195.get()).do(job195)\r\n elif day195.get()==\"5\":\r\n schedule.every().friday.at(time195.get()).do(job195)\r\n elif day195.get()==\"6\":\r\n schedule.every().saturday.at(time195.get()).do(job195)\r\n elif day195.get()==\"7\":\r\n schedule.every().sunday.at(time195.get()).do(job195)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day196.get()==\"1\":\r\n schedule.every().monday.at(time196.get()).do(job196)\r\n elif day196.get()==\"2\":\r\n schedule.every().tuesday.at(time196.get()).do(job196)\r\n elif day196.get()==\"3\":\r\n schedule.every().wednesday.at(time196.get()).do(job196)\r\n elif day196.get()==\"4\":\r\n schedule.every().thursday.at(time196.get()).do(job196)\r\n elif day196.get()==\"5\":\r\n schedule.every().friday.at(time196.get()).do(job196)\r\n elif day196.get()==\"6\":\r\n schedule.every().saturday.at(time196.get()).do(job196)\r\n elif day196.get()==\"7\":\r\n schedule.every().sunday.at(time196.get()).do(job196)\r\n\r\n while True:\r\n schedule.run_pending() \r\n if day197.get()==\"1\":\r\n schedule.every().monday.at(time197.get()).do(job197)\r\n elif day197.get()==\"2\":\r\n schedule.every().tuesday.at(time197.get()).do(job197)\r\n elif day197.get()==\"3\":\r\n schedule.every().wednesday.at(time197.get()).do(job197)\r\n elif day197.get()==\"4\":\r\n schedule.every().thursday.at(time197.get()).do(job197)\r\n elif day197.get()==\"5\":\r\n schedule.every().friday.at(time197.get()).do(job197)\r\n elif day197.get()==\"6\":\r\n schedule.every().saturday.at(time197.get()).do(job197)\r\n elif day197.get()==\"7\":\r\n schedule.every().sunday.at(time197.get()).do(job197)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day198.get()==\"1\":\r\n schedule.every().monday.at(time198.get()).do(job198)\r\n elif day198.get()==\"2\":\r\n schedule.every().tuesday.at(time198.get()).do(job198)\r\n elif day198.get()==\"3\":\r\n schedule.every().wednesday.at(time198.get()).do(job198)\r\n elif day198.get()==\"4\":\r\n schedule.every().thursday.at(time198.get()).do(job198)\r\n elif day198.get()==\"5\":\r\n schedule.every().friday.at(time198.get()).do(job198)\r\n elif day198.get()==\"6\":\r\n schedule.every().saturday.at(time198.get()).do(job198)\r\n elif day198.get()==\"7\":\r\n schedule.every().sunday.at(time198.get()).do(job198)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day199.get()==\"1\":\r\n schedule.every().monday.at(time199.get()).do(job199)\r\n elif day199.get()==\"2\":\r\n schedule.every().tuesday.at(time199.get()).do(job199)\r\n elif day199.get()==\"3\":\r\n schedule.every().wednesday.at(time199.get()).do(job199)\r\n elif day199.get()==\"4\":\r\n schedule.every().thursday.at(time199.get()).do(job199)\r\n elif day199.get()==\"5\":\r\n schedule.every().friday.at(time199.get()).do(job199)\r\n elif day199.get()==\"6\":\r\n schedule.every().saturday.at(time199.get()).do(job199)\r\n elif day199.get()==\"7\":\r\n schedule.every().sunday.at(time199.get()).do(job199)\r\n\r\n while True:\r\n schedule.run_pending() \r\n if day200.get()==\"1\":\r\n schedule.every().monday.at(time200.get()).do(job200)\r\n elif day200.get()==\"2\":\r\n schedule.every().tuesday.at(time200.get()).do(job200)\r\n elif day200.get()==\"3\":\r\n schedule.every().wednesday.at(time200.get()).do(job200)\r\n elif day200.get()==\"4\":\r\n schedule.every().thursday.at(time200.get()).do(job200)\r\n elif day200.get()==\"5\":\r\n schedule.every().friday.at(time200.get()).do(job200)\r\n elif day200.get()==\"6\":\r\n schedule.every().saturday.at(time200.get()).do(job200)\r\n elif day200.get()==\"7\":\r\n schedule.every().sunday.at(time200.get()).do(job200)\r\n\r\n while True:\r\n schedule.run_pending()\r\n \r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\ndef job408():\r\n \r\n if day161.get()==\"1\":\r\n schedule.every().monday.at(time161.get()).do(job161)\r\n elif day161.get()==\"2\":\r\n schedule.every().tuesday.at(time161.get()).do(job161)\r\n elif day161.get()==\"3\":\r\n schedule.every().wednesday.at(time161.get()).do(job161)\r\n elif day161.get()==\"4\":\r\n schedule.every().thursday.at(time161.get()).do(job161)\r\n elif day161.get()==\"5\":\r\n schedule.every().friday.at(time161.get()).do(job161)\r\n elif day161.get()==\"6\":\r\n schedule.every().saturday.at(time161.get()).do(job161)\r\n elif day161.get()==\"7\":\r\n schedule.every().sunday.at(time161.get()).do(job161)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day162.get()==\"1\":\r\n schedule.every().monday.at(time162.get()).do(job162)\r\n elif day162.get()==\"2\":\r\n schedule.every().tuesday.at(time162.get()).do(job162)\r\n elif day162.get()==\"3\":\r\n schedule.every().wednesday.at(time162.get()).do(job162)\r\n elif day162.get()==\"4\":\r\n schedule.every().thursday.at(time162.get()).do(job162)\r\n elif day162.get()==\"5\":\r\n schedule.every().friday.at(time162.get()).do(job162)\r\n elif day162.get()==\"6\":\r\n schedule.every().saturday.at(time162.get()).do(job162)\r\n elif day162.get()==\"7\":\r\n schedule.every().sunday.at(time162.get()).do(job162)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day163.get()==\"1\":\r\n schedule.every().monday.at(time163.get()).do(job163)\r\n elif day163.get()==\"2\":\r\n schedule.every().tuesday.at(time163.get()).do(job163)\r\n elif day163.get()==\"3\":\r\n schedule.every().wednesday.at(time163.get()).do(job163)\r\n elif day163.get()==\"4\":\r\n schedule.every().thursday.at(time163.get()).do(job163)\r\n elif day163.get()==\"5\":\r\n schedule.every().friday.at(time163.get()).do(job163)\r\n elif day163.get()==\"6\":\r\n schedule.every().saturday.at(time163.get()).do(job163)\r\n elif day163.get()==\"7\":\r\n schedule.every().sunday.at(time163.get()).do(job163)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day164.get()==\"1\":\r\n schedule.every().monday.at(time164.get()).do(job164)\r\n elif day164.get()==\"2\":\r\n schedule.every().tuesday.at(time164.get()).do(job164)\r\n elif day164.get()==\"3\":\r\n schedule.every().wednesday.at(time164.get()).do(job164)\r\n elif day164.get()==\"4\":\r\n schedule.every().thursday.at(time164.get()).do(job164)\r\n elif day164.get()==\"5\":\r\n schedule.every().friday.at(time164.get()).do(job164)\r\n elif day164.get()==\"6\":\r\n schedule.every().saturday.at(time164.get()).do(job164)\r\n elif day164.get()==\"7\":\r\n schedule.every().sunday.at(time164.get()).do(job164)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day165.get()==\"1\":\r\n schedule.every().monday.at(time165.get()).do(job165)\r\n elif day165.get()==\"2\":\r\n schedule.every().tuesday.at(time165.get()).do(job165)\r\n elif day165.get()==\"3\":\r\n schedule.every().wednesday.at(time165.get()).do(job165)\r\n elif day165.get()==\"4\":\r\n schedule.every().thursday.at(time165.get()).do(job165)\r\n elif day165.get()==\"5\":\r\n schedule.every().friday.at(time165.get()).do(job165)\r\n elif day165.get()==\"6\":\r\n schedule.every().saturday.at(time165.get()).do(job165)\r\n elif day165.get()==\"7\":\r\n schedule.every().sunday.at(time165.get()).do(job165)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day166.get()==\"1\":\r\n schedule.every().monday.at(time166.get()).do(job166)\r\n elif day166.get()==\"2\":\r\n schedule.every().tuesday.at(time166.get()).do(job166)\r\n elif day166.get()==\"3\":\r\n schedule.every().wednesday.at(time166.get()).do(job166)\r\n elif day166.get()==\"4\":\r\n schedule.every().thursday.at(time166.get()).do(job166)\r\n elif day166.get()==\"5\":\r\n schedule.every().friday.at(time166.get()).do(job166)\r\n elif day166.get()==\"6\":\r\n schedule.every().saturday.at(time166.get()).do(job166)\r\n elif day166.get()==\"7\":\r\n schedule.every().sunday.at(time166.get()).do(job166)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day167.get()==\"1\":\r\n schedule.every().monday.at(time167.get()).do(job167)\r\n elif day167.get()==\"2\":\r\n schedule.every().tuesday.at(time167.get()).do(job167)\r\n elif day167.get()==\"3\":\r\n schedule.every().wednesday.at(time167.get()).do(job167)\r\n elif day167.get()==\"4\":\r\n schedule.every().thursday.at(time167.get()).do(job167)\r\n elif day167.get()==\"5\":\r\n schedule.every().friday.at(time167.get()).do(job167)\r\n elif day167.get()==\"6\":\r\n schedule.every().saturday.at(time167.get()).do(job167)\r\n elif day167.get()==\"7\":\r\n schedule.every().sunday.at(time167.get()).do(job167)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day168.get()==\"1\":\r\n schedule.every().monday.at(time168.get()).do(job168)\r\n elif day168.get()==\"2\":\r\n schedule.every().tuesday.at(time168.get()).do(job168)\r\n elif day168.get()==\"3\":\r\n schedule.every().wednesday.at(time168.get()).do(job168)\r\n elif day168.get()==\"4\":\r\n schedule.every().thursday.at(time168.get()).do(job168)\r\n elif day168.get()==\"5\":\r\n schedule.every().friday.at(time168.get()).do(job168)\r\n elif day168.get()==\"6\":\r\n schedule.every().saturday.at(time168.get()).do(job168)\r\n elif day168.get()==\"7\":\r\n schedule.every().sunday.at(time168.get()).do(job168)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day169.get()==\"1\":\r\n schedule.every().monday.at(time169.get()).do(job169)\r\n elif day169.get()==\"2\":\r\n schedule.every().tuesday.at(time169.get()).do(job169)\r\n elif day169.get()==\"3\":\r\n schedule.every().wednesday.at(time169.get()).do(job169)\r\n elif day169.get()==\"4\":\r\n schedule.every().thursday.at(time169.get()).do(job169)\r\n elif day169.get()==\"5\":\r\n schedule.every().friday.at(time169.get()).do(job169)\r\n elif day169.get()==\"6\":\r\n schedule.every().saturday.at(time169.get()).do(job169)\r\n elif day169.get()==\"7\":\r\n schedule.every().sunday.at(time169.get()).do(job169)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day170.get()==\"1\":\r\n schedule.every().monday.at(time170.get()).do(job170)\r\n elif day170.get()==\"2\":\r\n schedule.every().tuesday.at(time170.get()).do(job170)\r\n elif day170.get()==\"3\":\r\n schedule.every().wednesday.at(time170.get()).do(job170)\r\n elif day170.get()==\"4\":\r\n schedule.every().thursday.at(time170.get()).do(job170)\r\n elif day170.get()==\"5\":\r\n schedule.every().friday.at(time170.get()).do(job170)\r\n elif day170.get()==\"6\":\r\n schedule.every().saturday.at(time170.get()).do(job170)\r\n elif day170.get()==\"7\":\r\n schedule.every().sunday.at(time170.get()).do(job170)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day171.get()==\"1\":\r\n schedule.every().monday.at(time171.get()).do(job171)\r\n elif day171.get()==\"2\":\r\n schedule.every().tuesday.at(time171.get()).do(job171)\r\n elif day171.get()==\"3\":\r\n schedule.every().wednesday.at(time171.get()).do(job171)\r\n elif day171.get()==\"4\":\r\n schedule.every().thursday.at(time171.get()).do(job171)\r\n elif day171.get()==\"5\":\r\n schedule.every().friday.at(time171.get()).do(job171)\r\n elif day171.get()==\"6\":\r\n schedule.every().saturday.at(time171.get()).do(job171)\r\n elif day171.get()==\"7\":\r\n schedule.every().sunday.at(time171.get()).do(job171)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day172.get()==\"1\":\r\n schedule.every().monday.at(time172.get()).do(job172)\r\n elif day172.get()==\"2\":\r\n schedule.every().tuesday.at(time172.get()).do(job172)\r\n elif day172.get()==\"3\":\r\n schedule.every().wednesday.at(time172.get()).do(job172)\r\n elif day172.get()==\"4\":\r\n schedule.every().thursday.at(time172.get()).do(job172)\r\n elif day172.get()==\"5\":\r\n schedule.every().friday.at(time172.get()).do(job172)\r\n elif day172.get()==\"6\":\r\n schedule.every().saturday.at(time172.get()).do(job172)\r\n elif day172.get()==\"7\":\r\n schedule.every().sunday.at(time172.get()).do(job172)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day173.get()==\"1\":\r\n schedule.every().monday.at(time173.get()).do(job173)\r\n elif day173.get()==\"2\":\r\n schedule.every().tuesday.at(time173.get()).do(job173)\r\n elif day173.get()==\"3\":\r\n schedule.every().wednesday.at(time173.get()).do(job173)\r\n elif day173.get()==\"4\":\r\n schedule.every().thursday.at(time173.get()).do(job173)\r\n elif day173.get()==\"5\":\r\n schedule.every().friday.at(time173.get()).do(job173)\r\n elif day173.get()==\"6\":\r\n schedule.every().saturday.at(time173.get()).do(job173)\r\n elif day173.get()==\"7\":\r\n schedule.every().sunday.at(time173.get()).do(job173)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day174.get()==\"1\":\r\n schedule.every().monday.at(time174.get()).do(job174)\r\n elif day174.get()==\"2\":\r\n schedule.every().tuesday.at(time174.get()).do(job174)\r\n elif day174.get()==\"3\":\r\n schedule.every().wednesday.at(time174.get()).do(job174)\r\n elif day174.get()==\"4\":\r\n schedule.every().thursday.at(time174.get()).do(job174)\r\n elif day174.get()==\"5\":\r\n schedule.every().friday.at(time174.get()).do(job174)\r\n elif day174.get()==\"6\":\r\n schedule.every().saturday.at(time174.get()).do(job174)\r\n elif day174.get()==\"7\":\r\n schedule.every().sunday.at(time174.get()).do(job174)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day175.get()==\"1\":\r\n schedule.every().monday.at(time175.get()).do(job175)\r\n elif day175.get()==\"2\":\r\n schedule.every().tuesday.at(time175.get()).do(job175)\r\n elif day175.get()==\"3\":\r\n schedule.every().wednesday.at(time175.get()).do(job175)\r\n elif day175.get()==\"4\":\r\n schedule.every().thursday.at(time175.get()).do(job175)\r\n elif day175.get()==\"5\":\r\n schedule.every().friday.at(time175.get()).do(job175)\r\n elif day175.get()==\"6\":\r\n schedule.every().saturday.at(time175.get()).do(job175)\r\n elif day175.get()==\"7\":\r\n schedule.every().sunday.at(time175.get()).do(job175)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day176.get()==\"1\":\r\n schedule.every().monday.at(time176.get()).do(job176)\r\n elif day176.get()==\"2\":\r\n schedule.every().tuesday.at(time176.get()).do(job176)\r\n elif day176.get()==\"3\":\r\n schedule.every().wednesday.at(time176.get()).do(job176)\r\n elif day176.get()==\"4\":\r\n schedule.every().thursday.at(time176.get()).do(job176)\r\n elif day176.get()==\"5\":\r\n schedule.every().friday.at(time176.get()).do(job176)\r\n elif day176.get()==\"6\":\r\n schedule.every().saturday.at(time176.get()).do(job176)\r\n elif day176.get()==\"7\":\r\n schedule.every().sunday.at(time176.get()).do(job176)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day177.get()==\"1\":\r\n schedule.every().monday.at(time177.get()).do(job177)\r\n elif day177.get()==\"2\":\r\n schedule.every().tuesday.at(time177.get()).do(job177)\r\n elif day177.get()==\"3\":\r\n schedule.every().wednesday.at(time177.get()).do(job177)\r\n elif day177.get()==\"4\":\r\n schedule.every().thursday.at(time177.get()).do(job177)\r\n elif day177.get()==\"5\":\r\n schedule.every().friday.at(time177.get()).do(job177)\r\n elif day177.get()==\"6\":\r\n schedule.every().saturday.at(time177.get()).do(job177)\r\n elif day177.get()==\"7\":\r\n schedule.every().sunday.at(time177.get()).do(job177)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day178.get()==\"1\":\r\n schedule.every().monday.at(time178.get()).do(job178)\r\n elif day178.get()==\"2\":\r\n schedule.every().tuesday.at(time178.get()).do(job178)\r\n elif day178.get()==\"3\":\r\n schedule.every().wednesday.at(time178.get()).do(job178)\r\n elif day178.get()==\"4\":\r\n schedule.every().thursday.at(time178.get()).do(job178)\r\n elif day178.get()==\"5\":\r\n schedule.every().friday.at(time178.get()).do(job178)\r\n elif day178.get()==\"6\":\r\n schedule.every().saturday.at(time178.get()).do(job178)\r\n elif day178.get()==\"7\":\r\n schedule.every().sunday.at(time178.get()).do(job178)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day179.get()==\"1\":\r\n schedule.every().monday.at(time179.get()).do(job179)\r\n elif day179.get()==\"2\":\r\n schedule.every().tuesday.at(time179.get()).do(job179)\r\n elif day179.get()==\"3\":\r\n schedule.every().wednesday.at(time179.get()).do(job179)\r\n elif day179.get()==\"4\":\r\n schedule.every().thursday.at(time179.get()).do(job179)\r\n elif day179.get()==\"5\":\r\n schedule.every().friday.at(time179.get()).do(job179)\r\n elif day179.get()==\"6\":\r\n schedule.every().saturday.at(time179.get()).do(job179)\r\n elif day179.get()==\"7\":\r\n schedule.every().sunday.at(time179.get()).do(job179)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day180.get()==\"1\":\r\n schedule.every().monday.at(time180.get()).do(job180)\r\n elif day180.get()==\"2\":\r\n schedule.every().tuesday.at(time180.get()).do(job180)\r\n elif day180.get()==\"3\":\r\n schedule.every().wednesday.at(time180.get()).do(job180)\r\n elif day180.get()==\"4\":\r\n schedule.every().thursday.at(time180.get()).do(job180)\r\n elif day180.get()==\"5\":\r\n schedule.every().friday.at(time180.get()).do(job180)\r\n elif day180.get()==\"6\":\r\n schedule.every().saturday.at(time180.get()).do(job180)\r\n elif day180.get()==\"7\":\r\n schedule.every().sunday.at(time180.get()).do(job180)\r\n\r\n while True:\r\n schedule.run_pending()\r\n (job409())\r\n\r\n\r\n\r\n\r\ndef job407():\r\n \r\n if day141.get()==\"1\":\r\n schedule.every().monday.at(time141.get()).do(job141)\r\n elif day141.get()==\"2\":\r\n schedule.every().tuesday.at(time141.get()).do(job141)\r\n elif day141.get()==\"3\":\r\n schedule.every().wednesday.at(time141.get()).do(job141)\r\n elif day141.get()==\"4\":\r\n schedule.every().thursday.at(time141.get()).do(job141)\r\n elif day141.get()==\"5\":\r\n schedule.every().friday.at(time141.get()).do(job141)\r\n elif day141.get()==\"6\":\r\n schedule.every().saturday.at(time141.get()).do(job141)\r\n elif day141.get()==\"7\":\r\n schedule.every().sunday.at(time141.get()).do(job141)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day142.get()==\"1\":\r\n schedule.every().monday.at(time142.get()).do(job142)\r\n elif day142.get()==\"2\":\r\n schedule.every().tuesday.at(time142.get()).do(job142)\r\n elif day142.get()==\"3\":\r\n schedule.every().wednesday.at(time142.get()).do(job142)\r\n elif day142.get()==\"4\":\r\n schedule.every().thursday.at(time142.get()).do(job142)\r\n elif day142.get()==\"5\":\r\n schedule.every().friday.at(time142.get()).do(job142)\r\n elif day142.get()==\"6\":\r\n schedule.every().saturday.at(time142.get()).do(job142)\r\n elif day142.get()==\"7\":\r\n schedule.every().sunday.at(time142.get()).do(job142)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day143.get()==\"1\":\r\n schedule.every().monday.at(time143.get()).do(job143)\r\n elif day143.get()==\"2\":\r\n schedule.every().tuesday.at(time143.get()).do(job143)\r\n elif day143.get()==\"3\":\r\n schedule.every().wednesday.at(time143.get()).do(job143)\r\n elif day143.get()==\"4\":\r\n schedule.every().thursday.at(time143.get()).do(job143)\r\n elif day143.get()==\"5\":\r\n schedule.every().friday.at(time143.get()).do(job143)\r\n elif day143.get()==\"6\":\r\n schedule.every().saturday.at(time143.get()).do(job143)\r\n elif day143.get()==\"7\":\r\n schedule.every().sunday.at(time143.get()).do(job143)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day144.get()==\"1\":\r\n schedule.every().monday.at(time144.get()).do(job144)\r\n elif day144.get()==\"2\":\r\n schedule.every().tuesday.at(time144.get()).do(job144)\r\n elif day144.get()==\"3\":\r\n schedule.every().wednesday.at(time144.get()).do(job144)\r\n elif day144.get()==\"4\":\r\n schedule.every().thursday.at(time144.get()).do(job144)\r\n elif day144.get()==\"5\":\r\n schedule.every().friday.at(time144.get()).do(job144)\r\n elif day144.get()==\"6\":\r\n schedule.every().saturday.at(time144.get()).do(job144)\r\n elif day144.get()==\"7\":\r\n schedule.every().sunday.at(time144.get()).do(job144)\r\n\r\n while True:\r\n schedule.run_pending() \r\n if day145.get()==\"1\":\r\n schedule.every().monday.at(time145.get()).do(job145)\r\n elif day145.get()==\"2\":\r\n schedule.every().tuesday.at(time145.get()).do(job145)\r\n elif day145.get()==\"3\":\r\n schedule.every().wednesday.at(time145.get()).do(job145)\r\n elif day145.get()==\"4\":\r\n schedule.every().thursday.at(time145.get()).do(job145)\r\n elif day145.get()==\"5\":\r\n schedule.every().friday.at(time145.get()).do(job145)\r\n elif day145.get()==\"6\":\r\n schedule.every().saturday.at(time145.get()).do(job145)\r\n elif day145.get()==\"7\":\r\n schedule.every().sunday.at(time145.get()).do(job145)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day146.get()==\"1\":\r\n schedule.every().monday.at(time146.get()).do(job146)\r\n elif day146.get()==\"2\":\r\n schedule.every().tuesday.at(time146.get()).do(job146)\r\n elif day146.get()==\"3\":\r\n schedule.every().wednesday.at(time146.get()).do(job146)\r\n elif day146.get()==\"4\":\r\n schedule.every().thursday.at(time146.get()).do(job146)\r\n elif day146.get()==\"5\":\r\n schedule.every().friday.at(time146.get()).do(job146)\r\n elif day146.get()==\"6\":\r\n schedule.every().saturday.at(time146.get()).do(job146)\r\n elif day146.get()==\"7\":\r\n schedule.every().sunday.at(time146.get()).do(job146)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day147.get()==\"1\":\r\n schedule.every().monday.at(time147.get()).do(job147)\r\n elif day147.get()==\"2\":\r\n schedule.every().tuesday.at(time147.get()).do(job147)\r\n elif day147.get()==\"3\":\r\n schedule.every().wednesday.at(time147.get()).do(job147)\r\n elif day147.get()==\"4\":\r\n schedule.every().thursday.at(time147.get()).do(job147)\r\n elif day147.get()==\"5\":\r\n schedule.every().friday.at(time147.get()).do(job147)\r\n elif day147.get()==\"6\":\r\n schedule.every().saturday.at(time147.get()).do(job147)\r\n elif day147.get()==\"7\":\r\n schedule.every().sunday.at(time147.get()).do(job147)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day148.get()==\"1\":\r\n schedule.every().monday.at(time148.get()).do(job148)\r\n elif day148.get()==\"2\":\r\n schedule.every().tuesday.at(time148.get()).do(job148)\r\n elif day148.get()==\"3\":\r\n schedule.every().wednesday.at(time148.get()).do(job148)\r\n elif day148.get()==\"4\":\r\n schedule.every().thursday.at(time148.get()).do(job148)\r\n elif day148.get()==\"5\":\r\n schedule.every().friday.at(time148.get()).do(job148)\r\n elif day148.get()==\"6\":\r\n schedule.every().saturday.at(time148.get()).do(job148)\r\n elif day148.get()==\"7\":\r\n schedule.every().sunday.at(time148.get()).do(job148)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day149.get()==\"1\":\r\n schedule.every().monday.at(time149.get()).do(job149)\r\n elif day149.get()==\"2\":\r\n schedule.every().tuesday.at(time149.get()).do(job149)\r\n elif day149.get()==\"3\":\r\n schedule.every().wednesday.at(time149.get()).do(job149)\r\n elif day149.get()==\"4\":\r\n schedule.every().thursday.at(time149.get()).do(job149)\r\n elif day149.get()==\"5\":\r\n schedule.every().friday.at(time149.get()).do(job149)\r\n elif day149.get()==\"6\":\r\n schedule.every().saturday.at(time149.get()).do(job149)\r\n elif day149.get()==\"7\":\r\n schedule.every().sunday.at(time149.get()).do(job149)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day150.get()==\"1\":\r\n schedule.every().monday.at(time150.get()).do(job150)\r\n elif day150.get()==\"2\":\r\n schedule.every().tuesday.at(time150.get()).do(job150)\r\n elif day150.get()==\"3\":\r\n schedule.every().wednesday.at(time150.get()).do(job150)\r\n elif day150.get()==\"4\":\r\n schedule.every().thursday.at(time150.get()).do(job150)\r\n elif day150.get()==\"5\":\r\n schedule.every().friday.at(time150.get()).do(job150)\r\n elif day150.get()==\"6\":\r\n schedule.every().saturday.at(time150.get()).do(job150)\r\n elif day150.get()==\"7\":\r\n schedule.every().sunday.at(time150.get()).do(job150)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day151.get()==\"1\":\r\n schedule.every().monday.at(time151.get()).do(job151)\r\n elif day151.get()==\"2\":\r\n schedule.every().tuesday.at(time151.get()).do(job151)\r\n elif day151.get()==\"3\":\r\n schedule.every().wednesday.at(time151.get()).do(job151)\r\n elif day151.get()==\"4\":\r\n schedule.every().thursday.at(time151.get()).do(job151)\r\n elif day151.get()==\"5\":\r\n schedule.every().friday.at(time151.get()).do(job151)\r\n elif day151.get()==\"6\":\r\n schedule.every().saturday.at(time151.get()).do(job151)\r\n elif day151.get()==\"7\":\r\n schedule.every().sunday.at(time151.get()).do(job151)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day152.get()==\"1\":\r\n schedule.every().monday.at(time152.get()).do(job152)\r\n elif day152.get()==\"2\":\r\n schedule.every().tuesday.at(time152.get()).do(job152)\r\n elif day152.get()==\"3\":\r\n schedule.every().wednesday.at(time152.get()).do(job152)\r\n elif day152.get()==\"4\":\r\n schedule.every().thursday.at(time152.get()).do(job152)\r\n elif day152.get()==\"5\":\r\n schedule.every().friday.at(time152.get()).do(job152)\r\n elif day152.get()==\"6\":\r\n schedule.every().saturday.at(time152.get()).do(job152)\r\n elif day152.get()==\"7\":\r\n schedule.every().sunday.at(time152.get()).do(job152)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day153.get()==\"1\":\r\n schedule.every().monday.at(time153.get()).do(job153)\r\n elif day153.get()==\"2\":\r\n schedule.every().tuesday.at(time153.get()).do(job153)\r\n elif day153.get()==\"3\":\r\n schedule.every().wednesday.at(time153.get()).do(job153)\r\n elif day153.get()==\"4\":\r\n schedule.every().thursday.at(time153.get()).do(job153)\r\n elif day153.get()==\"5\":\r\n schedule.every().friday.at(time153.get()).do(job153)\r\n elif day153.get()==\"6\":\r\n schedule.every().saturday.at(time153.get()).do(job153)\r\n elif day153.get()==\"7\":\r\n schedule.every().sunday.at(time153.get()).do(job153)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day154.get()==\"1\":\r\n schedule.every().monday.at(time154.get()).do(job154)\r\n elif day154.get()==\"2\":\r\n schedule.every().tuesday.at(time154.get()).do(job154)\r\n elif day154.get()==\"3\":\r\n schedule.every().wednesday.at(time154.get()).do(job154)\r\n elif day154.get()==\"4\":\r\n schedule.every().thursday.at(time154.get()).do(job154)\r\n elif day154.get()==\"5\":\r\n schedule.every().friday.at(time154.get()).do(job154)\r\n elif day154.get()==\"6\":\r\n schedule.every().saturday.at(time154.get()).do(job154)\r\n elif day154.get()==\"7\":\r\n schedule.every().sunday.at(time154.get()).do(job154)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day155.get()==\"1\":\r\n schedule.every().monday.at(time155.get()).do(job155)\r\n elif day155.get()==\"2\":\r\n schedule.every().tuesday.at(time155.get()).do(job155)\r\n elif day155.get()==\"3\":\r\n schedule.every().wednesday.at(time155.get()).do(job155)\r\n elif day155.get()==\"4\":\r\n schedule.every().thursday.at(time155.get()).do(job155)\r\n elif day155.get()==\"5\":\r\n schedule.every().friday.at(time155.get()).do(job155)\r\n elif day155.get()==\"6\":\r\n schedule.every().saturday.at(time155.get()).do(job155)\r\n elif day155.get()==\"7\":\r\n schedule.every().sunday.at(time155.get()).do(job155)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day156.get()==\"1\":\r\n schedule.every().monday.at(time156.get()).do(job156)\r\n elif day156.get()==\"2\":\r\n schedule.every().tuesday.at(time156.get()).do(job156)\r\n elif day156.get()==\"3\":\r\n schedule.every().wednesday.at(time156.get()).do(job156)\r\n elif day156.get()==\"4\":\r\n schedule.every().thursday.at(time156.get()).do(job156)\r\n elif day156.get()==\"5\":\r\n schedule.every().friday.at(time156.get()).do(job156)\r\n elif day156.get()==\"6\":\r\n schedule.every().saturday.at(time156.get()).do(job156)\r\n elif day156.get()==\"7\":\r\n schedule.every().sunday.at(time156.get()).do(job156)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day157.get()==\"1\":\r\n schedule.every().monday.at(time157.get()).do(job157)\r\n elif day157.get()==\"2\":\r\n schedule.every().tuesday.at(time157.get()).do(job157)\r\n elif day157.get()==\"3\":\r\n schedule.every().wednesday.at(time157.get()).do(job157)\r\n elif day157.get()==\"4\":\r\n schedule.every().thursday.at(time157.get()).do(job157)\r\n elif day157.get()==\"5\":\r\n schedule.every().friday.at(time157.get()).do(job157)\r\n elif day157.get()==\"6\":\r\n schedule.every().saturday.at(time157.get()).do(job157)\r\n elif day157.get()==\"7\":\r\n schedule.every().sunday.at(time157.get()).do(job157)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day158.get()==\"1\":\r\n schedule.every().monday.at(time158.get()).do(job158)\r\n elif day158.get()==\"2\":\r\n schedule.every().tuesday.at(time158.get()).do(job158)\r\n elif day158.get()==\"3\":\r\n schedule.every().wednesday.at(time158.get()).do(job158)\r\n elif day158.get()==\"4\":\r\n schedule.every().thursday.at(time158.get()).do(job158)\r\n elif day158.get()==\"5\":\r\n schedule.every().friday.at(time158.get()).do(job158)\r\n elif day158.get()==\"6\":\r\n schedule.every().saturday.at(time158.get()).do(job158)\r\n elif day158.get()==\"7\":\r\n schedule.every().sunday.at(time158.get()).do(job158)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day159.get()==\"1\":\r\n schedule.every().monday.at(time159.get()).do(job159)\r\n elif day159.get()==\"2\":\r\n schedule.every().tuesday.at(time159.get()).do(job159)\r\n elif day159.get()==\"3\":\r\n schedule.every().wednesday.at(time159.get()).do(job159)\r\n elif day159.get()==\"4\":\r\n schedule.every().thursday.at(time159.get()).do(job159)\r\n elif day159.get()==\"5\":\r\n schedule.every().friday.at(time159.get()).do(job159)\r\n elif day159.get()==\"6\":\r\n schedule.every().saturday.at(time159.get()).do(job159)\r\n elif day159.get()==\"7\":\r\n schedule.every().sunday.at(time159.get()).do(job159)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day160.get()==\"1\":\r\n schedule.every().monday.at(time160.get()).do(job160)\r\n elif day160.get()==\"2\":\r\n schedule.every().tuesday.at(time160.get()).do(job160)\r\n elif day160.get()==\"3\":\r\n schedule.every().wednesday.at(time160.get()).do(job160)\r\n elif day160.get()==\"4\":\r\n schedule.every().thursday.at(time160.get()).do(job160)\r\n elif day160.get()==\"5\":\r\n schedule.every().friday.at(time160.get()).do(job160)\r\n elif day160.get()==\"6\":\r\n schedule.every().saturday.at(time160.get()).do(job160)\r\n elif day160.get()==\"7\":\r\n schedule.every().sunday.at(time160.get()).do(job160)\r\n\r\n while True:\r\n schedule.run_pending()\r\n (job408())\r\n\r\n\r\n\r\n\r\n\r\ndef job406():\r\n \r\n if day121.get()==\"1\":\r\n schedule.every().monday.at(time121.get()).do(job121)\r\n elif day121.get()==\"2\":\r\n schedule.every().tuesday.at(time121.get()).do(job121)\r\n elif day121.get()==\"3\":\r\n schedule.every().wednesday.at(time121.get()).do(job121)\r\n elif day121.get()==\"4\":\r\n schedule.every().thursday.at(time121.get()).do(job121)\r\n elif day121.get()==\"5\":\r\n schedule.every().friday.at(time121.get()).do(job121)\r\n elif day121.get()==\"6\":\r\n schedule.every().saturday.at(time121.get()).do(job121)\r\n elif day121.get()==\"7\":\r\n schedule.every().sunday.at(time121.get()).do(job121)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day122.get()==\"1\":\r\n schedule.every().monday.at(time122.get()).do(job122)\r\n elif day122.get()==\"2\":\r\n schedule.every().tuesday.at(time122.get()).do(job122)\r\n elif day122.get()==\"3\":\r\n schedule.every().wednesday.at(time122.get()).do(job122)\r\n elif day122.get()==\"4\":\r\n schedule.every().thursday.at(time122.get()).do(job122)\r\n elif day122.get()==\"5\":\r\n schedule.every().friday.at(time122.get()).do(job122)\r\n elif day122.get()==\"6\":\r\n schedule.every().saturday.at(time122.get()).do(job122)\r\n elif day122.get()==\"7\":\r\n schedule.every().sunday.at(time122.get()).do(job122)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day123.get()==\"1\":\r\n schedule.every().monday.at(time123.get()).do(job123)\r\n elif day123.get()==\"2\":\r\n schedule.every().tuesday.at(time123.get()).do(job123)\r\n elif day123.get()==\"3\":\r\n schedule.every().wednesday.at(time123.get()).do(job123)\r\n elif day123.get()==\"4\":\r\n schedule.every().thursday.at(time123.get()).do(job123)\r\n elif day123.get()==\"5\":\r\n schedule.every().friday.at(time123.get()).do(job123)\r\n elif day123.get()==\"6\":\r\n schedule.every().saturday.at(time123.get()).do(job123)\r\n elif day123.get()==\"7\":\r\n schedule.every().sunday.at(time123.get()).do(job123)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day124.get()==\"1\":\r\n schedule.every().monday.at(time124.get()).do(job124)\r\n elif day124.get()==\"2\":\r\n schedule.every().tuesday.at(time124.get()).do(job124)\r\n elif day124.get()==\"3\":\r\n schedule.every().wednesday.at(time124.get()).do(job124)\r\n elif day124.get()==\"4\":\r\n schedule.every().thursday.at(time124.get()).do(job124)\r\n elif day124.get()==\"5\":\r\n schedule.every().friday.at(time124.get()).do(job124)\r\n elif day124.get()==\"6\":\r\n schedule.every().saturday.at(time124.get()).do(job124)\r\n elif day124.get()==\"7\":\r\n schedule.every().sunday.at(time124.get()).do(job124)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day125.get()==\"1\":\r\n schedule.every().monday.at(time125.get()).do(job125)\r\n elif day125.get()==\"2\":\r\n schedule.every().tuesday.at(time125.get()).do(job125)\r\n elif day125.get()==\"3\":\r\n schedule.every().wednesday.at(time125.get()).do(job125)\r\n elif day125.get()==\"4\":\r\n schedule.every().thursday.at(time125.get()).do(job125)\r\n elif day125.get()==\"5\":\r\n schedule.every().friday.at(time125.get()).do(job125)\r\n elif day125.get()==\"6\":\r\n schedule.every().saturday.at(time125.get()).do(job125)\r\n elif day125.get()==\"7\":\r\n schedule.every().sunday.at(time125.get()).do(job125)\r\n\r\n while True:\r\n schedule.run_pending() \r\n if day126.get()==\"1\":\r\n schedule.every().monday.at(time126.get()).do(job126)\r\n elif day126.get()==\"2\":\r\n schedule.every().tuesday.at(time126.get()).do(job126)\r\n elif day126.get()==\"3\":\r\n schedule.every().wednesday.at(time126.get()).do(job126)\r\n elif day126.get()==\"4\":\r\n schedule.every().thursday.at(time126.get()).do(job126)\r\n elif day126.get()==\"5\":\r\n schedule.every().friday.at(time126.get()).do(job126)\r\n elif day126.get()==\"6\":\r\n schedule.every().saturday.at(time126.get()).do(job126)\r\n elif day126.get()==\"7\":\r\n schedule.every().sunday.at(time126.get()).do(job126)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day127.get()==\"1\":\r\n schedule.every().monday.at(time127.get()).do(job127)\r\n elif day127.get()==\"2\":\r\n schedule.every().tuesday.at(time127.get()).do(job127)\r\n elif day127.get()==\"3\":\r\n schedule.every().wednesday.at(time127.get()).do(job127)\r\n elif day127.get()==\"4\":\r\n schedule.every().thursday.at(time127.get()).do(job127)\r\n elif day127.get()==\"5\":\r\n schedule.every().friday.at(time127.get()).do(job127)\r\n elif day127.get()==\"6\":\r\n schedule.every().saturday.at(time127.get()).do(job127)\r\n elif day127.get()==\"7\":\r\n schedule.every().sunday.at(time127.get()).do(job127)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day128.get()==\"1\":\r\n schedule.every().monday.at(time128.get()).do(job128)\r\n elif day128.get()==\"2\":\r\n schedule.every().tuesday.at(time128.get()).do(job128)\r\n elif day128.get()==\"3\":\r\n schedule.every().wednesday.at(time128.get()).do(job128)\r\n elif day128.get()==\"4\":\r\n schedule.every().thursday.at(time128.get()).do(job128)\r\n elif day128.get()==\"5\":\r\n schedule.every().friday.at(time128.get()).do(job128)\r\n elif day128.get()==\"6\":\r\n schedule.every().saturday.at(time128.get()).do(job128)\r\n elif day128.get()==\"7\":\r\n schedule.every().sunday.at(time128.get()).do(job128)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day129.get()==\"1\":\r\n schedule.every().monday.at(time129.get()).do(job129)\r\n elif day129.get()==\"2\":\r\n schedule.every().tuesday.at(time129.get()).do(job129)\r\n elif day129.get()==\"3\":\r\n schedule.every().wednesday.at(time129.get()).do(job129)\r\n elif day129.get()==\"4\":\r\n schedule.every().thursday.at(time129.get()).do(job129)\r\n elif day129.get()==\"5\":\r\n schedule.every().friday.at(time129.get()).do(job129)\r\n elif day129.get()==\"6\":\r\n schedule.every().saturday.at(time129.get()).do(job129)\r\n elif day129.get()==\"7\":\r\n schedule.every().sunday.at(time129.get()).do(job129)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day130.get()==\"1\":\r\n schedule.every().monday.at(time130.get()).do(job130)\r\n elif day130.get()==\"2\":\r\n schedule.every().tuesday.at(time130.get()).do(job130)\r\n elif day130.get()==\"3\":\r\n schedule.every().wednesday.at(time130.get()).do(job130)\r\n elif day130.get()==\"4\":\r\n schedule.every().thursday.at(time130.get()).do(job130)\r\n elif day130.get()==\"5\":\r\n schedule.every().friday.at(time130.get()).do(job130)\r\n elif day130.get()==\"6\":\r\n schedule.every().saturday.at(time130.get()).do(job130)\r\n elif day130.get()==\"7\":\r\n schedule.every().sunday.at(time130.get()).do(job130)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day131.get()==\"1\":\r\n schedule.every().monday.at(time131.get()).do(job131)\r\n elif day131.get()==\"2\":\r\n schedule.every().tuesday.at(time131.get()).do(job131)\r\n elif day131.get()==\"3\":\r\n schedule.every().wednesday.at(time131.get()).do(job131)\r\n elif day131.get()==\"4\":\r\n schedule.every().thursday.at(time131.get()).do(job131)\r\n elif day131.get()==\"5\":\r\n schedule.every().friday.at(time131.get()).do(job131)\r\n elif day131.get()==\"6\":\r\n schedule.every().saturday.at(time131.get()).do(job131)\r\n elif day131.get()==\"7\":\r\n schedule.every().sunday.at(time131.get()).do(job131)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day132.get()==\"1\":\r\n schedule.every().monday.at(time132.get()).do(job132)\r\n elif day132.get()==\"2\":\r\n schedule.every().tuesday.at(time132.get()).do(job132)\r\n elif day132.get()==\"3\":\r\n schedule.every().wednesday.at(time132.get()).do(job132)\r\n elif day132.get()==\"4\":\r\n schedule.every().thursday.at(time132.get()).do(job132)\r\n elif day132.get()==\"5\":\r\n schedule.every().friday.at(time132.get()).do(job132)\r\n elif day132.get()==\"6\":\r\n schedule.every().saturday.at(time132.get()).do(job132)\r\n elif day132.get()==\"7\":\r\n schedule.every().sunday.at(time132.get()).do(job132)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day133.get()==\"1\":\r\n schedule.every().monday.at(time133.get()).do(job133)\r\n elif day133.get()==\"2\":\r\n schedule.every().tuesday.at(time133.get()).do(job133)\r\n elif day133.get()==\"3\":\r\n schedule.every().wednesday.at(time133.get()).do(job133)\r\n elif day133.get()==\"4\":\r\n schedule.every().thursday.at(time133.get()).do(job133)\r\n elif day133.get()==\"5\":\r\n schedule.every().friday.at(time133.get()).do(job133)\r\n elif day133.get()==\"6\":\r\n schedule.every().saturday.at(time133.get()).do(job133)\r\n elif day133.get()==\"7\":\r\n schedule.every().sunday.at(time133.get()).do(job133)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day134.get()==\"1\":\r\n schedule.every().monday.at(time134.get()).do(job134)\r\n elif day134.get()==\"2\":\r\n schedule.every().tuesday.at(time134.get()).do(job134)\r\n elif day134.get()==\"3\":\r\n schedule.every().wednesday.at(time134.get()).do(job134)\r\n elif day134.get()==\"4\":\r\n schedule.every().thursday.at(time134.get()).do(job134)\r\n elif day134.get()==\"5\":\r\n schedule.every().friday.at(time134.get()).do(job134)\r\n elif day134.get()==\"6\":\r\n schedule.every().saturday.at(time134.get()).do(job134)\r\n elif day134.get()==\"7\":\r\n schedule.every().sunday.at(time134.get()).do(job134)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day135.get()==\"1\":\r\n schedule.every().monday.at(time135.get()).do(job135)\r\n elif day135.get()==\"2\":\r\n schedule.every().tuesday.at(time135.get()).do(job135)\r\n elif day135.get()==\"3\":\r\n schedule.every().wednesday.at(time135.get()).do(job135)\r\n elif day135.get()==\"4\":\r\n schedule.every().thursday.at(time135.get()).do(job135)\r\n elif day135.get()==\"5\":\r\n schedule.every().friday.at(time135.get()).do(job135)\r\n elif day135.get()==\"6\":\r\n schedule.every().saturday.at(time135.get()).do(job135)\r\n elif day135.get()==\"7\":\r\n schedule.every().sunday.at(time135.get()).do(job135)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day136.get()==\"1\":\r\n schedule.every().monday.at(time136.get()).do(job136)\r\n elif day136.get()==\"2\":\r\n schedule.every().tuesday.at(time136.get()).do(job136)\r\n elif day136.get()==\"3\":\r\n schedule.every().wednesday.at(time136.get()).do(job136)\r\n elif day136.get()==\"4\":\r\n schedule.every().thursday.at(time136.get()).do(job136)\r\n elif day136.get()==\"5\":\r\n schedule.every().friday.at(time136.get()).do(job136)\r\n elif day136.get()==\"6\":\r\n schedule.every().saturday.at(time136.get()).do(job136)\r\n elif day136.get()==\"7\":\r\n schedule.every().sunday.at(time136.get()).do(job136)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day137.get()==\"1\":\r\n schedule.every().monday.at(time137.get()).do(job137)\r\n elif day137.get()==\"2\":\r\n schedule.every().tuesday.at(time137.get()).do(job137)\r\n elif day137.get()==\"3\":\r\n schedule.every().wednesday.at(time137.get()).do(job137)\r\n elif day137.get()==\"4\":\r\n schedule.every().thursday.at(time137.get()).do(job137)\r\n elif day137.get()==\"5\":\r\n schedule.every().friday.at(time137.get()).do(job137)\r\n elif day137.get()==\"6\":\r\n schedule.every().saturday.at(time137.get()).do(job137)\r\n elif day137.get()==\"7\":\r\n schedule.every().sunday.at(time137.get()).do(job137)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day138.get()==\"1\":\r\n schedule.every().monday.at(time138.get()).do(job138)\r\n elif day138.get()==\"2\":\r\n schedule.every().tuesday.at(time138.get()).do(job138)\r\n elif day138.get()==\"3\":\r\n schedule.every().wednesday.at(time138.get()).do(job138)\r\n elif day138.get()==\"4\":\r\n schedule.every().thursday.at(time138.get()).do(job138)\r\n elif day138.get()==\"5\":\r\n schedule.every().friday.at(time138.get()).do(job138)\r\n elif day138.get()==\"6\":\r\n schedule.every().saturday.at(time138.get()).do(job138)\r\n elif day138.get()==\"7\":\r\n schedule.every().sunday.at(time138.get()).do(job138)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day139.get()==\"1\":\r\n schedule.every().monday.at(time139.get()).do(job139)\r\n elif day139.get()==\"2\":\r\n schedule.every().tuesday.at(time139.get()).do(job139)\r\n elif day139.get()==\"3\":\r\n schedule.every().wednesday.at(time139.get()).do(job139)\r\n elif day139.get()==\"4\":\r\n schedule.every().thursday.at(time139.get()).do(job139)\r\n elif day139.get()==\"5\":\r\n schedule.every().friday.at(time139.get()).do(job139)\r\n elif day139.get()==\"6\":\r\n schedule.every().saturday.at(time139.get()).do(job139)\r\n elif day139.get()==\"7\":\r\n schedule.every().sunday.at(time139.get()).do(job139)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day140.get()==\"1\":\r\n schedule.every().monday.at(time140.get()).do(job140)\r\n elif day140.get()==\"2\":\r\n schedule.every().tuesday.at(time140.get()).do(job140)\r\n elif day140.get()==\"3\":\r\n schedule.every().wednesday.at(time140.get()).do(job140)\r\n elif day140.get()==\"4\":\r\n schedule.every().thursday.at(time140.get()).do(job140)\r\n elif day140.get()==\"5\":\r\n schedule.every().friday.at(time140.get()).do(job140)\r\n elif day140.get()==\"6\":\r\n schedule.every().saturday.at(time140.get()).do(job140)\r\n elif day140.get()==\"7\":\r\n schedule.every().sunday.at(time140.get()).do(job140)\r\n\r\n while True:\r\n schedule.run_pending()\r\n (job407())\r\n\r\n\r\n\r\n\r\n\r\ndef job405():\r\n \r\n if day101.get()==\"1\":\r\n schedule.every().monday.at(time101.get()).do(job101)\r\n elif day101.get()==\"2\":\r\n schedule.every().tuesday.at(time101.get()).do(job101)\r\n elif day101.get()==\"3\":\r\n schedule.every().wednesday.at(time101.get()).do(job101)\r\n elif day101.get()==\"4\":\r\n schedule.every().thursday.at(time101.get()).do(job101)\r\n elif day101.get()==\"5\":\r\n schedule.every().friday.at(time101.get()).do(job101)\r\n elif day101.get()==\"6\":\r\n schedule.every().saturday.at(time101.get()).do(job101)\r\n elif day101.get()==\"7\":\r\n schedule.every().sunday.at(time101.get()).do(job101)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day102.get()==\"1\":\r\n schedule.every().monday.at(time102.get()).do(job102)\r\n elif day102.get()==\"2\":\r\n schedule.every().tuesday.at(time102.get()).do(job102)\r\n elif day102.get()==\"3\":\r\n schedule.every().wednesday.at(time102.get()).do(job102)\r\n elif day102.get()==\"4\":\r\n schedule.every().thursday.at(time102.get()).do(job102)\r\n elif day102.get()==\"5\":\r\n schedule.every().friday.at(time102.get()).do(job102)\r\n elif day102.get()==\"6\":\r\n schedule.every().saturday.at(time102.get()).do(job102)\r\n elif day102.get()==\"7\":\r\n schedule.every().sunday.at(time102.get()).do(job102)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day103.get()==\"1\":\r\n schedule.every().monday.at(time103.get()).do(job103)\r\n elif day103.get()==\"2\":\r\n schedule.every().tuesday.at(time103.get()).do(job103)\r\n elif day103.get()==\"3\":\r\n schedule.every().wednesday.at(time103.get()).do(job103)\r\n elif day103.get()==\"4\":\r\n schedule.every().thursday.at(time103.get()).do(job103)\r\n elif day103.get()==\"5\":\r\n schedule.every().friday.at(time103.get()).do(job103)\r\n elif day103.get()==\"6\":\r\n schedule.every().saturday.at(time103.get()).do(job103)\r\n elif day103.get()==\"7\":\r\n schedule.every().sunday.at(time103.get()).do(job103)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day104.get()==\"1\":\r\n schedule.every().monday.at(time104.get()).do(job104)\r\n elif day104.get()==\"2\":\r\n schedule.every().tuesday.at(time104.get()).do(job104)\r\n elif day104.get()==\"3\":\r\n schedule.every().wednesday.at(time104.get()).do(job104)\r\n elif day104.get()==\"4\":\r\n schedule.every().thursday.at(time104.get()).do(job104)\r\n elif day104.get()==\"5\":\r\n schedule.every().friday.at(time104.get()).do(job104)\r\n elif day104.get()==\"6\":\r\n schedule.every().saturday.at(time104.get()).do(job104)\r\n elif day104.get()==\"7\":\r\n schedule.every().sunday.at(time104.get()).do(job104)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day105.get()==\"1\":\r\n schedule.every().monday.at(time105.get()).do(job105)\r\n elif day105.get()==\"2\":\r\n schedule.every().tuesday.at(time105.get()).do(job105)\r\n elif day105.get()==\"3\":\r\n schedule.every().wednesday.at(time105.get()).do(job105)\r\n elif day105.get()==\"4\":\r\n schedule.every().thursday.at(time105.get()).do(job105)\r\n elif day105.get()==\"5\":\r\n schedule.every().friday.at(time105.get()).do(job105)\r\n elif day105.get()==\"6\":\r\n schedule.every().saturday.at(time105.get()).do(job105)\r\n elif day105.get()==\"7\":\r\n schedule.every().sunday.at(time105.get()).do(job105)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day106.get()==\"1\":\r\n schedule.every().monday.at(time106.get()).do(job106)\r\n elif day106.get()==\"2\":\r\n schedule.every().tuesday.at(time106.get()).do(job106)\r\n elif day106.get()==\"3\":\r\n schedule.every().wednesday.at(time106.get()).do(job106)\r\n elif day106.get()==\"4\":\r\n schedule.every().thursday.at(time106.get()).do(job106)\r\n elif day106.get()==\"5\":\r\n schedule.every().friday.at(time106.get()).do(job106)\r\n elif day106.get()==\"6\":\r\n schedule.every().saturday.at(time106.get()).do(job106)\r\n elif day106.get()==\"7\":\r\n schedule.every().sunday.at(time106.get()).do(job106)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day107.get()==\"1\":\r\n schedule.every().monday.at(time107.get()).do(job107)\r\n elif day107.get()==\"2\":\r\n schedule.every().tuesday.at(time107.get()).do(job107)\r\n elif day107.get()==\"3\":\r\n schedule.every().wednesday.at(time107.get()).do(job107)\r\n elif day107.get()==\"4\":\r\n schedule.every().thursday.at(time107.get()).do(job107)\r\n elif day107.get()==\"5\":\r\n schedule.every().friday.at(time107.get()).do(job107)\r\n elif day107.get()==\"6\":\r\n schedule.every().saturday.at(time107.get()).do(job107)\r\n elif day107.get()==\"7\":\r\n schedule.every().sunday.at(time107.get()).do(job107)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day108.get()==\"1\":\r\n schedule.every().monday.at(time108.get()).do(job108)\r\n elif day108.get()==\"2\":\r\n schedule.every().tuesday.at(time108.get()).do(job108)\r\n elif day108.get()==\"3\":\r\n schedule.every().wednesday.at(time108.get()).do(job108)\r\n elif day108.get()==\"4\":\r\n schedule.every().thursday.at(time108.get()).do(job108)\r\n elif day108.get()==\"5\":\r\n schedule.every().friday.at(time108.get()).do(job108)\r\n elif day108.get()==\"6\":\r\n schedule.every().saturday.at(time108.get()).do(job108)\r\n elif day108.get()==\"7\":\r\n schedule.every().sunday.at(time108.get()).do(job108)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day109.get()==\"1\":\r\n schedule.every().monday.at(time109.get()).do(job109)\r\n elif day109.get()==\"2\":\r\n schedule.every().tuesday.at(time109.get()).do(job109)\r\n elif day109.get()==\"3\":\r\n schedule.every().wednesday.at(time109.get()).do(job109)\r\n elif day109.get()==\"4\":\r\n schedule.every().thursday.at(time109.get()).do(job109)\r\n elif day109.get()==\"5\":\r\n schedule.every().friday.at(time109.get()).do(job109)\r\n elif day109.get()==\"6\":\r\n schedule.every().saturday.at(time109.get()).do(job109)\r\n elif day109.get()==\"7\":\r\n schedule.every().sunday.at(time109.get()).do(job109)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day110.get()==\"1\":\r\n schedule.every().monday.at(time110.get()).do(job110)\r\n elif day110.get()==\"2\":\r\n schedule.every().tuesday.at(time110.get()).do(job110)\r\n elif day110.get()==\"3\":\r\n schedule.every().wednesday.at(time110.get()).do(job110)\r\n elif day110.get()==\"4\":\r\n schedule.every().thursday.at(time110.get()).do(job110)\r\n elif day110.get()==\"5\":\r\n schedule.every().friday.at(time110.get()).do(job110)\r\n elif day110.get()==\"6\":\r\n schedule.every().saturday.at(time110.get()).do(job110)\r\n elif day110.get()==\"7\":\r\n schedule.every().sunday.at(time110.get()).do(job110)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day111.get()==\"1\":\r\n schedule.every().monday.at(time111.get()).do(job111)\r\n elif day111.get()==\"2\":\r\n schedule.every().tuesday.at(time111.get()).do(job111)\r\n elif day111.get()==\"3\":\r\n schedule.every().wednesday.at(time111.get()).do(job111)\r\n elif day111.get()==\"4\":\r\n schedule.every().thursday.at(time111.get()).do(job111)\r\n elif day111.get()==\"5\":\r\n schedule.every().friday.at(time111.get()).do(job111)\r\n elif day111.get()==\"6\":\r\n schedule.every().saturday.at(time111.get()).do(job111)\r\n elif day111.get()==\"7\":\r\n schedule.every().sunday.at(time111.get()).do(job111)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day112.get()==\"1\":\r\n schedule.every().monday.at(time112.get()).do(job112)\r\n elif day112.get()==\"2\":\r\n schedule.every().tuesday.at(time112.get()).do(job112)\r\n elif day112.get()==\"3\":\r\n schedule.every().wednesday.at(time112.get()).do(job112)\r\n elif day112.get()==\"4\":\r\n schedule.every().thursday.at(time112.get()).do(job112)\r\n elif day112.get()==\"5\":\r\n schedule.every().friday.at(time112.get()).do(job112)\r\n elif day112.get()==\"6\":\r\n schedule.every().saturday.at(time112.get()).do(job112)\r\n elif day112.get()==\"7\":\r\n schedule.every().sunday.at(time112.get()).do(job112)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day113.get()==\"1\":\r\n schedule.every().monday.at(time113.get()).do(job113)\r\n elif day113.get()==\"2\":\r\n schedule.every().tuesday.at(time113.get()).do(job113)\r\n elif day113.get()==\"3\":\r\n schedule.every().wednesday.at(time113.get()).do(job113)\r\n elif day113.get()==\"4\":\r\n schedule.every().thursday.at(time113.get()).do(job113)\r\n elif day113.get()==\"5\":\r\n schedule.every().friday.at(time113.get()).do(job113)\r\n elif day113.get()==\"6\":\r\n schedule.every().saturday.at(time113.get()).do(job113)\r\n elif day113.get()==\"7\":\r\n schedule.every().sunday.at(time113.get()).do(job113)\r\n\r\n while True:\r\n schedule.run_pending() \r\n if day114.get()==\"1\":\r\n schedule.every().monday.at(time114.get()).do(job114)\r\n elif day114.get()==\"2\":\r\n schedule.every().tuesday.at(time114.get()).do(job114)\r\n elif day114.get()==\"3\":\r\n schedule.every().wednesday.at(time114.get()).do(job114)\r\n elif day114.get()==\"4\":\r\n schedule.every().thursday.at(time114.get()).do(job114)\r\n elif day114.get()==\"5\":\r\n schedule.every().friday.at(time114.get()).do(job114)\r\n elif day114.get()==\"6\":\r\n schedule.every().saturday.at(time114.get()).do(job114)\r\n elif day114.get()==\"7\":\r\n schedule.every().sunday.at(time114.get()).do(job114)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day115.get()==\"1\":\r\n schedule.every().monday.at(time115.get()).do(job115)\r\n elif day115.get()==\"2\":\r\n schedule.every().tuesday.at(time115.get()).do(job115)\r\n elif day115.get()==\"3\":\r\n schedule.every().wednesday.at(time115.get()).do(job115)\r\n elif day115.get()==\"4\":\r\n schedule.every().thursday.at(time115.get()).do(job115)\r\n elif day115.get()==\"5\":\r\n schedule.every().friday.at(time115.get()).do(job115)\r\n elif day115.get()==\"6\":\r\n schedule.every().saturday.at(time115.get()).do(job115)\r\n elif day115.get()==\"7\":\r\n schedule.every().sunday.at(time115.get()).do(job115)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day116.get()==\"1\":\r\n schedule.every().monday.at(time116.get()).do(job116)\r\n elif day116.get()==\"2\":\r\n schedule.every().tuesday.at(time116.get()).do(job116)\r\n elif day116.get()==\"3\":\r\n schedule.every().wednesday.at(time116.get()).do(job116)\r\n elif day116.get()==\"4\":\r\n schedule.every().thursday.at(time116.get()).do(job116)\r\n elif day116.get()==\"5\":\r\n schedule.every().friday.at(time116.get()).do(job116)\r\n elif day116.get()==\"6\":\r\n schedule.every().saturday.at(time116.get()).do(job116)\r\n elif day116.get()==\"7\":\r\n schedule.every().sunday.at(time116.get()).do(job116)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day117.get()==\"1\":\r\n schedule.every().monday.at(time117.get()).do(job117)\r\n elif day117.get()==\"2\":\r\n schedule.every().tuesday.at(time117.get()).do(job117)\r\n elif day117.get()==\"3\":\r\n schedule.every().wednesday.at(time117.get()).do(job117)\r\n elif day117.get()==\"4\":\r\n schedule.every().thursday.at(time117.get()).do(job117)\r\n elif day117.get()==\"5\":\r\n schedule.every().friday.at(time117.get()).do(job117)\r\n elif day117.get()==\"6\":\r\n schedule.every().saturday.at(time117.get()).do(job117)\r\n elif day117.get()==\"7\":\r\n schedule.every().sunday.at(time117.get()).do(job117)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day118.get()==\"1\":\r\n schedule.every().monday.at(time118.get()).do(job118)\r\n elif day118.get()==\"2\":\r\n schedule.every().tuesday.at(time118.get()).do(job118)\r\n elif day118.get()==\"3\":\r\n schedule.every().wednesday.at(time118.get()).do(job118)\r\n elif day118.get()==\"4\":\r\n schedule.every().thursday.at(time118.get()).do(job118)\r\n elif day118.get()==\"5\":\r\n schedule.every().friday.at(time118.get()).do(job118)\r\n elif day118.get()==\"6\":\r\n schedule.every().saturday.at(time118.get()).do(job118)\r\n elif day118.get()==\"7\":\r\n schedule.every().sunday.at(time118.get()).do(job118)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day119.get()==\"1\":\r\n schedule.every().monday.at(time119.get()).do(job119)\r\n elif day119.get()==\"2\":\r\n schedule.every().tuesday.at(time119.get()).do(job119)\r\n elif day119.get()==\"3\":\r\n schedule.every().wednesday.at(time119.get()).do(job119)\r\n elif day119.get()==\"4\":\r\n schedule.every().thursday.at(time119.get()).do(job119)\r\n elif day119.get()==\"5\":\r\n schedule.every().friday.at(time119.get()).do(job119)\r\n elif day119.get()==\"6\":\r\n schedule.every().saturday.at(time119.get()).do(job119)\r\n elif day119.get()==\"7\":\r\n schedule.every().sunday.at(time119.get()).do(job119)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day120.get()==\"1\":\r\n schedule.every().monday.at(time120.get()).do(job120)\r\n elif day120.get()==\"2\":\r\n schedule.every().tuesday.at(time120.get()).do(job120)\r\n elif day120.get()==\"3\":\r\n schedule.every().wednesday.at(time120.get()).do(job120)\r\n elif day120.get()==\"4\":\r\n schedule.every().thursday.at(time120.get()).do(job120)\r\n elif day120.get()==\"5\":\r\n schedule.every().friday.at(time120.get()).do(job120)\r\n elif day120.get()==\"6\":\r\n schedule.every().saturday.at(time120.get()).do(job120)\r\n elif day120.get()==\"7\":\r\n schedule.every().sunday.at(time120.get()).do(job120)\r\n\r\n while True:\r\n schedule.run_pending()\r\n (job406())\r\n\r\n\r\n\r\n\r\ndef job404():\r\n \r\n if day81.get()==\"1\":\r\n schedule.every().monday.at(time81.get()).do(job81)\r\n elif day81.get()==\"2\":\r\n schedule.every().tuesday.at(time81.get()).do(job81) \r\n elif day81.get()==\"3\":\r\n schedule.every().wednesday.at(time81.get()).do(job81)\r\n elif day81.get()==\"4\":\r\n schedule.every().thursday.at(time81.get()).do(job81)\r\n elif day81.get()==\"5\":\r\n schedule.every().friday.at(time81.get()).do(job81)\r\n elif day81.get()==\"6\":\r\n schedule.every().saturday.at(time81.get()).do(job81)\r\n elif day81.get()==\"7\":\r\n schedule.every().sunday.at(time81.get()).do(job81)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day82.get()==\"1\":\r\n schedule.every().monday.at(time82.get()).do(job82)\r\n elif day82.get()==\"2\":\r\n schedule.every().tuesday.at(time82.get()).do(job82)\r\n elif day82.get()==\"3\":\r\n schedule.every().wednesday.at(time82.get()).do(job82)\r\n elif day82.get()==\"4\":\r\n schedule.every().thursday.at(time82.get()).do(job82)\r\n elif day82.get()==\"5\":\r\n schedule.every().friday.at(time82.get()).do(job82)\r\n elif day82.get()==\"6\":\r\n schedule.every().saturday.at(time82.get()).do(job82)\r\n elif day82.get()==\"7\":\r\n schedule.every().sunday.at(time82.get()).do(job82)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day83.get()==\"1\":\r\n schedule.every().monday.at(time83.get()).do(job83)\r\n elif day83.get()==\"2\":\r\n schedule.every().tuesday.at(time83.get()).do(job83)\r\n elif day83.get()==\"3\":\r\n schedule.every().wednesday.at(time83.get()).do(job83)\r\n elif day83.get()==\"4\":\r\n schedule.every().thursday.at(time83.get()).do(job83)\r\n elif day83.get()==\"5\":\r\n schedule.every().friday.at(time83.get()).do(job83)\r\n elif day83.get()==\"6\":\r\n schedule.every().saturday.at(time83.get()).do(job83)\r\n elif day83.get()==\"7\":\r\n schedule.every().sunday.at(time83.get()).do(job83)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day84.get()==\"1\":\r\n schedule.every().monday.at(time84.get()).do(job84)\r\n elif day84.get()==\"2\":\r\n schedule.every().tuesday.at(time84.get()).do(job84)\r\n elif day84.get()==\"3\":\r\n schedule.every().wednesday.at(time84.get()).do(job84)\r\n elif day84.get()==\"4\":\r\n schedule.every().thursday.at(time84.get()).do(job84)\r\n elif day84.get()==\"5\":\r\n schedule.every().friday.at(time84.get()).do(job84)\r\n elif day84.get()==\"6\":\r\n schedule.every().saturday.at(time84.get()).do(job84)\r\n elif day84.get()==\"7\":\r\n schedule.every().sunday.at(time84.get()).do(job84)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day85.get()==\"1\":\r\n schedule.every().monday.at(time85.get()).do(job85)\r\n elif day85.get()==\"2\":\r\n schedule.every().tuesday.at(time85.get()).do(job85)\r\n elif day85.get()==\"3\":\r\n schedule.every().wednesday.at(time85.get()).do(job85)\r\n elif day85.get()==\"4\":\r\n schedule.every().thursday.at(time85.get()).do(job85)\r\n elif day85.get()==\"5\":\r\n schedule.every().friday.at(time85.get()).do(job85)\r\n elif day85.get()==\"6\":\r\n schedule.every().saturday.at(time85.get()).do(job85)\r\n elif day85.get()==\"7\":\r\n schedule.every().sunday.at(time85.get()).do(job85)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day86.get()==\"1\":\r\n schedule.every().monday.at(time86.get()).do(job86)\r\n elif day86.get()==\"2\":\r\n schedule.every().tuesday.at(time86.get()).do(job86)\r\n elif day86.get()==\"3\":\r\n schedule.every().wednesday.at(time86.get()).do(job86)\r\n elif day86.get()==\"4\":\r\n schedule.every().thursday.at(time86.get()).do(job86)\r\n elif day86.get()==\"5\":\r\n schedule.every().friday.at(time86.get()).do(job86)\r\n elif day86.get()==\"6\":\r\n schedule.every().saturday.at(time86.get()).do(job86)\r\n elif day86.get()==\"7\":\r\n schedule.every().sunday.at(time86.get()).do(job86)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day87.get()==\"1\":\r\n schedule.every().monday.at(time87.get()).do(job87)\r\n elif day87.get()==\"2\":\r\n schedule.every().tuesday.at(time87.get()).do(job87)\r\n elif day87.get()==\"3\":\r\n schedule.every().wednesday.at(time87.get()).do(job87)\r\n elif day87.get()==\"4\":\r\n schedule.every().thursday.at(time87.get()).do(job87)\r\n elif day87.get()==\"5\":\r\n schedule.every().friday.at(time87.get()).do(job87)\r\n elif day87.get()==\"6\":\r\n schedule.every().saturday.at(time87.get()).do(job87)\r\n elif day87.get()==\"7\":\r\n schedule.every().sunday.at(time87.get()).do(job87)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day88.get()==\"1\":\r\n schedule.every().monday.at(time88.get()).do(job88)\r\n elif day88.get()==\"2\":\r\n schedule.every().tuesday.at(time88.get()).do(job88)\r\n elif day88.get()==\"3\":\r\n schedule.every().wednesday.at(time88.get()).do(job88)\r\n elif day88.get()==\"4\":\r\n schedule.every().thursday.at(time88.get()).do(job88)\r\n elif day88.get()==\"5\":\r\n schedule.every().friday.at(time88.get()).do(job88)\r\n elif day88.get()==\"6\":\r\n schedule.every().saturday.at(time88.get()).do(job88)\r\n elif day88.get()==\"7\":\r\n schedule.every().sunday.at(time88.get()).do(job88)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day89.get()==\"1\":\r\n schedule.every().monday.at(time89.get()).do(job89)\r\n elif day89.get()==\"2\":\r\n schedule.every().tuesday.at(time89.get()).do(job89)\r\n elif day89.get()==\"3\":\r\n schedule.every().wednesday.at(time89.get()).do(job89)\r\n elif day89.get()==\"4\":\r\n schedule.every().thursday.at(time89.get()).do(job89)\r\n elif day89.get()==\"5\":\r\n schedule.every().friday.at(time89.get()).do(job89)\r\n elif day89.get()==\"6\":\r\n schedule.every().saturday.at(time89.get()).do(job89)\r\n elif day89.get()==\"7\":\r\n schedule.every().sunday.at(time89.get()).do(job89)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day90.get()==\"1\":\r\n schedule.every().monday.at(time90.get()).do(job90)\r\n elif day90.get()==\"2\":\r\n schedule.every().tuesday.at(time90.get()).do(job90)\r\n elif day90.get()==\"3\":\r\n schedule.every().wednesday.at(time90.get()).do(job90)\r\n elif day90.get()==\"4\":\r\n schedule.every().thursday.at(time90.get()).do(job90)\r\n elif day90.get()==\"5\":\r\n schedule.every().friday.at(time90.get()).do(job90)\r\n elif day90.get()==\"6\":\r\n schedule.every().saturday.at(time90.get()).do(job90)\r\n elif day90.get()==\"7\":\r\n schedule.every().sunday.at(time90.get()).do(job90)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day91.get()==\"1\":\r\n schedule.every().monday.at(time91.get()).do(job91)\r\n elif day91.get()==\"2\":\r\n schedule.every().tuesday.at(time91.get()).do(job91)\r\n elif day91.get()==\"3\":\r\n schedule.every().wednesday.at(time91.get()).do(job91)\r\n elif day91.get()==\"4\":\r\n schedule.every().thursday.at(time91.get()).do(job91)\r\n elif day91.get()==\"5\":\r\n schedule.every().friday.at(time91.get()).do(job91)\r\n elif day91.get()==\"6\":\r\n schedule.every().saturday.at(time91.get()).do(job91)\r\n elif day91.get()==\"7\":\r\n schedule.every().sunday.at(time91.get()).do(job91)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day92.get()==\"1\":\r\n schedule.every().monday.at(time92.get()).do(job92)\r\n elif day92.get()==\"2\":\r\n schedule.every().tuesday.at(time92.get()).do(job92)\r\n elif day92.get()==\"3\":\r\n schedule.every().wednesday.at(time92.get()).do(job92)\r\n elif day92.get()==\"4\":\r\n schedule.every().thursday.at(time92.get()).do(job92)\r\n elif day92.get()==\"5\":\r\n schedule.every().friday.at(time92.get()).do(job92)\r\n elif day92.get()==\"6\":\r\n schedule.every().saturday.at(time92.get()).do(job92)\r\n elif day92.get()==\"7\":\r\n schedule.every().sunday.at(time92.get()).do(job92)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day93.get()==\"1\":\r\n schedule.every().monday.at(time93.get()).do(job93)\r\n elif day93.get()==\"2\":\r\n schedule.every().tuesday.at(time93.get()).do(job93)\r\n elif day93.get()==\"3\":\r\n schedule.every().wednesday.at(time93.get()).do(job93)\r\n elif day93.get()==\"4\":\r\n schedule.every().thursday.at(time93.get()).do(job93)\r\n elif day93.get()==\"5\":\r\n schedule.every().friday.at(time93.get()).do(job93)\r\n elif day93.get()==\"6\":\r\n schedule.every().saturday.at(time93.get()).do(job93)\r\n elif day93.get()==\"7\":\r\n schedule.every().sunday.at(time93.get()).do(job93)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day94.get()==\"1\":\r\n schedule.every().monday.at(time94.get()).do(job94)\r\n elif day94.get()==\"2\":\r\n schedule.every().tuesday.at(time94.get()).do(job94)\r\n elif day94.get()==\"3\":\r\n schedule.every().wednesday.at(time94.get()).do(job94)\r\n elif day94.get()==\"4\":\r\n schedule.every().thursday.at(time94.get()).do(job94)\r\n elif day94.get()==\"5\":\r\n schedule.every().friday.at(time94.get()).do(job94)\r\n elif day94.get()==\"6\":\r\n schedule.every().saturday.at(time94.get()).do(job94)\r\n elif day94.get()==\"7\":\r\n schedule.every().sunday.at(time94.get()).do(job94)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day95.get()==\"1\":\r\n schedule.every().monday.at(time95.get()).do(job95)\r\n elif day95.get()==\"2\":\r\n schedule.every().tuesday.at(time95.get()).do(job95)\r\n elif day95.get()==\"3\":\r\n schedule.every().wednesday.at(time95.get()).do(job95)\r\n elif day95.get()==\"4\":\r\n schedule.every().thursday.at(time95.get()).do(job95)\r\n elif day95.get()==\"5\":\r\n schedule.every().friday.at(time95.get()).do(job95)\r\n elif day95.get()==\"6\":\r\n schedule.every().saturday.at(time95.get()).do(job95)\r\n elif day95.get()==\"7\":\r\n schedule.every().sunday.at(time95.get()).do(job95)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day96.get()==\"1\":\r\n schedule.every().monday.at(time96.get()).do(job96)\r\n elif day96.get()==\"2\":\r\n schedule.every().tuesday.at(time96.get()).do(job96)\r\n elif day96.get()==\"3\":\r\n schedule.every().wednesday.at(time96.get()).do(job96)\r\n elif day96.get()==\"4\":\r\n schedule.every().thursday.at(time96.get()).do(job96)\r\n elif day96.get()==\"5\":\r\n schedule.every().friday.at(time96.get()).do(job96)\r\n elif day96.get()==\"6\":\r\n schedule.every().saturday.at(time96.get()).do(job96)\r\n elif day96.get()==\"7\":\r\n schedule.every().sunday.at(time96.get()).do(job96)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day97.get()==\"1\":\r\n schedule.every().monday.at(time97.get()).do(job97)\r\n elif day97.get()==\"2\":\r\n schedule.every().tuesday.at(time97.get()).do(job97)\r\n elif day97.get()==\"3\":\r\n schedule.every().wednesday.at(time97.get()).do(job97)\r\n elif day97.get()==\"4\":\r\n schedule.every().thursday.at(time97.get()).do(job97)\r\n elif day97.get()==\"5\":\r\n schedule.every().friday.at(time97.get()).do(job97)\r\n elif day97.get()==\"6\":\r\n schedule.every().saturday.at(time97.get()).do(job97)\r\n elif day97.get()==\"7\":\r\n schedule.every().sunday.at(time97.get()).do(job97)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day98.get()==\"1\":\r\n schedule.every().monday.at(time98.get()).do(job98)\r\n elif day98.get()==\"2\":\r\n schedule.every().tuesday.at(time98.get()).do(job98)\r\n elif day98.get()==\"3\":\r\n schedule.every().wednesday.at(time98.get()).do(job98)\r\n elif day98.get()==\"4\":\r\n schedule.every().thursday.at(time98.get()).do(job98)\r\n elif day98.get()==\"5\":\r\n schedule.every().friday.at(time98.get()).do(job98)\r\n elif day98.get()==\"6\":\r\n schedule.every().saturday.at(time98.get()).do(job98)\r\n elif day98.get()==\"7\":\r\n schedule.every().sunday.at(time98.get()).do(job98)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day99.get()==\"1\":\r\n schedule.every().monday.at(time99.get()).do(job99)\r\n elif day99.get()==\"2\":\r\n schedule.every().tuesday.at(time99.get()).do(job99)\r\n elif day99.get()==\"3\":\r\n schedule.every().wednesday.at(time99.get()).do(job99)\r\n elif day99.get()==\"4\":\r\n schedule.every().thursday.at(time99.get()).do(job99)\r\n elif day99.get()==\"5\":\r\n schedule.every().friday.at(time99.get()).do(job99)\r\n elif day99.get()==\"6\":\r\n schedule.every().saturday.at(time99.get()).do(job99)\r\n elif day99.get()==\"7\":\r\n schedule.every().sunday.at(time99.get()).do(job99)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day100.get()==\"1\":\r\n schedule.every().monday.at(time100.get()).do(job100)\r\n elif day100.get()==\"2\":\r\n schedule.every().tuesday.at(time100.get()).do(job100)\r\n elif day100.get()==\"3\":\r\n schedule.every().wednesday.at(time100.get()).do(job100)\r\n elif day100.get()==\"4\":\r\n schedule.every().thursday.at(time100.get()).do(job100)\r\n elif day100.get()==\"5\":\r\n schedule.every().friday.at(time100.get()).do(job100)\r\n elif day100.get()==\"6\":\r\n schedule.every().saturday.at(time100.get()).do(job100)\r\n elif day100.get()==\"7\":\r\n schedule.every().sunday.at(time100.get()).do(job100)\r\n\r\n while True:\r\n schedule.run_pending()\r\n (job405())\r\n\r\n\r\n\r\n\r\n\r\n \r\ndef job403():\r\n \r\n if day61.get()==\"1\":\r\n schedule.every().monday.at(time61.get()).do(job61)\r\n elif day61.get()==\"2\":\r\n schedule.every().tuesday.at(time61.get()).do(job61)\r\n elif day61.get()==\"3\":\r\n schedule.every().wednesday.at(time61.get()).do(job61)\r\n elif day61.get()==\"4\":\r\n schedule.every().thursday.at(time61.get()).do(job61)\r\n elif day61.get()==\"5\":\r\n schedule.every().friday.at(time61.get()).do(job61)\r\n elif day61.get()==\"6\":\r\n schedule.every().saturday.at(time61.get()).do(job61)\r\n elif day61.get()==\"7\":\r\n schedule.every().sunday.at(time61.get()).do(job61)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day62.get()==\"1\":\r\n schedule.every().monday.at(time62.get()).do(job62)\r\n elif day62.get()==\"2\":\r\n schedule.every().tuesday.at(time62.get()).do(job62)\r\n elif day62.get()==\"3\":\r\n schedule.every().wednesday.at(time62.get()).do(job62)\r\n elif day62.get()==\"4\":\r\n schedule.every().thursday.at(time62.get()).do(job62)\r\n elif day62.get()==\"5\":\r\n schedule.every().friday.at(time62.get()).do(job62)\r\n elif day62.get()==\"6\":\r\n schedule.every().saturday.at(time62.get()).do(job62)\r\n elif day62.get()==\"7\":\r\n schedule.every().sunday.at(time62.get()).do(job62)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day63.get()==\"1\":\r\n schedule.every().monday.at(time63.get()).do(job63)\r\n elif day63.get()==\"2\":\r\n schedule.every().tuesday.at(time63.get()).do(job63)\r\n elif day63.get()==\"3\":\r\n schedule.every().wednesday.at(time63.get()).do(job63)\r\n elif day63.get()==\"4\":\r\n schedule.every().thursday.at(time63.get()).do(job63)\r\n elif day63.get()==\"5\":\r\n schedule.every().friday.at(time63.get()).do(job63)\r\n elif day63.get()==\"6\":\r\n schedule.every().saturday.at(time63.get()).do(job63)\r\n elif day63.get()==\"7\":\r\n schedule.every().sunday.at(time63.get()).do(job63)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day64.get()==\"1\":\r\n schedule.every().monday.at(time64.get()).do(job64)\r\n elif day64.get()==\"2\":\r\n schedule.every().tuesday.at(time64.get()).do(job64)\r\n elif day64.get()==\"3\":\r\n schedule.every().wednesday.at(time64.get()).do(job64)\r\n elif day64.get()==\"4\":\r\n schedule.every().thursday.at(time64.get()).do(job64)\r\n elif day64.get()==\"5\":\r\n schedule.every().friday.at(time64.get()).do(job64)\r\n elif day64.get()==\"6\":\r\n schedule.every().saturday.at(time64.get()).do(job64)\r\n elif day64.get()==\"7\":\r\n schedule.every().sunday.at(time64.get()).do(job64)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day65.get()==\"1\":\r\n schedule.every().monday.at(time65.get()).do(job65)\r\n elif day65.get()==\"2\":\r\n schedule.every().tuesday.at(time65.get()).do(job65)\r\n elif day65.get()==\"3\":\r\n schedule.every().wednesday.at(time65.get()).do(job65)\r\n elif day65.get()==\"4\":\r\n schedule.every().thursday.at(time65.get()).do(job65)\r\n elif day65.get()==\"5\":\r\n schedule.every().friday.at(time65.get()).do(job65)\r\n elif day65.get()==\"6\":\r\n schedule.every().saturday.at(time65.get()).do(job65)\r\n elif day65.get()==\"7\":\r\n schedule.every().sunday.at(time65.get()).do(job65)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day66.get()==\"1\":\r\n schedule.every().monday.at(time66.get()).do(job66)\r\n elif day66.get()==\"2\":\r\n schedule.every().tuesday.at(time66.get()).do(job66)\r\n elif day66.get()==\"3\":\r\n schedule.every().wednesday.at(time66.get()).do(job66)\r\n elif day66.get()==\"4\":\r\n schedule.every().thursday.at(time66.get()).do(job66)\r\n elif day66.get()==\"5\":\r\n schedule.every().friday.at(time66.get()).do(job66)\r\n elif day66.get()==\"6\":\r\n schedule.every().saturday.at(time66.get()).do(job66)\r\n elif day66.get()==\"7\":\r\n schedule.every().sunday.at(time66.get()).do(job66)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day67.get()==\"1\":\r\n schedule.every().monday.at(time67.get()).do(job67)\r\n elif day67.get()==\"2\":\r\n schedule.every().tuesday.at(time67.get()).do(job67)\r\n elif day67.get()==\"3\":\r\n schedule.every().wednesday.at(time67.get()).do(job67)\r\n elif day67.get()==\"4\":\r\n schedule.every().thursday.at(time67.get()).do(job67)\r\n elif day67.get()==\"5\":\r\n schedule.every().friday.at(time67.get()).do(job67)\r\n elif day67.get()==\"6\":\r\n schedule.every().saturday.at(time67.get()).do(job67)\r\n elif day67.get()==\"7\":\r\n schedule.every().sunday.at(time67.get()).do(job67)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day68.get()==\"1\":\r\n schedule.every().monday.at(time68.get()).do(job68)\r\n elif day68.get()==\"2\":\r\n schedule.every().tuesday.at(time68.get()).do(job68)\r\n elif day68.get()==\"3\":\r\n schedule.every().wednesday.at(time68.get()).do(job68)\r\n elif day68.get()==\"4\":\r\n schedule.every().thursday.at(time68.get()).do(job68)\r\n elif day68.get()==\"5\":\r\n schedule.every().friday.at(time68.get()).do(job68)\r\n elif day68.get()==\"6\":\r\n schedule.every().saturday.at(time68.get()).do(job68)\r\n elif day68.get()==\"7\":\r\n schedule.every().sunday.at(time68.get()).do(job68)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day69.get()==\"1\":\r\n schedule.every().monday.at(time69.get()).do(job69)\r\n elif day69.get()==\"2\":\r\n schedule.every().tuesday.at(time69.get()).do(job69)\r\n elif day69.get()==\"3\":\r\n schedule.every().wednesday.at(time69.get()).do(job69)\r\n elif day69.get()==\"4\":\r\n schedule.every().thursday.at(time69.get()).do(job69)\r\n elif day69.get()==\"5\":\r\n schedule.every().friday.at(time69.get()).do(job69)\r\n elif day69.get()==\"6\":\r\n schedule.every().saturday.at(time69.get()).do(job69)\r\n elif day69.get()==\"7\":\r\n schedule.every().sunday.at(time69.get()).do(job69)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day70.get()==\"1\":\r\n schedule.every().monday.at(time70.get()).do(job70)\r\n elif day70.get()==\"2\":\r\n schedule.every().tuesday.at(time70.get()).do(job70)\r\n elif day70.get()==\"3\":\r\n schedule.every().wednesday.at(time70.get()).do(job70)\r\n elif day70.get()==\"4\":\r\n schedule.every().thursday.at(time70.get()).do(job70)\r\n elif day70.get()==\"5\":\r\n schedule.every().friday.at(time70.get()).do(job70)\r\n elif day70.get()==\"6\":\r\n schedule.every().saturday.at(time70.get()).do(job70)\r\n elif day70.get()==\"7\":\r\n schedule.every().sunday.at(time70.get()).do(job70)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day71.get()==\"1\":\r\n schedule.every().monday.at(time71.get()).do(job71)\r\n elif day71.get()==\"2\":\r\n schedule.every().tuesday.at(time71.get()).do(job71)\r\n elif day71.get()==\"3\":\r\n schedule.every().wednesday.at(time71.get()).do(job71)\r\n elif day71.get()==\"4\":\r\n schedule.every().thursday.at(time71.get()).do(job71)\r\n elif day71.get()==\"5\":\r\n schedule.every().friday.at(time71.get()).do(job71)\r\n elif day71.get()==\"6\":\r\n schedule.every().saturday.at(time71.get()).do(job71)\r\n elif day71.get()==\"7\":\r\n schedule.every().sunday.at(time71.get()).do(job71)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day72.get()==\"1\":\r\n schedule.every().monday.at(time72.get()).do(job72)\r\n elif day72.get()==\"2\":\r\n schedule.every().tuesday.at(time72.get()).do(job72)\r\n elif day72.get()==\"3\":\r\n schedule.every().wednesday.at(time72.get()).do(job72)\r\n elif day72.get()==\"4\":\r\n schedule.every().thursday.at(time72.get()).do(job72)\r\n elif day72.get()==\"5\":\r\n schedule.every().friday.at(time72.get()).do(job72)\r\n elif day72.get()==\"6\":\r\n schedule.every().saturday.at(time72.get()).do(job72)\r\n elif day72.get()==\"7\":\r\n schedule.every().sunday.at(time72.get()).do(job72)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day73.get()==\"1\":\r\n schedule.every().monday.at(time73.get()).do(job73)\r\n elif day73.get()==\"2\":\r\n schedule.every().tuesday.at(time73.get()).do(job73)\r\n elif day73.get()==\"3\":\r\n schedule.every().wednesday.at(time73.get()).do(job73)\r\n elif day73.get()==\"4\":\r\n schedule.every().thursday.at(time73.get()).do(job73)\r\n elif day73.get()==\"5\":\r\n schedule.every().friday.at(time73.get()).do(job73)\r\n elif day73.get()==\"6\":\r\n schedule.every().saturday.at(time73.get()).do(job73)\r\n elif day73.get()==\"7\":\r\n schedule.every().sunday.at(time73.get()).do(job73)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day74.get()==\"1\":\r\n schedule.every().monday.at(time74.get()).do(job74)\r\n elif day74.get()==\"2\":\r\n schedule.every().tuesday.at(time74.get()).do(job74)\r\n elif day74.get()==\"3\":\r\n schedule.every().wednesday.at(time74.get()).do(job74)\r\n elif day74.get()==\"4\":\r\n schedule.every().thursday.at(time74.get()).do(job74)\r\n elif day74.get()==\"5\":\r\n schedule.every().friday.at(time74.get()).do(job74)\r\n elif day74.get()==\"6\":\r\n schedule.every().saturday.at(time74.get()).do(job74)\r\n elif day74.get()==\"7\":\r\n schedule.every().sunday.at(time74.get()).do(job74)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day75.get()==\"1\":\r\n schedule.every().monday.at(time75.get()).do(job75)\r\n elif day75.get()==\"2\":\r\n schedule.every().tuesday.at(time75.get()).do(job75)\r\n elif day75.get()==\"3\":\r\n schedule.every().wednesday.at(time75.get()).do(job75)\r\n elif day75.get()==\"4\":\r\n schedule.every().thursday.at(time75.get()).do(job75)\r\n elif day75.get()==\"5\":\r\n schedule.every().friday.at(time75.get()).do(job75)\r\n elif day75.get()==\"6\":\r\n schedule.every().saturday.at(time75.get()).do(job75)\r\n elif day75.get()==\"7\":\r\n schedule.every().sunday.at(time75.get()).do(job75)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day76.get()==\"1\":\r\n schedule.every().monday.at(time76.get()).do(job76)\r\n elif day76.get()==\"2\":\r\n schedule.every().tuesday.at(time76.get()).do(job76)\r\n elif day76.get()==\"3\":\r\n schedule.every().wednesday.at(time76.get()).do(job76)\r\n elif day76.get()==\"4\":\r\n schedule.every().thursday.at(time76.get()).do(job76)\r\n elif day76.get()==\"5\":\r\n schedule.every().friday.at(time76.get()).do(job76)\r\n elif day76.get()==\"6\":\r\n schedule.every().saturday.at(time76.get()).do(job76)\r\n elif day76.get()==\"7\":\r\n schedule.every().sunday.at(time76.get()).do(job76)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day77.get()==\"1\":\r\n schedule.every().monday.at(time77.get()).do(job77)\r\n elif day77.get()==\"2\":\r\n schedule.every().tuesday.at(time77.get()).do(job77)\r\n elif day77.get()==\"3\":\r\n schedule.every().wednesday.at(time77.get()).do(job77)\r\n elif day77.get()==\"4\":\r\n schedule.every().thursday.at(time77.get()).do(job77)\r\n elif day77.get()==\"5\":\r\n schedule.every().friday.at(time77.get()).do(job77)\r\n elif day77.get()==\"6\":\r\n schedule.every().saturday.at(time77.get()).do(job77)\r\n elif day77.get()==\"7\":\r\n schedule.every().sunday.at(time77.get()).do(job77)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day78.get()==\"1\":\r\n schedule.every().monday.at(time78.get()).do(job78)\r\n elif day78.get()==\"2\":\r\n schedule.every().tuesday.at(time78.get()).do(job78)\r\n elif day78.get()==\"3\":\r\n schedule.every().wednesday.at(time78.get()).do(job78)\r\n elif day78.get()==\"4\":\r\n schedule.every().thursday.at(time78.get()).do(job78)\r\n elif day78.get()==\"5\":\r\n schedule.every().friday.at(time78.get()).do(job78)\r\n elif day78.get()==\"6\":\r\n schedule.every().saturday.at(time78.get()).do(job78)\r\n elif day78.get()==\"7\":\r\n schedule.every().sunday.at(time78.get()).do(job78)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day79.get()==\"1\":\r\n schedule.every().monday.at(time79.get()).do(job79)\r\n elif day79.get()==\"2\":\r\n schedule.every().tuesday.at(time79.get()).do(job79)\r\n elif day79.get()==\"3\":\r\n schedule.every().wednesday.at(time79.get()).do(job79)\r\n elif day79.get()==\"4\":\r\n schedule.every().thursday.at(time79.get()).do(job79)\r\n elif day79.get()==\"5\":\r\n schedule.every().friday.at(time79.get()).do(job79)\r\n elif day79.get()==\"6\":\r\n schedule.every().saturday.at(time79.get()).do(job79)\r\n elif day79.get()==\"7\":\r\n schedule.every().sunday.at(time79.get()).do(job79)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day80.get()==\"1\":\r\n schedule.every().monday.at(time80.get()).do(job80)\r\n elif day80.get()==\"2\":\r\n schedule.every().tuesday.at(time80.get()).do(job80)\r\n elif day80.get()==\"3\":\r\n schedule.every().wednesday.at(time80.get()).do(job80)\r\n elif day80.get()==\"4\":\r\n schedule.every().thursday.at(time80.get()).do(job80)\r\n elif day80.get()==\"5\":\r\n schedule.every().friday.at(time80.get()).do(job80)\r\n elif day80.get()==\"6\":\r\n schedule.every().saturday.at(time80.get()).do(job80)\r\n elif day80.get()==\"7\":\r\n schedule.every().sunday.at(time80.get()).do(job80)\r\n\r\n while True:\r\n schedule.run_pending()\r\n (job404())\r\n\r\n\r\n\r\n\r\n\r\n\r\n \r\n \r\ndef job402():\r\n \r\n if day41.get()==\"1\":\r\n schedule.every().monday.at(time41.get()).do(job41)\r\n elif day41.get()==\"2\":\r\n schedule.every().tuesday.at(time41.get()).do(job41)\r\n elif day41.get()==\"3\":\r\n schedule.every().wednesday.at(time41.get()).do(job41)\r\n elif day41.get()==\"4\":\r\n schedule.every().thursday.at(time41.get()).do(job41)\r\n elif day41.get()==\"5\":\r\n schedule.every().friday.at(time41.get()).do(job41)\r\n elif day41.get()==\"6\":\r\n schedule.every().saturday.at(time41.get()).do(job41)\r\n elif day41.get()==\"7\":\r\n schedule.every().sunday.at(time41.get()).do(job41)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day42.get()==\"1\":\r\n schedule.every().monday.at(time42.get()).do(job42)\r\n elif day42.get()==\"2\":\r\n schedule.every().tuesday.at(time42.get()).do(job42)\r\n elif day42.get()==\"3\":\r\n schedule.every().wednesday.at(time42.get()).do(job42)\r\n elif day42.get()==\"4\":\r\n schedule.every().thursday.at(time42.get()).do(job42)\r\n elif day42.get()==\"5\":\r\n schedule.every().friday.at(time42.get()).do(job42)\r\n elif day42.get()==\"6\":\r\n schedule.every().saturday.at(time42.get()).do(job42)\r\n elif day42.get()==\"7\":\r\n schedule.every().sunday.at(time42.get()).do(job42)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day43.get()==\"1\":\r\n schedule.every().monday.at(time43.get()).do(job43)\r\n elif day43.get()==\"2\":\r\n schedule.every().tuesday.at(time43.get()).do(job43)\r\n elif day43.get()==\"3\":\r\n schedule.every().wednesday.at(time43.get()).do(job43)\r\n elif day43.get()==\"4\":\r\n schedule.every().thursday.at(time43.get()).do(job43)\r\n elif day43.get()==\"5\":\r\n schedule.every().friday.at(time43.get()).do(job43)\r\n elif day43.get()==\"6\":\r\n schedule.every().saturday.at(time43.get()).do(job43)\r\n elif day43.get()==\"7\":\r\n schedule.every().sunday.at(time43.get()).do(job43)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day44.get()==\"1\":\r\n schedule.every().monday.at(time44.get()).do(job44)\r\n elif day44.get()==\"2\":\r\n schedule.every().tuesday.at(time44.get()).do(job44)\r\n elif day44.get()==\"3\":\r\n schedule.every().wednesday.at(time44.get()).do(job44)\r\n elif day44.get()==\"4\":\r\n schedule.every().thursday.at(time44.get()).do(job44)\r\n elif day44.get()==\"5\":\r\n schedule.every().friday.at(time44.get()).do(job44)\r\n elif day44.get()==\"6\":\r\n schedule.every().saturday.at(time44.get()).do(job44)\r\n elif day44.get()==\"7\":\r\n schedule.every().sunday.at(time44.get()).do(job44)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day45.get()==\"1\":\r\n schedule.every().monday.at(time45.get()).do(job45)\r\n elif day45.get()==\"2\":\r\n schedule.every().tuesday.at(time45.get()).do(job45)\r\n elif day45.get()==\"3\":\r\n schedule.every().wednesday.at(time45.get()).do(job45)\r\n elif day45.get()==\"4\":\r\n schedule.every().thursday.at(time45.get()).do(job45)\r\n elif day45.get()==\"5\":\r\n schedule.every().friday.at(time45.get()).do(job45)\r\n elif day45.get()==\"6\":\r\n schedule.every().saturday.at(time45.get()).do(job45)\r\n elif day45.get()==\"7\":\r\n schedule.every().sunday.at(time45.get()).do(job45)\r\n \r\n while True:\r\n schedule.run_pending()\r\n if day46.get()==\"1\":\r\n schedule.every().monday.at(time46.get()).do(job46)\r\n elif day46.get()==\"2\":\r\n schedule.every().tuesday.at(time46.get()).do(job46)\r\n elif day46.get()==\"3\":\r\n schedule.every().wednesday.at(time46.get()).do(job46)\r\n elif day46.get()==\"4\":\r\n schedule.every().thursday.at(time46.get()).do(job46)\r\n elif day46.get()==\"5\":\r\n schedule.every().friday.at(time46.get()).do(job46)\r\n elif day46.get()==\"6\":\r\n schedule.every().saturday.at(time46.get()).do(job46)\r\n elif day46.get()==\"7\":\r\n schedule.every().sunday.at(time46.get()).do(job46)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day47.get()==\"1\":\r\n schedule.every().monday.at(time47.get()).do(job47)\r\n elif day47.get()==\"2\":\r\n schedule.every().tuesday.at(time47.get()).do(job47)\r\n elif day47.get()==\"3\":\r\n schedule.every().wednesday.at(time47.get()).do(job47)\r\n elif day47.get()==\"4\":\r\n schedule.every().thursday.at(time47.get()).do(job47)\r\n elif day47.get()==\"5\":\r\n schedule.every().friday.at(time47.get()).do(job47)\r\n elif day47.get()==\"6\":\r\n schedule.every().saturday.at(time47.get()).do(job47)\r\n elif day47.get()==\"7\":\r\n schedule.every().sunday.at(time47.get()).do(job47)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day48.get()==\"1\":\r\n schedule.every().monday.at(time48.get()).do(job48)\r\n elif day48.get()==\"2\":\r\n schedule.every().tuesday.at(time48.get()).do(job48)\r\n elif day48.get()==\"3\":\r\n schedule.every().wednesday.at(time48.get()).do(job48)\r\n elif day48.get()==\"4\":\r\n schedule.every().thursday.at(time48.get()).do(job48)\r\n elif day48.get()==\"5\":\r\n schedule.every().friday.at(time48.get()).do(job48)\r\n elif day48.get()==\"6\":\r\n schedule.every().saturday.at(time48.get()).do(job48)\r\n elif day48.get()==\"7\":\r\n schedule.every().sunday.at(time48.get()).do(job48)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day49.get()==\"1\":\r\n schedule.every().monday.at(time49.get()).do(job49)\r\n elif day49.get()==\"2\":\r\n schedule.every().tuesday.at(time49.get()).do(job49)\r\n elif day49.get()==\"3\":\r\n schedule.every().wednesday.at(time49.get()).do(job49)\r\n elif day49.get()==\"4\":\r\n schedule.every().thursday.at(time49.get()).do(job49)\r\n elif day49.get()==\"5\":\r\n schedule.every().friday.at(time49.get()).do(job49)\r\n elif day49.get()==\"6\":\r\n schedule.every().saturday.at(time49.get()).do(job49)\r\n elif day49.get()==\"7\":\r\n schedule.every().sunday.at(time49.get()).do(job49)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day50.get()==\"1\":\r\n schedule.every().monday.at(time50.get()).do(job50)\r\n elif day50.get()==\"2\":\r\n schedule.every().tuesday.at(time50.get()).do(job50)\r\n elif day50.get()==\"3\":\r\n schedule.every().wednesday.at(time50.get()).do(job50)\r\n elif day50.get()==\"4\":\r\n schedule.every().thursday.at(time50.get()).do(job50)\r\n elif day50.get()==\"5\":\r\n schedule.every().friday.at(time50.get()).do(job50)\r\n elif day50.get()==\"6\":\r\n schedule.every().saturday.at(time50.get()).do(job50)\r\n elif day50.get()==\"7\":\r\n schedule.every().sunday.at(time50.get()).do(job50)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day51.get()==\"1\":\r\n schedule.every().monday.at(time51.get()).do(job51)\r\n elif day51.get()==\"2\":\r\n schedule.every().tuesday.at(time51.get()).do(job51)\r\n elif day51.get()==\"3\":\r\n schedule.every().wednesday.at(time51.get()).do(job51)\r\n elif day51.get()==\"4\":\r\n schedule.every().thursday.at(time51.get()).do(job51)\r\n elif day51.get()==\"5\":\r\n schedule.every().friday.at(time51.get()).do(job51)\r\n elif day51.get()==\"6\":\r\n schedule.every().saturday.at(time51.get()).do(job51)\r\n elif day51.get()==\"7\":\r\n schedule.every().sunday.at(time51.get()).do(job51)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day52.get()==\"1\":\r\n schedule.every().monday.at(time52.get()).do(job52)\r\n elif day52.get()==\"2\":\r\n schedule.every().tuesday.at(time52.get()).do(job52)\r\n elif day52.get()==\"3\":\r\n schedule.every().wednesday.at(time52.get()).do(job52)\r\n elif day52.get()==\"4\":\r\n schedule.every().thursday.at(time52.get()).do(job52)\r\n elif day52.get()==\"5\":\r\n schedule.every().friday.at(time52.get()).do(job52)\r\n elif day52.get()==\"6\":\r\n schedule.every().saturday.at(time52.get()).do(job52)\r\n elif day52.get()==\"7\":\r\n schedule.every().sunday.at(time52.get()).do(job52)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day53.get()==\"1\":\r\n schedule.every().monday.at(time53.get()).do(job53)\r\n elif day53.get()==\"2\":\r\n schedule.every().tuesday.at(time53.get()).do(job53)\r\n elif day53.get()==\"3\":\r\n schedule.every().wednesday.at(time53.get()).do(job53)\r\n elif day53.get()==\"4\":\r\n schedule.every().thursday.at(time53.get()).do(job53)\r\n elif day53.get()==\"5\":\r\n schedule.every().friday.at(time53.get()).do(job53)\r\n elif day53.get()==\"6\":\r\n schedule.every().saturday.at(time53.get()).do(job53)\r\n elif day53.get()==\"7\":\r\n schedule.every().sunday.at(time53.get()).do(job53)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day54.get()==\"1\":\r\n schedule.every().monday.at(time54.get()).do(job54)\r\n elif day54.get()==\"2\":\r\n schedule.every().tuesday.at(time54.get()).do(job54)\r\n elif day54.get()==\"3\":\r\n schedule.every().wednesday.at(time54.get()).do(job54)\r\n elif day54.get()==\"4\":\r\n schedule.every().thursday.at(time54.get()).do(job54)\r\n elif day54.get()==\"5\":\r\n schedule.every().friday.at(time54.get()).do(job54)\r\n elif day54.get()==\"6\":\r\n schedule.every().saturday.at(time54.get()).do(job54)\r\n elif day54.get()==\"7\":\r\n schedule.every().sunday.at(time54.get()).do(job54)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day55.get()==\"1\":\r\n schedule.every().monday.at(time55.get()).do(job55)\r\n elif day55.get()==\"2\":\r\n schedule.every().tuesday.at(time55.get()).do(job55)\r\n elif day55.get()==\"3\":\r\n schedule.every().wednesday.at(time55.get()).do(job55)\r\n elif day55.get()==\"4\":\r\n schedule.every().thursday.at(time55.get()).do(job55)\r\n elif day55.get()==\"5\":\r\n schedule.every().friday.at(time55.get()).do(job55)\r\n elif day55.get()==\"6\":\r\n schedule.every().saturday.at(time55.get()).do(job55)\r\n elif day55.get()==\"7\":\r\n schedule.every().sunday.at(time55.get()).do(job55)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day56.get()==\"1\":\r\n schedule.every().monday.at(time56.get()).do(job56)\r\n elif day56.get()==\"2\":\r\n schedule.every().tuesday.at(time56.get()).do(job56)\r\n elif day56.get()==\"3\":\r\n schedule.every().wednesday.at(time56.get()).do(job56)\r\n elif day56.get()==\"4\":\r\n schedule.every().thursday.at(time56.get()).do(job56)\r\n elif day56.get()==\"5\":\r\n schedule.every().friday.at(time56.get()).do(job56)\r\n elif day56.get()==\"6\":\r\n schedule.every().saturday.at(time56.get()).do(job56)\r\n elif day56.get()==\"7\":\r\n schedule.every().sunday.at(time56.get()).do(job56)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day57.get()==\"1\":\r\n schedule.every().monday.at(time57.get()).do(job57)\r\n elif day57.get()==\"2\":\r\n schedule.every().tuesday.at(time57.get()).do(job57)\r\n elif day57.get()==\"3\":\r\n schedule.every().wednesday.at(time57.get()).do(job57)\r\n elif day57.get()==\"4\":\r\n schedule.every().thursday.at(time57.get()).do(job57)\r\n elif day57.get()==\"5\":\r\n schedule.every().friday.at(time57.get()).do(job57)\r\n elif day57.get()==\"6\":\r\n schedule.every().saturday.at(time57.get()).do(job57)\r\n elif day57.get()==\"7\":\r\n schedule.every().sunday.at(time57.get()).do(job57)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day58.get()==\"1\":\r\n schedule.every().monday.at(time58.get()).do(job58)\r\n elif day58.get()==\"2\":\r\n schedule.every().tuesday.at(time58.get()).do(job58)\r\n elif day58.get()==\"3\":\r\n schedule.every().wednesday.at(time58.get()).do(job58)\r\n elif day58.get()==\"4\":\r\n schedule.every().thursday.at(time58.get()).do(job58)\r\n elif day58.get()==\"5\":\r\n schedule.every().friday.at(time58.get()).do(job58)\r\n elif day58.get()==\"6\":\r\n schedule.every().saturday.at(time58.get()).do(job58)\r\n elif day58.get()==\"7\":\r\n schedule.every().sunday.at(time58.get()).do(job58)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day59.get()==\"1\":\r\n schedule.every().monday.at(time59.get()).do(job59)\r\n elif day59.get()==\"2\":\r\n schedule.every().tuesday.at(time59.get()).do(job59)\r\n elif day59.get()==\"3\":\r\n schedule.every().wednesday.at(time59.get()).do(job59)\r\n elif day59.get()==\"4\":\r\n schedule.every().thursday.at(time59.get()).do(job59)\r\n elif day59.get()==\"5\":\r\n schedule.every().friday.at(time59.get()).do(job59)\r\n elif day59.get()==\"6\":\r\n schedule.every().saturday.at(time59.get()).do(job59)\r\n elif day59.get()==\"7\":\r\n schedule.every().sunday.at(time59.get()).do(job59)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day60.get()==\"1\":\r\n schedule.every().monday.at(time60.get()).do(job60)\r\n elif day60.get()==\"2\":\r\n schedule.every().tuesday.at(time60.get()).do(job60)\r\n elif day60.get()==\"3\":\r\n schedule.every().wednesday.at(time60.get()).do(job60)\r\n elif day60.get()==\"4\":\r\n schedule.every().thursday.at(time60.get()).do(job60)\r\n elif day60.get()==\"5\":\r\n schedule.every().friday.at(time60.get()).do(job60)\r\n elif day60.get()==\"6\":\r\n schedule.every().saturday.at(time60.get()).do(job60)\r\n elif day60.get()==\"7\":\r\n schedule.every().sunday.at(time60.get()).do(job60)\r\n\r\n while True:\r\n schedule.run_pending()\r\n (job403())\r\n\r\n\r\n\r\n\r\n \r\n\r\ndef job401():\r\n \r\n if day21.get()==\"1\":\r\n schedule.every().monday.at(time21.get()).do(job21)\r\n elif day21.get()==\"2\":\r\n schedule.every().tuesday.at(time21.get()).do(job21)\r\n elif day21.get()==\"3\":\r\n schedule.every().wednesday.at(time21.get()).do(job21)\r\n elif day21.get()==\"4\":\r\n schedule.every().thursday.at(time21.get()).do(job21)\r\n elif day21.get()==\"5\":\r\n schedule.every().friday.at(time21.get()).do(job21)\r\n elif day21.get()==\"6\":\r\n schedule.every().saturday.at(time21.get()).do(job21)\r\n elif day21.get()==\"7\":\r\n schedule.every().sunday.at(time21.get()).do(job21)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day22.get()==\"1\":\r\n schedule.every().monday.at(time22.get()).do(job22)\r\n elif day22.get()==\"2\":\r\n schedule.every().tuesday.at(time22.get()).do(job22)\r\n elif day22.get()==\"3\":\r\n schedule.every().wednesday.at(time22.get()).do(job22)\r\n elif day22.get()==\"4\":\r\n schedule.every().thursday.at(time22.get()).do(job22)\r\n elif day22.get()==\"5\":\r\n schedule.every().friday.at(time22.get()).do(job22)\r\n elif day22.get()==\"6\":\r\n schedule.every().saturday.at(time22.get()).do(job22)\r\n elif day22.get()==\"7\":\r\n schedule.every().sunday.at(time22.get()).do(job22)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day23.get()==\"1\":\r\n schedule.every().monday.at(time23.get()).do(job23)\r\n elif day23.get()==\"2\":\r\n schedule.every().tuesday.at(time23.get()).do(job23)\r\n elif day23.get()==\"3\":\r\n schedule.every().wednesday.at(time23.get()).do(job23)\r\n elif day23.get()==\"4\":\r\n schedule.every().thursday.at(time23.get()).do(job23)\r\n elif day23.get()==\"5\":\r\n schedule.every().friday.at(time23.get()).do(job23)\r\n elif day23.get()==\"6\":\r\n schedule.every().saturday.at(time23.get()).do(job23)\r\n elif day23.get()==\"7\":\r\n schedule.every().sunday.at(time23.get()).do(job23)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day24.get()==\"1\":\r\n schedule.every().monday.at(time24.get()).do(job24)\r\n elif day24.get()==\"2\":\r\n schedule.every().tuesday.at(time24.get()).do(job24)\r\n elif day24.get()==\"3\":\r\n schedule.every().wednesday.at(time24.get()).do(job24)\r\n elif day24.get()==\"4\":\r\n schedule.every().thursday.at(time24.get()).do(job24)\r\n elif day24.get()==\"5\":\r\n schedule.every().friday.at(time24.get()).do(job24)\r\n elif day24.get()==\"6\":\r\n schedule.every().saturday.at(time24.get()).do(job24)\r\n elif day24.get()==\"7\":\r\n schedule.every().sunday.at(time24.get()).do(job24)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day25.get()==\"1\":\r\n schedule.every().monday.at(time25.get()).do(job25)\r\n elif day25.get()==\"2\":\r\n schedule.every().tuesday.at(time25.get()).do(job25)\r\n elif day25.get()==\"3\":\r\n schedule.every().wednesday.at(time25.get()).do(job25)\r\n elif day25.get()==\"4\":\r\n schedule.every().thursday.at(time25.get()).do(job25)\r\n elif day25.get()==\"5\":\r\n schedule.every().friday.at(time25.get()).do(job25)\r\n elif day25.get()==\"6\":\r\n schedule.every().saturday.at(time25.get()).do(job25)\r\n elif day25.get()==\"7\":\r\n schedule.every().sunday.at(time25.get()).do(job25)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day26.get()==\"1\":\r\n schedule.every().monday.at(time26.get()).do(job26)\r\n elif day26.get()==\"2\":\r\n schedule.every().tuesday.at(time26.get()).do(job26)\r\n elif day26.get()==\"3\":\r\n schedule.every().wednesday.at(time26.get()).do(job26)\r\n elif day26.get()==\"4\":\r\n schedule.every().thursday.at(time26.get()).do(job26)\r\n elif day26.get()==\"5\":\r\n schedule.every().friday.at(time26.get()).do(job26)\r\n elif day26.get()==\"6\":\r\n schedule.every().saturday.at(time26.get()).do(job26)\r\n elif day26.get()==\"7\":\r\n schedule.every().sunday.at(time26.get()).do(job26)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day27.get()==\"1\":\r\n schedule.every().monday.at(time27.get()).do(job27)\r\n elif day27.get()==\"2\":\r\n schedule.every().tuesday.at(time27.get()).do(job27)\r\n elif day27.get()==\"3\":\r\n schedule.every().wednesday.at(time27.get()).do(job27)\r\n elif day27.get()==\"4\":\r\n schedule.every().thursday.at(time27.get()).do(job27)\r\n elif day27.get()==\"5\":\r\n schedule.every().friday.at(time27.get()).do(job27)\r\n elif day27.get()==\"6\":\r\n schedule.every().saturday.at(time27.get()).do(job27)\r\n elif day27.get()==\"7\":\r\n schedule.every().sunday.at(time27.get()).do(job27)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day28.get()==\"1\":\r\n schedule.every().monday.at(time28.get()).do(job28)\r\n elif day28.get()==\"2\":\r\n schedule.every().tuesday.at(time28.get()).do(job28)\r\n elif day28.get()==\"3\":\r\n schedule.every().wednesday.at(time28.get()).do(job28)\r\n elif day28.get()==\"4\":\r\n schedule.every().thursday.at(time28.get()).do(job28)\r\n elif day28.get()==\"5\":\r\n schedule.every().friday.at(time28.get()).do(job28)\r\n elif day28.get()==\"6\":\r\n schedule.every().saturday.at(time28.get()).do(job28)\r\n elif day28.get()==\"7\":\r\n schedule.every().sunday.at(time28.get()).do(job28)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day29.get()==\"1\":\r\n schedule.every().monday.at(time29.get()).do(job29)\r\n elif day29.get()==\"2\":\r\n schedule.every().tuesday.at(time29.get()).do(job29)\r\n elif day29.get()==\"3\":\r\n schedule.every().wednesday.at(time29.get()).do(job29)\r\n elif day29.get()==\"4\":\r\n schedule.every().thursday.at(time29.get()).do(job29)\r\n elif day29.get()==\"5\":\r\n schedule.every().friday.at(time29.get()).do(job29)\r\n elif day29.get()==\"6\":\r\n schedule.every().saturday.at(time29.get()).do(job29)\r\n elif day29.get()==\"7\":\r\n schedule.every().sunday.at(time29.get()).do(job29)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day30.get()==\"1\":\r\n schedule.every().monday.at(time30.get()).do(job30)\r\n elif day30.get()==\"2\":\r\n schedule.every().tuesday.at(time30.get()).do(job30)\r\n elif day30.get()==\"3\":\r\n schedule.every().wednesday.at(time30.get()).do(job30)\r\n elif day30.get()==\"4\":\r\n schedule.every().thursday.at(time30.get()).do(job30)\r\n elif day30.get()==\"5\":\r\n schedule.every().friday.at(time30.get()).do(job30)\r\n elif day30.get()==\"6\":\r\n schedule.every().saturday.at(time30.get()).do(job30)\r\n elif day30.get()==\"7\":\r\n schedule.every().sunday.at(time30.get()).do(job30)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day31.get()==\"1\":\r\n schedule.every().monday.at(time31.get()).do(job31)\r\n elif day31.get()==\"2\":\r\n schedule.every().tuesday.at(time31.get()).do(job31)\r\n elif day31.get()==\"3\":\r\n schedule.every().wednesday.at(time31.get()).do(job31)\r\n elif day31.get()==\"4\":\r\n schedule.every().thursday.at(time31.get()).do(job31)\r\n elif day31.get()==\"5\":\r\n schedule.every().friday.at(time31.get()).do(job31)\r\n elif day31.get()==\"6\":\r\n schedule.every().saturday.at(time31.get()).do(job31)\r\n elif day31.get()==\"7\":\r\n schedule.every().sunday.at(time31.get()).do(job31)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day32.get()==\"1\":\r\n schedule.every().monday.at(time32.get()).do(job32)\r\n elif day32.get()==\"2\":\r\n schedule.every().tuesday.at(time32.get()).do(job32)\r\n elif day32.get()==\"3\":\r\n schedule.every().wednesday.at(time32.get()).do(job32)\r\n elif day32.get()==\"4\":\r\n schedule.every().thursday.at(time32.get()).do(job32)\r\n elif day32.get()==\"5\":\r\n schedule.every().friday.at(time32.get()).do(job32)\r\n elif day32.get()==\"6\":\r\n schedule.every().saturday.at(time32.get()).do(job32)\r\n elif day32.get()==\"7\":\r\n schedule.every().sunday.at(time32.get()).do(job32)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day33.get()==\"1\":\r\n schedule.every().monday.at(time33.get()).do(job33)\r\n elif day33.get()==\"2\":\r\n schedule.every().tuesday.at(time33.get()).do(job33)\r\n elif day33.get()==\"3\":\r\n schedule.every().wednesday.at(time33.get()).do(job33)\r\n elif day33.get()==\"4\":\r\n schedule.every().thursday.at(time33.get()).do(job33)\r\n elif day33.get()==\"5\":\r\n schedule.every().friday.at(time33.get()).do(job33)\r\n elif day33.get()==\"6\":\r\n schedule.every().saturday.at(time33.get()).do(job33)\r\n elif day33.get()==\"7\":\r\n schedule.every().sunday.at(time33.get()).do(job33)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day34.get()==\"1\":\r\n schedule.every().monday.at(time34.get()).do(job34)\r\n elif day34.get()==\"2\":\r\n schedule.every().tuesday.at(time34.get()).do(job34)\r\n elif day34.get()==\"3\":\r\n schedule.every().wednesday.at(time34.get()).do(job34)\r\n elif day34.get()==\"4\":\r\n schedule.every().thursday.at(time34.get()).do(job34)\r\n elif day34.get()==\"5\":\r\n schedule.every().friday.at(time34.get()).do(job34)\r\n elif day34.get()==\"6\":\r\n schedule.every().saturday.at(time34.get()).do(job34)\r\n elif day34.get()==\"7\":\r\n schedule.every().sunday.at(time34.get()).do(job34)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day35.get()==\"1\":\r\n schedule.every().monday.at(time35.get()).do(job35)\r\n elif day35.get()==\"2\":\r\n schedule.every().tuesday.at(time35.get()).do(job35)\r\n elif day35.get()==\"3\":\r\n schedule.every().wednesday.at(time35.get()).do(job35)\r\n elif day35.get()==\"4\":\r\n schedule.every().thursday.at(time35.get()).do(job35)\r\n elif day35.get()==\"5\":\r\n schedule.every().friday.at(time35.get()).do(job35)\r\n elif day35.get()==\"6\":\r\n schedule.every().saturday.at(time35.get()).do(job35)\r\n elif day35.get()==\"7\":\r\n schedule.every().sunday.at(time35.get()).do(job35)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day36.get()==\"1\":\r\n schedule.every().monday.at(time36.get()).do(job36)\r\n elif day36.get()==\"2\":\r\n schedule.every().tuesday.at(time36.get()).do(job36)\r\n elif day36.get()==\"3\":\r\n schedule.every().wednesday.at(time36.get()).do(job36)\r\n elif day36.get()==\"4\":\r\n schedule.every().thursday.at(time36.get()).do(job36)\r\n elif day36.get()==\"5\":\r\n schedule.every().friday.at(time36.get()).do(job36)\r\n elif day36.get()==\"6\":\r\n schedule.every().saturday.at(time36.get()).do(job36)\r\n elif day36.get()==\"7\":\r\n schedule.every().sunday.at(time36.get()).do(job36)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day37.get()==\"1\":\r\n schedule.every().monday.at(time37.get()).do(job37)\r\n elif day37.get()==\"2\":\r\n schedule.every().tuesday.at(time37.get()).do(job37)\r\n elif day37.get()==\"3\":\r\n schedule.every().wednesday.at(time37.get()).do(job37)\r\n elif day37.get()==\"4\":\r\n schedule.every().thursday.at(time37.get()).do(job37)\r\n elif day37.get()==\"5\":\r\n schedule.every().friday.at(time37.get()).do(job37)\r\n elif day37.get()==\"6\":\r\n schedule.every().saturday.at(time37.get()).do(job37)\r\n elif day37.get()==\"7\":\r\n schedule.every().sunday.at(time37.get()).do(job37)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day38.get()==\"1\":\r\n schedule.every().monday.at(time38.get()).do(job38)\r\n elif day38.get()==\"2\":\r\n schedule.every().tuesday.at(time38.get()).do(job38)\r\n elif day38.get()==\"3\":\r\n schedule.every().wednesday.at(time38.get()).do(job38)\r\n elif day38.get()==\"4\":\r\n schedule.every().thursday.at(time38.get()).do(job38)\r\n elif day38.get()==\"5\":\r\n schedule.every().friday.at(time38.get()).do(job38)\r\n elif day38.get()==\"6\":\r\n schedule.every().saturday.at(time38.get()).do(job38)\r\n elif day38.get()==\"7\":\r\n schedule.every().sunday.at(time38.get()).do(job38)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day39.get()==\"1\":\r\n schedule.every().monday.at(time39.get()).do(job39)\r\n elif day39.get()==\"2\":\r\n schedule.every().tuesday.at(time39.get()).do(job39)\r\n elif day39.get()==\"3\":\r\n schedule.every().wednesday.at(time39.get()).do(job39)\r\n elif day39.get()==\"4\":\r\n schedule.every().thursday.at(time39.get()).do(job39)\r\n elif day39.get()==\"5\":\r\n schedule.every().friday.at(time39.get()).do(job39)\r\n elif day39.get()==\"6\":\r\n schedule.every().saturday.at(time39.get()).do(job39)\r\n elif day39.get()==\"7\":\r\n schedule.every().sunday.at(time39.get()).do(job39)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day40.get()==\"1\":\r\n schedule.every().monday.at(time40.get()).do(job40)\r\n elif day40.get()==\"2\":\r\n schedule.every().tuesday.at(time40.get()).do(job40)\r\n elif day40.get()==\"3\":\r\n schedule.every().wednesday.at(time40.get()).do(job40)\r\n elif day40.get()==\"4\":\r\n schedule.every().thursday.at(time40.get()).do(job40)\r\n elif day40.get()==\"5\":\r\n schedule.every().friday.at(time40.get()).do(job40)\r\n elif day40.get()==\"6\":\r\n schedule.every().saturday.at(time40.get()).do(job40)\r\n elif day40.get()==\"7\":\r\n schedule.every().sunday.at(time40.get()).do(job40)\r\n\r\n while True:\r\n schedule.run_pending()\r\n (job402())\r\ndef job400():\r\n \r\n if day1.get()==\"1\":\r\n schedule.every().monday.at(time1.get()).do(job1)\r\n elif day1.get()==\"2\":\r\n schedule.every().tuesday.at(time1.get()).do(job1)\r\n elif day1.get()==\"3\":\r\n schedule.every().wednesday.at(time1.get()).do(job1)\r\n elif day1.get()==\"4\":\r\n schedule.every().thursday.at(time1.get()).do(job1)\r\n elif day1.get()==\"5\":\r\n schedule.every().friday.at(time1.get()).do(job1)\r\n elif day1.get()==\"6\":\r\n schedule.every().saturday.at(time1.get()).do(job1)\r\n elif day1.get()==\"7\":\r\n schedule.every().sunday.at(time1.get()).do(job1)\r\n\r\n while True:\r\n schedule.run_pending() \r\n if day2.get()==\"1\":\r\n schedule.every().monday.at(time2.get()).do(job2)\r\n elif day2.get()==\"2\":\r\n schedule.every().tuesday.at(time2.get()).do(job2)\r\n elif day2.get()==\"3\":\r\n schedule.every().wednesday.at(time2.get()).do(job2)\r\n elif day2.get()==\"4\":\r\n schedule.every().thursday.at(time2.get()).do(job2)\r\n elif day2.get()==\"5\":\r\n schedule.every().friday.at(time2.get()).do(job2)\r\n elif day2.get()==\"6\":\r\n schedule.every().saturday.at(time2.get()).do(job2)\r\n elif day2.get()==\"7\":\r\n schedule.every().sunday.at(time2.get()).do(job2)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day3.get()==\"1\":\r\n schedule.every().monday.at(time3.get()).do(job3)\r\n elif day3.get()==\"2\":\r\n schedule.every().tuesday.at(time3.get()).do(job3)\r\n elif day3.get()==\"3\":\r\n schedule.every().wednesday.at(time3.get()).do(job3)\r\n elif day3.get()==\"4\":\r\n schedule.every().thursday.at(time3.get()).do(job3)\r\n elif day3.get()==\"5\":\r\n schedule.every().friday.at(time3.get()).do(job3)\r\n elif day3.get()==\"6\":\r\n schedule.every().saturday.at(time3.get()).do(job3)\r\n elif day3.get()==\"7\":\r\n schedule.every().sunday.at(time3.get()).do(job3)\r\n\r\n while True:\r\n schedule.run_pending() \r\n if day4.get()==\"1\":\r\n schedule.every().monday.at(time4.get()).do(job4)\r\n elif day4.get()==\"2\":\r\n schedule.every().tuesday.at(time4.get()).do(job4)\r\n elif day4.get()==\"3\":\r\n schedule.every().wednesday.at(time4.get()).do(job4)\r\n elif day4.get()==\"4\":\r\n schedule.every().thursday.at(time4.get()).do(job4)\r\n elif day4.get()==\"5\":\r\n schedule.every().friday.at(time4.get()).do(job4)\r\n elif day4.get()==\"6\":\r\n schedule.every().saturday.at(time4.get()).do(job4)\r\n elif day4.get()==\"7\":\r\n schedule.every().sunday.at(time4.get()).do(job4)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day5.get()==\"1\":\r\n schedule.every().monday.at(time5.get()).do(job5)\r\n elif day5.get()==\"2\":\r\n schedule.every().tuesday.at(time5.get()).do(job5)\r\n elif day5.get()==\"3\":\r\n schedule.every().wednesday.at(time5.get()).do(job5)\r\n elif day5.get()==\"4\":\r\n schedule.every().thursday.at(time5.get()).do(job5)\r\n elif day5.get()==\"5\":\r\n schedule.every().friday.at(time5.get()).do(job5)\r\n elif day5.get()==\"6\":\r\n schedule.every().saturday.at(time5.get()).do(job5)\r\n elif day5.get()==\"7\":\r\n schedule.every().sunday.at(time5.get()).do(job5)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day6.get()==\"1\":\r\n schedule.every().monday.at(time6.get()).do(job6)\r\n elif day6.get()==\"2\":\r\n schedule.every().tuesday.at(time6.get()).do(job6)\r\n elif day6.get()==\"3\":\r\n schedule.every().wednesday.at(time6.get()).do(job6)\r\n elif day6.get()==\"4\":\r\n schedule.every().thursday.at(time6.get()).do(job6)\r\n elif day6.get()==\"5\":\r\n schedule.every().friday.at(time6.get()).do(job6)\r\n elif day6.get()==\"6\":\r\n schedule.every().saturday.at(time6.get()).do(job6)\r\n elif day6.get()==\"7\":\r\n schedule.every().sunday.at(time6.get()).do(job6)\r\n\r\n while True:\r\n schedule.run_pending() \r\n if day7.get()==\"1\":\r\n schedule.every().monday.at(time7.get()).do(job7)\r\n elif day7.get()==\"2\":\r\n schedule.every().tuesday.at(time7.get()).do(job7)\r\n elif day7.get()==\"3\":\r\n schedule.every().wednesday.at(time7.get()).do(job7)\r\n elif day7.get()==\"4\":\r\n schedule.every().thursday.at(time7.get()).do(job7)\r\n elif day7.get()==\"5\":\r\n schedule.every().friday.at(time7.get()).do(job7)\r\n elif day7.get()==\"6\":\r\n schedule.every().saturday.at(time7.get()).do(job7)\r\n elif day7.get()==\"7\":\r\n schedule.every().sunday.at(time7.get()).do(job7)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day8.get()==\"1\":\r\n schedule.every().monday.at(time8.get()).do(job8)\r\n elif day8.get()==\"2\":\r\n schedule.every().tuesday.at(time8.get()).do(job8)\r\n elif day8.get()==\"3\":\r\n schedule.every().wednesday.at(time8.get()).do(job8)\r\n elif day8.get()==\"4\":\r\n schedule.every().thursday.at(time8.get()).do(job8)\r\n elif day8.get()==\"5\":\r\n schedule.every().friday.at(time8.get()).do(job8)\r\n elif day8.get()==\"6\":\r\n schedule.every().saturday.at(time8.get()).do(job8)\r\n elif day8.get()==\"7\":\r\n schedule.every().sunday.at(time8.get()).do(job8)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day9.get()==\"1\":\r\n schedule.every().monday.at(time9.get()).do(job9)\r\n elif day9.get()==\"2\":\r\n schedule.every().tuesday.at(time9.get()).do(job9)\r\n elif day9.get()==\"3\":\r\n schedule.every().wednesday.at(time9.get()).do(job9)\r\n elif day9.get()==\"4\":\r\n schedule.every().thursday.at(time9.get()).do(job9)\r\n elif day9.get()==\"5\":\r\n schedule.every().friday.at(time9.get()).do(job9)\r\n elif day9.get()==\"6\":\r\n schedule.every().saturday.at(time9.get()).do(job9)\r\n elif day9.get()==\"7\":\r\n schedule.every().sunday.at(time9.get()).do(job9)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day10.get()==\"1\":\r\n schedule.every().monday.at(time10.get()).do(job10)\r\n elif day10.get()==\"2\":\r\n schedule.every().tuesday.at(time10.get()).do(job10)\r\n elif day10.get()==\"3\":\r\n schedule.every().wednesday.at(time10.get()).do(job10)\r\n elif day10.get()==\"4\":\r\n schedule.every().thursday.at(time10.get()).do(job10)\r\n elif day10.get()==\"5\":\r\n schedule.every().friday.at(time10.get()).do(job10)\r\n elif day10.get()==\"6\":\r\n schedule.every().saturday.at(time10.get()).do(job10)\r\n elif day10.get()==\"7\":\r\n schedule.every().sunday.at(time10.get()).do(job10)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day11.get()==\"1\":\r\n schedule.every().monday.at(time11.get()).do(job11)\r\n elif day11.get()==\"2\":\r\n schedule.every().tuesday.at(time11.get()).do(job11)\r\n elif day11.get()==\"3\":\r\n schedule.every().wednesday.at(time11.get()).do(job11)\r\n elif day11.get()==\"4\":\r\n schedule.every().thursday.at(time11.get()).do(job11)\r\n elif day11.get()==\"5\":\r\n schedule.every().friday.at(time11.get()).do(job11)\r\n elif day11.get()==\"6\":\r\n schedule.every().saturday.at(time11.get()).do(job11)\r\n elif day11.get()==\"7\":\r\n schedule.every().sunday.at(time11.get()).do(job11)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day12.get()==\"1\":\r\n schedule.every().monday.at(time12.get()).do(job12)\r\n elif day12.get()==\"2\":\r\n schedule.every().tuesday.at(time12.get()).do(job12)\r\n elif day12.get()==\"3\":\r\n schedule.every().wednesday.at(time12.get()).do(job12)\r\n elif day12.get()==\"4\":\r\n schedule.every().thursday.at(time12.get()).do(job12)\r\n elif day12.get()==\"5\":\r\n schedule.every().friday.at(time12.get()).do(job12)\r\n elif day12.get()==\"6\":\r\n schedule.every().saturday.at(time12.get()).do(job12)\r\n elif day12.get()==\"7\":\r\n schedule.every().sunday.at(time12.get()).do(job12)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day13.get()==\"1\":\r\n schedule.every().monday.at(time13.get()).do(job13)\r\n elif day13.get()==\"2\":\r\n schedule.every().tuesday.at(time13.get()).do(job13)\r\n elif day13.get()==\"3\":\r\n schedule.every().wednesday.at(time13.get()).do(job13)\r\n elif day13.get()==\"4\":\r\n schedule.every().thursday.at(time13.get()).do(job13)\r\n elif day13.get()==\"5\":\r\n schedule.every().friday.at(time13.get()).do(job13)\r\n elif day13.get()==\"6\":\r\n schedule.every().saturday.at(time13.get()).do(job13)\r\n elif day13.get()==\"7\":\r\n schedule.every().sunday.at(time13.get()).do(job13)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day14.get()==\"1\":\r\n schedule.every().monday.at(time14.get()).do(job14)\r\n elif day14.get()==\"2\":\r\n schedule.every().tuesday.at(time14.get()).do(job14)\r\n elif day14.get()==\"3\":\r\n schedule.every().wednesday.at(time14.get()).do(job14)\r\n elif day14.get()==\"4\":\r\n schedule.every().thursday.at(time14.get()).do(job14)\r\n elif day14.get()==\"5\":\r\n schedule.every().friday.at(time14.get()).do(job14)\r\n elif day14.get()==\"6\":\r\n schedule.every().saturday.at(time14.get()).do(job14)\r\n elif day14.get()==\"7\":\r\n schedule.every().sunday.at(time14.get()).do(job14)\r\n\r\n while True:\r\n schedule.run_pending() \r\n if day15.get()==\"1\":\r\n schedule.every().monday.at(time15.get()).do(job15)\r\n elif day15.get()==\"2\":\r\n schedule.every().tuesday.at(time15.get()).do(job15)\r\n elif day15.get()==\"3\":\r\n schedule.every().wednesday.at(time15.get()).do(job15)\r\n elif day15.get()==\"4\":\r\n schedule.every().thursday.at(time15.get()).do(job15)\r\n elif day15.get()==\"5\":\r\n schedule.every().friday.at(time15.get()).do(job15)\r\n elif day15.get()==\"6\":\r\n schedule.every().saturday.at(time15.get()).do(job15)\r\n elif day15.get()==\"7\":\r\n schedule.every().sunday.at(time15.get()).do(job15)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day16.get()==\"1\":\r\n schedule.every().monday.at(time16.get()).do(job16)\r\n elif day16.get()==\"2\":\r\n schedule.every().tuesday.at(time16.get()).do(job16)\r\n elif day16.get()==\"3\":\r\n schedule.every().wednesday.at(time16.get()).do(job16)\r\n elif day16.get()==\"4\":\r\n schedule.every().thursday.at(time16.get()).do(job16)\r\n elif day16.get()==\"5\":\r\n schedule.every().friday.at(time16.get()).do(job16)\r\n elif day16.get()==\"6\":\r\n schedule.every().saturday.at(time16.get()).do(job16)\r\n elif day16.get()==\"7\":\r\n schedule.every().sunday.at(time16.get()).do(job16)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day17.get()==\"1\":\r\n schedule.every().monday.at(time17.get()).do(job17)\r\n elif day17.get()==\"2\":\r\n schedule.every().tuesday.at(time17.get()).do(job17)\r\n elif day17.get()==\"3\":\r\n schedule.every().wednesday.at(time17.get()).do(job17)\r\n elif day17.get()==\"4\":\r\n schedule.every().thursday.at(time17.get()).do(job17)\r\n elif day17.get()==\"5\":\r\n schedule.every().friday.at(time17.get()).do(job17)\r\n elif day17.get()==\"6\":\r\n schedule.every().saturday.at(time17.get()).do(job17)\r\n elif day17.get()==\"7\":\r\n schedule.every().sunday.at(time17.get()).do(job17)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day18.get()==\"1\":\r\n schedule.every().monday.at(time18.get()).do(job18)\r\n elif day18.get()==\"2\":\r\n schedule.every().tuesday.at(time18.get()).do(job18)\r\n elif day18.get()==\"3\":\r\n schedule.every().wednesday.at(time18.get()).do(job18)\r\n elif day18.get()==\"4\":\r\n schedule.every().thursday.at(time18.get()).do(job18)\r\n elif day18.get()==\"5\":\r\n schedule.every().friday.at(time18.get()).do(job18)\r\n elif day18.get()==\"6\":\r\n schedule.every().saturday.at(time18.get()).do(job18)\r\n elif day18.get()==\"7\":\r\n schedule.every().sunday.at(time18.get()).do(job18)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day19.get()==\"1\":\r\n schedule.every().monday.at(time19.get()).do(job19)\r\n elif day19.get()==\"2\":\r\n schedule.every().tuesday.at(time19.get()).do(job19)\r\n elif day19.get()==\"3\":\r\n schedule.every().wednesday.at(time19.get()).do(job19)\r\n elif day19.get()==\"4\":\r\n schedule.every().thursday.at(time19.get()).do(job19)\r\n elif day19.get()==\"5\":\r\n schedule.every().friday.at(time19.get()).do(job19)\r\n elif day19.get()==\"6\":\r\n schedule.every().saturday.at(time19.get()).do(job19)\r\n elif day19.get()==\"7\":\r\n schedule.every().sunday.at(time19.get()).do(job19)\r\n\r\n while True:\r\n schedule.run_pending()\r\n if day20.get()==\"1\":\r\n schedule.every().monday.at(time20.get()).do(job20)\r\n elif day20.get()==\"2\":\r\n schedule.every().tuesday.at(time20.get()).do(job20)\r\n elif day20.get()==\"3\":\r\n schedule.every().wednesday.at(time20.get()).do(job20)\r\n elif day20.get()==\"4\":\r\n schedule.every().thursday.at(time20.get()).do(job20)\r\n elif day20.get()==\"5\":\r\n schedule.every().friday.at(time20.get()).do(job20)\r\n elif day20.get()==\"6\":\r\n schedule.every().saturday.at(time20.get()).do(job20)\r\n elif day20.get()==\"7\":\r\n schedule.every().sunday.at(time20.get()).do(job20)\r\n\r\n while True:\r\n schedule.run_pending()\r\n (job401())\r\n \r\nmyButton = Button(second_frame, text= \" Ready! \", command=job400, cursor=\"hand2\")\r\nmyButton.pack()\r\n\r\n\r\n\r\nroot.mainloop() \r\n"
}
] | 2 |
lenarother/django-legaltext
|
https://github.com/lenarother/django-legaltext
|
3cb559ca96760fbaca9806a07b0f2d41bb865cef
|
45e3610d531905e2fe92d092cc876674e0224de0
|
4350f94fe34c1f0349ce6720e873be2c59281fc1
|
refs/heads/master
| 2022-10-15T10:04:30.778567 | 2020-06-12T12:33:49 | 2020-06-12T12:33:49 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7097156643867493,
"alphanum_fraction": 0.7168246507644653,
"avg_line_length": 27.133333206176758,
"blob_id": "5725611e5e18a9114d3766bf5a40f8294130099b",
"content_id": "4e71c204603209bffc293847837fa6465f20330d",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 844,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 30,
"path": "/examples/dynamic_legaltexts/models.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.urls import reverse\nfrom django.utils import timezone\n\nfrom legaltext.fields import LegalTextField\nfrom legaltext.models import LegalText\n\n\nclass Survey(models.Model):\n name = models.CharField(max_length=255)\n terms = models.ForeignKey(LegalText, related_name='+', on_delete=models.CASCADE)\n privacy = models.ForeignKey(LegalText, related_name='+', on_delete=models.CASCADE)\n\n def __str__(self):\n return self.name\n\n def get_absolute_url(self):\n return reverse('dynamic-form', args=(self.pk,))\n\n\nclass Participant(models.Model):\n name = models.CharField(max_length=255)\n\n accepted_terms = LegalTextField()\n accepted_privacy = LegalTextField()\n\n date_submit = models.DateTimeField(default=timezone.now)\n\n def __str__(self):\n return str(self.date_submit)\n"
},
{
"alpha_fraction": 0.5937621593475342,
"alphanum_fraction": 0.5945419073104858,
"avg_line_length": 34.625,
"blob_id": "15dd7b591f9bc0238f3038bb7e0506df0af739cb",
"content_id": "0d6486d3510ac822aa92d1d1011c2e254698253f",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2565,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 72,
"path": "/legaltext/widgets.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "import floppyforms.__future__ as forms\nfrom django.conf import settings\nfrom django.template.loader import render_to_string\nfrom django.utils.safestring import mark_safe\n\nfrom .models import LegalText\n\n\nclass LegalTextWidget(forms.widgets.MultiWidget):\n template_name = None\n\n def __init__(self, slug, attrs=None):\n self.version = LegalText.current_version(slug)\n self.checkboxes = list(self.version.checkboxes.all())\n\n super().__init__([forms.CheckboxInput() for checkbox in self.checkboxes], attrs)\n\n def get_template_name(self):\n if self.template_name:\n return self.template_name\n\n template_name = getattr(\n settings, 'LEGALTEXT_WIDGET_TEMPLATE', 'legaltext/widget.html')\n overrides = getattr(settings, 'LEGALTEXT_WIDGET_TEMPLATE_OVERRIDES', {})\n return overrides.get(self.version.legaltext.slug, template_name)\n\n def value_from_datadict(self, data, files, name):\n for i, checkbox in enumerate(self.checkboxes):\n if not data.get('{}_{}'.format(name, i)):\n return None\n return self.version.pk\n\n def decompress(self, value):\n # Overwrite initial value from LegalTextField.\n # Checkboxes are by default empty.\n return [None for checkbox in self.checkboxes]\n\n def render(self, name, value, attrs=None, renderer=None):\n if self.is_localized:\n for widget in self.widgets:\n widget.is_localized = self.is_localized\n\n if not isinstance(value, list):\n value = self.decompress(value)\n\n final_attrs = self.build_attrs(attrs or {})\n final_attrs.update(getattr(settings, 'LEGALTEXT_WIDGET_ATTRS', {}))\n id_ = final_attrs.get('id')\n\n checkboxes = []\n for i, widget in enumerate(self.widgets):\n try:\n widget_value = value[i]\n except IndexError:\n widget_value = None\n\n if id_:\n final_attrs = dict(final_attrs, id='%s_%s' % (id_, i))\n\n checkboxes.append((\n '{0}_{1}'.format(name, i),\n widget.render(name + '_%s' % i, widget_value, final_attrs),\n self.checkboxes[i].render_content()\n ))\n\n return mark_safe(render_to_string(self.get_template_name(), {\n 'required': self.is_required,\n 'errors': getattr(getattr(\n self, 'context_instance', {}).get('field'), 'errors', []),\n 'version': self.version,\n 'checkboxes': checkboxes\n }))\n"
},
{
"alpha_fraction": 0.7454931139945984,
"alphanum_fraction": 0.7486744523048401,
"avg_line_length": 30.433332443237305,
"blob_id": "14142cc7cae67aebe906aeec8e2a2cb2ba61892e",
"content_id": "08029708b105d24d2470dddcb8ac29b9a45acffc",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 943,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 30,
"path": "/testing/factories.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "import factory\nfrom django.utils import timezone\nfrom django.utils.text import slugify\n\nfrom legaltext.models import LegalText, LegalTextCheckbox, LegalTextVersion\n\n\nclass LegalTextFactory(factory.DjangoModelFactory):\n name = factory.Sequence(lambda i: 'Legal Text Test {0}'.format(i))\n slug = factory.LazyAttribute(lambda a: slugify((a.name)))\n\n class Meta:\n model = LegalText\n\n\nclass LegalTextVersionFactory(factory.DjangoModelFactory):\n legaltext = factory.SubFactory(LegalTextFactory)\n valid_from = timezone.now()\n content = factory.Sequence(lambda j: 'Legal Text test text test text {0}'.format(j))\n\n class Meta:\n model = LegalTextVersion\n\n\nclass LegalTextCheckboxFactory(factory.DjangoModelFactory):\n legaltext_version = factory.SubFactory(LegalTextVersionFactory)\n content = factory.Sequence(lambda k: 'Checkbox Label Test Text {0}'.format(k))\n\n class Meta:\n model = LegalTextCheckbox\n"
},
{
"alpha_fraction": 0.7634408473968506,
"alphanum_fraction": 0.7634408473968506,
"avg_line_length": 17.600000381469727,
"blob_id": "2a67dbf7de4a63ff80e9dcee8d55a2ffba574099",
"content_id": "27efc12001fe58a11973c3f1107f2fc8b5ec82bb",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 93,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/legaltext/apps.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass LegalTextConfig(AppConfig):\n name = 'legaltext'\n"
},
{
"alpha_fraction": 0.595683217048645,
"alphanum_fraction": 0.6012916564941406,
"avg_line_length": 36.71794891357422,
"blob_id": "2420955c8d8883e26b4caf7bce4d680c364a7c00",
"content_id": "6b924806e1f88723bc74e2e8b62d683cda705c1e",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5884,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 156,
"path": "/legaltext/models.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "import re\n\nfrom django.conf import settings\nfrom django.db import models\nfrom django.urls import reverse\nfrom django.utils import timezone\nfrom django.utils.text import normalize_newlines\nfrom django.utils.translation import gettext\nfrom django.utils.translation import gettext_lazy as _\nfrom markymark.fields import MarkdownField\nfrom markymark.renderer import render_markdown\n\n\nANCHOR_RE = re.compile(r'\\[anchor(?:\\:([^\\]]+))?\\](?:(.+?)\\[/anchor\\])')\nBLOCK_OPEN_NL_RE = re.compile(r'(?:\\n\\n|\\n)?(\\[block\\:[^\\]]+\\])(?:\\n\\n|\\n)?', re.DOTALL)\nBLOCK_CLOSE_NL_RE = re.compile(r'(?:\\n\\n|\\n)?(\\[/block\\])(?:\\n\\n|\\n)?', re.DOTALL)\nBLOCK_OPEN_RE = re.compile(r'(?:<p>)?\\[block\\:([^\\]]+)\\](?:</p>)?')\nBLOCK_CLOSE_RE = re.compile(r'(?:<p>)?\\[/block\\](?:</p>)?')\n\n\nclass LegalText(models.Model):\n name = models.CharField(_('Legal text'), max_length=64)\n slug = models.SlugField(_('Slug'), max_length=128, unique=True)\n url_name = models.SlugField(\n _('URL Name'), max_length=128, unique=True, blank=True, null=True, help_text=_(\n 'Optional URL name for the legal text. If not provided, the slug is used.'))\n\n class Meta:\n verbose_name = _('Legal text')\n verbose_name_plural = _('Legal texts')\n ordering = ('name',)\n\n def __str__(self):\n return self.name\n\n @classmethod\n def current_version(cls, slug):\n obj, created = LegalText.objects.get_or_create(\n slug=slug, defaults={'name': slug})\n return obj.get_current_version()\n\n def get_current_version(self):\n version = self.legaltextversion_set.filter(\n valid_from__lte=timezone.now()).first()\n if not version:\n version, created = LegalTextVersion.objects.get_or_create(legaltext=self)\n if created:\n version.checkboxes.create(content=gettext('I accept.'))\n\n return version\n\n def get_absolute_url(self):\n return reverse('legaltext', args=(self.url_name or self.slug,))\n\n\nclass LegalTextVersion(models.Model):\n legaltext = models.ForeignKey(\n LegalText, verbose_name=_('Legal text'), on_delete=models.CASCADE)\n valid_from = models.DateTimeField(_('Valid from'), default=timezone.now)\n\n content = MarkdownField(_('Text'), help_text=_(\n 'You can use [block:foo]Your text[/block] to create a block with an anchor. '\n 'Anchors ([anchor:foo]) can be used in checkbox texts to link to '\n 'specific parts of the legal text.'\n ))\n\n class Meta:\n verbose_name = _('Legal text version')\n verbose_name_plural = _('Legal text versions')\n ordering = ('legaltext__slug', '-valid_from')\n\n def __str__(self):\n return '{0} ({1:%x %X})'.format(\n self.legaltext.name, timezone.localtime(self.valid_from))\n\n @property\n def name(self):\n return self.legaltext.name\n\n def render_content(self):\n anchor_class = getattr(settings, 'LEGALTEXT_ANCHOR_CLASS', None)\n\n def block_nl_callback(match):\n return '\\n\\n{0}\\n\\n'.format(match.group(1))\n\n def block_open_callback(match):\n block_open_callback.count += 1\n return (\n '<div class=\"legaltext-block legaltext-block-{0}\">'\n '<span id=\"{0}\"{1}></span>'\n ).format(\n match.group(1),\n ' class=\"{0}\"'.format(anchor_class) if anchor_class else '',\n )\n block_open_callback.count = 0\n\n def block_close_callback(match):\n block_close_callback.count += 1\n return '</div>'\n block_close_callback.count = 0\n\n content = BLOCK_OPEN_NL_RE.sub(block_nl_callback, self.content)\n content = BLOCK_CLOSE_NL_RE.sub(block_nl_callback, content)\n\n content = render_markdown(content)\n content = BLOCK_OPEN_RE.sub(block_open_callback, content)\n content = BLOCK_CLOSE_RE.sub(block_close_callback, content)\n\n if block_open_callback.count == block_close_callback.count:\n return content\n return render_markdown(self.content)\n\n\nclass LegalTextCheckbox(models.Model):\n legaltext_version = models.ForeignKey(\n LegalTextVersion, verbose_name=_('Legal text version'), related_name='checkboxes',\n on_delete=models.CASCADE)\n\n content = MarkdownField(_('Text'), help_text=_(\n 'You can use [anchor]Your text[/anchor] to create a link to the full legal text. '\n 'If you use [anchor:foo]Your text[/anchor] the link will go to the block \"foo\" '\n 'inside the legal text.'\n ))\n order = models.PositiveIntegerField(_('Order'), blank=True, null=True)\n\n class Meta:\n verbose_name = _('Legal text checkbox')\n verbose_name_plural = _('Legal text Checkboxes')\n ordering = ('legaltext_version', 'order')\n unique_together = (('legaltext_version', 'order'),)\n\n def __str__(self):\n return gettext('Checkbox for {0} ({1})').format(\n self.legaltext_version.name,\n '{0:%x %X}'.format(timezone.localtime(self.legaltext_version.valid_from))\n )\n\n def render_content(self):\n def anchor_callback(match):\n return '<a href=\"{0}{1}\" class=\"legaltext-anchor\" target=\"_blank\">{2}</a>'.format(\n self.legaltext_version.legaltext.get_absolute_url(),\n '#{0}'.format(match.group(1)) if match.group(1) else '',\n match.group(2)\n )\n\n content = ANCHOR_RE.sub(\n anchor_callback,\n normalize_newlines(self.content).replace('\\n', '<br />')\n )\n return render_markdown(content).replace('<p>', '').replace('</p>', '')\n\n def save(self, *args, **kwargs):\n if not self.order:\n self.order = (self.legaltext_version.checkboxes.aggregate(\n next_order=models.Max('order'))['next_order'] or 0) + 1\n super().save(*args, **kwargs)\n"
},
{
"alpha_fraction": 0.6384567618370056,
"alphanum_fraction": 0.6384567618370056,
"avg_line_length": 28.759260177612305,
"blob_id": "6da4e8f3ab675cec0b150654fcf7c8727438c509",
"content_id": "c3eab7a958edff44696617a382fc08708a61b194",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1607,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 54,
"path": "/legaltext/fields.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "import floppyforms.__future__ as forms\nfrom django.db import models\nfrom django.utils.deconstruct import deconstructible\n\nfrom .models import LegalText, LegalTextVersion\nfrom .widgets import LegalTextWidget\n\n\n@deconstructible\nclass CurrentLegalText(object):\n\n def __init__(self, slug):\n self.slug = slug\n\n def __call__(self):\n return LegalText.current_version(self.slug).pk\n\n\nclass LegalTextField(models.ForeignKey):\n\n def __init__(self, slug=None, to=LegalTextVersion, **kwargs):\n self.slug = slug\n if slug:\n kwargs.setdefault('default', CurrentLegalText(slug))\n kwargs['limit_choices_to'] = {'legaltext__slug': slug}\n kwargs['related_name'] = '+'\n kwargs['on_delete'] = models.PROTECT\n kwargs['blank'] = True\n kwargs['null'] = True\n super().__init__(to, **kwargs)\n\n def deconstruct(self):\n name, path, args, kwargs = super().deconstruct()\n kwargs['slug'] = self.slug\n return name, path, args, kwargs\n\n\nclass LegalTextFormField(forms.BooleanField):\n\n def __init__(self, slug, *args, **kwargs):\n self.slug = slug\n kwargs.setdefault('widget', LegalTextWidget(self.slug))\n kwargs.setdefault('required', True)\n super().__init__(*args, **kwargs)\n\n label = property(lambda s: LegalText.current_version(s.slug).name, lambda s, v: None)\n\n def prepare_value(self, value):\n return bool(value)\n\n def to_python(self, value):\n if not value or value in self.empty_values:\n return None\n return LegalText.current_version(self.slug)\n"
},
{
"alpha_fraction": 0.5963455438613892,
"alphanum_fraction": 0.634551465511322,
"avg_line_length": 29.100000381469727,
"blob_id": "b6dd97f6115cebe6186be53e1c39d6361978d52c",
"content_id": "216406b80cb2b39b8c1dceb6430123169d4432c6",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 602,
"license_type": "permissive",
"max_line_length": 197,
"num_lines": 20,
"path": "/legaltext/migrations/0003_legaltext_url_name.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.10.7 on 2017-08-04 09:59\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('legaltext', '0002_legaltextcheckbox'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='legaltext',\n name='url_name',\n field=models.SlugField(blank=True, help_text='Optional URL name for the legal text. If not provided, the slug is used.', max_length=64, null=True, unique=True, verbose_name='URL Name'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7894737124443054,
"alphanum_fraction": 0.7894737124443054,
"avg_line_length": 27.5,
"blob_id": "573586369ef4f25ddab460d7f0428223b9118d51",
"content_id": "904a3f76ec84f8761811b048dd57cc9a05dbd0ad",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 399,
"license_type": "permissive",
"max_line_length": 57,
"num_lines": 14,
"path": "/examples/static_legaltexts/views.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "from django.urls import reverse_lazy\nfrom django.views.generic import CreateView, TemplateView\n\nfrom .forms import ParticipationForm\n\n\nclass StaticParticipantFormView(CreateView):\n template_name = 'form.html'\n form_class = ParticipationForm\n success_url = reverse_lazy('static-form-completed')\n\n\nclass StaticParticipantCompletedView(TemplateView):\n template_name = 'form-completed.html'\n"
},
{
"alpha_fraction": 0.5874679088592529,
"alphanum_fraction": 0.5874679088592529,
"avg_line_length": 31.02739715576172,
"blob_id": "dfacbe382bf72604865799d16f638b2b08b0255a",
"content_id": "df45e8bbc8fc0d8d973dac49e7495b906c463db2",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4676,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 146,
"path": "/testing/tests/test_templatetags.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "import pytest\nfrom django.template import Context, Template\nfrom django.template.exceptions import TemplateSyntaxError\nfrom django.urls import NoReverseMatch\n\nfrom testing.factories import LegalTextFactory\n\n\[email protected]_db\nclass TestLegaltextUrl:\n\n def test_slug(self):\n LegalTextFactory.create(slug='foo-bar-test')\n expected = '/foo-bar-test/'\n template = Template('{% load legaltext_tags %}{% legaltext_url \"foo-bar-test\" %}')\n context = Context({})\n\n rendered = template.render(context)\n\n assert rendered == expected\n\n def test_slug_as_variable(self):\n LegalTextFactory.create(slug='foo-bar-test')\n expected = '/foo-bar-test/'\n template = Template(\n '{% load legaltext_tags %}{% legaltext_url \"foo-bar-test\" as my_url %}'\n '{{ my_url }}')\n context = Context({})\n\n rendered = template.render(context)\n\n assert rendered == expected\n\n def test_slug_as_variable_not_rendered(self):\n LegalTextFactory.create(slug='foo-bar-test')\n template = Template(\n '{% load legaltext_tags %}{% legaltext_url \"foo-bar-test\" as my_url %}')\n context = Context({})\n\n rendered = template.render(context)\n\n assert rendered == ''\n\n def test_url_name(self):\n LegalTextFactory.create(slug='foo-bar-test', url_name='eggs')\n expected = '/eggs/'\n template = Template('{% load legaltext_tags %}{% legaltext_url \"eggs\" %}')\n context = Context({})\n\n rendered = template.render(context)\n\n assert rendered == expected\n\n def test_url_name_as_variable(self):\n LegalTextFactory.create(slug='foo-bar-test', url_name='eggs')\n expected = '/eggs/'\n template = Template(\n '{% load legaltext_tags %}{% legaltext_url \"eggs\" as my_url %}'\n '{{ my_url }}')\n context = Context({})\n\n rendered = template.render(context)\n\n assert rendered == expected\n\n def test_url_name_as_variable_not_rendered(self):\n LegalTextFactory.create(slug='foo-bar-test', url_name='eggs')\n template = Template(\n '{% load legaltext_tags %}{% legaltext_url \"eggs\" as my_url %}')\n context = Context({})\n\n rendered = template.render(context)\n\n assert rendered == ''\n\n def test_slug_and_url_name(self):\n LegalTextFactory.create(slug='foo-bar-test', url_name='eggs')\n expected = '/eggs/'\n template = Template('{% load legaltext_tags %}{% legaltext_url \"foo-bar-test\" %}')\n context = Context({})\n\n rendered = template.render(context)\n\n assert rendered == expected\n\n def test_no_legaltext(self):\n template = Template(\n '{% load legaltext_tags %}{% legaltext_url \"foo-bar-test\" %}')\n context = Context({})\n\n with pytest.raises(NoReverseMatch):\n template.render(context)\n\n def test_no_legaltext_as_variable(self):\n template = Template(\n '{% load legaltext_tags %}{% legaltext_url \"foo-bar-test\" as my_url %}'\n '{{ my_url }}')\n context = Context({})\n\n with pytest.raises(NoReverseMatch):\n template.render(context)\n\n def test_no_legaltext_silent(self, settings):\n settings.LEGALTEXT_SILENCE_TEMPLATE_ERRORS = True\n template = Template(\n '{% load legaltext_tags %}{% legaltext_url \"foo-bar-test\" %}')\n context = Context({})\n\n rendered = template.render(context)\n\n assert rendered == ''\n\n def test_no_legaltext_as_variable_silence(self, settings):\n settings.LEGALTEXT_SILENCE_TEMPLATE_ERRORS = True\n template = Template(\n '{% load legaltext_tags %}{% legaltext_url \"foo-bar-test\" as my_url %}'\n '{{ my_url }}')\n context = Context({})\n\n rendered = template.render(context)\n\n assert rendered == ''\n\n def test_no_args(self):\n with pytest.raises(TemplateSyntaxError):\n template = Template(\n '{% load legaltext_tags %}{% legaltext_url %}')\n context = Context({})\n\n template.render(context)\n\n def test_no_args_as_variable(self):\n with pytest.raises(TemplateSyntaxError):\n template = Template(\n '{% load legaltext_tags %}{% legaltext_url as foo %}')\n context = Context({})\n\n template.render(context)\n\n def test_to_many_args(self):\n with pytest.raises(TemplateSyntaxError):\n template = Template(\n '{% load legaltext_tags %}{% legaltext_url \"Foo\" \"Bar\" %}')\n context = Context({})\n\n template.render(context)\n"
},
{
"alpha_fraction": 0.7333333492279053,
"alphanum_fraction": 0.7333333492279053,
"avg_line_length": 29,
"blob_id": "a956e1be8f2cfec9ede31a80624b2a9c952e4ce5",
"content_id": "3f79120fa3d43f24d9af345fa3513162864f64ea",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 60,
"license_type": "permissive",
"max_line_length": 31,
"num_lines": 2,
"path": "/examples/static_legaltexts/constants.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "TERMS_SLUG = 'static-terms'\nPRIVACY_SLUG = 'static-privacy'\n"
},
{
"alpha_fraction": 0.663385808467865,
"alphanum_fraction": 0.6692913174629211,
"avg_line_length": 32.86666488647461,
"blob_id": "863fb855c70bcb5eb27e28725741fa5b261d3229",
"content_id": "71b6d794e048af6372e3641282b5bde8e3f26881",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1016,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 30,
"path": "/legaltext/views.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "from django.conf import settings\nfrom django.db.models import Q\nfrom django.shortcuts import get_object_or_404\nfrom django.views.generic import DetailView\n\nfrom .models import LegalText\n\n\nclass LegaltextView(DetailView):\n model = LegalText\n\n def get_object(self):\n return get_object_or_404(\n LegalText, Q(slug=self.kwargs['slug']) | Q(url_name=self.kwargs['slug']))\n\n def get_template_names(self):\n template_name = getattr(\n settings, 'LEGALTEXT_VIEW_TEMPLATE', 'legaltext/content.html')\n overrides = getattr(settings, 'LEGALTEXT_VIEW_TEMPLATE_OVERRIDES', {})\n return overrides.get(self.object.slug, template_name)\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n\n legaltext_version = self.object.get_current_version()\n context.update({\n 'current_version': legaltext_version,\n 'current_version_content': legaltext_version.render_content()\n })\n return context\n"
},
{
"alpha_fraction": 0.6722952127456665,
"alphanum_fraction": 0.6735459566116333,
"avg_line_length": 29.169811248779297,
"blob_id": "6244e5fbee912d3c7876270f55107b76c30756a9",
"content_id": "bc66250bb71aff368b6f220203f20d613a69a89c",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1599,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 53,
"path": "/legaltext/utils.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "\"\"\"\nHelper for admin inlines that support initial data\nImplementation based on:\nhttp://www.catharinegeek.com/how-to-set-initial-data-for-inline-model-formset-in-django/\n\"\"\"\nfrom functools import partialmethod\n\nfrom django.contrib import admin\nfrom django.forms.models import BaseInlineFormSet, ModelForm\n\n\nclass InitialExtraInlineFormset(BaseInlineFormSet):\n\n def initial_form_count(self):\n if self.initial_extra:\n return 0\n else:\n return BaseInlineFormSet.initial_form_count(self)\n\n def total_form_count(self):\n if self.initial_extra:\n count = len(self.initial_extra) if self.initial_extra else 0\n count += self.extra\n return count\n else:\n return BaseInlineFormSet.total_form_count(self)\n\n\nclass InitialExtraModelForm(ModelForm):\n\n def has_changed(self):\n has_changed = ModelForm.has_changed(self)\n return bool(self.initial or has_changed)\n\n\nclass InitialExtraStackedInline(admin.StackedInline):\n\n form = InitialExtraModelForm\n formset = InitialExtraInlineFormset\n\n def get_extra(self, *args, **kwargs):\n if 'initial' in kwargs:\n return len(kwargs['initial'])\n return super().get_extra(*args, **kwargs)\n\n def get_initial_extra(self, request, obj=None):\n return []\n\n def get_formset(self, request, obj=None, **kwargs):\n initial = self.get_initial_extra(request, obj)\n formset = super().get_formset(request, obj, **kwargs)\n formset.__init__ = partialmethod(formset.__init__, initial=initial)\n return formset\n"
},
{
"alpha_fraction": 0.6701680421829224,
"alphanum_fraction": 0.6701680421829224,
"avg_line_length": 29.70967674255371,
"blob_id": "e6b34a3f04ecae952cf3a40b53adc63e24bd5247",
"content_id": "e37614643a20631ec9845c23057937a9025a3669",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 952,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 31,
"path": "/examples/urls.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import include, url\nfrom django.contrib import admin\n\nfrom examples.dynamic_legaltexts.views import (\n DynamicParticipantCompletedView, DynamicParticipantFormView)\nfrom examples.static_legaltexts.views import (\n StaticParticipantCompletedView, StaticParticipantFormView)\n\n\nurlpatterns = [\n url(r'^admin/', include(admin.site.urls)),\n url(r'^legaltext/', include('legaltext.urls')),\n\n url(\n r'^static-legaltext/$',\n StaticParticipantFormView.as_view(),\n name='static-form'),\n url(\n r'^static-legaltext/completed/$',\n StaticParticipantCompletedView.as_view(),\n name='static-form-completed'\n ),\n url(\n r'^dynamic-legaltext/(?P<id>\\d+)/$',\n DynamicParticipantFormView.as_view(),\n name='dynamic-form'),\n url(\n r'^dynamic-legaltext/completed/$',\n DynamicParticipantCompletedView.as_view(),\n name='dynamic-form-completed'),\n]\n"
},
{
"alpha_fraction": 0.6488956809043884,
"alphanum_fraction": 0.6671743988990784,
"avg_line_length": 42.766666412353516,
"blob_id": "c4340a0fc5b4744e6bc79f1bb2d33ee7e7eeee4a",
"content_id": "ecef823ae9df34b9915b2d9cda604811a34620c4",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1313,
"license_type": "permissive",
"max_line_length": 273,
"num_lines": 30,
"path": "/examples/static_legaltexts/migrations/0001_initial.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.10.7 on 2017-08-03 07:21\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\nimport django.utils.timezone\nimport legaltext.fields\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ('legaltext', '0001_initial'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Participant',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=255)),\n ('date_submit', models.DateTimeField(default=django.utils.timezone.now)),\n ('accepted_privacy', legaltext.fields.LegalTextField(blank=True, default=legaltext.fields.CurrentLegalText('static-privacy'), null=True, on_delete=django.db.models.deletion.CASCADE, related_name='+', slug='static-privacy', to='legaltext.LegalTextVersion')),\n ('accepted_terms', legaltext.fields.LegalTextField(blank=True, default=legaltext.fields.CurrentLegalText('static-terms'), null=True, on_delete=django.db.models.deletion.CASCADE, related_name='+', slug='static-terms', to='legaltext.LegalTextVersion')),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.6373717188835144,
"alphanum_fraction": 0.6478391289710999,
"avg_line_length": 41.88444519042969,
"blob_id": "e7b2d43148e7270b6771c9b84b4bb77bc857392a",
"content_id": "6c847a13eb938ab66ba5600169c323cedd2dee73",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9649,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 225,
"path": "/testing/tests/test_models.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "from datetime import datetime\n\nimport pytest\nfrom django.db.utils import IntegrityError\nfrom django.utils import timezone\nfrom freezegun import freeze_time\n\nfrom legaltext.models import LegalText, LegalTextCheckbox, LegalTextVersion\nfrom testing.factories import (\n LegalTextCheckboxFactory, LegalTextFactory, LegalTextVersionFactory)\n\n\[email protected]_db\nclass TestLegalText:\n\n def test_str(self):\n legal_text = LegalTextFactory.create(name='Foo Bar Text')\n assert str(legal_text) == 'Foo Bar Text'\n\n def test_current_version_no_version_yet(self):\n version = LegalText.current_version('test-version')\n assert isinstance(version, LegalTextVersion)\n assert version.legaltext.slug == 'test-version'\n assert version.legaltext.name == 'test-version'\n assert version.content == ''\n assert version.checkboxes.count() == 1\n\n @freeze_time('2016-01-02')\n def test_current_version(self):\n legal_text = LegalTextFactory.create(name='Foo Bar Text', slug='foo-bar')\n\n LegalTextVersionFactory.create(\n legaltext=legal_text,\n valid_from=timezone.make_aware(datetime(2015, 1, 1, 10, 0)))\n version_present = LegalTextVersionFactory.create(\n legaltext=legal_text,\n valid_from=timezone.make_aware(datetime(2016, 1, 1, 10, 0)))\n LegalTextVersionFactory.create(\n legaltext=legal_text,\n valid_from=timezone.make_aware(datetime(2017, 1, 1, 10, 0)))\n\n version = LegalText.current_version('foo-bar')\n\n assert version.legaltext.slug == 'foo-bar'\n assert version.legaltext.name == 'Foo Bar Text'\n assert version.pk == version_present.pk\n\n def test_get_current_version_no_version_yet(self):\n legal_text = LegalTextFactory.create(name='Foo Bar Text')\n version = legal_text.get_current_version()\n assert isinstance(version, LegalTextVersion)\n assert version.legaltext.slug == 'foo-bar-text'\n assert version.legaltext.name == 'Foo Bar Text'\n assert version.content == ''\n assert version.checkboxes.count() == 1\n\n @freeze_time('2016-01-02')\n def test_get_current_version(self):\n legal_text = LegalTextFactory.create(name='Foo Bar Text', slug='foo-bar-test')\n\n LegalTextVersionFactory.create(\n legaltext=legal_text,\n valid_from=timezone.make_aware(datetime(2015, 1, 1, 10, 0)),\n content='Test content 1')\n version_present = LegalTextVersionFactory.create(\n legaltext=legal_text,\n valid_from=timezone.make_aware(datetime(2016, 1, 1, 10, 0)),\n content='Test content 2')\n LegalTextVersionFactory.create(\n legaltext=legal_text,\n valid_from=timezone.make_aware(datetime(2017, 1, 1, 10, 0)),\n content='Test content 3')\n\n version = legal_text.get_current_version()\n assert isinstance(version, LegalTextVersion)\n assert version.legaltext.slug == 'foo-bar-test'\n assert version.legaltext.name == 'Foo Bar Text'\n assert version.content == 'Test content 2'\n assert version.pk == version_present.pk\n\n def test_get_absolute_url(self):\n legal_text = LegalTextFactory.create(name='Foo Bar Text', slug='foo-bar-test')\n assert legal_text.get_absolute_url() == '/foo-bar-test/'\n\n def test_url_name_is_unique(self):\n LegalTextFactory.create(url_name='foo-bar-test')\n with pytest.raises(IntegrityError):\n LegalTextFactory.create(url_name='foo-bar-test')\n\n def test_url_name_is_unique_with_blank(self):\n LegalTextFactory.create(url_name='')\n with pytest.raises(IntegrityError):\n LegalTextFactory.create(url_name='')\n\n def test_url_name_is_not_unique_with_none(self):\n LegalTextFactory.create(url_name=None)\n LegalTextFactory.create(url_name=None)\n\n\[email protected]_db\nclass TestLegalTextVersion:\n\n def test_str(self):\n legal_text_version = LegalTextVersionFactory.create(legaltext__name='Foo Bar Text')\n assert 'Foo Bar Text' in str(legal_text_version)\n assert '{0:%x}'.format(legal_text_version.valid_from) in str(legal_text_version)\n\n def test_name(self):\n legal_text_version = LegalTextVersionFactory.create(legaltext__name='Foo Bar Text')\n assert legal_text_version.name == 'Foo Bar Text'\n\n def test_render_content(self):\n legal_text_version = LegalTextVersionFactory.create(content='Text Text Text')\n assert legal_text_version.render_content() == '<p>Text Text Text</p>'\n\n def test_render_content_with_block(self):\n legal_text_version = LegalTextVersionFactory.create(\n content='Text[block:foo]Text **bar** foo[/block] Text[block:bar]Text bar[/block]')\n\n assert legal_text_version.render_content().replace('\\n', '') == (\n '<p>Text</p><div class=\"legaltext-block legaltext-block-foo\"><span id=\"foo\">'\n '</span><p>Text <strong>bar</strong> foo</p></div><p>Text</p>'\n '<div class=\"legaltext-block legaltext-block-bar\">'\n '<span id=\"bar\"></span><p>Text bar</p></div>'\n )\n\n def test_render_content_with_multiline_block(self):\n legal_text_version = LegalTextVersionFactory.create(\n content='Text\\n\\n[block:foo]\\nText **bar**\\n\\nfoo\\n[/block]\\n\\n'\n 'Text\\n\\n[block:bar]\\nText bar\\n[/block] lorem'\n )\n\n assert legal_text_version.render_content().replace('\\n', '') == (\n '<p>Text</p><div class=\"legaltext-block legaltext-block-foo\"><span id=\"foo\">'\n '</span><p>Text <strong>bar</strong></p><p>foo</p></div><p>Text</p>'\n '<div class=\"legaltext-block legaltext-block-bar\">'\n '<span id=\"bar\"></span><p>Text bar</p></div><p>lorem</p>'\n )\n\n def test_render_content_with_nested_block(self):\n legal_text_version = LegalTextVersionFactory.create(\n content='Text\\n\\n[block:foo]Text Text\\n\\n[block:bar]Text bar[/block][/block]')\n\n assert legal_text_version.render_content().replace('\\n', '') == (\n '<p>Text</p><div class=\"legaltext-block legaltext-block-foo\"><span id=\"foo\">'\n '</span><p>Text Text</p><div class=\"legaltext-block legaltext-block-bar\">'\n '<span id=\"bar\"></span><p>Text bar</p></div></div>'\n )\n\n def test_render_content_unbalanced_blocks(self):\n legal_text_version = LegalTextVersionFactory.create(\n content='Text [block:foo]Text Text [block:bar]Text bar[/block]')\n\n assert legal_text_version.render_content().replace('\\n', '') == (\n '<p>Text [block:foo]Text Text [block:bar]Text bar[/block]</p>'\n )\n\n\[email protected]_db\nclass TestLegalTextCheckbox:\n\n def test_str(self):\n checkbox = LegalTextCheckboxFactory.create(\n legaltext_version__legaltext__name='Foo Bar Text')\n\n assert 'Checkbox' in str(checkbox)\n assert checkbox.legaltext_version.name in str(checkbox)\n assert '{0:%x}'.format(checkbox.legaltext_version.valid_from) in str(checkbox)\n\n def test_render_content(self):\n checkbox = LegalTextCheckboxFactory.create(content='Checkbox test text', )\n assert checkbox.render_content() == 'Checkbox test text'\n\n @pytest.mark.xfail\n def test_render_content_with_link(self):\n checkbox = LegalTextCheckboxFactory.create(\n content='Checkbox [[test]] text', anchor='',\n legaltext_version__legaltext__slug='test-1')\n\n assert checkbox.render_content() == (\n 'Checkbox <a href=\"/test-1/\" title=\"test\">test</a> text')\n\n def test_render_content_with_link_and_anchor(self):\n checkbox = LegalTextCheckboxFactory.create(\n legaltext_version__legaltext__slug='test-2',\n content='Text [anchor:foo]Text[/anchor] Text [anchor]bar[/anchor]')\n\n assert checkbox.render_content() == (\n 'Text <a href=\"/test-2/#foo\" class=\"legaltext-anchor\" target=\"_blank\">Text'\n '</a> Text <a href=\"/test-2/\" class=\"legaltext-anchor\" target=\"_blank\">bar</a>'\n )\n\n def test_render_content_with_linebreaks(self):\n checkbox = LegalTextCheckboxFactory.create(\n legaltext_version__legaltext__slug='test-2',\n content='Text Text\\nText foo\\n\\nbar')\n\n assert checkbox.render_content() == 'Text Text<br />Text foo<br /><br />bar'\n\n def test_save_checkbox(self):\n legal_text_version = LegalTextVersionFactory.create()\n checkbox_1 = LegalTextCheckboxFactory.create(legaltext_version=legal_text_version)\n checkbox_2 = LegalTextCheckboxFactory.create(legaltext_version=legal_text_version)\n\n assert checkbox_1.order == 1\n assert checkbox_2.order == 2\n\n def test_checkbox_ordering(self):\n legal_text_version = LegalTextVersionFactory.create()\n checkbox_3 = LegalTextCheckboxFactory.create(\n legaltext_version=legal_text_version, order=3)\n checkbox_1 = LegalTextCheckboxFactory.create(\n legaltext_version=legal_text_version, order=1)\n checkbox_2 = LegalTextCheckboxFactory.create(\n legaltext_version=legal_text_version, order=2)\n qs = LegalTextCheckbox.objects.all()\n\n assert list(qs) == [checkbox_1, checkbox_2, checkbox_3]\n\n def test_checkbox_order_unique(self):\n legal_text_version = LegalTextVersionFactory.create()\n LegalTextCheckboxFactory.create(legaltext_version=legal_text_version, order=5)\n\n with pytest.raises(IntegrityError):\n LegalTextCheckboxFactory.create(legaltext_version=legal_text_version, order=5)\n"
},
{
"alpha_fraction": 0.5810387134552002,
"alphanum_fraction": 0.6040432453155518,
"avg_line_length": 27.97979736328125,
"blob_id": "800d76abcd2946afa7224aae139486f7355944ca",
"content_id": "2087a459407afa188829d4cc2cb218c58c4cbd20",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2869,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 99,
"path": "/setup.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nfrom setuptools import find_packages, setup\n\n\nversion = '1.0.0'\n\n\n# TEMPORARY FIX FOR\n# https://bitbucket.org/pypa/setuptools/issues/450/egg_info-command-is-very-slow-if-there-are\nTO_OMIT = ['.git', '.tox']\norig_os_walk = os.walk\n\ndef patched_os_walk(path, *args, **kwargs):\n for (dirpath, dirnames, filenames) in orig_os_walk(path, *args, **kwargs):\n if '.git' in dirnames:\n # We're probably in our own root directory.\n print(\"MONKEY PATCH: omitting a few directories like .git and .tox...\")\n dirnames[:] = list(set(dirnames) - set(TO_OMIT))\n yield (dirpath, dirnames, filenames)\n\nos.walk = patched_os_walk\n# END IF TEMPORARY FIX.\n\n\nif sys.argv[-1] == 'publish':\n os.system('python setup.py sdist upload')\n os.system('python setup.py bdist_wheel upload')\n print('You probably want to also tag the version now:')\n print(' git tag -a %s -m \"version %s\"' % (version, version))\n print(' git push --tags')\n sys.exit()\n\n\n# allow setup.py to be run from any path\nos.chdir(os.path.normpath(os.path.join(os.path.abspath(__file__), os.pardir)))\n\nwith open(os.path.join(os.path.dirname(__file__), 'README.rst')) as readme:\n README = readme.read()\n\n\ninstall_requires = [\n 'Django>=2',\n 'django-floppyforms>=1.8',\n 'django-markymark>=2.0',\n]\n\n\ntest_requires = [\n 'pytest>=5.3,<5.4',\n 'pytest-cov>=2.8.1,<3',\n 'pytest-django>=3.9.0,<4',\n 'pytest-flakes>=4.0.0,<5',\n 'pytest-isort>=0.3.1,<1',\n 'pytest-pep8>=1.0.6,<2',\n 'factory-boy==2.12.0,<3',\n 'freezegun>=0.3.15,<1',\n 'isort>=4.3.21,<4.4',\n 'coverage>=4.0',\n 'tox',\n 'tox-pyenv',\n]\n\nsetup(\n name='django-legaltext',\n description='django-legaltext helps to manage legal text versioning.',\n version=version,\n keywords=['legaltext', 'django'],\n packages=find_packages(exclude=[\n 'testing*',\n 'examples*',\n ]),\n include_package_data=True,\n license='BSD',\n long_description=README,\n url='https://github.com/moccu/django-legaltext/',\n author='Moccu GmbH & Co. KG',\n author_email='[email protected]',\n extras_require={\n 'tests': test_requires,\n },\n install_requires=install_requires,\n tests_require=test_requires,\n classifiers=[\n 'Environment :: Web Environment',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: Apache Software License',\n 'Operating System :: OS Independent',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Framework :: Django',\n 'Framework :: Django :: 2.0',\n 'Framework :: Django :: 2.1',\n 'Framework :: Django :: 2.2',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n ],\n)\n"
},
{
"alpha_fraction": 0.6771217584609985,
"alphanum_fraction": 0.6771217584609985,
"avg_line_length": 29.11111068725586,
"blob_id": "bcd100e7496cc42927f56848e066ab3528365d27",
"content_id": "68c1a2e7bbb441c85345bf60d2e58a5df5dd9b65",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 542,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 18,
"path": "/examples/dynamic_legaltexts/forms.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "import floppyforms.__future__ as forms\n\nfrom legaltext.fields import LegalTextFormField\n\nfrom .models import Participant\n\n\nclass ParticipationForm(forms.ModelForm):\n\n class Meta:\n model = Participant\n exclude = ('date_submit',)\n\n def __init__(self, *args, **kwargs):\n self.survey = kwargs.pop('survey')\n super().__init__(*args, **kwargs)\n self.fields['accepted_privacy'] = LegalTextFormField(self.survey.privacy.slug)\n self.fields['accepted_terms'] = LegalTextFormField(self.survey.terms.slug)\n"
},
{
"alpha_fraction": 0.7434782385826111,
"alphanum_fraction": 0.75,
"avg_line_length": 24.55555534362793,
"blob_id": "4d13fa90e05a122d7f5243cb11338901e2cf8579",
"content_id": "8f32dadd1fa375c57365b6118b3ec7382e8af192",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 460,
"license_type": "permissive",
"max_line_length": 60,
"num_lines": 18,
"path": "/examples/static_legaltexts/models.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.utils import timezone\n\nfrom legaltext.fields import LegalTextField\n\nfrom .constants import PRIVACY_SLUG, TERMS_SLUG\n\n\nclass Participant(models.Model):\n name = models.CharField(max_length=255)\n\n accepted_terms = LegalTextField(TERMS_SLUG)\n accepted_privacy = LegalTextField(PRIVACY_SLUG)\n\n date_submit = models.DateTimeField(default=timezone.now)\n\n def __str__(self):\n return str(self.date_submit)\n"
},
{
"alpha_fraction": 0.6624175906181335,
"alphanum_fraction": 0.666373610496521,
"avg_line_length": 38.22413635253906,
"blob_id": "8d79f6b329e1f7d6648bbece2bcda849476ee1c7",
"content_id": "4345c3caaccab0caf5f13e92bee9a02971780f32",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2275,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 58,
"path": "/testing/tests/test_views.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "import pytest\nfrom django.urls import reverse\n\nfrom legaltext.models import LegalTextVersion\nfrom legaltext.views import LegaltextView\nfrom testing.factories import LegalTextFactory\n\n\[email protected]_db\nclass TestLegaltextView:\n\n def test_get_template_names_default(self):\n view = LegaltextView()\n view.object = LegalTextFactory.create(slug='foo')\n assert view.get_template_names() == 'legaltext/content.html'\n\n def test_get_template_names_custom(self, settings):\n settings.LEGALTEXT_VIEW_TEMPLATE = 'bar.html'\n view = LegaltextView()\n view.object = LegalTextFactory.create(slug='foo')\n assert view.get_template_names() == 'bar.html'\n\n def test_get_template_names_override(self, settings):\n settings.LEGALTEXT_VIEW_TEMPLATE_OVERRIDES = {'bar': 'baz.html'}\n view = LegaltextView()\n view.object = LegalTextFactory.create(slug='foo')\n assert view.get_template_names() == 'legaltext/content.html'\n view = LegaltextView()\n view.object = LegalTextFactory.create(slug='bar')\n assert view.get_template_names() == 'baz.html'\n\n def test_get(self, client):\n test_slug = 'test-foo-bar'\n LegalTextFactory.create(slug=test_slug)\n url = reverse('legaltext', kwargs={'slug': test_slug})\n response = client.get(url)\n\n assert response.status_code == 200\n assert isinstance(response.context['current_version'], LegalTextVersion)\n assert response.context['current_version'].legaltext.slug == test_slug\n assert url == '/test-foo-bar/'\n\n def test_get_with_url_name(self, client):\n test_slug = 'test-foo-bar'\n LegalTextFactory.create(slug=test_slug, url_name='foobar')\n url = reverse('legaltext', kwargs={'slug': 'foobar'})\n response = client.get(url)\n\n assert response.status_code == 200\n assert isinstance(response.context['current_version'], LegalTextVersion)\n assert response.context['current_version'].legaltext.slug == test_slug\n assert url == '/foobar/'\n\n def test_get_non_existing_legaltext(self, client):\n url = reverse('legaltext', kwargs={'slug': 'no-such-legaltext'})\n response = client.get(url)\n\n assert response.status_code == 404\n"
},
{
"alpha_fraction": 0.5457746386528015,
"alphanum_fraction": 0.672535240650177,
"avg_line_length": 13.947368621826172,
"blob_id": "889e259ea05f7d13a234120368d7b06d08ddd6db",
"content_id": "8b74e703973f710b2660d72fc7aa8c4859fd825c",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 284,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 19,
"path": "/tox.ini",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "[tox]\nskipsdist = True\nenvlist={py36,py37}-django{20,21,22}\n\n[tox:travis]\n3.6 = py36\n3.7 = py37\n\n[testenv]\nskip_install = True\nsetenv = PYTHONPATH={toxinidir}\ndeps =\n\t.[tests]\n\tdjango20: Django>=2.0<2.1\n\tdjango21: Django>=2.1<2.2\n\tdjango22: Django>=2.2<2.3\n\ncommands =\n\tpy.test --cov\n"
},
{
"alpha_fraction": 0.6902485489845276,
"alphanum_fraction": 0.6902485489845276,
"avg_line_length": 28.05555534362793,
"blob_id": "ab93e8dd238e1a0280cdfffe6e7ec7c039b09fd4",
"content_id": "469072220fe5a1a2e8bb6a949de9bcf8ae42e6a7",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 523,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 18,
"path": "/examples/static_legaltexts/forms.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "import floppyforms.__future__ as forms\n\nfrom legaltext.fields import LegalTextFormField\n\nfrom .constants import PRIVACY_SLUG, TERMS_SLUG\nfrom .models import Participant\n\n\nclass ParticipationForm(forms.ModelForm):\n\n class Meta:\n model = Participant\n exclude = ('date_submit',)\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.fields['accepted_privacy'] = LegalTextFormField(PRIVACY_SLUG)\n self.fields['accepted_terms'] = LegalTextFormField(TERMS_SLUG)\n"
},
{
"alpha_fraction": 0.7023026347160339,
"alphanum_fraction": 0.7023026347160339,
"avg_line_length": 20.714284896850586,
"blob_id": "3ced3bb74cb54afa125b96d75918514cebac8402",
"content_id": "ec3feb8d2b549cb919923bf0f2a5803e15adab74",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 608,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 28,
"path": "/Makefile",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": ".PHONY: tests coverage coverage-html devinstall clean-build\nOPTS=\n\nhelp:\n\t@echo \"tests - run tests\"\n\t@echo \"coverage - run tests with coverage enabled\"\n\t@echo \"coverage-html - run tests with coverage html export enabled\"\n\t@echo \"devinstall - install all packages required for development\"\n\t@echo \"clean-build - Clean build related files\"\n\ntests:\n\tpy.test ${OPTS}\n\ncoverage:\n\tpy.test ${OPTS} --cov\n\ncoverage-html:\n\tpy.test ${OPTS} --cov --cov-report=html\n\ndevinstall:\n\tpip install -e .\n\tpip install -e .[tests]\n\nclean-build:\n\t@rm -fr build/\n\t@rm -fr dist/\n\t@rm -fr *.egg-info src/*.egg-info\n\t@rm -fr htmlcov/\n"
},
{
"alpha_fraction": 0.6608315110206604,
"alphanum_fraction": 0.6626549959182739,
"avg_line_length": 32.0361442565918,
"blob_id": "9762c5346e2a614a9f8699bfd42108b7a73320e4",
"content_id": "64f43d22e4fb6a248b7fd3573af03c820e47d3e6",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2742,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 83,
"path": "/testing/tests/test_fields.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "import pytest\nfrom django import forms\nfrom django.db.models.fields import NOT_PROVIDED\n\nfrom legaltext.fields import CurrentLegalText, LegalTextField, LegalTextFormField\nfrom legaltext.models import LegalTextVersion\nfrom legaltext.widgets import LegalTextWidget\n\n\[email protected]_db\nclass TestCurrentLegalText:\n\n def test_init(self):\n obj = CurrentLegalText('foo')\n assert obj.slug == 'foo'\n\n def test_call(self):\n obj = CurrentLegalText('foo')\n version_id = obj()\n version = LegalTextVersion.objects.get(pk=version_id)\n assert version.legaltext.slug == 'foo'\n\n\[email protected]_db\nclass TestLegalTextField:\n\n def test_init_with_slug(self):\n field = LegalTextField('foo')\n assert field.slug == 'foo'\n assert isinstance(field.default, CurrentLegalText)\n assert field.get_limit_choices_to() == {'legaltext__slug': 'foo'}\n assert field.remote_field.related_name == '+'\n assert field.blank is True\n assert field.null is True\n\n def test_init_without_slug(self):\n field = LegalTextField()\n assert field.slug is None\n assert field.default == NOT_PROVIDED\n assert field.get_limit_choices_to() == {}\n assert field.remote_field.related_name == '+'\n assert field.blank is True\n assert field.null is True\n\n def test_deconstruct(self):\n field = LegalTextField('foo')\n assert field.deconstruct()[3]['slug'] == 'foo'\n\n\[email protected]_db\nclass TestLegalTextFormField:\n\n def test_init_without_kwargs(self):\n field = LegalTextFormField('foo')\n assert field.slug == 'foo'\n assert isinstance(field.widget, LegalTextWidget)\n assert field.widget.version.legaltext.slug == 'foo'\n assert field.required is True\n\n def test_init_with_kwargs(self):\n field = LegalTextFormField('foo', required=False, widget=forms.HiddenInput)\n assert field.slug == 'foo'\n assert isinstance(field.widget, forms.HiddenInput)\n assert field.required is False\n\n def test_label(self):\n field = LegalTextFormField('foo')\n assert field.label == 'foo'\n field.label = 'bar'\n assert field.label == 'foo'\n\n def test_prepare_value(self):\n field = LegalTextFormField('foo')\n assert field.prepare_value(None) is False\n assert field.prepare_value(0) is False\n assert field.prepare_value(1) is True\n\n def test_to_python(self):\n field = LegalTextFormField('foo')\n assert field.to_python(None) is None\n assert field.to_python(0) is None\n assert isinstance(field.to_python(1), LegalTextVersion)\n assert isinstance(field.to_python(True), LegalTextVersion)\n"
},
{
"alpha_fraction": 0.7330247163772583,
"alphanum_fraction": 0.7422839403152466,
"avg_line_length": 29.85714340209961,
"blob_id": "226a2944e6caf1f071c3accf6a4f3819c7e98969",
"content_id": "5d8d382df809d2ed590eaa29a9c7d21cff21cab5",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 648,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 21,
"path": "/examples/dynamic_legaltexts/views.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import get_object_or_404\nfrom django.urls import reverse_lazy\nfrom django.views.generic import CreateView, TemplateView\n\nfrom .forms import ParticipationForm\nfrom .models import Survey\n\n\nclass DynamicParticipantFormView(CreateView):\n template_name = 'form.html'\n form_class = ParticipationForm\n success_url = reverse_lazy('dynamic-form-completed')\n\n def get_form_kwargs(self):\n kwargs = super().get_form_kwargs()\n kwargs['survey'] = get_object_or_404(Survey, pk=self.kwargs['id'])\n return kwargs\n\n\nclass DynamicParticipantCompletedView(TemplateView):\n template_name = 'form-completed.html'\n"
},
{
"alpha_fraction": 0.642201840877533,
"alphanum_fraction": 0.6440367102622986,
"avg_line_length": 34.16128921508789,
"blob_id": "1d599f1a923e33113f0494a802c544a1a0744b0f",
"content_id": "d0c9c9de4e8c0a4a5e3f5788c331362540e10b05",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2180,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 62,
"path": "/legaltext/actions.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "import io\nimport zipfile\n\nfrom django.http import HttpResponse\nfrom django.utils import timezone\nfrom django.utils.timezone import localtime\nfrom django.utils.translation import gettext_lazy as _\n\n\nclass Exporter(object):\n\n @staticmethod\n def get_file_name(legaltext, checkbox_i=None):\n content_type = 'content'\n if checkbox_i:\n content_type = 'checkbox{0}'.format(checkbox_i)\n\n return '{dt}_{pk}_{slug}_{content_type}.md'.format(\n dt=localtime(legaltext.valid_from).strftime('%Y%m%d_%H%M%S'),\n pk=legaltext.pk,\n slug=legaltext.legaltext.slug,\n content_type=content_type,\n )\n\n @staticmethod\n def get_archive_name():\n dt_now = timezone.now().strftime('%Y-%m-%d_%H-%M-%S')\n return 'legaltext_export_{0}.zip'.format(dt_now)\n\n @classmethod\n def write_files(cls, queryset):\n buff = io.BytesIO()\n archive = zipfile.ZipFile(buff, 'w', zipfile.ZIP_DEFLATED)\n\n for legaltext in queryset:\n filename = cls.get_file_name(legaltext)\n archive.writestr(filename, legaltext.content)\n\n for i, checkbox in enumerate(legaltext.checkboxes.all()):\n checkbox_filename = cls.get_file_name(legaltext, checkbox.order or (i + 1))\n archive.writestr(checkbox_filename, checkbox.content)\n\n archive.close()\n buff.flush()\n legaltext_zip = buff.getvalue()\n buff.close()\n return legaltext_zip\n\n @classmethod\n def export_legaltext_version(cls, modeladmin, request, queryset):\n legaltext_zip = cls.write_files(queryset)\n zip_name = cls.get_archive_name()\n response = HttpResponse(content_type='application/zip')\n response['Content-Disposition'] = 'filename={0}'.format(zip_name)\n response.write(legaltext_zip)\n return response\n\n @classmethod\n def export_legaltext_version_action(cls, short_description=None):\n short_description = short_description or _('Export selected versions')\n setattr(cls.export_legaltext_version.__func__, 'short_description', short_description)\n return cls.export_legaltext_version\n"
},
{
"alpha_fraction": 0.6585366129875183,
"alphanum_fraction": 0.6585366129875183,
"avg_line_length": 19.5,
"blob_id": "207d8fa230470b5a69b43f2fa5804ddba2ec04f6",
"content_id": "085fbd6b9b2bcbdacc3ad349eac4cb0d46f32ff3",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 164,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 8,
"path": "/legaltext/urls.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\n\nfrom .views import LegaltextView\n\n\nurlpatterns = [\n url(r'^(?P<slug>[\\w\\-]+)/$', LegaltextView.as_view(), name='legaltext'),\n]\n"
},
{
"alpha_fraction": 0.6017634272575378,
"alphanum_fraction": 0.6171932220458984,
"avg_line_length": 39.02941131591797,
"blob_id": "08c85936aacb88676b1955a7f2cd48f0c4c4ec55",
"content_id": "5a3ca23aab22aefe4839e84e5a380f5b9c77b9e3",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1361,
"license_type": "permissive",
"max_line_length": 275,
"num_lines": 34,
"path": "/legaltext/migrations/0002_legaltextcheckbox.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.10.7 on 2017-08-04 08:14\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\nimport markymark.fields\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('legaltext', '0001_initial'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='LegalTextCheckbox',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('content', markymark.fields.MarkdownField(help_text='You can use [anchor]Your text[/anchor] to create a link to the full legal text. If you use [anchor:foo]Your text[/anchor] the link will go to the block \"foo\" inside the legal text.', verbose_name='Text')),\n ],\n options={\n 'verbose_name_plural': 'Legal text Checkboxes',\n 'ordering': ('legaltext_version',),\n 'verbose_name': 'Legal text checkbox',\n },\n ),\n migrations.AddField(\n model_name='legaltextcheckbox',\n name='legaltext_version',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, related_name='checkboxes', to='legaltext.LegalTextVersion', verbose_name='Legal text version'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6491366028785706,
"alphanum_fraction": 0.656985878944397,
"avg_line_length": 42.431819915771484,
"blob_id": "73a95ea92ffe8d27dd0e5102145ccfc4528e2b75",
"content_id": "e179548a2a843d884bad061442e3afa0b8418c8a",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3822,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 88,
"path": "/testing/tests/test_widgets.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "from unittest import mock\n\nimport floppyforms.__future__ as forms\nimport pytest\n\nfrom legaltext.models import LegalTextVersion\nfrom legaltext.widgets import LegalTextWidget\nfrom testing.factories import LegalTextCheckboxFactory, LegalTextVersionFactory\n\n\[email protected]_db\nclass TestLegalTextWidget:\n\n def setup(self):\n self.legal_text_version = LegalTextVersionFactory.create(content='foo')\n self.checkbox1 = LegalTextCheckboxFactory.create(\n legaltext_version=self.legal_text_version, content='cb1')\n self.checkbox2 = LegalTextCheckboxFactory.create(\n legaltext_version=self.legal_text_version, content='cb2')\n\n def test_init(self):\n widget = LegalTextWidget(self.legal_text_version.legaltext.slug)\n assert isinstance(widget.version, LegalTextVersion)\n assert len(widget.checkboxes) == 2\n\n assert len(widget.widgets) == 2\n assert isinstance(widget.widgets[0], forms.CheckboxInput)\n\n def test_get_template_name_attribute(self):\n widget = LegalTextWidget(self.legal_text_version.legaltext.slug)\n widget.template_name = 'foo.html'\n assert widget.get_template_name() == 'foo.html'\n\n def test_get_template_name_default(self):\n widget = LegalTextWidget(self.legal_text_version.legaltext.slug)\n assert widget.get_template_name() == 'legaltext/widget.html'\n\n def test_get_template_name_custom(self, settings):\n settings.LEGALTEXT_WIDGET_TEMPLATE = 'bar.html'\n widget = LegalTextWidget(self.legal_text_version.legaltext.slug)\n assert widget.get_template_name() == 'bar.html'\n\n def test_get_template_name_override(self, settings):\n settings.LEGALTEXT_WIDGET_TEMPLATE_OVERRIDES = {'bar': 'baz.html'}\n widget = LegalTextWidget('foo')\n assert widget.get_template_name() == 'legaltext/widget.html'\n widget = LegalTextWidget('bar')\n assert widget.get_template_name() == 'baz.html'\n\n def test_value_from_datadict(self):\n widget = LegalTextWidget(self.legal_text_version.legaltext.slug)\n assert widget.value_from_datadict({}, {}, 'field') is None\n assert widget.value_from_datadict({'field_1': 1}, {}, 'field') is None\n assert widget.value_from_datadict(\n {'field_0': 1, 'field_1': 1}, {}, 'field') == widget.version.pk\n\n def test_decompress(self):\n widget = LegalTextWidget(self.legal_text_version.legaltext.slug)\n assert widget.decompress(None) == [None, None]\n assert widget.decompress(1) == [None, None]\n\n @mock.patch('legaltext.widgets.render_to_string')\n def test_render(self, render_mock):\n render_mock.return_value = 'rendered widget'\n widget = LegalTextWidget(self.legal_text_version.legaltext.slug)\n field = mock.Mock()\n field.name = 'field'\n field.errors = [1]\n widget.context_instance = {'field': field}\n widget.render('field', None)\n assert render_mock.called is True\n assert render_mock.call_args[0][0] == 'legaltext/widget.html'\n assert render_mock.call_args[0][1] == {\n 'version': widget.version,\n 'checkboxes': [\n ('field_0', '<input type=\"checkbox\" name=\"field_0\">\\n', 'cb1'),\n ('field_1', '<input type=\"checkbox\" name=\"field_1\">\\n', 'cb2')],\n 'required': False,\n 'errors': [1]\n }\n\n @mock.patch('legaltext.widgets.render_to_string')\n def test_render_extra_attrs(self, render_mock, settings):\n settings.LEGALTEXT_WIDGET_ATTRS = {'class': 'field'}\n render_mock.return_value = 'rendered widget'\n widget = LegalTextWidget(self.legal_text_version.legaltext.slug)\n widget.render('field', None)\n assert 'class=\"field\"' in render_mock.call_args[0][1]['checkboxes'][0][1]\n"
},
{
"alpha_fraction": 0.637319028377533,
"alphanum_fraction": 0.6389537453651428,
"avg_line_length": 33.25600051879883,
"blob_id": "37cee9f7a242cb364dd089af238c9a168582ff92",
"content_id": "baf8dd38ea0353815beb53dde2b9c8101a832c48",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4282,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 125,
"path": "/legaltext/admin.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "from django import forms\nfrom django.contrib import admin\nfrom django.urls import reverse\nfrom django.utils import timezone\nfrom django.utils.translation import gettext\nfrom django.utils.translation import gettext_lazy as _\n\nfrom .actions import Exporter\nfrom .models import LegalText, LegalTextCheckbox, LegalTextVersion\nfrom .utils import InitialExtraStackedInline\n\n\nclass LegalTextVersionAdminForm(forms.ModelForm):\n\n class Meta:\n model = LegalTextVersion\n fields = '__all__'\n\n def __init__(self, *args, **kwargs):\n legaltext_id = (kwargs.get('initial') or {}).get('legaltext', None)\n if legaltext_id:\n current_version = LegalTextVersion.objects.filter(\n legaltext=legaltext_id).first()\n if current_version:\n kwargs.setdefault('initial', {})['content'] = current_version.content\n\n super().__init__(*args, **kwargs)\n\n\nclass LegalTextAdminForm(forms.ModelForm):\n\n class Meta:\n model = LegalText\n fields = '__all__'\n\n def clean_url_name(self):\n url_name = self.cleaned_data['url_name']\n if not url_name:\n return None\n return url_name\n\n\[email protected](LegalText)\nclass LegalTextAdmin(admin.ModelAdmin):\n list_display = ('name', 'current_version_link', 'add_new_version_link')\n search_fields = ('name',)\n form = LegalTextAdminForm\n\n def get_prepopulated_fields(self, request, obj=None):\n return {'slug': ('name',)} if obj is None else {}\n\n def get_readonly_fields(self, request, obj=None):\n return ('slug',) if obj else ()\n\n def current_version_link(self, obj):\n version = obj.get_current_version()\n return '<a href=\"{0}\">{1:%x %X}</a>'.format(\n reverse('admin:legaltext_legaltextversion_change', args=(version.pk,)),\n timezone.localtime(version.valid_from)\n )\n current_version_link.allow_tags = True\n current_version_link.short_description = _('Current version')\n\n def add_new_version_link(self, obj):\n return '<a href=\"{0}?legaltext={1}\">{2}</a>'.format(\n reverse('admin:legaltext_legaltextversion_add'),\n obj.pk,\n gettext('Add new version')\n )\n add_new_version_link.allow_tags = True\n add_new_version_link.short_description = _('Add new version')\n\n\nclass LegalTextCheckboxInline(InitialExtraStackedInline):\n model = LegalTextCheckbox\n extra = 0\n min_num = 1\n\n def get_readonly_fields(self, request, obj=None):\n if obj and obj.valid_from <= timezone.now():\n return ('content', 'order')\n return ()\n\n def get_max_num(self, request, obj=None):\n if obj and obj.valid_from <= timezone.now():\n return obj.checkboxes.count()\n return None\n\n def get_initial_extra(self, request, obj=None):\n initial = []\n if obj is None and request.method == 'GET' and 'legaltext' in request.GET:\n legaltext = LegalText.objects.filter(pk=request.GET['legaltext']).first()\n if legaltext:\n for checkbox in legaltext.get_current_version().checkboxes.all():\n initial.append({'content': checkbox.content, 'order': checkbox.order})\n return initial\n\n\[email protected](LegalTextVersion)\nclass LegalTextVersionAdmin(admin.ModelAdmin):\n list_display = ('legaltext_name', 'valid_from')\n list_filter = ('legaltext',)\n inlines = (LegalTextCheckboxInline,)\n form = LegalTextVersionAdminForm\n actions = (Exporter.export_legaltext_version_action(),)\n\n def get_fieldsets(self, request, obj=None):\n if obj is None or obj.valid_from > timezone.now():\n return super().get_fieldsets(request, obj)\n\n return ((None, {'fields': ('legaltext', 'valid_from', 'rendered_content')}),)\n\n def get_readonly_fields(self, request, obj=None):\n if obj and obj.valid_from <= timezone.now():\n return ('legaltext', 'valid_from', 'rendered_content')\n return ()\n\n def legaltext_name(self, obj):\n return obj.legaltext.name\n legaltext_name.short_description = _('Legal text')\n\n def rendered_content(self, obj):\n return obj.render_content()\n rendered_content.allow_tags = True\n rendered_content.short_description = _('Text')\n"
},
{
"alpha_fraction": 0.6784260272979736,
"alphanum_fraction": 0.7123473286628723,
"avg_line_length": 17.424999237060547,
"blob_id": "9dae1a3185798e3198af00a795bd2208a989e9ce",
"content_id": "7c969dbe8fe98620c12c9a05031ce86581a1d165",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 737,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 40,
"path": "/CHANGELOG.rst",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "=========\nChangelog\n=========\n\n1.0.0\n~~~~~\n\n* BREAKING CHANGE: This version supports Python 3.6+ and Django 2.0+\n\n\n0.3.0\n~~~~~\n\n* Add legaltext_url templatetag for getting url from slug or name\n* Add admin action for legaltext version export\n* Enlarge legaltext slug and name fields to 128 characters\n* Bugfixes\n\n0.2.2\n~~~~~\n\n* Improved markdown rendering inside custom html elements\n\n0.2.1\n~~~~~\n\n* Allow nested anchor blocks and newlines in checkbox texts.\n\n0.2.0\n~~~~~\n\n* Add optional url name for legal texts as an alternative to the default slug\n* Auto-created legal text versions now always have a checkbox added\n* Add setting to pass extra attributes to checkbox html elements\n* Bugfixes and typos\n\n0.1.0\n~~~~~\n\n* Initial release\n"
},
{
"alpha_fraction": 0.7279411554336548,
"alphanum_fraction": 0.729411780834198,
"avg_line_length": 31.380952835083008,
"blob_id": "5d9bfa390a563e1435908f97b6bc34ada46de858",
"content_id": "a18138266d8ade0b89ebca3e8e221b00f72f6fcd",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 680,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 21,
"path": "/legaltext/templatetags/legaltext_tags.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "from django import template\nfrom django.conf import settings\nfrom django.db.models import Q\nfrom django.urls import NoReverseMatch\nfrom django.utils.translation import gettext_lazy as _\n\nfrom ..models import LegalText\n\n\nregister = template.Library()\n\n\[email protected]_tag(takes_context=True)\ndef legaltext_url(context, name):\n legaltext = LegalText.objects.filter(Q(url_name=name) | Q(slug=name)).first()\n silent = getattr(settings, 'LEGALTEXT_SILENCE_TEMPLATE_ERRORS', False)\n if not legaltext:\n if silent:\n return ''\n raise NoReverseMatch(_('Legaltext with slug/name: {0} does not exist').format(name))\n return legaltext.get_absolute_url()\n"
},
{
"alpha_fraction": 0.6387665271759033,
"alphanum_fraction": 0.6469292640686035,
"avg_line_length": 42.60451889038086,
"blob_id": "5288d79f002ef21a9514600ea120af9799e398ea",
"content_id": "124529b11e6f637096bb809a3a6487c8e0974034",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7718,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 177,
"path": "/testing/tests/test_admin.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "from datetime import timedelta\n\nimport pytest\nfrom django.contrib import admin\nfrom django.urls import reverse\nfrom django.utils import timezone\nfrom freezegun import freeze_time\n\nfrom legaltext.admin import LegalTextAdmin, LegalTextCheckboxInline, LegalTextVersionAdmin\nfrom legaltext.models import LegalText, LegalTextCheckbox, LegalTextVersion\nfrom testing.factories import (\n LegalTextCheckboxFactory, LegalTextFactory, LegalTextVersionFactory)\n\n\[email protected]_db\nclass TestLegalTextAdmin:\n\n def setup(self):\n self.modeladmin = LegalTextAdmin(LegalText, admin.site)\n\n def test_prepopulated_fields(self, rf):\n assert 'slug' in self.modeladmin.get_prepopulated_fields(rf.get('/'), None)\n assert 'slug' not in self.modeladmin.get_prepopulated_fields(\n rf.get('/'), LegalTextFactory.create())\n\n def test_readonly_fields(self, rf):\n assert 'slug' not in self.modeladmin.get_readonly_fields(rf.get('/'), None)\n assert 'slug' in self.modeladmin.get_readonly_fields(\n rf.get('/'), LegalTextFactory.create())\n\n def test_current_version_link(self):\n legal_text = LegalTextFactory.create()\n html = self.modeladmin.current_version_link(legal_text)\n assert '/legaltextversion/{0}/change/'.format(\n legal_text.get_current_version().pk) in html\n\n def test_add_new_version_link(self):\n legal_text = LegalTextFactory.create()\n html = self.modeladmin.add_new_version_link(legal_text)\n assert '/legaltextversion/add/?legaltext={0}'.format(legal_text.pk) in html\n\n def test_url_name_is_unique(self, admin_client):\n url = reverse('admin:legaltext_legaltext_add')\n data = {'name': 'First', 'slug': 'first', 'url_name': 'first'}\n duplicated_data = {'name': 'Second', 'slug': 'second', 'url_name': 'first'}\n\n admin_client.post(url, data)\n response = admin_client.post(url, duplicated_data)\n\n assert response.status_code == 200\n assert LegalText.objects.count() == 1\n assert len(response.context['errors']) == 1\n\n def test_url_name_can_be_blank(self, admin_client):\n url = reverse('admin:legaltext_legaltext_add')\n data = {'name': 'First', 'slug': 'first', 'url_name': ''}\n other_data = {'name': 'Second', 'slug': 'second', 'url_name': ''}\n\n admin_client.post(url, data)\n response = admin_client.post(url, other_data)\n\n assert response.status_code == 302\n assert LegalText.objects.count() == 2\n\n\[email protected]_db\nclass TestLegalTextCheckboxInline:\n\n def setup(self):\n self.modeladmin = LegalTextCheckboxInline(LegalTextCheckbox, admin.site)\n\n def test_readonly_fields(self, rf):\n assert 'content' not in self.modeladmin.get_readonly_fields(rf.get('/'), None)\n assert 'content' not in self.modeladmin.get_readonly_fields(\n rf.get('/'), LegalTextVersionFactory.create(\n valid_from=timezone.now() + timedelta(days=1)))\n assert 'content' in self.modeladmin.get_readonly_fields(\n rf.get('/'), LegalTextVersionFactory.create(valid_from=timezone.now()))\n\n def test_get_max_num(self, rf):\n assert self.modeladmin.get_max_num(rf.get('/'), None) is None\n assert self.modeladmin.get_max_num(rf.get('/'), LegalTextVersionFactory.create(\n valid_from=timezone.now() + timedelta(days=1))) is None\n assert self.modeladmin.get_max_num(rf.get('/'), LegalTextVersionFactory.create(\n valid_from=timezone.now())) == 0\n\n def test_get_initial_extra_add_not_found(self, rf):\n assert self.modeladmin.get_initial_extra(\n rf.get('/'), None) == []\n\n assert self.modeladmin.get_initial_extra(\n rf.get('/', data={'legaltext': 1}), None) == []\n\n def test_get_initial_extra_add(self, rf):\n cb = LegalTextCheckboxFactory.create(content='foo')\n assert self.modeladmin.get_initial_extra(\n rf.get('/', data={'legaltext': cb.legaltext_version.legaltext.pk}), None\n ) == [{'content': 'foo', 'order': cb.pk}]\n\n def test_get_initial_extra_change(self, rf):\n assert self.modeladmin.get_initial_extra(\n rf.get('/'), LegalTextVersionFactory.create()) == []\n\n\[email protected]_db\nclass TestLegalTextVersionAdmin:\n\n def setup(self):\n self.modeladmin = LegalTextVersionAdmin(LegalTextVersion, admin.site)\n\n def test_get_fieldsets(self, rf, admin_user):\n request = rf.get('/')\n request.user = admin_user\n assert self.modeladmin.get_fieldsets(\n request, None\n )[0][1]['fields'] == ['legaltext', 'valid_from', 'content']\n assert self.modeladmin.get_fieldsets(\n request, LegalTextVersionFactory.create(\n valid_from=timezone.now() + timedelta(days=1))\n )[0][1]['fields'] == ['legaltext', 'valid_from', 'content']\n assert self.modeladmin.get_fieldsets(\n request, LegalTextVersionFactory.create(valid_from=timezone.now())\n )[0][1]['fields'] == ('legaltext', 'valid_from', 'rendered_content')\n\n def test_readonly_fields(self, rf):\n assert self.modeladmin.get_readonly_fields(rf.get('/'), None) == ()\n assert self.modeladmin.get_readonly_fields(\n rf.get('/'), LegalTextVersionFactory.create(\n valid_from=timezone.now() + timedelta(days=1))) == ()\n assert self.modeladmin.get_readonly_fields(\n rf.get('/'), LegalTextVersionFactory.create(valid_from=timezone.now())\n ) == ('legaltext', 'valid_from', 'rendered_content')\n\n def test_legaltext_name(self):\n legal_text_version = LegalTextVersionFactory.create(legaltext__name='foo')\n assert self.modeladmin.legaltext_name(legal_text_version) == 'foo'\n\n def test_rendered_content(self):\n legal_text_version = LegalTextVersionFactory.create(content='foo')\n assert self.modeladmin.rendered_content(\n legal_text_version) == legal_text_version.render_content()\n\n def test_add_no_form_initial(self, rf, admin_user):\n request = rf.get('/')\n request.user = admin_user\n response = self.modeladmin.add_view(request)\n assert response.status_code == 200\n assert response.context_data['adminform'].form.initial == {}\n\n def test_add_invalid_form_initial(self, rf, admin_user):\n request = rf.get('/', data={'legaltext': 1})\n request.user = admin_user\n response = self.modeladmin.add_view(request)\n assert response.status_code == 200\n assert response.context_data['adminform'].form.initial == {'legaltext': '1'}\n\n def test_add_form_initial(self, rf, admin_user):\n legal_text_version = LegalTextVersionFactory.create(content='foobar')\n request = rf.get('/', data={'legaltext': legal_text_version.legaltext.pk})\n request.user = admin_user\n response = self.modeladmin.add_view(request)\n assert response.status_code == 200\n assert response.context_data['adminform'].form.initial == {\n 'content': 'foobar', 'legaltext': '1'}\n\n @freeze_time('2016-01-02 09:21:55')\n def test_export_legaltext_version_action(self, admin_client):\n legal_text_version = LegalTextVersionFactory.create(content='foobar')\n url = reverse('admin:legaltext_legaltextversion_changelist')\n data = {\n 'action': 'export_legaltext_version',\n '_selected_action': [str(legal_text_version.pk)]\n }\n response = admin_client.post(url, data)\n assert response['Content-Type'] == 'application/zip'\n assert response['Content-Disposition'] == (\n 'filename=legaltext_export_2016-01-02_09-21-55.zip')\n"
},
{
"alpha_fraction": 0.704552412033081,
"alphanum_fraction": 0.704552412033081,
"avg_line_length": 25.18400001525879,
"blob_id": "55248dad91e31a503762dac2de9ed69f3dedd10e",
"content_id": "35045c5968d91ff29333fbafe72310154f4f7976",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 3273,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 125,
"path": "/README.rst",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "================\ndjango-legaltext\n================\n\n.. image:: https://badge.fury.io/py/django-legaltext.svg\n :target: https://pypi.python.org/pypi/django-legaltext\n :alt: Latest PyPI version\n\n.. image:: https://travis-ci.org/moccu/django-legaltext.svg?branch=master\n :target: https://travis-ci.org/moccu/django-legaltext\n :alt: Latest Travis CI build status\n\n\nLegaltext is a Django application to help managing legal text versioning (e.g.\nterms of condition, pr privacy policy). It also supports versioning of the\ncorresponding checkbox labels.\n\n\nFeatures\n========\n\nThe application consists of multiple parts and helpers:\n\n* Models to maintain legal texts, their versions and checkboxes\n* Model field to store the accepted version of a legal text (with support to\n auto-fetched default of current version)\n* Form field to render the widget which outputs the configured checkboxes just\n using the legal text slug\n* Admin interface to maintain the legal texts, adding new version with prefilling, and export\n* Templatetag legaltext_url\n\n\nInstallation\n============\n\nrequirements.txt\n~~~~~~~~~~~~~~~~\n\nJust add the following PyPI package to your requirements.txt\n::\n\n django-legaltext\n\n\nsettings.py\n~~~~~~~~~~~\n\nTo activate the application, add the following two packages to your `INSTALLED_APPS`\n::\n\n INSTALLED_APPS = (\n ...\n 'floppyforms', # needed for widget rendering\n 'markymark', # required for markdown rendering\n 'legaltext',\n )\n\n\nurls.py\n~~~~~~~\n\nTo register the url to output the legal texts, add the following to your `urls.py`.\n::\n\n urlpatterns = [\n ...\n url(r'^legaltext/', include('legaltext.urls')),\n ]\n\n\nUsage\n=====\n\nPlease refer to the examples to learn how to use the application.\n\nYou just need to add a new model field to your models and set the correct formfield\nin the corresponding forms.\n\n\n::\n\n class YourModel(models.Model):\n ...\n\n accepted_legaltext = LegalTextField('some-unique-slug')\n\n\n::\n\n class YourForm(forms.ModelForm):\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.fields['accepted_legaltext'] = LegalTextFormField('some-unique-slug')\n\n\nMake sure that you use the same slug on both (model and form) field.\n\n\nCustomization\n=============\n\nThere are some more settings you can set to change the applcation\n\n* `LEGALTEXT_ANCHOR_CLASS`\n Add an additional css class the the rendered anchor-span when using [anchor:foo]\n* `LEGALTEXT_VIEW_TEMPLATE`\n Change the template which is used to in the view to output the legal text\n* `LEGALTEXT_VIEW_TEMPLATE_OVERRIDES`\n Choose a different template to use in views for specific slugs\n* `LEGALTEXT_WIDGET_TEMPLATE`\n Change the template which is used to in the widget to output the checkboxes\n* `LEGALTEXT_WIDGET_TEMPLATE_OVERRIDES`\n Choose a different template to use in widget for specific slugs\n* `LEGALTEXT_WIDGET_ATTRS`\n Add extra attributes to checkbox input elements\n* `LEGALTEXT_SILENCE_TEMPLATE_ERRORS`\n Silence errors for legaltext_url templatetag if legaltext does not exist\n\n\nResources\n=========\n\n* `Code <https://github.com/moccu/django-legaltext>`_\n* `Usage example <https://github.com/moccu/django-legaltext/tree/master/examples>`_\n"
},
{
"alpha_fraction": 0.5738903284072876,
"alphanum_fraction": 0.584856390953064,
"avg_line_length": 40.630435943603516,
"blob_id": "9d02206bafa8edc7d8b2f0166e0f518ce2cdd8b9",
"content_id": "3bab16bdfe88bbed953fc741b0c7bf58868c3058",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1915,
"license_type": "permissive",
"max_line_length": 267,
"num_lines": 46,
"path": "/legaltext/migrations/0001_initial.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.4 on 2017-08-03 06:58\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\nimport django.utils.timezone\nimport markymark.fields\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='LegalText',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=64, verbose_name='Legal text')),\n ('slug', models.SlugField(max_length=64, unique=True, verbose_name='Slug')),\n ],\n options={\n 'verbose_name_plural': 'Legal texts',\n 'ordering': ('name',),\n 'verbose_name': 'Legal text',\n },\n ),\n migrations.CreateModel(\n name='LegalTextVersion',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('valid_from', models.DateTimeField(default=django.utils.timezone.now, verbose_name='Valid from')),\n ('content', markymark.fields.MarkdownField(help_text='You can use [block:foo]Your text[/block] to create a block with an anchor. Anchors ([anchor:foo]) can be used in checkbox texts to link to specific parts of the legal text.', verbose_name='Text')),\n ('legaltext', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='legaltext.LegalText', verbose_name='Legal text')),\n ],\n options={\n 'verbose_name_plural': 'Legal text versions',\n 'ordering': ('legaltext__slug', '-valid_from'),\n 'verbose_name': 'Legal text version',\n },\n ),\n ]\n"
},
{
"alpha_fraction": 0.5635220408439636,
"alphanum_fraction": 0.6125786304473877,
"avg_line_length": 30.799999237060547,
"blob_id": "c0281b004aabd11c03d9355daccc6ce46709662b",
"content_id": "5b9ceb1c3df7974074c4a066995537dfaea3d997",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 795,
"license_type": "permissive",
"max_line_length": 198,
"num_lines": 25,
"path": "/legaltext/migrations/0005_auto_20170922_0723.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.10.5 on 2017-09-22 12:23\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('legaltext', '0004_auto_20170913_0714'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='legaltext',\n name='slug',\n field=models.SlugField(max_length=128, unique=True, verbose_name='Slug'),\n ),\n migrations.AlterField(\n model_name='legaltext',\n name='url_name',\n field=models.SlugField(blank=True, help_text='Optional URL name for the legal text. If not provided, the slug is used.', max_length=128, null=True, unique=True, verbose_name='URL Name'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.8175182342529297,
"alphanum_fraction": 0.8175182342529297,
"avg_line_length": 18.571428298950195,
"blob_id": "01d65991857af4372532dea49b5b44b95b37df5f",
"content_id": "72b0f3ab3f5e821248e5fb2c46aecf82c7c54b84",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 137,
"license_type": "permissive",
"max_line_length": 39,
"num_lines": 7,
"path": "/examples/dynamic_legaltexts/admin.py",
"repo_name": "lenarother/django-legaltext",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\n\nfrom .models import Participant, Survey\n\n\nadmin.site.register(Participant)\nadmin.site.register(Survey)\n"
}
] | 36 |
flovera1/python-django
|
https://github.com/flovera1/python-django
|
b5f3785d2b9bf39386dbd10809caea87e6a0a220
|
09fcc575964471a2f8af325665a5abbc47a6ae0c
|
01b98eeb72db032961cdc823920625a20c16484f
|
refs/heads/master
| 2021-01-11T14:18:50.023530 | 2017-02-08T14:04:26 | 2017-02-08T14:04:26 | 81,335,871 | 0 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.72826087474823,
"alphanum_fraction": 0.729468584060669,
"avg_line_length": 29.629629135131836,
"blob_id": "e9116a011399608b37c1c9650f20553fcc6c483f",
"content_id": "721eb262bff00c9a439a5d1eb629f2cca09687b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 828,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 27,
"path": "/bugs/admin.py",
"repo_name": "flovera1/python-django",
"src_encoding": "UTF-8",
"text": "from bugs.models import Application, Component, Bug, Comment\nfrom django.contrib import admin\n\nclass ComponentInline(admin.TabularInline):\n model = Component\n extra = 5\n\nclass ApplicationAdmin(admin.ModelAdmin):\n inlines = [ComponentInline]\n search_fields = ['name']\n \nclass ComponentAdmin(admin.ModelAdmin):\n search_fields = ['name']\n \nclass BugAdmin(admin.ModelAdmin):\n list_display = ('title', 'status', 'priority', 'date_reported', 'date_changed')\n search_fields = ['title']\n list_filter = ['date_reported']\n date_hierarchy = 'date_reported'\n \nclass CommentAdmin(admin.ModelAdmin):\n search_fields = ['content']\n\nadmin.site.register(Application,ApplicationAdmin)\nadmin.site.register(Component,ComponentAdmin)\nadmin.site.register(Bug,BugAdmin)\nadmin.site.register(Comment,CommentAdmin)\n\n"
},
{
"alpha_fraction": 0.7256944179534912,
"alphanum_fraction": 0.7256944179534912,
"avg_line_length": 27.899999618530273,
"blob_id": "eece4fc8636538e4c06b08b29fed758b0379b4ab",
"content_id": "4ee3a7ffa95b5f25a4eed0d92ddd9c0c969b4042",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 288,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 10,
"path": "/social/admin.py",
"repo_name": "flovera1/python-django",
"src_encoding": "UTF-8",
"text": "from social.models import Message\nfrom django.contrib import admin\n\nclass MessageAdmin(admin.ModelAdmin):\n search_fields = ['content']\n list_display = ('content','date_sent')\n list_filter = ['date_sent']\n date_hierarchy = 'date_sent'\n\nadmin.site.register(Message,MessageAdmin)"
},
{
"alpha_fraction": 0.636313796043396,
"alphanum_fraction": 0.6385079622268677,
"avg_line_length": 41.1860466003418,
"blob_id": "bfe723a3fcacd10de6dafdd1452b5e6c4aac2252",
"content_id": "261a497dadc934b501f05dd59f8c00a14bc3b9b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1823,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 43,
"path": "/users/views.py",
"repo_name": "flovera1/python-django",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Create your views here.\n\nfrom django.contrib import messages\nfrom django.contrib.auth import authenticate, login, logout\nfrom django.contrib.auth.forms import UserChangeForm, UserCreationForm\nfrom django.contrib.auth.models import User\nfrom django.core.context_processors import csrf\nfrom django.core.urlresolvers import reverse\nfrom django.http import HttpResponseRedirect, HttpResponse\nfrom django.shortcuts import get_object_or_404, render_to_response, redirect\nfrom django.template import Context, loader, RequestContext\nfrom users.forms import BasicUserChangeForm\n\ndef sign_up(request):\n if request.method == 'POST':\n form = UserCreationForm(request.POST)\n if form.is_valid():\n form.save()\n messages.success(request, \"You have signed up successfully.\")\n return HttpResponseRedirect(\"/\")\n messages.error(request, \"Please verify your data and try again.\")\n else:\n form = UserCreationForm()\n return render_to_response('sign_up.html',\n {'form': form}, \n context_instance=RequestContext(request))\n \ndef update(request): \n \n if request.method == 'POST':\n form = BasicUserChangeForm(request.POST, instance=request.user)\n if form.is_valid():\n form.save()\n redirect_to = request.REQUEST.get('next', reverse('BTS_home'))\n return HttpResponseRedirect(redirect_to)\n else:\n form = BasicUserChangeForm(instance=request.user)\n redirect_to = request.REQUEST.get('next','')\n return render_to_response('update.html', \n {'form':form,\n 'next':redirect_to},\n context_instance=RequestContext(request))\n \n"
},
{
"alpha_fraction": 0.754923403263092,
"alphanum_fraction": 0.754923403263092,
"avg_line_length": 37.08333206176758,
"blob_id": "2b4190156fdefd2d6f62e7f00a725d6bec87f4d4",
"content_id": "e27532439b3ae6b85d2e8bac42460a12209bd825",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 457,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 12,
"path": "/social/urls.py",
"repo_name": "flovera1/python-django",
"src_encoding": "UTF-8",
"text": "\nfrom django.conf.urls import patterns, include, url\nfrom django.contrib.auth.decorators import login_required\nfrom django.core.context_processors import request\nfrom django.views.generic.detail import DetailView\nfrom django.views.generic.list import ListView\nfrom social.models import Message\n\nurlpatterns = patterns('',\n # regexp, view, options\n url(r'^(?P<user_id>\\d+)/$','social.views.send_message'),\n url(r'^$', 'social.views.message_list'),\n)"
},
{
"alpha_fraction": 0.8077921867370605,
"alphanum_fraction": 0.8155844211578369,
"avg_line_length": 47.125,
"blob_id": "8c1cb73395792f3534560e4122c3af6becf644a8",
"content_id": "fa7b946a6e5fc262ece53582c5ea4b2e8b363dfc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 385,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 8,
"path": "/BTS/views.py",
"repo_name": "flovera1/python-django",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import get_object_or_404, render_to_response\nfrom django.http import HttpResponseRedirect, HttpResponse\nfrom django.core.urlresolvers import reverse\nfrom django.template import Context, loader, RequestContext\nfrom django.contrib.auth.models import User\n\ndef home(request):\n return render_to_response('home.html', {} , context_instance=RequestContext(request))\n"
},
{
"alpha_fraction": 0.6416228413581848,
"alphanum_fraction": 0.6416228413581848,
"avg_line_length": 44.86206817626953,
"blob_id": "6d8ceda07943492d3a24825599ca79baffbf961a",
"content_id": "d8a34e04c38049db80bc32ab248673f2cf7de99c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1331,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 29,
"path": "/bugs/urls.py",
"repo_name": "flovera1/python-django",
"src_encoding": "UTF-8",
"text": "\nfrom bugs.forms import BugForm\nfrom bugs.models import Bug, Component, Application\nfrom django.conf.urls import patterns, include, url\nfrom django.contrib.auth.decorators import login_required\nfrom django.core.urlresolvers import reverse\nfrom django.views.generic.edit import CreateView\nfrom django.views.generic.list import ListView\n\nurlpatterns = patterns('bugs.views',\n url(r'^report/$', 'select_component'),\n url(r'^report/(?P<component_id>\\d+)/$', 'report_bug'),\n url(r'^browse/$', ListView.as_view(model=Application,\n template_name='applications/browse.html')),\n url(r'^browse/(?P<application_id>\\d+)/$', 'browse_components'), \n url(r'^browse/(?P<application_id>\\d+)/(?P<component_id>\\d+)/$', 'browse_bugs'),\n url(r'^browse/(?P<application_id>\\d+)/(?P<component_id>\\d+)/(?P<bug_id>\\d+)/$', 'detail'), \n url(r'^json/(?P<application_id>\\d+)/$', 'all_json_models'),\n url(r'^unconfirmed/$', 'list_unconfirmed_bugs'),\n url(r'^to_resolve/$','list_to_resolve_bugs'),\n url(r'^confirm/$','confirm_bug'),\n url(r'^update_status/(?P<bug_id>\\d+)/$', 'update_status'),\n url(r'^assign/$', 'assign'),\n)\n\nurlpatterns += patterns('',\n url(r'^components/create/$', CreateView.as_view(\n model=Component, template_name='components/create.html')\n )\n)\n"
},
{
"alpha_fraction": 0.6246153712272644,
"alphanum_fraction": 0.626153826713562,
"avg_line_length": 19.28125,
"blob_id": "7bc1f4585cefdc8d4c9bd480ac6bc55782a9cf20",
"content_id": "663611e6aeaf6fb8c5ebac37f1377eac1927fc39",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 650,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 32,
"path": "/bugs/templates/applications/browse.html",
"repo_name": "flovera1/python-django",
"src_encoding": "UTF-8",
"text": "{% extends \"base_bugs.html\" %}\n\n# Display a list of applications\n# requires a variable 'objects_list' of type query_set\n\n\n\n{% block content %}\n\n{% if object_list %}\n\n<table border=\"1\">\n\t<theader>\n\t\t<th id=\"name\">Application</th>\n\t\t<th id=\"components__count\">Components</th>\n\t\t<th id=\"description\">Description</th>\n\t</theader>\n{% for application in object_list %}\n\t<tr>\n\t\t<td><a href=\"/bugs/browse/{{ application.id }}/\">{{ application.name }}</a>\t </td>\t\n\t\t<td>{{ application.components.count }} </td>\n\t\t<td>{{ application.description }} </td>\n\t</tr>\n{% endfor %}\n</table>\n\n{% else %}\n\tThere's not applications created.\n\n{% endif %}\n\n{% endblock %}\t\t"
},
{
"alpha_fraction": 0.6096866130828857,
"alphanum_fraction": 0.6153846383094788,
"avg_line_length": 37.043479919433594,
"blob_id": "9feedb90ac28d401fd09fd1b408bdad9e0a0a375",
"content_id": "82211da56683124d91c9b591bddb6684c69c671b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1755,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 46,
"path": "/social/views.py",
"repo_name": "flovera1/python-django",
"src_encoding": "UTF-8",
"text": "# Create your views here.\nfrom debian.debtags import reverse\nfrom django.contrib.auth.decorators import login_required\nfrom django.contrib.auth.models import User\nfrom django.db.models.query_utils import Q\nfrom django.http import HttpResponseRedirect\nfrom django.shortcuts import render_to_response, get_object_or_404\nfrom django.template.context import RequestContext\nfrom social.forms import MessageForm\nfrom social.models import Message\n\n\n@login_required\ndef send_message(request, user_id):\n u = get_object_or_404(User, pk=user_id)\n if request.method == 'POST':\n form = MessageForm(request.POST)\n if form.is_valid():\n m = form.save(commit=False)\n m.sender = request.user\n m.receiver = u\n m.save()\n return HttpResponseRedirect(\"/social/%s/\" % user_id)\n else:\n form = MessageForm()\n messages = Message.objects.filter( Q(sender=request.user, receiver=u) | Q(receiver=request.user, sender=u)).order_by(\"-date_sent\")\n return render_to_response(\"send_message.html\", {'messages_list': messages,\n 'form': form}, \n context_instance=RequestContext(request))\n\n@login_required\ndef message_list(request):\n list_1 = Message.objects.filter(sender=request.user)\n list_2 = Message.objects.filter(receiver=request.user)\n list = []\n for l in list_1:\n if not (l.receiver in list):\n list += [l.receiver]\n \n for l in list_2:\n if not (l.sender in list):\n list += [l.sender]\n \n return render_to_response('message_list.html',\n {'object_list': list,\n 'user' : request.user})\n \n"
},
{
"alpha_fraction": 0.5641452074050903,
"alphanum_fraction": 0.5674735307693481,
"avg_line_length": 36.771427154541016,
"blob_id": "c50c24ca67c0e9d126acfb6c4d8f081860024838",
"content_id": "b46c1f5df534a17953c61a65e2a32d87f3a557fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6610,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 175,
"path": "/bugs/models.py",
"repo_name": "flovera1/python-django",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom django.contrib.auth.models import User\nfrom django.db import models\nfrom django.template.defaultfilters import default\nimport datetime\n\nclass Application(models.Model):\n name = models.CharField(max_length=30, unique=True)\n \n def __unicode__(self):\n return self.name\n\nclass Bug(models.Model):\n\n STATUS_UNCONFIRMED = 1\n STATUS_CONFIRMED = 2\n STATUS_ASSIGNED = 3\n STATUS_RESOLVED = 5\n STATUS_VERIFIED = 6\n STATUS_REOPENED = 7\n STATUS_CLOSED = 8\n STATUS_CHOICES = (\n (STATUS_UNCONFIRMED, 'Unconfirmed'),\n (STATUS_CONFIRMED, 'Confirmed'),\n (STATUS_ASSIGNED, 'Assigned'),\n (STATUS_RESOLVED, 'Resolved'),\n (STATUS_VERIFIED, 'Verified'),\n (STATUS_CLOSED, 'Closed'),\n (STATUS_REOPENED, 'Reopened')\n )\n PRIORITY_HIGH = 'H'\n PRIORITY_NORMAL = 'N'\n PRIORITY_LOW = 'L'\n PRIORITY_CHOICES = (\n (PRIORITY_HIGH,'High'),\n (PRIORITY_NORMAL,'Normal'),\n (PRIORITY_LOW,'Low'))\n title = models.CharField(max_length=50)\n status = models.IntegerField(choices=STATUS_CHOICES, default=STATUS_UNCONFIRMED)\n RESOLUTION_FIXED = 1\n RESOLUTION_DUPLICATED = 2\n RESOLUTION_WONTFIX = 3\n RESOLUTION_WORKSFORME = 4\n RESOLUTION_INVALID = 5\n RESOLUTION_CHOICES = (\n (RESOLUTION_FIXED,'Fixed'),\n (RESOLUTION_DUPLICATED,'Duplicated'),\n (RESOLUTION_WONTFIX,\"Won't fix\"),\n (RESOLUTION_WORKSFORME,\"Wrong resolution\"),\n (RESOLUTION_INVALID,\"Invalid\"))\n resolution = models.IntegerField(choices=RESOLUTION_CHOICES, null=True, blank=True)\n priority = models.CharField(max_length=1, choices=PRIORITY_CHOICES, default=PRIORITY_NORMAL)\n date_reported = models.DateTimeField('date reported', auto_now_add=True)\n date_changed = models.DateTimeField('date changed', null=True, blank=True)\n description = models.TextField()\n replication = models.TextField(verbose_name= \"How to replicate the error?\")\n visits = models.IntegerField(default=0)\n original = models.ForeignKey('Bug', related_name='duplicates', null=True, blank=True)\n reporter = models.ForeignKey(User, related_name='bugs_reported')\n resolver = models.ForeignKey(User, related_name='bugs_resolving', null=True, blank=True)\n component = models.ForeignKey('Component', related_name='bugs')\n \n def __unicode__(self):\n return self.title\n \n def is_assignable(self):\n return self.status in (Bug.STATUS_UNCONFIRMED,\n Bug.STATUS_CONFIRMED,\n Bug.STATUS_REOPENED,)\n \n def is_confirmable(self):\n return self.status in (Bug.STATUS_UNCONFIRMED,\n Bug.STATUS_ASSIGNED,)\n \n def is_resolvable(self):\n return self.status in (Bug.STATUS_UNCONFIRMED,\n Bug.STATUS_CONFIRMED,\n Bug.STATUS_REOPENED,\n Bug.STATUS_ASSIGNED,)\n \n def is_verifiable(self):\n return self.status in (Bug.STATUS_RESOLVED,)\n \n def is_closeable(self):\n return self.status in (Bug.STATUS_RESOLVED,\n Bug.STATUS_VERIFIED,)\n \n def is_reopenable(self):\n return self.status in (Bug.STATUS_CLOSED,\n Bug.STATUS_VERIFIED,)\n \n def has_been_confirmed(self):\n return self.status != self.STATUS_UNCONFIRMED\n \n def update_status(self, status, resolver=None, original=None, resolution=None):\n status = int(status)\n if status == Bug.STATUS_CONFIRMED:\n print \"Trying to update to confirmed\"\n if self.is_confirmable():\n self.resolver = None\n self.status = status\n print \"The bug has been confirmed\"\n else:\n return False\n elif status == Bug.STATUS_ASSIGNED:\n if self.is_assignable() and not resolver is None:\n self.resolver = resolver\n self.status = status\n else:\n return False \n elif status == Bug.STATUS_RESOLVED:\n if self.is_resolvable() and not resolution is None:\n if resolution == Bug.RESOLUTION_DUPLICATED:\n if original is None or original == self:\n return False\n self.original = original\n self.resolution = resolution\n self.status = status\n if not self.resolver: \n if resolver is None:\n return False\n self.resolver = resolver\n else:\n return False\n elif status == Bug.STATUS_VERIFIED:\n if self.is_verifiable() :\n self.status = status\n return True\n elif status == Bug.STATUS_CLOSED:\n if self.is_closeable() :\n self.status = status\n else:\n return False\n elif status == Bug.STATUS_REOPENED:\n if self.is_reopenable() :\n self.resolver = None\n self.resolution = None\n self.original = None\n self.status = status\n else:\n return False\n self.date_changed = datetime.date.today()\n return True\n \n def get_status_choices(self):\n choices = [(0, 'Select status')]\n if self.is_confirmable():\n choices.append((self.STATUS_CONFIRMED, 'Confirmed'))\n if self.is_assignable():\n choices.append((self.STATUS_ASSIGNED, 'Assigned'))\n if self.is_resolvable():\n choices.append((self.STATUS_RESOLVED, 'Resolved'))\n if self.is_verifiable():\n choices.append((self.STATUS_VERIFIED, 'Verified'))\n if self.is_closeable():\n choices.append((self.STATUS_CLOSED, 'Closed'))\n if self.is_reopenable():\n choices.append((self.STATUS_REOPENED, 'Reopened'))\n return choices\n\n\nclass Component(models.Model):\n name = models.CharField(max_length=30, unique=True)\n application = models.ForeignKey(Application, related_name='components')\n \n def __unicode__(self):\n return self.name\n \nclass Comment(models.Model):\n content = models.TextField()\n bug = models.ForeignKey(Bug)\n user_notes = models.ForeignKey(User)\n \n def __unicode__(self):\n return self.content\n"
},
{
"alpha_fraction": 0.6769067645072937,
"alphanum_fraction": 0.6769067645072937,
"avg_line_length": 33.96296310424805,
"blob_id": "86a7c5f443fe37d06bb3b07dab2b99291364e9d7",
"content_id": "ebc75ada4078af471546f6408445afc914b034b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 944,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 27,
"path": "/BTS/urls.py",
"repo_name": "flovera1/python-django",
"src_encoding": "UTF-8",
"text": "from BTS import settings\nfrom django.conf.urls import patterns, url, include\nfrom django.contrib import admin\nfrom django.contrib.staticfiles.urls import staticfiles_urlpatterns\n\n# Uncomment the next two lines to enable the admin:\nadmin.autodiscover()\n\nurlpatterns = patterns('',\n # Examples:\n # url(r'^$', 'BTS.views.home', name='home'),\n # url(r'^BTS/', include('BTS.foo.urls')),\n\n # Uncomment the admin/doc line below to enable admin documentation:\n # url(r'^admin/doc/', include('django.contrib.admindocs.urls')),\n\n # Uncomment the next line to enable the admin:\n url(r'^admin/', include(admin.site.urls)),\n url(r'^$', 'BTS.views.home', name='BTS_home'),\n url(r'^users/', include('users.urls')),\n url(r'^social/', include('social.urls')),\n url(r'^bugs/', include('bugs.urls')),\n (r'^comments/', include('django.contrib.comments.urls')),\n)\n\nif settings.DEBUG:\n urlpatterns += staticfiles_urlpatterns()\n"
},
{
"alpha_fraction": 0.5725667476654053,
"alphanum_fraction": 0.5796726942062378,
"avg_line_length": 46.835052490234375,
"blob_id": "91d29ab8ec4561b4bf2dc231772f391dfece8fee",
"content_id": "021bf3111b7437deff7e5c5eb096368fe92066c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9288,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 194,
"path": "/bugs/views.py",
"repo_name": "flovera1/python-django",
"src_encoding": "UTF-8",
"text": "# Create your views here.\nfrom BTS import settings\nfrom bugs.forms import BugForm, SelectComponentForm, SelectBugStatusForm, \\\n AssignBugForm, UpdateBugStatusForm\nfrom bugs.models import Component, Application, Bug\nfrom django.contrib import messages\nfrom django.contrib.auth.decorators import login_required, login_required, \\\n permission_required\nfrom django.contrib.auth.models import User, Group\nfrom django.contrib.comments.models import Comment\nfrom django.contrib.contenttypes.models import ContentType\nfrom django.contrib.sites.models import Site\nfrom django.core import serializers\nfrom django.core.exceptions import FieldError\nfrom django.core.paginator import Paginator, PageNotAnInteger, EmptyPage\nfrom django.core.urlresolvers import reverse\nfrom django.http import HttpResponseRedirect, HttpResponse, Http404\nfrom django.shortcuts import render_to_response, get_object_or_404, \\\n get_list_or_404\nfrom django.template.context import RequestContext\n\ndef browse_components(request,application_id):\n application = get_object_or_404(Application,pk=application_id)\n return render_to_response('components/browse.html', {'application': application},\n context_instance=RequestContext(request))\n\ndef browse_bugs(request,application_id, component_id):\n component = get_object_or_404(Component,pk=component_id)\n if not request.GET.__contains__('order_by'):\n orderby = 'title'\n else:\n orderby = request.GET.get('order_by') \n if orderby not in ('title','visits','priority','description'):\n orderby = 'title'\n\n bug_list = component.bugs.all().order_by(\n (request.GET.get('order') if request.GET.get('order') == \"\" or request.GET.get('order') == \"-\" else \"\" ) + orderby)\n \n paginator = Paginator(bug_list, 25) # Show 25 contacts per page\n\n page = request.GET.get('page')\n try:\n bugs = paginator.page(page)\n except PageNotAnInteger:\n # If page is not an integer, deliver first page.\n bugs = paginator.page(1)\n except EmptyPage:\n # If page is out of range (e.g. 9999), deliver last page of results.\n bugs = paginator.page(paginator.num_pages)\n return render_to_response('bugs/browse.html', {'component': component,\n 'bugs': bugs},\n context_instance=RequestContext(request))\n\ndef detail(request, application_id, component_id, bug_id):\n b = get_object_or_404(Bug,pk=bug_id)\n # THIS IS TOO SIMPLE, RELOAD THE PAGE WILL INCREASE THE VISITS\n b.visits += 1\n b.save()\n #f = AssignBugForm(initial={'bug_id': bug.id})\n #status_form = SelectBugStatusForm(initial={'status': bug.status,\n # 'bug_id': bug.id })\n update_form = UpdateBugStatusForm(bug=b)\n return render_to_response('bugs/detail.html', {'bug': b, \n # 'assign_form': f,\n # 'status_form': status_form,\n 'update_form': update_form}, \n context_instance=RequestContext(request))\n\ndef all_json_models(request, application_id):\n current_application = get_object_or_404(Application,pk=application_id)\n components = current_application.components.all()\n json_models = serializers.serialize(\"json\", components)\n return HttpResponse(json_models, mimetype=\"application/javascript\")\n\n@login_required\ndef report_bug(request,component_id): \n c =get_object_or_404(Component,pk=component_id)\n if request.method == 'POST':\n user = request.user\n bug = Bug(reporter=user,component=c)\n if (Group.objects.get(name='Gatekeeper') in user.groups.filter()):\n bug.update_status(status=Bug.STATUS_CONFIRMED)\n \n form = BugForm(request.POST, instance=bug)\n if form.is_valid():\n form.save()\n return HttpResponseRedirect(reverse('BTS_home')) \n else:\n form = BugForm(instance=Bug(component=c))\n return render_to_response('bugs/report.html', \n {'form': form },\n context_instance=RequestContext(request))\n \n@login_required\ndef select_component(request):\n if request.method == 'POST':\n form = SelectComponentForm(request.POST)\n if form.is_valid():\n return HttpResponseRedirect('/bugs/report/' + request.POST['component'] + '/')\n else: \n form = SelectComponentForm()\n return render_to_response('components/select.html',\n {'form': form },\n context_instance=RequestContext(request))\n\n@login_required\n@permission_required('users.gatekeeper')\ndef list_unconfirmed_bugs(request):\n bugs = Bug.objects.filter(status=Bug.STATUS_UNCONFIRMED)\n return render_to_response('bugs/unconfirmed.html', \n {'bugs': bugs },\n context_instance=RequestContext(request))\n \n@login_required\ndef list_to_resolve_bugs(request):\n bugs = Bug.objects.filter(resolver=request.user,status=Bug.STATUS_ASSIGNED)\n return render_to_response('bugs/to_resolve.html', \n {'bugs': bugs },\n context_instance=RequestContext(request))\n\n@login_required\ndef confirm_bug(request):\n bug = get_object_or_404(Bug,pk=request.POST['bug_id'])\n bug.status = \"X\"\n bug.save()\n f = AssignBugForm()\n return render_to_response('bugs/detail.html', {'bug': bug, 'f': f}, \n context_instance=RequestContext(request))\n\n@login_required\ndef update_status(request, bug_id):\n bug = get_object_or_404(Bug,pk=bug_id)\n if request.method == 'POST':\n f = UpdateBugStatusForm(request.POST, bug=bug)\n if f.is_valid():\n if not (request.user == bug.resolver or (bug.status != Bug.STATUS_ASSIGNED and request.user.has_perm(\"users.gatekeeper\"))):\n return Http404(\"You don't have privileges to change the status of this bug.\")\n resolver = (get_object_or_404(User,pk=f.cleaned_data['resolver']) if f.cleaned_data['resolver'] else request.user)\n original = (get_object_or_404(Bug,pk=f.cleaned_data['original']) if f.cleaned_data['original'] else None)\n resolution = f.cleaned_data['resolution']\n if bug.update_status(status=f.cleaned_data['status'], \n resolver=resolver, \n original=original, \n resolution=resolution):\n bug.save()\n c = Comment()\n c.content_type = ContentType.objects.get(app_label=\"bugs\", model=\"bug\")\n c.object_pk = bug.pk\n c.site = Site.objects.get(id=settings.SITE_ID)\n c.comment = '{0} has changed the status to {1}'.format(request.user.username,\n bug.get_status_display())\n c.save()\n messages.success(request, \"The status has been updated successfully.\")\n return HttpResponseRedirect('/bugs/browse/{0}/{1}/{2}'.format(\n bug.component.application.id,\n bug.component.id,\n bug.id))\n else:\n f = UpdateBugStatusForm(bug=bug)\n return render_to_response('bugs/detail.html',\n {'bug': bug,\n 'update_form': f},\n context_instance=RequestContext(request))\n \n@login_required\n@permission_required('users.gatekeeper')\ndef assign(request):\n if request.method == 'POST':\n assignForm = AssignBugForm(request.POST)\n if assignForm.is_valid():\n bug = get_object_or_404(Bug,pk=assignForm.cleaned_data['bug_id'])\n bug.status = Bug.STATUS_ASSIGNED\n bug.resolver = User.objects.get(pk=assignForm.cleaned_data['user'])\n bug.original = None\n bug.save()\n # HAY QUE GUARDAR EN LOS COMENTARIOS EL CAMBIO DE STATUS\n c = Comment()\n c.content_type = ContentType.objects.get(app_label=\"bugs\", model=\"bug\")\n c.object_pk = bug.pk\n c.site = Site.objects.get(id=settings.SITE_ID)\n c.comment = '{0} has assigned this bug to {1}. Its status has change to {2}'.format(\n request.user.username,\n bug.resolver.username,\n bug.get_status_display())\n c.save()\n return HttpResponseRedirect('/bugs/browse/{0}/{1}/{2}'.format(\n bug.component.application.id,\n bug.component.id,\n bug.id))\n else:\n messages.error(request, \"An error occur while trying to assign the bug.\")\n return HttpResponseRedirect(reverse('BTS_home'))\n else:\n return Http404()\n "
},
{
"alpha_fraction": 0.5796135663986206,
"alphanum_fraction": 0.5802798271179199,
"avg_line_length": 54.592594146728516,
"blob_id": "43b09e7c047b4c56e218fbd9ccc2bb33a81034bf",
"content_id": "3685b0f9a74627602f47b771404e6bfa40988c18",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1501,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 27,
"path": "/users/urls.py",
"repo_name": "flovera1/python-django",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom django.conf.urls import patterns, include, url\nfrom django.contrib.auth.forms import UserCreationForm, UserChangeForm\nfrom django.contrib.auth.models import User\nfrom django.contrib.auth.views import login, logout, password_change, \\\n password_reset\nfrom django.core.context_processors import request\nfrom django.template.context import RequestContext\nfrom django.views.generic.edit import CreateView, UpdateView\nfrom users.forms import BasicUserChangeForm\n\nurlpatterns = patterns('',\n #url(r'^sign_up/$', CreateView.as_view(form_class=UserCreationForm,\n # template_name='sign_up.html',\n # success_url='/')),\n url(r'^sign_up/$', 'users.views.sign_up'),\n url(r'^login/$', login, {'template_name':'login.html'}),\n url(r'^logout/$', logout, {'next_page':'/'}),\n url(r'^password_change/$', password_change, {'template_name': 'password_change.html',\n 'post_change_redirect': '/'}),\n url(r'^password_reset/$', password_reset, {'template_name': 'password_reset.html',\n 'email_template_name': 'password_reset_email.html',\n 'subject_template_name': 'password_reset_subject.txt',\n 'post_reset_redirect': '/'}),\n url(r'change/$', 'users.views.update'),\n# url(r'assign/$', assign_user)\n)\n"
},
{
"alpha_fraction": 0.7259953022003174,
"alphanum_fraction": 0.7259953022003174,
"avg_line_length": 34.58333206176758,
"blob_id": "db88671ce5c39fb266ba8581e028fd5410cf844e",
"content_id": "31bf923901847a175d1b86c8e72a77c3f2d9cb3f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 427,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 12,
"path": "/social/models.py",
"repo_name": "flovera1/python-django",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.contrib.auth.models import User\n# Create your models here.\n\nclass Message(models.Model):\n content = models.TextField()\n date_sent = models.DateTimeField('date sent',auto_now_add=True)\n sender = models.ForeignKey(User, related_name='messages_sent')\n receiver = models.ForeignKey(User, related_name='messages_received')\n\n def __unicode__(self):\n return self.content\n"
},
{
"alpha_fraction": 0.6615384817123413,
"alphanum_fraction": 0.6615384817123413,
"avg_line_length": 19.375,
"blob_id": "ddd2383fe4c3410c1ccd7e8e772e72f9da267047",
"content_id": "5b2c3952e46065d9d9d4c51372d274d18cdc9751",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 325,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 16,
"path": "/bugs/templates/applications/create.html",
"repo_name": "flovera1/python-django",
"src_encoding": "UTF-8",
"text": "{% extends \"base_bugs.html\" %}\n\n# Display a form to create a Application\n# requires a variable 'form' of type ApplicationForm\n\n{% block content %}\n\n<form action=\"/bugs/applications/create/\" method='POST'>\n{% csrf_token %}\n\t<table>\n\t{{ form.as_table }}\n\t</table>\n\t<input type=\"submit\" value=\"Create\" />\n</form>\n\n{% endblock %}"
},
{
"alpha_fraction": 0.700964629650116,
"alphanum_fraction": 0.700964629650116,
"avg_line_length": 27.272727966308594,
"blob_id": "b4b0e4fd271d7743f445095462489cc6713cb2aa",
"content_id": "a83787a5653a14695680abeb09e4189467bc4d21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 622,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 22,
"path": "/users/models.py",
"repo_name": "flovera1/python-django",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.contrib.auth.models import User\nfrom django.db.models.signals import post_save\n\n# Create your models here.\n\nclass UserProfile(models.Model):\n \n class Meta:\n permissions = (\n (\"gatekeeper\", \"The user is a gatekeeper\"),\n ) \n \n # Required field\n user = models.OneToOneField(User)\n\n# Asegurarse de crear el UserProfile luego de guardar una instancia de usuario\ndef create_user_profile(sender, instance, created, **kwargs):\n if created:\n UserProfile.objects.create(user=instance)\n\npost_save.connect(create_user_profile, sender=User)\n"
},
{
"alpha_fraction": 0.6480686664581299,
"alphanum_fraction": 0.6738197207450867,
"avg_line_length": 17,
"blob_id": "81da33d9bed85f6a55b161f7d6458b769467d0df",
"content_id": "f497acb31e23b1597838424823b20be49211fa97",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 233,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 13,
"path": "/social/forms.py",
"repo_name": "flovera1/python-django",
"src_encoding": "UTF-8",
"text": "'''\nCreated on May 10, 2012\n\n@author: tamerdark\n'''\nfrom django.forms.models import ModelForm\nfrom social.models import Message\n\nclass MessageForm(ModelForm):\n \n class Meta:\n model = Message\n fields = ('content',)"
}
] | 16 |
PeturSteinn/VEFTH2V-Lokaverkefni
|
https://github.com/PeturSteinn/VEFTH2V-Lokaverkefni
|
c6bf44b6adaf796148d21d25ae661e6cd1f1cc0e
|
d95dcb33132969855946fd1e0424915a760ef445
|
d6626fbb29346d66d3fe6d1d3dfb4318a2c26e1b
|
refs/heads/master
| 2020-03-13T05:02:43.144171 | 2018-05-29T00:28:58 | 2018-05-29T00:28:58 | 130,974,675 | 0 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.602830171585083,
"alphanum_fraction": 0.6188679337501526,
"avg_line_length": 25.399999618530273,
"blob_id": "e8cff2a47e8352eca84962821d5679ef917278ae",
"content_id": "1438947356dce179a2d2541eb9ecfa9251c70a41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1064,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 40,
"path": "/Testing_Environment.py",
"repo_name": "PeturSteinn/VEFTH2V-Lokaverkefni",
"src_encoding": "UTF-8",
"text": "\nfrom Database.HotelConnect import *\nfrom time import gmtime, strftime\nCustomerList = Customer()\nCommonPS = CommonPS()\nReservation=Reservation()\nRoom=Room()\norder_Room=Order_Has_Rooms()\n\n\n#print(CustomerList.CustomerList())\nkust_orders = CommonPS.CustomerOrders(21)\nprint(kust_orders)\norders = []\nprint('llb',CommonPS.TotalRoomBill(78))\nteljari = 0\n\nfor y in kust_orders:\n order = {}\n flokkur = CommonPS.TotalRoomBill(y[0]) # mundi skýra order en það er tekið\n orderprice = 0\n order['hotel'] = flokkur[0][7]\n order['herbergi'] = []\n for x in flokkur:\n herbergi = {}\n order['checkin'] = x[0]\n order['checkout'] = x[1]\n herbergi['type'] = x[2]\n herbergi['nuber'] = x[3]\n herbergi['price'] = x[4]\n herbergi['days'] =x[5]\n herbergi['totalprice'] = x[6]\n print(herbergi)\n order['herbergi'].append(herbergi)\n orderprice += int(x[6])\n order['orderprice'] = orderprice\n print(order)\n orders.append(order)\nprint('''''')\nfor x in orders:\n print(x['herbergi'])\n\n\n\n"
},
{
"alpha_fraction": 0.6095896363258362,
"alphanum_fraction": 0.6150755882263184,
"avg_line_length": 34.835914611816406,
"blob_id": "861814e136a9ef094dc407ef5e683c23db0dfdc7",
"content_id": "924290b9164d1034938e32ce7f5b4ea238dc9af6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 23150,
"license_type": "no_license",
"max_line_length": 281,
"num_lines": 646,
"path": "/Database/HotelConnect.py",
"repo_name": "PeturSteinn/VEFTH2V-Lokaverkefni",
"src_encoding": "UTF-8",
"text": "from mysql.connector import MySQLConnection, Error\nfrom .python_mysql_dbconfig import read_db_config\n\n\nclass DbConnector:\n def __init__(self):\n self.db_config = read_db_config()\n self.status = ' '\n try:\n self.conn = MySQLConnection(**self.db_config)\n if self.conn.is_connected():\n self.status = 'OK'\n else:\n self.status = 'connection failed.'\n except Error as error:\n self.status = error\n\n def execute_function(self, func_header=None, argument_list=None):\n cursor = self.conn.cursor()\n try:\n if argument_list:\n func = func_header % argument_list\n else:\n func = func_header\n cursor.execute(func)\n result = cursor.fetchone()\n except Error as e:\n self.status = e\n result = None\n finally:\n cursor.close()\n return result[0]\n\n def execute_procedure(self, proc_name, argument_list=None):\n result_list = list()\n cursor = self.conn.cursor()\n try:\n if argument_list:\n cursor.callproc(proc_name, argument_list)\n else:\n cursor.callproc(proc_name)\n self.conn.commit()\n for result in cursor.stored_results():\n result_list = [list(elem) for elem in result.fetchall()]\n except Error as e:\n self.status = e\n print(e)\n finally:\n cursor.close()\n return result_list\n\n\nclass CommonPS(DbConnector):\n def __init__(self):\n DbConnector.__init__(self)\n\n def HireEmployee(self, Param_Zip, Param_CityName, Param_CountryName, Param_StreetName, Param_BuildingNum, Param_HotelID, Param_EmpSSN, Param_Title, Param_LName, Param_FName, Param_Email, Param_Phone, Param_User, Param_Pass, Param_ApartNum=None,):\n new_id = 0\n result = self.execute_procedure('EmployeeHire_Bundle', [Param_Zip, Param_CityName, Param_CountryName, Param_StreetName, Param_BuildingNum, Param_ApartNum, Param_HotelID, Param_EmpSSN, Param_Title, Param_LName, Param_FName, Param_Email, Param_Phone, Param_User, Param_Pass])\n if result:\n new_id = int(result[0][0])\n return new_id\n\n def RegisterCustomer(self, Param_Zip, Param_CityName, Param_CountryName, Param_StreetName, Param_BuildingNum, Param_CusSSN, Param_LName, Param_FName, Param_Email, Param_Phone, Param_User, Param_Pass, Param_ApartNum=None):\n new_id = 0\n result = self.execute_procedure('CustomerRegister_Bundle', [Param_Zip, Param_CityName, Param_CountryName, Param_StreetName, Param_BuildingNum, Param_ApartNum, Param_CusSSN, Param_LName, Param_FName, Param_Email, Param_Phone, Param_User, Param_Pass])\n if result:\n new_id = int(result[0][0])\n return new_id\n\n def CheckAvailability(self, New_Start, New_End, Param_HotelID, Param_TypeID):\n result = self.execute_procedure('CheckAvailability', [New_Start, New_End, Param_HotelID, Param_TypeID])\n if result:\n return result\n else:\n return list()\n\n def TotalServiceBill(self, Param_OrderID):\n result = self.execute_procedure('TotalServiceBill', [Param_OrderID])\n if result:\n return result\n else:\n return list()\n\n def TotalRoomBill(self, Param_OrderID):\n result = self.execute_procedure('TotalRoomBill', [Param_OrderID])\n if result:\n return result\n else:\n return list()\n\n def ReservationAdd(self, Param_EmpID, Param_CusID, Param_OrderDate):\n new_id = 0\n result = self.execute_procedure('ReservationAdd', [Param_EmpID, Param_CusID, Param_OrderDate])\n if result:\n new_id = int(result[0][0])\n return new_id\n\n def ReservationRoomAdd(self, Param_OrderID, Param_RoomID, Param_CheckInDate, Param_CheckOutDate):\n new_id = 0\n print(\"HotelConnect\", Param_CheckInDate)\n print(\"HotelConnect\", Param_CheckOutDate)\n result = self.execute_procedure('ReservationRoomAdd', [Param_OrderID, Param_RoomID, Param_CheckInDate, Param_CheckOutDate])\n if result:\n new_id = int(result[0][0])\n return new_id\n\n def ServiceOrderAdd(self, Param_RoomID, Param_OrderID, Param_EmpID, Param_DateTimeOfService):\n new_id = 0\n result = self.execute_procedure('ServiceOrderAdd', [Param_RoomID, Param_OrderID, Param_EmpID, Param_DateTimeOfService])\n if result:\n new_id = int(result[0][0])\n return new_id\n\n\n def ServiceAddItem(self, Param_ServiceID, Param_ItemID, Param_Qty):\n new_id = 0\n result = self.execute_procedure('ServiceAddItem', [Param_ServiceID, Param_ItemID, Param_Qty])\n if result:\n new_id = int(result[0][0])\n return new_id\n\n def ServiceListOrdersByHotel(self, Param_HotelID):\n result = self.execute_procedure('ServiceListOrdersByHotel', [Param_HotelID])\n if result:\n return result\n else:\n return list()\n\n def HotelAbout(self):\n result = self.execute_procedure('HotelAbout')\n if result:\n return result\n else:\n return list()\n\n def GetWorkplaces(self, Param_EmpID):\n result = self.execute_procedure('GetWorkplaces', [Param_EmpID])\n if result:\n return result\n else:\n return list()\n\n def CustomerOrders(self, Param_CusID):\n result = self.execute_procedure('CustomerOrders', [Param_CusID])\n if result:\n return result\n else:\n return list()\n\n def RoomsOnOrder(self, Param_OrderID):\n result = self.execute_procedure('RoomsOnOrder', [Param_OrderID])\n if result:\n return result\n else:\n return list()\n\n def ServicesOnRooms(self, Param_OrderID, Param_RoomID):\n result = self.execute_procedure('ServicesOnRooms', [Param_OrderID, Param_RoomID])\n if result:\n return result\n else:\n return list()\n\n def ServiceDetails(self, Param_ServiceID):\n result = self.execute_procedure('ServiceDetails', [Param_ServiceID])\n if result:\n return result\n else:\n return list()\n\n def ServiceItemDetails(self, Param_OrderItemID):\n result = self.execute_procedure('ServiceItemDetails', [Param_OrderItemID])\n if result:\n return result\n else:\n return list()\n\n\nclass Address(DbConnector):\n def __init__(self):\n DbConnector.__init__(self)\n\n def AddressAdd(self, Param_Zip, Param_CityName, Param_CountryName, Param_StreetName, Param_BuildingNum, Param_ApartNum=None, Address_NewID=None):\n new_id = 0\n result = self.execute_procedure('AddressAdd', [Param_Zip, Param_CityName, Param_CountryName, Param_StreetName, Param_BuildingNum, Param_ApartNum, Address_NewID])\n if result:\n new_id = int(result[0][0])\n return new_id\n\n def AddressList(self):\n result = self.execute_procedure('AddressList')\n if result:\n return result\n else:\n return list()\n\n def AddressInfo(self, Param_AddressID):\n result = self.execute_procedure('AddressInfo', [Param_AddressID])\n if result:\n return result\n else:\n return list()\n\n def AddressUpdate(self, Param_AddressID, Param_Zip, Param_CityName, Param_CountryName, Param_StreetName, Param_BuildingNum, Param_ApartNum=None):\n rows_affected = 0\n result = self.execute_procedure('AddressUpdate', [Param_AddressID, Param_Zip, Param_CityName, Param_CountryName, Param_StreetName, Param_BuildingNum, Param_ApartNum])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\n def AddressDelete(self, Param_AddressID):\n rows_affected = 0\n result = self.execute_procedure('AddressDelete', [Param_AddressID])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\nclass Customer(DbConnector):\n def __init__(self):\n DbConnector.__init__(self)\n\n def CustomerAdd(self, Param_CusSSN, Param_AddressID, Param_LName, Param_FName, Param_Email, Param_Phone, Param_User, Param_Pass):\n new_id = 0\n result = self.execute_procedure('CustomerAdd', [Param_CusSSN, Param_AddressID, Param_LName, Param_FName, Param_Email, Param_Phone, Param_User, Param_Pass])\n if result:\n new_id = int(result[0][0])\n return new_id\n\n def CustomerList(self):\n result = self.execute_procedure('CustomerList')\n if result:\n return result\n else:\n return list()\n\n def CustomerInfo(self, Param_CusID):\n result = self.execute_procedure('CustomerInfo', [Param_CusID])\n if result:\n return result\n else:\n return list()\n\n def CustomerUpdate(self, Param_CusID, Param_CusSSN, Param_AddressID, Param_LName, Param_FName, Param_Email, Param_Phone, Param_User, Param_Pass):\n rows_affected = 0\n result = self.execute_procedure('CustomerUpdate', [Param_CusID, Param_CusSSN, Param_AddressID, Param_LName, Param_FName, Param_Email, Param_Phone, Param_User, Param_Pass])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\n def CustomerDelete(self, Param_CusID):\n rows_affected = 0\n result = self.execute_procedure('CustomerDelete', [Param_CusID])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\nclass Employee(DbConnector):\n def __init__(self):\n DbConnector.__init__(self)\n\n def EmployeeAdd(self, Param_EmpSSN, Param_AddressID, Param_Title, Param_LName, Param_FName, Param_Email, Param_Phone, Param_User, Param_Pass, Employee_NewID=None):\n new_id = 0\n result = self.execute_procedure('EmployeeAdd', [Param_EmpSSN, Param_AddressID, Param_Title, Param_LName, Param_FName, Param_Email, Param_Phone, Param_User, Param_Pass, Param_NewID])\n if result:\n new_id = int(result[0][0])\n return new_id\n\n def EmployeeList(self):\n result = self.execute_procedure('EmployeeList')\n if result:\n return result\n else:\n return list()\n\n def EmployeeInfo(self, Param_EmpID):\n result = self.execute_procedure('EmployeeInfo', [Param_EmpID])\n if result:\n return result\n else:\n return list()\n\n def EmployeeUpdate(self, Param_EmpID, Param_EmpSSN, Param_AddressID, Param_Title, Param_LName, Param_FName, Param_Email, Param_Phone, Param_User, Param_Pass):\n rows_affected = 0\n result = self.execute_procedure('EmployeeUpdate', [Param_EmpID, Param_EmpSSN, Param_AddressID, Param_Title, Param_LName, Param_FName, Param_Email, Param_Phone, Param_User, Param_Pass])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\n def EmployeeDelete(self, Param_EmpID):\n rows_affected = 0\n result = self.execute_procedure('EmployeeDelete', [Param_EmpID])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\nclass Hotel(DbConnector):\n def __init__(self):\n DbConnector.__init__(self)\n\n def HotelAdd(self, Param_AddressID, Param_HotelName):\n new_id = 0\n result = self.execute_procedure('HotelAdd', [Param_AddressID, Param_HotelName])\n if result:\n new_id = int(result[0][0])\n return new_id\n\n def HotelList(self):\n result = self.execute_procedure('HotelList')\n if result:\n return result\n else:\n return list()\n\n def HotelInfo(self, Param_HotelID):\n result = self.execute_procedure('HotelInfo', [Param_HotelID])\n if result:\n return result\n else:\n return list()\n\n def HotelUpdate(self, Param_HotelID, Param_AddressID, Param_HotelName):\n rows_affected = 0\n result = self.execute_procedure('HotelUpdate', [Param_HotelID, Param_AddressID, Param_HotelName])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\n def HotelDelete(self, Param_HotelID):\n rows_affected = 0\n result = self.execute_procedure('HotelDelete', [Param_HotelID])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\nclass Item(DbConnector):\n def __init__(self):\n DbConnector.__init__(self)\n\n def ItemAdd(self, Param_ItemName, Param_ItemDetails, Param_Cost):\n new_id = 0\n result = self.execute_procedure('ItemAdd', [Param_ItemName, Param_ItemDetails, Param_Cost])\n if result:\n new_id = int(result[0][0])\n return new_id\n\n def ItemList(self):\n result = self.execute_procedure('ItemList')\n if result:\n return result\n else:\n return list()\n\n def ItemInfo(self, Param_ItemID):\n result = self.execute_procedure('ItemInfo', [Param_ItemID])\n if result:\n return result\n else:\n return list()\n\n def ItemUpdate(self, Param_ItemID, Param_ItemName, Param_ItemDetails, Param_Cost):\n rows_affected = 0\n result = self.execute_procedure('ItemUpdate', [Param_ItemID, Param_ItemName, Param_ItemDetails, Param_Cost])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\n def ItemDelete(self, Param_ItemID):\n rows_affected = 0\n result = self.execute_procedure('ItemDelete', [Param_ItemID])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\nclass Reservation(DbConnector):\n def __init__(self):\n DbConnector.__init__(self)\n\n def ReservationAdd(self, Param_EmpID, Param_CusID, Param_OrderDate):\n new_id = 0\n result = self.execute_procedure('ReservationAdd', [Param_EmpID, Param_CusID, Param_OrderDate])\n if result:\n new_id = int(result[0][0])\n return new_id\n\n def ReservationList(self):\n result = self.execute_procedure('ReservationList')\n if result:\n return result\n else:\n return list()\n\n def ReservationInfo(self, Param_OrderID):\n result = self.execute_procedure('ReservationInfo', [Param_OrderID])\n if result:\n return result\n else:\n return list()\n\n def ReservationUpdate(self, Param_OrderID, Param_EmpID, Param_CusID, Param_OrderDate):\n rows_affected = 0\n result = self.execute_procedure('ReservationUpdate', [Param_OrderID, Param_EmpID, Param_CusID, Param_OrderDate])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\n def ReservationDelete(self, Param_OrderID):\n rows_affected = 0\n result = self.execute_procedure('ReservationDelete', [Param_OrderID])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\nclass Order_Has_Items(DbConnector):\n def __init__(self):\n DbConnector.__init__(self)\n\n def ServiceAddItem(self, Param_ServiceID, Param_ItemID, Param_Qty):\n new_id = 0\n result = self.execute_procedure('ServiceAddItem', [Param_ServiceID, Param_ItemID, Param_Qty])\n if result:\n new_id = int(result[0][0])\n return new_id\n\n def ServiceListItems(self):\n result = self.execute_procedure('ServiceListItems')\n if result:\n return result\n else:\n return list()\n\n def ServiceInfoItems(self, Param_OrderItemID):\n result = self.execute_procedure('ServiceInfoItems', [Param_OrderItemID])\n if result:\n return result\n else:\n return list()\n\n def ServiceUpdateItem(self, Param_OrderItemID, Param_ServiceID, Param_ItemID, Param_Qty):\n rows_affected = 0\n result = self.execute_procedure('ServiceUpdateItem', [Param_OrderItemID, Param_ServiceID, Param_ItemID, Param_Qty])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\n def ServiceDeleteItem(self, Param_OrderItemID):\n rows_affected = 0\n result = self.execute_procedure('ServiceDeleteItem', [Param_OrderItemID])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\nclass Order_Has_Rooms(DbConnector):\n def __init__(self):\n DbConnector.__init__(self)\n\n def ReservationRoomAdd(self, Param_OrderID, Param_RoomID, Param_CheckInDate, Param_CheckOutDate):\n new_id = 0\n result = self.execute_procedure('ReservationRoomAdd', [Param_OrderID, Param_RoomID, Param_CheckInDate, Param_CheckOutDate])\n if result:\n new_id = int(result[0][0])\n return new_id\n\n def ReservationRoomList(self):\n result = self.execute_procedure('ReservationRoomList')\n if result:\n return result\n else:\n return list()\n\n def ReservationRoomInfo(self, Param_OrderRoomID):\n result = self.execute_procedure('ReservationRoomInfo', [Param_OrderRoomID])\n if result:\n return result\n else:\n return list()\n\n def ReservationRoomUpdate(self, Param_OrderRoomID, Param_OrderID, Param_RoomID, Param_CheckInDate, Param_CheckOutDate):\n rows_affected = 0\n result = self.execute_procedure('ReservationRoomUpdate', [Param_OrderRoomID, Param_OrderID, Param_RoomID, Param_CheckInDate, Param_CheckOutDate])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\n def ReservationDelete(self, Param_OrderRoomID):\n rows_affected = 0\n result = self.execute_procedure('ReservationDelete', [Param_OrderRoomID])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\nclass Room(DbConnector):\n def __init__(self):\n DbConnector.__init__(self)\n\n def RoomAdd(self, Param_HotelID, Param_TypeID, Param_DoorNum):\n new_id = 0\n result = self.execute_procedure('RoomAdd', [Param_HotelID, Param_TypeID, Param_DoorNum])\n if result:\n new_id = int(result[0][0])\n return new_id\n\n def RoomList(self):\n result = self.execute_procedure('RoomList')\n if result:\n return result\n else:\n return list()\n\n def RoomInfo(self, Param_RoomID):\n result = self.execute_procedure('RoomInfo', [Param_RoomID])\n if result:\n return result\n else:\n return list()\n\n def RoomUpdate(self, Param_RoomID, Param_HotelID, Param_TypeID, Param_DoorNum):\n rows_affected = 0\n result = self.execute_procedure('RoomUpdate', [Param_RoomID, Param_HotelID, Param_TypeID, Param_DoorNum])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\n def RoomDelete(self, Param_RoomID):\n rows_affected = 0\n result = self.execute_procedure('RoomDelete', [Param_RoomID])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\nclass RoomType(DbConnector):\n def __init__(self):\n DbConnector.__init__(self)\n\n def RoomTypeAdd(self, Param_RoomType, Param_Desc, Param_Cost):\n new_id = 0\n result = self.execute_procedure('RoomTypeAdd', [Param_RoomType, Param_Desc, Param_Cost])\n if result:\n new_id = int(result[0][0])\n return new_id\n\n def RoomTypeList(self):\n result = self.execute_procedure('RoomTypeList')\n if result:\n return result\n else:\n return list()\n\n def RoomTypeInfo(self, Param_TypeID):\n result = self.execute_procedure('RoomTypeInfo', [Param_TypeID])\n if result:\n return result\n else:\n return list()\n\n def RoomTypeUpdate(self, Param_TypeID, Param_RoomType, Param_Desc, Param_Cost):\n rows_affected = 0\n result = self.execute_procedure('RoomTypeUpdate', [Param_TypeID, Param_RoomType, Param_Desc, Param_Cost])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\n def RoomTypeDelete(self, Param_TypeID):\n rows_affected = 0\n result = self.execute_procedure('RoomTypeDelete', [Param_TypeID])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\nclass ServiceOrder(DbConnector):\n def __init__(self):\n DbConnector.__init__(self)\n\n def ServiceOrderAdd(self, Param_RoomID, Param_OrderID, Param_EmpID, Param_DateTimeOfService):\n new_id = 0\n result = self.execute_procedure('ServiceOrderAdd', [Param_RoomID, Param_OrderID, Param_EmpID, Param_DateTimeOfService])\n if result:\n new_id = int(result[0][0])\n return new_id\n\n def ServiceOrderList(self):\n result = self.execute_procedure('ServiceOrderList')\n if result:\n return result\n else:\n return list()\n\n def ServiceOrderInfo(self, Param_ServiceID):\n result = self.execute_procedure('ServiceOrderInfo', [Param_ServiceID])\n if result:\n return result\n else:\n return list()\n\n def ServiceOrderUpdate(self, Param_ServiceID, Param_RoomID, Param_OrderID, Param_EmpID, Param_DateTimeOfService):\n rows_affected = 0\n result = self.execute_procedure('ServiceOrderUpdate', [Param_ServiceID, Param_RoomID, Param_OrderID, Param_EmpID, Param_DateTimeOfService])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\n def ServiceOrderDelete(self, Param_ServiceID):\n rows_affected = 0\n result = self.execute_procedure('ServiceOrderDelete', [Param_ServiceID])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\nclass Staff(DbConnector):\n def __init__(self):\n DbConnector.__init__(self)\n\n def StaffAdd(self, Param_EmpID, Param_HotelID):\n new_id = 0\n result = self.execute_procedure('StaffAdd', [Param_EmpID, Param_HotelID])\n if result:\n new_id = int(result[0][0])\n return new_id\n\n def StaffList(self):\n result = self.execute_procedure('StaffList')\n if result:\n return result\n else:\n return list()\n\n def StaffInfo(self, Param_StaffID):\n result = self.execute_procedure('StaffInfo', [Param_StaffID])\n if result:\n return result\n else:\n return list()\n\n def StaffUpdate(self, Param_StaffID, Param_EmpID, Param_HotelID):\n rows_affected = 0\n result = self.execute_procedure('StaffUpdate', [Param_StaffID, Param_EmpID, Param_HotelID])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n\n def StaffDelete(self, Param_StaffID):\n rows_affected = 0\n result = self.execute_procedure('StaffDelete', [Param_StaffID])\n if result:\n rows_affected = int(result[0][0])\n return rows_affected\n"
},
{
"alpha_fraction": 0.5956710577011108,
"alphanum_fraction": 0.6027676463127136,
"avg_line_length": 34.901275634765625,
"blob_id": "a636d3f3061523af9c3e899aae3286576195a0fa",
"content_id": "959ccdee7b90cc8265200d1cfdbc96cfbbace120",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11317,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 314,
"path": "/test.py",
"repo_name": "PeturSteinn/VEFTH2V-Lokaverkefni",
"src_encoding": "UTF-8",
"text": "from bottle import *\nfrom Database.HotelConnect import *\nfrom time import gmtime, strftime\n\nCustomerList = Customer()\ncom = CommonPS()\nres = Reservation()\norder_Room = Order_Has_Rooms()\n\n\norder_went_through = False\nerror = ''\n\n\n\n# Upsetning á hótelum\nresult = com.HotelAbout()\nhotels = list()\nfor i in result:\n item = dict()\n item['name'] = i[2]\n item['postcode'] = i[4]\n item['folder'] = i[5].lower()\n item['border'] = str(i[5].lower() + '.jpg')\n hotels.append(item)\n\n\ncookei = ['account', 'fname', 'lname', 'SSN', 'phone', 'mail', 'checkin', 'checkout', 'herbegi','Hotel']\n\n\ncookei = ['account', 'fname', 'lname', 'SSN', 'phone', 'mail', 'checkin', 'checkout', 'herbegi']\naccount = {'user':'nonni2000','passwd':'nonni','fname':'Nonni','lname':'Manni','SSN':'4567892345','simi':'5678903','mail':'[email protected]'}\n\n@route('/')\ndef index():\n global order_went_through\n check_order_went_through = order_went_through\n order_went_through = False\n for x in cookei:\n response.set_cookie('{}'.format(x), \"\", expires=0)\n return template('views/index', order=check_order_went_through)\n\n@route('/Hotel/<hotelid>')\ndef index_hotel(hotelid):\n temp_hotel = ''\n for x in cookei:\n response.set_cookie('{}'.format(x), \"\", expires=0)\n response.set_cookie('account', \"\", expires=0)\n for x in hotels:\n print(x)\n print('{}---{}'.format(x['folder'],hotelid))\n if x['folder']==hotelid:\n temp_hotel = x\n print('HOTELIÐ',temp_hotel)\n return template('views/index-hotel', hotel=temp_hotel)\n\n@route('/<hotelid>')\ndef order(hotelid):\n if hotelid == 'reykjavik' or hotelid == 'selfoss' or hotelid == 'akureyri':\n checkin = request.query.checkin\n checkout = request.query.ckeckout\n herbegi = request.query.Herbergi\n response.set_cookie('checkin', checkin, secret='my_secret_code')\n response.set_cookie('checkout', checkout, secret='my_secret_code')\n response.set_cookie('herbegi', herbegi, secret='my_secret_code')\n response.set_cookie('Hotel', hotelid, secret='my_secret_code')\n return redirect('/Hotel/order')\n else:\n return 'error'\n\n\n@route('/Hotel/order')\ndef orderroom():\n global error\n user = request.get_cookie('account', secret='my_secret_code')\n villa = error\n error=''\n if (user):\n fname = request.get_cookie('fname', secret='my_secret_code')\n lname = request.get_cookie('lname', secret='my_secret_code')\n ssn = request.get_cookie('SSN', secret='my_secret_code')\n phone = request.get_cookie('phone', secret='my_secret_code')\n mail = request.get_cookie('mail', secret='my_secret_code')\n user = {'name':user,'fname':fname,'lname':lname,'ssn':ssn,'phone':phone,'mail':mail}\n ifuser = True\n else:\n ifuser =False\n\n checkin = request.get_cookie('checkin', secret='my_secret_code')\n checkout = request.get_cookie('checkout', secret='my_secret_code')\n herbergi = request.get_cookie('herbegi', secret='my_secret_code')\n hotelid = request.get_cookie('Hotel', secret='my_secret_code')\n\n herbergi_uppl = {'checkin':checkin,'checkout':checkout,'herbergi':herbergi,'Hotel':hotelid}\n print(herbergi_uppl)\n\n return template('order', villa= villa,user=user, herbergi_uppl=herbergi_uppl,ifuser=ifuser)\n\n@route('/login', method='post')\ndef login():\n CustomerList = Customer() # NYTT\n customerlist = CustomerList.CustomerList()\n username = request.forms.get('user')\n password = request.forms.get('password')\n for x in customerlist:\n if username == x[7] and password == x[8]:\n response.set_cookie('account', x[7], secret='my_secret_code')\n response.set_cookie('fname', x[4], secret='my_secret_code')\n response.set_cookie('lname',x[3], secret='my_secret_code')\n response.set_cookie('SSN', x[1], secret='my_secret_code')\n response.set_cookie('phone', x[6], secret='my_secret_code')\n response.set_cookie('mail', x[5], secret='my_secret_code')\n return redirect('/Hotel/order')\n global error\n error = 'Vitlaust lykilorð eða password'\n return redirect('/Hotel/order')\n\n@route('/checkorder', method='post')\ndef klaraorder():\n CustomerList = Customer() # NYTT\n com = CommonPS() # NYTT\n res = Reservation() # NYTT\n order_Room = Order_Has_Rooms() # NYTT\n ssn = request.forms.get('ssn')\n hotel = request.forms.get('hotel')\n Guset = request.forms.get('Guset')\n Suites = request.forms.get('Suites')\n Executive = request.forms.get('Executive')\n checkin = request.forms.get('checkin')\n checkout = request.forms.get('checkout')\n options = [ssn, hotel, Guset, Suites, Executive, checkin, checkout]\n Guset = int(Guset)\n Suites = int(Suites)\n Executive = int(Executive)\n\n\n for x in options:\n if x == \"None\":\n aframm = False\n break\n else:\n aframm = True\n\n if aframm:\n print(checkin)\n global error\n # New_Start, New_End, Param_HotelID, Param_TypeID):\n all_cust =CustomerList.CustomerList()\n for x in all_cust:#hérna er fundið user idið\n if ssn == x[1]:\n user_ID = x[0]\n else:\n pass\n # ef nondani er ekki til\n\n # búa til pöntun\n datetime = (strftime(\"%Y-%m-%d %H:%M:%S\", gmtime()))# fá dagsetinguna þegar það var pantað\n res_id = res.ReservationAdd(1,user_ID, datetime)# 1= Id hjá strafsmanni sem er vefsíðan\n lausherbergi = (com.CheckAvailability(checkin, checkout, hotel, 3))\n if len(lausherbergi) < Guset:\n error = \"Það eru ekki nó og mörg laus Guest herbergi\"\n redirect('/Hotel/order')\n\n lausherbergi = (com.CheckAvailability(checkin, checkout, hotel, 2))\n if len(lausherbergi) < Suites:\n error = \"Það eru ekki nó og mörg laus Suites herbergi\"\n redirect('/Hotel/order')\n\n lausherbergi = (com.CheckAvailability(checkin, checkout, hotel, 1))\n if len(lausherbergi) < Executive:\n error = \"Það eru ekki nó og mörg laus Executive herbergi\"\n redirect('/Hotel/order')\n\n\n if Guset > 0:\n #(self, Param_OrderID, Param_RoomID, Param_CheckInDate, Param_CheckOutDate):\n for x in range(Guset):\n lausherbergi = (com.CheckAvailability(checkin, checkout, hotel, 3))\n order_Room.ReservationRoomAdd(res_id,lausherbergi[x][0], checkin, checkout) # lausherbergi[x][0] er id af lauasa herberginu.\n else:\n pass\n if Suites > 0:\n for x in range(Suites):\n lausherbergi = (com.CheckAvailability(checkin, checkout, hotel, 2))\n order_Room.ReservationRoomAdd(res_id,lausherbergi[x][0], checkin, checkout)# lausherbergi[x][0] er id af lauasa herberginu.\n else:\n pass\n if Executive > 0:\n for x in range(Executive):\n lausherbergi = (com.CheckAvailability(checkin, checkout, hotel, 1))\n order_Room.ReservationRoomAdd(res_id,lausherbergi[x][0], checkin, checkout) # lausherbergi[x][0] er id af lauasa herberginu.\n else:\n pass\n\n else:\n pass # senda til backa með villu\n for x in cookei:\n response.set_cookie('{}'.format(x), \"\", expires=0)\n global order_went_through\n order_went_through = True\n return redirect('/')\n\n@route('/bokun' , method='post')\ndef bokun():\n CustomerList = Customer() # NYTT\n customerlist = CustomerList.CustomerList()\n username = request.forms.get('user')\n password = request.forms.get('password')\n for x in customerlist:\n if username == x[7] and password == x[8]:\n response.set_cookie('account', x[7], secret='my_secret_code')\n response.set_cookie('accountID', x[0], secret='my_secret_code')\n return redirect('/bokun')\n else:\n global error\n error = 'vilaust notandanafn eða lykilorð'\n return redirect('/bokunn')\n\n@route('/bokunn')\ndef bokunlogin():\n global error\n villa = error\n error = ''\n orders = []\n\n return template('login', villa=villa)\n\n\n@route('/bokun')\ndef bokun():\n com = CommonPS() # NYTT\n accountID = request.get_cookie('accountID', secret='my_secret_code')\n account = request.get_cookie('account', secret='my_secret_code')\n response.set_cookie('account', '', expires=0)\n response.set_cookie('accountID', '', expires=0)\n global error\n villa = error\n error = ''\n orders = []\n\n teljari = 0\n\n if (account):\n kust_orders = com.CustomerOrders(accountID)\n print('vff',kust_orders)\n for y in kust_orders:\n order = {}\n flokkur = com.TotalRoomBill(y[0]) # mundi skýra order en það er tekið\n orderprice = 0\n order['hotel'] = flokkur[0][7]\n order['herbergi'] = []\n for x in flokkur:\n herbergi = {}\n order['checkin'] = x[0]\n order['checkout'] = x[1]\n herbergi['type'] = x[2]\n herbergi['nuber'] = x[3]\n herbergi['price'] = '{:,}-kr'.format(x[4])\n herbergi['days'] = x[5]\n herbergi['totalprice'] = '{:,}-kr'.format(x[6])\n print(herbergi)\n order['herbergi'].append(herbergi)\n orderprice += int(x[6])\n order['orderprice'] = '{:,}-kr'.format(orderprice)\n print(order)\n orders.append(order)\n\n\n return template('tabel', villa=villa, user= account, orders=orders)\n else:\n error='hefur ekki réttindi að fara á þessa síðu'\n return redirect('bokunn')\n\n\n@route('/signup' , method='post')\ndef signup():\n CustomerList = Customer() # NYTT\n com = CommonPS() # NYTT\n customerlist = CustomerList.CustomerList()\n username = request.forms.get('user')\n password = request.forms.get('password')\n for x in customerlist:\n if username == x[7]:\n global error\n error = 'Notandanafn tekið'\n return redirect('/Hotel/order')\n user = request.forms.get('user')\n password = request.forms.get('password')\n fname = request.forms.get('fname')\n lname = request.forms.get('lname')\n ssn = request.forms.get('ssn')\n mail = request.forms.get('mail')\n phone = request.forms.get('phone')\n CountryName = request.forms.get('CountryName')\n CityName = request.forms.get('CityName')\n StreetName = request.forms.get('StreetName')\n Zip = request.forms.get('Zip')\n BuildingNum = request.forms.get('BuildingNum')\n ApartNum = request.forms.get('ApartNum')\n if ApartNum == None:\n com.RegisterCustomer(Zip,CityName,CountryName,StreetName,BuildingNum,ssn,lname,fname,mail,phone,user,password,ApartNum)\n else:\n com.RegisterCustomer(Zip, CityName, CountryName, StreetName, BuildingNum, ssn, lname, fname, mail, phone,\n user, password)\n return redirect('/Hotel/order')\n\n\n\n@route('/static/<filename:path>')\ndef server_static(filename):\n return static_file(filename, root='./resources')\n\n#run(host=\"0.0.0.0\", port=os.environ.get('PORT'))\nrun(reloader=True, debug=True)\n"
},
{
"alpha_fraction": 0.5643564462661743,
"alphanum_fraction": 0.7623762488365173,
"avg_line_length": 19.200000762939453,
"blob_id": "1f6d53c0930a34edba046167ac741bbea62efe72",
"content_id": "521c79871e3c9487cd0dcf87d5699be65dd2574d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 101,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 5,
"path": "/Database/config.ini",
"repo_name": "PeturSteinn/VEFTH2V-Lokaverkefni",
"src_encoding": "UTF-8",
"text": "[mysql]\nhost = tsuts.tskoli.is\ndatabase = 0408982209_hoteldb\nuser = 0408982209\npassword = mypassword\n"
},
{
"alpha_fraction": 0.7275149822235107,
"alphanum_fraction": 0.7421718835830688,
"avg_line_length": 35.56097412109375,
"blob_id": "a9ec3cac5b517fbc7e8a2d9b74bf4e3a0cf5f2a2",
"content_id": "4c5a7aab2a3f0c2c323b9298de7ec9bc26ec0255",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1625,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 41,
"path": "/README.md",
"repo_name": "PeturSteinn/VEFTH2V-Lokaverkefni",
"src_encoding": "UTF-8",
"text": "\n# [Síðan](https://vefth2vf-verkefni-hraunhotel.herokuapp.com/)\n### Síðan er gerð í fartölvu og lýtur ekki jafn vel út á stærri eða minniskjáum!!.\nÞú getur notað þennan account hérna fyrir neðann.\nAccount= Larus password= Larus2000\n\n# Hraun Hótel\n\nHöfundar: *Pétur Steinn Guðmundsson, Helgi Tuan Helgason, Róbert Ingi Hálfdanarson.*\n\nHraun Hótel gildir sem lokaverkefni í eftirfarandi áföngum: **_FORR2HF05CU(2)_** | **_VEFÞ2VF05CU(2)_** | **_GAGN2HS05BU(1)_**\n\n## Yfirsýn\n\n### Lýsing\nHraun Hótel er hótel-keðja á Íslandi. Keðjan er með þrjár staðsetningar\ná Íslandi, má finna Hraun Hótel á eftirfarandi stöðum: **Reykjavík**, **Akureyri** og **Selfoss**.\n\nHraun Hótel hefur upp á að bjóða þrennskonar herbergistegundir: **Executive**, **Suite**, **Guest**.\n\nHægt er að panta þjónustu fyrir hvert herbergi, eins og mat ofl. (Eins og stendur er aðeins hægt að panta matvæli *11/5/18*)\n\n### Virkni\n\nViðskiptavinir getað pantað á netinu eða pantað á staðnum.\nViðskiptavinir getað pantað fleiri en eitt herbergi fyrir hverja pöntun.\nViðskiptavinir getað pantað þjónustu fyrir hvert herbergi.\n\nStarfsmaður ber ábyrgð á pöntun/þjónustu.\nStarfsfólki er skipt í þrjá hluta: **Stjórnendur**, **móttökuritarar**, **þjónustufólk**.\n\nStjórnandi er með fullt vald.\nMóttökuritari sér um bókanir.\nÞjónustufólk sér um að taka við þjónustupöntunum.\n\n## VEFÞ2VF05CU(2)\nHöfundar: *Pétur Steinn Guðmundsson, Helgi Tuan Helgason, Róbert Ingi Hálfdanarson.*\n\n### Lýsing\nVefsíða Hraun Hótels er fyrst og fremst hönnuð fyrir viðskiptavini bóka herbergi.\nViðskiptavinur verður að eiga reikning til að panta herbergi.\nHægt er að nýskrá sig á vefsíðunni.\n\n"
},
{
"alpha_fraction": 0.8717948794364929,
"alphanum_fraction": 0.8717948794364929,
"avg_line_length": 12,
"blob_id": "0eecc257f42d9f3d0ca5e0f809d839844b9bc10b",
"content_id": "d213653420a34c3a89caab6ea7dc94e42b44024c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 39,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 3,
"path": "/requirements.txt",
"repo_name": "PeturSteinn/VEFTH2V-Lokaverkefni",
"src_encoding": "UTF-8",
"text": "bottle\nrequests\nmysql-connector-python\n"
},
{
"alpha_fraction": 0.6644178628921509,
"alphanum_fraction": 0.6713764667510986,
"avg_line_length": 19.14358901977539,
"blob_id": "cf6e877913757a901b018e594adf3ed80af330e1",
"content_id": "d1fdeb19a4a7de83e80ed3c6eebe516df9d68356",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 23568,
"license_type": "no_license",
"max_line_length": 328,
"num_lines": 1170,
"path": "/Database/HotelDB_Stored_Procedures.sql",
"repo_name": "PeturSteinn/VEFTH2V-Lokaverkefni",
"src_encoding": "UTF-8",
"text": "USE 0408982209_test;\n\n-- Debug\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `log_msg` //\nCREATE PROCEDURE `log_msg`(\n`msg` VARCHAR(255)\n)\nBEGIN\n INSERT INTO `logtable`SELECT 0, `msg`;\nEND //\nDELIMITER ;\n\n\n-- Custom procedures\n\n-- Hire an employee\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `EmployeeHire_Bundle` //\nCREATE PROCEDURE `EmployeeHire_Bundle` (\n `Param_Zip` varchar(20),\n `Param_CityName` varchar(20),\n `Param_CountryName` varchar(20),\n `Param_StreetName` varchar(20),\n `Param_BuildingNum` varchar(5),\n `Param_ApartNum` varchar(5),\n `Param_HotelID` int,\n `Param_EmpSSN` varchar(20),\n `Param_Title` varchar(20),\n `Param_LName` varchar(20),\n `Param_FName` varchar(20),\n `Param_Email` varchar(60),\n `Param_Phone` varchar(15),\n `Param_User` varchar(20),\n `Param_Pass` varchar(20)\n)\nBEGIN\n DECLARE Address_NewID int;\n DECLARE Employee_NewID int;\n CALL `AddressAdd` (\n `Param_Zip`,\n `Param_CityName`,\n `Param_CountryName`,\n `Param_StreetName`,\n `Param_BuildingNum`,\n `Param_ApartNum`,\n @Address_NewID\n );\n\n SET Address_NewID := @Address_NewID;\n CALL `EmployeeAdd` (\n `Param_EmpSSN`,\n Address_NewID,\n `Param_Title`,\n `Param_LName`,\n `Param_FName`,\n `Param_Email`,\n `Param_Phone`,\n `Param_User`,\n `Param_Pass`,\n @Employee_NewID\n );\n\n SET Employee_NewID := @Employee_NewID;\n CALL `StaffAdd` (\n Employee_NewID,\n `Param_HotelID`\n );\n SELECT Employee_NewID;\nEND //\nDELIMITER ;\n\n-- Register a customer\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `CustomerRegister_Bundle` //\nCREATE PROCEDURE `CustomerRegister_Bundle` (\n `Param_Zip` varchar(20),\n `Param_CityName` varchar(20),\n `Param_CountryName` varchar(20),\n `Param_StreetName` varchar(20),\n `Param_BuildingNum` varchar(5),\n `Param_ApartNum` varchar(5),\n `Param_CusSSN` varchar(20),\n `Param_LName` varchar(20),\n `Param_FName` varchar(20),\n `Param_Email` varchar(60),\n `Param_Phone` varchar(15),\n `Param_User` varchar(20),\n `Param_Pass` varchar(20)\n)\nBEGIN\n DECLARE Address_NewID int;\n CALL `AddressAdd` (\n `Param_Zip`,\n `Param_CityName`,\n `Param_CountryName`,\n `Param_StreetName`,\n `Param_BuildingNum`,\n `Param_ApartNum`,\n @Address_NewID\n );\n\n SET Address_NewID := @Address_NewID;\n\n CALL `CustomerAdd` (\n `Param_CusSSN`,\n Address_NewID,\n `Param_LName`,\n `Param_FName`,\n `Param_Email`,\n `Param_Phone`,\n `Param_User`,\n `Param_Pass`\n );\n SELECT LAST_INSERT_ID();\nEND //\nDELIMITER ;\n\n\n-- List availalbe rooms by type and hotel\n\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `CheckAvailability` //\nCREATE PROCEDURE `CheckAvailability` (\n `New_Start` datetime,\n `New_End` datetime,\n `Param_HotelID` int,\n `Param_TypeID` int\n)\nBEGIN\n\n\tSELECT `Room`.RoomID, `Room`.DoorNum FROM `Order_Has_Rooms` RIGHT JOIN `Room` ON `Room`.RoomID = `Order_Has_Rooms`.RoomID\n\tWHERE `Room`.HotelID = `Param_HotelID`\n\tAND `Room`.TypeID = `Param_TypeID`\n\tAND `Room`.RoomID NOT IN\n (\n SELECT `Room`.RoomID FROM `Order_Has_Rooms` RIGHT JOIN `Room` ON `Room`.RoomID = `Order_Has_Rooms`.RoomID\n\tWHERE `New_Start` < `Order_Has_Rooms`.CheckOutDate\n\tAND `New_End` > `Order_Has_Rooms`.CheckInDate\n\tAND `Room`.HotelID = `Param_HotelID`\n\tAND `Room`.TypeID = `Param_TypeID`\n );\n\n\n\nEND //\nDELIMITER ;\n\n\n-- Get room bill not including service.\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `TotalRoomBill` //\nCREATE PROCEDURE `TotalRoomBill` (\n `Param_OrderID` int\n)\nBEGIN\n SELECT `Order_Has_Rooms`.CheckInDate, `Order_Has_Rooms`.CheckOutDate, `RoomType`.RoomType, `RoomType`.Cost, DATEDIFF(`Order_Has_Rooms`.CheckOutDate, `Order_Has_Rooms`.CheckInDate) AS DaysStayed, (`RoomType`.Cost * DATEDIFF(`Order_Has_Rooms`.CheckOutDate, `Order_Has_Rooms`.CheckInDate)) AS TotalRoomCost FROM `Order_Has_Rooms`\n INNER JOIN `Room` ON `Order_Has_Rooms`.RoomID = `Room`.RoomID\n INNER JOIN `RoomType` ON `Room`.TypeID = `RoomType`.TypeID\n WHERE `Order_Has_Rooms`.OrderID = `Param_OrderID`;\nEND //\nDELIMITER ;\n\n\n-- Get total service bill\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `TotalServiceBill` //\nCREATE PROCEDURE `TotalServiceBill` (\n\t`Param_OrderID` int\n)\nBEGIN\n\tSELECT `Room`.DoorNum, `Service_Order`.DateTimeOfService, `Item`.ItemName, `Item`.Cost, `Order_Has_Items`.Qty, (`Item`.Cost * `Order_Has_Items`.Qty) AS TotalItemCost FROM `Service_Order`\n INNER JOIN `Order_Has_Items` ON `Service_Order`.ServiceID = `Order_Has_Items`.ServiceID\n INNER JOIN `Item` ON `Order_Has_Items`.ItemID = `Item`.ItemID\n INNER JOIN `Room` ON `Service_Order`.RoomID = `Room`.RoomID\n WHERE `Service_Order`.OrderID = `Param_OrderID`;\nEND //\nDELIMITER ;\n\n\n-- Make a reservation\n\n/* CALL `ReservationAdd`();*/\n\n-- Add room to reservation\n\n/* CALL `ReservationRoomAdd`();*/\n\n-- Create a service request\n\n/*CALL `Service_OrderAdd`();*/\n\n-- Add item to cart (services)\n\n/*CALL `ServiceAddItem`(); */\n\n-- List hotels and their address\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `HotelAbout` //\nCREATE PROCEDURE `HotelAbout` ()\nBEGIN\n\tSELECT * FROM `Hotel`\n INNER JOIN `Address` ON `Hotel`.AddressID = `Address`.AddressID;\nEND //\nDELIMITER ;\n\n\n\n-- Standard procedures\n\n-- Employee\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `EmployeeAdd` //\nCREATE PROCEDURE `EmployeeAdd` (\n `Param_EmpSSN` varchar(20),\n `Param_AddressID` int,\n `Param_Title` varchar(20),\n `Param_LName` varchar(20),\n `Param_FName` varchar(20),\n `Param_Email` varchar(60),\n `Param_Phone` varchar(15),\n `Param_User` varchar(20),\n `Param_Pass` varchar(20),\n OUT `Employee_NewID` int\n)\nBEGIN\n INSERT INTO `Employee` (\n `EmpSSN`,\n `AddressID`,\n `Title`,\n `LName`,\n `FName`,\n `Email`,\n `Phone`,\n `User`,\n `Pass`\n )\n VALUES (\n `Param_EmpSSN`,\n `Param_AddressID`,\n `Param_Title`,\n `Param_LName`,\n `Param_FName`,\n `Param_Email`,\n `Param_Phone`,\n `Param_User`,\n `Param_Pass`\n );\n SELECT LAST_INSERT_ID() INTO `Employee_NewID`;\n\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `EmployeeList` //\nCREATE PROCEDURE `EmployeeList` ()\nBEGIN\n SELECT * FROM `Employee`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `EmployeeInfo` //\nCREATE PROCEDURE `EmployeeInfo` (\n `Param_EmpID` int\n)\nBEGIN\n SELECT * FROM `Employee`\n WHERE `EmpID` = `Param_EmpID`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `EmployeeUpdate` //\nCREATE PROCEDURE `EmployeeUpdate` (\n `Param_EmpID` int,\n `Param_EmpSSN` varchar(20),\n `Param_AddressID` int,\n `Param_Title` varchar(20),\n `Param_LName` varchar(20),\n `Param_FName` varchar(20),\n `Param_Email` varchar(60),\n `Param_Phone` varchar(15),\n `Param_User` varchar(20),\n `Param_Pass` varchar(20)\n)\nBEGIN\n UPDATE `Employee`\n SET\n `EmpSSN` = `Param_EmpSSN`,\n `AddressID` = `Param_AddressID`,\n `Title` = `Param_Title`,\n `LName` = `Param_LName`,\n `FName` = `Param_FName`,\n `Email` = `Param_Email`,\n `Phone` = `Param_Phone`,\n `User` = `Param_User`,\n `Pass` = `Param_Pass`\n WHERE `EmpID` = `Param_EmpID`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `EmployeeDelete` //\nCREATE PROCEDURE `EmployeeDelete` (\n `Param_EmpID` int\n)\nBEGIN\n DELETE FROM `Employee`\n WHERE `EmpID` = `Param_EmpID`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\n-- Address\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `AddressAdd` //\nCREATE PROCEDURE `AddressAdd` (\n `Param_Zip` varchar(20),\n `Param_CityName` varchar(20),\n `Param_CountryName` varchar(20),\n `Param_StreetName` varchar(20),\n `Param_BuildingNum` varchar(5),\n `Param_ApartNum` varchar(5),\n OUT `Address_NewID` int\n)\nBEGIN\n INSERT INTO `Address` (\n `Zip`,\n `CityName`,\n `CountryName`,\n `StreetName`,\n `BuildingNum`,\n `ApartNum`\n )\n VALUES (\n `Param_Zip`,\n `Param_CityName`,\n `Param_CountryName`,\n `Param_StreetName`,\n `Param_BuildingNum`,\n `Param_ApartNum`\n );\n SELECT LAST_INSERT_ID() INTO `Address_NewID`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `AddressList` //\nCREATE PROCEDURE `AddressList` ()\nBEGIN\n SELECT * FROM `Address`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `AddressInfo` //\nCREATE PROCEDURE `AddressInfo` (\n `Param_AddressID` int\n)\nBEGIN\n SELECT * FROM `Address` WHERE `AddressID` = `Param_AddressID`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `AddressUpdate` //\nCREATE PROCEDURE `AddressUpdate` (\n `Param_AddressID` int,\n `Param_Zip` varchar(20),\n `Param_CityName` varchar(20),\n `Param_CountryName` varchar(20),\n `Param_StreetName` varchar(20),\n `Param_BuildingNum` varchar(5),\n `Param_ApartNum` varchar(5)\n)\nBEGIN\n UPDATE `Address`\n SET\n `Zip` = `Param_Zip`,\n `CityName` = `Param_CityName`,\n `CountryName` = `Param_CountryName`,\n `StreetName` = `Param_StreetName`,\n `BuildingNum` = `Param_BuildingNum`,\n `ApartNum` = `Param_ApartNum`\n WHERE `AddressID` = `Param_AddressID`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `AddressDelete` //\nCREATE PROCEDURE `AddressDelete` (\n `Param_AddressID` int\n)\nBEGIN\n DELETE FROM `Address`\n WHERE `AddressID` = `Param_AddressID`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\n-- Hotel\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `HotelAdd` //\nCREATE PROCEDURE `HotelAdd` (\n `Param_AddressID` int,\n `Param_HotelName` varchar(40),\n `Param_TotalRooms` int\n)\nBEGIN\n INSERT INTO `Hotel` (\n `AddressID`,\n `HotelName`,\n `TotalRooms`\n )\n VALUES (\n `AddressID` = `Param_AddressID`,\n `HotelName` = `Param_HotelName`,\n `TotalRooms` = `Param_TotalRooms`\n );\n SELECT LAST_INSERT_ID;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `HotelList` //\nCREATE PROCEDURE `HotelList` ()\nBEGIN\n SELECT * FROM `Hotel`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `HotelInfo` //\nCREATE PROCEDURE `HotelInfo` (\n `Param_HotelID` int\n)\nBEGIN\n SELECT * FROM `Hotel` WHERE `HotelID` = `Param_HotelID`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `HotelUpdate` //\nCREATE PROCEDURE `HotelUpdate` (\n `Param_HotelID` int,\n `Param_AddressID` int,\n `Param_HotelName` varchar(40),\n `Param_TotalRooms` int\n)\nBEGIN\n UPDATE `Hotel`\n SET\n `AddressID` = `Param_AddressID`,\n `HotelName` = `Param_HotelName`,\n `TotalRooms` = `Param_TotalRooms`\n WHERE `HotelID` = `Param_HotelID`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `HotelDelete` //\nCREATE PROCEDURE `HotelDelete` (\n `Param_HotelID` int\n)\nBEGIN\n DELETE FROM `Hotel`\n WHERE `HotelID` = `Param_HotelID`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\n-- Room\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `RoomAdd` //\nCREATE PROCEDURE `RoomAdd` (\n `Param_HotelID` int,\n `Param_TypeID` int,\n `Param_DoorNum` int\n)\nBEGIN\n INSERT INTO `Room` (\n `HotelID`,\n `TypeID`,\n `DoorNum`\n )\n VALUES (\n `Param_HotelID`,\n `Param_TypeID`,\n `Param_DoorNum`\n );\n SELECT LAST_INSERT_ID();\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `RoomList` //\nCREATE PROCEDURE `RoomList` ()\nBEGIN\n SELECT * FROM `Room`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `RoomInfo` //\nCREATE PROCEDURE `RoomInfo` (\n `Param_RoomID` int\n)\nBEGIN\n SELECT * FROM `Room` WHERE `RoomID` = `Param_RoomID`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `RoomUpdate` //\nCREATE PROCEDURE `RoomUpdate` (\n `Param_RoomID` int,\n `Param_HotelID` int,\n `Param_TypeID` int,\n `Param_DoorNum` int\n)\nBEGIN\n UPDATE `Room`\n SET\n `HotelID` = `Param_HotelID`,\n `TypeID` = `Param_TypeID`,\n `DoorNUM` = `Param_DoorNum`\n WHERE `RoomID` = `Param_RoomID`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `RoomDelete` //\nCREATE PROCEDURE `RoomDelete` (\n `Param_RoomID` int\n)\nBEGIN\n DELETE FROM `Room`\n WHERE `RoomID` = `Param_RoomID`;\nEND //\nDELIMITER ;\n\n-- Customer\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `CustomerAdd` //\nCREATE PROCEDURE `CustomerAdd` (\n `Param_CusSSN` varchar(20),\n `Param_AddressID` int,\n `Param_LName` varchar(20),\n `Param_FName` varchar(20),\n `Param_Email` varchar(60),\n `Param_Phone` varchar(15),\n `Param_User` varchar(20),\n `Param_Pass` varchar(20)\n)\nBEGIN\n INSERT INTO `Customer` (\n `CusSSN`,\n `AddressID`,\n `LName`,\n `FName`,\n `Email`,\n `Phone`,\n `User`,\n `Pass`\n )\n VALUES (\n `Param_CusSSN`,\n `Param_AddressID`,\n `Param_LName`,\n `Param_FName`,\n `Param_Email`,\n `Param_Phone`,\n `Param_User`,\n `Param_Pass`\n );\n SELECT LAST_INSERT_ID();\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `CustomerList` //\nCREATE PROCEDURE `CustomerList` ()\nBEGIN\n SELECT * FROM `Customer`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `CustomerInfo` //\nCREATE PROCEDURE `CustomerInfo` (\n `Param_CusID` int\n)\nBEGIN\n SELECT * FROM `Customer` WHERE `CusID` = `Param_CusID`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `CustomerUpdate` //\nCREATE PROCEDURE `CustomerUpdate` (\n `Param_CusID` int,\n `Param_CusSSN` varchar(20),\n `Param_AddressID` int,\n `Param_LName` varchar(20),\n `Param_FName` varchar(20),\n `Param_Email` varchar(60),\n `Param_Phone` varchar(15)\n)\nBEGIN\n UPDATE `Customer`\n SET\n `CusSSN` = `Param_CusSSN`,\n `AddressID` = `Param_AddressID`,\n `LName` = `Param_LName`,\n `FName` = `Param_FName`,\n `Email` = `Param_Email`,\n `Phone` = `Param_Phone`\n WHERE `CusID` = `Param_CusID`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `CustomerDelete` //\nCREATE PROCEDURE `CustomerDelete` (\n `Param_CusID` int\n)\nBEGIN\n DELETE FROM `Customer`\n WHERE `CusID` = `Param_CusID`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\n-- Room type\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `RoomTypeAdd` //\nCREATE PROCEDURE `RoomTypeAdd` (\n `Param_RoomType` varchar(20),\n `Param_Desc` varchar(200),\n `Param_Cost` int\n)\nBEGIN\n INSERT INTO `RoomType` (\n `RoomType`,\n `Desc`,\n `Cost`\n )\n VALUES (\n `Param_RoomType`,\n `Param_Desc`,\n `Param_Cost`\n );\n SELECT LAST_INSERT_ID();\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `RoomTypeList` //\nCREATE PROCEDURE `RoomTypeList` ()\nBEGIN\n SELECT * FROM `RoomType`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `RoomTypeInfo` //\nCREATE PROCEDURE `RoomTypeInfo` (\n `Param_TypeID` int\n)\nBEGIN\n SELECT * FROM `RoomType` WHERE `TypeID` = `Param_TypeID`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `RoomTypeUpdate` //\nCREATE PROCEDURE `RoomTypeUpdate` (\n `Param_TypeID` int,\n `Param_RoomType` varchar(20),\n `Param_Desc` varchar(200),\n `Param_Cost` int\n)\nBEGIN\n UPDATE `RoomType`\n SET\n `RoomType` = `Param_RoomType`,\n `Desc` = `Param_Desc`,\n `Cost` = `Param_Cost`\n WHERE `TypeID` = `Param_TypeID`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `RoomTypeDelete` //\nCREATE PROCEDURE `RoomTypeDelete` (\n `Param_TypeID` int\n)\nBEGIN\n DELETE FROM `RoomType`\n WHERE `TypeID` = `Param_TypeID`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\n-- Item\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `ItemAdd` //\nCREATE PROCEDURE `ItemAdd` (\n `Param_ItemName` varchar(70),\n `Param_ItemDetails` varchar(200),\n `Param_Cost` int\n)\nBEGIN\n INSERT INTO `Item` (\n `ItemName`,\n `ItemDetails`,\n `Cost`\n )\n VALUES (\n `Param_ItemName`,\n `Param_ItemDetails`,\n `Param_Cost`\n );\n SELECT LAST_INSERT_ID();\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `ItemList` //\nCREATE PROCEDURE `ItemList` ()\nBEGIN\n SELECT * FROM `Item`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `ItemInfo` //\nCREATE PROCEDURE `ItemInfo` (\n `Param_ItemID` int\n)\nBEGIN\n SELECT * FROM `Item` WHERE `ItemID` = `Param_ItemID`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `ItemUpdate` //\nCREATE PROCEDURE `ItemUpdate` (\n `Param_ItemName` varchar(70),\n `Param_ItemDetails` varchar(200),\n `Param_Cost` int\n)\nBEGIN\n UPDATE `Item`\n SET\n `ItemName` = `Param_ItemName`,\n `ItemDetails` = `Param_ItemDetails`,\n `Cost` = `Param_Cost`\n WHERE `ItemID` = `Param_ItemID`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `ItemDelete` //\nCREATE PROCEDURE `ItemDelete` (\n `Param_ItemID` int\n)\nBEGIN\n DELETE FROM `Item`\n WHERE `ItemID` = `Param_ItemID`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\n-- Staff\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `StaffAdd` //\nCREATE PROCEDURE `StaffAdd` (\n `Param_EmpID` int,\n `Param_HotelID` int\n)\nBEGIN\n INSERT INTO `Staff` (\n `EmpID`,\n `HotelID`\n )\n VALUES (\n `Param_EmpID`,\n `Param_HotelID`\n );\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `StaffList` //\nCREATE PROCEDURE `StaffList` ()\nBEGIN\n SELECT * FROM `Staff`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `StaffInfo` //\nCREATE PROCEDURE `StaffInfo` (\n `Param_HotelID` int\n)\nBEGIN\n SELECT * FROM `Staff` WHERE `HotelID` = `Param_HotelID`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `StaffUpdate` //\nCREATE PROCEDURE `StaffUpdate` (\n `Param_EmpID_Old` int,\n `Param_HotelID_Old` int,\n `Param_EmpID_New` int,\n `Param_HotelID_New` int\n)\nBEGIN\n UPDATE `Staff`\n SET\n `EmpID` = `Param_EmpID_New`,\n `HotelID` = `Param_HotelID_New`\n WHERE `EmpID` = `Param_EmpID_Old`\n AND `HotelID` = `Param_HotelID_Old`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `StaffDelete` //\nCREATE PROCEDURE `StaffDelete` (\n `Param_EmpID` int,\n `Param_HotelID` int\n)\nBEGIN\n DELETE FROM `Staff`\n WHERE `EmpID` = `Param_EmpID`\n AND `HotelID` = `Param_HotelID`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\n-- Service_Order\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `Service_OrderAdd` //\nCREATE PROCEDURE `Service_OrderAdd` (\n `Param_RoomID` int,\n `Param_OrderID` int,\n `Param_EmpID` int,\n `Param_DateTimeOfService` datetime,\n OUT `Service_NewID` int\n)\nBEGIN\n INSERT INTO `Service_Order` (\n `RoomID`,\n `OrderID`,\n `EmpID`,\n `DateTimeOfService`\n )\n VALUES (\n `Param_RoomID`,\n `Param_OrderID`,\n `Param_EmpID`,\n `Param_DateTimeOfService`\n );\n SELECT LAST_INSERT_ID() INTO `Service_NewID`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `Service_OrderList` //\nCREATE PROCEDURE `Service_OrderList` ()\nBEGIN\n SELECT * FROM `Service_Order`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `Service_OrderInfo` //\nCREATE PROCEDURE `Service_OrderInfo` (\n `Param_ServiceID` int\n)\nBEGIN\n SELECT * FROM `Service_Order` WHERE `ServiceID` = `Param_ServiceID`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `Service_OrderUpdate` //\nCREATE PROCEDURE `Service_OrderUpdate` (\n `Param_ServiceID` int,\n `Param_RoomID` int,\n `Param_OrderID` int,\n `Param_EmpID` int,\n `Param_DateTimeOfService` datetime\n)\nBEGIN\n UPDATE `Service_Order`\n SET\n `RoomID` = `Param_RoomID`,\n `OrderID` = `Param_OrderID`,\n `EmpID` = `Param_EmpID`,\n `DateTimeOfService` = `Param_DateTimeOfService`\n WHERE `ServiceID` = `Param_ServiceID`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `Service_OrderDelete` //\nCREATE PROCEDURE `Service_OrderDelete` (\n `Param_ServiceID` int\n)\nBEGIN\n DELETE FROM `Service_Order`\n WHERE `ServiceID` = `Param_ServiceID`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\n-- Order / Reservation\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `ReservationAdd` //\nCREATE PROCEDURE `ReservationAdd` (\n `Param_EmpID` int,\n `Param_CusID` int,\n `Param_OrderDate` datetime\n)\nBEGIN\n INSERT INTO `Order` (\n `EmpID`,\n `CusID`,\n `OrderDate`\n )\n VALUES (\n `Param_EmpID`,\n `Param_CusID`,\n `Param_OrderDate`\n );\n SELECT LAST_INSERT_ID();\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `ReservationList` //\nCREATE PROCEDURE `ReservationList` ()\nBEGIN\n SELECT * FROM `Order`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `ReservationInfo` //\nCREATE PROCEDURE `ReservationInfo` (\n `Param_OrderID` int\n)\nBEGIN\n SELECT * FROM `Order` WHERE `OrderID` = `Param_OrderID`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `ReservationUpdate` //\nCREATE PROCEDURE `ReservationUpdate` (\n `Param_OrderID` int,\n `Param_EmpID` int,\n `Param_CusID` int,\n `Param_OrderDate` datetime\n)\nBEGIN\n UPDATE `Order`\n SET\n `EmpID` = `Param_EmpID`,\n `CusID` = `Param_CusID`,\n `OrderDate` = `Param_OrderDate`\n WHERE `OrderID` = `Param_OrderID`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `ReservationDelete` //\nCREATE PROCEDURE `ReservationDelete` (\n `Param_OrderID` int\n)\nBEGIN\n DELETE FROM `Order`\n WHERE `OrderID` = `Param_OrderID`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\n-- Order_Has_Rooms\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `ReservationRoomAdd` //\nCREATE PROCEDURE `ReservationRoomAdd` (\n `Param_OrderID` int,\n `Param_RoomID` int,\n `Param_CheckInDate` int,\n `Param_CheckOutDate` datetime\n)\nBEGIN\n INSERT INTO `Order_Has_Rooms` (\n `OrderID`,\n `RoomID`,\n `CheckInDate`,\n `CheckOutDate`\n )\n VALUES (\n `Param_OrderID`,\n `Param_RoomID`,\n `Param_CheckInDate`,\n `Param_CheckOutDate`\n );\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `ReservationRoomList` //\nCREATE PROCEDURE `ReservationRoomList` ()\nBEGIN\n SELECT * FROM `Order_Has_Rooms`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `ReservationRoomInfo` //\nCREATE PROCEDURE `ReservationRoomInfo` (\n `Param_OrderRoomID` int\n)\nBEGIN\n SELECT * FROM `Order_Has_Rooms` WHERE `OrderRoomID` = `Param_OrderRoomID`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `ReservationRoomUpdate` //\nCREATE PROCEDURE `ReservationRoomUpdate` (\n `Param_OrderRoomID` int,\n `Param_OrderID` int,\n `Param_RoomID` int,\n `Param_CheckInDate` datetime,\n `Param_CheckOutDate` datetime\n)\nBEGIN\n UPDATE `Order_Has_Rooms`\n SET\n `OrderID` = `Param_OrderID`,\n `RoomID` = `Param_RoomID`,\n `CheckInDate` = `Param_CheckInDate`,\n `CheckOutDate` = `Param_CheckOutDate`\n WHERE `OrderRoomID` = `Param_OrderRoomID`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `ReservationRoomDelete` //\nCREATE PROCEDURE `ReservationRoomDelete` (\n `Param_OrderRoomID` int\n)\nBEGIN\n DELETE FROM `Order_Has_Rooms`\n WHERE `OrderRoomID` = `Param_OrderRoomID`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\n-- Order_Has_Items\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `ServiceAddItem` //\nCREATE PROCEDURE `ServiceAddItem` (\n `Param_ServiceID` int,\n `Param_ItemID` int,\n `Param_Qty` int\n)\nBEGIN\n INSERT INTO `Order_Has_Items` (\n `ServiceID`,\n `ItemID`,\n `Qty`\n )\n VALUES (\n `Param_ServiceID`,\n `Param_ItemID`,\n `Param_Qty`\n );\n SELECT LAST_INSERT_ID();\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `ServiceListItems` //\nCREATE PROCEDURE `ServiceListItems` ()\nBEGIN\n SELECT * FROM `Order_Has_Items`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `ServiceInfoItems` //\nCREATE PROCEDURE `ServiceInfoItems` (\n `Param_OrderItemID` int\n)\nBEGIN\n SELECT * FROM `Order_Has_Items` WHERE `OrderItemID` = `Param_OrderItemID`;\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `ServiceUpdateItem` //\nCREATE PROCEDURE `ServiceUpdateItem` (\n `Param_OrderItemID` int,\n `Param_ServiceID` int,\n `Param_ItemID` int,\n `Param_Qty` int\n)\nBEGIN\n UPDATE `Order_Has_Items`\n SET\n `ServiceID` = `Param_ServiceID`,\n `ItemID` = `Param_ItemID`,\n `Qty` = `Param_Qty`\n WHERE `OrderItemID` = `Param_OrderItemID`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n\nDELIMITER //\nDROP PROCEDURE IF EXISTS `ServiceDeleteItem` //\nCREATE PROCEDURE `ServiceDeleteItem` (\n `Param_OrderItemID` int\n)\nBEGIN\n DELETE FROM `Order_Has_Items`\n WHERE `OrderItemID` = `Param_OrderID`;\n SELECT ROW_COUNT();\nEND //\nDELIMITER ;\n"
}
] | 7 |
Yuudachi530/Watchpoint-0522
|
https://github.com/Yuudachi530/Watchpoint-0522
|
b0849294bd7696765085ee250f207929c8d2c269
|
cc17e561425a8eb06ef6fa0cf11fba179c7282e5
|
67b03be734efbd794b266d98a339504f4e40f670
|
refs/heads/master
| 2020-05-25T13:55:44.235982 | 2019-06-01T13:04:39 | 2019-06-01T13:04:39 | 187,832,765 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4960835576057434,
"alphanum_fraction": 0.6370757222175598,
"avg_line_length": 6.490196228027344,
"blob_id": "ff19c26f300b42bdd71c0e1160578e1050ae35c9",
"content_id": "39de0365eebb60a7b2db224ae988808b30a468e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 383,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 51,
"path": "/README.md",
"repo_name": "Yuudachi530/Watchpoint-0522",
"src_encoding": "UTF-8",
"text": "# Watchpoint-0522\nL1 Introdunction\n\nMultiple Choice Answers\nEx1:\n\nA A B AD\n\n\nEx2:\n\nA A A\n\n\nEx3\n\nB B C C B\n\n\n'Ex4'\n\nSyntax Static semantics Semantics\n\n\nEx5'\n\nfloat int bool NoneType float\n\n\nEx6'\n\n15 6.0 4 3.3333 3.3333 20 14 9 4.41 6.6\n\n\nEx7\n\n5.0 4.0 error\n\n\nEx8\n\nF T F F T T F T F F T F\n\n\nEx9\nint bool\n\n\nEx10\n\nfloat 8.0 float 2.5 bool t float 2.5 int 3 float 7.0 bool t\n\n"
},
{
"alpha_fraction": 0.3270142078399658,
"alphanum_fraction": 0.3601895868778229,
"avg_line_length": 20.5,
"blob_id": "e5cbbd4c004873e29e27943013a56bab2fcc47c1",
"content_id": "ceafba85691a6ffec8bba740ad647c7040bb3e32",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 211,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 8,
"path": "/problem2.py",
"repo_name": "Yuudachi530/Watchpoint-0522",
"src_encoding": "UTF-8",
"text": "s = input('')\r\nc = 0\r\ncounter = 0\r\nwhile c != len(s)-2:\r\n if s[c] == \"b\" and s[c + 1] == \"o\" and s[c + 2] == \"b\":\r\n counter = counter + 1\r\n c = c + 1\r\nprint(counter)\r\n\r\n \r\n \r\n \r\n \r\n"
},
{
"alpha_fraction": 0.43478259444236755,
"alphanum_fraction": 0.52173912525177,
"avg_line_length": 28.66666603088379,
"blob_id": "bd6ece4d860453414dea4b757748f2ad7c79c26a",
"content_id": "d505f41e07c04825cd3693f48626d941a576376d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 184,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 6,
"path": "/problem1.py",
"repo_name": "Yuudachi530/Watchpoint-0522",
"src_encoding": "UTF-8",
"text": "s = input('')\r\ncounter = 0\r\nfor i in list(s):\r\n if ord(i) == 97 or ord(i) == 101 or ord(i) == 101 or ord(i) == 111 or ord(i) == 117:\r\n counter = counter + 1\r\nprint(counter)\r\n"
},
{
"alpha_fraction": 0.31111112236976624,
"alphanum_fraction": 0.31111112236976624,
"avg_line_length": 10.777777671813965,
"blob_id": "acea1c254f17aea6dbae1753f3d9e521947751e3",
"content_id": "4a6fc0b0a5ab377e7bf741665f8b93a613dbcc32",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 135,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 9,
"path": "/problem3.py",
"repo_name": "Yuudachi530/Watchpoint-0522",
"src_encoding": "UTF-8",
"text": "s=input(\"\")\r\ns=[s]\r\nc=\"a\"\r\no=[]\r\nfor i in s:\r\n if c <= i:\r\n o.append[i]\r\n c=i\r\nprint(\"\".join(o))\r\n \r\n \r\n"
}
] | 4 |
dnimm/Personal-Portfolio
|
https://github.com/dnimm/Personal-Portfolio
|
fe9e885288a1cd8534df6ab1ee150c52c530ccff
|
e119f6717b0e201262fb665c1b71d636aafcb2df
|
aa603ae128913a72bc4f00dd22f725af1aa7b173
|
refs/heads/main
| 2023-08-26T21:31:38.862851 | 2021-10-05T05:41:21 | 2021-10-05T05:41:21 | 413,537,438 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6579710245132446,
"alphanum_fraction": 0.6579710245132446,
"avg_line_length": 38.80769348144531,
"blob_id": "400701f92009d8faf24b4d66a2d97ded80febacb",
"content_id": "aa10638ae3223602ca6c9927c783bec348f40d60",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1035,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 26,
"path": "/home/views.py",
"repo_name": "dnimm/Personal-Portfolio",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, HttpResponse\nfrom home.models import Contact\n# Create your views here.\ndef home(request):\n #return HttpResponse(\"This is my homepage(/)\")\n context = {'name': 'Doyel', 'course': 'Django'}\n return render(request, 'home.html', context)\ndef about(request):\n #return HttpResponse(\"This is my about page(/about)\")\n return render(request, 'about.html')\ndef project(request):\n #return HttpResponse(\"This is my projects page(/project)\")\n return render(request, 'project.html')\ndef contact(request):\n if request.method == \"POST\":\n \n name = request.POST['name']\n email = request.POST['email']\n phone = request.POST['phone']\n desc = request.POST['desc']\n print(name,email,phone,desc)\n contact = Contact(name = name, email = email, phone = phone, desc = desc)\n contact.save()\n print(\"The data has been written to the db\")\n #return HttpResponse(\"This is my contact page(/contact)\")\n return render(request, 'contact.html')\n"
}
] | 1 |
dlhextall/.profile.d
|
https://github.com/dlhextall/.profile.d
|
ec9cb93f5c95f600ab864c099f23f1b4a2477199
|
e267d0e6903ebca5c8541267ca8a60cfcfd2944a
|
bf02f0c5599ee53a3ae62e670ae6045296774ce4
|
refs/heads/master
| 2023-01-28T20:46:34.462297 | 2023-01-27T19:18:19 | 2023-01-27T19:18:19 | 23,088,021 | 3 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5810276865959167,
"alphanum_fraction": 0.5968379378318787,
"avg_line_length": 22,
"blob_id": "3403fe4798385a59a8248c38859ca468a2bddf80",
"content_id": "812c0f5da5ba47ced5983e89c912047f7c37bd1e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 253,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 11,
"path": "/functions/java/get-java-version",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\njava_version=$(java -version 2>&1 | awk -F '\"' '/version/ {print $2}')\nmajor=${java_version%%.*}\nif [ $major -gt 1 ]; then\n version=$major\nelse\n minor_patch=${java_version#*.}\n version=${minor_patch%%.*}\nfi\necho \"$version\"\n"
},
{
"alpha_fraction": 0.7183708548545837,
"alphanum_fraction": 0.7253032922744751,
"avg_line_length": 31.05555534362793,
"blob_id": "7165e45304f8422b1fb9a808e5cae739b93ce2db",
"content_id": "15bac81f5613e1f3faaaa9f2474ee16329745c9a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1154,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 36,
"path": "/README.md",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "# Shell scripts\nThis is a collection of useful shell scripts for an OSX/\\*NIX environment.\n\n## Info\n### extract\nExtract multiple file archive types.\n### get-java-version\nReturns a minimal Java version number (1.8 -> 8, 11 -> 11, etc)\n### gi\nGenerate a .gitignore file, using [gitignore.io](https://www.gitignore.io/)\n### git-pull-all\nPull changes from multiple repositories.\n### git-recreate-branch\nDelete and recreate a branch in git.\n### incognito\nStart a bash session without a loaded profile .\n### my-ip\nPrint my IP address.\n### notif\nDisplay a notification in OSX.\n### phone-battery\nPrint the connected Android phone's battery level using ADB.\n### ql\nOpen a file in Quicklook mode (OSX only).\n### serve\nStart a python server from the specified repository.\n### set-title\nSet the terminal's window title.\n### weather\nFetch the weather for a specified location, using [wttr.in](http://wttr.in).\n\n## Dependencies\n - .profile\n - [homebrew](https://brew.sh/) with [bash completion](https://github.com/scop/bash-completion) (not needed if \\_\\_git\\_ps1 is installed)\n - phone-battery\n - [ADB](https://developer.android.com/studio/command-line/adb.html)\n"
},
{
"alpha_fraction": 0.5853174328804016,
"alphanum_fraction": 0.60317462682724,
"avg_line_length": 25.526315689086914,
"blob_id": "15adf6556f2d5dc2bb5a98fc66c52687694e8943",
"content_id": "f256b3a9a9a4bf6262a648bc28926c285ee6c59a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 504,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 19,
"path": "/functions/java/mvn-search-dependency",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\nfunction cd_and_mvn_dependency() {\n dependency=\"$0\"\n cd $( echo \"$1\" | sed 's,pom\\.xml,,g' )\n echo \"searching for $dependency in $( pwd )\"\n mvn clean dependency:list | grep $dependency\n echo \"\"\n cd - >/dev/null\n}\nexport -f cd_and_mvn_dependency\n\nif [[ -z \"$1\" ]]; then\n echo \"No dependency specified\"\n exit 1\nfi\nfind . -maxdepth \"${2:-2}\" -mindepth 1 -type f -name pom.xml -exec bash -c 'cd_and_mvn_dependency \"$1\"' \"$1\" {} \\;\n\nunset -f cd_and_mvn_dependency\n"
},
{
"alpha_fraction": 0.49836066365242004,
"alphanum_fraction": 0.5049180388450623,
"avg_line_length": 26.727272033691406,
"blob_id": "c1d40a7848036a1e4e708fd92e6401b82fe7cd13",
"content_id": "439cd33724bf856c1006c07a12354f4e0275eb4d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 610,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 22,
"path": "/functions/weather",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env sh\n\nlocation=$1\nif [[ -z $location ]]; then\n ip=$(my-ip)\n if [[ -n $ip ]]; then\n echo \"No location provided, defaulting to external IP address: $ip\"\n csv=$(curl -s freegeoip.net/csv/$ip) ## does not work currently\n if [[ -n $csv ]]; then\n IFS=',' read -ra coord <<< \"$csv\"\n lat=${coord[${#coord[@]} - 3]}\n long=${coord[${#coord[@]} - 2]}\n location=\"$lat,$long\"\n fi\n fi\n if [[ -z $location ]]; then\n echo \"Unable to resolve location for IP address\"\n exit 1\n fi\nfi\n\ncurl http://wttr.in/$location\n"
},
{
"alpha_fraction": 0.47979798913002014,
"alphanum_fraction": 0.4848484992980957,
"avg_line_length": 32,
"blob_id": "3bb60f31374b30f58097c657658488c0efce368c",
"content_id": "e598b29b232a622a86fc04100b858a71c41ba0f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 198,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 6,
"path": "/functions/make-and-load-kb",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\nkb=$1\nhex=\"${kb//[\\/:]/_}\"\nmcu=$( cat \"keyboards/${kb%%:*}/rules.mk\" | grep \"MCU = \" | sed 's/^.*= //' )\nmake \"${kb}\" && teensy_loader_cli -w -mmcu=\"${mcu}\" \".build/${hex}.hex\"\n"
},
{
"alpha_fraction": 0.5973154306411743,
"alphanum_fraction": 0.6174496412277222,
"avg_line_length": 20.285715103149414,
"blob_id": "d18fb5c3d19d473b2eebe02b0a5c7ffbc50cf40e",
"content_id": "c828bebd323441a1a96e2dc6b7a6e108d0b34cee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 149,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 7,
"path": "/functions/java/set-java-version",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\nif [[ -z $1 ]]; then\n echo \"No java version specified\"\n exit 1\nfi\necho export JAVA_HOME=$( /usr/libexec/java_home -v $1 )\n"
},
{
"alpha_fraction": 0.5608465671539307,
"alphanum_fraction": 0.5740740895271301,
"avg_line_length": 26,
"blob_id": "9f59f1d45513f1a3c21f95efbf6766c57000aa35",
"content_id": "585c153b6510d33fa113745dac5070d8998086d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 378,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 14,
"path": "/functions/git/git-pull-all",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\nfunction cd_and_git_pull() {\n cd $( echo \"$0\" | sed 's,\\.git,,g' )\n echo \"updating $( git remote get-url origin ) on branch $( git br --show-current )\"\n git ps\n echo \"\"\n cd - >/dev/null\n}\nexport -f cd_and_git_pull\n\nfind . -maxdepth \"${1:-2}\" -mindepth 1 -type d -name .git -exec bash -c 'cd_and_git_pull \"$0\"' {} \\;\n\nunset -f cd_and_git_pull\n"
},
{
"alpha_fraction": 0.6037441492080688,
"alphanum_fraction": 0.6053042411804199,
"avg_line_length": 31.049999237060547,
"blob_id": "dee1ec2f87f6c1952a3a56c0b3ca9271e1ce09a2",
"content_id": "86b32577e18769f325d55825f65cde1da19c563d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1282,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 40,
"path": "/functions/serve",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport argparse\nimport ssl\nfrom http.server import HTTPServer, SimpleHTTPRequestHandler\n\n\nclass CORSRequestHandler(SimpleHTTPRequestHandler):\n \n def end_headers(self):\n self.send_header('Access-Control-Allow-Origin', '*')\n SimpleHTTPRequestHandler.end_headers(self)\n\n\ndef parse_arguments():\n parser = argparse.ArgumentParser()\n parser.add_argument(\"-p\", \"--port\",\n help=\"Port on which the server will run.\",\n default=0,\n required=False)\n parser.add_argument(\"-s\", \"--ssl\",\n help=\"SSL certificate location to use. If no certificate is specified, it will run on HTTP only.\",\n required=False)\n return parser.parse_args()\n\n\ndef start_server(port, ssl_directory):\n httpd = HTTPServer(('', int(port)), CORSRequestHandler)\n if args.ssl:\n httpd.socket = ssl.wrap_socket(httpd.socket, \n keyfile=f\"{ssl_directory}/key.pem\", \n certfile=f\"{ssl_directory}/cert.pem\", \n server_side=True)\n print(f\"Started server on port {httpd.server_port}\")\n httpd.serve_forever()\n\n\nif __name__ == '__main__':\n args = parse_arguments()\n start_server(args.port, args.ssl)\n"
},
{
"alpha_fraction": 0.4669603407382965,
"alphanum_fraction": 0.47772884368896484,
"avg_line_length": 23.914634704589844,
"blob_id": "39b276f976f0777e138ed4e632fe643bd49ad704",
"content_id": "0545b7b352663f2c23180dc78a9b65d8916b9a13",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2043,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 82,
"path": "/functions/batch-handbrake",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\n_usage() {\n echo \"$( basename $0 ): usage\"\n echo \" -i --input directory in which to scan\"\n echo \" -x --extension file extension for output\"\n echo \" \"\n exit $1\n}\n\n#######################################\n# Since the HandBrakeCLI does not create a symlink,\n# nor does it provide an easily accessible $PATH,\n# this is required to get the executable.\n# Globals:\n# None\n# Arguments:\n# None\n# Returns:\n# The executable's path\n#######################################\n_get_handbrake_cli() {\n if hash HandBrakeCLI 2>/dev/null; then\n echo \"HandBrakeCLI\"\n elif [ -d \"/usr/local/Cellar/handbrake\" ]; then\n # Get latest install of HandBrakeCLI from HomeBrew\n echo \"/usr/local/Cellar/handbrake/$( ls '/usr/local/Cellar/handbrake' | sort -n -t . -r | head -n 1 )/bin/HandBrakeCLI\"\n else\n return 1\n fi\n}\n\n#######################################\n# Convert files matching $input to $extension\n# Globals:\n# None\n# Arguments:\n# input\n# extension\n# Returns:\n# None\n#######################################\n_convert() {\n executable=$( _get_handbrake_cli ) || { echo \" \"; echo \"ERROR: HandBrakeCLI not found\"; exit 1; }\n for f in $1; do\n output=${f%.*}.$2\n\n echo \"Encoding $f into $output\"\n\n $executable --input \"$f\" --encoder-preset Fast 1080p30 --output \"$output\"\n done\n}\n\nwhile [ \"$1\" != \"\" ]; do\n case $1 in\n -i | --input ) shift\n input=$1\n ;;\n -x | --ext ) shift\n extension=$1\n ;;\n -h | --help ) _usage 0\n ;;\n * ) _usage 1\n esac\n shift\ndone\n\n[[ -z $input || -z $extension ]] && { _usage 1; }\n\necho \"About to encode these files:\"\nls $input\necho \"To $extension\"\necho \" \"\n\nread -r -p \"Are you sure? [y/N] \" response\ncase \"$response\" in\n [yY]) _convert \"$input\" $extension\n ;;\n *) exit 0\n ;;\nesac\n"
},
{
"alpha_fraction": 0.7285714149475098,
"alphanum_fraction": 0.7428571581840515,
"avg_line_length": 22.33333396911621,
"blob_id": "4ae1016b73287aa45d814e90eebc7d1b334b19e2",
"content_id": "1e27836c7da77413e9e3e8fa81cf6da68d8b1194",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 70,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 3,
"path": "/functions/my-ip",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env sh\n\ndig +short myip.opendns.com @resolver1.opendns.com\n"
},
{
"alpha_fraction": 0.6187050342559814,
"alphanum_fraction": 0.6282973885536194,
"avg_line_length": 26.799999237060547,
"blob_id": "f58ccd3c170bafd2d24a9bc1be0d26250793d8fc",
"content_id": "935164719e6b19cda64afdec556b4de457671659",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 417,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 15,
"path": "/functions/git/git-pull-all-to-master",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\nfunction cd_and_git_pull() {\n cd $( echo \"$0\" | sed 's,\\.git,,g' )\n echo \"updating $( git remote get-url origin ) on branch master and cleaning merged branches\"\n git okbye\n echo \"\"\n cd - >/dev/null\n}\nexport -f cd_and_git_pull\n\n# TODO: make maxdepth configurable\nfind . -maxdepth 5 -mindepth 1 -type d -name .git -exec bash -c 'cd_and_git_pull \"$0\"' {} \\;\n\nunset -f cd_and_git_pull\n"
},
{
"alpha_fraction": 0.5857142806053162,
"alphanum_fraction": 0.5964285731315613,
"avg_line_length": 19,
"blob_id": "b166ff902b4a260a58508ca1598e0b2da8131524",
"content_id": "251bf8da71d80ef0a202027624313fc18dc437c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 280,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 14,
"path": "/functions/git/git-wipe-changes",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\nsource \"$(git --exec-path)/git-sh-setup\"\n\ngit reset HEAD --hard\nadded_files=$( git st --short | awk '{print $2}' )\nif [[ -z \"${added_files}\" ]]; then\n exit 0\nfi\nif [ hash trash 2>/dev/null ]; then\n trash ${added_files}\nelse\n rm -rf ${added_files}\nfi\n"
},
{
"alpha_fraction": 0.5394191145896912,
"alphanum_fraction": 0.5684647560119629,
"avg_line_length": 19.08333396911621,
"blob_id": "2077d155282045df36dcf4cf6f2361e4ad9423c3",
"content_id": "3f25e7223e9ffd33c5fc884258f0537e78347de1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 241,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 12,
"path": "/functions/countdown",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\nseconds=$1\nif [[ ! $seconds =~ ^[0-9]+$ ]]; then\n echo \"Invalid number of seconds\"\n exit 1\nfi\nwhile [ $seconds -gt 0 ]; do\n echo -ne \"Sleeping for ${seconds}s\\r\"\n sleep 1\n seconds=$(( $seconds - 1 ))\ndone\n"
},
{
"alpha_fraction": 0.5040000081062317,
"alphanum_fraction": 0.5440000295639038,
"avg_line_length": 14.625,
"blob_id": "ce1ab1424fc9d34255be7af3765d0c98f0e55b58",
"content_id": "0d54165562db01e9c1b3e03079eb2df3f0915485",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 125,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 8,
"path": "/functions/ql",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env sh\n\nif [ -f $1 ] ; then\n qlmanage -p 2>/dev/null $1\nelse\n echo \"'$1' is not a valid file\"\n exit 1\nfi\n"
},
{
"alpha_fraction": 0.5397630929946899,
"alphanum_fraction": 0.5431472063064575,
"avg_line_length": 22.639999389648438,
"blob_id": "065d7271b47c124000ae2c20355d7be63bb2251f",
"content_id": "b1d03c7ca53c2b244ddf1ea93134a05261801794",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 591,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 25,
"path": "/functions/ssh",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env sh\n\nif [[ \"$TERM_PROGRAM\" == \"Apple_Terminal\" ]]; then\n TERMINAL_APP=\"Terminal\"\nfi\n\nif [[ -n $TERMINAL_APP ]]; then\n set_bg () {\n osascript -e \"tell application \\\"$TERMINAL_APP\\\" to set current settings of window 1 to $1\"\n }\n\n on_exit () {\n set_bg \"default settings\"\n }\n trap on_exit EXIT\n\n HOSTNAME=`echo $@ | sed s/.*@//`\n if [[ \"$HOSTNAME\" == *\"prod\"* ]]; then\n set_bg \"settings set \\\"Red Sands\\\"\"\n elif [[ \"$HOSTNAME\" =~ (master|staging|sandbox) ]]; then\n set_bg \"settings set \\\"Novel\\\"\"\n fi\nfi\n\n/usr/bin/ssh \"$@\"\n"
},
{
"alpha_fraction": 0.5798319578170776,
"alphanum_fraction": 0.5966386795043945,
"avg_line_length": 13.875,
"blob_id": "d91441a8f0998ab5a773c0a3fdb59d72d5cc40c3",
"content_id": "5fcac453b24994ffaa0172e33920ac61b9245754",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 119,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 8,
"path": "/functions/find-process",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env sh\n\nport=$1\nif [[ -z $port ]]; then\n echo \"No port number specified\"\n exit 1\nfi\nlsof -i tcp:$port\n"
},
{
"alpha_fraction": 0.6193480491638184,
"alphanum_fraction": 0.6214510798454285,
"avg_line_length": 23.384614944458008,
"blob_id": "527106eb004154c480721ac32a1582fa380968da",
"content_id": "cb2cd59a9b867d98285c931fb8b8cd231e0e1ac9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 951,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 39,
"path": "/functions/docker-utils.sh",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "function docker-rm-all() {\n docker rm $(docker ps -a -q)\n}\n\nfunction docker-rmi-all() {\n docker rmi $(docker images -q)\n}\n\nfunction docker-rmn-all() {\n docker network rm $(docker network ls -q)\n}\n\nfunction docker-stop-all() {\n docker stop $(docker ps -a -q)\n}\n\nfunction docker-network-all() {\n docker network inspect $( docker network ls -q )\n}\n\nfunction docker-build-local() {\n docker build --pull --file Dockerfile --tag \"${PWD##*/}\":local \"$@\"\n}\n\nfunction docker-service-exec() {\n docker exec -it $( docker service ps -f \"desired-state=running\" --no-trunc --format \"{{.Name}}.{{.ID}}\" \"$1\" ) \"${@: 2}\"\n}\n\nfunction docker-service-update() {\n service_name=\"${SERVICE_NAME}\"\n if [[ -z \"$service_name\" ]]; then\n service_name=\"${DOCKER_STACK_NAME}_${PWD##*/}\"\n fi\n docker service update --force \"${service_name}\"\n}\n\nfunction docker-build-and-update-service() {\n docker-build-local . && docker-service-update\n}\n"
},
{
"alpha_fraction": 0.6268656849861145,
"alphanum_fraction": 0.6268656849861145,
"avg_line_length": 25.799999237060547,
"blob_id": "65eb87c98ea12680c4d5f4518a545be9c535af86",
"content_id": "c9075a3cd5c7856aab7d47ff6e94eee8c088bba0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 134,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 5,
"path": "/functions/git/git-clean-branches",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env sh\n\nsource \"$(git --exec-path)/git-sh-setup\"\n\ngit branch --merged | grep -v \\\\* | grep -v master | xargs git branch -D\n"
},
{
"alpha_fraction": 0.7080000042915344,
"alphanum_fraction": 0.7080000042915344,
"avg_line_length": 26.77777862548828,
"blob_id": "353b467d5151768da1c5a2237ba1ff58cb8cf646",
"content_id": "5bee7aeb56c5b25188dfa4f5500ce7b56daa2150",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 250,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 9,
"path": "/functions/git/git-rebase-with-default",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env sh\n\nsource \"$(git --exec-path)/git-sh-setup\"\n\ndefault_branch=$( git symbolic-ref refs/remotes/origin/HEAD | sed 's@^refs/remotes/origin/@@' )\ngit checkout ${default_branch}\ngit pull --rebase\ngit checkout -\ngit rebase ${default_branch}\n"
},
{
"alpha_fraction": 0.6030150651931763,
"alphanum_fraction": 0.6281406879425049,
"avg_line_length": 15.583333015441895,
"blob_id": "2d840708cc24e50421b4ba5a3755dfcc37899ec1",
"content_id": "3ebadbd4543ee1535bfc1c09d6a5c0d3af046f32",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 199,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 12,
"path": "/functions/git/git-recreate-branch",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env sh\n\nsource \"$(git --exec-path)/git-sh-setup\"\n\nif [[ -n $1 ]]; then\n\tgit branch -D $1\n\tgit push origin :$1\n\tgit checkout -b $1\n\tgit push origin -u $1\nelse\n\tdie \"No branch specified\"\nfi\n"
},
{
"alpha_fraction": 0.7099236845970154,
"alphanum_fraction": 0.7099236845970154,
"avg_line_length": 15.375,
"blob_id": "011eeff40d47401c512f87414bc74b476e387b5a",
"content_id": "97744ec321a52b8b4912a770ca84ea565be74b17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 131,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 8,
"path": "/functions/git/git-merge-master",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env sh\n\nsource \"$(git --exec-path)/git-sh-setup\"\n\ngit checkout master\ngit pull --rebase\ngit checkout -\ngit merge master\n"
},
{
"alpha_fraction": 0.6486486196517944,
"alphanum_fraction": 0.6486486196517944,
"avg_line_length": 11.333333015441895,
"blob_id": "3b44942a7a818161a7456ac2cd92af5307e341f1",
"content_id": "7444ad4f2c9e641d1ba62251649023f0ba7ce505",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 37,
"license_type": "no_license",
"max_line_length": 17,
"num_lines": 3,
"path": "/functions/refresh",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env sh\n\nsource ~/.profile\n"
},
{
"alpha_fraction": 0.5503802299499512,
"alphanum_fraction": 0.5646387934684753,
"avg_line_length": 21.382978439331055,
"blob_id": "cd7fd30737d243bbade840c99f9a41b1cd16c3bb",
"content_id": "a1b46cf90b5b8e93636759694d2ed74a53cd232e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2148,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 94,
"path": "/functions/phone-battery",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\n# Check if a device is connected\ndevice_found=$(adb devices | wc -l)\nif [[ $device_found -lt 3 ]]; then\n echo \"No device found\"\n exit 1\nfi\n\n# Defaults\ntotalBars=20\n\n# Help & arguments passing\nwhile [[ \"$1\" != \"\" ]]; do\n case $1 in\n \"-h\" | \"--help\" )\n echo \"sh $0 [options]\"\n echo \"This script displays the current battery level of the connected Android phone as an ASCII battery.\"\n echo \" \"\n echo \" -h, --help Displays this help message\"\n echo \" -s, --size Specify the size of the battery\"\n echo \" \"\n exit 0\n ;;\n \"-s\" | \"--size\" )\n shift\n totalBars=$1\n shift\n ;;\n esac\ndone\n\n# Getting the actual level\nlevel=$(adb shell cat /sys/class/power_supply/battery/capacity | sed 's/[^0-9]*//g')\nif [[ $level -gt 100 ]]; then\n level=$(adb shell cat /sys/class/power_supply/battery/capacity | sed 's/[^0-9]*//g')\nfi\nchargedBars=0\nif [[ -n \"$level\" ]]; then\n chargedBars=$((level*$totalBars/100))\nfi\n\n# Battery sides\nbattSide=\"\"\nfor (( i = 0; i < $totalBars; i++ )); do\n battSide+=\"═\"\ndone\n\n# Full battery bars\nbattString=\"║\"\nfor (( i = 0; i < $chargedBars; i++ )); do\n battString+=\"█\"\ndone\nfor (( i = $chargedBars; i < $totalBars; i++ )); do\n battString+=\"░\"\ndone\n\n# Battery level bar\nlimit=$((totalBars/2-3))\nchargedLimit=$limit\nlevelString=\"║\"\nif [[ $chargedBars -lt $chargedLimit ]]; then\n chargedLimit=$chargedBars\nfi\nfor (( i = 0; i < $chargedLimit; i++ )); do\n levelString+=\"█\"\ndone\nfor (( i = $chargedLimit; i < $limit; i++ )); do\n levelString+=\"░\"\ndone\nlevelString+=\" $level % \"\nlimit=$((totalBars/2+3))\nfor (( i = $limit; i < $chargedBars; i++ )); do\n levelString+=\"█\"\ndone\nif [[ $chargedBars -gt $limit ]]; then\n limit=$chargedBars\nfi\nfor (( i = $limit; i < $totalBars; i++ )); do\n levelString+=\"░\"\ndone\n\nif [[ $level -lt 100 ]]; then\n levelString+=\"░─║\"\nelse\n levelString+=\"─║\"\nfi\n\n\necho \"╔${battSide}╗\"\necho ${battString}╚╗\necho $levelString\necho ${battString}╔╝\necho \"╚${battSide}╝\"\n"
},
{
"alpha_fraction": 0.6409945487976074,
"alphanum_fraction": 0.6600970029830933,
"avg_line_length": 33,
"blob_id": "4ec509d534e55c6c8612233db81fc9867bc1625c",
"content_id": "caecbb547337e35318c783ec93ab97c004665d0a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 3298,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 97,
"path": "/.profile",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "# M1 Homebrew\nif [[ $( uname -p ) == \"arm\" ]]; then\n export HOMEBREW_PREFIX=\"/opt/homebrew\";\n export HOMEBREW_CELLAR=\"/opt/homebrew/Cellar\";\n export HOMEBREW_REPOSITORY=\"/opt/homebrew\";\n export PATH=\"/opt/homebrew/bin:/opt/homebrew/sbin${PATH+:$PATH}\";\n export MANPATH=\"/opt/homebrew/share/man${MANPATH+:$MANPATH}:\";\n export INFOPATH=\"/opt/homebrew/share/info:${INFOPATH:-}\";\nfi\n\n# OSX bash completion via homebrew\nif hash brew 2>/dev/null; then\n [ -r $(brew --prefix)/etc/bash_completion ] && . $(brew --prefix)/etc/bash_completion\n [ -r $(brew --prefix)/share/bash-completion/bash_completion ] && . $(brew --prefix)/share/bash-completion/bash_completion\n [ -r $(brew --prefix)/etc/profile.d/bash_completion.sh ] && . $(brew --prefix)/etc/profile.d/bash_completion.sh\nfi\n# *NIX bash completion\nif ! shopt -oq posix; then\n [ -r /usr/share/bash-completion/bash_completion ] && . /usr/share/bash-completion/bash_completion\n [ -r /etc/bash_completion ] && . /etc/bash_completion\nfi\n\n# TMUX\nexport SHELL=$( which bash )\n# Git values\nexport GIT_PS1_SHOWUNTRACKEDFILES=true\nexport GIT_PS1_SHOWDIRTYSTATE=true\nexport GIT_PS1_SHOWCOLORHINTS=true\n# Bash colors\nexport CLICOLOR=1\nexport LSCOLORS=GxFxCxDxBxegedabagaced\nexport LS_COLORS='di=1;36:ln=1;35:so=1;32:pi=1;33:ex=1;31:bd=34;46:cd=34;43:su=30;41:sg=30;46:tw=30;42:ow=34;43'\n# Use vim as the default editor\nexport EDITOR=vim\n# This file's location\nexport PROFILE_LOCATION=\"$( cd \"$( dirname \"${BASH_SOURCE[0]}\" )\" && pwd )\"\n# Ignore duplicates in bash history\nexport HISTCONTROL=\"erasedups:ignoreboth\"\n# Add time to history command\nexport HISTTIMEFORMAT=\"%F %T \"\n# Record the history right away (instead of at the end of the session)\nexport PROMPT_COMMAND='history -a'\n# Correct minor spelling mistakes\nshopt -s cdspell\nshopt -s dirspell\n[[ ! -f ~/.inputrc ]] && echo \"set completion-ignore-case On\" >> ~/.inputrc\n\n# Functions included in this library\nfor f in $PROFILE_LOCATION/functions/*.sh; do\n [[ ! -x $f ]] && source $f\ndone\n\nPATH=$(find $PROFILE_LOCATION/functions -maxdepth 2 -type d | tr '\\n' ':' | sed 's/:$//'):~/.bin:/usr/local/bin:/usr/local/sbin:$PATH\n\n# General aliases\nalias ..=\"cd ..\"\nalias ...=\"cd ../..\"\nls --color &>/dev/null && alias ls=\"ls --color\"\nalias ll=\"ls -lah\"\nalias tree=\"tree -C\"\nfunction mkcd() {\n ## Shell scripts are run in a subshell, so the cd command would never work in an external function\n mkdir -p \"$1\" && cd \"$_\"\n}\n\n# MacOS-specific aliases\nif [[ \"$OSTYPE\" == \"darwin\"* ]]; then\n alias prev=\"open -a Preview\"\n alias screensaver=\"open -a ScreenSaverEngine\"\nfi\n\n# Machine-specific .profile\nfor f in ~/.profile.*; do\n [[ -f $f ]] && source $f\ndone\n\n# direnv\n# https://direnv.net/\nhash direnv 2>/dev/null && eval \"$(direnv hook bash)\"\n\n# fuzzy finder\n# https://github.com/junegunn/fzf\n[ -f ~/.fzf.bash ] && source ~/.fzf.bash\n\n# thefuck\n# https://github.com/nvbn/thefuck\nhash thefuck 2>/dev/null && eval $( thefuck --alias )\n\n# Set PS1 with git if available\nif [[ $( ps -p $( ps -p $$ -o ppid= ) -o args= ) == *\"Hyper\"* ]]; then\n export PS1=\"\\u \\$ \"\nelse\n ps1_var=\"\\[\\e[1m\\]\\u\"\n hash __git_ps1 2>/dev/null && ps1_var=\"$ps1_var\\$(__git_ps1)\"\n export PS1=\"$ps1_var \\$ \\[\\e[0m\\]\"\n export PROMPT_COMMAND=\"$PROMPT_COMMAND\"'; set-title $( dirs -0 )'\nfi\n"
},
{
"alpha_fraction": 0.46846845746040344,
"alphanum_fraction": 0.5585585832595825,
"avg_line_length": 14.857142448425293,
"blob_id": "8257a49c12893c628ac7f43f75015d716d93da9b",
"content_id": "99b907c492f8bb5b241f510a466444f7c9f7db81",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 111,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 7,
"path": "/functions/set-title",
"repo_name": "dlhextall/.profile.d",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\nif [[ -z $1 ]]; then\n echo \"No title specified\"\n exit 0\nfi\necho -ne \"\\033]0;$1\\007\"\n"
}
] | 25 |
danielsuposan/trabajoo8_suposantamaria
|
https://github.com/danielsuposan/trabajoo8_suposantamaria
|
3b80d96f045a63fe0fa301598444dbfdb8a68dde
|
1d96b0494ff12ac899c457d94f3a8373cffca446
|
fed946816ee155f065a8f0030e709f67ba5b27c7
|
refs/heads/master
| 2020-12-14T15:10:57.001443 | 2020-01-19T00:26:10 | 2020-01-19T00:26:10 | 234,781,229 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7977527976036072,
"alphanum_fraction": 0.7977527976036072,
"avg_line_length": 21.25,
"blob_id": "d7e7a75f2588501c280c0d7b240cc15d39f6a316",
"content_id": "a92181b0b8918ef2c9ded027ffea9c503a8a3c23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 89,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 4,
"path": "/app12.py",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "import libreria\njuguetes= \"CARRO\"\nresultado= libreria.juguetes(\"CARRO\")\nprint(resultado)\n"
},
{
"alpha_fraction": 0.762499988079071,
"alphanum_fraction": 0.762499988079071,
"avg_line_length": 22,
"blob_id": "f8d6ebb643acb9a303cc12c701ecf4ab8b50b040",
"content_id": "121615f525a8c3643c9a0d0e7452694f57f4ff4c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 160,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 7,
"path": "/app18.py",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "import libreria\n\ncadena = \"Hola mundo\"\nbusqueda = \"mundo\"\nreemplazo = \"a todos\"\nresultado = libreria.reemplazar_cadena(cadena, busqueda, reemplazo)\nprint(resultado)"
},
{
"alpha_fraction": 0.8118811845779419,
"alphanum_fraction": 0.8118811845779419,
"avg_line_length": 19.399999618530273,
"blob_id": "133dcb9f911f32a608c519cdf2cba9d208c4703c",
"content_id": "1adac69ffdb0539d2ba98d37b3ca720b905bd9d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 101,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 5,
"path": "/app20.py",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "import libreria\n\ncadena = \"bienvenidos\"\ncantidad = libreria.contar_caracteres(cadena)\nprint(cantidad)"
},
{
"alpha_fraction": 0.7849462628364563,
"alphanum_fraction": 0.7849462628364563,
"avg_line_length": 22.25,
"blob_id": "ab745f620713426d274775fabf39dca37e91782f",
"content_id": "f20523aef39cff9fc7fda11f20958175a3d8b1ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 93,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 4,
"path": "/app10.py",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "import libreria\npescados= \"CABALLA\"\nresultado= (libreria.pescados(\"TOLLO\"))\nprint(resultado)\n"
},
{
"alpha_fraction": 0.8426966071128845,
"alphanum_fraction": 0.8426966071128845,
"avg_line_length": 21.25,
"blob_id": "4e332f9f17367488f605dedc3df452dd4869baac",
"content_id": "561044faa95581d9c93f8503060cc76f1ac07904",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 89,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 4,
"path": "/app4.py",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "import libreria\ndeporte=\"NATACION\"\nresultado=libreria.deportes(deporte)\nprint(resultado)\n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 19,
"blob_id": "9c348add738704e1fd59923aca764775763c176a",
"content_id": "d7c5c694c8bb7de028034bf649a0c9d562b6f0a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 80,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 4,
"path": "/app7.py",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "import libreria\ndias=\"LUNES\"\nresultado= libreria.es_dias(dias)\nprint(resultado)\n"
},
{
"alpha_fraction": 0.7631579041481018,
"alphanum_fraction": 0.8421052694320679,
"avg_line_length": 18,
"blob_id": "c99a7b9e07937e181c14538af9603a5b44b3d4cd",
"content_id": "49cea7393228a2f236e90b700664d741bf6e7e5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 38,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 2,
"path": "/README.md",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "# trabajoo8_suposantamaria\ntrabajo 08\n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.8095238208770752,
"avg_line_length": 20,
"blob_id": "4051e7f9f4921f68a9886a95e136dc8be5fb44e9",
"content_id": "d7601cc568569acf3022f1957ac24300765b3028",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 105,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 5,
"path": "/app1.py",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "import libreria\n#1\ngaseosa= \"ORO\"\nresultado= libreria.verifica_marcas_gaseosas(gaseosa)\nprint(resultado)\n"
},
{
"alpha_fraction": 0.7529411911964417,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 16.200000762939453,
"blob_id": "48e2e844afe2451b5391d78750d1a13b8efdb44a",
"content_id": "2937fdc5b445c182dbbaa21139cbdc4c2246b54f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 85,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 5,
"path": "/app17.py",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "import libreria\n\npago = 1300\nresultado = libreria.pago_mensual(pago)\nprint(resultado)"
},
{
"alpha_fraction": 0.8299999833106995,
"alphanum_fraction": 0.8299999833106995,
"avg_line_length": 24,
"blob_id": "1a6c70c6e0ee01de0246ff656b5e8ad8abe14bf8",
"content_id": "28ef89a0e94c7690650065f5980f5b21e7537b5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 101,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 4,
"path": "/app13.py",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "import libreria\nestaciones= \"ENERO\"\nresultado= libreria.estaciones_año(estaciones)\nprint(resultado)\n"
},
{
"alpha_fraction": 0.7900000214576721,
"alphanum_fraction": 0.7900000214576721,
"avg_line_length": 24,
"blob_id": "c79a4872c15b8f3941e8e91081684975faca6782",
"content_id": "88602340b7fa1f90b7b74ecd9cf589ecedfaaf31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 100,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 4,
"path": "/app11.py",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "import libreria\nutensilios= \"OLLA\"\nresultado= (libreria.utensilios_cocina(\"OLLA\"))\nprint(resultado)\n"
},
{
"alpha_fraction": 0.6700751185417175,
"alphanum_fraction": 0.696368932723999,
"avg_line_length": 27.873493194580078,
"blob_id": "1c5dea792a8252de6cfa5e6002a0068f759d0864",
"content_id": "25f65c99ce0c61a0c75655e32fb6e81f4d984192",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4795,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 166,
"path": "/test.py",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "import libreria\n\n#1\nassert(libreria.verifica_marcas_gaseosas(\"FANTA\") == \"SI\")\nprint(\"verifica_marcas_gaseosa OK\")\n\n#2\nassert (libreria.es_mayor(40) == \"MAYOR\")\nprint(\"es_mayor OK\")\n\n#3\nassert (libreria.es_animal(\"LEON\") == \"VERTEBRADO\")\nprint(\"es_animal OK\")\n\n#4\nassert(libreria.deportes(\"TENNIS\") == \"SI\")\nprint(\"deportes OK\")\n\n#5\nassert(libreria.sexo(\"JAVIER\") == \"MASCULINO\")\nprint(\"sexo OK\")\n\n#6\nassert(libreria.verifica_marca_zapatillas(\"ADIDAS\") == \"SI\")\nprint(\"zapatillas OK\")\n\n#7\nassert(libreria.es_dias(\"LUNES\") == \"SI\")\nprint(\"es_dias OK\")\n\n#8\nassert(libreria.colores(\"NEGRO\") == \"SI\")\nprint(\"colores OK\")\n\n#9\nassert(libreria.instituciones_educativas(\"BASADRE\") == \"MUJERES\")\nprint(\"instituciones_educativas OK\")\n\n#10\nassert(libreria.pescados(\"CABALLA\") == \"SI\")\nprint(\"pescados OK\")\n\n#11\nassert(libreria.utensilios_cocina(\"OLLA\") == \"SI\")\nprint(\"utensilios_cocina OK\")\n\n#12\nassert(libreria.juguetes(\"CARRO\") == \"NIÑO\")\nprint(\"juguetes OK\")\n\n#13.\nassert(libreria.estaciones_año(\"ENERO\") ==False)\nprint(\"estaciones_año OK\")\n\n#14.\nassert(libreria.convertir_minuscula(\"CADENA\") == \"cadena\")\nassert(libreria.convertir_minuscula(\"TELEVISION\") == \"television\")\nprint(\"convertir_minuscula OK\")\n\n#15\nassert(libreria.validar_fin(\"muebleria\",\"eria\") == True)\nprint(\"validar_fin OK\")\n\n#16\nassert(libreria.verificar_edad(20) == True)\nassert(libreria.verificar_edad(35) == True)\nprint(\"verificar_edad OK\")\n\n#17\nassert(libreria.pago_mensual(1300) == True)\nassert(libreria.pago_mensual(100) == False)\nprint(\"pago_mensual OK\")\n\n#18\nassert(libreria.reemplazar_cadena(\"Hola mundo\", \"mundo\", \"a todos\") == \"Hola a todos\")\nprint(\"reeplazar_cadena OK\")\n\n#19\nassert(libreria.eliminar_espacios(\" Hola \") == \"Hola\")\nprint(\"eliminar_espacios OK\")\n\n#20\nassert(libreria.contar_caracteres(\"bienvenidos\") == 11)\nprint(\"contar_caracteres OK\")\n\n#21\nassert ( libreria.es_respuesta_validad(\"Z\") == False)\nassert ( libreria.es_respuesta_validad(\"A\") == True)\nassert ( libreria.es_respuesta_validad(\"E\") == True)\nassert ( libreria.es_respuesta_validad(\"J\") == False)\nassert ( libreria.es_respuesta_validad(\"I\") == True)\nassert ( libreria.es_respuesta_validad(\"G\") == False)\nassert ( libreria.es_respuesta_validad(\"O\") == True)\nassert ( libreria.es_respuesta_validad(\"X\") == False)\nassert ( libreria.es_respuesta_validad(\"U\") == True)\nassert ( libreria.es_respuesta_validad(\"M\") == False)\nprint(\"es_respuesta_valida OK\")\n\n#22\nassert (libreria.es_letra_valida(\"A\") == False)\nassert (libreria.es_letra_valida(\"B\") == True)\nassert (libreria.es_letra_valida(\"I\") == True)\nassert (libreria.es_letra_valida(\"Z\") == False)\nassert (libreria.es_letra_valida(\"O\") == True)\nprint(\"es_letra_valida OK\")\n\n#23\nassert (libreria.es_cancion_valida(\"X\") == False)\nassert (libreria.es_cancion_valida(\"C\") == True)\nassert (libreria.es_cancion_valida(\"A\") == True)\nassert (libreria.es_cancion_valida(\"Z\") == False)\nassert (libreria.es_cancion_valida(\"C\") == True)\nassert (libreria.es_cancion_valida(\"I\") == True)\nprint(\"es_Cancion_valida OK\")\n\n#24\nassert (libreria.es_Alto(160) == True)\nassert (libreria.es_Alto(150) == False)\nassert (libreria.es_Alto(158) == False)\nassert (libreria.es_Alto(159) == False)\nassert (libreria.es_Alto(180) == True)\nprint(\"X_persona_es_Alta OK\")\n\n#25\nassert (libreria.mayor_de_edad(18) == True)\nassert (libreria.mayor_de_edad(21) == False)\nassert (libreria.mayor_de_edad(59) == False)\nassert (libreria.mayor_de_edad(19) == False)\nassert (libreria.mayor_de_edad(58) == True)\nprint(\"X_Mayor_de_edad Ok\")\n\n#26\nassert (libreria.gane_un_premio(\"A\") == False)\nassert (libreria.gane_un_premio(\"I\") == True)\nassert (libreria.gane_un_premio(\"P\") == True)\nassert (libreria.gane_un_premio(\"Z\") == False)\nassert (libreria.gane_un_premio(\"H\") == True)\nassert (libreria.gane_un_premio(\"O\") == True)\nassert (libreria.gane_un_premio(\"L\") == False)\nassert (libreria.gane_un_premio(\"N\") == True)\nprint(\"GANE UN PREMIO OK\")\n\n#27\nassert (libreria.es_Bueno_OK(12) == True)\nassert (libreria.es_Bueno_OK(10) == False)\nassert (libreria.es_Bueno_OK(8) == False)\nassert (libreria.es_Bueno_OK(6) == False)\nassert (libreria.es_Bueno_OK(18) == True)\nprint(\"X_persona_es_buena OK\")\n\n#28\nassert (libreria.es_impar_con_ltr(\"2\") == False)\nassert (libreria.es_impar_con_ltr(\"4\") == False)\nassert (libreria.es_impar_con_ltr(\"AA\") == False)\nassert (libreria.es_impar_con_ltr(\"1\") == True)\nassert (libreria.es_impar_con_ltr(\"F\") == True)\nassert (libreria.es_impar_con_ltr(\"l\") == False)\nprint(\"es_Impar_con_ltr OK\")\n\n#29\nassert (libreria.descuento_valido(\"A\", 300) == 0)\nassert (libreria.descuento_valido(\"Preferencial\", 100) == 10.0)\nassert (libreria.descuento_valido(\"PREFERENCIAL\", 100) == 10.0)\nassert (libreria.descuento_valido(\"PrEfErEnCiAl\", 100) == 10.0)\nassert (libreria.descuento_valido(\"\", 100) == 0)\nprint(\"descuento_valido OK\")"
},
{
"alpha_fraction": 0.7933884263038635,
"alphanum_fraction": 0.7933884263038635,
"avg_line_length": 23.399999618530273,
"blob_id": "6c4d3e01c14813abee43a6779b72fa3188f15fc0",
"content_id": "fdbc779e6089167009c7cf37f950edfafb6c49ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 121,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 5,
"path": "/app16.py",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "import libreria\ncadena = \"muebleria\"\nbusqueda = \"eria\"\nresultado = libreria.validar_fin(cadena,busqueda)\nprint(resultado)"
},
{
"alpha_fraction": 0.797468364238739,
"alphanum_fraction": 0.797468364238739,
"avg_line_length": 18.75,
"blob_id": "338eb537f1b2c6002728fceee6922e3ec2416883",
"content_id": "2a694565e13bcbfcb611a4ed557717809bf001e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 79,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 4,
"path": "/app5.py",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "import libreria\nsexo=\"DANIEL\"\nresultado=(libreria.sexo(sexo))\nprint(resultado)\n"
},
{
"alpha_fraction": 0.7765957713127136,
"alphanum_fraction": 0.7872340679168701,
"avg_line_length": 17.600000381469727,
"blob_id": "663161e835dbfb181a0ce399157e48a0ddf756bf",
"content_id": "57bfc8bc7e9b0af2030637d4caf8dd2f0eebd1f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 94,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 5,
"path": "/app3.py",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "import libreria\n#3\nanimal= \"ELEFANTE\"\nresultado= libreria.es_animal(animal)\nprint(resultado)\n\n"
},
{
"alpha_fraction": 0.5782747864723206,
"alphanum_fraction": 0.5954859256744385,
"avg_line_length": 23.5,
"blob_id": "5694feeaa54db4c9551e6024519cf4ab59eb92cb",
"content_id": "9758db7bab2cd86f7f22d8303e61719d7ee4870b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9714,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 396,
"path": "/libreria.py",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "#ejercicio 1\ndef verifica_marcas_gaseosas(strgaseosas):\n \"\"\"\n Verifica si su strgaseosas coinciden con la lista de gaseosas mencionads\n :param strgaseosas:\n :return: str\n \"\"\"\n if (strgaseosas == \"CASINELLI\" or strgaseosas == \"INKA KOLA\" or strgaseosas == \"FANTA\"):\n return \"SI\"\n else:\n return \"NO\"\n#2\ndef es_mayor(intedad):\n \"\"\"\n Verifica su intedad si es mayor o igual que 40\n :param intedad:\n :return: str\n \"\"\"\n if (intedad >= 40):\n return \"MAYOR\"\n else:\n return \"MENOR\"\n #fin_es_mayor\n#3\ndef es_animal(stranimal):\n \"\"\"\n Verifica si stranimal coinciden con los animales invertebrados o vertebrados de lista\n :param stranimal:\n :return: str\n \"\"\"\n if (stranimal == \"LEON\" or stranimal == \"JIRAFA\" or stranimal == \"ELEFANTE\"):\n return \"VERTEBRADO\"\n else:\n return \"INVERTEBRADO\"\n #fin_es_animal\n#4\ndef deportes(strdeportes):\n \"\"\"\n Verificar su strdeportes si coinciden con los deportes de la siguiente lista\n :param strdeportes:\n :return: str\n \"\"\"\n if (strdeportes == \"NATACION\" or strdeportes == \"VOLEY\" or strdeportes == \"TENNIS\"):\n return \"SI\"\n else:\n return \"NO\"\n #fin_deportes\n#5\ndef sexo(strsexo):\n \"\"\"\n Verifica si strsexo si so masculino o femenino en la siguiente lista.\n :param strsexo:\n :return: str\n \"\"\"\n if (strsexo == \"DANIEL\" or strsexo == \"DIEGO\" or strsexo == \"JAVIER\"):\n return \"MASCULINO\"\n else:\n return \"FEMENINO\"\n #fin_sexo\n#6\ndef verifica_marca_zapatillas(strzapatillas):\n \"\"\"\n verifica si strzapatillas si coinciden con las marcas dela lista\n :param strzapatillas:\n :return: str\n \"\"\"\n if (strzapatillas == \"ADIDAS\" or strzapatillas == \"PUMA\"):\n return \"SI\"\n else:\n return \"NO\"\n #fin_zapatillas\n\n#7\ndef es_dias(strdias):\n \"\"\"\n verifica si strdias coinciden con los dias mencionados\n :param strdias:\n :return: str\n \"\"\"\n if (strdias == \"LUNES\" or strdias == \"MIERCOLES\"):\n return \"SI\"\n else:\n return \"NO\"\n #fin_dias\n#8\ndef colores (color):\n \"\"\"\n verifica si strcolores coinciden con los colores mencionados en lista\n :param strcolores:\n :return: str\n \"\"\"\n if (color == \"NEGRO\" or color == \"BLANCO\"):\n return \"SI\"\n else:\n return \"NO\"\n #fin_colores\n#9\ndef instituciones_educativas (strinstituciones):\n \"\"\"\n verifica si strinstitucones coinciden con los mencionados\n :param strinstituciones:\n :return: str\n \"\"\"\n if (strinstituciones == \"BASADRE\" or strinstituciones == \"PERUANO ESPAÑOL\"):\n return \"MUJERES\"\n else:\n return \"HOMBRES\"\n #fin_instituciones\n#10\ndef pescados (strpescados):\n \"\"\"\n verifica si strpescados coiciden con los mencionados\n :param strpescados:\n :return: str\n \"\"\"\n if (strpescados == \"CABALLA\" or strpescados == \"TOLLO\"):\n return \"SI\"\n else:\n return \"NO\"\n #fin_pescados\n#11\ndef utensilios_cocina (strutensilios):\n \"\"\"\n verifica si strutensilios coinciden con los mencionados\n :param strutensilios:\n :return: str\n \"\"\"\n if (strutensilios == \"OLLA\" or strutensilios == \"CUCHARAS\"):\n return \"SI\"\n else:\n return \"NO\"\n #fin_utensilios\n\n#12\ndef juguetes (strjuguetes):\n \"\"\"\n verifica si strjuguetes coinciden con los de la lista mencionados\n :param strjuguetes:\n :return: str\n \"\"\"\n if (strjuguetes == \"CARRO\" ):\n return \"NIÑO\"\n else:\n return \"NIÑA\"\n #fin_juguetes\n\n#13.\ndef estaciones_año (estaciones):\n \"\"\"\n verifica que sea una estacion del año\n :param estaciones:\n :return: bool\n \"\"\"\n if (estaciones == \"PRIMAVERA\" and estaciones == \"VERANO\" and estaciones == \"OTOÑO\" and estaciones == \"INVIERNO\" ):\n return True\n else:\n return False\n#fin_estaciones_año\n\n\n#14\ndef convertir_minuscula(cadena):\n \"\"\"\n verifica que sea letra minuscula\n :param cadena:\n :return: cadena\n \"\"\"\n if (isinstance(cadena, str)):\n return cadena.lower()\n else:\n return False\n#fin_convetir_minuscula\n\n#15\ndef validar_fin(cadena,busqueda):\n \"\"\"\n Valida que una cadena inicie con un valor ingresado\n :param cadena:\n busqueda:\n :return: bool\n \"\"\"\n if(isinstance(cadena,str) and isinstance(busqueda,str)):\n return cadena.endswith(busqueda)\n else:\n return False\n\n\n#16\ndef verificar_edad(edad):\n \"\"\"\n comprobar si edad es un digito\n Param: edad\n Retorna: bool\n \"\"\"\n if(isinstance(edad,int)):\n return True\n else:\n return False\n\n#17\ndef pago_mensual(pago):\n \"\"\"\n Muestra el ciclo de vida de una persona segun la edad ingresada\n Param: edad\n Retorna: cadena\n \"\"\"\n if(pago >= 1200 and pago <= 2000):\n return True\n else:\n return False\n\n#18\ndef reemplazar_cadena(cadena, busqueda, reemplazo):\n \"\"\"\n reemplaza una cadena por otra\n Param: cadena => cadena a corregir\n\t\t\t busqueda => cadena a buscar\n\t\t\t reemplazo => cadena que reemplaza\n Retorna: str\n \"\"\"\n if(isinstance(cadena, str)):\n return cadena.replace(busqueda, reemplazo)\n else:\n return False\n\n#19\ndef eliminar_espacios(cadena):\n \"\"\"\n Elimina los espacios en blanco al inicio y final de la cadena\n :Param: cadena => cadena a corregir\n Retorna: str\n \"\"\"\n if(isinstance(cadena, str)):\n return cadena.strip()\n else:\n return False\n#Fin eliminar_espacios\n\n#20\ndef contar_caracteres(cadena):\n \"\"\"\n Cuenta los caracteres de una cadena\n Param: cadena => cadena a contar\n Retorna: int\n \"\"\"\n if(isinstance(cadena, str)):\n return len(cadena)\n else:\n return False\n#Fin contar_cadena\n\n#21\ndef es_respuesta_validad(strRspta):\n# verifique si la respuespuesta es valida. puede ser A,E,I,O o U\n# Parametro strRspta (Respuesta Utilizada en el examen)\n#retornar: bool\n\n#1. si la longitud de strRspta es 1\n if( len(strRspta) == 1 ):\n#1.1.si la strRspta no es A o E o I o O o U, devolver False, sino retornar True\n if( strRspta!= \"A\" and strRspta!= \"E\" and strRspta!= \"I\" and strRspta!= \"O\" and strRspta!= \"U\"):\n return False\n else:\n return True\n#2. si no retornar False\n return False\n#Fin_es_respuesta_valida\n\n#22\ndef es_letra_valida(strletra):\n \"\"\"\n Verifica si strletraes una letra valida del Bingo.Pueden ser B, I , N ,G ,O\n :param strletra:\n :return: bool\n \"\"\"\n #1\n if (len(strletra) == 1):\n\n #1.1\n if (strletra != \"B\" and strletra != \"I\" and strletra != \"N\" and strletra != \"G\" and strletra != \"O\"):\n return False\n\n #2\n else:\n return True\n #fin_es_letra_valida\n\n#23\ndef es_cancion_valida(strCancion):\n \"\"\"\n Verifica si strletraes una letra valida de la cancion .Pueden ser C, A, N , C ,I,O,N\n :param strletra:\n :return: bool\n \"\"\"\n #1\n if (len(strCancion) == 1):\n\n #1.1\n if (strCancion != \"C\" and strCancion != \"A\" and strCancion != \"N\" and strCancion != \"C\" and strCancion != \"I\" and\n strCancion != \"O\" and strCancion != \"N\" ):\n return False\n\n #2\n else:\n return True\n#fin_es_cancion_valida\n\n#24\ndef es_Alto(intAlto):\n \"\"\"\n Verifica si X persona es persona alta si esta entre 160cm y 180cm es par\n :param intAño: Entero positivo\n :return: int\n \"\"\"\n if ( intAlto == 160 or intAlto ==164 or intAlto == 168 or intAlto == 172 or\n intAlto == 174 or intAlto ==176 or intAlto == 180 ):\n return True\n else:\n return False\n\n#fin_Persona_alta\n\n#25\ndef mayor_de_edad(intMayor):\n \"\"\"\n Verifica si X persona es persona es mayor de edad si esta entre 18 y 60 años es par\n :param intAño: Entero positivo\n :return: int\n \"\"\"\n if ( intMayor == 18 or intMayor == 24 or intMayor == 26 or intMayor == 32 or\n intMayor == 36 or intMayor == 40 or intMayor == 58 ):\n return True\n else:\n return False\n\n#fin_Mayor_de_edad\n\n#26\ndef gane_un_premio(strPremio):\n \"\"\"\n Verifica si strletraes una letra valida del Premio.Pueden ser I, P , H ,O,N\n :param strletra:\n :return: bool\n \"\"\"\n #1\n if (len(strPremio) == 1):\n\n #1.1\n if (strPremio != \"I\" and strPremio != \"P\" and strPremio != \"H\" and strPremio != \"O\" and\n strPremio != \"N\"):\n return False\n\n #2\n else:\n return True\n#fin_gane_un_premio\n\n#27\ndef es_Bueno_OK(intBueno):\n \"\"\"\n Verifica si X persona es Bueno, si x persona saca notas entre 12 y 20 es par\n :param intAño: Entero positivo\n :return: int\n \"\"\"\n if ( intBueno == 12 or intBueno == 14 or intBueno == 16 or intBueno == 18 or\n intBueno == 20 ):\n return True\n else:\n return False\n\n#fin_es_bueno_Ok\n\n#28\ndef es_impar_con_ltr(strImpar):\n # 1. strNum puede ser un numero impar de 1-19 o letras de B-G\n if ( strImpar == \"1\" or strImpar == \"3\" or strImpar == \"5\" or\n strImpar == \"7\" or strImpar == \"9\" or strImpar == \"11\" or\n strImpar == \"13\" or strImpar == \"15\" or strImpar == \"17\" or\n strImpar == \"19\" or strImpar == \"B\" or strImpar == \"C\" or\n strImpar == \"D\" or strImpar == \"E\" or strImpar == \"F\" or\n strImpar == \"G\"):\n return True\n else:\n # Si no es ningun numero 1-19 ni letras de a-z\n return False\n#fin_es_impar_con_ltr\n\n#29\ndef descuento_valido(tipo, prestamo):\n # Si el tipo de cliente es PREFERENCIAL\n # Aqui se usa la funcion upper()\n if ( tipo.upper() == \"PREFERENCIAL\" ):\n return 0.10 * prestamo\n else:\n return 0\n#fin_descuento\n\n"
},
{
"alpha_fraction": 0.699999988079071,
"alphanum_fraction": 0.762499988079071,
"avg_line_length": 14.600000381469727,
"blob_id": "639de594ab4195033398c30bc163d2732fe2b2a5",
"content_id": "a5e644864ab711b8516c33e61d325f080482a1e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 80,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 5,
"path": "/app2.py",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "import libreria\n#2\nedad= 40\nresultado= libreria.es_mayor(56)\nprint(resultado)\n\n\n"
},
{
"alpha_fraction": 0.8392857313156128,
"alphanum_fraction": 0.8392857313156128,
"avg_line_length": 27,
"blob_id": "e29cd4d6ec11bcb04fa014dd6e0c9381e983762a",
"content_id": "f3ddf4c65a382c5b04dcc432f6c4eb0bce2b9679",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 112,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 4,
"path": "/app6.py",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "import libreria\nzapatillas=\"ADIDAS\"\nresultado=(libreria.verifica_marca_zapatillas(zapatillas))\nprint(resultado)\n"
},
{
"alpha_fraction": 0.7933884263038635,
"alphanum_fraction": 0.7933884263038635,
"avg_line_length": 23.399999618530273,
"blob_id": "3792346932f12e51e6be6024865254188a2c37d3",
"content_id": "91dcae8d622b9cb06a9b2c2d3a45cb6cf5b352f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 121,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 5,
"path": "/app15.py",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "import libreria\ncadena = \"carpeta\"\nbusqueda = \"car\"\nresultado = libreria.validar_inicio(cadena,busqueda)\nprint(resultado)"
},
{
"alpha_fraction": 0.7954545617103577,
"alphanum_fraction": 0.7954545617103577,
"avg_line_length": 21,
"blob_id": "d635a4debcb14bef705695de7b2c1cc0b7ddb95b",
"content_id": "517dbc39eb9fb4aff826d8f53cb061daf58b9922",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 88,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 4,
"path": "/app8.py",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "import libreria\ncolores= \"NEGRO\"\nresultado= libreria.colores(\"BLANCO\")\nprint(resultado)\n"
},
{
"alpha_fraction": 0.8347107172012329,
"alphanum_fraction": 0.8347107172012329,
"avg_line_length": 29.25,
"blob_id": "6d6d6a75401b49bb4ce2c67f30374fe5debbfac0",
"content_id": "a637d0ff48ce199a622dce9e6a4a76afc9b22bfe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 121,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 4,
"path": "/app9.py",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "import libreria\ninstituciones= \"BASADRE\"\nresultado=(libreria.instituciones_educativas(\"instituciones\"))\nprint(resultado)\n"
},
{
"alpha_fraction": 0.8118811845779419,
"alphanum_fraction": 0.8118811845779419,
"avg_line_length": 19.399999618530273,
"blob_id": "ff7e2c5a89dd899d8bcd909b1b76b45081efb9e1",
"content_id": "6e66d5a9cdd99c9e893df4e9bacc6b23cc54f66d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 101,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 5,
"path": "/app14.py",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "import libreria\n\ncadena = \"VIERNES\"\nresultado = libreria.convertir_minuscula(cadena)\nprint(resultado)"
},
{
"alpha_fraction": 0.6578947305679321,
"alphanum_fraction": 0.6578947305679321,
"avg_line_length": 11.666666984558105,
"blob_id": "19a1f444f8d51ddef85f7b392a596f61fc472bbb",
"content_id": "2c5f76e1c020d89aa45c0eeae6d21556de82f7e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 38,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 3,
"path": "/app21.py",
"repo_name": "danielsuposan/trabajoo8_suposantamaria",
"src_encoding": "UTF-8",
"text": "import libreria\n\ncadena = \"A,E,I,O,U\"\n"
}
] | 23 |
p--q/EventDrivenEmbeddedMacros
|
https://github.com/p--q/EventDrivenEmbeddedMacros
|
e1eea34aa1c0f0bb24992afc96db3c666a91824d
|
75fe0266e45b57bc7d95b5e5df731969bf29d2f8
|
fafc619db1c2f62621727a601061905f37f5c681
|
refs/heads/main
| 2023-01-05T02:28:22.603205 | 2020-11-01T13:33:38 | 2020-11-01T13:33:38 | 309,064,365 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8636363744735718,
"alphanum_fraction": 0.8636363744735718,
"avg_line_length": 43,
"blob_id": "4ad740f1a455e0bf6057c172e1914ea339fbf080",
"content_id": "f17ee39c7c87d8ebe3ce61c4ab526c3fb11a7340",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 88,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 2,
"path": "/README.md",
"repo_name": "p--q/EventDrivenEmbeddedMacros",
"src_encoding": "UTF-8",
"text": "# EventDrivenEmbeddedMacros\nEvent driven macros embedded in LibreOffice Calc documents.\n"
},
{
"alpha_fraction": 0.7429839968681335,
"alphanum_fraction": 0.7442273497581482,
"avg_line_length": 55.858585357666016,
"blob_id": "0c623baef5de38feab09e878af105d29399346fb",
"content_id": "7d0452cba48d3c0539277182737cbee66d1d34c2",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7128,
"license_type": "permissive",
"max_line_length": 186,
"num_lines": 99,
"path": "/EventDrivenEmbeddedMacro/tools/getEmbeddedScripts.py",
"repo_name": "p--q/EventDrivenEmbeddedMacros",
"src_encoding": "UTF-8",
"text": "#!/opt/libreoffice5.4/program/python\n# -*- coding: utf-8 -*-\nimport unohelper # オートメーションには必須(必須なのはuno)。\nimport glob\nimport os, sys\ndef main(): \n\tctx = XSCRIPTCONTEXT.getComponentContext() # コンポーネントコンテクストの取得。\n\tsmgr = ctx.getServiceManager() # サービスマネージャーの取得。\t\n\tsimplefileaccess = smgr.createInstanceWithContext(\"com.sun.star.ucb.SimpleFileAccess\", ctx) # SimpleFileAccess\n\tos.chdir(\"..\") # 一つ上のディレクトリに移動。\n\tods = glob.glob(\"*.ods\")[0] # odsファイルを取得。最初の一つのみ取得。\n\tsystempath = os.path.join(os.getcwd(), ods) # odsファイルのフルパス。\n\tdoc_fileurl = unohelper.systemPathToFileUrl(systempath) # fileurlに変換。\n\tdesktop = ctx.getByName('/singletons/com.sun.star.frame.theDesktop') # デスクトップの取得。\n\tcomponents = desktop.getComponents() # ロードしているコンポーネントコレクションを取得。\n\ttransientdocumentsdocumentcontentfactory = smgr.createInstanceWithContext(\"com.sun.star.frame.TransientDocumentsDocumentContentFactory\", ctx) # TransientDocumentsDocumentContentFactory\n\tfor component in components: # 各コンポーネントについて。\n\t\tif hasattr(component, \"getURL\"): # スタートモジュールではgetURL()はないためチェックする。\n\t\t\tif component.getURL()==doc_fileurl: # fileurlが一致するとき、ドキュメントが開いているということ。\n\t\t\t\ttransientdocumentsdocumentcontent = transientdocumentsdocumentcontentfactory.createDocumentContent(component)\n\t\t\t\tpkgurl = transientdocumentsdocumentcontent.getIdentifier().getContentIdentifier() # ex. vnd.sun.star.tdoc:/1\n\t\t\t\tpython_fileurl = \"/\".join((pkgurl, \"Scripts/python\")) # ドキュメント内フォルダへのフルパスを取得。\n\t\t\t\tif simplefileaccess.exists(python_fileurl): # 埋め込みマクロフォルダが存在する時。\n\t\t\t\t\tdest_dir = createDest(simplefileaccess) # 出力先フォルダのfileurlを取得。\n\t\t\t\t\tsimplefileaccess.copy(python_fileurl, dest_dir) # 埋め込みマクロフォルダを出力先フォルダにコピーする。\n\t\t\t\t\tprint(\"The embedded Macro folder in '{}' has been exported to '{}'.\".format(python_fileurl, dest_dir))\n\t\t\t\t\treturn\t# 関数を出る。\t\t\n\telse: # ドキュメントを開いていない時。\n\t\tpackage = smgr. createInstanceWithArgumentsAndContext(\"com.sun.star.packages.Package\", (doc_fileurl,), ctx) # Package。第2引数はinitialize()メソッドで後でも渡せる。\n\t\tdocroot = package.getByHierarchicalName(\"/\") # /Scripts/pythonは不可。\n\t\tif (\"Scripts\" in docroot and \"python\" in docroot[\"Scripts\"]): # 埋め込みマクロフォルダが存在する時。\n\t\t\tdest_dir = createDest(simplefileaccess) # 出力先フォルダのfileurlを取得。\n\t\t\tgetContents(simplefileaccess, docroot[\"Scripts\"][\"python\"], dest_dir) \n\t\t\tprint(\"The embedded Macro folder in '{}' has been exported to '{}'.\".format(ods, dest_dir))\n\t\t\treturn\t# 関数を出る。\t\n\tprint(\"The embedded macro folder does not exist in {}.\".format(ods)) # 埋め込みマクロフォルダが存在しない時。\ndef getContents(simplefileaccess, folder, pwd):\n\tfor sub in folder: # 子要素のオブジェクトについて。\n\t\tname = sub.getName() # 子要素のオブジェクトの名前を取得。\n\t\tfileurl = \"/\".join((pwd, name)) # 出力先のfileurlを取得。\n\t\tif sub.supportsService(\"com.sun.star.packages.PackageFolder\"): # PackageFolderの時はフォルダとして出力。\n\t\t\tif not simplefileaccess.exists(fileurl):\n\t\t\t\tsimplefileaccess.createFolder(fileurl)\n\t\t\tgetContents(simplefileaccess, sub, fileurl) # 子要素のオブジェクトについて同様に出力。\n\t\telif sub.supportsService(\"com.sun.star.packages.PackageStream\"): # PackageStreamのときはファイルとして出力。\n\t\t\tsimplefileaccess.writeFile(fileurl, sub.getInputStream()) # ファイルが存在しなければ新規作成してくれる。\t\t\t\ndef createDest(simplefileaccess): # 出力先フォルダのfileurlを取得する。\n\tsrc_path = os.path.join(os.getcwd(), \"src\") # srcフォルダのパスを取得。\n\tsrc_fileurl = unohelper.systemPathToFileUrl(src_path) # fileurlに変換。\n\tdestdir = \"/\".join((src_fileurl, \"Scripts/python\"))\n\tif simplefileaccess.exists(destdir): # pythonフォルダがすでにあるとき\n\t\ts = input(\"Delete the existing src/Scripts/python?[y/N]\").lower()\n\t\tif s==\"y\":\n\t\t\tsimplefileaccess.kill(destdir) # すでにあるpythonフォルダを削除。\t\n\t\telse:\n\t\t\tprint(\"Exit\")\n\t\t\tsys.exit(0)\n\tsimplefileaccess.createFolder(destdir) # pythonフォルダを作成。\n\treturn destdir\t\t\t\nif __name__ == \"__main__\": # オートメーションで実行するとき\n\tdef automation(): # オートメーションのためにglobalに出すのはこの関数のみにする。\n\t\timport officehelper\n\t\tfrom functools import wraps\n\t\timport sys\n\t\tfrom com.sun.star.beans import PropertyValue # Struct\n\t\tfrom com.sun.star.script.provider import XScriptContext \n\t\tdef connectOffice(func): # funcの前後でOffice接続の処理\n\t\t\t@wraps(func)\n\t\t\tdef wrapper(): # LibreOfficeをバックグラウンドで起動してコンポーネントテクストとサービスマネジャーを取得する。\n\t\t\t\ttry:\n\t\t\t\t\tctx = officehelper.bootstrap() # コンポーネントコンテクストの取得。\n\t\t\t\texcept:\n\t\t\t\t\tprint(\"Could not establish a connection with a running office.\", file=sys.stderr)\n\t\t\t\t\tsys.exit()\n\t\t\t\tprint(\"Connected to a running office ...\")\n\t\t\t\tsmgr = ctx.getServiceManager() # サービスマネジャーの取得。\n\t\t\t\tprint(\"Using {} {}\".format(*_getLOVersion(ctx, smgr))) # LibreOfficeのバージョンを出力。\n\t\t\t\treturn func(ctx, smgr) # 引数の関数の実行。\n\t\t\tdef _getLOVersion(ctx, smgr): # LibreOfficeの名前とバージョンを返す。\n\t\t\t\tcp = smgr.createInstanceWithContext('com.sun.star.configuration.ConfigurationProvider', ctx)\n\t\t\t\tnode = PropertyValue(Name = 'nodepath', Value = 'org.openoffice.Setup/Product' ) # share/registry/main.xcd内のノードパス。\n\t\t\t\tca = cp.createInstanceWithArguments('com.sun.star.configuration.ConfigurationAccess', (node,))\n\t\t\t\treturn ca.getPropertyValues(('ooName', 'ooSetupVersion')) # LibreOfficeの名前とバージョンをタプルで返す。\n\t\t\treturn wrapper\n\t\t@connectOffice # createXSCRIPTCONTEXTの引数にctxとsmgrを渡すデコレータ。\n\t\tdef createXSCRIPTCONTEXT(ctx, smgr): # XSCRIPTCONTEXTを生成。\n\t\t\tclass ScriptContext(unohelper.Base, XScriptContext):\n\t\t\t\tdef __init__(self, ctx):\n\t\t\t\t\tself.ctx = ctx\n\t\t\t\tdef getComponentContext(self):\n\t\t\t\t\treturn self.ctx\n\t\t\t\tdef getDesktop(self):\n\t\t\t\t\treturn ctx.getByName('/singletons/com.sun.star.frame.theDesktop') # com.sun.star.frame.Desktopはdeprecatedになっている。\n\t\t\t\tdef getDocument(self):\n\t\t\t\t\treturn self.getDesktop().getCurrentComponent()\n\t\t\treturn ScriptContext(ctx) \n\t\treturn createXSCRIPTCONTEXT() # XSCRIPTCONTEXTの取得。\n\tXSCRIPTCONTEXT = automation() # XSCRIPTCONTEXTを取得。\t\n\tmain()\n\t"
},
{
"alpha_fraction": 0.7695284485816956,
"alphanum_fraction": 0.7713916897773743,
"avg_line_length": 61.84684753417969,
"blob_id": "c6055c0ce79525bd2125c0b7ad75ace157696f3e",
"content_id": "65efccd671c58172ba3d9ce7a3fe4ce1b97c1b4c",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9263,
"license_type": "permissive",
"max_line_length": 194,
"num_lines": 111,
"path": "/EventDrivenEmbeddedMacro/tools/replaceEmbeddedScripts.py",
"repo_name": "p--q/EventDrivenEmbeddedMacros",
"src_encoding": "UTF-8",
"text": "#!/opt/libreoffice5.4/program/python\n# -*- coding: utf-8 -*-\nimport unohelper # オートメーションには必須(必須なのはuno)。\nimport glob\nimport os, sys\nfrom com.sun.star.beans import PropertyValue # Struct\nfrom com.sun.star.document import MacroExecMode # 定数\ndef main(): \n\tctx = XSCRIPTCONTEXT.getComponentContext() # コンポーネントコンテクストの取得。\n\tsmgr = ctx.getServiceManager() # サービスマネージャーの取得。\n\tos.chdir(\"..\") # 一つ上のディレクトリに移動。\n\tsimplefileaccess = smgr.createInstanceWithContext(\"com.sun.star.ucb.SimpleFileAccess\", ctx) # SimpleFileAccess\n\tsource_path = os.path.join(os.getcwd(), \"src\", \"Scripts\", \"python\") # コピー元フォルダのパスを取得。\t\n\tsource_fileurl = unohelper.systemPathToFileUrl(source_path) # fileurlに変換。\t\n\tif not simplefileaccess.exists(source_fileurl): # ソースにするフォルダがないときは終了する。\n\t\tprint(\"fileurl: {}\\nThe source macro folder does not exist.\".format(source_fileurl))\t\n\t\treturn\t\n\tods = glob.glob(\"*.ods\")[0] # odsファイルを取得。最初の一つのみ取得。\n\tsystempath = os.path.join(os.getcwd(), ods) # odsファイルのフルパス。\n\tdoc_fileurl = unohelper.systemPathToFileUrl(systempath) # fileurlに変換。\n\tdesktop = ctx.getByName('/singletons/com.sun.star.frame.theDesktop') # デスクトップの取得。\n\tflg = isComponentLoaded(desktop, doc_fileurl) # ドキュメントが開いていたら保存して閉じる。\n\tpython_pkgurl = getVndSunStarPkgUrl(ctx, smgr, doc_fileurl) # pkgurlの取得。\n\tif simplefileaccess.exists(python_pkgurl): # 埋め込みマクロフォルダがすでに存在する時。simplefileaccess.kill(pkgurl)では削除できない。\n\t\tpackage = smgr.createInstanceWithArgumentsAndContext(\"com.sun.star.packages.Package\", (doc_fileurl,), ctx) # Package。第2引数はinitialize()メソッドで後でも渡せる。\n\t\tdocroot = package.getByHierarchicalName(\"/\") # /Scripts/pythonは不可。\n\t\tfor name in docroot[\"Scripts\"][\"python\"].getElementNames(): # すでに存在する埋め込みマクロフォルダの各要素を削除。\n\t\t\tdel docroot[\"Scripts\"][\"python\"][name]\n\t\tpackage.commitChanges() # ファイルにパッケージの変更を書き込む。manifest.xmlも編集される。\t\n\telse: # 埋め込みマクロフォルダが存在しない時。\n\t\tpropertyvalues = PropertyValue(Name=\"Hidden\",Value=True),\n\t\tdoc = desktop.loadComponentFromURL(doc_fileurl, \"_blank\", 0, propertyvalues) # ドキュメントをバックグラウンドで開く。\n\t\tif doc is None: # ドキュメントが壊れているときなどはNoneになる。\n\t\t\tprint(\"{} may be corrupted.\".format(ods), file=sys.stderr)\n\t\t\tsys.exit()\n\t\tcreateEmbeddedMacroFolder(ctx, smgr, simplefileaccess, doc) # 埋め込みマクロフォルダを新規作成。開いているドキュメントにしか作成できない。\n\t\tdoc.store() # ドキュメントを保存する。\n\t\tdoc.close(True) # ドキュメントを閉じる。\n\tsimplefileaccess.copy(source_fileurl, python_pkgurl) # 埋め込みマクロフォルダにコピーする。開いているドキュメントでは書き込みが反映されない時があるので閉じたドキュメントにする。\n\tprint(\"Replaced the embedded macro folder in {} with {}.\".format(ods, source_path))\n\tprop = PropertyValue(Name=\"Hidden\",Value=True)\n\tdesktop.loadComponentFromURL(\"private:factory/swriter\", \"_blank\", 0, (prop,)) # バックグラウンドでWriterのドキュメントを開く。そうでないとsoffice.binが終了しないときがある。\n\tterminated = desktop.terminate() # LibreOfficeを終了しないとリスナーの変更が反映されない。\n\tif terminated:\n\t\tprint(\"\\nThe LibreOffice has been terminated.\") # 未保存のドキュメントがなくうまく終了出来た時。\n\telse:\n\t\tprint(\"\\nThe LibreOffice is still running. Someone else prevents termination.\\nListener changes will not be reflected unless LibreOffice has been terminated.\") # 未保存のドキュメントがあってキャンセルボタンが押された時。\n\tsys.exit() # これがないとsoffice.binが終わらないときもある。なぜか1回目の起動後の終了は2分程かかる。とりあえず1回は待たないと次も待たされる。soffice.binというものが1回目終了時に時間がかかる。1回LibreOfficeを起動して終了するとすぐ終わる?\ndef getVndSunStarPkgUrl(ctx, smgr, doc_fileurl): # pkgurlの取得。\n\turireferencefactory = smgr.createInstanceWithContext(\"com.sun.star.uri.UriReferenceFactory\", ctx) # UriReferenceFactory\n\turireference = urireferencefactory.parse(doc_fileurl) # ドキュメントのUriReferenceを取得。\n\tvndsunstarpkgurlreferencefactory = smgr.createInstanceWithContext(\"com.sun.star.uri.VndSunStarPkgUrlReferenceFactory\", ctx) # VndSunStarPkgUrlReferenceFactory\n\tvndsunstarpkgurlreference = vndsunstarpkgurlreferencefactory.createVndSunStarPkgUrlReference(urireference) # ドキュメントのvnd.sun.star.pkgプロトコールにUriReferenceを変換。\n\tpkgurl = vndsunstarpkgurlreference.getUriReference() # UriReferenceから文字列のURIを取得。\n\treturn \"/\".join((pkgurl, \"Scripts/python\")) # 開いていないドキュメントの埋め込みマクロフォルダへのフルパスを取得。\t\ndef isComponentLoaded(desktop, doc_fileurl): # ドキュメントが開いていたら保存して閉じる。\n\tcomponents = desktop.getComponents() # ロードしているコンポーネントコレクションを取得。\n\tfor component in components: # 各コンポーネントについて。\n\t\tif hasattr(component, \"getURL\"): # スタートモジュールではgetURL()はないためチェックする。\n\t\t\tif component.getURL()==doc_fileurl: # fileurlが一致するとき、ドキュメントが開いているということ。\n\t\t\t\tcomponent.store() # ドキュメントを保存する。\n\t\t\t\tcomponent.close(True) # ドキュメントを閉じる。\n\t\t\t\treturn True\n\telse:\n\t\treturn False\ndef createEmbeddedMacroFolder(ctx, smgr, simplefileaccess, component): # 埋め込みマクロフォルダを作成。\t\n\ttransientdocumentsdocumentcontentfactory = smgr.createInstanceWithContext(\"com.sun.star.frame.TransientDocumentsDocumentContentFactory\", ctx)\n\ttransientdocumentsdocumentcontent = transientdocumentsdocumentcontentfactory.createDocumentContent(component)\n\ttdocurl = transientdocumentsdocumentcontent.getIdentifier().getContentIdentifier() # ex. vnd.sun.star.tdoc:/1\n\tpython_tdocurl = \"/\".join((tdocurl, \"Scripts/python\")) # 開いているドキュメントの埋め込みマクロフォルダへのフルパスを取得。\t\n\tsimplefileaccess.createFolder(python_tdocurl) # 埋め込みマクロフォルダを作成。\nif __name__ == \"__main__\": # オートメーションで実行するとき\n\tdef automation(): # オートメーションのためにglobalに出すのはこの関数のみにする。\n\t\timport officehelper\n\t\tfrom functools import wraps\n\t\timport sys\n\t\tfrom com.sun.star.beans import PropertyValue # Struct\n\t\tfrom com.sun.star.script.provider import XScriptContext \n\t\tdef connectOffice(func): # funcの前後でOffice接続の処理\n\t\t\t@wraps(func)\n\t\t\tdef wrapper(): # LibreOfficeをバックグラウンドで起動してコンポーネントテクストとサービスマネジャーを取得する。\n\t\t\t\ttry:\n\t\t\t\t\tctx = officehelper.bootstrap() # コンポーネントコンテクストの取得。\n\t\t\t\texcept:\n\t\t\t\t\tprint(\"Could not establish a connection with a running office.\", file=sys.stderr)\n\t\t\t\t\tsys.exit()\n\t\t\t\tprint(\"Connected to a running office ...\")\n\t\t\t\tsmgr = ctx.getServiceManager() # サービスマネジャーの取得。\n\t\t\t\tprint(\"Using {} {}\".format(*_getLOVersion(ctx, smgr))) # LibreOfficeのバージョンを出力。\n\t\t\t\treturn func(ctx, smgr) # 引数の関数の実行。\n\t\t\tdef _getLOVersion(ctx, smgr): # LibreOfficeの名前とバージョンを返す。\n\t\t\t\tcp = smgr.createInstanceWithContext('com.sun.star.configuration.ConfigurationProvider', ctx)\n\t\t\t\tnode = PropertyValue(Name = 'nodepath', Value = 'org.openoffice.Setup/Product' ) # share/registry/main.xcd内のノードパス。\n\t\t\t\tca = cp.createInstanceWithArguments('com.sun.star.configuration.ConfigurationAccess', (node,))\n\t\t\t\treturn ca.getPropertyValues(('ooName', 'ooSetupVersion')) # LibreOfficeの名前とバージョンをタプルで返す。\n\t\t\treturn wrapper\n\t\t@connectOffice # createXSCRIPTCONTEXTの引数にctxとsmgrを渡すデコレータ。\n\t\tdef createXSCRIPTCONTEXT(ctx, smgr): # XSCRIPTCONTEXTを生成。\n\t\t\tclass ScriptContext(unohelper.Base, XScriptContext):\n\t\t\t\tdef __init__(self, ctx):\n\t\t\t\t\tself.ctx = ctx\n\t\t\t\tdef getComponentContext(self):\n\t\t\t\t\treturn self.ctx\n\t\t\t\tdef getDesktop(self):\n\t\t\t\t\treturn ctx.getByName('/singletons/com.sun.star.frame.theDesktop') # com.sun.star.frame.Desktopはdeprecatedになっている。\n\t\t\t\tdef getDocument(self):\n\t\t\t\t\treturn self.getDesktop().getCurrentComponent()\n\t\t\treturn ScriptContext(ctx) \n\t\treturn createXSCRIPTCONTEXT() # XSCRIPTCONTEXTの取得。\n\tXSCRIPTCONTEXT = automation() # XSCRIPTCONTEXTを取得。\t\n\tmain() "
},
{
"alpha_fraction": 0.8270573019981384,
"alphanum_fraction": 0.8283354640007019,
"avg_line_length": 67.2617416381836,
"blob_id": "17ee70e8fd6671f2cb86e79a68ac4d6ac7fb1ee7",
"content_id": "2dcf05b15be2f534c154ed20a7810c76805ea2e0",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13023,
"license_type": "permissive",
"max_line_length": 262,
"num_lines": 149,
"path": "/EventDrivenEmbeddedMacro/src/Scripts/python/embeddedmacro.py",
"repo_name": "p--q/EventDrivenEmbeddedMacros",
"src_encoding": "UTF-8",
"text": "#!/opt/libreoffice6.4/program/python\n# -*- coding: utf-8 -*-\ndef macro(documentevent=None): # 引数は文書のイベント駆動用。 \n\tdoc = XSCRIPTCONTEXT.getDocument() if documentevent is None else documentevent.Source # ドキュメントのモデルを取得。 \n\tctx = XSCRIPTCONTEXT.getComponentContext() # コンポーネントコンテクストの取得。\n\n\n\n\n\n\nimport sys\nfrom types import ModuleType\ndef macro(documentevent=None): # 引数は文書のイベント駆動用。 \n\tdoc = XSCRIPTCONTEXT.getDocument() if documentevent is None else documentevent.Source # ドキュメントのモデルを取得。 \n\tctx = XSCRIPTCONTEXT.getComponentContext() # コンポーネントコンテクストの取得。\n\tsmgr = ctx.getServiceManager() # サービスマネージャーの取得。\n\tsimplefileaccess = smgr.createInstanceWithContext(\"com.sun.star.ucb.SimpleFileAccess\", ctx) # SimpleFileAccess\n\tmodulefolderpath = getModuleFolderPath(ctx, smgr, doc) # 埋め込みpythonpathフォルダのパスを取得。\n\ttdocimport = load_module(simplefileaccess, \"/\".join((modulefolderpath, \"tdocimport.py\"))) # import hooks\n\ttdocimport.install_meta(simplefileaccess, modulefolderpath)\n\tfrom pqmyrs2 import listeners # ここでインポートしたモジュールの関数だけなぜかXSCRIPTCONTEXTが使えない。デコレーターも不可。\n\tlisteners.addLinsteners(tdocimport, modulefolderpath, XSCRIPTCONTEXT) # tdocimportとmodulefolderpathは最後にremoveするために渡す。\ndef load_module(simplefileaccess, modulepath):\n\tinputstream = simplefileaccess.openFileRead(modulepath)\n\tdummy, b = inputstream.readBytes([], inputstream.available()) # simplefileaccess.getSize(module_tdocurl)は0が返る。\n\tsource = bytes(b).decode(\"utf-8\") # モジュールのソースをテキストで取得。\n\tmod = sys.modules.setdefault(modulepath, ModuleType(modulepath)) # 新規モジュールをsys.modulesに挿入。\n\tcode = compile(source, modulepath, 'exec') # urlを呼び出し元としてソースコードをコンパイルする。\n\tmod.__file__ = modulepath # モジュールの__file__を設定。\n\tmod.__package__ = '' # モジュールの__package__を設定。\n\texec(code, mod.__dict__) # モジュールの名前空間を設定する。\n\treturn mod\ndef getModuleFolderPath(ctx, smgr, doc):\n\ttransientdocumentsdocumentcontentfactory = smgr.createInstanceWithContext(\"com.sun.star.frame.TransientDocumentsDocumentContentFactory\", ctx)\n\ttransientdocumentsdocumentcontent = transientdocumentsdocumentcontentfactory.createDocumentContent(doc)\n\ttdocurl = transientdocumentsdocumentcontent.getIdentifier().getContentIdentifier() # ex. vnd.sun.star.tdoc:/1\t\n\treturn \"/\".join((tdocurl, \"Scripts/python/pythonpath\")) # 開いているドキュメント内の埋め込みマクロフォルダへのパス。\ng_exportedScripts = macro, #マクロセレクターに限定表示させる関数をタプルで指定。\t\n\n#!/opt/libreoffice5.4/program/python\n# -*- coding: utf-8 -*-\n# embeddedmacro.pyから呼び出した関数ではXSCRIPTCONTEXTは使えない。デコレーターも使えない。import pydevd; pydevd.settrace(stdoutToServer=True, stderrToServer=True)でブレークする。\nimport unohelper # オートメーションには必須(必須なのはuno)。\nfrom . import commons, exceptiondialog2\nfrom com.sun.star.awt import XEnhancedMouseClickHandler\nfrom com.sun.star.document import XDocumentEventListener\nfrom com.sun.star.sheet import XActivationEventListener\nfrom com.sun.star.ui import XContextMenuInterceptor\nfrom com.sun.star.ui.ContextMenuInterceptorAction import IGNORED # enum\nfrom com.sun.star.util import XChangesListener\nfrom com.sun.star.view import XSelectionChangeListener\ndef invokeModuleMethod(name, methodname, *args): # commons.getModle()でモジュールを振り分けてそのモジュールのmethodnameのメソッドを引数argsで呼び出す。\n# \timport pydevd; pydevd.settrace(stdoutToServer=True, stderrToServer=True) # ここでブレークするとすべてのイベントでブレークすることになる。\n\ttry:\n\t\tm = commons.getModule(name) # モジュールを取得。\n\t\tif hasattr(m, methodname): # モジュールにmethodnameの関数が存在する時。\t\n\t\t\treturn getattr(m, methodname)(*args) # その関数を実行。\n\t\treturn None # メソッドが見つからなかった時はNoneを返す。ハンドラやインターセプターは戻り値の処理が必ず必要。\n\texcept: # UNO APIのメソッド以外のエラーはダイアログがでないのでここで捉える。\n\t\texceptiondialog2.createDialog(args[-1]) # XSCRIPTCONTEXTを渡す。\ndef addLinsteners(tdocimport, modulefolderpath, xscriptcontext): # 引数は文書のイベント駆動用。\n\tinvokeModuleMethod(None, \"documentOnLoad\", xscriptcontext) # ドキュメントを開いた時に実行するメソッド。他のリスナー追加前。リスナー追加後でもリスナーは発火しない模様。\n\tdoc = xscriptcontext.getDocument() # ドキュメントのモデルを取得。 \n\tcontroller = doc.getCurrentController() # コントローラの取得。\n\tchangeslistener = ChangesListener(xscriptcontext) # ChangesListener。セルの変化の感知に利用。列の挿入も感知。\n\tselectionchangelistener = SelectionChangeListener(xscriptcontext) # SelectionChangeListener。選択範囲の変更の感知に利用。\n\tactivationeventlistener = ActivationEventListener(xscriptcontext, selectionchangelistener) # ActivationEventListener。シートの切替の感知に利用。selectionchangelistenerを無効にするために渡す。\n\tenhancedmouseclickhandler = EnhancedMouseClickHandler(xscriptcontext) # EnhancedMouseClickHandler。マウスの左クリックの感知に利用。enhancedmouseeventのSourceはNone。\n\tcontextmenuinterceptor = ContextMenuInterceptor(xscriptcontext) # ContextMenuInterceptor。右クリックメニューの変更に利用。\n\tdoc.addChangesListener(changeslistener)\n\tcontroller.addSelectionChangeListener(selectionchangelistener)\n\tcontroller.addActivationEventListener(activationeventlistener)\n\tcontroller.addEnhancedMouseClickHandler(enhancedmouseclickhandler)\n\tcontroller.registerContextMenuInterceptor(contextmenuinterceptor)\n\tlisteners = changeslistener, selectionchangelistener, activationeventlistener, enhancedmouseclickhandler, contextmenuinterceptor\n\tdoc.addDocumentEventListener(DocumentEventListener(xscriptcontext, tdocimport, modulefolderpath, controller, *listeners)) # DocumentEventListener。ドキュメントとコントローラに追加したリスナーの除去に利用。\nclass DocumentEventListener(unohelper.Base, XDocumentEventListener):\n\tdef __init__(self, xscriptcontext, *args):\n\t\tself.xscriptcontext = xscriptcontext\n\t\tself.args = args\n\tdef documentEventOccured(self, documentevent):\n\t\teventname = documentevent.EventName\n\t\tif eventname==\"OnUnload\": # ドキュメントを閉じる時。リスナーを除去する。\n\t\t\ttdocimport, modulefolderpath, controller, changeslistener, selectionchangelistener, activationeventlistener, enhancedmouseclickhandler, contextmenuinterceptor = self.args\n\t\t\ttdocimport.remove_meta(modulefolderpath) # modulefolderpathをメタパスから除去する。\n\t\t\tdocumentevent.Source.removeChangesListener(changeslistener)\n\t\t\tcontroller.removeSelectionChangeListener(selectionchangelistener)\n\t\t\tcontroller.removeActivationEventListener(activationeventlistener)\n\t\t\tcontroller.removeEnhancedMouseClickHandler(enhancedmouseclickhandler)\n\t\t\tcontroller.releaseContextMenuInterceptor(contextmenuinterceptor)\n\t\t\tinvokeModuleMethod(None, \"documentUnLoad\", self.xscriptcontext) # ドキュメントを閉じた時に実行するメソッド。\n\tdef disposing(self, eventobject): # ドキュメントを閉じるときに発火する。\t\n\t\teventobject.Source.removeDocumentEventListener(self)\nclass ActivationEventListener(unohelper.Base, XActivationEventListener):\n\tdef __init__(self, xscriptcontext, selectionchangelistener):\n\t\tself.xscriptcontext = xscriptcontext\n\t\tself.selectionchangelistener = selectionchangelistener\n\tdef activeSpreadsheetChanged(self, activationevent): # アクティブシートが変化した時に発火。\n\t\tcontroller = activationevent.Source\n\t\tcontroller.removeSelectionChangeListener(self.selectionchangelistener) # シートを切り替えた時はselectionchangelistenerが発火しないようにSelectionChangeListenerをはずす。\n\t\tinvokeModuleMethod(activationevent.ActiveSheet.getName(), \"activeSpreadsheetChanged\", activationevent, self.xscriptcontext)\n\t\tcontroller.addSelectionChangeListener(self.selectionchangelistener) # SelectionChangeListenerを付け直す。\n\tdef disposing(self, eventobject):\n\t\teventobject.Source.removeActivationEventListener(self)\t\nclass EnhancedMouseClickHandler(unohelper.Base, XEnhancedMouseClickHandler): # enhancedmouseeventのSourceはNoneなので、このリスナーのメソッドの引数からコントローラーを直接取得する方法はない。\n\tdef __init__(self, xscriptcontext):\n\t\tself.xscriptcontext = xscriptcontext\n\tdef mousePressed(self, enhancedmouseevent): # セルをクリックした時に発火する。固定行列の最初のクリックは同じ相対位置の固定していないセルが返ってくる(表示されている自由行の先頭行に背景色がる時のみ)。\n\t\ttarget = enhancedmouseevent.Target # ターゲットのセルを取得。\n\t\tif target.supportsService(\"com.sun.star.sheet.SheetCellRange\"): # targetがチャートの時がありうる?\n\t\t\tb = invokeModuleMethod(target.getSpreadsheet().getName(), \"mousePressed\", enhancedmouseevent, self.xscriptcontext) # 正しく実行されれば、ブーリアンが返ってくるはず。\n\t\t\tif b is not None:\n\t\t\t\treturn b\n\t\treturn True # Falseを返すと右クリックメニューがでてこなくなる。\t\t\n\tdef mouseReleased(self, enhancedmouseevent):\n\t\treturn True # シングルクリックでFalseを返すとセル選択範囲の決定の状態になってどうしようもなくなる。\n\tdef disposing(self, eventobject): # eventobject.SourceはNone。\n\t\tself.xscriptcontext.getDocument().getCurrentController().removeEnhancedMouseClickHandler(self)\nclass SelectionChangeListener(unohelper.Base, XSelectionChangeListener):\n\tdef __init__(self, xscriptcontext):\n\t\tself.xscriptcontext = xscriptcontext\n\t\tself.selectionrangeaddress = None # selectionChanged()メソッドが何回も無駄に発火するので選択範囲アドレスのStructをキャッシュして比較する。\n\tdef selectionChanged(self, eventobject): # マウスから呼び出した時の反応が遅い。このメソッドでエラーがでるとショートカットキーでの操作が必要。\n\t\tselection = eventobject.Source.getSelection()\n\t\tif hasattr(selection, \"getRangeAddress\"): # 選択範囲がセル範囲とは限らないのでgetRangeAddress()メソッドがあるか確認する。\n\t\t\tselectionrangeaddress = selection.getRangeAddress()\n\t\t\tif selectionrangeaddress==self.selectionrangeaddress: # キャッシュのセル範囲アドレスと一致する時。Structで比較。セル範囲では比較できない。\n\t\t\t\treturn # 何もしない。\n\t\t\telse: # キャッシュのセル範囲と一致しない時。\n\t\t\t\tself.selectionrangeaddress = selectionrangeaddress # キャッシュを更新。\n\t\tinvokeModuleMethod(eventobject.Source.getActiveSheet().getName(), \"selectionChanged\", eventobject, self.xscriptcontext)\t\n\tdef disposing(self, eventobject):\n\t\teventobject.Source.removeSelectionChangeListener(self)\t\t\nclass ChangesListener(unohelper.Base, XChangesListener):\n\tdef __init__(self, xscriptcontext):\n\t\tself.xscriptcontext = xscriptcontext\n\tdef changesOccurred(self, changesevent): # Sourceにはドキュメントが入る。\n\t\tinvokeModuleMethod(changesevent.Source.getCurrentController().getActiveSheet().getName(), \"changesOccurred\", changesevent, self.xscriptcontext)\t\t\t\t\t\t\t\n\tdef disposing(self, eventobject):\n\t\teventobject.Source.removeChangesListener(self)\t\t\t\nclass ContextMenuInterceptor(unohelper.Base, XContextMenuInterceptor): # コンテクストメニューのカスタマイズ。\n\tdef __init__(self, xscriptcontext):\n\t\tself.xscriptcontext = xscriptcontext\n\tdef notifyContextMenuExecute(self, contextmenuexecuteevent): # 右クリックで呼ばれる関数。contextmenuexecuteevent.ActionTriggerContainerを操作しないとコンテクストメニューが表示されない。:\n\t\tcontextmenuinterceptoraction = invokeModuleMethod(contextmenuexecuteevent.Selection.getActiveSheet().getName(), \"notifyContextMenuExecute\", contextmenuexecuteevent, self.xscriptcontext) # 正しく実行されれば、enumのcom.sun.star.ui.ContextMenuInterceptorActionのいずれかが返るはず。\t\n\t\tif contextmenuinterceptoraction is not None:\n\t\t\treturn contextmenuinterceptoraction\n\t\treturn IGNORED # コンテクストメニューのカスタマイズをしない。\n"
}
] | 4 |
mrdremack/SmallCircle
|
https://github.com/mrdremack/SmallCircle
|
17702f379afc2e31f18ef3bf73df7e577c2288e8
|
376aff1477056088a37fc34125cf4fc338235210
|
4195c653c24f25aa833b14e905e6e17a63a18645
|
refs/heads/master
| 2021-01-12T04:31:48.912487 | 2017-01-13T00:31:40 | 2017-01-13T00:31:40 | 77,646,802 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7017623782157898,
"alphanum_fraction": 0.7038626670837402,
"avg_line_length": 25.11933135986328,
"blob_id": "bf48143c341e468edc70af4c67beca174e3962b7",
"content_id": "4673f698f8e9446fd24cfa78eba54d360dbe89ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10951,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 419,
"path": "/SmallCircle/smallcircle_app/views.py",
"repo_name": "mrdremack/SmallCircle",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, redirect, get_object_or_404 \nfrom django.http import HttpResponseRedirect, HttpResponse\nfrom django.contrib.auth.models import User \nfrom models import Category, Media, UserProfile\nfrom forms import CategoryForm, MediaForm, UserForm, UserProfileForm, ContactForm, PasswordRecoveryForm\nfrom django.contrib.auth import authenticate, logout, login \nfrom django.contrib.auth.decorators import login_required\nfrom datetime import datetime\nfrom search import run_query\n#from suggest import get_category_list\nfrom django.contrib.auth.forms import PasswordChangeForm\nfrom django.views.generic import FormView\nfrom django.core.urlresolvers import reverse_lazy\nfrom django.contrib.auth import update_session_auth_hash\n#from braces.views import LoginRequiredMixin\nfrom embed_video.fields import EmbedVideoField\nfrom django.views.decorators import csrf\nfrom django.views.decorators.csrf import csrf_protect\n\n\n# Create your views here.\ndef index(request):\n\tcontext_dict = {}\n\tvid_list = Media.objects.filter(category__name ='video')\n\taudio_list = Media.objects.filter(category__name ='audio')\n\tquote_list = Media.objects.filter(category__name ='quotes')\n\n\tcontext_dict['videos'] = vid_list\n\tcontext_dict['audio'] = audio_list\n\tcontext_dict['quote'] = quote_list\n\n\tresponse = render(request ,'index.html', context_dict)\n\n\treturn response\n\n\t#request.session.set_test_cookie()\n\t#if request.session.test_cookie_worked():\n\t#\tprint \">>> TEST COOKIE WORKED\"\n\t#\trequest.session.delete_test_cookie()\n\n\tcontext_dict={'boldmessage','SmallCircle'}\n\t\n\n\t#media_list = Media.objects.order_by('-updated_at')\n\n\t# page_list = Page.objects.order_by('-views')[:5]\n\t# context_dict['pages'] = page_list\n\n\t\n\t\n\t#context_dict['visits'] = visits\n\t\n\n\n\ndef user_profile(request, user_username):\n\tcontext_dict={}\n\tuser = User.objects.get(username = user_username)\n\tprofile = UserProfile.objects.get(user = user)\n\tcontext_dict['profile'] = profile\n\tvid_list = Media.objects.get(user=user).filter(category='video').order_by('-updated_at')\n\taudio_list = Media.objects.get(user=user).filter(category='audio').order_by('-updated_at')\n\tquote_list = Media.objects.get(user=user).filter(category='quotes').order_by('-updated_at')\n\n\tcontext_dict['videos'] = vid_list\n\tcontext_dict['audio'] = audio_list\n\tcontext_dict['quote'] = quote_list\n\treturn render(request, 'profile.html', context_dict)\n\n\t# #category_list = Category.objects.order_by('-likes')[:5]\n\t# #context_dict['media'] = category_list \n\t# #page_list = Page.objects.order_by('-views')[:5]\n\t# #context_dict['pages'] = page_list\n\n\t#visits = int(request.COOKIES.get('visits','1'))\n\t#visits = request.session.get('visits')\n\n\tif not visits:\n\t\tvisits = 1\n\n\treset_last_visit_time = False\n\n\tif 'last_visit' in request.COOKIES:\n\t\tlast_visit = request.COOKIES['last_visit']\n\tlast_visit = request.session.get('last_visit')\n\tif last_visit:\n\t\tlast_visit_time = datetime.strptime(last_visit[:-7], \"%Y-%m-%d %H:%M:%S\")\n\n\t\tif (datetime.now()-last_visit_time).days>0:\n\t\t\tvisits = visits +1\n\t\t\treset_last_visit_time = True\n\n\telse:\n\t\treset_last_visit_time = True\n\n\n\tif reset_last_visit_time:\n\t\tresponse.set_cookie('last_visit', datetime.now())\n\t\tresponse.set_cookie('visits', visits)\n\t\trequest.session['last_visit'] = str(datetime.now())\n\t\trequest.session['visits'] = visits\n\n\tcontext_dict['visits'] = visits\n\n\t\n\n\n\ndef about(request):\n\tcontext_dict = {}\n\tif request.session.get('visits'):\n\t\tcount = request.session.get('visit')\n\telse: count = 0\n\n\tcount = +1\n\tcontext_dict['visits']= count\n\n\treturn render (request,'about.html',context_dict)\n\t\n\n\n\n#Created cont_dict for results_list and query witout setting values to the dictionary.\n#\n#.strip- takes out extra spaces added in the search.\n#saved result_list that get returned after running a query on rooturl in search.py.\n#adding the returned result list to result list in context_dict.\n\n\ndef category(request, category_name_slug):\n\tcontext_dict = {}\n\tcontext_dict ['result_list'] = None\n\tcontext_dict['query'] = None\n\n\tif request.method == 'POST':\n\t\tquery = request.POST['query'].strip()\n\n\t\tif query:\n\t\t\tresult_list = run_query(query)\n\t\t\tcontext_dict['result_list'] = result_list\n\t\t\t#print result_list\n\t\t\tcontext_dict['query'] = query\n\n\ttry:\n\t\tcategory = Category.objects.get(slug=category_name_slug)\n\t\tmedia = Media.objects.filter(category=category)\n\n\t\tcontext_dict['category'] = category\n\t\tcontext_dict['media'] = media\n\n\texcept Category.DoesNotExist:\n\t\tpass\n\n\treturn render(request, 'category.html', context_dict)\n\n@login_required\ndef add_category(request):\n \t\tif request.method == 'POST':\n \t\t\tform = CategoryForm(request.POST)\n\t\t\tif form.is_valid():\n \t\t\t\tcat = form.save(commit=False)\n \t\t\t\tcat.user = request.user\n \t\t\t\tcat.save()\n\n \t\t\t\treturn index(request)\n \t\t\telse:\n \t\t\t\tprint form.errors\n \t\telse:\n\t\t\tform = CategoryForm()\n\n \t\treturn render(request,'add_category.html', {'form':form})\t\t\t\t\n\n#@login_required\ndef add_media(request, category_name_slug):\n\ttry:\n\t\t\tcat = Category.objects.get(slug=category_name_slug)\n\texcept Category.DoesNotExist:\n\t\t\tcat = None\n\n\tif request.method =='POST':\n\t\tform = MediaForm(request.POST)\n\n\t\tif form.is_valid():\n\t\t\tif cat:\n\n\t\t\t\tmedia = form.save(commit=False)\n\t\t\t\tmedia.user = request.user\n\t\t\t\tmedia.category = cat\n\t\t\t\tmedia.views = 0 \n\t\t\t\tprint cat.id\n \t\t\t \tmedia.save()\n\t\t\t\treturn category(request, category_name_slug)\n\t\t\telse:\n\t\t\t\tprint form.errors\n\t\telse:\n\t\t\tprint form.errors\n\telse:\n\t\tform = MediaForm()\n\n\t\tcontext_dict = {'form':form, 'category':cat, 'slug':category_name_slug}\n\n\treturn render(request, 'add_media.html', context_dict)\n\n\ndef register(request):\n\tregistered = False\n\tif request.method == 'POST':\n\t\t#Attempt to grab information from the raw form information.\n\t\t#Note that we make use of both UserForm and UserProfileForm.\n\t\tuser_form = UserForm(data=request.POST)\n\t\tprofile_form = UserProfileForm(data=request.POST)\n\n\t\tif user_form.is_valid() and profile_form.is_valid:\n\t\t\t# Save the user's form data to the database.\n\t\t\tuser = user_form.save()\n\n\t\t\tuser.set_password(user.password)\n\t\t\tuser.save()\n\n\t\t\tprofile = profile_form.save(commit = False)\n\t\t\tprofile.user = user\n\n\t\t\tif 'picture' in request.FILES:\n\t\t\t\tprofile.picture = request.FILES['picture']\n\n\t\t\tprofile.save()\n\n\t\t\tregistered = True\n\n\t\telse:\n\t\t\tprint user_form.errors, profile_form.errors\n\telse:\n\t\tuser_form = UserForm()\n\t\tprofile_form = UserProfileForm()\n\n\treturn render(request,'register.html', {'user_form': user_form, 'profile_form': profile_form, 'registered': registered} )\n\n\ndef user_login(request):\n\tif request.method == 'POST':\n\t\tusername = request.POST.get('username' )\n\t\tpassword = request.POST.get('password') \n\t\tuser = authenticate(username=username, password=password)\n\t\tif user:\n\t\t\tif user.is_active:\n\t\t\t\tlogin(request, user)\n\t\t\t\treturn HttpResponseRedirect('/')\n\t\t\telse: \n\t\t\t\t\treturn HttpResponse(\"Your account is disabled.\")\n\t\telse:\n\t\t\tprint \"Invalid login details: {0},{1}\". format (username, password)\n\t\t\treturn HttpResponse(\"Invalid login details supplied.\")\n\telse:\n\t\treturn render (request,'login.html',{})\n\n\ndef user_logout(request):\n\tlogout(request)\n\treturn HttpResponseRedirect('/')\n\n\ndef track_url(request):\n\tmedia_id = None #page id is the variable = none\n\turl = '/' #url = home\n\n\n\tif request.method == 'GET':\n\t\tif 'media_id' in request.GET: #page_id here = value\n\t\t\tmedia_id = request.GET['page_id']\n\t\t\ttry:\n\t\t\t\tmedia = Media.objects.get(id=media_id)\n\t\t\t\tmedia.views = media.views + 1\n\t\t\t\tm.save()\n\t\t\t\turl = media.url\n\t\t\texcept:\n\t\t\t\tpass \n\treturn redirect(url)\n\ndef user_profile(request, user_username):\n \tcontext_dict={}\n \tuser = User.objects.get(username = user_username)\n \tprofile = UserProfile.objects.get(user = user)\n \tcontext_dict['profile'] = profile\n \tcontext_dict['media'] = Media.objects.filter(user=user)\n\n \treturn render(request, 'profile.html', context_dict)\n\n@login_required\ndef edit_profile(request, user_username):\n\tprofile = get_object_or_404(UserProfile, user__username=user_username)\n\twebsite = profile.webiste\n\tpic = profile.picture\n\tbio = profile.bio\n\n\tif request.user != profile.user:\n\t\treturn HttpResponse('Access Denied')\n\n\tif request.method == 'POST':\n\t\tform = UserProfileForm(data = request.POST)\n\t\tif form.is_valid():\n\t\t\tif request.POST['website'] and request.POST['website'] != '':\n\t\t\t\tprofile.website = request.POST['website']\n\t\t\telse: \n\t\t\t\tprofile.website = website\n\n\t\t\tif request.POST['bio'] and request.POST['bio'] != '':\n\t\t\t\tprofile.bio = request.POST['bio']\n\t\t\telse:\n\t\t\t\tprofile.bio = bio\n\n\t\t\tif 'picture' in request.FILES:\n\t\t\t\tprofile.picture = request.FILES['picture']\n\t\t\telse:\n\t\t\t\tprofile.picutre= pic\n\n\t\t\tprofile.save()\n\n\t\t\treturn user_profile(request, profile.user.username)\n\n\t\telse:\n\t\t\tprint form.errors\n\telse:\n\t\tform = UserProfileForm()\n\treturn render(request, 'edit_profile.html', {'form':form, 'profile':profile})\n\n\ndef contact(request):\n\tif request.method == 'POST':\n\t\tform = ContactForm(request.POST)\n\n\t\tif form.is_valid():\n\t\t\tform.send_message()\n\n\t\t\treturn HttpResponseRedirect()\n\t\telse: \n\t\t\tprint form.errors\n\telse:\n\t\tform = ContactForm()\n\treturn render(request, 'contact.html', {'form':form})\n\n\n@login_required\ndef like_category(request):\n\tcat_id = None\n\tif request.method ==\"GET\":\n\t\tcat_id=request.GET['category_id']\n\n\tlikes = 0\n\n\tif cat_id:\n\t\tcat = Category.object.get(id=int(cat_id))\n\t\tif cat:\n\t\t\tlikes = cat.likes + 1\n\t\t\tcat.likes = likes\n\t\t\tcat.save()\n\n\treturn HttpResponse(likes)\n\n\ndef suggest_category(request):\n\tcat_list = []\n\tstarts_with =''\n\n\tif request.method == 'GET':\n\t\tstarts_with = request.GET['suggestion']\n\n\tcat_list = get_category_list(8, starts_with)\n\n\treturn render(request, 'cat.html', {'cats':cat_list})\n\n@login_required\ndef auto_add_media(request):\n\tcat_id= None\n\turl = None\n\ttitle = None\n\tUser = None\n\tmedia = None\n\tcontext_dict = {}\n\n\tif request.method =='GET':\n\t\tcat_id = request.GEt['category_id']\n\t\turl = request.GET['url']\n\t\ttitle = request.GET['title']\n\t\tuser = request.GET['user']\n\t\tmedia = request.GET['media']\n\n\t\tif cat_id and user:\n\t\t\tcategory = Category.objects.get(id=int(cat_id))\n\t\t\tuser = User.objects.get(username=user)\n\t\t\tM = Media.objects.get_or_create(category=category, user=user, title=title, url=url)\n\n\tmedia = Media.objects.filter(category=category).order_by('-views')\n\n\tcontext_dict['media'] = media\n\n\treturn render(request, 'media_list.html', context_dict)\n\n\n#class SettingsView(LoginRequiredMixin, FormView):\n\ttemplate_name='settings.html'\n\tform_class= PasswordChangeForm\n\tsuccess_url=reverse_lazy('index')\n\n\tdef get_form(self, form_class):\n\t\treturn form_class(user=self.request.user,**self.get_form_kwargs())\n\n\tdef form_valid(self, form):\n\t\tform.save()\n\t\tupdate_session_auth_hash(self.request, form.user)\n\t\treturn super(SettingsView, self).form_valid(form)\n\nclass PasswordRecoveryView(FormView):\n\ttemplate_name =\"passwordrecovery.html\"\n\tform_class = PasswordRecoveryForm\n\tsuccess_url = reverse_lazy('login')\n\n\tdef form_valid(self, form):\n\t\tform.reset_email()\n\t\treturn super(PasswordRecoveryView, self).form_valid(form)\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.7724137902259827,
"alphanum_fraction": 0.7724137902259827,
"avg_line_length": 19.714284896850586,
"blob_id": "5d41ee97d40dd1326f7e0282c238c8e46117721e",
"content_id": "e9c91fa87cd897d41ee61aa1f2d4318988f196f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 145,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 7,
"path": "/SmallCircle/smallcircle_app/apps.py",
"repo_name": "mrdremack/SmallCircle",
"src_encoding": "UTF-8",
"text": "from __future__ import unicode_literals\n\nfrom django.apps import AppConfig\n\n\nclass smallcircleAppConfig(AppConfig):\n name = 'smallcircle_app'\n"
},
{
"alpha_fraction": 0.5153754949569702,
"alphanum_fraction": 0.5266114473342896,
"avg_line_length": 31.209524154663086,
"blob_id": "dac70dbe1ed2766e292d99273299eed370123a7f",
"content_id": "80900780f68ef8218edc289cfa68e19d94947e32",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3382,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 105,
"path": "/SmallCircle/smallcircle_app/migrations/0002_auto_20170112_0411.py",
"repo_name": "mrdremack/SmallCircle",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.10.5 on 2017-01-12 04:11\nfrom __future__ import unicode_literals\n\nfrom django.conf import settings\nfrom django.db import migrations, models\nimport django.db.models.deletion\nimport embed_video.fields\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n migrations.swappable_dependency(settings.AUTH_USER_MODEL),\n ('smallcircle_app', '0001_initial'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Media',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('title', models.CharField(max_length=128)),\n ('url', models.URLField()),\n ('views', models.IntegerField(default=0)),\n ('likes', models.IntegerField(default=0)),\n ('audio', embed_video.fields.EmbedVideoField(blank=True)),\n ('artist', models.CharField(blank=True, max_length=128)),\n ('song', models.CharField(blank=True, max_length=128)),\n ('photo', models.ImageField(blank=True, upload_to='posts')),\n ('img_alt', models.CharField(blank=True, max_length=128)),\n ('quote', models.TextField(blank=True)),\n ('quoter', models.CharField(blank=True, max_length=128)),\n ('updated_at', models.DateTimeField(auto_now=True)),\n ('video', embed_video.fields.EmbedVideoField(blank=True)),\n ],\n ),\n migrations.DeleteModel(\n name='Account',\n ),\n migrations.RemoveField(\n model_name='audio',\n name='user',\n ),\n migrations.RemoveField(\n model_name='miscellaneous',\n name='user',\n ),\n migrations.RemoveField(\n model_name='page',\n name='category',\n ),\n migrations.RemoveField(\n model_name='page',\n name='user',\n ),\n migrations.RemoveField(\n model_name='photos',\n name='user',\n ),\n migrations.RemoveField(\n model_name='quotes',\n name='user',\n ),\n migrations.RemoveField(\n model_name='videos',\n name='user',\n ),\n migrations.RemoveField(\n model_name='category',\n name='likes',\n ),\n migrations.RemoveField(\n model_name='category',\n name='user',\n ),\n migrations.DeleteModel(\n name='Audio',\n ),\n migrations.DeleteModel(\n name='Miscellaneous',\n ),\n migrations.DeleteModel(\n name='Page',\n ),\n migrations.DeleteModel(\n name='Photos',\n ),\n migrations.DeleteModel(\n name='Quotes',\n ),\n migrations.DeleteModel(\n name='Videos',\n ),\n migrations.AddField(\n model_name='media',\n name='category',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='smallcircle_app.Category'),\n ),\n migrations.AddField(\n model_name='media',\n name='user',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7097539901733398,
"alphanum_fraction": 0.7218385934829712,
"avg_line_length": 27.956249237060547,
"blob_id": "b58dc311fad575b5f20b8931e14399f573f3fb8c",
"content_id": "7877a95367f1c335cdff4182f717a58a9b7ea944",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4634,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 160,
"path": "/SmallCircle/smallcircle_app/models.py",
"repo_name": "mrdremack/SmallCircle",
"src_encoding": "UTF-8",
"text": "from __future__ import unicode_literals\nfrom django.contrib.auth.models import User \nfrom django.db import models\nfrom embed_video.fields import EmbedVideoField\nfrom django.template.defaultfilters import slugify\n# Create your models here.\n\n\n\n\nclass UserProfile(models.Model):\n\t#This line is required. Links UserProfile to a User model instance.\n\tuser = models.OneToOneField(User)\n\n\t#The additional attributes we wish to include.\n\twebsite = models.URLField(blank=True)\n\tpicture = models.ImageField(upload_to='profile_images', blank=True)\n\tbio = models.TextField(blank=True)\n\n\t#Override the __unicode__()method to return out something meaningful:\n\tdef __unicode__(self):\n\t\treturn self.user.username\n\nclass Category(models.Model):\n\tname = models.CharField(max_length=128, unique=True)\n\tslug = models.SlugField()\n\n\tdef save(self, *args, **kwargs):\n\t\t\tself.slug = slugify(self.name)\n\t\t\tsuper(Category, self).save(*args, **kwargs)\n\t\t\n\tdef __unicode__(self):\n\t\treturn self.name\n\n\nclass Media(models.Model):\n\tuser = models.ForeignKey(User)\n\tcategory = models.ForeignKey(Category)\n\ttitle = models.CharField(max_length=128)\n\turl = models.URLField()\n\tviews = models.IntegerField(default=0)\n\tlikes = models.IntegerField(default=0)\n\taudio = EmbedVideoField(blank=True)\n\tartist = models.CharField(max_length=128, blank=True)\n\tsong = models.CharField(max_length=128, blank=True)\n\tphoto = models.ImageField(upload_to='posts', blank=True)\n\timg_alt = models.CharField(max_length=128, blank=True)\n\tquote = models.TextField(blank=True)\n\tquoter = models.CharField(max_length=128, blank=True)\n\tupdated_at = models.DateTimeField(auto_now=True)\n\tvideo = EmbedVideoField(blank=True)\n\n\n# class AccountManager(BaseUserManager):\n\n# \tdef create_user(self, email, password=None, **kwargs):\n# \t\tif not email:\n# \t\t\traise ValueError('User must have a valid address.')\n# \t\tif not kwargs.get('username'):\n# \t\t\traise ValueError('Users must have a valid username.')\n\n# \t\taccount = self.model( email=self.normalize_email(email), \n# \t\t\tusername=kwargs.get('username')\n# \t\t\t)\n\n# \t\taccount.set_password(password)\n\n# \t\taccount.save()\n\n# \t\treturn account \n\n# \tdef create_superuser(self, email, password, **kwargs):\n# \t\taccount = self.create_user(email, password, **kwargs)\n\n# \t\taccount.is_admin = True\n\n# \t\taccount.save()\n\n# \t\treturn account\n\n\n# class Account(AbstractBaseUser):\n# \temail = models.EmailField(unique=True)\n# \tusername = models.CharField(max_length=40, unique=True)\n# \tfirst_name = models.CharField(max_length=40)\n# \tlast_name = models.CharField(max_length=40)\n# \ttagline = models.CharField(max_length=40,blank=True)\n# \tis_admin = models.BooleanField(default=False)\n# \tcreated_at = models.DateTimeField(auto_now_add=True)\n# \tupdated_at = models.DateTimeField(auto_now=True)\n\n# \tobjects = AccountManager()\n\n# \tUSERNAME_FIELD = 'email'\n# \tREQUIRED_FIELDS = ['username']\n\n# \tdef __unicode__(self):\n# \t\treturn self.email\n\n# \tdef get_full_name(self):\n# \t\treturn ' '.join(self.first_name, self.last_name)\n\n# \tdef get_short_name(self):\n# \t\treturn self.first_name\t\t\n\n\n\n\t\n\n# class Page(models.Model):\n# \tuser = models.ForeignKey(User)\n# \tcategory = models.ForeignKey(Category)\n# \ttitle = models.CharField(max_length=128)\n# \turl = models.URLField()\n# \tviews = models.IntegerField(default=0)\n# \tlikes = models.IntegerField(default=0)\n\n# \tdef __unicode__(self):\n# \t\treturn self.title\n\n# class Audio(models.Model):\n# \t#This is linking the user ba\n# \tuser = models.ForeignKey(User)\n# \t#This is embeding the music from soundcloud.\n# \taudio = EmbedVideoField()\n# \tartist = models.CharField(max_length=128)\n# \tsong = models.CharField(max_length=128)\n# \tviews = models.IntegerField(default=0)\n# \tupdated_at = models.DateTimeField(auto_now=True)\n\n# class Photos(models.Model):\n# \tuser = models.ForeignKey(User)\n# \turl = models.URLField()\n# \ttitle = models.CharField(max_length=128)\n# \tviews = models.IntegerField(default=0)\n# \tupdated_at = models.DateTimeField(auto_now=True)\n\n\n# class Quotes(models.Model):\n# \tuser = models.ForeignKey(User)\n# \turl = models.URLField()\n# \tquoter = models.CharField(max_length=128)\n# \tviews = models.IntegerField(default=0)\n# \tupdated_at = models.DateTimeField(auto_now=True) \n\n\n# class Videos(models.Model):\n# \tuser = models.ForeignKey(User)\n# \tvideo = EmbedVideoField()\n# \ttitle = models.CharField(max_length=128)\n# \tviews = models.IntegerField(default=0)\n# \tupdated_at = models.DateTimeField(auto_now=True)\n\n\n#class Miscellaneous(models.Model):\n#\tuser = models.ForeignKey(User)\n#\turl = models.URLField()\n#\ttitle = models.CharField(max_length=128)\n#\tviews = models.IntegerField(default=0)\n#\tupdated_at = models.DateTimeField(auto_now=True)\n\n"
},
{
"alpha_fraction": 0.547305166721344,
"alphanum_fraction": 0.5576505661010742,
"avg_line_length": 47.723575592041016,
"blob_id": "a2800c70533b81570977c838dcb3d005b8aa54cb",
"content_id": "f163047a01216f78caad1ad6d0eecc0b7493a8c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5993,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 123,
"path": "/SmallCircle/smallcircle_app/migrations/0001_initial.py",
"repo_name": "mrdremack/SmallCircle",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.10.5 on 2017-01-08 08:04\nfrom __future__ import unicode_literals\n\nfrom django.conf import settings\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n migrations.swappable_dependency(settings.AUTH_USER_MODEL),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Account',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('password', models.CharField(max_length=128, verbose_name='password')),\n ('last_login', models.DateTimeField(blank=True, null=True, verbose_name='last login')),\n ('email', models.EmailField(max_length=254, unique=True)),\n ('username', models.CharField(max_length=40, unique=True)),\n ('first_name', models.CharField(max_length=40)),\n ('last_name', models.CharField(max_length=40)),\n ('tagline', models.CharField(blank=True, max_length=40)),\n ('is_admin', models.BooleanField(default=False)),\n ('created_at', models.DateTimeField(auto_now_add=True)),\n ('updated_at', models.DateTimeField(auto_now=True)),\n ],\n options={\n 'abstract': False,\n },\n ),\n migrations.CreateModel(\n name='Audio',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('artist', models.CharField(max_length=128)),\n ('song', models.CharField(max_length=128)),\n ('views', models.IntegerField(default=0)),\n ('updated_at', models.DateTimeField(auto_now=True)),\n ('user', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL)),\n ],\n ),\n migrations.CreateModel(\n name='Category',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=128, unique=True)),\n ('likes', models.IntegerField(default=0)),\n ('slug', models.SlugField()),\n ('user', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL)),\n ],\n ),\n migrations.CreateModel(\n name='Miscellaneous',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('url', models.URLField()),\n ('title', models.CharField(max_length=128)),\n ('views', models.IntegerField(default=0)),\n ('updated_at', models.DateTimeField(auto_now=True)),\n ('user', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL)),\n ],\n ),\n migrations.CreateModel(\n name='Page',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('title', models.CharField(max_length=128)),\n ('url', models.URLField()),\n ('views', models.IntegerField(default=0)),\n ('category', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='smallcircle_app.Category')),\n ('user', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL)),\n ],\n ),\n migrations.CreateModel(\n name='Photos',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('url', models.URLField()),\n ('title', models.CharField(max_length=128)),\n ('views', models.IntegerField(default=0)),\n ('updated_at', models.DateTimeField(auto_now=True)),\n ('user', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL)),\n ],\n ),\n migrations.CreateModel(\n name='Quotes',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('url', models.URLField()),\n ('Quoter', models.CharField(max_length=128)),\n ('views', models.IntegerField(default=0)),\n ('updated_at', models.DateTimeField(auto_now=True)),\n ('user', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL)),\n ],\n ),\n migrations.CreateModel(\n name='UserProfile',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('website', models.URLField(blank=True)),\n ('picture', models.ImageField(blank=True, upload_to='profile_images')),\n ('bio', models.TextField(blank=True)),\n ('user', models.OneToOneField(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL)),\n ],\n ),\n migrations.CreateModel(\n name='Videos',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('title', models.CharField(max_length=128)),\n ('views', models.IntegerField(default=0)),\n ('updated_at', models.DateTimeField(auto_now=True)),\n ('user', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL)),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.807692289352417,
"alphanum_fraction": 0.807692289352417,
"avg_line_length": 28.714284896850586,
"blob_id": "a530684ae50b575fcedb274096b10e0921dcd33a",
"content_id": "c16bbfa4764b768888b5d16e3c84c17fd30d2964",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 416,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 14,
"path": "/SmallCircle/smallcircle_app/admin.py",
"repo_name": "mrdremack/SmallCircle",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom embed_video.admin import AdminVideoMixin\nfrom models import Category, Media, UserProfile\n\n#Register your models here.\n\nclass MediaAdmin(AdminVideoMixin, admin.ModelAdmin):\n\tpass\nclass CategoryAdmin(admin.ModelAdmin):\n\t\tprepopulated_fields = {'slug':('name',)}\n\nadmin.site.register(Category, CategoryAdmin)\nadmin.site.register(Media, MediaAdmin)\nadmin.site.register(UserProfile)\n"
}
] | 6 |
jwhitebored/PHYS-512
|
https://github.com/jwhitebored/PHYS-512
|
3ff6d240c6cf527f4951b102cb03992e5fc067b3
|
bd93fa84f234950c381ab94dcaacc94d780be349
|
a851e39beadcf6e762fed2b89b84cd0ce9ddeca8
|
refs/heads/master
| 2022-12-20T18:02:49.888630 | 2020-09-26T13:27:48 | 2020-09-26T13:27:48 | 296,474,448 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6495052576065063,
"alphanum_fraction": 0.6790352463722229,
"avg_line_length": 36.718563079833984,
"blob_id": "86b429d3be554cc19669177056875a5beec43508",
"content_id": "6e36e005ba0f2b76013337d93792a36d1a34146f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6468,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 167,
"path": "/Assignment 1/PHYS 512 Assignment 1 P1.py",
"repo_name": "jwhitebored/PHYS-512",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nPHYS 512\r\nAssignment 1 Problem 1\r\n@author: James Nathan White (260772425)\r\n\"\"\"\r\n#I always import this stuff\r\nimport matplotlib.pyplot as plt\r\nimport random as r\r\nimport glob\r\nimport numpy as np\r\nfrom scipy.stats import chi2\r\nimport scipy.optimize as opt\r\nfrom scipy.stats import norm\r\nimport pandas as pd\r\n\r\n#The test values of x\r\nx = np.linspace(0, 5, 11)\r\n\r\n#The Machine Epsilon Values\r\nsingle_epsilon = np.power(10.0, -8)\r\ndouble_epsilon = np.power(10.0, -16)\r\n\r\n#Optimal delta values (see attached pdf for problem 1)\r\noptimal_single_delta = 2.5*np.power(10.0, -2)\r\noptimal_double_delta = 6.3*np.power(10.0, -4)\r\n\r\n#List of different delta values to see which is roughly best\r\ndouble_deltas = np.zeros(16)\r\nfor i in range(len(double_deltas)):\r\n double_deltas[i] = 6.3*np.power(10.0, -(i+1))\r\n\r\ndef exponentiate (x):\r\n return np.power(np.e, x)\r\n\r\ndef exponentiate_hundredth (x):\r\n x01 = [0.01*i for i in x]\r\n return np.power(np.e, x01)\r\n\r\ndef exp2 (x):\r\n x2 = [2.0*i for i in x]\r\n return np.power(np.e, x2)\r\n\r\ndef identity (x):\r\n return x\r\n\r\ndef f_plus_delta (func, x, delta):\r\n xplusdelta = [i + delta for i in x]\r\n return func(xplusdelta)\r\n\r\ndef f_plus_2delta (func, x, delta):\r\n xplus2delta = [i + 2*delta for i in x]\r\n return func(xplus2delta)\r\n\r\ndef f_minus_delta (func, x, delta):\r\n xminusdelta = [i - delta for i in x]\r\n return func(xminusdelta)\r\n\r\ndef f_minus_2delta (func, x, delta):\r\n xminus2delta = [i - 2*delta for i in x]\r\n return func(xminus2delta)\r\n\r\ndef num_derivative (func, x, delta, epsilon):\r\n fprime = np.zeros(len(x))\r\n FofX = func(x)\r\n FplusD = f_plus_delta(func, x, delta)\r\n Fplus2D = f_plus_2delta(func, x, delta)\r\n FminusD = f_minus_delta(func, x, delta)\r\n Fminus2D = f_minus_2delta(func, x, delta)\r\n \r\n for i in range(len(x)):\r\n fprime[i] = (1/12/delta)*(Fminus2D[i] - Fplus2D[i] + 8*FplusD[i] - 8*FminusD[i]) + (epsilon/delta)*FofX[i] + (epsilon/30)*np.power(delta, 4)\r\n \r\n return fprime\r\n\r\n#Calculates the \"true\" test values of e^(x) and e^(0.01x)\r\ntrue_derivative_of_e_to_x = exponentiate(x)\r\ntrue_derivative_of_e_to_x01 = [0.01*i for i in exponentiate_hundredth(x)]\r\n\r\n#calculates the numerical derivatives of e^(x) and e^(0.01x) respectively\r\nnumerical_derivative_of_e_to_x = num_derivative (exponentiate, x, optimal_double_delta, double_epsilon)\r\nnumerical_derivative_of_e_to_x01 = num_derivative (exponentiate_hundredth, x, optimal_double_delta, double_epsilon)\r\n\r\n#calculates the differences between the \"true\" and numerical derivatives\r\ndiff1 = [i - j for i,j in zip(true_derivative_of_e_to_x, numerical_derivative_of_e_to_x)]\r\ndiff2 = [i - j for i,j in zip(true_derivative_of_e_to_x01, numerical_derivative_of_e_to_x01)]\r\n\r\n\r\n#Prints Data Values\r\nprint(\"x values:\", x)\r\nprint()\r\n\r\nprint(\"True derivative of e^(x):\" '\\n', true_derivative_of_e_to_x)\r\nprint(\"Numerical derivative of e^(x)\" '\\n', numerical_derivative_of_e_to_x)\r\nprint(\"Value differences:\" '\\n', diff1)\r\nprint(\"Mean Error in Evaluating e^(x):\" '\\n', np.mean(diff1))\r\nprint()\r\n\r\nprint(\"True derivative of e^(0.01x):\" '\\n', true_derivative_of_e_to_x01)\r\nprint(\"Numerical derivative of e^(0.01x)\" '\\n', numerical_derivative_of_e_to_x01)\r\nprint(\"Value differences:\" '\\n', diff2)\r\nprint(\"Mean Error in Evaluating e^(0.01x):\" '\\n', np.mean(diff2))\r\nprint()\r\n\r\n#Calculates the mean error in the derivatives (of e^(x) and e^(0.01x) respectively) for varying values of Delta\r\nmean_diff1_varied = np.zeros(len(double_deltas))\r\nmean_diff2_varied = np.zeros(len(double_deltas))\r\nnum_deriv_eto_x_varied_delta = np.zeros(len(x))\r\n#num_deriv_eto_x_varied_delta = np.zeros(len(double_deltas))\r\nfor i in range(len(double_deltas)):\r\n num_deriv_eto_x_varied_delta = num_derivative (exponentiate, x, double_deltas[i], double_epsilon)\r\n mean_diff1_varied[i] = np.mean([true_derivative_of_e_to_x - j for j in num_deriv_eto_x_varied_delta])\r\n\r\nnum_deriv_eto_01x_varied_delta = np.zeros(len(x))\r\nfor i in range(len(double_deltas)):\r\n num_deriv_eto_01x_varied_delta = num_derivative (exponentiate_hundredth, x, double_deltas[i], double_epsilon)\r\n mean_diff2_varied[i] = np.mean([true_derivative_of_e_to_x01 - j for j in num_deriv_eto_01x_varied_delta])\r\n\r\nprint(\"Mean error in numerical derivative value (of e^x) for deltas ranging from 6.3e-0 to 6.3e-15:\" '\\n', \r\n mean_diff1_varied, '\\n')\r\nprint(\"Mean error in numerical derivative value (of e^0.01x) for deltas ranging from 6.3e-0 to 6.3e-15:\" '\\n',\r\n mean_diff2_varied, '\\n')\r\nprint(\"Conclusion: the roughly optimal values of Delta computed for problem 1 are indeed roughly optimal.\")\r\n\r\n\r\n######################## The following are just my tests I did while coding\r\n\"\"\"\r\n#Varies the value of Delta to see which minimizes error in the numerical derivatives\r\nprint(double_deltas)\r\nnum_deriv_eto_x_varied_delta = np.zeros(len(double_deltas))\r\nfor i in range(len(double_deltas)):\r\n num_deriv_eto_x_varied_delta[i] = num_derivative (exponentiate, x, double_deltas[i], double_epsilon)\r\n\r\nnum_deriv_eto_01x_varied_delta = np.zeros(len(double_deltas))\r\nfor i in range(len(double_deltas)):\r\n num_deriv_eto_01x_varied_delta[i] = num_derivative (exponentiate, x, double_deltas[i], double_epsilon)\r\n\r\n#Calculates the mean error in the derivatives (of e^(x) and e^(0.01x) respectively) for varying values of Delta\r\nmean_diff1_varied = np.zeros(len(double_deltas))\r\nmean_diff2_varied = np.zeros(len(double_deltas))\r\nfor j in range(len(double_deltas)):\r\n mean_diff1_varied[j] = np.mean([true_derivative_of_e_to_x - i for i in num_deriv_eto_x_varied_delta[j]])\r\n mean_diff2_varied[j] = np.mean([true_derivative_of_e_to_x01 - i for i in num_deriv_eto_01x_varied_delta[j]])\r\n\r\nprint(mean_diffq_varied)\r\n\"\"\"\r\n\r\n\"\"\" THIS WAS JUST A TEST OF e^(2x)\r\n#Calculates the true derivative of e^(2x)\r\ntrue_derivative_of_e_to_x2 = [2*i for i in exp2(x)]\r\n\r\n#calculates the numerical derivatives of e^(2x)\r\nnumerical_derivative_of_e_to_x2 = num_derivative (exp2, x, optimal_double_delta, double_epsilon)\r\ndiff3 = [i - j for i,j in zip(true_derivative_of_e_to_x2, numerical_derivative_of_e_to_x2)]\r\n\r\nprint(true_derivative_of_e_to_x2)\r\nprint(numerical_derivative_of_e_to_x2)\r\nprint(diff3)\r\nprint(np.mean(diff3))\r\n\"\"\"\r\n\r\n\"\"\" THESE JUST TEST MY DELTA FUNCTIONS WHICH WORK FINE\r\nprint(f_plus_delta(identity, x, 2))\r\nprint(f_plus_2delta(identity, x, 2))\r\nprint(f_minus_delta(identity, x, 2))\r\nprint(f_minus_2delta(identity, x, 2))\r\n\"\"\"\r\n\r\n"
},
{
"alpha_fraction": 0.6086956262588501,
"alphanum_fraction": 0.782608687877655,
"avg_line_length": 23,
"blob_id": "db46d47a3ff9871a0fbc099be15eeb41e8ea1de0",
"content_id": "60fb0a3dbdd21e47fcd6670abb17e7cd52bfdf95",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 23,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 1,
"path": "/README.md",
"repo_name": "jwhitebored/PHYS-512",
"src_encoding": "UTF-8",
"text": "# PHYS-512-Assignment-1"
},
{
"alpha_fraction": 0.5088512301445007,
"alphanum_fraction": 0.5849341154098511,
"avg_line_length": 37.90452194213867,
"blob_id": "ff4ae99f86f22060fd9517b31aa4bea91ff2ef8e",
"content_id": "4ca031354be1410d68a124da3ff45b4343ae2647",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7965,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 199,
"path": "/Assignment 1/PHYS 512 Assignment 1 P3.py",
"repo_name": "jwhitebored/PHYS-512",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nPHYS 512\r\nAssignment 1 Problem 3\r\n@author: James Nathan White (260772425)\r\n\"\"\"\r\n\r\n#I always import this stuff\r\nimport matplotlib.pyplot as plt\r\nimport random as r\r\nimport glob\r\nimport numpy as np\r\nfrom scipy.stats import chi2\r\nimport scipy.optimize as opt\r\nfrom scipy.stats import norm\r\nimport pandas as pd\r\nfrom scipy import interpolate\r\n\r\n###################################################################################################\r\n###################################### Cos(x) Fitting #############################################\r\n###################################################################################################\r\n\r\n#simulated data values:\r\nxdata = np.linspace((-0.5*np.pi), (0.5*np.pi), 16)\r\nydata = np.cos(xdata)\r\n\r\n########################################### Cubic Spline Stuff #############################\r\n#Making the Cubic Spline\r\nspline = interpolate.splrep(xdata, ydata)\r\n\r\n#Values for plotting the cubic spline\r\nsplineDomain = np.linspace(xdata[0], xdata[-1], 1000)\r\nsplineYData = interpolate.splev(splineDomain, spline)\r\n\r\n#Values for calculating the differences between the spline fit and the true values\r\nydataSplineFit = interpolate.splev(xdata, spline)\r\n\r\n################################## Rational Function Fit Stuff #############################\r\n#defining the rational function from class:\r\ndef rat_eval(p,q,x):\r\n top = 0\r\n for i in range(len(p)):\r\n top = top + p[i]*x**i\r\n bot = 1\r\n for i in range(len(q)):\r\n bot = bot + q[i]*x**(i+1)\r\n return top/bot\r\n\r\n#rational function fitting method from class:\r\ndef rat_fit(x,y,n,m):\r\n assert(len(x) == n+m-1)\r\n assert(len(y) == len(x))\r\n mat = np.zeros([n+m-1, n+m-1]) #Makes a matrix size [rows, columns] of zeros\r\n for i in range(n):\r\n mat[:,i] = x**i #replaces [all rows, column i] with with the column vector [x**i] up to nth column\r\n for i in range(1,m):\r\n mat[:,i-1+n] = -y*x**i #replaces [all rows, column i-1 +n] with the column vector [-yx**i] after nth column\r\n pars=np.dot(np.linalg.inv(mat),y)\r\n p=pars[:n]\r\n q=pars[n:]\r\n return p,q\r\n \r\n#Calculating the Rational Function Fit\r\nn=8\r\nm=9\r\np,q = rat_fit(xdata,ydata,n,m)\r\n\r\n#Values for plotting the cubic spline\r\nratDomain = np.linspace(xdata[0], xdata[-1], 1000)\r\nratYData = rat_eval(p,q,ratDomain)\r\n\r\n#Values for calculating the differences between the rational fit and the true values\r\nydataRatFit = rat_eval(p,q,xdata)\r\n\r\n############################################### Plots for Cos(x) ######################################\r\n\r\nfig, ax = plt.subplots(2, figsize=(10,10), gridspec_kw={'height_ratios': [2, 1]})\r\n\r\n#ax = f1.add_subplot(2,1,1)\r\nax[0].plot(xdata, ydata, \"m*\", label = 'Data')\r\nax[0].plot(splineDomain, splineYData, 'b', label = 'Cubic Spline Fit')\r\nax[0].plot(ratDomain, ratYData, 'r', label = 'Rational Fit')\r\nax[0].set_xlabel(\"x\")\r\nax[0].set_ylabel(\"y\")\r\nax[0].set_title(\"Cubic Spline and Rational Fits of y=cos(x)\")\r\n\r\n##Residuals\r\ndiff1 = [i-j for i,j in zip(ydataSplineFit, ydata)]\r\ndiff2 = [i-j for i,j in zip(ydataRatFit, ydata)]\r\n\r\n#ax2.yaxis.tick_right()\r\nax[1].plot(xdata, diff1, 'bo')\r\nax[1].plot(xdata, diff2, 'ro')\r\nax[1].plot(xdata, [0]*len(xdata), color = 'black')\r\nax[1].set_xlabel(\"x\")\r\nax[1].set_ylabel(\"Spline and Rational Fit Residuals\")\r\nplt.show()\r\n\r\n#I'm happy with both my spline and rational fits on this interval, but one thing I've noticed is that\r\n#by increasing the number of data points used to make the rational fit, the worse the fit becomes near x=0\r\n#It seems to develope a spike there. It reminds me of how the edges of a square wave have tips you can't\r\n#get rid of unless you actually have an infinite amount of terms to express the function, though I doubt\r\n#that's the case here\r\n\r\n\"\"\"\r\n#Testing how matrix filling works in a for loop\r\nmat1 = np.zeros([10,10])\r\nmat2 = np.zeros([10,10])\r\nx = [1,2,3,4,5,6,7,8,9,10]\r\nfor i in range(10):\r\n mat1[:,i] = i\r\n mat2[:,i] = x\r\n\r\nprint(mat1)\r\nprint(mat2)\r\n\"\"\"\r\n#######################################################################################################\r\n############################################ Lorentzian Fitting #######################################\r\n#######################################################################################################\r\n\r\n#simulated data values:\r\nxLdata = np.linspace(-1, 1, 34)\r\nyLdata = np.array([1/(1+i**2) for i in xLdata])\r\nLorentz = [1/(1+i**2) for i in np.linspace(-1,1,100)]\r\n\r\n########################################### Cubic Spline Stuff #############################\r\n#Making the Cubic Spline\r\nsplineL = interpolate.splrep(xLdata, yLdata)\r\n\r\n#Values for plotting the cubic spline\r\nsplineDomainL = np.linspace(xLdata[0], xLdata[-1], 1000)\r\nsplineYDataL = interpolate.splev(splineDomainL, splineL)\r\n\r\n#Values for calculating the differences between the spline fit and the true values\r\nydataSplineFitL = interpolate.splev(xLdata, splineL)\r\n\r\n################################## Rational Function Fit Stuff #############################\r\n#Calculating the Rational Function Fit\r\nN=34\r\nM=1\r\nP,Q = rat_fit(xLdata,yLdata,N,M)\r\n\r\n#Values for plotting the cubic spline\r\nratDomainL = np.linspace(xLdata[0], xLdata[-1], 1000)\r\nratYDataL = rat_eval(P,Q,ratDomainL)\r\n\r\n#Values for calculating the differences between the rational fit and the true values\r\nydataRatFitL = rat_eval(P,Q,xLdata)\r\n\r\n############################## Plots for Lorentzian 1/(1+x^2) ##############################\r\n\r\nfig2, ax2 = plt.subplots(2, figsize=(10,10), gridspec_kw={'height_ratios': [2, 1]})\r\n\r\n#ax = f1.add_subplot(2,1,1)\r\nax2[0].plot(xLdata, yLdata, \"m*\", label = 'Data')\r\nax2[0].plot(splineDomainL, splineYDataL, 'b', label = 'Cubic Spline Fit')\r\nax2[0].plot(ratDomainL, ratYDataL, 'r', label = 'Rational Fit')\r\nax2[0].plot(np.linspace(-1,1,100), Lorentz, 'g')\r\nax2[0].set_xlabel(\"x\")\r\nax2[0].set_ylabel(\"y\")\r\nax2[0].set_title(\"Cubic Spline and Rational Fits of y=1/(1+x^2)\")\r\n\r\n##Residuals\r\ndiff1L = [i-j for i,j in zip(ydataSplineFitL, yLdata)]\r\ndiff2L = [i-j for i,j in zip(ydataRatFitL, yLdata)]\r\n\r\n#ax2.yaxis.tick_right()\r\nax2[1].plot(xLdata, diff1L, 'bo')\r\nax2[1].plot(xLdata, diff2L, 'ro')\r\nax2[1].plot(xLdata, [0]*len(xLdata), color = 'black')\r\nax2[1].set_xlabel(\"x\")\r\nax2[1].set_ylabel(\"Spline and Rational Fit Residuals\")\r\nplt.show()\r\n\r\n#In this plot, the green curve (the true lortentzian graph) and the red curve(the rational approximation)\r\n#overlap entirely. This is nice, but the only values of N,M where M=N+1 that produce such a good result are 2,3\r\n#and this requires there to be LESS data points to interpolate from (N,M = 2,3 implies 4 data points)! \r\n#That's a horrible result. I did actually get the rational approximation to work very nicely for the following\r\n#N,M values: [24,2], [26,2], [28,2] which use 25, 27, and 29 data points respectively, and [N<36,M=1]. But all\r\n#of these N,M pairs, got WORSE as the number of data points increased.\r\n#Looking at the P list I believe these results are due to the fact that the expansion of 1/(1+x^2) for |x|<1 is\r\n\r\n# 1 - x^2 + x^4 - x^8 + x^16 - x^32 + x^64 - x^128 + x^256 -...\r\n\r\n#All to say I'm surprised how bad this result is, and I checked over my code for hours\r\n#(not that it gaurentees anything).\r\n\r\nprint(P)\r\nprint(Q)\r\n\r\n#for N,M=35,1 P=[ 9.97000102e-01 -9.16953053e-03 -1.00382580e+00 7.48501600e-02\r\n# 9.92984504e-01 -4.34249196e-01 -9.15164433e-01 1.08110869e+00\r\n# 7.77383152e-01 -1.36070037e+00 -2.50276502e-01 1.51638412e+00\r\n# -9.18426871e-01 -2.83326721e+00 1.71587729e+00 4.20068359e+00\r\n# -1.39774561e+00 -3.61621094e+00 7.19886780e-01 2.13671875e+00\r\n# -1.78497314e-01 -1.15625000e+00 -3.25843811e-01 4.29687500e-01\r\n# 5.63583374e-01 -1.56250000e-02 -4.31777954e-01 -1.56250000e-02\r\n# 2.07420349e-01 0.00000000e+00 -6.48155212e-02 7.81250000e-03\r\n# 9.21344757e-03 -4.88281250e-04]\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5463113188743591,
"alphanum_fraction": 0.5683993697166443,
"avg_line_length": 43.00666809082031,
"blob_id": "d06cf835b049096a430a3f85614273ba6940d7e7",
"content_id": "a4fb9aa0ee0f73b7bc75de8fb933d394d8344095",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6791,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 150,
"path": "/Assignment 2/PHYS 512 Assignment 2 P1 Draft Final.py",
"repo_name": "jwhitebored/PHYS-512",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nPHYS 512\r\nAssignment 2 Problem 1\r\n@author: James Nathan White (260772425)\r\n\"\"\"\r\n#I always import this stuff\r\nimport matplotlib.pyplot as plt\r\nimport random as r\r\nimport glob\r\nimport numpy as np\r\nfrom scipy.stats import chi2\r\nimport scipy.optimize as opt\r\nfrom scipy.stats import norm\r\nimport pandas as pd\r\nfrom scipy import interpolate\r\n################################################################################\r\n\r\n##### Variable-Step-Size-Integrator from Class (With Repetative Function Calls)#\r\ndef lorentz(x):\r\n return 1/(1+x**2)\r\n\r\ndef lazy_integrate_step(fun,x1,x2,tol):\r\n #print('integrating from ',x1,' to ',x2)\r\n x=np.linspace(x1,x2,5)\r\n y=fun(x)\r\n area1=(x2-x1)*(y[0]+4*y[2]+y[4])/6\r\n area2=(x2-x1)*( y[0]+4*y[1]+2*y[2]+4*y[3]+y[4])/12\r\n myerr=np.abs(area1-area2)\r\n neval=len(x) #let's keep track of function evaluations\r\n \r\n if myerr<tol:\r\n return area2, myerr, neval\r\n \r\n else:\r\n xm=0.5*(x1+x2)\r\n a1, leftErr, leftEval= lazy_integrate_step(fun,x1,xm,tol/2)\r\n a2, rightErr, rightEval = lazy_integrate_step(fun,xm,x2,tol/2)\r\n sumError = leftErr + rightErr\r\n totEval = neval + leftEval + rightEval\r\n\r\n return a1+a2, sumError, totEval\r\n\r\n################################################################################\r\n\r\n##### Variable-Step-Size-Integrator (Without Repetative Function Calls)#########\r\ndef integrate_step(fun,x1,x2,tol, XLIST = np.array([]), YLIST = np.array([])):\r\n# print('integrating from ',x1,' to ',x2)\r\n x=np.linspace(x1,x2,5)\r\n y=np.zeros(len(x))\r\n \r\n for i in range(len(x)):\r\n if x[i] in XLIST: #if the point x[i] for this iteration is already present\r\n index = np.where(XLIST == x[i])[0] #in the ongoing list of domain points for the entire \r\n y[i] = YLIST[index] #integral (XLIST), then y(x[i]) has already been calculated \r\n #and is not calculated again. Instead it is given the \r\n #precalculated value from the ongoing list of y-values for \r\n #the entire integral: YLIST\r\n \r\n else: #if the point x[i] is not in XLIST, then y(x[i]) is not in\r\n y[i] = fun(x[i]) #YLIST, so y(x[i]) is calculated here, and then XLIST and\r\n XLIST = list(np.append(XLIST, x[i])) #YLIST are updated to inclued x[i] and y(x[i]) in the\r\n YLIST = list(np.append(YLIST, y[i])) #correct order of x[i] ascending\r\n XLIST, YLIST = [list(tuple) for tuple in zip(*sorted(zip(XLIST, YLIST)))]\r\n XLIST = np.array(XLIST)\r\n YLIST = np.array(YLIST)\r\n \r\n area1=(x2-x1)*(y[0]+4*y[2]+y[4])/6\r\n area2=(x2-x1)*( y[0]+4*y[1]+2*y[2]+4*y[3]+y[4])/12\r\n myerr=np.abs(area1-area2)\r\n neval=len(YLIST) #By my above book-keeping, the number of times y(x) is \r\n #evaluated is simply len(YLIST)\r\n# print(\"y(x) evaluations so far:\", len(YLIST))\r\n if myerr<tol: #If error is tolerable, returns area for this portion\r\n return area2, myerr, neval, XLIST, YLIST #of the integral\r\n \r\n else: #If error is not tolerable, computes integral of each half\r\n xm=0.5*(x1+x2) #of the domain separately, doubling the precision. This is \r\n #done via recurssion\r\n a1, leftErr, leftEval, XLIST, YLIST= integrate_step(fun,x1,xm,tol/2, XLIST, YLIST)\r\n a2, rightErr, rightEval, XLIST, YLIST = integrate_step(fun,xm,x2,tol/2, XLIST, YLIST)\r\n sumError = leftErr + rightErr\r\n totEval = len(YLIST)\r\n return a1+a2, sumError, totEval, XLIST, YLIST\r\n \r\n###############################################################################\r\n\r\n#y=e^x integration with improved integrator\r\nEXPstart = -1\r\nEXPstop = 1\r\nEXPf,EXPerr,EXPneval,EXPxlist,EXPylist=integrate_step(np.exp,EXPstart,EXPstop,1e-3)\r\nEXPtrue=np.exp(EXPstop)-np.exp(EXPstart)\r\n\r\n#y=e^x integration with integrator from class\r\nlazyEXPf,lazyEXPerr,lazyEXPneval=lazy_integrate_step(np.exp,EXPstart,EXPstop,1e-3)\r\n\r\nprint(\"Numerical Integral of e^x from -1 to 1:\", EXPf)\r\nprint(\"Function Evaluations for Integral of e^x (Improved way):\", EXPneval)\r\nprint(\"Function Evaluations for Integral of e^x ('Lazy' way):\", lazyEXPneval, '\\n')\r\n\r\n\r\n#Lorentzian integration with improved integrator\r\nLORENTZstart = -1\r\nLORENTZstop = 1\r\nLORENTZf,LORENTZerr,LORENTZneval,LORENTZxlist,LORENTZylist=integrate_step(lorentz,LORENTZstart,LORENTZstop,1e-3)\r\n\r\n#Lorentzian integration with integrator from class\r\nlazyLORENTZf,lazyLORENTZerr,lazyLORENTZneval=lazy_integrate_step(lorentz,LORENTZstart,LORENTZstop,1e-3)\r\n\r\nprint(\"Numerical Integral of the Lorentzian from -1 to 1:\", LORENTZf)\r\nprint(\"Function Evaluations for Integral of the Lorentzian (Improved way):\", LORENTZneval)\r\nprint(\"Function Evaluations for Integral of the Lorentzian ('Lazy' way):\", lazyLORENTZneval, '\\n')\r\n\r\n\r\n#sin(x) integration with improved integrator\r\nSINstart = 0\r\nSINstop = np.pi\r\nSINf,SINerr,SINneval,SINxlist,SINylist=integrate_step(np.sin,SINstart,SINstop,1e-3)\r\n\r\n#sin(x) integration with integrator from class\r\nlazySINf,lazySINerr,lazySINneval=lazy_integrate_step(np.sin,SINstart,SINstop,1e-3)\r\n\r\nprint(\"Numerical Integral of sin(x) from 0 to pi:\", SINf)\r\nprint(\"Function Evaluations for Integral of sin(x) (Improved way):\", SINneval)\r\nprint(\"Function Evaluations for Integral of sin(x) ('Lazy' way):\", lazySINneval, '\\n')\r\n\r\n############### Plot of Sampled Points for e^x ################################\r\n\r\nfig, ax = plt.subplots(1, figsize=(10,10))\r\n#ax = f1.add_subplot(2,1,1)\r\n#ax.plot(np.linspace(EXPstart, EXPstop, 100), np.exp(np.linspace(EXPstart, EXPstop, 100)), 'r.')\r\nax.plot(EXPxlist, EXPylist, \"m*\", markersize = 15, label = 'sample points')\r\nax.set_xlabel(\"x\")\r\nax.tick_params(axis='x', labelsize=15)\r\nax.set_ylabel(\"y=e^x\")\r\nax.tick_params(axis='y', labelsize=15)\r\nax.set_title(\"Points Sampled to Compute Integral of e^x\")\r\nplt.show()\r\n\r\n\r\n############################# SCRAP ###########################################\r\n\"\"\"\r\ndef inlist(array, item):\r\n if item in array:\r\n itemindex = np.where(array==item)\r\n mylist = itemindex[0].tolist()\r\n return mylist #Returns index(es) of 'item' in 'array'\r\n else:\r\n return None#print(item, \" not in list\")\r\n\"\"\"\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5817568898200989,
"alphanum_fraction": 0.6004869937896729,
"avg_line_length": 38.450382232666016,
"blob_id": "9648fd74d6b56bffa0b0b7b1c48443bb80d8e7ec",
"content_id": "e6107c50d6cc465631b0992f59323514dccde90c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5339,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 131,
"path": "/Assignment 2/PHYS 512 Assignment 2 P2 Draft Final.py",
"repo_name": "jwhitebored/PHYS-512",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nPHYS 512\r\nAssignment 2 Problem 2\r\n@author: James Nathan White (260772425)\r\n\"\"\"\r\n\r\n#I always import this stuff\r\nimport matplotlib.pyplot as plt\r\nimport random as r\r\nimport glob\r\nimport numpy as np\r\nfrom scipy.stats import chi2\r\nimport scipy.optimize as opt\r\nfrom scipy.stats import norm\r\nimport pandas as pd\r\nfrom scipy import interpolate\r\nfrom scipy.special import legendre as LEG\r\n############################# Functions #######################################\r\n\r\n#finds the coeffictients to the Chebyshev polynomial of order 'ord' that model function 'fun' from 'xleft' to 'xright'\r\ndef cheb_fit(fun,xleft,xright,ord):\r\n x=np.linspace(xleft,xright,ord+1)\r\n y=fun(x)\r\n mat=np.zeros([ord+1,ord+1])\r\n mat[:,0]=1\r\n mat[:,1]=x\r\n for i in range(1,ord):\r\n mat[:,i+1]=2*x*mat[:,i]-mat[:,i-1]\r\n coeffs=np.dot(np.linalg.inv(mat),y)\r\n return coeffs\r\n\r\n#given Chebyshev polynomial coefficients, this function takes the first 'order' of them, and fits \r\ndef trunc_cheb_fit(coeffs, order, arrayx):\r\n coeffs=np.delete(coeffs,np.s_[order+1:]) #truncates the coeffs list\r\n assert(len(coeffs)==order+1)\r\n \r\n polyMatrix = np.zeros([len(arrayx), order+1]) #makes matrices with 'arrayx'\r\n polyYvalues = np.zeros(len(arrayx)) #rows and 'order' columnes\r\n polyMatrix[:,0] = 1\r\n polyMatrix[:,1] = arrayx\r\n \r\n for i in range(len(arrayx)):\r\n for j in range(1, order):\r\n polyMatrix[i,j+1] = 2*arrayx[i]*polyMatrix[i,j] - polyMatrix[i,j-1]\r\n \r\n polyYvalues[i] = np.dot(polyMatrix[i,:], coeffs)\r\n return polyYvalues\r\n\r\n###############################################################################\r\n \r\n############################### Chebyshev Fitting #############################\r\n#Chebyshev fitting works on -1 to 1 so I had to shift my log2 function to fit it properly\r\ndef shiftLog2(x):\r\n y=np.zeros(len(x))\r\n for i in range(len(x)):\r\n y[i]=x[i]+1.5\r\n return np.log2(y) \r\n\r\nfun = shiftLog2\r\ncomputationOrder = 50\r\nleftbound = -1\r\nrightbound = 1\r\n\r\ntruncationOrder = 7\r\nchebCoeffs = cheb_fit(fun,leftbound,rightbound,computationOrder) #Note the order of the polynomial is 'len(coeffs)+1'\r\n #due to x^0=1\r\nxCheb=np.linspace(leftbound,rightbound-1.5,101)\r\nchebfitYvalues = trunc_cheb_fit(chebCoeffs,truncationOrder,xCheb)\r\n\r\n############################## Legendre Fitting ###############################\r\nlegcoeffs = np.polynomial.legendre.legfit(xCheb,fun(xCheb),computationOrder)\r\n\r\ndef legendre_poly(coeffs, arrayx, order):\r\n leg = np.zeros([len(arrayx), order+1])\r\n legYvalues = np.zeros(len(arrayx))\r\n for i in range(len(arrayx)):\r\n for j in range(order+1):\r\n leg[i,j] = LEG(j)(arrayx[i])\r\n legYvalues[i] = np.dot(leg[i,:], coeffs)\r\n return legYvalues\r\n\r\nlegfitYvalues = legendre_poly(legcoeffs, xCheb, computationOrder)\r\n############################# PLOTS ###########################################\r\nxplot = [i+1.5 for i in xCheb]\r\nfig, ax = plt.subplots(2, figsize=(10,10), gridspec_kw={'height_ratios': [2, 1]})\r\n\r\n#ax = f1.add_subplot(2,1,1)\r\nax[0].plot(xplot, fun(xCheb), color = 'black', label = 'np.log2(x)')\r\nax[0].plot(xplot, chebfitYvalues, \"m*\", label = 'Chebyshev Fit')\r\nax[0].plot(xplot, legfitYvalues, 'b.', label = 'Legendre Fit')\r\nax[0].set_xlabel(\"x\")\r\nax[0].set_ylabel(\"y\")\r\nax[0].set_title(\"Chebyshev and Legendre Fits of np.log2(x)\")\r\nax[0].legend(loc=\"lower right\")\r\n\r\n##Residuals\r\ndiffcheb = [i-j for i,j in zip(chebfitYvalues, np.log2(xplot))]\r\ndiffleg = [i-j for i,j in zip(legfitYvalues, np.log2(xplot))]\r\n\r\n#ax2.yaxis.tick_right()\r\nax[1].plot(xplot, [0]*len(xplot), color = 'black')\r\nax[1].plot(xplot, diffcheb, 'm*')\r\nax[1].plot(xplot, diffleg, 'b.')\r\nax[1].set_xlabel(\"x\")\r\nax[1].set_ylabel(\"Chebyshev and Legendre Fit Residuals\")\r\n#plt.savefig('cheb_legend_fits.png')\r\nplt.show()\r\n\r\n#################### Question Responses #######################################\r\n\"\"\"\r\n1. How many terms do you need to get error < 10^-6?\r\n\r\nFor the life of me I can't get my error that low. After trying over a hundred\r\norders for the Chebyshev polynomials, I've found the error gets ludicrously\r\nworse for order > 50. I've read a fair amount on Chebyshev polys at this point\r\nand everything says this shouldn't happen, and that the error should remain\r\npractically fixed for high enough order (regardless of where I truncate it past\r\nsaid order). Before heavily modifying/improving it, I copied verbatum the code \r\nfrom class, and noticed that my laptop was producing different values than what \r\nwere achieved in class. This was specifically for fitting np.sin with a 51st \r\ndegree Chebyshev in lecture 4. Someone on slack seemed to have the same\r\nissue that they couldn't resolve and it was suggested machine round-off error\r\nwas getting the best of them. Perhaps this is the case\r\n\r\n2. Compare the max and rms error for both fits.\r\n\r\nFor the reasons above, the legendre fit has lesser values for both max and rms\r\nerror. This is blindingly evident in my plot for this problem (which I'm very\r\nproud turned out so nice).\r\n\"\"\"\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5331760048866272,
"alphanum_fraction": 0.5737090706825256,
"avg_line_length": 35.82105255126953,
"blob_id": "93980b2393e765f16b5262dceaf823f657cfc220",
"content_id": "152c2cfb5064c422d107e4eaa326186344307840",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7204,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 190,
"path": "/Assignment 1/PHYS 512 Assignment 1 P3-2 (Attempting a Singular Matrix).py",
"repo_name": "jwhitebored/PHYS-512",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nPHYS 512\r\nAssignment 1 Problem 3\r\n@author: James Nathan White (260772425)\r\n\"\"\"\r\n\r\n#I always import this stuff\r\nimport matplotlib.pyplot as plt\r\nimport random as r\r\nimport glob\r\nimport numpy as np\r\nfrom scipy.stats import chi2\r\nimport scipy.optimize as opt\r\nfrom scipy.stats import norm\r\nimport pandas as pd\r\nfrom scipy import interpolate\r\n\r\n###################################################################################################\r\n###################################### Cos(x) Fitting #############################################\r\n###################################################################################################\r\n\r\n#simulated data values:\r\nxdata = np.linspace((-0.5*np.pi), (0.5*np.pi), 16)\r\nydata = np.cos(xdata)\r\n\r\n########################################### Cubic Spline Stuff #############################\r\n#Making the Cubic Spline\r\nspline = interpolate.splrep(xdata, ydata)\r\n\r\n#Values for plotting the cubic spline\r\nsplineDomain = np.linspace(xdata[0], xdata[-1], 1000)\r\nsplineYData = interpolate.splev(splineDomain, spline)\r\n\r\n#Values for calculating the differences between the spline fit and the true values\r\nydataSplineFit = interpolate.splev(xdata, spline)\r\n\r\n################################## Rational Function Fit Stuff #############################\r\n#defining the rational function from class:\r\ndef rat_eval(p,q,x):\r\n top = 0\r\n for i in range(len(p)):\r\n top = top + p[i]*x**i\r\n bot = 1\r\n for i in range(len(q)):\r\n bot = bot + q[i]*x**(i+1)\r\n return top/bot\r\n\r\n#rational function fitting method from class:\r\ndef rat_fit(x,y,n,m):\r\n assert(len(x) == n+m-1)\r\n assert(len(y) == len(x))\r\n mat = np.zeros([n+m-1, n+m-1]) #Makes a matrix size [rows, columns] of zeros\r\n for i in range(n):\r\n mat[:,i] = x**i #replaces [all rows, column i] with with the column vector [x**i] up to nth column\r\n for i in range(1,m):\r\n mat[:,i-1+n] = -y*x**i #replaces [all rows, column i-1 +n] with the column vector [-yx**i] after nth column\r\n pars=np.dot(np.linalg.pinv(mat),y)\r\n p=pars[:n]\r\n q=pars[n:]\r\n return p,q\r\n \r\n#Calculating the Rational Function Fit\r\nn=8\r\nm=9\r\np,q = rat_fit(xdata,ydata,n,m)\r\n\r\n#Values for plotting the cubic spline\r\nratDomain = np.linspace(xdata[0], xdata[-1], 1000)\r\nratYData = rat_eval(p,q,ratDomain)\r\n\r\n#Values for calculating the differences between the rational fit and the true values\r\nydataRatFit = rat_eval(p,q,xdata)\r\n\r\n############################################### Plots for Cos(x) ######################################\r\n\r\nfig, ax = plt.subplots(2, figsize=(10,10), gridspec_kw={'height_ratios': [2, 1]})\r\n\r\n#ax = f1.add_subplot(2,1,1)\r\nax[0].plot(xdata, ydata, \"m*\", label = 'Data')\r\nax[0].plot(splineDomain, splineYData, 'b', label = 'Cubic Spline Fit')\r\nax[0].plot(ratDomain, ratYData, 'r', label = 'Rational Fit')\r\nax[0].set_xlabel(\"x\")\r\nax[0].set_ylabel(\"y\")\r\nax[0].set_title(\"Cubic Spline and Rational Fits of y=cos(x)\")\r\n\r\n##Residuals\r\ndiff1 = [i-j for i,j in zip(ydataSplineFit, ydata)]\r\ndiff2 = [i-j for i,j in zip(ydataRatFit, ydata)]\r\n\r\n#ax2.yaxis.tick_right()\r\nax[1].plot(xdata, diff1, 'bo')\r\nax[1].plot(xdata, diff2, 'ro')\r\nax[1].plot(xdata, [0]*len(xdata), color = 'black')\r\nax[1].set_xlabel(\"x\")\r\nax[1].set_ylabel(\"Spline and Rational Fit Residuals\")\r\nplt.show()\r\n\r\n#I'm happy with both my spline and rational fits on this interval, but one thing I've noticed is that\r\n#by increasing the number of data points used to make the rational fit, the worse the fit becomes near x=0\r\n#It seems to develope a spike there. It reminds me of how the edges of a square wave have tips you can't\r\n#get rid of unless you actually have an infinite amount of terms to express the function, though I doubt\r\n#that's the case here\r\n\r\n\"\"\"\r\n#Testing how matrix filling works in a for loop\r\nmat1 = np.zeros([10,10])\r\nmat2 = np.zeros([10,10])\r\nx = [1,2,3,4,5,6,7,8,9,10]\r\nfor i in range(10):\r\n mat1[:,i] = i\r\n mat2[:,i] = x\r\n\r\nprint(mat1)\r\nprint(mat2)\r\n\"\"\"\r\n#######################################################################################################\r\n############################################ Lorentzian Fitting #######################################\r\n#######################################################################################################\r\n\r\n#simulated data values:\r\nxLdata = np.linspace(-1, 1, 8)\r\nyLdata = np.array([1/(1+i**2) for i in xLdata])\r\nLorentz = [1/(1+i**2) for i in np.linspace(-1,1,100)]\r\n\r\n########################################### Cubic Spline Stuff #############################\r\n#Making the Cubic Spline\r\nsplineL = interpolate.splrep(xLdata, yLdata)\r\n\r\n#Values for plotting the cubic spline\r\nsplineDomainL = np.linspace(xLdata[0], xLdata[-1], 1000)\r\nsplineYDataL = interpolate.splev(splineDomainL, splineL)\r\n\r\n#Values for calculating the differences between the spline fit and the true values\r\nydataSplineFitL = interpolate.splev(xLdata, splineL)\r\n\r\n################################## Rational Function Fit Stuff #############################\r\n#Calculating the Rational Function Fit\r\nN=4\r\nM=5\r\nP,Q = rat_fit(xLdata,yLdata,N,M)\r\n\r\n#Values for plotting the cubic spline\r\nratDomainL = np.linspace(xLdata[0], xLdata[-1], 1000)\r\nratYDataL = rat_eval(P,Q,ratDomainL)\r\n\r\n#Values for calculating the differences between the rational fit and the true values\r\nydataRatFitL = rat_eval(P,Q,xLdata)\r\n\r\n############################## Plots for Lorentzian 1/(1+x^2) ##############################\r\n\r\nfig2, ax2 = plt.subplots(2, figsize=(10,10), gridspec_kw={'height_ratios': [2, 1]})\r\n\r\n#ax = f1.add_subplot(2,1,1)\r\nax2[0].plot(xLdata, yLdata, \"m*\", label = 'Data')\r\nax2[0].plot(splineDomainL, splineYDataL, 'b', label = 'Cubic Spline Fit')\r\nax2[0].plot(ratDomainL, ratYDataL, 'r', label = 'Rational Fit')\r\nax2[0].plot(np.linspace(-1,1,100), Lorentz, 'g')\r\nax2[0].set_xlabel(\"x\")\r\nax2[0].set_ylabel(\"y\")\r\nax2[0].set_title(\"Cubic Spline and Rational Fits of y=1/(1+x^2)\")\r\n\r\n##Residuals\r\ndiff1L = [i-j for i,j in zip(ydataSplineFitL, yLdata)]\r\ndiff2L = [i-j for i,j in zip(ydataRatFitL, yLdata)]\r\n\r\n#ax2.yaxis.tick_right()\r\nax2[1].plot(xLdata, diff1L, 'bo')\r\nax2[1].plot(xLdata, diff2L, 'ro')\r\nax2[1].plot(xLdata, [0]*len(xLdata), color = 'black')\r\nax2[1].set_xlabel(\"x\")\r\nax2[1].set_ylabel(\"Spline and Rational Fit Residuals\")\r\nplt.show()\r\n\r\n\r\n#using pinv greatly increased accuracy of all fits, but most importantly, the fits that are supposed to work\r\n#e.g. N,M = 2,4 since analytically\r\n\r\n# 1/(1+x^2) = (1-x^2)/(1-x^4)\r\n\r\n#Without using pinv the rational approximations were so horrible at approximating a RATIONAL FUNCTION. (see \r\n#the the comment at the end of the file \"PHYS 512 Assignment 1 P3.py\" for the majority of this discussion).\r\n#The biggest improvement is that using pinv, more data points make the fit better, not worse \r\n#(even N,M = 40,1 was a great fit). The splines were reliable throughout, which I appreciated.\r\n\r\nprint(P)\r\nprint(Q)\r\n\r\n#for N,M = 4,5 P=[ 1.00000000e+00 1.77635684e-15 -3.33333333e-01 0.00000000e+00]\r\n#for N,M = 4,5 Q=[ 0.00000000e+00 6.66666667e-01 -1.77635684e-15 -3.33333333e-01]\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n"
}
] | 6 |
ArpitaBawgi/Devops-Training
|
https://github.com/ArpitaBawgi/Devops-Training
|
3f65c95b6e411b712db27266cc3c06c18f5c8a6f
|
011e45491172cf077f71222b65c7d6cdbf5f6a8b
|
a9cad11839f80fbdfce526e00af2058408796a14
|
refs/heads/master
| 2020-06-05T20:55:39.031547 | 2019-06-18T13:21:45 | 2019-06-18T13:21:45 | 192,544,002 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6527777910232544,
"alphanum_fraction": 0.6527777910232544,
"avg_line_length": 16.75,
"blob_id": "ce03ec26292529784fa5cede3996aee287b27cda",
"content_id": "e240476a8fc4764fd01a8727aa728dcc47e0621d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 144,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 8,
"path": "/second.py",
"repo_name": "ArpitaBawgi/Devops-Training",
"src_encoding": "UTF-8",
"text": "\nname=''\nprint ('entername')\nyourname = str(input())\n\nwhile(name!= yourname):\n\tprint('please enter name')\n\tname = str(input())\nprint('thanku')\n\t"
},
{
"alpha_fraction": 0.6091954112052917,
"alphanum_fraction": 0.6436781883239746,
"avg_line_length": 10,
"blob_id": "9a767a41652fbcf9ba738c01225c9364afbe5810",
"content_id": "c6bc177d59bac594449b41d7021bb6b5bd3df017",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 87,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 8,
"path": "/factorial.py",
"repo_name": "ArpitaBawgi/Devops-Training",
"src_encoding": "UTF-8",
"text": "print('enter number')\nnum=int(input())\nn=1\nwhile(num>0):\n\tn=n*num\n\tnum=num-1\n\t\nprint(n)"
},
{
"alpha_fraction": 0.6302816867828369,
"alphanum_fraction": 0.6619718074798584,
"avg_line_length": 20.769229888916016,
"blob_id": "660a3c832d0d327e46472e59528f08b450e724a9",
"content_id": "c44e7e9ff41302102d7de3df80f5bfafc95c3b34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 284,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 13,
"path": "/first.py",
"repo_name": "ArpitaBawgi/Devops-Training",
"src_encoding": "UTF-8",
"text": "print(\"Enter name\")\n\nname = input()\nprint(\"Enter age\")\nage = int(input())\nif name == 'Alice':\n\tprint('Hi',name)\nelif age < 12: \n\tprint('you are not alice, kiddo')\nelif age>100 and age <2000:\n\tprint('your nt alice, grannie')\nelse: \n\tprint('unlike you, alice undead, imortal vampire')\n\n"
},
{
"alpha_fraction": 0.6421052813529968,
"alphanum_fraction": 0.678947389125824,
"avg_line_length": 13.692307472229004,
"blob_id": "d384b222d686d114abe4468c362779af830cb0c9",
"content_id": "76d401e512c479db9efba4e401341f3e0f22cafe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 190,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 13,
"path": "/harshad.py",
"repo_name": "ArpitaBawgi/Devops-Training",
"src_encoding": "UTF-8",
"text": "print('please enter number')\nnumber=int(input())\nnum=number\ns=0\nwhile(num>0):\n\ta= num%10\n\ts=s+a\n\tnum=int(num/10)\n\t\nif number%s==0:\n\tprint('harshad number')\nelse:\n\tprint('not harshad number')"
},
{
"alpha_fraction": 0.581632673740387,
"alphanum_fraction": 0.6020408272743225,
"avg_line_length": 15,
"blob_id": "ed30d642eae70a4bb1f6f261ba0c118929b22086",
"content_id": "cdfe9c2d519775f9681f9a213c24fc6e6ddbcfc0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 98,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 6,
"path": "/dict.py",
"repo_name": "ArpitaBawgi/Devops-Training",
"src_encoding": "UTF-8",
"text": "num=range( 1, int(input())+1)\nmydict={}\nfor n in num:\n\tmydict.update({n : n*n})\n\t\nprint(mydict)\n\n\n"
},
{
"alpha_fraction": 0.6496350169181824,
"alphanum_fraction": 0.6496350169181824,
"avg_line_length": 17.200000762939453,
"blob_id": "d21ea5dda881f239defc04d28018acc89ac99c86",
"content_id": "ca07ecd040f87e1351a27945c01ef93aa4265773",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 274,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 15,
"path": "/third.py",
"repo_name": "ArpitaBawgi/Devops-Training",
"src_encoding": "UTF-8",
"text": "name=''\ncondition=True\nwhile(condition):\n\tprint('who are you')\n\tname=input()\n\tif(name!='joe'):\n\t\tcontinue\n\telse:\n\t\tprint(\"Hello Joe, What is password?(it is fish)\");\n\t\tpassword=input();\n\t\tif(password =='swoardfish'):\n\t\t\t#condition=False;\n\t\t\tbreak;\n\nprint('Access Granted')\n\n"
}
] | 6 |
pyvista/pyiges
|
https://github.com/pyvista/pyiges
|
7749ca5806ecdd1b276711ce3075982c14e788fa
|
098a6d44f1e1c9f28679ef40e70c53ff2803c8c0
|
71d7ff14c5e7c72cff4e041ed227065ae8d9aefb
|
refs/heads/main
| 2023-07-09T20:13:55.085517 | 2023-07-04T01:39:18 | 2023-07-04T01:39:18 | 222,018,748 | 30 | 8 |
MIT
| 2019-11-15T23:20:09 | 2023-06-07T17:27:24 | 2023-07-05T14:33:44 |
Python
|
[
{
"alpha_fraction": 0.7214022278785706,
"alphanum_fraction": 0.7361623644828796,
"avg_line_length": 31.84848403930664,
"blob_id": "edbec10c14c72915304fa95ee05979d8af7f2e35",
"content_id": "c44f36e3f94339ef7ca0f025b64b87c1b25520f4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 1084,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 33,
"path": "/pyproject.toml",
"repo_name": "pyvista/pyiges",
"src_encoding": "UTF-8",
"text": "[build-system]\nrequires = ['setuptools']\nbuild-backend = 'setuptools.build_meta'\n\n[tool.isort]\nprofile = 'black'\nline_length = 100\n# Sort by name, don't cluster \"from\" vs \"import\"\nforce_sort_within_sections = true\n# Combines \"as\" imports on the same line\ncombine_as_imports = true\n\n[tool.blackdoc]\n# From https://numpydoc.readthedocs.io/en/latest/format.html\n# Extended discussion: https://github.com/pyvista/pyvista/pull/4129\n# The length of docstring lines should be kept to 75 characters to facilitate\n# reading the docstrings in text terminals.\nline-length = 75\n\n[tool.pytest.ini_options]\njunit_family='legacy'\nfilterwarnings = [\n 'ignore::FutureWarning',\n 'ignore::PendingDeprecationWarning',\n 'ignore::DeprecationWarning',\n # bogus numpy ABI warning (see numpy/#432)\n 'ignore:.*numpy.dtype size changed.*:RuntimeWarning',\n 'ignore:.*numpy.ufunc size changed.*:RuntimeWarning',\n 'ignore:.*Given trait value dtype \"float64\":UserWarning',\n 'ignore:.*The NumPy module was reloaded*:UserWarning',\n]\ndoctest_optionflags = 'NUMBER ELLIPSIS'\ntestpaths = 'tests'\n"
},
{
"alpha_fraction": 0.4828212857246399,
"alphanum_fraction": 0.5251621603965759,
"avg_line_length": 30.811790466308594,
"blob_id": "5956d3351226d276006c406aa7a769a2ce8494e1",
"content_id": "2b62fe52cac614860affe58690a3bee9c153946f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 28058,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 882,
"path": "/pyiges/geometry.py",
"repo_name": "pyvista/pyiges",
"src_encoding": "UTF-8",
"text": "import os\n\nimport numpy as np\n\nfrom pyiges.check_imports import assert_full_module_variant, pyvista as pv\nfrom pyiges.entity import Entity\n\n\ndef parse_float(str_value):\n \"\"\"\n This function converts a string to float just like the built-in\n float() function. In addition to \"normal\" numbers it also handles\n numbers such as 1.2D3 (equivalent to 1.2E3).\n \"\"\"\n try:\n return float(str_value)\n except ValueError:\n return float(str_value.lower().replace(\"d\", \"e\"))\n\n\nclass Point(Entity):\n \"\"\"IGES Point\"\"\"\n\n def _add_parameters(self, parameters):\n self._x = parse_float(parameters[1])\n self._y = parse_float(parameters[2])\n self._z = parse_float(parameters[3])\n\n @property\n def x(self):\n \"\"\"X coordinate\"\"\"\n return self._x\n\n @property\n def y(self):\n \"\"\"Y coordinate\"\"\"\n return self._y\n\n @property\n def z(self):\n \"\"\"Z coordinate\"\"\"\n return self._z\n\n @property\n def coordinate(self):\n \"\"\"Coordinate of the point as a numpy array\"\"\"\n return np.array([self._x, self._y, self._z])\n\n def __repr__(self):\n s = \"--- IGES Point ---\" + os.linesep\n s += f\"{self._x}, {self._y}, {self._z} {os.linesep}\"\n return s\n\n def __str__(self):\n return self.__repr__()\n\n @assert_full_module_variant\n def to_vtk(self):\n \"\"\"Point represented as a ``pyvista.PolyData`` Mesh\n\n Returns\n -------\n mesh : ``pyvista.PolyData``\n ``pyvista`` mesh\n \"\"\"\n return pv.PolyData([self.x, self.y, self.z])\n\n\nclass Line(Entity):\n \"\"\"IGES Straight line segment\"\"\"\n\n def _add_parameters(self, parameters):\n self._x1 = parse_float(parameters[1])\n self._y1 = parse_float(parameters[2])\n self._z1 = parse_float(parameters[3])\n self._x2 = parse_float(parameters[4])\n self._y2 = parse_float(parameters[5])\n self._z2 = parse_float(parameters[6])\n\n @property\n def coordinates(self):\n \"\"\"Starting and ending point of the line as a ``numpy`` array\"\"\"\n return np.array(\n [[self._x1, self._y1, self._z1], [self._x2, self._y2, self._z2]]\n )\n\n def __repr__(self):\n s = \"--- IGES Line ---\" + os.linesep\n s += Entity.__str__(self) + os.linesep\n s += f\"From point {self._x1}, {self._y1}, {self._z1} {os.linesep}\"\n s += f\"To point {self._x2}, {self._y2}, {self._z2}\"\n return s\n\n @assert_full_module_variant\n def to_vtk(self, resolution=1):\n \"\"\"Line represented as a ``pyvista.PolyData`` Mesh\n\n Returns\n -------\n mesh : ``pyvista.PolyData``\n ``pyvista`` mesh\n \"\"\"\n return pv.Line(\n [self._x1, self._y1, self._z1], [self._x2, self._y2, self._z2], resolution\n )\n\n\nclass Transformation(Entity):\n \"\"\"Transforms entities by matrix multiplication and vector\n addition to give a translation, as shown below:\n\n Notes\n -----\n | R11 R12 R13 | | T1 |\n R= | R21 R22 R23 | T = | T2 |\n | R31 R32 R33 | | T3 |\n\n ET = RE + T, where E is the entity coordinate\n\n \"\"\"\n\n def _add_parameters(self, parameters):\n \"\"\"\n Index in list\tType of data\tName\tDescription\n 1\tREAL\tR11\tFirst row\n 2\tREAL\tR12\t..\n 3\tREAL\tR13\t..\n 4\tREAL\tT1\tFirst T vector value\n 5\tREAL\tR21\tSecond row..\n ...\n 12\tREAL\tT3\tThird T vector value\n\n \"\"\"\n self.r11 = parse_float(parameters[1])\n self.r12 = parse_float(parameters[2])\n self.r13 = parse_float(parameters[3])\n self.t1 = parse_float(parameters[4])\n self.r21 = parse_float(parameters[5])\n self.r22 = parse_float(parameters[6])\n self.r23 = parse_float(parameters[7])\n self.t2 = parse_float(parameters[8])\n self.r31 = parse_float(parameters[9])\n self.r32 = parse_float(parameters[10])\n self.r33 = parse_float(parameters[11])\n self.t3 = parse_float(parameters[12])\n\n def __repr__(self):\n txt = \"IGES 124 Transformation Matrix\\n\"\n txt += str(self.to_affine())\n return txt\n\n def to_affine(self):\n \"\"\"Return a 4x4 affline transformation matrix\"\"\"\n return np.array(\n [\n [self.r11, self.r12, self.r13, self.t1],\n [self.r21, self.r22, self.r23, self.t2],\n [self.r31, self.r32, self.r33, self.t3],\n [0, 0, 0, 1],\n ]\n )\n\n @assert_full_module_variant\n def _to_vtk(self):\n \"\"\"Convert to a vtk transformation matrix\"\"\"\n vtkmatrix = pv.vtkmatrix_from_array(self.to_affine())\n import vtk\n\n trans = vtk.vtkTransform()\n trans.SetMatrix(vtkmatrix)\n return trans\n\n\nclass ConicArc(Entity):\n \"\"\"Conic Arc (Type 104)\n Arc defined by the equation:\n ``A*x**2 + B*x*y + C*y**2 + D*x + E*y + F = 0``\n\n with a Transformation Matrix (Entity 124). Can define\n an ellipse, parabola, or hyperbola.\n\n \"\"\"\n\n # The definitions of the terms ellipse, parabola, and hyperbola\n # are given in terms of the quantities Q1, Q2, and Q3. These\n # quantities are:\n\n # | A B/2 D/2 | | A B/2 |\n # Q1= | B/2 C E/2 | Q2 = | B/2 C | Q3 = A + C\n # | D/2 E/2 F |\n # A parent conic curve is:\n\n # An ellipse if Q2 > 0 and Q1, Q3 < 0.\n # A hyperbola if Q2 < 0 and Q1 != 0.\n # A parabola if Q2 = 0 and Q1 != 0.\n\n def _add_parameters(self, parameters):\n \"\"\"\n Index\tType\tName\tDescription\n 1\tREAL\tA\tcoefficient of xt^2\n 2\tREAL\tB\tcoefficient of xtyt\n 3\tREAL\tC\tcoefficient of yt^2\n 4\tREAL\tD\tcoefficient of xt\n 5\tREAL\tE\tcoefficient of yt\n 6\tREAL\tF\tscalar coefficient\n 7\tREAL\tX1\tx coordinate of start point\n 8\tREAL\tY1\ty coordinate of start point\n 9\tREAL\tZ1\tz coordinate of start point\n 10\tREAL\tX2\tx coordinate of end point\n 11\tREAL\tY2\ty coordinate of end point\n 12\tREAL\tZ2\tz coordinate of end point\n \"\"\"\n self.a = parameters[1] # coefficient of xt^2\n self.b = parameters[2] # coefficient of xtyt\n self.c = parameters[3] # coefficient of yt^2\n self.d = parameters[4] # coefficient of xt\n self.e = parameters[5] # coefficient of yt\n self.f = parameters[6] # scalar coefficient\n self.x1 = parameters[7] # x coordinate of start point\n self.y1 = parameters[8] # y coordinate of start point\n self.z1 = parameters[9] # z coordinate of start point\n self.x2 = parameters[10] # x coordinate of end point\n self.y2 = parameters[11] # y coordinate of end point\n self.z2 = parameters[12] # z coordinate of end point\n\n def __repr__(self):\n info = \"Conic Arc\\nIGES Type 104\\n\"\n info += f\"Start: ({self.x1:f}, {self.y1:f}, {self.z1:f})\\n\"\n info += f\"End: ({self.x2:f}, {self.y2:f}, {self.z2:f})\\n\"\n info += \"Coefficient of x**2: %f\" % self.a\n info += \"Coefficient of x*y: %f\" % self.b\n info += \"Coefficient of y**2: %f\" % self.c\n info += \"Coefficient of x: %f\" % self.d\n info += \"Coefficient of y: %f\" % self.e\n info += \"Scalar coefficient: %f\" % self.f\n return info\n\n @assert_full_module_variant\n def to_vtk(self):\n # a*x**2 + b*x*y + c*y**2 + d*x + e*y + f = 0\n # from sympy import Symbol\n # from sympy.solvers import Solve\n # a = Symbol('a')\n # b = Symbol('b')\n # c = Symbol('c')\n # d = Symbol('d')\n # e = Symbol('e')\n # f = Symbol('f')\n # x = Symbol('x')\n # y = Symbol('y')\n # solve(a*x**2 + b*x*y + c*y**2 + d*x + e*y + f, x)\n\n # x0 = (-b*y - d + sqrt(-4*a*c*y**2 - 4*a*e*y - 4*a*f + b**2*y**2 + 2*b*d*y + d**2))/(2*a)\n # x1 = -(b*y + d + sqrt(-4*a*c*y**2 - 4*a*e*y - 4*a*f + b**2*y**2 + 2*b*d*y + d**2))/(2*a)\n\n raise NotImplementedError(\"Not yet implemented\")\n\n\nclass RationalBSplineCurve(Entity):\n \"\"\"Rational B-Spline Curve\n IGES Spec v5.3 p. 123 Section 4.23\n See also Appendix B, p. 545\n \"\"\"\n\n def _add_parameters(self, parameters):\n self.K = int(parameters[1])\n self.M = int(parameters[2])\n self.prop1 = int(parameters[3])\n self.prop2 = int(parameters[4])\n self.prop3 = int(parameters[5])\n self.prop4 = int(parameters[6])\n\n self.N = 1 + self.K - self.M\n self.A = self.N + 2 * self.M\n\n # Knot sequence\n self.T = []\n for i in range(7, 7 + self.A + 1):\n self.T.append(parse_float(parameters[i]))\n\n # Weights\n self.W = []\n for i in range(self.A + 8, self.A + self.K + 8):\n self.W.append(parse_float(parameters[i]))\n\n # Control points\n self.control_points = []\n for i in range(9 + self.A + self.K, 9 + self.A + 4 * self.K + 1, 3):\n point = (\n parse_float(parameters[i]),\n parse_float(parameters[i + 1]),\n parse_float(parameters[i + 2]),\n )\n self.control_points.append(point)\n\n # Parameter values\n self.V0 = parse_float(parameters[12 + self.A + 4 * self.K])\n self.V1 = parse_float(parameters[13 + self.A + 4 * self.K])\n\n # Unit normal (only for planar curves)\n if len(parameters) > 14 + self.A + 4 * self.K + 1:\n self.planar_curve = True\n self.XNORM = parse_float(parameters[14 + self.A + 4 * self.K])\n self.YNORM = parse_float(parameters[15 + self.A + 4 * self.K])\n self.ZNORM = parse_float(parameters[16 + self.A + 4 * self.K])\n else:\n self.planar_curve = False\n\n def __str__(self):\n s = \"--- Rational B-Spline Curve ---\" + os.linesep\n s += Entity.__str__(self) + os.linesep\n s += str(self.T) + os.linesep\n s += str(self.W) + os.linesep\n s += str(self.control_points) + os.linesep\n s += f\"Parameter: v(0) = {self.V0} v(1) = {self.V1}\" + os.linesep\n if self.planar_curve:\n s += f\"Unit normal: {self.XNORM} {self.YNORM} {self.ZNORM}\"\n return s\n\n @assert_full_module_variant\n def to_geomdl(self):\n from geomdl import NURBS\n\n curve = NURBS.Curve()\n curve.degree = self.M\n curve.ctrlpts = self.control_points\n curve.weights = self.W + [1]\n curve.knotvector = self.T # Set knot vector\n return curve\n\n @assert_full_module_variant\n def to_vtk(self, delta=0.01):\n \"\"\"Set evaluation delta (controls the number of curve points)\"\"\"\n # Create a 3-dimensional B-spline Curve\n curve = self.to_geomdl()\n curve.delta = delta\n\n # spline segfaults here sometimes...\n # return pv.Spline(np.array(curve.evalpts))\n\n n_points = len(curve.evalpts)\n faces = np.arange(-1, n_points)\n faces[0] = n_points\n line = pv.PolyData()\n line.points = np.array(curve.evalpts)\n line.lines = faces\n return line\n\n\nclass RationalBSplineSurface(Entity):\n \"\"\"Rational B-Spline Surface\n\n\n Examples\n --------\n >>> import pyiges\n >>> from pyiges import examples\n >>> iges = pyiges.read(examples.impeller)\n >>> bsurfs = igs.bspline_surfaces()\n >>> bsurf = bsurfs[0]\n >>> print(bsurf)\n Rational B-Spline Surface\n Upper index of first sum: 3\n Upper index of second sum: 3\n Degree of first basis functions: 3\n Degree of second basis functions: 3\n Open in the first direction\n Open in the second direction\n Polynomial\n Periodic in the first direction\n Periodic in the second direction\n Knot 1: [0. 0. 0. 0. 1. 1. 1. 1.]\n Knot 2: [0. 0. 0. 0. 1. 1. 1. 1.]\n u0: 1.000000\n u1: 0.000000\n v0: 1.000000\n v1: 128.000000\n Control Points: 16\n\n >>> bsurf.control_points\n array([[-26.90290533, -16.51153913, -8.87632351],\n [-25.85182035, -15.86644037, -21.16779478],\n [-25.99572556, -15.95476156, -33.51982653],\n [-27.33276363, -16.77536276, -45.77299513],\n [-28.23297477, -14.34440426, -8.87632351],\n [-27.12992455, -13.78397453, -21.16779478],\n [-27.28094438, -13.86070358, -33.51982653],\n [-28.6840851 , -14.57360111, -45.77299513],\n [-29.29280315, -12.03305788, -8.87632351],\n [-28.14834588, -11.56293146, -21.16779478],\n [-28.3050348 , -11.62729699, -33.51982653],\n [-29.76084756, -12.22532372, -45.77299513],\n [-30.06701039, -9.61104189, -8.87632351],\n [-28.89230518, -9.2355426 , -21.16779478],\n [-29.05313537, -9.28695263, -33.51982653],\n [-30.54742519, -9.76460843, -45.77299513]])\n \"\"\"\n\n @property\n def k1(self):\n \"\"\"Upper index of first sum\"\"\"\n return self._k1\n\n @property\n def k2(self):\n \"\"\"Upper index of second sum\"\"\"\n return self._k2\n\n @property\n def m1(self):\n \"\"\"Degree of first basis functions\"\"\"\n return self._m1\n\n @property\n def m2(self):\n \"\"\"Degree of second basis functions\"\"\"\n return self._m2\n\n @property\n def flag1(self):\n \"\"\"Closed in the first direction\"\"\"\n return self._flag1\n\n @property\n def flag2(self):\n \"\"\"Closed in the second direction\"\"\"\n return self._flag2\n\n @property\n def flag3(self):\n \"\"\"Polynominal\n\n ``False`` - rational\n ``True`` - polynomial\n \"\"\"\n return self._flag3\n\n @property\n def flag4(self):\n \"\"\"First direction periodic\"\"\"\n return self._flag4\n\n @property\n def flag5(self):\n \"\"\"Second direction Periodic\"\"\"\n return self._flag5\n\n @property\n def knot1(self):\n \"\"\"First Knot Sequences\"\"\"\n return self._knot1\n\n @property\n def knot2(self):\n \"\"\"Second Knot Sequences\"\"\"\n return self._knot2\n\n @property\n def weights(self):\n \"\"\"First Knot Sequences\"\"\"\n return self._weights\n\n def control_points(self):\n \"\"\"Control points\"\"\"\n return self._cp\n\n @property\n def u0(self):\n \"\"\"Start first parameter value\"\"\"\n return self._u0\n\n @property\n def u1(self):\n \"\"\"End first parameter value\"\"\"\n return self._u1\n\n @property\n def v0(self):\n \"\"\"Start second parameter value\"\"\"\n return self._v0\n\n @property\n def v1(self):\n \"\"\"End second parameter value\"\"\"\n return self._v1\n\n def _add_parameters(self, input_parameters):\n parameters = np.array(\n [parse_float(param) for param in input_parameters], dtype=float\n )\n\n self._k1 = int(parameters[1]) # Upper index of first sum\n self._k2 = int(parameters[2]) # Upper index of second sum\n self._m1 = int(parameters[3]) # Degree of first basis functions\n self._m2 = int(parameters[4]) # Degree of second basis functions\n self._flag1 = bool(parameters[5]) # 0=closed in first direction, 1=not closed\n self._flag2 = bool(parameters[6]) # 0=closed in second direction, 1=not closed\n self._flag3 = bool(parameters[7]) # 0=rational, 1=polynomial\n self._flag4 = bool(\n parameters[8]\n ) # 0=nonperiodic in first direction , 1=periodic\n self._flag5 = bool(\n parameters[9]\n ) # 0=nonperiodic in second direction , 1=periodic\n\n # load knot sequences\n self._knot1 = parameters[10 : 12 + self._k1 + self._m1]\n self._knot2 = parameters[\n 12 + self._k1 + self._m1 : 14 + self._k2 + self._m1 + self._k1 + self._m2\n ]\n\n # weights\n st = 14 + self._k2 + self._m1 + self._k1 + self._m2\n en = st + (1 + self._k2) * (1 + self._k1)\n self._weights = parameters[st:en]\n\n # control points\n st = (\n 14\n + self._k2\n + self._k1\n + self._m1\n + self._m2\n + (1 + self._k2) * (1 + self._k1)\n )\n en = st + 3 * (1 + self._k2) * (1 + self._k1)\n self._cp = parameters[st:en].reshape(-1, 3)\n\n self._u0 = parameters[-3] # Start first parameter value\n self._u1 = parameters[-2] # End first parameter value\n self._v0 = parameters[-1] # Start second parameter value\n self._v1 = parameters[-0] # End second parameter value\n\n def __repr__(self):\n info = \"Rational B-Spline Surface\\n\"\n info += \" Upper index of first sum: %d\\n\" % self._k1\n info += \" Upper index of second sum: %d\\n\" % self._k2\n info += \" Degree of first basis functions: %d\\n\" % self._m1\n info += \" Degree of second basis functions: %d\\n\" % self._m2\n\n if self.flag1:\n info += \" Closed in the first direction\\n\"\n else:\n info += \" Open in the first direction\\n\"\n\n if self.flag2:\n info += \" Closed in the second direction\\n\"\n else:\n info += \" Open in the second direction\\n\"\n\n if self.flag3:\n info += \" Rational\\n\"\n else:\n info += \" Polynomial\\n\"\n\n if self.flag4:\n info += \" Nonperiodic in first direction\\n\"\n else:\n info += \" Periodic in the first direction\\n\"\n\n if self.flag5:\n info += \" Nonperiodic in second direction\\n\"\n else:\n info += \" Periodic in the second direction\\n\"\n\n info += \" Knot 1: %s\\n\" % str(self.knot1)\n info += \" Knot 2: %s\\n\" % str(self.knot2)\n\n info += \" u0: %f\\n\" % self.u0\n info += \" u1: %f\\n\" % self.u1\n info += \" v0: %f\\n\" % self.v0\n info += \" v1: %f\\n\" % self.v1\n\n info += \" Control Points: %d\" % len(self._cp)\n return info\n\n @assert_full_module_variant\n def to_geomdl(self):\n \"\"\"Return a ``geommdl.BSpline.Surface``\"\"\"\n from geomdl import BSpline\n\n surf = BSpline.Surface()\n\n # Set degrees\n surf.degree_u = self._m2\n surf.degree_v = self._m1\n\n # set control points and knots\n cp2d = self._cp.reshape(self._k2 + 1, self._k1 + 1, 3)\n surf.ctrlpts2d = cp2d.tolist()\n surf.knotvector_u = self._knot2\n surf.knotvector_v = self._knot1\n\n # set weights\n surf.weights = self._weights\n return surf\n\n @assert_full_module_variant\n def to_vtk(self, delta=0.025):\n \"\"\"Return a pyvista.PolyData Mesh\n\n Parameters\n ----------\n delta : float, optional\n Resolution of the surface. Higher number result in a\n denser mesh at the cost of compute time.\n\n Returns\n -------\n mesh : ``pyvista.PolyData``\n ``pyvista`` mesh\n\n Examples\n --------\n >>> mesh = bsurf.to_vtk()\n >>> mesh.plot()\n \"\"\"\n surf = self.to_geomdl()\n # Set evaluation delta\n surf.delta = delta\n\n # Evaluate surface points\n surf.evaluate()\n\n faces = []\n for face in surf.faces:\n faces.extend([3] + face.vertex_ids)\n\n return pv.PolyData(np.array(surf.vertices), np.array(faces))\n\n\nclass CircularArc(Entity):\n \"\"\"Circular Arc\n\n Type 100: Simple circular arc of constant radius. Usually defined\n with a Transformation Matrix Entity (Type 124).\n\n \"\"\"\n\n def _add_parameters(self, parameters):\n # Index in list Type of data Name Description\n # 1 REAL Z z displacement on XT,YT plane\n # 2 REAL X x coordinate of center\n # 3 REAL Y y coordinate of center\n # 4 REAL X1 x coordinate of start\n # 5 REAL Y1 y coordinate of start\n # 6 REAL X2 x coordinate of end\n # 7 REAL Y2 y coordinate of end\n self.z = parse_float(parameters[1])\n self.x = parse_float(parameters[2])\n self.y = parse_float(parameters[3])\n self.x1 = parse_float(parameters[4])\n self.y1 = parse_float(parameters[5])\n self.x2 = parse_float(parameters[6])\n self.y2 = parse_float(parameters[7])\n self._transform = self.d.get(\"transform\", None)\n\n @assert_full_module_variant\n def to_vtk(self, resolution=20):\n \"\"\"Circular arc represented as a ``pyvista.PolyData`` Mesh\n\n Returns\n -------\n mesh : ``pyvista.PolyData``\n ``pyvista`` mesh\n \"\"\"\n start = [self.x1, self.y1, 0]\n end = [self.x2, self.y2, 0]\n center = [self.x, self.y, 0]\n arc = pv.CircularArc(\n center=center, pointa=start, pointb=end, resolution=resolution\n )\n arc.points += [0, 0, self.z]\n if self.transform is not None:\n arc.transform(self.transform._to_vtk())\n\n return arc\n\n @property\n def transform(self):\n if self._transform is not None:\n return self.iges[self._transform]\n\n def __repr__(self):\n info = \"Circular Arc\\nIGES Type 100\\n\"\n info += f\"Center: ({self.x:f}, {self.y:f})\\n\"\n info += f\"Start: ({self.x1:f}, {self.y1:f})\\n\"\n info += f\"End: ({self.x2:f}, {self.y2:f})\\n\"\n info += \"Z Disp: %f\" % self.z\n return info\n\n\nclass Face(Entity):\n \"\"\"Defines a bound portion of three dimensional space (R^3) which\n has a finite area. Used to construct B-Rep Geometries.\"\"\"\n\n def _add_parameters(self, parameters):\n \"\"\"\n Parameter Data\n Index\tType\tName\tDescription\n Pointer\tSurface\tUnderlying surface\n 2\tINT\tN\tNumber of loops\n 3\tBOOL\tFlag\tOuter loop flag:\n True indicates Loop1 is outer loop.\n False indicates no outer loop.\n 4\tPointer\tLoop1\tPointer to first loop of the face\n 3+N\tPointer\tLoopN\tPointer to last loop of the face\n \"\"\"\n self.surf_pointer = int(parameters[1])\n self.n_loops = int(parameters[2])\n self.outer_loop_flag = bool(parameters[3])\n\n self.loop_pointers = []\n for i in range(self.n_loops):\n self.loop_pointers.append(int(parameters[4 + i]))\n\n @property\n def loops(self):\n loops = []\n for ptr in self.loop_pointers:\n loops.append(self.iges.from_pointer(ptr))\n\n return loops\n\n def __repr__(self):\n info = \"IGES Type 510: Face\\n\"\n # info += 'Center: (%f, %f)\\n' % (self.x, self.y)\n # info += 'Start: (%f, %f)\\n' % (self.x1, self.y1)\n # info += 'End: (%f, %f)\\n' % (self.x2, self.y2)\n # info += 'Z Disp: %f' % self.z\n return info\n\n\nclass Loop(Entity):\n \"\"\"Defines a loop, specifying a bounded face, for B-Rep\n geometries.\"\"\"\n\n def _add_parameters(self, parameters):\n \"\"\"Parameter Data\n Index Type Name Description\n 1 INT N N Edges in loop\n 2\tINT\tType1\t Type of Edge 1\n 0 = Edge\n 1 = Vertex\n 3\tPointer\tE1 First vertex list or edge list\n 4\tINT\tIndex1 Index of edge/vertex in E1\n 5\tBOOL\tFlag1 Orientation flag -\n True = Agrees with model curve\n 6\tINT\tK1 Number of parametric space curves\n 7\tBOOL\tISO(1, 1) Isoparametric flag of first\n parameter space curve\n 8\tPointer\tPSC(1, 1) First parametric space curve of E1\n .\n 6+2K1\tPointer\tPSC(1, K1) Last parametric space curve of E1\n 7+2K1\tINT\tType2 Type of Edge 2\n \"\"\"\n self.parameters = parameters\n self.n_edges = int(self.parameters[1])\n self._edges = []\n\n c = 0\n for i in range(self.n_edges):\n edge = {\n \"type\": int(self.parameters[2 + c]),\n \"e1\": int(self.parameters[3 + c]), # first vertex or edge list\n \"index1\": int(self.parameters[4 + c]), # index of edge in e1\n \"flag1\": bool(self.parameters[5 + c]), # orientation flag\n \"k1\": int(self.parameters[6 + c]),\n } # n curves\n curves = []\n for j in range(edge[\"k1\"]):\n curve = {\n \"iso\": bool(self.parameters[7 + c + j * 2]), # isopara flag\n \"psc\": int(self.parameters[8 + c + j * 2]),\n } # space curve\n curves.append(curve)\n c += 5 + 2 * edge[\"k1\"]\n\n edge[\"curves\"] = curves\n self._edges.append(edge)\n\n # @property\n # def edge_lists(self):\n # for\n\n def curves(self):\n \"\"\"list of curves\"\"\"\n pass\n\n def __repr__(self):\n info = \"IGES Type 508: Loop\\n\"\n return info\n\n\nclass EdgeList(Entity):\n \"\"\"Provides a list of edges, comprised of vertices, for specifying\n B-Rep Geometries.\"\"\"\n\n _iges_type = 504\n\n def _add_parameters(self, parameters):\n \"\"\"\n Parameter Data\n Index in list\tType of data\tName\tDescription\n INT\tN\tNumber of Edges in list\n 2\tPointer\tCurve1\tFirst model space curve\n 3\tPointer\tSVL1\tVertex list for start vertex\n 4\tINT\tS1\tIndex of start vertex in SVL1\n 5\tPointer\tEVL1\tVertex list for end vertex\n 6\tINT\tE1\tIndex of end vertex in EVL1\n .\n .\t.\n .\t.\n .\n 5N-3\tPointer\tCurveN\tFirst model space curve\n 5N-2\tPointer\tSVLN\tVertex list for start vertex\n 5N-1\tINT\tSN\tIndex of start vertex in SVLN\n 5N\tPointer\tEVLN\tVertex list for end vertex\n 5N+1\tINT\tEN\tIndex of end vertex in EVLN\n \"\"\"\n self.parameters = parameters\n self.n_edges = int(parameters[1])\n\n self.edges = []\n for i in range(self.n_edges):\n edge = {\n \"curve1\": int(parameters[2 + 5 * i]), # first model space curve\n \"svl\": int(parameters[3 + 5 * i]), # vertex list for start vertex\n \"s\": int(parameters[4 + 5 * i]), # start index\n \"evl\": int(parameters[5 + 5 * i]), # vertex list for end vertex\n \"e\": int(parameters[6 + 5 * i]),\n } # index of end vertex in evl n\n self.edges.append(edge)\n\n # @property\n # def curve(self, ):\n # for\n\n def __getitem__(self, indices):\n # TODO: limit spline based on start and end point\n ptr = self.edges[indices][\"curve1\"]\n return self.iges.from_pointer(ptr)\n\n def __len__(self):\n return len(self.edges)\n\n def __repr__(self):\n \"\"\"Return the representation of EdgesList.\"\"\"\n return \"IGES Type {self._iges_type}: Edge List\\n\"\n\n\nclass VertexList(Entity):\n \"\"\"Vertex List (Type 502 Form 1)\"\"\"\n\n _iges_type = 502\n\n def _add_parameters(self, parameters):\n \"\"\"Adds Parameter Data.\n\n Index in list\tType of data\tName\tDescription\n INT\tN\tNumber of vertices in list\n 2\tREAL\tX1\tCoordinates of first vertex\n 3\tREAL\tY1\n 4\tREAL\tZ1\n .\n .\t.\n .\t.\n .\n 3N-1\tREAL\tXN\tCoordinates of last vertex\n 3N\tREAL\tYN\n 3N+1\tREAL\tZN\n \"\"\"\n self.parameters = parameters\n self.n_points = int(parameters[1])\n self.points = []\n for i in range(self.n_points):\n point = [\n parse_float(self.parameters[2 + i * 3]),\n parse_float(self.parameters[3 + i * 3]),\n parse_float(self.parameters[4 + i * 3]),\n ]\n self.points.append(point)\n"
},
{
"alpha_fraction": 0.613103449344635,
"alphanum_fraction": 0.6241379380226135,
"avg_line_length": 32.72093200683594,
"blob_id": "188db3d8093d56e87a256344dd4726e7240494b7",
"content_id": "0c77a741a16f9b0f9785c7d7cb60b72a5931119b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1450,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 43,
"path": "/setup.py",
"repo_name": "pyvista/pyiges",
"src_encoding": "UTF-8",
"text": "\"\"\"Setup for pyiges\"\"\"\nfrom io import open as io_open\nimport os\n\nfrom setuptools import setup\n\n# Get version\n__version__ = None\nfilepath = os.path.dirname(__file__)\nversion_file = os.path.join(filepath, \"pyiges\", \"_version.py\")\nwith io_open(version_file, mode=\"r\") as fd:\n exec(fd.read())\n\nreadme_file = os.path.join(filepath, \"README.rst\")\n\nsetup(\n name=\"pyiges\",\n packages=[\"pyiges\", \"pyiges.examples\"],\n version=__version__,\n author=\"PyVista Developers\",\n author_email=\"[email protected]\",\n long_description=io_open(readme_file, encoding=\"utf-8\").read(),\n long_description_content_type=\"text/x-rst\",\n license=\"MIT\",\n classifiers=[\n \"Development Status :: 4 - Beta\",\n \"Intended Audience :: Science/Research\",\n \"Topic :: Scientific/Engineering :: Information Analysis\",\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: Microsoft :: Windows\",\n \"Operating System :: POSIX\",\n \"Operating System :: MacOS\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n ],\n description=\"Pythonic IGES reader\",\n url=\"https://github.com/pyvista/pyiges\",\n install_requires=[\"tqdm\", \"numpy\"],\n extras_require={\"full\": [\"geomdl\", \"pyvista>=0.28.0\"]},\n package_data={\"pyiges.examples\": [\"impeller.igs\", \"sample.igs\"]},\n)\n"
},
{
"alpha_fraction": 0.49758094549179077,
"alphanum_fraction": 0.5258652567863464,
"avg_line_length": 30.244186401367188,
"blob_id": "f05cf44e0738aee14a32eb356559fa740723fa09",
"content_id": "4d549d11a6dc6574b1f19927494b95c1cc79b7af",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2687,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 86,
"path": "/pyiges/entity.py",
"repo_name": "pyvista/pyiges",
"src_encoding": "UTF-8",
"text": "\"\"\"Module for the entity class.\"\"\"\nimport os\n\nfrom pyiges.constants import line_font_pattern\n\n\nclass Entity:\n \"\"\"Generic IGES entity\n\n Examples\n --------\n >>> import pyiges\n >>> from pyiges import examples\n >>> iges = pyiges.read(examples.impeller)\n >>> entity = iges[0]\n >>> entity.parameters\n [['314', '75.2941176470588', '75.2941176470588', '75.2941176470588', '']]\n\n >>> print(entity)\n ----- Entity -----\n 314\n 1\n 0\n Default\n 0\n None\n None\n 0\n 200\n 0\n 8\n 1\n 0\n \"\"\"\n\n def __init__(self, iges):\n self.d = dict()\n self.parameters = []\n self.iges = iges\n\n def add_section(self, string, key, type=\"int\"):\n string = string.strip()\n if type == \"string\":\n self.d[key] = string\n else:\n # Status numbers are made of four 2-digit numbers, together making an 8-digit number.\n # It includes spaces, so 0 0 0 0 is a valid 8-digit for which int casting won't work.\n if key == \"status_number\":\n # Get a list of four 2-digit numbers with spaces removed.\n separated_status_numbers = [\n string[i : i + 2].replace(\" \", \"0\")\n for i in range(0, len(string), 2)\n ]\n\n # Join these status numbers together as a single string.\n status_number_string = \"\".join(separated_status_numbers)\n\n # The string can now be properly cast as an int\n self.d[key] = int(status_number_string)\n elif len(string) > 0:\n self.d[key] = int(string)\n else:\n self.d[key] = None\n\n def __str__(self):\n s = \"----- Entity -----\" + os.linesep\n s += str(self.d[\"entity_type_number\"]) + os.linesep\n s += str(self.d[\"parameter_pointer\"]) + os.linesep\n s += str(self.d[\"structure\"]) + os.linesep\n s += line_font_pattern[self.d[\"line_font_pattern\"]] + os.linesep\n s += str(self.d[\"level\"]) + os.linesep\n s += str(self.d[\"view\"]) + os.linesep\n s += str(self.d[\"transform\"]) + os.linesep\n s += str(self.d[\"label_assoc\"]) + os.linesep\n s += str(self.d[\"status_number\"]) + os.linesep\n s += str(self.d[\"line_weight_number\"]) + os.linesep\n s += str(self.d[\"color_number\"]) + os.linesep\n s += str(self.d[\"param_line_count\"]) + os.linesep\n s += str(self.d[\"form_number\"]) + os.linesep\n s += str(self.d[\"entity_label\"]) + os.linesep\n s += str(self.d[\"entity_subs_num\"])\n\n return s\n\n def _add_parameters(self, parameters):\n self.parameters.append(parameters)\n"
},
{
"alpha_fraction": 0.5322033762931824,
"alphanum_fraction": 0.7152542471885681,
"avg_line_length": 35.875,
"blob_id": "3a5e5c20e3cdcac4337a607da32c54ab26fbde00",
"content_id": "7a8bf8c9a47973549bda85a126bb10d874d3791a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 295,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 8,
"path": "/.flake8",
"repo_name": "pyvista/pyiges",
"src_encoding": "UTF-8",
"text": "[flake8]\nexclude = venv, __init__.py, build, doc/source/examples\n# To be added after refactoring code to be compliant: E501\nselect = W191, W291, W293, W391, E115, E117, E122, E124, E125, E225, E231, E301, E303, F401, F403\ncount = True\nmax-complexity = 10\nmax-line-length = 100\nstatistics = True\n"
},
{
"alpha_fraction": 0.4174572229385376,
"alphanum_fraction": 0.5635241270065308,
"avg_line_length": 29.014986038208008,
"blob_id": "30c092c7a5571e4f7cd35299bd2b26a03de0a91e",
"content_id": "d53a3ad2aa32def6138e9ca63fbb64de7a222dff",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 22031,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 734,
"path": "/tests/test_pyiges.py",
"repo_name": "pyvista/pyiges",
"src_encoding": "UTF-8",
"text": "import functools\nimport os\n\nimport numpy as np\nimport pytest\n\nimport pyiges\nfrom pyiges import examples\n\nDIR_TESTS_REFERENCE_DATA = os.path.join(os.path.dirname(__file__), \"reference_data\")\n\n\ndef adjust_depending_on_package_variant(test_func):\n \"\"\"If the full module is present, run test as usual,\n otherwise assert that the error is triggered as intended.\n \"\"\"\n\n @functools.wraps(test_func)\n def generalized_test_func(*a, **kw):\n if pyiges.check_imports._IS_FULL_MODULE:\n return test_func(*a, **kw)\n else:\n with pytest.raises(Exception, match=r\"install pyiges\\[full\\]\"):\n return test_func(*a, **kw)\n\n return generalized_test_func\n\n\[email protected](scope=\"module\")\ndef sample():\n return pyiges.read(examples.sample)\n\n\[email protected](scope=\"module\")\ndef impeller():\n return pyiges.read(examples.impeller)\n\n\[email protected](scope=\"module\")\ndef surf(impeller):\n return impeller.bspline_surfaces()[0] # pyiges.geometry.RationalBSplineSurface\n\n\[email protected](scope=\"module\")\ndef curve(impeller):\n return impeller.bsplines(as_vtk=False)[0] # geometry.RationalBSplineCurve\n\n\[email protected](scope=\"module\")\ndef point(sample):\n return sample.points(as_vtk=False, merge=False)[0] # pyiges.geometry.Point\n\n\[email protected](scope=\"module\")\ndef carc(impeller):\n return impeller.circular_arcs()[0] # pyiges.geometry.CircularArc\n\n\[email protected](scope=\"module\")\ndef trafo(impeller):\n return impeller._entities[172] # pyiges.geometry.Transformation\n\n\[email protected](scope=\"module\")\ndef line(impeller):\n return impeller.lines()[0] # pyiges.geometry.Line\n\n\[email protected](scope=\"module\")\ndef entity(impeller):\n return impeller._entities[0] # pyiges.entity.Entity\n\n\ndef test_str(sample):\n assert \"Number of Entities: 5\" in str(sample)\n\n\ndef test_get_item(sample):\n assert \"0.0, 0.0, 0.0\" in str(sample.items[0])\n assert \"0.0, 0.0, 0.0\" in str(sample[1])\n\n\ndef test_parse_completeness1(impeller):\n assert len(impeller.bspline_surfaces()) == 247\n assert len(impeller.bsplines()) == 2342\n assert len(impeller.circular_arcs()) == 468\n assert len(impeller.conic_arcs()) == 0\n assert len(impeller.edge_lists()) == 0\n assert len(impeller.faces()) == 0\n assert len(impeller.lines()) == 98\n assert len(impeller.loops()) == 0\n assert len(impeller.points()) == 0\n assert len(impeller.vertex_lists()) == 0\n\n\ndef test_parse_completeness2(sample):\n assert len(sample.bspline_surfaces()) == 0\n assert len(sample.bsplines()) == 0\n assert len(sample.circular_arcs()) == 0\n assert len(sample.conic_arcs()) == 0\n assert len(sample.edge_lists()) == 0\n assert len(sample.faces()) == 0\n assert len(sample.lines()) == 0\n assert len(sample.loops()) == 0\n assert len(sample.points()) == 4\n assert len(sample.vertex_lists()) == 0\n\n\[email protected](\"merge\", [False, True])\n@adjust_depending_on_package_variant\ndef test_iges_to_vtk1(impeller, merge):\n items = impeller.to_vtk(delta=0.5, merge=merge)\n assert items.bounds == pytest.approx(\n (\n -50.516562808,\n 49.445007453,\n -49.510005208,\n 50.494748866,\n -997.9630126953125,\n 1011.0750122070312,\n )\n )\n\n\[email protected](\"merge\", [False, True])\n@adjust_depending_on_package_variant\ndef test_iges_to_vtk2(sample, merge):\n items = sample.to_vtk(merge=merge)\n assert items.bounds == pytest.approx((0.0, 1.0, 0.0, 1.0, 0.0, 0.0))\n\n\n@adjust_depending_on_package_variant\ndef test_surfaces_vtk(surf):\n mesh = surf.to_vtk(delta=0.1)\n\n assert mesh.area == pytest.approx(277.4757547644264)\n assert mesh.n_arrays == 0\n assert mesh.n_cells == 162\n assert mesh.n_faces == 162\n assert mesh.n_lines == 0\n assert mesh.n_open_edges == 36\n assert mesh.n_points == 100\n assert mesh.n_strips == 0\n assert mesh.n_verts == 0\n\n assert mesh.bounds == pytest.approx(\n (\n -30.547425187,\n -26.209437969209873,\n -16.775362758,\n -9.363301218200274,\n -45.772995131000016,\n -8.876323512,\n )\n )\n\n\n@adjust_depending_on_package_variant\ndef test_surfaces_to_geomdl(surf):\n gsurf = surf.to_geomdl()\n assert gsurf.data[\"control_points\"] == pytest.approx(\n (\n [-26.902905334, -16.51153913, -8.876323512],\n [-25.851820351, -15.866440371, -21.167794775],\n [-25.995725563, -15.954761558, -33.519826531],\n [-27.332763631, -16.775362758, -45.772995131],\n [-28.232974775, -14.344404257, -8.876323512],\n [-27.129924549, -13.783974529, -21.167794775],\n [-27.28094438, -13.860703585, -33.519826531],\n [-28.684085103, -14.573601108, -45.772995131],\n [-29.292803148, -12.033057876, -8.876323512],\n [-28.148345882, -11.562931461, -21.167794775],\n [-28.305034796, -11.62729699, -33.519826531],\n [-29.760847559, -12.225323719, -45.772995131],\n [-30.067010387, -9.611041892, -8.876323512],\n [-28.892305175, -9.235542604, -21.167794775],\n [-29.05313537, -9.286952628, -33.519826531],\n [-30.547425187, -9.764608432, -45.772995131],\n )\n )\n\n\ndef test_surfaces_parse(surf):\n assert surf.parameters == []\n assert surf.sequence_number == 3\n\n assert surf.flag1 is False\n assert surf.flag2 is False\n assert surf.flag3 is False\n assert surf.flag4 is False\n assert surf.flag5 is False\n assert surf.k1 == 3\n assert surf.k2 == 3\n assert surf.m1 == 3\n assert surf.m2 == 3\n assert surf.u0 == 1.0\n assert surf.u1 == 0.0\n assert surf.v0 == 1.0\n assert surf.v1 == 128.0\n\n assert surf.knot1 == pytest.approx([0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 1.0])\n assert surf.knot2 == pytest.approx([0.0, 0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 1.0])\n\n assert surf.weights == pytest.approx(\n np.array(\n [\n 1.0,\n 0.99569778,\n 0.99569778,\n 1.0,\n 0.99516272,\n 0.9908813,\n 0.9908813,\n 0.99516272,\n 0.99516272,\n 0.9908813,\n 0.9908813,\n 0.99516272,\n 1.0,\n 0.99569778,\n 0.99569778,\n 1.0,\n ]\n )\n )\n\n assert surf.control_points() == pytest.approx(\n np.array(\n [\n [-26.90290533, -16.51153913, -8.87632351],\n [-25.85182035, -15.86644037, -21.16779478],\n [-25.99572556, -15.95476156, -33.51982653],\n [-27.33276363, -16.77536276, -45.77299513],\n [-28.23297477, -14.34440426, -8.87632351],\n [-27.12992455, -13.78397453, -21.16779478],\n [-27.28094438, -13.86070358, -33.51982653],\n [-28.6840851, -14.57360111, -45.77299513],\n [-29.29280315, -12.03305788, -8.87632351],\n [-28.14834588, -11.56293146, -21.16779478],\n [-28.3050348, -11.62729699, -33.51982653],\n [-29.76084756, -12.22532372, -45.77299513],\n [-30.06701039, -9.61104189, -8.87632351],\n [-28.89230518, -9.2355426, -21.16779478],\n [-29.05313537, -9.28695263, -33.51982653],\n [-30.54742519, -9.76460843, -45.77299513],\n ]\n )\n )\n\n assert surf.d == {\n \"entity_type_number\": 128,\n \"parameter_pointer\": 2,\n \"structure\": 0,\n \"line_font_pattern\": 0,\n \"level\": 0,\n \"view\": None,\n \"transform\": None,\n \"label_assoc\": 0,\n \"status_number\": 1010000,\n \"line_weight_number\": 0,\n \"color_number\": 0,\n \"param_line_count\": 18,\n \"form_number\": 0,\n \"entity_label\": \"\",\n \"entity_subs_num\": 0,\n }\n assert repr(surf)\n assert str(surf)\n\n\ndef test_bsplines_parse(curve):\n assert curve.parameters == []\n assert curve.sequence_number == 5\n\n assert curve.A == 17\n assert curve.K == 14\n assert curve.M == 2\n assert curve.N == 13\n assert curve.V0 == pytest.approx(0.0)\n assert curve.V1 == pytest.approx(1.0)\n assert curve.XNORM == pytest.approx(0.0)\n assert curve.YNORM == pytest.approx(0.0)\n assert curve.ZNORM == pytest.approx(1.0)\n assert curve.prop1 == 1\n assert curve.prop2 == 0\n assert curve.prop3 == 1\n assert curve.prop4 == 0\n\n assert curve.T == pytest.approx(\n [\n 0.0,\n 0.0,\n 0.0,\n 0.25,\n 0.25,\n 0.375,\n 0.375,\n 0.5,\n 0.5,\n 0.625,\n 0.625,\n 0.75,\n 0.75,\n 0.875,\n 0.875,\n 1.0,\n 1.0,\n 1.0,\n ]\n )\n\n assert curve.W == pytest.approx(\n [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0]\n )\n\n assert curve.d == {\n \"entity_type_number\": 126,\n \"parameter_pointer\": 20,\n \"structure\": 0,\n \"line_font_pattern\": 0,\n \"level\": 0,\n \"view\": None,\n \"transform\": None,\n \"label_assoc\": 0,\n \"status_number\": 1010500,\n \"line_weight_number\": 0,\n \"color_number\": 0,\n \"param_line_count\": 10,\n \"form_number\": 0,\n \"entity_label\": \"\",\n \"entity_subs_num\": 0,\n }\n assert repr(curve)\n assert str(curve)\n\n\n@adjust_depending_on_package_variant\ndef test_bsplines_vtk(curve):\n mesh = curve.to_vtk()\n\n assert mesh.area == 0.0\n assert mesh.n_arrays == 0\n assert mesh.n_cells == 1\n assert mesh.n_faces == 1\n assert mesh.n_lines == 1\n assert mesh.n_open_edges == 0\n assert mesh.n_points == 100\n assert mesh.n_strips == 0\n assert mesh.n_verts == 0\n\n assert mesh.bounds == pytest.approx(\n (0.531027642, 0.559345007, 0.006617509, 0.127235606, 0.0, 0.0)\n )\n\n\n@adjust_depending_on_package_variant\ndef test_bsplines_to_geomdl(curve):\n gcurve = curve.to_geomdl()\n assert gcurve.data[\"control_points\"] == pytest.approx(\n (\n [0.531027642, 0.127235606, 0.0, 1.0],\n [0.53482791, 0.099559574, 0.0, 1.0],\n [0.537603234, 0.077944022, 0.0, 1.0],\n [0.539206635, 0.06545597, 0.0, 1.0],\n [0.540802737, 0.052996393, 0.0, 1.0],\n [0.542675511, 0.038377045, 0.0, 1.0],\n [0.544208805, 0.028733039, 0.0, 1.0],\n [0.546564848, 0.013914155, 0.0, 1.0],\n [0.548603824, 0.009169564, 0.0, 1.0],\n [0.551376925, 0.002716702, 0.0, 1.0],\n [0.554223526, 0.012546793, 0.0, 1.0],\n [0.556570985, 0.020653212, 0.0, 1.0],\n [0.557884113, 0.035401282, 0.0, 1.0],\n [0.55898716, 0.047789894, 0.0, 1.0],\n [0.559345007, 0.06395869, 0.0, 1.0],\n )\n )\n\n\n@adjust_depending_on_package_variant\ndef test_points_vtk(sample):\n points = sample.points(as_vtk=True, merge=True) # pv.PolyData\n\n assert points.n_cells == 4\n assert points.n_faces == 4\n assert points.n_lines == 0\n assert points.n_open_edges == 0\n assert points.n_points == 4\n assert points.n_strips == 0\n assert points.n_verts == 4\n\n assert points.bounds == pytest.approx((0.0, 1.0, 0.0, 1.0, 0.0, 0.0))\n assert points.points == pytest.approx(\n np.array([[0.0, 0.0, 0.0], [1.0, 0.0, 0.0], [1.0, 1.0, 0.0], [0.0, 1.0, 0.0]])\n )\n\n\ndef test_points_parse(sample):\n points = sample.points(as_vtk=False, merge=True) # pyiges.geometry.Point\n\n assert points[0].coordinate == pytest.approx((0.0, 0.0, 0.0))\n assert points[1].coordinate == pytest.approx((1.0, 0.0, 0.0))\n assert points[2].coordinate == pytest.approx((1.0, 1.0, 0.0))\n assert points[3].coordinate == pytest.approx((0.0, 1.0, 0.0))\n\n assert points[0].parameters == []\n assert points[1].parameters == []\n assert points[2].parameters == []\n assert points[3].parameters == []\n\n assert points[0].sequence_number == 1\n assert points[1].sequence_number == 3\n assert points[2].sequence_number == 5\n assert points[3].sequence_number == 7\n\n assert points[3].d == {\n \"entity_type_number\": 116,\n \"parameter_pointer\": 7,\n \"structure\": 0,\n \"line_font_pattern\": 0,\n \"level\": 0,\n \"view\": 0,\n \"transform\": 0,\n \"label_assoc\": 0,\n \"status_number\": 1,\n \"line_weight_number\": 0,\n \"color_number\": 0,\n \"param_line_count\": 2,\n \"form_number\": 0,\n \"entity_label\": \"POINT\",\n \"entity_subs_num\": 4,\n }\n assert repr(sample)\n assert str(sample)\n\n\ndef test_point_parse(point):\n assert point.parameters == []\n assert point.sequence_number == 1\n\n assert point.coordinate == pytest.approx(np.array([0.0, 0.0, 0.0]))\n\n assert point.d == {\n \"entity_type_number\": 116,\n \"parameter_pointer\": 1,\n \"structure\": 0,\n \"line_font_pattern\": 0,\n \"level\": 0,\n \"view\": 0,\n \"transform\": 0,\n \"label_assoc\": 0,\n \"status_number\": 1,\n \"line_weight_number\": 0,\n \"color_number\": 0,\n \"param_line_count\": 2,\n \"form_number\": 0,\n \"entity_label\": \"POINT\",\n \"entity_subs_num\": 1,\n }\n assert repr(point)\n assert str(point)\n\n\n@adjust_depending_on_package_variant\ndef test_point_vtk(point):\n point = point.to_vtk() # pv.PolyData\n\n assert point.n_arrays == 0\n assert point.n_cells == 1\n assert point.n_faces == 1\n assert point.n_lines == 0\n assert point.n_open_edges == 0\n assert point.n_points == 1\n assert point.n_strips == 0\n assert point.n_verts == 1\n\n assert point.bounds == pytest.approx((0.0, 0.0, 0.0, 0.0, 0.0, 0.0))\n assert point.points == pytest.approx(np.array([[0.0, 0.0, 0.0]]))\n\n\ndef test_circular_arcs_parse(carc):\n assert carc.parameters == []\n assert carc.sequence_number == 19\n\n assert carc.x == pytest.approx(0.0)\n assert carc.x1 == pytest.approx(-29.279537336)\n assert carc.x2 == pytest.approx(-28.792209864)\n assert carc.y == pytest.approx(0.0)\n assert carc.y1 == pytest.approx(-9.405469593)\n assert carc.y2 == pytest.approx(-10.805684432)\n assert carc.z == pytest.approx(-25.115661529)\n\n assert carc.d == {\n \"entity_type_number\": 100,\n \"parameter_pointer\": 86,\n \"structure\": 0,\n \"line_font_pattern\": 0,\n \"level\": 0,\n \"view\": None,\n \"transform\": None,\n \"label_assoc\": 0,\n \"status_number\": 1010000,\n \"line_weight_number\": 0,\n \"color_number\": 0,\n \"param_line_count\": 2,\n \"form_number\": 0,\n \"entity_label\": \"\",\n \"entity_subs_num\": 0,\n }\n assert repr(carc)\n assert str(carc)\n\n\n@adjust_depending_on_package_variant\ndef test_circular_arcs_vtk(carc):\n polydata = carc.to_vtk()\n\n assert polydata.n_arrays == 2\n assert polydata.n_cells == 1\n assert polydata.n_faces == 1\n assert polydata.n_lines == 1\n assert polydata.n_points == 21\n assert polydata.n_strips == 0\n assert polydata.n_verts == 0\n\n assert polydata.bounds == pytest.approx(\n (\n -29.2795372009277,\n -28.79220962524414,\n -10.80568408966064,\n -9.40546989440918,\n -25.11566162109375,\n -25.11566162109375,\n )\n )\n assert polydata.points == pytest.approx(\n np.array(\n [\n [-29.279537, -9.4054700, -25.115662],\n [-29.256779, -9.4760270, -25.115662],\n [-29.233849, -9.5465290, -25.115662],\n [-29.210750, -9.6169760, -25.115662],\n [-29.187483, -9.6873665, -25.115662],\n [-29.164043, -9.7577010, -25.115662],\n [-29.140436, -9.8279780, -25.115662],\n [-29.116660, -9.8981990, -25.115662],\n [-29.092712, -9.9683620, -25.115662],\n [-29.068598, -10.038467, -25.115662],\n [-29.044313, -10.108514, -25.115662],\n [-29.019860, -10.178502, -25.115662],\n [-28.995237, -10.248431, -25.115662],\n [-28.970448, -10.318300, -25.115662],\n [-28.945490, -10.388110, -25.115662],\n [-28.920362, -10.457859, -25.115662],\n [-28.895067, -10.527547, -25.115662],\n [-28.869604, -10.597175, -25.115662],\n [-28.843973, -10.666739, -25.115662],\n [-28.818176, -10.736243, -25.115662],\n [-28.792210, -10.805684, -25.115662],\n ]\n )\n )\n\n\ndef test_entity_parse(entity):\n assert entity.parameters[0][0] == \"314\"\n assert entity.sequence_number == 1\n\n assert list(map(float, entity.parameters[0][1:4])) == pytest.approx(\n [75.2941176, 75.2941176, 75.2941176]\n )\n\n assert entity.d == {\n \"entity_type_number\": 314,\n \"parameter_pointer\": 1,\n \"structure\": 0,\n \"line_font_pattern\": 0,\n \"level\": 0,\n \"view\": None,\n \"transform\": None,\n \"label_assoc\": 0,\n \"status_number\": 200,\n \"line_weight_number\": 0,\n \"color_number\": 8,\n \"param_line_count\": 1,\n \"form_number\": 0,\n \"entity_label\": \"\",\n \"entity_subs_num\": 0,\n }\n assert str(entity)\n assert repr(entity)\n\n\ndef test_line_parse(line):\n assert line.parameters == []\n assert line.sequence_number == 333\n\n assert line.coordinates == pytest.approx(\n np.array([[0.0, 0.0, -997.96301316], [0.0, 0.0, 2.03698684]])\n )\n\n assert line.d == {\n \"entity_type_number\": 110,\n \"parameter_pointer\": 1213,\n \"structure\": 0,\n \"line_font_pattern\": 0,\n \"level\": 0,\n \"view\": None,\n \"transform\": None,\n \"label_assoc\": 0,\n \"status_number\": 1010000,\n \"line_weight_number\": 0,\n \"color_number\": 0,\n \"param_line_count\": 1,\n \"form_number\": 0,\n \"entity_label\": \"\",\n \"entity_subs_num\": 0,\n }\n assert repr(line)\n assert str(line)\n\n\n@adjust_depending_on_package_variant\ndef test_line_vtk(line):\n polydata = line.to_vtk()\n assert polydata.n_arrays == 2\n assert polydata.n_cells == 1\n assert polydata.n_faces == 1\n assert polydata.n_lines == 1\n assert polydata.n_open_edges == 0\n assert polydata.n_open_edges == 0\n assert polydata.n_points == 2\n assert polydata.n_strips == 0\n assert polydata.n_verts == 0\n\n assert polydata.bounds == pytest.approx(\n (0.0, 0.0, 0.0, 0.0, -997.9630126, 2.0369868)\n )\n assert polydata.points == pytest.approx(\n np.array([[0.0, 0.0, -997.963], [0.0, 0.0, 2.0369868]])\n )\n\n\ndef test_transformation_parse(trafo):\n assert trafo.parameters == []\n assert trafo.sequence_number == 345\n\n assert trafo.r11 == pytest.approx(1.0)\n assert trafo.r12 == pytest.approx(-7.35035671743047e-15)\n assert trafo.r13 == pytest.approx(8.55166289179392e-31)\n assert trafo.r21 == pytest.approx(-7.35035671743047e-15)\n assert trafo.r22 == pytest.approx(-1.0)\n assert trafo.r23 == pytest.approx(6.98296267768627e-15)\n assert trafo.r31 == pytest.approx(-5.04721003363181e-29)\n assert trafo.r32 == pytest.approx(-6.98296267768627e-15)\n assert trafo.r33 == pytest.approx(-1.0)\n assert trafo.t1 == pytest.approx(-2.42609551059902e-30)\n assert trafo.t2 == pytest.approx(-1.98105732386527e-14)\n assert trafo.t3 == pytest.approx(5.67397368511119)\n\n assert trafo.d == {\n \"entity_type_number\": 124,\n \"parameter_pointer\": 1221,\n \"structure\": 0,\n \"line_font_pattern\": 0,\n \"level\": 0,\n \"view\": None,\n \"transform\": None,\n \"label_assoc\": 0,\n \"status_number\": 0,\n \"line_weight_number\": 0,\n \"color_number\": 0,\n \"param_line_count\": 5,\n \"form_number\": 0,\n \"entity_label\": \"\",\n \"entity_subs_num\": 0,\n }\n assert repr(trafo)\n assert str(trafo)\n\n\n@adjust_depending_on_package_variant\ndef test_transformation_vtk(trafo):\n trafo = trafo._to_vtk()\n m = trafo.GetMatrix()\n assert m.GetElement(2, 3) == pytest.approx(5.67397368511119)\n\n\ndef test_example_with_invalid_conic_arc_and_form1_global_line():\n # For this file, the conic arc cannot be parsed.\n # This is either because of a wrong format of the file or a bug in the parsing.\n # Despite the reason is unclear, we use this here to test the robust discarding mechanism\n iges = pyiges.read(os.path.join(DIR_TESTS_REFERENCE_DATA, \"example-arcs.iges\"))\n assert not iges.conic_arcs()\n assert len(iges.bsplines()) == 1\n assert len(iges.circular_arcs()) == 1\n\n\n@adjust_depending_on_package_variant\ndef test_to_vtk(impeller):\n lines = impeller.to_vtk(lines=True, bsplines=False, surfaces=False)\n assert lines.n_points\n assert lines.n_cells\n\n\[email protected](\n \"line, expected_separators\",\n [\n # possible forms 1-4, see http://paulbourke.net/dataformats/iges/IGES.pdf\n # p. 15\n (\",,\", (\",\", \";\")),\n (\"1Haa1Hba\", (\"a\", \"b\")),\n (\"1Haaa\", (\"a\", \";\")),\n (\",1Hb,\", (\",\", \"b\")),\n # typical special case of form 2\n (\"1H,,1H;,\", (\",\", \";\")),\n # invalid forms\n (\"xyz\", None),\n (\",2H\", None),\n (\"1Hxy\", None),\n ],\n)\ndef test_parse_separators_from_first_global_line(line, expected_separators):\n if expected_separators is None:\n with pytest.raises(RuntimeError, match=\"Invalid Global section format\"):\n pyiges.Iges._parse_separators_from_first_global_line(line)\n else:\n separators = pyiges.Iges._parse_separators_from_first_global_line(line)\n assert separators == expected_separators\n\n\ndef test_package_variant_detection(request):\n is_full_module_expected = request.config.getoption(\"--expect-full-module\")\n assert pyiges.check_imports._IS_FULL_MODULE == is_full_module_expected\n"
},
{
"alpha_fraction": 0.47208863496780396,
"alphanum_fraction": 0.495403915643692,
"avg_line_length": 35.66741180419922,
"blob_id": "1becfb1bd490288bb5df242b49f2f9151fa74dbe",
"content_id": "04854c4b6c78e445b58290c44b8233ef4c5d4bc8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16427,
"license_type": "permissive",
"max_line_length": 130,
"num_lines": 448,
"path": "/pyiges/iges.py",
"repo_name": "pyvista/pyiges",
"src_encoding": "UTF-8",
"text": "from tqdm import tqdm\n\nfrom pyiges import geometry\nfrom pyiges.check_imports import assert_full_module_variant, pyvista, vtkAppendPolyData\nfrom pyiges.entity import Entity\n\n\nclass Iges:\n \"\"\"pyiges.Iges object\n\n Parameters\n ----------\n filename : str\n Filename of an IGES file.\n\n Examples\n --------\n >>> import pyiges\n >>> from pyiges import examples\n >>> iges = pyiges.read(examples.impeller)\n pyiges.Iges object\n Description:\n Number of Entities: 4615\n \"\"\"\n\n def __init__(self, filename):\n self._read(filename)\n self._desc = \"\"\n\n def entities(self):\n \"\"\"Return a list of all entities\n\n Examples\n --------\n >>> iges.entities\n [<pyiges.geometry.Point at 0x7f7056069c10>,\n <pyiges.geometry.Point at 0x7f7056069790>,\n <pyiges.geometry.Point at 0x7f7056069a50>,\n <pyiges.geometry.Point at 0x7f7056069b10>,\n <pyiges.entity.Entity at 0x7f7056069910>]\n \"\"\"\n\n @assert_full_module_variant\n def to_vtk(\n self,\n lines=True,\n bsplines=True,\n surfaces=True,\n points=True,\n delta=0.025,\n merge=True,\n progress=tqdm,\n ):\n \"\"\"Converts entities to a vtk object\n\n Parameters\n ----------\n lines : bool, optional\n Convert lines.\n\n surfaces : bool, optional\n Convert B-Spline surfaces.\n\n points : bool, optional\n Convert points.\n\n delta : float, optional\n Resolution when converting spline entities. Higher\n resolution creates a better plot at the cost of computing\n time.\n\n merge : bool, optional\n Merge all converted entities into one output.\n\n progress: function, optional\n Report conversion progress by use of this function. Example::\n\n def silent_progress(iterable, *args, **kwargs):\n return iterable\n\n Passing progress=silent_progress will show no progress, the\n default is to use tqdm for progress reporting.\n\n Returns\n -------\n surf : pyvista.PolyData or pyvista.MultiBlock\n Geometry represented as ``pyvista.PolyData`` if merged or\n a ``MultiBlock`` if unmerged.\n\n Examples\n --------\n Convert all entities except for surfaces to vtk\n\n >>> lines = iges.to_vtk(surfaces=False)\n >>> print(lines)\n PolyData (0x7f700c79f3d0)\n N Cells:\t2440\n N Points:\t96218\n X Bounds:\t-4.299e+01, 6.912e+14\n Y Bounds:\t-4.255e+01, 6.290e+14\n Z Bounds:\t-9.980e+02, 6.702e+14\n N Arrays:\t0\n \"\"\"\n items = pyvista.MultiBlock()\n for entity in progress(self, desc=\"Converting entities to vtk\"):\n if isinstance(entity, geometry.RationalBSplineCurve) and bsplines:\n items.append(entity.to_vtk(delta))\n elif isinstance(entity, geometry.RationalBSplineSurface) and surfaces:\n items.append(entity.to_vtk(delta))\n elif isinstance(entity, geometry.Line) and lines:\n items.append(entity.to_vtk())\n elif isinstance(entity, geometry.Point) and points:\n items.append(entity.to_vtk())\n\n # merge to a single mesh\n if merge:\n afilter = vtkAppendPolyData()\n for item in items:\n afilter.AddInputData(item)\n afilter.Update()\n\n return pyvista.wrap(afilter.GetOutput())\n\n return items\n\n def points(self, as_vtk=False, merge=False, **kwargs):\n \"\"\"Return all points\"\"\"\n return self._return_type(geometry.Point, as_vtk, merge, **kwargs)\n\n def edge_lists(self, as_vtk=False, merge=False, **kwargs):\n \"\"\"All Edge Lists\"\"\"\n return self._return_type(geometry.EdgeList, as_vtk, merge, **kwargs)\n\n def vertex_lists(self, as_vtk=False, merge=False, **kwargs):\n \"\"\"All Point Lists\"\"\"\n return self._return_type(geometry.VertexList, as_vtk, merge, **kwargs)\n\n def lines(self, as_vtk=False, merge=False, **kwargs):\n \"\"\"All lines\"\"\"\n return self._return_type(geometry.Line, as_vtk, merge, **kwargs)\n\n def bsplines(self, as_vtk=False, merge=False, **kwargs):\n \"\"\"All bsplines\"\"\"\n return self._return_type(geometry.RationalBSplineCurve, as_vtk, merge, **kwargs)\n\n def bspline_surfaces(self, as_vtk=False, merge=False, **kwargs):\n \"\"\"All bsplines\n\n Examples\n --------\n Convert and plot all bspline surfaces. This takes a while\n since the geometry tessellation is done in pure python by\n ``geomdl``. Reduce the conversion time by setting delta to a\n larger than default value (0.025)\n\n >>> mesh = iges.bspline_surfaces(as_vtk=True, merge=True)\n >>> mesh.plot()\n\n Alternatively, just extract the B-REP surfaces and extract\n their parameters\n\n >>> bsurf = iges.bspline_surfaces()\n >>> bsurf[0]\n Rational B-Spline Surface\n Upper index of first sum: 3\n Upper index of second sum: 3\n Degree of first basis functions: 3\n Degree of second basis functions: 3\n Open in the first direction\n Open in the second direction\n Polynomial\n Periodic in the first direction\n Periodic in the second direction\n Knot 1: [0. 0. 0. 0. 1. 1. 1. 1.]\n Knot 2: [0. 0. 0. 0. 1. 1. 1. 1.]\n u0: 1.000000\n u1: 0.000000\n v0: 1.000000\n v1: 128.000000\n Control Points: 16\n \"\"\"\n return self._return_type(\n geometry.RationalBSplineSurface, as_vtk, merge, **kwargs\n )\n\n def circular_arcs(self, to_vtk=False, merge=False, **kwargs):\n \"\"\"All circular_arcs\"\"\"\n return self._return_type(geometry.CircularArc, to_vtk, merge, **kwargs)\n\n def conic_arcs(self, as_vtk=False, merge=False, **kwargs):\n return self._return_type(geometry.ConicArc, as_vtk, merge, **kwargs)\n\n def faces(self, as_vtk=False, merge=False, **kwargs):\n return self._return_type(geometry.Face, as_vtk, merge, **kwargs)\n\n def loops(self, as_vtk=False, merge=False, **kwargs):\n return self._return_type(geometry.Loop, as_vtk, merge, **kwargs)\n\n def _return_type(self, iges_type, to_vtk=False, merge=False, **kwargs):\n \"\"\"Return an iges type\"\"\"\n items = []\n for entity in self:\n if isinstance(entity, iges_type):\n if to_vtk:\n items.append(entity.to_vtk(**kwargs))\n else:\n items.append(entity)\n\n # merge to a single mesh\n if merge and to_vtk:\n afilter = vtkAppendPolyData()\n for item in items:\n afilter.AddInputData(item)\n afilter.Update()\n\n return pyvista.wrap(afilter.GetOutput())\n\n return items\n\n def __iter__(self):\n yield from self._entities\n\n def __len__(self):\n return len(self._entities)\n\n def __repr__(self):\n info = \"pyiges.Iges object\\n\"\n info += \"Description: %s\\n\" % self._desc\n info += \"Number of Entities: %d\" % len(self)\n return info\n\n def from_pointer(self, ptr):\n \"\"\"Return an iges object according to an iges pointer\"\"\"\n return self[self._pointers[ptr]]\n\n @staticmethod\n def _parse_separators_from_first_global_line(line):\n if line[0] == \",\":\n a = \",\"\n if line[1] == a:\n b = \";\"\n elif line[1:3] == \"1H\":\n b = line[3]\n else:\n raise RuntimeError(\"Invalid Global section format\")\n elif line[0:2] == \"1H\":\n a = line[2]\n if line[4:6] == \"1H\":\n b = line[6]\n elif line[3] == a:\n b = \";\"\n else:\n raise RuntimeError(\"Invalid Global section format\")\n else:\n raise RuntimeError(\"Invalid Global section format\")\n return a, b\n\n def _read(self, filename):\n with open(filename) as f:\n param_string = \"\"\n entity_list = []\n entity_index = 0\n first_dict_line = True\n first_global_line = True\n first_param_line = True\n global_string = \"\"\n pointer_dict = {}\n entities_to_discard = []\n\n # for line in tqdm(f.readlines(), desc='Reading file'):\n for line_no, line in enumerate(f.readlines(), start=1):\n data = line[:80]\n id_code = line[72]\n\n if id_code == \"S\": # Start\n desc = line[:72].strip()\n\n elif id_code == \"G\": # Global\n global_string += data # Consolidate all global lines\n if first_global_line:\n (\n param_sep,\n record_sep,\n ) = self._parse_separators_from_first_global_line(data)\n first_global_line = False\n\n elif id_code == \"D\": # Directory entry\n if first_dict_line:\n entity_type_number = int(data[0:8].strip())\n # Curve and surface entities. See IGES spec v5.3, p. 38, Table 3\n if entity_type_number == 100: # Circular arc\n e = geometry.CircularArc(self)\n elif entity_type_number == 102: # Composite curve\n e = Entity(self)\n elif entity_type_number == 104: # Conic arc\n e = geometry.ConicArc(self)\n elif entity_type_number == 108: # Plane\n e = Entity(self)\n elif entity_type_number == 110: # Line\n e = geometry.Line(self)\n elif entity_type_number == 112: # Parametric spline curve\n e = Entity(self)\n elif entity_type_number == 114: # Parametric spline surface\n e = Entity(self)\n elif entity_type_number == 116: # Point\n e = geometry.Point(self)\n elif entity_type_number == 118: # Ruled surface\n e = Entity(self)\n elif entity_type_number == 120: # Surface of revolution\n e = Entity(self)\n elif entity_type_number == 122: # Tabulated cylinder\n e = Entity(self)\n elif entity_type_number == 124: # Transformation matrix\n e = geometry.Transformation(self)\n elif entity_type_number == 126: # Rational B-spline curve\n e = geometry.RationalBSplineCurve(self)\n elif entity_type_number == 128: # Rational B-spline surface\n e = geometry.RationalBSplineSurface(self)\n\n # CSG Entities. See IGES spec v5.3, p. 42, Section 3.3\n elif entity_type_number == 150: # Block\n e = Entity(self)\n\n # B-Rep entities. See IGES spec v5.3, p. 43, Section 3.4\n elif entity_type_number == 186:\n e = Entity(self)\n\n # Annotation entities. See IGES spec v5.3, p. 46, Section 3.5\n elif entity_type_number == 202:\n e = Entity(self)\n\n # Structural entities. See IGES spec v5.3, p. 50, Section 3.6\n elif entity_type_number == 132:\n e = Entity(self)\n elif entity_type_number == 502:\n e = geometry.VertexList(self)\n elif entity_type_number == 504:\n e = geometry.EdgeList(self)\n elif entity_type_number == 508:\n e = geometry.Loop(self)\n elif entity_type_number == 510:\n e = geometry.Face(self)\n else:\n e = Entity(self)\n\n e.add_section(data[0:8], \"entity_type_number\")\n e.add_section(data[8:16], \"parameter_pointer\")\n e.add_section(data[16:24], \"structure\")\n e.add_section(data[24:32], \"line_font_pattern\")\n e.add_section(data[32:40], \"level\")\n e.add_section(data[40:48], \"view\")\n e.add_section(data[48:56], \"transform\")\n e.add_section(data[56:65], \"label_assoc\")\n e.add_section(data[65:72], \"status_number\")\n e.sequence_number = int(data[73:].strip())\n\n first_dict_line = False\n else:\n e.add_section(data[8:16], \"line_weight_number\")\n e.add_section(data[16:24], \"color_number\")\n e.add_section(data[24:32], \"param_line_count\")\n e.add_section(data[32:40], \"form_number\")\n e.add_section(data[56:64], \"entity_label\", type=\"string\")\n e.add_section(data[64:72], \"entity_subs_num\")\n\n first_dict_line = True\n entity_list.append(e)\n pointer_dict.update({e.sequence_number: entity_index})\n entity_index += 1\n\n elif id_code == \"P\": # Parameter data\n # Concatenate multiple lines into one string\n if first_param_line:\n param_string = data[:64]\n directory_pointer = int(data[64:72].strip())\n first_param_line = False\n else:\n param_string += data[:64]\n\n if param_string.strip()[-1] == record_sep:\n first_param_line = True\n param_string = param_string.strip()[:-1]\n parameters = param_string.split(param_sep)\n this_entity = entity_list[pointer_dict[directory_pointer]]\n try:\n this_entity._add_parameters(parameters)\n except Exception as err:\n print(\n \"Warning: Could not initialize entity from parameters with Parameter section \"\n \"ending on line {}. Possibly wrong or (yet) unsupported format. Entity will be discarded.\".format(\n line_no\n )\n )\n entities_to_discard.append(this_entity)\n\n elif id_code == \"T\": # Terminate\n pass\n\n for e in entities_to_discard:\n try:\n entity_list.remove(e)\n except:\n pass\n\n self._entities = entity_list\n self.desc = desc\n self._pointers = pointer_dict\n\n def __getitem__(self, index):\n \"\"\"Get an item by its pointer\"\"\"\n return self._entities[self._pointers[index]]\n\n @property\n def items(self):\n \"\"\"IGES items\n\n Examples\n --------\n >>> from pyiges import examples\n >>> import pyiges\n >>> sample = pyiges.read(examples.sample)\n >>> item = sample.items[0]\n >>> item\n --- IGES Point ---\n 0.0, 0.0, 0.0\n \"\"\"\n return self._entities\n\n\ndef read(filename):\n \"\"\"Read an iges file.\n\n\n Parameters\n ----------\n filename : str\n Filename of an IGES file.\n\n Examples\n --------\n >>> import pyiges\n >>> from pyiges import examples\n >>> iges = pyiges.read(examples.impeller)\n pyiges.Iges object\n Description:\n Number of Entities: 4615\n \"\"\"\n return Iges(filename)\n"
},
{
"alpha_fraction": 0.641686201095581,
"alphanum_fraction": 0.6510538458824158,
"avg_line_length": 17.565217971801758,
"blob_id": "f7ab9480e2ad23a1f5080b70c910fcd9c05ad4fb",
"content_id": "bd6590e9f4067b73a112f7a3c06d942c6f6c11f9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 427,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 23,
"path": "/docs/pyiges.rst",
"repo_name": "pyvista/pyiges",
"src_encoding": "UTF-8",
"text": "Pyiges Usage\n------------\n\nThere are two ways the ``pyiges`` module can open iges files. First,\nuse the ``read`` function:\n\n.. autofunction:: pyiges.read\n\n\nAlternatively, you can create an object directly from the ``Iges``\nclass:\n\n.. code:: python\n\n >>> import pyiges\n >>> iges = pyiges.Iges('my_file.iges')\n pyiges.Iges object\n Description:\n Number of Entities: 4615\n\n\n.. autoclass:: pyiges.Iges\n :members:\n"
},
{
"alpha_fraction": 0.71875,
"alphanum_fraction": 0.71875,
"avg_line_length": 13.222222328186035,
"blob_id": "ff3967e4bbcc939f73d04734715d1c938cc65715",
"content_id": "0382c5ef84f3ca5bf70602330a76aea6077e478f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 256,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 18,
"path": "/Makefile",
"repo_name": "pyvista/pyiges",
"src_encoding": "UTF-8",
"text": ".PHONY: help Makefile\n\ntest: .PHONY\n\tpytest -vx\n\ndocs: .PHONY\n\tmake -C docs html\n\ndeploy_docs: .PHONY\n\tmake -C docs html deploy\n\nbuild: test\n\trm dist/*\n\tpython setup.py bdist_wheel\n\tpython setup.py sdist\n\nupload: build\n\ttwine upload dist/* --skip-existing\n"
},
{
"alpha_fraction": 0.46857142448425293,
"alphanum_fraction": 0.5028571486473083,
"avg_line_length": 14.909090995788574,
"blob_id": "120e84363669f3555e4d1d15b4d798e6ba4c3c84",
"content_id": "bf48b0d87405dcafa1c51c176ad53618a7007002",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 175,
"license_type": "permissive",
"max_line_length": 21,
"num_lines": 11,
"path": "/pyiges/constants.py",
"repo_name": "pyvista/pyiges",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nline_font_pattern = {\n None: \"Default\",\n 0: \"Default\",\n 1: \"Solid\",\n 2: \"Dashed\",\n 3: \"Phantom\",\n 4: \"Centerline\",\n 5: \"Dotted\",\n}\n"
},
{
"alpha_fraction": 0.6402477025985718,
"alphanum_fraction": 0.6699690222740173,
"avg_line_length": 21.123287200927734,
"blob_id": "97943ea1a1c33da2541617950452ac729be525a8",
"content_id": "1eaa33b0768d5e8ea47cb0d876b4e716357379b0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 1615,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 73,
"path": "/docs/geometry.rst",
"repo_name": "pyvista/pyiges",
"src_encoding": "UTF-8",
"text": "Geometry Entities\n-----------------\nThe ``pyiges.Iges`` class stores each individual IGES entity\nseparately and each entity of an ``pyiges.Iges`` object can be\naccessed either via indexing or by querying for a specific type of entity\n\n.. code:: python\n\n >>> import pyiges\n >>> from pyiges import examples\n >>> iges = pyiges.read(examples.impeller)\n >>> type(iges[0])\n pyiges.entity.Entity\n\n >>> lines = iges.lines()\n >>> print(lines[0])\n --- Line ---\n ----- Entity -----\n 110\n 1213\n 0\n ...\n 0\n From point 0.0, 0.0, -997.963013157\n To point 0.0, 0.0, 2.036986843\n\nMany of the entities are not yet fully supported, and those entities\nare represented as a generic ``pyiges.geometry.Entity`` object.\nHowever, many entities are supported, including:\n\n- Vertex List (Type 502 Form 1)\n- Edge List\n- Loop (for specifying a bounded face for BREP geometries\n- Face\n- Circular arc\n- Rational B-Spline Surface\n- Rational B-Spline Curve\n- Conic Arc (Type 104)\n- Line\n- Point\n\n\nEntity Definitions\n~~~~~~~~~~~~~~~~~~\n.. autoclass:: pyiges.entity.Entity\n :members:\n\n.. autoclass:: pyiges.geometry.Point\n :members:\n\n.. autoclass:: pyiges.geometry.Line\n :members:\n\n.. autoclass:: pyiges.geometry.ConicArc\n :members:\n\n.. autoclass:: pyiges.geometry.RationalBSplineCurve\n :members:\n\n.. autoclass:: pyiges.geometry.RationalBSplineSurface\n :members:\n\n.. autoclass:: pyiges.geometry.CircularArc\n :members:\n\n.. autoclass:: pyiges.geometry.Face\n :members:\n\n.. autoclass:: pyiges.geometry.EdgeList\n :members:\n\n.. autoclass:: pyiges.geometry.VertexList\n :members:\n"
},
{
"alpha_fraction": 0.7404255270957947,
"alphanum_fraction": 0.7617021203041077,
"avg_line_length": 23.736841201782227,
"blob_id": "c6bf5e7565afbd1f6353cf703ed3378a68703ea2",
"content_id": "322acec50a6df6475e36cbf278a8a79b6b804dcf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 470,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 19,
"path": "/pyiges/faces.py",
"repo_name": "pyvista/pyiges",
"src_encoding": "UTF-8",
"text": "\"\"\"\nFace (Type 510)\nDefines a bound portion of three dimensional space (R^3) which has a\nfinite area. Used to construct B-Rep Geometries.\n\nParameter Data\nIndex in list\tType of data\tName\tDescription\nPointer\tSurface\tUnderlying surface\n2\tINT\tN\tNumber of loops\n3\tBOOL\tFlag\tOuter loop flag:\nTrue indicates Loop1 is outer loop.\nFalse indicates no outer loop.\n4\tPointer\tLoop1\tPointer to first loop of the face\n.\n.\t.\n.\t.\n.\n3+N\tPointer\tLoopN\tPointer to last loop of the face\n\"\"\"\n"
},
{
"alpha_fraction": 0.6957952380180359,
"alphanum_fraction": 0.7027422189712524,
"avg_line_length": 24.09174346923828,
"blob_id": "84a042d9aaaf526ecfb907b6e4768676a34d7b5b",
"content_id": "08b92e219f99649fdbe2a0eee87382ccba3b266f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 2735,
"license_type": "permissive",
"max_line_length": 157,
"num_lines": 109,
"path": "/docs/index.rst",
"repo_name": "pyvista/pyiges",
"src_encoding": "UTF-8",
"text": "pyIGES Documentation\n====================\nPython IGES reader with basic functionality to read an IGES file and\nconvert some entities to a ``pyvista`` or ``vtk`` mesh.\n\nThis module can read in and perform basic parsing of all entities and\ncan perform additional parsing and geometry visualization of the\nfollowing entities:\n\n- Vertex List (Type 502 Form 1)\n- Edge List\n- Loop (for specifying a bounded face for BREP geometries\n- Face\n- Circular arc\n- Rational B-Spline Surface\n- Rational B-Spline Curve\n- Conic Arc (Type 104)\n- Line\n- Point\n\nContents\n--------\n.. toctree::\n\n pyiges\n geometry\n\n\nInstallation\n------------\n\n``pyiges`` is offered in a \"full\" variant including the conversion features\nand a \"pure\" parsing module variant.\nThe pure variant has no conversion features, no dependencies to ``pyvista,geomdl``,\nand can be installed by removing the ``[full]`` specificator from the following commands.\n\nInstall with pip using:\n\n.. code::\n\n pip install pyiges[full]\n\nOtherwise, if you want the bleeding edge version, feel free to clone\nthis repo and install with:\n\n.. code:: bash\n\n git clone https://github.com/pyvista/pyiges\n cd pyiges\n pip install .[full]\n\nNote that the square brackets might need to be escaped or quoted when using ``zsh``.\n\n\nUsage\n-----\nThe ``pyiges`` module can read in many entities as raw text, but only\nNURBS surfaces and bsplines can be converted to ``pyvista`` meshes.\n\n.. code:: python\n\n import pyiges\n from pyiges import examples\n\n # load an example impeller\n iges = pyiges.read(examples.impeller)\n\n # print an invidiual entity (boring)\n print(iges[0])\n\n # convert all lines to a vtk mesh and plot it\n lines = iges.to_vtk(bsplines=True, surfaces=False, merge=True)\n lines.plot(color='w', line_width=2)\n\n # convert all surfaces to a vtk mesh and plot it\n mesh = iges.to_vtk(bsplines=False, surfaces=True, merge=True, delta=0.05)\n mesh.plot(color='w', smooth_shading=True)\n # control resolution of the mesh by changing \"delta\"\n\n # save this surface to file\n mesh.save('mesh.ply') # as ply\n mesh.save('mesh.stl') # as stl\n mesh.save('mesh.vtk') # as vtk\n\n\nLines\n~~~~~\n.. image:: https://github.com/pyvista/pyiges/raw/master/docs/images/impeller_lines.png\n\n\nSurfaces\n~~~~~~~~\n.. image:: https://github.com/pyvista/pyiges/raw/master/docs/images/impeller_surf.png\n\n\nAcknowledgments\n---------------\nSubstantial code was obtained from or inspired by https://github.com/cfinch/IGES-File-Reader\n\nIGES reference definitions were obtained from `Eclipse IGES Wiki <https://wiki.eclipse.org/IGES_file_Specification#Rational_B-Spline_Curve_.28Type_126.29>`_,\n\n\n\nIndices and tables\n==================\n\n* :ref:`genindex`\n* :ref:`modindex`\n* :ref:`search`\n"
},
{
"alpha_fraction": 0.7186378240585327,
"alphanum_fraction": 0.7230149507522583,
"avg_line_length": 35.848388671875,
"blob_id": "c2ba8d8ab0f4225439cc2d7a0ea9054fdd0f513d",
"content_id": "27b4178324ed3b9ac7f78a435a20e3cbd9479382",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 11423,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 310,
"path": "/CONTRIBUTING.rst",
"repo_name": "pyvista/pyiges",
"src_encoding": "UTF-8",
"text": "Contributing\n============\n\nWe absolutely welcome contributions and we hope that this guide will\nfacilitate an understanding of the PyIGES code repository. It is\nimportant to note that this PyVista software package is maintained on a\nvolunteer basis and thus we need to foster a community that can support\nuser questions and develop new features to make this software a useful\ntool for all users.\n\nThis page is dedicated to outline where you should start with your\nquestion, concern, feature request, or desire to contribute.\n\nBeing Respectful\n----------------\n\nPlease demonstrate empathy and kindness toward other people, other software,\nand the communities who have worked diligently to build (un)related tools.\n\nPlease do not talk down in Pull Requests, Issues, or otherwise in a way that\nportrays other people or their works in a negative light.\n\nCloning the Source Repository\n-----------------------------\n\nYou can clone the source repository from\n`<https://github.com/pyvista/pyiges>`_ and install the latest version by\nrunning:\n\n.. code:: bash\n\n git clone https://github.com/pyvista/pyiges.git\n cd pyiges\n python -m pip install -e .\n\n\nReporting Bugs\n--------------\nIf you stumble across any bugs, crashes, or concerning quirks while\nusing code distributed here, please report it on the `issues\npage <https://github.com/pyvista/pyiges/issues>`_ with an appropriate\nlabel so we can promptly address it. When reporting an issue, please be\noverly descriptive so that we may reproduce it. Whenever possible,\nplease provide tracebacks, screenshots, and sample files to help us\naddress the issue.\n\n\nFeature Requests\n----------------\nWe encourage users to submit ideas for improvements to PyIGES code\nbase. Please create an issue on the `issues\npage <https://github.com/pyvista/pyiges/issues>`_ with a *Feature\nRequest* label to suggest an improvement. Please use a descriptive title\nand provide ample background information to help the community implement\nthat functionality. For example, if you would like a reader for a\nspecific file format, please provide a link to documentation of that\nfile format and possibly provide some sample files with screenshots to\nwork with. We will use the issue thread as a place to discuss and\nprovide feedback.\n\nContributing New Code\n---------------------\n\nIf you have an idea for how to improve PyIGES, please first create an\nissue as a feature request which we can use as a discussion thread to\nwork through how to implement the contribution.\n\nOnce you are ready to start coding and develop for PyIGES, please see\nthe `Development Practices <#development-practices>`_ section for more\ndetails.\n\nLicensing\n---------\n\nAll contributed code will be licensed under The MIT License found in the\nrepository. If you did not write the code yourself, it is your\nresponsibility to ensure that the existing license is compatible and\nincluded in the contributed files or you can obtain permission from the\noriginal author to relicense the code.\n\n--------------\n\nDevelopment Practices\n---------------------\n\nThis section provides a guide to how we conduct development in the\nPyIGES repository. Please follow the practices outlined here when\ncontributing directly to this repository.\n\n\nContributing to PyIGES through GitHub\n~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\n\nTo submit new code to PyIGES, first fork the `pyiges GitHub\nRepository <https://github.com/pyvista/pyiges>`_ and then clone the forked\nrepository to your computer. Then, create a new branch based on the\n`Branch Naming Conventions Section <#branch-naming-conventions>`_ in\nyour local repository.\n\nNext, add your new feature and commit it locally. Be sure to commit\nfrequently as it is often helpful to revert to past commits, especially\nif your change is complex. Also, be sure to test often. See the `Testing\nSection <#testing>`_ below for automating testing.\n\nWhen you are ready to submit your code, create a pull request by\nfollowing the steps in the `Creating a New Pull Request\nsection <#creating-a-new-pull-request>`_.\n\nCoding Style\n^^^^^^^^^^^^\n\nWe adhere to `PEP 8 <https://www.python.org/dev/peps/pep-0008/>`_\nwherever possible, except that line widths are permitted to go beyond 79\ncharacters to a max of 99 characters for code. This should tend to be\nthe exception rather than the norm. A uniform code style is enforced\nby `black <https://github.com/psf/black>`_ to prevent energy wasted on\nstyle disagreements.\n\nAs for docstrings, follow the guidelines specified in `PEP 8 Maximum\nLine\nLength <https://www.python.org/dev/peps/pep-0008/#maximum-line-length>`_\nof limiting docstrings to 72 characters per line. This follows the\ndirective:\n\n Some teams strongly prefer a longer line length. For code maintained\n exclusively or primarily by a team that can reach agreement on this\n issue, it is okay to increase the line length limit up to 99\n characters, provided that comments and docstrings are still wrapped\n at 72 characters.\n\nOutside of PEP 8, when coding please consider `PEP 20 - The Zen of\nPython <https://www.python.org/dev/peps/pep-0020/>`_. When in doubt:\n\n.. code:: python\n\n import this\n\nPyIGES uses `pre-commit`_ to enforce PEP8 and other styles\nautomatically. Please see the `Style Checking section <#style-checking>`_ for\nfurther details.\n\nDocumentation Style\n^^^^^^^^^^^^^^^^^^^\n\nPyIGES follows the `Google Developer Documentation Style\n<https://developers.google.com/style>`_ with the following exceptions:\n\n- Allow first person pronouns. These pronouns (for example, \"We\") refer to\n \"PyVista Developers\", which can be anyone who contributes to PyVista.\n- Future tense is permitted.\n\nDocstrings\n^^^^^^^^^^\n\nPyIGES uses Python docstrings to create reference documentation for our Python\nAPIs. Docstrings are read by developers, interactive Python users, and readers\nof our online documentation. This section describes how to write these docstrings\nfor PyIGES.\n\nPyIGES follows the ``numpydoc`` style for its docstrings. Please follow the\n`numpydoc Style Guide`_ in all ways except for the following:\n\n* Be sure to describe all ``Parameters`` and ``Returns`` for all public\n methods.\n* We strongly encourage you to add an example section.\n* With optional parameters, use ``default: <value>`` instead of ``optional``\n when the parameter has a default value instead of ``None``.\n\nSample docstring follows:\n\n.. code:: python\n\n def slice_x(self, x=None, generate_triangles=False):\n \"\"\"Create an orthogonal slice through the dataset in the X direction.\n\n Parameters\n ----------\n x : float, optional\n The X location of the YZ slice. By default this will be the X center\n of the dataset.\n\n generate_triangles : bool, default: False\n If this is enabled, the output will be all triangles. Otherwise the\n output will consist of the intersection polygons.\n\n Returns\n -------\n pyvista.PolyData\n Sliced dataset.\n\n Examples\n --------\n Slice the random hills dataset with one orthogonal plane.\n\n >>> from pyvista import examples\n >>> hills = examples.load_random_hills()\n >>> slices = hills.slice_x(5, generate_triangles=False)\n >>> slices.plot(line_width=5)\n\n See :ref:`slice_example` for more examples using this filter.\n\n \"\"\"\n\n pass # implementation goes here\n\nNote the following:\n\n* The parameter definition of ``generate_triangles`` uses ``default: False``,\n and does not include the default in the docstring's \"description\" section.\n* There is a newline between each parameter. This is different than\n ``numpydoc``'s documentation where there are no empty lines between parameter\n docstrings.\n* This docstring also contains a returns section and an examples section.\n* The returns section does not include the parameter name if the function has\n a single return value. Multiple return values (not shown) should have\n descriptive parameter names for each returned value, in the same format as\n the input parameters.\n* The examples section references the \"full example\" in the gallery if it\n exists.\n\n\nBranch Naming Conventions\n^^^^^^^^^^^^^^^^^^^^^^^^^\n\nTo streamline development, we have the following requirements for naming\nbranches. These requirements help the core developers know what kind of\nchanges any given branch is introducing before looking at the code.\n\n- ``fix/``, ``patch/`` and ``bug/``: any bug fixes, patches, or experimental changes that are\n minor\n- ``feat/``: any changes that introduce a new feature or significant\n addition\n- ``junk/``: for any experimental changes that can be deleted if gone\n stale\n- ``maint/``: for general maintenance of the repository or CI routines\n- ``doc/``: for any changes only pertaining to documentation\n- ``no-ci/``: for low impact activity that should NOT trigger the CI\n routines\n- ``testing/``: improvements or changes to testing\n- ``release/``: releases (see below)\n- ``breaking-change/``: Changes that break backward compatibility\n\nTesting\n^^^^^^^\nAfter making changes, please test changes locally before creating a pull\nrequest. The following tests will be executed after any commit or pull\nrequest, so we ask that you perform the following sequence locally to\ntrack down any new issues from your changes.\n\nTo run our comprehensive suite of unit tests, install all the\ndependencies listed in ``requirements_test.txt`` and ``requirements_docs.txt``:\n\n.. code:: bash\n\n pip install -r requirements_test.txt\n pip install -r requirements_docs.txt\n\nThen, if you have everything installed, you can run the various test\nsuites.\n\n\nUnit Testing\n~~~~~~~~~~~~\nRun the primary test suite and generate coverage report:\n\n.. code:: bash\n\n python -m pytest -v --cov pyiges\n\n\nStyle Checking\n~~~~~~~~~~~~~~\nPyIGES follows PEP8 standard as outlined in the `Coding Style section\n<#coding-style>`_ and implements style checking using `pre-commit`_.\n\nTo ensure your code meets minimum code styling standards, run::\n\n pip install pre-commit\n pre-commit run --all-files\n\nIf you have issues related to ``setuptools`` when installing ``pre-commit``, see\n`pre-commit Issue #2178 comment <https://github.com/pre-commit/pre-commit/issues/2178#issuecomment-1002163763>`_\nfor a potential resolution.\n\nYou can also install this as a pre-commit hook by running::\n\n pre-commit install\n\nThis way, it's not possible for you to push code that fails the style\nchecks. For example, each commit automatically checks that you meet the style\nrequirements::\n\n $ pre-commit install\n $ git commit -m \"added my cool feature\"\n black....................................................................Passed\n isort....................................................................Passed\n flake8...................................................................Passed\n codespell................................................................Passed\n\nThe actual installation of the environment happens before the first commit\nfollowing ``pre-commit install``. This will take a bit longer, but subsequent\ncommits will only trigger the actual style checks.\n\nEven if you are not in a situation where you are not performing or able to\nperform the above tasks, you can comment `pre-commit.ci autofix` on a pull\nrequest to manually trigger auto-fixing.\n\n\n.. _pre-commit: https://pre-commit.com/\n.. _numpydoc Style Guide: https://numpydoc.readthedocs.io/en/latest/format.html\n"
},
{
"alpha_fraction": 0.6404494643211365,
"alphanum_fraction": 0.6404494643211365,
"avg_line_length": 24.95833396911621,
"blob_id": "77944e9fea4eecd5dfc5eb944d7cf7eaeacc3661",
"content_id": "b35740a678470eeff07bbb2e15c22f86e258307a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 623,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 24,
"path": "/pyiges/check_imports.py",
"repo_name": "pyvista/pyiges",
"src_encoding": "UTF-8",
"text": "try:\n import geomdl\n import pyvista\n from vtkmodules.vtkFiltersCore import vtkAppendPolyData\n\n _IS_FULL_MODULE = True\nexcept (ModuleNotFoundError, ImportError) as exc:\n pyvista = None\n geomdl = None\n vtkAppendPolyData = None\n _IS_FULL_MODULE = False\n _PROBLEM_MSG = (\n \"Import from '{}' failed, to support this feature \"\n \"please install pyiges[full]\".format(exc.name)\n )\n\n\ndef assert_full_module_variant(inner_func):\n def safe_func(*a, **kw):\n if not _IS_FULL_MODULE:\n raise Exception(_PROBLEM_MSG)\n return inner_func(*a, **kw)\n\n return safe_func\n"
},
{
"alpha_fraction": 0.7733333110809326,
"alphanum_fraction": 0.7733333110809326,
"avg_line_length": 36.5,
"blob_id": "93c45efbe31adeb196ecd30edac6cf1fdb564f63",
"content_id": "3e2adfa344431fa2c6e03663b20fe1be531ce465",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 75,
"license_type": "permissive",
"max_line_length": 39,
"num_lines": 2,
"path": "/pyiges/__init__.py",
"repo_name": "pyvista/pyiges",
"src_encoding": "UTF-8",
"text": "from pyiges._version import __version__\nfrom pyiges.iges import Iges, read\n"
},
{
"alpha_fraction": 0.7387387156486511,
"alphanum_fraction": 0.7387387156486511,
"avg_line_length": 54.5,
"blob_id": "b2575dce588ca48434ba6b4c9633f8d4bfdde1fa",
"content_id": "4120310400960b0ff89433c2457e2f878882aee2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 111,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 2,
"path": "/tests/conftest.py",
"repo_name": "pyvista/pyiges",
"src_encoding": "UTF-8",
"text": "def pytest_addoption(parser):\n parser.addoption(\"--expect-full-module\", action=\"store_true\", default=False)\n"
},
{
"alpha_fraction": 0.7152777910232544,
"alphanum_fraction": 0.7152777910232544,
"avg_line_length": 27.799999237060547,
"blob_id": "2198f0ac750edd126b0197355713b299cb2c6c6e",
"content_id": "8285877ef95be3e9d5df8789370675f532dd5790",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 144,
"license_type": "permissive",
"max_line_length": 49,
"num_lines": 5,
"path": "/pyiges/examples/__init__.py",
"repo_name": "pyvista/pyiges",
"src_encoding": "UTF-8",
"text": "import os\n\nfilepath = os.path.dirname(__file__)\nimpeller = os.path.join(filepath, \"impeller.igs\")\nsample = os.path.join(filepath, \"sample.igs\")\n"
}
] | 18 |
kmhabib/Email_Validator
|
https://github.com/kmhabib/Email_Validator
|
8e0bb664bed09b8b81cc716c7c4d44189fcba9c1
|
90474a1d58e91d328a1171e3cc19870267a9f7da
|
7d38d81ab60f7a6be4fca87db1a8a480e2ff370f
|
refs/heads/master
| 2021-01-12T09:39:52.100446 | 2017-01-03T11:12:36 | 2017-01-03T11:12:36 | 76,222,475 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6688384413719177,
"alphanum_fraction": 0.6811952590942383,
"avg_line_length": 29.90972137451172,
"blob_id": "a65c38b969d6012a84d032b33288f2b26ad63bec",
"content_id": "6506eb17661426c3b1e708ea2ae934ade17e534c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4451,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 144,
"path": "/verify_email.py",
"repo_name": "kmhabib/Email_Validator",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\nimport csv\nimport dns.resolver\nimport re\nimport socket\nimport smtplib\nimport sys\nimport os\nimport time\n\n\ndef open_emails(fname):\n\n\temail_list = []\n\twith open(fname, 'rb') as csvfile:\n\t\temailreader = csv.reader(csvfile, dialect='excel')\n\t\tfor row in emailreader:\n\t\t\tif any(\"@\" in s for s in row):\n\t\t\t\tif re.match(r'.*(gmail|yahoo|msn).*',row[0]):\n\t\t\t\t\tpass\n\t\t\t\telse:\n\t\t\t\t\temail_list.append(', '.join(row)) \n\tprint(\"The total # of emails in the CSV file you have uploaded is:\",len(email_list))\n\treturn email_list\n\ndef find_mx_host(records):\n\tcurrent = records[0].preference\n\tmx = records[0].exchange\n\t#print(\"current\", current)\n\tfor rdata in records:\n\t\t#print 'host', rdata.exchange, 'has preference', rdata.preference\n\t\tif rdata.preference < current:\n\t\t\tcurrent = rdata.preference\n\t\t\tmx = rdata.exchange\n\treturn str(mx)\n\ndef connect_validate(email_list):\n\n\tvalidated_emails = []\n\tinteresting_emails = []\n\n\ttimestr1 = time.strftime(\"%Y%m%d-%H%M%S\")\n\tfname1 = \"verified_emails_\" + timestr1 + \".csv\"\n\t#with open(os.path.join(\"output_files\",fname1), 'wb') as csvfile1:\n\t#\temailwriter1 = csv.writer(csvfile1, dialect='excel')\n\n\ttimestr2 = time.strftime(\"%Y%m%d-%H%M%S\")\n\tfname2 = \"interesting_emails_\" + timestr2 + \".csv\"\n\t#with open(os.path.join(\"output_files\",fname2), 'wb') as csvfile2:\n\t#\temailwriter2 = csv.writer(csvfile2, dialect='excel')\n\tcount = 0\t\n\tfor email in email_list:\n\t\tprint(email)\n\t\tmatch = re.match('^[_a-z0-9-]+(\\.[_a-z0-9-]+)*@[a-z0-9-]+(\\.[a-z0-9-]+)*(\\.[a-z]{2,4})$', email)\n\n\t\tif match == None:\n\t\t\tprint('Bad Syntax')\n\t\t\t#raise ValueError('Bad Syntax')\n\t\t\tcontinue\n\t\tusername,domain = email.split('@')\n\t\tprint(\"user,domain\", username,domain)\n\t\ttry:\n\t\t\trecords = dns.resolver.query(domain, 'MX')\n\t\texcept:\n\t\t\tprint(\"Domain\", domain, \" is not correct\")\n\t\t\tcontinue\t\t\t\n\t\t#min_pref = records[0].preference\n\t\tmxRecord = find_mx_host(records)\n\t\tprint(\"mxRecord\", mxRecord)\n\t\t# Get local server hostname\n\t\thost = socket.gethostname()\n\n\t\t# SMTP lib setup (use debug level for full output)\n\t\tserver = smtplib.SMTP()\n\t\tserver.set_debuglevel(0)\n\n\t\t# SMTP Conversation\n\t\ttry:\n\t\t\tserver.connect(mxRecord)\n\t\t\tserver.helo(host)\n\t\t\tserver.mail('[email protected]')\n\t\t\tcode, message = server.rcpt(str(email))\n\t\t\tserver.quit()\n\t\t\tcount = count + 1\n\t\texcept:\n\t\t\tprint(\"MX error\", mxRecord)\n\t\t\tcontinue\n\t\t#server.helo(host)\n\t\t#server.mail('[email protected]')\n\t\t#code, message = server.rcpt(str(email))\n\t\t#server.quit()\n\t\t# Assume 250 as Success\n\t\tif code == 250:\n\t\t\tprint('Success')\n\t\t\twith open(os.path.join(\"output_files\",fname1), 'wb') as csvfile1:\n\t\t\t\temailwriter1 = csv.writer(csvfile1, dialect='excel')\n\t\t\t\t#emailwriter1.writerow(validated_emails.append(email))\n\t\t\t\temailwriter1.writerow([email])\n\t\telse:\n\t\t\t#interesting_emails = numpy.array([[email,code,message]])\n\t\t\t#emailwriter2.writerow(interesting_emails.append(email+\" \"+ str(code) + \" \" +message)\n\t\t\tinteresting_string = email+\" \"+str(code) + \" \" +message\n\t\t\t#emailwriter2.writerow([email+\" \"+ str(code) + \" \" +message])\n\t\t\twith open(os.path.join(\"output_files\",fname2), 'wb') as csvfile2:\n\t\t\t\temailwriter2 = csv.writer(csvfile2, dialect='excel')\n\t\t\t\tprint interesting_string\n\t\t\t\temailwriter2.writerow([interesting_string])\n\t#return validated_emails, interesting_emails\n\n#print interesting_emails\n#write to verified_emails file\n\"\"\"\ndef write_verified( validated_emails):\n\ttimestr = time.strftime(\"%Y%m%d-%H%M%S\")\n\tfname = \"verified_emails_\" + timestr + \".csv\"\n\twith open(os.path.join(\"output_files\",fname), 'wb') as csvfile:\n\t\temailwriter = csv.writer(csvfile, dialect='excel')\n\t\tfor row in validated_emails:\n\t\t\temailwriter.writerow([row])\n\"\"\"\n\t\n\"\"\"\n#write to interesting_emails file\ndef write_interesting(interesting_emails):\n\ttimestr = time.strftime(\"%Y%m%d-%H%M%S\")\n\tfname = \"interesting_emails_\" + timestr + \".csv\"\n\twith open(os.path.join(\"output_files\",fname), 'wb') as csvfile:\n\t\temailwriter = csv.writer(csvfile, dialect='excel')\n\t\tfor row in interesting_emails:\n\t\t\temailwriter.writerow([row])\n\"\"\"\t\ndef main(fname1):\n\temail_list = open_emails(fname1) \t\n\t#validated_emails,interesting_emails = connect_validate(email_list)\n\tcount =connect_validate(email_list)\n\tprint(\"count is:\", count)\n\t#validated_emails,interesting_emails = connect_validate(email_list)\n #write_verified(fname2, validated_emails)\n\t#write_verified( validated_emails)\n #write_interesting(fname3, interesting_emails)\n\t#write_interesting(interesting_emails)\n\nif __name__ == '__main__':\n\tmain(sys.argv[1])\n"
},
{
"alpha_fraction": 0.5426339507102966,
"alphanum_fraction": 0.5549107193946838,
"avg_line_length": 27.35443115234375,
"blob_id": "993a5e0e56fcbd82400b76ad3d7be8433bb45f1d",
"content_id": "5eaec3ba7aad380d43cdc126bda3063816bfa32d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4480,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 158,
"path": "/verify_email_Python3.py",
"repo_name": "kmhabib/Email_Validator",
"src_encoding": "UTF-8",
"text": "import csv\nimport dns.resolver\nimport re\nimport socket\nimport smtplib\nimport sys\nimport os\nimport time\n\n\ndef open_emails(fname):\n\n email_list = []\n with open(fname, 'r') as csvfile:\n emailreader = csv.reader(csvfile, dialect='excel')\n for row in emailreader:\n if any('@' in s for s in row):\n if re.match(r'.*(gmail|yahoo|msn).*', row[0]):\n pass\n else:\n email_list.append(', '.join(row))\n print('The total # of emails in the CSV file you have uploaded is:'\n , len(email_list))\n return email_list\n\n\ndef find_mx_host(records):\n current = records[0].preference\n mx = records[0].exchange\n\n # print(\"current\", current)\n\n for rdata in records:\n\n # print 'host', rdata.exchange, 'has preference', rdata.preference\n\n if rdata.preference < current:\n current = rdata.preference\n mx = rdata.exchange\n return str(mx)\n\n\ndef connect_validate(email_list):\n\n validated_emails = []\n interesting_emails = []\n\n timestr1 = time.strftime('%Y%m%d-%H%M%S')\n fname1 = 'verified_emails_' + timestr1 + '.csv'\n\n # with open(os.path.join(\"output_files\",fname1), 'wb') as csvfile1:\n # ....emailwriter1 = csv.writer(csvfile1, dialect='excel')\n\n timestr2 = time.strftime('%Y%m%d-%H%M%S')\n fname2 = 'interesting_emails_' + timestr2 + '.csv'\n\n # with open(os.path.join(\"output_files\",fname2), 'wb') as csvfile2:\n # ....emailwriter2 = csv.writer(csvfile2, dialect='excel')\n\n count = 0\n for email in email_list:\n print(email)\n match = \\\n re.match('^[_a-z0-9-]+(\\.[_a-z0-9-]+)*@[a-z0-9-]+(\\.[a-z0-9-]+)*(\\.[a-z]{2,4})$'\n , email)\n\n if match == None:\n print( 'Bad Syntax')\n\n # raise ValueError('Bad Syntax')\n\n continue\n (username, domain) = email.split('@')\n print ('user,domain', username, domain)\n try:\n records = dns.resolver.query(domain, 'MX')\n except:\n print ('Domain', domain, ' is not correct')\n continue\n\n # min_pref = records[0].preference\n\n mxRecord = find_mx_host(records)\n print ('mxRecord', mxRecord)\n\n # Get local server hostname\n\n host = socket.gethostname()\n\n # SMTP lib setup (use debug level for full output)\n\n server = smtplib.SMTP()\n server.set_debuglevel(0)\n\n # SMTP Conversation\n\n try:\n server.connect(mxRecord)\n server.helo(host)\n server.mail('[email protected]')\n (code, msg) = server.rcpt(str(email))\n #print(code,msg)\n #print(type(msg))\n server.quit()\n count = count + 1\n except:\n print ('MX error', mxRecord)\n continue\n\n # server.helo(host)\n # server.mail('[email protected]')\n # code, message = server.rcpt(str(email))\n # server.quit()\n # Assume 250 as Success\n\n if code == 250:\n print('Success')\n with open(os.path.join('output_files', fname1), 'w') as \\\n csvfile1:\n emailwriter1 = csv.writer(csvfile1, dialect='excel')\n\n # emailwriter1.writerow(validated_emails.append(email))\n\n emailwriter1.writerow([email])\n else:\n str_code = str(code)\n str_msg = msg.decode(\"utf-8\")\n #print(type(msg))\n #print(message)\n interesting_string = email + ' ' + str_code + ' ' + str_msg\n with open(os.path.join('output_files', fname2), 'w') as \\\n csvfile2:\n emailwriter2 = csv.writer(csvfile2, dialect='excel')\n #print( interesting_string)\n #interesting_byte = bytes(interesting_string, 'utf-8')\n emailwriter2.writerow(interesting_string)\n\n\n# print interesting_emails\n# write to verified_emails file\n\ndef main(fname1):\n email_list = open_emails(fname1)\n\n # validated_emails,interesting_emails = connect_validate(email_list)\n\n count = connect_validate(email_list)\n #print ('count is:', count)\n\n\n # validated_emails,interesting_emails = connect_validate(email_list)\n # write_verified(fname2, validated_emails)\n # write_verified( validated_emails)\n # write_interesting(fname3, interesting_emails)\n # write_interesting(interesting_emails)\n\nif __name__ == '__main__':\n main(sys.argv[1])\n"
},
{
"alpha_fraction": 0.7760416865348816,
"alphanum_fraction": 0.7786458134651184,
"avg_line_length": 53.71428680419922,
"blob_id": "b0f72021ef6def47ac29629295d48ed3de9bb25c",
"content_id": "a4ec119157e2e66a10e02c1c4303e47e2fd0a9b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 398,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 7,
"path": "/README.md",
"repo_name": "kmhabib/Email_Validator",
"src_encoding": "UTF-8",
"text": "# Email_Validator\n\nRunning the email validator script\n* if installing the first time from git, make sure you “cd dnspython” director and type, \npython setup.py install && python3 setup.py install\n* make sure you have a “output_files” directory created in the folder you’re running. “mkdir output_files”\n* run the script with the following syntax: python verify_email.py csv_filename\n\n"
}
] | 3 |
Nikhilbhuyan/Even-Fibonaci-numbers
|
https://github.com/Nikhilbhuyan/Even-Fibonaci-numbers
|
e8d7580293db61fdb3a3f7acf1e42bc948e2c158
|
1656b2a6d48d84e7e742033440d04674b2fc7588
|
3bc60e42a4ebb0ff5c966bc8a188adf122c60efe
|
refs/heads/master
| 2021-04-27T03:07:31.460762 | 2018-02-24T06:03:33 | 2018-02-24T06:03:33 | 122,708,680 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7669903039932251,
"alphanum_fraction": 0.7766990065574646,
"avg_line_length": 102,
"blob_id": "519fba4d04de15d90652695af02d67d4dcb480d1",
"content_id": "0fb27d23d35063d5b24a2bc179c177f6c76fcab6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 206,
"license_type": "no_license",
"max_line_length": 181,
"num_lines": 2,
"path": "/README.md",
"repo_name": "Nikhilbhuyan/Even-Fibonaci-numbers",
"src_encoding": "UTF-8",
"text": "# Even-Fibonaci-numbers\nThis problem of getting all the even fibonaci nums b/w 1M is taken from projecteuler.net. You can find the solution in this repo I have created this on python3..GO AND CHECK OUT :-)\n"
},
{
"alpha_fraction": 0.6106194853782654,
"alphanum_fraction": 0.6238937973976135,
"avg_line_length": 36.965518951416016,
"blob_id": "aad38788e11c3fa9ab7e9d31ac421ea4df69d7b4",
"content_id": "a77154e458e8bb2a0856f78484d2296c40629ad9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1130,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 29,
"path": "/Fibonaci numbers/Fibonaci.py",
"repo_name": "Nikhilbhuyan/Even-Fibonaci-numbers",
"src_encoding": "UTF-8",
"text": "# THIS PROBLEM IS FETCHED BY PROJECTEULER.NET and IT is the solution for that PROBLEM!!! :-)\r\n\r\n# We have a list named as fb_nums which initially stores a var(1) inorder to get further vars\r\nfb_nums = [1]\r\n# The result or the even fibocani nums will be stroed in this empty list\r\nEven_fb_nums = []\r\n\r\n# Defining the function EvnFibNums()..which will take an argument rng i.e the limit for our fib_nums\r\ndef EvnFibNum(rng):\r\n n = 0 # n will increase everytime the loop runs\r\n res = 2*fb_nums[0]\r\n# Finding all the fibonaci nums within the limit\r\n while res <= rng:\r\n fb_nums.append(res)\r\n res += fb_nums[n]\r\n n += 1\r\n# Checking which of them are even....and the result will be stored in the Even_fb_nums[]!!\r\n for m in fb_nums:\r\n if m % 2 == 0:\r\n Even_fb_nums.append(m)\r\n print(Even_fb_nums) # Our Result....Yepp We Are Done!!The result is amazing\r\n\r\n#Calling the Function\r\nEvnFibNum(1000000)\r\n\r\n# This code is optimized\r\n # coded by :- Nikhil Bhuyan(Me)\r\n\r\n# IF THIS CODE CAN BE IMPROVED THEN PLZZ CONTACT ME ON MY E-MAIL ([email protected])\r\n"
}
] | 2 |
michaelsad10/words-lists
|
https://github.com/michaelsad10/words-lists
|
ea8189f134633737612dc1423539908b65d909ed
|
9a77a04205be5442863c112c470f58052b40d49e
|
1507eb207c95b1a2351fef3c57fb18c2ed94289c
|
refs/heads/master
| 2022-12-14T11:21:30.386184 | 2019-11-16T19:04:45 | 2019-11-16T19:04:45 | 221,775,147 | 0 | 1 | null | 2019-11-14T19:51:38 | 2019-11-16T19:06:20 | 2022-12-08T06:53:23 |
Python
|
[
{
"alpha_fraction": 0.42796608805656433,
"alphanum_fraction": 0.4307909607887268,
"avg_line_length": 28.54166603088379,
"blob_id": "6ac3a48b6d8c8a3aa1db77196140110b1748dc21",
"content_id": "ebca38631bf9568577d00c33ee87f1b89d4c9cfe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 708,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 24,
"path": "/templates/base.html",
"repo_name": "michaelsad10/words-lists",
"src_encoding": "UTF-8",
"text": "<html>\n <head>\n <link rel=\"stylesheet\" href=\"/static/wordstyle.css\">\n <script src=\"{{url_for('static', filename='request.js')}}\"></script>\n </head>\n <body>\n {% block navbar %}\n <nav>\n <h1> Word List - {{name}}</h1>\n </nav>\n {% endblock %}\n <div id=\"myModal\" class=\"modal\">\n <!-- Modal content -->\n <div class=\"modal-content\">\n <strong> Definition: </strong>\n <p id=\"def\"></p>\n <button onclick=\"closeModal()\">close</button>\n </div> \n </div>\n {% block content %}\n default content \n {% endblock %}\n </body>\n</html>"
},
{
"alpha_fraction": 0.5914844870567322,
"alphanum_fraction": 0.6156501770019531,
"avg_line_length": 34.91666793823242,
"blob_id": "f2a8c76778b36837cabfdea458a43637a33f19a9",
"content_id": "cbbd7777d43f2696802ea1c72d4c2079d87a6d3d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 869,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 24,
"path": "/static/request.js",
"repo_name": "michaelsad10/words-lists",
"src_encoding": "UTF-8",
"text": "function getDef(element) {\n var x = document.getElementById(\"def\").innerHTML = ''; \n var modal = document.getElementById(\"myModal\");\n modal.style.display = \"block\"; \n word = element.innerHTML; \n var request = new XMLHttpRequest(); \n // const url = 'http://127.0.0.1:5000/get-def?word=' + word; \n const url = 'https://shielded-shore-94512.herokuapp.com/get-def?word=' + word;; \n request.onreadystatechange=function(){\n if(request.readyState==4 && request.status==200){\n var response = JSON.parse(request.responseText); \n var def = response[0].shortdef[0]; \n var x = document.getElementById(\"def\").innerHTML = def; \n }\n }\n request.open(\"GET\", url);\n request.send(); \n}\n\n\nfunction closeModal() {\n var modal = document.getElementById(\"myModal\");\n modal.style.display = \"none\";\n}\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5254524946212769,
"alphanum_fraction": 0.5494909286499023,
"avg_line_length": 35.081634521484375,
"blob_id": "4777a120d6f68ee00d3f03626bf76ba8564b9a6a",
"content_id": "59fc0d3d9434908631cadbe400a0fbe8f14c62c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3536,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 98,
"path": "/app.py",
"repo_name": "michaelsad10/words-lists",
"src_encoding": "UTF-8",
"text": "from flask import Flask, request, Response, render_template\nimport requests\nimport itertools\nfrom flask_wtf.csrf import CSRFProtect\nfrom flask_wtf import FlaskForm\nfrom wtforms import StringField, SubmitField, SelectField\nfrom wtforms.validators import Regexp, ValidationError\nimport re\n\n\nclass WordForm(FlaskForm):\n avail_letters = StringField(\"Letters\", validators= [\n Regexp(r'^$|^[a-z]+$', message=\"must contain letters only\")\n ])\n pattern = StringField(\"Pattern\", validators=[\n Regexp(r'^$|^[a-z.]+$', message=\"must be regex pattern\")\n ])\n word_length = SelectField(u'Word Length', choices=[('', ''), ('3', 3), ('4', 4), ('5', 5), ('6',6), ('7',7), ('8',8), ('9',9), ('10',10)])\n submit = SubmitField(\"Go\")\n\n \ncsrf = CSRFProtect()\napp = Flask(__name__)\napp.config[\"SECRET_KEY\"] = \"row the boat\"\ncsrf.init_app(app)\n\n\n\[email protected]('/')\ndef index():\n form = WordForm() \n return render_template(\"index.html\", form=form, name=\"Michael Sadaghyani\")\n\[email protected]('/words', methods=['POST', 'GET'])\ndef letters_2_words():\n form = WordForm()\n if form.validate_on_submit():\n print(\"hello\")\n letters = form.avail_letters.data \n word_length = form.word_length.data\n pattern = form.pattern.data \n if word_length == '':\n x = 0\n else:\n x = int(word_length)\n if len(pattern) > x and x != 0:\n return render_template(\"index.html\", form=form, name=\"Michael Sadaghyani\", error='Pattern length is greater than word length')\n if len(pattern) == 0:\n pattern = \"^[a-z]+$\"\n elif len(pattern) <= x and len(pattern) != 0:\n x = len(pattern) \n pattern = \"^\" + pattern + \"$\"\n else:\n return render_template(\"index.html\", form=form, name=\"Michael Sadaghyani\")\n with open('sowpods.txt') as f:\n good_words = set(x.strip().lower() for x in f.readlines()) \n word_set = set() \n if letters == '':\n for word in good_words:\n if x == 0:\n wlist = re.findall(pattern, word)\n if len(wlist) != 0:\n word_set.add(wlist[0])\n wlist.clear \n elif len(word) <= x: \n wlist = re.findall(pattern, word)\n if len(wlist) != 0:\n word_set.add(wlist[0])\n wlist.clear \n else: \n for l in range(3, len(letters)+1):\n for word in itertools.permutations(letters,l):\n w = \"\".join(word) \n if w in good_words and x == 0:\n wlist = re.findall(pattern, w)\n if len(wlist) != 0:\n word_set.add(wlist[0])\n wlist.clear\n elif w in good_words and len(w) <= x: \n wlist = re.findall(pattern, w)\n if len(wlist) != 0:\n word_set.add(wlist[0])\n wlist.clear \n word_set = sorted(word_set, key=lambda x: (len(x), x))\n return render_template('wordlist.html', wordlist=word_set, name=\"Michael Sadaghyani\")\n\[email protected]('/get-def')\ndef getDef():\n word = request.args.get('word')\n url = 'https://www.dictionaryapi.com/api/v3/references/collegiate/json/' + word + '?key=b4648064-9416-46e0-b3d9-a94733cc65d3'\n response = requests.get(url)\n resp = Response(response.text)\n resp.headers['Content-Type'] = 'application/json'\n return resp \n\n\n\n# https://www.dictionaryapi.com/api/v3/references/collegiate/json/test?key=b4648064-9416-46e0-b3d9-a94733cc65d3\n"
},
{
"alpha_fraction": 0.5111111402511597,
"alphanum_fraction": 0.5111111402511597,
"avg_line_length": 17.75,
"blob_id": "fc15a5efa7ed0906d132a77e8c4181f62e2dbbe2",
"content_id": "656bc2a1975507da8bea4cdd2a3f0396056d5755",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 225,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 12,
"path": "/templates/wordlist.html",
"repo_name": "michaelsad10/words-lists",
"src_encoding": "UTF-8",
"text": "{% extends \"base.html\" %}\n\n{% block content %}\n\n<main>\n {% for word in wordlist: %}\n <!-- getDef(this) -->\n <div class=\"wordbox\" onclick=\"getDef(this)\"> {{ word }} </div>\n {% endfor %}\n</main>\n\n{% endblock %} "
}
] | 4 |
ymj4023/frostming
|
https://github.com/ymj4023/frostming
|
861b54fba76cece9c456f74b60322aeca973da25
|
a346914479569b221f5f9e228593c9246df7db7e
|
5cbd21c762e6ed860b4afc50c6a38c2ef24ac8b9
|
refs/heads/master
| 2023-03-10T03:26:37.399926 | 2021-02-24T22:39:55 | 2021-02-24T22:39:55 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7334446310997009,
"alphanum_fraction": 0.7729484438896179,
"avg_line_length": 294.2112731933594,
"blob_id": "a290c4d36a3ba03fe4355498b6e86ea2a50aea6a",
"content_id": "b5617236d2d7e6bd22e5863ce2b9eb04633969bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 20972,
"license_type": "no_license",
"max_line_length": 2238,
"num_lines": 71,
"path": "/README.md",
"repo_name": "ymj4023/frostming",
"src_encoding": "UTF-8",
"text": "<h1 align=\"center\">🦄 Frost Ming 🐍</h1>\n\n<div align=\"center\">\n\n[](https://t.me/frostming)\n[](https://twitter.com/frostming90)\n[](https://frostming.com)\n\n</div>\n\n<p align=\"center\">\n <img height=\"200\" src=\"https://github-readme-stats.vercel.app/api?username=frostming&show_icons=true&theme=dracula&include_all_commits=true\" />\n <img height=\"200\" src=\"https://github-readme-stats.vercel.app/api/top-langs/?username=frostming&theme=dracula&show_icons=true\" />\n</p>\n<div align=\"center\">\n \n\n\n\n\n\n\n</div>\n\n## :game_die: Join my community [Gomoku(五子棋)](https://en.wikipedia.org/wiki/Gomoku) game!\n\n<!--START_SECTION:gomoku-->\n\n\n\n\nEveryone is welcome to participate! To make a move, click on the blank cell you wish to drop your piece in.\n\n\nIt's the **white** team's turn to play. \n\n\n\n| |A|B|C|D|E|F|G|H|I|\n| - | - | - | - | - | - | - | - | - | - |\n| 1 | [](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CA1&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CB1&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CC1&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CD1&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CE1&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CF1&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CG1&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CH1&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CI1&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |\n| 2 | [](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CA2&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CB2&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CC2&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CD2&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CE2&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CF2&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CG2&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CH2&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CI2&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |\n| 3 | [](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CA3&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CB3&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CC3&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CD3&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CE3&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CF3&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CG3&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CH3&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CI3&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |\n| 4 | [](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CA4&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CB4&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CC4&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CD4&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CE4&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) | |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CG4&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CH4&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CI4&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |\n| 5 | [](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CA5&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CB5&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CC5&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CD5&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CE5&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CF5&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) | | |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CI5&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |\n| 6 | [](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CA6&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CB6&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CC6&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) | |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CE6&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CF6&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CG6&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) | | |\n| 7 | [](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CA7&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CB7&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CC7&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CD7&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CE7&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CF7&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CG7&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) | | |\n| 8 | [](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CA8&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CB8&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CC8&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CD8&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CE8&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CF8&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CG8&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) | |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CI8&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |\n| 9 | [](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CA9&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CB9&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CC9&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CD9&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CE9&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CF9&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CG9&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CH9&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |[](https://github.com/frostming/frostming/issues/new?title=gomoku%7Cdrop%7Cwhite%7CI9&labels=gomoku&body=Just+push+%27Submit+new+issue%27+without+editing+the+title.+The+README+will+be+updated+after+approximately+30+seconds.) |\n\n\n**:alarm_clock: Most recent moves**\n| Team | Move | Made by |\n| ---- | ---- | ------- |\n| black | I7 | [@ogonbat](https://github.com/ogonbat) |\n| white | F4 | [@GoooIce](https://github.com/GoooIce) |\n| black | G5 | [@DeepDarkStar](https://github.com/DeepDarkStar) |\n| white | H5 | [@stacklens](https://github.com/stacklens) |\n| black | H7 | [@MerleLiuKun](https://github.com/MerleLiuKun) |\n\n\n**:trophy: Hall of Fame: Top 10 players with the most game winning moves :1st_place_medal:**\n| Player | Wins |\n| ------ | -----|\n| [@Insutanto](https://github.com/Insutanto) | 1 |\n| [@pi-dal](https://github.com/pi-dal) | 1 |\n| [@yihong0618](https://github.com/yihong0618) | 1 |\n\n<!--END_SECTION:gomoku-->\n\n<a href=\"https://www.buymeacoffee.com/frostming\"><img src=\"https://img.buymeacoffee.com/button-api/?text=Buy me a coffee&emoji=&slug=frostming&button_colour=b2f0ec&font_colour=000000&font_family=Bree&outline_colour=000000&coffee_colour=FFDD00\"></a>\n"
},
{
"alpha_fraction": 0.5351047515869141,
"alphanum_fraction": 0.5424497723579407,
"avg_line_length": 35.44881820678711,
"blob_id": "d5aa1d055a7bd5496eb7cd0f334ff8d6ff10624e",
"content_id": "6c91eb58c02bfbd846d3889cd1d0245003d93341",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4629,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 127,
"path": "/chess/runner.py",
"repo_name": "ymj4023/frostming",
"src_encoding": "UTF-8",
"text": "import json\nimport os\nimport re\nfrom subprocess import check_call\nfrom typing import Literal, Union\n\nfrom jinja2 import Template\n\nfrom chess.gomoku import Game\n\n\nclass Runner:\n GAME_META = os.path.join(os.path.dirname(__file__), \"gomoku.json\")\n GAME_STATS = os.path.join(os.path.dirname(__file__), \"stats.json\")\n README = os.path.join(os.path.dirname(os.path.dirname(__file__)), \"README.md\")\n ROLES = {0: \"white\", 1: \"black\"}\n TEMPLATE = os.path.join(os.path.dirname(__file__), \"readme_template.j2\")\n\n def __init__(self) -> None:\n with open(self.GAME_META, encoding=\"utf-8\") as f:\n self.meta = json.load(f)\n with open(self.GAME_STATS, encoding=\"utf-8\") as f:\n self.stats = json.load(f)\n with open(self.README, encoding=\"utf-8\") as f:\n self.readme = f.read()\n with open(self.TEMPLATE, encoding=\"utf-8\") as f:\n self.template = Template(f.read())\n\n def play_game(\n self, role: Union[Literal[0], Literal[1]], pos: str, user: str\n ) -> None:\n \"\"\"Title: gomoku|drop|black|b4\"\"\"\n game = Game()\n assert (\n role == self.meta[\"role\"]\n ), f\"Current player role doesn't match, should be {self.ROLES[self.meta['role']]}\"\n game.load(self.meta[\"blacks\"], self.meta[\"whites\"])\n if game.is_draw() or self.meta[\"winner\"] is not None:\n raise ValueError(\"The game is already over, please start a new game.\")\n idx = game._pos_to_idx(pos)\n game.drop(idx, role)\n self.stats[\"all_players\"][user] = self.stats[\"all_players\"].get(user, 0) + 1\n self.meta[\"turn\"] += 1\n self.meta[\"last_steps\"].insert(\n 0, {\"user\": user, \"color\": self.ROLES[role], \"pos\": pos}\n )\n self.meta[\"blacks\"], self.meta[\"whites\"] = game.dump()\n winner = game.check_field(idx)\n if winner is not None:\n self.meta[\"winner\"] = winner\n self.stats[\"completed_games\"] += 1\n if winner == role:\n self.stats[\"winning_players\"][user] = (\n self.stats[\"winning_players\"].get(user, 0) + 1\n )\n else:\n self.meta[\"role\"] ^= 1\n\n def dump(self):\n with open(self.GAME_META, \"w\", encoding=\"utf-8\") as f:\n json.dump(self.meta, f, indent=2)\n with open(self.GAME_STATS, \"w\", encoding=\"utf-8\") as f:\n json.dump(self.stats, f, indent=2)\n with open(self.README, \"w\", encoding=\"utf-8\") as f:\n f.write(self.readme)\n\n def new_game(self):\n self.meta.update(\n turn=0, last_steps=[], blacks=[], whites=[], role=1, winner=None\n )\n\n def update_readme(self) -> None:\n game = Game()\n game.load(self.meta[\"blacks\"], self.meta[\"whites\"])\n top_wins = sorted(\n self.stats[\"winning_players\"].items(), key=lambda x: x[1], reverse=True\n )[:10]\n context = {\n \"total_players\": len(self.stats[\"all_players\"]),\n \"total_moves\": sum(self.stats[\"all_players\"].values()),\n \"completed_games\": self.stats[\"completed_games\"],\n \"winner\": self.ROLES.get(self.meta[\"winner\"]),\n \"draw\": game.is_draw(),\n \"dimension\": game.DIMENSION,\n \"field\": game.field(),\n \"color\": self.ROLES.get(self.meta[\"role\"]),\n \"last_steps\": self.meta[\"last_steps\"],\n \"top_wins\": top_wins,\n \"repo\": os.getenv(\"REPO\"),\n }\n self.readme = re.sub(\n r\"(<\\!--START_SECTION:gomoku-->\\n)(.*)(\\n<\\!--END_SECTION:gomoku-->)\",\n r\"\\1\" + self.template.render(**context) + r\"\\3\",\n self.readme,\n flags=re.DOTALL,\n )\n\n def commit_files(self, message: str):\n check_call([\"git\", \"add\", \"-A\", \".\"])\n check_call([\"git\", \"commit\", \"-m\", message])\n\n\ndef main():\n issue_title = os.getenv(\"ISSUE_TITLE\")\n parts = issue_title.split(\"|\")\n runner = Runner()\n user = os.getenv(\"PLAYER\")\n if len(parts) < 4 and \"new\" in parts:\n runner.new_game()\n message = f\"@{user} starts a new game\"\n else:\n *_, color, pos = parts\n input_role = 1 if color == \"black\" else 0\n runner.play_game(input_role, pos, user)\n message = f\"@{user} drops a {color} piece at {pos.upper()}\"\n message += f\"\\nClose #{os.getenv('ISSUE_NUMBER')}\"\n runner.update_readme()\n runner.dump()\n runner.commit_files(message)\n\n\nif __name__ == \"__main__\":\n main()\n # os.environ[\"REPO\"] = \"frostming/frostming\"\n # runner = Runner()\n # runner.update_readme()\n # runner.dump()\n"
}
] | 2 |
nfcariello/PortGuard
|
https://github.com/nfcariello/PortGuard
|
6e1fad23e0762121ebb7bf7b1d1d9abb70b058d1
|
a4502b924934f7c9e5331e57686141002c454edc
|
647375d7dfe8908b2278d9120acc875037250be4
|
refs/heads/master
| 2020-04-22T18:51:56.220892 | 2019-05-15T08:16:22 | 2019-05-15T08:16:22 | 170,589,949 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6157076358795166,
"alphanum_fraction": 0.6303609609603882,
"avg_line_length": 27.478370666503906,
"blob_id": "f00f568e33524820df09424b0cf1acd6d8ec441f",
"content_id": "8ca5c130eaea6d9701ee2d29cda3c2572b1674ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11192,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 393,
"path": "/ui.py",
"repo_name": "nfcariello/PortGuard",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\nfrom tkinter import *\nfrom tkinter import scrolledtext\nfrom tkinter.ttk import *\nfrom PIL import ImageTk, Image\nimport socket\nimport sqlite3\nimport sys\nimport map_network as map\nimport iptools as iptools\nimport requests\nfrom datetime import datetime\nfrom urllib.request import urlopen\nimport time\n\nwindow = Tk()\nwindow.title(\"PortGuard\")\n\nwindow.geometry('650x550')\n\nselected = IntVar()\n\nbar = Progressbar(window, length=400)\n\nfailure = 'FAILED'\nrunning = 'RUNNING'\ncompleted = 'COMPLETED'\nready = 'READY'\n\nLARGE_FONT = (\"Verdana\", 12)\n\n\ndef querysql(port_import):\n # Prepare SQL Statement to select the port information\n sql = \"SELECT DISTINCT * FROM main.port_information WHERE port = {}\".format(port_import)\n # Define the connection to the database for the vulnerabilities\n conn = sqlite3.connect('port_services.sqlite')\n # Set a cursor for the connection\n cursor = conn.cursor()\n # Try to execute the SQL statement in the database\n try:\n cursor.execute(sql)\n # Fetch all results from the database\n result = cursor.fetchall() # Get all matching entries\n # res = cursor.fetchone() # Get the first matching entry\n try:\n # Return the result\n return result\n except:\n return 0\n except sqlite3.Error:\n conn.rollback()\n return -1\n\n\ndef progress_math():\n sp = int(get_start_port_box())\n ep = int(get_end_port_box())\n\n frac = ep - sp + 1\n res = 100 / frac\n return res\n\n\ndef get_wan_ip():\n # get ip from http://ipecho.net/plain as text\n try:\n wan_ip = urlopen('http://ipecho.net/plain').read().decode('utf-8')\n print(wan_ip)\n return wan_ip\n except:\n return '0.0.0.0'\n\n\ndef get_remote_server_ip():\n remoteServer = get_wan_ip()\n remoteServerIP = socket.gethostbyname(remoteServer)\n return remoteServerIP\n\n\ndef get_setting():\n sel = selected.get()\n return sel\n\n\ndef set_ip_box(text):\n ip_box.delete(0, END)\n ip_box.insert(0, text)\n return\n\n\ndef get_start_port_box():\n sp = start_port_box.get()\n return sp\n\n\ndef get_end_port_box():\n ep = end_port_box.get()\n return ep\n\n\ndef set_start_port_box(text):\n start_port_box.delete(0, END)\n start_port_box.insert(0, text)\n return\n\n\ndef set_end_port_box(text):\n end_port_box.delete(0, END)\n end_port_box.insert(0, text)\n return\n\n\ndef set_status_box(text):\n enable_status_box()\n status_box.delete(0, END)\n status_box.insert(0, text)\n disable_status_box()\n return\n\n\ndef enable_status_box():\n status_box['state'] = 'normal'\n\n\ndef disable_status_box():\n status_box['state'] = 'disabled'\n\n\ndef lan_scan(ips, start, end):\n ui_console.insert(INSERT, '*' * 60 + '\\n')\n ui_console.insert(INSERT, \"Please wait, scanning network for connected devices \" + '\\n')\n print('Preparing to scan ' + str(ips) + ' from ports: ' + str(start) + ' to ' + str(end))\n print('jk lol')\n\n\n# TODO Catch cant reach host\n\ndef wan_scan(remote_ip, start, end):\n set_status_box(running)\n # Print a nice banner with information on which host we are about to scan\n ui_console.insert(INSERT, '*' * 60 + '\\n')\n ui_console.insert(INSERT, \"Please wait, scanning remote host \" + remote_ip + '\\n')\n ui_console.insert(INSERT, \"Scanning Port(s) \" + str(start) + \" through \" + str(end) + '\\n')\n ui_console.insert(INSERT, '*' * 60 + '\\n')\n ui_console.update()\n\n # Check what time the scan started\n t1 = datetime.now()\n\n # Using the range function to specify ports (here it will scans all ports between 1 and 65535)\n res = progress_math()\n\n # We also put in some error handling for catching errors\n open_ports = 0\n try:\n for port_scan in range(int(start), int(end)):\n sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n # result = sock.connect_ex((remote_ip, port_scan))\n cp_res = connected_ports(remote_ip, port_scan)\n # TODO Fix progress bar as it does not work, or sometimes hangs the program\n bar['value'] += res\n bar.update()\n\n if cp_res == 0:\n query = querysql(port_scan)\n if query == -1:\n ui_console.insert(INSERT, 'SQL Failed\\n')\n set_status_box(failure)\n return\n # sys.exit('SQL Failed')\n elif query == 0:\n query = 'None'\n\n open_ports += 1\n for r in query:\n insert_into_tree(remote_ip, port_scan, r[0], r[2], r[3])\n time.sleep(1)\n ui_console.update()\n sock.close()\n ui_console.insert(INSERT, 'SCAN COMPLETE\\n')\n\n except socket.gaierror:\n print('Hostname could not be resolved. Exiting')\n ui_console.insert(INSERT, 'Hostname could not be resolved.\\n')\n set_status_box(failure)\n return\n # sys.exit()\n\n except socket.error:\n print(\"Couldn't connect to server\")\n ui_console.insert(INSERT, 'Couldn\\'t connect to server\\n')\n set_status_box(failure)\n return\n # sys.exit()\n\n # Checking the time again\n t2 = datetime.now()\n\n # Calculates the difference of time, to see how long it took to run the script\n total = t2 - t1\n print(total)\n enable_inputs()\n set_status_box(completed)\n\n\n# UI Components\n\nstatus_label = Label(window, text='Status:')\nip_label = Label(window, text='IP:')\nstart_port_label = Label(window, text='Starting Port:')\nend_port_label = Label(window, text='Ending Port:')\n\nstatus_box = Entry(window, width=15, state='disabled')\nip_box = Entry(window, width=16)\nstart_port_box = Entry(window, width=5)\nend_port_box = Entry(window, width=5)\n\nstatus_box.grid(column=4, row=2, columnspan=2)\nstatus_label.grid(column=3, row=2, sticky=W)\nip_label.grid(column=0, row=2, sticky=W)\nip_box.grid(column=1, row=2, columnspan=2)\nstart_port_label.grid(column=0, row=3, columnspan=2, sticky=W)\nstart_port_box.grid(column=2, row=3)\nend_port_label.grid(column=3, row=3, columnspan=2, sticky=W)\nend_port_box.grid(column=5, row=3)\n\nlan_rad = Radiobutton(window, text='LAN', value=1, variable=selected)\nwan_rad = Radiobutton(window, text='WAN', value=2, variable=selected)\nlan_rad.grid(column=0, row=0, columnspan=2)\nwan_rad.grid(column=4, row=0, columnspan=2)\nui_console = scrolledtext.ScrolledText(window, width=85, height=7)\nui_console.grid(column=0, row=5, columnspan=6, rowspan=4)\nport_results = Treeview(window)\nport_results.grid(column=0, row=9, columnspan=6, rowspan=7)\nbar.grid(column=0, row=18, columnspan=6)\nport_results['columns'] = ('port', 'status', 'service', 'protocol', 'vulnerability')\nport_results.heading(\"#0\", text='IP', anchor='w')\nport_results.column(\"#0\", anchor=\"center\", width=20)\nport_results.heading('port', text='Port')\nport_results.column('port', anchor='center', width=13)\nport_results.heading('status', text='Status')\nport_results.column('status', anchor='center', width=20)\nport_results.heading('service', text='Service')\nport_results.column('service', anchor='center', width=100)\nport_results.heading('protocol', text='Protocol')\nport_results.column('protocol', anchor='center', width=10)\nport_results.heading('vulnerability', text='Vulnerability')\nport_results.column('vulnerability', anchor='center', width=100)\nport_results.grid(sticky=(N, S, W, E))\n\n\n# TODO Add a UI Reset when the user presses search again\n\n# TODO Remove custom IP.. doesn't make sense\n\n# TODO Change to a tabbed pane maybe, so that you can go from Single IP Scan (Supports WAN)\n# TODO Make a page for scanning a network, return the ip and devices on the network like Fing, and then scan those IPs\n\ndef connected_ports(ip, port):\n print(\"-Testing port connection from the internet to %s:%s...\" % (ip, port))\n data = {\n 'remoteHost': ip,\n 'start_port': port,\n 'end_port': port,\n 'scan_type': 'connect',\n 'normalScan': 'Yes',\n }\n\n output = requests.post('http://www.ipfingerprints.com/scripts/getPortsInfo.php', data=data)\n if 'open ' in output.text:\n return 0\n else:\n print(\"port is closed.\")\n return -1\n\n\ndef insert_into_tree(ip, port, service, protocol, vulnerability):\n port_results.insert('', 'end', text=ip, values=(port, 'OPEN', service, protocol, vulnerability))\n\n\ndef check_ip(ip):\n if iptools.ipv4.validate_ip(ip):\n return 0\n else:\n return -1\n\n\ndef check_port(start_port, end_port):\n if start_port == '' or end_port == '':\n return -1\n elif end_port < start_port:\n return -1\n elif int(start_port) > 65535 or int(start_port) < 0:\n return -1\n elif int(end_port) > 65535 or int(start_port) < 0:\n return -1\n else:\n return 0\n\n\n# TODO Fix this so that you can't pass bad values\n\n# TODO Make it so that the output dialog does not allow input\n\n\ndef start():\n i = ip_box.get()\n st = start_port_box.get()\n en = end_port_box.get()\n cp = check_port(st, en)\n cip = check_ip(i)\n\n # TODO Fix this it should be able accept any domain\n if cp == -1 | cip == -1:\n return\n else:\n # TODO sort by type of scan here\n disable_inputs()\n wan_scan(i, st, en)\n\n\ndef start_setting():\n setting = get_setting()\n if setting == 1:\n print('LAN Search')\n # port_results.insert(INSERT, 'LAN Search\\n')\n ips = map.map_network()\n lan_scan(ips)\n elif setting == 2:\n print('WAN Search')\n # port_results.insert(INSERT, 'WAN Search\\n')\n ip = get_remote_server_ip()\n start = 1\n end = 65535\n set_ip_box(ip)\n set_start_port_box(start)\n set_end_port_box(end)\n else:\n print('NOPE')\n\n\ndef cancel():\n print('Does nothing sorry :(')\n\n # TODO Implement cancel functionality\n\n\n# TODO enable a CLEAR button and functionality\n\n# TODO add a 'reset' for after a search\n\n# TODO add a functionality after search to return results, (num of open ports, time took, risk calculated)\n\n# TODO split the UI and port scanning into individual files\n\n# TODO Simplify UI to just allow for the entering of the IP\n\ncancel = Button(window, text=\"Cancel\", command=cancel, state='disabled')\ncancel.grid(column=2, row=4, sticky=E, columnspan=2)\n\nselect = Button(window, text=\"Select\", command=start_setting)\nselect.grid(column=2, row=1, columnspan=2)\n\nscan = Button(window, text=\"Scan\", command=start)\nscan.grid(column=2, row=4, sticky=W, columnspan=2)\n\n\ndef disable_inputs():\n ip_box['state'] = 'disabled'\n start_port_box['state'] = 'disabled'\n end_port_box['state'] = 'disabled'\n scan['state'] = 'disabled'\n select['state'] = 'disabled'\n lan_rad['state'] = 'disabled'\n wan_rad['state'] = 'disabled'\n cancel['state'] = 'normal'\n\n\ndef enable_inputs():\n ip_box['state'] = 'normal'\n start_port_box['state'] = 'normal'\n end_port_box['state'] = 'normal'\n scan['state'] = 'normal'\n select['state'] = 'normal'\n lan_rad['state'] = 'normal'\n wan_rad['state'] = 'normal'\n cancel['state'] = 'disabled'\n\n\nif __name__ == '__main__':\n set_status_box(ready)\n window.mainloop()\n"
},
{
"alpha_fraction": 0.5072435140609741,
"alphanum_fraction": 0.5260175466537476,
"avg_line_length": 33.22259521484375,
"blob_id": "5fd1e6c0038e617891a4fd8385f85f8fd5f884b4",
"content_id": "134691d2462b7c699151af310792f508cb153e4b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 20294,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 593,
"path": "/home.py",
"repo_name": "nfcariello/PortGuard",
"src_encoding": "UTF-8",
"text": "import socket\nimport sqlite3\nimport time\nimport tkinter as tk\nfrom datetime import datetime\nfrom tkinter import *\nfrom urllib.request import urlopen\nimport map_network as map_n\nimport iptools\nimport requests\nfrom PIL import ImageTk, Image\nimport tkinter.ttk as ttk\n\nLARGE_FONT = (\"Verdana\", 25)\nbackground_color = '#3a3e44'\n\nfailure = 'FAILED'\nrunning = 'RUNNING'\ncompleted = 'COMPLETED'\nready = 'READY'\ngetting_devices = 'GETTING DEVICES'\n\n\ndef get_wan_ip():\n # get ip from http://ipecho.net/plain as text\n try:\n wan_ip = urlopen('http://ipecho.net/plain').read().decode('utf-8')\n return wan_ip\n except:\n return '0.0.0.0'\n\n\ndef get_remote_server_ip():\n remote_server = get_wan_ip()\n remote_server_ip = socket.gethostbyname(remote_server)\n return remote_server_ip\n\n\nclass MainApplication(tk.Tk):\n\n def __init__(self, *args, **kwargs):\n tk.Tk.__init__(self, *args, **kwargs)\n container = tk.Frame(self)\n\n container.pack(side=\"top\", fill=\"both\", expand=True)\n\n container.grid_rowconfigure(0, weight=1)\n container.grid_columnconfigure(0, weight=1)\n\n self.frames = {}\n\n for F in (StartPage, PageOne, PageTwo):\n frame = F(container, self)\n\n self.frames[F] = frame\n\n frame.grid(row=0, column=0, sticky=\"nsew\")\n\n self.show_frame(StartPage)\n\n def show_frame(self, cont):\n frame = self.frames[cont]\n frame.tkraise()\n frame.configure(background='#3a3e44')\n\n\nclass StartPage(tk.Frame):\n\n def __init__(self, parent, controller):\n tk.Frame.__init__(self, parent)\n load = Image.open(\"portguard.png\")\n load = load.resize((350, 350), Image.ANTIALIAS)\n render = ImageTk.PhotoImage(load)\n img = Label(self, image=render, borderwidth=0, highlightthickness=0, fg=background_color, padx=0, pady=0)\n img.image = render\n img.pack()\n\n button = tk.Button(self, text=\"Scan My Network\", font=LARGE_FONT,\n command=lambda: controller.show_frame(PageOne))\n button.pack(pady='20', padx='20')\n\n button2 = tk.Button(self, text=\"Scan My External IP\", font=LARGE_FONT,\n command=lambda: controller.show_frame(PageTwo))\n button2.pack(pady='20', padx='20')\n\n\nclass PageOne(tk.Frame):\n\n def __init__(self, parent, controller):\n tk.Frame.__init__(self, parent)\n label = tk.Label(self, text=\"Scan My Network\", font=LARGE_FONT)\n label.pack(pady=10, padx=10)\n\n bar = ttk.Progressbar(self, length=500)\n\n iplist = []\n\n def reset_ui_for_search():\n bar['value'] = 0\n port_results.delete(*port_results.get_children())\n\n def querysql(port_import):\n # Prepare SQL Statement to select the port information\n sql = \"SELECT DISTINCT * FROM main.port_information WHERE port = {}\".format(port_import)\n # Define the connection to the database for the vulnerabilities\n conn = sqlite3.connect('port_services.sqlite')\n # Set a cursor for the connection\n cursor = conn.cursor()\n # Try to execute the SQL statement in the database\n try:\n cursor.execute(sql)\n # Fetch all results from the database\n result = cursor.fetchall() # Get all matching entries\n # res = cursor.fetchone() # Get the first matching entry\n try:\n # Return the result\n return result\n except:\n return 0\n except sqlite3.Error:\n conn.rollback()\n return -1\n\n def insert_into_tree(ip, port, service, protocol, vulnerability):\n port_results.insert('', 'end', text=ip, values=(port, 'OPEN', service, protocol, vulnerability))\n\n def insert_into_network_devices(ip):\n ip_devices.insert('', 'end', text=ip, values=('',))\n\n def check_port(start_port, end_port):\n if start_port == '' or end_port == '':\n return -1\n elif end_port < start_port:\n return -1\n elif int(start_port) > 65535 or int(start_port) < 0:\n return -1\n elif int(end_port) > 65535 or int(start_port) < 0:\n return -1\n else:\n return 0\n\n def disable_inputs():\n ip_box['state'] = 'disabled'\n start_port_box['state'] = 'disabled'\n end_port_box['state'] = 'disabled'\n start_single_scan['state'] = 'disabled'\n start_multi_scan['state'] = 'disabled'\n\n def enable_inputs():\n ip_box['state'] = 'normal'\n start_port_box['state'] = 'normal'\n end_port_box['state'] = 'normal'\n start_single_scan['state'] = 'normal'\n start_multi_scan['state'] = 'normal'\n\n def start_single_search():\n reset_ui_for_search()\n i = ip_box.get()\n st = start_port_box.get()\n en = end_port_box.get()\n cp = check_port(st, en)\n cip = check_ip(i)\n\n if cp == -1 | cip == -1:\n return\n else:\n disable_inputs()\n set_status_box(running)\n lan_scan(i, st, en)\n set_status_box(completed)\n enable_inputs()\n\n def start_multi_search():\n reset_ui_for_search()\n start = start_port_box.get()\n end = end_port_box.get()\n disable_inputs()\n set_status_box(running)\n iterate_lan_scan(iplist, start, end)\n set_status_box(completed)\n enable_inputs()\n\n def iterate_lan_scan(ip_list, start, end):\n print(ip_list)\n for ip in ip_list:\n lan_scan(ip, start, end)\n\n def set_start_port_box(text):\n start_port_box.delete(0, END)\n start_port_box.insert(0, text)\n return\n\n def set_end_port_box(text):\n end_port_box.delete(0, END)\n end_port_box.insert(0, text)\n return\n\n def enable_status_box():\n status_box['state'] = 'normal'\n\n def disable_status_box():\n status_box['state'] = 'disabled'\n\n def set_status_box(text):\n enable_status_box()\n status_box.delete(0, END)\n status_box.insert(0, text)\n disable_status_box()\n return\n\n def insert_network_devices():\n set_status_box(getting_devices)\n get_internal_ip()\n ips = get_ip_list()\n iplist.extend(ips)\n for ip in ips:\n insert_into_network_devices(ip)\n set_status_box(ready)\n\n def check_ip(ip):\n if iptools.ipv4.validate_ip(ip):\n return 0\n else:\n return -1\n\n def get_ip_list():\n ips = map_n.map_network()\n return ips\n\n def lan_scan(remote_ip, start, end):\n t1 = datetime.now()\n res = progress_math(start, end)\n open_ports = 0\n try:\n for port_scan in range(int(start), int(end)):\n sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n result = sock.connect_ex((remote_ip, port_scan))\n bar['value'] += res\n bar.update()\n\n if result == 0:\n query = querysql(port_scan)\n if query == -1:\n set_status_box(failure)\n return\n elif query == 0:\n query = 'None'\n open_ports += 1\n for r in query:\n insert_into_tree(remote_ip, port_scan, r[0], r[2], r[3])\n time.sleep(1)\n sock.close()\n bar['value'] += res\n\n except socket.gaierror:\n print('Hostname could not be resolved. Exiting')\n set_status_box(failure)\n return\n\n except socket.error:\n print(\"Couldn't connect to server\")\n set_status_box(failure)\n return\n\n t2 = datetime.now()\n\n total = t2 - t1\n print(total)\n\n def progress_math(start_port, end_port):\n frac = int(end_port) - int(start_port) + 1\n res = 100 / frac\n return res\n\n def set_ip_box(ip):\n ip_box.delete(0, END)\n ip_box.insert(0, ip)\n return\n\n def get_internal_ip():\n ip = map_n.get_my_ip()\n set_ip_box(ip)\n set_start_port_box(1)\n set_end_port_box(65535)\n\n return_home = tk.Button(self, text=\"Back to Home\", pady='8', command=lambda: controller.show_frame(StartPage))\n return_home.pack()\n\n get_my_internal_ip = tk.Button(self, text=\"Get My Internal IP\", pady='8', command=get_internal_ip)\n\n ip_box = Entry(self, width=16)\n start_port_box = Entry(self, width=5)\n end_port_box = Entry(self, width=5)\n ip_label = Label(self, text='IP:')\n start_port_label = Label(self, text='Starting Port:')\n end_port_label = Label(self, text='Ending Port:')\n\n ip_label.place(x=220, y=101)\n ip_box.place(x=250, y=100)\n get_my_internal_ip.place(x=260, y=140)\n\n start_port_label.place(x=240, y=191)\n start_port_box.place(x=340, y=190)\n end_port_label.place(x=240, y=231)\n end_port_box.place(x=340, y=230)\n\n status_box = Entry(self, width=15, state='disabled')\n status_label = Label(self, text='Status:')\n status_box.place(x=490, y=80)\n status_label.place(x=490, y=50)\n\n set_status_box(ready)\n\n start_multi_scan = tk.Button(self, text=\"Start Multi Scan\", pady='8', command=start_multi_search)\n start_multi_scan.place(x=180, y=280)\n\n start_single_scan = tk.Button(self, text=\"Start Single Scan\", pady='8', command=start_single_search)\n start_single_scan.place(x=380, y=280)\n\n ip_devices_label = Label(self, text='Network Devices:')\n ip_devices_label.place(x=10, y=10)\n\n ip_devices = ttk.Treeview(self)\n ip_devices.place(x=10, y=35)\n ip_devices['columns'] = ('scanned',)\n ip_devices.heading(\"#0\", text='IP', anchor='w')\n ip_devices.column(\"#0\", anchor=\"center\", width=120)\n ip_devices.heading('scanned', text='Scan?')\n ip_devices.column('scanned', anchor='center', width=40)\n\n ip_devices_get = Button(self, text=\"Get Network Devices\", pady='8', command=insert_network_devices)\n ip_devices_get.place(x=20, y=250)\n\n port_results = ttk.Treeview(self)\n port_results.pack(fill=X, padx='7', side='bottom')\n port_results['columns'] = ('port', 'status', 'service', 'protocol', 'vulnerability')\n port_results.heading(\"#0\", text='IP', anchor='w')\n port_results.column(\"#0\", anchor=\"center\", width=60)\n port_results.heading('port', text='Port')\n port_results.column('port', anchor='center', width=2)\n port_results.heading('status', text='Status')\n port_results.column('status', anchor='center', width=4)\n port_results.heading('service', text='Service')\n port_results.column('service', anchor='center', width=90)\n port_results.heading('protocol', text='Protocol')\n port_results.column('protocol', anchor='center', width=4)\n port_results.heading('vulnerability', text='Vulnerability')\n port_results.column('vulnerability', anchor='center', width=100)\n bar.pack(side='bottom', after=port_results, pady='5')\n\n\nclass PageTwo(tk.Frame):\n\n def __init__(self, parent, controller):\n tk.Frame.__init__(self, parent)\n label = tk.Label(self, text=\"Scan My External IP\", font=LARGE_FONT)\n label.pack(pady=10, padx=10)\n\n bar = ttk.Progressbar(self, length=500)\n\n def reset_ui_for_search():\n bar['value'] = 0\n port_results.delete(*port_results.get_children())\n\n def querysql(port_import):\n # Prepare SQL Statement to select the port information\n sql = \"SELECT DISTINCT * FROM main.port_information WHERE port = {}\".format(port_import)\n # Define the connection to the database for the vulnerabilities\n conn = sqlite3.connect('port_services.sqlite')\n # Set a cursor for the connection\n cursor = conn.cursor()\n # Try to execute the SQL statement in the database\n try:\n cursor.execute(sql)\n # Fetch all results from the database\n result = cursor.fetchall() # Get all matching entries\n # res = cursor.fetchone() # Get the first matching entry\n try:\n # Return the result\n return result\n except:\n return 0\n except sqlite3.Error:\n conn.rollback()\n return -1\n\n def connected_ports(ip, port):\n data = {\n 'remoteHost': ip,\n 'start_port': port,\n 'end_port': port,\n 'scan_type': 'connect',\n 'normalScan': 'Yes',\n }\n\n output = requests.post('http://www.ipfingerprints.com/scripts/getPortsInfo.php', data=data)\n if 'open ' in output.text:\n return 0\n else:\n return -1\n\n def check_ip(ip):\n if iptools.ipv4.validate_ip(ip):\n return 0\n else:\n return -1\n\n def insert_into_tree(port, service, protocol, vulnerability):\n port_results.insert('', 'end', text=port, values=('OPEN', service, protocol, vulnerability))\n\n def check_port(start_port, end_port):\n if start_port == '' or end_port == '':\n return -1\n elif end_port < start_port:\n return -1\n elif int(start_port) > 65535 or int(start_port) < 0:\n return -1\n elif int(end_port) > 65535 or int(start_port) < 0:\n return -1\n else:\n return 0\n\n def disable_inputs():\n ip_box['state'] = 'disabled'\n start_port_box['state'] = 'disabled'\n end_port_box['state'] = 'disabled'\n start_scan['state'] = 'disabled'\n\n def enable_inputs():\n ip_box['state'] = 'normal'\n start_port_box['state'] = 'normal'\n end_port_box['state'] = 'normal'\n start_scan['state'] = 'normal'\n\n def start():\n reset_ui_for_search()\n i = ip_box.get()\n st = start_port_box.get()\n en = end_port_box.get()\n cp = check_port(st, en)\n cip = check_ip(i)\n\n if cp == -1 | cip == -1:\n return\n else:\n disable_inputs()\n wan_scan(i, st, en)\n\n def set_start_port_box(text):\n start_port_box.delete(0, END)\n start_port_box.insert(0, text)\n return\n\n def set_end_port_box(text):\n end_port_box.delete(0, END)\n end_port_box.insert(0, text)\n return\n\n def enable_status_box():\n status_box['state'] = 'normal'\n\n def disable_status_box():\n status_box['state'] = 'disabled'\n\n def set_status_box(text):\n enable_status_box()\n status_box.delete(0, END)\n status_box.insert(0, text)\n disable_status_box()\n return\n\n def wan_scan(remote_ip, start, end):\n disable_inputs()\n set_status_box(running)\n\n t1 = datetime.now()\n\n res = progress_math(start, end)\n\n open_ports = 0\n try:\n for port_scan in range(int(start), int(end)):\n cp_res = connected_ports(remote_ip, port_scan)\n bar['value'] += res\n bar.update()\n\n if cp_res == 0:\n query = querysql(port_scan)\n if query == -1:\n set_status_box(failure)\n return\n elif query == 0:\n query = 'None'\n\n open_ports += 1\n for r in query:\n insert_into_tree(port_scan, r[0], r[2], r[3])\n time.sleep(1)\n bar['value'] += res\n\n except socket.gaierror:\n print('Hostname could not be resolved. Exiting')\n set_status_box(failure)\n return\n\n except socket.error:\n print(\"Couldn't connect to server\")\n set_status_box(failure)\n return\n\n t2 = datetime.now()\n\n total = t2 - t1\n print(total)\n enable_inputs()\n set_status_box(completed)\n\n def progress_math(start_port, end_port):\n frac = int(end_port) - int(start_port) + 1\n res = 100 / frac\n return res\n\n def set_ip_box(ip):\n ip_box.delete(0, END)\n ip_box.insert(0, ip)\n return\n\n def get_external_ip():\n ip = get_remote_server_ip()\n set_ip_box(ip)\n set_start_port_box(1)\n set_end_port_box(65535)\n\n return_home = tk.Button(self, text=\"Back to Home\", pady='8', command=lambda: controller.show_frame(StartPage))\n return_home.pack()\n\n get_my_external_ip = tk.Button(self, text=\"Get My External IP\", pady='8', command=get_external_ip)\n\n ip_box = Entry(self, width=16)\n start_port_box = Entry(self, width=5)\n end_port_box = Entry(self, width=5)\n ip_label = Label(self, text='IP:')\n start_port_label = Label(self, text='Starting Port:')\n end_port_label = Label(self, text='Ending Port:')\n\n ip_label.place(x=220, y=101)\n ip_box.place(x=250, y=100)\n get_my_external_ip.place(x=260, y=140)\n\n start_port_label.place(x=240, y=191)\n start_port_box.place(x=340, y=190)\n end_port_label.place(x=240, y=231)\n end_port_box.place(x=340, y=230)\n\n status_box = Entry(self, width=15, state='disabled')\n status_label = Label(self, text='Status:')\n status_box.place(x=490, y=80)\n status_label.place(x=490, y=50)\n\n set_status_box(ready)\n\n start_scan = tk.Button(self, text=\"Start Scan\", pady='8', command=start)\n start_scan.place(x=280, y=280)\n\n port_results = ttk.Treeview(self)\n port_results.pack(fill=X, padx='10', side='bottom')\n port_results['columns'] = ('status', 'service', 'protocol', 'vulnerability')\n port_results.heading('#0', text='Port', anchor='w')\n port_results.column('#0', anchor='center', width=13)\n port_results.heading('status', text='Status')\n port_results.column('status', anchor='center', width=20)\n port_results.heading('service', text='Service')\n port_results.column('service', anchor='center', width=100)\n port_results.heading('protocol', text='Protocol')\n port_results.column('protocol', anchor='center', width=10)\n port_results.heading('vulnerability', text='Vulnerability')\n port_results.column('vulnerability', anchor='center', width=100)\n bar.pack(side='bottom', after=port_results, pady='5')\n\n\napp = MainApplication()\napp.wm_geometry(\"650x550\")\napp.title(\"PortGuard\")\nwindowWidth = app.winfo_reqwidth()\nwindowHeight = app.winfo_reqheight()\npositionRight = int(app.winfo_screenwidth() / 3 - windowWidth / 3)\npositionDown = int(app.winfo_screenheight() / 3 - windowHeight / 3)\napp.geometry(\"+{}+{}\".format(positionRight, positionDown))\napp.configure(background='#3a3e44')\napp.resizable(False, False)\n\nif __name__ == '__main__':\n app.mainloop()\n"
}
] | 2 |
siddhi47/python-project-template
|
https://github.com/siddhi47/python-project-template
|
b25b13bf5c673154d5a659416282ffcd4711dc85
|
eea0c930cdc87771c712719ace5ccc5e2eaddd7d
|
0a8e9acd5834ba0ea8c075d5b5edd3818983dec7
|
refs/heads/main
| 2023-08-28T15:57:09.034334 | 2021-10-20T05:17:09 | 2021-10-20T05:17:09 | 419,194,332 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.807692289352417,
"alphanum_fraction": 0.807692289352417,
"avg_line_length": 25,
"blob_id": "39a1a7e48f44864263b50f3a5102b0bbc07f0ba5",
"content_id": "a4a26393fcfdb0042ce30797500bd90fcc39c175",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 52,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 2,
"path": "/README.md",
"repo_name": "siddhi47/python-project-template",
"src_encoding": "UTF-8",
"text": "# python-project-template\n# python-project-template\n"
},
{
"alpha_fraction": 0.7670454382896423,
"alphanum_fraction": 0.7670454382896423,
"avg_line_length": 28.33333396911621,
"blob_id": "73e2d6bbdf0653ebb352906441a8c190a076d6e0",
"content_id": "18b1bea3ed86840cf3fb1c9c90d8c7a33377f2fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 176,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 6,
"path": "/main.py",
"repo_name": "siddhi47/python-project-template",
"src_encoding": "UTF-8",
"text": "from utils.variables import vars\nfrom utils.logger import logger\n\nlogger.info(\"Start of the main file\")\nlogger.info(\"Executing program...\")\nlogger.info(\"End of the main file\")\n"
},
{
"alpha_fraction": 0.6040372848510742,
"alphanum_fraction": 0.6040372848510742,
"avg_line_length": 29.714284896850586,
"blob_id": "3383b4b8298a6e87185501cfb97e5d6494e26baa",
"content_id": "ebbdd050b65d4d23a7b08492241de39b1c44f3a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 644,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 21,
"path": "/utils/variables.py",
"repo_name": "siddhi47/python-project-template",
"src_encoding": "UTF-8",
"text": "import yaml\nimport os\nfrom utils.utils import ROOT_DIR\n\n\nclass Variables:\n def __init__(self) -> None:\n with open(os.path.join(ROOT_DIR,\"config\",\"config.yaml\"), \"r\") as stream:\n try:\n config = yaml.safe_load(stream)\n except yaml.YAMLError as exc:\n print(exc)\n database_credentials = config['database']\n self.user = database_credentials['user']\n self.password = database_credentials['password']\n self.host = database_credentials['host']\n\n logging_config = config['logging']\n self.log_level = logging_config['log_level']\n\nvars = Variables()"
}
] | 3 |
ArtSciBiz/Healthcare
|
https://github.com/ArtSciBiz/Healthcare
|
097fc260d3890164c1a26504b514694b5a1782a4
|
4d68bd3834ffb838866a9f30c4d07f6b3f64ae75
|
85b36920d094ad3b38eb8177af69fdd910446019
|
refs/heads/master
| 2020-12-02T08:47:04.207258 | 2020-04-06T20:47:55 | 2020-04-06T20:47:55 | 230,949,216 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7872806787490845,
"alphanum_fraction": 0.7872806787490845,
"avg_line_length": 90,
"blob_id": "3750037b08f8ca05379ba6f142154b44d9473b33",
"content_id": "227f979dc9c359b578fa17533ed170b641b2fd07",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 456,
"license_type": "no_license",
"max_line_length": 299,
"num_lines": 5,
"path": "/README.md",
"repo_name": "ArtSciBiz/Healthcare",
"src_encoding": "UTF-8",
"text": "# Capstone Project \nThis is an Applied Data Science Capstone Project Notebook. For questions send a note to [email protected] \n\n#### Regarding the data files here: \nThis Project Requires utilizing FourSquare APIs, but in the business of Web services (incl. REST APIs), what we have are generally blackboxes and there's not enough time to get the administrators open taps. Hence I store data to quickly create a loopback or mock Web services to finish unit testing. \n"
},
{
"alpha_fraction": 0.5916044116020203,
"alphanum_fraction": 0.6111704111099243,
"avg_line_length": 36.50685119628906,
"blob_id": "e0261213f6b0466dde19580c45596176c5b4581a",
"content_id": "eadc6272c36148b22a04bd75b1edd47ff32c7104",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2811,
"license_type": "no_license",
"max_line_length": 187,
"num_lines": 73,
"path": "/Covid19JHU.py",
"repo_name": "ArtSciBiz/Healthcare",
"src_encoding": "UTF-8",
"text": "import streamlit as st\r\nimport datetime\r\nfrom urllib.request import urlopen\r\nimport json\r\nimport pandas as pd\r\nimport plotly.express as px\r\n\r\nimport pytz\r\nfrom datetime import datetime, timedelta\r\n\r\n#tmz = pytz.timezone('US/Samoa')\r\n#now = datetime.now().astimezone(tmz)\r\n\r\n# GET CURRENT AND PAST DATE\r\ncdt = datetime.now()\r\npdt = cdt - timedelta(days=1)\r\n\r\ndt1 = cdt.strftime(\"%m-%d-%Y\")\r\ndt2 = pdt.strftime(\"%m-%d-%Y\")\r\n\r\n# DATES ARE NOT CREATE TWO URLS (SOME TIMES LATEST FILE IS FROM YESTERDAY)\r\n\r\nDATA_COLUMN = 'Deaths'\r\nDATA_URL1 = str('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_daily_reports/')+str(dt1)+str('.csv')\r\nDATA_URL2 = str('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_daily_reports/')+str(dt2)+str('.csv')\r\n#DATA_URL = 'https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_daily_reports/03-29-2020.csv'\r\n\r\n#print(DATA_URL)\r\n\r\[email protected]\r\ndef plotData():\r\n\r\n with urlopen('https://raw.githubusercontent.com/plotly/datasets/master/geojson-counties-fips.json') as response:\r\n counties = json.load(response)\r\n try:\r\n df = pd.read_csv(DATA_URL1, dtype={\"FIPS\": str})\r\n except:\r\n df = pd.read_csv(DATA_URL2, dtype={\"FIPS\": str})\r\n\r\n df.rename(columns={\"FIPS\":\"CountyCode\", \"Admin2\":\"County\", \"Province_State\":\"State\", \"Lat\":\"lat\", \"Long_\":\"lon\", \"Confirmed\":\"Infections\", \"Recovered\":\"Recoveries\"}, inplace=True)\r\n\r\n\r\n dfu = df[df.Country_Region == \"US\"]\r\n #dfu = df[(df['CountyCode'] >= 1000) & (df['CountyCode'] <= 99999)]\r\n dfv = dfu[['CountyCode','County','State','Last_Update','lat','lon','Infections','Deaths','Recoveries']]\r\n dfw = dfv[dfv.Deaths > 0]\r\n\r\n dfx = dfw.sort_values(by=['Deaths', 'CountyCode'], ascending=False)\r\n\r\n\r\n #maxDeaths = dfx['Deaths'].max()\r\n maxDeaths = 100\r\n\r\n fig = px.choropleth(dfx, geojson=counties, locations='CountyCode', color='Deaths',\r\n color_continuous_scale=px.colors.sequential.Reds,\r\n range_color=(0, maxDeaths),\r\n scope=\"usa\",\r\n labels={'Deaths':'Scale'}\r\n )\r\n fig.update_layout(margin={\"r\":0,\"t\":0,\"l\":0,\"b\":0})\r\n\r\n\r\n return fig, dfx\r\n\r\nfig, dfx = plotData()\r\n\r\nTITLE = str('Total CoVID Deaths in the US = ')+str(dfx['Deaths'].sum())\r\n\r\nst.title(TITLE)\r\nst.plotly_chart(fig, use_container_width=True)\r\nst.write(dfx[['State','County','Infections','Deaths','Recoveries']])\r\ndt2 = pdt.strftime(\"%m-%d-%Y\")\r\nst.text(str('AdelleTech. heat map rendered by Murali Behara on ')+cdt.strftime(\"%Y-%m-%d %H:%M:%S\")+str(', data: Johns Hopkins'))\r\n"
}
] | 2 |
graziegrazie/graph_slam
|
https://github.com/graziegrazie/graph_slam
|
d1f5ad6e3c1ddd926a5bca1bbae3a771934d0455
|
ef0ee2ac871d38c051860f4ec689651559d0f6a1
|
f3207ca3b016998840bebe961eb32c8287bfb160
|
refs/heads/master
| 2020-03-20T10:01:44.789844 | 2018-06-27T12:46:25 | 2018-06-27T12:46:25 | 137,356,662 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.523906409740448,
"alphanum_fraction": 0.5707019567489624,
"avg_line_length": 27.114286422729492,
"blob_id": "99a7e0b7daf5fe0a4d4272cec23e6e5e446bb3d6",
"content_id": "7fd58227efe231a3fb0caa8c4f1967c6e661b682",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 999,
"license_type": "no_license",
"max_line_length": 160,
"num_lines": 35,
"path": "/test_odom.py",
"repo_name": "graziegrazie/graph_slam",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nLOOP_INTERVAL = 0.2 # 200ms\nMU = 0\nSIGMA = 1\n\nX = 0\nY = 1\n\nif __name__ == '__main__':\n init_pose = np.array([0, 0], dtype=float)\n prev_pose = init_pose\n curr_pose = np.array([0.0, 0.0], dtype=float)\n\n V = np.array([1, 2])\n\n # 初期値をプロット\n plt.scatter(curr_pose[0], curr_pose[1], marker=\"*\", s=100)\n\n for i in range(10):\n noise = np.random.normal(MU, SIGMA, (1, 2))[0]\n\n delta_trans = np.array([V[X] + noise[X], V[Y] + noise[Y]])\n\n curr_pose[0] = prev_pose[0] + delta_trans[0]\n curr_pose[1] = prev_pose[1] + delta_trans[1]\n\n plt.scatter(curr_pose[0], curr_pose[1], marker=\"*\", s=100)\n plt.quiver(prev_pose[0], prev_pose[1], delta_trans[0], delta_trans[1], angles=\"xy\", scale_units=\"xy\", scale=1, color=\"gray\",label=\"guess robot motion\")\n\n prev_pose = np.array([curr_pose[0], curr_pose[1]], dtype=float)\n\n plt.pause(LOOP_INTERVAL)"
},
{
"alpha_fraction": 0.5321062803268433,
"alphanum_fraction": 0.558590829372406,
"avg_line_length": 38.63036346435547,
"blob_id": "3fe9a2200f931cadf6ee4638790d92d8a8fdb8bc",
"content_id": "a86648214b0fccb94daaf21185c453f26a02ba76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12195,
"license_type": "no_license",
"max_line_length": 160,
"num_lines": 303,
"path": "/test_pose_graph.py",
"repo_name": "graziegrazie/graph_slam",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom copy import deepcopy\nfrom scikits.sparse.cholmod import cholesky\n\nNUM_OF_LOOP = 10\nPLOT_UPDATE_INTERVAL = 0.2 # 500ms\n\nMU = 0\nSIGMA = 0.1\nALPHA_TRANS_VEL = 0.1\nALPHA_ANGULAR_VEL = 0.1\n\npose_array = np.empty((0, 2), float)\n\nvelocity = np.array([1.0, 1.0], dtype=float)\n\nclass PoseGraph:\n def __init__(self):\n self._origin_node = Node(0, Pose2D()) # define origin at (x, y, th) = [0, 0, 0]\n self._nodes = list(self._origin_node)\n self._edges = list()\n self._num_of_nodes = len(self._nodes)\n\n self._prev_cov_odometry = np.zeros((3, 3), dtype=float)\n\n def storePoseAsNode(self, x, y, th):\n latest_node = Node(self._num_of_nodes - 1, Pose2D(x, y, th)) # Be careful! Node ID and number of lists are different!\n self._nodes.append(latest_node)\n\n self._num_of_nodes = self._num_of_nodes + 1\n\n def storeEdge(self, prev_node, post_node, movement, info):\n latest_edge = Edge(prev_node, post_node, movement, info)\n self._edges.append(latest_edge)\n\n # cov_fuse = 1 / ((1 / cov_measure) + (1 / cov_odometry)) = cov_fuse = 1 / (info_measure + info_odometry)\n def calc_covariance(self, cov_measurement, cov_odometry, cov_fusion):\n cov_fuse = np.linalg.inv(cov_measurement) + np.linalg.inv(cov_odometry)\n cov_fuse = np.linalg.inv(cov_fuse)\n\n # @param[in] current_scan_point : scan robot got just now\n # @param[in] reference_scan_point : reference scan for matching\n # @param[in] sensor_pose : coordinate of sensor\n # @param[out] vertical_distance : vertical distance between current_scan and reference_scan\n def calc_vertical_distance(self, sensor_pose, current_scan_point, reference_scan_point, vertical_distance):\n tx = sensor_pose[0]\n ty = sensor_pose[1]\n th = sensor_pose[2]\n\n x = np.cos(th) * current_scan_point.x - np.sin(th) * current_scan_point.y + tx # clpを推定位置で座標変換\n y = np.sin(th) * current_scan_point.x + np.cos(th) * current_scan_point.y + ty\n\n vertical_distance = (x - reference_scan_point.x) * reference_scan_point.nx + (y - reference_scan_point.y) * reference_scan_point.ny # 座標変換した点からrlpへの垂直距離\n\n # 垂直距離を用いた観測モデルの式\n def calc_covariance_measurement(self, sensor_pose, current_scan, reference_scan, cov_measurement):\n ISOLATE = 3\n\n # INFO: These variables are parameter for this function\n dd = 0.00001\n dth = 0.00001\n\n temp_sensor_pose = Pose2D(sensor_pose.x, sensor_pose.y, sensor_pose.theta)\n \n vertical_distance_standard = np.zeros((3, 3), dtype=float)\n vertical_distance_dx = np.zeros((3, 3), dtype=float)\n vertical_distance_dy = np.zeros((3, 3), dtype=float)\n vertical_distance_dth = np.zeros((3, 3), dtype=float)\n\n cov_measurement = np.zeros((3, 3), dtype=float)\n\n for current_scan_point, reference_scan_point in zip(current_scan, reference_scan):\n # TODO: this is specific for LittelSLAM data format\n if reference_scan_point.type == ISOLATE:\n continue\n else:\n pass\n \n calc_vertical_distance(temp_sensor_pose, current_scan_point, reference_scan_point, vertical_distance_standard)\n\n temp_sensor_pose.x = temp_sensor_pose.x + dd\n calc_vertical_distance(temp_sensor_pose, current_scan_point, reference_scan_point, vertical_distance_dx)\n\n temp_sensor_pose.x = temp_sensor_pose.x - dd\n temp_sensor_pose.y = temp_sensor_pose.y + dd\n calc_vertical_distance(temp_sensor_pose, current_scan_point, reference_scan_point, vertical_distance_dy)\n\n temp_sensor_pose.y = temp_sensor_pose.y - dd\n temp_sensor_pose.theta = temp_sensor_pose.y + dth\n calc_vertical_distance(temp_sensor_pose, current_scan_point, reference_scan_point, vertical_distance_dth)\n\n Jx = (vertical_distance_dx - vertical_distance_standard) / dd\n Jy = (vertical_distance_dy - vertical_distance_standard) / dd\n Jth = (vertical_distance_dth - vertical_distance_standard) / dth\n\n cov_measurement[0][0] += np.dot(Jx * Jx)\n cov_measurement[0][1] += np.dot(Jx * Jy)\n cov_measurement[0][2] += np.dot(Jx * Jth)\n cov_measurement[1][1] += np.dot(Jy * Jy)\n cov_measurement[1][2] += np.dot(Jy * Jth)\n cov_measurement[2][2] += np.dot(Jth * Jth)\n\n # Utilize that Hessian is Symmetric Matrix\n cov_measurement[1][0] = cov_measurement[0][1]\n cov_measurement[2][0] = cov_measurement[0][2]\n cov_measurement[2][1] = cov_measurement[1][2]\n\n def calc_covariance_odometry(self, pose, velocity, dt, cov_odometry):\n # These value is Const. values\n ALPHA1 = 1\n ALPHA2 = 1.2\n ALPHA3 = 0.8\n ALPHA4 = 5\n\n theta = pose._theta\n\n v = velocity[0] # translation velocity\n w = velocity[1] # angular velocity\n\n Jx = np.array([[1, 0, -v * dt * np.sin(theta)],\n [0, 1, v * dt * np.cos(theta)],\n [0, 0, 1 ]])\n Ju = np.array([[dt * np.cos(theta), 0 ],\n [dt * np.sin(theta), 0 ],\n [0, dt]])\n\n # TODO: Probabilistic Roboticsの速度制御モデルの共分散の式を見る\n Sigma_u = np.array([[ALPHA1 * (v ** 2) + ALPHA2 * (w ** 2), 0 ],\n [0, ALPHA3 * (v ** 2) + ALPHA4 * (w ** 2)]])\n\n cov_odometry = np.dot(np.dot(Jx, self._prev_cov_odometry), Jx.T) + np.dot(np.dot(Ju, Sigma_u), Ju.T)\n self._prev_cov_odometry[:] = cov_odometry\n\nclass Pose2D:\n def __init__(self, x=0, y=0, theta=0):\n self.x = x\n self.y = y\n self.theta = theta\n\nclass Node:\n def __init__(self, id, pose):\n self.id = id\n self.pose = Pose2D(pose.x, pose.y, pose.theta)\n\nclass Edge:\n def __init__(self, prev_node, post_node, movement, info):\n self.prev_node = Node(prev_node.id, prev_node.pose)\n self.post_node = Node(post_node.id, post_node.pose)\n self.movement = Pose2D(movement.x, movement.y, movement.theta) # movement from Pose2D\n\n self.info = np.empty((3, 3), dtype=float)\n self.info[:] = info\n\ndef adjust_pose_graph(x_hat, constraints):\n num_of_nodes = len(x_hat)\n jacobian = np.empty((3, 6), dtype=float)\n\n F = 0\n threshold = 0.1\n\n while not (F < threshold):\n hessian = np.empty((num_of_nodes * 3, num_of_nodes * 3), dtype=float)\n info_vector = np.empty((num_of_nodes * 3), dtype=float)\n\n F = 0\n\n for c in constraints:\n i = c[0]._prev_node._id\n j = c[0]._post_node._id\n\n node_i = x_hat[i]\n node_j = x_hat[j]\n\n # Following section is programmed with motion model\n calc_jacobian(c, jacobian)\n\n A_ij = jacobian[0:3, 0:3]\n B_ij = jacobian[0:3, 3:6]\n Sigma_ij = c[1]\n\n # update H\n hessian[i*3:(i+1)*3, i*3:(i+1)*3] += np.dot(np.dot(A_ij.T, Sigma_ij), A_ij)\n hessian[i*3:(i+1)*3, j*3:(j+1)*3] += np.dot(np.dot(A_ij.T, Sigma_ij), B_ij)\n hessian[j*3:(j+1)*3, i*3:(i+1)*3] += np.dot(np.dot(B_ij.T, Sigma_ij), A_ij)\n hessian[j*3:(j+1)*3, j*3:(j+1)*3] += np.dot(np.dot(B_ij.T, Sigma_ij), B_ij)\n \n # update b\n info_vector[i*3:(i+1)*3] += np.dot(np.dot(A_ij.T, Sigma_ij), A_ij)\n info_vector[j*3:(j+1)*3] += np.dot(np.dot(A_ij.T, Sigma_ij), A_ij)\n \n hessian[0][0] += 10000 # to keep initial coordinates\n\n factor = cholesky(hessian)\n delta_x = factor(info_vector)\n x_hat += delta_x\n\n # calculate F(x) = e.T * Omega * e\n error = (node_i.pose - node_j.pose) - c[0].edge.pose\n F += np.dot(np.dot(error.T, c[1]), error)\n\ndef calc_jacobian(constaint, jacobian):\n global velocity\n\n theta1 = constaint[0][2]\n cos1 = np.cos(theta1)\n sin1 = np.sin(theta1)\n\n u = velocity[0]\n v = velocity[1]\n\n # This equation is from \"SLAM Introduction\" by Tomono\n jacobian = np.array([[1, 0, -(u * sin1 + v * cos1), cos1, -sin1, 0],\n [0, 1, (u * cos1 - v * sin1), sin1, cos1, 0],\n [0, 0, 1, 0, 0, 1]])\n\n# paran[in] velocity [vel_trans, vel_angular]\n# param[out] cov_mat covariance of velocity\ndef calc_cov_mat(velocity, cov_mat):\n cov_mat[0][0] = ALPHA_TRANS_VEL * (velocity[0] ** 2)\n cov_mat[1][1] = ALPHA_ANGULAR_VEL * (velocity[1] ** 2)\n\n# param[in] dx [m]\n# param[in] dtheta [deg]\n# param[out] jacobian_mat 3x6\ndef calc_jacobian_mat(dx, dtheta, jacobian_mat):\n temp_R = np.array([[ np.cos(np.radians(dtheta)), -np.sin(np.radians(dtheta))],\n [ np.sin(np.radians(dtheta)), np.cos(np.radians(dtheta))]])\n temp_dR = np.array([[-np.sin(np.radians(dtheta)), np.cos(np.radians(dtheta))],\n [ np.cos(np.radians(dtheta)), -np.sin(np.radians(dtheta))]])\n jacobian_mat[0:2, 0:2] = -temp_R.T\n jacobian_mat[0:2, 2] = np.dot(-temp_dR.T, dx)\n jacobian_mat[ 2, 2] = -1\n jacobian_mat[0:2, 3:5] = temp_R.T\n jacobian_mat[ 2, 5] = 1\n\n# ToDo: You should check this implementation is correct or not.\n# @param[in] jacobian_mat\n# @param[in] prev_cov_mat\n# @param[out] curr_cov_mat\ndef calc_curr_cov_mat(jacobian_mat, prev_cov_mat, velocity, curr_cov_mat):\n Jx_t = jacobian_mat[0:3, 0:3]\n Ju_t = jacobian_mat[0:3, 3:6]\n\n cov_u = np.zeros((2, 2))\n calc_cov_mat(velocity, cov_u)\n\n curr_cov_mat = np.dot(np.dot(Jx_t, prev_cov_mat), Jx_t.T) + np.dot(np.dot(Ju_t, cov_u), Ju_t.T)\n\n hessian_size = range(len(node_array))\n hessian_mat = np.zeros((hessian_size, hessian_size))\n\n b = np.zeros((hessian_size, 1))\n\n prev_cov_mat = np.empty((3, 6), dtype=float)\n curr_cov_mat = np.empty((3, 6), dtype=float)\n\n jacobian_mat = np.empty((3, 6), dtype=float)\n\n # ToDo: pose_arrayでループ回すようにする\n for i in range(hessian_size):\n for j in range(hessian_size):\n dx = 0\n dtheta = 0\n \n calc_jacobian_mat(dx, dtheta, jacobian_mat)\n jacobian_mat_i = jacobian_mat[0:3, 0:3]\n jacobian_mat_j = jacobian_mat[0:3, 3:6]\n\n calc_curr_cov_mat(jacobian_mat, prev_cov_mat, velocity, curr_cov_mat)\n curr_info_mat = np.linalg.inv(curr_cov_mat)\n\n temp_A = np.dot(jacobian_mat_i.T, prev_cov_mat)\n temp_B = np.dot(jacobian_mat_j.T, prev_cov_mat) \n\n # compute Hessian matrix\n hessian_mat[3*i:3*(i+1), 3*i:3*(i+1)] += np.linalg.inv(np.dot(temp_A, jacobian_mat_i))\n hessian_mat[3*i:3*(i+1), 3*j:3*(j+1)] += np.linalg.inv(np.dot(temp_A, jacobian_mat_j))\n hessian_mat[3*j:3*(j+1), 3*i:3*(i+1)] += np.linalg.inv(np.dot(temp_B, jacobian_mat_i))\n hessian_mat[3*j:3*(j+1), 3*j:3*(j+1)] += np.linalg.inv(np.dot(temp_B, jacobian_mat_j))\n\n # まず先にノードとエラーのセットを作っておく必要がある\n # calc_error_between_nodes()\n\n # compute coefficient vector\n b[3*i:3*(i+1), 0] += np.linalg.inv(temp_A, error_ij)\n b[3*j:3*(j+1), 0] += np.linalg.inv(temp_B, error_ij)\n\n factor = np.linalg.cholesky(hessian_mat)\n x_hat = factor(-b)\n \nif __name__ == '__main__':\n jacob = np.zeros((3, 6), dtype=float)\n \n calc_jacobian_mat(np.array([1, 2]), 0, jacob)\n\n for i in range(NUM_OF_LOOP + 1):\n pose_array = np.append(pose_array, np.array([[np.cos(np.radians(i * 360.0 / NUM_OF_LOOP)), np.sin(np.radians(i * 360.0 / NUM_OF_LOOP))]]), axis=0)\n\n plt.scatter(pose_array[i][0], pose_array[i][1])\n plt.pause(PLOT_UPDATE_INTERVAL)"
}
] | 2 |
kangheesu/TowerDefense
|
https://github.com/kangheesu/TowerDefense
|
725787974fd77f42c632d391163f54e0e3df8c67
|
c6d5b0a92c0c961174e3246c2c06af7bb14c87dd
|
9ebe40ef824ed37bf6ca5924a2c26e065edc323e
|
refs/heads/master
| 2021-08-28T11:22:30.238315 | 2017-12-12T04:00:29 | 2017-12-12T04:00:29 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6207841634750366,
"alphanum_fraction": 0.6245784163475037,
"avg_line_length": 33.384056091308594,
"blob_id": "b0377e7eb529e6e9f651123184dfdc0fd343547e",
"content_id": "344a6696295c7324b99c4b2aa8eaf64c1009f9e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4744,
"license_type": "no_license",
"max_line_length": 177,
"num_lines": 138,
"path": "/src087/towerdefense.py",
"repo_name": "kangheesu/TowerDefense",
"src_encoding": "UTF-8",
"text": "#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/\n#\n# Original Coder: Austin Morgan ([email protected])\n# Version: 0.8.7b\n#\n# If altering the code, please keep this comment box at least. Also, please\n# comment all changes or additions with two pound signs (##), so I can tell what's\n# been changed and what hasn't. Adding another comment box below this one with your\n# name will insure any additions or changes you made that make it into the next version\n# will be credited to you. Preferably, you'd leave your email and a little description\n# of your changes, but that's not absolutely needed.\n#\n# License:\n# All code and work contained within this file and folder and package is open for\n# use, however please include at least a credit to me and any other coders working\n# on this project.\n#\n#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/\n\n##/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#\n##\n## Gabriel Lazarini Baptistussi ([email protected])\n##\n## I just made a small change in localclasses.Enemy.move(), now the enemies\n## have a different picture for each direction they are moving.\n##\n##/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#/#\n\nimport sys\nimport pygame\nfrom pygame.locals import *\nfrom localdefs import *\nfrom localclasses import *\nfrom SenderClass import Sender\nimport MainFunctions\nimport time\nimport MainMenu\n\ndef main():\n pygame.init()\n print \"Pygame Initialized\"\n pygame.display.set_caption(\"PyGame Tower Defence Game\")\n pygame.mouse.set_visible(1)\n #localdefs: mapvar = Map()\n \n print \"Map Object Generated\"\n screen = pygame.display.set_mode((scrwid,scrhei))\n print \"Display Initialized\"\n clock = pygame.time.Clock()\n\n player.start()\n player.addScreen(screen,clock)\n\n background = mapvar.loadMap((scrwid,scrhei),MainMenu.main(screen,clock))\n\n genEnemyImageArray()\n run=True #Run loop\n wavenum = 0\n selected = None #Nothing is selected\n\n MainFunctions.makeIcons()\n \n print \"Begin Play Loop!!!\"\n\n font = pygame.font.Font(None,20)\n speed = 3\n frametime = speed/30.0\n while run:\n# timehold = list()\n starttime = time.time()\n# temptime = time.time()\n\n MainFunctions.tickAndClear(screen, clock, background, frametime)\n# timehold.append((\"tAC\",time.time()-temptime))\n# temptime = time.time()\n\n MainFunctions.workSenders(frametime)\n# timehold.append((\"wSe\",time.time()-temptime))\n# temptime = time.time()\n\n MainFunctions.workTowers(screen,frametime)\n# timehold.append((\"wTo\",time.time()-temptime))\n# temptime = time.time()\n\n MainFunctions.dispExplosions(screen,frametime)\n# timehold.append((\"dEx\",time.time()-temptime))\n# temptime = time.time()\n\n MainFunctions.dispText(screen,wavenum)\n# timehold.append((\"dTe\",time.time()-temptime))\n# temptime = time.time()\n\n MainFunctions.workEnemies(screen,frametime)\n# timehold.append((\"wEn\",time.time()-temptime))\n# temptime = time.time()\n\n screen,selected,wavenum,speed,timedel = MainFunctions.workEvents(screen, frametime, selected, wavenum, Sender, speed,pygame.font.Font(None,30),pygame.font.Font(None,25))\n# timehold.append((\"wEv\",time.time()-temptime))\n# temptime = time.time()\n\n starttime += timedel\n\n MainFunctions.dispStructures(screen,pygame.mouse.get_pos())\n# timehold.append((\"dSt\",time.time()-temptime))\n# temptime = time.time()\n\n screen.blit(mapvar.baseimg,mapvar.baserect)\n\n if selected and selected.__class__ == Icon:\n MainFunctions.selectedIcon(screen, selected)\n# timehold.append((\"sIc\",time.time()-temptime))\n# temptime = time.time()\n\n if selected and Tower is selected.__class__:\n MainFunctions.selectedTower(screen,selected,pygame.mouse.get_pos())\n# timehold.append((\"sTo\",time.time()-temptime))\n# temptime = time.time()\n\n screen.blit(openbuttoninfo[0],openbuttoninfo[1])\n\n MainFunctions.dispIcons(screen, pygame.mouse.get_pos(), font, frametime)\n# timehold.append((\"dIc\",time.time()-temptime))\n\n pygame.display.flip()\n\n frametime = (time.time() - starttime) * speed\n# timehold.sort(key=lambda x: x[1])\n# timehold.reverse()\n# print timehold\n\nmain()\n\n#Thanks to everyone who looks over this code, or tests this thing out. Feel free\n#to contact me at the email address listed above with any questions, comments, or\n#your own set of changes. I've wanted to do a game like this for a while, so I'll\n#stay committed as long as it has some interest in the community.\n\n#Have a nice day :)"
}
] | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.